/























































































































































































































































































































































































































































































































Author: Дейтел Х.М. Дейтел П.Дж. Чофенс Д.Р.
Tags: программирование операционные системы компьютерные науки переводная литература издательство бином
ISBN: 978-5-9518-0290-3
Year: 2009




Text
Opera ting Sys tems
Th ird Edition
N.M. Deitel
Deitel & Associates, Inc.
P.J. Deitel
Deitel & Associates, Inc.
D.R. Choffnes
Deitel & Associates, Inc.
Prentice <,,
Hall
Upper Saddle, NJ 0745
Х.М. Деите/i, П.Дэ/с. Дейтел, Д.Р. Чофнес
Операционные
системы
Третье издание
Том 1
Основы и принципы
Перевод с английского
под редакцией
С.М. Молявко
Москва
Издательство БИНОМ
2009
1евод с английского
гкоА.В., Гемба О. В., Молявко А.С., Пугач Д.В.
М. Дейтел, П.Дж. Дейтел, Д.Р. Чофнес
Операционные системы. Основы и принципы: Третье издание. Пер. с англ. —
.: ООО «Бином-Пресс», 2009 г. — 1024 с.: ил.
В книге подробно рассмотрены основные принципы построения и функционирования
грационных систем. Для иллюстрации излагаемых основ приводятся многочисленные
>имеры из наиболее популярных сегодня операционных систем Linux и Microsoft Win-
>ws ХР. Разбираются используемые в ОС принципы управления процессами и потока-
и, реальной и виртуальной памятью, дисками и файлами. Подробно анализируются
вменяемые алгоритмы асинхронного параллельного выполнения, опасности взаимо-
юкировок и бесконечного откладывания, механизмы планирования загрузки процессора
; том числе и в мультипроцессорных системах). Контрольные вопросы, учебные приме-
fi и проекты позволяют использовать эту книгу в качестве пособия по университетскому
рсу операционных систем.
Рекомендуется студентам и специалистам, желающим поднять свой профессиональ-
_1Й уровень. Второй том книги посвящен сетям, безопасности и подробному разбору
ринципов построения Linux и Windows ХР.
Все права защищены. Никакая часть этой книги не может быть воспроизведена в любой форме
или любыми средствами, электронными или механическими, включая фотографирование, маг-
нитную запись или иные средства копирования или сохранения информации без письменного раз-
решения издательства.
Authorized translation from the English language edition, entitled Operating Systems, 3rd Edition by
Deitel, Harvey M.; Deitel, Paul J.; and Chofthes, David R., published by Pearson Education, Inc.,
publishing as Prentice Hall, Copyright ©.
ISBN 978-5-9518-0290-3 (pyc.)
ISBN 0-13-182827-4 (англ.)
© Pearson Education Inc.
© Издание на русском языке.
Издательство Бином, 2009
Содержание
Предисловие..............................................................13
Часть L Введение в аппаратные средства, программное обеспечение
и операционные системы...................................................38
Глава 1. Введение в операционные системы.................................41
1.1 Введение..........................................................43
1.2 Что такое операционная система?...................................44
1.3 Ранняя история; 40-е и 50-е годы..................................45
1.4 60-е годы.........................................................46
1.5 70-е годы.........................................................52
1.6 80-е годы.........................................................54
1.7 История сети Интернет и Всемирной Паутины.........................56
1.8 90-е годы.........................................................60
1.9 2000-й год и позже................................................66
1.10 Базы приложений..................................................68
1.11 Среда операционной системы.......................................69
1.12 Компоненты и задачи операционной системы.........................73
1.12.1 Ключевые компоненты операционной системы....................73
1.12.2 Задачи операционной системы.................................76
1.13 Архитектура операционных систем..................................78
1.13.1 Монолитная архитектура......................................79
1.13.2 Многоуровневая архитектура..................................81
1.13.3 Архитектура на основе микроядра........................... 83
1.13.4 Сетевые и распределенные операционные сйстемы...............85
Глава 2. Концепции аппаратных средств и программного обеспечения . . . 109
2.1 Введение....................................................... 112
2.2 Развитие аппаратных устройств....................................113
2.3 Аппаратные компоненты............................................116
2.3.1 Материнские платы...........................................116
2.3.2 Процессоры..................................................118
2.3.3 Системный таймер............................................120
2.3.4 Иерархия памяти.............................................121
2.3.5 Основная память.............................................123
2.3.6 Вторичные запоминающие устройства...........................125
2.3.7 Шины........................................................127
2.3.8 Прямой доступ к памяти......................................128
2.3.9 Периферийные устройства.....................................130
2.4 Поддержка функций операционных систем аппаратными средствами. . . 133
2.4.1 Процессор...................................................133
2.4.2 Таймеры и часы..............................................138
2.4.3 Начальная загрузка..........................................138
2.4.4 Технология Plug-and-Play....................................140
2.5 Кэширование и буферизация........................................141
2.6 Обзор программного обеспечения...................................143
2.6.1 Машинный язык и язык ассемблера . .'........................143
2.6.2 Интерпретаторы и компиляторы................................144
2.6.3 Языки программирования высокого уровня......................146
2.6.4 Структурное программирование................................147
2.6.5 Объектно-ориентированное программирование...................148
2.7 Интерфейсы прикладного программирования..........................149
2.8 Процессы компиляции, связывания и загрузки.......................151
2.8.1 Компиляция..................................................151
2.8.2 Связывание..................................................152
2.8.3 Загрузка....................................................158
6
Операциенные еиетемы (Удержание
7
2.9 Встроенное программное обеспечение...........................
2.10 Межплатформное программное обеспечение.....................161
Чисть II. Прбъгсеы з потоки. .....................................
Глава 3. Концепции процесса.............................................
3.1 Введение.........................................................
3.1.1 Определение процесса.........................................
3.2 Состояния процессов: жизненный цикл процесса.....................
3.3 Управление процессом.............................................
3.3.1 Переход процесса из состояния в состояние....................
3^2 Блоки управления процессом и дескрипторы процессов.............
3^3 Операции над процессами........................................
3.3.4 Приостановка и возобновление работы процесса.................
З^з'б Переключение контекста.......................................
3.4 Прерывания . ....................................................
3.4.1 Обработка прерываний.........................................
3.4.2 Классы прерываний............................................
3.5 Взаимодействие процессов.........................................
3.5.1 Сигналы......................................................
3.5.2 Передача сообщений...........................................
3.6 Учебный пример: процессы в UNIX..................................
Глава 4. Концепции потока...............................................
4.1 Введение.........................................................
4.2 Определение потока...............................................
4.3 Мотивы использования потоков.....................................
4.4 Состояния потока: жизненный цикл потока..........................
4.5 Операции над потоками............................................
4.6 Модели потока....................................................
4.6.1 Потоки уровня пользователя...................................
4.6.2 Потоки уровня ядра...........................................
4.6.3 Совместное использование потоков уровня пользователя и уровня ядра . . . .
4.7 Вопросы реализации потоков.......................................
4.7.1 Доставка сигналов потоков....................................
4.7.2 Завершение работы потоков....................................
4.8 . POSIX и Pthread-потоки.........................................
4.9 Потоки в Linux..................................................
4.10 Потоки в Windows ХР............................................
4.11 Многозадачность в Java. Учебный пример, часть 1: знакомство
с потоками Java......................................................
183
185
186
188
189
190
192
194
196
199
200
202
205
208
208
209
212
231
233
235
236
239
241
243
243
245
247
251
251
255
255
258
260
264
Глава 5. Асинхронное параллельное выполнение............................
5.1 Введение.........................................................
5.2 Взаимоисключение.................................................
5.2.1 Многозадачность в Java. Учебный пример, часть 2: отношение
производитель-потребитель в Java..................................
5.2.2 Критические участки.........................................
5.2.3 Примитивы взаимоисключения..................................
5.3 Реализация примитивов взаимоисключения...........................
5.4 Программные решения проблемы взаимоисключения....................
5.4.1 Алгоритм Деккера............................................
5.4.2 Алгоритм Питерсона..........................................
5.4.3 Взаимоисключение для п потоков: алгоритм Лэмпорта...........
5.5 Аппаратные решения проблемы взаимоисключения.....................
5.5.1 Запрет прерываний...........................................
5.5.2 Команда Test-and-Set........................................
5.5.3 Команда Swap................................................
5.6 Семафоры.........................................................
5.6.1 Реализация взаимоисключения с помощью семафоров.............
5.6.2 Синхронизация потоков с помощью семафоров............... .
5.6.3 Считающие семафоры...................................... .
5.6.4 Реализация семафоров........................................
281
283
283
285
293
205
296
29?
297
308
313
319
319
320
323
326
327
328
330
331
Глава 6. Параллельное программирование...................................349
6.1 Введение..........................................................351
6.2 Мониторы..........................................................354
6.2.1 Переменные-условия...........................................356
6.2.2 Простое распределение ресурсов с помощью мониторов...........358
6.2.3 Пример монитора: кольцевой буфер.............................359
6.2.4 Пример монитора: читатели и писатели.........................363
6.3 Мониторы на языке Java............................................366
6.4 Многозадачность в Java. Учебный пример, часть 3: отношение
производитель-потребитель в Java......................................368
6.5 Многозадачность в Java. Учебный пример, часть 4: кольцевой буфер в Java. . 376
Глава 7. Взаимоблокировки и бесконечное откладывание..................
7.1 Введение.......................................................
7.2 Примеры взаимоблокировок.......................................
7.2.1 Транспортная пробка как пример взаимоблокировки............
7.2.2 Простой пример взаимоблокировки при распределении ресурсов . . .
7.2.3 Взаимоблокировки в системах спулинга.......................
7.2.4 Пример: Обедающие философы...................................
7.3 Похожая проблема — бесконечное откладывание....................
7.4 Концепция ресурсов.............................................
7.5 Четыре необходимых условия возникновения взаимоблокировки. . . .
7.6 Решения проблемы взаимоблокировок..............................
7.7 Предотвращение взаимоблокировок................................
7.7.1 Нарушение условия ожидания дополнительных ресурсов.........
7.7.2 Нарушение условия неперераспределяемости...................
7.7.3 Нарушение условия кругового ожидания.......................
7.8 Обход взаимоблокировок с помощью алгоритма банкира.............
7.8.1 Пример надежного состояния.................................
7.8.2 Пример ненадежного состояния...............................
7.8.3 Пример перехода из надежного состояния в ненадежное........
7.8.4 Распределение ресурсов согласно алгоритму банкира..........
7.8.5 Недостатки алгоритма банкира...............................
7.9 Обнаружение взаимоблокировок...................................
7.9.1 Графы распределения ресурсов...............................
7.9.2 Приведение графов распределения ресурсов...................
7.10 Восстановление после взаимоблокировок.........................
7.11 Стратегии борьбы с взаимоблокировками в современных
и будущих системах.................................................
Глава 8. Планирование работы процессора...............................
8.1 Введение........................................
8.2 Уровни планирования............................................
8.3 Планирование с приоритетным вытеснением и без него.............
8.4 Приоритеты......................................
8.5 . Цели планирования............................................
8.6 Критерии планирования..........................................
8-7 Алгоритмы планирования.........................................
о'1'l Планирование по принципу FIFO (первым-пришел-первым-ушел) . . . .
R 7 2 Циклическое планирование (RR)..............................
8 7 4 Планирование по принципу SPF (кратчайший процесс первым) . . . .
.4 Планирование по принципу HRRN (по наибольшему относительному
395
397
398
398
401
402
404
406
407
409
410
411
412
414
415
418
420
421
422
423
424
425
426
427
429
. 432
455
. 457
. 458
. 460
. 463
. 464
. 467
. 469
. 469
. 470
. 474
8 7 к Дремеии реакции).......................Г. ''.7.Г7Г..''. . . 476
8* 7 к Л?аниРование по принципу SRT (по наименьшему остающемуся времени) . . 476
о?- Многоуровневые очереди с обратной связью.........................478
8 8 IT ' Планирование по принципу FSS (справедливого раздела)...........482
8 0 ггланиР°вание по сроку завершения ..................................485
8 1 л 1ланировйние реального времени....................................487
Планирование потоков Java..........................................490
8
Операционные системы
Содержание
9
Я2
515
517
517
518
521
523
524
525
526
527
529
530
537
537
541
543
561
563
566
570
574
578
Часть III. Реальная и Виртуальная память.................. ..............
Глава 9. Оперативная память. Организация и управление.................;
9.1 Введение..........................................................
9.2 Организация памяти................................................
9.3 Управление памятью................................................
9.4 Иерархия памяти...................................................
9.5 . Стратегии управления памятью....................................
9.6 Выделение непрерывных и фрагментированных участков памяти ....
9.7 Выделение непрерывных блоков в однопользовательских системах ....
9.7.1 Оверлеи......................................................
9.7.2 Защита в однопользовательских системах.......................
9.7.3. Однопоточные пакетные системы...............................
9.8 Мультипрограммные системы с фиксированным распределением памяти. .
9.9 Мультипрограммные системы с изменяемым распределением памяти. . .
9.9.1 Характеристики изменяемых разделов...........................
9.9.2 Стратегии размещения в памяти................................
9.10 Мультипрограммные системы с подкачкой............................
Глава 10. Организация виртуальной памяти.................................
10.1 Введение.........................................................
10.2 Виртуальная память: основные понятия.......>.....................
10.3 . Размещение блоков..............................................
10.4 Страничные системы...............................................
10.4.1 Трансляция адресов прямым отображением в страничных системах. . .
10.4.2 Трансляция адресов ассоциативным отображением в страничных
системах..........................................................
10.4.3 Трансляция адресов смешанным прямым/ассоциативным
отображением в страничных системах................................
10.4.4 Многоуровневые страничные таблицы...........................
10.4.5 Обращенные страничные таблицы ..............................
10.4.6 Разделение ресурсов в страничной системе....................
10.5 Сегментация.....................................................
10.5.1 Трансляция адресов прямым отображением в сегментных системах. . .
10.5.2 Разделение ресурсов в сегментных системах...................
10.5.3 Защита и контроль доступа в сегментных системах.............
10.6 Сегментно-страничные системы....................................
10.6.1 Динамическая трансляция адресов в сегментно-страничных системах . »
10.6.2 Разделение ресурсов и защита в сегментно-страничной системе.
10.7 Практический пример: Виртуальная память архитектуры
IA-32 фирмы Intel...................................................
Глава 11. Управление виртуальной памятью.................................
11.1 Введение........................................................
11.2 Локальность.....................................................
11.3 Подкачка по требованию..........................................
11.4 Предварительная подкачка........................................
11.5 Замена страниц..................................................
11.6 Стратегии замены страниц........................................
11.6.1 Замена случайных страниц...................................
11.6.2 Стратегия замены «первый вошел — первый вышел» (FIFO)......
11.6.3 Аномалия FIFO..............................................
11.6.4 Стратегия замены дольше всего не использовавшихся страниц (LRU) . .
11.6.5 Стратегия замены реже всего используемых страниц (LFU).....
11.6.6 Стратегия замены давно не используемых страниц (NUR)... . .
11.6.7 Модификации стратегии FIFO: стратегия «второго шанса»
и круговая стратегия.............................................
11.6.8 Стратегия замены дальней страницы..........................
11.7 Модель рабочих наборов.........................................
11.8 Стратегия замены страниц по частоте страничных
промахов (PFF).....................................................
11.9 Освобождение страниц..............................’............
11.10 Размер страниц................................................
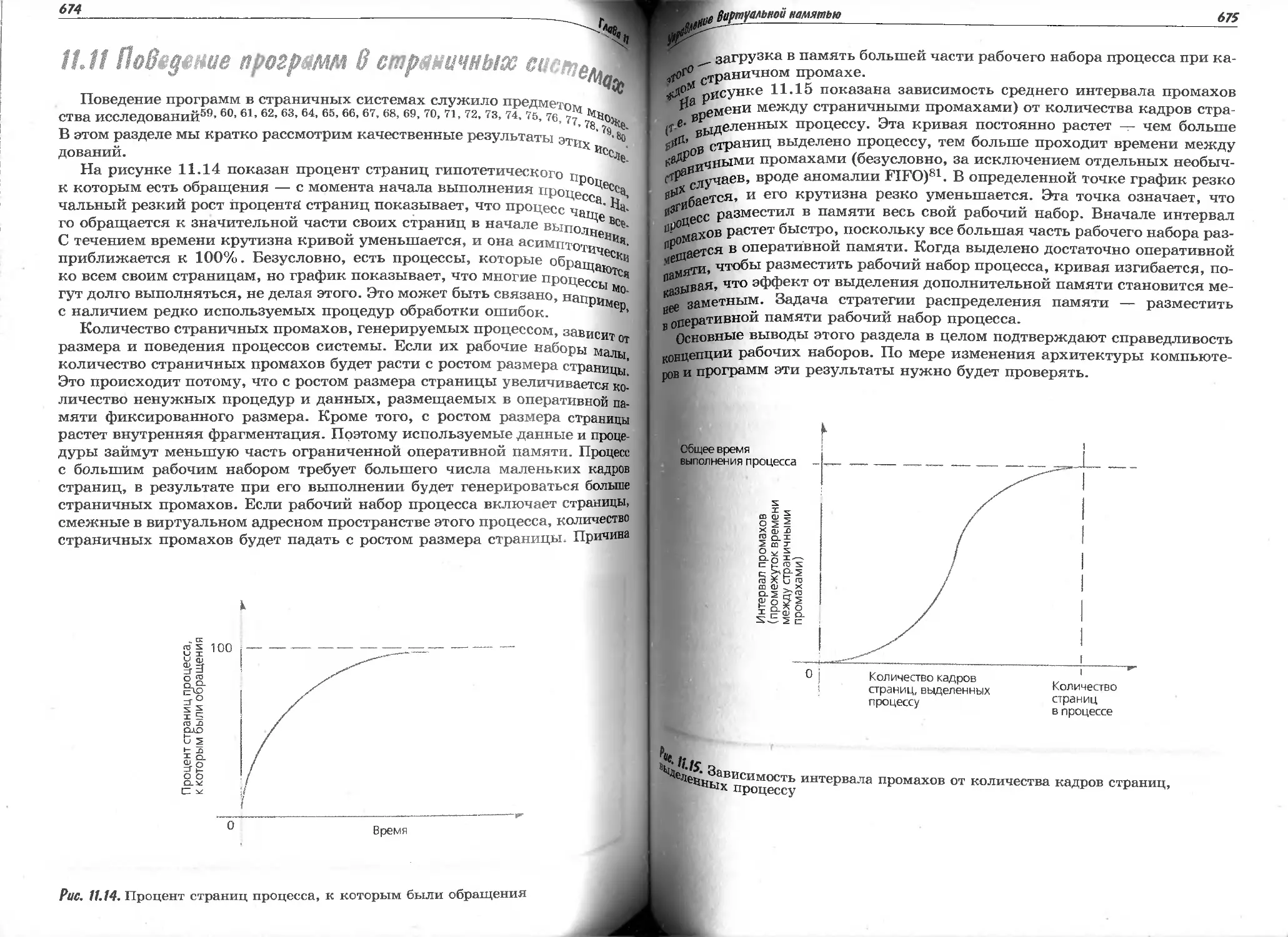
11.11 Поведение программ в страничных системах......................
580
581
584
587
591
594
597
599
601
604
605
609
611
641
643
644
645
648
650
651
652
652
654
655
657
657
660
661
662
668
670
670
674
уровня 0 (разделение данных)...................
уровня 1 (зеркальное отображение)..............
уровня 2 (побитовый контроль с коррекцией
уровня 3 (побитовый XOR-контроль и коррекция)
______Л а/!!.—-- "
11.12 Глобальная и локальная замена страниц........................
11.13 Практический пример: замена страниц в Linux..................
Часть IV. Внешние накопители, файлы и базы данных. ...»................
Глава 12. Оптимизация производительности дисковых накопителей . .
12.1 Введение...........................•_.....................
12.2 Развитие вторичных запоминающих устройств................
12.3 Характеристики накопителей с подвижными головками.........
12.4 Почему необходима диспетчеризация дисковых операций ....
12.5 Диспетчеризация дисковых операций........................
12.5.1 Алгоритм диспетчеризации FCFS........................
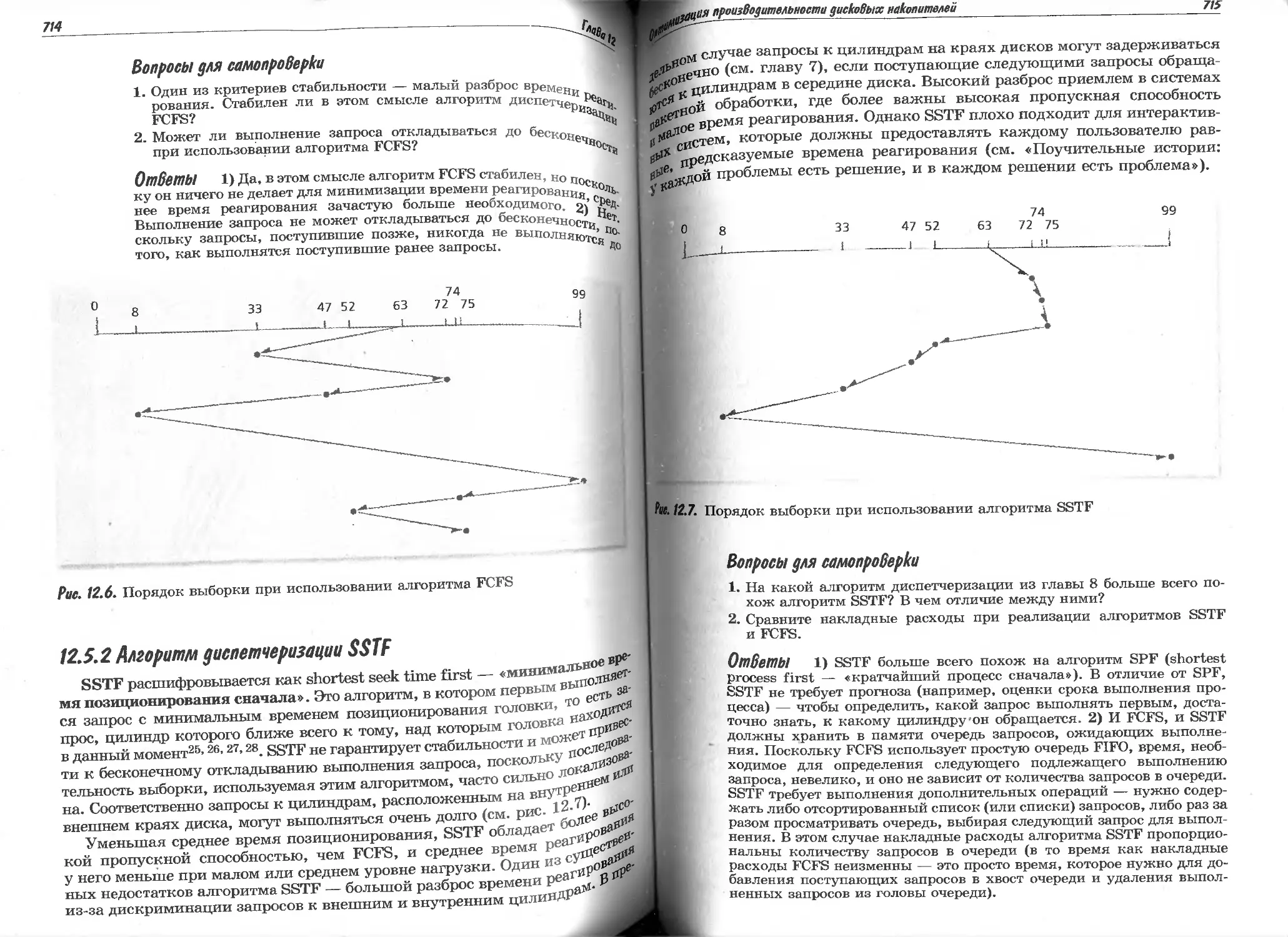
12.5.2 Алгоритм диспетчеризации SSTF........................
12.5.3 Алгоритм диспетчеризации SCAN...........................
12.5.4 Алгоритм диспетчеризации C-SCAN......................
12.5.5 Алгоритм диспетчеризации FSCAN и N-шаговый SCAN......
12.5.6 Алгоритм диспетчеризации LOOK и C-LOOK...............
12.6 Оптимизация по вращению..................................
12.6.1 Алгоритм диспетчеризации SLTF........................
12.6.2 Алгоритмы диспетчеризации SPTF и SATF................
12.7 Системные соображения....................................
12.8 Кэширование и буферизация................................
12.9 Другие приемы повышения производительности накопителей ....
12.10 RAID-массивы............................................
12.10.1 Обзор RAID-массивов.................................
12.10.2 RAID-массивы
12.10.3 RAID-массивы
12.10.4 RAID-массивы
по Хеммингу)
12.10.5 RAID-массивы ______v_________. .._
12.10.6 RAID-массивы уровня 4 (блочный XOR-контроль и коррекция) .
12.10.7 RAID-массивы уровня 5 (блочный XOR-контроль и коррекция
с распределением)...........................................
Глава 13. Файловые системы и базы данных..........................
13.1 Введение..................................................
13.2 Иерархия данных...........................................
13.3 Файлы.....................................................
13.4 Файловые системы..........................................
13.4.1 Директории............................................
13.4.2 Метаданные............................................
13.4.3 Монтирование..........................................
13.5 Организация файлов........................................
13.6 Размещение файлов.........................................
13.6.1 Непрерывное размещение файлов.........................
13.6.2 Размещение файлов в виде связных списков..............
13.6.3 Табличное фрагментированное размещение................
13.6.4. Индексированное фрагментированное размещение.........
13.7 Управление свободным пространством........................
13.8 Контроль доступа к файлам.................................
13.8.1 Матрица контроля доступа..............................
13.8.2 Контроль доступа по классам пользователей.............
13.9 Методы доступа к данным...................................
13.10 Защита целостности данных................................
13.10.1 Резервное копирование и восстановление...............
13-10.2 Целостность данных и журнальные файловые системы.....
13.11 Файловые серверы и распределенные системы................
13.12 Системы баз данных.......................................
13.12.1 Преимущества систем баз данных.......................
13.12.2 Доступ к данным......................................
13.12.3 Реляционная модель базы данных.......................
13.12.4 Операционные системы и системы баз данных............
676
677
700
703
705
705
706
710
711
713
714
716
717
719
720
722
722
723
726
728
730
734
734
738
739
741
744
746
. 747
. 777
. 779
. 779
. 781
. 782
. 784
. 789
. 791
. 793
. 794
. 795
. 796
. 798
. 801
. 805
. 807
. 807
. 809
. 810
. 811
. 811
. 814
. 818
. 819
. 819
. 820
. 821
. 824
to
Операционные системы
848
851
853
853
855
856
859
859
860
862
864
865
867
868
870
871
872
873
873
874
875
877
880
883
907
910
912
913
915
922
924
924
925
926
928
929
930
931
933
934
936
937
939
942
944
945
950
951
952
953
955
956
958
962
962
Часть И Производительность, процессоры мультипроцессорные системы.........
Глава 14. Производительность и архитектура процессоров....................
14.1 Введение.........................................................
14.2 Тенденции, влияющие на результирующую производительность.........
14.3 Назначение мониторинга и оценки производительности...............
14.4 Показатели производительности....................................
14.5 Методы оценки производительности.................................
14.5.1 Трассировка и профилирование.................................
14.5.2 Хронометраж и контрольные задачи микроуровня.................
14.5.3 Оценка производительности относительно приложения............
14.5.4 Аналитические модели.........................................
14.5.5 Наборы контрольных задач.....................................
14.5.6 Синтетические программы......................................
14.5.7 Моделирование................................................
14.5.8 Мониторинг производительности................................
14.6 Узкие места и насыщение..........................................
14.7 Обратные связи..............................................
14.7.1 Отрицательная обратная связь.................................
14.7.2 Положительная обратная связь.................................
14.8 Параметры производительности и архитектура процессора............
14.8.1 Полный набор команд..........................................
14.8.2 Архитектура процессоров с сокращенным набором команд.........
14.8.3 Второе поколение RISC-процессоров............................
14.8.4 Технология параллельной обработки команд с явным
параллелизмом (EPIC)................................................
Глава 15. Многопроцессорность.............................................
15.1 Введение.........................................................
15.2 Многопроцессорные архитектуры....................................
15.2.1 Классификация последовательных и параллельных архитектур.....
15.2.2 Схемы соединений процессоров.................................
15.2.3 Тесносвязанные и слабосвязанные системы......................
15.3 Организации многопроцессорных операционных систем................
15.3.1 Схема ведущий/ведомый........................................
15.3.2 Схема с раздельными ядрами...................................
15.3.3 Симметричная схема...........................................
15.4 Архитектуры доступа к памяти.....................................
15.4.1 Архитектура однородного доступа к памяти (UMA)...............
15.4.2 Архитектура неоднородного доступа к памяти (NUMA)............
15.4.3 Кэшевая архитектура памяти (СОМА)............................
15.4.4 Архитектура без доступа к удаленной памяти NORMA.............
15.5 Разделение памяти в многопроцессорных системах...................
15.5.1 Когерентность кэша...........................................
15.5.2 Репликация и миграция страниц................................
15.5.3 Общая виртуальная память.....................................
15.6 Планирование в многопроцессорных системах........................
15.6.1 Задачно-независимые алгоритмы планирования...................
15.6.2 Задачно-ориентированные алгоритмы планирования...............
15.7 Миграция процессов...............................................
15.7.1 Процедура миграции процесса . ...............................
15.7.2 Концепции миграции процессов ................................
15.7.3 Стратегии миграции процессов.................................
15.8 Балансировка нагрузки............................................
15.8.1 Статическая балансировка нагрузки............................
15.8.2 Динамическая балансировка нагрузки.............'.............
15.9 Взаимное исключение в многопроцессорных системах.................
15.9.1 Спин-блокировки..............................................
15.9.2 Блокировки с усыплением/пробуждением.........................
15.9.3 Блокировки чтения/записи.....................................
Предметный указатель....................................98$
Предисловие редактора
перевода
Учебник, который можно смело рекомендовать в качестве
базового курса для отечественных университетов
по специальности «Операционные системы».
Хороших книг всегда мало. Хороших учебников мало вдвойне. Эта кни-
га, безусловно, представляет собой хороший учебник по операционным
системам. Авторы поставили перед собой трудную цель и успешно ее дос-
тигли. Они рассмотрели в этой книге практически все вопросы из области
проектирования операционных систем. И речь идет не просто о том, что
подробно разбираются с теоретической точки зрения принципы функцио-
нирования компонентов и техника выбора подходящих алгоритмов. Суще-
ственным достоинством книги является наличие большого числа приме-
ров, иллюстрирующих теорию построения операционных систем на двух
наиболее популярных сегодня операционным системах конкурирующих
лагерей: Linux и Microsoft Windows ХР. К достоинствам книги следует от-
нести не только ее «ширину» в плане охвата различных программных ре-
шений, но и «глубину»: авторы внимательно рассматривают аппаратный
и микропрограммный фундамент реализации операционных систем —
стык между «железом» и программами — то узкое место, которое часто
сводит на нет преимущества отдельных программных решений, принятых
без учета возможностей аппаратуры.
Любой преподаватель университета, обучающий студентов информатике
и вычислительной технике, знает, что придумать подходящий пример про-
гРаммы, схемы, алгоритма или базы данных не сложно. Гораздо сложнее
найти иллюстрирующее проблему реальное проектное решение, которое при-
меняется на практике в бизнесе или в науке. Такое решение должно подтвер-
дить свою жизнеспособность, послужить предметом придирчивого изучения
со стороны конкурентов, проявить хорошие и плохие стороны, т.е. действи-
тельно стать сконцентрированным выражением человеческого интеллекта
11 Достижений технологии. Находить такие примеры трудно даже для препо-
давателей, отслеживающих передний фронт прогресса в своей области, а что
УЛсе говорить о студентах, которые зачастую даже не знают направления по-
иска. Здесь предлагаемая книга может оказать им существенную помощь,
каждая глава снабжена богатым списком рекомендуемой литературы,
Онерацаониые систем^
а ссылки на соответствующие первоисточники введены в основной текст глу
вы. В список литературы входят как фундаментальные работы классику
(Дейкстры, Кнута, Мура), так и свежие статьи и технические отчеты о по
следних достижениях в области операционных систем. Самые последние све
дения доступны, конечно, в Интернете, и каждая глава завершается списков
полезных Web-ссылок.
Предисловие
Нельзя не отметить тщательную методическую проработку материалу,
книги. Процесс изучения любого предмета предусматривает контроль (ид^
самоконтроль) знаний. Авторы книги знают об этом и позаботились
о включении в каждую главу списка контрольных вопросов. Кроме этоц
списка каждый параграф завершается парой вопросов, позволяющих сис.
Довольно жить частями. Только объединять...
тематизировать приобретенные знания. Авторы книги также помня, Эдвард Морган Форстер
о том, что знания приобретаются для практического применения, поэтому
во все главы включены учебные и программные проекты, которые могу,
в отечественной учебной традиции рассматриваться как аналоги курсовы?
работ и проектов.
Учиться по хорошей книге интересно, но это труд, причем часто труд
нелегкий. Авторы позаботились о том, чтобы «скрасить тяжелые будни»
учащихся: в книгу наряду с основными сведениями включены биографии
корифеев вычислительной техники, размышления о правильности прин Добро пожаловать в мир операционных систем. Эта книга предназначе-
ципов построения операционных систем, исторические иллюстрации раз- на в основном для использования как пособие в одно- и двухсеместровых
личных взглядов на прогресс, цивилизацию и технологию. курсах по операционным системам (согласно определению этих курсов
Возможно, это предисловие выглядит как восторженная ода, но книга в самой свежей версии учебных планов АСМ/IEEE), изучаемым в универ-
того заслуживает: редактору уже давно не приходилось держать в руках ситетах студентами младших, старших и выпускных курсов. Кроме того,
переводной учебник, который можно было бы смело рекомендовать в каче- эта книга может пригодиться в качестве справочника системным програм-
стве базового курса для отечественных университетов по специальности мистам и разработчикам операционных систем.
«Операционные системы». В книге содержатся подробные обзоры двух наиболее важных операци-
В русском переводе книга выходит в двух томах. Первым том содержи: онных систем современности — Linux (глава 20) и Windows ХР (глава 21).
главы, посвященные общим вопросам и принципам: аппаратура и програм Эти операционные системы воплощают две противоположные парадигмы
мы, процессы и потоки, асинхронное параллельное выполнение и парал- развития операционных систем — соответственно, открытое, нелицензи-
лельное программирование, взаимоблокировки и бесконечное откладыва онное и закрытое, корпоративное. В обзоре Linux приведена история раз-
нив, планирование загрузки процессора, управление физической и вирту- вития ядра вплоть до версии 2.6. В обзоре Windows ХР описаны состав-
альной памятью, управление дисками и файлами, оптимизацш ляющие новейшей версии самой распространенной операционной системы
производительности, мультипроцессорные системы. Второй том включае! Для персональных компьютеров. Эти обзоры позволят вам сравнить раз-
в себя главы, посвященные сетевым и распределенным системам, вопросам Личные философии проектирования и реализации, используемые в реаль-
безопасности и подробному разбору принципов построения систем LinuJ но существующих операционных системах.
и Windows ХР.
И Linux, и Windows ХР представляют собой сложные, объемистые опе-
рационные системы с миллионами строк исходных кодов. Мы рассмотрим
С.М. МолявнС основные компоненты каждой из этих операционных систем. В обзорах
Рассматриваются вопросы, возникающие при работе с персональными
компьютерами, рабочими станциями, многопроцессорными машинами,
Распределенными и встраиваемыми системами, а также детально обсужда-
ется причины популярности Linux и других Unix-образных операцион-
ных систем с открытым исходным кодом в корпоративной среде.
В данном введении излагается подход к обучению, используемый
в третьем издании «Операционных систем», а также описаны ключевые
элементы содержимого книги и ее оформления. Мы рассмотрим вспомога-
тельные материалы, включенные в книгу. В разделе «Обзор книги» кратко
°писаны аспекты операционных систем, рассматриваемые в книге.
14
Операционныесистемы
Третье издание «Операционных систем» рецензировалось многими из.
вестными учеными и специалистами промышленности; имена этих люде?}
и должности, занимаемые ими, перечислены в разделе «Благодарности».
Если при чтении этой книги у вас возникнут какие-либо вопросы, пожа-
луйста, свяжитесь с нами по электронной почте deitel@deitel.com; мы бу.
дем отвечать на письма по мере возможности. Кроме того, посетите нагц
сайт в Интернете, www.deitel.com, и подпишитесь на новостной бюллетень
Deitel® Buzz Online ПО адресу www.deitel.com/newsletter/subscribe.html.
С помощью нашего сайта и новостного бюллетеня мы сообщаем нашим читате-
лям о новых публикациях и услугах. Раздел сайта www. deitel. com/books/os3e
посвящен третьему изданию «Операционных систем». В этом разделе мы
регулярно публикуем различные вспомогательные материалы, полезные
для преподавателей и учащихся, включая схемы, обновления, сведения
о найденных ошибках, предлагаемые исследовательские проекты (группо-
вые проекты, проекты для исследований под руководством предподавате-
лей и тезисы) и библиографию к отдельным главам книги. Издательство
Prentice Hall также поддерживает в Интернете страницу, посвященную этой
книге, по адресу www.prenhall.com/deitel.
Оформление книги
В третьем издании «Операционных систем» используется совершенно
новый двухцветный стиль оформления, основой для которого послужили
работы Леонардо да Винчи. Определения ключевых терминов выделяются
полужирным шрифтом, чтобы их легко было заметить в тексте.
Особенности третьего издания ((Операционных
система
В третьем издании «Операционных систем» включено множество новых
сведений. Кроме того, мы пересмотрели и обновили материалы, присутство-
вавшие в предыдущих изданиях. Повышенное внимание, уделенное в книге
новым технологиям и проблемам, связанным с распределенными вычисле-
ниями, выделяет книгу на фоне других, посвященных операционным систе-
мам. В книгу добавлено несколько новых разделов, посвященных встраи-
ваемым системам, системам реального времени и распределенным систе-
мам. Ключевые элементы и особенности этого издания перечислены ниже-
• Содержимое книги соответствует всем требованиям курсов АСМ/1ЕЕЕ
СС2001 по операционным системам.
• Рассмотрены все упомянутые в СС2001 темы, касающиеся операцион-
ных систем, за исключением языков сценариев для оболочек.
Обновлено введение в аппаратуру, в него включены вопросы исполь-
зования новейших технологий и их влияния на развитие операцион-
ных систем.
15
Описаны задачи управления процессами, потоками, памятью и дис-
ковыми накопителями, отражающие потребности современных при-
ложений.
Рассмотрены системы общего назначения и концепции, существен-
ные для систем реального времени, встраиваемых и суперскалярных
архитектур.
Изложены основные методики оценки, позволяющие эффективно
проводить сравнительный анализ компонентов операционных систем.
Подробно рассмотрены сетевые концепции.
Всесторонне обсуждаются вопросы, связанные с безопасностью,
включая последние достижения в области механизмов аутентифика-
ции, протоколов безопасности, антивирусных средств, методов кон-
троля доступа и безопасности беспроводных сетей.
Приведен подробный обзор распределенных вычислительных систем
и отдана дань грандиозному влиянию Интернета и World Wide Web
на вычисления и операционные системы.
Рассмотрены элементы архитектуры Intel®.
Книга включает множество диаграмм, таблиц, примеров работающих
программ, фрагментов псевдокода и алгоритмов.
Отдельная глава посвящена потокам.
Многие примеры в книге написаны на псевдокоде с синтаксисом, по-
хожим на язык Java. Авторы учитывают широкое распространение
языков C/C++/Java — предполагается, что большинство изучающих
операционные системы владеют хотя бы одним из этих языков.
В книгу включены задачи по потокам с решениями в виде фрагментов
псевдокода и программ на языке Java, демонстрирующие основные
моменты, связанные с многопоточностью. Эти решения позволяют
преподавателям излагать материал так, как они сочтут необходимым.
Java впервые используется в этом издании книги, и ее применение
в обучении необязательно. Чтобы получить самую свежую версию
Java, посетите страницу java.sun.com/j2se/downloads.htnil. На
этой странице содержится ссылка на инструкции по установке Java
на компьютер.
Рассмотрены вопросы управления многопроцессорными системами.
Книга содержит новые разделы по диспетчеризации потоков и дис-
петчеризации в реальном времени.
Рассмотрены RAID-системы.
Приведен практический пример по процессам UNIX.
В книгу включены разделы с новейшими сведениями по стратегиям
диспетчеризации памяти и дисковых накопителей.
Важная тема ввода/вывода рассматривается во многих главах — пре-
жде всего в главах 2, 12, 13 и главах, посвященных отдельным опера-
ционным системам (20 и 21).
730 вопросов для самопроверки с ответами (обычно по 2 вопроса на
Раздел), позволяющих немедленно проверить усвоение прочитанного.
Обширный список использованных источников в конце каждой главы.
Операционные системы
16
Подход к ofy “шию
Книга разделена на восемь частей, и каждая часть состоит из взаимо-
связанных глав. Вот список частей:
1. Введение в аппаратные средства, программное обеспечение и опера-
ционные системы
2. Процессы и потоки
3. Реальная и виртуальная память
4. Внешние накопители, файлы и базы данных
5. Производительность, процессоры и мультипроцессорные системы
6. Сети и распределенные вычисления
7. Безопасность
8. Учебные примеры по операционным системам
Цитаты
В начале каждой главы приводится несколько цитат. Некоторые цита-
ты носят юмористический характер, некоторые — философский, а некото-
рые представляют собой подсказки к содержимому главы. Многие читате-
ли сообщали нам, что им нравится искать взаимосвязь между цитатами
и материалом глав. Смысл некоторых цитат может стать понятным вам
только после прочтения главы.
Цели
После цитат в начале каждой главы кратко описываются цели, пресле-
дуемые в этой главе. Прочтя главу, еще раз взгляните на список целей
и попытайтесь определить, достигли ли вы их.
Краткое содержание главы
Содержание главы позволяет разобраться, какой материал содержится
в главе и выбрать оптимальную последовательность его изучения.
Разделы и вопросы для самопроверки
Каждая глава состоит из небольших по размеру разделов, каждый из
которых посвящен какому-нибудь вопросу, имеющему отношение к опера-
ционным системам. В конце почти каждого раздела приведены два вопроса
для самопроверки с ответами. Эти вопросы позволят вам проверить свой
знания и убедиться в усвоении материала раздела. Кроме того, эти вопро-
сы готовят вас к упражнениям, предлагаемым в конце главы, и к тес-
там/экзаменам по курсу. На некоторые из вопросов нельзя ответить, ис-
пользуя только материал, изложенный в соответствующих разделах; что-
бы ответить на них, вам понадобится найти дополнительную информацию.
Предисловие
17
Ключевые термины
При первом упоминании каждого термина он выделяется полужирным
шрифтом. Кроме того, в каждой главе есть терминологический словарь,
котором собраны все ключевые термины из этой главы с их определения-
ми (в книге определено более 1800 терминов). В конце книги есть общий
словарь, в котором термины расположены в алфавитном порядке. Этот
словарь — превосходный справочный материал.
Рисунки
В тексте книги более 300 схем, диаграмм, примеров и иллюстраций, по-
ясняющих изложенные в ней концепции.
Веб-ресурсы
В каждой главе есть список веб-ресурсов — сайтов, на которых можно
найти ценные материалы по темам, рассматриваемым в этой главе.
Чтоги
В конце каждой главы есть раздел, в котором подводится краткий итог
всему изложенному в этой главе. Этот раздел позволяет быстро вспомнить
ключевые моменты главы.
Упражнения, проекты, исследования
В каждой главе предлагается множество упражнений разного уровня
сложности — от простейших вопросов, для ответа на которые нужно
вспомнить изложенный в главе материал, до задач, требующих долгих
размышлений и поиска информации (всего в книге более 900 упражне-
ний). Многие преподаватели задают учащимся курсовые проекты, поэтому
в книге есть разделы «Рекомендуемые исследовательские учебные проек-
ты» и «Рекомендуемые программные учебные проекты».
Рекомендуемая литература
В каждой главе есть список использованной литературы, а также крат-
кое описание наиболее важных источников, позволяющее выбрать литера-
ТУРУ для получения дополнительной информации.
Библиография
£ написании этой книги мы пользовались множеством источников,
лом СТе книги есть множество ссылок на литературные источники (в це-
O(l более 2300 ссылок). Каждая ссылка в тексте обозначается номером,
Ной МЛеННЫМ Как веРхний индекс. Это номер пункта в списке использован-
ют ЛИт®РатУРы в конце главы. Многие источники литературы представля-
с°бой веб-страницы. В предыдущих изданиях этой книги использова-
18
Операционные системь
лись только печатные источники; их часто было трудно найти, если чита-
тель желал к ним обратиться. Теперь ко многим источникам можно быстро
обратиться через Интернет; кроме того, с помощью поисковых систем мож
но найти дополнительную информацию по интересующим вопросам. Мно-
гие научные журналы доступны в Интернете — некоторые бесплатно, неко
торые — по подписке, причем подписка часто предоставляется членам опре-
деленных организаций или обществ. Интернет — богатейший источник
информации, оказывающий неоценимую помощь в учебе.
Врезки
Во втором издании «Операционных систем» присутствовала глава, по-
священная аналитическому моделированию, теории очередей и марков-
ским процессам. В этом издании такой главы нет — мы считаем, что опе-
рационные системы не относятся к математическим дисциплинам. В осно-
ве операционных систем лежит то, что мы предпочитаем называть
«системным мышлением» — проще говоря, операционные системы явля
ются в значительной степени областью эмпирических изысканий. Дабы
подчеркнуть это, мы включили в книгу ряд врезок (четырех разновидно-
стей), содержащих интересные материалы, которые, возможно, вас разве-
селят или заинтригуют.
Биографии
В книге приведены краткие жизнеописания людей, внесших существен-
ный вклад в развитие операционных систем: Эдсгер Дейкстра (Edsger
Dijkstra), Линус Торвальдс (Linus Torvalds), Дэвид Катлер (David Cutler),
Кен Томпсон (Ken Thompson), Деннис Ритчи (Dennis Ritchie), Дуг Энгель-
барт (Doug Engelbart), Тим Бернерс-Ли (Tim Berners-Lee), Ричард Стол-
лмен (Richard Stallman), Гордон Мур (Gordon Moore), Фернандо X. Корбато
(Fernando J. Corbato), Лесли Лэмпорт (Leslie Lamport), Пер Бринч Хансен
(Per Brinch Hansen), Питер Деннинг (Peter Denning), Сеймур Крей
(Seymour Cray), Билл Гейтс (Bill Gates), Рональд Ривест (Ronald Rivest),
Ади Шамир (Adi Shamir), Леонард Адлман (Leonard Adleman).
Учебные и практические примеры
Кроме подробных обзоров операционных систем Linux и Windows ХР,
в книге содержится 14 небольших примеров, описывающих другие опера
ционные системы, представляющие учебный, практический или историче-
ский интерес. Это Mach, CTSS и Multics, UNIX Systems, Операционные
системы реального времени, Atlas, Операционные системы мэйнфреймов
IBM, Ранняя история операционной системы VM, MS-DOS, Суперкомпью
теры, ОС Symbian, OpenBSD, Macintosh, User-Mode Linux (UML) и OS/2
19
Мучительные истории
Один из авторов книги, Харви Дейтел (HMD), собрал за свою долгую
карьеру огромную коллекцию анекдотов. Мы включили в текст 16 из них.
Некоторые из них — просто юмористические, а некоторые заставляют за-
думаться и носят философский характер. Каждый такой анекдот (мы наде-
емся на это) позволит вам немного отвлечься от технических дискуссий, а
в конце поучительной истории приведен вывод из нее, важный для разра-
ботчиков операционных систем.
Размышления об операционных системах
Ученые могут позволить себе роскошь изучать только интересующие их
части операционных систем, особенно эффективные алгоритмы, структу-
ры данных или, реже, области, хорошо поддающиеся анализу математиче-
скими методами. Практические специалисты вынуждены заниматься соз-
данием реальных, работоспособных систем, соответствующих предъявляе-
мым потребителями требованиям по стоимости, производительности
и надежности. Оба подхода обладают интересными особенностями. В мыш-
лении ученых и разработчиков есть и много общего, и существенные раз-
личия. Эта книга пытается выдержать баланс между академическими
и прикладными сторонами теории и практики операционных систем.
Что представляют собой «размышления об операционных системах»?
В книге есть 43 врезки с таким названием. Некоторые аспекты операцион-
ных систем поддаются анализу с помощью изощренных математических
методов. Но опыт работы автора (HMD) в компьютерной промышленно-
сти — 42 года, в том числе участие (в молодые годы) в создании больших
операционных систем в IBM и MIT, написание двух предыдущих изданий
этой книги и чтение десятков курсов по операционным системам — пока-
зал, что эти инструменты слишком сложны и мало пригодны для широко-
го применения студентами без глубоких фундаментальных знаний. Даже для
студентов старших курсов операционные системы (за исключением узких об-
ластей) слишком сложны, чтобы поддаваться математическому анализу.
Если невозможно оценивать аспекты операционных систем математиче-
ски, как можно вообще их оценить? Ответ — с помощью «системного
мышления», и именно этот подход используется в данной книге. Врезки
«Размышления об операционных системах» — это попытки выделить клю-
чевые концепции, особенно важные в проектировании и реализации опера-
ционных систем.
Вот список этих врезок: Изобретения и открытия; Относительная стои-
мость человеческих и компьютерных ресурсов; Производительность; При-
Рживаемся простоты; Архитектура; Кэширование; Унаследованное про-
аммное обеспечение и аппаратные средства; Принцип наименьшего
ЛО°ВНЯ пРивилегий; Защита; Эвристика; Пользователей интересуют при-
МеЖеНИЯ; СтРУктУРЬ1 данных ОС; Синхронность и асинхронность; Одновре-
Ма Н°е выполнение операций; Параллелизм; Соответствие стандартов;
ки СШтабиРуемость; Сокрытие информации; Ожидание, взаимоблокиров-
р и бесконечное откладывание; Накладные расходы; Предсказуемость;
н°Правие; Интенсивность управления ресурсами с учетом их относи-
20
Операциенныв системы
тельной стоимости; Безграничность роста вычислительной мощности, объ-
емов памяти и пропускной способности; Изменение — это правило, а не ис-
ключение; Пространственные ресурсы и фрагментация; Виртуализация;
Эмпирические результаты — локальность; Позднее выделение; Компью-
терная теория и операционные системы; Баланс между пространством
и временем; Насыщение и узкие места; Сжатие и распаковка данных; Из-
быточность; Жизненно важные системы; Отказоустойчивость; Шифрование
и дешифрование; Безопасность; Резервное копирование и восстановление;
Закон Мерфи и робастные системы; Плавное снижение эффективности; Реп-
ликация данных и когерентность; Вопрос этики разработки систем.
Учебные примеры
В главах 20 и 21 подробно рассматриваются соответственно операцион-
ные системы Linux и Windows ХР. Эти обзоры тщательно изучались веду-
щими разработчиками Linux и Windows ХР. Структура этих обзоров соот-
ветствует идее книги — описываются только принципы; практические
примеры демонстрируют, как эти принципы применяются в двух самых
распространенных операционных системах современности. В Linux рас-
сматривается самая свежая версия ядра (2.6); обзор снабжен 262 ссылками
на литературу. Обзор Windows ХР описывает возможности новейшей вер-
сии этой операционной системы и снабжен 485 ссылками.
Обзор книги
В этом разделе кратко описано содержание каждой части и главы
третьего издания «Операционных систем».
Часть 1 — «Введение в аппаратные средства, программное обеспечение
и операционные системы» — состоит из двух глав, в которых объяснено
назначение операционных систем, изложена история их развития и основ-
ные концепции построения программных и аппаратных элементов, рас-
сматриваемых в книге.
Глава 1 — «Введение в операционные системы» — содержит определе-
ние понятия «операционная система» и объясняет, почему операционные
системы стали необходимыми. В этой главе также описывается история
развития операционных систем, десятилетие за десятилетием, всю вторую
половину XX века. Упомянуты системы пакетной обработки 1950-х годов.
Мы рассмотрим появление параллелизма в 1960-х годах — зарождение
многопрограммных систем и интерактивных систем с разделением време-
ни. Вы узнаете историю создания важных операционных систем, включая
CTSS, Multics, СР/CMS и UNIX. В этой главе рассказывается о стиле мыш-
ления создателей операционных систем эпохи, в которую человеческие ре-
сурсы стоили куда дешевле, чем машинные (сегодня человеческие ресурсы
намного дороже машинных). Вы узнаете, как зарождались в 1970-х годах
компьютерные сети, Интернет и протоколы TGP/IP и как появились пер-
21
персональные компьютеры. Персональные компьютеры получили ши-
Bbie е распространение в начале 1980-х годов, когда на этот рынок вышли
Р°к ацИИ IBM и Apple. В компьютере Apple Macintosh был использован
КО’Х1ческий пользовательский интерфейс (Graphical User Interface —
ГТТП позже ставший общепринятым. Вы узнаете, как зарождались рас-
тленные вычислительные системы, и как появилась модель кли-
П₽е/сервер. В 1990-х годах произошел лавинный рост популярности Ин-
еН нета, причиной которого стало рождение World Wide Web. Компания
Microsoft стала доминирующим производителем программных продуктов
мире и выпустила свою операционную систему Windows NT (предшест-
венницу Windows ХР, рассматриваемой в главе 21). Объектная технология
стала основной парадигмой программирования, и широкое распростране-
ние получили, например, языки C++ и Java. Быстрое распространение
программного обеспечения с открытым исходным кодом стало причиной
феноменального успеха операционной системы Linux, которой посвящена
глава 20. Мы рассмотрим роль операционных систем в качестве платформ
для разработки приложений. Будут рассмотрены встраиваемые системы.
Мы выясним, почему для систем, выполняющих жизненно важные зада-
чи, прежде всего необходима исключительная надежность. Мы опишем ос-
новные компоненты операционных систем и задачи, которые должны ре-
шать операционные системы (практически во всех разделах книги особое
внимание уделяется достижению максимальной производительности в ка-
ждом компоненте операционных систем). Будут описаны различные архи-
тектуры операционных систем, включая монолитные, многоуровневые,
микроядерные и распределенные системы.
В главе 2 — «Концепции аппаратных средств и программного обеспече-
ния» — описаны аппаратные и программные ресурсы, с которыми должны
работать операционные системы. В этой главе рассказывается, как повлиял
на эволюцию операционных систем процесс развития аппаратных
средств — в первую очередь, феноменальный рост вычислительной мощно-
сти, емкости памяти и пропускной способности каналов связи. Будут рас-
смотрены основные аппаратные компоненты систем, включая материнские
платы, процессоры, таймеры, оперативную память, вторичные устройства
хранения, шины, механизмы прямого доступа к памяти и периферийные
устройства. Мы рассмотрим недавно появившиеся технологии и техноло-
гии, которые еще находятся в процессе становления, и обсудим необходи-
мость поддержки аппаратных возможностей в операционных системах,
включая разные режимы выполнения инструкций, привилегированные ин-
стРУкции, таймеры, тактовые генераторы, загрузчики и возможности горя-
чего подключения. Будут описаны методики повышения производительно-
сти, например, кэширование и буферизация. Описаны такие понятия про-
граммирования, как, например, компиляция, компоновка, загрузка,
инные языки, ассемблеры, интерпретаторы и компиляторы, языки вы-
Ние°Г° УР°ВНЯ’ структурное и объектно-ориентированное программирова-
j , ’ интерфейсы программирования приложений (Application Programming
г 1асе — API). Кроме того, в главе описано встроенное и системное про-
Раммное обеспечение.
Часть 2 — «Процессы и потоки» — состоит иЗ шести глав, описываю-
щих процессы, потоки, изменения состояний процессов и потоков, преры-
вания, переключения контекстов, асинхронность, взаимные исключения,
мониторы, взаимоблокировки и бесконечное откладывание, а также про-
цессорное планирование процессов и потоков.
С главы 3 — «Концепции процесса» — начинается изучение базовые
элементов операционной системы. В этой главе определено понятие про-
цесса. Мы рассмотрим жизненный цикл процесса как последовательность
переходов процесса из одних состояний в другие. Будет описано представ,
ление процесса его управляющим блоком или дескриптором, и особое вни-
мание будет уделено важности структур данных в операционных системах.
В главе изложены причины использования структур описания процессов
в операционной системе, и операции, которые можно выполнять над про-
цессами, например, приостановку и возобновление их выполнения. Кратко
описаны понятия, важные для многопрограммных систем, включая приос-
тановку выполнения процессов и переключение контекстов. В главе также
описаны прерывания — ключевой элемент реализации любой многопро-
граммной среды. Мы рассмотрим обработку прерываний и классы прерыва-
ний, а также межпроцессное взаимодействие с помощью сигналов и переда-
чи сообщений. Глава заканчивается описанием процессов системы UNIX.
Глава 4 — «Концепции потока» — продолжает обсуждение процессов.
В ней мы перейдем к более мелким элементам параллельно выполняемых
программ — потокам. В главе объяснено, что такое Лоток и как потоки со-
относятся с процессами. Описаны жизненные циклы потоков и переходы
потоков из одних состояний в другие. Также описаны различные варианты
потоковых архитектур, включая потоки пользовательского уровня, уровня
ядра и сочетания потоков разных уровней. Мы рассмотрим соображения,
касающиеся реализаций потоков, включая передачу сигналов потокам
и завершение потоков. Мы обсудим стандарт POSIX и его спецификацию
потоков, Pthreads. Глава завершается описанием реализаций потоков
в Linux, Windows ХР и Java. Описание потоков Java сопровождается лис-
тингами полностью работоспособных программ и примерами результатов
их выполнения. [Примечание: Исходный код всех программ на языке Java
из этой книги доступен по адресу www.deitel.com/books/os3e].
В главе 5 — «Асинхронное параллельное выполнение» — обсуждаются
вопросы, связанные с параллельным выполнением программ в многопро-
граммных системах. В этой главе излагается суть проблемы взаимных ис-
ключений и объясняется, как потоки должны управлять доступом к об-
щим ресурсам. В этой главе есть учебный пример многозадачной ситуаций
на Java — проблема отношения производитель-потребитель. В этом приме-
ре приведена готовая программа на Java и различные варианты результа-
тов ее выполнения, демонстрирующие, что может произойти, когда потоки
обращаются к общедоступным данным без синхронизации. Пример четко
показывает, что иногда параллельно выполняемые программы будут рабо-
тать правильно, а иногда — давать ошибочные результаты. В главе 6 мЫ
покажем, как решить эту проблему. Описана концепция критического
участка кода программы. Описаны несколько программных механизмов
защиты доступа к критическим участкам, включая алгоритм Деккера, ал-
горитм Питерсона и алгоритм Лэмпорта со взаимоисключением для п по-
ов. В этой главе также описаны аппаратные механизмы, позволяющие
Т°ализовать алгоритмы взаимного исключения — включая маскирование
Ре оь1Ваний, инструкции проверки-и-записи и инструкции обмена. И на-
ец, в главе описаны семафоры — высокоуровневый механизм реализа-
к° Симных исключений и синхронизации потоков. Описаны как двоич-
так и считающие семафоры.
Н В главе 6 — «Параллельное программирование» — вводится понятие
онйторов (высокоуровневых конструкций взаимных исключений). Затем
этой главе описано решение нескольких классических проблем парал-
лельного программирования. Сначала приводятся решения с мониторами,
записанные псевдокодом, а затем — готовые программы на Java с приме-
пами результатов работы. Описания мониторов приведены в виде псевдо-
кода с синтаксисом, похожим на синтаксис языков C/C++/Java. Мы объ-
ясним, как использование мониторов позволяет скрывать информацию,
и в чем переменные состояния мониторов отличаются от «обыкновенных»
переменных. В главе показано, как простой монитор можно применить
для контроля доступа к ресурсу, требующему строго упорядоченного дос-
тупа. Рассматриваются две классических проблемы параллельного про-
граммирования — кольцевой буфер и читатели-писатели — с псевдокода-
ми мониторов для их решения. Описаны также мониторы на языке Java
и различия между ними и мониторами, описанными в классической лите-
ратуре. В главе содержится продолжение примера на языке Java из преды-
дущей главы — задача отношения производитель-потребитель решена
с применением кольцевого буфера. Студенты могут воспользоваться этой
программой как основой для программы, решающей задачу взаимоотно-
шений читателей и писателей.
В главе 7 — «Взаимоблокировки и бесконечное откладывание» — опи-
саны два возможных следствия ожидания, которые могут оказаться ката-
строфическими — взаимоблокировки и бесконечное откладывание. Клю-
чевой вывод: системы, в которых существуют ожидающие объекты, нужно
проектировать очень тщательно, чтобы избежать упомянутых проблем.
В главе приведено несколько примеров взаимоблокировок, включая взаи-
моблокировку в транспортной пробке, взаимоблокировку на мосту с одно-
полосным движением, взаимоблокировку при распределении ресурсов,
взаимоблокировку в системах спулинга и взаимоблокировку в задаче
Дейкстры об обедающих философах. Рассмотрены основные принципы
Управления ресурсами, включая перераспределяемость, разделение досту-
па, реентерабельность и последовательное многократное использование,
главе формально определено понятие взаимоблокировки и описаны ме-
тоды обнаружения и предотвращения взаимоблокировок, а также методы
выхода из взаимоблокировок (как правило, сопряженные с потерями).
Исаны четыре необходимых условия возникновения взаимоблокировок,
Именно: взаимное исключение, ожидание дополнительных ресурсов, не-
перераспределяемость и круговое ожидание. Мы рассмотрим методы Ха-
Из Для пРеД°твращения взаимоблокировок за счет устранения одного
Последних трех условий. Избегание взаимоблокировок позволяет более
ко распределять ресурсы, чем устранение взаимоблокировок. В главе
На Сано избегание взаимоблокировок по алгоритму банкира с примерами
'межных и ненадежных состояний, а также переходов между этими со-
Операционные системы
стояниями. Обсуждаются слабые места алгоритма банкира. Мы разберем
методы обнаружения взаимоблокировок с помощью приведения графов
распределения ресурсов. Главу завершает обсуждение методик борьбы со
взаимоблокировками в современных и будущих системах.
Глава 8 — «Планирование работы процессора» — содержит описанце
концепций и алгоритмов выделения процессорного времени различны^
процессам и потокам. Описаны уровни планирования, его цели и Крите-
рии. Проведено сравнение вытесняющих и невытесняющих подходов
к планированию. Мы объясним, как правильно выбирать приоритеты
и размер кванта (минимального неделимого интервала процессорного вре-
мени) в алгоритмах планирования. Описаны несколько классических и со-
временных алгоритмов планирования, включая алгоритм FIFO
(first-in-first-out — «первым-пришел-первым-вышел»), циклический ал-
горитм (RR), алгоритм «кратчайший процесс — первым» (SPF), алгоритм
«следующим — процесс с максимальным временем реакции» (HRRN), ал-
горитм «с наименьшим остающимся временем» (SRT), многоуровневые
очереди и планирование по принципу справедливого раздела. Каждый ал-
горитм оценивается по таким критериям, как пропускная способность,
среднее время реагирования и разброс этого времени. Мы обсудим плани-
рование потоков в языке Java, планирование в мягком и жестком реаль-
ном времени и планирование по сроку завершения.
Часть 3 — «Реальная и виртуальная память» — состоит из трех глав,
в которых описана организация памяти в системах реальной и виртуаль-
ной памяти.
Глава 9 — «Оперативная память. Организация и управление» — начи-
нается с изложения истории организации оперативной памяти и управле-
ния этой памятью. Системы оперативной памяти развивались от простей-
ших до весьма замысловатых, причем целью всегда было максимально эф-
фективное использование относительно дорогой памяти. Мы рассмотрим
иерархию памяти, включая кэши, оперативную память и вторичные
(внешние) устройства хранения. Затем рассмотрим три категории страте-
гий управления памятью — стратегии загрузки, стратегии размещения
и стратегии замены. Мы рассмотрим схемы выделения непрерывных
и фрагментированных участков памяти. Будет рассмотрена однопользова-
тельская система с выделением непрерывных участков памяти, включая
оверлеи, защиту и однопоточную пакетную обработку. Мы проследим эво-
люцию организации памяти в многопрограммных системах — от систем
с фиксированным распределением памяти к системам с изменяемым рас-
пределением. Мы изучим проблемы внешней и внутренней фрагментации
и методы борьбы с ней, включая сращение и уплотнение памяти. В главе
описываются стратегии размещения в первых подходящих участках,
в наиболее подходящих участках и наименее подходящих участках.
Глава 10 — «Организация виртуальной памяти» — посвящена основ-
ным принципам построения виртуальной памяти и возможностям аппа-
ратных устройств, необходимым для организации виртуальной памяти.
В этой главе объясняются причины, по которым виртуальная память необ-
ходима, и описываются ее типичные реализации. В главе также описаны
ключевые подходы к организации виртуальной памяти — страничный
и сегментный — и их сильные и слабые стороны. Мы рассмотрим странич-
числеВие
е системы, трансляцию адресов прямым отображением и ассоциатив-
ным отображением, сочетание прямого и ассоциативного отображения,
Й ногоуровневые страничные таблицы, обращенные страничные таблицы
М пазделение ресурсов в страничных системах. Рассматривая сегментные
0исТемы, мы разберем трансляцию адресов прямым отображением, разде-
С ние ресурсов, защиту и контроль доступа в сегментных системах. Мы
также рассмотрим гибридные сегментно-страничные системы, обсудим ди-
намическую трансляцию адресов, разделение ресурсов и механизмы защи-
ты в таких системах. Завершает главу обзор реализации системы вирту-
альной памяти в популярной архитектуре IA-32 фирмы Intel.
Глава 11 — «Управление виртуальной памятью» — продолжает тему
виртуальной памяти. В этой главе рассказывается, как операционные сис-
темы пытаются оптимизировать производительность виртуальной памяти.
Поскольку наибольшее распространение получили страничные системы,
мы тщательно изучим вопрос распределения страниц, особенно стратегии
замены страниц. В главе описывается один из наиболее важных эмпириче-
ских результатов в области операционных систем — феномен локальности.
Мы рассмотрим эффекты как временной, так и пространственной локаль-
ности и обсудим, когда страницы нужно перемещать в оперативную па-
мять (предварительная подкачка и подкачка по требованию). Когда объем
доступной памяти уменьшается, закачиваемые в нее страницы приходится
записывать вместо уже находящихся в памяти. Стратегия, по которой сис-
тема определяет, какие страницы заменить новыми, может оказать огром-
ное влияние на производительность. В главе рассмотрено множество стра-
тегий замены страниц, в том числе: случайная, «первый вошел — первый
вышел» (FIFO) — включая аномалию FIFO, стратегия замены дольше все-
го не использовавшихся страниц (LRU), реже всего использовавшихся
(LFU) и давно не использовавшихся (NUR), стратегия второго шанса, стра-
тегия круговой замены, стратегии замены дальних страниц и замены по
частоте страничных промахов. Описана классическая модель рабочих на-
боров Деннинга и попытки реализовать ее с помощью различных страте-
гий замены страниц. В главе также описана возможность добровольного
освобождения страниц. Мы тщательно изучим аргументы в пользу стра-
ниц маленького и большого размеров, а также поведение программ в стра-
ничных системах. Главу завершают обзор стратегии замены страниц в опе-
рационной системе Linux и сравнение глобальных и локальных стратегий
замены страниц.
Часть 4 — «Внешние накопители, файлы и базы данных» —' состоит из
^Вух глав, в которых описаны методы, применяемые в операционных сис-
Мах для управления данными на вторичных устройствах хранения. 06-
Ках Даетвя оптимизация производительности накопителей на жестких дис-
д , ’ а также файловые системы и базы данных. Обсуждение систем вво-
уд 1воДа рассредоточено по всей книге, но более всего внимания ему
и vv- ° в главах 2, 12, 13 и обзорах операционных систем Linux
Гла °WS ХР (главы 20 и 21, соответственно).
лей» ЙВа — «Оптимизация производительности дисковых накопите-
г°лов ПосвяЩена характеристикам дисковых накопителей с подвижными
Мах рЯМИ „И Оптимизации их производительности в операционных систе-
этои главе рассматривается эволюция вторичных устройств хране-
I
26
Операционные систем)»
дрдисловие^
27
ния, и описываются основные характеристики накопителей с подвижным^
головками. Технологии дисковых накопителей с подвижными головкалщ
быстрыми темпами развиваются уже полвека, и при этом накопители это,
го класса остаются самыми распространенными. Мы объясним, почему не,
обходима диспетчеризация обращений к накопителям и покажем, почему
она должна использоваться для достижения высокой производительности.
Описана эволюция стратегий диспетчеризации доступа, включая FCFg
SSTF, SCAN, C-SCAN, FSCAN, N-шаговый SCAN, LOOK, C-LOOK и VSCA\
(эта стратегия описана в упражнениях), а также стратегии вращательно^
оптимизации, включая SLTF, SPTF и SATF. Обсуждаются и другие попу,
лярные методики оптимизации производительности, включая кэширова-
ние, буферизацию, дефрагментацию, сжатие данных и блокирование.
Одно из самых важных дополнений в третьем издании «Операционных
систем» — подробное описание систем RAID в этой главе. RAID (Redun.
dant Array of Independent Disks — избыточный массив независимых дис-
ков) — это набор технологий, позволяющих дисковым системам достичь
более высоких отказоустойчивости и производительности. В главе описа-
ны различные «уровни» RAID, включая уровни О (разделение дан-
ных), 1 (зеркальное отображение), 2 (побитовый контроль с коррекцией по
Хеммингу), 3 (побитовый XOR-контроль и коррекция), 4 (блочный
XOR-контроль и коррекция) и 5 (блочный XOR-контроль и коррекция
с распределением).
В главе 13 — «Файловые системы и базы данных» — описаны организа-
ция и управление данными в операционных системах, включая файлы
и базы данных. Мы рассмотрим ключевые концепции, включая иерархию
данных, файлы, файловые системы, директории, ссылки, метаданные
и монтирование. В главе рассказывается о различных организациях фай-
лов, разбираются файлы с последовательным, прямым, индексированным
прямым доступом и фрагментированные файлы. Описаны методики разме-
щения файлов, включая непрерывное размещение, размещение в виде
связных списков, табличное фрагментированное размещение и индексиро-
ванное фрагментированное размещение. Мы объясним методы контроля
доступа к файлам с помощью классов и матриц контроля доступа, опишем
методики доступа к данным в контексте простейших методов доступа и ме-
тодов с поддержкой очередей, а также разберем предварительную буфери-
зацию и отображение файлов в память. Мы рассмотрим методы обеспече-
ния целостности, включая защиту, резервное копирование и восстановле-
ние, ведение журналов, атомарные транзакции, откаты, фиксации,
создание контрольных точек, теневое копирование и журнальные файло-
вые системы. В главе описаны файловые серверы и распределенные систе-
мы, читателю предлагается подробнее изучить эти и другие темы в гла-
вах 16—18. Кроме того, в главе кратко рассказывается о базах данных, ана-
лизируются их преимущества, техника доступа к данным, реляционна^
модель баз данных, а также механизмы операционных систем, обеспечи-
вающие поддержку систем баз данных.
Часть 5 — «Производительность, процессоры и мультипроцессорный
системы» — состоит из двух глав, посвященных контролю производитель'
ности, методам ее измерения и оценки, а также вопросам повышения про-
изводительности за счет использования многопроцессорных систем.
Глава 14 — «Производительность и архитектура процессоров» — посвя-
на одной из самых важных целей разработки операционных систем,
°^.тижению максимальной производительности. В этой главе обсуждается
выбора разновидности процессора в достижении высокой производи-
Р° ьности. В главе рассматриваются показатели производительности,
Т также такие вопросы, как абсолютная производительность, простота ис-
аользования оценок, оборотное время, время отклика, время реакции сис-
ПеМы, разброс времени реакции, пропускная способность, рабочая нагруз-
ка мощность и степень загрузки. Мы обсудим методы измерения произво-
ительности, включая профилирование, хронометраж, тестирование на
микроуровне, оценку производительности для конкретных приложений,
аналитическое моделирование, тестовые программы, синтетические тесты,
моделирование и мониторинг производительности. Описаны узкие места
и насыщение. Производительность системы сильно зависит от производи-
тельности ее процессора (или процессоров), которая, в свою очередь, опре-
деляется наборами используемых инструкций. Мы рассмотрим основные
решения, включая архитектуры с полным набором инструкций (CISC —
Complex Instruction Set Computing), с сокращенным набором (RISC —
Reduced Instruction Set Computing) и новые архитектуры. Завершает главу
описание параллельной обработки команд с явным параллелизмом
(EPIC — Explicitly Parallel Instruction Computing).
Глава 15 — «Многопроцессорность» — содержит подробное описание ап-
паратных и программных компонентов многопроцессорных систем. Один из
способов создания очень мощных вычислительных систем — использование
одновременно большого количества процессоров. Глава начинается с крат-
кого обзора истории суперкомпьютеров и изложения биографии Сеймура
Крея — создателя суперкомпьютеров. Мы рассмотрим архитектуру много-
процессорных систем, включая классификацию последовательных и парал-
лельных архитектур, схемы соединения процессоров, слабые и сильные
места тесно- и слабосвязанных систем. В главе описаны схемы операцион-
ных систем, используемые в многопроцессорных машинах, включая схему
ведущий-ведомый, схему с раздельными ядрами и симметричную схему.
Мы изучим различные архитектуры доступа к памяти, включая UMA
(Uniform Memory Access — однородный доступ к памяти), NUMA
(N on -Uniform Memory Access — неоднородный доступ к памяти), СОМА
' aN?he-OnlV Memory Architecture — кэшевая архитектура памяти)
к ORMA (NO Remote Memory Architecture — архитектура без доступа
Удаленной памяти). В главе приводится описание методов разделения ре-
рсов в многопроцессорных системах, протоколов обеспечения когерент-
ной™ КЭше®’ Репликации и миграции страниц, а также общей виртуаль-
с памяти. Мы продолжим рассмотрение вопросов планирования процес-
задя ’ КотоРЫе начали рассматривать в главе 8 — мы рассмотрим
Вы т 'Независимые и задачно-ориентированные методы планирования,
ньпущ Же знаете, что такое миграция процессов и познакомитесь с основ-
ой в СТРатегиями миграции процессов. Мы обсудим балансировку нагруз-
НамичНОГОПР°НессоРнь1Х системах, рассмотрев как статические, так и ди-
как в еские варианты ее реализации. Кроме того, в главе рассказывается,
Многопроцессорных системах реализуется взаимное исключение —
28
Операционные систем^ .аисмВио
29
с помощью спин-блокировок, блокировок с усыплением/пробуждение^
и блокировок чтения/записи.
Часть 6 — «Сети и распределенные вычисления» — состоит из тре3(
глав, посвященных сетям, распределенным системам и веб-службам.
Глава 16 — «Сети» — представляет собой введение в компьютерные
сети и закладывает основу для рассмотрения тем, затрагиваемых в дву^
последующих главах. В этой главе рассматриваются топологии сете£
включая шины, кольца, сотовые и полносвязные сети, звезды и деревья
а также описываются специфичные задачи, связанные с беспроводны^
сетями. Мы рассмотрим как локальные сети (LAN — Local Area Network)
так и глобальные (WAN — Wide Area Network). Будет подробно рассмот’
рен стек протоколов TCP/IP, а также протоколы прикладного уровцч
HTTP (HyperText Transfer Protocol — протокол передачи гипертексту
и FTP (File Transfer Protocol — протокол передачи файлов). Мы разберец
протоколы транспортного уровня, включая TCP (Transfer Control
Protocol — протокол управления передачей) и UDP (User Datagram Proto-
col — пользовательский протокол дейтаграмм). Будут также описаны про-
токолы сетевого уровня IP (Internet Protocol — протокол Интернета) и его
новейшая версия IPv6 (Internet Protocol, version 6 — версия 6 протокола
Интернета). Кроме того, в главе рассмотрены протоколы Ethernet, Token
Ring, FDDI (Fiber Distributed Data Interface — интерфейс передачи данных
по волоконно-оптическим каналам) и IEEE 802.11 (для беспроводных се
тей). Завершают главу разделы по модели клиент-сервер и п-уровневым
системам.
Глава 17 — «Введение в распределенные системы» — рассказывает
о распределенных операционных системах и описывает характерные чер-
ты распределенных систем, анализирует их производительность, масшта-
бируемость, структуру, безопасность, надежность, отказоустойчивость
и прозрачность. Мы сравним сетевые и распределенные операционные сис-
темы, а также обсудим проблемы взаимодействия в распределенных систе-
мах и критически важную роль «посреднического» программного обеспе-
чения, включая удаленные вызовы процедур (RPC — Remote Procedure
Call), удаленные вызовы методов (RMI — Remote Method Invocation), типо-
вую архитектуру брокера объектных запросов (CORBA — Common Object
Request Broker Architecture) и технологию Microsoft DCOM (Distributed
Component Object Model — распределенная компонентная модель объек-
тов). В главе обсуждается миграция процессов, синхронизация и взаимно^
исключение в распределенных системах, а также взаимные исключены11
при отсутствии общей памяти и алгоритм взаимного исключения в распре-
деленных системах Агравала и Рикарта. Мы также обсудим особенности
взаимоблокировок в распределенных системах, в частности, предотвращ®'
ние и обнаружение взаимоблокировок. Завершают главу обзоры распред®'
ленных систем Sprite и Amoeba.
Глава 18 — «Распределенные системы и веб-службы» — продолжав
тему распределенных систем. Эта глава посвящена распределенным фай'
ловым системам, кластерам, сеточным вычислениям, модели распределен
ных вычислений Java и веб-службам. Глава начинается с обсужден!^
свойств и характерных черт распределенных систем, включая прозраИ
ность, масштабируемость, безопасность, отказоустойчивость и целое?'
В главе есть обзоры ключевых распределенных файловых систем,
Н°С пимер, NFS (Network File System — сетевая файловая система), AFS
Нд drew File System — файловая система Эндрю), файловых систем Coda
qDrite. Мы обсудим кластерные системы, включая высокопроизводи-
И ные кластеры, кластеры с высоким коэффициентом готовности и кла-
теЛрЬ1 с балансировкой нагрузки. Будут рассмотрены примеры кластеров,
° лючая кластеры Beowulf на основе Linux и Windows-кластеры. В главе
ВКкже рассматриваются одноранговые распределенные вычисления, в па-
рности, их отношение к приложениям клиент/сервер, централизованные
СТдецентрализованные одноранговые приложения, обнаружение одноран-
говых узлов и распределенный поиск. Мы рассмотрим проект JXTA фир-
мы Sun Microsystems и создание в нем платформы для построения одноран-
говых приложений. Вы также узнаете, что такое сеточные вычисления,
и как с их помощью для решения задач очень большой вычислительной
сложности используются свободные ресурсы персональных компьютеров по
всему миру. Мы обсудим ключевые моменты технологий распределенных
вычислений Java, включая сервлеты Java и Java Server Pages (JSP), Jini,
JavaSpaces и Java Management Extensions (JMX). Глава заканчивается об-
зором двух недавно появившихся интересных технологий — платформы
Microsoft .NET и платформы Sun ONE от Sun Microsystems.
Часть 7 — «Безопасность» — состоит из единственной главы.
Глава 19 — «Безопасность» — представляет собой общее введение в во-
просы компьютерной и сетевой безопасности, а также описывает методы,
с помощью которых операционные системы могут обеспечивать безопас-
ность вычислительной среды. В главе рассматриваются алгоритмы шифро-
вания с открытым и закрытым ключом, включая популярные схемы с от-
крытым ключом RSA и PGP (Pretty Good Privacy). Рассматриваются во-
просы аутентификации, включая парольную защиту, «засолку» паролей,
биометрическую идентификацию и смарт-карты, протокол Kerberos и од-
нократный ввод паролей. Мы обсудим контроль доступа, права доступа,
домены защиты, модели, механизмы и политики контроля доступа, вклю-
чая матрицы контроля доступа, списки доступа и списки прав. В главе
описано множество разновидностей атак на защищенные системы, вклю-
чая криптоанализ, вирусы, черви, распределенные DOS-атаки («атаки
с организацией отказа в обслуживании»), захваты управления программа-
ми и проникновения в защищенные системы. Мы также рассмотрим меры
противодействия атакам, включая брандмауэры, системы обнаружения
вторжений (IDS — Intrusion Detection System), антивирусные программы,
заплаты к системам безопасности и защищенные файловые системы. Мы
еРем официальную классификацию защищенных систем «Оранжевая
с 1га>> и ОПеРационную систему OpenBSD, которая (хотя и не официально)
саны етСЯ одп°и из самых безопасных операционных систем. В главе опи-
вьщ Методы безопасной связи, а также рассмотрены необходимые условия
тентигьеНИЯ безопасных транзакций — защищенность, целостность, ау-
клкл! кацИя» авторизация и невозможность отрицания. Мы рассмотрим
сторонь Те ПР°ТОКОЛЬ1 соглашений — процессы, с помощью которых две
Нал св Могут обменяться секретными ключами через незащищенный ка-
исклю ЗИ также познакомитесь с цифровой подписью — технологией,
чительно важной для развития электронной коммерции — и ее реа-
30
Операционные системы
лизацией. В главе подробно рассматривается инфраструктура открыты^
ключей, включая цифровые сертификаты и центры сертификации. Кроме
того, рассмотрены различные защищенные протоколы взаимодействия,
включая SSL (Secure Sockets Layer — уровень защищенных сокетов), VPhj
(Virtual Private Network — виртуальная частная сеть), IPSec и методы
обеспечения безопасности защищенных сетей. Мы изучим стеганогрд.
фию — интересную технологию сокрытия важной информации в большом
объеме вспомогательной. Эта технология позволяет прятать секретные со.
общения в открыто передаваемых; кроме того, с ее помощью можно дока,
зывать авторство, добавляя в документы цифровые эквиваленты водяных
знаков. В главе сравниваются коммерческие системы защиты и системы
с открытым исходным кодом, а также система безопасности операционной
системы UNIX.
Часть 8 — «Учебные примеры по операционным системам» — состоит
из двух глав, представляющих собой подробные обзоры ядра Linux вер.
сии 2.6 и Microsoft Windows ХР. Элементы операционных систем рассмот-
рены в таком порядке, который позволит читателям легко разобраться
в излагаемом материале.
Глава 20 — «Учебный пример: Linux» — представляет собой подробный
обзор Linux 2.6. Материал тщательно рецензировался ведущими разработ-
чиками Linux. В главе излагается история развития операционной систе-
мы, сообщество, ее создавшее, и версии дистрибутива, оставившие замет-
ный след в развитии самой популярной в мире операционной системы с от-
крытым кодом. Мы рассмотрим основные компоненты операционной
системы Linux, уделив особое внимание их реализации с точки зрения
концепций, рассмотренных в предыдущих главах. Будут описаны архи-
тектура ядра, управление процессами (процессы, потоки, планирование),
организация памяти и управление ей, работа с файлами (виртуальная фай-
ловая система, кэши виртуальной файловой системы, системы ext2fs
и proc fs), управление вводом/выводом (драйверы устройств, символьный
и блочный ввод/вывод, ввод/вывод через сетевые устройства, единая мо-
дель устройств, прерывания), синхронизация (спин-блокировки, блоки-
ровки чтения/записи, блокировки seqlock, семафоры уровня ядра), меж-
процессное взаимодействие (сигналы, каналы, сокеты, очереди сообще-
ний, разделяемая память и семафоры System V), сетевые возможности
(обработка пакетов, платформа netfilter и ловушки), масштабируемость
(симметричные мультипроцессорные системы, NUMA и другие возможно-
сти масштабируемости, встраиваемые системы) и система безопасности.
Глава 21 — «Учебный пример: Windows ХР» — описывает внутреннюю
структуру самой популярной в мире коммерческой операционной систе-
мы, Windows ХР. В этом обзоре описаны ключевые компоненты Windows
ХР и их взаимодействие, а также возможности, предоставляемые им#
пользователю. В главе есть краткие биографии Билла Гейтса и Дэвида КаТ'
лера. Вы познакомитесь с историей развития операционных систеМ
Windows, целями, поставленными при разработке Windows ХР, и ее архй'
тектурой, включая уровень абстракций аппаратуры (HAL — Hardware
Abstraction Layer), микроядро, среду выполнения, библиотеки динамичГ'
ской компоновки (DLL — Dynamic Link Library) и системные службы. Мь{
рассмотрим механизмы управления системой, включая реестр, диспетчер
3!
Л-ьектов, уровни запросов прерываний (IRQL -— Interrupt ReQuest Level),
° инхронные вызовы процедур (АРС — Asynchronous Procedure Call), от-
а^венные вызовы процедур (DPC — Deferred Procedure Call) и системные
Л тоКИ. Кроме того, мы рассмотрим организацию процессов и потоков,
л оки управления, локальную память потоков (TLS — Thread Local
storage), создание и завершение процессов, задач, нитей и пулов потоков.
В главе описаны методы планирования потоков, состояния потоков, алго-
тм планирования, определение приоритета потоков и планирование
Р многопроцессорных системах. Вы узнаете, как выполняется синхрониза-
ция потоков, познакомитесь с объектами диспетчеров, событий, взаимных
исключений, семафоров, объектами таймеров ожидания, блокировок уров-
ня ядра и другими инструментами синхронизации. Кроме того, мы рас-
смотрим управление памятью, ее организацию, выделение и замену стра-
ниц- Мы также рассмотрим файловую систему, ее драйверы и NTFS, вклю-
чая главную таблицу файлов (MFT — Master File Table), потоки данных,
сжатие и шифрование файлов, разреженные файлы, точки повторного ана-
лиза и монтируемые тома. Вы познакомитесь с управлением вводом/выво-
дом, драйверами устройств, возможностями Plug-and-Play, управлением
энергопотреблением, моделью драйверов Windows (WDM — Windows
Driver Model), пакетами запросов ввода/вывода (IORP — Input/Output
Request Packet), синхронным и асинхронным вводом/выводом, методами
передачи данных, обработки прерываний и управления файловыми кэша-
ми. Мы рассмотрим межпроцессное взаимодействие, включая каналы
(анонимные и именованные), почтовые ящики, общую память, локальные
и удаленные вызовы процедур. В главе содержится описание модели СОМ,
возможностей перетаскивания и составных документов. Мы также обсу-
дим сетевые возможности, включая сетевой ввод/вывод, архитектуру сете-
вых драйверов, сетевые протоколы (IPX, SPX, NetBEUI, NetBIOS для
TCP/IP, WinHTTP, WinINet и WinSock2), а также сетевые службы, вклю-
чая Active Directory, протокол Lightweight Directory Access Protocol
(LDAP) и службу удаленного доступа (RAS — Remote Access Service). Мы
рассмотрим новую технологию Microsoft .NET, пришедшую на смену
DCOM. Мы также изучим масштабируемость, симметричные многопроцес-
сорные системы и встраиваемые версии Windows ХР. Завершает главу об-
суждение вопросов безопасности, включая аутентификацию, авториза-
цию, брандмауэр ICF (Internet Connection Firewall) и другие элементы.
Все! Ну, по крайней мере, закончен «Обзор книги». В ней есть немало
интересного и для учащихся, и для профессионалов.
вспомогательные материалы к третьему изданию
«Операционных сиетем»
К
бор Третьему изданию «Операционных систем» прилагается обширный на-
сурСаСПОМОгатель11ь1Х материалов для преподавателей. Компакт-диск с ре-
°°ДавМИ ДЛЯ пРеподавателей (Instructor’s resource CD) содержит решения
виляющего большинства упражнений, приводимых в главах книги. Этот
32
Операционные систем^
33
компакт-диск преподаватели могут получить только через своих представцч
телей в издательстве Prentice-Hall. Посетите раздел vig.prenhall.com/rep^
locator, чтобы найти своего представителя в издательстве Prentice-Hall
[Примечание: Пожалуйста, не пишите нам писем с просьбами выслать это-j
компакт-диск. Он высылается только преподавателям, использующим ддц
ную книгу в качестве учебника в своих курсах. Эти преподаватели могут п0„
лучить компакт-диск от своих представителей в издательстве Prentice-Hall]
Кроме того, среди вспомогательных материалов есть тесты, содержащие вс(.
вопросы, в которых нужно выбирать правильные варианты ответов из не,
скольких предложенных. Все рисунки, диаграммы, чертежи и фрагменты
кода доступны в виде слайдов PowerPoint®. Преподаватели могут редактц.
ровать эти слайды, адаптируя их под свои курсы. Эти слайды доступны дл5
загрузки с сайта www.deitel.com и как часть раздела книги на сайте изда.
тельства Prentice Hall (www.prenhall.com/deitel). В этом разделе доступны
ресурсы, полезные как преподавателям, так и учащимся. Кроме того, на
сайте есть планировщик, позволяющий создавать приблизительные планы
курсов в интерактивном режиме.
Для учащихся на сайте книги тоже есть немало полезного, например:
• Заметки по лекциям в формате PowerPoint®, которые можно редакти-
ровать.
• Исходный код программ на Java.
Для отдельных глав на сайте доступны:
• Цели глав
• Содержание
• Итоги глав
• Веб-ссылки
Благодарности
Один из самых приятных моментов при написании книги — признание
вклада в нее множества людей, имена которых могут отсутствовать на об-
ложке, но работа которых, терпение и понимание были чрезвычайно важ-
ны. Многие из наших коллег по Deitel & Associates потратили долгие часЫ
на эту книгу и вспомогательные материалы к ней — например, Джефф
Листфилд (Jeff Listfield), Су Чанг (Su Zhang), Эбби Дейтел (Abby Deitel)'
Барбара Дейтел (Barbara Deitel) и Кристи Келси (Christy Kelsey).
Мы бы хотели особо поблагодарить Бена Видермана (Ben Wiedermann)
за организацию усилий по пересмотру материала из второго издания этой
книги. Он обновил солидную часть ранее использовавшихся рисунке®
и диаграмм, а также организовал команду работников Deitel & Associates'
собиравших последние новости из мира операционных систем и включай'
ших эти новости в текст книги. Сейчас Бен готовится к сдаче экзаменов й®
степень доктора философии в области компьютерных наук в университет®
штата Техас в Остине.
Мы хотим поблагодарить множество участников программы Collet®
Internship Program компании Deitel & Associates, работавших над книгой
вспомогательными материалами к ней: Джонатана Гольдштейна
0 nathan Goldstein) из Корнельского университета, Лукаса Балларда
Ballard) из университета Джона Хопкинса, Тима Кристенсена (Tim
rbristensen) из колледжа Бостона, Джона Пола Каселло (John Paul
Г iello) из Северо-восточного университета, Миру Мейерович (Mira
Severovich), кандидата в доктора философии в университете Брауна, Энд-
№еУЯнга (Andrew Yang) из университета Карнеги-Меллон, Кэтрин Рю
rKathryn Ruigh) из колледжа Бостона, Криса Гоулда (Chris Gould) из уни-
пситета штата Массачусетс в Лоуэлле, Марка Манару (Marc Мапага) из
Гарвардского университета, Джима О’Лири (Jim O’Leary) из Политехниче-
1 ого института Ренсселера, Джен Панг (Gene Pang) из Корнельского уни-
верситета и Рэнди Ху (Randy Xu) из Гарвардского университета.
Мы также хотим признать заслуги Ховарда Берковица (Howard
Berkowitz), работавшего в корпорации открытых систем — Corporation for
Open Systems International — в написании 16-й главы во втором издании
книги. Его работа послужила основой подробного рассмотрения сетей
и распределенных систем в главах с 16 по 18 в третьем издании.
Нам повезло работать с командой талантливых и опытных сотрудников
издательства Prentice Hall. Особо мы хотим отметить вклад в книгу нашего
редактора Кейт Харгетт (Kate Hargett), и нашего наставника в издатель-
ском деле, ее начальника Марсии Хортон (Marcia Horton), начальника от-
дела технических и компьютерных изданий в издательстве Prentice-Hall.
Винс О’Брайен (Vince O’Brien), Том Маншрек (Tom Manshreck), Джон Лоу-
элл (John Lowell) и Чираг Таккар (Chirag Thakkar) приложили массу уси-
лий к подготовке этой книги. Сара Паркер (Sarah Parker) руководила под-
готовкой вспомогательных материалов к книге.
Мы благодарим команду дизайнеров, придавших совершенно новый вид
третьему изданию «Операционных систем» — Кэрол Энсон (Carole Anson),
Пола Белфанти (Paul Belfanty), Джеффри Кассару (Geoffrey Cassar) и Джо-
на Рут (John Root). Мы хотим также поблагодарить работников Artworks:
Кэтрин Андерсон (Kathryn Anderson), Джей МакЭлрой (Jay McElroy), Рон-
да Уитсон (Rhonda Whitson), Патриция Бернс (Patricia Burns), Мэтт Хаас
(Matt Haas), Сяохонг Чу (Xiaohong Zhu), Дэн Миссилдайн (Dan Missildine),
Чэд Бейкер (Chad Baker), Сейн Хоган (Sean Hogan), Одри Симонетти
(Audrey Simonetti), Марк Ландис (Mark Landis), Ройс Копенхевер (Royce
openheaver), Стейси Смйт (Stacy Smith), Скотт Вибер (Scott Wieber), Пэм
^am Taylor), Анна Уолен (Anna Whalen), Кэти (Cathy), Шелли
(С 1 Кен Муни (Ken Mooney), Тим Нгуен (Tim Nguyen), Карл Смит
Ze^ Smith), Джо Томпсон (Jo Thompson), Хеленита Цейглер (Helenita
Я ег) и Расс Креншоу (Russ Crenshaw) вложили свой труд в эту книгу.
Чьи в°зм°жно выразить достаточную благодарность тысячам авторов,
Manv °ТЫ МЫ использовали при создании данной книги. Эти авторы упо-
и книг В списках использованной литературы — их статьи, заметки
Не сМОгли°СЛУЖИЛИ источником Ценнейших сведений, без которых мы бы
Мы так^гсо z-
Ционны Же ХОТим поблагодарить рецензентов третьего издания «Опера-
НиФер к СИстем>> и особо отметить Кэрол Снайдер (Carole Snyder) и Джен-
Ших Вс апелло (Jennifer Capello) из издательства Prentice Hall, управляв-
м процессом рецензирования. Следуя жесткому расписанию, они
34
Операционные cucmeMbi
смогли проработать текст, внеся бесчисленные предложения по улучще>
нию и уточнению его содержания. Мы рады, что с нами работали такие т^ч
лантливые профессионалы.
Рецензенты третьего издания:
Тигран Айвазян (Tigran Aivazian), Veritas Software, Ltd.
Джене Эксбой (Jens Axboe), SUSE Labs
Дибейенду Бакси (Dibuyendu Baksi), Scientific Technologies Corporation
Колумбус Браун (Columbus Brown), IBM
Фабьен Бустаманте (Fabien Bustamante), Северо-западный Университет
Брайан Кэтлин (Brian Catlin), Azius Developer Training
Стюарт Цедрой (Stuart Cedrone), Hewlett-Packard
Рэнди Чау (Randy Chow), Университет штата Флорида
Алан Кокс (Alan Сох), Red Hat UK
Мэтью Добсон (Matthew Dobson), независимый консультант
Ульрих Дреппер (Ulrich Drepper), Red Hat, Inc.
Алессио Гаспар (Alessio Gaspar), Университет Южной Флориды, кампус
Лейкленд
Эллисон Герке (Allyson Gehrke), Колорадский Технический Университет
Майкл Грин (Michael Green), Колледж Центрального Техаса
Роб Грин (Rob Green), Columbia Data Productions, Inc.
Джеймс Хадлстон (James Huddleston), независимый консультант
Скотт Каплан (Scott Kaplan), колледж Амхерст
Салахаддин Хан (Salahuddin Khan), Microsoft
Роберт Лав (Robert Love), MontaVista Software, Inc.
Барри Марголин (Barry Margolin), Level 3 Communications
Клифф Мэтер (Cliff Mather), Hewlett-Packard
Дженна Мэтьюз (Jenna Matthews), Университет Корнелла/Кларксона
Маниш Мехта (Manish Mehta), Syntel, India, Ltd.
Деян Миложичич (Dejan Milojicic), Hewlett-Packard
Эврипид Монтань (Euripides Montagne), Университет Центральной
Флориды
Эндрю Мортон (Andrew Morton), Diego, Inc.
Гэри Ньюэлл (Gary Newell), Университет Северного Кентукки
Билл О’Фаррелл (Bill O’Farrell), IBM
Майк Панетта (Mike Panetta), Robotic Sciences, Inc./Netplanner Systems, Inc.
Рохан Филипс, (Rohan Phillips), Microsoft
Атул Пракаш (Atul Prakash), Университет штата Мичиган
Бина Рамаморти (Bina Ramamurthy), SUNY Buffalo
Эрик Рэймонд (Eric Raymond), Thyrsus Enterprises
Джеффри Рихтер (Jeffrey Richter), Wintellect
Свен Шрайбер (Sven Schreiber), Platon Data Technology
Венни Вей Шу (Wennie Wei Shu), Университет штата Нью-Мексико
Дэвид Соломон (David Solomon), David Solomon Expert Seminars
Брэндон Тейлор (Brandon Taylor), Sun Microsystems
Боб Токсен (Bob Toxen), Fly-By-Day Consulting, Inc.
Джошуа Узиэль (Joshua Uziel), Sun Microsystems
Карл Валкарель (Carl Valcarel), EinTech, Inc.
Мелинда Уорд (Melinda Ward), Hewlett-Packard
35
ерард Уэзерби (Gerard Weatherby), Charles Consulting, LLC. / Rensellaer
^at Hartford
Сианг Xy (Xiang Xu), RSA Security, Inc.
ди, внесшие вклад в первое и второе издания
(и места их работы в то время):
V вард Берковиц (Howard Berkowitz), Corporation for Open Systems
Пайл а. Браун (Dale A. Brown), Колледж Вустера
Стивен Дж. Буров (Steven J. Buroff), AT&T Bell Laboratories
Пэвид Д- Буш (David D. Busch)
Джон X. Карсон (John H. Carson), Университет Джорджа Вашингтона
Рональд Кертис (Ronald Curtis), Canisius College
Ларри К. Флэниган (Larry К. Flanigan), Университет штата Мичиган
Джон Форрест (Jon Forrest), Sybase
Джей Гадри (Jay Gadre), Corporation for Open Systems
Карлос M. Гонсалес (Carlos M. Gonzalez), Университет Джорджа Мэйсона
Майк Халворсон (Mike Halvorson), Microsoft Press
Уэйн Хатауэй (Wayne Hathaway), Ultra Network Technologies
Кристофер T. Хэйнс (Christopher T. Haynes), Университет штата Индиана
Ли Холлаар (Lee Hollaar), Университет штата Юта
Уильям Хорст (William Horst), Corporation for Open Systems
Джеймс Джоаннес (James Johannes), Университет штата Алабама
Ральф Джонсон (Ralph Johnson), Университет штата Иллинойс
Деннис Кафура (Dennis Kafura), Политехнический институт Виргинии
Херб Кляйн (Herb Klein), Corporation for Open Systems
Майкл С. Коган (Michael S. Kogan), IBM
Томас ЛеБлан (Thomas LeBlanc), Университет Рочестера
T. Ф. Либфрид (Т. F. Leibfried), Хьюстонский университет, Клир-Лейк
Дэвид Литуок (David Litwack), Corporation for Open Systems
Марк Межерс (Mark Measures), Baylor University
Чарльз Уаллин мл. (Charles Oualline Jr.), Государственный университет
восточного Техаса
ави Сандху (Ravi Sandhu), Университет штата Огайо
Ичард Шлихтинг (Richard Schlichting), Университет штата Аризона
Алан Саутертон (Alan Southerthon)
Дж. Ценор (John J. Zenor), Калифорнийский Университет
р СИмс Петерсон (James Peterson), Университет Техаса в Остине
ПолЭрД Бексельблатт (Richard Wexelblatt), Sperry Univac
occ (Paul Ross), Millersville State University
Стш^п ' ^Юсидо (Anthony Lucido), Intercomp
Бапт г ЭРИС (Bteve Paris), Prime Computer
Натан Тоб<!РИ Guerreri), DSD Laboratories
IFpp^>z?<? (Kathan Tobol), Codex Corporation, глава подкомитета
Ларин И ПО скальным сетям
ВаРри Пг0ЛЬС<)Н (Баггу Nelson), AVCO Services
Близап гТ (®аггУ Shein), Гарвардский университет
Анат Гаф ФНИ (Eliezer Gafni), МТИ
Джозефи (Anet Gafni), Бостонский университет
на Бондок (Josefina Bondoc), Бостонский университет
36
Операционные еиетем^ ^^лоВао
37
Контактная информация
Мы будем искренне вам благодарны за замечания, критику, пожеланц^
и исправления к книге. Пожалуйста, отправляйте их по адресу
deitelSdeitel.com
Мы будем отвечать по мере возможности.
Новостной бюллетень Deitel® Buzz Online
Наш бесплатный новостной бюллетень, Deitel® Buzz Online, содержу
обновления к третьему изданию «Операционных систем», статьи по достд.
жениям промышленности и направлениям развития, ссылки на бесплат.
ные статьи и ресурсы из уже опубликованных и готовящихся к выходу
книг, а также планы выпуска книг, списки обнаруженных ошибок, зада-
чи, анекдоты, информацию о предлагаемых курсах и так далее. Чтобд
подписаться на бюллетень, посетите страницу
www.deitel.com/newsletter/subscribe.html
О компании Deitel & Associates, Inc.
Deitel & Associates, Inc. — это широко известная компания, занимаю
щаяся подготовкой специалистов и созданием курсов по Интернету, World
Wide Web, программированию, технологиям электронной коммерции,
объектной технологии, операционным системам и языкам программирова-
ния. Компания предоставляет курсы по Интернету и веб-программирова-
нию, программированию для беспроводных систем, объектной технологии
и основным языкам и платформам программирования, включая С, C++,
Visual C++® .NET, Visual Basic® .NET, C#, Java, J2EE, XML, Perl, Python
и другим. Основатели Deitel & Associates, Inc., — доктор Харви M. Дейтел
и Пол Дж. Дейтел. Среди клиентов компании — многие крупные компью-
терные компании, государственные организации, военные и коммерчески^
структуры. В течение 27-летнего партнерства с издательством Prentice
Hall компания Deitel & Associates, Inc. издает книги по программирова-
нию, справочники, интерактивные курсы на компакт-дисках Cybi;
Classroom, Complete Training Courses, веб-курсы и системы управлений
обучением, а также материалы для популярных систем WebCTTlf'
BlackBoard™ и CourseCompass™.
Чтобы получить дополнительные сведения о компании Deitel
Associates, Inc., ее публикациях и расписании курсов, обратитесь по адре
су www.deitel.com.
Желающие купить книги и учебные курсы компании могут сделать
в книжных магазинах, через онлайн-магазины и на следующих сайтах
www.deitel.com
www.prenhall.com/deitel
www.InformIT.com/deitel
www.InformIT.com/cyberclassrooms
Крупные заказы от корпораций и академических организаций необхо-
о адресовать непосредственно издательству Prentice Hall. За инструк-
ЯиМмИ по заказам обращайтесь по адресу www.prenhall.com/deitel и к ло-
д0ЯьньШ представителям издательства Prentice Hall.
КЛПобро пожаловать в мир операционных систем. Мы искренне надеемся,
Лям понравится наша книга.
чТ° Dr. Harvey М. Deitel
Paul J. Deitel
David R. Choffries
OB aBmopax
Доктор Харви M. Дейтел (Harvey M. Deitel), глава компании Deitel &
Associates, Inc., работает в течение 42 лет в области образования, компью-
терных наук и промышленности. Доктор Дейтел изучал операционные
системы в Массачусетском Технологическом Институте, в котором полу-
чил ученые степени бакалавра и магистра. Степень доктора философии он
получил в Бостонском университете. Работая в МТИ, он участвовал в про-
ектах операционных систем с виртуальной памятью в компании IBM
(OS/360 и TSS/360) и МТИ (Multics), в которых впервые появились меха-
низмы, ныне широко используемых в UNIX, Linux и Windows ХР. Он чи-
тал курсы по операционным системам более 20 лет — как в академиче-
ских, так и в промышленных организациях. Он работал главой департа-
мента компьютерных наук в Бостонском колледже, прежде чем основать
компанию Deitel & Associates, Inc. со своим сыном, Полом Дж. Дейтелом.
Он и Пол — соавторы более десятка книг и мультимедиа-сборников, и мно-
гие книги находятся в данный момент в процессе создания. Эти книги пе-
реводились на японский, немецкий, русский, испанский, китайский, ко-
рейский, французский, польский, итальянский, португальский, грече-
ский и турецкий языки. Доктор Дейтел вел семинары в крупных
корпорациях, правительственных и военных организациях.
Пол Дж. Дейтел (Paul J. Deitel) работает в Deitel & Associates, Inc. Он
выпускник школы менеджмента при Массачусетском Технологическом
нституте, в котором изучал информационные технологии и операцион-
ные системы. Работая в Deitel & Associates, Inc., он провел сотни курсов
и Компаниях из списка Fortune 500, академических, правительственных
в д°енных организациях и многих других структурах. Они читал лекции
Им °НСком отделе Ассоциации вычислительной техники. Вместе со сво-
Кн Дти’Ом> доктором Харви М. Дейтелом, он является автором множества
г по компьютерной технике.
в Ч°Фнес (David R. Choffnes) — выпускник колледжа Амхерст,
одновп °М °Н ПолУчил ученые степени по физике и французскому языку,
В облас еННо ИзУчая специализированные разделы компьютерных наук.
ПыотерОв еГ° ИнггеРесов входят операционные системы, архитектура ком-
Участво ' ВЬ1числительная биология и молекулярные компьютеры. Дэвид
и Simni В поДготовке ряда книг, включая Simply Java™ Programming
pLy Visual Basic® .NET.
Часть I
Введение в аппаратные
средства, программное
обеспечение
и операционные системы
Интеллект... это дар к созданию искусственны^
объектов, в частности, орудий для создания орудий
Анри Бергсо^
,
с
главах этой части дается определение терми-
и&гну «операционная система», приводятся фак-
iribi из истории операционных систем, и закладыва
ется основа понятии «аппаратные средства»
и «программное обеспечение». Изучая историю опера-
ционных систем, обращайте внимание на тот ак-
цент, который постоянно де. аётся на повышении
производительности и эффекта зности управления
ресурсами с целью достижения необходимой произво-
дительности. Вы увидите поразительный рост мощ-
ности аппаратных средств и не менее поразитель-
ное падение цен. Вы узнаете о рождении двухдомини-
рующих операционных систем, Linux и Windows J Р,
в контексте противостояв и двух подходов: откры-
того программного обеспечения (Linux) и прав на
собственность (Windows ХР). Вы ознакомитесь
с базовыми архитектурами операционных систем,
а также аппаратными средствами, которыми
управляют операционные системы, и аппаратными
средствами, реализующими функции операционных
систем. Вы изучите ос (рвные одходы к повышению
производшПеЛънбсти, пив, начнете заниматься как
раз тем, чему посвящена эта книга от начала до
конца.
Каждыйинструмент несет в себе дух создателя.
Вернер Карл Гейзенберг
Глава 1
Введение 6 операционные
системы
Целы
Каждый инструмент несет в себе дух создателя.!^ . ЕМ ~
Прочитав эту главу, вы должны усвоить:
Вернер Карл Гейзенберг^У
• что такое операционная система;
• краткую историю операционных систем;
Довольно жить частями. Только объединять., к. „ _
• краткую историю сети Интернет и Всемирной
Эдвард Морган Форстер Паутины;
• основные компоненты операционной системы;
Производительность позволяет выполнить работу! •задачи операционных систем
Эффективность позволяет выполнить работу правильно! е
архитектуры операционных систем.
Зиг Зиглер
Все течет* все меняете# fl
Гераклг ЗР”* '
Сим-сим, откройся
Сказка про Али-Бабу и сорок разбойников^
Краткое содержание главы
1.1. Введение
1.2. Что такое операционная система?
1.3. Ранняя история: 40s и 50-е годы
Размышления об операционных системах: Изобретения и открытия
1.4. 60s годы
Размышления об операционных системах:
Относительная стоимость человеческих и компьютерных ресурсов
Биографические заметки: Кеннет Томпсон и Деннис Ритчи
1.5. 70-е годы
Поучительные истории: Осторожность Авраама Линкольна
в использовании новых технологий
1.6. 80-е годы
Биографические заметки: Дуглас Энгельбарт
1.7. История сети Интернет и Всемирной Партины
Биографические заметки: Тим Бернерс-Ли
1.8. 90s годы
Биографические заметки: Линус Торвальдс
Биографические заметки: Ричард Столлмен
1.9. 2000-й год и позЖе
1.10. Базы приложений
1.11. Среда операционной системы
1.12. Компоненты и задачи операционной системы
1.12.1. Ключевые компоненты операционной системы
1.12.2. Задачи операционной системы
Размышления об операционных системах: Производительность
1.13. Архитектура операционных систем
1.13.1. Монолитная архитектура
Размышления об операционных системах: Придерживаемся простоты
Поучительные истории: Системный архитектор против системотехник
1.13.2. Многоуровневая архитектура
Размышления об операционных системах: Архитектура
1.13.3. Архитектура на основе микроядра
1.13.4. Сетевые и распределенные операционные системы
те В оно ационныо системы
43
/./ Введение
Лобро пожаловать в мир операционных систем. В течение нескольких
лних десятилетий вычислительная техника развивается небывалыми
П°СЛами. Мощь компьютеров продолжает возрастать с огромной скоро-
ТвМ в то время как цены стремительно падают. На сегодняшний день
С<ГЬ сп°Ряжении пользователей компьютеров имеются настольные рабочие
В Рнпии, которые выполняют миллиарды операций в секунду. Уже созда-
ст суперкомпьютеры, выполняющие более триллиона операций в секун-
НЬ1,2 Еще пару лет назад эти цифры казались невероятными.
^Процессоры становятся настолько дешевыми и мощными, что компью-
теры могут использоваться в любой сфере нашей жизни. При помощи пер-
сональных компьютеров пользователи могут редактировать документы,
играть в игры, слушать музыку, просматривать видеоизображения
и управлять своими денежными средствами. Компьютеры являются клю-
чевыми элементами портативных устройств, включая переносные вычис-
лительные машины (ноутбуки) и карманные компьютеры (Personal Digital
Assistant — PDA), мобильные телефоны и МРЗ-плееры. Проводные и бес-
проводные сетевые архитектуры укрепляют всеобщую человеческую взаи-
мозависимость. С их помощью пользователи могут мгновенно связываться
друг с другом на огромных расстояниях. Интернет и Всемирная Паутина
революционизировали бизнес, создав спрос на сети с большими и мощны-
ми компьютерами, которые выполняют огромное количество операций
в секунду. Компьютерные сети стали настолько мощными, что использу-
ются для выполнения сложных исследовательских проектов, таких как
моделирование климата Земли, имитация человеческого интеллекта и соз-
дание высококачественной объемной видеомультипликации. Такая мощ-
ная и всепроникающая вычислительная техника требует от операционных
систем иных форм и ставит перед ними новые задачи.
В этой книге мы рассмотрим основы операционных систем и обсудим са-
мые современные достижения в области компьютерных технологий, кото-
рые требуют совершенствования операционных систем. Мы изучим струк-
туры и задачи операционных систем. Такие свойства операционных систем,
как производительность, отказоустойчивость, безопасность, модульность
стоимость, будут тщательно проанализированы. Мы обратим также вни-
о ие на вопросы, которые возникают в ходе проектирования современных
ным гГ°ННЫХ систем Для распределенных вычислений, ставших возмож-
лагодаря сети Интернет и Всемирной Паутине.
оНа с торам пришлось усердно поработать над материалом книги, чтобы
т°РЬ1м Э ДЛЯ ВЭС соДеРжательн°й и интересной, поставив задачи, над ко-
те Пос ВЭМ придется немного поломать голову. Читая эту книгу, вы може-
и детад1^8^ наш веб-сайт (www.deitel.com) для получения более свежей
Электп„ЬН°и информации по каждой теме. Связаться с авторами можно по
Р Нной почте: deitel@deitel.com.
44
45
1.2 Что такое операционная система?
В 60-е годы определение операционной системы могло бы выгляди
так: программное обеспечение, которое управляет аппаратными средс2
вами. Но ландшафт компьютерного мира сильно изменился с тех пор, и j
перь нам необходимо более глубокое определение.
Современные аппаратные средства могут выполнять огромное множен
во разнообразных программных приложений. Чтобы повысить эффекту
ность использования аппаратуры, приложения проектируются в расчет
на то, что они будут работать одновременно друг с другом. Если эти прило
жения не были разработаны должным образом, то они будут создавав
ДРУГ ДРУГУ помехи. Во избежание этого было создано специальное ггр0
граммное обеспечение, которое называется операционной системой
(operating system). Операционная система отделяет приложения от ацца.
ратных средств, к которым они имеют доступ, и обеспечивает условия дЛг
безопасной и эффективной работы приложений.
Операционная система — это программное обеспечение, которое позво-
ляет приложениям взаимодействовать с аппаратными средствами компью-
тера. Комплекс программ, составляющих основу операционной системы,
называется ядром (kernel). Операционную систему можно обнаружит!
в самых различных устройствах от мобильных телефонов и автомобилей да
персональных компьютеров и универсальных вычислительных машин.
В большинстве компьютерных систем пользователь обращается к компью-
теру для выполнения действия (например, требует запустить приложение
или распечатать документ), а операционная система управляет программ
ным обеспечением и аппаратными средствами, чтобы получить желаемый
результат.
Для большинства пользователей операционная система — это «черньп
ящик», посредник между приложениями и аппаратными средствами, с ко
торыми они работают. Этот посредник обеспечивает необходимый результат
при наличии соответствующих исходных данных. Операционные систе
мы — это в первую очередь диспетчеры ресурсов, они управляют аппарат
ными средствами, включая процессоры, память, устройства ввода/вывоД’
и устройства связи. Они также должны управлять приложениями и друг11
ми программными элементами, которые в отличие от аппаратных средсИ
не являются физическими объектами.
В следующих разделах мы изложим краткую историю операционная
систем от простых однопользовательских систем пакетной обработки 5O'f
годов до сложных, многопроцессорных, распределенных, многопользоВ^
тельских платформ наших дней.
Вопросы для самопроверки
1. Операционные системы управляют только аппаратными средства-
ми? (Да/Нет).
2 Какие задачи операционной системы являются основными?
Ответы 1) Нет. Операционные системы управляют также приложе-
ниями и другими программными объектами, такими как виртуальные
машины. 2) Основными задачами операционной системы являются
обеспечение взаимодействия между приложениями и аппаратными
средствами компьютера, а также распределение программных и аппа-
ратных ресурсов системы.
1.3 Ранняя история: 40-е и 50-е годы
За последние 60 лет операционные системы прошли в своем развитии ряд
определенных этапов или поколений. Длительность каждого из этих этапов
составляет в среднем около 10 лет (см. «Размышления об операционных
системах. Изобретения и открытия»)3. В первых электронных цифровых
вычислительных машинах 40-х годов операционных систем не было4*5’6.
Компьютеры того времени были настолько примитивны, что программисты
вводили программы на машинном языке бит за битом при помощи ряда (ре-
гистра) механических переключателей. Позже эти программы вводились
при помощи перфокарт. Затем для ускорения программирования были раз-
работаны языки ассемблера, которые использовали английские аббревиату-
ры для представления основных операций компьютера.
В 50-х годах исследовательская лаборатория компании General Motors
разработала первую операционную систему для своего компьютера
IBM 7017. Системы того времени, как правило, были однозадачными и ис-
пользовали специальные приемы для «смягчения» перехода от одной зада-
чи к другой с целью наиболее эффективного использования компьютерной
системы8. Задача (job) состояла из последовательности программных ко-
манд, которые соотносились с определенным вычислительным заданием,
таким как расчет платежной или инвентаризационной ведомости. Как
правило, задачи выполнялись без ввода пользователем информации в диа-
логе и требовали для своего решения минут, часов или даже дней. Такие
компьютеры назывались однопоточными системами пакетной обработки
n£le-streain batch-processing system), так как программы и данные соби-
ТУ ИСЬ В Группы’ или пакеты путем последовательной загрузки их на лен-
Упо ЛИ Диск' Процессор обработки потока задач считывал операторы языка
няд Ления заданиями (которые определяли отдельные задачи) и выпол-
ка Постан°вку очередной задачи. По завершении текущей задачи из пото-
к еле ЙЧ Счятывались операторы языка управления, относящиеся уже
вИя заДаче, и выполнялись соответствующие служебные дейст-
сИстемь1 °®легчить переход к ней. Несмотря на то, что операционные
пР°грам годов сокращали время перехода от одной задачи к другой,
систем МИстам часто приходилось непосредственно контролировать такие
бЬ1ла м 6 ресУРсьП как память и устройства ввода/вывода. Эта работа
Пленной, сложной и утомительной. Кроме того, для работы про-
47
ГлаВ(
g операционные системы
граммы эти системы требовали ее полной загрузки в память. В виду это[.
программисты были вынуждены создавать небольшие программы с огц'
ниченными возможностями9.
Вопросы для самопроверки
1. Для чего были разработаны языки ассемблера?
2. Что в 50-е годы ограничивало размер и возможности программ?
Ответы 1) Языки ассемблера были разработаны для ускорен^
процесса программирования. Они позволили программистам специф^
цировать команды в виде английских аббревиатур, с которыми опера
тору было куда проще работать, чем с командами машинного язык»
2) Чтобы выполнить программу, ее надо было полностью загруз^
в память. Так как память в свою очередь была относительно дорого^
ее объем, доступный для компьютеров того времени, был небольшие ’
Размышления об операционных системах
Изобретения и открытия
Изобретения и открытия — это основная
проблема, с которой сталкиваются разра-
ботчики операционных систем Если мы со-
бираемся произвести крупное капиталовло-
жение, необходимое для выпуска новой
операционной системы или новых версий
уже существующих операционных систем,
мы должны постоянно уделять внимание но-
вым технологиям, новым приложениям
средств обработки данных и передачи ин
формации, а также новым подходам к по-
строению систем. Авторы собрали в этой
книге тысячи ссылок на книги и статьи и’сот-
ни Интернет-адресов, чтобы вы могли полу-
чить дополнительную информацию по инте-
ресующим вас темам. Вам следует поду-
мать о членстве в таких профессиональных
организациях, как Ассоциация по вычисли-
тельной технике (АСМ: www.acm.org), Ин-
ститут инженеров по электротехнике и элек-
тронике (IEEE: www.ieee.org) и USENIX
(www.usenix.org), которые издают журналы,
посвященные современным исследователь-
ским и проектным работам в области компь-
ютерных технологий. Вам следует чаще посе-
щать Интернет, чтобы быть в курсе важных
разработок в этой области. Ориентация на
технологические новинки и научные открЫ'
тия всегда связана с большим риском, но р6’
зультаты могут стоить того.
L4 60-е соды
Системы этого периода времени также были системами пакетной обр0'
ботки, но они использовали ресурсы компьютера с большей эффективн0'
стью путем выполнения нескольких задач одновременно. Эти систем01
включали много периферийных устройств, таких как устройства для сЧ^
тывания с перфокарт (ввода данных), карточные перфораторы, принтер01'
чные накопители и накопители на дисках. Редко одна отдельная за-
ЛвНТ°могла полностью задействовать все системные ресурсы. Обычная за-
Дача спользовала процессор в течение определенного периода времени пе-
дача и лнением операции ввода/вывода на одном из периферийных уст-
Р®Д ВЬ системы. А затем процессор оставался незадействованным, пока
Р°ЯСла ожидала завершения операции ввода/вывода.
зада стемы 60-х годов усовершенствовали механизм распределение ресур-
позволяя одной задаче использовать процессор, пока остальные ис-
с0В’ з0ВаЛи периферийные устройства. Фактически, выполнение сочета-
П0Л1>пазличных задач — тех, которые в основном использовали процессор
Г^ентированные на вычисления (compute-bound или processor-bound))
тех которые по большей части использовали периферийные устройства
Ориентированные на ввод/вывод (i/o-bound)) — оказалось наилучшим
способом оптимизации распределения ресурсов. В рамках этого подхода
разработчики операционных систем создали такую систему, которая рабо-
тала в мультипрограммном режиме и справлялась с несколькими задача-
ми одновременно10’ и> 12. В этом режиме операционная система быстро пе-
реключала процессор с одной задачи на другую, продолжая выполнять не-
сколько задач и использовать периферийные устройства одновременно.
Степень мультипрограммности (degree of multiprogramming) системы (ко-
торая также называется уровнем мультипрограммирования (level of
multiprogramming)) показывает, сколько задач может выполняться одно-
временно. Таким образом, операционные системы перешли от выполнения
одной задачи к одновременному выполнению нескольких.
В системах, работающих в мультипрограммном режиме, распределение
ресурсов является одной из первоочередных задач. Если ресурсы распреде-
ляются между несколькими процессами, и каждый из этих процессов мо-
жет осуществлять исключительный контроль над выделенными ему ресур-
сами, возможна ситуация, когда одному из процессов придется бесконечно
ожидать необходимый ресурс. Если это произойдет, данный процесс не
сможет выполнить свою задачу (зависнет), а это, возможно, потребует от
пользователя повторного запуска задачи, в результате которого будут уте-
ряны результаты всей работы этого процесса, выполненной им до этого мо-
мента. В главе 7 мы рассмотрим, каким образом операционные системы
могут справляться проблемами этого вида.
ко аК правило’ пользователи 60-х годов не находились возле компьютера,
да Т°Т считал их задачи. Последние готовились на перфокартах или
вок ОЧНЫХ носителях и сдавались на вычислительный центр в виде зая-
пыоТеаТеМ спейиальный сотрудник, оператор системы, загружал их в ком-
Реди ч ДЛЯ ВЬ1Полнения- Часто пользовательская задача ждала своей оче-
п°средсСаМИ ИЛИ даже «нами, прежде чем попадала на компьютер для не-
как отс ГВенного выполнения. Даже малейшая ошибка в программе, такая
3Ультате ТВИе точки или запятой, могла свести всю работу на «нет», в ре-
назад свое6ГО Пользователь (как правило, ужасно расстроенный) получал
задачу На Задание невыполненным, исправлял ошибку, заново переносил
ВЬ1ПолнениеРФ°К“РТЫ ИЛИ ленту и снова ждал часами следующей попытки
Ком режи Я СВ°еЙ задачи- Разработка программного обеспечения при та-
е Ра6оты требовала больших затрат времени и сил.
48 Глава j
В 1964 году компания IBM представила свое семейство компьютере^
System/360 (360 может ассоциироваться с полным кругом шкалы компасу
тем самым разработчики объявляли свое детище универсальной системой
общего назначения)13’ 14> 15, 16. Различные модели компьютеров этого се.
мейства были разработаны в рамках доктрины полной совместимости ац.
паратных средств. Использование единой для всех моделей компьютеров
операционной системы OS/360 позволяло быстро и безболезненно перен0-
сить задачи на более мощные компьютеры этой серии17. Со временем ком.
пания IBM перешла от архитектуры 360 к 370-й серии18’19, а совсем недав.
но к 390-й 20 и zSeries 21.
Усовершенствованные операционные системы были разработаны ддя
одновременного обслуживания многочисленных интерактивных пользо-
вателей (interactive users), которые осуществляют связь с задачами в про.
цессе их выполнения. В 60-е годы, пользователи осуществляли связь
с компьютером через «неинтеллектуальные терминалы» (то есть устройст-
ва, реализующие пользовательский интерфейс, но не мощность процессо-
ра), которые работали в оперативном режиме (online), т.е. были непосред-
ственно подсоединены к компьютеру через активное подключение. Посколь-
ку пользователь присутствовал при решении задачи и взаимодействовал
с ней, компьютерная система должна была быстро отвечать на его запросы;
в противном случае производительность процесса решения задачи могла
пострадать. В отдельной рубрике «Размышления об операционных систе-
мах: Относительная стоимость человеческих и компьютерных ресурсов»
мы упоминали, что повышение производительности стало важной целью
для разработчиков компьютеров, поскольку по сравнению с аппаратными
ресурсами, человеческие оставались слишком дорогими. Системы с раз-
делением времени (timesharing system) были разработаны для поддерж-
ки нескольких пользователей, одновременно работающих в диалоговом
режиме 22.
Многие из систем 60-х годов, работавших в режиме разделения време-
ни, были мультирежимными системами, поддерживающими как пакет-
ную обработку, так и приложения реального времени (например, промыш-
ленные системы управления технологическими процессами)23. Системы
реального времени (real-time system) должны отреагировать на запрос
в течение определенного промежутка времени. Например, термодатчики
на нефтеочистительном заводе, которые показывают слишком высокую
температуру, могли потребовать немедленного вмешательства для предот-
вращения взрыва. Ресурсы системы реального времени очень часто недоис-
пользуются — для таких систем более важен быстрый ответ, чем эффек-
тивное использование ресурсов. Решение и пакетных задач и задач реалЬ'
ного времени в рамках одной системы означало, что система должна
различать категории пользователей и предоставлять каждому из них об-
служивание соответствующего уровня. Задачи пакетной обработки моглИ
быть отложены на разумные сроки, поскольку интерактивные приложи'
ния требовали более приоритетного обслуживания, а задачи реального вре'
мени требовали обслуживания с наивысшим приоритетом (наивысший
уровнем привилегий).
К основным достижениям того периода в области разработок систем, ра-
ботающих в режиме разделения времени, относятся: CTSS (Совместима#
49
с разделением времени) 24- 25, разработанная Массачусетским Тех-
с11сте ким Институтом, TSS (Система с разделением времени) 26, раз-
°Ганная компанией IBM, и система Multics 27, разработанная совместно
РТИ Дженерал Электрик и компании Bell Labs, как преемница систем
и СР/CMS (Управляющая программа/Диалоговая мониторная сис-
СТЬ )’ Последняя, в конце концов, и превратилась в Операционную систе-
Т<? виртуальной машины (virtual memory — VM), созданную Научным
тром компании IBM в Кембридже 28’29. Эти системы были разработаны
среда для выполнения базовых интерактивных вычислительных задач
Сдельных пользователей, но наиболее ценным в них был принцип разде-
ния программ и данных, а также то, что они демонстрировали значи-
мость интерактивных вычислений при разработке программ.
Разработчики системы Multics были первыми, кто использовал термин
процесс (process) для описания программы во время ее выполнения в рам-
ках операционной системы. Часто пользователи предлагают задания,
включающие несколько процессов, способных выполняться одновременно.
В главе 3 мы обсудим, каким образом операционная система, работающая
в мультипрограммном режиме, может управлять несколькими процессами
одновременно.
Вообще говоря, параллельные процессы выполняются независимо друг
от друга, но мультипрограммные системы позволяют нескольким процес-
сам взаимодействовать для выполнения общей задачи. В главе бив главе 6
мы обсудим, как процессы согласуют и синхронизируют операции и как
операционные системы обеспечивают эту возможность. Мы продемонстри-
руем множество примеров параллельных программ, одни из которых пред-
ставлены в общих чертах на псевдокоде, а другие — на популярном языке
программирования Java™.
Длительность жизненного цикла задачи (turnaround time) — интервал
времени между постановкой задачи и возвратом результатов ее выполне-
ния — была уменьшена до минут, а порой и секунд. Программист больше
не должен был ждать часами или днями, чтобы исправить свои незначи-
тельные ошибки. Он мог ввести программу, скомпилировать ее, получить
список синтаксических ошибок, тут же исправить их, заново скомпилиро-
иать программу и продолжать этот цикл, пока в программе не будут устра-
нены все синтаксические ошибки. В результате программа могла быть вы-
полнена, отлажена, исправлена и сдана в готовом виде с существенной эко-
номией времени.
Значимость систем, работающих в режиме разделения времени, для
Лж^еССа РазРаб°тки программ была продемонстрирована, когда МТИ,
Ки Нерал Электрик и Bell Labs использовали систему CTSS для разработ-
оп ее ПРеемнийы, Multics. Эта система стала известна как первая крупная
(EP1J И°ННаЯ система’ написанная в основном на языке высокого уровня
ра р подмножество языка PL/1 компании IBM), а не на языке ассембле-
Ня С зработчики UNIX учли этот опыт; они создали язык высокого уров-
ных СПе^иально, чтобы реализовать систему UNIX. Семейство операцион-
8о£^ИСТе^’ основанных на UNIX, включающее Linux и BSD (Berkeley
чц и кГе distribution) UNIX, выросло из системы, созданной Деннисом Рит-
(см. D рНнетом Томпсоном в Bell Laboratories в конце 60-х годов XX века
У Рику «Биографические заметки: Кеннет Томпсон и Деннис Ритчи»).
50
Глава i
TSS, Multics и CP/CMS — все эти системы имели виртуальную памяти
(virtual memory), которую мы детально обсудим в главе 10 и в главе 1д
В системах с виртуальной памятью программы способны обращаться
к большему пространству адресов, чем фактически существует в основной
памяти, которая также называется реальной или физической 301 31. (Реалы
ная память рассматривается в главе 10.) Системы с виртуальной памятью
позволяют облегчить труд программистов в части управления памятью
давая им возможность сосредоточиться на разработке приложений.
Загруженные в основную память программы могли выполняться быст.
ро, тем не менее, основная память была слишком дорогой для одновремен,
ного хранения большого количества программ. До 60-х годов задачи в ос-
новном загружались в память с перфокарт или магнитных лент, — утоми,
тельная и отнимающая много времени работа, в процессе выполнения
которой систему нельзя было использовать для выполнения других задач.
Системы того времени включали устройства, которые сводили к минимуму
время простоя путем хранения большого объема перезаписываемых дан-
ных на относительно недорогих магнитных накопителях, таких как лен-
ты, диски и барабаны. Несмотря на то, что накопители на жестких дисках
по сравнению с магнитными лентами обеспечивали относительно быстрый
доступ к программам и данным, они работали значительно медленнее ос-
новной памяти. В главе 12 мы рассмотрим, как операционные системы мо-
гут управлять запросами ввода/вывода для дисков с целью повышения
производительности. В главе 13 мы обсудим, как операционные системы
объединяют данные в поименованные объекты, называемые файлами,
и управляют распределением пространства на таких устройствах, как дис-
ки. Мы также выясним, как операционные системы осуществляют защиту
данных от несанкционированного доступа и препятствуют их утрате при
сбое в работе системы или других аварийных ситуациях.
Вопросы для самопроверки
1. Каким образом применение интерактивного режима работы в рам-
ках проектного цикла программы повысило производительность
труда программистов?
2. Какую новую концепцию реализовали системы TSS, Multics
и CP/CMS? И почему она так помогла программистам?
Ответы 1) Время между постановкой задачи и возвратом резуль-
татов ее выполнения было сокращено от часов и дней до минут и даЖе
секунд. Это позволило программистам вводить, компилировать и ре*
дактировать программы в интерактивном режиме, вплоть до момента
устранения всех синтаксических ошибок. Затем аналогичный итера-
ционный цикл применялся для тестирования и отладки этих пр0'
грамм. 2) TSS, Multics и CP/CMS, — все эти системы включал11
виртуальную память, которая позволяет приложениям обращаться
к большему пространству памяти, чем физически существует в систс'
ме, что предоставило программистам возможность разработки боле®
мощных приложений. Системы с виртуальной памятью также избавИ'
ли программистов от задачи управления памятью.
в операционные системы
51
Я Размышления об операционных системах
Относительная стоимость человеческих
и компьютерных ресурсов
В 1965 году достаточно опытные про-
граммисты зарабатывали около 4 долларов
в час. Машинное время универсальных вы-
числительных машин (которые были далеко
не такими мощными, как современные на-
стольные компьютеры), как правило, оцени-
валось в 500 долларов и более за час - и это
в долларах того времени, которые в виду ин-
фляции приравниваются к тысячам долларов
по сегодняшнему курсу! Сегодня вы можете
приобрести очень мощный настольный ком-
пьютер старшей модели семейства за те же
деньги, что и взять в аренду на час универ-
сальную вычислительную машину куда мень
шей мощности 40 лет назад! Вследствие того,
что цены на вычислительную технику упали,
стоимость человеческого труда в долларах за
человеко-час настолько возросла, что на се-
годняшний день человеческие ресурсы стали
намного дороже компьютерных.
Компьютерные аппаратные средства, опе-
рационные системы и программные прило-
жения разрабатываются с целью свести к ми-
нимуму трудозатраты и повысить продуктив-
ность и производительность. Классически
примером этого процесса является появле-
ние в 60-х годах систем с разделением вре-
мени. Эти интерактивные системы (с практи-
чески мгновенной реакцией) в отличие от
систем с пакетной обработкой данных, реак-
цию которых приходилось ожидать часами,
а то и днями, позволяли программистам ра-
ботать со значительно большей продуктив-
ностью. Еще одним примером может послу-
жить появление графического интерфейса
пользователя (Graphical Userinterface — GUI),
разработанного в 70-х годах в исследова-
тельском центре фирмы Xerox в Пало Альто
(Palo Alto's Research Center - PARC). Имея
в своем распоряжении более дешевую и бо-
лее мощную вычислительную технику, а так-
же в виду быстро растущей относительной
стоимости человеческих ресурсов по сравне-
нию с вычислительными, разработчики опе-
рационных систем должны дать людям
власть над компьютерами, а не наоборот, как
это было в случае с самыми первыми опера-
ционными системами.
Глава i
Биографические заметки
Кеннет Томпсон и Деннис Ритчи
Кеннет Томпсон и Деннис Ритчи известны
своей деятельностью в области операционных
систем благодаря разработке операционной
системы UNIX и языка программирования С.
Они получили признание и несколько наград
за свои достижения, таких как ACM Turing
Award, National Medal of Technology, NEC C&C
Prize, IEEE Emmanuel Piore Award, IEEE
Hamming Award, а также были приняты в На-
циональную Инженерную Академию Соеди-
ненных Штатов и Bell Labs National Fellowship32.
КеннетТомпсон окончил Калифорнийский
университет в Беркли в 1966 году, где получил
степень бакалавра и магистра компьютерных
наук 33. По окончании колледжа он работал
в компании Bell Labs, где, в конце концов,
и присоединился к Деннису Ритчи во время
работы над проектом Multics34. Именно тогда
он создал язык В, на базе которого благодаря
Ритчи появился язык С 35. Проект Multics при-
вел к появлению операционной системы UNIX
в 1969 году. На протяжении 70-х Томпсон
продолжал разрабатывать UNIX, переписывая
ее на языке программирования С36. После того
как эта операционная система была заверше-
на, о нем заговорили снова в 1980 году благо-
даря компьютеру Belle. Этот компьютер, кото-
рый выиграл мировое первенство по шахма-
там среди компьютеров, был разработан
Томпсоном и Джо Кондоном. Томпсон рабо-
тал профессором в Калифорнийском универ-
ситете в Беркли и в Сиднейском университете
в Австралии. Он продолжал работать в ком-
пании Bell Labs до пенсии, на которую вышел
в 2000 году37.
Деннис Ритчи окончил Гарвардский уни-
верситет, получив степень бакалавра по фи-
зике и доктора философии по математике.
Ритчи продолжал работу в компании Bell
Labs, когда в 1968 году к нему присоединил-
ся Томпсон для выполнения проекта Multics.
Наибольшее признание Ритчи получил бла-
годаря своему языку С, работу над которым
он завершил в 1972 году38. Он наделил язык
В, созданный Томпсоном, дополнительными
возможностями, а также изменил синтаксис
для облегчения работы с ним. Ритчи до сих
пор работает в компании Bell Labs и продол-
жает трудиться над операционными систе-
мами ”. За последние десять лет он создал
две новые операционные системы. Plan 9
и Inferno40. Система Plan 9 была разработана
для повышения качества обмена информа-
цией и производства 4'. Система Inferno рас-
полагает дополнительными сетевыми воз-
можностями 42.
1.5 70-е годы
Системы того времени были в основном многорежимными мультипро-
граммными системами, которые поддерживали пакетную обработку, раз-
деление времени и приложения реального времени. Персональная вычис-
лительная техника находилась в начальной стадии своего развития, сти-
мулируемая предыдущими и продолжающимися разработками в сфере
микропроцессорных технологий 43. Экспериментальные системы с разде-
лением времени 60-х годов в 70-х годах превратились в успешный коммер-
53
еский продукт. Связь между компьютерными системами Соединенных
Штатов становилась все интенсивнее по мере того, как все более широкое
рименение получали коммуникационные стандарты TCP/IP Министерст-
а Обороны, особенно в военной и образовательной компьютерной сре-
44, 45, 46. Связь по локальной сети (LAN) стала возможной и недорогой
благодаря стандарту Ethernet, разработанному исследовательским цен-
тром компании Xerox в Пало Альто (PARC) 47- 48. В главе 16 мы обсудим
стандарты TCP/IP, Ethernet, а также фундаментальные концепции компь-
ютерных сетей.
Возросло и количество проблем, связанных с безопасностью, благодаря
увеличению объемов информации, передаваемой по уязвимым линиям
связи (см. рубрику «Поучительные истории: Осторожность Авраама Лин-
кольна в использовании новых технологий^). Огромное внимание начали
уделять шифрованию, крайне необходимым стало кодирование персональ-
ной и защищенной правами собственности информации таким образом,
чтобы она не представляла бы никакой ценности ни для кого, кроме полу-
чателей, для которых она была предназначена. В главе 19 мы обсудим то,
как операционные системы осуществляют защиту уязвимой информации
от несанкционированного доступа. В 70-х годах операционные системы
способствовали развитию компьютерных сетей и безопасных информаци-
онных технологий, а разработчики старались повысить их производитель-
ность, чтобы те отвечали требования рынка.
Революция в области персональных компьютеров началась в конце 70-х
с таких систем, как Apple II, и достигла своей кульминации в 80-х.
Вопросы для самопроверки
1. Какие разработки 70-х годов повысили качество связи между ком-
пьютерными системами?
2. Какие новые проблемы возникли в связи с ростом интенсивности
обмена информацией между компьютерами? Как программисты
пытались решить эти проблемы?
Ответы 1) Широкое применение получили сетевые коммуникацион-
ные стандарты TCP/IP Министерства Обороны — в первую очередь
в военной компьютерной среде и в сфере образования. Более того, иссле-
довательским центром компании Xerox в Пало Альто был разработан
стандарт Ethernet, который позволил относительно высокоскоростной
локальной сети стать более практичной и менее дорогой. 2) В виду
того, что данные посылались по незащищенным линиям связи, воз-
никли вопросы их безопасной передачи. Программисты прибегли
К шифрованию, чтобы исключить возможность чтения информации
кем-либо, кроме получателя, для которого она предназначена.
Поучительные истории
Осторожность Лвраалла Линкольне в использовании
новых технологий
История рассказывает о том, как во время
Гражданской войны один из молодых лейте-
нантов армии Авраама Линкольна подбежал
к нему с желанием обратиться.
— Что случилось, лейтенант?
— Господин президент, господин прези-
дент, на поле сражения мы прокладываем ка-
бель для удивительного нового устройства,
которое называется телеграфом. Вы пони-
маете, что это значит?
— Нет, лейтенант. А что это значит?
— Господин президент, это значит, что мы
сможем принимать решения со скоростью
света!
Старый и умудренный опытом президент
Линкольн взглянул на лейтенанта и спокойно
сказал:
— Конечно, лейтенант. Но мы сможем
принимать со скоростью света и неверные
решения!
Мораль для разработчиков операционных систем: каждая новая технология, которой вы
5удете давать оценку, имеет свои достоинства и недостатки. Вам неизбежно придется потра-
гить много времени, пребывая в раздумьях о целесообразности ее применения. Помните, что
тгремление ускорить процесс может иметь нежелательные последствия.
L6 80-е годы
80-е годы были десятилетием персональных компьютеров и рабочих
танций 49. Технология микропроцессоров достигла того уровня, при кото-
ом стало возможным производство настольных компьютеров с широкими
функциональными возможностями. Эти компьютеры назывались рабочи-
ми станциями и были такими же мощными, как и универсальные вычис-
ительные машины предыдущего десятилетия. Персональные компьюте-
ы IBM и Apple Macintosh, выпущенные в 1981 и 1984 годах, соответствен-
Р, предоставили отдельным лицам и малому бизнесу возможность иметь
)бственный предназначенный именно для них компьютер. Встроенные
них средства связи могли быть использованы для быстрого и недорогого
>мена информацией между системами. Вместо того, чтобы пересылать
иные для их обработки на большую центральную вычислительную ма-
йну, сами вычислительные средства были перенесены в те места, где они
дли необходимыми. Такие программные продукты, как программы таб-
шных вычислений, текстовые процессоры, базы данных и графически^
1кеты двигали вперед революцию в сфере персональной вычислительной
хники, поскольку представители бизнеса, ознакомившись с ними, осоз-
нали их необходимость для повышения эффективности коммерческих
юектов.
ggeggnue В опора ионные системы
55
Персональные компьютеры оказались довольно простыми в использова-
ния и обучении частично благодаря графическому интерфейсу пользова-
теля (Graphical User Interface — GUI), в котором использовались графиче-
ские элементы, такие как окна, значки и меню для облегчения общения
пользователя с программами. Исследовательский центр компании Xerox
в Пало Альто разработал мышь и GUI (для получения более детальной ин-
формации о появлении мыши, смотри рубрику «Биографические заметки:
Дуглас Энгельбарт»). Выпуск компанией Apple персонального компьютера
Macintosh в 1984 году способствовал их распространению. В компьютерах
Macintosh графический интерфейс пользователя был встроен в операцион-
ную систему, таким образом, все приложения могли выглядеть и воспри-
ниматься одинаково 50. Будучи уже знакомым с таким интерфейсом ком-
пьютера Macintosh, пользователь мог быстрее обучаться работе с новыми
приложениями.
По мере того, как технологические затраты уменьшались, передача ин-
формации посредством компьютерной сети становилась более практичной
и менее дорогой. Широкую популярность завоевали электронная почта,
пересылка файлов и удаленный доступ к базам данных. Распределенная
обработка данных (distributed computing) — т.е. использование множест-
ва независимых компьютеров для выполнения общей задачи — получила
широкое распространение в рамках модели «клиент-сервер». Клиенты
(client) — это компьютеры, которые запрашивают различные услуги; сер-
веры (server) — это компьютеры, которые предоставляют запрашиваемые
услуги. Как правило, серверы предназначены для решения задач опреде-
ленного типа, таких как формирование изображения, управление базами
данных и хранение веб-страниц.
Сфера разработки программного обеспечения продолжала развиваться,
причем одна из инициатив правительства Соединенных Штатов состояла
в осуществлении более жесткого контроля над программными разработка-
ми Министерства Обороны 51. К важным целям такой инициативы отно-
сится возможность повторного использования разработанного кода и ран-
него создания прототипов, чтобы разработчики и пользователи могли вно-
сить свои предложения об изменениях еще на первых этапах процесса
Разработки программного обеспечения 52.
Вопросы для самопроверки
1. Какая особенность персональных компьютеров, выпускаемых ком-
панией Apple Macintosh, делала их изучение и использование осо-
бенно простым?
2. Верно ли, что сервер не может быть клиентом? (Да/Нет)
Ответы 1) Графический интерфейс пользователя упрощал исполь-
зование персонального компьютера путем предоставления всем прило-
жениям единого и удобного для использования интерфейса. Это дало
пользователям возможность быстро обучаться работе с новыми прило-
жениями. 2) Нет. Компьютер может быть и клиентом, и сервером. На-
пример, веб-сервер может быть и тем, другим. Когда пользователи
запрашивают веб-страницу — это сервер; если же сервер сам запраши-
вает информацию из системы базы данных, то он становится клиентом
данной системы.
Биографические заметки
Дуглас Энгельбарт
Дуглас Энгельбарт изобрел компьютерную
мышь и был одним из первых разработчиков
оригинальных графических дисплеев и окон.
Энгельбарт специализировался в сфере
электроники. Во времена второй мировой
войны он работал специалистом по различ-
ным системам, например, радиолокацион-
ным и гидролокационным станциям. Поки-
нув ряды вооруженных сил, он вернулся
в штат Орегон, чтобы получить степень по
электротехнике в 1948 году ”. Дуглас Энгель-
барт продолжил обучение в Калифорний-
ском университете в Беркли и получил сте-
пень доктора философии, затем он поступил
на работу в Стэндфордский Исследователь-
ский Институт (Stanford Research Institute —
SRI), где впервые и столкнулся с компьютера-
ми 55. В 1968 году на Объединенной конфе-
ренции по компьютерам (Joint Computer
Conference) в Сан-Франциско, Энгельбарт
и его сотрудники представили свою компью-
терную систему NLS (oNLine System — это на-
звание можно перевести как «Диалоговая
система»), отличительными элементами ко-
торой были мышь и графический интерфейс
с окнами56. Эта оригинальная мышь, которая
называлась «Индикатором координат X-Y»
для системы вывода изображений, имела
только одну кнопку 5/. На ее нижней поверх-
ности находились два колесика, горизон-
тальное и вертикальное, для распознавания
направления движения. Мышь и графиче-
ские окна были взаимосвязаны. Благодаря
мыши переключение с одного окна нэ другое
значительно упрощалось, в то время как без
окон мышь уже не приносила столь значимой
пользы.
Дуглас Энгельбарт посвятил свою жизнь
повышению уровня человеческого интеллек-
та. Его изначальным замыслом, лежавшим
и в основе системы NLS, было создание сис-
темы, которая могла бы повысить уровень
интеллекта и помочь людям быстрее решать
проблемы. Он основал Институт Совершен-
ствования (Bootstrap Institute) с целью спо-
собствовать всеобщему пониманию его мис-
сии. Совершенствование, согласно Энгель-
барту, это развитие методов самого процесса
развития. Он верит в то, что этот путь являет-
ся наилучшим для повышения уровня чело-
веческого интеллекта59.
На сегодняшний день Энгельбарт все еще
сотрудничает с Институтом Совершенствова-
ния. За свои труды он получил широкое об-
щественное признание и награды, такие как
Lemelson-MIT Prize, National Medal of
Technology, а также место в National Inventors
Hall of Fame “.
/.7 История сети Интернет и Вселлирнои Паутины
В конце 60-х годов Управление перспективных исследовательских про-
'рамм (Advanced Research Projects Agency — ARPA) Министерства Обо-
юны США запланировало создание сети, которая бы соединяла около дю-
кины компьютерных систем университетов и научно-исследовательских
'Рганизаций, финансируемых этим управлением. Соединение должно
ьтло осуществляться посредством выделенных линий связи, передающих
elllltt В операционные системы
рМацию с удивительной для того времени скоростью 56 Кбит/с
*Кбит/с составляет 1024 бит в секунду). В те времена большинство поль-
П ПтеЛей (из тех немногих, кто мог) осуществляли подключение к компь-
3°ва аМ по телефонным линиям со скоростью 110 бит в секунду. Гарви М.
^“тел хорошо помнит ажиотаж, царивший на той конференции. Исследо-
Деи из Гарварда рассказывали о связи через всю страну с суперкомпью-
ваТем Univac 1108 в университете штата Юта для выполнения сложных
Те₽°ислений, связанных с их исследованиями в области компьютерной гра-
в ки Научные исследования были на пороге огромного прорыва. Вскоре
Фи ’ этой конференции, Управление перспективных исследовательских
П°ограмм приступило к реализации сети, которая очень быстро получила
азвание ARPAnet — прародителя современной сети Интернет (Internet).
Несмотря на то, что ARPAnet позволила исследователям объединить
свои компьютеры в сеть, ее главным достоинством оказалась возможность
быстрой и удобной связи посредством того, что стало называться электрон-
ной почтой (e-mail). Это важно и для сети Интернет: при помощи электрон-
ной почты мгновенная передача сообщений и файлов, облегчающая обмен
информацией между сотнями миллионов людей по всему миру, становится
все популярнее.
Сеть ARPAnet была создана для работы без централизованного управле-
ния. Это значит, что в случае выхода из строя любого узла сети, оставшие-
ся в рабочем состоянии узлы сохраняют возможность передачи пакетов
данных от отправителя к получателю по альтернативным маршрутам.
Протоколы (т.е. своды правил) для связи по ARPAnet получили назва-
ние Протокола управления передачей/Протокола Интернет (Transmis-
sion Control Protocol/Internet Protocol — TCP/IP). Они использовались для
управления обменом информации между приложениями. Протоколы га-
рантировали передачу сообщений по некоторому маршруту от отправителя
к получателю и обеспечивали их целостность. Появление TCP/IP способст-
вовало росту использования компьютеров во всем мире. На ранних этапах
сетью Интернет пользовались только университеты и исследовательские ор-
ганизации; позже, вооруженные силы также обратились к этой технологии.
В конце концов, правительство разрешило доступ к сети Интернет
в коммерческих целях. Такое решение вызвало некое беспокойство со сто-
роны исследователей и военных — предполагалось, что это негативно ска-
жется на времени ответа, когда сеть будет перегружена пользователями,
ни Самом же Деле> все произошло как раз наоборот. Коммерческие компа-
Пг. очень быстро осознали возможности использования сети Интернет для
Доставления более удобного и надежного сервиса своим клиентам. Они
или огромные денежные средства на развитие и расширение своего
владУТСТВИЯ В сети Интернет. Это привело к жесткой конкуренции между
нОГо ЛВЦ'ами линий связи, поставщиками аппаратных средств и программ-
йнфп еспечения, стремившихся к удовлетворению спроса разросшейся
т.е_ об ТруктУРы- Как результат, пропускная способность (bandwidth) —
Сети ИнвМ ИНфоРмаЧии’ которую можно передавать по линиям связи —
РаТур TepHeT Увеличилась во много раз, в то время как затраты на аппа-
ВСемИ сРеДства связи сильно сократились.
пЗДьЗОваРНая паУтина (World Wide Web — WWW) дает возможность
телям компьютеров размещать и просматривать мультимедиа-до
58 ГлаВц ।
кументы (т.е. текстовые, графические, анимационные, аудио- и видеофа^
лы) практически любой тематики. Несмотря на то, что сеть Интернет бы^
создана более тридцати лет назад, рождение Всемирной Паутины не явл^.
ется таким уж давним событием. В 1989 году Тим Бернерс-Ли из Европе^,
ской организации ядерных исследований (European Center for Nuclei
Research — CERN) занялся разработкой технологии совместного использо.
вания информации посредством текстовых документов, снабженных гц.
пересылками (смотри рубрику «Биографические заметки, Тим Бер.
нерс-Ли»). Для внедрения новой технологии, он создал язык HTRfi
(HyperText Markup Language — Гипертекстовый язык разметки). Он так.
же разработал и Протокол передачи гипертекстов (Hypertext Transfer
Protocol, HTTP), чтобы реализовать технологическую основу для своей но.
вой гипертекстовой информационной системы, которую он назвал Всемир.
ной Паутиной.
Очевидно, что историки внесут Интернет и Всемирную Паутину в спи-
сок самых важных и значительных творений человечества. В прошлом
большинство компьютерных приложений выполнялись на автономных ма-
шинах (тех, которые не были соединены между собой). Современные при-
ложения могут быть написаны для обмена информацией между сотнями
миллионов компьютеров во всем мире. Интернет и Всемирная Паутина со-
единяют вычислительные технологии и технологии связи воедино, делая
нашу работу более быстрой и легкой. Они предоставляют людям удобный
и мгновенный доступ к информации, позволяют отдельным лицам и ма-
лым фирмам заявить о себе перед всем миром, меняют наше представление
о бизнесе и жизни вообще. Они также меняют наше представление о прин-
ципах построения операционных систем. Сегодняшние операционные сис-
темы обеспечивают универсальный графический интерфейс пользовате-
лей, делая «связь с миром» через Интернет и Всемирную Паутину такой
же простой, как обращение к ресурсам своего компьютера. Операционные
системы 80-х годов в основном управляли ресурсами локальных компью-
теров.* Современные распределенные операционные системы могут совме-
стно использовать ресурсы компьютеров, которые находятся в разных точ-
ках нашей планеты. При этом возникает много интересных вопросов, кото-
рые мы рассмотрим на страницах этой книги, уделив им особое внимание
в главах 16... 19. В них речь будет идти о компьютерных сетях, распреде-
ленной обработке данных и безопасности.
ше о операционные системы_________
Вопросы для самопроверки
59
1. Чем сеть ARPAnet отличалась от обычных компьютерных сетей?
В чем в первую очередь заключалось ее преимущество?
2. Что разработал и внедрил Бернерс-Ли для упрощения совместного
использования данных через Интернет?
Ответы 1) Сеть ARPAnet была децентрализована, таким образом,
она не теряла способность передавать информацию в случае выхода из
строя некоторых ее узлов. В первую очередь преимущество этой сети
заключалось в возможности быстрой и удобной передачи информации
посредством электронной почты. 2) Бернерс-Ли разработал язык
HTML (HyperText Markup Language — Гипертекстовый язык размет-
ки) и Протокол передачи гипертекстовых файлов (Hypertex Transfer
Protocol — HTTP), что позволило воплотить идею Всемирной Паутины
в реальность.
ь
Биографические заметки
Тим Бернерс-/\и
Всемирная паутина была разработана
Тимом Бернерсом-Ли в 1990 году. Она дает
возможность пользователям компьютеров
размещать и просматривать мультиме-
диа-документы (т.е. текстовые, графиче-
ские, анимационные, аудио- и видеофайлы)
практически любой тематики.
Тим Бернерс-Ли окончил Королевский
колледж при Оксфордском университете со
степенью по физике в 1976 году. В 1980-м он
написал программу, которая называлась
Enquire и использовала гипертекстовые ссыл-
ки для облегчения работы с многочисленными
Документами большого проекта. В 1984 году
°н стал сотрудником Европейской организа-
ции ядерных исследований (European Center
for Nuclear Research, CERN), где и получил
Опыт работы с коммуникационным программ-
НЬ|м обеспечением для сетевых систем, рабо-
Рабг?ИХ В Режиме Рольного времени 61’ “ “.
°тая в Европейской организации ядерных
СслеД°ваний, в 1989 году Бернерс-Ли создал
Протокол передачи гипертекстовых файлов
(HyperText Transfer Protocol - HTTP), язык
HTML (Hypertext Markup Language - Гипер-
текстовый язык разметки), а также первый
сервер и навигатор для Всемирной Паути-
ны 64,65. Он хотел, чтобы Паутина стала меха-
низмом для открытого и свободного доступа
ко всем общим знаниям и опыту 66. До
1993 года Бернерс-Ли лично занимался из-
менениями и предложениями для протокола
передачи гипертекстовых файлов и языка
HTML, которые поступали от первых пользо-
вателей Паутиной. К 1994 году количество
последних стало настолько большим, что ему
пришлось учредить Консорциум Всемирной
Паутины (World Wide Web Consortium — W3C,
www.w3c.org) для создания стандартов
веб-технологий6' и контроля над ними. Буду-
чи директором этой организации, он активно
пропагандирует принципы свободного досту-
па к информации, предоставленной открыты-
ми технологиями.
60 _______
1.8 90-е годы
Для этого периода времени характерен экспоненциальный рост проца
водительности аппаратных средств 69. К концу десятилетия типичный пер,
сональный компьютер мог выполнять несколько сотен миллионов опера
ций в секунду и хранить более одного гигабайта информации на жестко^,
диске; некоторые компьютеры могли выполнять более триллиона опера,
ций в секунду 70. Дешевая вычислительная мощность и память предост^,
вили пользователям возможность работать на персональном компьютер^
с большими и сложными программами, малым и средним компаниям цс,
пользовать эти недорогие в обслуживании машины для работы с обширны,
ми базами данных и вычислительными задачами, которые когда-то пору,
чались универсальным вычислительным машинам. Снижение производст.
венных затрат также привело к увеличению количества домашних
персональных компьютеров, которые использовались как для работы, так
и для развлечений.
В 90-е годы создание Всемирной Паутины привело к огромному росту
популярности распределенных вычислений. Изначально операционные
системы осуществляли управление автономными ресурсами внутри одного
компьютера. Результатом создания Паутины и постоянно растущей скоро-
сти Интернет-подключений явилось то, что распределенные вычисления
стали обычным явлением среди персональных компьютеров. Пользователи
могли запрашивать данные, которые имели удаленное место хранения,
или выдавать запрос запуска программ на удаленных процессорах. Боль-
шие организации могли использовать распределенные мультипроцессоры
(т.е. сети, состоящие из компьютеров с несколькими процессорами) для
масштабирования ресурсов и повышения производительности 71. Тем не
менее, распределенные приложения все еще сталкивались с ограничения-
ми ввиду того, что связь по сети осуществлялась на относительно малень-
ких скоростях по сравнению со скоростями вычислений внутри отдельных
персональных компьютеров. Распределенные вычисления детально рас-
сматриваются в главе 17 и главе 18.
Поскольку требования к Интернет-подключениям росли, поддержка
операционными системами сетевых задач получила статус стандартной.
Домашние пользователи, а также пользователи организаций повышали
производительность своего труда, используя доступ к ресурсам компью-
терных сетей. Тем не менее, увеличившееся число подключений привело
к росту потенциальной опасности для компьютеров. Разработчики опера-
ционных систем занялись поисками методов защиты компьютеров от на-
падений. Все более изощренные формы атак продолжали бросать вызов
способности компьютерной промышленности противостоять нападениям-
В 90-е годы на первые позиции в сфере компьютерного бизнеса вышла
корпорация Microsoft. В 1981 году она выпустила первую версию своей
операционной системы DOS для персонального компьютера компаний
IBM. В середине 80-х годов корпорация разработала операционную систе'
му Windows, графический интерфейс пользователя, надстроенный поверх
операционной системы DOS. Выпуск Windows 3.0 приходится на 1990 го Д’
отличительной чертой новой версии был удобный для пользователя интер'
>Htie 8 euePa 0l,Hbl0 системы
61
- и разнообразные функциональные возможности. Операционная сис-
ФейС Windows завоевала широкую популярность после выпуска в 1993
теМаWindows 3.1, чьи преемники, Windows 95 и Windows 98, к концу 90-х
Г°^в фактически контролировали весь рынок операционных систем для
Г°Д°ольных персональных компьютеров. Эти операционные системы, по-
умствовавшие многие концепции, прежде реализованные операционны-
заЯсистемами Macintosh (как, например, значки, меню, окна), предостави-
140 пользователям возможность с легкостью управлять множеством парал-
ЛИ ьно выполняемых приложений. Корпорация Microsoft также вышла на
ла корпоративных операционных систем, выпустив в 1993 году
Windows NT, которая очень быстро стала основной операционной системой
ля корпоративных рабочих станций 72. Операционная система Windows
ХР, разработанная на базе Windows NT, будет рассмотрена в главе 21.
Объектная технология
Объектная технология стала популярной во многих областях вычисли-
тельной техники, поскольку количество приложений, написанных на объ-
ектно-ориентированных языках программирования, таких как C++
и Java, постоянно увеличивалось. Объектные принципы также способство-
вали росту популярности новых подходов к вычислению. Каждый про-
граммный объект заключает в себе набор атрибутов и набор действий. Это
позволяет создавать приложения из компонентов, которые могут быть по-
вторно использованы во многих приложениях, сокращая при этом время,
затрачиваемое на новые разработки. В объектно-ориентированных опера-
ционных системах (object-oriented operating systems — 000S) объектами
являются компоненты операционной системы и системные ресурсы 73. По-
нятия объектного ориентирования, такие как наследование и интерфейсы,
использовались для создания модульных операционных систем, которые
были проще в обслуживании и расширении, чем созданные по старым тех-
нологиям системы. Модульность способствует поддержке операционной
системой новых и альтернативных архитектур. Результатом спроса на объ-
ектную интеграцию множества платформ и языков явилась поддержка
объектов в языках программирования, таких как Java компании Sun и се-
мейство .NET корпорации Microsoft (например, Visual Basic .NET,
visual C++ .NET и С#).
Распространение исходного кода
одним событием в сфере вычислительной техники (а точнее в об-
од операционных систем) в 90-х годах стал переход к программному
(°Реп1еЧеНИЮ’ РаспРостРаняемомУ с исходным кодом (открытое ПО
Ся 'Source software)). Большая часть программного обеспечения создает-
сокого^™™ написания исходного кода на языке программирования вы-
°бесп уровня- Тем не менее, большая часть коммерческого программного
НЫм ечения продается в виде объектного кода (также называемого машин-
Рый м™ двоичным кодом) — это откомпилированный исходный код, кото-
Не при0Жет ®ыть непосредственно выполнен компьютером. Исходный код
лагается, что позволяет производителям скрыть информацию, кото-
62 ГлиВц J
рая представляет собой коммерческую тайну, и технологии программир0
вания. Несмотря на это, бесплатное открытое программное обеспечение
становилось в 90-е годы все более и более популярным. Такое программное
обеспечение распространяется вместе с исходным кодом, позволяя отдедь,
ным лицам проверять и модифицировать его, прежде чем компилировать
и запускать в действие. Например, операционная система Linux и веб-сер,
вер Apache, которые являются свободно-распространяемыми (бесплатны,
ми) и распространяются с исходным кодом, были загружены и установке,
ны миллионами пользователей на протяжении 90-х годов, а число загру,
зок в новом тысячелетии быстро растет 74. Операционная система Linux
созданная Линусом Торвальдсом (смотри «Биографические заметки: Ли,
нус Торвальдс»), будет рассмотрена в главе 21.
В 80-х годах, Ричард Столлмен, разработчик программного обеспечения
из Массачусетского Технологического Института, запустил проект, имев-
ший целью восстановить и усовершенствовать основные инструменты опе-
рационной системы UNIX компании AT&T, а также обеспечить бесплат-
ный доступ к коду. Столлмен (смотри «Биографические заметки, Ричард
Столлмен») учредил Фонд бесплатно распространяемых программ (Free
Software Foundation) и создал Проект свободного распространения про-
граммного обеспечения GNU (GNU — рекурсивное сокращение от «GNU
is Not Unix»), так как он был не согласен с политикой продажи прав на ис-
пользование программного обеспечения 75. Он полагал, что предоставление
пользователям свободы в отношении модифицирования и распространения
программного обеспечения приведет к улучшению качества последнего.
Программное обеспечение создается для пользователей, а не для получе-
ния прибыли. Когда Линус Торвальдс создавал оригинальную версию опе-
рационной системы Linux, он бесплатно использовал многие из средств,
опубликованных в рамках проекта свободно распространяемых программ,
согласно Открытому лицензионному соглашению (General Public License,
GPL). В этом документе, который доступен по адресу www.gnu.org/licen-
ses/gpl.html, указывается, что любой желающий имеет право на свободное
модифицирование и дальнейшее распространение программного обеспече-
ния согласно лицензии на него, при условии, если четко указаны внесен-
ные в программы модификации, и все измененное программное обеспече-
ние распространяется согласно GPL-лицензии 76. Несмотря на то, что боль-
шая часть программного обеспечения с этой лицензией может быть
получена бесплатно, данная лицензия требует только, чтобы ее программ-
ное обеспечение было свободным для модифицирования и дальнейшего
распространения. Следовательно, производители могут взыскивать платУ
за предоставление программного обеспечения с GPL-лицензией и его ИС'
ходного кода, но не могут препятствовать конечным пользователям в МО'
дифицировании и дальнейшем распространении данной продукции. В кой'
це 90-х была создана Инициативная группа по распространению открь1'
того программного обеспечения (Open Source Initiative — OSI) с целЫ°
защиты открытого программного обеспечения и популяризации преимУ'
ществ открытого программирования (смотри www.opensource.org).
Открытое ПО способствует совершенствованию программной продуй'
ции посредством предоставления любому члену сообщества разработчике®
возможности тестировать, отлаживать и улучшать приложения. Это увС'
щв В операционные системы
63
чивает вероятность того, что скрытые ошибки, которые могут привести
31 аРУшениям безопасности системы или логики решения задачи, будут
** яБлены и устранены. Более того, отдельные лица и корпорации могут
в1Л^инфицировать исходный код для создания заказных программных
дств, которые будут отвечать требованиям определенной среды. Многие
С онзводители открытого ПО получают прибыль, взыскивая плату с от-
ьных лиц и организаций за техническую поддержку и разработку про-
граммного обеспечения на заказ 88. Несмотря на то, что большинство сис-
id в 90-х годах все еще использовали операционные системы, которые
были защищены правом на собственность, такие как операционные систе-
мы для универсальных вычислительных машин компании IBM, системы
UNIX, системы Macintosh компании Apple и Windows компании Microsoft,
открытые операционные системы, например, Linux, FreeDSD и OpenBSD,
продемонстрировали свою жизнеспособность в условиях конкуренции.
В будущем они, безусловно, будут развивать свой успех в решении право-
вых вопросов, опираясь на повышение качества продукции, промышлен-
ную стандартизацию, увеличение возможностей взаимодействия (про-
граммных и аппаратных изделий разных поставщиков), технологию изго-
товления продукции по техническим условиям заказчика, а также
снижение себестоимости.
В 90-е годы операционные системы стали значительно удобнее для
пользователя. Элементы графического интерфейса пользователя, встроен-
ные в операционную систему Macintosh компании Apple в 80-е годы, в 90-х
годах стали намного изысканнее. Операционные системы также начали
поддерживать технологию «Plug-and-Play», предоставляя пользователям
возможность подключать и отключать аппаратные средства, не перена-
страивая операционную систему вручную. Операционные системы также
стали поддерживать профили пользователей, выполняя идентификацион-
ные функции и давая возможность каждому отдельному пользователю на-
страивать под себя интерфейс операционной системы.
Вопросы для самопроверки
1. Как объектно-ориентированная технология повлияла на операци-
онные системы?
2. Назовите некоторые из преимуществ разработки открытого ПО?
Ответы 1) Разработчики операционных систем могли повторно
использовать объекты при разработке новых компонентов. Увеличе-
ние модульности благодаря применению объектно-ориентированной
технологии способствовало поддержке операционными системами но-
вых и альтернативных архитектур. 2) Открытое ПО может быть про-
смотрено и модифицировано любым членом сообщества разработчиков
программного обеспечения. В виду того, что эти люди постоянно тес-
тируют, отлаживают и используют программное обеспечение, сущест-
вует большая вероятность того, что ошибки будут выявлены и устране-
ны. Более того, открытое ПО предоставляет отдельным пользователям
и организациям возможность модифицирования программ с целью
удовлетворения специфических требований.
64
Биографические заметки
Аинус Торвальдс
Линус Торвальдс родился в 1969 году
в Хельсинки, Финляндия. Будучи ребенком,
он учился программированию, играя
с Commodore VIC-20. В 1988 году он посту-
пил в Хельсинский университет для изучения
вычислительной техники. Там он написал
версию системы UNIX на основе Minix про-
фессора Эндрю Таненбаума для работы на
своем новом ПК 77'78. В 1991 году он завершил
первую версию основного ядра Linux, кото-
рое работало на процессоре Intel 80386 ”. Он
распространял Linux согласно Открытому ли-
цензионному соглашению GPL 80 в качестве
открытого кода, с благодарностью включив
в него предоставленные другими программи-
стами исправления, дополнения и прочие
программы8,,е2. К 1994 году система Linux на-
брала достаточное количество приложений
для того, чтобы стать полнофункциональной
и доступной для использования операцион-
ной системой, — была выпущена версия 1-.083.
Программистам и профессорам, использо-
вавшим UNIX для работы с большими смете
мами, ОС Linux очень понравилась
поскольку она смогла перенести возможно'
сти и ресурсы операционной системы UNIX
на недорогие настольные системы без де.
нежных затрат8485.
На сегодняшний день Торвальдс являет-
ся сотрудником Лаборатории по разработке
открытого программного обеспечения
(Open Source Development Labs - OSDL), ко-
торая финансирует отнимающую все его
время работу над ядром. Он продолжает ру-
ководить проектом, который посвящен от-
крытой операционной системе Linux, зани-
маясь изменениями и выпуском новых вер-
сий ядра В6'87. Операционная система Linux
стала одной из наиболее известных разра-
боток в области открытого ПО за всю исто-
рию существования компьютеров и пользу-
ется особым успехом на рынке серверов. Эта
операционная система будет рассмотрена
в главе 20.
66 ГAliBq i
1.9 2000-й год и позэке
В этом десятилетии посредническое программное обеспечен^
(middleware), т.е. программное обеспечение, которое является связующц^
звеном между двумя отдельными приложениями (как правило, посреди
вом сети) стало жизненно необходимым, поскольку приложения размещу
ются во Всемирной Паутине. Потребители обращаются к ним при помодод
доступных высокоскоростных Интернет-подключений по кабельным теле,
визионным и цифровым абонентским линиям (digital subscriber lines
DSL). Посредническое программное обеспечение доступно в качестве Ид.
тернет-приложений, в которых веб-сервер (приложение, которое отправля.
ет данные на Интернет-обозреватель пользователя) должен сформировать
информационный пакет для удовлетворения запроса пользователя при од.
мощи базы данных. Данное программное обеспечение выступает в роли
курьера для передачи сообщений между веб-сервером и базой данных уц.
рощая связь между множеством различных архитектур (поэтому его ино-
гда называют также межплатформенным ПО). Веб-службы (web services)
оперируют в соответствии с рядом согласованных стандартов, которые од.
зволяют двум компьютерным приложениям осуществлять связь и обмен
данными посредством сети Интернет. Веб-служба осуществляет связь по-
средством сети для передачи ряда специфических команд, которые могут
быть поданы отдельными приложениями. Данные передаются по сети с ис-
пользованием таких стандартных протоколов, как HTTP (этот же прото-
кол используется для передачи веб-страниц). Веб-службы выполняют свои
функции, используя открытые текстовые стандарты, которые обеспечива-
ют взаимодействие написанных на различных языках и платформах ком-
понентов. Они являются готовыми к использованию элементами про-
граммного обеспечения в сети Интернет.
Веб-службы помогут осуществить переход к полноценной распределен-
ной обработке данных. Например, компания Amazon.com, занимающаяся
розничной торговлей в режиме он-лайн, позволяет разработчикам созда-
вать он-лайн магазины, а также осуществлять поиск продукции в базах
данных компании Amazon и предоставляет детальную информацию об
этой продукции посредством веб-служб Amazon.com (www.amazon.coin/
gp/aws/landing.html). Поисковую машину Google также можно использо-
вать в рамках функциональных возможностей приложения посредство^
программных интерфейсов Интернет-приложений Google (www.goo#'
le.com/apis), которые обращаются к Google-индексам веб-узлов, используй
веб-службы. Более детально мы обсудим эти службы в главе 18.
Мультипроцессорные и сетевые архитектуры предоставляют огромны6
возможности для исследований и разработок новых подходов к проектир0'
ванию аппаратных средств и программного обеспечения. Языки послеД0'
вательного программирования, которые специфицировали выполнение оД'
ной операции за один шаг, теперь пополнились языками параллельно1^
программирования, такими как Java, которые сделали возможной cnciJ1
фикацию параллельных вычислений; в языке Java параллельная обрабо^
ка описывается посредством потоков. Мы обсудим потоки и методы орГ^
низации многопоточной обработки в главе 4.
те 6 операционные системы
67
Р стет число систем, которые демонстрируют массовый параллелизм
give parallelism); они включают большое количество процессоров, та-
^inaS образом, многие независимые процессы могут выполняться парал-
КИМ но Данный метод обработки, идеологически, существенно отличается
^Последовательного, который использовался в течение последних 60-ти
°Т В процессе разработки программного обеспечения, ориентированного
ЛеТ-гакой параллелизм, возникают важные и требующие огромных сил для
На ения проблемы. Мы обсудим параллельные вычислительные архитек-
туры в главе 15. „
Операционные системы стандартизируют интерфейсы пользователей
и приложений, таким образом, они становятся более удобными в использо-
вании и поддерживают большее число программ. Корпорация Microsoft
е объединила потребительскую и профессиональную линии операцион-
ной системы Windows в Windows ХР. В своей будущей операционной сис-
теме (под кодовым названием Longhorn) корпорация Microsoft планирует
объединить форматы различных типов файлов. Это, к примеру, разрешит
пользователям осуществлять в своей системе поиск всех файлов (докумен-
тов, электронных таблиц, электронных писем, и т.д.), которые содержат
определенные ключевые слова. Операционная система Longhorn также бу-
дет включать усовершенствованный трехмерный интерфейс пользователя,
более надежную систему безопасности и поддержку записываемых универ-
сальных цифровых дисков (DVD) 99> 10°. Открытые операционные системы,
такие как Linux, будут использоваться шире и будут применять стандарт-
ные программные интерфейсы приложений (application programming
interfaces, APIs), как, например, Интерфейс переносимых операционных
систем (Portable Operating System Interface — POSIX) для повышения со-
вместимости с другими операционными системами на базе UNIX.
Обработка данных на таких мобильных устройствах, как сотовые теле-
фоны и карманные компьютеры (Personal Digital Assistant — PDA), станет
более привычной по мере того, как они будут оснащаться все более и более
мощными процессорами. На сегодняшний день данные устройства уже
Реализуют такие операции, как отправление и получение электронных пи-
сем, просмотр веб-страниц, формирование цифрового изображения. При-
ложения, интенсивно использующие ресурсы, например, полномасштаб-
Cbj6 ВИдео’ станУт доступными на подобных устройствах. Поскольку ресур-
об Т™ устР°^ств ограничены их малыми размерами, распределенная
Р отка данных станет играть все большую роль по мере того, как кар-
обЪе Ые компьютеры и сотовые телефоны будут запрашивать все большие
мы данных и большую вычислительную мощность у удаленных ком-
Ь1°ТерОр„
Вопросы для самопроверки
1- При помощи каких технологий можно преодолеть пропасть, разде-
ляющую различные операционные системы? Каким образом эти
технологии позволяют выполнять одно и то же приложение на раз-
ных платформах?
2. Какую помощь оказывает распределенная обработка данных вы-
числениям, выполняемым на мобильных устройствах?
70 ___________rJLa6« I
Многие принципы построения универсальных вычислительных мащй^
применяются также к мощным веб-серверам и серверам баз данных на oq.
нове высокопроизводительных аппаратных средств. Операционные сист^
мы, предназначенные для работы в высокопроизводительной аппаратной
среде, необходимо разрабатывать в расчете на использование основной ца
мяти большого объема, специализированных аппаратных средств и бодь^
шого числа процессоров. Эти вопросы будут рассмотрены в главе 15.
Встроенные системы (embedded system) ставят перед разработчиками
операционных систем другие требования. Для них характерно небольшой
набор специализированных ресурсов, предназначенных для обеспечения
функциональных возможностей таких устройств, как сотовые телефону
и карманные компьютеры. В такой среде эффективное управление ресур.
сами является ключом к созданию успешной операционной системы. Объ.
ем памяти при этом, как правило, ограничен, следовательно, операцион.
ная система должна выполнять свои функции, используя программы ми-
нимальной длины. Необходимость управления режимом электропитания
и потребности в удобном для пользователя интерфейсе ставят перед разра-
ботчиками встроенных операционных систем специальные требования.
Системы реального времени должны решать свои задачи в рамках опре-
деленного (как правило, короткого) промежутка времени. Например, авто-
пилот самолета должен постоянно осуществлять измерение скорости, вы-
соты и направления. Подобные задачи не могут ожидать в течение неопре-
деленного промежутка времени (а иногда совсем не могут ожидать)
завершения выполнения других не столь важных задач. Операционные
системы данного типа должны предоставлять процессам возможность не-
медленно реагировать на важные события. Мягкие системы реального вре-
мени обеспечивают учет приоритета задач реального времени, но не гаран-
тируют своевременное завершение ни одной из них. Жесткие системы ре-
ального времени обеспечивают своевременное завершение выполнения
всех задач. В главах 20 и 21, соответственно, мы обсудим, каким образом
операционные системы Linux и Windows ХР управляют приложениями ре-
ального времени. Эти системы используются во многих сферах автомати-
ки, как, например, робототехнике, авиационной электронике и других
управляющих системах. Как правило, они находят применение в системах
для решения критически важных задач (mission-critical systems), для ко-
торых несвоевременное выполнение даже одной поставленной перед ними
задачи приводит к отказу. Сбой в работе таких систем, как система упраВ'
ления воздушным движением, система наблюдения за работой ядерного
реактора, система военного командования и контроля, может поставить
под угрозу человеческие жизни (поэтому иногда такие системы называют-
ся «жизненно-важными системами»).
Системы, разработанные для решения важных бизнес-задач (ответсТ'
венные бизнес-ориентированные системы (business-critical system)), та'
кие как веб-серверы и базы данных, должны отвечать специфическим тре'
бованиям. При организации электронной коммерции в сети Интернет П0'
добные системы гарантируют пользователям, совершающим покуп^11
в режиме он-лайн, быструю реакцию на их запросы. В больших корпор3'
циях благодаря этим системам служащие могут эффективно работать с об'
щими данными в режиме коллективного пользования, в то время как ва?#'
71
в оперши иные системы
информация в случае аварийных ситуаций, таких как нарушение
ваЯ снабжения и выход дисков из строя, остается неповрежденной. В от-
энерГОот систем для решения критически важных задач, невыполнении
ЛИЧИций бизнес-ориентированной системой далеко не всегда приводит
ФУ”тастрофическим последствиям.
К ть разновидность операционных систем, которые должны уметь
являть как доступными, так и недоступными в данной конфигурации
УПР оатными ресурсами вычислительной машины. Виртуальная машина
a*1- tual machine — VM) — это программный элемент, который функциони-
т таким же образом, как и пользовательское приложение, поверх базо-
РУй операционной системы 101. Операционная система виртуальной маши-
ны управляет ресурсами виртуальной машины. Одно из применений вир-
vanbHbix машин состоит в обеспечении параллельного выполнения
множества экземпляров операционных систем. Еще одно применение —
эмуляция, — использование программ и аппаратуры для имитации функ-
циональных возможностей программного обеспечения и аппаратных
средств, физически недоступных в системе.
Виртуальные машины взаимодействуют с аппаратными средствами сис-
темы при помощи базовой операционной системы. Пользовательские про-
граммы, в свою очередь, могут взаимодействовать с виртуальными маши-
нами. Такие машины используют программные компоненты, которые вы-
ступают в роли элементов физических систем, например, процессоров,
памяти, каналов связи, дисков, системных часов (рис. 1.2) 102. Это дает
многочисленным пользователям возможность работы с аппаратными сред-
ствами в режиме коллективного пользования при иллюзии непосредствен-
ного доступа к ресурсам базового компьютера. Создавая такую видимость,
виртуальные машины содействуют развитию мобильности (portability)
программного обеспечения (т.е. возможности программного обеспечения
Функционировать на различных платформах).
Виртуальная машина Java (Java Virtual Machine — JVM) является од-
ной из наиболее широко распространенных виртуальных машин. JVM —
это основа платформы Java. JVM позволяет всем приложениям Java вы-
полняться на любой системе при условии, что там установлена виртуаль-
ная машина JVM соответствующей версии. Компания VMware Software
поставляет виртуальные машины, в частности, для архитектуры Intel, по-
ляя владельцам компьютеров на основе семейства Intel х86 одновремен-
о работать с такими операционными системами как Linux и Windows на
Компьютере (каждая виртуальная машина отображается в своем
собственном окне) юз.
пРоизвТУаЛЬНЬ1е машины в большинстве случаев обладают более низкой
Прямо °'П'ительнос'гью» чем реальные машины, поскольку они не имеют
ФактиГ° достУпа к аппаратным средствам (или эмулируют те, которые
Доступ^ Не подключень1 к компьютеру). Косвенный или эмулируемый
Необхо К аппаРатным средствам увеличивает число программных шагов,
димых для выполнения каждой аппаратной операции 104.
74 Гм fa 1
Практически асе современные операционные системы поддерживают
мультипрограммную среду, в которой многочисленные процессы могут вы
полниться параллельно. К основным обязанностям операционной системы
относится определение того, на каком процессоре и в течение какого пе-
риода времени будет обрабатываться процесс.
Программа может включать в себя несколько элементов, которые со-
вместно используют данные и могут выполняться параллельно. Например,
Интернет-обозреватель может включать в себя несколько компонентов,
один из которых предназначен для чтения HTML-фрагментов веб-страниц,
другой — для декодирования аудиовизуальной информации (например,
иллюстраций, звуковых и анимационных фрагментов), а третий — для
отображения страницы посредством вывода ее содержимого в окне обозре-
вателя. Такие программные компоненты, которые выполняются независи-
мо друг от друга, но решают свои задачи в общей области памяти, называ-
ются потоками (thread). Потоки рассматриваются в главе 4.
Как правило, многие процессы соперничают за право использовать про-
цессор. Планировщик процессов может принимать решение на основе не-
скольких критериев, таких как важность процесса, предполагаемое время
его выполнения, или на основе того, как долго данный процесс находился
в очереди. Мы обсудим планирование загрузки процессора в главе 8.
Диспетчер памяти выделяет память для операционной системы и про-
цессов. Чтобы обеспечить невмешательство процессов в работу операцион-
ной системы или в работу друг друга, диспетчер памяти препятствует дос-
тупу процесса к памяти, выделенной не для него. Практически все совре-
менные операционные системы поддерживают виртуальную память. Эта
тема будет затронута в главах 10 и 11.
Еще одной ключевой функцией операционной системы является управ-
ление устройствами ввода/вывода компьютера. К устройствам ввода отно-
сятся клавиатура, мышь, микрофон и сканер; к устройствам вывода — мо-
нитор, принтер и акустическая система. Запоминающие устройства (на-
пример, накопители на жестких магнитных дисках, перезаписываемые
оптические диски и магнитные ленты), а также сетевые карты выполняют
обе функции — ввода и вывода. Если процесс намеревается получить дос-
туп к такому устройству, ему необходимо сформировать запрос операцион-
ной системе. Такой запрос впоследствии будет обработан драйвером уст-
ройства (device driver), который является программным компонентом опе-
рационной системы и взаимодействует непосредственно с аппаратными
ресурсами. Драйвер располагает специфическим для данного устройства
набором команд, предназначенных для выполнения запрашиваемых опе-
раций ввода/вывода.
Практически все компьютерные системы могут хранить данные даже
после выключения. В виду того, что объем основной памяти, как правило,
незначителен, а содержимое ее теряется после выключения компьютера,
прибегают к использованию внешних запоминающих устройств, сохра-
няющих данные даже в выключенном состоянии. В большинстве случаев
это накопители на жестких магнитных дисках. Операции дискового вво-
да/вывода осуществляются в тех случаях, когда процесс запрашивает дос-
туп к информации, хранящейся на дисковом устройстве (одна из наиболее
распространенных форм ввода/вывода).
в операционные системы
75
Однако внешнее запоминающее устройство работает намного медленнее
поцессора или основной памяти. Специальный компонент операционной
системы (планировщик дисковых операций (disk scheduler)) отвечает за
переупорядочение запросов дискового ввода/вывода для повышения про-
изводительности и сокращения времени ожидания процессом доступа
диску. Массив независимых дисковых накопителей с избыточностью
(Redundant Array of Independent Disks — RAID) предназначен для сокра-
щения этого времени посредством одновременного использования ряда
дисков для удовлетворения запросов ввода/вывода. Алгоритмы планиро-
вания работы дисков и массивы независимых дисковых накопителей с из-
быточностью будут рассмотрены в главе 12.
Файловые системы используются в операционных системах для органи-
зации и эффективного доступа к поименованным объектам, называемых
файлами, которые хранятся на запоминающих устройствах. Концепции
файловых систем будут рассмотрены в главе 13.
Как правило, процессы (или потоки) взаимодействуют между собой для
решения общей задачи. Поэтому многие операционные системы обеспечи-
вают межпроцессное взаимодействие (interprocess communication — IPC)
и предоставляют механизмы синхронизации для упрощения параллельно-
го программирования, связанного с взаимодействием процессов (или пото-
ков). Межпроцессное взаимодействие осуществляется посредством сообще-
ний, которыми обмениваются процессы (и потоки). Механизмы синхрониза-
ции предусматривают специальные структуры, которые могут применяться
для обеспечения корректного использования процессами (и потоками) об-
щих данных. Процессы и потоки рассматриваются в главах с 3 по 8.
Вопросы для самопроверки
1. Какие компоненты операционной системы выполняют каждую из
следующих операций?
а) запись информации на диск,
б) определение очередности выполнения процессов,
в) определение области памяти, в которую будет помещен новый
процесс,
г) упорядочение файлов на диске,
д) осуществление обмена данными между процессами.
2. Какие негативные последствия могут иметь попытки пользователя
прочитать или записать произвольную область памяти?
Ответы 1) а) диспетчер ввода-вывода; б) планировщик процессов;
в) диспетчер памяти; г) диспетчер файловой системы; д) диспетчер
межпроцессного взаимодействия. 2) Эти действия небезопасны, т. к.
пользователи могут случайно или умышленно перезаписать критиче-
ские элементы данных (таких как, файлы операционной системы) или
получить несанкционированный доступ к секретной информации (на-
пример, к конфиденциальным документам).
Глава 1
Размышления об операционных системах
Производительность
Одной из наиболее важных задач разра-
ботчиков операционных систем является
максимизация производительности системы.
Мы имеем дело с производительностью каж-
дый день: фиксируем расход топлива маши-
ной, записываем рекорды скорости, профес-
сора ставят оценки студентам, служащие по-
лучают от работодателей оценку своей
работы, результаты работы руководства кор-
порации измеряются доходами компании,
результаты деятельности политиков оценива-
ются количеством голосов избирателей в их
пользу и т.д.
Высокая производительность является не-
отъемлемым свойством удачных операцион-
ных систем. Тем не менее, о производитель-
ности, как правило, приходится судить поль-
зователю. Существует много способов
вычисления производительности операцион-
ной системы. Например, для систем пакетной
обработки данных огромное значение имеет
пропускная способность; для интерактивных
систем, работающих в режиме разделения
времени, более важным является короткое
время реакции.
Практически в каждом разделе этой кни-
ги приводятся примеры технических прие-
мов повышения производительности. На-
пример, в главе 8 описывается распределе-
ние времени процессора между процессами
для повышения производительности с пози-
ций интерактивности и пропускной способ-
ности. В главе 11 обсуждается распределе-
ние памяти между процессами для сокраще-
ния времени, затрачиваемого на их
выполнение. В главе 12 акцент делается на
повышении производительности дисков по-
средством переупорядочения запросов вво-
да/вывода. В главе 14 мы рассмотрим техни-
ку оценки систем по нескольким критериям
производительности. В главах 20 и 21 будут
обсуждаться вопросы производительности
конкретных операционных систем: Linux
и Windows ХР, соответственно.
1J3 Архитектура операционных систем
Современные операционные системы тяготеют к сложности, т. к. пре-
дставляют широкий спектр услуг и поддерживают различные аппарат-
ное и программные ресурсы (смотри «Размышления об операционных сис-
темах: Придерживаемся простоты» и «Поучительные истории»). Выбор
юдходящей архитектуры операционной системы может помочь разработ-
чикам в борьбе со сложностью путем упорядочения компонентов операци-
>нных систем и определения уровня привилегий этих компонентов. При
монолитной архитектуре все компоненты операционной системы входят
f состав ядра. Если архитектура системы построена на микроядре, в его со-
став входят только наиболее необходимые из компонентов. В этом разделе
гы детально изучим некоторые важные разновидности архитектур опера-
ионных систем (смотри «Размышления об операционных системах: Ар-
итектура»).
знче 6 операционные системы
/. /Л 1 Монолитная архитектура
Монолитная операционная система (monolithic operating Sv4t™i
наиболее ранняя и самая распространенная архитек™ пттДо У } ~ это
Каждый компонент такой операционнойсиХХлю»^™"™ СИС'
Жет непосредственно взаимодействовать с другимя компонеХамТ^ "°’
выполняя вызов соответствующей функции). Ядро как ппХТ (просто
ется с неограниченными правами доступа к necvnca™ правил^ выполня-
ционные системы OS/360, VMS и Linttx очень^аето пт Опера-
Монолитных «. Непосредственное взаимодейс^е Z™ “ Мтего>>™
делает монолитные операционные системы выСокотффе^ивн™ми°“0“™“
вследствие того, что монолитные ядра объедини™ У₽ективными. Однако
но, определение истопника сбоев п ош^ок пХ7 к<>мп«™«™ воеди.
,ей. Более того, т. к. весь код ядра выполняет^ с неХ"ХГнны “°Й Зада'
ми доступа к ресурсам, те системы, котопые п₽ава-
бенно уязвимы для ошибочного или вредительского кодГ™ °С°'
Приложения
t ..... 1
Интерфейс системных
вызовов
Пространство пользователя
Пространство ядра
: ММ
; |/о
Ядро
PS IPC ; FS
Net
ММ = Memory manager = Диспетчер памяти
'PS = Processor scheduler = Планировщик
j загрузки процессора
IPC = Interprocess communication =
^Межпроцессное взаимодействие
> 'FS = File system = Файловая система
.______... ^uFUivuun LULICMd
I/O = Input/output manager = Диспетчер
;ввода/вывода
‘Net - Network manager = Сетевой диспетчеру
^Чс. 1.3. Архитектура ядра монолитной операционной системы
Вопросы дпя самопроверки
1. Какое свойство является определяющим для монолитной операци-
онной системы?
2. Почему монолитные операционные системы считаются эффектив-
ными? В чем заключается недостаток монолитного ядра?
SZ Глава!
дзводительность системы снижается, в отличие от монолитного ядра, кото,
эому может понадобиться лишь один вызов, чтобы обслужить аналоги^,
тый запрос. Кроме того, т. к. все уровни наделены неограниченны^
доступом к ресурсам, многоуровневые ядра также уязвимы для ошибочно,
о или вредительского кода. Операционная система THE является раннц^
тримером многоуровневой операционной системы (рис. 1.4) 107. Многце
тз современных операционных систем, в том числе Windows ХР и 1дпцх
догут быть в определенном смысле отнесены к многоуровневым.
Вопросы дм самопроверки
1. В чем проявляется более высокая степень модульности многоуров.
невой операционной системы по сравнению с монолитной?
2. Почему многоуровневые операционные системы считаются менее
эффективными, чем монолитные?
Ответы 1) В многоуровневой операционной системе реализация
и интерфейс свои у каждого уровня, что позволяет проводить тестиро-
вание и отладку каждого уровня отдельно. Более того, это позволяет
разработчикам изменять реализацию каждого уровня, независимо от
других уровней. 2) В многоуровневых операционных системах для
осуществления связи между уровнями может понадобиться несколько
вложенных вызовов, в то время как в работе монолитных ядер такие
издержки отсутствуют.
Пространство пользователя
Пространство ядра
Уровень 4
Уровень 3
Уровень 2
Уровень 1
Уровень О
Пользователь
^Пользовательское приложен
Управление вводом/выводом
L------------
Интерпретатор сообщений
+----------------------г
Управление памятью
Распределение процессорных
ресурсов и планирование
процессов
1.4. Уровни операционной системы THE
83
В операционные системы
Размышления об операционных системах
црхитектура
Подобно тому, как архитекторы использу-
различные стили в проектировании зда-
й разработчики операционных систем ис-
Нользуют различные архитектурные подходы
П°разработке операционных систем. Иногда
выбранный подход предусматривают исполь-
зование единых принципов в разработке всей
системы. В некоторых случаях используются
смешанные подходы, объединяющие преиму-
щества нескольких архитектурных стилей.
Подход, к которому прибегает разработчик,
оказывает существенное влияние, как на пер-
вичную реализацию, так и на пути развития
операционной системы. Чем дальше вы про-
двигаетесь в процессе разработки, тем труд-
нее сменить выбранный подход. Таким обра-
зом, очень важно выбрать правильную архи-
дуктов, как операционные системы, является
многоуровневая архитектура. В соответствии
с этим подходом программное обеспечение
разбивается на модули, называемые уровня
ми, так что каждый из них решает определен-
ную группу задач. Каждый уровень запраши-
вает услуги, предоставляемые расположен-
ным непосредственно под ним уровнем, но
реализация этого уровня скрывается от уровня,
расположенного над ним. Такая иерархия со-
четает в себе преимущества модульного прин-
ципа разработки программного обеспечения
и принципа сокрытия информации, что помо-
гает заложить прочные основы высококачест-
венных систем. Применение многоуровневых
архитектур при разработке программного
обеспечения будут рассматриваться практиче-
тектуру еще на первых этапах разработки
системы. Чтобы проиллюстрировать суть этого
тезиса, приведем строительную аналогию
куда проще построить новое здание на другом
фундаменте, чем перестраивать старое.
Одним из наиболее распространенных ре-
шений в разработке таких программных про-
ски в каждой главе книги, начиная с историче-
ского упоминания о системе THE Эдсгера
Дейкстры (смотри раздел 1.13.2, Многоуров-
невая архитектура) и, завершая разбором
того, как данный подход был реализован при
разработке систем Linux и Windows ХР (смотри
главы 20 и 21, соответственно).
Архитектура на основе микроядра
sv , пеРаЦионная система на основе микроядра (microkernel operating
Вие ' пРеДОставляет лишь малый набор услуг — это необходимое усло-
МостиХраНеНИЯ Не®ольших размеров ядра и обеспечения его масштабируе-
ЛеНи ' ^аК пРавило’ в перечень этих услуг входят низкоуровневое управ-
хРони Памятью’ межпроцессное взаимодействие и базовые средства син-
пРоцесаЦИИ ДЛЯ °^еспечения совместного функционирования нескольких
т°в овС°В- В аРхитектУРах на основе микроядра большая часть компонен-
8 СеТи ?а15ионноп системы, таких как, управление процессами, работа
яДРа и дИловые операции и управление устройствами, выполняется вне
аолее низким уровнем привилегий (рис. 1.5)108’ 109> 110> 111.
Расцц1г; Ядра ДемонстРируют высокую степень модульности, что делает их
РЯемыми, мобильными и масштабируемыми 112. Более того, микро-
86
Глава i
Рис. 1.6. Модель «клиент-сервер» сетевой операционной системы
Вопросы для самопроверки
1. В чем заключается основное отличие между сетевыми и распреде-
ленными операционными системами?
2. В чем заключается основное преимущество распределенной опера-
ционной системы и основная проблема ее разработки?
Ответы 1) Сетевая операционная система управляет одним компь-
ютером, но взаимодействует с другими компьютерами сети. В распре-
деленной операционной системе одна операционная система
управляет большим количеством компьютеров, объединенных в сеть-
2) Основное преимущество заключается в том, что процессу не над0
знать расположение ресурсов, которые он использует, что в значи-
тельной мере упрощает технологию прикладного программирования-
Это преимущество достигается трудом системного программиста, ко-
торый должен реализовать сложные алгоритмы управления для того,
чтобы процессы могли взаимодействовать и совместно использовать
данные, хранящиеся на множестве компьютеров, создавая иллюзию
того, что все эти компьютеры являются частью одного мощного.
в операционные системы
87
Зеб-ресурсы
bell-labs.com/history/unix/
v,W'hht полную историю операционной системы UNIX, начиная с появления
^₽а Multics вплоть до современной зрелой операционной системы UNIX. Рас-
в систе т многие проектные и архитектурные решения использовавшиеся в ходе
сматри TTNTtv
эволюции UNIX.
softpanorama.org/History/os_history.shtml
Содержит исчерпывающую информацию об операционных системах в истори-
ческом ракурсе.
jeww microsoft.com/windows/WinHistorylntro.mspx
Освещает историю операционных систем семейства Microsoft Windows.
WWW.viewz.com/shoppingguide/os.shtml
Содержит сравнительные данные о некоторых популярных операционных сис-
темах, в том числе Windows, Linux и MacOS, а также содержит ретроспективную
информацию об их развитии.
developer.apple.com/darwin/history.html
Охватывает материал по эволюции ядра Darwin операционной системы OS X
компании Apple.
www.cryptonomicon.com/beginning.html
Содержит ссылку на статью Нила Стивенсона «В начале была командная стро-
ка». Это повествование на тему о недавней истории операционных систем с удач-
ным использованием анекдотов и метафор.
www.acm.org/sigcse/cc2001/225.html
Содержит рекомендации в отношении учебного плана для курсов по операцион-
ным системам от АСМ/IEEE Joint Task Force, завершившей осуществление проек-
та комплексного учебного плана Computing Curricula 2001 (СС2001). В этом учеб-
ном плане выделены ключевые разделы материала, которые должны войти в про-
грамму стандартных курсов по операционным системам.
whatis.techtarget.сот/
Содержит определения компьютерных терминов.
www.webopedia.сот/
Содержит словарь, функционирующий в оперативном режиме, и машину поис-
ка терминов компьютерной тематики и тематики Интернет.
“yw.wikipedia.org/
он 1\?ект Wikipedia направлен на создание бесплатной, открытой и точной
Тылаин энциклопедии. Каждый пользователь может модифицировать ее элемен-
нен КОто₽ые лицензированы согласно лицензии GNU по бесплатному распростра-
Документации (GNU Free Documentation License, GNUFDL).
Нес
Так: Про>ЛЬК° ЛеТ назаД определение операционной системы могло бы выглядеть
Ла8ДШа(1^РаММН0е обеспечение, которое управляет аппаратными средствами. Но
г° °пРепе компьютерного мира сильно изменился с тех пор, требуя более глубоко-
л°лсения Ления‘ Чтобы повысить эффективность использования аппаратуры, при-
с Другом 1рЭОектиРУются в расчете на то, что они будут работать одновременно друг
- Если эти приложения не были разработаны должным образом, то они бу-
;ачи гипертекстов (Hypertext Transfer Protocol — HTTP), чтобы реализоват
дологическую основу для своей новой гипертекстовой информационной систе
, которую он назвал Всемирной Паутиной.
Для 90-х годов характерен экспоненциальный рост производительности апц9
ных средств. Дешевая вычислительная мощность и память предоставили под^
:ателям возможность работать на персональном компьютере с большими и слод,
ми программами, малым и средним компаниям использовать эти недорог^
бслуживании машины для работы с обширными базами данных и вычислите.^
ми задачами, которые когда-то поручались универсальным вычислительны»,
пинам. В 90-е годы значительно ускорился переход к распределенным вычисде
м (т.е. использованию большого количества компьютеров для выполнения об'
й задачи). Поскольку требования к Интернет-подключениям росли, поддери^
^рационными системами сетевых задач получила статус стандартной. Домащ.
j пользователи, а также пользователи организаций повышали производитель.
:ть своего труда, используя доступ к ресурсам компьютерных сетей.
В 90-е годы на первые позиции в сфере компьютерного бизнеса вышла корпорд.
I Microsoft. Операционные системы Windows, позаимствовавшие многие идем
;жде реализованные операционными системами Macintosh (как, например,
чки, меню, окна), предоставили пользователям возможность с легкостью
>авлять множеством параллельно выполняемых приложений.
Объектная технология стала популярной во многих областях вычислительной
ники, поскольку огромное количество приложений было написано на объект-
ориентированных языках программирования, таких как C++ и Java. В объект-
эриентированных операционных системах объектами являются компоненты
рационной системы. Понятия объектного ориентирования, такие как наследо-
ие и интерфейсы, использовались для создания модульных операционных сис-
, которые были проще в обслуживании и расширении, чем созданные по ста-
л технологиям системы.
Большая часть коммерческого программного обеспечения продается в виде объ-
ного кода. Исходный код не прилагается, что позволяет производителям
ыть информацию, которая представляет собой коммерческую тайну, и техноло-
программирования. Открытое программное обеспечение распространяется
сте с исходным кодом, позволяя отдельным лицам проверять и модифищщо-
=• его, прежде чем компилировать и запускать в действие. Операционная систе-
-лпих и веб-сервер Apache являются свободно-распространяемыми (бесплатны-
и распространяются с исходным кодом.
3 80-х годах, Ричард Столлмен, разработчик программного обеспечения из
сачусетского Технологического Института, запустил проект, имевший целью
лановить и усовершенствовать основные инструменты операционной системы
X компании AT&T. Столлмен создал Проект свободного распространения про-
лмного обеспечения GNU, так как он был не согласен с политикой продажи
з на использование программного обеспечения. Открытое ПО способствует со-
пенствованию программной продукции посредством предоставления любому
iy сообщества разработчиков возможности тестировать, отлаживать и улуч-
ь приложения. Это увеличивает вероятность того, что скрытые ошибки, кото-
могут привести к нарушениям безопасности системы или логики решения зада-
будут выявлены и устранены. Более того, отдельные лица и корпорации могут
тфицировать исходный код для создания заказных программных средств, кото-
будут отвечать требованиям определенной среды.
> 90-е годы операционные системы стали значительно удобнее для пользовате-
Злементы графического интерфейса пользователя, встроенные в операционку!0
ему Macintosh компании Apple в 80-е годы, продолжали широко использовать-
о многих операционных системах и становились более изысканными. Опера'
гные системы также поддерживали технологию «Plug-and-Play», предостав-
пользователям возможность подключать и отключать аппаратные средства, не
настраивая операционную систему вручную.
g операционные системы
91
едническое программное обеспечение — это программное обеспечение, ко-
ПоС шляется связующим звеном между двумя отдельными приложениями, как
тоР°е я посредством сети и между несовместимыми машинами. Данное про-
правило, обеспечение имеет огромное значение для веб-служб, упрощая связь ме-
граммн еств0М различных архитектур. Веб-службы оперируют в соответствии
ЖДУ мн гласованных стандартов, которые позволяют двум компьютерным при-
с РЯД01*1 0Существлять связь и обмен данными посредством сети Интернет. Они
ЛОЯяются готовыми к использованию элементами программного обеспечения в сети
IlHn₽ Явление в 1981 году Персонального Компьютера IBM (часто называемого про-
1 ПК») послужило причиной возникновения и быстрого развития мощного рын-
ст° *пограммного обеспечения, в рамках которого независимые поставщики ПО
Т dependent Software Vendors — ISV) могли сбывать пакеты программ для персо-
ных компьютеров IBM, ориентированные на работу с операционной системой
K1S-DOS. Если некая операционная система представляет собой среду, удобную для
^ёгрой'и эффективной разработки приложений, то такая операционная система
аппаратные средства вероятней всего будут пользоваться спросом на рынке. Если
же база приложений (т.е. сочетание аппаратных средств и операционной системы,
в которой разрабатываются приложения) заняла прочные позиции, пользователей
и разработчиков программного обеспечения будет очень трудно склонить к переходу
на абсолютно новую среду разработки приложений в другой операционной системе.
Операционные системы, предназначенные для работы в среде с высокой произ-
водительностью, должны разрабатываться в расчете на использование основных
запоминающих устройств больших объемов, специализированных аппаратных
средств, а также большого количества процессов. Встроенным системам свойстве-
нен малый объем специализированных ресурсов, предназначенных для обеспече-
ния функциональных возможностей таких устройств, как сотовые телефоны
и карманные компьютеры. В такой среде эффективное управление ресурсами яв-
ляется ключом к созданию хорошей операционной системы.
Задачи систем реального времени должны решаться в течение определенного
(как правило, короткого) промежутка времени. Например, автопилот самолета
должен постоянно осуществлять измерение скорости, высоты и направления. Та-
кие задачи не могут ожидать в течение неопределенного промежутка времени (или
совсем не могут ожидать) завершения других не столь важных задач.
Есть разновидность операционных систем, которые должны уметь управлять как
Доступными, так и недоступными в данной конфигурации аппаратными ресурсами
вычислительной машины. Виртуальная машина (virtual machine — VM) — это про-
граммный элемент, который функционирует таким же образом, как и пользователь-
ское приложение, поверх базовой операционной системы. Операционная система
виртуальной машины управляет ресурсами последней. Одно из применений вирту-
ьных машин состоит в обеспечении параллельного выполнения множества экзем-
п Р°в опеРационных систем. Еще одно применение — эмуляция, — использование
ного^^ГМ И аппаРатУРы Для имитации функциональных возможностей программ-
вая Обеспечения и аппаратных средств, физически недоступных в системе. Созда-
и ИЛЛ1°зию непосредственного выполнения приложений на различной аппаратуре
МостиТ®™ системах’ виртуальные машины способствуют развитию переноси-
платфо^ЗМ)°ЖНОСТИ пР0гРаммн0г0 обеспечения функционировать на различных
сколькЬЗ°ВаТеЛЬ °®РаЩается к операционной системе посредством одного или не-
прилож Х пользовательских приложений, а также часто посредством специального
н°вные НИЯ’ называемого оболочкой. Совокупность программ, объединяющая ос-
к этим КОмпоненты операционной системы, называется ядром. Как правило,
ПетЧер в°мпонентам относятся: планировщик процессов, диспетчер памяти, дис-
Диспеттг в°^а"ВЬ1вода, диспетчер межпроцессного взаимодействия (IPC Manager),
чеР файлов.
94
Гипертекстовый язык разметки (HyperText Markup Language, HTML) — языь
который описывает содержимое и порядок отображения содержимого веб-ст^1
ницы, а также предоставляет гиперссылки для доступа к другим страница^
Графический интерфейс пользователя (Graphical User Interface, GUI) — УДобц
для пользователя средство доступа к операционной системе, включающее в Се^
графические элементы, такие как окна, значки и меню, предназначенные д,.4
упрощения работы с программами и файлами. 4
Диспетчер ввода/вывода (i/o manager) — компонент операционной системы,
торый принимает, анализирует и выполняет запросы ввода/вывода.
Диспетчер межпроцессного взаимодействия (interprocess communication (Ippj
manager) — компонент операционной системы, управляющий взаимодействие^
между процессами.
Диспетчер памяти (memory manager) — компонент операционной системы, управ
ляющий физической и виртуальной памятью.
Диспетчер файловой системы (file system manager) — компонент операционной
системы, управляющий размещением именованных объектов на запоминаю,
щих устройствах и предоставляющий интерфейс для доступа к данным на этих
устройствах.
Длительность жизненного цикла задачи (turnaround time) — время, которое про-
ходит от подачи запроса до возвращения системой результатов его выполнения
(иногда применяют термин .«оборотное время»).
Драйвер устройства (device driver) — программное обеспечение, посредством ко-
торого ядро взаимодействует с аппаратурой. Драйверы устройств хорошо знак»,
мы со спецификой устройств, которыми они управляют, например, дисковые
драйверы знают способ размещения данных на дисках. Драйверы пользуются
зависящим от устройства набором операций, например, для дисков это опера-
ции чтения и записи данных, открытия и закрытия накопителя. Драйверы под-
чиняются принципу модульности, так что они могут быть установлены и удале-
ны при изменении состава аппаратных компонентов системы, предоставляя
пользователям возможность легко подсоединять новые типы устройств. Тем са-
мым они обеспечивают расширяемость системы.
Живучая операционная система (robust operating system) — надежная и отказо-
устойчивая операционная система. Данная система не даст сбоя в работе из-за
неожиданных программных или аппаратных ошибок (если отказ все-таки про-
изойдет, он будет амортизирован). Живучая операционная система будет пре-
доставлять услуги приложениям, пока аппаратные средства, необходимые для
этого, не выйдут из строя.
1дача (job) — совокупность работ, которая должна быть выполнена компьютером-
пцита (protection) — механизм, реализующий политику безопасности системы
путем отказа приложениям, не имеющим соответствующего разрешения, в дос-
тупе к системным ресурсам и службам.
ццищенная операционная система (secure operating system) — операционная
система, препятствующая пользователям и программному обеспечению в полу-
чении несанкционированного доступа к услугам и данным.
чициативная группа по распространению открытого программного обеспечения
(Open Source Initiative, OSI) — организация, которая занимается поддержкой и по-
пуляризацией открытого программного обеспечения (см. www.opensource.com)-
ггерактивная операционная система (interactive operating system) — операЦй'
онная система, которая позволяет приложениям мгновенно реагировать на дей-
ствия пользователя.
[терактивные пользователи (interactive user) — пользователи, которые нахо-
дятся непосредственно возле машины, пока та решает их задачи. Интерактив-
ные пользователи взаимодействуют с задачами в процессе их решения.
ениевопера юнныо системы
(Internet) — сеть каналов связи, которая является технологической ос-
0ртеРв® телекоммуникаций и всемирной паутины. Каждый компьютер сети
ново ет определяет, какими услугами сети он пользуется, и какие услуги он
Цнтер^авляет другим компьютерам, подключенным к Интернету.
n₽n<heHC переносимых операционных систем (Portable Operating System
ццтерф се pOSIX) — программный интерфейс приложения (API), первоначаль-
& аботаиный для ранней операционной системы UNIX.
Й° (client) — процесс, который запрашивает услуги у другого процесса (серве-
Клиеят^аЩИна, на которой выполняется процесс пользователя, также называется
клиентом.
овый параллелизм (massive parallelism) — свойство системы, обладающей
^большим количеством процессоров, так что значительная часть вычислений мо-
жет выполняться параллельно.
М сштабируемая операционная система (scalable operating system) — операцион-
MaHaH система, которая может использовать ресурсы по мере их наращивания.
Она может повышать степень своей мультипрограммности для удовлетворения
потребностей пользователей.
Многоуровневая (многослойная) операционная система (layered operating
system) — модульная операционная система, которая располагает сходные ком-
поненты на отдельных уровнях. Каждый уровень прибегает к услугам соседнего
нижнего уровня, а результаты передает соседнему верхнему уровню.
Мобильная операционная система (portable operating system) — операционная сис-
тема, ориентированная на работы с различными конфигурациями аппаратуры.
Мобильность (portability) — возможность программного обеспечения функциони-
ровать на различных платформах.
Монолитная операционная система (monolithic operating system) — операцион-
ная система, ядро которой содержит все компоненты операционной системы.
Ядро в таких системах, как правило, обладает неограниченным доступом к ре-
сурсам компьютерной системы.
Мультипрограммность (multiprogramming) — возможность одновременного хра-
нения в памяти большого количества программ, так что они могут выполняться
параллельно.
Независимый поставщик программного обеспечения (Independent Software
Vendor, ISV) — организация, которая производит и распространяет программ-
ное обеспечение. Процветание независимых поставщиков программного обеспе-
чения началось с момента появления в продаже первых моделей персонального
Компьютера IBM.
Оболочка (shell) — приложение (как правило, текстовое или на базе графического
интерфейса пользователя), позволяющее пользователю «общаться» с операци-
онной системой.
^^>,еК(ТНО'°Ри<“нтиРованная операционная система (object-oriented operating
п eIns’ 000S) — операционная система, в которой ресурсы и компоненты
Какдставлень1 в виде объектов. Такие концепции объектного ориентирования,
си насл<’Дование и интерфейсы, помогают создать модульные операционные
чем * Ь1’ которые являются более простыми в обслуживании и расширении,
Мы *'°3дапнь1<' на основе более старых технологий. Многие операционные систе-
Но.п„СПОЛЬЗуют объекты, но не многие были полностью написаны на объект-
ОдвопоЗИеНТИ₽°ВаННЫХ языках-
batch-n НЯЯ • СИСтема пакетной обработки данных (single-stream
Рая п PrOceSslng system) — разновидность ранних компьютерных систем, кото-
Очерати едовательно выполняла ряд неинтерактивных задач, по одной за раз.
(т.е Р^жим (online) — состояние, которое характеризует включенный
тивный) и непосредственно подсоединенный к сети компьютер.
97
^^^jjnepaniioHHbio системы
программное обеспечение (open-source software) — программное обес-
О'ГВРЬ1^ „ к которому прилагается исходный код, и которое обычно распростра-
пеЧе согласно открытому лицензионному соглашению (GPL) или какой-либо
ляется^^^ лицензии. Такое программное обеспечение разрабатывается, как
гпуппами независимых программистов по всему миру.
правило,
осимая операционная система — см. Мобильная операционная система.
Переносимость - см. Мобильность.
11 Р повщик дисковых операций (disk scheduler) — компонент операционной
ПлаИ”еМЬ1 определяющий порядок обслуживания запросов диска на ввод/вывод
для повышения производительности.
„„повщик процессов (process scheduler) — компонент операционной системы,
^определяющий, какой процесс будет получать доступ к процессору и на какой
период времени.
Посредническое программное обеспечение (middleware) — прослойка программ-
ного обеспечения, которая позволяет различным приложениям взаимодейство-
вать друг с другом. Посредническое программное обеспечение упрощает при-
кладное программирование, поскольку берет на себя решение таких задач, как
передача данных по сети и преобразование данных из одного формата в другой.
Поток (thread) — независимо выполняемая последовательность программных ко-
манд (также называемая потоком выполнения или потоком управления). Пото-
ки упрощают параллельное выполнение одновременных действий внутри про-
цесса.
Практичная операционная система (usable operating system) — операционная
система, способная удовлетворить широкому спектру пользовательских запро-
сов путем предоставления удобного в использовании интерфейса и поддержки
множества разнообразных ориентированных на пользователя приложений.
Приоритет процесса (priority of a process) — важность или срочность выполнения
данного процесса по сравнению с остальными (уровень привилегий).
Программный интерфейс приложения (Application Programming Interface,
API) — спецификация, которая позволяет приложениям запрашивать услуги
У ядра посредством системных вызовов.
Проект свободного распространения программного обеспечения (GNU) — про-
ект, запущенный Столлменом в 80-х годах и ориентированный на создание от-
UhOC** операционной системы с возможностями и инструментарием системы
Производительность (throughput) — объем работы, выполненной за единицу вре-
мени.
Пропускная способность (bandwidth) — объем информации, который можно пере-
Давать по линиям связи в единицу времени.
НТтт>Л пеРеДачи гипертекстовых файлов (Hypertext Transfer Protocol,
Нткп сетевой протокол, используемый для обмена документами на языке
пг, Ь и Данными других форматов между клиентом и сервером. Это основной
п рот°кол всемирной паутины.
рг ^ол Управления передачей/протокол Интернет (Transmission Control
Ют с Col/lnternet Protocol, TCP/IP) — семейство протоколов, которые определя-
Проце ПосоРы обмена информацией в сети Интернет.
рас еСС (prc,cess) — выполняемая операционной системой программа.
большеленная обработка данных (distributed computing) — использование
₽аспп °ГО количества независимых компьютеров для решения общей задачи.
°ПеРацЛеННаЯ операционная система (distributed operating system) — единая
Распоп°ННаЯ система, которая предоставляет прозрачный доступ к ресурсам,
оженным на множестве компьютеров.
98 Гло д ।
Распределенная система (distributed system) — совокупность компьютеров, кот0
рые взаимодействуют для решения общей задачи.
Расширяемая операционная система (extensible operating system) — операцией
ная система, которая без затруднений может быть наделена новыми возможно'
стями.
Сервер (server) — процесс, предоставляющий услуги другим процессам, которЬ1
называются клиентами. Машина, на которой выполняются данный процессе
также называется сервером. ’
Сетевая операционная система (network operating system) — операционная систе
ма, которая может управлять ресурсами, имеющими удаленное расположение
и не скрывает местоположение этих ресурсов от приложений (как это могут де’
лать распределенные системы).
Система для решения критически важных задач (mission-critical systems) — Сис-
тема, которая должна функционировать должным образом, причем ошибка
этой системы может привести к ущербу собственности, денежным потерям и че-
ловеческим жертвам (поэтому иногда такая система называется «жизнен-
но-важной системой»).
Система реального времени (real-time system) — система, которая обслуживает
запросы в течение определенного (как правило, короткого) промежутка време-
ни. В ответственных системах реального времени (например, в системе управле-
ния воздушным движением или системе управления нефтеперерабатывающим
заводом) деньги, недвижимость и даже человеческие жизни могут быть постав-
лены под угрозу, если запросы не будут обслужены вовремя.
Система с разделением времени (timesharing system) — операционная система,
которая делает возможной одновременную работу многочисленных интерактив-
ных пользователей.
Системный вызов (system call) — вызов, осуществляемый пользовательским про-
цессом, который запрашивает у ядра обслуживание.
Совместимая система с разделением времени (CTSS) — операционная система
с разделением времени, разработанная массачусетским технологическим инсти-
тутом в 60-х годах.
Степень мультипрограммности (degree of multiprogramming) — количество про-
грамм, которое система может выполнять параллельно.
Управление перспективных исследовательских программ (Advanced Research
Projects Agency — ARPA) — правительственное учреждение в составе Мини-
стерства Обороны США, которое запланировало и приступило к реализации
сети Интернет; сейчас это Управление называется Управлением Перспективных
Исследований и Разработок Министерства Обороны США (Defense Advanced
Research Projects Agency — DARPA).
Управляющая программа/диалоговая мониторная система (CP/CMS) — опера-
ционная система с разделением времени, разработанная компанией IBM в 60-х
годах.
Уровень мультипрограммирования (level of multiprogramming) — см. Степень
мультипрограммности.
Эффективная операционная система (efficient operating system) — операционная
система, которая демонстрирует высокую пропускную способность и маЛУ10
длительность жизненного цикла задачи.
Ядро (kernel) — программа, которая включает основные компоненты операци011
ной системы.
д 0 рационные системы
99
уараокнения
Укажите, в чем заключается различие между мультипрограммным и мульти-
1Л- роцессорным режимами работы. Каковы основные причины их создания?
2 Кратко раскройте значение каждой из следующих систем, упомянутых
в этой главе:
а. MS-DOS
б. CTSS
в. Multics
г. OS/360
д. TSS
е. UNIX
ж. Macintosh
1 3 Какие достижения позволили воплотить в реальность идею «персонального
компьютера»?
14В чем заключается непрактичность использования виртуальной машины
на жесткой системе с разделением времени?
1 5. Какую роль сыграла разработка графического интерфейса пользователя
в революции персональных компьютеров?
1.6. Открытое лицензионное соглашение (GPL) позволяет свободно распростра-
нять открытое программное обеспечение. Каким образом данная лицензия
предоставляет такую свободу?
1.7. Каким образом распределенная обработка данных повлияла на разработку
операционных систем?
1.8. В чем заключаются преимущества и недостатки взаимодействия между
компьютерами?
1.9. Дайте определение каждого из следующих терминов и укажите, в чем за-
ключается их сходство и различие:
а. оперативный режим (он-лайн),
б. режим реального времени,
в. интерактивное вычисление,
г. режим разделения времени.
1.10. Каким образом посредническое программное обеспечение и веб-службы
способствуют взаимодействию (программных и аппаратных изделий раз-
ных поставщиков)?
1-11. Дайте оценку монолитной и многоуровневой (многослойной) архитекту-
рам, а также архитектуре на основе микроядра с точки зрения:
а. эффективности,
б. живучести,
в- Расширяемости,
г. защищенности.
Pfllc
0МеЦуемые исследовательские учебные проекты
Подготовьте доклад на тему: «Операционная система Linux». Раскройте
в нем следующие вопросы:
а- Каким образом эта операционная система отвечает взглядам Столлмена
б («целиком свободная») на программное обеспечение?
1.13 тт ЧеМ опеРаЦи°нная система Linux противоречит данной философии?
Дготовьте доклад на тему: «Интернет. Влияние его повсеместного рас-
Ространения на создание операционных систем».
ЮО Глава /
1.14. Подготовьте доклад на тему: «Распространение открытого программного
обеспечения». Обратите внимание на следующие вопросы:
а. Действительно ли открытое программное обеспечение является таковы^
в отношении «свободы» и «цены»?
6. Каким образом Открытое лицензионное соглашение и подобные ей лицец.
зии способствуют популяризации открытого программного обеспечения?
1.15. Подготовьте доклад на тему: «Эволюция операционных систем». Обратит^
внимание на основные технологии, связанные с аппаратными средствами
программным обеспечением и средствами связи, которые реализован^
в нововведениях операционных систем.
1.16. Подготовьте доклад на тему: «Будущее операционных систем».
1.17. Подготовьте доклад на тему: «Операционные системы». Дайте полную
классификацию операционных систем прошлого и настоящего.
1.18. Подготовьте доклад на тему: «Веб-службы». Укажите ключевые техноло-
гии, на которые опирается инфраструктура веб-служб. Рассмотрите вопрос
влияния доступности веб-служб на создание приложений.
1.19. Подготовьте доклад на тему: «Ответственные бизнес-приложения и крити-
чески важные приложения». Обратите внимание на основные характери-
стики, которыми должны обладать аппаратные средства, программные
средства связи и операционные системы и которые являются необходимы-
ми для создания систем, способных обеспечить должную работу данных
приложений.
1.20. Подготовьте доклад на тему: «Операционные системы виртуальных ма-
шин». Обратите особое внимание на операционную систему VM компании
IBM и виртуальную машину Java компании Sun.
1.21. Подготовьте доклад на тему: «Операционная система и закон». В докладе
необходимо рассмотреть правовые вопросы, связанные с операционными
системами.
1.22. Подготовьте доклад на тему: «Влияние операционных систем на экономику
и коммерческую деятельность».
1.23. Подготовьте доклад на тему: «Операционные системы: безопасность и кон-
фиденциальность». Раскройте проблемы, связанные с червями и вирусами.
1.24. Подготовьте доклад на тему: «Этические проблемы, которые должны учи-
тывать разработчики операционных систем». В этом докладе необходимо
затронуть проблемы червей и вирусов, использования компьютерных сис-
тем в военных целях и в ситуациях, когда под угрозой находятся человече-
ская жизнь, и др.
1.25. Назовите тенденции, которые определяют подходы к разработке будущих
операционных систем. Каким образом каждая из них оказывает влияние
на характер будущих операционных систем?
1.26. Подготовьте доклад на тему: «Разработка систем с массовым параллелиз-
мом». Сравните крупномасштабные мультипроцессорные системы (такие
как суперкомпьютер Superdome компании Hewlett-Packard, который мо-
жет иметь до 64 процессоров; www.hp.com/productsl/servers/scalableser-
vers/superdome/) с кластеризованными системами и серверными фермами,
в состав которых входят сотни и тысячи компьютеров низкой производи-
тельности, взаимодействующих для решения общих задач (для пример*
см. www.beowulf.org). Используйте материал сайта www.top500.org, кото
рый даст вам полный список самых мощных суперкомпьютеров в мир6’
чтобы определить характер задач, решаемых каждой из этих систем с мас
совым параллелизмом.
1.27. К чему может привести быстрый рост параллелизации вычислений? И®
проблемы какого характера разработчикам аппаратных средств и пр°
граммного обеспечения следует обратить внимание, прежде чем параллель'
ное вычисление получит широкое применение?
циево рйционныо системы
101
Подготовьте доклад на тему: «Сравнение исследовательских операционных
1.28- . тем Exokernel Массачусетского Технологического Института и Mach на
® Нове микроядра университета Карнеги-Меллона» 119. (О системе Exoker-
°1 см- www.pdos.lcs.mit.edu/exo.html; о системе Mach см. Www-2.cs.cmu.
nju/afs/cs.cmu.edu/project/mach/public/www/mach.html) В чем заключа-
ется основное предназначение этих систем? Обязательно обратите внима-
ние на то, каким образом исследователи организовали управление памя-
тью, планирование дисковых операций и управление процессами. Имела
ли хотя бы одна из этих систем (или обе) коммерческий успех? Повлияла
ли хотя бы одна из этих систем (или обе) на разработку других коммерче-
ски-успешных операционных систем?
д В чем причина популярности системы UNIX и других систем на ее основе
* в течение последних десятилетий? Какое влияние оказала операционная
система Linux на будущее систем на базе UNIX?
Рекомендуемая литература
Этот раздел включен в каждую главу с целью предоставить читателям ссылки
на книги, статьи и современные исследовательские проекты, содержащие плодо-
творные идеи по темам главы. Большинство упомянутых статей, материал кото-
рых используется в этой книге, можно найти в одном из журналов, публикуемых
Ассоциацией по вычислительной технике (Association of Computing Machinery,
ACM) и Институтом инженеров по электротехнике и электронике (Institute of
Electrical and Electronics Engineers, IEEE). Журнал Communications of the ACM яв-
ляется флагманским журналом Ассоциации по вычислительной технике, в кото-
ром публикуются доклады, редакционные статьи и очерки на актуальные темы
в области компьютерных наук. Эта ассоциация также финансирует несколько спе-
циальных проблемных групп (special-interested group, SIG), деятельность каждой
из которых относится к определенной области компьютерных наук. Специальная
группа по операционным системам (SIGOPS, www.acm.org/sigops/) проводит еже-
годную конференцию и издает журнал Operating System Review. Компьютерное об-
щество Института инженеров по электротехнике и электронике (IEEE Computer
Society, www.computer.org), самое крупное общество этого института, оно издает
нескольких журналов, посвященных компьютерным наукам, включая популяр-
ный журнал IEEE Computer (www.computer.org/computer/). Читатели получают
риглашение вступить в Ассоциацию по вычислительной технике, Специальную
Руппу по операционным системам и Компьютерное общество Института инжене-
р по электротехнике и электронике. Среди Интернет-источников представлен
Полг^а^1014 На сааты’ где хранятся материалы по истории операционных систем.
Моящ НУ*° «иФоРмаЦию о разработке и развитии операционной системы OS/360
сяц» 12оа^.ТИ в Книге Фредерика П. Брукса младшего «Мифический человеко-ме-
bistrib t дс1Га 1^еРа Бринча Хансена «Classic Operating Systems: From Batch to
Работк Systems» содержит перечень работ, которые подробно описывают раз-
ВИблио И Развитие новаторских и исследовательских операционных систем 121.
ЬооРс/ гРаФИя Для этой главы содержится на нашем веб-сайте: www.deitel.com/
/Os3e/Bibliography.pdf.
02
Глава i
1. «Evolution of the Intel Microprocessor: 1971-2007,» <www.berghell.com/white.
papers/Evolution% 20of20Intel% 20Microprocessors% 201971% 2O2O7.pdf>.
2. «Top 500 List for November 2002,» <www.top500.org/list/2002/ll/>.
3. Weizer, N., «А History of Operating Systems.» Datamation. January 1981, pp. 119-126
4. Goldstein, H., The Computer from Pascal to von Neumann. Princeton: Princeton
University Press. 1972.
5. Stem, N., From ENIAC to UNIVAC: An Appraisal of the Eckert-Manchly Com-
puters Bedford: Digital Press. 1981.
6. Bashe, C., et al., IBM’s Early Computers (Cambridge: MIT Press, 1986).
7. Weizer, N., «А History of Operating Systems,» Datamation. January 1981
pp. 119-126.
8. Grosch, H., «The Way It Was in 1957.» Datamation. September 1977.
9. Denning. P., «Virtual Memory.» ACM CSUR, Vol. 2, No. 3. September 1970
pp. 153-189.
10. Codd, E.; E, Lowry: E. McDonough: and C. Scalzi, «Multiprogramming
STRETCH: Feasibility Considerations.» Communications of the ACM, Vol. 2
1959, pp. 13-17.
11. Critchlow, A., «Generalized Multiprocessor and Multiprogramming Systems.»
Proc. AFIPS, FJCC, Vol. 24, 1963, pp. 107-125.
12. Belady, L., et al., «The IBM History of Memory Management Technology.» IBM
Journal of Research and Development, Vol. 25, No. 5, September 1981, pp.
491-503.
13. «The Evolution of S/390,» <www-ti.informatik.uni-tuebin-gen.de/os390/arch/
history.pdf>.
14. Amdahl, G.; G. Blaauw; and F. Brooks, «Architecture of the IBM System/360,»
IBM Journal of Research and Development, Vol. 8, No. 2, April 1964,
pp. 87-101.
15. Weizer, N., «А History of Operating Systems,» Datamation, January 1981,
pp. 119-126.
16. Evans, B., «System/360: A Retrospective View.» Annals of the History of Com-
puting, Vol. 8, No. 2, April 1986, pp. 155-179.
17. Mealy, G.; B. Witt; and W. Clark, «The Functional Structure of OS/360.» IBM
Systems Journal, Vol. 5, No. 1, 1966, pp. 3-51.
18. Case, R.; and A. Padeges, «Architecture of the IBM System/370,» Communica-
tions of the ACM, Vol. 21, No. 1, January 1978, pp. 73-96.
19. Gifford, D., and A. Spector, «Case Study: IBM’s System/360-370 Architecture,»
Communications of the ACM, Vol. 30, No. 4, April 1987, pp. 291-307.
20. «The Evolution of S/390,» <www-ti.informatik.uni-tuebin-gen.de/os390/arch/
history.pdf>.
21. Berlind, D., «Mainframe Linux Advocates Explain It All,» ZDNet, April 12, 2002,
<techupdate.zdnet.eom/techupdate/stories/main/0,14179,2860720,00.html>.
22. Frenkel, K., «Allan L. Scherr: Big Blue’s Time-Sharing Pioneer,» Communica-
tions of the ACM, Vol. 30, No. 10, October 1987, pp. 824-829.
23. Harrison, T., et al, «Evolution of Small Real-Time IBM Computer Systems,’
IBM Journal of Research and Development, Vol. 25, No. 5, September 1981>
pp. 441-451.
24. Corbato, F., et al., The Compatible Time-Shartng System, A Programmer’s Guide>
Cambridge: MIT Press, 1964.
д операционные системы
ЮЗ
. п Р_, et al., eds., The Compatible Time-Sharing System, Cambridge: MIT
25. Cris 1964.
A and W. Konigsford, «TSS/360: A Time-Shared Operating System,» Pro-
26. Let , > FaU joint Qomputer Conference, AFIPS, Vol. 33, Part 1, 1968,
Pp‘ Ifiissan A.; C. Clingen: and R. Daley. «The Multics Virtual Memory: Con-
27. Ben^ Designs,» Communications of the ACM, Vol. 15, No. 5, May 1972,
np₽ 308-318.
rvensv R., «The Origins of the VM/370 Time-Sharing System,» IBM Journal of
28 Research and Development, Vol. 25, No. 5, pp. 483-490.
Conrow, K., «The CMS Cookbook,» Computing and Networking Services. Kansas State
university, June 29, 1994, <www.ksu.edu/cns/pubs/cms/cms-cook/cms-cook.pdf>.
ЧП Denning, P-> «Virtual Memory,» ACM Computing Surveys, Vol. 2, No. 3, Septem-
ber 1970, pp. 153-189.
41 Parmelee, R., et al., «Virtual Storage and Virtual Machine Concepts,» IBM Sys-
tems Journal,. Vol. 11, No. 2, 1972.
32 Ritchie, D„ «Dennis M. Ritchie,» <cm.bell-labs.com/cm/cs/who/dmr/bigbiolst.html>.
33 Bell Labs Lucent Technologies, «Ken Thompson,» 2002, <www.bell-labs.com/
history/unix/thompsonbio.html>.
34. Mackenzie, R., «А Brief History of UNIX,» <www.stanford.edu/~rachelm/
cslu-197/unix.html>.
35. Cook, D.; J. Urban, and S. Hamilton, «UNIX and Beyond: An Interview with Ken
Thompson,» Computer, May 1999, pp. 58-64.
36. Cook. D.; J. Urban, and S. Hamilton. «UNIX and Beyond: An Interview with Ken
Thompson,» Computer, May 1999, pp. 58-64.
37. Bell Labs Lucent Technologies, «Ken Thompson,» 2002, <www.bell-labs.com/
history/unix/thompsonbio. html>.
38. Bell Labs Lucent Technologies, «Dennis Ritchie,» 2002, www.bell-labs.com/
about/history/unix/ri tchie-bio.html.
39. Bell Labs Lucent Technologies, «Dennis Ritchie,» 2002, www.bell-labs.com/
about/history/unix/ritchiebio.html>.
40. Ritchie, D., «Dennis M. Ritchie.» <cm.bell-labs.com/cm/cs/who/dmr/bigbiolst.html>.
41. Reagan, P., and D. Cunningham, «Bell Labs Unveils Open Source Release of Plan 9
Operating System,» June 7, 2000, www.bell-labs.com/news/2000/june/7/2.html.
42. Bell Labs, «Vita Nuova Publishes Source Code for Inferno Operating System,
Moving Network Computing into the 21st century,» <www.cs.bell-labs.com/in-
ferno>.
48 G-» «CP/М: A Family of 8- and 16-bit Operating Systems,» Byte, Vol. 6,
No. 6, June 1981, pp. 216-232.
• Quarterman, J. S., and J. C. Hoskins, «Notable Computer Networks,» Communi
cations of the ACM, Vol. 29, No. 10, October 1986, pp. 932-971.
• Stefik, M., «Strategic Computing at DARPA: Overview and Assessment,» Com-
46 ™unicati°ns of the ACM, Vol. 28, No. 7, July 1985, pp. 690-707.
’ Omer, D., Internetworking with TCP/IP: Principles, Protocols, and Architecture,
^nglewood Cliffs, NJ: Prentice Hall, 1988. Неоднократно издавался русский
еревод этой книги: Комер Д. Межсетевой обмен с помощью TCP/IP; текст
ЬнС.К/°/Г° пеРев°Да доступен на многих сайтах в Интернете, например,
47 /www.nbuv.gov.ua/libdoc/tcpip.htm.
J*’ ап<^ К- К. Chapman, Local Area Networks: Architectures and Imple-
48. од r'tations’ Englewood Cliffs, NJ: Prentice Hall, 1989.
Cm«Ca^e’ R"’ ап^ D- Boggs, «Ethernet: Distributed Packet Switching for Local
«iputer Networks,» Communications of the ACM, Vol. 19, No. 7, July 1976.
104
Глава
49 Balkovich, Е.; and S. Lerman; and R. Parmelee, «Computing in Higher Educa.
tion: The Athena Experience,» Computer, Vol. 18, No. 11, November 1985
pp. 112-127.
50. Zmoelnig, Christine, «The Graphical User Interface. Time for a ParadigJr.
Shift?» August 30, 2001, <www.sensomatic.com/chz/gui/history.html>.
51. Engelbart, D., «Who we are. How we think. What we do.» June 24, 2003
<www. doo ts trap. org/ index. html>.
52. Martin, E., «The Context of STARS,» Computer, Vol. 16, No. 11, November
1983, pp. 14-20.
53. Ecklund, J., «Interview with Douglas Engelbart,» May 4, 1994, <americanhis-
tory.si.edu/csr/comphist/engelbar.html>.
54. Stauth, D., «Prominent Oregon State Alum Receives Leading Prize for Inven-
tors,» April 9, 1997, <oregonstate.edu/dept/ncs/newsarch/1997/engelbart.htm>.
55. «Douglas Engelbart Inventor Profile,» 2002, <www.invent.org/hall_of_fame/53.html>.
56. «Engelbart’s Unfinished Revolution,» December 9, 1998, <stanford-online.Stan-
ford. edu/engelbart/>.
57. «Douglas Engelbart Inventor Profile,» 2002, <www.invent.org/hall_of_fame/53.html>.
58. World Wide Web Consortium, «Longer Bio for Tim Berners-Lee,»
<www.w3.org/People/Berners-Lee/Longer.html>.
59. «Engelbart’s Unfinished Revolution,» December 9, 1998, <stanford-online.Stan-
ford.edu/engelbart/> .
60. «Douglas Engelbart Inventor Profile,» 2002, <www.invent.org/hall_of_fame/53.html>.
61. World Wide Web Consortium, «Longer Bio for Tim Berners-Lee,»
<www.w3.org/People/Berners-Lee/Longer.html>.
62. Quittner, J., «Tim Berners-Lee,» March 29, 1999, <www.time.com/time/ti-
me 1 OO/scientist/prof i 1 e/bernerslee. html>.
63. Berners-Lee, T., et al, «The World-Wide Web,» Communications of the ACM,
Vol. 37, No. 8, August 1994, pp. 76-82.
64. World Wide Web Consortium, «Longer Bio for Tim Berners-Lee,»
<www.w3.org/People/Berners-Lee/Longer.html>.
65. Quittner, J., «Tim Berners-Lee.» March 29, 1999, <www.time.com/time/ti-
melOO/scientist/profile/bernerslee.html>.
66. Berners-Lee, T., et al, «The World-Wide Web,» Communications of the ACM,
Vol. 37, No. 8, August 1994, pp. 76-82.
67. World Wide Web Consortium, «Longer Bio for Tim Berners-Lee,»
<www.w3.org/People/Berners-Lee/Longer.html>.
68. Quittner, J., «Tim Berners-Lee,» March 29, 1999, <www.time.com/tinie/
time 100/scientist/profile/bemerslee. html>.
69. Moore, G., «Cramming More Components onto Integrated Circuits,» Electronics,
Vol. 38, No. 8, April 19, 1965.
70. «One Trillion-Operations-Per-Second,» Intel Press Release, December 17, 1996,
<www.intel.com/pressroom/archive/releases/cnl21796.htm>.
71. Mukherjee, В.; K. Schwan; and P. Gopinath, «А Survey of Multiprocessor Oper'
ating Systems,» Georgia Institute of Technology, November 5, 1993, p. 2.
72. «Microsoft Timeline,» <www.microsoft.com/museum/mustimeline.mspx>-
73. Lea, R.; P. Armaral; and C. Jacquemot, «COOL-2: An Object-oriented Supp01^
Platform Built Above the CHORUS Micro-kernel,» Proceedings of the Intern0,
1991^ Workshop on Object Orientation in Operating Systems 1991, October»
74. Weiss, A., «The Politics of Free (Software),» netWorker, September 2001, p- 26-
75. «The GNU Manifesto,» <www.delorie.com/gnu/docs/CNU/GNU>-
76. Weiss, A., «The Politics of Free (Software).» netWorker, September 2001, p. 27-
105
е В операционные системы
Brouwer, С., eds, «Linus Torvalds,» October 19, 2002, <www.thocp.net/biog-
anhies/torvaldsjinus.html >.
т month, M., «Giving It All Away,» May 8, 1997, <www.metroactive.com/pa-
78‘ pre/metro’/05.08.97/cover/linus-9719.html>.
Torvalds, L., «Linux History,» July 31, 1992, <www.li.org/linuxhistory.php>.
79• ° e Software Foundation, «GNU General Public License,» May 26, 2003,
8°‘ <www.gnu.org/copyleft/gpl.html >.
Torvalds, L., «Linux History,» July 31, 1992, <www.li.org/linuxhistory.php>.
? Ghosh, R., «What Motivates Free Software Developers?» 1998, <www.first-
82’monday.dk/issues/issue3_3/torvalds/>.
«3 Wirzenius, L., «Linux: The Big Picture,» April 28, 2003, <liw.iki.fi/liw/texts/
’ linux-the-big-picture.html>.
Я4 Learmonth, M„ «Giving It All Away,» May 8, 1997, <www.metro-ac-
tive.com/papers/metro/05.08.97/cover/linus-9719.html>.
85 Wirzenius, L., «Linux: The Big Picture,» April 28, 2003, <liw.iki.fi/Iiw/texts/
linux-the-big-picture.html>.
86 «Linux Creator Linus Torvalds Joins OSDL,» June 17, 2003, <www.osdl.org/
newsroom/press_releases/2003/2003_06 17_beaverton.html>.
87. de Brouwer, C., eds, «Linus Torvalds,» October 19, 2002, <www.thocp.net/biog-
raphies/torval ds_linus. html>.
88. Weiss, A., «The Politics of Free (Software),» networking, September 2001,
pp. 27-28.
89. Stallman, R., «А Serious Bio,» <www.stallman.org/#serious>.
90. Stallman, R., «Overview of the GNU Project,» June 7, 2003, <www.gnu.org/
gnu/gnu-history.html>.
91. DiBona, C.; S. Ockman; and M. Stone, eds., Open Sources: Voices from the Open
Source Revolution, Boston, MA: O’Reilly, 1999.
92. R. Stallman, «Overview of the GNU Project,» June 7, 2003, <www.gnu.org/
gnu/gnu-history .html>.
93. DiBona, C.; S. Ockman; and M. Stone, eds., Open Sources: Voices from the Open
Source Revolution, Boston, MA: O’Reilly, 1999.
94. Stallman, R.,«A Serious Bio,» <www.stallman.org/#serious>.
95. «Free Software Foundation,» June 12, 2002, <www.gnu.org/fsf/fsf.html>.
96. DiBona, C; S. Ockman; and M. Stone, eds., Open Sources: Voices from the Open
Source Revolution, Boston, MA: O’Reilly, 1999.
9 Leon, M., «Richard Stallman, GNU/Linux,» October 6, 2000, <archive.info-
world.com/articles/hn/xml/00/10/09/001009hnrs.xml>.
• Stallman, R., «А Serious Bio,» <www.stallman.org/#serious>.
«New Windows Could Solve Age Old Format Puzzle — at a Price,»
100 Tb March 13’ 2002’ <news.com.com/2009-1017-857509.html>.
‘ “Uirott, P., «Windows ‘Longhorn’ FAQ,» Paul Thurrott’s Super-Site for Win-
Ю1 q)WS’ mof4fied October 6, 2003, <www.winsuper-site.com/faq/longhom.asp>.
tiannon’ D., et al., «А Virtual Machine Emulator for Performance Evalua-
102 C! * Communications of the ACM, Vol. 23, No. 2, February 1980, p. 72.
annon, M. D., et al., «А Virtual Machine Emulator for Performance Evalua-
Юз Communications of the ACM, Vol. 23, No. 2, February 1980, p. 72.
Ware’ simplifying Computer Infrastructure and Expanding Possibilities»,
104 QWWw'vmware-com/company/>.
tior>nO1^ et al-> Virtual Machine Emulator for Performance Evalua-
105- «Sh 1*1 Communications °f the ACM, Vol. 23, No. 2, February 1980, p. 73.
Feioi ™ whatis.com, <www.searchsolaris.techtarget com/sDefinition/0„sidl2
KC121 2978,00.html>. ”
106 Главаj
106. Mukherjee, В.; К. Schwan; and Р. Gopinath, «А Survey of Multiprocessor Oper-
ating Systems,» Georgia Institute of Technology (GIT-CC-92/0), November 5
1993, p.4.
107. Dijkstra, E. W., «The Structure of the ‘THE’-Multiprogramming System,» Com-
munications of the ACM, Vol. 11, No. 5, May 1968, pp. 341-346.
108. Karnik, N. M., and A. R. Tripathi, «Trends in Multiprocessor and Distributed
Operating Systems,» Journal of Supercomputing, Vol. 9, No. 1/2, 1995, pp. 4-5.
109. Mukherjee, В.; K. Schwan; and P. Gopinath, «А Survey of Multiprocessor Oper-
ating System Kernels,» Georgia Institute of Technology (GIT CC 92/0), Novem
ber 5, 1993, p. 10.
110. Miljocic, D. S.; F. Douglis; Y. Paindaveine; R. Wheeler; and S. Zhou, «Process
Migration,» ACM Computing Surveys, Vol. 32, No. 3, September, 2000, p. 263.
111. Liedtke, J.; «Toward Real Microkernels,» Communications of the ACM, Vol. 39
No. 9, September, 1996, p. 75. Camp, T., and G. Oberhsause, «Microkernels: A
Submodule for a Traditional Operating Systems Course,» Communications of the
ACM, 1995, p. 155.
112. Liedtke, J., «Toward Real Microkernels,» Communications of the ACM, Vol. 39,
No. 9, September 1996, p. 75. Camp, T. and G. Oberhsause, «Microkernels: A
Submodule for a Traditional Operating Systems Course,» Communications of the
ACM, 1995, p. 155.
113. Miljocic, D. S.; F. Douglis; Y. Paindaveine; R. Wheeler; and S. Zhou, «Process
Migration,» ACM Computing Surveys, Vol. 32, No. 3, September 2000, p 263.
114. Tanenbaum, A. S., and R. V. Renesse, «Distributed Operating Systems,» Com-
puting Surveys, Vol. 17, No. 4, December 1985, p. 424.
115. Tanenbaum, A. S., and R. V. Renesse, «Distributed Operating Systems,» Com-
puting Surveys, Vol. 17, No. 4, December 1985, p. 424.
116 Blair, G. S.; J. Malik; J. R. Nicol; and J. Walpole, «Design Issues for the
COSMOS Distributed Operating System,» Proceedings from the 1988 ACM
SIGOPS European Workshop, 1988, pp. 1-2.
117. «MIT LCS Parallel and Distributed Operating Systems,» June 2, 2003,
<www. pdos. les. mit. edu>.
118. «Amoeba WWW Home Page,» April 1998, <www.cs.vu.nl/pub/amoeba/>.
119. Engler, D. R.; M. F. Kaashoek; and J. O’Toole, Jr., «Exokernel: An Operating
System Architecture for Application-Level Resource Management,» SIGOPS ‘95,
December 1995, p. 252.
120. Brooks, Jr., F. P., The Mythical Man-Month: Essays on Software Engineering,
Anniversary edition, Reading, MA: Addison-Wesley, 1995 (Неоднократно
издавался русский перевод, например, Брукс. Ф.П. Мифический
человеко-месяц. М. Символ-Плюс, 2000; кроме того, текст русского перевода
есть на многих сайтах, например, http://lib.ru/CTOTOR/BRUKS/mithsoft-
ware.txt).
121. Brinch Hansen, Р., Classic Operating Systems: From Hatch to Distributed Sys-
tems, Springer-Verlag, 2001.
Сейчас! Сейчас! — закричала королева. —
Быстрее! Быстрее!
Льюис Кэрролл
Без риска победив, без славы торжествуешь.
Пьер Корнель
Наша жизнь растрачивается по пустякам..»
Упрощайте, упрощайте.
Генри Дэйвид Торо
О, святая простота!
Ян Гуо
(Последние слова, произнесенные им, когда некая
женщина подкинула полено в костер»
на котором его сжигали.)
r
Глава 2
Концепции
on пи ротных средств
и программного обеспечения
Цели
Прочитав эту главу, вы должны усвоить:
@ какими аппаратными компонентами должна
управлять операционная система;
• какие изменения претерпели аппаратные средства
для поддержки функций операционных систем;
• каким образом можно достичь максимальной
производительности различных аппаратных
устройств;
• что такое «программный интерфейс приложения»
(API);
что представляют собой процессы компиляции,
связывания и загрузки.
Краткое содержание швы
2.1 Введение
2.2 Развитие аппаратных устройств
Биография.: Гордон Мур и его закон
2.3 Аппаратные компоненты
23.1 Материнские платы
2.3.2 Процессоры
2.3.3 Системный таймер
2.3.4 Иерархия памяти
2.3.5 Основная память
Размышления об операционных системах: Кэширование
2.3.6 Вторичные запоминающие устройства
2.3.7 Шины
2.3.8 Прямой доступ к памяти
2.3.9 Периферийные устройства
Размышления об операционных системах:
Унаследованное программное обеспечение и аппаратные средства
2.4 ПоддерМа функций операционных
систем аппаратными средствами
2.4.1 Процессор
Размышления об операционных системах:
Принцип наименьшего уровня привилегий
Размышления об операционных системах: Защита
Поучительные истории: Появление термина «Глюк»
2.4.2 Таймеры и часы
2.4.3 Начальная загрузка
2.4.4 Технология Plug-and-Play
2.5 Кеширование и буферизация
Размышления об операционных системах: Эвристика
2.6 Обзор программного обеспечения
2.6.1 Машинный язык и язык ассемблера
2.6.2 Интерпретаторы и компиляторы
2.6.3 Языки програллмирования высокого уровня
2.6.4 Структурное програллмирование
2.6.5 Объектно-ориентированное програллмирование
2.7 Интерфейсы прикладного программирования
2.8 Процессы компиляции, связывания и загрузки
2.8.1 Компиляция
2.8.2 Связывание
Учебный пример: Операционная система Mach
2.8.3 Загрузка
2.9 Встроенное программное обеспечение
2.10 МеЖплатформное программное обеспечение
//2 =—= Глава 2^
2.1 Введение
Благодаря современным компьютерным системам пользователи могут
обладать доступом к сети Интернет, просматривать веб-страницы, выво.
дить на экран графическое и видео изображение, прослушивать музыку
и играть в игры, а также многое другое. Персональные и офисные компью-
теры повышают производительность труда посредством управления дац.
ными огромных объемов, предоставляя инструменты для разработки при.
ложений и интуитивный интерфейс для работы со сложными структура-
ми. Работа компьютерных сетей согласована с целью выполнения
огромного количества операций и транзакций в секунду. Такие представи-
тели рынка мобильных вычислительных устройств, как сотовые телефоны
могут хранить в памяти телефонные номера, принимать и отправлять тек-
стовые сообщения и, более того, с их помощью можно фиксировать фото-
и видеоинформацию. В состав компьютеров всех категорий входят различ-
ные аппаратные средства и программное обеспечение, и всеми ими управ-
ляют операционные системы.
Поскольку операционная система в первую очередь является диспетче-
ром ресурсов, ее разработка должна быть максимально приближена к ап-
паратным и программным ресурсам, которыми она управляет. К этим ре-
сурсам относятся процессоры, память, вспомогательные запоминающие
устройства (такие как накопители на жестких магнитных дисках), другие
устройства ввода/вывода, процессы, потоки, файлы, базы данных и т.д. По
лере совершенствования компьютеров в операционных системах должны
учитываться появляющиеся технологии создания аппаратных средств
I программного обеспечения. При этом должна обеспечиваться совмести-
мость с уже используемой базой старых аппаратных средств и программно-
’о обеспечения. В этой главе вашему вниманию будут представлены общие
сонцепции построения аппаратных средств и программного обеспечения.
Вопросы для самопроверки
1. Перечислите некоторые из наиболее распространенных аппарат-
ных и программных ресурсов, которыми управляет операционная
система.
2. Перечислите разновидности информационных ресурсов, упомяну-
тых во введении.
Ответы 1) Процессоры, память, вспомогательные запоминающие
устройства (например, НЖМД), другие устройства ввода/вывода, про-
цессы, потоки, файлы, базы данных. 2) Веб-страницы, графические
данные, видеоинформация, музыка, игровые данные, офисные дан-
ные, данные транзакций; телефонные номера в сотовых телефонах,
текстовые сообщения; данные, хранящееся в памяти, данные, храня-
щиеся на вспомогательных запоминающих устройствах, данные, вве-
денные или выведенные при помощи устройств ввода/вывода,
и данные, обрабатываемые процессорами.
lU аппаратных средств а программного оьвспеченая ----
--------~
2 Развитие аппаратных устройств
пый раз, когда развитие технологий позволяет повышать скорости
^аЯ<ений, новые возможности мгновенно направляются на удовлетворе-
вЫч11С’"бовауИй, которые предъявляются к вычислительным ресурсам бо-
н«е ТР ныМИ приложениями. В свою очередь, само «вычисление» оказы-
лее мо неисчерПаемым ресурсом. Как было спрогнозировано законом
вается наи^олее интересные вопросы касаются доступности вычислитель-
МУ₽£систем растущей мощности (см. «Биографические заметки: Гордон
и его закон»). Данная ситуация нацоминает поговорку о яйце и кури-
Му^ак что же, постоянно растущие потребности приложений движут раз-
Це ием вычислительных технологий, или же достижения в области инфор-
мационных технологий заставляют нас задуматься о новых и более про-
грессивных приложениях?
F На первых этапах развития системное программирование (system
programming), включающее в себя написание кода для управления аппа-
ратными средствами и предоставления услуг программам, отличалось про-
стотой, поскольку операционные системы управляли небольшим количе-
ством программ и аппаратных ресурсов. Операционные системы упрощают
прикладное программирование (application programming), так как разра-
ботчики могут создавать программное обеспечение, которое запрашивает
у операционной системы услуги и ресурсы для выполнения задач (напри-
мер, редактирования текста, загрузки веб-страниц или банковских расче-
тов), не заботясь о написании кода для управления устройствами. По мере
увеличения количества производителей аппаратных средств и роста ассор-
тимента самих устройств, операционные системы становились все более
сложными. С целью облегчить процесс прикладного программирования
и обеспечить расширяемость, операционные системы создаются в соответ-
ствии с требованием независимости от определенных конфигураций аппа-
ратных средств системы. Операционные системы используют драйверы
Устройств, как правило, предоставляемые фирмой-производителем аппа-
ратных средств, для выполнения операций, связанных с устройствами вво-
да/вывода. Это позволяет операционной системе поддерживать новое уст-
ройство при помощи простой установки соответствующего драйвера уст-
ройства. На самом деле, драйверы устройств являются настолько
неотъемлемой частью современных систем, что, например, в ядре операци-
Н1??и СИСтемы Linux они составляют 60% исходного кода1.
с н°гие аппаратные компоненты разрабатываются для взаимодействия
мео1еРаи'ИОННО® системой с целью упрощения ее расширяемости. Напри-
jjOg’ Устройства plug-and-play самостоятельно определяются операцион-
зволС11СТеМ°й При их 11°Дключении к компьютеру (см. раздел 2.4.4). Это по-
ДРайвеТ °пераи'ионн°й системе выбирать и использовать соответствующий
УПРо Устройства при минимальном участии пользователя или без него,
Уотро^'Я Установку нового устройства. С точки зрения пользователя, такие
ся гот1СТВа’ подключаясь к системе, практически в ту же секунду являют-
Цр°ВЬ1ми к эксплуатации.
вНцм., РассмотРении аппаратных средств в нескольких следующих главах
Ие будет акцентироваться на универсальных вычислительных ма-
114
Главе
шинах (например, на персональных компьютерах и серверах). Вычисдц
тельные машины специального предназначения, например, используешь/
в автомобилях и сотовых телефонах, в данной книге рассматриваться ъ
будут. Вашему вниманию будут представлены простые аппаратные комц0
ненты, которые входят в состав типичных компьютерных систем, и апц/
ратные компоненты, разработанные специально для реализации функцц/
нальных возможностей операционных систем.
^ццепиии апП11РатнЬ1х cPeScm^ ° программного обеспечения
Биографические заметки
115
109
10®
2
а
ю7
/А
А
Q)
5
ю6
О
10s
8
Ю4
л
л
I'
1000
I
100
г
10
I
-L-- ..1____J_____L—___.........___________L-
0 jX 1970 1975 1980 1985 1990 1995 2000 2005
1965
Год
Рис. 2.1. График зависимости количества транзисторов в процессорах фирмы
Intel от года их выпуска
рорвон Мур Ч его закон
Доктор Гордон Мур получил степень ба-
Д ра по химии в Калифорнийском уни-
КаЛситете в Беркли и докторскую степень по
7мии и физике в Калифорнийском Техно-
логическом Институте2. Он был соучредите-
лем корпорации Intel, самого крупного
в промышленности средств вычислительной
техники производителя процессоров. На
данный момент Гордон Мур является почет-
ным председателем совета директоров кор-
порации Intel3. Он также прославился благо-
даря своему прогнозу скорости развития
вычислительной мощности, который полу-
чил название закона Мура (Moor's law).
Несмотря на благоприобретенное назва-
ние, сформулированная Муром закономер-
ность не доказана. В своей работе, опубли-
кованной в 1965 году, «Cramming More
Components onto Integrated Circuits», Myp
отметил, что число транзисторов в процес-
сорах с каждым годом практически
удваивается4. Транзисторы (transistor) —
это миниатюрные переключатели, которые
управляют электрическим током (аналогич-
но выключателю, который включает и вы-
ключает свет). Быстрее работает выключа-
тель - быстрее работает процессор; больше
транзисторов — больше число задач, которое
процессор может выполнить одновременно.
УР предполагал, что увеличение количест-
ок транзисторов теми же темпами продлится
тиров Десятилетия- К 1975 году он скоррек-
Вал св°й «закон», уточнив, что число
транзисторов будет удваиваться каждые 24
месяца.
На сегодняшний день показатели произ-
водительности процессоров удваиваются
практически каждые 18 месяцев, а число
транзисторов - каждые 24 (рис. 2.1). Ключе- .
вым фактором, который способствует этому,
является экспоненциальное падение цен на
каждый отдельный транзистор. Существуют
и другие тенденции, связанные с законом
Мура. Например, размер транзисторов экс-
поненциально уменьшается. Уменьшение
размеров транзисторов приводит к росту их
числа на кристалле (т.е. на микросхеме, где
расположен процессор), в результате более
высокая вычислительная мощность обеспе-
чивается процессорами меньших размеров
Более того, транзисторы меньших размеров
работают быстрее своих более крупных ана-
логов.
Последние достижения в области нано-
технологий (технологий масштаба молекул)
позволили производителям полупроводни-
ков создавать транзисторы, состоящие из не-
скольких атомов. В ближайшем будущем при
разработке транзисторов ученые будут огра-
ниченны размерами атома. Расширяя сферу
действия закона Мура, такие компании, как
Intel, занимаются исследованием новых тех-
нологий с целью изменения структуры тран-
зистора и поиска высокопроизводительных
альтернатив технологиям на основе
транзисторов5.
116
Вопросы для самопроверки
1. В чем заключается причина того, что разработка современных оц
рационных систем представляет собой куда более сложную задац®'
чем 50 лет назад? X
2. Каким образом драйверы и интерфейсы, такие как plug-and-pu
упрощают расширяемость операционных систем? ч
Ответы 1) Операционные системы пятидесятилетней давность
управляли малым количеством программ и аппаратных средств, г11
временные операционные системы, как правило, управляют огрОк,'
ным множеством программ и набором аппаратных средств, которЬ1-
может отличаться от компьютера к компьютеру. 2) Драйверы освобо*
ждают разработчиков операционных систем от решения таких задан
как работа с аппаратными средствами. Операционные системы Могу^
обеспечивать работу новых устройств путем простого использовании
соответствующего драйвера устройства. Устройства plug-and-play ц0.
зволяют операционной системе с легкостью определять аппаратные
ресурсы компьютера, что в свою очередь упрощает процесс установки
устройств и соответствующих им драйверов. С точки зрения пользова-
теля, устройство готово к эксплуатации сразу же после его установки.
23 Аппаратные компоненты
К аппаратным средствам компьютера относятся его физические устрой-
ства, такие как: процессор(ы), основная память, устройства ввода/вывода.
В следующих разделах рассматриваются аппаратные компоненты, которы-
ми управляет операционная система для удовлетворения вычислительных
потребностей пользователя.
2.3.1 Материнские платы
Чтобы удовлетворить требованиям системы, компьютеры организуют
взаимодействие многочисленных аппаратных устройств. Для осуществле-
ния взаимодействия независимых устройств, компьютеры оснащаются од-
ной или несколькими печатными платами (printed circuit board, РСВ), ко-
торые являются аппаратными компонентами и обеспечивают электриче-
ский контакт между устройствами, расположенными на плате.
Материнскую плату (mainboard или motherboard), главную печатнУ10
плату системы, можно назвать основой компьютера. Она оснащена расши-
рительными гнездами (слотами), к которым подключаются другие компо-
ненты, такие как процессоры, основная память и прочие аппаратные УсТ’
ройства. Эти гнезда обеспечивают электрический контакт между разлИ4'
ными аппаратными компонентами и дают пользователю возможное’1'*’
изменять конфигурацию аппаратных средств компьютера, подключ^
и отключая устройства от гнезд. Материнская плата является одним из **
тырех аппаратных компонентов, необходимых для выполнения прогр^1*1
на универсальной вычислительной машине. Остальные три — это проНеС_
сор (см. раздел 2.3.2), основная память (см. раздел 2.3.5) и внешнее зай°
минающее устройство (см. раздел 2.3.6).
117
к н^пИ"" аппаратных средств и
„партныв металлические провода слишком велики, чтобы обеспе-
СТ« дыпое количество электрических связей между компонентами со-
чцть ° ых систем при их малом размере. Поэтому материнские платы со-
рремен з несколькИх чрезвычайно тонких слоев пластмассы, содержащих
СТ°ЯТ скопические электрические проводники (trace). Они выступают
М0Кр° канадов связи и обеспечивают передачу сигналов на материнской
в Р°лИргучОК проводников образует высокоскоростной канал связи, назы-
ваемый шиной (bus).
В В состав большинства материнских плат входят несколько компьютер-
микросхем, предназначенных для выполнения операций низкого
НЬ1Х Например, в состав материнских плат, как правило, входит мик-
УР°хема базовой системы ввода/вывода, БИОС (Basic Input/Output
q°stem, BIOS), которая хранит инструкции, предназначенные для инициа-
лизации и управления аппаратными средствами. БИОС также несет ответ-
ственность за загрузку в память начального блока операционной системы.
Этот процесс называется начальной загрузкой (bootstrapping) (см. раз-
дел 2.4.3). После загрузки операционной системы материнская плата мо-
жет использовать БИОС для взаимодействия с аппаратными средствами
системы, чтобы выполнять низкоуровневые (т.е. базовые) операции вво-
да/вывода. Материнские платы также содержат микросхемы, называемые
контроллерами (controller), которые управляют процессами передачи дан-
ных по шинам платы. Набор микросхем (chipset) материнской платы —
это набор контроллеров, процессоров и других аппаратных средств, интег-
рированных на материнской плате, определяющий возможности аппарату-
ры системы (например, то, какие типы процессоров и памяти поддержива-
ет данная плата).
К последним тенденциям в сфере разработки материнских плат относит-
ся стремление интегрировать мощные аппаратные компоненты на печатной
плате. Как правило, многие из этих компонентов подключаются к гнездам
(слотам) в виде навесных плат или плат расширения (add-on card). Но боль-
шинство современных материнских плат включают микросхемы, выпол-
няющие обработку графической информации, передачу данных по сети,
а также управление RAID-накопителями. Эти расположенные на плате уст-
ройства — их называют внутренними устройствами (on-board device) —
Снижают полную стоимость системы и в значительной степени способству-
10т резкому падению цен на компьютеры. Их недостатком является постоян-
ное подключение к материнской плате и невозможность простой замены.
Вопросы дм самопроверки
1. В чем заключается основная функция материнской платы?
2. Почему базовая система ввода/вывода является неотъемлемой ча-
стью компьютерных систем?
Ответы 1) Материнская плата является основой взаимодействия
аппаратных компонентов. Они взаимодействуют посредством электри-
ческих контактов на материнской плате. 2) БИОС обеспечивает базо-
вую инициализацию и управление компьютером, а также загружает
в память начальный блок операционной системы. БИОС включает ин-
струкции, позволяющие операционной системе взаимодействовать
с аппаратными средствами компьютера.
118
[Щ.
23.2 Процессоры
Процессор (processor) — это аппаратный компонент, который выпод^
ет поток команд на машинном языке. В компьютере могут присутствовав
процессоры различных типов, как, например, центральный процесс 1
(central processing unit, CPU), графический сопроцессор (graphiM
coprocessor), цифровой процессор сигналов (digital signal processor, DSp?
Центральный процессор — это процессор, выполняющий команды
грамм; сопроцессор, например, графический, или цифровой процессор CjJr
налов, разработаны для эффективного выполнения ограниченного набор '
специальных команд (например, для трехмерного преобразования). Цра
цессоры встроенных систем могут решать специальные задачи, такие как I
преобразование цифрового сигнала в аналоговый аудиосигнал мобильного
телефона — это пример использования цифрового процессора сигналов I
Будучи главным процессором системы, центральный процессор способен
выполнять огромное количество команд, но может повысить производи.
• тельность всей системы путем переноса задач, требующих объемных вы-
числений, на сопроцессор, разработанный специально для задач этого
типа. В следующих главах книги центральный процессор будет называть-
ся просто «процессором» или «универсальным процессором».
Действия, которые могут выполняться процессором, определяются его
набором команд. Размер команды, или длина команды (instruction
length), зависит от архитектуры. Но даже внутри одной архитектуры неко- i
торые процессоры поддерживают различные размеры команд. Архитекту-
ра процессора также определяет объем данных, которые могут быть обра-
ботаны за раз. Например, 32-битовый процессор обрабатывает данные
32-битовыми порциями.
Современные процессоры выполняют множество операций распределе-
ния ресурсов между аппаратными средствами для повышения производи-
тельности. К этой категории операций относится поддержка виртуальной
памяти и аппаратные прерывания. Эти два важных понятия будут рас-
смотрены позже.
Несмотря на разнообразие архитектур, некоторые компоненты присуТ"
ствуют практически во всех современных процессорах. К таким компонеИ'
там относятся блок выборки команд, механизм прогнозирования ветвЛб'
ния, операционный блок, регистры, блоки кэш-памяти, а также иитер'
фейс шины (рис. 2.2). Блок выборки команд (instruction fetch unw
загружает команды в высокоскоростной блок памяти, называемый регйсТ
ром команд, и процессор может быстро выполнить команду. ДешифраТ°^
команд (instruction decode unit) преобразует команду и осуществляет
соответствующих данных в операционный блок для ее выполнения. Осно®
ную часть операционного блока составляет арифметико-логическое Ус’
ройство, АЛУ (arithmetic and logic unit, ALU), которое выполняет осн°®
ные арифметические и логические операции, такие как сложение,
жение и логическое сравнение (следует отметить, что для структур11®1*
схем характерно V-образное изображение АЛУ).
Интерфейс шины позволяет процессору взаимодействовать с памяти ,
и другими устройствами системы. Так как процессоры, как правило, Pa’,Oj
тают на более высоких скоростях, чем основная память, в их состав вход15
апйЩ
Рис. 2.2. Компоненты процессора
высокоскоростная память, называемая кэш-памятью, к р ппоизво-
пии данных из основной памяти. Блоки кэш-памяти повы пянным
дительность процессора путем предоставления быстрого досту о_
и командам. Ввиду того, что высокоскоростная кэш-память нами
же основной памяти, кэш, как правило, имеет относительно не~ °
емкость. Память данного типа подразделяется на уровни. Первв™
(Level 1, L1) представлен самыми быстрыми и наиболее дорогими блока
кэш-памяти, которые расположены в процессоре. Блок второго УР
(Level 2, L2), который обладает большей емкостью и меньшей сКОР°
п° сравнению с блоком кэш-памяти первого уровня, как правило, распо
*ен на материнской плате, но все чаще интегрируется в процессор дл
*пения производительности7. гкогттл-
ло^еГИСТры (register) — это высокоскоростные элементы памя™’ J
МЫреННЬ1е в процессоре и хранящие данные, непосредственно о Р они
дол ®₽ОЦессором. Прежде чем процессор начнет обработку да’
в л быть занесены в регистр. Хранение команд и ДакНЬ1Х р т к
пРоп °И дРУгой более медленной памяти является малоэффекти реги_
ПРо^ссор будет простаивать, ожидая получения доступа к данным. Реги
120
ГАдВд
стры «зашиты» в схему процессора и физически расположены возле опер^
ционных блоков, что делает доступ к ним более быстрым, нежели к бло^
кэш-памяти второго уровня. Разрядность регистров определяется колите
ством бит, которые процессор может обработать за одну операцию. Напр^
мер, 32-битовый процессор может хранить данные объемом 32 бита в ка^
дом регистре. Большинство процессоров в современных персональны^
компьютерах являются 32-битовыми; все большую и большую популяр
ность завоевывают 64-битовые процессоры8.
Набор регистров процессора определяется архитектурой, и каждый ре.
гистр решает определенную задачу. Например, процессор Intel Pentium 4
имеет 16 программно доступных регистров. Как правило, половина из цИх
используется приложениями для быстрого доступа к значениям данных
и указателям в процессе выполнения. Такие регистры называются регист-
рами общего назначения (general-purpose registers). Процессор PowerPC
970 фирмы IBM (используемый в компьютерах G5 фирмы Apple) имеет 32
регистра общего назначения. Остальные регистры (часто называемые
управляющими регистрами) хранят системные данные. К таким регистрам
относятся, например, счетчик команд, используемый процессором для оп-
ределения следующей команды, которую необходимо выполнить9.
Вопросы для самопроверки
1. В чем заключается отличие центрального процессора от сопроцессо-
ра? Каким образом присутствие нескольких процессоров (сопроцес-
соров) в системе влияет на ее производительность?
2. Перечислите характеристики системы, определяемые архитекту-
рой процессора?
3. Чем обеспечен более быстрый доступ к регистрам, нежели к памяти
любого другого типа, в том числе и к кэш-памяти первого уровня?
Ответы 1) Центральный процессор выполняет команды общего
назначения на машинном языке; сопроцессор обеспечивает быстрое
выполнение специализированных команд. Несколько процессоров по-
зволят системе выполнять несколько программ параллельно; несколь-
ко сопроцессоров повысят производительность системы, выполняя
обработку данных одновременно с центральным процессором. 2) Ар-
хитектура центрального процессора определяет набор команд компью-
тера, поддержку виртуальной памяти и структуру прерывании-
3) Регистры «зашиты» в схему процессора и физически расположены
возле операционных блоков.
233 Системный таймер
Машинное время, как правило, измеряется циклами или тактам**
(cycles), их еще называют тактами синхронизации (clocktick). Цикл соот-
ветствует одному полному периоду электрического сигнала, генерируемо60
системным синхрогенератором (тактовым генератором). Синхрогенератор
задает ритм работы компьютерной системы, подобно дирижеру в оркестр6.
Точнее сказать, синхрогенератор определяет частоту, с которой шины °е'
редают данные и которая, как правило, измеряется циклами в секуН/Й
или герцами (Гц). К примеру, системная шина (frontside bus, FSB), коТ°'
121
епц^ мпаРзтпЬ1Х сРе9ст^ и программного обеспечения
язывает процессор с модулями памяти, обычно работает на частоте
раЯ СВпьКИх сотен мегагерц (МГц, 1 МГц = 1000000 Гц).
яеСК° шинство процессоров современных настольных компьютеров рабо-
^на частотах в несколько сотен мегагерц или даже миллиардов герц,
та1°т ерц (ГГц), что, как правило, превышает скорость работы системной
Гиг Процессоры и другие устройства используют производные частоты
speed), умножая или разделяя частоту системной шины10. Напри-
те процессор с частотой 2 ГГц и частотой системной шины 200 МГц для
МеРроирования внутреннего синхросигнала использует умножитель на 10
системного синхросигнала, а звуковая карта с частотой 66 МГц — дели-
тель на 2,5.
Вопросы для самопроверки
1. (Да/Нет) Все компоненты системы работают с одинаковой тактовой
частотой.
2. Какие проблемы могут возникнуть, если один из компонентов на
шине использует умножитель частоты с очень большим коэффици-
ентом, а другой на этой же шине — делитель с очень большим коэф-
фициентом?
Ответы 1) Нет. Как правило, устройства используют умножители
или делители частоты, определяющие их скорость работы относитель-
но системной шины. 2) Узкое место может возникнуть, когда компо-
нент с делителем работает с намного меньшей скоростью, чем
компонент с умножителем. Второе устройство, ожидая данные, пере-
даваемые первым, будет простаивать.
2.3.4 иерархия памяти
Емкость и скорость работы памяти ограничиваются законами физики
и экономики. Практически все электронные устройства передают данные,
используя электрический сигнал, распространяющийся по проводникам
печатной платы. Существует предел скорости распространения электриче-
ского сигнала; чем больше длина проводника между двумя терминалами,
тем больше времени потребуется на передачу данных. Далее, оснащение
процессоров памятью огромной емкости, способной отвечать на запросы
данных со скоростью, равной (или практически равной) скорости процес
сора, приведет к выходу цены на них за пределы финансовых возможно-
сти заказчика.
Компромисс между стоимостью и производительностью определяет ие
Рархию памяти (memory hierarchy) (рис. 2.3).
Самая быстрая и наиболее дорогая память расположена наверху иерар
ХИи и обладает, как правило, наименьшей емкостью. Самая медленная
наименее дорогая память находится внизу и обладает, как правило,
льшой емкостью. Следует отметить, что рост размеров блоков на рисунке
ноРа5Кает Увеличение емкости для более медленных типов памяти (рису
выпоЛнен без учета масштаба).
Ме егистРы — это самый быстрый и наиболее дорогой тип памяти в систе-
’ °Ни работают на одинаковой с процессором скорости. Скорость кэш-па-
Яти измеряется ее задержкой — интервалом времени, необходимым для
ж:/л^
Задержка (в циклах процессора)
Pile. 2.3. Иерархия памяти
передачи данных. Задержка, как правило, измеряется в наносекундах или
в циклах процессора. К примеру, задержка кэш-памяти первого уровня
процессора Pentium 4 составляет 2 цикла процессора11. Задержка кэш-па-
мяти второго уровня составляет приблизительно 10 циклов. На сегодняШ"
ний день в большинстве случаев кэш-память первого и второго уровня ин-
тегрирована в процессор, таким образом, она может использовать высоко'
скоростные соединения процессора. Кэш-память первого уровня, как
правило, хранит десятки килобайт данных, тогда как кэш память второ1®
уровня хранит сотни килобайт или несколько мегабайт. Мощные пронес*
соры могут иметь кэш-память третьего уровня, которая медленнее кэШ-Па"
мяти второго уровня, но быстрее основной памяти.
Следующая ступень иерархии запоминающих устройств (ЗУ) принаД®6^
жит основной памяти (main memory), которая также называется опер®
тивной (real memory) или физической памятью (physical memory). Осно®
ная память служит источником дополнительной задержки, так как
ным по пути из нее в процессор необходимо пройти через системную щййУ’
которая, как правило, работает в несколько раз медленнее процессора-
новная память в современных архитектурах характеризуется задержи®
от десяти до сотни циклов процессора12. Емкость современной основН0®
памяти общего назначения колеблется в пределах от сотни мегабайт (пер'
123
^flllUa аппаратных средств и программного обеспечвпия
ядьные компьютеры) до нескольких сотен гигабайт (мощные серверы).
с0110вная память будет рассмотрена в разделе 2.3.5 и в главе 9. Регистры,
0е*1. память и основная память, как правило, являются энергозависимой
КЭпомИнаЮЩей средой (volatile media) — информация, которая хранится
38 ой среде, теряется при выключении электропитания.
р Накопители на жестких магнитных дисках (НЖМД) и другие внешние
доминающие устройства, такие как, накопители на компакт-дисках
fCD)’ универсальных цифровых дисках (DVD) и ленточные накопители,
относятся к наименее дорогим и наиболее медленным устройствам хране-
ния данных в компьютерных системах. Задержка дискового накопителя
дЖМД» как пРавило> измеряется в миллисекундах, что зачастую в милли-
он Раз превышает задержку кэш-памяти процессора. Чтобы не дать про-
цессору простаивать в то время как некоторый процесс ожидает получение
данных со вторичного запоминающего устройства, операционная система,
как правило, выполняет другой процесс для повышения эффективность
использования процессора. Основным преимуществом вторичных запоми-
нающих устройств, таких как, накопители на жестких магнитных дисках,
является их большая емкость, которая, как правило, составляет сотни ги-
габайт. Еще одним преимуществом является то, что данные здесь хранятся
в энергонезависимой среде, таким образом, информация не исчезает при
отключении питания устройства. Чтобы удовлетворить требованиям поль-
зователей, системотехники должны идти на компромисс между стоимо-
стью и производительностью различных запоминающих устройств (см.
«Размышления об операционных системах: Кэширование»).
Вопросы для самопроверки
1. В чем заключается разница между энергозависимыми ЗУ и ЗУ
с долговременным хранением данных?
2. Чем можно объяснить тот факт, что схема иерархия памяти имеет
вид пирамиды?
Ответы 1) Энергозависимые ЗУ в отличие от ЗУ с долговремен-
ным хранением данных (энергонезависимых) не сохраняют информа-
цию после выключения компьютера. Как правило, энергозависимые
ЗУ быстрее и дороже ЗУ с долговременным хранением данных.
2) Если запоминающее устройство дешевле, пользователь может по-
зволить себе купить такое устройство большей емкости, следователь-
но, емкость памяти системы увеличивается.
2'2 3 *'5 * * Основная память
access память (оперативное запоминающее устройство, ОЗУ (random
^НойТТ’ реализуется в виде энергозависимой памяти с произ-
ИзвольнаяЫ °рко”’ ЗУПВ (random access memory, RAM). Выражение «про-
с Данным вы°°Рка>> означает, что процессы могут обращаться к ячейкам
^Льном Jo В люб°м порядке. Напротив, к ячейкам с данными на последова-
Дйтсч обп поминак)Щем устройстве (например, на магнитной ленте) прихо-
ТеДей йа аЩаться последовательно. В отличие от магнитных лент и накопи-
Г° ^Реса еС7 КИХ ,магнитных дисках, задержка доступа к памяти для любо-
основной памяти является практически одинаковой.
124
Глиб^
Наиболее распространенной формой памяти с произвольной выбору
является динамическое оперативное запоминающее устройство, диналц
ческое ОЗУ (dynamic RAM), которое требует наличия схемы обновлена
(регенерации) для периодического чтения (несколько раз каждую милд^*
секунду) содержимого ячеек во избежание потери данных. Эта процедур
не является обязательной для статического ОЗУ (static RAM, SRAM),
торое не нуждается в регенерации для сохранения данных. Статичесцо
ОЗУ, обычно используемое в качестве кэш-памяти процессора, как праВ11
ло, быстрее и дороже динамического.
Производители динамических ОЗУ ставят перед собой важную задд
чу — уменьшить разницу между скоростью процессора и скоростью пере.
дачи данных памятью. Модули памяти разрабатываются таким образом
чтобы свести к минимуму задержку при обращении к данным внутри м0’
дуля и максимально увеличить скорость передачи информации. Современ-
ные технологии помогают уменьшить общую задержку и увеличить пропу-
скную способность (bandwidth) — объем информации, который можно пе-
редать в единицу времени. По мере разработки производителями новых
технологий памяти, скорость и емкость последней увеличиваются, тогда
как, согласно закону Мура, стоимость единицы памяти падает.
Размышления об операционных системах
Кэширование
Каждый из нас использует кэширование
в своей повседневной жизни. В общих чер-
тах, кэш — это легкодоступное место для хра-
нения необходимых вещей.
Пример кэширования могут привести
белки, которые запасаются на зиму желудя-
ми. Мы храним карандаши, ручки, сшивате-
ли, липкую ленту и скрепки для бумаг в ящи-
ках нашего письменного стола, таким обра-
зом, мы легко можем их взять, когда они нам
понадобятся (в противном случае нам при-
дется спускаться в холл к канцелярскому
ларьку). Операционные системы используют
ряд схем кэширования; как, например, кэ-
ширование данных и команд процесса в вы-
сокоскоростной кэш-памяти для быстрого
доступа, кэширование данных с диска в ос-
новной памяти для быстрого доступа к ним
в процессе выполнения программы.
Разработчикам операционных систем- сле-
дует быть осторожными в использовании кэ-
ширования, так как данные в кэше - это копия
данных, оригинал которых хранится в памяти
следующего уровня иерархии. Именно копия
данных в кэше первой претерпевает изменения;
таким образом, она очень быстро может стать
отличной от исходных данных, приводя к несо-
вместимости. Если система даст сбой в работе,
когда в кэше хранятся обновленные данные
вместо исходных, то изменения в данных могут
быть утеряны. По этой причине операционные
системы часто записывают данные из кэша н3
место исходных, этот процесс называется очИ'
сткой (или сбрасыванием) кэша. В pacnpf'Pe
ленных файловых системах кэш часто распола
гается как на сервере, так и на компьютере клИ'
ента, что значительно усложняет обеспечение
совместимости данных в кэше.
125
апИЧратпь1х сРе9сгп6 и программного обеспечения
------------
Вопросы дм самопроверки
1. Сравните основную память и накопители на дисках по таким пара-
' метрам, как время доступа, емкость и энергозависимость.
2. Почему основная память называется памятью с произвольной вы-
боркой?
Ответы 1) Время доступа для основной памяти намного меньше
времени доступа для накопителей на дисках. Последние, как правило,
обладают большей емкостью, чем основная память, так как стоимость
единицы дисковой памяти намного ниже, чем у основной памяти. Ос-
новная память, как правило, является энергозависимой, тогда как на
дисковых накопителях данные хранятся в течение долгого времени
даже при отключенном питании. 2) Процессор может обращаться
к ячейкам основной памяти в любом порядке и практически с одина-
ковой скоростью, независимо от адреса ячейки.
2.3.6 Вторичные запоминающие устройства
Из-за ограниченной емкости и энергозависимости основная память не
позволяет хранить данные в больших объемах или данные, которые долж-
ны быть сохранены после отключения питания. Для долговременного хра-
нения данных больших объемов, таких как файлы и программные прило-
жения, в компьютерах используются вторичные (внешние) запоминаю-
щие устройства (secondary storage) или, как их еще называют, устройства
долговременного хранения данных (persistant storage), или вспомога-
тельные запоминающие устройства (auxilary storage), которые обеспечи-
вают сохранность данных после выключения компьютера. В большинстве
компьютеров в качестве вторичных запоминающих устройств используют-
ся накопители на жестких магнитных дисках (НЖМД).
Несмотря на то, что данные накопители обладают большей емкостью
и стоят дешевле, чем оперативная память, они малоэффективны в роли
первичного запоминающего устройства, так как обращение к накопителю
на жестких магнитных дисках выполняется не так быстро, как к основной
памяти. Обращение к данным, которые хранятся на жестких дисках, тре-
Ует механического движения головок чтения/записи, сопряжено с враща-
тельной задержкой при считывании данных головкой и с затратами време-
на передачу при прохождении данных под головкой. Механическое обо-
Дование обладает быстродействием, намного меньшим быстродействия
ких ТР°Нн°й основной памяти. Более того, данные с накопителя на жест-
Де ч МагнитнЫх дисках должны быть загружены в основную память, преж-
нитнь К НИМ сможет обратиться процессор13. Накопитель на жестких маг-
(Ыоск Х] ^исках является примером устройства блочного ввода/вывода
объе Bvice)> так как передает данные блоками байтов фиксированного
jje (как правило, от сотни байт до десятков килобайт).
На ноеС°Т°РЬ1е И3 ВТ°РИЧНЫХ запоминающих устройств записывают данные
Ра» об Ители небольшой емкости, которые могут быть изъяты из компьюте-
ТеРами ^аЯ РезеРвное хранение данных и обмен данными между компью-
Кой за Тот вид вторичных запоминающих устройств обладает более высо-
стких е₽ЖК°й, чем Другие накопители, как, например, накопители на же-
магнитных дисках. Популярным запоминающим устройством такого
126 Глав.
рода является накопитель на компакт-дисках (compact disk, CD), которц.
может хранить до 700 Мб информации на одностороннем носителе. Данщ.
на компакт-дисках преобразуются в цифровой вид (единицы и нули) и «в^
жигаются» в виде серии впадин на гладкой поверхности носителя. Коц
пакт-диски с однократной записью и многократным считыванием (w^'
te-once/read-many disk, WORM disk), такие как, компакт-диски с однокр^
ной записью (CD-R) и универсальные цифровые диски с однократно^
записью (DVD-R), являются съемными. К другим видам накопителей с дОд
госрочным хранением данных относятся zip-диски, гибкие магнитные дИс
ки, карты флэш-памяти и магнитные ленты (стримеры).
Данные, записанные на перезаписываемый компакт-диск (CD-RW), хра
нятся на металлическом материале внутри пластикового диска. Лазерные
луч при записи изменяет отражательные свойства записываемого носителя
используя два состояния, представляющих 0 и 1. Компакт-диски с одно-
кратной записью (CD-R и CD-ROM) производятся из окрашенного материя,
ла, расположенного между слоями пластика. Свойства этого материала при
записи (прожигании лучом лазера) компакт-диска меняются необратимо.
За последнее время приобрела популярность технология универсальных
цифровых дисков (DVD), также называемых универсальными видеодиска-
ми. DVD изначально были рассчитаны на запись видеоинформации, но
в настоящее время используются и в качестве запоминающих устройств
для данных. Универсальные цифровые диски имеют такой же размер, как
и компакт-диски, но данные на них записаны при помощи более узких до-
рожек и информационных слоев (до двух на одной стороне). Такие диски
могут хранить до 5,6 Гб информации на одном слое.
Некоторые системы используют память, уровнем ниже вторичных запо-
минающих устройств. Например, большие системы обработки данных, как
правило, имеют библиотеку лент, доступ к которой осуществляется при
помощи механизированного архива. Такие запоминающие системы, кото-
рые обычно классифицируются как запоминающие устройства третьего
уровня, характеризуются большей емкостью и большим временем выбор-
ки, чем у вторичных запоминающих устройств.
Вопросы для самопроверки
1. Почему обращение к данным, которые хранятся на диске, требует
больше времени, чем к тем, которые расположены в основной памяти”
2. Сравните и сопоставьте компакт-диск с универсальным цифровым
диском.
Ответы 1) К основной памяти можно обратиться При помоп1й
только электрических сигналов, в то время как накопители на жест-
ких магнитных дисках для этой операции требуют участия механиз-
мов движения головок чтения/записи. При этом имеет место
вращательная задержка считывания данных головкой и задержка D®
редачи при прохождении данных под головкой. 2) Компакт-дисН
и универсальные цифровые диски имеют одинаковые размеры, а обра
щение к информации, которая хранится на этих носителях, осущесТ®
ляется при помощи лазерного луча, но данные на универсальны
цифровых дисках хранятся на нескольких слоях, используя при этом
тонкие дорожки. Таким образом, компакт-диски обладают меньИ[еИ
емкостью.
пцци а па!" ":Hblx cfe9 а программы обеспечения
Кв^,—~~~~~~
127
2jjUlunbi
__________это совокупность проводников (электрических соединений),
мощи которых осуществляется передача информации между аппа-
пР11 п° и коМпонентами компьютера. Подсоединенные к шине устройства
ратнЬ^ла1ОТ через шину электрические сигналы, чтобы связываться с дру-
пеРеС устройствами, подключенными к этой шине. Как правило, шина со-
гйми шины данных (data bus), которая передает данные, и адресной
стоИТ[ ^^regs bus), которая определяет получателя или источник этих
я1*1®**^ 14. Порт (port) — это шина, соединяющая только два устройства.
ДаНЯ которая совместно используется несколькими устройствами для
лнения операций ввода/вывода, также называется каналом вво-
па/вывода (I/O channel)15.
Доступ к основной памяти — главная причина конфликтных ситуации,
возникающих между каналами и процессорами. Как правило, в каждый
конкретный момент времени может осуществляться только одна операция
обращения к определенному модулю памяти. Но каналу ввода/вывода
и процессору может одновременно потребоваться обращение к основной
памяти. Во избежание конфликта между двумя сигналами на шине, аппа-
ратное устройство, называемое контроллером, определяет уровень приви-
легий каждого обращения к основной памяти, и, как правило, каналам
предоставляется преимущество перед процессорами. Обмен выполняется
посредством захвата цикла (cycle stealing), так как канал ввода/вывода
буквально «крадет» циклы у процессора. Каналы ввода/вывода использу-
ют лишь небольшой процент общего числа циклов процессора, что, как
правило, компенсируется более эффективным использованием устройств
ввода/вывода.
Еще раз напомним, что системная шина соединяет процессор с основной
памятью. По мере увеличения скорости системной шины, растет и объем
данных, передаваемых между основной памятью и процессором, что, как
правило, ведет к повышению производительности. Скорость обмена по
Шине измеряется мегагерцами (например, 133 МГц или 200 МГц). В неко-
торых микропроцессорных наборах используются системные шины с час-
тотой 200 МГц, фактически работающие на частоте 400 МГц, так как они
осуществляют две операции обмена данных с памятью за один такт син-
ронизации. Эта возможность, которая должна поддерживаться как мик-
опроцессорным набором, так и оперативной памятью, называется удвоен-
те СК°Р°стьк> передачи данных (double data rate, DDR). В некоторых сис-
По ЙХ Реализована учетверенная подкачка (quad pumping), которая
Личи ЛЯет пеРеДаьать до четырех пакетов данных за такт, фактически, уве-
вая пропускную способность памяти системы в четыре раза.
Рийт®* (Peripheral Component Interconnect bus) связывает перифе-
ТеМоГгГР°ЙСТВа’ такие как звуковые и сетевые платы, с остальной сис-
тада ‘ ^еРвая версия спецификации PCI требовала, чтобы шина PCI рабо-
Р°стьНа Частоте 33 МГц и была 32-битовой, что значительно снижало ско-
Expres°epe«a4H Данных на периферийные устройства и обратно. PCI
н°й щ" это последний стандарт, предусматривающий шины перемен-
К сйст ₽ИНЬ1’ Согласно этому стандарту каждое устройство подключается
еме при помощи каналов (lane), число которых может достигать 32,
128 Гмвц^
и по каждому из которых можно передавать 250 МБ данных в секуц^
в каждом направлении — в сумме пропускная способность может достц
гать 16 ГБ на соединение16.
Ускоренный графический порт (Accelerated Graphics Port, AGP) в пер
вую очередь используется графическими платами, которым, как правил0
необходимы десятки или сотни мегабайт оперативной памяти для обработ’
ки трехмерного изображения в реальном времени. Исходной специфика,
цией ускоренного графического порта предусматривалась 32-битовдя
шина с частотой 66 МГц, которая обеспечивала пропускную способность д0
260 МБ в секунду. Производители повысили скорость этой шины по срав.
нению с данной спецификацией, обозначив увеличение скорости посреди,
вом множителя: 2х для двукратного, 4х для четырехкратного и т.д. Совре.
менные спецификации предусматривают 2х-, 4х- и 8х-версии данного про.
токола, доводя пропускную способность до 2 ГБ в секунду.
Вопросы для самопроверки
1. Каким образом скорость системной шины влияет на производи-
тельность системы?
2. Каким образом контроллеры упрощают процесс обращения к со-
вместно используемым шинам?
Ответы 1) Системная шина определяет объем данных, которым
могут обмениваться основная память и процессоры за один цикл. Если
процессор генерирует запросы на большее количество данных, нежели
можно передать за один цикл, то это приводит к снижению производи-
тельности системы, так как процессору, возможно, придется ожидать
завершения запрошенной им передачи данных. 2) Контроллер упоря-
дочивает одновременные запросы на обращение к шине в соответствии
с их уровнем привилегий, таким образом, устройства не мешают рабо-
те друг друга.
2.3.8 Прямой доступ к памяти
Большинство операций ввода/вывода сопровождается обменом данны-
ми между основной памятью и устройством ввода/вывода. В первых ком-
пьютерах эти операции выполнялись при помощи программируемого вво*
да/вывода (programmed input/output, РЮ), определяющего байт данных
или слово, которым должны были обменяться основная память и устройст-
во ввода/вывода, и ожидающего в состоянии простоя выполнения этой
операции. Ожидание завершения операций программируемого ввода/вЫ-
вода приводило к потере огромного количества циклов процессора. Позя<е
разработчики начали использовать ввод/вывод по прерываниям, что по-
зволило процессору выдавать запрос на ввод/вывод, одновременно продол-
жая выполнять программные инструкции. Устройство ввода/вывода сооб-
щало процессору о выполнении операции посредством генерирований
прерывания17.
Прямой доступ к памяти (Direct Memory Access, DMA) делает описай'
ные технологии более совершенными, позволяя передавать блоки данный
непосредственно с устройств ввода/вывода в основную память и обратно»
что освобождает процессор для выполнения программных инструкций
аппаратных средств и программно! i обеспечения
129
ис 2.4). Канал прямого доступа к памяти использует контроллер вво-
(сМ* ₽ вода для управления передачей данных между устройствами вво-
,да/ Ь,вода и основной памятью. Для уведомления процессора контроллер
Дй'в /вь1Вода генерирует прерывание по завершении процесса обмена.
вв°Д ой доступ к памяти значительно повышает производительность тех
ИРЯ которые выполняют большое количество операций ввода/вывода
мэйнфреймы)18.
систем,
(например, серверы и
Оперативная память
1 Процессор посылает запрос на ввод/вывод контроллеру ввода/вывода который в свою
очередь посылает запрос диску. Процессор продолжает выполнять инструкции.
2 Диск передает данные контроллеру ввода/вывода; данные размещаются в ячейке памяти
с адресом, указанным командой прямого доступа к памяти.
। з > Диск посылает процессору прерывание для уведомления его о завершении выполнения
операции ввода/вывода.
2.4. Прямой доступ к памяти (Direct Memory Access, DMA)
Ры рям°й Доступ к памяти совместим с рядом шинных архитектур. В ста-
п архитектурах (тех, которые все еще используются, но практически не
став ЗВО’Л'ЯТСЯ)> таких как архитектура, соответствующая промышленному
стан^^7^ ISA (Industry Standard Architecture), расширенная архитектура
АгсЬч^8 ISA (EISA) или микроканальная архитектура (Micro Channel
Ваемь ^ure’ MCA), контроллер прямого доступа к памяти (также назы-
Повн <,ст°Р°нним устройством») управляет передачей данных между ос-
Раци°И Памятью и устройствами ввода/вывода (см. «Размышления об опе-
Ратн°ННЬ1х системах: Унаследованное программное обеспечение и аппа-
кПаЬ1е средства»). Шины PCI используют обычный прямой доступ
’«яти, прибегая к захвату шины (bus mastering) — устройство PCI для
130
ГПйвц%
выполнения операции берет шину под свой контроль. В целом, процеСс
обычного DMA-обмена эффективнее «сторонней» передачи, и он реализ0
ван в большинстве современных шинных архитектур19.
Вопросы для самопроверки
1. В чем заключается преимущество прямого доступа к памяти пере
программируемым вводом/выводом?
2. В чем заключается отличие обычного прямого доступа к памяти о?
стороннего прямого доступа к памяти?
Ответы 1) В системах, использующих программируемый ввод/вы.
вод, процессор ожидает в состоянии простоя завершения каждой оде-
рации обмена данными внешних устройств с памятью. Прямой доступ
к памяти освобождает процессор от выполнения работы, необходимой
для осуществления передачи информации между основной памятью
и устройствами ввода/вывода, что позволяет процессору выполнять
в это время программные инструкции. 2) При стороннем прямом дос-
тупе к памяти необходимо, чтобы контроллер управлял доступом
к шине. Обычный прямой доступ к памяти позволяет устройствам
управлять шиной без дополнительных аппаратных средств.
2.3.9 Периферийные устройства
Периферийное устройство — это любое аппаратное устройство компью-
тера, которое не является обязательным для выполнения программных
инструкций. К таким устройствам относится множество устройств вво-
да/вывода различных типов (например, принтеры, сканеры и мыши), сете-
вые устройства (сетевые интерфейсные карты и модемы), а также запоми-
нающие устройства (компакт-диски, универсальные цифровые диски
и жесткие диски). Такие устройства как процессор, материнские платы
и основная память не считаются периферийными. Внутренние (встроен-
ные) периферийные устройства (те, которые находятся внутри системного
блока) считаются интегрированными периферийными устройствами;
к ним относятся модемы, звуковые карты и внутренние дисководы. Пожа-
луй, наиболее распространенным встроенным периферийным устройством
является накопитель на жестких магнитных дисках. На рис. 2.5 представ-
лен список некоторых периферийных устройств20. Мыши и клавиатуры
являются примерами устройств посимвольного ввода (character device) —
они которые передают данные по одному символу за сеанс обмена. Перифе-
рийные устройства могут быть подключены к компьютеру посредством
портов и других шин21. Последовательные порты (serial port) передают
данные по одному биту. Как правило, их используют для подключения та-
ких устройств, как клавиатуры и мыши. Параллельные порты (parallel
port) передают данные по несколько битов за раз. Эти порты, как правило,
используются для подключения принтеров22. Универсальная последов3'
тельная шина (Universal Serial Bus, USB) и порт стандарта IEEE 1394
(IEEE 1394 port) являются популярными высокоскоростными последова-
тельными интерфейсами. Интерфейс малых компьютерных систем (Small
Computer Systems Interface, SCSI) — это широко распространенный параЛ'
лельный интерфейс.
131
аппаратных средств и программного обеспечения
ы универсальной последовательной шины (USB) позволяют обме-
д данными с такими устройствами, как внешние накопители на
Ирват цифрОВые камеры и принтеры, а также обеспечивают этим устрой-
дйска э’леКТрОПИТание. Устройства, работающие на USB-шине, могут быть
сТвам ень1> распознаны, а также отключены от компьютера без выклю-
электропитания, не повреждая при этом аппаратуру системы (тех-
ченИ известная как «горячая замена»). Универсальная последователь-
н°л°шина версии 1.1 позволяет передавать данные со скоростью 1,5 или 12
в секунду (мегабит = 1 миллион бит; 8 бит = 1 байт). Потребность
мпьютеров в быстром доступе к данным больших объемов явилась при-
К° ой разработки универсальной последовательной шины версии 2.0 для
беспечения передачи данных со скоростью до 480 Мбит в секунду23.
Устройство
Дисковод для перезаписы-
ваемых компакт-дисков
zip-дисковод
НГМД
Мышь
Клавиатура
Многофункциональное
печатающее устройство
Звуковая карта
Видеоускоритель
Сетевая карта
Цифровая камера
Биометрическое устройство
Инфракрасное устройство
Радиоустройство
беспроводное устройство)
Описание
Считывает данные с компакт-дисков и записывает данные на ком-
пакт-диски.
Считывает данные со сменных ZIP-дисков и записывает данные на
сменные ZIP-диски.
Считывает данные с гибких магнитных дисков и записывает данные
на гибкие магнитные диски.
Преобразует положение манипулятора в положения курсора в гра-
фическом интерфейсе пользователя (graphical user interface, GUI).
Вводит команды или символы, соответствующие клавишам, кото-
рые нажимает пользователь.
Предоставляет возможность печатать, копировать, пересылать по
факсу или сканировать документы.
Преобразует цифровой сигнал в звуковой аналоговый для подачи
на громкоговорители. Позволяет вводить звуковые сигналы при по-
мощи микрофона и преобразовывать их в цифровые.
Выводит графическое изображение на экран; ускоряет двухмерное
и трехмерное изображение.
Осуществляет передачу данных между компьютерами.
Записывает и, как правило, отображает цифровое изображение.
Сканирует такие параметры человека, как отпечатки пальцев и сет-
чатка глаза, как правило, для идентификации и аутентификации.
Осуществляет передачу данных между устройствами посредством
беспроводного подключения в пределах прямой видимости.
Осуществляет передачу данных между устройствами посредством
ненаправленного беспроводного подключения.
ftfc. 2.5.
Периферийные устройства
Sony ан^аРт IEEE 1934, получивший торговую марку iLink от компании
помий lreWire от Apple, как правило, используется видеокамерами и за-
на л?1аК)гЦими устройствами большой емкости (например, накопителями
скоросКаХ)' ₽амках стандарта FireWire возможна передача данных со
Ток с Тью до 800 Мбит в секунду; ожидается, что после будущих дорабо-
к°Р°сть достигнет 2 Гбит в секунду (гигабит = 1 миллиард бит). Так
132 Глава ?
же, как и универсальная последовательная шина, стандарт FireWire по.
зволяет осуществлять «горячую замену» устройств и обеспечивает этим
устройствам электропитание. Более того, спецификация FireWire позволя.
ет производить обмен информацией между различными устройствами, прц
этом не подключая их к компьютеру24. К примеру, пользователь может не.
посредственно соединить два накопителя на жестких магнитных дисках
спецификации FireWire, чтобы скопировать содержимое с одного накопи-
теля на другой.
К другим интерфейсам, которые используются для подключения пери,
ферийных устройств к системе, относятся интерфейс малых компьютер,
ных систем (Small Computer System Interface, SCSI) и спецификация АТД
(Advanced Technology Attachment, ATA), которая использует встроенный
интерфейс накопителей (Integrated Drive Electronics, IDE). Данные интер.
фейсы осуществляют передачу данных с таких устройств, как накопитель
на жестких магнитных дисках и накопитель на универсальных цифровых
дисках, на контроллер материнской платы, который направляет эти дан-
ные на соответствующую шину25. К современным интерфейсам относится
интерфейс Serial АТА (SATA), который предоставляет более высокую ско-
рость передачи данных, чем АТА, а также несколько беспроводных интер-
фейсов, включая Bluetooth (для ближних беспроводных подключений)
и IEEE 802.11g (для высокоскоростных беспроводных подключений сред-
ней дальности).
Интерфейс малых компьютерных систем (SCSI, произносится «ска-зи»)
был разработан в начале 80-х годов, как высокоскоростной способ подклю-
чения запоминающих устройств большой емкости. Этот интерфейс исполь-
зуется, главным образом, внутри высокопроизводительной среды для обме-
на с устройствами, обладающими большой пропускной способностью 26.
Первоначальная спецификация интерфейса малых компьютерных систем
позволяла осуществлять передачу данных с максимальной скоростью 5 МБ
в секунду и поддерживала восемь устройств на 8-битовой шине. Современ-
ные спецификации, такие как Ultra 320 SCSI, позволяют передавать данные
со скоростью до 320 МБ в секунду для 16 устройств на 16-битовой шине27-
Вопросы для самопроверки
1. В чем заключается основное отличие между таким периферийным
устройством, как принтер, и таким устройством, как процессор?
2. Сравните и сопоставьте универсальную последовательную шинУ
USB и спецификацию FireWire.
Ответы 1) Компьютеру не требуются периферийные устройства
для выполнения программных инструкций. В то же время, каждому
компьютеру необходим, по крайней мере, один процессор. 2) И уни'
нереальная последовательная шина USB, и спецификация FireWh’6
обеспечивают хорошую пропускную способность и предоставляют уст'
ройствам электропитание. Спецификация FireWire обладает более вы-
сокими параметрами, чем универсальная последовательная шина,
а также позволяет устройствам взаимодействовать без подключения
к компьютеру.
аппаратных средств и программного обеспечения
133
Размышления об операционных системах
Унаследованное программное обеспечение
и аппаратные средства
Современные операционные системы
создаются в расчете на современную аппара-
ту и следуя соображениям совместимости
с современным прикладным программным
обеспечением. Но значительную часть аппа-
ратуры и программ, эксплуатируемых в на-
стоящее время и на фирмах и домашними
пользователями, можно отнести к устаревше-
му. Даже желая установить новую операци-
онную систему, пользователь, как правило,
старается сохранить большую часть старой
аппаратуры и привычных программ. Такая
аппаратура и программы называются унас-
ледованными. Разработчики операционных
систем должны учитывать необходимость
поддержки создаваемыми продуктами унас-
ледованных программ и аппаратуры, чтобы
не ограничивать себе рынок сбыта.
2.4 Поддержка функций операционных систем
аппаратными средствами
Компьютеры содержат элементы, предназначенные для быстрого вы-
полнения функций операционной системы аппаратными средствами в це-
лях повышения производительности. Аппаратно реализуется также ряд
элементов, которые позволяют в значительной степени усилить защиту
операционной системы, что повышает безопасность и стойкость системы.
2*4.1 Процессор
Большая часть операционных систем полагается на процессоры в части
Реализации механизмов защиты посредством отказа процессам в доступе
к привилегированным командам или к областям памяти, не предназначен-
ным для этих процессов. Если процесс пытается нарушить защиту, процес-
Р Уведомляет об этом операционную систему, и она может отреагировать
ветствующим образом. Процессор также заставляет операционную
ему реагировать на сигналы, поступающие от аппаратных устройств.
^льзовательский реЖим, реЖим ядра, привилегированные команды
^рационные системы зачастую предусматривают несколько различ-
ны Исполнительных режимов или режимов работы (execution mode)28.
Ляет о>Кность перехода от одного режима работы машины к другому позво-
Пра СозДавать более практичные, живучие и безопасные системы. Как
Ило, когда машина работает в определенном режиме, приложения
134 Гла Bq
имеют доступ только к подмножеству команд машины. Для пользователе
ских приложений, подмножество команд, которые может выполнять подь
зователь в пользовательском режиме (user mode) также известном, ка{с
режим пользователя или заданный режим, исключает, например, прямОе
выполнение команд ввода/вывода. Пользовательское приложение, котор0
му разрешено выполнять произвольный ввод/вывод, может, к примеру
вывести на печать или экран список паролей системы, отобразить инфОр’
мацию любого другого пользователя или уничтожить операционную систе.
му. Операционная система обычно работает в привилегированном режиме
(также известном, как супервизорный режим или режим ядра (kernel
mode)); она имеет доступ ко всем командам в наборе команд машины. Црц
работе в режиме ядра процессор может выполнять привилегированные ко.
манды и обращаться к ресурсам для выполнения задач от имени процед.
сов. Такое противопоставление пользовательского режима/режима ядра
используется большей частью современных компьютерных систем. Тем не
менее, в системах с повышенной безопасностью, желательно, иметь более
двух режимов для обеспечения более сложной структуры системы защиты.
Наличие нескольких режимов позволяет организовать доступ по принци-
пу наименьшего уровня привилегий (principle of least privilege) — каж-
дый пользователь должен быть наделен минимальным достаточным уров-
нем привилегий и прав доступа, которые необходимы ему для выполнения
его задач (см. «Рассуждения об операционных системах: Принцип наи-
меньшего уровня привилегий»).
Следует отметить, что по мере совершенствования компьютерных архи-
тектур, количество привилегированных команд (privileged instruction), —
т.е. команд, недоступных в пользовательском режиме, — имеет склон-
ность увеличиваться. Это отражает общую тенденцию передачи аппарат-
ным средствам все большего числа функций операционных систем.
Ц Размышления ой операционных системах
Принцип наименьшего уровня привилегий
Если говорить обобщено, принцип наи-
меньшего уровня привилегий гласит, что в лю-
бой системе субъекты должны быть наделены
лишь возможностями, необходимыми им для
выполнения собственных задач, и никакими
другими. Правительство использует данный
принцип в определении категорий допуска.
Вы используете данный принцип при реше-
нии, кому отдать запасные ключи от вашего
дома. В деловой сфере данный принцип ис-
пользуется во время предоставления работ-
никам доступа к важной и секретной инфоР'
мации. Операционная система используеТ
данный принцип во многих областях.
135
цеиции аппаратных средств и программного обе
9ащит(1 памяти, управление памятью
лЬщинство процессоров реализует необходимые механизмы управле-
памятью и ее защиты. Защита памяти (memory protection), позволяю-
пресечь получение процессами доступа к памяти, не выделенной для
1ЯаЯ прОцессов (как, например, к памяти других пользователей или к па-
ЭТ03и операционной системы), реализуется посредством использования
мяТ иальных регистров процессора, которые могут быть изменены только
СПе вилегированными командами (см. «Рассуждения об операционных
я*5 темах: Защита»). Процессор проверяет значения этих регистров для
Сбеспечения невозможности получения процессами доступа к памяти, вы-
° ленной для других процессов. К примеру, в системах, не использующих
виртуальную память, каждому процессу выделяется только непрерывный
блок смежных адресов памяти. Система может помешать таким процессам
в получении доступа к другим областям памяти посредством ограничи-
тельных регистров (bounds register), которые определяют начало и конец
области памяти, выделенной для процесса. Защита реализуется посредст-
вом проверки, находится ли определенный адрес в пределах выделенного
блока. Большинство операций аппаратных средств, связанных с защитой,
выполняется одновременно с выполнением команд процессора, таким об-
разом, эти операции не снижают производительность.
Размышления об операционных системах
Защита
Первые компьютеры использовали при-
митивные операционные системы, способ-
ные выполнять только одну задачу в каждый
момент времени. Однако это положение из-
менилось, когда появились средства парал-
лельной обработки и распределенные сис-
темы, способные параллельно обрабаты-
вать несколько заданий в рамках локальной
ети или Интернета. Перед операционными
^Семами встало множество проблем, свя-
Вы ЫХ С защит°й, особенно при появлении
0Пе°Да в Интернет. Данные и программы
14ены^И°ННЬ1Х систем Должны быть защи-
Ренн °Т ПРеднамеРенных или непреднаме-
По Ь'х ИЗменений, которые может внести
зовательская программа. Пользова-
тельские программы следует также защи-
щать друг от друга. Подобная защита
должна быть реализована и в пределах од-
ного компьютера и в рамках целой сети со
многими компьютерами. Мы будем касать-
ся вопросов защиты во многих местах этой
книги, в особенности при рассмотрении
физической памяти (глава 9) и виртуаль-
ной памяти (глава 10). Мы рассмотрим ор-
ганизацию защиты путем контроля доступа
кфайлам (глава 13). Общие вопросы защи-
ты рассматриваются в основной части кни-
ги, а конкретные примеры реализации за-
щиты в существующих операционных сис-
темах Linux и Windows ХР — в главах 20 и 21
соответственно.
136 Гли80г
В состав большинства процессоров входят аппаратные средства, npeog
разующие виртуальные адреса, к которым обращаются процессы, в со<уг
ветствующие адреса основной памяти. Системы с виртуальной память^
позволяют программам обращаться к адресам, которые необязательц0
должны относиться к ограниченному диапазону действительных (физиче.
ских) адресов (real address), доступному в основной памяти29. Используя
аппаратные средства, операционная система динамически преобразует Во
время рабочего цикла команды виртуальные адреса процессов в реальные
адреса. Системы с виртуальной памятью позволяют процессам обращаться
к адресному пространству, размер которого значительно превосходит раз_
мер доступной основной памяти, что позволяет программистам создавать
приложения, (по большей части) независимые от ограничений физической
памяти. Виртуальная память также облегчает программирование в систе-
мах с разделением времени, так как процессам не нужно знать фактиче-
ское местоположение своих данных в основной памяти. Защита памяти
и управление памятью более детально будут рассмотрены в главах 9-11.
Прерывания и исключения
Процессор сообщает операционной системе о таких событиях, как
ошибки при выполнении программ и изменения в состоянии устройств
(например, получение сетевого пакета или завершение выполнения диско-
вой операции ввода/вывода). Процессор может решать эту задачу, перио-
дически запрашивая информацию о состоянии каждого устройства, т.е.
посредством механизма опроса (polling). Однако это может привести к зна-
чительным издержкам, если состояние опрашиваемого устройства долгое
время не меняется.
Вместо этого, большая часть устройств посылает сигнал, называемый
прерыванием (interrupt), процессору, если происходит какое-либо собы-
тие. Операционная система может реагировать на изменения в состоянии
устройств, извещая процессы, ожидающие эти события. Исключения
(exception) — это прерывания, которые генерируются в ответ на ошибки,
как, например, сбой в работе аппаратных средств, логические ошибки
и нарушение зашиты (см. «Поучительные истории: Появление термина
«Глюк»). Вместо того чтобы просто рассматривать такую ситуацию, как
повод для аварийного завершения работы системы, процессор, как прави-
ло, обращается к операционной системе, чтобы та определила, каким обра-
зом необходимо отреагировать на ошибку. Например, операционная систе-
ма может определить, что процесс, который вызвал ошибку, должен быть
завершен, или что система должна быть перезапущена. Если же все-так®
ситуация приводит к аварийному завершению работы, операционная сие
тема может сделать это достаточно мягко, сводя к минимуму объем утра
ченных результатов работы. Процессы могут регистрировать прот'РатЛ
мы-обработчики особых ситуаций в операционной системе. Когда операД0
онная система получает исключение соответствующего типа, °
обращается к обработчику исключительных ситуаций процесса, привей
шего к исключению, для выполнения необходимых операций. Механизм
прерываний и обработка исключительных ситуаций будут рассмотрев
в разделе 3.4.
^цииШ1наратпь1х средств
ипрограммноге обеспечения 137
Вопросы для самопроверки
1. В чем заключается основная причина использования нескольких
режимов работы?
2. В чем заключаются отличия исключений от прерываний?
Ответы 1) Использование нескольких режимов работы системы
позволяет организовать ее защиту, предотвращая умышленное или
случайное повреждение системы остальным программным обеспече-
нием, или отказывая данному программному обеспечению в доступе
к ресурсам без соответствующего разрешения. Некоторые операции
доступны только для режима ядра, который позволяет операционной
системе выполнять привилегированные команды. 2) Исключения со-
общают об ошибках (например, деление на нуль или нарушение защи-
ты) и обращаются к операционной системе, чтобы та определила,
каким образом необходимо отреагировать. Операционная система мо-
жет ответить бездействием или завершить процесс. Если операцион-
ная система сталкивается с серьезной ошибкой, которая препятствует
ее нормальной работе, система может перезапустить компьютер.
Поучительные истории
Появление термина «Глюк»
Существует ряд предположений относи-
тельно происхождения компьютерного тер-
мина «глюк» (glitch), который, как правило,
используется в качестве синонима термина
«сбой». Многие полагают, что этот термин
походит от еврейского слова «glitshen», ко-
торое означает «скользить». Существует
И другое мнение по этому поводу. В середи-
не 60-х годов, когда программа освоения
космоса шла полным ходом, одна из компа-
ний по производству сверхмощных компью-
теров разработала первую бортовую компь-
ютерную систему. Утром в день запуска эта
компания разместила на страницах самых
популярных во всем мире изданий полно-
страничные рекламные материалы, в кото-
рых говорилось, что компьютер
благополучно управлял полетом астронав-
тов в ходе их миссии. В тот же день компью-
тер дал сбой, что привело, практически,
к полной потере контроля над космическим
аппаратом, поставив под угрозу жизнь ас-
тронавтов. На следующее утро одна из наи-
более популярных газет ознаменовала это
событие следующим образом — «Самая
громкая неудача в истории компании!», что
на английском языке звучало как «Greatest
Lemon in the Company's History!»3
ДЛЯ Работников операционных систем: Всегда помните закон Мерфи: «Все что
ИСпоРтиться- портится». Не стоит забывать и о знаменитом продолжении: «... в самый
-Чходящий момент».
» АбГ~
пп ₽евиатура английского названия этой статьи как раз соответствует слову glitch —
PUj* ped. nepee.
138 Глава g
2.4.2 Таймеры и часы
Интервальный таймер (interval timer) периодически генерирует сиг-
налы прерывания, которые заставляют процессор переключаться на оце,
рационную систему. Последняя, как правило, использует интервальные
таймеры, чтобы не допустить монополизации процессора отдельным пр0,
цессом. К примеру, операционная система может реагировать на преры.
вание таймера удалением некоторого процесса из процессора, таким обра.
зом, позволяя выполняться другому процессу. Часы истинного времецц
(time-of-day clock) позволяют компьютеру следить за временем «внешнего
мира», как правило, с точностью до тысячных или миллионных долей се-
кунды. Некоторые из часов истинного времени питаются от специальной
аккумуляторной батареи, что позволяет им работать, даже если компью.
тер отключен от внешнего источника питания. Такие часы обеспечивают
непрерывность времени в системе. К примеру, при загрузке операционная
система может обращаться к часам истинного времени для определения те-
кущего времени и даты.
Вопросы для самопроверки
1. Каким образом интервальный таймер препятствует монополизации
процессора процессом?
2. В состав процессора часто входит счетчик, значение которого уве-
личивается на единицу после каждого цикла процессора, что позво-
ляет измерять время с точностью до наносекунд. Сравните данный
способ измерения времени с тем, который реализуется часами ис-
тинного времени.
Ответы 1) Интервальный таймер периодически генерирует сигна-
лы прерываний. Процессор реагирует на каждое прерывание передачей
управления операционной системе, которая впоследствии может пере-
дать процессор в распоряжение другого процесса. 2) Счетчик циклов
процессора позволяет системе с высокой точностью определить период
времени, который прошел между событиями, но он не сохраняет дан-
ную информацию при отключении питания. Часы истинного времени
питаются от аккумуляторной батареи, следовательно, они больше под-
ходят для измерения времени. Тем не менее, эти часы измеряют время
с большей погрешностью, чем счетчик циклов процессора.
2.4.3 Начальная загрузка
Прежде чем операционная система сможет начать управлять ресурса-
ми, она должна быть загружена в память. При включении компьютера
БИОС инициализирует аппаратуру системы, затем пытается загрузить
в основную память команды из специальной области, которая находится
на вторичном запоминающем устройстве (например, на НГМД, НЖ Д
или компакт-диске) и называется загрузочным сектором (boot sector)-
Данный процесс называется начальной загрузкой (см. рис. 2.6). Процес-
сору необходимо выполнить эти команды, которые, как правило, загрУ'
жают компоненты операционной системы в память, инициализируют ре"
гистры процессора и подготавливают систему к запуску пользователь-
ских приложений.
139
аппаратных средств и программного обеспечения
go многих системах БИОС может загрузить операционную систему из
предопределенного адреса ограниченного набора устройств (к примеру из
3агрУзоЧНОГО ceKTO₽a на НЖМД или на компакт-диске). Если загрузочный
сектОР на поддерживаемом устройстве найти невозможно, система не за-
грузится и пользователь не сможет получить доступ ни к одному из аппа-
ратных устройств компьютера. Для расширения функциональности во
время загрузки корпорация Intel разработала расширенный интерфейс
встроенного программного обеспечения (Extensible Firmware Interface,
EFI) как замену системе БИОС. Данный интерфейс поддерживает диалого-
вую оболочку, при помощи которой пользователь может получить непо-
средственный доступ к устройствам компьютера. Расширенный интерфейс
встроенного программного обеспечения включает драйверы устройств для
поддержки доступа к накопителям на жестких магнитных дисках и к сете-
вым ресурсам непосредственно после включения системы30.
Основная
память
Код
начальной
iзагрузки
i 6
Базовая
система
ввода/
вывода
fl")
Шина памяти
, . j Собирает информацию об аппаратных средствах
V .f и приводит систему в исходное состояние
/у'. Загружает данные из загрузочного сектора
в основную память
Загрузочный сектор
3 ) Процессор выполняет код начальной загрузки
4-
Процессор
1
>' /Г) Загружает операционную систему с диска
^ЧС, 2.6. Начальная загрузка
Вопросы для самопроверки
1. Каким образом расширенный интерфейс встроенного программного
обеспечения справляется с недостатками базовой системы вво-
да/вывода?
2. В чем заключается причина того, что операционная система долж-
на препятствовать пользователям в получении доступа к загрузоч-
ному сектору?
140 ГмВд*
Ответы 1) Стандартная базовая система ввода/вывода вклвдча^
команды низкого уровня, имеющие ограниченные функциональна
возможности и определяющие то, каким образом изначально загруи^
ется программное обеспечение. Расширенный интерфейс встроенног*
программного обеспечения поддерживает драйверы и предоставлЯет
оболочку, которая дает возможность пользователю взаимодействовать
с системой, а также настраивать параметры загрузки операционной
системы. 2) Если бы пользователь был наделен возможностью доступ-
к загрузочному сектору, то он мог бы случайно или намеренно изме.
нить код операционной системы, что привело бы систему в негодности
или позволило бы нарушителю контролировать систему.
2.4.4 Технология Plug-and-Play
Технология Plug-and-Play (РпР) позволяет операционной системе на-
страивать и использовать только что установленные аппаратные средства
без участия пользователя. Аппаратура, построенная по этой технологии
обладает следующими способностями:
1. PnP-устройства могут однозначно определять себя в рамках операци-
онной системы.
2. PnP-устройства могут связываться с операционной системой для ука-
зания ресурсов и служб, необходимых для нормальной работы уст-
ройства.
3. PnP-устройства могут определять необходимый драйвер и позволять
операционной системе использовать его для настройки устройства
(например, для задания устройству канала прямого доступа к памяти
и выделения устройству области в основной памяти).31
Данные особенности предоставляют пользователю возможность под-
ключать аппаратуру к компьютеру и немедленно использовать ее с соот-
ветствующей поддержкой операционной системы.
Ввиду роста популярности мобильных вычислительных устройств все
большее количество систем полагается на автономное питание. Поэтому
технология Plug-and-Play развивается с учетом возможности управления
питанием, что позволяет системе динамически регулировать потребление
энергии для увеличения продолжительности автономного питания. Специ-
фикация ACPI — усовершенствованный интерфейс управления конфигу
рированием и энергопотреблением (Advanced Configuration and Power
Interface) — определяет стандартный интерфейс операционной системы,
используемый для настройки устройств и управления их энергопитанием-
Все последние версии операционных систем Windows поддерживают тех-
нологию Plug-and-Play; операционная система Linux версии 2.6 совмести-
ма со многими устройствами, построенными на основе этой технологии32-
Вопросы для самопроверки
1. Почему, по вашему мнению, устройству на основе технологи1’
Plug-and-Play необходимо однозначно определять себя для оперй
ционной системы?
2. Почему управление энергопитанием является особенно важным во-
просом в отношении мобильных вычислительных устройств?
цзкдм аппаратных средств и программного обеспечения
141
Ответы 1) Прежде чем операционная система сможет настроить
устройство и сделать его доступным для пользователя, ей необходимо
определить потребности в ресурсах именно этого устройства. 2) Мо-
бильные вычислительные устройства питаются от батареи; управле-
ние энергопотреблением устройства позволяет продлить длительность
питания от батареи без подзарядки.
2,5 Кэширование и буферизация
В разделе 2.3.4 мы рассмотрели, каким образом в компьютерах организо-
вана иерархия запоминающих устройств с различным быстродействием.
Иля повышения производительности большинство систем выполняет кэши-
рование посредством размещения в высокоскоростном запоминающем уст-
ройстве копии информации с медленных устройств, к которой впоследствии
обращается процесс. Из-за высокой стоимости высокоскоростных запоми-
нающих устройств кэш-память может хранить лишь небольшие объемы ин-
формации, находящейся в низкоскоростных запоминающих устройствах.
Следовательно, распоряжаться содержимым кэша, также называемого эле-
ментами кэша (cache line), необходимо таким образом, чтобы свести к ми-
нимуму количество обращений к информации, не хранящейся в кэше. Та-
кое обращение к кэшу называется неудачным обращением или кэш-прома-
хом (cache miss). Когда происходит кэш-промах, системе приходится
извлекать данные из более медленного запоминающего устройства. Если ин-
формация, к которой обращаются, находится в кэше, то имеет место удач-
ное обращением к кэшу, кэш-попадание (cache hit), позволяющее системе
обращаться к данным с относительно высокой скоростью33.
Для повышения производительности путем кэширования операционной
системе необходимо позаботиться о том, чтобы значительная часть обраще-
ний к памяти приводила к кэш-попаданиям. Как следует из материала, ко-
торый будет рассмотрен в разделе 11.3, сложно наперед определить с высо-
кой точностью ту информацию, к которой в ближайшем будущем обратятся
процессы. Поэтому управление кэшами осуществляется с использованием
эвристики (heuristics), т.е. набора обобщающих практический опыт мето-
дов, которые приводят к хорошим результатам при относительно низких
накладных затратах (см. «Размышления об операционных системах: Эври-
стика»),
Примером кэш-памяти является кэш-память первого и второго уровней
процессора, в которой для минимизации количества циклов простоя про-
ссора хранятся использованные незадолго до этого данные. Многие опе-
ционные системы выделяют определенный объем основной памяти под
_ „ 'Память для информации с таких вторичных запоминающих уст-
Ря ТВ’ КаК диски’ которые, как правило, демонстрируют задержку на по-
большую, чем основная память.
Уфер (buffer) — это область памяти для промежуточного хранения
Вам Ь1Х ПРИ выполнении операций передачи информации между устройст-
вы И процессами, которые работают на разных скоростях34. Буферы по-
Й11 а1От производительность системы, позволяя программному обеспече-
и аппаратным устройствам обмениваться данными и запросами асин-
142 Гм6[2
р
хронно (asynchronous transmission), т.е. независимо друг от друга.
Примерами буферов могут служить буферы накопителей на жестких маг-
нитных дисках, буферы клавиатуры и принтеров35-36. Так как накопитель
на жестких магнитных дисках работает с намного меньшей скоростью чем
основная память, то операционные системы, как правило, буферизируют
данные при запросах записи. Буфер продолжает хранить данные до завер.
шения накопителем на жестких магнитных дисках операции записи, по-
зволяя операционной системе выполнять другие процессы в ожидании за-
вершения ввода/вывода. Буфер клавиатуры, как правило, используется
для хранения символов, вводимых пользователем, до тех пор, пока про-
цесс сможет отреагировать на соответствующие прерывания клавиатуры
и ответить на них.
Спулинг (spooling) — одновременное функционирование периферийных
устройств в оперативном режиме, — это технология, при которой в роли
посредника между процессом и низкоскоростным или ограниченным по
размеру буфера устройством ввода/вывода выступает связующее устройст-
во, например дисковый накопитель. К примеру, если процесс пытается
распечатать документ, в то время как принтер еще занят, процесс, не до-
жидаясь освобождения принтера, записывает выходные данные на диск.
Когда принтер освобождается, он распечатывает данные с диска. Спулинг
позволяет процессам обращаться к устройству за выполнением операции
даже в тот момент, когда устройство не готово к выполнению этого
запроса37. Данная процедура получила название «спулинг», так как напо-
минает намотку нитки на катушку (шпульку, «spool»), с тем, чтобы при
необходимости ее можно было размотать.
Вопросы дпя соАлопроверки
1. Каким образом кэширование повышает производительность систе-
мы?
2. В чем заключается причина того, что буферы по большей части не
повышают производительность системы, если устройство или про-
цесс выдают данные значительно быстрее, чем те используются?
Ответы 1) Кэш-память повышает производительность системы
путем размещения в высокоскоростном запоминающем устройстве ин-
формации, к которой вскоре может обратиться процесс; процессы мо-
гут обращаться к данным и командам, хранящимся в кэш-памяти,
значительно быстрее, чем к тем, которые хранятся в основной памяти-
2) Если источник работает значительно быстрее потребителя, то буфер
вскоре заполнится, и отношения между устройствами будут опреде-
ляться относительно низкой скоростью источника. Источнику придет-
ся замедлить свою работу, так как он постоянно будет находить буфер
полным, и ожидать (а не работать со свойственной ему большей скоро-
стью), пока потребитель не освободит место в буфере. Аналогично,
если потребительский модуль будет работать быстрее источника, он
снова и снова будет находить буфер пустым, и ему придется снизить
скорость своей работы практически до скорости источника.
еП11аи аппаратных средств и программного обеспечения
143
Размышления об операционных системах
Эвристика
Эвристика - это совокупность обобщаю
щих практический опыт методов - стратегия,
которая проверена на практике и при исполь-
зовании, как правило, дает хорошие результа-
ты Очень часто она не имеет под собой стро-
гого математического базиса, поскольку сис-
тема, к которой она применяется, является
достаточно сложной, чтобы ее можно было
просто описать с помощью аналитических ме-
тодов. Каждое утро, выходя из дома, вы мо-
жете использовать эвристику: «По прогнозу
будет дождь, надо взять зонтик». Вы поступае-
те так, исходя из своего опыта, «по прогнозу
будет дождь» — достаточно надежный (но не
на 100%) показатель того, что пойдет дождь.
Применяя это правило эвристики в прошлом,
вам удалось пару раз не намокнуть в ливень,
таким образом, вы склонны положиться на
него. Когда вы смотрите на кипу бумаг, кото-
рая лежит на вашем рабочем столе, и плани-
руете свой рабочий день, вы можете
применить еще одно правило эвристики: «За-
дания, требующие меньше времени, делают-
ся вначале». Оно даст положительные резуль-
таты — часть работы будет выполнена быстро;
но, с другой стороны, это правило дает неже-
лательный побочный эффект - вы отклады-
ваете (возможно, важные) задачи, требую-
щие больше времени для выполнения. Куда
хуже, если вам приходится выполнять посто-
янный поток новых кратковременных работ
и откладывать на неопределенный срок рабо-
ту, для выполнения которой необходимо
больше времени. Эвристика операционных
систем будет рассматриваться во многих гла-
вах книги, особенно в тех, где речь идет
о стратегии управления ресурсами, как, на-
пример, в главах 8 и 12.
2-6 Обзор программного обеспечения
в этом разделе мы рассмотрим основные концепции компьютерного
программирования и программного обеспечения. Программисты пишут
программы на различных языках программирования; некоторые из этих
языков воспринимаются компьютером непосредственно, тогда как другие
НР уют перевода (трансляции). В общем, языки программирования мож-
и КЛассифицировать следующим образом: машинные языки, ассемблеры
языки программирования высокого уровня.
Машинный язык и язык ассембАера
йЫй°МПЬЮтеР может непосредственно воспринимать только свой собствен-
Комц'1а1ПИннь1й язык (machine language). Будучи «естественным языком»
Ратц ЬЮТера °ДНОГО типа, машинный язык определяется структурой аппа-
с°сто>1Х среДств компьютера. Как правило, программы на машинном языке
к°То ЯТ И3 послеД°вательн°стей чисел (в конечном счете, единиц и нулей),
Рые указывают компьютерам, каким образом выполнять их наиболее
144 Глави 2
примитивные операции. Машинные языки являются машинно-зависимы,
ми: определенный машинный язык может быть использован на компыбте.
ре только одного типа. Следующий фрагмент ранней программы на'ма.
шинном языке, в котором суммируются «плата за сверхурочную работу»
и «основная заработная плата», а результаты хранятся в «итоговой зара.
ботной плате», демонстрирует непонятность машинного языка для людей:
1300042774
1400593419
1200274027
По мере роста популярности компьютеров программирование на ма-
шинном языке стало демонстрировать свои недостатки: малая производи-
тельность и высокая вероятность ошибок. Вместо того чтобы использовать
цепочки цифр, которые компьютер может непосредственно воспринять,
программисты начали использовать английские сокращения для представ-
ления основных операций компьютера. Эти сокращения получили назва-
ния языка ассемблера (assembly language). Программы-трансляторы, на-
зываемые ассемблерами (assembler), осуществляют перевод программ
с языка ассемблера на машинный язык. Следующий фрагмент упрощен-
ной программы на языке ассемблера также суммирует «плату за сверх-
урочную работу» (overTimePay) и «основную заработную плату» (basePay)
и сохраняет результат в «итоговой заработной плате» (grossPay), но пред-
ставляет отдельные операции в виде, более-менее понятном для человека:
LOAD basePay
ADD overTimePay
STORE grossPay
Данная программа на языке ассемблера является более понятной для
человека, но компьютер не сможет воспринять ее, пока она не будет пере-
ведена ассемблером на машинный язык.
Вопросы для самопроверки
1. (Да/Нет) Как правило, компьютеры выполняют программу непо-
средственно на языке ассемблера?
2. Пишется ли программное обеспечение на переносимом машинном
языке?
Ответы 1) Нет. Программы-трансляторы осуществляют перевод
программы с языка ассемблера на машинный язык, прежде чем ее
можно будет выполнить. 2) Нет. Машинные языки являются машин-
но-зависимыми, таким образом, программное обеспечение, написан-
ное на определенном машинном языке, воспринимается только
компьютерами одного типа.
2.6.2 Интерпретаторы и компиляторы
Несмотря на то, что программирование на языках ассемблерного типа
быстрее, чем на машинном языке, ассемблеры также требуют длинных по-
следовательностей команд для выполнения даже самых простых задач-
Для повышения производительности труда программиста были разработа
ны языки высокого уровня (high-level languages). Они позволяют решать
К0/Щ(',Ч11и l]nnilParr,Hblx средств и программного обеспечения
145
Ллдее сложные задачи, используя меньшее количество операторов (более
°ороткие программы), но нуждаются в трансляторах, которые называются
1<ов«гяляторами (comPilers)’ Для перевода программ, написанных на языке
К тсокого уровня, на машинный язык. Языки высокого уровня позволяют
оОГраммистам писать программы, которые похожи на обиходный англий-
ский язык и содержат стандартные математические обозначения. К приме-
V, приложение формирования платежной ведомости, написанное на язы-
ке высокого уровня, может содержать следующий оператор:
grossPay = basePay + overTimePay
При помощи этого оператора мы получаем результат, идентичный тому,
который был получен выше в программах на машинном языке и на языке
ассемблера.
В то время как компиляторы переводят программы с языка высокого
уровня на машинный язык, интерпретаторы (interpreters) являются при-
ложениями, которые непосредственно выполняют исходную программу на
языке высокого уровня или программу, переведенную на язык низкого
уровня, который не является машинным языком. Такие языки програм-
мирования как Java, переводятся в формат, известный как байт-код
(bytecode), который выступает в роли машинного кода для так называемой
виртуальной машины (несмотря на то, что язык Java может быть переве-
ден и на машинный язык). Таким образом, байт-код не зависит от физиче-
ской машины, на которой он выполняется, что способствует переносимо-
сти приложений. Интерпретатор языка Java анализирует каждый опера-
тор и выполняет его байт-код на физической машине. Учитывая потери
времени в ходе выполнения (из-за пооператорной трансляции), программы
выполняемые посредством интерпретаторов, как правило, работают мед-
леннее, чем переведенные на машинный язык38, 39.
Вопросы для самопроверки
1. Обсудите преимущества языков высокого уровня перед языками ас-
семблера.
2. Почему программы, переведенные в байт-код, обладают большей
переносимостью, чем те же программы на машинном языке?
Ответы 1) Программы, написанные на языке высокого уровня,
требуют намного меньше команд, чем программы, написанные на
языке ассемблера; программирование на языках высокого уровня так-
же является более простым, чем программирование на языках ассемб-
лера, так как языки высокого уровня имеют большую схожесть
с обиходным английским языком и оперируют стандартными матема-
тическими обозначениями. 2) Байт-код компилируется для выполне-
ния на виртуальной машине, которая может быть установлена на
различных платформах. Программа, переведенная на машинный
язык, может выполняться только на машине того типа, для которого
эта программа была переведена.
146 Глава i
2.63 Языки программирования высокого уровня
Несмотря на разработку сотен языков программирования высокого
уровня, только немногие из них получили широкое распространение. Со.
временные языки программирования, как правило, являются структурны,
ми и объектно-ориентированными. В этом разделе мы назовем некоторые
из наиболее популярных языков, а также обсудим, каким образом они со-
относятся с популярными программными стратегиями и технологиями.
В середине 1950-х компания IBM разработала язык ФОРТРАН (Fortran)
для создания научных и конструкторских приложений, которые требова-
ли сложных математических вычислений. Этот язык до сих пор широко
используется, по большей части в высокопроизводительной среде, к при-
меру, в суперкомпьютерах и мэйнфреймах.
Язык программирования для промышленных и правительственных уч-
реждений КОБОЛ (Common Business Oriented Language, COBOL) был раз-
работан группой производителей компьютеров, правительственных
агентств и промышленных пользователей компьютеров в конце 1950-х.
Кобол разработан для коммерческих приложений, которые оперируют
большими массивами данных. Значительная часть используемого сегодня
коммерческого программного обеспечения написана на этом языке.
Язык программирования С, разработанный Денисом Ритчи в лаборато-
рии компании Bell в начале 1970-х, получил широкое признание как
язык написания операционной системы UNIX. В начале 1980-х в этой же
лаборатории Бъярне Страуструп разработал язык C++, расширение язы-
ка С. Язык C++ предоставляет возможности для объектно-ориентирован-
ного программирования (object-oriented programming, OOP). Объекты
(object) — это программные компоненты многоразового использования,
которые модулируют элементы реального мира. Как правило, объект-
но-ориентированные программы легче понять, отладить и модифициро-
вать, чем программы, написанные при помощи предшествующих техно-
логий. Многие из современных операционных систем написаны на язы-
ке С или C++.
На рассвете популярности Всемирной Паутины в 1993 году компания
Sun Microsystems обратила внимание на возможность использования сво-
его нового объектно-ориентированного языка программирования Java для
создания приложений, которые можно было загружать через Веб для вы-
полнения посредством веб-браузеров. Компания публично заявила о языке
Java в 1995, обращая на себя внимание со стороны коммерческого сообще-
ства с его разнообразными интересами внутри Интернета. Язык Java стал
широко используемым языком программирования для создания про-
граммного обеспечения. Он используется для динамической генераций
веб-страниц, создания крупномасштабных корпоративных приложений,
улучшения работы веб-серверов, создания приложений для пользователь'
ских устройств (к примеру, для мобильных телефонов, пейджеров и персо-
нальных цифровых секретарей), а также для многих других целей.
В 2000-м году корпорация Microsoft анонсировала язык C# (читается
«Си-шарп», «С-Sharp») в рамках своей новой .NET-стратегии. Он разраба-
тывался специально как ключевой язык программирования для платфоР'
мы на основе технологии .NET; его корни уходят в такие языки, как С,
аппаратных средств а программного обеспечения
147
Java. Язык C# является объектно-ориентированным и обладает дос-
к огромной библиотеке уже разработанных компонентов технологии
позволяя программистам быстро создавать приложения.
C++ и
тупом
.net,
Вопросы для самопроверки
1. Классифицируйте каждый язык программирования как структур-
ный или объектно-ориентированный: а) С#, б) С, в) Java, г) C++.
2. Какими преимуществами обладает объектно-ориентированное про-
граммирование?
Ответы 1) а) объектно-ориентированный; б) структурный; в) объ-
ектно-ориентированный; г) объектно-ориентированный. 2) Как прави-
ло, объектно-ориентированные программы легче понять, отладить
и модифицировать, чем программы, написанные при помощи предше-
ствующих технологий. Объектно-ориентированное программирование
сфокусировано на создании программных компонентов многоразового
использования.
2.6.4 Структурное программирование
В 1960-е годы многие проекты разработки программного обеспечения не
уу ля дыня пись в плановые сроки, затраты во много раз превышали бюдже-
ты, а конечная продукция оказывалась ненадежной. Разработчики начали
осознавать, что создание программного обеспечения представляет собой
более сложное занятие, чем они первоначально себе представляли. Иссле-
довательская деятельность, направленная на решение этих проблем, при-
вела к развитию структурного программирования (structured program-
ming) — дисциплинированного подхода к созданию понятных, правиль-
ных и легко модифицируемых программ.
Исследования привели к созданию языка программирования Паскаль
(Pascal) профессором Никлаусом Виртом в 1971 году. Этот язык был на-
зван в честь математика и философа XVII века Блеза Паскаля. Разработан-
ный для обучения структурному программированию, язык Паскаль быст-
ро стал популярен в качестве вводного языка программирования в боль-
шинстве колледжей. Этому языку не хватало многих возможностей,
необходимых при написании коммерческих, промышленных и админист-
ративных приложений.
Язык программирования Ада (Ada) был разработан при спонсорской
оддержке Министерства обороны США в 1970-х — начале 1980-х. Его на-
Ле-Ли в честь леди Ады Лавлейс, дочери поэта лорда Байрона. Леди Лав-
принято считать первым программистом, она написала в середине
* века программу для механического вычислительного устройства —
°д1^ЛИтическ°й Машины, созданной Чарльзом Бэбиджем. Язык Ада был
Нйя Л И3 пеРвых языков программирования, разработанных для упроще-
aieD Параллельног° программирования, которое будет рассмотрено на при-
в псевдокоде и на языке Java в главах 5 и 6.
148
Глав9
Вопросы для самопроверки
1. Для решения каких проблем, существовавших на ранних эта11а
создания программного обеспечения, создавались языки структур
кого программирования? ***
2. Чем язык программирования Ада отличался от таких язык
структурного программирования, как Паскаль и С?
Ответы 1) На ранних этапах программирования у разработчик^
не было системного подхода к созданию сложных программ, что пр^8
водило к излишним затратам, нарушению проектных сроков и неня'
дежной продукции. Структурное программирование удовлетворил^
потребности в дисциплинированном подходе к разработке программ
ного обеспечения. 2) Язык Ада был разработан для упрощения процес’
са параллельного программирования.
2.6.5 Объектно-ориентированное программирование
Внедрение структурного программирования в 1970-х годах привело
к появлению технологии разработки программного обеспечения. Тем не
менее, лишь в 1980-х — 1990-х годах, когда объектно-ориентированное
программирование получило широкое распространение, разработчики
программного обеспечения поняли, что обладают необходимыми средства-
ми для реализации качественного сдвига в вопросе организации разработ-
ки программного обеспечения.
Объектная технология — это пакетная схема создания программных
элементов. Практически каждая сущность может быть представлена как
программный объект. Объектам присущи такие свойства (properties) или
атрибуты (attributes), как цвет, размер и вес; для них также характерны
некоторые действия (actions), иначе называемые методами (methods) или
линиями поведения (behaviors), как, например, движение, сон или рисо-
вание. Класс (class) — это тип объектов. К примеру, все машины относятся
к классу «автомобилей», даже если каждая из них имеет свою марку
и сильно отличается от других по цвету и характеру комплектации. Класс
определяет общий формат входящих в него объектов, а также свойства
и действия, доступные объекту в зависимости от класса. Объект имеет та-
кое же отношение к классу, как здание к своему архитектурному проекту-
До того как появились объектно-ориентированные языки программиро-
вания, процедурные языки программирования (procedural programming
languages), такие как ФОРТРАН, Паскаль, Бейсик и С, в большей степени
были сфокусированы на действиях (глаголах), чем на объектах (существй-
тельных), что делало программирование несколько неудобным. Используй
популярные на сегодняшний день объектно-ориентированные языки пр0'
граммирования, такие как C++, Java и С#, программисты создают пр0'
граммное обеспечение в рамках объектно-ориентированного подхода, кот°'
рый более естественным образом отображает то, как люди воспринимав
окружающий мир, что приводит к значительному росту производительно'
сти труда программистов.
Объектная технология позволяет повторно использовать ранее разраб0'
тайные классы в многочисленных проектах. Использование библиотек
классов дает возможность в значительной степени облегчить проектиров^'
Kffnu^
аппаратных средств и программного обеспечения
149
ие новых систем. Тем не менее, некоторые организации считают основ
яыМ преимуществом объектно-ориентированного программирования не
возможность многократного использования компонентов программного
обеспечения, а возможность разработки программного обеспечения, кото-
рое является более понятным ввиду лучшей организации и более простого
обслуживания.
Объектно-ориентированное программирование позволяет программи-
стам сконцентрироваться на «общей картине». Вместо того чтобы волно-
ваться о мелких деталях реализации многократно используемых объектов
они могут сфокусировать свои усилия на модификации одного объекта, не
беспокоясь о том, как это повлияет на другой объект. Карту дорог, отобра-
жающую каждое дерево, дом и дорогу, было бы сложно, если вообще воз-
можно, понять. Когда мелкие детали опускаются, а только необходимая
информация (основные дороги) остается, разбираться в карте становится
легче. Таким же образом, приложение, разбитое на объекты, легче понять,
проще модифицировать и обновлять, поскольку множество деталей скрыто
и не требует рассмотрения.
Вопросы для самопроверки
1. На чем сфокусировано основное внимание объектно-ориентирован-
ного программирования, в отличие от структурного программиро-
вания?
2. Каким образом объекты упрощают модификацию существующего
программного обеспечения?
Ответы 1) Объектно-ориентированное программирование фокуси-
рует внимание на управлении объектами (существительными), в то вре-
мя как процедурное программирование опирается на действия
(глаголы). 2) Объекты скрывают множество деталей приложения, по-
зволяя программистам сосредоточить свое внимание на общей картине.
Программисты могут сфокусировать свои усилия на модификации од-
ного объекта, не беспокоясь о том, как это повлияет на другие объекты.
2.7 интерфейсы прикладного
программирования
РьцущВРеМеННЬ1е пРил°жения требуют доступа ко многим ресурсам, кото-
и ДаннУПРаВЛЯеТ опеРаи,ионная система, например, к файлам на дисках
Должн Ь1М Нй удаленных компьютерах. Поскольку операционная система
пРепят ВЫПолнять Функции администратора ресурсов, как правило, она
преппо СТВует процессам в получении доступа к этим ресурсам без явного
дарительного запроса.
^И1егГас₽Фд рС пРиклаЛного программирования (Application Programming
с°бой н ИЛИ программный интерфейс приложений — предоставляет
3апрОс а °Р подпрограмм, которые могут использовать программисты для
яЫх оц СЛуж® операционной системы (рис. 2.7). В большинстве современ-
еРационных систем связь между программами и операционной сис-
темой осуществляется исключительно посредством интерфейсов приклад
ного программирования. Примерами таких интерфейсов могут служит^
POSIX-стандарты интерфейсов переносимых операционных систе^
(portable operating system interface standards, POSIX standards), а такд^е
интерфейс прикладного программирования Windows (Windows API) дЛз}
разработки приложений Windows компании Microsoft. Стандарт POSljj
определяет стандартные интерфейсы прикладного программирования ца
основе ранних систем UNIX, которые широко используются в операциоц.
ных системах на базе UNIX. Интерфейс Win32 API — это интерфейс ком.
пании Microsoft для приложений, работающих в среде Windows.
Процессы генерируют вызовы функций, определенных интерфейсом
прикладного программирования, для получения доступа к обслуживанию
предоставляемому более низким уровнем системы. Такие вызовы функций
могут порождать системные вызовы (system calls) для запроса обслужива-
ния у операционной системы. Системные вызовы сходны с аппаратными
прерываниями — когда генерируется системный вызов, система переклю-
чается в привилегированный режим (режим ядра), а операционная систе-
ма обслуживает системный вызов.
। Приложение I
Интерфейс прикладного программирования
Пространство пользователя
Пространство ядра
Память Диск Сеть
Рис. 2.7. Интерфейс прикладного программирования
Вопросы для мллопроберки
1. Почему процессы должны выдавать системные вызовы для получе-
ния обслуживания у операционной системы?
2. Каким образом стандарт POSIX пытается улучшить переносимость
приложений?
^^^^^аппаратных средств и программные обеспечения
151
Ответы 1) Чтобы защитить систему, операционная система не мо-
жет позволить процессам получать непосредственный доступ к ее
службам или привилегированным командам. Вместо этого, службы,
которые может предоставить операционная система, упакованы в ин-
терфейсах прикладного программирования. Процессы могут получить
доступ к этим службам только посредством интерфейса системных вы-
зовов, который по существу является средством управления операци-
онной системой. 2) Программное обеспечение, написанное с использо-
ванием определенного интерфейса прикладного программирования,
может работать только в системах, которые используют такой же ин-
терфейс. Стандарт POSIX пытается решить эту проблему посредством
определения стандартного интерфейса прикладного программирова-
ния для систем на базе UNIX. На сегодняшний день многие системы,
даже построенные не на базе UNIX, поддерживают этот стандарт.
2.8 Процессы компиляции, связывания
и загрузки
Прежде чем программа, написанная на языке высокого уровня, смо-
жет выполняться, ее необходимо перевести на машинный язык, связать
с другими программами на машинном языке, от которых она зависит,
и загрузить в основную память. В этом разделе мы обсудим, каким обра-
зом программы, написанные на языках высокого уровня, транслируются
или компилируются (compile) в машинный код, а также каким образом
компоновщики (редакторы связей) и загрузчики подготавливают объект-
ный код (оттранслированную программу) к выполнению40.
2.8.1 Компиляция
Несмотря на то, что каждый компьютер может воспринимать только
свой машинный язык, практически все программы пишутся на языках вы-
сокого уровня. Первой ступенью в процессе создания исполняемых про-
грамм является трансляция программы на языке высокого уровня в про-
грамму на машинном языке. Компилятор принимает исходную програм-
МУ (source code), написанную на языке высокого уровня, и выдает
ъектную программу (object code), содержащую подлежащие выполне-
нию команды на машинном языке. Практически все коммерчески доступ-
е программы распространяются в виде объектного кода, но некоторая
ь программных продуктов (например, открытое программное обеспе-
еВДе) содержит и исходный код41.
сь процесс компиляции можно разбить на ряд этапов. Один из вари-
зкдо в представления процесса компиляции представлен на рис. 2.8. На ка-
М0 fh',Tane программа модифицируется таким образом, чтобы результат
Пока >Икации мог быть обработан на следующем этапе, и так до тех пор,
пРог °На Не будет оттранслирована в машинный код. Сначала исходная
ай Римма поступает на лексер (lexer), также называемый лексическим
или сканером (lexical analyzer, lexical scanner), который
ляет поток символов исходного текста программы на лексемы
Глава
(token). Примерами лексем являются ключевые слова (if, else и int), идентц^
фикаторы (именованные переменные и константы), операторы (—, +, * и /)
а также знаки пунктуации (точка с запятой).
Исходный
текст
программы
Лексический
анализатор
1 "! Дерево
Лексемы ;Синтаксический1 абстрактного
Генератор про
межуточного
анализатор Г грамматической
| го разбора
----- —Оптимизатор j-
Язык низкого '
уровня _________I
Язык низкого
уровня
Генератор кода’ -----—г-
’ Команды на машинном
__ языке
Рис. 2.8. Стадии компиляции
Лексический анализатор передает порожденный поток лексем на син-
таксический анализатор (parser или syntax analyzer), который складыва-
ет их в синтаксически правильные операторы. Генератор промежуточного
кода (Intermediate code generator) трансформирует данную синтаксиче-
скую структуру в поток простых команд, сходных с языком ассемблера
(несмотря на то, что он не определяет регистры, используемые для каждой
операции). Оптимизатор (optimizer) пытается повысить производитель-
ность выполнения кода и снизить потребности программы в памяти. На за-
ключительном этапе генератор кода (code generator) генерирует объект-
ный файл, содержащий команды на машинном языке42’43.
вопросы для самопроверки
1. в чем заключается разница между компиляцией и трансляцией
при помощи ассемблера?
2. Могла бы программа на языке Java работать непосредственно на
физической машине, а не на виртуальной?
Ответы 1) При ассемблировании команды на языке ассемблера
просто переводятся на машинный язык. Компилятор транслирует код
на языке высокого уровня в код на машинном языке, а также может
оптимизировать его. 2) Программа на языке Java может выполняться
на физической машине после использования компилятора, который
оттранслирует исходный код на языке Java в соответствующий код на
машинном языке.
2.8.2 Связывание
Как правило, программы состоят из нескольких независимо разработай'
ных подпрограмм, которые называются модулями (modules). Функций»
выполняющие такие стандартные компьютерные операции, как управле-
153
тпаРап,ИЬ1х сРеЗстВ и программного обеспечения
Йце вводом/выводом данных или генерация последовательности случай-
ных чисел, объединены в предварительно скомпилированные модули на
Нываемые библиотеками (libraries). Связывание (linking) — это процесс
интеграции различных модулей, на которые ссылается программа, в еди-
Ljjjt исполняемый модуль программы.
Н Когда программа скомпилируется, соответствующий ей объектный модуль
будет содержать данные и команды программы, полученные из ее исходного
файла- Если программа обращалась к функциям и данным другого модуля
компилятор транслирует эти обращения во внешние ссылки (external
reference). Если же программа предоставляет доступ к своим данным и функ-
циям другим программам, каждый доступный элемент представляется как
внешнее имя (external name). Объектные модули хранят эти внешние имена
и ссылки в структуре данных, называемой таблицей имен (symbol table) (см
рис. 2.9). Интегральный модуль, созданный компоновщиком, называется за-
грузочным модулем (load module). На вход компоновщика могут подаваться
объектные модули, загрузочные модули и управляющие операторы, напри-
мер, задающие расположение библиотечных файлов44.
Л®- 2.9. Объектный модуль
Как правило, на вход компоновщика подается несколько объе*™*
Файлов, которые формируют единую программу. Эти объектные фа
обычно определяют расположение своих данных и команд, используя
Раса, которые отсчитываются от начала файла и называются относите
вЫми адресами (relative addresses).
На рис. 2.Ю символ X в объектном модуле А и символ Y в оЬъек
®*°ДУле В имеют одинаковые относительные адреса в своих модулях. о
оковщИк ПрИ объединении модулей для создания общей программы
еа модифицировать эти адреса таким образом, чтобы они указыв
г^ТВетствующие данные или команды. Перемещение (relocating)' _
°беспечивает однозначное определение адреса каждого элемента пр гр
154 Глава g
мы и данных посредством задания позиции внутри файла. При измененщ*
адреса все ссылки на него должны быть обновлены в соответствии с новьц^
расположением. В конечном загрузочном модуле X и Y были перемещен^
на новые относительные адреса, которые однозначно определяют позицц^
этих объектов внутри загрузочного модуля. Очень часто компоновщик^
также используют относительную адресацию в загрузочном модуле; адреса
отсчитываются от начала всего загрузочного модуля.
Рас. 2.10. Процесс связывания
Компоновщики также выполняют разрешение внешних ссылок (symbol
resolution), при котором внешние ссылки одного модуля привязываются
к соответствующим внешним именам другого модуля45’ 46. На рис. 2-11
внешняя ссылка на символ С в объектном модуле 2 связывается с внешни*1
именем С из объектного модуля 1. В случае если внешняя ссылка привязь1'
вается к соответствующему имени в другом модуле, адрес внешней ссылК11
должен быть модифицирован, чтобы удовлетворять размещению адресуем0'
го объекта в скомпонованном модуле.
аппаратных средств и программного обеспечения
155
{Сак правило, связывание осуществляется в два прохода. Первый про
хоД определяет размер каждого модуля и их объединения и создает табли-
цу имен. Таблица имен связывает каждый символ (например, имя пере
ценной) с адресом, что позволяет компоновщику выполнить разрешение
ссылок. На втором проходе компоновщик присваивает адреса блокам дан-
ных и команд, а также выполняет разрешение внешних ссылок на симво-
лы 47- Поскольку загрузочный модуль может быть использован в качестве
Компоновка
Код 2
Данные 1
.... ,.f Ссылка
Код 1 гна г
I символ С
Z
Данные 2
Загрузочный модуль
Таблица имен 2
Код
Ссылка
на символ С
Данные
Таблица имен 1
А
С
Выполняется разрешение внешних ссылок, так
что в связанном модуле внешних ссылок нет
Таблица имен
Z
С
X
Z11
Разрешение внешних ссылок
156 Главд g
входных данных при следующем сеансе работы компоновщика, в загрузощ
ный модуль включается таблица имен, в которой все символы являют^
внешними именами. Следует отметить, что на рис. 2.11 внешняя ссылщ^
на символ Y отсутствует в таблице имен загрузочного модуля, так как
нее уже выполнено разрешение.
Момент выполнения компоновки программы зависит от среды. Пр0
грамма может быть скомпонована во время компиляции, если програ^
мист обладает всем необходимым кодом в исходном файле, для того чтобы
разрешить все ссылки на внешние имена. При этом выполняется поиск
в исходном коде всех внешних ссылок и размещения соответствующих
внешних символов в итоговом объектном файле. Как правило, этот метод
не позволяет получить полноценный результат, поскольку многие про-
граммы полагаются на совместно используемые библиотеки (shared
library), содержащие совокупность функций, которые могут быть совмест-
но использованы различными процессами. Многие программы могут ссы-
латься на одни и те же функции (такие как функции библиотеки, которые
управляют входными и выходными потоками), не включая их в свой объ-
ектный код. Как правило, этот тип связывания осуществляется после ком-
пиляции, но перед загрузкой. Мы рассмотрим в разделе «Учебный пример:
Операционная система Mach», как совместно используемые библиотеки
позволяют микроядру системы Mach эмулировать множество операцион-
ных систем.
Этот же процесс может быть выполнен во время загрузки (см. раз-
дел 2.8.3). Иногда и компоновка (связывание) и загрузка могут выполнять-
ся одним приложением, которое называется связывающим загрузчиком
(linking loader). Связывание также может происходить во время выполне-
ния программы — процесс, называемый динамическим связыванием
(dynamic linking). В этом случае разрешение ссылок на внешние функции не
выполняется, пока процесс не загрузится в память или не выдаст запрос
функции. Это полезно для больших программ, использующих программы
сторонних разработчиков, так как при таком подходе нет необходимости пе-
рекомпоновывать динамически связанную программу, когда используемая
ей библиотека модифицируется 60. Более того, так как динамически связан-
ные программы не связываются, пока не будут загружены в память, код со-
вместно используемой библиотеки может храниться отдельно от кода ДРУ'
гих программ. Динамическое связывание также позволяет экономить место
на вторичных запоминающих устройствах, поскольку только одна копия
совместно используемой библиотеки хранится для любого количества ис-
пользующих ее программ.
gfiijUU anMPamr blx средств и программного обеспечения
157
Учебный пример
Операцаонная система Mach
в том, что она может эмулировать другие
операционные системы. Система Mach вы-
полняет эмуляцию посредством использова-
ния «прозрачных совместно используемых
библиотек»54. Такая библиотека отрабатыва-
ет системные вызовы операционной систе-
мы, которую она эмулирует, а после перехва-
тывает системные вызовы, сделанные про-
граммами, написанными для работы
в эмулируемой операционной системе 55,56
Перехваченные системные вызовы впослед-
ствии могут быть оттранслированы в систем-
ные вызовы системы Mach, а все возможные
результаты транслируются обратно в эмули-
рованную форму ”'58. Таким образом, нет не-
обходимости переносить программу пользо-
вателя в систему Mach. Более того, любое ко-
Операционная система Mach была раз-
ботана в Университете Карнеги-Меллон
^период с 1985 по 1994 гг. и основана на
панней исследовательской операционной
системе Accent этого же университета48. Про-
ектом руководил Ричард Ф. Рашид, главный
вице-президент компании Microsoft по
исследованиям49. Операционная система
Mach является одной из первых и наиболее
известных операционных систем на основе
микроядра (см. раздел 1.13.3). Она была
включена в более поздние системы, такие
как Mac OS X, NeXT и OSF/1, а также в значи-
тельной степени повлияла на Windows NT (и,
в конечном счете, на Windows ХР, которая
будет рассмотрена в главе 21 )50,5’- ”. Реали-
зация с открытыми кодами, GNU Mach, ис-
пользуется в качестве ядра для операцион-
ной системы GNU Hurd, которая сейчас нахо-
дится на стадии разработки53.
Огромный потенциал операционной сис-
темы Mach на основе микроядра заключается
личество таких прозрачных совместно
используемых библиотек может находиться
в памяти, таким образом, система Mach мо-
жет одновременно эмулировать множество
операционных систем59.
Вопросы для самопроверки
1. Каким образом связывание упрощает процесс разработки больших
программ, созданных большими коллективами разработчиков?
2. Какой возможный недостаток использования динамического ком-
поновщика вы можете назвать? В чем заключается преимущество
его использования?
Ответы 1) Связывание позволяет создавать программы в виде со-
вокупности отдельных модулей. Компоновщик связывает эти модули
в итоговый загрузочный модуль после компиляции всех частей про
граммы. 2) Если библиотеку не удается найти в процессе выполнения,
выполняемая программа будет завершена, возможно, с полной поте-
рей всех результатов, полученных вплоть до этого момента. Преиму-
щество заключается в том, что программы, которые связываютс
динамически, не надо перекомпоновывать, когда библиотека претер
певает изменения.
2.8.3 Загрузка
После того как компоновщик создал загрузочный модуль, он передает ег
программе загрузчику (loader). Загрузчик отвечает за размещение каждОг°
блока команд и данных по определенному адресу в памяти — процесс, наз^
ваемый адресным связыванием (address binding). Существует нескольк
методов загрузки программ в основную память, большая часть из которЬ1°
имеют значение только для систем, не поддерживающих виртуальную
мять. Если загрузочный модуль уже определяет физические адреса в памя'
ти, загрузчик просто размещает блоки команд и данных по адресам, опреде
ленным программистом или компилятором (при условии, что эти адреса
мяти доступны). Данный процесс называется абсолютной загрузКо^
(absolute loading). Перемещающая (настраивающая) загрузка (relocatable
loading) выполняется в случае, если в загрузочном модуле содержатся отно-
сительные адреса, которые необходимо трансформировать в абсолютные ад.
реса памяти. Загрузчик отвечает за запрашивание блока памяти для разме-
щения в нем программы, а затем, за преобразование адресов программы
чтобы та соответствовала своему расположению в памяти.
На рис 2.12 операционная система выделила программе блок памяти,
начиная с адреса 10000. Когда программа загружается, загрузчик должен
прибавить 10000 к каждому адресу в загрузочном модуле. На рис. 2.12 за-
грузчик меняет исходный относительный адрес 450 переменной Example
на 10450.
Динамическая загрузка (dynamic loading) — это подход, при котором
программные модули загружаются при первом использовании61. Во мно-
гих системах с виртуальной памятью каждому процессу присвоен собст-
венный набор виртуальных адресов, начинающихся с нуля, а загрузчик
отвечает за загрузку программы в действительную область памяти.
Мы можем проследить весь процесс компиляции, связывания и загруз-
ки (используя адресное связывание во время загрузки) от исходного кода
до выполнения на рис. 2.13. Программист начинает с написания исходного
кода на некотором языке высокого уровня — в данном случае на языке С.
Затем компилятор трансформирует файлы foo.c и Ьаг.с исходного кода
в машинный язык, создавая при этом объектные модули foo.o и bar.о.
В коде программист определил переменную X в foo.c и переменную Y
в Ьаг.с; обе они расположены по относительному адресу 100 в соответст-
вующих им объектных модулях. Объектные модули расположены на вто-
ричных запоминающих устройствах, пока пользователь или другой про-
цесс не укажет на необходимость их связывания.
На следующем этапе компоновщик объединяет два модуля в единый за-
грузочный модуль. Компоновщик решает свою задачу, собирая информ8'
цию о размерах модулей и внешних символах при первом проходе и связЫ"
вая файлы вместе при втором проходе. Следует обратить внимание, чт°
компоновщик перемещает переменную Y по относительному адресу 400-
На третьем этапе загрузчик запрашивает блок памяти под программу^
Операционная система предоставляет диапазон адресов от 4000 до 5050’
так что загрузчик перемещает переменную X по абсолютному адресу 4100’
а переменную Y по абсолютному адресу 4400.
159
„ч аппаратных средств и программного обеспечения
Кенией-----------------
0 300 Код Загрузка —
Данные
450 Переменная Example
Г > г
10000 10300 Код
Данные
10450 Переменная Example
Г / Hz t 3'
Рис. 2.12. Загрузка
Компилирует
foo.o
О
100
^ЧС. 2.13. Компиляция, связывание и загрузка
Вопросы дм самопроверки
1. Каким образом абсолютная загрузка может ограничить степень
мультипрограммности системы?
2. Каким образом динамическая загрузка повышает степень мульти-
программности системы?
Ответы 1) Две программы, использующие пересекающиеся адре-
са, не могут выполняться одновременно, так как только одна из них
может находиться в памяти в каждый конкретный момент времени.
2) Модули загружаются по необходимости, таким образом, в памяти
содержатся только те модули, которые используются.
160 Глава %
2.9 Встроенное программное обеспечение
Большинство компьютеров кроме аппаратных средств и обычного пр0_
граммного обеспечения также используют встроенное программное обес.
печение (firmware) — последовательности команд, хранящиеся в постояц,
ном запоминающем устройстве, встроенном в аппаратуру. Встроенное пр0.
граммное обеспечение создается при помощи микропрограммирование
(microprogramming), которое вводит дополнительный уровень средств пр0.
граммирования, расположенный ниже машинного языка компьютера.
Микрокод (microcode), т.е. команды микропрограмм, как правило
включают простые, основные команды, необходимые для реализации всех
операций машинного языка62. К примеру, типичная машинная команда
может задать выполнение аппаратными средствами операции сложения.
Микрокод для этой команды определяет простейшие действительные опе-
рации, которые должны выполнить аппаратные средства, такие как увели-
чение указателя, адресующего текущую машинную команду, сложение
чисел, хранение результата в новом регистре и выборка следующей
команды63’ 64.
Профессор Морис Уилкс, разработчик одного из первых компьютеров
EDSAC, впервые предложил принципы микропрограммирования в 1951
году 65. Однако начало широкого применения микрокода связано с появле-
нием IBM System/360 в 1964 г. Реализация наборов машинных команд
в микрокоде достигла пика своей популярности с операционной системой
VAX, но потеряла ее в течение последних лет, так как выполнение команд
микрокода ограничивают максимальную скорость процессора. В современ-
ных быстродействующих архитектурах операции, ранее выполнявшиеся
командами микрокода, теперь выполняются аппаратными средствами
процессора66. Сегодня многие аппаратные устройства, включая накопите-
ли на жестких дисках и периферийные устройства, содержат миниатюр-
ные процессоры. Команды для этих процессоров, как правило, реализуют-
ся при помощи микрокода 67.
Вопросы для самопроверки
1. (Да/Нет) Существует ли уровень команд, нижележащий по отноше-
нию к командам на машинном языке?
2. Опишите роль встроенного программного обеспечения в компью-
терной системе.
Ответы 1) Да. Микрокод определяет уровень программны^
средств, нижележащий по отношению к машинному языку компьюте-
ра. 2) Встроенное программное обеспечение определяет простые базо-
вые команды, необходимые для реализации всех операций
машинном языке.
^^^дппаппаратных средств а программного обваючоная
161
2 Ю МеЖпАатформное программное обеспечение
ГТпограммное обеспечение играет огромную роль в распределенных сис-
1 Р компьютеры которых связаны посредством сети. Часто компьюте-
тема^одЯщИе в состав распределенной системы, неоднородны — они ис-
Рь1’ „уют разные аппаратные средства, разные операционные системы,
Я<также взаимодействуют через разные сетевые архитектуры, используя
а этом различные сетевые протоколы. Распределенные системы нужда-
П₽ся в межплатформном программном обеспечении (связующем ПО) для
10 утпсствления взаимодействия по сети многочисленных процессов, вы-
полняющихся на одном или нескольких компьютерах.
Межплатформное программное обеспечение дает возможность приложе-
ниям, выполняющимся на одном компьютере, обменивается с приложени-
ем, которое выполняется на удаленном компьютере, позволяя взаимодейст-
вовать компьютерам в распределенных системах. Связующее ПО также по-
зволяет приложениям выполняться на неоднородных компьютерных
платформах, если на них установлено такое программное обеспечение. Свя-
зующее ПО облегчает процесс прикладного программирования, так как
у разработчиков нет необходимости знать детали того, каким образом свя-
зующее ПО выполняет свои задачи. Разработчики имеют возможность скон-
центрироваться больше на разработке программ, чем на разработке прото-
колов связи. Открытый интерфейс взаимодействия с базами данных (Open
DataBase Connectivity, ODBC) является примером интерфейса прикладного
программирования для доступа к базам данных. Он позволяет приложени-
ям получать доступ к базам данных посредством связующего ПО, называе-
мого драйвером ODBC. При разработке таких приложений разработчикам
необходимо лишь указать базу данных, к которой должно подключаться
приложение. Драйвер ODBC управляет подключением к базе данных и по-
лучением информации, необходимой приложению. В разделах с 17.3.1 по
17.3.4 будет рассмотрена реализация связующего ПО и протоколы, которые
Формируют основу многих распределенных систем.
Вопросы для самопроверки
1. В чем заключаются преимущества и недостатки использования
межплатформного программного обеспечения?
2. Каким образом связующее ПО упрощает проектирование неодно-
родных систем?
ОтвеПЫ 1) Межплатформное программное обеспечение повышает
степень модульности программ и упрощает процесс прикладного про-
граммирования, так как разработчику не нужно писать код для управ-
ления взаимодействием между процессами. Тем не менее, взаимодей-
ствие связующего ПО и процессов влечет за собой потери по сравне-
нию с прямой связью. 2) Межплатформное программное обеспечение
Упрощает взаимодействие между компьютерами, используя различ-
ные протоколы, посредством перевода сообщений в необходимые фор-
маты на их пути от отправителя к получателю.
162
Гливд
Web-ресурсы
www. pcguide. com
Содержит статьи, в которых рассматриваются различные аспекты компьютер
ных аппаратных средств, а также мотивация создания различных интерфейсов
охватывает широкий спектр тем в сфере компьютерных архитектур.
www.tomshardware.com
Ресурс Tom’s Hardware Guide является одним из интернет-изданий,
предоставляет наиболее полный обзор аппаратных средств в Веб.
которое
www.anandtech.com
Освещает новые аппаратные средства, включая те, которые только анонсируются.
developer.intel.com
Содержит документацию на продукцию компании Intel, статьи о современных
технологиях и информацию о научно-исследовательских разработках фирмы.
www.ieee.org
Институт инженеров по электротехнике и радиоэлектронике определяет стан-
дарты в сфере проектировании компьютерных аппаратных средств,
этой организации могут получить доступ к ее журналам в онлайн.
Сотрудники
sourceforge.net
Один из самых популярных в мире сайтов по разработке открытого программ-
ного обеспечения; содержит ресурсы и утилиты для разработчиков программного
обеспечения.
llmvzu
Операционная система в первую очередь является диспетчером ресурсов, поэто-
му при ее проектировании следует в полной мере учитывать характеристики аппа-
ратных и программных ресурсов, которыми она должна управлять.
Печатная плата является аппаратным компонентом, который обеспечивает
электрическое соединение устройств, конструктивно размещенных где-либо на
плате. Материнская плата — это печатная плата, к которой подключаются такие
устройства, как процессоры и основная память.
Процессор — это аппаратный компонент, который выполняет поток команд на
машинном языке. Центральный процессор — это процессор, выполняющий ко-
манды программы; сопроцессор эффективно выполняет ограниченный набор спе-
циальных команд (например, обрабатывает аудио и графическую информацию)'
В этой книге термин «процессор» используется для обозначения центрального пр0'
цессора. Регистры — это высокоскоростные блоки памяти, расположенные в пр°,
цессоре и хранящие данные для их непосредственного использования процесс®
ром. Прежде чем процессор начнет обработку данных, они должны быть занесен
в регистр. Длина команды — это размер команды на машинном языке. Некоторь*
процессоры поддерживают несколько различных размеров команд.
Машинное время измеряется циклами; каждый цикл — это один полный
од сигнала, генерируемого системным синхрогенератором. Как правило, скоР°с
процессоров измеряются в гигагерцах (ГГц — миллиардах циклов за секундУ/'
Иерархия памяти — это схема организации памяти, согласно которой,
дорогая и быстрая память находится вверху, а самая дешевая и медленная — вР
зу. Иерархия памяти на такой схеме имеет ступенчатую пирамидальную
в которой регистры занимают наивысшую ступень в иерархии, за ними следУ1!,
кэш-память первого уровня, кэш-память второго уровня, основная память, I
163
цегЛии оггаратных средств и программного обеспечения
запоминающие устройства и запоминающие устройства третьего уровня.
pii'iB61® память системы — это самое медленное хранилище данных в системе ие-
Основй паМЯТИ среди тех, к которым процессор может обращаться непосредствен-
рар**111 овная память является энергозависимой, т.е. она утрачивает данные при
во- °СЙ НЙИ питания. Вторичные запоминающие устройства, такие как накопите-
°ТКЛ1°жестких магнитных дисках, компакт-дисках CD, универсальных цифровых
дИ на рур), а также накопители на гибких магнитных дисках хранят огромные
^eMBi данных при низких затратах в пересчете на один бит даже при отключен-
м питании.
Й ТТТина__это совокупность проводников (обеспечивающих электрический кон-
) при помощи которых осуществляется передача данных между аппаратными
ТаК о'йствами. Порт — это шина, соединяющая два устройства. Каналы ввода/вы-
УСТР являются компонентами специального назначения, они используются для
Операций ввода/вывода независимо от главных процессоров компьютерной систе-
тлЫ »» _
Периферийное устройство — это аппаратный компонент, который не требует-
ся компьютеру как обязательный для выполнения программных инструкций.
К числу таких устройств относятся принтеры, сканеры и мыши; в тоже время
процессоры и основная память таковыми не являются.
Некоторые аппаратные устройства предназначены специально для повыше-
ния производительности и упрощения организации операционных систем. Опе-
рационные системы зачастую используют несколько различных исполнительных
режимов. Для приложений введены ограничения на подмножество команд, кото-
рое может выполнять программа в пользовательском режиме: исключено, к при-
меру, прямое выполнение команд ввода/вывода. Операционная система обычно
работает в привилегированном режиме (режиме ядра); в этом режиме процессор
может выполнять привилегированные команды и обращаться к ресурсам для вы-
полнения задач от имени процессов. Защита памяти, которая пресекает попытки
процессов получить доступ к памяти, не выделенной для этих процессов (как, на-
пример, к памяти других пользователей или к памяти операционной системы),
реализуется посредством использования регистров процессора, которые могут
оыть изменены только привилегированными командами. Большинство устройств
посылает сигнал, называемый прерыванием, процессору, если происходит ка-
кое-либо событие. Операционная система может реагировать на изменения в со-
стоянии устройств, извещая процессы, ожидающие соответствующих событий.
Программируемый ввод/вывод — это технология, в соответствии с которой про-
цессор простаивает, пока данные передаются между устройством и основной памя-
ра ' йЯ сРавнения’ прямой доступ к памяти позволяет устройствам и контролле-
стия НИВаТЬСЯ ®локами данных непосредственно с основной памятью без уча-
прОГр£^>ОцессоРа’ что освобождает процессор для выполнения инструкций
лы ^Р®Рываьгия позволяют аппаратным компонентам компьютера посылать сигна-
Ци°нна1;еСС0РУ’ кот°Рый уведомляет операционную систему о прерывании. Опера-
В к Я система Решает, каким образом отреагировать на прерывание.
ТеРваль П„ютеРах используется несколько разновидностей часов и таймеров. Ин-
Ним про ЫИ таамеР эффективен для исключения монополизации процессора од-
вание длЦеСС0М- ^осле определенного периода времени таймер генерирует преры-
Цессор в пРивлечения внимания со стороны процессора; в результате этого про-
®Ремени ОслеДСТвии может быть передан другому приложению. Часы истинного
НачалПо3в°Ляют компьютеру следить за временем «настенных часов».
°нВой загРУ3ка — это процесс загрузки первичных компонентов операци-
ЛьЮтера еМы в память. Он осуществляется базовой системой ввода/вывода ком-
з°вать тол°ГИЯ p^uS-and-play позволяет операционной системе настроить и исполь-
д?ко лто Установленную аппаратуру без участия пользователя. Для под-
fl Иной технологии устройство должно однозначно определяться операци-
/64
Гливц
онной системой, связываться с операционной системой для указания pecypCQg
и услуг, необходимых для его нормальной работы, а также определять драйву
который поддерживает устройство и позволяет программному обеспечению
строить устройство (например, назначить устройству канал прямого доступа к ца'
мяти).
Кэш-память — это относительно быстрая память, разработанная для повьцце
ния скорости выполнения программ посредством размещения в ней копий данных"
к которым в ближайшее время будет обращаться программа. Примером кэш-памя’
ти служит кэш-память процессора первого и второго уровней, а также кэш в основ"
ной памяти для накопителей на жестких магнитных дисках.
Буфер — это область памяти для промежуточного хранения данных при их це.
редаче во время ввода/вывода. В первую очередь, буферная память используеТСя
для координации передачи данных между устройствами, работающими на разных
скоростях. Буферы могут хранить данные для асинхронной обработки, координи.
ровать операции ввода/вывода между устройствами, работающими на различных
скоростях, или асинхронно передавать сигналы.
Спулинг — это технология буферизации, при которой в роли посредника между
процессом и низкоскоростным или ограниченным по размеру буфера устройством
ввода/вывода выступает связующее устройство, например дисковый накопитель.
Спулинг позволяет процессам запрашивать периферийные устройства, не дожида-
ясь освобождения устройства для удовлетворения данного запроса.
Существует три категории языков программирования: машинные языки, язы-
ки ассемблера и языки программирования высокого уровня. Программы на ма-
шинных языках состоят из потоков чисел (в конечном счете, единиц и нулей), ко-
торые указывают компьютерам, каким образом выполнять их наиболее примитив-
ные операции. Компьютер может воспринимать только собственный машинный
язык. Языки ассемблера используют команды на машинном языке с использова-
нием англоязычных обозначений®. Языки программирования высокого уровня по-
зволяют программистам писать команды, которые похожи на повседневный анг-
лийский язык и содержат стандартные математические обозначения. Они решают
более существенные задачи, используя меньшее количество операторов, но нужда-
ются в «трансляторах», которые называются компиляторами, для перевода про-
грамм, написанных на языке высокого уровня, на машинный язык. Языки С,
C++, Java и C# являются примерами языков программирования высокого уровня.
На сегодняшний день языки программирования высокого уровня, как правило,
подразделяются на два типа: структурные и объектно-ориентированные. Струк-
турное программирование — это дисциплинированный подход к разработке понят-
ных, корректных и легко модифицируемых программ. Языки Паскаль и Фортран
являются языками структурного программирования. Объектно-ориентированные
языки ориентированы на управление объектами (сущностями) для создания про-
граммного обеспечения многократного использования, которое можно легко по-
нять и модифицировать. Языки C++, Java и C# являются языками объектно-орИ’
ентированного программирования.
Интерфейсы прикладного программирования позволяют программе запраШИ"
вать службы операционной системы. Программы вызывают функции интерфЫ1С?
прикладного программирования, который может получить доступ к операционно
системе посредством системных вызовов.
Прежде чем программа, написанная на языке высокого уровня, сможет вып°
няться, ее необходимо перевести на машинный язык и загрузить в основную И
мять. Компиляторы транслируют код, написанный на языке программирован
высокого уровня, в машинный код. Компоновщики назначают относительные &+
реса различным программным блокам или блокам данных, а также разреши
а Во многих компьютерах отечественной разработки (в том числе и современных)
пользуются русские аббревиатуры для обозначения команд процессора — приМ- Ре
перев.
165
^^^аппаратных средств и программного обеспечения
е ссылки между подпрограммами. Загрузчики трансформируют эти адреса
вЯе1?0 вИтельные и помещают программные блоки или блоки данных в основную
в Дейс^
11амять'1цинство компьютеров содержат встроенное программное обеспечение, кото-
Боль лдет программные команды, но физически являются частью аппаратуры.
рое оПР .j чаСть встроенного программного обеспечения создается при помощи мик-
родыпа мирования, которое вводит дополнительный уровень средств программи-
ропр°гР нижележащий по отношению к машинному языку компьютера.
РОВм11»сплатформное программное обеспечение позволяет отдельным процессам,
^няющимся на одном или нескольких компьютерах, взаимодействовать через
вып мезкплатформное программное обеспечение способствует распространению
^однородных распределенных систем и упрощению процесса прикладного про-
^ммирования.
Ключевые термины
plug-and-play — технология, упрощающая установку драйверов и настройку аппа-
F ратных средств, выполняемую операционной системой.
Абсолютная загрузка (absolute loading) — технология загрузки, согласно которой
загрузчик размещает программы в памяти по определенному программистом
или компилятором адресу.
Адресная шина (address bus) — часть шины, определяющая область памяти, в ко-
торую или из которой должны быть переданы данные.
Адресное связывание (address binding) — выделение адресов памяти программ-
ным данным и командам.
Арифметико-логическое устройство (Arithmetic and Logic Unit, ALU) — компонент
процессора, который выполняет основные арифметико-логические операции.
Асинхронная передача (asynchronous transmission) — передача данных от одного
устройства к другому, которое работает независимо от первого, через буфер во
избежание необходимости блокировки. Отправитель может выполнять другую
работу, отослав данные в буфер, даже если получатель еще не прочитал их.
Ассемблер (assembler) — программа-транслятор, которая переводит программы
с языка ассемблера на машинный язык.
Атрибут (attribute) — см. Свойство (property).
а^?Вая система ввода/вывода, БИОС (Basic Input/Output System, BIOS) — про-
p ммные средства низкого уровня, которые контролируют инициализацию
уп₽авление основными аппаратными средствами.
Маз?' (bytecode) — промежуточный код, предназначенный для виртуальных
Биб Ин (к примеру, байткод Java работает на Виртуальной Машине Java).
ДульТеЧНЫ0 м?дуль (library module) — предварительно скомпилированный мо-
ввол/ КОТОРЫЙ выполняет обычные компьютерные операции, такие как
Блок /Вывод или математические функции.
-г₽~ команд (instruction fetch unit) — компонент процессора, который
п°лнены Т К0Манды из кэша команд, чтобы они могли быть дешифрованы и вы-
БУфер (buff
Ные во ег^ временно используемая область памяти, в которой хранятся дан-
с«орОстВре1*я onePan™ обмена между устройствами, работающими на разных
а°й ск ЯХ" БуФе₽ позволяет более быстрому устройству выдавать данные с пол-
УстРойсф°СТЬЮ (вплоть до заполнения буфера), не ожидая, пока более медленное
тво примет эти данные.
166
Внешнее имя (external name) — определяемый в модуле символ, к которому могу^
обращаться другие модули.
Внешняя ссылка (external reference) — ссылка из одного модуля на объект другоро
Внутреннее устройство (on-board device) — устройство, физически непосредствев
но подключенное к материнской плате компьютера.
Вспомогательная память (auxiliary storage) — см. вторичное запоминающее уСт
ройство (secondary storage)
Встроенное программное обеспечение (firmware) — микрокод, определяющий
простые базовые команды, необходимые для реализации команд машинного
языка.
Вторичное запоминающее устройство (secondary storage) — память, которая, кав
правило, используется для долговременного хранения больших объемов дав.
ных. Вторичное запоминающее устройство находится уровнем ниже основной
памяти в иерархии системной памяти. После включения компьютера информа-
ция пересылается между вторичным запоминающим устройством и основной
памятью, таким образом, процессор может получить доступ к данным и коман-
дам. Накопители на жестких магнитных дисках являются наиболее распростра-
ненной разновидностью вторичных запоминающих устройств.
Генератор кода (code generator) — часть компилятора, ответственная за получение
объектного кода для программ, написанных на языке программирования высо-
кого уровня.
Генератор промежуточного кода (intermediate code generator) — этап процесса
компиляции, на котором данные из синтаксического анализатора преобразуют-
ся в поток команд для оптимизатора.
Действительный адрес (real address) — адрес ячейки в основной памяти.
Дешифратор команд (instruction decode unit) — компонент процессора, который
интерпретирует команды и генерирует соответствующие управляющие сигна-
лы, заставляющие процессор выполнять команду.
Динамическая загрузка (dynamic loading) — способ загрузки, при котором адреса
памяти определяются во время выполнения программы.
Динамическое оперативное запоминающее устройство (dynamic RAM, DRAM) —
оперативное запоминающее устройство, содержимое которого должно постоянно
считываться схемой обновления для регенерации этой информации в памяти.
Динамическое связывание (dynamic linking) — механизм связывания, выполняю-
щий разрешение ссылок на внешние функции, когда процесс впервые осуществ-
ляет вызов этих функций. При таком подходе затраты на компоновку могут
быть снижены, так как внешние функции, которые никогда не вызываются
в ходе выполнения процесса, не компонуются.
Длина команды (instruction length) — количество битов, составляющих команду
в определенной архитектуре. Размер команды зависит от архитектуры. Некото-
рые архитектуры поддерживают команды различных размеров.
Загрузочный модуль (load module) — интегрированный модуль, созданный ком-
поновщиком, состоящий из объектного кода и использующий относительны
адреса.
Загрузочный сектор (boot sector) — определенное место на диске, где хранятся н»
чальные команды операционной системы; БИОС выдает указания аппаратнь
средствам загружать эти начальные команды при включении компьютера.
Загрузчик (loader) — приложение, загружающее связанные исполняемые модУл11
в память.
Задачный режим (problem state) — см. Пользовательский режим (user mode)-
^llU аппаратных средств и программного обеспечения
167
Мура (Moor’s law) — прогноз скорости развития мощности процессоров, ко-
3aS°® » предполагает удваивание количества транзисторов в процессоре практи-
чески каждые 18 месяцев.
4 цикла (cycle stealing) — прием, который предоставляет каналу приоритет
Захват
процессором при обращении к шине, чтобы избежать конфликтов между
"игцалами канала и процессора.
С т шины (bus mastering) — обмен данными в режиме прямого доступа к памя-
3»хва которой устройство берет под контроль шину (препятствуя другим уст-
ройствам в одновременном получении доступа к шине) для доступа к памяти.
₽ та памяти (memory protection) — механизм, препятствующий процессам
^аИпОлученИИ доступа к памяти, используемой другими процессами или операци-
онной системой.
-япхия памяти (memory hierarchy) — память компьютеров можно классифици-
*оовать, разбив на категории от самой быстрой, дорогой и обладающей наимень-
шей емкостью до самой медленной, дешевой и обладающей наибольшей емко-
стью.
Интервальный таймер (interval timer) — аппаратное устройство, генерирующее
периодические прерывания, которые позволяют запускать операционную систе-
му, что может гарантировать защиту процессора от преднамеренной и непредна-
меренной монополизации отдельными процессами.
Интерпретатор (interpreter) — приложение, которое может выполнять код, отлич-
ный от машинного (например, команды на языке высокого уровня).
Интерфейс малых компьютерных систем (Small Computer Systems Interface,
SCSI) — интерфейс, разработанный для поддержки многочисленных устройств
и высокоскоростных соединений. Данный интерфейс поддерживает большее ко-
личество устройств по сравнению с менее дорогим интерфейсом IDE и является
распространенным в системах Apple и компьютерах с большим числом подклю-
ченных периферийных устройств.
Интерфейс прикладного программирования (application Programming Interface,
API) — набор функций, позволяющий приложению запрашивать службы у бо-
лее низкого уровня системы (например, операционной системы или модуля биб-
лиотеки).
Интерфейс прикладного программирования Windows (Windows API) — интер-
фейс корпорации Microsoft для приложений, которые выполняются в среде
Windows. Интерфейс прикладного программирования позволяет прикладным
программистам запрашивать службы операционной системы, что освобождает
их от написания кода для выполнения низкоуровневых операций и позволяет
операционной системе защищать свои ресурсы.
лючение (exception) — ошибка, возникающая в ходе работы процесса. Исклю-
Вия обращают на себя внимание операционной системы, которая определяет,
Рабп*М °бРа'30м необходимо отреагировать. Процессы могут регистрировать об-
оотчиков исключений, которые выполняются, когда операционная система
лучает соответствующее исключение.
(к п ительный режим (execution mode) — режим работы операционной системы
ляет ИмеРу> пользовательский и привилегированный режимы), который опреде-
ЦСх ’ какие команды могут быть выполнены процессом.
языкеИ К°Д ^source c°de) — программный код, как правило, написанный на
лиров Вь1С0к0Го Уровня или на языке ассемблера, который должен быть скомпи-
^апал а™ ИЛИ транслирован, прежде чем компьютер сможет выполнить его.
этой Г‘° — связь между двумя точками на шине PCI Express. Устройства на
^ал нЛ'.*'.. соединяются посредством линии, которая может иметь до 32 каналов.
ВвоД^7вь*а/ВЬ1ВОДа channel) — компонент, ответственный за выполнение
/вывода устройствами независимо от центрального процессора.
168
Класс (class) — тип объекта. Определяет методы и атрибуты объекта.
Компакт-диск (compact disk, CD) — цифровой носитель, на котором информацц
хранится в виде микроскопических впадин на плоской поверхности. 4
Компакт-диск с однократной записью и многократным считыванием (Write-OnCe
Read-Many (WORM) medium) — носитель, данные на который можно запиСат’
только один раз, но доступ к ним можно получать неоднократно.
Компилировать (compile) — транслировать исходный код на языке высокого Ов
ня в машинный код.
Компилятор (compiler) — приложение, который транслирует исходный код На
языке высокого уровня в машинный код.
Компоновка — см. Связывание.
Контроллер (controller) — аппаратный компонент, который управляет доступов
устройства к шине.
Кэш-попадание (cache hit) — обращение к данным, находящимся в кэше.
Кэш-промах (cache miss) — обращение к данным, отсутствующим в кэше.
Лексемы (token) — цепочки символов в программе, выделяемые лексическим ана-
лизатором. Лексемы, как правило, представляют собой ключевые слова, идеи-
тификаторы, операторы и знаки препинания.
Лексер (lexer) — см. Лексический анализатор (lexical analyzer).
Лексический анализатор (lexical analyzer) — часть компилятора, которая разби-
вает исходный код на лексемы.
Материнская плата (mainboard или motherboard) — печатная плата, обеспечиваю-
щая электрическое соединение между такими компьютерными компонентами,
как процессор, память и периферийные устройства.
Машинный язык (machine language) — язык, который определяется структурой
аппаратных средств компьютера и может быть непосредственно воспринят им.
Метод (method) — часть объекта, управляющая его атрибутами или выполняющая
функцию.
Микрокод (microcode) — команды микропрограммирования.
Микропрограммирование (microprogramming) — уровень средств программирова-
ния, нижележащий по отношению к машинному языку компьютера и вклю-
чающий команды, необходимые для реализации операций машинного языка.
Это позволяет процессору разбивать большие и сложные команды на меньшие,
которые выполняются его исполнительным блоком.
Модуль (module) — независимо разработанная подпрограмма, которая может быть
объединена с другими подпрограммами для создания одной большой и сложной
программы. Программисты часто используют предварительно скомпилирован-
ные библиотечные модули для реализации обычных функций компьютера, та-
ких как, управление вводом/выводом или генерирование случайных чисел.
Набор микросхем (chipset) — совокупность контроллеров, сопроцессоров, и10®
и других аппаратных средств материнской платы, определяющих аппаратные
возможности системы.
Наиболее полномочный пользовательский уровень (most trusted user status) ''
см. Привилегированный режим или режим ядра (kernel mode).
Начальная загрузка (bootstrapping) — процесс загрузки начальных компонент®®
операционной системы в основную память, чтобы они могли загрузить оста
шуюся часть операционной системы.
Объект (object) — программный компонент многоразового использования, крТ®
рый может моделировать элементы реального мира посредством своих своНс
и действий.
169
mill аппаратных средств и программного обеспечения
КОнаеГ,ц
яо-ориентированное программирование (object-oriented programming,
__ концепция программирования, позволяющая разработчикам программ-
ой* 'о^еспечения быстро создавать сложные программные системы, используя
воГ°поНенты многоразового использования — объекты, созданные на основе
Йлонов — классов.
Ш НЫЙ КОД (object code) — код, генерируемый компилятором и содержащий
Объектны»
на машинном языке, которые должны быть связаны и загружены пе-
„ед выполнением.
и пчительный регистр (bounds register) — регистр, который хранит информа-
цию о диапазоне адресов, доступных процессу.
тивная память (real memory) — см. Основная память (main memory).
^^пативное запоминающее устройство, ОЗУ (random access memory, RAM) —
дамять, доступ к содержимому которой может осуществляться в произвольном
порядке.
панионная система Mach — ранняя операционная система на основе микрояд-
° разработанная в Университете Карнеги-Меллон командой, возглавляемой
Ричард Ж Рашидом. Операционная система Mach оказала влияние на разработ-
ку Windows NT и была использована для реализации Mac OS X.
Опрос (polling) — технология определения состояния аппаратных средств посред-
ством регулярной проверки каждого устройства. Последовательный опрос мо-
жет проводиться вместо генерирования прерываний, но, как правило, это сни-
жает производительность из-за растущих затрат.
Оптимизатор (optimizer) — часть компилятора, которая старается повысить эф-
фективность выполнения программы и уменьшить необходимый для нее объем
памяти.
Основная память (main memory) — энергозависимая память, в которой хранятся
команды и данные; это самая медленная память в системной иерархии, к кото-
рой процессор может обращаться непосредственно.
Открытый интерфейс взаимодействия с базами данных (Open DataBase
Connectivity, ODBC) — протокол встроенного программного обеспечения, кото-
рый позволяет приложениям получать доступ к различным базам данных, ис-
пользующим разные интерфейсы. Драйвер открытого интерфейса взаимодейст-
вия с базами данных обрабатывает подключения к базе данных и извлекает ин-
формацию, запрашиваемую приложениями. Это освобождает прикладного
программиста от написания кодов команд управления базой данных.
Относительный адрес (relative address) — адрес, определяемый на основе его рас-
положения по отношению к началу модуля.
Память с произвольной выборкой — см. Оперативное запоминающее устройство.
Параллельный порт (parallel port) — интерфейс к такому параллельному устрой-
ству ввода/вывода, как принтер.
-Ремещаемая загрузка (relocatable loading) — технология загрузки, при которой
относительные адреса в загрузочном модуле трансформируются в абсолютные
цеЧД₽еСа’ основанные на расположении запрашиваемого блока памяти.
е₽емещение (relocating) — процесс настройки адресов программного кода
Л и данных.
плата (printed circuit board, РСВ) — аппаратный компонент, обеспечиваю-
11Да электрический контакт между устройствами, расположенными на плате.
Во Расширения (add-on card) — устройство, расширяющее функциональные
Пона ОЭКности компьютера (например, звуковая или видеокарта).
^°ЛьзеВИе (behavior) — см. Метод (method).
Саь1°®?тельский режим (user mode) — режим работы, не позволяющий процес-
°бращаться непосредственно к системным ресурсам.
170 Глаба g
Порт (port) — шина, соединяющая два устройства.
Порт стандарта IEEE 1394 (IEEE 1394 port) — широко используемый последова
тельный порт, который обеспечивает скорость передачи данных до 800 Мб/С'
иногда питает устройства и позволяет производить их горячую замену; как пра’
вило, эти порты называются FireWire (в продукции компании Apple) и ПдцС
(в продукции компании Sony).
Последовательный порт (serial port) — интерфейс устройства, передающего цн
формацию побитово (например, клавиатуры и мыши).
Прерывание (interrupt) — сообщение, информирующее систему о том, что одно ц3
устройств выполнило операцию или на нем произошла ошибка. Прерывание за.
ставляет процессор приостановить выполнение программы и вызвать операцц,
оннуто систему, чтобы иметь возможность ответить на прерывание.
Привилегированная команда (privileged instruction) — команда, которая может
быть выполнена только в привилегированном режиме. Привилегированные ко-
манды выполняют операции, обладающие доступом к защищенным аппаратным
средствам и программным ресурсам (к примеру, переключение процессора с про-
цесса на процесс или обращение к накопителю на жестких магнитных дисках).
Привилегированный режим — см. Режим ядра.
Прикладное программирование (application programming) — разработка про-
граммного обеспечения, которая имеет целью написание кода, запрашивающе-
го услуги и ресурсы у операционной системы для выполнения прикладных за-
дач (к примеру, редактирования текста, загрузки веб-страниц или обработки
платежей).
Принцип наименьшего уровня привилегий (principle of least privilege) — полити-
ка доступа к ресурсам, которая определяет, что пользователю должен быть пре-
доставлен только тот уровень привилегий и доступа, который необходим для
выполнения его задач.
Проводник на печатной плате (trace) — тонкая электропроводящая линия, со-
ставляющая часть шины.
Программируемый ввод/вывод (programmed I/O, РЮ) — реализация ввода/выво-
да для устройств, которые не поддерживают прерывания и в которых передача
каждого слова из памяти должна контролироваться процессором.
Производная частота (derived speed) — фактическая частота синхросигнала уст-
ройства, определяемая умножителем или делителем частоты системной шины.
Пропускная способность (bandwidth) — количество данных, которое может быть
передано за единицу времени.
Процедурный язык программирования (procedural programming language) —
язык программирования, основанный больше на функциях, чем на объектах.
Процессор (processor) — аппаратный компонент, выполняющий команды на ма-
шинном языке и обеспечивающий защиту таких системных ресурсов, как ос-
новная память.
Прямой доступ к памяти (direct memory access, DMA) — механизм передачи дан-
ных с внешнего устройства в основную память (или обратно) посредством кон-
троллера, требующий только прерывания процессора по окончании транзак-
ции. Пересылка данных для ввода/вывода посредством прямого доступа к па-
мяти является более эффективной, чем программируемый ввод/вывод или
ввод/вывод по прерываниям, так как процессору не нужно следить за передачей
каждого слова или байта данных.
Разрешение внешних ссылок (symbol resolution) — процедура, выполняемая ком-
поновщиком, сопоставляющая внешние ссылки в одном модуле с соответствую-
щими внешними именами в другом.
171
пенный интерфейс встроенного программного обеспечения (Extensible
Interface, EFI) — интерфейс, разработанный компанией Intel и имею-
FirI.Tl яд усовершенствований по сравнению со стандартной базовой системой
*диИа/вывода, так, например, в нем реализована поддержка драйверов уст-
®в^тв и диалоговый интерфейс во время загрузки.
Р° (register) — быстрая память, расположенная в процессоре, в которой хра-
регнетР данные> непосредственно обрабатываемые процессором.
В п общего назначения (general-purpose register) — регистр, который может
Ре^сТР спользован процессом для хранения данных и значений указателей. К ре-
иограм специального назначения пользовательские процессы доступа не имеют.
ядра (kernel mode) — режим работы процессора, позволяющий процессам
выполнять привилегированные команды.
Свойство (property) — часть объекта, которая хранит данные о нем.
Связывание (linking) — процесс интеграции объектных модулей программы в еди-
ный исполняемый файл.
Связывающий загрузчик (linking loader) — приложение, выполняющее как свя-
зывание, так и загрузку.
Синтаксический анализатор (syntax analyzer или parser) — часть компилятора,
которая получает поток лексем от лексического анализатора и группирует их,
чтобы их можно было обработать генератором промежуточного кода.
Системная шина (frontside bus, FSB) — шина, соединяющая процессор с основной
памятью.
Системное программирование (system programming) — разработка программного
обеспечения для управления системными устройствами и приложениями.
Системный вызов (system call) — процедурный вызов, запрашивающий службу
операционной системы. Когда процесс выдает системный вызов, процессор пе-
реводится с пользовательского режима в привилегированный режим для выпол-
нения команд операционной системы, которые обрабатывают на вызов.
Сканер (scanner) — см. Лексический анализатор (lexical analyzer).
Совместно используемая библиотека (shared library) — совокупность функций,
совместно используемых несколькими программами.
Сопроцессор (coprocessor) — специализированный процессор, как, например, про-
цессор обработки графических или цифровых сигналов, разработанный для эф-
фективного выполнения ограниченного набора команд специального назначе-
ния (например, для трехмерной обработки изображений).
Спулинг (spool, simultaneous peripheral operations on-line) — метод ввода/вывода,
при котором процессы записывают данные на вторичное запоминающее устрой-
ство, используемое в качестве буфера, прежде чем они будут переданы устройст-
вам малого быстродействия.
татическое оперативное запоминающее устройство (static RAM, SRAM) — опе-
ративное запоминающее устройство, которое не нуждается в обновлении и хра-
нит данные, пока к нему поступает электропитание.
₽Уктурное программирование (structured programming) — дисциплинированный
Суп ДХ0Д к созданию понятных, правильных и легко модифицируемых программ.
®рвизорный режим (supervisor state) — см. Привилегированный режим или
Таб 5КИМ ^Pa (kernel mode).
бой^Я имен (symbol table) — часть объектного модуля, которая представляет со-
TaitT z ПеРечень внешних имен и внешних ссылок модуля.
ген — один полный период электрического сигнала. Количество циклов,
Цй®РиРУемых за секунду, определяют частоту работы устройства (к примеру,
Дл„ есс°ра, памяти и шины), эта величина может быть использована системой
измерения времени.
172 ГлаВц
Транзистор (transistor) — миниатюрный переключатель, который пропускает иэц.
не пропускает ток, позволяя процессорам выполнять операции по битам.
Удвоенная скорость обмена данными (Double Data Rate, DDR) — особенное^,
микропроцессорного набора, которая позволяет системной шине эффективн
работать со скоростью в два раза большей частоты тактового генератора, выц0^
няя два обращения к памяти за один такт. Эта особенность должна поддери^'
ваться микропроцессорным набором системы и оперативным запоминающи^
устройством.
Универсальная последовательная шнна (Universal Serial Bus, USB) — интерфедс
последовательной шины, который передает данные со скоростью до 480 Мбит/С
может подавать питание на устройства, а также поддерживает устройства
с функцией «горячей замены».
Ускоренный графический порт (Accelerated Graphics Port, AGP) — распростра-
ненная шинная архитектура, используемая для подключения графических уст.
ройств; как правило, ускоренные графические порты обладают пропускной спо-
собностью 260 МБ/с.
Усовершенствованный интерфейс управления конфигурированием и энергопо-
треблением (Advanced Configuration and Power Interface, ACPI) — интерфейс
которому должно соответствовать устройство Plug-and-Play, чтобы операцион-
ные системы Windows компании Microsoft могли управлять его энергопотребле-
нием.
Устройство блочного ввода/вывода (block device) — устройство, такое как диско-
вый накопитель, которое передает данные группами байтов определенного раз-
мера, в отличие от устройства посимвольного вводы/вывода, передающего дан-
ные порциями в один байт.
Устройство долговременного хранения данных (persistent storage) — см. Вторич-
ное запоминающее устройства (secondary storage).
Устройство посимвольного ввода/вывода (character device) — такое устройство,
как клавиатура или мышь, передающее информацию по байту за сеанс обмена,
в отличие от устройства блочного ввода/вывода, передающего данные группами
байтов определенного размера.
Учетверенная подкачка (quad pumping) — технология повышения производитель-
ности процессора посредством выполнения четырех обращений к памяти за
один такт.
Физическая память (physical memory) — см. Основная память (main memory).
Физический адрес (physical address) — см. Действительный адрес (real address).
Центральный процессор (central processing unit, CPU) — процессор, ответствен-
ный за общие вычисления в компьютере.
Часы истинного времени (time-of-day clock) — часы, отсчитывающие время, как
принято в обиходе, обычно, с точностью одна тысячная или миллионная часть
секунды.
Шина (bus) — совокупность проводников, образующих высокоскоростной канал
связи для обмена информацией между различными устройствами на материн-
ской плате.
Шина данных (data bus) — шина, передающая данные в область памяти (или из
нее), определенную адресной шиной.
Шина соединения периферийных устройств (Peripheral Components Interconnect
bus, PCI bus) — популярная шина, используемая для подключения периферий-
ных устройств, таких как сетевые и звуковые карты, к остальной части систе-
мы. Стандарт PCI предусматривает 16-битный или 32-битный интерфейс и поД"
держивает скорость передачи данных до 533 МБ/с.
КсНЧе'п1‘“‘ arl,aPt,mHblx еРе9ст1) ч ирогр^л^огснобеспвчвния ' " ~
чпонстика (heuristics) — методика решения сложных задач с использованием ап-
а проксимации и обобщающих практический опыт методов, которые приводят
к низким накладным затратам и, как правило, приносят хорошие результаты.
емеят кэша (cache line) — содержимое ячейки кэша.
«энергозависимое запоминающее устройство (volatile storage) — накопитель ут-
“рачивающий данные при отключении электропитания.
Язык С — процедурный язык программирования, разработанный Денисом Ритчи
П и использованный для создания системы UNIX.
Язык C# — объектно-ориентированный язык программирования, разработанный
корпорацией Microsoft и обеспечивающий доступ к библиотекам .NET.
Язык C++ — объектно-ориентированное расширение языка С, разработанное
Бъярне Страуструпом.
Язык Java — объектно-ориентированный язык программирования, разработан-
ный компанией Sun Microsystems. Он упрощает переносимость, обладая воз-
можностью исполнения на виртуальной машине.
Язык Ада (Ada) — параллельный процедурный язык программирования, разрабо-
танный министерством обороны США в период с 1970-х по 1980-е годы.
Язык ассемблера (assembly language) — язык низкого уровня, который представляет
основные операции компьютера в виде английских сокращений названий команд.
Язык Паскаль (Pascal) — структурный язык программирования, разработанный
в 1971 году Никлаусом Виртом и ставший популярным в рамках вводных кур-
сов программирования.
Язык программирования высокого уровня (high-level language) — язык програм-
мирования, использующий английские идентификаторы и простой синтаксис
для представления программы с применением меньшего количества операто-
ров, чем при программировании на языках ассемблера.
Язык программирования для промышленных и правительственных учреждений,
КОБОЛ (COmmon Business Oriented Language, COBOL) — процедурный язык про-
граммирования, разработанный в конце 1950-х годов для написания коммерче-
ского программного обеспечения, оперирующего большими массивами данных.
Язык ФОРТРАН (Fortran) — процедурный язык программирования, разработан-
ный компанией IBM в середине 1950-х годов для научных приложений, кото-
рые требовали сложных математических вычислений.
Упражнения
2.1. Назовите отличия между аппаратными средствами, программным обеспе-
чением и встроенным программным обеспечением.
2.2. Рассмотрим следующий список аппаратных средств.
i. Материнская плата
ii. Процессор
iii. Шина
iv. Память
V. Накопитель на жестких магнитных дисках
vi. Периферийное устройство
vii. Запоминающее устройство третьего уровня
viii. Регистр
ix. Кэш
Укажите для каждого из вышеперечисленных устройств наиболее подходя,
щее определение (Некоторые из пунктов могут иметь более одного ответа),
а. выполняет программные команды.
б. не требуется компьютеру для выполнения команд программы.
в. энергозависимое запоминающее устройство.
г. печатная плата, соединяющая процессоры с памятью, вторичными за.
поминающими устройствами и периферийными устройствами.
д. самая быстрая память в компьютерной системе.
е. набор проводников на печатной плате, передающих данные между аппа-
ратными компонентами.
ж. быстрая память, повышающая производительность приложений.
з. самая низкая ступень иерархии памяти, к которой процессор может об-
ращаться непосредственно.
2.3. Скорости процессоров возрастают вдвое почти каждые 18 месяцев. Растет
ли общая производительность компьютеров в тех же пропорциях? Да или
нет? В чем причина?
2.4. Постройте цепочку из перечисленных типов памяти от самой быстрой и до-
рогой до самой медленной и дешевой: вторичные запоминающие устройст-
ва, регистры, основная память, запоминающие устройства третьего уровня,
кэш-память второго уровня, кэш-память первого уровня. Почему в составе
системы присутствуют несколько запоминающих устройств различных ем-
костей и скоростей? Каковы предпосылки кэширования?
2.5. В чем заключаются преимущества и недостатки использования энергонеза-
висимого оперативного запоминающего устройства во всех кэшах и основ-
ной памяти?
2.6. Почему необходимо поддерживать унаследованные архитектуры?
2.7. Свяжите принцип наименьшего уровня привилегий с концепциями пользо-
вательского режима, привилегированного режима и привилегированных
команд.
2.8. Опишите некоторые из методов реализации политики защиты памяти.
2.9. Двойная буферизация — это технология, позволяющая каналу ввода/выво-
да и процессору работать параллельно. На входе с двойной буферизацией,
к примеру, пока процессор работает с одним набором данных в одном буфе-
ре, канал производит чтение следующего набора данных в другой буфер,
таким образом, данные (предположительно) будут готовы, когда процессор
захочет получить к ним доступ. Объясните детально, каким образом может
функционировать схема тройной буферизации? При каких условиях, трой-
ная буферизация будет эффективной?
2.10. Опишите две разные технологии связи между процессором и устройствами.
2.11. Объясните, каким образом прямой доступ к памяти повышает производи-
тельность системы и положительно влияет на захват циклов.
2.12. Почему контроллерам каналов свойственно захватывать циклы процессо-
ров при обращении к памяти?
2.13. Объясните что такое «спулинг» и укажите, в чем заключается его польза.
Как по-вашему работает система с подкачкой входных данных, разработан-
ная для чтения перфокарт с устройства чтения перфокарт?
2.14. Рассмотрим следующие разновидности языков программирования:
i. Машинный язык
ii. Язык ассемблера
iii. Язык высокого уровня
iv. Объектно-ориентированный язык программирования
V. Структурный язык программирования
ц/tiV1111 аппаратных средст/иптрогратмногооЬеспечения 17>
Укажите для каждой из вышеперечисленных категорий наиболее подходя-
щее определение (Некоторые из пунктов могут иметь более одного ответа):
а сфокусировано на управлении объектами (сущностями).
б нуждается в транслирующей программе для трансляции в код, который
может воспринять процессор.
Б пишется с использованием единиц и нулей.
г определяет дисциплинированный подход к разработке программного
обеспечения и фокусируется на действиях.
д определяет основные операции компьютера с использованием англоя-
зычных сокращений в командах.
е. языки Java и C++.
эк. Фортран и Паскаль.
з. позволяет программистам писать код с использованием повседневных
английских слов и математических обозначений.
215 Кратко опишите, каким образом программа, написанная на языке высоко-
го уровня, проходит подготовку перед выполнением.
2 16 Дайте сравнительную характеристику абсолютным и перемещающим за-
грузчикам. Укажите мотивацию использования концепции «перемещае-
мая загрузка».
2.17. Дайте определение микропрограммированию. Почему термин «встроенное
ПО» является подходящим для описания микрокода, который является ча-
стью аппаратуры?
Рекомендуемые учебные проекты
2.18. Подготовьте доклад на тему: «Магниторезистивное оперативное запоми-
нающее устройство MRAM, как форма энергонезависимого оперативного
запоминающего устройства» (см. Www.research.ibm.com/resources/news/
20Q30610_mram.shtml).
2.19. Подготовьте доклад на тему: «Вторичные запоминающие устройства на ос-
нове технологии микроэлектромеханических систем MEMS, как запоминаю-
щие устройства, предназначенные для сокращения времени доступа к нако-
пителям на жестких магнитных дисках» (см. www.pdl.cmu.edu/MEMS/).
2.20. Подготовьте доклад о различиях между интерфейсом малых компьютер-
ных систем SCSI и встроенным интерфейсом вторичных запоминающих
Устройств IDE. Почему встроенный интерфейс запоминающих устройств
завоевал большую популярность?
2.21. Подготовьте доклад о разработке и реализации инфрастуктуры .NET кор-
порации Microsoft.
Рекомендуем## литератур#
и к РяДе Учебников можно найти описание принципов организации компьютеров
пре МпьютеРНЬ1Х архитектур. Книга Джона Хэнесси и Дэвида Патерсона является
Расным кратким изложением материала по компьютерным архитектурам 68.
^г^Рри Блаув и Фредерик Брукс-младший также рассматривают компьютерные ap-
es ,р ТУРы, представляя детальный обзор компьютерных механизмов низкого уровня
цИя м не менее, только интернет-журналы могут предоставить материал для изуче-
дНаиболее «свежих» аппаратных технологий (см. раздел «Web-ресурсы»).
Опеп еВОСХоднь1м обзором процесса проектирования программного обеспечения
^ЗДо^11011110^ системы OS/360 является книга Фредерика Брукса «Мифический
Жда Веко-месяц» 70. Книга Стива Магьюира «Отладка в процессе разработки» обсу-
то, каким образом необходимо управлять проектной группой, исходя из
176
опыта автора на должности менеджера в корпорации Microsoft 71 - Книга Стив»
Мак-Коннелла «Все.о коде» — это ценный источник советов по приемам програы.
мирования и разработке программного обеспечения 72.
Обзор процесса проектирования компиляторов и технологий компиляции moj^.
но найти в учебниках Альфреда В. Ахо и др. 73. Тем, кто интересуется современны,
ми технологиями компиляции, необходимо обратить внимание на учебник Груц^
и др.74 Учебник Ливайна является прекрасным источником для студентов, интере.
сующихся проблемами и технологиями компоновки и загрузки приложений 75.
Библиография для данной главы размещена на нашей веб-странице по адресу-
www.deitel.com/books/os3e/Bibliography.pdf.
использованная литература
1. Wheeler, D. A., «More Than a Gigabuck: Estimating GNU/Linux’s Size.» June
30, 2001, updated July 29, 2002, Ver. 1.07, <www.dwheeler.com/sloc/>.
2. «Intel Executive Bio—Gordon E. Moore,» Intel Corporation, October 30, 2003
< www. intel. com/pressroom/kits /bios / moor e. htm>.
3. «Intel Executive Bio—Gordon E. Moore,» Intel Corporation, October 30, 2003,
<www.intel.com/pressroom/kits/bios/moore.htm>.
4. Moore, G., «Cramming More Components onto Integrated Circuits,» Electronics,
Vol. 38, No. 8, April 19, 1965.
5. «Expanding Moore’s Law: The Exponential Opportunity,» Intel Corporation, up-
dated Fall 2002, 2002
6. Gilheany, S., «Evolution of Intel Microprocessor: 1971 to 2007,» Berghell Associ-
ates, March 28, 2002, www.berghell.com/whitepapers/Evolution% 20of% 20Intel%
20Microprocessors% 201971% 20to% 202007.pdf.
7. «Processors,» PCTechGuide, <www.pctechguide.com/02procs.htm>.
8. PCGuide, <www.pcguide.com/ref/cpu/arch/int/compRegisters-c.html>.
9. PowerPC Microprocessor Family: Programming Environments Manual for 64-
and 32 bit Microprocessors, Ver. 2.0, IBM, June 10, 2003.
10. «Clock Signals, Cycle Time and Frequency,» PCGuide.com, April 17, 2001,
<www. peguide. com/intro/fun/clock. htm>.
11. «1А-32 Intel Architecture Software Developer’s Manual,» System Programmer s
Guide, Vol. 1, 2002, p. 41.
12. De Gelas, J., «Ace’s Guide to Memory Technology,» Ace’s Hardware, July 13,
2000, <www.aceshardware.com/Spades/read.php?article_id=5000172>.
13. «Hard Disk Drives,» PCGuide, April 17, 2001, <www.pcguide.com/ref/hdd>.
14. «System Bus Functions and Features,» PCGuide, <www.pcguide.com/ref/
mbsys/buses/func.htm>.
15. Gifford, D., and A., Spector, «Case Study: IBM’s System/360-370 Architec-
ture,» Communications of the ACM, Vol. 30, No. 4, April 1987, pp. 291-307.
16. «PCI Express,» PCI-SIG, <www.pcisig.com/specificacions/pciexpress/>.
*7. Scott, T. A., «Illustrating Programmed and Interrupt Driven I/O,» Proceedings
of the Seventh Annual CCSC Midwestern Conference on Small Colleges, October
2000, pp. 230-238.
18. Hennessy, J., and D. Patterson, Computer Organization and Design, San Fran*
cisco: Morgan Kaufmann Publishers, 1998. pp. 680-681.
19. «DMA Channel Function and Operation,» PCGutide.com, <www.pcguide.com/
ref/mbsys/res/dma/func.htms>.
20. «Peripheral Device,» Webopedia, December 14, 2001, <www.webopedia.com/
TERM/P/peripfieral_device.html>.
177
gunau аппаратных средств и программного обеспечения
«Serial Port,» CNET Glossary, <www.cnet.com/Resources/Info/Glossary/
Terms/serialport.html>.
Serial Port,» CNET Glossary, <www.cnet.com/resources/Info/Glossary/
Terms/serial port.html>.
USB,» Computer Peripherals, <peripherals.about.com/library/glossary/blde-
23‘ fusb.htm>.
Liu P-. 8ncl D- Thompson, «IEEE 1394: Changing the Way We Do Multimedia
24 Communications,» IEEE Multimedia. April 2000, <www.computer.org/multi-
media/articles/f irewire.htm>.
- «IDE/АТА vs. SCSI: Interface Drive Comparison,» PCGuide.com, <www.pcgui-
3‘ de.com/ref/hdd/i f/comp.htm>.
26 «SCSI FAQ,» <www.faqs.org/faqs/scsi-faq/partl/>.
27 <www-scsita.org/aboutscsi/termsTermin.html>.
Gifford, D., and A. Spector, «Case Study: IBM’s System/360-370 Architecture,»
Communications of the ACM, Vol. 30, No. 4, April 1987, pp. 291-307.
29. Denning. P., «Virtual Memory,» ACM Computing Surveys, Vol. 2,No. 3, Septem-
ber 1970. pp. 153-189.
30. «Intel Developer Forum Day 3 — More from the Tech Showcase,» Anandtech.com,
February 20, 2003, <www.anandtech.com/showdoc.html?i=1791&p=2>.
31. «Plug and Play Technology,» Microsoft Windows Platform Development, March
21, 2003, <www.microsoft.com/hwdev/tech/pnp/default.asp>.
32. «Plug and Play for Windows 2000 and Windows XP,» Microsoft Windows Plat-
form Development, March 21, 2003, <www.microsoft.com/hwdev/tech/PnP/
PnPNT5_2.asp>.
33. Smith, A., «Cache Memories,» ACM Computing Surveys, Vol. 14, No. 3, Septem-
ber 1982. pp. 473-530.
34. «Buffer,» Data Recovery Glossary, <www.datarecovery-group.com/glossary/
buffer.html>.
35. «Buffer,» Webopedia, September 1, 1997, <www.webopedia.com/TERM/b/buf-
fer.html>.
36. «Definition: Buffer,» FS-I037, August 23, 1996, <www.its.bldrdoc.gov/
fs-1037/dir-005/_0739.htm>.
37. «Spooling,» Sun Product Documentation: Glossary, Solaris 2.4 System Adminis-
trator AnswerBook, <docs.sun.com/db/doc/81-6628/6il08opae?a=view>.
38. Glass, R. L, «An Elementary Discussion of Compiler/Interpreter Writing,» ACM
Computing Surveys (CSUR), Vol. 1, No. 1, January 1969.
’ l^-uferpreter (Computer Software),» Wikipedia, The Free Encyclopedia, modified
February 19, 2003, <www.wikipedia.org/wiki/Interpreter., (compute r soft-
ware)^
' ?r®sser’ and J' White, «Linkers and Loaders,» ACM Computer Surveys, Vol.
41 n • 3’ Se₽tember 1972, PP- 149-151.
• * bject Code,» April 7, 2001. <Whatis.techtarget.com/definition/0,,sid9
42 ©*539287,OO.html>.
son°vA ’ аП<1 Ubman> Principles of Compiler Design, Reading, MA: Addi-
p "Wesley, 1977, pp. 6-7 (русский перевод последнего издания: Ахо А., Сети
Ви Ульман Дж- «Компиляторы: принципы, технологии, инструменты», М.
би.ЛЬЯМС 2°01 г’’ есть в электронном виде, например, в электронной
43. «с Лиотеке мехмата МГУ по адресу http://lib.mexmat.ru).
IBM Reference/Glossary, <www-l.ibni.com/ibm/history/refer-
44. pr e' glossary e.html>.
4 \8Ser’ b’’ and J- White, «Linkers and Loaders,» ACM Computer Surveys, Vol.
’ wo. 3, September 1972, p. 153.
178 Г.
45. Levine, J., Linkers and Loaders, San Francisco: Morgan Kaufman Publishers
2000, p. 5.
46. Presser, L. and J. White, «Linkers and Loaders,» ACM Computer Surveys, Voi
4, No. 1, September 1972, p. 164.
47. Levine, J., Linkers and Loaders, San Francisco: Morgan Kaufman Publisher
2000, p. 6.
48. Carnegie-Mellon University, «The Mach Project Home Page,» February 2j
1997, <www-2.cs.cmu.edu/afs/cs/project/mach/public/www/mach.html >. ’
49. Microsoft Corporation, «Microsoft-PressPass Rick Rashid Biography,» 2OO3
<www.microsoft.com/presspass/exec/rick/default.asp>. ’
50. Westmacott, I., «TheUNIX vs. NT Myth.» July 1997, <web-server.cpg.com/
wa/2.6>.
51. Carnegie-Mellon University, «The Mach Project Home Page,» February 21
1997, <www-2.cs.cmu.edu/afs/cs/project/mach/public/www/mach.html >. ’
52. Apple Computer, Inc, «Mac OS Technologies — Darwin,» 2003, <www.ap.
ple.com/macosx/technologies/darwin .html>.
53. Free Software Foundation, «GNU Mach,» May 26, 2003, <www.gnu.org/soft.
ware/hurd/gnumach.html>.
54. Rashid, R., et. al., «Mach: A System Software Kernel,» Proceedings of the 1989
IEEE International Conference, COMPCON 89, February 1989,
<ftp://ftp.cs.cmu.edu/project/mach/doc/published/syskernel.ps>.
55. Coulouris, G.; J. Dollimore; and T. Kindberg. «UNIX Emulation in Mach and
Chorus,» Distributed Systems: Concepts and Design, Addison-Wesley, 1994, pp.
597-584, <www.cdk3.net/oss/Ed2/UNIXEmulation.pdf>.
56. Rashid, R-, et. al., «Mach: A System Software Kernel,» Proceedings of the 1989
IEEE International Conference, COMPCON 89, February 1989,
<ftp://ftp.cs.cmu.edu/project/mach/doc/published/syskernel.ps>.
57. Coulouris, G.; J. Dollimore; and T. Kindberg. «UNIX Emulation in Mach and
Chorus,» Distributed Systems: Concepts and Design, Addison-Wesley, 1994, pp.
597-584, <www.cdk3.net/oss/Ed2/UNIXEmulation.pdf>.
58. Rashid, R., et. al., «Mach: A System Software Kernel,» Proceedings of the 1989
IEEE International Conference, COMPCON 89, February 1989,
<ftp://ftp.cs.cmu.edu/project/mach/doc/published/syskernel.ps>.
59. Rashid, R., et. al., «Mach: A System Software Kernel,» Proceedings of the 1989
IEEE International Conference, COMPCON 89, February 1989,
<ftp://ftp.cs.cmu.edu/project/mach/doc/published/syskernel.ps>.
60. Presser, L., and J. White, «Linkers and Loaders,» ACM Computer Surveys. Vol-
4, No. 3, September 1972, p. 151.
61. Presser, L., and J. White, «Linkers and Loaders,» ACM Computer Surveys, Vol-
4, No. 3, September 1972, p. 150.
62. Hennessy, J., and D. Patterson, Computer Organization and Design, San Fran-
cisco: Morgan Kaufmann Publishers, 1998. pp. 399-400.
63. Rauscher, T., and P. Adams, «Microprogramming: A Tutorial and Survey of Pe^
cent Developments,» IEEE Transactions on Computers, Vol. C-29, No. 1, JanU
ary 1980, pp. 2-20.
64. Hennessy, J., and D. Patterson, Computer Organization and Design, San Fr»11
cisco: Morgan Kaufmann Publishers, 1998. pp. 424-425.
65 Wilkes, M., «The Best Way to Design an Automatic Calculating Machine,» Л
port of the Machine University Computer Inaugural Conference, Electrical Enf>
neering Department of Manchester University, Manchester, England, July
pp.16 18.
66 Hennessy, J., and D. Patterson, Computer Organization and Design, San I'|£lJ1
cisco: Morgan Kaufmann Publishers, 1998. pp. 424-425.
ill апворатных средств и программного обеспечения
179
ai «Firmware,» PCGuide, April 17, 2001, <www.pcg-uide.com/ref/hdd/on/
6 lgicFirmware-c.html>. '
,.a Hennessy, J., and D. Patterson, Computer Organization and Design, San Fran
6®' |sCO; Morgan Kaufmann Publishers, 1998.
giaauw, G-> aI1d F. Brooks, Jr., Computer Architecture, Reading, Ma- Addi
” son- Wesley, 1997.
70 Brooks, F., P., The Mythical Man-Month, Reading, Ma: Addison-Wesley 1995
’ (Неоднократно издавался русский перевод, например, Брукс. ’ Ф П
Мифический человеке месяц. М. Символ-Плюс, 2000; кроме того, текст
русского перевода есть на многих сайтах, например, http://lib.ru/CTO
TOR/BRUKS/mi thsoftware.txt). ‘ '
71. Maguire, S., Debugging the Development Process: Practical Strategies for
Staying Focused, Hitting Ship Dates, and Building Solid Teams, Microsoft Press
1994.
72. McConnell, S., Code Complete, Microsoft Press, 1993.
73. Aho, A.; R- Sethi; and J. Ullman, Compilers: Principles, Techniques, and Tools
Reading, MA: Addison-Wesley, 1986 (русский перевод последнего издания:
Ахо А., Сети Р., Ульман Дж. «Компиляторы: принципы, технологии'
инструменты», М. Вильямс 2001 г.; есть в электронном виде, например’
в электронной библиотеке мехмата МГУ по адресу http://lib.mexmat.ru).
74. Grune, D., Н. Bal; С. Jacobs; and К. Langendoen, Modern Compiler Design New
York, John Willey, 2000. ’
75. Levine, J., Linkers and Loaders, San Francisco: Morgan Kaufman Publishers,
2000» 9
Процессы и потоки
Просто удивительно, что Природе удалось сравнителЫ1С
спокойно пройти свой счастливый процесс развит#*1
среди такой дьявольской кутерьМЙ
Стивен
Чтобы обеспечить максимальное быстродейст-
вие и удовлетворить нужды пользователей,
оПерационные сист мы позволяют одновременно вы-
полнять несколько задач, используя такие абстрак-
ции как процессы и потоки для отслеживания па-
раллельно выполняемых операций. В следующих
тести главах вы узнаете, как операционные систе-
мы управляют процессами и потоками, обеспечивая
их мирное сосуществование, беспрепятственное
взаимодействие и сотрудничество при выполнений
заданных операций. Кроме того, вы научитесь соз-
давать собственные многопоточные Java-приложе-
ния. Когда процессы и потоки ожидают освобожде-
ния ресурсов, состязаясь за право обладания ими, то
в результате неправильного управления объектами
в состоянии ожидания могут возникать проблемы
бесконечно? > откладывания и взаимоблокировки.
Вы узнаете, как система планирует использование
самого ценного аппаратного ресурса процессора,
чтобы.; добиться эффективной работы процессов
и потоков.
В любом деле важнее всего исполнение,
Джоз ф Аддисон
Учитесь работать и ждать.
Генри Уодсуорт Лонгфелло
И многие из спящих во прахе земли пробудятся,
одни для жизни вечной, другие на вечное
поругание и посрамление.
Даниил 12:2
Сделайте что-нибудь сами — и вЫ
лучше это поймете и запомните.
Роберт Браунинг
Просто удивительно, что Природе удалось сравнительив
спокойно пройти свой счастливый процесс развитий
среди такой дьявольской кутерьма1,
Стивен КреШ1
Глава
Концепции процесса
Прочитав эту главу, вы должны будете понимать:
• концепцию процесса;
• жизненный цикл процесса;
• состояние процесса и переходы из одного состояния
в другое;
• блок управления процессом (РСВ) и дескрипторы
процесса;
• как с помощью переключения контекста процессор
переходит от выполнения одного процесса к другому;
• как осуществляется взаимодействие между
аппаратным и программным обеспечением
с помощью прерываний;
• как процессы общаются друг с другом через механизм
взаимодействия процессов (IPC);
процессы в UNIX.
Краткое содержание главы
3.1 Введение
Размышления об операционных системах:
Пользователей интересуют приложения
3.1.1 Определение процесса
Учебный пример: CTSS и Multics
Биография: Фернандо X. Корбато
3.2 Состояния процессов: Жизненный цикл процесса
3.3 Управление процессом
3.3.1 Переход процесса из состояния В состояние
3.3.2 Блоки управления процессом и дескрипторы процессов
Размышления об операционных системах: Структуры данных ОС
3.3.3 Операции над процессалли
3.3.4 Приостановка и Возобновление работы процесса
3.3.5 Переключение контекста
3.4 Прерывания
Размышления об операционных системах: Синхронность и асинхронность
3.4.1 Обработка прерываний
3.4.2 Классы прерываний
3.5 Взаимодействие процессов
3.5.1 Сигналы
3.5.2 Передача сообщений
3.6 Учебный пример: процессы В UNIX
Учебный пример: Система UNIX
3j введение
. гие системы, встречающиеся в природе, способны одновременно вы-
несколько операций. Приведем, в качестве примера, человеческое
цоЛня биоЛОГИЧескуЮ систему, которая выполняет огромное количество
ТеЛ°’ пий одновременно — или, как мы будем говорить далее, параллель-
°Пе/? «currently). Дыхание, кровообращение, мыслительные процессы, пе-
в° 'СиЖение и пищеварение — все это происходит одновременно. То же са-
РеДВможно сказать и о человеческих чувствах — зрении и слухе, осязании,
Сиянии, вкусе. Компьютеры тоже могут выполнять операции одновре-
° ино Вполне обычным явлением для настольного компьютера является
М паллельное выполнение компиляции программы, отправка файла на
пойнтер, визуализация веб-страницы, проигрывание цифрового видеокли-
па и прием сообщений электронной почты (см. «Размышления об операци-
онных системах: Пользователей интересуют приложения»).
В этой главе мы расскажем вам о процессах (process). Процесс — это
центральное понятие, необходимое для разбора механизма одновременно-
го выполнения множества операций и наблюдения за ними в современных
компьютерных системах. Вы узнаете наиболее распространенные опреде-
ления термина «процесс». Мы представим вам концепцию дискретных со-
стояний процесса (process state) и обсудим, как и зачем процессы осущест-
вляют переход из одного состояния в другое. Кроме того, мы рассмотрим
операции, выполняемые операционной системой над процессами, напри-
мер их создание, удаление, приостановка, возобновление и пробуждение
процессов.
Измышления of) операционных системах
Пользователей интересуют приложения
Очевидно, что компьютеры предназна-
Чены для того, чтобы выполнять полезную
Работу. Разработчики операционных сис-
МОГУТ упустить это из виду, поскольку
Иервую очередь они сосредоточены на ре-
сложных технических вопросов ар-
Си КТУРЫ И проектирования операционной
ват бМЬ1 Однако система не может созда-
Из я в вакууме, разработчики обязаны
Ле-ЧИгь своих потенциальных пользовате-
ли ' разн°видности приложений, с которы-
Те собираются работать, и результаты, на
которые рассчитывают пользователи этих
приложений. В магазинах промышленных
товаров продается много инструментов для
выполнения работ по хозяйству. Произво-
дители инструментов должны понимать,
что мало кто покупает инструмент просто
так. Клиенты приобретают инструмент для
выполнения определенных задач. Ведь на
самом деле покупателю не нужна пила, мо-
лоток или дрель — им нужно что-то распи-
лить, забить гвоздь или просверлить отвер-
стие.
186 Глав,^
3.1.1 Определение процесса
Впервые термином «процесс» в контексте операционной системы вос
пользовались разработчики системы Multics в далеких 1960-х (см. «Уче^
ный пример: CTSS и Multics», а также «Биография: Фернардо В. Kopg
то»).1 С тех пор термин процесс, иногда заменяемый термином зада^
(task) и наоборот, приобрел множество значений, таких как: програм^
в стадии выполнения; асинхронная операция; «живая душа» процедур^
«концентрация средств управления» для выполняемой процедуры, прояв’
ляющаяся в существовании структуры данных, называемой «дескрипто
ром процесса» либо «блоком управления процессом» внутри операционной
системы; логический объект, которому выделяются процессоры и «диспет-
черизуемые» модули. Процесс по сравнению с программой — как неболь-
шое музыкальное произведение для одного инструмента по сравнению
с целой симфонией для оркестра.
В этих определениях представлены две ключевых концепции. Во-пер-
вых, процесс — это логический объект. Каждый процесс обладает собст-
венным адресным пространством, которое обычно состоит из области ко-
манд (text region), области данных (data region) и области стека (stack
region). В области команд находится программный код, выполняемый про-
цессором. В области данных хранятся переменные, в нее входит память,
динамически выделяемая процессу во время его выполнения. В области
стека размещаются инструкции и локальные переменные, используемые
при вызове процедур. Объем стека увеличивается при вызове вложенных
процедур и уменьшается по их завершении.13 Во-вторых, процессом назы-
вается «программа в стадии выполнения». Программа представляет собой
неодушевленный логический объект. Только когда процессор «вдыхает
жизнь» в программу, она превращается в активный логический объект,
который мы и называем процессом.
Вопросы для самопроверки
1. Зачем адресное пространство процесса поделено на отдельные об-
ласти?
2. (Да/Нет) Правда ли, что термины «процесс» и «программа» явля-
ются синонимами?
Ответы 1) Каждая область адресного пространства предназначена
для хранения информации, схожей по способу доступа. Например,
большинство процессов выполняют только чтение и выполнение инст-
рукций, но не их модификацию. Процессы считывают данные из стека
и ведут запись в него, придерживаясь алгоритма последний-при-
шел-первый-ушел. Поскольку, в принципе, процессы могут выполнять
операции чтения и записи данных в любом порядке, память поделена
на отдельные области для того, чтобы система могла обеспечить соблю-
дение вышеупомянутых правил доступа. 2) Нет. Процессом называется
программа в стадии выполнения, тогда как сама программа представ-
ляет собой неодушевленный логический объект.
В начале 60-х годов XX века, группа про-
граммистов под названием Project МАС из
Массачусетского технологического института,
руководимая профессором Фернардо Корба-
то, разработала Совместимую систему с раз-
делением времени (Compatible Time-Sharing
Systems, CTSS) для управления вычислитель-
ными ресурсами компьютера IBM 7090 (со
временем превратившегося в IBM 7094) с тер-
миналами, работающими по принципу пишу-
щей машинки.2 3 В CTSS при работе компьюте-
ра использовался традиционный пакетный ре-
жим обработки команд, но обеспечивалась
и быстрая реакция во время редактирования
и отладки программ со стороны интерактив-
ных пользователей. Вычислительные возмож-
пости CTSSтого времени напоминают возмож-
ности современных ПК, а именно: интерактив-
ную среду, в которой компьютер способен
быстро реагировать на большое количество
относительно простых запросов.
В 1965 та же группа из Массачусетского
технологического в содружестве с лаборато-
риями Bell и GE начала работу над созданием
Multics (MULTiplexed Information and Computing
Service), операционной системы — преемника
CTSS. Multics представляла собой массивную
и сложную систему, разработчики которой на-
рисовали в своем воображении средство для
обслуживания компьютера общего назначе-
ния, которое бы обеспечило «все возможные
Функции для любого пользователя». Хотя дан-
ной операционной системе не суждено было
^воевать коммерческий успех, ее долгое вре-
Исп°льзовали различные исследователь-
Центры — последний компьютер под
Рулением Multics работал до 2000 года.'1
Большое разнообразие функциональных
возможностей Multics оказало влияние на
разработку других операционных систем, та-
ких как UNIX, TSS/360, TENEX и TOPS-20.5
Операционная система Multics объединила
в себе технологии сегментации и страничной
организации виртуальной памяти, где управ-
ление страничной памятью целиком возлага-
лось на операционную систему, тогда как
с сегментами могли работать и пользова-
тельские программы.6 Multics стала одной из
первых операционных систем, написанных
на языке высокого уровня, в данном случае
на PL/1 от IBM.7,8 Именно разработчики
Multics начали применять термин «процесс»
в его современном значении в контексте ОС.
В операционной системе Multics много вни-
мания было уделено безопасности. В нее
была включена технология избирательного
контроля доступа, реализованная с помощью
списков контроля доступа ACL (Access
Control List), которые представляли собой пе-
речень разрешений для сегментов памяти —
модель, знакомая пользователям UNIX. В по-
следующих версиях появился еще и мандат-
ный контроль доступа, реализованный с по-
мощью метода изоляции доступа AIM
(Access Isolation Mechanism), являющегося
развитием ACL. AIM позволят связывать
пользователей и объекты с классификатора-
ми безопасности. Благодаря этому Multics
стала первой операционной системой, кото-
рой правительство США присвоило катего-
рию безопасности В2.9,101' В 1976 году была
выпущена первая коммерческая система
управления реляционными базами данных —
Multics Relational Data Store.12
188
Глае9
Биографические заметки
Фернандо X. Корбато
Фернандо Хосе Корбато получил степень
доктора философии по физике в Массачусет-
ском технологическом институте в 1956 году.
Корбато работал профессором Массачусет-
ского технологического института с 1965 по
1996 год, выйдя на пенсию в звании заслу-
женного профессора кафедры электротехни-
ки и компьютерных наук.14 Он был одним из
основателей Project МАС в МТИ, руководил
разработкой CTSS и Multics.15,16 Фернандо Кор-
бато — соавтор технической документации по
Multics и по менеджменту совместных проек-
тов Project МАС Массачусетского технологиче-
ского института, General Electric и Bell Labs.
За свой вклад в разработку
и Multics в 1990 году Корбато был удост0
ен премии Тьюринга.17 В своей лекцр^
«О создании систем, которые подвержен^
сбоям» на церемонии вручения, он, базц.
руясь, в основном, на своем опыте
с Multics, рассказал, как сложная внутрец_
няя архитектура крупных либо инновэцц.
онных проектов всегда порождает ошиб-
ки. В своем выступлении он посоветовал
разработчикам всегда исходить из пред-
положения, что та или иная ошибка веро-
ятна и изначально предусматривать меры
для ее исправления.18
3.2 Состояния процессов: Жизненный цикл
процесса
Операционная система обязана предоставлять каждому процессу доста-
точное количество процессорного времени. На самом деле, в любой системе
действительно параллельно может выполняться ровно столько процессов,
сколько процессоров в ней установлено. На практике количество процес-
сов обычно намного превосходит количество процессоров в системе. Таким
образом, в каждый конкретный момент времени в системе выполняется
определенное количество процессов, в то время как остальные процессы
бездействуют.
Жизненный цикл процесса состоит из последовательности дискретных
состояний (process state). Переход процесса из одного состояния в дрУг°е
может быть спровоцирован самыми разнообразными событиями. Говоря?’
что процесс выполняется (running state), т.е. находится в состоянии вЫ'
полнения, если в данный момент ему выделен центральный процессор. Г°'
ворят, что процесс готов (ready state), т.е. находится в состоянии готов'
ности, если он мог бы сразу использовать процессор, предоставленнЫ11
в его распоряжение. Говорят, что процесс заблокирован (blocked state), т°
есть находится в состоянии блокировки, если для того, чтобы продолжит1*
работу, ему необходимо дождаться наступления определенного событий
(например, события завершения операции ввода/вывода). Существуя^
gfneu процесса
189
гИе состояния процессов, но в данный момент мы сосредоточимся на
jf ^^отрении трех вышеперечисленных.
р*с£ я простоты рассмотрим однопроцессорную систему, хотя все приве-
bie ниже рассуждения нетрудно распространить и на многопроцессор-
Де0 (сМ. главу 15). В однопроцессорной системе в каждый конкретный мо-
времени может выполняться только один процесс, но при этом не-
ко процессов системы могут находиться в состоянии готовности,
СК°есколько — в состоянии блокировки. Поэтому операционная система
8 лает список готовых (к выполнению) процессов (ready list), называе-
с к также таблицей готовности и список заблокированных процессов
blocked list). Процессы размещены в списке готовых в порядке приорите-
та так что следующим процессом, получающим в свое распоряжение про-
цессор, станет первый процесс из этого списка (то есть процесс с наивыс-
щим приоритетом). Список заблокированных процессов, как правило, хра-
нится в неупорядоченном виде, так как никакого приоритетного порядка
разблокировки процессов не предусматривается — разблокировка процес-
сов осуществляется в том порядке, в котором происходят ожидаемые ими
события. Немного позже мы рассмотрим ситуации, в которых могут ока-
заться заблокированные процессы, ожидающие одного и того же события;
в этих случаях учитывается приоритет ожидающих процессов.
Вопросы для самопроверки
1. (Да/Нет) Правда ли, что в каждый конкретный момент времени
в системе может выполняться только один процесс?
2. Процесс переходит в состояние блокировки, ожидая наступления
определенного события. Назовите несколько событий, которые мо-
гут вызвать переход процесса в состояние блокировки.
Ответы 1) Нет. В многопроцессорной системе в каждый конкрет-
ный момент времени может выполняться столько процессов, сколько
процессоров установлено В системе. 2) Процесс может перейти в со-
стояние блокировки в случае отправки запроса к данным, которые
хранятся на оборудовании, обладающем большой задержкой доступа,
например, на жестком диске, либо при обращении к ресурсам, зани-
маемым другим процессом, и потому недоступным в текущий момент
времени. Процесс также может перейти в состояние блокировки, ожи-
дая действий со стороны пользователя, например, нажатия клавиши
либо перемещения курсора мыши.
Упруление процессом
ет ^ОСколькУ на самом деле операционная система попеременно выполня-
ИоГрСК°Лько процессов, управление процессами должно быть организова-
ть ам°тно, чтобы при прерывании и возобновление работы того или ино-
ьОз °U’ecca не возникали ошибки. Кроме того, процессы должны обладать
ТаКц ЗКностью взаимодействия с операционной системой для выполнения
СцСт Х Элементарных задач, как запуск нового процесса либо уведомления
bIbI °б окончании работы предыдущего. В этом разделе мы рассмот-
’ как система выполняет базовые операции над процессами — включая
™_________________________
создание либо уничтожение процессов, их приостановку и возобновлен^
изменение приоритета процесса, блокирование, выведение процесса 6’
спящего режима, диспетчеризацию или выбор процесса для выполнен^13
организацию взаимодействия между процессами через IPC и т.д. Кр0Л
того, мы обсудим вопрос управления ресурсами процессов со стороны он
рационной системы; это управление дает процессам возможность одновтС
менно активно соревноваться за процессорное время.
33.1 Переход процесса из состояния 6 состояние
Когда пользователь запускает определенную программу, создается
цесс, помещаемый в таблицу готовности. Этот процесс постепенно проды,
гается к головной части списка — по мере завершения выполнения предЬ1
дущих процессов. Когда процесс оказывается в начале списка готовых пр0.
цессов, тогда как только освобождается процессор, происходит выделение
процессора данному процессу, и мы говорим, что произошла смена состоя-
ний (state transition) — переход процесса из состояния готовности в со-
стояние выполнения (см. рис. 3.1). Предоставление центрального процес-
сора первому процессу из списка готовых процессов называется диспетче-
ризацией (dispatching) или выбором процесса для выполнения.
Диспетчеризация выполняется при помощи системной программы, назы-
ваемой диспетчером (dispatcher). Процессы, пребывающие в состоянии го-
товности или выполнения называются бодрствующими, поскольку они
активно состязаются за процессорное время. Сменой состояний управляет
операционная система, стараясь наилучшим образом распределить исполь-
зование процессора между процессами. Чтобы предотвратить случайный
либо умышленный монопольный захват ресурсов системы одним процес-
сом, операционная система задает в специальном аппаратном таймере
прерываний (interrupting clock), называемом также интервальным тай-
мером (interval timer), некоторое значение или квант времени (quantum),
в течение которого данному процессу пользователя разрешено занимать
процессор. Если процесс добровольно не отдаст процессор по истечении вы-
деленного ему кванта времени, таймер прерываний выработает сигнал пре-
рывания, по которому управление будет передано операционной системе
(см. раздел 3.4). Операционная система переведет ранее выполнявшийся
процесс из состояния выполнения в состояние готовности, а первый про-
цесс из списка готовых — из состояния готовности в состояние выполни
ния. Если выполняющийся процесс до истечения выделенного ему кванта
времени начнет операцию ввода/вывода, он тем самым добровольно осво-
бодит процессор, ожидая завершения операции ввода/вывода, прежде че1й
снова приступить к использованию процессора. В этом случае процесс бло
кирует сам себя, откладывая завершение операции ввода/вывода. ПроД^
сы в состоянии блокировки называют спящими, поскольку они не могУт
выполняться даже в том случае, если освободится процессор. Еще одна рР
пустимая смена состояний, которая может произойти с процессом в на111^
модели с тремя состояниями по завершении операции ввода/вывода (ли®1
при наступлении другого ожидаемого процессом события) — это переход
процесса из состояния блокировки в состояние готовности.
Итак, мы определили четыре возможных перехода между состояниями.
При запуске процесса, он переходит из состояния готовности в состояние
выполнения. По окончании выделенного кванта времени происходит об-
ратный переход — из состояния выполнения в состояние готовнос т i.
гда процесс блокируется, он переходит из состояния выполнения в состоя-
ние блокировки. И, наконец, когда процесс просыпается в результате на-
ступления ожидаемого им события, происходит переход из состояния
блокировки в состояние готовности. Обратите внимание, что единствен
ная смена состояний, которую может инициировать сам пользовательский
процесс — это переход в состояние блокировки, все остальные смены со-
стояний инициируются операционной системой.
В этом разделе мы исходили из предположения, что операционная систе-
ма выделяет каждому процессу определенный квант времени. В ряде ран
операционных систем, которые выполнялись на процессорах, лишен-
аппаратного таймера прерываний, была реализована кооперативная
^*г°задачиость (cooperative multitasking), то есть процесс должен был
Ровольно возвращать процессор для того, чтобы другой процесс смог на-
-ь СВое выполнение. В современных системах кооперативная многозадач-
ликть используется редко, поскольку она позволяет процессам случайно
(йа Умышленно осуществлять монопольный захват ресурсов процессора
gJ^PHMep, при вхождении в бесконечный цикл либо просто при отказе ос-
Дить процессор по окончанию выделенного кванта времени).
192
Вопросы для само проверки
1. Каким образом в операционных системах предотвращается Мон
польный захват процессора одним процессом? °-
2. Чем отличаются бодрствующие процессы от спящих?
Ответы 1) Таймер прерываний вырабатывает сигнал прерывай,,
по истечении заданного промежутка времени, после чего операцИо 4
ная система выбирает для выполнения другой процесс. Процесс, в?*'
полнение которого было прервано, возобновляет работу, достигав
начала списка готовых процессов, при условии доступности процес^
ра. 2) Бодрствующие процессы постоянно соревнуются за процессов
ное время, спящий процесс не может использовать процессор, дазкё
если тот снова станет доступен.
3.3.2 Блоки управления процессом и дескрипторы процессов
Во время создания нового процесса операционная система, как правило
выполняет целую последовательность операций. Во-первых, процессы не-
обходимо каким-то образом различать между собой — для этого каждому
процессу присваивается идентификационный номер процесса (process
identification number, PID). Затем система создает блок управления про-
цессом (process control block, РСВ), называемый также дескриптором про-
цесса (process descriptor), в который помещается информация, необходи-
мая операционной системе для управления процессом. В блоке управления
процессом обычно содержится следующая информация:
• PID;
• текущее состояние процесса (выполняется, готов или блокирован);
• программный счетчик (program counter) или счетчик команд — оп-
ределяющий, какую по счету инструкцию программы процессор дол-
жен будет выполнить следующей;
• приоритет процесса;
• полномочия (данные, определяющие перечень ресурсов, к которым
может иметь доступ данный процесс);
• указатель на родительский процесс (parent process), то есть процесс,
создавший данный;
• указатели на дочерние процессы (child processes), то есть процессьь
созданные данным процессом, если таковые имеются;
• указатели данных и инструкций процесса в памяти;
• указатели выделенных процессу ресурсов (например, файлов).
Кроме того, в блоке управления процессом хранится содержимое реги-
стров, называемое контекстом выполнения (execution context) процессор8»
перед выходом из состояния выполнения. Контекст выполнения зависит от
архитектуры системы, и обычно включает в себя содержимое регистров об-
щего назначения (где хранятся данные процесса, к которым он может о
ращаться напрямую) и регистров управления процессом, с указателями и8
адресное пространство процесса, например. Благодаря этому операцион-
ная система может восстанавливать контекст выполнения процесса в слу-
чае возвращения процесса в состояние выполнения.
193
Таблица процессов
РСВ ~
PID
'Блок управления процессом (РСВ)
' Программный счетчик
Регистры
Состояние
Приоритет
Адресное пространство
Родительский процесс
Дочерние процессы
Открытые файлы
I* Н Другие флаги
Блок управления процессом (РСВ)
Программный счетчик
| Блок управления процессом (РСВ)
г Программный счетчик
Регистры
I ......................!
Состояние
Приоритет
Адресное пространство
Родительский процесс
Дочерние процессы
Открытые файлы
। Другие флаги
Регистры
Состояние
Приоритет
Адресное пространство
Родительский процесс
Дочерние процессы
, Открытые файлы
Другие флаги
Рис. 3.2. Таблица процессов и блоки управления процессами.
При переходе процесса из одного состояния в другое, операционная сис-
тема должна обновить информацию в блоке управления процессом, ак
правило, операционная система хранит указатели на блоки управления про-
цессами в системной либо пользовательской таблице процессов (process
table), чтобы ускорить доступ к нужной информации (см. рис. 3.2). Таблица
процессов принадлежит к тем структурам данных операционной системы,
которые будут обсуждаться в этой главе (см. «Размышления об операцион-
ных системах: Структуры данных ОС»). По завершении работы процесса
(Добровольно либо принудительно со стороны операционной системы), ОС
освобождает память процесса и другие занимаемые им ресурсы, удаляет ин
Формацию о нем из таблицы процессов, предоставляя память процесса и ре-
сурсы для других процессов. Вскоре мы обсудим и другие операции над про-
цессами.
Вопросы для самопроверки
1. Зачем нужна таблица процессов?
2. (Да/Нет) Правда ли, что структура блока управления процессом за-
висит от реализации операционной системы?
Ответы 1) Таблица процессов позволяет находить блоки управле-
ния процессами. 2) Да.
194
I
Размышления об операционных системах
Структуры данных ОС
Как правило, студенты кафедры компью-
терных наук в обязательном порядке изуча-
ют структуры данных, являющиеся главной
темой дисциплины и составной частью мно-
гих отдельных предметов, преподаваемых
на старших курсах, например, компилято-
ров, баз данных, сетей и операционных сис-
тем. Структуры данных применяются в опе-
рационных системах повсеместно. Очереди
используются там, где логические объекты
вынуждены пребывать в состоянии ожида-
ния — например, когда процессы ожидают
освобождения процессора, запросы вво-
да /вывода ожидают освобождения затребо-
ванных устройств, процессы ожидают воз-
можности войти в критический участок вц
полнения и т.д. Стеки используются для под
держки механизма возвращения из вызц
ваемой функции. Деревья применяются дЛя
представления структуры каталогов файл0.
вой системы, мониторинга выделения дцс.
кового пространства под хранение файлов
построения иерархических структур катало-
гов страниц с целью поддержки виртуаль-
ной трансляции адресов и т.д. Графы ис-
пользуются при изучении структуры сети,
ситуаций взаимоблокировки ресурсов
и т.п. Хэш-таблицы используются для уско-
рения доступа к РСВ (используя PID в каче-
стве ключа).
3.3.3 Операции над процессами
Операционная система должна иметь возможность выполнять опреде-
ленные операции над процессами, в том числе:
• создание процесса,
• уничтожение процесса,
• приостановка процесса,
• возобновление процесса,
• изменение приоритета процесса,
• блокирование процесса,
• пробуждение процесса,
• запуск (выбор) процесса,
• обеспечение взаимодействия процессов.
Процесс может порождать (spawn) новые процессы. В этом случае пор0
ждающий процесс называют родительским (parent process), а второй, с°3
данный процесс — дочерним (child process). Каждый дочерний проИе°
имеет один родительский процесс. В результате такого подхода формирУ
ется иерархическая структура процессов (hierarchical process structm®^
изображенная на рисунке 3.3, в которой у дочернего процесса есть толь1/
один родительский (например, процесс А является родительским по отН
шению к процессу С; Н — родительским процессом для I), но каждый Р°"
дительский процесс может иметь произвольное количество дочерних ПР°"
195
/например, процессы В, С и D являются дочерними по отношению
аесс°£ и q_дочерними по отношению к С). В UNIX-подобных системах,
к AU каК Linux, многие процессы порождаются главным процессом init,
т8кИх м вО время загрузки ядра (см. рис. 3.4). В Linux в роли таких
cO3fl сов выступают ksivapd, xfs и khubd — эти процессы управляют па-
Пр011 файловой системой и устройствами, соответственно. Более подроб-
мЯТЬи процессы РассматРиваются в главе 20. Процесс login отвечает за ау-
1,0 ЭТ^)ИкаЦИЮ пользователей в операционной системе, требуя от пользова-
ТбВ ввести свое имя и пароль. Другие способы аутентификации
теЛ матриваются в главе 19. После прохождения пользователем аутенти-
раССяции с помощью процесса login, он порождает процесс оболочки, на-
Ф ер bash (Bourne-again s/iell), дающий возможность пользователю
содействовать с операционной системой (см. рис. 3.4). После этого
пользователь может задавать команды в оболочке командной строки, на-
пример, запустить программу vi (текстовый редактор) или finger (утилиту,
отображающую информацию о пользователе). Уничтожение процесса под-
разумевает его полное удаление из системы. Занимаемая им память и ре-
сурсы возвращаются в распоряжение системы, информация о нем стирает-
ся из всех системных списков или таблиц, удаляется блок управления про-
цессом, после чего память, выделенная под хранение РСВ данного
процесса, становится доступной другим процессам системы. Удалить про-
цесс, породивший другие процессы, сложнее. В некоторых операционных
системах все созданные процессы уничтожаются автоматически при унич-
тожении родительского, в других ОС созданные процессы существуют не-
зависимо от родительских, и уничтожение родительского процесса
не влияет на дочерние.
Иерархия создания процессов
Рис. 3.4. Иерархия процессов в Linux
Изменение приоритета процесса, как правило, подразумевает измене-
ние значения приоритета в блоке управления процессом. В зависимости от
реализованного механизма планирования процессов в операционной систе-
ме, может понадобиться перемещение указателя на РСВ в другую очередь
приоритетов (см. главу 8). Другие перечисленные в этом разделе операции
поясняются в следующих разделах.
Вопросы для самопроверки
1. (Да/Нет) Правда ли, что процесс может вообще не иметь родитель-
ского процесса?
2. В чем преимущества иерархии процессов перед связным списком?
Ответы 1) Да. Первый создаваемый процесс, например, intt
в UNIX не имеет родительского процесса. Кроме того, в некоторых
системах, при уничтожении родительского процесса, дочерние про-
цессы могут продолжить свое существование независимо от родитель-
ского процесса. 2) Иерархия процессов позволяет операционной
системе отслеживать взаимоотношения типа родительский/дочернии
между процессами. Это упрощает выполнение таких операций, к811
локализация всех дочерних процессов в случае завершения работы ро
дительского процесса.
3.3.4 Приостановка и возобновление работы процесса
В большинстве операционных систем администраторам, пользователя^
либо самим процессам разрешено приостанавливать выполнение проДе
сов. Приостановленные (suspended) процессы на некоторое время выч^Р,
киваются из списка процессов, соревнующихся за процессорное время,
при этом не удаляются из системы. Раньше операция приостановки поз
ляла оператору вручную корректировать загруженность системы и/11
реагировать на угрозы сбоя. Быстродействие современных
позволяет выполнять ручную настройку. Тем не менее,
или пользователи, обеспокоенные результатами работы
компьютеров 11
администратор
процесса, могУ
197
процесса
довить его выполнение (вместо аварийного завершения (abort) ра-
ПР11°ст тех пор, пока пользователь не удостоверится в нормальном функ-
ботЫ) д нии процесса. Приостановка выполнения процесса использует-
диоНИР влениЯ угроз безопасности (например, для обнаружения вредо-
сЯ Д^Я » программного кода) и в целях отладки нового программного
обеспечени & показана диаграмма смены состояний (упрощенный ва-
На которой был представлен на рисунке 3.1), модифицированная с уче-
риаНТ е аций приостановки и возобновления. В диаграмму введены два
Т°М ° состояния — приостановлен готов (suspended-ready) и приостанов-
Й°ВЬблокирован (suspended-blocked). На рисунке выше пунктирной линии
Л<б ажены активные состояния (active states), ниже — состояния приос-
тановки (suspended states).
Активные
состояния
Состояния
приостановки
Состояние
«приостановлен
готов»
Завершение ввода/вывода
либо наступление события
Завершение ввода/вывода
либо наступление события
Состояние
готовности
Ожидание
ввода/вывода
либо наступления
события
(а)
Состояние
выполнения
^Ue‘3s TJ
11 Bo-Cjt ДИаграмма состояний процесса с операциями приостановки
*ад°Новления
198
главс
Инициатором приостановки может выступать либо данный процесс, лцд
другой процесс. В однопроцессорной системе выполняющийся процесс м °
жет приостановить только сам себя, как изображено на рисунке 3.5 (а)-
один другой процесс не в состоянии работать одновременно с ним, чтобы
дать сигнал приостановки. Кроме того, процесс в состоянии выполнения
жет приостановить дальнейшую работу процесса в состоянии готовности
либо блокировки, как показано на рисунке 3.5 (Ь) и (с). В многопроцессоъ
ной системе выполняющийся процесс может быть приостановлен другц^
процессом, выполняющимся в этот момент на другом процессоре.
Очевидно, что процесс может сам приостановить свое выполнение, толь
ко тогда, когда он выполняется. При этом происходит переход процесса ца
состояния выполнения в состояние приостановлен готов. Процесс в состоя-
нии приостановлен готов может быть переведен в состояние готовности
то есть возобновлен (resume) другим процессом. Заблокированный процесс
может быть переведен в состояние приостановлен блокирован другим про-
цессом. Процесс, находящийся в состоянии приостановлен блокирован, мо-
жет быть активизирован другим процессом, в результате чего произойдет
переход из состояния приостановлен блокирован в состояние блокировки.
У читателя может возникнуть вопрос, не лучше ли вместо перевода за-
блокированного процесса в состояние приостановки подождать, пока не за-
вершится выполнение операции ввода-вывода или не произойдет другое со-
бытие, необходимое для того, чтобы данный процесс стал готовым к выпол-
нению. При этом процесс будет приостановлен и переведен в состояние
приостановлен готов. К сожалению, завершение операции ввода-вывода
или ожидаемое событие может никогда не произойти или может задержать-
ся на неопределенно долгий срок. Поэтому перед разработчиком возникает
дилемма: либо выполнять приостановку заблокированного процесса, либо
предусмотреть механизм, который позволял бы переводить процесс из со-
стояния готовности в состояние приостановки, когда завершится опера-
ция ввода-вывода или наступит другое ожидаемое событие. Поскольку при-
остановка обычно является операцией высокого приоритета, она выполня-
ется немедленно. Когда ожидаемое событие, в конце концов, происходит
(если оно все-таки происходит), процесс, находящийся в состоянии приос-
тановлен блокирован, меняет свое состояние на приостановлен готов.
Вопросы для самопроверки
1. Какие три способа перевода процесса в состояние приостановлен
готов существуют?
2. В какой ситуации лучше приостановить выполнение процесса, че1Л
инициировать аварийное завершение?
Ответы 1) Процесс может перейти в состояние приостановлен
тов сам, приостановив свое выполнение; будучи переведен из состо
ния готовности другим выполняющимся процессом; либо
завершении операции ввода-вывода или наступления другого оЖИДа
мого события, изменив состояние приостановлен блокирован на пр
остановлен готов. 2) Когда действия процесса вызывают подозрейй
у пользователя либо системного администратора, предпочтительй6
перевести процесс в состояние приостановки, что понаблюдать за еГ
поведением.
199
----------------
, Переключение контекста
Операционная система выполняет переключение контекста (context
pitching), чтобы завершить работу выполняемого процесса и запустить
процесс, который Ранее находился в состоянии готовности.20 Для пеое
Хочения контекста ядро системы вначале должно сохранить контекст
лыполяения процесса, пребывающего в состоянии выполнения, в блоке
управления процессом РСВ, а затем загрузить контекст выполнения наме-
ченного к выполнению процесса, находящегося в состоянии готовности
из его РСВ (см. рис. 3.6).
Процессор
Процесс Р, выполняется
на процессоре
Pi
После поступления
сигнала прерывания,
ядро принимает решение
о выборе нового
процесса и инициирует
переключение контекста
Процессор
Pi
Ядро загружает контекст
выполнения процесса Р2
из его РСВ в памяти
Ядро сохраняет контекст
выполнения процесса Р,
в его РСВ в памяти
Процессор
Процесс Р2 выполняется
на процессоре р2
3.6. Переключение контекста
Вой спе^еДУРа пеРеключения контекста, жизненно важная в многозадач-
Рационне’~ ТребУет мастерских дизайнерских решений при разработке опе-
Ляться п°И системы' С оДной стороны, переключение контекста должно яв-
Их вьшол°3₽аЧНЫМ ДЛЯ пР°йессов> то есть процессы не должны знать, что
°Р°ЦессоЛНеНИе ®ыло пРиостановлено. Во время переключения процесса
JiteT РещР Не может выполнять «полезные вычисления» — то есть он мо-
^ет выпо Ь за^ачи’ необходимые самой операционной системе, но не мо-
Й11е КоцТеЛНЯТЬ инструкции от имени какого-либо процесса. Переключе-
8°лЬцо ЧаКСТа это накладные расходы в чистом виде, имеющие место до-
ЙРсМя, 3f)aCT°’ поэтомУ операционная система старается минимизировать
рачиваемое на проведение этой операции.
200
Г/,авв^
Операционная система очень часто обращается к блокам управлец^ I
процессом РСВ. Поэтому большинство процессоров имеет встроенные per 51 I
стры, которые ссылаются на РСВ выполняющегося процесса, ускоряя п
реключение контекста. Когда операционная система инициирует перекл 6'
чение контекста, процессор сохраняет контекст выполнения текущего щ/'
цесса в РСВ. Благодаря этому предотвращается перезапись значецц-
регистров процессора со стороны операционной системы либо других
цессов. Кроме того, процессор упрощает и ускоряет переключение конт^
ста, используя специальные инструкции сохранения и восстановлен^
контекста выполнения процесса в или из блока управления процессор
РСВ, соответственно.
В архитектуре IA-32 операционная система запускает новый процесс
задавая местоположение РСВ в памяти. Затем процессор выполняет пере'
ключение контекста, сохраняя контекст выполнения предыдущего процес.
са. В архитектуре IA-32 не используются специальные команды сохраве.
ния или восстановления контекста выполнения процесса, поскольку про.
цессор выполняет эти операции самостоятельно без вмешательства
программного обеспечения.21
Вопросы для самопроверки
1. Откуда операционная система берет контекст выполнения процес-
са, выбранного для запуска во время очередного переключения
контекста?
2. Почему операционная система вынуждена минимизировать время,
затрачиваемое на переключение контекста?
Ответы 1) Запускаемый процесс хранит свой контекст в блоке
управления процессом РСВ. 2) Во время переключения контекста про-
цессор не может выполнять инструкции от имени процессов, что сни-
жает производительность системы.
3.4 Прерывания
Мы уже обсуждали в главе 2, что прерывания позволяют программному
обеспечению реагировать на сигналы, поступающие от аппаратуры. Д-®1
обработки каждой разновидности прерываний в составе операционной сис-
темы предусмотрены специальные программы, называемые обработчика'
ми прерываний (interrupt handlers). С их помощью операционная система
получает в свое распоряжение процессор для того, чтобы контрол ироваТь
системные ресурсы.
Процессор может выдать сигнал прерывания в результате выполнен#1’
команд процесса (в этом случае речь идет о ловушке (trap), которая явЛ^
ется синхронной (synchronous) по отношению к операциям процесса). С> ”
хронные прерывания имеют место при попытках процесса выполнить 30
прещенные операции, например, деление на ноль либо обращение к загД”
щенной области памяти.
201
Конкег
ивания могут быть вызваны и другими событиями, не связанными
рением текущих инструкций процесса (такие прерывания называ-
свЫп° иЯХронными (asynchronous), см. «Размышления об операционных
jo-гсЯ аС синхронность и асинхронность»). Аппаратура формирует асин-
сцсТеМ е прерывания, чтобы уведомить процессор об изменении своего со-
хР°0бЬ Например, клавиатура генерирует прерывание в случае нажатия
сТоЯЙ ' пользователем, мышь генерирует прерывания при ее перемеще-
кЛйВИибо нажатии какой-либо кнопки.
ЙЙгГг>епывания — это наименее ресурсоемкий способ привлечь внимание
1 ессора- Альтернативой прерываниям является периодический опрос
Пр0 яВИЯ каждого устройства со стороны процессора. Подобный подход,
С°СТтваемый последовательным опросом (pooling) повышает накладные
ВЯ ходы и увеличивает сложность компьютерной системы. Прерывания
избавляют процессор от необходимости постоянно опрашивать системные
устройства.
Поясним различия мёжду последовательным опросом и прерываниями
на примере микроволновой печи. Шеф-повар может установить таймер,
который сработает через определенное время (звук таймера по истечении
заданного интервала прервет выполнение шеф-поваром других операций)
либо регулярно заглядывать через окно микроволновой печи, проверяя го-
товность продукта (такие периодические обращения можно сравнить с по-
следовательным опросом).
Системы, в которых используются прерывания, могут подвергаться пе-
регрузкам — если прерываний слишком много, система может не спра-
виться. Оператор центра управления полетами, к примеру, также может
растеряться в ситуации, когда слишком много самолетов окажется в огра-
ниченной области пространства.
В системах, подключенных к сети, в распоряжении сетевого интерфейса
имеется небольшой объем памяти, в котором хранятся пакеты с данными,
полученными от других компьютеров. Каждый раз, когда сетевой интер-
фейс получает определенный пакет, он генерирует прерывание, чтобы про-
информировать процессор о готовности данных к обработке. Если процес-
су Не В состоянии обработать данные, поступающие от сетевого интерфей-
п ’ До того как память интерфейса переполнится, пакеты могут быть
ЩихРЯНЬ1- Обычно системы используют очереди для хранения поступив-
шее на обработку прерываний в ожидании освобождения процессора. Ес-
вреМя Н°’ поД°бные очереди занимают память, которой всегда мало. Во
в оче Пиковоя загрузки может оказаться так, что системе не хватит места
Чег0 в ДИ ДЛЯ Разме1Чения всех поступающих прерываний, в результате
которые из них могут быть потеряны.
202
£^ввз
Размышления об операционных системах
Синхронность и асинхронность
Когда мы говорим о том, что некоторые
события являются асинхронными по отноше-
нию к процессу, мы имеем в виду, что они
происходят независимо от процесса. Опера-
ции ввода/вывода могут выполняться па-
раллельно, то есть одновременно с выполне-
нием процесса. Инициировав асинхронную
операцию ввода/вывода, процесс может
продолжать работу до тех пор, пока в систе-
ме будет выполняться асинхронная опера-
ция ввода/вывода. Процесс будет уведом-
лен об окончании выполнения операции
ввода/вывода. Уведомление может прийти
в любой момент времени. Процесс может
обработать прерывание завершения опера-
ции ввода/вывода сразу либо сначала за
кончить выполнение других операци^
Поэтому прерывания часто называют аСцн
хронным механизмом взаимодействия. п0
следовательный опрос, наоборот, являетщ
примером синхронного механизма взаимо
действия. Процессор постоянно проверЯег
состояние устройств, пока операция ВВо.
да/вывода не завершится. В синхронных
механизмах много времени тратится на
ожидание и повторную проверку устройства
до тех пор пока не наступит событие. Асин-
хронные механизмы позволяют продолжать
работу, не расходуя время на ожидание со-
бытий. Как правило, асинхронная методика
позволяет повысить производительность
системы.
Вопросы для самопроверки
1. Что такое синхронные прерывания?
2. Какая существует альтернатива прерываниям и почему она редко
используется?
Ответы 1) Синхронные прерывания связаны с выполнением про-
граммного кода. 2) Система может выполнять последовательный
рос состояния оборудования. Однако эта технология используется
достаточно редко, поскольку она связана со значительными наклаД,
ными расходами при опросе устройств, статус которых не меняется
временем. Благодаря прерываниям системе удается избежать под0
ных накладных расходов, поскольку процессу отсылается уведомл
ние только в случае изменения состояния устройства.
3.4.1 Обработка прерываний
В этом разделе мы обсудим, каким образом обычная компьютерная с11
тема осуществляет обработку аппаратных прерываний. (Учтите, что по
мо нижеперечисленных существуют и другие схемы обработки прерЫ
ний).
203
Пиния, по которой передается прерывание, — электрическое соеди-
1- рЯИе между материнской платой и процессором — становится ак-
ВиВдым. Разнообразные устройства, такие как таймеры, периферий-
ые платы и контроллеры посылают сигналы, которые делают актив-
ой линию прерываний для того, чтобы проинформировать
поцессор о наступлении события (например, об истечении проме-
ясутка времени либо окончании обслуживания запроса ввода/выво-
а) Большинство процессоров обладают встроенным контроллером
прерываний, сортирующим прерывания в соответствии с их приори-
тетом, обеспечивая первоочередную обработку высокоприоритетных
прерываний. Другие прерывания добавляются в очередь до тех пор,
пока не будут обслужены все высокоприоритетные прерывания.
Обнаружив активизацию линии прерываний процессор завершает
выполнение текущих инструкций, после чего приостанавливает вы-
полнение текущего процесса. Чтобы прервать выполнение процесса,
процессор должен сохранить достаточно информации для последую-
щего возобновлении работы процесса с нужного места и с правильной
информацией в регистрах. В ранних IBM-системах эта информация
хранилась в структурах данных, называемых словами состояния
программы (program status words, PSW). Начиная с архитектуры
IA-32, информацию о состоянии называют сегментом состояния зада-
чи (task state segment, TSS). Обычно TSS помещают в блок управле-
ния процессом РСВ.22
3. Далее процессор передает управление соответствующему обработчи-
ку прерываний. Каждому типу прерываний присваивается уникаль-
ное значение, используемое процессором в качестве индекса вектора
прерываний (interrupt vector). Вектор прерываний представляет со-
бой массив указателей на обработчики прерываний, который хранит-
ся в области памяти, недосягаемой для обычных процессов, благода-
ря чему процессы, совершающие ошибки, не смогут запортить этот
массив.
4. Обработчик прерываний выполняет соответствующие операции, ос-
новываясь на типе прерываний.
5. По завершении работы обработчика прерываний, состояние прерван-
ного процесса (либо некоего «следующего» процесса, если ядро ини-
Циировало переключение контекста) восстанавливается.
Прерванный процесс (либо некий «следующий» процесс) продолжает
выполнение. За определение того, какой процесс выполняется в дан-
ный момент (прерванный либо некий «следующий» процесс), ответ-
ственность возлагается на операционную систему. Это важное реше-
Вие’ могущее серьезно повлиять на уровень обслуживания каждого
РИложения, рассматривается в главе 8. Например, если сигнал пре-
вания уведомляет о завершении операции ввода/вывода, повлек-
за собой переход высокоприоритетного процесса из состояния
Де К1^овки в состояние готовности, операционная система вынуж-
са а бУдет выполнить приоритетное вытеснение прерванного процес-
и запустить высокоприоритетный процесс.
204
Главе
205
Рассмотрим взаимодействие операционной системы и аппаратного обесц^ I
чения в ответ на прерывания таймера (см. рис. 3.7). Интервальный таймер t.^' I
нерирует прерывания через определенные временные интервалы, позводя I
операционной системе выполнять операции управления системой, наприме?
планирование процессов. В этом случае таймер генерирует прерывание 2) й’ I
время выполнения процессором процесса Pr (1). После поступления преры^
ния процессор обращается к записи вектора прерываний, соответствующей
тервальному таймеру (3). Процессор сохраняет контекст выполнения процеСс^
Р} в памяти (4), чтобы не потерять его при запуске обработчика прерываний.2з
Затем процессор начинает выполнение обработчика прерываний, определяю, I
щего, как системе нужно реагировать на прерывания (5). Обработчик прерыва, I
ний может восстановить состояние ранее выполнявшегося процесса (Рх) либ0
вызвать планировщик процессора операционной системы с целью выбора еле.
дующего процесса для выполнения. В этом случае обработчик вызывает пла.
нировщик процессов, который принимает решение о передаче процессора
в распоряжение высокоприоритетного процесса Р2 (6). Далее контекст процес-
са Р2 загружается из РСВ, размещенного в основной памяти, а контекст выпод. I
нения процесса Рх, наоборот, сохраняется в РСВ в основной памяти.
----------------------
Вопросы для самопроверки
1 Почему информация о размещении обработчиков прерываний ред-
" ко хранится в виде связного списка?
2 Зачем при запуске обработчика прерываний контекст выполнения
‘ прерванного процесса сохраняется в памяти?
Ответы 1) Чтобы избежать перегрузки системы, операционная сис-
тема должна максимально быстро обслуживать каждое прерывание.
Просмотр связного списка требует много времени, что может значи-
тельно замедлить время реакции системы при увеличении числа пре-
рываний. Поэтому, в большинстве систем применяются векторы
прерываний (то есть массивы) для ускорения доступа к местоположе-
нию обработчика прерываний. 2) Если не сохранить в памяти контекст
выполнения процесса, обработчик прерываний может перезаписать
значение регистров, используемых процессом.
д4.2 Классы прерываний
Перечень прерываний, поддерживаемых системой, зависит от ее архи-
тектуры. Некоторые типы прерываний используются в большинстве архи-
тектур. В этом разделе мы обсудим структуру прерываний, поддерживае-
мую спецификацией Intel IA-32,24 реализованной в процессорах Intel®
Pentium®. В 2002 году доля компании Intel на рынке процессоров для пер-
сональных компьютеров составила более 80% .25
В спецификации IA-32 различаются два вида сигналов, которые может
принимать процессор: прерывания и исключения. Прерывания (interrupt)
уведомляют процессор о наступлении того или иного события (например,
об истечении временного интервала) либо об изменении статуса внешнего
устройства (например, завершении операции ввода/вывода). В архитекту-
ре IA-32 предусмотрены программные прерывания (software-generated
interrupt), которые используются процессами для вызова системных функ-
ции. Исключения (exceptions) сигнализируют об ошибке, аппаратной или
программной. Кроме того исключения используются для приостановки
олнения процесса по достижении точки останова внутри кода.26
и тройства, генерирующие прерывания в виде сигналов ввода/вывода,
ПодогГЬ1ВаНИЯ Та^1меРа являются внешними по отношению к процессору.
НяютНЫе ПреРЫВаННЯ не являются синхронными по отношению к выпол-
струКци^СЯ пРоЧессУ, поскольку их формирование никак не связано с ин-
пРИмео1ЯМИ’ вьтолняемыми процессором. Программные прерывания, на-
к вЫпо ВЫзов системных функций, наоборот, синхронны по отношению
В1>111олнеНЯ1Ои*емУся 11Р°ЦессУ’ поскольку они генерируются в результате
Pbie типы*1*1 ОПределенных инструкций. На рисунке 3.8 показаны некото-
прерываний, различаемые в спецификации IA-32.
Рис. 3.7. Обработчики прерываний
206
г*авс
Тип прерывания
Ввод/вывод
Таймер
Межпроцессорное
Описание
Сигналы прерываний данного типа формируются оборудованием
ввода/вывода. Они уведомляют процессор об изменении состояния канала
либо устройства. Прерывания ввода/вывода возникают, например, по
завершении операций ввода/вывода.
В системе могут присутствовать устройства, генерирующие прерывания
через определенные промежутки времени. Эти прерывания могут
использоваться в целях хронометража либо мониторинга
производительности. С помощью таймера операционная система
определяет момент истечения выделенного процессу кванта.
Такие прерывания позволяют одному процессору отсылать сообщения
другому процессору в многопроцессорной системе.
Рис. 3.8. Распространенные типы прерываний, распознаваемые в спецификации
Intel IA-32
В архитектуре IA-32 предусмотрены следующие классы исключений:
промахи (faults), ловушки (traps) и аварийные завершения (aborts)
(см. рис. 3.9). Промахи и ловушки позволяют обработчику исключений
продолжать выполнение процесса. Промах означает ошибку, которая мо-
жет быть скорректирована обработчиком исключений. Например, стра-
ничный промах возникает тогда, когда процесс пытается обратиться к дан-
ным, которые отсутствуют в основной памяти (страничные промахи рас-
сматриваются в главе 10 и в главе 11). Операционная система в состоянии
исправить эту ошибку, переместив запрошенные данные в оперативную
память. После исправления ошибки, процессор продолжит выполнение
процесса, вызвавшего исключение, с той инструкции, которая послужила
причиной этого исключения.
Класс исключения
Промах
Ловушка
Аварийное завершение
Описание
Промахи могут быть вызваны самыми разнообразными причинами во
время выполнения программных инструкций на машинном языке.
К таковым относится: деление на ноль, неверный формат данных,
попытки выполнения запрещенных операций, попытки обратится по
адресу, выходящему за пределы физического адресного пространства,
попытки пользовательского процесса выполнить привилегированные
инструкции и попытки обращения к защищённым ресурсам.
Ловушки могут быть вызваны такими исключениями, как ошибки
переполнения (например, при попытке сохранения в регистр значения,
превышающего его разрядность), либо достижением контрольной
точки останова программы.
Наступает в случае обнаружения процессором ошибки, после которой
процесс восстановиться не в состоянии. Например, если процедура
обработки исключений сама выдаст исключение, процессор не смоЖе
справиться с двумя ошибками сразу. Такую ситуацию называют
исключением двойного промаха, и она приводит к завершению
породившего ее процесса.
Рис. 3.9. Классы исключений в спецификации Intel IA-32
207
тпки редко соответствуют поддающимся корректировке ошибкам,
Л°вУ илО, они связаны с ситуациями переполнения либо точками оста-
каК ПРНапример, когда процесс передает процессору команду увеличить
яова- п в сумматоре, результат может превысить максимально возмож-
збачеи чение в сумматоре. В этом случае, операционная система просто
0ое 30 а т Процесс об ошибке переполнения. После запуска обработчика
увеДО ия ловушки, процессор возобновляет работу процесса со следую-
йСК„ЛдЯСтрукции после той, которая вызвала исключение.
Ще1 оИйное завершение возникает тогда, когда процесс (или даже систе-
п,елом) не в состоянии продолжить работу, например в результате ап-
ма В ного сбоя. При этом процессор не гарантирует надежность сохране-
ПЭР контекста выполнения процесса. Обычно в такой ситуации операцион-
йИЛ система вынуждена аварийно завершать работу процесса.
НЯ В подавляющем большинстве операционных систем прерывания делят-
ся по приоритетам, поскольку одни прерывания требуют немедленной об-
работки, тогда как другие могут немного подождать. К примеру, аппарат-
ный сбой важнее события завершения операции ввода/вывода. Приорите-
ты прерываний могут быть реализованы как программно, так и аппаратно.
Процессор блокирует либо помещает в очередь прерывание с более низким
приоритетом, чем то, которое обрабатывается процессором в текущий мо-
мент времени. Временами ядро системы оказывается настолько перегру-
жено прерываниями, что больше не может реагировать на них. Быстрое
реагирование на прерывания и быстрый возврат управления прерванному
процессу важен для повышения эффективности использования ресурсов
и достижения высокого уровня интерактивности. Поэтому большинство
процессоров позволяют ядру запрещать (disable) либо маскировать (mask)
определенные типы прерываний. Процессор просто игнорирует прерыва-
ния данного типа либо сохраняет их в очереди отложенных прерываний,
обслуживание которой начинается с момента повторного разрешения пре-
рываний. В архитектуре IA-32 в процессоре предусмотрен регистр, служа-
щий индикатором маскирования прерываний.27
Вопросы для самопроверки
1. Какие два типа сигналов может принимать процессор в архитекту-
ре IA-32?
2. Чем отличает промах от (системной) ловушки в архитектуре IA-32?
Ответы 1) Процессор распознает два типа сигналов: прерывания
и исключения. Прерывания используются для уведомления о наступ-
лении определенных событий. Исключения сообщают о возникнове-
нии ошибок. 2) В случае промаха возобновление работы процесса
начинается с инструкции, вызвавшей исключение. Промахи обычно
связаны с ошибками, поддающимися корректировке. Системная ло-
вушка перезапускает процесс, начиная с инструкции, следующей не-
посредственно за той, которая вызвала исключение. Ловушки
используются в основном при вызове системных функций и для орга-
низации контрольных точек останова программы.
208
3S Взаимодействие процессов
В многозадачной и сетевой среде процессы должны как-то обща?»
друг с другом. В большинстве операционных систем предусмотрены Меу^
низмы взаимодействия процессов (IPC), например, текстовый редактор«Л
жет отсылать документ в спулер печати или веб-браузер, извлекать дани °
с удаленного сервера. Взаимодействие процессов играет важную роль д
процессов, которые обязаны координировать (то есть синхронизировав
свои усилия для достижения общего результата. С реализацией взаимоде*
ствия процессов в наиболее популярных на сегодняшний день операцц^'
ных системах вы познакомитесь в учебных примерах по Linux (см. ра'
дел 20.10) и Windows ХР (см. раздел 21.10).
3.5.1 Сигналы
Сигналами (signals) называют программные прерывания, уведомляю,
щие процесс о наступлении определенного события. В отличие от других
обсуждаемых в данной книге механизмов взаимодействия процессов, сиг-
налы не позволяют процессам обмениваться друг с другом какой-либо ин-
формацией.28 Системные сигналы зависят от операционной системы и ти-
пов программных прерываний, поддерживаемых определенным процессо-
ром. При поступлении сигнала операционная система сначала определяет,
кому предназначен данный сигнал, а потом — как процесс должен на него
отреагировать.
Процессы могут перехватывать сигналы, игнорировать их либо маскиро-
вать. Процесс перехватывает (catches) сигнал и определяет процедуру, вы-
зываемую операционной системой в случае поступления сигнала.29 Процесс
может проигнорировать (ignores) сигнал, то есть переложить ответствен-
ность за выполнение действия по умолчанию (default action) по обработке
сигнала на операционную систему. Чаще всего по умолчанию задается ава-
рийное завершение (abort) процесса. Другой, не менее распространенной
операцией по умолчанию является дамп памяти (memory dump), который
аналогичен аварийному завершению процесса, только перед завершением
генерируется файл ядра (core file) процесса, содержащий контекст выпоЛ'
нения процесса и данные из адресного пространства, что облегчает отладку
программ. Третьим вариантом действия по умолчанию является игнорИР0'
вание сигнала. Два других действия по умолчанию вызывают приостановку I
выполнения процесса и его последующее возобновление.30
Процесс может заблокировать обработку сигнала путем его маскир°ва
ния (masking). Когда процесс маскирует сигнал определенного типа (йй
пример, сигнал приостановки), операционная система блокирует сигнал
этого типа до тех пор, пока маскирование сигнала не будет отключено. К г
правило, процесс блокирует сигналы того типа, который обрабатывает
в текущий момент времени. Подобно замаскированным прерываниям, I
кированные сигналы могут быть потеряны (это зависит от конкретной Ре I
лизации операционной системы).
209
----------------------
Вопросы для самопроверки
1. Назовите основные недостатки использования сигналов при взаи-
модействии процессов.
2. Назовите три варианта реакции процесса на сигнал.
Ответы 1) Сигналы не поддерживают обмен данными между про-
цессами. 2) Процесс может перехватывать, игнорировать либо маски-
ровать сигналы.
$ ^2 Передача сообщений
с пазвитием распределенных систем возрос интерес к взаимодействию
пессов с помощью сообщений.31’32’33’34’35’36 В этом разделе мы обсудим
Пйтпие вопросы взаимодействия процессов на основе сообщений. Вопросы,
связанные с конкретной реализацией взаимодействия процессов, вы най-
я учебных примерах, посвященных операционным системам Linux
Windows ХР
Сообщения могут передаваться в одном направлении — тогда для лю-
бого сообщения один процесс является отправителем, а другой — получа-
телем. Передача сообщений может также являться двунаправленной, то
есть каждый процесс во время взаимодействия одновременно может яв-
ляться и отправителем и получателем. В одной из моделей передачи сооб-
щений передача и прием сообщений процессом задается путем следую-
щих вызовов:
send (receiverProcess, message);
receive (senderProcess, message);
Прием и отправка сообщений обычно реализуется в виде вызова систем-
ных функций, доступных в большинстве языков программирования.
В случае блокирующей передачи (blocking send) процесс вынужден ожи-
дать до тех пор, пока сообщение не будет доставлено получателю, требуя
подтверждения приема. При неблокирующей передаче (nonblocking send)
процесс-отправитель может продолжить выполнение других операций,
даже если сообщение еще не было доставлено получателю (либо он не уве-
домил об этом отправителя). Чтобы реализовать неблокирующую переда-
ЧУ» необходимо использовать механизм буферизации сообщений для хра-
пения сообщений до момента их доставки получателю. Блокирующая пе-
едача представляет собой пример синхронной связи, тогда как
локирующая передача — асинхронной. Во время отправки сообщения
сл Н° Указать процесс-получатель либо опустить имя процесса, в таком
ае будет произведена широковещательная (broadcast) передача сооб-
** Всем процессам системы (либо «рабочей группе», с которой в основ-
общается отправитель).
вуетСИНхР°Нная связь в сочетании с неблокирующей передачей способст-
ОзКц Увели^нию быстродействия системы за счет уменьшения времени
щЛе*ания Различных событий процессами. Например, если процесс ото-
Ицфо инФ°Рмацию на занятый сервер печати, система будет хранить эту
вреад Р^аЦию до тех пор, пока сервер печати не будет готов ее принять, в то
Здд Я яак процесс-отправитель сможет продолжить выполнение других
ИИ, не ожидая освобождения сервера печати.
210
Если никакое сообщение не отправлялось, используется блокируют
вызов получения, который заставляет получателя ждать, либо небло^
рующий вызов получения, который наоборот, позволяет получателю в
должить выполнение других задач перед следующей попыткой приема
общения. С помощью вызова получения можно задать определенного
правителя либо настроить прием сообщений от любых процессов
отдельных групп). 11
Популярной реализацией механизма передачи сообщений являет
канал (pipe) — защищенная операционной системой область памяти,
торая выступает в качестве буфера, позволяющего нескольким процесса^
обмениваться между собой данными. Операционная система синхронизм
рует доступ к буферу — после того, как записывающий процесс закончит
вести запись в буфер (вероятно, заполнив его), система приостановит ра
боту записывающего процесса, позволив считывающему процессу начать
чтение данных из буфера. По мере считывания данных из буфера, канал
освобождается. После того как считывающий процесс закончит чтение
данных из буфера (вероятно, опустошив его), операционная система
в свою очередь, приостановит его выполнение, позволив записывающему
процессу снова начать запись информации в буфер.39 Более подробно
о функционировании каналов вы прочтете в учебных примерах операци-
онных систем Linux и Windows ХР (см. раздел 20.10.2 и раздел 21.10.2,
соответственно).
Обсуждая взаимодействие процессов, выполняемых на одном компью-
тере, мы предполагаем, что обмен информацией происходит без ошибок.
В распределенных системах при передаче данных могут возникать ошиб-
ки, в ряде случаев приводящие к потере информации. Поэтому отправите-
ли и получатели часто взаимодействуют между собой при помощи прото-
кола квитирования (acknowledgment protocol) используемого для подтвер-
ждения факта приема информации. Механизм тайм-аута применяется для
ограничения времени ожидания уведомления о доставке. Если уведомле-
ние о доставке сообщения не поступит по истечении заданного интервала,
сообщение будет отправлено повторно. Системы передачи сообщений
с функций повторной передачи данных позволяют идентифицировать но-
вые сообщения по их порядковому номеру. Получатель должен проверять
эти номера, чтобы знать, все ли сообщения были доставлены, и при необхо-
димости, расставлять их в правильном порядке. Если подтверждение
о приемке сообщения потеряется, и отправитель решит передать сообщу
ние повторно, новому сообщению присваивается тот же самый порядковый
номер, который принадлежал потерянному сообщению. При этом получа-
тель, приняв несколько сообщений с одинаковым номером, будет знать.
что сохранить он должен только одно из них.
Одной из проблем распределенных систем является присвоение у00'
кальных имен процессам при передаче/приеме сообщений. Конечно»
можно использовать некий централизованный механизм присвоений
имен во время создания либо уничтожения процессов, но это связано с°
значительными накладными расходами при передаче данных, поскольку
отдельные компьютеры вынуждены будут спрашивать разрешение на ИС'
пользование нового имени. Альтернативный подход состоит в гарантир0'
вании уникальности имени процесса в пределах одного компьютера, т°'
211
оцессам можно будет обращаться с помощью сочетания имени
гда к пР и имени компьютера. Это, в свою очередь, требует централизо-
проДеСса оНТроля над назначением уникальных имен компьютерам в со-
ваН0ОГ° педеленной системы, что также может привести к значитель-
сТаве раС ддным расходам, если конфигурация сети часто меняется. На
jjtiM яа передача сообщений между компьютерами в распределенных
праКТИК^’ОСу1цествляется через нумерованные порты, прослушиваемые
система ымИ ПрОцесСами, что позволяет избежать проблемы присвое-
°Й₽еимеН (см. главу 16>-
яИ» стпе убедитесь, прочитав главу 17, организация связи на основе
как кы с л J
ений в распределенных системах чревата серьезными проблемами
соооЩ сносТИ Одной из них является проблема аутентификации (authen-
^3<tion problem). Каким образом получатель и отправитель сообщения мо-
tX быть уверены в том, что они общаются именно с тем процессом, за ко-
Г^оый тот себя выдает, а не с самозванцем, пытающимся украсть либо ис-
портить информацию? Несколько способов аутентификации описаны
в главе 19.
В данной книге рассматривается несколько механизмов взаимодействия
процессов. Помимо сигналов и каналов, процессы могут общаться друг
с другом с помощью разделяемой памяти (см. главу 10), сокетов (см. гла-
ву 16) и удаленного вызова процедур (см. главу 17). Чтобы синхронизиро-
вать свои действия, процессы используют семафоры и мониторы (см. гла-
ву 5 и главу 6, соответственно).
Вопросы для самопроверки
1. Почему в распределенных системах вместо сигналов используется
технология передачи сообщений?
2. Когда процесс выполняет блокирующую передачу, для разблокиро-
вания он должен получить уведомление о доставке сообщения. Ка-
кая проблема может возникнуть при использовании данной схемы
и как ее можно избежать?
Ответы 1) Как правило, типы распознаваемых сигналов зависят
от архитектуры системы, что чревато несовместимостью сигналов, вы-
рабатываемых одними компьютерами в составе распределенной систе-
мы, с сигналами других компьютеров. Кроме того, сигналы не
позволяют процессам обмениваться данными, без чего не в состоянии
обойтись большинство распределенных систем. 2) Получатель может
не дождаться уведомления о доставке, что приведет к бесконечному
блокированию процесса. Для решения этой проблемы используется
механизм тайм-аута — если уведомление о приеме сообщения не по-
ступит через заданный промежуток времени, считается, что передача
сообщения не увенчалась успехом и данное сообщение будет отослано
повторно.
at
3.6 Учебный пример: процессы 6 UNIX
Реализация процесса в операционной системе UNIX и UNIX-подобю
системах впоследствии была позаимствована рядом других операционнь *
систем (см. «Учебный пример: Система UNIX»). В этом разделе мы погов *
рим о структуре процессов UNIX, обсудим специальные возможност'
UNIX, о которых пойдет речь в последующих главах, и разберемся в то^
как система UNIX позволяет своим пользователям управлять работой цр0’
цессов.
Каждому процессу во время работы нужно где-то хранить программны^
код, данные и стек. На практике процессы извлекают эту информацию Из
памяти, обращаясь по определенным физическим адресам. Диапазон дос-
тупных адресов памяти для каждого процесса определяется исходя из пол-
ного объема основной памяти и объема памяти, занимаемой другими про-
цессами. Поскольку в UNIX применяется концепция виртуальной памяти
каждый процесс в UNIX имеет собственный диапазон адресов памяти, на-
зываемый виртуальным адресным пространством (virtual address space),
которое предназначено для хранения необходимой информации. Вирту,
альное адресное пространство процесса состоит из области команд, области
данных и области стека.40
Ядро системы хранит блок управления процессом в защищенной облас-
ти памяти, недоступной для пользовательских процессов. В UNIX-систе-
мах блок управления процессом хранит содержимое регистров процессора,
идентификатор процесса (PID), значение программного счетчика и систем-
ный стек.41’42 РСВ всех процессов перечислены в таблице процессов, что
дает возможность операционной системе получать доступ к информации
о любом процессе (например, о его приоритете).43
Процессы UNIX могут взаимодействовать с операционной системой пу-
тем вызова системных процедур. На рисунке 3.10 перечислены некоторые
из доступных системных процедур. Одни процессы могут порождать дру-
гие процессы, вызывая системную функцию fork, которая создает копию
родительского процесса.44’45 В распоряжение дочернего процесса перехо-
дит копия данных родительского процесса, сегменты стека и все остальные
ресурсы.46’47 К области команд, содержащей доступные только для чтения
инструкции родительского процесса, получает доступ и дочерний процесс.
Немедленно после вызова функции fork родительский и дочерний процес-
сы содержат одинаковые данные и инструкции. Это означает, что оба про-
цесса будут выполнять идентичные операции, пока кто-то из них как-ни-
будь себя не идентифицирует. Поэтому в результате вызова системной
функции fork возвращаются разные значения, родительскому процессу
присваивается PID дочернего процесса, а дочернего процессу — ноль. Бла-
годаря данному соглашению только что созданный дочерний процесс полу-
чает возможность идентифицировать себя, как только что созданный-
Придерживаясь данного соглашения, разработчики приложений могут за-
давать инструкции, предназначенные для выполнения именно дочерни#1
процессом.
Процесс может вызвать системную функцию ехес для загрузки новой
программы из файла. Функция ехес часто вызывается дочерним процес-
----------------------------------------------------
педственно после его создания.67 Когда родительский процесс
0М йеП°Счерний процесс, родительский процесс может вызвать систем-
созД0еТ Д°цию wait, которая блокирует родительский процесс до тех пор,
лую ФуВВ ет завершена работа порожденного дочернего процесса. Завер-
110ка В<1 ту процесс вызывает системную функцию exit. Таким образом,
Л1ая раб°ится в известность об окончании работы процесса. Ядро системы
яДР° сТЭ т освобождая всю память процесса и другие занимаемые им ре-
Реа^тРУна^ример, открытые файлы. В случае завершения работы роди-
сурсЫ> процесса, дочерние процессы поднимаются вверх по иерархии
тельс140^ превращаясь в прямых потомков процесса init.69’70 Если же ро-
ИРоце^скИ’й процесс был завершен командой kill, все дочерние процессы
ДаЗже уничтожаются.
it иоритеты процессов в UNIX обозначаются целыми числами от -20
19 (включая крайние значения), которые система использует для
Д° л чтобы определить, какой процесс должен быть запущен следую-
т ’ Чем меньше значение, тем более высоким приоритетом обладает
поцесс при планировании.71 Процессы операционной системы, назы-
ваемые процессами ядра, обычно имеют отрицательное значение при-
оритета, то есть их приоритет выше приоритета пользовательских про-
цессов.72 Процессы операционной системы, периодически выполняю-
щие служебные операции (демоны), как правило, выполняются с самым
низким приоритетом.
Многим приложениям для работы требуется взаимодействие с целым
рядом независимых компонентов. В UNIX предусмотрено несколько меха-
низмов, позволяющих процессам обмениваться данными друг с другом,
например, с помощью сигналов либо каналов (см. раздел 3.5 и раз-
дел 20.10.2).73
Системная функция Описание
fork Порождает дочерний процесс, предоставляя ему копию ресурсов родительского процесса.
ехес Загружает инструкции и данные процесса из файла в его адресное
wait пространство. Блокирует выполнение вызывающего процесса до тех пор, пока не будет
signal завершена работа дочернего процесса. Позволяет процессу задавать обработчик сигналов для определенного типа сигналов.
exit nice Завершает работу вызывающего процесса. Изменяет приоритет процесса.
Системные функции UNIX
Рие- 3.10.
214
Учебный пример
Система UNIX
Во времена, когда не было Windows,
Macintosh, Linux и даже DOS, операционные
системы, как правило, предназначались для
работы на одной определенной модели ком-
пьютера: для управления системными ресур-
сами, выполнения потоковой обработки паке-
тов и, возможно, еще каких-то дополнитель-
ных функций.48 С 1965 по 1969 год группа
исследователей из Bell Laboratories, General
Electric и Project MAC Массачусетского техно-
логического института занималась разработ-
кой операционной системы Multics для ком-
пьютеров общего назначения под девизом
«все возможные функции для любого пользо
вателя».49 Эта система была громоздкой, до-
рогостоящей и сложной. В 1969 Bell Labs от-
странилась от участия в этом проекте, собрав
собственную небольшую команду разработ-
чиков, под руководством Кена Томпсона, ко-
торая взялась за разработку более практичной
операционной системы для компьютеров Bell
Labs. Томпсон отвечал за реализацию базовых
компонентов операционной системы, назван-
ной Брайаном Керниганом UNICS, в противо-
вес MULTICS. В конце концов, обозначение
было изменено на UNIX. Через несколько лет
операционная система UNIX была переписана
на интерпретируемом языке Томпсона В (ос-
нованном на языке программирования BCPL,
авторство которого принадлежит Мартину Ри-
чардсу), а вскоре после этого — на более быст-
ром компилируемом языке С (создателем ко-
торого является Денис Ритчи).50
Из-за федерального анти-трастового иска,
компания AT&T (владеющая Bell Labs) была
лишена права продажи компьютерных про-
дуктов, поэтому она занялась распростране-
нием исходных кодов UNIX среди учебных за
ведений за небольшую плату, покрывающую
только стоимость изготовления магнитны
лент. Группа студентов Калифорнийского
университета в Беркли, которой руководил
Билл Джой (позднее ставший соучредителем
Sun Microsystems), модифицировала исход,
ные коды UNIX, превратив операционную
систему в то, что сегодня нам известно под
именем Berkeley Software Distribution UNIX
(BSD UNIX)51
Отраслевые разработчики программного
обеспечения переходили на UNIX, привле-
ченные ее бесплатностью, компактностью
и широким возможностям настройки. Чтобы
работать в UNIX разработчики должны были
учить язык С, который им явно нравился.
Большинство разработчиков в те годы обуча-
лись в колледжах, где в курсах по програм-
мированию предпочтения понемногу сме-
щались от Pascal в сторону языка С. Компания
Sun Microsystems взяла за основу своей
SunOS именно версию BSD UNIX, и только
позднее в сотрудничестве с AT&T разработа-
ла операционную систему Solaris в основу
которой лег System V Release 4 UNIX °т
AT&T.52 Другая группа разработчиков UNIX,
обеспокоенная тем, что сотрудничество Sun
и AT&T ставит компанию Sun в неравные кон-
курентные условия перед другими разработ-
чиками UNIX, сформировала Фонд открь1'
того программного обеспечения (Ор611
Software Foundation, OSF) для создания соб
ственной открытой версии UNIX под назва
нием OSF/1. Жесткая конкуренция меЖДУ
OSF и AT&T, за спиной которой стояла $uf1'
получила название «войн UNIX».5’
снов6 технологии UNIX было создано
к*э° известных операционных систем.
неСК°7гоДУ профессор Эндрю Таненбаум из
В198/ситета Врейе (Vrije) в Амстердаме
^Роперационную систему Minix - уре-
С03ДЭю версию ОС, предназначенную специ-
занну й обучения основам проектирова-
аЛьН°перационных систем, которая до сих
НИЯ используется в этих целях в программ-
ах курсах некоторых колледжей. Линус
Торвальдс, финский студент-аспирант, ис-
пользовал Minix в качестве основы при соз-
дании хорошо известной ныне операцион-
ной системы Linux, распространяемой по
принципу «открытого кода» (см. главу 20).*
ную систему с открытыми кодами, и такие
компании, как IBM, Hewlett Packard, Sun
Microsystems и Intel предлагают версии Linux
для своих серверов. Другим проектом с откры -
тыми кодами стала операционная система
OpenBSD, разработанная под руководством
Тео де Раадта, которая считается самой за-
щищенной операционной системой в мире
(см. главу 1 9).55'56'57'58 Еще одна операцион-
ная система с открытыми кодами — FreeBSD,
которая славится простотой использова-
ния.59 Другой потомок BSD, NetBSD ориенти-
рована в первую очередь на переносимость
между различными системами.606’ В основу
ОС AIX, разработанной компанией IBM, лег-
ли System V и BSD,62 — под управлением этой
системы работают некоторые серверы IBM.
Компания IBM заявила о высоком уровне
совместимости исходных кодов AIX с Linux.63
Сильным конкурентом для операционных
систем AIX и Solaris стала операционная
система HP-UX от Hewlett-Packard, которая
получила высокие оценки во всех номина-
циях в отчете за 2002 год от D. Н. Brown
Associates, опередив такие ОС как AIX
и Solaris.64'65'66
Вопросы для самопроверки
1. Почему родительский и дочерний процесс могут получать общий
доступ к области команд родительского процесса после вызова сис-
темной функции fork?
2. Почему процесс вынужден использовать механизм взаимодействия
процессов (IPC) для обмена информацией с другими процессами?
Ответы 1) В области команд содержатся инструкции, которые не
могут модифицироваться ни одним процессом. В результате, дочерний
и родительский процессы выполняют один и те же инструкции неза-
висимо от того, сколько копий области команд существует в памяти.
Таким образом операционная система экономит память, предоставляя
общий доступ для родительского и дочернего процесса к одной и той
же области команд в памяти. 2) Операционная система запрещает не
связанным между собой процессам получать общий доступ к сегмен-
там данных из своего адресного пространства. Поэтому, чтобы сделать
данные одного процесса доступными для другого, операционная систе-
ма вынуждена прибегать к специальным механизмам.
216
Веб-ресурсы
msdn.microsoft.com/library/en-us/dllproc/base/
about_processes_and_threads
Описание процессов в Windows XP. ' a®₽
www.freebsd.org/handbook/basics-processes.html
Описание методики управления процессами в операционной системе Freejtan
Программный код операционной системы Mac OS X частично основан на п ’
граммном коде FreeBSD. Р°-
www.linux—tutorial.info/cgi-bin/display.pl?83&99980&0&3
Здесь обсуждается тема управления процессами в Linux.
docs.sun.com/db/doc/806-4125/6jd7pe6bg?a=view
Диаграмма смены состояний процесса в операционной системе Solaris, разрабо.
тайной компанией Sun Microsystems.
www.beyondlogic.org/interruptsZinterupt.htm
Обзор темы прерываний с детальным описанием обработки прерываний в архи-
тектуре Intel.
developer.apple.com/documentation/Hardware/DeviceManagers/pci_srvcs/
pci_cards_drivers/PCI_BOOK.16d.html
Документация по модели прерываний для компьютеров Apple Macintosh.
Umozu
Процесс, представляющий собой программу в стадии выполнения, является
центральным звеном, необходимым для понимания работы современных компью-
терных систем, в том числе и вопроса многозадачности. Каждый процесс обладает
собственным адресным пространством, которое делится на область команд, об-
ласть данных и область стека. Во время своего существования процесс переходит
из одного состояния в другое. Процесс может находиться в состоянии выполнения,
готовности или блокировки. Ссылки на процессы, которые не работают в теку-
щий момент времени можно найти в списке готовых к выполнению процессов либо
в списке заблокированных процессов.
Когда процесс оказывается первым в списке готовых и когда освобождается
процессор, этому процессу выделяется процессор, и происходит смена состояний
процесса — он переходит из состояния готовности в состояние выполнения. Пре'
доставление процессора первому процессу из списка готовых процессов называется
запуском или выбором процесса для выполнения (диспетчеризацией). Чтобы пре"
дотвратить случайный либо умышленный монопольный захват ресурсов системы
одним процессом, операционная система настраивает аппаратный таймер преры-
ваний (называемый также интервальным таймером), регламентируя выполнение
процессов в течение определенных временных интервалов или квантов. Если вЫ
полняющийся процесс до истечения отпущенного ему кванта времени инициирУ
операцию ввода/вывода, он заблокирует сам себя до завершения операции вв
да/вывода. Альтернативным вариантом является реализация кооперативной мн°
гозадачности, при которой каждый процесс выполняется до тех пор, пока у него
закончатся инструкции либо пока он добровольно не передаст процессор в расй
ряжение другого процесса. Такой подход таит в себе опасность монопольного 30
хвата процессора отдельным процессом.
Как правило, во время создания процесса операционная система выполняет Я®
сколько операций, в том числе присвоение процессу идентификационного номер
пание блока управления процессом (РСВ) либо дескриптора процесса, со-
р)Р)> с° о программный счетчик команд (то есть указатель на следующую инст-
Р р>}са1ЯеГ° торая должна быть выполнена процессом), PID, приоритет при плани-
К контекст выполнения процесса. Операционная система хранит указате-
каждого процесса непосредственно в таблице процессов, благодаря чему
Рд на аетСя быстрый доступ к блокам управления любого процесса. Когда про-
обесПе'1йВ чИВает свою работу (либо его завершает операционная система), сведе-
аесс закаНуДаляются из таблицы процессов, после чего высвобождаются все зани-
0ля ° Не^цессом ресурсы, включая память.
j4aei*Ibie р может породить новый процесс. В таком случае порождающий процесс
ПРоЦ^родительским процессом, а другой, только что созданный — дочерним,
называю черНего процесса родительским может являться только один опреде-
длялю цесс Таким образом формируется иерархия процессов. В некоторых
данный случае уничтожения родительского процесса, автоматически заверша-
систе®^ порожденные им процессы; в других системах дочерние процессы сущест-
ютсЯ аезависимо от родительских, и уничтожение родительского процесса никак
не влияет на дочерние. „
В Поиостановленныи процесс на неопределенный промежуток времени выбывает
осгязания за процессорное время, не подвергаясь при этом уничтожению. Пре-
1,3 „ный процесс может находиться в состоянии приостановлен готов либо приос-
тановлен блокирован. Приостановка выполнения процесса может быть иницииро-
вана как самим процессом, так и любым другим процессом; но для возобновления
работы приостановленного процесса требуется вмешательство со стороны другого
процесса.
Когда операционная система осуществляет выборку следующего процесса из спи-
ска готовых процессов для запуска на процессоре, в это же время выполняется опе-
рация по переключению контекста. Процедура переключения контекста должна яв-
ляться прозрачной для процессов. Во время переключения контекста процессор не
может выполнять какие-либо полезные вычисления, поэтому операционная система
старается минимизировать время переключения контекста. В ряде архитектур на-
кладные расходы, связанные с необходимостью переключейия контекста, могут
быть снижены благодаря аппаратной реализации переключения контекста.
С помощью прерываний программное обеспечение может реагировать на сигна-
лы, поступающие от оборудования. Прерывание может быть инициировано выпол-
няющимся процессом (в этом случае его называют ловушкой, считая его синхрон-
ным по отношению к процессу) либо некоторым событием, не обязательно связан-
ным с активным процессом (тогда оно считается асинхронным). Альтернативное
Решение (без использования прерываний) состоит в постоянном опрашивании со-
яния всех устройств, то есть последовательном опросе.
пыот₽^РЫ?аНИЯ важны Для обеспечения быстродействующей и защищенной ком-
По ря°и среды. Приняв прерывание, процессор запускает одну из функций ядра
еноте₽ао°ТКе п₽еРываний. Обработчик прерываний определяет, каким образом
ботчи ,1'Олжна отреагировать на то или иное прерывание. Местоположение обра-
РЫвани“ ЧРеРываний хранится в массиве указателей, называемом вектором пре-
тУры си*" ”а®°Р поддерживаемых компьютером прерываний зависит от архитек-
и ИсКлючеМЫ аРхитектуре IA-32 распознаются два типа сигналов: прерывания
с°в, кор116 опеРационные системы реализуют механизмы взаимодействия процес-
СеРвера рЫе’ например, позволяют веб-браузеру извлекать данные с удаленного
сы о настчИГНаЛамИ называют программные прерывания, уведомляющие процес-
сам обмен ПЛении того или иного события. Однако сигналы не позволяют процес-
ли(?ВаТЬСЯ Данными между собой. Процессы могут перехватывать, игнори-
Вза11мо ° “аскировать сигналы.
11 ДвуиеИСТВИя пР°Иессов с помощью сообщений может быть однонаправлен-
ная, Что п ап'3авленным- В одной из моделей передачи сообщений предусматрива-
Роцессы отправляют и принимают сообщения путем вызова системных
________-_______-_________-_______-_______-________-________________________________________________
функций. Популярной реализацией механизма передачи сообщений является
нал — защищенная операционной системой область памяти, с помощью кот0
могут обмениваться информацией несколько процессов. Одна из проблем п
ма-передачи сообщений в распределенной системе связана с необходимостью , Ле-
кального именования процессов, чтобы при явном вызове можно было корреР^-
указать отправителя и получателя сообщения.
Процессы UNIX получают в свое распоряжение область адресов памяти, На
ваемую виртуальным адресным пространством, которая состоит из области 11
манд, области данных и области стека. В UNIX-системах в блоке управления
цессом хранятся разнообразные сведения, включая содержимое регистров пр01 *>а
сора, идентификатор процесса (PID), счетчик команд и системный с^с'
Информация о процессах размещается в таблице процессов, с помощью кототЛ
операционная система может получить сведения о любом из них. Процер ®
в UNIX взаимодействуют с операционной системой путем вызова системных фун
ций. Процесс может породить дочерний процесс, вызвав системную функций
fork, которая создает точную копию родительского процесса. Приоритет процесс
в UNIX определяется с помощью целочисленных значений в диапазоне от -20 до jg
(включительно). Система использует значение приоритета, чтобы определить, ца
кой процесс должен быть выполнен следующим. Меньшее числовое значение соот-
ветствует более высокому приоритету при планировании. Кроме того, в ядре систе-
мы реализованы механизмы взаимодействия процессов, например каналы, кото-
рые позволяют обмениваться данными не связанным между собой процессам.
Ключевые термины
BSD UNIX (Berkeley Software Distribution UNIX) — модифицированная версия
UNIX, выпущенная группой разработчиков во главе с Биллом Джоем из Кали-
форнийского университета в Беркли. ОС BSD UNIX стала родоначальницей не-
скольких разновидностей UNIX.
Multics Relational Data Store (MRDS) — первая коммерческая реляционная сис-
тема баз данных, включенная в состав операционной системы Multics.
OSF/1 — клон UNIX, созданный организацией OSF, чтобы конкурировать с ОС
Solaris.
Solaris — версия UNIX, сочетающая в себе программный код System V Release 4
и SunOS, созданная в результате совместной работы компаний AT&T и Sun.
Аварийное завершение (abort) — операция досрочного прекращения выполнения
процесса. В спецификации IA-32 — невосстановимая ошибка процесса.
Адресное пространство (address space) — область памяти, с которой может рабо-
тать процесс.
Блок управления процессом (process control block, РСВ) — структура данных, с°
держащая информацию о процессе (PID, адресное пространство и состоянИ г
Другое название — дескриптор процесса.
Вектор прерываний (interrupt vector) — защищенный массив в памяти, в котор0
хранятся указатели на местоположение обработчиков прерываний. f
Виртуальное адресное пространство (virtual address space) — диапазон аДРе°
в памяти, на которые может ссылаться процесс. Виртуальное адресное nV
странство позволяет процессу работать с объемом памяти, превышающим об'ь
физической памяти, установленной в системе.
Возобновление (resume) — вывод процесса из состояния приостановки.
Дескриптор процесса (process descriptor) — см. Блок управления процессом-
Диспетчер (dispatcher) — компонент операционной системы, отбирающий для
пуска на процессоре первый процесс из списка готовых к выполнению процесс0
219
„ я ооцесса
“ процесс (child process) — новый процесс, созданный родительским про-
Дочерний процесс располагается на один уровень ниже родительского
А дессоИ- <7 создания процессов. В UNIX-системах дочерние процессы создаются
в йера₽ «зова системной функции fork.
путем вь скирование прерываний (disable/mask interrupts) — при запре-
За1’Ре,яе^маскировании определенного типа прерываний, прерывания указанного
денки/ тавЛЯЮТся процессу, запретившему (замаскировавшему) их. В этом
тцпа яепрерывания либо добавляются в очередь для последующей доставки
^УД^яются процессором.
локационный номер процесса (process identification number, PID) — зна-
ДдентиФ уинкцдьным образом идентифицирующее процесс.
Чв ическая структура процессов (hierarchical process structure) — структура
Церар* озавИСИМОСТИ процессов, согласно которой родительский процесс может
^пождать множество дочерних, но при этом для каждого дочернего процесса
только один процесс может являться родительским.
Интервальный таймер — см. Таймер прерываний.
п лючение (exception) — аппаратный сигнал, вызванный ошибкой. В специфика-
ИСции IA-32 исключения делятся на ловушки, промахи и аварийные завершения.
Канал (pipe) — механизм передачи сообщений, формирующий прямой поток дан-
ных между двумя процессами.
- кваНт (quantum) — промежуток времени, в течение которого процессор остается
выделенным одному процессу. Использование квантов позволяет предотвратить
монопольный захват процессора одним процессом.
Кооперативная многозадачность (cooperative multitasking) — технология плани-
рования выполнения процессов, при которой процесс занимает процессор до тех
пор, пока добровольно не передаст управление другому процессу.
Ловушка (trap) — в спецификации IA-32, исключение, возникающее, например, в ре-
зультате ошибок переполнения (когда значение, которое должно быть сохранено
в регистре, превышает его разрядность). Кроме того, ловушки формируются при вы-
полнении программы, когда в ее коде встречается контрольная точка останова.
Метод изоляции доступа (Access Isolation Mechanism, AIM) — реализация мандат-
ного контроля доступа в Multics.
Область данных (data region) — часть адресного пространства процесса, содержа-
щая данные (а не инструкции). Эта область доступна для изменений.
ласть команд (text region) — часть адресного пространства процесса, содержа-
щая инструкции, предназначенные для выполнения процессором.
сть стека (stack region) — область адресного пространства процесса, содержа-
Щ я инструкции и данные для открытых процедур. Размер стека увеличивается
Об л^Чае вызова вложенных процедур и уменьшается по их завершении.
пп„°ТЧик ирерываний (interrupt handler) — код ядра, выполняемый в ответ на
Пар РЫвание-
РаздееЛЬН°е выполнение программ (concurrent program execution) — механизм
ми. £ ения процессорного времени между несколькими активными процесса-
Не в с однопР°цессорной системе, параллельные процессы в действительности
тем«» о. Стоянии выполняться одновременно, тогда как в многопроцессорной сис-
ПеРеда °Возможно-
С®.°®1цепий (message passing) — механизм, позволяющий не связанным
^еРекл С°бОЙ пР°йессам общаться путем обмена информацией.
М°й 01?ение контекста (context switching) — выполняемая операционной систе-
1гРоце(-/ Ра|Р1я отбора процессора у одного процесса и его выделения другому
ВаемОгСУ‘ ^Ри эт°м операционная система обязана сохранить состояние преры-
са, ЙЬ1(_ пРоцесса. Аналогично, система должна восстановить состояние процес-
иРаемого для запуска из списка готовых к выполнению.
Порождение процесса (spawning a process) — создание дочернего процесса д
тельским. °Аи
Последовательный опрос (polling) — механизм проверки состояния устройств
тем периодического тестирования каждого устройства. Последовательный
рос может использоваться вместо прерываний, но применение данного меха OtI-
ма приводит к снижению производительности системы.
Прерывание (interrupt) — аппаратный сигнал, сообщающий о наступлении о>>
деленного события. Прерывания заставляют процессор выполнять послед0^'
тельность программных инструкций, называемых обработчиком преры аний
Прерывание завершения ввода/вывода (I/O completion interrupt) — сообщев
выдаваемое устройством по окончании обслуживания запроса ввода/вывода ’
Приоритет процесса (process priority) — значение, определяющее важность дан»
го процесса по сравнению с другими.
Программный счетчик или счетчик команд (program counter) — указатель на cjJ
дующую инструкцию процесса, которая должна быть выполнена процессоров
После выполнения этой инструкции, значение счетчика команд корректирует^
таким образом, чтобы тот ссылался на следующую инструкцию процесса.
Промах (fault) — в спецификации IA-32 вид исключения, вызванного ошибкой де-
ления на ноль либо запрещенной операцией доступа к памяти. Некоторые про-
махи могут быть исправлены с помощью соответствующих обработчиков исклю-
чений операционной системы.
Процесс (process) — логический объект, описывающий программу в стадии вы-
полнения.
Разблокирование (unblock) — вывод процесса из состояния блокировки при появ-
лении ожидаемого события.
Родительский процесс (parent process) — процесс, породивший один или несколь-
ко дочерних процессов. В UNIX создание процессов осуществляется путем вы -
ва системной функции fork.
Сигнал (signal) — вырабатываемое программным обеспечением сообщение, инфор-
мирующее о наступлении определенного события либо возникновении ошибки.
Сигналы не позволяют передавать какие-либо данные.
Смена состояний (state transition) — процедура перехода процесса из одного со-
стояния в другое.
Состояние блокировки (blocked state) — состояние процесса, в котором он ожида-
ет наступления определенного события, например, завершения операции вво-
да/вывода. Процесс в этом состоянии не может использовать процессор, Даясе
если процессор свободен.
Состояние выполнения (running state) — состояние процесса, если в данный М°
мент ему выделен процессор.
Состояние готовности (ready state) — состояние процесса, в котором он мог 6Ы
сразу использовать процессор, предоставленный в его распоряжение.
Состояние приостановки (suspended state) — состояние процесса (приостанови,
блокирован или приостановлен готов), в котором он на некоторое время выбы
ет из борьбы за процессорное время, не прекращая при этом своего существо^,
ния. Раньше с помощью перевода процесса в это состояние оператор системы .
вручную менять загрузку системы и/или реагировать на угрозу системных об
Состояние приостановлен блокирован (suspendedblocked state) — состояние
цесса, получаемое в результате приостановки процесса, находящегося в с°с^а
нии блокировки. При возобновлении процесса он возвращается в состояние
кировки.
Состояние приостановлен готов (suspendedready state) — состояние процесса, .,
лучаемое в результате приостановки процесса, находящегося в состоянии г0
ности. При возобновлении процесса он возвращается в состояние готов нос/71
е процесса (process state) — статус процесса (выполняется, готов, блоки
т-Д-)-
рови отовых (к выполнению) процессов (ready list) — структура данных ядра,
Сдйсо1С Г°ой в упорядоченном виде хранятся указатели на все готовые к выполне-
в дот°Р ссь1 системы. Сортировка списка готовых к выполнению процессов
вцю °Р оСущестВляется в соответствии с их приоритетом.
обич11° блОКИрОванНых процессов (blocked list) — структура данных ядра, со-
СПЙСОК за указатели на все заблокированные процессы. Данный список не упо-
рядочен по приоритету.
контроля доступа (Access Control List, ACL) — реализация избирательного
контроля Достуиа в Multics.
К а готовности (ready list) — см. Список готовых к выполнению процессов.
Та ца процессов (process table) — структура данных, в которой хранятся указа-
тели на все процессы системы.
"мер прерываний (interrupting clock или interval timer) — аппаратно реализо-
ванный таймер, вырабатывающий сигналы прерывания через определенные
поомежутки времени (называемые квантами) для того чтобы не допустить моно-
польного захвата процессора одним процессом.
фонд открытого программного обеспечения (Open Software Foundation, OSF) —
коалиция разработчиков UNIX, создавших клон OSF/1 UNIX, в целях конку-
ренции с ОС Solaris от компаний AT&T и Sun. Организация OSF и совместное
предприятие AT&T и Sun прославились своим участием в так называемых «вой-
нах UNIX».
Упражнения
3.1.
3.2.
3.3.
3.4.
Дайте несколько определений процесса. Почему, как вы думаете, не суще-
ствует общепринятого универсального определения процесса?
Иногда термины пользователь и процесс являются взаимозаменяемыми.
Дайте определение для каждого термина. В каких случаях они приобрета-
ют близкий смысл?
Почему упорядочивание списка заблокированных процессов по приоритету
лишено смысла?
Способность одного процесса порождать новые процессы чрезвычайно важ-
на, однако с этой возможностью связаны свои опасности. Рассмотрите по-
следствия, к которым могло привести разрешение пользователю запускать
процесс, показанный на рисунке 3.11. Считаем, что f ork() представляет со-
оои вызов системной функции, порождающей дочерние процессы.
а- Предположим, что система разрешит запуск этого процесса, каковы воз-
можные последствия?
• Вас, как разработчика операционной системы, попросили обезопасить
систему от запуска подобных процессов. Нам известно (из «проблемы
останова» в теории вычислимости), что в общем случае невозможно
предсказать поведение выполняемой программы. Как отразится выше-
упомянутый фундаментальный принцип компьютерных наук на вашей
в способности предотвращать запуск подобных процессов?
Предположим, вы пришли к выводу, что отклонять выполнение опреде-
ленных процессов неразумно, и наилучшим подходом является контро-
лирование этих процессов во время их выполнения. Какими средствами
контроля может воспользоваться операционная система для обнаруже-
ния процессов, подобных вышеупомянутому, во время их выполнения?
—-----М
г. Смогут ли предложенные вами средства контроля помешать проц6с
создавать новые дочерние процессы?
д. Каким образом предложенная вами реализация средств контроля
влияет на механизм обработки прерываний в системе? Чо.
1 int main() {
2
3 while (true ) {
4 fork () ;
5 }
6
7 )
PlIC. 3.11. Программный код к упражнению 3.4
3.5.
3.6.
3.7.
В системе, предназначенной для работы одного пользователя, достаточно
легко обнаружить попадание программы в бесконечный цикл. Однако
в многопользовательской системе, где запущено большое количество про.
цессов, выявить зацикливание программы сложнее.
а. Как операционная система может определить факт попадания процесса
в бесконечный цикл?
б. Встраивание какие мер безопасности в операционную систему может
быть оправдано в целях предотвращения бесконечного пребывания про-
цесса в замкнутом цикле?
Выбор правильного размера кванта времени важен для эффективной рабо-
ты операционной системы. Вопрос подбора размера кванта мы обсудим
в деталях чуточку позже. На данном этапе попробуем предугадать ряд свя-
занных с этим проблем.
Рассмотрим однопроцессорную систему с разделением времени и с под-
держкой большого количества интерактивных пользователей. Каждый раз,
когда процессор поступает в распоряжение процесса, таймер прерываний
выдает прерывания по окончании заданного кванта времени. Это позволяй
операционной системе предотвращать монопольный захват процессора от-
дельным процессом и обеспечивает быстрое реагирование на запросы инте-
рактивных процессов. При этом для всех процессов системы используется
один и тот же квант времени.
а. К какому эффекту приведет установка экстремально большой величины
кванта, например, 10 минут?
б. Что произойдет, если установить экстремально малое значение кванта>
например, несколько процессорных циклов?
в. Очевидно, что приемлемое значение размера кванта находится где-то в пР°
межутке между значениями, указанными в пунктах (а) и (Ь). ПреДИИ”,
жим, вы можете варьировать значение кванта, постепенно увеличивая?6
Как определить момент, когда вы достигнете «правильного» значения-
г. Какие факторы делают это значение правильным с точки зрения поль
вателя? у
д. Какие факторы делают это значение правильным с точки зрения систему
В механизме блокирования/пробуждения процесс может заблокиров^
сам себя в ожидании определенного события. При этом наступление о
даемого события должно быть обнаружено другим процессом, котор
и разбудит заблокированный процесс. Возможна ситуация, когда про11
блокирует сам себя в ожидании события, которое никогда не наступит-
223
^ожет ли операционная система выявить заблокированный процесс,
а ожидающий событие, которое никогда не наступит?
Какие меры безопасности нужно внедрить в операционную систему, что-
предотвратить бесконечное ожидание событий процессом?
из причин использования квантов для прерывания работы процессов
3.8- Одя^стечении ОПТИМального промежутка времени заключается в возврате
П° пессора назад в распоряжение операционной системы, чтобы ОС могла
пР?шествить запуск следующего процесса. Предположим, что в системе от-
°С\твует таймер прерываний и единственным способом освобождения про-
с" „ора является его добровольное возвращение процессом. Кроме того, бу-
Ц м считать, что в операционной системе не предусмотрены механизмы вы-
борки и запуска следующих в очереди процессов.
Опишите, каким образом совместная работа пользовательских процес-
сов позволяет добиться создания управляемого пользователем механиз-
ма диспетчеризации.
б Какие потенциальные опасности присущи данной схеме?
в Назовите преимущества данного механизма для пользователей по срав-
нению с контролируемыми системой механизмами диспетчеризации.
39В некоторых системах дочерний процесс уничтожается автоматически при
удалении родительского. В других системах дочерние процессы существу-
ют независимо от родительских и уничтожение родительского процесса ни-
как не влияет на дочерние.
3.10.
3.11.
3.12.
3.13.
а. Обсудите преимущества и недостатки каждого похода.
6. Придумайте ситуацию, в которой уничтожение родительского процесса ни
в коем случае не должно привести к уничтожению дочерних процессов.
Когда прием прерываний от большинства устройств запрещен, их обслужи-
вание откладывается до тех пор, пока данный тип прерываний не будет раз-
решен повторно. Новые прерывания от этих устройств не принимаются.
Работа самих устройств временно приостанавливается. Однако в системах
реального времени, среда, формирующая прерывания, как правило, суще-
ствует независимо от компьютерной системы и продолжает генерировать
прерывания в любом случае. В подобной ситуации прерывания могут быть
потеряны.
а. Обсудите, к каким последствиям может привести потеря прерываний.
6. Что более приемлемо в системе реального времени: потеря отдельных
прерываний либо временная приостановка работы системы до тех пор,
пока она не сможет снова принимать прерывания?
Как вы уже не раз могли убедиться в данной книге, управление ожиданием
представляет собой важную функцию любой операционной системы. Из
этой главы вы должны были запомнить ряд состояний ожидания процесса
(^°тов, блокирован, приостановлен готов и приостановлен блокирован).
ассмотрите, как процесс может входить в каждое из вышеперечисленных
состояний, чего могут ожидать процессы и какова вероятность того, что
Процесс попадет в состояние бесконечного ожидания.
акие функциональные возможности должны быть встроены в операцион-
Ую систему, для предотвращения ситуаций ожидания процессом события,
оторое никогда не наступит?
н идающий процесс потребляет разнообразные системные ресурсы. Мож-
ли саботировать работу системы, постоянно создавая процессы, ожидаю-
rv ейСобытий, которые никогда не произойдут? Какие защитные меры мо-
быть предприняты в этом случае?
жет ли в однопроцессорной системе возникнуть ситуация, когда ни один
Роцесс не будет находиться в состоянии готовности или выполнения?
Раведливо ли применить к такой системе термин «тупиковое состоя-
ие»? Поясните ваш ответ.
224
3.14.
3.15.
3.16.
3.17.
Зачем понадобилось добавление тупикового состояния (состояния слгев
в диаграмму смены состояний?
Система А позволяет каждому пользователю выполнять только один
цесс. Система В позволяет каждому пользователю выполнять нескод^Ч-
процессов. Изучите организационные различия между операционц
системами А и В в плане поддержки процессов. ь\
Сравните между собой такие механизмы взаимодействия процессов
сигналы и передача сообщений. ’ *4
Как мы уже говорили в разделе 3.6, в операционной системе UNIX пр0,
сы могут изменять свой приоритет путем вызова системной функции п
Какие ограничения должно накладывать ядро UNIX на вызов этой
ции и почему?
Рекомендуемые исследовательские учебные проекты
3.18. Сравните информацию, хранимую в блоке управления процессом ррь
в Linux, Microsoft Windows ХР и Apple OS X. Какие состояния процессу
определены в каждой из перечисленных операционных систем?
3.19. Изучите усовершенствования, внесенные со временем в методику перекл».
чения контекста. Каким образом было оптимизировано время, затрачивав-
мое на переключение контекста? Каким образом процедура переключения
контекста может быть аппаратно ускорена?
3.20. Семейство процессоров Intel Itanium для высокоскоростных вычислений, соз-
давалось в соответствии со спецификацией IA-64 (64-разрядных вычислений)
Сравните рассмотренный в этой главе метод обработки прерываний в архитек-
туре IA-32 с обработкой прерываний в архитектуре IA-64 (посетите веб-стра-
ницу ПО адресу development. intel. com/design/itanium/manuals/245318 .pdf).
3.21. Обсудите схему прерываний, отличающуюся от рассмотренной в этой гла-
ве. Сравните эти две схемы.
Рекомендуемая литература
Рендел и Хорнинг описывают в своей книге базовые концепции процессов,
в том числе и управление многозадачностью.74 Лампсон рассматривает некоторые
базовые концепции процессов, включая переключение контекста.75 КвотермаЯ,
Силбершац и Петерсон обсуждают тему управления процессами в BSD UNIX 4.3.
В учебных примерах в части 8 данной книги также уделяется внимание теме ре®-
лизации процессов и управления ими в операционных системах Linux и Wind0”
ХР. Информация по обработке прерываний процессами доступна в литературе»
священной архитектуре компьютера, например в книге Computer Organization аП°
Design под авторством Патерсона и Хэнесси.77 t
Взаимодействие процессов является центральным вопросом функционировав
микроядра (см. раздел 1.13.3), а также архитектуры внешней части ядра операП0
ной системы. Поскольку быстродействие подобных систем очень сильно зависит от
фективности взаимодействия между процессами, немало внимания следует уделить
просу повышения быстродействия операций по взаимодействию между процесс®^
Ранние архитектуры78 взаимодействия процессов на основе сообщений, такие .
Chorus, представляли собой распределенные операционные системы, когда в 1986 г
было разработано микроядро Mach.79 Перечень усовершенствований, внесенных в
ханизмы взаимодействия процессов, которые поспособствовали эффективной поДДе₽
ке микроядра, отражены в литературе.80’81 #
Каждой операционной системе присущи характерные отличия механизмов вз
модействия процессов. В большинстве UNIX-систем используются механизм1
225
ые в этой главе. Описания подробностей реализаций можно найти на
дСтавЛеЯ ковОДства по Linux. Кроме того, мы советуем вам сначала прочесть гла-
иге Understanding the Linux Kernel9,2 обсуждаются механизмы взаимо-
f^20. В кН цессов в Linux, а в книге Inside Windows 2000s3 рассматриваются меха-
®еЙств11Я П₽^одействия процессов в Windows 2000 (большинство из которых реали-
йИзМЫ в3аИя операционной системы Windows ХР). Свежую библиографию для этой
зовая14иУйдете по адресу www.deitel.com/books/os3e/Bibliography.pdf.
главы вЬ1
Используемая литература
n 1 v Robert С., and Jack В. Dennis, «Virtual Memory, Processes, and Sharing
1 2Mu'ltics,» Proceedings of the ACM Symposium on Operating System Princi-
ples, January 1967.
Corbato, F.; M. Merwin-Daggett, and R.C. Daley, «An Experimental
*' Time-Sharing System,» Proceedings of the Spring Joint Computer Conference
(AFIPS), Vol. 21, 1962, pp. 335-344.
3 Van Vleck, Т.» «The IBM 7094 and CTSS,» March 3, 2003, <www.multi-
' cians.org/thw/7094.html>.
4. Van Vleck, T, «Multics General Information and FAQ,» September 14, 2003,
<www.multicians.org/general.html>.
5. Van Vleck, T, «Multics General Information and FAQ,» September 14, 2003,
<www.multicians.org/general. html>.
6. Green, P., «Multics Virtual Memory: Tutorial and Reflections,» 1993,
<ftp://ftp.stratus.com/pub/vos/multics/pg/mvm.html>.
7. Van Vleck, T, «Multics General Information and FAQ,» September 14, 2003,
< www. multicians. or g/general. html>.
8. Green, P., «Multics Virtual Memory: Tutorial and Reflections,» 1993,
<ftp://ftp.stratus.com/pub/vos/multics/pg/mvm.html>.
9. Van Vleck, T, «Multics General Information and FAQ,» September 14, 2003,
<www.multicians.org/general. html>.
10. Van Vleck, T, «Multics Glossary — A,» <www.multicians.org/mga.html>.
11. Van Vleck, T, «Multics Glossary — B,» <www.multicians.org mgb.html>.
!-• McJones, P., «Multics Relational Data Store (MRDS),» <www.mcjones.org/Sys-
tem_R/mrds.html>.
' Peterson, J. L.; J. s. Quarterman; and A. Silbershatz, «4.2 BSD and 4.3 BSD as
Samples of the UNIX System,» ACM Computing Surveys, Vol. 17, No. 4, De-
14 Smber 1985’ P- 388‘
Ра^ога1'огУ for Computer Science, «Prof. F. J. Corbato,» April 7, 2003,
p w-lcs.mit.edu/people/bioprint.php3?PeopleID=86>.
rin °58a^°’ M. Merwin-Daggett, and R.C. Daley, «An Experimental Time-Sha-
16. Mit stem,» Proc. Spring Joint Computer Conference (AFIPS), 335-344.
<Ww i^°ra^ory ^ог ComPuter Science, «Prof. F. J. Corbato,» April 7, 2003,
17. Mit ^'^cs’m^t.edu/people/bioprint.php3?PeopleID=86>.
’^Ww аЬога^гУ for Computer Science, «Prof. F. J. Corbato,» April 7, 2003,
18. p q w_Jcs.mit.edu/people/bioprint.php3?PeopleID=86>.
Vol ^°’ *^n Building Systems That Will Fail,» Communications of the ACM,
♦Unix No’ 9’ SePtember 1991, pp. 72-81.
„ tem „ Bystem Calls Links,» <www.softpanorama.org/Internals/unix_sys-
20. La^1~callsJinks.shtml>.
Uliini n’ B. W„ «А Scheduling Philosophy for Multiprocessing System,» Com-
nations of the ACM, Vol. 11, No. 5, 1968, pp. 347-360.
s Manual, Vol. 3, System Progr^
21. IA-32 Intel Architecture Software Developer’s Manual, Vol. 3, System Progv
mer’s Guide, 2002, pp. 6-1—6-15.
22. IA-32 Intel Architecture Software Developer’s Manual, Vol. 3, System Prog>
mer’s Guide, 2002. %
23. IA-32 Intel Architecture Software Developer’s Manual, Vol. 3, System Prog>
mer’s Guide, 2002, pp. 5-16. 4
24. IA-32 Intel Architecture Software Developer’s Manual, Vol. 3, System Proe-rv
mer’s Guide, 2002. ^4).
25. Krazit, T, «Study: Intel’s Q2 Market Share Up, AMD’s Down,» InfoWorld, July»
2002, <archive.infoworld.com/articles/hn/xml/02/07/31 /020731hnstudy.xmlx '
26. IA-32 Intel Architecture Software Developer’s Manual, Vol. 3, System Proe»/
mer’s Guide, 2002, pp. 5-2, 5-5. !)1-
27. IA-32 Intel Architecture Software Developer’
mer’s Guide, 2002, pp. 2-8.
28. Bar, M., «Kernel Korner: The Linux Signals Handling Model,» Linux JourIls,
May 2000, <www.linuxjoumal.com/article.php?sid=3985>. N
29. Bovet, D., and M. Cesati, Understanding the Linux Kernel, O’Reilly, 2001, p. 253
30. Bar, M., «Kernel Korner: The Linux Signals Handling Model,» Linux Journal
May 2000, <www.linuxjournal.COM/article.php?sid=3985>.
31. Gentleman, W. M., «Message Passing Between Sequential processes: The Reply
Primitive and the Administrator Concept,» Software — Practice and Experience.
Vol. 11, 1981, pp. 435-466.
32. Schlichting, R. D., and F. B. Schneider, «Understanding and Using Asynchronous
Message Passing Primitives,» in Proceedings of Symposium on Principles of Dis-
tributed Computing, August 1982, Ottawa, Canada, ACM, New York, pp. 141-147.
33. Stankovic, J. A., «Software Communication Mechanisms: Procedure Calls versus
Messages,» Computer, Vol. 15, No. 4, April 1982.
34. Staustrup, J., «Message Passing Communication versus Procedure Call Commu-
nication,» Software — Practice and Experience, Vol. 12, No. 3, March 1982,
pp. 223-234.
35. Cheriton, D. R., «An Experiment Using Registers for Fast Message-Based
Interprocess Communications,» Operating Systems Review, Vol. 18, No. 4, Octo-
ber 1984, pp. 12-20.
36. Olson, R., «Parallel Processing in a Message-Based Operating System,» IE®®
Software, Vol. 2, No. 4, July 1985, pp. 39-49.
37. Andrews, G. R., «Synchronizing Resources,» ACM Transactions on Program-
ming Languages and Systems, Vol. 3, No. 4, October 1981, pp. 405-430.
38. Andrews, G., and F. Schneider, «Concepts and Notations for Concurrent Pr°"
gramming,» ACM Computing Surveys, Vol. 15, No. 1, March 1983, pp. 3-44.
39. Bovet, D., and M. Cesati, Understanding the Linux Kernel, O’Reilly, 200 ।
pp. 524-532.
40. Thompson, K., «UNIX Implementation,» UNIX Programer’s Manual: 7th e°"’|
Vol. 2b, January 1979, <cm.bell-labs.com/7thEdMan/bswv7.html>. ,
41. Thompson, K., «UNIX Implementation,» UNIX Programer’s Manual: 7th ed‘’
Vol. 2b, January 1979, <cm.bell-labs.com/7thEdMan/bswv7.html>.
42. FreeBSD Handbook: Processes, 2002, <www.freebsd.org/handbook/basics-Pr
cesses.html>. ,
43. Thompson, K., «UNIX Implementation,» UNIX Programer’s Manual: 7th
Vol. 2b, January 1979, <cm.bell-labs.com/7thEdMan/bswv7.html>.
44. Thompson, K., «UNIX Implementation,» UNIX Programer’s Manual: 71
Vol. 2b, January 1979, <cm.bell-labs.com/7thEdMan/bswv7.html>.
45. Ritchie, D., and K. Thompson, «The UNIX Time-Sharing System», ComnuU11
tions of the ACM, July 1974, pp. 370-372.
227
оЧП Handbook: Processes, 2002, <www.freebsd.org/handbook/basics-pro-
46. Fre«Ps html>.
cess j< ; «UNIX Implementation,» UNIX Programer’s Manual: 7th ed.,
47. Tho,1lP January 1979, <cm.bell-labs.com/7thEdMan/bswv7.html>.
t ’ technologies, «The Creation of the UNIX Operating System, 2002,
48-bell-labs.com/history/unix/>.
<WWnick E., The Multics System: An Examination of Its Structure, Cambridge,
49’MA MIT Press, 1972.
' x Technologies, «The Creation of the UNIX Operating System», 2002,
50 <^w.bell-labs.com/history/unix/>.
Microsystems, «Executive Bios: Bill Joy,» <www.sun.com/aboutsun/me-
51‘ dS/ceo/mgtjoy.html>.
minSj B., «The History of Solaris,» December 15, 2001, <unixed.com/Re-
52sources/history_of_solaris.pdf>.
Lucent Technologies, «The Creation of the UNIX Operating System», 2002,
<www.bell-labs.com/history/unix/>.
54 Torvalds, L., «Linux History,» July 31, 1992, <www.li.org/linuxhistory.php>.
55 Holland, N., «1 — Introduction to OpenBSD,» July 23, 2003, <www.openbsd.org/
faq/faql-html>.
56 Howard, J., «Daemon News: The BSD Family Tree,» April 2001, <www.daemon-
news.org/200104/bsd_family.html>.
57. Jorm, D., «An Overview of OpenBSD Security,» August 8, 2000, <www.onlamp.com/
pub/a/bsd/2000/08/08/OpenBSD.html>.
58. Security Electronics Magazine, «OpenBSD: Secure by Default,» January 2002,
<ww w. semweb .com/jan02 /itsecurityj an. h tm>.
59. Howard, J., «Daemon News: The BSD Family Tree,» April 2001, <www.daemon-
news.org/200104/bsd_family.html>.
60. The NetBSD Foundation, Inc., «About the NetBSD Project,» July 17, 2003,
<ww w. netbsd. or g/Misc/ about. html >.
61. Howard, J., «Daemon News: The BSD Family Tree,» April 2001, <www.daemon-
news.org/200104/bsd_f amily. html>.
62. Coelho, J., «comp.aix.unix Frequently Asked Questions (Part 1 of 5),» October
10, 2000, <www.faqs.org/faqs/aix-faq/partl/>.
63. IBM, «А1Х Affinity with Linux: Technology Paper,» <www-1.ibm.com/serv-
ers/aix/products/aixos/linux/affinitylinux .pdf >.
4‘ Springer, I., «comp.sys.hp.hpux FAQ,» September 20, 2003, <www.faqs.org/
g tac<s/hp/hpux-faq/>.
• Hewlett-Packard Company, «HP-UX Hi Operating System,» <www.hp.com/
рУо ^ctsl/unix/operati.ng/>-,
’ . ewIett-Packard Company, «Hewlett Packard Receives Top UNIX Ranking
I 30may02b" ®rown’* May 30, 2002, <www.hp.com/hpinfo/newsroom/press/
FreeBSD Hypertext Man Pages, 2002 <www.freebsd.org/cgi/man.cgi?query=
6g jPeCve&sektion=2>.
К. Thompson, «The UNIX Time-Sharing System,» Communica-
69. , of the ACM, July 1974, pp. 370-372.
^e’ D., and K. Thompson, «The UNIX Time-Sharing System,» Communica-
7°- «Е t the ACM’ July 1974’ PP’ 370-372.
tion < The °Pen GrouP Base Specifications, Issue 6, IEEE Std 1003.1, 2003 Edi-
71. UjR’y?Www-°Pengroup.org/onlinepubs/007904975/functions/_Exit.html>.
7^ lelp for Users, Version 1.3.2: Nice, <unixhelp.ed.ac.uk/CCI/man-cgi?nice>.
Vo°mPson> K., «UNIX Implementation,» UNIX Programer’s Manual: 7th ed.,
‘ ^b, January 1979, <cm.bell-labs.com/7thEdMan/bswv7.html>.
228
73. The Design and Implementation of 4.4BSD Operating System: Interprocess Соишщщ I
tion, 2002, <www.freebsd.org/doc/enJJS.IS08859-l/books/design-44bsd/x659.htrulx * I
74. Horning, J. J., and B. Randell, «Process Structuring,» ACM Computing »' I
veys, Vol. 5, No. 1, March 1973, pp. 5-29.
75. Lampson, B. W., «А Scheduling Philosophy for Multiprocessing System,» c
munications of the ACM, Vol. 11, No. 5, 1968, pp. 347-360.
76. Peterson, J. L.; J. S. Quarterman; and A. Silbershatz, «4.2BSD and 4.3BSJ)
Examples of the UNIX System,» ACM Computing Surveys, Vol. 17, No. 4,
cember 1985, p. 388.
77. Hennessy, J., and D. Patterson, Computer Organization and Design, San Fra
cisco: Morgan Kaufmann Publishers, Inc., 1998.
78. Guillemont, M., «The Chorus Distributed Operating System: Design and ImpL
mentation,» Proceedings of the ACM International Symposium on Local Con,
puter. Networks, Firenze, April 1982, pp. 207-223.
79. Accetta, M. J.; R. V. Baron; W. Bolosky; D. B. Golub; R. F. Rashid; A. Tevania^.
and M. W. Young, «Mach: A New Kernel Foundation for UNIX Development,,
Proceedings of the Usenix Summer’86 Conference, Atlanta, Georgia, June iggg
pp. 93-113.
80. Liedtke, Jochen, «Improving IPC by Kernel Design,» Proceedings of the Four,
teenth ACM Symposium on Operating Systems Principles, December 5-8, 1993
pp.175-188.
81. Liedtke, Jochen, «Toward Real Microkernels,» Communications of the ACM, Vol
39, No. 9, September 1996, pp. 70-77.
82. Bovet, D., and M. Cesati, Understanding the Linux Kernel, O’Reilly, 2001,
p. 253.
83. Solomon, D., and M. Russinovich, Inside Windows 2000, 3d ed., Redmond:
Microsoft Press 7000 (есть русский перевод: «Внутреннее устройство Microsoft
Windows 2000», Давид Соломон, Марк Руссинович, изд. «Питер»).
Но как же просто и легко паук I
На тонкой нити повисает вдруг!
Александр Поуп
Нельзя постичь множество, не поняв единицу-
Платон
Есть время для слов, а есть время для снэ-
ГомеР
Жить — значит действовав'
Генри Дэйвид
Только сигнал и отдаленный голос в темнот6'^
Генри Уодсуорт ЛонгфеЛ^0
Глава 4
Концепции потока
Цели
Прочитав эту главу, вы должны будете понимать:
• причины создания потоков:
• сходства и различия между процессами и потоками;
• различные уровни поддержки потоков;
• жизненный цикл потока;
• сигналы и отмена выполнения потоков;
• основы потоков в POSIX, Linux, Windows ХР и Java.
Краткое содержание главы
4.1 Введение
Размышления об операционных системах:
Одновременное выполнение операций
4.2 Определение потока
43 Мотивы использования потоков
Размышления об операционных системах: Параллелизм
4.4 Состояния потока: Жизненный цикл потока
43 Операции над потоками
4.6 Модели потока
4.6.1 Потоки уровня пользователя
4.6.2 Потоки уровня ядра
4.6.3 Совместное использование потоков уровня пользователя и уровня ядра
Размышления об операционных системах: Соответствие стандартов
4.7 Вопросы реализации потоков
4.7.1 Доставка сигналов потоков
Поучительные истории: Дело техники
4.7.2 Завершение работы потоков
4.8 РОЗIX и Pthread-nomoku
Поучительные истории: Стандарты, их согласование
и конструктивная совместимость
4.9 Потоки в Linux
Размышления об операционных системах: Масштабируемость
4.10 Потоки в Windows ХР
4.11 Многозадачность в Java. Учебный пример, часть 1:
знакомство с потоками Java
233
Kceuej”
4 j ^Ведение
операционные системы позволяли выполнять нескольких про-
0ервые менно> однако языки программирования того времени не
граМм программистам пользоваться преимуществами одновременного
позволял операций (см. «Размышления об операционных системах: Од-
вьЦ1ОЛНеННое выполнение операций»). В языках программирования того
цовреме1111 ^усматривался набор простейших структур управления, кото-
времени возможность создавать только один управляющий поток. Типы
рые ДаВ мЫХ компьютером параллельных операций обычно реализовыва-
вЫП°в примитивах операционной системы, понятных только системным
ЛИСгоаммистам с большим опытом.
DP Я да программирования Ada, разработанный Министерством обороны
иненных Штатов в конце 70-х — начале 80-х годов прошлого века,
С°еД одним из первых языков программирования, в котором предусматри-
ваюсь явное задание примитивов одновременного выполнения. Язык Ada
получил широкое распространение среди оборонных подрядчиков, зани-
мающихся созданием оперативных систем управления для военных. В то
ясе время язык Ada был мало распространен в учебных заведениях и ком-
мерческих организациях.
В последние годы в состав большинства языков программирования об-
щего назначения, включая Java, С#, Visual C++ .NET, Visual Basic .NET
и Python, были включены примитивы для реализации параллелизма при-
кладными программистами. Программисты получили возможность фор-
мировать «выполняемые потоки» приложения, из тех фрагментов кода
программы, которые могут выполняться одновременно с другими. Данная
технология, получившая название многопоточности (multithreading), пре-
доставила в распоряжение программистов мощные функциональные воз-
можности, недоступные непосредственно в таких языках программирова-
ния как С и C++, на которых основаны C# и Java. Языки С и C++ считают-
ся однопоточными. [Примечание: Во многих платформах многопоточность
программ, написанных на С или C++, реализуется с помощью специаль-
АКГч®и®ли°тек, которые, однако не являются частью спецификации
я /ISO стандартных версий этих языков.] Разумеется, для поддержки
необх>В> В КОТОРЫХ реализована семантика управления многопоточностью,
На°ДИмо наличие поддержки со стороны операционной системы.
триви. Исание программ, состоящих из нескольких потоков, — далеко не
вРемР ьная задача. Хотя человеческий мозг в состоянии выполнять одно-
п«ем ° Неск°лько функций, люди испытывают сложности с переключе-
втом М(>Н<ДУ параллельными «потоками мыслей». Чтобы разобраться
ТЬ1вать °Чем^ мн°гопоточные приложения так трудно разбирать и разраба-
!1а Перв,0^°'а'ела^те следующий эксперимент: откройте три разных книги
Из о И странице и попробуйте читать их одновременно. Прочтите стро-
ВеРниТесН°И КНиги, затем строку из второй, потом из третьей, после чего
T*teiiTa вы К ?ервоЙ книге и читайте дальше по кругу. После этого экспери-
l£JIl04ejjiT п°Имете основные проблемы многопоточности — сложность пере-
^аМоСТь я с одной книги на другую, краткие промежутки чтения, необхо-
Помнить место, на котором вы остановились в каждой книге, необ-
234
ходимость придвигать читаемую в данный момент книгу ближе, ч? 1
лучше видеть, и отодвигать остальные книги в сторону — и при всем
этом еще пытаться уловить смысл! 11Ц
Размышления об операционных системах
Одновременное Выполнение операций
В данной книге приведены многочислен-
ные примеры операций, которые могут вы-
полняться одновременно. Например, опера-
ции ввода/вывода могут осуществляться од-
новременно с выполнением основной части
программы, в системе могут одновременно
работать несколько процессоров и с ней мо-
гут одновременно работать несколько поль-
зователей. Несколько процессов могут пы
таться одновременно обратиться к одним
и тем же данным. Несколько компьютеров
могут одновременно работать в одной сети.
Мы будем изучать вопросы параллелиз-
ма, то есть одновременного выполнения опе-
раций, на протяжении всей книги. В главах 3
и 4 изучаются процессы и потоки - абстрак-
ции, используемые операционной системой
для управления параллельным выполнением
операций. Глава 5 и глава 6 посвящены па-
раллельному программированию и тонко-
стям параллельного выполнения процессов
и потоков для решения проблем согласова-
ния и общего доступа к данным. В главе 7
речь пойдет о взаимоблокировках и беско-
нечном откладывании параллельно вып0
няющихся процессов и потоков. Глава
посвящена теме распределения процессор,
ного времени между параллельно выпои'
няющимися потоками и процессами. Главад
и 11 посвящены организации памяти и во-
просам управления параллельными потока-
ми и процессами. В главе 15 рассматривают-
ся параллельные процессы и потоки в кон-
тексте многопроцессорных систем. Глава 16
рассказываете компьютерных сетях и прото-
колах, используемых для того, чтобы гаран-
тировать отсутствие столкновений при рабо-
те компьютеров в сети. В главе 17 и 18 под-
нимаются вопросы написания приложений
для распараллеленного выполнения, фраг-
менты которых распределяются по компью-
терной сети. В главе 19 уделено внимание
вопросам безопасности и защиты пользова-
телей, параллельно работающих с локальны-
ми либо сетевыми компьютерами. В учебных
примерах по Linux и Windows ХР на практике
показана реализация управления параде
лизмом в операционных системах.
Вопросы для самопроверки
1. Мы упомянули, что функции многопоточности отсутствуют в ТВ
языках программирования как С и C++. Каким образом прогР $
мистам удается управлять многопоточным кодом в этих язь
программирования?
2. Какие ключевые преимущества имеет выполнение многопото
приложений в многопроцессорной системе по сравнению с одВ°
цессорной?
235
—--------------------------------------------------------------
1(еИЧ111Ц
OfijReiflbl 1) Существую специальные библиотеки, помогающие рев-
изовать многопоточность. Однако эти библиотеки не являются ча-
Л ью стандарта ANSI/ISO языков программирования С и C++, поэтому
вписанные с их помощью программы не обладают такой же перено-
симостью, как «стандартные программы» на С и C++. 2) В многопро-
цессорной системе несколько потоков одного процесса могут
ыполняться действительно параллельно на разных процессорах, уве-
личивая скорость работы приложения.
л 2 Определение потоки
голаря птирокой поддержке многопоточности в языках программиро-
драктически во всех современных операционных системах существу-
^*^0 крайней мере, минимальная поддержка многопоточности. Поток, для
е^’ П°ачения которого иногда используется термин легковесный процесс
JyXtweighted process, LWP) обладает доступом к большинству атрибутов
базового процесса. Расписание выполнения потоков задается процессором,
при этом каждый поток может выполнять свой набор инструкций независи-
о от других процессов и потоков, что, однако, не означает обособленность
существования потоков. Как правило, потоки являются частью традицион-
ных процессов, называемых тяжеловесными (heavyweight process, HWP).
Потоки одного процесса обладают общим доступом к большинству принад-
лежащих ему ресурсов, в первую очередь, к адресному пространству и от-
крытым файлам, чтобы повысить эффективность выполнения операций.
Термин «поток» обозначает определенный поток инструкций либо управ-
ляющий поток. Потоки одного процесса могут выполняться параллельно
и взаимодействовать друг с другом для решения общих задач. В многопро-
цессорной системе одновременно может выполняться несколько потоков.
Потоки владеют подмножеством ресурсов процесса. Такие ресурсы, как
регистры процессора, стек и другие специфичные данные потока, напри-
МеР маски сигналов (сведения, описывающие, какие сигналы разрешены
и о запрещены потоком — см. раздел 4.7.1) являются локальными по от-
ск еНИ1° к каждому потоку, тогда как адресное пространство процесса,
т°РЫм работают его потоки, является глобальным по отношению к ним
ЩМ. Рис 4. 1Ъ ТЭ о
Ф°рме ' Ь зависимости от реализации потоков на определенной плат-
либо * управление потоками может осуществлять операционная система
Х^°ЗДаВШее Их пользовательское приложение.
к°нкрет н^ДеРЖпа потоков включена во многие операционные системы,
ПотцКи спос°бы реализации потоков имеют значительные различия,
примеры ^-потоки2 и потоки POSIX3 — все они представляют собой
ИсПоЛЬЗу и®лиотечных потоков с несопоставимыми API. Потоки Win32
^aido\vs-°rCH В семействе 32-разрядных операционных систем Microsoft
^ach (Ва’ потоки создаются с помощью библиотеки потоков микроядра
пОд Кот°Р°м основана операционная система Macintosh OS X), и кото-
саецИф^ЗКива1отся в операционных системах Solaris и Windows NT.
аем ПоТо КаРИи POSIX определен стандарт Pthreads. Основным назначе-
Ов Pthreads является обеспечение межплатформенной перено-
236
Симости. Спецификация POSIX была реализована во многих
ных системах, включая Solaris, Linux и Windows ХР.
операц^
Тяжеловесный процесс
Информация, глобальная
по отношению ко всем
потокам процесса
Адресное пространство
Другие глобальные данные процесса
Информация, локальная
по отношению к каждому
потоку процесса
Рис. 4.1. Взаимоотношения процессов с потоками
Вопросы для самопроверки
1. Почему традиционные процессы называют тяжеловесными?
2. В чем сложность создания переносимых многопоточных приложе-
ний?
Ответы 1) Главное различие между относительным «весом» тра-
диционных процессов и потоков заключается в способе выделения 8Д'
ресного пространства. При создании потока в его распоряжеяЯ®
поступает адресное пространство процесса, поэтому потоки имеК”
меньший вес, чем процессы. 2) В отсутствии стандартных библиотек
для работы с потоками, которые были бы реализованы на всех пла
формах.
4.3 Мотивы использования потоков
В предыдущей главе мы познакомили вас с концепцией процесса и Р
сказали, как компьютерная система может выиграть благодаря повЫ
нию эффективности и быстродействия в случае одновременного выпо .
ния нескольких процессов. Когда в 60-х годах XX века с выходом пр° л
Multics впервые была сформирована концепция процесса, на больший .
компьютеров устанавливалось не более одного процессора, а прилоЖ6 ~
были относительно невелики по размеру.4 В то время процессы испо^Ь j
/ я выполнения в каждый момент времени одного управляющего
радйс1’ $ а одном процессоре. Последующие тенденции разработки про-
^отоК0 и аппаратного обеспечения показали, что система выигрывает
сраМ^^гОдользования нескольких потоков выполнения в рамках одного
За счеТ факторами мотивации, которые поспособствовали развитию
проточности, стали:
мноГ° итеКтура ПО. За счет модульности и структуры современных ком-
• торов, большинство современных приложений содержит фрагмен-
ПИЛкода, которые могут выполняться независимо друг от друга. Выде-
тЬ1 ие независимых фрагментов кода в отдельные сегменты способству-
л^увеличению быстродействия приложений и облегчает написание
агментов кода, которые должны выполняться параллельно
(ем «Размышления об операционных системах: Параллелизм»).
Производительность. Проблема однопоточных приложений состоит
в том, что независимые операции не могут выполняться на разных
процессорах. В многопоточном приложении потоки могут обладать
общим доступом к процессору (либо группе процессоров), в результа-
те чего несколько задач могут выполняться параллельно. Одновре-
менное параллельное выполнение позволяет значительно сократить
время, необходимое для завершения задачи многопоточному прило-
жению, особенно в многопроцессорных системах, тогда как однопо-
точное приложение может выполняться только на одном процессоре,
и вынуждено последовательно выполнять все операции. В многопо-
точных процессах потоки в состоянии готовности могут выполняться,
в то время как другие потоки заблокированы (например, ожидая за-
вершения операции ввода/вывода).
• Взаимодействие. Большинство приложений с целью синхронизации
и обмена информацией друг с другом используют независимые компо-
ненты. До появления потоков эти компоненты реализовывались
в виде множества «тяжеловесных» процессов, вынужденных общать-
ся между собой с помощью каналов ядра.5,6 В случае использования
«легковесной» многопоточности быстродействие, как правило, на-
много выше, чем при использовании нескольких «тяжеловесных»
процессов, поскольку потоки одного процесса могут общаться друг
с Другом с помощью общего адресного пространства.
в В современных компьютерных системах многопоточные приложения
позв ЧаЮТСЯ ПОВС1°ДУ- Одной из областей, в которой применение потоков
тИВн ляет значительно повысить уровень производительности и интерак-
КартиСТИ’ ЯВЛЯ1°тся веб-серверы. Как правило, запросы к веб-страницам,
Чтоб Нкам и файлам веб-сервера поступают от удаленных приложений.
Пр0111 ^Работать каждый запрос веб-сервер создает отдельный поток.
п°тОк ’ отвечаюЩий за прием запросов, может использовать отдельный
в°г<э з ^ЛЯ °ЖиДания поступления запросов из Интернета. По приходу но-
яР°са создается новый поток, предназначенный для его интерпрета-
(°бь1Чн ЗВЛечения затребованной веб-страницы и передачи ее клиенту
Т°к пРо Ве®"браузеру). После порождения нового потока родительский по-
6еб,с Д°лжает ожидание новых входящих запросов. Поскольку многие
d°TqKob PbI построены на основе многопроцессорных систем, несколько
могут одновременно принимать и обрабатывать несколько запро-
238
сов, что позволяет повысить скорость обработки и ускорить реакцию сцс ]
мы. Однако с созданием и уничтожением потоков связаны значителы?6']
накладные расходы. Поэтому многие современные веб-серверы исполь;д,^е
пул потоков, из которого выделяются потоки для обслуживания посту^^
щих запросов. Эти потоки не уничтожаются по окончанию обслуживает
запроса, а передаются в распоряжение пула, который, в свою очередь
деляет их для обслуживания новых запросов. Более подробно тема nv*4
потоков рассматривается в разделе 4.6.3.
В текстовых редакторах потоки используются для повышения проиаъ-
дительности труда пользователей и интерактивности приложения. При h '
жатии клавиши операционная система принимает прерывание от клавд
туры и передает сигнал текстовому редактору. Текстовый редактор сохра
няет символ в памяти и отображает его на экране. Поскольку современнее
компьютеры в состоянии выполнить сотни миллионов инструкций межЛА,
двумя последовательными нажатиями клавиш, текстовый редактор может
одновременно выполнять несколько других потоков. Например, большив-
ство современных текстовых процессоров позволяют обнаруживать опечат-
ки во время набора слов и периодически сохранять содержимое документа
во избежание потери данных. Каждая из вышеперечисленных функций
реализуется при помощи отдельного потока — поэтому текстовый редак-
тор может реагировать на прерывания клавиатуры даже тогда, когда один
или несколько его потоков заблокированы из-за операций ввода/вывода
(например, сохранения данных на диск).
Размышления об операционных системах
Параллелизм
Один из способов реализации паралле-
лизма заключается в использовании на ло-
кальном компьютере технологий многоза-
дачности, многопоточности и массового па-
раллелизма. Создается такое аппаратное
обеспечение, которое было бы в состоянии
выполнять обработку данных параллельно
с операциями ввода/вывода. Строятся мно-
гопроцессорные системы, обеспечивающие
одновременную работу нескольких процес-
соров — массовый параллелизм подразуме-
вает возможности подключения сотен
и даже тысяч одновременно работающих
процессоров.
В настоящее время все большую популяр-
ность приобретает другой вид параллелизма.
называемый «распределенными вычисле-
ниями в компьютерных сетях». Теме распре-
деленных вычислений посвящены главы с 16
по 18. в них изучаются компьютерные сети
и вопросы построения распределенных опе-
рационных систем. Операционная система,
в первую очередь, выступает в роли диспатче
ра ресурсов. К этим ресурсам относится аппа
ратное и программное обеспечение и данеь16,
хранимые на локальной системе. Соврем66
ные распределенные операционные систе
должны управлять ресурсами независимо
их местоположения, будь те размещены
локальном компьютере либо в компьютере
системе, доступ к которой возможен чер
компьютерную сеть, подобную сети Интере6
„ине ^ка-
234
Вопросы для самопроверки
1. Каким образом усовершенствованная архитектура программного
обеспечения позволяет увеличить быстродействие многопоточных
приложений?
2. Почему взаимодействие потоков одного процесса между собой более
эффективно, чем взаимодействие отдельных процессов?
Ответы 1) Большинство приложений содержат фрагменты кода,
которые могут выполняться независимо от остальной части приложе-
ния. Если выделить эти фрагменты в отдельные потоки, можно будет
выполнять их одновременно на разных процессорах. 2) Потоки, при-
надлежащие одному процессу, могут обмениваться друг с другом дан-
ными с помощью общего адресного пространства, обходясь без
механизма взаимодействия процессов, подразумевающего обращение
к ядру.
4А Состояния потоки: Жизненный цикл потока
Как мы уже говорили в разделе 3.2, существование любого процесса
можно представить в виде последовательности переходов от одного дис-
кретного состояния к другому. В данной модели каждый процесс содержит
один управляющий поток, в то же время можно сказать, что каждый
управляющий поток проходит через серию дискретных состояний. Если
процесс содержит несколько управляющих потоков, можно рассматривать
каждый поток, как переходящий между дискретными состояниями пото-
ка (thread state). Таким образом, описание состояний процессов и перехо-
дов между ними, изложенное в разделе 3.2, по большей части применимо
к потокам и их состояниям.
Рассмотрим, в качестве примера следующую группу состояний, базиру-
ясь на реализации потоков в языке Java (см. рис. 4.2).7 В Java новый поток
начинает свой жизненный цикл с состояния рождения (born). В этом со-
стоянии он пребывает до тех пор, пока программа не запустит поток, пере-
ведя его в состояние готовности (ready). В других операционных систе-
мах поток запускается непосредственно с момента его создания, минуя со-
яние рождения. Поток в состоянии готовности с наивысшим
в °₽итет°м входит в состояние выполнения (running), как только про-
сор окажется в его распоряжении.
также1°ЛНЯЮЩ’Ийся поток входит в тупиковое состояние, называемое
РУкци^Остоянием смерти (dead) по окончанию выполнения всех инст-
Рые б 1^Ли®° в Результате завершения потока по иным причинам. Некото-
верща ЛИОтеки’ предназначенные для работы с потоками, позволяют за-
в тУг1Ик ВЬШОлнение одних потоков с помощью других, переводя первые
Свобож °ВОе с°стояние. После перехода потока в тупиковое состояние, вы-
ПОТо тся занимаемые им ресурсы, и он удаляется из системы.
°Н вЬ1 ПеРеходит в состояние блокировки (blocked) в тех случаях, когда
^Киц >Кл'ен ожидать завершения операции ввода/вывода (например, при
СР°Цесс^аННЬ1х с Диска)- Заблокированный поток не может использовать
°Р пока не будет завершена операция ввода/вывода, даже если про-
240
цессор будет предоставлен в его распоряжение. По завершению операп
ввода/вывода поток может перейти в состояние готовности и продол
свое выполнение, как только процессор освободится.
рожден
Рис. 4.2. Жизненный цикл потока
Когда процесс ожидает определенного события (например, перемет6'
ния указателя мыши либо поступления сигнала от другого потока), гов°
рят, что он находится в состоянии ожидания (waiting). Поток возврат8
ется в состояние готовности, когда о наступлении ожидаемого события 6го
уведомляет (notifies) или будит (awakens) другой поток. Получив увеД01^
ление о некотором событии, поток переходит из состояния ожидания в с°
стояние готовности.
Поток в состоянии выполнения может войти в состояние сна (sleep) ®
определенный промежуток времени, называемый интервалом сна (sle v
interval). Спящий поток возвращается в состояние готовности по окон*18
нию заданного интервала сна. Спящие потоки не могут использовать ПР°
241
зке если он доступен. Потоки переходят в состояние сна, если
цеСс°Р’ “ момент времени им не нужно выполнять никаких операций. На-
р дарЯЬ1Ипоток текстового редактора может периодически сохранять ко-
ррИМеР’ на диск для восстановления в случае сбоя. Если в промежут-
ок) этим поток не будет переходить в состояние сна, он будет впус-
ках ^^ить процессорные циклы, постоянно проверяя, не пора ли
туЮ тРа очередное сохранение копии документа на диск. В результате
BbinoJia отбирать драгоценное процессорное время, снижая производи-
роток УД системы> и не выполняя при этом никакой полезной работы,
гедьно сЛуЧае, гораздо эффективнее задать для потока интервал сна
В й промежутку времени между последовательными операциями ре-
(равнь копИрования) в течение которого процесс будет пребывать в со-
зервн сна jjo истечении интервала сна поток перейдет в состояние го-
сТ° я когда освободится процессор, сохранит копию документа на
^дСк после чего снова возвратится в состояние сна.
Вопросы для самопроверки
1. Когда поток входит в состояние смерти (тупиковое состояние)?
2. Что общего между состояниями ожидания, блокировки и сна?
В чем различия между ними?
Ответы 1) Поток переходит в тупиковое состояние по окончании
выполнения поставленных задач либо в случае его завершения другим
потоком. 2) Поток, пребывающий в любом из вышеперечисленных со-
стояний, не может использовать процессор, даже если тот доступен.
Заблокированный поток не может выступать в роли кандидата для по-
следующего выполнения, поскольку он ожидает завершения запро-
шенной операции ввода/вывода. В этой ситуации за разблокирование
процесса в конечном итоге отвечает операционная система. Поток
в состоянии ожидания не сможет запуститься до тех пор, пока не дож-
дется от аппаратного либо программного обеспечения появления собы-
тия, которое инициируется не операционной системой (например,
нажатия клавиши либо сигнала от другого потока). В этом случае опе-
рационная система не в состоянии проконтролировать, наступит ли
когда-нибудь пробуждение потока. Поток в состоянии сна не может
выполняться, поскольку он явным образом уведомил систему о том,
что он не должен продолжать работу до окончания интервала сна.
Операции над потоками
NlIioroePfiI^HOHHaa система может выполнять над потоками и процессами
0 Щих операций, в том числе:
создание,
* Заверщение,
* Постановка,
е В°3°бновление,
I 3асЫпание,
пРобуисдение.
242
Механизм создания потока во многом напоминает создание проце
Когда процесс порождает поток, библиотека по работе с потоками инип
лизирует специфические для потока структуры данных, где хранится
держимое регистров, программный счетчик и ID потока. Но в отлич11еС°'
процедуры создания процесса, во время создания потока не требуется и °*
шательство операционной системы для инициализации ресурсов, явл 6'
щихся разделяемыми между родительским процессом и принадлежа ।
ему потоками (например, адресного пространства). В большинстве оцр^11
ционных систем получение общего доступа к ресурсам требует выполнен
меньшего числа инструкций, чем инициализации ресурса, поэтому в 2*4
ких системах создание потоков происходит быстрее, чем создание процес
сов.8 Аналогично, завершение потока осуществляется быстрее, чем завеп
шение процесса. Меньший объем накладных расходов при создании и за
вершении потоков, стимулирует разработчиков программного обеспечения
реализовывать параллельное выполнение задач там, где это возможно, при
помощи несколько потоков, а не процессов.
Операционная система может выполнять над потоками ряд операций
которые не имеют эквивалента среди операций над процессами:
• отмена (cancel) — поток или процесс могут досрочно завершить вы-
полнение другого потока путем его отмены. В отличие от процедуру
завершения процесса, отмена выполнения потока не гарантирует его
завершения по причине того, что потоки могут запрещать либо мас-
кировать прием сигналов отмены. Если поток маскирует сигналы от-
мены, он не отреагирует на сигнал, пока прием сигналов не будет сно-
ва разрешен.9 В то же время поток не может маскировать сигналы
аварийного завершения.
• присоединение (join) — в некоторых операционных системах (напри-
мер, Windows ХР) при инициализации процесса создается так назы-
ваемый первичный поток (primary thread). Работа первичного потока
ничем не отличается от любого другого потока, за тем лишь исключе-
нием, что при возврате из первичного потока, завершается выполне-
ние всего процесса. Чтобы не допустить завершения процесса до окон-
чания выполнения всех остальных потоков, первичный поток, как
правило, переходит в состояние сна до тех пор, пока не закончат свою
работу все созданные им потоки. В этом случае, говорят, что первич-
ный поток присоединяет все созданные им потоки. Если один поток
присоединяет к себе другой поток, выполнение первого потока при0е
танавливается до тех пор, пока не закончит свою работу второй и0-
ток.10
Хотя рассмотренные в данном разделе операции поддерживаются бо^*
шинством реализаций потоков, нередко перечень конкретных операй
которые могут выполняться над потоками в данной системе, определяй
библиотеками для работы с потоками. В следующих разделах мы РаСС
жем вам о популярных вариантах реализации потоков и обратим Bl111
ние на вопросы, которые возникают у разработчиков при создании библ
тек для работы с потоками.
243
---------------------
Вопросы для самопроверки
1 Чем сигнал отмены отличается от сигнала аварийного завершения,
рассмотренного в разделе 3.5.1?
2 Почему создание потоков требует, как правило, меньшего числа
процессорных циклов, чем создание процесса?
Ответы 1) в случае приема сигнала аварийного завершения, по-
ток прекращает свое выполнение немедленно (поскольку потоки не
могут маскировать сигналы аварийного завершения). Если же поток
получил сигнал отмены, он может продолжать выполняться до тех
пор, пока не демаскирует сигналы отмены. 2) В отличие от процедуры
создания процесса, создание потока требует от операционной системы
инициализации только тех ресурсов, которые являются локальными
по отношению к управляющему потоку. К глобальным ресурсам про-
цесса (например, его адресному пространству) поток получает общий
доступ с помощью указателей, на что требуется гораздо меньше про-
цессорных циклов, чем на инициализацию.
4.6 Модем потока
Способы реализации потоков в различных операционных системах мо-
гут различаться, но практически во всех операционных системах поддер-
живается одна из трех моделей потока. Именно об этих трех наиболее по-
пулярных моделях потока и пойдет речь в этом разделе: о потоках уровня
пользователя, потоках уровня ядра и комбинированной модели.
4.6.1 Потоки уровня пользователя
Первые операционные системы поддерживали процессы с одним
текстом выполнения.11 В результате каждый многопоточный процесс а
отвечал за хранение информации о состоянии процесса, задавая распис
ние выполнения потоков и обеспечивая примитивы для их синхрони
ции. Эти потоки, названные потоками уровня пользователя (user ev
threads), подразумевают выполнение операций над потоками в пространст
ве пользователя, что означает создание потоков библиотеками времени вы
волнения, которые не могут выполнять привилегированные инструкц
либо напрямую обращаться к примитивам ядра.12 Потоки пользователь-
ского уровня являются прозрачными для операционной системы, котора
ь Ссь1атривает каждый многопоточный процесс в виде одного контек
ьшолнения. Операционная система запускает многопоточный процесс ц -
ток 0ГД’ не имея возможности выбирать для выполнения отдельные его п
fjj, Поэтому, говорят, что потоки уровня пользователя связаны отно
Вит Многих-к-одному (many-to-one), так как операционная система ста-
обцЗ^рвптветствие всем потокам в составе многопоточного процесса од
j. контекст выполнения (см. рис. 4.3).
ваци Г^а процесс вызывает поток уровня пользователя, операции планир
Посип И 3апУска потока выполняются библиотеками уровня пользовател ,
Ков _ЛькУ операционная система ничего не знает о том, из скольких пото-
°стоИт процесс. Многопоточные процессы продолжают выполняться
244
до тех пор, пока не закончиться выделенный им квант времени либо п
не произойдет приоритетное вытеснение со стороны ядра.13
Реализация потоков в пространстве пользователя имеет несколько
имуществ по сравнению с реализацией потоков в пространстве ядра, г/1^'
ки пользовательского уровня не нуждаются в поддержке со стороны оп^0'
ционной системы. Поэтому пользовательские потоки обладают более вк т
кой переносимостью, поскольку они не зависят от API реализации п<>То С°'
в конкретной операционной системе. Дополнительное преимущество °8
ключается в том, что поскольку расписание выполнения потоков Кон-лЛ
лирует библиотека работы с потоками, а не операционная система, раз!
ботчики приложений получают возможность более тонкой настройки адг
ритма планирования в библиотеке работы с потоками под ну^п I
конкретного приложения.14 61
Кроме того, потоки уровня пользователя не требуют обращения к ядт
для принятия решений по поводу планирования либо для выполнения пр0У
цедуры синхронизации. Вспомним (см. раздел 3.4.1), что система тратщ
много процессорных циклов на накладные расходы, связанные с обработ-
кой прерываний, например, при вызове системных функций. Поэтому
многопоточные процессы пользовательского уровня, которые часто вывод
няют операции над потоками (такие как планирование и синхронизация)
выигрывают за счет уменьшения накладных расходов, по сравнению с по-
токами, которые с этой целью обращаются к ядру.15
Один процесс
Рис. 4.3. Потоки уровня пользователя
Поток
Контекст
выполнения
И0'
Быстродействие потоков уровня пользователя зависит от системы 0
ведения процесса. Многие недостатки потоков уровня пользователя 0 #
словлены тем, что ядро рассматривает многопоточный процесс как
управляющий поток. В результате, потоки уровня пользователя 0jI°
245
„яются масштабированию до уровня многопроцессорных систем так
яДР° не В состоянии одновременно запускать разные потоки данного
тгесса ₽» различных процессорах системы, не позволяя достичь опти
Явного быстродействия в многопроцессорных системах.16 Если поток
' «чан отношением многих-к-одному, при необходимости выполнения one
С!пии ввода/вывода блокируется весь процесс целиком, так как операпи
Рнная система распознает только один управляющий поток. Даже если
"йогопоточный процесс содержит несколько потоков, пребывающих в со
стоянии готовности, ни один из них не сможет начать свое выполнение
пока не останется ни одного процесса в состоянии блокировки. Данное об-
стоятельство может затормозить работу часто блокируемого многопоточно
го процесса. Из-за блокирования потока уровня пользователя, ядро может
запустить другой процесс, возможно, состоящий из потоков с более низ
ким приоритетом, чем потоки в состоянии готовности заблокированного
процесса. В результате получается, что потоки уровня пользователя не
поддерживают планирование выполнения с учетом приоритетов на уровне
системы, что может оказаться просто-таки губительным для многопоточ
ных процессов реального времени.17 Эта проблема может быть решена с по
мощью некоторых библиотек управления потоками, которые переводят
блокирующие вызовы системных функций в неблокирующие вызовы 16
Вопросы дпя самопроверки
1. Объясните, почему потоки уровня пользователя обладают лучшей
переносимостью по сравнению с потоками уровня ядра.
2. Почему, когда поток связан отношением многих-к-одному, опера-
ционная система блокирует работу всего процесса в случае блоки-
ровки единственного потока?
Ответы 1) Потоки уровня пользователя представляют для прило-
жений собственный API, который не зависит от API операционной
системы. 2) С точки зрения операционной системы весь многопоточ-
ный процесс представляет собой один управляющий поток. Поэтому,
когда операционная система получает блокирующий запрос ввода/вы-
вода, она блокирует весь процесс.
^•2 Потоки уровня ядра
нця пот'11 УР°1!НЯ ядра (kernel-level thread) позволяют обойти ограниче-
кгщТексоков УР°ВНЯ пользователя, связывая каждый поток с отдельным
Hbi отноп°М ВЫПОлнения- Поэтому говорят, что потоки уровня ядра связа-
Я°льзовя ением °Дин-к-одному (one-to-one) (см. рис.4.4), то есть каждому
т°Рого тельскомУ потоку ставится в соответствие поток ядра, запуск ко-
°т тяжел>>КеТ Вьшолнять операционная система. Потоки ядра отличаются
СтРацСТВо°Веснь1х процессов тем, что они разделяют общее адресное про-
чие данцьПР°ЦеССа‘ Кроме того, каждый поток ядра хранит специфиче-
T°Ra. ECJI1Jie ПОТоКа> такие как содержимое регистров и идентификатор по-
®Ь1зов Си пользовательский процесс запрашивает поток ядра, используя
?ВеРацИо ТСМНЬ1Х функций, определяемых API операционной системы,
°Дьз0в Ная система создает поток ядра для выполнения инструкций
тельского потока.
246
Один процесс
Каждый
пользовательский
поток обладает
собственным
контекстом
выполнения
Рис. 4.4. Потоки уровня ядра
Пространство
пользователя
Пространство
ядра
- Поток
Потоки, связанные отношением один-к-одному, имеют свои преимуще-
ства. Ядро может одновременно запускать на разных процессорах потоки
одного процесса, что позволяет повысить производительность приложе-
ний, предназначенных для параллельного выполнения.19 Кроме того, ядро
в состоянии управлять каждым потоком по отдельности, то есть система
может запустить поток, находящийся в состоянии готовности, даже если
другие потоки данного процесса заблокированы. Таким образом, приложе-
ния, выполняющие блокирующий ввод/вывод могут без проблем запус-
кать другие потоки, ожидая завершения операции ввода/вывода. Это по-
зволяет повысить интерактивность приложений, которые должны реаги-
ровать на вводимые пользователем данные, а также общее быстродействие
в тех случаях, когда приложение может выиграть от параллельного вы-
полнения фрагментов кода.
Потоки уровня ядра позволяют диспетчеру операционной системы Рас'
познавать отдельные потоки каждого пользователя. Если в ОС реализовал
алгоритм планирования выполнения процессов на основе приоритетов!
процесс, использующий потоки уровня ядра, может менять присвоенные
операционной системой приоритеты потоков, задавая приоритет планир0"
вания для каждого своего потока.20 Например, процесс может добиться п0"
вышения интерактивности, назначив более высокий приоритет потока ’
отвечающим за обработку запросов пользователей, и более низкий приор
тет всем остальным потокам. &
Потоки уровня ядра не всегда можно назвать оптимальным решен#
для многопоточных приложений. Реализация потоков уровня ядра ча
является менее эффективной, чем реализация потоков уровня пользов»
ля, поскольку операции планирования и синхронизации для таких п°
ков требуют обращения к ядру, что связано с дополнительными наклаДй. I
ми расходами. Вдобавок, программное обеспечение, использующее пото
уровня ядра является менее переносимым, чем ПО с потоками ур°в J
247
-------------------------------------------------------
теля — разработчики приложений, использующие потоки уровня
0дьз°®а УжДень1 переделывать свои приложения для работы с API пото-
ядРа’ ВЬ1жД°й операционной системе.21 Операционные системы, разрабо-
^ор да к соОТВетствии со стандартом POSIX, позволяют избежать этой
(см- «Размышления об операционных системах: Соответствие
Еще одним недостатком потоков уровня ядра является по-
сТаг^ - большего количества ресурсов по сравнению с потоками уровня
треблен1 я 22 и, наконец, потоки уровня ядра требуют, чтобы операци-
аоль30®^,^^ уПравЛяла всеми потоками в системе. Если библиотека
одяая пользователя может понадобиться для управления десятком либо
уровня потоКОВ> операционная система должна быть способной обслужи-
е°тае^сячу. Поэтому разработчики приложений должны учитывать спо-
₽а«Ьлсти к масштабированию подсистем управления памятью и диспетче-
ртзации операционной системы.
Вопросы для самопроверки
1. В каких случаях потоки уровня ядра представляют собой более эф-
фективное решение, чем потоки уровня пользователя?
2. Почему программное обеспечение, рассчитанное на использование
потоков уровня ядра, является менее переносимым, чем программ-
ное обеспечение, рассчитанное на использование потоков уровня
пользователя?
Ответы i) Если приложение содержит блокируемые потоки либо
оно построено таким образом, что некоторые инструкции могут вы-
полняться параллельно. 2) Работа программного обеспечения, напи-
санного из расчета на использование потоков уровня ядра, зависит от
API для работы с потоками конкретной операционной системы.
4.6.3 Совместное использование потоков уровня
пользователя и уровня ядра
и W’ некотоРых операционных системах, таких как, например, Solaris
Windows ХР предпринимались попытки ликвидировать разрыв между
роками, связанными отношениями многих-к-одному, и потоками, свя-
эапии1111 Отношениями один-к-одному, путем создания гибридной реали-
гих- ПОтоков- В гибридной модели потоки связываются отношением мно-
назвК° Многим (many-to-many) (см. рис. 4.5).23 Как предполагает данное
ся в аНие’ в этой модели нескольким потокам уровня пользователя ставит-
и°льз °ТВетствие группа потоков ядра. Для такой модели отношения ис-
ПоЛь ТСЯ °®означение m-к-п, поскольку количество потоков уровня
ПОтВателя и потоков ядра может не совпадать.24
^ИовнаяСИ> связанные отношением один-к-одному требуют, чтобы опера-
яДра> в СИСтема выделяла структуры данных для представления потоков
ядт/3е3^ЛЬтате’ объем памяти, занимаемой структурами данных пото-
в сИсТе а’ Значительно увеличивается с увеличением количества потоков
гНХ-Ко е‘ Накладные расходы для потоков, связанных отношением мно-
^Ьгеад н°гим, уменьшаются благодаря использованию пула потоков
l^ec»001^). Данная технология позволяет приложению задавать ко-
требуемых потоков уровня ядра. Процессу Р] на рис. 4.5, напри-
мер, требуется три потока уровня ядра. Обратите внимание, что потоку J
и Т2 связаны с одним потоком уровня ядра — пример отношения j. \
гих-к-одному. В этом случае приложение должно хранить информа^в
о состоянии для каждого своего потока. Разработчикам приложений р^11
мендуется использовать отношения многих-к-одному для потоков, хап^'
теризующихся низким уровнем параллелизма (т.е. неспособных вч—
от параллельного выполнения). Все остальные потоки процесса Pi (Т-
связаны с отдельным потоком уровня ядра каждый. Управление этими
токами осуществляет сама операционная система,
в предыдущем разделе.
,В“ИЧ
-'ЗИТ.
MTJ и)
как уже обсуждг^Л
4}
Рис. 4.5. Гибридная модель потока
Применение пула потоков позволяет существенно уменьшить количест-
во ресурсоемких операций по созданию и уничтожению потоков. Напри-
мер, веб-серверы и системы баз данных часто создают отдельные потоки
для обработки новых поступающих запросов пользователей. При исполь-
зовании пула потоков, потоки ядра не будут уничтожаться после уничто-
жения связанных с ними потоков пользователя. Таким образом, под ну#'
ды созданного позднее пользовательского потока практически всегда М°"
жет быть выделен поток ядра. Это позволяет ускорить работу веб-сервер^’
поскольку потоки, которые должны будут обрабатывать поступившие за
просы, уже существуют в пуле и готовы к использованию. Такие поток15’
которые существуют постоянно, называются рабочими потоками (woi’K
threads), поскольку они могут выполнять самые разнообразные функп.11^’
в зависимости от того, какие пользовательские потоки связаны с ними^.
Преимущество потоков, связанных отношением многих-к-одному
ключается в том, что приложения, в состав которых они входят, позво
ют повышать производительность библиотеки работы с потоками за с >
настройки алгоритма планирования. Однако как мы уже говорили в Р&3^е.
ле 4.6.1, в случае блокирования одного потока уровня пользователя, 0
249
система вынуждена блокировать весь многопоточный процесс.
^дИ°йв оГраничение для потоков, связанных отношением многих-к-од-
gifle °^Н°лючается в невозможности одновременного выполнения потоков
1?оМУ’ заКоцесса на разных процессорах. Предпринимаются попытки обой-
одЯоГ° ограничение для потоков уровня пользователя с помощью техно-
ги Д0ЙЙ°етИВации планировщика. Активацию планировщика (scheduler
дог011 а \ выполняет поток ядра, уведомляющий библиотеку работы с по-
activatl° овНЯ пользователя о наступлении определенных событий (напри-
тоКаМИ^^кИровании потока либо освобождении процессора). Данный тип
мер» ° ядра носит название «потоков активации планировщика», по-
вогоков ^и^лиотека работы с потоками уровня пользователя может выпол-
сК°ЛЬоперации планирования выполнения потоков только после «актива-
НЯТЬ Г прихода уведомления о появлении события), — иногда данную мето-
ЦИХ называют upcall механизмом.
Я Пои создании многопоточного процесса операционная система создает
гугок активации планировщика, запускающий код инициализации биб-
ПиОТеки управления потоками уровня пользователя, в результате чего соз-
аются потоки и, при необходимости, запрашиваются дополнительные
процессоры для потоков. Операционная система создает дополнительный
поток активации планировщика для каждого процессора, выделяемого
в распоряжение процесса, позволяя библиотекам уровня пользователя од-
новременно запускать различные потоки для выполнения на разных про-
цессорах.
В случае блокирование потока уровня пользователя, операционная систе-
ма сохраняет состояние потока в его поток активации планировщика, а за-
тем создает новый поток активации планировщика, чтобы уведомить биб-
лиотеку уровня пользователя о блокировании одного из потоков. Библиоте-
ка работы с потоками уровня пользователя впоследствии может сохранить
состояние заблокированного потока, используя его поток активации плани-
ровщика и назначить для активации планировщика другой поток. Подоб-
ный механизм предотвращает блокирование всего многопоточного процесса
из-за блокирования одного из потоков.26
Главным ограничением модели потоков многих-ко-многим является ус-
Нение архитектуры операционной системы, а также отсутствие стан-
SolaH°r° СПОс°ба реализации данной модели потоков.27 Например, в ОС
^-2, модель потоков многих-ко-многим позволяет задавать в поль-
kohr ЛЬСком приложении количество потоков ядра, связанных с каждым
тИвапГНЬ1М nP°heccOM’ тогда как в Solaris 2.6 используется механизм ак-
Многц И ПланиР°вщика. Что любопытно, в Solaris 8 вместо модели потоков
СХ(“Ма Ко'Мн°гим была использована более простая и масштабируемая
Р°вщиСВЯЗИ Один'к'°Дн°мУ-28 В Windows ХР механизм активации плани-
в пуле а Не поДДеРживается, а изменение количества рабочих потоков
Ь1Ы.2э,зо11РОИсхоДИт динамически, в ответ на изменение загрузки систе-
250
251
Размышления об операционных системах
Соответствие стандартов
Представьте себе вашу работу с сетью Ин-
тернет, если бы не существовало стандарти-
зованных сетевых протоколов. Либо пред-
ставьте покупку лампы накаливания, если бы
не существовало стандарта на размер патро-
на у светильников. Если хотите, представьте
себе более глобальный пример того, что бы
могло произойти, если бы в правилах вожде-
ния в различных городах не был принят еди-
'ный стандарт толкования сигналов светофо-
ра. Существует целый ряд национальных
и международных организаций, занимаю-
щихся разработкой и утверждением стандар-
тов в компьютерной индустрии, таких как
POSIX, ANSI (Американский национальный
институт стандартизации США), ISO (Между
народная организация стандартизации).
ляются к разрабатываемой им сИСт
в плане соответствия стандартам. Нер^ж
подобные стандарты не являются стат'К*|
ными, они постепенно эволюционип
вместе с изменением потребностей 1
вого компьютерного сообщества и польз I
вателей. Наличие стандартов имеет i CB0|fl
оборотную сторону: они могут замедлИт
либо полностью подавить внедрение ин I
новаций. Организации по разработке one-
рационных систем (и не только эти органи-
зации) вынуждены тратить много времени ।
и денег, чтобы добиться согласования сог-
ромным массивом стандартов, многие из
которых весьма туман ны и давно не обнов-
лялись. В этой книге мы еще не раз будем
упоминать различные стандарты и органи-
7 Вопросы реализации потоков
- раздел посвящен обсуждению различий в реализации потоков,
даН0Ь1И ₽ способами доставки сигналов и отмены выполнения потоков.
рЯзайЯЬ1Х Ся выдвигают на первый план фундаментальные вопросы, свя-
0Т11 РазЛИоПерациями над потоками и управлением ими.
3аЯрь1е с
а 71 Доставка сигналов потоков
** * ы прерывают выполнение процессов, как и аппаратные прерыва-
Сигналь^ вырабатываются программным обеспечением — опе-
ния> н0 ? системой либо пользовательским процессом. Сигналы превра-
рационн^ ставдартнЬ1й механизм взаимодействия процессов после своего
тились^я в операционной системе UNIX. В оригинальной версии UNIX
П°сутствовала поддержка потоков, поэтому сигналы создавались для рабо-
фы с процессами.31
Как мы уже говорили в разделе 3.5.1, когда операционная система пере-
ет сигнал процессу, тот, реагируя на него, приостанавливает свое выпол-
нение и вызывает обработчик сигналов (signal handler). Когда обработчик
сигналов закончит работу, процесс возобновляет свое выполнение (если не
произошел выход из процесса).33
Существует два типа сигналов: синхронные и асинхронные. Синхрон-
ный сигнал (synchronous signal) возникает непосредственно в результате
выполнения команд процессом или потоком. Например, если процесс или
группа OMG (Группа управления объектами),
консорциум W3C и многие другие.
Разработчик операционной системы
обязан знать, какие требования предъяв-
зации, занимающиеся их разработкой
и утверждением, тщательно описывая на-
значение этих стандартов и рассматривая I
поток выполнит запрещенную операцию над памятью, операционная сис-
тема выработает синхронный сигнал для процесса, чтобы уведомить о воз-
никновении исключения. Асинхронный сигнал (asynchronous signal) фор-
важность вопросов соответствия им.
Вопросы для самопроверки
1. Почему' задавать размер пула потоков, превышающий максимал^
ное количество пользовательских потоков в состоянии готовнос ।
в любой момент выполнения приложения, неэффективно?
2. Каким образом механизм активации планировщика позволяет Я?
высить производительность в модели потоков многих-ко-многим I
Ответы 1) Каждый рабочий поток из пула потоков потребляет
темные ресурсы, например память. Если количество рабочих поТатл>
превысит число пользовательских потоков в состоянии готовно
это приведет к накладным расходам, связанным с созданием не
ных потоков и неэффективным выделением памяти. 2) Механизм
тивации планировщика позволяет приложениям самостоя
планировать выполнение потоков с целью обеспечения максималь
быстродействия.
мируется в результате появления событий, не связанных с выполнением
текущих инструкций, поэтому в нем обязательно должен задаваться ID
процесса, чтобы система имела возможность определить получателя сигна-
ля. Асинхронные сигналы, как правило, используются для уведомления
пР°Цесса о завершении операции ввода/вывода, приостановке выполнения
процесса, продолжении выполнения процесса, либо уведомления о том,
Вто процесс должен завершить свое выполнение (см. раздел 20.10.1 —
есь перечисляются поддерживаемые POSIX сигналы).
До СЛи каждый процесс системы состоит из одного управляющего потока,
xpQTaBKa СИгналов осуществляется вполне прозрачно. Если сигнал син-
раци ыи (например, он возник в результате выполнения запрещенной опе-
Моме памятью), он доставляется тому процессу, который в данный
(вЬ11) J ®Ремени выполняется на процессоре, инициировавшем этот сигнал
РацИг. Отавщем прерывание). Если же сигнал является асинхронным, опе-
есдц вНная система сможет доставить сигнал целевому процессу, только
^аЦпо1/*аНнь1й момент времени он выполняется, в противном случае опе-
система добавит сигнал в очередь отложенных сигналов
ТеЛь Q ® signals), чтобы осуществить его доставку после того, как получа-
Теце^ейдат в состояние выполнения.
С15НХр0^ь Рассмотрим вариант с многопоточным процессом. Если сигнал
к ®Иый, он доставляется тому потоку, который в текущий момент
252
253
------------------------------------------------------------
времени выполняется процессором, выступившим в роли инициатору I
нала (путем выработки прерывания). Если же сигнал является асицх^'
ным, операционная система должна каким-то образом идентифицир0^Ч
получателя. Один из вариантов решения предполагает задание ID rir, <
отправителем. Однако если процесс вызовет библиотеку потока ур0 х
пользователя, операционная система будет не в состоянии определить^
кому потоку нужно направить сигнал. ’ Ч
В качестве альтернативы, операционная система может реализо^ 1
сигналы так, чтобы заставить отправителя указывать ID процесса. В та >
случае решение о доставке сигнала одному, нескольким либо всем пото^
процесса возлагается на операционную систему. Может показаться стп
ным, но именно такая модель сигналов принята в качестве стандарта л
операционных систем UNIX и в спецификации POSIX, чтобы обеспечив |
совместимость с приложениями, изначально написанными для операцИоД
ной системы UNIX (см. «Поучительные истории: Дело техники»), I
Согласно спецификации POSIX, процессы, вырабатывая сигнадЛ
должны задавать идентификатор процесса, а не потока. Чтобы рещЛ
проблему с доставкой сигналов определенному потоку, в спецификации ।
POSIX предусмотрен механизм маскирования сигналов. Маскирование
сигнала (mask a signal) позволяет потоку запретить прием сигналов опре.
деленного типа. Поток может запретить прием всех сигналов кроме тех,
которые его интересуют (см. рис. 4.6). При таком подходе операционная!
система принимает сигналы, предназначенные для процесса, и передает
его всем потокам данного процесса, которые не маскируют сигналы давно-1
го типа. В зависимости от типа сигнала и выбранного по умолчанию дейст-1
вия (см. раздел 3.5.1), сигналы могут добавляться в очередь для последую-!
щей обработки после демаскирования либо просто удаляться. На рисун-
ке 4.6 разные фигуры обозначают сигналы разного типа (например,
приостановки, возобновления или завершения). В данном случае операци-
онная система пытается доставить многопоточному процессу сигнал, об°"
значенный треугольником. Обратите внимание, что потоки 1 и 3 блокирУ"
ют сигналы этого типа. Поток 2, наоборот, разрешает прием таких сигн»;
лов. Поэтому операционная система доставляет сигнал, обозначенный
треугольником, потоку 2, который, в свою очередь, вызывает соответсТ
вующий обработчик сигнала.
Маскирование сигналов позволяет процессу распределить обрабо^\
сигналов между потоками. В состав текстового редактора может вход111'
поток, маскирующий все сигналы, кроме прерываний от клавиатур
Единственной целью данного потока является запись последовательй°с
нажатия клавиш. Маскирование сигналов позволяет операционной си
ме управлять доставкой сигналов конкретным потокам.
Чтобы реализовать механизм доставки сигналов POSIX, операционн
система должна располагать маской сигналов для каждого пользоват®"^
ского потока. Потоки, связанные отношением один-к-одному, облеШ^
решение данной проблемы, поскольку операционная система может Д° л
лять маску сигналов каждому потоку ядра, который соответствует
пользовательскому потоку. Если же в системе реализована модель отЯ°_}^|
ния многих-ко-многим, воплотить в жизнь маскирование сигналов сЛ
нее. Рассмотрим случай, когда процессу доставлен асинхронный сйГР
---------------------------------------------------=
венный поток, который разрешает сигнал этого типа, в данный
0 емени не выполняется. Тогда операционная система вынуждена
В Ме«т В^гнал либо поместить его в очередь отложенных сигналов. Общее
гдалйТЬ таково, что поскольку сигналы чаще всего уведомляют процессы
араРиЛ° 0 важных событиях, операционная система не должна их уда-
Ц ^^тТоимечание: В спецификации POSIX говорится о том, что операци-
пдть- рТеМа может удалить сигнал в том случае, если все потоки процес-
онНаЯ с dViot сигнал данного типа и в качестве действия обработчика сиг-
с« ^аСЯ^анОВлено игнорирование сигнала.33]
над°в У сПОСОбов реализации откладывания сигналов в модели потоков,
О*1* отношением многих-ко-многим, заключается в создании пото-
связа® каждого многопоточного процесса, осуществляющего монито-
КЯ it доставку асинхронных сигналов. В операционной системе Solaris 7
Ри оЛЬЗуются потоки, называемые легковесными процессами асинхрон-
Иых сигналов (Asynchronous Signal Lightweight Process, ASLWP), которые
ведут мониторинг сигналов и управляют доставкой отложенных сигналов
нужным потокам, в том случае если поток не выполнялся в момент поступ-
ления сигнала.34
Если многопоточный процесс использует библиотеку уровня пользова-
теля, операционная система просто доставляет все сигналы в процесс, по-
скольку она не различает между собой отдельные потоки. Библиотека
уровня пользователя регистрирует в операционной системе обработчики
сигналов, которые выполняются при их получении. Впоследствии библио-
тека потоков уровня пользователя может доставлять сигналы любым пото-
кам, которые их не маскируют.35’36
Поучительные истории
винтик не влезает в нужное отверстие —
помогите ему молоточком, и он взлезет».
Конечно, подобное толкование звучит до-
вольно-таки грубо, но оно хорошо отража-
ет находчивость разработчиков операци-
онных систем.
Дело техники
Более точным для описания методики
реализации операционных систем являет-
ся термин «дело техники», а не «дело нау
Ки». Один мой друг однажды высказал мне
свое определение термина «дело техники».
"Если фасад поцарапан — подкрасьте, если много углу-
^Рокдля разработчиков операционных систем. на^ Наглядные примеры только чт -
бо^ся В архитектуру операционной системы, и вы увидите нагляд
^санного нами принципа.
т-----------------------------------------Jx,
к
Условные обозначения
Немаскируемый
< - Маскируемый
Сигнал
Рас. 4.6. Маскирование сигналов
Вопросы для самопроверки
1. Почему осуществить доставку синхронного сигнала проще, чем Д°с'
тавку асинхронного?
2. Поясните, каким образом потоки ASLWP решают проблему обР8
ботки сигналов в модели многих-ко-многим.
Ответы 1) В отличие от асинхронного сигнала, синхронный с1^9
нал генерируется процессом или потоком, который выполняется
процессоре в текущий момент времени. Поэтому операционная си
ма может легко вычислить получателя сигнала, определив, какой
ток или процесс в текущий момент времени выполняется 9
процессоре и выработав сигнал прерывания. 2) Операционная сИС^г
может создать поток, в котором будут храниться все асинхронны6
налы до тех пор, пока получатель не войдет в состояние выполи
(когда можно будет доставить сигнал).
2.
2 Завершение Pa^ombl потоков
$•1' дроцесс завершает работу обычным образом (например, путем вь
^темной функции exit библиотеки работы с потоками, либо при вь
gOpa сИСТметода, содержащего код потока), операционная система неме;
%оДе 113 ляет поток из системы. Выполнение потока может завершитьс
дей00 УД в результате исключения (например, при обращении к запрещен
доср°^я°стИ паМяти) либо по приходу сигнала отмены от процесса или пс
дой °б^осКОЛьку потоки взаимодействуют между собой, внося изменени
т°Ка ляемые данные, приложение может выдать незаметные на первы
в разрубочные результаты в случае непредвиденного завершения однс
лзгляД отоков. Поэтому библиотека работы с потоками должна очень вне
Г° И3 ьно следить за тем, когда и каким образом можно будет удалить пс
маТ о системы. Поток может запретить прием сигналов отмены с поме
ю маскирования. Обычно, он делает это только при выполнени:
лпягментов программного кода, которые нельзя прерывать до полного за
вершения, например, кода модификации разделяемых переменных.37
Вопросы для самопроверки
1. Назовите три способа завершения работы потока.
2. Зачем потокам предоставляется возможность запрета сигналов от
мены?
Ответы 1) Поток может быть завершен в результате нормальног
окончания работы, по причине возникновения критического исключе
ния либо по сигналу отмены. 2) Поток, выполняющий модификацш
значений в разделяемом адресном пространстве процесса, может оста
вить данные в противоречивом состоянии в случае преждевременног
завершения по приходу сигнала отмены.
POSIX и Р th read-потоки
ЕПу-ТандаРт POSIX (Portable Operating System Interface for Compute
ЛяетГ°ПГП~П^ — интерфейс переносимой операционной системы) представ
ванн Целый набор стандартов для операционных систем, опублико
Митет™ Комитетом PASC (Portable Application Standards Committee — ко
Комп П° станДаРтам переносимых приложений) института IEEE. Это1
System “анДаРт°в в значительной части основывается на системе ITND
Взаим ~ Спецификация POSIX определяет стандартный интерфей
Риц. Леиствия между потоками и библиотекой (см. «Поучительные исто
тоди нДарты, их согласование и конструктивная совместимость»). По
^0кОвСрОЛЬЗУюЩие API потоков POSIX, носят название Pthread (то ест1
т^ифик IX’ или, если быть более точным, потоков POSIX 1003.1с).3
т*л с пОтИКа^я PCSIX не затрагивает детали реализации интерфейса рабо
'?1,1о’ГекаОКами — Pthread-потоки могут быть реализованы в ядре либо биб
Согл УРовня пользователя.
11 стандарту POSIX, содержимое регистров процессора, стег
сигналов должны храниться для каждого потока отдельно, тогд!
256
как остальные ресурсы должны быть доступны для всех потоков пр0^ |
са.40 Кроме того, в POSIX определена модель сигналов, которая касщ>'
большинства вопросов, обсуждавшихся в разделе 4.7. Согласно POSIX ч
гда поток генерирует синхронный сигнал в результате исключения ’F.
званного, к примеру, выполнением запрещенной операции с памятью'
нал будет доставлен только этому потоку. Если же сигнал не связан с
кретным потоком, например, если это сигнал уничтожения всего процес
тогда библиотека работы с потоками доставляет сигнал тем потокам, К
рые его не маскируют. Если несколько потоков оставляют сигнал ущщ^
жения немаскируемым, сигнал будет доставлен одному из этих поток^И
Необходимо отметить, что необязательно использовать сигнал Уничто^'В
ния для завершения отдельного потока — если поток примет сигнал уцц»И
тожения, весь процесс, включая все его потоки, будет завершен. Данны
пример демонстрирует еще одно важное свойство модели сигналов Posijj. I
хотя маски сигналов хранятся отдельно для каждого потока, обработчик» I
сигналов являются глобальными по отношению ко всем потокам процес
са.41-42
Для завершения отдельного потока в спецификации POSIX предусмот-
рена операция отмены, в которой необходимо указать целевой поток. Ре.
зультаты применения этой операции зависят от режима, в котором нахо-
дится поток. Если целевой поток пребывает в режиме асинхронной отме-
ны (asynchronous cancellation), он может быть завершен в любой момент
времени. Если же поток пребывает в режиме отложенной отмены
(deferred cancellation), такой поток нельзя будет завершить до тех пор,
пока он явным образом не проверит наличие запроса отмены. Режим отло-
женной отмены позволяет потоку довести до конца выполнение важных I
операций, прежде чем он будет завершен. Поток может выбрать режим за-
прета отмены (disabled cancellation), в таком случае он ничего не узнает
о поступлении запроса отмены.43
Помимо общих операций, которые рассматривались в разделе 4.5, в спе-
цификации POSIX предусмотрен ряд дополнительных операций. Эти опе-
рации позволяют приложению задавать уровни параллелизма и разнос
разные политики планирования, включая определяемые пользователе!* I
алгоритмы и планирование реального времени. Спецификация POSIX
же разрешает вопросы синхронизации, связанные с использованием е 1
кировок, семафоров и переменных, зависимых от условий (см. г I
ву 5).44,45,46
Только несколько наиболее популярных современных операци011
систем обладают встроенной реализацией Pthread-потоков в ядре. ₽
гих операционных системах применяются библиотеки POSIX для Ра0 I.
с потоками. Хотя по умолчанию операционная система Linux и не c0°Ig$ I
ствует спецификации POSIX, существует проект NPTL (Native Р I
Thread Library — встроенной библиотеки для работы с потоками I 4 дРо-
занимающийся разработкой библиотеки работы с потоками POSIX, I
ляющей реализовывать потоки уровня ядра в Linux.47 Аналогично, 11
фейс семейства операционных систем Microsoft Windows (называв*
Win32 API) не согласуется со стандартом POSIX, однако пользователь $
жет самостоятельно установить подсистему POSIX. [Примечание'-
Solaris 9 от компании Sun Microsystems есть две библиотеки, предВа
----Z-Ч
257
яля управления потоками: библиотека Pthreads, соответствующая
Д и унаследованная от предыдущих версий Solaris библио-
равлел— потоками Ul-threads. Между потоками Pthreads и потока-
теК» ^iTris немного различий — архитектура ОС Solaris допускает вызов
। Pthreads и Solaris из одного приложения.]48
бк ценные для управ
J стандарту POSIX,
тема управления г
ми Solaris немнот
дикций потоков
фУ«
Поучительные истории
^Сгпандарты, их согласование и конструктивная
совместимость
Эта история началась с того, что моло-
дой и агрессивный производитель накопи-
телей на магнитной ленте в 60-х годах XX
века захотел производить приводы, эквива-
лентные по функциональным возможно-
стям тем приводам, которые выпускались
основным поставщиком компьютерной тех-
ники. Их коммерческая стратегия заключа-
лась в позиционировании своих приводов,
как «конструктивно совместимых» с приво-
дами основного производителя компьюте-
ров того времени, но доступных по более
низкой цене. Накопители были разработа-
ны вточном соответствии со спецификация-
ми основного производителя компьютеров.
Урок доя разработчиков операционных систем: мы живем в век обилия развивающихся
^ндартов Совместимость в плане стандартов жизненно важна для коммерческого успеха
Ив менн°й операционной системы. Только не забывайте, что ошибка может вкрасться
стандарт, и в программные коды операционной системы.
Однако при попытке подключения этих лен-
точных приводов к компьютерной системе
основного производителя, выяснилось, что
приводы не работают. Новые приводы
были протестированы, и оказалось, что они
в точности соответствуют спецификациям.
«Почему же они не работают?» — задавали
себе вопрос разработчики. После проведе-
ния тщательного анализа было обнаруже-
но, что в спецификации были допущены
ошибки. В конце концов, они исправили
ошибки, пошутив, что им следовало рекла-
мировать свои приводы как «совместимые
по ошибкам» с приводами основного про-
изводителя компьютеров.
Вопросы для самопроверки
1. Какова основная причина создания стандартного интерфейса пото-
ков, такого как Pthread?
2. Реализации какой модели потока требует стандарт POSIX?
Ответы 1) Стандартизованный интерфейс потоков повышает пере-
носимость приложений, сокращая время разработки программного
обеспечения, предназначенного для работы на различных платфор-
мах. 2) Стандарт POSIX не требует реализации определенной модели.
Потоки могут быть реализованы в виде потоков уровня пользователя,
Уровня ядра либо гибридных потоков.
258
4.9 Потоки 0 Linux
Поддержка потоков уровня пользователя впервые появилась в опер
онной системе Linux версии 1.0.9, а потоков уровня ядра ___ с
сии 1.3.56.49 Хотя операционная система Linux поддерживает Пото6®'
важно отметить, что подсистема ядра Linux не различает между собой*5’
токи и процессы. В действительности Linux выделяет одинаковые д **0’
рипторы процесса и процессам и потокам, причем для обозначения и **'
и других в ОС Linux используется термин задача (task). В Linux, J6)!
и в UNIX, для создания дочерних процессов вызывается системная фу
ция fork. В результате вызова системной функции fork Linux создаст у I
вую задачу, в распоряжение которой поступит копия ресурсов родите^'
ской задачи (например, адресного пространства, регистров и стека).
В целях обеспечения поддержки потоков, в Linux предусмотрена модц
фицированная версия системной функции fork под названием clone. По
добно fork, функция clone создает копию вызывающей задачи, которая
согласно иерархии потоков, становится дочерней по отношению к задаче
инициировавшей вызов функции clone. Функция clone отличается од
fork возможностью задания аргументов, определяющих, какие ресурсы
будут являться разделяемыми с дочерним процессом. На самом высоком
уровне разделения ресурсов, задачи, созданные при помощи функции
clone, соответствуют потокам, рассмотренным в разделе 4.2.
В версии ядра 2.6 в Linux была включена поддержка потоков, связан-
ных отношением один-к-одному, благодаря которой стало возможным под-
держивать произвольное количество потоков в системе. Все задачи управ-
ляются одним и тем же планировщиком, то есть система предоставляет
одинаковый уровень сервиса и процессам, и потокам с одинаковым при-
оритетом. Планировщик написан таким образом, чтобы обеспечить воз-
можность масштабирования при наличии большого количества процессов
и потоков. Использование отношения один-к-одному и эффективного алго-
ритма планирования облегчает реализацию масштабирования при управ-
лении потоками (см. «Размышления об операционных системах: Масшта-
бируемость»). Хотя в Linux потоки POSIX по умолчанию не поддержива-
ются, в состав дистрибутива входит библиотека, предназначенная р№
работы с ними. В Linux 2.4 библиотека управления потоками, под назва-
нием LinuxTreads хотя и обеспечивает функциональность POSIX, однак°
не полностью соответствует спецификациям POSIX. Более поздний пр°е
NPTL позволил добиться практически полного соответствия специфика^1’
ям POSIX, и весьма вероятно, что вскоре он превратится в стандартна
библиотеку ядра 2.6.50
Каждая задача в таблице процессов хранит информацию о своем тес0.
щем статусе (выполняется, остановлена, завершена и т.д.). Задача в
стоянии выполнения может быть запущена процессором (см. рис. 4.7)-
дача переходит в состояние сна в результате засыпания, блокирован
либо по иной причине, приведшей к невозможности ее выполнения П&
цессором. Задача входит в состояние остановки при получении сигнал^,
танова (например, приостановки). Состояние зомби говорит о том, что
полнение задачи завершилось, но она еще не удалена из системы. НаПг I
259
ЛИ в состав задачи входило несколько потоков, она будет пребывать
j^ep’ еС нИи зомби, пока не уведомит остальные потоки о получении сигна-
^Co^of тения. Задача в состоянии смерти (тупиковом состоянии) может
да заВв ободно удалена из системы. Более подробно все эти состояния рас-
бЫтЬ СВпЯются в разделе 20.5.1.
сМаТРива
Вопросы для самопроверки
1. Объясните различия между системными функциями fork и clone
в Linux.
2. Чем отличается состояние зомби от состояния смерти?
Ответы 1) Когда задача вызывает системную функцию fork, в ре-
зультате порождается дочерняя задача, в распоряжение которой по-
ступает копия всех ресурсов родительского процесса. При вызове
системной функции clone можно задать список конкретных роди-
тельских ресурсов, которые будут доступны для дочерней задачи. За-
дачи, созданные с помощью системной функции clone, аналогичны
потокам. 2) Задача в состоянии зомби не удаляется из системы пока
другие потоки не будут уведомлены о ее завершении. Задача в состоя-
нии смерти может быть удалена из системы немедленно.
Размышление об операционных системах
—Кй
Масштабируемость
Объемы выполняемых пользователями вы-
числений со временем увеличиваются. Поэто-
му операционная система должна обладать
способностью к масштабированию, то есть ди-
намическому изменению своих параметров по
мере добавления нового программного и ап-
паратного обеспечения. Многопроцессорные
Грационные системы, например, должны
легко менять свою конфигурацию, чтобы при-
к управлению двумя, четырьмя
Льшим количеством процессоров. Вы уви-
«й--
дите, что в архитектуре большинства совре-
менных систем используются драйверы
устройств, позволяющие легко добавлять но-
вые типы устройств, даже если какой-то тип не
существовал на момент выпуска операцион-
ной системы. На страницах данной книги мы
обсудим технологии создания масштабируе-
мых операционных систем. В заключение вас
ожидает рассмотрение вопроса масштабируе-
мости на примере конкретных операционных
систем: Linux и Windows ХР.
260
Прекращение выполнения
задачи
Смерть процесса
Рис. 4.7. Диаграмма переходов из состояния в состояния в Linux
4 JO Потоки в Windows ХР
В Windows ХР любой процесс состоит из программного кода, контекст®
выполнения, ресурсов (например, открытых файлов) и одного или
скольких связанных потоков. Контекст выполнения включает в себя так
элементы, как виртуальное адресное пространство процесса и различи
атрибуты (к примеру, атрибуты безопасности). Потоки представляют со0и.
элементарную единицу выполнения, потоки выполняют фрагменты ко/*
процесса в контексте процесса, используя ресурсы процесса. Помимо к®
текста процесса, поток имеет свой собственный контекст выполнен
включающий в себя стек времени выполнения, состояние машинных Ре1
стров и ряд атрибутов (например, атрибуты планирования).51
Когда система инициализирует процесс, она создает для него пер®
ный поток (primary thread). Первичный поток (называемый также гЛ
ным) работает точно так же, как любой другой поток за тем лишь исклЮ
IWIHO^L
цри выходе из первичного потока, выполнение процесса завер-
яем» ЧТ°р[оток может создавать другие потоки в рамках данного
^ае'гсЯ" 52 Все потоки, принадлежащие одному и тому же процессу, обла-
0роДеС2а' и1Л доступом к его виртуальному адресному пространству. Свои
паЮ'г °t,U1 * данные потоки хранят в локальной памяти потока (thread local
stTrS’ TLS)‘
" и могут создавать нити (fiber), которые по своим характеристи-
^°Т°оминают потоки за тем лишь исключением, что планирование рас-
каМ на выполнения нитей осуществляет создавший их поток, а не плани-
писания ти облегчают разработчикам перенос приложений, содержа-
Р°В1Цпотоки уровня пользователя. Сама нить выполняется в контексте
Давшего ее потока.53
С Нить должна хранить информацию о состоянии, например, указатель
следующую операцию, которую необходимо проделать над регистрами
Нооиессорами. Поток хранит информацию о состоянии каждой созданной
им нити. Сам по себе поток также является единицей выполнения, и по-
этому вынужден преобразовывать себя в нить, чтобы отделить информа- .
цию о своем состоянии от информации о состоянии других нитей, выпол-
няемых в данном контексте. Действительно, интерфейс Windows API при-
нудительно конвертирует поток в нить перед тем, как позволить ему
создать и спланировать выполнение другой нити. При этом контекст пото-
ка остается нетронутым и все нити, связанные с данным потоком, выпол-
няются в его же контексте.54
Каждый раз, когда ядро планирует выполнение потока, который был
преобразован в нить для выполнения, запускается конвертированная нить
либо другая нить, принадлежащая данному потоку. Как только процессор
поступит в распоряжение нити, она будет выполняться до тех пор, пока не
произойдет приоритетное вытеснение создавшего ее потока либо управле-
ние не перейдет к другой нити данного потока. Аналогично потокам, кото-
рые используют локальную память потока для размещения своих данных,
нити имеют свою локальную память нити (fiber local storage, FLS), кото-
рая играет для нити ту же роль, что локальная память потока для потока.
Роме того, нить может обращаться за необходимой информацией к ло-
бо йамяти своего потока. Если нить удалит себя (то есть завершит ра-
Уь то же самое сделает создавший ее поток.55
Пум» потоков
Br^n^°Ws ХР создает для каждого процесса пул потоков, состоящий из
^овЦяЛеННОГО количества рабочих потоков, роль которых играют потоки
вате„ я^Ра, выполняющие функции, запрашиваемые со стороны пользо-
скамиСКИХ поток°в. Поскольку число функций, задаваемых пользователь-
Ков, Ау?отоками, может превысить количество доступных рабочих пото-
Пул nolnf'°WS добавляет запросы на выполнение функций в очередь.
До Тех Т°КОв состоит из рабочих потоков, пребывающих в спящем режиме
^°®aBng°^’„nOKa в очеРеДь пула не будет добавлен новый запрос.56 Поток,
Ший запрос в очередь, должен задать функцию для выполнения
262
S1
и указать контекстную информацию.57 Пул потоков создается при пет> 1
обращении потока к нему.
Пул потоков используется в различных целях. Веб-серверы и базы |
ных могут использовать его для управления клиентскими запросами SI
пример, от веб-браузеров). Вместо выполнения ресурсоемких опера 5
создания и последующего удаления потоков для обслуживания KajK>S
нового запроса, процесс будет просто ставить запросы в очередь пула пак I
чих потоков. Кроме того, несколько потоков, большую часть времени пЛ
бывающих в спящем состоянии (например, в ожидании событий) Moj^’I
заменить одним рабочим потоком, который пробуждался бы при настур j
нии любого из ожидаемых событий. Более того, приложения могут исцОдП
зовать пул потоков для выполнения асинхронных операций ввода/выводц
добавляя запросы в очередь пула рабочих потоков на период для выподр
ния процедур завершения ввода/вывода. Использование пула потоков р0
зволяет повысить эффективность работы приложения и упростить его раз
работку, поскольку программистам не нужно будет писать код для созда.
ния и удаления множества потоков. Пулы потоков перекладывают часть
функций управления потоками с плеч программиста на систему, что ве
всегда гарантирует оптимальное быстродействие приложения. Например,
при изменении количества поступающих запросов система автоматически
увеличивает либо уменьшает размер пула потоков процесса, хотя в некото-
рых случаях программисту лучше известно, сколько именно потоков пона-
добится.58
Состояния потоков
В Windows ХР потоки могут находиться в одном из восьми состояний
(см. рис. 4.8). Жизненный цикл потока начинается с состояния инициали-
зации (initialized). После завершения инициализации поток переходит
в состояние готовности (ready). Потоки в состоянии готовности ожидают
освобождения процессора. Поток, выбранный диспетчером для выполне-
ния в следующий момент времени, пребывает в ждущем (standby) состоя-
нии, ожидая освобождения процессора. Поток может находиться в ЖДУ"
щем состоянии, например, во время переключения контекста. Как
процессор будет выделен новому потоку, говорят, что поток перешел в с0
стояние выполнения (running). Поток выходит из состояния выполнен051
по завершении работы, по окончании выделенного ему кванта времена
в случае приоритетного вытеснения, приостановки либо при необходим0
сти вынужденного ожидания объекта. Закончив выполнение всех сво
программных инструкций, поток переходит в состояние заверив
(terminated). Система не всегда немедленно удаляет поток в состоянии
вершения, что позволяет избежать ресурсоемкой операции создания и
ка в случае его повторной инициализации процессом. Система удаляет
ток только после того, как все занимаемые им ресурсы будут освобожДе
Если выполняющийся поток подвергнется приоритетному вытеснен^
либо истечет выделенный ему квант времени, он вернется в состояние
товнос ти.
Рис. 4.8. Диаграмма переходов потоков из состояния в состояние в Windows ХР
Выполняющийся поток переходит в состояние ожидания (waiting), если
ему приходится ждать события (например, завершения операции ввод
вода). Кроме того, другой поток (с достаточными правами доступа) либо сис-
тема может приостановить выполнение потока, переведя его в состо
ожидания до момента возобновления. По завершении ожидания поток
Жет перейти в состояние готовности либо в переходное (transition) сос
Ние • Система помещает поток в переходное состояние, если данные п°
® текущий момент времени недоступны (например, из-за того, что
авно не выполнялся, и система воспользовалась занимаемой им па
® ДРУГИХ целях), но в остальных отношениях поток полностью готов квы-
Л^иению. Далее, как только система загрузит стек ядра потока назад в п
др ’ поток перейдет в состояние готовности. Если состояние потока
ВаЛТЬ Невозможно (как правило, в результате ошибки), говорят, что
Дится в состоянии неизвестности (unknown).5' ’
Вопросы для само проВерки
1- Зачем нужны нити в Windows ХР?
2. Чем первичный (главный) поток отличается от остальных потоков?
Ответы i) Нити ПОЗВОЛЯЮТ ПОВЫСИТЬ совместимость С npiijj 1
ниями, которые управляют своими потоками самостоятельно (то°М
потоками уровня пользователя). 2) В отличие от других потоков
выходе из первичного потока, выполнение процесса, к которому 0’ ,,Ц
носится, также завершается. ' 01Ц
4.11 Многозадачность 0 Java. Учебный пример,
часть 1: знакомст0о с потоками Java
Как вы убедитесь в последующих главах, вопрос параллелизма прОв
сов и потоков оказывает большое влияние на архитектуру приложен»^
В этом и последующих дополнительных учебных примерах, мы привел*1
примеры реальных программ, демонстрирующих и разрешающих про^
мы, связанные с параллелизмом. Для реализации этих программ мы вы
брали язык Java за его переносимость между рядом популярных цЛат
форм. Изучение данного примера предполагает наличие базовых знаний jd
языку программирования Java.
В этом разделе мы рассмотрим ряд методов Java API, предназначенных
для управления потоками. Многие из этих методов используются в работаю-
щих примерах программного кода. За более подробной информацией по ис-
пользованию каждого метода, и, особенно, по поводу вырабатываемых ими
исключений, следует обращаться непосредственно к документации по Java
API:(java.sun.com/j2se/l.4/docs/api/java/lang/Thread.html).
Класс Thread (пакета java.lang) содержит несколько конструкторов.
Конструктор
public
Thread (String ИмяПотока)
создавать объекты Thread с именем ИмяПотока. Конструктор
Thread ()
создавать объекты Thread, имена которых образуются пут0*
с порядковым номером, напримвР
позволяет
public
позволяет
объединения строки «Thread-»
Thread-1, Thread-2 и Т.Д.
Программный код, выполняющий «реальную работу» над потоком, поМ®"
щен в метод run. Метод run может быть перегружен в подклассе Thread ля_£
реализован в виде объекта Runnable. Runnable представляет собой интерФ®
Java, позволяющий программисту контролировать жизненный цикл пот°
с помощью метода run в объектах класса, не поддерживающих Thread.
Программа начинает выполнение потока, вызывая метод start,
рый, в свою очередь, вызывает метод run. После того как метод start
пустит поток, произойдет немедленный возврат из метода start в
вающий поток. После этого вызывающий поток продолжит свое выпоя
ние параллельно с запущенным потоком.
Метод sleep класса static вызывается с аргументом, задающим
тельность сна (в миллисекундах) выполняемого в текущий момент ®PJjerI
ни потока. Засыпая, поток выбывает из конкурентной борьбы за I
сорное время, позволяя выполняться другим, потокам. Таким образом» I
доставляется шанс выполнения низкоприоритетным потокам. 1
265
setName позволяет задавать имя объекта Thread, чтобы облегчить
стам отладку, благодаря возможности идентифицировать вы-
роГРаМ^ g в данный момент времени поток. Метод getName позволяет вы-
М» объекта Thread. Метод tostring возвращает строку (string),
йСЙцть ид имени потока, его приоритета и группы (ThreadGroup) —
ростоя^^дительского процесса для группы потоков. Статический метод
ййаЛ°га ead возвращает ссылку на выполняемый в данный момент вре-
с^ток (объект Thread).
мени jOin ожидает поток, которому должно быть доставлено сообще-
Ме авершении, прежде чем вызывающий поток Thread сможет продол-
В0е ° з вое выполнение. Отсутствие аргумента либо аргумент со значени-
}КИрЬмИЛлисекунд для метода join означает, что поток будет бесконечно
еМ U ть завершения целевого потока, прежде чем продолжить свое выпол-
ов р такое длительное ожидание таит в себе опасность, и может привес-
156 к двум чрезвычайно серьезным проблемам, известным как взаимобло-
кировка и бесконечное откладывание (см. главу 7).
В Java реализован механизм передачи сигналов потокам при помощи
метода interrupt. Вызов метода interrupt для заблокированного процесса
(в результате вызова методов wait, join или sleep) вызывает обработчик
исключений interruptedException. Статический метод interrupted воз-
вращает true, если имело место прерывание выполняемого в текущий мо-
мент времени потока, и false в противном случае. Программа может так-
же воспользоваться специальным методом потока islnterrrupted, чтобы
определить, имело ли место прерывание потока.
Создание и запуск потоков
На рисунке 4.9 продемонстрирована базовая технология создания пото-
ков: создание объектов Thread и применение к ним метода sleep. В этой
программе создается три потока. Каждый поток выводит на экран сообще-
ние о переходе в спящий режим через вычисляемый произвольным обра-
зом временной интервал (в диапазоне от 0 до 5000 миллисекунд), что
Происходит по истечению этого времени. В момент пробуждения поток
Свое°Дит свое имя, сообщение о выходе из спящего состояния, завершает
з- ВЫполнение и переходит в состояние смерти. Обратите внимание, что
ди ₽П1ение метода main (то есть главного выполняемого потока) происхо-
Со,*° завеРшения самого приложения. Программа состоит из двух клас-
^овКЛаССа ThreadTester (строки 4-23), отвечающего за создание трех no-
run НИ КЛасса PrintThread (строки 25-59), в теле которого помещен метод
1£Ла*п°ЛНяк>щий все необходимые операции PrintThread.
PrintThread (строки 25-59) расширяет возможности объекта
^Ласс о п°3в°ляя выполняться одновременно всем объектам PrintThread.
Т°Ра (Ст Ст°ит из экземпляра переменной sleepTime (строка 27), конструк-
С°Дер5к^Оки 29-36) и метода run (строки 38-57). В переменной sleepTime
^УДтоПТСЯ ц-елое число, вычисляемое случайным образом при вызове кон-
р еКт0 а Нового объекта PrintThread. Любой поток, контролируемый
е аРом ₽rintThread, пребывает в спящем состоянии в течение временно-
ч*аЕ>с. ^Утка, задаваемого параметром sleepTime соответствующего объ-
ntThread, выводя свое имя сразу по выходу из спящего состояния.
__________________________________________________________
/ Рис. 4.9: ThreadTester. Java
Разные потоки выводят сообщения на экран в разные моменты времени.
public class ThreadTester (
5
6 public static void main! String [] args )
7 {
8 // Создание потоков и присвоение им имен
9 PrintThread threadl = new PrintThread! "threadl” );
10 PrintThread thread2 = new PrintThread ( "thread?” );
11 PrintThread threadl = new PrintThread! ''threadl'1 };
12
11 System.err.prihtln( "Запуск потоков" );
14
15 threadl.start О; // запуск потока 1> переход в состояние готовности
16 thread?.start(); // запуск потока 2, переход в состояние готовности
17 threadl.start О; // запуск потока 3, переход в состояние готовности
19 System.err.printin! "Потоки запущены, конец части main\n" );
20
21 ) // конец главной функции
22
23 } // конец тела класса ThreadTester ,
24
25 // класс PrintThread контролирует работу потоков
26 class PrintThread extends Thread {
27 private int sleepTime;
28
29 // присвоение имени потоку путем вызова конструктора суперкласса
30 public PrintThread! String name )
31 (
32 super( name ) ;
33
34 // выбор произвольного времени сна процесса <от 0 до 5 сек.)
35 sleepTime >= ( int ) ( Math.random!) * 5001 );
36 } // завершение конструктора PrintThread
37
38 // следующий поток осуществляет запуск метода run
39 public void run!)
40 {
41 // перевод потока в спящий режим на время sleepTime
42 try {
43 System.err.printin( getName!) + " уснет на " +
44 sleepTime + ” миллисекунд" .);
45
46 Thread.sleep( sleepTime );
47 ) // завершение функции try
48
49 // Если сен потока прерван, распечатать стек
50 catch ( InterruptedException exception ) {
51 exception.printStackTrace();
52 } // завершение функции catch
53
54 // вывод имени потока
55 System.err.printin! getName!) + " вышел из сна" );
56
57 ) // завершение метода run
58
59 } 7/ завершение класса PrintThread
Рис. 4.9. Сценарий ThreadTester на Java (часть 1 из 2)
„епч^0-
267
результаты выполнения программ
дапУск потоков ? *** (1& вари
Потоки запущены, 7
threadl
thread?
threads
threads
threadl
thread?
конец части main
уснет
уснет
уснет
вышел
ВЫП1ОЛ
вышел
на
на
на
из
из
из
1217 миллисекунд
3989 миллисекунд
662 миллисекунд
сна
сна
сна
314 миллисекунд
1990 миллисекунд
конец <аасти main
Результаты выполнения программы (2-й ва™,^ >
Запуск потоков раант)
threadl уснет на
thread2 уснет на
Потоки запущены,
thread3 уснет на
threadl вышел из
thread2 вышел из
3016 миллисекунд
сна
сна
Рис. 4.9‘ Сценарий ThreadTester на Java (часть 2 из 2)
Конструктор PrintThread (строки 2Й-36) инициализирует переменную
sleepTime с помощью случайного значения в диапазоне от 0 до 5000. Когда
конструктору PrintThread впервые выделяется процессор, начинается вы-
полнение метода run. В строках 43-44 на экран выводится сообщение
с именем выполняющегося в данный момент потока и информацией о том,
что данный поток перейдет в спящий режим на заданное количество мил
лисекунд. Чтобы узнать имя выполняющегося в данный момент потока,
в строке 43 вызывается метод getName. Полученное имя потока передается
в виде строкового аргумента конструктору PrintThread и далее конструк
тору суперкласса Thread в строке 32. Обратите внимание, что в строке
Для вывода сообщений используется функция System.err, поскольку она
является небуферизируемой, позволяя выводить все аргументы на, печать
немедленно после ее вызова. В строке 46 вызывается статический метод
sleeP потока для перевода потока в состояние сна. На этом этапе поток вы
^вобоясдает процессор, и система получает возможность запуска другого
с^°Ка" ^Ри пробуждении потока он повторно входит в состояние гошовно
qkJ1’ в котором и пребывает до момента освобождения процессора.
в^КТ PrintThread снова переходит в состояние выполнения, строка с
Пос>т^ИТ ИМя потока вместе с сообщением о выходе из спящего состояния,
вСОс® Чег° Работа метода run завершается. В результате поток переходит
М?Яаие Смерти, освобождая все занимаемые им ресурсы.
PcintT°^ ma-*'n класса TreadTester (строки 1-6) создает три о ъекта
Чие v hread (строки 9-11). При отладке многопоточной программы нали
& стплПОТоков уникальных имен позволяет отличать их друг от друга,
start ^ах 15-17 для каждого потока в отдельности вызывается метод
e°nz0 ’ К°торый переводит эти потоки из состояния рождения в состояние
а°с«ги. Выход из метода start происходит немедленно после оконча-
еРации над потоком. В строке 19 выводится сообщение о том, что
268
все потоки запущены. Обратите внимание, что весь программный
в этой программе, за исключением кода метода run, выполняется вцЛ
главного потока main. Конструктор PrintThread также выполняется ь
ри потока main, поскольку все объекты PrintThread были созданы вн,,
потока main. Когда происходит завершение метода main (строка 21),
программа продолжает выполняться, поскольку в ней остаются актив44*4
потоки (то есть такие потоки, которые были запущены и еще не усц^4®
достигнуть состояния смерти, а также не являются демонами). Завер^
ние программы происходит после уничтожения последнего потока. Ко 6
система в первый раз предоставляет процессор в распоряжение объек^
PrintThread, поток входит в состояние выполнения, в результате чего
пускается метод run потока.
Программа выводит на экран имена потоков и время пребывания в СПд
щем состоянии. Поток с наименьшей длительностью сна обычно просьцщ
ется первым, сообщая нам о выходе из состояния сна и завершая свое вы
полнение. Обратите внимание во второй группе результатов, что потоки
threadl и thread? выводят свои имена и время сна до того, как метод main
завершит свое выполнение, иллюстрируя тот факт, что когда несколько
потоков переходят в состояние готовности, начать выполняться может
любой поток.
Вопросы для самопроверки
1. Зачем программисты присваивают имена потокам Java?
2. Каким образом язык Java позволяет программистам создавать по-
токи из объектов, не являющихся расширением объекта Thread?
Ответы 1) Присвоение имен облегчает идентификацию отдельных
потоков во время отладки программистами. 2) В классе может быть
реализован интерфейс Runnable, позволяющий объектам класса кон-
тролировать жизненный цикл потоков с помощью метода run.
Веб-ресурсы
www.serpentine.com/~bos/threads-faq/
Здесь находится страничка часто задаваемых вопросов о потоках. Помимо о
тов на базовые вопросы, касающиеся потоков, вы найдете ссылки на литерагУ
о потоках; обсуждения основных подводных камней, с которыми сталкиваются
граммисты при реализации поддержки потоков операционной системой; а также
реса, по которым вы сможете загрузить целые пакеты потоков из сети Интерн
www. linux-mag. com/2001-05/compile_01 . html pgS'
Статья Бенджамина Челфа в журнале Linux Magazine посвящена обзорУ ку-
личных вариантов реализации потоков. Челф подробно описывает, как в Lin
ганизована работа с Pthread, приводя примеры программного кода Linux.
publib.boulder.ibm.com/iseries/v5rl/ic2924/index.htm?infо/apis/
rzah4mst •
Содержит полное описание API для программирования PThread, а также ° I
деление базовых концепций потока.
269
redhat.com/pthreads-win32/
s<++ce ' реализацию потоков Pthread для 32-разрядной среды Windows.
ГодеР^ ‘
com/docs/books/tutorial/essential/threads/
jaVg^e материалы по потокам Java от компании Sun.
sun.eom/j2se/l.4.l/docs/api/
jaVra'jovn включая спецификацию класса Thread.
Др! Ja*a»
. devx.com/dotnet/articles/pa061702/pa061702-l.asp
аГсЬ1д рассматривающая многопоточность на платформе .NET, включая крат-
Сдредставление концепций многопоточности.
rnicrosoft.com/msj/0499/pooling/pooling.aspx
Статья, посвященная описанию пула потоков в Windows ХР.
va sun.com/docs/hotspot/threads/threadS.html
Официальный документ, описывающий связь между потоками Java и Solaris.
developer.apple.com/documentation/MacOSX/Conceptual/Systemoverview/
InverEnvironissues/chapter_14_section_3.html
Описывает диспетчер потоков в Macintosh OS X.
Итоги
В последние годы языки программирования общего назначения, такие как
Java, С#, Visual C++ .NET, Visual Basic .NET и Python сделали примитивы парал-
лельной работы доступными для программистов. Программист может создать при-
ложение, состоящее из нескольких потоков выполнения, формируемых из фраг-
ментов программного кода, которые могут выполняться одновременно с другими
фрагментами. Такая технология, называемая многопоточностью, предоставляет
программисту обширные возможности. Для языков программирования, обеспечи-
вающих семантику работы с многопоточностью, необходимо также наличие под-
держки потоков со стороны операционной системы.
Потоки, иногда называемые легковесными процессами (LWP), разделяют боль-
шое количество ресурсов — обычно все адресное пространство процесса, что повы-
ЧенТ эФФективность выполнения задач. Термин «поток» используется для обозна-
ОднИЯ опРеДеленного потока инструкций (управляющего потока); потоки в рамках
сУРсы° Процесса выполняются параллельно для достижения общей цели. Такие ре-
(TSDj КЙК РегистРЬ1 процессора, стек и другие данные, специфичные для потока
ному пЯВЛЯЮтСя локальными по отношению к каждому потоку, в то время к адрес-
РиантаР°СТРаНСТВУ своего процесса имеют доступ все потоки. В зависимости от ва-
1еМа лйй?ЛИЗа1|,ии управление потоками может осуществлять операционная сис-
Б° Мно пользовательские приложения. Хотя поддержка потоков присутствует
ИМетг., Х операционных системах, конкретные варианты их реализации могут
ИсполЩеСтвенные ОТЛИЧИЯ-
^₽ованиьзование потоков расширяется благодаря тенденциям в области програм-
?°Ток в я’ ВКлючая поддержку масштабируемости и взаимодействия. Каждый
^°токц и Чение жизненного цикла проходит через серию дискретных состояний.
ь°а°бнов пР°Цессы обладают рядом общих операций, таких как создание, выход,
я*16 Потокение и приостановка. В отличие от процедуры создания процессов, созда-
тРе®Ует от операционной системы инициализации ресурсов, которые
д?Р> адр Разделяемыми между родительским процессом и его потоками (напри-
р 5Ием и v°r° пространства). Поэтому ресурсоемкость операций, связанных с соз-
^^“м потоков, меньше, чем ресурсоемкость аналогичных опе-
Д процессами. Существуют операции над потоками, которые не имеют со-
ответствия среди операции над процессами, например, операции ontj\ie.
и присоединения. Ч
Хотя в различных операционных системах поддержка потоков организов»
по-разному, в большинстве систем поддерживаются потоки уровня пользовате4
потоки уровня ядра либо их сочетание. Потоки уровня пользователя выполц^4'
операции над потоками в пространстве пользователя. Это означает, что потоки с*0*
даются библиотеками времени выполнения, не позволяющими выполнять при^3-
легированные инструкции либо напрямую получать доступ к примитивам ЯдJ1'
Потоки уровня ядра нередко называют потоками, связанными отношением м»
гих-к-одному, поскольку операционная система связывает все потоки многопот °
ного процесса с одним контекстом выполнения. Хотя быстродействие потоке
уровня пользователя зависит от конкретного приложения, многие недостатки т 8
ких потоков вызваны тем, что с точки зрения ядра подобный многопоточный mjl
цесс выглядит как один управляющий поток.
Потоки уровня ядра пытаются обойти ограничения потоков уровня пользовате
ля, связывая каждый поток со своим собственным контекстом выполнения. В ре"
зультате потоки уровня ядра можно описать отношением один-к-одному. Среда
преимуществ потоков уровня ядра можно отметить высокую масштабируемость
интерактивность и производительность. Однако из-за дополнительных накладных
расходов и низкой переносимости, потоки уровня ядра не всегда являются опти-
мальным решением для многопоточных приложений.
Комбинированная модель потоков уровня пользователя и потоков уровня ядра
описывается отношением многих-ко-многим (либо отношением т-к-п, поскольку
количество потоков уровня пользователя и потоков уровня ядра не всегда совпада-
ет). Реализация отношения многих-ко-многим требует меньше накладных расхо-
дов, чем реализация отношения одного-к-одному, благодаря использованию пула
потоков, с помощью которого приложения могут задавать количество необходимых
потоков уровня ядра. Постоянно существующие потоки ядра, занимающие пул по-
токов, называются рабочими потоками. Технология, позволяющая библиотекам
уровня пользователя планировать выполнение потоков, носит название «активации
планировщика». Активация планировщика происходит в тех случаях, когда опера-
ционная система вызывает библиотеку работы с потоками уровня пользователя, ко-
торая заявляет о необходимости изменения расписания выполнения одного из своих
потоков. Активация планировщика позволяет уменьшить накладные расходы, свя-
занные с переключением контекста из-за некорректного планирования ядром, раз-
решая библиотеке управления потоками самостоятельно определять политику пла-
нирования, которая бы наилучшим образом соответствовала нуждам приложения.
Когда операционная система доставляет сигнал процессу, выполнение процесса
прерывается, и он вызывает соответствующий обработчик сигналов. Существу®1
два типа сигналов: синхронные (которые возникают непосредственно в результате
выполнения определенных инструкций) и асинхронные (которые возникают в Ре"
зультате событий, не связанных с выполнением инструкций). Доставка сигнал0®
связана с рядом проблем в архитектуре реализации потоков. Библиотека управД®
ния потоками должна определить получателя каждого сигнала, чтобы обеспечит®
корректную доставку асинхронных сигналов. Каждому потоку обычно предназВ®
чается целая группа отложенных сигналов, которые были доставлены во время ®
выполнения. Один из способов управления приемом сигналов, состоит в задаЯ
каждым потоком маски сигналов, запрещающих сигналы определенного типа,
ким образом, потоки могут маскировать любые сигналы за исключением сигнал
того типа, который их интересует. а.
Процедуры завершения либо отмены потока также отличаются в различных
риантах реализации. Поскольку несколько потоков обладают общим достуЯ
к одному и тому же адресному пространству, досрочное завершение потока
вызвать незаметные на первый взгляд ошибки. В некоторых вариантах Ре&л^1(^(г
ции потоки могут самостоятельно определять, когда разрешено завершать их ра
ту, чтобы не допустить вхождение потока в противоречивое состояние.
271
потоки
использующие для работы API POSIX, называют Pthread-потоками
цоТо1<и’ таЮке называют потоками POSIX либо, если быть более точными, то
,й0огДа HXpOSIX 1003.1с). В соответствии со спецификацией POSIX содержимое
процессора, стек и маска сигналов хранятся отдельно для каждого пото-
а гисТРоВвсе остальные ресурсы являются доступными для всех потоков про-
Ла ецификация POSIX определяет способ доставки сигналов в потоки
«есса‘ Я и задает несколько режимов отмены потоков.
pthread ИОННой системе Linux и для потоков, и для процессов (которые здесь на-
В опер задачами) выделяется один и тот же тип дескриптора. Для создания до-
эывак>тся в Linux вызывается системная функция fork (как и в UNIX). Чтобы
черяих поддержку потоков, в Linux предусмотрена модифицированная версия
обеспечить
fork, под названием clone, которая позволяет указывать аргу-
олстемн^ деляющие, какие ресурсы будут доступны для дочерних потоков. На са-
менты> коМ уровне разделения ресурсов, задачи, созданные при помощи систем-
м°н 1ЪГНкции clone соответствуют потокам, которые обсуждались в разделе 4.2.
B0IR Windows ХР именно потоки (а ие процессы) выбираются процессором для по-
лющего запуска; потоки выполняют фрагменты кода процесса в контексте про-
СЛбгя используя принадлежащие ему ресурсы. Помимо контекста процесса, поток
де еет собственный контекст выполнения, включающий в себя стек времени выпол-
нения, состояние машинных регистров и несколько атрибутов (например, атрибут
приоритета планирования). При инициализации процесса системой, создается пер-
вичный поток процесса, по выходу из которого, как правило, автоматически завер-
шается выполнение процесса. Потоки в Windows ХР могут создавать нити, являю-
щиеся по своей структуре аналогами потоков, за тем лишь исключением, что плани-
рование выполнения нитей осуществляется создавшим их потоком, а не системным
планировщиком. Windows ХР выделяет под нужды каждого процесса свой пул по-
токов, состоящий из набора рабочих потоков уровня ядра, которые выполняют
функции, задаваемые пользовательскими потоками.
Язык программирования Java позволяет программистам создавать переносимые
потоки, совместимые с разнообразными платформами. В Java используется класс
Thread, предназначенный для создания потоков, который выполняет код, задавае-
мый в методе run объекта Runnable. В языке Java поддерживаются операции при-
своения имен, запуска и присоединения потоков.
Ключевые термины
И1оеоз 1сПОТОК POSIX 1003Лс) — поток, соответствующий стандарту POSIX
Акти
лио^ИЯ планиР°вщика (scheduler activation) — механизм, позволяющий биб-
Аси КаМ уровня пользователя планировать выполнение потоков ядра.
°тме°аВаЯ отмена (asynchronous cancellation) в спецификации POSIX — режим
отмены ПРИ КОТОРОМ поток завершается немедленно после получения сигнала
как*н^ВНЫй сигнал (asynchronous signal) — сигнал, вызванный причинами, ни-
^ЛавНы” СВязанными с выполнением текущей инструкции активного потока.
с Создй ПОТок (main thread of execution) — поток, создаваемый одновременно
^аДача Ием nP°4ecca (также используется термин первичный поток).
й п°тОка) 8а представление контекста выполнения в Linux (для процесса либо
*1е®Ьг, в а 4 °™ена (disabled cancellation) в спецификации POSIX — режим от-
котором поток не принимает отложенные сигналы отмены.
272
ы
Интервал сна (sleep interval) — период времени (задаваемый потоком, которые ]
бирается войти в состояние сна) в течение которого поток может пребывать11
стоянии сна. ’ й «о.
Легковесный процесс (lightweight process, LWP) — одиночный поток прогп
ных инструкций (называемый также потоком выполнения либо управляй)
потоком). Потоки считаются «легковесными» поскольку они разделяют об^*1
адресное пространство с другими потоками этого процесса.
Локальная память нити (fiber local storage, FLS) — область адресного простьа
ва процесса в Windows ХР, где нить хранит свои данные, к которым никто v ’
ме нее не может получить доступ.
Локальная память потока (thread local storage, TLS) — способ хранения епе
фичных данных потока, реализованный в Windows ХР. Поток может облал '
общим доступом к адресному пространству процесса наравне с другими потол^
ми, и при этом хранить свои собственные данные в TLS.
Маскирование сигнала (mask a signal) — механизм запрета доставки сигнал0
Маскирование сигнала позволяет многопоточному процессу определять, каки
потоки будут обрабатывать сигналы того или иного типа.
Многопоточность (multithreading) — технология, позволяющая включать в состав
процесса несколько работающих потоков для выполнения параллельных опера-
ций, возможно даже одновременно.
Нить (fiber) — единица выполнения в Windows ХР, создаваемая и управляемая
потоком. Использование нитей повышает переносимость приложений, которые
самостоятельно распределяют процессорное время между своими потоками.
Обработчик сигналов (signal handler) — программный код, запускаемый по при-
ходу сигналов определенного типа.
Отложенная отмена (deferred cancellation) в спецификации POSIX — режим отме-
ны, в котором поток завершает свою работу только после того, как разрешит
прием сигналов отмены и проверит их наличие.
Отложенный сигнал (pending signal) — сигнал, не доставленный потоку по причи-
не того, что поток в данный момент времени не выполняется либо маскирует
сигналы этого типа.
Отмена потока (cancellation of a thread) — операция над потоком, позволяющая
завершить целевой поток. Существует три режима отмены: запрещенная, отло-
женная и асинхронная отмена.
Отношение многих-к-одному (many-to-one thread mapping) — модель потоков, со-
гласно которой все потоки уровня пользователя одного процесса связываются
с одним потоком ядра.
Отношение многих-ко-многим (ш-к-п) (many-to-many (m-to-n) thread mapping) ''
модель потоков, согласно которой группе пользовательских потоков стави
в соответствие группа потоков ядра, таким образом, что приложение полу48
преимущества и от использования потоков уровня ядра, и от использова
функциональности потоков уровня пользователя (например, активации пла^це
ровщика). На практике количество потоков пользователя должно быть боль
либо равно числу потоков ядра в системе — в целях экономии памяти.
Отношение одного-к-одному (one-to-one mapping) — модель потоков, согласно,
торой каждому потоку уровня пользователя ставится в соответствие один п
уровня ядра.
Первичный поток (primary thread) — поток, создаваемый одновременно с co3^4go-
ем процесса (также используется термин главный поток). Возврат из перви
го потока означает завершение выполнения процесса в целом.
273
bread)__логический объект, описывающий последовательность независи-
тоК ^^лвяемых программных инструкций (называемый также выполняемым
вЬ1П являющим потоком). Потоки позволяют воспользоваться преимущест-
либо ^“раллельного выполнения операций в рамках процесса.
ваМ’5 пользователя (user-level thread) — модель потоков, согласно кото-
потоки процесса связываются с одним контекстом выполнения.
рой ®се ядра (kernel-level thread) — поток, создаваемый самой операцион-
00ток УР^ (его также называют потоком ядра).
Н°я threads — потоки, поддержка которых изначально была реализована
П'”0** поядре Mach (на основе которого построена ОС Macintosh X).
в м Win32 (Win32 thread) — потоки, разработанные специально для использо-
сеМействе 32-разрядных операционных систем Windows.
ваяия в „
мнение (join) — операция над потоком, вследствие которой вызывающий
дрисое,
I блокирует свое выполнение до тех пор, пока не завершится выполнение
П°Т соединенного к нему потока. Обычно первичный поток присоединяет к себе
ПР созданные потоки, поэтому соответствующий процесс сможет завершить
свою работу только после того, как закончится выполнение всех его потоков.
Побуждение (wake) — операция над потоком, переводящая его из состояния ожи-
дания в состояние готовности.
Пул потоков (thread pooling) — механизм работы с потоками, предусматриваю-
щий использование определенного количества потоков ядра, которые бы посто-
янно существовали в течение всей жизни процесса. Использование подобной
технологии позволяет повысить производительность системы за счет снижения
числа ресурсоемких операций по созданию и уничтожению потоков.
Рабочий поток (worker thread) — поток ядра, входящий в состав пула потоков. Ра-
бочий поток может быть связан с любым пользовательским потоком процесса,
создавшего данный пул потоков.
Сигнальная маска (signal mask) — структура данных, определяющая, доставка
каких типов сигналов разрешена потоком. В зависимости от типа сигнала и дей-
ствия по умолчанию, маскируемые сигналы могут добавляться в очередь либо
просто удаляться.
Синхронный сигнал (synchronous signal) — сигнал, возникший в результате вы-
полнения текущих инструкций исполняемого в данный момент потока.
стояние блокировки (blocked state) — состояние потока, ожидающего уведомле-
ния о появлении определенного события, например завершения операции вво-
Сост ВЫВОда’ что®ы полУЧить возможность перейти в состояние готовности.
ояние выполнения (running state) — состояние потока, которому в данный
СоХ ВЫДелен процессор.
сРазНИе готовности (ready state) — состояние потока, при котором он мог бы
В WindИСпользовать процессор, предоставленный в его распоряжение,
стояв °WS ХР из состояния готовности поток сначала переходит в ждущее, со-
С°стОяв И ТОЛько затем в состояние выполнения.
ЧоцЧ11 е 3авеРШепия (terminated state) — в Windows ХР состояние потока, за-
С°СТояни Щего выполнение всех заданных операций.
Чосле ег (initialized state) — состояние потока в Windows ХР
^°СТоЯиие° СОздания операционной системой.
°аРеде Неизвестности (unknown state) — означает, что состояние потока не
еН°’ Например, в результате ошибки.
Чог° Д,Ля>ЗКи^ания (standby state) — в Windows ХР состояние потока, выбран-
последующего запуска.
274
-------------------------------------------------------------------
Состояние ожидания (waiting state) — состояние потока, когда он не моц(е '
чать свое выполнение до тех пор, пока не будет переведен в состояние
сти в результате операции пробуждения либо уведомления.
Состояние перехода (transition state) — в Windows ХР состояние потока, i:(n,
закончил ожидание, но не может начать выполнение, поскольку стек ядг>
выгружен из памяти. %,
Состояние потока (thread state) — статус потока (например, выполняется
блокирован и т.д.). ’’fy
Состояние рождения (born state) — состояние потока в самом начале жи;ш<»
цикла.
Состояние смерти (dead state) или Тупиковое состояние — состояние, в кото
пребывает поток после выполнения всех своих инструкций либо завертеНи
иным причинам. °о
Состояние сна (sleeping state) или состояние бездействия — состояние, когда
ток не может выполняться до тех пор, пока не закончится интервал сна, и одЯ
сможет вернуться в состояние готовности.
Тупиковое состояние — см. Состояние смерти.
Тяжеловесный процесс (heavyweight process, HWP) — традиционный процесс, ко
торый может состоять из одного или нескольких потоков. Процесс называют то.
желовесным по той причине, что во время его создания ему выделяется отдель-
ное адресное пространство.
Уведомление (notify) — операция над потоком, переводящая целевой поток из со-
стояния ожидания в состояние готовности.
Упражнения
4.1. Сравните способ выбора потоков для выполнения при использовании моде-
ли потоков уровня ядра и модели потоков уровня пользователя.
4.2. Если перед вами стоит задача одновременного выполнения ряда независи-
мых операций (например, при умножении двух матриц), какой алгоритм
более эффективен: с использованием потоков либо без них? Почему на этот
вопрос сложно ответить однозначно?
4.3. Приведите примеры двух случаев, в которых бы пригодилось использован»®
пула потоков (кроме веб-серверов и серверов баз данных). В качестве еще
ной весьма распространенной области применения многопоточности моЛ®.
назвать онлайновые интерактивные многопользовательские игры. В не1С01е.
рых играх одновременно могут поддерживаться сотни активных поДКЛЮ’1
ний, каждое из которых представляется в виде потока. В такой среде, Я
пользователи часто подключаются к игре и снова отключаются от нее, й
более эффективным способом выделения потоков является применение
потоков. В общем, выиграть от использования пула потоков может
система, где потоки часто создаются и уничтожаются, но при этом их ° |
количество в любой момент времени приблизительно одинаково.
4.4. Почему механизм активации планировщика обладает меньшей пере®
мостью, чем потоки уровня пользователя либо потоки уровня ядра'
4.5. В разделе 4.7.1 мы говорили о задании получателей сигналов с поМс
идентификаторов потоков и процессов. Предложите альтернативный ^.ji
соб реализации сигналов для решения проблемы асинхронной Д°с
сигналов.
275
зделе 4.7.1 обсуждалась реализация асинхронных легковесных процес-
g. В Ра.aSLWP) для отслеживания и последующей доставки отложенных
со® ^ронНЫх сигналов в Solaris 7. Как можно было бы упростить это реше-
аСЙЙеспи бы операционная система представляла потоки, связанные отно-
®^нием одного-к-одному?
С авните асинхронную, отложенную и запрещенную отмену в потоках
4-^‘ pthread.
отличаются между собой в Linux системные функции fork и clone?
4-8‘ Хо в них общего?
ям отношением, согласно разделу 4.10 связаны потоки, поддерживае-
4-9‘ S в Windows ХР?
Р комендуемые исследовательские учебные проекты
’ изучите схемы реализации потоков в Windows ХР, ОС X и Linux. Сравните
4-1В' между собой. Чем эти схемы отличаются от реализации потоков Pthread
в спецификации POSIX?
4 И Подготовьте исследовательский отчет по реализации потоков на языке
Java. Какую информацию о потоках отслеживает виртуальная машина
Java? Зависит ли реализация потока от платформы, на которой запущена
виртуальная машина Java?
4 12. Изучите совместимую с Solaris библиотеку потоков. Подготовьте исследо-
вательский отчет по работе этой библиотеки. Каким образом в ней органи-
зовано управление доставкой сигналов потокам и устранение известных
проблем? Согласуется ли данная библиотека со спецификацией POSIX?
Исследуйте три разновидности систем, в которых используются пулы пото-
ков. Какое среднее количество потоков используется в каждой системе?
Изучите вопрос управления потоками в многопроцессорных и распределен-
ных системах.
4.13.
4.14.
Рекомендуемая литература
Изобретателем концепции легковесного процесса стала компания Sun
тепм°в^ет'61 Термин «легковесный процесс» очень скоро превратился в синоним
<<поток», во многом благодаря разработке спецификации POSIX Pthread
t«bho ЛеНИЮ языка программирования Java. Поскольку программисты начали ак-
сИстемИСПОЛЬЗОВать в своих приложениях потоки, разработчики операционных
ПеШных₽е^ЛОЖИлИ несколько уровней поддержки потоков. Одной из наиболее ус-
тами бг'1оЛа моДель активации планировщика, придуманная Андерсоном с кол-
Уровця ’ Ь этой статье также рассматриваются вопросы, связанные с потоками
м°>Кно на „ЛЬЗователя и уровня ядра. Аналогичное обсуждение моделей потоков
Го,1оточво ТИ У Бенджамина.63 Читатель увидит, что расширение поддержки мно-
^еЛЬнойСТв в операционной системе Solaris от компании Sun Microsystem, в зна-
8bl* систем*^6 ®Ыло продиктовано изменениями архитектуры других операцион-
Вь п°сле В ПЛане Реализации потоков.64
nJ* 0Г[ерац Ие ГОДЫ значительно расширилась поддержка Pthread среди различ-
р|i1r°HHbIX систем. Блеллок описывает в своей книге вопросы реализации
Геаа и приводит учебный пример потоков Solaris.65 Книга Бутенхофа
еание потоков POSIX посвящена спецификации POSIX и способам
Ров^а°ВацИмВа11ия с помощью Ptrhread.66 Более подробную информацию по ис-
at/e с Потоков вы можете найти в книге Клеймана и соавторов Программи-
^Оцо п°П10^'0л^ованием потоков67 либо книге Бирелла Введение в программиро-
6 Mojjj °®- 8 Аустерхаут рассматривает, как неправильное использование по-
> привести к снижению быстродействия.69
276
Использованная литература
1. «Process and Thread Functions,» MSDN Library, Microsoft Corporation p I
ary 2003, <msdn.microsoft.com/library/default.asp?url=/library/en-us/(]n\i
/base/p rocessan d_t bread functions. asp>.
2. Manual Pavon Valderrama, «The Unofficial GNU Mach IPC Beginner’s Guide
gust 19, 2002, <www.nongnu.org/hurdextras/ipc_guide/niach ipc_cthreads Ь
3. IEEE Standards Press, 1996, 9945-1:1996 (ISO/IEC) [IEEE/ANSI Std ЮОЗ д
Edition] Information Technology-Portable Operating System Interface (POgJy
Part 1: System Application: Program Interface (API) [C Language] (ANSI)
4. Daley, Robert C., and Jack B. Dennis, «Virtual Memory, Pro-Bind Sharjj, I
Multics,» Proceedings of the ACM Symposium on Operating System РппсЛ **
January 1967. ₽4
5. «Multithreading in the Solaris Operating Environment, A Technical White ь I
per,» Sun Microsystems, 2002. a'
6. O’Sallivan, B., «Answers to Frequently Asked Questions for comp.progra
ming.threads: Part 1 of 1,» Rev, 1.10, Last modified September 3, igS I
<www.serpentine.com/~bos/threads-faq/>.
7. «Lesson: Threads: Doing Two or More Tasks at Once,» The Java Tutorial, Sun Micn,l
systems, Inc., <java.sun.com/docs/books/tutorial/essential/threads/index.html>. I
8. Appleton, R., «Understanding a Context Switching Benchmark,» Modified October
23, 2001, <cs.nmu.edu/~randy/Research/Papers/Scheduler/understanding.html>,
9. «prhread cancel,» Documentation Overview, Glossary, and Master Index, ©Digital
Equipment Corporation 1996, All Rights Reserved; Product Version: Digital Unit
Version 4.0 or higher, March 1996, <www.cs.arizona.edu/coniputer.help/pol-
... icy/DIGITAL_unix/AA-Q2DPC-TKTl_html/thrdO115.html#pt_cancel 13>. I
10. «2.1.4 Waiting for a Thread to Terminate,» Documentation Over view, Glossary, and
Master Index, Product Version: Digital UNIX Version 4.0 or higher, March 1996,
<www.cs.arizona.edu/computer.help/policy/DIGITAL_unix/M-QZDPC- TKTlhtml
thrdOO21 .html# j oin_thread_sec>.
11. «Comp.os.research: Frequently Answered Questions, The History of Threads,» Mod-
ified August 13, 1996, <www.faqs.org/faqs/os-research/partl/section-10.html>- I
12. Anderson, T. E.; B. N- Bershad; E. D. Lazowska; and H. M. Levy, «Scheduler Ac
tivations: Effective Kernel Support for User-Level Management of Parallelism,1
ACM Transactions on Computer Systems, Vol. 10, No. 1, February 1992, p- 54- |
13. Benjamin, C., «The Fibers of Threads,» Compile Time (Linux Magazine), b®
2001, <www.linux-mag.com/2001-05/compile_06.html>.
14. Anderson, T. E.; B. N. Bershad; E. D. Lazowska; and H. M. Levy, «Scheduler c(
tivations: Effective Kernel Support for User-Level Management of Parallels ’ I
ACM Transactions on Computer Systems, Vol. 10, No. 1, February 1992, p- ® Lj
15. D.G. Feitelson, «Job Scheduling in Multiprogrammed Parallel Systems,»
Research Report RC19790, October 1994, 2d rev., August 1997, p. 121- ^1
16. C. Benjamin, «The Fibers of Threads,» Compile Time (Linux Magazine),
2001, <www.linux-mag.com/2001-05/compile_06.html>.
17. Feitelson, D. G., «Job Scheduling in Multiprogrammed Parallel Systems,»
Research Report RC 19790, October 1994, 2d rev., August 1997, p. 121-
18. «Package java.nio.channels,» Java 2 Platform SE vl.4.2, 2003 <java.suB^ j
j2se/l.4.2/docs/api/java/nio/channels/package-summary.html#multiple^
19. Benjamin, C., «The Fibers of Threads,» Compile Time (Linux Magazine),
2001, <www.linux-mag.com/2001-05/compile_06.html>. jJJr
20. Feitelson, D. G., «Job Scheduling in Multiprogrammed Parallel Systems,»
Research Report RC 19790, October 1994, 2d rev., August 1997, p. 121-
277
D G., «Job Scheduling in Multiprogrammed Parallel Systems,» IBM
feitelsO^’Beport RC 19790, October 1994, 2d rev., August 1997, p. 121.
21’ Bese&rcri T E . в. N. Bershad; E. D. Lazowska; and H. M. Levy, «Scheduler Ac-
Ariders011’ ’ ’tive Kernel Support for User-Level Management of Parallelism,»
22’ tivstif’nS:nsaCtions on Computer Systems, Vol 10, No. 1, February 1992, p. 54.
дСМ T^a c ^he Fibers of Threads,» Compile Time (Linux Magazine), May
s penjain^w’lnnux.mag.Com/2001-05/compile_06.html>.
2001, c <The fibers of Threads,» Compile Time (Linux Magazine), May
Й&: iinux-mag.eom/2001-05/ compile_06.html >.
2001 > J «New Windows 2000 Pooling Functions Greatly Simplify Thread
25- Richter’ iept „> Microsoft Systems Journal, April 1999, <www.micro-
M«rom/msj70499/pooling/pooling.aspx>.
S - П C «The Fibers of Threads,» Compile Time (Linux Magazine), May
26. onniaI<www-iinux-mag.com/2001-05/compile_06.html >.
2 . ’ - c «The Fibers of Threads,» Compile Time (Linux Magazine), May
27'?001Я <www.iinux-mag.com/2001-05/compile_06.html>.
M Itithreading in the Solaris Operating Environment, A Technical White Pa-
28‘ *er7> Sun Microsystems, 2002.
oo I’ve Got Work To Do — Worker Threads and Work Queues,» NT Insider, Vol. 5,
No. 5, October 1998 (updated August 20, 2002), <www.osronline.com/arti-
cle.cfm?id=65>.
30 «System Worker Threads,» MSDN Library, June 6, 2003, <msdn.micro-
’ soft.com/en-us/kmarch/hh/kmarch/synchro_9ylz.aspx>.
31. McCracken, D., «POSIX Threads and the Linux Kernel,» Proceedings of the Ot-
tawa Linux Symposium 2002, p. 335.
32. Troan, E., «А Look at the Signal API,» Linux Magazine, January 2000,
<www.linux-mag.com/2000-01/compile_01.html>.
33. Drepper, Ulrich, «Requirements of the POSIX Signal Model,» modified May 17,
2003, <people.redhat.com/drepper/posix-signal-model.xml>.
34. «Multithreading in the Solaris Operating Environment, A Technical White Pa-
per,» Sun Microsystems, 2002.
5. «Multithreading in the Solaris Operating Environment, A Technical White Pa-
per,» Sun Microsystems, 2002.
36. Drepper, Ulrich, «Requirements of the POSIX Signal Model,» modified May 17,
2003, <people.redhat.com/drepper/posix-signal-model.xml>.
7- Butenhof, David R., Programming with POSIX Threads, Boston, Addison-Wes-
ley, 1997, p. 144.
' «POSIX Thread API Concepts,» IBM iSeries information Center, <publib.boul
Qer.ibm.com/iseries/v5rl/ic2924/index.htm7info/apis/whatare.htm>, modified
39 2?tober Ю, 2002
Sullivan, B., «Answers to Frequently Asked Questions for comp.program-
*ning.threads: Part 1 of 1,» rev. 1.1, <www.serpentine.com/~bos/threads-faq/>,
40, j^S„m°di-lled September 3, 1997.
taw r?°ken, D., «POSIX Threads and the Linux Kernel,» Proceedings of the Ot-
41. B ;a L1nux Symposium 2002, p. 332.
son David R., Programming with POSIX Threads, Boston, MA: Addi-
42. Dre €sley’ 1997’ PP- 214-215.
200з₽еГ’ Ulrich, «Requirements of the POSIX Signal Model,» modified May 17,
43. but ’ j7PeoPle-redhat.com/drepper/posix-signal-model.xml>.
son 'u,hof’ David R., Programming with POSIX Threads, Boston, MA: Addi-
4< blen Tley’ 1997’ PP’ 143 144-
leliS12CP’ D. E., and G. J. Narlikar, «Pthreads for Dynamic and Irregular Paral-
tugs 1* Conference on High Performance Networking and Computing, Proceed-
01 the 1998 АСМ/IEEE Conference on Supercomputing, 1998, San Jose, CA.
278
45. Rangaraju, К., «Unravel the Complexity of Thread Programming,» <w\Vv_.
cette.com/javapro/2002_02/magazine/features/krangaraju/>. 4ц I
46. «Threads Index,» The Open Group Base Specifications, Issue 6, n |
<www.opengroup.org/onlinepubs/007904975/idx/threads.html>.
47. Drepper, U, and I. Molnar, «The Native POSIX Thread Library for Linux,» т
ary 30, 2003, <people.redhat.com/drepper/nptl-design.pdf>.
48. «Multithreaded Programming Guide,» Sun Microsystems, May 2002, pp. ц
49. Walton, S., «Linux Threads Frequently Asked Questions,» January 21 ijA
<www.tldp.org/FAQ/Threads-FAQ/>. ’ *9?
50. Drepper, U, and I. Molnar, «The Native POSIX Thread Library for Linux,» j
ary 30, 2003, <people.redhat.com/drepper/nptl-design.pdf>. ^4
51. «Processes and Threads,» MSDN Library, <msdn.microsoft.com/library/eil I
dllproc /base/about_processes_and_threads .asp>. ’W
52. «About Processes and Threads,» MSDN Library, February <msdn.mjc
soft.com/library/en-us/dllproc/base/about_processes_and_threads.asp>. °'
53. «Fibers,» MSDN Library, February 2003, <msdn.microsoft.com/library/en.Us,
dllproc/base/fibers.asp>. '
54. «Convert Thread To Fiber,» MSDN Library, February 2003, <msdn.micro
soft.com/library/en-us/dllproc/base/convertthreadtofiber.asp>.
55. «Fibers,» MSDN Library, February 2003, <msdn.microsoft.com/library/en-us/
dllproc/base I fibers. asp >.
56. «Thread Pooling,» MSDN Library February 2003, <msdn.microsoft.com/li.
brary/en-us/dllproc/base/thread_pooling.asp>.
57. «Queue User Worker Item,» MSDN Library, February 2003, <msdn.micro-
soft.com/library/en-us/dllproc/base/queueuserworkitem.asp>.
58. Richter, J., «New Windows 2000 Pooling Functions Greatly Simplify Thread
Management,» Microsoft Systems Journal, April 1999, <www.microsoft.com/
ms j /0499/pooling/pooling. asp>.
59. «Win 32 Thread,» MSDN Library, July 2003, <msdn.microsoft.com/li-
brary /еп-us / wmisdk / wmi / win32_thread. asp>.
60. Solomon, D., and M. Russinovich, Inside Windows 2000, 3d ed., Redmond:
Microsoft Press, 2000, pp. 348-349 (есть русский перевод: «Внутреннее
устройство Microsoft Windows 2000», Давид Соломон, Марк Руссинович, изд-
«Питер»).
61. Sun Microsystems, «Lightweight Processes,» SunOS System Service Overview,
Mountain View, CA: Sun Microsystems, December 1987, pp. 143-174. J
62. Anderson, T. E.; B. N. Bershad; E. D. Lazowska; and H. M. Levy, «Sheduler
tivations: Effective Kernel Support for User-Level Management of Parallels ’
ACM Transactions on Computer Systems, Vol. 10, No. 1, February 1992, P-
63. Benjamin, C., «The Fibers of Threads,» Compile Time (Linux Magazine),
2001, <www.linux-mag.com/2001-05/compile_06.html>. ря.
64. «Multithreading in the Solaris Operating Environment, A Technical White
per,» Sun Microsystems, 2002. al-
65. Blelloch, G. E., and G. J. Narlikar, «Pthreads for Dynamic and Irregular ^gd-
lelism,» Conference on High Performance Networking and Computing, i’1
ings of the 1998 АСМ/IEEE Conference on Supercomputing, 1998, San Jose,
66. Butenhof, David R., Programming with POSIX Threads, Boston, MA-
son-Wesley, 1997: pp. 143—144.
67. Kleiman, S.; D. Shah; and B. Smaalders, Programming with Threads, Pre
Hall PTR, 1997. p(/
68. Birell, A. D., An Introduction to Programming with Threads, Technical ggS;
35, Digital Equipment Corporation, System Research Center, Palo Alto, CA, >>
69. Outsterhout, J., «Why threads are a bad idea (for most purposes).» In US i
Technical Conference (Invited Talk), Austin, TX, January 1996.
Не втягивай меня, ведь я разбор
Уильям Шеке
Глава 5
Асинхронное парМАеАЫюе
п выполнение
Человек, имеющий одни часы, всегда можя
с уверенностью сказать, сколько времени, !___
и этим выгодно отличается от того, у кого двое чюфрочитав эту главу, вы должны будете понимать:
Послов
Активный досу
Иоганн Элиас Шлегь
проблемы синхронизации параллельных процессов
и потоков;
критические участки и необходимость
взаимоисключения;
как реализовать примитивы взаимоисключения
6 программном обеспечении;
Аппаратные примитивы взаимоисключения;
исп°лъзование семафоров и их реализация.
По-настоящему занятой человек ник°Д
не знает, сколько он i;CC|i
Эдгар Уотсон
Задержки плодят г₽^1
Джон Л
Откладывая, сохраняем
Энний $4
и &
Краткое содержание глаВы
5.1 Введение
5.2 Взаимоисключение
5.2.1 Многозадачность в Java. Учебный пример,
часть 2: отношение производитель-потребитель в Java
5.2.2 Критические участки
5.2.3 Примитивы Взаимоисключения
5.3 Реализация примитивов взаимоисключения
5.4 Программные решения проблемы взаимоисключения
5.4.1 Алгоритм Деккера
Поучительные истории: Вы уверены, что ваше программное
обеспечение функционирует правильно?
5.4.2 Алгоритм Питерсона
5.4.3 Взаимоисключение для п потоков: алгоритм Аэмпорта
Биография: Лесли Лэмпорт
5.5 Аппаратные решения проблемы взаимоисключения
5.5.1 Запрет прерываний
5.5.2 Команда Test-and-Set
5.5.3 Команда Swap
5.6 Семафоры
Биография: Эдсгер В. Дейкстра
5.6.1 Реализация взаимоисключения с помощью семафоров
5.6.2 Синхронизация потоков с помощью семафоров
5.6.3 Считающие семафоры
5.6.4 Реализация семафоров
Поучительные истории: Нечеткие требования
~eggapa/iflMыюе выполнение
283
,1 Ведение
предыдущих главах мы рассказали вам о концепции абстракт-
р Дв57Хйп (блоков) выполнения — процессах и потоках. В данной главе
основное внимание обсуждению потоков, хотя большинство из-
ц)ь1У'яеЛ о здесь материала справедливо и для процессов. Если в опреде-
д0зКее?<^1омент времени в системе существует более одного потока, то о та-
qeB0bIIIoKax говорят, что они параллельны (concurrent).1>2’3 Два парал-
кцх п° потока могут работать совершенно независимо друг от друга либо
деДь0Ь1^ствОвать между собой. Если независимо работающим потокам
в3аиМОД периодически синхронизироваться и взаимодействовать для
аеоах°л общей задачи, говорят, что они асинхронны (asynchronously).4’5
ре®6 оОНность — весьма сложная тема. В главах 5 и 6 обсуждаются вопро-
АсИ ганизации и управления системами, поддерживающими асинхрон-
СЫ параллельные потоки (asynchronous concurrent threads).
ЯЬ1Мы начнем главу с рассмотрения примеров на языке Java, которые
олжны продемонстрировать сложность создания корректных программ,
в состав которых входит хотя бы пара асинхронных параллельных потоков.
В случае неправильного написания такие программы могут выдавать неже-
лательные и непредсказуемые результаты. В оставшейся части главы мы
будем обсуждать разнообразные приемы, применяемые программистами
для создания корректных программ с асинхронными параллельными пото-
ками. В следующей главе мы расскажем вам о двух классических пробле-
мах асинхронности и их решении на примере приложений на языке Java.
Вопросы для самопроверки
1. (Да/Нет) Правда ли, что взаимодействие и синхронизация нужны
только в асинхронно выполняющихся потоках?
2. (Да/Нет) Правда ли, что периодически взаимодействующие между
собой потоки, которые большую часть времени работают независи-
мо ДРУГ от друга, называются синхронными?
ОпвеМЫ 1) Нет. Между собой взаимодействуют и синхронизируют-
ся не только асинхронные потоки, но и асинхронные процессы. 2) Нет.
Говорят, что такие процессы выполняются асинхронно.
Взаимоисключение
р°вАецци^Им почтовый сервер, отвечающий за обработку почтовой коррес-
в Челой организации. Мы хотим, чтобы система с первого дня по-
т^Те сИсем апнабЛЮДеНИе За количеством отправленных по электронной
ц3®^Тся 0 ' положим, что получение электронного сообщения обраба-
oi Эт11Х Пото1ИМ И3 параллельных потоков сервера. Каждый раз, когда один
елйчИвК°В пРинимает °т пользователя сообщение электронной почты,
6 ЙеТ На * значение разделяемой переменной mailcount, глобаль-
«X процесса. Рассмотрим ситуацию, когда два потока одновре-
285
284
^рдмельное выполнение
Вопросы для самопроверки
1 Могут ли в вышеприведенном примере с переменной mailCount не-
" сколько потоков одновременно читать значение переменной, если
ни одному потоку не нужно ее модифицировать?
2 (Да/Нет) Предположим, что обоим потокам, обладающим общим
' доступом к переменной, на каком-то этапе своего выполнения необ-
ходимо изменять ее значение. Правда ли, что если в потоках не реа-
лизовано взаимоисключение для обновления этой переменной, то
запуск этой программы обязательно вызовет сбой системы?
Ответы 1) Да. Взаимоисключение необходимо реализовывать толь-
ко в случае, если потоки модифицируют разделяемую переменную.
2) Нет. Вполне возможна ситуация, когда каждый поток выполнит об-
новление разделяемой переменной в свое время, и программа сможет
корректно завершить работу.
, ,„„20задачность в Java. Учебный пример, часть 2: отношение
^оизбодитель-потребитель 6 Java
В отношении производитель-потребитель (producer/consumer relation-
ИСЬ ship), производителем (producer) называют часть приложения, генерирую-
щую данные и записывающую их в разделяемые объекты, а потребителем
"° (consumer) — часть приложения, которая считывает данные из разделяе-
1111 мых объектов. Распространенным примером отношения производи-
тель-потребитель является выполнение спулинга печати. Текстовый ре-
Причиной некорректного результата стад механизм сохранения: ра з * дактор сбрасывает данные в буфер (обычно, в файл), после чего данные
емой прпрмрпгглй Пггоюттттттг, тт™ _____ ____считываются принтером, выполняющим печать документа. Аналогично,
приложение для записи данных на компакт-диск сначала помещает ин-
формацию в буфер фиксированного размера, который опустошается по
мере того, как привод CD-RW записывает данные на компакт-диск.
Рассмотрим реализацию многопоточного отношения производитель-по-
реоитель на языке Java, которая включает в себя поток производителя
менно попытаются увеличить значение переменной mailCount. Пускай |
ждый поток выполняет следующий программный код на Ассемблере. ’ I
LOAD mailCount
ADD 1
STORE mailCount
Команда load копирует значение переменной mail Count из памятц I
гистр, команда add прибавляет к значению в регистре константу Ч
ную 1, а команда store — сохраняет значение регистра в памяти.
значение переменной mailCount в данный момент равно 21687. Посд J
полнения команд load и add первым потоком в значение регистра С15
вится равным 21688, тогда как значение переменной mailCount в ца Ч
по-прежнему равно 21687. Затем, в результате истечения кванта, iiepj
поток теряет процессор, и система выполняет переключение контекст J
второй поток. Второй поток выполняет все три инструкции, установив!1
чение переменной в памяти, равным 21688. Затем второй поток возвра^
ет управление процессором первому потоку, который продолжает вып*
нение с команды store и также помещает значение 21688 в перемен^
mailCount. Таким образом, из-за нескоординированного доступа к раз>
ляемой переменной mailCount, система, в сущности, теряет одну запись,
правильное количество электронных писем равно 21689. В случае с щ._
жением, управляющим обработкой электронной почты, подобная оши(—
может показаться несущественной, но за такую же ошибку в приложен]
предназначенных для решения жизненно важных задач, например, в ца
тре управления полетами, придется заплатить человеческими жизнями. |
Г °
ляемой переменной mailCount. Очевидно, что множество параллель™
потоков могут одновременно считывать данные, не сталкиваясь с подобна
проблемой. Но если один поток будет считывать данные, в то время №
другой поток будет осуществлять их запись либо если оба потока будут №
ти запись одновременно, это приведет к непредсказуемым результатам-"] на языке java которая включает в сеоя ниток приилвидтслл
Эту задачу можно решить, если предоставить каждому потоку экскл** (producer thread), формирующий данные, помещаемые в буфер (способный
зивный (монопольный) доступ (exclusive access) к переменной mailCoW" хранить только одно значение), и поток потребителя (consumer thread),
Пока один поток увеличивает значение разделяемой переменной, все считывающий данные из буфера. Если производитель, ожидающий воз-
тальные потоки, планирующие сделать то же самое, вынуждены И® м°жности произвести запись дополнительных данных в буфер, обнаружи-
ожидать. Когда выполняющийся поток закончит обращение к пер^ *ает> что потребитель еще не успел считать из буфера предыдущую инфор-
ной, система разрешит продолжить работу одному из потоков, нах Д51® я’’”—
ся в состоянии ожидания. Данный механизм называют последователь]
доступом (serializing). Таким образом, каждый поток, обращаю111 J
к разделяемым данным, исключает для всех других потоков возмо?#]
одновременного с ним обращения к этим данным. Это называется »з Л
исключением (mutual exclusion).9>10>п Как вы увидите в этой и слеДУ Л
главах, обращаться с потоками в состоянии ожидания следует ч₽еза^<Я
но аккуратно, чтобы те могли закончить свою работу в течение разу
промежутка времени.
Мацию*1и±реиитель еще не успел считать из буфера предыдущую инфор-
®wre«io ПР°Изводитель должен вызвать функцию wait, чтобы дать потре-
Се₽езап 1Панс лРочесть неизмененные данные до того, как они будут
ЬЬ1зВать Сань1, После того как потребитель прочитает данные, он обязан
й°, йах0МеТОд n°tify для того, чтобы разрешить производителю (возмож-
°°tify кДЯ1ЦемУся в режиме ожидания) сохранение новых данных. Метод
ect переводит поток из состояния ожидания в состояние
pU’ Если потребитель обращается к пустому буферу (когда произ-
пред*11,0 Не Успел сгенерировать первые данные) либо обнаруживает,
Ро'"’ '1тоб'*1Ц'ая инФ°Рмация уже была им считана, он вызовет метод
Иоь^^тель ПеРевести себя в состояние ожидания. Если этого не сделать,
Ч^Рную ФРочитает «мусор» из пустого буфера либо по ошибке начнет
ДйИцЬ1еС^Ра^откУ Данных. После того как производитель поместит но-
в буфер, производитель должен вызвать метод notify для того,
286
287
аллельное Выполнение
чтобы разрешить потоку потребителя (возможно, находящемуся в ре I
ожидания) продолжить чтение данных. Обратите внимание, что фуа
notify не возымеет эффекта, если ни один из потоков приложения не
дится в состоянии ожидания.
Напишем реализацию данной программы на языке Java, чтобы ]
зать на примере, как возникают логические ошибки в том случае, ес*5^
синхронизировать доступ к разделяемым данным со стороны нескол 1 ж
потоков. На рисунках 5.1-5 5 реализуется отношение производите^ •
требитель, в котором поток производителя последовательно генерц?д
и записывает числа от 1 до 4 в разделяемый буфер — область памят^Ф
щим доступом к которой обладают два потока (разделяемый буфер Dp’
зован в виде одной переменной типа int, названной buffer на рцс & Ч
Поток потребителя считывает данные из разделяемого буфера и вуво/Л
их на экран. Результатами работы программы (три варианта показании
рисунке 5.5) являются значения, записываемые производителем в раз
ляемый буфер, и значения, считываемые потребителем из разделяем^]
буфера.
Каждое значение, записанное в разделяемый буфер производителе»!
должно быть прочитано потребителем только один раз (и в правильном п-
рядке). Однако в данном примере потоки не синхронизированы между с»
бой, то есть они не взаимодействуют друг с другом в ходе выполнения |«
ставленных задач (что, как мы уже убедились, чрезвычайно важно, ксгд
один из потоков осуществляет обновление данных в буфере). Поэтому дм
ные (вероятно, несколько значений) могут быть потеряны, если произвол
тель поместит в буфер новые данные, прежде чем потребитель успеет про
честь предыдущие данные; данные могут быть продублированы (возмо»|
но, несколько раз), если потребитель считает данные повторно, преждечв
производитель успеет их обновить. Последствия поскоординированней
доступа к разделяемым данным можно сравнить с последствиями отсутсн
вия светофора на перегруженном перекрестке.
Чтобы продемонстрировать все подстерегающие нас опасности, потре®
тель в нашем примере будет хранить сумму всех прочитанных значеЕ»
Производитель последовательно генерирует числа от 1 до 4. В традИДй0
ном отношении производитель-потребитель, потребитель считывает
дое сгенерированное значение один и только один раз. Кроме того, noV!
битель не может считать новое значение пока оно не будет сгенерир°®^Я
производителем. Поэтому производитель должен всегда генерировать
вое значение до того, как потребитель захочет его прочесть, а сумме » J
значений должна быть равна 10. Однако если вы запустите программ^,
сколько раз, вы обнаружите (см. результаты на рисунке 5.5), что 0
сумма редко будет равна 10. Потоки потребителя и производителя в
ном примере переходят в режим сна на произвольные временные йР Я
жутки, длительностью до 3-х секунд, перед выполнением заданных
ций, эмулируя длительные задержки, которые на практике могУ-ГЯ
связаны с ожиданием реакции пользователя либо появления неК0’’'^
события. Таким образом, мы не можем знать, ни когда производите-1 }
полнит обновление значения, ни когда потребитель произведет чтеИ I
чения из буфера.
Программа на Java состоит из интерфейса Buffer (см. рис. 5.1)
flaiJa х классово Producer (см. рис. 5.2), Consumer (см. рис. 5.3),
tje'rI,IPen£zedBuffer (см. рис. 5.4) И SharedBufferTest (см. рис. 5.5).
lIflsyr’ct j)gHCe Buffer объявляются методы set и get, которые необходимо
а ц0а'еР для того, чтобы поток Producer мог записывать значения
рв^11 а поток Consumer — считывать значения из Buffer, соответствен-
р guff еГ’ аЦИЯ данного интерфейса показана на рисунке 5.4 (строка 4).
ро- Реал prOducer (см. рис. 5.2), представляющий собой подкласс класса
КлаСВ ока 5), состоит из поля sharedLocation (строка 7), конструктора
Thread (и метода run (строки 18-40). Конструктор инициализирует
(cTPOI^ocation ссылкой на объект, реализующий интерфейс Buffer (стро-
Этот объект создается внутри функции main (см. рис. 5.5, стро-
ке л-18), а затем передается конструктору в качестве параметра shared
КЙ оис. 5.2, строка 10); конструктор инициализирует переменную sha-
^Location (строка 13) ссылкой на параметр shared. В данной программе
Г6 ок производителя выполняет задачи, определенные в методе run (стро-
ки 18-40). Цикл for в строках 20-35 выполняется четыре раза. В каждом
проходе вызывается метод sleep объекта Thread (строка 25), который пере-
водит поток производителя в состояние сна на произвольный временной
нтервал длительностью от 0 до 3 секунд (чтобы симулировать длительные
задержки).
[Примечание: Обычно поток пробуждается по окончании интервала сна.
Но спящий поток может быть разбужен раньше, если другой поток вызовет
метод interrupt для спящего потока. В этом случае метод sleep выработает
исключение (типа Interrupt-edException), служащее индикатором того,
что поток досрочно вышел из состояния сна. В языке Java, данное исключе-
ние должно быть обработано, поэтому в блоке try со следующим обработчи-
ком catch необходимо вызвать метод sleep. В блоке try содержится про-
граммный код, который может вырабатывать исключения. Обработчик
catch задает тип обрабатываемых им исключений. В данном примере обра-
св ик catch выводит содержимое стека, после чего программа продолжает
выполнение с команды, следующей за конструкцией try. . .catch].
свое
1
2
3
4
5
6
8
// иИС" Buffer-iava
нтерфейс Buffer определяет методы доступа к данным буфера
Public interface Buffer
pubv'^c v°id set (int value); // метод для записи значений в буфер
} lnt 9et (); // метод для извлечения значений из буфера
* Иц
еРфейс Buffer, используемый в отношении производитель-потребитель
Р^ем^Ной°бУЗКДеНИЯ потока стР°ка 26 передает значение управляющей
сТроТь AanHb°Unt методу set объекта Buffer, который может модифици-
в РазДеляемом буфере. По окончанию цикла ожидания
ejlb aaj{ **8 в окно консоли выводится сообщение о том, что произво-
°ачил генерировать данные, и его работа завершена. Далее за-
I
288
вершает свою работу метод run (строка 40), после чего поток произво^
ля переходит в тупиковое состояние. Следует заметить, что любой ще/1
вызванный из метода run данного потока (например, метод set объеЛ
Buffer в строке 26) представляет собой часть выполняемого пот
По сути, каждый поток имеет свой собственный стек для вызова метод^Ч
1 // Рис. 5.2 Producer.java
2 // Метод run управляет потоком Producer, который сохраняет
3 // знания от 1 до 4 в sharedLocation интерфейса Buffer
4
5 public class Producer extends Thread
6 {
7 private Buffer sharedLocation; // ссылка на разделяемый объеКт
8
9 // конструктор Producer
10 public Producer (Buffer shared )
11 {
12 super( "Producer" ); II создание потока Producer
13 SharedLocation = shared; // инициализация sharedLocation
14 } // окончание конструктора Producer
15
16 // Метод run потока Producer сохраняет значения
17 // от 1 до 4 в sharedLocation интерфейса Buffer
18 public void run()
19 {
20 for ( int count = 1; count <= 4; count++ )
21 {
22 // засыпание на 0 - 3 сек., затем сохранение значения в Buffer
23 try
24 {
25 Thread.sleep( ( int ) ( Math.randomO * 3001 ) );
26 sharedLocation.set( count ); // запись в буфер
27 } // окончание функции try
28
29 // в случае прерывания спящего потока, вывести содержимое стека
30 catch ( InterruptedException exception )
31 {
32 exception.printStackTrасе();
33 } // окончание функции.catch
34
35 } окончание цикла for
36 „ ,
37 System.err.printin( getNameO +• " заканчивает генерирование.
38 "ХпЗавершение потока " + getName () =
39
40 } // окончание метода run
41
42 } // окончание класса Producer
Рис. 5.2. Класс Producer, представляющий поток производителя в отнопзенй11
производитель-потребитель
В состав класса Consumer (см. рис. 5.3) входит собственный эк3е1^^1»
переменной sharedLocation (строка 7), конструктор (строки 9-14) И
run (строки 16—41). Конструктор инициализирует переменную shar
cation (строка 13), задавая в ней ссылку на объект, реализующий
фейс Buffer. Объект создается внутри функции main (см. рис. 5.5) 11 I
1
289
^п^имельное Выполнение________________________________
инструктору в виде параметра shared (см. рис. 5.3, строка 10). Как
Я0вТсЯ К( м. рис. 5.5, строки 12-13), это тот же самый объект Unsynchro-
рНД0'1'6 Уfe'r, который используется для инициализации объекта Producer;
®iZedBu прО’иЗВодитель, и потребитель совместно используют этот объект.
есть 11 требителя в данной программе выполняет задачи, определяемые
jjotok п ^un (см. рис. 5.3, строки 16-41). Цикл for в строках 22-36 вы-
е методе четыре раза. В каждой итерации осуществляется вызов метода
цолняет ^eKTa Thread (строка 27) для перевода потока потребителя в со-
sleeP сна на временной интервал от 0 до 3 секунд. Далее, в строке 28 ис-
стояние метод get обЪекта Thread для извлечения числа, записанного
пользу eMbIg буфер, а затем его прибавление к переменной sum. По завер-
в разд кла в строках 38-39 осуществляется вывод на дисплей получен-
щевии
// Рис. 5.3: Consumer.java
// Метод run контролирует поток Consumer, который проходит цикл
// четыре раза, каждый раз считывая значение из sharedLocation
5 public class Consumer extends Thread
7 private Buffer sharedLocation; //ссылка на разделяемый объект
8
9 // конструктор Consumer
10 public Consumer( Buffer shared )
11 {
super( "Consumer" ); // создание потока потребителя
13 sharedLocation = shared; / / инициализация переменной
sharedLocation
14 } // окончание конструктора Consumer
15
// четырехкратное считывание значений и их суммирование
17 public void run ()
18 {
79 int sum = 0;
20
‘у // альтернатива между бездействием и считыванием значения из буфера
for ( int count = 1; count <=4; ++count )
23 {
25 // бездействие 0-Зсек, считывание буфера и его суммирование
26 ^Гу
27 1
28 Thread.sleep( ( int ) ( Math.random() * 3001 ) >;
29 sum += sharedLocation.get();
30 J
31 //
32 // в случае прерывания спящего потока, вывести содержимое стека
33 catch ( InterruptedException exception )
34 {
35 exception.printStackTrace();
36 } // окончание функции catch
> // окончание цикла for
J8
У sYstem.err.printin( getName() + " сумма прочитанных значений: "
4j + sum + ".ХпЗавершение потока " + getName() + );
| ^ // окончание метода run
окончание класса Consumer
tipojp3.
аб°ДИтепС Consumer, представляющий поток потребителя в отношении
1 ь-потребител ь
B gape/uieflbHOe Выполнение
291
290
-------------------------------------------------------------Л1
ной суммы и сообщения о завершении работы потока потребителя. § |
происходит завершение метода run (строка 41), и поток потребителя
ходит в тупиковое состояние.
[Примечание: Мы генерируем продолжительность сна случайным |
зом методом sleep в методе run в потоке Producer и в потоке Consum
того, чтобы подчеркнуть тот факт, что в многопоточных прилоя^
трудно предсказать, сколько времени будет выполняться тот или
ток. Обычно, решение вопросов, связанных с планированием потоков
лагается на операционную систему. В данной программе наши потоку
полняют достаточно простые задачи: производитель четыре раза в
осуществляет запись значения в разделяемый буфер, а потребитель чеп> ч
раза в цикле осуществляет чтение значений из разделяемого буфера и
бавление полученного значения к общей сумме sum. Если бы мы не в^
вали метод sleep, и при этом поток производителя выполнялся бы п
вым, высока вероятность того, что он бы закончил свое выполнение Л
того, как поток потребителя успел прочесть хотя бы одно значение. рД
же наоборот, первым свою работу начал бы поток потребителя, то, скорЛ
всего, он бы четыре раза прочитал «нулевое» значение (величину -1( Л
данную в строке 6 класса unsynchronizedBuffer на рис. 5.4), выдав поза.
вершению неправильный результат (-4), прежде чем производитель ycnj
записать в буфер хотя бы одно значение.]
Класс UnsynchronizedBuffer (см. рис. 5.4) реализует интерфейс Buffe
(строка 4), описанный на рис. 5.1, объявляя переменную buffer (строкам
вляется разделяемой между потоками Producer и Consumer. Пе-
fOpa0-> puffer присваивается начальное значение -1. Данное значение
^еВ000оует ситуацию, когда поток Consumer пытается прочитать значе-
Аера Д° того’ как оно будет туда записано потоком Producer. Ме-
,1це 03 ° (строки 8-15) и get (строки 17-24) не обеспечивают синхрониза-
set па к полю buffer (строка 23). Обратите внимание, что каждый
дцИ #°с ользует статический метод currentThread объекта Thread для
^етоД 0С0 ссылки на выполняемый в данный момент времени поток, а за-
доЛУ1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26®0 пается к методу потока getName, чтобы выяснить имя потока для
теМ об?на экран (строки 11 и 20).
в1дроДа sharedBufferTest (см. рис. 5.5) содержит метод main (стро-
^1^ который запускает данное приложение. В строке 9 порождается
кВ ’ разделяемого объекта UnsynchronizedBuffer, который присваи-
экзе переменной sharedLocation интерфейса Buffer. В этом объекте
веется данные, разделяемые между потоками производителя и потреби-
ХР В строках 12-13 осуществляется создание объекта producer класса
тел0‘ сег и объекта consumer класса Consumer. Каждый вызов конструкто-
й в этих строках сопровождается передачей переменной sharedLocation
в качестве аргумента (строки 9-14 на рис. 5.2 для класса Producer и стро-
ки 9-14 на рис. 5.3 для класса Consumer), в результате чего каждый поток
обращается к одному и тому же интерфейсу Buffer. Затем, в строках 15
и 16 на рисунке 5.5, вызывается метод start для потоков producer и con-
sumer, соответственно, который переводит их в состояние готовности.
1 // Рис. 5.4: UnsynchronizedBuffer.java
2 // UnsynchronizedBuffer представляет одну разделяемую целую переменную!
3
4 public class'UnsynchronizedBuffer implements Buffer
5 {
6 private int buffer = -1; // разделяемая переменная
7
8 // запись значения в буфер
9 public void set( int value )
10 {
11 System.err.printin( Thread.currentThread().getName() +
12 " записывает " + value );
13
14 buffer = value;
15 } // окончание метода set
16
17 // извлечение значения из буфера
18 public int get()
19 (
20 System.err.printin( Thread.currentThread().getName() +
21 " считывает " + buffer );
22
23 return buffer;
24 } // окончание метода get
25
26 } // окончание класса UnsynchronizedBuffer
В итоге начинается их выполнение путем неявного вызова метода run для
каждого потока. Метод run потока вызывается в тот момент, когда процес-
сор впервые выделяется данному потоку. После запуска обоих потоков, ме-
тод main (то есть главный выполняемый поток) завершает свою работу, пе-
реходя в тупиковое состояние. Как только оба потока, producer и con-
sumer, перейдут в тупиковое состояние (что произойдет после завершения
выполнения ими метода run), работа программы будет завершена.
ватьСП°МНИМ’ что по условиям примера поток Producer должен генериро-
Дое ЗНачения Д° того, как поток Consumer захочет их прочесть, и что каж-
п°токаЧеНИе’ сгенеРиР°ванное потоком Producer, должно быть прочитано
рав ом Consumer только один раз. Тем не менее, изучив выводимые на эк-
Мц Уви ЛЬТаТЫ пеРвого варианта выполнения программы на рисунке 5.5,
21ИтельуИМ’ ЧТО потРебитель извлекает из буфера -1 прежде чем произво-
ление Спеет записать в буфер новое значение. В то же время, первое зна-
тРи Раза реРиР°ванное потоком производителя (1) потребитель прочтет
^йзво ’ °Лее того, потребитель закончит свое выполнение до того, как
3^Ьтате Тель получит возможность сгенерировать значения 2, 3 и 4, в ре-
(2) 0Г° все эти ТРИ значения будут потеряны. Соответственно, общая
Также не будет отвечать ожидаемому результату.
Pl/С. 5.4. Класс UnsynchronizedBuffer, поддерживающий разделяемый бУ
доступ к которому имеют потоки производителя и потребителя с помош
методов set и get
1 // Рис.5.5: SharedBufferTest.java
2 // SharedBufferTest создает потоки производителя и потребителя
4 public class SharedBufferTest
5 {
6 public static void main( String (] args )
7 {
8 // создание разделяемого объекта для потоков
9 Buffer sharedLocation = new UnsynchronizedBuffer();
10
11 // создание объектов потребителя и производителя
12 Producer producer = new Producer( sharedLocation );
13 Consumer consumer = new Consumer( sharedLocation );
14
15 producer.start(); // запуск потока производителя
16 consumer.start(); /7 запуск потока потребителя
17
18 } // окончание функции main
19
20 } // окончание класса SharedCell
Результаты выполнения программы, 1-й вариант
Consumer считывает -1
Producer записывает 1
Consumer считывает 1
Consumer считывает 1
Consumer считывает 1
Consumer сумма прочитанных значений: 2
Завершение потока Consumer.
Producer записывает 2
Producer записывает 3
Producer записывает 4
Producer заканчивает генерирование.
Завершение потока Producer.
Результаты выполнения программы, 2-й вариант
Producer записывает 1
Producer записывает 2
Consumer считывает 2
Producer записывает 3
Consumer считывает 3
Producer записывает 4
Producer заканчивает генерирование.
Завершение потока Producer.
Consumer считывает 4
Consumer считывает 4
Consumer сумма прочитанных значений: 13
Завершение потока Consumer.
Результаты выполнения программы, 3-й вариант
Producer записывает 1
Consumer считывает 1
Producer записывает 2
Consumer считывает 2
Producer записывает 3
Consumer считывает 3
Producer записывает 4
Producer заканчивает генерирование.
Завершение потока Producer.
Consumer считывает 4
Consumer сумма прочитанных значений: 10
Завершение потока Consumer.
Рис. 5.5. Класс SharedBuffer, использующий потоки для модификации
разделяемых объектов без синхронизации
293
vt нароМольнее выполнение
м варианте, мы видим, что поток потерял значение 1, посколь-
$о вТ°ря 1 и 2 были сгенерированы, прежде чем поток потребителя
У з#аЧеН ь чтение 1 (в результате чего, хранимая в буфере 1 оказалась пе-
сМ°г Ha4ta более новым значением 2). Кроме того, значение 4 было прочи-
рез^^^ды. В итоге мы снова получили неправильный результат. В по-
J^go Два арианте показано, что при определенной доле везения можно по-
слеДнеМправИЛЬный результат, однако рассчитывать с достоверностью на
9то BeJIb3Ig пример доказывает, что доступ к разделяемым объектам со сто-
ДаН дяддельных потоков должен контролироваться весьма тщательно,
программа начнет выдавать некорректные результаты. О том, как
иначе *еШИТЬ данНую проблему вы узнаете из следующей главы. В остав-
м03?Н° части главы обсуждается, каким образом потоки могут контролиро-
^^параллельное обращение к разделяемым данным, предоставляя к ним
®з^моисключающий монопольный доступ.
Вопросы для самопроверки
1. (Да/Нет). Правда ли, что в примере отношения производитель-по-
требитель, который показан на рисунках 5.1—5.5, непротиворечи-
вости и постоянства выходного результата можно добиться, если
удалить из программного кода вызов функции sleep?
2. Какое самое маленькое и самое большое значение может принимать
переменная sum в конце выполнения примера, показанного
на рис. 5.1—5.5, и при каких условиях можно этого добиться?
Ответы 1) Нет. Вызов функции sleep всего лишь подчеркивает
тот факт, что порядок и время выполнения тех или иных команд
в системе определить невозможно. Кроме того, мы не можем предска-
зать скорость выполнения этих потоков, поэтому результаты могут
оказаться некорректными. 2) Наименьшее значение переменная sum
примет в том случае, если потребитель выполнит все четыре операции
чтения из буфера, прежде чем производитель успеет записать хотя бы
одно сгенерированное значение. В этом случае общая сумма соста-
вит —4. Самое большое значение будет получено в том случае, если
производитель сгенерирует все четыре значения до того, как потреби-
тель успеет прочитать хотя бы одно из них. Тогда потребитель прочи-
тает максимальное значение четыре раза, и переменная sum окажется
равной 16.
в *
?^а10Тся11СКЛ1ОЧеНИе необх°Димо только в том случае, когда процессы об-
к Разделяемым данным, которые подвергаются изменениям.
lIblM cutJ1OTOKh выполняют операции, которые не приводят к конфликт-
^«OCTb n гЯМ <напРимеР. чтение переменных) они должны иметь воз-
ст2Чеь1Ым₽аб°ТатЬ паРаллельно- Когда поток производит обращение к раз-
е (critic^THHbIM’ то ГОВ°РЯТ> что он находится в своем критическом уча-
т0еейдао а section) или в своей критической области (critical region).12
чТо х Hiji ЧТ° ДЛЯ того’ чтобы предупредить возникновение ошибок, о ко-
Речь в предыдущем разделе, система должна гарантировать,
в °Дин поток в текущий момент времени будет выполнять инст-
Св°ем критическом участке. Если некоторый процесс пытается
294
войти в свой критический участок, когда другой процесс находится в г
ем критическом участке, ему придется ожидать, пока выполняют^?0'
в текущий момент времени поток не покинет свой критический учас-г^
Когда поток выходит из своего критического участка, то одному из оста0*5,
ных процессов, ожидающих входа в свои критические участки, долъ/^
быть разрешено продолжение работы. Остальные потоки, которые не
буют вхождения в критические участки, могут выполняться независим^'
того, занимает ли кто-нибудь критический участок. 01
Система, обеспечивающая взаимоисключение должна очень тщатель
контролировать вхождение и выполнение потоков в их критических уда^°
ках. Когда поток находится в своем критическом участке, он имеет искЛ1о
чительное право доступа к разделяемым данным, а всем остальным ц0Та
кам, которым в то же самое время требуется доступ к этим данным,
дится ждать. Поэтому потоки должны как можно быстрее проходить свол
критические участки и не должны в этот период блокироваться, так чТо
критические участки необходимо кодировать очень тщательно (чтобы, на.
пример, не допустить возможности зацикливания внутри критического уча.
стка). Если поток, находящийся в своем критическом участке, завершается
естественным, либо аварийным путем, то операционная система при выпол-
нении служебных операций завершения потока (termination housekeeping)
должна отменить режим взаимоисключения, с тем чтобы другие потоки по-
лучили возможность входить в свои критические участки.
Обеспечение взаимоисключающего эксклюзивного доступа к критиче-
ским участкам является одной из ключевых проблем параллельного про-
граммирования. Было придумано множество различных решений пробле-
мы: программные и аппаратные; низкоуровневые и высокоуровневые; ре-
шения, требующие добровольного взаимодействия между потоками,
и решения, требующие сурового следования протоколам. Многие из этих
решений мы рассмотрим в следующих разделах.
Вопросы для самопроверки
1. Почему для потока так важно как можно быстрее пройти свой кри
тический участок?
2. Что произойдет, если операционная система не станет выполнять
служебные операции завершения потоков?
Ответы 1) Если другие потоки ожидают возможности войти в
критические участки, они не смогут это сделать до тех пор, п°касТ1{е-
бы одни поток продолжает находиться в своем критическом У
Поэтому, если потоки не будет быстро проходить критические У $0.
ки, это может повлиять на общую производительность системы- >0^
ток может быть завершен в момент пребывания в крити
участке, в результате чего режим взаимоисключения никогда не
отменен. По этой причине потоки, ожидающие вхождения в сво
тические участки, никогда не продолжат выполнение. В гла®^до>
поговорим о том, как такие потоки могут приводить к взаимо
ровкам.
\ьное выполнение
295
rjpu/viiiiniiSbi взаимоисключения
ющая программа на псевдокоде правильно реализует механизм
Cjieflколичества сообщений электронной почты, рассмотренный в раз-
цоДсЧе^а обратите внимание на используемые нами выражения enterMu-
ДеЯ!?' 'ion О и exitMutualExclusion(). Эти команды представляют со-
tualExC рукции, которые обрамляют критический участок потока. Перед
бой к° вОйти в свой критический участок, поток должен выполнить кон-
теМ каК enterMutualExclusion (), а при выходе из критического участка
сТрУк оЛдаеН выполнить конструкцию exitMutualExclusion (). Посколь-
дот°к конструкции вызывают выполнение фундаментальных опера-
кУ „^обеспечивающих реализацию взаимоисключения, их иногда называ-
И примитивами взаимоисключения (mutual exclusion primitives).
while (true) { _
Получение электронной почты //выполняется за пределами
enterMutualExclus ion()
Приращение mailCount
критического участка
вход в критический участок
выполняется внутри
критического участка
выход из критического участка
реализуется взаимоисключение.
exitMutualExclusion() //
}
Рассмотрим, как в этих примитивах
Для простоты в этом и последующих примерах будем считать, что на од-
ном процессоре у нас выполняется всего два параллельных потока. Обра-
ботка п параллельных процессов или потоков представляет собой намного
более сложную задачу, которая обсуждается в разделе 5.4.3. Кроме того,
мы коснемся вопроса взаимоисключения в многопроцессорных системах.
Предположим, что в системе выполняются два потока: Tj и Т2, относящие-
ся к одному процессу. Каждый поток управляет сообщениями электронной
почты, и каждый из потоков содержит команды, соответствующие приведен-
ному выше псевдокоду. Когда процесс Tj доходит до строки с выражением
enterMutualExclusion (), система обязана проверить, не находится ли поток
®НУТРИ своего критического участка. Если поток Т2 в данный момент вре-
нения>а^°ТаеТ ВНе кРитического участка, в свой критический участок выпол-
мой Вх°аит поток Ть выполняющий операцию приращения над разделяе-
с^еРеМеННОЙ nailCount и вызов конструкции exitMutualExclusion (),
еп1егмИЗИРУЯ ° своем выходе из критического участка. Если же Tj выполнит
^астке malExclusion0 ’ когда Т2 будет находиться в своем критическом
к°Нстп1А<. 1 ВЬ1нУжДен будет ожидать до тех пор, пока поток Т2 не выполнит
Всвойк ЙИЮ exitMutualExclusion (), после чего поток Tj сможет войти
6nterMut ИТИЧеский Участок. Если потоки Tj и Т2 одновременно выполняют
a UalExciusion (), то одному из них будет разрешено продолжить ра-
^ТеЛь» У^МУ придется ждать, причем мы будем предполагать, что «побе-
5®Ух Пот ВЬ1°иРается случайным образом. [Позже вы увидите, что если из
. асТок Ков» пытающихся одновременно войти каждый в свой критический
Остоянно будет выбираться один и тот же поток, такая политика
Ис мВеСТИ К ситУаЦии бесконечного откладывания.] В последующих
bI ойсУДим различные механизмы реализации примитивов взаимо-
а enterMutualExclusion() И exitMutualExclusion().
296
Вопросы для самопроверки
1. Что произойдет, если поток не вызовет примитив enterMutualp
elusion () перед обращением к разделяемым переменным в крв '
веском участке?
2. Что произойдет, если поток, находящийся в своем критичес
участке не выполнит примитив exitMutualExclusion () ?
Ответы 1) Если в критический участок войдет какой-то другой
ток, это может привести к неопределенности результата с серьезнв^?"
последствиями. 2) Все остальные потоки, ожидающие возможной
войти в свои критические участки, не смогут сделать это. В главе 7
увидите, что все эти потоки в конечном итоге окажутся в ситуад
взаимоблокировки. ц а
53 Реализация примитивов взаимоисключения
Любое решение проблемы взаимоисключения, которое мы хотим найти
должно обеспечивать реализацию примитивов enterMutualExclusionQ
и exitMutualExclusion () с соблюдением следующих четырех ограничений:
1. Задача должна быть решена чисто программным способом на маши-
не, не имеющей специальных команд взаимоисключения. Каждая
команда машинного языка выполняется как неделимая операция
(indivisibly), т.е. каждая начатая операция завершается без прерыва-
ния. Если в системе установлено несколько процессоров, то несколь-
ко потоков могут попытаться обратиться к одним и тем же данным
одновременно. Многие решения проблемы взаимоисключения для
однопроцессорных систем основываются на механизмах доступа
к разделяемым данным, что означает невозможность их применения
в многопроцессорных системах (см. раздел 15.9). Чтобы упростить
рассмотрение, будем считать, что в системе установлен один процес-
сор. Обсуждение данной проблемы для многопроцессорной системы
будет приведено ниже.
2. Не должно быть никаких предположений об относительных скор0
стях выполнения асинхронных параллельных потоков. То есть лЮ00®
решение должно учитывать возможность приоритетного вытеснеНИ'"
потока и его последующего возобновления в любой момент време
а скорость выполнения каждого потока не является постоянной и
поддается предсказанию.
3. Потоки, находящиеся вне своих критических участков, не могут
пятствовать другим потокам входить в их собственные критике
участки. ccOt
4. Не должно быть бесконечного откладывания момента входа проД
в их критические участки. [Примечание: Оказавшись внутри несеб£
ректно написанного критического участка, поток может повести^
«неправильно», вызвав бесконечное откладывание или даже ®за
блокировку. Более подробно эти вопросы рассматриваются в главе
^ое параллельное Выполнение
297
Вопросы для самопроверки
1. Почему следует исходить из того, что не должно быть никаких
предположений об относительных скоростях выполнения асин-
хронных параллельных потоков?
2. Каким образом неправильное написание программного кода крити-
' ческого участка может привести к ситуации бесконечного отклады-
вания и даже к взаимоблокировке?
Ответы 1) Одной из причин выступает тот факт, что аппаратные
прерывания могут происходить через случайные промежутки времени
и таким образом прерывать выполнение в любой момент времени.
В любой выбранный период времени наличие подобных прерываний
может привести к тому, что одни потоки будут выполняться дольше
других. Кроме того, нюансы в алгоритмах планирования ресурсов мо-
гут привести к смещению приоритета в сторону определенных пото-
ков. 2) Если поток не покинет свой критический участок (например,
в результате зацикливания), это, в конце концов, приведет к ситуации
бесконечного откладывания либо взаимоблокировки с любым другим
потоком, который попытается войти в свой критический участок.
5.4 Программные решения проблемы
Взаимоисключения
Изящную программную реализацию механизма взаимоисключения
впервые предложил голландский математик Деккер. В следующем разделе
мы рассмотрим усовершенствованный вариант алгоритма Деккера
(Dekker’s algorithm), разработанный Дейкстрой — реализацию взаимоис-
ключения для двух потоков.13 Представленный программный код демонст-
рирует ряд тонкостей, характерных для параллельного программирова-
ния, превращающих его в интересное поле для исследований. Затем мы об-
сУДИм более простые и эффективные алгоритмы Питерсона14 и Лэмпорта.15
5'4-1 Алгоритм Деккера
п
Кд этом Разделе мы изучим различные способы реализации взаимоис-
лУ1пЧеы„ия- В каждой реализации содержится ошибка, исправленная в сле-
гРам еИ ВеРсии- В конце раздела приводится окончательная версия про-
в3аи Ь1 Реализации взаимоисключения, в которой решены все проблемы
блокировок и бесконечного откладывания.
версия (с Жесткой синхронизацией и активным оокиданием)
Чцс ₽исУнке 5.6 показана первая попытка реализации механизма взаи-
^’ ,10Доб1ОЧе“НИЯ междУ Двумя потоками. Приведенный псевдокод имеет
тРед j. НЬ1И синтаксис. Каждую команду потока можно отнести к одной из
некритичные команды (то есть инструкции, которые не
еСтЬц11ЯЮт модификации разделяемых данных), критичные команды (то
тРукции, выполняющие модификацию разделяемых данных) и ко-
’ обеспечивающие взаимоисключение (т.е. функции, реализующие
298
Гщ
примитивы входа взаимоисключения и выхода взаимоисключения
enterMutualExclusion() и exitMutualExclusion () ). Каждый поток Перц^
дически входит в свой критический участок и выходит из него, пока не
кончит выполнение всех поставленных перед ним задач.
В данной версии реализации взаимоисключения система использует h
ременную threadNumber, обозначающую номер потока, доступом к котор0»
обладают оба потока. Перед тем как система начнет выполнение потоков
значение переменной threadNumber устанавливается в 1 (строка 3). Зат *
система запускает оба потока. Примитив enterMutualExclusion () реализи
ется в виде цикла while, работа в котором продолжается до тех пор, пода
переменная threadNumber не станет равна номеру данного процесса (См
строки 13 и 31 в потоках и Т2, соответственно). Примитив exitMutu
alExclusion () реализуется в виде одной команды, которая присваивает це
ременной threadNumber значение, равное номеру другого процесса (см
строки 17 и 35 в потоках Tj и Т2, соответственно).
Рассмотрим один из вариантов развития событий в данной реализации
Предположим, поток Ti начал выполняться первым. Поток начинает рабо-
ту в цикле while, действующего в роли примитива enterMutualExclu-
sion () . Поскольку изначально в переменной threadNumber содержится 1,
Ti входит в свой критический участок (программный код, обозначаемый
комментарием в строке 15). Теперь, пускай система приостанавливает вы-
полнение потока Ti и запускает поток Т2. Второй поток определяет, что
в переменной threadNumber содержится 1 и остается «заблокированным»
в цикле while (строка 31). Таким образом гарантируется взаимоисключе-
ние, поскольку поток Т2 не сможет войти в собственный критический уча-
сток до тех пор, пока из него не выйдет поток Tj, установив в переменной
threadNumber значение 2 (строка 17).
В конце концов, поток Т] пройдет свой критический участок (мы исхо-
дим из предположения, что в критическом участке отсутствуют бесконеч-
ные циклы и поток не может быть уничтожен либо заблокирован, пока он
находится внутри критического участка). На данном этапе поток Т, уста-
навливает значение переменной в 2 (строка 17) и продолжает выполнять
некритичные команды. С этого момента поток Т2 получает возможность
войти в собственный критический участок. Хотя программа, пред став лей'
ная на рисунке 5.6 гарантирует взаимоисключение, однако весьма дорог»0
ценой. В примитиве enterMutualExclusion () поток использует процессор']
не выполняя, по сути, никакой полезной работы (поскольку он постояв
проверяет значение переменной threadNumber). Говорят, что такой п°т
находится в состоянии активного ожидания (busy waiting). Механизм Р
лизации взаимоисключения с использованием активного ожидания не
фективен в однопроцессорной системе. Вспомним, что одной из целей М
гозадачности является повышение коэффициента использования про ?
сора. В нашем примитиве взаимоисключения расход процессорных
на выполнение бесполезных для потока операций представляет собой
тую трату процессорного времени. Такие накладные расходы, однако,
рактерны для коротких временных промежутков (когда два потока с г
нуются за право вхождения в свои критические участки).
юе параллельное выполнение
299
1
2
3
4
5
6
7
8
9
Ю
П
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
Система.:
int threadNumber = 1;
startThreads() ; // инициализация и запуск обоих потоков
Поток Tj:
void main () {
while ( !done )
while ( threadNumber == 2 ); // enterMutualExclusion
// код внутри критического участка
threadNumber = 2; // exitMutualExclusion
// код за пределами критического участка
} Ц окончание внешнего цикла while
} окончание потока Т1
Поток Тг>
void main() {
while ( !done )
(
while ( threadNumber == 1 ) ; // enterMutualExclusion
// код внутри критического участка
threadNumber = 1; // exitMutualExclusion
// код за пределами критического участка
} // окончание внешнего цикла while
1 окончание потока Т2
5.6.
Реализация взаимоисключения — версия 1
1П
цОго 66 сеРьезным недостатком данной версии является нарушение ею од-
тцВь1ИЗ КлЮчевых ограничений, определенных нами в разделе 5.3. Прими-
Ra> Не °ПРеделяюи1ие’ что поток находится вне своего критического участ-
KDnTlrt5°JI'>KHbI оказывать влияния на потоки, которые хотят войти в свои
СНИЙ еские участки. Например, поток Ti должен входить в свой критиче-
в первым, поскольку система первоначально устанавливает
ЬЬ11Ч рМеННой threadNumber 1. Если поток Т2 попытается начать работу пер-
® Ч°НцГО ПОПытки войти в критический участок не увенчаются успехом.
Уч КонЦ°в> когда начнет выполняться поток Ti, он войдет в критиче-
а при выходе из него установит в переменной threadNumber
6 ^З'за зтог°, выполнение потока Т2 может значительно задер-
’ в°ка он сможет войти в свой критический участок. По сути, потоки
И^енЫ входить в свои критические участки и выходить из них, при-
держиваясь строгого чередования. Если одному потоку понадобится
дить в критический участок чаще, чем другому, более быстрый поток Вь
жден будет замедлить скорость выполнения до скорости медленного iiotq'
В таком случае говорят о проблеме жесткой или пошаговой синхронизм
(lockstep synchronization) [Примечание: Разумеется, проблема в ра^Ч|
ле 5.2.1 требует выполнения жесткой синхронизации, поскольку буф, р
вен размеру блока. Однако в большинстве реализуемых буферов содерл;^'
несколько элементов, поэтому введение жесткой пошаговой синхрониза;
приводит к неэффективной работе системы, если производитель и
тель работают с разными скоростями.] Рассмотрим следующий вариант rj1'
лизации взаимоисключения, в котором вышеупомянутая проблема исщиЛ
лена, но вслед за ней возникает новая проблема.
Вторая Версия (нарушение Взаимоисключения)
Вторая версия программы, представленная на рисунке 5.7, позводЯб1
избежать проблемы жесткой синхронизации, которая существовала в пер
вой версии программной реализации взаимоисключения. В первой версии
имелась только одна глобальная переменная, в результате чего возникала
вышеупомянутая проблема. Поэтому во второй версии мы используем две
булевы переменные — tllnside и t2Inside, которые имеют истинное зна-
чение, если поток Ti и поток Т2, соответственно, находятся внутри своих
критических участков.
Благодаря использованию двух переменных, управляющих доступом
к критическим участкам (по одной для каждого потока) нам удается избе-
жать необходимости жесткой синхронизации в нашем втором примере реа-
лизации взаимоисключения. Поток Ti сможет входить в свой критический
участок столько раз, сколько это будет необходимо пока значение перемен-
ной t2Inside ложно. Кроме того, если поток Т, входит в критический уча-
сток, делая значение переменной tllnside истинным, поток Т2 переходит
в режим активного ожидания. В конце концов, поток Т, закончит выпол-
нение в своем критическом участке и выполнит программный код выходя
взаимоисключения, изменив значение переменной tllnside на ложное.
Хотя данное решение позволяет избежать проблемы жесткой синхронй"
зации, оно не гарантирует полное взаимоисключение. Рассмотрим следУ#"
щую ситуацию. Пусть значение обеих переменных tllnside и t2Insi е
ложно и оба потока одновременно пытаются войти каждая в свой крити^
ский участок. Поток Ti проверяет значение переменной t2lnside (стР“
ка 14), которое в данный момент ложно и переходит к выполнению
дующей команды. Теперь представим, что система выполнила приор# j
ное вытеснение потока Тх прежде, чем он успел выполнить код в строй®
(необходимый для того, чтобы не допустить вхождения в критически#
сток другого потока). Поток Т2 начинает свое выполнение, определи#’
значение переменной tllnside ложно, и спокойно входит в свой крИт1^(Г
ский участок. Приоритетное вытеснение потока Т2 происходит в тот
мент, когда он пребывает в своем критическом участке, после чего # $
Ti возобновляет свою работу со строки 16, устанавливая значение пере J
ной tllnside равным true и осуществляя вход в собственный критиг ®
участок. Таким образом, оба потока выполняются параллельно в с
критических участках, нарушая условие взаимоисключения.
’мраллельное Выполнение
301
Система:
1
2 ьоо1еап
3 boolean
tllnside
t2Inside
5 startTnreads();
= false;
- false;
// инициализация и запуск обоих потоков
7
8
9
Ю
И
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
ПОТОК И •
void main () {
while ( Idone )
while ( tZInside ) ; // enterMutualExclusion
tllnside = true; // enterMutualExclusion
// код внутри критического участка
tllnside false; fl exitMutualExclusion
// код за пределами критического участка
} // окончание внешнего цикла while
} окончание потока Т1
Поток Т2‘.
void main () {
while ( Idone )
' {
while ( tllnside ); // enterMutualExclusion
t2Inside = true; // enterMutualExclusion
/I код внутри критического участка
t2lnside = false; // exitMutualExclusion
// код за пределами критического участка
} // Окончание внешнего цикла while
} окончание потока Т2
Рие- SJ.
Реализация взаимоисключения — версия 2
Версия (появление взаимоблокировок)
^°гДа п М Местом программы версии 2 является то, что между моментом,
‘’ДТц оток, находящийся в цикле ожидания, определяет, что он может
Ь1Це (СТР°КИ 14 и 34), и моментом, когда этот поток устанавлива-
ли (ст ^Ризнак, говорящий о том, что он вошел в свой критический уча-
цп Ки 16 и 36), проходит достаточно времени, чтобы другой поток
°®еРить еще не установленный флаг и войти в свой критический
• Поэтому необходимо, чтобы, в то время как один поток выпол-
302
няет свой цикл ожидания, другой поток не мог выйти из своего собст '
него цикла ожидания. В программе версии 3 (см. рис. 5.8) для рещ^
этой проблемы предусматривается установка каждым потоком своего
ственного флага перед выполнением цикла ожидания. Поток Тх зая^Ч
о своем желании войти в критический участок, устанавливая значе
переменной tlWantsToEnter равным true. Если в этот момент знад^
переменной t2WantsToEnter ложно, поток Тх получает возможность ; 1
в критический участок, не давая сделать то же самое потоку Т2. в
случае взаимоисключение гарантируется, и, казалось бы, нам
%
ч
ч
1 эч
1 Система:
2
3 boolean tlWantsToEnter = false;
4 boolean t2WantsToEnter = false;
5
6 startThreads(); // инициализация и запуск обоих потоков
7
8 Поток Тг:
9
10 void main() {
11
12 while ( 'done )
13 {
14 tlWantsToEnter = true; // enterMutualExclusion
15
16 while (t2WantsToEnter) ; // enterMutualExclusion
17
18 // код внутри критического участка
19
20 tlWantsToEnter = false; // exitMutualExclusion
21
22 // код за пределами критического участка
23
24 } // окончание внешнего цикла while
25
26 } окончание потока Т1
27
28 Лоток Т2,:
29
30 void main() {
31
32 while ( I done )
33 {
34 t2WantsToEnter = true; // enterMutualExclusion
35
36 while ( tlWantsToEnter ); // enterMutualExclusion
37
38 // код внутри критического участка
39
40 t2WantsToEnter <= false; // exitMutualExclusion
41
42 // код за пределами критического участка
43
44 } // окончание внешнего цикла while
45
46 } окончание потока Т2
Рис. 5.8. Реализация взаимоисключения — версия 3
303
. илммельное Выполнение
iHoe^r------------------
дзение проблемы, ведь теперь поток предупреждает о своем наме-
ойти в критический участок, после чего другой поток не сможет
ре^елать-
gfO СД я версия программы позволила решить еще одну проблему, одна-
ДайН смену сразу же пришла новая. Если каждый поток перед вхожде-
ко ей на ожидания установит свой флаг и обнаружит, что флаг другого
йцеМв ц тановлен, то этот поток будет бесконечно оставаться в цикле
соТ°кадУа версия программы может служить примером взаимоблокиров-
while’ jioCk) для двух потоков, которая более подробно рассматривается
кН <dea 7
В главе ь
це1Йдер1пая версия (бесконечное откладывание)
п я создания эффективной реализации взаимоисключения нам нужно
“и способ «разорвать» бесконечные циклы ожидания, возникающие
Впедыдущсй версии. Для этого в четвертой версии программы (см. рис. 5.9)
В елусматривается периодическая кратковременная установка ложного
значения флага каждым вошедшим в цикл потоком. Благодаря этому дру-
гой поток получает возможность выйти из своего цикла ожидания при
по-прежнему установленном собственном флаге.
В программе версии 4 гарантируется взаимоисключение и отсутствие
взаимоблокировок, однако возникает другая потенциальная проблема,
также очень неприятная, а именно бесконечное откладывание (indefinite
postponement). Поскольку мы не можем делать никаких предположений
об относительных скоростях выполнения асинхронных параллельных по-
токов, мы должны проанализировать все возможные последовательности
выполнения программы. Потоки здесь могут, например, выполняться
«тандемом», друг за другом в следующей последовательности: каждый
поток может установить истинное значение своего флага (строка 14), про-
извести проверку в начале цикла (строка 16), войти в тело цикла, устано-
ВИть ложное значение своего флага (строка 18), выждать в течение выби-
раемого случайным образом промежутка времени (строка 20), снова уста-
ить истинное значение флага (строка 22) и повторить всю эту
б еД°вательность, начиная с проверки при входе в цикл. Когда потоки
Дут ВЬ1Полнять все эти действия, условия проверки (строки 18 и 45) бу-
маловеаВаТЬСЯ истинными- Естественно, подобный режим работы весьма
— °Днако все же в принципе возможен. Программу, реали-
МеР, в взаимоисключение таким способом, нельзя применять, напри-
йЫм ДвСИСТеМе УпРавления космическими полетами, управления воздуш-
₽°яТйостЖеНИеМ ли®° в кардиостимуляторах человека, где даже малая ве-
Састеь1Ь1ТЬ бесконечного откладывания процесса и последующий отказ
°КазыВа В Ц'елом категорически недопустимы. Поэтому версия 4 также
ется неприемлемой.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
.18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
Система:
boolean tlWantsToEnter - false;
boolean t2WantsToEnter = false;
startThreads(); // инициализация и запуск обоих потоков
Поток Тг.
void main () {
while ( !done )
{
tlWantsToEnter - true; // enterMutualExclusion
while (t2WantsToEnter); // enterMutualExclusion
{
tlWantsToEnter = false; // enterMutualExclusion
// ожидание в течение небольшого случайного промежутка времени
tlWantsToEnter = true;
) // окончание Цикла while
// код внутри критического участка
tlWantsToEnter - false; // exitMutualExclusion
// код за пределами критического участка
} // окончание внешнего цикла while
} окончание потока Т1
Поток Т2:
void main () {
while ( !done )
{
t2WantsToEnter = true; // enterMutualExclusion
while ( tlWantsToEnter ); // enterMutualExclusion
{
t2WantsToEnter = falsp; // enterMutualExclusion
I/ ожидание в течение небольшого случайного промежутка времени
t2WantsToEnter - true;
} // окончание цикла while
//' код внутри критического участка
t2WantsToEnter = false; // exitMutualExclusion
// код за пределами критического участка
} // окончание внешнего цикла while
} окончание потока Т2
Рис. 5.9.
Реализация взаимоисключения — версия 4
мьное Выполнение
305
ПИТМ, предложенный Деккером (см. рис. 5.10), позволяет решить
длГ0Ривз^имоисключения дЛЯ двух потоков, не требуя при этом нали-
лИбо специальных аппаратно-реализованных команд. В алго-
Л ккера также используются флаги-признаки, уведомляющие о же-
0тМе ” оКа войти в критический участок, но при этом реализуется кон-
данИ0 ° <(предпочтительного потока», которому будет позволено войти
деЛййЯ есКий участок в случае конфликта (когда два потока одновремен-
в крит свОем желании войти в критический участок),
но за«вят
1
Система:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
int favoredThread = 1;
bo lean tlWantsToEnter - false?
boolean t2WaritsToEnter = false;
startThreads() ; // инициализация и запуск обоих потоков
Поток Tii
void main() (
while ( '.done )
{
tlWantsToEnter = true;
while (t2WantsToEnter)
{
if( favoredThread == 2 )
{
tlWantsToEnter = false;
while( favoredThread == 2) ; // активное ожидание
tlWantsToEnter = true;
} //' окончание конструкции if
} // окончание цикла while
// код внутри критического участка
favoredThread = 2;
tlWantsToEnter = false;
// код за пределами критического участка
} II окончание внешнего .цикла while
1 окончание потока Т1
ЙОТод. j> .
V°id main () {
“hile ( Idone )
t2WantsToEnter « true;
г°Ритм взаимоисключения Деккера (часть 1 из
2)
-------------------------------------------------------------------я
47 while ( tlWantsToEnter )
48 {
49 if { favoredThread == 1 )
50 {
51 t2WantsToEnter - false;
52 while( favoredThread == 1); // активное ожидание
53 t2WantsToEnter = true;
54 } // окончание конструкции if
55
56 } // окончание цикла while
57
58 // код внутри критического участка
59
60 favoredThread = 1;
61 t2WantsToEnter = false;
62
63 // код за пределами критического участка
64
65 } // окончание внешнего цикла while
66
67 } окончание потока Т2
Рис. 5.10. Алгоритм взаимоисключения Деккера (часть 2 из 2)
Рассмотрим, каким образом алгоритм Деккера исключает возможность
бесконечного откладывания потоков, из-за которых программа версии 4
оказалась неприемлемой. Прежде всего, обратим внимание, что в этом ал-
горитме примитив enterMutualExclusion () реализуется в строках 15-26
и 45-56; примитив exitMutualExclusion () реализуется в строках 30-31
и 60-61. Поток Тх уведомляет о желании войти в свой критический уча-
сток, устанавливая свой флаг (строка 15). Затем он переходит к циклу
(строка 17), в котором проверяет, не хочет ли также войти в свой критиче-
ский участок и поток Т2. Если флаг потока Т2 не установлен, то Т] пропус-
кает тело цикла ожидания и входит в свой критический участок (стро-
ка 28).
Предположим, однако, что Tj^ при выполнении цикла проверки (стро-
ка 17) обнаруживает, что флаг Т2 установлен. В этом случае возникает ей-1
туации соревнования между потоками за право вхождения в свои критИ4®!
ские участки. Это заставляет поток Ti войти в тело своего цикла ожидв0
while. Здесь он анализирует значение переменной favoredThread, коТ0^
используется для разрешения конфликтов, возникающих в случае, ко I
оба потока одновременно хотят войти в свой критический участок (с * J
ка 19). Если избранным потоком является Т15 он пропускает тело сВ^,& I
оператора if и повторно выполняет цикл проверки в ожидании моМ
когда Т2 сбросит флаг t2wantsToEnter. (Мы вскоре увидим, что Т2 со вр
нем должен это сделать.) Если поток Ti определяет, что преимуществен^
право принадлежит потоку Т2 (строка 19), он входит в тело констрУ ~
if, где устанавливает значение флага tlWantsToEnter равным false ( Л
ка 21), а затем блокируется в цикле ожидания, пока избранным по
остается Т2 (строка 22). Сбрасывая свой флаг, Tj дает возможность п°
Т2 войти в свой критический участок. срОМ
Со временем Т2 выйдет из своего критического участка и выполнит I
код выхода взаимоисключения (строки 60—61). Эти операторы обес
параллельное Выполнение
307
I преимущественного права процессу Тх и сброс флага t2WantsToEn-
яОзВраТ ррь У Т1 появляется возможность выйти из внутреннего цикла
%г. ^еП while (строка 22) и установить собственный флаг tiwantsToEn-
true (строка 23). Затем Тц выполняет внешний цикл проверки
ег Р0^7). Если флаг t2WantsToEnter (недавно сброшенный) по-прежнему
(сТР°ка ачёние false, то Ti входит в свой критический участок. Если, од-
цМееТг^ пазу же пытается вновь войти в свой критический участок, то его
цаК0’"2°ntsioEnter будет установлен, и Ti снова придется войти в тело
фЛаГ t гО цикла while (строка 19).
рцеЮ11 на этот раз «бразды правления» находятся уже у потока Тх, по-
сейчас именно он является избранным. Поэтому Тх пропускает
сК°ль ^оВНОй конструкции if и многократно выполняет внешний цикл
ТвЛ° рки (строка 17), пока Т2 «смиренно» не сбросит собственный флаг,
йровер я прОцессу Tj войти в свой критический участок.
П° ддёори™ Деккера гарантирует взаимоисключение, предупреждая воз-
квовение взаимоблокировок и бесконечного откладывания. Однако до-
Я зательство данного утверждения не очевидно, из-за сложной природы
взаиМоисключения. Рассмотрим сейчас следующую интересную возмож-
ность. Когда Ti выходит из внутреннего цикла активного ожидания (стро-
ка 22), он может потерять процессор в результате приоритетного вытесне-
ния до того, как поток Тх успеет установить значение флага tlWantsToEn-
ter, а поток Т2 в это время пройдет цикл и вновь попытается войти в свой
критический участок. При этом Т2 первым установит свой флаг и вновь
войдет в свой критический участок. Когда Ti снова захватит процессор, он
установит свой флаг. Поскольку сейчас будет очередь процесса Ti (и флаг
tlWantsToEnter установлен), то поток Т2, если он попытается вновь войти
в свой критический участок (строка 47), должен будет сбросить флаг
t2wantsToEnter и перейти на внутренний цикл активного ожидания (стро-
ка 52), так что Тх получит возможность входа в свой критический участок.
Этот прием позволяет решить проблему бесконечного откладывания. Стро-
гое доказательство того, что алгоритм исключает возможность бесконечно-
откладывания, — намного более сложная задача (см. «Поучительные
ории: Вы уверены, что ваше программное обеспечение функционирует
в Ильно?»), решение которой любознательный читатель может поискать
°полнительной литературе.16
Вопросы для самопроверки
1. Укажите ключевую проблему в каждой из четырех попыток реали-
зации механизма взаимоисключения.
(Да/Нет) Правда ли, что если алгоритм, представленный на рисун-
ке 5.9, модифицировать таким образом, чтобы потоки находились
в своих циклах ожидания в течение различных промежутков вре-
мени (например, поток Tj находился в ожидании от О до 0.2, поток
Т2 — от 0.5 до 0.7 секунд), этот алгоритм перестал бы быть подвер-
жен бесконечному откладыванию.
Ответы i) Версия 1: необходимо, чтобы поток Т* всегда Нач>>
работу первым и происходило строгое чередование выполнения пМ
ков друг с другом. Версия 2: нарушение взаимоисключения; оба
ка могут войти в свои критические участки в одно и то же в^М
Версия 3: возможность взаимоблокировки двух потоков, в резуд ’Ч
чего ни один из них не сможет войти в свой критический участой
сия 4: возможно, хотя и маловероятно, возникновение ситуации еР-
конечного откладывания, в случае, если два потока будут рал
в «тандеме». 2) Нет. Согласно определенным нами условиям9
должно высказываться никаких предположений об относится?1
скоростях выполнения асинхронных параллельных потоков
если выбираемые случайным образом интервалы ожидания не cri е
дают, мы не знаем, насколько быстро будет выполнена оставил*'
часть алгоритма.
Поучительные истории
Вы уверены, что ваше программное обеспечение
функционирует правильно?
Дейкстра всегда выдавал идеи, которые
заставляли задумываться других людей. Вот
одна из наиболее ярких его идей: предполо-
жим, у вас есть программа, вычисляющая, яв-
ляется ли данное большое число простым.
Если программа определила, что данное чис-
ло не является простым, она выводит его
множители, перемножив которые между со-
бой вы можете убедиться в правильности
разложения оригинального числа. Но если
программа утверждает, что данное число
простое, то где доказательства?
Урок для разработчиков операционных систем: Вероятно, это один из наиболее важных
моментов, касающихся вычислительной техники, о котором вы могли никогда не задумы-
ваться. Мы доверяем компьютерам свою личную жизнь и нашу карьеру. Но можем ли мы
уверены в том, что сложные программные продукты действительно в точности выполняют^-
ставленные перед ними задачи? Как нам убедиться в том, что программа функционируй^'
вильно, особенно, если мы знаем, что вряд ли сможем провести исчерпывающее тестир0^
ние программного продукта? Ответ лежит в исследовательском поле, называемом «До1(
тельство корректности программ». Для данной области характерно наличие мноЖ
важных нерешенных проблем — на сегодняшний день можно доказать правильность <УУ
ционирования только для небольших и относительно простых программ. Отличная гей
диссертации кандидатам в доктора философии по компьютерным наукам.
5.4.2 Алгоритм Питерсона
Рассмотренный в предыдущем разделе алгоритм Деккера скрывает в се^а<1'
нюансов, связанных с природой параллелизма и асинхронности в мг,С)Г
ных системах. В течение многих лет данный алгоритм отражал прак >'
состояние дел в сфере взаимоисключения с активным ожиданием. Вы
параллельное выполнение
309
гТйТерсон опубликовал упрощенный алгоритм взаимоисключения для
Л- с0В с использованием активного ожидания (см. рис. 5.II).17
«вУ* °Р°Й проиллюстрировать правильность работы алгоритма Питерсона,
^тобЫ последовательность операций, выполняемых потоком Tj. Пе-
овссМ°тр войти в свой критический участок, Tj уведомляет о своих на-
реД теМ устанавливая переменную tlWantsToEnter равной true (стро-
МвР6011 по’избежание бесконечного откладывания, поток Т] устанавливает
1^)- переменной favoredThread равным 2 (строка 16), позволяя пото-
3яа«енИ^тй в свой критический участок. Затем поток Ti пребывает в со-
ку Тг в аКТивНОГО ожидания до тех пор, пока флаг t2WantsToEnter уста-
сТоЯНй1^ значение favoredThread равно 2. Если одно из двух вышеупомя-
Вовлен лоВИй перестанет быть истинным, поток Tj сможет спокойно
нутЫ* критический участок (строка 20). После прохождения крити-
войтИ^ уЧастКа, Tj сбросит флаг tlWantsToEnter (строка 22), чтобы уведо-
чесК систему о своем выходе из критического участка.
*Теперь посмотрим, каким образом приоритетное вытеснение может повли-
на поведение потока Tj. Если никто не соревнуется за право вхождения
в критический участок, когда поток Tj выполняет команды входа взаимоис-
ключения, флаг t2WantsToEnter сброшен, когда поток Tj выполняет стро-
ку 18, то поток Tj входит в собственный критический участок (строка 20).
Рассмотрим случай, когда поток Т| теряет процессор сразу после входа в кри-
тический участок. Поскольку поток Т2 обязан установить значение перемен-
ной favoredThread равным 1 (строка 37), проверка, выполняемая потоком Т2
в строке 39, заставит Т2 пребывать в состоянии активного ожидания до тех
пор, пока Tj не выйдет из критического участка и не сбросит свой флаг.
В то же время, если флаг t2WantsToEnter установлен в тот момент, когда
поток Tj пытается войти в свой критический участок (строка 18), тогда у пото-
ка Т2 необходимо будет отобрать процессор, если он попытается войти в свой
критический участок. Приоритетное вытеснение Т2, пребывающего в своем
критическом участке, возможно в том случае, если значение переменной
favoredThread будет равно 2, а флаг t2WantsToEnter установлен. Тогда поток
Удет нах°даться в активном ожидании в строке 18, пока Т2 не закончит
ловия10”01^ В критическом участке, сбросив флаг t2WantsToEnter, нарушая ус-
Цикла while в строке 18 и позволяя потоку Tj продолжить выполнение.
Изд fa ПоТок Tj обнаружит, что флаг t2WantsToEnter установлен и перемен-
j^^^voredThread равна 2, Tj перейдет в режим активного ожидания внутри
BenocnWhlle (стР°Ка 18), поскольку переменная favoredThread станет равна 2
Тех Иор^СТВеНН° пеРеД выполнением строки 18. Поток Tj будет ожидать до
redThr ' ПОка п°ток Т2 не возвратит себе процессор и не установит для f avo-
^Идан знзчение 1 (строка 37). На этом этапе перейти в режим активного
---------------- '
ВетСя в
’’hll- ~ —*
К? В°ЙТ1
•
В есКий Геа<^ Равна 1 в строке 18, Tj сможет безопасно войти в свой кри-
ь Этом УЧас----- - -
Сь°ем
а ВынУжден будет поток Т2, поскольку флаг tlWantsToEnter уста-
। Ве₽еменная favoredThread равна 1. После того как процессор вер-
поражение потока Tj, он сможет выполнить проверку в цикле
, --и в свой критический участок (строка 20).
! ~1 обнаружит, что флаг t2WantsToEnter установлен и переменная
Участок, поскольку его собственный флаг также установлен.
ожидать придется потоку Т2, пока Tj не закончит выполне-
критическом участке и не сбросит свой флаг.
310
м
Сейчас мы приведем формальное доказательство того, что алгоритм. 1
терсона гарантирует взаимоисключение. Для этого мы докажем, что г,
Т2 не сможет войти в критический участок, пока поток Т| находится
ри своего критического участка. Обратите внимание, что алгоритм Не и
менится, если мы переставим индексы потоков местами (то есть помрь
местами потоки Ti и Т2). Таким образом, доказав, что Т2 не сможет ца ’’Ч
выполнение в критическом участке до тех пор, пока в своем критичес
1 Система:
2
3 int favoredThread = 1;
4 boolean tlWantsToEnter ₽ false;
5 boolean t2WantsToEnter = false;
6
7 startThreads(); // инициализация и запуск обоих потоков
8
9 Поток Т2:
10
11 void main О {
12
13 while ( !done )
14 {
15 tlWantsToEnter = true;
16 favoredThread = 2
17
18 while (t2WantsToEnter && favoredThread = 2);
19
20 // код внутри критического участка
21
22 tlWantsToEnter = false;
23
24 // код за пределами критического участка
25
26 } // окончание цикла while
27
28 } окончание потока Т1
29
30 Поток Тг:
void main О (
while ( ’done )
{
t2WantSToEnter = true;
favoredThread = 1
while ( tlWantsToEnter &s favoredThread -= 1);
// код внутри критического участка
t2WantsToEnter и false;
// код за пределами критического участка
} // окончание цикла while
} окончание потока Т2
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
Рис. 5.11. Алгоритм взаимоисключения Питерсона
парвМельное выполнение
зн
аХодится поток Ti, мы докажем, что и Tj не сможет войти в кри-
-•асТ1*6 ? участок, пока из него не выйдет поток Т2.
дачать доказательство, заметим, что значение переменной f avo-
тЯ tjfo6b5 дадается непосредственно перед входом потока в цикл ожидания
,dThr®a лее того, каждый поток задает значение favoredThread таким об-
^iie- ^°о избранным считается другой поток, если оба потока пытаются
разо*1’ 4 роИ критические участки. Флаг tlWantsToEnter контролируется
аойт11 В С еЛьно потоком Тх; аналогично, исключительное право на моди-
цсКя1°Ч® флага t2WantsToEnter принадлежит потоку Т2. Теперь предполо-
фикай11 поТОК ф( является единственным потоком, который выполняется
ЯСИН, чТ° ити4еском участке, тогда tlWantsToEnter = true, а переменная
В cB°er^Thread = 1 либо t2WantsToEnter = false.
fav°re ° [£ТОбы поток Т2 смог войти в свой критический участок (стро-
а ^необходимо, чтобы:
Ка, tlWantsToEnter = false,
, favoredThread = 2 либо
• tlWantsToEnter = false и favoredThread = 2
Мы будем вести доказательство от противного, предположив, что поток
Т успешно вошел в свой критический участок, когда в своем критическом
участке находился поток Т2 и доказав, что в алгоритме Питерсона такая
ситуация невозможна. В первом варианте (если tlWantsToEnter = false),
Т2 без проблем входит в свой критический участок поскольку флаг потока
Ti сброшен, а значение переменной favoredThread в этом случае не играет
для нас никакой роли. Но, как мы говорили в предыдущем разделе, флаг
tlWantsToEnter должен быть установлен, если в данный момент времени
поток Tt также находится внутри своего критического участка. Флаг
tlWantsToEnter может быть сброшен только в случае, если Tj вышел из
своего критического участка (строка 22) и не пытается войти туда повтор-
но (строка 15). Поэтому поток Т2 не сможет войти в критический участок,
поскольку флаг tlWantsToEnter = false. Из этого также следует, что по-
ток Т2 не сможет войти в критический участок согласно третьему условию
когда tlWantsToEnter = false и favoredThread = 2).
стОкаМ осталось доказать, что Т2 не сможет войти в свой критический уча-
ЧЙТь И СогласНо второму условию, поскольку favoredThread не может полу-
СтКа ™ачение 2» пока поток Ti находится внутри своего критического уча-
Флаг ( Я ВХ°ДО в критический участок, поток Т2 должен установить свой
ТемКак^°Ка 36)’ а в переменной favoredThread задать 1 (строка 37), перед
тод-р он вЫйдет из цикла ожидания в строке 39. Таким образом, если по-
вЫп^ПОЛНЯется в своем критическом участке в то же время, когда поток
’«П’Ься НЯеТся в своем, значение переменной favoredThread должно изме-
Что га/°СЛе того, как поток Т2 дойдет до строки 37. Обратите внимание,
BxgredThread = 2 только тогда, когда поток Tj выполняет строку 16
Л°То уъЛа взаим°исключения, требуя, чтобы вышел из своего критиче-
ТКа’ Учтите, что в то же время поток Т2 установил свой флаг
6 с®ой н nter в строке 36. Следовательно, когда поток Тх попытается вой-
Этический участок в строке 18, он вынужден будет перейти в ре-
с1тЬгеаВВЫого ожидания, поскольку t2WantsToEnter = false и favo-
' 2. Хотя поток Т2 может войти в свой критический участок, Ti
312
должен ожидать, пока Т2 не выйдет из него, а это противоречит
предположению, что оба потока одновременно находятся в своих Крц 6)W
ских участках. Таким образом, доказав от противного, что потоки
могут одновременно выполняться внутри своего критического участц
доказали, что алгоритм Питерсона гарантирует взаимоисключение. Ч
Алгоритм Питерсона не допускает взаимоблокировок либо бескоцРЪ
откладывания, если завершение потоков происходит естественным
зом. [Примечание. Как всегда, мы предполагаем, что взаимоблокип°^'
либо бесконечное откладывание не могут быть вызваны кодом входа J
выхода взаимоисключения. Тем не менее, такая вероятность, хотя и о
малая, все же существует, если потоки начнут вести себя некоррек6®1
внутри своих критических участков.] Взаимоблокировка может вози^°
нуть в случае, если оба потока одновременно окажутся в режиме активы 1
ожидания в своих циклах while. Этого не произойдет, поскольку перем0Г°
ная favoredThread принимает только значения 1 или 2, и она не Модца I
цируется внутри циклов ожидания, а это означает, что проверка внутод
цикла while не увенчается успехом только для одного потока, позводщ
другому войти в свой критический участок. Для того чтобы возникла од
туация бесконечного откладывания, один из потоков должен все время вы-
ходить из критического участка и снова входить в него, заставляя другой
поток находится в состоянии активного ожидания. Однако так как каж
дый поток перед входом в цикл while устанавливает в переменной
favoredThread значение, указывающее на другой поток, алгоритм Питер-
сона гарантирует, что два потока будут входить в критические участки по
очередно, то есть бесконечное откладывание в данном случае исключается.
Вопросы для самопроверки
1. Что общего между алгоритмом Деккера и алгоритмом Питерсона?
2. Какие переменные необходимы для предотвращения бесконечной
откладывания?
Ответы 1) В обоих алгоритмах используются одни и те же три гло-
бальных переменных. 2) Удалив переменную favoredThread, вы созда-
дите условия для возникновения ситуации бесконечного откладывания-
5.43 Взаимоисключение для п потоков: алгоритм Лэмпорта
Программное решение проблемы реализации примитивов в-заимоиск^.
чения для п потоков первым предложил Дейкстра.18 Затем Кнут усовери1
ствовал алгоритм Дейкстры, исключив возможность бесконечного oTI<‘\efiy
вания процессов, однако в варианте Кнута некоторый процесс no-npe3It
мог испытывать (потенциально) длительную задержку.19 В связи с
многие ученые начали искать алгоритмы, обеспечивающие более коР°
задержки. Так, Эйзенберг и Макгайр предложили решение, гарант0^
щее, что процесс будет входить в свой критический участок не более 4
п-1 попыток. Лэмпорт разработал алгоритм, применимый, в частности^-
распределенных систем обработки данных (см. «Биография: ЛесЛЙ ‘
порт»). Алгоритм Лэмпорта предусматривает «предварительное поЛ^1^г1
номерка», подобно тому, как это делается в модных пиццериях или р
,е алмМвльиое выполнение
313
за что он и ПОЛУЧИЛ наименование алгоритма Лэмпорта или алго-
ерСя115<’ цдитера (Lamport’s Bakery Algorithm). Бернс с соавторами также
f или свое решение проблемы взаимоисключения для п потоков с по-
иной разделяемой переменной.22 Карвало и Рукаирол изучают
°ниге тему взаимоисключения в компьютерных сетях.23
вс₽°еЙ пт первым предложил алгоритм, позволяющий потокам быстро
ДэМП Р свОИ критические участки, если никакого состязания за право
рхоДвТЬ „ в критический участок в данный момент не наблюдается (что
довольно часто).24 Однако подобный алгоритм быстрого взаимо-
сЛУч8е^еЯИЯ (fast mutual exclusion algorithm) может оказаться неэффектив-
за право входа в свой критический участок действительно сорев-
цЫ^’ несКОлько потоков. Андерсон и Ким предложили еще один алго-
нУ®тсЯводволЯЮщИй быстро входить в критический участок при отсутствии
рИТМ,^ иррдандентов на выполнение этой операции, обеспечивающий при
ДР^Г достаточно высокое быстродействие в случае соревнования.25
^Большинство ранних вариантов решения проблемы взаимоисключения
п потоков были сложны для понимания по причине того, что в этих ал-
горитмах использовалось большое количество разделяемых переменных
и сложных циклов, определяющих возможность входа потока в критиче-
ский участок. Алгоритм Лэмпорта предусматривает простое решение, по-
заимствованное из реальной жизненной ситуации — обслуживания клиен-
тов в пиццерии. Кроме того, алгоритм Лэмпорта не требует, чтобы все опе-
рации являлись атомарными.
Алгоритм Лэмпорта работает по принципу кондитерской, в которой
один служащий выполняет заказы клиентов на кондитерские изделия
(либо на пиццу, если говорить о пиццерии), причем одновременно он мо-
жет обслуживать только одного клиента. Если очередь состоит всего из од-
ного клиента, все предельно просто: клиент заказывает заинтересовавшую
его выпечку, продавец достает товар, клиент расплачивается за получен-
ный товар и выходит из кондитерской. Но если необходимо обслужить сра-
зу несколько клиентов, продавец должен определить, в каком порядке сле-
дует это делать. В некоторых кафе-кондитерских посетителям выдаются
я°Мерки, по которым они и обслуживаются в порядке очереди (согласно
в НЦипУ первым-пришел-первым-обслужен). Номерки присваиваются по
Ном Станию (то есть если первый номерок имеет значение п, следующий
КдИе Ок будет иметь значение п +1 и т.д.) После обслуживания очередного
о<Та’ слеДУЮщим обслуживается клиент с наименьшим номером, в со-
ЦаСТВИи с вышеупомянутым принципом.
к°н. gPHcyHKe 5.12 представлена реализация алгоритма Лэмпорта для п пото-
’^вхцеп-)11^11™6 ^:)мпоРта каждый поток символизирует собой клиента, полу-
>Кет в0йтНомерок’ с помощью которого определяется, когда данный поток смо-
йся в в свой критический участок. Если в распоряжении потока оказыва-
в°а,«0}101о*ЭОК Со значением, наименьшим из всех оставшихся, он получает
^Tca ш в°йти в свой критический участок. Взаимоисключение гаранти-
а ^сТКа сброса значения номерка после выхода потока из критического
М отличие от реальной кондитерской, алгоритм Лэмпорта позволяет
потокам получать одинаковый номер, но при этом он включает
ОзИет Разрешения конфликтов, гарантирующий, что только один поток
I Работать в своем критическом участке в текущий момент времени.
314
^иогРаФи(,€С^ие сметки
кесли Лэмпорт
В 1972 году в университете Брандейса
Лесли Лампорту была присвоена степень док-
тора философии по математике.26 Он успел
поработать во многих компаниях: Massa-
chusetts Computer Associates, SRI International,
Digital Equipment/Compaq, а в настоящее вре-
мя работает в исследовательском отделе
Microsoft.27 Своим самым важным достиже-
нием он считает разработку метода структу-
рирования логических доказательств в ие-
рархическом виде,28 хотя большую извест-
ность он получил благодаря своему вкладу
в решение проблемы взаимоисключения
процессов, работающих с разделяемыми
данными.
Одним из основных достижений Лампор-
та в области компьютерных наук стал предло-
женный им алгоритм кондитера для синхро-
низации процессов, обслуживаемых по
принципу первым-пришел-первым-обслу-
жен (см. раздел. 5.4.3). Важными особенно-
стями алгоритма Лэмпорта является решение
проблемы бесконечного откладывания и ус-
тойчивость алгоритма в случае досрочного
завершения процессов. Этот простой алго-
ритм применяет принцип синхронизации, ис-
пользуемый при обслуживании клиентов
в кафе-кондитерских.29 Каждому процессу,
запрашивающему вход в свой критический
участок, присваивается номерок, больший
того номера, который был присвоен преды-
дущему процессу, точно так же, как следую- синхронизации распределенных
щему посетителю кафе-кондитерской выда-
ется новый порядковый номерок для обслу-
живания. Когда процесс выходит из
критического участка, «оглашается» следую-
щий номер, после чего процессу с этим номе-
ром будет разрешено продолжить работу.30
Лэмпорт является автором многих I
по методам разработки формальных
фикаций для параллельных программ I
казательства правильности их выполи
В рамках работы над методами док-jj
тельств он разработал логическую cncJ” 1
под названием Temporal Logic of д^
(TLA) - временная логика действий, КОт ^1
может применяться для верификации KJ
аппаратной логики (логики схем), так и про I
граммной логики.31,32
Работы Лэмпорта по реализации взаи-
моисключения продемонстрировали тог'
факт, что взаимоисключение может быть
достигнуто без помощи атомарных выра-
жений, требующих специальной аппарат-
ной поддержки.33 Он разработал, по край-
ней мере, четыре алгоритма различной
сложности и степени отказоустойчивости “
Кроме того, он изобрел первый алгоритм
взаимоисключения, выполняющийся в те-
чение короткого фиксированного проме-
жутка времени, если втекущий момент вре-
мени ни один процесс не находится в своем
критическом участке.35
Самая знаменитая работа Лэмпорта «Вре
мя, часы и сортировка событий в распр6^ |
ленных системах» посвящена описанию)
ханизма логических часов, использу
для определения порядка следования |
тий, и метода, использующего эти часН
пр°а
сов.36-37-38 uje-
Помимо исследований в области и
ния проблем взаимоисключения, Б I
году Лэмпорт разработал издательскУ Д
тему LaTeX, основанную на языке Д°
Кнута ТеХ.39
^йраМвльное Выполпепие
315
I
2
3
4
5
6
7
8
9
10
П
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
массив, регистрирующий потоки с номерками
boolean choosing[nJ;
начальное значение номерка для каждого потока равно 0
(^/ticket [п];
tThreadsO; //инициализация и запуск всех потоков
[]O?OK ?*'
void main() {
x = threadNumber(); // сохранение номера текущего потока
while ( !done )
{
// получение номерка
choosing[х] = true; // начинаем выбор номерка
ticket[х] - maxValue( ticket ) + 1;
choosing[х] = false; // заканчиваем выбор номерка
// определяем номер потока, который будет обслужен следующим,
// сравнивая текущий номерок с номерками других потоков
for ( int 1=0; i < n; i++)
{
if ( i == x )
{
continue; // проверять собственный номерок не нужно
} // окончание конструкции if
// активное ожидание, пока выбран i-й поток
while ( choosing[i] != false );
// активное ожидание, пока текущий номерок является наименьшим
while ( ticket[i] != 0 & ticket[i] < ticket[x] );
// для равных номерков выбираем поток с меньшим номером потока
if (ticket[i] == ticket[х] && i < x )
//ожидаем, пока i-й поток не выйдет из критического участка
while ( ticket[i] != 0 ); //активное ожидание
} // окончание конструкции for
// код внутри критического участка
ticket[х] =0; // exitMutualExclusion
// код за пределами критического участка
’ // окончание цикла while
* окончание потока Тх
Алг
оритм Лэмпорта (алгоритм кондитера)
316
г;
^раллельное Выполнение
317
В строках 3—7 объявляются два массива, общим доступом к которЬт 1
ладают все п потоков, участвующих во взаимоисключении. Массив ? I
вых значений choosing (строка 4) имеет размерность п; если пот^М
в данный момент осуществляет выбор номерка, то значение элемент
сива choosing [х] истинно. В противном случае значение элемента ма^'
choosing[х] будет ложным. В массиве целочисленных значений
(строка 7) хранятся сами значения номерков, причем индекс элемецт Xc|tJ
сива соответствует номеру потока. Номерок для потока Тх хранится
менте ticket [х]. В данном примере начальным значением номеру
всех потоков является 0.
В строках 13-54 представлен код, выполняемый потоком Тх, одни I
п потоков, пытающихся войти в свой критический участок. Каждые
ток, участвующий в алгоритме кондитера, выполняет одинаковые к я
рукции входа взаимоисключения (строки 19-44) и выхода взаимоискД
чения (строка 48). После запуска поток начинает свое выполнение
манды в строке 15, сохраняя в переменной х целое значение, которой
уникальным образом идентифицировало поток. Поток использует
значение для определения соответствующих записей в массивах choosjj
и ticket.
Потоки получают свои номерки в строках 19-22. В строке 20 поток J
общает о своем желании получить номерок, присваивая элементу Маса®
choosing [х] значение true. Вскоре мы увидим, что такой шаг необхода
для обеспечения взаимоисключения в том случае, если сразу несколько и
токов одновременно захотят завладеть этим номерком. Далее поток визы
вает метод maxValue (строка 21), возвращающий наибольшее целое чиск
из массива ticket. После этого к наибольшему значению будет прибавлеЛ
единица, и полученное значение будет использовано в качестве нового №
мерка ticket [х] (строка 21). Обратите внимание, что если в системе вы»
полняется большое количество потоков, на выполнение метода maxValsi
может уйти много времени, что повышает вероятность приоритетного вы'
теснения метода maxValue до момента его завершения. После присвоен®
номерка потоку (записи значения в ticket [х]) (строка 21), поток устав®
ливает значение элемента массива choosing[х] равным false (строками
показывая тем самым, что поток закончил процедуру выбора номерка. 1
тите, что когда поток выходит из критического участка (строка 48), зНа
ние номерка сбрасывается в ноль, то есть номерок принимает неНУ-пе^
значение только тогда, когда поток намеревается войти в критИЧесК '
участок.
В отличие от реальной жизненной ситуации в кафе-кондитерской,J
продавец вызывает для обслуживания клиентов в соответствии с °че^^
стью присвоенных им номерков, алгоритм кондитера требует, чтоб#
дый поток сам определял, когда он может войти в свой критически0
сток (строки 24—44). Перед тем, как войти в критический участок, ЛД
должен выполнить цикл for (строки 26-44), чтобы определить сосТ
других потоков системы. Если поток Тх> выполняющий в данный
инструкцию for (строка 28), оказывается проверяемым потоком Т/, ° ,
полняет инструкцию continue (строка 30), пропуская остальные ко
внутри цикла for, чтобы перейти непосредственно к инструкции пр0г
ния i в строке 26.
яВ11°м случае Тх определяет, не занят ли поток Тг в данный мо-
₽ 11Р°^чеНием номерка (строка 34). Если поток Тх не подождет, пока Т,
И°Л5^мерок, перед тем как войти в свой критический участок, усло-
"‘^учИ’1' Н°цсключения будет нарушено. Чтобы разобраться, почему так
®ЗЙЙМт давайте вначале рассмотрим два других условия, которые
в каждой итерации цикла for.
рроВеРЯ1°ке 37 мы проверяем, обладает ли выполняемый в текущий мо-
стр° и Процесс номерком, значение которого меньше либо равно
ВР ноМерка проверяемого потока. Можно провести аналогию данно-
3ааЧ®0й^ с реальной жизненной ситуации в кафе-кондитерской — каж-
го УсЛ° к вынужден дожидаться пока у него не окажется номерок с наи-
Д#й raiM (ненулевым) значением.
ме0ь1В отличие от реальной жизненной ситуации, нескольким пото-
ка темы может быть присвоен один и тот же номерок. Пускай поток Та
KflM яет процессор после возвращения из метода maxValue, не успев увели-
П0Т значение номерка на 1 (строка 21). Если следующий выполняемый
ЧЙТЬк вызовет maxValue, этот метод возвратит то же самое значение, что
D0 ля Т • В результате несколько потоков могут получить одинаковые но-
мерки. Строка 40 позволяет выбрать из таких потоков для выполнения по-
ток с наименьшим номером потока.
Вернемся к строке 34, чтобы посмотреть, как нарушается условие взаи-
моисключения, если поток Тх не будет ждать пока Т, получит номерок. На-
пример, рассмотрим, что произойдет, если поток Та будет вытеснен после
возврата из метода maxValue, но перед добавлением 1 к номерку (стро-
ка 21). В нашем примере метод maxValue возвращает значение 215. После
приоритетного вытеснения потока Та, несколько других потоков начинают
выполнять свой код входа взаимоисключения. Потоки Tj, и Тс выполняют-
ся после приоритетного вытеснения потока Та и при этом успевают закон-
чить процедуру получения номерка (строки 19-22), в результате чего пото-
ку Т6 будет выдан номерок 216 (учтите, что текущее значение Та — нуль),
аТс получит номерок 217. Поток может выполнить код выхода взаимо-
исключения (строки 19—44), пройти критический участок (строка 46)
выити из него (строка 48) прежде, чем поток Та вновь завладеет процес-
ще°М" •Алал°гичная возможность входа в критический участок до возвра-
Есл ПРоцессоРа потоку Та существует и для потока Тс.
КриТиИ Поток Тс потеряет процессор во время выполнения кода внутри
т°тзяЧеСК°ГО Участка и процессор окажется в распоряжении потока Та,
вып°лнение кода в строке 21, получив номерок 216, который
ахода чем У потока Тс. Таким образом, поток Та сможет выполнить код
5ег° вьт“ ИЬ1ОИСКлючения и войти в критический участок до того, как из
аИл. Дет поток Тс, нарушив, таким образом, условия взаимоисключе-
пРогЭТ°й пРичине поток Тх должен подождать, пока поток Т, не закон-
С₽аанеии АУРУ получения номерка (строка 34) перед тем, как выполнить
^Осдее НомеРков в строках 36-43.
РУетСя Вь1полнения всех проверок потоком Тх (строки 28—43), ему гаран-
М0Нопольный доступ к своему критическому участку. Выйдя из
t 4 УЧастка’ поток Тх обнулит значение номерка (строка 48), со-
с'1”' самым об окончании своей работы в критическом участке и от-
Чамерения войти туда повторно.
Помимо простоты, алгоритм Лэмпорта или кондитера обладает I
интересных свойств. Например, он не требует, чтобы выполняемые нну^ч
алгоритма команды являлись атомарными. Вспомним (см. раздел 5.3) ^41
в наших примерах предъявлялось требование к атомарности оперд
Атомарность была необходима потому, что и в алгоритме Деккера, и
горитме Питерсона несколько потоков модифицируют разделяемую п
менную, управляющую доступом к критическим участкам. Если несд
ко потоков в состоянии одновременно обращаться к данной перемен1"
и модифицировать ее на разных процессорах, это может привести к
нию противоречивых значений. В результате два потока могут одцОц
менно войти в свой критический участок, нарушая условие взаимоиск»!!’
чения. Хотя во многих архитектурах предусмотрен ограниченный
атомарных инструкций (см. раздел 5.5), сложно найти многопроцессорюЛ
систему, в которой была бы аппаратно реализована защита от одновреме*°
ного считывания и записи данных.
Алгоритм Лэмпорта предлагает изящное решение проблемы взаимоис
ключения для многопроцессорных систем, поскольку каждому потоку д»
значается свой собственный набор переменных, управляющих доступу
к критическим участкам. Хотя все потоки в системе обладают общим дос
тупом к массивам choosing и ticket, поток Тх единственный, который мо-
жет модифицировать значения элементов choosing[х] и ticket [х]. Таким
образом, другие потоки защищены от считывания противоречивых дан-
ных, поскольку переменная, проверяемая в коде входа взаимоисключе-
ния, не может в это же время модифицироваться другим потоком.
Еще одним интересным свойством алгоритма кондитера является то
что потоки, ожидающие входа в свой критический участок, обслуживают-
ся по принципу первым-пришел-первым-обслужен, если все потоки владе-
ют разными номерками. И, наконец, алгоритм Лэмпорта может гарантиро-
вать взаимоисключение даже в случае сбоя в работе одного или несколь-
ких потоков, обеспечивая установку значение false в соответствующих
элементах массива choosing, и нуля в соответствующих элементах массива
ticket. Благодаря последнему пункту алгоритм кондитера не подверж®
взаимоблокировкам и бесконечному откладыванию. Это свойство очень
важно для многопроцессорных и распределенных систем, где сбой оборУ'
дования, например одного из процессоров, не должен привести к краХ^
системы в целом.
Вопросы для самопроверки
1. Поясните, почему реализация взаимоисключения для п IIOT0f"ce-
связана с определенными сложностями в распределенных ли&
тевых системах.
2. Что произойдет, если система не выполнит такие служебные о
ции, как сброс значения номерка в ноль и установку значения
мента массива choosing равным false?
3. Предположим, что несколько потоков получили один и тот Ж® gj,-
мерок. В приводимом примере программного кода поток с наи
шим уникальным значением номера потока входит и
критический участок первым. Имеет ли значение, в каком
потоки с одинаковыми номерками будут входить в свои крй
ские участки?
1ельнов Выполнение
31!
ОтбстЫ 1) В распределенных и сетевых системах возможны за
держки между отправкой сообщения одним компьютером и его полу
чением другим компьютером. Поэтому алгоритмы взаимоисключения
должны учитывать задержки между моментом модификации пазле
ляемой переменной одним потоком и попыткой входа в критический
участок другим потоком. 2) От проблемы бесконечного откладывания
может пострадать вся система. Предположим, что аварийное заверше
ние потока произошло во время процедуры получения номерка в пе
зультате чего значение соответствующего элемента массива choosincr
теперь всегда будет являться истинным. Из-за этого другие потоки
также намеревающиеся войти в свой критический участок, могут до
бесконечности ожидать, когда же значение элемента массива choo-
sing станет равным false. 3) Если только программист не пожелает
присвоить приоритеты потокам, обладающим одинаковыми номерка
ми, порядок, в котором потоки с одинаковыми номерками будут вхо
дить в свои критические участки, не будет иметь никакого значения
Строки 34 и 37 (см. рис. 5.12) гарантируют, что ни один поток со зна
чениями номерков больше или меньше обслуживаемого в данный мо-
мент значения номерка не сможет войти в свой критический участок
до тех пор, пока не будут обслужены все потоки с одинаковым номер-
ком. Системе нужно будет позаботиться только о том, чтобы все потоки
с одинаковым номерком, в конце концов, вошли в свой критический
участок.
5.5 Аппаратные решения проблемы
Взаимоисключения
В предыдущих разделах, рассматривая программные реализации про-
блемы взаимоисключения, мы сделали ряд допущений относительно набо-
ра системных команд и аппаратных возможностей. Как уже говорилось
в главе 2, разработчики аппаратного обеспечения стремятся воплотить
программные механизмы в аппаратном виде для того, чтобы увеличить
производительность приложений и сократить время на их разработку,
этом разделе мы рассмотрим несколько подобных аппаратно-реализован-
ных механизмов, позволяющих решить проблему взаимоисключения.
Запрет прерываний
Ир?е°бХоДимость использования примитивов взаимоисключения в одно-
тесце соРНь1х системах в основном обусловлена тем, что приоритетное вы-
к pa?1116 позволяет нескольким потокам асинхронно получать доступ
&Ытес ляемь1м данным, что может привести к программным ошибкам.
МеРа /НеНие потоков может происходить из-за прихода прерываний от тай-
обе°Л^ЧеНИЯ сигнала истечения кванта). Поэтому простейшим спосо-
Г1^РЬ1аСПеЧ?Ния взаимоисключения является запрет (или маскирование)
Череааий‘ К сожалению, запрет прерываний накладывает ограничения
Уч*6111" опеРаЦий, которые могут выполняться программой в критиче-
vxaCTKe- ®е,аь поток, попавший в бесконечный цикл внутри критиче-
И °ДНотт!аСТКа после запрета прерываний, никогда не освободит процессор.
к РпЦессорной системе операционная система не сможет воспользо-
320
-Л
параллельное Выполнение
321
ваться прерываниями от таймера, чтобы отобрать процессор, что ,\1(j 1
привести к «зависанию» системы. В реальной жизненной ситуац ц
пример, в системах управления полетами, такое поведение системы Ст’ V
под угрозу человеческие жизни.
Запрещение прерываний в целях обеспечения взаимоисключения це 1
ходит и для многопроцессорных систем. В конце концов, их запрещЧ*
должно предотвращать приоритетное вытеснение, но в многопроцессць?111
системах в один и тот же момент времени может выполняться сразу не^^Ч
ко потоков, причем каждый на своем процессоре. Если эти потоки
синхронизированы между собой, запрет прерываний не помешает им 0
временно входить в свои критические участки. Поэтому простой запрет пк
рываний на одном из процессоров (либо на нескольких) неэффективен в
не обеспечения взаимоисключения. В целом, разработчики операциоцв/
систем стараются не запрещать прерывания для обеспечения взаимоискдцЖ
ния. Однако существует ряд ситуаций, в которых оптимальным вариант/
является запрещение прерываний для заслуживающего доверия кода, на i
полнение которого требуется небольшое количество времени. Смотрите учеб
ные примеры Linux и Windows ХР, в главах 20 и 21, соответственно, из кото,
рых вы узнаете о том, как в современных операционных системах для обеспе
чения взаимоисключения используется запрет прерываний.
Вопросы для самопроверки
1. (Да/Нет) Правда ли, что если поток войдет в бесконечный циклю
еле запрещения прерываний в многопроцессорной системе, опера-
ционная система прекратит свою работу?
2. Почему поток в однопроцессорной системе должен избегать опера
ций блокирующего ввода/вывода, если он находится внутри крити-
ческого участка, в котором запрещены прерывания?
Ответы 1) Нет. Операционная система может продолжить работ,
на другом процессоре, где прерывания не запрещены. Поток, попавШ®
в бесконечный цикл, может быть аварийно завершен либо перезаИ
щен, но при этом разделяемые данные могут оказаться в противоре^
вом состоянии, что вызовет программные ошибки. 2) Если п°
запросит блокирующую операцию ввода-вывода, операционная сисТ -а,
заблокирует поток до появления события завершения ввода/вЫ»*И
Поскольку сигналы о подобных событиях вырабатываются в резу-пь^,
аппаратных прерываний, операционная система не получит этот
нал до тех пор, пока прерывания остаются запрещенными. В 11'гоГ/
ток будет заблокирован в ожидании события, которое никогд^Л
наступит. Перед вами пример взаимоблокировки, которые обсуЖД^
ся в главе 7.
делать эту операцию атомарной (то есть неделимой).40,41 Подоб-
° яции над памятью называют также атомарными операциями чте-
оПеР фЯКацИи-записи (read-modify-write, RMW), поскольку процес-
ялЛ-1й°'Я лняет последовательность операций чтения данных из памяти,
соР вЬ1110 ции их в регистрах и записи измененного значения в память как
МоД11<^ неделимую операцию.42
дыдущих примерах программных решений проблемы взаимоис-
В поток считывал значение переменной, чтобы определить, что
КЛ1°Ч о другой поток не выполняется в своем критическом участке, затем
в11КаК°Иал в эту переменную новое значение, то есть устанавливал блоки-
зайИСЬ означающую, что поток выполняется в своем критическом
ройИУ _ Сложности обеспечения взаимоисключения для критических уча-
У43^ при программной реализации заключались в том, что поток мог под-
стК°в я приоритетному вытеснению в промежутке между операцией
ве₽веркй доступности критического участка и заданием блокировки, за-
ПР пающей другим потокам входить в свои критические участки. Коман-
П₽ testAndSet (проверить-и-установить) устраняет возможность приори-
тетного вытеснения в этот момент.
Команда testAndSet ( а, Ь ) работает следующим образом. Вначале она
читает значение логической переменной Ь, копирует его в а, а затем уста-
навливает для Ь значение true — и все это в рамках одной неделимой опе-
рации.
На рисунке 5.13 показан пример использования потоком команды
testAndSet при реализации взаимоисключения. Переменная occupied ло-
гического типа имеет значение true, когда любой из потоков находится
в своем критическом участке, и значение false в противном случае. Поток
Tj принимает решение о входе в критический участок в зависимости от
значения своей локальной логической переменной pl must Wait (первый по-
ток должен ожидать). Если эта переменная имеет значение true, поток Т]
Должен Ждать, в противном случае он имеет право войти в критичекий
Участок. Изначально Т, присваивает переменной plmustwait значение
иГре’Д Затем многократно выполняет команду testAndSet для plmustwait
овальной логической переменной occupied. Если Т2 находится вне
Ком еского Участка, переменная occupied будет иметь значение false.
ВИе да testAndSet запишет это значение в plmustwait и присвоит значе-
Резул переменной occupied. При проверке в цикле while будет получен
МенН0ЬГ false> и Ti войдет в свой критический участок. Поскольку пере-
Ти<}ескицССир^ес1 присвоено значение true, Т2 не сможет войти в свой кри-
й°токОм гр?Часток Д° тех пор, пока переменная occupied не будет сброшена
5.5.2 Команда "(est-and-Set J
На практике для решения проблемы синхронизации запрещение
ваний применяется редко, а другие методы включают использовали ун-
циальных аппаратных инструкций. Вспомним из предыдущего пр
что разделяемые данные могут быть запорчены, если система отбе Л
цессор у потока после того, как он прочитает данные из памяти, К°
де, чем он успеет обновить их в памяти. Команда test-and-set поз®
322
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
Система:
boolean occupied = false;
startThreadsО;// инициализация и запуск обоих потоков
Поток Т,:
void main()
{
boolean plmustWait = true;
while ( !done )
{
while ( plmustWait )
{
testAndSet ( plmustWait, occupied);
}
// код внутри критического участка
plmustWait = true;
occupied = false;
// код за пределами критического участка
} // окончание цикла while
} окончание потока Т1
Поток Тг:
void main()
{
boolean p2mustWait = true;
while ( !done )
{
while ( p2mustWait )
{
testAndS.et ( p2mustWait, occupied ) ;
}
// код внутри критического участка
p2mustWait = true;
occupied = false;
// код за пределами критического участка
) // окончание цикла while
} окончание потока Т2
Рис. 5.13. Использование команды testAndSet для реализации
взаимоисключения
,е параллельное Выполнение
323
Теперь предположим, что Т2 уже находится в своем критическом участ
р когда Тг уведомляет о своем желании войти в критический участок
п этом случае значение переменной occupied будет оставаться равным
Brl3e, пока Л находится внутри цикла while. Поэтому Тх будет продолжать
Дивное ожидание до тех пор, пока поток Т2 не покинет свой критический
^асток и не присвоит переменной occupied значение false. Далее коман
L testAndSet копирует значение переменной occupied в переменную
^stWait, позволяя потоку Ti войти в критический участок.
Р Хотя команда testAndSet в том виде, в котором она приводится злеет,
и гарантирует взаимоисключение, однако такой способ реализации не ис’
ключает бесконечного откладывания. Существует вероятность, что поток
при выходе из критического участка попадет в цикл, вызвав комоду
CeStAndnoe™7e’ ДРУГ°МУ П°ТОКУ ПР^СТ“и-.я шанс продолжись
свое выполнение.
Вопросы для самопроверки
1. Позволяет ли алгоритм, приведенный на рисунке 5.13, исключить
возможность бесконечного откладывания?
2. (Да/Нет) Правда ли, что команда testAndSet гарантирует взаимо-
исключение?
Ответы 1) Нет. Для того чтобы исключить бесконечное отклады-
вание, в алгоритме на рисунке 5.13 нужно добавить переменную
favoredProcess, как описано в разделе 5.4.1. 2) Нет. Команда
testAndSet сама по себе является для программистов лишь вспомога-
тельным инструментом, позволяющим упростить программное реше-
ние проблемы взаимоисключения.
5-5-3 Команда Swap
Чтобы упростить написание программного кода для выполнения син-
хронизации и повысить эффективность работы программ, во многих архи-
ватьУРЭХ пйеДУСм°трен РЯД атомарных команд. Однако необходимо учиты-
’ Что каждая архитектура поддерживает свой набор атомарных опера-
> поэтому команда testAndSet может оказаться недоступной для
вНм ИСения либо системного программиста. В этом разделе мы расскажем
Чтев Том» как другие инструкции, выполняющие атомарные операции
test»51 'м°ДиФикации-записи над памятью позволяют заменить команду
LAndSet.
3Начев И3 Распространенных операций в программах является обмен
аЛг°РитЯЛ1И меэкДУ Двумя различными переменными (возьмем, к примеру,
- быстР°й сортировки). Хотя данная концепция очень проста, для
вЬ1Со 0 завеРшения операции в большинстве языков программирова-
tenip Ког° уровня понадобится выполнить целых три команды:
а а
b % ь
^Ос teiTlp
°ЛькУ такие команды выполняются регулярно, во многих архитек-
’ОГЦд Решениях предусмотрена специальная инструкция swap, позво-
Двум переменным обмениваться значениями друг с другом.
324
Команда swap (a, b) выполняется следующим образом. Сначала н0 I
менный регистр загружается переменная ь, которая может принимать
чение true или false. Затем в переменную Ь копируется значение перр^Ч
ной а, а в переменную а — значение из временного регистра.
На рисунке 5.14 показано, каким образом поток использует ком '
swap для обеспечения взаимоисключения. Как и на рисунке 5.13, здесщл
пользуется глобальная логическая переменная occupied, значение ко-ц?!
истинно, если поток находится внутри своего критического участка. Ц *4
Ti принимает решение о входе в критический участок в зависимости от^
чения локальной логической переменной plmustwait. Аналогично, потпь. J
принимает решение о входе в критический участок в зависимости от ЗВа г
ния логической переменной p2mustWait. Обратите внимание, что в данв
алгоритме инструкция swap взаимозаменяема с командой testAndSet. Едв
ственное различие между программными фрагментами, представленный
на рисунках 5.13 и 5.14, состоит в том, что в коде на рисунке 5.14 мы сод^
ли условия «быстрого входа» в критический участок, позволяющие войц
в него, выполнив на одну команду меньше (выполнив проверку условия
цикла после команды swap).
1 Система:
2
3 boolean occupied = false;
4
5 startThreadsО;// инициализация и запуск обоих потоков
6
7 Поток Тг:
8
9 void main ()
10 {
11 boolean plmustwait = true;
12
13 while ( '.done )
14 {
15 do
16 {
17 swap ( plmustwait, occupied);
18 } while ( plmustwait )
13
20 // код внутри критического участка
21
22 pimustWait =* true;
23 occupied = false;
24
25 // код за пределами критического участка
26
27 } // окончание цикла while
28
29 } окончание потока Т1
30
31 Лоток Тг:
32
33 void main()
34 { .
35 boolean p2mustWait = true;
36
Pae. 5.14. Использование команды swap для реализации взаимоисключенИ
(часть 1 из 2)
крамольное Выполнение
325
38
39
40
41
42
43
44
45
46
4?
48
49
50
51
52
53
while
{
( !done )
swap ( p2mustWait, occupied );
while ( p2mustwait )
код внутри критического участка
p2mustWait = true;
occupied = false;
// кол за Пределами критического участка
// окончание цикла while
>
окончание потока Тг
{
}
}
4/4 Использование команды swap для реализации взаимоисключения
(Ъь2из2)
Вопросы для самопроверки
1. Почему в системах чаще встречается реализация команды swap,
чем testAndSet?
Ответы 1) Во многих алгоритмах требуется выполнять тот или
иной вид сортировки, поэтому аппаратно-реализованная команда
swap чрезвычайно полезна для самых разнообразных алгоритмов, а не
только для алгоритма обеспечения взаимоисключения.
Семафоры
Еще одним механизмом реализации взаимоисключения в системе являются
мафоры (semaphore), описанные Дейкстрой в своей статье о взаимодействии по-
3аш^тельнЬ1Х процессов (см. «Биография: Эдсгер Дейкстра»).43 Семафор — это
^^Щенная переменная (protected variable), значение которой после начальной
опевя]Си^13а1^ИИ МОЖно опрашивать и менять только при помощи специальных
содрав и К [Примечание: Обозначения операций Р и V представляют собой
Что озня1014 голлаВДСкого словаproberen, что означает «проверять» и verhogen,
°ПеРацие- *пРиРаЩивать».] Поток вызывает операцию Р (называемую также
И К1ЗДания (wait)), когда он намеревается войти в свой критический
0j,0eeineBltO^ePaa^IK> (называемую также операцией сигнализации (signal) или
CTfta’ Пепр Когда У него возникает необходимость выйти из критического уча-
использованием семафора в целях синхронизации его необходимо
К°11ааЬ1Вак)0ВаТЬ' Инициализация задает значение защищенной переменной,
ЧТ° 1Ш один поток не вьпюлняется внутри критического участка.
йуД ^оздается очередь ссылок на защищенные семафором потоки, ожи-
вои критические участки. Учтите, что операции Р и V представ-
•^^П°йсцп?*л:1'0 лишь абстракции, инкапсулирующие в себе детали реализации
ecTB<jbl ЧеНия. Эти операции могут быть применены к системе с любым ко-
83аимодействующих между собой потоков.
326
Биографические заметки
Эдсгер В. Дейкстра
Одним из самых знаменитых и наиболее
плодовитых исследователей своего времени
можно назвать Эдсгера Вайба Дейкстру. Он
родился в 1930 году в Нидерландах, здесь же,
в Амстердамском университете, получил сте-
пень доктора философии компьютерных наук.
Дейкстра работал программистом в Матема-
тическом центре в Амстердаме, затем профес-
сором математики в Эйндховенском техноло-
гическом институте, а позднее — профессором
компьютерных наук в Техасском университете
в Остине. Дейстра умер в 2002 году."14
Вероятно, самым известным вкладом, сде-
ланным Дейкстрой в развитие компьютерных
наук, стала статья, послужившая толчком к ре-
волюции в области структурного программи-
рования «GOTO Considered Harmful» («О вреде
конструкции GOTO»),45 которая была опубли-
кована в журнале Communications of the ACM
в марте 1968. Дейкстра утверждал, что опера-
тор GOTO в случае неаккуратного использова-
ния приводит к возникновению так называе-
мого «кода спагетти» — запутанных программ,
проследить ход работы которых практически
невозможно.46
Главными вкладами Дейкстры в развитие
архитектуры операционных систем стали: изо-
бретение конструкции семафоров (первого
объекта, специально придуманного для приме-
нения в алгоритмах взаимоисключения) и мно-
гоуровневая архитектура программного обес-
печения (усовершенствование старого моно-
литного подхода, позволившее группировать
компоненты со схожей функциональностью по
отдельным уровням). Обе концепции были во-
площены в жизнь в многозадачной системе
THE (THE multiprogramming system) — ОС, раз-
работанной специально для компьютеров Dutch
EL Х8.47 Позднее он расширил концепцию мно-
гоуровневой системы для создания операцион-
ной системы общего назначения, в которой усо-
вершенствованная многоуровневая архитектура
могла бы использоваться для написания о
ЦИОННОЙ системы ДЛЯ любого КОМПЬК*'
В своем описании системы THE он излагает
цепцию использования семафоров в целях
хронизации. Известность Дейкстре при,?*1'
также формулировка проблемы синхрон^
ции «обедающих философов», иллюстрипи!
щей нюансы параллельного программна
ния (см. раздел 7.4.2).
В 1972 году Дейкстра получил премию
Тьюринга - наиболее престижную награду
в сфере компьютерных наук - за разработку
языка программирования ALGOL, в котором
впервые была представлена блочная струпу,
ра (для определения областей видимости пе
ременных и оформления управляющих струк-
тур) и другие концепции, используемые
в большинстве современных языков програм-
мирования.49-505' Еще одним достижением!
Дейкстры стал названный его именем алго-
ритм Дейкстры (Dijkstra’s Algorithm), пред-
назначенный для поиска кратчайшего nyw
между двумя узлами взвешенного графа.
Дейстра являлся автором более 1300
статей, преимущественно в виде коротка
эссе, написанных в его особом стиле (n°J
названием EWD — по первым буквам
фамилии). Эти работы отсканированы,
талогизированы и в настоящее времяД
тупны и в электронном виде.57 Одни из
были написаны со всей серьезностью-
гие же, например «Как можно гов
правду, если она может навредить^
с изрядной долей юмора. В одной из
статей — «Конецкомпьютерныхнау*- 'ис-
писанной в 2000 году - он критиков^,
чество современного программного
печения, заявляя о необходимости
дения большего числа те°РеТк1терХ|
исследований в области компьЮ
наук в целях совершенствования
концепций проектирования.54
иирмлельное Выполнение
327
I реализация взаимоисключения с помощью семафоров
5'^' йСунке 5.15 показана реализация взаимоисключения при помощи
На Р в Система инициализирует семафор occupied, записывая в него 1.
се^^емафоР называют бинарным или двоичным (binary semaphore). За-
ТаК0Й я нем значение 1 говорит о том, что критический участок доступен
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
Система:
// создание семафора, установка его значения равным 1
Semaphore occupied = new Semaphored);
startThreads(); // инициализация и запуск обоих потоков
Поток Тх .
void main()
while ( !done )
{
p( occupied ); // ожидание
// код внутри критического участка
V( occupied ); // сигнал
// код за пределами критического участка
} // окончание цикла while
) окончание потока ТХ
Рис. 5.15. Взаимоисключение с использованием семафоров
В программе на рисунке 5.15 операции Р и V используются вместо п₽и
митивов входа и выхода взаимоисключения, соответственно (см. р
Дел 5.2.3). Когда поток сообщает о своем намерении войти в критический
Участок, защищенный семафором S, операция Р над семафором записыва-
йся как P(S) и выполняется следующим образом.
If s > о
s = s - 1
Else
взывающий поток помещается в очередь ждущих потоков семафора
одЛ°СКолькУ наш семафор был инициализирован значением 1, только
Пот°к сможет войти в критический участок в любой момент времеш
йЫм о поток вызывает операцию Р, значение семафора становится рав
Дет Если же другой поток запрашивает выполнение операции , он У
Г1о°Кир0ван-
ЧЗЬ1вЛе Того как поток закончит свою работу в критическом участке, он
ает операцию V(S), выполняемую следующим образом:
и более потоков ожидают семафора S
£iSe °6новить работу следующего потока из очереди ждущих
S -
" s + 1
328
Таким образом, если в очереди ожидания семафора находится хот
один поток, выполнение перейдет к следующему потоку, а уж какой и»
но поток будет выбран на роль следующего, зависит от конкретной ре
зации семафора. В противном случае значение семафора S увеличя
на 1, что позволит войти в свой критический участок еще одному пото^^
Корректная реализация семафоров требует, чтобы операции Р и V «Л'
лись неделимыми. Кроме того, если одновременно Несколько потоков зап I
сят выполнения операции P(S), необходимо гарантировать, что тол?°'|
один поток сможет продолжить работу. Остальным потокам придется по
ждать, однако операции Р и V обязаны исключать ситуацию бесконечней
откладывания. Например, если поток блокируется из-за ожидания семал^
ра, система может выделить ему место в очереди семафора. Если другой я
ток в это время вызовет операцию Р, система сможет выбрать один из Пот0\
ков в очереди, позволив ему продолжить работу. Мы будем предполагать
что очередь потоков, заблокированных из-за ожидания семафора, обслужи
вается в соответствии с дисциплиной «первый-пришел-первый-ушел» (Что
бы исключить бесконечное откладывание).
Вопросы для самопроверки
1. Что произойдет, если поток вызовет операцию V, не вызвав перед
этим операцию Р?
2. Что произойдет, если при обслуживании заблокированных семафо-
ром потоков не будет соблюдаться дисциплина «первый-при-
шел-первый-ушел»? ]
Ответы 1) Один из возможных сценариев: начальное значение се-
мафора 1, при этом ни один поток не находится в состоянии ожида-
ния. Вызов операции V приведет к тому, что значение семафора
увеличится до 2. Теперь два потока смогут одновременно войти в своя
критические участки с помощью операции Р. 2) Поток может оказать-
ся в ситуации бесконечного откладывания.
появлений о
1Н С иимищол, —
Т2 вызывает опер
5.6.2 Синхронизация потоков с помощью семафоров
В предыдущем разделе мы показали, как использовать семафор ДлЯ
щиты доступа к критическому участку потока. Семафоры также могут У
меняться в целях синхронизации двух и более параллельных потоков » л
ду собой. Предположим, что первый поток, Т17 хочет знать о 1-
ределейного события. При этом другой поток, Tg, в состоянии обнарУ л
появление этого события. Чтобы синхронизировать эти два потока, по
выполняет некоторые подготовительные команды, затем запрашивает^
рацию Р для семафора, который был инициализирован с помощью
значения, блокируя поток Тр В конце концов, поток 7 2
V для того, чтобы уведомить о наступлении данного события другие
Благодаря этому поток Tj получает возможность продолжить работУ
время как значение семафора по-прежнему остается равным О).
Этот механизм позволяет достичь успеха даже тогда, когда поток ^-00
руживает появление события и оповещает поток Ti с помощью опер 3Л
прежде, чем тот войдет в состояние ожидания с помощью операций
чение семафора увеличится с О до 1, поэтому, когда поток вызовет । ,
йврамельное Выполнение
329
ячение семафора просто уменьшится с 1 до О, и поток Тх продел-
аю ?’ работу, минуя состояние ожидания.
сВО1^ним примером синхронизации потоков является отношение «про-
gnie ° .„потребитель», рассматриваемое в разделе 5.2.1. На рисунке 5.16
ЛЗвоДйТеаЛГОрИтм реализации отношения производитель-потребитель с по-
[ЮКа3аНсемафоров. Оба потока имеют доступ к разделяемой переменной
мо1йь1° 1ие. Производитель генерирует значения и записывает их в эту пе-
stared ® а потребитель опрашивает ее и обрабатывает считываемые значе-
ре”е1?Уб^му потоку может понадобиться ожидать появления определенных
J чтобы закончить выполнение поставленных перед ним задач. По-
собьгг необходимо подождать, пока производитель сгенерирует значе-
требй чем семафор просигнализирует с помощью valueProduced); произво-
нИб ль вынужден ждать, пока не будет считано предыдущее значение (по-
ДИебитель просигнализирует об этом с помощью семафора valueConsumed).
1 Система;
2 // семафоры, Синхронизирующие доступ к sharedValue
3 semaphore valueProduced - new Semaphore(0);
4 Semaphore valueCor.ciuned = new Semaphore(1);
5 int sharedValue; // разделяемая переменная производителя-потребителя
6
7 startThreads (); // инициализация и запуск обоих потоков
8
9 Поток производителя Producer:
10
11 void main ()
12 {
int nextValueProduced; // хранилище генерируемого значения
14
15 While ( idone )
16 {
nextValueProduced = generateTheValue(); // генерация значения
₽( valueConsumed ) ; // ожидаем, пока значение не будет считано
sharedValue = nextValueProduced; // критический участок
v ( valueProduced ); II сигнализируем о создании значения
22 I / ,
2з 1 // окончание цикла while
24 . „
25 ' окончание потока Producer
27 Поток потребителя Consumer:
28 . .
29 '°id main()
30 * .
nt nextValueConsumed; I/ хранилище полученного значения
7hile ( !dOnG )
34 {
valueProduced ); //ждем, пока значение не будет сгенерировано
nextValueConsumed ~ sharedValue; // критический участок
h ( valueConsumed ); // сигнализируем о считывании значения
Л. PtocessTheValue( nextValueConsumed ); // обработка значения
^0 1 / /
4j ' окончание цикла while
°НЧание потока Consumer
’ *«б.
®ЧлИзация отношения производитель-потребитель с помощью семафоров
330
Программный код каждого потока должен быть понятен. Производи
генерирует новое значение (строка 17), затем ожидает семафора valUe '
sumed (строка 18). Начальное значение семафора 1 (строка 4), поэтому
водитель записывает новое значение nextValueProduced в разделяемую п
менную sharedValue (строка 19). Затем производитель сигнализирует о ак I
ботке значения с помощью valueProduced (строка 20). Потребитель ожиМ
семафора (строка 34), и, когда его уведомит об этом производитель с гт1!
щью сигнала valueProduced (строка 20), потребитель скопирует даннь1й
разделяемой переменной sharedValue в локальную переменную nextVaj
Consumed (строка 35). Далее потребитель сигнализирует об этом при
семафора valueConsumed (строка 36), что позволит производителю щщ?^
пить к выработке нового значения, после чего все начинается с начала. Са/Я
форы обеспечивают взаимоисключающий доступ к разделяемой перемещу 1
sharedValue, а также чередование работы потоков, так что считывают»» I
процесс потребителя будет всегда считывать именно то значение, KoTopdl
было сформировано до этого производителем.
Вопросы для самопроверки I
1. (Да/Нет). Правда ли, что в любой момент времени поток может щ.
ходиться в очереди ожидания только одного семафора?
2. Что произойдет, если в ходе инициализации переменной valuePro-
duced будет присвоен не 0, а 1?
Ответы 1) Да. При помещении в очередь ожидания семафора по
ток блокируется, будучи не в состоянии выполнять программный кед,
из-за которого он мог бы оказаться в очереди ожидания другого сема-
фора. 2) Возможно считывание значения потребителем до того, как
оно будет записано в разделяемую переменную производителем.
5.63 Считающие семафоры
Считающие семафоры (counting semaphore), называемые также o6fflf
ми семафорами (general semaphore), могут принимать неотрицательна j
целые значения, как правило, больше единицы. Считающие семафоры
бенно полезны в случае, если некоторый ресурс выделяется из пула ИД 1
тичных ресурсов. При инициализации подобного семафора в его счетч j
указывается количество ресурсов в пуле. Каждая операция Р выаЫ^И
уменьшение значения счетчика семафора на 1, показывая, что некоторая
процессу для использования выделен один ресурс из пула. Каждая о I
ция V вызывает увеличение значения счетчика семафора на 1, показ
что процесс возвратил в пул ресурс и этот ресурс может быть выделе
перь другому процессу. Если делается попытка выполнить операцию
гда в счетчике семафора уже нуль, то соответствующему процессу 11лл
ся ждать момента, пока в пул не будет возвращен освободившийся Р
т.е. пока не будет выполнена операция V.
Вопросы для самопроверки
1. Расскажите, как можно реализовать бинарный семафор 1?а
считающего семафора. ।
2. (Да/Нет) Правда ли, что операция V для считающего семаф v
гда увеличивает значение этого семафора на единицу?
м параллельное Выполнение
331
Ответы i) Для этого достаточно задать в качестве начального зна-
чения считающего семафора единицу. 2) Нет. Если один и более пото-
ков находятся в состоянии ожидания, операция V позволит одному из
потоков возобновить выполнение, не увеличивая значение счетчика.
7‘v’' „ могут быть реализованы в пользовательских приложениях
Семаф дмея в СВоем распоряжении алгоритм Деккера либо машинные
цдй я,дРе’и testAndSet и swap, можно легко реализовать операции Р и V
лрстрУ активного ожидания. Однако активное ожидание приводит
с п0Р1 ной трате процессорных циклов, которым в многозадачной систе-
к Йа°жно было бы найти лучшее применение. В главе 3 вы изучили меха-
ме М°перехода из состояния в состояние. Мы обратили ваше внимание на
ЯИЗчТо потоки, запрашивающие операции ввода/вывода добровольно бло-
т°’ гют сами себя до момента завершения операции ввода/вывода. Блоки-
киР’ поток не может находиться в состоянии активного ожидания —
пованныи
он остается в спящем состоянии до тех пор, пока система не разбудит его,
после чего он сможет перейти в список готовых процессов.
Операции над семафорами могут быть реализованы в ядре путем блоки-
рования ждущих потоков, чтобы исключить активное ожидание.55 Сема-
фор представлен защищенным значением и очередью, внутри которой по-
токи ожидают V операций. Когда поток пытается выполнить операцию Р
над семафором, который равен нулю, поток освобождает процессор и бло-
кирует себя в ожидании операции V над семафором. Система помещает
значение в очередь потоков, ожидающих семафора. (Мы считаем, что жду-
щие потоки обслуживаются в соответствии с принципом первый-при-
шел-первый-ушел. Применение других дисциплин находится на стадии
изучения.)56 После этого система может выделить процессор следующему
потоку из списка готовых. Любой ждущий семафора поток постепенно
поднимается в начало очереди. Последующая операция V удаляет поток из
Реди семафора и помещает его в список готовых потоков.57
и азумеется, для потоков, одновременно запрашивающих выполнение Р
чаю1°П^>а^И^1 наД семаФ°Ром> ядро обязано гарантировать взаимоисклю-
РацИи р Доступ к семафору. В однопроцессорной системе, поскольку опе-
чить п И коРоткие, атомарность (неделимость) операций можно обеспе-
Чае дпу7г^М зацРещения прерываний на время их выполнения. В этом слу-
аьПлеуп Й пот°к не сможет отобрать процессор до полного завершения
^Рибег^^^Утых операций (когда снова будут включены прерывания).
^РИвестл К 3апРетУ прерываний следует осторожно, поскольку это может
СНИЖению производительности или даже возникновению взаи-
з ^аДре°В°К ^СМ' * Поучительные истории: Нечеткие требования»).
к 6ЗтьСя М11ог°процессорной системы, один из процессоров может исполь-
Из п Я ТОг°» чтоб управлять списком готовых потоков и определять,
R реая °Ц’еСсоров за выполнение какого потока отвечает.58 Другой под-
>ЛьДоСтЛ3ации яДРа многопроцессорной системы подразумевает кон-
^ОКо ^>9° ПОМОщью активного ожидания) разделяемого списка гото-
>зой ' Ядро распределенной операционной системы также может
ь отдельный процессор для управления списком готовых про-
332
цессов, но, как правило, каждый процессор управляет своим собств<
списком готовых потоков и по сути, имеет свое собственное ядро.6°.щ 6
По мере того как поток передается на выполнение от одного процес
к другому в распределенной системе, ответственность за управление
потоком также переходит от одного ядра к другому.
Вопросы для самопроверки
1. Какое главное преимущество реализации семафоров в ядре?
2. Рассмотрим семафор, позволяющий потоку с наивысшим Щ)И
тетом выполняться во время вызова операции V. К каким поте»®*'
альным проблемам может привести такая конструкция?
Ответы 1) Семафоры позволяют избежать режима активного ом,
Дания. Ядро приостановит выполнение потока, запрашивающего о
рацию Р, если текущее значение семафора равно О, и возвратит °8
•в очередь готовых потоков после вызова операции V. Это позволяет пл
высить производительность. 2) Высокоприоритетные потоки
привести к бесконечному откладыванию потоков в очереди ожидави
семафора.
Поучительные истории
Нечеткие требования
В первые годы своей работы в компью-
терной отрасли, Харви Дейтел работал
в компании, которая занималась разработ-
кой программного обеспечения на заказ.
Один из клиентов — представитель страхо-
вой компании - сформулировал к програм-
ме следующие требования: программа
должна выводить список «пенсионеров из
Коннектикута, которые умерли в этом году
в алфавитном порядке». Такое утверждение
резало слух, так как пенсионеры, конечно,
редко умирают в алфавитном порядке. Дей-
Урок для разработчиков операционных систем: перед тем как приступать к рз3Р~\1
сложного элемента программного обеспечения, например важного компонента оГ1у
ной системы, убедитесь, что требования к данному компоненту сформулированы а
четко. Вам необходимо не просто «правильно решить проблему», в первую очередь
но «решить правильную проблему». / .
тел не мог связаться с клиентом в течение
нескольких дней, поэтому он написал пр
грамму так, как он считал, она должна ра-
ботать - программа выводила список в«1
пенсионеров из Коннектикута, умер^1®
в текущем году и отсортированным по3
фавиту — именно то, чего хотел клиентл
озаглавив отчет «пенсионеры, УмеР^
в алфавитном порядке». Это научил I
ента в дальнейшем более ответств
подходить к формулировке трео° I
к программным продуктам.
параллельное Выполнение
333
^-реерр™
.. _com/documents/s=924/ddj9801g/9801.htm
WV,W аие методов реализации взаимоисключения на Java. Здесь рассматрива-
ОдИСа ка реализации взаимоисключения между потоками, как в общих чер-
еТсЯ и применительно к Java.
1вХ’ s.utexas.edu/users/EWD/
wWW ь находятся электронные копии Статей, написанных Дейкстрой, включая
bvK) работу по концепции семафоров.
gfO ПаР®У
osdata.com/topic/language/asm/coproc.htm
сание ряда команд машинных языков, созданных специально для поддерж-
4, параллелизма, таких как test-and-set и swap.
eloper.j ava.sun.com/developer/Books/performance2/chap3.pdf
Глава из книги по многопоточному и сетевому программированию в Sun. Эта
посвящена вопросам взаимоисключения в Java. В ней рассматриваются не-
Глторые проблемы, избежать которых помогает взаимоисключение, а также спосо-
бы реализации взаимоисключения.
www. teamten.сот/lawrence/242.paper/2 42.paper.html
Анализ алгоритмов взаимоисключения, реализуемых операционной системой,
запущенной в многопроцессорной среде.
Итоги
Потоки называются параллельными, если они существуют в системе одновре-
менно. Два параллельных потока могут выполняться совершенно независимо друг
от друга либо взаимодействовать между собой. Процессы или потоки называются
асинхронными, если они выполняются независимо друг от друга, но при этом им
требуется периодически синхронизироваться и взаимодействовать.
Если один поток считывает данные, записываемые другим потоком, либо если
®a потока одновременно осуществляют изменение одних и тех же данных, это мо-
ет привести к непредсказуемым последствиям. Данную проблему можно решить,
ЕслД0СТаВИВ каждомУ потоку монопольный доступ к разделяемой переменной,
пр Один поток намерен модифицировать значение разделяемой переменной, то
д03к е потоки, которых хотят выполнить подобную операцию, должны будут по-
чит пяцЬ' Это и называется взаимоисключением. Когда выполняемый поток закон-
ной цп ОТу с Разделяемой переменной, система разрешит одному из ждущих пото-
Д°ступ дол>Кить свою работу. Таким образом обеспечивается последовательный
К одцИмК ^азделяемой переменной. В этом случае потоки не смогут обращаться
В ОтиИ тем же разделяемым данным одновременно.
Дь1е и за ОЦ1ении производитель-потребитель, поток производителя генерирует дан-
и исывает их в разделяемый объект, тогда как поток потребителя считывает
СДие оцщб ЭТ0Г0 объекта. На примере этого отношения мы показали вам, как логиче-
д e>ttAy По Ки могУт привести к потере синхронизации доступа к разделяемым данным
ель ц0 оками — например, данные могут быть потеряны в случае, если произво-
д^Чееть ^ecTIir новые данные в разделяемый буфер прежде, чем потребитель успеет
Л^)111Роваи11НЬ1е’ записанные ранее. И, наоборот, данные могут быть по ошибке про-
За Ь1’ если потребитель повторно считает их из буфера до того, как произво-
®гцет в него новую информацию. Если такая логика будет применяться
Ч11,бКц ад6’ ИСпользуемой, например, в центре управления полетами, то подобные
[ гут привести к катастрофическим последствиям.
, параллельное выполнение
33$
334
-
Взаимоисключение должно обеспечиваться только в случае, когда потоки
щаются к разделяемым данным, которые могут изменяться. Если потоки вьщ I
ют операции, не вызывающие конфликтов между собой (например, чтение дац^Ч
система позволит потокам выполняться параллельно друг с другом. Если поте 41
ращается к разделяемым данным, доступным для изменения, то говорят, что с,
ходится в своем критическом участке (критической области). Чтобы предо'п
возникновение ошибок, подобных рассмотренным нами ранее, когда один из
ков находится в своем критическом участке, для всех остальных потоков Во Boio.U
ность вхождения в критические участки должна быть исключена. Если один it1' I
попытается войти в критический участок в то время, как другой поток нахол'т11
внутри своего критического участка, первому потоку придется ожидать до тех
пока второй поток не завершит работу внутри критического участка. Как только^'
ток выйдет из своего критического участка, один из ждущих потоков сможет во^0'
и начать работу внутри своего критического участка. Если поток, находящц^
в своем критическом участке, завершается, либо естественным, либо аварийны^! В
тем, то операционная система при выполнении служебных операций заверще^ I
потоков должна отменить режим взаимоисключения, с тем чтобы другие потоки ц I
лучили возможность входить в свои критические участки.
Мы рассмотрели примитивы входа и выхода взаимоисключения (enterMutu I
alExlusion () и exitMutualExlusion () ), включающие в себя фундаментальные one
рации, необходимые для реализации взаимоисключения. Эти примитивы должны I
соответствовать следующим ограничениям: каждая команда на машинном языке
должна являться неделимой; не должно высказываться никаких предп ложений
касательно относительной скорости асинхронных параллельных потоков; поток, I
выполняющий команды вне критического участка не должен мешать другим пото-
кам входить в свои критические участки; поток не должен попасть в ситуацию бес-
конечного откладывания из-за входа в свой критический участок.
Изящная программная реализация примитивов взаимоисключения была впер-
вые предложена Деккером. Мы изучили алгоритм Деккера, усовершенствованный |
Дейкстрой, который гарантирует взаимоисключение, исключая проблемы актив-
ного ожидания, пошаговой синхронизации, взаимоблокировок и бесконечного от-
кладывания. Затем мы обсудили более простые и эффективные алгоритмы, пред-
ложенные Питерсоном и Лэмпортом. Алгоритм кондитера или алгоритм Лэмпор-
та, предназначенный для распределенных систем, демонстрирует программное
решение проблемы взаимоисключения для п потоков, которое может исполнив
ваться в многопроцессорных системах, не требуя при этом, чтобы вышеупомянЯ
тые операции являлись атомарными (неделимыми). ДI
Чтобы помочь в решении проблемы взаимоисключения, используются неК°ч{.В
рые аппаратные механизмы. Простейшим способом обеспечения взаимоискл I
ния является запрещение (или маскирование) прерываний. Такое решение bi
рывает за счет своей простоты; однако, запрет прерываний может привести к~ 1
строфическим последствиям в случае некорректного поведения потока в
критического участка. Более того, запрещение прерываний ничего не даст в м
процессорной системе. Были разработаны и другие способы аппаратной п0,Я
ки, включая использование специальных аппаратных инструкций. НаличИв^^И
ратно-реализованных операций test-and-set и swap позволяет потокам вЫП
атомарные операции чтения-модификации-записи над памятью. Эти кома Д
дотвращают возможность приоритетного вытеснения между моментом oBl’ c(0f
ния команды, определяющей возможность входа потока в критический I
и командой установки переменной, запрещающей вход в критический учас
других потоков. кОцС1
Альтернативным механизмом реализации взаимоисключения является р 1
ция семафоров, сформулированная Дейкстрой. Семафор содержит защИ® лрбйуж ъ
лочисленное значение, которое после инициализации может опрашиваться -i
меняться только путем вызова одной из двух операций: Р или V. Поток в I
операцию Р (называемую также операцией ожидания), когда он намере
_ этический участок; поток вызывает операцию V (называемую также опера-
роЙ ^^^дизации или оповещения) в тот момент, когда он хочет выйти из крити-
₽с^сцг«^а7 Перед тем как приступить к использованию семафора в целях син-
^Kof0 ни его необходимо инициализировать. При инициализации в защищен-
врОай3аЯменные записываются значения, показывающие, что ни один поток не
°ePgTCfl в своем критическом участке. Считающий семафор (который иногда
выПоЛНЯ общим семафором) может принимать значения, большие единицы. Счи-
раэ^^демафоры особенно полезны в случае, если некоторый ресурс выделяется из
таЮ1Дйе „тИчных ресурсов. Семафоры могут быть реализованы в пользовательских
пуЛа иДрНИЯХ либо в ядре. Располагая алгоритмом Деккера или аппаратной реали-
манд test-and-set и swap, несложно реализовать операции Р и Vс исполь-
заДие м активного ожидания. Однако активное ожидание означает напрасную тра-
3оваН1,е
гессорных циклов, которым в многозадачной системе нашлось бы лучшее
ту нР неНие. Операции над семафорами могут быть также реализованы в ядре без
СР” м и активного ожидания, путем блокировки ждущих потоков.
Ключевые термины
gwap_команда для обмена значениями двух переменных. Наличие данной ко-
манды упрощает реализацию взаимоисключения, исключая возможность при-
оритетного вытеснения потока во время выполнения операции чтения-модифи-
кации-записи памяти.
test-and-set — аппаратно-реализуемая команда, выполняющая в виде одной неде-
лимой операции проверку значения логической переменной и установку значе-
ния в true. Наличие данной команды упрощает реализацию взаимоисключе-
ния, исключая возможность приоритетного вытеснения потока во время выпол-
нения операции чтения-модификации-записи памяти.
THE Multiprogramming System — первая операционная система с многоуровне-
вой архитектурой, созданная Эдсгером Дейкстрой.
Активное ожидание (busy waiting) — режим ожидания, пребывая в котором поток
постоянно проверяет условия, позволяющие ему продолжить работу. Во время
Ад^КТИВного ожидания поток занимает процессорные циклы.
“ритм быстрого взаимоисключения (fast mutual exclusion algorithm) — pea-
зан'ИЯ взаимоисключения, позволяющая избежать накладных расходов, свя-
Яа ых с выполнением потоком множества повторных проверок, в случае если
Гори од ® критический участок не претендует ни один другой поток. Первый ал-
Аягп быстрого взаимоисключения был предложен Лампортом.
кРатча“ ^ейкстРы (Dijkstra’s Algorithm) — эффективный алгоритм поиска
Ад^^^кшего пути во взвешенном графе.
Kji,°4№ ^еккеРа (Dekker’s Algorithm) — алгоритм, обеспечивающий взаимоис-
И взаи ® ДЛя Двух потоков и предотвращающий бесконечное откладывание
облокировки.
^ЭМПоРта или Алгоритм кондитера (Lamport’s Bakery Algorithm) —
а Взаимоисключения для п потоков, основанный на присвоении специ-
С^хРо *Н°МеРКОв* процессам.
^op*”Ые паРаллельные потоки (asynchronous concurrent threads) — потоки,
ДруГа с^1Чествуют в системе одновременно и выполняются независимо друг
’ н° Периодически должны синхронизироваться и взаимодействовать.
<а °перация (atomic operation) — операция, непрерывно выполняемая от
140 конца.
откладывание (indefinite postponement) — ситуация, когда поток
Появления события, которое может никогда не произойти.
336
4j
Блокировка взаимоисключения (mutual exclusion lock) — переменная, ц0}, I
вающая, что определенный поток в данный момент времени находится в
критическом участке. Если блокировка показывает, что поток выпол1}°4
внутри критического участка, другим потокам запрещается входить в их
венные критические участки.
Взаимоблокировка (deadlock) — состояние потока, когда он не в состоянии
должить работу по причине ожидания события, которое никогда не произой^-
Взаимоисключение (mutual exclusion) — ограничение, в соответствии с кото
выполнение одного потока внутри своего критического участка исключае Ч
полнение других потоков внутри критических участков. Взаимоисключ 8ь*-
жизненно важно для обеспечения корректной работы нескольких потоков
ращающихся к одним и тем же разделяемым данным с целью их модификав °®"
Двоичный семафор (binary semaphore) -— семафор, который не может принц»,
значения, большие единицы. Обычно двоичные семафоры используются
предоставления доступа к отдельным ресурсам.
Жесткая (пошаговая) синхронизация (lockstep synchronization) — ситуац»
в которой асинхронные потоки выполняются строго поочередно.
Запрещение прерываний (disable interrupts) — выполняется в случае, когда необ.
ходимо временно игнорировать прерывания в однопроцессорной системе ддя
обеспечения атомарности операций внутри критического участка.
Защищенная переменная (protected variable) — целочисленное значение, в кото-
ром хранится состояние семафора. Опросить либо изменить это значение можно
только с помощью операций Р и V.
Критическая область (critical region) — см. Критический участок.
Критический участок (critical section) — фрагмент кода, выполняющий операции
над разделяемым ресурсом (например, запись значения в разделяемую перемен-
ную). Чтобы добиться корректной работы программы, в своем критическом уча-
стке в любой момент времени должен находиться только один поток.
Неделимая операция (indivisible operation) — см. Атомарная операция.
Общий семафор (general semaphore) — см. Считающий семафор.
Операция У (V operation) — операция, позволяющая увеличивать значение сема-
фора, если внутри него отсутствуют какие-либо ждущие потоки. Если в состоя-
нии ожидания находится несколько потоков, операция V разбудит один из них-
Операция ожидания (wait) — если значение семафора равно 0, данная операй^
блокирует вызывающий поток. Если же значение семафора больше 0, ^aH“L
операция уменьшает значение семафора на единицу и разрешает вызываю*®
потоку продолжить работу. Операцию ожидания также называют Р операДИ
Операция Р (Р operation) — одна из двух операций, позволяющих менять з1
ние семафора. Если значение семафора равно 0, операция Р блокирует де-
вающий поток. Если значение переменной больше 0, операция уменьшит
ние переменной на 1 и позволит вызывающему потоку продолжить раб
Оповещение — см. Сигнализация.
Отношение производитель-потребитель (producer/consumer relationship) /
модействие между потоками, генерирующими данные (производителям > #
токами, считывающими эти данные (потребителями), которое иллюстриг
которые нюансы асинхронной параллельной работы программ.
Параллельный процесс/поток (concurrent) — определение, характер ^(0?
процесс или поток, существующий в системе одновременно с другим пР 1
или потоком.
Последовательный доступ (serialize) — разновидность доступа к раздеЛЯ®
ременной, когда только один поток может одновременно получать д0< ’
деляемой переменной; другой поток сможет опросить значение пер i
только после того, как с ней закончит работать первый поток.
/дрвллельное Выпелнвние
337
требителя (consumer thread) — поток, основным назначением которого
^оК ПтсЯ чтение или обработка данных из разделяемого объекта.
црЛ3 оизводителя (producer thread) — поток, который создает данные и запи-
их в разделяемый объект.
С*1®36 еЯЪ (consumer) — приложение, осуществляющее чтение данных из разде-
0оТребИ*о объекта и их обработку.
лЯе^г«вЫ взаимоисключения (mutual exclusion primitives) — фундаментальные опе-
црИ»*,ггИЯнеобходимые для реализации взаимоисключения: enterMutualExclusion ()
P^tMutualExclusion ().
0 6 питель (producer) — поток или процесс, который генерирует данные и за-
flP^fJaeT их в разделяемый объект.
пНСЫВа
(semaphore) — абстракция, используемая при реализации взаимоисклю-
Семаф V j* которОй применяются две атомарные операции (Р и V) для доступа к за-
46 тленным переменным, определяющим, могут ли потоки входить в свои кри-
тические участки.
„гттализация (signal) — операция над семафором, которая увеличивает значение
^переменной в семафоре. Если у данного семафора ждущие потоки находятся
в спящем режиме, операция сигнализации (оповещения) будит один из этих по-
токов, позволяя ему продолжить работу, и увеличивает значение семафора на 1.
Служебные операции завершения потоков (termination housekeeping) — в алго-
ритмах взаимоисключения служебные операции, выполняемые операционной
системой для того, чтобы обеспечить соблюдение требований взаимоисключе-
ния и возможности восстановления работы потока в случае его завершения
внутри критического участка.
Считающий семафор (counting semaphore) — семафор, который может принимать
значения больше единицы. Считающие семафоры обычно применяются в случае,
когда необходимо выделить некоторый ресурс из пула идентичных ресурсов.
Чтение-модификация-запись памяти (read-modify-write memory operation) — не-
делимая операция, опрашивающая значение переменной, изменяющая его (воз-
можно, в зависимости от считанного значения) и записывающая новое значение
в память. Эти операции упрощают алгоритмы взаимоисключения благодаря
своей атомарности.
Упражнения
5.1.
5.2.
5.3.
5-4.
Чем вызвана необходимость изучения проблемы параллелизма и почему
№о так важно для студентов курса по операционным системам.
оясните, почему следующее выражение является ложным: «если не-
сколько потоков одновременно считывают разделяемые данные из основ-
ой памяти, необходимо гарантировать взаимоисключение, чтобы исклю-
ть возможность получения непредсказуемых результатов».
Г/51 реализации взаимоисключения может использоваться алгоритм Дек-
Вит ’ КОМанДы test-and-set, swap и операции над семафорами Р и V. Срав-
ДостаВЬ1ШеПеРечисленные механизмы. Рассмотрите их преимущества и не-
ни7а ^Ва потока одновременно пытаются выполнить вход взаимоисключе-
0бс* МЫ пРедполагаем> что «победитель» выбирается случайным образом.
Те C^IITe альтернативные варианты. Предложите лучший метод. Подумай-
Те’Каким образом этот метод может быть реализован в многозадачной сис-
!£Л ’ гДе несколько потоков могут попытаться выполнить вход взаимоис-
*°Чения практически одновременно.
™------------------------------------------------------------------2^
5.5. Прокомментируйте использование примитивов взаимоисключения на
сунке 5.17. Ц,
1 //выполнение команд вне критического участка
2
3 enterMutualExclusion();
' 4
5 //выполнение команд внутри критического участка
6
7 enterMutualExclusion();
8
9 // выполнение команд внутри вложенного критического участь-
10 " а
11 exitMutualExclusion О ;
12
13 //выполнение команд внутри критического участка
14
15 exitMutualExclusion() ;
16
17 //выполнение команд вне критического участка
Рис. 5.17. Программный код к примеру 5.5
5.6. В чем главное значение алгоритма Деккера?
5.7. В алгоритме Деккера (см. рис. 5.10), поток Т2 может покинуть критиче-
ский участок, выполнить код выхода взаимоисключения, затем выполнить
код входа взаимоисключения и снова войти в критический участок преж-
де, чем поток Т] успеет воспользоваться долгожданной возможностью вой-
ти в свой критический участок. Может ли поток Т2 несколько раз выпол-
нить повторный вход в свой критический участок прежде, чем такой шанс
представится потоку Т]? Если это возможно, объясните подробно, как это
происходит. Можно ли данную ситуацию рассматривать как пример беско-
нечного откладывания? Если это невозможно, подробно поясните, каким
образом данная ситуация исключается.
Поясните, как параллельно выполняющаяся программа, обеспечивающей
взаимоисключение с помощью команды testAndSet (см. рис. 5.13) может
вызвать бесконечное откладывание. Объясните, почему такая ситуация
крайне нежелательна. При каких обстоятельствах имеет смысл использо
вать данную технологию взаимоисключения? В какой ситуации этот алг°
ритм абсолютно непригоден?
Проведите тщательный анализ алгоритма Деккера. Существуют ли в
слабые места? Если нет, поясните почему. && |
Решение проблемы взаимоисключения для п потоков, предложенное
зенбергом и МакГуайером64 гарантирует, что любой процесс сможет во
в свой критический участок не более чем за п-1 попытку. Есть ли Пр»..
пиальная возможность получить более высокое быстродействие для и
5.8.
5.9.
5.10.
5.11.
5.12.
5.13.
цессов?
Примитивы взаимоисключения могут быть реализованы при помоШ11
тивного ожидания либо путем блокирования. Сравните сферу примяв
и преимущества каждого подхода.
Поясните, каким образом двоичные семафоры и операции над ними М
реализовать внутри ядра операционной системы. $0'
Поясните, каким образом разрешение и запрещение прерываний моЖ о^е^1
способствовать реализации примитивов взаимоисключения в однопр I
сорной системе.
параллельное выполнение
339
Покажите, как реализовать операции над семафорами с помощью команды
5-14 testAndSet.
некоторых компьютерах аппаратно реализована команда swap, которая,
® и testAndSet, упрощает реализацию примитивов взаимоисключения,
«манда swap упрощает обмен значениями между двумя логическими пе-
енными, не требуя места для хранения промежуточных значений; при
₽ м команда swap является неделимой.
Э Оформите команду swap как заголовок процедуры на языке программи-
а рования высокого уровня.
Продемонстрируйте использование вашей процедуры swap (предпола-
гая, что она является атомарной) для реализации примитивов входа
и выхода взаимоисключения.
Как y»e упоминалось в тексте, критические участки, работающие с непе-
песекающимися группами разделяемых переменных, действительно могут
выполняться одновременно. Предположим, что примитивы взаимоисклю-
чения были модифицированы таким образом, чтобы включать в список па-
раметров определенные разделяемые переменные, которые используются
в критическом участке.
а. Прокомментируйте использование новых примитивов взаимоисключе-
ния на рисунке 5.18.
б. Предположим, что два потока, представленных на рисунке 5.19, выпол-
няются одновременно. Каковы могут быть последствия такой ситуации?
5 17. Что случится (если случится) с алгоритмом Деккера, если поменять места-
ми два оператора присвоения в коде выхода взаимоисключения?
5.18. Докажите, что алгоритм Питерсона (см. рис. 5.11) является четко
ограниченным65 т.е. поток не может попасть в ситуацию бесконечного от-
кладывания при любых задержках, вызванных бесконечным повторением
программного кода. В частности, докажите, что любому потоку, ожидаю-
щему возможности войти в свой критический участок, придется ожидать
не дольше, чем другому потоку понадобится времени для однократного
входа и выхода из критического участка.
Проведите детальный анализ алгоритма Питерсона, чтобы убедиться в кор-
ректности его работы. Докажите, в частности, невозможность возникнове-
ния взаимоблокировки, бесконечного откладывания и гарантию взаимоис-
ключения.
J, //выполнение команд вне критического участка
4 enterMutualExclusion(a);
5 //
6 //выполнение команд внутри критического участка
7
8 enterMutualExclusion(b);
9
О // выполнение команд внутри вложенного критического участка
11
12 exitMutualExclusion(Ь);
13
1<5 //выполнение команд внутри критического участка
16 x^t-^utualExclusi on (а) ;
/ /
* Вьи°лнение команд вне критического участка
овые примитивы взаимоисключения к упражнению 5.16(a)
Поток 1
1 enterMutualExclusion(a);
2
3 enterMutualExclusion(b);
4
5 exitMutualExclusion(b>;
6
7 exitMutualExclusion(a);
Поток 2
1 enterMutualExclusion(b);
2
3 enterMutualExclusion(a);
4
5 exitMutualExclusion(a);
6
7 exitMutualExclusion(b);
Puc. 5.19. Пример кода для упражнения 5.16 (б)
5.20. Докажите, что если система, реализующая алгоритм Лэмпорта, не буп
выполнять служебные операции завершения потоков, в ней может возник
нуть ситуация бесконечного откладывания.
5.21. Основываясь на вашем понимании ядра и механизма обработки прерыВа.
ний, опишите, как реализуются операции над семафорами в однопроцес.
сорной системе.
5.22. Мы говорили о том, что активное ожидание представляет собой напрасную
трату процессорных циклов. Всегда ли справедливо данное утверждение?
Назовите преимущества и недостатки активного ожидания.
1 Система:
2
3 .int turn » 1;
4 boolean tlWantsToEnter = false;
5 boolean t2WantsToEnter = false;
6
7 startThreads(); // инициализация и запуск обоих потоков
8
9 Поток Ti’.
10
11 void main()
12 (
13 while ( '.done }
14 {
15 tlWantsToEnter = true;
16
17 while { turn .,1* 1 )
18 {
19 while ( t2WantsToEnter );
20
21 turn = 1;
22 } // окончание цикла while
23
24 // код- внутри критического участка
25
PlIC. 5.20. Алгоритм к упражнению 5.28 (часть 1 из 2)
,ge цпрпллельное выполнение
341
tlWantsToEnter - false;
2^
// код вне критического участка
j // окончание внешнего цикла while
2§ , // окончание потока Т1
30 ' "
поток Т2‘-
33
34
35
Зб
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
void main ()
* while ( .'done )
{
t2WantsToEnter = true;
while ( turn != 2 )
t
while ( tlWantsToEnter );
turn = 2;
) // окончание цикла while
// код внутри критического участка
t2Want$ToEnter = false;
// код вне критического участка
} // окончание внешнего цикла while
} // окончание потока Т2
Рве. 5.20. Алгоритм к упражнению 5.28 (часть 2 из 2)
5.23.
5 24.
5.25.
5.26.
5.27.
5-28.
5-29.
Если несколько потоков пытаются выполнить операцию Ркому из них бу-
дет разрешено продолжить работу? Какие ключевые проблемы связаны
с этим? По какому критерию можно выбирать поток, которому будет разре-
шено продолжить работу в однопроцессорной системе? Какой критерий
можно использовать в многопроцессорной системе?
Пускай в системе поддерживаются только двоичные семафоры. Как с их
помощью имитировать считающие семафоры?
Одно из требований, предъявляемых к реализации операций Р и ^заключается
в их неделимости, то есть любая операция должна выполняться непрерывно
°т начала до конца. Приведите пример простой ситуации, в которой невоз-
можно гарантировать взаимоисключение, если операции не будут являться
неделимыми.
Предположим, что в системе единственным примитивом взаимоисключе-
ния, доступным для потоков уровня пользователя, является запрещение
прерываний в течение последующих 32 инструкций, после чего прерыва-
ния включаются повторно. Расскажите преимущества и недостатки подоб-
ного подхода.
Ким образом взаимодействующие между собой потоки могут реализовать
РИмитивы взаимоисключения внутри системы, упомянутой в предыду-
щем Упражнении?
еопечивает ли код на рисунке 5.20 взаимоисключение? Если нет, проде-
ц нстрируйте ситуацию, в которой взаимоисключение не гарантируется.
азовите одно из ограничений взаимоисключения, нарушаемое алгорит-
мом на рисунке 5.20.
342
Рекомендуемые исследовательские учебные проекты
5.30.
5.31.
5.32.
5.33.
5.34.
5.35.
Подготовьте исследовательскую статью по алгоритму быстрого взаи»
ключения Лэмпорта. Каким образом он работает? Где он использует
Изучите алгоритм взаимоисключения в распределенной системе. Как^^
следования были проделаны в данной области? 116
Изучите алгоритм взаимоисключения для многопроцессорной сис
Почему данный алгоритм проще, чем алгоритм взаимоисключения Bej,4
пределенных системах?
Большинство алгоритмов взаимоисключения проверяются при пОъ,
компьютерных программ. Проанализируйте, как таким программам ул*8
ся проверить правильность определенного алгоритма.
Наибольшую славу Дейкстра завоевал, вероятно, благодаря своему алгорд
кратчайшего пути. Кроме того, он внес большой вклад в развитие других^
ластей компьютерных наук. Например, теперь вам известно, что именно
придумал концепцию семафоров. Подготовьте доклад о биографии Дейкств°8
перечислив наиболее значимые его вклады в развитие компьютерных нау»
Посетите с этой целью веб-страничку www.cs.utexas.edu/users/EWD/.
Изучите примитивы параллелизма в языке Ada. Каким образом в Ada га
рантируется взаимоисключение?
Рекомендуемые программные учебные проекты
5. 36. Создайте несколько семафоров на языке Java. Воспользуйтесь ими для син-
хронизации двух потоков в программе, реализующей отношение произво-
дитель-потребитель.
Рекомендуемая литература
Проблема синхронизаций процессов подымается в литературе давно и довольно
часто.66’67,68 Связанная с ней проблема взаимоисключения также подробно рассмат-
ривается в литературе и вы можете найти немало источников, описывающих совре-
менные способы решения данной проблемы.69,70,71 Впервые проблема взаимоисклю-
чения была описана Дейкстрой, который выделил понятие критических участков
и применил алгоритм Деккера для решения этой проблемы.72 Впоследствии’
Питерсон73 и Лэмпорт74 представили новые подходы к реализации программно
взаимоисключения, упростив программный код за счет лучшего структурирован^
Хотя Дейкстра первым предложил решение проблемы взаимоисключения для я
токов, Кнут,75 Эйзенберг и Макгуайер,76 Лэмпорт,77 Андерсон и Ким78 и
продолжили исследования по усовершенствованию оригинального алгоритма.
ме того Дейкстра сформулировал концепцию семафоров в одной из своих пер з8
статей по проблеме взаимоисключения.79 Вдохновленные этим, ученые взяли
совершенствование концепции семафоров.80,81,82,83 Свежую библиографию ДЛЯ
главы вы найдете по адресу: www.deitel.com/books/os3e/Bibliography.pdf-
параллельное Выполнение
343
„ользованная литература
, т w «Concurrency in Operating Systems,» Computer, Vol. 9, No. 10,
lATnber 1976,’pp. 18-26.
0fiL r H., «А Majority Consensus Approach to Concurrency Control,» ACM
g ToinaS’ctions on Database Systems, Vol. 4, 1979, pp. 180-209.
Tran p and A. Smolka, «Processes, Tasks and Monitors: A Comparative
3. We£T1R .* Concurrent Programming Primitives,» IEEE Transactions on Software
inking, Vol. SE-9, No. 4, 1983, pp. 446-462
En^J and J. Misra, «Asynchronous Distributed Simulation via a Sequence
^parallel Computations,» Communications of the ACM, Vol. 24, No. 4, April
a^hHchting, R- D., and F. B. Schneider, «Understanding and Using Asynchron-
5- Message Passing Primitives,» Proceedings of the Symposium on Principles of
Distributed Computing, August 18-20, 1982, Ottawa, Canada, ACM, New York,
pp. 141-147.
Bernstein, A. J., «Program Analysis for Parallel Processing,» IEEE Transactions
on Computers, Vol. 15, No. 5, October 1966, pp. 757-762.
7 Courtois, P.J.; Heymans, F.; and D. L. Parnas, «Concurrent Control with
Readers and Writers,» Communications of the ACM, Vol. 14, No. 10, October
1971, pp. 667-668.
8. Lamport, L., «Concurrent Reading and Writing,» Communications of the ACM,
Vol. 20, No. 11, November 1977, pp. 806-811.
9. Rigart, G., and A. K. Agrawala, «An Optimal Algorithm for Mutual Exclusion in
Computer Networks,» Communications of the ACM, Vol. 24, No. 1, January
1981, pp. 9-17.
10. Jones, D. W., «An Empirical Comparison of Priority Queue and Event Set Imple-
mentations,» Communications of the ACM, Vol. 29, No. 4, April 1986,
pp. 300-311.
11. Raynal, M., Algorithms for Mutual Exclusion, Cambridge, MA: MIT Press,
1986.
12. Dijkstra, E. W., «Cooperating Sequential Processes,» Technological University,
Eindhoven, Netherlands, 1965, reprinted in F. Genuys, ed., Programming Lan-
13 New York: Academic Press, 1968, pp. 43-112.
Dijkstra, E. W„ «Cooperating Sequential Processes,» Technological University,
indhoven, Netherlands, 1965, reprinted in F. Genuys, ed., Programming Lan-
14 pUases’ New York: Academic Press, 1968, pp. 43-112.
• eterson, G. L., «Myths About the Mutual Exclusion Problem,» Information
15 Lrocessing Letters, Vol. 12, No. 3, June 1981, pp. 115- 116.
Co ₽Or^’ L-, «А New Solution of Dijkstra’s Concurrent Programming Problem,»
16. Dj7munications of the ACM, Vol. 17, No. 8, August 1974, pp. 453-455.
Eindh9’ E’ W» «Cooperating Sequential Processes,» Technological University,
gUa 10ven, Netherlands, 1965, reprinted in F. Genuys, ed., Programming Lan-
17. Pete*68’ New York: Academic Press, 1968, pp. 43-112.
Pro/^011’ L., «Myths About the Mutual Exclusion Problem,» Information
^•Dijkst81^ Letters’ VoL 12’ No- 3’ June 1981’ PP- I15’116-
Сотт"9’ E’ «Solution of a Problem in Concurrent Programming Control,»
Knut?Unications of the ACM, Vol. 8, No. 5, September 1965, p. 569.
2 Сощг i D’’ «Additional Comments on a Problem in Concurrent Programming
J Eis °* ’* Communications of the ACM, Vol. 9, No. 5, May 1966, pp. 321-322.
rent p rg’ A., and M. R. McGuire, «Further Comments on Dijkstra’s Concur-
No ,.r°&ramming Control Problem,» Communications of the ACM, Vol. 15,
’ November 1972, p. 999.
344
21. Lamport, L., «А New Solution to Dijkstra’s Concurrent Programming Prob] I
Communications of the ACM, Vol. 17, No. 8, August 1974, pp. 453-455.
22. Burns, J. E.; P. Jackson; N. A. Lynch; M. J. Fischer; and G. L. Peterson, <(Tv ’
Requirements for Implementation of N-Process Mutual Exclusion Using а с- 4]
Shared Variable,» Journal of the ACM, Vol. 29, No. 1, January 1982, pp. I83
23. Carvalho, 0. S. F., and G. Roucairol, «On Mutual Exclusion in Computer к '
works,» Communications of the ACM, Vol. 26, No. 2, February 1983, pp. 14g . 6t
24. Leslie Lamport, «А Fast Mutual Exclusion Algorithm,» ACM Transaction
Computer Systems (TOCS), Vol. 5, No. 1, pp. 1- 11, Feb. 1987. 18 °h
25. Anderson, James H., and Yong-Jik Kim, «An Improved Lower Bound for *
Time Complexity of Mutual Exclusion,» Proceedings of the Twentieth Ann 6
ACM Symposium on Principles of Distributed Computing, pp. 90-99,
2001, Newport, Rhode Island, United States.
26. Lamport, L., «The Writings of Leslie Lamport,» September 8, 2003,
search.microsoft.com/users/lamport/pubs/pubs.html>.
27. Lamport, L., «The Writings of Leslie Lamport,» September 8, 2003, <r
search.microsoft.com/users/Iamport/pubs/pubs.html>.
28. Milojicic, D., «А Discussion with Leslie Lamport,» September 2002,<dsonlj
ne. computer, org/0208/f/lamprint .htm>.
29. Anderson, J., «Lamport on Mutual Exclusion: 27 Years of Planting Seeds,» August
2001, <www.cs.unc.edu/~anderson/papers/lamport.pdf >, Proceedings of the 20th
Annual ACM Symposium on Principles of Distributed Computing, pp. 3-12.
30. Lamport, L., «А New Solution of Dijkstra’s Concurrent Programming Problem,»
Communications of the ACM, Vol. 17, No. 8, August 1974, pp. 453-455, <re
search, microsoft .com/users/lamport/pubs/bakery .pdf >.
31. Lamport, L., «TLA: The Temporal Logic of Actions,» August 26, 2003, «re-
search . microsoft. com/users/lamport/tla/tla. html>.
32. Lamport, L., et al., «Specifying and Verifying Systems with TLA+,» September
2002, <research.microsoft.com/users/lamport/pubs/spec-and-verifying.pdf>.
33. Anderson, J., «Lamport on Mutual Exclusion: 27 Years of Planting Seeds,» Au
gust 2001, <www.cs.unc.edu/~anderson/papers/lamport.pdf>, Proceedings of the
20th Annual ACM Symposium on Principles of Distributed Computing, pp. 3-12.
34. Anderson, J., «Lamport on Mutual Exclusion: 27 Years of Planting Seeds,» Au-
gust 2001, <www.cs.unc.edu/~anderson/papers/lamport.pdf>. Proceedings of the
20th Annual ACM Symposium on Principles of Distributed Computing, pp- 3-12-
35. Lamport, L., «А Fast Mutual Exclusion Algorithm,» November 14, 1985, <re‘
search.microsoft.com/users/lamport/pubs/fast-mutex.pdf>.
36. Lamport, L., «The Writings of Leslie Lamport,» September 8, 2003, <re"
search.microsoft.com/users/lamport/pubs/pubs.html>. *
37. Anderson, I, «Lamport on Mutual Exclusion: 27 Years of Planting Seeds,» Aug
2001, <www.cs.unc.edu/~anderson/papers/lamport.pdf>. Proceedings of the
Annual ACM Symposium on Principles of Distributed Computing, pp. 3-12-
38. Lamport, L., «Time, Clocks, and the Ordering of Events in a Distributed
tern,» Communications of the ACM, Vol. 21, No. 7, July 1978, pp.558-565»
search.microsoft.com/users/lamport/pubs/time-clocks.pdf>.
39. The LaTeX Project, «LaTeX Project home page,» 27, 2003, <www.lateX
ject.org/>. pjf-
40. Gilbert, Philip, and W. J. Chandler, «Interference Between Communicating
allel Processes,» Communications of Vol. 15, No. 6, June 1972, p. 436. J yS
41. Presser, Leon, «Multiprogramming Coordination,» ACM Computing Ь
(CSUR), Vol. 7, No. 1, January 1975, p. 38. pO*
42. Kruskal, Clyde P.; Larry Rudolph; and Marc Snir, «Efficient synchroniza 1
Multiprocessors with Shared Memory,» ACM Transactions on Programming
guages and Systems (TOPLAS), October 1988, p. 580. 1
параллельное Выполнение
345
L--kstra, Е- W., «Cooperating Sequential Processes,» Technological University,
13-^Ahov’en, Netherlands, 1965, reprinted in F. Genuys, ed., Programming Lan-
Ein°eS New York: Academic Press, 1968, pp. 43-112.
gliag uter Science Department of the University of Texas at Austin, «Е. W.
44- CoITftra Archive: Obituary,» August 2002, <www.cs.utexas.edu/users/EWD/
^•tuary.html>.
kstra, E., «GOTO Considered Harmful,» March 1968, <www.acm.org/clas-
45- £/nct95/>. Reprinted from Communications of the ACM, Vol. 11, No. 3
£ch 1968, PP- 147-148.
’kstra, E., «GOTO Considered Harmful,» March 1968, <www.acm.org/clas-
^Е^/ос^бЛ. Reprinted from Communications of the ACM, Vol. 11, No. 3
gch 1968, pp. 147-148.
n ikstra, E., «Appendix of The Structure of the «THE» Multiprogramming Sys-
9 м’ау 1968, <www.acm.org/classics/mar96/>. Reprinted from Communi-
cations of the ACM, Vol. 11, No. 5, May 1968, pp. 345-346.
Diikstra E., «Structure of an Extendable Operating System,» November 1969,
4 <www.cs.utexas.edu/users/EWD/ewd02xx/EWD275.PDF>.
49 Computer Science Department of the University of Texas at Austin, «Е. W.
Dijkstra Archive: Obituary,» August 2002, <www.cs.utexas.edu/us-
ers/EWD /obituary.html>.
T Whaley, «CS 313-Edsger Wybe Dijkstra,» <cs.wlu.edu/~whaleyt/classes/
313/Turing/Grieco-Dijkstra.htm>.
51. Department of Computer and Information Science of the University of Michigan
at Dearborn, «The ALGOL Programming Language,» November 24, 1996,
<www.engin.umd/umich.edu/CIS/course.des/cis400/algol/algol.html>.
52. Computer Science Department of the University of Texas at Austin, «Е. W.
Dijkstra Archive: Obituary,» August 2002, <www.cs.utexas.edu/users/EWD/
obituary.html>.
53. Dijkstra, E., «How Do We Tell Truths That Might Hurt?» 1975,
<www.cs.utexas.edu/users/EWD/ewd04xx/EWD498.pdf>.
54. Dijkstra, E., «The End of Computing Science?» 2000, <www.cs.utexas.edu/us-
ers/EWD/ewdl3xx/EWD13O4.PDF>.
55. Hansen, P. Brinch, «The Nucleus of a Multiprogramming System,» Communica-
tions of the ACM, Vol. 13, No. 4, April 1970, pp. 238-241, 250.
• Stark, Eugene, «Semaphore Primitives and Starvation-Free Mutual Exclusion,»
inn018-' Association for Computing Machinery, Vol. 29, No. 4, October
1982, pp. 1049-1071
e™ing, P- J-; Dennis, T. D.; and J. A. Brumfield, «Low Contention Semaphores
_n Lists,» Communications of the ACM, Vol. 24, No.10, October 1981,
58 в 687‘699.
Exr> ° • ”ansen’ P-> «Edison: A Multiprocessor Language,» Software Practice and
59-Lin еПСе’ VoL U’ No> 4’ April 1981’ pp- 325'361-
kernel source code, version 2.5.75, <miller.cs.wm.edu/lxr3.linux/http/
60,g^ce/4>c/sem.c?v=2. 5.75>.
сер^р1’ P' Brinch, «Distributed Processes — a Concurrent Programming Con-
el. Laln’ boniInunications of the ACM, Vol. 21, No. 11, November 1978, pp. 934-941.
tem L-J «Time, Clocks, and the Ordering of Events in a Distributed Sys-
Lamp Lommunications of the ACM, Vol. 21, No. 7, July 1978, pp. 558-565.
a tems 01l> L.; «The Implementation of Reliable Distributed Multiprocessor Sys-
4‘^icart L°mputer Networks, Vol. 2, No. 2, April 1978, pp. 95-114.
Comp,’’ anfl A. K. Agrawala, «An Optimal Algorithm for Mutual Exclusion in
1981 er Networks,» Communications of the ACM, Vol. 24, No. 1, January
PP. 9-17.
346
-м
64. Eisenberg, М. A., and М. R. McGuire, «Further Comments on Dijkstrs’s Q. 1
rent Programming Control Problem,» Communications of the ACM V ,41
No. 11, November 1972, p. 999. ’ °J. Я
65. Andrews, G. R., and F. B. Schneider, «Concepts and Notations for Соц
Programming,» ACM Computing Surveys, Vol. 15, No. 1, March 1983, ppC'il'l'eJ
66. Bernstein, A. J., «Program Analysis for Parallel Processing,» IEEE Trane
on Computers, Vol. 15, No. 5, October 1966, pp. 757-762. асМ(^
67. Courtois, P. J.; F. Heymans; and D. L. Pamas, «Concurrent Control
Readers and Writers,» Communications of the ACM, Vol. 14, No 10 cuW
1971, pp. 667-668. ’
68. Lamport, L.; «Concurrent Reading and Writing,» Communications of thP л
Vol. 20, No. 11, November 1977, pp. 806-811.
69. Ricart, G., and A. K. Agrawala, «An Optimal Algorithm for Mutual ExcluS’
Computer Networks,» Communications of the ACM, Vol. 24, No. 1 j
1981, pp. 9-17. ’
70. Jones, D, W., «An Empirical Comparison of Priority Queue and Event Set In
mentations,» Communications of the ACM, Vol. 29, No. 4, April loo
pp. 300-311 .
71. Raynal, M., Algorithms for Mutual Exclusion, Cambridge, MA: MIT pr<1
1986. e88'
72. Dijkstra, E. W, «Cooperating Sequential Processes,» Technological University
Eindhoven, Netherlands, 1965, reprinted in F. Genuys, ed., ProgrammingЬад’
guages, New York: Academic Press, 1968, pp. 43-112.
73. Peterson, G. L., «Myths About the Mutual Exclusion Problem,» Informal®
Processing Letters, Vol. 12, No. 3, June 1981, pp. 115- 116.
74. Lamport, L., «А New Solution of Dijkstra’s Concurrent Programming Problem,।
Communications of the ACM, Vol. 17, No. 8, August 1974, pp. 453-455.
75. Knuth, D., «Additional Comments on a Problem in Concurrent Programming
Control,» Communications of the ACM, Vol. 9, No. 5, May 1966, pp. 321-322.
76. Eisenberg, M. A., and M. R. McGuire, «Further Comments on Dijkstra’s Concur-
rent Programming Control Problem,» Communications of the ACM, Vol. 15,No.
11, November 1972, p. 999.
77. Lamport, L., «А New Solution to Dijkstra’s Concurrent Programming Problem.’
Communications of the ACM, Vol. 17, No. 8, August 1974, pp. 453-455.
78. Anderson, James H., and Yong-Jik Kim, «An Improved Lower Bound fort,
Time Complexity of Mutual Exclusion,» Proceedings of the Twentieth AnnUs(
ACM Symposium on Principles of Distributed Computing, pp. 90-99, Aug
2001, Newport, Rhode Island, United States. .„
79. Dijkstra, E. W, «Cooperating Sequential Processes,» Technological Univers^
Eindhoven, Netherlands, 1965, reprinted in F. Genuys, ed., Programming
guages, New York: Academic Press, 1968, pp. 43-112. .
80. Denning, P. J.; Dennis, T.D.; and J. A. Brumfield, «Low Contention e a
and Ready Lists,» Communications of the ACM, Vol. 24, No. 10, October
pp. 687-699. , gyS'
81. Lamport, L., «Time, Clocks, and the Ordering of Events in a Distribute
tem,» Communications of the ACM, Vol. 21, No. 7, July 1978, pp. 558- §
82, Lamport, L., «The Implementation of Reliable Distributed MultiproceS
terns,» Computer Networks, Vol. 2, No. 2, April 1978, pp. 95-114. -рр’5
83. Ricart, G., and A. K. Agrawala, «An Optimal Algorithm for Mutual Exc
Computer Networks,» Communications of the ACM, Vol. 24, No. 1’
1981, pp. 9-17.
Глава 6
Пцитльш
программирование
Высокие мысли требуют высокого си
Ар и с то
„ 1рочитав эту главу, вы должны будете понимать:
Чем больше писателен, тем ленивей читате'-
как использовать мониторы для синхронизации
Оливер Голде.,. дющ/па к данным;
как использовать переменные-условия;
И когда последний читатель перестанет читат^р , s _
г решения классических проблем параллельного
Оливер Уэнделл Xoi программирования, таких как производители
и потребители, а также кольцевой буфер;
Моя первая заповедь — никогда ?&№0нитпоры на Java;
не принимать на веру, пока У ^ленный вызов процедур.
не появится полная убежденно^
в истинности данного утвержДе1Ч
Рене
Это показывает, насколько легче критикой
чем быть пра^
Бенджамин Дизр
Краткое содержание главы
6.1 Введение
Поучительные истории: Исчерпывающее тестирование невозмо31Сн
6.2 Мониторы
Размышления об операционных системах: Сокрытие информации
6.2.1 Переменные-условия
Биография: Пер Бринч Хансен
6.2.2 Простое распределение ресурсов с помощью мониторов
6.2.3 Пример монитора: кольцевой буфер
6.2.4 Пример монитора: читатели и писатели
6.3 Мониторы на языке Java
6.4 Многозадачность в Java. Учебный пример, часть 3:
отношение производитель-потребитель в Java
6.5 Многозадачность в Java. Учебный пример, часть 4:
кольцевой буфер в Java
351
, ^едение
\0) *
идущей главе мы представили алгоритм Деккера для реализации
р взаимоисключения и описали семафоры, которые предложил
Однако эти средства обеспечения взаимодействия процессов
уязвимых мест. Они настолько элементарны, что с их помощью
Р писывать решение серьезных проблем параллельных вычислений,
трудн° ° ьЗОВание в параллельных программах еще больше усложняет
а ИС пьство корректности подобных программ. Неправильное исполь-
доКа3а эТих примитивов, умышленное, либо непреднамеренное, может
зС®аЯ^ги к нарушению работоспособности системы параллельной обработ-
ки ^ч^даости, подход с использованием семафоров имеет много уязви-
® мест-1 Если опустить операцию Р, гарантировать взаимоисключение
МЬ1Х астся. Если же будет опущена операция V, поток может ожидать бес-
8 рчно, из-за блокирования операции Р. Как только начнется выполне-
К° операции Р, поток не сможет вернуться назад и выбрать другой путь
выполнения, пока используется семафор. В любой момент времени поток
может находиться в ожидании только одного семафора; это может вызвать
взаимоблокировку во время выделения ресурсов. Например, каждый
в паре потоков может удерживать некий ресурс, освобождения которого
ожидает другой поток. Перед вами пример классической ситуации взаимо-
блокировки двух потоков, о которой мы поговорим в главе 7.
Чтобы преодолеть данную проблему, были разработаны конструкции
взаимоисключения высокого уровня, упрощающие решение сложных про-
блем параллелизма и обеспечивающие доказательство правильности про-
грамм, которые к тому же сложно испортить либо использовать не по на-
значению.
Параллельное программирование гораздо сложнее последовательного,
рограммы, работающие параллельно намного сложнее создавать, отла-
нияТ’ модиФии'иРовать и доказывать корректность их функционирова-
ние 'См- * Поучительные истории: Исчерпывающее тестирование невоз-
Mv__°*'- Почему же программисты так стремятся перейти к параллельно-
Ег₽аммир?ванию?
ЯсНяст^1Ц1еННЬ1^ ИнтеРес к языкам параллельного программирования объ-
РЫе яв Я ТбМ’ что они позволяют более естественно решать задачи, кото-
ПаРалле Ются параллельными по своей природе. Кроме того, настоящий
Ву15)и ИЗМ С адпаратной поддержкой в многопроцессорных (см. гла-
‘,сИоЛьзо₽аспРеДеленных (см. главу 17) системах возможен только в случае
^°'ГеНц11^1аНия параллельного программирования. Существует множество
т ^Ной Ьных сфер применения параллельного программирования.
раС1^НИГе °бсуждаются проблемы параллелизма в компьютерных се-
^ееьЧдцЬ1Ред'еленных системах3-4-5’6-7 и системах реального времени.8-9-10
tumble Оп и важным примером параллельных систем являются совре-
ц361«Ь1у еРаЦионные системы. Параллельными можно также назвать
ЧЙМеСис₽аВления полетами, жизненно-важные системы, автоматизиро-
е» ца емы управления реального времени (например, в нефтеперера-
ИМических производствах либо в пищевой промышленности).
352
„пограммирование
353
Распространено мнение, что человеческое зрение также представлю I
бой параллельный процесс. Метеорология, к примеру, в плане пардЛдЧ»
ма вырвалась далеко вперед, поскольку в погодных предсказаниях
зуются структуры массивного параллелизма, включающие в себя
арды и даже триллионы параллельно работающих процессоров. Ч.И
В этой главе мы рассмотрим высокоуровневые конструкции и язьц^ I
раллельного программирования. В частности, мы уделим внимание
торам, особым переменным-условиям, взаимодействию процессов
мощи удаленного вызова процедур и возможностям параллельного j?0’
граммирования на языке Java. В примерах псевдокода, в разделе (Я
используется С-подобный синтаксис. Во всех остальных разделах гдЗ I
приводятся полные версии программ на языке Java. В завершении гд^ I
вы найдете длинный список рекомендуемой и использованной литеру
ры, что свидетельствует о широких возможностях для поиска инфорМа^
по вопросам параллельного программирования.
Какой поход следует использовать программистам при создании соврь.
менных параллельных систем? До начала 90-х к языкам программиро^
ния, поддерживающим параллелизм, относились: Ada,11 Parallel Pascal,
Distributed Processes,14 Parallel C, Communicating Sequential Processes'M
Modula-2,18’19’20 VAL21 и *MOD (предназначенный для распределенного
программирования).22 За исключением Ada, все остальные языки были
разработаны учеными в исследовательских целях и поэтому в них отсутст-
вуют многие возможности, необходимые для создания реальных систем.
На сегодняшний день функции параллелизма поддерживаются олышн-
ством популярных языков программирования, включая Java, С#, Visu-
al C++ .NET, Visual Basic .NET и Python. Языки для написания параллель-
но выполняющихся программ позволяют студентам курсов компьютерных
наук готовить основы своей карьеры в данной отрасли, ведь в этом непро
стом вопросе не так уж много профессионалов.
Вопросы для самопроверки
1. Зачем исследователи создали высокоуровневые конструкции вз’Ч
моисключения? aJJ
2. Какие известные языки программирования с поддержкой паР0е^
лизма, разработанные до начала 90-х, обладают функциям0’
ходимыми для построения реальных систем?
Ответы 1) Подобные конструкции облегчают доказательней
вильности работы программ и их трудно испортить либо лепра
использовать. 2) Язык Ada.
Поучительные истории
^черпывиющее тестирование невозможно
........................... граничное значение счетчика, тогда тест за-
кончится, и «ошибка» в программе не будет
обнаружена.
Дейкстра обратил внимание пользовате-
лей на тот факт, что «тестирование позволяет
доказать наличие ошибок, но не их отсутст-
вие». Поскольку невозможно выполнить ис-
черпывающее тестирование каждой создан-
ной системы, это означает, что даже если
система прошла подобное «тщательное» тес-
тирование, в ней все равно могут содержать-
ся скрытые ошибки, которые проявятся уже
после того, как система получит широкое
распространение. Это возлагает тяжелую
ношу на плечи разработчиков операционных
систем. Как можно утверждать, что система
готова к использованию? Очевидно, что при-
нятие решения зависит от природы системы.
Является ли данная система жизненно-важ-
ной для человека либо бизнеса? Не может ли
отказ системы поставить под угрозу челове-
ческую жизнь? Предназначена ли данная
система для специального использования
в ограниченном кругу контролируемых кли-
ентов либо же она является системой общего
назначения, которой можно найти самые
разнообразные сферы применения, многие
из которых невозможно было определить на
стадии разработки?
ование работы программы - не-
Те<ГГ задача. Возможно, вы изучали тео-
пРоСТЗЯтоматов, где говорилось о том, что
Ри1° 36 о можно рассматривать как машину
к<*',пь ым числом состояний. Сколько же
с К°Няний может быть у компьютера? Одно из
видных решений заключается в том, что
компьютер может хранить г бит, то чис-
ло возможных состояний составит 2 в степени
л Таким образом, даже у компьютера с очень
малым по сегодняшним меркам объемом па-
мЯТИ _ скажем, несколько десятков мега-
байт-количество состояний превысит число
атомов во вселенной1 Проведем следующий
эксперимент: сложная программа использует
О или 1 в качестве входных данных и выдает 1
или 0 в качестве выходных данных. Каждый
раз, когда отладчик задает 1, программа воз-
вращает ему в ответ 1; каждый раз, когда от-
ладчик задает 0 — программа возвращает 0.
Отладчик приходит к выводу, что данная про-
Рамма просто передает входные данные, и,
etn™eTCTBeHH0' ра®отает правильно. Но что,
Bce6flHa Самом деле программа включает
Woro)СЧ6ТЧИК' и после определенного (боль-
Нять дГИЧеСТВЭ попытак начинает выпол-
^ьного^10 °пе|Эацию (возможно, разруши-
^^^ИрРактеРа) Если при тестировании
у попыток окажется меньше, чем
РдзРаботчиков операционных систем: поскольку провести исчерпывающее тес-
1^Пригодно(:тДаНН0^ вами системы невозможно, вы должны выполнять проверку на контро-
к Гесг0Рова ' ЧТ°^Ы 'минимизировать риск возможных ошибок и предусмотреть возможно-
РдСг,Ростг^ НИЯ' а также помочь тестировщикам системы доказать, что ваша система готова
'Ранению
354
} программирование
355
н из ожидающих потоков мог войти в монитор и занять данный
06i>i арсДИ поток сигнализирует о возвращении (иногда называемом ос-
4 сУРС' цем) ресурса и в это время нет потоков, ожидающих данного ре-
подобное оповещение не вызывает никаких других последствий,
СрсЯ, Т° что монитор естественно вновь вносит ресурс в список свобод-
С.рО^е Т°Ги’дно, что ресурс поступает в распоряжение монитора, чтобы дру-
0Че« имел возможность заполучить этот ресурс. Для того чтобы ис-
дОГ0 ^есКОНечное откладывание, монитор присваивает более высокий
{jjjjo4®Tb т даВно ждущим потокам, чем только что прибывшим.
6.2 Мониторы
Монитор (monitor) — это механизм организации параллелизма
рый содержит как данные, так и процедуры, необходимые для реалц *%!
динамического распределения конкретного общего ресурса или rnv-^%j|
щих ресурсов. Концепция монитора впервые была предложена
рой,23 затем ее переработал Бринч Хансен24,25 и усовершенствовал )£
Эта важной теме посвящено немало литературы.27,28,29,30,31,32,33-34,35 Ал
торы стали важной программной конструкцией — в языке Java они i
ко применяются в целях реализации взаимоисключения.
Чтобы обеспечить выделение нужного ему ресурса, поток должен I
титься к процедуре входа в монитор (monitor entry routine). Необзс
мость входа в монитор в различные моменты времени может возник^
у многих потоков. Однако вход в монитор находится под жестким конт11
лем — здесь осуществляется взаимоисключение потоков, так что н v
дыи момент времени только одному потоку разрешается воити в монитп
Потокам, которые хотят войти в монитор, когда он уже занят, приурдцЛ
ждать. Поскольку механизм монитора гарантирует взаимоисключение по.
токов, исключаются серьезные проблемы, связанные с параллельным ре
жимом работы (например, проблема неоднозначности результатов).
Внутренние данные монитора могут быть либо глобальными (доступны-
ми всем процедурам монитора), либо локальными (доступными только од
ной конкретной процедуре). Ко всем этим данным можно обращаться толь-
ко изнутри монитора; потоки, находящиеся вне монитора, просто не могу?
получить доступа к данным монитора. Такое структурное решение, значи-
тельно упрощающее разработку программных систем повышенной надеж-
ности с модульной структурой, называют сокрытием или инкапсуляцией
информации (information hiding) (см. «Размышления об операционных!
системах: Сокрытие информации»).
Обращаясь к процедуре входа в монитор в тот момент, когда больше 0
один поток не выполняется внутри монитора, данный поток блокирует Mfr
нитор и осуществляет вход в него. После входа потока в монитор, ДРУ^И
потоки не смогут войти в монитор, чтобы получить доступ к ресурсу-
поток обратится к процедуре входа в монитор, когда тот заблокирован,
ток должен будет ожидать вне монитора, пока монитор не освободится^
есть пока поток внутри монитора не закончит свою работу). Когда П
войдет в монитор, может оказаться, что ему придется ожидать с гг
ния ресурса, выделенного другому потоку. Поскольку внутри монитор8^
рантируется взаимоисключение, потоку придется ожидать за пр' Д
монитора, чтобы дать возможность другому потоку возвратить ресурс
ниторе. ЛТс1“
В конце концов, поток, который занимал данный ресурс, обр |
к монитору, чтобы возвратить ресурс системе. Соответствующая пр°’ рс
монитора при этом может просто принять уведомление о возвраЩе^ро^ I
сурса, а -затем ждать, пока не поступит запрос от другого потока, ко |
потребуется этот ресурс. Однако может оказаться, что уже имеются ур» ег0
ки, ожидающие освобождения данного ресурса. В этом случае пр°
входа в монитор выполняет примитив оповещения (сигнализации) j I
Вопросы для самопроверки
1. Почему поток должен ожидать освобождения ресурса вне монито-
ра?
2. Каким образом монитор предотвращает одновременное выполнение
нескольких потоков внутри монитора?
Ответы 1) Если бы поток ожидал освобождения ресурса внутри мо-
нитора, ни один другой поток не смог бы войти в монитор, чтобы вер-
нуть ресурс системе. В главе 7 вы узнаете, что такая ситуация может
привести к взаимоблокировке всех процессов, ожидающих освобожде-
ния ресурса. 2) Взаимоисключение гарантируется внутри монитора при
помощи алгоритмов, описанных в главе 5.
Размышления об операционных системах
Сокрытие информации
Сокрытие или инкапсуляция информации
является одним из фундаментальных принци-
Яов Разработки программного обеспечения.
к 0пеРаЦионных системах сокрытие или ин-
вымцПйЦИЯ инФ°РмаЦии реализуется различ-
способами. Когда одна функция либо
вьзь ВЬ13ЫБает Другую функцию либо метод,
fiCTar^a,0L4eMy объекту необязательно знать
й°стат РеализаЦии вызываемого объекта, ему
ВЬ|вв ваем° ЗНать'как Работать с интерфейсом
М°*.но °Г0 °бЪекта - какие аргументы
ВозРеДавать и в каком порядке, а также
и Ка^раШаемые значения следует ожи-
>кРЬ|тИя , Их Интерпретировать. Технология
Целы ИНкапсУляЦии) информации обла-
ЙВнЫх йв ряА°м преимуществ. Одним из
°бъ ЯеТСЯ УпР01Цение задач вызываю-
е|<'та. Нет никакой необходимости
изучать подробности реализации (которых
может оказаться огромное количество) вызы-
ваемого объекта. При этом облегчается зада-
ча модификации системы — вы без проблем
можете заменить вызываемую функцию, не
внося никаких изменений в вызывающую,
если первая будет обладать аналогичным ин-
терфейсом. Современные операционные сис-
темы состоят из десятков тысяч (и более) ком
понентов, которые постоянно модифициру-
ются, чтобы обеспечить поддержку нового
аппаратного и программного обеспечения
и оптимизировать быстродействие сущест-
вующего. Инкапсуляция информации просто
необходима для того, чтобы можно было ра-
зобраться в сегодняшних системах с высокой
степенью модульности и сделать их обслужи-
вание реальным
356
6.2.1 Переменные-умовия
Мониторы позволяют реализовать взаимоисключение и синхронц3
потоков. Поток, находящийся внутри монитора вынужден ожидать
бождения ресурса вне монитора, пока другой поток не закончит выц^®0-
ние операций внутри монитора. В отношении производитель-потреб^,?^-
например, производитель, обнаруживший, что потребитель еще це
считать значение из общего буфера, должен будет подождать вне мп ^1
ра, управляющего разделяемым буфером, пока потребитель не прочтет
держимое буфера. Аналогично, потребитель, обнаружив, что разделяе С°
буфер пуст, должен будет ожидать вне монитора, пока производите^*1^
запишет информацию в монитор. При этом поток внутри монитора исп
зует условные переменные или переменные-условия (condition variabl
чтобы дождаться наступления определенного условия вне монитора, м ’
нитор связывает каждую переменную-условие с определенной причиной
по которой поток может быть переведен в состояние ожидания. В связ»
с этим команды ожидания (wait) и сигнализации (signal) модифицируй
ся — в них включаются имена условий:
wait (переменная-условие)
signal (переменная-условие)
Переменные-условия совершенно не похожи на «обычные» переменные,
с которыми мы привыкли иметь дело. Когда определяется такая перемен-
ная, заводится очередь. Поток, выдавший команду ожидания, включается
в эту очередь (когда поток включается в очередь, он выходит из монитора,
предоставляя другому потоку возможность войти в монитор и вызвать ко-
манду signal), а поток, выдавший команду сигнализации, тем самым по-
зволяет ожидающему потоку выйти из очереди и войти в монитор. Мы мо-
жем предполагать, что используется дисциплина обслуживания очереди
«первый-пришел-первый-ушел», однако в некоторых случаях более полез
ными могут оказаться различные приоритетные схемы.36’37
Перед тем как поток сможет повторно войти в монитор, из монитор8
должен будет выйти поток, выдавший команду сигнализации. Бринч Л
сен (см. «Биография: Пер Бринч Хансен»), заметивший, что °пеРаТЛ.
return (то есть оператору выхода из монитора) часто предшествует мн0 ..
ство операторов signal, предложил понятие монитора сигна
ции-и-выхода (signal-and-exit), в котором поток выходит из монитор8
зу после выдачи команды сигнализации.38 В последующих пример83^^
сматриваются именно мониторы сигнализации-и-выхода. СуШеС J
также альтернатива в виде мониторов сигнализации-и-продол
(signal-and-continue), позволяющая потокам, которые выполняются^^
ри монитора, оповещать о скором освобождении монитора. Поток
выйти из монитора при необходимости ожидания переменноИ-У
либо в результате завершения выполнения кода, защищаемого мон
Поток, освобожденный монитором сигнализации-и-продолжения,
ожидать, пока не закончит свою работу внутри монитора поток, BbI\LIIfCr
команду сигнализации. В разделе 6.3 вы узнаете, как создавать М°
сигнализации-и-продолжения на языке Java.
ipoSauuo
357
Вопросы для самопроверки
1. Какая проблема может возникать, если вместо дисциплины «пер-
вый-пришел-первый-ушел» для переменных-условий использовать
очередь с приоритетами?
2. (Да/Нет) Правда ли, что каждый монитор имеет ровно одну пере-
менную-условие?
Ответы 1) Поток с низким приоритетом может оказаться в ситуа-
ции бесконечного откладывания из-за множества высокоприоритет-
ных потоков, вызывающих функцию ожидания монитора при входе
в приоритетную очередь. 2) Нет. Монитор имеет отдельные перемен-
ные-условия для каждой отдельной ситуации, которая может привес-
ти к вызову команды ожидания в мониторе.
| Биографические заметки
Пер Бринч Хансен
Пер Бринч Хансен посвятил свои исследо-
вания параллельному программированию.
а именно, технологии создания программно-
го обеспечения, которое могло бы выпол-
няться в параллельном режиме. Он получил
степень магистра по электротехнике в Техни-
ческом университете Дании в 1962 году, ра-
ботал в качестве профессора в Калифорний-
ском технологическом институте. Универси-
тете в Южной Калифорнии и Университете
в Копенгагене, Дания. В настоящее время он
и тает профессором по электротехнике
раК°узд^ТеРНЬ1м наукам в университете в Си-
ненгаг °ТЭЯ В КОмпании Regnecentralen в Ко-
3аДачцеНе' БРИНЧ Нансен разработал много-
^(Req10 СистемУ RC 4000 для компьютеров
н°йсисте <~entra'en^ 4000 в этой операцион-
Нь‘ефум^Ме впеРвые были выделены систем-
Б₽иНчЦ^в ^ль адра.40
КхИт НСен пРеДл°жил свою концеп-
Ь|й бы обеъКТуРЬ| мониторов — объекта, кото-
Ь'е И пРо е^ИНял в се®е разделяемые дан-
^еДУры, выполняющие действия
над ними. Эта идея изложена в его книге
Принципы операционных систем, опублико-
ванной издательством Prentice Hall в 1973
(см. раздел 6.2).41 Он включил мониторы
в разработанный им язык программирова-
ния Concurrent Pascal (расширение языка
Pascal, в исходной версии поддерживающего
только последовательное программирова-
ние), чтобы пользователи могли контроли-
ровать доступ к разделяемым данным, а про-
граммы, написанные на Concurrent Pascal,
можно было бы проверять во время компи-
ляции на предмет нарушения ограничений.42
В качестве демонстрации возможностей язы-
ка Concurrent Pascal, Бринч Хансен предло-
жил Solo, простую, но достаточно защищен-
ную операционную систему (в том смысле,
что в ней ошибки в программах обнаружива-
ются системой, не приводя к аварийному за-
вершению программ — а не в обычном пони-
мании защищенности от атак взломщиков)
без использования аппаратной поддерж-
ки.43'44,45 Позднее он разработал язык парал-
лельного программирования Joyce.46
358
Гл
6.2.2 Простое распределение ресурсов с помощью мониторов
Предположим, что нескольким потокам необходим доступ к опреде
ному ресурсу, который может быть использован в каждый конкретней!
мент времени только одним потоком. На рис. 6.1 рассматривается цг>
монитор-распределитель ресурсов, обеспечивающий выделение и осеой”
дение подобного ресурса.
В строке 4 объявляется переменная состояния inUse, отслеживаю
использование ресурса. В строке 5 объявляется переменная-условце^
значением которой следит поток, ожидающий освобождения определе ’ !
го ресурса, и которая оповещает поток об этом (делая ресурс Достудц^
В строках 7-17 и 19-25 задаются две процедуры входа в монитор. хкЛ
отличать процедуры входа в монитор от процедур, предназначенных л
выполнения внутри монитора, в определении каждой процедуры в дан^
псевдокоде используется ключевое слово monitorEntry.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
// Рис. 6.1: Монитор для выделения ресурсов
// однократная инициализация монитора
boolean inUse = false; // простая переменная состояния
Condition available; // переменная-условие
// опрос ресурса
monitorEntry void getResource()
{
if ( inUse ) // используется ли ресурс?
{
wait( available ); // ожидание доступности ресурса
} // конец конструкции if
inUse = true; // показывает, что ресурс занят
) // окончание функции getResource
// возвращение ресурса
monitorEntry void returnResource()
{
inUse = false; // показывает, что ресурс занят
signal( available ); // позволяет ждущему потоку продолжить раоо
} // окончание функции returnResource
PtIC. 6.1. Простое распределение ресурсов с помощью монитора
Со строки 8 начинается тело метода getResource, вызываемого
который запрашивает ресурс, связанный с переменной-условием ava
Состояние переменной inUse проверяется в строке 10 — так мы оПргД
используется ли интересующий нас ресурс в данный момент времени- #
логическая переменная inUse принимает значение true, следовател
сурс используется другим потоком и вызывающий поток должен °0^Я
переменную-условие available (строка 12). После выдачи команды
ния, поток выходит из монитора и включается в очередь, связанную'
менной-условием available. Как мы еще увидим, благодаря этому, I J
программирование
359
ресурс потоку разрешается войти в монитор и освободить занимае-
суре, выдав команду сигнализации для переменной-условия
Р1 е Если ресурс больше не используется, запросивший его поток вы-
aVailab"c^pOKy 15, устанавливающую значение переменной inUse равным
0оЛ0йе^обы обеспечить эксклюзивный доступ к ресурсу.
ttue’ 4 оке 20 начинается определение метода returnResource, предназна-
В сТР для освобождения ресурса. В строке 22 переменной inUse присваи-
4е00ОГдНачение false, что означает, что данный ресурс больше не исполь-
раеТсЯ додает перейти в распоряжение другого потока. В строке 23 вызы-
дуется фуН1<ция сигнализации для переменной-условия available, чтобы
ь ждущие потоки об освобождении ресурса. Если в очереди пото-
оЯ° оЖИдаю1ЦИх переменную-условие available, присутствует хотя бы
К°В’ поток (в РезУльтате выполнения строки 12), он получит возможность
°ДИ ВОЙТИ в монитор и выполнить строку 15, чтобы получить эксклюзив-
СВ°Й доступ к ресурсу. Если в очереди нет потоков, ожидающих перемен-
ншо-условие available, команда сигнализации не будет иметь эффекта.
^Преимущества монитора, показанного на рисунке 6.1 в том, что он ведет
себя в точности, как двоичный семафор, где метод getResource аналогичен
операции Р, а метод returnResource — операции V. Поскольку подобный
монитор, контролирующий доступ к одному конкретному ресурсу, можно
использовать вместо семафора, можно сказать, что функциональные воз-
можности мониторов, как минимум, включают в себя функциональные воз-
можности семафоров (но не ограничиваются ими). Обратите внимание, что
инициализация монитора (строки 3-5) выполняется до того, как потоки на-
чинают его использование; в этом случае переменной inUse присваивается
значение false, что означает изначальную доступность ресурса.
Вопросы для самопроверки
1. Что произойдет, если метод returnResource () не выдаст команду
сигнализации для переменной available?
2. Какой цели служит используемое нами ключевое слово monitor-
Entry?
Ответы 1) Все потоки, ожидающие переменную-условие availab-
le, окажутся заблокированными — их ожидание будет продолжаться
бесконечно долго. 2) Мы применяем ключевое слово monitorEntry для
того чтобы отличать процедуры входа в монитор, доступ к которым мо-
жет получить любой поток системы, но выполнять которые в любой мо-
мент времени разрешено только одному потоку, от частных методов
Монитора, доступных только потокам внутри монитора.
3 1,Р°влер монитора: кольцевой буфер
Разделе мы рассмотрим так называемый кольцевой буфер
который иногда называют ограниченным буфером
Ног Ut*er)’ и покажем, каким образом он может применяться в слу-
ц ЦОсДа Поток-производитель должен передать данные потоку-потреби-
ц/Ч Исе °ЛЬКу пРоизвоДитель и потребитель обладают доступом к одним
ж0 об,лазДеляемь1м Данным, работая при этом с разными скоростями,
Печить синхронизацию между двумя этими потоками.
программирование
361
360
Для реализации кольцевого буфера можно использовать массив.
кольцевой буфер используется для решения проблемы отношения w
водитель-потребитель, производитель записывает данные в последов^ Ч
ные элементы массива. Затем производитель считывает и удаляет их
же порядке, в каком они были записаны в массив (согласно прцН)?в
«первый-пришел-первый-ушел»). При таком подходе производителе д
жет опережать потребителя на несколько элементов. В конце концов, Лж
изводитель заполнит все элементы массива. Если производителю ц0{1 М
бится записать дополнительные данные, он должен будет начать
данных с начала массива (разумеется, мы предполагаем, что потребцц,^
уже успел удалить из начала массива данные, помещенные до этого
производителем). В результате массив обрабатывается как замкнутое Ко
цо, что и позволило назвать эту структуру кольцевым буфером.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
следующая ячейка для записи
следующая ячейка для чтения
количество ячеек с данными
переменная-условие
переменная-условие
// Рис. 6.2: монитор кольцевого буфера
char circularBuffer[] = new chart BUFFER_SIZE ]; // буфер
int writerPosition = 0
int readerPosition = 0
int occupiedSlots = 0;
Condition hasData;
Condition hasSpace;
монитор производителя для записи
{
// процедура входа в
monitorEntry void putChar( char slotData )
// ожидание переменной-условия hasSpace если буфер
if( occupiedSlots == BUFFER_SIZE )
{
wait( hasSpace ); // ожидаем переменную-условие
t // окончание конструкции if
к
данных
заполнен
hasSpace
// запись символа в буфер
circularBuffer[writerPosition] = slotData;
++occupiedSlots; // еще в одной ячейке появились данные
writerPosition = (writerPosition +1) % BUFFERSIZE;
signal( hasData ); // оповещение о доступности данных
// окончание функции putChar
{
]
// процедура входа в монитор потребителя для чтения данных
monitorEntry void getChar( outputparameter slotData )
// ожидание переменной-условия hasData если буфер пуст
if( occupiedSlots == 0 )
wait( hasData ); // ожидаем переменную-условие hasData
J // окончание конструкции if
// считывание символа в выходной параметр slotData
slotData = circularBuffer[readposition];
occupiedSlots—; // стало на одну ячейку с данными меньше
readerPosition = (readerposition + 1) % BUFFER_SIZE;
signal( hasSpace ); // оповещение о прочтении данных
// окончание функции getChar
Pl/C. 6.2. Реализация кольцевого буфера с помощью монитора
о#*? РазмеР кольцевого буфера является фиксированным, может
момент, когда все элементы массива окажутся заполненными.
настУ^^тоизводителю придется подождать, пока потребитель не освободит
^огДа П один элемент массива. Возможна и обратная ситуация: потреби-
хота прочесть следующее значение, однако массив значений пуст;
?еЛЬ 31 сЛучае потребителю придется дожидаться, пока производитель не
в эТ°Мйт какие-нибудь данные в массив. Монитор на рисунке 6.2 (основан-
ий^^ приглеРе’ предложенном Хоаром)47 позволяет реализовать кольце-
н^/фер и соответствующие механизмы синхронизации для управления
в0Й производитель-потребитель.
°Т11Лы предполагаем’ что массив CircularBuffer содержит BUFFER_SIZE
символьных элементов (строка 3). Переменные writerPosition й~геа-
°flBposition (строки 4-5) показывают, в какой элемент кольцевого буфера
d®r т вестись запись производителем, и из какого элемента будет выпол-
чтение потребитель, соответственно.
^Производитель помещает данные в буфер путем вызова метода putChar
(строки 10-24). В строке 14 проверяется уровень заполнения буфера. Если
в буфере не осталось свободных элементов,, производителю придется ожи-
дать переменную-условие hasSpace (строка 16). Когда это произойдет, про-
изводитель покинет монитор и будет добавлен в очередь, связанную с пере-
менной-условием hasSpace. Как вы вскоре убедитесь, это позволит потре-
бителю проникнуть в монитор, прочесть данные из кольцевого буфера
и выдать оповещение переменной-условия hasSpace. В результате произво-
дитель сможет продолжить свою работу, записать данные в буфер (стро-
ка 20), увеличить значение счетчика занятых ячеек (строка 21) и обновить
значение переменной writerPosition (строка 22). Наконец, в строке 23 вы-
дается команда оповещения (сигнализации) переменной-условия hasData,
чтобы ожидающий своей очереди потребитель, если таковой имеется, смог
продолжить свою работу.
(строОТРе^ТеЛЬ считывает Данные из буфера с помощью метода getChar
Ра з1КИ 26~40^ Обратите внимание на использование выходного парамет-
в строк^гт^ псевдокоде (выделенного ключевым словом outputparameter
Данные6 А* Подобная возможность поддерживается во многих языках.
ДОступнь Помещенные в выходные параметры, моментально становятся
ется про1 ДЛЯ аргументов вызывающих потоков. В строке 30 осуществля-
Пе₽еменн6РКа заполнения буфера. Если буфер пуст, потребитель ожидает
пР°ДоЛзкиУЮ'условиа hasData (строка 32). Как только потребитель сможет
Ь СВОЮ работу’ он скопирует данные из буфера непосредственно
ЧйИ д Параметр slotData (строка 36), обеспечив доступность инфор-
и^^Мцает аргумента вызывающего объекта. После этого потребитель
Ла11е пере^Начевие счетчика занятых элементов (строка 37) и меняет зна-
ь°л*Да reader₽ositi°n (строка 38). В строке 39 выдается ко-
белю ттг, ИзаЦии переменной-условия hasSpace, разрешающая произ-
ьИеВо °Д°Лжить Работу.
Потреби буФер хорош тем, что он позволяет производителю опере-
теля- Производителю не обязательно дожидаться, пока по-
^,Феъ,С',1оНиеОЧТет сгенерированные ранее данные (что являлось необходи-
соСт М в отношении производитель-потребитель с использованием
°ящего из одного элемента). Новые данные помещаются в пус-
.1 программирование
363
362
тые ячейки кольцевого буфера, при этом производитель продолжает
тывать значения в правильном порядке. Кольцевой буфер уменьщае СЧ f
личество времени, затрачиваемого производителем на ожидание
ности сгенерировать следующее значение, что позволяет повысить
быстродействие системы. При увеличении объема кольцевого буфера°% Г
изводитель может сгенерировать большее количество значений, Пр^Ч
чем ему придется ждать, когда потребитель прочтет их и освободит а ’Ч'
ячейки для записи. Если производитель и потребитель работают прцблОбЧ
тельно с одинаковой скоростью, применение кольцевого буфера позво^'
увеличить общую скорость работы приложения. Если же средние скоп^7
работы производителя и потребителя отличаются, данное преимуц-^Ч
будет сведено к нулю. Например, если производитель постоянно iiepp^i
данные быстрее, чем потребитель может их принять, кольцевой ।
очень скоро окажется переполнен и будет оставаться в таком состояние11
стоянно, заставляя производителя дожидаться пока потребитель не осво^В
дит новый элемент массива, считав из него данные. И наоборот, если Потт»,I!
потребителя работает быстрее производителя, через некоторое время тщ.
требитель начнет сталкиваться с пустым кольцевым буфером, вынужден,
ный дожидаться пока производитель сгенерирует новое значение. В
последних описанных случаях применение кольцевого буфера ничем не
оправдано, и будет означать только напрасную трату памяти.
Операционные системы используют кольцевой буфер для управления I
спулингом. В качестве распространенного примера спулинга можно ш
звать генерирование данных для передачи на относительно медленные уст
ройства вывода, например, принтер. Поскольку потоки способны форми
ровать данные намного быстрее, чем принтер в состоянии их печатать и по
скольку потокам необходимо завершать свою работу в кратчайшие сроки
сформированные данные могут быть записаны в кольцевой буфер. Физиче-
ски кольцевой буфер может быть размещен на первичном устройстве хра-
нения либо на диске. Поток, генерирующий данные для печати, часто на-
зывают спулером (spooler). Другой поток, часто называемый деспулсР**
(despooler), считывает данные из кольцевого буфера и передает их при№
ру, но при этом он выполняется с меньшей скоростью, чем первый. Ь ,
правило, в кольцевом буфере хватает места, чтобы сгладить Разлй^
в скоростях выполнения этих потоков. Разумеется, мы исходим из пРе
ложения, что система не станет до бесконечности генерировать даН! ые
печати, намного опережая возможности печати. Если это произойДеТ’
фер будет постоянно переполнен, и никакой пользы от его применен11 I
не получите.
Вопросы для самопроверки Л
1. Назовите две ситуации, в которых кольцевой буфер менее зфФ j/
вен, чем обычный буфер, который используется в отношен
изводитель-потребитель, позволяя хранить только одно зн , ,9?
2. Может ли 1______ ««лта-
ним производителем и двумя потребителями,
рованное им значение должно быть прочитано толи*-- _
потребителем? Почему?
4 Пример монитора: читатели и писатели
числительные системы обычно оперируют двумя видами потоков: по-
елями, которые читают данные (и потому называются «читателя-
тРе°. и производителями, которые записывают данные (и потому называют-
МИ«писателями»). Так, в системе предварительной продажи авиационных
билетов может быть гораздо больше читателей, чем писателей, поскольку
к базе данных, содержащей всю существующую информацию о рейсах само-
летов, будет произведено много обращений по запросам кассира-оператора,
прежде чем пассажир реально выберет и купит билет на конкретный рейс.
Потоки-читатели не меняют содержимого базы данных, поэтому не-
сколько таких потоков могут обращаться к ней одновременно. А вот по-
ток-писатель может изменять данные, поэтому он должен обладать моно-
польным, исключительным доступом к базе данных. Когда работает по-
ток-писатель, никакие другие писатели и читатели работать не должны.
Конечно, такой режим монопольного доступа следует предусматривать
только на уровне работы с индивидуальными записями — не обязательно
предоставлять потоку-писателю монопольный доступ к целой базе данных.
фоблему проектирования параллельной программы для управления
ли Тупом Пот°ков-читателей и писателей к базе данных впервые сформу-
леа0Вали и Решили Куртуа, Хеймане и Парнас.48 На рисунке 6.3 представ-
Т£щ ^енитор, решающий задачу читателей и писателей, который разрабо-
ЭТот°СНОВе пРеДложенного Хоаром алгоритма.
п°Ы ДЛЯМОНИТ°Р может быть использован как средство управления досту-
с°Держа Ц,ел°41 базы данных, для некоторого подмножества базы данных,
т°й 3anj^ero МНого или лишь несколько записей, и даже для отдельно взя-
г«х сл\^,И’ ^РИВеДенные ниже рассуждения справедливы для любого из
Т°ЛьКо Ол аев" ® каждый конкретный момент времени может работать
t е®вая Н Писатель; когда какой-либо писатель работает, логическая пе-
йе B?riteLock (строка 4) имеет истинное значение. Ни один из чита-
Геацег 5кет Работать во время работы какого-либо писателя. Перемен-
»• с чИТа8 (стРока 3) указывает количество активных читателей. Когда
“-----пм пазпеле монитор работ^Х) Ч^*сате^еЙ оказывается равным нулю (строка 29), ожидающий не-
рассмотренный в Данн Отелями, если кажД°е or 1 Чь? ^або-г. , (если таковой имеется в системе) получает возможность на-
водителем и быть прочитано тольК СтР°Ка 31). Новый поток-читатель не может продолжить свое
\ е’ ®ока условие canRead не станет истинным, а новый поток-пи-
°Ка не станет истинным условие canWrite (строка 42).
1DV-L --J — X
быть записаны в кольцевой буфер. Физиче
Ответы d Если средние скорости работы производителя и потреби-
теля значительно отличаются, преимущество от использования кольце-
вого буфера сведется к нулю. Если производитель постоянно опережает
потребителя, буфер будет постоянно заполнен, и производителю каждый
раз придется дожидаться, пока потребитель не прочтет предназначенные
для него данные. Если же потребитель работает быстрее производителя
то буфер практически постоянно будет пустым и потребителю придется
ожидать записи значения производителем. В вышеописанных ситуаци-
ях использование простого буфера, поддерживающего хранение одного
значения, не скажется на производительности. 2) Может. Монитор по-
зволяет гарантировать взаимоисключение, поэтому производитель будет
работать точно также. В то же время только один потребитель сможет
получать данные, предназначенные для потребителя.
365
364
а программирование
1 ,
2
3
4 1
5 !
6 '
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
// рис. 6.3: проблема читателей-писателей
’ * - 0; // количество читателей
int readers =0; // количестве 5SX1X- еж х с;,» х
boolean writeLock = false; // true, если писатель записывает Дани,
Condition canWrite; ' ' —~»»“«я-условие
Condition canRead;
// переменная-условие
// переменная-условие
// процедура входа в монитор перед началом чтения данных
monitorEntry void beginRead()
{
// ожидание вне монитора, если писатель осуществляет запись лис
// ожидает возможности начать запись
if! writeLock I| queue! canWrite ) )
{
wait! CanRead ); // ожидаем, пока чтение не будет разрешено
} // окончание конструкции if
++readers; // появляется еще один читатель
signal( canRead); позволяем ждущим потокам продолжить свою
// окончание метода beginRead
входа в монитор после чтения данных
}
// процедура .
monitorEntry void endRead!)
{
—readers; // на одного читателя стало меньше
// если больше нет читателей, разрешаем работать писателю
if( readers = 0 )
!
signal ( canWrite ); // разрешаем писателю продолжать
// окончание конструкции if
окончание метода endRead
// п монитор перед началом записи данных
monitorEntry void beginWrite!)
{
}
// процедура входа в
ожидаем в случае выполнения чтения или записи данных
потоку-читателю необходимо выполнить чтение данных, он вы-
оцедуру входа в монитор beginRead (строки 8-21); по окончанию
.₽ает °"чТения читатель вызывает метод endRead (строки 23-34). Новый
$роаеССа может находиться внутри метода beginRead, пока никакой дру-
не пишет данные и не претендует на выполнение записи данных
*1°Т°^3). Последнее условие чрезвычайно важно для предотвращения
(cTpoKaqHoro откладывания ожидающих своей очереди писателей. Данное
^с1<ойе прОВерЯется при помощи булевой функции queue, которая опреде-
усЛ°вйе еСТВуют ли потоки, ожидающие переменную-условие, указанную
лЯеТ’ Срумент. Обратите внимание, что процедура beginRead завершается
едениеМ пе₽еменной canRead (строка 20), чтобы другие ждущие пото-
оп°ве продолжить чтение данных. В результате поток-читатель из
ки и получает возможность продолжить свое выполнение, оповестив
очеР щий поток-читатель, что и тот может продолжить работу. Подобная
слеД"я пеакция», называемая также каскадной, продолжается до тех
> цепная
пока все ждущие потоки-читатели не станут активными. Во время
П°пной реакции все новые потоки, обратившиеся к этим данным, чтобы
произвести чтение, вынуждены будут дожидаться своей очереди — мони-
тор соблюдает правило, согласно которому ждущие потоки должны быть
обслужены до того, как начнется обслуживание только что прибывших по-
токов. Если разрешить обслуживание новых потоков, то в случае непре-
рывного обращения новых потоков, потоки-писатели, ожидающие своей
очереди, могут попасть в ситуацию бесконечного откладывания. Посколь-
ку читатели не мешают работе друг друга и могут параллельно выполнять-
ся в многопроцессорной системе, данный способ организации обслужива-
ния этих потоков весьма эффективен.
Когда поток заканчивает чтение данных, он вызывает процедуру входа
в монитор endRead (строки 23-34), которая уменьшает на 1 значение
в счетчике читателей (строка 26). В конце концов, в системе не останется
ни одного читателя, после чего поток выдаст команду оповещения
naK^rite’ чт°бы ждущий своей очереди поток-писатель смог продолжить
с т\/и’ тем самым, исключить бесконечное откладывание ждущих пи-
ТС
пРоцрДа ПОТокУ"писателю необходимо произвести запись, он вызывает
входа в монитор beginWrite (строки 36—46). Поток-писатель
8 Текут ™лаДать монопольным доступом к базе данных, поэтому, если
^РУгой И Момент уже есть работающие потоки-читатели или какой-либо
По,г'оясдяКТИВНЬ1Й поток-писатель (строка 40), данному писателю придется
Ко ’ Пока значение переменной-условия canWrite не станет истин-
г Писатель получает возможность продолжить работу (после опо-
£ТР°Ка nWr;i te в строке 31 или 60), логическая переменная writeLock
читат® jiix ) прцНимает ИСТИНное значение. Тем самым доступ к базе дан-
Частям блокируется для всех остальных потоков-писателей
Чо гДапо‘
в м ОТок'Писатель заканчивает свою работу, он вызывает процедуру
ь HllToP endWrite (строка 48-63) и устанавливает для переменной
т^ЧТор ЛОй£н°е значение (строка 51). Тем самым, открывается вход
ЛЛя ДРУГИХ потоков. Затем он должен выдать очередному ожи-
Потоку сигнал о том, что можно продолжить работу (стро-
t- < бету
работу!
if (readers > 0 Ij writeLock )
{
VvclJLLy ______„ r
} // окончание конструкции if
writeLock = true; // блокируем всех читателей и писателей
// окончание метода beginWrite
и trrt" ч монитор по окончанию записи данных
monitorEntry void endWrite()
writeLock - false; // высвобождаем блокировку
// если читатель ждет входа, оповестить об этом
if( queue( canRead ) )
(
Signal! canRead ); // каскадное оповещение всех ждущих
} // окончание конструкции if
else II оповещаем писателя, если ожидающих читателей нет
{
signal! canWrite ); // один писатель может продолжить
} // окончание конструкции else
// окончание метода endWrite
wait ( canWrite ) ; // ожидаем, пока не будет разрешена запись ,
}
// процедура входа в
{
}
Рас. 6.3. Монитор, предназначенный для решения проблемы читат
Ра
ПйС»
366
ки 53-61). Должен ли он при этом отдавать предпочтение ожидающе^ '
току-читателю или ожидающему потоку-писателю? Если он отдаст /У Не-
почтение ожидающему писателю, то может возникнуть такая ситуа^1
когда постоянный поток приходящих писателей приведет к бесконеч * Ч
откладыванию ожидающих потоков-читателей. Поэтому писатель, 3
шивший свою работу, прежде всего, проверяет, нет ли ожидающего
теля. Если есть, то выдается сигнал canRead (строка 56), так что этот
дающий читатель получает возможность продолжить работу. Если нц ч
ного ожидающего читателя нет, то выдается сигнал canWrite (строка гЧ
в результате чего получает возможность продолжить выполнение жгппЛ
писатель.
Вопросы для самопроверки
1. В коде на рисунке 6.3 реализована каскадная активизация о» I
дающих читателей. Почему на практике никогда не используй
каскадная активизация ждущих писателей?
2. Какие меры предосторожности предусмотрены для того, чтобы mJ
дотвратить бесконечное откладывание писателя потоком постоянно
приходящих читателей.
Ответы 1) Потоки-читатели не мешают выполнению друг друга,
поэтому в системе одновременно могут выполнять чтение сразу не-
сколько читателей. В то же время каждому потоку-писателю необхо-
дим монопольный доступ к данным. В противном случае результаты
могут быть непредсказуемыми. 2) Если в системе присутствуют писа-
тели, ожидающие возможности произвести запись (строка 13), то для
продолжения работы потоки-читатели должны дождаться выдачи сиг-
нала canRead (строка 15) в процедуре входа в монитор beginRead.
63 Мониторы ни языке Juvu
В следующих разделах мы рассмотрим полноценное рабочее много®
точное Java-приложение, позволяющее решать типичные проблемы иаР^
дельного программирования. Каждому объекту в Java назначается
монитор. Мониторы представляют собой главный механизм обеспеч^^
взаимоисключения и синхронизации в многозадачных приложениях^^»
Ключевое слово synchronized накладывает ограничение взаимоиск
ния на объект Java. Кроме того, в этом разделе мы обсудим, чем мой^с8^
на Java отличаются от мониторов на псевдокоде, которые были °п
в предыдущем разделе. _
Когда поток намеревается выполнить метод, защищенный при $$
монитора на Java (метод, объявленный как synchronized), он дол»
чале попасть в очередь входа (entry set или entry queue), представЛ $0
собой группу потоков, ожидающих возможности войти в монитор
в системе больше никто не претендует на вход в монитор, ДаН11Ь1^влУ^
сможет войти в монитор немедленно. Если поток уже находится I
монитора, другим потокам придется подождать в очереди входа, п°
монитор не освободится.
программирование
367
оы на Java обычно называют мониторами сигнализации-и-про-
fjoU1' 50 Вспомним, что монитор сигнализации-и-продолжения позво-
выполняемому внутри монитора, оповещать другие потоки
^ет г10Т°ящеМ освобождении монитора, но при этом удерживать блоки-
СРе^С'Г° итора до момента выхода из него. Поток может выйти из монито-
3 0кУ М°дЬтате ожидания переменной-условия либо завершив выполнение
S S ^яЩИЩенного монитором.
цоДа’ за выполняющийся внутри монитора, который вынужден дожидать-
^°Т°меННОЙ-условия, выдает команду ожидания. Метод wait заставляет
сЯ ^^.дять блокировку с монитора и подождать безымянную перемен-
0отоК После вызова метода wait, поток помещается в очередь ожида-
нУ10'^ -х ggf или wait queue), в которой находятся потоки, ожидающие воз-
яЯя ти снова войти в монитор. Потоки остаются в очереди ожидания до
МоЯС п пока им не просигнализирует другой поток. Поскольку перемен-
теХ условия задаются в Java неявным образом, поток может получить опове-
йе войти в монитор и там обнаружить, что ожидаемое им условие не со-
блюдается. В результате может получиться так, что поток получит уведомле-
ние несколько раз, прежде чем ожидаемое им условие будет соблюдено.
Потоки выдают команды сигнализации (оповещения) путем вызова ме-
дов notify и notifyAll. Метод notify будит единственный поток в очере-
ди ожидания. Для определения потока, который сможет войти в монитор
следующим, применяются различные алгоритмы, зависящие от реализа-
ции виртуальной машины Java. В итоге, программист не может рассчиты-
вать на определенную дисциплину очереди при вызове метода notify.
Еще один подводный камень метода notify заключается в том, что по-
рядок удаления потоков из очередей входа и ожидания в некоторых реали-
зациях Java может приводить к значительным задержкам — создавая ве-
роятность бесконечного откладывания. В результате, если доступом к мо-
нитору обладает более двух потоков, лучше использовать метод notifyAll,
оповещающий все потоки в очереди входа и очереди ожидания. При пробу-
По/ии всех потоков планировщик самостоятельно определяет, какому
ре у следует предоставить данный монитор. Обычно в планировщике
I Дьшавд^Я52ДИСЦИПЛИна очеРеДи’ предотвращающая бесконечное откла-
возщовЛ" ' Поскольку метод notifyAll будит все потоки, ожидающие
тодЬко СТи войти в монитор (в отличие от метода notify, который будит
! 1£ЛаДйЫхДИН Поток)’ его использование связано с большим количеством на-
°tify Расходов. В простом случае синхронизации двух потоков, метод
СТРаДая в еспеЧивэет более высокое быстродействие, чем notifyAll, не
Данном случае от проблемы бесконечного откладывания.
Вопросы для самопроверки
В чем различие между мониторами сигнализации-и-продолжения
и мониторами сигнализации-и-выхода? Какого типа мониторы ис-
L пользуются в языке Java?
^^Вепы 1) В Java используются мониторы сигнализации-и-продол-
Ск НИя’ О™ позволяют потоку оповещать другие потоки о предстоящем
Ви°Р°м освобождении монитора, продолжая удерживать контроль над
Им. Мониторы сигнализации-и-выхода требуют, чтобы поток снимал
к Локировку с монитора немедленно после выдачи команды оповещения.
368
6.4 Многозадачность в Java. Учебный пример, I
часть 3: отношение произбодитепь-потребите^ I
в Java
g программироваиао^
369
1
2
3
a
В этом разделе речь пойдет о реализации отношения производите^ J
требитель, рассмотренного в разделе 5.2.1, на языке Java. На рисуцк '
и 6.5 показано, как производители и потребители обращаются к оби,
разделяемому буферу, в то время как за синхронизацию доступа ответу
монитор. Производитель генерирует новое значение только в случае, |
буфер пуст, заполняя его; потребитель считывает данные, только есдц I
фер заполнен, опустошая его. В данном примере повторно испольну^Ж
интерфейс Buffer (рис. 5.1), класс Producer (рис. 5.2) и класс Cons^
(рис. 5.3) из примера в разделе 5.2.1. Повторное использование этих
сов из примера, не использующего синхронизации, позволяет продемовс
рировать, что потоки, обращающиеся к разделяемому объекту, ничего*
знают о синхронизации. Программный код для выполнения синхро Л
цйи размещен в методах set и get класса SynchronizedBuf fer (рис. 6.)
реализующего интерфейс Buffer (строка 4). Таким образом методы i.
классов Producer и Consumer просто обращаются к методам set и getp.
дел немого объекта, как в примере из раздела 5.2.1.
Класс SynchronizedBuffer (рис. 6.4) включает в себя две переменные!!
buffer (строка 6) и occupiedBuffers (строка 7). Метод set (строки 9-
и метод get (строки 45-79) теперь являются синхронизированы^
(synchronized) (строки 10 и 46); поэтому только один поток может ода
временно войти в один из этих методов конкретного объекта SynchrJ
nizedBuffer. Как видим, occupiedBuffers по смыслу представляет СОТ
переменную-условие, но имеет целочисленный тип — такой способ
ления выбран потому, что в Java отсутствует тип объектов, с помощь»
торого можно было бы непосредственно представить переменную-ус
Методы класса SynchronizedBuffer используют переменную occupi
ffers в операциях сравнения (строка 16 и 52), чтобы определить о
ность выполнения следующей задачи (производителем либо пот
лем). Если переменная occupiedBuffers равна нулю, это означает,
фер пуст и производитель может записать в него некоторое 311 л
(строка 34). Это условие (строка 52) также означает, что потребите#
дется подождать (строка 59) в методе get, прежде чем он сможет ПРЛ
новое значение (опять-таки, по причине того, что буфер в данный А
пуст). Если значение переменной occupiedBuffers равно 1, поТР j
получает возможность прочесть информацию из буфера, посколь J
теперь содержатся новые данные. Это условие (строка 16) также о
что производителю придется ожидать возможности поместить в I
вое значение, поскольку тот заполнен.
о
7
8
9
ю
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
57
58
il рис- 6.4:' SynchronizedBuffer. java
// SynchronizedBuffer синхронизирует доступ к разделяемым данным
ublic class SynchronizedBuffer implements Buffer
* private int buffer = -1; // доступ производителя и потребителя
private int occupiedBuffers =0; // счетчик занятости буфера
// помещаем значение в буфер
public synchronized void set( int value )
{
// запрашиваем имя потока, вызвавшего данный метод для отображения
String name = Thread.currentThread().getName();
// если нет пустых элементов, переведем поток в состояние ожидания
while( occupiedBuffers == 1 )
// выводим информацию о потоке и буфере, затем ждем
try
{
System.err.printin( name + "пытается начать запись");
displaystate("Буфер заполнен. " + name + " ожидает.");
wait(); // ожидаем, пока буфер не будет опустошен
} // окончание метода try
//в случае прерывания потока, выводится содержимое стека
catch( InterrruptedException exception )
{
exception.printStackTrace() ;
} // окончание catch-конструкции
} // окончание цикла while
buffer = value; // запись в буфер нового значения
// запрещаем производителю записывать новые данные до тех пор,
// пока потребитель не прочтет существующие данные
++occupiedBuffers;
displaystate( name = " записывает " + buffer );
notify () ; // разрешаем ждущему потоку войти в состояние готовности
// окончание метода set; снимаем блокировку с SynchronizedBuffer
// извлечение данных из буфера
Public synchronized int get()
// запрашиваем имя потока, вызвавшего данный метод для отображения
String name = Thread,currentThread().getName();
/ если данных для чтения нет, перевод потока в состояние ожидания
while ( occupiedBuffers = 0 )
// выводим информацию о потоке и буфере, затем ждем
try
{
System.err,println( name + "пытается начать чтение.");
displaystate("Буфер пуст. " + name + " ожидает." );
^Г011^ге4^и|^1-ащ^еть°1Т^ ° 2)К РазделяемомУ буферу с помощью Java-класса
370
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
wait(); // ожидаем записи новых данных в буфер
} // окончание метода try
//в случае прерывания потока, выводится содержимое ст=.
catch (InterruptedException exception )
{
exception.printStackTrace() ;
} // окончание catch-конструкции
) // окончание цикла while
// разрешаем производителю запись новых данных в буфер
// поскольку потребитель считал старые данные из буфера
—occupiedBuffers;
displaystate( name = " считывает " + buffer );
notify () ,// разрешаем ждущему потоку войти в состояние готовности
return buffer;
} // окончание метода get; снимаем блокировку с SynchronizedBuffer
// выводим информацию о текущей операции и состоянии буфера
public void displaystate( String operation )
{
StringBuffer outputLine = new StringBuffer( operation );
outputLine.setLength( 40 );
outputLine.append( buffer + "\t\t" + occupiedBuffers );
System.err.printin( outputLine );
System.err.printin();
} // окончание метода displaystate
) // окончание класса SynchronizedBuffer
Рис. 6.4. Синиони.чация доступа к разделяемому буферу с помощью Java-класса
SynchronizedBuffer (часть 2 из 2)
Когда метод run производителя обращается к синхронизированному ме-
тоду set (строка 26 рисунка 5.2), поток пытается установить блокировку
объекта монитора SynchronizedBuffer. [Примечание: Когда мы говори*1
«установить блокировку» в контексте монитора на Java, мы подразумев0
ем получение монопольного взаимоисключающего доступа к монитору
о чем говорилось в разделе 6.2.] Если блокировка доступна, она передаеТ
в распоряжение потока Producer. Затем с помощью цикла в методе 3
(строки 16-32 на рисунке 6.4) проверяется, не равна ли перемен
occupiedBuffers единице. Если да, значит, буфер заполнен, и в CTPoK^Cjj
выводится сообщение, уведомляющее о том, что поток Producer пЫТа
выполнить запись данных, а в строке 22 вызывается метод displayst^
(строки 81-89) для вывода другого сообщения о том, что буфер запо-0
и что поток Producer находится в состоянии ожидания. Обратите вН
ние, что в объявлении метода displaystate не используется ключевое
во Synchronized, поскольку данный метод вызывается из метода
(строка 18 на рис. 6.5) до того как потоки производителя либо потреби _
будут созданы и он станет доступен только для синхронизированных $
дов set и get (строки 10 и 46 на рисунке 6.4). Одновременно только ° I
foe ni
?раммирование
~37Т
ясеТ ВЫПОЛНЯТЬСЯ внутри монитора SynchronizedBuffer, а доступ
в10 dispiayState может быть получен только изнутри монитора. Та-
11 МеТ°Д' ом, монопольный взаимоисключающий доступ можно получить,
обраобъявляя метод displaystate как Synchronized.
не ° 23 вызывается метод wait (унаследованный SynchronizedBu-
? р сТР°пясса Object; все Java-классы прямо или косвенно являются на-
f£et °7 и класса Object) чтобы перевести поток, вызвавший метод set
сдеДн01<г1ОТОк Producer) в состояние ожидания и снять блокировку с объек-
(тОеСТЬ ronizedBuf fer. Это очень важно, поскольку в этот момент поток не
таЗУпС и выполнять поставленные перед ним задачи, а блокировка не
в с°сТ°дМОЖности работать с данным объектом другим потокам. Такая си-
ДаеТ Б может привести к взаимоблокировке, поскольку переменная-усло-
тУацИ0тору1О ожидает первый поток, не меняется. После того как поток
в116’ двОдителя вызовет метод wait в строке 23, другой поток сможет уста-
п₽00 блокировку объекта SynchronizedBuffer и вызвать методы set
Н°В Теперь поток потребителя сможет опустошить буфер, позволив жду-
щему производителю продолжить работу.
И Поток производителя остается в состоянии ожидания до тех пор, пока
другой поток не уведомит его о возможности продолжить выполнение —
с этого момента поток производителя возвратится в состояние готов но
сти и будет ожидать освобождения процессора. Перейдя в состояние вы-
полнения, поток производителя неявным образом попытается восстано-
вить блокировку объекта SynchronizedBuffer. Если блокировка доступна,
производитель получит ее в свое распоряжение, после чего выполнение ме-
тода set продолжится с оператора, следующего за wait. Поскольку опера-
тор wait вызывается в цикле (строки 15-32), возможность продолжения
работы потоком проверяется условиями нахождения в цикле. Если усло-
вия нахождения в цикле соблюдаются, функция wait вызывается повтор-
но, если нет, выполнение метода set продолжается с оператора, следующе-
го непосредственно за последним оператором цикла.
В строке 34 в методе set в буфер записывается аргумент value. В стро-
° Увеличивается значение счетчика occupiedBuf fers, поскольку буфер
из занят (т-е- потребитель может приступить к чтению данных, а про-
выч ДИТель пока не может выполнить запись новых данных). В строке 40
СОди ается метод displaystate для вывода строки состояния в окне кон-
фер ’^формирующей о выполнении производителем записи данных в бу-
°bje . хСтР°ке 42 мы вызываем метод notify (унаследованный от класса
8 состс) ^Сли Поток производителя находится в очереди, он переходит
будет ЯНие готовности, чтобы продолжить свою работу, как только ему
Ди not. Делен процессор. Сразу после этого осуществляется выход из мето-
ду. [/> У’ после чего метод set передает управление вызывающему пото-
’Иль 1ечание: Вызов метода notify корректно работает в этой програм-
^Ься ° ПотомУ, что в любой момент времени к методу get может обра-
>oro^b °дин поток (потребителя). В программе, где наступления
Вс Т°Д to ^Словия ожидают несколько потоков, необходимо использовать
е^11 По 1 чтобы гарантировать правильное получение уведомлений
Ся бдов ками-] При выходе из метода set, неявным образом освобожда-
ировка объекта SynchronizedBuffer.
Методы set и get реализованы схожим образом. Когда метод run ПоГп
потребителя вызывает метод get типа Synchronized (строка 28 рис. 5.з/°
ток пытается наложить блокировку на объект SynchronizedBuffer. Г1°-
установки блокировки в цикле ожидания while (строки 51-68 на рцс.
проверяется значение переменной occupiedBuffers. Если оно равно
значит, буфер пуст, и в строке 57 выводится сообщение, информируй х
о том, что поток потребителя находится в состоянии ожидания, а в
ке 58 с помощью метода displaystate выдается сообщение о том,
фер пуст и поток потребителя ждет данных. В строке 59 вызывается м
wait, который переводит поток потребителя, вызвавший метод get в
стояние ожидания объекта SynchronizedBuffer. Опять-таки, вызов Мет^
wait приводит к тому, что вызывающий поток снимает блокировку с пги8
екта SynchronizedBuffer, так что другой поток может попытаться запод”"
чить блокировку и вызвать методы set и get объекта. Если блокиров
SynchronizedBuffer недоступна (то есть поток производителя еще не вц
шел из метода set), поток потребителя будет заблокирован до тех по I
пока блокировка не станет доступна. ’
Поток потребителя остается в состоянии ожидания до тех пор, пока про
изводитель не уведомит его о возможности продолжения работы — с этой]
момента поток потребителя возвратится в состояние готовности и будет
ждать освобождения процессора. Когда поток перейдет в состояние выпол-
нения, он снова попытается неявным образом заблокировать объект
SynchronizedBuffer. Если блокировка доступна, ею воспользуется поток
потребителя, после чего метод get продолжит выполняться с оператора,
следующего за wait. Поскольку оператор wait вызывается в цикле (стро-
ки 51-68), нам необходимо проверить условия нахождения в цикле, чтобы
узнать, может ли поток продолжить свое выполнение. Если нет, оператор
wait вызывается повторно; в противном случае, выполнение метода get
продолжается с оператора, следующего непосредственно за последним опе-
ратором цикла. В строке 72 уменьшается значение счетчика occupiedBu-
ffers, так как буфер освободился, строка 74 выводит на консоль значение,
которое только что было прочитано потребителем, а в строке 76 вызывает-
ся метод notify. Если поток производителя ожидает возможности полу-
чить блокировку для объекта SynchronizedBuffer, он входит в состояние
готовности. Как только процессор поступит в распоряжение потока, ой по-
пытается снова установить блокировку и продолжить выполнение своих
задач. Выход из метод notify будет осуществлен немедленно, после ЧЙ®
метод get возвратит значение буфера вызывающему потоку (строка ' '
[Примечание: Опять-таки, вызов метода notify корректно работает в э
программе только потому, что в любой момент времени к методу set мо5^а
обратиться только один поток (производителя).] При выходе из мет
get, блокировка с объекта SynchronizedBuffer снимается.
Структура класса SharedBufferTest2 (рисунок 6.5) во многом наП°йгГ-
нает структуру класса SharedBufferTest (рисунок 5.5). Класс share^jjid
f ferTest2 включает в себя метод main (строки 6-27), который осуШеС'1\вЯ#
ет запуск приложения. В строке 9 создается разделяемая переде
sharedLocation класса SynchronizedBuffer, которой присваивается c<^yj0
ка на новый объект SynchronizedBuffer. Мы используем переМ®11
SynchronizedBuffer вместо Buffer для того, чтобы иметь возможное'!'1’
' >гЬ меТ°л di3P^yState класса SynchronizedBuffer, отсутствующий
fer. В объекте SynchronizedBuffer хранятся данные, которые явля-
разделяемыми между потоками производителя и потребителя
Ю’** J-a* И"18 ВЬ1ВОДЯТСЯ заголовки столбцов. В строке 2J-22 создаются
₽сТктЫ Producer и Consumer, соответственно. Каждому конструктору пе-
обфС тсЯ значение переменной sharedLocation, благодаря чему каждый
РеДа5т инициализируется ссылкой на один и тот же объект Synchron i -
°6TLffer- 'ЦаЛее’ В стР°ках 24-25 вызывается метод start для потоков
СзВодителЯ и потРебителя’ который переводит их в состояние готовно-
и. В результате происходит запуск этих потоков и первоначальный вы-
Спп меТОДа run для каждого потока. И, наконец, метод main завершается
3°повременно с потоком выполнения main.
Посмотрите на три варианта возможных результатов выполнения про-
граммы на рисунке 6.5. Обратите внимание, что каждое сгенерированное
производителем целое число считывается ровно один раз. Благодаря син-
хронизации и переменной occupiedBuf fers мы гарантируем строгую оче-
редность выполнения потоков производителя и потребителя. Производи-
тель должен начинать работу первым; потребитель должен ждать, пока
производитель не сгенерирует новое значение, после того как потребите-
лем было прочитано предыдущее; производитель же должен подождать,
пока сгенерированное им значение не будет прочитано потребителем. Об-
ратите внимание на комментарии, которые присутствуют в первом и "вто-
ром варианте результатов выполнения программы — они информируют
о ситуациях, когда одному потоку приходится ожидать другого для того
чтобы продолжить свою работу. Как видите, в третьем варианте результа-
тов выполнения обоим потокам удалось избежать циклов ожидания.
Вопросы для самопроверки
1. Почему метод displaystate не нужно объявлять как synchronized?
2. (Да/Нет) Правда ли, что если мы не вызовем метод notify из метода
get, производитель не сможет закончить генерирование значения,
поскольку это вызовет бесконечное откладывание потока-производи-
теля в строке 23 на рисунке 6.4.
Ответы 1) Хотя переменная occupiedBuf f ers является разделяе-
мой, метод displaystate может быть вызван только изнутри синхро-
низированных методов либо когда программа состоит из одного
потока. 2) Нет. Возможна ситуация, когда буфер так и не будет запол-
нен, поэтому поток производителя так и не дойдет до строки 23. По-
добная ситуация наблюдается в третьем варианте на рис. 6.5.
374
1 // Рис. 6.5: SharedBufferTest?.java
2 3 // SharedBufferTest? создает потоки производителя и потребителя
4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 public class SharedBufferTest2 { public static void main( String [] args ) { // создание разделяемого объекта для .Использования потока SynchronizedBuffer sharedLocation = new SynchronizedBuffe^ // вывод на экран заголовков столбцов StringBuffer columnHeads = new StringBuffer("Операция"); columnHeads.setLength( 40 ); columnHeads.append( "Значение буфера\1\1Индикатор занятост > System.err.printin( columnHeads ); System.err.printin(); sharedLocation.displayState ( "Начальное состояние" ); // создание объектов производителя и потребителя Producer producer = new Producer( sharedLocation ); Consumer consumer new Consumer( sharedLocation ); producer.start(); // запуск потока производителя consumer.start(); // запуск потока потребителй } // окончание функции main
29 } > Ч окончание класса SharedBufferTest2
Результаты выполнения программы, 1-й вариант
Операция Значение буфера Индикатор занятости
Начальное состояние -1 0
Consumer пытается начать чтение. Буфер пуст. Consumer ожидает. -1 0
Producer записывает 1 1 1
Consumer считывает 1 1 0
Consumer пытается начать чтение. Буфер пуст. Consumer ожидает. 1 0
Producer записывает 2 2 1
Consumer считывает 2 2 0
Producer записывает 3 3 1
Consumer считывает 3 3 0
Consumer пытается начать чтение. Буфер пуст. Consumer ожидает. 3 0
Producer записывает 4 4 1
Consumer считывает 4 Producer заканчивает генерирование. Завершение потока Producer. Consumer сумма прочитанных значений:10 Завершение потока Consumer. 4 0
Рис. 6.5. Синхронизация потоков, выполняющих модификацию разделяеМоГ0
объекта (часть 1 из 2)
375
ирограммированио
выполнения программы, 2-й вариант
ОпеР°
рдЧЗЛЬЯОе
Consumer
БуФеР Г--'‘
producer
Consumer
Producer
producer
Буфер 3ai
Consumer
Producer
Consumer
Producer
Producer
состояние
пытается начать чтение.
„,,гТ. Consumer ожидает.
ПУ'-"1
записывает 1
считывает 1
записывает 2
,ел пытается начать запись,
заполнен. Producer ожидает.
считывает 2
записывает 3
считывает 3
записывает 4
_______ заканчивает генерирование,
завершение потока Producer.
Consumer считывает 4
Consumer сумма прочитанных значений:10
Завершение потока Consumer.
Значение
буфера
-1
-1
1
1
2
2
2
3
3
4
4
Индикатор
занятости
О
0
1
О
1
1
о
1
о
1
о
Результаты выполнения программы, 3-й вариант
Операция Значение Индикатор
буфера занятости
Начальное состояние -1 0
Producer записывает 1 1 1
Consumer считывает 1 1 0
Producer записывает 2 2 1
Consumer считывает 2 2 о
Producer записывает 3 3 х
Consumer считывает 3 3 п
roducer записывает 4 Producer Завег>п заканчивает генерирование. Ccr,sZ e потока Producer. 4 и 1
4 0
. nSumer считывает 4
‘°nsumer oi ЗавеР111 Умма прочитанных значений: 10 ’ие потока Consumer.
^екта онизация потоков, выполняющих модификацию разделяемого
376
~~-гм
6.5 Многозадачность в Java. Учебный пример,
часть 4: кольцевой буфер в Java
Чтобы обеспечить корректную работу двух потоков с данными в п
ляемом буфере, программа на рисунке 6.4 использует механизм синхв^®*
зации потоков. Однако данный подход не гарантирует оптимальную пп
водительность приложения. Если два потока выполняются с разными °113'
ростями, один из них будет тратить большую часть времени на оэкиля^
другого. Если поток производителя генерирует данные значения быст^Т®
чем их в состоянии считать потребитель, производитель будет тра^ ’
большую часть времени на ожидание потребителя. И наоборот, если пот ГЬ
битель считывает данные быстрее, чем их генерирует производитель, тог
в состоянии ожидания большую часть времени будет находиться потреб
тель. Даже если потоки работают с одинаковыми относительными скор^
стями, через определенные промежутки времени может возникать ситуа
ция рассинхронизации потоков, когда один поток вынужден будет ояси.
дать другого. Одно из рассмотренных выше правил гласит, что мы не
можем и не должны делать предположений об относительных скоростях
выполнения асинхронных параллельных потоков. Это связано с тем, что
в операционной системе происходит слишком много взаимодействий меж-
ду системными, пользовательскими и сетевыми компонентами, что лиша-
ет нас возможности предсказать скорость выполнения потоков. В нашем
примере отношения производитель-потребитель одному из потоков при-
дется дожидаться другого. Если потоки будут тратить большую часть вре-
мени на ожидание, программа станет менее эффективной, система начнет
медленно реагировать на запросы интерактивных пользователей, в резуль-
тате чего приложение может работать с большими задержками из-за неэф-
фективного использования процессора.
Чтобы минимизировать периоды ожидания для потоков, выполняю
щихся с одинаковой средней скоростью, которые должны работать с разде*
ляемыми ресурсами, мы можем создать кольцевой буфер, куда бы проИЗ*
водитель записывал новые данные, если в какие-то промежутки времен!
он выполняется быстрее потребителя, и откуда потребитель бы считывав
данные, когда он начинает опережать поток производителя. g
Кольцевой буфер нужен для хранения данных в те моменты, когда еД
поток работает быстрее другого. Если со временем мы обнаружим, что
изводитель часто опережает потребителя более чем на три элемента
ра, мы можем создать буфер с большим количеством элементов.
личество ячеек буфера слишком мало, потокам чаще придется оЯ'ИД
если слишком велико — это будет означать напрасную трату памяти-
В программе на языке Java, приведенной на рисунках 6.6 и 6.7, РаС
ривается применение кольцевого буфера потоками производителя и
бителя (в данном случае, разделяемого массива из трех элементов) 11
лельно с синхронизацией. В данной версии отношения производите
требитель, потребитель получает возможность считывать данные из М pf
только, если тот не является пустым, а производитель в состоянии г
ровать новое значение только в том случае, если массив не заполнен-
программирование
377
много модифицировали класс Producer по сравнению с версией
jjfci ]3 новой версии генерируются значения в диапазоне от 11 до 20
ар0с" дО 4). Класс Consumer также был модифицирован по сравнению
® ре °т „ ga рИс. 5.3 — теперь поток потребителя считывает из кольцевого
с ве₽с,1ецеЛь1Х 10 значений вместо 4.
буфеРа йтеЛЬНЬ1м модификациям на рис. 6.4-6.5 подвергся кольцевой бу-
ддачИ larguffer (рис. 6.6), заменивший SynchronizedBuffer (рис. 6.4).
феР cirCUcuiarBuf fer включает в себя четыре компонента. Массив buffers
КЛ»сС 1g) реализует кольцевой буфер в виде массива из трех целочислен-
(СтРоКа ментов. Переменная-условие occupiedBuffers (строка 11) исполь-
цЫх 9 того, чтобы определить, может ли производитель выполнять за-
Зуется 1Х в кольцевой буфер (это возможно в случае, если значение пе
сИсь Д occupiedBuf fers меньше общего количества элементов буфера),
PeI*ie же может ли потребитель считывать значения из буфера (это возмож-
случае, если значение переменной occupiedBuffers больше 0). Пере-
н° ® readLocation (строка 14) указывает позицию в массиве buffers,
^куда поток потребителя должен будет читать следующее значение. Пере-
менная writeLocation (строка 15) указывает позицию в массиве buffers,
куда поток производителя должен будет записать следующее значение.
1 // Рисунок 6.6: CircularBuffer.java
2 // CircularBuffer позволяет синхронизировать доступ
3 //к массиву разделяемых значений
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
public class CircularBuffer implements Buffer
{
// каждый элемент массива представляет собой буфер
private int buffers[] = { -1, -1, -1 };
// occupiedBuffers - счетчик занятых элементов массива
private int occupiedBuffers;
// Переменные, отслеживающие позиции чтения и записи
private int readLocation = 0;
Private int writeLocation = 0;
// запись данных в элемент буфера
Public synchronized void set( int value )
I/ запрашиваем имя потока, вызвавшего данный метод
String name = Thread.currentThread().getName();
I/ если буфер заполнен, переводим поток в состояние ожидания
while ( occupiedBuffers == buffers.length )
{
// выводим Информацию о потоке и буфере, затем ждем
try
{
System.err.printin( "\nBce элементы заполнены. " +
name + " ожидает.");
wait(); //ждем освобождения элементов буфера
} // окончание конструкции try
Правление доступом к массиву разделяемых переменных (часть 1 из 3)
378
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
------------------------------------------------------------
//в случае прерывания потока, распечатываем содержимое ст»
catch ( InterruptedException exception )
{
exception.printStackTrace();
} // окончание конструкции catch
} // окончание цикла while
// записываем данные в элемент буфера с номером writeLoc-ь-
buffers [writeLocation] = value; ,1сг,
// выводим сгенерированное значение
System.err.printin( "\n" + name + ” записывает " +
buffers[writeLocation] + " " );
// увеличиваем счетчик занятых элементов буфера на единицу
++occupiedBuffers;
// обновляем переменную writeLocation для последующей записи
writeLocation = ( writeLocation + 1 ) % buffers.length;
// выводим значения элементов разделяемого буфера
System.err.printin( createStateOutput() );
notify(); // возвращаем ждущий поток в состояние готовности
} // окончание метода set
// извлекаем данные из буфера
public synchronized int get О
{
// запрашиваем имя потока, вызвавшего данный метод
String name = Thread.currentThread().getName();
// пока буфер пуст, помещаем поток в состояние ожидания
while ( occupiedBuffers == 0 )
{
// выводим сведения о потоке и буфере, затем ждем
try
{
System.err.printin( "\nBce элементы пустые. " +
name + " ожидает.");
wait(); //ждем записи в элементы буфера
} // окончание конструкции try
//в случае прерывания потока, распечатываем содержимое стек
catch ( InterruptedException exception )
{
exception.printStackTrace();
} // окончание конструкции catch
} // окончание цикла while
// читаем данные из элемента буфера с номером readLocati0
int readValue = buffers[ readLocation ];
// выводим прочитанное значение
System.err.println( ”\n" + name + " считывает " +
readValue + " ");
// уменьшаем счетчик занятых элементов буфера на едичинУ
—occupiedBuffers;
2
Рис. 6.6. Управление доступом к массиву разделяемых переменных (часть
программирование
379
95
9б
V
9В
99
100
101
102
Ю?
104
105
106
107
108
109
1Ю
1Н
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
J5S
}5б
}57
158
15g
// обновляем переменную readLocation для последующего чтения
readLocation = ( readLocation + 1 ) % buffers.length;
/I выводим значения элементов разделяемого буфера
System.err.printin( createStateOutput!) );
notifyO; // возвращаем ждущий поток в состояние готовности
return readValue;
j I/ окончание метода get
// выводим информацию о состоянии
public String createStateOutput()
' // первая строка информации о состоянии
String output = "(занято элементов: " +
occupiedBuffers + ")\псодержимое:
for ( int i = 0; i < buffers.length; ++i )
output += " " + buffers[ i ] + "
} // окончание цикла for
// вторая строка с информацией о состоянии
output += "\п
for ( int i - 0; i < buffers.length; ++i )
{
output += "----";
} // окончание цикла for
// третья строка информации о состоянии
output += ”\п ";
II добавляем указатели readLocation (R) и writeLocation (W)
// под соответствующими элементами буфера
for ( int i - 0; i < buffers.length; ++i )
{
if ( i = writeLocation &&
writeLocation == readLocation )
{
output += " WR ”;
) // окончание конструкции if
else if ( i == writeLocation )
{
output += " W
} // окончание конструкции if
else if ( i == readLocation )
{
output += " R **;
} II окончание конструкции if
else
{
output += "
} // окончание конструкции else
1 // окончание цикла for
output += "\n";
} z/eturn output;
!I окончание метода CreateStateOutput
^Окончание класса CircularBuffer
Правление доступом к массиву разделяемых переменных (часть 3 из 3)
380
;.'1K
i'i'’
fl
Метод set класса CircularBuffer (строки 17-59) выполняет те же с j
задачи, что и SynchronizedBuffer на рисунке 6.4, хотя и с некоторыми
чиями. Цикл while в строках 23—40 определяет условия ожидания ц
дителем другого потока (когда все элементы буфера заполнены). Если
водителю приходится ждать потребителя, информация об этом вывод
консоль в строках 29-30. Затем в строке 31 вызывается метод wait,
переводит поток производителя в состояние ожидания объекта Circuj а j
f fer. Когда производитель, наконец, сможет продолжить работу со стр
(по завершении цикла while), сгенерированное им значение будет запц*1^
в кольцевой буфер в позицию, определяемую переменной writeLocati0riC|?l
лее в строках 46-47 выводится сгенерированное производителем знаде
В строке 50 увеличивается значение счетчика occupiedBuffers — Те
в массиве присутствует, по крайней мере, одно ненулевое значение, кощ
может прочесть потребитель. В строке 53 изменяется значение перемени”
writeLocation, чтобы она указывала на правильную позицию при следуй
щем вызове метода set объекта CircularBuffer. Вывод информации накоц
соль возобновляется в строке 56 путем вызова метода createstateoutpui
(строки 107-157), с помощью которого ца экране отображается число заня-
тых элементов массива, содержимое каждого из них, а также значения пере-
менных writeLocation и readLocation. И, наконец, в строке 58 вызывается
метод notify, позволяющий уведомить о том, что поток потребителя, ожи-
дающий освобождения объекта CircularBuffer (если это действительно так),
может продолжить свою работу.
Метод get (строки 61-105) класса CircularBuffer позволяет выполнять
те же операции, что и на рисунке 6.4, хотя он также претерпел некоторые
изменения. Цикл while в строках 67-84 определяет, должен ли потребитель
ждать (например, если все ячейки буфера пустые). Если потоку потребителя
необходимо подождать, строки 73-74 выводят на экран информацию о том,
что потребитель ожидает возможности продолжить свою работу. Затем
в строке 75 вызывается метод wait, который переводит поток производите-
ля в состояние ожидания объекта CircularBuffer. Когда выполнение про-
граммного кода продолжится со строки 87 по окончании цикла while, пере-
менной readValue будет присвоено содержимое элемента кольцевого буФ^
ра, на который указывает переменная readLocation. В строках
осуществляется вывод считанного значения. В строке 94 мы уменьы^И
значение счетчика occupiedBuffers — это означает, что теперь в оуч^И
есть, по крайней мере, одна ячейка, куда производитель может з е
вое сгенерированное значение. Затем в строке 97 обновляется значенИе(;То-
ременной readLocation для того, чтобы она правильно указывала на
положение следующего элемента для чтения методом get объекта дЯ
larBuffer. В строке 100 вызывается метод createStateOutput, к
выводит на консоль количество занятых элементов буфера, их содер
и текущие значения переменных readLocation и writeLocation. 1
в строке 102 вызывается метод notify, позволяющий уведомить о т°
поток производителя, ожидающий освобождения объекта circular рО1»
(если это действительно так), может продолжить свою работу, а в стр (У I
вызывающему методу возвращается считанное потребителем значен I
ратите внимание, что поскольку в Java реализуются мониторы си ,
ции-и-продолжения, в этой программе нам не понадобится выходно
метр, который рассматривался в разделе 6.2.2.
программирование
381
CircularBufferTest (рис. 6.7) состоит из метода main (стро-
который выполняет запуск приложения. В строке 13 создается
,Л 8^4'’ redLocation класса CircularBuffer. В строке 19 20 создаются
s^odUCer и consumer, а в строках 22—23 осуществляется их запуск.
₽ть1 выполнения программы включают информацию о текущем ко
резУльТа занятых элементов буфера, содержимом каждого элемента и те-
дЛ^^дозИЦИИ указателей readLocation и writeLocation. В результатах
j-yOl®11 ия программы буквы W и R обозначают текущую позицию запи-
ия? соответственно. Обратите внимание, что если третье сгенери-
сИ й 41 значение помещается в третий элемент массива, то четвертое сге-
ровав нное значение записывается в начальный (первый) элемент мас-
0ерйР° в этом и заключается эффект кольцевого буфера,
сив» — в
1
2
з
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
// Рис. 6.7: CircularBufferTest.java
// CircularBufferTest демонстрирует, как два потока управляют
// кольцевым буфером.
//создание потоков производителя и потребителя и их запуск
public class CircularBufferTest
(
public static void main ( String args[] )
{
/7 создаем разделяемый буфер для потоков; используем ссылку на
// CircularBuffer вместо Buffer, .чтобы иметь возможность вызвать
// метод createStateOutput класса CircularBuffer
CircularBuffer sharedLocation = new CircularBuffer));
// выводим начальное состояние элементов буфера CircularBuffer
System.err.printin( sharedLocation.createStateOutput() );
// создаем потоки
Producer producer = new Producer( sharedLocation );
Consumer consumer = new Consumer( sharedLocation );
producer.start(); II запуск потока производителя
consumer.start() ; // запуск потока потребителя
1 // окончание функции main
I // окончание класса CircularBufferTest
ваыпаты выполнения программы
содер^ Эшментов; 0)
“'Ржимое: -i
WR
енты пустые. Consumer ожидает.
<tOd4cer „
4аНято записывает 11
СОДеР^оеГе11°Е: -V
R W
Kji
CircularBufferTest, порождающий потоки производителя
Ля (часть 1 из 3)
Consumer считывает 11
(занято элементов: 0)
содержимое: 11 -1 -1
WR
Producer записывает 12
(занято элементов: 1)
содержимое: 11 12 -1
R W
Producer записывает 13
(занято элементов: 2)
содержимое: 11 12 13
W R
Consumer считывает 12
(занято элементов: 1)
содержимое: 11 12 13
W R
Producer записывает 14
(занято элементов: 2)
содержимое: 14 12 13
W R
Producer записывает 15
(занято элементов: 3)
содержимое: 14 15 13
WR
Все элементы заполнены. Producer ожидает.
Consumer считывает 13
(занято элементов: 2)
содержимое: 14 15 13
R W
Producer записывает 16
(Занято элементов: 3)
содержимое: 14 15 16
WR
Все элементы заполнены. Producer ожидает.
Consumer считывает 14
(занято элементов: 2)
содержимое: 14 15 16
W R
Producer записывает 17
(занято элементов: 3)
содержимое: 17 15 16
WR
Рис. 6.7. Класс CircularBufferTest, порождающий потоки производителя
и потребителя (часть 2 из 3)
383
s нроцмммировянио
. считывает 15
(^еР^ое- —
w
г считывает 16
гоП^1^1 элементов. 1)
<^ое: _U_ 2L
' R W
„рг считывает 17
c°nSUTO элементов: 0)
(s^Je- 17 15
содеР^ ______________
WR
producer записывает 18
(занято элементов.1)
содержимое: _17_ _1°_
16
R
16
16
16
R W
Consumer считывает 18
(занято элементов: 0)
содержимое: 17 18 16
WR
Все элементы пустые. Consumer ожидает.
Producer записывает 19
(занято элементов: 1)
содержимое: 17 18 19
W R
Consumer считывает 19
(занято элементов: 0)
содержимое: 17 18 19
WR
Producer
'3ЗНЯТО
С01>еРжим
записывает 20
элементов: 1)
Ое: 20 18
19
R W
Reducer
3авершИи,. аканчивает генерирование.
ние потока Producer.
Consume с
3аНято °ЧИТЬ1Вает 20
Содерж1, элементов: 0)
₽зкимое: 20 18 19
WR
^Puiep„CyMMa прочитанных значений: 155
е потока Consumer.
% z
CircularBufferTest, порождающий потоки производителя
сля (часть 3 из 3)
Вопросы для самопроверки
1. В чем состоят потенциальные преимущества и недостатки
ния размера кольцевого буфера?
2. Что произойдет, если опустить строку 102 на рис. 6.6?
Ответы 1) Потенциальное преимущество заключается в
производитель может генерировать новые значения и ему pe.Ot4,
дется ждать, если в какие-то моменты времени потребитель пяк
медленнее производителя. Однако это может означать напрасцу^Я
ту памяти, если производитель и потребитель работают с один. гРа.
ми скоростями, если один поток работает гораздо быстрее
либо если производитель очень редко опережает потребителя^ т0го
воспользоваться преимуществами дополнительного простраи*0®18!
2) Поток потребителя закончит свою работу, не оповестив об эч CTfia
ток производителя. Если по счастливому стечению обстоятельств^0'
случается крайне редко), производителю не придется ждать потгимГ0
теля, система будет работать безошибочно. Но, что более верой1
если производитель вынужден будет ожидать потребителя, то из-за 01
сутствия уведомления производитель может оказаться в ситуап°Т
взаимоблокировки. 488
веб-ресурсы
developer.java.sun.сот/developer/Books/performance2/chap4.pdf
На этой странице веб-сайта компании Sun вы найдете детальное описание тех-
ники использования мониторов Java.
hissa.nist.gov/rbac/5277/titlerpc.html
Здесь сравнивается несколько популярных реализаций удаленного вызова про-
цедур.
java.sun.сот/docs/books/tutorial/essential/threads/synchronization - html
Пример реализации взаимоисключения в отношении производитель-потреби-
тель на языке Java от компании Sun.
итоги
Программы, выполняемые в параллельном режиме, гораздо сложнее в нал
нии, отладке, модификации и доказательстве правильности, чем последов»
ные программы. Тем не менее, растущий интерес к языкам параллельного,^,
граммирования обусловлен возможностью более естественного решения ПР° удз»'
которые по своей природе являются параллельными. Распространение и
дачных и распределенных систем, а также архитектур массивного паралл
подогрели этот интерес еще больше. сОдеР'
Монитор — это конструкция параллельного программирования, котор*я jjjH
жит как данные, так и процедуры, необходимые для управления распред®
общего ресурса или группы общих ресурсов. Информация спрятана внут!
тора, процессы, обращающиеся к монитору, не знают, какие данные на
внутри монитора, и не имеют к ним доступа. Чтобы выполнить команду ®
ния ресурсов при помощи монитора, поток должен обратиться к процедур
в монитор. Несколько потоков могут намереваться войти в монитор в Рв лрЯ
моменты времени, однако взаимоисключение жестко обеспечивается на гр
385
Программирование
Поток, пытающийся войти в монитор, когда тот используется, будет пе-
<.й*ор состояние ожидания.
s с оВцов, поток, обладающий определенным ресурсом, вызовет процеду-
ре^(<oflUe лнитор, чтобы вернуть его. Поскольку в системе могут присутствовать
в ^н, ожидающие освобождения ресурса, процедура входа в монитор вы-
рУ ,rlIe 0°ТО v сигнализации, позволяя одному из ждущих потоков заполучить ре-
k°msH распоряжение и войти в монитор. Чтобы исключить возможность бес-
Хс в ^вкладывания, монитор отдает предпочтение давно ждущему потоку пе-
fMje4B°r° потоком, пытающимся войти в монитор.
*\д цовЫм каК один поток сможет войти в монитор, другой поток, выдавший ко-
ПереЛ д„лизации (оповещения) должен вначале выйти из монитора. Мониторы
АййДУ с1’яЦИи-и-выхода требуют, чтобы поток осуществлял выход из монитора
сигв8^03 ле выдачи команды сигнализации. В то же время мониторы сигнализа-
сразУ п°СоЛОЛжения позволяют потоку внутри монитора сигнализировать о скором
ццИ-и'пР нии монитора, удерживая при этом блокировку монитора до момента
ос8°б° него_ Поток может выйти из монитора, когда ему нужно ждать перемен-
выхода £ Либо по завершении выполнения программного кода, защищаемого
8 цогюшью монитора.
С Потоку внутри монитора может понадобиться подождать за пределами монито-
пока другой поток не выполнит требуемые задачи внутри монитора. Каждой
Ра’ „ьН0 взятой причине, по которой поток может быть переведен в состояние
°ясидания, соответствует своя переменная-условие. Когда определяется такая пе-
оеменная, тем самым устанавливается очередь. Поток, выдающий команду ожида-
ния wait, включается в эту очередь; поток, выдающий команду сигнализации
signal, позволяет ожидающему потоку выйти из очереди и войти в монитор.
Кольцевой буфер — это структура данных, широко применяемая в операцион-
ных системах для буферизации обмена между потоком-производителем и пото-
ком-потребителем. Потребитель считывает данные в том порядке, в котором они
были записаны производителем (следуя дисциплине первый-пришел-пер-
вый-ушел). Производитель может на несколько позиций опережать потребителя.
В конце концов, производитель запишет данные в последний элемент массива.
Если он продолжит генерировать данные дальше, ему придется перейти по кругу
к началу массива, чтобы начать запись данных в первый элемент.
благодаря фиксированному размеру кольцевого буфера, со временем все эле-
менты массива будут заполнены; в этом случае производитель должен будет подо-
пока потРебитель не освободит один или несколько элементов массива. Воз-
Ланны ВозниКнОвение и обратной ситуации, когда потребитель готов считывать
Л1°, По ’ Н° ВСе Элементы буфера пусты; в этом случае ждать придется потребите-
Если8 П₽Оизводитель не запишет в массив хотя бы одно новое значение.
6°at>ujVIf?Ba ПОтока работают с разными скоростями, то один из них будет тратить
ЧевИя бь Часть вРемени на ожидание. Если производитель будет генерировать зна-
^атить б ^ее’ Чем потРебитель сможет их считывать, поток производителя будет
Х°Тя бы °ЛЬП1УЮ часть времени на ожидание того, когда потребитель освободит
Острец Ч^ИН Элемент массива. И, наоборот: если потребитель считывает данные
с*11 йостод?1 пР°изводитель успевает их записывать, поток потребителя практиче-
На,1еНие НО Вынужден будет ждать, пока производитель запишет в массив новое
Bfcle в КЯдаттл" «
ЙЮтОки “ждои компьютерной системе есть потоки, которые считывают дан-
богЛьку Чи читатели), и потоки, которые их записывают (потоки-писатели). По-
M0(J Ть с Heg Тели не вносят изменений в содержимое базы данных, они могут ра-
Ч°аольный аРаЛЛелЬНО- писателям’ которые модифицируют данные, нужен
ДОСТУП- Если поток-писатель не осуществляет запись, новый по-
м°ясет работать до тех пор, пока другой поток-писатель не захочет
а°»в ь 1J°ToKvb данных. Каждый новый поток-читатель сообщает следующему жду-
°а®ИКя Читателю о том, что тот может продолжить свою работу. Таким обра
ет некое подобие «цепной реакции», продолжающейся до тех пор,
386
пока все ждущие читатели не будут разбужены. Во время такого каскадного
щения обслуживание всех только что прибывших потоков-читателей буп
жено. Кроме того, в этот период ни один из только что прибывших потоков Т
жет войти в монитор, поскольку монитор придерживается правила, соглас %
рому ждущие потоки должны быть обслужены до того, как начнется выц0°
только что прибывших потоков. Если разрешить обработку новых прибыг^М
читателей, тогда непрерывный поток читателей может вызвать бесконечное011^
дывание ждущих потоков. Когда последний поток-читатель покинет мони
оповестит об этом поток-писатель, чтобы тот мог продолжить работу. КогдТ°®’ Ч
тель заканчивает свою работу, он, в свою очередь, сначала проверяет, нет '111Ч
гих потоков-читателей, ожидающих возможности приступить к выполнен11*^
ставленных задач. Если таковые присутствуют, они смогут продолжить
сразу после оповещения писателем (в результате цепной реакции пробужпГ
Если потоки-читатели отсутствуют, работу сможет продолжить поток -писате!
На сегодняшний день мониторы являются главным механизмом обесцечЛ,>'
взаимоисключения и синхронизации в многопоточных приложения Java.
вое слово synchronized обеспечивает взаимоисключение объектов Java. МонлЛ
ры Java представляют собой мониторы сигнализации-и-продолжения, позвол^
щие потоку выдавать команду сигнализации о скором освобождении монитор
и при этом удерживать блокировку монитора до момента своего выхода из него
В языке Java вызов метода wait означает необходимость освобождения блоке,
ровки монитора вызывающим потоком в ожидании переменной-условия. После
выдачи команды wait поток помещается в очередь ожидания, в которой он остает-
ся до тех пор, пока не будет разбужен другим потоком. Поскольку переменные-ус-
ловия объявляются в Java неявным образом, поток может получить оповещение,
войти в монитор и только после этого обнаружить, что ожидаемое им условие не
соблюдается.
Потоки выдают команды сигнализации (оповещения) путем вызова методов
notify и notifyAll. Метод notify пробуждает поток из очереди ожидания. Еслв
доступом к монитору обладают более двух потоков, тогда лучше использовать ме-
тод notifyAll, который разбудит все потоки в очереди ожидания. Поскольку метод
notifyAll пробуждает все потоки, которые намереваются войти в монитор, в неко-
торых приложениях более высокое быстродействие можно получить за счет ис-
пользовании метода notify. И
Ключевые термины
notify — метод Java, выполняющий пробуждение одного потока из очереД з8.
Дания монитора. Алгоритм выбора потока для пробуждения зависит от ре |
ции виртуальной машины Java.
notifyAll — метод Java, с помощью которого можно разбудить все поТОКЙп0р8?8
реди ожидания монитора и очереди входа. Метод notifyAll исключает
ние ждущих потоков в ситуацию бесконечного откладывания, но при
связан с большим количеством накладных расходов по сравнению с
notify. _
Solo — небольшая операционная система, которую написал Пер Бринч
демонстрации принципов отказоустойчивого параллельного прогр8
ния. ,
synchronized — ключевое слово в Java, обеспечивающее монопольный
к коду внутри объекта.
Инкапсуляция информации — см. Сокрытие информации.
программ роВанио
387
„ буФеР (circular buffer или bounded buffer) — область разделяемой па-
ссированного размера в отношении производитель-потребитель, в кото-
<<*йЛяятся значения, генерируемые производителем. Если производитель на-
ой ’сРаЯрнерировать данные быстрее, чем потребитель их принимает, наличие
РцИаеТ Г го буфера позволяет уменьшить время, затрачиваемое на ожидание по-
производителем, по сравнению с использованием одноэлементного
^.ребител^сЛИ ПОТребитель временно начинает работать быстрее производителя,
буфера- буфер также позволяет уменьшить время ожидания потребителем
йоЛьИеВ сГенерированных производителем.
де®®14 ’ п^ог) — это конструкция параллелизма, которая содержит как дан-
*>»***« и процедуры, необходимые для управления взаимоисключением при
йые> та елении общего ресурса или группы общих ресурсов.
РаСПре’^.игнализации-и-выхода (signal-and-exit monitor) — монитор, который
от пОтока немедленного выхода из монитора после выдачи команды опо-
ТР ения о доступности другому потоку.
В тпп сигнализации-и-продолжения (signal-and-continue monitor) — монитор,
М°вИ „ый позволяет потоку, выдавшему команду сигнализации о скорой доступ-
к° „и монитора, продолжать выполнение внутри монитора и не снимать блоки-
Н ЕКу до тех пор, пока поток не закончит работу и не выйдет из монитора. С это-
го момента войти в монитор сможет поток, получивший оповещение.
Очередь входа (entry queue или entry set) — в Java очередь потоков, ожидающих
возможности войти в монитор после вызова метода synchronized.
Очередь ожидания (wait queue или wait set) — группа потоков в Java, ожидающих
возможности повторно наложить блокировку на монитор.
Переменная-условие (condition variable) — переменная, которая содержит опреде-
ленное значение и которой может быть выделена очередь. Если потоку необхо-
димо дождаться переменной-условия в тот момент, когда он находится внутри
монитора, он выходит из монитора и попадает в очередь ожидания перемен-
ной-условия. Потоки пребывают в этой очереди до тех пор, пока не получат опо-
вещения от других потоков.
Последовательно используемый разделяемый ресурс (serially reusable shared
resource) — ресурс, который в любой момент времени может использоваться
только одним потоком.
Цедура входа в монитор (monitor entry routine) т- процедура монитора, к ко-
оди И может обратиться любой поток, но выполнять которую может только
ра поток в данный момент времени. В отличие от частных процедур монито-
вхопЯКОТОРым МогУт обращаться только потоки внутри монитора, процедуры
СВв В МОнитоР гарантируют взаимоисключение.
хРонн Зачия (synchronization) — координация взаимодействия между асин-
Па к Пд1МИ пг|Раллельными потоками для обеспечения последовательного досту-
^°КрЬ1т 3ДеляемЬ1м ресурсам.
етвУюц1я,В^>О₽мации (information hiding) — программная архитектура, способ-
йеЧосре Я РазРаботке наиболее стабильных систем благодаря предотвращению
Дственного доступа к данным объекта со стороны внешних объектов.
^Жненая
Ког ^Ите использование мониторов и операции над семафорами.
Ь-3 ЦРеДц ₽есУРс возвращается потоком, вызвавшим монитор, монитор отдает
°чтение давно ждущему потоку перед свежими потоками. Почему?
cMbi ЯеРеменные-условия отличаются от обычных переменных? Имеет ли
L Инициализация переменных-условий?
6.4. Мы постоянно говорили, что при реализации многопоточности не 4
лать никаких предположений об относительных скоростях асин*11'3’!
параллельных потоков. Почему?
6.5. Какие факторы, по вашему мнению, могут повлиять на выбор Пр0
стом количества элементов буфера?
6.6. Почему намного сложнее тестировать, отлаживать и доказывать
ность работы программ, которые выполняются в параллельном реа^^Ч}
сравнению с программами с последовательным кодом?
Мы говорили о том, что сокрытие (инкапсуляция) информации пре
ет собой одну из технологий построения системных структур, котов
собствовала разработке более надежных программных систем. Почем
вы думаете, это так? У> ц
Еще раз изучите монитор на рисунке 6.2 и ответьте на следующие во1ТГич
а. Какая процедура помещает данные в кольцевой буфер?
б. Какая процедура удаляет данные из кольцевого буфера?
в. Какая дисциплина обслуживания очереди наилучшим образом on 1
вает работу с кольцевым буфером? вС1*-
г. Справедливо ли утверждение: writerPosition>=readerPosition?
д. Какие операторы используются для инициализация монитора?
е. Какие операторы позволяют «разбудить» поток, ожидающий перещщ.
позволяют перевести поток в «спящий» режим?
позволяют возвратиться к началу буфера?
6.7.
6.8.
6.9.
6.10.
6.11.
ную-условие?
ж. Какие операторы
з. Какие операторы
и. Какие операторы модифицируют совместно используемые переменные
с целью демонстрации доступности очередного элемента буфера?
Почему в мониторе с потоками-читателями и писателями, представленииI
на рисунке 6.3, желательно организовать каскадное оповещение всех пото-
ков-читателей? Не приведет ли это к бесконечному откладыванию пото-
ков-писателей? При каких условиях следует ограничивать количество опо-
вещаемых читателей из числа ожидающих своей очереди, когда чтение
снова будет разрешено?
(Проблема спящего парикмахера)53 В парикмахерской есть зал для стриж-
ки для одного клиента и комната ожидания для п клиентов. Клиенты заЯ1
дят в комнату ожидания по одному, если в ней есть место, либо ух®
стричься в другой салон, если все места заняты. После того как паРикМпЯ|»
заканчивает стрижку, клиент покидает салон и к парикмахеру 3 г
следующий клиент (если таковой имеется). Клиенты могут по о-Дн0М^яЯас»
дить в комнату ожидания и также по одному заходить в зал для
(если он свободен), причем эти два события являются взаимоисклЮ
ми. Если парикмахер видит, что в зале ожидания никого нет, он п₽ ons-
вается вздремнуть в этом зале. Новый клиент, обнаружив дремлЮ -jjet
рикмахера, будит его, и тот стрижет клиента; в противном случае
ший клиент должен будет подождать. Воспользуйтесь монитора
скоординировать действия парикмахера и клиентов. Если вы
с языком программирования Java, напишите монитор для этого пр
Java.
(Проблема курильщиков)54 [Примечание: Один из авторов даяя ГР^р1
Харви Дейтел работал вместе с С. Патилем и Джеком Деннисоп^ ^с^у
вычислительных структур проекта Мас Массачусетского техноло^^^
института.] Данная проблема была отнесена к одной из классиче р <
блем управления параллелизмом. Представим трех курильщик
щью потоков SI, S2 и S3, а трех производителей сигарет — в
VI, V2 и V3. Каждому курильщику нужен табак, папиросная бум
торую нужно завернуть табак, чтобы сделать сигарету и спичкЯ-
эти три компонента доступны, курильщик может выкурить
t программирование
389
,hVIb готовым при случае закурить снова. У S1 есть табак, у S2 — папи-
И оЬаЯ бумага, а у S3 — спички. VI поставляет табак и папиросную бумагу,
папиросную бумагу и спички, и, наконец, V3 — спички и табак. По-
V2 V2 и V3 выполняются во взаимоисключающем режиме — то есть
Т°КИвпеменно может выполняться только один из вышеперечисленных по-
оДя причем следующий поставщик сможет продолжить работу только
ТоКО ’ огО, как ресурсы, которыми занимается предыдущий поставщик,
я°слт доставлены курильщику. Воспользуйтесь монитором, чтобы скоор-
пировать действия курильщиков и поставщиков.
L ^мафоры имеют функциональные возможности, которые, по крайней
6.12- 4/6 е не меньше чем у мониторов. Покажите, как можно реализовать мо-
Sop С помощью семафоров.
Воспользуйтесь семафорами для решения проблемы читателей и писателей.
6Пводумайте решение проблемы читателей и писателей. Смоделируйте его,
6-Н’ ^пользовавшись решением проблемы потоков-читателей и потоков-писа-
телей, приведенной на рисунке 6.2 и Java-решениями, в которых приме-
нялся’ кольцевой буфер на рисунках 6.6 и 6.7.
5 Должен ли давно ждущий поток иметь преимущество перед потоком, кото-
6’ рый впервые обращается к монитору? Какую схему приоритетов следует
применять к ждущим потокам?
рекомендуемые исследовательские учебные проекты
6.16. Подготовьте исследовательскую статью по теме параллельного программи-
рования для видеоприставок. Предусмотрены ли аппаратные примитивы
взаимоисключения для прикладных программистов?
Рекомендуемые программные учебные проекты
6.17. Усовершенствуйте реализацию отношения производитель-потребитель, не
прибегая к помощи кольцевого буфера, используемого на рисунке 6.1, для
обслуживания нескольких производителей.
^омендуешя литературе
вольно'пя6 Решения проблемы параллельного программирования известны уже до-
Ли₽°вано П °~ Пе₽вое полноценное решение проблемы параллелизма было сформу-
ЛистЫ в ^нкртрой, после чего свои решения предложили многие другие специа-
^Овсключе11Н011 °®ласти-56,57’58’59 Последние разработки в сфере алгоритмов взаи-
ц1ПоэТому в ИЯ пРеДназначены, в первую очередь, для распределенных систем
ЭД Мся ДанньХ°ДЯТ Зй ₽амки Рассмотрения данной главы. Читателям, интересую-
®!i Пробл 1М ВОпР°СОм> мы рекомендуем изучить статьи Лэмпорта, содержащие
X °’61 ПеМЫ взаимоисклЮчения и ряд убедительных результатов ее реше-
оО(}СеВ62 и ДР®ондчальную концепцию мониторов усовершенствовал Бринч
®о&^*8ается °а₽’ Автором отличной обзорной статьи по мониторам, в которой
’’У, s'16 cBeneIIX Исто₽ия, систематика и использование, является Бур.64 Более под-
,*|<гр0Ь1 вайде~Ия по программированию на языке Java, в том числе параллельно-
е в книге Как программировать на Java65 и Параллельное програм-
аиа: принципы и шаблоны проектирования, 2-е изд.66 Свежую биб-
6*tei Ля этой главы вы найдете на нашем веб-сайте по адресу:
orn/books/os3e/Bibl iography.pdf.
390
Использованная литература
1. «Rationale for the Design of the Ada Programming Language,» AGM Slcn
Notices, Vol. 14, No. 6, June 1979, Part B.
2. Carvalho, O. S. F., and G. Roucairol, «On Mutual Exclusion in Compute
works,» Communications of the ACM, Vol. 26, No. 2, February 1983, pp. ^et
3. Liskov, B., R. Scheifler, «Guardians and Actions: Linguistic Support for f?
Distributed Programs,» ACM Transactions on Programming Languages ana
terns, Vol. 5, No. 3, 1983, pp. 381-404. ‘ ‘ ° 8У^
4. Shatz, S. M., «Communication Mechanisms for Programming Distributed 0
terns,» Computer, Vol. 17, No. 6, June 1984, pp. 21-28. 8У«-
5. Fisher, D. A., and R. M. Weatherly, «Issues in the Design of a Distributed о
ating System for Ada,» Computer, Vol. 19, No. 5, May 1986, pp. 38-47. U®er’
6. Liskov, В., M. Herlihy; and L. Gilbert, «Limitations of Synchronous Commute
tion with Static Process Structure in Languages for Distributed Computing'
Proceedings of the 13th ACM Symposium on Principles of Programming La
guages, St. Petersburg, Florida, January 1986.
7. Shatz, S. M., and J. Wang, «Introduction to Distributed-Software Engineering
Computer, Vol. 20, No. 10, October 1987, pp. 23-32.
8. Roberts, E. S.; A. Evans, Jr.; C. R. Morgan; and E. M. Clarke, «Task Manage,
ment in Ada — A critical Evaluation for Real-Time Multiprocessors,» Soft
ware — Practice and Experience, Vol. 11, No. 10, October 1981, pp. 1019-1051.
9. Nielsen, K. W., and K. Shumate, «Designing Large Real-Time Systems with
Ada,» Communications of the ACM, Vol. 30, No. 8, August 1987, pp. 695-715.
10. Ford, R., «Concurrent Algorithms for Real-Time Memory Management», IEEE
Software, Vol. 5, No. 5, September 1988, pp. 10-24.
11. «Preliminary Ada Reference Manual,» ACM SIGPLAN Notices, Vol. 14, No. 6,
June 1979, Part A.
12. Brinch Hansen, P., «The Programming Language Concurrent Pascal,» IE®
Transactions on Software Engineering, Vol. SE-1, No. 2, June 1975, pp. 199-207.
13. Coleman, D.; Gallimore, R. M.; Hughes, J. W.; and M. S. Powell, «An Assess-
ment of Concurrent Pascal,» Software — Practice and Experience, Vol. 9, 1"? 1
pp. 827-837. p
14. Brinch Hansen, P., «Distributed Processes: A Concurrent Programming Concep I
Communications of the ACM, Vol. 21, No. 11, November 1978, pp. 934-941-
15. Gehani, N. H., and W. D. Roome, «Concurrent C,» Software — Practice an
perience, Vol. 16, No. 9, 1986, pp. 821-844. ntl8J
16. Kieburtz, R. B., and A. Silberschatz, «Comments on ‘Communicating 1
Processes,» ACM Transactions on Programming Languages and Systems, 1
No. 2, 1979, pp. 218-225
17. Hoare, C. A. R., Communicating Sequential Processes, Englewood Cli
Prentice-Hall, 1985 (есть русский перевод: Ч. Хоар, «ВзаимодействУ
последовательные процессы», М.: «Мир», 1989, 264 с).
18. Hoppe, J., «А Simple Nucleus Written, in Modula-2: A Case Study,» S°*
Practice and Experience, Vol. 10, No. 9, September 1980, pp.697-706.
19. Wirth, N., Programming in Modula-2, New York: Springer-Verlag,
русский перевод: H. Вирт, «Программирование на языке МодУла
«Мир», 1987, 224 с „gg. I
20. Ogilvie, J. W. L., Modula-2 Programming, New York: McGraw-Hill,
21. McGraw, J. R., «The VAL Language: Description and Analysis,» A< gg. .
tions on Programming Languages, Vol. 4, No. 1, January 1982, pp- j
22. Cook, R. P., « •’MOD — A Language for Distributed Programming,» lEE i j
actions on Software Engineering, Vol. SE-6, No. 6, 1980, pp. 563-571- I
)S программирование
391
tra E. W., «Hierarchical Ordering of Sequential Processes,» Acta
„3. P^matica, Vol. 1, 1971, pp. 115-138.
' h Hansen, P., «Structured Multiprogramming,» Communications of the
Mjvol. 15, No. 7, July 1972, pp. 574-578.
ACIV ’. Hansen, P., Operating System Principles, Englewood Cliffs, N.J.:
2* prentice Hall, 1973.
C A. R-» «Monitors: An Operating System Structuring Concept,» Com-
26- P^ations of the ACM, Vol. 17, No. 10, Octoberl974, pp. 549-557. Corrigen-
1111111 Communications of the ACM, Vol. 18, No. 2, February 1975, p. 95.
^"nch Hansen, P., «The Solo Operating System: Processes, Monitors, and
2* ppgses,» Software — Practice and Experience, Vol. 6, 1976, pp. 165-200.
«/«rd J- H., «Proving Monitors,» Communications of the ACM, Vol. 19, No.
3*5°May 1976, pp. 273-279.
Howard, J. H., «Signaling in Monitors,» Second International Conference on
Software Engineering, San Francisco, October 1976, pp. 47-52.
Lister, A. M., and K. J. Maynard, «An Implementation of Monitors,» Soft-
ware — Practice and Experience, Vol. 6, No. 3, July 1976, pp. 377-386.
U Kessels, J. L. W, «An Alternative to Event Queues for Synchronization in Moni-
tors,» Communications of the ACM, Vol. 20, No. 7, July 1977, pp. 500-503.
2 Keedy, J-, «On Structuring Operating Systems with Monitors,» Australian Com-
puter Journal, Vol. 10, No. 1, February 1978, pp. 23-27, reprinted in Operating
Systems Review, Vol. 13, No. 1, January 1979, pp. 5-9.
33. Lampson, B. W, and D. D. Redell, «Experience with Processes and Monitors in
MESA,» Communications of the ACM, Vol. 23, No. 2, February 1980, pp. 105-117.
34. Wegner, P., and S. A. Smolka, «Processes, Tasks and Monitors: A Comparative
Study of Concurrent Programming Primitives,» IEEE Transactions on Software
Engineering, Vol. SE-9, No. 4, July 1983, pp. 446-462.
35. Buhr, P. A.; Fortier, M.; and Coffin, M.; «Monitor Classifications,» ACM Com-
puting Surveys, Vol. 27, No. 1, March 1995, pp. 63-107.
•’>•>. Hoare, C. A. R., «Monitors: An Operating System Structuring Concept,» Com-
munications of the ACM, Vol. 17, No. 10, October 1974, pp. 549-557.
!7. Buhr, P. A.; Fortier, M.; and Coffin, M., «Monitor Classification,» ACM Com-
puting Surveys, Vol. 27, No. 1, March 1995, pp. 63-107.
Brinch Hansen, P., «The Programming Language Concurrent Pascal,» IEEE
:jn ransactions on Software Engineering, No. 2, June 1975, pp. 199-206.
Byracusa University, «Biography,» <web.syr.edu/~pbhansen/html/biography.html>.
41 _ . cuseUniversity, «Biography,» <web.syr.edu/~pbhansen/html/biography.html>.
Рг^-' Hansen, P-, Operating System Principles, Englewood Cliffs, N.J.:
42. Bri Ce Hal1’ 1973-
term? ^anscn> Р-» «The Purpose of Concurrent Pascal,» Proceedings of the In-
43 Syrac, 1On&l Conference on Reliable Software, pp.305-309, 1975.
4^-Bri ?Se University, «Biography,» <web.syr.edu/-pbhansen/html/biography.html>.
No*1/1 Hansen, P., «Java’s Insecure Parallelism,» SIGPLAN Notices, Vol. 34,
&riiichPP 33~45> April 1999.
. ^^nserl’ P-> «The Solo Operating System,» Software — Practice and Ex-
Brinch HVoL 6’ N°’ 2’ pp- 141-205’ April-June 1976.
tehis » c/Ken’ P-’ «Joyce — A Programming Language for Distributed Sys-
4' 29.5(1 ware — Practice and Experience, Vol. 17, No. 1, January 1987,
a^hicgS' A- R., «Monitors: An Operating System Structuring Concept,» Com-
c 10ns of the ACM, Vol. 17, No. 10, Octoberl974, pp. 549-557. Corrigen-
°nimunications of the ACM, Vol. 18, No. 2, February 1975, p. 95.
Мы лучше подождем и увидим.
Герберт Генри Асквит
Любой человек является центром круга, ейти
за пределы которого он не в состоянии.
Джон Джеймс Ингалс
Удержи меня, но осторожно, узамиi
Одного бессмертного взгляде
Роберт Epay^UJil I
Расследование есть, или, по крайней ме
должно быть точной наукой, коТ°д1^1
требует холодного Ра
и отсутствия I
Сэр Артур Конан Д I
Бывают гибельны отср0
Уильям
ВзяимобАокиройки
и бесконечное тк ajbidme
, Цели
Прочитав эту главу, вы должны понимать:
• проблему взаимоблокировок или тупиковых ситуаций;
• четыре условия, необходимых для возникновения
взаимоблокировки;
проблему бесконечного откладывания;
вопросы предотвращения, обнаружения, обхода
взаим°б локирован и восстановления после них;
алг°Ритмы обнаружения и обхода взаимоблокировок;
Постановить систему после взаимоблокировки.
Краткое содержание главы
7.1 Введение
7.2 Примеры взаимоблокировок
7.2.1 Транспортная пробка как пример взаимоблокировки
Поучительные истории: Мост с одной полосой
7.2.2 Простой пример взаимоблокировки при распределении ресурсов
7.2.3 Взаимоблокировки в системах спулинга
Размышления об операционных системах:
Ожидание, взаимоблокировки и бесконечное откладывание
7.2.4 Пример: Обедающие философы
7.3 ПохоЖая проблема — бесконечное откладывание
7.4 Концепция ресурсов
7.5 Четыре необходимых условия
возникновения взаимоблокировки
7.6 Решения проблемы взаимоблокировок
7.7 Предотвращение взаимоблокировок
Поучительные истории: Никаких болтов, винтов и гаек
7.7.1 Нарушение условия оЖидания дополнительных ресурсов
7.7.2 Нарушение условия неперераспределяемости
7.7.3 Нарушение условия кругового оЖидания
7.8 Обход взаимоблокировок с помощью алгоритма банкира
Поучительные истории: Акронимы
7.8.1 Пример надежного состояния
7.8.2 Пример ненадежного состояния
7.8.3 Пример перехода из надежного состояния в ненадежное
7.8.4 Распределение ресурсов согласно алгоритму банкира
7.8.5 Недостатки алгоритма банкира
7.9 Обнаружение взаимоблокировок
7.9.1 Графы распределения ресурсов
7.9.2 Приведение графов распределения ресурсов
7.10 Восстановление после взаимоблокировок
7.11 Стратегии борьбы с взаимоблокировками
в современных и будущих системах
'(и и &оночное откмдыВанио
397
f ^Ведение
тяущие четыре главы были посвящены рассмотрению асинхрон-
аллельных процессов и потоков. Многозадачная система обладает
ajjx па₽оеимуществ, но, как уже говорилось в главе 6, программирование
рЯД°м ^гозадачной системы вносит дополнительную сложность. Одна из
ддЯ МЙ°аЛьных проблем многозадачной системы — взаимоблокировки
n^Sck) или тупиковые ситуации. Процесс или поток попадают в состоя-
(dea«‘° блокировки (или тупика), когда они вынуждены ожидать появ-
18116 В3 события, которое никогда не наступит. Взаимоблокировка либо ту-
дейИЛ сИТуация системы («зависание») наступает тогда, когда один или
рроцессов оказываются в состоянии тупика.1’2 в этой главе мы в ос-
будем говорить о процессах, однако большая часть изложенной
000 информации распространяется и на потоки.
^^многозадачной компьютерной системе вопрос разделения ресурсов яв-
ся одним из самых важных. Когда ресурсы совместно используются
многими процессами, каждому из которых предоставляется право исклю-
чительного управления выделенными ему конкретными ресурсами, впол-
не возможно возникновение взаимоблокировок, из-за которых процессы
некоторых пользователей никогда не смогут завершить работу. Результа-
том может стать потеря данных, падение производительности системы
либо фатальный сбой.
В этой главе обсуждается проблема взаимоблокировок, и приводятся че-
тыре основных направления научных исследований в области взаимобло-
кировок: предотвращение (prevention), обход (avoidance), обнаружение
(detection) взаимоблокировок и восстановление (recovery) после них. Рас-
сматривается также родственная проблема бесконечного откладывания
(indefinite postponement или starvation), когда процесс, даже не находя-
щийся в состоянии взаимоблокировки, ожидает события, которое может
никогда не произойти, либо произойдет неизвестно когда в отдаленном бу-
дущем из-за ошибочного выбора политики планирования ресурсов. В неко-
ей ЫХ Сл^Чаях Цена, которую приходится платить за то, чтобы сделать
Ряд еМУ Св°б°Дн°й от взаимоблокировок, слишком высока. Однако есть
Дач СИТуаций’ например, в системах для решения жизненно важных за-
Кипой°ГДа ПР°СТО нет иного выбора, поскольку возникновение взаимобло-
с°3Дат И МОжет привести к катастрофическим последствиям, в том числе,
МисснЬ1 УГР°3^ человеческой жизни. Мы рассмотрим возможные компро-
б°Рьбы Ре1Цения с точки зрения накладных затрат на включение средств
Мцх (и- ° взаим°блокировками и бескойечным откладыванием и ожидае-
мого выгод.
398
Вопросы для самопроверки
1. Системный программист решил исключить любую возмог,
взаимоблокировки, написав многозадачную систему, в кото
поддерживается разделение ресурсов. Что не так в его поду ?
2. Что общего между взаимоблокировками и бесконечным откп '
нием? ЛгЧч
Отве(ПЫ 1) Такая система будет работать крайне неэффективп
скольку каждому процессу понадобится свой набор ресурсов.
того, асинхронные параллельные программы часто не в состоянии 'Ч
тись без таких разделяемых ресурсов, как семафоры. 2) Взаимоб0^
ровки и бесконечное откладывание схожи в том, что и те и
возникают тогда, когда процесс ожидает определенного события
моблокировки возникают в случае, если событие никогда не пр'ои^
дет; бесконечное откладывание возникает, если процесс ожв3°®'
события, которое произойдет неизвестно когда или может не проИЗ(у?1
вообще (из-за ошибочного выбора политики планирования ресурСо^т®
7.2 Примеры взаимоблокировок
Взаимоблокировки могут возникать по многим причинам. Если процесс
будет все время ждать определенного события, но в системе не предусмот-
рена сигнализация о наступлении этого события, мы столкнемся с приме-,
ром тупиковой ситуации для одного процесса.3 Подобные взаимоблокиров-
ки очень сложно обнаружить. В реальных системах во взаимоблокировку
оказываются вовлеченными многие процессы, соревнующиеся за право об-
ладания ресурсами различных типов. Приведем несколько наглядных
примеров.
7.2.1 Транспортная пробка как пример взаимоблокировки
На рис. 7.1 показана транспортная пробка, которая периодически воз
никает в наших городах. Несколько автомобилей пытаются проехать чер
перегруженный транспортом участок города, однако движение оказыва J
ся полностью парализованным. Здесь образовался абсолютный затору
что необходимо вмешательство регулировщиков, чтобы постепенно и
рожно подать автомобили назад из зоны затора и тем самым лиКВИД
вать «пробку». В конце концов, нормальное движение машин восстала^ j
вается, однако подобные ситуации связаны с большими неприятное'1' е
затратами нервов и значительными потерями времени (см. «Поучите
истории: Мост с одной полосой»).
f«e. 7.1.
Транспортная пробка как пример взаимоблокировки4
Вопросы дм самопроверки
1- Предположим, что в заторе участвует ровно столько машин, сколь-
ко изображено на рисунке 7.1 (то есть под многоточием другие ма-
шины не подразумеваются). Сколько машин нужно будет подать
назад, чтобы восстановить нормальное движение транспорта, и ка-
кие машины следует выбрать на эту роль?
2. Если бы вы могли просто приподнять в воздух любой автомобиль,
изображенный на рисунке 7.1, сколько машин понадобилось бы уб-
рать, чтобы избавиться от затора?
Ответы 1) На рисунке 7.1, чтобы восстановить нормальное движе-
ние транспорта, вам нужно будет подать назад всего две последних ма-
шины на любой улице. 2) Вам достаточно будет приподнять всего одну
Из любых четырех машин, перегораживающих перекрестки.
400
Г.
Поучительные истории
Мост с одной полосой
Бывший студент курса по операцион-
ным системам, который читал Харви Дей-
тел, ставший одним из первых разработчи-
ков персонального компьютера фирмы
IBM, рассказал во время лекции по взаимо-
блокировкам один анекдот. Едут по мосту
с одной полосой навстречу друг другу два
водителя. Доезжают до середины
Выходят из машины и становятся
клицу. Один водитель говорит
стану из-за какого-то идиота в
<<лИЧн0
ся назад». На что другой, садясь
и сдавая назад, отвечает: «ладно
сделаю я».
в
т°гда
Урок для разработчиков операционных систем: процессы не могут быть упрямыми
сговорчивыми, поэтому взаимоблокировка в лучшем случае будет означать для вас зА
на приобретение опыта. Обычно одному или нескольким процессам приходится выпол!
откат, что приводит к частичной или полной потере проделанной ими работы
Рис. 7.2. Пример взаимоблокировки ресурсов. Данная система попала ® сурс>
взаимоблокировки по причине того, что каждый процесс удерживает Р ’ь
в котором нуждается другой процесс и ни один процесс не желает отда
занимаемый им ресурс
•а! и бесконечное откладывание
401
I л остой пример взаимоблокировки при распределении ресурсов
J ' сТВО взаимоблокировок в системе возникают по причине нор-
оикУРенции за п₽аво обладания выделенными ресурсами
Я Resources), то есть такими ресурсами, которые могут в разные
'jedic0*®11 огут использоваться разными процессами, но в любой момент
оМевТЬ1 х может использовать только один конкретный процесс. Для
"оеМ6*111 1 а таких ресурсов еще используется термин ресурсы носледова-
^озй0че двторного использования (serially reusable resources). В качест-
можно привести принтер, который в любой момент времени
ве оРи1йе,дОлнять задания только одного потока (в противном случае рас-
цоЖеТ листы различных заданий просто перемешаются). Простей-
печата взаимоблокировки ресурсов показан на рисунке 7.2. На изо-
изий ПР здесь графе распределения ресурсов (resource allocation graph)
°™ сы представлены в виде прямоугольников, а ресурсы — в виде
fllX®eKoB. Стрелки от ресурса к процессу показывают, какому процессу
КРУ вЫделен данный ресурс. Стрелка от процесса к ресурсу показывает,
о процесс запросил данный ресурс, но тот еще не был ему выделен. На
иаграмме показана ситуация взаимоблокировки: процесс ₽! удерживает
ресурс Ri» но для продолжения работы ему нужен ресурс R2. Процесс Р2
удерживает ресурс Ri, но для продолжения работы ему необходим ресурс
Rp Получается, что оба процесса ожидают друг друга. Наличие подобного
кругового ожидания (circular wait) является главным признаком взаимо-
блокировки в системе (см. «Размышления об операционных системах:
Ожидание, взаимоблокировки и бесконечное откладывание»). Для обозна-
чения ситуации такого прочного удерживания ресурсов иногда использу-
ют термин клинч (deadly embrace).
Вопросы для самопроверки
1. Если взаимоблокировку на примере транспортной пробки, изобра-
женную на рисунке 7.1, представить с помощью графа распределе-
ния ресурсов, то какие элементы нам следует выбрать на роль
процессов, а какие — на роль ресурсов?
2. Предположим, что в графе распределения ресурсов от одного про-
цесса отходит несколько стрелок к ресурсам. Что это означает? Как
это может повлиять на вероятность взаимоблокировок?
Ответы 1) В роли процессов должны выступать автомобили,
а в роли ресурсов — следует выбрать участки дороги, занятые маши-
нами. Каждый автомобиль удерживает блокировку участка дороги не-
2?ч>еДСтвенн0 П°Д собой и запрашивает участок дороги перед собой.
) ото означает, что для работы процесса необходимо несколько ресур-
Вероятность взаимоблокировки зависит от того, используются ли
3й ₽есуРсы другими процессами, которые могут в свою очередь запро-
ть Ресурсы, удерживаемые данным процессом.
402
7.23 Взаимоблокировки в системах спулинга
Средства спулинга применяются для повышения производитед
системы путем изолирования программ от такого низкоскоростное
ферийного оборудования, как, например принтеры. Если, скажем
грамме, выдающей строки данных на принтер, приходится ждать ’
чатки каждой строки перед передачей следующей строки, то такая^
грамма будет выполняться медленно. Чтобы повысить CRo *Фо.
выполнения программы, строки данных, предназначенные для
вначале записываются на более высокоскоростное устройство, наип^1
дисковый накопитель, где они временно хранятся до момента распеча
Системы спулинга могут быть подвержены взаимоблокировкам. В тЛ
торых системах спулинга программа должна сформировать все выхОп
данные — только после этого начинается реальная распечатка. В Сй ***
с этим несколько незавершенных заданий, формирующих строки данк 3,1
и записывающих их в файл спулинга для печати, могут оказаться в тупи
ковой ситуации, если доступная емкость диска будет заполнена прежда
чем завершится выполнение какого-либо задания. В качестве одного из
способов восстановления работоспособности можно предложить уничтоже-
ние пользователем или системным администратором одного или несколь-
ких заданий, пока у остающихся заданий не окажется достаточно свобод-
ного места в буфере, чтобы они могли закончить.
Обычно системный администратор задает размер буферных файлов для
спулинга. Один из способов уменьшить вероятность взаимоблокировок
при спулинге заключается в том, чтобы предусмотреть значительно боль-
ше места для файлов спулинга, чем необходимо согласно предварительной
оценке. Подобное решение не всегда осуществимо, если память дефицит-
на. Более распространенное решение состоит в том, что для процессов
входного спулинга устанавливаются ограничения, чтобы они не могли
принимать дополнительные задания, если заполнение файлов спулинга
достигает некоторого порога насыщения (saturation threshold), например-
они оказываются заполненными на 75%. Такой подход может привести
к некоторому снижению производительности системы, однако это
цена, которую приходится платить за уменьшение вероятности взаимо
КИрОВКИ.
Современные системы являются в этом смысле гораздо более совер
ными. В них можно начать печать до того, как завершится переда1#*,
редного задания, позволяя полному или почти полному файлу d У
освобождаться полностью или частично уже в процессе выполнения ?
ния. Данная концепция применяется к потоковому аудио и видео, до
возможность начинать проигрывание аудио- и видео-файлов заД°
того, как файл будет загружен полностью. Во многих системах преД-
рено динамическое распределение памяти, так что, если отведение!
в памяти оказывается мало, для файлов спулинга выделяется Д°
тельная память.
403
>Вки ч бесконечное откладывание
^1
ИИ размышления ob о аиион i
бзаимобАокировки и бесконечное
вкладывание
иионные системы должны справ-
0ПеР^амыми разнообразными ситуация-
лятьсЯ С имя пля чего широко применяются
Процессы и потоки ожидают осво-
°Чере^ия процессора, нередко им прихо-
б0?КД ждать завершения операций вво-
Д*7ывода или того, чтобы запрошенные ими
Десурсы снова стали доступны. Запросы вво-
Ра/вывода сами по себе должны ожидать,
пока освободятся устройства ввода/вывода.
Процессам и потокам, разделяющие данные,
иногда приходится ожидать пока процесс или
поток, работающий с этими данными в теку-
щий момент, закончат работу и выйдут из
критического участка. В отношении произво-
дитель-потребитель, производитель переда-
ет информацию потребителю через область
разделяемой (совместно используемой) па-
мяти. Когда эта область памяти заполняется,
производитель больше не может генериро-
еать яанные и ему приходится ждать, пока
потребитель не удалит из буфера лишние
'^ь'е П°СЛе их прочтения; если область па-
подо УДвТ Пуста' потребитель должен будет
dvpt. аТЬ' пока производитель не сгенери-
УеТвНовые данные.
примеру КНИГе вы встРетите множество
°нныес СЦенаРиев ожидания. Операци-
₽3тн° у:"6- Д0ЛЖНЬ| чрезвычайно акку-
*ЙТь двуРЭВЛЯТЬ ожиДанием, чтобы избе-
рем- Вз* СеРьезных потенциальных про-
и*иоблокировок и бесконечного
откладывания, которые подробно обсуж-
даются в данной главе. В случае развития
сценария взаимоблокировки, процессы
и потоки будут вынуждены ожидать собы-
тий, которые никогда не произойдут. В про-
стейшем примере взаимоблокировки двух
процессов, каждый процесс ожидает осво-
бождения ресурса, работать с которым раз-
решается только в монопольном режиме,
и при этом данный ресурс занят другим
процессом. Таким образом, оба процесса
блокируют дальнейшую работу друг друга,
что может привести к фатальным последст-
виям в системе, предназначенной для ре-
шения жизненно важных задач, от работы
которой зависят человеческие жизни. Бес-
конечное откладывание обычно возникает
тогда, когда процессы ожидают в очереди,
в то время как другие процессы, вероятно,
с более высоким приоритетом, добавляют-
ся в начало очереди, не давая закончить ра-
боту другим процессам. Постоянно прибы-
вающие высокоприоритетные процессы
могут привести к бесконечному откладыва-
нию других низкоприоритетных процессов.
Последствия этого в системах, предназна-
ченных для решения жизненно важных за-
дач, могут быть аналогичны последствиям
взаимоблокировок. Поэтому отнеситесь
к проблеме ожидания серьезно - при от-
сутствии должного управления могут воз-
никать системные сбои.
Вопросы для самопроверки
1. Предположим, что порог насыщения системы спулинга сост
75%, а ограничение на максимальный размер файла____25'/
щего пространства, выделенного под спулинг. Может ли в эт
теме возникнуть взаимоблокировка? Ctl
2. Предположим, что порог насыщения системы спулинга сост
75%, а ограничение на максимальный размер файла -— 25%
щего пространства, выделенного под спулинг. Опишите про,Ч.
соб предотвращения взаимоблокировок в этой системе. Поя?с*1о-
как это может привести к неэффективному распределению pecyp8.
Ответы 1) да, в такой системе могут возникать взаимоблокипп
Например, несколько заданий могут начать передачу данных одн
менно. Когда размер файла спулинга достигнет 75% порога, i рие
вых заданий будет заблокирован. Однако выполнение уже °'
заданий продолжится, что может привести к взаимоблокировке
в файле спулинга не хватит места для завершения обработки текут)П|
заданий. 2) Достаточно запретить работу всех заданий спулинга,
одного при достижении заданного порога. Неэффективность дащ^т!
алгоритма заключается в том, что максимальный размер задания к?
раздо меньше всего доступного пространства для спулинга.
7.2.4 Пример: Обедающие философы
Описанная Дейкстрой проблема обедающих философов (Dining Philoso-
phers),5’6 иллюстрирует многие нюансы параллельного программирова-
ния. Суть проблемы такова:
Пять философов сидят вокруг круглого стола. Упрощенно мы считаем,
что жизнь каждого философа состоит из раздумий и поедания спагетти.
Перед каждым философом стоит блюдо со спагетти, куда постепенно до-
бавляется пища по мере ее съедания. На столе лежит ровно пять вилок,
по одной между каждыми двумя соседними тарелками. Поедание спагет-
ти (в соответствии с правилами этикета) подразумевает использование I
двух вилок (одновременно). Разработайте программу, моделирующую
ведение философов, которая, работая в параллельном режиме, не была
подвержена взаимоблокировкам и бесконечному откладыванию.
Если при решении этой проблемы мы допустим возникновение ®за1^Д
блокировок либо бесконечного откладывания, один или несколько
фов могут умереть с голоду. Естественно, программа должна
вать взаимоисключение — два философа не могут одновременно восп°-
ваться одной и той же вилкой. Обычно философ ведет себя так,
описано на рисунке 7.3. отК^'
Проблема взаимоисключения, взаимоблокировок и бесконечного
дывания заключается в реализации метода питания eat. Рассмотрите-
стой, но опасный вариант реализации на рисунке 7.4. Поскольку
фы действуют асинхронно и параллельно, любой философ может
нить строку 3 до того, как другой философ выполнит строку 4-
случае в распоряжении каждого философа окажется ровно
и больше на столе не останется ни одной свободной вилки. В резу 6
один философ не даст поесть другому философу, то есть возникни
ция взаимоблокировки и все философы начнут страдать от голоДа>
405
F ь воВки и бесконечное откладывание
id tyPicalPhiiosoPherО
2 1 while (true )
3 {
>, think(); // размышление
5 eat(); // питание
. /I окончание цикла while
7
8 оКончание typicalPhxlosopher
9 1
fill, 1$'
1
2
3
4
5
6
7
8
Поведение философа за обедом
void eat О И питание
(
}
pickUpLeftForkOI И философ берет левую вилку
pickUpRightFork(); // философ берё® правую вилку
eatForSomeTimei); II философ некоторое время ест
putDownRightForkО; //философ кладет правую вилку
putDownLeftForkOi- //философ кладет левую Вилку
// завершение метода eat
Рос. 7.4. Реализация метода eat
Один из способов предотвращения взаимоблокировки является зада-
ние условия, согласно которому, если философ держит в левой руке вил-
ку, то один или несколько других философов должны будут положить
свои левые вилки на стол, чтобы первый философ смог воспользоваться
одной из лежащих вилок в качестве правой вилки. Для реализации этого
правила, необходимо задать в функции pickUpRightFork (), чтобы фило-
соф клал на стол левую вилку, если правая ему недоступна. Но и в этом
случае существует, хотя и весьма малая, вероятность того, что каждый из
ософов будет постоянно то класть, то брать левую вилку, в результате
ни один из философов не получит одновременно две вилки, необхо-
ВаМи ° ДЛЯ того’ чт°бы приступить к поеданию спагетти — теперь перед
Фы т пРИМеР бесконечного откладывания, в результате которого филосо-
смот %е начнУт страдать от голода. В нашем решении мы должны преду-
йечНь^ТЬ Не только исключение взаимоблокировок, но и борьбу с беско-
софа вкладыванием, гарантируя, что в распоряжении каждого фило-
6 от времени будет оказываться две вилки. В упражнениях
йЧе прокГЛавы вам будет предложено самостоятельно разработать реше-
лемы обедающих философов.
Вопросы для самопроверки
1. Позволяет ли реализация метода eat на рисунке 7.4 гармонично со-
существовать философам, не страдая от голода?
2. Рассмотрите метод eat на рисунке 7.4. Если заменить строки 3 и 4
методом pickUpBothForksAtOnce(), позволит ли это предотвратить
возникновение взаимоблокировок? Поможет ли это предотвратить
голодание философов?
Ответы i) Да. Мы не можем высказывать предположения ar 1 1
сительных скоростях асинхронных параллельных процессов, р Ч I
но, что не все пять философов одновременно поднимут леву';,,
Тогда некоторые философы смогут получить в свое распорядке b,Q
нужных им вилки, а затем положить их, предоставив другим а11®!
фам возможность покушать. 2) Да, это позволит предотвратить
блокировки, если считать, что операция pickUpBothForksAe3^
будет являться атомарной, но при этом по-прежнему остается в
ность возникновения бесконечного откладывания. Это может г^^Ч
ти, например, в случае, если два философа будут постоянно
вилки, кушать, класть вилки назад на стол и снова брать их
чем эти вилки смогут взять какие-либо другие философы; в резч^Ч
другие философы начнут страдать от голода. yjibJ
73 ПохоЖая пробнема — бесконечное
откладывание
В системе, где процессам приходится ожидать принятия решения ц
распределению ресурсов и планированию, возможно возникновение ситуа
ции, при которой предоставление процессора некоторому процессу будет
откладываться на неопределенно долгий срок, в то время как система бу-
дет уделять внимание другим процессам. Такая ситуация, называемая бес
конечным откладыванием, часто может приводить к столь же неприятнык
последствиям, что и взаимоблокировка.
Бесконечное откладывание процесса может происходить из-за «дискрими-
национной» политики планировщика ресурсов системы. Когда ресурсы рас
пределяются по приоритетному принципу, может случиться, что данный
процесс будет бесконечно долго ожидать выделения нужного ему ресурса, по-
скольку будут постоянно приходить процессы с более высокими приоритета-
ми. Ожидание — непременный фактор нашей жизни и, безусловно, важны®
аспект внутренней работы вычислительных машин, поэтому при разработку
операционных систем необходимо предусматривать справедливое и
тивное управление процессами, находящимися в состоянии ожидания, п
которых системах бесконечное откладывание предотвращается благ Д
тому, что приоритет процесса увеличивается по мере того, как он
выделения нужного ему ресурса. Это называется старением (aging) 111Э°И11рИ-
В конце концов, ожидающий процесс получит более высбкое значение
оритета, чем у всех приходящих процессов, и будет обслужен.
Вопросы для самопроверки
1. Алгоритмы Деккера и Питерсона предотвращают бесконечн^^Л
дывание вхождения процесса в свой критический участок р
каким образом в этих алгоритмах предотвращается бескон
кладывание. Как это связано со старением процессов? сса^Т
2. Предположим, что выполнение интерактивного процесса
остановилось, т.е. он «завис». Означает ли это полную в
кировку? Возможно ли, что процесс оказался в ситуации
ного откладывания? Существуют ли другие объяснения-
uffka и бесконечное откладывание
407
Ответы 1) В обоих алгоритмах используется концепция предпоч-
тительного процесса при обслуживании ресурса, который становится
нова доступным. Данная концепция аналогична концепции старе-
ния, поскольку приоритет процесса увеличивается по мере того, как
оН ожидает выделения нужного ему ресурса. 2) Это весьма любопыт-
ный вопрос. Пользователю может показаться, что выполнение процес-
а прекратилось, если система перестанет отвечать на его
интерактивные запросы. Возможно, этот процесс действительно попал
в тупиковую ситуацию или подвергся бесконечному откладыванию,
но это не обязательно. Данный процесс может ожидать появления со-
бытия, которое вот-вот наступит, пребывать в бесконечном цикле либо
выполнять ресурсоемкие вычисления, которые должны быть заверше-
ны в самое ближайшее время. Любому, кто сталкивался с «зависшей»
системой, известно, насколько неоднозначной может являться ситуа-
ция. Какие услуги должна предоставлять операционная система, что-
бы помочь пользователю разобраться в этой ситуации? Мы будем
рассматривать эти проблемы в данной и следующих главах книги.
14 Концепция ресурсов
Операционная система выполняет функции администратора ресурсов.
Она отвечает за распределение обширных наборов ресурсов различных ти-
пов. Отчасти именно благодаря такому разнообразию типов ресурсов раз-
работка операционных систем является столь интересной темой. Рассмот-
рим ресурсы, которые являются динамически перераспределяемыми
(preemptible), такие как процессор и основная память. В вычислительной
машине самым динамичным ресурсом является, по-видимому, процессор.
Процессор должен работать в режиме быстрого переключения (мультип-
лексирования), обслуживая большое число конкурирующих процессов,
чтобы все эти процессы могли продвигаться с приемлемой скоростью. Если
конкретный процесс достигает точки, когда он не может эффективно ис-
пользовать процессор (как это бывает в течение длительного периода ожи-
ВЬ1мя завеРшения операции ввода-вывода), право управления централь-
про nP°tI'eccoPOM отбирается у этого процесса и предоставляется другому
осВОцССУ‘ Программа, занимающая в данный момент некоторую область
ву 9 ,2й памяти, может быть вытеснена или удалена из памяти (см. гла-
Ресу’рс ’ 11)’ Таким, образом, организация динамического переключения
ФекТив в является исключительно важным фактором для обеспечения эф-
ОцрИ°и Работы многозадачных вычислительных систем.
еЛеНные ВИДЫ ресурсов являются динамически неперераспреде-
Рать у й и (nonpreemptible) в том смысле, что их нельзя произвольно отби-
^Чессов, за которыми они закреплены, пока сами процессы добро-
Откажутся от их использования. К примеру, накопители на маг-
или сканеры, выделяются конкретным процессам на
^еКоТ(?Т ^скольких минут до нескольких часов.
виды ресурсов допускают разделение (shared) между не-
ft 1ц0 И процессами, другие же отличаются тем, что предусматривают
°Польное использование индивидуальными процессами. Хотя
Условиях один процессор одновременно работает только с од-
408
ним процессом, он в состоянии быстро переключаться между нескод
процессами, создавая иллюзию одновременной работы. Дисковые
тели иногда закрепляются за отдельными процессами, однако чащ^
жат файлы, принадлежащие многим процессам. Дисковые накопи-Г(,С%[|
гут быстро передаваться в распоряжение другие процессов, кото
ходимо выполнить операции ввода/вывода.
Данные и программы — это также ресурсы, которые требуют coothJ
вующей организации управления и распределения. Так, в многозадд6^-
системах многим пользователям может одновременно понадобиться^1^
бегнуть к услугам программы-редактора. Однако иметь собственную^’
пию редактора в основной памяти для каждого пользователя было §
экономно. Поэтому в память записывается одна копия кода подобной1 Ве
граммы, которая делается доступной для всех пользователей. Поско
с таким кодом могут одновременно работать многие пользователи, Оц J
должен изменяться. Код программы, который не может изменяться в0 Ве
мя выполнения, называется реентерабельным (reentrant). Код, котоп^
может изменяться, но предусматривает повторную инициализацию Пп
каждом выполнении, называется кодом последовательного (многократво
го) использования (serially reusable). С реентерабельным кодом могут рабо-
тать несколько процессов одновременно, а с кодом последовательного исполь-
зования — только один процесс в каждый конкретный момент времени.
Когда речь идет о конкретных разделяемых ресурсах, мы должны четко
представлять себе, могут ли они реально использоваться несколькими про
цессами одновременно или же только одним из них в каждый момент вре-
мени- Именно с ресурсами второго вида чаще всего оказывается связанным
возникновение взаимоблокировок (тупиков).
Вопросы дм самопроверки
1. (Да/Нет) Правда ли, что процессы не могут оказаться в
взаимоблокировки в результате обычной конкурентной борь
за процессорное время? I
2. (Да/Нет) Правда ли, что к динамически неперераспределяемЫ»
сурсам относится только аппаратное обеспечение?
Ответы 1) Да. Процессор представляет собой динамически
пределяемый ресурс, который можно легко забрать у одного
и вернуть его ожидающему, позволяя продолжить нормальную
2) Нет. К динамически неперераспределяемым ресурсам т к®е
относиться программное обеспечение — например, мониторы-
и бесконечное откладывание
409
хоДИ1
1.
2-
Це^Ыр^ необходимых условия возникновения
^блокировки
Элфик и Шошани7 сформулировали следующие четыре необ-
КофФм ’овця возникновения взаимоблокировки:
[Mb# монопольного управления ресурсом может запрашиваться
. РРа одним процессом в каждый конкретный момент времени —
'гоЛ ие взаимоисключения (mutual exclusion condition).
тт цессы удерживают за собой ресурсы, уже выделенные им, ожидая
1 то же время выделения дополнительных ресурсов —- условие ожида-
®яя дополнительных ресурсов (wait-for condition или hold-and-wait
condition). '
Ресурсы нельзя отобрать у удерживающих их процессов, пока эти ре-
сурсы используются этими процессами — условие неперераспреде-
ляемости (nopreemption condition).
Существует замкнутая цепочка процессов, в которой каждый процесс
удерживает за собой один или более ресурсов, требующихся следующе-
му процессу в цепочке — условие кругового ожидания (circular-wait
condition).
Вышеперечисленные условия являются необходимыми, то есть для воз-
никновения взаимоблокировки должно соблюдаться все эти условия. Такой
подход позволяет нам разрабатывать схемы для предотвращения возникно-
вения взаимоблокировок. Вместе, эти четыре условия являются необходи-
мыми и достаточными условиями наличия взаимоблокировки (если все че-
тыре условия соблюдаются, значит, взаимоблокировка существует).
3.
4.
Вопросы для самопроверки
1. Сформулируйте четыре необходимых условия возникновения взаи-
моблокировки применительно к системам спулинга.
2. Какое из четырех вышеперечисленных условий возникновения
взаимоблокировки будет нарушено в случае, если пользователь
сможет удалять задания в системах спулинга?
Ответы 1) Никакие два задания не могут одновременно произво-
Дить запись в одно и то же место файла спулинга. В системах спулинга
в файле спулинга может храниться часть задания, пока не освободит-
ся дополнительное место для сохранения задания целиком. Задания
не могут вытеснять другие задания из файла спулинга. И, наконец,
в случае переполнения файла спулинга, каждое последующее задание
вынуждено будет ожидать, пока другие задания не освободят занимае-
мое пространство. 2) В данном случае будет нарушено условие непере-
Р&спределяемости.
410
Г.
7.6 Решения проблемы Взаимоблокировок '
Одни из наиболее интересных исследований в области инфор^
и операционных систем были проведены в связи с проблемой взаимоб W
ровок. В исследованиях по проблеме взаимоблокировок можно
следующие четыре основных направления: предотвращение взаимод Ч
ровок, обход взаимоблокировок, обнаружение взаимоблокировок и
новление после взаимоблокировок.
При предотвращении взаимоблокировок (deadlock prevention) п
является обеспечение условий, исключающих возможность возник*
ния тупиковых ситуаций. Такой подход является вполне корректны^
шением в том, что касается самой взаимоблокировки, однако он часть 1
водит к нерациональному использованию ресурсов. Ч
Цель средств обхода взаимоблокировок (deadlock avoidance) заключ
ся в том, чтобы можно было предусматривать менее жесткие ограничен861
чем в случае предотвращения взаимоблокировок, и тем самым обеспЛ
лучшее использование ресурсов. При наличии средств обхода взаимобло
кировок не требуется такой реализации системы, при которой опасное^
тупиковых ситуаций даже не возникает. Напротив, методы обхода взаимо-
блокировок учитывают подобную возможность, однако в случае увеличе-
ния вероятности конкретной тупиковой ситуации здесь принимаю™
меры по аккуратному обходу взаимоблокировки.
Методы обнаружения взаимоблокировок (deadlock detection) приме®
ются в системах, которые допускают возможность возникновения тупико-
вых ситуаций. Цель средств обнаружения взаимоблокировок — уста®
вить сам факт возникновения тупиковой ситуации, причем точно опреде-
лить те процессы и ресурсы, которые оказались вовлеченными в данную
тупиковую ситуацию.
Методы восстановления после взаимоблокировок (deadlock recovery)
применяются для устранения тупиковых ситуаций, с тем чтобы систем*
могла продолжать работать, а процессы, попавшие в тупиковую ситуаи®^
могли завершиться с освобождением занимаемых ими ресурсов. ...
новление — это, мягко говоря, весьма серьезная проблема, так что в о
шинстве систем оно осуществляется путем полного выведения одного
более процессов, попавших в тупиковую ситуацию. Затем выведенные
цессы обычно перезапускаются с самого начала, так что почти вся ]
даже вся работа, проделанная этими процессами, теряется.
Вопросы для самопроверки
1. Сравните между собой стратегии предотвращения и обхода в
блокировок. пгМЧИ
2. В некоторых системах проблема взаимоблокировок nPoCL
руется. Расскажите о преимуществах и недостатках подо»
хода.
и бесконечное обкрадывание
411
Ответы 1) Целью средств предотвращения взаимоблокировок яв-
ляется исключение возможности возникновения тупиковых ситуа-
ций, что, однако часто приводит к нерациональному использованию
есУРс0В- ® случае обхода взаимоблокировок, возможность возникно-
вения взаимоблокировки учитывается, и при увеличении вероятности
конкретной тупиковой ситуации принимаются меры по аккуратному
обходу взаимоблокировки, благодаря чему обеспечивается лучшее ис-
пользование ресурсов. 2) Системы, игнорирующие взаимоблокировки,
могут сбоить в случае возникновения тупиковой ситуации. Рисковать
подобным образом в системах, предназначенных для решения жиз-
ненно важных задач, недопустимо, но там, где взаимоблокировки воз-
никают крайне редко и цена случайной взаимоблокировки ниже, чем
затраты на реализацию схем предотвращения и обхода взаимоблоки-
ровок, такой подход оправдан.
7 7 Предок Вии^&АокироЗ^к
В этом разделе рассматриваются различные методы предотвращения
взаимоблокировок, и изучается их влияние на пользователей и системы,
в особенности с точки зрения производительности.8,9,10,и,12,13 Хавендер14
показал, что возникновение тупика невозможно, если нарушено хотя бы
одно из указанных выше четырех необходимых условий. Он предложил
следующие стратегии предотвращения взаимоблокировок:
• Каждый процесс должен запрашивать все требуемые ему ресурсы сра-
зу, причем процесс не может начать выполняться до тех пор, пока все
они не будут ему предоставлены.
• Если процесс, удерживающий определенные ресурсы, получает отказ
в удовлетворении запроса на дополнительные ресурсы, этот процесс
должен освободить удерживаемые им с самого начала ресурсы и при
необходимости запросить их снова вместе с дополнительными.
Следует ввести для всех процессов линейную упорядоченность ресур-
сов по типам; другими словами, если процессу выделены ресурсы дан-
ного типа, в дальнейшем он может запросить только ресурсы более
Далеких по порядку типов.
СлеДУЮщих разделах мы рассмотрим эти стратегии отдельно и обсу-
В
Дим, как ' х-----------------------1---------г-------------1-----------------------------J
’Поуч^ кажДая из стратегий нарушает одно из необходимых условий (см.
^авенп ельные истории: Никаких болтов, винтов и гаек»). Отметим, что
в«е, а,. р преДлагает три стратегии, а не четыре. Первое необходимое усло-
л^ают енно Условие взаимоисключения, согласно которому процессы по-
^оти^Р8®0 на монопольное управление выделяемыми им ресурсами, мы
ь>Кц0Ст1Наруша'гь> поскольку нам, в частности, нужно предусмотреть воз-
С11еДов Работы с выделенными (dedicated) ресурсами (то есть ресурсами
ательного повторного использования).
412
с
Вопросы для самопроверки
1. Какое основное допущение сделал Хавендер в своих исслел
методов предотвращения взаимоблокировок? ’Ч°в^й„
ч
Ответы 1) Взаимоблокировка не может возникнуть в
если хотя бы одно из четырех необходимых условий ее возникн10*6^
не соблюдается. °8e4itl
Д| Поучительные истории
Никаких болтов, винтов и гаек
Несколько лет назад Харви Дейтел имел
возможность посетить автоматизированное
производство одного из крупнейших произ-
водителей компьютеров. В это время завод,
практически целиком обслуживаемый робо-
тами, занимался выпуском недорогих прин-
теров для персональных компьютеров. Глава
предприятия имел особое мнение о техноло-
гии производства принтеров. Он сделал вы-
вод, что современные принтеры имеют
слишком много движущихся частей, и учел
наблюдения инженеров компании, регист-
рировавших отказы предыдущей серии
в связи с попаданием внутрь винтов, болтов
и гаек, раскручивающихся в результате дви-
жения и вибраций. Поэтому при разраб0ТКе
новой серии принтеров дизайнеры приняли
решение о том, что все комплектующие час-
ти принтера (а их насчитывалось около 80
включая оболочку) необходимо собирать
без помощи винтов, болтов и таек. Руково-
дитель производства вручную собрал один
из принтеров из отдельных частей. Закончив
сборку, он включил принтер в розетку и рас-
печатал несколько страниц, чтобы проде-
монстрировать его работоспособность.
Кроме того, руководитель упомянул, что
среднее время наработки на отказ значи-
тельно превышает тот же параметр по срав-
нению с предыдущими сериями.
Урок для разработчиков операционных систем: одна из методик минимизации риска си
темных сбоев заключается в уменьшение количества возможных точек отказа на стадИ^ггц.
работки. Данная методика хорошо сочетается с другим принципом разработки, вырз
ным опытным путем — стремлению к простоте. Обе методики кажутся привлекатель
хотя иногда они могут быть сложны в реализации. Читая эту книгу, не забывайте о т
изложенном принципе, стараясь разыскать места отказа, от которых можно было
виться при разработке следующих версий операционных систем.
7.7.1 Нарушение условия оЖидания дополнительных ресурсов
Первая стратегия Хавендера требует, чтобы процесс сразу же '
вал все ресурсы, которые ему понадобятся. Система должна преД°с
эти ресурсы по принципу «все или ничего». Если набор ресурсов, уЛ
димый процессу, доступен, то система может предоставить все этй
данному процессу сразу же, так что он получит возможность пр°Д Jf
^gflku и бесконечное откладывание
413
Гели в текущий момент полного набора ресурсов, необходимых
нет, этому процессу придется ждать, пока они не освободятся.
РроЛеСС^’огда процесс находится в состоянии ожидания, он не должен
Кть какие-либо ресурсы. Благодаря этому предотвращается воз-
.дер^иВ ие условия ожидания дополнительных ресурсов, и тупиковые си-
д0К0°ве^,аНовятся просто невозможными.
туай011 яанаая стратегия позволяет успешно предотвращать взаимоблоки-
' Х^^одобный подход может привести к нерациональному использова-
ров00’ vpcOB. Например, программа, которой в какой-то момент работы
дйЮ Ре четыре накопителя на магнитной ленте, должна запросить —
тРеВУ\гйТь_все четыре устройства, прежде чем начать выполнение. Если
В цоЛУ устройства необходимы программе в течение всего времени вы-
все д то Это не приведет к серьезным потерям. Рассмотрим, однако,
в0Л й когда программе для начала работы требуется только одно устрой-
^Гили, что еще хуже, ни одного), а оставшиеся устройства потребуются
Сщпь через несколько часов. Таким образом, требование о том, что про-
I ямма должна запросить и получить все эти устройства, чтобы начать вы-
полнение, на практике означает, что значительная часть ресурсов компью-
тера будет использоваться вхолостую в течение нескольких часов.
Один подход, к которому часто прибегают разработчики систем с целью
улучшения использования ресурсов в подобных обстоятельствах, заключа-
ется в том, чтобы разделить программу на несколько потоков, выполняе-
мых относительно независимо друг от друга. Благодаря этому можно осу-
ществлять выделение ресурсов для каждого потока программы, а не для
целого процесса. Это позволяет уменьшить нерациональное использование
ресурсов, однако связано с увеличением накладных расходов на этапе про-
ектирования прикладных программ, а также на этапе их выполнения.
Стратегия Хавендера существенно повышает вероятность бесконечного
укладывания, если, например, предпочтение будет отдано процессу с не-
ольшими требованиями к ресурсам, а не процессу, пытающемуся нако-
пить для выполнения много разных ресурсов. Постоянно прибывающие
“Родессы со сравнительно небольшими требованиями к ресурсам могут ме-
бов ВЬ1полнению процессов с более высокими запросами. Один из спосо-
8ЫмРеЦ1еНИЯ данной проблемы заключается в задании дисциплины пер-
КодлеРИШел’Первым-обслужен для ждущих процессов. К сожалению, на-
пр «Ие Полного набора ресурсов для нуждающегося в них процесса
ПлИвяДИТ К НеэФФективному использованию ресурсов, поскольку все нака-
не бу Ые Ресурсы должны будут находиться в состоянии простоя, пока
В 0 т с°браны все ресурсы, необходимые для работы процесса.
6Уют Пт.01Иении мэйнфрейм-систем с дорогостоящими ресурсами сущест-
^Ьзуе °ТивоположнЬ1е мнения о том, кто должен платить за эти неис-
&есУрСЬ1МЬ1е РесУРсы- Некоторые разработчики считают, что, поскольку
Накапливаются для конкретного пользователя, этот пользователь
ПЛатить за них, даже в течение периода простоя ресурсов. Однако
Разработчики считают, что это привело бы к нарушению принципа
Пол^еМОсти платы за ресурсы (predictability of resource charges);
^^КкцЬЗОВатель ПОПЬ1тается выполнить свою работу в период пиковой
^Шины, ему придется платить гораздо больше, чем в случае, ко-
I ПНа относительно свободна.
414
Вопросы для самопроверки
1. Поясните, каким образом нарушение условия ожидания
тельных ресурсов понижает степень многозадачности сие-^У^Д
2. При каких обстоятельствах процесс может оказаться в ситу 1
конечного откладывания в результате использования схем '111’'1 (к
дера по нарушению условия ожидания дополнительных j
Ответы 1) Если процессы системы нуждаются в большем I
стве ресурсов, чем может быть доступно при параллельном B50J14e
нии с другими программами, система заставит некоторые п
подождать, пока другие процессы не закончат свою работу и не °Це<Ч
занимаемые ими ресурсы. В худшем случае система может раз Ье^У)
выполнение только одного процесса в один момент времени
цесс может запросить большое количество системных ресурСОв Йо-
операционная система отдает предпочтение процессам, нуждаю/ ^8
в меньшем количестве системных ресурсов, процесс с более выеп Мс’
требованиями к ресурсам может попасть в ситуацию бесконечнотп^Я
кладывания, в то время как другие процессы с меньшими требова° °Т
ми к ресурсам будут продолжать выполняться. “"Иия.
7.7.2 Нарушение условия неперераспределяемости
Вторая стратегия Хавендера нарушает условие неперераспределяемо-
сти. Предположим, что система позволяет процессам, запрашивающим до-
полнительные ресурсы, удерживать за собой ранее выделенные ресурсы.
Если у системы достаточно свободных ресурсов, чтобы удовлетворять все
запросы, тупиковая ситуация не возникнет. Посмотрим, что произойдет,
если какой-то запрос удовлетворить не удастся. В этом случае один про-
цесс удерживает ресурсы, которые могут потребоваться второму процессу
для продолжения работы, а этот второй процесс может удерживать ресур-
сы, необходимые первому. Это и есть взаимоблокировка.
Вторая стратегия Хавендера требует, чтобы процесс, имеющий в своем
распоряжении некоторые ресурсы, если он получает отказ на запрос о вы-
делении дополнительных ресурсов, должен освободить все удерживаемы®
им ресурсы и при необходимости запросить их снова вместе с дополнитеЛд
ными. Такая стратегия нарушает условие неперераспределяемости, п°3®^
ляя забирать ресурсы у удерживающих их процессов до завершения
процессов. св010
Но этот способ предотвращения тупиковых ситуаций также имеет
цену. Если процесс в течение некоторого времени использует оПРе^ра-
ные ресурсы, а затем освобождает эти ресурсы, он может потерять в
боту, проделанную до данного момента. На первый взгляд такая He &
жет показаться слишком высокой, однако необходим реальный о^аЯсИ'
вопрос «насколько часто приходится платить такую цену?» Если
туация возникает редко, то можно считать, что в нашем распор**^,
имеется относительно недорогой способ предотвращения тупиков-^
однако, такая ситуация встречается часто, то подобный способ о»
дорого, причем приводит к печальным результатам, особенно когда^ ?
ется вовремя завершить высокоприоритетные или срочные проЩ'с
Может ли данная стратегия привести к бесконечному откладЫ
При определенных обстоятельствах, да. Если система отдает преДП0
jBku и бесконечное откладывание
415
запрашивающему небольшое количество ресурсов, перед процес-
no'&ecC^' щими запросами, процесс с высокими требованиями к ресурсам
с боль ь в ситуацию бесконечного откладывания. В худшем случае
<^еТ п° йЯ Хавендера требует, чтобы процесс, имеющий в своем распо-
М а сТР^декоторые ресурсы, если он получает отказ на запрос о выделе-
3^еаиИ нИтельных ресурсов, освободил свои ресурсы и при необходимо-
сти ДО^^цивал их снова вместе с дополнительными. Поэтому в загружен-
заЯРаеме может возникать бесконечное откладывание. Кроме того,
ной сиС ратегия требует, чтобы все ресурсы являлись динамически пере-
даИДаЯ еЛдемыми, что не всегда возможно (например, принтер не может
р8сПРе^пределЯТЬся в момент выполнения им задания печати).
Вопросы для самопроверки
1. Какую цену приходится платить за нарушение условия неперерас-
пределяемости?
2. Какая из первых двух стратегий Хавендера по предотвращению
взаимоблокировок считается более привлекательной? Почему?
Ответы 1) Процесс может потерять всю работу, проделанную до
момента перераспределения ресурсов. Кроме того, процесс может по-
страдать от бесконечного откладывания при некоторых политиках вы-
деления ресурсов системой. 2) Большинство предпочитают первую
стратегию, согласно которой процесс запрашивает все необходимые
ему ресурсы сразу. Вторая стратегия требует, чтобы процесс возвра-
щал имеющиеся в его распоряжении ресурсы, что может привести
к потере всей проделанной работы. Однако первый стратегический
принцип также не лишен недостатков, поскольку может приводить
к нерациональному использованию ресурсов, захватываемых процес-
сами до того, как они действительно им понадобятся.
7.73 Нарушение условия кругового оЖидания
cajJPeTbH стратегия Хавендера исключает круговое ожидание. Всем ресур-
3м (например, дисковому устройству, принтеру, сканеру, файлу), с кото-
чемИ ₽а^отает система, присваиваются уникальные номера, благодаря
Цр0У осуществляется линейное упорядочивание (linear ordering) ресурсов.
МеРзд ССЫ должны запрашивать ресурсы строго в порядке возрастания но-
декс з РесуРСов- Например, если процесс запрашивает ресурс R3 (где ин-
^^^ЗНачает поРяДковый номер ресурса), в дальнейшем процесс может
сУрса1^ТЬрЯ ТОлько к ресурсам с номером большим 3. Поскольку всем ре-
3а11Рац1яРИСваива1ЮТСЯ уникальные номера и поскольку процессы должны
^ННки Вать Ресурсы в порядке возрастания номеров, круговое ожидание
Ь Не может (рис. 7.5). [Примечание: Доказать данное утвержде-
ь ^opoiH?10 РассмотРим систему с линейно упорядоченными ресурсами,
евНо, и и, и Rj представляют собой ресурсы с номерами i и j, соответст-
схТогд Чем z * Если система попадает в ситуацию кругового ожида-
Э’ СОгласно рис. 7.5, по крайней мере, одна стрелка (либо группа
йо У,{азьаРиведет назаД от Rj К Rj и одна стрелка (либо группа стрелок) бу-
Вать от И, к Rp В то же время линейное упорядочивание ресурсов
$оеВает’ что процессы должны запрашивать ресурсы строго в по-
I 3Растания номеров ресурсов, следовательно, стрелка запроса не
416
может вести от Rj к Rj, если j > i. Поэтому возникновение взаимобдо
ки в такой системе невозможно.]
Стратегия нарушения условия кругового ожидания реализована
операционных систем, однако это оказалось сопряжено с определи 6
трудностями. 15.16,17,1.8 Существенным недостатком данной страте
ется ее ограниченность в плане гибкости и динамичности по cpag
с тем, что можно ожидать. Поскольку процессы должны запращцв,Ге
сурсы в порядке возрастания номеров, и поскольку номера ресурсов
чаются при установке машины и должны «существовать» в течение^-
тельных периодов времени (месяцев или даже лет), то в случае
в машину новых типов ресурсов может возникнуть необходимость це 4
ботки существующих программ и систем.
Другая проблема связана с определением порядка следования ресуп
Очевидно, что назначаемые номера ресурсов должны отражать норм?I
ный порядок, в котором большинство заданий фактически используют
сурсы. Для заданий, выполнение которых соответствует этому поряд^
можно ожидать высокой эффективности. Если, однако, заданию требуй
ся ресурсы не в том порядке, который предполагает вычислительная систе
ма, то ему, быть может, придется захватывать и удерживать ресурсы Н
задолго до того, как они будут фактически использоваться. А это означает
потерю эффективности.
Одной из самых важных задач современных операционных систем явля-
ется обеспечение переносимости программного обеспечения между разнооб-
разными средами. Программисты должны иметь возможность разрабаты-
вать свои прикладные программы, не будучи связаны ограничениями, на
кладываемыми недостаточно удачными аппаратными и прог аммными
решениями. Последовательный порядок заказа ресурсов, предложенный
Хавендером, действительно исключает возможность возникновения круго-
вого ожидания, однако при этом, безусловно, отрицательно сказывается®
возможности пользователя свободно и легко писать прикладные программы
с максимальной производительностью.
Вопросы дм самопроверки
1. Каким образом последовательный порядок заказа ресурсов сни#*'
ет переносимость приложений? з8.
2. (Да/Нет) Правда ли, что требование последовательного п°РяДавес
каза ресурсов позволяет повысить производительность по Р,
нию с ситуацией нарушения условия неперераспределяем ос
-ела^
Ответы 1) Обычно в разных системах присутствуют
ры ресурсов, которые могут быть упорядочены различным
в результате чего, приложение, написанное для одной системы»
потребовать переработки, чтобы эффективно выполняться н длтО^
системе. 2) Нет. При определенных обстоятельствах произв
ность приложения может быть выше как в одном, так и во вт
чае, поскольку оба решения не требуют значительных н
расходов. Если системные процессы запрашивают не связа ус^рГ
ду собой группы ресурсов эффективна стратегия наруше
неперераспределяемости. В случае же, когда задачи испол т£)Гд»f
сурсы в том порядке, в котором они предлагаются системой,
лее высокую производительность можно будет получить с 1Я
стратегии нарушении условия кругового ожидания.
1ки и бесконечное откладыВанно
417
Процесс Р, удерживает ресурсы R3, R4, R6 и R7,
и запрашивает ресурс Rg (показано пунктирной
линией). Круговое ожидание не может
возникнуть, поскольку все линии со стрелками
должны идти в одном направлении
в^0льз^Ам^1оженнЬ1®[ Кавендером последовательный порядок заказа ресурсов,
уемыи для предотвращения взаимоблокировок
418 ,
7.8 Обход Взаимоблокировок с помощью алгорц^
банкира 1
Для некоторых систем реализация стратегии предотвращения вч
блокировок, описанной в предыдущих разделах, неэффективна. Тем
нее, даже если в системе присутствуют необходимые условия возни***•
ния взаимоблокировки, вы еще можете избежать тупиковой ситуа*06®’
если внимательно подойдете к вопросу распределения ресурсов. Веро
наиболее популярным алгоритмом обхода взаимоблокировок являете
горитм банкира, предложенный Дейкстрой (Dijkstra’s Banker’s
rithm). Алгоритм получил такое любопытное название потому, что оц
бы имитирует действия банкира, который, располагая определенным^
зервом капитала, выдает ссуды и принимает платежи. 19,20,21,22,23 иИДсе
изложим этот алгоритм применительно к проблеме распределения peevn"
сов в операционных системах. С тех пор, как Дейкстрой был предложен
алгоритм банкира, было проделано немало работы, направленной на редж
ние вопроса обхода взаимоблокировок.24,25,26,27,28,29,30,31
Алгоритм банкира определяет, каким образом конкретная система мо-
жет избежать тупиковых ситуаций, тщательным образом контролируя вы-
деление ресурсов пользователям (см. «Поучительные истории: Акрони-
мы»). Система классифицирует все ресурсы, с которыми она работает, по
типам (resource types). Каждый тип объединяет ресурсы, схожие по функ-
циональности. Чтобы упростить представление алгоритма банкира, мы
рассмотрим систему, управляющую ресурсами одного типа. Данный алго-
ритм распространяется и на группы ресурсов различных типов; читателю
будет предложено сделать такое расширение в упражнениях, которые при-
водятся в конце главы.
Алгоритм банкира позволяет предотвращать взаимоблокировки в опе-
рационной системе, которая обладает следующими свойствами:
• В системе существует фиксированное число ресурсов, t, и фиксиРЧ
ванное число процессов, п.
• Каждый процесс сразу указывает максимальное число ресурсов,
буемых ему для завершения работы. J
• Операционная система принимает запрос от процесса только в том
чае, если максимальные потребности (maximum need) процесса и
вышают общего количества ресурсов, доступных в системе (то еС ^е).
цесс не может запросить больше ресурсов, чем существует в сис
• Иногда процессу может понадобиться подождать освобожДе ^уе1,
полнительных ресурсов, однако операционная система тара
что время ожидания будет конечно.
• Если операционная система в состоянии удовлетворить маК^ес^4
ные запросы ресурсов от процесса, процесс гарантирует, что
будут находиться в использовании и затем освободятся по И
конечного временного промежутка.
Зки и бесконечное откладывание
419
Поучительные истории
кропимы
им компьютерным специалистам
^известен акроним WYSIWYG, кото-
xoPoUJOвводится как «что видишь, то и по-
рь,й пе^ (What You See Is What You Get)-.
лУчиШ мецьшему числу известны акрони-
r°jWWlWWlWI И YGWIGWIGI, идеально
МЫ ходящие для описания отношений ме-
процессом, запрашивающим ресурсы
и операционной системой, которая зани-
мается их распределением. Процесс заяв-
ляет «я хочу то, чего я хочу, когда я хочу
этого» (I Want What I Want When I Want It).
На что операционная система отвечает:
«ты получишь, то что у меня будет, когда я
это получу» (You’ll Get What I've Got When I
Get It).
Говорят, что система находится в надежном состоянии (safe state), если
система в состоянии гарантировать, что все текущие процессы смогут за-
вершить работу за разумное время. В противном случае текущее состояние
системы называется ненадежным (unsafe state).
Определим также четыре понятия, описывающие распределение ресур-
сов среди процессов:
• Пусть тах(Р^) — это максимальное количество ресурсов, которые не-
обходимы процессу Pj во время работы. Например, если процессу Р3
для работы всегда требуется не более двух ресурсов, то тах(Рз) = 2.
• Пусть loan (Pi) — представляет количество ресурсов, выделенных
процессу системой. Например, если система выделила процессу Р5 че-
тыре ресурса, то 1оап(Р5) = 4.
* ВУСТЬ claimfPi) обозначает количество дополнительных ресурсов, не-
обходимых процессу для выполнения работы, которое равно макси-
мальным потребностям процесса в ресурсах минус число ресурсов,
попавших в распоряжение процесса. Например, если максималь-
е потребности процесса Р7 составляют 6 ресурсов, и на данный мо-
40av еМУ ^Же УДалось заполучить в свое распоряжение четыре, то мы
da'fn(P7) = max(P7) - loan(P7) = 6-4 = 2
^1усть r
Число В ₽аспо₽яжении операционной системы имеются t устройств.
Тогда УстР°йств, остающихся для распределения, обозначим через а.
Лиин а Равно * минус суммарное число устройств, выделенных раз-
ым процессам, т.е.
loan(Pi)
3=5
„разом, если в системе выполняется три процесса, и вее ь,
жхии находится 12 ресурсов, причем два ресурса были выделены4011^
цессу Pi, один — процессу Р2, а еще четыре — процессу Р3, то в распоп
нии системы останется пять свободных ресурсов:
а= 12-(2+ 1 +4) = 12-7 = 5
Алгоритм банкира, который предложил Дейкстра, исходит из того
выделять ресурсы процессам можно только в случае, если после очеп ’
го выделения ресурсов состояние системы остается надежным. При
все процессы будут постоянно находиться в надежном состоянии хп^0’1
ключает вероятность тупиковой ситуации в системе. v
Вопросы для самопроверки
1. (Да/Нет) Правда ли, что ненадежное состояние означает
взаимоблокировки?
2. Опишите ограничения, которые накладываются на процессы алго
ритмом банкира.
Ответы 1) Нет. Процесс, находящийся в ненадежном состоянии
может, в конце концов, попасть в тупиковую ситуацию, а может за
кончить свое выполнение без каких бы то ни было проблем. Ненадеж-
ное состояние — это состояние, в котором система не может
гарантировать успешное завершение всех процессов. Система в нена-
дежном состоянии не гарантирует, что все процессы смогут закончить
работу, поэтому данное состояние со временем может привести к взаи-
моблокировке. 2) Любой процесс перед началом работы должен ука-
зать максимальное число ресурсов, которые понадобятся ему во время
работы. Ни один процесс не может запросить число ресурсов, большее
количества всех существующих ресурсов в системе. При этом каждый
процесс должен гарантировать, что, получив ресурс в свое распоряже-
ние, он вернет его системе в течение конечного времени.
состояние
7.8.1 Пример надеЖного состояния
Предположим, что в системе имеются двенадцать одинаковых
которые распределяются между тремя процессами, как показано на
ке 7.6. Во втором столбце указаны максимальные потребности для к
го процесса, в третьем столбце — число ресурсов, которые уже вЫД
процессу, а в четвертом — число дополнительных ресурсов, необход
для работы процесса. Количество доступных ресурсов, а, равно 2,
чение мы получили, вычтя количество ресурсов, которые уже на
в распоряжении процесса, из общего числа ресурсов, присутст У
в системе (12). эеМ1^
Это состояние надежное, поскольку оно дает возможность всем удвГ
цессам закончить работу. Отметим, что в текущий момент процесс
живает четыре выделенных ему ресурса и со временем потребует
шесть, т.е. еще два дополнительных ресурса. В распоряжении сис ге
ются двенадцать ресурсов, из которых десять в настоящий момент
а два — в резерве. Если эти два резервных ресурса, имеющихся в
выделить процессу Р2, удовлетворяя тем самым максимальную но Н
этого процесса, то он сможет довести работу до конца. После зав
ки а бесконечное откладывание
421
р освободит все шесть своих ресурсов так что система сможет выде-
лР°йеСС процессу Pi (3) и процессу Р3 (3), позволяя завершить работу обоим
оЦессам. Таким образом, основной критерий надежного состоя-
ть! существование последовательности действий, позволяющей всем
Ч ятелям закончить работу (см. рис. 7.6).
max(P|) loan(Pj) сЫт(Р,)
процесс (максимальная потребность) (в использовании) (требуется дополнительно)
4 1 3
6 4 2
8 5 3
число ресурсов, f ~ 12 Доступных ресурсов, а = 2
Pi
Рг
Рз
Общее
fuc 7.6- Надежное состояние
Вопросы для самопроверки
1. Как должны выполняться процессы Рх и Pg после завершения про-
цесса Pg (см. рис. 7.6)? Обязаны ли они выполняться последова-
тельно, друг за другом, либо их работа может происходить
параллельно?
2. Почему мы в первую очередь обратили внимание на завершение
процесса Р2, а не на работу процесса Pj или Pg?
Ответы 1) И процессу Pi, и процессу Pg для завершения работы
требуется три дополнительных ресурса. Поскольку процесс Р2, после
завершения освободит 6 ресурсов, этого достаточно, чтобы процессы
Р1 и Р3 смогли продолжить выполнение параллельно. 2) Потому что
Рг это единственный процесс, для завершения работы которого необ-
ходимо всего два дополнительных ресурса.
Пример ненадежного состояния
^в'ПОЛожим> ЧТО ДвенаДЦать ресурсов, имеющихся в системе, распре-
ивычт СОГЛасно Рисунку 7.7. Просуммируем значения в третьем столбце
ЦЦати еМ ПолУченное число из 12. В результате, окажется, что из двена-
®°Те и РесУРСов системы одиннадцать в настоящий момент находятся в ра-
°т Того Лько °дно остается в резерве (а). В подобной ситуации независимо
ГаРавтипаК°й пР°Цесс запросит этот дополнительный ресурс, мы не можем
^ДИодо Вать’ что все три процесса закончат работу. И действительно,
УстрОй>Ким’ что процесс Pj запрашивает и получает последнее оставшее-
Ко Тво- При этом тупиковая ситуация может возникать в трех слу-
У°Дц0Да Лк>бому из трех процессов потребуется запросить по крайней
Д°Полнительное устройство, не возвратив некоторое количество
с В °бщий пул ресурсов. Здесь важно отметить, что термин «нена-
^аиоТ°ЯЫИе>> не предполагает, что в данный момент существует или
^кгь^орИ Т° ВРемя обязательно возникнет тупиковая ситуация. Он про-
11 Соб.Т ° 3°м’ что в случае некоторой неблагоприятной последователь-
1 ^Ий система может зайти в тупик.
422
%
Процесс
max(P|) loanfPJ claimfP,)
(максимальная потребность) (в использовании) (требуется дополнитель
10
5
3
Pi
Р2
Рз
Общее число ресурсов, f = 12
8 2
2 3
1 2
Доступных ресурсов, а = 1
Put. 7.7. Ненадежное состояние
Вопросы дАя самопроверки
1. Почему вход системы в ненадежное состояние не предполагает
зательного возникновения тупиковой ситуации, а лишь гово '
о том, что в случае некоторой неблагоприятной последовательна^81
событий система может зайти в тупик? СТв
2. Какое минимальное количество ресурсов необходимо добавить в св
тему на рисунке 7.7 для того, чтобы сделать состояние надежным?
Ответы 1) lip и благоприятном развитии событии процессы могут
вернуть занимаемые ими ресурсы до запроса дополнительных, увели-
чив число доступных устройств в системе, благодаря чему система мо-
жет перейти в надежное состояние и дать возможность завершиться
всем процессам. 2) При добавлении всего одного ресурса, количество
доступных ресурсов в системе станет равным 2, благодаря чему про-
цесс Pi сможет закончить свою работу и освободить используемые ре-
сурсы, давая возможность завершить работу оставшимся процессам Pg
и Р3. Таким образом, новое состояние можно назвать надежным.
7.8.3 Пример переходи из надежного состояния в ненадежное
Наш механизм распределения ресурсов должен тщательно анализиро-
вать все запросы на выделение ресурсов, прежде чем удовлетворять их.
в противном случае процесс из надежного состояния может перейти в не
дежное. Предположим, что текущее состояние системы надежное, как
зано на рисунке 7.6. Текущее число доступных ресурсов, а, равно 2.1е
предположим, что процесс Р3 запрашивает дополнительный ресурс. К
система удовлетворила этот запрос, она перешла бы в новое состоя! I ’
занное на рисунке 7.8. В этом состоянии количество устройств в р' зе₽ про-
но 1, что недостаточно для удовлетворения текущих запросов любо
цесса, поэтому такое состояние считается ненадежным.
Процесс
тах(Р|)
(максимальная потребность)
loan(Pj) daim(Pj) итеЛьН0)
(в использовании) (требуется дополни
Р, 4
Р2 б
Р3 8
Общее число ресурсов. t= 12
1 3
4 2
6 2
Доступных ресурсов, а = 1
Рис. 7.8. Переход из надежного состояния в ненадежное
ЫИровка в бесконечное откладывание
423
Вопросы для самопроверки
1. Если процесс Р2 запросит один дополнительный ресурс в ситуации,
' изображенной на рисунке 7.6, в каком состоянии окажется систе-
ма: надежном или ненадежном?
2. (Да/Нет) Правда ли, что система не может перейти из ненадежного
состояния обратно в надежное?
Ответы 1) Система сохранит надежное состояние, поскольку су-
ществует такая последовательность действий, которая позволяет избе-
жать тупиковой ситуации. Например, если процесс Р2 запросит
дополнительный ресурс, он сможет завершить работу. После заверше-
ния процесса Р2 в системе появится шесть свободных ресурсов, чего
хватит для того, чтобы свою работу смогли успешно завершить два ос-
тавшихся процесса: Pi и Р3. 2) Нет. Если процессы будут освобождать
занимаемые ими ресурсы, число свободных устройств в системе может
значительно увеличиться, давая возможность системе перейти из не-
надежного в надежное состояние.
7 8.4 Распределение ресурсов согласно алгоритму банкира
Сейчас уже должно быть ясно, каким образом осуществляется распреде-
ление ресурсов согласно алгоритму банкира, который предложил Дейкст-
ра. Условия «взаимоисключения», «ожидания дополнительных ресурсов»
и «неперераспределяемости» выполняются. Процессам реально разрешает-
ся удерживать за собой ресурсы, запрашивая и ожидая выделения допол-
нительных ресурсов, причем ресурсы нельзя отбирать у процесса, которо-
му они выделены. Как правило, процессы могут претендовать на моно-
польное использование ресурсов, которые им нужны. Процессы облегчают
системе задачу диспетчеризации, запрашивая в каждый момент времени
только один ресурс. Система может либо удовлетворить, либо отклонить
каждый запрос. Если запрос отклоняется, пользователь удерживает за со-
гои уже выделенные ему ресурсы и ждет в течение определенного конечно-
интервала, пока этот запрос, в конце концов, не будет удовлетворен,
ется МЭ УДОВлетво1)Яет только те запросы, при которых ее состояние оста-
де^ЖНЬ1м- Запрос процесса, приводящий к переходу системы в нена-
деТв,е Сост°яние, откладывается до момента, когда его все же можно бу-
8 8аДезк°ЛНИТЬ" ^аким образом, поскольку система всегда поддерживается
Все зап Ном состоянии, рано или поздно (т.е. в течение конечного времени)
Св0Ю Jr'?ы можно будет удовлетворить, и все процессы смогут завершить
Работу.
Вопросы для самопроверки
!• (Да/Нет) Правда ли, что состояние, показанное на рисунке 7.9, яв-
ляется надежным?
2- Какое минимальное количество дополнительных ресурсов необхо-
димо добавить в систему, изображенную на рисунке 7.9, чтобы она
перешла в надежное состояние?
424
Ответы 1) Нет. В данной ситуации невозможно гарант^
что все процессы закончат свою работу. Процесс Р2 сможет а - Ч>,
свою работу, воспользовавшись двумя оставшимися ресурсагвК°^Л
ко после его завершения в системе останется только три Св11-
устройства, чего явно недостаточно ни для завершения про>°®°Д!й5
ни для завершения процесса Р3 (которым для продолжения рак00* Р
обходимо 4 и 5 дополнительных ресурсов, соответственно). 2)
бавлении одного дополнительного ресурса, по завершении проц ’’Дь
будут свободны четыре ресурса, которые позволят завершить г Т
боту процессу Pi, а тот, в свою очередь, завершив работу, осВО|°Ч-
пять ресурсов, достаточных для завершения процесса Р3. ’
Процесс max(Pj) loan(Pj) daim(Pj)
Р1 5 1 4
Р2 3 1 2
Рз 10 5 5
а = 2
Рис. 7.9. Описание состояний трех процессов
7.8.5 Недостатки алгоритма банкира
Алгоритм банкира представляет для нас интерес потому, что он позво-
ляет продолжать выполнение таких процессов, которым в случае системы
с предотвращением взаимоблокировок пришлось бы ждать. Однако и у это-
го алгоритма имеется ряд недостатков.
• Алгоритм банкира исходит из фиксированного количества распреде-
ляемых ресурсов. Поскольку устройства, представляющие ресурсы,
зачастую требуют технического обслуживания (например, из-за воз-
никновения неисправностей, либо в целях профилактики), мы не но
жем считать, что количество ресурсов всегда остается фиксиро 1
ным. По этой же причине он не подходит для операционных ^иС й'
поддерживающих работу с устройствами «горячей» замены (наусТ.
мер, устройствами USB), поскольку в таких системах количеств I
ройств в системе динамически изменяется.
• Алгоритм требует, чтобы число работающих процессов оставалось®
стоянным. Подобное требование также является нереалист
В современных интерактивных многозадачных системах ко
работающих процессов все время меняется. ест)’
• Алгоритм требует, чтобы банкир-распределитель ресурсов
система) гарантированно удовлетворял все запросы за некотор ко-
нечный период времени. Очевидно, что для реальных систе л’ее
бенно для систем реального времени, необходимы гораздо
кретные гарантии.
• Аналогично, алгоритм требует, чтобы клиенты (т.е. задания
цессы) гарантированно «платили долги» (т.е. возвращали
ные им ресурсы) в течение некоторого конечного времени. <- J
для реальных систем требуются гораздо более конкретные
Jl(U а бесконечное откладывание
425
' питм требует, чтобы процессы заранее указывали свои максималь-
• ^потребности в ресурсах. По мере того как распределение ресурсов
дь16 иТСя все более динамичным, все труднее оценивать максималь-
сТ^дотребности процесса. Вообще-то, одно из главных преимуществ со-
енных языков программирования высокого уровня и «дружествен-
вРеМ по отношению к пользователю графических интерфейсов состоит
вЬ1Х* чТ0 пользователю не нужно знать детали реализации низкого
в Твня, например, заботиться о том, какие ресурсы ему потребуются,
гг пьзователь либо программист ожидает от системы, что та «напечатает
либо «отправит сообщение», и его не волнует, какие ресурсы по-
Ч ^адобятся системе для обслуживания подобных запросов.
пипеперечисленным причинам, в современных операционных сис-
[алгоритм банкира, предложенный Дейкстрой, не используется.
тема?ствИтельности, немногие системы могут себе позволить накладные
8 № яы связанные с применением стратегий обхода взаимоблокировок,
расходы»
Вопросы для самопроверки
1. Почему алгоритм банкира, предложенный Дейкстрой, не подходит
для систем, поддерживающих «горячую» замену устройств?
Ответы 1) Алгоритм требует, чтобы число ресурсов в системе оста-
валось постоянным. Устройства «горячей» замены могут подключать-
ся к системе либо отключаться от нее в любой момент времени, что
означает постоянное изменение числа доступных ресурсов в системе.
7.9 Обнаружение взаимоблокировок
Мы рассмотрели две стратегии, призванные обеспечить отсутствие в сис-
^еме тупиковых ситуаций: стратегию предотвращения и стратегию обхода
моблокировок. Существует еще одна стратегия, которая допускает воз-
кализВеНИе В системе тупиковых ситуаций, однако при этом позволяет ло-
1(8 (de°H|TI> ИХ И’ по возможности» удалить. Обнаружение взаимоблокиров-
ситуац Ock detection) — это установление факта возникновения тупиковой
с и’ и определение процессов и ресурсов, вовлеченных в эту тупико-
Розок> ^a4HK)-32’33'34’35’36'37’38’39’4() Алгоритмы обнаружения взаимоблоки-
^Ия, и Ч’ввило, определяют, не возникла ли ситуация кругового ожи-
УсловРИМеНЯЮтСЯ в системах» где выполняются первые три необходи-
^Риые ИЯ Возникновения тупиковой ситуации.
^еделеение алгоритмов обнаружения взаимоблокировок сопряжено
8 °®РазпНЫМИ Д°полнительными затратами процессорного времени. Та-
с^^Црощ14’ Здесь мы снова сталкиваемся с необходимостью прибегать
^Ссным решениям, столь распространенным в операционных
%. уДУт ли накладные расходы, связанные с реализацией алгорит-
тупиковых ситуаций, в достаточной степени оправданы
д Дац11НЬ^Ми выгодами от локализации и устранения взаимоблокиро-
Ь1и Момент мы этот вопрос рассматривать не будем, а лучше со-
ту СВое внимание на описании алгоритмов, позволяющих обнару-
i йКовые ситуации.
7.9.1 Графы распределения ресурсов
При рассмотрении задачи обнаружения взаимоблокировок прим
ся весьма распространенная нотация (рис. 7.10), согласно которо^4®».
пределение ресурсов и запросы изображаются в виде направленного
фа.41 Квадраты обозначают процессы, а большие кружки — классы 1^®-
тичных ресурсов. Малые кружки, находящиеся внутри боль^6®-
используются для изображения отдельных ресурсов каждого класса4111*’
пример, если в большом кружке с меткой Ri содержатся три м
кружка, это говорит о том, что система располагает тремя эквивален
ми ресурсами типа Rx. Т®Ь|-
На рис. 7.10 показаны отношения, которые могут быть представл
в графе запросов и распределения ресурсов. На рис. 7.10 (а) показано 5ы
процесс Рх запрашивает ресурс типа RP Стрелка от квадрата Рг дох'оп^
только до большого кружка — это говорит о том, что в текущий момент з *
прос от процесса на выделение данного ресурса находится в стадии рас
смотрения.
(а) Процесс запрашивает один из
двух идентичных ресурсов типа R,
(Ь) Процессу Р2 выделен один из
двух идентичных ресурсов типа R2
Рис. 7.10. Граф запросов и распределения ресурсов
\ufoBku и бесконечное откладывание
427
т_с. 7.10 (Ь) показано, что процессу Р2 выделен ресурс типа R2 (один
идентичных ресурсов), — здесь стрелка прочерчена от малого
з аВ^Х находящегося внутри большого кружка R2, до квадрата Р2. Это
что система уже выделила определенный ресурс данного типа
зца'10еТ’
flpofieCC^c 7.Ю (с) показана ситуация, в некоторой степени приближаю-
" потенциальной взаимоблокировке: процесс Р3 запрашивает ресурс
(Доделенный процессу Р4.
р3, м 7.10 (d) показана небольшая система в тупиковой ситуации, ко-
Т pa P _сС р5 запрашивает ресурс типа R4, единственный экземпляр кото-
гДа°₽ыделен процессу Pg. Процесс Р6 в свою очередь запрашивает ресурс
рог° единственный экземпляр которого выделен процессу Р5, который
f0®0 очередь запрашивает ресурс типа R4 — это пример «кругового ожи-
всВ типичного для системы в состоянии взаимоблокировки.
Д81Гоафы запросов и распределения ресурсов динамично меняются по мере
как процессы запрашивают ресурсы, получают их в свое распоряже-
ние а через какое-то время возвращают операционной системе.
Вопросы для самопроверки
1. Предположим, что процесс управляет ресурсом типа R4. Имеет ли
значение, какой именно из малых кружков связан стрелкой с про-
цессом в графе запросов и распределения ресурсов?
2. Какое необходимое условие возникновения взаимоблокировки лег-
че идентифицировать с помощью графа распределения ресурсов,
чем анализируя данные распределения ресурсов для всех систем-
ных процессов?
Ответы 1) Нет; все ресурсы одного типа обеспечивают идентич-
ную функциональность, поэтому не имеет никакого значения, какой
именно малый кружок внутри кружка Rj будет связан стрелкой
с процессом. 2) С помощью графа распределения ресурсов легче всего
локализовать условие «кругового ожидания».
7 ^2 Приведение графов распределения ресурсов
5и^аЙМ Из с™собов обнаружения взаимоблокировок является приведе-
МоГуЙЛИ РОДУкция графа, — она позволяет определять процессы, которые
^дий3^Тииться’ и процессы, которые будут оставаться в тупиковой си-
Есдй а Также вовлеченные в эту ситуацию ресурсы).42
То3апР°сы ресурсов для некоторого процесса могут быть удовлетво-
**есс. fa МЬ1 ГоВоРим» что граф можно редуцировать (reduced) на этот про-
ЙЯ РеДУкЦия эквивалентна преобразованию графа к такому виду,
J/ty и вОз Н буДет иметь в случае, если данный процесс завершит свою ра-
c^obojk 7 ВРатит ресурсы системе. Редукция графа на конкретный процесс
ц (т.е Дется исключением стрелок, идущих к этому процессу от ресур-
сУРсов, выделенных данному процессу) и стрелок от этого про-
бой). Е ^сам (т-е- текущих запросов данного процесса на выделение ре-
c*riya 111 гРаФ можно редуцировать на все процессы, значит, тупико-
иет, а если этого сделать нельзя, то все «нередуцируемые»
г образуют набор процессов, вовлеченных в тупиковую ситуацию.
428
на процесс Р8
Рис. 7.11. Приведение графа
пробки и бесконечное откладывание
429
Г цсуяке 7-11 показана последовательность действий по приведению
Р оТОрые, в конце концов, позволяют убедиться в том, что для этого
Кного набора процессов тупиковой ситуации нет. На рисунке 7.10(d)
%jjKPeT набор процессов, которые являются «нередуцируемыми» и, таким
р0Ка3аЙ представляют систему в тупиковой ситуации. Здесь важно отме-
обРаз01^о порядок, в котором осуществляется редукция графа, не имеет
0iTi” . оКончательный результат в любом случае будет тем же самым.
30ачеВ ливость такого утверждения продемонстрировать относительно
£iipaB д чИТдтель может сам это сделать в качестве упражнения (см. уп-
7.29).
Вопросы для самопроверки
1. Почему стратегия обнаружения взаимоблокировок может оказать-
ся более эффективной, чем стратегии предотвращения и обхода
взаимоблокировок? В каком случае данная стратегия может ока-
заться менее эффективной?
2. Предположим, что система пытается уменьшить накладные расхо-
ды, связанные с обнаружением взаимоблокировок только в случае,
если в системе выполняется большое количество процессов. Назо-
вите недостатки подобной стратегии.
Ответы 1) В общем, стратегия обнаружения взаимоблокировок
накладывает меньшее число ограничений, позволяя более эффективно
использовать имеющиеся ресурсы. Но с другой стороны, алгоритм об-
наружения взаимоблокировок должен выполняться регулярно, что со-
пряжено со значительными накладными расходами. 2) Поскольку
взаимоблокировки возникают внутри пары процессов, то система мо-
жет не обнаружить некоторые виды взаимоблокировок, если число
процессов в системе невелико.
Восстановление после 6заимо6локир< М
Си
одно СТеМУ’ оказавшуюся в тупике, необходимо вывести из него, нарушив
Моб ИЛИ нескольк° из четырех необходимых условий существования взаи-
п0Лн иР°вки. При этом, как правило, несколько процессов частично или
г°Разд^ЬЮ потеРЯЮт Уже проделанную ими работу. Однако это обойдется
Не См Дешевле, чем оставлять систему в тупиковой ситуации, когда она
Сло еТ ИСПольз°вать некоторые свои ресурсы.
Чин, 0- Ность восстановления системы, т.е. ее вывода из тупиковой ситуа-
м СЛовливается рядом факторов. Прежде всего, в первый момент во-
бЬ1ть неочевидно, что система попала в тупиковую ситуацию.
80 многих системах есть процессы, которые периодически про-
s <с0яч1?Я’ выполняют определенные задачи, а затем снова погружаются
д()У>>’ ПосКолькУ подобные процессы не завершают свою работу
Ьа^б5соДят 3авеРшения работы системы, и по причине того, что они редко
В актианое состояние, определить, не попали ли они в состояние
^0ста^КИ₽ОВ,<и’ Д°статочн° сложно. Во-вторых, в большинстве систем
ССаавеТ°Чно эффективных средств, позволяющих приостановить про-
°пределенно долгое время, вывести его из системы и возобновить
430
----------------------------------------------------------
его выполнение позднее (не теряя проделанную им работу). В действц 1
ности некоторые процессы, например процессы реального времени Tej,J
ны работать непрерывно и не допускают приостановки и последуют
зобновления. Если даже в системе существуют эффективные средства ° *4
остановки/возобновления процессов, то их использование требует
правило, значительных накладных затрат, а также внимания выс0 '
лифицированного системного администратора. А подобного системно0^6®'
министратора может и не быть. И, наконец, восстановление после Вза°
блокировки может быть осложнено большим количеством вовлечен10'
в нее процессов (десятков или даже сотен). Исходя из этого, даже вор1Ь05
новление после взаимоблокировки небольших масштабов требует осуп СТз'
вления немалого объема работ; крупная же взаимоблокировка, в котоп 1
вовлечено более сотни процессов, может потребовать громадной работу **
В современных системах восстановление после взаимоблокировки обк
но выполняется путем принудительного выведения некоторого процесса
системы, чтобы можно было использовать его ресурсы.43’44 Этот выведи
ный процесс обычно теряет все свои результаты, однако теперь остальные
процессы получают возможность завершить свою работу. В некоторых слу.
чаях необходимо уничтожить несколько процессов, чтобы освободить ко-
личество ресурсов, достаточное для завершения работы остающихся про-
цессов. Здесь сам термин «восстановление» кажется в какой-то степени не-
правомерным, поскольку восстановление работоспособности одних
процессов происходит за счет уничтожения других.
Процессы могут выводиться из системы в соответствии с приоритетом.
Здесь мы также сталкиваемся с некоторыми трудностями. Например, про-
цессы, вовлеченные в тупиковую ситуацию, могут не иметь конкретных
приоритетов, так что системе придется принимать произвольное решение.
Значения приоритетов могут оказаться неправильными или в какой-то
степени нарушаться из-за определенных особых соображений, например,
в случае планирования по конечному сроку (deadline scheduling), некото-
рый процесс с относительно низким приоритетом временно получает выо>-|
кий приоритет ввиду приближающегося конечного срока. Поэтому, чТ0’М
оптимальным образом определить, какой из процессов следует вывести
системы, могут потребоваться значительные усилия. в
Механизм приостановки/возобновления (suspend/resume) прои
позволяет нам кратковременно переводить процессы в состояние
ния (освобождая занимаемые ими ресурсы), а затем активизировать g
дающие процессы, причем без потери результатов работы. Исследо
в этой области имеют большое значение не только в связи с проблем
хода из тупиковых ситуаций. Механизм приостановки/возобновле
жет оказаться весьма эффективным, если необходимо на какое-' 0
выключить систему, а затем запустить ее снова с той же точки без
промежуточных результатов. Данная технология встраивается в° о*
мобильные системы, в которых ограниченное время автономной Р
батарей заставляет пользователей минимизировать потребление -
Согласно спецификации ACPI (Advanced Configuration аП
Interface — усовершенствованный интерфейс управления конфиг с
нием и энергопотреблением) предусмотрен спящий режим, в кот
держимое памяти, регистров и другая информация о состоянии
бровки и бесконечное откладывание
431
L ваЮтСЯ на энергонезависимые носители информации (например,
^ji0cbIg диск), после чего питание системы выключается. В Windows ХР
ясим так и называется «спящим». После повторного запуска систе-
э1°л' продолжает выполнение с того места, на котором она вошла в спя-
не теРяя проделанной работы.45
jjjH# ₽е сеМенных базах данных широко применяется механизм контроль-
Рс° чек/отката (checkpoint/rollback) — предшественник механизма
gbi* Сновки/возобновления. С помощью контрольных точек/отката сис-
Лрцо0 орйВляется со сбоями и тупиковыми ситуациями, пытаясь сберечь
нНую работу в случае завершения процесса. Средства отката с кон-
0роДел .. точкой обеспечивают приостановку/возобновление вычислений
тр°л твоей результатов только после последней контрольной точки
С °ckpoint) (от момента, когда запоминалось состояние системы). В слу-
^^завершения работы процесса или системы (случайно либо преднаме-
ч0ено в результате срабатывания алгоритма восстановления после взаимо-
блокировки), система выполняет откат (rollback), отменяя все операции,
выполненные процессом с последнего момента сохранения состояния (по-
следней контрольной точки).
Когда в распоряжении базы данных имеется большое количество ресур-
сов (миллионы и более), к которым необходимо получать эксклюзивный
доступ, существует риск возникновения тупиковой ситуации. Чтобы обес-
печить непротиворечивость данных в базе в случае завершения процессов,
вовлеченных во взаимоблокировку, распределение ресурсов в системах баз
данных, как правило, организуется с помощью транзакций (transactions).
Изменения, выполненные в рамках одной транзакции, фиксируются толь-
ко в случае, если выполнение транзакции завершилось успешно. Более
подробно тема транзакций рассматривается в главе 13 данной книги.
Тупиковые ситуации могут приводить к катастрофическим последстви-
ям в некоторых системах реального времени. Так, система управления
процессами реального времени, ответственная за нормальную работу неф-
теперерабатывающего предприятия, просто обязана непрерывно функцио-
"Ровать, поскольку от этого зависит безопасность и нормальная деятель-
с ть предприятия. Электронный кардиостимулятор должен в буквальном
лей Ле Не пропустить ни одного биения сердца. В подобных условиях ма-
делать^ ^Иска возникновения взаимоблокировки быть не должно. Что же
х°Дймо WJIH тУпиковая ситуация все же возникнет? Очевидно, что ее необ-
Мозкао? ~ГНовенно обнаруживать и устранять. Однако всегда ли это воз-
Разраб <,Т° лишь некоторые из проблем, не позволяющих спокойно спать
°тчикам операционных систем.
Вопросы для самопроверки
(Да/Нет) Правда ли, что система может устранять взаимоблокиров-
ки, случайным образом выбирая «нередуцируемый» процесс в гра-
фе распределения ресурсов?
2. Почему система, выполняющая рестарт процесса, предварительно
уничтоженного для разрешения тупиковой ситуации, может стра-
дать от низкой производительности?
432
Гл
Ответы 1) Нет. К моменту обнаружения взаимоблокировки
теме может существовать несколько циклов «кругового озкил’6^
2) Во-первых, при уничтожении процесса теряется вся проде К,15Ц
им работа. Во-вторых, поскольку перезапущенный процесс бу
полнять тот же программный код, который изначально привел Т
никновению тупиковой ситуации, то в случае, если состояние е R
не изменилось, система снова попадет в тупиковую ситуацию ИСТе1Я
7.11 Стратегии борьбы с взаимоблокировками
в современных и будущих системах I
В современных вычислительных системах тупиковые ситуации обьга
рассматриваются как неприятность ограниченного характера. В больш
стве систем реализуются основные стратегии предотвращения тупиков
предложенные Хавендером, тогда как в других системах взаимоблокиров’
ки вообще игнорируются — причем такой подход выглядит вполне удовле-
творительным. Несмотря на то, что игнорирование взаимоблокировок мо-
жет показаться опасным, данная стратегия в действительности является
довольно эффективной. Рассмотрим тот факт, что в современной системе
могут присутствовать тысячи и даже миллионы объектов, предназначен-
ных для многократного использования, в ходе работы с которыми процес-
сы и потоки могут попадать в тупиковые ситуации. Время, необходимое
для выполнения алгоритма обнаружения взаимоблокировки возрастает
экспоненциально при увеличении количества повторно используемых объ-
ектов. Если в данной системе тупиковые ситуации редки, то процессорное
время, затрачиваемое на проверку наличия взаимоблокировок, значитель-
но понижает производительность системы. В системе, не выполняющей жиз-
ненно важных задач, отдав предпочтение стратегии игнорирования взаимо-
блокировок, можно значительно выиграть в производительности, жертвуя
при этом возможностью разрешения случайных взаимоблокировок.
Хотя некоторые системы игнорируют взаимоблокировки, которые слу
чаются по вине пользовательских процессов, намного важнее предотвра
щать взаимоблокировки внутри самой операционной системы. В та
системах как Microsoft Windows предусмотрен отладчик, который п
ляет разработчикам тщательно тестировать драйверы и приложения,
бы убедиться в том, что запросы к ресурсам с их стороны не np«B q.
к взаимоблокировкам (т.е. программный код не попытается захватит®^,
кировки в рекурсивных функциях либо задать конкретную последо®6 0Ой
ность получения блокировок).46 Любопытно, что после выхода ФиН ,^еР
версии какой-либо программы, подобные механизмы тестирования °
отключаются для обеспечения максимальной эффективности.4'
В системах реального времени, а также системах, выполняют ,сТцМ°'
ненно важные задачи, возникновение тупиковой ситуации
Исследователи разработали технологии управления взаимоблоки 0 сОхРа
дающие возможность минимизировать потерю данных и при этом е $
нить высокую производительность. Взаимоблокировки или тупик ji
туации нередко возникают в системах распределенных баз данных,
gku и бесконечное откладывание
433
обеспечивать параллельный доступ к миллиардам записей для
я пользователей из тысяч разных городов.48 Из-за огромного раз-
#0# распределенных баз данных, в них невозможно реализовать
С0СТ предотвращения ли®° обхода взаимоблокировок. Надежность
^ра^^добных систем обеспечивается за счет стратегии обнаружения
,тЬ1« кировок и восстановления после взаимоблокировок при помощи
£>°бЛнь1Х точек/отката (применяя транзакции).49 Обсуждение этих ме-
1#в,гР0^хоДИт за Рамки Данной главы; более подробно о них вы сможете
в главе 17.
рр°че ртом современных тенденции, взаимоблокировки остаются важной
С У4 дЛЯ исследований по следующим причинам:
лыдинство крупномасштабных систем в гораздо большей степени
* оиентированы на асинхронную параллельную работу, чем прежние
системы с преобладанием последовательного режима. Всеобщее рас-
пространение получили многопроцессорные архитектуры, и ожидает-
ся что вскоре параллельные вычисления займут доминирующее по-
ложение. Повсеместно используются сети и распределенные системы.
Попросту говоря, теперь в системах гораздо больше операций, выпол-
няемых одновременно, что сопряжено с увеличением числа конфлик-
тов за ресурсы и, как следствие, увеличением вероятности возникно-
вения тупиковых ситуаций. Таким образом, активизируются иссле-
дования, направленные на обнаружение взаимоблокировок и восста-
новление после них в распределенных системах.
• Среди разработчиков операционных систем все большую популяр-
ность приобретает подход, в рамках которого данные рассматривают-
ся как ресурс, и в связи с этим количество ресурсов, которыми долж-
ны управлять операционные системы, резко увеличивается. Наиболее
ярко это проявляется для веб-серверов и систем баз данных, нуждаю-
щихся в высокой производительности и эффективном использовании
ресурсов. В подобных системах большинство технологий предотвра-
щения взаимоблокировок неэффективны, поэтому большую важность
приобретают алгоритмы восстановления после взаимоблокировок.
Исследователи разработали усовершенствованные алгоритмы, осно-
ванные на транзакциях, которые обеспечивают высокую эффектив-
ность использования ресурсов при сохранении низкой стоимости вос-
I ановления после взаимоблокировки.50
W миллионов компьютеров встроены в устройства широкого по-
сот Ления» особенно компактные и мобильные устройства, такие как
^овые телефоны, КПК и навигационные приборы. Подобные систе-
м ’ Называемые «однокристальными системами» (SoC), ограничены
8 Dp111 °®ъемами ресурсов, но при этом должны выполнять задачи
Во3в Ьном времени.51’52 Распределение ресурсов, не допускающее
этах иовения тупиковых ситуация, имеет большую важность для
14ВйиСИСТем’ ПОСКОЛЬКУ их пользователи не могут положиться на ад-
Леаия Т*затоРа в задачах обнаружения взаимоблокировок и восстанов-
системы после них.
434
ч
Вопросы для самопроверки
1. Почему для многих операционных систем вопрос предотв
взаимоблокировок не имеет первостепенного значения?
2. Почему обнаружить тупиковую ситуацию в распределении >•
ме гораздо сложнее, чем на отдельном компьютере? 11
Ответы 1) В персональных компьютерах тупиковые ситуя
никают редко и обычно рассматриваются как неприятность огп^Ч.
ного характера, поскольку для пользователей ПК на первп^811^
находится производительность и функциональность операционн
темы. 2) В распределенной системе гораздо сложнее выявить т°^с^.
вые ситуации из-за того, что компьютеры, входящие
распределенной системы, могут управляться различными orienC0CTa*
ными системами, а для построения графа распределения ресурСо?^08-
ходимо, чтобы каждая операционная система собирала инфот,8®06'
с других компьютеров.
Веб-ресурсы
www.diee.unica.it/~giua/PAPERS/CONF/03smc_b.pdf
Обсуждение эффективного подхода к предотвращению взаимоблокировок в сис-
темах реального времени.
www.db.fmi.uni-passau.de/publications/techreports/dda.html
Решение проблемы обнаружения взаимоблокировок в распределенных системы.
www.linux-mag.сот/2001-03/compile_01.html
Статья, описывающая решение проблемы взаимоблокировок на примере «обе-
дающих философов». В начале статьи кратко рассматриваются примитивы взаи-
моисключения (например, семафоры) и параллельное программирование.
Umoeu
_31*
Одна из проблем, которая может возникать в многозадачных системах
проблема взаимоблокировок. Процесс или поток попадает в тупиковую сй УсОбы-
либо ситуацию взаимоблокировки в случае, если он ожидает наступления
тия, которое никогда не произойдет. Системная взаимоблокировка xapai т Р
ся попаданием в тупиковую ситуацию одного или нескольких процессов^^и
шинство взаимоблокировок возникают в результате нормальной конкУР^
борьбы за право обладания теми или иными ресурсами (например,
торые в каждый конкретный момент времени могут использоваться тОЛ1^круГ0®£Г
пользователем). Для системы в тупиковой ситуации характерно наличие
го ожидания». х сИ^.
Примером системы, работа которой чревата возникновением тупиков
ций, является система спулинга. Стандартное решение проблемы взашя
вок в системах спулинга состоит в ограничении поступления данных,
мых спулерами, так что файлы спулинга по достижению некоторого ур°
нения, не дают возможности принимать новые задания на печать.
системы печати построены таким образом, что они позволяют начинать гиХ/
до того, как получат все задание целиком, благодаря чему полностью "
заполненный файл спулинга может быть опустошен или частично освобои^рА
время, когда задание еще продолжает выполняться. Данная концепция j
\а и бесконечное откладывание
435
оцгрывании потокового аудио и видео, когда просмотр аудио и видео
jjpfl ь еще до того, как аудио- или видеоклип будет загружен полностью,
^jjo ,,яЧ? системе, которая заставляет процессы ожидать, пока система выпол-
д^^-еление ресурсов и задаст план выполнения процессов, возможно воз-
расОРе^с11Туации бесконечного откладывания одних процессов, в то время как
^|’^а°ве11йе1стемы сосредоточено на других процессах. Ситуация бесконечного от-
С может приводить к таким же катастрофическим последствиям, как
’"яДЫ6®Рокировки. Бесконечное откладывание возникает в случае, когда систе-
(-твуется предпочтениями в плане распределения ресурсов. В некото-
руКаВ°Д аХ бесконечное откладывание предотвращается благодаря тому, что
сИс1е процесса увеличивается по мере того, как он ожидает выделения нуж-
Прй°РйТе ресурса. Это называется старением процесса.
еого , могут быть динамически перераспределяемыми (например, процессор
ресурс паМяТЬ^ то есть они могут отбираться у одного процесса и передаваться
Boc0oBHg потери работы, проделанной первым процессом, или неперераспреде-
другоМУ
в том смысле, что их нельзя произвольно отбирать у процессов, за которы-
Данные и программы представляют собой ресурсы, которые
140 0BI\ контролироваться и распределяться операционной системой. Программ-
Я°Л"Ккод который не может изменяться во время выполнения, называют реентера-
ВЬ1Иным’. Код, который может изменяться, но предусматривает повторную инициа-
ла пию при каждом выполнении, называется кодом последовательного (много-
оатного) использования. С реентерабельным кодом могут коллективно работать
несколько процессов одновременно, а с кодом последовательного использования —
только один процесс в каждый конкретный момент времени. Когда речь идет о кон-
кретных разделяемых ресурсах, мы должны четко представлять себе, могут ли они
реально использоваться несколькими процессами одновременно или только одним
из нескольких процессов в каждый момент времени. Именно с ресурсами второго
вида чаще всего оказывается связанным возникновение взаимоблокировок (тупико-
вых ситуаций).
Для возникновения тупиковой ситуации должны быть удовлетворены четыре
необходимых условия: «взаимоисключение», когда процессы заявляют исключи-
тельные права на управление своими ресурсами; «ожидание дополнительных ре-
сурсов», когда процессы могут удерживать за собой ресурсы, ожидая выделения
Д°полнительных запрошенных ресурсов; «неперераспределяемость», когда ре-
УРСЬ1 нельзя принудительно отнимать у процессов; и «круговое ожидание», когда
р^ствует замкнутая цепочка процессов, в которой каждый процесс удерживает
сурсР ’ запРлшиваемый другим процессом, который в свою очередь удерживает ре-
веви’я3ап₽ап1иваемый следующим процессом, и т.д. Эти четыре условия возникно-
Вааие заим°блокировки являются необходимыми, а это означает, что существо-
’Ти чет, аимо(-,локировки влечет за собой выполнение всех этих условий. Вместе
Р°вкц (т Je Условия необходимы и достаточны для существования взаимоблоки-
Основн” если они выполнены, взаимоблокировка неизбежна).
П1>еДотвпяЬ1е напРавления научных исследований в области взаимоблокировок:
взаим°блокировок, обход взаимоблокировок, обнаружение взаи-
Ри6л°кИров°К И Восстановление после взаимоблокировок. Предотвращение взаи-
cjCl! поДРазУМевает перевод системы в такое состояние, при котором
иссл(?Новения тупиковой ситуации полностью исключается. В результате
яевОзД°ВаНий Кавендер пришел к выводу, что возникновение взаимоблоки-
с'Уцгр О5КН0 в системе, где нарушается хотя бы одно из необходимых усло-
1,Че ®°ван ТВования- Нельзя нарушать только первое из необходимых условий
взаимоблокировки — условие взаимоисключения, поскольку про-
д0 Ы Иметь право на монопольное использование требуемых ресурсов,
РавРешать использование выделенных (то есть многократно ис-
'6 Чток РесУРСов. Нарушение условия ожидания дополнительных ресурсов
°Чет ы процессы заблаговременно запрашивали все необходимые ресурсы,
Ривести к нерациональному использованию ресурсов и усложнить во-
прос платы за ресурсы. Нарушение условия непераспределяемости имеет л 4
цену, поскольку при этом, как правило, несколько процессов частично ил 1
стью потеряют уже проделанную ими работу. Кругового ожидания мож
пустить, если потребовать, чтобы пользователи запрашивали ресурсы в п ° 4
заранее определенном в системе порядке. Данная стратегия обеспечивает6*^0^
ние эффективности работы, хотя и не без трудностей.
Цель стратегии обхода взаимоблокировок заключается в том, чтобы моя,- I
предусматривать менее жесткие ограничения, чем в случае предотвращен 110 '
моблокировок, и тем самым обеспечить более эффективное использование рЙЯ
Средства обхода взаимоблокировок не требуют такой реализации системы*^
торой опасность тупиковых ситуаций даже не возникает. Напротив, метода! 11
взаимоблокировок учитывают подобную возможность, однако в случае увел
вероятности конкретной тупиковой ситуации здесь принимаются меры по а
ному обходу взаимоблокировки. В качестве примера алгоритма обхода взаи*?И
кировок можно назвать алгоритм банкира, предложенный Дейкстрой. В алгг, J1(k
банкира система гарантирует, что процесс не сможет запросить ресурсов б ®ЙТ1,е
чем доступно в системе. Считается, что состояние системы надежно, если hmj
возможность завершить выполнение всех процессов за конечное время. Говоря^]
состояние ненадежно, если нельзя гарантировать завершение работы всех ппл Ч1°
сов. Алгоритм банкира, предложенный Дейкстрой, требует, чтобы выделение в₽е
сов процессов происходило при условии сохранения надежного состояния системы
Алгоритм банкира обладает рядом недостатков (например, требование фиксирован
кого числа процессов и ресурсов), которые не позволяют использовать его в совре-
менных операционных системах.
Методы обнаружения взаимоблокировок применяются в системах, которые до-
пускают возможность возникновения тупиковых ситуаций. Цель стратегии обна-
ружения взаимоблокировок — установить сам факт возникновения тупиковой си
туации, причем точно определить те процессы и ресурсы, которые оказались во-
влеченными в данную тупиковую ситуацию. Выполнение алгоритмов
обнаружения взаимоблокировок может быть связано со значительными накладны-
ми расходами. Для обнаружения взаимоблокировок используется направленный
граф распределения ресурсов и запросов. Тупиковые ситуации можно выявить пу-
тем приведения или редукции графа. Если система в состоянии обслужить запро-
сы ресурсов процессом, то говорят, что граф можно редуцировать на этот процесс.
Если граф можно редуцировать на все процессы, значит, тупиковой ситуации®»
а если этого сделать нельзя, то все «нередуцируемые» процессы образуют на V
процессов, вовлеченных в тупиковую ситуацию.
Методы восстановления после взаимоблокировок применяются для УсТРа®_й],
тупиковых ситуаций, с тем чтобы система могла продолжать работать, а ПР й!4ае|
попавшие в тупиковую ситуацию, могли завершиться с освобождением за “Jw
мых ими ресурсов. Восстановление после обнаружения взаимоблокировки 0 о1.
осуществляется путем выведения из системы одного или нескольких про в0.
вовлеченных в тупиковую ситуацию. Механизм приостановки/возобновЛ
зволяет системе на краткое время отбирать у процесса занимаемые им Pot J
когда позволят условия, возобновить работу процесса, не теряя продела
ты. Средства отката с контрольной точкой обеспечивают приостановку/
ление вычислений с потерей результатов только после последней контрол
ки (от момента, когда запоминалось состояние системы). В случае завеР1
боты процесса или системы (случайно либо преднамеренно в Р®те14а
срабатывания алгоритма восстановления после взаимоблокировки), сиС
полняет откат, отменяя все операции, выполненные процессом с момеИт0б^^г I
него запоминания состояния системы (последней контрольной точки).
печить непротиворечивость данных в базе в случае завершения проце
ченных во взаимоблокировку, распределение ресурсов в системах баз Д
правило, организуется с помощью транзакций.
437
и бесконечное откладывание
ценных вычислительных системах тупиковые ситуации обычно рассмат-
р неприятность ограниченного характера. В большинстве систем реали-
оВные стратегии предотвращения тупиков, предложенные Хавендером,
Р^сЯ в ДРУгиХ системах взаимоблокировки вообще игнорируются — причем та-
3 ffl9 д выглядит вполне удовлетворительным. Несмотря на то, что игнорирова-
блокировок может показаться опасным, данная стратегия в действитель-
b°te рзейМяетСЯ довольно эффективной. Если взаимоблокировки возникают редко,
^LjpHoe время, расходуемое на обнаружение взаимоблокировок, может зна-
дроДеС уХудшить производительность системы. С учетом современных тенден-
чйтедьН°я^0блокировки остаются важной областью для исследований, поскольку
дИ®’ В3^во одновременно выполняемых процессов и число существующих ресурсов
увеличивая вероятность возникновения тупиковых ситуаций в много-
будет Ра пВ^1Х и распределенных системах. Кроме того, многие системы реального
проИесС РпоЛучающие все большее распространение, нуждаются в такой реализа-
®₽е>,еВСПРеДеления РесУРсов» которая бы исключала возможность возникновения
да™-
Ключевые термины
.ppj_сМ. Усовершенствованный интерфейс управления конфигурированием
и энергопотреблением.
Алгоритм банкира, предложенный Дейкстрой (Dijkstra’s Banker’s Algorithm) —
алгоритм обхода взаимоблокировок, который управляет распределением ресур-
сов, основываясь на количестве ресурсов, принадлежащих системе, количестве
ресурсов, которые удерживает каждый конкретный процесс, и максимальном
количестве ресурсов, которые могут понадобиться процессу во время выполне-
ния. Данный алгоритм выделяет ресурсы процессам только в случае, если при
этом не нарушается надежное состояние системы. (См. также Надежное состоя-
ние и Ненадежное состояние).
Взаимоблокировка — см. Тупиковая ситуация.
Восстановление после взаимоблокировок (deadlock recovery) — процесс восста-
новления системы после возникновения тупиковой ситуации. Механизм восста-
новления включается в себя временную приостановку процесса (с сохранением
проделанной им работы) или, в некоторых случаях, уничтожение процесса с по-
следующ11м перезапуском (с потерей всей проделанной работы).
^синый ресурс (dedicated resource) — ресурс, который в каждый конкретный
cVnreHT времени может использоваться только одним процессом. Иногда такой ре-
Г₽аф также называют ресурсом последовательного повторного использования.
Пр0?аспреДеления ресурсов (resource allocation graph) — граф, показывающий
Чесс ССЬ1 И РесУРсьг в системе. Стрелка от процесса к ресурсу показывает, что про-
в₽°Цес11₽ОСИЛ даннь1я ресурс. Стрелка от ресурса к процессу показывает, какому
Ддлич ®Ь1Л выДелен данный ресурс. С помощью этого графа можно определить
ДосТат ие тУпиковой ситуации, и выявить попавшие в нее процессы и ресурсы.
^®adlonv?e УСловия возникновения взаимоблокировки (sufficient conditions for
ОзКЦдац четыре условия: взаимоисключения, неперераспределяемости,
^хоЛ?, Дополнительных ресурсов и кругового ожидания, которые являются
7УДц1г,Д1')^Ь1Ми и достаточными условиями для возникновения и существования
ситУапии-
д^^тИя IIP°*'ecca (starvation) — ситуация, когда поток ожидает наступления
Которое может никогда не произойти, синоним бесконечного откла-
(d
Sadly embrace) — см. Тупиковая ситуация.
438
Ко.
Воз.
* кругового
Код последовательного повторного использования (serially reusable codel
граммный код, который может модифицироваться при выполнении ц
инициализируется при каждом повторном использовании. Такой код
пользоваться только одним процессом в каждый конкретный момент 03itel ь
Контрольная точка (checkpoint) — точка, в которой запоминается состо^^Ч
темы для последующего восстановления в случае преждевременного ”11е
ния процесса (например, в результате срабатывания алгоритма восстав
после взаимоблокировки).
Контрольной точки/отката механизм (checkpoint/rollback) — метод
ния системы после взаимоблокировки, в котором отменяются все дейст
транзакции), выполненные процессом с момента последнего сохранения*14
ния (последней контрольной точки).
Круговое ожидание (circular wait) — условие существования тупиковой сит
когда два и более процесса образуют замкнутую цепочку, в которой
процесс удерживает за собой один и более ресурсов, требующихся 3itnr,1L
процессу в цепочке.
Линейное упорядочивание Хавендера (linear ordering) — принцип, согласно
торому процессы системы должны запрашивать ресурсы строго в порядке
растания номеров ресурсов. Этот метод позволяет нарушить условие
ожидания», необходимое для возникновения взаимоблокировки.
Максимальные потребности (maximum need) (алгоритм банкира, пре,
Дейкстрой) — атрибут, используемый в алгоритме банкира, означающий мак”
симальное число ресурсов (конкретного типа), Которые могут понадобиться про-
цессу в ходе выполнения.
Надежное состояние (safe state) -— состояние системы в алгоритме банкира, пред-
ложенном Дейкстрой, для которого существует последовательность действий,
позволяющая всем процессам завершить работу, не допуская попадания систе-
мы в тупиковую ситуацию.
Ненадежное состояние (unsafe state) — состояние системы в алгоритме банкира,
предложенном Дейкстрой, которое со временем может привести систему в тупи-
ковое состояние, поскольку в ней может оказаться недостаточно ресурсов для
завершения работы всех процессов.
Необходимое условие возникновения взаимоблокировки (necessary condition №
deadlock) — условие, соблюдение которого требуется для того, чтобы взаимоо
кировка (тупиковая ситуация) могла возникнуть. Существует четыре необх L
мых условия возникновения взаимоблокировки: условие взаимоисключе^’
условие неперераспределяемости, условие кругового ожидания и условие
дания дополнительных ресурсов.
Непераспределяемый ресурс (nonpreemptible resource) — ресурс, который не М
быть динамически отобран у конкретного процесса, например, накопитель
нитной ленте. Подобные ресурсы чаще всего попадают в тупиковые ситу
Обедающие философы (Dining Philosophers) — классическая задача, на 1 °пара5
впервые обратил внимание Дейкстра, иллюстрирующая такие проблем
лельного программирования, как взаимоблокировки и бесконечное ть'
ние. Согласно условиям задачи, необходимо, чтобы никто из группы
софов, сидящих за круглым столом, на котором разложены п вилок,
щихся только размышлениям и потреблением пищи, не умер с голодУ»
заполучить для еды две вилки, требуемых правилами этикета.
Обнаружение взаимоблокировок (deadlock detection) — методы, при
для установления самого факта возникновения тупиковой ситуации-
наружения взаимоблокировки принимаются меры по удалению ее И3 J
что, как правило, означает полную или частичную потерю проделан110
след*Хй?
'(а а бесконечное откладывание
439
/ «моблокировок (deadlock avoidance) — стратегия, учитывающая воз-
ВзЯ возникновения взаимоблокировки, но гарантирующая, что конкрет-
^^КсВ°СТковая ситуация никогда не настанет. Алгоритмы обхода взаимоблоки-
ТУП зводякэт достичь более высокой производительности по сравнению с ал-
по®011 °°мИ предотвращения взаимоблокировок. См. также Алгоритм банкира,
Яр^^ениыи Дейкстрой.
„являемый ресурс (preemptible resource) — ресурс, который может ди-
пеРеРаСП кН перераспределяться между процессами, например, процессор и ос-
I ддмять. Подобные ресурсы могут быть вовлечены во взаимоблокировки.
0°вна е по конечному сроку (deadline scheduling) — метод задания плана вы-
согласно которому выполнение процесса должно завершиться к опреде-
моменту. С этой целью процесс с относительно низким приоритетом вре-
менно получает высокий приоритет ввиду приближающегося конечного срока.
МвВЯ сьпцения (saturation threshold) — уровень использования ресурсов, при дос-
0ор°гЯ которого в последующем выделении ресурсов процессам будет отказано.
11 атрибут был разработан для уменьшения вероятности возникновения взаимо-
^окировок, однако его применение приводит к падению производительности.
„-вращение взаимоблокировок (deadlock prevention) — стратегия, исклю-
чающая возможность возникновения тупиковых ситуаций путем нарушения
одного из четырех необходимых условий возникновения взаимоблокировки.
Приведение графа (graph reduction) — последовательность действий над графом
распределения ресурсов, включающих в себя удаление процессов, которые мо-
гут быть завершены. Редукция графа на конкретный процесс изображается ис-
ключением стрелок, идущих к этому процессу от ресурсов (т.е. ресурсов, выде-
ленных данному процессу) и стрелок к ресурсам от этого процесса (т.е. текущих
запросов данного процесса на выделение ресурсов). Говорят, что граф можно ре-
дуцировать на некоторый процесс, если могут быть удовлетворены все запросы
ресурсов для этого процесса, что позволяет довести выполнение процесса до
конца и освободить все удерживаемые им ресурсы.
Приостановки/возобновления механизм (suspend/resume) — метод останова вы-
полнения процесса, сохранения его текущего состояния, освобождения зани-
маемых им ресурсов с передачей другим процессам и последующим продолже-
наем выполнения процесса с возвращением необходимых ему ресурсов.
Делаемый ресурс (shared resource) — ресурс, доступом к которому могут обла-
р дать сРазу несколько процессов.
Дукция графа — см. Приведение графа.
^^Рабельный код (reentrant code) — код, который не может изменяться во
и j. выполнения и поэтому допускает совместное использование процессами
^токами.
см «?°слеДовательного повторного использования (serially reusable resource) —
С»арея Ь1^еленный ресурс.
Реалдз (aging) — метод предотвращения бесконечного откладывания, который
ет БЫдеТСЯ пУтем увеличения приоритета процесса по мере того, как он ожида-
ли рес ления нужного ему ресурса.
!*'аазак Са (resource type) — категория ресурсов, выполняющих общие задачи.
р1®’ Кот* (inansaction) — атомарная или неделимая операция взаимоисключе-
°Рая должна быть либо выполнена целиком, либо полностью отменена.
цТо Изменений в записи базы данных часто реализуется в виде транзак-
Ту.°сТц во Позв°Ляет обеспечить высокую производительность при низкой стои-
*б**коь становления при возникновении взаимоблокировок.
ситуация (deadlock) — ситуация, когда процесс или поток ожидает со-
°торое никогда не произойдет.
440
Условие взаимоисключения, необходимое для возникновения взаимобл
ки (mutual exclusion necessary condition for deadlock) — одно из четыре ’
димых условий возникновения взаимоблокировки. Согласно данному
для существования взаимоблокировки необходимо, чтобы процессы
лучить ресурс в монопольное использование. °ГЛ11 ад
Условие кругового ожидания, необходимое для возникновения взаимобл
ки (circular wait necessary condition for deadlock) — одно из четырех ц 0lCftPo4
мых условий возникновения взаимоблокировки. Согласно данному
для существования взаимоблокировки необходимо, чтобы два и более тт°В!1>о
составляли замкнутую цепочку, в которой каждый процесс удерживает
один и более ресурсов, требующихся следующему процессу в цепочке ЗЭ С°®°й
Условие непераспределяемости, необходимое для возникновения взаимок
ровки (no-preemption necessary condition for deadlock) — одно из четырехЛо,£в-
ходимых условий возникновения взаимоблокировки. Согласно данному
вию взаимоблокировка может возникнуть только в случае, если в системе ^Сл°'
пускается принудительное отбирание ресурсов у процессов. Ве До-
Условие ожидания дополнительных ресурсов (wait-for condition) — одно из ч
рех необходимых условий возникновения взаимоблокировки. Согласно дани Tbt
условию взаимоблокировка (тупиковая ситуация) может возникнуть тол
в случае, если процессу разрешается запрашивать дополнительные ресурсы ко°
гда он уже удерживает определенные ресурсы.
Усовершенствованный интерфейс управления конфигурированием и энергопо-
треблением (Advanced Configuration and Power Interface, ACPI) — специфика-
ция управления энергопотреблением, поддерживаемая большинством операци-
онных систем. Позволяет системе выключать некоторые или все устройства без
потери проделанной ими работы.
Уприокнеиия
7.5.
7.6.
7.7.
7.1. Дайте определение взаимоблокировки или тупиковой ситуации.
7.2. Приведите пример тупиковой ситуации с участием только одного процесса
и одного ресурса.
7.3. Приведите пример простой взаимоблокировки ресурсов, участниками кото
рой являются три процесса и три ресурса. Начертите соответствую
граф распределения ресурсов. оТ.|
7.4. Что такое бесконечное откладывание? Чем бесконечное откладывание
личается от взаимоблокировки? Что между ними общего?
Предположим, система допускает бесконечное откладывание для опр^^е
ных логических объектов (сущностей). Какие меры вы, как разработчик^^ |
мы, должны предусмотреть для предотвращения бесконечного откладыв
Рассмотрите последствия бесконечного откладывания для прйв я
ниже типов систем:
а. система пакетной обработки;
б. система с разделением времени;
в. система реального времени. «8^^-
Система требует, чтобы прибывающие процессы ожидали обслУ^
пока необходимые для их работы ресурсы удерживаются другим $
сами. В системе не используется механизм старения для повыШ
оритетов ждущих процессов с целью предотвращения бесконечИ
дывания. К каким еще средствам можно прибегнуть для предот
бесконечного откладывания?
iffBku u бесконечное откладывание
441
йстеме, состоящей из п процессов, подмножество из т процессов в настоя-
Рс время страдает от бесконечного откладывания. Можно ли определить
'' ^таКОЙ системе’ какие процессы подверглись бесконечному откладыванию?
8 бодающие философы). Одним из наиболее важных вкладов Дейкстры
звИтие параллельного программирования стало рассмотрение пробле-
в ₽ обедающих философов.53,54 Данная проблема иллюстрирует многие ню-
параллельного программирования.
я® _ задача сводится к написанию параллельно работающей программы
/монитором), которая бы воспроизводила поведение философов. В ней не
С лзкны возникать тупиковые ситуации и ситуации бесконечного отклады-
Д°яия__иначе один или несколько философов могут просто умереть с голо-
Разумеется, ваша программа должна обеспечивать взаимоисключе-
ние — два философа не могут одновременно использовать одну вилку.
На рисунке 7.12 смоделировано поведение обычного философа. Проком-
ментируйте реализацию модели поведения философа в каждом фрагменте
I программного кода.
а. См. рис. 7.13.
б. См. рис. 7.14.
в. См. рис. 7.15.
г. См. рис. 7.16.
1 typicalPhilosopher()
2 (
while ( true )
4 (
5 think() ; // размышление
eat(); // питание
} // окончание цикла while
8 } // окончание класса typicalPhilosopher
fw. 7.12. Обычное поведение философа за обедом (к упражнению 7.9)
1
2
3
4
5
6
7
8
9
10
И
12
13
14
15
16
typicalPhilosopher()
while { true )
(
think(); // размышление
pickUpLeftForkO; // философ берет левую вилку
pickUpRightFork(); // философ берет правую вилку
eat<); // питание
putDownLeftFork(); //философ кладет левую вилку
putDownRightFork(); //философ кладет правую вилку
' // окончание цикла while
Ь 77 окончание класса typicalPhilosopher
доведение философа за обедом (к упражнению 7.9(a))
442
ч,
1 typicalphilosopher ()
2 {
3 while ( true )
4 5 { think (); // размышление
6
7 8 pickUpBothForksAtOnce(); // философ берет обе вилки сРаэу
9 10 11 12 ) eat (); putDownBothForksAtOnce(); // окончание цикла while // питание // философ кладет обе вилки сразу
13
14 > // окончание класса typicalPhilosopher
Рис. 7.14. Поведение философа за обедом (к упражнению 7.9(6))
1 typicalPhilosopher()
2 {
3 while ( true )
4 (
5 think(); // размышление
6
7 while ( notHoldingBothForks ) // философ не держит обе вилки
8 (
9 pickUpLeftFork () ; // философ берет левую вилку
10
11 if ( rightForkNotAvailable ) // правая вилка недоступна 1
12 {
13 putDownLeftFork(); //философ кладет левую вилку
14 } // окончание конструкции if
15 else
16 <
17 pickUpRightFork(); // философ берет правую вилку
18 } // окончание конструкции else
19 } // окончание цикла while
20
21 eat(); // питание
22
23 putDownLeftFork(); //философ кладет левую вилку
24 putDownRightFork(); //философ кладет правую вилку
25 } // окончание цикла while
26
27 } // окончание класса typicalPhilosopher
Рис. 7.15. Поведение философа за обедом (к упражнению 7.9(b))
,f6ku и бесконечное откладывание
443
1
г
з
4
ralPhilosopher ()
СУ?1
(
while ( true )
think();
// размышление
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
2Э
24
25
26
27
28
if ( philosopherlD mod 2 == 0 ) //четный философ
pickUpLeftFork(); // философ берет левую вилку
pickUpRightFork(); // философ берет правую вилку
eat(); // питание
putDownLeftForkO; //философ кладет левую вилку
putDownRightForkО; //философ кладет правую вилку
} // окончание конструкции if
else
{
pickUpRightFork(); // философ берет правую вилку
pickUpLeftFork(); // философ берет левую вилку
eat О; // питание
putDownLeftForkO; //философ кладет левую вилку
putDownRightFork(); //философ кладет правую вилку
} // окончание конструкции else
} // окончание цикла while
29 ) // окончание класса typicalPhilosopher
fot. 7.16. Поведение философа за обедом (к упражнению 7.9(г))
7.10.
Дайте определение и опишите каждую из перечисленных ниже концепций
ресурса.
динамически перераспределяемый ресурс;
неперераспределяемый ресурс;
разделяемый ресурс;
выделенный ресурс;
реентерабельный код;
Код последовательного повторного использования;
Динамическое распределение ресурсов.
! четыре необходимых условия существования взаимоблокировок,
г-,—‘ краткое обоснование причин, по которым каждое отдельно взя-
р6 Условие необходимо.
С —каждое из необходимых условий существования тупиковой
уаЦии на примере дорожной пробки, показанной на рис. 7.1.
е четыре направления научных исследований по проблеме взаимобло-
СтраВ°К Упомянуты в главе? Кратко рассмотрите каждое из них.
Пол2*ГИя Хавендера, направленная на нарушение условия ожидания до-
валиТеЛьных Ресурсов» требует, чтобы процессы предварительно запраши-
'•1ч *®се цСб Не°бхоДимые им ресурсы. Система выделяет ресурсы по принципу
”• Поч ЛИ ничего». Назовите преимущества и недостатки данного метода.
стц ц у предложенное Хавендером нарушение условия непераспределяемо-
стало популярным средством исключения возможности взаимобло-
Р°Ьок?
7И.
712.
713.
Ч
7
а.
б.
в.
г.
Д.
е.
ж.
Назовите ч
Приведите
7—
^смотрите
7.16.
7.17.
7.18.
7.19.
7.20.
Обсудите достоинства и недостатки стратегии Хавендера, наруща1о 1
ловия кругового ожидания. 1
Каким образом механизм линейного упорядочивания Хавендера 1
значенный для нарушения условия кругового ожидания, предок
образование замкнутых циклов в графе распределения ресурсов?
Процесс постоянно запрашивает, а затем освобождает ресурсы тип ь
по одному в указанном порядке. В системе существует по oahomv 11 h
каждого типа. Второй процесс время от времени также запрашивае
бождает эти ресурсы. При каких условиях может возникнуть взаим И
ровка? Что можно сделать для ее предотвращения?
В чем привлекательность механизма обхода взаимоблокировок по
нию с механизмом предотвращения взаимоблокировок?
Охарактеризуйте в контексте алгоритма банкира, предложенного Дейк
каким является каждое из состояний, показанных на рисунках 7.17
(надежным или ненадежным). Если состояние является надежным, ощ»
те последовательность действий, которая бы позволила завершить своиел®‘
ту всем процессам. Если состояние ненадежное, продемонстрируйте пос₽а6°1
вательность действий, которая может привести к взаимоблокировке.
Процесс
тах(Р;)
Pl
Р2
Рз
Р4
4
6
8
2
1оап(Р;) claim(Pj)
1 3
4 2
5 3
0 2
а = 1
Рас. 7.17. Описание ресурсов для состояния А
Процесс max(Pj) loan(Pj) claimfPj)
Pi 8 4 4
₽2 8 3 5
Рз 8 5 3
a- 2
Рас. 7.18. Описание ресурсов для состояния В
7.21. Ненадежность состояния не означает, что система обязательно
в тупиковой ситуации. Объясните, почему. Приведите пример н®®
состояния и продемонстрируйте такую последовательность деист
которой все процессы смогут завершить работу без возникновений
блокировок. -ом J
7.22. Алгоритм банкира, предложенный Дейкстрой, обладает целым Р
достатков, которые мешают его эффективному использованию в
системе. Объясните, почему каждое из перечисленных ниже огр
можно рассматривать как недостаток алгоритма банкира,
а. число ресурсов в системе должно оставаться постоянным;
б. количество процессов в системе не должно изменяться;
\и и бесконечное откладыВани
445
' пераЦнонная система должна гарантировать, что запросы ресурсов бу-
В- 0 т удовлетворены в течение конечного времени;
Пользователи гарантируют, что они вернут ресурсы в течение конечного
, времени,
дьзователи должны заранее сообщать о максимальном количестве ре-
Д' °°рСов, которое им понадобится.
„ритм банкира для ресурсов разных классов). Рассмотрим алгоритм
^^ира, предложенный Дейкстрой (см. раздел 7.8). Предположим, что
В ^аН стеме, использующей схему обхода взаимоблокировок, имеются п про-
В С ов и Ш типов ресурсов; предположим, что в системе существует по не-
деС ву экземпляров ресурса каждого типа, причем количество ресурсов
СКжлого типа известно. Разработайте такую разновидность алгоритма бан-
которая позволила бы обойти взаимоблокировки в данной системе.
подумайте, при каких обстоятельствах конкретный процесс
гарантировано завершит свою работу и возвратит ресурсы в пул.]
Сможет ли алгоритм банкира корректно функционировать, если ресурсы
7-2^' будут запрашиваться группами? Детально поясните свой ответ.
В системе, использующей алгоритм банкира, предназначенный для обхода
взаимоблокировок, существует пять процессов (1, 2, 3, 4 и 5), которые ис-
пользуют ресурсы четырех различных типов (А, В, С и D). Причем в систе-
ме присутствует несколько экземпляров ресурса каждого типа. Можно ли
назвать состояния, изображенные на рис. 7.19 и 7.20 надежными? Поясни-
те ваш ответ. Если система находится в надежном состоянии, приведите по-
следовательность действий, при которой все процессы успешно завершат
свою работу. Если система находится в ненадежном состоянии, опишите
такую последовательность действий, которая может привести к тупиковой
ситуации.
Процесс Используется Максимальные потребности Требуется дополнительно
А В С D А В С D А В С D
1 10 2 0 3 2 12 2 2 2 2
2 0 3 12 3 5 12 3 2 0 0
3 2 4 5 1 2 7 7 5 0 3 2 4
4 3 0 0 6 5 5 0 8 2 5 0 2
5 4 2 1 3 6 2 14 2 0 0 1
fW.7./9
Использур стояние системы, описывающее максимальные потребности, число
усмых и требуемых дополнительно ресурсов
ц*веЧигп„
0,0 Ресурсов Доступных ресурсов
А В г „
’3 L D А В С D
9 13 3 4 0 1
С
Вв Ло^2ТОяние системы, описывающее общее количество ресурсов и число
лдгУпных
446
7.26.
7.27.
7.28.
7.29.
7.30.
7.31.
7.32.
7.33.
7.34.
7.35.
7.36.
7.37.
Предположим, что в системе, состоящей из п процессов и пгидентц
сурсов, для обхода взаимоблокировок используется алгоритм бан
пишите логическую функцию boolean isSafeStatel ( int[] [] &
int[][] loans, int [ ] available) с помощью которой можно опред^'-'1!Я
факт, что система находится в надежном состоянии.
Предположим, что в системе, имеющей п процессов и пгтипов pecv
чем в ней существует по нескольку экземпляров ресурса каждого РС°6,
обхода взаимоблокировок используется алгоритм банкира. Налип 4л
ческую функцию boolean isSafeState2( int[][] maximumNeed
loans, int[] available)с Помощью Которой можно определить'т
что система находится в надежном состоянии. ТОт
При каких обстоятельствах вы бы воспользовались алгоритмом об
ния взаимоблокировок в системе, в которой допускается возникноп ^Ум-
никовых ситуаций? НйеТу.
Покажите, что в алгоритме обнаружения взаимоблокировок путем
дения графа распределения ресурсов, результат редукции графа не
от порядка редуцирования процессов. [ЛодсказкоУчтите, что незави*1 1
от порядка после каждой редукции пул доступных ресурсов будет уве СИ®°
ваться.]
Почему восстановление после взаимоблокировок является столь ттп™
проблемой? РУДНои.
Почему так сложно выбрать, какие процессы должны быть уничтожены
для восстановления после взаимоблокировки?
Один из методов восстановления после взаимоблокировки подразумевает
уничтожение одного или нескольких процессов, попавших в тупиковую си-
туацию, с самым низким приоритетом. Впоследствии выполняется рестарт
этих процессов, что позволяет возобновить соревнование за право облада-
ния теми или иными ресурсами. Какая потенциальная проблема характер-
на для системы, использующей данный алгоритм? Каким образом вы мо-
жете разрешить эту проблему?
Почему в будущем проблема возникновения тупиковых ситуаций может
встать еще более остро, чем сегодня?
Способно ли неправильное функционирование программы, приведшее к не-
доступности тех или иных ресурсов повысить или понизить вероятное^
возникновения тупиковых ситуаций и бесконечного откладывания? По
ните ваш ответ.
Подавляющее большинство современных компьютерных систем допуск“И
возникновение, по крайней мере, некоторых разновидностей взаимо
ровок и ситуаций бесконечного откладывания, причем во многих из
предусмотрены автоматические средства обнаружения и восстано |
системы после найденных проблем. В действительности, многие Р^^цост*
ки считают, что утверждать, что система полностью исключает вер
возникновения взаимоблокировок либо ситуаций бесконечного от
ния, практически невозможно. Покажите, каким образом иссЛ яЧе00ь!?
в этой области должны повлиять на разработку систем, предна
для выполнения жизненно важных задач. в0М &
В таблице на рис. 7.21 показана система, находящаяся в ненаДе , коТГ|
стоянии. Опишите такую последовательность выполнения проИ
рая бы позволила системе обойти взаимоблокировку. др° pt
В системе имеются 3 процесса и 4 идентичных ресурса. КаЖД едгУ*г ,
в любой конкретный момент времени может использовать не бо
сурсов.
,о8ки и бесконечное откладывание
447
а-
б.
дооЖет ли взаимоблокировка возникнуть в этой системе? Поясните от-
вет-
Рели в системе выполняется т процессов, каждый из которых может за-
носить п ресурсов, то сколько всего ресурсов должно присутствовать
системе, чтобы полностью исключить возможность возникновения ту-
пиковой ситуации?
Если в системе существует т процессов и г ресурсов, какое максималь-
ое число ресурсов, п, может запросить каждый процесс, если этот мак-
симум должен быть одинаков для всех процессов?
в.
loan(Pj) max(Pj) daim(Pj)
ПроЧеСС 1 5 4
Pi 1 3 2
Р2 5 10 5
Рз а= 1
fit 7 Пример системы в ненадежном состоянии
Рекомендуемые исследовательские учебные проекты
7.38. Подготовьте исследование по проблеме борьбы с тупиковыми ситуациями
в современных операционных системах.
7.39. Изучите, каким образом в системах реального времени исключается воз-
можность возникновения взаимоблокировки. Как удается избежать взаи-
моблокировок при сохранении высокой производительности?
7.40. Объясните, каким образом разрешается проблема взаимоблокировок на
веб-серверах и в других важных коммерческих системах.
Рекомендуемые программные проекты
7-41. (Проект по обнаружению взаимоблокировок и восстановлению после них).
Напишите программу, моделирующую обнаружение взаимоблокировок
в системе, включающей п идентичных ресурсов и т процессов. Заставьте
каждый процесс сгенерировать необходимый ему набор ресурсов (напри-
МеР. три ресурса типа А, один ресурс типа В и пять ресурсов типа С). Затем
Каждый раз запрашивайте из конкретного набора ресурс одного определен-
I °Е° Типа в произвольном порядке и с паузами разной длительности. Сде-
ите так, чтобы каждый процесс удерживал полученные ресурсы, пока не
Дс>Т УДОвлетв°рены все его дополнительные запросы. С этого момента
I ®НЬ1 начать возникать взаимоблокировки. Запустите другой поток, ко-
g р и бы проверял наличие взаимоблокировок каждые несколько секунд.
I эТомЧае возникновения тупиковой ситуации он должен будет сообщить об
. цс и начать уничтожение процессов, вовлеченных во взаимоблокировку.
I Про Таите Различные эвристические подходы по выбору жертвы среди
? 6PeM»CC°B и пР°анализируйте, при использовании какого метода среднее
(ту между возникновением взаимоблокировок является наименьшим.
вРог дымный проект по предотвращению взаимоблокировок). Напишите
РоВо₽аммУ для сравнения различных схем предотвращения взаимоблоки-
-Раггг ’ ₽ассмотРанных в разделе 7.7. В частности, сравните схему предот-
НИя взаимоблокировок за счет нарушения условия ожидания допол-
ЛьНых ресурсов (раздел 7.7.1) со схемой нарушения условия непере-
448
распределяемое™. Ваша программа должна моделировать О6
множества пользователей, появление новых пользователей, их
к ресурсам (исходя из того, что в системе существует п идентичн
сов) в терминах максимальных потребностей к ресурсам и числа
ресурсов т.д. Результаты каждого моделирования должны включа^^Я
стику о длительности цикла обработки, использовании ресурсов Tb cvl
повременно выполняющихся заданий (исходя из предположения 4®Cjie'
ния могут продолжать выполняться, даже когда в их распоряжек*1*0ааЛ
дится только часть необходимых ресурсов) и т.д. Проанал
результаты моделирования и сделайте выводы об эффективност
схемы предотвращения взаимоблокировок.
7. 43. {Программный проект по обходу взаимоблокировок). Напишите пп
для измерения производительности системы, состоящей из п Иде
ресурсов и т процессов, в которой для распределения ресурсов прим Й'%
алгоритм банкира. Используйте в качестве основы программу, напцеЙЯе,Ч
для упражнения 7.42. Запустите программу и сравните результаты
ты с результатами моделирования схем предотвращения взаимоблокв6
а-ал. V/ v/л^хуа л л^р/ч-и-^л.глл £5’J<l*41VlO(jJJQp'11
Сделайте вывод об эффективности стратегии обхода взаимоблокипок011
сравнению с изученными схемами их предотвращения.
7. 44. {Сравнение стратегий предотвращения взаимоблокировок и их обх я J
Напишите программу, которая бы моделировала поступление новых я»
ний с различными потребностями в ресурсах (с указанием каждого иеоб^
димого ресурса и времени, к которому оно должно понадобиться). Это мо-
жет быть управляющая программа, использующая генератор лучайнщ
чисел. Воспользуйтесь программой для того, чтобы определить, каким об
разом стратегии предотвращения и обхода взаимоблокировок могут поспо-
собствовать более эффективному использованию ресурсов.
Рекомендуемая литература
Хотя во многих операционных системах проблема взаимоблокировок просто иг-
норируется, проводятся обширные исследования по созданию эффективных алго-
ритмов для решения этой проблемы. Дейкстра, Ислур, Марсланд55 и Зобель Р
смотрели проблему взаимоблокировок. Дейкстра стал одним из первых, кто в
изучать проблему взаимоблокировок в многозадачных системах, сформулир|
проблему обедающих философов и написав алгоритм банкира для обхода в
блокировок.57,58 Коффман, Элфик и Шошами позднее построили фундаме
исследований в этой области, сформулировав четыре необходимых уело® ре
никновения взаимоблокировок.59 Холт60,61 разработал графы распределе^^
сурсов, которые должны были помочь в решении задач предотвращения ^де-
блокировок, а Хаберман62 представил семейство технологий обхода взаи
ровок. Рассматривая операционную систему UNIX System V, Бах ПО1Й1 63
могут возникать взаимоблокировки, например, при обработке прерывали •
с коллегами обсудили обнаружение и обработку взаимоблокировок в
ной системе VAX/VMS от Digital Equipment Corporation.64 й
В современных операционных системах редко реализуются алгорит ддЯР7
вращения либо обхода взаимоблокировок. В действительности, наприм а
пределенных систем традиционные механизмы предотвращения или о
моблокировок непригодны, поскольку в распределенной системе кажД
тер может находиться под управлением своей операционной систем
разработали стратегии обнаружения65 взаимоблокировок в сочетаний .ц Р,
мами контрольных точек/отката66 для уменьшения потерь при выпол 1
ты. Исследования в сфере взаимоблокировок в настоящее время СосреД
449
„одки и бесконечное откладывание
эффективных алГ(,Ритмов предотвращения взаимоблокировок, которые
^бо^дрцменяться в распределенных системах, сетях и других средах, подвер-
р»",л 6Ы с^11МОбЛОКировкам.67 Свежую библиографию для этой главы вы найдете
е ₽б сайте ПО адресу: www.deitel.com/books/os3e/Bibliography.pdf.
0*
моньзвбонная литература
Я S., and Т. A. Marsland, «The Deadlock Problem: An Overview,» Com-
1-1^’ Vol. 13, No. 9, September 1980, pp. 58-78.
P и l’ D «The Deadlock Problem: A Classifying Bibliography,» Operating Sys-
2-^ Review, Vol. 17, No. 4, October 1983, pp. 6-16.
R. C., «Some Deadlock Properties of Computer Systems,» ACM Computing
& Survey8» Vol. 4, No. 3, September 1972, pp. 179-196.
r ffman E. G., Jr.; Elphick, M. I; and A. Shoshani, «System Deadlocks,» Com-
4’ uting Surveys, Vol. 3, No. 2, June 1971, p. 69.
niikstra, E. W., «Cooperating Sequential Processes,» Technological University,
5 Eindhoven, Netherlands, 1965, reprinted in F. Genuys, ed., Programming Lan-
guages, New York: Academic Press, 1968.
г Dijkstra, E. W., «Hierarchical Ordering of Sequential Processes,» Acta
’ informatica, Vol. 1, 1971, pp. 115-138.
7. Coffman, E. G., Jr.; Elphick, M. J.; and A. Shoshani, «System Deadlocks,» Com-
puting Surveys, Vol. 3, No. 2. June 1971, pp. 67-78.
8 Habermann, A. N., «Prevention of System Deadlocks,» Communications of the
ACM, Vol. 12, No. 7, July 1969, pp. 373-377, 385.
9. Holt, R. C, «Comments on the Prevention of System Deadlocks,» Communica-
tions of the ACM, Vol. 14, No. 1, January 1971, pp. 36-38.
10. Holt, R. C., «On Deadlock Prevention in Computer Systems,» Ph.D. Thesis,
Ithaca, NY: Cornell University, 1971.
H Parnas, D. L., and A. N. Haberman, «Comment on Deadlock Prevention
Method,» Communications of the ACM, Vol. 15, No. 9, September 1972,
PP. 840-841.
^’Newton, G., «Deadlock Prevention, Detection, and Resolution: An Annotated
PP 33^ГаР^1^'* ACM Operating Systems Review, Vol. 13, No. 2, April 1979,
3 g^rnter, D., «А DAG Based Algorithm for Prevention of Store-and-Forward
eadlock in Packet Networks,» IEEE Transactions on Computers, Vol. C-30,
14. H°’ 10, Stober 1981, pp. 709-715.
JftlVender. J- W., «Avoiding Deadlock in Multitasking Systems,» IBM Systems
15. в“ Па1’ Vol. 7, No. 2, 1968, pp. 74-84.
11а'цС ig^gnsen’ Р"» Operating System Principles, Englewood Cliffs, NJ: Prentice
' д
Part TT’. • E-, «Functional Structure of IBM Virtual Storage Operating Systems,
No 4 • OS/VS2-2 Concepts and Philosophies,» IBM Systems Journal, Vol. 12,
7-AUs1; *973> PP- 382-400.
^tiij сГ’ A..; Larkin, D. C; and A. L. Scherr, «The Evolution of the MVS Op-
it> ^81 ® System,» IBM Journal of Research and Development, Vol. 25, No. 5,
8 4a’P₽- 471-482.
1ft 3 * S * 7 84ct; k- Il Goldenberg, R. E.; and S. F. Bate, VAX/VMS Internals and Data
n^hch Version 4.4, Bedford, MA: Digital Press, 1988.
IQ?118611’ Operating System Principles, Englewood Cliffs, NJ: Prentice
450
20. Dijkstra, Е. W., Cooperating Sequential Processes, Technological Uni
Eindhoven, The Netherlands, 1965.
21. Dijkstra, E. W., Cooperating Sequential Processes, Technological Un' *
Eindhoven, Netherlands, 1965, Reprinted in F. Genuys, ed., Programm'Vetsiti>
guages, New York: Academic Press, 1968. lrig цл
22. Habermann, A. N., «Prevention of System Deadlocks,» Communication
ACM, Vol. 12, No. 7, July 1969, pp. 373-377, 385. °8 of
23. Madduri, H., and R. Finkel, «Extension of the Banker’s Algorithm for p
Allocation in a Distributed Operating System,» Information Processing г
Vol. 19, No. 1, July 1984, pp. 1-8. ё ^tte^
24. Havender, J. W., «Avoiding Deadlock in Multitasking Systems,» IBM q
Journal, Vol. 7, No. 2, 1968, pp. 74-84.
25. Fontao, R. О., «А Concurrent Algorithm for Avoiding Deadlocks,» proc
ACM Symposium on Operating Systems Principles, October 1971, pp 72:7r9hir<i
26. Frailey, D. J., «А Practical Approach to Managing Resources and AvnH-
Deadlock,» Communications of the ACM, Vol. 16, No. 5, May 1973, pp. 323 32 г
27. Devillers, R., «Game Interpretation of the Deadlock Avoidance Problem » о ’’
munications of the ACM, Vol. 20, No. 10, October 1977, pp. 741-745. ’ V°ni'
28. Lomet, D. B., «Subsystems of Processes with Deadlock Avoidance,» IEEE Tran
actions on Software Engineering, Vol. SE-6, No. 3, May 1980, pp. 297-304^
29. Merlin, P. M., and P. J. Schweitzer, «Deadlock Avoidance in Store-and-Forward
Networks-I: Store and Forward Deadlock,» IEEE Transactions on Commuiiica
tions, Vol. COM-28, No. 3, March 1980, pp. 345-354.
30. Merlin, P. M., and P. J. Schweitzer, «Deadlock Avoidance in Store-and-Forward
Networks—II: Other Deadlock Types,» IEEE Transactions on Communications
Vol. COM-28, No. 3, March 1980, pp. 355-360.
31. Minoura, T., «Deadlock Avoidance Revisited,» Journal of the ACM, Vol. 29, No.
4, October 1982, pp. 1023-1048.
32. Murphy, J. E., «Resource Allocation with Interlock Detection in a Multitask Sys-
tem,» AFIPS FJCC Proc., Vol. 33, No. 2, 1968, pp. 1169-1176.
33. Newton, G., «Deadlock Prevention, Detection, and Resolution: An Annotated
Bibliography,» ACM Operating System Review, Vol. 13, No. 2, April 1979,
pp. 33-44.
34. Gligor, V, and S. Shattuch, «On Deadlock Detection in Distributed
IEEE Transactions on Software Engineering, Vol. SE-6, No. 5, September 19’
pp. 435-440.
35. Ho, G. S., and С. V. Ramamoorthy, «Protocols for Deadlock Detection in V
uted Database Systems,» IEE on Software Engineering, Vol. SE-8, 1
Novel 554-557. rti°nS
36. Obermarck, R., «Distributed Deadlock Detection Algorithm,» ACM Transa
on Database Systems, Vol. 7, No, 2, June 1982, pp. 187-208. aI1SaC-
37. Chandy, К. M., and J. Misra, «Distributed Deadlock Detection,» ACM r
tions on Computer Systems, Vol. I, No. 2, May 1983, pp. 144-156. pgadl0^
38. Jagannathan, J. R., and R. Vasudevan, «Comments on ‘Protocols for
Detection in Distributed Database Systems’,» IEEE Transactions on Sot
gineering, Vol. SE-9, No. 3, May 1983, p. 371. nj
39. Kenah, L. J.; Goldenberg, R. E.; and S. F. Bate, VAX/VMS Internals a
Structures, version 4.4, Bedford, MA: Digital Press, 1988. dlo^ jl
40. Pun H. Shiu, YuDong Tan, Vincent J. Mooney, «А Novel Parallel I grpah0<f
tection Algorithm and Architecture» Proceedings of the Ninth In И
Symposium on Hardware/Software Codesign, April 2001. I
41, Holt, R. C, «Some Deadlock Properties of Computers Systems,» ACM
Surveys, Vol. 4, No. 3, September 1972, pp. 179-196.
)Вки и боеконочное откладывание
451
R С, «Some Deadlock Properties of Computers Systems,» ACM Computing
g. H0,t’ s, Vol. 4, No. 3, September 1972, PP. 179-196.
L. J»> R. E- Goldenberg; and S. F. Bate, VAX/VMS Internals and Data
дЗ -^e ctures, version 4.4, Bedford, MA: Digital Press, 1988.
Strtl K_, Programming Locking Applications, IBM Corporation, 2001,
4^- ^^°^-124.ibm.com/developerworks/oss/dlm/currentbook/dlmbook_index.html>.
Computer Corporation, Intel Corporation, Microsoft Corporation, Phoe-
g Coi^Ppenologies Ltd., Toshiba Corporation, «Advanced Configuration and
er Management,» rev. 2.0b, October 11, 2002, p. 238.
ver Development Tools: Windows DDK, Deadlock detection,» Microsoft
46- * qpjnj Library, June 6, 2003, <msdn.microsoft.com/library/en-us/ddtools/hh/
&s/dv_8pkj.asp>.
Kernel-Mode Driver Architecture: Windows DDK, Preventing Errors and Dead-
17-‘ £s While Using Spin Locks, Microsoft MSDN Library, June 6, 2003,
^gdn.microsoft.com/library/en-us/kmarch/hh/kmarch/synchro_5ktj.asp>.
Krivokapic, R; Kemper, A.; and E. Gudes, «Deadlock Detection in Distributed
Database Systems: A New Algorithm and Comparative Performance Analysis,»
The VLDB Journal- The International Journal on Very Large Data Bases, Vol. 8,
No. 2, 1999, pp. 79-100.
49 Krivokapic, R; Kemper, A.; and E. Gudes, «Deadlock Detection in Distributed
Database Systems: A New Algorithm and Comparative Performance Analysis,»
The VLDB Journal— The International Journal on Very Large Data Bases, Vol. 8,
No. 2, 1999, pp. 79-100.
50. Krivokapic, R; Kemper, A.; and E. Gudes, «Deadlock Detection in Distributed
Database Systems: A New Algorithm and Comparative Performance Analysis,»
The VLDB Journal- The International Journal on Very Large Data Bases, Vol. 8,
No. 2, 1999, pp. 79-100.
51. Magarshack, P., and P. Paulin, «System-on-chip Beyond the Nanometer Wall,»
Proceedings of the 40th Conference on Design Automation, Anaheim, CA: ACM
Press, 2003, pp. 419-124.
52. Benini, L.; Macci, A.; and M. Poncino, «Energy-Aware Design of Embedded
Memories: A Survey of Technologies, Architectures, and Techniques,» ACM
Transactions on Embedded Computer Systems (TECS), Vol. 2, No. 1, 2003,
PP. 5-32.
Dijkstra, E. W., «Solution of a Problem in Concurrent Programming Control,»
54 p5Klmunicati°ns of the ACM, Vol. 8, No. 5, September 1965, p. 569.
• Jkstra, E. W„ «Hierarchical Ordering of Sequential Processes,» Acta
55 рГОГП1а^са, Vol. 1, 1971, pp. 115-138.
s oor, s. S., and T. A. Marsland, «The Deadlock Problem: An Overview,» Com-
Sh.Zob i’ V°L 13, No’ 9’ Se₽tember 1980’ PP- 58 78-
te e rD-. «The Deadlock Problem: A Classifying Bibliography,» Operating Sys-
57 Dijk Keview> Vo1- 17, No. 4, October 1983, pp. 6-16.
®iridVra’ E' * Cooperating Sequential Processes,» Technological University,
gu„ °ven, Netherlands, 1965, reprinted in F. Genuys, ed., Programming Lan-
5$. ^ijkst8' ^ew York: Academic Press, 1968.
- E. W., «Hierarchical Ordering of Sequential Processes,» Acta
9’Coffm atica- Vol. 1, 1971, pp. 115-138.
.. Putin„aQ’ C., Jr.; Elphick, M. J.; and A. Shoshani, «System Deadlocks,» Com-
• Hoit vurveys, Vo1- 3> No. 2> June 1971, pp. 67-78.
«Comments on the Prevention of System Deadlocks,» Communica-
' НоЦ IneACM, Vol. 14, No. 1, January 1971, pp. 36-38.
^haco xrP* «®n Deadlock Prevention in Computer Systems,» Ph.D. Thesis,
У** NY.; Cornell University, 1971.
452
62. Habermann, A. N., «Prevention of System Deadlocks,» Communicatin
ACM, Vol. 12, No. 7, July 1969, pp. 373-377, 385. 118 0{
63. Bach, M. J., The Design of the UNIX Operating System, Englewood Ci-
Prentice Hall, 1986. lf41
64. Kenah, L. J.; Goldenberg, R. E.; and S. F. Bate, VAX/VMS Internals I
Structures, version 4.4, Bedford, MA: Digital Press, 1988. a,1d n
65. Obermarck, R., «Distributed Deadlock Detection Algorithm,» ACM Tran
on Database Systems, Vol. 7, No. 2, June 1982, pp. 187-208.
66. Krivokapic, N.; Kemper, A.; and E. Gudes, «Deadlock Detection in Dist
Database Systems: A New Algorithm and Comparative Performance An^tw
The VLDB Journal— The Inter national Journal on Very Large Data ] я a ysis,
8, No. 2,1999, pp. 79-100. fis-
67. Shiu, P. H.; Tan, Y; and V. J. Mooney, «А Novel Parallel Deadlock Detect’
gorithm and Architecture,» Proceedings of the Ninth International 8ушп°ПА
on Hardware/Software Codesign, April 2001.
Даже сами небеса, планеты и центр мирозданш
соблюдают ранг, очередность и место..;
Уильям Шекспир
..л.***^ '.$8v / * 1
Ничто не может в процессе развития точно
следовать первоначальному плану-
Рассчитывать на это —. все равно, что пытатв
укачивать взрослого человека в колыбели младев«а-
Эдмунд
s*
Каждая задача имеет одно простое, очевпД11^
на первый взгляд, неправильное реШ6 1
Генри Луис
В любом деле важнее всего испоЛ#е^ 4
Джозеф Эд^^
Прочитав эту главу, вы должны усвоить:
• цели планирования;
• планирование с приоритетным вытеснением
и без него;
• значение приоритетов при планировании;
• критерии планирования;
• Распространенные алгоритмы планирования;
(понятие планирования по сроку завершения
( планирования реального времени;
I _ь^ирование потоков Java.
Краткое содержание глабы
8.1 Введение
8.2 Уровни планирования
8.3 Планирование с приоритетным вытеснением и без него
Размышления об операционных системах: Накладные расходь
8.4 Приоритеты
8.5 . Цели планирования
Размышления об операционных системах: Предсказуемость
Размышления об операционных системах: Равноправие
8.6 Критерии планирования
8.7 Алгоритмы планирования
8.7.1 Планирование по принципу FIFO (первым-пришел-первым-ушел)
8.7.2 Циклическое планирование (RR)
8.7.3 Планирование по принципу SPF (кратчайший процесс первым)
8.7.4 Планирование по принципу HRRN
(по наибольшему относительному времени реакции)
8.7.5 Планирование по принципу SRT (по наименьшему остающемуся времени)
8.7.6 Многоуровневые очереди с обратной связью
8.7.7. Планирование по принципу FSS (справедливого раздела)
8.8 Планирование по сроку завершения
Размышления об операционных системах: Интенсивность
управления ресурсами с учетом их относительной стоимости
8.9 Планирование реального времени
Учебный пример: Операционные системы реального времени
8.10 Планирование потоков Java
vifoinbl процессера
457
'f ^едение
говорили о том, что многозадачность позволяет операционной
рДь1 У^елее эффективно использовать ресурсы. Когда система стоит пе-
стеМе каким процессам выделять процессор, она должна руково-
с„ вь’б0 определенной стратегией, называемой политикой или дисцип-
^тво®аТ^аЯИрОВания процессора (processor scheduling policy/discipline).
пЛ ика позволяет определить, какой процесс следует запустить
п°леТНЫЙ момент времени. Политика планирования должна удовле-
8 койКР оПределенным критериям производительности, например, ста-
твоРяТЬ елИчить количество процессов, которые могут завершить свою
р8ться за единицу времени (производительность), стараться уменьшить
рабоТУо?кИдаНия каждого процесса перед началом выполнения (задержку),
ВРеМотвраШать ситуации бесконечного откладывания процессов, и гаран-
п₽еЯ.ТЬ1 что каждый процесс завершит свою работу до наступления пре-
тир ного'срока либо добиваться максимально эффективного использова-
ния процессора. Некоторые из вышеперечисленных задач, например, мак-
симально эффективное использование процессора и производительность,
являются взаимодополняющими. Другие же конфликтуют, например, сис-
тема, в которой гарантируется завершение процессов по сроку заверше-
ния, не всегда в состоянии обеспечить максимальную производительность.
В этой главе мы рассмотрим проблемы, связанные с решением того, когда
следует выделять процессоры и каким именно процессам. Хотя в первую
очередь мы будем говорить именно о процессах, большая часть тем, кото-
рые здесь рассматриваются, распространяются также на задания и потоки.
Вопросы для самопроверки
1. В каких случаях система, гарантирующая завершение процессов по
сроку завершения, не сможет достичь максимальной производи-
тельности?
2. Какой критерий производительности наиболее важен для операци-
онной системы? Почему на этот вопрос трудно ответить?
утиеты 1) Это может произойти в том случае, когда выполнение
нескольких коротких процессов откладывается из-за того, что систе-
ма выбрала для выполнения длительный процесс, который нужно ус-
петь закончить до предельного срока. 2) Не существует критерия
производительности, который был бы одинаково важен для всех опе-
рационных систем. Все зависит от тех целей, которые поставлены пе-
ред этой системой. Например, в системах реального времени
Немедленное предсказуемое обслуживание процессов и потоков на-
много важнее, чем эффективность использования процессора. В су-
перкомпьютерах, выполняющих вычисления в течение длительного
нремени, наоборот, эффективное использование процессора важнее,
чем уменьшение случайных задержек.
458
8.2 Уровни планирования
В этом разделе мы рассмотрим три основных уровня планиъ
(см. рис. 8.1). Планирование на верхнем уровне (high-level sche<j
которое еще называют планированием заданий (job scheduling) иду ДЧ)
1Доч
Задания,
ожидающие
ввода
в систему
Ввод заданий
Задания,
ожидающие
запуска
Запуск заданий
Планирование
на верхнем уровне
Приостанов- »
ленные
процессы,
ожидающие
активизации
Активизация
Приостановка
Планирование
на промежуточном уровне
Активные
процессы
Блокирование
или истечение
кванта времени
Пуск
Планирование
на нижнем уровне
Выполняю-
щиеся
процессы
Завершение
Завершенные
процессы
Рос. 8.1. Уровни планирования
459
дланированием (long-term scheduling), определяет, каким зада-
* разрешено активно конкурировать за захват ресурсов системы.
бУ# т вид планирования называют планированием допуска (admis-
*' огДа ЭТ jing), поскольку на этом уровне определяются задания, которые
щены в систему. Вошедшие в систему задания становятся про-
дут пи группами процессов. Политика планирования на верхнем
jjecca^11 рМИрует степень многозадачности (degree of multiprogram-
,роВве общее количество процессов в системе в конкретный момент вре-
п’*п^\^Г[оявление в системе слишком большого количества процессов мо-
ести к загрузке всех системных ресурсов, и, как следствие, резко-
^ет пр производительности. В этом случае в политике планирования
МУ паЯ еМ уровне необходимо временно запретить поступление новых за-
08 Бе? пока не будут завершены несколько предыдущих.
д8гтЙле того как политика планирования на верхнем уровне допустила
1 ие (которое может состоять из одного или нескольких процессов)
заД*у, политика планирования на промежуточном уровне (interme-
vCte.level scheduling) определяет, каким процессам будет разрешено со-
стязаться за захват процессора. Планировщик промежуточного уровня
оперативно реагирует на текущие колебания загрузки системы, кратковре-
менно приостанавливая и вновь активизируя (или возобновляя) процессы,
что обеспечивает равномерную работу системы и помогает достижению оп-
ределенных глобальных целевых скоростных характеристик. Таким обра-
зом, планировщик промежуточного уровня выполняет как бы роль буфера
между средствами допуска заданий в систему и средствами предоставле-
ния процессора для выполнения этих заданий.
Политика планирования на нижнем уровне (low-level scheduling) оп-
ределяет, какому из готовых к выполнению процессов будет предостав-
ляться освободившийся процессор. В большинстве современных систем
существуют только планировщики нижнего и промежуточного уровней,
этом случае запуск заданий осуществляется планировщиком проме-
в Чного уровня.) Планировщики верхнего уровня используются
б0,„ ПНЫх мэйнфрейм-системах, предназначенных для пакетной обра-
По Данных-
Ку про17111™ планиРования на нижнем уровне часто присваивают каждо-
ср°Цесса СУ св°й приоритет (priority), отражающий важность данного
®МеНно ДЛЯ Систе«ы. Чем важнее процесс, тем выше вероятность, что
РаеСМо -- nP°Hecc окажется выбран для последующего выполнения. Мы
w 8-4. Ц М пРиоРитеты в этой главе, уделив им особое внимание в разде-
J ^нДанировщик нижнего уровня, называемый также диспетчером
,fe'r ег0 z' выделяет процессор выбранному процессу, то есть осуществ-
а0Л°Льк0 СПетчеРизацию (dispatching). Диспетчер выполняет операции
В секУнДУ и поэтому должен постоянно находиться в основ-
Чъ?4- Кал<-ГЛаВе мы Осудим многие политики планирования нижнего
118^ 11 Дри^ад ПОлитика будет представлена в контексте определенных
Чу ’ с°0Тве теРиев планирования (о которых пойдет речь в разделе 8.5
C°6otj »?Ственно), кроме того, мы расскажем вам, как они связаны ме
°Ффман и Клейнрок изучали популярные политики планиро-
К Ьхвая, каким образом пользователи, которые знают, какие по-
460
литики используются в системе, могут добиться более высокой проп
тельности, приняв соответствующие меры.2 Рушицка и Фабп
классификацию алгоритмов планирования, формализовав понятц
оритета.3 е
Вопросы для самопроверки
1. Каким образом планировщик промежуточного уровня деле-
гировать на колебания системной загрузки? “
2. Планировщик какого уровня должен оставаться резидентна
новной памяти? Почему? м 6 ot.
ОыВеПЫ 1) Планировщик промежуточного уровня может
щать процессам доступ к планировщику нижнего уровня, если с 3ai1^-
перегружена, и осуществлять диспетчеризацию этих процессов Сте1*8
загрузка системы возвращается к нормальному уровню. 2>
щик нижнего уровня должен оставаться резидентным в основной п ₽°В'
ти, поскольку код планировщика необходимо выполнять достаток8
часто, чтобы оперативно реагировать для уменьшения накладных^
ходов, связанных с планированием выполнения процессов. ₽ас'
83 ПАаиировиние с приоритетным вытеснением
и без него
Дисциплины планирования могут допускать приоритетное вытеснение или
запрещать его. Если после предоставления процессора в распоряжение некото-
рого процесса отобрать процессор у этого процесса нельзя, то говорят о дисцип-
лине планирования без приоритетного вытеснения (nonpreemptive). Если же
процессор можно отобрать, то говорят о дисциплине планирования с при-
оритетным вытеснением (preemptive). При использовании дисциплин^
без приоритетного вытеснения, каждый процесс, которому был выД
процессор, выполняется до конца либо до момента добровольного в°н(1Г1.
щения процессора в распоряжение системы. В случае применения
лины с приоритетным вытеснением, процессор может выполнить
программного кода процесса, после чего осуществить переключение
текста. рцсте»»8*'
Планирование с приоритетным вытеснением необходимо в <- в0и^8
в которых процессы высокого приоритета требуют немедленною^^
ния. Например, в системах реального времени (см. раздел 8.9)
ного важного сигнала прерывания может привести к катастроф
последствиям.4’5’6-7 В интерактивных системах разделения времен
рование с приоритетным вытеснением играет важную роль, поск гр
зволяет гарантировать приемлемые времена ответа. Планирован
бующее контекстных переключений, сопряжено с определенны
ными расходами (см. раздел «Размышления об операционных
Накладные расходы»). Чтобы обеспечить эффективность такого
вания, в основной памяти должно размещаться много процессов, -я
бы в большинстве случаев очередной процесс был готов для вЫ
461
F ей работы процессора___________________________________________
„обождается процессор. В главе 10 мы поговорим о том, что в ос-
Памяти, как правило, находится только часть программного кода
г 90.оЯ ОрОцесса; редко используемые части программы обычно хранятся
л Д1,СЪ темах планирования без приоритетного вытеснения коротким за-
fl g сиСпрЯХодится больше ждать из-за выполнения длительных заданий,
г лительность циклов обработки здесь более предсказуема, посколь-
оД0й1<О пающие задания высокого приоритета не могут вытеснять уже
hy °°с щие задания. Поскольку в системе без приоритетного вытеснения
оя<иДа отобрать процессор у процесса, пока процесс не завершит свою ра-
0ельзЯ ограммы, выполняющиеся с ошибками, которые могут никогда не
бо^У’р10ться (например, из-за попадания в бесконечный цикл) не дадут
жНОсти системе вернуть контроль над процессом. Кроме того, в сис-
в°зМ без приоритетного вытеснения менее важный процесс может заста-
теМе ожидать более важный процесс.
ВЙ Чтобы не допустить монопольного захвата системы (случайно или пред-
меоенно), система с приоритетным вытеснением должна иметь возмож-
ость отбирать процессор у процессов. В главе 3 мы говорили о том, что
.днный принцип реализуется с помощью интервального таймера, периоди-
чески вырабатывающего прерывания, позволяя выполнять код операцион-
ной системы. После выделения процессора определенному процессу, этот
процесс выполняется до тех пор, пока он добровольно не вернет процессор
в систему либо пока интервальным таймером не будет выработано преры-
вание. Затем операционная система решает, должен ли запущенный про-
цесс продолжать работу или же процессор необходимо отобрать в пользу
следующего процесса.
Интервальный таймер помогает гарантировать приемлемые времена
ответа для пользователей, работающих в диалоговом режиме, предотвра-
щать «зависание» системы из-за зацикливания какой-то программы
пользователя, а также позволяет процессам соответствующим образом
Реагировать на события, привязанные ко времени. Процессы, которые
ны выполняться периодически, зависят от работы интервального
гаимера.
ве^И пР°ектиРовании механизма планирования с приоритетным вытес-
схем Разработчик должен тщательно рассмотреть множество различных
°Рйтет^И°РИТетов’ в том числе и практически произвольную схему при-
сРИори В’ СМЬ1сла создавать сложную, тщательно обоснованную схему
°Р«теть1етн°Го вытеснения, в то время как в действительности сами при-
вазначаются далеко не обосновано.
Вопросы для самопроверки
1- Когда лучше использовать планирование без приоритетного вытес-
нения, чем планирование с приоритетным вытеснением?
2. Может ли программа, вошедшая в бесконечный цикл выполнения,
монопольно захватить систему с приоритетным вытеснением?
462
Ответы 1) Планирование без приоритетного вытеснения об
вает предсказуемое время реакции, что немаловажно для Си есЧ&, I
кетной обработки данных, которые должны гарантироваТ|С(е^ ь
время завершения заданий для пользователя. 2) Все зависит
оритета данной программы и используемой политики планиг °Т Оц?
В общем случае система с приоритетным вытеснением, один^З
цессов в которой вошел в бесконечный цикл, испытает сниже Из W
изводительности, но при этом будет в состоянии периоВИе
выполнять и другие процессы. В то же время высокоприоп^11^^^
процесс, вошедший в бесконечный цикл, может выполняться Тет,1М
ниченно долго, если все остальные процессы системы HMei<j'ltOtT-a
низкий приоритет. Общий вывод таков, что система с приорцт 6ojl«e
вытеснением менее устойчива в таких ситуациях, чем систр
приоритетного вытеснения. Операционная система справляется8
добными ситуациями, ограничивая максимальное время, в*ТрС®0-
которого конкретный процесс может использовать процессор Чев®е
Размышления об операционных системах
Накладные расходы
Очевидно, что компьютеры предназначе-
ны для того, чтобы выполнять программы
пользователей. Хотя сами операционные сис-
темы, разумеется, выполняют много важных
задач, они расходуют при этом драгоценные
ресурсы. Такой расход ресурсов называют на-
кладными расходами, поскольку в данной
ситуации ресурсы не используются пользова-
тельскими приложениями непосредственно
для выполнения полезной работы. Разработ-
чики операционных систем пытаются найти
способы свести накладные расходы к мини-
муму, чтобы больше системных ресурсов пе-
решли непосредственно в распоряжение
пользователя. Накладные расходы способны
увеличить производительность системы бла-
годаря более эффективной организации ис-
пользования ресурсов; в то же время наклад-
ные расходы могут привести и к падению
производительности, из-за поддержки бо-
лее высокого уровня защиты и безопасности.
Поскольку мощность вычислительных сис-
тем возрастает, а стоимость снижается, поте-
ря ресурсов, связанная с накладными расхо-
дами, перестает быть столь важной Темне
менее, рассчитывая накладные расход
разработчики должны быть осведомлень1
о загрузке системы. Большие накладные р
ходы при малой загрузке системы могут .
заться сравнительно невелики при |е
загрузке системы; а небольшие н
расходы при малой загрузке системы^^!
обернуться большими накладными р
при большой загрузке системы. \
юты процессора
463
4 Приоритеты
„овщики часто используют приоритеты для того, чтобы опреде-
м процессам следует выделить процессор в той или иной ситуа-
^^оритеты могут являться статическими, а могут назначаться дина-
с помощью приоритетов оценивается относительная важность
а0Чес00'
0роцесС°цеские приоритеты (static priorities) не изменяются. Механизмы
С,аТ _кой приоритетности легко реализовать, и они сопряжены с отно-
сТйТИ ио небольшими издержками. Однако они не позволяют реагировать
рнения в окружающей ситуации, изменения, которые могут сделать
да03 ельной корректировку приоритетов для повышения производитель-
#еЛаТсистемы и уменьшения задержек.
В°Механизмы динамических приоритетов (dynamic priorities) реагируют
изменения в ситуации. Например, система может захотеть повысить
88 ооитет процесса, удерживающего важный ресурс, необходимый для ра-
боты высокоприоритетного процесса. После того как первый процесс осво-
бодит занимаемый ресурс, система понижает его приоритет, давая возмож-
ность продолжить выполнение высокоприоритетному процессу. Схемы ди-
намической приоритетности гораздо сложнее в реализации и связаны
с большими издержками по сравнению со статическими схемами. Однако
предполагается, что эти издержки оправдываются повышением реактив-
ности системы.
В многопользовательских системах операционная система должна каче-
ственно обслуживать большой контингент пользователей, но при этом пре-
дусматривать ситуации, когда одному из пользователей понадобится приви-
легированное обслуживание. Пользователь, которому необходимо срочно
выполнить свое задание, может с готовностью пойти на дополнительную оп-
лату более высокого уровня обслуживания, то есть купить приоритет
Purchase priority). Такая дополнительная оплата вполне оправдана, по-
ДейЛЬКу ДЛЯ этого процесса могут потребоваться ресурсы других пользовате-
ир1ДПлатя1Пих за них деньги' ®сли не взималась повышенная плата за
обслИЛегии’ то все пользователи запрашивали бы более высокий уровень
Вопросы для самопроверки
!• Чем оправданы более высокая стоимость и повышенные издержки
механизмов динамических приоритетов?
2. Почему динамический планировщик отдает предпочтение процессу
с низким приоритетом, запросившим недоиспользованный ресурс?
ОгпвеПЫ 1) Тщательно спроектированный механизм динамических
Приоритетов позволяет обеспечить меньшие времена ответа системы,
чем при использовании механизмов статического приоритета. 2) Вы-
сока вероятность того, что малоиспользуемый ресурс окажется свобод-
ным, что позволит низкоприоритетному процессу быстрее завершить
вою работу, еще до того, как высокоприоритетный процесс дождется
Освобождения занятого ресурса.
464
8.5. Цели паи ни робиния
В ходе разработки дисциплины планирования разработчик Си
должен учесть множество факторов, включая тип системы и треб0 TetlM
пользователя. Дисциплина планирования, предназначенная для си
реального времени должна отличаться от дисциплины, используемо^^
терактивной настольной системе, поскольку пользователи ждут Сй В й{1-
ных результатов от систем различных типов. В зависимости от сист^^'
пользователи и разработчики ожидают, что планировщик будет: l4tl.
• Обеспечивать максимальную пропускную способность сисще I
Дисциплина планирования должна стремиться к обслуживанию ***•
симально возможного количества процессов в единицу времени Мак‘
• Гарантировать максимальному числу пользователей, работаю»
в интерактивном режиме, приемлемые времена ответа.
• Обеспечивать максимальное использование ресурсов. Механизм пла
нирования должен стремиться к повышению коэффициента исполь
зования системных ресурсов.
• Исключать бесконечное откладывание. Процессы не должны стал-
киваться с неограниченным временем ожидания перед или во время
получения обслуживания.
• Учитывать приоритеты. В системах, в которых процессам присваи-
ваются приоритеты, механизм планирования должен оказывать пред-
почтение процессам с более высокими приоритетами.
• Минимизировать накладные расходы. Интересно отметить, что дале-
ко не все специалисты считают подобную цель одной из наиболее важ-
ных. Накладные расходы обычно рассматриваются как потеря ресур-
сов. Однако определенная часть системных ресурсов, относящаяся
к категории накладных расходов, может в действительности значи-
тельно улучшить общие характеристики системы.
• Обеспечивать предсказуемость. Уменьшая статистический Раз®^
времени ответа, система должна гарантировать, что процессы п°
чат предсказуемый уровень обслуживания (см. «Размышления
операционных системах: Предсказуемость»). &&
Система может добиваться выполнения этих целей несколькими
бами. В некоторых случаях планировщик предотвращает бесконеч ^е.
кладывание, учитывая старение процесса — с увеличением интерв ур-
мени, в течение которого процессу приходится ожидать некоторого
са, приоритет этого процесса должен расти. В конце концов, Г1Р*
окажется настолько высоким, что процессу будет предоставлен
Ресурс. оТда®а*
Планировщик может повышать производительность системь . рОрИ^'
предпочтение процессам, запросы которых легче и быстрее удовJ,eTeCypc^'
либо завершение которых позволит освободить дополнительные Р&$ отД
необходимые для работы других процессов. Одна из таких страте
ет предпочтение процессам, которые удерживают ключевые ре^У
пример, может возникнуть ситуация, когда процесс, даже имею
кий приоритет, удерживает за собой некоторый ключевой ресурс»
работы процессора
465
процессам с более высоким приоритетом. Если этот ресурс не яв-
ебУетСлИяамически перераспределяемым, то механизм планирования
^e^cfI Создавать для процесса лучшие, чем обычно, условия, чтобы этот
>е* быстрее освободил удерживаемый им ключевой ресурс. Такая тех-
проаесС носит название инверсии приоритетов (priority inversion), по-
0оЛ°гиЯ отНосительные приоритеты процессов меняются, благодаря чему
с1;оЛь1<У норитетный процесс, в конце концов, получает в свое распоряже-
ррсоВ0 ^Одимый ресурс и может продолжить свою работу. Аналогично,
0ре 0е° вдик должен отдавать предпочтение процессу, запрашивающему
цЛй0И волЬзуемь,е ресурсы, поскольку вероятность того, что система смо-
!л8л°иСовлетвОрить подобный запрос за меньший промежуток времени,
^ет УД
’^гГкоторые из вышеперечисленных целей противоречат друг другу, пре-
П яя планирование в довольно трудную задачу. Например, наилучший
8РоасОб гарантировать малые времена ответа — это иметь достаточно сво-
ей ыХ ресурсов, чтобы их можно было использовать сразу, как только
они понадобятся. Подобная стратегия приводит к снижению общего коэф-
фициента использования ресурсов. В системах реального времени, где тре-
буется высокая реактивность системы и предсказуемость времен ответа,
эффективность использования ресурсоц не так важна. В системах других
типов экономические причины требуют более эффективного использова-
ния имеющихся ресурсов.
Несмотря на все различия в целях для разных систем, большинству дис-
циплин планирования присущи схожие свойства:
• Равноправие (fairness). Дисциплина планирования считается спра-
ведливой, если ко всем процессам она относится одинаково и ни один
процесс не может пострадать от бесконечного откладывания по при-
чине несправедливых предпочтений планировщика (см. раздел «Раз-
мышления об операционных системах: Равноправие»).
• Предсказуемость (predictability). Данный процесс должно выпол-
няться приблизительно за одно и то же время при приблизительно
одинаковой нагрузке на систему.
Масштабируемость (scalability). Механизм планирования не должен
сразу же терять работоспособность под тяжестью большой системной
Сгрузки.
Вопросы для самопроверки
1- В чем противоречие между задачей уменьшения разброса во време-
нах ответа системы и задачей обеспечения соблюдения приоритет-
ности?
2. Всегда ли издержки планирования представляют собой бесполез-
ную трату ресурсов?
^ЫветЫ 1) В системах с приоритетным вытеснением высокопри-
оритетные процессы могут вытеснять низкоприоритетные процессы
в любой момент времени, увеличивая, таким образом, разброс во вре-
мени реакции различных процессов. 2) Нет. Накладные расходы, свя-
занные с эффективными операциями планирования, позволяют
повысить коэффициент использования ресурсов.
400
Размышления об операционных системах
Предсказуемость
Предсказуемость также важна в повсе-
дневной жизни, как и в компьютерах. Что де-
лать, если вы будете вынуждены остановить-
ся на красный свет светофора, и при этом
красный свет будет оставаться красным го-
раздо дольше чем вы когда-либо наблюда-
ли. Вы, вероятно, станете раздраженным
и суетливым, а по истечению приемлемого,
по вашему мнению, интервала, если свето-
фор не переключится, решитесь ехать на
красный свет — потенциально небезопасное
действие.
Точно так же существуют приемлемые пе-
риоды ожидания от компьютера выполнения
общих заданий. Обеспечение предел
сти времени выполнения - непросгая^Я
для операционной системы, особен
дя из того, что загруженность системы J
сильно меняться в зависимости от самой J
темы и разновидностей выполняемых3 СИ
Предсказуемость особенно важна лпо ,
%. ИНтр
рактивных пользователей, которым необх
димы постоянные кратчайшие времена отвь
та. Не менее важна предсказуемость и для за
даний реального времени, от выполнения
которых зависят человеческие жизни
(см. раздел 8.9). В данной книге мы еще не
раз коснемся вопроса предсказуемости.
Размышления об операционных системах
Равноправие
Сколько раз в своей жизни вы раздражен- к ним несправедливость. «Это нечестно.^
но выкрикивали: «Это нечестно!». И, скорее 'скажете вы, однако нельзя игнорирс®^
всего, вам известна фраза «жизнь — неспра-
ведлива». Все мы знаем, что такое честность
и равноправие и большинство людей соглас-
ны с тем, что это, конечно, хорошо, но не все-
гда достижимо. Вопросы равноправия обсу-
ждаются во многих главах данной книги. Вы
узнаете о стратегиях планирования на основе
приоритетов, обеспечивающих высокую про-
изводительность для большинства пользова-
телей, процессов, потоков, запросов вво-
да/вывода и т.д., которые, однако, делают
это за счет других пользователей, процессов,
потоков, запросов ввода/вывода, проявляя
.riaiKU потел - . - J—
и тот факт, что вышеупомянутые стра I
позволяют добиться поставленных
например повышения глобальных сК°^ая
ных характеристик системы. ОпераИи° 0.
система не должна забывать о справ
сти и равноправии, но рассматривать
просы необходимо в контексте дрУ^ррИ
дений. Равноправие чрезвычайно ва ^ре-
разработке стратегий планирования^,
деления ресурсов, в чем мы убеди
чая планирование загрузки 1
в данной главе и тему диспетчер^3
ковых операций в главе 12.
r^[t работы процессора
467
, Критерии планирования
и”
гО чтобы реализовать перечисленные выше цели планирования,
ДДЯ планирования должен учитывать поведение процесса. Процес-
^%а0й3 дсивно использующие процессор (processor-bound), как правило,
И0*6его в течение всего выделенного им времени. Процессы, ин-
JjCpo)Ib яСпользующие ввод/вывод (I/0-bound), обычно занимают про-
лИщь кратковременно, прежде чем сформировать запрос ввода/вы-
аесС°^Г1 поцессы, интенсивно использующие процессор, как следует из на-
еоДя' большую часть времени активно используют процессор, тогда как
зВ0ВИЯ’ы интенсивно использующие ввод/вывод, большую часть времени
йрой на ожидание внешних ресурсов (например, принтеров, дисковых
тРаТй^1телей, сетевых соединений и т.д.), которые должны будут обслу-
н₽к° иХ запросы, и при этом мало используют процессор.
#*Писциплина планирования должна учитывать, является ли процесс па-
отным или интерактивным (диалоговым). Пакетный процесс (batch
ocess) включает в себя задания, которые не требуют для своего выполне-
ния присутствия пользователей. Интерактивный процесс (interactive
process) нуждается в постоянном вводе информации пользователем. Систе-
ма должна обеспечивать быструю реакцию для интерактивных процессов,
тогда как процессы, выполняющиеся в пакетном режиме, могут без ущер-
ба переносить значительные задержки. Дисциплина планирования должна
учитывать срочность выполнения процесса. Процесс, выполняющийся но-
чью в пакетном режиме, вряд ли потребует немедленной реакции системы.
А система управления технологическими процессами реального времени,
контролирующая работу нефтеочистительного предприятия, требует ис-
ключительно быстрого ответа, быть может, для предотвращения взрыва.
На момент опубликования второго издания этой книги, взаимодействие
пользователей с процессами, как правило, происходило с помощью доволь-
но тривиальных запросов, вводимых с клавиатуры. В подобной ситуации
ировщик мог отдавать предпочтение процессу, работающему в диало-
Ск Режиме, практически не оказывая влияния на другие процессы, по-
браэк j ДЛя °®слУживания интерактивных процессов (например, для ото-
Вь^ения текста на экране) требовалось ничтожное время. С увеличением
1{лЧЦнЛИТеЛЬНЫХ м°Щностей компьютеров, разработчики систем и при-
вЛтеп(Ъ е~ ПРОГРаммисты начали включать в свои продукты графические
Исы’ чтобы обеспечить «дружественность» пользователю. Хотя
^HcTg РЬ1Х системах до сих пор используется текстовый интерфейс, боль-
6ьщОд с°вРеменных пользователей работают с GUI, используя мышь для
НИя таких операций, как открытие, закрытие, перетаскивание
Чйц, ,,НИе Размера окон. Пользователи ожидают от системы быстрой ре-
°^Ы ЭТИ °перации выполнялись гладко. В отличие от текстового
Л^ва,гьаДача многокРатной перерисовки содержимого экрана может по-
°т системы большого объема вычислений. Если система отдаст
J °иа Н11е подобным процессам, работающим в интерактивном режи-
вбссОцем самым значительно понизит уровень обслуживания других
Системы. В случае с пакетным процессом, подобное временное
I е обслуживания может быть вполне приемлемым, но для про-
46g
' Ч
цессов, выполняемых в режиме реального времени (например,
ний мультимедиа), такие задержки недопустимы.
В системе с поддержкой приоритетов предпочтение должно отл
процессам с более высоким приоритетом. Планировщик принимае
ния, основываясь на том, насколько часто данный процесс останам
ся из-за переключения на процесс более высокого приоритета. В сс
вии с некоторыми дисциплинами часто приостанавливаемым ПГ)
создаются менее благоприятные условия для продолжения работ^6^^
объясняется тем, что для запуска подобного процесса операционной^ *4
ме каждый раз приходится идти на определенные накладные р С?1с*е-
связанные с переключением контекста, а короткое время работы m
перед приостановкой не окупает издержек. Некоторые разработчик^6^
тают, что подобным запросам, наоборот, следует создавать более благ
ятные условия, чтобы оправдаться в несправедливом отношении раи°11^й‘
Политики планирования с приоритетным вытеснением часто учи I
ют информацию о том, сколько времени уже получил данный проц9]
Некоторые разработчики считают, что предпочтение должно оказывав
процессу, который получил меньше времени. Другие разработчики сч
тают, что процесс, которому уже выделено много времени, должен быть
ближе к завершению и поэтому ему надо оказывать предпочтение, чтобы
помочь завершиться, освободить ресурсы, которые он занимает, чтобы
передать их другим процессам, и как можно быстрее покинуть систему.
Механизм планирования может произвести оценку времени, требуемого
для завершения процесса. Среднее время ожидания можно уменьшить,
если раньше других запускать процессы, требующие меньшего времени
для своего завершения. К сожалению, системе лишь в редких случаях
точно известно, сколько времени необходимо каждому процессу для за-
вершения.
Вопросы для самопроверки
1. К какой разновидности можно, как правило, отнести иНТеРа^1
ные процессы: к интенсивно использующим процессор или ин
сивно использующим ввод/вывод? Что вы можете сказать
поводу процессов, выполняемых в пакетном режиме?
2. Планировщику редко бывает точно известно, сколько времени^.,
обходимо каждому процессу для завершения. Рассмотрите си
которая задает план выполнения процессов, основываясь (0Л(1тй-
оценке. Как процессы могут начать злоупотреблять данной
кой?
Л
Ответы 1) Интерактивные процессы часто вынуждены о?00оо’г
ввода данных от пользователя, поэтому в первую очередь их М т0
нести к процессам, интенсивно использующим ввод/вывод- f0
время такие процессы могут переходить в стадию интенсй
пользования процессов. Процессы, выполняемые в пакетном
не взаимодействуют с пользователем, и поэтому их обычн^
к процессам, интенсивно использующим процессор. Если oll0fe0rfl
ный пакетный процесс часто обращается к дисковым нак
или другим устройствам ввода/вывода, то его классифиНиРд
процесс, интенсивно использующий ввод/вывод. 2) Пройе &
неправильно указывать ожидаемое время завершения, 41
чить лучшие условия обслуживания со стороны планировШ
F йе работы процессора _________________тох
-ill О
' Алгоритмы планирования
тпущих разделах мы говорили о политиках планирования, исхо-
g пРеД - которые ставятся перед планировщиком (например, обеспече-
цЗ °еЛпмальной производительности или же поддержка приоритетно-
-* мы обсудим алгоритмы планирования, которые непосредствен-
ен)- ^емя выполнения позволяют определить, какой процесс должен
flo в° щен следующим. С помощью этих алгоритмов определяется, ко-
б^ть за к долго должен выполняться тот или иной процесс; они делают вы-
гдаиКаК я и3 возможности приоритетного вытеснения, значений приори-
бор исХ емени выполнения, срока завершения, равноправия и других ха-
тета, иК процессов. Вы сможете убедиться в том, что некоторые
РаК'1е£ь1 требуют использования определенного типа планировщика (на-
[ ЙЙ!Те п системам реального времени нужен планировщик на основе при-
°РИМТов, поддерживающий вытеснение). Другие же основываются на по-
। нии процесса при принятии соответствующих решений (например, от-
Вавая предпочтение процессам, интенсивно использующим ввод/вывод).
^Планирование по принципу FIFO (первылл-пришел-первылл-ушел)
По-видимому, наиболее простая дисциплина планирования использует
принцип FIFO (первым-пришел-первым-ушел — first-in-first-out)
(см. рис. 8.2). Процессор поступает в распоряжение процессов в порядке
их прихода в очередь готовности. Принцип FIFO не поддерживает приори-
тетное вытеснение — после захвата процессора процесс продолжает свое
выполнение до полного завершения. Политика FIFO справедлива в том
смысле, что она задает план выполнения процессов, исходя из порядка по-
ступления в очередь, поэтому все процессы для нее являются равноценны-
ми. Но ее можно считать и несправедливой, поскольку процессы, требую-
Ие длительного времени выполнения, заставляют ожидать процессы,
тРебующие короткого времени выполнения, что может привести к ситуа-
^Ии, когда менее важные для системы процессы заставят ждать своей оче-
етед б°лее важные процессы. Принцип планирования FIFO не рекоменду-
ет ’ФИменять для обслуживания интерактивных процессов, поскольку
в состоянии гарантировать хорошие времена ответа.
_ Очередь готовности
I Завершение
"з Р2 Р|--------------------------Процессор -------------------
Санирование по принципу FIFO
470
-
В современных системах принцип FIFO редко используется Са
тельно в качестве основной дисциплины обслуживания, а чаще комб
ется с другими схемами. Например, во многих схемах планировани
сматривается диспетчеризация процессов в соответствии с их ripj
ми, однако выбор следующего для запуска процесса среди цр₽1Г1'е>И
с одинаковыми уровнями приоритета, осуществляется по принципу I
Вопросы для самопроверки
1. Может ли в системе, использующей принцип планировани
возникнуть ситуация бесконечного откладывания? При отвеЯ
дите из предположения, что все процессы должны обязательно6
шить свою работу (то есть в них отсутствуют бесконечные i и« 3afieF
2. (Да/Нет) Правда ли, что в современных системах принцип п ’ 1
рования FIFO используется редко? ЛаНц.
Ответы 1) Нет. Бесконечное откладывание не может возникв
поскольку все прибывающие процессы будут помещены в конец очмЛ
ди, не мешая выполняться ждущим процессам. 2) Нет. Дисцищ^|
обслуживания FIFO можно встретить во многих современных алгол?'
мах планирования (например, в алгоритме планирования на основе
приоритетов, где процессы с одинаковым приоритетом обслуживают
ся по принципу FIFO).
8.7.2 Циклическое планирование (RR)
При циклическом, или круговом (round-robin, RR) планировании (см.
• рис. 8.3) диспетчеризация процессов осуществляется по принципу FIFO,
однако каждый раз в распоряжение процесса выделяется ограниченное ко-
личество процессорного времени, называемое временным квантом (time
slice или quantum).8 Если процесс не закончит работу до истечения выде-
ленного ему кванта времени, процессор у него отбирается и предоставляет-
ся следующему ожидающему процессу. Процесс, у которого отобрали про-
цессор, переходит в конец списка готовых к выполнению процессов, не
рис. 8.3 процесс Pi получает в свое распоряжение процессор и работает ДО
тех пор, пока не выполнит все поставленные задачи, после чего он покиДО
ет систему, либо до момента истечения выделенного ему кванта вРеме^
после чего он подвергается приоритетному вытеснению и помещается в
нец списка готовых к выполнению процессов. Затем планировщик з
кает процесс Р-2.
Дисциплина циклического планирования эффективна для Ра
в интерактивной среде, когда система должна гарантировать приемл^^,
времена ответа для всех пользователей. Накладные расходы на ПР
тетное вытеснение здесь удается снизить за счет эффективных м< 0о-
мов контекстного переключения и благодаря предоставлению доста *
го объема основной памяти, чтобы процессы могли размещаться я
новременно. е*1^
Подобно дисциплине FIFO, циклическое планирование часто в<
ся в качестве части сложных алгоритмов планирования загрузки н 0
ра, и при этом редко применяется самостоятельно. В этом раздел
раз сможете убедиться, что большинство сложных алгоритмов пляй
fr/ процессора
Г работе с процессами, обладающими одинаковым приоритетом,
х СР11 ,г к принципу FIFO либо дисциплине циклического планирова-
jjdef0 нНо поэтому принцип FIFO и дисциплина циклического планиро-
^^ючены в число трех обязательных алгоритмов планирования, ко-
^Ля®Кпзкны присутствовать в системах реального времени согласно спе-
^рь,еД°иИ POSIX (мы поговорим о планировании реального времени
о Я 9).9
; разделе 8-}
Очередь готовности
Приоритетное вытеснение
Завершение
Процессор 5—-----------'
Рис. 8.3. Циклическое планирование
Эгоистичное циклическое планирование (SRR)
В работе Клейнрок описана разновидность циклического планирования
под названием эгоистичное циклическое планирование (selfish round-robin,
SRR), в котором применяется принцип старения процессов, позволяющий
увеличивать приоритет процесса по мере ожидания.10 Согласно данной
схеме каждый прибывший в систему процесс сначала помещается в оче-
редь ожидания, где он пребывает до тех пор, пока длительность ожидания
ае позволит ему достичь уровня приоритета, который бы позволил процес-
СУ перейти в очередь активных процессов. С этого момента рассматривав-
ши процесс обслуживается по принципу обычного циклического плани-
8 ания Вместе с другими активными процессами из данной очереди. Пла-
°чег,ВЦ'15к осУЩествляет диспетчеризацию процессов только из активной
стеМцИ’ то есть долго ждущие процессы имеют приоритет по сравнению
ц процессами, которые только поступили в систему.
са Возъ Использ°вании планирования по принципу SRR, приоритет процес-
С1с°Рос аСТаеТ со скоростью °’ пока он находится в очереди ожидания, и со
с0й. g Ь1° где b < а, если процесс перешел в очередь активных процес-
"’вм Вл*1 & < а, то процессы в очереди ожидания будут «стареть» быстрее,
031С11Дац Ц’ессы Из активной очереди, что позволит процессам из очереди
6стУПцт^Я’ в конце концов, перейти в очередь активных процессов, чтобы
в борьбу за процессорное время. С помощью параметров а и б
. С^Дц1г, Рать’ как возраст процесса будет влиять на производительность
10 задержку. Например, если параметр а значительно больше Ъ, то
°Че1>ел Ц^Ие в систему процессы будут проводить очень мало времени
4 ожидания, и дисциплина SRR вырождается в обычное цикличе-
472
Л*
ское планирование. Если же а = Ъ, все процессы в системе стареют
новой скоростью, и таким образом, дисциплина SRR превращаем
циплину FIFO. В упражнении 8.23 вам будет предложено исслед
которые свойства схемы SRR. Л
че.
Величина кВанта Времени
Определение величины кванта времени q имеет критическое
для эффективной работы вычислительной системы с приоритетным^®^
нением.11 Какой должна быть длительность кванта? Должна ли
ляться фиксированной или же переменной? Следует ли задавать oin?a Яв-
же значение длительности кванта времени для всех процессов или й т°
определять его индивидуально для каждого процесса? СЛеДУет
Прежде всего, рассмотрим поведение системы в тех случаях
квант времени становится либо очень большим, либо очень малень°И
Если квант времени становится очень большим, то каждому процессу^*1'
доставляется практически столько времени, сколько требуется ему для
вершения, так что циклическое планирование, по сути, вырождает^'
в планирование по принципу FIFO. Если квант времени становится очень
маленьким, то накладные расходы на контекстные переключения начина-
ют играть доминирующую роль, причем характеристики системы, в конце
концов, настолько ухудшаются, что с какого-то момента основное время
затрачивается на переключение процессора, так что лишь незначительная
часть времени остается, если вообще остается, на выполнение полезных
вычислений.
Так какое же значение между нулем и бесконечностью следует выбрать
для величины кванта времени q? Рассмотрим следующий эксперимент.
Предположим, что существует некая круговая шкала, имеющая метки от
q = 0 до q = с, где с означает какое-то очень большое число. Мы начинаем
эксперимент с момента, когда ручка шкалы указывает на нуль. При пово-
роте ручки величина кванта времени для системы меняется. Предполо-
жим, что система работает и обслуживает много интерактивных проДеС
сов. Когда мы только начинаем поворачивать ручку шкалы, значен^
кванта времени близки к нулю и накладные расходы на переключения
нимают основную часть процессорного времени. Перед интерактив
процессами предстает неповоротливая система, характеризующаяся^^
тельными временами ответа. При дальнейшем повороте ручки вел
кванта времени увеличивается, и времена ответа системы улучШ f0.
В какой-то момент мы достигаем точки, когда процент накладных ^ссЬ1.
дов настолько снижается, что процессор начинает обслуживать пр
Однако времена ответа по-прежнему остаются не слишком хорош1
При дальнейшем повороте ручки времена ответа продолжаю’1'
шаться. В определенный момент система начинает быстро реагирс®
большинство запросов со стороны интерактивных процессов. Одна
еще не ясно, оптимально ли установленное таким образом значение^ eifle
времени. Ручка поворачивается несколько дальше, и времена отв 0 вр\
немного улучшаются. Однако затем при дальнейшем повороте рУ рР
мена ответа снова начинают расти. Это происходит потому, что к Ci Р
мени достигает размера, достаточного для того, чтобы каждый про
473
. плботы процессора
tuivj:——— ——
л в свое распоряжение процессор, успевал завершить свою про-
^Р^При эТОМ Дисциплина циклического планирования вырождается
1FIFO, при котором более длительные процессы заставляют
ее короткие, причем среднее время ожидания увеличивается, по-
<* РаТь более длительные процессы выполняются до конца, прежде
>ь1Хнить процессор.
М Усту тлим предположительно оптимальное значение кванта времени
4 расстЛ ю дОлю секунды), при котором обеспечиваются хорошие време-
(0еб°льС1У Чем именно характеризуется подобный квант времени? Он дос-
«Д^релик, так что подавляющее большинство интерактивных запро-
та’Г°ч0х еТ для своего обслуживания меньшего времени, чем длительность
С(?втРе°|г0Гда интерактивный процесс начинает выполняться, он, как пра-
лваНта’споЛЬЗует процессор в течение некоторого времени, после чего гене-
вЯл°’ запрос ввода/вывода. Когда запрос ввода/вывода сгенерирован,
рир>еТ с уСТупает процессор следующему процессу. Таким образом, ве-
эТ0Т а кванта больше, чем время вычислений до формирования запроса
лИ /вывода. Каждый раз, когда процесс пользователя получает в свое
обряжение процессор, он с большой вероятностью доработает до момен-
выдачи запроса ввода/вывода. Благодаря этому обеспечивается макси-
мальное использование ресурсов ввода/вывода и относительно короткие
времена ответа. Причем влияние на процессы, интенсивно использующие
процессор, сводится к минимуму — в их распоряжении остается львиная
доля процессорного времени, потому что процессы, ориентированные на
интенсивный ввод/вывод, используют процессор в течение коротких про-
межутков времени.
Так какова же оптимальная величина кванта времени? Очевидно, что
она меняется не только от системы к системе, но и в зависимости и от на-
грузок. Она меняется также от процесса к процессу, однако наш экспери-
мент не рассчитан на измерение различий для отдельных процессов.
В Linux величина кванта, выделяемого по умолчанию каждому процес-
до'?г^ВНа ЮО миллисекундам, но может изменяться в диапазоне от 10
| Вы ° МИЛЛИ(:екунд, в зависимости от приоритета и поведения процесса.
ВвоД/в°ПРИОРИТеТНЫМ процессам и процессам, ориентированным на
вым 1ВОд’ выделяются большие размеры квантов, чем низкоприоритет-
^гР°Цессам и процессам, интенсивно использующим процессор.12
ЧЙ1о °WS величина кванта, выделяемого каждому процессу по умол-
^мИл*л3аВИСИТ °Т аРхитектУРы системы, и в большинстве случаев равна
пРоцессИсекУнДам. Это значение может также меняться, если, например,
Й6ТеРфрцЬ1ПОлняется в Феновом режиме по отношению к графическому
к. в^ Пользователя-13
I i(la^bieBCe пР°Цессы системы интенсивно используют процессор, то на-
>е8и Расх°ДЬ1 на переключение процессов будут приводить только
пр0 пРоизводительности. Однако даже если активными являются
1 вЦессы> интенсивно использующие процессор, приоритетное вы-
йРоцеСе Же оправдано. Рассмотрим процесс, интенсивно использую-
РедыСѰВ КОТ°РЬ1Й управляет жизненно важной системой, работаю-
”Ме Реального времени — вход процесса в бесконечный цикл
Ч’ СтаДию выполнения, где он требует больше процессорного вре-
°Жидалось, может привести к разрушительным последствиям.
474
Кроме того, большинство систем, интенсивно использующих Пр01
также поддерживают отдельные интерактивные процессы, поэтом 6сЧЯ
оритетное вытеснение все же необходимо для того, чтобы гарант^ Чя
приемлемые времена ответа для этих процессов.
Вопросы для самопроверки
1. Представьте, что вы вращаете ручку настройки величины
для системы, состоящей только из процессов, интенсивно
зующих ввод/вывод. После того как вы дошли до точки о=
нейшее увеличение размера кванта практически не вли ’
производительность системы. Что в данном случае будет 0,Яет Ч
число с, и почему производительность системы не будет
ваться, когда q>c“i
2. В этом разделе мы определили оптимальную величину квант 1
мени, позволяющую процессам, интенсивно используй
ввод/вывод, выполняться ровно столько времени, сколько и.-,г
ходимо, чтобы сгенерировать запрос ввода/вывода, а затем В,е°^
вать процессор следующему процессу. Почему эта схема тпу J
в реализации?
Ответы 1) Величина с будет означать самый длинный интерна
вычислений между запросами ввода/вывода любых процессов систе-
мы. Увеличение размера кванта q выше с никак не повлияет на други
процессы, поскольку каждый процесс перейдет в состояние блокпров.
ки до окончания выделенного ему кванта, и поэтому процессы не с.чо-
гут воспользоваться преимуществами дополнительного времени,
которое было им выделено. 2) В общем случае невозможно спрогнози-
ровать ход выполнения программы, то есть система не может точзо
сказать, когда процесс сгенерирует запрос ввода/вывода. Потому к
и сложно определить оптимальную величину кванта времени, так как
она различна для каждого процесса и может со временем изменяться.
8.7.3 Планирование по принципу SPF (кратчайший процесс первым}
Планирование по принципу кратчайший процесс первым (shortest-pl
cess-first, SPF) представляет собой дисциплину, не поддерживающую^
оритетное вытеснение. Следующим для выполнения выбирается -
процесс с минимальным оценочным рабочим временем, остающимся д
вершения. Принцип SPF обеспечивает уменьшение среднего времени
дания по сравнению с дисциплиной FIFO.14 Однако времена ожидая
этом колеблются в более широких пределах (т.е. менее предсказуе
в случае FIFO, особенно для больших процессов. лИ0^
Дисциплина SPF оказывает предпочтение коротким заданиям ( c^fs
цессам) за счет более длительных процессов. Многие РазРаб°тчИе110Я<'Щ
ют, что чем короче процесс, тем лучшие условия для его выполне
дует создавать. Далеко не все специалисты придерживаются
мнения, поскольку такая стратегия не учитывает приоритетность^
(характеризующую важность процессов). Интерактивные проДеС
но «короче» процессов, интенсивно использующих процесс"!
данная дисциплина обеспечивает хорошие времена реакции- П ° е,11 J
стоит в том, что в ней не поддерживается приоритетное вытесн
за-
юты процессора
475
бщем случае, только что прибывшим интерактивным процессам не
ро, в ° кидать быстрого обслуживания.
°изм SPF выбирает для обслуживания процессы таким образом,
оедной процесс завершался и покидал систему как можно быст-
ра! 0 ,одаря этому обеспечивается уменьшение количества ожидающих
Le- а также количества процессов, стоящих в очереди за длинными
в результате дисциплина SPF позволяет свести к минимуму
upofiecC ремя ожидания для процессов, проходящих через систему.
^реДвее аЯ проблема, связанная с реализацией принципа SPF, состоит
Г^тО он требует точно знать, сколько времени будет выполняться про-
в'г°м’ такая информация обычно отсутствует. Поэтому принцип SPF вы-
десс> а поЛагаться на оценочные значения времен выполнения, указывае-
вУ^^^ьзователями либо системой. В рабочих условиях, когда одни и те
мЫе п° чИ выполняются регулярно, система в состоянии предоставить Ao-
s'6 3 точные и обоснованные оценки. Однако в проектной среде пользо-
Б°ЛЬли редко знают, как долго будут выполняться их программы.
в^Еще одна проблема, связанная с ориентацией механизма планирования
оценки пользователей может приводить к тому, что пользователи, зная,
то система оказывает предпочтение заданиям с малыми оценочными вре-
менами выполнения, могут умышленно задавать малые оценочные време-
на. Можно, однако, спроектировать планировщик заданий таким образом,
чтобы избавить их от подобного соблазна. Если процесс выполняется доль-
ше оценочного времени, система может приостановить его выполнение
и понизить приоритет, возможно даже прибегнув к штрафным санкциям.
Второе возможное решение заключается в том, чтобы выполнять процесс
в течение указанного оценочного времени плюс небольшой дополнитель-
ный процент, а затем «консервировать» процесс, т.е. запоминать его в те-
кущем виде, с тем, чтобы впоследствии можно было вновь продолжить его
выполнение.15
Дисциплину SPF можно рассматривать как потомок дисциплины SJF
ortest-job-first — кратчайшее задание первым), которая отлично подхо-
годцаДЛЯ ПланиР°вания заданий на производстве, однако, очевидно не при-
ццпчррЯ гланиР°вания нижнего уровня в операционных системах. Прин-
вытеСн Подо®ен FIFO — это дисциплина обслуживания без приоритетного
х°ДимоеНИЯ’ ПоэтомУ ее не рекомендуется применять в системах, где необ-
ГаРантировать приемлемые времена ответа.
Вопросы для самопроверки
?очемУ предпочтительнее использовать дисциплину SPF, чем
FIFO, когда основной целью системы является обеспечение высо-
кой пропускной способности?
2. Почему дисциплина SPF не подходит для планирования нижнего
Уровня в современных операционных системах?
1) Благодаря дисциплине SPF уменьшается среднее время
процессов, что позволяет повысить пропускную способ-
°сть. 2) Дисциплина SPF не гарантирует процессам быстрые времена
Реакции, что важно для современных дружественных пользователю
многозадачных интерактивных систем.
Ответы
Оэкйдания
8.7.4 Планирование по принципу HRRN
(по наибольшему относительному Времени реакции)
Бринч Хансен разработал стратегию планирования по наибольщ
носительному времени реакции (highest-response-ratio-next,
торая компенсирует некоторые недостатки дисциплины SPF, в ча '•
чрезмерное предубеждение против длинных процессов и чрезмерщ,
госклонность по отношению к коротким новым процессам. HRp^i %,
дисциплина планирования без приоритетного вытеснения, согласий
рой приоритет каждого процесса является не только функцией време
служивания этого процесса, но также времени, затраченного процес
ожидание обслуживания. После того как процесс получает в свое раг^^
жение процессор, он выполняется до завершения. Динамические пп •
теты при дисциплине HRRN вычисляются по формуле: °®*-
время ожидания + время обслуживания
приоритет =----=----------------=-----------
время_ обслуживания
Поскольку время обслуживания находится в знаменателе формул
предпочтение будет оказываться более коротким процессам. Однако по.
скольку в числителе имеется время ожидания, более длинные процессы
которые уже довольно долго ждут, будут также получать определенное
предпочтение. Этот подход напоминает механизм старения, предотвращая
бесконечное откладывание процессов.
Вопросы для самопроВерки
1. (Да/Нет) Правда ли, что при использовании принципа планирова-
ния HRRN, выполнение коротких процессов всегда будет назва-
чаться раньше, чем более длинных?
2. Процесс Pi оценивает необходимое ему время обслуживания в бее-
кунд и при этом ожидает уже в течение 20 секунд. Процесс Рг °
нивает необходимое ему время обслуживания в 3 секунды И j
этом ожидает уже в течение 9 секунд. Какой процесс будет задув*
первым в соответствии с дисциплиной HRRN?
Ответы 1) Нет. Чем дольше ожидает процесс, тем выШ2)Ввд’*
ность, что он будет запущен раньше, чем короткий процесс. 'оЭ^)й
ном случае приоритет процесса Pi равен 5, а процесса ₽2 4’
первым будет запущен процесс Pj.
8.7.5 Планирование по принципу SR1 (по наименьшему останМ^
Времени)
Принцип наименьшего остающегося времени (shortest-reniain^jiii*4
SRT) представляет собой аналог принципа SPF. Но SRT
приоритетное вытеснение, стараясь повысить скорость обслу>кй®^эс1>^1
ротких новых процессов. Дисциплина SRT эффективно приМ(
систем обработки заданий, которые характеризовались постоЯн
ком новых заданий, однако она не находит применения в со
операционных системах. По принципу SRT всегда выполня .0 W
имеющий минимальное оценочное время до завершения. СогЛ
ты процессера
477
ще
1 v Процесс, который запущен в работу, выполняется до заверше-
S* принципу SRT выполняющийся процесс может быть вытеснен
$ & плении нового процесса, имеющего более короткое оценочное
*0 Р00 боТы. Чтобы механизм SRT продемонстрировал свою эффектив-
ная РаятЬ-таки нужны достаточно точные оценки будущего поведения
"сгь ° причем разработчик системы должен позаботиться о мерах про-
^роИесса^отребления прикладными программистами особенностями стра-
fU® ^лавировании-
пзация принципа SRT требует, чтобы регистрировались истекшие
РеаЛ обслуживания, и изредка выполнялось приоритетное вытеснение.
в систему короткие процессы будут выполняться практиче-
АоСТУ11 овейно. Однако более длительные процессы будут иметь даже боль-
рднее время ожидания и больший разброс времени ожидания, чем
&ее яе с SPF- Все эти факторы приводят к более высоким накладным рас-
ВСЛам при использовании дисциплины SRT по сравнению с SPF.
^Теоретически принцип SRT обеспечивает минимальные времена ожида-
Однако из-за издержек приоритетного вытеснения может оказаться
igK что в определенных ситуациях в действительности лучшие показате-
ли будет иметь SPF. Предположим, что текущий процесс уже почти завер-
шается, а в этот момент поступает новый процесс с очень малым оценоч-
ным временем обслуживания. Следует ли выполнять приоритетное вытес-
нение выполняемого в данный момент времени процесса? Механизм
планирования, реализующий чистый принцип SRT, произвел бы вытесне-
ние, однако целесообразно ли это? Проблему можно решить, если преду-
смотреть некоторое пороговое значение остающегося времени выполнения,
с тем чтобы в случае, если текущему процессу требуется для своего завер-
шения меньше указанного количества времени, система гарантировала бы
его завершение без прерываний.
Похожая проблема возникает, когда в систему поступает процесс, оце-
ночное время которого лишь немногим меньше времени, необходимого для
РШения текущего процесса. Хотя алгоритм вполне корректно может
оПти Нить приоритетное вытеснение, однако данное решение не является
Bb4naio ЬНЫМ ®сли накладные расходы на приоритетное вытеснение пре-
ТекУЩег РазНость времен обслуживания обоих процессов, то прерывание
цельго процесса приведет к снижению производительности системы.
Ки°пег) ВСеХ Этих примеров состоит в том, чтобы показать, что разработчи-
Ь1еха1ЦИоннь1Х систем должны тщательно взвешивать накладные расхо-
и^13Мов Управления ресурсами в сравнении с прогнозируемыми вы-
ПОл11ПРИМенения- Кроме того, мы вйдим, что даже относительно про-
хода Т11Ки планирования могут давать низкое быстродействие по не
евидным причинам.
Вопросы для самопроВерки
Можно ли назвать механизм SRT достаточно эффективным алго-
Ритмом планирования для интерактивных систем?
• Почему механизм SRT непригоден для планирования процессов ре-
ального времени?
478
Ответы 1) На первый взгляд дисциплина планирования о 1
жет произвести впечатление довольно эффективного алгоп 1
интерактивных процессов, если перед генерацией запросов
вода эти процессы выполняют короткие задачи. Тем не i _ "
лина SRT определяет приоритет, основываясь на времени
до завершения, а не времени выполнения до генерации .
да/вывода. Некоторые интерактивные процессы, такие
мер, оболочка командной строки, выполняются в течение вср’-
пользователя, и поэтому, по алгоритму SRT оболочка должна б
получить самый низкий уровень приоритета. 2) Дисциплина
рактеризуется большими разбросами времен ответа, тогда как Xj
сы реального времени требуют минимальных различий во вп^01^
ответа, которые бы гарантировали, что всякая задача будет зав1
в течение определенного интервала времени.
менееВ>^ '
1И 3aiwS
8.7.6 Многоуровневые очереди с обратной связью
Когда процесс получает в свое распоряжение процессор, особенно
процесс до сих пор не имел возможности каким-то образом проявить себя
(например, чтобы показать, сколько времени он обычно выполняется, пр«
жде чем сгенерировать запрос ввода/вывода, или какие области памяти]
предпочитает использовать процесс), планировщик не имеет ни малейшего
представления о том, какое именно количество процессорного времени по-
требуется данному процессу. Процессы, интенсивно использующие
ввод/вывод, обычно используют процессор кратковременно, перед тем как
сгенерировать запрос ввода/вывода. Процессы, интенсивно использующие)
процессор, могут занимать его часами, если в системе не предполагается
приоритетное вытеснение. Механизм планирования должен оказывать
предпочтение коротким заданиям, а также создавать лучшие условия про-
цессам, интенсивно использующим ввод/вывод, чтобы обеспечить хоро-
ший коэффициент использования устройств ввода/вывода и хорошие вре-
мена реакции для интерактивных процессов. Кроме того, планировЩ
должен как можно быстрее определять характер процесса и соответству
щим образом планировать выполнение этого процесса. J
Многоуровневые очереди с обратными связями (multilevel 1ееостВ1
queue) (см. рис. 8.4) представляют структуру, которая обеспечивает д g
жение вышеперечисленных целей.17 Новый процесс входит в сеть о
с конца верхней очереди. Он перемещается по очереди, реалиаУ
принцип FIFO, пока не получит в свое распоряжение процессор. ^apepiDe'
цесс завершается или освобождает процессор, чтобы подождать тОэТ°т
ния операции ввода/вывода или наступления некоторого события,
процесс выходит из сети очередей. Если выделенный квант врем6
кает до того, как процесс добровольно освободит процессор, эТ0^сЛи
помещается в конец следующей очереди более низкого уровня. ррсР1'?
ный процесс продолжит использовать полный квант времени, одеР^
ляемый на каждом уровне, он и дальше будет переходить в конетрЦР^Ш
следующего нижележащего уровня. Обычно в системе предусма
некоторая очередь самого нижнего уровня, которая реализуе1?^руе в<г
циклического обслуживания и в которой данный процесс цирЯ^
тех пор, пока не закончит свою работу. Этот процесс в следую®
лучит в свое распоряжение процессор, когда он достигнет начал
m p^°mbl пРечессоРа
479
тсокого уровня среди непустых очередей в сети многоуровневых
1|Кг0 „ обратной связи. Выполнение данного процесса может быть пре-
слУ4^ прибытия нового процесса в одну из очередей более высоко-
Использо- Завершение
вание
процессора
Уровень 3
(дисциплина I
Уровень 2
(дисциплина
Завершение
Завершение
Уровень п
(циклическое
планирование)
Приоритетное вытеснение
Исполь- Завершение
эованйе
процессора
g -
• Многоуровневые
очереди с обратными
связями
480
Такая организация может привести к тому, что процесс в очепР
него уровня пострадает от бесконечного откладывания, если в очег> М
лее высокого уровня постоянно будет находиться хотя бы одицР6^^
Подобная ситуация возникает, если в систему постоянно пост
шое количество процессов, нуждающихся в обслуживании либо в
присутствует несколько процессов, интенсивно использующих л
ввода/вывода, которые выполняются в выделенном им кванте
В ряде вариантов многоуровневых очередей с обратными связ: е®4- *
времени, предоставляемый данному процессу при переходе в очерел
низкого уровня, увеличивается. Таким образом, чем дольше
процесс в сети очередей, тем больший квант времени выделяется ем
ждым разом, когда он получает в свое распоряжение процессор. BCR У СЧ
рассмотрим преимущества данного решения.
Рассмотрим, каким образом подобный механизм реагирует на пя
ные типы процессов. Многоуровневые очереди с обратными связями
ют предпочтения процессам, интенсивно использующим функции0*^
да/вывода, и другим процессам, нуждающимся в небольших порциях
цессорного времени, поскольку они входят в сеть очередей с высовдЗ
приоритетом и быстро получают процессор в свое распоряжение. Квад
времени для первой очереди выбирается достаточно большим, с тем, чтобы
подавляющее большинство процессов, связанных с вводом/выводом (в тед
числе интерактивных), успевали выдать запрос ввода/вывода еще до исте-
чения первого кванта. Когда подобный процесс выдает запрос ввода/выво-
да, он выходит из сети очередей, получив истинно приоритетное обслужи-
вание, что и требовалось. Повторный вход процесса в сеть происходит то-
гда, когда он снова переходит в состояние готовности.
Теперь рассмотрим процесс, интенсивно использующий процессор. Про
цесс поступает в очередь сети с самым высоким приоритетом. На этом эта
пе очередь не знает, к какой категории относится данный процесс -
и цель сети определить это как можно быстрее. Процесс получает в свое
распоряжение процессор весьма быстро, однако после истечения выдел®
ного ему кванта времени процесс переходит в конец очереди следу#®1
нижележащего уровня. Теперь этот процесс будет иметь более низкий
оритет, так что поступающие процессы будут первыми получать в сво
поряжение процессор. Таким образом, интерактивные процессы буДУ
должать получать хорошие времена ответа, даже если многие про
интенсивно использующие процессор, постоянно теряют приоритет,*^,
ходя на очереди нижележащих уровней. В конце концов, процесс, gy
сивно использующий процессор, получит его в свое распоряжение,
дет выделен квант времени большей величины, чем в очереди наИоН бУ^е
приоритета, но он снова использует этот квант полностью. Затем ^обг
помещен в конец очереди следующего нижележащего уровня.
зом, данный процесс будет продолжать переходить в очереди с
кими приоритетами, будет дольше ждать в промежутках меЖДУ тЬ
мыми ему квантами времени и каждый раз полностью использо
квант, когда будет получать в свое распоряжение процессор ('
не будет происходить приоритетного вытеснения из-за посту
цесса с более высоким приоритетом). В конце концов, этот вЫ1*
ный процесс окажется в очереди самого низкого уровня с цикли
служиванием, где и будет циркулировать, пока не завершится-
ыытЫ процессора
—
повневые очереди с обратными связями — это идеальный меха-
М0^ одяюгций разделять процессы на категории в соответствии с их
п°3тЯМИ в процессорном времени. Когда процесс выходит из сети
он может быть помечен признаком очереди самого низкого уров-
*’°ере^е11’0рой оН побывал. Когда этот процесс впоследствии вновь войдет
® педей, он будет направлен прямо в ту очередь, в которой он по-
с'е^ °- аз завершил свою работу. Здесь планировщик действует на осно-
1вД011Й Р тпего эвристического правила: поведение процесса в недавнем
c3ie^ рдожет служить хорошим ориентиром для определения его пове-
оро^0 ближайшем будущем. Благодаря этому планировщик не помещает
деВйЯ В т интенсивно использующие процессор, в очереди более высоких
про^., ’где те только мешали бы обслуживать короткие процессы высо-
vp°pljeI1’ ритета или процессы, связанные с вводом/выводом.
К°Г° жалению, если процессы всегда помещать в сеть очередей на самый
в й уровень, который они занимали прошлый раз, то система не смо-
вйЗКоеагироваТь на изменения характера процесса, например на то, что
^песс, по преимуществу интенсивно использующий процессор, начинает
П римущественно использовать ввод/вывод. Эту проблему можно решить,
если в метке, которой сопровождается процесс, указывать также степень
использования им выделенных квантов времени во время последнего пре-
бывания в сети очередей. Если процессор полностью использует выделен-
ный ему квант времени, система поместит его в очередь более низкого
уровня (если таковая доступна). Если же процесс сгенерирует запрос вво-
да/вывода до того, как закончится выделенный ему квант времени, он мо-
жет быть помещен в очередь более высокого уровня. Если процесс войдет
в новую фазу, в которой он вместо интенсивного использования процессора
станет интенсивно использовать ввод/вывод, первоначально он будет не-
сколько страдать от «неповоротливости» схемы, пока система не опреде-
лит, что характер процесса изменился. Тем не менее, описываемый меха-
аизм планирования довольно быстро реагирует на подобные изменения.
в п н^е 0ДИн способ обеспечения быстрой реакции системы на изменения
едении процесса состоит в том, чтобы позволить процессу переме-
льно На °дин УР°вень вверх в сети очередей каждый раз, когда он добро-
меаа °св°бодит процессор еще до истечения выделенного ему кванта вре-
8РеМя о алогично планировщик, присваивая приоритет, может учитывать
Цц, ме Идания обслуживания процессом. Планировщик может использо-
К°г° УровНИЗМ СТаРения процессов, помещая процесс в очередь более высо-
°^С''1У5КиваЯ ПОСле того» как процесс провел определенное время, ожидая
с о«ИЗ РаспРостраненных вариантов механизма многоуровневых оче-
^РКудатными связями является схема, в которой процесс несколько
цГ° яйзке Рует в каждой очереди, прежде чем перейти в очередь следую-
алегкаЩего уровня. Как правило, количество подобных циклов
6 ^Рова11е^ди Увеличивается по мере перехода процесса на нижележа-
Ч^есСов и ™акоя подход позволяет еще более улучшить обслуживание
айте Нтенсивн° использующих ввод/вывод по сравнению с процес-
асивн° использующими процессор. Многоуровневые очереди
We ~ связями — показательный пример адаптивного механизма
chanism), т.е. механизма, который позволяет реагировать на
482
\
изменение поведения контролируемой им системы.18’19 Адаптивнь
низмы, как правило, требуют больших накладных расходов, чем 6
тивные, однако присущая им чувствительность к изменениям ре,к11еЧИ
боты делает систему более реактивной и компенсирует накладны^*4®D
ды. В разделе 20.5.2 мы поговорим о планировщике процессов в
который перенял адаптивный механизм из схемы многоуровневых
дей с обратной связью. [Примечание-. В литературе термины плани
процессов и планирование процессора (планирование загрузки прои60^
являются взаимозаменяемыми.] Сс°Ра)
Вопросы для самопроверки
1. Какие цели планирования необходимо учитывать при выбопр
чества уровней для использования в многоуровневых очереля^°Лй'
ратной связью? с об.
2. Почему в современных планировщиках предпочтение отдается
тивным механизмам? ала®-
Ответы 1) Одной из основных целей планирования являете I
уменьшение разброса во временах ответа. При увеличении числа vdo^
ней процессы, интенсивно использующие процессор, вынуждеаы
дольше ожидать, что приводит к большему разбросу времен ответа
С другой стороны необходимо учитывать эффективность использова-
ния ресурсов. С увеличением числа уровней многим процессам удает
ся завершить работу и сгенерировать запрос ввода/вывода прежде,
чем истечет выделенный им квант времени, что позволяет эффектив-
нее использовать процессорное время и устройства ввода/вывода.
2) В современных вычислительных системах встречается много при-
ложений, которые могут одновременно интенсивно использовать как
процессор, так и функции ввода/вывода. Например, проигрыватель
потокового видео должен генерировать запросы ввода/вывода, чтобы
загрузить видеоданные с удаленного сервера, а затем должен выпол-
нять большие объемы вычислений для декодирования видео и после
дующего вывода на экран. Интерактивная игра (например, лет?
симулятор) должна быстро реагировать на действия пользователям
пример, на перемещение джойстика) при расчете трехмерных
Адаптивный механизм позволяет системе по-разному реагиров
работу этих процессов, в случае изменения их поведения
интенсивного использования процессора к интенсивному исп
нию ввода/вывода).
8.7.7 Планирование по принципу FSS (справедливого раздела) ,
Обычно группирование процессов в системе осуществляется 1^)ВецО11'
общим признакам. Например, в UNIX (как и в других многополь
ских системах) процессы группируются по принадлежности к рвзДе^,
ному пользователю. Планирование по принципу справедливого*
(fair share scheduling, FSS) позволяет задавать план выполнени^^е4
дельных групп.20,21,22,23 Справедливый раздел позволяет системе
вать равноправный статус групп процессов, выделяя каждой
деленный набор системных ресурсов. В среде UNIX стратегия оС?з^
ния FSS была разработана специально для того, чтобы «п
определенный заранее уровень системных ресурсов... группам и
лей, выполняющим схожие функции.»24
щботы прецесеера
483
оТрпм пример эффективного применения планирования по прин-
PacCbI аведливого раздела. Итак, перед вами исследовательская группа,
иУ сПРт0рой работают с одной многопользовательской системой. Исследо-
группа поделена на две подгруппы. Меньшая подгруппа, пред-
тая собой основной исследовательский состав, использует систему
ддения важных заданий, требующих большого объема вычисле-
на 01411 риМер, моделирования. Ко второй подгруппе относятся остальные
«ЦЙ’ нЯ уппы испытателей, выступающие в роли ассистентов, которые ис-
у систему менее интенсивно — в основном для накопления инфор-
иоДьзУ распечатки результатов. Теперь представим, что в текущий момент
май011 с системой работает большое число ассистентов и только один ис-
вРе1',е тель из основного состава. Поскольку ассистентов много, они могут
след0* почти все процессорное время, что губительно скажется на работе
^^пователя из основного состава, которому необходимо выполнять более
йССЛяую работу. Но если сделать так, чтобы система запрещала подгруппе
®а гггтентов исследователей использовать более 25% процессорного време-
8 оставляя до 75% процессорного времени исследователям из основного
состава, то последние не пострадают от снижения уровня обслуживания.
Подобная разновидность планирования по принципу справедливого раздела
обеспечивает зависимость уровня обслуживания только от числа пользова-
телей в каждой группе, а не от общего числа пользователей системы.
Рассмотрим механизм планирования по принципу справедливого разде-
ла в UNIX-системе. Обычно UNIX следит за уровнем использования ресур-
сов всеми процессами (см. рис. 8.5). При использовании дисциплины FSS,
система распределяет ресурсы между различными группами справедливо-
100%
планировщик процессов UNIX. Планировщик
пР°цессор в распоряжение пользователей, каждый из которых
„Ть множество процессов (Собственность архивов AT&T.
я с разрешения AT&T.)27
484
го раздела (fair share groups) (см. рис. 8.6). Согласно этой схеме п
неиспользуемые одной группой, передаются другой группе прОцС^
нально нуждам той или иной группы. °Я
Создание групп справедливого раздела и привязка пользо»
к этим группам осуществляется с помощью команд UNIX.25 При pa&T%i
рении данного вопроса будем считать, что UNIX применяет схем^^л
оритетного циклического планирования процессов.26 Каждый д
имеет свой приоритет, и планировщик связывает процессы данног^е
оритета с очередью, обладающей таким приоритетом. Планировщд^
цессов отбирает готовые процессы из головы очереди с самым вы
приоритетом. Процессы с одинаковым приоритетом обслуживают*1 Й|1
принципу циклического планирования. Уровень приоритета проце
который не успел завершиться и потому требует дополнительного обе Л
живания, понижается непосредственно перед приоритетным вытесне
ем. Приоритеты ядра всегда выше пользовательских приоритетов и в Я
ются только тех процессов, которые выполняются в ядре. События, СВа
занные с дисковыми накопителями, имеют более высокий приоритет, Че|(
терминальные события. Приоритет, присваиваемый пользователю плане
ровщиком, выражается отношением уровня использования процессора
и3
и,
р
и4
р
U2
р
Рис. 8.6. Планировщик справедливого раздела. Планировщик раздели~
емкость ресурсов на части, каждая из которых выделяется планиров i
процессов различным группам справедливого раздела. (Собственност
AT&T. Публикуется с разрешения AT&T.)28
485
У Мёрты процессора__________________________________________________________
e время к прошедшему реальному времени. Чем меньше про-
иоСле^мени, тем выше приоритет процесса.
итет групп справедливого раздела зависит от того, насколько
flp110? йЛи иная группа к достижению определенных целей по исполь-
ресурсов. Группы, страдающие от недостатка обслуживания, по-
>01° овышенный приоритет, приоритет групп, выполнение задач кото-
1У^й1°рОдВигается ХОРОШ°, понижается.
рР*
Вопросы для самопроверки
1. Почему при использовании планирования на основе справедливого
' раздела, группам, которые недоиспользуют ресурсы, присваивает-
ся более высокий приоритет?
2. Чем дисциплина FSS отличается от стандартных дисциплин плани-
рования процессов?
Ответы 1) Процессы, использующие меньшее количество ресур-
сов, чем определено их целями по использованию ресурсов, вероятнее
всего, страдают от низкого уровня обслуживания. Увеличивая их при-
оритет, система полагает, что эти процессы выполняются достаточно
долго для того, чтобы воспользоваться необходимыми им ресурсами.
2) Согласно дисциплине планирования на основе справедливого разде-
ла, ресурсы распределяются между группами процессов, тогда как
стандартные механизмы планирования процессов позволяют всем
процессам соревноваться за право обладания любыми ресурсами на
равных условиях.
8>8 Планирование по сроку завершения
При планировании по предельному сроку или по сроку завершения
eadline scheduling) принимаются все меры для того, чтобы выполнение
определенных процессов заканчивалось к заранее обусловленному време-
чметЛИ конечномУ сроку. Результаты выполнения этих процессов могут
бессТЬ ®Ольшую важность, если они будут получены вовремя, и оказаться
^слезными после назначенного срока.29,30,31
стямиаНрРОвание По СРОКУ завершения связано с определенными трудно-
^сУрс'ь1 °'ПеРВЬ1х’ пользователь должен заранее точно указывать, какие
ПотРебуются для выполнения его процесса в срок, а подобную ин-
8ьЦ1о 10 можно иметь лишь в редких случаях. Во-вторых, система долж-
*Яця ЛНяТь процессы к сроку без серьезного снижения уровня обслужи-
^Овать ГИХ п°льзователей. Кроме того, система должна тщательно пла-
^одесса ^гРузку своих ресурсов вплоть до указанного срока завершения
ble цГ А Эт° м°жет быть достаточно трудно, поскольку могут поступать
с’ {‘аЙ0црЦ'ессь1’ предъявляющие к системе непредсказуемые требования.
Ч 1,1 Для если приходится иметь дело одновременно со многими процес-
27ьЬ1Чяй К°ТОРЬ1Х задается срок выполнения, то планирование может
^ьаЫ1оР° Усложниться-
IV у aafie Управление ресурсами, необходимое при планировании по
м'ДЯд, Рвения, может быть связано со значительными накладными
(см. раздел «Размышления об операционных системах: Интен-
486
сивность управления ресурсами с учетом их относительной стоим
Интенсивность использования системных ресурсов через сеть мо®е,
гать высокого показателя, вызывая понижение уровня обслуживав
гих процессов. 4
В следующем разделе вы узнаете о важности планирования по сп
вершения для процессов, выполняющихся в режиме реального впЧ
В работах Дертоуз продемонстрировано, что когда все процессы в
нии завершить свою работу до истечения конечного срока незави^001®4-
порядка выполнения, оптимальным вариантом является запуск в
очередь тех процессов, срок завершения которых наступает раньще зг®^
нако если система находится в состоянии перегрузки, она должна
лять значительную часть процессорного времени планировщику,
тот определял надлежащий порядок выполнения процессов, дающий®11
можность завершить работу всех процессов в срок. В последних исслеп J
ниях особое внимание уделялось скорости33’34 и количеству35 процессоЛ
которые система должна выделить планировщику, чтобы соблюсти все
данные сроки завершения.
Вопросы для самопроверки
1. Почему важно, чтобы пользователь заранее точно указывал, какие
ресурсы потребуются для выполнения его процесса?
2. Почему иногда бывает сложно добиться, чтобы процесс завершит,
свое выполнение в срок?
ОтветЫ 1) Это позволит планировщику гарантировать, что необ-
ходимые процессу ресурсы будут доступны, позволяя ему завершить
работу до срока завершения. 2) В систему могут поступать новые про-
цессы, предъявляющие непредсказуемые требования к системе, кото-
рые могут помешать уже исполняемым процессам завершиться
в срок, может произойти отказ ресурса, процесс может резко изменить
поведение и т.д.
Размышления об операционных системах
Интенсивность управления ресурсами с учетом №
относительной стоимости
Операционная система отвечает за управ-
ление аппаратными и программными ресур-
сами. В этой книге мы не раз будем отмечать,
что интенсивность, с которой операционной
системе нужно управлять конкретными ре-
сурсами, пропорциональна относительной
ценности этих ресурсов для операционной
системы. Например, процессор и быстродей-
ствующая кэш память должны УПРсТройсГ
более интенсивно, чем вторичные
ва хранения и другие устройства в
вода. Разработчик операционной^^»
должен учитывать тенденции изМ pgtyP^
носительной ценности систем ных^рр
и пользовательского времени, и ]
гировать на происходящие пере^е .
работы процессора
487
о Планирование реального времени
V* '
ной целью алгоритмов планирования, представленных в разде-
Осв°явЛЯлось обеспечение высокого коэффициента использования ре-
дс Процессы, кот°Рь1е Должны выполняться периодически (напри-
сУРс°₽ в минуту) требуют иного подхода к планированию. Например, не-
Жируемое время ожидания для дисциплины SPF (кратчайший
рроГв __ первым) может привести к катастрофическим последствиям,
0роЦеСС идет о процессе, проверяющем температуру ядерпого реактора.
Этично, система, выполняющая планирование по наименьшему ос-
муся времени для процесса, осуществляющего воспроизведение ви-
Тв5° может вызывать рывки при проигрывании видео. Планирование ре-
Де°’ 0 времени (real-time scheduling) позволяет удовлетворить нужды
аЛЬ ессов, которые должны формировать корректные результаты к опро-
шенному времени (т.е. обладающих временными ограничениями (timing
й nstraint)).36 Процесс, выполняемый в режиме реального времени, может
поделить свою последовательность инструкций на отдельные задачи, каж-
дая из которых должна быть решена к определенному сроку. Некоторые
процессы реального времени должны выполнять поставленные перед ними
задачи периодически, например, обновлять сведения о местоположении
самолетов в системе управления воздушным движением. Планировщики
реального времени должны обеспечивать соблюдение этих временных ог-
раничений (см. «Учебный пример: Операционные системы реального вре-
мени»).
Дисциплины планирования реального времени классифицируются по
тому, насколько хорошо они позволяют соблюдать сроки завершения про-
цессов. Мягкое планирование реального времени (soft real-time schedu-
tog) обеспечивает запуск процессов реального времени перед другими про-
цессами, однако не гарантирует их соответствие временным ограничени-
• если таковые имеются.37-38 Мягкое планирование реального времени
чно реализуется в персональных компьютерах, где желательным явля-
ли Плавное проигрывание мультимедиа, хотя случайные приостановки
р°вацЬ1С0КО^ загРУзке системы вполне терпимы. Системы мягкого плани-
®8Цйй Я реального времени могут выиграть за счет частой выдачи преры-
°ДИца ЧТ° позволяет предотвратить зависание системы, выполняющей
®Ь1й ilbIT0T Же пРоцесс, когда другие процессы не укладываются в выделен-
Те,1ьВЫеСРОК завеРшения- В то же время система может испытывать значи-
®СеМо)Кр3адеРЖКи’ если прерывания происходят слишком часто, что так-
зеПо привести к низкой производительности либо несоблюдению сро-
бл^т?51116111151-57
гао е Планирование реального времени (hard real-time scheduling)
зя „₽антиРует соблюдение временных ограничений для процесса. Ка-
ЕЧа’ определенная в виде процесса жесткого реального времени,
’1Ть завершена до предельного срока. Несоблюдение сроков завер-
яет привести к катастрофическим последствиям, включая не-
Работу, сбой системы и даже нанесение вреда пользователям
Системы жесткого реального времени могут включать перио-
Процессы (periodic processes), регулярно выполняющие некото-
488
рый объем вычислений (например, каждую секунду собирая данные
мы управления воздушным движением), и асинхронные IID с,1Ск
(asynchronous processes), выполняемые в ответ на определенные с
(например, в случае возрастания температуры ядерного реактора) во
45
fy Учебный пример
Операционные системы реального Времени
Системы реального времени отличаются
от стандартных систем тем, что любая опера-
ция в рамках такой система должна не только
давать правильные результаты, но и предос-
тавлять их в течение определенного интерва-
ла времени.39 Системы реального времени
используются в приложениях, для которых
время выполнения задачи является критич-
ным, например, в датчиках, предназначен-
ных для мониторинга. Часто таковыми явля-
ются небольшие системы, встраиваемые
в оборудование. К разработке операционных
систем реального времени (real-time
operating systems, RTOS), которые могли бы
соблюдать подобные требования, следует
подходить очень тщательно (см. раздел 8.9,
касающийся вопроса планирования процес-
сов реального времени).
Вероятно, первой операционной системой
реального времени можно считать управляю-
щую программу проекта SAGE (Semi Automatic
Ground Environment — полуавтоматизирован-
ная система управления войсками ПВО США
и Канады).40''" Данный проект был предназна-
чен для защиты от возможного бомбового
удара во времена Холодной войны.42 Введен-
ный в эксплуатацию в конце 1950-х годов,
этот проект включал в себя 56 цифровых лам-
повых компьютеров IBM AN/FSQ-7, которые
собирали данные с радарных систем по всей
стране, ведя наблюдение за воздушным про-
странством Соединенных Штатов.43,44 Система
анализировала полученную информацию
и направляла в нужный район самолеты-пере-
хватчики, что требовало от системы пр I
в режиме реального времени.45 Оперли "I
ная система, предназначенная для выпол^]
ния этих задач, считается самой болыад
компьютерной программой того времени46
Современные системы реального време
ни стремятся к компактности. На рынке су-
ществует множество систем реального вре
мени, но лидерами считаются QNX
и VxWorks. Операционная система QNXpea
лизует API стандарта POSIX со своим собст-
венным микроядром и широко использует-
ся во встраиваемых системах. Кроме того,
для реализации взаимодействия процессов
в ней используется механизм передачи со-
общений.47 Подобную систему с микро-
ядром представляет собой VxWorks, кото
рая соответствует стандартам POSIX и шире
ко применяется в роли встроенных сИ5ге”
Операционная система QNX лучше ра °т^
на платформах Intel х8649, чем VxWor s,^
нако до версии 6.1 (текущая веРсиЯе(^3
QNX не могла работать с другими пр0*-1
рами.50 VxWorks, в свою очередь.
жде всего, нацелена на п
и имеет свою историю кроссплатф 1
совместимости.5’ Самой распро°тР&
операционной системой для У‘
встроенными системами является
момент именно VxWorks?' К <ир^ГеМеНи
ционным системам реального еФ 6. (р 1
носятся Windows СЕ .NET? °
и некоторые дистрибутивы Linux,
CLinux.56 U
'юты процессора
489
Г Г дСрие алгоритмы планирования реального времени
веские алгоритмы планирования реального времени (static
,cheduling algorithms) не позволяют изменять приоритет процес-
его выполнения. Поскольку вычисление приоритета происхо-
Г в° Б₽екратно, статические алгоритмы планирования реального времени,
(ТоДн иЛО> проще в реализации, и не связаны с большими издержками.
KaIt ^область применения таких алгоритмов ограничена, поскольку они
дай61*0 т реагировать на изменение поведения процессов, а возможность
0е м°г^ниЯ временных ограничений зависит от состояния ресурсов.
I емах жесткого реального времени обычно используются статические
В сИ^ы планирования, поскольку такие алгоритмы не связаны с больши-
g.irop1 1аднь1ми расходами, и в них достаточно легко доказать, что каждый
мй Весс может гарантировать соблюдение своих временных ограничений,
й’^плина планирования RM (rate-rnonotonic), к примеру, представляет со-
“ основанный на приоритетах циклический алгоритм, который линейно (то
®°и монотонно) повышает приоритет процесса при увеличении частоты его
^полнения. Этот статический алгоритм выполнения создает более благопри-
ятные условия для периодических процессов, которые должны выполняться
чаще.61 Алгоритм планирования DRM (deadline rate-monotonic) используется
в тех случаях, когда для периодических процессов задан срок завершения,
который не совпадает с периодом выполнения.62
Динамические алгоритмы планирования реального времени
Динамические алгоритмы планирования реального времени (dynamic
real-time scheduling algorithms) могут менять приоритет процессов во вре-
мя выполнения, что связано со значительными издержками. Некоторые
алгоритмы пытаются минимизировать накладные расходы на планирова-
ние, присваивая одним процессам статические приоритеты, а другим —
динамические.63
Алгоритм планирования по принципу EDF (earliest-deadline-first — бли-
BUg1111111 сРок завершения — первым) поддерживает приоритетное вытесне-
ПеРвУю очередь выполняя запуск процессов с ближайшим сроком за-
аерц1рНИя' Если только что прибывший процесс имеет более ранний срок за-
ЧеМ текУЩий’ система осуществляет приоритетное вытеснение
®P°hecca и запускает новый процесс. Целью данного алгоритма
°Оеспечение максимальной производительности путем соблюдения
11₽еМени/ВеРЦ1ения для максимального количества процессов за единицу
(чт(/П°д°бНо алгоритму SRT) и минимизации среднего времени ожида-
ли ПпоПОЗВОЛяет пРеД°твРатить несоблюдение сроков завершения корот-
I % Дерт вССами во вРемя выполнения более длительных процессов). В pa-
il 4Tehioe У3 доказано, что если в системе предусмотрено аппаратное при-
ВЬ1Теснение (например, с помощью интервального таймера)
I 111116 процессы реального времени являются независимыми друг
I ^ДИс11иплина планирования EDF позволяет уменьшить время, на
^64 запоздать самый медлительный процесс относительно срока
[ Я’ Однако во многих системах реального времени аппаратная
я Приоритетного вытеснения не предусмотрена, поэтому в таких
1 е°бходимо прибегать к помощи других алгоритмов.65
490
Дисциплина планирования минимальное растяжение во вреЛ1
первым (minimum-laxity-first) напоминает алгоритм EDF, однако
деление приоритетов в нем происходит на основе такого парамет
растяжение процесса во времени (laxity). Растяжение во времени^’ \
теризует важность процесса исходя из времени, оставшегося до ца
ния срока завершения процесса и количества времени, необходимо
цессу для завершения поставленных задач (которые могут период °
повторяться). Растяжение вычисляется по формуле:
L = D-(T + C),
где L означает растяжение, D — срок завершения процесса, Т_Те
время, а С — время, оставшееся процессу до завершения задания. На
мер, если текущее время 5, срок завершения равен 9, а процессу ну®
единицы времени до завершения работы, получаем, что растяжение в
цесса равно 1. Если растяжение процесса равно 0, такой процесс необхо J
мо запустить немедленно, иначе он пропустит свой срок завершения. При
оритеты в дисциплине минимального растяжения во времени вычисляют
ся точнее, чем в алгоритме EDF, поскольку они учитывают процеет^Д
время, необходимое процессу для завершения работы. К сожалению, по-
добная информация редко бывает доступна.66
Вопросы для самопроверки
1. Почему большинство алгоритмов жесткого планирования реальво-
го времени являются статическими?
2. В каких случаях, если это возможно, алгоритм минимального рас-
тяжения во времени — первым может выродиться в дисциплину
EDF?
Ответы 1) Системы жесткого реального времени должны гаранти-
ровать соблюдение сроков завершения процессов. Статические ал№
ритмы планирования обеспечивают достижение этой цели Д»|
конкретной системы при малых накладных расходах, связаН®5
с реализацией планирования. 2) Алгоритм минимального растяжки
во времени — первым может вырождаться в дисциплину
значение С одинаково для всех процессов в любой момент вр
А такая ситуация возможна, хотя и весьма маловероятна.
8.10 Планирование потоков Java
В разделе 4.6 мы говорили о том, что в операционных система- fit-
смотрены различные уровни поддержки потоков. При задании и
полнения многопоточных процессов, реализованных в виде поток
зовательского уровня, операционной системе ничего не известно
стве потоков процесса, поэтому она оперирует им как единым .j Л
требуя наличия библиотеки уровня пользователя для планиро
полнения потоков, входящих в состав данного процесса. Если сЛС11лЯД|
держивает потоки уровня ядра, она может задавать план выполНе -g с
дого потока независимо от других потоков этого процесса. НекОт°
работы процессора
491
еде поддерживают активацию планировщика, ставящую процесс
jjjJ тВИе потоку уровня ядра, что дает возможность библиотеке уров-
^с00^е ователя процесса выполнять операции планирования.
ffi ЦО^ботчики системы должны определить, как следует выделять кван-
ра3₽а и а также в каком порядке и с каким приоритетом следует пла-
вЬ1полнение потоков одного процесса. Например, согласно прин-
цр°еаТЬраВеДЛИвого раздела» квант времени, выделенный процессу, рас-
тру <<с зТСВ между всеми принадлежащими ему потоками. Благодаря
0реДеЛ оГОПОточный процесс не может потребовать повышенный уровень
этоМУ ^ивания, просто создав большое количество потоков. Далее, поря-
I котором происходит выполнение потоков, может значительно вли-
доК» е прОИзводительность, если работа потоков зависит друг от друга.
яТЬ разделе мы обсудим вопрос планирования потоков Java. Тема пла-
1 В 310 яНИЯ потоков в Windows ХР рассматривается в разделе 21.6.2. Меха-
ВИР планирования в Linux (дающий возможность запускать как процес-
0й3”ак и потоки) рассматривается в разделе 20.5.2.
СЫ’одна из характерных функциональных возможностей языка программи-
вания Java и виртуальной машины Java состоит в том, что любой Java-an-
влет или приложение являются многопоточными. Приоритет любого пото-
ка Java может находиться в пределах от Thread.min priority (константа,
равная 1) До Thread.MAX_PRIORITY (константа, равная 10). По умолчанию,
каждому потоку присваивается приоритет Thread.NORM PRIORITY (констан-
та, равная 5). Каждый новый поток получает приоритет, равный приорите-
ту породившего его потока.
В зависимости от платформы, потоки Java могут быть реализованы
в пространстве пользователя или ядра (см. раздел 4.6).67>68 Если потоки
реализуются в пространстве пользователя, Java-библиотеки времени вы-
полнения используют квантование времени (timeslicing') для задания пла-
на выполнения с приоритетным вытеснением. Если бы не подход с разделе-
вием времени на кванты, каждый поток среди группы потоков одинаково-
пРИ0Ритета выполнялся бы до завершения, если только он по
киппМ либо причинам не перешел в состояние ожидания, спячки или бло-
кИм и либо его выполнение не было бы прервано потоком с более высо-
^ляет Иоритетом- При использовании квантования, каждому потоку вы-
цЛаа Квант времени, в течение которого он может выполняться.
а₽ИоРитИр°вЩик потоков Java гарантирует, что поток с самым высоким
ВсИстемеТОМ В виРтУальн°й машине Java будет выполняться всегда. Если
ддя сУЩествует несколько потоков с таким высоким уровнем приори-
”е- На пИХ обслУЖивания будет использоваться циклическое планирова-
^П)аЦИяС^НКе 8'?' показана многоуровневая очередь потоков Java. Ил-
116ь1|юл Приведена Для однопроцессорного компьютера, где потоки А
щ,;,йце лютея в течение определенных квантов времени согласно дис-
0,Сов. з ^лического планирования до самого завершения работы обоих
вЬ1П^)*еМ’ до самого конца выполняется поток С. Потоки D, Е и F
в^ЛНЯЮТСЯ до полног° завершения в течение выделенных им
е Мени в дисциплине циклического планирования. Обратите
СорТ° В некотоРЬ1Х операционных системах, прибывающие потоки
с _ °г° приоритета могут привести к бесконечному откладыванию
°Лее низким приоритетом.
492
Поток может вызвать метод yield класса Thread, чтобы предОс
шанс запуститься другим потокам. Поскольку операционная систе
ществляет приоритетное вытеснение текущего потока, как только^01
с более высоким приоритетом перейдет в состояние готовности, пОт
разрешено вызывать метод yield для других потоков с более высокй°^
оритетом. Метод yield всегда дает возможность продолжить вып^
готовому потоку с наивысшим приоритетом, поэтому, если все поток*^
стоянии готовности имеют более низкий приоритет, чем текущий И 6'
вызвавший метод yield, это означает, что данный поток имеет Наивь*0*1
приоритет в системе, и таким образом он сможет продолжить работ^1
зываемая потоком функция yield дает шанс продолжить выполнен^
Рис. 8.7. План выполнения потоков Java по приоритетам
ты процессора
493
с таким же приоритетом. В системе, где используется кванто-
цоТ° ое1дени это необязательно, поскольку все потоки с одинаковым
Г^е 110 м выполняются в течение своего кванта времени (или до тех
С0₽111Тпо тем или иным причинам процессор не будет у них отобран),
°°КаЛя их обслуживания используется дисциплина циклического
яния. Поэтому необходимость в функции yield существует толь-
в которых не поддерживается квантование времени (напри-
° них версий ОС Solaris69), в которых поток обычно выполняется до
jjep< Ра9Нйя прежде, чем другой поток с таким же приоритетом получит
з^Р^ность продолжить выполнение.
Вопросы для самопроверки
1. Зачем в Java предусмотрен метод yield? Зачем программисты ис-
пользуют этот метод?
2. (Да/Нет) Правда ли, что поток Java с более низким приоритетом
никогда не сможет начать работу, пока поток более высокого при-
оритета находится в состоянии готовности?
Ответы 1) Метод yield позволяет текущему потоку добровольно
освобождать процессор, чтобы позволить выполняться потоку с таким
же приоритетом. Поскольку приложения Java нацелены на переноси-
мость между платформами и поскольку программист не всегда может
быть уверен в том, что конкретная платформа поддерживает квантова-
ние времени, программисты применяют yield, чтобы гарантировать
корректную работу своего приложения на любой платформе. 2) Да.
Механизм планирования Java будет выполнять поток с самым высо-
ким приоритетом, находящийся в состоянии готовности.
Ы-ресурсы
^P-//www. linux-tutorial.info/modules.php?name=Tutorial&pageid=85
bhdorq Мент Учебного пособия по Linux, в котором описываются механизмы пла-
йя процессов в Linux.
Оцйс\°РеГ'аРр1е•сот/techpubs/mac/Processes/Processes-16.html
ие механизма планирования процессов в Apple Macintosh.
catal°4/linuxkernel/chapter/chl0 .html
®Ы ЬеРсия книги от издательства O’Reilly по ядру Linux. На этой страни-
II ете Детали планирования процессов в Linux версии 2.4.
.сот/javaworld/jw-07-2002/jw-0703-javal01.html
sStc планирования потоков на Java.
edu/rt • Shtml
Чу^^ально6 РезУльтаты исследований по планированию в операционных систе-
0 времени, проведенные Калифорнийским университетом, Санта
ICa®He 'edu 1 ku r t1
iPHbg созданного в университете Канзаса планировщика реального време-
УЮщего модифицированное ядро Linux.
494
Итоги
Когда перед системой встает проблема, какой процесс следует выбрат
следующего запуска, ей необходимо избрать определенную стратегию — Ь ь
мую политикой (или дисциплиной) планирования процесса. Планиров'193'4^
верхнем уровне — иногда называемое планированием заданий или дол о Ь
планированием — позволяет определять, каким заданиям системы разрещ
тивно соревноваться за системные ресурсы. Политика планирования н 6110
уровне определяет степень многозадачности — общее количество процес о ерхЧе1(
теме в данный момент времени. После того как политика планирования и В Ct,c
нем уровне допустит в систему задание (которое может состоять из одного Э Ве^-
скольких процессов) политика планирования на промежуточном уровне опп
ет, каким процессам будет разрешено состязаться за захват процессора. Пол
планирования промежуточного уровня оперативно реагирует на текущИе Ик>
ния загрузки системы. Политика планирования на нижнем уровне определяет* i
кому из готовых к выполнению процессов будет предоставлен освободивщ ’ **
процессор. Политики планирования на нижнем уровне часто присваивают кюк
му процессу свой приоритет, отражающий важность данного процесса для сист
мы. Чем важнее процесс, тем выше вероятность, что именно этот процесс будет вы
бран для последующего выполнения.
Дисциплины планирования могут допускать приоритетное вытеснение или за-
прещать его. Чтобы предотвратить монопольный захват системы (случайный или
преднамеренный) со стороны определенного пользователя, в механизмах планиро-
вания с приоритетным вытеснением предусмотрена периодическая выработка пре-
рываний интервальным таймером. Приоритеты могут назначаться статически
либо изменяться динамически в ходе выполнения процесса.
При разработке дисциплины планирования разработчик системы должен учи-
тывать цели, которые ставятся перед системой, тип данной системы и требования,
которые предъявляются к ней пользователями. К этим целям может относиться
обеспечение максимальной производительности, увеличение числа интерактив-
ных пользователей, которые бы получали приемлемые времена ответа, повышение
коэффициента использования ресурсов, предотвращение ситуаций бесконечно
откладывания, поддержка заданных приоритетов, уменьшение накладных рас
дов и обеспечение прогнозируемости времен ответа. Чтобы добиться воплоп^
в жизнь поставленных задач, в системе могут быть реализованы механизмы
Ния процессов и создания благоприятных условий тем процессам, запросы пда
рых необходимо удовлетворить как можно быстрее. Большинство г1ИСЦИП^,1)уе«С1
нирования обладают свойствами равноправия, предсказуемости и масштао Р
СТИ’ ирцели^"
Разработчики операционных системы должны использовать заданные^яИроВ»'
определения критериев, по которым могут приниматься решения при п’прОдесс°'
нии. Вероятно, самым важным вопросом является способ использования
BUlipulUM МпЛлШСл CllVCVV HLllв
ра (процесс может интенсивно использовать процессор или интенсивно
вать ввод/вывод). Дисциплина планирования также должна учитывать1 p^je1^
ли процесс пакетным или интерактивным. В системе с поддержкой i дрИ°Р
планировщик должен отдавать предпочтение процессам с более высоки
тетами. во3^
Планировщики реализуют алгоритмы, которые позволяют учитыва
ность приоритетного вытеснения, приоритеты, время выполнения и ДР ^з^^у
теристики процессов. Дисциплина планирования FIFO (иногда ее TaKMtTopiJI,gX
FCFS) представляет собой алгоритм без приоритетного вытеснения, к
ществляет диспетчеризацию процессов в соответствии с моментом их * .
в очередь готовых к выполнению процессов. При циклическом планир
диспетчеризация процессов осуществляется по принципу FIFO, одн .
раз процессу предоставляется ограниченное количество процессорно
Di работы процессора
495
временным квантом. Существует разновидность циклического плани-
пЛ названием эгоистичное циклическое планирование (SRR). В соответ-
0 а00*1 П ЯНОЙ дисциплиной сначала процесс помещается в очередь ожидания,
с ?0он пребывает до тех пор, пока длительность ожидания не позволит ему
' овня приоритета, достаточного для перехода в очередь активных про-
УРэТОГО момента рассматриваемый процесс обслуживается по принципу
*Sc<>b- циклического планирования вместе с другими активными процессами из
цеди. Определение размера кванта имеет критическое значение для эф-
°Ч- работы вычислительной системы с приоритетным вытеснением. Размер
^.цтИвВ0 н быть достаточно большим для того, чтобы подавляющему болыпин-
особ ввода/вывода и интерактивных запросов требовалось для заверше-
(<вУ заП ще времени, чем длина этого кванта. Оптимальный размер кванта меня-
0110 ^системы к системе и зависит от ее загрузки.
^ся °т „ование по принципу «кратчайший процесс первым» (SPF) представляет
Ялайсциплину, не поддерживающую приоритетное вытеснение, согласно кото-
соб°и ’ щ и для выполнения выбирается ожидающий процесс с минимальным
рой сЛ ым рабочим временем, остающимся до завершения. Принцип SPF обеспе-
°ПеВет уменьшение среднего времени ожидания по сравнению с дисциплиной
иГО однако времена ожидания при этом колеблются в более широких пределах,
и ия’пиП наименьшего остающегося времени (SRT) представляет собой аналог
* индипа SPF, который поддерживает приоритетное вытеснение, стараясь повы-
сить производительность обслуживания небольших постоянно прибывающих про-
цессов. Теоретически принцип SRT обеспечивает минимальные времена ожида-
ния. Однако из-за издержек приоритетного вытеснения может оказаться так, что
в определенных ситуациях в действительности лучшие показатели будет иметь
SPF. Стратегия планирования по наибольшему относительному времени ответа
(HRRN) — это дисциплина планирования без приоритетного вытеснения, согласно
которой приоритет каждого процесса является не только функцией времени обслу-
живания этого процесса, но также времени, затраченного процессом на ожидание
обслуживания.
Многоуровневые очереди с обратными связями представляют схему, которая
обеспечивает планировщик возможностью динамически реагировать на изменения
поведении процесса. Следующим процессом, который получает в свое распоря-
кымИе nP°4eccoP, становится процесс, достигший головы непустой очереди с са-
ПРОВВМСОКИМ пРиоРитетом в сети многоуровневых очередей с обратной связью.
аИ)Кн сы’ интенсивно использующие процессор, помещаются в очередь самого
“^Нчно УР0ВНЯ’ тогда как процессы, интенсивно использующие ввод/вывод,
Чесса п а°МеЩаются в очереди более высоких уровней. Выполнение текущего про-
^г°УровЬ1ВаеТСЯ В слУчае поступления процесса с более высоким приоритетом.
Пр,,меп я вневые очереди с обратной связью представляют собой показательный
механизма.
I г?Ть Расггп°ВаНИе по принципу справедливого раздела (FSS) позволяет планиро-
^ВеддЛ!даление ресурсов между группами связанных процессов и потоков.
6ссов ЫИ раздел позволяет системе обеспечить равноправие между группами
Де иЬ]ту’1Деляя кажД°й группе определенный набор системных ресурсов.
I V *пред стРатегия планирования FSS была разработана специально для того,
||10ЛЬзОв?ставлять определенный заранее уровень системных ресурсов... груп-
пЛанателе11’ выполняющим схожие функции».
h °ОреДел Ровании по сроку завершения принимаются меры, чтобы выполне-
?<ЧьРеАелЛ*1нЫх процессов заканчивалось к заранее обусловленному времени
, %сроку. Результаты выполнения этих процессов могут иметь
ц ЗНачение, если они будут получены вовремя, и могут оказаться бес-
Цл^Дец...Сле назначенного срока. Планирование по конечному сроку связано
> Чров.И тРУДностями.
РшИе Реального времени должно постоянно обеспечивать соблюдение
щения работающих в системе процессов. Мягкое планирование реаль-
496
ного времени обеспечивает первоочередное обслуживание системой прОп
ботающих в режиме реального времени. Механизм жесткого планирован^0®, ’
ного времени гарантирует, что процесс завершит работу к назначение
Процессы, требующие жесткого планирования реального времени долж С1Ч>
няться в срок, последствия несоблюдения временных ограничений МогуНЬ1
тастрофическими, включая некорректную работу системы, ее сбой и дамг^ТьД
ние вреда пользователям системы. Дисциплина планирования RM пнп 6 ЬаНег ’
собой статический алгоритм циклического планирования на основе ппи
в котором приоритет процесса может возрастать (монотонно) пропорц
частоте, с которой процесс фигурирует в плане выполнения. Дисциплина i
вания по принципу EDF (процесс с ближайшим сроком завершения_________
представляет собой алгоритм планирования с приоритетным вытеснениеПе^ВЬ1,<)
рый создает лучшие условия тем процессам, срок завершения которых
в самое ближайшее время. Алгоритм планирования по минимальному D
нию во времени напоминает EDF, хотя в нем приоритет процесса вычиеляе^45**®'
основании растяжения процесса, которое выражается разностью между щ)р Тся
необходимым процессу для завершения и временем, оставшимся до наступи861,1
предельного срока. е0®Я
Операционная система может осуществлять диспетчеризацию потоков ппоп
по отдельности либо оперировать многопоточным процессом как единым блоигЛ
требуя использования библиотек уровня пользователя для планирования выполде
ния потоков. Разработчики системы должны определить, как следует выделять
кванты времени, а также в каком порядке и с каким приоритетом следует плави
ровать выполнение потоков одного процесса. В Java значение приоритета каждого
потока может находиться в пределах от 1 до 10. В зависимости от платформы, щ.
токи Java могут быть реализованы в пространстве пользователя либо пространстве
ядра (см. раздел 4.6). В случае реализации потоков в пространстве пользователя
библиотеки времени выполнения Java прибегают к квантованию времени для ор-
ганизации планирования с приоритетным вытеснением. Планировщик потоков
Java обеспечивает постоянное выполнение потока с наивысшим приоритетом
в виртуальной машине Java. Если несколько потоков обладают одинаковым уров
нем приоритета, они обслуживаются в соответствии с дисциплиной циклического
планирования. Поток может вызвать метод yield для того, чтобы предоставить
другим потокам с таким же приоритетом шанс начать свое выполнение.
Ключевые термины
.__доеХЯ'
DRM, дисциплина планирования (deadline rate-monotonic scheduling) гВа0
низы планирования в системах реального времени, позволяющий оо B0bIJloe
периодически выполняющиеся процессы со сроком завершения, не Ра
риоду их выполнения.
EDF — см. Ближайший срок завершения — первым, планирование.
FIFO (first-in-first-out), дисциплина планирования нервым-пришел-пе
механизм планирования, согласно которому процессор поступает в Р
процессов в порядке их поступления в очередь готовых процессов.
FSS — см. По принципу справедливого раздела, планирование.
HRRN — см. По наибольшему относительному времени реакции, "лаЯ
RM, дисциплина планирования (rate-monotonic (RM) scheduling)
планирования реального времени, согласно которому значение пр е I
цесса является пропорциональным частоте, с которой процесс Д°
няться в системе.
SPF — см. Кратчайший процесс — первым, планирование.
дцНЧв p«Dor”' pv еесора
ЧУ/
CM. Эгоистичное циклическое планирование.
,pjl сМ Цо наименьшему остающемуся времени, планирование.
яый механизм (adaptive mechanism) — механизм, позволяющий реагиро
л изменение поведения контролируемой им системы.
Я»1'1’ аЯый процесс реального времени (asynchronous real-time process) — про-
^^?^еального времени, который выполняется в ответ на события.
Р UeC J срок завершения — первым, планирование (earliest-deadline-first) —
г^ чТМ планирования, согласно которому процессор выделяется тому процес
&11Г<чей срок завершения истекает в самое ближайшее время.
СУ’ ые ограничения (timing constraint) — интервал, в течение которого долж-
ЧР* быть завершено выполнение процесса (или подмножества инструкций про-
несся)- .
справедливого раздела (fair share group) — группа процессов, получаю-
rpy®7B свое распоряжение определенный процент процессорного времени соглас-
^дИСДиплине планирования справедливого раздела (FSS)
мический алгоритм планирования реального времени (dynamic real-time
^BBheduling algorithm) — дисциплина планирования, позволяющая изменять
приоритет процесса во время его выполнения с учетом предельного срока завер-
тения.
Диспетчер (dispatcher) — модуль, отвечающий за предоставление процессора про-
цессам.
Диспетчеризация (dispatching) — операция по выделению процессора процессам.
Дисциплина планирования процессора (processor scheduling discipline) — см. По-
литика планирования процессора.
Долгосрочное планирование (long-term scheduling) — см. Планирование на верх-
нем уровне.
Жесткое планирование реального времени (hard real-time scheduling) — дисципли-
на планирования, гарантирующая своевременное завершение работы процессов.
Задержка (latency) (планирование процессов) — время, в течение которого задача
пребывает в системе, прежде чем она будет обслужена.
Иитерактивный процесс (interactive process) — процесс, которому во время рабо-
ты Необходимо вести диалог с пользователем.
®Вавт (quantum или time slice) — временной интервал, в течение которого процесс
g М0Жет использовать процессор до момента приоритетного вытеснения.
итивание времени (timeslicing) — задание для процессов плана выполнения,
гласно которому каждый процесс может выполняться в течение не более чем
1^чнОго Кванта до момента приоритетного вытеснения.
процесс — первым, планирование (shortest-process-first (SPF)
aullng) — алгоритм планирования, не поддерживающий приоритетное вы-
g04t_ НИе- Планировщик выбирает для выполнения процесс с наименьшим оце-
Ма. им временем до завершения и выполняет его до самого конца.
Пдав **РУемость (scalability) — характеристика планировщика, означающая
Снижение производительности при увеличении загрузки системы.
fy-fir *\Ное Растяжение во времени — первым, планирование (minimum-laxi-
тет п Дисциплина планирования, согласно которой более высокий приори-
. Boj, 1 исваивается процессам, которые могут закончить работу при минималь
Спользовании процессора.
>Д?тОД“еВаЯ очередь с обратными связями (multilevel feedback queue) —
и авляет Структуру, обеспечивающую группирование процессов с одинако
j °РИтетом в одну очередь, для обслуживания которой применяется алго-
Циклического планирования. Процессы, интенсивно использующие про-
Р» помещаются в очереди более низкого приоритета, поскольку пакетные
процессы обычно не требуют малых времен ответа. Процессы, интенс
пользующие ввод/вывод, которые используют процессор кратковремецИВВ() |
работой с устройствами ввода/вывода, остаются в высокоприоритетны*0 *^3
дях. В роли подобных процессов обычно выступают интерактивные г/*
которые нуждаются в малых временах ответа.
Мягкое планирование реального времени (soft real-time scheduling)_
планирования, обеспечивающая предоставление лучших условий прогт^111'^
ального времени. Чеес^1вЯ
Пакетный процесс (batch process) — процесс, который может работать без
тельства пользователя. ВМеЧ1а.
Периодически выполняющиеся процессы реального времени (periodic г
process) — процессы реального времени, которые выполняют вычисления
определенные временные интервалы. я ЧеРеа
Планирование без приоритетного вытеснения (nonpreemptive scheduling)
литика планирования, которая не позволяет системе отбирать процессов ~~ П°‘
цесса до тех пор, пока сам процесс не отдаст его добровольно либо закончив
работу. т св°ю
Планирование допуска (admission scheduling) — см. Планирование на вевх I
уровне. Вем
Планирование заданий (job scheduling) — см. Планирование на верхнем уровне
Планирование на верхнем уровне (high-level scheduling) — определение задании
которые могут быть допущены в систему для активного участия в соревновании
за системные ресурсы.
Планирование иа нижием уровне (low-level scheduling) — определение процесса,
который должен получить управление процессором.
Планирование на промежуточном уровне (intermediate-level scheduling) —
на этом уровне планирования определяется, какие процессы будут допущены
к планировщику на нижнем уровне с тем, чтобы начать соревнование за процес-
сорное время.
Планирование по принципу DRM — см. DRM, дисциплина планирования.
Планирование по принципу FIFO — см. FIFO, дисциплина планирования.
Планирование по принципу RM — см. RM, дисциплина планирования.
Планирование реального времени (real-time scheduling) — дисциплина планиро-
вания, в которой приоритеты устанавливаются исходя из временных ограниче-
ний.
Планирование с приоритетным вытеснением (preemptive scheduling) — политик8
планирования, позволяющая отбирать процессор у процесса.
По наибольшему относительному времени реакции, планирование (highest Г J
ponse-ratio-next, HRRN) — политика планирования, в которой при РасЧ ^gcjiy-
оритетов учитывается время обслуживания процесса и время ожидания
живания.
По наименьшему остающемуся времени, планирование (shortest-remaining gjj.
(SRT) scheduling) — аналог алгоритма SPF, но с поддержкой приоритете
теснения. Согласно этому алгоритму планировщик выбирает для вып
процесс с наименьшим оценочным временем до завершения.
По принципу справедливого раздела, планирование (fair share scbe
FSS) — дисциплина планирования, разработанная для системы UNIX °т вре^я
в которой процессы распределяются по группам, после чего процессоре
выделяется отдельным группам.
По сроку завершения, планирование (deadline scheduling) — дисциплина 8
рования, в которой приоритеты процессам присваиваются исходя из "И в, I
завершения, чтобы обеспечить своевременное выполнение этих проце
оЯоритетов (purchase priority) — получение более высокого приоритета
ме с отдельной оплатой такой услуги.
fl^ с<’сТб планирования процессора (processor scheduling policy) — стратегия,
ИГТ***^ оторой система определяет, когда и на какое время следует назначить
А^деДУ51 ие процессора в распоряжение процесса.
рЫДеЛ мость (predictability) — цель алгоритма планирования, которая гаран-
ппеДс,<Я3^чтО выполнение процесса займет конкретное время независимо от за-
системы.
гр" т /priority) — мера важности потока (процесса), используемая для опре-
0p*°P,,TeJ порядка и продолжительности его выполнения.
ДеЛ итеЛьность (throughput) — показатель, характеризующий число процес-
^ершающих свою работу в единицу времени.
С°В* интенсивно использующий ввод/вывод (I/0-bound) — процесс, который
кратковременно использует процессор перед генерацией запроса вво-
па/вывода- „
' с интенсивно использующии процессор (processor-bound) — процесс, рас-
flpon*^’ -j в ходе выполнения весь отведенный ему квант времени. Подобные
процессы обычно интенсивно проводят вычисления и генерируют мало запросов
ввода/вывода.
равноправие (fairness) — одно из свойств алгоритмов планирования, подразуме-
вающее одинаково справедливое отношение ко всем процессам в системе.
Растяжение во времени (laxity) — значение, вычисляемое путем вычитания сум-
мы текущего момента времени и интервала времени, необходимого процессу
для завершения работы, из предельного срока завершения процесса.
Старение приоритета (aging of priorities) — постепенное повышение приоритета
процесса по мере того, как длительность выполнения процесса в системе увели-
чивается.
Статический алгоритм планирования реального времени (static real-time
scheduling algorithm) — алгоритм планирования, в котором используются вре-
менные ограничения, на основе которых процессам присваиваются приоритеты
до начала выполнения.
Степень многозадачности (degree of multiprogramming) — общее количество про-
Цессов в системе в конкретный момент времени.
^^Яическое планирование (round-robin (RR) scheduling) — политика планирова-
иия, согласно которой каждый процесс в состоянии готовности может выпол-
/ТЬся в течение не более чем одно кванта в каждом цикле. После того как по
Разу будет запущен каждый процесс из очереди, планировщик начнет
Эгп И Рикл’ запустив на выполнение первый процесс из очереди.
Ра ИЧВое Циклическое планирование (selfish round-robin (SRR) scheduling) —
исхо ИлноСть Циклического планирования, в которой старение процессов про-
Редь 7 с разными скоростями. При входе в систему процесс помещается в оче-
стдд ОэкиДания, где пребывает до тех пор, пока его приоритет не повысится на-
СоУЧаК°’ ЧТ° ОН перейдет в очередь активных процессов, получая возможность
аовать в соревновании за процессорное время.
500
/к.
"«б.
Упражнения
8.1.
8.2.
8.3.
8.4.
Укажите различия между планировщиками следующих трех урОВн
а. планировщик верхнего уровня; eiJ:
б. планировщик промежуточного уровня;
в. диспетчер.
Планировщик какого уровня должен принимать решение по каж
следующих вопросов: 'Чо’аУ
а. Какому из готовых к выполнению процессов следует предоставь
цессор, когда он освободится? ь Оро.
б. Какое из ряда ожидающих пакетных заданий, ранее введенных в
вую память, должно быть инициировано следующим?
в. Какие процессы следует временно приостановить, чтобы снять коп
пик нагрузки на процессор? ТКйй
г. Какой из кратковременно приостановленных процессов (о котором
вестно, что он интенсивно использует ввод/вывод) следует активна И3
вать, чтобы сбалансировать многозадачную смесь? Р0'
Укажите различия между принципами планирования и механизмами ила
нирования.
Дисциплина планирования должна, как правило, реализовать следующие
принципы:
а. быть справедливой;
б. обеспечивать максимальную пропускную способность системы;
в. обеспечивать приемлемые времена ответа для максимального числа ин-
терактивных пользователей;
г. обеспечивать предсказуемость;
д. обеспечивать минимальные накладные расходы;
е. обеспечивать сбалансированное использование ресурсов;
ж. обеспечивать сбалансированность между временем ответа и коэффици-
ентом использования ресурсов;
з. исключать бесконечное откладывание;
и. учитывать приоритеты;
к. оказывать предпочтение процессам, занимающим ключевые PecyPc^L
л. устанавливать низкий приоритет обслуживания процессов с высок
накладными расходами; ва.
м. постепенно снижать уровень производительности- при увеличении
грузок.
Укажите, какой из указанных принципов имеет наиболее непосрВД
ное отношение к каждому из следующих случаев: преД-
i. Если некий пользователь уже давно ждет, ему следует оказать
почтение.
ii. Пользователь, который выполняет задание по составлению
ной ведомости для компании, имеющей 1000 служащих, РаСойбл<в
ет, что на выполнение этого задания будет затрачиваться пр
тельно одинаковое количество времени каждую неделю.
В систему следует в первую очередь допускать такие зада Я
рые создают смесь, обеспечивающую занятость для болыии
ройств.
Система должна оказывать предпочтение наиболее важным 3
Важный процесс, поступивший в систему, не может выН efP
поскольку необходимые ему ресурсы в данный момент заНИ
цесс меньшей важности.
iii.
iv.
работы процессора
501
в течение пиковых периодов система не должна терять работоспособ-
ность из-за чрезмерных накладных расходов, необходимых для мани-
пулирования большим количеством процессов.
Система должна отдавать предпочтение процессам, интенсивно ис-
VU' пользующим ввод/вывод.
... Контекстные переключения должны происходить настолько быстро,
V ' насколько это возможно.
е перечисляются обычные критерии планирования:
8.5- П интенсивность использования процессом ввода-вывода;
д' интенсивность использования процессом процессора;
является ли данный процесс пакетным или интерактивным;
' обязателен ли быстрый ответ;
’ приоритет процесса;
’ частота приоритетных вытеснений из-за появления процессов более вы-
сокого приоритета;
лс приоритеты процессов, ожидающих освобождения ресурсов, которые за-
няты другими процессами;
з. суммарное время ожидания;
л, суммарное время выполнения;
к. оценочное время, необходимое для завершения процесса.
Укажите, какой из перечисленных выше критериев планирования имеет
наиболее непосредственное отношение к каждому из следующих случаев:
1. В системе реального времени, управляющей космическим полетом,
компьютер должен немедленно реагировать на сигналы, принимае-
мые с космического корабля.
11. Время от времени процессор предоставляется в распоряжение процесса,
однако в его выполнении наблюдается лишь номинальный прогресс.
ill. Как часто данный процесс добровольно освобождает процессор для
выполнения операции ввода/вывода до того, как выделенный ему
квант времени истечет?
iv. Присутствует ли пользователь на машине и ждет ли он ответа при ра-
боте в диалоговом режиме или пользователь отсутствует?
v. Одна из целей планирования — обеспечить минимизацию средних
времен ожиданий.
vi. Процессы удерживают ресурсы, запрошенные со стороны других про-
цессов, имеющих более высокие приоритеты.
vii. Процессы, близкие к завершению, должны получать более высокий
g 6 приоритет.
Ка®ите, какие из приведенных ниже утверждений истинны, а какие лож-
а'Объясните, почему вы так считаете.
Планирование является планированием с приоритетным вытеснением,
если у процесса нельзя принудительно отобрать выделенный ему про-
цессор.
® системах реального времени применяется, как правило, планирова-
ние с приоритетным вытеснением.
системах разделения времени применяется, как правило, планирова-
ние без приоритетного вытеснения.
Ремена ответа являются более предсказуемыми в системах с приори-
тетным вытеснением, чем без него.
в?Ин из недостатков схем с приоритетным вытеснением заключается
Ом, что система будет точно соблюдать приоритеты, однако сами при-
РИтеты могут устанавливаться далеко не разумно.
--------------------------------„ —устанавливать интерваль-
- таймер?
б.
в.
Д.
РЦ., --. * .1 л 1 ОЛИ ДО.ПЧМ) ли: |ЛЛЛ.
Вьпчей1У нельзя разрешать пользователям самим
Тяйтлт„^9
502
8.12.
8.13.
ч,
8.8. Укажите, какие из следующих утверждений касаются статическ
оритетов, а какие динамических? l:ilX
а. легче реализовать;
б. требуют меньше накладных расходов времени выполнения-
в. более чувствительны к изменениям в условиях выполнения п
г. требуют более тщательного обдумывания при выборе начальньЧ6^8’
ний приоритетов. х а?Ч
8.9. Укажите несколько причин, обуславливающих сложность орг
планирования по предельному сроку.
8.10. Приведите пример, показывающий, почему принцип FIFO является
ходящей дисциплиной планирования для интерактивных пользоватНбп°Д-
8.11. На примере из предыдущего пункта покажите, почему циклическое ЁЛеЧ
рование является более приемлемым для обслуживания интера Пла^-
пользователей. ТИв®Ых
Определение размера кванта времени — сложная и важная задача П
ложим, что среднее время контекстного переключения при переходе
цесса на процесс есть s, а среднее количество времени, которое забцП₽°
процесс, интенсивно использующий ввод/вывод, до момента формиЛ?61
ния запроса ввода-вывода, есть t (t>s). Обсудите, к каким последетв Л
приведет выбор каждого из следующих значений кванта времени:
a. q немного больше нуля;
б. q=s;
в. s<q<t;
г. q=t;
Я- q>t;
е. q = бесконечность.
Обсудите последствия, к которым приведет реализация каждого из следую-
щих методов назначения qt
a. q выбирается фиксированным и идентичным для всех пользователей;
б. q выбирается фиксированным и уникальным для каждого процесса;
в. q выбирается переменным и идентичным для всех процессов;
г. q выбирается переменным и уникальным для каждого процесса.
1.
Расположите перечисленные выше принципы в порядке возрастания на-
кладных расходов процессорного времени от минимума к максимуму-
Расположите перечисленные выше принципы в порядке возрастай
чувствительности к изменениям характеристик индивидуал
процессов и нагрузки системы.
Установите связь между своими ответами для заданий (i) и 91"'
Й пР°'
ii.
8.14.
8.15.
8.16.
Ь.
с.
d.
ill.
Укажите, почему неправильно каждое из следующих утверждении-~
а. Планирование по принципу SPF всегда характеризуется менЫЦеИ
изводительностью, чем SRT.
Планирование по принципу SPF является справедливым. етР
Чем короче задание, тем лучшие условия обслуживания Д°л
предоставляться. щйМ» еГ°
Поскольку принцип SPF отдает предпочтение коротким зада!
целесообразно применять в системах разделения времени.
Укажите некоторые недостатки принципа SRT. Каким образом I!TlJbie
бы его модифицировать, чтобы обеспечить более высокие скор
рактеристики? еД-’10^
Ответьте на каждый из следующих вопросов, относящихся к пр
ной Бринчем Хансеном стратегии планирования HRRN: j
а. Каким образом стратегия HRRN предотвращает бесконечное отклаД
тботы процессора
503
fill
в-17-
8.18-
8.19-
8.20.
8.21.
&-22.
Каким образом стратегия HRRN уменьшает предпочтение, оказываемое
б- оугими стратегиями коротким новым заданиям?
Предположим, что два задания находятся в режиме ожидания прибли-
В- 1 Цельно одинаковое время. Являются ли их приоритеты приблизитель-
но одинаковыми? Объясните свой ответ.
ажите, каким образом многоуровневые очереди с обратными связями
д дечивают достижение каждой из следующих целей планирования:
°° оказывать предпочтение коротким заданиям;
а оказывать предпочтение заданиям, интенсивно использующим ввод/вы-
®' вОд, чтобы обеспечить хорошую загрузку устройств ввода/вывода;
определять характер задания как можно быстрее и соответствующим об-
р‘ разом планировать выполнение этого задания.
О Но из эвристических правил, часто используемых планировщиками про-
ссора, заключается в том, что прошлое поведение процесса может слу-
деИТь хорошим ориентиром для прогнозирования его поведения в будущем.
Приведите пример ситуации, когда планировщик, следующий этому эври-
стическому правилу, выберет плохое решение.
Разработчик операционной системы предложил механизм очередей с об-
ратными связями, имеющий 5 уровней. Квант времени, выделяемый на
первом уровне, составляет 1/2 секунды. Размер кванта времени для каждо-
го нижележащего уровня увеличивается вдвое по сравнению с размером
кванта предыдущего уровня. Выполнение процесса нельзя прерывать, пока
выделенный ему квант времени не истечет. Система рассчитана на выпол-
нение как пакетных, так и интерактивных процессов, которые в свою оче-
редь могут делиться на процессы, интенсивно использующие процессор
и процессы, интенсивно использующие ввод/вывод.
а. Почему предложенная схема неудачна?
6. Какие минимальные изменения предложили бы вы ввести в эту схему,
чтобы сделать ее более приемлемой для предусмотренной смеси заданий?
Дисциплину планирования SPF можно считать оптимальной в том смысле,
что она позволяет минимизировать средние времена ответа. Доказать это
можно эмпирически, перебрав все возможные варианты порядка выполне-
ния пяти процессов. В следующем пункте вы сможете доказать это на са-
мом деле. Предположим, что пять различных процессов ожидают обслужи-
вания и для этого им требуется 1, 2, 3, 4 и 5 единиц времени, соответствен-
Но- Напишите программу, которая бы генерировала все возможные
варианты последовательности выполнения для пяти процессов (5! = 120)
и вычисляла бы среднее время ожидания для каждого варианта. Отсорти-
руйте эти варианты по порядку от наименьшего до наибольшего времени
ожидания и выведите среднее время ожидания рядом с каждым вариантом
Рестановки процессов. Объясните полученные результаты.
укажите, что дисциплина планирования SPF является оптимальной в том
Сл,Ь1сле’ что она позволяет минимизировать средние времена ответа. [Лод-
НееЗКа: Возьмите список процессов, для каждого из которых известно сред-
о 1!Ремя ответа. Произвольным образом выберите два процесса. Пусть
ц. н процесс больше другого, продемонстрируйте, каким образом меньший
са рвсс окажется впереди большего по времени ожидания каждого процес-
д ’ Делайте соответствующие выводы.]
ц11я я основными задачами политик планирования является минимиза-
а. ®Ремен ответа и максимально эффективное использование ресурсов,
б. ъясните, как решения этих двух задач противоречат друг другу.
Роанализируйте все приведенные в данной главе дисциплины плани-
ования с двух точек зрения. Какие политики направлены в первую оче-
едь на уменьшение времен ответа пользователям? Какие политики на-
Равлены на повышение коэффициента использования ресурсов?
1Ы процессера
505
504
8.26.
8.27.
8.28.
8.29.
в. Разработайте такую политику планирования, которая бы позвотг
страивать систему на достижение оптимального баланса при
двух поставленных задач. ь
8.23. При использовании схемы эгоистичного циклического планирован * i
оритет процесса, пребывающего в очереди ожидания увеличивается Чръ
ростью а до тех пор, пока не достигнет такого же уровня приорцт С° %
и процессы в активной очереди, после чего приоритет процесса будег^а>
жать расти но уже со скоростью Ъ. Раньше мы считали, что Ъ < а. ра,
те поведение системы эгоистичного циклического планирования, КОг *1о'гРц.
8.24. Чем механизм планирования справедливого раздела отличается Отаб5“-
ционного механизма планирования процессов? ТОаДи.
8.25. Сколько может быть различных планов выполнения для п процессов
нопроцессорной системе? в °д-
Рассмотрим систему, в которой реализованы многоуровневые очереди
ратной связью. Как можно адаптировать этот механизм планироВаС °5’
чтобы организовать планирование по следующему принципу: Ия> 1
а. по принципу FIFO;
б.- по принципу циклического планирования.
Сравните между собой алгоритмы планирования EDF и SPF.
Когда лучше использовать статические алгоритмы планирования реально-
го времени, чем динамические?
До того как компания Sun выпустила свою систему Solaris, в версии системы
UNIX от компании Sun,70 которая использовалась на рабочих станциях ра-
нее, планировании процессов осуществлялось на основе базовых приорите-
тов (значение базового приоритета могло находиться в пределах от -20 до 20,
причем самым высоким считался приоритет со значением - 20) с их после-
дующей корректировкой. Корректировка приоритетов производилась в слу-
чае изменения условий в системе. Чтобы получить текущее значение при-
оритета, к базовому приоритету прибавлялись вычисленные поправки. Про-
цесс с наибольшим значением приоритета обслуживался в первую очередь.
При вычислении поправок к приоритету лучшие условия создавались тем
процессам, которые в последнее время получали мало процессорного време
ни. Алгоритм планирования достаточно быстро забывал хронологию иса0 I
зования процессора, чтобы обеспечить выигрыш в случае изменения пов
ния процессора. Алгоритм забывал 90% информации об интенСИВ1*чеС1Я01
пользования процессора за 5*п секунд, где п — среднее всол1',ьте ва
выполняющихся в системе процессов за последнюю минуту. ‘ Тропессо®:
приводимые ниже вопросы для данного алгоритма планирования пр д(1м
а. Когда предпочтение отдается процессам, интенсивно исполь
процессор: если система загружена сильно или слабо? geO°'
б. Как ведет себя процесс, интенсивно использующий ввод/выв
средственно после завершения операции ввода/вывод; д8ть &
в. Может ли процесс, интенсивно использующий процессор> с
бесконечного откладывания? исП^
г. Как с увеличением нагрузки на систему процессы, интенСИВ BgjjX
зующие процессор, могут влиять на времена ответа интеракт
цессов? оТ а1гТ‘,дОд«
д. Каким образом этот алгоритм реагирует на переход процесс 1
го использования процессора к активному использованию в
и наоборот?
ерационная система VAX/VMS72 использовалась в самых разнообразных
Р^дьютерах: от маленьких до больших. В ОС VAX/VMS приоритет про-
выражается значениями от 0 до 31, где 31 — это наибольшее возмож-
[ 11 значение приоритета, присваиваемое критичным процессам, выпол-
f - Г я10щиМСЯ в режиме реального времени. Обычные процессы получают при-
I й йТеты в диапазоне от 0 до 15, процессы реального времени — в диапазоне
if} до 31. Как правило, приоритет процессов реального времени не изме-
°яется, и к ним не применяются поправки. Процессы реального времени
Н0одолжают работу (не страдая от окончания кванта времени) до тех пор,
пока не произойдет их вытеснение со стороны процесса с таким же или бо-
лее высоким приоритетом либо до тех пор, пока они не войдут в какое-либо
цз состояний ожидания.
Остальные процессы рассматриваются как обычные процессы с приорите-
тами от 0 до 15. К таковым относятся, помимо прочего, интерактивные
п пакетные процессы. Приоритеты обычных процессов изменяются. Хотя
базовый приоритет процесса в обычных условиях остается без изменений,
к ним может применяться динамическая поправка, причем предпочтение
обычно отдается процессам, интенсивно использующим ввод/вывод, перед
процессами, интенсивно использующими процессор. Обычный процесс вы-
полняется до тех пор, пока он не будет вытеснен более важным процессом,
войдет в особое состояние, например, ожидания события, или же пока не
истечет выделенный ему квант времени. Процессы с одинаковым приорите-
том обслуживаются согласно дисциплине циклического планирования.
Поправка приоритета для обычного процесса может составлять от 0 до 6
единиц по сравнению с базовым приоритетом. Такое приращение присваи-
вается тогда, когда освобождается запрошенный данным процессом ресурс,
либо при наступлении ожидаемых процессом условий. Процессы, интен-
сивно использующие ввод/вывод, часто получают приращение приоритета,
а процессы интенсивно использующие процессор, обычно сохраняют зна-
чение приоритета, близкое к базовому. Ответьте на каждый из приведен-
ных ниже вопросов, касающихся механизмов планирования процессов для
операционной системы VAX/VMS:
а- Почему в обычных условиях приоритеты процессов реального времени
остаются без изменений?
б. Почему процессы реального времени не обращают внимания на истече-
ние кванта времени?
Какой разновидности обычных процессов отдает предпочтение система:
тем, которые интенсивно используют процессор, или тем, которые ин-
тенсивно используют ввод/вывод?
При каких условиях процессор может быть отобран у процесса реально-
го времени?
е П^И КаК11х Условиях процессор может быть отобран у обычного процесса?
о какому принципу обслуживаются обычные процессы с одинаковыми
приоритетами?
Ри каких условиях обычные процессы получают приращение приоритета?
Ч. ^УемЫе исследовательские учебные проекты
8 сОцД[°Х?.Вьте сравнительное исследование по вопросу планирования процес-
2’ So?® Wlndows ХР> Linux и Mac OS X.
сИстем& планиР°вание процессов и потоков обычно отвечает операционная
ВРициЛ’ В некот°Рых ОС решения по вопросам планирования могут также
ать пользователи системы. Изучите, каким образом в операцион-
ист. w Истемах с внешним ядром реализуется планирование процессов
В°Ток^М’рс303 ’lcs-mit-edu/Pubs .html#Exokernels), а также планирование
Ов уровня пользователя и активации планировщика.
506
8. 33. Изучите реализацию планирования реального времени во встроен
темах.
8. 34. Рассмотрите политику и механизмы планирования, наиболее част
зуемые в системах баз данных. °
Рекомендуемые программные проекты
8. 35. Для решения проблемы бесконечного откладывания используется м
старения процессов, согласно которому приоритет процесса по мер^^аь
ния им обслуживания увеличивается. Разработайте несколько алг
старения и напишите программу, которая бы измеряла их относи
производительность. При реализации алгоритмов старения можно
так, чтобы приоритет процесса линейно возрастал со временем.
сколько внимания в каждом алгоритме будет выделяться ждущИм ^СвЧте,
сам по сравнению с прибывающими процессами с высоким приоритета4®0"
8.36. Для планирования с поддержкой приоритетного вытеснения харак
одна проблема: накладные расходы, связанные с переключением конт^8®
могут значительно нагружать систему, если система не будет настроен*448
ответствующим образом. Напишите программу, которая бы опредал С>
влияние на производительность системы, оказываемое соотношением
кладных расходов на переключение контекста с размером кванта. Обсуди^
факторы, влияющие на объем накладных расходов, связанных с переклю
чением контекста, и факторы, позволяющие вычислить оптимальный раз-
мер кванта. Покажите, каким образом достижение оптимального баланса
между этими двумя показателями (то есть тонкая настройка системы) мо-
гут оказать существенное влияние на производительность системы.
Рекомендуемая мте^атура
Коффман и Клейнрок обсуждают популярные механизмы планирования, демон-
стрируя, каким образом пользователи, знакомые с реализацией политики планиро-
вания в системе, могут добиться повышения производительности путем nP,IH®L
соответствующих мер.73 Рушицка и Фабри приводят классификацию алГорИкоН.
планирования, формализуя понятие приоритета.74 Чтобы добиться РешеНИ^та10г
кретных задач, современные механизмы планирования, как правило, со
в себе несколько схем, большинство из которых были описаны в данной гла® ' еВи
следние исследования в области планирования загрузки процессоров срсреД0
на оптимизации производительности веб-серверов, систем реального време
ройств со встроенными операционным системами. Станкович с соавтор8 g0i'
ставляет в своей статье обсуждение вопросов планирования реального ®^рОе0дН-
Поп с коллегами рассматривает вопросы планирования в устройствах со в и л80г-
ми операционным системами,76 а Бендер с соавторами обсуждает техноЛ°^стИ мУ
рования транзакций на веб-серверах.77 В ответ на возрастание популярн
тимедиа-приложений для рабочих станций и персональных компьютеров,
работана «умная» технология SMART (Scheduler for Mulimedia H0).J 0-
applications — планирование приложений мультимедиа и реального в
В работе Дертуа показано, что если все процессы укладываются в ср ^роД^т
симо от порядка их выполнения, оптимальным способом планирования насТ^\р(г
является выбор в первую очередь процессов, срок завершения которы
раньше.79 Однако в случае перегрузки системы, оптимальную п
вания можно реализовать, не выделяя планировщику слишком мног
ного времени. Последние исследования в этой области сосреД°
скорости80,81 или количестве82 процессоров, которые система долЖН
пику, чтобы добиться соблюдения предельных сроков завершения про-
1г ?5КУК) библиографию для этой главы вы найдете на нашем веб-сайте по
Irlnp- deitel.com/books/os3e/Bibliography.pdf.
ц^сУ: "WW‘
минованная литература
ki Т.; Abdel-Wahab, Н. М.; and Т. Kameda, «Design of Minimum-Cost
। I^aljlo^]{-Free Systems,» Journal of the ACM, Vol. 30, No. 4 October 1983,
^750.
P‘ ffman, E. G., Jr., and L. Kleinrock, «Computer Scheduling Methods and Their
2 ^°onterineasures,» Proceedings of AFIPS, SJCC, Vol. 32, 1968, pp. 11-21.
° «chitzka, M., and R. S. Fabry, «А Unifying Approach to Scheduling,» Com-
3 ications of the ACM, Vol. 20, No. 7, July 1977, pp. 469-477.
L Abbot C, «Intervention Schedules for Real-Time Programming,» IEEE Transac-
4 tions on Software Engineering, Vol. SE-10, No. 3, May 1984, pp. 268-274.
Pflinamritham, K., and J. A. Stanovic, «Dynamic Task Scheduling in Hard
5 Real-Time Distributed Systems,» IEEE Software, Vol. 1, No. 3, July 1984,
pp. 65-75. ,
6 Volz, R. A., and T. N. Mudge, «Instruction Level Timing Mechanisms for Accu-
rate Real-Time Task Scheduling,» IEEE Transactions on Computers, Vol. C-36,
No. 8, August 1987, pp. 988-993.
7. Potkonjak, M., and W. Wolf, «А Methodology and Algorithms for the Design of
Hard Real-Time Multitasking ASICs,» ACM Transactions on Design Automation
of Electronic Systems (TODAES) Vol. 4, No. 4, October 1999.
8. Kleinrock, L., «А Continuum of Time-Sharing Scheduling Algorithms,» Proceed-
ings of AFIPS, SJCC, 1970, pp. 453-458.
9. «sched.h-Execution Scheduling (REALTIME),» The Open Group Base Specifica-
tions Issue 6, IEEE Std. 1003.1, 2003 edition, <www.opengroup.org/onlinepubs/
007904975/basedefs/sched.h.html>.
10- Kleinrock, L., «А Continuum of Time-Sharing Scheduling Algorithms,» Proceed-
ings of AFIPS, SJCC, 1970, pp. 453-458.
1-Potter, D.; Gelenbe, E.; and J. Lenfant, «Adaptive Allocation of Central Pro-
cessing Unit Quanta,» Journal of the ACM, Vol. 23, No. 1, January 1976,
PP- 97-102.
'bvIQlX.Source coc’e> version 2.6.0-test3, sched.c, lines 62-135 <miller.cs.wm.edu/
13 g «•linux/http/source/kernel/sched.c?v=2.6.0-test3>.
° onion, D., and M. Russinovich, Inside Windows 2000, 3rd ed., Redmond:
^^CFosoft Press, 2000, pp. 338, 347 (есть русский перевод: Соломон Д.,
2опчИ^°ВИч М- «Внутреннее устройство Windows» М.: «Русская редакция»,
14. Br 112 с.).
Неф*0’ I’ Coffman, Е. G., Jr.; and R. Sethi, «Scheduling Independent Tasks to
I97.ce Mean Finishing Time,» Communications of the ACM, Vol. 17, No. 7, July
’S-bei^jPP- 382-387.
M.I/n’iF M., «Absentee Computations in a Multiple Access Computer System,»
J^oiect MAC, MAC-TR-52, Advanced Research Projects Agency, Depart-
brincB defence, 1968.
Hansen, P-> «Short-Term Scheduling in Multiprogramming Systems,»
b ^etbhoSymposium on Operating Systems Principles, Stanford University,
Klei°®r 1971’ PP- ЮЗ-105.
Continuum of Time-Sharing Scheduling Algorithms,» Proceed-
of AFIPS, SJCC, 1970, pp. 453-458.
18. Blevins, P. R., and С. V. Ramamoorthy, «Aspects of Dynamically Adanti Ц
ating System,» IEEE Transactions on Computers, Vol. 25, No. 7 т ,
pp. 713-725. ’ и1У ijjt.
19. Potier, D.; Gelenbe, E.; and J. Lenfant, «Adaptive Allocation of Cent
cessing Unit Quanta,» Journal of the ACM, Vol. 23, No. 1, Jan,: b
pp. 97-102. arV
20. Newbury, J. P., «Immediate Turnaround — An Elusive Goal,» Software '
and Experience, Vol. 12, No. 10, October 1982, pp. 897-906.
21. Henry, G. J., «The Fair Share Scheduler,» Bell Systems Technical Jon»
63, No. 8, Part 2, October 1984, pp. 1845-1857. n4
22. Woodside, С. M., «Controllability of Computer Performance Tradeoffs Ok
Using Controlled-Share Queue Schedulers,» IEEE Transactions on Softw®*^
gineering, Vol. SE-12, No. 10, October 1986, pp. 1041-1048. аг<1£
23. Kay, J., and P. Lauder, «А Fair Share Scheduler,» Communications of th
Vol. 31, No. 1, January 1988, pp. 44-45.
24. Henry, G. J., «The Fair Share Scheduler,» Bell Systems Technical Jo
Vol. 63, No. 8, Part 2, October 1984, p. 1846. °Ur»4
25. «Chapter 9, Fair Share Scheduler,» Solaris 9 System Administrator Col]erf
November 11, 2003, <docs.sun.com/db/doc/806-4076/6jd6amqqo?a=view> °в’
26. Henry, G. I, «The Fair Share Scheduler,» Bell Systems Technical Journ
Vol. 63, No. 8, Part 2, October 1984, p. 1848.
27. Henry, G. I, «The Fair Share Scheduler,» Bell Systems Technical Journal
Vol. 63, No. 8, Part 2, October 1984, p. 1847.
28. Henry, G. I, «The Fair Share Scheduler,» Bell Systems Technical Journal
Vol. 63, No. 8, Part 2, October 1984, p. 1846.
29. Nielsen, N. R., «The Allocation of Computing Resources — Is Pricing the An-
swer?» Communications of the ACM, Vol. 13, No. 8, August 1970, pp. 467-474.
30. McKell, L. J.; Hansen, J. V.; and L. E. Heitger, «Charging for Computer Re-
sources,» ACM Computing Surveys, Vol. 11, No. 2, June 1979, pp. 105-120.
31. Kleijnen, A. J. V., «Principles of Computer Charging in a University-Type Orga-
nization,» Communications of the ACM, Vol. 26, No. 11, November 1983,
pp. 926-932. I
32. Dertouzos, M. L., «Control Robotics: The Procedural Control of Physical Pro-
cesses,» Proc. IFLP Congress, 1974, pp. 807-813. I
33. Kalyanasundaram, B., and K., Pruhs, «Speed Is As Powerful As Clairvoyance,’
Journal of the ACM (JACM), Vol. 47, No. 4, July, 2002, pp.617-643.
34. Lam, T., and K. To, «Performance Guarantee for Online Deadline Schedu и ।
the Presence of Overload,» Proceedings of the TWELFTH ANNUal АСГ>
Symposium on Discrete Algorithms, January 7-9, 2001, pp. 755-764. ^r.
35. Koo, C.; Lam, T.; Ngan, T.; and K. To, «Extra Processors Versus Futm
mation in Optimal Deadline Scheduling,» Proceedings of the Fourteen!
ACM Symposium on Parallel Algorithm and Architectures, 2002, PP- 1ГуеУ®'
36. Stancovic, J., «Real-Time and Embedded Systems,» ACM Computing
Vol. 28, No. 1, March 1996, pp. 205-208.
37. Xu, J., and D. L. Parnas, «On Satisfying Timing Constraints in Hard- pe*
Systems,» Proceedings of the Conference on Software for Critical Sys
Orleans, Louisiana, 1991, pp. 132-146. „eColif4
38. Stewart, D., and В P. Khosla, «Real-Time Scheduling of Dynamically g^te
urable Systems,» Proceedings of the IEEE International Conference о
Engineering, Dayton, Ohio, August 1991, pp. 139-142. (VefSJ
39. van Beneden, B., «Comp.realtime: Frequently Asked Questions (FA pt
3.6),» May 16, 2002 <www.faqs.org/faqs/realtime-computing/faq/-’’
40. MITRE Corporation, «MITRE — About Us — MITRE History — Sen^'
Ground Environment (SAGE),» January 7, 2003, <www.mitre.org/about/S
rds» P-> «SAGE,» The Closed World, Cambridge, MA: MIT Press, 1996,
ВТ si'.umich.edu/-pne/PDF/cw.ch3.pdf>.
P*» «SAGE,» The Closed World, Cambridge, MA: MIT Press, 1996,
I. .sj’.umich.edu/~pne/PDF/cw.ch3.pdf>.
И Z.^rRE Corporation, «MITRE-About Us — MITRE History — Semi-Automatic Ground
a bOv^nnent (SAGE),» January 7, 2003, <www.mitre.org/about/sage.html>.
Envir0»q P-, «SAGE,» The Closed World, Cambridge, MA: MIT Press, 1996,
si’umich.edu/-pne/PDF/cw.ch3.pdf>.
Corporation, «MITRE-About Us — MITRE History — Semi-Automatic Ground
15-^^•ronment (SAGE),» January 7, 2003, <www.mitre.org/about/sage.html>.
rds P-, «SAGE,» The Closed World, Cambridge, MA: MIT Press, 1996,
46. E^^vsi’umich.edu/-pne/PDF/cw.ch3.pdf>.
Software Systems Ltd., «The Philosophy of QNX Neutrino,» <www.qnx.com/
i7- a veloper/docs/momentics621_docs/neutrino/sys_arch/intro.html>.
.. л River Systems, Inc., «VxWorks 5.x.» <www.win-driver.com/products/
48‘ Xw°rks5/VXwOrks5x-dS‘pdf>’
Dedicated Systems Experts, «Comparison between QNX RTOS V6.1, VxWorks
j 1( and Windows CE .NET,» June 21, 2001, <www.eontrade.com/data/
QNX/QNX61_VXAE_CE.pdf>.
'0 QNX Software Systems Ltd., «QNX Supported Hardware,» <www.qnx.com/sup-
° port/sd_hardware/platform/processors.html>.
51 Timmerman, M., «RTOS Evaluation Project Latest News,» Dedicated Systems
Magazine, 1999, <www.omimo.be/magazine/99ql/ 1999qi_p009.pdf>.
52. Wind River Systems, Inc., «VxWorks 5.x.,» <www.windriver.com/products/
vxworks5/vxworks5x_ds.pdf>.
53. Microsoft Corporation, «Windows CE .NET Home Page,» <www.microsoft.com/
windows/embedded/ce.net/default.asp>.
54. Radisys Corporation, «RadiSys: Microware OS-9,» <www.radisys.com/oem_prod-
ucts/op-os9.cfm?MS=Microware% 20Enhanced% 200S-9% 20Solution>.
55. Enea Embedded Technology, «Welcome to Enea Embedded Technology,»
<www. ose.com>.
56. Real Time Linux Foundation, Inc., «Welcome to the Real Time Linux Foundation
WebSite,» <www.realtimelinuxfoundation.org>.
‘Etsion, Y.; Tsafrir, D.; and D. Feiteelson, «Effects of Clock Resolution on the
cheduling of Interactive and Soft Real-Time Processes,» SIGMETRICS’O3, June
58 X14’ 2°03’ pp- 172-183.
’ fj1’ J*’ Parnas, D. L., «On Satisfying Timing Constraints in Hard-Real-Time Sys-
ipniS’>> Proceedings of the Conference on Software for Critical Systems, New Or-
59. St s’ Louisiana, 1991, pp. 132-146.
D-» and P. Khosla, «Real-Time Scheduling of Dynamically Reconfigur-
gine ifs^ems»» Proceedings of the IEEE International Conference on Systems En-
Хц >Г1Г^’ Dayton, Ohio, August 1991, pp. 139-142.
Syste’and D- L. Parnas, «On Satisfying Timing Constraints in Hard-Real-Time
Orlen s,>> Proceedings of the Conference on Software for Critical Systems, New
61 St6w S’ Louisiana, 1991, pp. 132-146.
^leSv ’« D’’ ar*d P- Khosla, «Real-Time Scheduling of Dynamically Reconfigur-
es Йцее . ™,» Proceedings of the IEEE International Conference on Systems En-
Potk0 • g’ Dayton, Ohio, August 1991, pp. 139-142.
R W- Wolf, «А Methodology and Algorithms for the Design of
°f Elf.,.f “‘Time Multitasking ASICs,» ACM Transactions on Design Automation
Хц> J ironic Systems (TODAES), Vol. 4, No. 4, October 1999.
and D’ L- Parnas, «On Satisfying Timing Constraints in Hard-Real-Time
u4ean ’* Proceedings of the Conference on Software for Critical Systems, New
s’ Louisiana, 1991, pp. 132-146.
5Ю
Гл
64. Dertouzos, М. L., «Control Robotics: The Procedural Control of Physj
cesses,» Information Processing, Vol. 74, 1974. ' Cal J>f
65. Stewart, D., and P. Khosla, «Real-Time Scheduling of Dynamically Re„ i
able Systems,» Proceedings of the IEEE International Conference on Sv<u°n^&i
gineering, Dayton, Ohio, August 1991, pp. 139-142. leihs|j •
66. Stewart, D., and P. Khosla, «Real-Time Scheduling of Dynamically Rec
able Systems,» Proceedings of the IEEE International Conference on Svst°ri^?li>
gineering, Dayton, Ohio, August 1991, pp.139-142. eitlsEn'
67. «A Look at the JVM and Thread Behavior,» June 28, 1999, <Ww ]
world. com/javaworld/javaqa/1999-07/04-qa-jvmthreads.html>.
68. Austin, G, «Java Technology on the Linux Platform: A Guide to C
Started,» October 2000, <developer.java.sun.com/developer/technicalA
Programming/linux/>. 1ска/
69, Holub, A., «Programming Java Threads in the Real World, Part 1,» JavaWorld
tember 1998, <www.javaworld.com/java-world/jw-09-1998/jw-09-threads •htmii*®-
70. Courington, W., The UNIX System: A Sun Technical Report, Mountain v’
CA: Sun Microsystems, Inc., 1985.
71. Courington, W., The UNIX System: A Sun Technical Report, Mountain V
CA: Sun Microsystems, Inc., 1985. e*’
72. Kenah, L. J.; Goldenberg, R. E.; and S. F. Bate, VAX/VMS Internals and Dai
Structures: Version 4.4, Bedford, MA: Digital Equipment Corporation, 1988
73. Coffman, E. G, Jr., and L. Kleinrock, «Computer Scheduling Methods and Their
Countermeasures,» Proceedings of AFIPS, SJCC, Vol. 32, 1968, pp. 11-21.
74. Ruschitzka, M., and R. S. Fabry, «А Unifying Approach to Scheduling,» Com
munications of the ACM, Vol. 20, No. 7, July 1977, pp. 469-477.
75. Stankovic, J. A.; Spuri, M.; Natale, M. D.; and G. C. Buttazzo, «Implicationsof
Classical Scheduling Results for Real-Time Systems,» IEEE Computer, Vol. 28,
No. 6, 1995, pp. 16-25.
76. Pop, P.; Eles, P.; and Z. Peng, «Scheduling with Optimized Communication for
Time-Triggered Embedded Systems,» Proceedings of the Seventh Internationa!
Workshop on Hardware/Software Codesign, March 1999.
77. Bender, M. A.; Muthukrishnan, S.; and R. Rajarama, «Improved Algorithms for
Stretch Scheduling,» Proceedings of the Thirteenth Annual ACM-SIAM SymP0'
slum on Discrete Algorithms, January 2002. J .
78. Nieh, J., and M. S. Lam, «The Design, Implementation and Evaluation
SMART: a Scheduler for Multimedia Applications,» ACM SIGOPS Operating
terns Review, Proceedings of the Sixteenth ACM Symposium on Operating V
terns Principles, October 1997. . , pr0-
79. Dertouzos, M. L., «Control Robotics: The Procedural Control of Physic 1
cesses,» Proc. IFIP Congress, 1974, pp. 807-813. aI)Ce,>
80. Kalyanasundaram, B., and K., Pruhs, «Speed Is As Powerful as Clairvo
Journal of the ACM (JACM), Vol. 47, No. 4, July 2002, pp. 617-643. gjj
81. Lam, T, and K. To, «Performance Guarantee for Online Deadline Sch®,Л glA'*
the Presence of Overload,» Proceedings of the TWELFTH ANNUal A
Symposium or Discrete Algorithms, January 7-9, 2001, pp. 755-764.
82. Koo, C; Lam, T; Ngan, T; and K. To, «Extra Processors Versus Future дц!Д
tion in Optimal Deadline Scheduling,» Proceedings of the Fourteen^ ^k-
ACM Symposium on Parallel Algorithms and Architectures, 2002, PP-
Часть II
i»i^®a3smw^w«3w«w»£^^
Реальная и Виртуат
память I
«jfl|
Веди меня от нереального к PeaJl 2
Упан^1
4 '*7- £ £' Я
амятъ — второй после процессора по важно-
сти и интенсивности использования компо-
, компьютера, управляемый операционной сис-
К той. Три следующие главы рассматривают спосо-
организации памяти в их развитии от простых
№ опользователъских систем реальной памяти к со-
° е.мепиым мультипрограммным системам с вирту-
в?льНой памятью. Мы изучим мотивацию использова-
ния виртуальной памяти и разберем механизмы ее
еализации —* сегментный и страничный, а также
Технику их совместного применения. Мы уделим
внимание трем стратегиям управления памятью:
подкачке (по требованию и предварительной), раз-
мещению страниц и их замене. Мы покажем, что
наиболее важным фактором повышения производи-
тельности систем виртуальной памяти является
корректный выбор стратегии замещения страниц
при недостатке доступной памяти, и опишем ряд
доступных стратегий, включая модель рабочих на-
боров программ, предложенную Деннингом.
Соображение есть не что иное, как освобождение
памяти от уз времени и пространства.
Сэмюэл Тэйлор Колридж
Ничто не истинно без опыта, ведь даже притчи смысл
не трогает нам душу, пока жестокой жизни репетий1
доходчиво ее не объясни^
Джон Китс
Дано будет тому, кто слышит тихий голос Божий,
Пусть даже заглушенный громом суеты,
Тому, кто знает: к истине дущЦ
Обязан испытать все тяготы пути.
Томас Харди
Пограничные знаки на межах полей неприкосновенны-
Аменемо^
Защита не принцип организай^!
а средство достижения Д
Бенджамин Ди3Ра \
Обладающий обширной памятью еще не Фй‘
и не всякий знающий множество слов — г! < л
Преподобный Джон Генри •**
Глава 9
перативная м
Организация и управление
Цели
Прочитав эту главу, вы должны понимать:
• необходимость управления реальной (иногда
называемой физической) памятью;
• как организована иерархия памяти;
• как выполняется выделение непрерывных
и Фрагментированных областей памяти;
* 6 чем суть мультипрограммирования
с Фиксированным и изменяемым
Определением памяти;
ак Функционирует подкачка памяти;
Q ие стратегии размещения данных
йЛ1яти существуют.
Краткое содерэкание швы
9.1. Введение
9,2. Организация памяти
9.3. Управление памятью
Размышления об операционных системах: Безграничность рос
вычислительной мощности, объемов памяти и пропускной способно^
9.4. Иерархия памяти
9.5. Стратегии управления памятью
9.6. Выделение непрерывных и фрагментированных
участков памяти
9.7. Выделение непрерывных блоков
в однопользовательских системах
9.7.1. Оверлеи
9.7.2. Защита в однопользовательских системах
9.7.3. Однопоточные пакетные системы
Размышления об операционных системах:
Изменение — это правило, а не исключение
9.8. Мультипрограммные системы с фиксированным
распределением памяти
Поучительные истории: Разделение
Размышления об операционных системах:
Пространственные ресурсы и фрагментация
9.9. Мультипрограммные системы с изменяемым
распределением памяти
9.9.1. Характеристики изменяемых разделов
9.9.2. Стратегии разллещения в памяти
9.10. Мультипрограммные системы с подкачкой
/ ^едение
способа организации и управления оперативной памятью (real
^б°Нназываемой также основной памятью (main memory), физиче-
е1Л°гУ ятью (physical memory) и первичной памятью (primary memory))
существенное влияние на решения, принимаемые при проекти-
оКвзь1Ваеоперационной системы1. Вторичные устройства хранения® (обыч-
& иЛИ ленточный накопитель) предоставляют дешевое и емкое
1ЦС для программ и данных, которые должны быть готовы к ис-
дню. Но при этом вторичные устройства хранения характеризу-
ооЛЬ3° яь1Соким быстродействием и напрямую для процессора недоступ-
pTcfL -следственно обрабатываемые данные и выполняемые программы
нЫ-11 находиться в основной памяти.
^^этоЙ и следующих двух главах мы обсудим ряд популярных моделей
Вднзации оперативной памяти компьютера и управления ею. Данная
°Рга посвящена физической памяти, в главах 10 и 11 мы обратимся
гЛ^рТуальной памяти. Рассматривая модели, мы будем стараться следо-
кать хрОнологии их появления. Большинство современных систем работа-
ют с виртуальной памятью, поэтому данная глава в значительной мере ис-
торически-описательная. Но даже при работе с виртуальной памятью, опе-
рационная система должна управлять физической памятью. Более того,
некоторые системы, в частности встроенные системы и системы реального
времени, не могут позволить себе роскошь поддержки виртуальной памя-
ти, поэтому для них первостепенное значение имеет управление памятью
физической. Многие из рассматриваемых в этой главе концепций лежат
в основе технологий управления виртуальной памятью, разбираемых
в следующих двух главах.
Организация памяти
вос"° времен создания первых компьютеров основная память считается от-
зи ельно дорогим ресурсом, и разработчики систем стараются оптими-
Ро Ть ее использование. Несмотря на то, что оперативная память быст-
®главеевеет (приблизительно в соответствии с законом Мура, описанным
РоСТа 2’ См- «Размышления об операционных системах: Безграничность
стцЛ ВЬ1ЧИслительной мощности, объемов памяти и пропускной способно-
5еМу ’ее Ст°имость по сравнению со стоимостью внешней памяти по-преж-
с°Ка- Кроме того, потребности современных приложений и опера-
СИстем в оперативной памяти непрерывно растут (рис. 9.1). На-
р ^eSsi' ДЛЯ нормальной работы операционной системы Windows ХР
коРпорация Microsoft рекомендует использовать оперативную
об,ьемом не менее 256 МБ.
ч
%СсТо Вя,
Ч’ЦИм <13Ь1вают также внешними устройствами хранения, внешней памятью или
Накопителями — прим. ред. перев.
518
С точки зрения разработчика операционной системы важен вон
ганизации памяти (memory organization). В частности, необхол о!
шить, будет ли операционная система располагать в оперативной b|
только один процесс или несколько (т.е. обеспечивать мультицр^^Чк
ный режим). При работе со многими процессами следует подумать
как разделять между ними память: выделять ли всем им равные
(их иногда называют разделами (partition)) или размер этих Порц^-^И^
жен меняться от программы к программе. Выделять ли программе И
фиксированного размера на все время ее работы или менять размеп &3^еЧ
мически в зависимости от потребностей программы? Следует ли пп
вать программы к определенным разделам или они могут выполц»
в любом подходящем разделе? Будем ли мы выделять для раздела
рывную область памяти, или можно разбивать раздел на несколько блЯ
и располагать их в разных местах оперативной памяти? ОперацИ0н
системы в настоящее время используют все описанные альтернат^11*
В данной главе мы рассмотрим каждую из упомянутых моделей орган»
ции оперативной памяти.
Вопросы дм самопроверки
1. Почему в общем случае неэффективно размещать в памяти только
один процесс в каждый отдельный момент времени?
2. Что произойдет, если операционная система позволит нескольким
процессам одновременно находиться в оперативной памяти, но за-
претит деление памяти на разделы?
Ответы 1) Если единственный выполняемый процесс остановится
в ожидании завершения операции ввода/вывода, процессор будет про-
стаивать. 2) Каждый процесс будет использовать всю память одновре-
менно с другими процессами. Любая ошибка любого процесса может
нанести ущерб другим процессам.
93 Управление памятью
Независимо от того, какую модель организации памяти мы
для разрабатываемой операционной системы, необходимо решить
вопрос выбора стратегии, позволяющей добиться оптимальной ПР01^ 1ГПеВ*
тельности памяти. Стратегии управления памятью (memory man К р83-
strategies) определяют поведение выбранной организации памяти дуег
личных уровнях нагрузки. Управление памятью, как правило, Ре г[Пера'1'
ся с помощью комплекса программных и специализированных
ных средств.
Г !,амяпь' Организация и управление — 519
.ионная система Дата появления Минимальная Рекомендуемая память
необходимая память
,с 1 0 Ноябрь 1985 256 КБ
^2 03 о И0*5 uwdovtf 95 endows NT4-° endows 9S Window ME Endows 2000 Professional Window XP Home Windows XPProfesaonal Ноябрь 1987 Март 1990 Апрель 1992 Август 1995 Август 1996 Июнь 1998 320 КБ 896 КБ 2,6 МБ 8 МБ 32 МБ 24 МБ 1 МБ 4 МБ 16 МБ 96 МБ 64 МБ
Сентябрь 2000 Февраль 2000 Октябрь 2001 Октябрь 2001 32 МБ 64 МБ 64 МБ 128 МБ 128 МБ 128МБ 128 МБ 256 МБ
р f. Потребности операционных систем Microsoft Windows в памяти3-4-5
Рис.
Диспетчер памяти (memory manager) — это компонент операционной
системы, реализующий выбранную модель организации памяти и страте-
гию управления этой памятью. Диспетчер памяти определяет, способ вы-
деления процессам доступной оперативной памяти и реакцию операцион-
ной системы на изменение потребностей процесса в ресурсах памяти. Он
также взаимодействует со специальными аппаратными устройствами
управления памятью (если таковые есть в данном компьютере) в целях по-
вышения производительности. В данной и двух следующих главах мы рас-
смотрим ряд стратегий организации и управления памятью.
Чтобы выяснить, чем отличается данная стратегия управления памя-
тью от других, следует выяснить, как эта стратегия отвечает на следующие
Опросы. Когда данная стратегия загружает новую программу и ее данные
оперативную память? Загружает ли данная стратегия программу и ее
ные только после запроса операционной системы, или она старается
ДУгадать подобные запросы заранее? Где в оперативной памяти эта
Пыт еГИЯ ₽азмеЩает подлежащую выполнению программу и ее данные?
Ли стратегия поплотнее расположить данные и программы в дос-
бочен^ п₽°странстве памяти, минимизируя затраты памяти, или она оза-
«Ыеи МИНимизацией времени выполнения программы, располагая дан-
ЕСЛи₽огРаммы в первом подходящем разделе?
,,^Ог₽амм°ЗНИКаеТ нео^ходимость разместить в оперативной памяти новую
И данные> а свободного места для них не хватает, какие про-
ХТи и Данные будут рассматриваться данной стратегией как наиболее
Ь1е кандидаты на удаление из оперативной памяти? Будут ли уда-
%аТо^1₽0гРаммы и данные, которые находятся в ней дольше других кан-
ДольК°Т°Рые используются реже других, или которые не обрабатыва-
ЧЬсе других? В современных операционных системах используют-
__Е'П.т„011исаннь1е альтернативы и ряд других стратегий управления
Вопросы для самопроверки
1. Когда стратегия минимизации свободной памяти может па
ваться как подходящая диспетчером памяти? <lCc<4q1,
2. Почему стратегии организации и управления памятью ** I
быть как можно более прозрачными для процессов? I
Ответы 1) Когда память считается более дорогим ресур
процессорное время, можно потратить немного времени на бо °14’
ное расположение программ в оперативной памяти. Эта страте 66
же оправдывает себя в случае, когда необходимо постоянно Г13я
наготове непрерывный свободный раздел памяти максима тьц'6®®1^
мера для ожидаемых к загрузке программ и данных. 2) Прозп°Г° Раз.
стратегии управления памятью делает приложения более мобЧй°сТь
ми и упрощает их разработку, поскольку разработчику пpиллIJIЬ^,*•
нет необходимости заботиться о выборе и реализации стратегии^11®
ме того, прозрачность стратегий управления памятью позволя
нять стратегии без необходимости переписывать приложения Т Ме'
Ж
Размышления об операционных системах
Безграничность роста Вычислительной мощности,
объемов памяти и пропускной способности
Компьютеры — чрезвычайно динамичная
сфера информационной индустрии. Быстро-
действие процессоров непрерывно растет
(и они становятся все дешевле в пересчете на
одну выполненную инструкцию в секунду),
оперативная память становится все больше
(и все дешевле в пересчете на один бит емко-
сти), вторичные устройства хранения тоже
становятся все более емкими (и опять таки
дешевле в пересчете на один бит емкости),
а каналы связи — все более быстрыми (и де-
шевыми в пересчете на один бит в секунду
пропускной способности). Кроме того, появ-
ляются все новые устройства, которые
встраиваются в компьютеры или взаимодей-
ствуют с ними.
Разработчики операционных систем
должны постоянно следить за новыми вея-
ниями и их развитием. Эти новые веяния мо-
гут оказать огромное влияние на возможно-
сти, необходимые операционным системам.
В ранних операционных системах не было
поддержки для компьютерной графики, гра-
фического пользовательского интерфейса,
компьютерных сетей, распределенных вы-
числений, Web-служб, многопроцессорно-
сти, многопоточности, массового паралле-
лизма, виртуальной памяти, систем баз дан-
ных. мультимедиа, средств поддержки
людей с физическими ограничениями, ок
тем безопасности и так далее. Все эти воз
можности, развившись в последние дес^
летия, оказали глубокое воздействие н j
бования, возникающие при проектиро^
современных операционных систем. д
дитесь в этом, познакомившись с Дета ТИ
ми обзорами операционных систеК' еТст
и Windows ХР в главах 20 и 21, ^°°!.одаР
венно. Все это стало возможным Л ^коб1’
росту вычислительной мощности,
устройств хранения и пропуски
ности каналов связи. Развитие про
ся, и с течением времени будут
все более замысловатые ПР Hbiecl’
и поддерживающие их операнд0
темы.
У д пц/лять. Организация и управление
521
[1ер#РХ1/я памяти
нО х и 1960-х годах оперативная память была чрезвычайно доро-
₽ оть до доллара за бит. Чтобы понять, насколько это много, пред-
вП ege> что 256 мегабайт памяти, рекомендуемых для использования
^аРьТе С %р Professional, обошлись бы вам более чем в 2 миллиарда долла-
\V'ifld°'vS аботчики тщательно продумывали, сколько оперативной памяти
рдв! Ра3^ть в системе. Учреждение могло купить только память, необходи-
мей0® выполнения операционной системы и требуемого количества про-
чую задача заключалась в том, чтобы купить минимальное ее количест-
сеСС°Второгг) было бы достаточно для эффективного выполнения работы
во> К°елах экономических возможностей учреждения.
в j-jaMMbi и данные нужно загрузить в оперативную память, прежде
1 система сможет выполнить или обработать их. Все, что системе не
чеМ в данный момент, может находиться во вторичных устройствах
енИЯ, а позже быть загруженным в оперативную память. Носители
яных во вторичных устройствах хранения — например, диски или лен-
ты — стоят намного меньше в пересчете на единицу емкости, чем опера-
тивная память, и емкость этих устройств намного больше. Однако доступ
к оперативной памяти требует гораздо меньшего времени — в современ-
ных системах разница в скоростях доступа может достигать шести
порядков6- 7.
Иерархия памяти (memory hierarchy) состоит из уровней, каждый из ко-
торых характеризуется определенным быстродействием и стоимостью. Сис-
темы перемещают данные и программы между разными уровнями
иерархии8’ 9. Эта переброска может поглощать системные ресурсы, напри-
мер, процессорное время, которое в противном случае могло бы использо-
ваться более продуктивно. Чтобы увеличить эффективность, в современных
системах используются аппаратные устройства, называемые контроллера-
ми памяти, выполняющие операции перемещения данных практически без
3 Ладных расходов со стороны процессора. В результате системы, исполь-
иерархии памяти, выигрывают в стоимости и емкости.
чИть 60-х годах разработчикам стало очевидно, что можно резко увели-
®авИть°ИЗВО'П'ИТельность и эффективность использования памяти, если до-
УровеНьВ Ие₽аРХию еще один верхний уровень10’ п. Этот дополнительный
тйвная ' Называемый кэшем (cache), работает намного быстрее, чем опера-
1'1)исталПаМЯТЬ’ и в современных системах обычно размещается на одном
иЛе С иРоЦессором^’ 13. Процессор может напрямую работать с дан-
^орогаНСТрукциями’ находящимися в его кэше. Кэш-память чрезвычай-
П° ерэвнению с оперативной, и поэтому используются кэши срав-
16, оце Не^Оль|[1их объемов. На рис. 9.2 показаны связи между кэш-памя-
ЙТ11ВН0Й памятью и вторичными устройствами хранения.
Цро Мять вводит в систему еще один уровень передачи данных в сис-
перемещаются из оперативной памяти в кэш перед вы-
tj ®> программы, находящиеся в кэше, выполняются намного бы-
11ах°ДяЩиеся в оперативной памяти. Поскольку многие процес-
а й Ющиеся к коду и данным, вероятно, будут обращаться к ним
й>Кайшем будущем (это явление называется временной локаль-
522
костью (temporal locality)), даже относительно маленький кэш
метно повысить производительность (по сравнению с системой
В некоторых системах используются несколько уровней кэша.
ч,
Время доступа
падает
Скорость
доступа растет
Оперативная память
I
Процессор может обрашат
к программам и данным01
напрямую
Стоимость
хранения одного
бита растет
Емкость падает
Вторичные и третичные
устройства хранения
Система должна перенести
программы и данные
в оперативную память
прежде чем процессор
сможет к ним обратиться
Рас. 9.2. Иерархическая организация памяти
Вопросы для самопроверки
1. (Да/Нет) Дешевизна оперативной памяти в сочетании с ростом ее
емкости сделала использование сложных стратегий управления па-
мятью ненужным в большинстве систем.
2. Как наличие кэш-памяти повлияет на выполнение программ,
держащих циклы?
Ответы 1) Нет. Несмотря на дешевизну и большую емКОСТД^Пдо<:'
тивной памяти, все еще существуют задачи, поглощающие _л?к0ьх
тупную память. Кроме того, стратегии управления памятно
применяться к кэшу, состоящему из дорогой памяти малой
В любом случае, если память полностью заполнена, систем^£
применить стратегию управления памятью, чтобы как M°epjjcaIfl®
эффективно распорядиться этой памятью. 2) Программа,
циклы, раз за разом выполняет одни и те же последователь
рукций, а возможно, и обращается к одним и тем же данны осг
инструкции и данные помещаются в кэш, процессор 1м р оИе
щаться к ним намного быстрее, чем, если бы они находил
тивной памяти, и производительность возрастет.
523
гд цц/лять. Организация и управление____________
L Стратегии управления памятью
' егии управления памятью создаются с целью достичь наилучшего
СтРа^вания оперативной памяти. Они делятся на:
”сГ1<>ЛСтРа’гегиИ загрузки
Р Стратегии размещения
I Стратегии замены
Н теГЯЯ загрузки (fetch strategies) определяют, когда нужно переме-
Л^овые данные или инструкции в оперативную память со вторичных
да'1’’ „стВ хранения. Они делятся на две категории: стратегии загрузки по
устР°в яяЮ (demand fetch) и стратегии предварительной загрузки
««fetch). В течение многих лет считалось, что эффективнее при-
загрузку по требованию, при использовании которой система за-
МеВ ает новые блоки инструкций или данных только тогда, когда выПол-
юШаЯСЯ программа явно к ним обращается. Разработчики считали, что,
поскольку нельзя в общем случае предсказать последовательность выпол-
нения программы, то накладные расходы, связанные с попытками преду-
гадывания, намного превысят ожидаемый выигрыш в производительно-
сти. Однако сейчас многие системы заметно увеличили производитель-
ность за счет применения стратегий предварительной загрузки,
пытающихся загрузить фрагменты программ и данных в оперативную па-
мять до того, как программы к ним обратятся.
Стратегии размещения (placement strategies) определяют, где в опера-
тивной памяти система должна размещать загружаемые программы
и данные14- 15. В этой главе мы рассмотрим стратегии размещения в Пер-
ми подходящих участках (first-fit), в наиболее подходящих участках
(best-fit), и в наименее подходящих участках (worst-fit). Когда мы будем
Рассматривать страничные системы виртуальной памяти в главах 10 и 11,
Увидим, что программы и данные можно делить на фрагменты фикси-
вЛ1п-НОа длины’ называемые страницами, которые могут размещаться
стаВпЫх достУпных кадрах страниц. В таких системах задачи размещения
Ес^ТСя очень простыми.
®РоГра ОпеРативная память слишком заполнена, чтобы вместить новую
6 Даин*^’ система должна удалить некоторые (или все) программы
'trategi находящиеся в памяти. Стратегии замены (replacement
' определяют, какие элементы нужно удалять из памяти.
Вопросы для самопроверки
!• Что важнее для стратегии размещения — минимальные накладные
расходы или эффективное использование ресурсов?
*, Назовите две категории стратегий загрузки и опишите, в каких
случаях могут оказаться удобнее стратегии каждой категории.
524
ОмвеМЫ 1) Ответ зависит от назначения системы и Относ
ценности ресурсов и накладных расходов. В общем случае pa.^^^h 1
операционной системы должен стараться выдерживать балан
накладными расходами и эффективностью использования пам С
бы достичь требуемых целей. 2) Эти две категории — стратеги^1’
ки по требованию и стратегии предварительной загрузки. Если1
не может точно предсказать дальнейшие потребности программ
ти, то низкие накладные расходы стратегий загрузки по трог."
позволяют достичь лучших производительности и использов-
сурсов (поскольку система не будет загружать с диска ненул-и111151 рГ
ные). Однако если поведение программ предсказуемо, стЬ1е
предварительной загрузки могут улучшить производительность^^
жая элементы данных или программ в оперативную память л Заг^-
как они понадобятся. До того5
9.6 Выделение непрерывных
и фрагментированных участков памяти I
Чтобы выполнить программу на первых моделях компьютеров на заре
эры кибернетики, системный оператор или операционная система должны
были найти непрерывный свободный участок в оперативной памяти, дос-
таточный для размещения этой программы целиком. Если такого участка
не было, программу невозможно было выполнить. В этой главе мы обсудим
ранние реализации этого метода, известного как выделение непрерывных
участков памяти (contiguous memory allocation), и связанные с ним про
блемы. Когда исследователи попытались решить эти проблемы, стало
ясно, что системы могут выиграть от фрагментированного выделения
памяти16.
При выделении фрагментированных участков памяти (non contiguous
memory allocation) программа делится на блоки или сегменты, к0Т°Р
система может разместить в несмежных участках оперативной па
Это позволяет задействовать свободные участки в памяти, размер к°опер8.
слишком мал для размещения в них всей программы. Хотя такие 3.
ции требуют больших накладных расходов, это может быть оправд ойес-
росшей степенью мультипрограммности (т.е. ростом количества
сов, которые могут одновременно размещаться в оперативной cllCre*
В этой главе мы рассмотрим подходы, приведшие к появлению^
с фрагментированным выделением памяти. В следующих двух гЛ
рассмотрим сегментационные и страничные системы виртуальной
требующие фрагментированного выделения.
Вопросы для самопроверки
1. В каких случаях фрагментированное выделение памяти I
тельнее выделения непрерывных участков? йТцг I
2. Какие накладные расходы могут быть связаны с фра1,
ным выделением памяти?
525
F айця память. ация и управление
Ответы i) Если в оперативной памяти нет непрерывного свободно-
го участка достаточного размера для размещения программы, но есть
несколько участков, суммарный размер которых достаточен для этого.
2) Накладные расходы, связанные с необходимостью отслеживать сво-
бодные блоки, контролировать принадлежность блоков к разным про-
цессам, и выполнять размещение этих блоков в памяти.
, выделение непрерывных блоков
Однопользовательских системах
„аНних компьютерных системах в любой момент времени мог рабо-
на машине только один пользователь. Ему были доступны все ресурсы
^нины- И взимание платы тоже было простым — пользователь платил за
В ресурсы независимо от того, использовал ли он их. Вообще говоря, оп-
дата взималась согласно «времени по настенным часам» (wall clock time).
Системный оператор предоставлял пользователю машину на какое-то вре-
мя и взимал плату за это время.
На рис. 9.3 показана организация памяти в однопользовательских сис-
темах с выделением непрерывных блоков (single-user contiguous memory
allocation system). Изначально не существовало операционных систем как
таковых — программист писал весь код, необходимый для решения ка-
кой-то задачи, включая детальные инструкции для взаимодействия с уст-
ройствами ввода/вывода. Вскоре разработчики систем создали библиоте-
ки, реализовавшие стандартные функции — системы управления вво-
дом/выводом (Input/Output Control System — IOCS)17. Программист
Операционная система
Пользователь
Не используется
'Пользовательская система с выделением непрерывных блоков
526
вызывал процедуры IOCS для выполнения стандартных задач, вмест
чтобы «изобретать велосипед» заново в каждой программе. IOCS
упростила написание программ. Реализация систем управленц
дом/выводом, возможно, была первым шагом на пути к современцьв
рационным системам. lfiI
9.7.1 Оверлеи
Мы обсудили ограничения, связанные с выделением для програм
прерывных областей оперативной памяти. Один из широко испольч
шихся способов преодоления этих ограничений — создание овев8*-
(overlays), позволявших системе выполнять программы, большие n<j 68
меру, чем ее оперативная память. На рис. 9.4 показан типичный оверле^
Программист разделяет программу на логические блоки. Когда в
грамме становится ненужным какой-то блок, программа может удад^'
его из памяти и разместить на его месте какой-то другой блок или его
часть18.
Оверлеи позволяли программистам «расширять» оперативную память
Однако ручное создание оверлеев требовало тщательного и долгого плани-
с
1 Загрузить фазу инициализации в Ь и выполнить
2 Затем загрузить фазу обработки в b и выполнить
3 Затем загрузить фазу вывода в b и выполнить
Рис. 9.4. Структура оверлеев
527
намять. Организация и управление
и программистам требовались глубокие знания об организации
системе. Программа со сложной структурой оверлеев часто с тру-
Вавалась изменению. По некоторым оценкам, по мере роста слож-
^0 ^^рграмм до 40% затрат на программирование прйходились на орга-
оверлоев19- Стало ясно, что операционная система должна изоли-
^здЯ1110 оГраммистов от сложных задач управления памятью, таких, как
’Ча'гЬ п j£aK мы увидим в следующих главах, системы виртуальной памя-
^еРлеЙа11Яют потребность в использовании создаваемых программистами
тЛ УсТ^ _точно так же, как системы IOCS избавили программистов от
овеРлееВ мОСти заново писать низкоуровневые процедуры ввода/вывода
^*а*Дой пР°граммы-
Вопросы для самопроВерка
1. Каким образом появление IOCS упростило разработку программ?
2. Опишите преимущества и сложности создания оверлеев.
ОтВеты х> Появилась возможность выполнять ввод/вывод в про-
граммах без необходимости каждый раз писать стандартные процеду-
ры, «изобретая велосипед». 2) Оверлеи позволили программистам
писать программы, большие, чем объем оперативной памяти, но
управление оверлеями усложняло программы, увеличивало их размер
и стоимость разработки.
17.2 Защита В однопользовательских системах
В однопользовательских системах с выделением непрерывных блоков
вопрос защиты формулируется просто. Как нужно защищать операцион-
ную систему от повреждения пользовательскими программами?
Пользовательский процесс может обратиться в область памяти, занятую
операционной системой — или намеренно, или случайно — и заменить ка-
?Ю'Т0 часть операционной системы другими кодами. Если в результате
РаЦионная система будет повреждена, то выполнение процесса станет
t>neMM0JKHbIM’ Если процесс попытается обратиться к памяти, занятой
выцОд 0Нн°й системой, пользователь может обнаружить это, прервать
I ^емуНеНИе пР°Цссса, после чего, возможно, ему удастся устранить про-
Прии ^ново запустить процесс.
I сПстему°ТСуТствии защиты процесс имеет право «мягко» модифицировать
С1УчайНф< НесмеРтельнь1м>> образом. Предположим, например, что процесс
6ь1во ИЗменяет какие-то процедуры ввода/вывода, и система обрезает
bfl|>TaTbffiMbIe записи- Процесс по-прежнему может выполняться, но ре-
До за Удут некорректными. Если пользователь не просмотрит резуль-
4 ^°Ра °РШения работы процесса, машинные ресурсы будут потрачены
К Из^° хУЖе то, что повреждение операционной системы может при-
! енениям в результатах работы процесса, которые трудно будет
ЧссОв Ь' Очевидно, операционная система должна быть защищена от
I ’Ч^'Гу в
I Однопользовательских системах с выделением непрерывных
в ет обеспечить один регистр — регистр границы (boundary
1 троенный в процессор (см. рис. 9.5), содержимое которого мо-
528
52V
гут изменять только привилегированные инструкции. В этом регцСт
нится адрес в оперативной памяти, с которого начинается область
вательской программы. При каждом обращении процесса к опера
памяти адрес обращения сравнивается с хранящимся в регистре ГрТ11%*
Если адрес обращения больше или равен хранящемуся в регистре
обслуживает обращение. В противном случае программа пытаете
титься к системной области памяти, и система прерывает ее выц0
с соответствующим сообщением об ошибке. Аппаратные устройств
полняющие контроль границы, работают достаточно быстро, чтобы Вь>-
медлять выполнение инструкций. 116 За.
Процессор
О
Операционная система
а
Регистр границы
а
Пользователь
Система предотвращает обращения
пользовательской программы
к адресам, меньшим, чем а
b
Не используется
с
Рис. 9.5. Защита памяти в однопользовательских системах с выделением
непрерывных блоков
onepafl”
Разумеется, процесс должен время от времени обращаться к
онной системе, например, чтобы выполнять ввод/вывод. Систем gJt3opa
обслуживать отдельные вызовы, называемые вызовами с^)ПераИ11<^
(supervisor calls), которые позволяют обращаться к службам о
ной системы. Когда процесс генерирует системный вызов (на!
записи данных на диск), система обнаруживает этот вызов и
ется из пользовательского режима в режим ядра (или приви I
ный режим (executive mode)). В режиме ядра процессор мож
инструкции операционной системы и обращаться к дан I
необходимые процессу операции. Выполнив требуемые О1"’^а^озвРа i
ма переключается обратно в пользовательский режим й 1
управление процессу20. Л
gi/аЯ память. Организация и управление
0>>
очный регистр границы представляет собой простой механизм за-
0Дя^jo мере усложнения операционных систем разработчики встраива-
% более замысловатые механизмы защиты операционной системы
I»1 ® Йцессов и процессов друг от друга. Позже мы подробно рассмотрим
Механизмы.
Вопросы для самопроверки
1. Почему одного регистра границы будет недостаточно для защиты
в многопользовательских системах?
2. Почему операционная система должна предоставлять процессу воз-
можность генерировать системные вызовы?
Ответы 1) Потому что один регистр сможет защитить операцион-
ную систему от повреждения пользовательскими процессами, но не
защитит пользовательские процессы от повреждения другими про-
цессами. 2) Системные вызовы дают возможность пользовательским
процессам запрашивать операции, выполняемые операционной сис-
темой, и в то же время гарантируют защиту операционной системы
от этих процессов.
9.7.3. Однопоточные пакетные системы
Ранние однопользовательские системы с реальной памятью позволяли
выполнять одновременно только одну задачу, и для ее выполнения выделя-
лись все ресурсы системы. Задачи обычно требовали заметного времени
подготовки (setup time), в течение которого загружалась операционная сис-
тема, монтировались ленточные и дисковые накопители, помещались фор-
мы в принтер и так далее. На завершение выполнения задачи также уходи-
ло время — время выключения (teardown time), в течение которого снима-
лись ленточные и дисковые носители, удалялась бумага из принтеров и так
Далее. Во время подготовки и выключения компьютер бездействовал.
Разработчики поняли, что если им удастся автоматизировать различ-
8Ь1е этапы переходов между задачами (job-to-job transition), то потери
времени на эти переходы можно будет заметно уменьшить. Это привело
появлению систем пакетной обработки (batch processing systems) (см.
а веК1Ь1ШЛеНИЯ °® операционных системах: Изменение — это правило,
Ьа^Исключение»). В однопоточных пакетных системах (single-stream
сдец ₽rocessing systems) задачи объединяются в пакеты при помощи по-
задХ7ТеЛЬН°Й записи этих задач на ленту или диск. Процессор потока
'’адачц °° s^ream processor) считывает инструкции на языке управления
control language), описывающие очередную задачу, и.подго-
йеТ СистемУ к выполнению этой задачи. Он выдает директивы сис-
‘У оператору и выполняет множество функций, которые раньше опе-
Вает.СнВЬ1п°лнял вручную. Когда выполнение задачи завершается, считы-
ВеРед0 ОпИсаыие следующей задачи, и выполняются необходимые для
К ,!ыполнению этой задачи операции обслуживания. Системы па-
Л*Со8 ^обработки намного увеличили эффективность использования ре-
р помогли убедиться в ценности операционных систем и активного
%1деевИя ресурсами (intensive resource management). Однопоточные па-
сИстемы были последним словом техники в начале 1960-х годов.
530
Вопросы для самопроверки
1. (Да/Нет) Системы пакетной обработки не нуждались в прИс
системного оператора.
2. В чем заключалось основное новшество в пакетных система ?
Ответы 1) Нет. Системный оператор должен был настраив
тему для выполнения задач и выполнять операции обслужив;^1, сЧе.
еле завершения выполнения этих задач. 2) Они автоматиз/114 Чо-
различные этапы переходов между задачами, заметно уменьща^°Ва^
ри времени и улучшая использование ресурсов. я ’'от®.
Размышления об операционных системах
Изменение — это правило, а не исключение
В истории, изменения — более распро-
страненное явление, чем неизменное со-
стояние, и часто изменения происходят бы-
стрее, чем ожидалось. Кроме того, они часто
оказываются более резкими, чем- можно
было вообразить. В компьютерной области
подтверждения этого тезиса появляются
ежедневно. Просто взгляните на список ве-
дущих компьютерных компаний 1960-х
и 1970-х годов: сегодня многие из этих ком-
паний вообще не существуют, а другие стали
менее известными и заметными. Посмотри-
те на компьютеры и операционные системы
тех лет: современные системы часто рази-
тельно от них отличаются. В этой книге мы
рассмотрим множество архитектурных во-
просов и аспектов создания программ, ко-
торые нужно учесть, чтобы создавать опера-
ционные системы, легко адаптирующиеся
к изменениям.
9.8 Мультипрограммные системы
с фиксированным распределением памяти
Даже с появлением операционных систем пакетной обработки °oJJI0
пользовательские системы все равно бесполезно тратили заметную
вычислительных ресурсов (рис. 9.6). Типичный процесс использует
цессорное время, чтобы сгенерировать запрос на ввод/вывод; затем ^0.
нение процесса приостанавливается, пока не выполнится этот заир сс<>'
скольку скорости ввода/вывода намного меньше, чем скорости пР
ров (и тогда, и сейчас), процессор загружался намного слабее, чем э
ВОЗМОЖНО.
Разработчикам стало ясно, что можно увеличить уровень загр>
цессора, реализовав мультипрограммные системы, в которых >1
пользователей поочередно используют системные ресурсы. ПроРе ’
дающий выполнения операции ввода/вывода, передает процессор
процессу, готовому к вычислениям. При этом ввод/вывод и вЫ1*
1аЯ память. Организация и управление
531
ыдолняться одновременно. Такой подход заметно увеличивает за-
-оГУ* процессора и пропускную способность системы.
извлечь максимум пользы из мультипрограммности, нужно раз-
Е ^Т° в оперативной памяти системы несколько процессов одновремен-
^ес,г^тЬ этОм если первый процесс запрашивает операцию ввода/вывода,
^^сор может переключиться на выполнение второго процесса и про-
ройе выполнять вычисления без задержки, связанной с необходимо-
агрузкИ программ со вторичного устройства хранения. Когда этот
сть10 о процесс освобождает процессор, третий процесс может быть готов
в^Р^ользовать. Реализовано множество разных схем мультипрограмм-
ен 11 jyfЬ1 рассмотрим эти схемы в этом и следующих разделах.
для процесса, связанного с интенсивными вычислениями:
Затемненная область означает
«процессор используется»
Для процесса, регулярно выполняющего ввод/вывод:
Процессор
используется
— гд---------
Процессор
используется
Процессор
используется
Процессор
используется
Ожидается завершение
ввода/вывода
Ожидается завершение Ожидается завершение
ввода/вывода ввода/вывода
A z
• ^пользование процессора в однопользовательской системе.
Вв°Да/дЧани<г' многих однопользовательских задачах длительность операций
/ ьгвода намного больше длительности периодов использования процессора]
g
гРамме₽^.Ь1х мультипрограммных системах использовался мультипро-
Иод m J*1?1 Режим с фиксированным распределением памяти (fixed-parti-
а ^Programming)21. В этом режиме система делит оперативную па-
раз Только разделов (partitions) фиксированного размера. В каж-
еле Размещается одна задача, и система быстро переключает
между задачами, чтобы создать впечатление одновременного
Ж>»е^еаия этих задач22. Такой подход позволяет системе реализовать
Ие возможности мультипрограммности. Очевидно, таким систе-
Обуется больше оперативной памяти, чем однопользовательским.
Ыгоды от улучшения использования ресурсов процессора и пери-
г>Х УстР°йств превосходят затраты на увеличение объемов опера-
оамяти.
-- ----
В первых мультипрограммных системах программист транслиро
дачу с помощью абсолютного транслятора или компилятора (cjjJ
дел 2.8). Хотя такой подход упрощал распределение памяти, его ис
вание означало, что задачи должны были размещаться в намят] .
указанным адресам, определенным до их запуска, и могли Bbinojj
только в заданных разделах (рис. 9.7). Такое ограничение приводи^ Ч
прасным тратам памяти. Если задача была готова к выполнению, а т,°15 Ч
значенный для нее раздел был занят, то ей приходилось ожидать ос
дения этого раздела, даже если другие разделы были обо*'
Рисунок 9.8 — это предельный пример. Все задачи в системе должн
полниться в разделе 3 (т.е. инструкции во всех программах начина 8bI
с адреса с). Поскольку этот раздел занят, все задачи вынуждены Жда^0^
смотря на то, что свободны два других раздела, в которых могут ’ tle'
J * вЫЦп»
няться задачи (если они скомпилированы для этих разделов).
Чтобы устранить проблему нерационального использования оператг
ной памяти, разработчики создали перемещаемые трансляторы, комцц °
торы и загрузчики. Эти инструменты позволили создавать перемещаемы
программы, которые могли выполняться в любом достаточно большом раз-
деле оперативной памяти (см. раздел 9.9). Эта схема устраняет часть по-
терь памяти, свойственных мультипрограммным системам с абсолютной
трансляцией и загрузкой; однако перемещаемые трансляторы и загрузчи-
ки сложнее своих абсолютных аналогов.
Эти задачи могут
выполняться только
в разделе 1
Эти задачи могут
выполняться только
в разделе 2
Эти задачи могут
выполняться только
в разделе 3
Рис. 9.7. Мультипрограммные системы с фиксированным распределением
памяти, абсолютной трансляцией и загрузкой
” я память. Организация и управление
533
Очередь задач для раздела 1
О
Операционная система
а
(Нет задач, ожидающих
выполнения в разделе
Очередь задач для раздела 2
Раздел 1 (пусто)
b
(Нетзадач, ожидающих
выполнения в разделе
Очередь задач для раздела 3
Раздел 2(пусто)
с
Раздел 3 (занято)
d
Pi/C. 9-8. Потери памяти в мультипрограммной системе с фиксированным
распределением памяти, абсолютной трансляцией и загрузкой
Очередь задач
Задача может размещаться в любом
подходящем по размеру разделе
Пеп ТипРОгРа.ммные системы с фиксированным распределением
Ремещаемой трансляцией и загрузкой
534
~~ Ч9
По мере усложнения организации памяти разработчики вынужде
усиливать и средства ее защиты. В однопользовательских система*^
было только защищать операционную систему от пользовательское
са. В мультипрограммной системе нужно защищать операционную
от всех пользовательских процессов и защищать каждый процесс от Са<?г%
тальных процессов. В системах с выделением непрерывных областей
защита часто строилась на наборах регистров границ. Система может
чить каждый раздел двумя регистрами — верхней и нижней границ °Г₽а5ц-
также называются базовым регистром (base register) и регистром К°Т°М
(limit register) (см. рис. 9.10). Когда процесс генерирует обращение к^б4а
тивной памяти, система проверяет, не меньше ли запрашиваемый алп обо-
значение в базовом регистре, и не больше ли он, чем значение в регист ’
дела (см. «Поучительные истории: Разделение»). Если запрос корреКте Df>e'
выполняется; в противном случае система аварийно завершает выпод^’ °8
программы и выводит сообщение об ошибке. Как и в однопользователь
системах, в мультипрограммных предусмотрены системные вызовы по
ляющие пользователям обращаться к службам операционных систем. °
О
а
b
с
Операционная система
Раздел 1
Раздел 2
Верхняя граница
Процессор
2 Используемый в данный
момент раздел
Ь Нижняя граница
Раздел 3
d
Рис. 9.10. Защита памяти в мультипрограммных системах с выделением
непрерывных областей памяти
Одна из проблем, существующих при любой организации па еСдЛ
проблема фрагментации (fragmentation). О фрагментации говор ’0
система не может использовать некоторые свободные области naW!^eCyPw
«Размышления об операционных системах: Пространственны®
и фрагментация»)23. Системы с фиксированным распределением оТоР9
страдают от внутренней фрагментации (internal fragmentation),^
проявляется, если объем программной части процесса и его Да^й jjjj х
ше, чем объем раздела, в котором этот процесс выполняется •
смотрим внешнюю фрагментацию в разделе 9.9.
память i юанизация и управление
535
| о1С 9.11 иллюстрирует проблему внутренней фрагментации. Три
ельских раздела системы заняты, но каждая из программ мень-
д>3°радмерУ» чем Раздел, в котором она размещена. В результате, хотя
(jo Ра3 мОдает быть достаточно свободной оперативной памяти для вы-
других процессов, она не может их выполнять, поскольку у нее
^^/Гдных разделов. Соответственно, часть ресурсов системы расходу-
сР° пользы. В следующем разделе мы рассмотрим другую схему орга-
б®3 памяти, которая пытается решить эту проблему. Мы увидим, что,
схема и улучшает ситуацию, использующая ее система все же мо-
^^дять от Фрагментации.
о
Операционная система
а -
Раздел 1
Ь
Раздел 2
с
Раздел 3
d
Используемая память
Неиспользуемая память
сл'ик ®нУтРенняя фрагментация в мультипрограммных системах
* ксиРованным распределением памяти
Вопросы для самопроверки
1. Объясните причины появления перемещаемых компиляторов,
трансляторов и загрузчиков.
2. Объясните преимущества и недостатки больших и маленьких раз-
меров разделов.
Ответы 1) До появления этих инструментов программистам при-
ходилось вручную указывать раздел, в котором программы должны
оыли выполняться. При этом могли напрасно расходоваться память
И процессорное время, кроме того, уменьшалась переносимость прило-
жений. 2) В больших разделах могут размещаться большие програм-
мы, но если в них размещаются маленькие программы, то появляется
сильная внутренняя фрагментация. В маленьких разделах внутрен-
няя фрагментация меньше, и они позволяют достичь большей степени
мультипрограммности, однако маленькие разделы ограничивают раз-
мер программ.
536
Поучительные истории
ч
Разделение
Когда Харви Дейтел проходил собеседо-
вания при поступлении на работу в Службу
компьютерной безопасности в Пентагоне
в заключительной беседе участвовал со-
трудник, отвечающий за все компьютерные
системы Пентагона. Когда ему предложили
работу, Харви был полон энтузиазма: «Сэр,
если я буду работать в Пентагоне
жу все усилия, чтобы защитить
ютеры от происков врага». Нани^”1
улыбнулся и ответил: «Харви, менМйТе,|ь
волнуют враги. Я всего лишь хочу” МаПс
флот не знал, чем занимаются воан ЧТо^
душные силы».
Мораль для разработчиков операционных систем: ключевой момент в проектирова
операционных систем - разделение задач. Операционные системы должны предоставлю
рабочую среду, в которой множество разных пользователей могут работать одновременно
и быть уверенными, что их программы и данные останутся конфиденциальными и будут не
доступны для других.
Размышления об операционных системах
Пространственные ресурсы и фрагментация
Рассмотрим стандартный сценарий: вла-
делец ресторана в торговом центре хочет
расширить свое заведение, но в центре нет
свободных помещений большей площади,
и владельцу приходится ожидать, пока не
освободятся смежные с его рестораном по-
мещения, а затем убирать стены, чтобы по-
лучить большее помещение. Офисное зда-
ние изначально может представлять собой
пустую коробку; по мере того, как площадь
в здании выкупается, строятся стены для
разделения офисов. Если клиент желает
расширить свой офис, это может оказаться
сложным делом — если не доступна боль-
шая площадь и уже заняты соседние офис«
В обоих случаях желающие расширЯ^Д
структуры не могутэтого делать
ствия цельных областей доста го'
мера и могут быть вынуждены
вать несколько отдельных меньшг’^^?
тей. Такое положение часто
в операционных системах
фрагментацией. Из этой книги
о проявлениях фрагментации в^ей
ной памяти и на устройствах вне
ти, а также о мерах, с помоШь^^ах
разработчики операционных с
рются с фрагментацией.
з-заотсУ1
>чного Ра3
испогьз0
... обл*'
встр^ае'^
и
оПеР
№
ffi-
г ff урбанизация и управление
537
дтации. Очевидно, оптимальное решение состоит в том, что нужно
>пяГ’*е каждому процессу ровно столько памяти, сколько ему требуется
объема, доступного в оперативной памяти). Такой режим на-
памяти
памяти
памяти.
0 Мультипрограммные системы с изменяемым
Отделением памяти
программным системам с фиксированным распределением па-
МУльТ^ственны ограничения, приводящие к неэффективному использо-
jjif^^^cypcoB. Например, раздел может оказаться слишком маленьким,
Честить ожидающий выполнения процесс, или настолько боль-
то система потеряет значительный объем памяти из-за внутренней
«педелях
(в 14 мультипрограммным с изменяемым распределением
liable-partition multiprogramming)25- 26- 27.
<) 9.1 Характеристики изменяемых разделов
рисунок 9.12 демонстрирует последовательность выделения
в мультипрограммных системах с изменяемым распределением
Мы продолжим рассматривать исключительно схемы с выделением не-
рерывных областей, в которых программа должна занимать смежные
ячейки в памяти. Очередь в верхней части рисунка содержит доступные
задачи и сведения об их потребностях в памяти. Операционная система не
делает никаких предположений о размерах задач (за исключением того,
что задачи не превышают по объему доступную оперативную память).
Система просматривает очередь и размещает каждую задачу в доступной
области оперативной памяти, после чего задача становится процессом.
На рисунке 9.12 в оперативной памяти могут поместиться первые четыре
задачи; мы предполагаем, что объем свободного пространства в оператив-
и памяти после их размещения будет меньше 14 МБ (размера следую-
а^ачи в очеРеди).
8eg , темЬ1 с изменяемым распределением памяти не страдают от внутрен-
аГМенТаи'ии’ ПОСКОЛЬКУ каждому процессу выделяется раздел, соот-
часТь Ю1Ций размеру этого процесса. Но при любой организации памяти
Чам Мяти тратится бесполезно. В системах с изменяемым распределени-
Ч цОсл потеРи неочевидны, пока процессы не заканчивают выполнять-
Чего в памяти появляются дыры (holes), как показано
цое 9-13. Система может размещать в этих дырах новые процессы,
я ьсе° меРе того, как процессы продолжают завершаться, дыры стано-
fr «РоцеМеНЬШе’ и’ в KOHPe концов, в них уже невозможно поместить но-
3!^llleiltaVC ^Т° явление называется внешней фрагментацией (external
ЙООП" 3Десь общий объем дыр достаточен, чтобы вместить новый
’’ Г1Роп Ка„жДая Дыра в отдельности слишком мала для размещения
538
%
Л»
Рис. 9.12. Первичное выделение разделов в мультипрограммной системе
с изменяемым распределением памяти
й фр^
Система может принять некоторые меры для уменьшения внеП1^1Яти 3s'
ментации. Когда процесс в системе с изменяемым распределением п
вершается, система может определить, является ли освободивши51 к Cf°
смежной с уже свободными областями. Затем система запишет в с
бодных областей (free memory list), что либо (1) появилась новая (то®\
область, либо (2) уже существующая свободная область увеличила з0 рг
объединит уже существующую дыру и только что образовавшую13 > 3&ер^.
цесс объединения смежных свободных областей в одну большего I#
зывается сращением (coalescing) и показан на рис. 9.14. Сраш
система получает максимально возможные непрерывные участ
памяти.
’ egntatnb. Организация а управление
У39
рационная
^стема
Операционная
система
-------------------1
Операционная
система
Р2 заканчи-
вает выпол-
няться и ос-
вобождает
занятую им
память
Дыра
Дыра
г4 * Р4заканчи
вает выпол-
няться и ос-
вобождает
Р5 занятую им
память
Дыра
Дыра
Дыра
fit. 9.13. Дыры в оперативной памяти в мультипрограммных системах
с изменяемым распределением памяти
Операционная
система
Г
(Операционная
система
Операционная
система
Другие процессы
Другие процессы
Другие процессы
Ободная область
(2 МБ)
Свободная область
(2 МБ)
Р1 (5 МБ)
Р,заканчи-
| вает выпол-
няться и ос- ,
; вобождает
Др f занятую им
епроцессы память
I Свободная обла
(5 МБ)
Свободная область
(7 МБ)
Операцион-
ная система
объединяет
i смежные
свободные
области
Другие процессы : иформиру-
! ет из них
одну
Другие процессы
! .
ение ДЫР в оперативной памяти в мультипрограммных системах
। “г распределением памяти
540
Ч5
Даже если операционная система может сращивать свободные
их размещение в разных областях памяти может приводить к цо
метных объемов — иногда достаточных в сумме для размещен^
процесса, причем ни одна свободная область недостаточна для эт 4
дельности.
Еще одна методика уменьшения внешней фрагментации назыв "
лотнением памяти (memory compaction) (рис. 9.15). В рамках этойyj
ки процессы в памяти перемещаются к краю адресного прострд1461^
При этом образуется единая свободная область вместо множества ^CTs^>
ных свободных областей памяти, обычных в мультипрограммных
мах с изменяемым распределением памяти. В результате вся свобод
мять составляет единую непрерывную область, и ждущий процесс аяЧа
запускать, если он помещается в области, образовавшейся в результ^^
лотнения. Иногда уплотнение памяти называют трамбовкой п
(memory burping). Более распространенный термин с тем же значение* 1
сборка мусора (garbage collection)32.
Операционная Операционная
система система
Операционная система размещает
рядом все используемые блоки
и формирует единую большую
свободную область
Рис. 9.15. Уплотнение памяти в мультипрограммных системах с изме
распределением памяти
За уплотнение памяти приходится платить. Накладные РаС с-л-
лотнение потребляют системные ресурсы, которые в против
могли бы использоваться более продуктивно. Кроме того, на вР
нения уплотнения выполнение всех процессов должно приост j
память. Организация и управление
541
оясет привести к непредсказуемому времени отклика для Инте-
ле пользователей и к катастрофическим последствиям для систем
впемени. Кроме того, при уплотнении нужно перемещать про-
разместившиеся в оперативной памяти. Для этого нужно хра-
формацию об их перемещаемости, которая обычно теряется по за-
•Lj, и загрузки программ. Если задачи быстро сменяют друг друга, то
иЯ придется проводить часто. Выигрыш от уплотнения может не
дот06 потребления системных ресурсов.
>ДаТЬ
Вопросы для самопроверки
1, Объясните разницу между внутренней и внешней фрагментацией.
2. Опишите две методики уменьшения внешней фрагментации
в мультипрограммных системах с изменяемым распределением па-
мяти.
Ответы 1) Внутренняя фрагментация присутствует в средах
с фиксированными разделами, если процессу выделяется больше про-
странства, чем ему нужно. При этом часть памяти в каждом разделе
не используется. Внешняя фрагментация появляется в средах с изме-
няемыми разделами, поскольку память в промежутках между разде-
лами процессов не используется. 2) Сращение объединяет свободные
блоки памяти в блоки большего размера. Уплотнение памяти переме-
щает разделы ближе друг к другу, объединяя свободную память
в один блок.
9.9.2 Стратегии размещения в памяти
В мультипрограммных системах с изменяемым распределением памя-
та часто приходится выбирать область памяти из нескольких подходя-
чих для размещения процесса. Стратегия размещения в памяти
emory placement strategy) определяет, в каких областях в оперативной
тоиЯТИ ₽азме1Чаются загружаемые программы и данные33- 34> 35. Три пас-
ет п 10льзУемые и рассматриваемые в литературе стратегии иллюстриру-
₽ИСУНОК 9.1636.
Стратегия размещения в первых подходящих участках (first-fit
размещает задачу в первом же найденном свободном участке
ей Rar°4Horo размера. Интуитивно эта стратегия привлекательна сво-
* £ Ь1стРотой принятия решений.
81ццТег?я Размещения в наиболее подходящих участках (best-fit
к За Размещает задачу в свободном участке, наиболее близком
Для е по размеру, чтобы оставить минимальную по размеру дыру.
йодх °гих людей такая стратегия ближе всего — но поиск наиболее
тОг, ягЧего участка требует некоторых накладных расходов, а, кро-
к J эта стратегия оставляет в памяти много мелких, непригод-
3аИИсц11СПОЛЬЗОванию ДЫР' Заметьте, что на рисунке 9.16 мы храним
„В СПИске свободных блоков в порядке роста размеров блоков;
°Ртировка довольно дорого обходится.
(а) Стратегия размещения в первых подходящих участках
Задача размещается в первом блоке из списка
свободных блоков, в котором она может поместиться
о
а
Список свободных блоков (Неупорядочен.)
Адрес
начала Длина
Запрос
на 13 МБ
d
е
f
е
5 MB
Операционная
система
дыра объемом
16 МБ
Используется
Используется
дыра объемом 5 Мб
с
14МВ
д
Используется
g
зо мв
(б) Стратегия размещения в наиболее подходящих участках
Задача размещается в наименьшем по размеру блоке,
в котором она может поместиться
h
~б
дыра объемом
30 МБ
-------------
а
Ь
Список свободных блоков
Адрес
начала
(Список отсортирован
в порядке возрастания
объемов дыр.)
е
Длина
5 МВ
Запрос
на 13 МБ ,
дыра объемом 5 МБ
е
f
Операционная
система
дыра объемом
16 МБ _
Используется
дыра объемом
14МБ
Используется
а 16 МВ
Используется
д
g
30 МВ
дыра объемом
30 МБ
(в) Стратегия размещения в наименее подходящих участках
Задача размещается в наибольшем по размеру блоке,
в котором она может поместиться
h
О
а
b
Список свободных блоков
Адрес
начала Длина
(Список отсортирован
в порядке уменьшения
объемов дыр.)
с
а
е
16 МВ
"5 МВ
с
14МВ
g
30 МВ
d
Запрос
на 13 МБ
е
дыра объемом
' 30 МБ
Операционная
система
дыра объемом
16МБ
Используется 1
дыра объемом I
14МБ
Используется I
дыра объемом 5 МБ,
Используется
Рис. 9.16. Стратегии размещения в первых подходящих, наиболее поДх
и наименее подходящих участках памяти
’ одтегия размещения в наименее подходящих участках (worst-fit
^"tegy) на первый взгляд может показаться противоестественной.
е^Г«аКО при более близком рассмотрении у нее тоже обнаруживаются
^увлекательные стороны. Эта стратегия помещает задачу в дыру,
г 11 оторУ10 она подходит хуже всего (т.е. в самую большую дыру). Ин-
Р к тИвно аргументация понятна: если задача помещена в самую боль-
тУ1* ДЫРУ’ то остающаяся дыра будет тоже велика и сможет вместить
одну довольно большую программу. Поиск наименее подходяще-
е1Д-счастка тоже связан с накладными расходами, и эта стратегия, как
ГдредыДУШая, оставляет в памяти много мелких, непригодных к ис-
пользованию дыр.
ествует вариант стратегии размещения в первых подходящих уча-
размещение в следующем подходящем участке (next-fit), когда
сТ1<аХ подходящей дыры начинается в том месте, где закончился предыду-
flO0“ поиск37- В упражнении 9.20 в конце данной главы эта стратегия рас-
^атривается подробнее.
Вопросы для саллопроВерки
1. В чем привлекательность стратегии размещения в первом подходя-
щем участке?
2. (Да/Нет) Ни одна из стратегий, рассмотренных в этом разделе, не
приведет к появлению внутренней фрагментации.
Ответы 1) Ее интуитивная привлекательность состоит в том, что
не нужно каким-то образом упорядочивать список свободных блоков,
соответственно, накладные расходы для использования этой страте-
гии невелики. Однако она может работать медленно, если дыры в на-
чале списка слишком малы для размещения нового процесса. 2) Да.
ЫО Мультипрограммные системы с подкачкой
сист° ВСеХ РассмотРенных нами до сих пор схемах мультипрограммных
вИя пРоцесс находится в оперативной памяти все время его выполне-
ЬтеРнатив°й такому подходу является использование подкачки
Мятц п^)а, когда процессу не обязательно находиться в оперативной па-
с:е вРемя его выполнения.
8о®Ремр°ТО₽Ых системах с подкачкой (рис. 9.17) в оперативной памяти од-
цОр Но находится только один процесс. Этот процесс выполняется до
Ха ц ’ п°Ка он может продолжать использование процессора (например,
а °яьзоЦеССУ Не потРебуется выполнить операцию ввода/вывода). Если
311116 ПР°рессора приостанавливается, процесс передает память
к °Р Другому процессу. В результате система поочередно передает
(ЯсДому процессу. Когда процесс освобождает ресурс, система вы-
ц з Укачивает) предыдущий процесс на вторичное устройство хра-
с- Чт0^РУЖает (закачивает) в оперативную память следующий про-
К. Выгрузить процесс из оперативной памяти, система сохраняет
ЬгЧНой литературе часто применяют также термин «свопинг» — прим.ред. перев.
544
Ч,
содержимое выделенной процессу памяти (включая блок управлеи '
цессом) на вторичном устройстве хранения. Когда система закачцд
цесс обратно в оперативную память, содержимое памяти процесса
значения извлекаются обратно со вторичного устройства хранена
но система выкачивает содержимое процесса из оперативной памя ’
качивает его обратно множество раз за время выполнения процесеТи *1 з4
Многие ранние системы с разделением времени были реализс
описанному выше принципу. При небольшом числе пользователей
можно было гарантировать нормальное время реакции, но разрабBllOjl5e
виртуальной щ*
следующих двух
понимали, что для поддержки большего числа пользователей им
мы лучшие методы. Системы начала 1960-х годов с подкачкой
родительницами современных страничных систем
Страничные системы подробно рассматриваются
вах, посвященных виртуальной памяти.
в
Образы оперативной памяти процессов, хранящиеся на
вторичном устройстве хранения с произвольным доступом
Рз Рд Ps Р6 Р7
а а а а
i
i
Область подкачки
I
s ।
i
ь ------------------------1
Оперативная память
0
Операционная
система
а —-J
1 Одновременно в оперативной памяти находится только один про-
цесс.
2 .Процесс выполняется пока не
а) генерируется запрос на ввод/вывода
б) истекает интервал времени
в) завершается самостоятельно.
З.Затем система выгружает процесс из оперативной памяти, копируя
содержимое его области памяти на вторичное устройство хранения
4.Система загружает в оперативную память следующий процесс,
считывая образ его области оперативной памяти в область подкачки.
Новый процесс выполняется, пока он не будет выгружен из памяти,
затем начинает выполняться следующий процесс, и так далее.
И
Рис. 9.17. Мультипрограммность в системе с подкачкой, когда в памятй
находиться одновременно только один процесс
545
f Kf!^g 1,амягЛЬ' ОрганизаЧия и управление
х былн созданы более сложные системы с подкачкой, в которых
(1°3^тивной памяти могло одновременно находиться несколько
оцеРа4 38, 39. Здесь система выгружает процесс из оперативной памяти
^’еСС°сЛИ память требуется новому процессу. При достаточном объеме
иОй памяти в таких системах можно резко снизить затраты вре-
0*еР яа подкачку-
Вопросы для самопроверки
1. Объясните суть накладных расходов при использовании подкачки
с точки зрения загруженности процессора. Предполагайте, что
в памяти может одновременно находиться только один процесс.
2. Почему системы с подкачкой, в которых только один процесс мог
находиться в памяти одновременно, не подходили для многополь-
зовательских интерактивных систем?
Ответы 1) Во время выгрузки процессов из оперативной памяти
и их загрузки обратно процессор фактически простаивает. 2) Системы
с подкачкой такого типа не могли обеспечить приемлемые времена
реагирования при больших количествах пользователей, что было кри-
тично для интерактивных систем.
М-ресуреы
www.kingston.com/tools/umg/default.asp
Описывает роль память в компьютере. Хотя обсуждение в основном касается
современных компьютеров, которые используют виртуальную память (она рас-
сматривается в следующих главах), рассмотрены и многие фундаментальные по-
нятия.
WWW. 1 i nux- mag. com/ 2 о 0 1 - 0 6 / c ompi 1 e_01.html
ваемИСЫВаеТ ₽аботУ функции malloc () языка С, выделяющей память под созда-
Ые пеРеменные. В статье также описаны некоторые простейшие стратегии вы-
п°дхо Я памяти, рассмотренные выше (включая стратегии размещения в первом
Не). /,Я1цем блоке, в следующем подходящем блоке и наименее подходящем бло-
Oup'^m^ymanagement .com
’УВед слоВает метоДы управления памятью и сборки мусора. На сайте также дос-
^тво по&РЬ И3 б°лее чем терминов из области управления памятью, и руко-
Управлению памятью для начинающих.
""’огв
ИЯ реальной памяти (также называемой основной памятью, физиче-
^Ц^вТью* ИЛИ пеРвичной памятью) в компьютерной системе и управление
®°Льп ОКазь1вают огромное влияние на разработку операционных систем.
К11®»«*с’гРаиИЫСТВе совРеменных систем реализована виртуальная память, в неко-
Ч 4jleMo Jiae',Iblx системах и системах реального времени ее использование не-
и управление реальной памятью критически важно для таких сис-
546
^9
Независимо от того, какую схему управления памятью мы примени
кретной системе, мы должны решить, с помощью каких стратегий мы gv 8 и
ваться оптимальной производительности памяти. Стратегии управления^61'’
определяют, как себя ведет конкретная организация памяти в разных об Пак,Чг '
ствах. Обычно управление памятью выполняется с помощью, как прОгпСТ°чЧлЛ
и специализированных аппаратных устройств. Диспетчер памяти — э,
нент операционной системы, определяющий, как доступное пространств0
распределяется между процессами и как нужно реагировать на изменен
пользовании этой памяти процессами. Диспетчер памяти также взаимод^55 в И?
со специальными аппаратными устройствами управления памятью (если
есть) с целью повышения производительности. Та1<08Ц.
Программы и данные нужно поместить в оперативную память, прежде
тема сможет выполнить или обработать их. Иерархия памяти состоит из Л6^8^-
характеризующихся скоростью и ценой. Системы с несколькими уровнями Ве®’
ти перемещают программы и данные между разными уровнями. Над уровне Па,<я‘
ративной памяти в иерархии находится кэш, который работает намного бь °ае‘
оперативной памяти и в современных системах обычно располагается на
кристалле с процессором. Программы переносятся в кэш из оперативной пам^01*
после чего выполняются намного быстрее, чем в оперативной памяти. Поскол^0,
многие процессы, однажды обратившись к инструкциям и данным, будуТ
щаться к ним и в дальнейшем (явление, известное как временная локальность»
даже кэш сравнительно маленького объема может заметно повысить производи
тельность по сравнению с системами без кэша.
Стратегии управления памятью делятся на три категории. Первая — это стра-
тегии загрузки, определяющие, когда нужно загружать очередной фрагмент про
граммы или данных в оперативную память со вторичного устройства хранения.
Вторая — это стратегии размещения, определяющие, где в оперативной памяти
должны размещаться загружаемые программы и данные. Третья — стратегии за-
мены, определяющие, какие фрагменты программ или данных можно заменить
новыми, чтобы разместить в оперативной памяти загружаемые программы или
данные.
В системах с выделением непрерывных блоков программы хранятся в непре-
рывных областях памяти. В системах с фрагментированным выделением програм-
мы делятся на блоки или сегменты, которые могут размещаться в разных областях
оперативной памяти. Это позволяет системе использовать дыры (вакантные ФР®8
менты) в оперативной памяти, которые слишком малы, чтобы вместить всю Р
грамму. Хотя операционная система с фрагментированным выделением сло
чем система с выделением непрерывным, это усложнение оправдывается пов
нием степени мультипрограммности (т.е. количества программ, которое мо
новременно находиться в оперативной памяти). одно^
Первые компьютеры позволяли одновременно использовать их только JJagoj-
человеку. Обычно в них отсутствовали операционные системы. Позднее ₽ вх
чики систем создали наборы стандартных функций ввода/вывода, обт ед хОдй
в системы управления вводом/выводом (IOCS), чтобы программисту не оверл®в’
лось каждый раз писать инструкции ввода/вывода заново. Используй оцеР^
система могла исполнять программы, которые не помещались целиком
тивной памяти. Однако ручное создание оверлеев требует тщательного даДиЛс
планирования, и программисту часто требуются глубокие знания орган
мяти в системе. ^ет
При отсутствии защиты в однопользовательской системе процесс ь пРЧ^-
титься к области памяти, в которой размещается операционная система
меренно, или случайно — и заменить содержимое этой памяти ДРуги
В однопользовательских системах с выделением непрерывных блоков ^po^jjf
ративной памяти реализуется с помощью одного регистра границы,
в процессор. Процессы должны время от времени обращаться к < луж с 1
онной системы, например, для выполнения ввода/вывода. В операцио
память. Организация и управление
547
«смотрены специальные вызовы (иногда их называют вызовами супервизор
мощы° которых можно обращаться к ее службам.
\ с г1°нцх однопользовательских системах с реальной памятью выделенное для
р ^пемя расходовалось не только на ее выполнение, но и на загрузку и завер-
BQgbi4no на подготовку задачи к выполнению и завершение выполнения
е^е' заметное время, в течение которого компьютер простаивал. Создание сис-
лОД11'ЯС1.>тной обработки сделало использование компьютера более эффективным.
Пользовательских пакетных системах задачи собирались в пакеты путем по-
роДйОП^едьного размещения этих задач на лентах или дисках. Но даже в пакет-
оДОдьзовательских системах значительное количество ресурсов расходова-
ть!* ^полезно. Это привело к созданию мультипрограммных систем, в которых
дсь бе о пользователей могут по очереди использовать разные ресурсы системы.
0есКоЛр вЫХ мультипрограммных системах использовалось фиксированное рас-
® рние памяти — система делила оперативную память на несколько областей
°Ретэованного размера и размещала по одной задаче в каждой области. Система
Ф^^переключала процессор между задачами, создавая впечатление одновре-
^ого их выполнения. Чтобы преодолеть проблему напрасного расхода памяти,
”еВгпаммисты создали перемещаемые компиляторы, трансляторы и загрузчики.
мультипрограммных системах с выделением непрерывных блоков памяти за-
а часто реализуется с помощью наборов регистров границ. Каждому процессу
^ответствуют два регистра — базовый регистр и регистр предела. Одна из про-
блем, свойственных всем схемам организации памяти — проблема фрагментации,
фрагментация появляется, если система не может использовать отдельные облас-
ти свободной памяти. Системам с фиксированным распределением памяти свойст-
венна внутренняя фрагментация, появляющаяся, если размер данных и кода зада-
чи меньше размера раздела, в котором эта задача размещается в памяти.
Системы с изменяемым распределением памяти позволяют процессу занимать
ровно столько памяти, сколько ему нужно для работы (в пределах доступного объ-
ема оперативной памяти). Потери памяти неочевидны, пока процессы не заверша-
ются и не освобождают выделенную им память. При этом появляется внешняя
фрагментация. Система может предпринять меры для ее уменьшения — использо-
вать список свободных блоков и сращивать смежные свободные блоки, или выпол-
вять уплотнение памяти.
Стратегия размещения в оперативной памяти определяет, где в памяти будут
змещаться загружаемые программы и данные. Стратегия первого подходящего
4logTKa помещает загружаемую задачу в первый участок, достаточно большой,
дач вместить эту задачу. Стратегия наиболее подходящего участка помещает за-
ВместифСаМЬ1й Маленький из свободных участков, достаточно большой, чтобы ее
Страт ь пРи этом останется минимальное количество неиспользуемой памяти.
^Двый*151 наименее подходящего участка помещает задачу в самый большой сво-
С11)атеГиУ“аСТОК‘ Ва₽иант стратегии первого подходящего участка, называется
с Wo м еИ слеДУющего подходящего участка и начинает поиск участка для задачи
ПоДк Ста’ где закончился предыдущий поиск.
®°й Памя Ка — это механизм, позволяющий процессу не находиться в оператив-
Wj ВьТи все время его выполнения. Если процесс, находящийся в памяти, не
ц3агРУ5КЯПОЛНЯТЬСЯ’ система выгружает его на вторичное устройство хранения
Ра* НЯ его место в оперативной памяти новый процесс. Были созданы и бо-
п1е Системы с подкачкой, позволявшие одновременно находиться в опе-
аМяти нескольким процессам. В этих системах процесс выгружается из
ЧесСу и памяти только, если занимаемое им пространство требуется новому
548
Ключевые термины
IOCS (input/output control system — система управления вводом/выво
предшественница современных операционных систем, предоставлявц^01^ х
граммистам стандартный набор базовых процедур ввода/вывода. йя
Активное управление ресурсами (intensive resources management) — подх
котором часть ресурсов расходуется на выполнение управляющих
чтобы более эффективно использовать остальные ресурсы.
Базовым регистр (base register) — регистр, содержащий наименьший адре
мяти, к которому может обращаться процесс. в Па.
Внешняя фрагментация (external fragmentation) — явление в мультипрощ
ных системах с изменяемым распределением памяти, при котором в адпр^1*'
пространстве есть неиспользуемые области, слишком маленькие, чтобьг 0|<
стить процесс. ®lJe-
Внутренняя фрагментация (internal fragmentation) — явление в мультппрогпя
ных системах с фиксированным распределением памяти, когда размер вд!?’
и данных процесса меньше, чем размер раздела, в котором это процесс размет
ется.
Временная локальность (temporal locality) — свойство событий, заключающееся
в том, что они происходят в близкие моменты времени. В обращениях к памяти
временная локальность появляется, если процесс многократно обращается к од
ним и тем же элементам данных за короткие промежутки времени.
Время выключения (teardown time) — время, необходимое оператору и операци-
онной системе для удаления задачи из системы по окончании выполнения этой
задачи.
Время подготовки (setup time) — время, необходимое оператору и операционной
системе для подготовки задачи к выполнению.
Время по настенным часам (wall clock time) — время, прошедшее с точки зрения
пользователя.
Выделение непрерывных участков памяти (contiguous memory allocation) — ме
тод выделения памяти, при котором все адреса, выделенные процессу, образую*
непрерывную последовательность.
Выделение фрагментированных участков памяти (noncontiguous nW
allocation) — метод выделения памяти, делящий программу на нескольк ,
можно, несмежных, фрагментов, которые система размещает в оператив 1
мяти.
Вызов супервизора (supervisor call) — см. системным вызов. pea-10'
Диспетчер памяти (memory manager) — компонент операционной систем^сд-
зующий механизм организации памяти в системе и стратегию управл
мятью. vCU3^
Дыра (hole) — свободная область в памяти в мультипрограммных систе
няемым распределением памяти. исте1|!Ь1 *
Иерархия памяти (memory hierarchy) — модель, разделяющая память
несколько уровней по быстродействию, емкости и стоимости.
Кэш-память (cache memory) — быстродействующая, дорогая и малая^
память, в которой хранятся копии данных и программ для ускоре
к ним. (*яГ^'
Мультипрограммным режим с изменяемым распределением
partition multiprogramming) — организация оперативной памяти, р
ждому процессу выделяется ровно столько памяти, сколько ему ну
боты.
я память. Организация и управление
549
W ^tnorpaMMHbI® режим с фиксированным распределением памяти (fixed-
multiprogramming) — организация оперативной памяти, в которой вся
0 раздал память делится на несколько разделов фиксированного размера.
И ИЗ этих разделов размещается по одной задаче.
В /oVerlay) — подход, позволяющий выполняться программам, большим по
л6ерЛсИ' чем доступная в системе оперативная память. Программы делятся на
° об^^/дх называют оверлеями), которым не обязательно нужно находиться
часТ“яти одновременно.
8 П зовательская система с выделением непрерывных блоков (single-user
t^Hguous memory allocation system) — система, в которой программы разме-
с датся в непрерывной области памяти и выполняются по одной за раз.
08 точная пакетная система (single-stream batch processing system) — систе-
0дяо° азмещающая готовые к выполнению задачи из одной очереди в доступные
ма, Р
разделы- .
изация памяти (memory organization) — представление оперативном памяти
^^истеме, определяющее, например, сколько процессов могут одновременно на-
Вопиться в памяти, где в памяти размещаются программы и данные, и когда
□ня заменяются другими программами и данными.
Прпсход между задачами (job-to-job transition) — время, в течение которого в од-
вопоточной пакетной системе не выполняется работа, поскольку одна задача за-
вершается, а следующая — загружается и подготавливается к выполнению.
Подкачка (swap) — копирование содержимого области памяти процесса на вторич-
ное устройство хранения, удаление процесса из памяти и передача освободив-
шегося пространства другому процессу.
Привилегированный режим (executive mode) — см. режим ядра.
Процессор потока задач (job stream processor) — элемент в однопоточных пакет-
ных системах, управляющий переходами от задачи к задаче.
Раздел (partition) — в оперативной памяти — часть памяти, выделенная процессу
в мультипрограммной системе. Программы помещаются в разделы, чтобы опе-
рационная система могла защитить себя от пользовательских процессов и про-
цессы — от других процессов.
егистр границы (boundary register) — в однопользовательских системах — ре-
I jBCT₽* ^пользующийся для защиты памяти посредством разграничения облас-
р памяти ядра и пользовательской области памяти.
продела (limit register) — регистр, в котором в мультипрограммных сис-
| х с фиксированным распределением памяти хранится адрес конца области
I ^е*Нм ТИ’ ВЬ1деленн°й процессу.
I п°лняДРа (kernel mode) — защищенный режим, в котором процессор может вы-
I ^орКа ТЬ ИНСтРУКции операционной системы от имени пользователя.
(|,стем^,У<:О₽а (^агка8'е collection) — см. уплотнение памяти.
('||с»е1аа^₽авленмя вводом/выводом (input/output control system) — см. IOCS.
р сКоГо " ®Ызов (system call) — запрос к операционной системе от пользователь-
* 'Wqk иРиЦесса на выполнение некоторой операции.
г сИстеЬ1Во6°Дш.1х блоков (free memory list) — структура данных в оперативной
^Держащая данные о свободных блоках оперативной памяти.
Ь*"* <^₽ В Памяти (coalescing the memory holes) — механизм слияния смеж-
4сПреде ОДных областей памяти в мультипрограммной системе с изменяемым
Ч|’ОзКноеНиеМ памяти- Он позволяет создать свободные области максимально
10 РазмеРа Для размещения загружаемых программ и данных.
“ “е», рагРУЗКи (fetch strategy) — подход, с помощью которого система опре-
1Ого загружать следующий фрагмент программы или данных со вто-
। Устройства хранения в оперативную память.
550
%
Стратегия загрузки по требованию (demand fetch strategy) — стратеги
жающая фрагменты программ и данных в оперативную память, когда Ч’
менты запрашиваются процессами.
Стратегия замены (replacement strategy) — стратегия, определяюща
фрагменты программ и данных в оперативной памяти заменяются новь
Стратегия предварительной загрузки (anticipatory fetch strategy) — Ме
ки страниц в оперативную память, загружающий их до того, как он t 3агРуд
бятся, чтобы они были сразу доступны при обращении к ним. Требует
дывания последующих действий программ. ПреДУгв
Стратегия размещения (placement strategy) — в оперативной памяти_Стп
определяющая, где в оперативной памяти будут размещаться загружавм
граммы и данные. Ые про’
Стратегия размещения в наиболее подходящих участках памяти m
memory placement strategy) — стратегия, размещающая загружаемую
в наименьшем достаточном по размеру свободном участке памяти.
Стратегия размещения в наименее подходящих участках памяти (Wor.
memory placement strategy) — стратегия, размещающая загружаемую зал
в наибольшем по размеру свободном участке памяти, достаточном для разме
ния этой задачи. ™
Стратегия размещения в первых подходящих участках памяти (first-fit meniorv
placement strategy) — стратегия, размещающая загружаемую задачу в первом
найденном достаточном по размеру свободном участке памяти.
Стратегия размещения в следующих подходящих участках памяти (next-fit
memory placement strategy) — стратегия, начинающая поиск участка для разме-
щения задачи в том месте, где закончился предыдущий поиск.
Стратегия управления памятью (memory management strategy) — методика, по
которой конкретная организация памяти выполняет загрузку данных в память,
их размещение и замену другими данными.
Трамбовка памяти (burping the memory) — см. уплотнение памяти.
Уплотнение памяти (memory compaction) — перемещение всех разделов в мульти-
программной системе с изменяемым распределением памяти к одному краю ад-
ресного пространства, чтобы создать свободную область максимально возможно^
го размера.
Фрагментация (fragmentation) — в оперативной памяти — невозможность испо
зовать некоторые области свободной оперативной памяти.
Язык управления задачами (job control language) — интерпретируемые nP°cTe(iy
ром потока задач команды, описывающие задачи и подготавливающие с
для выполнения этих задач (в однопоточных пакетных системах).
Упражнения
9.1. В иерархических системах памяти перемещения программ и Да
ду различными уровнями связаны с определенными накладные !пере»^
ми. Объясните, почему выгоды от использования таких систем
вают накладные расходы. лг0^’°^'
9.2. Почему загрузка по требованию оставалась общепринятой так A°eJS де6*
му предварительная загрузка гораздо более популярна сейчас, Л
летия назад? г$#гЛ
9.3. Обсудите проявления фрагментации памяти в каждой из схем ор
памяти, описанных в этой главе.
551
9>-
g.6-
Jfgfflfiija/vuiinb. Организация а управление
rr и каких обстоятельствах могут быть полезны оверлеи? Когда оверлей
q 4. ^Рдно размещать в оперативной памяти поверх другого оверлея? Как ис-
I ^о^зование оверлеев влияет на длительность разработки программ? Как
я°л вЛияет на пригодность программ к модификации?
° Л удите причины появления мультипрограммных систем. Какие свойства
огтэамм и машин делают мультипрограммность привлекательной? В ка-
обстоятельствах она нежелательна?
В 1 работаете с иерархической системой памяти, состоящей из четырех
** овНей — кэша, оперативной памяти, вторичных и третичных устройств
^анения. Предположим, что можно исполнять программы, хранящиеся
Х1дюбом уровне иерархии. Все уровни имеют одинаковый объем, и адрес-
ные пространства их идентичны. Программы, находящиеся в кэше, выпол-
няются быстрее всего, оперативная память в десять раз медленнее кэша,
вторичные устройства хранения вдесятеро медленнее оперативной памяти,
а третичные — вдесятеро медленнее вторичных. В системе есть только один
процессор, и может одновременно выполняться только одна программа.
а. Предположим, что программы и данные могут перемещаться между лю-
быми двумя уровнями под управлением операционной системы. Время,
необходимое на перемещение, определяется самым медленным из уров-
ней, между которыми выполняется перемещение. Почему операцион-
ная система может решить перемещать данные напрямую из кэша во
вторичное устройство хранения, не используя оперативную память? По-
чему данные и программы могут перемещаться на более низкие уровни
иерархии? Почему нужно перемещать их на более высокие уровни?
б. Описанная выше схема несколько необычна. В большинстве случаев дан-
ные и программы могут перемещаться только между соседними уровня-
ми иерархии. Приведите несколько аргументов против перемещений из
кэша на низшие уровни иерархии в обход оперативной памяти.
В качестве системного программиста большой мультипрограммной системы
с фиксированным распределением памяти вам нужно определить, требуется
ли изменение действующего в данный момент распределения памяти.
а. Какая информация вам пригодится для принятия решения?
6. Если бы эта информация была непосредственно доступна вам, как бы вы
определили идеальное разбиение памяти на разделы?
в. Каковы последствия изменения разбиения на разделы в такой системе?
Простой способ перемещения программ в мультипрограммных системах —
использование одного регистра перемещения в процессоре. Все программы
транслируются для адресов, начинающихся с нулевого, но в процессе ис-
°лнения программ к каждому адресу прибавляется значение из регистра
перемещения. Обсудите использование такого регистра и управление им
Мультипрограммной системе с изменяемым распределением памяти. Ка-
9.9 р 1м образом можно использовать регистр перемещения в системе защиты?
ратегии размещения определяют, где в памяти размещаются загружае-
а программы и данные. Предположим, что задача, ожидающая выпол-
До ИЯ* тРебУет объема памяти, который можно выделить в данный момент,
и ли система немедленно загрузить эту задачу в оперативную память
0. ачать ее выполнять?
сИсРтеДеление тарифов на использование ресурсов в мультипрограммных
а ^емах может оказаться сложной задачей.
однопользовательской системе обычно взимается плата за использова-
е всей системы сразу. Предположим, что в мультипрограммной систе-
в какой-то момент работает только один пользователь. Должна ли
Него взиматься плата за использование всей системы?
9.7.
9.8.
552
9.11.
9.12.
9.13.
ч,
б. Мультипрограммные операционные системы обычно потребляю,,
ное количество ресурсов, управляя многопользовательскими с
Должны ли пользователи платить за эти ресурсы, или они долж₽е;^Я
глощаться» операционными системами? ‘
в. Большинство людей согласны, что плата за использование ком
ных систем должна быть «справедливой», но немногие могут o6Ubl°1’®b.
смысл понятия «справедливый». Другой атрибут схем тарифу
более легкий для определения — предсказуемость. Резонно -к
что если плата за выполнение задачи сегодня составляет некото
личину, то выполнение ее завтра при тех же условиях будет стог 6е'
близительно столько же. Предположим, что плату за исполнюU₽l{'
мультипрограммной системы мы взимаем соответственно врем Ваа*Ч
настенным часам, то есть за все реальное время от запуска задачи °0
вершения ее выполнения. Будет ли такая методика давать предо За‘
мне результаты? Почему? Казуе.
Обсудите преимущества и недостатки выделения фрагментированных
ластей памяти. 06
Многие разработчики считают, что операционным системам всегда еле
предоставлять статус «максимального доверия». Некоторые разработчиц1
считают, что даже операционным системам следует ставить некоторые or
раничения, особенно в части обращений к определенным областям памяти"
Обсудите доводы за и против предоставления операционной системе посто-
янного полного доступа ко всей оперативной памяти в системе.
Развитие операционных систем обычно несет эволюционный, а не револю-
ционный характер. Опишите мотивы, побудившие разработчиков ввести
следующие изменения в операционных системах:
а. Переход от однопользовательских систем к мультипрограммным.
б. Переход от мультипрограммных систем с фиксированным распределе-
нием памяти, абсолютной трансляцией и загрузкой программ к систе-
мам с перемещаемой трансляцией и загрузкой программ.
в. Переход от мультипрограммных систем с фиксированным распределе-
нием памяти к мультипрограммным системам с изменяемым распреде-
лением памяти.
г. Переход от систем с выделением непрерывных областей памяти к систе-
мам с выделением фрагментированных областей. о
д. Переход от однопользовательских систем с ручной подготовкой зад
к однопоточным пакетным системам. №
9.14. Представьте себе следующую ситуацию: задачи находятся в очереди
пуск, ожидая, пока в системе освободится достаточно оперативной
для их размещения. Если очередь представляет собой простую стру_аТ.
«первый-вошел-первый-вышел», то для размещения в памяти можетР^^и
риваться только первое задание в очереди. При использовании
структур можно просматривать все задачи в очереди и выбирать сл^ ^осУ1
задачу для загрузки и выполнения. Покажите, как такие стру
увеличить пропускную способность по сравнению с простой очереД
проблемы могут возникнуть при использовании таких структур-
9.15. Пессимистически настроенный разработчик операционных си<1 ра31^
тил, что, в конечном счете, неважно, какая используется страз
щения данных в оперативной памяти. Раньше или позже, но gy^yT др-
равно достигнет стабильного состояния, в котором все стратегии g^i
водить к одинаковым результатам. Согласны ли вы с таким mi *
гументируйте свой ответ. х
9.16. Другой пессимистически настроенный разработчик операцией р
считает, что бессмысленно присваивать стратегиям официал
вроде «стратегии размещения в первых подходящих участках п
«управление
553
„ерждает, что эта стратегия эквивалентна простому случайному разме-
рддгю- Согласны ли вы с таким мнением? Аргументируйте свой ответ.
Лпедставьте себе систему с подкачкой, использующую несколько разделов.
Абсолютная версия такой системы потребовала бы постоянных перемеще-
" й программ между вторичным устройством хранения и одним из разде-
ле Перемещаемая система позволила бы программам размещаться в любом
Л зделе, достаточном для них по размеру, причем, возможно, в разных раз-
Р лаХ при последовательных перемещениях. Предположим, что объем опе-
ративной памяти во много раз больше, чем размер средней задачи. Обсудите
Преимущества такой многопользовательской системы с подкачкой по срав-
нению с однопользовательской системой, описанной ранее в этой главе.
Разделяемые процедуры и данные позволяют уменьшить суммарные по-
требности задач в оперативной памяти, увеличив, тем самым, степень
мультипрограммности. Объясните, как можно реализовать механизм раз-
деляемого доступа для каждой из перечисленных ниже систем. Если вы
считаете, что в какой-то из этих систем разделяемый доступ бессмысленен,
объясните, почему.
а. Мультипрограммная система с фиксированным разделением памяти,
абсолютной трансляцией и загрузкой.
9-^'
9.1®-
б. Мультипрограммная система с фиксированным разделением памяти,
перемещаемой трансляцией и загрузкой.
в. Мультипрограммная система с изменяемым распределением памяти.
г. Мультипрограммная система с подкачкой, позволяющая только двум
задачам одновременно находиться в оперативной памяти, но в общей
сложности позволяющая запускать одновременно более двух задач.
9.19. В большинстве дискуссий в этой главе подразумевалось, что оперативная
память относительно дорога и необходима тщательная ее диспетчеризация.
Представьте себе, что оперативная память стала настолько дешевой и ем-
кой, что пользователи могут получать такие объемы для своих задач, какие
захотят. Обсудите влияние такого события на:
а. Разработку операционных систем и стратегий управления памятью.
б. Разработку прикладных программ.
• в этом упражнении мы рассмотрим стратегию размещения в следующем
подходящем участке и сравним ее со стратегией размещения в первом под-
ходящем участке.
а- Чем будут отличаться структуры данных, используемые в стратегии
размещения в следующем подходящем участке от структур, используе-
мых в стратегии размещения в первом подходящем участке?
• Что произойдет в системе, использующей стратегию первого подходя-
щего участка, если будут просмотрены все доступные блоки памяти и не
будет найден блок подходящего размера?
в- Что произойдет в системе, использующей стратегию следующего подхо-
дящего участка, если последний блок в списке свободных будет недоста-
г *°ЧНОГо размера?
д' т»акая стратегия использует память более равномерно?
тгСиользование какой стратегии приведет к накоплению маленьких сво-
е ??ДНь1х блоков в младших адресах памяти?
акая стратегия будет лучше обеспечивать наличие больших свободных
блоков?
5S4
9.21.
9.22.
9.23.
ч,
(Правило пятидесяти процентов). Математически подкованные читат
гут попытаться доказать «правило пятидесяти процентов», выв^^ч]
Кнутом40’ 41. Это правило говорит, что мультипрограммная систем;;
няемым распределением памяти в процессе работы постепенно д С
стабильного состояния, в котором количество свободных областей
тельно равно половине количества занятых областей. Это правило пв
гает, что подавляющее большинство задач не точно соответствует цр
рам свободным областям, в которые эти задачи загружаются (т.е. >
задачи в свободную область не уменьшает количество свободных обд
Мультипрограммная система с изменяемым распределением памо™^).
пользует список свободных блоков для учета доступной оперативной111 ®с-
ти. В данный момент список содержит записи о свободных участках Па‘'|,а'
ром 150 КБ, 360 КБ, 400 КБ, 625 КБ и 200 КБ. Система получает заг^1®’
на 215 КБ, 171 КБ, 86 КБ, и 481 КБ, в указанном порядке. Определи^0®11
держимое списка свободных блоков после выполнения этих запросов^0'
использовании следующих стратегий размещения: п₽в
а. размещения
б. размещения
в. размещения
г. размещения
В этом упражнении анализируются стратегии размещения в наиболее
и наименее подходящих участках, рассмотренные в разделе 9.9, с исполь-
зованием различных структур данных.
а. Обсудите эффективность стратегии размещения в наименее подходящем
участке при поиске подходящего блока памяти, если сведения о свобод-
ных участках хранятся в:
1) неотсортированном массиве;
2) массиве, отсортированном по размеру блока;
3) неотсортированном связном списке;
4) связном списке, отсортированном по размеру блока;
5) бинарном дереве;
6) сбалансированном бинарном дереве.
б. Обсудите эффективность стратегии размещения в наиболее подходяще*1
участке при поиске подходящего блока памяти, если сведения о сво
ных участках хранятся в:
1) неотсортированном массиве;
2) массиве, отсортированном по размеру блока;
3) неотсортированном связном списке;
4) связном списке, отсортированном по размеру блока;
5) бинарном дереве;
6) сбалансированном бинарном дереве. чтоор’5
в. Сравнив результаты из пунктов А и Б, вы можете прийти к выводу.
из алгоритмов эффективнее другого. Почему такое заключение не
наиболее подходящем участке,
первом подходящем участке,
наименее подходящем участке,
следующем подходящем участке.
в
в
в
в
Рекомендуемые обзорные проекты
9.24. Подготовьте доклад об использовании управления реальной память!0
темах реального времени. ягл^'
9.25. Подготовьте доклад о разновидностях традиционной иерархии
память. Организация и управление
555
gug емые исследовательские проекты
Создайте программу моделирования для выяснения относительной эффек-
тивности стратегий размещения в первом подходящем, наиболее подходя-
щем и наименее подходящем участках памяти. Программа должна изме-
рять степень использования памяти и среднее время выполнения запроса
лЯ каждой стратегии. Предполагайте, что емкость системы реальной па-
мяти равна 1 ГБ, из которых 300 МБ зарезервировано для операционной
системы. Новые процессы появляются с переменными интервалами от 1
по Ю минут (интервалы кратны 1 минуте), а размеры процессов случайны
(от 50 МБ до 300 МБ с интервалом в 10 МБ). Продолжительность выполне-
ния процессов может изменяться от 5 минут до 60 минут с шагом в 5 ми-
нут. Единица времени — 1 минута. Программа должна моделировать ис-
пользование каждой стратегии в течение достаточно долгого времени,
чтобы система достигала стабильного состояния. При моделировании
предполагайте, что время принятия решения о размещении задачи пре-
небрежимо мало.
а. Обсудите относительную сложность реализации каждой стратегии.
б. Сообщите о замеченных вами существенных различиях в производи-
тельности.
в. Измените интервалы появления новых задач и распределение их размеров
и изучите влияние изменений на результаты работы каждой стратегии.
г. Исходя из результатов наблюдений, выберите стратегию, которую вы бы
использовали при создании реальной системы управления оперативной
памятью.
д. Исходя из результатов наблюдений, предложите новую стратегию разме-
щения, которая, по вашему мнению, будет эффективнее, чем рассмотрен-
ные выше. Промоделируйте ее поведение. Каковы результаты моделиро-
вания?
9.27. Промоделируйте систему, изначально содержащую 100 МБ свободной опе-
ративной памяти, в которой задачи часто начинаются и завершаются. Объ-
ем задач — от 2 до 35 МБ, и время их выполнения — от 2 до 5 секунд. Час-
тота появления новых задач — от двух задач в секунду до одной за 5 се-
кунд. Оцените уровень использования памяти и пропускную способность
системы при использовании стратегий размещения в первом подходящем,
наиболее подходящем и наименее подходящем участках памяти. Исполь-
зуя одну и ту же стратегию, изменяйте алгоритм выбора задачи для запус-
ка, чтобы оценить его влияние на пропускную способность и среднее время
ожидания. Реализуйте алгоритмы выбора из главы 8, например, FIFO
и SPF, и выясните эффективность других алгоритмов, например, алгорит-
ма «наименьшая задача — первой» и «наибольшая задача — первой». Оп-
ределите, страдает ли какой-либо из этих алгоритмов от бесконечного от-
гадывания запуска задач.
Р L
литература
ШиР°кого распространения виртуальной памяти многие моменты,
1|^(^ега1^н^е в этой главе, уже не обсуждаются в литературе. Белади
^Д^Крм, Ит подробно описал историю технологий управления памятью в систе-
Чи’М с 1 Митра43, а также Пом и Смэй44 дали описание иерархии памяти,
Ст анДартом на много десятилетий. Байс45 и Стефенсон45 представили ос-
ЭТегии выделения памяти и размещения в ней данных. Деннинг47 опи-
”Ь1е трудности, свойственные однопользовательским системам с выделе-
нием непрерывных областей памяти. Найт48, а также Коффман и Райан49 Х
способы реализации систем с выделением фрагментированных областей
гии размещения изучали Кнут50, Стефенсон51, а также Олдехофт и Аллан'бг ,Iwl
низмы подкачки, критически важные для систем виртуальной памяти ’
рассматриваются в следующей главе.
Недавние исследования сосредотачивались на оптимизации исполь
иерархии памяти. Некоторые стратегии управления памятью фокусип30Ьа^И
на более быстром и дорогом ресурсе — кэш-памяти53. В литературе так
сывается настройка памяти под конкретные приложения для повк е
производительности54’ 55.
Встраиваемые системы проектируются не так, как системы общего и
ния. Системы общего назначения должны содержать достаточно ресурсов 3Ila<ie.
волнения широкого круга разнообразных задач одновременно, а во встг>ЛЯ ВЬ|-
мых системах доступны только ресурсы, достаточные для решения задач Ва«-
торых эти системы проектируются. В целях предельного удешевд4
и уменьшения габаритов ресурсы во встраиваемых системах значительно
скудны, чем в системах общего назначения. Публикации в ACM Transaction
Embedded Computing Systems от ноября 2002 и февраля 2003 годов достать °П
подробно описывают методы управления памятью во встраиваемых системах^0
Библиография к этой главе доступна на Web-сайте по адресу www.deitei
books/os3e/Bibliography.pdf.
используемая литература
1. Belady, A.; Parmelee, R. Р.; and С. A. Scalzi, «The IBM History of Memory Man-
agement Technology», IBM Journal of Research and Development, Vol. 25, No.
5, September 1981, pp. 491-503.
2. Belady, A.; Parmelee, R. P.; and C. A. Scalzi, «The IBM History of Memory Man-
agement Technology», IBM Journal of Research and Development, Vol. 25, No.
5, September 1981, pp. 491-503. «How Much Memory Does My Software Need?»
<www.crucial.com/library/softwareguide.asp>, просматривалось 15 июля
2003 года.
3. Belady, A.; Parmelee, R. P.; and C. A. Scalzi, «The IBM History of Mejnoff
Management Technology», IBM Journal of Research and Development, Vol-’
No. 5, September 1981, pp. 491-503. «How Much Memory Does My aJI0CI>
Need?» <www.crucial.com/library/softwareguide.asp>, просматрив ।
15 июля 2003 года. tirneli-
4. «Microsoft/Windows Timeline», <www.technicalminded.com/windows_ П
ne.htm>, последнее изменение 16 февраля 2003 года. -j=httP:^
5. «Windows Version History», <support.microsoft.com/default.aspx•''s’31 tssp.
sypport.microsoft.com:80/support/kb/articles/Q32/9/05.asp&NoWebCon
последнее обновление 20 сентября 1999 года. , ged8^
6. Anand Lal Shimpi, «Western Digital Raptor Preview: 10,000 RPM
АТА», AnandTech.com, March 7, 2003, <www.anandtech.com/storage/
html?i=1795&p=9>. ber 1
7. Todd Tokubo, «Technology Guide: DDR RAM», GamePC.com, Sepj
2000, <www.gamepc.com/labs/view_content.asp?id=ddrguide&page
8. Baskett, F.; Broune, J. C.; and W. M. Raike, «The Management of
Non-paged Memory System», Proceedings Spring Joint Computer '
1970, pp. 459-465. „оГУ^'
9. Lin, Y. S., and R. L. Mattson, «Cost-Performance Evaluation of p-
chies», IEEE Transactions Magazine, MAG-8, No. 3, September 1 ‘
память. Организация и управление
557
,.tra D., «Some Aspects of Hierarchical Memory Systems», J ACM, Vol. 21,
,(). Y January 1974, p. 54.
Is A. V., and T. A. Smay, «Computer Memory Systems», IEEE Computer,
11-fiber 1981, pp. 93-110.
u . m A. V., and T. A. Smay, «Computer Memory Systems», IEEE Computer,
12-fiber 1981, pp. 93-110.
I v -th A J-, «Cache Memories», ACM Computing Surveys, Vol. 14, No. 3, Sep-
,3'Sberl982, pp. 473-530.
о vs С , «А Comparison of Next-fit, First-Fit, and Best-fit», Communications of
14- &”aCM, Vol. 20, No. 3, March 1977, pp. 191-192.
ltephenson, C. J., «Fast Fits: New Methods for Dynamic Storage Allocation»,
0- Proceedings of the 9th Symposium on Operating Systems Principles, ACM, Vol.
17, No. 5, October 1983, pp. 30-32.
peJady, A.; Parmelee, R. P.; and C. A. Scalzi, «The IBM History of Memory Man-
0' vement Technology», IBM Journal of Research and Development, Vol. 25, No.
5 September 1981, pp. 491-503.
„ Feiertag, R- J-, and Organick, E. I., «The Multics Input/Output System», ACM
Symposium on Operating Systems Principles, 1971, pp. 35-41.
18 Denning, P- J., «Third Generation Computer Systems», ACM Computing Sur-
veys, Vol. 3, No. 4, December 1971, pp. 175-216.
19. Denning, P. J., «Third Generation Computer Systems», ACM Computing Sur
veys, Vol. 3, No. 4, December 1971, pp. 175-216.
20. Dennis, J. В., «А Multiuser Computation Facility for Education and Research»,
Communications of the ACM, Vol. 7, No. 9, September 1964, pp. 521-529.
21. Belady, A.; Parmelee, R. P.; and C. A. Scalzi, «The IBM History of Memory Man-
agement Technology», IBM Journal of Research and Development, Vol. 25, No.
5, September 1981, pp. 491-503.
22. Knight, D. C., «An Algorithm for Scheduling Storage on a Non-paged Com-
puter», Computer Journal, Vol. 11, No. 1, February 1968, pp. 17-21.
23. Denning, P., «Virtual Memory», ACM Computing Surveys, Vol. 2, No. 3, Sep-
tember 1970, pp. 153-189.
24. Randell, В., «А Note on Storage Fragmentation and Program Segmentation»,
Communications of the ACM, Vol. 12, No. 7, July 1969, pp. 365-372.
45-Knight, D. C., «An Algorithm for Scheduling Storage on a Non-paged Com-
„ Puter», Computer Journal, Vol. 11, No. 1, February 1968, pp. 17-21.
• Coffman, E. G., and T. A. Ryan, «А Study of Storage Partitioning Using a Math-
ematical Model of Locality», Communications of the ACM, Vol. 15, No. 3, March
27 I972- PP. 185-190.
elady, A.; Parmelee, R. P.; and C. A. Scalzi, «The IBM History of Memory Man-
agement Technology», IBM Journal of Research and Development, Vol. 25,
2g pO> 5, September 1981, pp. 491-503.
С0П<1е*1’ *A Note on Storage Fragmentation and Program Segmentation»,
29. Ju mmlinications of the ACM, Vol. 12, No. 7, July 1969, pp. 365-372.
^golin, В. H., Parmelee, R. P., and C. A. Schatzoff, «Analysis of Free-Storage
3o.B gonthms», IBM Systems Journal, Vol. 10, No. 4, 1971, pp. 283-304.
I Эйе^11’ G"’ Buco, W.; Daly, T. P.; and W. H. Tetzlaff, «Analysis of Free-Stor-
br> /“Sorithms — Revisited», IBM Systems Journal, Vol. 23, No. 1, 1984,
3} H»- 44-66.
F*’ Broune, J. C.; and W. M. Raike, «The Management of a Multi-level
» 197n^age<^ Memory System», Proceedings Spring Joint Computer Conference,
’Ч Da °’ PP- 459-465.
D’ J- M-, «Memory Occupancy Patterns in Garbage Collection Systems»,
munications of the ACM, Vol. 27, No. 8, August 1984, pp. 819-825.
33. Knuth, D. E., The Art of Computer Programming: Fundamental д/„
Vol. 1, 2nd ed., Reading, MA: Addison-Wesley, 1973. ’
34. Stephenson, C. J., «Fast Fits: New Methods for Dynamic Storage All
Proceedings of the 9th Symposium on Operating Systems Princini^^bti
Vol. 17, No. 5, October 1983, pp. 30-32. P s’
35. Oldehoeft, R. R., and S. J. Allan, «Adaptive Exact-Fit Storage Mana I
Communications of the ACM, Vol. 28, No. 5, May 1985, pp. 506-5Ц
36. Shore, J., «On the External Storage Fragmentation Produced by First f
Best-Fit Allocation Strategies», Communications of the ACM, Vol. 18 N
gust 1975, pp. 433-440. ’
37. Bays, С., «А Comparison of Next-fit, First-Fit, and Best-fit», Communicnr
the ACM, Vol. 20, No. 3, March 1977, pp. 191-192. tl°nSof
38. Ritchie, D. M., and К. T. Thompson, «The UNIX Time-sharing System» r
nications of the ACM, Vol. 17, No. 7, July 1974, pp. 365-375. ’ Ottlrr»i-
39. Belady, A.; Parmelee, R. P.; and C. A. Scalzi, «The IBM History of Memory Nr 1
agement Technology», IBM Journal of Research and Development Vol
No. 5, September 1981, pp. 491-503. ’ ’ ^5,
40. Knuth, D. E., The Art of Computer Programming: Fundamental Algorith
Vol. 1, 2nd ed., Reading, MA: Addison-Wesley, 1973. (Многократно издавав’
перевод на русский язык, например, Кнут Д. «Искусство программирован^
для ЭВМ, т. 1», М. «Мир» 1976)
41. Shore, J. Е., «Anomalous Behavior of the Fifty-Percent Rule», Communications
of the ACM, Vol. 20, No. 11, November 1977, pp. 812-820.
42. Belady, A.; Parmelee, R. P.; and C. A. Scalzi, «The IBM History of Memory Man-
agement Technology», IBM Journal of Research and Development, Vol. 25,
No. 5, September 1981, pp. 491-503.
43. Mitra, D., «Some Aspects of Hierarchical Memory Systems», JACM, Vol. 21,
No. 1, January 1974, p. 54.
44. Pohm, A. V., and T. A. Smay, «Computer Memory Systems», IEEE Computer,
October 1981, pp. 93-110.
45. Bays, C., «A Comparison of Next-fit, First-Fit, and Best-fit», Communications of
the ACM, Vol, 20, No. 3, March 1977, pp. 191-192.
46. Stephenson, C. J., «Fast Fits: New Methods for Dynamic Storage Allocation».
Proceedings of the 9th Symposium on Operating Systems Principles, ACM,
Vol. 17, No. 5, October 1983, pp. 30-32.
47. Denning, P. J., «Third Generation Computer Systems», ACM Computing SW
veys, Vol. 3, No. 4, December 1971, pp. 175-216.
48. Knight, D. C., «An Algorithm for Scheduling Storage on a Non-paged 0
puter», Computer Journal, Vol. 11, No. 1, February 1968, pp. 17-21.
49. Coffman, E. G., and T. A. Ryan, «А Study of Storage Partitioning Using а^агСи
ematical Model of Locality», Communications of the ACM, Vol. 15, No. a,
1972, pp. 185-190. Vol-
50. Knuth, D. E., The Art of Computer Programming: Fundamental Algorith1118,
1, 2nd ed., Reading, MA: Addison-Wesley, 1973. ati°n”
51. Stephenson, C. J., «Fast Fits: New Methods for Dynamic Storage All°c дсМ-
Proceedings of the 9th Symposium on Operating Systems Principle <
Vol. 17, No. 5, October 1983, pp. 30-32.
52. Oldehoeft, R. R., and S. J. Allan, «Adaptive Exact-Fit Storage Manage
Communications of the ACM, Vol. 28, No. 5, May 1985, pp. 506-511-
53. Luk, C. and Mowry, T. C., «Architectural and Compiler Support for Ef (JO*
struction Prefetching: A Cooperative Approach», ACM Transactions
puter Systems (TOCS), Vol. 19, No. 1, February 2001.
..-r-Crummey, J-! Whalley, D.; and К. Kennedy, «Improving Memory Hierar-
. performance for Irregular Applications», Proceedings of the 13th Interna-
’ сЬУ . Conference on Supercomputing, May 1999.
r_Crummey, J.; Fowler, R.; and D. Whalley, «Tools for the Application-ori-
л Me j performance Tuning», Proceedings of the 15th International Conference on
ea^rcomputing, June 2001.
Sur в. an(j g. Bhattacharyya, «Introduction to the Two Special Issues on Mem-
sg. JaC ’aCM Transactions on Embedded Computer Systems (TECS), February
$S, Vol. 2, No.l.
Воображение есть не что иное, как освобождение
памяти от уз времени и пространства.
Сэмюэл Тэйлор Колридж
Веди меня от нереального к реальному.
Упанишады
О счастливое прегрешение, явившее нам образ
и силу Спасителя.
Миссал — Англиканская Богослужебная книга
У всякой страницы большие п°^1
Которые служат корДой^а
Квадратику текста, что в центре л
Лишь пятнышко, да, и не 1
Альфред Тенн^ Ч
ь
Адреса позволяют нам скрыва
истинное местонахоД1 Д )
С„Ки ,Г. X.
ЯМ»
организация биртуальнсй
памяти
Цели
После прочтения этой главы вы должны понимать,
что собой представляют:
• концепция виртуальной памяти;
• страничные системы виртуальной памяти;
* сегментные системы виртуальной памяти;
1 к°мбинированные сегментно-страничные системы
виРтуальной памяти;
с°вМестный доступ и защита в системах
виртуальной памяти;
* Qn
/1р^а^а?Пное обеспечение, делающее возможным
I х Мнение виртуальной памяти;
1^и3а^и,я виртуальной памяти в архитектуре
| Фирмы Intel.
Краткое содержание главы
10.1. Введение
Практический пример: Atlas
Размышления об операционных системах: Виртуализация
Биографические заметки: Питер Деннинг
10.2. Виртуальная память: основные понятия
Поучительные истории: Виртуальная память необязательна
10.3. Размещение блоков
10.4. Страничные системы
10.4.1. Трансляция адресов прямым отображением в страничных системах
10.4.2. Трансляция адресов ассоциативным отображением в страничных систем
10.4.3. Трансляция адресов смешанным прямым/ассоциативным отображении
в страничных системах
Размышления об операционных системах:
Эмпирические результаты — локальность
10.4.4. Многоуровневые страничные таблицы
10.4.5. Обращенные страничные таблицы
10.4.6. Разделение ресурсов в страничной системе
Размышления об операционных системах: Позднее выделение
10.5. Сегментация
10.5.1. Трансляция адресов прямым отображением в сегментных системах
10.5.2. Разделение ресурсов в сегментных системах
10.5.3. Защита и контроль доступа в сегментных системах
10.6. Сегментно-страничные системы
10.6.1. Динамическая трансляция адресов в сегментно-страничных систем®
10.6.2. Разделение ресурсов и защита в сегментно-страничной системе
10.7. Практический пример: Виртуальная память
архитектуры IA-32 фирмы Intel м
Практический пример: Операционные системы мэйнфреймов
Практический пример: Ранняя история операционной системы
/ ^едение
ЫДУЩе^ главе мы рассмотрели основные методы управления па-
р 0Ре^аЯсдый из КОТ°РЫХ’ так или иначе, связан с ограниченностью ее
^ддо из решений проблемы ограниченности — просто увеличить
^еМа‘ о памяти в системе; однако часто стоимость больших объемов
дамяти делает его неприемлемым. Другое решение — создать ил-
^сТР°й адичия большого объема памяти. Это фундаментальная идея, реа-
ая в виде виртуальной памяти (virtual memory)1’ 2> 3, которая
^зоВ®0 появилась в компьютере Atlas, созданном в университете Манче-
8йеРвЬ1еднглии в 1960 году (см. «Практический пример: Atlas»)4’ 5> 6> 7.
стер® В,.нке 10.1 показана эволюция систем организации памяти — от од-
fl® РИСо0вательских систем с реальной памятью к многопользовательским
яоП°Л«ам с сегментно-страничной виртуальной памятью.
В этой главе рассматривается реализация виртуальной памяти в систе-
й(см. «Размышления об операционных системах: Виртуализация»),
т^нее говоря, мы обсудим методы, используемые операционными систе-
мами и аппаратными устройствами для преобразования виртуальных ад-
песов в физические; мы также изучим два самых распространенных мето-
да фрагментированного распределения памяти — страничный и сегмент-
ный. Трансляция адресов и фрагментированное выделение памяти
позволяют системам виртуальной памяти создавать иллюзию большего
объема памяти и повышать степень мультипрограммности. В следующей
главе мы сосредоточимся на управлении процессами в виртуальной намя-
та для оптимизации производительности. Значительная часть приводи-
мых фактических сведений заимствована из обзора систем виртуальной
памяти, сделанного Деннингом (см. «Биографические заметки: Питер Ден-
нинг»)18.
Ильная
Однополь-
Реальная
Виртуальная
3°ватель-
Скиеспе-
-иализи-
^анные
ис’емы
Мультипрограммные системы
с реальной памятью
Мультипрограммные системы
с виртуальной памятью
Системы с фикси-
. Ревенным распре-
делением памяти
Системы с изме- стра.
няемым распреде- НИч°ые
пением памяти
Стра- Сегментные
Сегментно-
страничные
Абсолют- Переме
Ь1е щаемые
’Ч 3
В°ЛЮЦИЯ способов
организации памяти
564
В конце главы (перед разделом «Веб-ресурсы») вы найдете дВа
ческих примера, посвященные операционным системам мэйвд^чЯ
фирмы IBM и ранней истории операционной системы VM. Изучив
ву, вы будете иметь представление об эволюции организации
ной, так и виртуальной памяти. История операционных систем мэ"
мов фирмы IBM тесно связана с этой эволюцией.
Учебный пример
Atlas
Проект Atlas был организован в универ-
ситете Манчестера в Англии в 1956 году.
Проект, изначально называвшийся MUSE
(сочетание греческой литеры MU (ц — мик-
ро) и аббревиатуры SE (second — секунда),
т.е. микросекунда), был запущен с целью
разработки оборудования, способного кон-
курировать с высокопроизводительными
компьютерами, производимыми Соединен-
ными Штатами8. В 1959 году к проекту в ка-
честве спонсора присоединилась фирма
Ferranti Ltd., и первый компьютер Atlas был
готов к концу 1962 года9. Хотя компьютер
Atlas выпускался всего около 10 лет, он оста-
вил немалый след в истории компьютерной
техники. Многие из реализованных в нем
новшеств входят в состав его операционной
системы - Atlas Supervisor.
Эта операционная система впервые ис-
пользовала виртуальную память10. Устано-
вив новый стандарт производительности,
Atlas Supervisor была способна исполнять до
16 задач одновременно”. Она также предос-
тавляла операторам детальную статистику
выполнения задач, в то время как большин-
ство других систем требовали вычисления
подобных параметров вручную. Машина
Atlas была одной из первых систем в I
рой основные принципы устройства апгеЯ
туры были определены на ранних стЯ
проектирования, чтобы упростить систем
ное программирование12
Хотя на момент его появления в 1962
году Atlas был самым мощным компьюте-
ром, он остался практически незамеченным
промышленностью13. Было продано только
три компьютера Atlas, последний - в 1965
году, всего через три года после завершения
разработки14. Одной из причин недолгой
жизни компьютеров Atlas стало то, что про-
граммы для них приходилось писать на А®
Autocode - языке, похожем на Algol 60, но*
принятом большинством программистов •
Разработчики Atlas были вынуждены ре
зовать задним числом более популя.
языки, например, FORTRAN16- ^Шбь|0°еро!
причиной быстрого ухода этих комп ТИ
со сцены стала ограниченность вЫД
для их разработки ресурсов. Через
выпуска Atlas компания ICT пРи°прекргпв
пьютерные проекты Ferranti. ICT п,^
выпуск компьютеров Atlas, преДТ°
сто них свою серию компьютеров,
как 190017.
Виртум ’ней памяти
565
Вопросы для самопроверки
1. Приведите пример программы, которую неэффективно загружать
в память целиком перед исполнением.
2. Почему наращивание объема оперативной памяти — неэффектив-
ное решение проблемы ограниченности этого объема?
Ответы 1) Во многих программах есть функции обработки оши-
бок, которые редко используются, если используются вообще. Загруз-
ка этих функций в память уменьшает объем памяти, доступный
процессам. 2) Покупка дополнительной оперативной памяти не всегда
экономически оправдана. Как мы увидим далее, лучше создать иллю-
зию наличия в системе объема памяти, заведомо большего, чем может
понадобиться программам.
Размышления об операционных системах
Виртуализация
В этой книге приведено множество при-
меров того, как с помощью программ ресурсы
можно заставить выглядеть не такими, какими
они есть на самом деле. Этот прием называет-
.я виртуализацией. Мы изучим виртуальную
тамять, которая представляется имеющей го-
раздо больший объем, чем физическая па-
«эть, установленная на компьютере. Мы рас-
смотрим виртуальные машины, создающие
ЧВзию, что компьютер, используемый для
аую°ЛНеНИЯ пРогРамм, отличается от сущест-
вуете» в действительности. Виртуальная ма-
Л’расЯЗЫ1<'а Java позволяет программистам
’г°РЫеТЬ1ВаТЬ пеРеносимые приложения,
п°д МОгут Работать на разных компьюте-
и<теЬ| ^Убавлением разных операционных
Чц) g с Разными аппаратными устройст-
Реализация — это один из способов
применения впечатляющей вычислитель-
ной мощи для предоставления дополни-
тельных возможностей пользователям. По
мере усложнения компьютеров приемы
виртуализации могут скрывать сложные
элементы компьютеров от пользователей,
которые будут видеть более простую в при-
менении виртуальную машину, определен-
ную операционной системой. Виртуализа-
ция повсеместно применяется в распреде-
ленных системах, которые мы детально
рассмотрим в главах 17 и 18.Распределен-
ные операционные системы создают иллю-
зию существования одной большой маши-
ны, хотя на самом деле ее образуют множе-
ство компьютеров и других ресурсов,
соединенных в замысловатые структуры
с помощью сетей, например, Интернета.
Биографические заметки
Питер Деннинг
Питер Деннинг (Peter Denning) более все-
го известен благодаря своей работе в облас-
ти виртуальной памяти в 1960-х годах. Одна
из его основных публикаций — «The Working
Set Model for Program Behavior», вышла из
печати в 1968 году, когда он получил сте-
пень доктора философии в Массачусетском
технологическом институте”. В этой работе
он предложил концепцию рабочих наборов
(обсуждаемую в разделе 11.7) для примене-
ния в системах управления виртуальной па-
мятью, и объяснил, почему использование
рабочих наборов при замене страниц может
улучшить производительность по сравнению
с другими схемами замены20. Теория Ден-
нинга основывается на следующем эмпири-
чески обнаруженном феномене: программы
в течение большей части времени обраща-
ются только к небольшому количеству стра-
ниц из числа выделенных для них. Именно
эти наиболее часто требуемые страницы он
и назвал рабочим набором. Подобный на-
бор изменяется стечением времени, по мере
того, как программа выполняет разные фазы
работы. Он предположил, что программа бу-
дет выполняться эффективно, если ее рабо-
чий набор всегда будет находиться
ной памяти. в О(ЧВ
Позже Деннинг преподавал в п и
ском Университете, основал Исслед НСТОн‘
ский институт компьютерных наук (R^^
Institute for Advanced Computer Science)SJ
следовательском центре NASA, возгда
отделение компьютерных наук в унивепс
те Джорджа Мэйсона (George
University) в Пэрдью и Военно-морскую щГ
лу для аспирантов (Naval Postgrad^
School). Он опубликовал сотни статей и не
сколько книг о компьютерах и был президен-
том АСМ в 1980-1982 годах.
Деннинг внес существенный вклад вобу-
чение компьютерным наукам. Он получил
несколько наград за преподавательскую
деятельность, руководил созданием цифро-
вой библиотеки ACM (ACM Digital Library)-
онлайн-коллекции статей из журналов
АСМ, и возглавлял отдел образования АСМ
(ACM Education Board), публикующий учеб-
ные планы АСМ22. Он также приложил зна-
чительные усилия к просвещению «нетехни
ческого сообщества» в области компыот1
ных наук23.
10.2 Виртуальная память: основные понятия
Как мы уже говорили в предыдущем разделе, системы виртуа71^^,^
мяти создают для процессов иллюзию наличия большего объема
чем реально существует в компьютере (см. «Поучительные ист°Р\^
туальная память необязательна»). Поэтому в системах виртуаль ойес”
ти есть две разновидности адресов: те, по которым обращаются рОЯ
и те, которые доступны в оперативной памяти. Адреса, по котоР
щаются процессы, называются виртуальными адресам”
addresses). Адреса, доступные в оперативной памяти, называют”51
Л яресами (physical addresses), или реальными (действительными)
.^0 и (real addresses). [Примечание-. В этой главе термины «физиче-
г>> «реальный адрес» и «адрес в оперативной памяти» равно-
каждом обращении процесса по виртуальному адресу система
3 преобразовать этот адрес в реальный. Эти обращения происходят
о часто, что использование обычного процессора общего назначе-
дреобразования адресов сильно снизит производительность систе-
()Я ^ЯтОму системы виртуальной памяти используют специальные аппа-
м1д. уСТройства, называемые устройствами управления памятью
ря'101’1 v management unit — MMU), способные быстро преобразовывать
(^^дьные адреса в реальные.
бйРт- туаЛьное адресное пространство (virtual address space) процесса —
это множество виртуальных адресов, по которым может обращаться
1" Множество реальных адресов, доступных в конкретной системе,
° ывается реальным адресным пространством (real address space) этой
Ва3-гемЫ, R. Количество адресов в V обозначается |V], а количество адресов
С R обозначается |R|. В системах виртуальной памяти обычно [V] > |J?|, то
^сть виртуальное адресное пространство намного больше реального.
Если мы собираемся сделать виртуальное адресное пространство поль-
зователя большим, чем реальное, мы должны предоставить средства раз-
мещения данных и программ на большом вспомогательном устройстве
хранения. Обычно это достигается применением двухуровневой памяти
(см. рис. 10.2). Первый уровень — это оперативная память (и кэши), в ко-
торых должны храниться данные и выполняемые процессором при работе
Вторичное, или вспомогательное,
устройство хранения
Другие типы
вспомогательных
(устройств
хранения
Диски
п„ , ; Оперативная
Р°Чессор(ы) i(f память
< и кэши
'0,г
^®УхурОвневая память
Ci
процесса инструкции. Второй уровень — вторичное устройство хп
состоящее из носителей большой емкости (обычно дисков), сцо
хранить программы и данные, которые не помещаются в orpaHjlC°6jL
оперативную память.
Когда система готова запустить процесс, она загружает код и '
этого процесса со вторичных устройств хранения в оперативную
Для выполнения процесса достаточно, чтобы в оперативной павдя~
только небольшая часть кода и данных. На рисунке 10.3 показа^1
уровневая память, в которой в оперативной памяти размещены раз
элементы из пространств виртуальной памяти множества процессов®1^
Ключ к реализации систем виртуальной памяти — механизм прео^
вания виртуальных адресов в реальные. Поскольку процессы ИспольаЗ
только виртуальные адреса, но должны выполняться в реальной гго
системе приходится преобразовывать виртуальные адреса в физичес
в ходе выполнения процессов (см. рис. 10.4). Преобразование должно
полняться быстро, иначе падение производительности сведет на нет
рыш, получаемый от применения виртуальной памяти.
Вспомогательное устройство хранения
Пространство
виртуальной
памяти
процесса 2
Пространство
виртуальной
памяти
процесса 3
Пространство
основной
памяти
Пространство
виртуальной
памяти
процесса 1
Виртуальной памяти
процесса не обязательно
быть непрерывной даже
на вторичных устройствах
хранения
Pl/С. 10.3. Фрагменты адресных пространств в оперативной памяти
и на вторичных устройствах хранения
цпувАЬиеи памяти
Виртуальная
10.4. Преобразование виртуальных адресов в реальные
Механизмы динамической трансляции адресов (Dynamic Address
Мя ns,ation — DAT) преобразуют виртуальные адреса в физические во вре-
ВЬ1Пол нения программ. Системы, использующие динамическую транс-
црес адресов, позволяют отображать непрерывные области виртуальных
8Ь1Х пР°странств процессов во фрагментированные области физиче-
’Дью ^ам.яти — эта особенность называется искусственной непрерывно-
₽eeCg и contiguity) (см. рис. 10.5)24. Динамическая трансляция ад-
tty, о Искусственная непрерывность освобождают программистов от за-
С°3ДаватьЗД1е1^еНии программ в памяти (т.е. программисту не нужно
°ВеРлеи» чтобы программа могла разместиться в памяти). Про-
Мо5кет сосредоточиться на создании наиболее эффективных алго-
Л Исцо СтРУКтур программ, а не на аппаратных устройствах, которые бу-
5^ ьЮткЬЗ°Ваться при исполнении этих программ. Компьютер является
Так Рассматриваться как) исполнитель алгоритмов в логическом
ении» а не как физическое устройство с уникальными характери-
’ которые могут замедлить процесс разработки программы.
570
Поучительные истории
Виртуальная память необязательна
Когда впервые была предложена концеп-
ция виртуальной памяти, разработчики меч-
тали о системе, которая могла бы хранить
в оперативной памяти миллион слов. Они
считали, что в такой системе виртуальная па-
мять стала бы ненужной. В те времена такая
мечта казалась неосуществимой и к
даны системы виртуальной памяти рЛИ<:03-
гих современных настольных компь°Ьн°'
объем памяти в тысячу раз больше
в большинстве этих компьютеров и'
ется виртуальная память. 0ЛьзУ-
Мораль для разработчиков операционных систем. Помните о законе Мура. Возмо
аппаратуры растут по экспоненте, но и потребности программного обеспечения растит
же быстро. СТа,ь
Вопросы для самопроверки
1. Объясните различия между виртуальным адресным пространством
процесса и физическим адресным пространством системы.
2. Объясните преимущества искусственной непрерывности.
Ответы 1) Виртуальное адресное пространство процесса — это
множество адресов, по которым процесс может обращаться к памяти,
работая под управлением системы виртуальной памяти. Процессы не
используют физических адресов, соответствующих реальным облас-
тям в оперативной памяти. 2) Искусственная непрерывность упроща-
ет программирование, позволяя процессу работать с его памятью ка»
с непрерывной областью, даже если данные и код рассеяны по опер
тивной памяти.
10.3. Разллещение блоков
храН»0
Механизмам динамической трансляции адресов приходится
карты (таблицы) трансляции адресов (address translation maps)» я, де-
вающие, какие части виртуального адресного пространства V в Да
мент находятся в оперативной памяти, и где они размещены. ^СЛа{1иМ^
кие карты содержали информацию о каждом адресе в V, они бы (fl
больше места, чем доступно в оперативной памяти, т.е. оказались^
полезными. На практике объем информации в картах должен бь
чительным по сравнению с размером оперативной памяти, ин по-
могут оставить слишком мало памяти для операционной систе
зовательских процессов. дНР
Самое широко применяемое решение этой проблемы — сгр>
данные в блоки (blocks); при этом система отслеживает размегце
р- диртуилипии нитяпга--------------------------------------------этт
’ рцой памяти в физической памяти®. Чем больше средний размер
м меньше нужно хранить информации о размещении блоков. Од-
т одЬЗование больших блоков может привести к значительной внут-
агМентации, кроме того, такие блоки требуют много времени на
й0е111 ние между оперативной памятью и вторичными устройствами
spiitfeH ь1й вопрос: должны ли все блоки быть одинакового размера? Если
блоков одинаков (или есть несколько фиксированных размеров),
р83^еР й называются страницами (pages), а соответствующая организация
Jo дои памяти носит название страничной (paging). Если блоки могут
8йРтУавоизвольных размеров, они называются сегментами (segments), а ор-
бь!Ть виртуальной памяти — сегментной (segmentation)25’ 26. В некото-
г^^нстемах оба подхода совмещаются, и сегменты реализуются как блоки
рь1* СеНного размера, состоящие из страниц фиксированного размера. Стра-
и сегментные системы подробно обсуждаются в следующих разделах.
®дрИ использовании виртуальной памяти с блочным размещением
. k mapping) система представляет адреса в виде упорядоченных пар.
Чтобы обратиться к отдельному элементу в своем виртуальном адресном
Непрерывная
область
виртуальной
памяти
1 1скУСственная непрерывность
Ха«изм иногда называют также отображением блоков, имея в виду, что вир-
® Память отображается на физическую — прим. ред. перее.
572
пространстве, процесс должен указать блок, в котором этот элеме11
дится, и смещение (displacement или offset) элемента относительг о
блока (см. рис. 10.6). Виртуальный адрес v представляется как v
ченная пара (b, d), где b — номер блока, в котором находится трек° Ц?
элемент, ad — смещение этого элемента относительно начала бд0
Номер блока
Ь
Смещение
d
Виртуальный адрес
v = (b, d)
Рис. 10.6. Формат виртуального адреса в системе с блочным размещением
Преобразование виртуального адреса v = (b, d) в реальный адрес г п
текает следующим образом (см. рис. 10.7). Система хранит в памяти
лицу размещения блоков (block map table) для каждого процесса. В этой
таблице содержится по одной записи для каждого блока процесса, и запи-
си хранятся последовательно (например, запись блока 0 идет перед запи-
сью блока 1). При переключении контекста система определяет реальный
адрес а, соответствующий адресу таблицы размещения блоков нового про-
цесса в оперативной памяти. Этот адрес записывается в специальный быст-
родействующий регистр, называемый регистром адреса таблицы разме-
щения блоков (block map table origin register). В ходе выполнения процесс
обращается по виртуальному адресу v = (b, d). Система суммирует номер
блока b с базовым адресом а таблицы размещения блоков процесса, чтобы
получить реальный адрес записи о блоке b в таблице. [Примечание: Для
упрощения мы считаем, что размер записи в таблице постоянен и по каж
дому адресу в памяти хранится одна запись.] В записи по вычисленное^
адресу хранится адрес Ь’ физической памяти. Затем система прибавл 11
величину смещения d к адресу начала блока Ь’, чтобы получить
требуемого элемента в реальной памяти. Таким образом, система выч
ет реальный адрес г по виртуальному адресу v = (b, d), используя Ф°Р^ + j
г = Ь’ + d, где Ь’ хранится в физической памяти в ячейке с адресом I
в таблице размещения блоков. сег
Все способы пересчета адресов блоков, используемые в страничн |
ментных и сегментно-страничных системах, похожи на изоб а дря®1’
на рисунке 10.7. Важно отметить, что пересчет адресов блоков в хо?е
ся быстродействующими аппаратными устройствами динамичес
выполнения программы. Если пересчет адресов реализован неэфФ j-pbi^?
то накладные расходы на него поглотят значительную часть в ^0°^
в производительности, получаемого за счет использования вир^е ‘
памяти. Например, две операции сложения, показанные на рису^ с#0^-1
должны выполняться намного быстрее, чем обычные инструкД е \
ния машинного языка процессора. Они выполняются при отра . I
дой инструкции, обращающейся к памяти по виртуальному дО^^ j
адресное сложение будет занимать столько же времени, сколько
виртуальной памяти
he. 10.7. Трансляция виртуальных адресов в системе с блочным размещением
Реализованное как инструкция машинного языка, компьютер будет рабо-
’ать в несколько раз медленнее, чем при использовании только реальной
яти. Аналогично, механизм трансляции адресов блоков должен обра-
к с\к записям в таблице размещения блоков намного быстрее, чем
уг°и информации в памяти. Системы обычно помещают записи из таб-
^^В®*еЩения блоков в быстродействующий кэш, чтобы резко умень-
6Ремя доступа к ним.
Вопросы для самопроверки
1. Предположим, что система пересчета адресов представляет вирту-
альный адрес v = (b, d) в виде 32-битового значения. Если величина
d смещения блока хранится в п битах, сколько блоков может содер-
жаться в виртуальном адресном пространстве? Объясните, как по-
влияет на фрагментацию памяти и объем информации о размещении
значение п, равное 6, 12 и 24.
2. Почему адрес а начала таблицы размещения блоков процесса хра-
нится в специальном быстродействующем регистре?
574
Ответы 1) Система будет содержать 232 п блоков. Если п -
будет маленьким, и фрагментация памяти незначительной ®> б
будет так много, что реализация системы станет бессмыслен
п = 24, то блок будет большим, и внутренняя фрагментация Нс *
метной, но таблица размещения блоков будет очень маленьСТа?еТа
п = 12 будет достигнут своего рода баланс между внутренней Hi?'
тацией и размером таблицы размещения блоков. Значение zj
вольно часто применялось в страничных системах. Размер с °* *2 д
при п = 12 будет равен 212 = 4096 байт, как мы увидим в
2) Поместив а в специальный быстродействующий регистр Ла®е 11
жем быстро преобразовывать адреса, что критично для эффейт^Ь1
используемых систем виртуальной памяти. ^Дос^
10.4 Cmfmme системы
В страничных системах виртуальные адреса представляются в виде v
рядоченных пар (р, d), где р — номер страницы в виртуальной памяти на
которой находится требуемый элемент, ad — смещение этого элемента ва
странице (см. рис. 10.8). Процесс может выполняться, если страница, к ко-
торой он обращается, в данный момент находится в оперативной памяти
Когда система перемещает страницу со вторичного устройства хранения
в оперативную память, она помещает страницу в блок памяти, называе-
мый кадром страницы (page frame), размер которого равен размеру стра-
ницы. При рассмотрении страничных систем в этой главе мы подразумева-
ем, что система использует страницы одного фиксированного размера.
В главе 11 мы поговорим о том, что современные системы обычно поддер-
живают несколько размеров страниц27. Кадры страниц начинаются с фи-
зических адресов, кратных размеру страницы ps (см. рис. 10.9). Система
может поместить поступившую страницу в любой свободный кадр.
В страничных системах динамическая трансляция адресов выполняется
так (см. рис. 10.10). Выполняющийся процесс обращается к памяти
виртуальному адресу и = (р, d). Механизм отображения страниц наХ°зЬ1.
страницу р в таблице размещения страниц (page map table), иногда
ваемой просто страничной таблицей (page table), и определяет, что*™
ница р размещается в кадре р’. Заметьте, что р’ — это не адрес в 011с
ской памяти, а номер кадра страницы. Предполагая, что номера
выглядят как {0, 1, 2, ..., п}, адрес в физической памяти, с которо
нается страница р’, будет произведением номера р’ и размера сг а * cJio-
т.е. р’ X ps. Адрес, по которому выполняется обращение, формирУ ря-
жением физического адреса начала страницы и смещения d. 1а
зом, адрес в физической памяти г = (р’ X ps) + d.
Номер страницы
Р
Смещение
d
Виртуальный адр<?с
v = (р, d)
Рис. 10.8. Формат виртуального адреса в страничной системе
575
Кадр страницы О
Кадр страницы 1
Кадр страницы 2
Кадр страницы 3
Кадр страницы 4
Кадр страницы 5
Кадр страницы 6
Кадр страницы 7
Номер
кадра
страницы
О
1
2
3
4
5
6
7
Размер Диапазон
кадра физических
страницы адресов памяти
Ps О Р5 - ’
Ps Ps -г 2ps - 1
Ps 2Ps -r3ps-1
Ps 3ps-r4ps-1
Ps 4Ps ~^5ps-1
Ps 5Ps -r6ps-1
Ps 6Ps -^2Ps-1
Ps 7ps -r-8ps-1
’ Основная
память, разделенная на кадры страниц
^асс
Ч, и &ОтРим систему, использующую п битов для представления и реаль-
Ча см адресов; номер страницы хранится в п-т старших би-
tP&J!teTabeiI'eHHe — в т младших. Реальный адрес элемента данных можно
* ^ЧЦЬ[ТЬ В ВИде упорядоченной пары, г = (р\ d), где р’ — номер кадра
а — смещение требуемого элемента на странице. Система мо-
Л1 ЙТь реальный адрес конкатенацией р’ и d, помещая р’ в старшие
Ч а и — в младшие. Например, рассмотрим 32-битовую систему
ВА^Использующую страницы размером 4 КБ (т = 12). Номер каждого
*ицы представляется 20 битами, так что, например, странице 15
'етствовать значение 00000000000000001111. Смещение 200 бу-
дет представлено в виде 000011001000. 32-битовый адрес ячейки
тивной памяти формируется конкатенацией двух приведенных зца,.
в результате мы получим значение 0000000060000000111100001
Этот пример демонстрирует упрощение отображения блоков за счет Ч
рования адресов реальной памяти с помощью конкатенации. При
вании блоков переменного размера для формирования адреса реаль Д
мяти из пары г = (р’, d) нужно выполнять сложение.
Номер страницы Смещение
Виртуальный адрес, по которому
обращается выполняющийся процесс
<
к
Р
d
Оперативная память
Механизм
отображения
страниц
Ps
Кадр
страницы 0
Виртуальная страница р,
соответствующая кадру
страницы р'
P'*Ps
Кадр
страницы 1
d Кадр страницы р'
Ячейка оперативной памяти,
соответствующая виртуальному
адресу (р, d)
т паМ^г”
Рае. 10.10. Соответствие между адресами виртуальной и физической
в страничной системе
Ц,1 falpWaAb>IOU памяти
ргуъ рассмотрим динамическую трансляцию адресов подробнее,
л преимуществ страничной системы виртуальной памяти состоит
е Я3 яе ВСе страницы, принадлежащие процессу, должны находиться
0^, ной памяти одновременно — в оперативной памяти нужно дер-
страницу (или страницы), к которым процесс обращается
JgTb t0? момент. Следовательно, в оперативной памяти можно одновре-
да^^з^естить большее число процессов. Недостатком такой системы
усложнение механизма трансляции адресов. Поскольку обычно
()аЯЯеТС*!раницы процесса находятся в основной памяти, в таблице разме-
рВ<?<! страниц нужно указывать для каждой страницы, находится ли
„ в данный момент в оперативной памяти. Если да, то в таблице
ffP900 быть указан номер кадра страницы, в котором находится эта стра-
нет, то в таблице должны храниться сведения о месте хранения
пЫ на вторичном устройстве хранения. Если процесс обращается
с!?8® нИпе, которой в данный момент нет в оперативной памяти, процес-
14 С генерирует страничный промах (page fault), и операционная система
C°P»tH8 загрузить требуемую страницу в оперативную память со вторично-
„устройства хранения.
Не рисунке 10.11 показана типичная запись в таблице размещения
страниц, или просто запись страничной таблицы (Page Table Entry —
Е). Бит резидентное™ (г) устанавливается в 1, если страница загружена
оперативную память, и в 0, если нет. Если страница не загружена в опе-
ративную память, то поле s содержит ее адрес на вторичном устройстве
хранения. Если страница находится в оперативной памяти, то в поле р’
указан номер ее кадра. Ниже мы рассмотрим несколько реализаций меха-
низма отображения страниц.
Бит Адрес на вторичном устройстве Номер кадра страницы (если
резидентное™ хранения (если страницы нет страница есть в оперативной
страницы в оперативной памяти) памяти)
г= 0 страницы нет в оперативной памяти
т= 1 страница есть в оперативной памяти
Запись страничной таблицы
Вопросы для самопроверки
Требует ли механизм отображения страниц, чтобы р’ и s хранились
в отдельных ячейках РТЕ, как показано на рис. 10.11?
2- Объясните различие между понятиями страницы и кадра страни-
цы.
М
Ответы 1) Нет. Чтобы уменьшить объем памяти, 3at,
РТЕ, многие системы используют только одно поле, значецц ^^еД
воспринимается либо как номер кадра, либо как адрес ца ~
устройстве хранения. Если бит резидентности установлен
жит номер кадра страницы, а не адрес на вторичном устройся® Со?Ч
ния; если бит сброшен, РТЕ содержит адрес на вторичном v Ве Ча
хранения, но не номер кадра страницы. 2) Страницы и кадрь ройсИ
одинаковы по размеру; страница — это постоянный по разм
виртуального адресного пространства процесса, а кадр стт^^
это постоянный по размеру блок оперативной памяти. Ci
туальной памяти должна быть загружена в кадр страницы в Ьц?
ной памяти, прежде чем процесс сможет обращаться к содеп1е^а'г’1й.
этой страницы.
10.4.1 Трансляция адресов прямым отображением в страничных
системах
Здесь мы рассмотрим трансляцию виртуальных адресов в физическ
методом прямого отображения (direct mapping) в страничных системах
Принцип реализации этого метода показан на рисунке 10.12.
Процесс обращается по виртуальному адресу v = (p.d). При гереключе-
нии контекстов операционная система загружает адрес, по которому в one
ративной памяти размещается страничная таблица процесса, в регистр на-
чала страничной таблицы (page table origin register). Чтобы определить ре-
альный адрес, соответствующий некоторому виртуальному, система
Регистр начала
страничной
таблицы
| Базовый адрес]
страничной
таблицы b '
цв Виртуальной памяти
579
прибавляет базовый адрес Ь (адрес начала) страничной таблицы
к номеру страницы р, к которой обращается процесс (т.е. р являет-
^^^соМ в страничной таблице). Результат Ь + р — это адрес, по которо-
ДшЛеКоаТивной памяти хранится РТЕ страницы р. [Примечание: Для уп-
. 5 °0 jygj считаем, что размер записи в таблице постоянен и по каждому
..Цг памяти хранится одна запись.] Эта РТЕ указывает, что странице р
сТВУет кадР Р ’ Система выполняет конкатенацию р’ со смещением d
сС^^чает реальный адрес г. Это пример прямого отображения, поскольку
0 ^"чная таблица содержит по одной записи для каждой страницы в вир-
м адресном пространстве V процесса. Если процесс хранит в V в об-
ложности п стРаний’ то страничная таблица для прямого отображения
W жит последовательно расположенные записи для страниц 0, 1, 2, ...,
^дрямое отображение сильно напоминает доступ к элементам массива по
ксу; система может прямо обратиться к любой записи в таблице.
0ВСйСтема хранит преобразуемый виртуальный адрес и базовый адрес
паяичной таблицы в быстродействующих регистрах процессора, чтобы
Грации с этими адресами производились как можно быстрее (за один
диКл исполнения инструкции). Однако сама страничная таблица для пря-
ч0ГО отображения может быть весьма велика и поэтому хранится в опера-
тивной памяти. Соответственно, на обращение к страничной таблице ухо-
дит как минимум один цикл обращений к памяти. Поскольку доступ к па-
мяти обычно занимает основную часть времени выполнения инструкции,
а нам потребуется дополнительное обращение к памяти для преобразова-
ния адреса, применение прямого отображения адресов снизит скорость вы-
полнения программы приблизительно вдвое (или еще больше, если маши-
на поддерживает многоадресные инструкции). Чтобы ускорить трансля-
цию адресов, можно целиком поместить страничную таблицу
в быстродействующую кэш-память. Но из-за дороговизны кэш-памяти
и ольших объемов виртуальных адресных пространств обычно этот под-
Х0Д непрактичен. Решение этой проблемы мы обсудим в разделе 10.4.3.
Вопросы дм самопроверки
1. Почему записи в страничной таблице должны быть одинаковыми
по размеру?
2- Какие специальные аппаратные устройства нужны для трансляции
адресов прямым отображением в страничных системах?
Ответы 1) Для реализации виртуальной памяти важно, чтобы
трансляция адресов выполнялась как можно быстрее. Если записи
в таблице одинаковы по размеру, процедура поиска нужной записи
Роста, и трансляция адресов страниц будет выполняться быстро.
) Для хранения базового адреса страничной таблицы нужен быстро-
действующий регистр в процессоре.
580
'Ч
10.4.2 Трансляция адресов ассоциативным отображением
в страничных системах
Один из способов повышения скорости динамической трансляцц
сов — размещение всей страничной таблицы в ассоциативной ** %?
(associative memory), в которой выборка данных осуществляется не ц0Па4Ч>
а по содержимому. У этой памяти скорость доступа должна быть как
на порядок выше, чем у оперативной памяти28’ 29>30131. На рисунке Ю
зана схема трансляции адресов ассоциативным отображением. Проц^ а°Ч
щается по виртуальному адресу v = (p,d). Все записи в ассоциативной п
просматривается одновременно в поисках нужной страницы р. Резуль
поиска является значение р’ — номер кадра страницы, соответствующего1^
нице р. Конкатенацией р‘ с величиной смещения d формируется реальный^’
рес г. Заметьте, что на рисунке 10.13 стрелки в ассоциативной таблице
дят в каждую ячейку, показывая тем самым, что поиск значения, соотв»^
вующего р, выполняется одновременно во всех ячейках. Эта особенно/
делает ассоциативную память очень дорогой, даже по сравнению с кэгц₽
требуемым для прямого отображения. Из-за этой дороговизны чистое аедЛ
циативное отображение не применяется на практике; здесь оно показано ва
случай, если экономическое положение станет более приемлемым.
Рис. 10.13. Трансляция адресов ассоциативным отображением в страничВ61*
системах
giB ртуал^пои тмяттг — — ----- — ------— — ---
пазование кэш-памяти для реализации прямого отображения или
^тивяой памяти для реализации ассоциативного отображения в по-
аетл большинстве систем неприемлемо из-за дороговизны. В ре-
многие разработчики применяют компромиссную схему, обла-
преимуществами обоих подходов при меньшей цене. Эту схему
^^ссмотрим в следующем разделе.
Вопросы для самопроверки
11. Почему трансляция адресов ассоциативным отображением не ис-
пользуется на практике?
2. Нужны ли
трансляции
системах?
Ответы 1) . ...
кэш-память, используемая при прямом отображении. Поэтому сис-
тема, содержащая достаточно ассоциативной памяти для хранения
всех РТЕ всех процессов, будет стоить слишком дорого. 2) Этот ме-
тод требует наличия ассоциативной памяти. Однако он не требует
специального регистра для хранения базового адреса страничной
таблицы, поскольку поиск в ассоциативной памяти ведется по зна-
чению, а не по адресу.
какие-то специальные аппаратные устройства для
адресов ассоциативным отображением в страничных
Ассоциативная память стоит еще дороже, чем
10.4.2 Трансляция адресов смешанным прямым/ассоциативным
отображением в страничных системах
Значительная часть обсуждения до сих пор была связана с аппаратными
устройствами, необходимыми для эффективной реализации виртуальной
памяти. Представление аппаратных устройств при этом было скорее логи-
ческим, чем физическим. Нас интересует не точная структура устройств,
а их функциональная организация и быстродействие. Именно таким дол-
жен быть подход разработчика операционных систем, особенно в условиях
стоянно развивающейся аппаратной базы.
СтоРически аппаратные устройства эволюционировали намного быст-
при’вЧем программное обеспечение. Разработчики последнего привыкли не
докрываться к конкретной аппаратуре, потому что скоро все равно
а ПоявИться лучшая. Однако разработчики операционных систем
Иеств Ь1 Использ°вать возможности и характеристики оборудования, су-
Чиат2101Цего в данный момент. Быстродействующие кэши и схемы ассо-
4>есн ои памяти слишком дороги, чтобы хранить данные о виртуальных
Х ПР°стРанствах всех процессов. Поэтому появился компромисс-
- ЗгОт ааизм со смешанным отображением.
>РомМ:ХаНИЗМ использует схему ассоциативной памяти, называемую
^быстрой трансляции (Translation Lookaside Buffer — TLB), в ко-
?Ссa (CjiJMteT храниться только небольшая часть страничной таблицы про-
с' Рис- 10.14). Содержимое TLB может контролироваться операци-
СТеМой Или аппаратными устройствами, в зависимости от
За Ь1 ’ В этой главе мы предполагаем, что TLB управляется аппа-
к^^ЦамИСИ стРаничн°й таблицы, помещаемые в TLB, соответствуют
> К которым недавно обращался процесс. Такой подход основан
582
ч
на предположении, что к страницам, к которым процесс обращался д
но, он будет вновь обращаться и в ближайшем будущем. Это при
кальности (точнее — временной локальности), феномена, подробна
даемого в главе 11 (см. также в текущей главе «Размышления об
онных системах: Эмпирические результаты — локальность»)
является неотъемлемой частью современных систем управления пам ^43
Регистр начала
страничной таблицы
Базовый адрес
страничной
таблицы b
Виртуальный адрес
v = (p, d)
I
{ + ~--------------
Выполняется только ।
при отсутствии •
нужного адреса J
в ассоциативной '
памяти у Сначала
. - попытка
/ ассоциативного
/ поиска
Номер страницы ! Смещение
Буфер быстрой трансляции (TLB)
(только наиболее активные страницы)
Только при
безуспешном
_______
Реальный адрес г
ассоциативном
поиске
Рис. 10.14. Трансляция адресов смешанным прямым/ассоциативным
отображением в страничных системах
ццЯ виртуальной памяти
ой схеме динамическая трансляция адресов протекает следующим
0 Процесс обращается по виртуальному адресу v= (p,d). Механизм
лбРа мнения страниц сначала пытается найти данные о странице р в TLB.
Г успешен, то результатом его будет значение р’ — адрес кадра,
Г твующего странице р. После этого конкатенацией р’ и значения
соО'1'веТ]Ия d получается реальный адрес г. Обнаружение данных о страни-
называется попаданием в TLB (TLB hit). Поскольку TLB хранит
jlfP 5 1 в быстродействующей памяти, то трансляция будет выполнена на
за^^ально возможной в системе скорости. Конечно, из-за своей высокой
*J8J<C0 сти ассоциативная память может использоваться для хранения
cToUW йебольшой части адресов виртуального адресного пространства,
^^основная задача — выбрать такой объем ассоциативной памяти, что-
ЗДеСЬ нрцемлемых экономических показателях как можно большее чис-
бпащений к TLB приводило к попаданиям.
Л° Если в TLB нет записи о странице р, то есть произошел промах в TLB
т n miss), система находит запись о странице в страничной таблице в опе-
^ативной памяти. При этом скорость трансляции падает. Адрес Ь, храня-
щийся в регистре начала страничной таблицы, суммируется с номером
страницы р, чтобы найти запись страницы р в страничной таблице. В этой
записи содержится р’ — адрес кадра, в котором размещена страница р.
Конкатенацией р’ и значения смещения d получается реальный адрес г.
Затем система помещает запись о странице р в TLB, чтобы последующие
обращения к этой странице транслировались быстрее. Если TLB заполнен,
то одна из записей удаляется из него (обычно запись о наименее часто тре-
буемой странице), и на ее место заносится запись о странице р.
Исходя из эмпирических соображений, количество записей в TLB не
обязательно должно быть большим, чтобы достичь хорошей производи-
тельности. На практике системы, использующие TLB объемом 64 или 128
записей (при объеме страницы 4 КБ это соответствует 256-512 КБ вирту-
ального адресного пространства), часто достигают производительности
'° или более от производительности, возможной при использовании пол-
®°^ью ассоциативного отображения. Обратите внимание, что при промахе
чИТьК пР°цессор должен обратиться к оперативной памяти, чтобы полу-
уцравНомер каДРа страницы. В зависимости от аппаратуры и стратегии
Лов ВЛения памятью такие промахи могут стоить десятков или сотен цик-
вее ПР°П'ессоРа, поскольку оперативная память обычно работает медлен-
процессор33* 34> 35.
I %бра°ЛЬЗование комбинированного механизма ассоциативного/прямого
еПИЯ — это инженеРное решение, основанное на экономических
I ^°Этом ₽Истиках и возможностях существующих аппаратных платформ.
разРаботчикам и студентам, специализирующимся в области опе-
4 ^здр систем, важно отслеживать появление новых технологий.
I ‘Рекомендуемая литература» и «Веб-ресурсы» указаны не-
Документов, посвященных этим технологиям.
584
.Г)
Вопросы для самопроверки
1. (Да/Нет) Для достижения высокой производительности hVjv
нить в TLB большую часть РТЕ процесса. *
2. Почему система должна сделать недействительной запис 1
о странице, перенесенной на вторичное устройство хранен^ ® Тц
Ответы 1) Нет. Процессы часто достигают производите
90 % или более от производительности, возможной при испЬ®°с»ь
нии полностью ассоциативного отображения, если в TLB х°ЛЬа°Ц
только небольшая часть РТЕ процесса. 2) Если эту запись
недействительной, TLB вернет при обращении кадр не находС^елЧ
в памяти страницы, что может привести к чтению некорректно
ных или инструкций (например, со страницы, принадлежащей *
му процессу). ^РУгс.
Размышления об операционных системах
Эмпирические результаты — локальность
В некоторых областях компьютерных наук
важную роль играет математически обосно-
ванные теоретические построения. В опера-
ционных системах действительно есть аспек-
ты, теоретические исследования которых
очень полезны. Но в большинстве случаев
проектирование операционных систем еще
со времен создания первых операционных
систем в 1950-х годах опирается на эмпири-
ческие (т.е. основанные на наблюдениях)
результаты и эвристические решения, пред-
ложенные разработчиками. Рассмотрим, на-
пример, эмпирические феномены времен-
ной и пространственной локальности, кото-
рые замечены в ходе наблюдений. Если в ва-
шем городе солнечно, то, вероятно (но не на-
верняка), поблизости от него тоже солнечно.
Если сейчас в городе хорошая погода, то, ве-
роятно (но не наверняка), она была хорошей
некоторое время назад и останется хорошей
еще некоторое время в будущем. В компью-
терных системах имеет место множество
проявлений локальности, и мы изучим рВД
эвристических решений, основанных на ней,
например, в системах управления виртуз^
ной памятью. Возможно, самое знаменит
эвристическое решение в операционных
темах, основанное на локальности - м
рабочих наборов Питера Деннинга, коТ
мы рассмотрим в главе 11.
10.4.4 Многоуровневые страничные таблицы
Одно из ограничений, свойственных преобразованию адресов
отображением состоит в том, что все записи в страничной таблиДе рОр^
храниться в оперативной памяти и храниться последовательно
номеров страниц. Кроме того, для этих таблиц могут требовать ^ра#^
объемы памяти. Рассмотрим, например, виртуальное адресное ДР0
с 32-битовыми адресами, состоящее из 4-килобайтных страниц. Р т у
теме размер страницы равен 212 байт и, соответственно, существу
f 20 разных номеров страниц. Поэтому в страничной таблице каждого
0 2 ’ „ого адресного пространства может быть около миллиона записей,
на каждую запись, при необходимости адресовать около 4 милли-
о0^ йт. А виртуальное адресное пространство с 64-битовыми адресами,
6-rjonjee 4-мегабайтные страницы, потребует около 4 триллионов за-
^°ЯКоанение такой огромной таблицы в оперативной памяти (даже если
для этого хватит) сильно ограничит пространство, остающееся для
цв^йррограмм. Кроме того, хранить такие огромные таблицы не имеет
поскольку процессам могут потребоваться для работы только не-
части их адресных пространств.
боль^^уровневые (multilevel), или иерархические (hierarchical), стра-
^в<р таблицы позволяют системам хранить в оперативной памяти толь-
ввЧ0\1асти страничных таблиц, которые активно используются процесса-
к° ^Поугие части могут создаваться при первом их использовании и пере-
МИ ться на вторичные устройства хранения, когда их интенсивное
б°СоЛЬзование прекращается. Многоуровневые таблицы реализуются в ие-
ЙСПхичеСКОМ виде — каждый уровень иерархии представляет собой табли-
^указателей на таблицы более низкого уровня. Самый нижний уровень
состоит из таблиц с информацией о страницах виртуального адресного про-
странства.
Для примера рассмотрим систему с двумя уровнями страничных таблиц
(см. рис. 10.15). Виртуальный адрес будет представлять собой упорядочен-
ную тройку значений v = (р, t, d), в котором упорядоченная пара (р, t) ука-
зывает номер страницы, ad — смещение на этой странице. Сначала систе-
ма суммирует р с адресом а в оперативной памяти, с которого начинается
таблица директорий страниц (этот адрес хранится в регистре начала табли-
цы директорий). Запись в ячейке по адресу а + р содержит адрес начала со-
ответствующей страничной таблицы, Ь. Сложением tub система получает
адрес в таблице записи, по которому хранится номер кадра страницы р’. И,
наконец, конкатенацией р’ и d система формирует реальный адрес.
В большинстве систем каждая таблица в иерархии по размеру равна од-
ной странице, что позволяет системе легко переносить страничные табли-
аимМе5кДУ оперативной памятью и вторичным устройством хранения. Оце-
в ’ насколько двухуровневая таблица уменьшает расход памяти по срав-
8 4 10 с прямым отображением адресов в системе с 32-битовыми адресами
ВоМрИ^°®ан'ГНЫМи страницами (для таких страниц требуются 20-битовые
“ каждая страничная таблица будет состоять из 220, или 1048576
Aecjj-, В* В связи с тем, что в системах часто выполняются одновременно
8бСьМа * а Иногда — и сотни процессов, расход памяти на таблицы будет
^тн> 4 С^Ц^ественнь1М- Если каждая запись в таблице будет занимать 32
110 На Мегаб&йта непрерывного адресного пространства потребуется толь-
г’г-са, рГанизацию виртуального адресного пространства для одного про-
дет й Ли это пространство будет слабо заполнено (т.е. использоваться
^Иц^^ного записей из таблицы), то потери памяти на фрагментацию
, tlcjuj fragmentation) станут весьма заметными.
^СйОгПР°Цесс использует не более 1024 первых страниц виртуального
МРРс’С^’Рэиства, системе нужно хранить только 1024 (210) записи
’ Таблицы директорий и 1024 записи в одной страничной табли-
1 Как общая страничная таблица для прямого отображения содер-
Регистр начала
таблицы директорий
Виртуальный адрес и= (р, t, d)
10 битов р 0 битов 12 битов
Адрес страничной
таблицы
директорий^----
Страничная
таблица
Кадр j ’I
; страницы । Смещение d
| Р' I
Реальный адрес г
Рис. 10.15. Многоуровневая трансляция адресов страниц
жала бы более миллиона записей. Многоуровневые страничные таблицы
позволяют системам уменьшить фрагментацию таблиц более чем на 99 /°-
Накладные расходы, связанные с использованием многоуровневых
лиц, обусловлены необходимостью еще одного обращения к памяти
трансляции адреса. На первый взгляд может показаться, что это ДоП°
тельное обращение приведет к снижению производительности по СР
нию с прямым отображением. Однако вследствие локальности обра
и наличия быстродействующего TLB после занесения страницы ® вцЙ
дальнейшие обращения к ней не требуют дополнительных
к памяти. Поэтому системы, использующие многоуровневые стра ррс
таблицы, полагаются на очень высокий уровень попаданий в ТЫ> А
тижения высокой производительности. Пр0^
Многоуровневые страничные таблицы становятся все более РаС
ненными в страничных системах виртуальной памяти. НаприМ^Р^ pfA
тектура IA-32 поддерживает два уровня страничных таблиц рА'
дел 10.7, «Практический пример: Виртуальная память архитектур
фирмы Intel»).
tgi/Я Виртральпой памяти
Вопросы дм самопроверки
587
1. Оцените преимущества и недостатки многоуровневых страничных
таблиц по сравнению с использованием одной таблицы для прямого
отображения.
2. Разработчик предлагает уменьшить расход памяти на страничные
таблицы за счет увеличения размера страницы. Оцените последст-
вия такого решения.
Ответы 1) Многоуровневые системы расходуют намного меньше
оперативной памяти на хранение информации для отображения, чем
системы с одной таблицей. Однако в многоуровневых системах требу-
ется больше обращений к памяти для трансляции адреса, если страни-
ца, к которой обращается процесс, не занесена в TLB, и теоретически
это может привести к снижению производительности. 2) Если предпо-
лагать, что размер адреса в виртуальном адресном пространстве оста-
нется тем же, то увеличение размера страницы уменьшит количество
записей в страничной таблице. Кроме того, накладные расходы на
трансляцию адресов будут меньше, чем при использовании много-
уровневых страничных таблиц. Однако с ростом размера страницы бу-
дет расти уровень внутренней фрагментации. Вполне возможно, что
потери памяти на внутреннюю фрагментацию превысят выигрыш за
счет уменьшения размера страничной таблицы.
WA.5 Обращенные страничные таблицы
В предыдущем разделе мы выяснили, что многоуровневые страничные
таблицы уменьшают количество записей, которое должно одновременно на-
ходиться в оперативной памяти для каждого процесса — по сравнению
с системами прямого отображения. При этом мы предполагали, что процес-
сы обращаются только к небольшим, непрерывным группам страниц своих
виртуальных адресных пространств, и система может уменьшить наклад-
ные расходы, храня только страничные таблицы с записями об используе-
Мых областях виртуальных адресных пространств. Однако процессы ком-
ического и научного характера могут работать с большими объемами дан-
и использовать большие части своих 32-битовых виртуальных
цщнНЬ1Х пространств. В этом случае использование многоуровневых таб-
товы^е °^язательно приведет к уменьшению фрагментации таблиц. В 64-би-
ц, ц Системах, содержащих несколько уровней страничных таблиц, затра-
ЯТи на информацию о размещении страниц могут оказаться сущест-
Обр^И'
ионная страничная таблица (inverted page table) решает эту про-
*етстве?аня По одной РТЕ для каждого страничного кадра в системе. Соот-
°’ количество РТЕ, которое нужно хранить в оперативной памяти,
°НаЛЬНО объемУ этой памяти, а не объему виртуального адресного
Тва- Страничные таблицы инвертируются относительно обычных
и-РТЕ индексируются по номерам кадров страниц, а не номерам
о аметьте> что обращенные страничные таблицы не хранят инфор-
Мг^еИцч РЯзмеЩении нерезидентных страниц на вторичных устройствах
ЧчЛ ее <^Та информация должна поддерживаться операционной систе-
? ^Иоутствие в таблицах не обязательно. Например, операционная
бц ЗКет хРанить информацию о размещении нерезидентных страниц
Парного дерева, чтобы ее можно было быстро найти.
588
В обращенных страничных таблицах для отображения вирТу
страниц в РТЕ используются функции хэширования37’ 38. Функци
рования (hash function) — это математическая функция, прин к *
в качестве аргумента число и возвращающая лежащее в опреде н
пазоне число, называемое хэш-кодом (hash code). Хэш-таблиц^ ** *%*
table) хранит каждое значение в ячейке, соответствующей хэщ-код
значения. Поскольку номеров страниц виртуальной памяти обычно
ше, чем кадров страниц, то для разных входных значений могут по
ся одинаковые хэш-коды — эти совпадения называются столкновр
(collisions). Во избежание перезаписи одних элементов другими
жаемыми в те же ячейки хэш-таблицы, в обращенных страничных°Т°^-
цах может использоваться механизм сцепления (chaining) для устра^18,
столкновений. Этот механизм работает следующим образом. Если хэщвИ*
некоторого элемента совпадает с хэш-кодом другого, то к хэш-коду пп^
няется новая функция. Результирующее значение используется в Ta6ji
как индекс ячейки, в которую помещается входное значение. Чтобы гав
тировать, что элемент будет найден при обращении к нему, указатель
его ячейку присоединяется к записи в ячейке, соответствующей изначаль-
ному хэш-коду элемента. Процесс повторяется при каждом столкновения
В обращенных страничных таблицах для сцепления элементов обычно ис-
пользуются связные списки.
В страничной системе, использующей обращенные страничные табли
цы, каждый виртуальный адрес представляется упорядоченной парой а =
(р, d). Чтобы быстро найти в хэш-таблице запись, отвечающую виртуаль-
ной странице р, система применяет к значению р хэш-функцию, получая
результат q (см. рис. 10.16). Если q-ая ячейка в обращенной траничной
таблице содержит значение р, система проверяет значение цепного указа-
теля в этой ячейке. Если это null-указатель, то страницы в памяти нет,
и процессор сообщает о страничном промахе. При этом операционная сис
тема должна извлечь страницу со вторичного устройства хранения. В про-
тивном случае по этому индексу в таблице имело место столкновение»
и в этой ячейке хранится указатель на следующий элемент цепочки.
тема будет переходить по указателям в цепочке до тех пор, пока не н
значение р, или пока не найдет null-указатель (при этом процессору
дется сообщить о страничном промахе, поскольку требуемая стран
резидентна и в оперативной памяти ее нет, так что операционная
должна извлечь страницу со вторичного устройства ХР 8 до
На рисунке 10.16 система находит запись о странице р после пере
одному указателю к ячейке р’, поэтому р находится в кадре р •
Хотя удачный выбор функции хэширования может уменыш ть g це-
ство столкновений в хэш-таблице, каждый последующий указа л ц»
почке требует от системы дополнительного обращения к опеРаТ^сЯ-
мяти, и время трансляции адреса может существенно уве пцТь^
уменьшения количества столкновений можно попытаться pad
пазон выходных значений хэш-функции. Поскольку размер хЭ
должен оставаться постоянным, чтобы обеспечить прямое от _й
в кадры страниц, в большинстве систем диапазон выходных ;-
ширяется за счет использования якорной хэш-таблицы (а^
table), представляющей собой таблицу указателей на записи
хэШ'7^*
вовр”"
виртуальпои памяти
МУ
^цой таблице (см. рис. 10.17). Использование якорной хэш-таблицы
Одного дополнительного обращения к памяти при трансляции ад-
оМОЩью обращенной страничной таблицы, и увеличивает фрагмен-
та с Птаблиц. Однако если якорная хэш-таблица достаточно велика, ко-
о столкновений в обращенной страничной таблице мож.ет сущест-
^^уменьшиться, и скорость трансляции адресов возрастет. Размер
Хэш-таблицы нужно тщательно выбирать, чтобы выдержать рав-
rfOpмежДУ расходом памяти и скоростью трансляции адресов39- 40.
Я^йпященные страничные таблицы обычно используются в высокопроиз-
О^ьяых архитектурах, например, Intel IA-64 и HP РА-RISC, но они
«о^^реализованы в архитектуре PowerPC, которая используется в серии
Иверов Apple.
Номер страницы Смещение
является номером кадра страницы
t
Тпя
^“Нсляция адреса страницы с помощью обращенной страничной
$90
Номер страницы
Смещение
Р
Реальный адрес г
Якорная хэш-таблица
уменьшает количество
столкновений
Если столкновения нет,
—— — то хэш-код является
номером кадра страницы
Номер кадра
Р'
Рис. Ю.17. Обращенная страничная таблица, использующая якорную хэш-таблиДЛ
Якорная
хэш-таблица
Обращенная
страничная
таблица
В случае
столкнове- 1 2 *
ния следуем I
по цепочке I
указателей ।
Вопросы для самопроверки
1. Сравните обращенные страничные таблицы (без якорных т04
лиц) со страничными таблицами для прямого отобрг ''и сляй^
ки зрения эффективности использования памяти и трав
адресов. в0 раз»'6'
2. Почему в обращенных страничных таблицах РТЕ болыУе
ру, чем в страничных таблицах для прямого отобразкея
V
и
^^^^рпуамнои намята ivi
Ответы i) Обращенные страничные таблицы занимают меньше
памяти, чем страничные таблицы для прямого отображения, посколь-
ку в обращенных страничных таблицах для каждого физического кад-
ра страницы хранится только одна РТЕ, а в страничных таблицах для
прямого отображения каждой виртуальной странице соответствует
своя РТЕ. Однако трансляция адресов с помощью обращенных стра-
ничных таблиц может быть намного медленнее, чем с помощью пря-
мого отображения, поскольку в случае столкновения системе
приходится обращаться к оперативной памяти несколько раз, следуя
по цепочке указателей. 2) В РТЕ в обращенной страничной таблице
нужно хранить не только номер виртуальной страницы, но и указа-
тель на следующую РТЕ в цепочке на случай столкновения. В РТЕ
в страничной таблице для прямого отображения нужно хранить толь-
ко номер кадра страницы и бит резидентности.
104 6 Разделение ресурсов в страничной системе
я мультипрограммных компьютерных системах, особенно в системах
азделением времени, разные пользователи обычно выполняют одновре-
с₽а„_ лпни и те же программы. Если система выделит индивидуальные
копии программ для каждого пользователя, большая часть оперативной
памяти будет истрачена напрасно. Очевидное решение — предоставить
множеству пользователей доступ к общим страницам памяти как к разде-
иемому ресурсу.
Система должна четко контролировать разделение ресурсов, чтобы не
позволить одному процессу изменять данные, к которым обращается дру-
гой процесс. В большинстве современных систем, поддерживающих совме-
стное использование ресурсов, программы рассматриваются как совокуп-
ности процедур и данных. Неизменяемые процедуры называются чистыми
процедурами, процедурами многократного обращения или реентерабель-
еими (reentrant). Изменяемые данные не могут рассматриваться как рав-
няемый ресурс без аккуратного управления одновременным исполнени-
ярограмм. Неизменяемые данные разделить легко. Изменяемые проце-
Раз разДелить нельзя (хотя и можно придумать пример, в котором такое
пеа еВие с помощью некоей формы управления одновременным испол-
gc^M будет иметь смысл).
ЭТ° o6c™B™e подводит нас к мысли о том, что нужно пометить ка-
°1>оцес ₽аниЦУ как разделяемую или неразделяемую. Если страницы всех
“Чет В Поме’!ены таким образом, разделение в страничных системах
Рграаи сняться так, как показано на рисунке 10.18. Если записи
Рь> ст НЫХ та®лицах различных процессов указывают на одни и те же
РазДел НИЦ” то эти каДРы разделены между процессами (используются
,1 требу Яе^ый ресурс). Разделение уменьшает объем оперативной памя-
МЬ1В ДЛЯ эффективной работы группы процессов, и позволяет
иУВеличпвать степень мультипрограммности.
ПриМеР°в того, как разделение страниц может существенно
'Ч'4 Дро ПотРебление памяти — системный вызов fork в системе UNIX.
Ч^сс Разветвляетсяа> Данные и инструкции родительского про-
\ Цесса-потомка изначально идентичны. Вместо создания в памя-
ч.
₽еводе «разветвляться» или «расходиться» — прим, перев.
592
ти идентичной копии данных для процесса-потомка, операциоцн
ма может просто предоставить ему доступ к виртуальному адр6Сй 4
странству родительского процесса, создавая для каждого из ц0#1^Ир
иллюзию работы в отдельном, независимом виртуальном адрег.
стпянстве. Это повышает пооизводительность. поскольку ь. 6
странстве. Это повышает производительность, поскольку умен ** Ир?
время инициализации процесса-потомка и потребление памяти Дв
цессами (см. «Размышления об операционных системах: Позднее Я
ние»). Однако поскольку родительский процесс и процесс-потомок*^^-
ют о разделении, операционная система должна гарантировать, что**6
вступят в конфликт при изменении содержимого страниц. 01,11
Страница данных А
Страничная
таблица
процесса 9
Оперативная память
' ---—----------
Процедура А (1 -я страница^
Процедура А (2 -я страница
Страничная
таблица
процесса 1
Страничная
таблица
процесса 2
Процедура А (1 -я страница) '
^Процедура А (2-я страница
Страница данных А
Кадр
страницы 2
Кадр
страницы 3
Кадр
страницы О
Кадр
страницы 1
Процедура А - 2-я
страница (совместно
' используется
процессами 1,2 и 9)
Кадр ,
страницыj
Процедура А (1 -я страница)*
Процедура А (2-я страница
। . n i • -----1
Кадр
страницы«
КаДР .„ьП
страниД1’
Процедура А - 1 -я
страница (совместно
используется
процессами 1,2 и 9)
Страница данных А
(совместно
используется
процессами 2 и 9)__
КаДР11|Ь|6
страницы
Л
(ТОЙ С,,<"
Рис. 10.18. Разделение (совместное использование) ресурсов в страни
Виртуальной памяти
593
I многих операционных системах для решения этой проблемы использу-
5° 0дХоД, называемый копированием при записи (copy-on-write). Изна-
^сЯ ° сИСТема хранит в памяти одну копию каждой разделяемой (совместно
3уемОй) страницы для процессов от Р] до Р„, как описано выше. Если
р, выполняет запись на разделяемую страницу, операционная систе-
цроОе яСТ копию этой страницы и поместит ее в виртуальное адресное про-
^^гтво процесса Pj. Неизмененная копия страницы останется отображен-
сТР^здресные пространства всех процессов, между которыми она разделяет-
пт подход гарантирует, что если один из процессов изменит содержимое
сЯ- " лЯемой страницы, то изменение не повлияет на другие процессы.
многих архитектурах в РТЕ хранится бит чтения/записи (read/write
^значение которого процессор проверяет при каждом обращении по адресу,
сЯщемуся к соответствующей странице. Если бит сброшен, содержимое
о1® н0ць1 можно читать, но не изменять. В противном случае содержимое
Куницы можно и читать, и изменять. Поэтому копирование при записи в та-
х архитектурах можно реализовать, пометив все разделяемые страницы как
пстулные только для чтения. Если процесс попытается выполнить запись на
таКую страницу, процессор, на котором выполняется этот процесс, сообщит
мру системы о страничном промахе. При этом ядро определит, что процесс по-
лытался выполнить запись на страницу, и создаст новую копию страницы.
Копирование при записи ускоряет создание процессов и уменьшает потреб-
ление памяти процессами, не изменяющими при работе больших объемов дан-
ных. Однако оно может привести к низкой производительности, если значи-
тельная часть разделяемых данных программы будет изменяться в ходе ее вы-
полнения. В этом случае страничный промах будет происходить каждый раз,
когда процесс попытается изменить содержимое разделяемой страницы. На-
кладные расходы на обращение к ядру при каждом исключении могут быстро
превзойти выигрыш от копирования при записи. В следующей главе мы под-
робно рассмотрим влияние разделения на управление виртуальной памятью.
Вопросы для самопроверки
1. Почему реализация разделения страниц с помощью обращенных
страничных таблиц может оказаться сложной?
2. Как разделение страниц повлияет на производительность, если опе-
рационная система перенесет страницу из оперативной памяти на
вторичное устройство хранения?
Ответы 1) Разновидность страничного разделения, рассмотренная
в этом разделе, реализуется за счет того, что РТЕ в страничных табли-
цах разных процессов указывают на одни и те же страничные кадры.
Поскольку обращенные страничные таблицы хранят в памяти по од-
ному РТЕ для каждого кадра, операционной системе придется хра-
нить информацию о разделении в структуре вне обращенной
страничной таблицы. Одна из сложностей здесь будет заключаться
в необходимости определения того, находится ли разделяемая страни-
ца в памяти, поскольку какой-то процесс обращался к ней до того, как
к ней впервые обратился другой. 2) Если операционная система пере-
носит разделяемую страницу на вторичное устройство хранения, она
должна обновить соответствующие этой странице РТЕ у каждого про-
цесса, для которого эта страница рассматривается как разделяемая.
Если таких процессов много, то накладные расходы могут быть намно-
го больше таковых при переносе неразделяемой страницы.
-
Размышления об операционных системах
Позднее Выделение
Схемы с поздним выделением ресурсов
(его называют также отложенным выделени-
ем) выделяют ресурсы в последний момент,
когда эти ресурсы непосредственно запраши-
ваются процессами или потоками Для запро-
шенных ресурсов, которые в итоге могут по
какой-то причине не понадобиться, схемы
с поздним выделением ресурсов эффектив-
нее, чем схемы с предварительным выделе-
нием — последние могут зря тратить ресурсы,
которыми, в конце концов, никто не восполь-
зуется. Для ресурсов, которые гарантировано
будут использоваться, схемы с предваритель-
ным выделением эффективнее схем с позд-
ним, поскольку они предоставят процессам
и потокам нужные ресурсы к тому моменту,
когда эти ресурсы потребуются, и процес-
сам/потокам не придется ждать выделения
ресурсов. Позднее выделение будет рассмат-
риваться в этой книге в разных контекстах.
Один из классических примеров позднего
выделения — выделение страниц по требова-
нию, которое мы подробно рассм
в этой и следующей главах. При чцСТо°ТрИм
делении по требованию страницы по ВЬ|'
или потока переносятся в память только 3
явном обращении к этим страницам
имущество такого подхода состоит в т™ Ре
ом, чТо
накладные расходы на перенос страни
в оперативную память со вторичного устрой
ства хранения никогда не появляются если
страница не нужна. С другой стороны по
скольку такая схема ожидает обращения
к странице, прежде чем перенести эту стра-
ницу в оперативную память, процесс испыта-
ет заметную задержку в выполнении, по-
скольку вынужден будет ожидать заверше-
ния операции дискового ввода/вывода.
А пока процесс или поток ждут, часть их стра-
ниц, уже находящаяся в оперативной памя-
ти, просто занимает место, которое могло бы
использоваться другими выполняющимися
процессами. Копирование при записи - еще
один пример позднего выделения.
10.5 Сегментация
В предыдущей главе мы рассмотрели, как мультипрограммная сИС^ер.
с изменяемым распределением памяти может размещать программу Б
вом, в наиболее или в наименее подходящем участке. В мультипрогр^0
ной системе с изменяемым распределением памяти данные и инстру
каждой программы занимают непрерывные области, называемые р
ми (partition). Альтернатива такому подходу — использование сег е#е
ции (segmentation) памяти (см. рис. 10.19). При ее использовании
и инструкции программы делятся на блоки, называемые сегм од-
(segments). Каждый сегмент представляет собой непрерывную оол
нако сегменты не обязательно должны быть одинаковы по разм Р
размещены рядом друг с другом в памяти. сИс^д
Одно из преимуществ систем с сегментацией перед страничным
мами — то, что первые являются скорее логическими, чем физи
щ виртуальной памяти
595
Г яЦИ. В их самой общей форме сегменты не ограничиваются ка-
определенным размером. Вместо этого они могут быть (в разумных
настолько малы или велики, насколько это нужно. Сегмент, со-
0реДе0 вующий массиву, будет иметь тот же размер, что и этот массив. Сег-
X соответствующий модулю процедурного кода, сгенерированного
^еИ’г’ пятором, имеет размер, необходимый и достаточный для того, чтобы
fto’1® оГ поместиться этот модуль.
---1, имеет размер, необходимый и достаточный для того, чтобы
поместиться этот модуль.
Jo
нтированное выделение памяти в системе реальной памяти
596
~"Ч
В системах виртуальной памяти с сегментацией мы можем
в оперативной памяти только те сегменты, которые нужны програ^9^
работы в данный момент; остальные сегменты могут находиться 'я
ном устройстве хранения41. Процесс может выполняться, пока ег^0^
щие инструкции и данные находятся в сегментах, размещенных в°
тивной памяти. Если процесс обращается к памяти в сегменте, к
загружен в основную память, система виртуальной памяти д
влечь этот сегмент со вторичного устройства хранения. В сегментн 9а-
темах сегменты переносятся из внешней памяти как неделимые ел Cl!c-
и все ячейки одного сегмента размещаются в непрерывной последо^^Ч
ности адресов в оперативной памяти. Загружаемый сегмент может aTejIb-
щаться в любой доступной и подходящей по размеру области операт
памяти. Стратегии размещения сегментов в системах с сегментацией
логичны используемым в мультипрограммных системах с изменяеааа'
распределением памяти42. Мьа*
Адрес в сегментной системе виртуальной памяти представляет сов I
упорядоченную пару v = (s, d), где s — номер сегмента в виртуальной пам°Й
ти, в которой находится требуемый элемент данных, ad — смещение этого
элемента от начала сегмента s (см. рис. 10.20).
Номер сегмента
5
Смещение
d
Виртуальный адрес
v = (s; d)
Рис. 10.20. Формат виртуального адреса в сегментной системе
Вопросы для самопроверки
1. (Да/Нет) В сегментных системах виртуальной памяти отсутствуй
фрагментация.
2. Чем сегментация отличается от мультипрограммности с измевЯ
мым распределением памяти?
Ответы 1) Нет. В сегментных системах виртуальной памяти^
жет возникать внешняя фрагментация, точно так же, как в
программных системах с изменяемым распределением „мевяе-
2) В отличие от программ в мультипрограммных системах с и те#а*
мым распределением памяти, программы в сегментные саТЯвВя?
виртуальной памяти могут быть большего размера, чем опеР
память, и в памяти может находиться только часть их Ii0C
и данных. Кроме того, в мультипрограммных системах с eIIpePbISj
мым распределением памяти процесс размещается в одной 0 9
ной области оперативной памяти, а в сегментных с с
необязательно.
r ц/ifi ВиртУально‘' ммяг”и ----------------------------------
Трансляция адресов прямым отображением в сегментных
Лцвк
I гТвует множество стратегий трансляции адресов в сегментных сис-
СУ^Система может использовать прямое отображение, ассоциативное
ге^ ет&ние прямого и ассоциативного. В этом разделе мы рассмотрим
^цлю адресов прямым отображением с хранением полной сегмент-
-гр’^йлиды в кэш-памяти быстрого доступа.
та _Jia мы рассмотрим случай, в котором трансляция адреса протекает
Сй® а затем обсудим несколько возможных проблем. Динамическая
„15Я адресов при сегментации выполняется так. Процесс обращается
^^«альной памяти по адресу v = (s, d). Чтобы определить, где в опера-
к в1,Р^ паМЯти находится требуемый сегмент, система суммирует номер сег-
f0BS° s с адресом начала сегментной таблицы Ъ, хранящимся в регистре на-
меЯТа сегментной таблицы (segment map table origin register) (см.
,вЛв10.21). Результат сложения b + s — это адрес записи о нужном сегменте
^сегментной таблице. [Примечание: Для упрощения мы считаем, что раз-
мер записи в таблице постоянен и по каждому адресу в памяти хранится
одна запись.] В каждой записи хранится ряд сведений о соответствующем
ей сегменте, и механизм отображения использует эту информацию для пре-
образования виртуального адреса в физический. Если сегмент в данный мо-
Регистр начала
сегментной
таблицы
Трансляция виртуального адреса в сегментной системе
- {’ojj
мент располагается в оперативной памяти, то в записи указан
(базовый адрес) этого сегмента в оперативной памяти — s’. Система
рует величину смещения d и этот адрес, чтобы получить реальны
требуемого элемента данных — г = s’ + d. Получить нужный адрес И
конкатенацией нельзя, поскольку сегменты могут быть разного раз^^Чм
На рисунке 10.22 подробно показана структура типичной запцСц а-
ментной таблице. Бит резидентности г показывает, находится ли о 6 С-Г-
ствующий сегмент в данный момент в оперативной памяти. Если °Тв®г.
s' — это адрес начала сегмента в оперативной памяти. В противном
а — это адрес на вторичном устройстве хранения, с которого нужно^^^М
зить сегмент при обращении к нему. Все обращения к сегменту проВр3а1Ч-
ся относительно длины сегмента I, чтобы гарантировать, что они вьит0*!
ются в пределах сегмента. Каждое обращение к сегменту также соцро^ I
дается проверкой битов защиты (protection bits), чтобы гарантировать 03й'
затребованная операция разрешена. Например, если биты защиты пока410
вают, что сегмент доступен только для чтения, то ни один процесс не см0
жет изменить содержимое этого сегмента. Защиту в сегментных системах
мы подробно рассмотрим в разделе 10.5.3.
В ходе динамической трансляции адреса, после нахождения в таблице за-
писи о сегменте s, нужно проверить значение бита резидентности г, чтобы
определить, находится ли этот сегмент в оперативной памяти. Если нет, ге-
нерируется сегментный промах (missing-segment fault), и управление пере-
дается операционной системе, чтобы она загрузила требуемый сегмент, рас-
положенный по адресу а на вторичном устройстве хранения. После загруз-
ки сегмента трансляция адреса продолжается. Значение смещения d
сравнивается с длиной сегмента I. Если оно больше длины сегмента, генери-
руется исключение выхода за пределы сегмента (segment-overflow
exception) и управление передается операционной системе, чтобы, скорее
всего, аварийно завершить выполнение процесса. Если смещение меньше
длины сегмента или равно ей, проверяются биты защиты, чтобы убедиться,
Адрес на вторич-
ном устройстве
Бит хранения (если Адрес начала сегмент
резидентности не в оперативной Длина Биты (если в оперативной
сегмента памяти) сегмента защиты памяти)
га’/ s
I________L__.______L_________________.- _ и
4
г = 0 если сегмент не в оперативной памяти
г = 1 если сегмент в оперативной памяти
Рис. 10.22. Запись в сегментной таблице
йиртуальпои памяти
•>уу
^рбоВанная операция разрешена. Если это так, то адрес требуемого
зат?ер реальной памяти получается сложением базового адреса сегмен-
‘?1^еЯ'га тИвной памяти s’ с величиной смещения d, взятой из виртуально-
v (S; d). Если затребованная операция не разрешена, генерирует-
^вДРеС0ченяе защиты сегмента (segment-protection exception), и управле-
„рТСя операционной системе для аварийного завершения процесса.
РереД
Вопросы для самопроверки
1. Почему нельзя получить адрес элемента в реальной памяти простой
конкатенацией s’ и d?
2. Требует ли механизм отображения страниц, чтобы s’ и а хранились
в отдельных ячейках записи в сегментной таблице, как показано
на рис. 10.22?
Ответы 1) В отличие от номера кадра страницы р’, базовый адрес
сегмента s’ — это адрес в оперативной памяти. Конкатенация s’ и d при-
ведет к получению адреса, выходящего за пределы адресного простран-
ства оперативной памяти. Кроме того, конкатенация работает
в страничных системах, потому что размер страницы — это всегда сте-
пень двойки, и количество битов, отведенных под номер кадра страни-
цы, равно длине адреса минус количество битов, необходимых для
адресации содержимого кадра. 2) Нет. Чтобы уменьшить объем памяти,
занимаемый записями сегментной таблицы, многие системы используют
только одно поле, значение которого воспринимается либо как базовый
адрес сегмента, либо как адрес на вторичном устройстве хранения. Если
бит резидентности установлен, значит, в записи содержится адрес в опе-
ративной памяти, а не адрес на вторичном устройстве хранения; если бит
сброшен, в записи содержится адрес на вторичном устройстве хранения,
но не базовый адрес сегмента в оперативной памяти.
М2 Разделение ресурсов в сегментных системах
Совместный доступ к сегментам требует меньших накладных расходов,
’ем разделение в страничных системах с прямым отображением. Напри-
в чт°бы организовать совместный доступ к массиву, хранящемуся
ДетвХ С половиной страницах, страничная система должна хранить от-
в 1е Данные о совместном доступе для каждой из страниц, на которой
Мас^Ится часть массива. Проблема еще более усложняется, если размер
Динамически изменяется, поскольку информация о разделении
Вйю ? ИйМеняться в ходе выполнения программы соответственно измене-
’Мхс Личества страниц, занятых массивом. С другой стороны, в сегмент-
^Х°ДИм еК1ЭХ РазмеР структур данных может изменяться свободно, без не-
На п Ости изменения информации о совместном доступе к сегменту.
'*еа'гйойС^НКе Ю-23 показано, как реализуется разделение ресурсов в сег-
а- Системе. Доступ к сегменту разделен между двумя процессами,
ь 1Си в их сегментных таблицах указывают на один и тот же сег-
^ХоТяПеРативной памяти.
Ь1?ГРЫш от совместного доступа очевиден, с ним также связан оп-
1и Риск. Например, один из процессов может преднамеренно или
ВЬ1Полнить действие с сегментом, которое отрицательно повлияет
Работающие с этим сегментом процессы. Поэтому система, под-
600
Сегментная
таблица
процесса 1
Рис. 10.23. Разделение (совместное использование) ресурсов в сегментной системе
Вопросы для самопроверки \
1. Каким образом сегментные системы уменьшают накладные Р
ды на разделение по сравнению со страничными системам ^с.
2. Можно ли реализовать копирование при записи в сегмент
темах, и если да, то как?
Ответы 1) Сегментация позволяет всему блоку совместно с1!ст^_
зуемой памяти размещаться в одном сегменте, и операционн рсТг
нужно хранить информацию о разделении для одного сегмен
ничных системах сегмент может занимать несколько страни >
ционной системе придется хранить отдельную 11
о разделении для каждой страницы. 2) Да. Копирование пр у £
можно реализовать посредством выделения процессу-пото р^ \
сегментной таблицы родительского процесса. Если проце ъСоЦе^!
тельский процесс или процесс-потомок) попытается измени
мое сегмента S, операционной системе нужно будет измени g.
в сегментной таблице этого процесса, занеся в нее новый аДР
Виртуальной памяти
601
" Защита и контроль доступа В сегментных системах
' йТация поощряет разбиение программ на модули и позволяет эф-
Се^6 р использовать память за счет фрагментированного выделения
нОго доступа. Однако ценой этих преимуществ становится возрос-
с^^ясность. Например, одной пары регистров, хранящих информацию
с$° яХ сегмента, уже не достаточно, чтобы защитить каждый процесс
0 rPRl11 ц1ения другими процессами. Кроме того, становится сложнее огра-
раэрУ дазоны доступа конкретных программ. Один из способов реали-
я^^ащиты памяти в сегментных системах — использование ключей
з8ййй памяти (memory protection keys) (см. рис. 10.24). В этом случае
Й процесс ассоциируется со значением, которое называется ключом
ка## операционная система жестко контролирует этот ключ, так что
могут обращаться только привилегированные инструкции. Ключи
применяются следующим образом. Во время переключения сег-
Операционная система
Процесс 1
1
1
- 2
Ч 2
3
Процесс 1
Процесс 2
Процесс 2
Процесс 3
Процесс 1
Процесс 3
Процесс 3
Процесс 2
Процесс 2
Процесс 1
Процесс 1
Процесс 4
Процесс 4
Процесс 4
Ключ
защиты
памяти
в процессоре
Ключи защиты памяти
для отдельных блоков
памяти
^4.
^т1ащита памяти с помощью ключей в мультипрограммных системах
*ированным выделением памяти
602
ментов операционная система загружает ключ защиты процесса
процессора. Когда процесс обращается к какому-либо сегменту г
проверяет ключ защиты блока, содержащего требуемый элеме^всЗ
ключи защиты процесса и этого блока совпадают, процесс
щаться к сегменту. Например, на рисунке 10.24 процесс 2 Мо^ет
щаться только к блокам с ключом защиты 2. Если он попытается orT
ся к блокам с другими ключами защиты, аппаратура запретит это
ние и передаст управление ядру (с помощью исключения
сегмента). Хотя ключи защиты памяти — не самый распространен341^111^
ханизм защиты в современных системах, они реализованы в арди Ь1^
IA-64 (то есть в процессорах Itanium), и обычно применяются в си Кт^
содержащих одно виртуальное адресное пространство43.
Операционная система может усилить защиту, указывая, какие
бы доступа к сегменту разрешены и для каких процессов. Это достиг*1000'
выделением каждому процессу определенных прав доступа (access ri
к сегментам. На рисунке 10.25 перечислены наиболее распространена
способы доступа, используемые в современных системах. Если у процРрЫе
есть доступ для чтения (read access) к сегменту, он может считывать дав
ные из любой ячейки этого сегмента. Если у него есть доступ для записи
(write access), то процесс может изменять содержимое сегмента и добав-
лять в него новые данные. Процесс, обладающий доступом для исполне-
ния (execute access) к сегменту, может передавать управление инструкци-
ям этого сегмента для их исполнения процессором. Доступ для исполнения
к сегментам данных обычно не предоставляется. Процесс, обладающий
доступом для дополнения (append access) к сегменту, может записывать
в конец сегмента новую информацию, но не может изменять уже сущест-
вующую.
По-разному сочетая эти способы доступа, можно создать 16 разных ре-
жимов контроля доступа (access control modes). Некоторые из этих режи-
мов весьма интересны, а другие — просто бессмысленны. Для упрощеви
мы рассмотрим восемь разных сочетаний доступа для чтения, записи и
полнения, перечисленных на рисунке 10.26. J
В режиме 0 доступ к сегменту полностью закрыт. Это полезно в^тв0Г0
мах безопасности, в которых нужно предотвратить доступ конкр _ов1
процесса к сегменту. В режиме 1 процесс обладает к сегменту Д°
только на исполнение (execute-only access). Этот режим полезен, не -j.
грамме разрешается исполнять инструкции из сегмента, но не Ра ₽ сЛей-
ся изменять их или копировать. Режимы 2 и 3 бесполезны — °eccr0 cofleP
но разрешать сегменту выполнять запись в сегмент, но не читать чтевВй
жимое. Режим 4 предоставляет к сегменту доступ только
(read-only access). Этот режим полезен для чтения данных, к qfe®®
должны изменяться. Режим 5 предоставляет процессу доступ !,Л}1
и исполнения (read/execute access) к сегменту. Этот режим полез‘
ентерабельного кода. Процесс сможет при необходимости создать
ную копию этого сегмента, в которую в дальнейшем будет вноси з»^,
ния. Режим 6 предоставляет процессу доступ для чтения
(read/write access) к сегменту. Этот режим полезен при работе
которые можно читать и изменять, но нужно защитить от i
полнения (это не исполняемые инструкции). Режим 7 — это ре
аЛ Вир памяти
[-«rttoro доступа (unrestricted access). Он нужен, чтобы процесс мог
работать с собственными сегментами (например, с самомодифи-
О<имся кодом), и предоставляется доверенным процессам для рабо-
^У^ментами других процессов.
^сСС
Тип^Па длячтеВИЙ длязаПИСИ о р,яДОполнеН Сокращение R W Е А
Описание
Содержимое сегмента можно читать
Можно выполнять запись в сегмент.
Можно запускать содержимое сегмента на исполнение.
Можно дописывать информацию в конец сегмента.
f Ре?кимы КОНТР°ЛЯ доступа
режим Режим 0 Чтение Запись Исполнение Нет Описание Нет доступа Применение Защита
Нет Нет
Режим 1 Нет Нет Да Только для исполнения Сегмент доступен для процессов, которые не могут читать его содержимое или изменять, но могут запускать на исполнение.
Режим 2 Режим 3 Нет Нет Да Да Нет Да Только для записи Запись/исполнение, но не чтение Эти режимы бессмысленны, поскольку предоставлять право записи без права чтения бесполезно.
Режим 4 Да Нет Нет Только для чтения Извлечение информации.
Режим 5 Да Нет Да Чтение/исполнение Программы, которые можно копировать и исполнять, но нельзя изменять.
Режим 6 Да Да Нет Чтение/запись, но не исполнение Защищает данные от попыток исполнения вместо кода.
Режим 7 Да Да Да Неограниченный доступ Для доверенных пользователей.
^5, /Q «z и°3в°ляю “°3MO5KHbie сочетания доступа для чтения, записи и исполнения, юЩие получить полезные режимы контроля доступа
ъ Механизм контроля доступа, описанный в этом разделе, лежит
I ^рцг.66 заЩиты сегментов, реализованной во многих системах.
Нке Ю.27 показан один из способов реализации контроля досту-
w®HHo, с помощью включения битов защиты в запись в сегментной
I запИси хранятся четыре бита — по одному для каждого типа
I еЦеРь система сможет контролировать доступ на этапе трансля-
I °В" К°гда процесс обращается к сегменту в виртуальной памяти,
проверяет значения битов защиты, чтобы определить, есть ли
са нужные права доступа. Например, если процесс попытается пе-
I Исполнение содержимое сегмента, к которому у этого процесса
604
нет доступа для исполнения, то будет сгенерировано исключение
сегмента, и управление будет передано операционной системе дЛя
ного завершения процесса.
X,
Адрес на вто-
ричном уст-
ройстве хра-
Бит нения(если не
резидентности в оперативной Длина
сегмента памяти) сегмента
Биты
защиты
Адрес начала
сегмента (есл
в оперативной
памяти)
Биты защиты (1 = да. О = нет)
R — доступ для чтения
W — доступ для записи
Е — доступ для исполнения
А — доступ для дополнения
Рис. 10.27. Запись в сегментной таблице с битами защиты
Вопросы для самопроверки
1. Какие права доступа потребуются для сегмента стека процесса-
2. Какие специальные аппаратные устройства необходимы для I*
зации ключей защиты памяти?
Ответы 1) Процессу нужны возможности чтения данных
и записи в него, а также право добавлять в стек новые эл flgy-
2) Для хранения ключа защиты памяти текущего процесса ну
стродействующий регистр.
10,6 Сегментно-страничные системы
И сегментные, и страничные системы виртуальной памяти
своими преимуществами. Начиная с середины 1960-х годов, ci Т
бенно TSS, созданная фирмой IBM, и Multics, сочетали сег
и страничный доступ44, 45, 461 47, 48, 49. Такие системы использу й
щества двух организаций виртуальной памяти, рассмотренных f
в этой главе. В смешанных сегментно-страничных системах
обычно состоят из множества страниц. Не обязательно всем стра
цИ gupmya/ibuou памяти
605
«ходиться в оперативной памяти одновременно, и смежные страни-
ца 0 альной памяти не обязательно должны быть смежными в опера-
такой системе адреса виртуальной памяти представляют
^цой 1оряДоченные тРиады v = Р>d)' где s — номер сегмента, р — но-
^ниДЫ в сегменте, a d — величина смещения нужного элемента от
f ер ^страницы (см. рис. 10.28).
Номер сегмента I Номер страницы I Смещение
i Виртуальный адрес
! V— (s, р. d)
p 10 28. Формат виртуального адреса в сегментно-страничной системе
\0 6.1 Динамическая трансляция адресов в сегментно-страничных
тсшемах
Рассмотрим трансляцию виртуальных адресов в сегментно-страничной
системе с помощью смешанного ассоциативного/прямого отображения,
как показано на рисунке 10.29.
Процесс обращается к виртуальной памяти по адресу v = (s, р, d). Стра-
ницы, к которым недавно были обращения, указаны в ассоциативной таб-
лице (т.е. в TLB). Механизм трансляции выполняет ассоциативный поиск,
пытаясь найти пару (а, р). Если поиск успешен, то результатом его будет
Р’ — номер кадра страницы, в котором находится страница р сегмента а.
Конкатенацией этого номера с величиной смещения d формируется реаль-
ный адрес г.
Если TLB не содержит записи о паре (а, р), процессор должен выполнить
®°лное прямое отображение следующим образом. Базовый адрес b сегмент-
Рез ТабЛИЦЫ (В опеРативн°й памяти) суммируется с номером сегмента а.
Це gIbTaTOM сложения будет адрес записи о сегменте а в сегментной табли-
(в о ЭТои записи указан базовый адрес s’ страничной таблицы сегмента а
ым е₽ативной памяти). Процессор суммирует номер страницы р с базо-
в Ст^₽сс°м s’, чтобы определить адрес записи о странице р сегмента а
И,ЧНОЙ таблице этого сегмента. В искомой записи в этой таблице
НОМеР кадра страницы, в котором хранится страница р. Конка-
г еи этого номера с величиной смещения d формируется реальный ад-
' Ч JeMa трансляции подразумевает, что процесс корректно обратился
и Что вся информация, необходимая для трансляции адреса, на-
В В °пеРативной памяти. Однако во многих случаях для успешной
адресов потребуются дополнительные операции. При поиске
в таблице может оказаться, что сегмент s не находится в опера-
Ы,яти. При этом будет сгенерирован сегментный промах, и опера-
I ’• с0 Системе придется найти сегмент на вторичном устройстве хране-
Дать для него страничную таблицу и загрузить нужную страницу
606
Регистр начала
сегментной таблицы
Адрес начала
сегментной
таблицы, Ь
b
b + s
s
(s,p)
Номер
страницы
Сегментная
таблица
для этого
процесса
Сначала
пробуем так
Номер
сегмента
s
Ассоциативная
таблица (только
самые активные
страницы)
Виртуальный адрес
v= (s, р, d)
I Смещение
I d
p + s
Номер кадра
Р'
Смешение
d
. । --
Реальный адрес г
Выполняем
только
при отсутствии
записи
в ассоциативной
таблице
Страничная
таблица дл1
сегмента s
ой СИС^^
Рис. 10.29. Трансляция виртуальных адресов в сегментно-страничн
с помощью смешанного ассоциативного/прямого отображения
607
ь> Если сегмент находится в оперативной памяти, при поиске
ра1*1 нчной таблице может выясниться, что нужной страницы нет в опе-
я памяти, и будет сгенерирован страничный промах. При этом
ение будет передано операционной системе, и ей придется найти
на вторичном устройстве хранения и загрузить ее в оперативную
^ра#0 Ероме того, возможна ситуация, когда процесс обратится по адре-
да^^одящемуся за пределами сегмента, и будет сгенерировано исключе-
су, б^хода за пределы сегмента. Или биты защиты могут показать, что за-
g«eB аНная операция по указанному виртуальному адресу запрещена,
. сгенерировано исключение защиты сегмента. Операционная систе-
и б^ддена. предусматривать все эти возможности.
дгсОциативная память (равно как и быстродействующая кэш-память)
бхоДима Для эффективной работы этого механизма динамической
0е°яслядии адресов. Если бы использовался механизм прямого отображе-
ТРя адресов, и в оперативной памяти хранились бы все таблицы, то при ка-
рпом обращении к виртуальной памяти для трансляции адреса потребова-
лось бы обратиться к оперативной памяти три раза. Первым было бы обра-
щение к сегментной таблице, вторым — обращение к страничной таблице
сегмента за номером кадра, а третьим — собственно обращение к требуемо-
му элементу данных. Соответственно, система работала бы в несколько раз
медленнее, чем при работе с реальной памятью, и выгоды от использова-
ния виртуальной памяти были бы сведены к нулю.
На рисунке 10.30 показана подробная структура таблиц, необходимых
для сегментно-страничных систем. Верхний уровень иерархии — это таб-
лица процессов, в которой содержится по одной записи для каждого про-
цесса в системе. В каждой записи о процессе содержится указатель на сег-
ентную таблицу этого процесса. Каждая запись о сегменте в сегментной
таблице содержит указатель на страничную таблицу этого сегмента. Каж-
ая запись в страничной таблице содержит или номер кадра, в котором
Размещена соответствующая страница в оперативной памяти, или адрес,
g которому страница размещена на вторичном устройстве хранения.
л Системе с большим количеством процессов, сегментов и страниц эти таб-
Ве8и М°Гут значительную часть оперативной памяти. Преимущество хра-
всех таблиц в оперативной памяти заключается в ускорении транс-
вцТся аДРесов при выполнении программ. Однако чем больше таблиц хра-
В Памяти, тем меньше процессов может поддерживать система, и тем
вЫп ПР°изв°ЛитеЛьность- При разработке операционной системы нуж-
вЫда э<ЪгьКИВать баланс во множестве подобных ситуаций, чтобы система
Евч л Активной и обеспечивала достаточно быструю реакцию на дейст-
ильзователей.
608
Оперативная
память
Рис. 10.30. Структура таблиц для сегментно-страничной системы
/щппумьной памяти
609
Вопросы для самопроверки
1. Какие специальные аппаратные устройства необходимы для сег-
ментно-страничных систем?
2. Какие виды фрагментации присущи сегментно-страничным систе-
мам?
Ответы 1) Для сегментно-страничных систем нужны: быстродей-
ствующий регистр для хранения базового адреса сегментной таблицы,
быстродействующий регистр для хранения базового адреса соответст-
вующей страничной таблицы и схема ассоциативной памяти (TLB).
2) В сегментно-страничных системах может появляться внутренняя
фрагментация, если сегмент меньше страницы (страниц), в которой он
размещается. Возможна также фрагментация таблиц, поскольку
и сегментная таблица, и страничные таблицы хранятся в оперативной
памяти. В сегментно-страничных системах нет внешней фрагмента-
ции (если все страницы в системе одного размера), поскольку, в конеч-
ном счете, вся память делится на кадры равного размера, в которых
может помещаться любая страница.
/а 6.^ Разделение ресурсов и защита в сегментно-страничной
истеме
Сегментно-страничные системы виртуальной памяти сочетают архитек-
турную простоту страничных систем и возможности контроля доступа сег-
ментных. В таких системах преимущества совместного доступа к сегмен-
там становятся существенными. Два процесса используют совместный дос-
туп к памяти, если в сегментной таблице каждого процесса есть запись,
указывающая на одну и ту же страничную таблицу, как показано
на рисунке 10.31.
Совместный доступ к памяти — равно в страничной, сегментной или
сегментно-страничной системе — требует тщательного контроля со сторо-
аы операционной системы. Представьте себе, что произойдет, если, напри-
^еР> новая извлеченная со вторичного устройства хранения страница
аое на заменить в оперативной памяти старую, переносимую на вторич-
пр УстР0йство хранения. Если к старой странице обращались несколько
в СОп Сов’ система должна будет обновить значения резидентных битов
ТаВ1цр етствУк>Щих записях страничных таблиц каждого процесса, рабо-
с этой страницей. Могут понадобиться значительные накладные
и КахИе р а то’ чт°бы определить, какие процессы работали со страницей
0(j ^Е в их страничных таблицах нужно заменить. В разделе 20.6.4
^ШДИМ’ КйК В операционной системе Linux эти накладные расходы
ав4ц^аются за счет хранения связного списка РТЕ, записи которого ука-
На совместно используемую страницу.
610
Страничная таблица
для одного
из сегментов процесса 1
Оперативная па1и
Сегментная таблица
для процесса 1
Совместно
используемая
страничная таблица
Страница,
принадлежащая
только процессу 1
Сегментная таблица
для процесса 2
Страница, совмест-
но используемая
процессами 1 и 2
Страница,
принадлежащая
только процессу 2
Страничная таблица
для одного из
сегментов процесса
процессами
Рае. 10.31. Дня процесса, совместно использующие сегмент
в сегментно-страничной системе
ig виртуальной памяти
611
Вопросы для самопроверки
1. Чем привлекательны сегментно-страничные системы?
2. В чем сильные и слабые стороны хранения связного списка РТЕ, за-
писи которого указывают на совместно используемую страницу?
Ответы 1) Сегментно-страничные системы сочетают архитектур-
ную простоту страничных систем и возможности контроля доступа
сегментных. 2) Связный список РТЕ позволяет системе быстро обнов-
лять записи при замене совместно используемой страницы. В против-
ном случае системе придется полностью просмотреть страничные
таблицы процессов, чтобы выяснить, какие РТЕ нужно обновить — на
это может уйти немало времени. Недостаток хранения связного спи-
ска РТЕ — необходимость дополнительных затрат памяти. Однако
в современных системах накладные расходы из-за необходимости до-
полнительных обращений к оперативной памяти обычно перевешива-
ют накладные расходы, связанные с поддержкой связного списка.
10.7 Практический пример: Виртуальная память
врмтектуры IA-32 фирмы Intel
В этом разделе мы изучим реализацию виртуальной памяти в архитек-
туре IA-32 фирмы Intel (т.е. в процессорах серии Pentium), поддерживаю-
щей либо чисто сегментную, либо сегментно-страничную систему вирту-
альной памяти50. Множество адресов, содержащееся в каждом сегменте,
навивается логическим адресным пространством (logical address space),
и его размер зависит от размера сегмента. Сегменты размещаются в дос-
тупных областях линейного адресного пространства (linear address space)
системы, представляющего собой 32-битовое (т.е. 4 ГБ) виртуальное адрес-
аое пространство. При работе в сегментном режиме процессор использует
Линейные адреса для обращения к оперативной памяти. Если разрешен
драничный доступ линейное адресное пространство делится на кадры
Раниц фиксированного размера, расположенные в оперативной памяти.
ЛРРвый этап динамической трансляции адресов отображает сегментные
^йльные адреса в линейное адресное пространство. Поскольку отклю-
Вце /^пментацию, согласно спецификации IA-32, невозможно, это отображе-
1'АлЛ°и5ХоДит при каждом обращении к памяти. Каждый сегментный вир-
И аДРес можно представить в виде упорядоченной пары v = (s, d), как
^се В ^азДеле Ю.5.1. В архитектуре IA-32 s представляется 16-разряд-
НещейеКтоР°мсегмента (segment selector), ad — 32-разрядным смещением
отсчитывается от адреса начала сегмента s’, в котором находится
| ЯгДтЬ1И ЭЛемент данных). Индекс сегмента — 13 старших битов селектора
Ц^т°бь Называет на 8-байтовую запись в сегментной таблице.
Ч Ипе^СКо1)ить трансляцию адресов в сегментном режиме, в архитектуре
^Усмотрено шесть сегментных регистров (segment register), обозна-
Qg ’ SS, ES, FS и GS, в которых хранятся селекторы сегментов про-
T'KiHo операционная система использует регистр CS для хранения се-
К^Яе °^а пР°ц'есса (обычно он соответствует сегменту, в котором хранятся
I МЫе инструкции), DS — для селектора данных процесса (обычно он
612
соответствует сегменту, содержащему данные), а регистр SS — для №
стека (обычно он соответствует сегменту стека времени выполнения)
pax ES, FS и GS можно хранить селекторы других сегментов процесс
тем, как процесс сможет обратиться по адресу, соответствующий этом!,'
селектор сегмента должен быть загружен в сегментный регистр. Это г
процессу обращаться к памяти по 32-битовому смещению и не указыв
дый раз 16-битовый селектор сегмента при каждом обращении. aTbl4i^_
Чтобы найти запись в сегментной таблице, процессор умному
ментный индекс на 8 (количество байт в каждой записи сегментной Т Сбг-
цы) и суммирует полученное значение с Ь — адресом, хранящимся
стре начала сегментной таблицы. В архитектуре IA-32 есть два пе Рег*’-
начала сегментных таблиц — регистр глобальной таблицы дескрип
(Global Descriptor Table Register — GDTR) и регистр локальной таб
дескрипторов (Local Descriptor Table Register — LDTR). Значения в СПт4
и LDTR загружаются при переключении контекста.
Основная сегментная таблица системы — это глобальная таблица дескп
торов (Global Descriptor Table — GDT), в которой хранятся 8192 (213) зали
размером 8 байт каждая. Первая запись процессором не используется — обра
щение к сегменту, соответствующему этой записи, приведет к генерации
ключения. Операционная система загружает значение, соответствующее этой
записи, в неиспользуемые сегментные регистры (обычно ES, FS и GS), чтобы
предотвратить обращения процессов к некорректному сегменту. Если система
использует одну сегментную таблицу для всех ее процессов, то GDT остается
единственной сегментной таблицей в системе. Для случаев, когда операцион-
ной системе нужно более 8192 сегментов, или нужно хранить отдельные сег-
ментные таблицы для разных процессов, то архитектура IA-32 предост
локальные таблицы дескрипторов (Local Descriptor Table — LDT), в каждой
из которых может храниться 8192 записи. Базовые адреса всех LDT хранятся
в GDT, поскольку процессор размещает LDT в сегментах. Для быстрой транс-
ляции адресов базовый адрес LDT, Ь, хранится в LDTR. Используя LDT, опера-
ционная система может создать до 8191 отдельной сегментной таблицы (вспои
ните, что первая запись в GDT не используется процессором). сеГ.
В каждой записи в сегментной таблице, называемой дескрипторе®*^
мента (segment descriptor), хранится 32-битовый базовый адрес
address) s’, по которому в линейном адресном пространстве начинается
мент. Система формирует линейный адрес, суммируя величину см
d и базовый адрес s’ сегмента. В сегментном режиме работы величина
будет реальным адресом. й битй
При каждом обращении к памяти процессор проверяет 3Ha4<?tjeM обР8
резидентное™ и битов защиты в дескрипторе сегмента, прежде втор®
титься к оперативной памяти. Бит присутствия (present bit) в ДесК
сегмента показывает, находится ли сегмент в оперативной пам
да, то трансляция адресов выполняется как обычно. В против!^
процессор генерирует исключение отсутствия сегмента (segm с0
sent exception), и операционная система должна загрузить сегм 0 «
ричного устройства хранения. [Примечание: Термины «про®10 орИ
ключение» в этом разделе используются не в том смысле, в на ^ут
пользуются в остальном тексте (см. раздел 3.4.2). Исключение сраИ
сегмента соответствует сегментному промаху.] Процессор такЖе
шЯ Виртуальной памяти
птение в каждом обращении с 20-битовой границей сегмента
с^е . limit), I, указывающей размер сегмента. По значению бита грану-
tfg’^zgranularity bit) система определяет, как воспринимать значение
1 сегмента. Если этот бит сброшен, то сегменты могут изменяться
е от 1 байта (Z = О) до 1 МБ (Z = 220 - 1) с шагом в 1 байт. В этом слу-
gpa31*1 р d > Z, система генерирует исключение общей ошибки защиты
qfle, еС, protection fault — GPF), показывая, что процесс попытался обра-
(?ереГ к памяти за пределами сегмента. [Примечание: Еще раз заметим,
т0ть?=пмин «fault» — «промах» или «ошибка» — в этом разделе имеет не
<ffO те\,сЛ что в остальном тексте.]. Если бит грануляции установлен, то
гот CI*'Tbi могут изменяться в размере от 4 КБ (Z — О) до 4 ГБ (Z = 220 - 1)
м в 4 КБ. В этом случае исключение GPF, указывающее на обращение
с01аГяти за пределами сегмента, будет сгенерировано, если d > (Z * 212).
к ^ава процессов на доступ к сегментам в архитектуре IA-32 хранятся
яоде типа (type) в записи сегментной таблицы. Бит кода/данных
8 ode/data bit) в этом поле определяет, хранятся ли в соответствующем сег-
( те данные или исполняемый код. Если этот бит установлен, к сегменту
зоешен доступ для исполнения. В поле типа также содержится бит чте-
дцл/зяписи (read/write bit), значение которого определяет, доступен ли
сегмент только для чтения или и для чтения, и для записи.
Если разрешен страничный режим, операционная система может поде-
лить линейное адресное пространство (т.е. виртуальное адресное пространст-
во, в котором располагаются сегменты) на страницы фиксированного разде-
ла. Как мы убедимся в следующей главе, размер страницы может серьезно
повлиять на производительность. Архитектура IA-32 поддерживает страни-
цы размером 4 КБ, 2 МБ и 4 МБ. При использовании 4 КБ страниц архитек-
тура IA-32 преобразует линейный адрес в физический с помощью двухуров-
невого механизма трансляции страничных адресов. В этом случае каждый
ЗДрес представляется в виде v’ = (t, р, d), где t — 10-битовый номер странич-
нои таблицы, р — 10-битовый номер страницы в таблице, a d — 12-битовая
Дичина смещения. Трансляция страничных адресов выполняется точно
’как рассказано в разделе 10.4.4. Чтобы найти запись о странице, значе-
(аи t сУммиРУется со значением из регистра начала таблицы директорий
ад °ГИчного Регистру начала страничной таблицы). В каждой 4-байтовой
си в таблице директорий (Page Directory Entry — PDE) указан b, базо-
страничной таблицы, содержащей 4-байтовые РТЕ. Чтобы сформи-
Ццце Физический адрес, по которому размещается запись в страничной таб-
₽Ует ’ пР°Цессор умножает р на 4 (поскольку размер РТЕ — 4 байта), и сумми-
®Роцес^Льтат с Ь. Наиболее часто используемые РТЕ и PDE хранятся в TLB
Цри Ора Для ускорения трансляции виртуальных адресов в физические.
Использовании 4 МБ страниц каждый 32-битовый адрес представ-
\иде v’ ~ где Р — Ю-битовый номер записи в таблице дирек-
° — 22-битовая величина смещения. В этом случае трансляция
аДРесов выполняется так» как описано в разделе 10.4.3.
Л1! ь р>Ар°бРаЩение к памяти сопровождается проверкой бита чтения/за-
и РТЕ. Если этот бит установлен, все страницы, указанные в стра-
МВДце аблице этой PDE, доступны только для чтения; в противном случае
И °®Ра1Цения Для записи. Аналогично, биты чтения/записи в РТЕ
права доступа для чтения/записи к соответствующим страницам.
614
Одно из ограничений 32-битовых физических адресов — невозмоъ,
адресации более 4 ГБ памяти. Поскольку в некоторых системах
больше, в архитектуре IA-32 предусмотрена возможность paciiiHpeJ^’hd
зических адресов (Physical Address Extension — РАЕ) и расширен
меров страниц (Page Size Extension — PSE), позволяющие систем МП
щаться по 36-разрядным физическим адресам, соответствующим
мальному объему памяти в 64 ГБ. Реализация этих возможностей 3Ма1ссИ.
рассматривается; однако при желании с ней можно ознакомиться в Сь
фикации стандарта IA-32, которую можно найти в руководстве^6^11'
Architecture Software Developer’s Manual, том 3, по адресу develope/^
tel.com/design/Pentium4/manuals/. В разделе «Веб-ресурсы» есть се
на несколько руководств, описывающих реализацию виртуальной ца
в других архитектурах, например, Power PC и РА-RISC.
Учебный пример
Операционные системы мэйнфреймов IBM
Первым коммерческим компьютером об-
щего назначения с транзисторной логикой
был IBM 7090, появившийся в 1959 году. Его
операционная система называлась IBSYS ' ”.
Она состояла из приблизительно двух дюжин
компонентов, включая модули для языков
программирования COBOL и FORTRAN, а так-
же диспетчеры ресурсов53.
В 1964 IBM представила новый проект —
серию System/360, включавшую несколько
моделей различной производительности,
объединенных общей архитектурой54,5S. Наи-
менее производительные модели работали
под управлением дисковой операционной
системы (Disk Operating System - DOS), а на
остальных использовалась операционная сис-
тема OS/36056 57,58. Использование одной опе-
рационной системы на нескольких разных мо-
делях компьютеров в то время было относи-
тельно новой концепцией59. OS/360
существовала в нескольких вариантах: РСР,
MET и MVT60,61. Система OS/360-PCP (Principal
Control Program — основная управляющая про-
грамма) была однозадачной и предназнача-
лась для наименее мощных моделей
семейства System/360; однако на практике на
этих моделях использовалась DOS (илиТ05-
Таре Operating System - в системах, оснащен-
ных только ленточными накопителями) ' •
Системы OS/360-MFT и OS/360-MVT были
многозадачными — первая для постоянного
количества задач, вторая для переменного-
Это значило, что в системах под управлением
MFT распределение памяти выполнялось
ратором, а в работавших под УпРаВ1^1а(Ц
MVT память распределялась aBT°^aJ
по мере появления новых задании $^rjng
шой проект, названный TSS (Time
System - система с разделением В|ЭВ льэо-
целью которого было создание много
вательской операционной сиСГеГи1Ь'|<оГда
рента Multics, был позже свернут- иОй
оказалась слишком большой и неН
Функциональность TSS была Ре
в виде TSO (Time-Sharing Option б8
разделения времени) в 1971 ГОДУ
,)ИЦЧЯ Виртуальной памяти
615
машин System/370, которые IBM
в 1970 году, поддерживалась
ьНаЯ память69. Для ее поддержки
е^п MFT была обновлена и переимено-
0$/Збnc/VSl, a MVT после аналогичного об-
взНаВ стала называться OS/VS2 SVS
новЛ^НVirtual Storage - единая виртуальная
№ Ё) поскольку она поддерживала только
п’^^ртуальное адресное пространство
оДн0 в 16 МБ, распределенное между
°6l,elV проИессами™ ” • ПозДнее эта система
^"еьцв Раз обновлена для поддержки мно-
^Ь'Ла=а таких адресных пространств и стала
*зываться OS/VS2 MVS или просто MVS
(MuStiple Virtual Storages - множественная
виртуальная память)2
Вскоре MVS была доработана до
MVS/370, получив поддержку возможно-
сти разделения в памяти данных' и кода,
предоставленной новыми аппаратными
устройствами System/37074, Кроме того,
поскольку 16 МБ виртуальные пространства
быстро заполнялись растущими програм-
мами, процессоры стали использовать
26-разрядную адресацию, что позволяло
работать с памятью объемом до 64 МБ. Од
нако хотя MVS/370 поддерживала такие
объемы реальной памяти, для адресации
В!1₽туальных адресных пространств исполь-
зовались только 24 разряда, что ограничи-
ло их объем 16 МБ76 ’7.
цес^мя позже IBM перешла на про-
370<у>Ь| 3°81, использованные в серии
(extended Architecture — расширен-
ная архитектура)7879. MVS/370 была дорабо
тана, в нее была добавлена новая
функциональность, и новая версия была вы-
пущена как MVS/ХА в 1983 году80 81. Эта ОС
позволяла адресовать до 2 ГБ виртуальной
памяти, чего с легкостью хватало для удовле-
творения любых потребностей программ87.
В 1988 году IBM еще раз обновила аппа-
ратную часть систем, перейдя на процессоры
ES/3090 и архитектуру ESA/370 (Enterprise
System Architecture — архитектура систем
масштаба предприятия)83. В ESA появились
пространства памяти, предназначенные
только для данных, что облегчало перемеще-
ние данных при обработке84. Операционная
система MVS/ХА была доработана до
MVS/ESA для использования на новых
системах85'86. MVS/ESA была существенно об-
новлена в 1991 для новой серии аппаратуры
ESA/390, которая включала в себя механиз-
мы связывания машин IBM в свободные кла-
стеры (SYSPLEX)87 и средства изменения на-
строек устройств ввода/вывода без необхо-
димости отключения машин (ESCON)88.
MVS по прежнему лежит в основе опера-
ционных систем для мэйнфреймов IBM —
MVS/ESA была обновлена до OS/390 в 1996
году для машин System/39089; сейчас она на-
зывается z/OS и работает на мэйнфреймах
zSeries90. Кроме того, операционные системы
IBM сохраняют обратную совместимость,
и в OS/390 можно выполнять приложения,
написанные для MVS/ESA, MVS/ХА, OS/VS2
и даже OS/3609'.
616
Учебный пример
Ранняя история операционной системы VM
Виртуальная машина — это иллюзия ре-
альной машины, созданная операционной
системой виртуальной машины (virtual
machine operating system), которая может
представить одну реальную машину как не-
сколько реальных машин. С точки зрения
пользователя, виртуальные машины могут
выглядеть как реально существующие маши-
ны или радикально отличаться от них. Такая
концепция оказалась весьма ценной, и было
создано множество операционных систем
виртуальных машин. Одна из наиболее ши-
роко распространенных среди этих систем —
система VM фирмы IBM.
VM управляла машинами System/370
фирмы IBM (или совместимыми с ними)92'93,
создавая иллюзию того, что каждому из не-
скольких пользователей предоставлялась от-
дельная машина System/370, включая мно-
жество устройств ввода/вывода. Каждый
пользователь мог выбрать свою операцион-
ную систему. VM может выполнять одновре-
менно несколько операционных систем, каж-
дую на отдельной виртуальной машине. Се-
годня пользователи VM могут выполнять
версии OS/390, z/OS, TPF, VSE/ESA, CMS
и Linux94.
Обычные многопрограммные системы
разделяют ресурсы системы между несколь-
кими процессами. Каждому из этих процес-
сов выделяется порция ресурсов реальной
машины. Каждый процесс видит менее мощ-
ную машину с меньшими возможностями,
чем машина, на которой действительно вы-
полняется процесс.
Мультипрограммные системы виртуаль-
ных машин (см. рис. 10.32) разделяют ресур-
сы единственной машины по-другому. Они
создают иллюзию того, что одна реадь
шина - это на самом деле несколько ЭЯ
Они создают виртуальные процессе MaUJV1H
ройства хранения и ввода/вывода в *’ Уст‘
но, с куда большими емкостями и в'озм М°*’
стями, чем таковые у реальной машины
Основные компоненты VM - ЭТо
(Control Program - программа управлений
CMS (Conversational Monitor Subsystem '
подсистема диалогового монитора), RSCS
(Remote Spooling Communications Subsys-
tem - подсистема удаленного обмена), ipcs
(Interactive Problem Control System - интерак-
тивная система управления задачами) и CMS
Batch Facility (пакетный модуль CMS). СР
создает среду, в которой могут работать вир-
туальные машины. Она обеспечивает под-
держку различных операционных систем,
обычно используемых для работы на
System/370 и совместимых машинах. СР
управляет реальной машиной, лежащей
в основе виртуальной машины. Она предос-
тавляет каждому пользователю доступ к уст
ройствам реальной машины, например, пР°
цессору, накопителям и устройствам ,
да/вывода. СР управляет одновреме^|
несколькими целыми виртуальными
нами, а не отдельными задачами иЛ^еН(1р
цессами. CMS - это система пРиЛ°тивНой
с мощными возможностями ИНТбра gjjjK
разработки программ. Она содер при-
торы, трансляторы языков, разди
кладные библиотеки и инструмеНт^е роЛ
Виртуальные машины, работа*®^
управлением СР, работают почти л^нее,
и реальные их аналоги, но мед 0дцОе^1
скольку VM выполняет операииИ^иН
менно множества виртуальных ма
| .мя ечр ^ельнои памяп,и
t обность VM одновременно выпол-
^^колько ог:еРационнЬ1Х систем имеет
’^тво применений95, 96. Она облегчает
между различными операционными
rf6* мй или различными версиями одной
сИ£те^иоНной системы. Она позволяет поль-
onePaU м обучаться одновременно с выпол-
|0ВатеЛ рабочих задач. Клиенты могут испол-
н^одиовременн0 разные операционные
H”Tb чтобы пользоваться их преимущест-
о*-ге Одновременное выполнение разных
•**Л’иИОцных систем обеспечивает своего
’’^резерв отказоустойчивости. Разработ-
₽°й цдосуттестировать новые системы, чтобы
^"еделить, будет ли полезно обновление;
это можно делать, не прерывая выполнения
основной работы.
Процессы, выполняющиеся на виртуаль-
ных машинах, управляются не СР, а опера-
ционными системами, работающими на
этих виртуальных машинах. Эти операцион-
ные системы выполняют все свои обычные
функции, включая управление устройства-
ми хранения, планирование загрузки про-
цессора, управление вводом/выводом, за-
щиту пользователей друг от друга, защиту
операционной системы от пользователей,
мУльтипрограммность, управление процес-
ЙМи и задачами, обработку ошибок и так
Далее.
чую^ ИМИТИрует целую машину, выделен-
8и 0Дн°му пользователю. Пользователь
том аЛЬНОЙ машины оперируетэквивален-
оесур^ой Реальной машины, а не набором
Кот°РЬ|й он разделяет со множест-
пользователей.
ЭЛьнэя 5 заРождалась как эксперимен-
та бь^Стема 6 1964 году. Она должна
Раздр ь системой второго поколения
АинД), <- Ием времени, работающей на
,анНая ys^/360'. Изначально разра-
Аля внутренних нужд в исследова -
_____________________________________617
тельском центре IBM в Кембридже, она
скоро приобрела популярность в качестве
инструмента для оценки производительно-
сти других операционных систем.
Первая рабочая версия, состоявшая из
СР-40 и CMS, появилась в 1966 году. Эти
компоненты предназначались для работы
на модифицированной машине 360/40,
включавшей новые аппаратные устройства
для динамической трансляции адресов.
Примерно в то же время IBM выпустила но-
вую версию мощного компьютера 360/65.
Новая система — 360/67 — содержала аппа-
ратные устройства для динамической транс-
ляции адресов и предоставляла возмож-
ность использования утилиты разделения
времени TSS/36098. Проект TSS, выполняв-
шийся независимо от СР/CMS, столкнулся
со множеством трудностей (типичных для
больших программных проектов середины
1960-х годов). В то же время СР/CMS была
успешно перенесена на 360/67, и постепен-
но реализовала все возможности TSS.
СР/CMS была усовершенствована до
VM/370, которая стала доступной в 1972
году для машин System/370 с виртуальной
памятью99.
CTSS, успешно применявшаяся в Масса-
чусетском технологическом институте
в 1974 году, более всего повлияла на разви-
тие СР/CMS. Разработчики последней обна-
ружили, что с CTSS трудно работать. Они по-
считали, что более модульный подход будет
эффективнее, и отделили часть системы, от-
вечавшую за управление ресурсами, от
пользовательской части — соответственно,
СР и CMS. СР предоставляет отдельные вы-
числительные среды, дающие каждому
пользователю полный доступ к виртуальной
машине; CMS работает на созданных СР
виртуальных машинах как однопользова-
тельская интерактивная система.
618
\j Учебный пример
%
Ранняя история операционной системы VM
(продолжение)
Самым важным решением при разработке
СР стало решение о полном повторении реаль-
ной машины виртуальными. Было ясно, что ар-
хитектура семейства System/ЗбО рассчитана на
долговременное использование программ;
пользователи, которым требовались более
мощные машины, просто переходили на более
мощные модели того же семейства с более бы-
стродействующими процессорами, большими
объемами памяти и накопителей и большим
количеством устройств ввода/вывода. Реше-
ние создавать виртуальные машины, omJ
шиеся от реальных машин System/j^'
вероятно, привело бы к провалу сисг^'
СР/CMS. Однако система СР/CMS оказал^
весьма удачной, и VM стала одной из двух^
новных операционных систем фирмы |вц
в 1990-х годах. IBM продолжает разрабаты-
вать новые версии VM для своих серверов -
последней из них на данный момент является
z/VM, поддерживающая архитектуру 64-би-
товых машин IBM
Мультипро-
граммная
виртуальная
Вирту-
альная j
машина /
Рис. 10.32. Мультипрограммность в виртуальных машинах
я Виртуальной памяти
619
dhat • com/docs/manuals/linux/RHL-8.О-Manual/admin-primer/
wWw're sl-memory-concepts.html
виртуальной памяти Red Hat (распространителя одной из версий Linux).
® howstuffworks.com/virtual-memory.htm
W63°P виртуальной памяти.
memorymanagement.org
*'**' пЯСИТ словарь терминов и руководство по управлению физической и вирту-
^памятью.
rieVeloPer•intel’сога
° „пжит техническую документацию по продуктам фирмы Intel, включая
,соры серий Pentium и Itanium. Руководства системных программистов
®POlLM процессорам (например, для Pentium 4 — developer.intel.com/design/
к ЭТ -, 4/manuals/) содержат информацию об организации и доступе к памяти
в системах Intel.
WWw-3. ibm.com/chips/techlib/techlib.nsf/productfamilies/
PowerPC_Microprocesors_and_Embedded_Processors
Содержит техническую документацию по процессорам PowerPC, используемым
в компьютерах Apple. Описания систем управления виртуальной памятью этих
процессоров находятся в справочных руководствах по программному обеспечению
(например, для процессора PowerPC 970, используемого в компьютерах Apple G5,
по адресу www-3.ibm.сот/chips/techlib/techlib.nsf/productfamilies/PowerPC_
970_Microprocesor).
h21007.www2.hp.сот/dspp/tech/tech_TechDocumentDetailPage_IDX/
1,1701,9581131253, 00.html
Описывает организацию виртуальной памяти в процессорах РА-RISC. Архи-
тектура РА-RISC обычно используется в высокопроизводительных средах.
См. также http://devresource.hp.com/drc/STK/docs/archive/rad_ll_0_32.pdf.
Ыпоги
в РтУальная память решает проблему ограниченности объемов памяти, созда-
ствцТеЛ103И10 присутствия в системе большего объема памяти, чем доступно в дей-
Рьцц 0(?ЬНости- В системах виртуальной памяти есть два типа адресов: те, по кото-
1*ати- дац^а,О1’с-я процессы, и те, по которым хранятся данные в оперативной па-
^®есами ^дСа’ по КОТОРЫМ обращаются процессы, называются виртуальными
’’и) адйИ’ ^МРеса в оперативной памяти называются физическими (или реальны-
КажДый раз, когда процесс обращается по виртуальному адресу,
е,!Ия гта 0®Раз°вать виртуальный адрес в реальный; это делает устройство управ-
<мми>-
ЬН°е адресное пространство процесса — V — это диапазон адресов, по
ДСрь цаГ°Т пР°несс может обращаться. Диапазон доступных в системе реальных
йИпЗЬ1Вается реальным адресным пространством системы — R. Если мы по-
(•7хЦаоват уальн°му адресному пространству быть больше реального, мы должны
в°зможность хранения данных и программ на большом вторичном
хРанения. Система обычно предоставляет такую возможность за счет
Двухуровневой схемы хранения, состоящей из оперативной памяти
*'*'д Х накопителей. Когда система готова к запуску процесса, она загружа-
и Данные со вторичных накопителей в оперативную память. Для выпол-
620
^2
нения процесса достаточно, чтобы в памяти в каждый конкретный момент
лась только небольшая часть его кода и данных.
Механизмы динамической трансляции адресов (DAT) преобразуют в
ные адреса в реальные в ходе исполнения программ. Системы, исполь
DAT, обеспечивают искусственную непрерывность — в них непрерывные ЗУ101,<йь
адресов в виртуальном адресном пространстве не обязательно должны соот °^JlacTu
вать непрерывным областям в физической памяти. Динамическая трансл ВеТст®о
ресов и искусственная непрерывность освобождают программиста от забот аЛ-
щении программ в памяти (т.е. программисту не нужно создавать оверлеи Ра31’е.
гарантировать, что программа поместится в памяти). Механизмы динами,?'10^
трансляции адресов должны хранить таблицы трансляции адресов, пока ес®ой
щие, какие области виртуального адресного пространства процесса сейчас ЗЫва,°-
жаются в оперативную память, и где эти области размещены. °т°бра-
Системы виртуальной памяти не могут отображать по отдельности кажл
рес, поэтому данные размещаются в блоках и система отслеживает разме **
блоков виртуальной памяти в оперативной памяти. Если блоки одинаковы тю
меру, они называются страницами, а использующая их система виртуальной1*83
мяти — страничной. Если размер блоков может изменяться, они называются ПЭ"
ментами, а система виртуальной памяти — сегментной. В некоторых системах*^
вмещаются оба подхода — сегменты реализуются как блоки произвольно
размера, состоящие из страниц фиксированного размера.
В системе виртуальной памяти с блочным размещением система представляет
адреса в виде упорядоченных пар. Чтобы обратиться к элементу данных в вирту-
альном адресном пространстве процесса, процесс указывает блок, в котором разме-
щается этот элемент, и смещение элемента от начала блока. Виртуальный адрес в
записывается в виде упорядоченной пары (fc, d), где Ь — номер блока, в котором
размещается элемент данных, ad — смещение элемента от начала блока. Система
хранит в памяти таблицу размещения блоков для каждого процесса. Реальный ад-
рес а, соответствующий адресу этой таблицы в оперативной памяти, хранится
в специальном регистре процессора, называемом регистром адреса таблицы разме-
щения блоков. При выполнении программы она обращается по виртуальному ад-
ресу v = (б, d). Система суммирует номер блока б с базовым адресом а таблицы раз-
мещения блоков и получает реальный адрес записи о блоке б в таблице. В -этой за-
писи указан адрес б’ начала блока б в оперативной памяти. Затем к адресу
прибавляется величина смещения d и получается реальный адрес г требуемого эле-
мента данных. 3.
В страничных системах выполняется размещение блоков фиксированного
мера — страниц; страничные системы не используют сегментацию. Виртуал^^И1
адрес в страничной системе — это упорядоченная пара (р, d), где р — номер^
ницы виртуальной памяти, в которой хранится требуемый элемент данных,
смещение этого элемента на странице р. Когда система переносит страницу
ричного устройства хранения в оперативную память, страница размещав ^че-
ке реальной памяти, который называется кадром страницы. Кадры СТ,Си^8
наются с адресов в памяти, кратных фиксированному размеру страниць •
может поместить страницу в любом доступном кадре. тр0^с.
Динамическая трансляция адресов в страничных системах анало!и оМу а?
ляции адресов блоков. Выполняющийся процесс обращается по виртУ а дач^9
ресу v = (р, d). Механизм отображения использует значение из регис р-
страничной таблицы, чтобы найти в этой таблице запись (РТЕ) о стра _ер’(Ре-
зались в страничной таблице указывает, что страница р находится в К
это номер кадра, а не адрес в физической памяти). Адрес г в реальной
ответствующий виртуальному адресу V, формируется конкатенацией г о
ния d элемента данных от начала кадра, при этом р’ помещается в стар .
адреса, a d — в младшие. т и о{\с^'
Когда процесс обращается к странице, которой в данный момент с .
тивной памяти, процессор генерирует страничный промах, и операцио
^циЯ Виртуальной памяти
621
р ва загрузить нужную страницу в память со вторичного устройства хране-
я Д°рТЕ страницы бит резидентное™ г устанавливается в О, если страницы нет
® тИВной памяти, и в 1 в противном случае.
едяция адреса в страничных системах может выполняться прямым отобра-
fp8® аССОциативным отображением или смешанным прямым/ассоциативным
„Ием. Из-за дороговизны быстродействующей кэш-памяти и сравнитель-
Lf^pa^Loro объема программ хранение всей страничной таблицы в кэш-памяти
я0б°^ь!вает невозможным. Вследствие этого трансляция адресов прямым отобра-
часто замедляется, поскольку для ее выполнения требуется обращаться
вНой оперативной памяти. Один из способов ускорения динамической
к ии адресов — помещение страничной таблицы в ассоциативную память
гр»®Данией по содержимому, время рабочего цикла которой иногда на порядок
с аДРь qeM у оперативной памяти. В этом случае все записи в ассоциативной па-
будут просматриваться одновременно в поисках записи о странице р. В по-
^^яюшем большинстве систем использование кэш-памяти для реализации пря-
ДавЛ ^бражения или ассоциативной памяти для реализации ассоциативного ото-
*°г° нИЯ невозможно из-за дороговизны.
% результате многие разработчики применяют более дешевые компромиссные
рмы, обладающие многими преимуществами схем, использующих кэш-память
ассоциативную память. В этих компромиссных схемах используется ассоциатив-
ная память, называемая буфером быстрой трансляции — TLB, в которой может по-
иеститься лишь небольшая часть полной страничной таблицы процесса. РТЕ, хра-
нящиеся в этой памяти, обычно соответствуют недавно использовавшимся страни-
цам (такой выбор основан на наблюдении, что к страницам, к которым недавно
были обращения, вероятно, будут обращения и в ближайшем будущем). Это при-
мер локальности (точнее — временной локальности, то есть локальности во време-
ни). Если система находит запись о странице р в TLB, то происходит попадание
вТЬВ; в противном случае происходит промах в TLB, и системе приходится обра-
щаться к медленной оперативной памяти. Опыт показывает, что из-за проявления
локальности, не обязательно использовать TLB большой емкости для достижения
высокой производительности.
Многоуровневые (или иерархические) страничные таблицы позволяют системе
хранить части страничных таблиц процессов во фрагментированных областях па-
“яти- Уровни страничных таблиц образуют иерархию, каждый уровень которой
устоит из таблиц указателей на таблицы более низкого уровня. Таблицы самого
Г01?него уровня содержат данные, использующиеся для трансляции адресов. Мно-
Уровневые страничные таблицы могут уменьшить расход памяти за счет необхо-
сти Дополнительных обращений к ней при преобразованиях адресов, отсутст-
лощих в TLB.
КаАра₽а1ЧеННЫе стРаничные таблицы содержат ровно по одной РТЕ для каждого
8^ХтяраМЯТИ В системе- Эти таблицы обращены относительно обычных странич-
бцц й ЛИЦ> поскольку РТЕ индексируются по номерам кадров, а не номерам стра-
Дгщ льных адресных пространствах. В обращенных адресных таблицах
М»«ения страниц в РТЕ и получения номеров кадров используются
8^Ми к К£^Ии и сцепление указателей. Накладные расходы, связанные с обраще-
п а®Метч1аМЯТИ ДЛЯ Д°стУпа к каждому из указателей в цепочке, могут быть весь-
Поскольку размер обращенной страничной таблицы должен быть
к сИсте 114 ДЛЯ выполнения прямого отображения в кадры страниц, в болыпинст-
С'Табл Для Уменьшения количества столкновений используются якорные
ЦМ- Однако для доступа к последним тоже необходимо дополнительное
К памяти-
^ЯРМй^ннне совместного доступа к памяти в мультипрограммных системах
Расход памяти программами, использующими общие данные и/или ин-
8 F В° тРебует обозначения каждой страницы как разделяемой или неразде-
* рСЛи Записи в страничных таблицах разных процессов указывают на одну
страницу, страница разделяется (совместно используется) между этими
622
Чо
процессами. Копирование при записи использует память совместного ДОс
уменьшения времени создания процесса за счет разделения адресного про 118 Ал
ва родительского процесса с процессом-потомком. При каждой записи в с
используемую страницу операционная система создает копию этой страну ЙК1еС1ъ'
пись о копии вносится в страничную таблицу процесса, выполняющего^Ь1, И
Операционная система может пометить совместно используемые страни
доступные только для чтения, и система будет генерировать исключен ЦЬ1, «а*
процессы попытаются изменять содержимое таких страниц. При обработке4’ есла
чений операционная система выделит отдельную копию страницы процесс HCltJUo
рировавшему исключение. Копирование при записи может привести к сн» ^Не-
производительности, если большинство совместно используемых данных тт '>Ке®|*Ю
изменяется в ходе его работы. ₽0Чесс5
В сегментных системах данные и исполняемые коды программы дел
блоки, называемые сегментами. Каждый сегмент содержит некоторую част СЯ 8а
граммы, например, процедуру или массив. Каждый сегмент представляет
непрерывную область; однако сегменты могут различаться по размеру и не
тельно размещаются рядом в оперативной памяти. Процесс может выполнят5^
пока его инструкции и данные, к которым они обращаются, находятся в оп8’
тивной памяти. Если процесс обращается к памяти в сегменте, которого в данн^
момент нет в оперативной памяти, система виртуальной памяти должна извле **
этот сегмент со вторичного устройства хранения. Стратегии размещения сегмен*
тов аналогичны используемым в мультипрограммных системах с изменяемым
распределением памяти.
В сегментной системе виртуальной памяти адрес представляет собой упорядо-
ченную пару v = (s, d), где s — номер сегмента в виртуальной памяти, в котором
находится требуемый элемент данных, ad — смещение этого элемента от начала
сегмента s. Система суммирует номер сегмента s с адресом начала сегментной таб-
лицы Ь, хранящимся в регистре начала сегментной таблицы. Результат сложения,
b + s — это адрес записи о нужном сегменте в сегментной таблице. Если сегмент
в данный момент находится в оперативной памяти, то запись в сегментной таблице
содержит физический адрес s’ начала сегмента. Система суммирует величину сме-
щения d и этот адрес, чтобы получить реальный адрес r= s’ + d требуемого элемен-
та данных. Получить нужный адрес простой конкатенацией s’ и d, как в странич-
ной системе, нельзя, поскольку сегменты могут быть разного размера. Если сег-
мента нет в оперативной памяти, генерируется сегментный промах и управлеот
передается операционной системе, которая должна загрузить этот сегмент со
ричного устройства хранения.
Все обращения к сегменту проверяются относительно длины сегмента I,
гарантировать, что они выполняются в пределах сегмента. Если величина
ния d больше I, генерируется исключение выхода за пределы сегмента, и У р еЯЙе
ние передается операционной системе, чтобы, аварийно завершить ВЬ1П°„ g0To»
процесса. Каждое обращение к сегменту также сопровождается проверке
защиты в записи сегментной таблицы, чтобы гарантировать, что затре 3»-
операция разрешена. Если операция не разрешена, генерируется исключ е0йя
щиты сегмента, и управление передается операционной системе для за а£,хОдоВ'
процесса. Совместный доступ к сегментам требует меньших накладных Р
чем в страничных системах, поскольку информация о совместном досту
ждого сегмента (который может занимать несколько страниц памяти;
в одной записи в сегментной таблице. стр0®0^*
Одна из схем реализации защиты памяти в сегментных системах по
ключах защиты памяти. В этой схеме каждому процессу присваивается
называемое ключом защиты. Когда процесс обращается к некоторому с се^е^
проверяет ключ защиты этого сегмента. Если ключи защиты процесса ус^д||
совпадают, то доступ к сегменту разрешен. Операционная система
контроль доступа, указывая разрешенные различным процессам спос
к сегментам. Это достигается присваиванием различным процессам К
'Ои пиМЯПНГ
I ступа, напРимеР’ права на чтение, на запись, на исполнение или на допол-
'г1разРеШая или 8апРегЦая различные виды доступа, можно задавать различ-
«симы контроля доступа.
г е щанных сегментно-страничных системах сегменты занимают по одной
(5 сгДрТраниц- Всем страницам сегмента не обязательно одновременно находить-
0оЛее оативной памяти, и страницы, смежные в виртуальной памяти, не обяза-
” в ^„оджны быть смежными в физической. В этих системах адреса виртуаль-
j>0° представляют собой упорядоченные триады v = (s, р, d), где s — номер
ii1X0 а р_номер страницы в сегменте, ad — величина смещения нужного эле-
начала страницы. Когда процесс Обращается по виртуальному адресу v =
0f8 0 сиСтема пытается найти запись о нужном кадре р’ в TLB. Если такой запи-
(SiP’,rT В нет, система сначала просматривает сегментную таблицу, в которой нахо-
си г " с начала страничной таблицы, а затем использует номер страницы р как
г в страничной таблице, чтобы найти РТЕ, содержащую номер кадра р’. За-
лнкатенацией р’ и величины смещения d формируется реальный адрес. Эта
tf’’’ к трансляции подразумевает, что процесс сделал корректное обращение к па-
c]ieM0 0 qTO ВСе данные, необходимые для трансляции адреса, находятся в опера-
01’g памяти. Однако во многих случаях трансляция адреса потребует дополни-
Т0Вьных шагов или будет безуспешной.
16 В сегментно-страничных системах используется совместный доступ к сегменту
амяти двумя процессами, если в сегментных таблицах обоих процессов есть запи-
си указывающие на одну и ту же страничную таблицу. Совместный доступ, равно
в страничных, сегментных или сегментно-страничных системах, требует строгого
контроля со стороны операционной системы.
Архитектура IA-32 фирмы Intel поддерживает или сегментную, или сегмент-
во-страничную организацию виртуальной памяти. Множество адресов, отвечаю-
щее одному сегменту, называется логическим адресным пространством; сегменты
размещаются в любом доступном месте линейного адресного пространства систе-
мы, представляющего собой 32-битовое виртуальное адресное пространство (объе-
мом до 4 Гб). При использовании чистой сегментации, линейный адрес элемента
данных есть его адрес в оперативной памяти. Если используется страничный ре-
жим, линейное адресное пространство делится на кадры фиксированного размера,
размещающиеся в оперативной памяти. Трансляция сегментных адресов выполня-
ется прямым отображением с использованием быстродействующих регистров про-
®°Ра хРанения базовых адресов сегментных таблиц. Используются регистр
дД^о**10** таблиЧЬ1 дескрипторов (GDTR) и регистр локальной таблицы дескрип-
в (LDTR), в зависимости от количества сегментных таблиц в системе. Для ус-
ния трансляции адресов процессор хранит номера сегментов, называемые де-
ЧеВТнТ0₽ами сегментов» в быстродействующих регистрах. При использовании сег-
Идрес^)'стРаничной организации сегменты размещаются в 4 ГБ линейном
1*®тй ДМ 1гР°стРанстве5 разделенном на кадры, размещающиеся в оперативной па-
°браз’ ₽ХитектУРа IA-32 использует двухуровневые страничные таблицы для пре-
к°Пкате НИЯ ЯомеР°в страниц в номера кадров. Реальные адреса формируются
1аЦией номеров кадров и величин смещений.
^ШРВые термины
**еНт ersa^ona 1 Monitor System — подсистема диалогового монитора) — ком-
-•\^^аМмСТеМЬ1 пРедставляк>Щий собой интерактивную среду разработки
Facility (Пакетный модуль CMS) — компонент системы VM, позволяю-
^РццаП°Лнять требующие много времени задачи на отдельных виртуальных
1 х, чтобы пользователи могли продолжать диалоговую работу.
624
Ct
СР (Control Program — программа управления) — компонент системы Vivr
тающий на физической машине и создающий среду для работы випт ’
машин. J Ч.
DAT — см. динамическая трансляция адресов.
GDT (Global Descriptor Table — глобальная таблица дескрипторов) — в ап
ре IA-32 фирмы Intel — сегментная таблица, содержащая информацию Ит®’(»ъ
щении сегментов или локальных таблиц дескрипторов (LDT), содерЖа °
формацию о размещении сегментов процессов.
GPF (General Protection Fault — общая ошибка защиты) — в архитектур
фирмы Intel — исключение при обращении процесса к сегменту, к к₽е ^А-Зг
у него нет доступа, или при обращении за пределы сегмента. т°Роцу
IBSYS — операционная система для мэйнфрейма IBM 7090.
IPCS (Interactive Problem Control System — интерактивная система управлет,
дачами) — компонент системы VM, выполняющий анализ и предлагающий”
собы устранения проблем в программах VM. Сп»
LDT (Local Descriptor Table — локальная таблица дескрипторов) — в архичудгт I
IA-32 фирмы Intel — сегментная таблица, содержащая информацию о разм1^
нии сегментов процесса. В системе может быть до 8191 LDT, в каждой из
рых может быть до 8192 записей.
MMU (Memory Management Unit — устройство управления памятью) — специаль-
ное аппаратное устройство, выполняющее, в частности, трансляцию виртуаль-
ных адресов в физические.
MVS (Multiple Virtual Storages — множественная виртуальная память) — опера-
ционная система фирмы IBM для машин System/370, позволявшая использо-
вать множество виртуальных адресных пространств объемом до 16 МБ каждое.
OS/360 — операционная система фирмы IBM для машин System/360. Существова-
ла в двух версиях — MFT (Multiprogramming with Fixed number of Tasks — с по-
стоянным количеством задач) и MVT (Multiprogramming with Variable number
of Tasks — с переменным количеством задач). OS/360-MVT позднее была усо-
вершенствована до MVS, предка современной операционной системы для мэйн-
фреймов фирмы IBM — z/OS.
РАЕ (Physical Address Extension — расширение физических адресов) — в архитек-
туре IA-32 фирмы Intel — механизм, позволяющий процессорам этой архиге
туры адресовать до 64 ГБ оперативной памяти.
РТЕ (Page Table Entry — запись в страничной таблице) — запись, в которой х^
нится номер кадра страницы, соответствующего странице виртуальной п
Кроме того, в этой записи хранится другая информация о странице, напр^
разрешения на доступ к ней и информация о том, находится ли эта стр
в данный момент в памяти.
RSCS (Remote Spooling Communications Subsystem — подсистема удаленного ц и0'
на) — компонент системы VM, предоставляющий возможность отправл
лучать файлы в распределенной системе. бы®1^
TLB (Translation Lookaside Buffer — буфер быстрой трансляции) — схе юли4®0’??
действующей ассоциативной памяти, в которой хранится небольшое к оцер
записей о страницах виртуальной памяти и соответствующих им ка^Р
тивной памяти. Обычно в TLB хранятся данные о страницах, к которь^^^Щ
были обращения, что повышает производительность процессов, °
локальностью. n<>cJie^
z/OS — операционная система для мэйнфреймов zSeries фирмы IBM»
версия MVS.
тивная память (associative memory) — память, в которой поиск данных
{Ответвляется по их значению, а не по адресу; быстродействующая ассоциа-
память помогает реализовать высокоскоростные механизмы динамиче-
тЯ®?атрансляции адресов.
сК0*1 тивное отображение (associative mapping) — использование ассоциатив-
К-^^пляти (с выборкой по содержимому) для трансляции виртуальных адресов
* и°й11 етствующие им реальные адреса; все записи в ассоциативной памяти про-
0С°трИваются одновременно.
с’’8 дудяции (granularity bit) — в архитектуре IA-32 фирмы Intel — бит, значе-
gMfторого определяет, как процессор интерпретирует размер сегмента, ука-
й1,е Ктй 20-битовым значением. Если этот бит сброшен, размер сегментов может
заВК от 1 байта до 1 МБ, с шагом в 1 байт. Если бит установлен, размер сегмен-
®ь1Т^[Ожет быть от 4 КБ до 4 ГБ, с шагом в 4 КБ.
T°B/block) — Область пространства памяти (реального или виртуального), пред-
^^дляющая собой диапазон смежных адресов.
*ер быстрой трансляции — см. TLB.
бальная директория страниц (page global directory) — в двухуровневых стра-
^яичных системах это таблица, в которой хранятся адреса частей страничной
таблицы процесса. Глобальные директории страниц — это вершины иерархий
страничных таблиц процессов.
Глобальная таблица дескрипторов — см. GDT.
Блочное размещение (block mapping) — механизм в системе виртуальной памяти,
который уменьшает количество записей для преобразования виртуальных адре-
сов в реальные за счет отображения блоков виртуальной памяти в блоки реаль-
ной.
Виртуальная память (virtual memory) — концепция, позволяющая решить про-
блему ограниченной емкости оперативной памяти за счет предоставления каж-
дому процессу виртуального адресного пространства (возможно, большего объе-
ма, чем объем оперативной памяти машины) для хранения данных и исполняе-
мых инструкций.
Виртуальный адрес (virtual address) — адрес, по которому процесс обращается
к системе виртуальной памяти; виртуальные адреса динамически преобразуют-
ся в физические в ходе выполнения программ.
Дескриптор сегмента (segment descriptor) — в архитектуре IA-32 фирмы Intel —
запись в сегментной таблице, в которой хранится базовый адрес сегмента, бит
Резидентности, данные о размере сегмента и биты защиты.
Мическая трансляция адресов (dynamic address translation — DAT) — меха-
& ®1’ преобразующий виртуальные адреса в физические во время выполнения
оч гРаммы; чтобы не замедлять выполнение, трансляция должна выполняться
^УПл6ЫСТР°-
доци^ЛЯ Дополнения (append access) — право доступа, позволяющее процессу
см СЬ1Вать в конец сегмента новые данные, но не изменять записанные ранее;
ДоСт^ Кже доступ для записи, доступ для исполнения и доступ для чтения.
йЯТь Ддя записи (write access) — право доступа, позволяющее процессу и.зме-
ДостуС0^ержимое страницы или сегмента; см. также доступ для дополнения,
Для исполнения и доступ для чтения.
Исп0,?Ля исполнения (execute access) — право доступа, позволяющее процессу
п д ЯТь инструкции, хранящиеся в странице или сегменте; см. также доступ
^Стул п°лнения, доступ для записи и доступ для чтения.
^Ля чтения (read access) — право доступа, позволяющее процессу считы-
д Иные из страницы или сегмента; см. также доступ для дополнения, дос-
L я записи и доступ для исполнения.
626
Запись в страничной директории (page directory entry — PDE) — в apx
IA-32 фирмы Intel — запись в таблице, содержащей адреса страничныхЙТе1с»Я
Запись в страничной таблице — см. РТЕ. Ta6ji^
Исключение выхода за пределы сегмента (segment-overflow exception) __
чение, возникающее при попытке процесса обратиться по адресу за п Ис,^ю
сегмента.
Исключение защиты сегмента (segment-protection exception) — исключе
никающее при попытке процесса обратиться к сегменту в запрещенном1116’ в°а.
(например, при попытке записи в сегмент, доступный только для чтен
Искусственная целостность (artificial contiguity) — подход, используемь ”
темах виртуальной памяти, создающий для программ иллюзию хран В СИс-
инструкций и данных в непрерывных областях, хотя в реальности фраг*1®
кода и данных рассеяны по оперативной памяти; искусственная целостно МбНТЬ|
рощает программирование. СТьУп.
Кадр страницы (page frame) — блок оперативной памяти, в котором может п
щаться страница виртуальной памяти. В системах с единым размером сто М6
страницу можно поместить в любой доступный кадр. Ранм
Карта трансляции адресов — см. таблица трансляции адресов.
Копирование при записи (copy-on-write) — механизм, ускоряющий создание ппп.
цессов за счет совместного использования информации о размещении данных
в памяти между родительским процессом и процессом-потомком. Если один из
процессов пытается изменить содержимое совместно используемой страницы
для него создается отдельная копия этой страницы. Это может вызвать значи-
тельное замедление работы, если родительский процесс или процесс-потомок
будут вносить изменения в большое количество страниц.
Линейное адресное пространство (linear address space) — в архитектуре IA-32
фирмы Intel — 4 ГБ адресное пространство. В сегментном режиме это адресное
пространство прямо отображается в оперативную память. В сегментно-странич-
ном режиме оно делится на кадры страниц, которые отображаются в оператив-
ную память.
Локальная таблица дескрипторов — см. LDT.
Локальность (locality) — эмпирическая закономерность, связывающая близкие во
времени или пространстве события. В применении к последовательностям обра-
щений к памяти пространственная локальность означает, что процесс, обращав-
шийся ранее по некоторому адресу, вероятно, будет обращаться и по близки
к нему адресам; временная локальность означает, что процесс, обращавши
недавно по какому-то адресу, вероятно, скоро обратится по нему снова.
Логическое адресное пространство (logical address space) — в архитектуре IA
фирмы Intel — множество адресов, относящихся к сегменту. одв0.
Многоуровневая страничная система (multilevel paging system) — система, ° аТЬ
ляющая раздельно хранить части страничной таблицы процесса и заГ₽^о11ес-
в оперативную память только те из них, которые активно используются ./g
сом. Многоуровневые страничные таблицы реализуются в виде иерархиш^^.
торых в таблицах верхнего уровня хранятся указатели на таблицы более
го уровня. Нижний уровень иерархии составляют таблицы указателе на с0С-
страниц. Такая система позволяет сократить расход памяти по сравнени,хОд#-
темой с одноуровневыми таблицами, но замедляет трансляцию из-за н
мости дополнительных обращений к памяти, если информации о тре”
странице нет в TLB.
Виртуальной памяти
627
Г иная страничная таблица (inverted page table) — страничная таблица, со-
щая по одной записи для каждого кадра физической памяти. Использова-
таблиц снижает фрагментацию памяти по сравнению с использовани-
£ чНых страничных таблиц, которые обычно содержат информацию о ко-
еМ °°тве страниц, большем, чем количество кадров в системе. Хэш-функции
'^Лпажают номера страниц в индексы в обращенных страничных таблицах.
°T° Р онная система виртуальной машины (virtual machine operating system) —
Г ^Кпамма, создающая и обслуживающая виртуальные машины.
оступа (access right) — право, определяющее, к каким ресурсам может об-
дов»0 "тьСЯ программа. В памяти права доступа определяют, к каким страницам
р8®1 сегментам может обращаться процесс и каким образом (для чтения, для за-
йлИ для исполнения и/или для дополнения).
11 е отображение (direct mapping) — механизм трансляции адресов, в котором
Й^нсдяция выполняется с помощью таблицы, хранящейся в памяти с выбор-
ной по адресу.
реальный адрес — см. физический адрес.
‘ истр адреса таблицы размещения блоков (block map table origin register) —
Регистр, в котором хранится адрес, по которому в оперативной памяти размеща-
ется таблица размещения блоков процесса; этот быстродействующий регистр
обеспечивает быструю трансляцию виртуальных адресов.
Регистр начала сегментной таблицы (segment map table origin register) — ре-
гистр, в котором хранится адрес сегментной таблицы процесса в оперативной
памяти. Хранение этого адреса в быстродействующем регистре позволяет быст-
ро транслировать виртуальные адреса в реальные.
Регистр начала страничной таблицы (page table origin register) — регистр, в кото-
ром хранится адрес, по которому в памяти размещена страничная таблица про-
цесса; хранение этого адреса в быстродействующем регистре позволяет быстро
транслировать виртуальные адреса в реальные.
Режим контроля доступа (access control mode) — набор прав (на чтение, на запись,
на выполнение, на дополнение), которые определяют, каким образом можно об-
ращаться к странице или сегменту памяти.
Сегмент (segment) — переменного размера непрерывная область виртуального ад-
ресного пространства, управляемая как единое целое. Размер сегмента обычно
соответствует размеру некоей части программы — например, процедуры или
массива, что позволяет системе защищать такие части грануляцией, задавая
Четкие правила доступа к ним. Например, сегменту данных обычно назначают-
я права доступа только для чтения или для чтения и записи, но не для исполне-
НоЯ" Аналогично, Для сегмента, содержащего исполняемые инструкции, обыч-
Ни Назначается доступ для чтения и исполнения, но не для записи. Использова-
Но сегментов обычно приводит к внешней фрагментации оперативной памяти,
СеГ]и Не к внутренней фрагментации.
ШевТаЬ1” п₽омах (missing-segment fault) — ситуация, возникающая при обра-
тить 1<уК сегменту, который в данный момент не загружен в оперативную па-
-Meijj Операционная система реагирует на этот промах, загружая нужный сег-
де,г с° вторичного устройства хранения в оперативную память, когда в ней бу-
С^^Доступен участок нужного объема.
TObOg® сегмента (segment selector) — в архитектуре IA-32 фирмы Intel — 16-би-
. значение, указывающее смещение, по которому в сегментной таблице рас-
,ец дескриптор сегмента (т.е. запись сегментной таблицы).
Ч Чдг.Ие (displacement или offset) -— разность между адресом элемента данных
L сом начала его блока, страницы или сегмента.
628
Столкновение (collision) — в хэш-таблицах — событие, происходят
хэш-функция возвращает одинаковые коды для двух разных входц'^6®’ ]
ний. При этом одна запись в хэш-таблице соответствует двум элемент**
которых хэш-таблицах для разрешения столкновений используется сцД^' Ь
Страница (page) — определенного размера участок виртуального адрес Ле®йе '
странства процесса, который управляется как единое целое. В страниц*010
жатся порции данных и/или кода процесса. Страницы размещаются с°Деь.
ных кадрах страниц в оперативной памяти. Е
Страничная таблица (page table или page шар table) — таблица, в которой
ся записи о номерах кадров, в которых размещаются страницы. В -г Х^а®ят.
таблице индексом является номер виртуальной страницы, и такая таб
держит по одной записи для каждой страницы процесса. со.
Страничные системы (paging systems) — системы виртуальной памяти в к
она делится на фиксированного размера непрерывные блоки. В пример14*
к виртуальному адресному пространству эти блоки называются страни енаи
В страницах хранятся инструкции и данные процессов. В применении к ЦаМа'
ному адресному пространству блоки называются кадрами страниц. Стрсщ"*
хранятся на вторичных устройствах хранения и при необходимости загруз?"14
ся в кадры страниц в оперативной памяти. Страничная организация упрош*'
решения о распределении памяти и не обладает внешней фрагментацией (ecjT
системы используют страницы одного размера); в страничных системах имеет
место внутренняя фрагментация.
Страничный промах (missing-page fault) — ситуация, возникающий при обраще-
нии к странице, которая в данный момент не загружена в оперативную память.
Если происходит такой промах, операционная система должна загрузить тре-
буемую страницу со вторичного устройства хранения.
Сцепление (chaining) — в хэш-таблицах — метод разрешения столкновений с по-
мощью помещения отдельных уникальных элементов данных с общим хэш-ко-
дом в структуры данных (обычно — связные списки). Позиция, в которой про-
изошло столкновение в хэш-таблице, содержит указатель на такую структуру
данных.
Таблица процессов (process table) — таблица известных процессов. В сегмент-
но-страничных системах каждая запись этой таблицы содержит, помимо дру-
гих данных, указатель на виртуальное адресное пространство соответствующего
процесса.
Таблица размещения блоков (block map table) — таблица, содержащая заП®И
о размещении виртуальных блоков процесса в блоках реальной памяти (есл®
ковые есть). Блоками в виртуальной памяти являются сегменты или стран
Таблица трансляции адресов (address translation map) — таблица, помог
в преобразовании виртуальных адресов в соответствующие им реальные ад
Физический адрес (physical address или real address) — адрес ячейки в оп
ной памяти. че-
Физическое адресное пространство (physical address space) — диапазон ц^те-
ских адресов, соответствующий объему оперативной памяти данногс к t8j<
ра. Физическое адресное пространство может быть меньше (и часто
и есть), чем виртуальное адресное пространство. И3'
Фрагментация таблицы (table fragmentation) — ситуация, когда возник
лишние затраты памяти на страничные таблицы. При использован
малого размера размер таблиц растет, и растет фрагментация таблиц-
Хэш-код (hash value) — возвращаемое хэш-функцией значение, соответст
записи в хэш-таблице.
Виртуальнойпамяти
(hash function) — функция, принимающая число в качестве входно-
ЛлИЦа (hash table) — структура данных, индексирующая элементы данных
Имла%э1П-кодам; используется в сочетании с хэш-функциями для быстрого со-
”*нИя и извлечения информации.
цр®-3 ция (hash function) — функция, принимающая число в качестве входно-
чения и возвращающая другое число, лежащее в определенных пределах,
ч‘го еМое хэш-кодом. Хэш-функции используются при записи и извлечении
^^рмации из хэш-таблиц.
хэШ.таблица (hash anchor table) — хэш-таблица, содержащая указатели
иси в обращенной страничной таблице. Увеличение размера якорной
л ва Зтаблицы уменьшает количество столкновений, повышая скорость трансля-
хэй1'адресов, за счет дополнительных обращений к памяти, в которой хранится
^таблица.
10.3.
10.4.
10.5.
Упражнения
101 Приведите несколько причин, по которым полезно разделять виртуальное
1 ' ' адресное пространство процесса и его физическое адресное пространство.
10 2. Одно из привлекательных свойств виртуальной памяти — то, что пользова-
телям не нужно ограничивать размеры своих программ, чтобы они помеща-
лись в физической памяти. Стиль программирования может стать более
свободным. Обсудите воздействие этого фактора на производительность
в мультипрограммной среде с виртуальной памятью. Перечислите положи-
тельные и отрицательные эффекты.
Опишите различные способы отображения виртуальных адресов в реаль-
ные в страничных системах.
Обсудите сильные и слабые стороны каждого из перечисленных ниже спо-
собов отображения адресов виртуальной памяти.
а. Прямое отображение
б. Ассоциативное отображение
в. Смешанное прямое/ассоциативное отображение
Объясните способ преобразования виртуальных адресов в реальные в сег-
ментных системах.
Представим страничную систему с 32-битовыми адресами (каждый адрес
соответствует одному байту памяти). Пусть в ней 128 МБ оперативной па-
мяти и используются 8 КБ страницы.
а- Сколько страничных кадров содержит эта система?
б. Сколько битов нужно использовать в этой системе для хранения вели-
чин смещений d?
1q Вф Сколько битов нужно для хранения номеров страниц р?
Представим страничную систему, использующую три уровня страничных
таблиц и 64-битовые адреса. Каждый виртуальный адрес представляет со-
бой упорядоченный набор v = (р, т, t, d), где упорядоченная триада (р, т,
1 номер страницы, ad — величина смещения. Каждая запись в странич-
®°и таблице занимает 64 бита (8 байтов). Количество битов, отведенных
ПоД хранение р, равно пр, под хранение т — пт, под хранение t - nt.
Предположим, что пр = пт = nt = 18.
1) Каким будет размер таблицы на каждом уровне многоуровневой стра-
ничной таблицы?
2) Каким будет размер таблицы в байтах?
Ю.6.
630
гх.
ч.
10.8.
10.9.
10.10.
10.11.
10.12.
10.13.
10.14.
10.15.
10.16.
a.
б.
б. Предположим, что пр = пт = nt = 14.
1) Каким будет размер таблицы на каждом уровне многоуровн
ничной таблицы?
2) Каким будет размер таблицы в байтах?
в. Обсудите положительные и отрицательные стороны использо
леньких и больших таблиц. ВавЧч
Объясните, как реализуется защита памяти в сегментных систем
альной памяти. ах
Обсудите возможности аппаратуры, полезные для реализации си
туальной памяти. Tei*t Вцр
Обсудите проявления фрагментации в каждой из перечисленных »
новидностей систем виртуальной памяти. 5X6 Ра3.
а. Сегментные
б. Страничные
в. Сегментно-страничные
В любой компьютерной системе, независимо от того, использует
виртуальную или только реальную память, компьютер редко будет и<-И °Ва
зовать все инструкции и данные, загруженные в оперативную память °НЬ
зовем это явление осколочной фрагментацией (chunk fragmentation)
скольку она появляется вследствие обработки элементов в памяти в’бло
ках, а не по отдельности. Этот тип фрагментации может в реальности
приводить к большим потерям памяти, чем все остальные типы фрагмента-
ции, вместе взятые.
Почему, в таком случае, этот вид фрагментации не рассматривается
в литературе так же подробно, как остальные виды фрагментации?
Почему в системах виртуальной памяти с динамическим выделением
уровень этой фрагментации намного ниже, чем в системах с реальной
памятью?
Как повлияет на уровень осколочной фрагментации применение стра-
ниц малого размера?
Какие соображения — как теоретические, так и практические — не по-
зволяют полностью устранить осколочную фрагментацию?
Что может каждый из перечисленных ниже специалистов сделать для
минимизации осколочной фрагментации?
1) Программист
2) Разработчик аппаратных устройств
3) Разработчик операционных систем
Опишите способ преобразования виртуальных адресов в физические
ментно-страничных системах. 0Оду
В мультипрограммных средах использование совместного достУпа0е.
и данным может значительно уменьшить объемы оперативной naMonI1’njB-
обходимые для эффективного выполнения групп процессов. ^РаТК°,.дой 03
те способы, которыми можно реализовать совместный доступ в к
перечисленных ниже систем. nai0010
а. Мультипрограммная система с фиксированным распределение^^^
б. Мультипрограммная система с изменяемым распределением
в. Страничная система
г. Сегментная система
д. Сегментно-страничная система , i.h0*’
Почему совместный доступ к коду и данным в системах с виртУ _ ре&
мятью гораздо естественнее, чем в системах, использующих то
ную память? еМ-
Обсудите различия и общие черты страничных и сегментных сь
Сравните сегментные системы и сегментно-страничные.
в.
д.
я Виртуальной памяти
<гпедположим, что вас попросили реализовать сегментацию на машине,
^которой есть аппаратные устройства для поддержки страничных систем,
У рет аппаратных устройств для поддержки сегментации. Вы можете ис-
и0 программные решения. Возможно ли это? Поясните
вас попросили реализовать страничную виртуальную
1.’Р'
«о —
дользовать только
свой ответ.
Предположим, что
_ j0. 1 Рмять на машине, у которой есть аппаратные устройства для поддержки
*м‘ ^гментации, но нет аппаратных устройств для поддержки страничных
се „ем- Вы можете использовать только программные решения. Возможно
С и это? Поясните свой ответ.
хг к главный разработчик новой системы виртуальной памяти, вы должны
|0шить, нужно ли реализовать страничную систему или сегментную (но не
pge одновременно). Какую систему вы выберете? Почему?
Предположим, что стала доступной дешевая ассоциативная память. Как
10.2®- моЖИо использовать такую память в архитектуре новых компьютеров, что-
бы повысить производительность аппаратных устройств, операционных
систем и прикладных программ?
. Укажите столько отличий, сколько сможете, между способами выполне-
1®* ’ ниЯ программ в виртуальной памяти и способами выполнения тех же про-
грамм в реальной памяти. Заставят ли вас эти отличия предпочесть вирту-
альную или реальную память?
1022 Укажите столько, сколько сможете причин появления локальности как на-
блюдаемого реального явления. Приведите столько, сколько сможете си-
туаций, в которых локальность не проявляется.
10.23. Одна популярная операционная система предоставляет отдельные вирту-
альные адресные пространства каждому процессу, а другая операционная
система разделяет между всеми процессами одно большое адресное про-
странство. Сравните преимущества и недостатки этих подходов.
10.24. Использование механизмов трансляции виртуальных адресов требует до-
полнительных затрат. Перечислите столько, сколько сможете, факторов,
которые могут увеличить затраты при использовании механизма трансля-
ции виртуальных адресов в физические. Как эти факторы влияют на разви-
тие аппаратных устройств и программного обеспечения систем, поддержи-
вающих механизмы трансляции адресов?
и-4э. В изначальной версии операционной системы Multics были предусмотрены
Два размера страниц. Предполагалось, что множество мелких структур
данных можно будет размещать в маленьких по размеру страницах, а боль-
шую часть других процедур и структур данных — в одной или нескольких
больших. Чем отличается схема организации памяти, поддерживающая
несколько размеров страниц, от схемы с единственным размером страниц?
Предположим, что система поддерживает п разных размеров страниц. Чем
ее структура будет отличаться от структуры Multics? Будет ли система,
поддерживающая множество разных размеров страниц, практически экви-
10.2g ^лентна сегментной? Поясните свой ответ.
Бри использовании многоуровневых страничных таблиц РТЕ могут ини-
циализироваться при загрузке процессов, или при первых обращениях
к соответствующим страницам. Аналогично, вся многоуровневая структу-
ра страничных таблиц может храниться в оперативной памяти или части ее
1<1 /°ГУТ переноситься на вторичные устройства хранения. Каковы преимуще-
2? ЛВа и недостатки каждого из этих подходов?
°чему виртуальная память стала важным элементом компьютерных сис-
м • Почему возможностей реальной памяти стало недостаточно? Развитие
У^Пих современных технологий может уменьшить полезность виртуальной
памяти?
632
Гл«8«
10.28. Какая особенность страничных систем с единственным размера
делает алгоритмы замены страниц более простыми, чем алгоритм Сг1*аъ
сегментов? Какие возможности аппаратных устройств или прОг bI <1
но использовать для поддержки замены сегментов, чтобы сделат*9"111
такой же «прямолинейной», как и замену страниц в системах с o' 6е Чо^"
мером страниц?
10.29. Какое свойство ассоциативной памяти с выборкой по содержим
тирует, что такая память, вероятно, останется более дорогой, Га1>ав
кэш-память с выборкой по адресу?
10.30. Предположим, что вы разрабатываете часть операционной систе
бующую быстрого извлечения информации (например, механизм * тРе.
ции виртуальных адресов). Предположим, что вам предложили ТрайСля-
реализовать ли механизм поиска и извлечения информации прЯмЬ1б11ать,
бражением с помощью быстродействующего кэша или реализовать Ь М °т°'
мощью ассоциативного отображения. Какие факторы определят if Г° с п°-
шение? Ответ на какие интересные вопросы можно получить за одно 6
щение к ассоциативной памяти, но нельзя получить за одно обпя
к системе с прямым отображением? ™еВ0е
10.31. Выбор записей, которые нужно хранить в TLB, критичен для эффекти
работы системы виртуальной памяти. Процент обращений, ответ на
рые будет получен из TLB, называется уровнем попаданий в TLB (TLB hit
ratio). Сравните производительности систем трансляции виртуальных ад
ресов, одна из которых характеризуется высоким уровнем попаданий
в TLB (около 100%), а другая — низким (около 0%). Предложите несколь-
ко эвристических решений, не упомянутых в книге, которые, по вашему
мнению, позволят достичь высоких уровней попаданий. Опишите обстоя-
тельства, при которых каждое из этих решений будет неэффективно, т.е.
станет помещать в TLB ненужные записи.
Рекомендуемые проекты
10.32.
10.33.
10.34.
10.35.
Опишите, как архитектура IA-32 позволяет процессам адресовать до 64
оперативной памяти. См. developer.intel.com/design/Pentium4/manuals-
Сравните реализацию виртуальной памяти в архитектуре 1ВМ/М° о
PowerPC с реализацией виртуальной памяти в архитектуре IA-32. Ч"/
влияние 64-битового размера на организацию памяти в Powerr •
developer.intel.com/design/Pentium4/manuals И www-3.ibm.cOrl jgnbe'
techlib/techlib.nsf/productfamilies/PowerPC_Microprocesors_an _
dded_Processors. еКтУРе
Сравните реализацию виртуальной памяти в 64-битовой ар* пацят0
РА-RISC фирмы Hewlett-Packard и реализацию виртуальной nUa;s
в архитектуре IA-32. См. developer.intel.com/design/Pentium ,
И http://devresource.hp.com/drc/STK/docs/archive/rad 11_0_^‘ ' „0ЙвР
« — Q9 бИТО^ т/
Изучите различия между реализациями виртуальной памяти .ntei.c01'
хитектуры IA-32 и 64-битовой архитектуры IA-64. См. developer. i^nUajs
design/Pentium4/manuals Л . developer. intel. сот/design/itaniu _
iiasdmanual.htm (выберите раздел Volume 2: System Architectur
^/щгтуальной памяти
633
арендуемая литература
Ut пия виртуальной памяти была предложена несколько десятилетий на-
|СО0йе g *подробный обзор был сделан Деннингом101. Выгоды использования
п °ерВЬ1ой памяти привели к разработке специализированных аппаратных уст-
ее производительность и пригодность к практическому
^С1В, ПиЮ102. Схемы ассоциативной памяти для динамической трансляции ад-
50Меб2и предложены Хэнлоном103, и их роль в хранении записей в TLB была
пес°® б" изучена104.
^!датеЛ нГ обсуждает в своей работе страничные системы виртуальной памяти;
Де0ИИ,1е системы были подробно рассмотрены Деннисом105. Дальнейшее раз-
сеГ0С0ТН ганизации виртуальной памяти, например, совмещение сегментных
5010е °₽яЧНых систем, можно отследить по статьям Дэли и Денниса106
0 стр00 aio7 Джейкоб и Мадж108 опубликовали прекрасный обзор подходов
йДе0Йизации виртуальной памяти и их реализаций в современных системах,
к °₽ГапУЛярные книги, содержащие описание устройств управления памятью —
ДвеВ Паттерсона и Хеннесси «Computer Organization and Design»109 и книга
KBI«ca «Computer Architecture»110. Библиография к этой главе доступна на
Web-сайте по адресу www.deitel.com/books/os3e/Bibliography.pdf.
Используемая литература
1.Shiell, J., «Virtual Memory. Virtual Machines», Byte, Vol. 11, No. 11, 1986,
pp. 110-121.
2. Leonard, T. E., ed., VAX Architecture Reference Manual, Bedford, MA: Digital
Press, 1987.
3-Kenah, L. J.; R. E. Goldenberg; and S. F. Bate, VAX/VMS Internals and Data
Structures, Bedford, MA: Digital Press, 1988.
4. Fotheringham, J., «Dynamic Storage Allocation in the Atlas Computer, Includ-
ing the Automatic Use of the Backing Store», Communications of the ACM,
Vol. 4, 1961, pp. 435-436.
“’Kilburn, T.; D. J. Howarth; R. B. Payne; and F. H. Summer, «The Manchester
University Atlas Operating System, Part I: Internal Organization», Computer
6 "°Urnal, Vol. 4, No. 3, October 1961, pp. 222-225.
•Kilburn, T.; R. B. Payne; and D. J. Howarth, «The Atlas Supervisor», Proceed-
-j ‘ngs of the Eastern Joint Computer Conference, AFIPS, Vol. 20, 1961.
В «avinSton, U- «The Manchester Mark I and Atlas: A Historical Perspective»,
8,^mrnunications of the ACM, Vol. 21, No. 1, January 1978, pp. 4-12.
^011chester University Department of Computer Science, «The Atlas», 1996,
9. Ww-c°mputer50.org/kgill/atlas/atlas.html>.
Hie f*1 ester University Department of Computer Science, «History of the Depart-
tOr ob Computer Science», December 14, 2001, <www.cs.man.ac.uk/Visi-
-Subweb/history.php3>.
4ie^^ester University Department of Computer Science, «History of the Depart-
tor Computer Science», December 14, 2001, <www.cs.man.ac.uk/Visi-
‘1. I^fubweb/hi8tory.php3>.
COfnngt°n, S. H. «The Manchester Mark I and Atlas: A Historical Perspective»,
^nicatlons of the ACM, Vol. 21, No. 1, January 1978, pp. 4-12.
634
12. Lavington, S. H. «The Manchester Mark I and Atlas: A Historical per
Communications of the ACM, Vol. 21, No. 1, January 1978, PP. 4-12.Speetivl
13. Manchester University Department of Computer Science, «The Дм
<www.computer50.org/kgill/atlas/atlas.html>. as»,
14. Lavington, S. H. «The Manchester Mark I and Atlas: A Historical Per
Communications of the ACM, Vol. 21, No. 1, January 1978, pp. 4-lT^4
15. Lavington, S. H. «The Manchester Mark I and Atlas: A Historical per
Communications of the ACM, Vol. 21, No. 1, January 1978, pp. 4-12 Spective,
16. Manchester University Department of Computer Science, «The Дца
<www.computer50.org/kgill/atlas/atlas.html>. *> 199g
17. Lavington, S. H. «The Manchester Mark I and Atlas: A Historical Pers
Communications of the ACM, Vol. 21, No. 1, January 1978, pp. 4.12 Pec^e,i
18. Denning, P., «Virtual Memory», ACM Computing Surveys, Vol. 2 No
tember 1970, pp. 153-189. ’ Sep.
19. George Mason University, «Peter J. Denning — Biosketch», January 1 чц»
<cne.gmu.edu/pjd/pjdbio.html>. ’
20. Denning, P., «The Working Set Model for Program Behavior», Communicar
of the ACM, Vol. 11, No. 5, May 1968, pp. 323-333. t,onji
21. George Mason University, «Peter J. Denning — Biosketch», January 1, 2003
<cne. gmu .edu/p j d/pj dbio. html>.
22. George Mason University, «Peter J. Denning — Biosketch», January 1, 2003
<cne.gmu.edu/pjd/pjdbio.html>.
23. ACM, «Peter J. Denning — ACM Karlstrom Citation 1996», 1996,
<cne. gmu .edu/pjd/pjdkka96.html>.
24. Randell, B., and C. J. Kuehner, «Dynamic Storage Allocation Systems», Proceed-
ings of the ACM Symposium on Operating System Principles, January 1967,
pp. 9.1-9.16.
25. McKeag, R. M., «Burroughs B5500 Master Control Program», in Studies in Op-
erating Systems, Academic Press, 1976, pp. 1-66.
26. Oliphint, C., «Operating System for the В5000», Datamation, Vol. 10, No. 5,
1964, pp. 42-54. Д
27. Talluri, M.; S. Kong; M. D. Hill; and D. A. Patterson, «Tradeoffs in Supporting
Two Page Sizes», in Proceedings of the 19th International Symposium on °
puter Architecture, Gold Coast, Australia, May 1992, pp. 415-424.
28. Hanlon, A. G, «Content-Addressable and Associative Memory Systems
vey», IEEE Transactions on Electronic Computers, August 1966.
29. Lindquist, A. B.; R. R. Seeder; and L. W. Comeau, «А Time-Sharing ^Ув
Using an Associative Memory», Proceedings of the IEEE, Vol. 54,
1774-1779. Reseat
30. Cook, R., et al., «Cache Memories: A Tutorial and Survey of Current
Directions», ACM/CSC-ER, 1982, pp. 99-110.
31. Wang, Z.; D. Burger; K. S. McKinley; S. K. Reinhardt; and С. C. o8ch’'
«Guided Region Prefetching: A Cooperative Hardware/Software ^^rch^eC
Proceedings of the 30th Annual International Symposium on Compute
ture, 2003, p. 388. t L’n’
32. Jacob, B. L, and T. N. Mudge, «А Look at Several Memory Manage111® of i
TLB-Refill Mechanisms, and Page Table Organizations», Proceedi
Eighth International Conference on Architectural Support for Progra
guages and Operating Systems, 1998, pp. 295-306.
ULyi Циртр/льнои памяти------
diraju, G. В.; and A. Sivasubramaniam, «Characterizing the d-TLB Behavior
., KaqpEC2000 Benchmarks», ACM SIGMETRICS Performance Evaluation Re-
:,' of ^proceedings of the 2002 ACM SIGMETRICS International Conference on
^^gurement and Modeling of Computer Systems, Vol. 30, No. 1, June 2002.
№a , g.. r. Min; Z. Xu, and Y. Hu, «А Study of Memory System Performance
U-^Multiaiedm Applications», ACM SIGMETRICS Performance Evaluation Re-
oi proceedings of the 2001 ACM SIGMETRICS International Conference on
^^’sarement and Modeling of Computer Systems, Vol. 29, No. 1, June 2001.
M diraju, Gokul B., and Anand Sivasubramaniam, «Going the Distance for TLB
35-^aIfetching: An Application-Driven Study», ACM SIGARCH Computer Archi-
• e News, Proceedings of the 29th Annual International Symposium on Corn-
er Architecture, Vol. 30, No. 2, May 2002.
b В and T. Mudge, «Virtual Memory: Issues of Implementation», IEEE
Computer, Vol. 31, No. 6, June 1998, p. 36.
b p and T. Mudge, «Virtual Memory: Issues of Implementation», IEEE
^'Computer, Vol. 31, No. 6, June 1998, p. 37-38.
a 4hvu L, «Virtual Address Translation for Wide-Access Architectures», ACM
3 giGOPS Operating Systems Review, Vol. 29, No. 4, October 1995, pp. 41-42.
„ jjoiliday, M. A., «Page Table Management in Local/Remote Architectures», Pro-
ceedings of the Second International Conference on Supercomputing, New York:
ACM Press, June 1988, p. 2.
40. Jacob, B., and T. Mudge, «Virtual Memory: Issues of Implementation», IEEE
Computer, Vol. 31, No. 6, June 1998, p. 37-38.
41. Dennis. J. B., «Segmentation and the Design of the Multiprogrammed Computer
Systems», Journal of the ACM, Vol. 12, No. 4, October 1965, pp. 589-602.
42. Denning, P., «Virtual Memory», ACM Computing Surveys, Vol. 2, No. 3, Sep-
tember 1970, pp. 153-189.
43. Intel Itanium Software Developer’s Manual, Vol. 2, System Architecture,
Rev. 2.1, October 2002, pp.2-431-2-432.
44. Daley, R. C., and J. B. Dennis, «Virtual Memory, Processes and Sharing in
Multics», CACM, Vol. 11, No. 5, May 1968, pp. 306-312.
45. Denning, P. J., «Third Generation Computing Systems», ACM Computing Sur-
veys, Vol. 3, No. 4, December 1971, pp. 175-216.
46. Bensoussan, A.; С. T. Clingen, and R. C. Daley, «The Multics Virtual Memory:
Concepts and Design», Communications of the ACM, Vol. 15, No. 5, May 1972,
PP. 308-318.
•Crganick, E. I., The Multics System: An Examination of Its Structure, Carn-
age, MA: M.I.T. Press, 1972.
РрГ2?’3^ *Virtual Memory», Computer, Vol. 9, No. 10, October 1976,
^elady, L. A.; R. P. Parmelee; and C. A. Scalzi, «The IBM History of Memory
I Jjnn^ement Technology», IBM Journal of Research and Development, Vol. 25,
5o °’ 5> September 1981, pp. 491-503.
mP • ^rdel Architecture Software Developer s Manual, Vol. 3, System Program-
Guide, 2002, pp. 3-1-3-38.
tor,9luz’ «The IBM 7090», July 2003, <www.columbia.edu/acis/his-
090-html>-
4^’ d-> «7090/94 IBSYS Operating System», August 23, 2001,
L ww-frobenius.com/ibsys.htm>.
636
Ч?
53. Harper, J., «7090/94 IBSYS Operating System», August 94
<www.frobenius.com/ibsys.htm>. ®>
54. Poulsen, L., «Computer History: IBM 360/370/3090/390», October 9 1
<www.beagle-ears.com/lars/engineer/comphist/ibm360.htm>. 2Qq
55. Suko, R., «MVS ... a Long History», December 15, 2002, <os39o_n I
mart.net/mvshist.htm>.
56. Poulsen, L., «Computer History: IBM 360/370/3090/390», October 2fi I
<www.beagle-ears.com/lars/engineer/comphist/ibm360.htm>. 20gj
57. Suko, R., «MVS ... a Long History», December 15, 2002, <os390.m
mart.net/mvshist.htm>. Vs’hypet.
58. Mealy, G., «The Functional Structure of OS/360, Part 1: Introductory 4
IBM Systems Journal, Vol. 5, No. 1, 1966, <www.research.ibm r игУеУ»
nal/sj/051/ibmsj0501b.pdf>. ’ 0пУ10щ..
59. Mealy, G., «The Functional Structure of OS/360, Part 1: Introductory ч
IBM Systems Journal, Vol. 5, No. 1, 1966, Urvey»,
60. Poulsen, L., «Computer History: IBM 360/370/3090/390», October 26 2fi
<www.beagle-ears.com/lars/engineer/comphist/ibm360.htm>. ’ ^01,
61. Suko, R., «MVS ... a Long History», December 15, 2002, <os390-mvs.hvn
mart.net/mvshist.htm>. ’ yper'
62. Poulsen, L., «Computer History: IBM 360/370/3090/390», October 26, 2001
<www .beagle-ears. com/lars/engineer/comphist/ibm360.htm>.
63. Suko, R., «MVS ... a Long History», December 15, 2002, <os390-mvs.hyper-
mart.net/mvshist.htm>.
64. Poulsen, L., «Computer History: IBM 360/370/3090/390», October 26, 2001,
<www.beagle-ears.com/lare/engineer/comphist/ibm360.htm>.
65. Suko, R., «MVS ... a Long History», December 15, 2002, <os390-mvs.hyper-
mart. net /mvshist. htm>.
66. Poulsen, L., «Computer History: IBM 360/370/3090/390», October 26, 2001,
<www.beagle-ears. com/lare/engineer/comphist/ibm360. htm>.
67. Poulsen, L., «Computer History: IBM 360/370/3090/390», October 26, 2001,
<www.beagle-ears.com/lars/engineer/comphist/ibm360.htm>.
68. Suko, R., «MVS ... a Long History», December 15, 2002, <os390-mvs.hyper
mart.net/mvshist.htm>. .
68. Clark, C„ «The Facilities and Evolution of MVS/ESA», IBM Systems ^ur"{a>'
Vol. 28, No. 1, 1989, <www.research.ibm.com/journal/sj/281/ibmsj2801 -P
70. Poulsen, L., «Computer History: IBM 360/370/3090/390», October 26, 4
<www.beagle-eare.com/lare/engineer/comphist/ibm360.htm>. . er.
71. Suko, R., «MVS ... a Long History», December 15, 2002, <os390-mvs.
mart.net/mvshist.htm>. 2001'
72. Poulsen, L., «Computer History: IBM 360/370/3090/390», October 2
<www.beagle-ears.com/lars/engineer/comphist/ibm360.htm>. hyPer
73. Suko, R., «MVS ... a Long History», December 15, 2002, <os390-mv
mart.net/mvshist.htm>. -с.ЬУР^
74. Suko, R., «MVS ... a Long History», December 15, 2002, <os390-i"n
mart, net/mvshist.htm>. joHrrlf'
75. Clark, C., «The Facilities and Evolution of MVS/ESA», IBM {.
Vol. 28, No. 1, 1989, <www.research.ibm.com/journal/sj/281/ibi!1' -1
76. Suko, R., «MVS ... a Long History», December 15, 2002, <os390 hi
mart.net/mvshist.htm>.
Виртуальной намят и
r Vass, D., «MVS Systems Programming: Chapter 3a — MVS Internals»,
i7-^iv5. 19981 <www.mvsbook.fsnet.co.uk/chap03a.thm>.
J11 У «MVS ... a Long History», December 15, 2002, <os390-mvs.hyper-
'fi- ’net/mvshist. htm>.
’’’к С.» «The Facilities and Evolution of MVS/ESA», IBM Systems Journal,
'9 ^¥28, No. 1, 1989, <www.research.ibm.com/joumal/sj/281/ibmsj2801I.pdf>.
У0 ’ p ( «MVS ... a Long History», December 15, 2002, <os390-mvs.hyper-
gO- S^°’net/mvshist.htm>.
111 к C «The Facilities and Evolution of MVS/ESA», IBM Systems Journal,
VoL 28, No. 1,1989, <www.research.ibm.com/journal/sj/281/ibmsj2801I.pdf>.
, „Vass, D., «MVS Systems Programming: Chapter 3a — MVS Internals»,
g2• -ц]у 5, 1998, <www.mvsbook.fsnet.co.uk/chap03a.thm>.
ко R-> «MVS ... a Long History», December 15, 2002, <os390-mvs.hyper-
83' SUart’net/mvshist.htm>.
Clark C., «The Facilities and Evolution of MVS/ESA», IBM Systems Journal,
Vol 28, No. 1, 1989, <www.research.ibm.com/joumal/sj/281/ibmsj2801I.pdf>.
guko, R., «MVS ... a Long History», December 15, 2002, <os390-mvs.hyper-
8 niart’net/mvshist.htm>.
86 Clark, C., «The Facilities and Evolution of MVS/ESA», IBM Systems Journal,
Vol. 28, No. 1, 1989, <www.research.ibm.com/joumal/sj/281/ibmsj2801I.pdf>.
87 Mainfranies.com, «Mainframes.com — SYSPLEX», <www.mainframes.com/
sysplex.html>.
88.Suko, R., «MVS ... a Long History», December 15, 2002, <os390-mvs.hyper-
mart. net/mvshist. htm>.
89. IBM, «S/390 Parallel Enterprise Server and OS/390 Reference Guide», May 2000,
<www-l.ibm.com/servers/eserver/zseries/library/refguides/pdf/g3263070.pdf>.
90. IBM, «IBM eServer zSeries Mainframe Servers», <www-1.ibm.com/serv-
ers/eserver/zseries/>.
91.Spruth, W., «The Evolution of S/390», July 30, 2001, <www-ti.informa-
tik.uni-tuebingen.de/os390/arch/history .pdf >.
92- Case, R. P., and A. Padegs, «Architecture of the IBM System/370», Communica-
tions of the ACM, January 1978, pp. 73-96.
* Gifford, D., and A. Spector, «Case Study: IBM’s System/360-370 Architecture»,
Communications of the ACM, April 1987, pp. 291-307.
«z/VM General Information, V4.4», 2003, <www.vm.ibm.com/pubs/pdf/
HCSF8A60.PDF>.
"5. ,
u-nick, D., «Whither VM?», Datamation, December 1, 1985, pp. 73-78.
fooan’ W., «Amdahl Multiple-Domain Architecture», Computer, October
97 л . pp‘ 20-28.
* Sv^r’ 11 • Bay!es; L. W. Comeau; and R. J. Creasy, «А Virtual Machine
эЛ for the 360/40», Cambridge, MA: IBM Scientific Center Report
98-Ut 7’ May 1966‘
tgV"’ A-. S., and W. L. Konigsford, «TSS/360: A Time-Shared Operating Sys-
Proceedings of the Fall Joint Computer Conference, AFIPS, 1968,
99. Cf ntvale, NJ: AFIPS Press, pp. 15-28.
«The Origin of the VM/370 Time-Sharing System», IBM Journal
September 1981, pp. 483-490.
41 «IBM z/VM and VM/ESA Home Page», <www.vm.ibm.com/>.
638
%
3’ ч
101. Denning, Р-, «Virtual Memory», ACM Computing Surveys, Vol. 2
tember 1970, pp. 153-189. ’ °-
102. Randell, B., and C. J. Kuehner, «Dynamic Storage Allocation Systems» 'W
ings of the ACM Symposium on Operating System Principles, ja.,?’^oc
pp. 9.1-9.16. Uar*
103. Hanlon, A. G, «Content-Addressable and Associative Memory System
vey», IEEE Transactions on Electronic Computers, August 1966.
104. Smith, A. J., «Cache Memories», ACM Computing Surveys, Vol. 14 ю ,
tember 1982, pp. 473-530. ’ °’ 3,
105. Dennis, J. B., «Segmentation and the Design of the Multiprogrammed C
Systems», Journal of the ACM, Vol. 12, No. 4, October 1965, PP. 589:6°0>^
106. Daley, R. C., and J. B. Dennis, «Virtual Memory, Processes and Sh
Multics», CACM, Vol. 11, No. 5, May 1968, pp. 306-312. aritlg in
107. Denning, P. J., «Third Generation Computing Systems», ACM Cornputi
veys, Vol. 3, No. 4, December 1971, pp. 175-216. ng Sur-
108. Jacob, B„ and T. Mudge, «Virtual Memory: Issues of Implementation» n?
Computer, Vol. 31, No. 6, June 1998. ’
109. Patterson, D., and J. Hennessy, Computer Organization and Design, San F
cisco: Morgan Kaufmann Publishers, Inc., 1998.
110. Blaauw, G. A., and F. P. Brooks, Jr., Computer Architecture, Reading Ma
ACM Press, 1997. ’
Ожидаемое происходит редко, чаще происходит то,
чего мы меньше всего ждем.
Бенджамин Дизраэли
Время потечет вспять и возвратится Рай блаженный.
Джон Милыпон
Безошибочность в борьбе с ошибка*^*
Роберт БраУн11Н
Как! Грех — карать, а грешника н
Уильям
Соберите оставшиеся куски, чтобы ничего не
Евангелие от ИоанНа ]
Глава 11
Управление Виртуальной
мллятью
Цели
После прочтения этой главы вы должны знать
и понимать:
• положительные и отрицательные стороны
предварительной подкачки и подкачки
по требованию;
сложности, возникающие при замене страниц,
несколько популярных стратегии замены страниц
и их сравнение с оптимальной заменой страниц,
влияние размера страницы на производительность
виРпгуальной памяти;
введение программ при использовании подкачки.
Краткое содержание ела Вы
11.1. Введение
11.2. Локальность
11.3. Подкачка по требованию
Размышления об операционных системах:
Компьютерная теория и операционные системы
Размышления об операционных системах:
Баланс между пространством и временем
11.4. Предварительная подкачка
11.5. Замена страниц
11.6. Стратегии замены страниц
11.6.1. Замена случайных страниц
11.6.2. Стратегия замены «первый вошел — первый вышел» (FIFO)
11.6.3. Аномалия FIFO
11.6.4. Стратегия замены дольше всего не использовавшихся страниц (LRU)
11.6.5 Стратегия замены реЖе всего используемых страниц (LFU)
11.6.6. Стратегия замены давно не используемых страниц (NUR)
11.6.7. Модификации стратегии FIFO:
стратегия «второго шанса» и круговая стратегия
11.6.8. Стратегия замены дальней страницы
11.7. Модель рабочих наборов
11.8. Стратегия замены страниц по частоте
страничных промахов (PFF)
11.9. Освобождение страниц
11.10. Размер страниц
11.11. Поведение программ в страничных системах
11.12. Глобальная и локальная замена страниц
11.13. Практический пример: замена страниц в Linux
64J
Виртуальной памятью
f I Введение
аве 9 мы рассматривали стратегии загрузки данных в память, их
Р 1 ения и замещения — для реальной памяти. В главе 10 мы обсужда-
р»3 анизаЦию виРтУальн°й памяти, сосредоточившись на страничных,
орг йЫх и сегментно-страничных системах. В этой главе мы изучим
cefpie ление памятью в системах виртуальной памяти.
уЦр®® ятегии загрузки данных в виртуальную память определяют, когда
или страница должны перемещаться в оперативную память со вто-
сеГ^ устройства хранения. Стратегии загрузки по требованию ждут,
р1’40 ороцесс обратится к странице или сегменту, и только при появлении
г^ен гя загружают их в оперативную память. Стратегии предваритель-
" загрузК11 пытаются предугадать, какие страницы или сегменты вскоре
вСЙдпобятся процессу — если вероятность обращения к каким-то незагру-
°° иным страницам или сегментам высока, а в оперативной памяти есть
^ободное пространство, система будет загружать страницы или сегменты
оперативную память до того, как процесс явно обратится к ним. При
этом скорость выполнения обращения возрастет.
В страничных системах — как чисто страничных, так и сегментно-стра-
ничных — использующих страницы одного размера, решения о размеще-
нии принимаются по относительно простому алгоритму, поскольку загру-
жаемую страницу можно поместить в любой доступный кадр страницы.
Сегментные страницы требуют применения стратегий размещения, анало-
гичных используемым в мультипрограммных системах с изменяемым рас-
пределением памяти (см. раздел 9.9).
Стратегии замены определяют, какие страницы или сегменты будут пе-
ремещены из оперативной памяти на вторичное устройство хранения, что-
бы освободить место для требующихся процессу. В этой главе мы сконцен-
трируемся на стратегиях замены страниц (page-replacement strategies),
кОТорЬ1е при правильной реализации позволяют оптимизировать произво-
п»к^ЬНОСТЬ в стРзничных системах. В этой главе рассматривается модель
очих наборов программ, предложенная Деннингом. Эта модель предос-
rDa Яет основу для наблюдения, анализа и улучшения выполнения про-
м в страничных системах1.
Вопросы для самопроверки
1- Объясните разницу между стратегиями загрузки по требованию
и предварительной загрузки в системах виртуальной памяти. Приме-
нение каких стратегий связано с большими накладными расходами?
2. Почему стратегии размещения просты в страничных системах с од-
ним размером страниц?
Ответы 1) Стратегии загрузки по требованию загружают страницы
Или сегменты в оперативную память только тогда, когда процесс явно
обращается к ним. Применение стратегий предварительной загрузки
требует накладных расходов, поскольку система должна тратить время
на определение вероятности того, что к сегменту или странице будут об-
ращения; как мы увидим, эти накладные расходы зачастую невелики.
2) Поскольку любую загружаемую в оперативную память страницу
Можно поместить в любой доступный кадр страницы.
644
11.2 Локальность
В основе большинства стратегий управления памятью лежит Кп
локальности — склонность процесса обращаться к расположен
друг к другу ячейкам памяти2’ 3. Локальность проявляет себя ка
странстве, так и во времени. Временная локальность — это локаль Ь Чв
времени. Например, если в вашем городе солнечно в 3 часа попол^0С,в
вероятно (хотя, конечно, и не наверняка), что в нем было солнечно^11’ то
ловине третьего, и будет солнечно в половине четвертого. Прог ;тра И 6 Чо.
ная локальность (spatial locality) означает, что близко располож^8®”'
объекты обычно схожи. Еще раз возьмем в качестве примера пог6Ва,<*
если в вашем городе солнечно, то, вероятно (но не наверняка), сол^ "
и в городах, расположенных поблизости от него. ечво
Локальность наблюдается и в мире операционных систем, особенно
ласти управления памятью. Это скорее эмпирическое (отмеченное в
наблюдений), чем теоретически обоснованное свойство. Локальность ник^
гда не гарантируется, но часто весьма вероятна. Например, в граничных
системах мы можем заметить, что процесс чаще всего обращается к опре
деленным группам своих страниц, и эти группы часто бывают компактно
расположенными в виртуальном адресном пространстве процесса. Такое
поведение не предотвращает возможности обращения процесса к новой
странице, расположенной в другой области его виртуального адресного
пространства.
На самом деле проявления локальности в компьютерных системах
вполне объяснимы, если учесть методику написания программ и организа-
ции данных. Циклы, функции, процедуры и переменные, i спользуемые
для счета и хранения сумм, отвечают за проявление временной локально-
сти. В этих случаях процесс, вероятно, будет обращаться к ячейкам памя-
ти, к которым он обращался недавно. Просмотр массивов, последователь-
ное выполнение инструкций и привычка программистов (и компилятора
размещать рядом определения взаимосвязанных переменных часто П°Р
дают сгруппированные обращения к компактно расположенным в па
ячейкам.
Вопросы для самопроверки
1. Будет ли более эффективной с учетом локальности подкачка
бованию или предварительная подкачка? дор0'
2. Объясните, каким образом циклическое обращение к мае
ждает и пространственную, и временную локальность. I
Ответы 1) Локальность приводит к большей эффективному
верительной подкачки, поскольку операционная система еСс ®*ро-
сокой вероятностью предугадать, какие страницы ’
использовать. 2) Циклические обращения к массиву пор
странственную локальность, поскольку элементы массив ВРе1Л^1’
положены в непрерывной области виртуальной памяти- ^ofo
локальность проявляется потому, что элементы обычно н сОс^Я
ше по размеру, чем страница. Поэтому обращения к дВ^ вРеМ
элементам массива, происходя за короткий промежут10
обычно направляются к одной и той же странице.
It вар1гЧ'альней памятью
- f1ogk^a по требованию
тейшая стратегия загрузки данных, реализуемая в системах вирту-
ПР?СпаМяти — это подкачка по требованию (demand paging)4. Если ис-
в^01ртсЯ эта стратегия, то в начале выполнения процесса система загру-
оПеративную память страницу, содержащую первую инструкцию
^0еТ В опесса. После этого другие страницы загружаются в память, толь-
гтоГ° у процессор явно обращается к ним. У такого подхода есть несколь-
ко 1:0 вЛекательных черт. Теория вычислений, а точнее, проблема оста-
к° арИ говорит нам, что в общем случае невозможно предсказать последо-
0ОВКЙнсють выполнения программы (см. «Размышления об операционных
Р®1* мах: Компьютерная теория и операционные системы»)5’ 6. Поэтому
с0С попытки загружать страницы заранее, до того, как процесс к ним
тится, могут привести к загрузке ненужных страниц. Накладные рас-
08 ы связанные с предварительной загрузкой страниц, могут снизить
Хпоизводительность всей системы.
Применение подкачки по требованию гарантирует, что в оперативную
память будут загружены только те страницы, которые действительно нуж-
ны процессу. Теоретически это позволяет разместить в оперативной памя-
ти больше процессов — пространство не «засоряется» страницами, к кото-
рым не будет обращений в ближайшем времени или совсем.
Однако с подкачкой по требованию связаны и некоторые проблемы. Про-
цесс в системе с подкачкой по требованию будет получать требуемые страни-
цы по одной за раз. При обращении к новой странице процесс должен ожи-
дать загрузки этой страницы в оперативную память. Если процесс уже хра-
нит в оперативной памяти множество страниц, то эта задержка может быть
особенно заметной, поскольку большая часть оперативной памяти будет за-
нята процессом, который не может выполняться. Этот фактор часто влияет
на значение пространственно-временного показателя (space-time product)
nP°4ecca — времени выполнения процесса, умноженного на объем опера-
^°й памяти, занимаемый процессом (см. «Размышления об операцион-
системах: Баланс между пространством и временем»)7. Пространствен-
^временной показатель иллюстрирует не только время, которое процесс
йаТЬст на ожидание, но и количество памяти, которое не может использо-
ОсьпЯ В° в₽емя этого ожидания. Эта концепция показана на рисунке 11.1.
ИеСс рДИнат показывает количество кадров в памяти, выделенных под про-
°сь а®сц-исс — время по «настенным часам». Пространственно-вре-
Показатель соответствует площади под «кривой» на графике; пунк-
в линии показывают, что процесс обратился к страницам, которых
еративн°й памяти, и ожидает их загрузки со вторичного устройства
Mi ц Я‘ Заштрихованные области обозначают пространственно-времен-
азатель процесса при выполнении им продуктивных операций. Не-
Ч Ojk Ованные области обозначают пространственно-временной показа-
в^ан,ия процессом загрузки страниц. [Примечание: Период ожида-
Действительности намного больше, чем показано на рисунке.]
Незаштрихованные области соответствуют периодам, когда выде-
процесс память не может использоваться. Уменьшение про-
I Пно-временного показателя ожидания процесса для улучшения
646
использования памяти является важной задачей стратегий управле
мятью. По мере роста среднего времени ожидания загрузки страниц Ч
ет выгодность подкачки по требованию8. 111
F— среднее время загрузки страницы
Рис. 11.1. Пространственно-временной показатель при подкачке по требованию
Вопросы для самопроверки
1. Почему пространственно-временной показатель процессов nP^g.
пользовании подкачки по требованию выше, чем при исп
нии предварительной подкачки? я соД"
2. Как подкачка по требованию (в отличие от предварительно^^?
качки) может увеличить степень мультипрограммности с
Как подкачка по требованию может уменьшить степень му
граммности системы?
щи» Виртуальной памятью 647
ОтВвтЫ 1) Потому, что процесс хранит в памяти страницы, к кото-
рым не обращается во время ожидания загрузки требующихся ему
страниц. Этот эффект наблюдается и при использовании предвари-
тельной подкачки. Страницы, загруженные в память до обращения
к ним, будут занимать кадры страниц, не давая другим процессам ис-
пользовать эти кадры. Как мы увидим далее, методы предварительной
подкачки загружают страницы в оперативную память группами, что
обычно снижает время ожидания страницы по сравнению со временем
ожидания при загрузке страниц по отдельности подкачкой по требова-
нию. 2) Подкачка по требованию может увеличить степень мультипро-
граммности, поскольку система будет загружать в память только
страницы, действительно требующиеся процессам. Поэтому в физиче-
ской памяти сможет разместиться большее количество процессов. Од-
нако для выполнения процессов требуется больше времени, поскольку
им чаще приходится ожидать загрузки страниц со вторичного устрой-
ства хранения (по сравнению с групповой загрузкой страниц при ис-
пользовании предварительной загрузки). Пока операционная система
извлекает страницы со вторичного устройства хранения, память, за-
нятая процессом, не используется, и степень мультипрограммности
может уменьшиться (по сравнению с возможной при предварительной
подкачке).
Размышления об операционных системах
Компьютерная теория и операционные системы
В компьютерной науке есть множество
изящных теоретических областей. Теория
вычислимости позволяет нам определить,
что могут, и что не могут делать программы,
имер, операционные системы. Про-
ема остановки в теории вычислимости
^воритнам, что в общем случае невозмож-
написать программу, которая сможет
ни ДСКазать последовательность выполне-
<РУГ°Й пРогРаммы- Этот тезис имеет
>исте^СТВО послеДствий для операционных
Ц|6 ' ^СЛи бы мы смогли предсказать по-
Юность выполнения программы,
аЛьи,У!оМОГЛИ' напРимеР' Реализовать иде-
еНия СтРат®гию предварительного выде-
РесУрсов, чтобы ресурсы были готовы
без задержек (если это вообще возможно),
когда они потребуются процессу. Зная, что
могут, и что не могут делать компьютеры,
мы можем с помощью теории сложности
оценить, будут ли конкретные операции
выполняться и насколько эффективно (или
неэффективно). Теория автоматов позво-
ляет нам осознать сложность различных
вычислительных устройств; это позволяет
нам понять (см. главу 6), что современные
компьютерные системы слишком сложны,
чтобы провести полное тестирование всех
возможных состояний их аппаратных
и программных компонентов. Последнее
замечание особенно важно, если вы долж-
ны создать высоконадежную систему.
648
Размышления об операционных системах
Баланс меокду пространством и временем
Примеры выигрыша во времени за счет
использования большего пространства из-
вестны и в компьютерах, и в других областях.
Если при переезде на новую квартиру у вас
есть больший грузовик, вы сможете перевез-
ти обстановку за меньшее количество поез-
док, но вам придется заплатить больше за
аренду большего грузовика. Изучая проце-
дуры поиска и сортировки в структурах дан-
ных и теории алгоритмов, вы увидите, что
производительность может возрасти, если
доступна дополнительная память (напри-
мер, для хэш-таблиц). Такие примеры ба-
ланса часто встречаются и в компьютерных
системах. Если операционная система выде-
лит выполняющейся программе больше опе-
ративной памяти, то программа, возможно,
будет выполняться намного быстрее. Если
память дорога и объем ее невелик, операци-
онная система должна тщательно уПрав
ее распределением, более интенсивно^
гружая процессор. Если памятьдещева.Ка'
много, операционная система можету 66
лять ею более небрежно, возможно пп.. В
с ' "РИНЦ.
мая более грубые решения за счет меньшей
нагрузки на процессор. Рассматривад
RAID-системы в главе 12, мы увидим, чт0
хранение избыточных копий данных может
увеличить пропускную способность систе-
мы. Однако мы увидим, что выделение про-
цессу большего объема памяти не всегда
приводит к более быстрой работе этого про-
цесса — мы познакомимся с аномалией FIFO,
которая покажет, что в некоторых случаях
увеличение объема памяти, доступного
процессу, снижает производительность.
К счастью, это происходит только в редких
случаях.
//. 4 Предварительная подкачка
Основной мотив в распределении ресурсов состоит в том, что чем
ресурсы, тем тщательнее должно быть и управление их распределен
Стоимость аппаратного обеспечения все больше снижается, а сООТН°ра3ра-
цены человеческого времени и цены машинного времени все растет.
ботчики операционных систем стремятся свести к минимуму время»
рое люди проводят в ожидании результатов работы компьютеров
Как мы показали в предыдущем разделе, один из способов умен ^По-
времени ожидания — устранение задержек в системах подкачки по ^0.
ванию. Используя предварительную подкачку (anticipatory pag1 1дуга*
гда — prefetching или prepaging) операционная система пытается
дать, какие страницы понадобятся процессу, и загрузить их в опера
память, если в ней есть свободное пространство. Если система пр
выберет страницы для загрузки, общее время работы процесса
уменьшиться11’ 12.
^мВартуалыюа памятью
. пяД важных факторов, определяющих успех стратегий предвари-
«$ДагрузкИ:
0бъем памяти, доступный для размещения предварительно загружае-
* Jibix страниц.
количество страниц, предварительно загружаемых за один заход.
* Алгоритм выбора предварительно загружаемых страниц (с использо-
* ванием временной или пространственной локальности)13.
аТегии предварительной подкачки нужно проектировать тщательно.
I тегия, требующая заметных ресурсов (процессорного времени, кадров
и операций дискового ввода/вывода) для работы, может проде-
стР сТрировать худшую производительность, чем стратегия подкачки по
^бованию.
Часто стратегии предварительной подкачки сочетаются с подкачкой по
„рбованию; система загружает сразу несколько страниц, если процесс об-
гдается к странице, которой нет в оперативной памяти. Такие стратегии
обычно основываются на пространственной локальности — предполагает-
ся что процесс, обратившийся к некоторой странице, вероятно, вскоре об-
ратится и к страницам, расположенным рядом с ней. в виртуальном адрес-
ном пространстве. Если в процессе происходит страничный промах, систе-
ма загружает требуемую страницу и несколько страниц, расположенных
поблизости от нее в виртуальном пространстве.
Однако страницы, смежные в виртуальном адресном пространстве про-
цесса, могут быть несмежными на вторичных устройствах хранения. В от-
личие от оперативной памяти, эти устройства (т.е. жесткие диски) облада-
ют неодинаковой скоростью доступа к данным, расположенным в разных
областях, и время загрузки нескольких страниц со вторичного устройства
хранения может быть намного больше времени загрузки одной страницы.
В этом случае процесс может страдать от еще большего времени загрузки
страницы, чем при подкачке по требованию.
Одно из решений этой проблемы — компактное размещение на вторич-
ных устройствах хранения страниц, смежных в виртуальном адресном
пространстве процесса14. Как мы увидим в главе 12, разница между време-
нем загрузки нескольких страниц, расположенных рядом на диске, и вре-
йаяем загРУЗки одной страницы, будет невелика. Поэтому предваритель-
но ПоДкачка может использоваться без заметного увеличения задержек
С подкачк°й по требованию. Например, в системе Linux,
Ядро пР°Цесс обращается к странице, которой нет в оперативной памяти,
^ет ПЬ1тается воспользоваться пространственной локальностью и загру-
цОд с Диска не только требуемую страницу, но и несколько страниц, рас-
11° умеНнЬ1х Рядом с ней в виртуальном адресном пространстве процесса.
КВ Е лчанию система загружает с диска четыре смежные страницы (16
Илц ®Рхитектуре IA-32), если объем оперативной памяти меньше 16 МБ,
смежных страниц (32 КБ в архитектуре IA-32) в противном
а8Пяю Этот подход может дать хорошие результаты для процессов, про-
чих пространственную локальность.
650
%!
Вопросы для самопроверки
1. В каких случаях стратегия предварительной подкачки, не
мая в системе Linux, окажется неэффективной? ’ П°л,>3уе
2. Почему предварительная подкачка, вероятно, продемон
лучшую производительность, чем подкачка по требованикгГ^Уе»
ких случаях она может продемонстрировать худшую пг> ' ® *а
тельность? ₽О113вод^
Ответы 1) Если процесс обращается к страницам в случай
следовательности, то Linux, вероятно, будет загружать в памя
ницы, не нужные процессу, и засорять ее. Если оперативнаяТЬ СТ{>а-
мала по объему, это может заметно уменьшить количество
доступное другим процессам и увеличить количество страничаЛ^1^11,
махов. 2) Она может проявить лучшую производительность, ПоХ.В1>0'
ку эффективнее загрузить несколько рядом расположенных СтСКоль-
за одну операцию ввода/вывода, чем выполнять отдельные опеп^811
для загрузки каждой страницы (как при подкачке по требованию)
нако производительность может снизиться, если процессу будут '
нужны загруженные страницы. 5 Не
11.5 Замена страниц
В страничной системе виртуальной памяти все кадры страниц могут
быть заняты, когда процесс обратится к странице, которой нет в оператив-
ной памяти. В этом случае системе придется определить, какую страницу
в оперативной памяти можно заменить (т.е. перенести на вторичное уст-
ройство хранения или просто пометить как доступную для перезаписи),
прежде чем загружать новую страницу со вторичного устройства хране-
ния. В этом и нескольких последующих разделах мы будем рассматривать
стратегии замены страниц.
Вспомните, что страничный промах возникает, если процесс обращает-
ся к странице, которой нет в оперативной памяти. В этом случае система
управления памятью должна найти нужную страницу на вторичном У
ройстве хранения, загрузить ее в оперативную память и обновить соотв
ствующую запись в страничной таблице. Стратегии замены страниц 0
но пытаются уменьшить количество страничных промахов процесса,
самым, возможно, уменьшая время его выполнения. ней3"
Если содержимое страницы, которую решено заменить, осталось я,
менным после загрузки ее с диска, то новую страницу можно просто &
сать поверх старой. Если содержимое старой страницы изменилось^рй.
нужно сначала перенести на вторичное устройство хранения, чтооь
нить ее содержимое. Бит изменения (modified bit или dirty bit) Б^этлеъА'
страничной таблицы установлен в 1, если содержимое страницы
лось, и в 0, если нет. вЫ110'Я
Запись, выгрузка или сброс (flushing) страницы на диск требует д8-
нения операции ввода/вывода, поэтому время ожидания процесс»1р^М^’
мене страницы растет. Некоторые операционные системы, Н‘1
Linux и Windows ХР, периодически сбрасывают измененные стр»1
диск, чтобы увеличить вероятность того, что можно будет замен11
651
_ |Г<д Виртуальной памятью
J ges необходимости предварительно записывать содержимое заменяе-
Л0* траниЦ на диск. Поскольку это периодическое сбрасывание может
° одить асинхронно с выполнением процесса, связанные с ним на-
$р0$с те расходы будут невелики. Если процесс обращается к сбрасывае-
Я^^анице до завершения сброса, то сброс отменяется, чтобы не выпол-
Медленную операцию извлечения страницы со вторичного устройства
^ййНИЯ.
яра11 нИВая стратегии замены страниц, мы часто будем сравнивать их с так
7 Маемой оптимальной стратегией замены страниц (optimal page repla-
nt® strategy), обозначаемой ОРТ или MIN. Эта стратегия исходит из
c6,Ii что Для достижения максимума производительности нужно заменять
которая дольше всего не понадобится в дальнейшем16* 17>18> 19* 20.
сТ^яая стратегия увеличивает производительность за счет уменьшения ко-
Д8® тва страничных промахов. Она может быть оптимальной, но она не-
Иь^гчурмя. поскольку в общем случае мы не можем точно предсказать по-
^пение процессов. Однако эта стратегия может служить эталоном для оцен-
кя реализуемых стратегий. Хорошая стратегия замены страниц
выдерживает баланс между минимальным количеством страничных прома-
хов и минимальными накладными расходами на предсказание будущих об-
ращений к страницам.
Вопросы для самопроверки
1. Какие факторы усложняют создание стратегий замены для сег-
ментных систем (по сравнению с системами, использующими стра-
ницы)?
2. Возможно ли создание оптимальной стратегии замены для ка-
ких-то процессов? Если да, приведите пример такого процесса.
Ответы 1) Такие системы должны учитывать размеры сегментов,
которые нужно загружать, и размеры сегментов, на место которых их
можно поместить. 2) Да. Тривиальный пример такого процесса — про-
цесс с одной страницей данных, к которой он интенсивно обращается,
и строго последовательным выполнением инструкций кода.
^•6 Стратегии замены страниц
МЫ РассмотРим несколько стратегий, используемых для выбора
Kajj ^Р* на место которых будут помещены новые страницы. Каждая та-
К>тСя РНтегия основывается на некотором принципе, по которому выбира-
•Ui ^^Раницы для замены. От этого принципа зависят и накладные расхо-
tibi jj ^^изацию соответствующей стратегии. Некоторые стратегии заме-
*^0йз Первый взгля« весьма привлекательны, но проявляют низкую
Стельность из-за неудачного выбора принципа. Другие стратегии
с Чх й предсказывают будущие обращения к страницам, но связанные
п°льзованием накладные расходы могут заметно снизить произво-
°СТь- Мы также обсудим, как специальные аппаратные устройства
Х?Меньшить накладные расходы на реализацию стратегий замены
652
%,
11.6.1 Замена случайных страниц
Стратегия случайной замены (random page replacement — RANn\
ста в реализации и требует незначительных накладных расходов п
пользования. При ее использовании каждая страница в оперативной Я 11с-
ти может быть заменена с равной вероятностью. Одна из свойств
RAND проблем — то, что случайно может быть заменена страница
рой обращается процесс (а это, безусловно, худший выбор страниц К°Т°'
замены). Преимущества RAND — быстрота выбора страницы для за *
и стабильность. Поскольку обычно выбор производится из очень боль
количества страниц, вероятность замены страницы, которая вскоре д0*01,0
буется процессу, невелика. Однако из-за непредсказуемости заменяе
страниц эта стратегия редко используется.
Вопросы для самопроверки
1. В каком смысле RAND — стабильная стратегия? Почему этот тип
стабильности не подходит для стратегий замены страниц? ТИП
2. Может ли RAND работать так же эффективно, как ОРТ?
Ответы 1) RAND стабильна в том смысле, что все страницы в па-
мяти могут заменяться новыми с одинаковой вероятностью. Однако
такая стабильность мало подходит для стратегий замены, которые для
уменьшения количества страничных промахов должны избегать заме-
ны тех страниц, что скоро потребуются процессам. 2) Да, RAND мо-
жет случайно заменять страницы в той же последовательности, что
и ОРТ, но вероятность этого настолько ничтожна, что лучше ответить
на этот вопрос «Нет».
11.6.2 Стратегия замены «первый вошел — первый вышел» (FIFO)
Стратегия замены страниц FIFO (first-in-first-out page replacement) за-
меняет страницы, дольше всего находящиеся в оперативной
На рисунке 11.2 показан простой пример использования стратегии г*
для процесса, которому выделены три кадра страниц. В левом столбце
зана последовательность обращений процесса к страницам. Каждая стР^
в таблице указывает состояние очереди FIFO после прибытия новой &
ницы; новые страницы добавляются в хвост очереди, слева, и выход
головы очереди, справа. к за-
При замене страниц по стратегии FIFO система отслеживает п°Ря^нйду,
грузки страниц в оперативную память. Когда нужно заменить стра йТсЯ
стратегия выбирает для замены страницу, которая дольше всего н^1ГдядЛт
в оперативной памяти. С интуитивной точки зрения эта стратегия в
разумной — у этой страницы был шанс, она должна дать шанс нОВ одЬзУе'
нице. К несчастью, стратегия FIFO может заменять интенсивно и
мые страницы. Например, в больших системах с разделением врем
жество пользователей часто работает в одних и тех же программах^
мер, текстовых редакторах. Все пользователи используют °'HH^Tpai'ef5g.l
копию программы для ввода и редактирования своих текстов.
FIFO при использовании в такой системе может решить, что
нить интенсивно используемую страницу с кодом редактора. Это ПЛ
653
e виртуальной памятью
дольку почти Фазу же придется снова загрузить эту страницу назад
В* дивную память, и частота страничных промахов возрастет. Хотя
о0еРа1Ью очереди стратегию FIFO можно реализовать с незначительными
с {spli° цыми расходами, она непрактична для большинства систем. Но, как
0вК-паЯлИм в разделе 11.6.7, модификации стратегии FIFO (стратегия «вто-
нса» и круговая стратегия FIFO) служат основой различных практи-
аð Используемых стратегий замены страниц.
Требуемая
страница Результат
Стратегия замены
страниц FIFO с тремя
доступными кадрами
страниц
Промах
Промах
Промах
Нет
промаха
Промах
страница А заменяется
страница В заменяется
А Промах
РйС. 11.2. Стратегия замены страниц FIFO
Вопросы для самопроверки
1. Почему стратегия замены страниц FIFO обладает слабой производи-
тельностью для многих процессов?
2. Сравните эффективность стратегии FIFO и стратегии ОРТ в процес-
се, выполняющем цикл обращений к п страницам, если в оператив-
ной памяти может поместиться не более п-1 страницы.
Ответы 1) Стратегия FIFO заменяет страницы согласно их возрас-
ту, который, в отличие от локальности, является плохой основой для
предсказания будущих обращений к страницам. 2) Предположим, что
страницы пронумерованы — от О до га-1. В этом случае, когда процесс
обратится к странице га-1, FIFO заменит первую страницу, к которой
процесс обращался в цикле. Однако именно к этой странице процесс
обратится сразу после страницы га-1. Чтобы освободить место для пер-
вой страницы, FIFO заменит вторую. Но именно к ней процесс будет
обращаться далее. Оптимальная Стратегия ОРТ заменила бы страни-
цу, к которой дольше всего не будет обращений в будущем — а это
страница, к которой только что обращался процесс. В этом случае ис-
пользование стратегии ОРТ привело бы к одному страничному прома-
ху за один проход цикла, а использование FIFO — к га промахам за
один проход.
654
%
11.63 Аномалия FIFO
Здравый смысл подсказывает, что, чем больше кадров страниц
но процессу, тем реже он будет генерировать страничные промахи
Нельсон и Шедлер обнаружили, что в некоторых случаях при исп еЛаДи
нии стратегии замены страниц FIFO и обращениях к страницам в Ьа°Ч
ленной последовательности количество страничных промахов растет*1^6-
том количества доступных страничных кадров21. Это явление назь С^°с-
аномалией FIFO (FIFO anomaly) или аномалией Белади (р
anomaly). 6 a^y’s
Пример такой аномалии показан на рисунке 11.3. В левой табли
казана последовательность загрузки и замены страниц (по стпц П°'
FIFO), если система выделила процессу три кадра страниц. Правая т
таОЛц.
Требуемая страница А Результат Промах Замена страниц по стратегии FIFO стремя доступными кадрами страниц —, —...—, А - ~ Промах Замена страниц по стратегии FIFO с четырьмя доступными кадрами страниц а га
В Промах В А - Промах - в А —
С Промах с В А Промах с В А
D Промах 0 С В Промах X D С В А
А Промах А D С Нет промаха s D С В А
В Промах В А D Нет Su промаха D С В А J
Е Промах / Е . В А Промах Е D с В
А >Нет V промаха у- Е В А Промах fy Е D С
В ‘Нет С промаха х Е В А Промах В А Е D
С Промах С Е i 4 В Промах С В А Е
D Промах ( D С Г Е Промах D С В А
Е Нет V промаха ь С Е Промах Е 0 С В
Три «не промаха» Два «не промаха»
Рае. 113. Аномалия FIFO — рост количества страничных промахов при Р
количества выделенных процессу кадров страниц
г Нир1чуалы<ой памятью_________
_Ь1вает последовательность загрузки и замены страниц при той же
аТельности обращений к страницам, но с четырьмя доступными
Слева от каждой таблицы мы показываем, сопровождается ли об-
к новой странице страничным промахом. Если процесс работает
кадрами, то в ходе выполнения он генерирует на один странич-
’'веТ^Р маХ больше, чем при работе с тремя кадрами.
я^далия FIFO — скорее любопытный курьез, чем практически важ-
А#° уЛЬтат. Вероятно, основная его ценность — в возможности убе-
gjj# Р. о0ерационные системы представляют собой сложные объекты, ко-
дИ^^рлогда ведут себя не так, как нам подсказывает интуиция.
Вопросы дм самопроверки
1. (Да/Нет) При использовании стратегии замены страниц FIFO коли-
чество страничных промахов всегда растет при увеличении количе-
ства кадров страниц, выделенных процессу.
Ответы 1) Нет. Обычно, если процессу выделено больше кадров,
он будет генерировать меньше страничных промахов, поскольку боль-
шая часть необходимых ему страниц будет находиться в оперативной
памяти, и меньше будут шансы того, что нужной страницы в опера-
тивной памяти не будет. Наблюдение Белади — это аномалия; заме-
ченное им поведение встречается нечасто.
11.6.4 Стратегия замены дольше всего не использовавшихся страниц
т
Стратегия замены страниц LRU (least-recently-used page replacement)
(рис. 11.4) основывается на предположении, что поведение процесса в бу-
дущем будет похоже на его поведение в прошлом (временная локальность).
Если процесс требует замены страницы, стратегия LRU заменяет ту стра-
ВиИУ в оперативной памяти, к которой дольше всего не было обращений.
Хотя LRU может обеспечить лучшую производительность, чем FIFO,
Достигается за счет больших накладных расходов22. LRU можно реали-
т0ГоТь с помощью списка, содержащего по одной записи для Каждого заня-
Ги j ^адра оперативной памяти. При каждом обращении к странице памя-
*Ит будет помещать запись об этой странице в голову списка (это слу-
аа11йпРИзнаком того, что к странице обращались последней). Более старые
Цу будут отодвигаться к хвосту списка. Когда нужно заменить страни-
СйсТеН°ВуК)’ страница, подлежащая замене, выбирается из хвоста списка.
МЭ Осв°бождает соответствующий кадр страницы (возможно, при
Мнившееся содержимое страницы переписывается на вторичное
^Ре В° хРанения)> помещает в освободившийся кадр новую страницу
вещает запись об этом кадре в голову списка (поскольку к этой стра-
>^РаЩались последней). Такая схема будет надежной реализацией
^с*0дОвИ °Днако ее использование требует значительных накладных
^Раъ ’ поскольку список должен обновляться при каждом обращении
Kj Цам-
6 цр°Лзкны всегда быть осторожными, применяя эвристические подхо-
оптировании операционных систем; эвристика — например, та,
656
что лежит в основе LRU — может подвести нас в некоторых стай
ситуациях. Например, страница, к которой дольше всего не был<з
ний, может потребоваться следующей в программах, циклическ^Ч^
щающихся к страницам из определенных наборов. Если такую е 11
заменить, ее придется почти сразу же загружать обратно.
Требуемая страница Результат Стратегия замены страниц LRU с тремя доступными кадрами страниц
А Промах А — -
В Промах В А -
С Промах С В А
Нет
В промаха В С А
Нет
в промаху В С А
Нет )
А промаха А в С
D Промах D А В
Нет
А промаха А D В
Нет
В промаха В А D
F Промах F В А
Нет
В промаха В F А
Рис. 11.4. Стратегия замены страниц LRU
Вопросы для самопроверки
1. (Да/Нет) Стратегия LRU предназначена для повышения
выполнения процессов с пространственной локальностью-
2. Почему «чистая» LRU применяется редко?
Ответы 1) Нет. LRU повышает скорость выполнения
с временной локальностью. 2) Потому что она требует зна стР^
накладных расходов на поддержание упорядоченного спис
и его переупорядочение.
’ Вирту кои памятью ---------—--------
г г^пратегия замены реЖе всего используемых страниц (LFU)
//-*' тегИя замены страниц LFU (least-frequently-used page replacement)
I ^Егает решения о замене страниц, исходя из интенсивности использова-
др^^лсдой страницы. Система заменяет страницы, к которым процесс
Г его обращался. Эта стратегия основывается на привлекательной на
® взГЛЯд идее: страница, к которой редко обращаются, вряд ли пона-
в ближайшем будущем. Стратегию LFU можно реализовать с помо-
Л^счетчиков, учитывающих количество обращений к каждой странице,
jilt10 саЯ реализация потребует значительных накладных расходов.
go та атегия LFU легко может выбрать для замены неправильные страни-
^апример» реже всего используемая страница может быть страницей,
й^- vK» позже всего загрузили в память. Эту страницу использовали толь-
К°Т пнаЖДЫ, а все остальные страницы — по нескольку раз. В этом случае
!° анизм замены страниц заменит новую страницу, хотя эта страница
М «ти наверняка сразу же понадобится. Ниже мы рассмотрим стратегию,
П ебуюЩУю незначительных накладных расходов, но принимающую в ос-
новном разумные решения.
Вопросы для самопроверки
1. Почему частота использования страницы — плохое основание для
попыток предвидения будущего использования этой страницы?
2. Использование какой стратегии замены страниц связано с больши-
ми накладными расходами: LRU или LFU?
Ответы 1) Частота определяет количество обращений к странице,
но не определяет, сколько из них сЬпровождалось страничными про-
махами. Поскольку страничные промахи требуют, чтобы процесс до-
жидался загрузки страницы со вторичного устройства хранения, их
следует считать более значимыми, чем обращения к страницам, уже
находящимся в оперативной памяти. Если обращения к странице час-
то сопровождаются страничными промахами, то эта страница активно
используется, и ее размещение в оперативной памяти, вероятно,
уменьшит количество промахов в будущем. Однако это не всегда верно
для находящихся в оперативной памяти страниц, к которым процесс
часто обращался, поскольку количество обращений не указывает, ак-
тивно ли используется страница сейчас. 2) Ответ зависит от реализа-
ции этих стратегий. Обе стратегии в их чистом виде должны
обновлять свои служебные данные при каждом обращении к памяти,
следовательно, их уровни накладных расходов будут приблизительно
одинаковыми. Стратегии LFU нужно обновлять значения в счетчиках,
a LRU — переупорядочивать связный список; последнее, вероятно, по-
требует больших накладных расходов.
Стратегия замены давно не используемых страниц (NUR)
Ил^д^Улярный метод аппроксимации стратегии LRU при небольших на-
1х Расходах — стратегия замены страниц NUR (not-used recently
%b_replacement). В основе этой стратегии лежит идея, что давно не ис-
страница вряд ли понадобится в ближайшем будущем. Эта.
Mj 3 ГИя реализуется с помощью двух аппаратно хранимых битов в каж-
РИси страничной таблицы:
1
658
%
• бита обращения (referenced bit) — этот бит устанавливается в о
к странице обращений не было, и в 1 — если были.
• бита изменения (modified bit) — этот бит устанавливается в п
содержимое страницы не изменялось, и в 1, если изменялось eCjty
Бит обращения иногда называется битом доступа (accessed bit) г
гия NUR работает следующим образом. Изначально система устанав ^1е'
биты обращения всех страниц в О. Когда процесс обращается к нек
странице, система устанавливает бит обращения этой страницы в 1
изменения для всех страниц также изначально установлены в 0. р btlTbi
держимое страницы изменяется, бит изменения этой страницы уста с°'
вается в 1. Когда нужно заменить страницу, стратегия NUR сначала
ется найти страницу, к которой не было обращений (поскольку NUR ^Та-
ется аппроксимировать поведение LRU). Если таких страниц нет си
должна заменить страницу, к которой были обращения. В этом сллп^8
NUR проверяет бит изменения, чтобы определить, изменялось ли со 86
жимое страницы. Если нет, то соответствующая страница выбирается л ₽
замены. Если страниц, к которым были обращения, но содержимое кото
рых не изменялось, нет, то нужно заменять страницу, содержимое Которой
изменялось. Вспомните, что замена страницы с изменившимся содержи-
мым требует дополнительной операции ввода/вывода для записи этой
страницы на вторичное устройство хранения. Однако заметьте, что перио-
дический сброс измененных страниц может уменьшить или вообще устра-
нить эту дополнительную задержку.
Конечно, в многопользовательской системе оперативная память будет
интенсивно использоваться, и постепенно биты обращения всех страниц
будут установлены в 1. В таком случае стратегия NUR не сможет найти
страницы, которые лучше всего заменять. Для предотвращения таких си-
туаций широко применяется следующий прием. Периодически система
сбрасывает в 0 все биты обращений, после чего продолжает работать как
обычно. Безусловно, этот прием делает активно используемые страницы
временно уязвимыми для замены, но период их уязвимости непродолжи-
телен — биты обращений этих страниц будут почти сразу же вновь уста-
новлены в 1.
В схеме NUR страницы могут быть разбиты на четыре ГР^ е
(см. рис. 11.5). Страницы из групп с наименьшими номерами — пе₽
кандидаты на замену, а из групп с наибольшими номерами — пОСЛе2чаЙ-
Среди страниц одной группы выбор одной страницы производится
ным образом. Обратите внимание, что группа 2 описывает нереалисти
ситуацию — страницы, содержимое которых изменялось, но к котор ^це.
было обращений. Такая ситуация может возникнуть после сброса
ний битов обращения (но не битов изменения). одДеР”
Схемы, похожие на NUR, можно реализовать и на машинах, не
живающих аппаратно битов обращения и изменения23. Эти биты
поддерживаются аппаратной частью компьютеров и устанавл gjrro®
в ходе выполнения инструкций машинного кода. Каждый из эти
можно имитировать, перехватывая обработчики промахов опера
системы и обработчики выполнения, как описано ниже.
659
Виртуальной памятью
Бит обращения Г<1 0 ГР<% 0 ГР< 1 гр<4 -1 груп^4 Бит изменения Описание 0 Лучший выбор для замены 1 [выглядит нереалистично] 0 1 Худший выбор для замены
Г , классификация страниц в стратегии NUR
fit-
обращения можно имитировать, реализовав соответствующий бит
тюаммах и инициализируя каждую запись в страничной таблице, что-
в с^°оКазать, что страница отсутствует. Когда процесс обращается к стра-
& п генерирует страничный промах, управление передается обработчи-
81IrtioMaxa, который устанавливает бит обращения в 1 и возобновляет нор-
ьное выполнение процесса. Бит изменения имитируется за счет
^означения всех страниц как доступных только для чтения. Когда про-
ге пытается изменить содержимое страницы, возникает исключение не-
корректного обращения к памяти; обработчик этого исключения устанав-
ливает программно-управляемый бит изменения в 1 и разрешает доступ
к соответствующей странице для чтения/записи. Конечно, механизм реа-
лизации бита изменений должен защищать от нежелательного доступа
к страницам, которые доступны только для чтения, так что операционная
система должна учитывать, какие страницы доступны для чтения и запи-
си, а какие — только для чтения. Операционная система также должна пе-
риодически сбрасывать в О биты обращений; интервал между сбросами
критичен для эффективной работы стратегии МиКПоследовательность ин-
струкций, необходимых для выполнения этих действий, вероятно, будет
невелика по размеру и выполняться быстро. Почти все современные про-
цессоры поддерживают аппаратные биты обращения и изменения, что по-
зволяет повысить производительность систем управления памятью.
Вопросы для самопроверки
1. Как бит изменения может повысить производительность стратегии
NUR?
2. В каких обстоятельствах NUR может заменить хуже всего подходя-
щую для замены страницу?
3. В каком случае может оказаться, что содержимое страницы изме-
нялось, но обращений к ней не было?
Ответы 1) Бит изменения позволяет операционной системе опре-
делить, какие страницы можно заменять без необходимости предвари-
тельного сброса их на диск. Выбор для замены страниц
с неизмененным содержимым уменьшает потребность в операциях
ввода/вывода при замене страниц. Обратите внимание, что стратегия
NUR — если следовать ее принципам — все же заменит страницы с из-
менившимся содержимым, к которым не было обращений, прежде
чем заменять страницы с изменившимся содержимым, к которым
были обращения. 2) Если бит обращения страницы, к которой сейчас
будут обращения, был сброшен непосредственно перед моментом, ко-
гда нужно заменить страницу. 3) На самом деле обращения к этой
странице были, но биты обращений периодически сбрасываются в О.
660
11.6.7 Модификации стратегии FIFO: стратегия «второго щдНс
и круговая стратегия G>>
Очевидный недостаток стратегии FIFO — то, что она может
активно используемую страницу, которая находится в оперативщр-461*^
ти в течение долгого времени. Этот недостаток можно устранить Г1а^я
вав FIFO в сочетании с битами обращения для страниц, и заменяя
страницы, бит обращения у которых сброшен в 0.
Такая вариация FIFO, называемая стратегией «второго
(second-chance), проверяет значение бита обращения у страницы, дол^^69*
го находящейся в памяти; если этот бит сброшен в 0, то эта страница б ВСе'
выбрана для замены. Если бит обращения установлен в 1, алгоритм г;г,
вает этот бит и перемещает запись о странице в хвост очереди FIFO грЬ1'
страница воспринимается, практически, как только что загруженная
мять страница. С течением времени запись об этой странице снова окаж °а'
в голове очереди. Если к тому времени, когда она окажется в голове очепе 1
ее бит обращения будет сброшен, то страница будет выбрана для заменьх ’
Активные страницы будут раз за разом перемещаться в хвост списка по-
скольку их биты обращений будут устанавливаться, поэтому эти страницы
будут оставаться в оперативной памяти. Страница, содержимое которой из-
менилось, должна быть выгружена на вторичное устройство хранения до
того, как ее можно будет заменить; если бит обращения этой страницы сбро-
шен, эта страница будет «временно незаменимой», пока система не завер-
шит выгрузку ее содержимого. Если процесс обращается к странице до за-
вершения выгрузки, то выгрузка отменяется, чтобы не выполнять медлен-
ную операцию извлечения страницы со вторичного устройства хранения.
Стратегия круговой замены страниц (clock page replacement strategy),
дающая практически те же результаты, что и стратегия «второго шанса»,
организует циклический, а не линейный список страниц24. При каждом
страничном промахе указатель в списке перемещается по списку, каК
стрелка по циферблату часов. Если бит обращения страницы сброшен, Ука
затель перемещается на следующий элемент в списке (имитируя пере
страницы в хвост очереди FIFO). Загружаемые в оперативную память с
ницы помещаются на место первой страницы в направлении «по часо
стрелке» со сброшенным битом обращения.
Вопросы для самопроверки
1. Использование какой стратегии — стратегии «второго
стратегии круговой замены — связано с меньшими нак
расходами? эфФеК'
2. Почему стратегии «второго шанса» и круговой замены более
тивны, чем LRU?
Отве/ПЫ 1) Стратегия второго шанса требует, чтобы систе а
кала страницу из очереди и вновь добавляла в очередь прi сЛУ4^. J
сбросе бита обращения. Стратегия круговой замены в об сбРа^.
связана с меньшими накладными расходами, поскольку Ш
вании значения бита обращения нужно только изменять У
2) Эти алгоритмы уменьшают количество обновлений иНФ
об использовании страницы.
f виртуальной памятью
661
дтратегия замены дальней страницы
(/,*' ь1полнении программы часто обращаются к данным и фрагментам
jlp1* ®едСказуемых последовательностях. Стратегия замены дальних
₽ (far page-replacement strategy) использует графы для принятия ре-
замене страниц, исходя из предсказуемости этих последовательно-
^еА*^1°ащений. Как показывают математические выкладки, такая страте-
й обр давать близкие к оптимальным результаты, но она сложна в реали-
. требует заметных накладных расходов для использования25' 261 27.
*тегия замены дальних страниц создает граф обращений (рис. 11.6),
Сдающий последовательности обращений процесса. Каждая вершина
оС^ь^бращеиий соответствует одной из страниц процесса. Ребро графа,
гР8^анЯ10щее вершины и и w, означает, что процесс может обращаться
с°еДЙянице w после обращения к странице V. Например, если инструкция
К Каницы v обращается к данным в странице w, то вершины v и w графа
90 v т соединены ребром. Аналогично, если вызов функции со страницы х
I бУ₽бует возврата на страницу у, вершины х и у будут соединены ребром,
р целом граф, который может быть весьма велик, описывает возможные
последовательности обращений к страницам процесса в ходе его работы.
Графы можно создавать на основе анализа скомпилированного кода про-
граммы до ее выполнения — при этом выясняется, к каким страницам об-
ращаются инструкции с каких страниц. На построение графа может потре-
боваться заметное время. [Примечание’. Большинство работ о стратегии за-
мены дальней страницы подразумевает, что граф обращений создается до
запуска страницы, но создание графа в ходе выполнения процесса тоже
изучалось.]28 Граф доступа на рисунке 11.6 показывает, что после обраще-
ния к странице В процесс обратится к странице С, D или Е, но не может об-
ратиться к странице G до обращения к странице Е.
Эта стратегия замены работает в фазах, почти так же, как и алгоритм
круговой замены. Изначально все вершины графа помечаются как не полу-
Чавшие обращений. Когда процесс обращается к странице, алгоритм отме-
®ет соответствующую этой странице вершину графа как получившую об-
е,1Ие- Если алгоритму нужно выбрать страницу для замены, он выби-
й£ег страницу, к которой не было обращений и расположенную дальше
jag. От страниц, к которым были обращения (на рисунке 11.6 это верши-
ну Ь Интуитивная привлекательность этого алгоритма в том, что страни-
от’с 1£0ТоР°й не было обращений, и расположенная дальше всего в графе
ниц, к которым были обращения, вероятно, дольше всего не понадо-
°6p0D И в будущем. Если в графе нет ни одной вершины, к которой не было
Как ИВ’ текУЩйя фаза завершена, и стратегия помечает все вершины
ВолУчавшие обращений, чтобы начать новую фазу29. В этот момент
^Чеср1'1 заменяет страницу, наиболее удаленную от страницы, к которой
^Теоп обРаЩался последней.
т я графов предлагает алгоритмы для построения и просмотра гра-
ебУемые в этой стратегии. Однако вследствие больших накладных
%1ет°В 11 сложности стратегия замены дальних страниц пока что не при-
L ся в реальных системах.
662
Рис. П.6. Стратегия замены дальних страниц — граф обращений
Вопросы для самопроверки
1. Несмотря на практически оптимальный уровень производительно'
сти, стратегия замены дальних страниц не получила широкого Р
пространения. Почему?
2. В каких случаях стратегия замены дальних страниц может
нить страницу, которая скоро понадобится?
Ответы 1) Эта стратегия сложна в реализации и требует зн£
тельных накладных расходов для использования. 2) Процес вОз-
«пройти» по графу прямо к странице, которая была заменен , есл”
никнет страничный промах. Это может произойти, напри гЮ'
процесс обращается к процедурам обработки ошибок или с
следовательности вызовов вложенных процедур.
1L 7 Модель рабочих наборов
Локальность в обращениях подразумевает, что процесс может (^е,О1д0^
выполняться, даже если в оперативной памяти в данный момент
небольшая часть его страниц. Созданная Деннингом теория рабочий
в поведении программ (working set theory of program behavior) за1111 J
1(п^ольнои памятью
Г днем рабочего набора программы и размещением его в оперативной
ИП^е я достижения максимальной производительности30’ 31.
ество проведенных исследований демонстрируют существование
’’’^‘’’^локальности. На рисунке 11.7 показан график обращений процес-
инам памяти32. Затемненные области соответствуют адресам па-
^кстРй1 которым были обращения в соответствующие моменты времени.
01, к хОрОшо иллюстрирует выделение наборов страниц в каждой фазе
Прения процесса.
^^тетическое поведение процессов, показанное на рисунке 11.8, также
ГЧЙ° пользу существования локальности. На этом рисунке показана за-
^<.ТЬ частоты страничных промахов процесса от объема оперативной
s0clibI д0СТупной для размещения страниц. Прямая линия показывает эту
^я^ость Для процессов, в случайной последовательности обращающих-
завйС еМ их страницам. Кривая линия ниже показывает типичное поведе-
сй
jK^0cSCJrr?OBaTejIbHOCTb обращений к устройству хранения, проявляющая
(воспроизводится по разрешению из IBM Systems journal. © 1971
uai Business Machines Corporation)
664
ние большинства процессов. По мере уменьшения количества Ка '
тупных процессу, сначала частота страничных промахов изменяет^0®’ д’
Но при дальнейшем уменьшении количества кадров эта частота^4
резко возрастать. График показывает, что частота страничных
процесса остается постоянной, пока наиболее часто используемые*1^014^
ницы остаются в оперативной памяти. Но если система не может c*]j6
процессу достаточно кадров, чтобы разместить одновременно все
цы, то частота страничных промахов резко возрастает (поскольку СТ₽а^
постоянно обращается к недавно замененным страницам).
Часть страниц процесса, расположенных
в оперативной памяти
Рис. 11.8. Зависимость частоты страничных промахов от количества памяти,
выделенного под страницы процесса
преД^’
Принцип локальности и поведение процессов, показанное на к
щих рисунках, подтверждают теорию Деннинга33134. Эта теория ^ТВтйр^
ет, что процесс может эффективно выполняться, даже если в опер g04ilJl
памяти в данный момент находится небольшая часть его страниД^^ьС^
набор). В противном случае выполнение процесса будет сопров ^gccor
интенсивной подкачкой страниц, и уровень полезной загрузки ДР
будет оставаться небольшим. Эта интенсивная подкачка страДиД^^цЛу
ется метаниями (thrashing) и объясняется постоянными переме
нужных страниц между оперативной памятью и вторичными УсТР
ми хранения35. Один из способов предотвращения метаний — в
ц! Виртуальной памятью
процессу достаточного количества кадров для размещения поло-
о страниц. К несчастью, правила наподобие этого часто приводят
^014 еГ йе консервативному распределению памяти, и, в конце концов,
ограничивают количество процессов, которое может эффективно
Ититься в оперативной памяти.
аспределении памяти на основе рабочих наборов в оперативной
F flpH
нужно стремиться держать только страницы из рабочих наборов
ХТЙов36, 37. 38, 39 Решение добавить новый процесс к уже активным
fp°fle еличить степень мультипрограммности) принимается в зависимо-
(т.е- ^оГО, хватает ли системе оперативной памяти для размещения рабо-
ст” °Табора страниц нового процесса. Это решение — особенно для только
^запущенных процессов — обычно принимается на основе эвристиче-
чт° 3соображений, поскольку в общем случае невозможно заранее преду-
сКИ*ь размер рабочего набора процесса.
гайрисунок 11.9 иллюстрирует строгое определение понятия рабочего на-
ла (working set). Ось абсцисс соответствует времени процесса (т.е. време-
g[j в течение которого процесс выполняется процессором, а не времени по
(иастенным часам»), а значение t соответствует текущему моменту време-
ни процесса. Значение w — это размер окна рабочего набора (working set
window size), определяющее, как далеко в прошлое система должна загля-
дывать, определяя рабочий набор процесса. Рабочий набор страниц
H(t, w) — это набор страниц, к которым процесс обращался в интервале
времени от t - w до t.
। ।
I Wft - wi = {2, 6, 7, 8, 9, 10} I
Страницы, к которым процесс
обращался в этом временном
интервале, образуют рабочий
набор W(t, w)
4 ^9.
Определение рабочего набора страниц процесса
666
гч
Эффективность управления памятью с применением рабочи х
зависит от правильности выбора размера окна рабочего наб^
На рисунке 11.10 показана зависимость размера рабочего набег,
ра окна, используемого для его определения. Эта зависимость_Рда **’•
математического определения рабочего набора, и она не обязате
жает эмпирически наблюдаемые размеры рабочих наборов. «ца
рабочий набор процесса это просто набор страниц, которые доСТ°Я11М
ходиться в памяти, чтобы процесс эффективно выполнялся.
Рис. 11.10. Зависимость размера рабочего набора от размера окна
Рабочий набор изменяется в ходе выполнения программы40. Иногда
страницы добавляются или удаляются. Иногда происходят резкие измене-
ния рабочих наборов, если процесс входит в новую фазу (т.е. для дальв
шего выполнения ему нужен новый рабочий набор). Поэтому любые пре
положения о размере и составе изначального рабочего набора проЧесС°
обязательно верны для рабочих наборов, которые потребуются пр
в дальнейшем. Это затрудняет точное распределение памяти стра
рабочих наборов. еНйеМ
На рисунке 11.11 видно, как процесс, работающий под упРаВ д0Вать
стратегии распределения памяти по рабочим наборам, может испо
оперативную память. Сначала, когда процесс по очереди требует
цы, входящие в его начальный рабочий набор, система постепенно огЛу Мс'
ет ему достаточно памяти для хранения этого рабочего набора. К Я0
менту потребности процесса в оперативной памяти стабилизирУ1°^ерр^“
скольку он будет активно работать со страницами из своего
рабочего набора. Постепенно процесс перейдет ко второму рабоч ^боР
ру, как показывает кривая линия от первого ко второму рабочему^ р<гоР^
Вначале эта кривая поднимается выше, чем количество страниц
рабочем наборе, поскольку в процессе перехода происходит ин
загрузка в память новых страниц. Система не может определить,
умьно памятью
eHa рабочего набора или расширение старого. Когда процесс
дИ С рт новый рабочий набор, система обнаружит, что в пределах окна
т обращения к меньшему количеству страниц, и уменьшит вы-
^оД1яти под процесс до количества страниц в его новом рабочем на-
° каЖдом переходе между рабочими наборами растущая и спадаю-
4£ре-^₽Иая показывает адаптацию системы к новому рабочему набору.
^Р^задач распределения памяти по модели рабочих наборов — как
рв тстрее уменьшить высоту кривой до высоты следующего рабочего
длЯ этого, разумеется, нужно, чтобы система быстро определила,
я8^°Ра границы из предыдущего рабочего набора не входят в новый (если
страницы еСТЬ)*
D#Kn ' ‘ выделение оперативной памяти при распределении памяти методом
™°чих наборов
'’йза 01 РИсУНок иллюстрирует одну из сложностей, возникающих при реа-
ц ^Ии Управления памятью с помощью рабочих наборов. Рабочие набо-
1i8jbc енчивы, и следующий рабочий набор процесса может сильно отли-
д0 <>т Используемого в данный момент. Стратегия распределения памя-
8сде На Упитывать это, чтобы избежать излишнего выделения памяти,
Ие к°торого могут начаться метания. Реализация распределения
^ЧццЬ1 Мет°Дом рабочих наборов может потребовать существенных на-
t ₽асх°Д°В’ в частности, потому, что состав рабочих наборов может
Изменяться. Моррис обсуждает использование специальных аппа-
.Устройств для повышения эффективности распределения памяти
Г Рабочих наборов41.
668
Вопросы для самопроверки
1. Почему сложно определить размер рабочего набора пр0
2. Между какими требованиями нужно выдержать баланс
размера окна ш? '
Ответы 1) Если строго следовать определению, предл
Деннингом, то определить размер рабочего набора просто
чество разных страниц, к которым процесс обращался в црел Эт° Ко?у
w. Если же нас интересует размер «настоящего» рабочего н
количество страниц, которое процессу необходимо держат^ Ра, г
тивной памяти для эффективного выполнения, то задача ус В
ся. Один из признаков того, что процесс разместил в опеь0,1<ввет
памяти свой рабочий набор — низкая (или даже нулевая)158®0^
страничных промахов. Это может означать, что процесс ДещкиЧасТ()Та
ративной памяти слишком много страниц. Если мы начнем * а °Ве-
шать количество кадров страниц, выделенных процессу, то в к
момент частота страничных промахов возрастет, возможно, ре^ °®'т°
личество кадров страниц, после которого начался рост частоты п°
хов, и есть размер рабочего набора процесса. 2) Если w слишком м°Ма
то рабочий набор процесса может не весь находиться в ператвд^’
памяти, и начнутся метания. Если w слишком велико, возможен mH
расход оперативной памяти, поскольку в ней могут разместиться стоя
ницы, не входящие в рабочий набор процесса, и степень
мультипрограммности системы может уменьшиться.
11.8 Стратегия замены страниц по частоте
страничных промахов (PFF)
Один из критериев, по которым можно судить об эффективности выпол-
нения процесса в страничной среде — его частота страничных промахов.
Процесс, постоянно генерирующий страничные промахи, может находить-
ся в состоянии метаний, поскольку ему не хватает кадров страниц ДДд ₽
мещения рабочего набора в оперативной памяти. Процессу, почти со
не генерирующему страничных промахов, возможно, выделено ели
много кадров страниц, и он подавляет выполнение других процессов^^
теме (или мешает операционной системе увеличить степень м^ЛЬпрОме-
граммности). В идеале процессы должны находиться в некотором^^
жуточном состоянии между этими двумя крайностями. Алгорит рОцть
страничных промахов (page-fault-frequency — PFF) пытается К^траЦй<1
набор страниц процесса в оперативной памяти, исходя из част ы
ных промахов процесса42’ 43> 44> 45> 46. В качестве альтернативы F
настраивать набор страниц, исходя из интервалов времени мезКДУ
ными промахами — интервалов промахов (interfault time). страТеГяй-
Алгоритм PFF требует меньших накладных расходов, чем^ наСтР^
управления памятью с помощью рабочих наборов, поскольку о1^
вает набор страниц только после страничного промаха; стратег др*1
наборов должна работать при каждом обращении к памяти. Ко
пользовании алгоритма PFF обращение процесса к памяти
к страничному промаху, стратегия вычисляет интервал между Д
afibHou памятью
страничными промахами. Если этот интервал больше, чем вели-
еД^^'хнего порога, система освобождает все страницы, к которым не
дений в этом интервале времени. Если интервал меньше, чем ве-
°^аркнего порога, то требуемая страница включается в набор стра-
лесса в оперативной памяти.
ЛцИ р₽° ительная сторона PFF в том, что он настраивает набор страниц
0 оперативной памяти динамически, соответственно поведению
Сройесса Если процесс переходит на больший рабочий набор, то он будет
ироИеСса‘ерИрОВать страничные промахи, и алгоритм PFF выделит для эго-
ист0 ге сса дополнительные кадры страниц. Когда процесс накопит новый
го ПРОЙ„ набор, частота страничных промахов стабилизируется, и PFF бу-
раб°41® ерживать набор страниц в оперативной памяти постоянным или
дет n°jHT его. Ключ к эффективной и корректной работе алгоритма
выбор правильных значений порогов.
Ркоторые системы могут повышать производительность, подстраивая
- алгоритмы управления задачами под частоту страничных промахов
^^ессов. Подразумевается, что процесс, генерирующий мало страниц-
ах промахов, сформировал свой рабочий набор в оперативной памяти.
Пподессы, генерирующие много страничных промахов, еще не сформиро-
вали рабочих наборов. Обычно считается, что следует отдавать предпочте-
ние процессам, сформировавшим рабочие наборы. С другой точки зрения,
процессы с высокой частотой страничных промахов должны получать
больший приоритет, поскольку они используют процессор недолго, прежде
чем выдать запрос на ввод/вывод. Процесс, часто генерирующий странич-
ные промахи в рабочем наборе, может оказаться интенсивно использую-
щим ввод/вывод. Образовав рабочий набор, процесс придет в «нормаль-
ное» состояние стабильной работы: одни процессы интенсивно используют
процессор, другие — устройства ввода/вывода.
Вопросы для самопроверки
1. Каким образом алгоритм PFF аппроксимирует модель рабочих на-
боров?
2. Какие проблемы могут появиться при слишком маленькой величине
верхнего порога PFF? При слишком большой величине нижнего?
Ответы 1) И алгоритм PFF, и модель рабочих наборов динамиче-
ски изменяют размер пространства, выделенного процессу в оператив-
ной памяти, чтобы предотвратить метания. Однако модель рабочих
наборов выполняет подстройку после каждого обращения к памяти,
а алгоритм PFF — только после страничных промахов. 2) Если ниж-
ний порог будет слишком высоким, система выделит процессу больше
кадров страниц, чем нужно, и память будет расходоваться напрасно.
Если верхний порог будет слишком низким, система будет удалять из
памяти страницы рабочего набора процесса, и возникнут метания.
670
Г'Ч,
11. 9 ОсбобиЖдение страниц
При распределении памяти с помощью рабочих наборов прОцес
щает, какие страницы ему нужны, прямо обращаясь к этим стр ° с°0б
Страницы, которые процессу больше не нужны, должны быть удад11^
его рабочего набора. Однако при существующих стратегиях pacnpe,/ Ilbl Jj
памяти ненужные страницы часто остаются в памяти, пока страт eJletitia
сможет обнаружить, что эти страницы больше не нужны. Альтерн *₽
такой ситуации может стать отдача процессом команд добровольн TtIM
вобождения страницы (voluntary page release) для освобождения СтпГ° °с’
которые ему больше не нужны. Это устранит задержку, связанную с
ждением страницы в рабочем наборе до ее удаления стратегией расп58*0’
ления памяти. ^е-
Добровольное освобождение страниц может ускорять выполнение
грамм во всей системе. Одна из возможностей реализации добровольн₽°
освобождения страниц — обнаружение компиляторами и операционными
системами ситуаций, в которых такое освобождение возможно. Приче
эти ситуации должны обнаруживаться быстрее, чем в стратегиях рабочих
наборов. Практически, пользователь не может принимать такие решения
но системные и прикладные программисты могут.
Вопросы для самопроверки
1. Почему добровольное освобождение страниц позволит достичь бо-
лее высокой производительности, чем использование стратегии за-
мены страниц с помощью рабочих наборов?
2. Почему добровольное освобождение страниц мало распространено
в современных системах?
Ответы 1) Стратегия рабочих наборов обладает определенной ла-
тентностью (зависящей от размера окна, w), которая приводит к тощ,
что ненужные страницы «висят» в рабочих наборах до их 3ari®
Добровольное освобождение страниц позволит освобождать их
рее, и память будет использоваться более эффективно. 2)
проблема в том, что сложно точно определить, можно ли освО °нево3.
конкретную страницу. Это сложно, поскольку, как мы зна®^’ звОль-
можно точно предсказать последовательность выполнения про
ной программы.
II. 10 Размер страниц
Важная характеристика системы со страничной организацие^^о'1’
ти — размер страниц и страничных кадров, поддерживаемых с
В современных системах нет единого «промышленного стандарт^’ ра3^\-
мер страницы, и многие архитектуры поддерживают по нескольку
размеров, демонстрируя заметный прирост производительности
рая размер страницы (или размеры), проектировщик долже! У И
сколько факторов, связанных с назначением проектируемой сис
ограничениями.
дартуальной памятью
671
I чсество ранних исследований — и теоретических, и практиче-
М110 указывают, что нужны страницы малого размера48’ 49> 50. По мере
^б^емов памяти и размеров программ появляется потребность в стра-
рст8 °хоЛьшего размера. Какие соображения определяют, должна ли стра-
большой или маленькой? Несколько важных факторов перечис-
» „Я бытс
te₽** пьпюй размер страницы увеличивает область памяти, которой со-
• деТствует одна запись в TLB. Это увеличивает вероятность попада-
° га в TLB, и производительность динамической трансляции адресов
возрастает51.
В общем случае большой размер страницы может уменьшить коли-
* чество операций ввода/вывода, необходимых для перемещения стра-
ницы между оперативной памятью и вторичным устройством хране-
ния. Эти операции занимают много времени. Система, перемещаю-
щая данные маленькими блоками, может потребовать нескольких
операций ввода/вывода, вследствие чего увеличится пространствен-
но-временной показатель процесса (см. раздел 11.3). Однако предва-
рительная подкачка и (как мы обсудим в следующей главе) алгорит-
мы диспетчеризации доступа к дискам могут уменьшить значение
этого недостатка.
• Процессы часто проявляют локальность в обращениях к небольшим
участкам своих адресных пространств, и страницы меньшего размера
могут позволить процессу создать более компактный рабочий набор,
оставив больше памяти для других процессов52.
• Использование страниц малого размера приводит к росту количест-
ва страниц и кадров страниц, соответственно, растет и размер стра-
ничных таблиц. Как мы уже говорили в разделе 10.4.4, эти табли-
цы могут занять существенную часть оперативной памяти (т.е. воз-
никнет фрагментация таблиц). Использование страниц большого
размера уменьшит фрагментацию таблиц за счет уменьшения коли-
чества записей в таблицах (однако при этом возрастет внутренняя
Фрагментация).
• В смешанных сегментно-страничных системах может возникать внут-
ренняя фрагментация, поскольку процедуры и элементы данных ред-
ко занимают целые страницы, и в сегментах могут присутствовать
Как почти полностью заполненные, так и практически пустые страни-
цы (см. рис. 11.12). Поэтому каждый сегмент расходует, в среднем,
оловину страницы на внутреннюю фрагментацию. Большая фраг-
ентация приводит к большим рабочим наборам программ53. Система
Жет уменьшить внутреннюю фрагментацию, используя страницы
‘«еныпего размера54.
672
Т
Длина сегмента
Вторая
страница
сегмента
Первая
страница
сегмента
.В среднем последняя
страница сегмента
используется
'наполовину
Последняя
страница
сегмента
PlIC. 11.12. Внутренняя фрагментация в страничных и сегментных системах
Хотя поддержка нескольких размеров страниц позволяет воспользо-
ваться преимуществами страниц как большого, так и малого размера,
у нее есть и свои недостатки. Во-первых, операционным системам требует-
ся аппаратная поддержка нескольких размеров страниц для эффективной
динамической трансляции адресов. Это значит, что аппаратные устройства
трансляции страничных адресов должны поддерживать и страницы боль-
шого, и страницы малого размера. В процессоре Pentium 4 фирмы Intel это
достигается использованием нескольких TLB, каждый из которых пред®*
значен для хранения РТЕ для страниц одного размера. Растущая ся
ность аппаратуры приводит к росту ее стоимости. Кроме того, исполь
ние страниц разных размеров приводит к возможности внешней ФР^^у
тации, аналогичной фрагментации в сегментных системах, поск
блоки будут разных размеров55. азвЫ'
На рисунке 11.13 перечислены размеры страниц, используемые Р
ми системами. Обратите внимание на маленькие размеры страниц,
зовавшихся в старых моделях компьютеров, и на рост размеров еро₽
в новых моделях одновременно с появлением поддержки разных Р
страниц.
Hl 6иргпУаАЬ11ои памятью 673
оИзВ°Дитель Модель Размер(ы) страниц Размер реального адреса
Multics 1 КБ 36 бит
370/168 4 КБ 32 бита
PDP-10 и PDP-20 512 байт 36 бита
рЕс VAX 8800 512 байт 32 бит
80386 4 КБ 32 бита
intel mtel/AMD Pentium 4 / Athlon ХР 4 КБ или 4 МБ 32 или 36 бит
UltraSparc II 8 КБ, 64 КБ, 512 КБ, 4 МБ 44 бита
. «п Opteron 1 Athlon 64 4 КБ, 2 МБ и 4 МБ 32, 40 или 52 бита
дМО Itanium, Itanium 2 4 КБ, 8 КБ, 16 КБ, 64 КБ, 256 КБ, Между
intel ’г1Р 1 МБ, 4 МБ, 16 МБ, 64 МБ, 256 МБ 32 и 63 битами
IBM PowerPC 970 4 КБ, 128 КБ, 256 КБ, 512 КБ, 1 МБ, 2 МБ, 4 МБ, 8 МБ, 16 МБ, 32 МБ, 64 МБ, 1 28 МБ, 256 МБ 32 или 64 бита
foe.
11.13- Размеры страниц в разных процессорных архитектурах56- 57- 58
Вопросы для самопроверки
1. Почему в современных системах страницы большого размера пред-
почтительнее, чем десятилетия назад?
2. Каковы отрицательные стороны использования нескольких разме-
ров страниц?
Ответы 1) Память дешевеет, системы содержат все большие объе-
мы памяти и выполняют требующие все больше памяти программы.
В современных системах стоимость внутренней фрагментации из-за
большого размера страниц часто меньше, чем она была десятилетия
назад, когда память была намного дороже. Кроме того, большой раз-
мер страниц уменьшает количество операций ввода/вывода, требуе-
мых для загрузки частей виртуального адресного пространства
процесса в память. Однако есть множество случаев, в которых опера-
ционная система должна хранить данные, занимающие только часть
страницы. В этом случае поддержка страниц разных размеров позво-
лит эффективнее использовать память ценой дополнительных затрат
на ее распределение. 2) И операционная система, и аппаратное обеспе-
чение должны поддерживать страницы разных размеров, чтобы обес-
печить эффективное управление памятью. Операционные системы
приходится переписывать, чтобы они эффективно работали со страни-
цами разных размеров. Разработка новых программ дорого обходится.
Сложность процессоров, поддерживающих страницы разных разме-
ров, тоже растет, вследствие чего растет их стоимость.
674
А’
//.// Победыше программ в страничных систем 1
Поведение программ в страничных системах служило предметов
ства исследований59,60,61 62,63,64, 65,66,67, 68, 69, 70, 71,72> 73> 74- 75, 76, 7^**°^
В этом разделе мы кратко рассмотрим качественные результаты этц 80
дований. ИссЛе"
На рисунке 11.14 показан процент страниц гипотетического
к которым есть обращения — с момента начала выполнения процес ^ессв,
чальный резкий рост процента страниц показывает, что процесс ча
го обращается к значительной части своих страниц в начале выподц , Вс*'
С течением времени крутизна кривой уменьшается, и она асимптота
приближается к 100%. Безусловно, есть процессы, которые обращ eCltIi
ко всем своим страницам, но график показывает, что многие процесс®
гут долго выполняться, не делая этого. Это может быть связано, нацрцмМ°’
с наличием редко используемых процедур обработки ошибок. е₽’
Количество страничных промахов, генерируемых процессом, зависит
размера и поведения процессов системы. Если их рабочие наборы малы
количество страничных промахов будет расти с ростом размера страницы’
Это происходит потому, что с ростом размера страницы увеличивается ко-
личество ненужных процедур и данных, размещаемых в оперативной па-
мяти фиксированного размера. Кроме того, с ростом размера страницы
растет внутренняя фрагментация. Поэтому используемые данные и проце-
дуры займут меньшую часть ограниченной оперативной памяти. Процесс
с большим рабочим набором требует большего числа маленьких кадров
страниц, в результате при его выполнении будет генерироваться больше
страничных промахов. Если рабочий набор процесса включает страницы,
смежные в виртуальном адресном пространстве этого процесса, количество
страничных промахов будет падать с ростом размера страницы. Причина
Рис. 11.14. Процент страниц процесса, к которым были обращения
Виртуальной памятью
675
загрузка в память большей части рабочего набора процесса при ка
^г° Страничном промахе.
^до^ цсунке 11.15 показана зависимость среднего интервала промахов
^мени между страничными промахами) от количества кадров стра-
е- ®^ь1деленных процессу. Эта кривая постоянно растет — чем больше
® сТраниц выделено процессу, тем больше проходит времени между
(!аДр°®х1НЬ1МИ промахами (безусловно, за исключением отдельных необыч-
стр^дучаев, вроде аномалии FIFO)81. В определенной точке график резко
бается, и его крутизна резко уменьшается. Эта точка означает, что
вЗГ*1 разместил в памяти весь свой рабочий набор. Вначале интервал
ЯХОВ растет быстро, поскольку все большая часть рабочего набора раз-
пР дется в оперативной памяти. Когда выделено достаточно оперативной
яти, чтобы разместить рабочий набор процесса, кривая изгибается, по-
°а «вая, что эффект от выделения дополнительной памяти становится ме-
заметным. Задача стратегии распределения памяти — разместить
В оперативной памяти рабочий набор процесса.
В Основные выводы этого раздела в целом подтверждают справедливость
концепции рабочих наборов. По мере изменения архитектуры компьюте-
ров и программ эти результаты нужно будет проверять.
(jg It </
Зависимость
Генных процессу
интервала промахов от
количества кадров страниц,
676
г^ее
Вопросы для самопроверки
1. Как поведение программы в страничной системе поддеру
пользование позднего выделения, при котором система не ИЬает ь
процессу кадры страниц, пока процессор явно не обрати ЙЬ1;,еЛя'
вым страницам? Тс« к
2. (Да/Нет) Интервал промахов процесса всегда растет с рост
чества кадров страниц, выделенных этому процессу. т°м
Ответы 1) Из рисунка 11.14 видно, что операционная сцс
прасно затратит существенное количество ресурсов, если выделит6*43 Ча-
су память, которую он долгое время не будет использовать. Одн П^°Чес.
процесс обращается к страницам в предсказуемой последователи} ° 6CJI1’
предварительная подкачка может повысить производительность °СТй’10
шив время ожидания страниц. 2) Нет. Обычно это так, но если «. УЛ1е’!ь-
подвержен аномалии Белади, то интервал промахов может Уменьццщ^Я
U.12 Глобальная а локальная замена страниц
При оценке стратегий замены страниц, описанных в предыдущих разде
лах, мы рассматривали последовательности обращений отдельного произ
вольного процесса. В большинстве реальных случаев операционная систе
ма должна предлагать стратегию замены страниц, дающую хорошие ре
зультаты для большого количества разных процессов.
При реализации страничной системы виртуальной памяти разработчик
операционной системы должен решить, следует ли применять стратегию
замены страниц ко всем процессам в совокупности (т.е. глобально) или
рассматривать каждый процесс отдельно (т.е. локально). Глобальные стра-
тегии замены страниц обычно игнорируют характеристики поведения от-
дельных процессов; локальные стратегии замены страниц позволяют сис-
теме настраивать выделение памяти соответственно относительной важно-
сти разных процессов, чтобы повысить производительность.
Ниже мы увидим, что метод, дающий хорошие результаты, будучи прим
к отдельному процессу, может привести к низкой производительности, еслиИ
применить к системе в целом. Интуитивно убедиться в этом нельзя уу--
мер, Linux использует глобальную стратегию замены страниц, a Windows
локальную (см. раздел 20.6.3 и раздел 21.7.3, соответственно)82. ьзоваЧ
Глобальная стратегия LRU (gLRU) заменяет страницы, не исполь , э?8
шиеся дольше всего в системе в целом. Выбирая страницу для зам ^ойес-
простая стратегия не пытается анализировать поведение отдельных
сов или их относительную важность. Рассмотрим, например, систе (дЦЙ
пределяющую ресурсы процессам по круговому принципу — <^Е|тОмс'’1^
выполняемый процесс есть процесс, который дольше всего ждет. В час^
чае страницы, принадлежащие следующему выполняемому проЦе
будут оказываться реже всего использовавшимися страницами, и & 03роА
жет их заменить. Заметьте, что gLRU может проявить низкую пР
тельность независимо от поведения отдельных процессов, если с
пользует вариант кругового распределения ресурсов для процессоР-^^
Гласс и Цао предлагают глобальную стратегию замены стра
(sequence — последовательность), которая представляет собой М <
677
це Виртуальной памятью
' 1RU с внесением изменений в стратегию в зависимости от поведения
(Jo^ „83. В общем случае SEQ использует стратегию LRU для выбора
^и.есС подлежащих замене. Как упоминалось в разделе 11.6.4, LRU ра-
гр^^^лохо, если процесс выполняет циклические обращения к последо-
осТЯм страниц, которые не могут целиком разместиться в опера-
памяти. В этом случае лучше всего заменить страницу, которая ис-
^рЯ^ралась последней, поскольку к ней дольше всего не будет
ди (Д° следующего прохода по циклу). Соответственно, стратегия
сбРа1й дает, что процесс, генерирующий один за другим страничные про-
Р пи обращении к последовательно расположенным страницам, про-
Мв*11' циклическое поведение. Если обнаруживается такое поведение, то
явЛЯеНяется стратегия замены недавно использовавшихся страниц
nPlOl recently-used — MRU), оптимальная при таких последовательностях
(1110 иеНий- Если процесс генерирует страничные промахи, обращаясь
„яницам, расположенным вдалеке друг от друга, SEQ использует стра-
К иЮ LRU, пока не обнаружит новую последовательность страничных
промахов при обращениях к последовательно расположенным страницам.
/Ш Практический пример: замена страниц
6 Linux
В этом разделе мы рассмотрим стратегию замены страниц, применяе-
мую в операционной системе Linux. Дополнительную информацию об
управлении памятью в Linux можно найти в разделе 20.6. Если физиче-
ская память заполнена, и процесс или ядро запрашивают данные из стра-
ииц, которых нет в физической памяти, нужно освободить кадры страниц,
чтобы выполнить запрос. Страницы делятся на активные и неактивные.
т°бы считаться активной, страница должна была недавно получить обра-
. „Ние‘„^Дна из заДач системы управления памятью — хранить текущий
чий набор в активных страницах84.
Сй Пих использует вариацию алгоритма круговой замены, чтобы аппрок-
Мята₽°Вать стратегию замены страниц LRU (см. рис. 11.16). Диспетчер па-
j. Использует два связных списка: активный список содержит актив-
ч?НИЦЬ1’ а неактивный — неактивные. Эти списки организованы та-
^лаз0₽аЗОМ’ Что страницы, использовавшиеся позже всего, находятся
сти от головы активного списка, а использовавшиеся раньше все-
Лиз°сти от хвоста неактивного списка85.
^етсд СтРаница впервые загружается в оперативную память, она поме-
В Неактивный список и помечается как получавшая обращения —
₽Э1денин устанавливается в 1. Диспетчер памяти периодически,
ПРИ страничных промахах, проверяет, были ли новые обраще-
Ит.стРанице. Если бит обращения страницы сброшен, он устанав-
^ак и алгоритм круговой замены, этот подход гарантирует, что
^пользовавшиеся страницы не будут выбраны для замены.
неактивна и к ней поступает второе обращение (бит обра-
| °и страницы уже установлен), диспетчер памяти переносит стра-
678
ницу в голову активного списка и сбрасывает бит обращена
страницы86. Это позволяет ядру определить, было ли к странице бод
одно обращение. Если да, страница помещается в активный список ее
она не была выбрана для замены. Чтобы гарантировать, что в акт^0^
списке будут только интенсивно используемые страницы, диспетче
ти периодически переносит все страницы активного списка, к кото^ ^’’Ч-
было обращений, в голову неактивного списка.
Этот алгоритм повторяется, пока требуемое количество страниц Не
носится из хвоста активного списка в голову неактивного. Страница
активного списка будет оставаться в памяти, пока не будет выбрана ЛИЗ
мены. Однако пока страница находится в активном списке, она не м" За'
быть выбрана для замены8'. ^ет
Активный список
Хвост
Неактивный список
Голова
Голова
Освободившие'-”
страницы
Вторичное
устройство
хранения
Рис. 11.16. Механизм замены страниц в Linux
о7У
W цдв виртуальной памятью
^-рееуреы
f -£16-boulder.ibm.com/pseries/en_US/aixbman/admnconc/vmm_overview.htm
P^tjBaeT управление виртуальной памятью в AIX — операционной системе
основанной на UNIX.
$$ sn.ul.ie/~mel/projects/vm/
сывает управление виртуальной памятью в ядре Linux версии 2.4.
inform!t.com/isapi/product_id~%7B6D5ACA10-5AB0-4627-81E5-
65B9F6E080AC%7D/content/index. asp
Описывает управление виртуальной памятью в Windows 2000 для процессоров
<86 фирмы Intel.
eveloper-apple.com/documentation/mac/Memory/Memory-2.html
Описывает управление виртуальной памятью в операционной системе Apple
jlacintos11’
nisdn.microsoft.сот/library/default.asp?url=/library/en-us/appendix/hh/
appendix/enhancements5_3oc3.asp
Описывает улучшения в системе управления памятью в Windows ХР.
www. nondot.org/~sabre/os/articles/MemoryManagement/
Содержит ссылки на несколько статей, посвященных управлению памятью.
Итоги
Метод, по которому система выбирает подлежащие замене страницы, когда
оперативная память заполнена, называется стратегией замены страниц. Алго-
ритм заполнения определяет, когда страницы или сегменты загружаются в опе-
ративную память. Стратегии загрузки по требованию ожидают обращений про-
цесса к страницам или сегментам, прежде чем загружать эти страницы или сег-
м|иты. Стратегии предварйтельной загрузки пытаются по определенным
ирйнципам предугадать, к каким страницам или сегментам процесс будет вскоре
Ращаться, и загружают эти страницы или сегменты. Стратегии размещения on-
fl ляют, в какой области памяти размещаются загружаемые страницы или сег-
вЯТиЫ' ^тРаничные системы с единственным размером страницы упрощают при-
8 лшк Т„аких Решений, поскольку в них загружаемую страницу можно поместить
Тегц °И Д°стУпный кадр страницы. Сегментные системы используют те же стра-
РазмеЩения, что и мультипрограммные системы с изменяемым распреде-
памяти.
8осТ1!°СНове большинства стратегий управления памятью лежит концепция локаль-
Ь стр - т-е. склонности процессов обращаться к памяти в компактных областях.
ИЧНЬ1Х системах процессы в основном работают с небольшим количеством
’ И эти страницы часто расположены компактно в виртуальных адресных
^lo. Ствах процессов. Простейшая стратегия загрузки — загрузка по требова-
>цИп°Гда процесс начинает выполняться, в оперативную память загружается
в С его первой инструкцией. После этого другие страницы процесса загружа-
й с°ПеРативную память только в том случае, если процесс явно обращается
За рГРани1|'ам- Эта стратегия загружает требующиеся процессу страницы по од-
3’ в Результате чего часто возрастает пространственно-временной показа-
^есса’ Равный времени его выполнения (т.е. времени, в течение которого он
Память), умноженному на объем занимаемой им оперативной памяти.
680
S
При использовании стратегий предварительной загрузки операционн
ма пытается предсказать, какие страницы потребуются процессу, и зарац^Я
жает эти страницы в оперативную память при наличии в ней свободного j
ства. При проектировании стратегий предварительной загрузки нужно %
не уменьшат ли производительность системы накладные расходы на их и
вание. Стратегии предварительной загрузки по требованию загружает ст-1*0'11^
в оперативную память группами при обращении процесса к странице, кот
в оперативной памяти. Такой подход может быть эффективным, если прО11
являет пространственную локальность. Ссйра
Если процесс генерирует страничный промах, система управления
должна найти требуемую процессом страницу на вторичном устройстве хра 41,1,0
загрузить ее в кадр страницы и обновить соответствующую запись в страа
таблице. В большинстве современных архитектур поддерживаются биты иИчМ
ний в записях страничных таблиц; этот бит устанавливается в 1, если содеп»
страницы изменялось, и в О, если нет. Операционная система использует этот fi°*
чтобы быстро определять, содержимое каких страниц изменялось. За счет ч Ит’
можно улучшить производительность, избегая замены страниц с изменивши^0
содержимым — такие страницы нужно предварительно записывать (выгруЖаСя
на диск.
Оптимальная стратегия замены страниц утверждает, что для достижения одти
мальной производительности нужно заменять страницы, к которым дольше всего
не будет обращений в будущем. Оптимальность этой стратегии (она обозначается
ОРТ или MIN) можно доказать.
Стратегия замены случайных страниц (RAND) требует небольших накладных
расходов для использования и не отдает предпочтения какой-то конкретной разно-
видности процессов. При ее использовании шансы страницы быть замененной оди-
наковы для каждой из страниц. Проблема заключается в том, что может быть за-
менена страница, которая тут же потребуется процессу.
Стратегия замены страниц «первый вошел — первый вышел» (FIFO) заменяет
страницы, дольше всего находившиеся в оперативной памяти. К несчастью, эта
стратегия с большой вероятностью будет заменять интенсивно используемые стра-
ницы, поскольку причиной долгого пребывания страницы в оперативной памя
могут быть частые обращения к ней. Хотя стратегия FIFO может использоваться
с небольшими накладными расходами, она непрактична для большинства си
При ее использовании некрторые последовательности обращений к стРан ва
приводят к росту количества страничных промахов при увеличении к0Л^мЫСду
кадров страниц, выделенных процессу — это противоречащий здравому
феномен, называемый аномалией Белади или аномалией FIFO. рЬ]Ва-
Стратегия замены дольше всего не использовавшихся страниц (LRU) ос
ется на временной локальности. Эта стратегия заменяет страницу, к кото₽
ше всего не было обращений. Хотй ее использование может дать лучшие ^оЛь-
ты, чем использование стратегии FIFO, это улучшение достигается за
ших накладных расходов. К несчастью, дольше всего не исполЬ^сКц обРа
страница может оказаться следующей нужной процессу, если он цикли
щается к нескольким страницам по очереди. стр^^й-
Стратегия замены реже всего используемых страниц (LFU) заменяет^ с0о»
к которой реже всего обращается процесс. Эта стратегия основывается тсД в
ражении, что страница, к которой редко обращались, вряд ли понадо
жайшем будущем. LFU может выбрать для замены неправильную стр ^ру35^
пример, реже всего используемой может оказаться страница, последней 1
ная в оперативную память — а эту страницу любая разумная стратегий
бы оставить в оперативной памяти.
681
Виртуальной памятью________________________________________________
тегия замены давно не использовавшихся страниц (NUR) аппроксимирует
ю LRU при невысоком уровне накладных расходов, используя биты обра-
биты изменений, чтобы определить, какие страницы можно заменить бы-
вший Й го. Схемы, похожие на NUR, могут быть реализованы и на машинах, не
ВС ивающих аппаратно битов обращения и битов изменения.
1р>Р*ВЙДность алгоритма FIFO, называемая стратегией «второго шанса», прове-
tps3,! обращений страницы, дольше всего находящейся в оперативной памяти.
оЯеТ Кг бит сброшен, то эта страница выбирается для замены. Если бит установ-
ил# он сбрасывается, и страница перемещается в хвост очереди FIFO. Это гаран-
те, т° чТ0 активные страницы будут заменяться с минимальной вероятностью.
f)ipyeT’ разновидность алгоритма «второго шанса» организует страницы в цикли-
КрУг°Га не линейный список. Когда бит обращения страницы сбрасывается, указа-
чес#01’’ мещается на следующий элемент списка (имитируя перемещение страни-
теЛЬ хв°ст очеРеДи FIFO). Использование алгоритмов «второго шанса» и круговой
яь1 в дает практически одинаковые результаты.
^Стратегия замены дальних страниц создает граф обращений, описывающий
дедовательности обращений процесса к памяти. Алгоритм выбирает для за-
в°с страницу, дальше всего отстоящую в графе от страниц, к которым были
^-ятдения. Хотя эта стратегия работает с эффективностью, близкой к опти-
°адьвой, она не используется в реальных системах, поскольку поиск в графе об-
ращений сложен, и этот граф трудно создавать и обслуживать без аппаратной
поддержки.
Предложенная Деннингом теория рабочих наборов в поведении программ ут-
верждает, что для эффективного выполнения программы система должна хранить
в оперативной памяти набор чаще всего требующихся процессу страниц — его ра-
бочий набор. В противном случае система может страдать от избыточных операций
подкачки, снижающих полезную загрузку процессора. Эти избыточные операции
подкачки называются метаниями — они связаны с постоянными перемещениями
часто требуемых страниц между оперативной памятью и вторичными устройства-
ми хранения. Стратегии управления памятью, на основе рабочих наборов стремят-
ся разместить в оперативной памяти только страницы, входящие в рабочий набор
процесса. Решение о добавлении нового процесса к активному набору процессов
Должно приниматься в зависимости от того, достаточно ли свободного места в опе-
ративной памяти, чтобы разместить рабочий набор этого процесса. Размер окна ра-
чего набора определяет, как далеко в прошлое система должна заглядывать, оп-
Деляя рабочий набор процесса. Одна из сложностей при создании стратегий
и 5?Вления памятью на основе рабочих наборов — изменчивость рабочих наборов
Роятность резких различий между текущим рабочим набором процесса и сле-
чу1°Щим.
ДабоЛГО₽И™ замены страниц по частоте страничных промахов (PFF) подстраивает
^ац СТРан11й процесса в оперативной памяти, исходя из частоты возникновения
ачных промахов при выполнении процесса. Кроме того, PFF может подстраи-
стРаниц, исходя из интервала времени между страничными промахами.
-Ч ppj,ri^ecTBO PFF перед стратегией рабочих наборов — меньшие накладные расхо-
^Чог ПодстРаивает набор страниц в оперативной памяти при возникновении стра-
не г 0 промаха, а механизм рабочих наборов должен обрабатывать каждое обраще-
г амяти- Если процесс переключается на больший рабочий набор, то он будет
®еРиРОвать страничные промахи, и PFF выделит ему дополнительные кадры
' К°гДа процесс сформирует новый рабочий набор, частота его страничных
стабилизируется, и PFF будет либо поддерживать набор страниц в опера-
РадПаМяти неизменным, либо уменьшит его. Ключом к правильной и эффектив-
Те PFF является выбор правильных величин порогов.
682
h
Во всех стратегиях управления памятью ненужные страницы могут ост
в оперативной памяти, пока стратегии не обнаружат, что эти страницы ст '
нужными и не заменят их — на это может потребоваться немало времени
способов решения этой проблемы — добровольное освобождение процессом
цы, чтобы освободить кадр страницы, который ему больше не нужен. При
чезнет задержка, связанная с постепенным вытеснением страницы из рабоч^14 Ц:
бора процесса. Основные надежды здесь связаны с возможностью встря 6Г° Ч
в компиляторы систем обнаружения ситуаций, в которых какие-то странит
новятся ненужными. Эти системы должны работать намного быстрее, чем см
образования рабочих наборов процессов. CTeMi|
Важная характеристика страничной системы виртуальной памяти___
страниц и кадров страниц, поддерживаемый этой системой. Производитель
некоторых систем и эффективность использования памяти в них повышаю- СТь
счет поддержки нескольких разных размеров страниц. Страницам маленького 5'За
мера свойственна меньшая внутренняя фрагментация, и для хранения в них ₽аз'
чего набора процесса может потребоваться меньший объем оперативной пагл °"
При этом для других процессов останется больше свободной памяти. Страни 1
большого размера уменьшают потери памяти вследствие фрагментации табл»11
позволяют каждой записи в TLB относиться к большей области памяти и уменьцщ
ют количество операций ввода/вывода, необходимых для загрузки в память pagn.
чего набора процесса. Использование нескольких размеров страниц требует как
программной, так и аппаратной поддержки, которые могут оказаться дорогими
в реализации. Кроме того, использование страниц разных размеров может привес-
ти к внешней фрагментации.
Процессы чаще всего обращаются к некоторой части своих страниц в начале ра-
боты, а затем обращаются к оставшимся страницам (к большей их части) в течение
остального времени. Средний интервал промахов (т.е. промежуток времени между
страничными промахами) в целом увеличивается — чем больше кадров страниц
выделено процессу, тем больше интервалы промахов (безусловно, за исключением
ряда случаев вроде аномалии FIFO).
При реализации страничной виртуальной памяти разработчик операционной
системы должен решить, будут ли в его системе использоваться глобальная страте-
гия замены страниц, рассматривающая все процессы сразу, или локальная, рас-
сматривающая каждый процесс по отдельности. Глобальные стратегии замены
страниц игнорируют характеристики и поведение отдельных процессов; локаль-
ные стратегии позволяют системе регулировать распределение памяти соответст-
венно относительной важности каждого процесса, чтобы повысить производитель
ность. Глобальная стратегия LRU (gLRU) заменяет дольше всего не использо
шуюся страницу в системе в целом. Глобальная стратегия SEQ испольэу
стратегию LRU, чтобы заменять страницы, если не обнаруживает последов
ностей страничных промахов при обращении к последовательно расположен
страницам — в этом случае она использует стратегию замены позже всего и
зовавшихся страниц (MRU).
~6S3
r m/в Виртуальной памятью_
$ ifl
^чеЗые термины
я FIFO (FIFO anomaly) — явление в стратегии замены страниц FIFO, за-
^щееся в росте числа страничных промахов процесса при увеличении ко-
*Hf'JII°4TBa выделенных этому процессу кадров страниц; обычно число странич-
Лй<1ес р°махов падает при увеличении количества доступных кадров.
йЬ1Х я Белади — см. аномалия FIFO.
Дв0” меиения (modified bit или dirty bit) — поле в записи страничной таблицы,
gH* ^чение которого указывает, изменялось ли содержимое страницы. Если этот
зра „таНовлен, то перед заменой этой страницы на новую ее содержимое нужно
®яТиИровать на вторичное устройство хранения.
С1^5оаЩения (accessed bit или referenced bit) — поле в записи страничной табли-
₽йТ значение которого указывает, были ли недавно обращения к странице. Не-
Илторые стратегии периодически сбрасывают этот бит, чтобы точнее опреде-
лять, как давно к странице были обращения.
Пппвовольное освобождение страницы (voluntary page release) — принудительное
освобождение процессом кадра страницы, который ему больше не нужен. По-
зволяет улучшить производительность за счет уменьшения количества неис-
пользуемых кадров, выделенных процессу, и увеличения объема доступной па-
мяти.
Интервал промахов (interfault time) — время, проходящее между двумя странич-
ными промахами процесса. Оно используется в стратегии замены страниц, осно-
ванной на частоте страничных промахов, чтобы определить, увеличивать или
уменьшать выделение кадров страниц для процесса.
Круговая стратегия замены страниц (clock page-replacement strategy) — разно-
видность стратегии замены страниц «второго шанса», которая организует
страницы в циклический, а не линейный список. Указатель списка перемеща-
ется по списку, как стрелка по циферблату часов, и заменяется ближайшая
к нему страница, бит обращения которой сброшен.
Метания (thrashing) — избыточная активность системы подкачки, сопровождаю-
щаяся низкой загрузкой процессора, возникающая, когда объем выделенной
процессу памяти меньше объема рабочего набора этого процесса. Это явление
приводит к низкой производительности, поскольку большую часть времени
процесс ждет загрузки нужных ему страниц.
Имальная стратегия замены страниц (ОРТ page-replacement strategy) — не-
реализуемая стратегия замены страниц, заменяющая страницу, которая доль-
е Всего не будет использоваться в будущем. Как показывают исследования, эта
п ₽атегия будет оптимальной.
ь Чка по требованию (demand paging) — метод подкачки, при котором стра-
с 3агРУжаются в оперативную память, только когда процесс явно обращает-
Г[р 4 к ним.
цетаРИтельная подкачка (anticipatory paging, prepaging или prefetching) —
рОи°,а'’ загружающий в оперативную память страницы процесса, к которым ве-
',1ы обращения в ближайшем будущем. Стратегии предварительной под-
И^ессо ПЬ1таются уменьшить количество страничных промахов при работе про-
684
Пространственная локальность (spatial locality) — эмпирическое свойст
рое в системах подкачки проявляется в том, что процесс в основном °’
с некоторой частью своих страниц, размещенных поблизости друг
(компактно) в виртуальном адресном пространстве процесса. Проц(.с°Т
редно обращающийся к элементам массива, проявляет пространстве ’ П°°Ч?
кальность. НаУЮ
^0
Пространственно-временной показатель (space-time product) — значение
произведению времени выполнения процесса (т.е. его нахождения в 0 ' РавДо«
ной памяти) и объема оперативной памяти, занятого этим процессом. веРат«й.
стратегии распределения памяти должны уменьшать этот показатель t
высить степень мультипрограммности системы. bbl по.
Рабочий набор (working set) — набор часто используемых процессом
в оперативной памяти. Если окно рабочего набора — и>, то рабочий набг РаВиЧ
ниц процесса W(t, w) есть набор страниц, к которым он обращается за ии СТ®а"
времени от t - w до t. ₽Вал
Размер окна рабочего набора (working set window size) — значение, определяю
насколько продолжительный интервал времени система должна принимать66’
внимание, определяя, какие страницы входят в рабочий набор процесса. 8°
Резидентный набор страниц (resident page set) — набор страниц процесса, в дан
ный момент находящихся в оперативной памяти; к этим страницам процесс мо
жет обращаться без Возникновения страничных промахов. Размер этого набора
может отличаться от размера рабочего набора процесса — набора страниц, кето-
рые должны находиться в оперативной памяти для эффективной работы про-
цесса.
Сброс страницы (flushing a page) — копирование содержимого измененной стра-
ницы на вторичное устройство хранения, чтобы поместить в кадр этой страницы
Другую страницу. При сбросе страницы сбрасывается бит изменения этой стра-
ницы, что позволяет операционной системе быстро определить, что поверх стра-
ницы можно записать другую страницу. За счет этого уменьшаются интервалы
ожидания страниц.
Стратегия замены дальних страниц (far page-replacement strategy) — использую-
щая графы стратегия замены страниц, анализирующая последовательность о -
ращений процесса к памяти, чтобы определить, какие страницы нужно заме
нять. Эта стратегия заменяет страницу, к которой не было обращений, и наи
лее удаленную от других страниц в графе, к которым были обращения.
Стратегия замены страниц (page-replacement strategy) — стратегия, опРед^^о
щая, какие страницы убирать из оперативной памяти, чтобы освободить
для требуемых в данный момент. Стратегии замены страниц пытаются о.
зировать производительность за счет предугадывания дальнейшего исполь
ния страниц. За-
Стратегия замены страниц FIFO (FIFO page-replacement strategy) — CTPa
мены страниц, заменяющая страницу, которая дольше всего находилась^^^
ти. Эта стратегия связана с низкими накладными расходами, но обычно
предсказывает будущие обращения к страницам.
Стратегия замены страниц gLRU (gLRU page-replacement strategy) rJ °06paJlie.
стратегия замены страниц, заменяющая страницу, к которой не былоеКтИ₽^
ний дольше всего во всей системе. LRU может обладать низкой эф
стью, поскольку варианты циклического поведения системы могутсТрат®^г
к вызовам страниц, которые давно не вызывались. Вариант SE4
gLRU пытается улучшить эффективность, заменяя страницы, к кот
цесс обращался недавно, если обнаруживает цикличность в пос ледова
обращений.
^gliue виртуальной памятью
гЯЯ замены страниц LFU (LFU page-replacement strategy) — стратегия за-
страниц, заменяющая страницу, которая реже всего используется или
b ^^торой реже всего обращается процесс. Эта стратегия проста в реализации,
К K°gbi4HO плохо предсказывает будущие обращения к страницам.
Й° сия замены страниц LRU (LRU page-replacement strategy) — стратегия за-
СТРаТе, страниц, заменяющая страницу, к которой дольше всего не обращался
МеВ Эта стратегия обычно хорошо предсказывает будущие обращения
И?^раницам, но она связана со значительными накладными расходами.
в гия замены страниц NUR (NUR page-replacement strategy) — аппроксима-
СТРаТ сТратегии замены страниц LRU, требующая меньших накладных расходов
J использовании. Эта стратегия использует биты изменения и биты обраще-
Для выбора подлежащих замене страниц. Сначала стратегия NUR пытается
8 менить страницу, к которой недавно не было обращений и содержимое кото-
не изменялось. Если таких страниц нет, стратегия заменяет изменявшиеся
^гоаницы, к которым недавно не было обращений, чистую страницу, к которой
недавно были обращения, или страницу, к которой недавно были обращения —
в перечисленном порядке.
фратегия замены страниц PFF (PFF page-replacement strategy) — алгоритм, под-
страивающий набор хранящихся в памяти страниц процесса, исходя из частоты
страничных промахов этого процесса. Если процесс переходит на больший рабо-
чий набор, промахи появляются часто, и PFF выделит дополнительные кадры
страниц. Когда процесс накопит новый рабочий набор, частота страничных про-
махов стабилизируется, и PFF будет поддерживать количество страничных кад-
ров неизменным или уменьшит его. Ключ к эффективной и корректной работе
PFF — правильный выбор пороговых значений. •
Стратегия замены страниц RAND (RAND page-replacement strategy) — стратегия
замены страниц, заменяющая страницы в случайном порядке с равной вероят-
ностью. Хотя эта стратегия показывает стабильные результаты и требует незна-
чительных накладных расходов, она не пытается предвидеть будущие обраще-
ния к страницам.
Стратегия замены страниц «второго шанса» (second-chance page-replacement
strategy) — стратегия замены страниц, использующая бит обращения и очередь
FIFO для выбора подлежащей замене страницы. Если бит обращения самой ста-
рой страницы сброшен, стратегия заменяет эту страницу; в противном случае
бит обращения этой страницы сбрасывается и она помещается в конец очереди
flFO. Если бит обращения установлен, стратегия сбрасывает его и проверяет
следующую страницу или страницы, пока не находит страницу, бит обращения
которой сброшен.
РИя рабочих наборов (working set theory of program behavior) — предложенная
Меннингом теория, утверждающая, что для эффективного выполнения про-
Рэммы система должна хранить в оперативной памяти набор избранных стра-
Ч (т.е. рабочий набор). Если окно рабочего набора — w, то рабочий набор стра-
Е в Ч Процесса VF(t, и>) есть набор страниц, к которым он обращается за интервал
уПт>М<:ни от t ~ w Д° *• Выбор размера окна, w, критически важен при реализации
Руления памятью с помощью рабочих наборов.
686
Упразднения
ил.
11.2.
11.3.
в.
защищенности,
Объясните задачи каждой из следующих стратегий управления
в контексте страничных виртуальных систем:
а. стратегия загрузки страниц,
б. стратегия размещения страниц,
стратегия замены страниц.
Объясните, почему управление памятью в сегментных системах
с управлением памятью в мультипрограммных системах с изменя^03*1®
распределением памяти.
Некоторая компьютерная система поддерживает виртуальную п
с сегментно-страничной организацией. Степень мультипрограммност МЯТь
темы равна 10. Страницы инструкций (многократно вызываемый Кол\ СИС'
мещаются отдельно от страниц данных (данные могут изменяться). Вы
чили систему в работе и заметили следующее: (1) большинство сегменЗУ*
процедур состоят из множества страниц, и (2) большинство сегментов
ных используют только небольшую часть страницы.
Ваш коллега предложил для лучшего использования памяти объединить
несколько сегментов данных в отдельную страницу. Прокомментируйте это
предложение, учитывая соображения:
а. эффективности использования памяти,
б. эффективности исполнения программы,
в.
г. разделения доступа.
11.4. Сейчас проявляется большой интерес к предварительной подкачке и пред-
варительному выделению ресурсов в целом. Какую полезную информацию
механизм предварительной подкачки может получить от:
а. программистов,
б. компилятора,
в. операционной системы,
г. протокола предыдущих выполнений программы.
11.5. Известно, что в общем случае мы не можем предсказать последователь-
ность выполнения произвольной программы. Если бы мы могли это делать,
мы бы решили проблему остановки, которая, как известно, неразрешим •
Объясните последствия этой ситуации с точки зрения механизмов предва
рительного выделения ресурсов.
ll-б. Предположим, что диспетчер памяти должен решить, какую из двух
ниц заменить. Предположим, что одна из этих страниц совместно ис
зуется несколькими процессами, а вторая используется только однИМсТра-
цессом. Должен ли диспетчер памяти всегда заменять неразделенную
ницу? Аргументируйте свой ответ. сЛе0'
11.7. Обсудите несколько перечисленных ниже необычных (если не бессМ1^^#-
ных) стратегий замены страниц с точки зрения системы виртуальной
ти, обслуживающей как пакетные, так и интерактивные процессы-
«Глобальная LIFO» — заменяется страница, последней загрУ
в память.
«Локальная LIFO» — заменяется страница, последней загру
в память для процесса, который требует загрузить новую стран боЛ6’
«Усталая страница» — заменяется страница, к которой поступ
ше всего обращений.
б.
в.
337
Виртуальной памятью
'ff(S
, «Побитая страница» — заменяется страница, содержимое которой чаще
' всего изменялось. Один из вариантов этой стратегии должен вести под-
счет операций записи в странице. Второй вариант должен учитывать
процент содержимого страницы, подвергшегося изменению.
Предположим, что диспетчер памяти решает, какие страницы заменять,
0.^- включительно па основании проверок значений битов изменения и битов
обращения в кадрах страниц. Опишите несколько ситуаций, в которых
диспетчер примет неправильные решения.
Перечислите несколько причин, по которым необходимо предотвращать
удаление некоторых страниц из оперативной памяти.
Почему обычно желательно заменять страницы, содержимое которых не
1’1' и3менялось, а не страницы с изменявшимся содержимым? В каких обстоя-
тельствах может быть полезнее замена изменившихся страниц?.
11 Для каждой из приведенных ниже пар стратегий замены страниц опишите
11’1 ситуации, в которых обе стратегии выберут для замены (1) те же страницы,
(2) разные страницы.
a. LRU, NUR;
б. LRU, LFU;
в. LRU, FIFO;
г. NUR, LFU;
д. LFU, FIFO;
е. NUR, FIFO.
11.12.
11.13.
>1.14.
П.15.
>1.16.
>1.17
1,-18.
%.
Оптимальная (MIN) стратегия замены страниц в общем случае нереализуе-
ма, поскольку предвидеть будущее невозможно. Однако есть ситуации,
в которых такую стратегию можно реализовать. Что это за ситуации?
Предположим, что диспетчер памяти выбрал измененную страницу для за-
мены. Страница должна быть перенесена на вторичное устройство хране-
ния, прежде чем в ее кадр может быть помещена новая страница. Поэтому
диспетчер памяти запрашивает операцию ввода/вывода для записи страни-
цы. В список операций ввода/вывода, ожидающих выполнения, вносится
запись о запрошенной операции. Страница будет оставаться в оперативной
памяти, пока эта операция не будет выполнена. А теперь представьте, что
при выполнении других запросов ввода/вывода работающий процесс потре-
бует заменить страницу. Как должен отреагировать диспетчер памяти?
Разработайте эксперимент, который продемонстрирует феномены времен-
ной и пространственной локальности в страничной системе.
Программист, пишущий программу так, чтобы она проявляла локаль-
ность, может ожидать заметного роста эффективности ее выполнения. Пе-
речислите несколько стратегий, которые программист может применить,
чтобы улучшить локальность. Какие конструкции языков высокого уровня
стоит применять в такой программе?
Представьте, что шина между оперативной памятью и вторичным устрой-
ством хранения сильно нагружена передачей страниц. Означает ли это по-
явление метаний? Аргументируйте свой ответ.
Почему глобальная стратегия замены страниц (в которой новая страница
Может заменять страницу любого процесса) может быть более чувствитель-
ной к метаниям, чем локальная (в которой новая страница может заменять
только страницу процесса, запросившего ее загрузку)?
Обсудите плюсы и минусы выделения каждому процессу большего количе-
ства кадров, чем необходимо ему (чтобы предотвратить метания) и возни-
кающей в результате фрагментации оперативной памяти.
Предложите эвристический критерий, который диспетчер памяти может
Применить, чтобы определить, не перегружена ли оперативная память.
11.21.
11.22.
11.23.
11.24,
11.25.
11.20. Рабочий набор процесса можно определить несколькими способам
дите преимущества и недостатки следующих способов определен '
ниц, образующих рабочий набор процесса: Ия с^’
а. Страницы, к которым процесс обращался за последние w секун I
ни настенных часов. ' д
б. Страницы, к которым процесс обращался за последние w секун
ального времени (т.е. времени, в течение которого процесс вып
процессором). ‘ ЛНзй1сй
в. Последние k различных страниц, к которым обращался процеССо
г. Страницы, содержавшие г последних инструкций или элементе^'
ных, к которым обратился процесс. в Дэд.
д. Страницы, к которым процесс обращался за последние w секунд в
ального времени с частотой более f раз в секунду. ВиРту.
Приведите пример обстоятельств, в которых стратегия замены страпи
бочего набора должна заменить: 4 ₽а-
а. лучшую возможную страницу,
б. худшую возможную страницу.
Одна из сложностей реализации стратегии управления памятью с помощь
рабочих наборов состоит в том, что если процесс запрашивает новую стра
ницу, сложно определить, переходит он к новому рабочему набору или рас-
ширяет свой текущий рабочий набор. В первом случае лучше будет, если
диспетчер памяти заменит одну из страниц процесса; во втором лучше бу-
дет выделить для процесса дополнительные кадры страниц. Как диспетчер
памяти может решить, что нужно делать?
Предположим, что все активные процессы образовали в памяти свои рабо-
чие наборы. По мере изменения локальностей рабочие наборы могут расти,
и оперативная память может оказаться переполненной, вследствие чего
начнутся метания. Обсудите преимущества и недостатки следующих стра-
тегий предотвращения подобных ситуаций:
а. Не запускать новый процесс, если оперативная память заполнена на
80% и более.
6. Не запускать новый процесс, если оперативная память заполнена на
97% и более.
в. При запуске нового процесса назначить ему максимальный размер рабо-
чего набора и не разрешать ему превысить этот размер.
Взаимодействие между различными компонентами операционной системы
критично для достижения высокой производительности. Обсудите взаимо_
действие между диспетчером памяти и инициатором задач (т.е. планиров
щиком) в мультипрограммной системе с виртуальной памятью. В час
сти, предположите, что диспетчер памяти использует методику рабочих
боров. а.
Представьте себе описанный ниже эксперимент и объясните результаты
блюдений: „ Вывел-
Процесс выполняется независимо на машине со страничной системой-
нение процесса начинается с первой страницы. В ходе его выполнений ‘ gcT_
страницы загружаются по требованию в доступные кадры страниц-
во доступных кадров намного превышает количество страниц процесс0^^#-
ко в системе есть переключатель, позволяющий человеку установить
мальное количество кадров, которое процесс может использовать. о.п
Изначально переключатель установлен на два кадра, и программ0 ь.адр0’
няется до завершения. Затем переключатель устанавливается на три
и программа снова выполняется до завершения. Этот процесс повт ор
пока переключатель не будет установлен в положение, соответст
памятью
Обу
сему количеству кадров в оперативной памяти, и процесс выполнится
последний раз. При каждом выполнении процесса замеряется время, не-
обходимое для его завершения.
наблюдении*
При переключении с двух страниц на три, а затем с трех на четыре время
авершения процесса резко сокращается. При переключениях от четырех
3 шести страниц это время продолжает сокращаться, но не так заметно.
£[ри семи страницах и более время выполнения остается практически неиз-
менным.
разработчик операционной системы предложил стратегию управления па-
мятью PD, работающую следующим образом. Каждому активному процес-
су выделяется ровно по два кадра страниц. В этих кадрах находятся стра-
нИца процедур, к которой последней обращался процесс (Р-страница),
и страница данных, к которой последней обращался процесс (D-страница).
Когда происходит страничный промах при обращении к странице проце-
дур, стратегия заменяет P-страницу, а бели — при обращении к странице
данных, стратегия заменяет D-страницу.
Разработчик утверждает, что преимущество этой системы в упрощении
всех процедур управления памятью и низких накладных расходах.
Ц>
а. Как при таком подходе должны реализоваться следующие стратегии:
1) стратегия загрузки страниц,
2) стратегия размещения страниц,
3) стратегия замены страниц.
6. В каких ситуациях стратегия PD даст лучший результат, чем управле-
ние памятью с помощью рабочих наборов?
в В каких ситуациях стратегия PD приведет к низкой производительности?
11.27. Сделайте обзор аргументов за и против (1) страниц малого размера и (2)
страниц большого размера.
11.28. Изначально система Multics должна была поддерживать страницы из 64 слов
и 1024 слов (позднее схема с двумя размерами страниц была отброшена),
а Как вы думаете, какие факторы определили такое решение разработчиков?
б. Какое воздействие окажет подход с двумя размерами страниц на страте-
гии управления памятью?
В Обсудите применение следующих аппаратных устройств в системах вирту-
альной памяти:
а. механизм динамического отображения адресов,
б. ассоциативная память,
в. кэш-память,
г- бит обращения к странице,
Д бит изменения страницы,
е- бит перемещения страницы (этот бит указывает, что страница в данный
момент перемещается в кадр страницы).
Если программы в страничных системах аккуратно написаны и обращения
к памяти локализованы в небольшое количество страниц, то рост произво-
дительности может быть впечатляющим. Большая часть современных про-
грамм пишется на языках высокого уровня, и программисты обычно не
имеют доступа ко всей информации, которая нужна для хорошей организа-
ции программ. Поскольку последовательности выполнения программ пре-
ДУгадать нельзя, сложно заранее предвидеть, какие части кода будут ин-
тенсивно использоваться.
Дна из потенциальных возможностей улучшения организации программ
Связана с динамической реструктуризацией программ. Этот способ требует,
чтобы операционная система отслеживала характеристики выполнения
690
Ч„
11.31.
11.32.
J 1.33.
11.34.
11.35.
11.36.
11.37.
программы и переупорядочивала код и данные так, чтобы более а
элементы располагались рядом на страницах. ^Т11Ч
а. Какие характеристики исполнения больших программ нужно 1
вать, чтобы выполнять их динамическую реструктуризацию? °TcjlejJt
б. Как механизм динамической реструктуризации может прим) И
ченную информацию, чтобы принимать эффективные решенцЯГЬ D°Ji-
руктуризации? я 0
Ключ к эффективной и корректной работе стратегии замен
PFF — правильный выбор пороговых значений. Ответьте на прИ8СТ₽айНц
ниже вопросы: Деввые
а. Каковы последствия выбора слишком большого верхнего значе
б Каковы последствия выбора слишком маленького нижнего зна ”
з. Должны ли значения быть фиксированными, или они должнь
страиваться динамически? с°д-
г. Какие критерии вы бы применили для динамической подстройки значе
Сравните стратегию замены страниц PFF со стратегией замены стран
пользующей рабочие наборы. Примите во внимание следующие моментьИС
а накладные расходы на использование стратегий;
б. затраты памяти на хранение данных, требуемых для использован
стратегий.
Потенциально слабое место стратегии замены страниц «второго шанса» с
стоит в том, что если список страниц короток, активная страница, только
что переместившаяся в конец списка после сброса ее бита обращения, мо-
жет быстро оказаться в начале списка и быть заменена, прежде чем ее бит
обращения будет снова установлен. Прокомментируйте это явление. Явля-
ется ли оно аномальным для этой стратегии замены страниц? Тщательно
аргументируйте свой ответ.
Предположим, что в данный момент метаний в системе нет. Перечислите
столько, сколько сможете факторов, которые могут привести к появлению
метаний. Какие меры должна предпринять операционная система при об-
наружении метаний? Могут ли метания быть вообще предотвращены? Если
да, то какой ценой? Если нет, объясните, почему.
Система получает обращения к страницам в следующей последовательно-
сти: 1, 1, 3, 5, 2, 2, 6, 8, 7, 6, 2, 1, 5, 5, 5, 1, 4, 9, 7, 7. У системы есть пл»
кадров страниц. Если все кадры изначально пусты, подсчитайте количест
во страничных промахов при использовании каждого из перечислен
ниже алгоритмов:
a. FIFO,
б. LRU,
в. «второго шанса»,
г. ОРТ. лчнь>х
Нужно ли штрафовать процесс, генерирующий множество стр
промахов? Ппомах0®п
Представьте себе процесс, генерирующий много страничных .гакоГс
Опишите эффект, если таковой будет, от увеличения приоритета
процесса.
f $ fitfpfflya/IDNOU ttU/VWIHDIU
НекотОРь1е типы процессов проявляют высокую производительность в со-
4 С^ации с одними стратегиями замены страниц и низкую — в сочетании
пугими. Обсудите возможность создания диспетчера памяти, который
с^дамически определял бы тип процесса и выбирал бы оптимальную для
0 стратегию замены страниц.
„„положим, что вы знаете, какая стратегия замены страниц использует-
40- 1 в МНОГОпользовательской системе с разделением времени, в которой вы
СЯ0Отаете. Для каждой из рассмотренных в этой книге стратегий, какие
Р0иемы вы бы применили, чтобы заставить эту стратегию предпочитать
вагпи процессы другим, если обычно операционная система должна посту-
рать по-другому? Какие меры операционная система может предпринять,
чтобы обнаружить такие процессы и предотвратить получение ими преиму-
ществ? Подготовьте доклад о вашем решении.
Подготовьте статью, описывающую поддержку трех разных размеров стра-
П-* нин в процессоре Pentium 4 фирмы Intel. Как процессор выбирает, какой
размер страниц использовать? Кроме того, есть ли какое-либо взаимодейст-
вие между TLB?
И 41 Подготовьте статью об аппаратной поддержке модели рабочих наборов.
рекомендуемые исследовательские проекты
11.42. Создайте программу моделирования, которая позволит сравнивать работу
стратегий замены страниц, описанных в этой главе. Ваша программа долж-
на учитывать переходы между страницами в виртуальном адресном про-
странстве, но не выполнение отдельных инструкций программ. Назначьте
не равную единице, но высокую вероятность того, что следующая инструк-
ция находится на той же странице, что и исполняемая сейчас. Когда проис-
ходит переход между страницами, вероятность перехода на следующую
(или предыдущую) страницу в виртуальном адресном пространстве должна
быть больше, чем вероятность перехода на далеко расположенную страни-
цу. Предположите, что уровень загрузки системы средний, и решения о за-
мене страниц принимаются довольно часто. Предположите, что для всех
процессов в моделируемой системе в течение всего времени моделирования
применяется одна и та же стратегия замены страниц. Программа моделиро-
вания должна собирать статистические данные о результатах работы стра-
тегий замены страниц. Предусмотрите возможности тонкой настройки про-
граммы; например, необходима возможность изменять размер окна рабоче-
го набора, пороговые значения частот страничных промахов и так далее.
Когда программа моделирования будет готова, разработайте новую страте-
143 ГИЮ замены страниц и сравните ее с описанными в книге.
Создайте программу- моделирования, чтобы изучить влияние изменения
количества страниц, выделенных для процесса, на количество генерируе-
мых им страничных промахов. Используйте последовательности обраще-
»ий, имитирующие пространственную локальность для больших и малых
°бластей и временную локальность для больших и малых интервалов вре-
мени. Проведите также моделирование для случайных последовательно-
сти обращений. Укажите оптимальный алгоритм замены страниц для ка-
ждой из последовательностей. Возможно, вам также захочется исследовать
Ффект мультипрограммности — чередование различных последовательно-
стей обращений.
692
11 .44. Создайте программу, моделирующую стратегию замены страниц р», ’I
определенной последовательности обращений. Определите резуЛь* л,
хранения пороговых значений от предыдущих исполнений прогр;,.,'^ с
пользуйте последовательности обращений, имитирующие просто А,Ь1, И
ную локальность для больших и малых областей и временную лов Э
для больших и малых интервалов времени. Проведите также мод1
ние для случайных последовательностей обращений. Укажите он-
ный алгоритм замены страниц для каждой из последовательное-!
шите программу моделирования так, чтобы она автоматически Поде-
ла значения порогов соответственно последовательностям обпи^1*^-
которые она получает.
11 .45. Создайте программу, сравнивающую стратегию замены страцИ1
и стратегию замены страниц с использованием рабочих наборов дЛя о
ленной последовательности обращений. Определите результаты со
ния пороговых значений для стратегии PFF и размера окна для страт
рабочих наборов от предыдущих исполнений программы. ИспользуйТеГ,1а
следовательности обращений, имитирующие пространственную док
ность для больших и малых областей и временную локальность для бп 1
ших и малых интервалов времени. Проведите также моделирование
случайных последовательностей обращений. Опишите оптимальный алго
ритм замены страниц для каждой из последовательностей.
Рекомендуемая литература
Из-за широкого применения в операционных системах управление виртуаль-
ной памятью — обширная область со множеством публикаций. Основополагающие
работы, например, рассмотрение Деннингом модели рабочих наборов88 и его обзор
концепций виртуальной памяти89 дают хорошее описание основных задач управ-
ления виртуальной памятью, большая часть которых актуальна по сей день. Стра-
тегии загрузки страниц обсуждались Ахо и его сотрудниками90 и в дальнейшем
анализировались Капланом с коллегами91. - Я
Оптимальная замена страниц обсуждалась Белади92, обнаружившим аномал№
FIFO93. Простые алгоритмы, такие, как FIFO и приближения LRU, могут быть
тями некоторых механизмов управления памятью, обычно они не использ}
в чистом виде. В литературе предлагались более замысловатые алгоритмы с и
зованием графов и раскрасок94’ 95. Моррис обсуждает использование специал
аппаратных устройств для повышения эффективности управления памятью?
Вопрос оптимального размера страницы также обсуждался в литературе дес-
Чтобы соответствовать потребностям различных приложений, современные q ^оВе-
соры общего назначения обрели поддержку нескольких размеров страниц '^ест
дение программ в системах с подкачкой продолжает оставаться предметом
ва исследований, цель которых — повысить пропускную способность и 1
тельность системы за счет уменьшения количества страничных промахов aflpeC-
104, 105, 106, 107, 108. Библиография к этой главе доступна на Web-сайте п
www.deitel.com/books/osЗе/Bibliography.pdf.
Виртуальной памятью
Ъ^ьзуемая литература
nning Р. J-» «The Working Set Model for Program Behavior», Communica-
Lr?®„q of the ACM, Vol. 11, No. 5, May 1968, pp. 323-333.
n lady, L. А., «А Study of Replacement Algorithms for Virtual Storage Com-
2 uters», IBM Systems Journal, Vol. 5, No. 2, 1966, pp. 78-101.
n er J-» and G. R. Sager, «Dynamic Improvement of Locality in Virtual Memory
^gystems», IEEE Transactions on Software Engineering, Vol. SE-1, March 1976,
pp. 54-62.
Aho, A. V.; P- J- Denning; and J. D. Ullman, «Principles of Optimal Page Re-
placement», Journal of the ACM, Vol. 18, No. 1, January 1971, pp. 80-93.
Minsky, M. L., Computation: Finite and Infinite Machines, Englewood Cliffs,
N.J.: Prentice-Hall, 1967.
C Rennie, F., Introduction to Computability, Reading, MA: Addison-Wesley, 1977.
7 Buzen, J. P-, «Fundamental Laws of Computer System Performance», Proceed-
ings of the 1976 ACM SIGMETRICS Conference on Computer Performance
Modeling Measurement and Evaluation, 1976, pp. 200-210.
8. Randell, B., and C. J. Kuehner, «Dynamic Storage Allocation Systems», CACM,
Vol. 11, No. 5, May 1968, pp. 297-306.
9. Lorin, H., and H. Deitel, Operating Systems, Reading, MA: Addison-Wesley,
1981. (издан русский перевод: Г. Лорин, X. Дейтел, Операционные системы,
М.: Финансы и статистика, 1984)
10. Trivedi, К. S., «Prepaging and Applications to Array Algorithms», IEEE Trans-
actions on Computers, Vol. C-25, September 1976, pp. 915-921.
11. Smith, A. J., «Sequential Program Prefetching in Memory Hierarchies», Com-
puter, Vol. 11, No. 12, December 1978, pp. 7-21.
12. Trivedi, K. S., «Prepaging and Applications to Array Algorithms», IEEE Trans-
actions on Computers, Vol. C-25, September 1976, pp. 915-921.
13. Kaplan, S., et al., «Adaptive Caching for Demand Prepaging», Proceedings of the
Third International Symposium on Memory Management, 2002, pp. 114-116.
14. Linux Source, <lxr.linux.no/source/mm/memory.c?v=2.5.56>, строка 1010
(swapin readahead).
Linux Source, <lxr.linux.no/source/mm/swap.c?v=2.6.0-test2>, строка 100
(swap-setup).
•Belady, L. А., «А Study of Replacement Algorithms for Virtual Storage Com-
Puters», IBM Systems Journal, Vol. 5, No. 2, 1966, pp. 78-101.
'•benning, P. J., «Virtual Memory», ACM Computing Surveys, Vol. 2, No. 3, Sep-
18 «^ber 1970, pp. 153-189.
^attson, R. L.; J. Gecsie; D. R. Slutz; and I. L. Traiger, «Evaluation Techniques
19 ^Storage Hierarchies», IBM Systems Journal, Vol. 9, No. 2, 1970, pp. 78-117.
rieve, B. G., and R. S. Fabry, «VMIN — An Optimal Variable Space Page Re-
acement Algorithm», Communications of the ACM, Vol. 19, No. 5, May 1976,
20. g₽‘ 295-297.
for^biski, R.; E. Davidson; W. Mayeda; and H. Stone, «DMIN: An Algorithm
^Computing the Optimal Dynamic Allocation in a Virtual Memory Computer»,
r,,. , Transactions on Software Engineering, Vol. SE-7, No. 1, January 1981,
113-121.
te»T,a°y’ L- A., and C. J. Kuehner, «Dynamic Space Sharing in Computer Sys-
ls>>> Communications of the ACM, Vol. 12, No. 5, May 1969, pp. 282-288.
694
м
22. Turner, R., and H. Levy, «Segmented FIFO Page Replacement», Proceed-
the 1981 ACM SIGMETRICS Conference on Measurement and Modeling r«
puter Systems, 1981, pp. 48-51.
23. Babaoglu, O., and W. Joy, «Converting a Swap-Based System to Do Pa„j
Architecture Lacking Page-Referenced Bits», Proceedings of the Eighth
sium on Operating Systems Principles, ACM, Vol. 15, No. 5, Decenil1(,
pp. 78-86. r
24. Carr, R. W-, Virtual Memory Management, UMI Research Press, 1984
25. Borodin, A.; S. Irani; P. Raghavan; and B. Schiebler, «Competitive Pagjn
Locality in Reference», in Proceedings of the 23rd Annual ACM Symposi^
Theory of Computing, New Orleans, Louisiana, May 1991, pp. 249-259 Uni °n
26. Irani, S.; A. Karlin; and S. Phillips, «Strongly Competitive Algorithm
Paging with Locality in Reference», Proceedings of the Third Annual ACM-Sr ^°r
Symposium on Discrete Algorithms, 1992, pp. 228-236.
27. Albers, S.; L. Favrholdt; and O. Giel, «On Paging with Locality in Referen
Proceedings of the Thirty-Fourth Annual ACM Symposium on Theory of Como
tion, 2002, pp. 258-267. ' l a
28. Fiat, A., and Z. Rosen, «Experimental Studies of Access Graph Based Heuristics-
Beating the LRU Standard?» in Proceedings of the Eighth Annual ACM-SIam
Symposium on Discrete Algorithms, New Orleans, Louisiana, January 1997
pp. 63-72.
29. Fiat, A., and Z. Rosen, «Experimental Studies of Access Graph Based Heuristics:
Beating the LRU Standard?» in Proceedings of the Eighth Annual ACM-SIAM
Symposium on Discrete Algorithms, New Orleans, Louisiana, January 1997,
pp. 63-72.
30. Denning, P. J., «The Working Set Model for Program Behavior», Communica-
tions of the ACM, Vol. 11, No. 5, May 1968, pp. 323-333.
31. Denning, P. J., «Resource Allocation in Multiprocess Computer Systems», Ph.D.
Thesis, Report MAC-TR-50 M.I.T. Project MAC, May 1968.
32. Hathfield, D., «Experiments on Page Size, Program Access Patterns, and Virtual
Memory Performance», IBM Journal of Research and Development, Vol. 15, No.
1, January 1972, pp. 58-62.
33. Denning, P. J., «The Working Set Model for Program Behavior», Communica
tions of the ACM, Vol. 11, No. 5, May 1968, pp. 323-333.
34. Denning, P. J., «Working Sets Past and Present», IEEE Transactions on Soft
ware Engineering, Vol. SE-6, No. 1, January 1980, pp. 64-84.
35. Denning, P. J., «Thrashing: Its Causes and Preventions», AFIPS Conference
ceedings, Vol. 33, 1968 FJCC, pp. 915-922.
36. Rodriguez-Rossell, J., «Empirical Working Set Behavior», Communicatio
the ACM, Vol. 16, No. 9, 1973, pp. 556-560.
37. Fogel, M., «The VMOS Paging Algorithm: A Practical Implementation о
Working Set Model», Operating Systems Review, Vol. 8, No. 1, January
pp. 8-16. VAX/VMS
38. Levy, H. M., and P. H. Lipman, «Virtual Memory Management in the
Operating System», Computer, Vol. 15, No. 3, March 1982, pp. 35-41-
39. Kenah, L. J.; R. E. Goldenberg; and S. F. Bate, VAX/VMS Internals an
Structures, Bedford, MA: Digital Press, 1988. Pe'
40. Bryant, P., «Predicting Working Set Sizes», IBM Journal of Reseat ch
velopment, Vol. 19, No. 3, May 1975, pp. 221-229.
te UiipmyufibHSU памятью
t rris, J- В., «Demand Paging through the use of Working Sets on the Ma
4I ^.°c П», Communications of the ACM, Vol. 15, No. 10, October 1972, pp. 867-872.
I E W. W., and H. Opderdeck, «The Page Fault Frequency Replacement Algo-
iim» Proceedings AFIPS Fall Joint Computer Conference, Vol. 41, No. 1,
Й?”ррМГ609.
1 derdeck, H., and W. W. Chu, «Performance of the Page Fault Frequency Algo-
43- in a Multiprogramming Environment», Proceedings of the IFIP Congress,
Й74, PP- 235-241.
c jeh, E., «An Analysis of the Performance of the Page Fault Frequency (PFF)
p placement Algorithm», Proceedings of the Fifth ACM Symposium on Oper-
ating Systems Principles, November 1975, pp. 6-13.
rhu W. W., and H. Opderdeck, «Program Behavior and the Page-Fault-Fre-
uency Replacement Algorithm», Computer, Vol. 9, No. 11, November 1976,
pp. 29-38.
Gupta, R. K., an(l M- A. Franklin, «Working Set and Page Fault Frequency Re-
K placement Algorithms: A Performance Comparison», IEEE Transactions on
Computers, Vol. C-27, August 1978, pp. 706-712.
, Ganapathy, N., and C. Schimmel, «General Purpose Operating System Support
for Multiple Page Sizes», Proceedings of the USENIX Conference, 1998.
48 Batson, A. P.J S. Ju; and D. Wood, «Measurements of Segment Size», Communi-
cations of the ACM, Vol. 13, No. 3, March 1970, pp. 155-159.
49. Chu, W. W., and H. Opderdeck, «Performance of Replacement Algorithms with
Different Page Sizes», Computer, Vol. 7, No. 11, November 1974, pp. 14-21.
50. Denning, P. J., «Working Sets Past and Present», IEEE Transactions on Soft-
ware Engineering, Vol. SE 6, No. 1, January 1980, pp. 64-84.
51. Ganapathy, N., and C. Schimmel, «General Purpose Operating System Support
for Multiple Page Sizes», Proceedings of the USENIX Conference, 1998.
52. Talluri, M.; S. Kong; M. D. Hill; and D. A. Patterson, «Tradeoffs in Supporting
Two Page Sizes», in Proceedings of the 19th International Symposium on Com-
puter Architecture, Gold Coast, Australia, May 1992, pp. 415-424.
Talluri, M.; S. Kong; M. D. Hill; and D. A. Patterson, «Tradeoffs in Supporting
Two Page Sizes», in Proceedings of the 19th International Symposium on Com-
puter Architecture, Gold Coast, Australia, May 1992, pp 415-424.
54. McNamee, D., «Flexible Physical Memory Management», Department of Com-
puter Science and Engineering, University of Washington, 1995.
55. Talluri, M.; S. Kong; M. D. Hill; and D. A. Patterson, «Tradeoffs in Supporting
Two Page Sizes», in Proceedings of the 19th International Symposium on Com-
_ Puter Architecture, Gold Coast, Australia, May 1992, pp. 415-424.
Ia-32 Intel Architecture Software Developer’s Manual, Vol. 3, System Program
mer’s Guide, Intel, 2002, p. 3-19.
* UltraSPARC II Detailed View», Modified July 29, 2003, <www.sun.com/pro-
58 Cessors/UTtraSparc-II/details.html>.
'P°werPc Microprocessor Family: Programming Environments Manual for 64
59 32-Bit Microprocessors, Version 2.0, IBM, June 10, 2003, pp. 258, 282.
elady, L. А., «А Study of Replacement Algorithms for Virtual Storage Com-
5() ^ters», IBM Systems Journal, Vol. 5, No. 2, 1966, pp. 78-101.
lne, E. G.; C. W. Jackson; and P. V. Mclsaac, «Dynamic Program Behavior un-
64 Paging», ACM 21st National Conference Proceedings, 1966, pp. 223-228.
. offman, E. G. Jr., and L. C. Varian, «Further Experimental Data on the Behav-
, ' of Programs in a Paging Environment», Communications of the ACM,
ol- 11, No. 7, July 1968, pp. 471-474.
696
62. Freibergs, I. F., «The Dynamic Behavior of Programs», Proceedings AFft, 1
Joint Computer Conference, Vol. 33, Part 2, 1968, pp. 1163-1167. ?а>
63. Hathfield, D., «Experiments on Page Size, Program Access Patterns, and V
Memory Performance», IBM Journal of Research and Development л/^Uai
No. 1, January 1972, pp. 58-62. ’ °1.
64. Freibergs, I. F., «The Dynamic Behavior of Programs», Proceedings AFrp
Joint Computer Conference, Vol. 33, Part 2, 1968, pp. 1163-1167. ® ^'q((
65. Spirn, J. R., and P. J. Denning, «Experiments with Program Locality»
Conference Proceedings, Vol. 41, 1972 FJCC, pp. 611-621. ’
66. Morrison, J. E., «User Program Performance in Virtual Storage Systems
Systems Journal, Vol. 12, No. 3, 1973, pp. 216-237. **
67. Rodriguez-Rossell, J., «Empirical Working Set Behavior», Communicati
the ACM, Vol. 16, No. 9, 1973, pp. 556-560. °ns of
68. Chu, W. W., and H. Opderdeck, «Performance of Replacement Algorithms •
Different Page Sizes», Computer, Vol. 7, No. 11, November 1974, pp.
69. Oliver, N. A., «Experimental Data on Page Replacement Algorithms» pror
ings ofAFIPS, 1974 NCC 43, Montvale, N.J.: AFIPS Press, 1974, pp. 179484
70. Opderdeck, H., and W. W. Chu, «Performance of the Page Fault Frequency Д]с
rithm in a Multiprogramming Environment», Proceedings of the IFIP Congress
1974, pp. 235-241.
71. Sadeh, E., «An Analysis of the Performance of the Page Fault Frequency (PFF)
Replacement Algorithm», Proceedings of the Fifth ACM Symposium on Oper-
ating Systems Principles, November 1975, pp. 6-13.
72. Baer, J., and G. R. Sager, «Dynamic Improvement of Locality in Virtual Memory
Systems», IEEE Transactions on Software Engineering, Vol. SE-1, March 1976,
pp. 54-62.
73. Potier, D., «Analysis of Demand Paging Policies with Swapped Working Sets»,
Proceedings of the Sixth ACM Symposium on Operating Systems Principles, No-
vember 1977, pp. 125-131.
74. Franklin, M. A.; G. S. Graham; and R. K. Gupta, «Anomalies with Variable Par-
tition Paging Algorithms», Communications of the ACM, Vol. 21, No. 3, March
1978, pp. 125-131.
75. Gupta, R. K., and M. A. Franklin, «Working Set and Page Fault Frequency Re-
placement Algorithms: A Performance Comparison», IEEE Transactions
Computers, Vol. C-27, August 1978, pp. 706-712. ,
76. Denning, P. J., «Working Sets Past and Present», IEEE Transactions on So
ware Engineering, Vol. SE-6, No. 1, January 1980, pp. 64-84.
77. Irani, S.; A. Karlin; and S. Phillips, «Strongly Competitive Algorithms^
Paging with Locality in Reference», Proceedings of the Third Annual ACM
Symposium on Discrete Algorithms, 1992, pp. 228-236. epCe
78. Glass, G., and Pei Cao, «Adaptive Page Replacement Based on Memory
Behavior», Proceedings of the 1997 ACM SIGMETRICS International
ence on Measurement and Modeling of Computer Systems, PP-
June 15-18, 1997, Seattle, Washington. cupP0^
79. Ganapathy, N., and C. Schimmel, «General Purpose Operating System
for Multiple Page Sizes», Proceedings of the USENIX Conference, 19 гецсе*’
80. Albers, S.; L. Favrholdt; and O. Giel, «On Paging with Locality in Re
Proceedings of the Thirty-Fourth Annual ACM Symposium on Theory of
tion, 2002, pp. 258-267.
г Mlie виртуальной памятью
* f Inklin, М. A.; G. S. Graham; and R. К. Gupta, «Anomalies with Variable Par-
□j. Paging Algorithms», Communications of the ACM, Vol. 21, No. 3, March
&, PP- 125131.
i =я G., and Pei Cao, «Adaptive Page Replacement Based on Memory Reference
havior», Proceedings of the 1997 ACM SIGMETRICS International Confer
p on Measurement and Modeling of Computer Systems, pp. 115-126,
tie 15-18’ 1997, Seattle, Washington, United States.
rl ss G., and Pei Cao, «Adaptive Page Replacement Based on Memory Reference
havior», Proceedings of the 1997 ACM SIGMETRICS International Confer-
^се on Measurement and Modeling of Computer Systems, pp. 115-126,
June 15-18, 1997, Seattle, Washington, United States.
A Arcangeli, «Le novita’ nel Kernel Linux», December 7, 2001, <old.lwn.net/
2001/1213 /аа-vm-talk/mgpOOOO 1. html>.
A Arcangeli, «Le novita’ nel Kernel Linux», December 7, 2001, <old.lwn.net/
8°' 2001/1213/aa-vm-talk/mgp00001 ,html>.
Исходные коды ядра Linux, версия 2.5.75, <www.kernel.org>.
g7 Исходные коды ядра Linux, версия 2.5.75, <www.kernel.org>.
Denning, Р. J., «The Working Set Model for Program Behavior», Communica-
tions of the ACM, Vol. 11, No. 5, May 1968, pp. 323-333.
89. Denning, P. J., «Virtual Memory», ACM Computing Surveys, Vol. 2, No. 3, Sep-
tember 1970, pp. 153-189.
90. Aho, A. V.; P. J. Denning; and J. D. Ullman, «Principles of Optimal Page Re-
placement», Journal of the ACM, Vol. 18, No. 1, January 1971, pp. 80-93.
91. Kaplan, S., et al., «Adaptive Caching for Demand Prepaging», Proceedings of the
Third International Symposium on Memory Management, 2002, pp. 114-116.
92. Belady, L. А., «А Study of Replacement Algorithms for Virtual Storage Com-
puters», IBM Systems Journal, Vol. 5, No. 2, 1966, pp. 78-101.
93. Belady, L. A., and C. J. Kuehner, «Dynamic Space Sharing in Computer Sys-
tems», Communications of the ACM, Vol. 12, No. 5, May 1969, pp. 282-288.
94. Irani, S.; A. Karlin; and S. Phillips, «Strongly Competitive Algorithms for
Paging with Locality in Reference», Proceedings of the Third Annual ACM SIAM
Symposium on Discrete Algorithms, 1992, pp. 228-236.
95. Albers, S.; L. Favrholdt; and O. Giel, «On Paging with Locality in Reference»,
Proceedings of the Thirty-Fourth Annual ACM Symposium on Theory of Computa-
tion, 2002, pp. 258-267.
Morris, J. B., «Demand Paging through the use of Working Sets on the Maniac
Communications of the ACM, Vol. 15, No. 10, October 1972, pp. 867-872.
• Batson, A. P.; S. Ju; and D. Wood, «Measurements of Segment Size», Communi-
oations of the ACM, Vol. 13, No. 3, March 1970, pp. 155-159.
Chu, W. W., and H. Opderdeck, «Performance of Replacement Algorithms with
. Afferent Page Sizes», Computer, Vol. 7, No. 11, November 1974, pp. 14-21.
•Benning, p. J_, «Working Sets Past and Present», IEEE Transactions on Soft-
ly ^are Engineering, Vol. SE-6, No. 1, January 1980, pp. 64-84.
Banapathy, N., and C. Schimmel, «General Purpose Operating System Support
Or Multiple Page Sizes», Proceedings of the USENIX Conference, 1998.
I ,r®ibergs, I. F., «The Dynamic Behavior of Programs», Proceedings AFIPS Fall
lOg Computer Conference, Vol. 33, Part 2, 1968, pp. 1163-1167.
fcf^^eld, D., «Experiments on Page Size, Program Access Patterns, and Virtual
L >jeniory Performance», IBM Journal of Research and Development, Vol. 15,
°- 1, January 1972, pp. 58-62.
698_______________________________________
J03' Systeras-. S
,n, 4nd₽h E «An Analysis of the Performance of the Page Fault Frequency
^Replacement Algorithm», Proceedings of the Fifth ACM Symposium 0^}
ating Systems Principles, November 1975, pp. 6-13. Per.
1ПЧ. Punta R К and M. A. Franklin, «Working Set and Page Fault Frequen
placement Algorithms: A Performance Comparison», IEEE Transact*^
Computers, Vol. C-27, August 1978, pp. 706-712. °n
106 Denning P. J., «Working Sets Past and Present», IEEE Transactions on Sof.
“Ti&neertW, Vol. SE-6, No. 1, January 1980. pp. 64 84. «Л-
107 Irani, S.; A. Karlin; and S. Phillips, «Strongly Competitive Algorithms fOr
Paging with Locality in Reference», Pr°ceedln8s°f t^hlrd Annual ACM-Sj^j
Symposium on Discrete Algorithms, 1992, pp. 228-236.
108 Albers S.; L. Favrholdts; and 0. Giel, «On Paging with Locality in Reference,
Proceedings of the Thirty-Fourth Annual ACM Symposium on Theory of Сотри*,
tion, 2002, pp. 258-267.
айлы и базы данныаЛ
омпъютеры хранят программы и огромные объ-
данных в виде файлов и баз данных на
ещних накопителях. В следующих двух главах мы
Усмотрим, как операционные системы организуют
лнные на накопителях. Мы изучим работу широко
° Кпространенных накопителей на магнитных дис-
с подвижными головками и покажем, как дос-
максимальной производительности при помо-
щи оптимизаций доступа по вращению и позициони-
рованию. Будут рассмотрены также массивы RAID
(Redundant Arrays of Independent Disks — Избыточ-
ные массивы независимых накопителей), обеспечи-
вающие высокие уровни отказоустойчивости и про-
изводительности. Мы обсудим файловые системы
и рассмотрим размещение файлов на дисках, управ-
ление свободным пространством, защиту файлов
и доступ к ним. Будет уделено внимание файловым
серверам и их применению в распределенных систе-
мах. Мы кратко рассмотрим системы баз данных,
\ реляционные базы данных и службы операционных
систем, обеспечивающие поддержку этих приложе-
ний.
Когда желанье справедливо, то #
молча следовать е л
Твердо помни, о чем шла речь...
Замкну в душе, а ключ возьми с собой.
Уильям Шекспир
Наши цели — рядом, не ищите их вдали
Мен-цзы
Когда желанье справедливо, то надо
молча следовать ему.
Данте
В поисках глубоко скрытой истины следует полагаться
на тот самый инстинкт, которым живет собака,
безошибочно находя аппетитную кость-J
Уильям Джейкс
Отправляясь куда-нибудь, пс
что кто-то уже там пс бы I
Генри Дэвид Т0?
Самому скрипучему колесу болыпе
нужна сын
Генри Уиллер 1
Глава 12
Оптимизация
производительности
дисковых накопителей
После прочтения этой главы, вы должны понимать:
как выполняется дисковый ввод / вывод;
важность оптимизации производительности
дисковых накопителей;
Оптимизацию поиска и оптимизацию по вращению;
* Различные алгоритмы диспетчеризации дисковых
°ПеРаций;
датирование и буферизацию;
другие методы повышения производительности
1 Исковых накопителей;
10с^овньде элементы реализации избыточных
а ?ueoe независимых накопителей (redundant
!• of independent disks — RAID).
Краткое содержание глабы
12.1 Введение
12.2 Развитие вторичных запоминающих устройств
12.3 Характеристики накопителей с подвиЖными головками
12.4 Почему необходима диспетчеризация дисковых операций
12.5 Диспетчеризация дисковых операций
12.5.1 Алгоритм диспетчеризации FCFS
12.5.2 Алгоритм диспетчеризации SSTF
Поучительные истории: У каждой проблемы есть решение
и в каждом решении есть проблема
12.5.3 Алгоритм диспетчеризации SCAN
12.5.4 Алгоритм диспетчеризации C-SCAN
12.5.5 Алгоритм диспетчеризации FSCAN и N-шаговый SCAN
12.5.6 Алгоритм диспетчеризации LOOK и C-LOOK
12.6 Оптимизация по вращению
12.6.1 Алгоритм диспетчеризации SL TF
12.6.2 Алгоритмы диспетчеризации SPTF и SATF
12.7 . Системные соображения
Размышления об операционных системах: Насыщение и узкие места
12.8 Кэширование и буферизация
12.9 Другие приемы повышения производительности накопителей
Размышления об операционных системах: Сжатие и распаковка данных
Размышления об операционных системах: Избыточность
12.10 RAID-массивы
12.10.10бзор RAID-массивов ы
Размышления об операционных системах: Жизненно важные системы
Размышления об операционных системах: Отказоустойчивость
12.10.2 RAID-массивы уровня О (разделение данных)
12.10.3 RAID-массивы уровня 1 (зеркальное отображение) ]
12.10.4 RAID-массивы уровня 2 (побитовый контроль с коррекцией по Хе№а
12.10.5 RAID-массивы уровня 3 (побитовый XOR-контроль и коррекц^'
12.10.6 RAID-массивы уровня 4 (блочный XOR-контроль и коррекции) >
12.10.7 RAID-массивы уровня 5 (блочный XOR-контроль и коррекция с распре
\jj« произродитвлопоети диекоошж никипштяапг
л / введение
учение последних лет производительность процессора и оперативной
И и растет быстрее, чем производительность вторичных (внешних) за-
0^ а1Ощих устройств, например, жестких дисков. В результате в работе
01й ессов, запрашивающих данные с внешних запоминающих устройств,
црой вОзникают задержки. В этой главе мы обсудим характеристики дис-
в»010 накопителей с подвижными головками и рассмотрим, как создате-
rf ^ерапИОННЬ[Х систем могут обеспечить более высокий уровень произ-
1# °теЛЬности, управляя этими устройствами. Мы изучим, как оптимизи-
^^ть производительность дисков, переупорядочивая обращения к диску
Р°в повышения пропускной способности, уменьшения времени выполне-
запросов и разброса этого времени. Мы также рассмотрим, как опера-
6 онные системы реорганизуют данные на дисках и используют буферы
Д кэши для повышения производительности. И, наконец, мы рассмотрим
RAID-массивы, уменьшающие время доступа к накопителям и повышаю-
щие отказоустойчивость путем обработки запросов с помощью одновремен-
ного использования нескольких накопителей.
12.2 Развитие вторичных запоминающих
устройств
В первых компьютерах для долговременного хранения данных исполь-
зовались перфокарты и перфоленты, наличие/отсутствие отверстий в кото-
рых соответствовало значениям битов данных1. Написание программ и их
ввод в компьютер с помощью таких носителей было медленным и трудоем-
ким процессом. Потребность в недорогих, перезаписываемых носителях
информации привела к появлению магнитных устройств хранения, в кото-
ив^ значения битов определялись направлением намагничивания облас-
ти поверхности носителя. Чтобы обратиться к данным на таких носите-
(?Х> СПеЦиальное устройство, называемое головкой чтения/записи
ao/write head), перемещалось над лентой. При считывании данных го-
На измеряла изменение тока, вызванное намагниченным носителем;
Записи ток, проходящий через головку, изменял намагниченность но-
те ЛЯ‘ ^Дн°й из основных сложностей в создании таких устройств было
Во'ьТ° Головка должна находиться очень близко от поверхности носителя,
е касаться его.
С951 году в компьютере UNIV АС 1 (UNIVersal Automatic Computer —
еРсальный автоматический вычислитель) появились накопители на
а^^тной ленте (magnetic tape storage). Эти накопители позволяли пере-
1|^Чвать данные, и данные сохранялись при выключении питания2.
Ит«ая лента допускает только последовательный доступ к данным,
^^«пример, в аудио- и видеокассетах. Такие носители не подходят, на-
Для программ обработки транзакций, в которых система должна
I |Щ1Ть> считывать или изменять данные за доли секунды. Чтобы решить
706
эту проблему, в 1957 году корпорация IBM создала первый коммеп
накопитель на жестком диске — RAMAC (Random Access
Accounting and Control — Произвольный доступ для учета и упра
Жесткие диски — это устройства с произвольным доступом (Ино еайч)
называют прямым или непосредственным доступом), поскольку %
требуют обращаться к данным обязательно в порядке их записи, Е
устройства RAMAC составляла 5 мегабайт, и стоило оно 50 000 до™ КОс1,ь
Обычно оно сдавалось в наем за сотни долларов в месяц3’ 4. Хотя iiri
дительность жестких дисков была выше, чем у ленточных накопи 1?ЗВб'
их дороговизна ограничивала их распространение. ТеЛей,
С течением времени емкость и производительность жестких дисков
ли, а стоимость падала. В 1990-х годах емкость типичных накопит^*00'
в персональных компьютерах выросла с нескольких сотен мегабайт доВ
скольких гигабайт, а стоимость упала до нескольких центов за мегаб “**
К 2003 году емкость жестких дисков выросла до 200 гигабайт, а стоимо 1
упала до менее чем доллара за гигабайт5. Из-за механических ограничЬ
ний, которые мы подробнее рассмотрим в следующем разделе, производи
тельность жестких дисков росла медленнее, чем их емкость. По мере роста
быстродействия процессоров и объемов данных, обрабатываемых прило-
жениями, скорость дискового ввода/вывода стала одним из основных фак-
торов, ограничивающих производительность систем6.
Исследования в области устройств хранения данных продолжаются,
а объем и производительность дисковых накопителей растут. Кроме того,
перспективные исследования выполняются в области новых технологий
и носителей данных.
Вопросы для самопроверки
1. Почему производительность многих современных систем зависит
от скорости ввода/вывода?
2. Почему для хранения данных диски удобнее ленточных накопителей?
Ответы 1) Потому что быстродействие процессоров росло быстрее»
чем производительность дисковых накопителей. 2) Ленточные иако
тели удобно использовать только в системах, в которых нуЖН°ш£ций
гцаться к данным последовательно. В системах обработки тРаНЗм1ЦиМ
и многопрограммных системах, обращения к внешним запомни ^оМ
устройствам от множества процессов могут поступать в произво
порядке. В этом случае необходим произвольный доступ к дан
12.3 Харак еристики накопителей с nogBuoleHbi^
головками
В отличие от оперативной памяти, предоставляющей практическй^^^-
ковый по скорости доступ ко всему ее содержимому, накопители с
ными головками обладают разной скоростью доступа к данным ,nnciUelJlJ,ac'
сти от относительного положения головки чтения/записи и заир
данных. На рисунке 12.1 показана упрощенная схема накопителя с
накопителей
I а головками7-8’ °. Данные записываются на наборах магнитных дисков,
В^ваемых пластинами (platters), насаженных на шпиндель (spindle), вра-
с большой скоростью (обычно — тысячи оборотов в минуту10).
Рос. 12.1. Схема дискового накопителя с подвижными головками
Доступ к данным на каждой поверхности пластины осуществляется от-
дельной головкой чтения/записи, которую от поверхности диска отделяет
Дуйь небольшой зазор (намного меньше, чем размер частички дыма). Напри-
Ме₽’ накопитель на рисунке 12.1 состоит из двух дисков, у каждого из кото-
Рь® есть две поверхности (верхняя и нижняя), и четырех головок чтения/за-
си, по одной для каждой поверхности. Время, за которое при вращении
^Ска Данные переместятся в позицию головки, называется вращательным
®*енем задержки (rotational latency time). Среднее вращательное время за-
для накопителя равно половине периода вращения диска. У боль-
ства накопителей оно равно нескольким миллисекундам (рис. 12.2).
Съп^и вращении дисков каждая из головок может прочитать данные
Ч в ов°й дорожки на своей поверхности диска. Каждая головка крепит-
ц,1ч а к°нце консоли (disk arm), прикрепленной другим концом к общему
г0доВсех головок стержню — приводу блока головок (actuator). Консоль
перемещается в плоскости, параллельной плоскости диска. Когда
^Упность консолей головок перемещается в новую позицию, становит-
СтУпным для обращений новый вертикальный набор дорожек на дис-
йазЬ1ваемый цилиндром (cylinder). Перемещение консоли в новую по-
Ч ив Назь1вается позиционированием головки (seek operation)11-12. Что-
Легчать поиск небольших объемов данных, дорожки делятся на
708
небольшие фрагменты, называемые секторами (sectors), объем каж»
которых часто равен 512 байтам13 (рис. 12.3). При использовании се^0*0^
операционная система может находить данные, указывая головку (и
ветственно, поверхность диска, с которой должны быть считаны да ’ С°°г.
цилиндр (определяющий номер дорожки, с которой должны быть сч
данные) и сектор, в котором находятся нужные данные. ТаНц
Модель (среда)
Maxtor DiamondMax Plus 9
(высокоуровневая настольная система)
WD Caviar
(высокоуровневая настольная система)
Toshiba MK8025GAS
(портативный компьютер)
WD Raptor (серверы)
Cheetah 15К.З (серверы)
Среднее время Среднее вращатель^
позиционирования (мс) время задержки (mcj
9.3 4,2
8,9 4,2
12,0 7,14
5,2 2,99
3,6 2,0
Рис. 12.2. Время позиционирования и время задержки для разных моделей
накопителей14-15>16-17-18
Рис. 12.3. Схематическое изображение структуры поверхности диска
щИЯ производительности дисковых накопителей
709
"бы обратиться к конкретной записи на накопителе с подвижными
обычно необходимы несколько операций (рис. 12.4). Сначала
переместить головку к нужному цилиндру (т.е. выполнить опера-
йУ^Одиционирования). Время, необходимое для перемещения головки
цХ10 цилиндра, на котором она находится сейчас, к нужному цилиндру,
о? 'г°ваеТся временем позиционирования (seek time). Затем диск должен
йуться так, чтобы нужный сектор оказался под (или над) головкой.
°0 м запись, длина которой может быть разной, должна полностью прой-
Ме л Головкой в ходе вращения диска. Время прохождения называется
^,еЯем передачи (transmission time). Поскольку каждая из этих опера-
дддючает механическое перемещение, общее время обращения к дис-
д1%асто занимает заметную часть секунды (по меньшей мере, несколько
длисекунд). За этот период времени процессор может выполнить десят-
1411 или даже сотни миллионов инструкций.
7Ю
Вопросы для самопроверки
1. Одно из основных направлений совершенствования накоп
увеличение плотности записи (то есть количества данныуИТе’’1еЙ
ваемых на единицу площади). Как само по себе увеличени'
сти записи влияет на скорость доступа? е
2. (Да/Нет) Вращательное время задержки остается одинако
каждом обращении к диску? БЬ1М
Ответы 1) При росте количества данных, записанных на
площади, растет количество данных, записанных на каждой деДИ1111Це
Если нужные данные хранятся в одной дорожке, то время п^05!С1се.
уменьшается по сравнению с таковым у накопителя с меньщД^6^1^
костью записи, поскольку за тот же промежуток времени мож йл°т
читать больше данных. 2) Нет. Вращательное время задержки чя° Й^°’
от положения начального сектора нужной записи относительно^^111
ки в момент запроса. г°лов.
12А Почему необходима диспешчеризшш
дисковых операций I
Процессы могут генерировать запросы на чтение и запись данных на диск
одновременно. Поскольку иногда запросы возникают быстрее, чем они могут
выполняться, создаются очереди для их хранения. В некоторых старых компь-
ютерных системах запросы выполнялись просто в порядке их поступления
(система FCFS, first-come-first-served — «первым пришел, первым обслужи-
ли»)19. FCFS — это стабильная система обслуживания, но по при высокой час-
тоте поступления запросов (request rate), или большой нагрузке (load) между
поступлением запроса и его выполнением может пройти много времени.
FCFS демонстрирует случайный порядок выборки (random seek pattern),
при котором следующие друг за другом запросы могут вызывать длительные
операции позиционирования, перемещающие головку от внешних дороже*
к внутренним и обратно. Чтобы уменьшить время, затрачиваемое на позидио
нирование, целесообразно упорядочить каким-то образом очередь 3an?oC?^j| |
Этот процесс, называемый диспетчеризацией дисковых операнд11 '
scheduling), может существенно увеличить пропускную способность •
Диспетчеризация дисковых операций включает анализ подлежат {jX
полнению запросов для определения максимально эффективного пор
выполнения. Диспетчер выясняет позиционные отношения между °н йД чТОбЫ
ми выполнения запросами, и переупорядочивает очередь запросов так,
все запросы были выполнены с минимумом механических перемеще ^0.
Поскольку FCFS не переупорядочивает очередь, он часто считае^ раС
стейшим алгоритмом диспетчеризации доступа к диску. Два са
пространенных способа оптимизации — это оптимизация по по , opt^
рованию (seek optimization) и оптимизация по вращению (rot'allf' че
mization). Поскольку время позиционирования обычно боль м
задержка вследствие вращения диска, большинство алгоритмов Д 0jiP ,
ризации концентрируется на минимизации общего времени поэйН р°
F .мця произВодитвльносггнГдиекьпых наканичгтси —-----------------------
' йиР°вания 11 заДеРжкой вследствие вращения минимизация послед-
ний0 е может существенно улучшить производительность, особенно при
нагрузках на накопитель.
Вопросы для самопроверки
1. Для каждого из нижеприведенных случаев укажите наиболее эф-
фективный тип алгоритма диспетчеризации дисковых операций:
если время позиционирования намного больше вращательной за-
держки; если время позиционирования и вращательная задержка
практически равны; если время позиционирования существенно
меньше вращательной задержки.
2. Какие характеристики геометрии диска наиболее существенны при
оптимизации по позиционированию и оптимизации по вращению?
Ответы 1) Если время позиционирования намного больше враща-
тельной задержки, то на время доступа больше всего влияют операции
позиционирования, и система должна использовать оптимизацию по
позиционированию. Если время позиционирования и вращательная
задержка практически равны, то целесообразным будет использова-
ние, как вращательной оптимизации, так и оптимизации по позицио-
нированию. Если же время позиционирования существенно меньше
вращательной задержки, то выгоднее использовать вращательную оп-
тимизацию. Поскольку современные процессоры обладают высокой
производительностью, то для повышения производительности лучше
всего реализовать оба типа оптимизаций. 2) Для оптимизации време-
ни позиционирования важнее всего положение цилиндров, а для опти-
мизации вращательной задержки —положение секторов.
12.$ Диспетчеризация дисковых операций
Алгоритмы диспетчеризации дисковых операций, используемые систе-
мой, зависят от назначения этой системы, но большинство алгоритмов оце-
ииваются по следующим общим критериям:
• Пропускная способность (throughput) — количество запросов, вы-
полняемых в единицу времени.
* Среднее время реагирования (mean response time) — среднее время,
проходящее между поступлением запроса и его выполнением.
• Разброс времени реагирования (variance of response times) — уровень
предсказуемости времени реагирования на запрос. Каждый запрос дол-
Жен выполняться в течение определенного периода времени (т.е. алго-
0 не Д°лжен откладывать выполнение запроса до бесконечности).
Uujo е®идно, алгоритм диспетчеризации должен стремиться к достиже-
Мецл^^симальной пропускной способности и минимального среднего вре-
^еагиРования. Многие алгоритмы пытаются достичь этих целей, сво-
прц и«имуму время, уходящее на длинные операции позиционирования.
Тимизации производительности и среднего времени реагирования
’’bty ется средняя производительность системы, но выполнение отдель-
пР°с°в может задерживаться.
^°с вРемени реагирования определяет отличие времен выполнения
HbIX запросов от среднего времени. Чем меньше этот разброс, тем ве-
К > что запросы выполняются за приблизительно одинаковые интер-
712
валы времени. Поэтому разброс времени реагирования можно счит
рой стабильности и предсказуемости системы. Мы стремимся создатаТь Ч
ритм диспетчеризации, минимизирующий разброс (или, по крайне4'
удерживающую его на разумном уровне), чтобы избежать непредС1^
большой длительности выполнения запросов. В системах, решающ^^Мо
чи с жесткими временными рамками, например, Web-серверах, б0
разброс времен реагирования может привести к потерям клиентов
мер, если запросы на покупку товаров будут постоянно откладывать^1^11'
медленно выполняться. В системах, решающих жизненно важные за” ИЛй
последствия задержек могут быть катастрофическими. Лачи,
В следующих разделах рассматриваются несколько широко прим
мых алгоритмов диспетчеризации. Мы используем последовательность ве'
ращений к диску, показанную на рисунке 12.5, чтобы продемонстриров^
®ать
Очередь обращений к цилиндрам (режим FIFO - «первым вошел,
первым вышел»): 33,72,47,8,99, 74,52,75.
Положение головки: цилиндр 63
Pl№. 12.5. Последовательность обращений к диску
а/цйя производительности дисковых накопителей
713
татьх использования каждого рассматриваемого алгоритма на произ-
р^^оЙ последовательности запросов. Такой подход позволит оценить,
fO31^ Кдый алгоритм упорядочивает поступающие запросы, но это не обя-
о демонстрирует производительность каждого алгоритма в реаль-
з^'^стеме. В следующих примерах мы предполагаем, что диск содержит
СиЛиндров, с номерами 0-99, и что головка чтения/записи изначально
jOO ЙйТСя на цилиндре 63, если явно не указано иное. Для простоты мы
00 • будем полагать, что диспетчер уже определил номера цилиндров,
^^етствующие каждому запросу.
Вопросы для самопроверки
1. Почему минимизация разброса времени реагирования важна при
диспетчеризации дисковых операций?
2. Мы упоминали, что FCFS — стабильный алгоритм диспетчериза-
ции дисковых операций. Какой из рассмотренных только что кри-
териев более других отвечает за стабильность?
Ответы 1) В противном случае система может иногда выполнять
запросы в непредсказуемо долгие интервалы времени. В бизнес-систе-
мах это может привести к потере компанией клиентов; в системах, ре-
шающих жизненно важные задачи, это может привести к катастрофам,
включая гибель людей. 2) Алгоритм FCFS стабилен в том смысле, что
поступающие в данный момент запросы не могут выполниться раньше,
чем запросы, поступившие ранее. Это позволяет уменьшить разброс
времени реагирования.
Алгоритм диспетчеризации FCFS
Алгоритм диспетчеризации FCFS использует очередь FIFO («первым во-
шел — первым вышел»), и запросы выполняются в порядке их
поступления22’ 23> 24. FCFS стабилен в том смысле, что положение запроса
8 очереди не изменяется в зависимости от запросов, поступающих следую-
щими. Это гарантирует, что ни один запрос не будет откладываться до бес-
р°Нечности, но это также означает, что при выполнении каждого запроса
должен выполнять продолжительные операции позиционирования,
если дальше в очереди есть запрос, цилиндр которого расположен бли-
’ и выполнить который можно быстрее. Этот алгоритм требует неболь-
Накладных расходов при реализации, но он может привести к низкой
Пускной способности из-за множества операций позиционирования.
4Ли запросы равномерно распределены по поверхности диска, FCFS об-
К~ет случайным порядком выборки, поскольку он игнорирует соотноше-
в°3Иций различных запросов в очереди (см. рис. 12.6). Это приемлемо,
5^ НагРузка на накопитель невелика. Однако с ростом нагрузки FCFS
4^(7 насыщается, достигая предельной производительности, и время
t;tpQ нения запроса становится слишком большим (очередь запросов бы-
Е^Унеличивается). Случайная последовательность выборки в алгоритме
%С(^пРиводит к малому разбросу времени реагирования (поскольку за-
4$^ ’ поступившие позже, не могут оказаться в очереди впереди посту-
ИL Раньше), но это мало утешает запрос, находящийся в конце очере-
. На головка мечется над диском, исполняя лихорадочные танцы.
714
Вопросы для самопроверки
1. Один из критериев стабильности — малый разброс вреМе
рования. Стабилен ли в этом смысле алгоритм диспатч Ни Pea*
FCFS? ериЧ^’
2. Может ли выполнение запроса откладываться до беек
при использовании алгоритма FCFS? О11еЧв0с^
Ответы 1) Да, в этом смысле алгоритм FCFS стабилен, но
ку он ничего не делает для минимизации времени реагировал n°C!<OjIb'
нее время реагирования зачастую больше необходимого ИД’ среД-
Выполнение запроса не может откладываться до бесконечное ^ет-
скольку запросы, поступившие позже, никогда не выполняю*1’ п°-
того, как выполнятся поступившие ранее запросы. ТС55 До
Рис. 12.6. Порядок выборки при использовании алгоритма FCFS
12.5.2 Алгоритм диспетчеризации SSTF
SSTF расшифровывается как shortest seek time first — «минимальное^,
мя позиционирования сначала». Это алгоритм, в котором первым вь1П^сТЬ за-
сл запрос с минимальным временем позиционирования головки, ^^ддтс9
прос, цилиндр которого ближе всего к тому, над которым головка етПР0ВТ
в данный момент25*26> 27> 28. SSTF не гарантирует стабильности и мож едов8
ти к бесконечному откладыванию выполнения запроса, поскольку ^^зо^
тельность выборки, используемая этим алгоритмом, часто сильно л gjj
на. Соответственно запросы к цилиндрам, расположенным на ^). 0.
внешнем краях диска, могут выполняться очень долго (см. рис. 1 •
Уменьшая среднее время позиционирования, SSTF обладает .ров9?' д.
кой пропускной способностью, чем FCFS, и среднее время Ре ,.1леС’гВ\д
у него меньше при малом или среднем уровне нагрузки. Один из
ных недостатков алгоритма SSTF — большой разброс времени Ре0‘а^. Р $
из-за дискриминации запросов к внешним и внутренним цилиНДР
щия производительности дисковых накопителей
7/5
случае запросы к цилиндрам на краях дисков могут задерживаться
ед^°„чно (см. главу 7), если поступающие следующими запросы обраща-
цилиндрам в середине диска. Высокий разброс приемлем в системах
^ой обработки, где более важны высокая пропускная способность
е время реагирования. Однако SSTF плохо подходит для интерактив-
иСТем, которые должны предоставлять каждому пользователю рав-
предсказуемые времена реагирования (см. «Поучительные истории:
пой проблемы есть решение, и в каждом решении есть проблема»).
ук»3*^
fuc. 12.7. Порядок выборки при использовании алгоритма SSTF
Вопросы для самопроберки
1. На какой алгоритм диспетчеризации из главы 8 больше всего по-
хож алгоритм SSTF? В чем отличие между ними?
2. Сравните накладные расходы при реализации алгоритмов SSTF
и FCFS.
Ответы 1) SSTF больше всего похож на алгоритм SPF (shortest
process first — «кратчайший процесс сначала»). В отличие от SPF,
SSTF не требует прогноза (например, оценки срока выполнения про-
цесса) — чтобы определить, какой запрос выполнять первым, доста-
точно знать, к какому цилиндру юн обращается. 2) И FCFS, и SSTF
должны хранить в памяти очередь запросов, ожидающих выполне-
ния. Поскольку FCFS использует простую очередь FIFO, время, необ-
ходимое для определения следующего подлежащего выполнению
запроса, невелико, и оно не зависит от количества запросов в очереди.
SSTF требует выполнения дополнительных операций — нужно содер-
жать либо отсортированный список (или списки) запросов, либо раз за
разом просматривать очередь, выбирая следующий запрос для выпол-
нения. В этом случае накладные расходы алгоритма SSTF пропорцио-
нальны количеству запросов в очереди (в то время как накладные
расходы FCFS неизменны — это просто время, которое нужно для до-
бавления поступающих запросов в хвост очереди и удаления выпол-
ненных запросов из головы очереди).
716
Поучительные истории
У каЖдой проблемы есть решение, и В каЖдом
решении есть проблема
Этот реальный случай произошел с моей
соседкой, которая никак не связана с компь
ютерной промышленностью. Ее муж уехал на
работу незадолго до нее, и забыл закрыть
дверь гаража. Когда соседка собралась
ехать на работу, она вошла в гараж и обнару-
жила скунса, пробравшегося туда и сидев-
шего рядом с дверью ее машины, пожирая
объедки. Она позвонила в службу работы
с животными, но в этой службе была чрезвы-
чайная ситуация, и ей сообщили, что никто
не сможет приехать раньше, чем через не-
сколько часов. Однако соседке сообщили.
что скунсам нравится бекон, и пред^
зажарить бекон и бросить его на г *Или
дом с гаражом, чтобы скунс убрался 0°Н ₽Я'
Тогда она смогла бы сесть в машинГ^'
ехать из гаража, закрыть его дверь ио'
виться на работу. Соседка последовала^
вету. Однако ее привел в бешенство втогзд
скунс - когда она бросила поджаренный бе”
кон на газон, этот скунс вышел из кустов
и принялся поедать бекон, пока первый про.
должал рыться в объедках в гараже. В тот
день соседка опоздала на работу на не-
сколько часов.
Мораль для разработчиков операционных систем. Всегда старайтесь предусмотреть все
последствия ваших решений.
12.53 Алгоритм диспетчеризации SCAN
Деннинг разработал алгоритм диспетчеризации SCAN, чтобы умень-
шить нестабильность и разброс времени реагирования, свойственные алго-
ритму SSTF. SCAN выбирает из очереди запрос, которому соответствует
минимальное время позиционирования в предпочитаемом направле
(preferred direction)29. Например, если в данный момент предпочитав^
направление — к внешнему краю диска, алгоритм SCAN выбирает
с минимальным временем позиционирования в направлении к внеШ
краю диска. Алгоритм не изменяет предпочитаемого направления
пор, пока не достигается внешний или внутренний цилиндр- Из-за аТОр-
иногда его называют алгоритмом лифта (elevator algorithm) или эл н11л,
пым алгоритмом, поскольку лифт тоже двигается в одном наир ^ч11ра-
выполняя запросы, пока не выполнит их все, и только после этого
ет двигаться в обратном направлении. сЯ выс°’
Алгоритм SCAN ведет себя так же, как и SSTF в том, что касае в0диа'
кой пропускной способности и хорошего среднего времени реагиь
Однако поскольку SCAN гарантирует, что все запросы с позицио' ^о0пР°
ем в одном направлении будут выполнены прежде запросов с позз
ванием в другом направлении, он обладает меньшим разбросом j
реагирования, чем SSTF. Как и SSTF, SCAN является ориентирУ
г идиндры алгоритмом. Поскольку головки чтения/записи перемеща-
00 11 ^ежду внутренними и внешними краями дисков, внешние дорожки
FfC\naiOTCH реже, чем дорожки в середине диска, но все же чаще, чем в ал-
00е® е SSTF. Поскольку прибывающие запросы могут выполняться пре-
гоР^запросов, уже находящихся в очереди, и SSTF, и SCAN могут откла-
ть выполнение отдельных запросов до бесконечности.
Рис. 12.8. Порядок выборки при использовании алгоритма SCAN
Вопросы для самопроверки
1. Один из недостатков алгоритма SCAN — то, что он может выпол-
нять ненужные операции позиционирования. Покажите такие опе-
рации на рисунке 12.8.
2. Может ли выполнение запроса бесконечно-откладываться в алго-
ритме SCAN?
Ответы 1) Ненужные операции позиционирования выполняются
после выполнения запроса к цилиндру 8. Поскольку в предпочитае-
мом направлении запросов больше нет, было бы эффективнее изме-
нить предпочитаемое направление сразу же после выполнения этого
запроса. Мы рассмотрим модификации алгоритма SCAN, в которых
отсутствует этот недостаток, в разделе 12.5.6 — алгоритмы LOOK
и C-LOOK. 2) Можно представить себе сценарий, в котором постоянно
поступают запросы к одному и тому же цилиндру, и головка никуда не
смещается. При этом запросы к другим цилиндрам будут отклады-
ваться до бесконечности.
Алгоритм диспетчеризации C-SCAN
So? Модификации алгоритма SCAN, известной как C-SCAN (circular
к '— круговой SCAN) консоль головок двигается от внешнего цилинд-
К внутреннему, выполняя запросы (см. рис. 12.9), затем быстро (без вы-
еНия запросов) возвращается к внешнему цилиндру и вновь начинает
718
перемещаться к внутреннему цилиндру, выполняя запросы. ДЛг
C-SCAN позволяет достичь высокой производительности, удержив-
брос времени выполнения на невысоком уровне, поскольку исключа&Я
криминацию внутренних и внешних цилиндров по сравнению с цк п Т
ми в середине диска30- 31. Как и в алгоритме SCAN, в C-SCAN запрос**^
гут откладываться до бесконечности, если непрерывно будут пос Ь1 Sl°'
запросы к одному и тому же цилиндру (хотя это и менее вероятно
в SCAN или SSTF). В следующих разделах мы рассмотрим модцфИк’ ЧеМ
SCAN, лишенные этого недостатка. аЧйц
Результаты моделирования, приведенные в литературе, показы
что лучшие алгоритмы диспетчеризации обращений работают ц0
уровневой схеме32. При небольшом уровне нагрузки лучше всего рабо
алгоритм SCAN. При средних и высоких уровнях нагрузки лучшие рез^Я
таты дают алгоритмы C-SCAN и другие модификации алгоритма SCAM*
Алгоритм C-SCAN в сочетании с вращательной оптимизацией хорошо
рекомендовал себя при высоких уровнях нагрузки33.
Рис. 12.9. Порядок выборки при использовании алгоритма C-SCAN
Вопросы для самопроверки
1. По какому критерию алгоритм C-SCAN улучшает доступ к на-
2. (Да/Нет) Реализация алгоритма C-SCAN требует того же УР°
кладных расходов, что и SCAN?
Ответы 1) C-SCAN уменьшает разброс времени реагирование#
сравнению с алгоритмом SCAN, поскольку он чаще о !Tirop«,rp’\
к внешним и внутренним цилиндрам. 2) Нет. Реализация аГ)аВнеН11’г
C-SCAN требует дополнительных накладных расходов по с₽ егЛуй**е
со SCAN, когда он завершает перемещение головки к внутре* в
линдру и начинает перемещать ее к внешнему, не выполн
этого последнего перемещения запросы.
fjai/ия производительности ди РоВькс накопителен
г $ Алгоритм диспетчеризации FSCAN и N-шагобый SCAN
К ЛГОРИТМЬ1 F®CAN и N-Шаговый SCAN устраняют опасность бесконеч-
I ^откладывания запросов34’ 35. В алгоритме FSCAN обслуживаются со-
$0?° о алгоритму SCAN только те запросы, которые поступили до начала
fl№c яйого прохода (буква F в названии алгоритма означает «freezing» —
Изживающий», то есть оставляющий запросы в очереди на некоторое
{^я) Запросы, поступившие за время прохода, остаются в очереди и упо-
чиваются для выполнения во время обратного прохода (рис. 12.10).
pflfr шаговый SCAN обслуживает первые N запросов в очереди согласно
ритму SCAN. В ходе одного прохода выполняются N запросов, в ходе
дующего — следующие N и так далее. Поступающие запросы помеща-
в конец очереди (см. рис. 12.11). Алгоритм N-шагового SCAN может
страиваться изменением числа N. При N = 1 алгоритм сводится к алго-
vL,My FCFS. При стремлении N к бесконечности он приближается к алго-
ритму SCAN.
Запрос для цилиндра 37 поступил во время обслуживания запроса цилиндра 47
Запрос для цилиндра 80 поступил во время обслуживания запроса цилиндра 72
12.10.
Порядок выборки при использовании алгоритма FSCAN
*04FSCAN и N-шаговый SCAN обладают хорошей производительностью
рвДствие большой пропускной способности и малых средних времен реа-
Пр0 Вания. Поскольку они предотвращают бесконечное откладывание за-
й^с°в, они также характеризуются меньшим разбросом времени реагиро-
11я’ чем SSTF и SCAN, особенно в случаях, когда в SSTF и SCAN запро-
f вкладывались бы до бесконечности.
Запрос для цилиндра 37 поступил во время обслуживания запроса цилиндра 47
Запрос для цилиндра 80 поступил во время обслуживания запроса цилиндра 72
Рис. 12.11. Порядок выборки при использовании алгоритма N-шаговый SCAN (N = 3)
Вопросы для самопроверки
1. Объясните, в каких случаях FSCAN может обладать худшей пропу-
скной способностью, чем SCAN.
2. Сравните и найдите различия между алгоритмами FSCAN и N-ша-
говый SCAN.
Ответы 1) Если запрос к цилиндру в предпочитаемом направлении
поступает после того, как очередь «замораживается», головка пройд
над цилиндром этого запроса, не выполнив запрос до тех пор, пока я
начнется следующий проход. 2) В обоих алгоритмах использу
SCAN для выполнения части очереди запросов, чтобы избежать &еоче.
нечного откладывания запросов. FSCAN выполняет все запросы ® иИ-
реди, прежде чем начнется движение головок в обратном иапра®
N-шаговый SCAN выполняет только следующие N запросов в очер
12.5.6 Алгоритм диспетчеризации LOOK и С-LOOK о
Разновидность алгоритма SCAN, известная как LOOK, смотрит ®neE^ie-
конца текущего прохода головок, выбирая следующий запрос для и
ния. Если в текущем направлении запросов больше нет, LOOK и3^д£)-
предпочитаемое направление и начинает новый проход (см. РиС‘ дцФт
В этом смысле его можно назвать «алгоритмом лифта», посколь
движется в одном направлении, пока в этом направлении есть подл 5де'
выполнению запросы, после чего начинает двигаться в обратном
нии. Этот алгоритм избавляет от ненужных операций позицион Р те •де
присутствующих в других разновидностях алгоритма SCAN щра
вую сторону рисунка 12.12 и левую сторону рисунка 12.8).
производительности дисковых накопителей
f «ггов°й LOOK — C-LOOK — использует ту же методику, что и C-SCAN,
^уменьшить дискриминацию запросов к цилиндрам на краях диска,
текущем проходе внутрь диска запросов больше нет, головка чте-
₽писи перемещается к цилиндру запроса, ближайшему к внешнему
00/ ЗЙ11Ска (не выполняя по пути других запросов) и начинает новый проход.
цтМ C-LOOK обладает потенциально меньшим разбросом времени реа-
ния, чем LOOK, и высокой пропускной способностью (хотя обычно
дтей, чем LOOK)36. На рисунке 12.13 кратко охарактеризованы все рас-
И‘ме опные до сих пор алгоритмы диспетчеризации доступа к диску.
c?JoTPew
Ли. 12.12. Порядок выборки при использовании алгоритма LOOK
Алгоритм Описание
FCFS
SSTF
SCAN
C$CAN
fSCAN
Шаговый SCAN
lc0K
Выполняет запросы в порядке их поступления.
Выполняет первым запрос с минимальным временем позиционирования.
Головка перемещается вперед и назад, выполняя запросы по алгоритму SSTF
в предпочитаемом направлении.
Головка движется от внешних цилиндров к внутренним, выполняя запросы
по алгоритму SSTF в предпочитаемом направлении (вовнутрь). По достижении
внутреннего края диска головка перемещается к внешнему краю и начинает
выполнять запросы при новом проходе ко внутренним цилиндрам.
Запросы выполняются так же, как в алгоритме SCAN, но выполнение
поступающих запросов откладывается до следующего прохода. Устраняет
опасность бесконечного откладывания Запроса.
Выполняет запросы, как FSCAN, но только N запросов за проход. Устраняет
опасность бесконечного откладывания запроса.
Аналогично SCAN, за исключением того, что направление движения головки
С'*-00К
изменяется при отсутствии запросов в предпочитаемом направлении.
Аналогично С-SCAN, за исключением того, что головка останавливается после
выполнения последнего запроса в предпочитаемом направлении, а затем
выполняет запрос к цилиндру, ближайшему к противоположному краю диска.
•>3. Сводная таблица алгоритмов оптимизации по позиционированию
722
Вопросы для самопроверки
1. Почему пропускная способность алгоритма С-LOOK обыч
чем таковая у алгоритма LOOK? ' 4£i0
2. В каком порядке алгоритм С-LOOK выполнил бы запросы
ные на рисунке 12.5? ’ 110Каз^
Ответы 1) Время, потраченное в конце прохода на переме
ловки от края пластины к цилиндру, самому дальнему из треб?еН11е Го
запросам, увеличивает среднее время реагирования, соотвХе?Ь1х Но
уменьшая пропускную способность. 2) 52, 47, 33, 8, 99, 75, 74<ТВечНо
12.6 Оптимизация по вращению
Поскольку основной составляющей времени доступа в ранних м,.
_ , "НОПй-
телях было время позиционирования, первые разработки фокусировали
на оптимизации по позиционированию. Однако в современных накопите-
лях время позиционирования и средняя вращательная задержка имеют
одинаковый порядок, и оптимизация по вращению может существенно по-
высить производительность37. Процессы, обращающиеся к данным после-
довательно, часто считывают данные, занимающие целые дорожки, и их
выигрыш от оптимизации по вращению невелик. Однако при наличии
множества запросов к данным, случайным образом распределенным по ци-
линдрам диска, оптимизация по вращению может существенно повысить
производительность. В этом разделе мы рассмотрим, как совместить опти-
мизацию по вращению и по позиционированию, чтобы достичь максималь-
ной производительности.
12.6.1 Алгоритм диспетчеризации SLTF
Когда блок головок чтения/записи перемещен к определенному цилинд-
ру, в очереди может присутствовать несколько независимых запросов к раз-
ным дорожкам этого цилиндра. Алгоритм SLTF (shortest latency tuI^
first — «кратчайшая задержка сначала») просматривает все эти запрос
и выполняет первым запрос с минимальной вращательной
(см. рис. 12.14). Этот алгоритм близок к теоретически оптимальному и с^а
нительно несложен в реализации38. Вращательную оптимизацию иногда
зывают секторным упорядочением (sector queuing); запросы к сеК^од-
упорядочиваются согласно позициям секторов на диске, и первыми в
няются запросы к ближайшим в направлении вращения секторам-
Рис. !Zf4. Алгоритм диспетчеризации SLTF. Запросы будут выполнены
в указанном порядке независимо от порядка их получения
Вопросы для самопроверки
1. Почему секторное упорядочение легко реализовать?
2. Подходит ли вращательная оптимизация для современных накопи-
телей? Почему?
Ответы 1) Секторное упорядочение определяет лучший порядок
доступа к секторам дорожки. Если предполагать, что сектора располо-
жены в фиксированных местах на дорожке и что диск может вращать-
ся только в одном направлении, секторное упорядочение сводится
к простой задаче сортировки. 2) Да, вращательная оптимизация под-
ходит для современных накопителей. В современных накопителях
времена позиционирования и вращательные задержки имеют одина-
ковый порядок величины.
Л
,б-Алгоритмы диспетчеризации SPTF и SA TF
ц0А^г°ритм SPTF (shortest positioning time first — «кратчайшее время
Зонирования сначала») обслуживает первым запрос с минималь-
но ®Ременем позиционирования — суммой времени, необходимого на
головки, и вращательной задержки. Как и SSTF, SPTF обла-
®Ь1сокой пропускной способностью и малым средним временем реаги-
724
%
рования, но он может бесконечно откладывать выполнение отдедь
просов к внешним и внутренним цилиндрам39. Нь,Х
Разновидность алгоритма SPTF — алгоритм SATF (shortest асе
first — «кратчайшее время доступа сначала») выполняет первым^
с минимальным временем доступа, то есть суммой времени позицц3911^
вания и времени передачи. У SATF пропускная способность выц.01*1’^
у SPTF, но выполнение больших запросов может откладываться в ч ’
горитме до бесконечности при наличии непрерывных запросов Маль
емов данных. Производительность и алгоритма SATF, и алгоритма
можно улучшить, реализовав механизмы «прогноза», описанные г,
ле 12.5.640. ' ₽азДе.
На рисунке 12.15 показана разница между алгоритмами SATF и ЧРтг,
На рисунке 12.15(a) диск получает два запроса к блокам данных один
вого размера — А и В, расположенным на соседних цилиндрах. Лави, К°'
расположены на том же цилиндре, что и головка чтения/записи, но п
близительно в половине оборота диска от головки. Данные В расположе*
под головкой, но на соседнем цилиндре. В этом случае время передачи оди
наково для данных А и для данных В, поскольку эти блоки данных одина
ковы по размеру, и алгоритм SATF аналогичен SPTF. Поэтому для данного
диска и SATF, и SPTF выполнят первым запрос В, поскольку на перемеще-
ние головки на один цилиндр нужно меньше времени, чем на поворот дис-
ка на 180 градусов. Если время перемещения достаточно мало, то накопи-
тель может выполнить запрос к данным В, переместить головку и выпол-
нить запрос к данным А за один оборот диска. В то же время, алгоритм
SSTF выполнил бы сначала запрос А, и на выполнение двух запросов
у него ушло бы больше одного оборота диска. Поэтому алгоритмы SATF
и SPTF могут улучшать пропускную способность по сравнению с SSTF.
а)
Направление вращения
б)
Консоль
головки
В
Начало
блока
данных В
А
А
7'
Рис. 12.15. Примеры работы алгоритмов SPTF (а) и SATF (б)
хациЯ производительности дисковых накопителей
rzt>
теперь рассмотрим случай, когда данные В занимают целую дорожку,
йЫе А хранятся в одном секторе, как показано на рис. 12.15(6). Пред-
вД#в ,нМ, что положение первого байта каждой записи то же, что в преды-
^ЬДО^случае. В этом случае алгоритм SPTF выполнит запросы так же,
аНьШе> поскольку времена позиционирования останутся неизмен-
на# 0 однако алгоритм SATF сначала выполнит запрос А, поскольку на
лД1®0'пОлнение нужно время половины оборота диска плюс время переда-
ем ВЬдЛя выполнения запроса В нужно время, равное сумме времени вра-
тельной задержки и времени передачи, то есть времени одного оборота
#йСдл^оритмы SATF и SPTF требуют знания характеристик накопителя,
ючая времена задержек, времена перемещения головок между цилинд-
В1< и и относительные позиции секторов. К сожалению, многие современ-
Р накопители предоставляют некорректные сведения о геометрии. На-
'имер, многие накопители скрывают от операционной системы данные,
используемые для поиска и устранения ошибок (чтобы эти данные не мог-
ли быть случайно или умышленно изменены), и сектора с последователь-
ными номерами на этих дисках могут располагаться не в непрерывных об-
ластях диска. На некоторых системах при обнаружении сбойных секторов
назначаются альтернативные номера секторов. Например, если сектор 15
становится нерабочим, запросы могут отправляться к сектору, не располо-
женному рядом с секторами 14 или 16. Эти альтернативные сектора могут
размешаться в произвольных местах на диске, и для чтения из них данных
могут потребоваться непредусмотренные алгоритмами операции позицио-
нирования.
Такие механизмы, как использование альтернативных секторов, повы-
шают целостность данных, но противодействуют усилиям, направленным
на повышение производительности диска с помощью диспетчеризации дос-
тупа к нему, поскольку накопители предоставляют операционной системе
неполную или некорректную информацию41. Хотя некоторые архитекту-
ры и накопители предусматривают команды, позволяющие получить све-
дения о действительной геометрии диска, эта возможность поддерживает-
Ся не всеми накопителями. Архитектурные особенности некоторых нако-
пителей затрудняют применение диспетчеризации доступа; за
Дополнительной информацией обращайтесь к Web-ресурсам, указанным
® соответствующем разделе в конце главы.
прямолинейный подход к повышению производительности накопите-
и заключается в уменьшении вращательной задержки путем повышения
Рости вращения. Однако разработчики столкнулись со значительными
УДностями при повышении скоростей вращения накопителей. Высоко-
ь Р°тные накопители потребляют больше энергии (это весьма существен-
бол^31 портативных компьютеров с батарейным питанием), излучают
тепла, обладают более высоким уровнем шума и требуют более до-
вел СТоягЧих механических и электронных устройств управления42.
Тут ДСтвие этих и других трудностей скорости вращения накопителей рас-
слишком быстро (на несколько процентов в год в течение последнего
тИлетия) — до 5400 или 7200 оборотов в минуту для настольных сис-
11 Д0 10000-15000 оборотов в минуту для серверов и высокоуровневых
и1'ем4з.
726
rx
Вопросы для самопроверки
1. В чем различие между алгоритмами SPTF и SATF? Поле
ботчик может предпочесть один из них?
2. Какие факторы мешают операционным системам получат
сведения о геометрии дисков в накопителях? ь
Ответы 1) Алгоритм SPTF выполняет запрос, выполнение
го может начаться быстрее всего. SATF выполняет запрос в
ние которого может закончиться быстрее всего. Хотя у ’алЬ1По-Пце',
SATF пропускная способность выше, он предпочитает выпо TH°PlITh,a
просы малого объема. Поэтому SATF удобнее для систем, вы ЯТЬ За-
много запросов малого объема. SPTF удобнее для систем’ выд31011*11*
запросы как малого, так и большого объема, поскольку о’н не
мает во внимание размер запроса. 2) Некоторые типы накоп1РИ8й’
скрывают служебную информацию, например, положение ля1346®
контроля ошибок и сбойных секторов. данНЫх
12.7 Системные соображения
Когда полезно применять диспетчеризацию доступа к диску? В каких
случаях оно может снизить производительность? На эти вопросы нужно
отвечать, рассматривая систему в целом. В следующих разделах рассмат-
ривается ряд моментов, которые могут оказать влияние на принимаемые
решения.
Устройства хранения как ограничивающий фактор
Если дисковые накопители становятся узким местом в системе, некото-
рые разработчики рекомендуют добавить в нее дополнительные накопите-
ли (см. «Размышления об операционных системах: Насыщение и узкие
места»). Это не всегда решает проблему, поскольку узкие места могут по-
являться из-за больших нагрузок на относительно небольшое количество
дисков. При обнаружении такой ситуации для устранения узкого места
и повышения производительности можно использовать диспетчеризацию
доступа к диску.
Нагрузка на систему
Алгоритм диспетчеризации дисковых операций может принести
пользы в системах пакетной обработки, где количество одновременно Р
тающих программ невелико. Эффект от диспетчеризации доступа к Д
увеличивается по мере роста количества случайных запросов к дис ^0.
множества программ. Например, файловые серверы в локальных
гут получать запросы на передачу файлов от сотен пользователей-
нагрузка соответствует случайному порядку выборки данных, и в. федТ-
ных ситуациях диспетчеризация доступа к диску дает хороший э цде
Аналогично, системы онлайн-обработки транзакций (OLTP " да®'
transaction processing systems), например, Web-серверы и сервер®1 да®'
ных, обычно получают множество запросов к небольшим фрагмент
ных, случайным образом расположенным на дисках (т.е. НТМЬ-Ф
^ция производительности дисковых накопителей
сЯм баз данных). Исследования показывают, что алгоритмы диспет-
адии доступа, например, С-LOOK и SATF (с прогнозом) могут повы-
производительность систем такого типа44’ 4S.
Размышления об операционных системах
Насыщение и узкие места
ррерадионным системам часто приходит-
правлять различными сочетаниями про-
мм и аппаратных устройств. Если произво-
Г₽ рпьность системы мала, возможно, вы ста-
рете говорить о «системе в целом», отмечая,
чТо «вся система малопроизводительна». Од-
нако в действительности часто бывает так, что
насыщены (то есть полностью задействованы
и не могут обрабатывать большее количество
запросов) только один или несколько ресур-
сов. Такие ресурсы называются узкими мес-
тами (bottleneck — буквально «бутылочное
горлышко») системы. Поиск узких мест и их
устранение с помощью добавления ресурсов
в одном или нескольких местах системы мо-
жет привести к существенному повышению
производительности всей системы. Системы
должны быть устроены таким образом, чтобы
поиск узких мест не требовал чрезмерных
усилий. В главе 14 подробно рассматривают-
ся вопросы производительности, включая на-
сыщение и узкие места.
НераВномерное распределение запросов
Многие авторы компьютерных статей при выполнении анализа подразу-
мевают, что запросы доступа распределяются равномерно. Заключения,
полученные с учетом равномерного распределения запросов, могут быть
неверны для систем, в которых запросы распределены неравномерно на по-
еерхности дисков. Неравномерное распределение запросов (nonuniform
request distribution) часто встречается в ряде ситуаций, и такое распреде-
лив тоже исследовалось46. В одной из работ Линч (Lynch) определил, что
Подавляющее большинство обращений к диску выполняется к тем же ци-
лпндрам, что и непосредственно предшествующие обращения47.
Чцна из часто встречающихся причин сильно локализованных неравно-
PHbix распределений запросов — использование больших файлов после-
ательного доступа на отдельных накопителях. Когда операционная сис-
фЛ выделяет пространство для соседних записей в последовательном
гд ^Ле’ Она обычно размещает эти записи на одной и той же дорожке. Ко-
д0 ^°Р°жка заполняется, последующие записи размещаются на других
ОДках в том же цилиндре; а когда заполняется цилиндр, не помещаю-
Седеся Записи размещаются в соседних цилиндрах. Поэтому запросы к со-
L "вУЮщим записям в таких файлах часто вообще не требуют выполне-
°ПерацИй позиционирования. При необходимости выполняются ко-
йе операции позиционирования, перемещающие головки к соседним
ЙНдрам. Очевидно, что в таких случаях оптимальным будет алгоритм
728
диспетчеризации доступа FCFS. Более того, накладные расходы
ные с использованием сложных алгоритмов диспетчеризации дост СВя'’Ч
гут привести здесь к падению производительности. '
Схемы организации файлов
Как мы покажем в главе 13, применение изощренных схем оргя
файлов может привести к появлению большого количества ч 3аЧкц
с большими временами позиционирования. Иногда в подобных ем^°с°в
извлечение данных из файла требует обращения к общему указателю*^1^
зателю цилиндра, а затем собственно к месту хранения данных. В х ’
го процесса возникает ряд задержек из-за выполнения промежуто ЭТ°'
операций позиционирования. Поскольку основной указатель и указа HbIX
цилиндров обычно хранятся на диске (но отдельно от собственно дани
эти операции могут дорого обойтись. Такие схемы организации файд
удобны для разработчиков приложений, но могут привести к падению °В
изводительности. П₽о'
Вопросы для самопроверки
1. Почему во многих системах распределение запросов является не-
равномерным?
2. Почему эффективность применения диспетчеризации доступа
к диску растет с ростом нагрузки на систему?
Ответы 1) Данные в файлах часто хранятся в смежных блоках,
и за запросом к некоторому цилиндру может следовать запрос к этому
же цилиндру или к цилиндру, близкому к нему. 2) С ростом нагрузки
на систему последовательности выборки данных становятся все более
случайными, соответственно, растет нагрузка на накопители. Диспет-
черизация доступа повышает производительность, уменьшая количе-
ство ненужных операций позиционирования.
12.8 Кеширование и буферизация
Многие системы используют дисковый буфер (disk cache buffer),
ставляющий собой область в оперативной памяти, которую операди
система резервирует для дисковых данных. С одной стороны, зарезер
ванная память используется в качестве кэша, позволяя процессам аТЬ
получать данные, которые в противном случае нужно было бы счит
с диска. С другой стороны, зарезервированная память использует
буфер записи, позволяя системе отложить запись измененных даН
тех пор, пока накопитель не будет слабо нагружен или пока диск дй-
ловка не переместится в удобную позицию, чтобы увеличить пр дадеР'
тельность ввода/вывода. Например, операционная система
живать запись измененных данных на диск, чтобы позволить неск
запросам к смежным областям собраться в очередь, так, чтобы иХ
было выполнить одним пакетным запросом ввода/вывода. ~ ра3Р0
Организация дискового буфера связана с рядом сложностей ДЛ дОл
ботчиков операционных систем. Поскольку размер дискового буФ
}Оция производительности дисковых накопителей
~rzy
Г йыть ограничен, чтобы активным процессам оставалось достаточно па-
° разработчик должен реализовать какую-то стратегию замещения,
^замещения дискового буфера схож с вопросом замещения страниц
ро^Рдьной памяти, и разработчики используют для их решения похо-
иеМы. Чаще всего разработчики выбирают алгоритм, замещающий
ПвСего неиспользуемую часть в буфере.
дй^^вая сложность связана с тем, что использование буфера может при-
к нарушению целостности данных. Дисковые буферы размещаются
розависимой памяти, и если энергоснабжение системы будет нару-
р момент, когда в буфере находятся измененные данные, изменения
^е14° потеряны. Чтобы защититься от этой угрозы, содержимое буфера пе-
ически переносится на накопители; это уменьшает вероятность поте-
Ри0„анных при сбоях в системе.
^Система, в которой реализовано кэширование с отложенной записью
«rite-back caching), не записывает изменившиеся данные на диск немед-
енно. Вместо этого содержимое буфера записывается на диск периодиче-
ки что позволяет запросам ввода/вывода накапливаться и выполняться
пакетами во время одной операции ввода/вывода. Система, использующая
кэширование со сквозной записью (write-through caching), записывает
данные и в буфер, и на диск при каждом изменении данных. Этот подход
не дает накапливать запросы ввода/вывода, но уменьшает опасность нару-
шения целостности данных в случае сбоя в системе48.
Многие из современных накопителей содержат независимый высоко-
скоростной буфер (иногда называемый встроенным кэшем), объемом в не-
сколько мегабайт49. Если запрашиваемые данные хранятся в этом буфере,
то накопитель может передать их очень быстро, почти со скоростью работы
оперативной памяти. Кроме того, некоторые контроллеры дисковых ин-
терфейсов (в основном SCSI или RAID) содержат собственные буферы, от-
дельные от оперативной памяти. Если запрашиваемые данные не находят-
ся в буфере в оперативной памяти, то буфер накопителя может увеличить
производительность, выполняя запросы без выполнения относительно
медленных механических операций50. Однако в одной из работ показано,
что накопители со встроенным кэшем обычно используют алгоритмы заме-
щения, слабо приспособленные к случайным последовательностям запро-
> что приводит к производительности, меньшей, чем оптимальная51.
®сьма вероятно также, что буфер в оперативной памяти и встроенный бу-
Накопителя будут содержать одни и те же данные, что приведет к не-
*Ч*ективному использованию ресурсов.
Вопросы для самопроверки
1. Какие параметры зависят от размера дискового буфера системы?
2. Объясните, когда лучше использовать кэширование с отложенной
записью, а когда — кэширование со сквозной записью, и почему.
730
Ответы 1) Дисковый буфер маленького объема предоставп
ше памяти активным процессам, но в нем, скорее всего, ря->Яет%
только маленькая часть нужных данных, и многие запросы
подняться непосредственно накопителем. Кроме того, малень ь 4
ограничивает количество запросов на запись, которые можно
и данные придется часто переносить на диск. При болыцо
нужно будет выполнять меньше операций ввода/вывода, но д,?1
сов и данных останется меньше свободной памяти, что может Я
к аварийным остановам процессов или сильному замедлению j, ИвесТи
нения. 2) Кэширование с отложенной записью позволяет снеге* Bbltl0Jr
пливать измененные данные и уменьшать количество
к накопителям, но оно повышает опасность потери данных пп
или отключениях питания. Поэтому кэширование с отложенно“ С®ОчХ
сью подходит для систем, в которых производительность важ * 3аПй'
дежности (например, в некоторых суперкомпьютерах). Кэширова^
сквозной записью немедленно записывает измененные данные наНИе С°
и оно хорошо подходит для систем, в которых потеря данных нед0**’
тима (например, для серверов баз данных). д
12.9 Другие приемы повышения
производительности накопителей
Мы рассмотрели оптимизацию производительности накопителей с по-
мощью алгоритмов диспетчеризации доступа и оптимизации системной
архитектуры. В этом разделе мы рассмотрим несколько дополнительных
приемов оптимизации производительности.
По мере добавления и удаления записей данные становятся все более
рассеянными по поверхности диска, или фрагментированными (fragmen-
ted). Даже файлы последовательного доступа, которые вроде бы должны
представлять собой непрерывные последовательности секторов и обеспечи-
вать возможность быстрого доступа, бывают сильно фрагментированными,
что увеличивает время доступа. Многие операционные системы предостав-
ляют возможности дефрагментации (defragmentation) или реорганизации
диска (disk reorganization), которые могут периодически использоват^
для реорганизации файлов. Соответствующие программы размещают
дующие друг за другом фрагменты файлов в непрерывных последова
ностях секторов на дисках. Системы, использующие некруговые раз
ности алгоритмов SCAN для диспетчеризации доступа к накопител
ращаются к средним дорожкам чаще, чем к краевым. В таких си
файлы, к которым часто обращаются, могут размещаться на сред
рожках, чтобы ускорить доступ к ним. тОрЫе’
Кроме того, операционные системы могут помещать файлы, чгОб^
вероятно, будут изменяться, рядом со свободными частями диска,
уменьшить вероятность фрагментации. По мере роста файлов н г[ецВ1’1Х
ные будут помещаться в свободных соседних областях, а не в
местах диска. Некоторые операционные системы позволяют раз ^олЬ^°
на несколько разделов (partition), и файл может располагатьс
в одном разделе. Это также уменьшает фрагментацию52. Однако 'c^pgfic -
вание разделов может привести к бесполезной трате дискового пр
^ация производительности дисковых накопителей
I яаЛ°гичн0 внутренней фрагментации в страничных системах вирту-
гИй памяти.
которые системы используют сжатие, или упаковку данных (data
? 0е ssion), чтобы уменьшить объем, занимаемый информацией на диске
^^размышления об операционных системах: Сжатие и распаковка дан-
(СЙ' \ Сжатие данных уменьшает размер записей, заменяя часто встре-
иеся последовательности битов последовательностями меньшего раз-
Поэтому сжатые данные занимают меньше места, но при сжатии ин-
^^"япия не теряется. Это может, в конечном итоге, уменьшить
форм
зество операций позиционирования и время передачи. Однако при
«и и последующей распаковке данных весьма заметно нагружается
рессор системы.
(Системы, которым нужно быстро получать доступ к каким-то данным,
„прают от размещения нескольких копий этих данных в разных местах
(см. «Размышления об операционных системах: Избыточность»),
дго может существенно ускорить доступ, но дополнительные копии могут
ряять заметную часть диска. Этот прием более удобен для неизменяю-
дцхся данных, которые будут только читаться, или для данных, которые
будут изменяться редко. Необходимость частых изменений уменьшит эф-
фективность этого приема, поскольку понадобится изменить каждую ко-
пию данных. Кроме того, при отказе системы данные могут утратить цело-
стность и синхронность, если будет изменена только часть копий.
В многодисковой системе, в которой может выполняться в любой мо-
мент только одно обращение к дискам, производительность можно увели-
чить репликацией часто требуемых данных на нескольких дисках, что по-
высит пропускную способность. Некоторые RAID-массивы, рассматривае-
мые в разделе 12.10, реализуют такой подход.
Кроме того, можно существенно повысить производительность, собирая
записи в блоки. Если смежные записи считываются и записываются цель-
ным блоком, то для этого нужна одна операция позиционирования; если
они считываются или записываются по отдельности, то нужна одна опера-
ция позиционирования на каждую запись.
Системы, отслеживающие операции доступа к диску, могут попытаться
^писать часто требуемые данные в выгодную позицию в иерархии памяти
•е- в основной памяти или в кэше), а редко требуемые данные — на более
"^ленный носитель (т.е. на жесткий диск или компакт-диск). Такой под-
к5 П0ВЬ1и1ает производительность в целом, но понижает скорость доступа
&Ые^К° тРебУемым данным. Это неприемлемо, если редко требуемые дан-
₽Нз Принадл^ат высокоприоритетным приложениям. Иногда целесооб-
1ц,_Н° выделить отдельный диск отдельному высокопроизводительному
Г^^ению.
Kqjj ° Многих системах можно выделить временные интервалы, когда к на-
11ЬтрТеЛям Нет запросов, ожидающих выполнения. В течение подобных
3^ РВалов консоль головки остается неподвижной, ожидая следующего
Са • Если консоль головки перемещена к краю диска, то, вероятно,
Ч ®Ь1Полнения следующего запроса потребуется длинная операция пози-
Н, к ₽°вания. А если консоль перемещена к середине диска или к облас-
L которой часто поступают запросы, то операция позиционирования,
Ятн°, будет короткой. Перемещение консоли головки к позиции, кото-
рая сведет к минимуму вероятное время последующего позицИо
ния, называется упреждающим позиционированием головки <r-ifoptj
anticipation)54. Wlsk
Упреждающее позиционирование головки может быть полезно
мах, где последовательности обращений к диску часто ограничива В
дельными областями. Для достижения наилучших результатов ТСа0т
должна перемещаться к области, для которой часто поступают Г°ЛовКа
(а не к центру диска). Если процесс выдает запросы к последователь311^00^
положенным точкам на диске, то перемещение головки к центру ди °^вс-
еле выполнения каждого запроса приведет к необходимости Не, Ка п°'
операций позиционирования. В этом случае упреждающее позицищщ Й14х
ние головки может снизить производительность55.
Вопросы для самопроверки
1. Каким образом дефрагментация и реорганизация диска повьп
производительность? апа®т
2. Почему сжатие данных может получить большее распространи
в будущем? Ие
3. При каких обстоятельствах нецелесообразно сдвигать головки
к центру диска при отсутствии обращений к диску?
4. Почему одновременное выполнение нескольких программ услож-
няет задачу упреждения запросов к диску?
Ответы 1) Дефрагментация собирает данные в непрерывные бло-
ки на поверхности диска, соответственно уменьшая суммарное время
доступа к ним за счет уменьшения потребности в позиционировании
головок при доступе к последовательно размещенным данным. Реор-
ганизация диска помещает часто требуемые данные в более удобные
места на диске (например, в средние дорожки для некруговых алго-
ритмов диспетчеризации доступа), чтобы уменьшить среднее время
позиционирования. 2) Между производительностью процессоров
и пропускной способностью каналов связи существует все увеличи-
вающийся разрыв. Уменьшающееся за счет сжатия данных в₽®“®
доступа может перевесить накладные расходы, связанные с Heot)"g.
димостью сжатия и распаковки данных. 3) Если программы часто
ращаются к отдельным областям диска, и эти области 11ахо,дя1\-гст.
в центре диска, то перемещение головки к центру диска при °яцИй
вии обращений приведет к необходимости дополнительных опе₽мвая
позиционирования при появлении обращений. 4) Многопрогра меяН0
система может обслуживать запросы от нескольких одновр* g^c-
выполняющихся процессов, и на диске может быть несколько оПре-
тей, к которым часто поступают запросы. В этом случае труд кОгД»
делить, в какую позицию должна перемещаться головка,
к диску нет обращений.
,ия производительности дискоиых накооиглелеи
Размышления об операционных системах
^атие и распаковка данных
коасным применением дешевой
^рной вычислительной мощности со
.^НЬ1Х процессоров являются сжатие
Й^иковка данных. На жестких дисках они
уменьшать объемы, занимаемые
мИ Сжатие данных важно также при
аче их по сетям. Полоса пропускания
’е₽е?оВ глобальных сетей растет значительно
пеннее, чем вычислительная мощь про-
fccopoe- Капитальные вложения в сетевую
Оргструктуру, особенно в каналы переда-
ли данных, огромны. Просто нереально об-
делять всю сетевую инфраструктуру в мире
каждый раз при появлении более быстрой
технологии передачи данных. Это значит, что
отношение вычислительной мощности про-
цессоров к скорости передачи растет с тече-
нием времени, и вычислительная мощь об-
ходится дешевле, чем пропускная способ-
ность каналов. Сжатие данных позволяет
уменьшать размер сообщений и передавать
их по относительно медленным сетям, прак-
тически увеличивая их пропускную способ-
ность. После получения сжатые сообщения
приходится распаковывать, чтобы их можно
было использовать. Механизмы сжатия
и распаковки данных все чаще встраиваются
в операционные системы.
^^Лразмышления об операционных систе ах
Избыточность
На практике вам встретится множество
Учаев применения избыточности в опера-
п НЬ|Х системах. Часто избыточность ис-
Ч1обЗУ10Т ДЛЯ создания резервных копий,
ной га|ЭантиРОвать, что в случае потери од-
иовлК°ПИИ ИнФ°рмации она будет восста-
ет и 9 В многопроцессорной системе мо-
ЦесСо Пользоваться набор идентичных про-
иПоТо В' К0Т0Рые выделяются процессам
мзбь|Т Ка,и По мере необходимости. У такой
S Н°сти есть несколько преимуществ.
может функционировать и
^Ита Веннь,м процессором, наличие до-
%ВоЛЬНых процессоров дает прирост
Ращ7еЛьности' поскольку процессоры
^Чеп °тать параллельно. Избыточность
лезна сточки зрения отказоустойчи-
если один из процессоров выходит
из строя, система может продолжать рабо-
тать. RAID-массивы уменьшают время дос-
тупа к данным на дисках, помещая
избыточные копии данных на различных
дисках, которые могут работать параллель-
но. Можно также разместить избыточные
копии данных в разных областях одного
и того же диска, чтобы свести к минимуму
перемещение головки чтения/записи и ко-
личество оборотов диска, нужных для дос-
тупа к данным. При этом повышается произ-
водительность. Безусловно, за избыточ-
ность приходится расплачиваться. Ресурсы
стоят денег, а аппаратное и программное
обеспечение, управляющее ими, становится
сложнее. Это еще один пример необходи-
мости выдерживать баланс стоимость/про-
изводительность в операционных системах.
734
Г.
12JO RAID-Maccijtfbi
RAID (Redundant Array of Independent Disks — Избыточный м
зависимых дисков) — это совокупность средств, с помощью котор CCllfi
висимые диски организуются в группы с целью повышения nD
тельности и/или надежности. RAID был впервые предложен Патт 13б°Д15
(Patterson), Гибсоном (Gibson) и Кацем (Katz). В их статье в аббре1₽С°5°М
RAID литера I обозначала Inexpensive — «недорогой», но это 3В11а'гУ1>е
было позже изменено на Independent — «независимый», посколз
следние годы для реализации RAID весьма часто используются В 11°"
высокопроизводительные накопители56. 14 Р°гие
Авторы статьи заметили, что быстродействие процессоров, объем
тивной памяти объемы внешних накопителей росли быстро, а СКрПе₽а'
ввода/вывода (особенно для дисковых накопителей) — намного медлен^8
Компьютерные системы становились все более зависимыми от ввода/вк
да — они не могли выполнять запросы на ввод/вывод так быстро, как а
запросы возникали, и не могли передавать данные так быстро, как этидад
ные потреблялись. Чтобы увеличить скорость передачи и пропускную спо
собность, авторы предложили создавать массивы дисков, к которым мож-
но будет обращаться одновременно57.
12.10.1 Обзор RAIO-moccu0o0
В своей статье Паттерсон и его коллеги предложили пять различных ор-
ганизаций, или уровней (disk levels) дисковых массивов58. Каждый уровень
RAID-массива характеризуется разделением данных (data striping) и избы-
точностью (redundancy). Разделение данных означает, что пространство
устройства хранения делится на блоки фиксированного размера, называе-
мые полосами (strips). Следующие друг за другом блоки файла размещают-
ся на соседних полосах на разных накопителях массива, и запросы к дан
ным файла могут обрабатываться сразу несколькими накопителями,
уменьшает время доступа. Лента (stripe) представляет собой совокупи
одинаковых областей на разных накопителях (например, дорожек с °^л0_
ковыми номерами). На рисунке 12.16 часть файла делится на четыре
сы одинаковой длины, каждая из которых размещается на своем нак
ле. Поскольку эти полосы размещены на одинаковых местах в накоп льКЙ.
они образуют ленту. Разделение данных распределяет их между не5К(^10с<’б'
ми накопителями, что позволяет достичь более высокой пропускной есТв-
ности, чем для одиночного накопителя, поскольку одновременно о У
ляется доступ к данным на нескольких накопителях. в°
При выборе размера полосы разработчик системы должен пРиа3меРа’
внимание средний размер запросов к диску. Полосы небольшого Р ^0*^
называемые тонкими полосами (fine-grained strips), распределяю^^ bbJ
между несколькими дисками. Соответственно они уменьшают вР^^с'
полнения запросов и увеличивают скорости передачи, посколькУ^^ ([о ,
во дисков одновременно передают или принимают данные запР зацр°ь
эти диски выполняют запрос, они не могут выполнять другие
в очереди, поддерживаемой системой.
щая производительности дисковых накопителей
М-еУд большого размера, называемые широкими полосами (соаг-
fl0? ed strips), позволяют небольшим файлам целиком размещаться на
ае4гЯцакопителе. В этом случае некоторые запросы могут целиком вы-
ЗР^гьсЯ отдельными накопителями массива. В результате увеличивает-
ятность того, что можно будет одновременно выполнять несколько
И ®еР° Однако малые по объему запросы будут выполняться отдельны-
Зй’4* цителями, и скорость передачи для них будет меньше, чем при ис-
„яНИИ ТОНКИХ ПОЛОС.
5оЛь3°
12.16.
Лента и полосы, созданные для одиночного файла в RAID-массивах
акие системы, как Web-серверы и серверы баз данных, выигрывают от
Но енения широких полос, поскольку при их использовании могут вы-
•Я'гься сразу несколько операций ввода/вывода. Системы класса супер-
8Ь1и Ь1°ТеР°в’ тРебующие быстрого доступа к небольшому числу записей,
%^Ь1Вак)т от использования узких полос, поскольку они дают большие
у СТи передачи при выполнении отдельных запросов59.
Личение скорости передачи достигается в RAID-массивах немалой
°сть Увеличением количества накопителей в массивах растет вероят-
того, что один из накопителей выйдет из строя. Например, если
’То вач наработка на отказ (Mean Time То Failure — MTTF) для одиноч-
но в ак°пителя составляет 200 000 часов (около 23 лет), то для массива из
°Нителей она составит 2 000 часов (около 3 месяцев)60. Если один
®ье обителей откажет, то будут повреждены все файлы, полосы которых
н<ены на этом накопителе. В системах, решающих критичные, жиз-
|®азкные задачи, потеря данных может иметь катастрофические по-
следствия (см. «Размышления об операционных системах: Жизнев
ные системы»). Поэтому RAID-массивы должны хранить дополнит
информацию, которая позволит восстановить данные в случае по
ошибок — подход, называемый избыточностью. RAID-массивы
ют избыточность для достижения отказоустойчивости (т.е. способу,
хранить данные при возникновении отказов; см. «Размышления
ционных системах: Отказоустойчивость»),
Прямолинейный подход к обеспечению избыточности — дублип
дисков (disk mirroring), при котором каждый уникальный элемент
записывается на двух накопителях. Недостаток этого подхода в т вйЬ1Х
только половина емкости массива используется непосредственно дл ’ ',То
нения уникальных данных. Как мы покажем далее, некоторые
RAID-массивов используют изощренные методики, позволяющие иг
зовать дисковое пространство более эффективно61. °ль-
Чтобы совместить улучшение производительности с избыточное
система должна эффективно разделять файлы на полосы, формиров
файлы из полос, определять местоположение полос в массивах и обеспе Tl
вать поддержку избыточности. Использование для выполнения этих one
раций процессора общего назначения может существенно снизить произво]
дительность, отнимая заметную часть процессорного времени. Поэтому во
многих RAID-массивах для быстрого выполнения нужных операций ис-
пользуется специальный аппаратно реализованный RAID-контроллер
(RAID controller). Аппаратные RAID-контроллеры также упрощают реали
зацию RAID-массивов, позволяя системе просто передавать им запросы hi
чтение и запись данных, причем контроллеры сами выполняют разделен»
данных на полосы и поддержку избыточности информации. Однако апла
ратные RAID-контроллеры могут заметно повысить стоимость системы.
Размышления об операционных системах
Жизненно ВаЖные системы
Существуют системы, в которых цена от-
каза настолько высока, что для обеспечения
их нормальной работы и предотвращения от-
казов предпринимаются огромные усилия
и затрачиваются гигантские средства. Такие
системы часто называют жизненно важны-
ми системами (mission critical systems) или
системами для решения критически-важ-
ных задач. Если откажет система управле-
ния воздушным движением, то могут погиб-
нуть люди. Если выйдет из строя система
Нью Йоркской Фондовой Биржи, могут рух-
нуть мировые фондовые рынки. Поэтому
операционные системы должны проектир0
ваться так. чтобы соответствовать треб00*’
ниям к надежности и производительно^'
предъявляемым отдельными г,Ри-г,0>ке^иС-
ми. В некоторых случаях операционная^
тема должна выделять некоторым пр14
ниям намного больше ресурсов, чеМ рбра-
В разделах, посвященных изучению
ционных систем Linux и Windows удо
дим, например, что особого внимЗ'
спаиваются приложения реального ВР
Размышления об операционных системах
Отказоустойчивость
мпьютерные системы сегодня - это не-
* лемый атрибут нашего бизнеса и быта,
высчитываем на отсутствие отказов ком-
^'Ыв. Отказоустойчивые системы созда-
^так, чтобы сохранить работоспособность
Ы при наличии проблем, которые обычно
®а*т прИвести к отказу системы. Избыточ-
м _ широко применяемый метод обеспе-
чения отказоустойчивости: если компонент
называет, другой аналогичный компонент
используется вместо отказавшего. Реализа-
цияотказоустойчивости в системе стоит неде-
шево, но стоимость проектирования может
быть меньше, чем стоимость отказа проекти-
руемой системы, особенно в жизненно важ-
ных системах. Мы рассматриваем вопросы
отказоустойчивости во многих частях этой
книги, особенно тщательно — при обсужде-
нии RAID-массивов, при обсуждении много-
процессорных систем в главе 15, компьютер-
ных сетей в главе 16, распределенных систем
в главе 17, распределенных файловых сис-
тем в главе 18 и безопасности компьютерных
систем в главе 19.
Разработчики систем, решая вопрос использования в системах
RAID-массивов, должны выбирать между стоимостью, производительно-
стью и надежностью системы. Обычно улучшение любой из этих характе-
ристик ухудшает две другие. Например, чтобы уменьшить стоимость сис-
темы, можно уменьшить количество накопителей в массиве. Уменьшение
количества дисков часто приводит к падению производительности вслед-
ствие уменьшения скорости передачи и может понизить надежность
вследствие уменьшения способности массива к хранению избыточной ин-
формации.
Вопросы для самопроверки
1. Объясните, в каких случаях выгоднее использовать RAID-массивы
с широкими, а в каких случаях — с узкими полосами.
2. Почему RAID-массивы должны обеспечивать определенный уро-
вень отказоустойчивости?
Ответы 1) Узкие полосы выгодны, если нужно обеспечивать бы-
строе выполнение отдельных операций ввода/вывода. Широкие поло-
сы выгодны, если важнее возможность одновременно выполнять
множество запросов ввода/вывода. 2) Чем больше накопителей в мас-
сиве, тем вероятнее, что один из них выйдет из строя. Поэтому
в RAID-массивах должны применяться определенные меры обеспече-
ния отказоустойчивости.
738
12.10.2 RAID-массивы уровня О (разделение данных)
RAID уровня О использует массив разбитых на полосы накопите
избыточности. На рис. 12.17 показан массив уровня RAID 0 из четь ^еа
копителей. Если приложение запрашивает чтение данных из полос а
данные из этих полос могут считываться одновременно, поскольк 11
расположены на разных накопителях (Dr и D2). Кроме того, конт 01111
RAID может одновременно записывать данные к полосе К, расп< п °Ллер
в накопителе D3.
RAID уровня 0 не является одним из пяти изначально предлож
уровней RAID. Часто его не считают «истинным» RAID, поскольку6^1111111
обладает отказоустойчивостью. Если один из накопителей выходи^ Не
строя, то все данные в файлах, части которых располагались на этом н Из
пителе, теряются. При определенных размерах полосы данных выхо^^
строя одного накопителя может привести к потере всех Из
в массиве62. Даннь*
RAID уровня 0 прост в реализации и не требует дополнительных расхо
дов на накопители для обеспечения отказоустойчивости. Кроме того
RAID-массив уровня О из п дисков может выполнять чтение и запись со
скоростью, превышающей скорость одиночного накопителя в п раз.
RAID-массивы уровня 0 пригодны для систем, в которых высокая произво-
дительность и низкая стоимость важнее надежности63’ 64.
Рис. 12.17. RAID уровня О (разделение данных)
миия производите^. ти дисковых накопителей
739
Вопросы для самопроверки
1. Почему RAID уровня О не считается «истинным» RAID?
2. Каковы преимущества RAID уровня О?
Ответы 1) RAID уровня О не обеспечивает отказоустойчивости
применением избыточности. 2) RAID уровня О предоставляет высокие
скорости передачи, прост в реализации и не требует дополнительных
расходов на накопители для обеспечения отказоустойчивости.
RAID-массивы уровня / (зеркальное отображение)
'одП) уровня 1 использует зеркальное отображение, или дублирование
’rroring, иногда — shadowing) для обеспечения избыточности, и дубли-
Г каждый накопитель в массиве. Полосы в массивах RAID уровня 1 не
тлеются, что одновременно упрощает аппаратуру и снижает производи-
I I льность. RAID-массив уровня 1 изображен на рис. 12.18. Обратите вни-
мание, что накопители D4 и Da содержат одинаковые данные, и накопите-
ли Из и D4 тоже содержат одинаковые данные. Чтобы обеспечить целост-
ность, изменяемые данные должны записываться на два диска, поэтому
запросы на запись к одной и той же паре накопителей должны выполнять-
ся по одному за раз. Заметьте, что на рис. 12.18 запросы чтения к блокам А
и В могут выполняться накопителями Di и Da в то время, когда запрос на
запись к блоку I выполняется накопителями D3 и D4.
Хотя RAID уровня 1 обеспечивает наибольший уровень отказоустойчи-
вости из всех уровней RAID, • для хранения неповторяющихся данных
в нем может использоваться только половина емкости массива. Соответст-
венно, стоимость хранения единицы данных в массиве RAID уровня 1
вдвое превышает таковую в массиве RAID уровня 0. Поскольку каждый
блок данных хранится на паре дисков, система может (в некоторых случа-
ях) сохранять данные при множественных отказах дисков. Например,
если откажет накопитель D3, то система может продолжать работать с зер-
кальной копией данных на накопителе D4. Позже можно установить но-
вЬ1и накопитель в качестве D3. Подключение нового накопителя и переме-
щение на него нужных данных называется регенерацией данных (data
generation). Обратите внимание на то, что при отказе обоих накопителей
ком-либо пары данные с этой пары будут утеряны65.
Некоторые RAID-системы содержат «запасные» накопители, иногда на-
ие^ые накопителями горячей замены (hot spare disks), или накопите-
Нцти ОНлайн-замены (online spares). Этими накопителями можно заме-
не <?Казавшие> как проколотую шину в автомобиле можно заменить за-
о*°й- Некоторые системы позволяют выполнить такую замену без
Сцс °Ва системы, и регенерация данных будет выполняться в ходе работы
Фу/МЬ1- ^акая возможность необходима в системах, которые должны
h)atI йи°ниРовать непрерывно — например, в системах онлайн-обработки
®3аКций66.
740
к
А, В I
fl-
Запрос
на чтение
Запрос
на запись
Рис. 12.18. RAID уровня 1 (зеркальное отображение)
Массивы RAID уровня 1 обладают следующими преимуществами и не-
достатками:
• Высокие накладные расходы — только половина общей емкости маС"
сива используется для хранения неповторяющихся данных.
• Высокая средняя скорость чтения — к данным, хранящимся на одн°в
и той же зеркальной паре, могут одновременно выполняться два
проса на чтение.
• Невысокая средняя скорость записи — запросы на запись к зер
ной паре должны выполняться по одному за раз. Однако запр
запись к разным парам могут выполняться одновременно. тОрь1*
• Высокая отказоустойчивость — RAID уровня 1 может в неко 0fl}1
случаях выносить множественные отказы накопителей > от-
данные и обеспечивая доступ к ним. Он обеспечивает наиболь
казоустойчивость из всех популярных уровней RAID.
• Высокая стоимость — накладные расходы увеличивают УД
стоимость хранения данных. 0JJ л&'
RAID уровня 1 лучше всего подходит для задач, в которых вь1С°сТлб7-
дежность важнее низкой стоимости или высокой производительно
^дция производительности дискевых накопителей
Вопросы для самопроверки
1. Сравните RAID уровня О и RAID уровня 1 с точки зрения стоимо-
сти, надежности и производительности.
2. Почему RAID уровня 1 подходит для критических и жизненно важ-
ных систем?
Ответы 1) Массив RAID уровня 0 стоит меньше, чем RAID уровня
1 при той же емкости. Производительность при чтении и записи зави-
сит от уровня нагрузки и размера полос, но и RAID уровня 0, и RAID
уровня 1 могут одновременно выполнять запросы на чтение к разным
накопителям; RAID уровня 1 может выполнять одновременно и запро-
сы на запись к разным зеркальным парам накопителей. Вероятность
отказа массива RAID уровня 0 гораздо выше, чем одиночного накопи-
теля, a RAID уровня 1 — гораздо меньше. 2) Потому что в этих систе-
мах производительность, надежность хранения и доступность данных
важнее стоимости. RAID уровня 1 обеспечивает высокую производи-
тельность при чтении и очень высокую надежность, и (с некоторым
снижением производительности) может работать при отказе одного,
а иногда — и нескольких накопителей.
12.10.4 RAID-массивы уровня 2 (побитовый контроль с коррекцией по
Хеммингу)
В массивах RAID уровня 2 данные делятся на полосы на уровне отдель-
ных битов, и в каждой полосе хранится один бит. Массивы RAID уровня 2
не используют зеркального отображения, и накладные расходы на хране-
ние данных в них меньше, чем в массивах уровня 1. Если в массиве RAID
уровня 2 отказывает один из накопителей, то результат аналогичен ре-
зультату искажения или потери части сообщения при передаче по нена-
дежным каналам связи. Проблема ненадежных каналов связи хорошо изу-
чена, и существует несколько ее решений (варианты таких решений мож-
во найти, например, по адресу www.eccpage.com). RAID уровня 2
использует метод, обычно применяемый в модулях оперативной памяти —
иодирование с коррекцией по Хеммингу (Hamming error-correcting codes,
10111 Hamming ECC). Этот метод основан на использовании битов четности
Аля поиска и устранения ошибок при передаче данных с дисков68.
биты четности могут вычисляться следующим образом. Представим
р 6 массив, в котором каждая полоса хранит четыре бита. Когда
^D-система получает запрос на запись данных ОНО в полосу, она вы-
Дяет четность (parity) суммы битов, то есть определяет, является ли
битов четной или нечетной. В нашем случае сумма (2) будет чет-
соот И Система разместит полосу по четырем накопителям в массиве, а О,
ветствующий четной сумме, запишет на накопителе, на котором хра-
УьОйЯ сУммы. [Примечание: Хотя данные делятся на полосы на битовом
Я0?ае> большинство запросов обращаются сразу к данным в нескольких
ах» которые могут записываться одновременно для повышения про-
д. ДИтельности.] RAID-системы обычно хранят биты четности на от-
ObI накопителе, чтобы запись и чтение данных из каждой полосы
ВЬ1полняться одновременно. При следующем обращении к полосе
Ма считывает ее и соответствующий ей бит четности, вычисляет зна-
I е Четности для считанной полосы и сравнивает вычисленное и счи-
742
%
тайное значения четности. Если сбой на диске приведет к изме
третьего записанного бита с 1 на 0 (то есть будет храниться
ние 0100), то вычисленное значение четности не совпадет со счи 3®аЧе
с диска и система обнаружит ошибку.
Ограничение описанного метода в том, что он не обнаружит чет
личество ошибок. Например, если и второй, и третий биты измена °е
на 0 (то есть будет считано значение 0000), то четность искаженного^ с 1
ния будет совпадать с четностью исходного. Кроме того, этот метод 3lia,Je-
зволит определить, в каком именно бите возникла ошибка. йе °о.
Коды коррекции ошибок по Хеммингу (Hamming ЕСС) использую
лее тонкий подход, позволяющий системе обнаружить до двух ошибок
править одну ошибку и определить место ошибки в полосе (собственно ИС'
горитм генерации кодов четности по Хеммингу в этой книге не рассмя
вается; его описание можно найти по адресу http://dmivic.chat
inform/Hemming. htm). Размер кодов Хемминга и, соответственно колич^
ство накопителей, необходимых для их хранения, растет пропорционально
двоичному логарифму количества накопителей с данными. Например, для
массива из десяти накопителей с данными необходимо четыре накопителя
с кодами Хемминга; для массива из двадцати пяти накопителей с данными
необходимо пять накопителей с кодами Хемминга69. Поэтому массивы
RAID уровня 2 обладают значительно меньшим уровнем накладных расхо-
дов, чем массивы уровня 1.
Накопители сданными
(хранят полосы сданными)
Накопители с кодами четности
(хранят полосы с кодами четности)
( А, -ЕЛ
fl-
Запрос на запись
Рис. 12.19. RAID уровня 2 (побитовый контроль и коррекция ошибок)
f/щия про Родительности дисковых накопителей
743
В рисунке 12.19 показан массив RAID уровня 2 с четырьмя накопителями
B^gHbix и тремя дисками для хранения кодов четности. Полоса А будет де-
яа ленты А1-А4, первые в накопителях Dr-D4. Коды Хемминга для по-
Д будут храниться в первых лентах — Ах—А^, — на накопителях Pj-Pg.
сМотрим запрос на запись, требующий сохранить данные в полосах Аъ
Bi и В2. В этом случае, поскольку коды Хемминга вычисляются при
As> записи, контроллер должен выполнить запись в полосах А и В и запи-
Я^^одЫ Хемминга для этих полос. Несмотря на то, что в полосе В изменяются
два бита, нужно считать всю полосу В целиком и записать вычисленные
1°^нее коды Хемминга. Эта операция снижает производительность, поскольку
ма должна обращаться к массиву дважды при каждой операции записи,
называется циклом чтение-изменение-запись (read-modify-write cycle).
^Хотя использование накопителей с кодами четности уменьшает наклад-
е расходы на избыточность по сравнению с зеркальным отражением,
о может уменьшить производительность, поскольку запросы нельзя вы-
полнять одновременно. Каждый запрос на чтение требует считывания дан-
лых со всех накопителей, вычисления их кодов четности, считывания ко-
лов четности с накопителей, на которых они хранятся, и сравнения вычис-
ленных и считанных кодов четности. Некоторые системы уменьшают
критичность этого узкого места, вычисляя коды четности только при за-
просах на запись. Однако система должна обращаться ко всем накопите-
лям, чтобы вычислять коды четности при записи, поэтому запросы на за-
пись все равно должны выполняться по одному за раз.
Можно увеличить количество одновременно выполняемых запросов на
чтение и запись, разделив накопители в системе на несколько отдельных
массивов RAID уровня 2. Однако при таком подходе резко растет количе-
ство накопителей, необходимых для хранения кодов четности. Например,
один массив уровня 2 из 32 накопителей требует шести накопителей для
кодов четности. Если разделить его на восемь групп по четыре накопителя,
ТО потребуется 24 накопителя для кодов четности70.
Основная причина, по которой RAID уровня 2 в современных системах
ее используется, состоит в том, что в современных накопителях коды Хем-
МИнга или сравнимые с ними по надежности используются на аппаратном
^°вВе. Почти все современные накопители — и SCSI, и IDE — содержат
щггР°енные механизмы мониторинга и обнаружения ошибок.
Вопросы для самопроверки
1. Как разделение большого массива RAID уровня 2 на части повлия-
ет на производительность, стоимость и надежность?
2. Почему RAID уровня 2 редко реализуется?
Ответы 1) Разделение массива уровня 2 на части повышает произ-
водительность, поскольку делает возможным одновременное выполне-
ние нескольких запросов. Разделение не влияет на надежность,
поскольку для каждой подгруппы выполняются те же процедуры кон-
троля. В целом для подгрупп потребуется больше накопителей для
хранения кодов четности, и, соответственно, возрастет стоимость.
2) Поскольку современные аппаратные устройства содержат встроен-
ные механизмы обнаружения ошибок и мониторинга, выполняющие
те же проверки, что и массивы уровня 2, разработчики ищут более де-
шевые и производительные методы обеспечения отказоустойчивости.
12.10.5 RAID-массивы уровня 3 (побитовый XOR-контроль
и коррекция)
В массивах RAID уровня 3 данные делятся на полосы по битам «л
там. Вместо алгоритма Хемминга для генерации контрольных И
в RAID уровня 3 используется алгоритм XOR-контроля и коррекпИиК°д°в
бок — XOR ЕСС (XOR расшифровывается как exclusive OR — Искл °О14'
щее ИЛИ). Этот алгоритм значительно проще алгоритма Хемминга
зывается алгоритмом XOR, поскольку использует операцию логичесН Йа'
исключающего ИЛИ: к°го
(a XOR Ь) = 0, если а= Ь;
= 1 в противном случае;
Соответственно, (a XOR (Ь XOR с)) = 0, только если четное количество ап
ментов равно 0 или 1. RAID уровня 3 использует этот факт, чтобы, выполняя
вложенные операции исключающего ИЛИ над каждым байтом, генерировать
контрольные коды. Например, рассмотрим полосу А на рисунке 12.20. Пусть
Ai = 1, А2 = 0, Аз = 0 и А4 = 1. Записывая более кратко, А = 1001. Система ис-
пользует вложенные операции исключающее ИЛИ для вычисления четно-
сти А. Если количество нулей или единиц четно, то бит четности Ар = о,
в противном случае Ар = 1. В нашем случае единиц две, поэтому Ар = 0. Если
система разделяет данные на полосы по байтам, то коды XOR ЕСС вычисля-
ются для каждого бита, и каждая полоса четности хранит 8 битов.
Алгоритм XOR ЕСС использует для хранения данных о четности един-
ственный накопитель, независимо от количества накопителей с данными.
Заметьте, что, в отличие от алгоритма Хемминга, алгоритм XOR ЕСС не
позволит определить, в каком бите произошел сбой. Это приемлемо, по-
скольку большинство сбоев в данных в массивах RAID появляется вследст-
вие отказов целых накопителей, которые довольно легко обнаружить. На-
пример, предположим, что отказал накопитель D2 (рис. 12.20). В этом слу-
чае, попытавшись прочитать полосу А, система получит А = 1x01, где х —
неизвестное значение, и Ар = 0. Поскольку Ар = 0, в полосе А должно быть
четное количество единиц. Исходя из этого, система определит, что А2 _ >
и восстановит потерянные данные. Такой подход позволяет восстановить
данные после отказа любого одного накопителя. Если откажет накопи
с данными о четности, то для восстановления данных на нем нужно п Р
считать коды четности для всех данных в массиве72.
Из-за тонких полос большинство операций чтения требуют °бРа^еТВ0-
ко всем накопителям в массиве. Кроме того, из-за генерации кодов &сС}1.
сти операции записи должны выполняться по одной за раз. Как и в 0.
ве RAID уровня 2, это дает высокие скорости передачи при чтении и зй
си больших файлов, но в целом может выполняться только один за Р
раз73. Основное преимущество RAID уровня 3 в том, что он прост в
зации, обладает такой же надежностью, что и RAID уровня 2 и
значительно меньших накладных расходов74.
745
м'Миия производительности дисковых накопителей
d4
о3
a2b2c2d2 ...
A3B3C3D3
02
АдВдСдОд
Сравнить со старыми данными,
чтобы определить изменения
в четности
Контроллер
vA-Az
Помещен
в очередь
Запрос Запрос
на запись на запись
flit. 12.20. RAID уровня 3 (побитовое разделение, один накопитель с данными
° четности)
Вопросы для самопроверки
1. Сравните RAID уровня 2 и RAID уровня 3.
2. Почему использования алгоритма XOR ЕСС вместо алгоритма Хем-
минга достаточно для большинства RAID-систем?
Ответы 1) И RAID уровня 2, и RAID уровня 3 обеспечивают отка-
зоустойчивость за счет использования кодов четности, чтобы умень-
шить накладные расходы по сравнению с зеркальным отображением.
Оба используют отдельные накопители для хранения кодов четности
и, в общем, оба не могут выполнять одновременно несколько запросов.
RAID уровня 2 обладает более высоким уровнем накладных расходов,
чем RAID уровня 3. 2) Хотя алгоритм XOR ЕСС не позволяет опреде-
лить, какой накопитель отказал, система может с легкостью опреде-
лить это, поскольку отказавший накопитель не отвечает на запросы.
Поэтому система может регенерировать данные с помощью единствен-
ного диска с кодами четности.
746
12,10.6 RAID-массивы уровня 4 (блочный XOR-контроль и корр^
В массивах RAID уровня 4 данные делятся на полосы по блокам *
рованного размера (обычно блок намного больше байта), а для ген
кодов четности используется алгоритм XOR ЕСС. Для хранения код^8^
ности используется единственный накопитель. Массив RAID уровнял* ',ег-
бражен на рисунке 12.21. Заметьте, что единственное отличие м
RAID уровней 3 и 4 в том, что RAID уровня 4 хранит больше данных6^
ждой полосе. в
Рис. 12.21. RAID уровня 4 (блочный XOR-контроль и коррекция)
В массивах RAID уровней 2 и 3 данные, требуемые любым запросом,
обычно хранятся на всех накопителях массива. В массивах RAID уровня 4
используются более широкие полосы, и, возможно, данные для запроса бу-
дут храниться только на части накопителей массива. Поэтому, если не про-
верять четность при каждом чтении данных, система теоретически может
выполнять одновременно несколько запросов на чтение. Поскольку коды
четности используются в основном для регенерации данных, а не для поис
ка и исправления ошибок, во многих системах проверки при чтении не в
полняются, чтобы можно было одновременно выполнять несколько за
сов на чтение75.
Однако при выполнении запроса на запись система должна обновки
информацию о четности, чтобы гарантировать сохранение данных в
отказа диска. При использовании широких полос запросы на запись 1>чТ0
изменяют данные сразу на всех накопителях в массиве. Не забывайте»*^
обращение к каждому накопителю в массиве для вычисления чемОя<е'г
приводит к значительным накладным расходам. К счастью, система
вычислять новые коды четности Ар’, используя содержимое блока Д
до изменения — Arf, после него — А/ и соответствующего «старого»
четности — Ар:
Ар’ = (AdXOR A/) XOR Ар76
.^ация производительности дисковых накопителей
747
I а упражнениях к этой главе попробуйте доказать правильность этого
Мщения. Такой подход устраняет лишние операции ввода/вывода, по-
при записи не требуется доступ ко всему массиву. Однако посколь-
1<о^7кдый запрос на запись должен изменять данные на диске с кодами
iiyтИт запросы на запись должны выполняться по одному за раз, что
Ж® дает Узкое место- Как вы увидите в следующем разделе, RAID уров-
устраняет его, поэтому RAID уровня 4 реализуется редко77- 781 79- 80.
Вопросы для самопроверки
1. Каким образом RAID уровня 4 обеспечивает более высокую произ-
водительность, чем RAID уровня 3?
2. Почему массивы RAID уровня 4 могут выполнять только по одной
операции записи за раз?
Ответы 1) RAID уровня 4 позволяет использовать широкие поло-
сы данных. Это дает возможность выполнять одновременно несколько
запросов на чтение и уменьшает количество накопителей, задейство-
ванных в каждом запросе на запись. 2) RAID уровня 4 использует
один накопитель для хранения кодов четности, к которому нужно об-
ращаться при каждой операции записи, чтобы обновить коды четно-
сти при изменении данных.
12.10.7 RAID-массивы уровня 5 (блочный XOR-контроль и коррекция
{распределением)
В массивах RAID уровня 5 данные делятся на полосы по блокам и ис-
пользуется алгоритм контроля XOR ЕСС. При этом блоки четности распре-
деляются по разным накопителям в массиве (см. рис. 12.22)81. Заметьте,
что на рисунке 12.22 блок четности для первой полосы помещен на нако-
питель D5, а для второй полосы — на накопитель D4. Поскольку блоки чет-
ности распределены между несколькими накопителями, можно обращать-
Ся одновременно к нескольким таким блокам, и узкое место при записи
многих запросов устраняется. Для примера рассмотрим выполнение
*®Роса на запись в массиве RAID уровня 5 к лентам А4 и С2. Контроллер
обращается к накопителю D2, чтобы записать ленту А4, и к накопителю
5> Чтобы обновить соответствующий блок четности Ар. Одновременно кон-
а ллер может обратиться к накопителю D4, чтобы записать ленту С2>
Накопителю D3, чтобы обновить блок четности Ср.
дед °Тя RAID уровня 5 повышает производительность при записи, распре-
Яя блоки четности между накопителями, массивы этого уровня все рав-
Д°ЛзКны выполнять цикл чтение-изменение-запись при каждом запросе
°ись, Для чего требуется как минимум четыре операции ввода/выво-
Hajj сли система выполняет много операций записи небольших объемов
%, Ь1Х> то большое количество медленных операций ввода/вывода может
। 0 снизить производительность82.
748
Запрос Запрос
на запись на запись
Рис. 12.22. RAID уровня 5 (блочный XOR-контроль и коррекция с распределением)
Для этой проблемы предложено несколько решений. Кэширование не-
давно запрашивавшихся данных и блоков с контрольными данными мо-
жет уменьшить количество операций ввода/вывода в цикле чтение-изме-
нение-запись. Промежуточное хранение блоков четности (parity logging)
может повысить производительность массивов RAID уровня 5, сохраняя
разницу между старыми контрольными данными и новыми (эта разница
называется образом обновления (update image)) в памяти вместо выполне-
ния цикла чтение-изменение-запись. Поскольку в одном образе обновле-
ния могут храниться контрольные данные для нескольких запросов на за-
пись, система может уменьшить накладные расходы по вводу/выводу, »Ы'
, полняя одно обновление блока с контрольными данными в массиве после
выполнения нескольких операций записи83. Похожий метод повышения
производительности называется AFRAID (A Frequently Redundant Ar™
о Independent Disks — Часто избыточный массив независимых дисков
Вместо того чтобы генерировать данные четности во время выполнен
цикла чтение-изменение-запись при каждом запросе на запись, это
ся в моменты небольшой нагрузки на систему. Такой прием может о
существенно повысить производительность в системах, где время от вр®
ни возникают вспышки активности с большим количеством запр°с0
запись небольших объемов данных84.
д^?ТЯ RAID уровня 5 обладает более высокой производительность^’
уровней 2-4, он сложен в реализации и его стоимость выше-
того, поскольку блоки четности распределены между несколькими че#
пителями, регенерацию данных в RAID уровня 5 выполнять сложи6 ’
0дция производительности дисковых накопителей
749
V *тр других уровней85. Несмотря на эти недостатки, RAID уровня 5
Игеняется весьма часто из-за хорошего соотношения стоимости, надеж-
и производительности. Массивы RAID уровня 5 считаются массива-
Р^бгцего назначения, и часто используются в серверах приложений, фай-
jtfl0 серверах, системах планирования ресурсов масштаба предприятия
Л°®1^1Мерческих серверах86. На рисунке 12.23 приведены сравнительные
И 5<°ьСтеристики шести уровней RAID, описанных в этой главе.
уровень RAID 0 1 Возможность Возможность Избыточность Уровень
одновременных операций чтения Есть Есть одновременных операций записи Есть Нет Нет Зеркальное отображение разделения на полосы По блокам Нет
2 Нет Нет Коды Хемминга По битам
3 Нет Нет Коды XOR ЕСС По битам/по байтам
4 Есть Нет КодыХСЖ ЕСС По блокам
5 Есть Есть Распределенные коды XOR ЕСС По блокам
Рис. 12.23. Сравнение уровней RAID 0-5
Д/уж уровни RAID
Существует много других уровней RAID, которые являются производ-
ными от рассмотренных в предыдущих разделах87. К несчастью, стандарт-
ной системы обозначений для уровней RAID не существует, и часто можно
встретить непонятные или просто запутанные обозначения. Некоторые
Распространенные уровни RAID перечислены ниже:
• RAID уровня 6 — RAID уровня 5, в котором блоки четности распреде-
ляются по два на полосу, чтобы повысить устойчивость к отказам
накопителей88.
• RAID уровня 0+1 — набор накопителей с разделенными на полосы
Данными (уровень 0), зеркально отображенный на другой набор нако-
пителей (уровень 1).
f • RAID уровня 10 — набор зеркально отображенных данных (уро-
вень 1), разделенный на полосы в другом наборе дисков (уровень 0),
Для чего требуется минимум четыре накопителя.
Л 5д^ествуют и другие уровни RAID — например, 0+3, 0+5, 50, 1+5, 51
• RAID уровня 7 (RAID Level 7), представляющий собой дорогое вы-
^^Рпизводительное решение, является зарегистрированной торговой
к°й Storage Computer Corporation90.
Вопросы для самопроверки
1. Каким образом в RAID уровня 5 устранена малая произво
ность при записи, свойственная RAID уровня 4? Л11Те-Ч-
2. Какие приемы используются для повышения производите
RAID-массивов в системах с большим количеством запросоЛЬ110с,'Л
пись малых объемов данных? Б аа За
Ответы 1) RAID уровня 5 распределяет блоки четности п
накопителям массива, что делает возможным одновременное в* ВСб1'1
нение нескольких операций записи. 2) Кэширование недавно Ь1п°л-
шивавшихся данных повышает производительность За Пре-
уменьшения количества необходимых операций ввода/вывода в °Чет
лах чтение-изменение-запись. Задержка обновления блоков чети41114'
повышает производительность за счет уменьшения количества в°СТй
пителей, к которым нужно обращаться при выполнении операции1*0"
писи. 4 1 За'
Веб-ресурсы
www.disk-tape-data-recovery.com/storage-history.htm
Содержит краткую историю устройств и носителей для долговременного хране-
ния данных.
http://www.almaden.ibm.com/st/data_storage/index.shtml
Описывает физические ограничения устройств хранения данных и перспек-
тивные области, в которых IBM ведет исследования для преодоления этих огра-
ничений.
colossalstorage.net/colossalll.htm
Содержит ссылки на сайты, описывающие развитие технологий хранения дан-
ных.
www.cosc.brocku.ca/~cspress/HelloWorld/1999/03-mar/disk_scheduling_
algorithms.html
Содержит статью из журнала Hello World, предназначенного для студентов
компьютерных специальностей; в статье содержится обзор алгоритмов диспетче-
ризации доступа к накопителям.
www.pcguide.com/ref/hdd/index.htm
Описывает характеристики накопителей.
www.microsoft.com/windows2000/techinfo/administration/fileandprint/
, defrag-asp
Описывает использование утилит дефрагментации дисков в Windows
www.pcguide.com/ref/hdd/perf/raid/
Подробное руководство по RAID.
www.acnc.com/04_00.html
Содержит описание большинства уровней RAID.
linas.org/linux/raid.html
Содержит статьи о RAID и их реализации в системах Linux.
www.pdl. emu. edu/RAID/ -j, СВ15’
Содержит обзор RAID и ссылки на статьи по современным исследованй
занным с RAID.
производительности дисковых накопителей
751
скольку быстродействие процессора и оперативной памяти росло намного
чем быстродействие внешних устройств хранения информации, оптими-
б*’1с"(5ь1стродействия устройств хранения стала критичной для оптимизации бы-
йствия систем в целом. Магнитные накопители записывают информацию,
c,fpoJi направление намагниченности областей носителя, представляющих биты
®3#ie ix Для обращения к данным используется головка, перемещающаяся над
?псителет'1'
В большинство современных компьютеров используют в качестве внешних уст-
’ хранения информации накопители на жестких магнитных дисках. При
Р°я ии пластин в таких устройствах головка прорисовывает круговые дорожки
п0Верхностью этих пластин. Все головки чтения/записи крепятся на концах
рсолей головок, прикрепленных к приводу блока головок. При перемещении го-
К вок в новую позицию становится возможным обращение к новому цилиндру —
^вборУ дорожек. Процесс перемещения головок к новому цилиндру называется
операцией позиционирования. Время, необходимое для перемещения головок с те-
кущего цилиндра на цилиндр, содержащий требуемые данные, называется време-
нем позиционирования. Время, за которое вследствие вращения диска данные бу-
дут перемещены под головку, называется вращательным временем задержки. Что-
бы запись, размер которой может быть произвольным, была прочитана, она
должна вся пройти под головкой. Время, необходимое для этого, называется вре-
менем передачи.
В один и тот же момент к накопителю может обращаться множество процессов.
Поскольку эти процессы иногда генерируют запросы быстрее, чем накопитель мо-
жет их выполнять, для хранения ожидающих исполнения запросов используются
очереди. Некоторые ранние компьютерные системы обслуживали запросы по
принципу «первым пришел — первым обслужили» (first come first served, FCFS),
то есть запрос, полученный первым, выполнялся первым. FCFS — стабильный ме-
тод выполнения запросов, но при высокой нагрузке на накопитель промежутки
времени между поступлением запросов и их выполнением могут стать неприемле-
мо большими.
FCFS обладает случайной последовательностью выборки, и при выполнении за-
просов могут выполняться длительные операции позиционирования, перемещаю-
Чие головки от внешних к внутренним цилиндрам и обратно. Чтобы уменьшить
Расходы времени на позиционирование, можно попытаться переупорядочить оче-
Дь запросов. Этот прием называется диспетчеризацией дисковых операций. Два
Иболее распространенных вида такой диспетчеризации — оптимизация по пози-
°нированию и оптимизация по вращению. Эффективность алгоритма (страте-
J Диспетчеризации часто оценивается по обеспечиваемым им пропускной спо-
^®Ости, среднему времени реагирования и разбросу этого времени.
Ряв г°₽и™ FCFS использует очередь FIFO, в которой запросы выполняются в по-
е их поступления. Хотя этот подход связан с небольшими накладными расхо-
’ Он может привести к низкой производительности из-за длительных опера-
Позиционирования.
Яцд ГоРитм SSTF (shortest seek time first — «минимальное время позиционирова-
Свачала») выполняет первым запрос, для которого время позиционирования
Д^альнс (то есть Данные для которого ближе всего к головке чтения/записи),
Дцч яеЛИ ОН не стоит первым в очереди. Уменьшая среднее время позиционирова-
Дее ’ достигает более высокой пропускной способности, чем FCFS, и его сред-
Ремя реагирования обычно меньше при средних уровнях нагрузки. Однако
УЩественным недостатком является высокий разброс времени реагирования,
752
поскольку выполнение запросов к внутренним и внешним цилиндрам часто
го откладывается. В предельном случае запросы к данным, находящимся
от головки, могут откладываться бесконечно.
Алгоритм SCAN уменьшает нестабильность и разброс времени реагин
выбирая запрос с минимальным временем позиционирования в предпоч(°Ва111Ч
направлении. Например, если в данный момент предпочитаемое напрак ![(’fаем°!«
к внешнему краю диска, то алгоритм SCAN выберет запрос с минимальным ВИе
нем позиционирования, в котором головки будут перемещаться к внешнем B₽etle-
диска. SCAN ведет себя примерно так же, как и SSTF в том смысле, что он пкК₽а,°
чивает высокую пропускную способность и малое среднее время реагировани 6CQe'
нако поскольку SCAN гарантирует, что все запросы в одном направлении а
выполнены до того, как начнут выполняться запросы в другом, он обеспеч
меньший разброс времени реагирования, чем SSTF. Вает
Алгоритм C-SCAN (Circular SCAN — круговой SCAN) представляет собой м
фикацию алгоритма SCAN, в которой головка всегда движется от внешних ци ДИ
дров ко внутренним, выполняя запросы с минимальным временем позиционип 18
ния в этом направлении. Достигая внутреннего цилиндра, головка перемещает
обратно к внешнему цилиндру, не выполняя никаких запросов, и вновь начинает
двигаться к внутреннему цилиндру, выполняя запросы. Этот алгоритм обеснечива
ет высокую пропускную способность, еще более уменьшая разброс времени реаги-
рования, поскольку устраняет дискриминацию близких к краям цилиндров
SCAN часто называют алгоритмом лифта.
Модификации алгоритма SCAN, Называемые FSCAN и N-шаговый SCAN, уст-
раняют опасность бесконечного откладывания выполнения запросов. Алгоритм
FSCAN использует тот же подход, что и SCAN, но выполняет только запросы, по-
лученные до начала прохода головок (F расшифровывается как «freezing» — «за-
мораживающий», поскольку поступающие запросы «замораживаются» до начала
нового прохода головок). Запросы, поступившие во время прохода, группируются
и упорядочиваются так, чтобы обеспечить оптимальное их выполнение во время
следующего прохода головок. N-шаговый алгоритм SCAN выполняет по алгоритму
SCAN первые N запросов из очереди за один проход головок. При следующем про-
ходе головок выполняются следующие N запросов, и так далее. Поступающие за-
просы помещаются в конец очереди, и их выполнение никогда не откладывается
до бесконечности. И FSCAN, и N-шаговый SCAN обеспечивают хорошую произво-
дительность благодаря высокой пропускной способности, малому среднему време-
ни реагирования и меньшему его разбросу, чем у алгоритмов SSTF и SCAN.
Алгоритм LOOK, тоже являющийся модификацией SCAN, просматривает оче
редь, определяя, есть ли в ней запросы, которые можно выполнить при текуЩеМ
правлении движения головок. Если таких запросов нет, то направление двиЖ
меняется на обратное, при этом головка останавливается на цилиндрах, к ко Р
обращаются запросы. Такой подход устраняет ненужные операции позиционир
ния, присутствующие в других модификациях алгоритма SCAN, и устраняет
мещение головок к цилиндрам на краях рабочей области диска, если 3
к этим цилиндрам нет. риеМ<
Алгоритм C-LOOK (Circular LOOK — круговой LOOK) использует тот же яйЛИн-
что и C-SCAN, чтобы устранить задержки выполнения запросов к краевым гоЛо₽-
драм. Если запросов в текущем направлении движения головок не осталось
ка перемещается к самому близкому к краю цилиндру, к которому есть за рИтМ
выполняя запросов при перемещении) и начинает новый проход. Этот
характеризуется потенциально меньшим разбросом времени реагировав
LOOK, и хорошей пропускной способностью, хотя и меньшей, чем у LO
производительности дисксвыаГнакопителеи
многих системах бывают периоды, когда запросов в очереди нет, и накопи-
0° выполняет никаких операций. Если переместить головки к средним ци-
«дЬ 0 й или в область, к которой часто поступают запросы, то можно уменьшить
е время позиционирования. Перемещение головок в область, к которой ожи-
среД0е запросы, называется упреждающим позиционированием головок. Оно мо-
да«°т^ЯтЬ полезно в системах, где последовательности выборки привязаны к огра-
0 областям на дисках и хватает времени для упреждающего позициони-
между запросами. Если во время упреждающего позиционирования
ро»00 ет запрос, то время его выполнения увеличивается. Если упреждающее по-
росТ рдцрование можно прерывать при поступлении запроса, то прирост произво-
з*00 нОСти будет максимальным.
Оптимизация по вращению широко использовалась в старых накопителях
ксированными головками, например, в магнитных барабанах, но она может
С ^ичить производительность и в современных дисковых накопителях, где время
^ипионирования и вращательная задержка — величины одного порядка. Алго-
в° SLTF просматривает все ожидающие выполнения запросы и выполняет пер-
рИ запрос с минимальной вращательной задержкой. Иногда вращательную за-
В ««tkv называют секторным упорядочением; запросы упорядочиваются соответ-
Овеяно их позициям на диске, и сначала выполняются запросы к ближайшим
секторам.
Алгоритм SLTF хорошо работает для накопителен с фиксированными голов-
ками, но оиа не учитывает время позиционирования в накопителях с подвижны-
ми головками. Алгоритм SPTF выполняет первым запрос, для которого мини-
мальна сумма времени позиционирования и вращательной задержки. Этот алго-
ритм обеспечивает высокую пропускную способность и малое среднее время
реагирования, но, как и SSTF, может бесконечно откладывать выполнение запро-
сов к цилиндрам на краях рабочей области дисков.
Разновидностью SPTF является алгоритм SATF, в котором следующим выпол-
няется запрос с минимальным временем доступа (то есть суммой времени позицио-
нирования, вращательной задержки и времени передачи). SATF обеспечивает бо-
лее высокую пропускную способность, чем SPTF, но он может бесконечно откла-
дывать выполнение запросов большого объема, выполняя малые по объему
запросы. Запросы к краевым цилиндрам могут бесконечно откладываться при на-
личии запросов к цилиндрам в середине рабочей области. Можно улучшить произ-
водительность SPTF и SATF, используя технику «прогноза», применяемую в алго-
ритмах LOOK и C-LOOK.
Одна из причин редкого использования алгоритмов SATF и SPTF состоит в том,
Чт° они требуют точного знания характеристик диска, включая задержки, время
ПеРемещения головок от дорожки к дорожке и относительное размещение секто-
в- К сожалению, многие современные накопители скрывают эту информацию
и сообщают неточные данные вследствие наличия скрытых секторов со служеб-
информацией или сбойных секторов.
р .ГСли Дисковые накопители становятся узким местом в системе, некоторые раз-
пр рЗ^ики рекомендуют увеличить количество накопителей. Это не всегда решает
лему, поскольку узкое место может обуславливаться большой нагрузкой толь-
^которые из накопителей. В случае обнаружения такой ситуации можно по-
1цеваться устранить ее, применяя диспетчеризацию дисковых операций для повы-
ли Ия производительности. Диспетчеризация дисковых операций может принес-
6Ьц^эло пользы в системах пакетной обработки, где количество одновременно
ti0 °Лняемых программ невелико. Ее применение становится более эффективным
Роста количества работающих одновременно программ, увеличения на-
Vj. Ки на систему и уменьшения предсказуемости последовательности выборки
L Hbix с накопителей.
754
Неравномерное распределение запросов часто встречается в определен
туациях, и последствия такого распределения хорошо исследованы. Одно и*14* th
дований показало, что подавляющее большинство запросов обращается г 3
цилиндру, что и непосредственно предшествующие запросы. ИзощренныеТ°Му
организации файлов могут вызвать увеличение количества запросов с бо Мет°Д^
временами позиционирования. Такие методы могут быть удобными для
чиков приложений, но могут усложнять реализацию и уменьшать произво
ность.
Во многих системах поддерживается дисковый буфер, или кэш, предст
щий собой область в оперативной памяти, которую операционная система n > Влч,°-
рует для данных с накопителя. В одном контексте выделенная память Hcno^6^'
ся как кэш, позволяя процессам быстро получать данные, которые в прот 3^6Т'
случае пришлось бы запрашивать с накопителя. В другом контексте памятьН0><
пользуется как буфер, позволяя системе откладывать запись данных для нов Йс'
ния производительности ввода/вывода. Такой буфер может создать ряд ппоб^'
для разработчиков операционных систем, поскольку выделение под него пам
уменьшает ее объем, доступный для процессов. Кроме того, поскольку дан И
в оперативной памяти теряются при отключении питания, использование бу4₽ в
может привести к потерям и несоответствиям в данных.
При кэшировании с отложенной записью данные из буфера записываются на
диск через определенные промежутки времени, позволяя операционной системе
использовать один запрос для выполнения множества операций ввода/вывода. Это
может повысить производительность системы. Кэширование со сквозной записью
записывает данные и в буфер, и на диск при каждом изменении данных в буфере.
Этот подход не позволяет выполнять по нескольку запросов зй одну операцию вво-
да/вывода, но уменьшает вероятность повреждения данных в случае отказа систе-
мы.
Многие современные накопители содержат независимый внутренний буфер
(часто называемый кэшем) объемом в несколько мегабайт. Если запрошенные дан-
ные хранятся в буфере, накопитель может передать их со скоростью, сравнимой со
скоростью работы основной памяти. Однако одно из исследований показало, что
накопители со встроенными буферами обычно используют алгоритмы замещения
данных, слабо приспособленные к случайным последовательностям выборки, что
приводит к сниженной производительности.
Данные на дисках постепенно становятся все более фрагментированными в про-
цессе работы, по мере добавления и удаления файлов и записей. Во многих опера-
ционных системах есть программы дефрагментации (или реорганизации) накопи-
телей, которые можно периодически использовать для реорганизации файлов.^
позволяет разместить следующие друг за другом записи последовательных Фай
в непрерывных областях диска. Кроме того, операционные системы могут Ра
щать файлы, которые с большей вероятностью будут изменяться, рядом со сво
ным местом на дисках. Некоторые операционные системы дают возможность
зователям разделить пространство диска на несколько разделов. Файлы не
размещаться в нескольких разделах одновременно, и фрагментация уменьши #
В некоторых системах для уменьшения пространства, требуемого для хра #
данных, используется сжатие данных. Сжатие данных уменьшает требуемое
их хранения пространство, заменяя часто встречающиеся последовательное
тов более короткими последовательностями. Это позволяет уменьшать время
ционирования, вращательную задержку и время передачи, но может потр ^с.
существенной части времени процессора на сжатие данных при записи и на
паковку при чтении.
^цция производительности дисковых накопителей
L-емы, которым необходим быстрый доступ к определенной информации,
ыиграть, разместив эту информацию в нескольких копиях в разных местах
/^«опителе. Это может существенно уменьшить время позиционирования
лИ^цательные задержки, но избыточные копии могут занять существенную
7° емкости накопителя. Кроме того, если одна из копий изменяется, нужно из-
и все остальные копии, вследствие чего может упасть производительность,
запись может также дать существенный прирост производительности —
^яовательности записей можно размещать в непрерывных блоках, для чтения
0°С ьт„ понадобится одна операция позиционирования. Системы, выполняющие
ко10^,оринг обращений к накопителям, могут попытаться переместить часто за-
1401111 иваемые данные в удобное место в иерархии памяти (т.е. в оперативную па-
йРаВ1йЛи в кэш), а редко требуемые данные — на более медленный носитель (на-
^мер, жесткий диск или компакт-диск).
(RAID расшифровывается как Redundant Array of Independent Disks —
«пйыточный массив независимых накопителей) — это семейство технологий, ис-
** пьзуюгфих массивы накопителей для решения проблемы сравнительно медлен-
в обмена данными с накопителями. Массив любой структуры, называемой
В овеем RAID, характеризуется разделением данных и избыточностью. Объем уст-
ройства хранения делится на полосы фиксированного размера. Непрерывные по-
лосы на каждом из накопителей обычно содержат данные, не являющиеся непре-
рывными, например, данные из разных файлов. Лента состоит из набора полос, за-
нимающих одинаковые позиции в каждом из накопителей массива.
При выборе размера полосы проектировщик системы должен учесть средний раз-
мер запросов к диску. При использовании полос маленького размера (тонкие поло-
сы) файлы обычно распределяются по нескольким накопителям. Такие полосы
уменьшают время выполнения отдельных запросов и увеличивают скорости обмена,
поскольку несколько накопителей одновременно извлекают или записывают нуж-
ные данные. Пока накопители выполняют запрос, они не могут выполнять другие
запросы из очереди.
Полосы большого размера (широкие полосы) позволяют файлам целиком раз-
мещаться на одном накопителе. В этом случае для выполнения некоторых запро-
сов может использоваться только часть накопителей массива, и иногда возможно
одновременное выполнение нескольких запросов. Однако малые по объему запро-
сы все равно выполняются накопителем по одному за раз, что уменьшает скорости
обмена для отдельных запросов.
Такие системы, как Web-серверы и серверы баз данных, которые обычно обра-
*Цаются одновременно ко множеству записей малого объема, выигрывают от ис-
альзования широких полос, поскольку они позволяют одновременно выполнять
Только операций ввода/вывода; системы класса суперкомпьютеров, требую-
Чие быстрого доступа к небольшому числу записей, больше выигрывают от ис-
8ЛЬзования тонких полос, дающих более высокие скорости обмена для отдель-
х запросов.
Ростом количества накопителей в массиве растет вероятность того, что один
выйдет из строя. Вероятность этого определяется средним временем нара-
ц£аКи Ва отказ (mean-time-to-failure, MTTF). Большинство RAID-массивов содер-
Копии данных, позволяющие восстанавливать информацию в случае отказов
^опителей — этот подход называется избыточностью. Зеркальное отображе-
И э " Эт° вариант избыточности, при котором делается две копии любых данных,
Лт0 Копии хранятся на разных накопителях. Недостаток такого подхода в том,
{>я1оТ°Лько половина всей емкости массива используется для хранения неповто-
*Цихся данных.
756
Чтобы выиграть от повышения производительности разделенных на
дисков, использующих избыточность, система должна эффективно рачП°^ос^
файлы по полосам, собирать их из полос, определять положение нужных
в массиве и поддерживать избыточность. Многие RAID-массивы содержат
альный аппаратный компонент — RAID-контроллер, выполняющий необх
операции. Выбирая уровень RAID-массива, разработчик должен выдержив^1114^®
ланс между стоимостью, производительностью и надежностью. Обычно улуч&ТЬ ®а-
одной характеристики ухудшает две другие.
RAID уровня 0 использует массив разделенных на полосы дисков без изд
ности. Массивы уровня 0 уязвимы для отказов: если отказывает один из нак ЬГГо<1'
лей в массиве, то теряются все данные, части которых хранились на отказа °Те'
накопителе. При определенном размере полосы отказ одного накопителя м 01611
привести к потере всех данных в массиве. Хотя RAID уровня 0 и не обладает Осет
зоустойчивостью, он прост в реализации, обеспечивает высокие Скорости
и не требует накладных расходов на хранение информации.
RAID уровня 1 использует зеркальное отображение накопителей для обесиеч
ния избыточности, и любые данные в массиве существуют в двух копиях. В мае
сивах уровня 1 разделение на полосы не используется, вследствие чего уменыпа"
ется как сложность аппаратуры, так и производительность системы. Хотя этот
уровень и обладает наибольшей отказоустойчивостью из всех уровней RAID
только половина емкости накопителей может использоваться для хранения непо-
вторяющихся данных, вследствие чего растет стоимость. Каждая зеркальная
пара может выполнять одновременно два запроса на чтение, но только один за-
прос на запись. Восстановление данных после отказа накопителя, называемое ре-
генерацией данных, состоит в копировании избыточных данных на накопитель,
установленный взамен отказавшего. Если отказывают оба накопителя в паре, то
данные этой пары теряются.
В некоторых RAID-массивах существуют «запасные» накопители (иногда на-
зываемые накопителями горячей замены), которые могут подключаться вместо
отказавших, примерно так, как запасные покрышки в автомобиле. В некоторых
системах есть возможность замены накопителей без отключения питания. В та-
ких системах данные регенерируются во время работы системы — это критично
для систем, которые должны гарантировать непрерывный доступ, например, сис-
тем онлайн-обработки транзакций. RAID уровня 1 лучше всего подходит для
жизненно важных систем, в которых надежность важнее стоимости и производи-
тельности.
Массивы RAID уровня 2 делят данные на полосы по битам, и каждая поЛ°^
хранит один бит. Эти массивы созданы, чтобы уменьшить накладные расходы
хранение, возникающие при обеспечении избыточности путем зеркального
жения. Вместо хранения двух копий каждого элемента данных, RAID уровня
пользует метод, основанный на хранении кодов четности, называемых код
Хемминга. Эти коды позволяют обнаруживать до двух ошибок, исправлять
ошибку и определять место ошибки в полосе. Размер кодов Хемминга и, соотв
венно, количество накопителей для их хранения, растет пропорционально Д®
ному логарифму от количества накопителей с данными. Поэтому массив УР° gJj
состоящий из большого количества накопителей, будет иметь меныпии УР
накладных расходов, чем массив уровня 1. хра®6’
Хотя использование кодов четности уменьшает накладные расходы на адд-
ние по сравнению с зеркальным отражением, оно может уменьшить npoi cOj.
тельность, поскольку невозможно одновременно выполнять несколько за а, в®1'
Каждый запрос на чтение должен обратиться ко всем накопителям массп 4g0>
числить коды четности, и сравнить их со считанными из массива. Ана1°н^
при выполнении запроса на запись нужно вычислять и записывать код 4
м/ция производительности дисковых иакопителой
757
I лзКД°й записываемой полосы. Кроме того, система должна выполнять циклы
.Изменение-запись, что еще больше снижает производительность, посколь-
выполнения записи нужно дважды обращаться к массиву. Один из прие-
му ^позволяющий выполнять одновременно несколько запросов — разделение
ji0®’ я RAID уровня 2 на несколько меньших массивов, но при этом растут на-
расходы на хранение и стоимость массива. Основная причина редкого ис-
RAID уровня 2 состоит в том, что современные накопители использу-
цО-Я1’ Хемминга или сравнимую с ними по надежности защиту скрытым обра-
to’r а уровне аппаратуры.
3°^ RAID уровня 3 данные делятся на полосы по битам или байтам. RAID 3 ис-
I ** veT контрольные коды XOR ЕСС, вычисляемые с использованием логической
55^пии исключающего ИЛИ. При этом для хранения кодов четности использу-
тоЛько один накопитель, независимо от размера массива. Система может ис-
е1<\3овать биты четности, чтобы восстановить данные при отказе одного накопи-
й « Если отказывает накопитель с кодами четности, то для регенерации данных
теля* тг
’•жно заново вычислить коды для всех данных в массиве. Для проверок четности
операции чтения и записи в массивах уровня 3 требуют обращений ко всем нако-
пителям массива. Как и в массивах уровня 2, это обеспечивает высокую пропуск-
0ую способность для запросов большого объема, но одновременное выполнение не-
скольких запросов невозможно.
В массивах RAID уровня 4 данные делятся на полосы по блокам (размер блоков
обычно намного больше байта), и для генерации кодов четности, хранимых на од-
ном накопителе, используется алгоритм XOR ЕСС. Поскольку в массивах уровня 4
используются широкие полосы, теоретически они могут выполнять несколько за-
просов на чтение одновременно, если для каждого запроса не нужно проверять чет-
ность. Однако при записи необходимо обновлять коды четности, чтобы гарантиро-
вать, что данные не будут потеряны при отказе накопителя. Это значит, что запро-
сы на запись должны выполняться по одному за раз, и запись является узким
местом в массивах уровня 4.
В массивах RAID уровня 5 данные делятся на полосы по блокам, и для генера-
ции кодов четности используется алгоритм XOR ЕСС. Однако блоки четности рас-
пределены по накопителям массива, вследствие чего можно одновременно обра-
щаться к нескольким таким блокам. Благодаря этому узкое место при записи для
многих запросов исчезает. Хотя RAID уровня 5 повышает производительность при
записи, распределяя блоки четности, массивы этого уровня все равно должны вы-
полнять цикл чтение-изменение-запись для каждого запроса на запись, то есть вы-
полнять как минимум четыре операции ввода/вывода на один запрос.
Кэширование недавно запрашивавшихся данных и блоков четности может
Уменьшить количество операций ввода/вывода в циклах чтение-изменение-за-
Сь- Промежуточное хранение блоков четности может повысить производитель-
Сть массивов RAID уровня 5 за счет хранения отличий (называемых образом об-
ления) между старой четностью и новой в памяти вместо выполнения цикла
ы ^^^изменение-запись. Часто избыточный массив независимых накопителей
4^*tAID) повышает производительность за счет откладывания генерации кодов
ости до периода небольшой нагрузки на систему.
^ец °ТЯ нроизводительность RAID уровня 5 выше, чем RAID уровней 2-4, он сло-
^®ТнВ 1)еализаП'ии и» соответственно, более дорог. Кроме того, поскольку блоки
дее °Сти распределены по разным накопителям, регенерация данных в нем слож-
liy ’ ЧеМ в RAID других уровней. Несмотря на эти ограничения, RAID уровня 5 по-
Lt яРен из-за хорошего сочетания стоимости, надежности и производительности.
Ивы RAID уровня 5 считаются массивами общего назначения, и часто исполь-
°Я В сеРвеРах приложений, системах планирования ресурсов уровня предпри-
Файловых серверах и других коммерческих системах.
758
Существует много других уровней RAID, каждый из которых сочетает в
рактеристики одного или нескольких описанных выше уровней. К нес^6 Ч-
стандартная система обозначений для уровней RAID отсутствует, и часто аСТь>о
встретить непонятные или просто запутанные обозначения.
КлючеВые термины
AFRAID (A Frequently Redundant Array of Independent Disks — часто избыт
массив независимых накопителей) — реализация RAID, в которой гене>ЧвЬ1®
кодов четности откладывается до тех пор, пока нагрузка на систему не ум^Ия
шается, чтобы улучшить производительность при выполнении множества
раций записи небольших объемов данных. °®®'
C-LOOK (C-LOOK disk scheduling) — алгоритм диспетчеризации дисковых one
ций, при котором головки перемещаются в одном направлении, выполняя ₽Э
просы в порядке роста их времен позиционирования. Если в текущем прохо
запросов больше не осталось, головки перемещаются в противоположном на
правлении к самому дальнему из цилиндров, к которым есть запросы (не выпол
няя запросов при перемещении). Этот алгоритм характеризуется потенциально
меньшим разбросом времени реагирования, чем LOOK, и сравнительно высокой
пропускной способностью (хотя и меньшей, чем LOOK).
C-SCAN (C-SCAN disk scheduling) — алгоритм диспетчеризации дисковых опера-
ций, при котором головки перемещаются в одном направлении, выполняя за-
просы в порядке роста их времен позиционирования. Когда движение головок
в одном направлении завершается, они перемещаются (не выполняя запросов)
к самому удаленному цилиндру и вновь начинают двигаться, выполняя запро-
сы. Алгоритм C-SCAN обеспечивает высокую пропускную способность, ограни-
чивая разброс времени реагирования за счет устранения дискриминации край-
них и внутренних цилиндров.
FCFS (FCFS disk scheduling) — алгоритм диспетчеризации дисковых операций,
при котором запросы выполняются в порядке их поступления. Это стабильный
метод выполнения запросов, но при высокой нагрузке (то есть частом поступле-
нии запросов) использование FCFS может привести к большим временам выпол-
нения запросов. FCFS обладает случайной последовательностью выборки, при
которой выполнение запросов может быть связано с длительными перемеЩ6"
ниями головок от внешних цилиндров к внутренним и обратно.
FSCAN (FSCAN disk scheduling) — алгоритм диспетчеризации дисковых опере
ций, при котором по алгоритму SCAN выполняются запросы, поступившие^
начала очередного прохода головок (F расшифровывается как «freezing»
мораживающий», поскольку поступающие запросы «замораживаются» Д° н
ла нового прохода головок). Запросы, поступившие за время прохода, упор
чиваются для оптимальной последовательности выполнения и выполни
при обратном проходе.
LOOK (LOOK disk scheduling) — разновидность алгоритма диспетчеризации
вых операций SCAN, при котором очередь запросов просматривается вп
чтобы определить, можно ли выполнить какие-то запросы при текущем н
лении движения головок. Если таких запросов нет, то направление дви
головок изменяется на противоположное, и запросы выполняются, наЧ{1^еТ
с запроса с наименьшим временем позиционирования. Этот алгоритм
ненужные операции позиционирования, присутствующие в других РаЗН°емОстВ
стях алгоритма SCAN, поскольку головки не перемещаются без необходИ
к дорожкам на внешних или внутренних краях дисков.
мция производительности дисковых накопителей
759
f ГОВЫЙ SCAN (N-step SCAN disk scheduling) — алгоритм диспетчеризации
H' сковых операций, при котором по алгоритму SCAN выполняются первые N
ггООсОВ из очереди. После завершения прохода головок при обратном проходе
I 9долняются следующие N запросов. Поступающие запросы помещаются в ко-
**** очереди. Этот алгоритм характеризуется хорошей производительностью
дедстви® высокой пропускной способности, малого среднего времени реагиро-
В0Вия и меньшего его разброса, чем у алгоритмов SSTF и SCAN.
ID (Redundant Array of Independent Disks — избыточный массив независимых
ID*" копителей) — семейство технологий, использующих массивы накопителей
для повышения скоростей обмена и обеспечения отказоустойчивости.
лтп-контроллер (RAID controller) — специальное аппаратное устройство, эф-
/Ьективно выполняющее такие операции, как разделение файлов на полосы,
сборку файлов из полос, выбор нужных полос из массива и поддержку отказо-
устойчивости массива.
RAID уровня О (RAID level 0) — этот уровень RAID использует массив разделен-
ных на полосы дисков без избыточности. Массивы уровня 0 уязвимы для отка-
зов: если отказывает один из накопителей в массиве, то теряются все данные,
части которых хранились на отказавшем накопителе. При определенном разме-
ре полосы отказ одного накопителя может привести к потере всех данных в мас-
сиве. Хотя RAID уровня 0 и не обладает отказоустойчивостью, он прост в реали-
зации, дает высокие скорости обмена и не требует накладных расходов на хра-
нение информации. Массивы уровня 0 используются в системах, в которых
производительность важнее надежности, например, в суперкомпьютерах.
RAID уровня 1 (RAID level 1) — этот уровень использует зеркальное отображение
накопителей для обеспечения избыточности, и любые данные в массиве сущест-
вуют в двух копиях. В массивах уровня 1 разделение на полосы не использует-
ся, вследствие чего уменьшается как сложность аппаратуры, так и производи-
тельность системы. Хотя этот уровень и обладает наибольшей отказоустойчиво-
стью из всех уровней RAID, только половина его емкости может использоваться
Для хранения неповторяющихся данных, вследствие чего растет стоимость.
Массивы уровня 1 используются в системах, где надежность и доступность дан-
ных важнее, чем стоимость, например, в серверах баз данных.
“AID уровня 2 (RAID level 2) -— массивы этого уровня делят данные на полосы по
битам, и каждая полоса хранит один бит. Эти массивы созданы, чтобы умень-
пиггь накладные расходы на хранение, возникающие при обеспечении избыточ-
ности путем зеркального отражения. Вместо хранения двух копий каждого эле-
мента данных, RAID уровня 2 использует метод, основанный на хранении кодов
Четности, называемых кодами Хемминга. Эти коды позволяют обнаруживать до
Двух ошибок, исправлять одну ошибку и определять место ошибки в полосе.
Размер кодов Хемминга и, соответственно, количество накопителей для их хра-
нения, растет пропорционально двоичному логарифму от количества накопите-
лей с данными. Поэтому массив уровня 2, состоящий из большого количества
Накопителей, будет обладать меньшим уровнем накладных расходов, чем мас-
Сав Уровня 1.
AID уровня 3 (RAID level 3) — в этих массивах данные делятся на полосы по би-
там или байтам. RAID 3 использует контрольные коды XOR ЕСС, вычисляемые
с Использованием логической операции исключающего ИЛИ. При этом для хра-
нения кодов четности используется только один накопитель, независимо от раз-
мера массива. Система может использовать биты четности, чтобы восстановить
Данные при отказе одного накопителя. Если отказывает накопитель с кодами
L Четности, то для регенерации данных нужно заново вычислить коды для всех
I Данных в массиве. Вследствие проверок четности операции чтения и записи
760
л^«/г
в массивах уровня 3 требуют обращений ко всем накопителям массив
и в массивах уровня 2, это обеспечивает высокую пропускную способно
запросов большого объема, но одновременное выполнение нескольких 35
невозможно. П^°соь
RAID уровня 4 (RAID level 4) — в массивах RAID уровня 4 данные делятся
лосы по блокам (размер блоков обычно намного больше байта), и для гет tt0-
кодов четности, хранимых на одном накопителе, используется алгорцт
ЕСС. Поскольку в массивах уровня 4 используются широкие полосы, Тео1^
ски они могут выполнять несколько запросов на чтение одновременно, ее ЙЧе'
каждого запроса не нужно проверять четность. Однако при записи необхсГ ЛЛя
обновлять коды четности, чтобы гарантировать, что данные не будут поте ДИм°
при отказе накопителя. Это значит, что запросы на запись должны выполни
по одному за раз, и запись является узким местом в массивах уровня 4 ЬСя
RAID уровня 5 (RAID level 5) — в массивах этого уровня данные делятся на по
сы по блокам, и для генерации кодов четности используется алгоритм
ЕСС. Однако блоки четности распределены по накопителям массива, вследствп
чего можно одновременно обращаться к нескольким таким блокам. В результ
те узкое место при записи для многих запросов исчезает. Хотя производитель'
ность при записи RAID уровня 5 больше, чем RAID уровней 2-4, массивы уров-
ня 5 сложны в реализации и сравнительно дорогостоящи. Эти массивы считают-
ся массивами общего назначения и широко применяются в файловых серверах
серверах приложений, системах планирования ресурсов уровня предприятия
и других коммерческих системах.
RAMAC (Random Access Method of Accounting and Control — Произвольный метод
доступа для учета и управления) — первый коммерческий накопитель на жест-
ком диске, выпущенный IBM.
SATF (SATF disk scheduling) — алгоритм диспетчеризации дисковых операций,
обслуживающий первым запрос с минимальным временем доступа (то есть сум-
мой времени позиционирования и времени передачи). Алгоритм SATF обладает
более высокой пропускной способностью, чем SPTF, но выполнение больших по
объему запросов может бесконечно откладываться при наличии запросов мало-
го объема, а запросы к краевым цилиндрам могут откладываться при наличии
запросов к средним цилиндрам.
SCAN (SCAN disk scheduling) — алгоритм диспетчеризации дисковых операций,
уменьшающий нестабильность и разброс времени реагирования по сравнению
с SSTF, выполняя первым запрос, ближайший к головке чтения/записи в првД-
почитаемом направлении. SCAN похож на SSTF своей высокой пропускной спо-
собностью и хорошим средним временем реагирования. Однако посколь У
SCAN выполняет все запросы в выбранном направлении, прежде чем начинать
выполнять запросы в обратном направлении, он обладает меньшим разброс
времени реагирования, чем SSTF. Этот алгоритм иногда называют алгоритм
лифта. „
SLTF (SLTF disk scheduling) — алгоритм диспетчеризации дисковых операП^^
просматривающий все ожидающие выполнения запросы и выполняющий
вым запрос с минимальной вращательной задержкой. Этот алгоритм о
к теоретически оптимальному и относительно прост в реализации.
SPTF (SPTF disk scheduling) — алгоритм диспетчеризации дисковых опеР0^ад-
выполняющий запросы в порядке роста их времен позиционирования. до-
горит м, как и SSTF, обладает малым средним временем реагирования и
кой пропускной способностью, но может бесконечно откладывать выполн
запросов к внутренним и внешним цилиндрам.
# (SSTF disk scheduling) — алгоритм диспетчеризации дисковых операций, об-
кивающий первым запрос к цилиндру, ближайшему к головке чтения/запи-
если этот запрос не стоит первым в очереди. Уменьшая среднее время
СлзиДиоНИРования’ этот алгоритм дает большую пропускную способность, чем
SrFS, и среднее время реагирования у этого алгоритма меньше при среднем
I товне нагрузки. Существенный его недостаток — значительный разброс време-
5Жреагирования, поскольку запросы к цилиндрам на внешнем и внутреннем
диска могут откладываться бесконечно при наличии запросов к средним
цилиндрам.
rtjfVAC 1 (UNIVersal Automatic Computer — Универсальный автоматический вы-
^цислитель) — первый компьютер, в котором использовались накопители на маг-
нитных лентах.
ддгоритм лифта (elevator algorithm) — см. SCAN.
к (block) — элемент данных фиксированного размера, обычно намного болыпе-
чем байт. Размещение следующих друг за другом записей в блоках позволя-
ет системам уменьшать количество операций ввода/вывода, необходимых для
извлечения этих записей.
Вращательная задержка (rotational latency) — время, необходимое, чтобы требуе-
мые данные переместились под головку чтения/записи вследствие вращения
диска.
Время передачи (transmission time). Время, необходимое для прохождения дан-
ных под головкой чтения/записи.
Время позиционирования (seek time) — время, необходимое для перемещения го-
ловки чтения/записи к цилиндру, содержащему запрашиваемые данные.
Головка чтения/записи (read/write head) — компонент накопителя, перемещаю-
щийся над поверхностью диска, считывая и записывая данные при вращении
диска.
Дефрагментация (defragmentation) — перемещение частей файлов таким образом,
чтобы файлы размещались в непрерывных областях дисков. Дефрагментация
позволяет уменьшить время доступа к файлам при последовательном чтении
данных или последовательной записи.
Дисковый буфер (disk cache buffer) — область в оперативной памяти, которую
операционная система выделяет для данных накопителя. В одном случае эта об-
ласть используется как кэш, позволяя процессам быстро получать данные, ко-
торые в противном случае потребуется запрашивать с накопителя. В другом
случае эта область используется как буфер, позволяя операционной системе от-
кладывать запись данных на накопитель и группировать несколько операций
записи в одно обращение к накопителю, повышая производительность вво-
Да/вывода.
диспетчеризация дисковых операций (disk scheduling) — стратегия, упорядочи-
вающая запросы к накопителю для достижения максимальной пропускной
способности и минимизации времени реагирования и его разброса. Алгоритмы
Диспетчеризации обращений к диску повышают производительность за счет
Уменьшения времен позиционирования и вращательных задержек.
°Роэкка (track) — кольцевая область на диске. Последовательности битов дан-
ft ®Ь1Х из файлов обычно размещаются в непрерывных областях на одной и той
> ’Ке Дорожке, чтобы уменьшить потребность в операциях позиционирования
Соловок.
Зеркальное отображение (disk mirroring) — в RAID-массивах так называет
тод обеспечения избыточности, при котором существует две хранящиеся Ся
ных накопителях копии любых данных. Этот метод обеспечивает высо На
дежность и упрощает регенерацию данных, но связан со значительна
кладными расходами, за счет чего увеличивается стоимость. Ц.
Избыточность (redundancy) — использование нескольких идентичных п
для обеспечения отказоустойчивости.
Исключающее ИЛИ (XOR, или exclusive OR) — логическая операция над
битами, возвращающая 1, если значения этих битов различны, или 0, есл^В^4
чения равны. Эта операция используется в массивах RAID уровней 3-5 дПя 3tIa'
рации кодов четности. * ГеИе-
Коды Хемминга (Hamming error-correcting codes, или Hamming ЕСС)__корп
рующие коды, позволяющие системам обнаруживать и исправлять ошибки КТИ'
дельных битах при передаче данных. °’г‘
Кэширование с отложенной записью (write-back caching) — метод кэпщрова
данных, при использовании которого данные из буфера записываются на нак *
питель периодически, позволяя операционной системе объединять несколько
запрошенных операций ввода/вывода в одну, за счет чего может возрасти про.
изводительность системы.
Кэширование со сквозной записью (write-through caching) — метод кэширования
данных, при использовании которого данные записываются одновременно и на
накопитель, и в буфер при каждом их изменении. Этот метод не позволяет груп-
пировать запросы ввода/вывода, но уменьшает вероятность потери целостности
данных при отказе.
Лента (stripe) — в массивах RAID — набор полос, размещенных в одинаковых по-
зициях на накопителях массива. Разделение данных на полосы позволяет мас-
сивам RAID повышать скорость доступа к ним за счет того, что запрос выполня-
ется по частям сразу несколькими накопителями.
Нагрузка (load) — см. частота запросов.
Надежность (reliability) — мера отказоустойчивости. Чем более надежен ресурс,
тем меньше вероятность его отказа.
Накопители горячей замены (hot spare disks или online spare disks) — в RAID-мас-
сивах — накопители, которые не используются до отказа одного из используе-
мых накопителей. При регенерации поврежденных данных накопители горячей
замены используются вместо отказавших.
Накопители онлайн-замены (online spares) — см. накопители горячей замены-
Накопитель на жестком диске (hard disk drive) — магнитное устройство хранения
данных, размещающее информацию на вращающихся дисках, предоставля
щее возможность долговременного хранения данных и произвольного дос У
к ним.
Накопитель на магнитной ленте (magnetic tape storage) — устройство хран
данных с возможностью перезаписи и последовательным доступом к Да
Последовательный доступ делает его непригодным для приложений, тР
щих быстрого доступа к данным. с.
Неравномерное распределение запросов (nonuniform request distribution) g^ac-
пределение запросов по поверхности дисков, при котором к некоторым дес-
тям запросы поступают чаще, чем к другим. Оно возникает потому, что ™
сы обращаются только к части данных, хранящихся на дисках.
в//щзация производитель^ д скоВых накопителей
763
з обновления (update image) — в RAID-массивах — объект, позволяющий
Г0бР®ецЬшить затраты времени на вычисление кодов четности за счет хранения
^зНИДЫ м£™ новыми и старыми кодами четности в оперативной памяти вме-
Е Р® вЫполнения циклов чтение-изменение-запись.
сТ<^я.обработка транзакций (online transaction processing, OLTP) — процесс,
00^® тчно генерирующий множество запросов небольшого объема к случайным об-
0 стям на накопителях. Такие процессы характерны, например, для Web-серве-
718 и серверов баз данных. Скорость выполнения таких процессов существенно
Р личивается при использовании диспетчеризации дисковых операций.
оация позиционирования (seek operation) — операция перемещения головки
^чтения/записи к другому цилиндру.
л-тимязация по вращению (rotational optimization) — алгоритм диспетчеризации
и йСковых операций, уменьшающий время доступа за счет того, что первым вы-
полняется запрос к сектору, ближайшему к головке чтения/записи в текущем
цилиндре.
Оптимизация по позиционированию (seek optimization) — алгоритм диспетчери-
зации дисковых операций, уменьшающий время доступа за счет того, что пер-
выми выполняются запросы с минимальными временами позиционирования.
Пластина (platter) — магнитный носитель для хранения данных.
Полоса (strip) — в массивах RAID — минимальный обрабатываемый элемент дан-
ных. Набор полос, размещенных в одинаковых позициях на разных накопите-
лях массива, называется лентой.
Предпочитаемое направление (preferred direction) — в семействе алгоритмов
SCAN — направление перемещения головок чтения/записи.
Привод блока головок (actuator, boom или disk arm) — поворачивающийся стер-
жень, позволяющий перемещать головки чтения/записи параллельно поверх-
ностям дисков.
Промежуточное хранение блоков четности (parity logging) — прием, увеличиваю-
щий производительность RAID-систем при записи за счет откладывания записи
на накопитель с блоками четности при высоких нагрузках на системы. По-
скольку при этом данные о четности хранятся в оперативной памяти, они могут
быть потеряны при отключении питания.
Разделение данных (data striping) —- в RAID-системах — прием, разделяющий не-
прерывные данные на полосы фиксированной длины, которые могут разме-
щаться на разных накопителях. Это позволяет задействовать несколько накопи-
телей при выполнении запросов.
Регенерация данных (data regeneration) — в RAID-системах так называется вос-
становление данных, потерянных или поврежденных из-за ошибок или отказов
Накопителей.
Рганизация диска (disk reorganization) — перемещение файлов на диске для
Уменьшения времени доступа к ним. Одна из методик реорганизации диска —
Дефрагментация, пытающаяся разместить последовательные данные в непре-
рывных областях диска. Другой подход подразумевает перемещение часто за-
крашиваемых данных на дорожки, среднее время позиционирования головок
КОторые невелико.
eit’op (sector) — наименьшая часть дорожки, к которой может обращаться запрос
с Ев°да/вывода.
торное упорядочение (sector queuing) — то же самое, что и вращательная опти-
мизация (см. оптимизация по вращению).
764
Сжатие данных (data compression) — прием, позволяющий уменьшить объе
нимаемый данными, за счет замены часто встречающихся последователь/*1’ 3^-
битов последовательностями меньшей длины. Это позволяет уменьшить р°Сгей
на позиционирования и передачи данных, но может потребовать существ ₽ebte-
вычислительной мощи от процессора для сжатия данных перед их зя
и для их распаковки после чтения. Ись1с
Случайная последовательность выборки (random seek pattern) — последов
ность запросов к цилиндрам, случайным образом располагающимся на
Алгоритм FCFS обладает такой последовательностью выборки, привод СКе’
к большому времени реагирования и малой пропускной способности. Н1Чей
Среднее время реагирования (mean response time) — при обращениях к нако
лям — среднее время между поступлением запроса и его выполнением. Те'
Средняя наработка на отказ (mean-time-to-failure, MTTF) — среднее время д0
каза накопителя (или другого устройства). от'
Тонкие полосы (fine-grained strips) — способ разбивки на полосы малого размел»
в RAID-массивах, при использовании которого файлы среднего размера разда
ляются на много полос. При этом время доступа для отдельно взятых запросе
уменьшается, и скорости обмена растут, поскольку при выполнении запросов
одновременно извлекают данные все накопители массива.
Узкое место (bottleneck) — ресурс в системе, который получает запросы чаще, чем
может их выполнять, вследствие чего замедляется выполнение процессов
и уменьшается уровень использования других ресурсов. Накопители на жест-
ких дисках являются узким местом в большинстве систем.
Упреждающее перемещение (anticipatory movement) — перемещение головок при
их упреждающем позиционировании.
Упреждающее позиционирование головок (disk arm anticipation) — перемеще-
ние консолей головок в позицию, сводящую к минимуму перемещение головок
при следующем запросе. Упреждающее позиционирование может оказаться
полезным в системах с частыми обращениями к небольшим областям на дис-
ках и периодами времени, позволяющими перемещать головки при отсутствии
запросов.
Уровень (level) — в RAID-массивах — способ их организации, например, 1
(с зеркальным отображением) или 2 (с кодами Хемминга). См. также RAID
уровня О, RAID уровня 1, RAID уровня 2, RAID уровня 3, RAID уровня ,
RAID уровня 5.
Фрагментированный диск (fragmented disk) — диск, на котором файлы хранят0®
в несмежных блоках в результате множества операций удаления и создан
файлов. Такие диски обладают большими временами позиционирования прй
следовательном чтении файлов. Времена позиционирования для них м
уменьшить, выполнив дефрагментацию.
Цикл чтение-изменение-запись (read-modify-write cycle) — в массивах RAID
последовательность операций, считывающая полосу из массива, изменяют
содержимое и соответствующие ей коды четности и записывающая язме^доМ
обратно в массив. Эта последовательность операций выполняется при к „opbie
запросе записи в массивах RAID, использующих контроль четности. Неко
системы уменьшают количество таких операций, кэшируя полосы или
ляя коды четности через определенные периоды времени. одН°м
Цилиндр (cylinder) — набор дорожек, к которым можно обращаться при
и том же положении консолей головок.
оТа запросов (request rate) — количество запросов, поступающее за единицу
^^емени. Чем выше частота запросов, тем больше нагрузка на систему. Системы
аРусской частотой запросов часто выигрывают от тщательной диспетчеризации
%сКОвых операций.
" петь (parity) — прием, позволяющий обнаруживать некоторые ошибки при
едаче данных. Контрольные данные генерируются посредством определе-
И ° я количества нулей или единиц в данных. Эти же данные генерируются по-
0 приема данных и сравниваются с принятыми контрольными данными.
0 „у корректировки ошибок (error-correcting codes, или ЕСС), например,
11Ы Хемминга или XOR, используют четность строки битов для обнаружения
0 управления ошибок. Четность позволяет RAID-массивам обеспечивать от-
казоустойчивость с меньшими накладными расходами, чем зеркальное отобра-
жение.
ягйоокая полоса (coarse-grained strip) — способ разбивки на полосы большого раз-
***jIepa в RAID-массивах, позволяющий файлам среднего размера размещаться
в небольшом количестве полос. При использовании широких полос для выпол-
нения некоторых запросов может потребоваться только часть накопителей мас-
сива. Это увеличивает вероятность того, что можно будет одновременно выпол-
нять несколько запросов. Если запросы требуют малые объемы данных, они вы-
полняются только одним накопителем, вследствие чего уменьшаются средние
скорости передачи данных для этих запросов.
Шпиндель (spindle) — вращающийся стержень, на котором закреплены диски.
Упражнения
12.1. Каковы основные цели диспетчеризации дисковых операций? Почему важ-
на каждая из них?
12.2. Предположим, что на конкретной модели накопителя среднее время пози-
ционирования приблизительно равно средней вращательной задержке. Как
это может повлиять на выбор разработчиком алгоритмов диспетчеризации
дисковых операций?
!2.3. Чем определяется стабильность конкретного алгоритма диспетчеризации
дисковых операций? Насколько важна стабильность по сравнению с други-
ми целями диспетчеризации?
12.4. Нестабильные алгоритмы диспетчеризации дисковых операций обычно
дают больший разброс времени реагирования, чем алгоритм FCFS. Почему
это так?
В®. К какому алгоритму диспетчеризации дисковых операций сводятся почти
все рассмотренные в этой главе алгоритмы при небольших уровнях нагруз-
jо ки? Почему?
6. Один из критериев, определяющий желательность использования диспет-
черизации дисковых операций, — накладные расходы, связанные с диспет-
черизацией. Какие факторы определяют уровень этих накладных расхо-
дов? Предположим, что t — среднее время позиционирования для системы
с алгоритмом диспетчеризации FCFS. Предположим, что s — приблизи-
тельное время диспетчеризации среднего запроса, если бы использовался
Другой алгоритм планирования. Предположим, что все остальные факторы
благоприятствуют использованию диспетчеризации в системе. Оцените вы-
игрыш от диспетчеризации в каждом из следующих случаев:
766
а. S = o.oit
б. S = O.lt
в. S = t
г. S = lot
12.7. Вращательная оптимизация дает небольшой выигрыш в произв
ности, за исключением случаев очень большой нагрузки на сис-г°*'11Тели
чему? По.
В интерактивных системах важно обеспечить приемлемое время п
системы на действия пользователя. Уменьшение разброса времени в
вания существенно, но его недостаточно, чтобы гарантировать невг»1^
ность бесконечной задержки реакции на действия отдельных пользо^0^'
лей. Какой дополнительный механизм можно встроить в алгоритм ате'
черизации доступа для интерактивной системы, чтобы гаранти-пл0^
приемлемое время реагирования и устранить возможность бесконечна“Ь
держки? и За'
Поясните, почему некоторые специалисты не считают FCFS алгоритм
диспетчеризации дисковых операций. Есть ли схемы выполнения залп
сов, которые еще менее подходят под определение алгоритма диспетчериза"
ции дисковых операций?
В каком смысле алгоритм LOOK стабильнее алгоритма SSTF? В каком
смысле алгоритм C-LOOK стабильнее, чем алгоритм LOOK?
Объясните с точки зрения статистики, почему алгоритм FCFS обладает не-
большим разбросом времени реагирования.
Объясните, почему алгоритм SSTF предпочитает запросы к средним цилин-
драм запросам к внешним и внутренним цилиндрам?
В главе 7 предлагалась схема, позволявшая избегать бесконечного откла-
дывания выполнения заданий. Предложите схему, подходящую для алго-
ритма SSTF, позволяющую избегать бесконечного откладывания. Сравните
новую версию алгоритма с обычным SSTF с точки зрения пропускной спо-
собности, среднего времени реагирования и разброса этого времени.
Возможна ситуация, в которой во время выполнения запроса к некоторому
цилиндру поступает новый запрос к этому же цилиндру. Некоторые алго-
ритмы планирования доступа выполнят новый запрос сразу после выпол-
няющегося в данный момент. Другие алгоритмы отложат выполнение но-
вого запроса до обратного прохода головки над этим же цилиндром. Какие
опасные ситуации могут возникнуть при использовании алгоритма, пОЗВ0
ляющего выполнить новый запрос сразу же после выполняемого в мом
его поступления?
Почему разброс среднего времени реагирования у алгоритма SCAN мен
чем у SSTF?
Сравните пропускную способность алгоритмов FSCAN и SCAN.
Сравните пропускную способность алгоритмов C-SCAN и SCAN.
Как работает вращательная оптимизация?
— --> накопи,
у U VX1V Д \JXJу ------ Цбй ’
телей, не всегда удается устранить за счет добавления новых накоп на
12.20. Как количество одновременно исполняемых в системе программ вл
потребность в диспетчеризации дисковых операций? gjjrb
12.21. Предположим, что имеет место насыщение контроллера. Может mOjkB0
полезной диспетчеризация дисковых операций? Какие еще меры
предпринять?
12.8.
12.9.
12.10.
12.11.
12.12.
12.13.
12.14.
12.15.
12.16.
12.17.
12.18.
12.19. Почему узкое место в системе, обусловленное производительностью
производительности дисковых
-накопителей
12.23-
12.24.
Почему предпочтительно считать распределение запросов равномерным?
В системах каких типов можно наблюдать приблизительно равномерное
распределение запросов? Приведите несколько примеров систем с неравно-
мерным распределением запросов.
Будет ли полезной диспетчеризация дисковых операций в однопользова-
тельской системе с выделенным накопителем для приложения обрабаты-
вающего последовательные файлы? Почему?
Алгоритм диспетчеризации доступа к дискам VSCAN сочетает алгоритмы
SSTF и SCAN с помощью переменной В91. VSCAN определяет, какой запрос
выполнять следующим, используя алгоритм SSTF, но расстояние до каждо-
го цилиндра, для перемещения к которому необходимо изменить направле-
ние движения головок, умножается на коэффициент R. «Расстояния» к ци-
линдрам в противоположном направлении вычисляются следующим обра-
зом. Если С — количество цилиндров на диске, aS — количество
цилиндров между тем, над которым головка находится в данный момент
и тем, к которому нужно переместиться, то VSCAN считает, что расстояние
D = S + R* С. Таким образом, VSCAN использует вес R для увеличения рас-
стояния до запросов в направлении, обратном предпочитаемому.
Если R = О, то в какой алгоритм превратится алгоритм VSCAN?
Если R — 1, то в какой алгоритм превратится алгоритм VSCAN?
Оцените выигрыш от выбора значения R из интервала между 0 и 1.
12.25. В каких случаях применение алгоритмов диспетчеризации доступа может
привести к падению производительности по сравнению с алгоритмом
FCFS?
12.26. Сравните основные цели диспетчеризации доступа с таковыми у диспетче-
ризации процессорного времени. В чем они схожи? В чем отличаются?
12.27. Какие факторы обуславливают необходимость позиционирования?
12.28.
12.29.
12.30.
12.31.
12.32.
,г-зз.
Последовательный файл, «правильно» размещенный на пустом диске,
можно извлечь с минимумом операций позиционирования. Но по мере до-
бавления и удаления файлов, данные обычно становятся сильно фрагмен-
тированными. Поэтому последовательные обращения к «соседним» запи-
сям в файле могут требовать солидного количества операций позициониро-
вания. Обсудите возможность использования реорганизации файлов для
минимизации потребности в позиционировании. В каких случаях файлы
нужно реорганизовывать? Нужно ли реорганизовывать каждый файл на
Диске или только отдельные файлы?
Разработчик предложил использовать несколько независимых консолей
с головками, чтобы радикально увеличить производительность дисковой
подсистемы. Оцените преимущества и недостатки такого подхода.
Мы упоминали, что алгоритм планирования доступа LOOK по образу рабо-
ты похож на лифт в здании. С каких точек зрения эта аналогия верна?
Предложите приемы, сводящие к минимуму потребность в позиционирова-
нии, не основанные на реорганизации диска и диспетчеризации доступа
к нему.
Алгоритм SCAN часто демонстрирует намного большую пропускную спо-
собность, чем C-SCAN. Однако разработчики систем часто предпочитают
использовать алгоритм C-SCAN. Почему?
В разделе 12.10.6 говорилось, что RAID-массив может уменьшить количе-
ство операций ввода/вывода, вычисляя новые коды четности по формуле
Ар’ = (Ad XOR A/) XOR Ар. Докажите истинность этой формулы для лю-
бых значений Ар, Ad и А/.
768
12.34. Для каждой из перечисленных ниже задач выберите оптимальный
RAID: О, 1 или 5. Аргументируйте свой выбор.
Хранение данных о счетах в финансовой организации.
Хранение изображений высокого разрешения с телескопа, скопи™
с магнитной ленты, перед их обработкой на суперкомпьютере.
Работа персонального Web-сервера.
12.35.
12.36.
12.37.
Рекомендуемые исследовательские учебные проекты
Изучите диспетчеризацию дисковых операций в системе Linux. Ка
горитмы диспетчеризации в ней используются? Как они реализованы?6
дение в диспетчеризацию доступа к диску в Linux содержится ^®е'
ле 20.8.3. ₽азДе-
ГГодготовьте научную статью, описывающую приемы, применяемые пп
водителями накопителей для повышения производительности. Восп
зуйтесь ссылками из раздела «Веб-ресурсы». Оль'
Подготовьте доклад, кратко описывающий пять уровней RAID, не рассм
ривавшихся в этой главе. т'
Рекомендуемые программные учебные проекты
12.38.
12.39.
12.40.
Создайте программы мониторинга (см. главу 6), реализующие следующие
алгоритмы диспетчеризации дисковых операций:
a. FCFS
б. SSTF
в. SCAN
г. N-шаговый SCAN
д. C-SCAN
В этой главе мы рассмотрели несколько алгоритмов диспетчеризации дис-
ковых операций, ориентированных на цилиндры — FCFS, SSTF, SCAN,
N-шаговый SCAN, C-SCAN, F-SCAN, LOOK и C-LOOK. Напишите програм-
му моделирования, позволяющую сравнить производительность этих алго-
ритмов при низких, средних и высоких уровнях нагрузок. Низким уровнем
нагрузки считайте уровень, при котором очередь запросов пуста или содер-
жит только один запрос. Средним уровнем загрузки считайте уровень, ПРИ
котором к каждому цилиндру в очереди есть 0 или 1 запрос. Высоким УР0В"
нем загрузки считайте уровень, при котором ко многим цилиндрам есть по
нескольку запросов. Используйте генерацию случайных чисел для иМИ^
ции моментов поступления запросов и номеров цилиндров, к которым
запросы обращаются.
Доступность накопителей с подвижными головками сыграла важную Р
в распространении современных компьютерных систем. Такие накоПм0Ь1М
предоставляют сравнительно быстрый произвольный доступ к ОГР° пОль-
объемам информации. Согласно прогнозам, эти накопители будУт и со3-
зоваться и развиваться еще долгое время, и исследователи продольна
давать все новые алгоритмы диспетчеризации дисковых операции в сраВ-
накопителях. Предложите новый алгоритм планирования доступа и
ните его с уже существующими. стИ110
Создайте программу, моделирующую работу накопителя с двумя пл g5
ми (т.е. четырьмя поверхностями), четырьмя головками чтения/зап ^oJl-
цилиндрами и 20 секторами на каждой дорожке. Накопитель дол^к це-
нить текущую позицию головок чтения/записи и выполнять операП
рация производительности дисковых наксгптелви
Ния, записи и позиционирования. Эти операции должны возвращать время
в миллисекундах, необходимое на выполнение запроса (для примера мож-
но задать время перемещения между дорожками 2 мс, среднее время пози-
ционирования 10 мс и вращательную задержку 5 мс). После этого напиши-
те программу, генерирующую равномерно распределенные запросы с ука-
занием пластины, цилиндра, сектора и количества запрашиваемых
секторов. Эти запросы должны отправляться диспетчеру дисковых опера-
ций, который будет упорядочивать их и посылать накопителю для выпол-
нения. Накопитель должен выполнять операции чтения, записи и позицио-
нирования. Используйте возвращаемые накопителем величины, чтобы оп-
ределять пропускную способность каждого алгоритма, время его
реагирования и разброс этого времени.
д! Улучшите программу моделирования из предыдущего задания, чтобы она
*** учитывала вращательную задержку. Улучшилась или ухудшилась произ-
водительность для каждого из алгоритмов?
Рекомендуемая литература
Поскольку накопители являются узким местом во многих системах, оптимиза-
ция их производительности является предметом активных исследований и анали-
за в литературе. Деннинг обсуждал повышение производительности за счет ис-
пользования алгоритмов диспетчеризации дисковых операций92. По мере того,
как дисковые накопители становились доминирующей разновидностью устройств
хранения, интенсивность работ по повышению их производительности
возрастала93, 94 951 96, 97, 98, ". Исследователи регулярно проводят сравнительные
исследования алгоритмов диспетчеризации, часто используя изощренные средства
моделирования работы накопителей36, 39. Паттерсон с коллегами впервые описал
RAID в своей статье100. Последующие исследования подробно оценили преимуще-
ства и недостатки различных уровней RAID101, 102. Поскольку разрыв в произво-
дительности накопителей и электронных компонентов компьютеров продолжает
Расти, MEMS-устройства (microelectromechanical storage — микроэлектромехани-
ческие устройства хранения), использующие тысячи головок чтения/записи для
Доступа к прямоугольным носителям, становятся многообещающей альтернативой
НаКопителям на магнитных дисках103,104. Свежая библиография к этой главе дос-
"tyllHa на Web-сайте по адресу www.deitel.com/books/os3e/Bibliography.pdf.
^пользуемая литература
^•Kozierok, С., «Life Without Hard Disk Drives», PCGuide, April 17, 2001,
www.pcguide.com/ref/hdd/histWithout-c.html>.
Khurshudov, A., The Essential Guide to Computer Data Storage, Upper Saddle
River, NJ:Prentice Hall PTR., 2001, p. 6.
«RAMAC», Whatis.com, April 30, 2001, <searchstorage.techtarget.com/
s0efinition/0,,sid5_gci548619,00.html>.
Khurshudov, A., The Essential Guide to Computer Data Storage, Upper Saddle
River, NJ:Prentice Hall PTR., 2001, p. 90.
• «Cost of Hard Drive Space», September 20, 2002, <www.littletechshop.com/
nsl625/ winchest. html>.
770
Ч
6. Patterson, D.; G. Gibson; and R. Katz, «А Case for Redundant Arrays f 1
pensive Disks», Proceedings of the ACM SIG-MOD, June 1988, p. I09 °*
7. Gotlieb, С.» and G. MacEwen, «Performance of Movable-Head Disk Stor
vices,» Journal of the ACM, Vol. 20, No. 4, October 1973, pp. 604-б2за^еЬе
8. Smith, A., «On the Effectiveness of Buffered and Multiple Arm Disks» p
ings of the Fifth Symposium on Computer Architecture, 1978, pp. 109 ] 12°°^
9. Pechura, M. A., and J. D. Schoeffler, «Estimating File Access Time of pi
Disks,» Communications of the ACM, Vol. 26, No. 10, October 1983, pp. 754 °₽Jty
10. Kozierok, C., «Spindle Speed», PCGuide, April 17, 2001, <www.pcguid
ref/hdd/spinSpeed-c.html>. е'с°Ч1/
11. Waters, S. J., «Estimating Magnetic Disc Seeks,» Computer Journal V 1
No. 1, 1973, pp. 12-18. ’ °1’ 18,
12. Kollias, J. G., «An Estimate of Seek Time for Batched Searching of Random or Ind
Sequential Structured Files,» Computer Journal, Vol. 21, No. 2, 1978, pp. 132-133^
13. Kozierok, C., «Hard Disk Tracks, Cylinders and Sectors», modified April 17
2001, <www.pcguide.com/ref/hdd/geom/tracks.htm>. '•
14. «DiamondMax Plus 9», Maxtor Corporation, May 14, 2003, <www.maxtor com/
en/documentation/data_sheets/diamondmax_plus_9_data_sheet.pdf>.
15. «WD Caviar Hard Drive 250GB 7200 RPM», October 28, 2003, <www.westerndi-
gital . com/en/products/Products. asp?Dr iveID=41 >.
16. «MK8025GAS», Toshiba America, Inc., October 28, 2003,
<sdd. toshiba. com/main. aspx ?Path= /
81820000000700000000100000659800001516/
81820000011d00000000100000659c000003fd/
8182000001c800000000100000659c00000599/
8182000001e500000000100000659c000005cb/
8182000006db00000000100000659c00001559>.
17. «WD Raptor Enterprise Serial ATA Hard Drive 36.7 GB 10,000 RPM», October
28, 2003, <www.westerndigital.com/en/products/WD360GD.asp>.
18. «Cheetah 15К.З», Seagate Technology, March 27, 2003, <www.seagate.com/
docs/pdf/datasheet/disc /ds_cheetahl 5k. 3.pdf >.
19. Wilhelm, N., «An Anomaly in Disk Scheduling: A Comparison of FCFS and SSTF
Seek Scheduling Using an Empirical Model for Disk Accesses,» Communicatio
of the ACM, Vol. 19, No. 1, January 1976, pp. 13-17.
20. Wong, С. K., «Minimizing Expected Head Movement in One-Dimensional an
Two-Dimensional Mass Storage Systems,» ACM Computing Surveys, Vol- 1 ’
2, 1980, pp. 167-178.
m- qharina
21. Frank, H., «Analysis and Optimization of Disk Storage Devices for Time-o
Systems,» Journal of the ACM, Vol. 16, No. 4, October 1969, pp- 602
22. Teorey, T., «Properties of Disk Scheduling Policies in Multiprogrammed
puter Systems,» Proceedings AFIPS FJCC, Vol. 41, 1972, pp. l-H-
23. Wilhelm, N., «An Anomaly in Disk Scheduling: A Comparison of FCFS
Seek Scheduling Using an Empirical Model for Disk Accesses,» Communi
of the ACM, Vol. 19, No. 1, January 1976, pp. 13—17. of^'
24. Hofri, M„ «Disk Scheduling: FCFS vs. SSTF Revisited,» Communications
ACM, Vol. 23, No. 11, November 1980, pp. 645-653. edin^S
25. Denning, P. J., «Effects of Scheduling on File Memory Operations,» Proce
of AFIPS SJCC, Vol. 30, 1967, pp. 9-21. d col”'
26. Teorey, T., «Properties of Disk Scheduling Policies in Multiprogramme
puter Systems,» Proceedings AFIPS FJCC, Vol. 41, 1972, pp. 1-11-
I Wilhelm, N., «An Anomaly in Disk Scheduling: A Comparison of FCFS and SSTF
^7- Scheduling Using an Empirical Model for Disk Accesses,» Communications
| of the ACM, Vol. 19, No. 1, January 1976, pp. 13-17.
Wnfri, M., «Disk Scheduling: FCFS vs. SSTF Revisited,» Communications of the
^ /CM. Vol. 23, No. 11, November 1980, pp. 645-653.
nenning, P. J-, «Effects of Scheduling on File Memory Operations,» Proceedings
of AFIPS, SJCC, Vol. 30, 1967, pp. 9-21.
Teorey, T., «Properties of Disk Scheduling Policies in Multiprogrammed Com-
puter Systems,» Proceedings AFIPS FJCC, Vol. 41, 1972, pp. 1-11.
fotlieb, C., and G. MacEwen, «Performance of Movable-Head Disk Storage De-
vices,» Journal of the ACM, Vol. 20, No. 4, October 1973, pp. 604—623.
ijeorey, T., and T. Pinkerton, «А Comparative Analysis of Disk Scheduling Pol-
I icies,» Communications of the ACM, Vol. 15, No. 3, March 1972, pp. 177—184.
В Thomasian, A., and C. Liu, «Special Issue on the PAPA 2002 Workshop: Disk
' ' Scheduling Policies with Lookahead», ACM SIGMETRICS Performance Evalua-
tion Review, Vol. 30, No. 2, September 2002, p. 36.
34 Teorey, T., «Properties of Disk Scheduling Policies in Multiprogrammed Com-
puter Systems,» Proceedings AFIPS FJCC, Vol. 41, 1972, pp. 1-11.
35. Teorey, T., and T. Pinkerton, «А Comparative Analysis of Disk Scheduling Pol-
icies,» Communications of the ACM, Vol. 15, No. 3, March 1972, pp. 177—184.
36. Worthington, B.; G. Ganger; and Y. Patt, «Scheduling Algorithms for Modern
Disk Drives», Proceedings of the 1994 ACM SIGMETRICS Conference, May
1994, p. 243.
37. «Hard Disk Specifications», viewed October 2, 2003, <www.storagereview.com/
guide2000/ref/hdd/perf /perf/spec/index. html>.
38. Stone, H., and S. Fuller, «On the Near Optimality of the Shortest-La-
tency-Time-First Drum Scheduling Discipline», Communications of the ACM,
Vol. 16, No. 6, June 1973, pp. 352-353.
39. Thomasian, A., and C. Liu, «Special Issue on the PAPA 2002 Workshop: Disk
Scheduling Policies with Lookahead», ACM SIGMETRICS Performance Evalua
tion Review, Vol. 30, No. 2, September 2002, p. 33.
40. Thomasian, A., and C. Liu, «Special Issue on the PAPA 2002 Workshop: Disk
Scheduling Policies with Lookahead», ACM SIGMETRICS Performance Evalua
Hon Review, Vol. 30, No. 2, September 2002, p. 36.
41- Kozierok, C., «Logical Geometry», PCGuide, April 17, 2001, <www.pcguide.com/
refhdd/perf/perf/extp/pcCaching-c.html>.
Khurshudov, A., The Essential Guide to Computer Data Storage (Upper Saddle
River, NJ:Prentice Hall PTR.), 2001, pp. 106-107.
«Dell — Learn More — Hard Drives», 2003, <www.dell.com/us/en/dhs/
44 Iearnniore/learnmore_harddr ivesdesktoppopupdimen.htm>.
•Chaney, R., and B. Johnson, «Maximizing Hard Disk Performance: How Cache
Memory Can Dramatically Affect Transfer Rate», Byte, May 1984, pp. 307-334.
°’Thomasian, A., and C. Liu, «Special Issue on the PAPA 2002 Workshop: Disk
Scheduling Policies with Lookahead», ACM SIGMETRICS Performance Evalua
iOtl Review’ Vol. 30, No. 2, September 2002, p. 38.
r ' V^ilhelm, N., «An Anomaly in Disk Scheduling: A Comparison of FCFS and SSTF
®ek Scheduling Using an Empirical Model for Disk Accesses,» Communications
4-, the ACM, Vol. 19, No. 1, January 1976, pp. 13—17.
Cynch, W., «Do Disk Arms Move?», Performance Evaluation Review, ACM
^ignetics Newsletter, Vol. 1, December 1972, pp. 3-16.
48. Kozierok, C., «Cache Write Policies and the Dirty Bit», PCGuide, April 17
<www.pcguide.com/ref/nibsys/cache/funcWrite-c.html>. ’
49. Thomasian, A., and C. Liu, «Special Issue on the PAPA 2002 Workshon-
Scheduling Policies with Lookahead», ACM SIGMETRICS Performance p
tion Review, Vol. 30, No. 2, September 2002, p. 32. ! q^q.
50. Kozierok, C., «Operating System and Controller Disk Caching», Pqq
April 17, 2001, <www.pcguide.com/refhdd/perf/perf/extp/pcCaching-c
51. Thomasian, A., and C. Liu, «Special Issue on the PAPA 2002 Workshop-
Scheduling Policies with Lookahead», ACM SIGMETRICS Performance E, » Slt
tion Review, Vol. 30, No. 2, September 2002, p. 31.
52. «Disk Optimization Can Save Time and Resources in a Windows NT/2000 F
ronment», Raxco Software, <www.raxco.dk/raxco/perfectdisk2000/dr?^
load/Optimization_Can_Save_Time.pdf >. Wn-
53. King, R., «Disk Arm Movement in Anticipation of Future Requests», Ac л
Transactions in Computer Systems, Vol. 8, No. 3, August 1990, p. 215. ' ™
54. King, R., «Disk Arm Movement in Anticipation of Future Requests», 40»»
Transactions in Computer Systems, Vol. 8, No. 3, August 1990, p. 214.
55. King, R., «Disk Arm Movement in Anticipation of Future Requests», ACAf
Transactions in Computer Systems, Vol. 8, No. 3, August 1990, pp. 220, 226
56. «RAID Overview», <www.masstorage.com/html/raid_overview.html>.
57. Patterson, D.; G. Gibson; and R. Katz, «А Case for Redundant Arrays of Inex-
pensive Disks», Proceedings of the ACM SIG-MOD, June 1988, p. 109.
58. Patterson, D.; G. Gibson; and R. Katz, «А Case for Redundant Arrays of Inex-
pensive Disks», Proceedings of the ACM SIG-MOD, June 1988, pp. 109-110.
59. Chen, P.; E. Lee; G. Gibson; R. Katz; and D. Patterson, «RAID: High-Perfor-
mance, Reliable Secondary Storage», ACM Computing Surveys, Vol. 26, No. 2,
June 1994, pp. 151-152.
60. Chen, P.; E. Lee; G. Gibson; R. Katz; and D. Patterson, «RAID: High-Perfor-
mance, Reliable Secondary Storage», ACM Computing Surveys, Vol. 26, No. 2,
June 1994, p. 147.
61. Chen, P.; E. Lee; G. Gibson; R. Katz; and D. Patterson, «RAID: High-Perfor-
mance, Reliable Secondary Storage», ACM Computing Surveys, Vol. 26, No. 2>
June 1994, p. 152.
62. «RAID 0: Striped Disk Array without Fault Tolerance», <www.raid.coin/
04_01_00.html>.
63. «RAID 0: Striped Disk Array without Fault Tolerance», <www.raid.com
04_01_00.html>.
64. Chen, P.; E. Lee; G. Gibson; R. Katz; and D. Patterson, «RAID: High-P®^^
mance, Reliable Secondary Storage», ACM Computing Surveys, Vol. 26,
June 1994, p. 152.
65. Patterson, D.; G. Gibson; and R. Katz, «А Case for Redundant Arrays of
pensive Disks», Proceedings of the ACM SIG-MOD, June 1988, p. П2.
66. «RAID Overview», <www.massstorage.com.com/html/raid_overview.htin
67. «RAID 1: Mirroring and Duplexing», <www.raid.com/04_01_01.html>.
68. «RAID 2: Hamming Code ЕСС», <www.raid.com/04_01_02.html>.
f In®*
69. Patterson, D.; G. Gibson; and R. Katz, «А Case for Redundant Arrays
pensive Disks», Proceedings of the ACM SIG-MOD, June 1988, p. 112.
ацзйция производительное! gud вых КО ---------- -------------
Patterson, D.; G. Gibson; and R. Katz, «А Case for Redundant Arrays of Inex-
{О- pensive Disks», Proceedings of the ACM SIG-MOD, June 1988, p. 112.
«RAID Overview», <www.masstorage.com/html/raid_overview.html>.
Patterson, D.; G. Gibson; and R. Katz, «А Case for Redundant Arrays of Inex-
f2- JenSive Disks», Proceedings of the ACM SIG-MOD, June 1988, p. 112.
Chen, P.; E* Dee; G. Gibson; R. Katz; and D. Patterson, «RAID: High-Perfor-
ane’e, Reliable Secondary Storage», ACM Computing Surveys, Vol. 26, No. 2,
June 1994, p. 156.
RAID 2: Parallel Transfer with Parity», <www.raid.com/04_01_03.html>.
74-
Patterson, D.; G. Gibson; and R. Katz, «А Case for Redundant Arrays of Inex-
pensive Disks», Proceedings of the ACM SIG-MOD, June 1988, p. 113.
Patterson, D.; G. Gibson; and R. Katz, «А Case for Redundant Arrays of Inex-
' " pensive Disks», Proceedings of the ACM SIG-MOD, June 1988, p. 113.
77 «RAID Overview», <www.masstorage.com/html/raid_overview.html>.
-g «RAID 5: Independent Data Disks with Distributed Parity», <www.raid.com/
04_01_05.html>.
79. «RAID Level 4», PCGuide.com, <www.pcguide.com/ref/hdd/perf/raid/levels/
singlelevel4-c .html>.
80. Patterson, D.; G. Gibson; and R. Katz, «А Case for Redundant Arrays of Inex-
pensive Disks», Proceedings of the ACM SIG-MOD, June 1988, p. 114.
81. Patterson, D.; G. Gibson; and R. Katz, «А Case for Redundant Arrays of Inex-
pensive Disks», Proceedings of the ACM SIG-MOD, June 1988, p. 114.
82. Savage, S., and J. Wilkes, «AFRAID — A Frequently Redundant Array of Inde-
pendent Disks», Proceedings of the 1996 Usenix Conference, January 1996, p. 27.
83. Chen, P.; E. Lee; G. Gibson; R. Katz; and D. Patterson, «RAID: High-Perfor-
mance, Reliable Secondary Storage», ACM Computing Surveys, Vol. 26, No. 2,
June 1994, pp. 166-168.
84. Savage, S., and J. Wilkes, «AFRAID — A Frequently Redundant Array of Independ-
ent Disks», Proceedings of the 1996 Usenix Conference, January 1996, pp. 27, 37.
85. «RAID 5: Independent Data Disks with Distributed Parity», <www.raid.com/
04_01_05.html>.
86. «RAID Level 5», PCGuide.com, <www.pcguide.com/ref/hdd/perf/raid/lev-
els/singleleve!5-c.html>.
81. «Multiple (Nested) RAID Levels», PCGuide.com, <www.pcguide.com/ref/hdd/
perf/raid/mult.htm>.
®8- «RAID 6: Independent Data Disks with Two Independent Parity Schemes»,
<www. raid. com/04 01_06. htm 1>.
89- «Multiple (Nested) RAID Levels», PCGuide.com, <www.pcguide.com/ref/hdd/
Perf/raid/mult.htm>.
• «RAID Level 7», PCGuide.com, <www.pcguide.com/ref/hdd/perf/raid/lev-
els/singlelevel7-c.html>.
Se^st’ R"» an(I S- Daniel, «А Continuum of Disk Scheduling Algorithms», ACM
Upnsactions in Computer Systems, Vol. 5, February 1, 1987, p. 78.
Penning, P. J., «Effects of Scheduling on File Memory Operations,» Proceedings
of AFIPS SJCC, Vol. 30, 1967, pp. 9-21.
‘ Teorey, T„ «Properties of Disk Scheduling Policies in Multiprogrammed Com-
puter Systems,» Proceedings API PS FJCC, Vol. 41, 1972, pp. 1-11.
7/4
94. Wilhelm, N., «Ап Anomaly in Disk Scheduling: A Comparison of FCFS anrl
Seek Scheduling Using an Empirical Model for Disk Accesses,» Commun-
of the ACM, Vol. 19, No. 1, January 1976, pp. 13-17. С<гг«оп8
95. Hofri, M., «Disk Scheduling: FCFS vs. SSTF Revisited,» Communication
ACM, Vol. 23, No. 11, November 1980, pp. 645-653. s °f th*
96. Geist, R-, and S. Daniel, «А Continuum of Disk Scheduling Algorithms,
Transactions in Computer Systems, Vol. 5, February 1, 1987, p. 78. >>,4сЛ?
97. King, R., «Disk Arm Movement in Anticipation of Future Requests»
Transactions in Computer Systems, Vol. 8, No. 3, August 1990, p. 215 ’
98. Thomasian, A., and C. Liu, «Special Issue on the PAPA 2002 Worksho • re-
scheduling Policies with Lookahead», ACM SIGMETRICS Performance E ,
tion Review, Vol. 30, No. 2, September 2002, p. 33. Valua-
99. Patterson, D.; G. Gibson; and R. Katz, «А Case for Redundant Arrays of I
pensive Disks», Proceedings of the ACM SIG-MOD, June 1988, p. 109. Пех'
100. Patterson, D.; G. Gibson; and R. Katz, «А Case for Redundant Arrays of In
pensive Disks», Proceedings of the ACM SIG-MOD, June 1988, p. 114. ex'
101. Chen, P.; E. Lee; G. Gibson; R. Katz; and D. Patterson, «RAID: High-Perfor
mance, Reliable Secondary Storage», ACM Computing Surveys, Vol. 26, No 2
June 1994, pp. 151-152.
102. Savage, S., and J. Wilkes, «AFRAID — A Frequently Redundant Array of Independ-
ent Disks», Proceedings of the 1996 Usenix Conference, January 1996, pp. 27, 37.
103. Griffin, J. L.; S. W. Schlosser; G. R. Ganger; and D. F. Nagle, «Operating System
Management of MEMS-based Storage Devices», Proceedings of the Fourth Sympo-
sium on Operating Systems Design and Implementation (OSDI), 2000, pp. 227-242.
104. Uysal, M.; A. Merchant; and G. A. Alvarez, «Using MEMS-based Storage in Disk
Arrays», Proceedings of the Second USENIX Conference on File and Storage
Technologies, March, 2003.
Замкну в душе, а ключ возьми с собой.
Уильям Шекспир
Е pluribus unum.
(Из многих единое.)
Цицерон
Мне остается только надеяться, что документы J
с грифом «Не регистрировать» подшиваются!
в папку с названием «нерегистрируемые <
документы»-
Сенатор Фрэнк Черч<
Слушания сенатской следственной комиссии, 197$
Форма правления, которая не является результатов
длинной цепи совместных усилий, попыток ]
и экспериментов, никогда не смоЖе<г j
пустить кор***1' у
Наполеон Бонапарт Л
Глава 13
а иловые системы и базы
данных
УТосле прочтения этой главы вы должны понимать:
• необходимость файловых систем:
• файлы, директории и операции, которые можно
над ними выполнять;
^организацию и управление данными и свободным
пространством на накопителях;
• Управление доступом к данным в файловой системе;
'Резервное копирование, восстановление и механизмы
обеспечения целостности в файловых системах;
* системы и модели баз данных.
Краткое содержание главы
13.1 Введение
13.2 Иерархия данных
13.3 Файлы
13.4 Файловые системы
13.4.1 Директории
Размышления об операционных системах: Шифрование и дешифрование
13.4.2 Метаданные
13.4.3 Монтирование
13.5 Организация файлов
13.6 Размещение файлов
13.6.1 Непрерывное размещение файлов
13.6.2 Размещение файлов в виде связных списков
13.6.3 Табличное фрагментированное размещение
Практический пример: MS-DOS
13.6.4. Индексированное фрагментированное размещение
13.7 . Управление свободным пространством
13.8 . Контроль доступа к файлам
13.8.1. Матрица контроля доступа
Размышления об операционных системах: Безопасность
13.8.2. Контроль доступа по классам пользователей
13.9 . Методы доступа к данным
13.10 . Защита целостности данных
13.10.1. Резервное копирование и восстановление
Размышления об операционных системах:
Резервное копирование и восстановление
13.10.2. Целостность данных и Журнальные файловые системы
Размышления об операционных системах: Закон Мерфи и робастные системы
13.11 . Файловые серверы и распределенные системы
13.12 . Системы баз данных
13.12.1. Преимущества систем баз данных
13.12.2. Доступ к данным
13.12.3. Реляционная модель базы данных
13.12.4. Операционные системы и системы баз данных
фцИхвВью системы и базы данных
779
0,1 Введение
Большинство пользователей компьютеров знакомы с концепцией файла
/Г1е) — именованного набора данных, с которым можно выполнять раз-
ичные операции. Файлы обычно размещаются на внешних накопителях,
^пример, жестких дисках, оптических накопителях и лентах, хотя фай-
ды могут существовать и непосредственно в энергозависимой оперативной
па1Ляти. В этой главе мы изучим, как системы организуют данные в фай-
дах и обращаются к ним таким образом, чтобы обеспечить быстрое извле-
чение данных с накопителей, обладающих большими задержками. Мы
также узнаем, как операционные системы могут создавать интерфейсы,
дающие возможность пользователям выполнять навигацию в файловых
системах. Поскольку внешние накопители часто содержат информацию,
важную для нескольких пользователей, мы рассмотрим способы контроля
доступа к данным в файлах. Во многих системах в файлах хранятся важ-
ные данные — о счетах, платежах или имуществе. Мы обсудим, как систе-
мы могут защитить такие данные от повреждения или потери вследствие
отказов накопителей или отключения питания. И, наконец, мы обсудим
выгоды применения баз данных вместо файлов в системах, распоряжаю-
щихся большими объемами совместно используемых данных.
13,2 Иерархия данных
Информация хранится в компьютерах в соответствии с определенной
иерархией данных (data hierarchy). Самый нижний уровень этой иерар-
хии состоит из битов. Сочетания битов (bit patterns), составляющие двоич-
ные коды, используются для представления всех данных в компьютерных
системах. В последовательности из п битов можно хранить 2" различных
сочетаний битов.
Следующий уровень иерархии — это последовательности битов фикси-
рованной длины, например, байты (bytes), символы и слова. Байт в приме-
нении к устройствам хранения обычно состоит из восьми битов. Слово
(word) — это цепочка битов, которую процессор может обработать одновре-
менно. Например, слово состоит из четырех байтов для 32-разрядного про-
фессора и из 8 байтов для 64-разрядного.
Символы (characters) — это значения байтов (или групп байтов), ис-
сользуемые для представления цифр, букв, знаков пунктуации и специ-
^ьных знаков. Во многих системах символ состоит из 8 битов, поэтому
8 ваборах символов (character sets) этих систем может существовать 28,
256 различных символов. Три наиболее распространенных на сегодня
8абора символов — это ASCII (American Standard Code for Information
ttterchange — Американский стандартный код для обмена информацией),
“CDIC (Extended Binary-Coded Decimal Interchange Code — Расширенный
Ч8°йчно-десятичный код обмена информацией) и Unicode®.
В ASCII символы хранятся в 8-битовых байтах, поэтому в этом наборе
>5Кет быть до 256 различных символов. Из-за этого ограничения в ASCII
780
не поддерживаются международные наборы символов. Набор EBCDIC I
то применяется для представления данных в мэйнфреймах, особенно в
темах производства IBM; он также использует 8 битов для представлрС1*С'
символа1.
Unicode — это международный стандарт, широко распространена
в Интернете и в многоязычных приложениях. Его предназначение____Dbl®
доставить уникальный код каждому символу каждого языка в мир^а
В Unicode есть 8-, 16- и 32-битовые форматы представления символ ’
Чтобы упростить преобразование символов из ASCII в Unicode, 8-6htorB
представление Unicode, известное как UTF-8 (Unicode character Ji
Translation Format-8 bit), прямо соответствует таблице ASCII. HTML-фа^
лы обычно записываются в кодировке UTF-8. Кодировки UTF-16 или
UTF-32 предоставляют таблицы символов большего объема, и позволяют
приложениям хранить информацию, состоящую из символов множества
алфавитов, например, кириллицы, греческого или китайского. Однако
файлы этих кодировок, хранящие то же количество символов, больше по
размеру, чем файлы кодировки UTF-8. Например, 12-символьная строка
«Hello, world» займет 12 байтов при использовании 8-битовых символов,
24 байта при использовании 16-разрядных и 48 байтов при использова-
нии 32-битовых.
Поле (field) — это группа символов (например, имя человека, его ад-
рес или номер телефона). Запись (record) — это набор полей. Запись
о студенте может состоять из полей для идентификатора, имени, адреса,
номера телефона, среднего балла за время учебы, специальности, ожи-
даемой даты выпуска и так далее. Файл — это группа взаимосвязанных
записей. Например, файл с данными о студентах может содержать от-
дельную запись для каждого студента в университете; файл банковских
счетов может содержать отдельную запись для каждого счета в банке.
Самый высокий уровень иерархии — это файловая система или база дан-
ных. Файловые системы — это наборы файлов, а базы данных — это на-
боры данных (базы данных рассматриваются в разделе 13.12, «Системы
баз данных»).
Термин том (volume) обозначает часть накопителя, в которой может
размещаться множество файлов. Физический том ограничивается в разме-
ре емкостью одного накопителя, а логический — например, используемый
в виртуальной машине — может быть распределен по множеству физиче-
ских накопителей. Примеры томов — накопители на жестких дисках, ДйС
кеты, CD, DVD и кассеты ленточных накопителей.
Вопросы для самопроверки
1. Каковы преимущества и недостатки больших наборов символов^
2. Сколько различных символов можно представить в 16-бит
32-битовом и 64-битовом наборах символов? Как вы считаете,
му 64-битовые наборы символов пока что не реализованы.
м системы и базы данных
Ответы 1) Большие наборы символов, например, Unicode, позво-
ляют хранить и передавать данные на множестве различных языков.
Однако в больших наборах символов для представления одного симво-
ла используется большое количество битов, и объем хранимых дан-
ных возрастает. 2) 16-битовый набор символов может содержать 216,
или 65536 различных символов. 32-битовый набор может содер-
жать 232, или более 4 миллиардов различных символов. 64-битовый
набор может содержать 264, или более 16 квинтиллионов символов. На
сегодняшний день 64-битовые наборы символов еще не реализованы,
поскольку они потребуют значительных объемов для хранения каждо-
го символа, и позволяют представлять намного больше различных
символов, чем может потребоваться в обозримом будущем.
в.З Файлы
Файл представляет собой именованный набор данных, над которым
можно выполнять, в частности, следующие операции:
• Открывать (open file) — подготавливать файл к обращениям.
• Закрывать (close file) — блокировать дальнейшие обращения к файлу
до нового открытия.
• Создавать (create file) — создавать новый файл.
• Уничтожать (destroy file) — удалять файл.
• Копировать (copy file) — копировать содержимое файла в другой файл.
• Переименовывать (rename file) — изменять имя файла.
• Отображать (list file) — выводить содержимое файла на экран или
распечатывать.
Отдельные элементы данных, хранящиеся в файлах, могут подвергать-
ся, в частности, следующим операциям: _
• Читать (read data) — копировать данные из файла в память процесса.
• Записывать (write data) — копировать данные из памяти процесса
в файл.
• Обновлять (update data) — изменять содержимое существующего эле-
мента данных в файле.
• Вставлять (insert data) — добавлять в файл новый элемент данных.
• Удалять (delete data) — удалять элемент данных из файла.
Файлы могут характеризоваться следующими свойствами:
• Размером (size of file) — количеством данных, хранящихся в файле.
• Расположением (location of file) — местом, где хранится файл (на на-
копителе или в логической структуре файлов системы).
• Режимом доступа (accessibility of file) — ограничениями на доступ
к файлу.
• Типом (type of file) — назначением файла. Например, исполняемый
файл содержит исполняемые инструкции для процесса. Для файла
данных может быть указано приложение, предназначенное для рабо-
ты с его содержимым.
--/лг
/3
• Изменчивостью (volatility of file) — частотой внесения измеце
в данные, хранящиеся в файле. н,1й
• Активностью (activity of file) — процентом записей в файле, к кот
рым выполняются обращения в течение заданного периода времени'
Файлы могут состоять из одной или более записей. Физическая запи I
(physical record), или физический блок (physical block) — это единица и*
формации, считываемая с накопителя или записываемая на него. Логих.1
ская запись (logical record), или логический блок (logical block) — это не'
бор данных, воспринимаемый как единица программами. Если физич '
ская запись содержит ровно одну логическую, то говорят, что файл состоит
из неблокированных записей (unblocked records). Если физическая запись
содержит несколько логических, то говорят, что файл состоит из сблоки-
рованных записей (blocked records). В файле с фиксированной длиной за-
писи все записи имеют одинаковую длину; в файле с записями произволь-
ной длины записи могут иметь любую длину вплоть до размера блока.
Вопросы для самопроверки
1. Сравните физические и логические записи.
2. Почему, по вашему мнению, накладные расходы при использова-
нии записей переменной длины больше, чем при использовании за-
писей постоянной длины?
Ответы 1) Физическая запись — это единица информации, считы-
ваемая с накопителя или записываемая на него. Логическая запись —
это набор данных, воспринимаемый как единица программами. 2) По-
тому что система должна определять длину каждой записи. Есть два
распространенных способа определения этой длины: можно помечать
конец каждой записи специальным маркером или указывать длину
каждой записи в специальном поле в начале этой записи. Оба способа
требуют использования дополнительного пространства. Системе, рабо-
тающей с записями фиксированной длины, длину нужно указать
только однажды.®
13.4 Файловые системы
Файловая система (file system) организует файлы и управляет досту-
пом к хранящимся в них данным3. Файловая система отвечает за:
• Управление файлами (file management) — реализует механизмы хра^
нения файлов, обращения к ним, их разделения и обеспечения
безопасности.
• Управление вспомогательными устройствами хранения (auxil -
storage management) — выделяет пространство под файлы на втор
ных и третичных устройствах хранения.
Если в записях фиксированной длины большая часть выделенного пространств
ется неиспользованной, то бывает выгоднее использовать записи переменной
несмотря на необходимость хранить данные о длине каждой записи или поме
ее конец — прим, перев.
783
ужовые системы и базы данных
Целостность файлов (file integrity) — гарантирует, что хранимая
* в файлах информация не будет повреждена. Если целостность файлов
гарантируется, то в файлах будет только та информация, которая
должна быть.
Методы доступа (access methods) — методы, позволяющие получить
доступ к хранимым данным.
файловая система в основном занимается управлением вторичными
пойствами хранения, особенно дисковыми накопителями, но она может
вращаться и к Данным в файлах, хранящихся на других носителях (т.е.
, основной памяти).
файловые системы позволяют пользователям создавать, изменять
й удалять файлы; они также должны предоставлять возможность структу-
пирования файлов способами, удобными для приложений и переноса дан-
вых между файлами. Пользователи должны иметь возможность предос-
тавлять другим пользователям доступ к своим файлам. Механизм разделе-
ния файлов (совместного доступа к файлам) должен реализовать
различные типы контролируемого доступа — например, доступ для чте-
ния (read access), доступ для записи (write access), доступ для выполнения
(execute access) и их сочетания.
Файловые системы должны обладать аппаратной независимостью
(device independence) — пользователи должны иметь возможность обра-
щаться к файлам по символьным именам (symbolic names), а не по физи-
ческим именам (physical names). Символьные имена — это логические,
дружественные пользователям имена, например, myDirectory:Myfile.txt.
Физические имена указывают, где расположен файл, например, на дис-
ке 2, в блоках 782-791. Символьные имена дают системе возможность реа-
лизовать для пользователей логическое представление (logical view) их
данных, присваивая осмысленные имена файлам и операциям над файла-
ми. Физическое представление (physical view) связано с размещением дан-
ных файла на физическом накопителе и специфичными для накопителя
операциями работы с данными. Пользователю не нужно интересоваться
Физическими накопителями, на которых хранятся его данные, формой,
которую эти данные принимают на накопителях или физическими метода-
ми передачи данных с накопителей или на накопители.
Для проектирования файловой системы требуется знать параметры
йользователей, включая количество пользователей, среднее число и раз-
МеР файлов отдельного пользователя, среднюю продолжительность сеанса
Работы, характер выполняемых в системе приложений и так далее. Эти
Факторы нужно тщательно взвесить, чтобы определить наиболее опти-
мальную организацию файлов и структуру директорий.
Чтобы предотвратить как случайную потерю данных, так и их намерен-
ие Уничтожение, система должна располагать возможностями резервного
°пирования (backup), позволяющими создавать избыточные копии дан-
х> и возможностями восстановления (recovery), позволяющими восста-
навливать потерянные или поврежденные данные. В средах, решающих
6 ^ные задачи, где данные должны быть защищены от несанкциониро-
^Вного доступа, например, в банковских системах, системах хранения
аеративно-следственных данных или медицинских системах, файловые
сТемы могут также предоставлять возможности шифрования (епсгур-
/64
tion) и дешифрования (decryption) данных. Эти возможности делают да
ные доступными только для тех, для кого они предназначены — тех, к8'
обладает ключами к шифрам (шифрование и дешифрование обсуждают
в разделе 19.2; см. также «Размышления об операционных система *
Шифрование и дешифрование»).
Вопросы для самопроверки
1. Да/Нет) Файловые системы работают только с данными на вторив
ных устройствах хранения.
2. В чем заключается сходство между файловыми системами и систе
мами управления виртуальной памятью.
Ответы 1) Нет. Файловые системы работают с файлами, представ-
ляющими собой именованные наборы данных, которые могут хра-
ниться на любом носителе, включая оперативную память
2) Файловые системы должны управлять выделением пространства на
накопителях, скрывать физическое представление носителя от прило-
жений и контролировать доступ к накопителю.
13.4.1 Директории
Представьте себе большую систему с разделением времени, поддержи-
вающую множество пользователей. У каждого пользователя может быть
несколько профилей; в каждом профиле может быть множество файлов.
Некоторые файлы могут быть маленькими, например, сообщения элек-
тронной почты. Другие файлы могут быть большими, например, списки
частей в системе учета инвентаря.
Весьма часто пользовательские профили состоят из сотен или даже ты-
сяч файлов. Если сообщество пользователей состоит из нескольких тысяч
членов, то на накопителях системы могут храниться миллионы файлов.
К этим файлам нужно обращаться быстро, чтобы ограничить время реак-
ции системы.
Чтобы организованно размещать и быстро находить файлы, файловые
системы используют директории (directories). Это файлы, содержащие
списки имен файлов и информацию об их размещении в системе. В отли-
чие от других файлов, директории не хранят пользовательские данные.
На рисунке 13.1 перечислены типичные поля файла директории.
Поле Описание
Имя Символьная строка, содержащая имя файла.
Местоположение Физический блок или логический адрес файла в файловой системе (например, путь к файлу)
Размер Тип Время обращения Время изменения Время создания Количество байтов, занимаемое файлом Описание назначения файла (например, файл данных или файл директории)- Время последнего обращения к файлу Время последнего изменения файла. Время создания файла.
Рис. 13.1. Пример содержимого файла директории4- 5-6
Иловые системы и базы данных
785
J Размышления об операционных системах
Шифрование и дешифрование
В прошлом, когда информация, обрабаты-
вавшаяся компьютером, в основном храни-
сь на нем, доступ к ней было легко ограни-
чиТь. Операционные системы, работающие на
современных мощных компьютерах, переда-
ют огромные объемы информации между
компьютерами через сети, в частности, через
Интернет. Каналы передачи незащищены
и уязвимы, поэтому для защиты передавае-
мых данных операционные системы часто
предоставляют возможности шифрования
и дешифрования. Обе эти операции могут на-
столько сильно загружать процессор, что их
широкое применение было нецелесообразно
несколько лет назад. Однако по мере роста
вычислительной мощности процессоров, воз-
можности шифрования и дешифрования ста-,
ли появляться во все большем количестве;
приложений, особенно в приложениях, рабо-
тающих с уязвимыми сетями.
Одноуровневые файловые системы
Простейшая организация файловой системы — это одноуровневая
(single-level) или плоская (flat) файловая система. В таких системах все
файлы хранятся в одной директории7. В одноуровневых системах имя ка-
ждого файла должно быть уникальным. Поскольку в большинстве сред су-
ществует большое количество файлов, многие из которых используют оди-
наковые имена, одноуровневые системы применяются редко.
Иерархически структурированные файловые системы
Для большинства сред лучше подходит файловая система, организован
ная следующим образом (см. рис. 13.2). Корень (root) отмечает, в какой
позиции устройства хранения начинается корневая директория (rooi
directory). Директории — это файлы, которые могут указывать на другие
Файлы и директории. На рисунке 13.2 корневая директория указывает на
Различные пользовательские директории (user directories). Пользователь-
ская директория содержит запись о каждом находящемся в ней пользова-
Тельском файле; каждая такая запись указывает позицию, в которой соот-
ветствующий файл находится на устройстве хранения.
Имена файлов должны быть уникальными только в пределах одной
11 той же пользовательской директории. В таких иерархически структури-
рованных файловых системах каждая директория может иметь несколько
Поддиректорий, но только одну родительскую директорию. Имя файлг
Обычно формируется как путь (pathname) к этому файлу из корневой ди-
ректории. Например, в двухуровневой файловой системе с пользователями
MlTH, JONES и DOE, в которой у пользователя JONES есть файль:
AYROLL и INVOICES, путь к файлу PAYROLL можно записать в вид г
**POT:JONES:PAYROLL. В этом примере ROOT обозначает корневую ди-
ректорию, а символ двоеточия (:) разделяет части пути.
786
ГлаВв
Большинство файловых систем общего назначения принадлежит к це
рархическим, но имена корневых директорий и разделяющие символы м0
гут отличаться. В файловой системе Windows корневая директория обозца
чается буквой, за которой следует двоеточие (например, с:), а в UNIX-ф^
ловых системах именем корневой директории является символ косо^
черты (/). В системах Windows разделяющим символом является символ
обратной косой черты (например, C:\Jones\Payroll), а в UNIX — символ
обычной косой черты (например, /jones/payroll). Различные файловые
системы из систем Windows ХР и Linux подробно рассматриваются в учеб,
ных проектах (см. раздел 20.7.3 и раздел 21.8.2).
Рис. 13.2. Двухуровневая иерархическая файловая система
Относительные пути
Многие системы поддерживают концепцию рабочей директору*
(working directory), чтобы упростить навигацию с применением путей-
бочая директория (обозначаемая символом точки «» в W п
и UNIX-системах) дает возможность пользователям задавать пути, g
пинающиеся из корневой директории. Предположим, что текущей рао
директорией выбрана home/hmd/ в файловой системе на рисунке 13.3-
,gbie системы и базы данных
787
^тельный путь (relative path) к директории /home/hmd/os/chapterl3
, еТ выглядеть как os/chapterl38. Такой прием позволяет сокращать
1'1ти при обращениях к файлам. Если файловая система встречает относи-
1'яЬный путь, она формирует абсолютный путь (absolute path), то есть
^ъ, начинающийся из корня, выполняя конкатенацию рабочей директо-
А й относительного пути. Затем система обращается к требуемому файлу
L абсолютному пути.
файловая система обычно хранит ссылку на родительскую директорию
inarent directory) рабочей директории, то есть директорию уровнем выше
Рабочей в системной иерархии. Например, на рисунке 13.3 home — роди-
Сдьская директория директорий hmd, pjc и drc. В системах Windows
й Unix родительская директория обозначается двумя точками — « . . »9.
-Директория
-Файл
13.3. Пример содержимого иерархической файловой системы
кылки
Ссылка (link) — это запись в директории, ссылающаяся на файл данных
директорию, обычно размещенные в другой директории10. Пользовате-
Ли часто используют ссылки для упрощения навигации в системе и для со-
нетного использования файлов. Например, предположим, что рабочая ди-
^Ктория пользователя — /home/dre/, и пользователь использует также
другого пользователя, хранящиеся в директории /home/hmd/os/.
°3Давая ссылку на директорию /home/hmd/os/ в своей рабочей директо-
пользователь может обращаться к совместно используемым файлам,
₽°сто используя относительный путь os/.
I Мягкая ссылка (soft link), также называемая символьной ссылкой
^UNIX-системах, ярлыком (shortcut) в системах Windows и псевдонимом
(alias) в системах MacOS — это запись в директории, содержащая 1
к файлу. Файловая система находит файл, на который указывает ссьцй/Ч
перемещаясь в системе директорий по указанному в ссылке пути11. 1 I
Жесткая ссылка (hard link) — это запись в директории, указываю^ I
позицию файла (обычно номер блока) в устройстве хранения. ФайлОвч
система находит данные из указываемого ссылкой файла, прямо обрац/
ясь к заданному физическому блоку12. 1
На рисунке 13.4 показана разница между мягкими и жесткими ссыл^
ми. Файлы foo и bar размещаются, соответственно, в блоках 467 и 843. за
пись в директории f oo hard представляет собой жесткую ссылку, поскодь
ку она указывает тот же номер блока, что и запись в директории файда
foo. Запись foo soft представляет собой мягкую ссылку, поскольку в ней
указан путь к файлу foo (в данном случае — ,\foo).
Вспомните, что в разделе 12.9 говорилось о реорганизации и дефрагмен-
тации диска для повышения производительности. Во время таких опера,
ций размещение файлов может изменяться, и файловая система должна
будет обновлять записи о файлах в директориях. Поскольку жесткие ссыл-
ки ориентируются на физическое размещение файлов, они станут некор-
ректными, если это размещение изменяется. Чтобы устранить эту пробле-
му, система может хранить в файле указатель на каждую жесткую ссылку
на этот файл. Если размещение файла изменяется, то по указателям мож-
но найти и обновить все жесткие ссылки.
Директория
467
843
Имя Размещение
foo
bar
Мягкая
ссылка
foo_hard
foo_soft
467
./foo
Жесткая ссылка на foo
Рис. 13.4. Ссылки в файловой системе
Поскольку в мягких ссылках хранятся логические позиции Ф80 дц
в файловых системах, которые не изменяются при дефрагментации
реорганизации дисков, то нет нужды обновлять мягкие ссылки при
мещении данных файла. Однако если пользователь перемещает
в другую директорию или переименовывает его, мягкие ссылки на
файл станут некорректными. Этот эффект в некоторых случаях м
быть полезным. Например, пользователю может понадобиться зам
^цобыо системы и базы данных
78У
программы новым файлом с тем же именем. В этом случае файл, на
Кюрый изначально указывала ссылка, можно переместить в другое ме-
г удалить или просто заменить новым, а мягкая ссылка останется кор-
1<^тной (она будет указывать на новый файл). Обычно файловые системы
обновляют мягкие ссылки при перемещениях файлов в другие дирек-
<ории-
Если пользователь уничтожает ссылку на файл, файловая система
оджна определить, уничтожать ли сам файл. Для этого системы обычно
<дут учет жестких ссылок на файлы. Если на какой-то файл не указывает
вд одна жесткая ссылка, и этот файл можно удалять. Поскольку мягкие
ссылки не указывают физического расположения данных, они не учитыва-
ется при таких проверках.
Вопросы для самопроверки
1. Почему одноуровневые файловые системы не подходят для боль-
шинства систем?
2. Объясните различия между мягкими и жесткими ссылками.
Ответы 1) Потому, что в большинстве систем н^жно хранить мно-
жество файлов с совпадающими именами, что невозможно в одноуров-
невых файловых системах. 2) Жесткие ссылки — это записи
в директориях, указывающие на размещение файлов на устройствах
хранения. Мягкие ссылки содержат только путь к файлу. Жесткие
ссылки указывают на одни и те же данные, даже если имя файла из-
менится. Мягкие ссылки находят файлы по их логическому размеще-
нию в файловой системе. Поэтому данные, на которые указывает
мягкая ссылка, могут изменяться при сохранении по указанному
в этой ссылке пути другого файла.
13.4.2 Метаданные
В большинстве файловых систем хранятся не только пользовательские
Данные и директории, но и специальные данные, например, о свободных
блоках накопителей (чтобы гарантировать, что новые данные не будут за-
писаны поверх записанных ранее), о времени последнего изменения фай-
лов (для целей учета). Эта информация, называемая метаданными
(metadata), обеспечивает целостность файловой системы и не может быть
Непосредственно изменена пользователем.
Перед тем, как файловая система сможет обратиться к данным, ее нако-
пители обычно форматируются. Форматирование — это системная опера-
ция, которая обычно включает проверку накопителя на наличие нерабо-
чих областей, стирание ранее хранившихся на нем данных и создание кор-
невой директории. Многие файловые системы также создают суперблок
(superblock), в котором хранится информация, обеспечивающая целост-
8°сть файловой системы. Суперблок может содержать:
• Идентификатор файловой системы (file system identifier), однознач-
но определяющий тип используемой файловой системы.
• Информацию о количестве блоков в файловой системе.
I • Информацию о расположении свободных блоков.
I • Информацию о расположении корневой директории.
rfbie системы и базы данных
Глт
Z
• Дату и время последнего изменения файловой системы.
• Информацию, показывающую, нуждается ли файловая система в DJ
верке (например, вследствие отказа системы, при котором данные!
буфера не были записаны на накопитель)13’ 14> 15. 1
Если суперблок будет поврежден или уничтожен, файловая система J
жет быть не в состоянии обратиться к данным в файлах. Незначительна
ошибки в данных суперблока (например, в данных о свободных блоках
копителя) могут привести к повреждению данных пользователей. Что^
уменьшить риск повреждения или потери данных, большинство файловы,
систем хранят избыточные копии суперблока, распределенные по накопи
телю. Поэтому, если система определит, что суперблок поврежден, оь.
сможет заменить его одной из копий.
Дескрипторы файлов
При открытии файла операционная система сначала находит информа.
цию о файле, просматривая структуру директорий. Чтобы избежать много,
кратных (и, возможно, длительных) просмотров, система хранит в опера-
тивной памяти таблицу, ведущую учет открытых файлов. Во многих систе-
мах операция открытия файла возвращает дескриптор файла (file
descriptor), неотрицательное целое число, являющееся индексом для таб-
лицы открытых файлов. Все дальнейшие операции с файлом выполняются
через дескриптор.
Таблица открытых файлов часто содержит блоки управления файлами
(file control blocks). В этих блоках содержится информация, нужная систе-1
ме для управления файлом, иногда называемая атрибутами файла (file
attributes). Файловые атрибуты сильно отличаются в разных системах. |
Например, в блоке управления файлом может содержаться:
• символьное имя файла;
• данные о его расположении на накопителе;
• организационная структура (например, файл
тупа или произвольного доступа);
• сведения о типе накопителя (например, жесткий диск или ком-
пакт-диск);
• данные управления доступом (например, о том, какие пользователи
могут обращаться к файлу и какие они могут выполнять операции).
• данные о типе файла (файл данных, файл объектного кода, файл про-
граммы на языке С и так далее);
• характер файла (постоянный или временный);
• дата и время создания файла;
• счетчики обращений к файлу (например, количество операций чте
ния).
Обычно блоки управления файлами хранятся на накопителях. Они счи
тываются в основную память при открытии файлов, чтобы повысить э*
фективность работы.
Вопросы для самопроверки
1. Почему желательно хранить избыточные копии важных метадан-
ных, например, суперблоков?
2. Почему файловые системы не дают возможности пользователям не-
посредственно обращаться к метаданным?
Ответы 1) Потому что в метаданных, например, в суперблоках,
хранится информация, идентифицирующая файловую систему и ука-
зывающая расположение файлов и свободного пространства, и файло-
вая система может быть разрушена при повреждении суперблока.
Хранение нескольких копий суперблока позволит системе восстано-
вить его в случае повреждения, и уменьшает риск потери данных.
2) Если доступ к метаданным не ограничивать, то случайное непра-
вильное их использование может привести к потере целостности дан-
ных или их уничтожению.
\i4.3 Монтирование
Часто пользователям требуется доступ к информации, не являющейся
«стыо «родной» файловой системы (файловой системы, которая постоян-
но смонтирована в системе и корень которой является корневой директо-
рией). Например, многие пользователи хранят данные на втором винчесте-
ре, на DVD, или на другой рабочей станции в сети. Поэтому в файловых
системах предусматривается возможность монтирования (mounting) мно-
жества файловых систем. Монтирование объединяет множество файловых
систем в общее пространство имен (namespace) — набор файлов, к кото-
рым может обратиться одна файловая система. Объединенное пространст-
во имен предоставляет пользователям доступ к данным из разных источни-
ков, как если бы все файлы находились в родной файловой системе16.
Команда монтирования назначает в родной файловой системе директорию,
называемую точкой монтирования (mount point), корневой директорией мон-
Пфуемой файловой системы. В ранних версиях файловых систем Windows
структура монтирования была плоской; каждая монтируемая файловая систе-
ма обозначалась буквой и размещалась на одном и том же уровне структуры
‘Зфекторий. Например, файловая система, содержащая файлы операционной
системы, обозначалась С:, а следующая файловая система — D:.
UNIX-совместимые файловые системы (например, UNIX File System,
nst File System и Second Extended File System), и Windows NTFS вер-
сий 5.0 и более поздних позволяют размещать точки монтирования где
'’ГОДНО в файловой системе. Содержимое системной директории родной
Файловой системы в точке монтирования временно скрывается, пока дру-
ая файловая система монтирована в этой директории17’ 18.
В системах UNIX некоторые файловые системы монтируются в одну из
п°ДДиректорий в директории /mnt/. Посмотрите на рисунке 13.5. Команда
'’Оптирования помещает корень файловой системы В поверх директории
nt/newfs/ файловой системы А. После выполнения операции монтиро-
6ания файлы из системы В доступны в директории /mnt/newfs/ в файло-
системе А. Например, к директории /usr/Ып/ файловой системы В
‘’О’Кно будет обратиться как к /mnt/newfs/usr/bin/ в системе А. После
^Оптирования файловой системы исходное содержимое директории, в ко-
°Рую выполняется монтирование, недоступно до отмены монтирования.
на накопителе;
последовательного дос-
Файловая система В смонтирована в директории /mnt/newfs/ в файловой системе А
home mnt
xfs newfs
home ) ( mnt ~4
....—4. —
После монтирования
bin
Рис. 13.5. Монтирование файловой системы
Файловые системы управляют директориями монтирования с помощью
таблиц монтирования (mount tables). В этих таблицах содержится инфор-
мация о путях к директориям, используемым как точки монтирования,
и устройствах, на которых хранятся монтируемые файловые системы.
Если родная файловая система сталкивается с точкой монтирования, она
по таблице монтирования определяет устройство и тип файловой системы,
смонтированной в этой директории. Большинство операционных систем
поддерживают множество видов файловых систем для сменных носите-
лей — например, Universal Disk Format (UDF) для DVD и ISO 9660 ДЛЯ
компакт-дисков. После того как операционная система определила тй
файловой системы, используемой в устройстве, она использует эту файл^
вую систему для получения доступа к нужному файлу. Команда отме
монтирования позволяет пользователю отсоединять смонтированные Ф
ловые системы. Вызов этой команды обновляет таблицу монтировал _
и позволяет обращаться к файлам, ранее скрытым смонтированной Фай
вой системой19.
Пользователи могут создавать мягкие ссылки на файлы в смонтир°в
ных файловых системах. Находя мягкую ссылку, файловая система 0
. Me системы и базы данных
Г «лается по структуре директорий согласно содержащемуся в ссылке
Когда файловая система сталкивается с точкой монтирования, она
ибает перемещаться по директориям, начиная с корневой директории
^нтИрованной в этой точке файловой системы. Однако жесткая ссылка
^зЫвает номер блока, связанный с устройством, на котором хранится эта
’1'алКа. В общем случае пользователи не могут создавать жесткие ссылки
*\{ду двумя файловыми системами, поскольку они часто связаны с раз-
овыми устройствами хранения.
Вопросы для самопроверки
1. (Да/Нет) Смонтированная файловая система и родная файловая
система должны быть одного типа.
2. Может ли файловая система создавать жесткие ссылки на файлы
в смонтированной файловой системе?
Ответы 1) Нет. Основное преимущество монтирования файловых
систем состоит в том, что оно позволяет нескольким различным фай-
ловым системам быть доступными через единый интерфейс. 2) Нет.
Жесткие ссылки указывают специфичные для устройства номера бло-
ков, соответствующие файловой системе, в которой они хранятся,
и они не могут использоваться для указания физического размещения
данных в других файловых системах.
3.5 Организация файлов
Организацией файлов (file organization) называется способ размеще-
ния записей файла на устройстве хранения20. Используется несколько спо-
собов организации файлов:
• Последовательная (sequential) — размещение записей в их физиче-
ском порядке. «Следующей» записью будет та, что идет сразу за пре-
дыдущей. Такая организация естественна для файлов, хранящихся
на магнитной ленте, то есть носителе с последовательным доступом.
Дисковые файлы тоже могут использовать последовательную органи-
зацию, но по различным причинам, подробно рассмотренным далее
в этой главе, записи в последовательном дисковом файле редко хра-
нятся в виде непрерывной последовательности.
• Прямая (direct) — к записям возможен прямой (произвольный) дос-
туп по их физическим адресам на устройстве хранения с прямым дос-
тупом (direct access storage device — DASD). Пользователь приложе-
ния помещает записи в устройство хранения в том порядке, в каком
это удобно для приложения21.
• Индексированная последовательная (indexed sequential) — записи
на диске размещаются в логической последовательности согласно
ключу, содержащемуся в каждой записи. Система поддерживает ин-
декс, содержащий физические адреса определенных основных запи-
сей. К индексированным последовательным записям можно обра-
щаться последовательно в порядке их ключей, или напрямую, с помо-
щью поиска в созданном системой индексе.
------------------ ~ Т—— ------- --------------------Г |
• Разделенная (partitioned) — в такой организации файл практик 1
делится на ряд последовательных подфайлов. Каждый подфайл I
вается членом (member). Начальный адрес каждого члена храц^’
в директории файла. Разделенные файлы используются для храцей1
библиотек программ или макросов (по этой причине такую оргаа^*
цию называют также библиотечной).
Вопросы для самопроверки
1. Какая организация файлов лучше всего подходит для файлов,
нящихся на магнитной ленте? Почему? ’
2. Для каких носителей лучше всего подходит прямая организащ.
файлов?
Ответы 1) Для файлов, хранящихся на магнитной ленте, лучще
всего подходит последовательная организация, поскольку магнитная
лента — это носитель с последовательным доступом. 2) Прямая орга.
низация файлов лучше всего подходит для устройств хранения с цр0.
извольным доступом, например, оперативной памяти или дисковых
накопителей с подвижными головками.
13.6 Размещение файлов
Проблема размещения файлов и освобождения пространства на вторич-
ных устройствах хранения в чем-то похожа на проблему управления памя-
тью в многопрограммных средах. По мере создания и уничтожения файлов
свободное пространство устройства хранения обычно становится все более
и более фрагментированным, а файлы распределяются по рассеянным бло-
кам. Это может привести к падению производительности22. В разделе 12.9
мы уже говорили о том, что система может выполнять дефрагментацию, но
ее выполнение во время активного использования системы может сильно
увеличить время реагирования.
Поскольку процессы часто обращаются к последовательным частям
файла, очевидно, стоит хранить все данные файла в непрерывной последо-
вательности, чтобы увеличить производительность. Например, пользовате-
ли, ищущие в файле нужную информацию, часто используют операции
сканирования для перехода к следующей или предыдущей записи. Эти
операции должны выполняться с минимально необходимым временем п°
зиционирования.
Пространственная локализация запросов говорит нам, что если проП
обратился к каким-то данным на странице, он, вероятно, обратится
к другим данным на этой странице. Кроме того, он, вероятно, обратится
к данным на страницах, следующих за данной страницей в виртуаль
адресном пространстве пользователя. Поэтому желательно хранить л
чески следующие друг за другом страницы пользовательского аДРеС
пространства виртуальной памяти в физически следующих друг за ДР"
страницах на вторичном устройстве хранения, особенно если в одном
зическом блоке хранится несколько страниц.
jbie системы и базы данных
Поскольку часто размер файлов изменяется с течением времени, а поль-
1 тели редко знают заранее, каков будет размер их файлов, системы
•^делением непрерывного пространства в основном заменены более ди-
^\,чНыми системами с выделением фрагментированного пространства,
ми увидим далее, эти системы пытаются размещать части файлов по-
яовательно, чтобы эффективно использовать пространственную локали-
С й№ запросов, но позволяют размеру файлов изменяться с незначитель-
накладными расходами.
Вопросы для самопроверки
1. Сравните проблемы фрагментации в файловых системах и системах
виртуальной памяти.
2. Почему полезно выделять пространство в блоках, равных по разме-
ру странице или кратных ей по размеру?
Ответы 1) В обоих случаях фрагментация может привести к бес-
полезному расходованию памяти, если нет элементов данных, доста-
точно маленьких, чтобы заполнить неиспользуемые участки.
В отличие от оперативной памяти, в которой время доступа к любой
ячейке практически одинаково, во вторичных устройствах хранения,
например, в дисковых накопителях, время доступа может существен-
но увеличиться, если данные сильно фрагментированы, поскольку
устройству хранения придется выполнять множество операций пози-
ционирования, чтобы обратиться к данным. 2) Это позволяет системе
воспользоваться пространственной локализацией и с помощью един-
ственной операции ввода/вывода загружать в память несколько стра-
ниц, которые, вероятно, понадобятся в ближайшем будущем.
В. 6.1 Непрерывное размещение файлов
Файловые системы, реализующие непрерывное размещение файлов,
выделяют под файлы непрерывные участки адресов в пространствах уст-
ройств хранения. Пользователь заранее указывает размер области, кото-
рую нужно выделить под файл. Если непрерывную область заданного раз-
мера выделить невозможно, файл создан не будет.
Преимущество непрерывного размещения в том, что следующие друг за
Другом логические записи обычно оказываются размещенными рядом
и Физически. Соответственно, скорость доступа к ним больше, чем в систе-
Мах> в которых эти записи оказываются рассеянными по пространству уст-
ройства хранения, требуя дополнительных операций позиционирования,
юиск данных файла выполняется просто, поскольку в директориях нуж-
н° Хранить только информацию о месте, в котором файл начинается, и
° Длине файла.
Недостаток систем с непрерывным размещением файлов в том, что им
Рисущи те же проблемы с внешней фрагментацией, что и системам выде-
ния памяти для динамических многопрограммных сред (см. раздел 9.9).
8^°Ме того, системы с непрерывным размещением файлов могут обладать
Ч зк°й производительностью, если размер файлов будет изменяться с те-
ф®Ием времени. Если размер файла превышает изначально заданный, то
Ил должен быть целиком перенесен на новый участок подходящего раз-
На это требуются дополнительные операции ввода/вывода. Чтобы
Ч
системы и базы данных _________________
-1 сцеплении (chaining) блоков каждая запись в директории указыва-
первый блок в файле (см. рис. 13.6). Блоки, принадлежащие к одно-
1 г, состоят из двух разделов: раздела данных и раздела указателя
' 'дедующий блок файла. Минимальной единицей объема, которая мо-
быть выделена под файл, будет блок, обычно состоящий из несколь-
секторов. Поиск нужной записи в файле потребует просмотра цепочки
‘^j-ob вплоть до блока, содержащего нужную запись. Цепочку блоков
-jkBO просматривать с начала, и если блоки рассеяны по диску (как это
'учно и бывает), процесс поиска может быть медленным из-за перемеще-
пй головки от блока к блоку. Операции вставки и удаления сводятся к из-
'елеиию указателей в блоках. В некоторых системах для ускорения поис-
'а используются двухсвязные списки; каждый блок связан не только со
-"”м, но и с предыдущим блоком, и поиск может идти в любом на-
предотвратить такие операции переноса, пользователи могут заранее з(1, 1
вать размер файла большим, чем нужно, вследствие чего будет неэффЛ I , р
тивно расходоваться пространство устройства хранения. Непрерывное p’s ф»ЙЛУ
мещение файлов очень удобно на однажды записываемых носителях, ? ~"хги
пример, компакт-дисках и DVD, где размер файлов неизменен во време^
Вопросы для самопроверки
1. Объясните преимущества систем с непрерывным размещением ф^
лов.
2. Объясните недостатки систем с непрерывным размещением ф^
лов.
Ответы 1) Поиск донных в таких системах реализуется прос^ — тиМ
Кроме того, можно быстро обращаться к файлам, поскольку накопит^ I ^еДУ10®
лю не нужно выполнять медленные операции позиционирования п0 Ьпав№иИ ‘
еле того, как найден первый блок файла. 2) Эти системы могут
привести к существенной внешней фрагментации и низкой производи,
тельности, если файл становится слишком большим, чтобы его можно
было хранить в непрерывной области, в которой он размещается в дан-
ный момент — при этом файл приходится переносить в новое место.
Адрес
Пользовательская директория
Файл
Данные
данные
Данные
Данные
Данные
13.6.2 Размещение файлов в виде связных списков
Большинство файловых систем, используемых на перезаписываемых
носителях, используют фрагментированное (в виде несмежных частей)
размещение файлов. Один из способов реализации фрагментированного
размещения — с использованием связного списка секторов. В такой реали-
зации каждая запись в директории указывает на первый сектор, занятый
файлом на накопителе с подвижными головками, например, жестком дис-
ке. Раздел данных сектора содержит данные файла; раздел указателя со-
держит указатель на следующий сектор, занятый файлом. Поскольку фай-
лы могут занимать множество секторов, головка чтения/записи должна
последовательно обращаться к каждому сектору файла, пока не найдет за-
прошенную запись.
Фрагментированное размещение файлов устраняет некоторые пробле-
мы, свойственные системам с непрерывным размещением, но у него есть
свои недостатки. Поскольку записи из файла могут быть рассеяны по дис-
ку, прямой и последовательный доступ к логическим записям может по-
требовать множества операций позиционирования помимо первой, необхо
димой для чтения начального сектора файла. Кроме того, необходимость
хранения указателей в списке уменьшает объем, доступный для хранен»31
собственно данных в каждом секторе.
Одна из схем, используемых для увеличения эффективности Ра®°
с внешними устройствами хранения и уменьшения накладных расход^
при обращении к файлам — схема с блочным размещением (ь
allocation). В этой схеме вместо выделения отдельных секторов выделя
ся непрерывные последовательности секторов — блоки (block или ext
Система пытается выделять под файлы новые блоки, выбирая блоки
симально близкие к существующим, предпочтительно на том же цил .
ре. Каждое обращение к файлу требует определения нужного блока И
тора в блоке.
Данные
Null-указатель
Данные
р
13.6. Размещение файлов в виде связных списков
Размер блока может существенно повлиять на производительность сис-
2 ^Ь1- Если блоки делятся между файлами (т.е. файл, занимающий
15 блока, занимает на диске 3 блока), то большой размер блока может
Рйвести к заметной внутренней фрагментации. Однако большие по разме-
ру блоки уменьшают количество операций ввода/вывода, необходимое»
доступа к данным в файлах. Блоки малого размера могут привести к раа,
лению данных между множеством блоков и их рассеиванию по диску, pi
зультатом может стать низкая производительность. Практически обы», '
используются блоки размером от 1 до 8 килобайт23' 24’ 25. ‘
Вопросы для самопроверки
1. Каков основной недостаток размещения файлов в виде связт,
списков?
2. Каковы преимущества и недостатки блоков различных размеров
Ответы 1) В худшем случае системе нужно обратиться к кажд011.|
блоку файла (если используется односвязный список) или к половн8
блоков (если используется двухсвязный список), чтобы найти нужн^
данные, на что потребуется много времени. В следующих разделах мц
увидим, что ряд популярных методов доступа к файлу устанавливают
нижний предел времени доступа к файлам, что позволяет улучшить
производительность. 2) При большом размере блока для извлечения
нужной записи требуется меньше операций ввода/вывода, но на внут.
реннюю фрагментацию расходуется более заметная часть пространст-
ва накопителя. Блок меньшего размера уменьшает внутреннюю
фрагментацию, но увеличивает время доступа, если данные оказыва
ются рассеянными по поверхности диска.
13.6.3 Табличное фрагментированное размещение
Файловая система, реализующая табличное фрагментированное разме-
щение, хранит указатели на блоки файлов, чтобы уменьшить потребность
в операциях позиционирования для доступа к нужным данным (рис. 13.7).
Записи в директориях указывают на первые блоки файлов. Например, пер-
вый блок файла С на рисунке 13.7 — блок 2. Номер блока в таблице выде-
ления блоков используется в качестве индекса, по которому определяется
следующий блок файла. То есть номер следующего блока файла С хранит-
ся в ячейке 2 таблицы выделения блоков. В данном случае следующий за
блоком 2 блок файла С — блок 5. Запись в ячейке таблицы, индексом кото-
рой является номер последнего блока файла, содержит значение Null-
Поскольку указатели, по которым находятся данные, хранятся цен
трализованно, их таблицу можно загрузить в кэш и быстро определять
цепочки блоков, в которых хранятся файлы, соответственно уменьшая
время доступа. Поиск последней записи в файле может потребовать пе-
ребора всех указателей в таблице выделения блоков. Чтобы уменыпить
время доступа, эта таблица должна храниться на диске в непрерывной
блоке и кэшироваться в оперативной памяти. Если файловая система со
стоит из небольшого количества блоков, это несложно сделать. НаПРй
мер, дискета объемом 1,44 МБ, разбитая на блоки объемом 1 кБ, буДе
содержать 1440 блоков, к которым можно обращаться по 11-битово^-
индексу. Размер соответствующей таблицы есть количество блоков, У'
воженное на длину индекса одного блока — в рассматриваемом слу4
приблизительно 2000 байт.
Таблица выделения блоков
22
Null
5
26
9
20
10
17
1
14
Null - Null-указатель
Свободный блок
Null
24
25
26
27
18
19
12
13
14
15
16
17
18
12
Физические блоки на накопителе
Блок 0 8(4) Блок 1 8(10) Блок 2 С( 1) Блок 3 А(4) Блок 4 В(8) Блок 5 С(2) Блок 6 В(1)
Блок 7 Свободный блок г — Блок 8 А(1) Блок 9 8(9) Блок 10 В(2) Блок 11 Свободный блок Блок 12 А(3) Блок 13 8(7)
Блок 14 8(3) Блок 15 Свободный блок Блок 16 Свободный блок Блок 17 А(2) Блок 18 8(6) Блок 19 С(5) Блок 20 В(3)
Блок 21 Свободный блок Блок 22 8(5) Блок 23 , С(4) Блок 24 Свободный блок Блок 25 Свободный блок Блок 26 А(5) Блок 27 Свободный блок
• 13.7. Табличное фрагментированное размещение файлов
800
801
-----------------------------------
кажлойФЛпигТ1Х ° «СТеМ’ содеРжаЩих большое количество блоков, раам
большими Н таблице выделения блоков и размер самой таблиц J6y>
пЛТ? НапримеР’ жесткий диск объемом 200 ГБ, разбитый на бЛ
по 4 кБ будет содержать 50000000 блоков, к каждому из которых мп Kli
будет обратиться по 26-битовому индексу. В этом случае объем табл?0
?°КОВ бУДеТ СВЫШе 160 МБ- в пРеДыДУЩем примере табл?
выделения блоков занимала только два блока; а в этом случае она зай?
Десятки тысяч блоков, что может привести к ее фрагментации. Если бл?
файла рассеяны по диску, то и записи в таблице об этих блоках тоже п *
сеяны по таблице. Поэтому системе может понадобиться загрузить B₽J
мять несколько блоков таблицы, что может сильно ухудшить время рея?
рования. Кроме тою, кэширование такой большой Таблицы может заХ
существенную часть оперативной памяти. ЯТь
Вопулярная РеалязаЧия табличного фрагментированного размер
в ОС MS DOS? п ?ирмы MjTcrosoft- Впервые Microsoft применила Гд?
ОС MS-DOS версии 1.0 (см. «Практический пример: MS-DOS»)26. В систр
ме FAT хранится информация о каждом блоке, включая то, используется
в данный момент блок или свободен, и номер следующего блока в файле
Первая версия системы FAT, называвшаяся FAT12, использовала 12 битов
ГАТ12^?Хг3аПИСИ В та?ице- Это значило, что диск под управлением
FAT12 не мог содержать более 212 (4096) секторов. Этого было достаточно
^?Л>ЬКИХ fИСКОВ с небольшим количеством файлов, но использова-
ние ГА112 для больших дисков приводило к большим потерям дискового
б4°7^?аНСТВа‘ !*апримеР’ чтобы адресовать пространство диска объемом
64 МЬ, нужно было использовать блоки размером не менее 16 кБ. По мере
роста емкостей дисков Microsoft создавала системы FAT16 и FAT32, кото-
рые увеличивали максимальное количество адресуемых блоков и позволя-
ло работать с более емкими дисками, используя блоки небольшого
размера^'- 2В.
Когда Microsoft впервые представила систему FAT в начале 1980-х, ем-
кость накопителей была невелика, FAT была эффективна и занимала не-
много места. FAT эффективна и сейчас для носителей малой емкости, на-
пример, дискет29.
Вопросы для самопроверки
1. Почему табличное фрагментированное размещение файлов эффек'
тивнее размещения в виде связных списков?
2. В чем заключалось основное ограничение FAT12? Как это ограни-
чение снималось в последующих версиях FAT? Почему FAT не под-
ходит для работы с современными накопителями?
Ответы 1) Таблицы выделения блоков могут хранить информацию
о размещении данных в непрерывном виде, и количество операций по
зиционирования, необходимых для доступа к данным, уменьшается-
Л) Система FAT12 не могла адресовать более 4096 блоков, и ее исполь-
зование на накопителях большой емкости приводило к значительна1
внутренней фрагментации. FAT16 и FAT32 решали эту проблему, У®е_'
личивая количество адресуемых блоков за счет использования больпю
го количества битов на одну запись. При этом увеличивался
самой таблицы размещения файлов, за счет чего росло время достУ11
к файлам и затраты памяти на кэширование таблицы.
^£^)ые системы и базы данных
| Учебный пример
MS-DOS
qC MS-DOS фирмы Microsoft была осно-
на дисковой операционной системе, на-
ганной Тимом Патерсоном для компании
battle Computer Products (SCP) в 1980-м
зо в yq время SCP требовалась ОС для их
Г°одуля памяти, ориентированного на новый
^.разрядный процессор Intel 80 863’. Тогда
самой распространенной ОС для микроком-
пьютеров была СР/М (Control Program for
Microcomputers) фирмы Digital Research, но
к моменту начала продаж модуля памяти об-
новленная версия этой ОС для процессоров
8086 не была готова32. Патерсона попросили
написать новую операционную систему, ко-
торую назвали QDOS (Quick and Dirty
Operating System - в буквальном переводе
это название звучит, как «быстрая и грязная
операционная система»). В полном соответ-
ствии с названием, она была написана всего
за несколько месяцев, но не была-полностью
протестирована и отлажена. До конца года
Патерсон улучшил свою операционную сис-
тему, которая была выпущена как 86-DOS .
При создании ОС 86-DOS преследова-
лось несколько целей. Во-первых, она долж-
на была быть совместимой с программами,
написанными для ОС СР/М, чтобы дать воз-
можность использовать множество приклад-
ных программ. Поэтому 86-DOS должна
была иметь тот же API (Application
Programming Interface - интерфейс при-
кладного программирования)34,3' . Чтобы
сделать 86-DOS более эффективной, чем
СР/М, Патерсон написал ее на ассемблере
и встроил в нее модуль работы с накопите-
лями FAT, основанный на автономной систе-
ме работы с накопителями из интерпретато-
ра языка BASIC фирмы Microsoft (см. раздел
1 3.6.3)37,38,39.
В 1981 году компания IBM разыскивала
производителя операционной системы для
своей первой серии персональных
компьютеров40. Она попыталась получить ли-
цензию на популярную ОС СР/М, но автор
СР/М Гэри Килдалл отказался подписать
строгие договоры о неразглашении, как того
требовала IBM41. В то время IBM работала
с Microsoft над разработкой программ для
новых IBM PC42. Microsoft использовала
86-DOS по лицензии SCP для разработки
программ, и IBM попросила Microsoft купить
все права на 86-DOS43,44,45. SCP приняла пред-
ложение, и 86-DOS, переименованная
в MS-DOS, стала стандартной операционной
системой для IBM PC и совместимых с ними
микрокомпьютеров46.
К.6.4. индексированное фрагментированное размещение
Еще один популярный метод фрагментированного pa3Me^®™”
Л°В — использование индексных блоков (index bloc s), ука «ппКов
^нные в файлах. У каждого файла есть один или более индексных блокав.
Индексный блок содержит список указателей, указывающих
Данными из файла. Запись о файле в его директории содержит
116 индексный блок этого файла. Чтобы найти требуемую запись, Фаял°вая
^тема просматривает директории и находит на диске ивдешм.блок
Файла. Затем она загружает индексный блок в память и использу Д Р
803
жащиеся в нем указатели, чтобы определить физический адрес I
блока с данными. Часто для больших по размеру файлов требуется бодьд I
указателей, чем может поместиться в одном индексном блоке. В болыц^
стве реализаций индексных блоков последние несколько записей в ।
зервируются для хранения указателей на другие индексные блоки, Qj I
прием называется сцеплением (chaining) (см. рис. 13.8).
Основное преимущество сцепления индексных блоков перед просты-
связными списками состоит в том, что поиск выполняется собственно в jJ
дексных блоках. Они могут храниться близко друг от друга на диске,
бы свести к минимуму потребность в операциях позиционирования Чтоб^
ускорить просмотр файлов, индексные блоки обычно кэшируются в опера
тивной памяти. После обнаружения нужной записи с помощью индексных
блоков содержащий эту запись блок считывается в оперативную память
Сцепление индексных блоков аналогично хранению отдельной таблицу
выделения блоков для каждого файла. Такой подход может быть эффек.
тивнее, чем хранение общей таблицы выделения блоков для всех файлов
в системе, поскольку ссылки на блоки каждого файла хранятся в виде не
прерывной последовательности в пределах индексного блока. Файловьк
системы обычно размещают индексные блоки рядом с блоками данных, на
которые они ссылаются, и к блокам данных можно быстро обращаться по-
сле считывания индексного блока.
В операционных системах, основанных на UNIX, индексные блоки на-
зываются индексными узлами (inodes — index nodes)47. В индексном узле
файла хранятся атрибуты файла — например, его владелец, размер, время
создания и время последнего изменения. Кроме того, в нем хранятся адре-
са некоторых блоков данных файла и указатели на индексные блоки с про-
должениями, называемые косвенными блоками (indirect blocks). Структу-
ры индексных узлов поддерживают до трех уровней косвенных блоков
(рис. 13.9). В косвенных блоках первого уровня хранятся указатели на
блоки данных. В косвенных блоках второго уровня хранятся только указа-
тели на косвенные блоки первого уровня. В косвенных блоках третьего
уровня хранятся только указатели на косвенные блоки второго уровня.
Сильная сторона такой системы в малом количестве указателей, по кото-
рым нужно перейти — для поиска любого блока с данными нужно выпол-
нить максимум четыре перехода по указателям (указатель из индексного
узла и максимум три указателя из косвенных блоков).
Индексные узлы подробно рассмотрены в главе об ОС Linux (Ра3
дел 20.7.3). Индексные блоки также используются в файловой системе
NTFS фирмы Microsoft, рассматриваемой в главе о Windows ХР (Ра3
дел 21.8.2). Индексированное фрагментированное размещение файлов Да
хороший уровень производительности при невысоких накладных расход^
в различных средах и реализовано во многих компьютерных системах
щего назначения.
Адрес
файл
Блоки
данных
Блок
индекса
Блок с продолжением
индекса
Null- казатель
йме системы и базы данных
—
Сцепление индексных блоков
Рис. 13.8.
Блоки
данных
804
Индексный узел
Блок управления файлом
Дважды
косвенный указатель
Указатели на блоки данных
Косвенный указатель
Блоки данных
Блоки данных
I ’ ГТ Г
Указатели на блоки данных
Трижды
косвенный указатель
г Косвенные указатели
Указатели на блоки данных
-р» Указатели на блоки данных
Указатели на блоки данных
Блоки данных
—,, Дважды косвенные указатели
Блоки данных
Рис. 13.9. Структура индексных узлов
f л -..gb/e системы и базы данных 80S
pl рт"'’
Вопросы для самопроверки
1. Почему размещение индексных блоков рядом с блоками данных
уменьшает время доступа?
2. Сравните табличное фрагментированное размещение файлов и ин-
дексированное фрагментированное размещение для случая, когда
файлы в основном малы по размеру (т.е. меньше по размеру, чем
один блок).
Ответы 1) При считывании индексного блока головка будет близко
от блоков данных, на которые ссылается индексный блок, и потребность
в позиционировании будет уменьшена или вообще исчезнет. 2) При таб-
личном фрагментированном размещении для маленького файла потребу-
ется один блок данных и одна запись в таблице выделения блоков. При
индексированном фрагментированном размещении для файла потребу-
ется блок данных и еще один блок для индекса, что приведет к значи-
тельным затратам дискового пространства. Кроме того, загрузив
в память один блок таблицы выделения блоков, можно найти несколько
файлов малого размера. Файловой системе с индексированным фрагмен-
тированным размещением придется обращаться к новому индексному
блоку для каждого следующего файла, и доступ может замедлиться
из-за дополнительных операций позиционирования.
I3J Управление свободным пространством
С течением времени файлы увеличиваются и уменьшаются, и файловые
системы ведут учет блоков, доступных для записи новых данных, т.е. сво-
бодных блоков. Файловая система может использовать список свободных
блоков (free list). Список свободных блоков — это связный список блоков,
в котором указано размещение свободных блоков. Последняя запись в бло-
ке списка свободных блоков хранит указатель на следующий блок этого
списка; последняя запись в последнем блоке списка хранит null-указатель,
чтобы показать, что данный блок — последний в списке свободных блоков.
Когда системе нужно выделить для файла новый блок, она находит адрес
свободного блока в списке свободных блоков, записывает данные в этот
блок и удаляет запись об этом блоке из списка.
Обычно файловая система выделяет блоки из начала списка и добавляет
освободившиеся блоки в конец списка. Указатели на начало и конец спи-
ска могут храниться в суперблоке файловой системы. Свободный блок
^оэкно найти, выполнив один переход по указателю; добавление нового
лока в список тоже требует добавления одного указателя. Поэтому такой
подход требует небольших накладных расходов для поддержки списка сво-
бодных блоков. Однако по мере создания и удаления файлов свободное
Пространство на накопителе становится все более фрагментированным,
и соседние записи в списке свободных блоков будут указывать на несмеж-
ЙЬ1е блоки накопителя. В результате следующие друг за другом данные мо-
гУт быть записаны в далеко отстоящие друг от друга блоки, и время досту-
па к этим данным может возрасти. В качестве альтернатив этому подходу
Система может просматривать список в поисках последовательности сво-
°°ДНых блоков нужного размера или сортировать список, но оба этих под-
*°да требуют заметных накладных расходов48.
I
I
I
I
I
I
Блок списка
свободных блоков
Вторичное устройство хранения
Рис. 13.10. Управление свободным пространством с помощью списка свободных
блоков
Блоки
Еще один широко применяемый способ управления свободным простран-
ством — с помощью битового массива (bitmap) (см. рис. 13.11). Каждый бит
в битовом массиве соответствует одному из блоков накопителя. В одном иа
вариантов реализации бит содержит значение 1, если соответствующий ему
блок занят, и 0, если свободен49. Обычно сам битовый массив занимает не-
сколько блоков. При этом, если блок, например, состоит из 32 битов, то 15-и
бит 3-го блока соответствует 79-му блоку данных. Одно из основных пре
I
I
I
I
I
Битовый массив
Накопитель
Битовый массив хранится
в первом блоке накопителя
и описывает первые три
строки этого накопителя
Блоки/биты
1
- Занятые
-Свободные
I
Рис. 13.11. Управление свободным пространством с помощью битового массива
системы и базы данных
гщсств битовых массивов перед списками свободных блоков — то, что
Уповая система может быстро определить, доступны ли в некоторой об-
j0iI". накопителя непрерывные последовательности свободных блоков. На-
1&СТмер, если пользователь дописывает данные в конец файла, заканчиваю-
на блоке 60, система может прочитать значение 61-го бита в массиве
йеГ ределить, свободен ли блок 61. Недостаток битовых массивов заключа-
11 °я в необходимости просмотра всего массива при поиске свободного блока.
еТС | просмотр требует накладных расходов, но во многих случаях ими
оЖно пренебречь — в современных системах скорость работы процессоров
много больше скорости ввода/вывода накопителей.
Вопросы для самопроверки
1. Сравните списки свободных блоков и битовые массивы с точки зре-
ния времени поиска следующего свободного блока, добавления но-
вого свободного блока и поиска непрерывной последовательности
блоков.
2. Какой из описанных в этом разделе методов управления свободным
пространством обеспечивает наименьший уровень накладных рас-
ходов?
Ответы 1) Список свободных блоков эффективнее при выделении
одного свободного блока, поскольку для этого в нем нужно только вы-
полнить переход по указателю в начало списка. Битовые массивы требу-
ют выполнения поиска для нахождения свободного блока. Однако при
поиске последовательности свободных блоков битовые массивы эффек-
тивнее — их можно прямо просматривать в поисках соответствующих
участков, а списки свободных блоков нужно просматривать или сортиро-
вать, на что потребуется заметное дополнительное время. 2) Часто бито-
вый массив занимает меньше места, чем список свободных блоков,
поскольку в битовом массиве каждому блоку соответствует один бит, а
в списке — номер блока, который может состоять из 32 или даже 64 би-
тов. Размер битового массива файловой системы будет неизменным,
а размер списка свободных блоков зависит от количества свободных бло-
ков на накопителе. Поэтому, если на накопителе мало свободных блоков,
то список будет занимать меньше места, чем битовый массив.
'О Контроль доступа к файлам
Часто в файлах хранятся важные данные, например, номера кредитных
карточек, пароли, коды социального страхования и так далее, и файловые
системы должны содержать механизмы, контролирующие доступ пользо-
вателей к файлам (см. «Размышления об операционных системах: Безо-
пасность»), В следующих разделах мы рассмотрим наиболее распростра-
ненные методы управления доступом к файлам.
Матрица контроля доступа
Один из способов управления доступом к файлам — создание двумерной
атрицы контроля доступа (access control matrix) (см. рис. 13.12), в кото-
11 перечислены все пользователи и все файлы в системе. В ячейке ai} мат-
—Д'5
" ! сиетемы и 6азы 9°пных
809
рицы хранится 1, если пользователь i может обращаться к файлу j; в д.1
тивном случае Оу = О. Например, на рисунке 13.12 пользователь 5 мо^,
обращаться к десяти файлам, а пользователь 4 — только к файлу 1. В С1)|
теме с большим количеством пользователей и множеством файлов Раз^,
матрицы будет весьма большим. Поскольку разрешение пользователю
ращаться к файлам другого пользователя — скорее исключение, чем ц^,
вило, матрица будет весьма разреженной. Чтобы сделать концепцию мй,
рицы пригодной для практического применения, нужно использовать раз
личные коды для обозначения разных видов доступа — только для чтещц
только для записи, только для исполнения, для чтения и записи и так i
лее. Это существенно увеличит размер матрицы.
Рис. 13.12. Матрица контроля доступа
Вопросы для самопроверки
1. Почему необходим контроль доступа?
2. Почему матрицы контроля
систем?
Ответы 1) Любой пользователь может обращаться к любому пУ^
в файловой системе. Файловые системы контролируют доступ к Фа"
лам, чтобы защитить важную и ценную информацию от пользоват
лей, не обладающих соответствующими правами. 2) МатрИц
контроля доступа обычно велики по размеру и сильно разрежены, п
этому их хранение приводит к бессмысленным затратам пространен
на накопителях и большому времени обращения при реализации ко
троля доступа.
доступа непригодны для большинства
Размышления об операционных системах
Безопасность
безопасность всегда была важным мо-
еНтом в компьютерах, в особенности для
1|0Дей, работающих в ответственных и жиз-
' енно-важных системах. Но характер вопро-
сов безопасности изменяется с изменениями
технологии, и разработчики операционных
систем всегда должны анализировать появ-
ляющиеся технологии и оценивать их уязви-
мость к атакам. Ранние компьютеры весили
тонны и размещались в охраняемых поме-
щениях; компьютерных сетей еще не суще-
ствовало. Современные компьютеры, осо-
5енно портативные, лэптопы - и даже
обычные персональные компьютеры — лег-
ко украсть. Кроме того, почти все системы
обладают сетевыми возможностями, и при
передаче важных данных по незащищен-
ным каналам связи возникает множество
трудностей. Старые алгоритмы шифрова-
ния легко взламываются современными
мощными компьютерами, поэтому созданы
новые, более изощренные алгоритмы.
В этой книге мы неоднократно касаемся
темы безопасности, а глава 19 целиком по-
священа этой теме В главах, посвященных
ОС Linux и Windows ХР, мы рассмотрим воз-
можности и характеристики этих популяр-
ных ОС.
13.8.2 Контроль доступа по классам пользователей
Существует метод, требующий гораздо меньшего дискового пространст-
ва, чем матрица контроля доступа. Это метод, основанный на использова-
нии классов пользователей (user classes). Как правило, классификация
пользователей с точки зрения доступа к файлам выглядит так:
• Владелец (owner) — обычно это пользователь, создавший файл.
Владелец обладает неограниченным доступом к файлу и, как пра-
вило, может изменять права других пользователей на доступ к это-
му файлу.
• Указанный пользователь (specified user) — пользователь, которому
владелец предоставил права на доступ к файлу.
• Группа (group) или проект (project). Пользователи часто принадле-
жат к группам, работающим над конкретными проектами. В этом
случае члены группы могут обладать доступом к связанным с проек-
том файлам других членов группы.
• Общедоступный (public) — большинство систем позволяет создавать
общедоступные файлы, обращаться к которым могут все пользовате-
ли. Обычно по умолчанию общедоступные файлы можно читать или
запускать, но не изменять.
Данные контроля доступа могут храниться в виде части блока управле-
я Файлом, занимая незначительное дисковое пространство. Обеспечение
Опасности — важная задача в разработке операционной системы, и этой
чДаче посвящена глава 19.
ио_________________________________________________________________
Вопросы для самопроверки
1. Почему использование классов пользователей уменьшает расхо
дискового пространства на информацию контроля доступа?
2. Опишите преимущества и недостатки хранения данных контр0^
доступа как части блока управления файлом.
Ответы 1) Классы пользователей дают возможность владельцу
файла выдавать разрешения группам пользователей с помощью одно^
записи. 2) Преимущество такого подхода в отсутствии накладных рас.
ходов, если пользователю разрешен доступ к файлу — файловой систе.
ме в любом случае нужно прочитать блок управления файлом при
открытии файла. Однако если доступ к файлу запрещен, файловая
система выполнит несколько ненужных операций, обращаясь к блоку
управления файла, который пользователь не может открыть.
13.9 Методы доступа к данным
Во многих системах несколько процессов могут по очереди запрашивать
данные из разных файлов, расположенных в разных областях диска, и для
выполнения запросов потребуется выполнять медленные операции пози-
ционирования. Вместо того, чтобы немедленно выполнять поступивший
запрос ввода/вывода, операционная система может применять ряд прие-
мов, повышающих производительность.
Современные операционные системы обычно предоставляют множество
методов доступа. Иногда эти методы разделяют на простые методы досту-
па (basic access methods) и методы с поддержкой очередей (queued access
methods). Методы с поддержкой очередей обладают большими возможно-
стями, чем простые методы.
Методы с поддержкой очередей применяются, если последовательность,
в которой будут обрабатываться записи, можно предугадать — например,
при последовательном или последовательном индексном доступе. Эти ме-
тоды выполняют предварительную буферизацию (anticipatory buffering)
и планирование операций ввода/вывода. Они пытаются подготовить сле-
дующую запись для обработки сразу же по завершении обработки текущей
записи. В оперативной памяти одновременно хранится более одной записи,
это позволяет объединять операции обработки и ввода/вывода, повышая
производительность.
Простые методы доступа обычно используются в случаях, когда после-
довательность обращений к записям невозможно предсказать, особенно
при произвольном доступе. Кроме того, есть много ситуаций, например»
в приложениях баз данных, в которых прикладные программы требую1
контроля обращений к записям без предварительной буферизации. ПР°
стые методы доступа считывают и записывают данные в виде физически
блоков; объединение записей в физические блоки и разделение блоков
записи (если они нужны) выполняются приложениями.
Отображаемые в память файлы (memory-mapped files) отобража
хранящиеся в них данные в виртуальное адресное пространство проШ'С ’
а не в файловый кэш системы50. Поскольку обращения к этим файлам в
полняются в пределах виртуального адресного пространства, диспетИ
фиНлоВые системы и базы данных
811
пТуальной памяти может принимать решения о замене страниц, исходя
?1 порядка обращений процесса к страницам. Кроме того, отображение
!13йпов в память упрощает программирование приложений, поскольку
ограммы могут обращаться к данным в файлах с помощью указателей,
‘ ре операций чтения, записи и позиционирования.
8 Если процесс выдает запрос на запись, данные обычно записываются
буфер в оперативной памяти (для повышения производительности вво-
8 /вывода), и соответствующая страница помечается. При замене поме-
ченной страницы отображаемого в память файла содержимое этой страни-
цы записывается в соответствующий файл на накопителе. При закрытии
файла система записывает на накопитель все помеченные страницы. Дабы
уменьшить риск потери данных из-за отказов системы, содержимое поме-
ченных страниц обычно записывается на накопитель через определенные
промежутки времени51.
Вопросы для самопроверки
1. Сравните простые методы доступа и методы с поддержкой очере-
дей.
2. Почему отображение файлов в памяти упрощает программирование
приложений?
Ответы 1) Методы с поддержкой очередей выполняют предвари-
тельную буферизацию, пытаясь загрузить в оперативную память
блок, который, вероятно, будет вскоре затребован. Простые методы
доступа не пытаются планировать или буферизовать операции вво-
да/вывода, и эти методы удобнее, если система не может предугадать
будущие запросы или должна свести к минимуму риск потери данных
вследствие отказов. 2) Отображение файлов в память позволяет про-
граммам обращаться к данным по указателям вместо операций чте-
ния, записи и позиционирования.
13*10 Защита целостности данных
Компьютерные системы часто хранят критически важную информа-
цию, например, данные об имуществе, финансовые данные и/или личную
^формацию. Отказы систем, стихийные бедствия и действия злоумыш-
ленников могут уничтожить или повредить информацию. Результаты та-
ких событий могут быть катастрофическими52. Операционные системы
и системы хранения данных должны быть отказоустойчивыми в том смыс-
ле. что они должны учитывать возможность таких событий и предостав-
лять возможности восстановления после них.
еМы. Кроме т
*УТ ЙРттттггттатг
^•1OJ Резервное копирование и восстановление
большинстве систем реализованы возможности резервного копирова-
Ия для создания избыточных копий информации и возможности восста-
Вления, позволяющие восстанавливать информацию после отказов спе-
того, стратегии резервного копирования и восстановления мо-
.................. от выяпянных пользователями событий, например,
812
от непреднамеренного удаления важных данных (см. «Размышлец,,
об операционных системах: Резервное копирование и восстановление»)*^
Физические меры защиты — это первый уровень обеспечения безопась
сти данных. Такие меры, например, замки и системы сигнализации, могъ!
предотвратить нежелательный доступ к компьютерам, на которых хранят^
важные данные. Поскольку оперативная память компьютеров обычно тер^
ет данные при отключении питания, отказы систем электропитания MoiyJ
привести к потерям данных, не перенесенных из оперативной памяти
вторичные устройства хранения. Источники бесперебойного питания (ИВр>
могут защитить данные от повреждений при сбоях электропитания53.
Чрезвычайные происшествия, например, пожары или землетрясения
могут уничтожить все данные, хранящиеся в каком-то месте. Поэтому цс'
которые организации создают географически распределенные места для
хранения резервных копий данных, чтобы защитить данные в случае поте-
ри основного рабочего центра54. Хотя эти меры и важны, они не защищают
данные от отказов операционных систем или накопителей.
Периодическое резервное копирование — самый распространенный ме-
тод предотвращения потерь данных. Физическое резервное копирование
(physical backup) создает копию содержимого устройства хранения на бито-
вом уровне. В некоторых случаях выполняется копирование только заня-
тых данными блоков. Физическое резервное копирование просто реализо-
вать, но оно не сохраняет информацию о логической структуре файловой
системы. Данные файловой системы могут храниться в разных форматах,
зависящих от архитектуры системы, и физические резервные копии мо-
жет быть трудно использовать для восстановления данных в системах
с другой архитектурой. Кроме того, поскольку физическая резервная ко-
пия не учитывает логическую структуру файловой системы, она не может
разделить содержащиеся в ней файлы. Поэтому физические резервные ко-
пии должны содержать всю файловую систему целиком, чтобы гарантиро-
вать, что все данные продублированы, даже если большая часть данных
файловой системы не изменялась со времени предыдущего резервного
копирования55.
Логическое резервное копирование (logical backup) сохраняет данные
файловой системы и ее логическую структуру. Логические резервные ко
пии просматривают структуру директорий и определяют, какие файлы
нужно скопировать, а затем записывают эти файлы на устройство резерв-
ного копирования (например, ленточный накопитель, устройство завися
CD или DVD) в стандартном, часто сжатом, формате архива. НаприМе₽’
формат tar (tape archive — ленточный архив) часто используется для хр8
нения, транспортировки и резервного копирования множества фаи-<
в системах семейства UNIX (см. www.gnu.org/software/tar/tar.html)-4
скольку логические резервные копии хранят данные в стандартном ф°Р
те в виде структуры директорий, они позволяют операционным систем
с различными собственными форматами файлов считывать и восставав^
вать данные из резервных копий, и данные могут восстанавливаться
множестве разнородных систем. Кроме того, логические резервные ко
позволяют восстанавливать из них только отдельные файлы (напр15
случайно удаленные), и это делается быстрее, чем восстановление Фа ..I
вой системы целиком. Однако поскольку логическое резервное копир
ф^сВые системы и базы данных
813
р считывает только данные, предоставляемые файловой системой, оно
”0?кет пропустить, например, скрытые файлы или метаданные, которые
ли бы скопированы при побитовом физическом резервном копировании
° копителя системы. Сохранение файлов в стандартном формате может
* ггь неэффективным из-за накладных расходов, связанных с преобразова-
0 .ем между форматом архива и исходным форматом файла56.
Ь Инкрементное резервное копирование (incremental backup) — это логи-
ческое резервное копирование, при котором копируются только данные
файловой системе, изменившиеся со времени предыдущего копирования.
Система может запоминать, какие файлы изменялись, и периодически за-
писывать их в файл резервного копирования. Поскольку инкрементное ре-
зервное копирование требует меньшего времени и количества ресурсов,
чем резервное копирование всей файловой системы целиком, оно может
выполняться чаще и уменьшать риск потери данных из-за чрезвычайных
происшествий.
Размышления об операционных системах
Резервное копирование и восстановление
Приходилось ли вам терять результаты не-
скольких часов работы из-за отказа системы?
Компания HMD работала над большим проек-
том, в котором были заняты сотни программи-
стов, когда в здание ударила молния, и мы по-
теряли все обновления системы за последнюю
неделю. К счастью, у каждого из нас были ре-
зервные копии его работы, но все же на вос-
становление нам понадобилось несколько
Дней - дорогой и малоприятный опыт Долж-
ны ли пользователи отвечать за резервное ко-
пирование (и тратить на него свое время) или
060 Должно выполняться автоматически? Ре-
Эфвное копирование требует немалых ресур-
сов. Как часто оно должно выполняться?
Какой объем данных должен копироваться
каждый раз? Должны ли резервные копии
быть полными побитовыми образами систе-
мы или достаточно инкрементных логических
копий каждого изменения в системе? Ответы
на эти вопросы требуют от системного адми-
нистратора выбора компромисса между на-
кладными расходами на частое резервное ко-
пирование и риском потери данных из-за
редкого резервного копирования. Встраива-
ние в операционные системы возможностей
резервного копирования и восстановления
абсолютно необходимо.
Вопросы для самопроверки
1. Сравните физическое резервное копирование и логическое.
2. Почему физические меры защиты недостаточны для обеспечения
безопасности данных при чрезвычайных происшествиях?
814
Ответы 1) Логические резервные копии можно прочитать в а. I
левых системах с разными форматами файлов, они поддерживают ЛI
крементное резервное копирование и позволяют восстановление**^]
частям, например, восстановление отдельных файлов. Физические)?'
зервные копии обычно проще создавать, поскольку не нужно проста
ривать структуру файловой системы. Однако они не поддерживав
инкрементного резервного копирования и не позволяют выполця
восстановление по частям. Кроме того, физические резервные кощ?
обычно несовместимы с другими системами. 2) Физические меры
щиты предотвращают нежелательный доступ к данным, но не пред^’
вращают их потери в случае чрезвычайных происшествий, напримб1)
пожаров или землетрясений, отказов аппаратуры или электронит-?
ния. Вообще говоря, не существует метода, гарантирующего сохраа|
ность файлов при любых обстоятельствах.
13.10.2 Целостность данных и оку реальные файловые системы
Заметьте, что все рассмотренные выше методики подразумевают, что
между моментом создания резервной копии и моментом отказа может про-
изойти заметное изменение данных (см. «Размышления об операционных
системах: Закон Мерфи и робастные системы»). Кроме того, резервное ко-
пирование подразумевает последующее долгое восстановление системы,
в течение которого она будет в нерабочем состоянии.
В системах, которые не могут быть выключены и в которых нельзя до-
пустить потери данных, применяются RAID-массивы и транзакционные
файловые системы. В разделе 12.10 мы рассматривали, как RAID-массивы
уровней 1-5 увеличивают среднюю наработку системы на отказ и могут
восстанавливать данные в случае отказа одного из накопителей. Мы также
рассматривали, как зеркальное отображение и использование накопителей
горячей замены позволяет RAID-массивам работать постоянно, обеспечи-
вая непрерывную доступность данных.
Размышления об операционных системах
Закон Мерфи и робастные системы
Всякому известна та или иная форма зна-
менитого «Закона Мерфи», названного по
имени капитана ВВС США Эдварда Мерфи,
так отозвавшегося об одном из своих техни-
ков: «Если есть способ сделать что-то непра-
вильно, он найдет этот способ». Сегодня этот
закон чаще всего упоминается в форме «Если
что-то может сломаться, оно сломается». Час-
то закон дополняют: «в самое неподходящее
время». Разработчикам операционных систем
необходимо всегда помнить о законе Мерфи.
Нужно постоянно задавать себе вопросы
вроде «Что может пойти не так?», «Какова
вероятность возникновения проблемы?”1
«Каковы будут ее последствия?», «Как можно
предотвратить эту проблему при проектир0
вании системы?», «Если проблему нельзя
устранить, как операционная система дол*
на ее решать?». Робастная система способна
решать множество проблем и выходить Р3
внештатных ситуаций, оставаясь в работе
состоянии
системы и базы данных - —
^копирование и теневое копирование
Venn во время операции записи произойдет отказ системы, то возможна
оя целостности данных. Например, при электронном переводе денег
г,0Тковской системе требуется снять деньги с одного счета и положить их
пугой. Если отказ произойдет, когда деньги уже сняты, но еще не по-
1,3 -ены на другой счет, то деньги могут быть потеряны. Ведение журнала
10 язакций уменьшает риск потери данных с помощью применения ато-
Р ойых транзакций (atomic transactions), которые или выполняют группу
” йствий целиком, или не выполняют ни одного действия из группы. Если
й выполнении транзакции возникает ошибка, вследствие которой завер-
шить выполнение невозможно, то выполняется откат (rollback) транзак-
й____система возвращается в состояние, в котором она была до начала
выполнения транзакции57.
Атомарные транзакции могут реализовываться посредством записи ре-
зультата каждой операции в транзакции в протокольный файл вместо из-
менения существующих данных. После завершения транзакции она фик-
сируется (commit) — в файл протокола записывается специальное значе-
ние. В дальнейшем в какой-то момент содержимое протокола переносится
на постоянное устройство хранения. Если в системе происходит отказ до
завершения выполнения транзакции, операции, выполненные после по-
следней зафиксированной транзакции, игнорируются. При восстановле-
нии системы она считывает файл протокола и сравнивает его с данными
в файловой системе, чтобы определить ее состояние в последней точке фик-
сации.
Чтобы позволить системе отменить любое количество операций, во мно-
гих системах файл протокола не удаляется после переноса его содержимо-
го на постоянное устройство хранения. Поскольку протоколы могут стать
большими по объему, возврат по транзакциям к состоянию системы в по-
следней точке фиксации может быть длительным процессом. Чтобы сокра-
тить необходимое на него время, большинство транзакционных систем
поддерживают контрольные точки (checkpoints), указывающие на послед-
нюю транзакцию, результаты которой переносились на постоянное устрой-
ство хранения. При отказе системы нужно только просмотреть транзак-
ции, следующие за последней контрольной точкой.
Теневое копирование (shadow paging) реализует атомарные транзак-
ции, записывая измененные данные в свободный блок, а не в тот, где хра-
нятся исходные данные. После фиксации транзакции файловая система
поновляет метаданные так, чтобы они указывали на блок с измененными
Энными, а блок с исходными данными — теневую страницу (shadow
Page) помечает как пустой. Если транзакцию не удается завершить, файло-
вая система выполняет откат, помечая выделенные под результат транзак-
ции блоки как пустые58.
журнальные файловые системы
^чет транзакций и теневое копирование препятствуют возникновению
Ротиворечий в данных, но они не обязательно гарантируют, что сама фай-
Вая система будет избавлена от противоречий. Например, перенос файла
°Дной директории в другую требует, чтобы файловая система удалила
Глщ
запись о файле в исходной директории и создала запись о нем в целевой д.
ректории. Отказ системы (например, из-за отключения питания) в перД
между удалением исходной записи и созданием новой может приве<<
к потере файла. Чтобы устранить эту опасность, журнальная файлов/
система (LFS — Logged File System), также называемая протоколирую^/
файловой системой (journalizing file system), выполняет все операц/
с файлами как протоколируемые транзакции59. Примеры журнальщ/
файловых систем — NTFS Journaling File System фирмы Microsoft и фа^
ловая система ext3 в ОС Red Hat Linux60’ 61.
В LFS весь диск занят файлом журнала, в котором записываются траа
закции. Новые данные записываются последовательно в свободном про
странстве этого файла. Например, на рис. 13.13 LFS получает запрос ца
создание файлов foo и bar в новой директории. Выполняя этот запрос
файловая система сначала записывает данные файла foo в журнал, затем
записывает метаданные файла foo (т.е. индексный узел), позволяющие
системе найти данные из этого файла. Аналогичным образом LFS записы-
вает данные файла bar и его метаданные. После этого в журнал добавляет-
ся запись о новой директории. Обратите внимание — если система запишет
сначала метаданные файла, а потом данные, и в системе возникнет отказ,
то метаданные будут указывать на некорректные блоки (т.е. в блоках бу-
дут отсутствовать данные файла).
Поскольку измененные директории и метаданные всегда записываются
в конец журнала, LFS может понадобиться просмотреть весь журнал, чтобы
найти конкретный файл. Соответственно, производительность при чтении
может оказаться низкой. Дабы уменьшить серьезность данной проблемы,
LFS кэширует информацию о размещении файлов в файловой системе и вре-
мя от времени записывает карты индексных узлов (inode maps) или супер-
блоки, указывающие размещение других метаданных (см. рис. 13.13). Это
позволяет операционной системе находить и кэшировать метаданные фай-
лов достаточно быстро при загрузке системы. Впоследствии файлы можно
находить быстро, определяя их размещение по данным в кэшах системы.
С увеличением емкости файлового кэша системы его производительность
растет за счет уменьшения объема памяти, доступного прикладным
процессам62.
Чтобы уменьшить накладные расходы, некоторые файловые системы
хранят в журналах только метаданные. В этом случае система сначала из-
меняет метаданные, внося в журнал новую запись, а затем обновляет дан-
ные в файловой системе. Операция фиксируется только после обновлений
метаданных и в журнале, и в файловой системе. Это гарантирует целост-
ность файловой системы при относительно небольших накладных Р°дХ°"
дах, но не гарантирует сохранения целостности при отказах системы^ •
Поскольку в LFS данные записываются последовательно, каждый за
прос на запись выполняется также последовательно, и время записи суй6
ственно уменьшается. Системы с фрагментированным размещением ФаИ
лов могут потребовать просмотра системы директорий для выполнения за
писи, и время записи в них может оказаться заметно большим.
rfbie системы а базы данных
ап.
Данные
Запись файла foo
Журнал
(свободное
пространство)
. 1______, _ I
Данные Метаданные
файла foo файла foo
Метаданные
файла bar
Помещение файлов
foo и bar в новую директорию
Запись файла bar
Данные
файла bar
13.13. Журнальная файловая система
Когда в журнале больше не остается свободного места, система должна
определить, как освободить место для поступающих данных. LFS может
Периодически просматривать журнал и определять, какие блоки можно ос-
вободить, поскольку другие блоки содержат измененные копии данных из
Этих блоков. Затем можно размещать новые данные в освободившихся бло-
ках, но при этом новые данные, вероятно, окажутся сильно фрагментиро-
ванными. К несчастью, такой подход может снизить производительность
819
ЬаВ,,.
при чтении и записи до уровней более низких, чем свойственные обычцЬ1J
файловым системам, поскольку для доступа к данным будет требовать |
множество операций позиционирования. Чтобы решить эту проблему, 1
может создавать непрерывные свободные участки в журнале, копируя
ные в конец журнала. Однако в ходе выполнения этой операции произво.
дительность системы может падать из-за необходимости выполнения мно
жества операций ввода/вывода.
Вопросы для самопроверки
1. Объясните, как могут возникнуть противоречия в данных, храня,
щихся в массиве RAID уровня 1, обеспечивающего высокий ур0.
вень избыточности.
2. Объясните разницу между протоколированием и теневым копире,
ванием.
Ответы 1) Если отказ произошел во время записи данных на зер-
кальную пару, в массиве могут содержаться неполные копии данных
или метаданных на обоих накопителях пары. 2) При протоколирова-
нии отслеживается начало транзакции и ее конец. Если транзакцию
невозможно завершить, выполняется откат до последней точки фикса-
ции. При теневом копировании для записи новых данных выделяются
новые блоки, а старые блоки данных обозначаются как свободные по
завершении транзакции.
13.11 Файловые серверы и распределенные
системы
Один из способов поддержки обращений к нелокальным файлам в ком-
пьютерной сети — передавать все такие обращения файловому серверу
(file server) — компьютеру, предназначенному для обеспечения межкомпь-
ютерного доступа65,66,67,68, 69. Этот подход централизует управление таки-
ми обращениями, но файловый сервер может стать узким местом, посколь-
ку все клиентские компьютеры будут отправлять свои запросы серверу-
Более эффективно было бы разрешить различным компьютерам напрямую
общаться друг с другом; именно такой подход лежит в основе сетевой фай-
ловой системы (Network File System) NFS фирмы Sun Microsystems-
В сети, использующей эту файловую систему, на каждом компьютере ис-
пользуется файловая система, которая может быть как сервером, так
и клиентом.
В 1970-х годах файловые системы обычно управляли файлами, хранив-
шимися на одном компьютере. В многопользовательских системах с раздб'
лением времени файлы всех пользователей управлялись централизован-
ной файловой системой. Сейчас место таких систем постепенно занимают
распределенные файловые системы (distributed file systems) компьютер'
ных сетей70, 71« 72, 73. Основная сложность здесь заключается в разнообра'
зии объединяемых в сети компьютерных устройств и используемых на ник
операционных и файловых систем.
системы и базы данных___________________________________________
распределенная файловая система дает возможность пользователям вы-
мять операции с файлами на удаленных компьютерах точно так же, как
^скальными файлами74, 75, 76, 77, 78. NFS предоставляет возможности рас-
1 еделенной файловой системы для сетей с разнородными компьютерами;
11 я используется так широко, что стала международным стандартом79.
^айл°вь1е сеРвеРы и распределенные файловые системы обсуждаются в раз-
деле 18-2.
Вопросы для самопроверки
1. Почему использование одного файлового сервера неудобно для
больших организаций?
2. Каково основное преимущество того, что каждый клиент в распре-
деленной файловой системе может быть и сервером?
Ответы 1) Если файловый сервер выйдет из строя, вся система
окажется в нерабочем состоянии. Кроме того, централизованный фай-
ловый сервер может стать узким местом. 2) Это устраняет узкое ме-
сто — централизованный файловый сервер — и позволяет файловой
системе оставаться работоспособной даже при выходе из строя части
клиентов.
13.12 Системы ваз данных
База данных (database) — это централизованно управляемый, интегри-
рованный набор данных; система баз данных (database system) включает
собственно данные, аппаратные устройства, на которых хранятся эти дан-
ные, и программы, обеспечивающие доступ к данным (обычно эти про-
граммы называются системами управления базами данных (database
management systems) — СУБД (DBMS)). Базы данных часто используются
в Web-серверах и системах онлайн-обработки транзакций, на которых
множество процессов могут одновременно требовать доступа к большим
объемам хранимых данных.
^.12.! Преимущества систем баз данных
В обычных файловых системах множество приложений часто хранит
одну и ту же информацию в разных файлах и разных форматах (например,
ТеКст может храниться в формате PostScript и в формате PDF). Для устра-
йения этой избыточности системы баз данных организуют данные согласно
Их смыслу, а не месту хранения. Например, на Web-сайте может использо-
®аться несколько приложений, одно из которых снимает плату по заказам
° кредитных карточек покупателей, второе отсылает счета этим покупате-
лям, а третье — печатает ярлыки для пакетов, которые должны быть дос-
ТаВлены покупателям. Всем этим приложениям нужна информация о по-
купателях, например, их имена, адреса, номера телефонов и так далее. Од-
ак° каждое приложение должно отображать эту информацию по-своему,
тобы решить свои задачи (например, отослать информацию о кредитной
карточке или напечатать ярлык). В базе данных может храниться только
820
одна копия информации о каждом покупателе, и база позволит кажд0.
приложению получать нужную ему информацию, а затем преобразовывав
ее в нужный формат. Чтобы обеспечить такой доступ к распределен^
данным, в базах данных используется механизм запросов, позволяюшм
приложениям указывать, какая информация им нужна.
В системах баз данных используются стандартизированные способы Ор
ганизации информации (например, иерархические, реляционные, объе^
но-ориентированные), и приложения не могут изменять эти способы. Систе
мы баз данных уязвимы для атак вследствие централизованного характера
хранения данных и управления ими, и они снабжаются продуманными ме.
ханизмами безопасности80, 81.
Вопросы для самопроверки
1. Каким образом базы данных уменьшают избыточность данных ц0
сравнению с обычными файловыми системами?
2. Почему для систем баз данных очень важны вопросы безопасности?
Ответы 1) Системы баз данных организуют данные по их содер-
жимому, и никакие две записи не содержат одинаковую информацию.
Например, в базе данных может храниться одна копия информации
о покупателе, к которой множество приложений может обращаться
с помощью запросов. 2) Системы баз данных предоставляют возмож-
ности централизованного управления большими объемами данных,
которые могут включать важную информацию. Если злоумышленник
получит доступ к такой системе, он сможет обратиться к любым хра-
нящимся в ней данным. Это гораздо опаснее, чем в традиционной фай-
ловой системе, в которой права доступа обычно хранятся по
отдельности для каждого файла, и пользователь, получивший доступ
к системе, не обязательно получит доступ ко всем хранящимся в ней
файлам.
13.12.2 Доступ к данным
Данные в системах баз данных обладают независимостью (data
independence), поскольку организация и внутренняя структура базы дан-
ных скрыты от приложений. В отличие от иерархически структурирован-
ных файловых систем, в которых все приложения обращаются к файлам
по одним и тем же именам и путям, система с независимостью данных по-
зволяет различным приложениям обращаться к одним и тем же данным
с помощью различных логических представлений. Рассмотрим информа-
цию о покупателе, хранящуюся на Web-сайте из предыдущего раздела-
В этом случае приложение, выполняющее транзакции с данными о кредит*
ных карточках, может выбирать из информации о покупателях только
список номеров кредитных карточек и дат окончания их действия; прило
жение, отвечающее за рассылку счетов, может использовать только имей
покупателей, их адреса и суммы, которые нужно указать в счетах. НезавИ
симость данных позволяет системе изменять структуру хранения даннь
и способы доступа к ним в соответствии с требованиями новых прилож
ний без необходимости изменять уже используемые приложения.
Языки баз данных (database languages) обеспечивают независимое^
данных за счет предоставления стандартного способа доступа к этим Да
821
^обые системы и базы данных
Язык баз данных состоит из языка описания данных (Data
finiti°n Language — DDL), языка обработки данных (Data Manipulation
j nguage — DML) и языка запросов (query language). DDL описывает op-
низацию элементов данных и отношения между ними, a DML — способы
вменения данных. Язык запросов позволяет пользователям создавать за-
1 oCbi, выбирающие данные из базы по заданным критериям. Языки баз
«иных могут использоваться как непосредственно из командной строки,
так и через программы, написанные на языках высокого уровня, напри-
мер. C++ или Java. Структурированный язык запросов (Structured Query
Language — SQL), состоящий из DDL, DML и языка запросов — это попу-
лярный язык запросов, дающий возможность пользователям находить эле-
менты данных, обладающие определенными свойствами, создавать табли-
цы, задавать ограничения целостности, управлять базами данных и обес-
печивать безопасность82- 83- 84.
Распределенная база данных (distributed database) — это база данных,
распределенная по компьютерам, объединенным в сеть. Распределенные
базы данных обеспечивают эффективный доступ к данным, разбитым на
наборы, размещенные на разных компьютерах85. В таких системах каж-
дый элемент данных обычно хранится на том компьютере, который чаще
всего обращается к этому элементу, но доступ к нему возможен и с других
компьютеров. Распределенные системы сочетают управляемость и эффек-
тивность локальной обработки с преимуществами доступности информа-
ции для географически распределенной организации. Однако они могут
быть дороги в реализации и применении и могут страдать от уязвимостей
к атакам и брешей в системах безопасности.
Вопросы для самопроверки
1. Каким образом базы данных предоставляют приложениям доступ
к данным?
2. Объясните разницу между DDL и DML.
Ответы 1) Языки баз данных обеспечивают независимость дан-
ных, и приложения могут обращаться к данным через логические
представления, наиболее удобные для них. 2) DDL описывает органи-
зацию элементов данных и отношения между ними, a DML — способы
изменения данных.
13.12.3 Реляционная модель базы данных
Базы данных основываются на моделях, описывающих представлени»
Данных и отношений между ними. Реляционная модель, разработанная
Роддом, является скорее логической, чем физической; принципы управле
н«я реляционными базами данных можно изучать, не затрагивая физиче
СкУЮ реализацию используемых структур данных86’ 87’ 88, 89, 90.
Реляционная база состоит из таблиц, или отношений (relations). На рисун
Ке 13.14 показано отношение, которое может использоваться в системе учет
персонала. Имя этого отношения — EMPLOYEE, и оно предназначено для ор
Ганизации различных атрибутов каждого работника. Каждому работник:
е таблице соответствует отдельная строка (row или tuple). Таблица на рисун
Ке состоит из шести строк. В нашем примере первый атрибут (столбец) в каж
дой строке — номер работника, который используется в качестве первично^
ключа (primary key) для выбора данных в отношении. Каждая строка в Tag.
лице содержит уникальное значение первичного ключа.
Таблица: EMPLOYEE
. Number Name Department Salary Location
23603 Jones, А. I413 I 1100 New Jersey
24568 Kerwin, R. Ll3 I „4 I 2000 New Jersey
Строка | 34589 Larson, P. ~ _£4i| 1800 Los Angeles
35761 Myers, B. ‘leu I 1400 Orlando
47132 Neumann, C. |413 । 9000 New Jersey
78321 Stevens, T. |б11 | L . » 8500 Orlando
Первичный ключ Атрибут
Рис. 13.14. Таблица в реляционной базе данных
Каждый атрибут в отношении принадлежит к определенному домену
(domain). Строки должны быть уникальны в пределах отношения, но зна-
чения отдельных атрибутов могут повторяться в разных строках. Напри-
мер, на рисунке 13.14 номер отдела 413 содержится в трех разных стро-
ках. Количество атрибутов в отношении называется степенью (degree) от-
ношения. Отношения степени 2 называются бинарными (binary relations)
вотношения степени 3 — тернарными (ternary relations) отношения степе-
ни п — n-арными отношениями (n-ary relations).
Пользователям баз данных часто требуется выделять различные эле-
менты данных и отношения между ними. Большинству пользователей тре-
буются только некоторые из столбцов и строк таблицы. Многим требуется
совмещать данные из нескольких таблиц в общие таблицы и создавать бо-
лее сложные отношения. Кодд назвал операцию выделения частей таблиц
проецированием (projection), а совмещение нескольких таблиц — объеди-
нением (join).
На основе отношения с рисунка 13.14 можно, например, операцией пр0'
ецирования создать новое отношение с названием DEPARTMENTLOCA-
ТОКпредназначенное для определения размещения отделов (рис. 13.15)-
Язык SQL предназначен для работы с реляционными базами данных-
SQL-запрос, изображенный на рисунке 13.16, генерирует таблиДУ
ие системы и базы данных
825
пиеУнка 13.15. Строка 1 начинается с символов «—», обозначающих
Сомментарий в языке SQL. Оператор SELECT в следующей строке указы-
ь рт столбцы, Department и Location новой таблицы. Ключевое слово
nigTlNCT указывает, что все строки таблицы должны быть уникальными,
опция FROM указывает таблицу, из которой должна выполняться проек-
(EMPLOYEE) (см. рис. 13.14). В строке 4 опция ОИПЕЕВУуказывает
сТОдбец (в нашем случае — Department по значениям которого будут сорти-
оваться строки новой таблицы, a ASC указывает, что сортировка выпол-
няется в порядке от меньших значений к большим.
Отношение. DEPARTMENT-LOCATOR
Department Location
413 611 642 NEW JERSEY ORLANDO LOS ANGELES
Рис. /J./У. Отношение, сформированное с помощью проецирования
1 — SQL-запрос, формирующий таблицу рис. 13.15.
2 SELECT DISTINCT Department, Location
3 FROM EMPLOYEE
4 ORDER BY Department ASC
5
Puc. 13.16. SQL -запрос
У реляционной модели есть несколько преимуществ:
1. Табличное представление, используемое в реализациях реляционной
модели, просто реализуется в физических системах баз данных.
2. В реляционную модель несложно преобразовать практически любую
Другую структуру базы данных. Поэтому реляционную модель мож-
но воспринимать как универсальную форму представления.
Операции проецирования и объединения просты в реализации и де-
лают простым создание новых отношений, требуемых приложения-
ми баз данных.
4. Контроль доступа к базам данных элементарен. Важные данные про-
сто разносятся по разным отношениям, доступ к которым контроли-
руется некоторым механизмом авторизации или контроля доступа.
Вопросы для самопроверки
1. В чем разница между операциями проецирования и объединения
в реляционных базах данных?
2. (Да/Нет) Значения каждого атрибута должны быть уникальны
для всех строк отношения.
824
Ответы 1) Операция объединения формирует отношения из ». I
или более отношений; операция проецирования формирует отно^
ния из части атрибутов одного отношения. 2) Нет. Одно и то же
ние атрибута может содержаться во множестве строк отношения.
13.12.4 Операционные системы и системы баз данных
Стоунбрейкер рассматривает различные службы операционных систем
поддерживающие системы управления базами данных, а именно служб^
управления буфером, файловую систему, службы планирования, управде
ния процессами, межпроцессного взаимодействия, контроля целостности
и виртуальной памяти91. Он отмечает, что поскольку большинство этих
служб не оптимизировано специально для нужд СУБД, разработчики
СУБД предпочитают создавать свои собственные службы, а не полагаться
на предоставляемые системой. По его мнению, для поддержки СУБД, рас.
полагающих собственными оптимизированными службами, лучше всего
использовать минимизированные операционные системы. Поддержка баз
данных в современных системах получает все большее распространение.
Например, Microsoft собирается применять базу данных для хранения
всех пользовательских данных в следующей версии Windows92.
/
Вопросы для самопроверки
1. Почему операционным системам стоит в целом избегать прямой
поддержки систем баз данных?
2. Почему в будущем будет расти число операционных систем, прямо
поддерживающих системы баз данных?
Ответы 1) У каждой системы баз данных могут быть собственные
требования, которые сложно предвидеть разработчикам операционных
систем. Системы баз данных обычно обеспечивают лучший уровень
производительности, если используют собственные оптимизированные
службы. 2) Если операционная система использует базу данных как ос-
новное средство хранения пользовательской информации, она должна
предоставлять службы, оптимизированные под эту базу данных.
Веб-ресурсы
www.linux-tutorial.info/cgi-bin/display.pl?95&0&0&0&3
Содержит учебную информацию о файловых системах в операционной систе
Linux.
www.redhat.com/docs/manuals/linux/RHL-8.О-Manual/admin-primer/
sl-storage-basics.htm
Обзор концепций файловых систем.
www.itworld.com/nl/db_mgr/
Содержит статьи о стратегиях управления данными.
www.winnetmag.сот/articles/index.cfm?articleid=3455
Содержит информацию о файловой системе Windows NT.
це системы и базы д, х
825
.wv. .osta.org/specs/pdf/udf201 .pdf
Содержит описание версии 2.01 файловой системы UDF (Universal Disk
— Универсальный формат дисков), обычно используемой для организации
ио DVD.
storageconference.org/
Содержит статьи и презентации с общей конференции по устройствам хранения
алЖ-NASA, освещающие методы и технологии, связанные с устройствами массо-
Э хранения.
sqlsource.сот/
Интерактивный обучающий курс по основам языка SQL.
Итоги
Информация в компьютерах хранится в рамках определенной иерархии данных.
Самый низкий уровень иерархии — биты данных. Биты объединяются в сочетания,
представляющие все элементы данных в компьютерных системах. Следующий уро-
вень иерархии данных — сочетания битов фиксированного размера, например, бай-
ты, символы и слова. Байт обычно состоит из 8 битов. Размер слова равен количеству
битов, которое процессор может обрабатывать одновременно. Символы — это храни-
мые в байтах (или группах байтов) знаки, например, буквы, цифры и знаки пунктуа-
ции. Три наиболее широко используемых сегодня набора символов — это ASCII
(American Standard Code for Information Interchange — американский стандартный
код для обмена информацией), EBCDIC (Extended Binary-Coded Decimal Interchange
Code — расширенный двоично-десятичный код обмена информацией) и Unicode.
Поле представляет собой группу символов. Запись — это группа полей. Файл —
это группа записей. Самым высоким уровнем в иерархии данных на компьютере
является файловая система или база данных. Том — это часть пространства уст-
ройства хранения, в которой может храниться множество файлов.
Файл — это именованный набор данных, который может обрабатываться как
единое целое с помощью таких операций, как открытие, закрытие, чтение, запись,
Удаление, копирование и переименование. Характеристики файла включают его
Расположение, доступность, тип, способ хранения и активность. Файлы могут со-
стоять из одной или более записей.
Файловая система организует файлы и управляет доступом к хранящимся
в Файлах данным. Файловые системы отвечают за управление файлами и вспомо-
гательными устройствами хранения, за механизмы контроля целостности и досту-
Па к файлам. В основном файловая система занята управлением пространством
Вт°Ричных устройств хранения, особенно дисковых накопителей.
Файловые системы должны быть независимы от конкретных типов уст-
ройств — пользователи должны иметь возможность обращаться к файлам по сим-
вольным именам, а не по физическим именам, связанным с устройствами. Файло-
вые системы также должны предоставлять возможности резервного копирования
восстановления данных, чтобы предотвратить случайную потерю данных или их
иЧтожение злоумышленниками. Файловые системы могут также предоставлять
3Можности шифрования и дешифрования, чтобы защитить информацию от не-
Ыционированного доступа к ней.
чтобы упорядочивать и быстро находить файлы, файловые системы использу-
Директории — специальные файлы, содержащие имена и информацию о разме-
ц Нии других файлов в системе. Запись о файле в директории хранит информа-
с 10 °б имени файла, его размещении, а также, например, размере, типе, временах
л Дания, изменения файла и последнего обращения к файлу. Простейший вид
^йловых систем — одноуровневые (или плоские) файловые системы, в которых
файлы хранятся в одной директории. В таких файловых системах все имена
файлов должны быть уникальными, и файловая система должна просматрВв4 1
все содержимое директории, чтобы найти нужный файл, что может прцВв М
к низкой производительности. 'Ч]
В иерархической файловой системе используется корень, указывающий, в I
ком месте пространства накопителя начинается корневая директория. Корде*М
директория содержит указатели на другие директории и файлы. В каждой из ЛМ
гих директорий тоже могут содержаться указатели на директории и файлы, в ,
ких системах имена файлов должны быть уникальными только в пределах одвД|
директории. Полное имя файла обычно формируется из собственно его имрД
и пути к нему из корневой директории. й
Многие файловые системы поддерживают понятие рабочей директории, ц03в
ляющее упростить навигацию с помощью путей. Рабочая директория дает возмог
ность пользователям указывать пути, начинающиеся не в корневой директор^
(т.е. относительные пути). Если файловая система встречает относительный пуд,
она формирует из него абсолютный путь (т.е. путь из корневой директории), соеди
няя путь в рабочую директорию и относительный путь.
Ссылка представляет собой запись в директории, указывающую на файл или
директорию, расположенные в другой директории. Ссылки позволяют организо-
вывать совместное использование данных и облегчают пользователям доступ
к файлам, расположенным в разных местах структуры директорий. Мягкая ссыл-
ка — это запись в директории, содержащая путь к другому файлу. Жесткая ссыл-
ка — это запись в директории, указывающая размещение файла (обычно номера
блоков) на накопителе. Поскольку жесткая ссылка указывает физическое разме-
щение файла, она станет некорректной, если файл будет перемещен. Поскольку
мягкие ссылки содержат логическое имя файла в файловой системе, их не нужно
обновлять при физическом перемещении файла. Но если файл, на который они
ссылаются, будет переименован или перемещен в другую директорию, мягкие
ссылки станут некорректными.
Метаданные — это информация, обеспечивающая целостность файловой систе-
мы, которая не может быть непосредственно изменена пользователями. Многие
файловые системы хранят суперблок, содержащий жизненно-важную информа-
цию, обеспечивающую целостность файловой системы — например, идентифика-
тор файловой системы и размещение свободных областей на накопителе. Дабы
уменьшить риск потери данных, большинство файловых систем создают резерв-
ные копии суперблоков и хранят их в разных местах накопителей.
Операция открытия файла возвращает дескриптор файла, представляющий со-
бой неотрицательное целое число. Дескриптор является индексом в таблице от-
крытых файлов. После открытия файла работа с ним выполняется через дескрип-
тор. Чтобы ускорить доступ к информации о файле, например, к разрешениям ва
работу с ним, таблицы открытых файлов часто содержат блоки управления фалла-
ми, называемые иногда атрибутами файлов. Структура этих блоков зависит от сис-
тем, они могут содержать, например, символьные имена файлов, информацию о
их размещении на накопителях, данные управления доступом к файлам.
Операция монтирования позволяет совместить в одном пространстве имен мво
жество файловых систем и обращаться к ним из общей корневой директории, **
манда монтирования назначает в качестве корневой директории монтируемой Фа
ловой системы директорию в родной файловой системе. Эта директория называ
ся точкой монтирования. Файловые системы управляют смонтированнЫ
директориями с помощью таблиц монтирования, содержащих информацию с
мещении точек монтирования и устройствах, на которые они указывают. ь
родная файловая система встречает точку монтирования, она использует табл
монтирования, чтобы определить смонтированное в ней устройство и тип исп
зуемой на нем файловой системы. Пользователи могут создавать мягкие ссылки
файлы в смонтированных файловых системах, но создавать жесткие ссылки W
ду разными файловыми системами нельзя.
827
системы и базы данных
файловая организация определяет способ размещения записей в файле на вто-
ом устройстве хранения. Есть различные способы файловой организации,
^ючая последовательную, прямую, индексированную последовательную и раз-
^енную (библиотечную).
J Проблема выделения и освобождения пространства накопителя в чем-то напо-
ает проблему выделения и освобождения памяти в многопрограммных систе-
>,1! с динамическим распределением памяти. Поскольку размеры файлов изме-
кггся с течением времени, и поскольку пользователи редко знают заранее раз-
п создаваемых файлов, системы с хранением файлов в виде непрерывных
•'"оков в основном уступили место Системам с фрагментируемым динамическим
^метением.
* файловые системы с непрерывным размещением файлов размещают файлы
вепрерывных последовательностях блоков на накопителях. Преимущество та-
ких систем — то, что обычно логически смежные записи оказываются смежными
и физически. Системы с непрерывным размещением файлов сталкиваются с теми
дее проблемами внешней фрагментации, что и системы динамического выделе-
НЙЯ памяти в многопрограммных системах. Выделение непрерывных блоков па-
мяти может привести к низкой производительности, если размер файлов изменя-
ется со временем. Если размер файла увеличивается настолько, что его нельзя
разместить в области, в которой он размещался ранее, его приходится целиком
переносить в новую область, затрачивая на этот перенос дополнительные опера-
ции ввода/вывода.
В секторной фрагментированной схеме выделения пространства с использова-
нием связных списков запись в директории содержит указатель на первый сектор
файла. Часть сектора, отведенная для хранения данных, хранит содержимое фай-
ла; часть, отведенная под указатель, содержит указатель на следующий сектор
файла. Сектора, принадлежащие файлу, образуют связный список.
При выделении блоков система выделяет непрерывные последовательности сек-
торов. При образовании связных списков записи в директориях указывают на пер-
вые блоки файлов. Блоки, в которых размещается файл, состоят из двух частей:
области данных и указателя на следующий блок. При поиске нужной записи при-
ходится просматривать список блоков файла с начала, и если блоки рассеяны по
поверхности диска (как это обычно и бывает), процесс поиска может затягиваться
из-за выполнения множества операций позиционирования. Операции вставки
и удаления сводятся к изменению указателей в предыдущем блоке.
Использование блоков большого размера может привести к большим потерям
емкости накопителя из-за внутренней фрагментации. Использование маленьких
блоков может привести к рассеянию данных по множеству блоков в разных местах
Диска и снижению производительности, поскольку для чтения всех блоков потре-
буется множество операций позиционирования.
В системах с табличным фрагментированным размещением для уменьшения
Потребности в операциях позиционирования используются таблицы, в которых
хРанятся указатели на занятые файлами блоки. Записи в директориях содержат
Указатели на первые блоки файлов. Номер блока используется в качестве индекса
® таблице выделения блоков, по которому находится номер следующего занятого
файлом блока. Если текущий блок — последний в файле, то соответствующая его
°Меру запись в таблице содержит null-указатель. Поскольку указатели, по кото-
выполняется поиск данных в файлах, хранятся централизованно, их таблицу
_ Озкно считать в кэш и в дальнейшем быстро определять цепочки блоков, которые
У’Кно просматривать при поиске данных. За счет этого ускоряется доступ к фай-
" м- Однако чтобы найти последнюю запись в файле, системе придется просмот-
Есть множество указателей в таблице, на что может потребоваться заметное время,
ъ.Ли пространство накопителя разбито на большое количество блоков, таблица
тР Леления блоков может стать большой и фрагментированной, снижая производи-
^ьность системы. Файловая система FAT фирмы Microsoft — пример системы
табличным фрагментированным размещением.
828
Гла&
В системах с индексируемым фрагментированным размещением у каждОг
файла есть один или несколько индексных блоков. В индексных блоках содер^-5
ся списки указателей на блоки данных файла. Запись в директории содержит уСл
затель на индексный блок файла, в котором несколько последних записей могы
быть зарезервированы под указатели на другие индексные блоки. Этот прием
зывается сцеплением. *
Основное преимущество сцепления индексных блоков перед простыми систем
ми со связными списками состоит в том, что поиск может выполняться в самих
дексных блоках. Файловые системы обычно размещают индексные блоки Ряд0!<
с теми блоками данных, на которые они указывают, чтобы к блокам данных mojk
но было обратиться сразу же после считывания индексного блока. В системах се-
мейства UNIX индексные блоки называются индексными узлами (inode).
Некоторые системы используют список свободных блоков — связный список
блоков, содержащих указатели на свободные блоки — для управления свободны^
пространством накопителей. Обычно файловая система выделяет блоки из начала
списка свободных блоков и добавляет указатели на освободившиеся блоки в конец
списка. Этот подход требует небольших накладных расходов на операции под-
держки списка, но файлы часто размещаются в фрагментированном виде, и время
доступа к ним увеличивается.
Битовые массивы содержат по одному биту на каждый блок накопителя, и г-тый
бит соответствует i-тому блоку. Основное преимущество битовых массивов перед
списками свободных блоков — возможность быстро определить, есть ли в какой-то
области накопителя последовательности свободных блоков нужного размера. Недос-
таток битовых массивов — необходимость просмотра всего массива для поиска сво-
бодных блоков, что может привести к существенным накладным расходам.
В двумерных матрицах контроля доступа ячейка ау содержит 1, если пользова-
тель i может обращаться к файлу j; в противном случае atj = О. В системах с боль-
шим количеством пользователей и множеством файлов матрица будет большой
и сильно разреженной. Метод контроля доступа, основанный на классах пользова-
телей, требует значительно меньшего пространства накопителя. Классами пользо-
вателей могут быть: владелец файла, указанные пользователи, группы пользовате-
лей. Файл может быть общедоступным или доступным только пользователям, уча-
ствующим в каком-то проекте. Такой метод контроля доступа позволяет хранить
контрольные данные в блоках управления файлами, требуя незначительного про-
странства на накопителе.
Современные операционные системы обычно предоставляют различные методы
доступа — как простые, так и с использованием очередей. Методы с использовани-
ем очередей применяются в случаях, когда можно предсказать последователь-
ность, в которой будут поступать обращения, например, при последовательном
или индексированном последовательном доступе. Эти методы выполняют предва-
рительную буферизацию и планирование операций ввода/вывода. Простые методы
доступа обычно используются, если последовательность поступления запросов
нельзя предугадать, особенно при произвольном доступе.
Отображаемые в памяти файлы отображают данные в виртуальном адресно
пространстве процесса в оперативной памяти, а не в файловом кэше системы- В
скольку обращения к этим файлам выполняются в адресном пространстве пронес
са, диспетчер виртуальной памяти может принимать решения о замене страви
исходя из последовательности обращений к ним.
В большинстве файловых систем предусмотрены возможности резервного ко
рования для создания избыточных копий информации и возможности восстал
ления, позволяющие системам восстанавливать данные после отказов. ФизИсЯ.
ские меры безопасности, такие как замки и системы сигнализации, образуют
мый нижний уровень защиты данных. Периодическое резервное копирование
самый распространенный метод гарантирования постоянной доступности даН»
Физические резервные копии дублируют содержимое устройств хранения на би &
вом уровне. Логические резервные копии хранят данные файловой системы »
фцймВь/е системы и базы данных
829
«ческую структуру. При логическом резервном копировании файловая система
^осматривается в поисках файлов, который нужно скопировать, затем эти файлы
^Р-писываются на резервное устройство хранения, обычно в стандартном архив-
5 м формате. Инкрементное резервное копирование — это логическое резервное
®°пйрование, при котором сохраняются только данные, изменившиеся после пре-
^дущего копирования.
Д в системах, где недопустимы потери данных и нерабочие состояния, применя-
_я RAID-массивы и протоколирование транзакций. Если при выполнении опе-
10 пии записи произойдет отказ, данные в файле могут утратить целостность. Тран-
Р кцИонные файловые системы уменьшают риск потери данных, используя ато-
марные транзакции, которые либо выполняют группы операций целиком, либо не
ыполняют их совсем. Если возникает ошибка, делающая невозможным заверше-
ние транзакции, выполняется откат — система возвращается в то состояние, в ко-
тором она была до начала выполнения транзакции.
Атомарные транзакции можно реализовать, записывая результат каждой опе-
рации в файл протокола вместо того, чтобы изменять существующие данные. Ко-
гда выполнение транзакции завершается, ее результат фиксируется записью спе-
циального значения в протокол. Для уменьшения времени, необходимого на откат
транзакций в протоколе, в большинстве транзакционных систем используются
контрольные точки, указывающие на последнюю транзакцию, результат которой
был перенесен на устройство хранения. В случае отказа системы нужно просмот-
реть только транзакции после контрольной точки. Теневое копирование реализует
атомарные транзакции, записывая измененные данные в свободные блоки, а не
в блоки, в которых хранятся исходные данные.
Журнальные файловые системы (LFS), иногда называемые протоколирующими
файловыми системами, выполняют все файловые операции как протоколируемые
транзакции, чтобы гарантировать, что в случае отказа сохранится целостность
данных. В LFS весь диск занят файлом журнала. Новые данные записываются по-
следовательно в свободное пространство в этом файле. Поскольку изменяющиеся
директории и метаданные всегда записываются в конце журнала, LFS может пона-
добиться просмотреть весь журнал, чтобы найти конкретный файл. Соответствен-
но, производительность при чтении может оказаться низкой. Чтобы уменьшить
критичность данной проблемы, LFS кэширует сведения о размещении метаданных
и периодически записывает в файл протокола карты индексных узлов или супер-
блоки, указывающие размещение других метаданных, позволяя операционной
системе быстро находить и кэшировать метаданные при загрузке. В некоторых
Файловых системах накладные расходы, свойственные журнальным файловым
системам, пытаются уменьшить, записывая в протокол только метаданные. Это га-
рантирует целостность файловой системы при сравнительно небольших наклад-
ных расходах, но не гарантирует целостности данных в случае отказа системы.
Поскольку данные записываются последовательно, каждая операция записи
в LFS требует только одной операции позиционирования, если на диске есть непре-
рывный свободный участок. Когда протокол занимает весь диск, файловая система
освобождает пространство в виде фрагментированных участков, что может умень-
шить производительность при чтении и записи до уровней более низких, чем свой-
ственные обычным файловым системам. Чтобы решить эту проблему, LFS может
создавать непрерывные свободные участки, перемещая данные, которые нужно со-
Ранить, в непрерывную область в конце протокола.
Один из способов обработки обращений к нелокальным файлам в компьютер-
°и сети — передача всех таких обращений файловому серверу, т.е. компьютеру,
Цециально предназначенному для разрешения межкомпьютерных обращений
Файлам. Такой подход централизует управление этими обращениями, но файло-
Ыи сервер легко может стать узким местом, поскольку он вынужден обрабаты-
®ть запросы всех клиентов. Более эффективное решение состоит в том, чтобы раз-
Пить отдельным компьютерам напрямую взаимодействовать друг с другом.
База данных — это централизованно управляемое хранилище данных, п>^ 1
ставленных в стандартизованном формате; система баз данных состоит из cogj
венно данных, аппаратных устройств, на которых эти данные хранятся, и ц?'|
грамм, управляющих доступом к данным (эти программы называются систем"'I
управления базами данных — СУБД). Базы данных позволяют уменьшить изб |
точность данных и предотвращают возникновение противоречий. Избыточной,
уменьшается за счет совмещения данных из разных файлов. Кроме того, базы да?
ных обеспечивают совместное использование данных (разделяемый доступ).
Важный аспект баз данных — независимость данных, то есть отсутствие необ.
ходимости прямого взаимодействия приложений с физической структурой дай
ных. С точки зрения разработчика независимость данных дает возможность изце
нять стратегии хранения данных и доступа к ним в соответствии с изменяющими
ся требованиями приложений без необходимости изменять уже существующие
приложения.
Языки баз данных обеспечивают независимость данных, предоставляя стандар.
тизованный способ доступа к этим данным. Язык баз данных состоит из языка опи-
сания данных (DDL), языка обработки данных (DML) и языка запросов. DDL описи,
вает организацию элементов данных и отношения между ними, a DML — способы
изменения данных. Язык запросов — это часть DML, позволяющая пользователям
составлять запросы, по которым база данных разыскивает данные, отвечающие за-
данным критериям. Сейчас одним из самых популярных языков баз данных являет-
ся SQL.
Распределенная база данных — это база данных, распределенная по объединен-
ным в сеть компьютерам. Она предоставляет эффективный доступ к данным, разде-
ляя их на наборы, хранящиеся на разных компьютерах.
Базы данных основываются на моделях, описывающих представление данных
и отношений между ними. Реляционная модель является скорее логической
структурой, чем физической; принципы управления реляционными базами дан-
ных не зависят от физической реализации структур данных. Реляционная база
данных состоит из отношений, показывающих различные атрибуты сущностей.
Элементы отношения называются строками. Каждый атрибут (столбец) отноше-
ния принадлежит к одному домену. Количество атрибутов в отношении называет-
ся степенью отношения. Операция проецирования формирует подмножество атри-
бутов; операция объединения сочетает отношения, формируя более сложные отно-
шения. Реляционная модель баз данных довольно проста в реализации.
Для поддержки СУБД используются различные службы операционных систем,
в частности, службы управления буферизацией, файловые системы, службы плани-
рования, управления процессами, межпроцессного взаимодействия, контроля цело-
стности и управления виртуальной памятью. Большинство этих служб не оптимизи-
ровались специально для работы с СУБД, и разработчики последних часто создаю1
собственные службы, которые и используют вместо предоставляемых операционны-
ми системами.
Ключевые термины
ASCII (American Standard Code for Information Interchange — Американский стан
дартный код обмена информацией) — набор символов, широко применяем
в персональных компьютерах и системах обмена данными, хранящий симво
в 8-битовых байтах.
EBCDIC (Extended Binary-Coded Decimal Interchange Code — Расширенный Дв0^в>
но-десятичный код обмена информацией) — восьмибитовый набор символ*
используемый для представления данных в больших компьютерах, особе1
производства IBM.
i
системы и базы данных
831
гг (File Allocation Table — таблица размещения файлов) — реализация файло-
F gOii системы с табличным фрагментированным размещением, разработанная
фирмой Microsoft.
с (Log-structured File System — журнальная файловая система) — файловая
^система, выполняющая все операции с файлами в виде транзакций, чтобы га-
антировать целостность файловой системы и метаданных. LFS обычно облада-
ет хорошей производительностью при записи, поскольку данные просто записы-
ваются в конец протокола, файл которого занимает все пространство накопите-
ля. Для повышения производительности при чтении LFS обычно распределяет
по протоколу метаданные и использует объемистые кэши для хранения мета-
данных, чтобы быстро находить запрашиваемые данные.
yfS-DOS — популярная операционная система для первых компьютеров IBM PC
и совместимых с ними.
п-арное отношение (n-ary relation) — отношение степени п.
pjpg (Network File System — сетевая файловая система) — файловая система, раз-
работанная фирмой Sun Microsystems, в которой каждый компьютер поддержи-
вает виртуальную файловую систему, которая может использоваться и как сер-
вер, и как клиент.
SQL (Structured Query Language — структурированный язык запросов) — язык
баз данных, позволяющий разыскивать данные, обладающие заданными свой-
ствами, а также создавать таблицы, задавать ограничения целостности и на-
стройки безопасности.
Unicode — набор символов, поддерживающий международные кодировки и широ-
ко применяющийся в Интернете и многоязычных приложениях.
Абсолютный путь (absolute path) — путь, начинающийся из корневой директо-
рии.
Активность (activity) — в файлах — процент записей в файле, к которым были об-
ращения за заданный промежуток времени.
Аппаратная независимость (device independence) — возможность обращений
к файлам по их символьным именам, а не именам, связанным с устройствами,
на которых хранятся эти файлы.
Атомарная транзакция (atomic transaction) — группа операций, которая не влия-
ет на состояние системы до тех пор, пока не завершаются все операции группы.
Атрибут файла (file attribute) — см. блок управления файлом.
База данных (database) — централизованно управляемое хранилище данных,
представленных в стандартизованном формате; данные можно просматривать
в соответствии с определенными логическими взаимосвязями между ними.
В базах данных данные организуются по их содержанию, а не размещению, за
счет чего можно уменьшить или исключить избыточность данных.
Байт (byte) — второй снизу уровень иерархии данных. Обычно байт состоит из 8
битов.
Библиотечный файл — см. разделенный файл.
Бинарное отношение (binary relation) — отношение степени 2 в реляционных ба-
зах данных.
Битовые последовательности (bit patterns) — нижний уровень иерархии данных.
Битовые последовательности — это группы битов, представляющие практиче-
Ски все элементы данных в компьютерных системах.
“товый массив (bitmap) — средство управления свободным пространством нако-
пителя, в которой каждому блоку накопителя соответствует один бит, причем
'-тый бит соответствует /-тому блоку. Битовые массивы позволяют файловым
системам выделять непрерывные блоки эффективнее, чем списки свободных
секторов, но на поиск свободных участков с помощью битовых массивов может
потребоваться заметное время.
Блок управления файлом (file control block) — метаданные, содержащие необу
димую файловой системе информацию о файле, например, информацию контЛ
ля доступа. и-
Блочное размещение (block allocation) — прием, позволяющий файловым сист
мам более эффективно распоряжаться пространством накопителей и уменьща,'
накладные расходы при просмотре файлов за счет размещения файлов в непр^
рывных областях (последовательностях секторов).
Владелец (owner) — в файлах — пользователь, создавший файл.
Восстановление (recovery) — возврат данных в нормальное состояние после отказа.
Вставка (insertion) — в файлах — операция добавления в файл нового элемент
данных.
Группа (group) — в механизмах контроля доступа к файлам — коллектив пользе-
вателей с одинаковыми правами доступа к файлам (например, пользователи, ра.
ботающие над общим проектом).
Дескриптор файла (file descriptor) — неотрицательное целое число, являющееся
индексом в таблице открытых файлов. Процесс обращается к дескриптору вме-
сто имени файла, чтобы получить доступ к данным файла без необходимости пе-
ремещаться по структуре директорий.
Директория (directory) — файл, хранящий ссылки на другие файлы. В записях
в директориях часто содержатся имена файлов, типы и размеры.
Домен (domain) — множество допустимых значений атрибута в реляционной базе
данных.
Доступ для записи (write access) — разрешение пользователю выполнять запись
в файл.
Доступ для исполнения (execute access) — разрешение пользователю запускать
файл на исполнение.
Доступ для чтения (read access) — разрешение пользователю читать содержимое
файла.
Доступность (accessibility) — в файлах — свойство, определяющее, какие пользо-
ватели обладают доступом к данным в файле.
Жесткая ссылка (hard link) — запись в директории, указывающая размещение
файла на накопителе.
Зависящее от данных приложение (data-dependent application) — приложение, за-
висящее от методов доступа и организации конкретной файловой системы.
Заданный пользователь (specified user) — в контроле доступа к файлам — отдель-
но взятый пользователь (но не владелец), который может обращаться к файлу.
Закрытие (closing) — операция, прекращающая работу с файлом до его повторного
открытия.
Запись (record) — в иерархии данных — группа полей (например, все поля, храня-
щие информацию о конкретном покупателе или студенте).
Запись (write) — в файлах — операция вывода данных в файл.
Зафиксированная транзакция (committed transaction) — успешно завершившая'
ся транзакция, результаты которой перенесены на накопитель.
Идентификатор файловой системы (file system identifier) — значение, однознач-
но идентифицирующее файловую систему, используемую устройством.
Иерархически структурированная файловая система (hierarchically structured fd®
system) — файловая система, в которой у каждой директории может быть мно
дочерних, но только одна родительская директория.
faiigbie системы и базы данных
833
архия данных (data hierarchy) — классификация, группирующая различные
'Последовательности битов для представления осмысленных значений. Последо-
ятельности битов, байты и слова содержат небольшие количества битов, интер-
претируемые аппаратными устройствами и низкоуровневыми программами.
Поля, записи и файлы могут содержать множества битов, интерпретируемые
операционными системами и пользовательскими приложениями.
менчивость (volatility) — частота добавлений и удалений данных в файле,
«йдексный блок (index block) — блок, содержащий список указателей на блоки
1 с данными файла.
Индексный узел (inode) — индексный блок в системах семейства UNIX, содержа-
* щий блок управления файлом и указатели на единожды, дважды и трижды кос-
венные индексные блоки указателей на данные файла.
индексированная последовательная организация файла (indexed sequential file
organization) — организация файла, при которой записи упорядочиваются в ло-
гическом порядке согласно их ключам.
Инкрементное резервное копирование (incremental backup) — методика резервно-
го копирования, при которой копируются только данные, изменившиеся со вре-
мени предыдущего резервного копирования.
Карта индексных узлов (inode map) — блок метаданных, записываемый в прото-
кол журнальной файловой системы. В этом блоке содержится информация
о размещении индексных узлов. Карты индексных узлов повышают производи-
тельность LFS, уменьшая время поиска файлов.
Классы пользователей (user classes) — способ классификации, указывающий
группы или отдельных пользователей, обладающих определенными правами
доступа к файлам.
Контрольная точка (checkpoint) — маркер, указывающий, результаты каких
транзакций в протоколе уже записаны на накопитель. Чтобы определить со-
стояние файловой системы, системе нужно отменить выполнение только тран-
закций после контрольной точки, а не всех транзакций в протоколе, за счет чего
повышается скорость работы.
Копирование (copying) — операция, создающая дубликат файла под другим именем.
Корневая директория (root directory) — директория, содержащая указатели на
пользовательские директории.
Корень (root) — начало иерархической структуры файловой системы.
Косвенный блок (indirect block) — индексный блок, содержащий указатели на
блоки данных в файловых системах с индексными узлами.
Логическая запись (logical record) — набор данных, воспринимаемых программа-
ми как единое целое.
Логический блок (logical block) — см. логическая запись.
Логическое представление (logical view) — представление файлов, скрывающее
Устройства, на которых эти файлы хранятся, формат файлов и методы физиче-
ского доступа системы.
Логическое резервное копирование (logical backup) — методика резервного копи-
рования, при которой копируются данные файлов и информация о директориях
файловой системы, часто в стандартном сжатом формате.
Матрица контроля доступа (access control matrix) — двумерный список всех поль-
зователей и прав их доступа к файлам в системе.
Четаданные (metadata) — недоступные непосредственно пользователям данные,
с помощью которых файловая система управляет файлами. Примеры метадан-
ных — суперблоки и индексные узлы.
834
Методы доступа с поддержкой очередей (queued access methods) — методы доСт,.
па к файлам, которые не начинают выполнять запрос на ввод/вывод немедлеЛ
после его поступления. Это может улучшить производительность, если послед °
вательность, в которой записи будут запрашиваться, можно предугадать и пеГ)[
упорядочить запросы с целью минимизации времени доступа.
Механизм обеспечения целостности файла (file integrity mechanism) — меха
низм, гарантирующий, что данные в файле не повреждены. Если целостно^
файла гарантируется, в файле содержится только та информация, котор^
должна в нем содержаться.
Монтирование (mount operation) — операция, объединяющая две отдельные фа^
ловые системы в одно пространство имен, делая их доступными из общей корце
вой директории.
Мягкая ссылка (soft link) — файл, содержащий путь к другому файлу, на который
он ссылается.
Набор символов (character set) — таблица, содержащая определенное конечное
множество символов. К популярным наборам символов относятся ASCH
EBCDIC и Unicode.
Независимость данных (data independence) — способность приложений не пола
гаться на конкретные организацию файлов и методы доступа к ним.
Неблокированные записи (unblocked records) — записи, в которых одной физиче-
ской записи соответствует одна логическая.
Область (extent) — непрерывная последовательность секторов.
Обновление (update) — в файлах — операция изменения уже существующего эле
мента данных.
Общедоступный (public) — файл, к которому может обращаться любой пользова-
тель.
Объединение (join) — в базах данных — операция совмещения отношений.
Одноуровневая структура директорий (single-level directory structure) — см. пло-
ская структура директорий.
Организация файлов (file organization) — способ размещения данных файла на
накопителе (например, последовательная организация, прямая, индексирован-
ная последовательная или разделенная).
Откат транзакции (rolling back a transaction) — возврат системы в состояние, в ко-
тором она пребывала до начала выполнения транзакции.
Открытие (opening) — операция подготовки файла к обращениям.
Относительный путь (relative path) — путь, указывающий размещение файла от-
носительно текущей рабочей директории.
Отношение (relation) — набор строк в реляционной базе данных.
Отображаемый в памяти файл (memory mapped file) — файл, данные которого
отображаются в адресном пространстве виртуальной памяти процесса, и пр°
цесс может обращаться к данным файла как к любым другим данным. О обря-
жаемые в памяти файлы удобно применять в программах, интенсивно работа»
щих с файлами.
Первичный ключ (primary key) — в реляционной базе данных — сочетание атри
бутов, позволяющее однозначно идентифицировать строку.
Переименование (renaming) — операция изменения имени файла.
Плоская структура директорий (flat directory structure) — файловая система, с°
держащая только одну директорию.
Поле (field) — в иерархии данных группа символов (например, имя человека,
адрес или номер телефона).
системы и базы данных
пьзовательские директории (user directories) — директории, содержащие запи-
си 0 пользовательских файлах; каждая запись указывает размещение файла на
ваКопителе.
ледовательная организация файла (sequential file organization) — метод орга-
дизации файлов, в котором записи физически размещаются последовательно.
«Следующая» запись физически следует за «предыдущей».
дварительиая буферизация (anticipatory buffering) — прием, позволяющий
* совмещать операции обработки и ввода/вывода за счет буферизации в оператив-
ной памяти сразу нескольких записей.
Лпоецирование (projection) — в базах данных — операция выделения подмноже-
ства атрибутов.
Просмотр (list) — операция вывода на экран или на печать содержимого файла.
Пространство имен (namespace) — набор файлов, которые могут идентифициро-
ваться файловой системой.
Простые методы доступа (basic access methods) — методы доступа к файлам, в ко-
торых операционная система выполняет поступившие запросы на ввод/вывод
немедленно. Они применяются, если невозможно предугадать последователь-
ность поступления запросов, особенно при произвольном доступе.
Протоколирующая файловая система (journaling file system) — см. LFS.
Прямая организация файлов (direct file organization) — метод организации фай-
лов, при котором к записи можно непосредственно обращаться по ее физическо-
му адресу на устройстве хранения с произвольным доступом (Direct Access
Storage Device — DASD).
Путь (pathname) — строка, обозначающая файл или директорию их логическими
именами, разделяя директории символами-разделителями (например, «/» или
«\»). Абсолютный путь указывает размещение файла или директории, начиная
с корневой директории; относительный путь указывает их размещение, начи-
ная с текущей рабочей директории.
Рабочая директория (working directory) — директория, содержащая непосредст-
венно доступные пользователю файлы.
Разделенный файл (partitioned file) — файл, состоящий из последовательных под-
файлов. Используется также термин Библиотечный файл.
Размер (size) — у файла — количество хранящейся в файле информации.
Распределенная база данных (distributed database) — база данных, распределен-
ная по объединенным в сеть компьютерам.
Распределенная файловая система (distributed file system) — файловая система,
распределенная по объединенным в сеть компьютерам.
Расшифровка (decryption) — последовательность операций, противоположная
Шифрованию, восстанавливающая исходный вид зашифрованных данных.
Резервное копирование (backup) — создание избыточных копий информации.
Реляционная модель (relational model) — предложенная Коддом модель данных,
лежащая в основе большинства современных систем баз данных.
Родительская директория (parent directory) — в иерархически структурирован-
ных файловых системах — директория, содержащая указатель на данную ди-
ректорию.
^локированные записи (blocked records) — записи, в которых в одной физиче-
ской могут содержаться несколько логических записей.
РйМвол (character) — в иерархии данных — последовательность битов фиксиро-
ванной длины, обычно — 8, 16 или 32 бита.
иМвольное имя (symbolic name) — аппаратно-независимое имя (например, путь
К файлу).
Система баз данных (database system) — определенный набор данных, аппарат
ных устройств, на которых эти данные хранятся, и программ, управляю^,,'
доступом к данным (эти программы называются системой управления бя->3
данных — СУБД).
Система управления базой данных — СУБД (database management system
DBMS) — программы, отвечающие за организацию базы данных и работу с ней
Слово (word) — цепочка битов, которую может одновременно обработать процес
сор (процессоры) системы. В иерархии данных слова располагаются на уровень
выше байтов.
Создание (creating) — операция, создающая новый файл.
Список свободных блоков (free list) — связанный список блоков, содержащих ад.
реса свободных блоков.
Ссылка (link) — запись в директории, ссылающаяся на существующий файл. Же-
сткие ссылки указывают на размещение файла на накопителе; мягкие ссылки
указывают на логическое имя файла.
Степень (degree) — количество атрибутов в отношении в реляционной базе данных.
Строка (row) — элемент отношения, сочетание всех атрибутов одного объекта.
Суперблок (superblock) — блок, содержащий жизненно важную для обеспечения
целостности файловой системы информацию (например, список или битовый
массив свободных блоков, идентификатор файловой системы и расположение
корневой директории).
Сцепление (chaining) — метод индексированного фрагментированного размеще-
ния, при котором в каждом индексном блоке последние несколько записей заре-
зервированы под указатели на другие индексные блоки, которые в свою очередь
указывают на блоки данных. Сцепление позволяет индексным блокам указы-
вать размещение больших файлов, распределяя указатели на блоки данных по
нескольким блокам.
Таблица монтирования (mount table) — таблица, в которой хранятся данные
о точках монтирования и соответствующих им устройствах.
Таблица размещения файлов (file allocation table) — таблица, в которой хранятся
указатели на блоки с данными файлов в файловой системе FAT фирмы
Microsoft.
Теневая страница (shadow page) — блок данных, измененное содержимое которо-
го записывается в новый блок. Теневые страницы — один из способов реализа-
ции транзакций.
Теневое копирование (shadow paging) — способ реализации транзакций, записы-
вающий изменившиеся блоки в новые блоки. Исходные блоки помечаются как
свободные после фиксации транзакции.
Тернарное отношение (ternary relation) — отношение степени 3.
Тип (type) — у файла — описание назначения этого файла (исполняемый файл,
файл данных, директория и т.п.)
Том (volume) — часть пространства накопителя, в которой может храниться мно-
жество файлов.
Точка монтирования (mount point) — заданная пользователем директория в ие
рархии родной файловой системы, в которую команда монтирования помета
корневую директорию монтируемой файловой системы.
Удаление (deletion) — операция удаления элемента данных из файла.
Уничтожение (destruction) — операция удаления файла из файловой системы-
Управление вспомогательными устройствами хранения (auxiliary store#
management) — задача файловой системы, сводящаяся к выделению простр
ства под файлы на вторичных устройствах хранения.
ibie системы иьазы данных
„явление файлами (file management) — задача файловой системы, в которую
ходит обеспечение возможностей хранения файлов, выполнения обращений
® ним, совместного использования файлов и безопасности.
й (file) — именованный набор данных, который может обрабатываться как
Единое целое с помощью таких операций, как открытие, закрытие, чтение, за-
пись, удаление, копирование и переименование. Отдельные элементы данных
в файле могут подвергаться, например, операциям чтения, записи, обновления,
вставки и удаления. Характеристики файла включают его расположение, дос-
тупность, тип, способ хранения и активность. Файлы могут состоять из одной
Иди более записей.
ЛяЙловая система (file system) — часть операционной системы, занимающаяся
организацией файлов и обеспечением доступа к ним. Файловые системы обеспе-
чивают как логическую (с помощью путей), так и физическую (с помощью мета-
данных) организацию файлов. Они также управляют свободным пространством
накопителей, обеспечивают безопасность, поддерживают целостность данных
и так далее.
файловый сервер (file server) — система, предоставляющая удаленный доступ
к хранящимся в ней файлам.
физическая запись (physical record) — единица информации, считываемая с нако-
пителя или записываемая на него.
физический блок (physical block) — см. физическая запись.
физическое имя устройства (physical device name) — имя файла, специфичное для
данного устройства.
физическое представление (physical view) — представление данных, связанное
с конкретными устройствами, на которых эти данные хранятся; форма, кото-
рую принимают данные на этих устройствах, и физические способы обмена дан-
ными с этими устройствами.
Физическое резервное копирование (physical backup) — копирование каждого
бита на накопителе; попытки интерпретировать содержимое накопителя при
физическом резервном копировании не предпринимаются.
Форматирование накопителя (formatting of storage device) — подготовка накопи-
теля для файловой системы. При форматировании, например, выполняется про-
верка содержимого накопителя и запись на него управляющих данных.
Чтение (reading) — операция извлечения данных из файла в память.
Шифрование (encryption) — последовательность операций, преобразующая данные
с целью предотвращения несанкционированного доступа к ним.
Элемент (member) — последовательный подфайл разделенного файла.
Язык баз данных (database language) — язык, позволяющий организовывать, из-
менять и просматривать структурированные данные.
Язык запросов (query language) — язык, позволяющий просматривать данные,
Хранящиеся в базе данных, и изменять их.
Язык обработки данных (Data Manipulation Language — DML) — язык, позволяю-
щий изменять данные в базе данных.
Язык описания данных (Data Definition Language — DDL) — язык, описывающий
организацию данных в базе данных.
системы и базы данных
Упражнения
13.1.
13.2.
13.3.
Система виртуальной памяти использует страницы размера р, а соответ^,
вующая ей файловая система использует блоки размера b и записи фиг/'
рованной длины размера г. Обсудите различные разумные отношения р *
и г. Объясните, почему каждое из этих отношений имеет смысл.
Подробно перечислите причины, по которым записи в последователь^,
файле не обязательно могут храниться в непрерывной последовательности
Предположим, что распределенная система использует центральный
ловый сервер, содержащий множество последовательных файлов для
пользователей. Приведите несколько причин,
данных может не выполняться
гим способом).
13.4. Приведите несколько причин, по которым
сотев
по которым упорядочены
регулярно (динамически или каким-то др.
может быть неудобно хранит,
из пространства виртуальной памяти про.
на накопителе.
логически смежные страницы
цесса в непрерывных областях
13.7.
13.8.
13.9.
13.10.
13.11.
13.12.
13.13.
13.5. В некоторой файловой системе используются «общесистемные» имена, то
есть если один из пользователь использует какое-то имя для файла, то дру.
гие пользователи уже не могут использовать это имя. Однако в большинст-
ве больших файловых систем имена должны быть уникальными только
для отдельных пользователей — любые два пользователя могут использо-
вать одно и то же имя без проблем. Обсудите преимущества этих подходов,
учитывая и вопросы реализации, и вопросы применения.
13.6. В некоторых системах совместное использование файлов выполняется за
счет разрешения нескольким пользователям одновременно читать данные
из файла. В других системах каждому пользователю предоставляется от-
дельная копия совместно используемого файла. Оцените сильные и слабые
способы каждого метода.
Индексированные последовательные файлы пользуются популярностью
у разработчиков приложений. Однако опыт показывает, что произвольный
доступ к индексированным файлам может быть медленным. Почему это
так? В каких случаях эффективнее последовательный доступ к файлам?
В каких случаях разработчику лучше использовать файлы произвольного
доступа, а не индексированные последовательные?
Если происходит отказ компьютерной системы, необходимо иметь возмож-
ность быстро восстановить файловую систему. Предположим, что файловая
система позволяет создавать сложные структуры из указателей и межфа0'
ловых ссылок. Какие меры может предпринять разработчик для обеспече-
ния надежности и целостности такой системы?
В некоторых файловых системах есть множество классов пользователей,
в то время как в других — только несколько. Обсудите преимущества и ие
достатки каждого подхода. Какой из них лучше применять в сильно заШ®
щенных средах? Почему? . I
Сравните механизмы выделения пространства под файлы на вторичнь#
устройствах хранения и механизмы динамического выделения операт®
ной памяти под программы в многопрограммных системах.
В каких обстоятельствах может быть полезно уплотнение накопителе®
Какие с ним связаны опасности? Как их можно избежать?
Каковы мотивы иерархического структурирования файловых систем?
Одна из проблем, связанных с индексированными последовательными
ми — то, что при добавлении в файл новых данных их потребуется размес
в уже занятых областях. Как это может повлиять на производительность-
можно сделать, чтобы повысить производительность в таких случаях?
05-
13Д6-
1317.
13.18.
13.19.
Пути в иерархической файловой системе могут достигать значительной
длины. Учитывая, что подавляющее большинство обращений выполняется
к собственным файлам пользователя, какой прием можно использовать для
минимизации использования длинных путей?
В некоторых файловых системах данные хранятся в точности в том форма-
те, который задал пользователь. В других системах делаются попытки оп-
тимизации хранения за счет сжатия данных. Расскажите, как бы вы попы-
тались реализовать механизм сжатия и распаковки данных. Такой меха-
низм в любом случае обеспечивает выигрыш в используемом пространстве
накопителя за счет уменьшения производительности. В каких случаях та-
кой выигрыш приемлем?
Предположим, что технологический прорыв в области производства опера-
тивной памяти позволит создать память настолько емкую, быструю и деше-
вую, что все программы и данные в системе можно будет хранить в одном
чипе. Как изменится структура файловой системы для такого одноуровне-
вого устройства хранения по сравнению с используемыми сегодня в иерар-
хических системах хранения?
Вас попросили провести исследование системы безопасности в компьютер-
ной системе. Системный администратор подозревает, что структура указа-
телей в файловой системе была нарушена, позволив нескольким неавтори-
зованным пользователям получить доступ к критически важной системной
информации. Расскажите, какие действия вы бы предприняли, чтобы вы-
яснить личность нарушителя и образ его действий.
В большинстве компьютерных систем только небольшая часть резервных
копий файлов хотя бы однажды применяется для восстановления. Поэтому
при создании резервных копий приходится идти на компромисс. Переве-
шивают ли последствия отсутствия резервной копии, когда она нужна, за-
траты на выполнение периодического резервного копирования? Какие фак-
торы говорят в пользу периодического резервного копирования, а какие —
против? Какие факторы определяют частоту, с которой нужно выполнять
резервное копирование?
Последовательный доступ к последовательным файлам выполняется на-
много быстрее, чем последовательный доступ к индексированным последо-
вательным файлам. Почему в таком случае многие разработчики приложе-
ний создают системы, в которых используется последовательный доступ
к индексированным последовательным файлам?
13.20. Как можно применять классы доступа к файлам «владелец», «заданный
пользователь», «группа», «общедоступный» в университетской среде? Обсу-
дите использование компьютерной системы, как для академических расче-
тов, так и для административных нужд. Учтите также возможность исполь-
зования ее в грантовых исследованиях, а не только в академических курсах.
13.21. Файловые системы предоставляют доступ не только к собственным фай-
лам, но и к файлам монтируемых файловых систем. Файлы каких типов
лучше всего хранить в родной файловой системе, а каких типов — в монти-
руемых системах? Какие специфические проблемы связаны с управлением
монтируемыми файловыми системами?
Какой тип резервного копирования и как часто лучше применять в следую-
щих системах?
а. В системе пакетной обработки счетов, используемой раз в неделю.
б. В банковской системе поддержки банкоматов.
в. В системе рассылки счетов за лечение пациентов в госпитале.
г. В системе бронирования авиабилетов, позволяющей заказывать билеты
на срок вплоть до года вперед.
В распределенной системе разработки программ, используемой группой
из 100 программистов.
1;122
д.
13.23.
13.24.
13.25.
13.26.
В большинстве банков на сегодняшний день используются для перевод
системы онлайн-обработки транзакций. Каждая транзакция работает °*
счетами клиентов, сохраняя балансы точными и правильными. Ouiug^
в таких системах недопустимы, но из-за отказов компьютеров и отклю»,'
ний электропитания эти системы все же периодически дают сбои. ОщщЛ
те, как вы бы реализовали систему резервного копирования и восстанови
ния, чтобы гарантировать, что все выполняемые транзакции будут вноси»,
нужные изменения в данные о счетах. Кроме того, транзакции, заверщ^
ные только частично на момент отказа, не должны фиксироваться.
Почему полезно время от времени реорганизовывать индексированные ц0
следовательные файлы? По каким критериям файловая система может су
дить о необходимости реорганизации?
13.27.
13.28.
13.29.
Объясните разницу между простыми методами доступа и методами с под.
держкой очередей.
Каким образом может пригодиться избыточность программ и данных црй
создании высоконадежных систем? Системы баз данных могут сильно
уменьшить избыточность при хранении данных. Значит ли это, что снеге-
мы баз данных могут оказаться менее надежными, чем традиционные фай.
ловые? Аргументируйте ваш ответ.
Во многих системах хранения, которые мы рассматривали, при размеще-
нии информации на накопителях интенсивно используются указатели.
При случайном или умышленном повреждении указателей может быть по
теряна вся структура данных. Обсудите возможность использования таких
структур в высоконадежных системах. Предложите способ, позволяющий
сделать эти структуры более устойчивыми к повреждениям указателей.
Обсудите проблемы, связанные с разрешением распределенной системе из
однородных компьютеров воспринимать доступ к удаленным файлам, как
доступ к локальным (по крайней мере, с точки зрения пользователей).
Обсудите реализацию прозрачности в распределенных файловых системах
из разнородных компьютеров. Как распределенная файловая система ре-
шает проблемы, связанные с обеспечением доступа к компьютерам различ-
ных архитектур, работающих под управлением разных операционных сис-
тем? Как она предоставляет всем системам в сети удаленный доступ к фай-
лам независимо от особенностей этих систем?
13.30. На рисунке 13.9 изображена структура индексных узлов. Предположим,
что файловая система, использующая эту структуру, полностью заполнила
файл, использующий единожды и дважды косвенные блоки указателей.
Сколько обращений к накопителю потребуется, чтобы записать в файл еде
один байт? Предполагайте, что индексные узлы и битовый массив свобод-
ных блоков загружены в оперативную память, но файлового буфера нет-
Также предполагайте, что инициализировать блоки не нужно.
13.31. Файловая система может отслеживать свободные блоки с помощью либо
списка, либо битового массива. Система содержит в общей сложности t бло-
ков размера Ь. и из которых уже используются. Для хранения номера одно-
го блока нужно s битов.
а. Выразите размер (в битах) битового массива свободных блоков этой сис
темы, используя перечисленные выше переменные.
б. Выразите размер (в битах) списка свободных блоков этой системы, иС
пользуя перечисленные выше переменные. Не учитывайте пространств
под указатели, необходимые для связывания блоков списка между собой-
13.32. Предположим, что система использует 1-килобайтные блоки и 16-битовь^
(2-байтовые) адреса. Каков максимальный размер файла для этой систем**
при следующих организациях индексных узлов?
13.33-
а. Индексный узел может содержать 12 указателей на блоки данных.
б. Индексный узел может содержать 12 указателей на блоки данных
и один — на косвенный блок. Предположим, что косвенный блок ис-
пользует все 1024 байта для хранения указателей на блоки данных.
в. Индексный узел содержит 12 указателей на блоки данных, один — на
косвенный блок и один — на дважды косвенный блок.
Почему удобно хранить в директориях записи фиксированной длины? Ка-
кие ограничения это накладывает на имена файлов?
уекомендуемые исследовательские учебные проекты
13 34- Подготовьте научный доклад о разрабатываемой файловой системе WinFS
и сравните ее с файловой системой NTFS. Какие свойственные NTFS про-
блемы решает WinFS?
13 .35. Подготовьте научный доклад о реализации и применении распределенных
баз данных.
13 .36. Изучите средства шифрования и дешифрования данных в системах
Windows и Linux.
Рекомендуемые программные учебные проекты
13 .37. Разработайте файловую систему. Какую информацию вы разместите в ин-
дексных узлах (информация для файлов и директорий должна отличать-
ся)? Какие метаданные вам понадобятся? Разработав систему, реализуйте
ее на выбранном вами языке. Реализуйте следующие функции: создание
файлов, открытие, закрытие, чтение, запись, переход в другую директорию
и вывод списков файлов в директориях. Если у вас еще есть время, предло-
жите способ сохранения файловой системы в виде файла и загрузки ее из
этого файла.
Рекомендуемая литература
Исследования в области файловых систем продолжаются, и постоянно появляют-
ся все новые реализации файловых систем, адаптирующиеся к изменяющимся тре-
бованиям приложений. Голден и коллеги создали обзор многих стандартных функ-
ций файловых систем93. За информацией о файловой системе можно обратиться
К книге Кастер «Inside the Windows NT File System»94. Журнальные файловые сис-
темы подробно рассматриваются Розенблюмом95. Ванг описывает реализацию на-
страиваемых файловых систем пользовательского уровня для повышения произво-
дительности Интернет-серверов, требующих интенсивного ввода/вывода96. Библио-
1 рафия к этой главе доступна на Web-сайте по адресу www.deitel.com/books/os3e/
''ibli ography. pdf.
Использованная литература
1
Searle, S., «Brief History of Character Codes in North America, Europe,
East Asia», modified March 13, 2002, <tronweb.super-nova.co.jp/chara
dehist.html>.
cco.
2. «The Unicode® Standard: A Technical Introduction», March 4, 200s
<www.unicode.org/standard/principles.html>.
3. Golden, D., and M. Pechura, «The Structure of Microcomputer File Systems»
Communications of the ACM, Vol. 29, No. 3, March 1986, pp. 222-230.
4. Исходный код ядра Linux, версия 2.6.0-test2, ext2 fs.h, строки 506-5Ц
<lxr.linux.no/source/include/linux/ext2 _fs.h?v=2.6.0-test2>.
5. Исходный код ядра Linux, версия 2.6.0-test2, iso_fs.h, строки 144-156
<lxr.linux.no/source/include/linux/iso fs.h?v=2.6.0-test2>.
6. Исходный код ядра Linux, версия 2.6.0-test2, msdos_fs.h, строки 151-162
<lxr.linux.no/source/include/linux/msdos_fs.h?v=2.6.0-test2>.
7. Golden, D., and M. Pechura, «The Structure of Microcomputer File Systems»,
Communications of the ACM, Vol. 29, No. 3, March 1986, pp. 224.
8. Peterson, J. L.; J. S. Quarterman; and A. Silberschatz, «4.2BSD and 4.3BSDas
Examples of UNIX System», ACM Computing Surveys, Vol. 17, No. 4, December
1985, p.395.
9. Appleton, R., «А Non-Technical Look Inside the EXT2 File System», Kernel
Korner, August 1997.
10. Peterson, J. L.; J. S. Quarterman; and A. Silberschatz, «4.2BSD and 4.3BSD as
Examples of UNIX System», ACM Computing Surveys, Vol. 17, No. 4, December
1985, p.395.
11. Peterson, J. L.; J. S. Quarterman; and A. Silberschatz, «4.2BSD and 4.3BSD as
Examples of UNIX System», ACM Computing Surveys, Vol. 17, No. 4, December
1985, p.395.
12. Peterson, J. L.; J. S. Quarterman; and A. Silberschatz, «4.2BSD and 4.3BSD as
Examples of UNIX System», ACM Computing Surveys, Vol. 17, No. 4, December
1985, p.395.
13. Исходный код ядра Linux, версия 2.6.0-test2, ext2_fs_sb.h, строки 25-55,
<lxr.linux.no/source/include/linux/ext2_fs sb.h?v=2.6.0-test2>.
14. Исходный код ядра Linux, версия 2.6.0-test2, iso fs sb.h, строки 7-32,
<lxr. linux. no/source/include/linux/iso_f s_sb .h?v= 2.6.0-test2>.
15. Исходный код ядра Linux, версия 2.6.0-test2, msdos fs_sb.h, строки 38-63,
<lxr.linux.no/source/include/linux/msdos fs_sb.h?v=2.6.0-test2>.
16. Thompson, K., «UNIX Implementation», UNIX Time-Sharing System: UNIX
Programmer’s Manual, 7th ed., Vol. 2b, January 1979, p. 9.
17. Levy, E., and A. Silberschatz, «Distributed File Systems: Concepts and Exam
pies», ACM Computing Surveys, Vol. 22, No. 4, December 1990, p. 329.
18. «Volume Mount Points», MSDN Library, February 2003, <msdn.microsoft.com
library/default.asp?url=/library/en-us/fileio/base/volume_mount_points.asp>-
19. Thompson, K., «UNIX Implementation», UNIX Time-Sharing System: UNIX
Programmer's Manual, 7th ed., Vol. 2b, January 1979, p. 9.
20. Larson, P., and A. Kajla, «File Organization: Implementation of a Method Gi‘a^
anteeing Retrieval in One Access», Communications of the ACM, Vol. 27, No.
July 1984, pp.670-677.
системы и базы данных
84:
К Enbody, R. J., and Н. С. Du, «Dynamic Hashing Schemes», АСМ Computing Sur
I veys, Vol. 20, No. 2, June 1988, pp. 85-113.
,>'> Koch, P. D. L., «Disk File Allocation Based on the Buddy System», ACM Trans-
actions on Computer Systems, Vol. 5, No. 4, November 1987, pp.352-370.
03 McKusick, M.; W. Joy; S. Leffler; and R. Fabry, «А Fast File System for UNIX»,
'* ACM Transactions on Computer Systems, Vol. 2, No. 3, August 1984,
pp.183-184.
•>4. «Description of FAT32 File System», Microsoft Knowledge Base, February 21,
2002, <support.microsoft.com/default.aspx?scid=kb;[LN];Q154997>.
>5. Card, R.; T. Ts’o, and S. Tweedie, «Design and Implementation of the Second Ex-
tended Filesystem», September 20, 2001, <e2fsprogs.sourceforge.net/ext2in-
tro.html>.
26. Kozierok, C., «DOS (MS-DOS, PC-DOS, etc.)», PCGuide, April 17, 2001,
<www. pcguide.com/ref/hdd/file / osDOS-c. html>.
27. Kozierok, C., «Virtual FAT (VFAT)», PCGuide, April 17, 2001, <www.pcgui-
de.com/ref/hdd/file/fileVFAT-c.html>.
28. Kozierok, C., «DOS (MS-DOS, PC-DOS, etc.)», PCGuide, April 17, 2001,
<www.pcguide.com/ref/hdd/file/osDOS-с. html>.
29. «FAT32», MSDN Library, <msdn.microsoft.com/library/default.asp?url=/li-
brary/еп-us/fileio/storage 29v6. asp>.
30. Paterson, T., «А Short History of MS-DOS», June 1983, <www.pateson-
tech. com/Dos/Byte/History. html >.
31. Rojas, R., «Encyclopedia of Computers and Computer History — DOS», April
2001, <www.patersontech.com/Dos/Encyclo.htm>.
32. Hunter, D., «Tim Patterson: The Roots of DOS», March 1983, <www.paterson-
tech.com/Dos/Softalk/Softalk.html>.
33. Hunter, D., «Tim Patterson: The Roots of DOS», March 1983, <www.paterson-
tech .com/Dos/Sof talk/Sof talk. html>.
34. Paterson, T., «An Inside Look at MS-DOS», June 1983, <www.patesontech.com/
Dos/Byte/InsideDos. html>.
35. Rojas, R., «Encyclopedia of Computers and Computer History — DOS», April
2001, <www.patersontech.com/Dos/Encyclo.htm>.
36. Rojas, R., «Encyclopedia of Computers and Computer History — DOS», April
2001, <www.patersontech.com/Dos/Encyclo.htm>.
37. Hunter, D., «Tim Patterson: The Roots of DOS», March 1983, <www.paterson-
tech.com/Dos/Softalk/Softalk.html>.
38. Paterson, T., «An Inside Look at MS-DOS», June 1983, <www.patesontech.com/
Dos/Byte/InsideDos. html >.
39. Rojas, R., «Encyclopedia of Computers and Computer History — DOS», April
2001, <www.patersontech.com/Dos/Encyclo.htm>.
40. The Online Software Museum, «CP/М: History», <museum.sysun.com/museum/
cpmhist.html>.
41. The Online Software Museum, «CP/М: History», <museum.sysun.com/mu-
seum/cpmhist.html>.
42. Rojas, R., «Encyclopedia of Computers and Computer History — DOS», April
2001, <www.patersontech.com/Dos/Encyclo.htm>.
43. Hunter, D., «Tim Patterson: The Roots of DOS», March 1983, <www.paterson-
tech.com/Dos/Sof talk /Sof talk. html>.
44. Rojas, R., «Encyclopedia of Computers and Computer History — DOS», AjJf
2001, <www.patersontech.com/Dos/Encyclo.htm>.
45. The Online Software Museum, «CP/М: History», <museum.sysun.com/uj.
seum/cpmhist.html>. ”
46. Rojas, R., «Encyclopedia of Computers and Computer History — DOS», Арм
2001, <www.patersontech. com/Dos/Encyclo.htm>.
47. McKusick, M.; W. Joy; S. Leffler; and R. Fabry, «А Fast File System for UNIX,
ACM Transactions on Computer Systems, Vol. 2, No. 3, August 1984, p. I83 ’
48. Hecht, M., and J. Gabbe, «Shadowed Management of Free Disk Space with a
Linked List», ACM Transactions on Database Systems, Vol. 8, No. 4, Decembp»
1983, p. 505.
49. Hecht, M., and J. Gabbe, «Shadowed Management of Free Disk Space with a
Linked List», ACM Transactions on Database Systems, Vol. 8, No. 4, December
1983, p. 503.
50. Betoume, C., et al., «Process Management and Resource Sharing in the
Multiaccess System ESOPE», Communications of the ACM, Vol. 13, No. 12, De-
cember 1970, p. 730.
51. Green, P., «Multics Virtual Memory — Tutorial and Reflections»,
<ftp://ftp.stratus.com/pub/vos/multics/pg/mvm.html>, 1999.
52. Choy, M.; H. Leong; and M. Wong, «Disaster Recovery Techniques for Database
Systems», Communications of the ACM, Vol. 43, No. 11, November 2000, p. 273.
53. Chen, P.; W. Ng.; S. Chandra; C. Aycock; G. Rajamani; and D. Lowell, «The Rio
File Cache; Surviving Operating System Crashes», Proceedings of the Seventh In
ternational Conference on Architectural Support for Programming Languages
and Operating Systems, 1996, p. 74.
54. Choy, M.; H. Leong; and M. Wong, «Disaster Recovery Techniques for Database
Systems», Communications of the ACM, Vol. 43, No. 11, November 2000, p. 273.
55. Hutchinson, N.; S. Manley; M. Federwisch; G. Harris; D. Hitz; S. Kleiman; and
S. O’Malley, «Logical vs. Physical File System Backup», Proceedings of the Third
Symposium on Operating Systems Design and Implementation, 1999,
pp. 244-245.
56, Hutchinson, N.; S. Manley; M. Federwisch; G. Harris; D. Hitz; S. Kleiman; and
S. O’Malley, «Logical vs. Physical File System Backup», Proceedings of the Third
Symposium on Operating Systems Design and Implementation, 1999.
pp. 240, 242-243.
57. Tanenbaum, A., and R. Renesse, «Distributed Operating Systems», Computing
Surveys, Vol. 17, No. 4, December 1985, p. 441.
58. Brown, M.; K. Kolling; and E. Taft, «The Alpine File System», ACM Transac-
tions on Computer Systems, Vol. 3, No. 4, November 1985, pp. 267-270.
59. Ousterhout, J. K., and M. Rosenblum, «The Design And Implementation of a
Log-structured File System», ACM Transactions on Computer Systems, Vol. ” ,
No. 1, February 1992.
60. «What’s New in File and Print Services», June 16, 2003, <www.microsoft.com/
windowsserver2003/evaluation/overview/technologies/fileandprint.mspx>-
61. Johnson, M. K., «Whitepaper: Red Hat’s New Journaling File System: ext3»>
2001, <www.redhat.com/support/wpapers/redhat/ext3/>.
62. Ousterhout, J. K., and M. Rosenblum, «The Design And Implementation of a
Log-Structured File System», ACM Transactions on Computer Systems, Vol.
No. 1, February 1992.
63. Piernas, J.; Cortes; and J. M. Garcia, «DualFS: A New Journaling File System
without Meta-Data Duplication», Proceedings of the 16th International Confer-
ence on Supercomputing, 2002, p. 137.
g4. Matthews, J. N.; D. Roselli; A. M. Costello; R. Y. Wang; and T. E. Anderson,
«Improving the Performance of Log-Structured File Systems with Adaptive
Methods», Proceedings of the Sixteenth ACM Symposium on Operating Systems
Principles, 1997, pp. 238-251.
65. Birrell, A. D., and R. M. Needham, «А Universal File Server», IEEE Transac-
tions on Software Engineering, Vol. SE-6, No. 5, September 1980, pp. 450-453.
66. Mitchell, J. G., and J. Dion, «А Comparison of Two Network-Based File
Servers», Proceedings of the Eighth Symposium on Operating Systems Principles,
Vol. 15, No. 5, December 1981, pp. 45-46.
67. Christodoulakis, S., and C. Faloutsos, «Design and Performance Considerations
for an Optical Disk-Based, Multimedia Object Server», Computer, Vol. 19,
No. 12, December 1986, pp. 45-56.
68 Mehta, S., «Serving a LAN», LAN Magazine, October 1988, pp. 93-98.
69. Fridrich, M., and W. Older, «The Felix File Server», Proceedings of the Eighth
Symposium on Operating Systems Principles, Vol. 15, No. 5, December 1981,
pp. 37-44.
70. Wah, B. W., «File Placement on Distributed Computer Systems», Computer,
Vol. 17, No. 1, January 1984, pp. 23-32.
71 Mullender, S., and A. Tanenbaum, «A Distributed File Service Based on Optimis-
tic Concurrency Control», Proceedings of the 10th Symposium on Operating Sys-
tems Principles, ACM, Vol. 19, No. 5, December 1985, pp. 51-62.
72. Morris, J. H.; M. Satyanarayanan; M. H. Conner; J. H. Howard; D. S. H.
Rosenthal; and F. D. Smith, «Andrew: A Distributed Personal Computing Envi-
ronment», Communications of the ACM, Vol. 29, No. 3, March 1986, pp.
184-201.
73. Nelson, M. N.; В. B. Welch; and J. K. Ousterhout, «Caching in the Sprite Net-
work File System», ACM Transactions on Computer Systems, Vol. 6, No. 1, Feb-
ruary 1988, pp. 134-154.
74. Walsh, D.; R. Lyon; and G. Sager, «Overview of the Sun Network File System»,
USENIX Winter Conference, Dallas, 1985, pp. 117-124.
75. Sandberg, R., et al. «Design and Implementation of the Sun Network File Sys-
tem», Proceedings of the USENIX 1985 Summer Conference, June 1985, pp.
119-130.
76. Sandberg, R., «The Sun Network File System: Design, Implementation and Expe-
rience», Mountain View, CA: Sun Microsystems, Inc., 1987.
77. Lazarus, J., Sun 386i Overview, Mountain View, CA: Sun Microsystems, Inc.,
1988.
78. Schnaidt, P., «NFS Now», LAN Magazine, October 1988, pp. 62-69.
79. Shepler, S.; B. Calaghan; D. Robinson; R. Thurlow; C. Beame; M. Eisler; and D.
Noveck, «Network File System (NFS) version 4 Protocol», RFC 3530, April 2003,
<www.ietf.org/rfc/rfc3530.txt>.
80. Date, C. J., An Introduction Database Systems, Reading, MA: Addison-Wesley,
1981.
81. Silberschatz, A.; H. Korth; and S. Sudarshan, Database System Concepts, 4th
ed., New York: McGraw-Hill, 2002, pp. 3-5.
82. Silberschatz, A.; H. Korth; and S. Sudarshan, Database System Concepts, 4.. I
ed., New York: McGraw-Hill, 2002, pp. 135-182. ‘‘I
83. Chen, P., «The Entity-Relationship Model — Toward a Unified View of Data I
ACM Transactions on Database Systems, Vol. 1, No. 1, 1976, pp. 9-36. 1
84. Markowitz, V. M.; and A. Shoshani, «Representing Extended Entity-RelatiOll I
ship Structures in Relational Databases: A Modular Approach», ACM Tran$a I
tions on Database Systems, Vol. 7, No. 3, 1992, pp. 423-464.
85. Winston, А., «А Distributed Database Primer», UNIX World, April 19gs
pp. 54-63.
86. Codd, E. F., «А Relational Model for Large Shared Data Banks», Communica.
tions of the ACM, June 1970.
87. Codd, E. F., «Further Normalization of the Data Base Relational Model», Соц
rant Computer Science Symposia, Vol. 6, Data Base Systems, Englewood Cliffs
NJ: Prentice Hall, 1972.
88. Blaha, M. R.; W. J. Premerlani; and J. E. Rumbaugh, «Relational Database De-
sign Using an Object-Oriented Methodology», Communications of the ACM
Vol. 13, No. 4, April 1988, pp. 414-427.
89. Codd, E. F., «Fatal Flaws in the SQL», Datamation, Vol. 34, No. 16, August 15
1988, pp. 45-48.
90. Relational Technology, INGRES Overview, Alameda, CA: Relational Technology,
1988.
91. Stonebraker, M., «Operating System Support for Database Management», Com
munications of the ACM, Vol. 24, No. 7, July 1981, pp. 412-417.
92. Ibelslymser, O., «The WinFS File System for Windows Longhorn: Faster and
Smarter», Tom’s Hardware Guide, June 17, 2003, <www.tomshardware.com
/storage/20030617/>.
93. Golden, D., and M. Pechura, «The Structure of Microcomputer File Systems»,
Communications of the ACM, Vol. 29, No. 3, March 1986, pp. 222-230.
94. Custer, Helen, Inside the Windows NT File System, Redmond, WA: Microsoft
Press, 1994 (есть русский перевод: Кастер Хелен Основы Windows NT и NTFS:
пер. с англ. — М..’Русская Редакция, 1996. — 438 с).
95. Rosenblum, М., and J. К. Ousterhout, «The Design and Implementation of a
Log-Structured File System», ACM Transactions on Computer Systems (TOCS),
Vol. 10, No. 1, February 1992.
96. Wang, Jun; Rui Min; Zhuying Wu; and Yiming Hu, «Boosting I/O Performance
of Internet Servers with User-Level Custom File Systems», ACM SIGMETRICS
Performance Evaluation Review, Vol. 29, No. 2, September 2001, pp. 26-31.
Часть V
Производительность,
процессоры
и мультипроцессорные
системы
Не говори мне, как усердно ты трудишься.
Скажи лучше, сколько ты сделал-
Джеймс Лин^
двух следующих главах мы продолжим рас-
сматривать вопросы производительности.
Глава 14 обсуждает показатели производительно-
сти, технику их измерения, мониторинг, понятия
узкого места, насыщения и обратной связи. Уделяет-
ся также внимание влиянию набора команд процес-
сора на производительность. Глава 15 обсуждает во-
просы существенного улучшения производительно-
сти, которое возможно в многопроцессорных
системах, особенно в системах с большим числом
процессоров. В следующем десятилетии ожидается
повсеместное внедрение параллельных вычислений
с переходом персональных систем на мультипроцес-
сорную базу и распространением распределенных
систем. Эта глава посвящена мультипроцессорным
системам и обсуждает их архитектуру, организа
цию операционных систем, средства совместного
доступа к памяти, диспетчеризацию ресурсов, ми-
грацию процессов, балансировку загрузки и взаимоис-
ключение.
Самое общее определение красоты... Многое в едином.
Самюэль Тэйлор Кольридж
Меру во всем соблюдай,
и дела свои вовремя делай.
Гесиод
Не говори мне, как усердно ты трудишься.
Скажи лучше, сколько ты сделал.
Джеймс Линг
Не позволительно честному человеку
быть судьей в собственном деле.
Блез Паскаль
Все это лишь слова, а действий нет»
Филипп Мессинджер
Глава 14
I Производительность
и архитектура процессоров
Це,
Прочитав эту главу, вы должны усвоить:
• необходимость измерения производительности;
• общие показатели производительности;
• некоторые методы, используемые при измерении
производительности системы;
• понятия узкого места, насыщения и обратной связи;
• популярные подходы к проектированию
архитектуры процессоров;
• методы проектирования процессоров, направленные
на повышение производительности.
Краткое содерэкание главы
14.1. ^Ведение
14.2. Тенденции, Влияющие на результирующую
производительность
143. Назначение мониторинга и оценки производительности
14.4. Показатели производительности
14.5. Методы оценки производительности
14.5.1. ТрассироВка и профилирование
14.5.2. Хронометраэк и контрольные задачи макроуровня
14.53. Оценка производительности относительно приложения
14.5.4. Аналитические модели
14.5.5. Наборы контрольных задач
14.5.6. Синтетические программы
14.5.7. Моделирование
14.5.8. Мониторинг производительности
14.6. Узкие места и насыщение
14.7. Обратные сВязи
14.7.1. Отрицательная обратная сВязь
14.7.2. Положительная обратная сВязь
14.8. Параметры производительности
и архитектура процессора
14.8.1. Полный набор команд
14.8.2. Архитектура процессоров с сокращенным набором команд
14.83. Второе поколение RISC-процессороВ
14.8.4. Технология параллельной обработки команд с яВным параллелизмом (EPIC)
^зво j юность и архитектура процессоров
14,1 Введение
Одно из предназначений операционной системы состоит в управлении
еСурсами, следовательно, для разработчиков операционных систем, адми-
нистраторов и пользователей важно иметь возможность определить на-
сколько эффективно та или иная подсистема управляет выделенными ей
пеСурсами. Измерение системной производительности позволяет потреби-
телям принимать более обоснованные решения, а разработчикам — стро-
нь более эффективные системы. В данной главе описываются проблемы,
связанные с производительностью, и методы исследования, применяемые
для измерения, мониторинга и оценки производительности. Использова-
ние рассматриваемых методов может помочь разработчикам, администра-
торам и пользователям достичь максимальной эффективности вычисли-
тельных систем.
Производительность системы определяется не только аппаратным обес-
печением и операционной системой, но и характером их взаимодействия.
Следовательно, мы будем рассматривать ряд методов оценки, измеряющих
производительность вычислительной системы в целом, а не только опера-
ционной системы. Мы познакомимся также с методиками проектирования
процессоров, получившими наибольшее распространение, и способами по-
вышения производительности, принятыми в каждой из них.
Вопросы для самопроверки
1. Какие преимущества, по вашему мнению, может дать оценка про-
изводительности разработчикам операционных систем, системных
администраторам и пользователям?
2. Какой ресурс вычислительной системы (предположительно) оказы-
вает наибольшее влияние на ее производительность?
Ответы 1) Оценка производительности предоставляет возмож-
ность потребителям выполнить сравнение различных систем, разра-
ботчикам — получить информацию о том, как следует проектировать
программное обеспечение с точки зрения эффективного использова-
ния компонентов системы, пользователям — облегчить настройку сис-
темы в соответствии с конкретными требованиями. 2) Процессор(ы).
14.2 Тенденции, влияющие на результирующую
производительность
В начальный период развития вычислительных систем аппаратное обес-
печение составляло основную часть их стоимости, и исследования произво-
дительности велись первоначально в данной области. Сейчас стоимость ап-
паратного обеспечения относительно невысока и продолжает снижаться.
Сложность программного обеспечения растет одновременно с широким
Распространением многопоточных, мультипроцессорных, распределенных
систем, систем управления базами данных, графических интерфейсов
'Гмва ц
гьзователя и различных систем поддержки приложений. Программное
спечение обычно скрывает от пользователя работу аппаратуры, созда-
i виртуальную машину с заданными рабочими характеристиками. Гро.
здкое программное обеспечение является причиной низкой производи-
[ьности даже систем, построенных на мощном аппаратном обеспечении
этой причине важно рассмотреть как эффективность системного про-
шмного обеспечения, так и эффективность работы аппаратного обеспе-
яия.
Техника оценки производительности систем развивается. Грубые и по-
щиально вводящие в заблуждение показатели, такие как тактовая час-
га и пропускная способность влияют на потребительский рынок, по-
рльку поставщики разрабатывают свои продукты, ориентируясь именно
данные критерии. Однако разрабатываются и другие критерии произво-
тельности. Например, проектировщики разрабатывают более сложные
нтрольные задачи, получают лучшие данные трассировки и проектиру-
г более полные (комплексные) модели для моделирования вычислитель-
>й системы — мы изучим все эти методы в данной главе. Появляются Ho-
le стандартные контрольные задачи и комплексные оценочные програм-
Li. К сожалению, до сих пор единого стандарта в этой области не
ществует. Критики полагают, что результаты измерений производитель-
>сти неточны и обманчивы, поскольку методы оценки эффективности за-
детую измеряют вовсе не те характеристики программ, для которых они
зедназачены1.
Вопросы для самопроверки
1. Каким образом менялся подход к исследованию производительно-
сти со временем?
2. Используя материал предыдущих глав, приведите несколько при-
меров того, как операционная система может повысить эффектив-
ность вычислительной системы.
Ответы I) В начальный период развития вычислительных систем
аппаратное обеспечение составляло основную часть их стоимости,
и исследования производительности велись преимущественно в дан-
ной области. Сегодня сложное программное обеспечение в основном
определяет производительность системы. 2) Операционные системы
могут усовершенствовать политику планирования загрузки процессо-
ра и использования жесткого диска, реализовывать эффективные про-
токолы синхронизации потоков, более эффективно управлять
файловой системой, рационально выполнять переключение контек-
стов, улучшать алгоритмы управления памятью и т.п.
14.3 Назначение мониторинга и оценки
ироизводитеАЬности
В своем классическом труде2 Лукас называет три общие цели оценки
производительности.
• Оценка при выборе (selection evaluation) — выполняется при приня-
тии решения о целесообразности приобретения вычислительной сис-
темы или приложения конкретного производителя.
• Прогноз производительности (performance projection) — выполняет-
ся при оценке производительности системы, не существующей в дан-
ный момент. Это может быть как совершенно новая система, так и ра-
нее существовавшая, но с новыми аппаратными либо программными
компонентами.
• Мониторинг производительности (performance monitoring) — выпол-
няется путем сбора данных о производительности имеющихся систем
или компонентов с целью анализа возможности достижения плани-
руемых параметров. Мониторинг производительности может также
помочь оценить влияние планируемых изменений и обеспечить сис-
темных администраторов информацией, необходимой для принятия
стратегических решений, например, модифицировать ли существую-
щую систему назначения приоритетов или модернизировать аппарат-
ную часть.
На ранних этапах разработки новой системы производители пытаются
прогнозировать специфику приложений, которые будут на ней запускать-
ся и объем выполняемых ими работ. Оценка и прогнозирование производи-
тельности используются с первых этапов разработки и реализации новой
системы для определения наилучшей аппаратной организации, стратегий
управления ресурсами, которые должны быть реализованы в операцион-
ной системе, а также для определения, соответствует ли проектируемая
система требуемому уровню производительности. С выходом продукта на
рынок производитель должен быть готов ответить на вопросы потенциаль-
ных потребителей о том, сможет ли система выполнить определенные при-
ложения с заданным уровнем эффективности. Пользователи зачастую свя-
зывают выбор той или иной конфигурации системы с необходимым для
нее сервисом.
После установки системы на узле пользователя, как пользователь, так
и производитель заинтересованы в достижении оптимальной производи-
тельности. Администраторы выполняют окончательную настройку систе-
мы под операционную среду пользователя. Данный процесс, называемый
настройкой системы (system tuning), часто приводит к резкому улучше-
нию производительности системы, поскольку учитывает индивидуальные
особенности среды.
Вопросы для самопроверки
1. В каких случаях следует использовать прогноз производитель^
сти, а в каких — оценку при выборе?
2. Каким образом мониторинг производительности способствует ца
стройке системы?
Ответы 1) Опенка производительности при выборе выполняется
для существующих систем. Прогноз производительности помогает
оценить данный параметр для системы, которая на данный момент це
существует, а также спрогнозировать результаты модификации суще.
ствующей системы. 2) Мониторинг производительности позволяет оц.
ределить модификации, с наибольшей вероятностью приводящие
к повышению производительности.
14.4 Показатели производительности
Под производительностью мы подразумеваем эффективность достиже-
ния системой поставленных целей. Таким образом, производительность
является скорее относительной величиной, чем абсолютной, хотя мы часто
говорим об абсолютных показателях производительности (absolute
performance measure), таких как суммарное время, за которое вычисли-
тельная система может выполнить определенную вычислительную задачу.
Однако полученный абсолютный показатель производительности может
быть использован и для сравнения.
Оценка производительности зачастую зависит от точки зрения. Напри-
мер, начинающий музыкант найдет исполнение пятой симфонии Бетхове-
на в высшей степени совершенным, тогда как дирижер оркестра заметит
небольшую фальшь вторых скрипок в некотором пассаже. Подобным же
образом владелец большой системы резервирования авиабилетов может
быть доволен ее высокой загрузкой, отражающей большой объем запросов,
обрабатываемых системой, тогда как пользователь испытывает ощутимую
задержку при попытке зарезервировать билет.
Определение величины некоторых параметров производительности, на-
пример, удобства использования (ease of use), достаточно сложно, тогда
как определение других, скажем, скорости обмена данными между диском
и оперативной памятью, не составляет труда. Эксперт, оценивающий про-
изводительность, должен быть аккуратен при учете параметров обоих ти-
пов, хотя точную статистику можно получить только для параметров вто-
рого типа. Некоторые параметры производительности, например, время
отклика системы, ориентированы на пользователя, другие, такие как сте-
пень загрузки процессора, являются системно-ориентированными.
Некоторые показатели производительности могут вводить в заблужде-
ние. К примеру, некоторая операционная система может сосредоточиться
на рациональном использовании ресурса памяти путем выполнения слоЖ"
ных алгоритмов замещения страниц, тогда как другая система постарается
избежать сложных процедур и тем самым сэкономит процессорное время
для выполнения пользовательских программ. Первый подход будет выгля-
деть более результативным для систем с быстрыми процессорами, вто-
шзводительность и архитект ра процессоре
0$ — для систем с большим объемом оперативной памяти. К тому же, не- _
.оторые методы позволяют эксперту выполнить измерения производи-
тельности для малых частей системы, т.е. для ее отдельных компонентов.
^акие средства могут быть полезны для локализации определенных про-
чем, но не показывают общей картины. Эксперт может обнаружить, что
оПераЦионная система эффективно выполняет все базовые операции, кро-
ме одной. На данный факт можно не обращать внимания до тех пор, пока
Неэффективная базовая операция не начнет интенсивно использоваться.
Если не учитывать частоту использования каждой из базовых операций,
результаты измерений могут ввести в заблуждение. Аналогичным обра-
зом, программы, разработанные для оценки системы в определенной сре-
де, в другой среде могут дать ложный результат.
Некоторые общие показатели производительности перечислены ниже.
• Оборотное время (turnaround time) — интервал времени от поступле-
ния задания в систему до момента выдачи результата пользователю.
6 Время отклика (response time) — оборотное время интерактивной
системы, определяемое, обычно, как интервал времени от момента
нажатия пользователем клавиши Enter или щелчка кнопкой мыши
до появления соответствующей реакции на экране.
• Время реакции системы (system reaction time) — в интерактивных
системах данный показатель определяется как интервал времени от
момента нажатия пользователем клавиши Enter или щелчка кнопкой
мыши до первого временного кванта, предоставленного для обработки
данного запроса пользователя.
Данные показатели являются вероятностными величинами, при модели-
ровании и имитации они рассматриваются как случайные переменные
(random variable). Случайные переменные могут принимать значения из не-
которого диапазона, причем каждое из значений обладает некоторой веро-
ятностью (появления). Мы, к примеру, говорим о распределении времени
отклика (distribution of response times), поскольку всякий пользователь
знает, что в каждой конкретной интерактивной системе на некотором мно-
жестве операций существует большой разброс времен отклика. Распределе-
ние вероятности может выразительно охарактеризовать данный диапазон.
В том случае, когда мы говорим о математическом ожидании expected
value) случайной переменной, мы подразумеваем ее среднее значение
(mean). Однако среднее значение может ввести в заблуждение. Одно и то же
среднее значение может быть получено как при усреднении множества оди-
наковых или близких значений, так и при усреднении значений, имеющих
значительный разброс по величине. Следовательно, кроме названных выше,
Необходимо рассмотреть дополнительные показатели производительности:
• Дисперсия (dispersion) времени отклика или другой случайной пере-
менной. Дисперсия времени отклика является мерой отклонения. Ма-
лое отклонение является признаком того, что величины времени от-
клика, полученные пользователем, близки к вычисленному среднему
значению. Большая величина дисперсии свидетельствует о том, что
пользователи получили времена отклика, значительно отличающиеся
от среднего, как в большую, так и в меньшую сторону. Это значит, что
одним сервис был предоставлен очень быстро, то другим пришлось
подождать. Таким образом, дисперсия времени отклика отражает
к™Главам
предсказуемость, что является важным показателем производитель,
ности для пользователей интерактивных систем.
• Пропускная способность (throughput) — измеряется как количество
заданий, выполненных за единицу времени.
• Рабочая нагрузка (workload) — показатель объема работ, поступив-
ших в систему. Как правило, эксперты определяют приемлемый ур0.
вень производительности для типовой рабочей нагрузки вычисли-
тельной среды. Системные оценки осуществляются относительно до-
пустимого уровня.
• Мощность (capacity) — максимальная пропускная способность систе-
мы, которая может быть достигнута при отсутствии простоев (т.е. за-
дания в систему поступают по мере ее готовности к их выполнению).
• Степень использования или степень загрузки (utilization) — доля
времени, в течение которой используется тот или иной ресурс. Дан-
ный параметр может ввести в заблуждение. Хотя высокая степень ис-
пользования выглядит привлекательно, она может быть результатом
неэффективной работы. Один из способов получения высокой степени
использования процессора состоит в запуске приложения с вечным
циклом! Взгляд с другой стороны на использование процессора также
приводит к интересным выводам. Рассмотрим процессор во время
простоя, в режиме ядра и в пользовательском режиме. В пользова-
тельском режиме процессор выполняет операции, заданные пользова-
телем, в режиме ядра — решает задачи операционной системы. Неко-
торая часть времени уходит на переключение контекста, т.е. пред-
ставляет собой непроизводительные издержки, которые могут дос-
тичь значительной величины в некоторых системах. Таким образом,
измеряя степень использования процессора, мы должны определить,
какая часть загрузки определяется выполнением задач пользователя,
а какая — системными непроизводительными издержками. Удиви-
тельно, но «малая степень использования» может рассматриваться
как достоинство для некоторых видов систем, например, для систем
реального времени, в которых системные ресурсы должны быть гото-
вы к немедленному реагированию на входящую задачу, иначе может
возникнуть аварийная ситуация. Такого рода системы более ориенти-
рованы на быстрый отклик, чем на загрузку ресурсов.
Вопросы для самопроверки
1. Укажите различия между временем отклика и временем реакции
системы.
2. (Да/Нет) Если процессор большую часть времени находится в поль-
зовательском режиме, система характеризуется высокой степенью
использования процессора.
ОтВеты 1) Время отклика представляет собой интервал времени,
необходимый для завершения ответа на запрос пользователя; время
реакции системы представляет собой интервал времени, необходимый
системе для того, чтобы начать обработку запроса пользователя. Нача-
лом отсчета и в том, и в другом случае является момент появления за-
проса в системе. 2) Нет. Например, если процессор занят выполнением
бесконечного цикла, его использование системой нельзя считать эф-
фективным.
14.5 Методы оценки производительности
После того как мы рассмотрели некоторые используемые на практике па-
раметры производительности, необходимо обсудить способы получения их
значений. В данном разделе описан ряд важных методов оценки производи-
тедьности.3’4’5 Некоторые из них выделяют различные компоненты системы
и оценивают производительность каждого их них в отдельности, позволяя
разработчику идентифицировать границы неэффективности. Другие мето-
ды ориентированы на систему в целом и позволяют потребителям произве-
сти сравнение между системами. Кроме того, существуют методы для спе-
циализированных приложений, допускающие только косвенное сравнение
данной системы с другими. В следующих разделах будет описаны различ-
ные методы оценки и измеряемые аспекты системной производительности.
14.5.1 Трассировка и профилирование
В идеальном случае, эксперт, проводящий оценку производительности,
должен выполнить измерения на нескольких системах, работающих
в идентичных условиях. Обычно это условие невозможно выполнить, осо-
бенно в случае, когда аппаратное обеспечение является сложным и его
трудно сдублировать. Такой процесс может быть достаточно утомитель-
ным и совершенно бесполезным. В случае, когда производительность сис-
темы должна быть определена для заданной среды, разработчик, как пра-
вило, использует трассировку (trace). Трассировка представляет собой
протокол действий системы — обычно журнал регистрации запросов поль-
зователей и приложений к операционной системе.
Эксперт, выполняющий оценку системы, может использовать данные
трассировки для характеристики среды выполнения заданной системы пу-
тем определения частоты, с которой процессы, работающие в режиме поль-
зователя, запрашивают сервисы, предоставляемые ядром. Перед установ-
кой новой вычислительной системы эксперт может протестировать ее, ис-
пользуя рабочую нагрузку, рассчитанную по данным трассировки, либо
сам протокол трассировки. Данные трассировки зачастую модифицируют-
ся для оценки возможных вариантов. К примеру, системному администра-
тору может понадобиться определить, насколько новый Web-сайт повлия-
ет на производительность Web-сервера. Имеющаяся трасса может быть из-
менена для оценки того, как система будет обрабатывать новую нагрузку.6
В том случае, когда операционная система работает в нескольких схожих
средах, могут быть разработаны стандартные трассы для выполнения срав-
нения параметров аналогичных сред. При этом трассировки, полученные
Для одной инсталляции операционной системы, могут оказаться непригод-
ными для другой. Такого рода данные представляют собой (в лучшем слу-
чае) только некоторую аналогию системных действий другой инсталляции.
К тому же, журнал регистрации пользователей рассматривается как при-
надлежность системы, в которой ведутся записи, и крайне редко такие жур-
налы распространяются в рамках сообщества разработчиков или производи-
телей. Как следствие, наблюдается дефицит доступных данных трассировки
Для сравнения и оценки.7
Еще одним методом получения параметров среды выполнения вычисли,
тельной системы является профилирование. Профили (profile) записыва-
ют системные действия, исполняемые в режиме ядра, такие как диспетче-
ризация процессов, управление памятью и устройствами ввода-вывода.
Например, профиль может зафиксировать, какая из операций ядра выпол-
няется наиболее часто. В качестве альтернативы профиль может вести ре-
гистрацию всех вызовов функций, выполняемых операционной системой.
Профиль указывает, какие из базовых операций операционной системы
наиболее активно используются, позволяя системным администраторам
определить возможные объекты оптимизации и настройки.8 Эксперты по
оценке производительности должны часто применять дополнительные ме-
тоды оценки производительности в сочетании с профилированием для оп-
ределения наиболее эффективных способов повышения эффективности ра-
боты системы.
Вопросы для самопроверки
1. Каким образом данные трассировки могут использоваться при
оценке производительности?
2. В чем состоит различие между трассировкой и профилированием?
ОтВеты 1) Данные трассировки позволяют экспертам сравнить
производительность нескольких различных систем, работающих
в одинаковых вычислительных средах. Трассы описывают исследуе-
мую среду, и эксперт может получить информацию о производитель-
ности, соответствующую используемой системе. 2) Трассы фиксируют
пользовательские запросы, тогда как профили регистрируют действия
в режиме ядра. Таким образом, трассы описывают вычислительную
среду, перехватывая запросы пользователя к определенному сервису,
ядру (без учета базовой системы), профили же учитывают действия
операционной системы в заданной вычислительной среде.
14.5.2 Хронометраже и контрольные задачи микроуровня
Хронометраж (timing) позволяет выполнить быстрое сравнение аппа-
ратного обеспечения вычислительных систем. Первые вычислительные
системы часто оценивались по длительности выполнения операции сложе-
ния либо по длительности цикла памяти. Хронометраж полезен для под-
счета «лошадиных сил» какой-либо вычислительной системы, выражае-
мый зачастую в таких единицах измерения как MIPS (millions of
instructions per second —. миллион операций в секунду) или BIPS (billions
of instructions per second — миллиард операций в секунду). Некоторые
вычислительные системы работают в диапазоне TIPS (trillion of
instructions per second — триллион операций в секунду).
С появлением семейств вычислительных систем (family of computers),
таких как IBM 360 (представлено в 1964 году) или Intel Pentium, которое
является продолжением серии Intel х86, появившейся в 1978 году, произ-
водители аппаратного обеспечения стали широко использовать практику
предложения потребителям вычислительных систем, позволяющих вы-
полнять замену процессоров на более быстрые (без замены других компо-
нентов вычислительной системы) по мере роста потребностей пользовате-
лей. Вычислительные системы, входящие в семейство, являются про-
Глава I ррощбодительность и
граммно совместимыми, т.е. могут выполнять одни и те же программные
приложения, но скорость выполнения зависит от выбранной модели се-
мейства. Хронометраж обеспечивает удобный способ сравнения моделей
семейства вычислительных систем.
Контрольные задачи микроуровня (microbenchmark) измеряют время,
требуемое на выполнение элементарных действий операционной системы
(например, на создание процесса). Данные задачи полезны для определе-
ния того, насколько изменения, вносимые в проект, влияют на скорость
определенной операции. Набор контрольных задач микроуровня (micro-
benchmark suite) представляет собой набор программ, измеряющий ско-
рость ряда важных базовых инструкций операционной системы, таких как
операции с памятью, создание процессов и время переключения контек-
ста.9 Эксперты применяют данные наборы программ для определения сис-
темной производительности конкретных операций, например, при опреде-
лении пропускной способности чтения/записи (т.е. сколько данных систе-
ма может передать за единицу времени при чтении или записи) или
задержки сетевого соединения.10
Контрольные задачи микроуровня позволяют определить, насколько
быстро система выполняет отдельную операцию, но не отображают частоту
выполнения данной операции. Следовательно, с их помощью невозможно
учесть такие важные критерии, как пропускная способность и степень ис-
пользования. Тем не менее, данные задачи оказываются полезным средст-
вом при определении действий, приводящих к потере производительности
системы, особенно в совокупности с данными о способе использования тех
или иных операций.11
До начала 90-х годов не существовало единого набора контрольных за-
дач микроуровня, демонстрирующего влияние аппаратных компонентов
на производительность базовых элементов операционной системы. В 1995
году был представлен контрольный набор задач Imbench, позволяющий
выполнить оценку и сравнение системной производительности на различ-
ных платформах UNIX.12 Несмотря на предоставляемые Imbench возмож-
ности получения оценочных данных и выполнения сравнения несколь-
ких платформ, он оказался непоследовательным с точки зрения формиро-
вания статистических отчетов. Некоторые тесты предоставляли результа-
ты, усредненные для нескольких запусков, тогда как другие — только ре-
зультат однократного запуска. Для Imbench также характерно требование
выполнения измерения один раз в миллисекунду, поскольку в нем исполь-
зовался достаточно грубый механизм хронометража программного обеспе-
чения, что не позволяло выполнять измерения для операций с высокой
скоростью и хронометража аппаратных компонентов. Исследователи Гар-
вардского университета сняли указанные ограничения в контрольном
наборе задач hbench, предоставившем стандартную и точную модель ста-
тистических отчетов, которая позволила экспертам выполнять более эф-
фективный анализ взаимосвязей между базовыми элементами операци-
онной системы и аппаратными компонентами.13 Рассмотренные наборы
(hbench и Imbench) представляют различные подходы к разработке набо-
ров контрольных задач. Imbench ориентирован на переносимость, позво-
ляющую исследователям выполнить сравнение параметров различных
архитектур; hbench предназначен, прежде всего, для выявления взаимо-
связей между операционной системой и аппаратным обеспечением в аа
данной вычислительной системе.14’15
Вопросы дм самопроверки
1. Каким образом результаты, полученные на основе хронометру
и выполнения контрольного набора задач, могут ввести исследив?
теля в заблуждение? В каких случаях эти результаты могут быт.
полезны? 1
2. Какие показатели производительности могут быть использованы
в сочетании с контрольными задачами микроуровня для оценки
производительности операционной системы?
Ответы 1) Контрольные задачи микроуровня измеряют время, тре-
буемое для выполнения определенной базовой операции (к примеру
создания процесса), хронометраж обеспечивает быстрое сравнение ап-
паратных операций (скажем, инструкций сложения). Ни тот, ни другой
метод в отдельности не позволяет оценить производительность системы
в целом. Но данные походы позволяют определить возможные области
неэффективной работы и оценить влияние изменений на производи-
тельность. 2) Для оценки производительности операционной системы
в сочетании с контрольными задачами микроуровня могут быть ис-
пользованы профили, фиксирующие частоту использования того или
иного базового компонента операционной системы.
14.5.3 Оценка производительности относительно приложения
Несмотря на то, что общая производительность является важным пара-
метром системы, многих пользователей намного больше интересует, как бы-
стро будет выполняться некоторое приложение в имеющейся системе. В ра-
боте Вельтцера и др.16 была предложена векторная методология
(vector-based methodology) для оценки, ориентированной на приложение,
основанная на объединении данных трассировки и профилирования с ре-
зультатами хронометража и выполнения контрольных задач микроуровня.
Согласно данной методологии эксперт записывает результаты выполне-
ния контрольных задач микроуровня для отдельных базовых инструкций
операционной системы. Затем выполняется построение вектора путем раз-
мещения полученных значений в соответствующих элементах системного
вектора (system vector). На следующем этапе эксперт выполняет профили-
рование системы при выполнении исследуемого приложения и строит вто-
рой вектор — вектор приложения (application vector), — в отдельные эле-
менты которого включаются потребности в определенных базовых опера-
циях системы. Каждый элемент системного вектора описывает
длительность выполнения операционной системой той или иной базовой
операции; соответствующий ему элемент вектора приложений характери-
зует число запросов исследуемого приложения к данной базовой операции
системы. Например, если первый элемент системного вектора соответству-
ет производительности операции создания процесса, то первый элемент
вектора приложения содержит величину, отображающую количество пр°"
цессов, создаваемых при работе исследуемого приложения (или группы
приложений). Характеристика производительности рассматриваемой сис-
темы при выполнении исследуемого приложения вычисляется как
s _i-й. элемент системного вектора, а, — i-й элемент вектора приложе-
п — размерность векторов.17
рассмотренный метод полезен для сравнения эффективности выполне-
я определенного приложения (или группы приложений) в средах раз-
личных операционных систем с учетом числа запросов приложения к раз-
личным базовым операциям системы. Векторный метод может быть ис-
пользован для определения базовых операций системы, требующих
настройки для повышения производительности.
Поведение некоторых приложений зависит как от самого приложения,
так и данных, вводимых пользователем. Например, характер запросов
приложения, использующего базы данных, зависят от числа активных
в данный момент пользователей. Простое профилирование системы без
учета типового потока запросов пользователей даст неверные результаты.
В рассматриваемом случае системная среда определяется как приложени-
ем, так и запросами пользователя. Следовательно, для обеспечения более
точной оценки системы, векторная методология должна быть дополнена
данными трассировки (авторы назвали предложенный подход гибридной
методологией (hybrid methodology)). Данные трассировки позволяют по-
строить вектор приложения с учетом того, каким образом данное приложе-
ние и типовой поток пользовательских запросов влияют на потребности
в базовых операциях системы.18
Программа ядра (kernel program) представляет собой еще одно средство
оценки производительности относительно приложения, хотя и не часто ис-
пользуемое. Программа ядра может характеризовать как целостную про-
грамму, так и отдельный алгоритм, например, обращение матрицы. При
наличии оценочных временных параметров (полученных от производите-
лей) для отдельных инструкций, выполнение программы ядра позволяет
получить временные характеристики для исследуемой машины. Сравне-
ние результатов производится на основе различий в ожидаемом времени
выполнения. Программы ядра в действительности выполняются «на бума-
ге», а не в реальной вычислительной системе. Они используются для оцен-
ки системы при выборе до ее приобретения. [Примечание: Термин «ядро»
в данном случае не следует путать с ядром операционной системы].19
Программы ядра дают лучшие результаты по сравнению с хронометра-
жем и контрольными задачами микроуровня, но требуют «ручного труда»
и времени для подготовки теста. Одним из ключевых преимуществ боль-
Шей части программ ядра является то, что они представляют собой завер-
шенные программы, которые пользователь может выполнять на сравни-
ваемых вычислительных системах.
Программы ядра могут помочь при оценке некоторых программных
Компонентов системы. Например, два различных компилятора могут гене-
рировать различный код, и программы ядра смогут помочь исследователю
«Определить, какой из вариантов кода более эффективен.20
6ЬЧ____________________________________________________________________________[лаВ^
Вопросы для самопроверки
1. Назовите преимущества и недостатки оценки производительност
относительно приложения?
2. Каковы с вашей точки зрения причины редкого использования пс.
грамм ядра? ро'
Ответы 1) Оценка производительности относительно приложена
полезна при определении, будет ли система эффективно работать пгц
выполнении заданного приложения и указанных настройках. Недос
татком является необходимость оценки системы для каждого набора
настроек — указание только одного из возможных вариантов не имеет
смысла. 2) Программы ядра требуют времени и сил на разработку
и выполнение. Кроме того, они выполняются «на бумаге» и могут вно-
сить в результат ошибки, обусловленные «человеческим фактором»
Зачастую проще выполнить обычную программу или сценарий на ре
альной системе, чем рассчитывать время выполнения для программы
ядра.
14.5.4 Аналитические модели
Аналитические модели (analytic model) являются математическим
представлением вычислительных систем или их компонентов.21- 22> 23-24- 25
В настоящее время используется множество разновидностей аналитиче-
ских моделей; наиболее популярны модели, построенные в рамках теории
массового обслуживания, и модели с применением марковских процессов,
поскольку они относительно просты в управлении и полезны.
Исследователи, склонные к занятиям математикой, легко смогут созда-
вать и модифицировать аналитические модели. Большая часть необходи-
мых математических результатов уже существует в настоящий момент,
так что эксперт сможет быстро и с достаточной точностью выполнить оцен-
ку производительности данной вычислительной системы или компонента.
Однако ряд недостатков аналитических моделей сдерживают их примене-
ние. Один из них состоит в том, что от эксперта требуется высокий уровень
математической подготовки, что достаточно редко встречается в сфере
коммерческого применения компьютеров. Другим недостатком является
то, что для сложных систем затруднительно составить точную модель; чем
сложнее система, тем менее полезна ее аналитическая модель.
Современные системы зачастую настолько сложны, что разработчик мо-
дели вынужден вносить множество упрощающих допущений, которые
снижают практическое значение и применимость модели. Следовательно,
эксперт, выполняющий оценку, должен наряду с аналитическими моделя-
ми пользоваться другими способами (например, контрольными задачами
микроуровня). В некоторых случаях результаты оценки, полученные с по-
мощью только аналитических моделей, могут быть признаны недействи-
тельными на основе исследований, выполненных другими способами. Час-
то различные методики оценки используются с целью подтвердить резуль-
таты друг друга, демонстрируя действительность выводов, сделанных на
основе моделирования.
Вопросы для самопроверки
1. Назовите достоинства сложных и простых моделей.
2. Каковы преимущества использования аналитических моделей?
Ответы 1) Сложные аналитические модели более точны, но не все-
гда можно построить точную математическую модель поведения сис-
темы. Задача облегчается при представлении поведения системы более
простой моделью, но при этом теряется точность моделирования сис-
темы. 2) Исследователь может получить множество результатов при
помощи аналитической модели, в том числе точные данные о произво-
дительности системы. Аналитическая модель может быть относитель-
но легко модифицирована при внесении изменений в систему.
/455 Наборы контрольных задач
Контрольные задачи (benchmark) представляют собой программы, вы-
полняемые для оценки характеристик вычислительной системы. В общем
случае контрольные задачи являются реальными рабочими программами
(production program), типовыми для большинства конфигураций системы.
Эксперту, выполняющему оценку, хорошо известна производительность
контрольных задач на определенном оборудовании, что позволяет ему сде-
лать обоснованные выводы по результатам запуска тех же программ на но-
вом аппаратном обеспечении.26’ 27 Ряд организаций, например, Группа по
оценке системной производительности (System Performance Evaluation
Cooperative — SPEC, www.specbench.org) и Группа по оценке производи-
тельности бизнес-приложений (Business Application Performance Corpora-
tion — BAPCo, www.bapco.com) разработали контрольные задачи, соответ-
ствующие промышленным стандартам и предназначенные для различных
систем (начиная от Web-серверов и кончая персональными компьютера-
ми). Эксперт может выполнять данные задачи для сравнения систем одно-
го класса от различных производителей.
Одним из преимуществ контрольных задач является то, что множество
тестов этого класса уже разработано. Это дает возможность эксперту про-
сто выбрать одну из известных рабочих программ или тест, являющийся
промышленным стандартом. При этом не требуется времени на настройку
отдельного продукта. Программа просто запускается на реальной машине
с текущими данными, так что компьютер выполняет большую часть рабо-
ты. Вероятность внесения ошибки оператором минимальна, поскольку
вРемя выполнения контрольных задач замеряется компьютером без уча-
стия человека. При наличии в вычислительной среде многозадачного ре-
жима, режима разделения времени, параллельной обработки, баз данных,
обмена данными и систем реального времени, контрольные задачи приоб-
ретают особую ценность, поскольку выполняются на существующей маши-
и в реальных условиях. Эффективность таких сложных систем может
Ыть определена непосредственно, а не путем оценки.
При разработке контрольных задач необходимо учитывать несколько
критериев. Во-йервых, результаты должны быть повторяемыми; в частно-
тй, каждый запуск одной и той же контрольной задачи на некоторой сис-
еМе должен давать близкие по значению результаты. Полученные резуль-
аты не должны быть идентичными (изредка они могут совпадать), по-
скольку на их значение влияют элементы среды, например, размещен, I
сохраняемых данных на диске. Во-вторых, контрольные задачи дол^ц.
точно соответствовать типам приложений, выполняемых в исследуеь^
системе. И, наконец, эти задачи должны широко использоваться для об^с
печения точного сравнения исследуемых систем. Качественные контрод^
ные задачи, являющиеся промышленными стандартами, удовлетворяв
перечисленным требованиям; однако два последних требования зачасту^
приводят к конфликту при проектировании тестов. Если некоторые код
трольные задачи специфичны для некоторой системы, они не могут шцр0
ко использоваться; с другой стороны, задача, разработанная с учетом осо.
бенностей множества систем, может не обеспечить точности результатов
для какого-либо конкретного случая.28
Контрольные задачи используются для оценки как аппаратного, так
и программного обеспечения, даже в условиях сложной операционной ере-
ды. Особую ценность они приобретают при сравнении результатов, полу,
ченных до и после внесения некоторых изменений в систему. Однако кон-
трольные задачи не могут быть использованы для прогноза результатов
возможных изменений до их фактического внесения в реальную систему.
Контрольные задачи, вероятно, являются наиболее широко используе-
мым (как организациями, так и отдельными пользователями) инструмен-
том при выборе приобретаемого оборудования от нескольких конкурирую-
щих производителей. Их популярность в качестве такого средства привела
к необходимости определения промышленного стандарта контрольных за-
дач. Группа SPEC была основана в 1988 году для оказания содействия
в разработке стандарта контрольных задач. Ею опубликован ряд контроль-
ных задач (так называемых SPEC-тестов (SPECmark)), которые могут ис-
пользоваться для оценки широкого диапазона систем (от серверов до вир-
туальных машин Java). Она также регулярно публикует полученные с их
помощью результаты (рейтинги) для тысяч серийно выпускаемых систем.
Рейтинг SPEC полезен для принятия обоснованного решения при покупке
компонентов вычислительной системы. Однако в первую очередь необхо-
димо определить назначение каждого SPEC-теста при оценке определен-
ной системы. Например, набор контрольных задач SPECweb выполняет изме-
рение производительности систем, включающих работающий Web-сервер,
и не должен использоваться для оценки систем с другой конфигурацией/
Если режим работы определенного Web-сервера отличается от «типового»,
рейтинг SPEC может оказаться несостоятельным. Более того, в отношений
некоторых SPEC-тестов были высказаны критические замечания, касаю-
щиеся узкого диапазона применения. Причина этих высказываний состоя-
ла в попытке ряда исследователей рассматривать «типовую» рабочую
грузку как точное приближение реальной рабочей нагрузки выбранной
системы. Для снятия данных ограничений SPEC непрерывно дорабатывает
собственные наборы контрольных задач, улучшая их соответствие соврб'
менным системам.30’31
Несмотря на то, что SPEC выпускает множество широко известных набо-
ров контрольных задач, существует ряд других популярных тестов и орга
низаций, занятых их разработкой. ВАРСо выпускает несколько наборой’
включая SYSmark (для настольных систем), MobileMark (для систем, Уста
навливаемых на мобильные устройства) и WebMark (для Internet-npnno^6*
867
зводительность и архитектура прочее в
цЙ)-32 Среди других популярных наборов контрольных задач следует на-
;рать Transaction Processing Performance Council (TPC), используемый для
30СТем с базами данных,33 и Standard Application (SAP), предназначенный
1 аЯ оценки масштабируемости систем.34
Вопросы для самопроверки
1. Каким образом наборы контрольных задач могут быть использова-
ны для прогнозирования результатов вносимых в систему измене-
ний?
2. Почему не существует универсального «стандартного» набора кон-
трольных задач?
Ответы 1) В общем случае применение наборов контрольных задач
эффективно только в случае определения результатов фактически вне-
сенных изменений или для сравнения производительности двух сис-
тем, но не для прогнозирования эффекта от предлагаемых изменений
системы. Однако если предлагаемые изменения соответствуют конфи-
гурации какой-либо существующей системы, то результаты выполне-
ния набора контрольных задач на данной системе и составят требуемый
прогноз. 2) Контрольная задача представляет собой реальную програм-
му, выполняемую в конкретной вычислительной среде, но каждая вы-
числительная машина может включать свое аппаратное обеспечение
и выполнять различные наборы программ. Поэтому разработчики кон-
трольных задач предусматривают типовые наборы приложений, кото-
рые регулярно модернизируются с целью улучшения соответствия
определенным конфигурациям.
14.5.6 Синтетические программы
Синтетические программы (synthetic program), называемые также син-
тетическими контрольными задачами (synthetic benchmark), подобны на-
борам контрольных задач, но ориентированы на исследование отдельных
компонентов системы, например подсистемы ввода-вывода или запоми-
нающей подсистемы. В отличие от контрольной задачи, которая представ-
ляет собой типовую (не специализированную) реальную программу, синте-
тический тест формируется с определенной целью (назначением). Напри-
мер, такой тест может предназначаться для исследования отдельного
компонента операционной системы (скажем, файловой системы) или для
выяснения частот использования отдельных инструкций в большом наборе
программ. Одним из преимуществ синтетических программ является то,
Что они позволяют изолировать определенный компонент и не тестировать
всю систему в целом.35, 36, 37, 38, 39
Синтетические тесты полезны в процессе разработки. Как только новая
Функциональность системы становится доступной, можно воспользоваться
синтезированной программой для проверки работоспособности этой функ-
циональности. К сожалению, эксперты, не всегда располагают достаточным
временем для кодирования и отладки синтетических тестов, и зачастую
°тЬ1скивают уже существующую контрольную задачу, наиболее соответст-
вующую исследуемой характеристике. Возможно также использование син-
тетических программ в сочетании с наборами контрольных задач и задача-
ми Микроуровня для всесторонней оценки системы. Три названных подхода
Рассматривают различные уровни абстракции (система в целом, отдельный
ц
компонент системы и базовая операция) и вместе обеспечивают эксперта
формацией о производительности как системы в целом, так и ее отдельна]
составляющих.
Синтетические программы Whetstone и Dhrystone являются классиче
скими примерами такого рода тестов. Whetstone измеряет, насколько эф
фективно система выполняет вычисления с плавающей запятой, и, тащц.
образом, представляет ценность при исследовании научных программ
Dhrystone измеряет эффективность выполнения системных программ ца
заданной архитектуре. Поскольку Dhrystone занимает малый объем памя.
ти, ее эффективность особенно чувствительна к размеру кэша процессора-
если данные и код Dhrystone помещаются в кэш, тест выполняется значц'
тельно быстрее по сравнению с ситуацией, когда процессор должен обра-
щаться к оперативной памяти. Фактически, поскольку Dhrystone помеща.
ется в кэш большинства современных процессоров, данный тест измеряет
тактовую частоту процессора и не отображает эффективность подсистемы
управления памятью. Одной из широко используемых сегодня синтетиче-
ских программ является WinBench 99, которая позволяет тестировать гра-
фическую подсистему, диски и видеосистему в среде Microsoft Windows.40
Другие популярные синтетические контрольные задачи: lOStone (для тес-
тирования файловых систем),41 Hartstone (для систем реального време-
ни)42 и STREAM (для подсистем памяти).43
Вопросы для самопроверки
1. Поясните причины использования синтетических программ в про-
цессе разработки вычислительных систем.
2. Может ли синтетическая программа самостоятельно использовать-
ся для оценки производительности? Почему?
Ответы 1) Синтетический тест может быть довольно быстро напи-
сан и использован для тестирования разрабатываемой функционально-
сти. 2) Нет. Синтетические тесты представляют собой «искусственные»
программы, предназначенные для тестирования определенного компо-
нента или функциональности большого набора программ (но не одной
программы в отдельности). Следовательно, хотя такие тесты и генери-
руют определенные результаты, они не обязательно описывают, на-
сколько эффективно система в целом будет выполнять реальные
приложения. Обычно синтетические тесты используются в сочетании
с другими методами оценки производительности.
14.5.7 Моделирование
Моделирование (simulation) представляет собой подход, при котором ^экс-
перт разрабатывает компьютерную модель исследуемой системы.44’ 45-
Эксперт тестирует модель, моделирующую исследуемую систему, для полу46'
ния данных о производительности данной системы.
Моделирование позволяет создать модель еще не существующей систе
мы и исследовать поведение проектируемой системы в некоторых условй^
ях. Несомненно, результаты моделирования в итоге должны быть подтвер
ждены (validate) контролем параметров работы реальной системы. МоД6
лирование может обнаружить проблемы на ранних этапах разрабо^14
системы. Компьютерное моделирование стало особенно популярным в к°с
.^ческой промышленности и транспорте, поскольку выход из строя систе-
му в данных отраслях может привести к серьезным последствиям.
Программы моделирования делятся на две разновидности:
• Управляемые событиями (event-driven simulator) — процесс модели-
рования в такой программе управляется событиями, генерируемыми
в соответствии с указанным распределением вероятностей.
• Управляемые сценариями (script-driven simulator) — процесс моде-
лирования в такой программе управляется данными, тщательно по-
добранными для отображения ожидаемой конфигурации моделируе-
мой системы; эксперт получает эти данные на основе эмпирических
наблюдений.
Моделирование требует высокой квалификации эксперта и значитель-
ного времени вычислений. Программы моделирования в общем случае
формируют огромные наборы результирующих данных, требующих тща-
тельного анализа. Однако если программа моделирования разработана,
она может эффективно и выгодно неоднократно использоваться.
Как и в случае аналитических моделей, затруднительно выполнить точ-
ное моделирование сложной системы. Некоторые характерные ошибки яв-
ляются причиной большей части погрешностей. Ошибки в программе мо-
делирования, безусловно, приведут к ошибочным результатам в оценке
производительности. Даже тщательно продуманные умолчания, которые
ставят целью необходимое упрощение программы моделирования, также
могут привести к недействительным результатам. В этом состоит большая
часть проблем простых программ моделирования. Сложные программы
моделирования дополнительно страдают от недостаточной детализации.
Такие программы пытаются моделировать все части системы, но они, ко-
нечно, не могут промоделировать все с одинаковой точностью. Сопутст-
вующие ошибки также могут снижать эффективность моделирования. Та-
ким образом, для получения достоверных оценок производительности,
важно подтвердить результаты моделирования данными, полученными на
реальной системе.50
Вопросы для саллопроВерки
1. Какое моделирование — событийное или управляемое сценария-
ми — обеспечивает получение более устойчивых результатов?
2. (Да/Нет) Сложные программы моделирования всегда более эффек-
тивны, чем простые.
ОтВеты 1) Программы, управляемые сценариями, формируют
почти идентичные результаты при каждом запуске, поскольку систе-
ма моделирования использует одни и те же входные данные. Событий-
ные программы моделирования динамически генерируют входные
данные на основе распределения вероятностей, и, следовательно, фор-
мируемые ими результаты меньше повторяются. 2) Нет. Несмотря на
то, что сложные моделирующие программы пытаются наиболее полно
промоделировать систему, они не обеспечивают требуемой точности.
"°______________.hah tl
14.5.8 Мониторинг производительности
Мониторинг производительности представляет собой сбор и анализ инфоь
мадии о производительности существующих систем.51, 52> 53 Мониторинг
жет помочь при определении таких показателей производительности
пропускная способность, время отклика и предсказуемость. Мониторинг про
изводительности может быстро определить причину неэффективности и ц0
мочь системному администратору найти способ повысить системную произво
дительность.
Пользователи могут выполнять мониторинг производительности как
программными, так и аппаратными средствами. Программные мониторы
могут искажать данные о производительности системы, поскольку сами яв-
ляются потребителями системных ресурсов. Известными примерами про-
граммных мониторов производительности являются Диспетчер задач (Task
manager) Microsoft Windows54 и файловая система proc в Linux55 (см. раз-
дел 20.7.4). Аппаратные мониторы, как правило, являются более дорого-
стоящими, но при этом они очень слабо либо вообще не влияют на систем-
ную производительность. Многие современные процессоры располагают
счетными регистрами, используемыми для мониторинга производительно-
сти путем подсчета событий, включая такты синхрогенератора, TLB-прома-
хи и операции с памятью (например, запись в основную память).56
В общем случае мониторы генерируют огромный объем данных, кото-
рый необходимо проанализировать, возможно, используя большой объем
вычислительных ресурсов. Однако полученные сведения точно показыва-
ют, каким образом система функционирует, поэтому данная информация
является ценной. Сказанное особенно актуально для инструментальных
сред, где результаты наблюдения за работой системы могут послужить ос-
новой для принятия ключевых проектных решений.
Трассы выполнения инструкций или модулей помогут определить наи-
более часто используемые компоненты системы. Трассировка выполнения
на модульном уровне может показать, например, что большую часть вре-
мени используется незначительное подмножество модулей. Если разработ-
чики сконцентрируют свои усилия на оптимизации именно этих модулей,
они смогут повысить производительность системы, не затрачивая силы
и ресурсы на усовершенствование редко используемых частей системы.
На рисунке 14.1 приведен обзор методов оценки производительности.
Вопросы для самопроверки
1. Почему программные мониторы оказывают большее влияние на ис-
следуемую систему, чем аппаратные?
2. Поясните важность мониторинга производительности.
Ответы 1) Программные мониторы производительности занимав4
системные ресурсы, которые были бы выделены приложениям, работу
которых эти мониторы оценивают. Данный факт является причине
неточности получаемых данных о производительности. Аппаратны
мониторы работают параллельно с системным аппаратным обеспечени
ем, так что измерения не влияют на производительности исследуемо
системы. 2) Мониторинг производительности позволяет системным w*
министраторам обнаружить неэффективность, анализируя даннЫ •
описывающие функционирование системы.
/зВодительность и архитектура процессоров
Метод
Трассировка
Профилирование
Хронометраж
Контрольные задачи микроуровня
Оценка относительно приложения
Аналитическое моделирование
Набор контрольных задач
Синтетический тест
Моделирование
Мониторинг производительности
Описание
Протоколирование запросов реального приложения
к операционной системе, характеризующее рабочую
нагрузку в системе
Протоколирование действий ядра в течение определенной
сессии. Характеризует относительное использование базовых
операций системы
Необработанные результаты измерений аппаратной
производительности, которые могут быть использованы для
быстрого сравнения родственных систем
Необработанные результаты измерений скорости
выполнения операционной системой отдельной операций
Оценка, определяющая степень эффективности выполнения
системой конкретного приложения
Метод, подразумевающий построение и анализ
математической модели вычислительной системы
Программа, обладающая типовыми характеристиками
программ, выполняемых на исследуемой системе.
Используется для сравнения систем
Программа, выделяющая показатели производительности
определенного компонента операционной системы
Метод, использующий вычислительную модель исследуемой
системы. Результаты моделирования должны быть
подтверждены измерениями на реальной вычислительной
системе
Оперативная оценка системы, выполняемая с момента ее
установки, позволяющая администраторам выяснить степень
соответствия системы поставленным требованиям
и определить, какие параметры производительности требуют
улучшения
Рис. 14.1. Обзор методов оценки производительности
14 6 Узкие места и насыщение
Операционные системы управляют набором ресурсов, взаимодействую-
щих и согласовывающих свои действия с помощью сложных механизмов.
Время от времени отдельные ресурсы становятся узким местом
(bottleneck), ограничивающим суммарную производительность системы,
Поскольку решают свои задачи медленнее других ресурсов. В то время, ко-
гДа другие системные ресурсы испытывают недогрузку, ресурсы, ставшие
Узким местом системы, не успевают передавать им задания достаточно бы-
стро для их полноценной эксплуатации. 57> 58> 59
Некоторый ресурс может стать узким местом, если его рабочая нагрузка
н8чинает приближаться к расчетной. В этом случае говорят, что ресурс
®Ходит в состояние насыщения (saturation) — т.е. процессы конкурируют
За начало обслуживания, мешая друг другу, поскольку каждый из них
Должен ожидать освобождения ресурса другим процессом.60 Классическим
^Римером является пробуксовка системы виртуальной памяти (см. гла-
orx.
Глава /<*
ВУ 11)- Данное явление имеет место в системе страничной подкачки в сц.
туации, когда основная память перегружена, и рабочие наборы всех актцв.
ных процессов не могут быть в ней размещены одновременно. Активный
процесс мешает использованию памяти другим процессом, вынуждая сис-
тему сбрасывать на диск рабочие наборы страниц некоторых процессов
с целью освобождения пространства памяти для его рабочего набора. На-
сыщение можно обойти, снизив нагрузку на систему. Например, пробук.
совка памяти может быть снята путем временной приостановки некритич-
ных, не интерактивных процессов, если такие процессы существуют.
Каким образом можно обнаружить узкие места? Данная задача решает-
ся достаточно просто путем мониторинга очередей запросов к каждому из
ресурсов. Если очередь начинает быстро увеличиваться, это означает, что
частота поступления запросов (arrival rate) ресурса выше, чем его интен-
сивность обслуживания (service rate), другими словами, ресурс входит
в насыщение.
Исключение узких мест является важной частью настройки системы.
Узкое место может быть удалено путем увеличения мощности ресурса, до-
бавлением дополнительных ресурсов того же типа в систему, или, наобо-
рот, — путем снижения нагрузки на определенный ресурс. Удаление узко-
го места не всегда приводит к повышению пропускной способности, по-
скольку в системе могут проявиться другие узкие места. Настройка
системы часто включает выявление и удаление узких мест до тех пор, пока
производительность системы не достигнет достаточного уровня.
Вопросы для самопроверки
1. Почему важно определить узкие места в системе?
2. Следствием насыщения какого ресурса является пробуксовка? Как
операционная система может определить наличие пробуксовки?
Ответы 1) Выявление узких мест позволяет разработчикам скон-
центрировать усилия на оптимизации тех разделов системы, которые
ответственны за потерю производительности. 2) Основной памяти. Опе-
рационная система должна обратить внимание на высокую частоту за-
мещения страниц — страницы, которые были вытеснены для
освобождения места, через короткое время вновь загружаются в основ-
ную память.
14.7 Обратные связи
Обратная связь (feedback loop) представляет собой механизм, в рамках
которого информация о текущем состоянии системы оказывает влияние на
частоту поступления запросов. Запросы могут быть перенаправлены, если
обратная связь сигнализирует о том, что система испытывает трудности по
их обработке. Обратная связь может быть отрицательной, если она ведет
к снижению частоты поступающих запросов, или положительной, если
она ведет к увеличению числа поступающих запросов в единицу времени-
Несмотря на то, что ниже выделены два подраздела, рассматривающие от-
рицательную и положительную обратную связь отдельно, с точки зрения
стельность и архитектура процессоров
873
еализации эти категории не различаются. Более того, частота поступле-
ния запросов к тому или иному ресурсу может использоваться для органи-
ации как положительной, так и отрицательной обратной связи.
/4.7./ Отрицательная обратная связь
В случае отрицательной обратной связи (negative feedback) частота по-
ступления новых запросов может быть снижена по результатам измере-
ний. Например, автомобилист, подъехавший к заправочной станции, и за-
стивший, что около каждого насоса выстроилась очередь ожидающих ав-
томобилей, может принять решение проехать далее по улице к менее
загруженной заправке.
В распределенных системах часто можно выполнить распечатку данных
на одном из нескольких одинаковых серверов печати. Если к одному из
серверов выстроилась достаточно длинная очередь, новое задание может
быть перемещено в более короткую очередь.
Отрицательная обратная связь способствует устойчивости (stability)
систем обслуживания запросов. Если планировщик, не задумываясь, ста-
нет направлять поступающие задания на загруженное устройство, очередь
к этому устройству может расти, даже если другие аналогичные устройст-
ва будут недогружены.
Вопросы для самопроверки
1. Поясните, каким образом отрицательная обратная связь может
улучшить производительности операции чтения в RAID первого
уровня (зеркальное отображение).
2. Почему отрицательная обратная связь способствует устойчивости
системы?
Ответы 1) Если к одному из дисков зеркального набора выстрои-
лась длинная очередь запросов на чтение, часть этих запросов может
быть перенаправлена к другому диску (если очередь к нему короче).
2) Отрицательная обратная связь предотвращает перегрузку одного
из ресурсов заданиями при одновременном простое идентичных ему
других.
14.7.2 Положительная обратная связь
В случае положительной обратной связи (positive feedback) частота по-
ступления новых запросов может быть увеличена по результатам измере-
ний. Классическим примером является мультипроцессорная система с вир-
туальной памятью страничной организации. Предположим, операционная
система определила, что некоторый процессор недогружен. Система отдает
Распоряжение планировщику процессов направить большее число процес-
сов в очередь к данному процессору, в предположении, что нагрузка на дан-
ный процессор возрастет. С ростом числа выполняемых процессов уменьша-
ется объем памяти, выделяемый каждому из них, и» следовательно, возрас-
тает число страничных промахов (поскольку рабочие наборы всех процессов
°ДНовременно не помещаются в оперативной памяти). Коэффициент исполь-
зования процессора в результате уменьшается по причине пробуксовки сис-
874
Глава ц
темы. Неудачно спроектированная операционная система может приндть
решение назначить данному процессору еще несколько процессов, что, без
условно, приведет к дальнейшему снижению показателя его использование
Разработчики операционных систем должны быть внимательны дрё
проектировании механизмов, работающих по принципу положительно^
обратной связи, для предотвращения неустойчивых ситуаций, аналоги^,
ных описанной. Влияние каждого изменения в сторону увеличения долэк,
но отслеживаться для подтверждения получения ожидаемого результата
Если некоторое изменение привело к снижению производительности, это
означает, что операционная система вошла в зону нестабильности, и стра.
тегии выделения ресурсов должны быть изменены для возврата в состоя-
ние устойчивости.
Вопросы для самопроверки
1. В некоторых больших серверных системах пользователи направля-
ют запросы внешнему серверу, который направляет их внутренне-
му серверу для обработки. Каким образом внешний сервер может
обеспечить сбалансированную нагрузку нескольких одинаковых
внутренних серверов, используя обратную связь?
2. В разделе описана ситуация, в которой положительная обратная
связь привела к увеличению пробуксовки системы. Предложите ре-
шение данной проблемы.
Ответы 1) Внутренний сервер с длинной очередью запросов должен
организовать отрицательную обратную связь с внешним сервером,
а простаивающий внутренний сервер — положительную. Внешний сер-
вер может использовать данные, получаемые посредством этих обрат-
ных связей для посылки запросов к недогруженным серверам вместо
перегруженных. 2) Система может отслеживать число повторно загру-
жаемых страниц и отказать в назначении данному процессору дополни-
тельных процессов при возникновении пробуксовки.
14.8 Параметры производительности
и архитектура процессора
Эффективность системы в значительной степени зависит от производи-
тельности ее процессоров. Мысленно процессор может быть представлен
как совокупность системы команд (instruction set), т.е. машинных ко-
манд, выполняемых процессором, и аппаратуры, которая эти команды вы-
полняет. Система команд может состоять из небольшого числа базовых ко-
манд, выполняющих только элементарные функции, такие как загрУзка
из памяти в регистр либо сложение двух чисел. Альтернативно система ко-
манд может содержать избыточное множество более сложных команд,,та
ких как решение определенного полиномиального уравнения. Платой за
поддержку большого числа сложных команд является более сложное аПИа
ратное обеспечение, которое повышает стоимость процессора и может сН11
зить скорость выполнения простых команд; преимуществом является В
лее высокая скорость выполнения сложных программ.
^мзводительность и архитектура процессоров
875
Архитектура системы команд (instruction set architecture — ISA) про-
бора представляет собой интерфейс процессора, включающий систему
^оМанд, число регистров и объем памяти. ISA является аппаратным экви-
валентом API операционной системы. Несмотря на то, что конкретная ISA
е определяет аппаратную реализацию, элементы ISA непосредственно
дляют на конструкцию аппаратуры и, следовательно, в значительной сте-
пеНи воздействуют на производительность. Подходы к построению ISA
эволюционировали со временем. Данный раздел рассматривает сущест-
вуюЩие подходы и дает оценку того, каким образом проектное решение
1SA влияет на производительность.
Вопросы для самопроверки
1. Какие потенциальные достоинства и недостатки должны быть взве-
шены при включении в систему команд одиночных инструкций,
выполняющих сложные операции?
2. Почему важен выбор ISA?
Ответы 1) Недостатком включения таких команд является повы-
шение сложности аппаратного обеспечения, что может замедлить вы-
полнение более часто используемых инструкций; достоинством —
более быстрое выполнение сложных программ. 2) ISA определяет про-
граммный интерфейс между аппаратурой и низкоуровневым про-
граммным обеспечением; следовательно, архитектура системы команд
влияет на то, насколько легко может быть сгенерирован код для дан-
ного процессора, и какой объем памяти данный код будет занимать.
ISA также непосредственно влияет на аппаратную реализацию про-
цессора, в том числе на его стоимость и производительность.
14.8.1 Полный набор команд
До середины 80-х существовала определенная тенденция представлять
часто используемые фрагменты кода в виде отдельных инструкций на ма-
шинном языке, чтобы обеспечить более быстрое выполнение данных фраг-
ментов и упростить код на языке ассемблера. Такая логика была привлека-
тельной, судя по количеству ISA с весьма обширными наборами команд.
Этот подход был назван архитектурой с полным набором команд (complex
mstruction set computing — CISC), в некоторой степени в качестве ответа
аа известный термин архитектура с сокращенным набором команд
(reduced instruction set computing — RISC), рассматриваемый в следую-
щем разделе.62
CISC-процессоры появились в период, когда большинство системных
программ разрабатывалось на языке ассемблера. Система команд включа-
па инструкции, каждая из которых выполняла множество операций, по-
зволяя программистам, пишущим на ассемблере, создавать программы
Меньшего объема (в пересчете на строки кода), повышая собственную про-
изводительность труда. CISC-архитектура оставалась привлекательной
*’ При широком применении высокоуровневых языков программирования
'таких как С и C++ в исходных кодах UNIX), поскольку в наборы команд
Ь1ли добавлены специализированные инструкции для адаптации под тре-
°вания оптимизирующих компиляторов. Оптимизирующие компиляторы
Изменяют структуру оттранслированной программы (но не ее семантику)
i76.___________________________________________________________
для достижения более высокой производительности на заданной архитец
туре. CISC-команды отображают сложные операции языков высокого
уровня, а не простые операции, которые могут быть выполнены за одца
или два такта процессора. Такие системы сложных команд, как правило
реализуются в виде микропрограмм. Микропрограммирование представ’
ляет уровень программного обеспечения, расположенный ниже уровня ма.
шинных языков; данный уровень определяет реальные базовые операции
выполняемые процессором, такие как выборка команды из памяти (см. бо’
лее подробное описание в разделе 2.9). В CISC-архитектуре инструкции ма-
шинного языка интерпретируются и, таким образом, сложные команды
выполняются как последовательности более простых команд микропро.
граммы.63
CISC-процессоры стали еще более популярны в результате снижения
стоимости аппаратного обеспечения при одновременном росте затрат на
разработку программного обеспечения на языке ассемблера. CISC-процес-
соры стремились перенести сложность с программного обеспечения на ап-
паратное. Как побочный эффект, CISC-процессоры позволили уменьшить
размер программ, объем требуемой памяти и упростить отладку. Другой
особенностью некоторых CISC-процессоров была тенденция к сокращению
числа регистров общего назначения, снижению стоимости и увеличению
пространства, доступного остальным CISC-структурам, таким как дешиф-
ратор команд.64’ 65
Одним из мощных методов повышения эффективности, разработанным
в эру CISC-архитектуры, была организация конвейерной обработки (кон-
вейеризация). При конвейерной обработке информационный канал про-
цессора (т.е. узел процессора, выполняющий обработку данных) разделя-
ется на отдельные секции. В течение одного такта на каждой из секций мо-
жет выполняться одна инструкция, позволяя процессору одновременно
выполнять несколько команд. В начале 1960-х IBM разработала первый
конвейерный процессор — IBM 7030 (названный Stretch®, поскольку он
выражал попытку расширить возможности вычислительной техники).
Конвейер процессора 7030 состоял из четырех секций, разбивая отработку
команду на четыре этапа: выборка команды, декодирование команды, вы-
борка операндов и выполнение. Процессор одновременно выполнял одну
операцию, выбирал данные (операнды) для следующей, декодировал еще
одну операцию и выбирал из памяти четвертую. С началом каждого такта
процессора инструкции передвигались на следующую секцию конвейера,
что позволяло одновременно обрабатывать четыре инструкции и значи-
тельно повысить производительность.66-67-68
По мере того, как технология производства процессоров совершенство-
валась, размер кристалла и пропускная способность памяти утратили оп-
ределяющее значение. Более того, новые компиляторы легко выполняли
множество задач оптимизации кода, ранее решавшихся системой команд
CISC-архитектуры.69 Несмотря на это, CISC-процессоры остаются популяр'
ными во многих моделях персональных компьютеров; можно их найти
в некоторых высокопроизводительных компьютерах. Процессоры In
а Слово stretch на русский язык можно перевести как «растягивание, удлинение»
прим. ред. перев.
tfogumefibHoctnb и архитектура процессоров
n-ntilim (www. intel. com/products/desktop/processors/pentium4/) Advanced
\(icro Devices (AMD) Athlon (www.amd.com/us-en/Processors/Froductln-
'Ormation/0,, 30_118_756,00 .html) являются CISC-процессорами.
Вопросы для самопроверки
1. (Да/Нет) Широкое использование языков программирования высо-
кого уровня исключает необходимость использования сложных ин-
струкций.
2. Что послужило причиной появления идеи CISC-архитектуры?
Ответы 1) Нет. Дополнительные сложные инструкции были раз-
работаны для удовлетворения потребностям оптимизирующих компи-
ляторов высокоуровневых языков. 2) Первые операционные системы
были написаны преимущественно на языке ассемблера, поэтому при-
менение сложных инструкций упрощало программирование, позво-
ляя выполнить в рамках одной команды несколько операций.
14.8.2 архитектура процессоров с сокращенным набором команд
С развитием технологии производства аппаратного обеспечения и разра-
ботки компиляторов множество преимуществ CISC-процессоров оказались
несущественными. Кроме того, разработчики осознали, что микрокод, тре-
бующий интерпретации сложных инструкций, выполняется медленнее,
чем набор простых команд. Разнообразные исследования показали, что
значительное число программ, генерируемых распространенными компи-
ляторами, использует только небольшую часть набора команд, доступного
тому или иному процессору. Например, в исследованиях IBM отмечено,
что 10 наиболее часто исполняемых инструкций из сотен имеющихся в ар-
хитектуре System/370 (см. рис. 14.2) составляют две трети исполняемого
кода.70 Дополнительные инструкции, включенные в систему команд CISC
для сокращения времени разработки программного обеспечения, исполь-
зуются крайне редко. Простейшие с точки зрения реализации инструк-
ции, такие как обмен данными регистров с памятью (загрузка и сохране-
ние), являются наиболее часто используемыми.
Исследование IBM, ориентированное на статический анализ программ,
Написанных на языке ассемблера для IBM Series/1, предоставило дополни-
тельные доказательства того, что расширенная система команд CISC-архи-
тектуры может быть неэффективна. Проведенная работа показала, что про-
граммисты, работающие с расширенными машинными языками IBM
Series/1, склонны генерировать «семантически эквивалентные последова-
тельности инструкций». Авторы исследования резюмировали, что посколь-
ку такие последовательности сложно определить автоматически, то либо на-
бор инструкций должен быть сокращен, либо программисты должны огра-
ничивать себя в использовании инструкций.71 Данное исследование
предоставило неопровержимые доводы в пользу философии сокращенного
Набора команд (reduced instruction set computing — RISC). Данная филосо-
фия проектирования процессоров проповедует следующий принцип: архи-
текторы вычислительных устройств могут оптимизировать производитель-
ность, концентрируя свои усилия на том, чтобы сделать простые команды,
Такие как ветвление, загрузка и сохранение, более эффективными.72,73
RISC-процессоры выполняют основные команды эффективно благодад
реализации относительно небольшого числа инструкций, большинство ц
которых являются простыми и могут быть выполнены быстро (т.е. за од^
такт процессора). Это означает, что большая часть сложности программ^
го обеспечения перекладывается с уровня аппаратного обеспечения
компилятор, что позволяет упростить RISC-процессоры и оптимизировав
их для небольшой системы команд. Более того, управляющее устройства
RISC-процессора реализуется аппаратно, что снижает накладные расходы
на выполнение по сравнению с микрокодом. RISC-инструкции, занимаю,
щие в памяти слова фиксированной длины, декодируются быстрее и про.
ще, чем инструкции переменной длины. Кроме того, RISC-процессоры пы-
таются уменьшить количество обращений к основной памяти за счет ис-
пользования множества высокоскоростных регистров общего назначения
позволяющих программам манипулировать данными.74
Код операции Операция % исполнений
ВС Branch Condition - условное ветвление 20,2
L Load — загрузка 15,5
ТМ Test Under Mask - маскированная проверка 6,1
ST Store - сохранение 5,9
LR Load Register - загрузка регистра 4,7
LA Load Address — загрузка адреса 4,0
LTR Test Register — тест регистра 3,8
BCR Branch Register - ветвление по регистру 2,9
МУС Move Character — пересылка символа 2,1
LH Load Half Word — загрузка полуслова 1,8
Рис. 14.2. Десять наиболее часто выполняемых инструкций архитектуры IBM
System/370.75 (По данным корпорации International Business Machines.)
Поддержка только простых команд фиксированной длины позволяет
RISC-процессорам более эффективно, чем процессорам с CISC-архитекту-
рой, использовать конвейер. Конвейерное выполнение на CISC-архитекту-
ре может быть замедлено по причине длительной обработки сложных ин-
струкций; что приводит к простою секций конвейера, занятых обработкой
простой команды. Кроме того, конвейер CISC-процессора часто содержит
. множество секций и требует сложного аппаратного обеспечения для под-
держки инструкций переменной длины. Конвейер RISC-процессора вклю-
чает небольшое число секций и относительно прост в реализации, посколь-
ку большинство инструкций выполняются в течение одного такта.76
Простой и остроумный метод оптимизации, используемый во многих
RISC-процессорах, называется отсроченным ветвлением (delayed bran
ching).77’ 78 При выполнении условного перехода следующая (после про
верки условия) выполняемая инструкция зависит от значения проверяем10
го условия. Отсроченное ветвление позволяет начать выполнение следУ10
щей (за операцией ветвления) инструкции независимо от результа
проверки, и в том случае, если переход не состоялся, ее выполнение пр°
\Водительность и архитектрра процессоров_______
[ дается, в противном случае, прерывается. Оптимизирующие компиля-
^пЫ RISC-процессоров часто переставляют машинные инструкции так,
1 обы операции вычисления (выполняемые независимо от результатов
ЕфЛения) были расположены непосредственно за инструкцией ветвле-
3Jl5j. Поскольку ветвления происходят гораздо чаще, чем многие могут
ебе представить (каждая пятая инструкция для наиболее распространен-
ЫХ архитектур), данный подход обеспечивает существенное повышение
производительности.79 В работе Лилья был проведен всесторонний анализ
отсроченного ветвления и некоторых других методов, позволяющих значи-
тельно снизить так называемые издержки ветвлений (branch penalty)
‘ конвейерных архитектурах.80
Наиболее значительным недостатком RISC-философии является то, что
ее простой, сокращенный набор команд и архитектура с множеством реги-
стров, повышают трудоемкость переключения контекста.81 RISC-архитек-
тура должна сохранять большое количество регистров в основной памяти
при переключении контекста, что снижает эффективность данной проце-
дуры по сравнению с CISC-архитектурой вследствие роста числа обраще-
ний к памяти. Поскольку переключение контекста представляет собой на-
кладные расходы в чистом виде и выполняется достаточно часто, увеличе-
ние числа регистров ощутимо снижает системную производительность.
В дополнение к увеличению времени переключения контекста,
у RISC-архитектуры имеется еще один недостаток. В одном интересном ис-
следовании было проанализировано влияние сложности инструкций на
производительность на примере трех подмножеств команд VAX-компьюте-
ров с возрастающей сложностью. Были сделаны следующие выводы:82
1. Программы, написанные для простейшего из рассмотренных наборов
команд, требовали в 2,5 раза больше памяти по сравнению с програм-
мами, написанными для сложного набора.
2. Процент промахов при обращении к кэшу значительно больше для
программ, использующих простейший набор команд.
3. Объем передаваемых по шине данных для программ, использующих
простейший набор команд, приблизительно вдвое превышает данный
показатель для программ, использующих наиболее сложный набор
команд.
Данные результаты и аналогичные им показывают, что использование
^ISC-архитектуры может привести к отрицательным последствиям.
Операции с плавающей запятой выполняются быстрее на CISC-архитек-
тУ₽е. Кроме того, CISC-процессоры более производительны при запуске
гРафических или научных программ, в которых часто выполняются слож-
ные операции. Программное обеспечение данного типа эффективнее вы-
полняется на CISC-машинах с оптимизированными сложными операция-
ми по сравнению с аналогичными RISC-машинами.83
На рисунке 14.3 приведено сравнение характеристик архитектур CISC
11 RISC. Примерами RISC-процессоров являются UltraSPARC (www. sun. сот/
Processors), MIPS (www.mips . com), G5 (www. apple. com/powermac/specs.html).
880 Глава
Характеристика CISC-процессор RISC-процессор
Длина инструкции переменная, обычно от 1 до 10 байт постоянная, обычно 4 байта
Декодирование инструкции с помощью микрокода аппаратная
Число инструкций в системе большое (обычно несколько сотен) небольшое (обычно менее
команд включая множество сложных инструкций сотни)
Количество инструкций в одной программе незначительное число большое количество (часто на 20% превышает объем программы для CISC архитектуры)
Количество регистров общего назначения как правило, небольшое (например, восемь в процессоре Intel Pentium 4)84 большое (обычно 32)
Сложность на уровне аппаратуры на уровне компилятора
Возможности использования параллельного выполнения в конвейере ограниченные широкие
Основной принцип реализация как можно более полного набора команд оптимизация по скорости наиболее часто используемых инструкций
Рис. 143. Сравнение архитектур CISC и RISC
{ Вопросы для самопроверки
> 1. Почему RISC-процессоры используют конвейеры более эффективно
Н по сравнению с CISC-процессорами?
2. Почему переключение контекста в RISC-архитектуре является бо-
лее ресурсоемкой операцией по сравнению с CISC-архитектурой?
Ответы 1) RISC-инструкции имеют фиксированную длину и обыч-
но выполняются в течение одного такта, следовательно, распаралле-
лить такие команды на нескольких секциях конвейера относительно
просто. Переменная длина инструкций CISC-процессоров иногда при-
водит к простою части секций конвейера. 2) RISC-процессоры исполь-
зуют намного большее число регистров по сравнению
' с CISC-процессорами, что требует большего количества операций об-
мена данными с памятью в процессе переключения контекста.
| 1
14.83 Второе поколение RISC-процессоров
Параллельно с развитием CISC и RISC-процессоров было разработано
(и внедрено) множество независимых методов повышения производитель-
] ности отдельных элементов той и другой архитектуры.85, 86> 87 Часть дан-
I ных методов повысила сложность набора команд либо переместила опти-
j мизацию производительности на уровень аппаратуры. Такое сближение
| архитектур сделало менее четкой границу между архитектурами CISC
' и RISC. Подходы, появившиеся после распространения CISC и RISC-архи-
I тектур, были ориентированы на повышение производительности любым
1 возможным способом, и породили архитектуры, которые были названы
производительность и архитектура процессоров
архитектурами с быстродействующим набором команд (fast instruction
set computing — FISC) или «вторым поколением RISC-процессоров»
(post-RISC).88
Однако часть разработчиков осталась верна традиционной терминоло-
гии CISC и RISC. Они считают, что эти разновидности процессоров не были
объединены, аргументируя свое мнение тем, что термины CISC и RISC от-
носятся исключительно к архитектуре системы команд, а не к способу ее
реализации (т.е. дополнительная сложность аппаратного обеспечения не
имеет отношения к рассматриваемому вопросу). Далее, говорят они, основ-
ное различие состоит в том, что RISC-команды имеют фиксированную дли-
ну и выполняются, в основном, за один такт, что не характерно для
CISC-команд. Как показано в данном разделе, сближение архитектур
в значительной степени явилось результатом роста подобия сложности ап-
паратного обеспечения CISC и RISC-машин и расширения набора команд
в архитектуре RISC. Оба данных аспекта не являются центральными прин-
ципами архитектуры системы команд.89
Следующие подразделы описывают подходы, используемые вторым по-
колением RISC-процессоров для повышения производительности. Мы уви-
дим, что данные подходы приводят к росту сложности аппаратного обеспе-
чения процессоров, что влечет за собой рост стоимости и отход от принципа
RISC-архитектуры, заключающегося в сохранении простоты аппаратуры.
Суперскалярная архитектура
Суперскалярная архитектура (superscalar architecture) позволяет в те-
чение каждого такта параллельно выполнить более одной команды. Дан-
ная архитектура включает множество операционных блоков на едином
кристалле и до последнего времени преимущественно использовалась
в CISC-процессорах для снижения времени декодирования сложных ко-
манд. Сегодня суперскалярное выполнение можно обнаружить практиче-
ски во всех процессорах общего назначения, поскольку данный подход
обеспечивает повышение производительности. Например, процессоры
Pentium 4 и G5 используют суперскалярную архитектуру. Рассматривае-
мая архитектура включает сложную аппаратуру, обеспечивающую кон-
троль выполнения зависимых инструкций. Например, если процессор вы-
полняет операцию условного перехода, то инструкции, расположенные по-
сле ветвления, не будут выполнены до тех пор, пока не будет определено
значение условия ветвления.90, 91, 92
исполнение с изменением последовательности
Исполнение с изменением последовательности (out-of-order execution
(ООО)) представляет собой подход, в соответствии с которым во время вы-
полнения команды динамически переупорядочиваются с целью оптимиза-
ции производительности и выделения групп команд, которые могут быть
выполнены одновременно. Данный метод способствует организации кон-
вейерной и суперскалярной обработки, которые требуют от процессора или
компилятора определения групп независимых команд, допускающих па-
раллельное выполнение.93, 94
882
Глава ц
Как механизм, общий для CISC и RISC-архитектур, рассматриваемый
метод нарушает принцип RISC, выносящий оптимизацию на уровень ком.
пилятора. Исполнение с изменением последовательности требуем значи-
тельного дополнительного аппаратного обеспечения для определения зави-
симостей и обработки исключений. При возникновении и обработке ис-
ключительной ситуации процессор должен удостовериться, что программа
находится в том же состоянии, в котором она находилась бы при выполне-
нии без изменения последовательности операций.95> 96
Прогнозирование ветвления
При прогнозировании ветвления (branch prediction) процессор исполь-
зует эвристики для определения наиболее вероятного результата вычисле-
ния условия ветвления. Процессор помещает прогнозируемые для выпол-
нения инструкции в конвейер для немедленной обработки сразу же после
ветвления. Если прогноз окажется ошибочным, процессору придется уда-
лить весь прогнозируемый код из конвейера с потерей выполненной рабо-
ты. Такой исход ненамного хуже по сравнению с ожиданием конвейером
результата ветвления. Однако если прогноз оправдается, производитель-
ность возрастет, поскольку процессор сможет продолжить выполнение ин-
струкций непосредственно после ветвления. Для достижения высокой про-
изводительности на основе прогнозирования ветвления процессор должен
включать блок точного предсказания ветвления, повышающий сложность
аппаратуры.97’ 98
Встроенные операции с плавающей точкой и поддерэ/ска векторной обработки
данных
Многие современные процессоры включают встроенный исполнитель-
ный блок, называемый сопроцессором. Разработчики оптимизируют со-
процессоры для выполнения специфических операций, которые арифмети-
ко-логические устройства (АЛУ) обычного процессора выполняют медлен-
но. Сопроцессоры делятся на сопроцессоры операций с плавающей точкой
и векторные сопроцессоры. Векторные сопроцессоры выполняют вектор-
ные операции на наборах данных, применяя одни и те же действия к каж-
дому элементу набора (например, добавление единицы к каждому элемен-
ту одномерного массива). Размещение сопроцессора на одном кристалле
с процессором уменьшает задержку обмена данными между процессором
и сопроцессором, что, в свою очередь, ведет к резкому повышению скоро-
сти выполнения операций, но, к сожалению, также и к росту сложности
аппаратного обеспечения.99
Дополнительные редко используемые команды
Возможно, наиболее важным отклонением от принципов архитектуры
RISC в современных, так называемых RISC-процессорах является расши-
рение набора команд. При этом в систему команд стремятся включить ка-
ждую инструкцию, повышающую общую производительность, не обращая
внимания на сложность аппаратуры, требуемую для ее выполнения.100 На-
пример, процессор Apple PowerMac G5, на который многие ссылаются как
Производительность и ароситект ри процессоров ----
0а RISC-процессор, реализует на сотню больше инструкций, чем его пред-
шественник G3. Эти дополнительные команды предназначены для работы
с 128-разрядными целыми числами или для выполнения повторяющихся
операций на множестве блоков данных (в рамках векторной обработки). 101
СбпиЖение CISC и RISC-apxumekmyp
В то время как аппаратное обеспечение RISC-процессоров становилось
все сложнее, CISC-процессоры стали заимствовать некоторые компоненты
RISC-архитектуры. Например, современные CISC-процессоры зачастую
включают оптимизированное базовое подмножество наиболее употреби-
тельных команд, декодирование и выполнение которых выполняется с вы-
сокой скоростью, обеспечивая для данного подмножества производитель-
ность, сравнимую с RISC-процессорами. В сущности, процессор Intel
Pentium 4 перед передачей команд в исполнительный блок преобразует их
в последовательности простых микроопераций (micro-op) фиксированной
длины. Часто единственной причиной того, что некоторая сложная коман-
да присутствует в архитектуре CISC, является необходимость обеспечения
обратной совместимости с кодом, разработанным для более ранних версий
данного процессора. Таким образом, CISC-процессоры пользуются преиму-
ществами простых инструкций, характерных для RISC-архитектуры.
Вопросы для самопроверки
1. Несмотря на рост сложности дополнительного аппаратного обеспе-
чения, по каким основным характеристикам отличаются современ-
ные RISC-процессоры от CISC-процессоров?
2. (Да/Нет) RISC-процессоры становятся более сложными, тогда как
CISC-процессоры — более простыми.
Ответы 1) Большинство современных RISC-процессоров по-преж-
нему используют команды фиксированной длины, выполняемые в те-
чение одного такта. 2) Нет. RISC-процессоры действительно становятся
более сложными, но хотя CISC-процессоры и используют подходы
RISC-архитектуры, сложность их аппаратного обеспечения продолжает
расти.
14.8.4 Технология параллельной обработки команд с явным
параллелизмом {EPIC)
Такие подходы как суперскалярная архитектура, конвейерная обработ-
ка и выполнение с изменением последовательности позволили во втором
поколении RISC-процессоров использовать параллелизм. Стоимость аппа-
ратного обеспечения, требуемого для реализации данных подходов, воз-
растает с увеличением числа операционных блоков до неприемлемых раз-
меров. В результате разработчики компаний Intel и Hewlett Packard пред-
ложили новый проектный подход, названный технологией параллельной
обработки команд с явным параллелизмом (Explicitly Parallel Instruction
Computing — EPIC). Данный подход направлен на снижение сложности
аппаратного обеспечения процессора при обеспечении высокого уровня па-
раллелизма. Подход EPIC требует, чтобы компилятор, а не аппаратура, оп-
— — — —ГмВа
Как механизм, общий для CISC и RISC-архитектур, рассматриваемы^
метод нарушает принцип RISC, выносящий оптимизацию на уровень коц.
пилятора. Исполнение с изменением последовательности требуем значу,
тельного дополнительного аппаратного обеспечения для определения заву,
симостей и обработки исключений. При возникновении и обработке ис.
ключительной ситуации процессор должен удостовериться, что программа
находится в том же состоянии, в котором она находилась бы при выполне-
нии без изменения последовательности операций.95, 96
Прогнозирование ветвления
При прогнозировании ветвления (branch prediction) процессор исполь-
зует эвристики для определения наиболее вероятного результата вычисле-
ния условия ветвления. Процессор помещает прогнозируемые для выпол-
нения инструкции в конвейер для немедленной обработки сразу же после
ветвления. Если прогноз окажется ошибочным, процессору придется уда-
лить весь прогнозируемый код из конвейера с потерей выполненной рабо-
ты. Такой исход ненамного хуже по сравнению с ожиданием конвейером
результата ветвления. Однако если прогноз оправдается, производитель-
ность возрастет, поскольку процессор сможет продолжить выполнение ин-
струкций непосредственно после ветвления. Для достижения высокой про-
изводительности на основе прогнозирования ветвления процессор должен
включать блок точного предсказания ветвления, повышающий сложность
аппаратуры.97, 98
встроенные операции с плавающей точкой и поддержка векторной обработки
данных
Многие современные процессоры включают встроенный исполнитель-
ный блок, называемый сопроцессором. Разработчики оптимизируют со-
процессоры для выполнения специфических операций, которые арифмети-
ко-логические устройства (АЛУ) обычного процессора выполняют медлен-
но. Сопроцессоры делятся на сопроцессоры операций с плавающей точкой
и векторные сопроцессоры. Векторные сопроцессоры выполняют вектор-
ные операции на наборах данных, применяя одни и те же действия к каж-
дому элементу набора (например, добавление единицы к каждому элемен-
ту одномерного массива). Размещение сопроцессора на одном кристалле
с процессором уменьшает задержку обмена данными между процессором
и сопроцессором, что, в свою очередь, ведет к резкому повышению скоро-
сти выполнения операций, но, к сожалению, также и к росту сложности
аппаратного обеспечения.99
Дополнительные редко используемые команды
Возможно, наиболее важным отклонением от принципов архитектуры
RISC в современных, так называемых RISC-процессорах является расШи'
рение набора команд. При этом в систему команд стремятся включить ка-
ждую инструкцию, повышающую общую производительность, не обраЩаЯ
внимания на сложность аппаратуры, требуемую для ее выполнения.100 На
пример, процессор Apple PowerMac G5, на который многие ссылаются как
цВодительность и архитектура процессоров
003
а RISC-процессор, реализует на сотню больше инструкций, чем его пред-
,ественник G3. Эти дополнительные команды предназначены для работы
128-разрядными целыми числами или для выполнения повторяющихся
,)11ераций на множестве блоков данных (в рамках векторной обработки). 101
^риЖение CISC и RISC-apxumekmyp
В то время как аппаратное обеспечение RISC-процессоров становилось
вСе сложнее, CISC-процессоры стали заимствовать некоторые компоненты
plSC-архитектуры. Например, современные CISC-процессоры зачастую
рключают оптимизированное базовое подмножество наиболее употреби-
тедьных команд, декодирование и выполнение которых выполняется с вы-
сокой скоростью, обеспечивая для данного подмножества производитель-
ность, сравнимую с RISC-процессорами. В сущности, процессор Intel
Pentium 4 перед передачей команд в исполнительный блок преобразует их
в последовательности простых микроопераций (micro-op) фиксированной
длины. Часто единственной причиной того, что некоторая сложная коман-
да присутствует в архитектуре CISC, является необходимость обеспечения
обратной совместимости с кодом, разработанным для более ранних версий
данного процессора. Таким образом, CISC-процессоры пользуются преиму-
ществами простых инструкций, характерных для RISC-архитектуры.
Вопросы для самопроверки
1. Несмотря на рост сложности дополнительного аппаратного обеспе-
чения, по каким основным характеристикам отличаются современ-
ные RISC-процессоры от CISC-процессоров?
2. (Да/Нет) RISC-процессоры становятся более сложными, тогда как
CISC-процессоры — более простыми.
Ответы 1) Большинство современных RISC-процессоров по-преж-
нему используют команды фиксированной длины, выполняемые в те-
чение одного такта. 2) Нет. RISC-процессоры действительно становятся
более сложными, но хотя CISC-процессоры и используют подходы
RISC-архитектуры, сложность их аппаратного обеспечения продолжает
расти.
14.8.4 Технология параллельной обработки команд с явным
параллелизмом {EPIC)
Такие подходы как суперскалярная архитектура, конвейерная обработ-
ка и выполнение с изменением последовательности позволили во втором
Поколении RISC-процессоров использовать параллелизм. Стоимость аппа-
ратного обеспечения, требуемого для реализации данных подходов, воз-
растает с увеличением числа операционных блоков до неприемлемых раз-
меров. В результате разработчики компаний Intel и Hewlett Packard пред-
ложили новый проектный подход, названный технологией параллельной
°бработки команд с явным параллелизмом (Explicitly Parallel Instruction
Computing — EPIC). Данный подход направлен на снижение сложности
аппаратного обеспечения процессора при обеспечении высокого уровня па-
раллелизма. Подход EPIC требует, чтобы компилятор, а не аппаратура, оп-
ределял, какие команды могут быть выполнены параллельно. Рассматрц
ваемый подход использует параллелизм уровня команд (instruction-leve|
parallelism — ILP), основанный на наборе машинных команд, выполняе.
мых параллельно (т.е. машинные команды из данного набора выполняют,
ся независимо друг от друга).
Для поддержки параллелизма уровня команд EPIC использует разц0.
видность архитектуры компьютера с командными словами сверхболь,
шой длины (Very Long Instruction Word — VLIW).103 В рамках этой архи-
тектуры компилятор определяет, какие инструкции должны быть выпод.
йены параллельно, что позволяет упростить аппаратуру, оставляя болыце
пространства операционным блокам. Процессор Multiflow — первый ком-
пьютер с командными словами сверхбольшой длины — включал 28 опера-
ционных блоков, что значительно превышает параметры современных су-
перскалярных процессоров.104 Однако некоторые зависимости становятся
известными только во время выполнения (например, из-за операций ветв-
ления), а рассматриваемая архитектура строила путь выполнения про-
граммы до ее запуска, что ограничивало уровень параллелизма.105
EPIC позаимствовала идеи как VLIW, так и суперскалярной архитекту-
ры. EPIC-процессор помогает компилятору, обеспечивая предсказуе-
мость, — отказ от применения техники выполнения с изменением последо-
вательности (ООО) позволяет EPIC-компилятору выполнить оптимизацию
наиболее подходящего пути (или путей) выполнения. Однако компилятору
зачастую трудно оптимизировать все пути выполнения программы. Если
прогноз пути выполнения программы сделан некорректно, процессор вы-
полнит проверку правильности программы (например, путем проверки за-
висимости по данным).106
Типовые CISC и RISC-процессоры используют прогнозирование ветвле-
ния для вероятностного определения результата ветвления. ЕР1С-процес-
соры, напротив, параллельно выполняют все возможные операции, сле-
дующие за ветвлением, но используют только результат истинной ветви
после вычисления условного выражения — предиката (predicate).107 Дан-
ный метод называется предикацией ветвления (branch predication).
На рисунке 14.4 показано выполнение программы в EPIC-процессоре (а)
и в RISC-процессоре второго поколения (Ь). EPIC-компилятор генерирует
мультиоперационную команду (multi-op instruction), представляющую со-
бой пакет команд, выполняемых параллельно. Количество команд в пакете
определяется процессором. Процессор преобразует мультиоперационную
команду в ряд элементарных операций, выполняемых одновременно на не-
скольких операционных блоках. Поскольку EPIC-процессор содействует
компилятору путем предоставления гарантии предсказуемости, в нем не
выполняются изменения в последовательности команд, и соответствующий
аппаратный блок не нужен. На рисунке 14.4(b) RISC-процессор второго по-
коления анализирует поток выполняемых команд и переупорядочивает их
в поиске двух инструкций, которые могли бы выполняться одновременно-
Найденные операции процессор размещает в двух операционных блоках
(суперскалярной архитектуры) и выполняет одновременно.
Помимо повышения производительности за счет параллелизма,
EPIC-процессоры используют упреждающую загрузку (speculative loa-
ding) — метод, направленный на снижение задержек обращения к памяти-
Глава
VF' I __„ллгл тгГ
^ри оптимизации программного кода компилятор выполняет преобразова-
ние команды загрузки в операцию упреждающей загрузки с последующей
проверкой. Упреждающая загрузка извлекает из памяти данные для инст-
оукиии> выполнение которой только планируется в данный момент. Следо-
вательно, процессор может выполнить упреждающую загрузку до возник-
новения запроса к текущим данным. Контроль загрузки обеспечивает про-
I jepKy состоятельности данных, полученных при упреждающей загрузке
(т.е. проверку того факта, что значения, полученные при упреждающей за-
грузке, не были после этого модифицированы в памяти). Процессор может
работать с высокой эффективностью при условии контроля упреждающей
загрузки, устраняя большую часть затрат на обращение к памяти. Однако
если при контроле оказалось, что данные, полученные при упреждающей
загрузке, несостоятельны, процессор должен будет подождать до тех пор,
пока из памяти не будут загружены правильные данные.108
единичная
операция Ех
"единичная Ех Результат
Результат
результат
Кэш
команд
мультиоперационная
г.1 команда
результат
D
а)
единичная F
-*т>перация — г tx
—единичная —г Ех
операция
"единичная —— Ех —«- Результат
операция
единичная
операция
Рх —г Результат
ООО
Кэш
команд
Блок изменения
последовательности
операции
единичная
операция
единичная
операция
Ех
Результат
Результат
Ех
D Блок декодирования
мультиоперационной команды
рх Декодирование и выполнение
единичной операции
Ь)
Рис. 14.4. Выполнение команд в процессоре архитектуры EPIC (а)
и RISC-процессоре второго поколения (Ь)
ООО
Вопросы для самопроверки
1. Назовите причины появления подхода EPIC в проектировании пр0
цессоров.
2. Каким образом в архитектуре EPIC снижаются потери производи,
тельности при ветвлениях?
Ответы 1) Суперскалярная архитектура является плохо масшта-
бируемой, поскольку объемы требуемого аппаратного обеспечения
экспоненциально возрастают с увеличением дополнительных процес-
сорных блоков. Архитектура EPIC реализует попытку перенести
сложность на уровень компилятора для использования параллелизма
на уровне команд. 2) Компиляторы EPIC используют прогнозирование
ветвления для выполнения обеих возможных ветвей программы (по-
сле ветвления). После вычисления условия ветвления одна из ветвей
отбрасывается, а другая оказывается готовой к дальнейшему выполне-
нию.
Веб-ресурсы
www.opersys.com/LTT/
Представляет инструментарий трассировки для ОС Linux.
www.eecs.harvard.edu/~vino/perf/hbench
Содержит информацию о контрольных задачах микроуровня hbench. Сайт со-
держит ссылки на загружаемую копию набора контрольных задач, документацию
и публикации по соответствующей тематике.
www.specbench.org
SPEC является организацией, выполняющей разработку стандартов контроль-
ных задач. Данный сайт содержит описания ряда контрольных задач (SPECmark),
используемых для оценки различных систем, и публикации результатов тестов
данных задач на реальных системах.
http://www.veritest.com/services/benchmark.asp
Veritest предоставляет услуги по оценке вычислительных систем. На данной
странице web-сайта содержится информация о нескольких коммерческих наборах
сонтрольных задач и синтетических контрольных задачах.
arstechnica.com/cpu/4q99/risc-cisc/rvc-1.html
В статье рассматриваются RISC и CISC подходы к проектированию, а также
(ана характеристика RISC-процессоров второго поколения.
www.intel.com/products/server/processors/server/itanium/
Описание процессора Intel Itanium — одного из первых поступивших на рынок
'PIC-процессоров.
www.bapco.сот
ВАРСо — организация, разрабатывающая стандартные наборы контрольных
адач для процессоров (например, известный набор SYSmark). На web-сайте содер-
Рится подробное описание наборов контрольных задач.
I www.linuxjournal.org/article.php&sid=2396
Описание мониторинга производительности в Linux.
Итоги
Производительность системы в большой степени зависит от аппаратного обеспе-
чения, операционной системы и взаимодействия между ними. Громоздкое про-
раммное обеспечение является причиной низкой производительности системы,
построенной на мощном аппаратном обеспечении, поэтому важно наряду с произ-
водительностью аппаратуры рассматривать производительность программного
обеспечения.
Три наиболее общих случая оценки производительности: оценка при выборе,
прогнозирование производительности и мониторинг производительности. В каче-
стве показателей производительности могут быть названы оборотное время, время
отклика, время реакции системы, дисперсия времени отклика, пропускная спо-
собность и мощность. Некоторые результаты измерения производительности мо-
гут ввести в заблуждение, если оценка выполнялась при несоответствующей рабо-
чей нагрузке или для малой части системы.
Трассировка представляет собой запись действий системы — обычно регистра-
цию запросов пользователей и приложений к операционной системе. Профилиро-
вание выполняет запись действий системы при работе в режиме ядра. Данный под-
ход полезен при оценке системы, рабочая нагрузка которой в значительной степе-
ни определяется системной исполнительной средой.
Хронометраж позволяет выполнить быстрое сравнение аппаратного обеспече-
ния вычислительных систем. Хронометраж определяет, какое количество инст-
рукций в секунду может выполнить система. Аналогично, контрольные задачи
микроуровня позволяют эксперту выполнить быстрое сравнение операционных
систем (или систем в целом). Контрольные задачи микроуровня замеряют длитель-
ность выполнения определенных действий (например, создания процесса) опера-
ционной системой.
Оценка производительности относительно приложения позволяет определить
степень соответствия некоторой системы и некоторой конфигурации. Векторная
методология использует взвешенную среднюю величину результатов контрольных
задач микроуровня относительно рассматриваемого приложения. Гибридная мето-
дология дополнительно использует трассировку для определения относительных
весов каждой составляющей, учитываемой при расчете средней величины. Про-
грамма ядра представляет собой типовую программу, которая может быть выпол-
нена на заданной конфигурации системы; она выполняется «на бумаге» с исполь-
зованием временных оценок от производителя системы для выполнения отдель-
ных инструкций.
Аналитические модели являются математическим представлением вычисли-
тельных систем или их компонентов. К настоящему моменту накоплен большой
объем математических результатов аналитического моделирования, что позволяет
быстро и с высокой точностью выполнять оценку заданных вычислительных сис-
тем.
Контрольные задачи представляют собой программы, выполняемые для оценки
вычислительной системы. Ряд организаций разрабатывает контрольные задачи,
соответствующие промышленным стандартам и предназначенные для различных
систем. Эксперты используют результаты выполнения данных задач для сравне-
ния систем. Контрольные задачи должны обеспечивать повторяемость результа-
тов, соответствовать приложениям, выполняемым в исследуемой системе, и широ-
ко использоваться для обеспечения возможности сравнения исследуемых систем.
Синтетические программы ориентированы на исследование отдельных компо-
нентов системы; они могут быть написаны, к примеру, для исследования распреде-
ления частоты использования отдельных инструкций в большом наборе программ.
Синтетические тесты полезны в процессе разработки. Как только новая функцио-
нальность системы становится доступной, можно воспользоваться синтетической
программой для проверки работоспособности этой функциональности.
888
Глава iq
Моделирование представляет собой подход, при котором эксперт разрабатывает
компьютерную модель исследуемой системы. Выполнение процедуры моделирова
ния позволяет определить возможную производительность системы до этапа её
реализации.
Мониторинг производительности представляет собой сбор и анализ информц.
ции о производительности существующих систем. Некоторые ресурсы в опреде-
ленных ситуациях становятся узким местом системы, ограничивающим ее сум.
марную производительность, поскольку не могут эффективно выполнить возло-
женные на них задачи. Ресурс может войти в состояние насыщения, если це
обладает достаточной мощностью для обслуживания поступающих запросов. Об.
ратная связь представляет собой механизм, в рамках которого информация о теку,
щем состоянии ресурса (насыщен или используется недостаточно) оказывает влия-
ние на частоту поступления запросов к данному ресурсу. При отрицательной об-
ратной связи частота поступающих запросов в единицу времени будет снижена-
при положительной — увеличена.
Архитектура системы команд (instruction set architecture — ISA) процессора
представляет собой интерфейс процессора, включающий систему команд, чиело
регистров и объем памяти. ISA является аппаратным эквивалентом API операци-
онной системы.
В архитектуре CISC выражена тенденция включения в набор команд значитель-
ного числа инструкций, большая часть которых выполняется в течение несколь-
ких циклов процессора; длина инструкций может быть различной. Множество
реализаций CISC-архитектуры включает небольшое число регистров общего назна-
чения и сложное аппаратное обеспечение. Популярность CISC-процессоров объяс-
няется тем, что их применение способствует снижению стоимости памяти и облег-
чению ассемблерного программирования.
Архитектура RISC использует малый набор инструкций, причем практически
все они выполняются за один цикл процессора; длина инструкций фиксирована.
Реализации RISC-архитектуры характеризуются большим числом регистров обще-
го назначения и простым аппаратным обеспечением. Оптимизация набора команд
выполняется для наиболее часто используемых инструкций. Популярность
RISC-процессоров объясняется эффективной организацией конвейерной обработки
и исключением громоздкого аппаратного обеспечения, что привело к повышению
их производительности.
В настоящее время наблюдается сближение подходов к проектированию CISC
и RISC-архитектур, приведшее к появлению FISC-архитектур или второго поколе-
ния RISC-процессоров. Часть разработчиков осталась верна традиционной терми-
нологии CISC и RISC. В значительной степени сближение архитектур явилось ре-
зультатом повышения сложности аппаратного обеспечения и увеличения числа
команд в архитектуре RISC, а также появления оптимизированного набора инст-
рукций в CISC-процессорах.
Технология параллельной обработки команд с явным параллелизмом (EPIC) на-
правлена на расширение масштабируемости суперскалярной архитектуры.
EPIC-процессоры перекладывают на компилятор задачу определения последова-
тельности выполняемых команд и используют множество операционных блоков
для обеспечения высокого уровня параллелизма. EPIC-процессоры также снижают
затраты на доступ к основной памяти за счет выполнения упреждающей загрузки
данных (до выполнения загруженной инструкции). Процессор выполняет кон-
троль загрузки для обеспечения состоятельности предварительно загруженных
данных. Если при контроле оказалось, что данные, полученные при упреждающей
загрузке, несостоятельны, процессор должен подождать до тех пор, пока из памя-
ти не будут загружены правильные данные.
^ризбодительность и архитектура нроцессороВ
^ючевые термины
BiPS (billion instructions per second) — миллиард операций в секунду, единица
измерения, обычно используемая для оценки производительности отдельной
вычислительной системы; производительность в 1 BIPS означает, что процессор
может выполнить 1 миллиард операций в секунду.
Dhrystone — классическая синтетическая программа, измеряющая эффектив-
ность выполнения системных программ на определенной архитектуре.
flartstone — распространенный синтетический набор контрольных задач для
оценки систем реального времени.
hbench — распространенный набор контрольных задач микроуровня, позволяю-
щий эффективно выполнить анализ зависимостей между элементарными инст-
рукциями операционной системы и компонентами аппаратного обеспечения.
jOStone — популярный синтетический набор контрольных задач для оценки фай-
ловых систем.
Imbench — набор контрольных задач микроуровня, позволяющий выполнять из-
мерение и сравнение системной производительности для различных платформ
UNIX.
MIPS (millions of instructions per second) — миллион операций в секунду, едини-
ца измерения, обычно используемая при определении производительности от-
дельной вычислительной системы. Производительность в 1 MIPS означает, что
процессор может выполнить один миллион инструкций в секунду.
MobileMark — распространенный набор контрольных задач для оценки систем,
установленных на мобильных устройствах. Разработан Группой по оценке про-
изводительности бизнес-приложений (ВАРСо).
SAP (Standard Application) — распространенный набор контрольных задач, ис-
пользуемый для оценки системной масштабируемости.
SPEC-тест (SPECmark) — стандартный набор контрольных задач для тестирова-
ния вычислительных систем, разрабатываемый Группой по оценке системной
производительности (Standard Performance Evaluation Corporation — SPEC).
STREAM — популярная синтетическая контрольная задача для тестирования под-
системы памяти.
SYSmark — распространенная контрольная задача для настольных вычислитель-
ных систем. Разработана ВАРСо.
TIPS (trillion instructions per second) — триллион операций в секунду, единица
измерения, обычно используемая при определении производительности отдель-
ной вычислительной системы. Производительность в 1 TIPS означает, что про-
цессор может выполнить один триллион инструкций в секунду.
ТРС (Transaction Processing Performance Council) — популярная контрольная за-
дача, предназначенная для работы с системами баз данных. Разработана Сове-
том по вопросам производительности обработки транзакций.
WebMark — популярная контрольная задача для оценки производительности при-
ложений, использующих Интернет-технологии. Разработана ВАРСо.
Whetstone — классическая синтетическая программа, измеряющая параметры
выполнения системой операций с плавающей запятой. Полезна для оценки на-
учных программ.
W inBench 99 — распространенная синтетическая программа, которая позволяет
тестировать графическую подсистему, диски и видеосистему в среде Microsoft
Windows.
—"— -__________~ _____________________________________________Гмйдц
Абсолютный показатель производительности (absolute performance measure)
показатель эффективности, с которой вычислительная система достигает
ставленных целей, выражаемый в абсолютных величинах, например, перц0
времени, за который система решает определенную контрольную задачу. Сущ^
ствуют также относительные показатели производительности, предназначен
ные только для сравнения различных систем.
Аналитическая модель (analytic model) — математическое представление вычцс
лительной системы или компонента вычислительной системы для быстрой и от
носительно точной оценки ее производительности.
Архитектура компьютера с командными словами сверхбольшой длины (very
long instruction word — VLIW) — архитектура, при которой компилятор выбц.
рает, какие команды процессора будут выполнены параллельно, и упаковывает
их в единое командное слово большой длины. Компилятор гарантирует, что ца.
раллельно выполняемые команды не зависят друг от друга.
Архитектура с быстродействующим набором команд (fast instruction set
computing (FISC)) — термин, описывающий подход к проектированию процес-
соров, появившийся в результате слияния подходов RISC и CISC. Подход FISC
состоит в использовании любых конструктивных решений, повышающих про-
изводительность.
Архитектура с полным набором команд (complex instruction set computing —
CISC) — архитектура процессора, включающая расширенный набор команд, от-
дельные инструкции которого выполняют совокупности элементарных опера-
ций.
Архитектура с сокращенным набором команд (reduced instruction set
computing — RISC) — архитектура процессора с небольшим набором простых
команд, оптимизированным с точки зрения наиболее частого использования.
Архитектура системы команд (instruction set architecture — ISA) — интерфейс
процессора, включающий систему команд, число регистров и объем памяти.
Вектор приложения (application vector) — вектор, содержащий информацию о ко-
личестве запросов каждой элементарной инструкции операционной системы от-
дельным приложением. Используется при оценке производительности относи-
тельно приложения.
Векторная методология (vector-based methodology) — метод оценки производи-
тельности относительно приложения, основанный на вычислении взвешенной
средней величины результатов контрольных задач микроуровня для заданных
элементарных операций; веса определяются частотой обращения исследуемого
приложения к той или иной элементарной операции.
Время отклика (response time) — в интерактивных системах интервал времени от
нажатия пользователем клавиши Ввод (Enter) или щелчка мышью до момента
выдачи системой результирующего отклика.
Время реакции системы (system reaction time) — интервал времени от поступле-
ния задачи в систему до начала первого выделенного ей кванта времени.
Гибридная методология (hybrid methodology) — метод оценки производительно-
сти, объединяющий векторную методологию с данными трассировки для изме-
рения производительности относительно приложения, поведение которого
в сильной степени зависит от ввода пользователя.
Группа по оценке производительности бизнес-приложений (Business Application
Performance Corporation — BAPCo) — некоммерческая организация, разраба-
тывающая типовые контрольные задачи, такие как известный набор контроль-
ных задач SYSMark для процессоров.
группа по оценке системной производительности (Standard Performance Evalua-
tion Corporation — SPEC) — некоммерческая организация, разрабатывающая
стандартные наборы контрольных задач (например, SPECmarks), используемые
для оценки производительности различных систем. SPEC публикует результа-
ты тестовых прогонов контрольных задач на реальных системах.
дисперсия (dispersion) — характеристика разброса величины случайной перемен-
ной.
0здержки ветвлений (branch penalty) — потеря производительности в конвейер-
ной архитектуре, связанная с инструкциями ветвления; имеет место в том слу-
чае, когда процессор не может начать обработку команд, расположенных после
ветвления, до тех пор, пока не будет вычислен результат ветвления. Издержки
ветвления могут быть снижены за счет применения предикации ветвления, про-
гнозирования ветвления или отсроченного ветвления.
Интенсивность обслуживания (service rate) — скорость, с которой удовлетворяют-
ся запросы ресурса.
Исполнение с изменением последовательности (out-of-order execution (ООО)) —
подход, в соответствии с которым процессор анализирует поток команд и дина-
мически изменяет их порядок следования, выделяя группы независимых инст-
рукций для параллельного выполнения.
Контрольная задача (benchmark) — приложение, используемое экспертом для
оценки того, насколько эффективно исследуемая система выполняет данное
приложение; используется для сравнения систем.
Контрольные задачи микроуровня (microbenchniark) — инструментарий для
оценки производительности, используемый для измерения скорости выполне-
ния элементарных операций системы (например, создания процесса).
Математическое ожидание (expected value) — сумма ряда значений, каждое из ко-
торых умножено на собственную вероятность появления.
Микроперация (micro-op) — простая инструкция, аналогичная используемым
в архитектуре RISC; представляет собой разновидность инструкций, непосред-
ственно выполняемых процессором Pentium. Дешифратор команд Pentium пре-
образует сложные команды в последовательность микроопераций.
Моделирование (simulation) — метод оценки производительности, использующий
вычислительную модель исследуемой системы.
Мониторинг производительности (performance monitoring) — сбор и анализ ин-
формации о производительности реально существующей системы; информация
включает пропускную способность системы, время отклика, предсказуемость,
узкие места и т.п.
Мощность (capacity) — мера максимальной пропускной способности, достижимой
в системе, в предположении отсутствия в ней простоев.
Мультиоперационная команда (multi-op instruction) — командное слово, исполь-
зуемое в архитектуре EPIC, представляет собой пакет инструкций, выполняе-
мых параллельно.
Набор контрольных задач микроуровня (microbenchmark suite) — программа,
включающая несколько контрольных задач. Обычно используется для оценки
множества важных процессов операционной системы.
Настройка системы (system tuning) — процесс точной настройки системы, осно-
ванный на мониторинге производительности, выполняемый для оптимизации
работы системы в определенной рабочей среде.
Насыщение (saturation) — состояние ресурса, при котором его производитель-
ность не может быть увеличена для обработки поступающих запросов.
Оборотное время (turnaround time) — интервал времени от поступления задания
до завершения его выполнения.
Главц
Обратная связь (feedback loop) — механизм, в рамках которого информация о те
кущем состоянии системы может влиять на число запросов, поступаю^,
к тому или иному ресурсу (существуют петли положительной и отрицательной
обратной связи). :
Отклонение времени отклика (variance in response times) — разброс значений от
дельных величин времени отклика от среднего значения.
Отрицательная обратная связь (negative feedback) — механизм, в рамках которо.
го данные, информирующие систему о том, что ресурс не справляется с обеду
живанием поступающих запросов, заставляют процессор снизить частоту посту,
пления запросов для данного ресурса.
Отсроченное ветвление (delayed branching) — метод оптимизации, применяемый
в конвейерных процессорах, при котором компилятор размещает непосредст.
венно после ветвления те инструкции, которые должны быть выполнены неза-
висимо от ветвления. Процессор начинает обработку этих инструкций парад,
лельно с определением результата ветвления.
Оценка при выборе (selection evaluation) — оценка производительности, выпол-
няемая при принятии решения о целесообразности приобретения вычислитель-
ной системы или приложения конкретного производителя.
Параллелизм уровня команд (instruction-level parallelism — ILP) — параллелизм,
позволяющий выполнить две (не зависящие друг от друга) машинные команды
одновременно.
Подтвердить достоверность модели (validate a model) — означает доказать, что
компьютерная модель является точным отображением реальной системы, кото-
рую она представляет.
Положительная обратная связь (positive feedback) — механизм, в рамках которо-
го данные, информирующие систему о том, что некоторый ресурс имеет избы-
точную мощность, заставляют процессор увеличить частоту поступлений запро-
сов для данного ресурса.
Предикат (predicate) — логическое выражение, принимающее некоторое значение
в зависимости от входящих в него условий, используемое для принятия реше-
ния (например, для ветвления по результатам сравнения).
Предикация ветвления (branch predication) — метод, используемый в EPIC-npo-
цессорах, в соответствии с которым процессор параллельно выполняет все воз-
можные инструкции, следующие за ветвлением, но использует результат толь-
ко истинной ветви после вычисления условия ветвления.
Предсказуемость (predictability) — мера изменчивости некоторой величины, на-
пример, времени отклика. Предсказуемость особенно важна для интерактив-
ных систем, пользователи которых ожидают предсказуемого (или короткого)
времени отклика.
Прогноз производительности (performance projection) — оценка производительно-
сти проектируемой (реально не существующей) системы. Используется при при-
нятии решения о построении новой системы либо о модификации существу»'
щей.
Прогнозирование ветвления (branch prediction) — метод, в соответствии с кото-
рым процессор использует эвристики для определения наиболее вероятного Ре"
зультата ветвления в коде; если прогноз оказался правильным, производитель-
ность повышается, поскольку процессор может продолжать вычисления сразу
после ветвления.
Программа моделирования, ориентированная на события (event-driven
simulator) — процесс моделирования в такой программе управляется события
ми, генерируемыми в соответствии с указанным распределением вероятностей-
I ^оизводшпельность и архитектура процессоров
893
Программа моделирования, ориентированная на сценарий (script-driven
* simulator) — процесс моделирования в такой программе управляется данными,
тщательно подобранными для отображения ожидаемой конфигурации модели-
руемой системы; эксперт получает эти данные на основе эмпирических наблю-
дений.
Программа ядра (kernel program) — типовая программа, которая может быть за-
пущена на заданной конфигурации; выполняется «на бумаге» с использованием
временных параметров операций, определенных производителем и использует-
ся для оценки производительности относительно приложения.
Пропускная способность (throughput) — мера производительности, отражающая
количество заданий, выполненных за единицу времени.
Профиль, совокупность параметров (profile) — запись действий ядра, выполняе-
мая в ходе реальной сессии. Позволяет определить наиболее часто выполняемые
операционной системой действия, подлежащие оптимизации.
Рабочая нагрузка (workload) — мера количества работы, поступившей в систему;
эксперты определяют типовые рабочие нагрузки для системы и с их помощью
выполняют оценку параметров системы.
Рабочая программа (production program) — программа, которая регулярно выпол-
няется на данной инсталляции.
Распределение времени отклика (distribution of response times) — набор значений
времени отклика для задач в рассматриваемой системе с указанием относитель-
ной частоты получения каждого значения.
Семейство вычислительных систем (family of computers) — ряд программно-со-
вместимых вычислительных систем, т.е. способных выполнять одни и те же
программы.
Синтезированная контрольная задача (synthetic benchmark) — см. синтезирован-
ная программа.
Синтезированная программа (synthetic program) — специальная программа, ис-
пользуемая для оценки определенного компонента системы или сконструиро-
ванная для воспроизведения характеристик большого набора программ.
Система команд (instruction set) — набор машинных команд, которые процессор
способен выполнить.
Системный вектор (system vector) — вектор, состоящий из результатов прогона
контрольных задач микроуровня для ряда элементарных инструкций заданной
системы. Используется при оценке производительности относительно приложе-
ния.
Случайная переменная (random variable) — переменная, принимающая значения
из некоторого диапазона, причем каждое из значений обладает определенной
вероятностью появления.
Среднее значение (mean) — среднее значение набора величин.
Степень использования (utilization) — доля времени, в течение которого ресурс
используется.
Суперскалярная архитектура (superscalar architecture) — архитектура процессо-
ра, включающая множество операционных блоков и позволяющая параллельно
в течение одного цикла выполнять несколько команд.
Технология параллельной обработки команд с явным параллелизмом, техноло-
гия EPIC (Explicitly Parallel Instruction Computing (EPIC)) — подход к проекти-
рованию процессоров, целью которого является обеспечение высокой степени
параллелизма уровня команд, снижение сложности аппаратного обеспечения
процессора и повышение производительности.
Трассировка (trace) — запись последовательности действий системы, которая ис-
пользуется для анализа обработки системой заданной рабочей нагрузки.
Глава ц
Удобство использования (ease of use) — критерий (мера) удобства использования
системы.
Узкое место (bottleneck) — ресурс, замедляющий работу системы по причине не.
эффективного выполнения своих задач.
Упреждающая загрузка (speculative loading) — метод, при котором процессор за.
прашивает данные из памяти для инструкции, планируемой для выполнения
в ближайший момент. При выполнении инструкции процессор выполняет про-
верку состоятельности загруженных данных.
Устойчивость (stability) — особенность системы, функционирующей без ошибок
I или значительной потери производительности.
Хронометраж (timing) — непосредственное измерение параметров производитель-
ности выделенного аппаратного обеспечения, например, скорости выполнения
операций, используемое для быстрого сравнения систем.
Частота поступления запросов (arrival rate) — скорость поступления запросов ка-
кого-либо ресурса.
Упражнения
I 14.1.
j 14.2.
I
14.3.
I
I
14.4.
114.5.
14.6.
Г
14.7.
I
14.8.
14.9.
Поясните, почему мониторинг и оценка производительности системного
программного обеспечения также важны, как мониторинг и оценка произ-
водительности аппаратного обеспечения системы.
Некоторые ранние операционные системы, работавшие в режиме разделе-
ния времени, при регистрации пользователя печатали общее число зареги-
стрировавшихся пользователей.
а. Почему эта информация представляла для пользователя интерес?
б. В каких случаях данная информация не отражала реальную загрузку?
в. Какие факторы способствуют тому, чтобы данная информация соответ-
ствовала реальной загрузке системы, работающей в режиме разделения
времени с поддержкой множества пользователей?
Проведите краткое обсуждение следующих целей оценки производительно-
сти:
а. оценка при выборе;
б. прогнозирование производительности;
в. мониторинг производительности.
Что собой представляет настройка системы? Поясните ее важность.
Проведите различие между показателями производительности, ориентиро-
ванными на пользователя и на систему.
Дайте определение времени отклика системы. Для каких задач данный па-
раметр является более критичным: для ориентированных на вычисления
или на ввод-вывод? Поясните свой ответ.
Почему среднее значение для обсуждаемых в разделе случайных величин
может ввести в заблуждение?
Какие другие показатели производительности полезны для определения
того, насколько близко значения случайных величин расположены от их
среднего значения?
Почему предсказуемость является важным атрибутом вычислительных
систем.
Для каких типов систем предсказуемость особенно критична?
Ниже перечислены некоторые общие показатели производительности:
i. оборотное время;
ii. пропускная способность;
производительность и архитектура проче<л«1ппг _ _____
Hi. время отклика;
iv. рабочая нагрузка;
v. время реакции системы;
vi. производительность;
vii. отклонение времени отклика;
viii. степень использования.
Укажите для каждого из перечисленных ниже параметров, какому (каким)
показателю (показателям) производительности, они соответствуют?
а. предсказуемость системы;
б. текущие потребности системы;
в. максимальные возможности системы;
г. процентное отношение использования ресурса;
д. количество заданий, выполненных в единицу времени;
е. оборотное время в интерактивных системах.
14.10. Какие методы измерения производительности представляют наибольший
интерес для:
а. интерактивных пользователей;
Ь. пользователей пакетной обработки;
с. разработчиков систем управления процессами в реальном времени;
d. менеджеров, занятых выпиской счетов за использованные ресурсы;
е. менеджеров, занятых прогнозированием системной нагрузки на следую-
щий бюджетный год;
f. менеджеров, занятых прогнозом изменения производительности в ре-
зультате:
i. наращивания памяти,
ii. увеличения тактовой частоты процессора,
iii. добавления дисководов.
Поясните свой ответ.
14.11. Существует ограничение на количество измерений, выполняемых в той
или иной системе. В силу каких соображений вы могли бы отказаться от
тех или иных измерений?
14.12. Моделирование представлено в большинстве наиболее широко применяе-
мых технологий оценки производительности.
а. Приведите несколько причин такой популярности.
б. Хотя моделирование применяется широко, но не настолько, как ожида-
лось. Почему?
14.13. Ниже приведены некоторые популярные методы мониторинга и оценки
производительности:
i. хронометраж;
ii. контрольные задачи микроуровня;
iii. синтетические программы;
iv. векторная методология;
v. моделирование;
vi. программы ядра;
vii. аппаратные мониторы;
viii. аналитические модели;
ix. программные мониторы;
х. контрольные задачи.
Укажите, к каким из перечисленных методов наиболее подходят приведен-
ные ниже высказывания (в некоторых случаях может быть указано не-
сколько методов):
|4.16
14-17-
14.18.
машины-
и.
к.
л.
14.19.
м.
14.20.
б.
в.
-1 --------------------Гива ц | ^рнВодительноеть и apxumektnypajP^^^L
а. их достоверность может быть подвергнута риску при внесении упр^
щающих допущений;
б. взвешенное среднее временных параметров элементарных операций;
в. разработанные квалифицированными математиками;
г. модели, запускаемые в вычислительной системе;
д. полезные для быстрого сравнения грубых оценок мощности аппаратного
обеспечения;
е. представляют особую ценность в сложной программной среде;
ж. реальные программы, исполняемые в реальной среде;
з. заказные программы для исследования определенных свойств
” реальная программа, исполняемая «на бумаге»;
программный продукт;
обычно разрабатывается с использованием теории массового обслужива-
ния и марковских процессов;
часто используется, если разработка синтетических программ обходится
слишком дорого или требует значительных временных затрат.
14.14 . Какой метод оценки производительности является наиболее подходящим
в каждой из приведенных ниже ситуаций? Поясните свои ответы.
а. Страховая компания имеет стабильную нагрузку, состоящую из боль-
шого числа длительных процессов, выполняющих пакетную обработку
данных. По причине слияния компания должна увеличить свои мощно-
сти на 50%. Компания желает заменить свое оборудование новой вычис-
лительной системой.
Страховая компания, описанная в пункте а) желает увеличить мощ-
ность за счет закупки дополнительной памяти и каналов.
Компьютерная компания проектирует новую сверхвысокоскоростную
вычислительную систему и желает оценить несколько альтернативных
проектов.
Консалтинговая фирма, специализирующаяся на обработке коммерче-
ских данных подписала с военным ведомством крупный контракт, тре-
бующий обширных математических вычислений. Компания желает оп-
ределить, сможет ли имеющееся в ее распоряжении вычислительное обо-
рудование обработать ожидаемый объем математических вычислений.
Управление в части мультикомпьютерных сетей требует оперативного оп-
ределения узких мест и соответствующего перераспределения трафика.
Системный программист предполагает, что один из программных моду-
лей вызывается более часто, чем первоначально ожидалось. Програм-
мист хочет удостовериться в своих предположениях, прежде чем затра-
чивать существенные усилия на перепрограммирование модуля с целью
повышения его эффективности.
Производитель операционных систем должен протестировать все возмож-
ности системы перед коммерческим распространением своего продукта.
14.15 . В некоторой вычислительной системе процессор содержит BIPS-измери-
тель, записывающий число инструкций, выполняемых процессором в се-
кунду (в миллиардах инструкций в секунду). Измеритель откалиброван от
0 до 4 BIPS с шагом 0,1 BIPS. Все рабочие станции в системе используются-
Поясните, каким образом могли иметь место следующие
а. Измеритель зафиксировал 3,8 BIPS, и терминальные
метили хорошее (т.е. малое) время отклика системы.
б. Измеритель зафиксировал 0,5 BIPS, и терминальные
метили хорошее время отклика системы.
в. Измеритель зафиксировал 3,8 BIPS, и терминальные
метили плохое (т.е. большое) время отклика системы.
г. Измеритель зафиксировал 0,5 BIPS, и терминальные
метили плохое время отклика системы.
Вы работаете в группе оценки производительности на фирме, занимающей-
ся производством компьютеров. Ваше задание заключается в разработке
обобщенной синтетической программы для облегчения оценки совершенно
новой вычислительной системы с оригинальным набором команд,
а. В чем заключается ценность такой программы?
б. Какими свойствами должна обладать ваша программа, чтобы действи-
тельно быть широко используемым инструментом оценки?
Укажите различия между моделированием, управляемым событиями и мо-
делированием, управляемым сценариями.
Что означает «проверка достоверности модели»? Каким образом можно
проверить достоверность модели небольшой (существующей) системы
с разделением времени с дисковой памятью, несколькими экранными тер
миналами и лазерным принтером общего доступа?
Какую информацию может получить эксперт по оценке производительно-
сти из трассы выполнения операций? Из модульной трассы выполнения?
Какая из названных трасс более информативна при анализе работы отделы
ной программы? А при анализе работы системы?
Каким образом могут быть обнаружены узкие места? Как их можно уда-
лить? Если узкое место удалено, можем ли мы ожидать улучшения произ-
водительности системы? Поясните свой ответ.
14.21. Что означает термин «петля обратной связи»? Укажите различия между
отрицательной и положительной обратной связью. Какая из них способст
вует стабильности системы? Какая из разновидностей обратных связей яв
ляется причиной неустойчивости? Почему?
14.22. Контроль рабочей нагрузки является важной частью изучения производи
тельности. Мы должны знать, как поведет себя вычислительная система,
если мы увеличим нагрузку на нее. Какие измерения вы провели бы для
определения показателей рабочей нагрузки в следующих системах:
система с разделением времени, предназначенная для разработки про-
граммного обеспечения;
система с пакетной обработкой, используемая для формирования месяч-
ных счетов за потребляемую электроэнергию для пятисот тысяч клиен-
тов;
усовершенствованная рабочая станция, используемая одним инжене-
ром;
г. микропроцессор, имплантированный в грудную клетку для регулирова-
ния сердечного ритма;
д. локальная вычислительная сеть, выполняющая поддержку активно ис-
пользуемой системы электронной почты в крупном офисном центре;
е. система управления полетами, применяемая для исключения столкно-
вений;
вычислительная сеть прогноза погоды, получающая по линиям связи
значения температуры, влажности, атмосферного давления и т.п. из
10000 пунктов, расположенных по всей стране;
з. система управления медицинской базой данных, обеспечивающая меди-
цинской информацией врачей всего мира;
и. вычислительная сеть управления движением, применяемая для монито-
ринга и управления потоками движения транспорта в крупном городе.
14.23 Производитель вычислительной техники разрабатывает новый мультипро-
цессор. Система имеет модульное строение, что позволяет добавлять новые
процессоры по мере необходимости, но каждое присоединение обходится
дорого. Производитель должен обеспечить дополнительные модули для
подключения, поскольку установка модулей в корпус «в Тюлевых услови-
ях» также является дорогостоящей процедурой. Производитель желает оп-
ределить оптимальное число модулей обеспечения связи с дополнительны-
а.
б.
Д.
в.
е.
ж.
ситуации:
пользователи
от-
от-
пользователи
от-
пользователи
от-
пользователи
14.24.
14.25.
14.26.
=====^5
Поясните свой ответ. еспечения связи на этапе проектирования?
Почему RISC-программы обычно ллиннрр стер
те же действия? Почему при
Сравните прогнозирование ветвления и предикацию ветвления Какой
етодов более пригоден для повышения производительности? Почему?
Для каждого из атрибутов современных процессоров, приведенных нй«,
°™”” его влияние на пронааодительноегв и S
QjgQ процессор наблюдается во всем диапазоне архитектур от RISC д0
*1. суперскалярная архитектура;
б. исполнение с изменением последовательности;
в. прогнозирование ветвления;
Г’ Запятой; К₽ИСТаЛЛ ВеКТОризадия и поддержка операций с плаваю-
Д; большой набор команд;
е’ тактик3™6 СЛОЖНЫХ’ многотактных команд в более простые одно-
тактные инструкции. н
14 27 Укажит^пГСЯ Процессоры ЕР1С от RISC-процессоров второго поколения?
„ “я (°сновываясь на перечисленных отличиях) препятствия для рас-
пространения процессоров EPIC. р
Рекомендуемые исследовательские учебные проекты
14.28. ~
14.29.
14.30.
14.31.
14.32.
14.33.
Т измерить производительность, не влияя на получаемые
залячя™ Исследуите Различные способы, используемые в контрольных
мой сист^ыМИНИМИЗаЦИИ ИХ воздеиствия на производительность исследуе-
ной°гт«™НИе Г0ДЫ Технол<л’ии визуализации графики достигли феноменаль-
ХйПР"^ДИТеЛЬНОСТИ- ПровеДите исследование архитектурных особенно-
го-,’ ствующих повышению производительности графических карт,
уд те также методы оценки производительности графических карт.
Pow₽ZXT^T4eCC°? Р™егРС 970’ на котором построена серия
сопя? К фирмы Apple. Какой тип набора инструкций у данного процес-
сора. Какие методы повышения производительности в нем используются?
сследуите свойства gprof или какого-либо другого профайлера с точки
р ния предоставляемых им возможностей разработчикам программного
ооеспечения.
Подготовьте обзор современных исследований, выполняющих сравнение
производительности RISC и CISC-архитектур. Опишите достоинства и не-
достатки каждой из проектных философий в современных системах.
главе отмечалось, что один из недостатков архитектуры RISC состоит
в резком росте накладных расходов на переключение контекста. Дайте под-
робное объяснение причин данного явления. Опишите процедуру переклю-
НИЯ контекста. Обсудите различные используемые подходы. Сформули-
руйте предложения по повышению эффективности процедуры переключе-
ния контекста для систем с архитектурой RISC.
рекомендуемые программные учебные проекты
14.34. Возьмите один из известных иСЖ
I СвХГвГ^ —-Х компьютерах
™нит₽ полученные результаты. Насколько полученные вами результа-
ты похожи на опубликованные разработчиками? В силу каких причин они
могут отличаться? Опишите свой эксперимент с использованием набор
контрольных задач и синтетических программ.
i t 35 В данном проекте вы проведете умеренно детализированное модельное ис
14' ' следование Вам необходимо написать программу, выполняющую модели-
рование, управляемое событиями, с использованием генератора случайных
е пакетной обработкой «ВИЙ
дство потребовало решить, какая стратегия размещения задании в па“я™
приведет ₽к наивысшей производительности. Центр запустил компьютер
с большим объемом основной памяти, использующим многозадачны*[ре-
жим с разделами переменного размера. Каждая пользовательская прогр
м^ работала^одной области смежных ячеек памяти. Пользователи указы-
вай неХдамые им объемы памяти заблаговременно, и операционная
система выделяла каждому пользователю требуемую память при инициа-
лизации его задания. Для пользовательских программ было доступно в об-
щем 1024 МБ основной памяти.
Объемы памяти, требуемые заданиями при их инициализации, перечне е-
ны ниже:
10 МБ —
20 МБ —
30 МБ —
40 МБ —
50 МБ —
Время выполнения заданий не зависело от требуемых объемов памяти,
и распределялось следующим образом.
1 минута — 30% заданий;
2 минуты — 20% заданий;
5 минут — 20% заданий
10 минут — 10% заданий;
20 минут — 10% заданий;
60 минут — 10% заданий.
Загрузка системы такова, что, по крайней мере, одно задание всегда ждет
инициализации. Задания обрабатываются строго в поряд^ ™7ь ™кая
Напишите программу моделирования, которая помогла бы решить, кака
стратегия размещения заданий в памяти должна использоваться в описан
' номГпентпе Программа должна использовать генератор случайных чисел
для формирования запрашиваемых объемов памяти и времени выполнена
заданий в соответствии с приведенными выше распределениями. Исследу
те^производительность системы в течение восьмичасового периода путем
изменения пропускной способности, использования памяти и других инте-
ресующих вас параметров для каждой из следующих стратегии раз Щ
ния заданий в памяти:
а. первый подходящий;
б. наиболее подходящий;
в. наиболее неподходящий.
заданий;
заданий;
заданий;
заданий;
заданий.
30%
20%
25%
15%
10%
14.36. Руководство вычислительного центра, описанного в предыдущей задаче
предположило, что обработка заданий в порядке их поступления не опти-
мальна. В частности, было замечено, что выполнение длительных заданий
приводит к росту очереди ожидающих краткосрочных заданий. Исследова-
ние ожидающих заданий показало, что, по крайней мере, 10 заданий все-
гда ожидают инициализации (т.е. если 10 заданий ожидают в очереди
и одно из них инициализируется, то в систему немедленно поступает ещё
одно задание). Измените программу моделирования из предыдущей задачи
таким образом, чтобы задания обрабатывались по правилу «самое корот.
кое — первое». Каким образом это повлияет на параметры производитель-
ности с учетом стратегий размещения в памяти? Какие новые проблемы
возникнут при использовании предложенного порядка обработки заданий?
Рекомендуемая литература
Статья Лукаса «Оценка производительности и мониторинг», вышедшая
в 1971 г., содержала исследование вопроса оценки производительности.109 Обсуж-
дение последних тенденций в сфере оценки производительности, в частности, на-
боров контрольных задач, приведено в документе «The Seventh Workshop on Hot
Topics in Operating Systems», в разделе «Lies, Damn Lies, and Benchmark».110- 111
Web-сайты SPEC (www.specbench.org) и VeriTest (www.veritest.com/bemchmarks/
default.asp) 112 предоставляют информацию о коммерческих наборах контроль-
ных задач. Монография Паттерсона и Хенесси «Архитектура и проектирование
компьютеров» описывает архитектуру процессоров.113 В работах, которые пред-
ставили Стоукс114 и Алетан115 дан обзор истории и философии процессоров RISC
и CISC. Флинн, Митчелл и Малдер116 рассмотрели некоторые преимущества под-
хода CISC. Шланскер и Рау рассмотрели принципы архитектуры EPIC117. Подроб-
ная библиография данной главы размещена в сети Интернет по адресу
www.deitel.com/books/ os3e/Bibliography.pdf
Цспользуемая литература
1. Mogul, J., «Brittle Metrics in Operating System Research.» Proceedings of the
Seventh Workshop on Hot Operating System Topics, March 1999, pp. 90-95.
2. Lucas, H., «Performance Evaluation and Monitoring.» ACM Computing Surveys,
Vol. 3, No. 3, September 1971, pp. 79-91.
3. Lucas, H., «Performance Evaluation and Monitoring.» ACM Computing Surveys,
Vol. 3, No. 3, September 1971, pp. 79-91.
4. Ferrari, D.; G. Serazzi; and A. Zeigner, Measurement and Tuning of Computer
Systems, Englewood Cliffs, NJ: Prentice Hall, 1983.
5. Anderson, G., «The Coordinated Use of Five Performance Evaluation Methodol-
ogies,» Communications of the ACM. Vol. 27, No. 2, February 1984.
pp. 119-125.
6. Seltzer, M., et al., «The Case for Application-Specific Benchmarking,» Proceed-
ings of the Seventh Workshop on Hot Topics in Operating Systems, March 1999.
pp. 105-106.
7. Seltzer, M., et al., «The Case for Application-Specific Benchmarking,» Proceed-
ings of the Seventh Workshop on Hot Topics in Operating Systems, March 199 >
pp. 105-106.
8. Spinellis, D., «Trase: A Tool for Logging Operating System Call Transactions,»
ACM SIGOPS Operating System Review, October 1994, pp.56-63.
9. Bull, J. M., and O’Neill, «А Microbenchmark Suite for OpenMP 2.0,» ACM
SIGARCH Computer Architecture Notes, Vol. 29, No. 5, December 2001,
pp. 41-48.
10. Keckler, S., et al «Exploiting Fine-Grain Thread Level Parallelism on the MIT
Multi-ALU Processor,» Proceedings of the 25th Annual International Sympo-
sium on Computer Architecture, October 1998, pp. 306-317.
11. Brown, A., and M. Seltzer, «Operating System Benchmarking in the Wake of
Lmbench: A Case Study on the Performance of Net-BSD on the Intel x86 Archi-
tecture,» ACM SIGMETRICS Conference on Measurement and Modeling of Com-
puter Systems, June 1997, pp. 214-224.
12. McVoy, L., and C. Staelin «Imbench: Portable Tools for Performance Analysis,»
In Proceedings of the 1996 USENIX Annual Technical Conference, January
1996, pp.279-294.
13. Brown, A., and M. Seltzer, «Operating System Benchmarking in the Wake of
Lmbench: A Case Study on the Performance of Net-BSD on the Intel x86 Archi-
tecture,» ACM SIGMETRICS Conference on Measurement and Modeling of Com-
puter Systems, June 1997, pp. 214-224.
14. McVoy, L., and C. Staelin «Imbench: Portable Tools for Performance Analysis,»
In Proceedings of the 1996 USENIX Annual Technical Conference, January
1996, pp.279-294.
15. Brown, A., and M. Seltzer, «Operating System Benchmarking in the Wake of
Lmbench: A Case Study on the Performance of Net-BSD on the Intel x86 Archi-
tecture, » ACM SIGMETRICS Conference on Measurement and Modeling of Com-
puter Systems, June 1997, pp. 214-224.
16. Seltzer, M., et al., «The Case for Application-Specific Benchmarking,» Proceed-
ings of the Seventh Workshop on Hot Topics in Operating Systems, March 1999,
pp 105-106.
17. Seltzer, M., et al., «The Case for Application-Specific Benchmarking,» Proceed-
ings of the Seventh Workshop on Hot Topics in Operating Systems, March 1999,
pp 105-106.
18. Seltzer, M., et al., «The Case for Application-Specific Benchmarking,» Proceed-
ings of the Seventh Workshop on Hot Topics in Operating Systems, March 1999,
pp 102-107.
19. Lucas, H., «Performance Evaluation and Monitoring.» ACM Computing Surveys,
Vol. 3, No. 3, September 1971, pp. 79-91.
20. Lucas, H., «Performance Evaluation and Monitoring.» ACM Computing Surveys,
Vol. 3, No. 3, September 1971, pp. 79-91.
21. Lucas, H., «Performance Evaluation and Monitoring.» ACM Computing Surveys,
Vol. 3, No. 3, September 1971, pp. 79-91.
22. Svobodova, L., Computer Performance Measurement and Evaluation Methods:
Analysis and Applications. New York: Elsevier, 1977.
23. Kobayashi, H., «Modeling and Analysis: An Introduction to System Performance
Evaluation Methodology, Reading, MA: Addison-Wesley 1978.
24. Lazowska, E., «The Benchmarking, Tuning, and Analytic Modeling of
VAX/VMS,» Conference on Simulation, Measurement and Modeling of Computer
Systems, August 1979, pp. 57-64.
25. Sauer, C.., and K. Chandy, Computer Systems Performance Modeling,
Englewood Cliffs, NJ: Prentice Hall, 1981.
26. Lucas, H., «Performance Evaluation and Monitoring.» ACM Computing Surveys,
Vol. 3, No. 3, September 1971, pp. 79-91.
27. Hindin, H., and M. Bloom. «Balancing Benchmarks Against Manufacturers’
Claims,» UNIX World, January 1988, pp. 42-50.
28. Mogul, J., «Brittle Metrics in Operating System Research.» Proceedings of the
Seventh Workshop on Hot Operating System Topics, March 1999, pp. 90-95,
29 *SpecWeb99,” SPEC (Standard Performance Evaluation Corporation), Septem.
her 26, 2003, <www.specbench.org/web99/>.
30. Mogul, J., «Brittle Metrics in Operating System Research.» Proceedings of the
Seventh Workshop on Hot Operating System Topics, March 1999, pp. 90-95.
31. Seltzer, M., et al., «The Case for Application-Specific Benchmarking,» Proceed,
ings of the Seventh Workshop on Hot Topics in Operating Systems, March 199g
pp 102-107.
32. «ВАРСо Benchmark Products,» ВАРСо, August 5. 2002, <www.bapco.com/
products. htm>.
33. «Overview of the TPC Benchmark C,» Transaction Processing Performance
Council, August 12. 2003, <www.tpc.org/tpcc/detail.asp>.
34. «SAP Standard Application Benchmarks,» August 12. 2003, <www.sap.com/
benchmarks
35. Bucholz, W., «А Synthetic Job for Measuring System Performance,» IBM Jour-
nal of Research and Development, Vol. 8, No. 4, 1969, pp. 309-308.
36. Lucas, H., «Performance Evaluation and Monitoring.» ACM Computing Surveys,
Vol. 3, No. 3, September 1971, pp. 79-91.
37. Weicker, R., «Dhrystone: A Synthetic Systems Programming Benchmark,» Com-
munications of the ACM, Vol. 21, No. 10, October 1984, pp. 1013-1030.
38. Dronek, G., «The Standards of System Efficiency,» Unix Review, March 1985,
pp. 26-30.
39. Wilson. P.. «Floating-Point Survival Kit.» Byte. \’o\. 2i. No. 3. March 19SK.
pp. 217-226.
40. «WinBench,» PC Magazine, September 2. 2003, <www.etest-inglabs.com/bench-
marks/winbench/winbench.asp>.
41. «lOStone: A Synthetic File System Benchmark,» ACM SIGARCH Computer Ar-
chitecture News, Vol. 18, No. 2, June 1990, pp. 45-52.
42. «Hartstone: Synthetic Benchmark Requirements for Hard Real-Time Applica-
tions,» Proceedings of the Working Group on ADA Performance Issues, 1990,
pp. 126-136.
43. «Unix Technical Response Benchmark Info Page,» May 17. 2002, <www.unix.
ualberta.ca/Benchmarks/benchmarks.html>.
44. Lucas, H., «Performance Evaluation and Monitoring.» ACM Computing Surveys,
Vol. 3, No. 3, September 1971, pp. 79-91.
45. Nance, R., «The Time and Slate Relationships in Simulation Modeling,» Commu-
nications of the ACM. Vol. 24, No. 4, April 1981, pp. 173-174.
46. Keller, R., and F. Lin, «Simulated Performance of a Reduction-Based
Multiprocessor.» Computer, Vol. 17, No. 7, July 1984, pp. 70-82.
47. Overstreet, C., and R., Nance, «А Specification Language to Assist in Analysis of
Discrete Event Simulation Models,» Communications of the ACM, Vol. 28, No. 2,
February 1985, pp. 190-201.
48. Jefferson, D., et al., «Distributed Simulation and the Time Warp Operating Sys-
tem.» Proceeding of the 11th Symposium on Operating System Principles, Vol.
21, No. 5, November 1987, pp. 77-93.
49. Overstreet, C., and R., Nance, «А Specification Language to Assist in Analysis of
Discrete Event Simulation Models,» Communications of the ACM, Vol. 28, No. 2,
February 1985, pp. 190-201.
50. Gibson, J., et al., «FLASH vs. (Simulated) FLASH: Closing the Simulation
Loop.» ACM SIGPLAN Notices, Vol. 35, No. 11, November 2000, pp. 52-58.
51. Lucas, H., «Performance Evaluation and Monitoring.» ACM Computing Surveys.
Vol. 3, No. 3, September 1971, pp. 79-91.
производительность и архитектура нроцес о но . —
52. Plattner, В., and J. Nivergelt, «Monitoring Program Execution: A Survey,»
Computer, Vol. 14, No. 11, November 1981, pp. 76-92.
53. Irving, R.; C. Higgins; and F. Safayeni, «Computerized Performance Monitoring
Systems: Use and Abuse.» Computer Technology Form No. SA23-1057, 1986.
54. «Windows 2000 Performance Tools: Leverage Native Tools for Performance Moni-
toring and Tuning,» InformIT January 15.2001, <www.informit.com/content/in-
dex.asp?product Jd=% 7BA085E192-E708-4AAB-999E-5C33956OEAA6%7D>.
55. Gavin, D., «Performance Monitoring Tools for Linux,» Linux Journal, No. 56,
December 1. 1998, <www.linuxjournal.com/article.php?sid=2396>.
56 «1А-32 Intel Architecture Software Developer’s Manual,» Vol. 3, System Pro-
grammer’s Guide, 2002.
57. Lucas, H., «Performance Evaluation and Monitoring.» ACM Computing Surveys,
Vol. 3, No. 3. September 1971, pp. 79-91.
58. Ferrari, D.; G. Serazzi; and A. Zeigner, Measurement and Tuning of Computer
Systems, Englewood Cliffs, NJ: Prentice Hall, 1983.
59. Bonomi, M., «Avoiding Coprocessor Bottlenecks,» Byte, Vol. 13, No. 3, March
1988, pp. 197-204.
60 Coutois, P., «Decomposability, Instability, and Saturation in Multiprogramming
Systems,» Communications of the ACM, Vol. 18, No. 7, 1975, pp. 371-376.
61. Hennessy, J., and D. Patterson, Computer Organization and Design, San Fran-
cisco, CA: Morgan Kaufmann Publishers, Inc., 1998, p. G-7.
62 Stokes, J., «Ars Technica: RISC vs. CISC in the Post RISC Era,» October 1999,
<arstechnica. com/cpu/4q99/risc-cisc/rvc-1 ,html>.
63. Stokes, J., «Ars Technica: RISC vs. CISC in the Post RISC Era,» October 1999,
<arstechnica.com/cpu/4q99/risc-cisc/rvc-1 ,html>.
64 Daily, S., «Killer Hardware for Windows NT,» Window IT Library, January 1998
< www. windowsitlibrary, com / Content435/02/ toe. html>.
65. DeMone, P., «RISC vs. CISC Still Matters,» February 13. 2000, <ctas.east.asu.edu/
bgannod/CET520/Spring02/Project/demone.htm>.
66. Hennessy, J., and D. Patterson, Computer Organization and Design, San Fran-
cisco, CA: Morgan Kaufmann Publishers, Inc., 1998, p. 525.
67. Rosen, S., «Electronic Computers—A Historical Survey» ACM Computing Sur-
veys, Vol. 1, No. 1, January 1969, pp. 26-28.
68. Ramamoorthy, С. V., and H. F. Li, «Pipeline Architecture,» ACM Computing
Surveys, Vol. 9, No. 1, January 1977, pp. 62-64.
69. Aletan, S., «An Overview of RISC Architecture,» Proceedings of the 1992
ACM/SIGAPP Symposium on Applied Computing Technological Challenges of
the 1990’s, 1992, pp. 11-12.
70. Hopkins M., «Compiling for the RT PC ROMP,» IBM RT Personal Computer
Technology, 1986, pp. 81.
71. Coulter, N. S., and N. H. Kelly, «Computer Instruction Set Usage by Program-
mers: An Empirical Investigation,» Communications of the ACM, Vol. 29, No. 7,
July 1986, pp. 643-647.
72. Serlin, 0., «MIPS. Dhrystones, and Other Tales,» Datamation Vol. 32, No. 11,
June 1. 1986, pp. 112-118.
73. Aletan, S., «An Overview of RISC Architecture,» Proceedings of the 1992
ACM/SIGAPP Symposium on Applied Computing Technological Challenges of
the 1990’s, 1992, p. 13.
74. Patterson, D. A., «Reduced Instruction Set Computers,» Communications of the
ACM, Vol. 28, No. 1, January 1985, pp. 8-21.
75. Hopkins M., «Compiling for the RT PC ROMP,» IBM RT Personal Computer
Technology, 1986, pp. 81.
76. Patterson, D. A., «Reduced Instruction Set Computers,» Communications of the
ACM, Vol. 28, No. 1, January 1985, pp. 8-21.
I™,™’. & Ак„: Communications of the
Ж^21%:В?!1ЙУ1^,В^!"47-ЙШ1‘У “ P1PeliMd P"~- Computer.
79' 2S£kr'^X«e%°f.?Peline<i >n1 Structural Reordering Con
8ой“^
“ PiP<!li“d Pr~>> Computer,
81' ,or B°“t in S[“"”Computer °-
82’ Fn pldSOn’ J’cW” ar\d R’ A- Vau£han> «The Effect of Instruction Set Complexitv
tioJaTc^f1 S1Ze and лМТ°ГУ Performance>» Proceedings of the Second Intend
Support ,or I-ws -d op:
“• sYgSi^S^Sl,Or B“Sl “ Computer De.
S4' Xmer^i „йе^Ог" ®°П™Гв De™1°per’= Vol. 3. System Pre.
85' Stat^TTn^” e! an *Bfyond RISC - The Post-RISC Architecture,» Michigan
MarchU1QOR ty Department of Computer Science, Technical Report CPS-96-П
86. Stokes, J., «Ars Technica: RISC vs. CISC in the Post RISC Era,» October 1999
arstechmca.com/cpu/4q99/risc-cisc/rvc-l .html>. ’
87. Stokes, J., «Ars Technica: RISC vs. CISC in the Pos RISC Era,» October 1999
<arstechnica.com/cpu/4q99/risc-cisc/rvc-1. html>
89- XS413'2000'
90‘ S“ta’m’ and ? Patterso£’ Computer Organization and Design, San Fran-
cisco, CA. Morgan Kaufmann Publishers, Inc., 1998, p. 510.
91. Jouppi N,« Superscalar vs. Superpipelined Machines,» ACM SIGARCH Com-
puter Architecture News, Vol. 16, No. 3, June 1988, pp. 71-80
гЛн n°ie: fnd B‘ Pal®afi’ *Dual Use Superscalar Datapath for Tran-
АСм'тр Ejection and Recovery,» Proceedings of the 34th Annual
АСМ/IEEE International Symposium on Microarchitecture, December 2001,
pp. Z14-ZZ4.
ЭЗ. Stokes, J., «Ars Technica: RISC vs. CISC in the Post RISC Era,» October 1999,
arstechmca.com/epu/4q99/risc-cisc/rvc-l.html>.
Э4. Hwu, W W., and Y. Patt, «Checkpoint Repair for Out-of-Order Execution Ma-
JuTTssrP;f ;fe*64th ^“««^»»лгеы.
9.э . Chuang, W., and B. Calder, «Predicate Prediction for Efficient Out-of-Order Ex-
X jX SoT ррПЙ‘192. A““‘ Terence o„ Supemompu-
96‘ S^s'/' *Ars Vedmlre RISC vs. CISC in the Post RISC Era,» October 1999,
arstechnica.com/cpu/4q99/risc-cisc/rvc-l.html>.
’ *ArS Technica: RISC vs- CISC in the Post RISC Era,» October 1999,
<arstechnica.com/cpu/4q99/risc-cisc/rvc-l.html>.
’ C’’ ?>nd M-’ Smith’ «Static Correlation Branch Prediction,» ACM Trans-
10ооП1 °nin9figXming Languages and Systems, Vol. 21, No. 5, September
isyy, pp. lUZo-lU70.
99 Stokes, J., «Ars Technica: RISC vs. CISC in the Post RISC Era,» October 1999,
IjOO. B*SC Era,» OtoUr 1999.
101 «JutiCec Fact^t^Motoril^Corporation, 2002, <e-www.motorola.com/files/
101‘ 32bit/doc/fact sheet/ ALTIVECGLANCE.pdf>.
102. Stokes, J., «Ars Technica: RISC vs. CISC in the Post RISC Era,» October 1999,
<arstechnica.com/cpu/4q99/risc-cisc/rvc-l.html>.
103 Schlansker, M., and B. Rau. «EPIC: Explicitly Parallel Instruction Computing,»
Computer, Vol. 33, No. 2, February 2000, pp. 38-39.
104. Lowney, P., et al., «’The Multiflow Trace Scheduling Compiler,» Journal of
Supercomputing, Vol. 7, May 1993: 51-142. .
105 Hennessy, J., and D. Patterson, Computer Organization and Design, San Fran-
cisco, CA: Morgan Kaufmann Publishers, Inc., 1998, p. 528.
106 Schlansker, M., and B. Rau. «EPIC: Explicitly Parallel Instruction Computing,»
Computer, Vol. 33, No. 2, February 2000, pp. 38-39.
107 Schlansker, M., and B. Rau. «EPIC: Explicitly Parallel Instruction Computing,»
Computer, Vol. 33, No. 2, February 2000, pp. 41-44.
108 Schlansker, M., and B. Rau. «EPIC: Explicitly Parallel Instruction Computing,»
I Computer, Vol. 33, No. 2, February 2000, pp. 41-44
109. Lucas, H., «Performance Evaluation and Monitoring.» ACM Computing Surveys,
Vol. 3, No. 3, September 1971, pp. 79-91.
110. Mogul, J., «Brittle Metrics in Operating System Research^» Proceedings of the
Seventh Workshop on Hot Operating System Topics, March 1999, pp. 90-95.
111. Seltzer, M„ et al., «The Case for Application-Specific Benchmarking^» Proceed-
ings of the Seventh Workshop on Hot Topics in Operating Systems, March 1999,
pp 105-106. . « « ,
112. «PC Magazine Benchmarks from VeriTest,» PC Magazine <www.ventest.com/
benchmarks/default.asp?visitor=>. . „
113 Hennessy, J., and D. Patterson, Computer Organization and Design, San Fran-
' cisco, CA: Morgan Kaufmann Publishers, Inc., 1998, P- 528.
114. Stokes, J., «Ars Technica: RISC vs. CISC in the Post RISC Era,» October 1999,
<arstechnica.com/cpu/4q99/risc-cisc/rvc-l.html>.
115. Aletan, S., «An Overview of RISC Architecture,» Proceedings of the 1992
I ACM/SIGAPP Symposium on Applied Computing Technological Challenges о
the 1990’s, 1992, pp. 11-12.
116. Flynn, M. J.; C. L. Mitchell; and J. M. Mulder, «And Now a Case for More Com-
plex Instruction Sets,» Computer, Vol. 20, No. 9, September 1987 pp. 71-83.
117 Schlansker, M„ and B. Rau. «EPIC: Explicitly Parallel Instruction Computing,»
Computer, Vol. 33, No. 2, February 2000, pp. 41-44.
Распараллеливание работы — вот главная забота
ближайшего десятилетия.
Дэвид Как, цитата в TIME, 28 марта 1988 года
«Вопрос в том, кто из нас здесь хозяин», —
сказал Шалтай-Болтай. — «Вот в чем вопрос!»
Льюис Кэрролл
Мили и сроки придут к концу,
Я знаю, но тем верней,
Мой Лоцман, мы встанем лицом к лицу
За пологом миль и дней.
Альфред Теннисон (перевод А. М. Геймана)
«Когда б служанка, взяв метлу,
Трудилась дотемна,
Смогла бы вымести песок
За целый день она' »
Льюис Кэрролл
Самое общее определение красоты... Многое в едином-
Самюэль Тэйлор Кольридж
Глава 15
Многопроцессорность
После прочтения этой главы вы должны понимать:
• многопроцессорные архитектуры и организацию
операционных систем;
« архитектуры памяти в многопроцессорных
системах;
• задачи проектирования, специфичные
для многопроцессорных сред;
• алгоритмы планирования и диспетчеризации
в многопроцессорных системах;
♦ миграцию процессов в многопроцессорных системах;
• балансирование нагрузки в многопроцессорных
системах;
• технику взаимного исключения в многопроцессорных
системах.
Краткое содержание главы
15.1 Введение
Практический пример: Суперкомпьютеры
Биографические заметки: Сеймур Крей
15.2. Многопроцессорные архитектуры
15.2.1 Классификация последовательных и параллельных архитектур
15.2.2. Схемы соединений процессоров
15.2.3. Тесно связанные и слабосВязанные системы
15.3. Организации многопроцессорных операционных систем
15.3.1. Схема Ведущий/Ведомый
15.3.2. Схема с раздельными ядрами
15.3.3. Симметричная схема
Размышления об операционных системах:
Плавное снижение эффективности
15.4. Архитектуры доступа к памяти
15.4.1. Архитектура однородного доступа к памяти (UMA)
15.4.2. Архитектура неоднородного доступа к памяти (NUMA)
15.4.3. КзшеВая архитектура памяти (СОМА)
15.4.4. Архитектура без доступа к удаленной памяти NORMA
15.5. Разделение памяти В многопроцессорных системах
Размышления об операционных системах:
Репликация данных и когерентность
15.5.1. Когерентность кэша
15.5.2. Репликация и миграция страниц
15.5.3. Общая Виртуальная память
15.6. Планирование В многопроцессорных системах
15.6.1. Задачно-незаВисимые алгоритмы планирования
15.6.2. Задачно-ориентированные алгоритмы планирования
15.7. Миграция процессов
15.7.1. Процедура миграции процесса
15.7.2. Концепции миграции процессов
15.7.3. Стратегии миграции процессов
15.8. Балансировка нагрузки
15.8.1. Статическая балансировка нагрузки
15.8.2 Динамическая балансировка нагрузки
15.9. Взаиллное исключение в ллногопроцессорных систеллах
15.9.1 Спин-блокировки
15.9.2 Блокировки с усыплением/пробуэкдением
15.9.3. Блокировки чтения/записи
/5.1 Введение
В течение десятилетий закон Мура обеспечивал весьма точное предска-
зание экспоненциального роста количества транзисторов в процессорах
и их производительности. Но, несмотря на этот прирост, исследователям
разработчикам, инженерам и бизнесменам постоянно требовались системы
более мощные, чем основанные на любом существующем процессоре. В ре-
зультате во многих областях стали применяться многопроцессорные сис-
темы (multiprocessing systems) — компьютеры, в которых используются
сразу несколько процессоров.
Большие инженерные и исследовательские приложения, выполняемые
на суперкомпьютерах, обеспечивают прирост производительности за счет
параллельной обработки данных на нескольких процессорах. Коммерче-
ские и научные организации используют многопроцессорные системы для
повышения производительности, предоставления задачам достаточных ре-
сурсов и достижения высокой надежности.1 Например, компьютер Earth
Simulator, находящийся в Иокогаме (Япония) — самый мощный компью-
тер по состоянию на июль 2003 года — содержит 5120 процессоров, каж-
дый из которых работает на частоте 500 МГц (см. «Практический пример:
Суперкомпьютеры»). Система может выполнять 35,6 ТФлоп (триллионов
операций над числами с плавающей запятой в секунду), позволяя ученым
моделировать климат, предсказывать стихийные бедствия и оценивать
влияние деятельности человека на природу.
Многопроцессорные системы должны уметь адаптироваться под различ-
ные задачи. В частности, операционные системы таких компьютеров
должны гарантировать, что:
• Все процессоры загружены работой.
• Процессы равномерно распределены в системе.
• Выполнение взаимосвязанных процессов синхронизировано.
• Процессы работают с состоятельными копиями данных, хранящих
в общей памяти.
• Обеспечивается взаимное исключение.
Методики, используемые для выхода из тупиковых ситуаций в много-
процессорных и распределенных системах, схожи, и рассматриваются
в главе 17.
В этой главе рассматриваются архитектуры многопроцессорных систем
и методы их оптимизации. Эти методы должны повышать производитель-
ность, стабильность, отказоустойчивость и эффективность. Часто улучше-
ние в одном из этих параметров достигается за счет ухудшения других. Мы
также рассмотрим влияние на производительность многопроцессорных
систем решений, принимаемых при проектировании.
Вопросы для самопроверки
1. Почему возникла потребность в многопроцессорных системах?
2. Чем отличаются задачи операционных систем для многопроцессор-
ных и однопроцессорных компьютеров?
Ответы i) Для многих приложений требуется производитель-
ность, намного большая, чем предоставляемая однопроцессорными
компьютерами. Например, в коммерческих системах многопроцессор-
ные системы позволяют наращивать производительность и масштаби-
ровать ресурсы соответственно потребностям задач. 2) Операционная
система должна распределять нагрузку между процессорами, обеспе-
чивать взаимное исключение в системах, в которых процессоры могут
работать одновременно, и гарантировать, что процессоры уведомляют-
ся об изменениях данных в общей памяти.
Учебный пример
Суперкомпьютеры
Суперкомпьютер (supercomputer) - это
просто термин, используемый для обозначе-
ния наиболее мощных на данный момент
компьютеров. Первые суперкомпьютеры
сильно уступают по производительности
обычным современным настольным ПК. Бы-
стродействие суперкомпьютеров измеряется
во флопах (flops - floating-point operations
per second, операций над числами с плаваю-
щей запятой в секунду).
Первым суперкомпьютером была машина
CDC 6600 производства Control Data Corpora-
tion, спроектированная Сеймуром Креем.
Сеймур Крей стал известен как создатель су-
перкомпьютеров (см. «Биографические за-
метки: Сеймур Крей»)2,3. Этот компьютер, вы-
пущенный в начале 1960-х годов, выполнял 3
миллиона инструкций в секунду.4,5 Этот ком-
пьютер также стал первым, использовавшим
архитектуру RISC (reduced instruction set
computing - вычисления с сокращенным на-
бором инструкций).6,7 Примерно десятью го-
дами и несколькими компьютерами позже
Крей создал Cray-1, одну из первых векторных
машин.8 (Векторные процессоры подробно
Рассматриваются в разделе 15.2.1). Супер-
компьютеры, созданные Креем, доминирова-
ли в области высокопроизводительных вы-
числений в течение многих лет.
Согласно отчетам организации, отслежи-
вающей достижения суперкомпьютеров,
ТорБОО (www.top500.org), самым быст-
рым компьютером в мире (на момент публи-
кации этой книги) является Earth Simulator
фирмы NEC, находящийся в Японии. Его пи-
ковая производительность составляет около
35 Терафлоп, более чем вдвое превосходя
производительность второго компьютера
в рейтинге и в десятки тысяч раз — произво-
9, 10
дительность персональных компьютеров.
Earth Simulator состоит из 5120 процессоров,
разбитых на 640 групп по 8 процессоров. Ка-
ждая такая группа содержит 16 гигабайт об-
щей памяти, и общий объем памяти состав-
ляет 10 терабайт.’' '2 Группы соединены в об-
щей сложности 1500 милями сетевого
кабеля и подключены к дисковой системе
емкостью 640 терабайт и системе ленточных
накопителей общей емкостью более 1,5 пе-
табайта (1 500 000 000 000 000 байт).'3,14
Вся эта вычислительная мощь используется
в исследованиях климата и окружающей
среды, а также в предсказаниях погоды
и природных явлений.
Биографические заметки
Сеймур Крей
Сеймур Крей (Seymour Cray) известен как
создатель суперкомпьютеров. Вскоре после
получения степени магистра в области при-
кладной математики в университете Минне-
соты в 1951 году он начал работать
в Engineering Research Associates (ERA), одной
из первых компаний, производивших циф-
ровые компьютеры.'8'19,21 Работая в этой ком-
пании, Крей разработал машину 1103, пер-
вый компьютер, созданный для научных рас-
четов, но хорошо продававшийся на
коммерческом рынке.20,22
В 1957 году Крей ушел из ERA вместе
с Уильямом Норрисом (William Norris), осно-
вателем компании. Вдвоем они основали
компанию Control Data Corporation (CDC).23,24,
25 К 1960 году Крей создал CDC 1604, первый
компьютер, в котором электронные лампы
были полностью заменены транзисторами.26,
27,28 В 1962 году он создал CDC 6600, первый
настоящий суперкомпьютер, а затем — CDC
7600.29,30,31 Крей всегда стремился к простоте,
и CDC 6600 основывалась на упрощенной ар-
хитектуре с усеченным набором инструк-
ций — такой подход много позже назвали
RISC (Reduced Instruction Set Computing - Др.
хитектура с сокращенным набором ко-
манд).32,33,34
В 1972 году Крей основал компанию Cray
Research, чтобы продолжать создавать боль-
шие суперкомпьютеры для научных расче-
тов.35 В 1976 году был выпущен Cray-1, один
из первых векторных компьютеров (см раз-
дел 15.2.1 ).36 Cray-1 был намного меньше по
размерам, чем CDC 7600, но гораздо мощ-
нее.3' Он обладал весьма необычным внеш-
ним видом, представляя собой вертикально
стоящий цилиндр с отверстием вдоль оси,
снабженный выступом в нижней части по
внешнему периметру и на первый взгляд на-
поминал круглый диван.38 Его производи-
тельность составляла 133 МФлоп, что на то
время было очень много, но большинство со-
временных ПК гораздо производительнее.39
За Cray-1 последовали еще три модели, каж-
дая из которых была меньше и производи-
тельнее предыдущей. Вычислительный мо-
дуль (без учета банков памяти и системы ох-
лаждения) в машине Сгау-4 был по
_ 40
размерам меньше человеческого мозга.
/5.2 Многопроцессорные архитектуры
Термин «многопроцессорная система» может обозначать любую систему
с более чем одним процессором. Примеры многопроцессорных систем
это и двухпроцессорные персональные компьютеры, и мощные серверы со
множеством процессоров, и распределенные системы из групп рабочих
станций, совместно выполняющих общие задачи.
В этой главе мы рассмотрим несколько способов классификации много-
процессорных систем. В данном разделе мы будем классифицировать эти сис-
темы по их физическим свойствам, например, по структуре канала обработки
данных в системе (то есть части процессора, выполняющей операции над дан-
ными), по схеме соединения процессоров и способу распределения ресурсов.
]цог » щесеорность
15.2.1 Классификация последовательных и параллельных архитектур
Флинн создал первую схему классификации компьютеров с различной
степенью параллелизма. Эта схема содержит четыре категории, отражаю-
щие различия потоков, используемых процессорами.41 Поток (stream) —
это просто последовательность байтов, передаваемая процессору. Процес-
сор принимает два потока — поток инструкций и поток данных.
Архитектуры с одним потоком команд и одним потоком данных
(SISD — single instruction stream, single data stream) — это самая простая
категория. К ней относятся традиционные однопроцессорные компьюте-
ры, в которых процессор поочередно исполняет одну инструкцию за дру-
гой, обрабатывая один за другим соответствующие элементы данных. Ме-
ханизмы вроде конвейерного выполнения, VLIW (very long instruction
word — очень длинные слова инструкций) и суперскалярных структур мо-
гут внести элементы параллелизма в архитектуры SISD. Конвейерное вы-
полнение разделяет последовательность выполнения инструкции на от-
дельные независимые этапы. Это позволяет процессору выполнять в одно
и то же время несколько инструкций, при условии, что каждый участок
конвейера, ответственный за свой этап исполнения, в любой момент време-
ни занят не более чем одной инструкцией. VLIW и суперскалярные архи-
тектуры позволяют одновременно передавать процессору несколько инст-
рукций (из одного потока), если для выполнения этих инструкций исполь-
зуются разные блоки процессора. VLIW полагается на компилятор
в задаче расположения инструкций в оптимальной для выполнения после-
довательности. Суперскалярные архитектуры полагаются в этой задаче на
сам процессор.42 Кроме того, технология гиперпотоков (Hyper-Threading),
используемая в процессорах Intel, вносит в систему параллелизм, пред-
ставляя один физический процессор как два виртуальных. Если система
с таким процессором поддерживает многопроцессорность, она видит два
процессора, каждый из которых работает на частоте, немного меньшей,
чем половина частоты физического процессора.43
Архитектуры с одним потоком данных и несколькими потоками ко-
манд (MISD — multiple instruction stream, single data stream) используют-
ся довольно редко. В таких архитектурах несколько процессоров должны
выполнять некоторые действия (каждый процессор — свои) над одним по-
током данных. Каждый процессор будет передавать результат выполнения
инструкции своего потока следующему процессору.44
Архитектуры с одним потоком команд и несколькими потоками дан-
ных (SIMD — single instruction stream, multiple data stream) используют
инструкции, одновременно обрабатывающие несколько элементов данных.
Компьютер SIMD-архитектуры содержит один или несколько процессоров.
Процессор выполняет SIMD-инструкцию, выполняя одну и ту же опера-
цию над несколькими элементами данных (например, прибавляя единицу
к значению каждого элемента массива). Если элементов данных, которые
нужно обработать, больше, чем процессоров, то следующая порция данных
загружается во время следующего такта. Такой подход может повысить
производительность по сравнению с SISD-архитектурами, в которых такие
операции выполнялись бы над каждым элементом данных по очереди с по-
мощью цикла. В цикле содержится множество вспомогательных опера-
ций — сравнения, перехода и так далее, кроме того, SISD-процессору при-
шлось бы декодировать инструкцию множество раз и считывать данные из
памяти элемент за элементом, а затем записывать их обратно в память
SIMD-процессор считывает данные сразу целыми блоками, уменьшая за-
траты времени на передачу данных между памятью и регистрами.
SIMD-архитектуры наиболее эффективны в задачах, в которых часто необ-
ходимо выполнять одинаковые операции над множеством элементов дан-
ных.45, 46
В векторных процессорах (vector processor) и матричных процессорах
(array processor) используется SIMD-архитектура. Векторный процессор —
это отдельный процессор, выполняющий инструкции над набором элемен-
тов данных, причем над каждым элементом набора выполняются одна и та
же операция. Векторные процессоры достигают высокой производительно-
сти за счет длинных конвейеров, состоящих из множества сегментов, и вы-
соких тактовых частот. Длинные конвейеры позволяют процессорам рабо-
тать одновременно с несколькими инструкциями, обрабатывая сразу не-
сколько элементов данных. Матричные процессоры — иногда их называют
массово-параллельными процессорами (massively parallel processors) —
могут состоять из десятков тысяч процессорных элементов. Такие процес-
соры наиболее эффективны при обработке очень больших объемов данных.
Векторные и матричные процессоры применяются в научных расчетах
и задачах компьютерной графики, в которых одинаковые операции долж-
ны выполняться над множеством элементов (например, при матричных
преобразованиях).47,48 Пример машин с матричными процессорами — сис-
темы Connection Machine (СМ) производства компании Thinking Machines,
Inc.49
Компьютеры архитектуры с множеством потоков команд и данных
(MIMD — multiple instruction stream, multiple data stream) — это системы
с полностью независимыми друг от друга процессорными элементами.50
Такие системы обычно содержат специальные устройства, позволяющие
процессорам синхронизироваться между собой и обращаться к общим
внешним устройствам.
I
Вопросы для самопроверки
1. Параллелизм на уровне потоков (TLP — thread-level parallelism) —
это одновременное исполнение нескольких независимых потоков.
В системах какой из рассмотренных выше архитектур он возмо-
жен?
2. (Да/Нет) Параллелизм присутствует только в системах SIMD-архи-
тектуры.
Ответы 1) Несколько потоков одновременно могут исполнять
только системы архитектур MISD и MIMD. Однако потоки, выполняе-
мые в MISD-системах, работают с одними и теми же данными, и пото-
му не являются независимыми. Поэтому в полной мере параллелизм
на уровне потоков свойственен только MIMD-системам.. 2) Нет.
В SISD-системах параллелизм проявляется при использовании кон-
вейеров, VLIW и суперскалярных архитектур; в MISD-системах одно-
временно выполняются несколько потоков; проявление параллелизма
на уровне потоков в MIMD-системах описано в предыдущем ответе.
Г wCajs | 1Ццогопр рноыпь
Схемы соединений процессоров
Схемы соединений процессоров (interconnection scheme) описывают
способ физического соединения процессоров системы и других ее компо-
нентов, например, модулей памяти. Эти схемы очень важны при проекти-
ровании многопроцессорных систем, поскольку они определяют произво-
дительность системы, ее надежность и стоимость. Схемы соединений со-
стоят из узлов (nodes) и связей (links). Узлы — это компоненты системы
и/или коммутаторы (switch), передающие сообщения между компонента-
ми. Связи — это каналы, по которым между узлами передается информа-
ция. Во многих системах в узле могут содержаться один или несколько
процессоров, связанный с ними кэш, модуль памяти и коммутатор.
Б крупномасштабных многопроцессорных системах мы иногда абстрагиру-
ем понятие узла и рассматриваем несколько связанных узлов как один су-
перузел.
Разработчики оценивают схемы соединений по нескольким парамет-
рам. Степень (degree) узла — это количество узлов, с которыми он связан.
Разработчики пытаются свести к минимуму степень всех узлов, чтобы
уменьшить стоимость и сложность коммуникационных интерфейсов уз-
лов. Узел более высокой степени требует использования более сложных
интерфейсов взаимодействия с соседними узлами (то есть с узлами, связан-
ными с данным).51
Один из методов оценки отказоустойчивости схемы соединений сводит-
ся к подсчету количества связей, которые нужно разорвать, чтобы сеть ста-
ла неработоспособной. Этот параметр можно оценить как ширину сечения
(bisection width) — минимальное количество связей, которое нужно разо-
рвать, чтобы разделить сеть на две несвязанные части. Чем больше шири-
на сечения сети, тем больше ее отказоустойчивость, поскольку тем больше
компонентов сети надо отключить, чтобы она перестала работать.
Производительность, обеспечиваемая схемой соединений, в значитель-
ной степени определяется задержками при обмене информацией по кана-
лам. Эти задержки — латентность — можно измерять разными методами,
например, находя среднее значение задержки. Еще один критерий произ-
водительности — это диаметр сети (network diameter). Диаметр сети — это
кратчайшее расстояние между двумя наиболее удаленными узлами на схе-
ме соединений этой сети. Чтобы определить диаметр сети, переберите все
пары узлов в сети и найдите кратчайший путь между узлами в каждой
паре. Подсчитайте количество связей в самом длинном из этих путей — это
и будет диаметр сети. Если диаметр сети мал, значит, у нее высокая произ-
водительность и малая латентность. Кроме того, проектировщики стара-
ются минимизировать стоимость схемы соединений (cost of an intercon-
nection scheme), равную общему количеству связей в схеме.52
В последующих подразделах мы рассмотрим несколько удачных мо-
делей схем и оценим их по приведенным выше критериям. Эти модели
используются во многих реальных системах, иногда с некоторыми ва-
риациями. Например, в реальные системы могут добавляться дополни-
тельные связи с целью повышения отказоустойчивости (за счет увеличе-
ния ширины сечения) и производительности (за счет уменьшения диа-
метра сети).
________________________________________________________ Глава
Общая шина
Сети с топологией общей шины (shared bus) используют общий канад
связи (то есть путь передачи сообщений) между всеми процессорами и мо-
дулями памяти (см. рис. 15.1).53 Операциями обмена данными занимаются
шинные интерфейсы компонентов. Сама шина пассивна, и компоненты оц.
ределяют очередность ее использования, общаясь друг с другом. В любой
момент времени по шине может передаваться только один элемент дац.
ных, поскольку шина не может передавать одновременно два электриче-
ских сигнала. Поэтому прежде чем компонент начнет передачу, он должен
убедиться, что шина свободна, а компонент, которому предназначены дан-
ные, готов их принять. Одна из проблем, характерных для общей шины —
шинные конфликты (contention) или конкуренция за шину — проявляет-
ся, когда шину одновременно хотят использовать несколько компонентов.
Чтобы уменьшить частоту шинных конфликтов и нагрузку на шину, каж-
дый процессор использует локальный кэш, как показано на рисунке 15.1.
Если система может выполнить запрос процессора, обратившись к его ло-
кальному кэшу, процессору не нужно занимать шину, связываясь с моду-
лем памяти. Другой вариант решения проблемы — использование архи-
тектуры с несколькими общими шинами (multiple shared bus architectu-
re), которая уменьшает вероятность шинных конфликтов, предоставляя
несколько шин для выполнения запросов обмена данными. Однако в таких
архитектурах используются изощренные схемы управления шинами и до-
полнительные связи, вследствие чего их стоимость возрастает.54’ 55
Общая шина — простой и дешевый способ организации связи между не-
сколькими процессорами. Новые компоненты можно добавлять в систему,
просто подключая их к уже существующей шине, и программное обеспече-
ние выполняет обнаружение и распознавание подключенных компонен-
тов. Однако из-за шинных конфликтов системы этой архитектуры могут
содержать только небольшое количество процессоров (на практике — не
больше 16 или 32).56 Шинные конфликты усугубляются тем, что произво-
дительность процессоров растет быстрее, чем пропускная способность
шин, и чем быстрее процессоры, тем меньше их нужно, чтобы полностью
загрузить шину.
Рис. 15.1. Многопроцессорная система с общей шиной
Многопроцессорность
Г
Общие шины представляют собой динамические сети, поскольку кана-
Ь1 связи в них формируются и исчезают во время работы системы. Поэто-
му критерии оценки производительности схем соединения, рассмотренные
ами выше, нельзя применять к архитектурам с общей шиной — они го-
лтся только для систем со статическими связями, не изменяющимися во
„ремя работы. Однако по сравнению с другими архитектурами при неболь-
шом количестве процессоров общая шина — дешевая и эффективная архи-
тектура, хотя и не особенно отказоустойчивая — если шина отказывает,
компоненты не могут взаимодействовать друг с другом.57
Разработчик должен оценить преимущества и недостатки общей шины
дЛя многопроцессорной системы с большим количеством процессоров,
g таких системах использование одной общей шины (или нескольких
шин) для соединения всех процессоров становится непрактичным, по-
скольку шина быстро загружается до предела. Однако разработчик может
разделить компоненты системы (включая процессоры и память) на не-
сколько суперузлов. Ресурсы в суперузле связываются друг с другом по об-
щей шине, а суперузлы связываются между собой по одной из рассмотрен-
! ных ниже схем, которые лучше подходят для крупных систем. В системах
с суперузлами разработчик пытается удержать большую часть трафика
в пределах суперузлов, чтобы воспользоваться преимуществами быстрых
каналов обмена.58 В большинстве многопроцессорных систем с небольшим
количеством процессоров, например, в двухпроцессорных настольных ПК,
используется архитектура с общей шиной.59
Переключающая матрица
Архитектура с переключающей матрицей (crossbar-switch matrix) по-
зволяет связывать любой процессор с любым модулем памяти
(см. рис. 15.2).60 Например, если в системе п процессоров и т модулей па-
мяти, то в матрице будет п х т переключателей, позволяющих соединить
любой процессор с любым модулем памяти. Можно представить себе про-
цессоры как строки таблицы, а модули памяти — как столбцы. В сетях
большего размера узлы часто содержат и процессоры, и модули памяти.
Это повышает производительность при обращениях к памяти (если процес-
сор обращается к памяти в одном с ним узле). В системе с переключающей
матрицей такой подход приводит также к снижению цены схемы соедине-
ний. В такой системе каждый узел соединен с переключателем степени
Р~1, где р — количество узлов процессор-память в системе (в этом случае
ю = п, поскольку в каждом узле содержится одно и то же количество моду-
лей памяти и процессоров).61’ 62
Переключающая матрица может обеспечивать одновременную передачу
Данных всеми узлами, но в любой момент времени каждый узел может
принимать только один поток данных. Сравните такую возможность с воз-
можностью передавать только один элемент данных одновременно по об-
щей шине. Переключатели используют алгоритм вроде «обслужить запрос
от процессора, который не обслуживался данным переключателем дольше
всего», чтобы выбрать, какой запрос выполнять первым. Архитектуры
с переключающей матрицей характеризуются высокой производительно-
стью. Поскольку каждый узел связан со всеми остальными узлами, а пере-
дача данных через узлы-переключатели незначительно снижает произво-
дительность, диаметр сети практически равен единице. Любой процессор
может связаться с любым модулем памяти, поэтому, чтобы разделить ца.
двое сеть архитектуры с переключающей матрицей, нужно перерезать по.
ловину связей между процессорами и модулями памяти. Количество свя.
зей в матрице равно произведению п и т, так что ширина сечения равца
(п * т) / 2, и отказоустойчивость системы будет велика. Как видц0
из рисунка 15.2, чтобы отправить по назначению данные, можно выбрать
множество разных путей.
Недостаток архитектуры с переключающей матрицей — ее дороговиз-
на. Цена такой матрицы растет пропорционально п х т, и большие матри-
цы становятся чрезмерно дорогими для практического использования.^
Поэтому эта архитектура используется в системах с небольшим количест-
вом процессоров (например, с 16 процессорами). Однако аппаратное обес-
печение постепенно дешевеет, и матрица используется все чаще в больших
системах. Архитектура с переключающей матрицей используется в систе-
мах Sun UltraSPARC-Ill для организации совместного доступа к памяти.64
Рис. 15.2. Многопроцессорная система с переключающей матрицей
- Переключатель
ДВумерная ячеистая сеть
В схеме соединений, называемой двумерной ячеистой сетью (2-D mesh
network), каждый узел содержит один или несколько процессоров и модуль
памяти. В простейшем варианте (см. рис. 15.3) узлы в сети расположены
в виде прямоугольной матрицы с п строками и т столбцами, и каждый узел
соединен с соседними сверху, снизу, слева и справа от него. Такая сеть на-
зывается четырехсвязной двумерной ячеистой сетью (4-connected 2-D mesh
^огопроцессорность
919
etwork). В ней степень каждого узла остается небольшой, независимо от
количества процессоров в системе — у угловых узлов степень равна двум,
Тдругих узлов на краях сетки — трем, а у внутренних узлов — четырем.
0а рисунке 15.3, где п = 4 и т = 5, сеть можно разделить на две части, пере-
резав пять связей между узлами второй и третьей строк. Собственно говоря,
когда п — четное, а т — нечетное, то ширина сечения равна т + 1, если
л > и, или п в противном случае. Если и количество столбцов, и количество
^рок — четные, то ширина сечения равна т или п, в зависимости от того,
4то меньше. Хотя такая архитектура и не настолько отказоустойчива, как
архитектура с переключающей матрицей, она более отказоустойчива, чем,
например, архитектура с общей шиной. Поскольку максимальная степень
узла равна четырем, архитектура двумерной ячеистой сети будет образовы-
вать сети слишком большого диаметра при большом количестве процессо-
ров. Однако эта архитектура используется при построении больших систем,
в которых обмен данными преимущественно выполняется между соседними
узлами. Например, архитектура двумерной ячеистой сети используется
в многопроцессорных системах Intel Paragon.65
Рис. 153. Четырехсвязная двумерная ячеистая сеть
Гиперкуб
N-мерный гиперкуб (hypercube) состоит из 2п узлов, каждый из которых
связан с п соседними узлами. Поэтому двумерный гиперкуб представляет
собой двумерную ячеистую сеть размером 2 X 2, а трехмерный гиперкуб —
просто куб.66 На рисунке 15.4 показаны связи между узлами в трехмерном
(а) и четырехмерном (Ь) гиперкубах.67 Заметьте, что трехмерный гипер-
куб — это практически два двумерных гиперкуба, в которых связаны меж-
ду собой соответствующие узлы. Точно так же четырехмерный гиперкуб —
это два трехмерных гиперкуба, в которых связаны между собой соответст-
вующие узлы.
Производительность в гиперкубах масштабируется лучше, чем в дву-
мерных ячеистых сетях, поскольку каждый узел гиперкуба связан п свя-
зями с другими узлами. Это уменьшает диаметр сети по сравнению с дву-
мерной ячеистой сетью. Рассмотрим, например, 16-узловую многопроцес-
сорную систему, реализованную сначала в виде ячеистой сети 4x4,
а затем — в виде четырехмерного гиперкуба. У ячеистой сети 4x4 дц.1
метр будет равен 6, а у четырехмерного гиперкуба — 4. В некоторых rjj
перкубах разработчики добавляют дополнительные связи, чтобы еще бодь
ше уменьшить диаметр сети.68 Отказоустойчивость гиперкуба тоже луч1це
чем других схем соединений. Однако большое количество связей у кажд0’
го узла увеличивает цену гиперкуба по сравнению с ячеистой сетью.69 I
Гиперкуб — удобная схема соединений для небольшого количества пр0 I
цессоров, более дешевая, чем переключающая матрица. Системы nCUBj
используемые в потоковой обработке видеоданных, используют гиперкуб^ ]
размером вплоть до 13 измерений (8192 узла).70
(а) Узлы (Ь)
Рис. 15.4. 3- и 4-мерные гиперкубы
Многоуровневая сеть
Существует альтернативная схема соединения процессоров — много-
уровневая сеть (multistage network).71 Как и в схеме с переключающей
матрицей, некоторые узлы в такой схеме представляют собой коммутато-
ры, а не процессоры и модули памяти. Коммутаторные узлы просты, малы
по размеру и могут быть плотно упакованы, за счет чего повышается про-
изводительность. Чтобы понять преимущества многоуровневой сети перед
переключающей матрицей, представьте себе задачу авиаперелета из одно-
го небольшого города в другой. Вместо того, чтобы предлагать маршруты
для каждой пары небольших городов с аэропортами, авиакомпании обыч-
но используют большие города в качестве центров. Перелет между двумя
небольшими городами приходится выполнять в несколько этапов. Сначала
нужно совершить перелет из исходного города в ближайший центр, за-
тем — из этого центра в тот, из которого есть рейс в город назначения, а за-
тем — еще один перелет, чтобы добраться до места. Коммутаторы в много-
уровневой сети выполняют ту же роль, что и центры в только что рассмот-
ренной схеме авиаперелетов.
Есть множество структур многоуровневых сетей. На рисунке 15.5 пока-
зана популярная структура такой сети, называемая базовой сетью
(baseline network).72 Узлы в правой части диаграммы — это те же узлы, что
и в ее левой части. Если одному процессору нужно связаться с другим, его
сообщение перемещается через последовательность коммутаторов. КоммУ'
yzi
аТоры в первом слева столбце соответствуют младшему (первому справа)
zjjiy идентификатора процессора, коммутаторы в среднем столбце — сред-
-еМУ биту, а в правом столбце — старшему (первому слева) биту.
Рис. 15.5. Многоуровневая базовая сеть
Например, рассмотрим выделенный жирным путь на рисунке 15.5 — от
исходного процессора с идентификатором 001 до целевого процессора
с идентификатором 110. Начнем с прослеживания пути от процессора 001
к коммутатору. Проверим младший бит идентификатора целевого процессо-
ра (110) и проследим соответствующий путь от коммутатора к следующему
коммутатору. От второго коммутатора следуем по пути, соответствующему
среднему биту (то есть 1). И, наконец, он третьего коммутатора следуем по
Пути, соответствующему старшему биту (тоже 1) в идентификаторе целевого
Процессора.
Многоуровневые сети представляют собой попытку достичь компромис-
са между ценой и производительностью. Они позволяют с помощью про-
стых устройств объединять большое количество процессоров. Любой про-
фессор может связаться с любым другим, не передавая данные промежу-
точным процессорам. Однако диаметр многоуровневой сети может быть
весьма велик, и обмен данными по ней идет медленнее, чем по схеме с пе-
реключающей матрицей — каждое сообщение должно проходить через не-
сколько коммутаторов. Кроме того, может возникнуть конкуренция (шин-
ные конфликты в отдельных коммутаторах) и производительность снизит-
ся- Многоуровневые сети используются для объединения процессоров
н машинах SP компании IBM, включая серию POWER4. Пример машины
Глава
этой серии — суперкомпьютер ASCI-White на мультипроцессор^
POWER3-II, производительность которого свыше 100 триллионов опере
ций в секунду.73’ 74
Вопросы для самопроверки
1. В восьмисвязной двумерной ячеистой сети каждый узел связан с0
всеми соседними узлами, включая соседние по диагонали. Сравни
те четырехсвязные и восьмисвязные двумерные ячеистые сети ц0
критериям, описанным в этом разделе
2. Сравните многоуровневую сеть и переключающую матрицу. Како-
вы преимущества и недостатки каждой схемы соединений?
Ответы о В восьмисвязной двумерной ячеистой сети степень ка-
ждого узла увеличивается примерно вдвое по сравнению с четырех-
связной и, соответственно, приблизительно вдвое возрастает цена.
Однако диаметр сети уменьшается, и возрастает ширина сечения сети,
поскольку в сети становится больше связей. Поэтому отказоустойчи-
вость и цена восьмисвязной двумерной ячеистой сети выше, чем четы-
рехсвязной, а латентность ниже. 2) Многоуровневая сеть дешевле, чем
переключающая матрица, но ее производительность и отказоустойчи-
вость ниже.
\ацогопроцессорность -
Тесносвязанные системы работают эффективнее, но менее гибки. Такие
.цстемы не очень хорошо масштабируются, поскольку частота конфликтов
^,рИ доступах к разделяемым ресурсам быстро возрастает с ростом количе-
,‘тва процессоров. Поэтому большинство систем с большим количеством
процессоров являются слабосвязанными. В тесносвязанной системе разра-
ботчики могут оптимизировать взаимодействие между компонентами, что-
бы повысить производительность системы. Однако это понижает гибкость
бцстемы и ее отказоустойчивость, поскольку каждый компонент полагает-
cfl в работе на другие компоненты. Двухпроцессорные системы с процессо-
рами Pentium фирмы Intel — пример тесносвязанных систем.77
с
р
Ввод/
Вывод
Разделяемые ресурсы
с
р
Ввод/
Вывод
15.2.3 Тесносвязанные и слабосвязанные системы
Еще одна характеристика многопроцессорных систем — способ распре-
деления ресурсов между процессорами. В тесносвязанной системе (tightly
coupled system) (см. рис. 15.6) процессоры совместно используют большую
часть системных ресурсов. В тесносвязанных системах часто используются
общие шины, и процессоры обычно обмениваются данными через общедос-
тупную память. Всеми компонентами системы обычно управляет центра-
лизованная операционная система. В слабосвязанных системах (loosely
coupled systems) (см. рис. 15.7) компоненты обычно соединяются специ-
альными каналами связи.75 Иногда процессоры обладают общим доступом
к памяти, но часто у каждого процессора есть собственная память, к кото-
рой он может обращаться намного быстрее, чем к остальной памяти систе-
мы. В других случаях передача сообщений является единственным спосо-
бом взаимодействия процессоров, и общей памяти в системе нет.
В общем случае слабосвязанные системы являются более гибкими
и масштабируемыми, чем тесносвязанные. Если компоненты системы сла-
бо связаны друг с другом, разработчик легко может добавлять в систему
новые компоненты или удалять их. Кроме того, слабая связанность компо-
нентов увеличивает отказоустойчивость, поскольку компоненты могут
функционировать независимо друг от друга. Однако слабосвязанные систе-
мы обычно менее эффективны, чем тесносвязанные, поскольку в них ком-
поненты взаимодействуют с помощью передачи сообщений по каналам
связи — этот способ взаимодействия медленнее, чем через общую память-
Кроме того, создание системного программного обеспечения для слабосвя-
занных систем сложнее, поскольку оно должно обеспечивать передачу со-
общений для прикладных программ. Пример слабосвязанной системы
японский суперкомпьютер Earth Simulator.76
с
Р
Ввод/
Вывод
-Процессор с собственным кэшем
Система ввода/вывода
Рис. 15.6. Тесносвязанная система
м
М
М
— Модуль памяти
р
Ввод/ '
Вывод
Канал связи
С
с
Р
- Процессор с собственным кэшем
Ввод/
Вывод
Ввод/ _ система ввода/вывода
Вывод
Рис. 15.7. Слабосвязанная система
Вопросы для самопроверки
1. Почему многие многопроцессорные системы с небольшим колич]
ством процессоров строятся в виде тесносвязанных систем? Поче^
системы с большим количеством процессоров обычно создают^
слабосвязанными?
2. Некоторые системы состоят из нескольких групп тесносвязанньц
компонентов, соединенных каналами связи в слабосвязанную сис.
тему. Обсудите причины использования таких схем.
Ответы 1) Маленькая система может быть тесносвязанной, По.
скольку в ней невысока вероятность конфликтов при доступе к разде.
ляемым ресурсам. Поэтому разработчики могут оптимизировать
взаимодействие компонентов системы, повышая тем самым ее произ.
водительность. Большие системы обычно создаются слабосвязанны,
ми, чтобы уменьшить вероятность конфликтов при доступе
к разделяемым ресурсам и вероятность выхода системы из строя при
отказе одного компонента. 2) Такие схемы — попытка совместить пр«.
имущества тесносвязанных и слабосвязанных систем. Каждая группа
мала по размеру, и в ней тесносвязанная архитектура обеспечивает
высокую производительность. Использование в системе в целом слабо-
связанной схемы уменьшает вероятность конфликтов при доступе
к разделяемым ресурсам и увеличивает гибкость системы и ее отказо-
устойчивость.
153 Организации многопроцессорных
операционных систем
С точки зрения организации и структуры операционные системы для
многопроцессорных компьютеров существенно отличаются от операцион-
ных систем для однопроцессорных машин. В этом разделе мы будем клас-
сифицировать многопроцессорные системы по разделению в них различ-
ных функций операционных систем. Основные схемы организаций опера-
ционных систем для многопроцессорных компьютеров: ведущий/ведомый,
схема с раздельными ядрами и схема с симметричным (или анонимным)
обслуживанием всех процессоров.
15.3.1 Схема ведущий/ведомый
Организация многопроцессорной системы ведущий/ведомы»
(master/slave multiprocessor organization) делает один процессор ведущим
(главным), а остальные — ведомыми (подчиненными) (см. рис. 15.8).78 На
ведущем процессоре исполняется собственно операционная система, а на
ведомых — только пользовательские программы. Ведущий процессор
управляет вводом/выводом и выполняет вычисления. Ведомые процессо-
ры могут эффективно выполнять задачи, интенсивно использующие про-
цессор, но если выполняемые на них задачи требуют интенсивного вво-
да/вывода, то ведомые процессоры будут часто обращаться к ведущему
процессору. С точки зрения отказоустойчивости: вычислительная эффек-
тивность падает при отказе одного из ведомых процессоров, но система ос-
гается работоспособной. Отказ ведущего процессора приводит к катастро-
фе -— система становится полностью неработоспособной. Системы с органи-
зацией ведущий/ведомый являются тесносвязанными, поскольку все
ведомые процессоры зависят от ведущего.
Ввод/ ___________ Ведущий ______________Устройство л____________ Ведомый
Вывод процессор хранения процессор
Рис. 15.8. Многопроцессорная система схемы ведущий/ведомый
Основной проблемой в системах с такой организацией является асим-
метричность аппаратуры — операционная система выполняется только на
ведущем процессоре. Когда процессу, выполняющемуся на ведомом про-
цессоре, требуется внимание операционной системы, ведомый процессор
генерирует прерывание и ожидает, пока ведущий процессор обработает это
прерывание.
Гиперкубы систем nCUBE являются примерами систем ведущий/ведо-
мый. В них множество ведомых процессоров выполняют задачи, требую-
щие интенсивных вычислений, связанных с обработкой видео- и аудиодан-
ных.79
Вопросы для самопроВерки
1. (Да/Нет) Системы схемы ведущий/ведомый хорошо масштабиру-
ются до больших размеров.
2. Для каких сред схема ведущий/ведомый подходит лучше всего?
Ответы 1) Нет. Операционная система выполняется только на од-
ном процессоре. Между пользовательскими процессами, выполняю-
щимися на других процессорах, возникнет конкуренция при
обращении к функциям, выполняемым основным процессором (на-
пример, к функциям ввода/вывода). 2) Системы такой схемы лучше
всего подходят для сред, в которых большая часть задач связана с ин-
тенсивными вычислениями. Эти задачи будут выполняться ведомыми
процессорами без частых обращений к ведущему.
15.3.2 Схема с раздельными ядрами
В многопроцессорной системе с раздельными ядрами (separate-kernels
multiprocessor organization) на каждом процессоре выполняется своя опера-
ционная система, реагирующая на прерывания от пользовательских процес-
сов, выполняющихся на этом процессоре.80 Процесс, запущенный на опре-
деленном процессоре, выполняется на этом процессоре до завершения.
В операционной системе есть несколько структур, содержащих информа-
цию глобального характера, например, список всех процессов, известных
системе. Доступ к этим структурам должен контролироваться механизмами
взаимного исключения, которые мы рассмотрим в разделе 15.9. Системы
построенные по схеме с раздельными ядрами, являются слабосвязанными.
Эта схема более отказоустойчива, чем схема ведущий/ведомый — если откд.
жет один процессор, вряд ли выйдет из строя вся система. Однако процессы
выполнявшиеся на отказавшем процессоре, не смогут выполняться, пока це
будут перезапущены на другом процессоре.
В схеме с раздельными ядрами каждый процессор работает с ресурсами,
доступными только ему — например, файлами и устройствами ввода/вьь
вода. Прерывания ввода/вывода обрабатываются теми процессорами, ко-
торые их инициируют.
Такая схема выигрывает от минимальной конкуренции при доступе к ре.
сурсам операционной системы, поскольку эти ресурсы распределены между
множеством операционных систем. Однако процессоры не кооперируются
при выполнении отдельных процессов, и некоторые процессоры могут про.
стаивать, в то время как на других выполняются многопоточные процессы.
Система Tandem, популярная в областях с критически важными приложе-
ниями, является примером системы с раздельными ядрами; поскольку
в ней операционная система распределена между слабосвязанными процес-
сорными узлами, полный отказ системы практически невозможен.81
Вопросы для самопроверки
1. Почему схема с раздельными ядрами более отказоустойчива, чем
схема ведущий/ведомый?
2. Для каких сред схема с раздельными ядрами подходит лучше всего?
Ответы 1) Схема с раздельными ядрами является слабосвязанной.
У каждого процессора есть свои ресурсы, и он не взаимодействует
с другими процессорами при выполнении своих задач. Если один из
процессоров выходит из строя, остальные продолжают работать.
В схеме ведущий/ведомый при отказе ведущего процессора ни один
ведомый процессор не сможет выполнять функции операционной сис-
темы, которые должны выполняться ведущим процессором. 2) Схема
с раздельными ядрами удобна в средах, в которых процессы не взаи-
модействуют между собой, например, в кластерах рабочих станций,
на которых пользователи выполняют независимые программы.
15.3.3 Симметричная схема
Многопроцессорные системы симметричной схемы (symmetrical
multiprocessor organization) — самые сложные из таких систем, но одно-
временно и самые мощные.82’83 [Примечание'. Эти схемы не следует путать
с симметричными многопроцессорными системами (Symmetric Multipro-
cessor — SMP), которые мы рассмотрим в разделе 15.4.1]. Операционная
система распоряжается набором одинаковых процессоров, любой из кото-
рых может обращаться к любому устройству ввода/вывода и к любому уст-
ройству хранения. Такая симметрия позволяет распределять нагрузку бо-
лее равномерно и точно, чем другие схемы.
Поскольку операционная система может выполняться одновременно на
множестве процессоров, нужно гарантировать взаимное исключение при
работе с общими структурами данных. Кроме того, важны методы разре-
шения аппаратных и программных конфликтов.
Многопроцессорные системы симметричной схемы в целом являются
самыми отказоустойчивыми. Если один из процессоров выходит из строя,
операционная система удаляет его из набора процессоров, с которыми она
работает. Производительность системы плавно снижается, а затем восста-
вав чивается по завершении ремонта (см. «Размышления об операционных
системах: Плавное снижение эффективности»). Кроме того, процесс, вы-
полняющийся в многопроцессорной системе симметричной схемы, можно
передать любому процессору. Поэтому процесс не привязан к конкретному
процессору, как в схеме с раздельными ядрами. Операционная система
«перетекает» от одного процессора к другому.
Один из недостатков многопроцессорных систем симметричной схе-
мы — конкуренция при доступе к ресурсам операционной системы, напри-
мер, глобальным структурам данных. Очень важно тщательно продумать
организацию таких структур, чтобы предотвратить ненужное блокирова-
ние данных, исключающее выполнение операционной системы на несколь-
ких процессорах сразу. Чаще всего для минимизации количества кон-
фликтов глобальные структуры данных делятся на отдельные элементы,
доступ к которым может осуществляться независимо.
Даже в системах полностью симметричной схемы добавление нового
процессора не приводит к увеличению производительности системы на
полную величину производительности этого процессора. Тому есть множе-
ство причин, включая дополнительные накладные расходы на поддержку
процессора операционной системой, рост конкуренции при обращении
к ресурсам и аппаратные задержки при переключении и перенаправлении
сообщений между растущим количеством компонентов. Был выполнен ряд
исследований производительности таких систем; одна из первых систем,
BBN Butterfly с 256 процессорами, была в 180-230 раз быстрее, чем одно-
процессорная система.84
Вопросы для самопроверки
1. Почему удвоение количества процессоров в многопроцессорной сис-
теме симметричной схемы не увеличивает в два раза ее производи-
тельность?
2. Каковы преимущества симметричной схемы перед схемой веду-
щий/ведомый и схемой с раздельными ядрами?
Ответы 1) Добавление в систему новых процессоров приводит
к росту конкуренции при обращении к ресурсам и увеличивает на-
кладные расходы при работе операционной системы, поэтому часть
производительности добавленных процессоров теряется. 2) Симмет-
ричная схема лучше масштабируется, чем схема ведущий/ведомый,
поскольку операционная система может выполняться на всех процес-
I сорах; кроме того, это обеспечивает хорошую отказоустойчивость.
I Симметричная схема обеспечивает лучшую кооперацию между про-
I цессорами, чем схема с раздельными ядрами. Она позволяет обеспе-
чить взаимодействие процессов и эффективнее выполнять процессы
в параллельном режиме.
Размышления об операционных системах
Плавное сниэ/сение эффективности
Ничто не вечно. Отдельные компоненты
систем выходят из строя. Целые системы
тоже выходят из строя. Вопрос, о котором
всегда нужно помнить: «Что делать, если
в системе что-то вышло из строя?». Многие
системы могут плавно снижать эффектив-
ность своей работы, то есть продолжать ра-
ботать при отказе некоторых компонентов,
но с меньшей эффективностью. Классиче-
ский пример плавного снижения эффектив-
ности встречается в многопроцессорных сис-
темах симметричной схемы, в которых лю-
бой процесс может выполняться на любом
процессоре. Если один из процессоров вы-
ходит из строя, оставшиеся процессоры мо-
гут продолжать работать, но производитель-
ность системы снизится. Плавное снижение
эффективности свойственно многим диско-
вым системам, в которых при обнаружении
нерабочей области диска она помечается
и в дальнейшем не используется, но диск
в целом продолжает работать. Если в Интер-
нете выходит из строя маршрутизатор, Ин-
тернет продолжает работать, передавая
данные через маршрутизаторы, которые ос-
тались работоспособными. Обеспечение
возможности плавного снижения эффек-
тивности — важная задача при проектирова-
нии операционных систем, особенно с уче-
том того, что люди все больше полагаются
на устройства, которые рано или поздно от-
казывают.
/5.4 Архитектуры доступа к памяти
До сих пор мы классифицировали многопроцессорные системы по ха-
рактеристикам их аппаратных составляющих и структуре операционных
систем. Многопроцессорные системы можно также классифицировать по
способам их работы с памятью. Рассмотрим, к примеру, систему с неболь-
шим количеством процессоров и небольшим объемом памяти. Если па-
мять сосредоточена в нескольких модулях, к которым может легко обра-
титься любой процессор (например, через общую шину), то система мо-
жет обеспечить быстрый доступ к памяти. Однако если процессоров
и модулей памяти много, то произойдет насыщение шины. В этом случае
часть памяти можно тесно связать с процессором, чтобы он мог быстро
к ней обращаться. Поэтому при выборе архитектуры доступа к памяти
разработчики системы должны принимать во внимание соображения про-
изводительности, стоимости и масштабируемости. В следующих разделах
описаны часто используемые в многопроцессорных системах архитекту-
ры доступа к памяти.
Многопроцессорность vn
---. - . -
15.4.1 Архитектура однородного доступа к памяти (UMA)
UMA расшифровывается как Uniform Memory Access — однородный
доступ к памяти. Эта архитектура предоставляет всем процессорам одина-
ковые возможности доступа к основной памяти системы (см. рис. 15.9).
Это просто прямолинейное расширение архитектуры памяти, используе-
мой в однопроцессорной системе, за счет использования нескольких про-
цессоров и модулей памяти. Обычно у каждого процессора есть своя
кэш-память, использование которой позволяет уменьшить нагрузку на
шину и повысить производительность. Время доступа к памяти одинаково
для всех процессоров, за исключением случаев, когда процессор обращает-
ся к элементу данных в кэше или когда возникает конкуренция при обра-
щении к шине. Системы архитектуры UMA также называются симмет-
ричными многопроцессорными системами (SMP — symmetric multipro-
cessor), поскольку в них любой процесс может выполняться на любом
процессоре, и все ресурсы (включая память, устройства ввода/вывода
и процессы) доступны для всех процессоров. В системах архитектуры UMA
с небольшим количеством процессоров обычно используются общая шина
или переключающая матрица. Устройства ввода/вывода прямо подсоеди-
нены к этим шинам или матрицам и доступны для всех процессоров.85
Архитектура UMA обычно используется в небольших многопроцессор-
ных системах (обычно — от двух до восьми процессоров). Эта архитектура
не очень хорошо масштабируется — в ней легко возникает насыщение
шины, если одновременно большое количество процессоров обращается
к памяти, а переключающие матрицы весьма дороги даже при использова-
нии в системах скромного размера.86» 87
Модуль памяти
Процессор
с собственным
кэшем
Рис. 15.9. Многопроцессорная система архитектуры UMA
Вопросы для самопроверки
1. Почему ячеистые сети и гиперкубы — неподходящие схемы соеди-
нений процессоров в системах архитектуры UMA?
2. Почему системы архитектуры UMA называются симметричными?
Глава is I Многопроцессорность
931
Ответы 1) В ячеистых сетях и гиперкубах процессоры и память раз.
мещаются в каждом узле, и обращения к локальной памяти выполняют-
ся быстрее, чем к удаленной; поэтому доступ к памяти в этих схемах
соединений не будет однородным. 2) Они называются симметричными
потому что в них любой процессор может выполнить любую операцию
и обратиться к любому ресурсу (включая память, устройства ввода/вьг-
вода и процессы).
15.4.2 Архитектура неоднородного доступа к памяти (NUMA)
NUMA расшифровывается как Non-Uniform Memory Access — неодно-
родный доступ к памяти. Эта архитектура призвана решить проблемы
масштабируемости, свойственные архитектуре UMA. Основное узкое место
в больших системах архитектуры UMA — доступ к общей памяти. Произ-
водительность в них падает из-за конкуренции при обращении множества
процессоров к общей шине. Если вместо общей шины используется пере-
ключающая матрица, то ее стоимость может резко возрасти из-за необхо-
димости обеспечения множества каналов доступа к общей памяти. Много-
процессорные системы архитектуры NUMA решают эти проблемы, ослаб-
ляя требования фиксированного времени доступа к памяти.
В системах архитектуры NUMA используется общая память, доступная
всем процессорам. Эта память делится на модули, и в каждом узле систе-
мы в качестве локальной памяти используется один из этих модулей.
На рисунке 15.10 показана система, в которой в каждом узле содержится
один процессор, но это не всегда так. Хотя могут использоваться разные
схемы соединения, процессоры всегда напрямую соединены с их локаль-
ной памятью и не напрямую (то есть через одну из схем соединений, рас-
смотренных в разделе 15.2.2) с остальной памятью. Такая структура обес-
печивает более быстрый доступ к локальной памяти, чем к остальной па-
мяти системы, поскольку доступ к остальной памяти требует обращения
к схеме соединений.
Архитектура NUMA прекрасно масштабируется, поскольку она умень-
шает количество конфликтов при доступе к шине — большая часть запро-
сов процессоров к памяти сводится к обращениям к локальной памяти.
В архитектуре NUMA можно реализовать стратегию, перемещающую стра-
ницы в локальную память процессора, который обращается к ним чаще
всего — такая стратегия называется миграцией страниц. Она подробно об-
суждается в разделе 15.5.2. Обычно в системах архитектуры NUMA боль-
ше процессоров, чем в системах архитектуры UMA, и системы с большим
количеством процессоров, построенные по архитектуре NUMA, могут быть
слишком дорогими.88, 89
Вопросы для самопроверки
1. Перечислите несколько преимуществ и недостатков архитектуры
NUMA по сравнению с UMA.
2. Какие дополнительные задачи возникают перед программистами
и операционными системами при использовании архитектуры
NUMA?
Ответы 1) Системы архитектуры NUMA лучше масштабируются,
чем системы архитектуры UMA, потому что в архитектуре NUMA уст-
ранено узкое место архитектуры UMA — ограниченность пропускной
способности каналов доступа к памяти. Системы UMA эффективнее,
чем системы NUMA, при небольшом количестве процессоров, по-
скольку они обеспечивают быстрый доступ ко всей памяти для всех
процессоров. 2) Если два процесса, выполняющихся на процессорах из
разных узлов, используют для взаимодействия общую память, то хотя
бы для одного из этих процессов требуемые данные будут находиться
в удаленной памяти, и производительность снизится. Поэтому при
проектировании операционной системы разработчики стремятся раз-
местить процессы и память, с которой эти процессы работают, в одном
узле. Это может потребовать размещения процесса на одном и том же
процессоре при каждом его запуске. Кроме того, в операционной сис-
теме должна быть предусмотрена возможность перемещения страниц
между модулями памяти по требованию.
М _ Модуль памяти
15.4.5 Кэшевая архитектура памяти /СОМА)
Сеть соединений
Р - Процессор
с собственным
кэшем
Г™
— м
Рае. 15.10. Многопроцессорная система архитектуры NUMA
В предыдущем разделе мы выяснили, что в каждом узле системы
NUMA есть своя локальная память, к которой могут обращаться и процес-
соры из других узлов. Часто время доступа к локальной памяти гораздо
меньше, чем к удаленной (то есть к памяти в другом узле). Задержка из-за
промаха в кэше (cache-miss latency), то есть время, необходимое для полу-
чения данных, отсутствующих в кэше, может оказаться очень большой,
если запрошенных данных нет в локальной памяти. Один из способов
Уменьшения таких задержек — уменьшение количества запросов, для вы-
полнения которых нужно обращаться к удаленной памяти. Вспомните, что
Б системах NUMA данные размещаются в локальной памяти процессора,
который обращается к ним чаще всего. Такой подход неудобно реализовы-
®ать в компиляторах и программах, поскольку последовательности обра-
щений к данным динамически изменяются. Описанную проблему в опера-
ционной системе можно решить, однако при этом необходимо перемещать
Целые страницы данных, в результате чего миграция данных может замед-
литься. Кроме того, разные элементы данных на одной странице часто тре-
буются процессорам из разных узлов.90
Архитектура СОМА (Cache-Only Memory Architecture — кэшевая архи-
тектура памяти) — это разновидность архитектуры NUMA. Системы архи-
тектуры СОМА пытаются решить только что описанную проблему доступа
к памяти (см. рис. 15.11). В таких системах есть один или несколько процес-
соров с выделенной кэш-памятью и частью общей памяти. Память, связанная
с каждым узлом, организована в виде большого кэша, известного как при-
влеченная память (AM — Attraction Memory). Ее использование позволяет
аппаратуре эффективно выполнять миграцию данных фрагментами разме-
ром в одну строку памяти (memory line). Строка памяти — это эквивалент
строки кэша, но она располагается в оперативной памяти, и размер этой стро-
ки обычно равен четырем или восьми байтам.91 Кроме того, поскольку ло-
кальная память каждого процессора воспринимается как кэш, в разных AM
могут находиться копии одних и тех же строк памяти. При такой схеме дан-
ные обычно находятся в памяти процессоров, чаще всего к ним обращающих-
ся, и средняя задержка из-за промаха в кэше становится меньше. Недостатки
такой схемы — дополнительные затраты памяти на хранение повторяющих-
ся копий данных в разных модулях, и изощренные аппаратные и программ-
ные средства, обеспечивающие синхронизацию данных в AM разных процес-
соров. Эти недостатки приводят к тому, что если запрос требует обращения
к удаленной памяти, то он выполняется дольше.92
AM AM
Сеть соединений
AM I - Привлеченная память
р с _ Процессор с собственным
J кэшем
Рис. 15.11. Многопроцессорная система архитектуры СОМА
Вопросы для самопроверки
1. Какие проблемы архитектуры NUMA пытается решить архитекту-
ра СОМА?
2. (Да/Нет). Архитектура СОМА всегда производительнее архитекту-
ры NUMA.
Ответы 1) Промахи в кэше, требующие обращений к удаленной
памяти в архитектурах NUMA и СОМА, обычно приводят к большим
задержкам, чем промахи, требующие обращений к локальной памяти.
В отличие от систем NUMA, в системах СОМА есть аппаратура, пере-
мещающая копии элементов данных в локальную память (в привле-
ченную память) процессора, который к ним обратился. 2) Нет.
В системах СОМА уменьшается вероятность того, что промах в кэше
потребует обращения к удаленной памяти, но в них увеличиваются
накладные расходы на обращения к удаленной памяти, поскольку та-
кие обращения требуют синхронизации данных, скопированных
в привлеченную память разных процессоров.
15.4.4 Архитектура без доступа к удаленной памяти NORMA
Многопроцессорные системы архитектур UMA, NUMA и СОМА являют-
ся тесносвязанными. Хотя системы архитектуры NUMA (и, в меньшей сте-
пени, СОМА) хорошо масштабируются, для их построения требуются
сложные аппаратные и программные средства. Программное обеспечение
управляет доступом к общим ресурсам, например, к памяти; аппаратура
отвечает за реализацию схемы соединений. В системах архитектуры без
доступа к удаленной памяти (NO Remote Memory Access, NORMA) общей
памяти нет, и такие системы являются слабосвязанными (см. рис. 15.12).
В каждом узле таких систем есть собственная память, и в системах
NORMA часто реализуется общая виртуальная память (SVM — Shared
Virtual Memory). Если в системах, использующих SVM, процесс запраши-
вает данные, которых нет в локальной памяти его процессора, операцион-
ная система загружает нужную страницу в эту локальную память из дру-
гого модуля памяти (то есть с другого компьютера в сети или с жесткого
диска).93, 94 Узлы в системах NORMA, не использующих SVM, вынуждены
использовать протоколы передачи сообщений для обмена данными. Поис-
ковый портал Google, службы которого выполняются с помощью 15 000
серверов начального уровня, разбросанных по всему миру — пример рас-
пределенной многопроцессорной системы архитектуры NORMA.95
Устройство ввода/вывода (например,
дисковый накопитель или сетевой
интерфейс)
Рис. 15.12. Многопроцессорная система архитектуры NORMA
Системы архитектуры NORMA строить проще всего, поскольку для это-
го не нужно использовать сложную схему соединений. Однако отсутствие
общей памяти требует реализации в приложениях протоколов взаимодей-
ствия, обеспечивающих обмен сообщениями и удаленный вызов процедур.
Во многих системах использование общей виртуальной памяти неэффек-
тивно, поскольку системам придется передавать целые страницы данных
от одного процессора другому через медленные каналы связи.96 Мы рас-
смотрим SVM подробнее в разделе 15.5.3.
Поскольку системы архитектуры NORMA являются слабосвязанными,
в них сравнительно легко добавлять или удалять узлы. Системы NORMA
представляют собой распределенные системы, управляемые одной опера-
ционной системой, а не сети компьютеров, управляемых разными опера-
ционными системами. Если узел системы NORMA выходит из строя, поль-
зователь может просто переключиться на другой узел и продолжать рабо-
тать. Если в системе NORMA вышел из строя 1% узлов, она станет
работать на 1% медленнее.97
Вопросы для самопроверки ,
1. Почему архитектура NORMA очень хорошо подходит для создания
кластеров рабочих станций?
2. В каких средах архитектура NORMA будет бесполезна?
Ответы 1) Пользователи в кластере рабочих станций обычно не
обращаются к памяти, используемой другими пользователями. Одна-
ко они используют общие ресурсы, например, файловую систему
и процессоры. Архитектура NORMA обеспечивает доступ к этим ре-
сурсам. Кроме того, в системах архитектуры NORMA легко добавлять
и удалять узлы, что позволяет масштабировать возможности систем.
2) Системы NORMA бесполезны в средах, в которых нужен доступ
к общей памяти, особенно в системах с одним пользователем или с не-
большим количеством процессоров. В таких средах лучше использо-
вать архитектуры UMA или NUMA.
15.5 Разделение памяти 6 многопроцессорных
системах
Когда множество процессоров с отдельными кэшами и локальными об-
ластями памяти обращаются к общедоступной памяти, разработчик дол-
жен решать проблему обеспечения когерентности памяти (memory
coherence). Память считается когерентной, если любое значение, получен-
ное при чтении по определенному адресу, всегда будет значением, которое
последним записано по этому адресу.98 Рассмотрим, к примеру, два про-
цессора, каждый из которых хранит в своей локальной памяти копию од-
ной и той же страницы. Если один из процессоров внесет изменения в эту
страницу, система должна гарантировать, что вторая копия страницы бу-
дет обновлена соответственно этим изменениям. В многопроцессорных сис-
темах, в которых в любой момент времени в памяти находится только одна
копия страницы (это системы UMA и небольшие системы NUMA), нужно
Многопроцессорность 935
g—------
гарантировать когерентность кэша (cache coherence) — то есть гарантиро-
вать, что запись в кэше соответствует самой свежей версии данных.
В крупных системах (например, системах NORMA или больших NUMA)
одна и та же страница может находиться в локальной памяти нескольких
процессоров одновременно. В таких системах когерентность памяти долж-
на обеспечиваться их общей виртуальной памятью.
Другие важные проблемы проектирования — проблема размещения
страниц и репликации. Доступ к локальной памяти выполняется куда бы-
стрее, чем доступ к глобальной, и если удастся гарантировать, что нужные
процессору данные будут находиться в его локальной памяти, то можно бу-
дет добиться солидного прироста производительности. Есть два распро-
страненных метода решения этой проблемы. Репликация страниц (page
replication) создает несколько копий страницы памяти, позволяя быстро
обращаться к ней из разных узлов (см. «Размышления об операционных
системах: Репликация данных и когерентность»). Миграция страниц
(page migration) переносит страницы в узел (или узлы, если используется
совместно с репликацией страниц), из которого к этим страницам чаще
всего поступают обращения. В разделе 15.5.2, мы рассмотрим реализации
этих двух подходов.
Вопросы для самопроверки
1. Почему важно обеспечивать когерентность памяти?
2. В чем преимущество одновременного существования нескольких
копий одной страницы в системе?
Ответы 1) Если когерентность памяти не обеспечивать, то не будет
гарантии, что каждая копия данных содержит их самую свежую версию.
Данные должны быть когерентными, чтобы выполнение приложений
давало правильные результаты. 2) Если два процесса, выполняющихся
на разных процессорах, часто считывают данные из одной и той же стра-
ницы, то репликация страницы позволит обоим процессорам хранить ее
в локальной памяти и быстро получать нужные данные.
Размышления об операционных системах
Репликация данных и когерентность
Можно привести несколько примеров
Дублирования данных в операционных сис-
темах с различными целями. Иногда данные
Дублируются для создания резервных копий,
из которых их можно будет восстановить при
Потере основных копий. Иногда они дублиру-
ются для повышения производительности.
если доступ к одной копии может выполнять-
ся намного быстрее, чем к другой. Часто бы-
вает необходимо обеспечить когерентность
данных, то есть гарантировать, что все копии
данных или идентичны, или станут идентич-
ными, прежде чем различия между ними
станут причиной проблем.
/5.5./ Когерентность кэша
Вопросы когерентности памяти впервые начали обсуждаться^ когда
появилась кэш-память, поскольку архитектуры компьютеров предостав-
ляли несколько путей доступа к данным (то есть доступ к копии в кэше
или к копии в основной памяти). В многопроцессорных системах задача
обеспечения когерентности усложняется, поскольку у каждого процессора
есть свой кэш.
Когерентность кэша в архитектуре UMA
Обеспечение когерентности кэшей в архитектуре UMA — сравнительно
простая задача, поскольку шина, по которой процессоры обмениваются
с данными, относительно быстро работает. Когда процессор обновляет зна-
чение элемента данных, система должна обновить или очистить все экзем-
пляры этого элемента данных в оперативной памяти и кэшах других про-
цессоров." Этого можно достичь с помощью слежения за шиной (bus
snooping), иногда называемого слежением за кэшами (cache snooping).
При использовании этого подхода процессор «отслеживает» шину, опреде-
ляя, относится ли запрос на запись от другого процессора к элементу дан-
ных, который есть в кэше данного процессора. Если этот элемент данных
есть в кэше, процессор удаляет его из кэша. Слежение за шиной просто
реализовать, но оно генерирует дополнительный трафик. Альтернативой
такому подходу служит централизованная таблица, в которой перечисля-
ются все элементы данных, находящиеся в каждом из кэшей. Эта таблица
показывает, когда нужно удалять из кэшей устаревшие данные (то есть
данные, не соответствующие последним изменениям). Еще один подход —
разрешение хранения любого элемента данных только в одном кэше одно-
временно.100
NUMA с когерентным кэшем (CC-NUMA)
NUMA с когерентным кэшем — это системы NUMA, в которых обеспе-
чивается когерентность кэшей. В большинстве систем CC-NUMA каждый
физический адрес в памяти ассоциирован с домашним узлом (home node),
отвечающим за хранение данных по этому адресу (часто домашний узел
определяется просто по старшим битам этого адреса). Если в узле происхо-
дит промах в кэше, этот узел связывается с домашним узлом адреса, по ко-
торому нужно обратиться к памяти. Если запрошенный элемент данных
чист (то есть ни у одного узла нет в кэше измененной версии этого элемен-
та), то домашний узел передает этот элемент в кэш запросившего узла-
Если элемент не является чистым (то есть другие узлы выполняли запись
в этот элемент в кэшах после того, как он обновлялся в памяти), то домаш-
ний узел передает запрос узлу, который последним изменял этот элемент;
изменявший узел передает измененный элемент и домашнему узлу, и за-
просившему. Запросы на изменение данных тоже выполняются через до-
машний узел. Узел, желающий изменить данные, расположенные в памя-
ти по некоторому адресу, запрашивает право на исключительное пользова-
ние этими данными. Самая свежая версия данных (если ее нет в кэше узла,
пытающегося изменить данные) получается таким же образом, как и при
Многопроцесоорность
запросе на чтение. После изменения данных их домашний узел сообщает
об изменении всем узлам, в которых есть копии этих данных.101
Этот протокол относительно прост в реализации, поскольку все опера-
ции чтения или записи требуют обращений к домашним узлам. Он может
показаться неэффективным, но его выполнение требует проведения макси-
мум трех операций связи по сети (сравните это с протоколом, в котором
для выполнения записи потребовалось бы связываться со всеми узлами
сети). Кроме того, этот протокол позволяет легко распределять нагрузку
в системе — для этого достаточно сделать каждый узел домашним для при-
мерно равного количества адресов — и обеспечивает хорошую отказоустой-
чивость и низкую вероятность конфликтов. Однако он может сильно сни-
зить производительность, если в системе часто возникают обращения
к данным в удаленных узлах.
Вопросы для самопроверки
1. Каковы преимущества и недостатки слежения за шиной?
2. Почему системе может быть сложно выбрать домашний узел для
данных, к которым часто обращаются несколько узлов? Как можно
модифицировать протокол CC-NUMA с домашними узлами для раз-
решения этой проблемы?
Ответы 1) Слежение за шиной просто реализовать, и оно позволяет
обеспечить когерентность кэшей. Однако его использование приводит
к дополнительной нагрузке на шину. 2) Если последовательности обра-
щений к области памяти часто изменяются, то сложно определить, ка-
кой узел должен быть домашним для этой области. Хотя в какой-то
интервал времени к этой области может в основном обращаться один
узел, в последующий интервал большая часть обращений будет посту-
пать от другого узла. Эту проблему можно попытаться решить, динами-
чески изменяя домашний узел данной области памяти (это, разумеется,
будет связано с изменением физических адресов элементов данных).
15.5.2 Репликация и миграция страниц
Для систем NUMA характерны большие задержки при доступе к памяти,
чем у систем UMA, и это ограничивает производительность систем NUMA,
Поэтому максимизация количества промахов в кэше, обслуживаемых ло
кальной памятью, становится важной задачей при проектировании систем
NUMA.102 Архитектура СОМА, рассмотренная в разделе 15.4.3 — это одв<
из попыток решить проблему больших задержек при доступе к памяти в ар
хитектуре NUMA. В системах CC-NUMA проблема больших задержек реша
ется за счет реализации стратегий миграции и репликации страниц.103
Репликация страниц выполняется весьма просто. Система копирует вс
данные из страницы, расположенной в удаленном модуле памяти, в ло
кальную память процессора, который запросил эту страницу. Чтобы обес
печить когерентность памяти, система использует структуру данных, учи
тывающую расположение всех продублированных страниц. Мы рассмсп
рим различные методы обеспечения когерентности памяти в следующе
разделе. Миграция страниц выполняется аналогичным образом, но при е
использовании после копирования страницы ее оригинал удаляется, а и
кэша и TLB удаляются все записи о ней.104
-——1
Глава 1$
Хотя миграция и репликация страниц обладают вполне очевидными
преимуществами, их применение может сильно снизить производитель-
ность системы, если их неправильно реализовать. Например, выполнить
удаленное обращение к странице можно быстрее, чем репликацию или ми-
грацию этой страницы. Поэтому если процесс обратился к удаленной стра-
нице только один раз, то разумнее будет не выполнять ее репликацию или
миграцию.105 Кроме того, некоторые страницы лучше реплицировать, чем
мигрировать, а некоторые — наоборот. Например, страницу, с которой
часто считывают данные разные процессы, лучше реплицировать, позво-
лив всем процессам обращаться к ее копиям в локальной памяти. При этом
недостаток репликации — необходимость обеспечения когерентности при
записи — не будет иметь значения для страниц, с которых выполняется
только чтение. Страница, которую часто модифицирует один процесс —
хороший кандидат для миграции. Но если другие процессы выполняют
чтение с этой страницы, то реплицировать ее будет невыгодно, поскольку
придется постоянно получать ее обновленные версии из узла, который вы-
полняет запись в нее. Страницы, в которые часто выполняют запись сразу
несколько процессов, лучше не подвергать ни репликации, ни миграции,
поскольку их придется обновлять после каждой операции записи.106
Чтобы определить наилучшую стратегию, во многих системах собира-
ются данные об истории обращений к страницам. Эту информацию можно
использовать, чтобы определить, к каким страницам часто требуется дос-
туп — это кандидаты для репликации или миграции. Накладные расходы
на репликацию и миграцию страницы не оправдываются для страниц,
к которым редко бывают обращения. Кроме того, система может собирать
информацию о том, какие процессоры обращаются к каждой странице,
и выполняют ли эти процессоры запись на страницу или только чтение
с нее. Чем больше информации о страницах соберет система, тем более эф-
фективными будут принимаемые ей решения. Однако сбор этой информа-
ции и ее модификация связаны с накладными расходами. Поэтому система
должна собирать достаточно информации, чтобы принимать эффективные
решения о репликации и миграции, но избегать больших затрат на сбор.107
Вопросы для самопроверки
1. Каким образом может снизить производительность неэффективная
стратегия репликации/миграции страниц?
2. Для каких страниц эффективна репликация? Для каких страниц
лучше использовать миграцию?
Ответы 1) Миграция и репликация — более дорогостоящие опера-
ции, чем удаленное обращение к странице. Они полезны только в слу-
чае, если к странице будет множество удаленных обращений с одного
и того же узла. Неэффективная стратегия может, например, выполнять
репликацию или миграцию страниц, в которые будут вносить измене-
ния множество узлов. При этом будут необходимы частые обновления,
которые снизят производительность. Кроме того, сбор и обработка ин-
формации об обращениях к страницам связаны с накладными расхода-
ми и тоже снижают производительность. 2) Страницы, с которых часто
считывают информацию (но не изменяют ее) несколько процессоров,
нужно реплицировать. Страницы, на которые часто выполняет запись
один удаленный узел, нужно мигрировать на этот узел.
Многопроцессорность 939
Общая виртуальная память
Разделение памяти в маленьких, тесносвязанных многопроцессорных
системах, например, архитектуры UMA, представляет собой просто рас-
ширенное применение концепции разделенной памяти однопроцессорных
систем, поскольку все процессоры обращаются по одним и тем же физиче-
ским адресам с одинаковыми скоростями. Такая стратегия трудно реали-
зуема для крупных систем архитектуры NUMA из-за больших задержек
при доступе к удаленной памяти, и вовсе нереализуема в системах
NORMA, в которых нет общей физической памяти. Поскольку IPC в общей
памяти легче программировать, чем IPC через передачу сообщений, во
многих системах процессам разрешено совместное использование памяти,
расположенной в разных узлах (а возможно, и в разных физических адрес-
ных пространствах) через механизм общей виртуальной памяти (SVM).
SVM расширяет концепцию виртуальной памяти однопроцессорных сис-
тем, обеспечивая когерентность памяти в страницах, к которым обраща-
ются разные процессоры.108
Две основные задачи, возникающие при использовании SVM — выбор про-
токола обеспечения когерентности и выбор моментов его применения. Два ос-
новных протокола обеспечения когерентности — протокол с пометками о не-
действительности страниц и протокол с широковещательной записью. Снача-
ла мы опишем эти протоколы, а затем рассмотрим их реализации.
Недействительность страниц
В протоколе с пометками о недействительности (invalidation) страниц
только один процессор может обращаться к странице во время ее измене-
ния — этот подход называется владением страницей. Чтобы получить
страницу во владение, процессор должен сначала пометить как недействи-
тельные (заблокировать для доступа) все копии этой страницы, кроме той,
с которой собирается работать. После этого режим доступа к странице из-
меняется на чтение/запись, и процессор копирует страницу в свою локаль-
ную память, чтобы работать с ней. Чтобы получить доступ к этой странице
Для чтения, процессор должен запросить систему изменить режим доступа
процессора, изменявшего страницу, с чтение/запись на чтение. Если за-
прос удовлетворяется, другие процессоры могут скопировать страницу
в свою локальную память и считывать с нее данные. Обычно система все-
гда удовлетворяет такие запросы, за исключением случаев, когда процес-
сор ожидает получения страницы во владение; в этих случаях запрос от-
клоняется, и запрашивающий процессор должен подождать, пока страни-
ца не станет доступной. Заметьте, что если содержимое страницы
одновременно изменяют несколько процессоров, то такой подход приведет
к низкой производительности, поскольку конкурирующие процессоры по-
очередно помечают как недействительные все копии страницы.109
Широковещательная запись
В протоколе с широковещательной записью (write broadcast) процес-
сор, выполняющий запись, передает информацию о ней всей системе. В од-
ной из версий такого подхода только один процессор может получать стра-
Глава 1$
ницу во владение. Вместо того, чтобы помечать все остальные копии стра-
ницы как недействительные, этот процессор обновляет все эти копии.110
В другой версии для повышения эффективности право записи предостав-
ляется нескольким процессорам. Поскольку в этой схеме записывающим
процессорам страница не предоставляется во владение, процессоры долж-
ны гарантировать, что обновления страницы выполняются в правильной
последовательности, что может потребовать значительных накладных рас-
ходов.111
Реализация протоколов обеспечения когерентности
Есть несколько способов реализации протоколов обеспечения когерент-
ности, но в любом случае разработчики должны стремиться ограничить
трафик по шинам обмена данными. Гарантирование того, что каждая опе-
рация записи будет отражена во всех узлах, может снизить производитель-
ность; однако ослабление ограничений на когерентность может привести
к сбоям в работе, если программы будут получать устаревшие данные.
В общем случае реализация протоколов должна обеспечивать баланс меж-
ду производительностью и целостностью данных.
Системы, в которых используется последовательная состоятельность
(sequential consistency), гарантируют, что результаты всех операций запи-
си немедленно отражаются во всех копиях страниц. Такие системы плохо
масштабируются до больших размеров из-за больших затрат на перемеще-
ние данных и взаимодействие. Обмен данными между узлами выполняется
медленнее, чем обращения к локальной памяти; если процесс постоянно
обновляет одну и ту же страницу, то будут выполняться много ненужных
операций связи между узлами. Кроме того, поскольку операционная сис-
тема работает со страницами, на каждой из которых часто содержится
множество элементов данных, такая стратегия может привести к ложному
совместному использованию (false sharing), если процессам, выполняю-
щимся на разных узлах, нужен доступ к разным элементам данных с од-
ной страницы. В этом случае последовательная состоятельность практиче-
ски потребует разделения страницы между двумя процессами, несмотря на
то, что выполняемые ими операции независимы.112
Системы, в которых используется ослабленная состоятельность (re-
laxed consistency), выполняют операции обеспечения когерентности через
определенные интервалы времени. Преимущество этой стратегии — то,
что задержка восстановления когерентности данных на удаленных узлах
на несколько секунд обычно незаметна для пользователя и может повы-
сить производительность и уменьшить эффект ложного совместного ис-
пользования .113
В системах, обеспечивающих состоятельность при освобождении (re-
lease consistency) последовательности обращений начинаются с операции
захвата (acquire operation) и заканчиваются операциями освобождения
(release operation). Все обновления между захватом и освобождением груп-
пируются в одно сообщение об обновлении после освобождения.114 В систе-
мах с отложенным обеспечением состоятельности при освобождении
(lazy release consistency) обновление откладывается до следующей попыт-
ки захвата памяти с изменившимися данными. Этот подход уменьшает
трафик в сети, поскольку не требует обеспечения когерентности для стра-
ниц, к которым нет обращений.115
Одно из интересных свойств систем с отложенным обеспечением состоя-
тельности при освобождении — то, что обновленные данные получает
только узел, пытающийся обратиться к изменившимся данным. Если этот
узел тоже модифицирует данные, то третьему узлу придется обработать
два обновления, прежде чем он сможет приступить к обработке данных.
Это может привести к существенным накладным расходам на обновление
страниц. Один из способов снижения этих накладных расходов — приме-
нение глобальных моментов синхронизации, в которые выполняется обес-
печение состоятельности всех данных.116 Еще один способ снижения этих
расходов — использование домашней состоятельности (home-based
consistency), похожей на метод обеспечения когерентности кэшей в архи-
тектуре CC-NUMA. Домашний узел каждой страницы отвечает за хране-
ние обновленной версии этой страницы. Узлы, пытающиеся захватить
страницу, которая была обновлена после ее освобождения, должны полу-
чить обновление с ее домашнего узла.117
Стратегия отложенной состоятельности (delayed consistency) требует
передачи обновлений при освобождении страниц, но узлы, получающие
эти обновления, не применяют их до следующего захвата. Эти обновления
можно накапливать до новой попытки захвата, и при захвате применить
все сразу. Этот подход не снижает сетевой трафик, но повышает произво-
дительность, поскольку узлам не приходится выполнять операции обеспе-
чения когерентности слишком часто.118
Отложенное распространение данных (lazy data propagation) сообщает
всем узлам, что страница изменилась, в момент ее освобождения. Эти сооб-
щения не содержат измененных данных, за счет чего снижается нагрузка
на каналы связи. Прежде чем узел получает данные для изменения, он
проверяет, изменял ли эти данные другой узел. Если да, то первый получа-
ет информацию об изменениях от второго. У отложенного распростране-
ния данных те же преимущества и недостатки, что и у отложенного обеспе-
чения состоятельности. Эта стратегия заметно снижает трафик, но требует
наличия механизма ограничения количества обновлений, например, гло-
бальных моментов синхронизации.119
Вопросы для самопроверки
1. В чем заключается преимущество ослабленной состоятельности?
Каков ее недостаток?
2. Во многих реализациях ослабленной состоятельности данные могут
оставаться некогерентными несколько секунд. Всегда ли это будет
приводить к проблемам? Приведите пример среды, в которой это
приведет к проблемам.
Ответы 1) Использование ослабленной состоятельности снижает
сетевой трафик и повышает производительность. Однако данные в па-
мяти системы могут быть некогерентными в течение существенных
промежутков времени, поэтому увеличивается вероятность того, что
процессоры будут работать с устаревшими данными. 2) Описанная
проблема несущественна во многих средах, особенно с учетом того, что
даже в системах с последовательной состоятельностью задержки
в обеспечении когерентности могут достигать нескольких секунд. Од-
нако задержки такой величины нежелательны в суперкомпьютерах,
в которых процессы взаимодействуют и обмениваются данными через
общую память. Дополнительные задержки будут снижать производи-
тельность из-за частого устаревания данных.
15.6 Планирование в многопроцессорных
системах
У планирования в многопроцессорных системах те же цели, что и в од-
нопроцессорных — оно должно обеспечивать максимальную производи-
тельность и минимальное время реагирования для всех процессов. Кроме
того, система должна гарантировать соблюдение приоритета процессов.
В отличие от алгоритмов планирования, используемых в однопроцессор-
ных системах, алгоритмы для многопроцессорных систем должны опреде-
лять не только порядок выполнения процессов, но и то, на каких процессо-
рах эти процессы должны выполняться. За счет этого растет сложность ал-
горитмов. Например, алгоритмы планирования для многопроцессорных
систем должны гарантировать, что процессоры в системе не будут простаи-
вать, если есть процессы, ожидающие выполнения.
Когда нужно определить, на каком процессоре должен выполняться
процесс, планировщик должен принять во внимание несколько моментов.
Например, в некоторых стратегиях планирования целью является макси-
мальное распараллеливание работы, полное использование возможностей
системы по одновременному выполнению программ. Взаимодействующие
процессы в системах часто объединяются в задачи. Параллельное выполне-
ние процессов задачи позволяет повысить производительность, поскольку
процессы выполняются действительно одновременно. В данном разделе мы
рассмотрим несколько алгоритмов планирования с временным разделени-
ем (timesharing scheduling), пытающихся воспользоваться такой парал-
лельностью при планировании размещения взаимодействующих процес-
сов на разные процессоры.120 Это позволяет процессам более эффективно
синхронизировать свою одновременную работу.
Другие стратегии сосредотачиваются на привязке задач к процессорам
(processor affinity) — взаимосвязи процесса и процессора, его локальной
памяти и кэша. Процесс, сильно привязанный к процессору, выполняется
на этом процессоре в течение большей части своего жизненного цикла.
Преимущество такого подхода в том, что процесс будет чаще получать тре-
буемые данные из кэша этого процессора, и в случае систем NUMA или
NORMA будет, возможно, не так часто обращаться к страницам на удален-
ных узлах, как в случае исполнения на нескольких процессорах по очере-
ди. Алгоритмы планирования, пытающиеся разместить процесс на один
процессор на все время выполнения этого процесса, обеспечивают мягкую
привязку (soft affinity), а алгоритмы, размещающие процесс всегда на од-
ном и том же процессоре, обеспечивают жесткую привязку (hard
affinity).121
Алгоритмы планирования с пространственным разделением (spa-
ce-partitioning scheduling algorithms) пытаются добиться максимальной
привязки задач к процессорам, направляя взаимодействующие процессы
для выполнения на один процессор (или на группу тесносвязанных процес-
соров). Эти алгоритмы подразумевают, что взаимодействующие процессы
будут работать с одними и теми же данными, и эти данные, скорее всего,
удастся разместить в кэшах процессоров и их локальной памяти.122 Поэто-
му алгоритмы планирования с пространственным разделением увеличива-
ют частоту успешных обращений к кэшу и локальной памяти. Однако они
могут ограничить производительность, поскольку при их использовании
взаимодействующие процессы обычно не исполняются одновременно.123
Алгоритмы планирования в многопроцессорных системах обычно де-
лятся на задачно-ориентированные (job-aware) и задачно-независимые
(job-blind). Задачно-независимые алгоритмы требуют для своего использо-
вания минимальных накладных расходов, поскольку они не пытаются до-
биться максимального распараллеливания или воспользоваться привязкой
задачи к процессору. Задачно-ориентированные алгоритмы оценивают
свойства каждой задачи и пытаются достичь максимального ее распарал-
леливания или привязки к процессору, таким образом повышая произво-
дительность за счет повышенных накладных расходов.
Во многих алгоритмах планирования для многопроцессорных систем
процессы организуются в глобальную очередь выполнения (global run
queue).124 Каждая такая очередь содержит все процессы в системе, кото-
рые готовы к выполнению. Глобальные очереди выполнения можно ис-
пользовать для сортировки процессов по их приоритетам, по задачам, к ко-
торым они относятся, или по тому, какой процесс выполнялся послед-
ним.125
В системах могут также использоваться процессорные очереди выпол-
нения (per-processor run queue). Использование таких очередей характер-
но для больших, слабосвязанных систем (например, систем архитектуры
NORMA), в которых нужно добиться как можно большего уровня успеш-
ных обращений к кэшу и локальной памяти. В процессорных очередях вы-
полнения процессы ассоциируются с определенным процессором, и систе-
ма реализует определенный алгоритм планирования для каждого процес-
сора. В некоторых системах используются узловые очереди выполнения
(per-node run queue); в таких системах в каждом узле может находиться по
несколько процессоров. Эти очереди эффективны в системах, в которых
процессы связаны с определенными группами процессоров. Мы рассмот-
рим также проблему миграции процессов, связанную с проблемой их пла-
нирования. Миграция процессов — это перенос процессов из одной процес-
сорной или узловой очереди в другую. Она рассматривается в разделе 15.7.
z-rir
Глава
Вопросы для самопроверки
1. Какие типы процессов будут выигрывать от использования плани-
рования с временным разделением? Какие — от использования
планирования с пространственным разделением?
2. В каких случаях узловые очереди выполнения более эффективны,
чем глобальные?
Ответы d При планировании с временным разделением взаимо-
связанные процессы выполняются одновременно, и производитель-
ность при выполнении взаимодействующих процессов растет,
поскольку эти процессы могут быстро реагировать на сообщения или
изменения в совместно используемой памяти. Планирование с про-
странственным разделением больше подходит для процессов, которые
должны последовательно обращаться к совместно используемой памя-
ти (и другим ресурсам), поскольку их процессоры, вероятно, будут со-
держать в кэшах совместно используемые данные, за счет чего
возрастет производительность. 2) Узловые очереди выполнения эф-
фективнее глобальных в слабосвязанных системах, в которых процес-
сы выполняются намного менее эффективно, если им приходится
обращаться к памяти в удаленных узлах.
15.6.1 Заданно-независимые алгоритмы планирования
Задачно-независимые алгоритмы планирования размещают задачи
и процессы для выполнения на любом доступном процессоре. Три алгорит-
ма, которые мы рассмотрим в этом разделе — это примеры задачно-незави-
симых алгоритмов. В общем, любой алгоритм планирования для однопро-
цессорных систем (эти алгоритмы рассматривались в главе 8) можно ис-
пользовать как задачно-независимый алгоритм планирования для
многопроцессорных систем.
Алгоритм планирования FCFS
FCFS расшифровывается как first-come-first-served («первым при-
шел — первым Обслужен»). Этот алгоритм помещает поступающие про-
цессы в глобальную очередь выполнения. Когда появляется свободный
процессор, программа планирования размещает на этом процессоре пер-
вый процесс из очереди выполнения и выполняет его до тех пор, пока про-
цесс не освободит процессор.
Алгоритм FCFS относится ко всем процессам справедливо с той точки
зрения, что он отправляет процессы на выполнение в порядке их поступле-
ния. Однако такое отношение можно счесть и несправедливым, поскольку
долго выполняющийся процесс заставляет ожидать все остальные процес-
сы, включая и быстро выполняющиеся, и может возникнуть ситуация,
в которой процессу с высоким приоритетом придется ожидать окончания
выполнения процесса с низким приоритетом. Обычно алгоритм FCFS не-
пригоден для планирования интерактивных процессов, поскольку он не
может обеспечить малого времени реагирования. Однако этот алгоритм
прост в реализации, и в нем нет опасности бесконечного откладывания вы-
полнения процесса — как только процесс встал в очередь на выполнение,
никакой процесс не сможет попасть в очередь впереди него.126, 127
Круговой алгоритм планирования
Крутовой алгоритм планирования процессов (round-robin process
scheduling) помещает все готовые к выполнению процессы в глобальную
очередь выполнения. Этот алгоритм в многопроцессорных системах рабо-
тает почти так же, как и в однопроцессорных — процесс выполняется в те-
чение максимум одного полного кванта времени, а затем приходит очередь
другого процесса. Ранее выполнявшийся процесс помещается в конец гло-
бальной очереди выполнения. Использование этого алгоритма также пре-
дотвращает бесконечное откладывание выполнения процесса, но он не
обеспечивает высокую степень параллельности или хорошей привязки
к процессорам, поскольку игнорирует связи между процессами.128’ 129
Алгоритм планирования SPF
SPF расшифровывается как shortest-process-first («кратчайший про-
цесс — первым»). При использовании этого алгоритма планирования пер-
вым запускается процесс, на полное выполнение которого требуется мень-
ше всего времени.130 Как вытесняющая, так и невытесняющая версии дан-
ного алгоритма демонстрируют меньшее время ожидания для
интерактивных процессов, чем алгоритм FCFS, поскольку интерактивные
процессы обычно являются «короткими». Однако при использовании алго-
ритма SPF запуск на выполнение «длинного» процесса может бесконечно
откладываться, если в системе один за другим появляются более «корот-
кие» процессы. Как и все задачно-независимые алгоритмы планирования,
SPF не обращает внимания на параллелизм и привязку к процессорам.
Вопросы для самопроверки
1. В каких системах удобнее применять задачно-независимые алго-
ритмы планирования процессов — UMA или NUMA?
2. Какой из только что рассмотренных алгоритмов лучше всего подхо-
дит для систем пакетной обработки? Почему?
Ответы 1) Задачно-независимые алгоритмы лучше применять
в системах UMA. В системах NUMA часто можно добиться существен-
ного выигрыша в производительности за счет отслеживания привязки
процессов к процессорам, поскольку время доступа к памяти в этих
системах зависит от того, в каком узле находится эта память, а в узлах
систем NUMA есть локальная память. 2) Лучше всего использовать
алгоритм SPF, поскольку он обладает высокой пропускной способно-
стью, а это очень важно для систем пакетной обработки.
15.6.2 Задачно-ориентированные алгоритмы планирования
Хотя задачно-независимые алгоритмы просты в реализации, и их ис-
пользование требует незначительных накладных расходов, они не учитыва-
ют моментов, специфичных для планирования процессов в многопроцессор-
ных системах. Например, если два процесса, интенсивно взаимодействую-
щие друг с другом, будут выполняться неодновременно, то существенную
часть времени они будут просто ожидать ответа на свои запросы, и произво-
дительность системы упадет. Кроме того, в большинстве многопроцессор-
ных систем у каждого процессора есть собственный кэш. Процессы из одной
задачи часто обращаются к общим элементам данных в памяти, и планиро-
вание этих процессов на один и тот же процессор может увеличить частоту
попаданий в кэш и повысить производительность работы с памятью. В це.
лом задачно-ориентированные алгоритмы планирования пытаются достичь
максимального распараллеливания и привязки к процессорам за счет уве-
личения сложности алгоритмов.
Алгоритм планирования SNPF
SNPF расшифровывается как smallest-number-of-processes-first («наи-
меньшее количество процессов — первым»). Этот алгоритм может быть
как вытесняющим, так и невытесняющим, но в обоих вариантах он ис-
пользует глобальную очередь выполнения. Приоритет задачи в такой оче-
реди будет обратно пропорционален количеству процессов в этой задаче.
Если задачи с одинаковым количеством процессов конкурируют, пытаясь
занять один и тот же процессор, задача, которая дольше ожидала, получа-
ет приоритет. В невытесняющей версии алгоритма SNPF, когда процессор
становится доступным, алгоритм выбирает процесс из задачи в начале оче-
реди выполнения и позволяет ему выполняться до завершения. В вытес-
няющей версии, если в очереди появляется новая задача с малым количе-
ством процессов, она получает высокий приоритет и ее процессы начинают
выполняться так скоро, как это возможно.131’ 132 Алгоритмы SNPF улуч-
шают параллелизм, поскольку процессы из одной задачи часто могут вы-
полняться одновременно. Однако эти алгоритмы не улучшают привязки
к процессорам. Кроме того, при их использовании возможна ситуация, ко-
гда выполнение задачи с большим количеством процессов будет отклады-
ваться бесконечно.
Круговой алгоритм планирования
Круговой алгоритм планирования задач (round-robin job scheduling)
помещает все готовые к выполнению задачи в глобальную очередь выпол-
нения. Из этой очереди каждая задача назначается для выполнения груп-
пе процессоров (хотя и необязательно одной и той же группе каждый раз,
когда до задачи доходит очередь выполняться). У каждой задачи есть соб-
ственная очередь процессов. Если в системе есть р процессоров, и она ис-
пользует кванты продолжительности q, то задача получает в общей слож-
ности р xq процессорного времени при ее отправке на выполнение. Обычно
в задаче не точно р процессов, каждый из которых расходует целиком по
одному кванту (то есть выполнение процесса может блокироваться до исте-
чения кванта времени). Поэтому в алгоритме кругового планирования про-
цессы задачи отправляются на выполнение, пока задача не израсходует
в общей сложности р х q времени, пока она не выполнится до конца или
пока не заблокируются все ее процессы. Кроме того, алгоритм может по-
ровну разделить р х q времени между всеми процессами задачи, позволяя
каждому процессу выполняться, пока он не израсходует свой лимит време-
ни, не завершится или не заблокируется. Альтернатива: если в задаче
больше, чем р процессов, то алгоритм может выбрать р процессов для вы-
полнения в течение кванта времени длиной о.133
Ifaotont Oi ecco H
mo-------------------------------------
Как и в задачно-независимой версии алгоритма кругового планирова-
ния, в этой версии невозможно бесконечное откладывание выполнения за-
дачи. Кроме того, поскольку процессы из одной задачи будут выполняться
одновременно, этот алгоритм обеспечивает хороший уровень параллелиз-
ма- Однако дополнительные накладные расходы на переключение контек-
стов могут снизить производительность системы, использующей данный
алгоритм.134-135
Алгоритмы копланирования
Алгоритмы копланирования, или совместного планирования (cosche-
duling или gang scheduling) используют глобальную очередь выполнения
с циклическим доступом. Цель этих алгоритмов — выполнять процессы из
одной задачи одновременно, вместо того, чтобы обеспечивать их макси-
мальную привязку к процессорам.136 Есть несколько реализаций алгорит-
мов копланирования — матричные, непрерывные и неразделяющие. Мы
рассмотрим только неразделяемую реализацию, поскольку она лишена не-
которых слабых мест матричных и непрерывных реализаций.
Неразделяющий алгоритм копланирования (undivided coscheduling
algorithm) помещает процессы из одной задачи в смежные позиции в гло-
бальной очереди выполнения (см. рис. 15.13). Планировщик использует
окно, размер которого равен количеству процессоров в системе. Все процес-
сы, попадающие в окно, выполняются параллельно в течение максимум од-
ного кванта. Выполнив обработку группы процессов, окно перемещается
к следующей группе, которая тоже выполняется параллельно в течение од-
ного кванта. Чтобы добиться максимальной загрузки процессоров, исполь-
зуется следующий подход: если процесс, попавший в окно, не может выпол-
няться, окно расширяется на один процесс вправо, и в течение одного кван-
та выполняется также следующий процесс в очереди, даже если он не
принадлежит к задаче, выполняемой в данный момент.
Окно для кванта / Окно для кванта /+ 7
।Гповальная
I очередь
J выполнения
Вторые три
процесса для
кванта i+2
Первые три
процесса для
кванта i+2
Рис. 15.13. Алгоритм копланирования (неразделяющая версия)
ГаоВс
Поскольку в алгоритмах копланирования используется циклический
доступ к очереди выполнения, при их использовании невозможно беско-
нечное откладывание выполнения задачи. Кроме того, процессы из одной
задачи часто выполняются одновременно. Поэтому алгоритмы копланиро-
вания позволяют программам, рассчитанным на параллельное выполне-
ние, получать преимущество от работы в многопроцессорных системах.
К сожалению, процесс может выполняться на разных процессорах каждый
раз, когда до него доходит очередь, поэтому привязка его к процессору бу.
дет слабой.137
Динамическое разделение
Динамическое разделение (dynamic partitioning) сводит к минимуму
потери производительности вследствие промахов в кэше, пытаясь поддер-
живать максимальную привязку процессов к процессорам.138 Планиров-
щик поровну распределяет процессоры системы между задачами. Количе-
ство процессоров, которое достанется каждой задаче, всегда меньше или
равно количеству доступных для выполнения процессов в этой задаче.
Например, рассмотрим систему с 32 процессорами, в которой должно
выполняться три задачи — первая с 8 процессами, доступными для выпол-
нения, вторая — с 16 процессами, а третья с 20. Если бы планировщик по-
ровну разделял процессоры между задачами, одна задача получила бы 10
процессоров, а две остальные — по 11 каждая. В рассматриваемом приме-
ре в первой задаче только 8 процессов, поэтому планировщик выделит ей 8
процессоров и поровну разделит оставшиеся 24 процессора между двумя
оставшимися задачами (по 12 процессоров каждой) (см. пример 1
на рис. 15.14). Поэтому каждая задача будет всегда выполняться на одних
и тех же процессорах, если только в системе не появятся новые задачи.
Этот алгоритм можно усовершенствовать так, что каждый процесс будет
всегда выполняться на одном и том же процессоре. Если в каждой задаче
содержится по одному процессу, то динамическое разделение превратится
в обычный круговой алгоритм планирования.139
Если в систему поступают новые задачи, система динамически изменяет
распределение процессоров. Предположим, что в систему поступила чет-
вертая задача, включающая 10 доступных для выполнения процессов (см.
пример 2 на рис. 15.14). Первой задаче, как и раньше, выделяется 8 про-
цессоров, но вторая и третья задачи передают часть своих процессоров чет-
вертой задаче. Процессоры будут поровну распределены между задача-
ми — по 8 процессоров каждой задаче.140 Алгоритм будет изменять выде-
ление процессоров для каждой задачи каждый раз, когда начинается или
завершается выполнение задачи, или процесс в задаче будет изменять свое
состояние — из выполнения в ожидание и обратно. Хотя количество про-
цессоров, достающихся задаче, изменяется, задача все равно выполняется
на подмножестве или надмножестве процессоров, доставшихся ей изна-
чально, и привязка к процессорам улучшается.141 Чтобы динамическое
разделение было эффективным, прирост производительности от повыше-
ния уровня попаданий в кэше должен перевесить падение производитель-
ности от переразделения.142
Пример 1 Три задачи
Процессоры
для задачи 1 (8)
Процессоры
для задачи 2(12)
Процессоры
для задачи 3(12)
Список ожидающих выполнения
процессов из задачи 2 (4)
Список ожидающих выполнения
процессов из задачи 3 (8)
Пример 2: Четыре задачи
Процессоры Процессоры Процессоры Процессоры
для задачи 1(8) для задачи 2 (8) для задачи 3 (8) для задачи 4 (8)
Список ожидающих
выполнения процессов
из задачи 2(8)
тттптпттп
Список ожидающих
выполнения процессов
из задачи 3(12)
Список ожидающих
выполнения процессов
из задачи 4(2)
Рис. 15.14. Динамическое разделение
Вопросы для самопроверки
1. Чем похожи алгоритмы задачно-ориентированного кругового пла-
нирования и копланирования? Чем они отличаются?
2. Опишите сильные и слабые стороны использования глобальной
стратегии планирования с максимизацией привязки к процессо-
рам, например, динамического разделения, вместо отдельных оче-
редей выполнения для каждого из процессоров.
Ответы 1) Эти алгоритмы схожи тем, что они позволяют одновре-
менно выполнять процессы из задачи. Неразделяемый алгоритм копла-
нирования просто размещает процессы одной задачи рядом друг
с другом в глобальной очереди выполнения, и они ожидают, пока не ос-
вободится хотя бы один процессор. Алгоритм задачно-ориентированно-
го кругового планирования выполняет планирование только задач
в целом. 2) Глобальное планирование обладает большей гибкостью, по-
скольку оно переназначает процессы на разные процессоры в зависимо-
сти от нагрузки системы. Однако отдельные очереди выполнения для
каждого процессора проще в реализации и могут быть более эффектив-
ными, чем хранение глобальной очереди выполнения.
_______'________________________________________________Глава i$
15.7 Миграция процессов
Миграция процессов (process migration) представляет собой перенос
процесса с одного процессора на другой.143’144 Этот перенос может потребо-
ваться, например, при отказе или перегрузке процессора.
Возможность исполнения процесса на любом процессоре дает множест-
во преимуществ. Первое и самое очевидное из них состоит в том, что при
наличии этой возможности процессы можно переносить на слабо загру-
женные процессоры и таким образом уменьшать время реагирования и по-
вышать производительность и пропускную способность.145- 146 (Мы опи-
шем этот прием, называемый балансировкой нагрузки, в разделе 15.8).
Кроме того, возможность миграции процессов повышает отказоустойчи-
вость.147 Представим, например, себе программу, которая должна интен-
сивно, без сбоев выполнять вычисления. Если машину, на которой выпол-
няется эта программа, требуется выключить или она начинает работать не-
устойчиво, полученные программой результаты могут быть потеряны.
Миграция процессов позволит программе переместиться на другую маши-
ну и продолжить вычисления.
Далее, возможность миграции позволяет улучшить разделение ресур-
сов. В больших системах некоторые ресурсы не продублированы во всех
узлах. Например, в системах NORMA процессы могут выполняться на ма-
шинах, поддерживающих различные аппаратные устройства. Процесс мо-
жет потребовать доступа к RAID-массиву, который возможен только через
одну машину. В этом случае процессу стоит мигрировать на эту машину
для повышения производительности.
И, наконец, возможность миграции процессов повышает эффективность
взаимодействия. Два процесса, тесно взаимодействующие друг с другом,
должны выполняться на одном узле или близко расположенных узлах,
чтобы уменьшить задержки при взаимодействии. Поскольку каналы связи
часто формируются динамически, можно воспользоваться миграцией про-
цессов и сделать размещение процессов тоже динамическим.148
Вопросы для самопроверки
1. Какие преимущества предоставляет возможность миграции процес-
сов?
2. На системах какой архитектуры (UMA, NUMA или NORMA) полез-
нее всего использовать миграцию процессов?
Ответы 1) Возможность миграции процессов повышает отказо-
устойчивость, позволяя переносить процессы из сбойных узлов, улуч-
шает балансировку нагрузки, может уменьшить задержки при
взаимодействии процессов и помогает обеспечить разделение ресур-
сов. 2) Миграцию процессов полезнее всего использовать в крупных
системах архитектур NUMA или NORMA, в которых используются
очереди выполнения для отдельных процессоров или узлов. Миграция
процессов позволяет таким системам выполнять балансировку нагруз-
ки и разделять ресурсы, являющиеся локальными для отдельных уз-
лов.
югопроце! с но иь
1$. 7.1 Процедура миграции процесса
Хотя в разных архитектурах миграция процессов реализована по-разно-
му, многие реализации используют стандартную последовательность ша-
ров (см. рис. 15.15). Сначала узел генерирует запрос миграции к удаленно-
му узлу. В большинстве схем миграцию начинает отправитель запроса, по-
скольку его узел перегружен или выполняющемуся на нем процессу нужен
доступ к ресурсу, расположенному на удаленном узле. В некоторых схемах
слабо загруженный узел может запросить процессы у других узлов. Если
отправитель и получатель соглашаются осуществить миграцию, отправи-
тель приостанавливает выполнение процесса, подлежащего миграции. От-
правитель создает очередь сообщений, в которую записывает все сообще-
ния для мигрирующего процесса. Затем отправитель собирает данные о со-
стоянии процесса. Для этого выполняется копирование содержимого
выделенной процессу памяти (то есть страниц, помеченных как используе-
мые в виртуальной памяти процесса), копирование содержимого регист-
ров, состояния открытых файлов и другой связанной с процессом инфор-
N2
О
Рис. 15.15. Миграция процесса
Шаг 1: Узлы соглашаются выполнить миграцию
процесса
Шаг 2: Узел N1 приостанавливает выполнение
процесса и создает очередь сообщений. Узел N2
создает «пустой» процесс для размещения нового
^Сообщение процесса
Шаг 3: Состояние процесса передается между
узлами
Шаг 4: Сообщения для мигрирующего процесса
передаются на узел N2
Шаг 5: Остальные узлы уведомляются о миграции
Глава is
Мн гопроцессорность
мации. Отправитель передает все собранные данные получателю, и получа-
тель помещает их в специально созданный «пустой» процесс. Затем
отправитель и получатель уведомляют все остальные узлы о новом месте
размещения мигрировавшего процесса. И, наконец, получатель запускает
новый экземпляр процесса, отправитель передает ему все сообщения, на-
копившиеся в очереди сообщений, и уничтожает свой экземпляр процес-
са 149, 150
Вопросы для самопроверки
1. Перечислите несколько элементов, составляющих состояние про-
цесса, которые нужно переносить при миграции процесса.
2. Какие накладные расходы связаны с миграцией процесса?
Ответы 1) При миграции процесса нужно передавать, например,
содержимое памяти процесса, содержимое регистров и состояние от-
крытых файлов. 2) Накладные расходы при миграции процессов свя-
заны с переносом состояния процесса на другой узел,
перенаправлением сообщений на этот узел, поддержкой в течение ко-
роткого промежутка времени двух экземпляров процесса (исходного
экземпляра и «пустого» процесса), приостановкой выполнения про-
цесса на короткий промежуток времени и отправлением другим узлам
сообщений о новом месте расположения мигрировавшего процесса.
15.7.2 Концепции миграции процессов
Самая длительная часть процедуры миграции процесса — перенос дан-
ных в памяти.151 Чтобы свести к минимуму стоимость миграции с точки
зрения производительности, остаточная зависимость (residual dependen-
cy) процессов — то есть их привязка к исходному узлу — должна быть как
можно слабее. Например, исходный узел процесса может содержать часть
рабочего набора процесса, или выполнять процессы, с которыми взаимо-
действовал мигрировавший процесс. Если при миграции остается большая
остаточная зависимость, то при выполнении мигрировавшего процесса на
новом узле этому узлу придется часто связываться с исходным. За счет это-
го возрастает трафик в каналах связи, а из-за задержек на взаимодействие
падает производительность. Кроме того, остаточная зависимость приводит
к падению отказоустойчивости, поскольку успешное выполнение мигриро-
вавшего процесса будет требовать корректного функционирования обоих
узлов.152
Часто стратегии, приводящие к самым высоким уровням остаточной за-
висимости, перемещают страницы из узла-отправителя только в случае,
если процесс на узле-получателе обращается к этим страницам. Такие
стратегии называют стратегиями поздней миграции (lazy migration) или
миграции по требованию (on-demand migration). Они уменьшают началь-
ное время миграции процессов — то есть время, на которое приостанавли-
вается выполнение процесса. При использовании поздней миграции со-
стояние процесса (и другая необходимая информация) передается получа-
телю, но страницы процесса остаются на исходном узле. В ходе
выполнения процесса на узле-получателе он должен выполнять операцию
переноса данных в памяти при первом обращении к каждой странице, ос-
тавшейся на исходном узле. Хотя такие стратегии и обеспечивают быст-
рый запуск мигрировавшего процесса, задержки при последующих обра-
щениях его к памяти могут сильно снизить производительность. Позднюю
миграцию лучше всего использовать, если процессу не требуется частый
доступ к удаленным адресным пространствам.153- 154
Чтобы миграция была успешной, мигрирующие процессы должны обла-
дать рядом свойств. Мигрирующий процесс должен быть прозрачным — то
есть его миграция не должна приводить к отрицательным последствиям
(за исключением, возможно, роста времени реагирования). Другими слова-
ми, процесс не должен при миграции терять адресованных ему сообщений
от других процессов или дескрипторов открытых файлов.155 Кроме того,
система должна быть масштабируемой — если остаточная зависимость
процесса растет с каждой миграцией, система может захлебнуться в пото-
ке сетевых сообщений от процессов, обращающихся к страницам на уда-
ленных узлах. И, наконец, достижения в технологиях связи создали по-
требность в гетерогенной миграции процессов — процессы должны иметь
возможность миграции между разными архитектурами в распределенных
системах. Поэтому информация о состоянии процесса должна храниться
в платформенно-независимом формате.156 В разделе 17.3.6 гетерогенная
миграция обсуждается более подробно.
Вопросы для самопроверки
1. Почему остаточная зависимость — нежелательное свойство процес-
сов? Почему иногда она может быть полезной?
2. Почему стратегия миграции, приводящая к значительной остаточ-
ной зависимости, может оказаться немасштабируемой?
Ответы 1) Остаточная зависимость нежелательна, поскольку она
уменьшает отказоустойчивость и снижает производительность после
миграции процесса. Одна из причин, по которым остаточная зависи-
мость может оказаться полезной, состоит в том, что она позволяет сни-
зить начальное время запуска процесса после переноса. 2) Если
процесс, уже обладающий остаточной зависимостью, снова мигриру-
ет, он будет зависеть в своей работе от трех узлов. С каждой миграци-
ей объем информации о состоянии процесса будет расти (процессу
будет требоваться все больше разных страниц памяти), а отказоустой-
чивость будет падать.
15.7.3 Стратегии миграции процессов
Стратегии миграции процессов должны поддерживать равновесие меж-
ду потерями производительности при переносе больших объемов данных,
принадлежащих процессам, и выигрышем от минимизации остаточной за-
висимости процессов. В некоторых системах разработчики предполагают,
что большая часть адресного пространства мигрировавшего процесса будет
восстановлена на новом узле. В таких системах часто используется полная
миграция (eager migration), при которой во время начальной миграции пе-
реносятся все страницы процесса. Это позволяет процессу выполняться на
новом узле так же эффективно, как и на старом. Однако если процесс не
собирается обращаться к большей части своего адресного пространства, то
__________________________________________________________Глава i$
начальная задержка и большая загрузка каналов связи при полной мигрд.
ции превращаются в накладные расходы.157, 158
Дабы уменьшить начальную стоимость полной миграции, используется
полная миграция для активных страниц (dirty eager migration). При этой
стратегии переносу подвергаются только страницы, помеченные как ис-
пользуемые. Эта стратегия подразумевает, что в системе есть вторичное
устройство хранения (например, жесткий диск), к которому могут обра-
титься и узел-отправитель, и узел-получатель. Все неиспользуемые стра-
ницы загружаются со вторичного устройства хранения, если процесс обра-
щается к ним с узла-получателя. Этот подход снижает начальное время пе-
ремещения процесса и устраняет остаточную зависимость. Однако при
каждом доступе к нерезидентной странице возникает задержка, отсутст-
вующая при полной миграции.159
Один из недостатков полной миграции для активных страниц — необхо-
димость использования вторичного устройства хранения. Оно требуется
мигрирующему процессу для извлечения неиспользованных страниц. Ми-
грация с копированием при обращении (copy-on-reference migration) по-
хожа на полную миграцию для активных страниц, но при ее использова-
нии мигрирующий процесс может запрашивать неиспользованные страни-
цы, как со вторичного устройства хранения, так и с исходного узла. Эта
стратегия обладает всеми преимуществами стратегии полной миграции
для активных страниц, но, кроме того, позволяет диспетчеру памяти вы-
бирать, откуда запрашивать страницы — доступ к памяти на удаленном
узле может выполняться быстрее, чем доступ к дисковому накопителю.
Однако стратегия миграции с копированием при обращении может привес-
ти к росту нагрузки на память в узле-отправителе.160, 161
Разновидность стратегии миграции с копированием при обращении, ис-
пользующая позднее копирование (lazy copying), передает во время на-
чального перемещения только минимально необходимый объем информа-
ции о состоянии процесса; часто при этом не передается ни одна страница.
Это приводит к большой остаточной зависимости, заставляет узел-отпра-
витель хранить все страницы в своей памяти и увеличивает задержки на
обращение к памяти по сравнению со стратегиями, использующими пере-
мещение активных страниц. Однако стратегия с поздним копированием
сильно уменьшает начальную задержку при миграции процесса.162,163 Эта
задержка может быть совершенно неприемлемой для процессов реального
времени и неудобна для многих других процессов.164
Все упомянутые выше стратегии приводят или к остаточной зависимо-
сти, или к большой начальной задержке при миграции. Есть метод, уст-
раняющий значительную часть начальной задержки и остаточной зави-
симости. Это стратегия со сбросом содержимого (flushing). В этой стра-
тегии отправитель записывает все страницы памяти на общедоступное
вторичное устройство хранения в начале процесса миграции; во время
этой записи мигрирующий процесс должен быть приостановлен. Затем
мигрировавший процесс обращается к страницам на вторичном устройст-
ве хранения по мере необходимости. Поэтому реального переноса страниц
при начальной миграции процесса нет, и у процесса не появляется оста-
точная зависимость от предыдущего узла. Однако эта стратегия уменьша-
ет производительность процесса в новом узле, поскольку процессу прихо-
дится загружать требуемые страницы в оперативную память при стра-
ничных промахах.165’166
Еще одна стратегия, устраняющая большую часть начальной задержки
при миграции и остаточной зависимости — стратегия с предварительным
копированием (precopy). При ее использовании узел-отправитель начина-
ет передавать используемые страницы еще до приостановки выполнения
процесса. Любая переданная страница, к которой процесс обращается до
его миграции, помечается как подлежащая повторной передаче. Чтобы га-
рантировать, что процесс все-таки мигрирует, система определяет нижний
порог количества оставшихся используемых страниц, при котором можно
начинать миграцию процесса. Когда этот порог достигается, процесс не
приходится приостанавливать надолго (по сравнению с другими стратегия-
ми, например, полным копированием и копированием при обращении),
а доступ к памяти в узле-получателе будет быстрым, поскольку большая
часть данных уже скопирована в этот узел. Кроме того, эта стратегия обес-
печивает минимальную остаточную зависимость. В течение короткого про-
межутка времени рабочий набор процесса оказывается дублированным (то
есть существует на обоих узлах, задействованных в миграции), но это не-
значительный недостаток.167’168
Вопросы для самопроверки
1. Какую стратегию миграции лучше всего использовать для процес-
сов реального времени?
2. Хотя стратегия предварительного копирования обеспечивает мини-
мальную начальную задержку и остаточную зависимость, попро-
буйте выяснить, какие скрытые потери в производительности
связаны с ее применением.
Ответы 1) Процессы реального времени нельзя надолго приоста-
навливать, поскольку при этом у них возрастет время реагирования.
Поэтому для процессов «почти реального времени» лучше всего ис-
пользовать стратегии вроде позднего копирования, сброса содержи-
мого, копирования при обращении и предварительного копирования.
Процессы «строго реального времени» не должны подвергаться ми-
грации, поскольку она вносит непредсказуемую задержку в их рабо-
ту. 2) Процесс продолжает выполняться на узле-отправителе, пока
его состояние копируется на другой узел. Поскольку было принято
решение о миграции процесса, разумно предположить, что продол-
жающееся исполнение процесса на узле-отправителе нежелательно,
и потому стратегия предварительного копирования требует дополни-
тельных затрат.
15.8 Бала ней робка нагрузки
Один из показателей эффективности работы многопроцессорной систе-
мы — общий уровень загрузки процессоров. Во многих случаях система
работает эффективнее всего, когда процессоры загружены почти полно-
стью. В большинстве многопроцессорных систем (особенно NUMA
и NORMA) нужно стремиться добиться максимальной привязки процес-
сов к процессорам. Это позволяет повысить эффективность, поскольку
процессору реже приходится обращаться к удаленным ресурсам, но мо-
жет понизить уровень загрузки процессоров, если все процессы, выпол-
няющиеся на каком-то процессоре, завершатся. Этот процессор будет
простаивать, пока процессы, назначенные другим процессорам и привя-
занные к ним, будут продолжать выполняться. Балансировка нагрузки
(load balancing) — это механизм, с помощью которого система пытается
равномерно распределить вычислительную нагрузку между своими про-
цессорами. Это повышает уровень загрузки процессоров и сокращает оче-
реди выполнения для перегруженных процессоров, уменьшая среднее
время реагирования процессов.169
Алгоритм балансировки нагрузки может выделить для выполнения за-
дачи фиксированное количество процессоров, когда эта задача начинает
выполняться. Этот подход называется статической балансировкой на-
грузки (static load balancing). Он требует незначительных накладных рас-
ходов, поскольку тратит немного времени на определение того, на каком
процессоре будет выполняться задача. Однако статическая балансировка
нагрузки не учитывает того факта, что количество процессов в задаче мо-
жет изменяться с течением времени. Например, вначале в задаче может
быть много процессов, но затем их станет намного меньше. Это может при-
вести к несбалансированности очередей выполнения и простою процессо-
ров.170
Динамическая балансировка нагрузки (dynamic load balancing) пыта-
ется решить эту проблему, изменяя количество процессоров, выделенное
каждой задаче, в ходе ее выполнения. Исследования показали, что дина-
мическая балансировка нагрузки дает лучшие результаты, чем статиче-
ская, если время переключения контекстов мало, а уровень загрузки сис-
темы высок.171
Вопросы для самопроверки
1. В чем преимущества использования балансировки нагрузки?
2. Какие алгоритмы планирования выиграют от балансировки нагрузки?
Ответы 1) Некоторые из преимуществ балансировки нагрузки —
более высокий уровень загрузки процессоров и, соответственно, более
высокая пропускная способность, и меньшее время реагирования про-
цессов. 2) Балансировка нагрузки полезна для алгоритмов планирова-
ния, пытающихся добиться максимальной привязки процессов
к процессорам, например, алгоритма с динамическим разделением.
Кроме того, от балансировки нагрузки могут выиграть системы, в ко-
торых используются процессорные или узловые очереди выполнения.
15.8.1 Статическая балансировка нагрузки
Статическая балансировка нагрузки полезна в системах, где задачи при
каждом запуске выполняют одни и те же проверки и инструкции и, соот-
ветственно, демонстрируют предсказуемое поведение (например, в систе-
мах для научных расчетов).172 Это поведение можно представить в виде
графов, с помощью которых можно выполнять планирование. Представим
процессы в системе как вершины графа, а связи между процессами — как
его ребра. Например, если в системе есть приложение, в котором один из
процессов непрерывно анализирует одни и те же данные и передает резуль-
таты другому процессу, то эти два процесса можно обозначить на графе
двумя вершинами, соединенными одним ребром. Поскольку такая связь
будет существовать в течение всего времени работы приложения, граф не
придется модифицировать.
Из-за наличия общего кэша и физической памяти взаимодействие меж-
ду процессами, выполняющимися на одном процессоре, идет намного бы-
стрее, чем между процессами с разных процессоров. Поэтому алгоритмы
статической балансировки нагрузки пытаются разделить граф на подгра-
фы равного размера (чтобы каждому процессору досталось равное количе-
ство процессов), причем разделение выполняется таким образом, чтобы ко-
личество рассеченных ребер было минимальным — это необходимо, чтобы
уменьшить обмен данными между процессорами.173 Однако такая методи-
ка может потребовать значительных накладных расходов, если в системе
выполняется много задач.174 Взгляните на граф на рисунке 15.16. Две
пунктирные линии обозначают возможные сечения графа, делящие про-
цессы примерно поровну между процессорами. Сечение 1 дает четыре взаи-
мосвязи между процессорами, а сечение 2 — только две, причем оно обес-
печивает еще и лучшую группировку процессов.
Рис. 15.16. Статическая балансировка нагрузки с помощью графов
Статическая балансировка нагрузки может оказаться непригодной,
если взаимосвязи между процессами изменяются динамически, или если
процессы завершаются, а на их месте не появляются новые процессы.
В первом случае эффективность работы системы может упасть из-за боль-
ших задержек при обмене данными. Во втором случае может упасть уро-
вень загрузки процессоров, даже если в системе есть процессы, которым
нужно выделить процессор. В этих случаях использование динамической
балансировки нагрузки позволяет повысить производительность.175
Вопросы для самопроверки
1. В каких случаях статическая балансировка нагрузки может ока-
заться полезной? В каких — нет?
2. На рисунке 15.16 сечение 1 заметно отличается от сечения 2. Учи-
тывая то, что при больших количествах задач трудно найти эффею
тивные сечения, что можно сказать об ограничениях статической
балансировки нагрузки?
Ответы 1) Статическая балансировка нагрузки полезна в систе.
мах, где процессы обладают предсказуемым поведением. Она беспо.
лезна в системах, где последовательности взаимодействия процессор
динамически изменяются, а процессы возникают и завершаются в не.
предсказуемые моменты времени. 2) Различие между сечениями 1
(с четырьмя рассеченными каналами взаимодействия между процес.
сами) и 2 (с двумя рассеченными каналами) демонстрирует последст.
вия неудачного выбора сечений. В большинстве систем придется
использовать приближенные методы оценки и поиска эффективных
сечений, и неправильная оценка может сильно снизить производи,
тельность.
15.8.2 Динамическая балансировка нагрузки
Алгоритмы динамической балансировки нагрузки выполняют мигра-
цию процессов после их создания в зависимости от нагрузки на систему.
Операционная система собирает статистическую информацию о загрузке
процессоров, например, количество активных и блокированных процессов
на каждом процессоре, средний уровень его загрузки, время оборота и за-
держки.176’ 177 Если многие процессы на процессоре блокированы или об-
ладают большими временами оборота, процессор, скорее всего, перегру-
жен. Если у процессора низкий уровень загрузки, значит, на него можно
переместить дополнительные процессы.
Для определения моментов, когда необходимо выполнять миграцию
процессов, используются различные методы. Метод с инициацией отпра-
вителем (sender-initiated policy) используется, если система определяет,
что один из процессоров сильно загружен. Только в этом случае система
попробует найти менее загруженные процессоры и переместить на них
часть задач с перегруженного процессора. Такой метод лучше всего подхо-
дит для слабо загруженных систем, поскольку миграция процессов — до-
рогостоящая операция, а в слабо загруженных системах она будет выпол-
няться нечасто.178’ 179
Метод с инициацией получателем (receiver-initiated policy) лучше под-
ходит для перегруженных систем. В таких средах система инициирует ми-
грацию процесса, если есть слабо загруженный процессор.180, 181
В большинстве систем встречаются как периоды сильной, так и перио-
ды слабой загрузки. В таких системах эффективен симметричный метод
(symmetric policy), представляющий собой сочетание двух предыдущих.
Этот метод универсален и может адаптироваться к состоянию среды.182,183
И наконец, случайная стратегия (random policy), случайным образом вы-
бирающая процессор, на который будет перемещен процесс, тоже показала
хорошие результаты из-за простоты ее реализации и (в среднем) равномер-
ного распределения процессов. Мотивация использования случайного ме-
тода состоит в том, что у целевого процессора при миграции процесса уро-
вень загрузки будет, вероятно, меньше, чем у исходного, если исходный
сильно перегружен.184, 185
В следующих подразделах кратко описываются алгоритмы, определяю-
щие, необходимо ли выполнять миграцию процессов. В этом обсуждении
мы будем считать, что многопроцессорная система представлена графом,
в котором процессоры и их локальная память — это вершины, а каналы
связи между процессорами — ребра.
Алгоритм аукциона
Алгоритм аукциона (bidding algorithm) — это простая разновидность
метода с инициацией отправителем. Слабо загруженные процессоры «тор-
гуются» за получение процесса с перегруженного процессора, как на аук-
ционе. Величины «ставок» определяются уровнями загрузки торгующих-
ся процессоров и расстоянием между этими процессорами и перегружен-
ным процессором на графе системы. Чтобы уменьшить стоимость
миграции процесса, ставки процессоров, расположенных ближе к перегру-
женному, увеличиваются. Перегруженный процессор принимает только
ставки от процессоров, расположенных не дальше определенного предела
от него. Если перегруженный процессор получает слишком много ставок,
он приближает этот предел, если слишком мало — удаляет. Процесс пере-
дается процессору, давшему наибольшую ставку.186
Чертежный алгоритм
Чертежный алгоритм (drafting algorithm) — это реализация метода
с инициацией получателем. В этом алгоритме загрузка каждого процессо-
ра оценивается как низкая, средняя или высокая. Каждый процессор хра-
нит таблицу, в которой указаны уровни загрузки остальных процессоров
по этой шкале. Часто в больших или распределенных системах процессор
хранит только информацию о загрузке соседних процессоров. Каждый раз,
когда уровень загрузки процессора изменяется, процессор сообщает об
этом процессорам из таблицы. Когда процессор получает сообщение об из-
менении уровня загрузки, он добавляет в него информацию о своей загруз-
ке и передает сообщение своим соседям. Таким образом информация об
уровне загрузки процессоров постепенно достигает всех узлов сети. Слабо
загруженные процессоры используют эту информацию, чтобы запраши-
вать процессы с перегруженных процессоров.187
Вопросы Взаимодействия
Неэффективные или неправильные стратегии взаимодействия могут
привести к тому, что система захлебнется в потоках данных. Например,
в некоторых реализациях миграции процессов используются общесистем-
ные широковещательные передачи данных. Поток широковещательных
сообщений может забить каналы связи. Вследствие наличия задержек при
связи многие перегруженные процессоры могут получить запрос на мигра-
цию процесса одновременно и передать свои процессы слабо загруженному
процессору.188
Для устранения этих проблем был предложен ряд стратегий. Например,
алгоритм может разрешать процессорам связываться только с соседними
процессорами. При этом уменьшится количество передаваемых сообще-
ний, но возрастет время, необходимое на то, чтобы информация достигла
каждого узла в системе.189 Альтернативный подход состоит в том, что про-
цессоры могут через определенные интервалы времени выбирать случай-
ный процессор, с которым можно обмениваться информацией. В этом слу-
чае процессы будут мигрировать от более загруженного процессора на ме-
нее загруженный.190 В случаях, когда один процессор сильно перегружен,
а остальные слабо загружены, этот метод приведет к быстрому рассредото-
чению процессов.
На рисунке 15.17 показано рассредоточение процессов в системе, в кото-
рой узлы могут связываться только с соседними узлами. Перегруженный
процессор (центральный узел графа) выполняет 17 процессов, а все осталь-
ные процессоры — по одному. После первой итерации перегруженный про-
цессор связывается с соседними и передает каждому из них по три процесса.
Теперь на этих процессорах будет по четыре процесса — это больше, чем на
соседних с ними процессорах. На второй итерации процессоры с четырьмя
процессами перешлют часть своих процессов соседним узлам. И, наконец,
на третьей итерации перегруженный процессор еще раз пересылает часть
процессов своим соседям. Теперь на самом загруженном процессоре выпол-
няются три процесса. Этот пример показывает, что даже если процессоры
могут связываться только с соседними процессорами, балансировка нагруз-
ки позволяет эффективно распределить процессы в системе.
Система в начале:
После первой итерации
Рис. 15.17. Рассредоточение нагрузки в системе (часть 1 из 2)
... После второй итерации
_. После третьей итерации
Рис. 15.17. Рассредоточение нагрузки в системе (часть 2 из 2)
Вопросы для самопроверки
1. В каких системах лучше всего использовать методы с инициацией
отправителем, а в каких — с инициацией получателем? Аргументи-
руйте свой ответ.
2. Каким образом большие задержки при взаимодействии могут сни-
зить эффективность балансировки нагрузки?
Ответы 1) В системах с низким уровнем загрузки лучше использо-
вать методы с инициацией отправителем, а в сильно загруженных —
с инициацией получателем. В обоих случаях это приведет к снижению
количества ненужных миграций, поскольку в слабо загруженных сис-
темах будет мало отправителей, а в сильно загруженных — мало полу-
чателей. 2) Слабо загруженный узел, отправляющий сообщение,
может оказаться перегруженным к тому времени, как это сообщение
получат другие узлы. Поэтому, получив сообщение, узел может еще
больше разбалансировать нагрузку системы, передав перегруженному
узлу дополнительные процессы.
т ГмВа
15.9 Взаимное исключение в многопроцессорных
системах
Многие механизмы взаимного исключения, описанные в главе 5, непри-
менимы в многопроцессорных системах. Например, блокирование преры-
ваний, предотвращающее выполнение других процессов за счет блокиров-
ки вытеснения в однопроцессорных системах, не гарантирует взаимного
исключения в многопроцессорных системах, поскольку на разных процес-
сорах может одновременно исполняться несколько процессов сразу. Инст-
рукции проверить-и-установить (test-and-set) могут стать неэффективны-
ми, если данные, с которыми они работают, расположены в памяти уда-
ленного узла. У таких инструкций есть и еще одно слабое место: каждая из
операций в этих инструкциях требует отдельного обращения к памяти.
Эти обращения выполняются последовательно, поскольку обычно в любой
момент времени к ячейке памяти может выполняться только одно обраще-
ние. Такие конфликты могут привести к быстрому насыщению сетей со-
единений, сильно снижая производительность. Учитывая одновременное
выполнение процессов и большие затраты на взаимодействие между уда-
ленными узлами, разработчики создали ряд специальных механизмов вза-
имного исключения, пригодных для использования в многопроцессорных
системах. В этом разделе мы рассмотрим только механизмы взаимного ис-
ключения для нераспределенных многопроцессорных систем. Механизмы
для распределенных систем рассматриваются в разделе 17.5.
15.9.1 Спин-блокиробки
В операционных системах, поддерживающих многопроцессорные кон-
фигурации, например, Windows ХР и Linux, для обеспечения взаимного
исключения часто используются спин-блокировки (spin lock). Спин-блоки-
ровка называется блокировкой потому, что процесс, которому принадле-
жит данная спин-блокировка, обладает исключительным правом на доступ
к ресурсу, который защищен этой спин-блокировкой (например, структуре
данных в памяти или критическому блоку кода). Другим процессам доступ
к этому ресурсу блокирован. Если этот ресурс требуется другим процессам,
они должны непрерывно проверять, стал ли он доступен. В однопроцессор-
ных системах использование спин-блокировок излишне, поскольку на них
будут тратиться рабочие циклы процессора, которые можно использовать
более производительно. В многопроцессорных системах процесс, которому
принадлежит блокировка, может освободить блокированный ресурс, когда
другой процесс ожидает этого. В этом случае эффективнее будет использо-
вать ожидание с проверками доступности ресурса, если время, необходи-
мое на переключение контекста, больше, чем среднее время цикла ожида-
ния с проверками.191 Кроме того, если у процессора в очереди выполнения
нет процессов, к выполнению которых можно приступить, то имеет смысл
продолжать непрерывно проверять доступность ресурса, чтобы свести
к минимуму время реагирования, когда ресурс освободится.192’ 193
Многопроцессорность
963
Если процессор оставляет ресурс блокированным надолго (по сравнению
со временем переключения контекста), обычные блокировки становятся
более эффективными. Отложенное блокирование (delayed blocking) — это
подход, в рамках которого процессы ожидают доступа к ресурсу в течение
коротких интервалов времени; если доступ не получен, процесс блокирует-
ся.194 Заявленная блокировка для процесса (APL — advisable process
lock) — альтернатива отложенному блокированию. При использовании
APL указывается интервал времени, в течение которого будет использо-
ваться блокировка. Исходя из этого интервала другие процессы, ожидаю-
щие доступа, могут решить, будет ли эффективнее проверять доступность
ресурса или заблокироваться.195
Адаптивные блокировки (adaptive locks), иногда называемые конфигу-
рируемыми (configurable locks) добавляют гибкости реализации взаимных
исключений. В некоторых случаях, например, если в системе мало актив-
ных процессов, удобнее использовать спин-блокировки, поскольку при их
использовании процесс сможет получить доступ к ресурсу вскоре после
того, как ресурс освободится. Но если система сильно загружена, исполь-
зование спин-блокировок приводит к трате циклов процессора, и лучше
использовать обычное блокирование. Адаптивные блокировки позволяют
процессу динамически изменять тип используемой блокировки. Эти бло-
кировки могут становиться спин-блокировками или отложенными блоки-
ровками, а могут и поддерживать элементы APL; их возможности могут
использоваться по-разному в зависимости от уровня загрузки системы
и потребностей приложения.196
Если освобождения ресурса, закрытого спин-блокировкой, ожидают од-
новременно несколько процессов, может возникнуть бесконечное отклады-
вание выполнения процесса. Такие ситуации можно предотвратить, если
обеспечить доступ к спин-блокировке по принципу «первым пришел —
первым обслужен», или отслеживая время ожидания процессов, как опи-
сано в разделе 7.3.
Вопросы для самопроверки
1. Почему спин-блокировки полезны в многопроцессорных системах?
В каких обстоятельствах их использование в многопроцессорных
системах нежелательно? Почему спин-блокировки бесполезны в од-
нопроцессорных системах?
2. Почему APL-блокировка может оказаться бесполезной в некоторых
ситуациях?
Ответы 1) Спин-блокировки могут оказаться полезными, по-
скольку они сводят к минимуму интервал времени между освобожде-
нием ресурса и получением его другим процессом. Они неудобны
в сильно загруженных системах, если ожидаемое время освобожде-
ния ресурса больше, чем время переключения контекста — в таких
обстоятельствах на постоянные проверки доступности ресурса ухо-
дят драгоценные такты процессора. Спин-блокировки бесполезны
в однопроцессорных системах, поскольку они блокируют выполне-
ние процесса, которому принадлежит блокируемый ресурс.
2) APL-блокировка бесполезна, если процесс не может определить,
в течение какого интервала времени он будет блокировать ресурс.
964
Глава 15
15.9.2 Блокировки с усыплением/пробуокдением
Блокировка с усыплением/пробуждением (sleep/wakeup lock) предос-
тавляет те же возможности синхронизации, что и спин-блокировка, но
уменьшает бесполезные затраты циклов процессора и трафик по шине.
Представьте себе процессы Рг и Р2, каждый из которых обращается к ре-
сурсу, защищенному блокировкой с усыплением/пробуждением. Pj запра-
шивает ресурс первым и получает блокировку во владение. Когда Р2 запра-
шивает ресурс, принадлежащий Pi и не получает его, Р2 переходит в спя-
щее состояние (то есть блокируется). Как только Pi снимает блокировку,
он будит процесс с максимальным приоритетом из тех, что ожидают осво-
бождения ресурса (в нашем случае, Р2). В отличие от спин-блокировок (пе-
редающих блокировку следующему ожидающему процессу) блокировки
с усыплением/пробуждением позволяют планировщику процессора обес-
печивать соблюдение приоритетов процессов. Использование блокировок
с усыплением/пробуждением в сочетании с некоторыми алгоритмами пла-
нирования может привести к бесконечному откладыванию выполнения
процессов.
Заметьте, что в отличие от однопроцессорной реализации, пробуждает-
ся только процесс с наибольшим приоритетом. Если пробуждаются все по-
токи, могут возникнуть логические гонки (race condition), поскольку два
потока одного процесса могут обратиться к защищенному блокировкой ре-
сурсу в непредсказуемой очередности. Логических гонок следует избегать,
поскольку они могут стать причиной трудных для обнаружения и отладки
ошибок. В однопроцессорных системах даже если разбудить все процессы,
логические гонки никогда не возникнут, поскольку в любом случае одно-
временно выполняется только один процесс (обычно — процесс с наиболь-
шим приоритетом), который и получает блокировку во владение. В много-
процессорной системе широковещательное сообщение может привести
к пробуждению множества процессов, каждый из которых попытается за-
хватить блокировку, и возникнут логические гонки. Кроме того, если про-
будилось множество процессов, и один из них захватил блокировку, ос-
тальные процессы будут проверять доступность ресурса, защищенного бло-
кировкой, убеждаться, что ресурс недоступен и засыпать вновь. При этом
потери процессорного времени будут весьма заметными из-за множества
переключений контекстов. Такое явление называют «несущимся стадом»
(thundering herd).197
Вопросы для самопроверки
1. В чем преимущества и недостатки блокировок с усыплением/про-
буждением по сравнению со спин-блокировками?
2. В чем различие между реализациями блокировок с усыплени-
ем/пробуждением в однопроцессорных и многопроцессорных сре-
дах?
Мн гопроцессорноеть
965
Ответы 1) Блокировка с усыплением/пробуждением не требует
траты циклов процессора, характерной для спин-блокировок. Кроме
того, блокировки с усыплением/пробуждением гарантируют, что
следующим получит доступ к ресурсу процесс с наибольшим приори-
тетом из всех, ожидающих этого доступа. Недостаток этих блокиро-
вок — замедление реакции процессов, поскольку они должны
сначала проснуться и получить процессор для выполнения. 2) В мно-
гопроцессорных системах блокировки должны пробуждать только
один процесс, чтобы избежать явления «несущегося стада», которое
приводит к потерям процессорного времени и загружает каналы свя-
зи. В однопроцессорных системах это явление не возникает.
15.9.3 Блокировки чтения/записи
Гарантирование взаимоисключающего доступа к общей памяти в много-
процессорной системе может снизить производительность. Исключительный
доступ к ресурсу нужен только при записи, а для чтения, в общем случае,
к любой ячейке памяти может обращаться какой угодно процесс. Поэтому во
многих системах общая память защищается более универсальными блоки-
ровками чтения/записи (read/write locks), а не стандартными блокировками
со взаимным исключением.198 Блокировка чтения/записи обеспечивает те же
возможности взаимного исключения, что и рассмотренные при обсуждении
проблемы читателей и писателей в разделе 6.2.4. Блокировка чтения/записи
позволяет множеству процессов доступ для чтения (эти процессы не будут из-
менять общедоступные данные). Однако в отличие от примера из разде-
ла 6.2.4, процессу, которому нужно выполнить запись, придется ждать, пока
все процессы, выполняющие чтение или запись, не выйдут из критических
участков, и только потом ожидающий процесс сможет войти в свой критиче-
ский участок.199
Чтобы эффективно реализовать такие блокировки, механизм взаимного
исключения должен поддерживать общую память. Однако в системах,
в которых нет общей памяти, например, системах NORMA, для его реали-
зации необходимо использовать передачу сообщений. Мы рассмотрим та-
кие реализации в разделе 17.5.
Вопросы для самопроверки
1. В каких ситуациях блокировки чтения/записи будут эффективнее
спин-блокировок ?
2. Примитивная реализация блокировок чтения/записи позволяет
любому читателю войти в критический участок, если ни один писа-
тель в данный момент не находится в критическом участке. Как мо-
жет такая реализация вызвать бесконечное откладывание
выполнения процессов-писателей? Какая реализация будет более
справедливой?
966
Глава 15
Ответы 1) Блокировки чтения/записи эффективнее спин-блоки-
ровок, если множеству процессов необходимо только считывать дан-
ные из ячейки памяти, а не записывать их. В этом случае множество
процессов могут одновременно находиться в критических участках.
2) Такая реализация приведет к бесконечному откладыванию, если
читатели будут постоянно входить в свои критические участки до
того, как писатель сможет войти в свой. Более справедливая реализа-
ция позволила бы читателю войти в критический участок только
в случае, если нет писателей, находящихся в критическом участке
или собирающихся войти в него, как обсуждалось в разделе 6.2.4.
Веб-ресурсы
www.winnetmag.com/Ar tides / Index.cfm?ArticleID=303 &pg=l&show=495
В этой статье описывается планирование в многопроцессорных системах под
управлением Windows NT.
www.aceshardware.com/Spades/read.php?artide_id=30ООО187
В этой статье рассматриваются методы обеспечения когерентности кэшей в сис-
темах на процессорах AMD Athlon (с двумя процессорами). Кроме того, обсуждает-
ся слежение за шиной.
www.mosix.org
Этот сайт посвящен MOSIX, набору программ для систем UNIX, реализующему
автоматическую миграцию процессов и балансировку нагрузки.
www.teamten.com/lawrence/242.paper/242.paper.html
Эта статья посвящена алгоритмам взаимного исключения для многопроцессор-
ных систем.
users.win.be/W0005997/UNIX/LINUX/IL/atomicity-eng.html
На этом сайте рассказывается об использовании спин-блокировок для реализа-
ции взаимных исключений в Linux.
Umoeu
Для многих приложений требуется куда большая вычислительная мощность,
чем та, которую способен предоставить один процессор. В результате часто исполь-
зуются многопроцессорные системы — компьютеры, в которых для выполнения
задач используются сразу несколько процессоров. Термином «многопроцессорная
система» можно обозначать любую систему с более чем одним процессором, вклю-
чая двухпроцессорные персональные компьютеры, мощные серверы со множест
вом процессоров и распределенные группы рабочих станций, работающих совмест
но над общими задачами.
Есть несколько разных классификаций многопроцессорных систем. Флинн соз-
дал одну из первых схем классификации систем различной степени параллельно-
сти, основанную на типах потоков, используемых процессорами. Системы SISD
(single instruction stream, single data stream — один поток команд, один поток дан-
ных) — это обычные однопроцессорные компьютеры, поочередно выполняющие
инструкции над элементами данных. Системы MISD (multiple instruction streams,
single data stream — несколько потоков команд, один поток данных) используются
нечасто. В этих системах используется множество процессоров, и каждый из них
передает результат выполнения своей операции следующему. Системы SIMD
Многопроцессорность f
(single instruction stream, multiple data streams — один поток команд, несколько
потоков данных), примерами которых являются векторные и матричные компью-
теры, параллельно выполняют одну и ту же инструкцию для нескольких элемен-
тов данных. Системы MIMD (multiple instruction streams, multiple data streams —
несколько потоков команд, несколько потоков данных) содержат множество про-
цессоров, каждый из которых выполняет свою последовательность инструкций
над своим потоком данных.
Схема соединений в многопроцессорной системе определяет структуру физиче-
ской связи между компонентами этой системы, например, процессорами и модуля-
ми памяти. Схемой соединений в значительной степени определяются производи-
тельность системы, ее надежность и стоимость, поэтому ее правильный выбор при
проектировании системы очень важен. Общая шина — это высокопроизводитель-
ная в небольших системах и дешевая схема, но она плохо масштабируется из-за
быстрого насыщения при большом количестве процессоров. Переключающая мат-
рица обеспечивает высокую отказоустойчивость и хорошую производительность,
но она неэффективна для маленьких систем, в которых наиболее эффективна схе-
ма UMA (uniform memory access — однородный доступ к памяти). Двумерная
ячеистая сеть — это простая схема, обеспечивающая приемлемую производитель-
ность и отказоустойчивость при невысокой стоимости, но она тоже плохо масшта-
бируется. Гиперкуб масштабируется лучше, чем двумерная ячеистая сеть, и обес-
печивает более высокую производительность, но и дороже стоит. Многоуровневые
сети представляют собой попытку достичь компромисса между стоимостью и про-
изводительностью — они могут использоваться для построения очень больших
многопроцессорных систем.
В тесносвязанных системах процессоры совместно используют большую часть
системных ресурсов. В слабосвязанных системах компоненты соединены через
специальные каналы связи, и большая часть ресурсов не является общедоступной.
Слабосвязанные системы более гибки, лучше масштабируются и более отказо-
устойчивы, чем тесносвязанные, но их производительность ниже. Кроме того, сис-
темное программирование для слабосвязанных систем сложнее, поскольку оно
должно обеспечивать возможность взаимодействия процессов через IPC, а не через
общую память.
Многопроцессорные системы также можно классифицировать по распределе-
нию обязанностей операционной системы. В системах, организованных по прин-
ципу «ведущий/ведомый», операционная система выполняется только на ведущем
процессоре. Прикладные задачи выполняются на ведомых процессорах. В систе-
мах с раздельными ядрами на каждом процессоре выполняется отдельная опера-
ционная система, и общесистемная информация хранится в специальных структу-
рах в памяти. В симметричных системах любой процессор может управлять любы-
ми устройствами и обращаться к любым накопителям. Такая организация
позволяет системам более эффективно распределять нагрузку.
В многопроцессорных системах используются различные способы распределе-
ния памяти. В системах UMA все процессоры делят между собой общую память —
такие системы плохо масштабируются. Системы NUMA (non-uniform memory
access — неоднородный доступ к памяти) делят память на модули, и каждый такой
модуль считается локальной памятью одного из процессоров. Системы СОМА
(cache-only memory arcliitecture — кэшевая архитектура памяти) похожи на
NUMA, но они воспринимают всю память как большой кэш, чтобы повысить веро-
ятность размещения запрашиваемых данных в локальной памяти запрашивающе-
го процессора. Системы NORMA (no remote memory access — системы без доступа
к удаленной памяти) являются слабосвязанными и вовсе не содержат общей памя-
ти. Архитектура NORMA используется для построения крупномасштабных рас-
пределенных систем.
Память считается когерентной, если значение, полученное при чтении из ее
ячейки, всегда будет значением, которое последним записывалось в эту ячейку.
В системах UMA для обеспечения когерентности памяти используются слежение
за шиной и кэшем. В системах CC-NUMA (NUMA с когерентным кэшем) чаще все-
го за когерентность данных по каждому адресу памяти отвечает домашний узел
этого адреса.
Системы, использующие репликацию страниц, могут содержать сразу по не-
сколько экземпляров одной и той же страницы, чтобы ускорить доступ разных
процессоров к данным с этой страницы. Системы, использующие миграцию стра-
ниц, перемещают страницы в локальную память процессора, чаще всего обращаю-
щегося к этим страницам. Эти подходы можно совмещать для достижения опти-
мальной производительности.
Общая виртуальная память (SVM — shared virtual memory) создает иллюзию
наличия общей физической памяти в больших многопроцессорных системах. Для
обеспечения когерентности виртуальной памяти используются протоколы с помет-
ками о недействительности и с широковещательной записью. Эти протоколы мож-
но соблюдать строго, но часто их строгое соблюдение бывает неэффективным. Ос-
лабленная состоятельность, при использовании которой система может быть неко-
герентной в течение нескольких секунд, позволяет повысить эффективность, но
снижает отказоустойчивость.
Алгоритмы планирования в многопроцессорных системах должны определять,
на каком процессоре запустить процесс, и когда это сделать. Некоторые алгорит-
мы пытаются добиться максимальной привязки процесса к процессору и его ло-
кальной памяти, выполняя взаимосвязанные процессы на одних и тех же процес-
сорах. Другие пытаются добиться максимального распараллеливания, выполняя
взаимосвязанные процессы одновременно на разных процессорах. В некоторых
системах используются глобальные очереди выполнения, а в других (обычно круп-
номасштабных) — узловые или процессорные.
Миграция процесса — это операция переноса процесса между двумя процессо-
рами или компьютерами. Использование миграции процессов может повысить
производительность, распределение ресурсов и отказоустойчивость. Чтобы выпол-
нить миграцию, с узла-отправителя на узел-получатель нужно отправить инфор-
мацию о состоянии процесса, включая страницы памяти, принадлежащие процес-
су, содержимое регистров, состояние открытых файлов и контекст ядра. Стратегии
миграции, разрешающие остаточную зависимость (зависимость процесса от его
первоначального узла) снижают отказоустойчивость и производительность процес-
са после миграции, однако устранение остаточной зависимости приводит к замед-
лению самого процесса миграции. В попытках достичь компромисса между скоро-
стью миграции и остаточной зависимостью был создан целый набор стратегий ми-
грации.
Балансировка нагрузки — это попытка добиться равномерной нагрузки всех
процессоров системы, чтобы повысить загрузку процессоров и снизить время реак-
ции процессов. Алгоритмы статической балансировки выделяют для выполнения
задачи фиксированное количество процессоров, когда эта задача запускается на
выполнение. Такие алгоритмы эффективны в системах, где взаимодействие про-
цессов и время их выполнения можно предсказать, например, в системах, занятых
научными расчетами. Алгоритмы динамической балансировки изменяют распре-
деление процессов задачи по процессорам в ходе выполнения этой задачи. Они бо-
лее эффективны, если взаимодействие между процессами невозможно предска-
зать, а сами процессы могут запускаться и завершаться в неизвестные заранее мо-
менты времени.
Многие механизмы взаимного исключения, используемые в однопроцессорных
системах, неэффективны или неработоспособны в многопроцессорных системах,
поэтому для многопроцессорных систем были созданы специальные механизмы.
Спин-блокировка — это механизм взаимного исключения, при использовании ко-
торого процессы, требующие доступа к заблокированному ресурсу, постоянно про-
веряют, доступен ли этот ресурс. Спин-блокировки эффективны при невысокой на-
грузке на систему, если время проверки доступности ресурса незначительно по
сравнению со временем переключения контекста. Использование спин-блокировок
Многопроцессорность
позволяет снизить время реагирования процессов на открытие доступа к ресурсам.
При использовании блокировки с усыплением/пробуждением процесс, освобож-
дая ресурс, будит процесс с наивысшим приоритетом из всех, ожидающих освобо-
ждения этого ресурса. Блокировка передается пробужденному процессу. Это
уменьшает трату процессорных циклов по сравнению со спин-блокировками. Бло-
кировки чтения/записи позволяют нескольким читателям или одному писателю
находиться в критических участках одновременно.
КлючеВые термины
APL (Advisable Process Lock — заявленная блокировка для процесса) — механизм
блокировки для процесса, в котором процесс, захватывающий контроль над ре-
сурсом, заявляет, в течение какого времени он собирается использовать ресурс.
Другие процессы, узнав это время, могут решить, нужно ли им заблокироваться
или продолжать проверять, свободен ли ресурс.
CC-NUMA (cache-coherent NUMA — NUMA с когерентным кэшем) — системы
NUMA, в которых (обычно с помощью домашних узлов) обеспечивается коге-
рентность кэшей.
СОМА (Cache-Only Memory Architecture — кэшевая архитектура памяти) — архи-
тектура многопроцессорных систем, в которой каждый узел состоит из процес-
сора с кэшем и модуля памяти. Основная память в таких системах организована
как кэш большого объема.
FCFS (first-come-first-served — «первым пришел — первым обслужен») — задач-
но-независимый алгоритм планирования процессов, помещающий новые про-
цессы в очередь. Процесс в голове очереди выполняется до его завершения, по-
сле чего на освободившемся процессоре начинает выполняться следующий про-
цесс из очереди.
MIMD — см. архитектура с множеством потоков команд и данных.
MISD — см. архитектура с одним потоком данных и несколькими потоками ко-
манд.
NORMA (NO Remote Memory Access — без доступа к удаленной памяти) — архи-
тектура многопроцессорных систем, в которой нет общей памяти, есть только
локальная память компьютеров-узлов. В таких системах используется общая
виртуальная память.
NUMA (Non-Uniform Memory Access — неоднородный доступ к памяти) — архи-
тектура многопроцессорных систем, в которой каждый узел состоит из процес-
сора с кэшем и модуля памяти. Доступ к памяти, находящейся в том же узле,
выполняется намного быстрее, чем к памяти, расположенной в других узлах.
NUMA с когерентным кэшем — см. CC-NUMA.
SIMD — см. архитектура с одним потоком команд и несколькими потоками дан-
ных.
SISD — см. архитектуры с одним потоком команд и одним потоком данных.
SMP (Symmetric MultiProcessor — симметричные многопроцессорные системы) —
системы, в которых у всех процессоров есть равные возможности по доступу
к любому ресурсу, включая память, устройства ввода/вывода и процессы.
SNPF (Smallest-Number-of-Processes-First — «наименьшее количество процес-
сов — первым») — задачно-ориентированный алгоритм планирования процес-
сов, использующий глобальную приоритетную очередь, в которой приоритет за-
дачи обратно пропорционален количеству процессов в ней.
SPF (Shortest-Process-First — «кратчайший процесс — первым») — задачно-неза-
висимый алгоритм планирования процессов в многопроцессорных системах, ис-
пользующий глобальную очередь выполнения. Этот алгоритм сначала отправ-
ляет на выполнение процессы с наименьшим предполагаемым временем выпол-
нения.
UMA (Uniform Memory Access — однородный доступ к памяти) — архитектура
многопроцессорных систем, позволяющая всем процессорам обращаться к об-
щей памяти; в общем случае время доступа к памяти в такой системе постоян-
но, независимо от того, какой процессор запрашивает данные, за исключением
случаев, когда требуемые данные находятся в кэше процессора.
Адаптивная блокировка (adaptive lock) — блокировка в механизмах взаимного
исключения, которая может становиться как спин-блокировкой, так и обычной
блокировкой в зависимости от текущего состояния системы.
Алгоритм аукциона (bidding algorithm) — алгоритм динамической балансировки
нагрузки, в котором слабо загруженные процессоры «торгуются» за получение
задач с сильно загруженных. Величины ставок процессоров определяются уров-
нем их загрузки и расстоянием от них до сильно загруженного процессора.
Архитектура без доступа к удаленной памяти — см. NORMA.
Архитектура с множеством потоков команд и данных (MIMD — multiple
instruction stream, multiple data stream) — архитектура компьютеров, состоя-
щих из множества отдельных процессоров, каждый из которых выполняет свою
последовательность инструкций над своим потоком данных; это архитектура
настоящих многопроцессорных систем.
Архитектура с несколькими общими шинами (multiple shared bus architecture) —
схема соединений, использующая несколько общих шин для соединения про-
цессоров и памяти. Использование нескольких шин уменьшает вероятность
шинных конфликтов, но увеличивает стоимость системы.
Архитектура с одним потоком данных и несколькими потоками команд (MISD —
multiple instruction stream, single data stream) — архитектура компьютеров, со-
держащих несколько процессоров, выполняющих независимые потоки опера-
ций над одним потоком данных. Эти системы довольно редко используются на
практике
Архитектура с одним потоком команд и несколькими потоками данных (SIMD —
single instruction stream, multiple data stream) — архитектура компьютеров, со-
стоящих из нескольких процессорных элементов, одновременно выполняющих
одни и те же инструкции над различными элементами данных.
Архитектура с одним потоком команд и одним потоком данных (SISD — single
instruction stream, single data stream) — архитектура компьютеров, в которой
один процессор последовательно выполняет инструкцию за инструкцией из по-
тока команд над элементами данных из одного потока данных; к этой архитек-
туре относятся традиционные однопроцессорные компьютеры.
Базовая сеть (baseline network) — разновидность многоуровневых сетей.
Балансировка нагрузки (load balancing) — механизм, пытающийся равномерно
распределить нагрузку между процессорами системы.
Блокировка с усыплением/пробуждением (sleep/wakeup lock) — блокировка,
обеспечивающая взаимное исключение, при использовании которой процессы,
ожидающие доступа к ресурсу, блокируются, а после освобождения ресурса
пробуждается только процесс с наибольшим приоритетом из ожидающих этого
ресурса.
Блокировка чтения/записи (read/write lock) — блокировка, позволяющая одному
записывающему процессу (который будет изменять данные) или множеству
считывающих процессов (которые не будут изменять данные) одновременно
входить в критический участок.
Векторный процессор (vector processor) — разновидность SIMD-компьютера, в ко-
тором используется один процессор, одновременно выполняющий одну и ту же
инструкцию над несколькими элементами данных.
Гиперкуб (hypercube) — схема соединения в многопроцессорных системах, содер-
жащая 2п узлов (п — целое число). Каждый узел в такой схеме связан с п сосед-
ними узлами.
Глобальная очередь выполнения (global run queue) — очередь планирования про-
цессов, используемая в некоторых алгоритмах планирования для многопроцес-
сорных систем. Эта очередь не привязана ни к одному процессору в системе,
и именно в нее помещаются все подлежащие выполнению задачи и процессы.
Двумерная ячеистая сеть (2-D mesh network) — схема соединения в многопроцес-
сорных системах, в которой узлы организованы в прямоугольник размера т * п.
Диаметр сети (network diameter) — длина кратчайшего пути между двумя самыми
удаленными узлами сети.
Динамическая балансировка нагрузки (dynamic load balancing) — методика, пы-
тающаяся равномерно распределить процессы по системе, изменяя количество
процессоров, выделенных задаче, в ходе выполнения этой задачи.
Динамическое разделение (dynamic partitioning) — задачно-ориентированный ал-
горитм планирования процессов, поровну распределяющий процессоры систе-
мы между выполняемыми задачами, за исключением того, что задаче выделяет-
ся не больше процессоров, чем в этой задаче готовых к выполнению процессов.
Этот алгоритм стремится добиться максимальной привязки процессов к процес-
сорам.
Домашний узел (home node) — узел, в котором физически расположены адрес па-
мяти или страница. Этот узел обеспечивает когерентность данных этого адреса
или страницы.
Домашняя состоятельность (home-based consistency) — стратегия обеспечения ко-
герентности памяти, при использовании которой процессоры отправляют ин-
формацию о когерентности домашнему узлу страницы, на которую выполняет-
ся запись. Домашний узел передает информацию об обновлениях другим узлам,
в дальнейшем обращающимся к этой странице.
Жесткая привязка (hard affinity) — разновидность привязки процесса к процессо-
ру, при которой алгоритм планирования гарантирует, что процесс будет выпол-
няться на одном и том же узле все время его выполнения.
Задачно-независимое планирование (job-blind scheduling) — алгоритмы планиро-
вания процессов, не обращающие внимания на свойства процессов. Обычно эти
алгоритмы просты в реализации.
Задачно-ориентированное планирование (job-aware scheduling) — алгоритмы
планирования процессов, учитывающие при планировании процессов свойства
этих процессов; эти алгоритмы обычно пытаются добиться максимального рас-
параллеливания выполнения процессов или их максимальной привязки к про-
цессорам.
Задержки при промахах в кэше (cache-miss latency) — дополнительные затраты
времени на доступ к данным, отсутствующим в кэше.
Заявленная блокировка для процесса — см. APL.
Инициация отправителем (sender-initiated policy) — метод динамической балан
сировки нагрузки, в котором перегруженные процессоры пытаются найти слабс
нагруженные процессоры и перенести на них часть своих процессов.
Инициация получателем (receiver-initiated policy) — метод динамической балан
сировки нагрузки, в котором недогруженные процессоры пытаются найти силь
но нагруженные процессоры и перенести с них часть процессов себе.
Глава t$ [ Многопроцессорность
Когерентность кэша (cache coherence) — свойство системы, в которой любой эле-
мент данных, считанный из кэша, имеет значение, равное последнему записан-
ному в этот элемент.
Когерентность памяти (memory coherence) — состояние системы, в котором значе-
ние, извлеченное из любой ячейки памяти, всегда является значением, которое
было последним записано в эту ячейку.
Коммутатор (switch) — узел, пересылающий сообщения межд^ узлами-компонен-
тами.
Конкуренция (contention) — в многопроцессорной системе — ситуация, в которой
несколько процессоров одновременно пытаются воспользоваться одним и тем
же ресурсом.
Конфигурируемая блокировка (configurable lock) — то же самое, что адаптивная
блокировка.
Копланирование — см. совместное планирование.
Кратчайший процесс — первым — см. SPF.
Круговой алгоритм планирования задач (round-robin job scheduling) — задач-
но-ориентированный алгоритм планирования, помещающий все задачи в одну
глобальную циклическую очередь и поочередно запускающий каждый из них
на выполнение.
Круговой алгоритм планирования процессов (round-robin process scheduling) —
задачно-независимый алгоритм планирования, помещающий все процессы
в одну глобальную циклическую очередь и поочередно запускающий каждый из
них на выполнение.
Кэшевая архитектура памяти — см. СОМА
Логические гонки (race condition) — состояние, возникающее, когда несколько по
токов одновременно обращаются к одному и тому же ресурсу, причем порядок
этих обращений точно не определен. Такие обращения могут стать причиной
трудно обнаружимых и устранимых ошибок, и их следует избегать.
Ложное совместное использование (false sharing) — ситуация, возникающая
в случаях, когда процессы, выполняющиеся на разных процессорах, вынужде-
ны обращаться к одной странице, поскольку каждому из них требуются данные
с этой страницы (но не одни и те же данные).
Массово-параллельный процессор — см. Процессор с полным распараллелива-
нием.
Матричные процессоры (array processors) — SIMD-системы, состоящие из множе-
ства (до десятков тысяч) простых процессоров, каждый из которых выполняет
такое же действие, как и остальные процессоры системы, но над своим элемен-
том данных.
Миграция по требованию (on-demand migration) — вариант названия поздней ми-
грации.
Миграция процесса (process migration) — перенос процесса и связанных с ним
данных с одного процессора на другой.
Миграция с копированием при обращении (copy-on-reference migration) — метод
миграции процессов, при которой сразу перемещаются только использованные
страницы памяти процесса. Позже процесс сможет запросить неиспользовав-
шиеся страницы или с узла-отправителя, или со вторичного устройства хране-
ния.
Миграция страниц (page migration) — методика перемещения страниц в узел наи-
более часто обращающегося к ней процессора (или процессоров, если использу-
ется совместно с репликацией страниц).
Многопроцессорная система (multiprocessor system) — вычислительная система,
использующая для обработки данных более одного процессора.
Многопроцессорная система с раздельными ядрами (separate-kernels multiproces-
sor organization) — система, в которой на каждом процессоре выполняется от-
дельная операционная система, но процессы могут обращаться к некоторой гло-
бальной информации.
Многопроцессорная система симметричной схемы (symmetrical multiprocessor
organization) — схема делегирования полномочий по выполнению операцион-
ной системы, в которой каждый процессор может выполнять отдельную опера-
ционную систему.
Многопроцессорная система схемы ведущий/ведомый (master/slave
multiprocessor organization) — система, в которой на одном процессоре (веду-
щем, главном) выполняется операционная система, а остальные процессоры (ве-
домые, подчиненные) заняты выполнением только пользовательских задач.
Многоуровневая сеть (multistage network) — схема соединения процессоров, в ко-
торой используются специальные узлы-коммутаторы и концентраторы для свя-
зи между отдельными процессорными узлами, снабженными локальной памя-
тью. '
Мягкая привязка (soft affinity) — вид привязки процесса к процессору, при кото-
ром алгоритм планирования попытается (но не гарантирует успеха попытки)
разместить процесс в одном узле на все время выполнения этого процесса.
Наименьшее количество процессов — первым — см. SNPF.
Неоднородный доступ к памяти — см. NUMA.
Неразделяющий алгоритм копланирования (undivided coscheduling algorithm) —
задачно-ориентированный алгоритм планирования, при использовании которо-
го процессы из одной задачи размещаются в смежных позициях циклической
глобальной очереди выполнения и отправляются на выполнение в круговом по-
рядке.
Несущееся стадо (thundering herd) — явление, возникающее при одновременном
пробуждении множества процессов, ожидавших доступа к одному и тому же ре-
сурсу; при этом процессы начинают одновременно проверять доступность ресур-
са и опять уходить в спячку, в результате сильно нагружаются процессоры и ка-
налы связи.
Общая виртуальная память (shared virtual memory, SVM) — расширение концеп-
ции виртуальной памяти, используемое в многопроцессорных системах; SVM
создает иллюзию присутствия в системе общей физической памяти и обеспечи-
вает когерентность страниц, к которым обращаются разные процессоры.
Общая шина (shared bus) — схема соединения компонентов в многопроцессорных
системах, в которой все компоненты, включая процессоры и модули памяти, со-
единены одной шиной.
Однородный доступ к памяти — см. UMA
Операция захвата (acquire operation) — в некоторых стратегиях обеспечения коге-
рентности памяти так называется операция, показывающая, что процесс соби-
рается обратиться к общей памяти.
Операция освобождения (release operation) — в некоторых стратегиях обеспече-
ния когерентности памяти так называется операция, сообщающая, что процесс
завершил обращение к общей памяти.
Ослабленная состоятельность (relaxed consistency) — группа стратегий обеспече-
ния когерентности памяти, позволяющих системе в течение некоторого времени
после выполнения записи находиться в некогерентном состоянии. Их использо-
вание позволяет повысить производительность системы по сравнению со страте
гиями строгой состоятельности.
Остаточная зависимость (residual dependency) — зависимость мигрировавшего
процесса от его узла-отправителя, связанная с тем, что процессу необходима
какие-то ресурсы с этого узла.
Гмва 15
Отложенная состоятельность (delayed consistency) — стратегия обеспечения коге-
рентности памяти, в которой процессоры посылают сведения об изменениях
данных после освобождения, но узлы, получившие эти сведения, не учитывают
их, пока не выполняют захват памяти.
Отложенное блокирование (delayed blocking) — подход, в рамках которого про-
цесс проверяет доступность ресурса в течение некоторого времени, прежде чем
заблокироваться; в основе этого подхода лежит предположение, что если про-
цесс не получит ресурс быстро, то имеет смысл заблокировать его, поскольку он
все равно будет вынужден долго ожидать доступности этого ресурса.
Отложенное обеспечение состоятельности при освобождении (lazy release
consistency) — стратегия обеспечения когерентности памяти, при которой про-
цессор не рассылает сведений об изменениях в памяти, пока другой процессор
не пытается обратиться к изменившейся странице.
Отложенное распространение данных (lazy data propagation) — методика, при ко-
торой процессор, выполняющий запись, распространяет уведомление об измене-
ниях после освобождения, но не передает сами изменившиеся данные. Другие
процессоры запрашивают эти данные, обращаясь к некогерентной странице.
Первым пришел — первым обслужен — см. FCFS.
Переключающая матрица (crossbar-switch matrix) — схема соединения процессо-
ров, обеспечивающая отдельный путь от каждого узла-отправителя к каждому
узлу-получателю.
Планирование с временным разделением (timesharing scheduling) — стратегия
планирования для многопроцессорных систем, пытающаяся добиться макси-
мального распараллеливания за счет размещения взаимодействующих процес-
сов на разных процессорах и их одновременного выполнения.
Планирование с пространственным разделением (space-partitioning schedu-
ling) — стратегия планирования для многопроцессорных систем, пытающаяся
добиться максимальной привязки процессов к процессорам за счет размещения
взаимодействующих процессов на один процессор (или на одну группу тесносвя-
занных процессоров); в основе алгоритма лежит предположение о том, что взаи-
модействующие процессы будут обращаться к одним и тем же данным.
Позднее копирование (lazy copying) — стратегия миграции процессов в многопро-
цессорных системах, передающая страницы с узла-отправителя на узел-получа-
тель только если процесс обращается к этим страницам.
Поздняя миграция (lazy migration) — стратегия миграции процессов в многопро-
цессорных системах, при использовании которой в ходе начальной миграции
передается только часть страниц процесса. Это увеличивает остаточную зависи-
мость, но уменьшает начальное время миграции.
Полная миграция (eager migration) — метод миграции процессов, при использова-
нии которого вместе с процессом сразу перемещается все его адресное простран-
ство, чтобы полностью устранить остаточную зависимость процесса.
Полная миграция для активных страниц (dirty eager migration) — метод мигра-
ции процессов, при использовании которого вместе с процессом перемещаются
только использовавшиеся страницы памяти; неиспользовавшиеся страницы из-
влекаются из вторичного устройства хранения.
Пометки о недействительности (invalidation) — протокол обеспечения когерент-
ности, в котором процесс сначала помечает все экземпляры страницы как не-
действительные (устаревшие), а затем выполняет запись на эту страницу.
Последовательная состоятельность (sequential consistency) — категория страте-
гий обеспечения когерентности памяти, в которых операции обеспечения коге-
рентности выполняются немедленно после операции записи в общую память.
Поток (stream) — последовательность данных или инструкций, передаваемых про-
цессору.
[ Многопроцессорность____________________________________
Привлеченная память (Attraction Memory, AM) — основная память в системах
СОМА, организованная в виде кэша.
Привязка процесса к процессору (processor affinity) — зависимость процесса от
определенного процессора и связанного с ним банка памяти.
Процессор с полным распараллеливанием (massively parallel processor) — про-
цессор, одновременно выполняющий множество инструкций над большими на-
борами данных; матричные процессоры часто называют процессорами с полным
распараллеливанием или массово-параллельными процессорами.
Процессорная очередь выполнения (per-processor run queue) — очередь процес-
сов, направленных для выполнения на конкретный процессор. Процессы из
этой очереди планируются к выполнению, независимо от процессов из очередей
других процессоров.
репликация страниц (page replication) — механизм, позволяющий системе созда-
вать несколько экземпляров страницы в разных узлах, чтобы обеспечить быст-
рый доступ к этой странице.
Связь (network link) — соединение между двумя узлами сети.
Симметричная многопроцессорная система — см. SMP.
Симметричный метод (symmetric policy) — метод динамической балансировки на-
грузки, сочетающий в себе методы с инициацией отправителем и с инициацией
получателем, чтобы добиться максимальной гибкости и приспособляемости
к условиям среды.
Слабосвязанная система (loosely coupled system) — система, в которой каждый
процессор не может напрямую обратиться к любому ресурсу; такие системы
гибче и отказоустойчивое, чем тесно связанные, но менее производительны.
Слежение за кэшем (cache snooping) — протокол обеспечения когерентности, осно-
ванный на слежении за шиной.
Слежение за шиной (bus snooping) — протокол обеспечения когерентности, в кото-
ром процессоры «следят» за шиной, определяя, относится ли запрошенная опе-
рация записи к данным, находящимся в их кэшах или локальной памяти (если
такая память есть).
Случайная стратегия (random policy) — метод динамической балансировки на-
грузки, при котором система случайным образом выбирает процессор, на кото-
рый будет перемещен процесс с перегруженного процессора.
Совместное планирование (coscheduling) — задачно-ориентированный алгоритм
планирования процессов, пытающийся добиться параллельного выполнение
процессов из одной задачи за счет их размещения в смежных позициях глобаль-
ной очереди выполнения.
Состоятельность при освобождении (release consistency) — стратегия обеспечени/
когерентности памяти, в которой последовательность из множества обращений
к памяти считается одной операцией; такие последовательности начинаются
с захвата страницы и заканчиваются ее освобождением. После освобождена
выполняются действия, необходимые для восстановления когерентности па
мят и.
Спин-блокировка (spin lock) — блокировка в системах взаимного исключения
при использовании которой ожидающие процессы постоянно проверяют доступ
ность закрытого блокировкой ресурса; такое поведение уменьшает время реак
ции процесса на освобождение этого ресурса.
Статическая балансировка нагрузки (static load balancing) — категория алгори!
мов балансировки нагрузки, выделяющих задаче фиксированное количеств
процессоров в начале ее выполнения.
Степень узла (degree of node) — количество узлов, непосредственно соединенны
с данным узлом.
Гм8а 15
Стоимость схемы соединений (cost of interconnection scheme) — общее количество
соединений в схеме.
Стратегия с предварительным копированием (precopy) — стратегия миграции
процессов, при использовании которой отправитель начинает передавать ис-
пользованные страницы памяти до того, как выполнение процесса приостанав
ливается; как только количество непереданных использованных страниц падает
ниже некоторого предела, выполняется миграция процесса.
Стратегия со сбросом содержимого (flushing) — стратегия миграции процессов,
при использовании которой узел-отправитель записывает все страницы памяти
процесса на общедоступный накопитель в начале миграции. В дальнейшем миг-
рировавший процесс извлекает эти страницы с накопителя по мере надобности.
Строка памяти (memory line) — запись в памяти, хранящая одно машинное слово
данных, чаще всего — четыре или восемь байт.
Схема соединений (interconnection scheme) -определяет способ соединения компо-
нентов многопроцессорной системы, например, процессоров и модулей памяти.
Тесносвязанная система (tightly coupled system) — система, в которой каждому
процессору доступно большинство ее ресурсов; такие системы менее отказо-
устойчивы и гибки, но более производительны, чем слабосвязанные.
Узел (node) — компонент системы, например, процессор, модуль памяти или ком-
мутатор, подключенный к сети. Иногда группу соединенных друг с другом уз-
лов тоже считают узлом.
Узловая очередь выполнения (per-node run queue) — очередь ожидающих выпол-
нения процессов, направленных для выполнения на конкретный узел. Процес-
сы из этой очереди планируются к выполнению независимо от процессов других
узлов.
Чертежный алгоритм (drafting algorithm) — алгоритм динамической балансиров-
ки нагрузки, классифицирующий загрузку каждого процесса как высокую,
среднюю или низкую. Каждый процессор хранит таблицу с классификацией за-
грузки других процессоров, и система использует эту информацию для распре-
деления процессов.
Четырехсвязная двумерная ячеистая сеть (4-connected 2-D mesh network) — дву-
мерная ячеистая сеть, в которой узел связан с соседними сверху, снизу, слева
и справа.
Ширина сечения (bisection width) — минимальное количество связей, которые
нужно перерезать, чтобы разделить сеть на две несвязанные части.
Широковещательная запись (write broadcast) — протокол обеспечения когерент-
ности памяти, при использовании которого процессор, выполняющий запись,
сообщает об этой записи всей системе.
Упражнения
15.1. Схема соединения компонентов в многопроцессорной системе влияет на
производительность, надежность и стоимость этой системы.
а. Какие из рассмотренных в этой главе схем лучше всего подходят для ма-
леньких систем, а какие — для больших?
б. Почему некоторые схемы соединения хороши для маленьких сетей,
а некоторые — для больших, но ни одна из них не подходит одновремен-
но и для больших, и для маленьких сетей?
15.2. Для каждой из перечисленных ниже организаций многопроцессорных сис-
тем укажите среду, в которой ее можно эффективно применять. Укажите
также недостаток этой организации.
Многопроцессорность У”
а. Организация «ведущий/ведомый».
6. Организация с раздельными ядрами.
в. Симметричная организация.
15.3. Для каждой из перечисленных ниже сред выберите оптимальную архитек-
туру — UMA, NUMA или NORMA. Аргументируйте свой выбор.
а. Среда с несколькими интерактивными процессами, взаимодействующи-
ми через общую память.
б. Тысячи рабочих станций, выполняющих общую задачу.
в. Крупная многопроцессорная система с 64 процессорами в одном корпусе,
г. Двухпроцессорный персональный компьютер.
15.4. Как уже говорилось в этой главе, важная, но труднодостижимая цель архи-
тектуры NUMA — максимизация количества обращений к памяти, кото-
рые можно обслужить, обращаясь к локальной памяти узла. Опишите все
три стратегии — СОМА, репликацию страниц и их миграцию — используе-
мые для достижения этой цели, и обсудите преимущества и недостатки ка-
ждой из них.
а. Системы СОМА.
б. Миграция страниц.
в. Репликация страниц.
I' 15.5. Классифицируйте каждый из перечисленных ниже алгоритмов планирова-
ния и опишите систему, в которой будет эффективно его применение. Аргу-
ментируйте ваши ответы.
а. Задачно-независимые алгоритмы планирования.
б. Задачно-ориентированные алгоритмы планирования.
в. Планирование с помощью процессорных или узловых очередей выпол-
нения.
15.6. Опишите воздействие миграции процессов на каждый из перечисленных
ниже параметров (выигрыш, который можно получить по этому параметру
при использовании миграции процессов, и проигрыш, который может воз-
никнуть при неэффективной ее реализации).
а. Производительность.
б. Отказоустойчивость.
в. Масштабируемость.
15.7. Обсуждая балансировку нагрузки, мы описывали, как процессоры решают,
когда и куда нужно мигрировать процесс. Однако мы не описывали, как
процессоры решают, какой именно процесс должен мигрировать. Предло-
жите характеристики, в результате анализа которых система сможет опре-
делить, какие процессы нужно мигрировать. [Подсказка'. Подумайте, ка-
кую пользу получает система от миграции процесса, кроме балансировки
нагрузки].
15.8. Может ли бесконечно откладываться выполнение процесса, ожидающего
освобождения ресурса, закрытого спин-блокировкой, если гарантируется,
что все процессы выйдут из своих критических участков за конечный ин-
тервал времени? А если вместо спин-блокировки используется блокировка
с усыплением/пробуждением?
Рекомендуемые исследовательские учебные проекты
15.9. Подготовьте научную статью, описывающую поддержку систем архитекту-
ры CC-NUMA в операционной системе Linux. Опишите используемый
в Linux алгоритм планирования, протоколы обеспечения когерентности кэ-
шей и памяти и механизмы взаимного исключения. В рамках исследова-
ния обязательно просмотрите некоторые файлы исходного кода системы.
У'В
Глава 15
15.10. Стоимость и производительность различных аппаратных устройств изме-
няется со временем, но с разными скоростями. Например, аппаратные уст-
ройства все больше дешевеют, а производительность процессоров растет
быстрее, чем пропускная способность шин. Напишите статью, посвящен-
ную направлениям развития схем соединений. Какие схемы становятся бо-
лее популярными, а какие — теряют популярность? Почему?
15.11. Подготовьте научную статью, описывающую используемые в наше время
алгоритмы балансировки нагрузки. Какие соображения лежат в основе ка-
ждого алгоритма? Для каких сред предназначен каждый алгоритм? Явля-
ются ли большинство из них статическими или динамическими?
15.12. Подготовьте научную статью, описывающую реализацию протоколов обес-
печения когерентности памяти в различных операционных системах.
Включите в статью подробное описание такого протокола и хотя бы одной
его реализации в конкретной операционной системе.
Рекомендуемые программные учебные проекты
15.13. С помощью потоков языка Java смоделируйте многопроцессорную систему.
Каждый поток должен соответствовать одному процессору. Обязательно
синхронизируйте процессы с помощью глобальных переменных. Реализуй
те общую память в виде массива, причем в роли адресов памяти должен вы-
ступать индекс этого массива. Определите класс объектов Process. Случай-
ным образом создавайте объекты класса Process и реализуйте для них алго-
ритм планирования. Для каждого объекта нужно определять, сколько
времени он будет выполняться до блокирования и когда его выполнение за-
вершится. Кроме того, нужно указывать, когда ему понадобится обратить-
ся к общей памяти и по какому адресу.
15.14. Расширьте программу моделирования. Реализуйте в ней процессорные оче-
реди выполнения и алгоритм балансировки нагрузки. Создайте структуру
данных, имитирующую локальную память процессора, и реализуйте метод
класса Process, случайным образом добавляющий ячейки в эту память. Ло-
кальная память процесса должна мигрировать вместе с ним.
Рекомендуемая литература
Флинн и Радд предложили обзор параллельных и последовательных архитектур
в своей статье «Parallel Architectures»200, написанной в 1996 году. Кроули в своей
статье «Ап Analysis of MIMD Processor Interconnection Networks for Nanoelectronic
Systems»201 рассматривает различные схемы соединения процессоров.
По мере того, как многопроцессорные системы становятся все более распростра-
ненными, все больше внимания уделяется оптимизации их производительности.
Макхирджи с сотрудниками представляют обзор концепций многопроцессорных
систем в работе «А Survey of Multiprocessor Operating Systems»202. Недавно Трипа-
ти и Карник рассмотрели множество важных тем, включая диспетчеризацию, дос-
туп к памяти и блокировки, в своей статье «Trends in Multiprocessor and
Distributed Operating System Designs»203.
За дополнительной информацией по алгоритмам планирования в многопро-
граммных средах обращайтесь к работе Лейтенеггера и Вернона «The Performance
of Multiprogrammed Multiprocessor Scheduling Policies»204 и более свежей работе
Банта «Scheduling in Multiprogrammed Parallel Systems»205. Лаи и Худак обсужда-
ют когерентность виртуальной памяти в своей работе «Memory Coherence in Shared
Virtual Memory Systems»206. Ифтоде и Сингх рассматривают различные реализа-
ции протоколов обеспечения когерентности памяти в работе «Shared Virtual
Мно. опроцвссорность УТ
Memory: Progress and Challenges»207. Подробный обзор миграции процессов, напи-
санный Миложичичем, называется «Process Migration»208. Связанная с миграцией
процессов проблема балансировки нагрузки тщательно изучена Лангендорфером
и Петри в работе «Load Balancing and Fault Tolerance in Workstation Clusters:
Migrating Groups of Processes»209. Библиография к этой книге доступна на нашем
веб-сайте по адресу www.deitel.com/books/os3e/Bibliography.pdf.
Библиография
1. Mukherjee, В.; К. Schwan; and Р. Gopinath, «А Survey of Multiprocessor Oper-
ating Systems», GIT-CC-92/05, November 5, 1993, p. 1.
2. Mitchell, R., «The Genius: Meet Seymour Cray, Father of the Supercomputer,»
Business Week, April 30, 1990, <www.businessweek.com/1989-94/pre88/
b31571.htm>.
I 3. Breckenridge, C., «Tribute to Seymour Cray,» November 19, 1996,
<www.cgl.ucsf.edu/home/tef/cray/tribute.html>.
1 4. Mitchell, R., «The Genius: Meet Seymour Cray, Father of the Supercomputer,»
BusinessWeek, April 30, 1990, <www.businessweek.com/1989-94/pre88/
b31571.htm>.
5 Breckenridge, C., «Tribute to Seymour Cray,» November 19, 1996,
<www.cgl.ucsf.edu/home/tef/cray/tribute.html>.
6. Mitchell, R., «The Genius: Meet Seymour Cray, Father of the Supercomputer,»
BusinessWeek, April 30, 1990, <www.businessweek.com/1989-94/pre88/
b31571.htm>.
7. Breckenridge, C., «Tribute to Seymour Cray,» November 19, 1996,
<www.cgl.ucsf.edu/home/tef/cray/tribute.html>.
8. Mitchell, R., «The Genius: Meet Seymour Cray, Father of the Supercomputer,»
BusinessWeek, April 30, 1990, <www.businessweek.com/1989-94/pre88/
b31571.htm>.
9. ТорбОО, «ТОР500 Supercomputer Sites: TOP500 List 06-2003,»
<www.top500.org/list/2003/06/7page>.
10. van der Steen, А., «ТОР500 Supercomputer Sites: Intel Itanium 2,»
<www. top500. org/0RSC/2002/itanium. html>.
11. Habata, S.; M. Yokokawa; and S. Kitawaki, «The Earth Simulator System,» NEC
Research and Development, January 2003, <www.nec.co.jp/techrep/en
r_and_d/r03/r03-nol/rd06.pdf>.
12. JAMSTEC, «Earth Simulator Hardware,» <www.es.jamstec.go.jp/esc/eng/ES
hardware.html>.
13. Habata, S.; M. Yokokawa; and S. Kitawaki, «The Earth Simulator System,» NEC
Research and Development, January 2003, <www.nec.co.jp/techrep/en
r_and_d/r03/r03-nol/rd06.pdf>.
14. JAMSTEC, «Earth Simulator Hardware,» <www.es.jamstec.go.jp/esc/eng/ES
hardware.html>.
15. JAMSTEC, «Earth Simulator Mission,» <www.es.jamstec.go.jp/esc/eng/ES
mission.html>.
16. «ТОР500 Supercomputer Sites,» June 1, 2003, <www.top500.org/list/2003/06/!>
17. «Our Mission and Basic Principles», The Earth Simulator Center, October 17
2003, <www.es.j amstec.go.jp/esc/eng/ESC/mission.html>.
18. Allison, D., «Interview with Seymour Cray», May 9, 1995, <americanhistc
ry.si.edu/csr/comphist/cray.htm>.
19. Breckenridge, C., «Tribute to Seymour Cray,» November 19, 199C
<www.cgl.ucsf.edu/home/tef/cray/tribute.html>.
Supercomputer,»
,/1989-94/pre88/
Allison, D., «Interview with Seymour Cray», May 9, 1995, <americanhisto
ry. si. edu/csr/comphist/cray. htm>.
21. Mitchell, R., «The Genius: Meet Seymour Cray, Father of the
BusinessWeek, April 30, 1990, < www.businessweek.con
b31571.htm>.
22. Breckenridge, C., «Tribute to Seymour Cray,» November 19, 1996,
<www.cgl.ucsf.edu/home/tef/cray/tribute.html>.
23. Allison, D., «Interview with Seymour Cray», May 9, 1995, <americanhisto-
r у. si. ed u/csr / comphist /cray.htm>.
24. Breckenridge, C., «Tribute to Seymour Cray,» November 19, 1996,
<www.cgl.ucsf.edu/home/tef/cray/tribute.html>.
25. Mitchell, R., «The Genius: Meet Seymour Cray. Father of the Supercomputer,»
BusinessWeek, April 30, 1990, <www.businessweek.com/1989-94/pre88,
b31571.htm>.
26. Allison, D., «Interview with Seymour Cray», May 9, 1995, <americanhisto-
ry.si.edu/csr/comphist/cray.htm>.
27. Breckenridge, C., «Tribute to Seymour Cray,» November 19, 1996,
<www.cgl.ucsf.edu/home/tef/cray/tribute.html>.
28. Mitchell, R., «The Genius: Meet Seymour Cray, Father of the Supercomputer,»
BusinessWeek, April 30, 1990, <www.businessweek.com/1989-94/pre88/
b31571.htm>.
29. Allison, D., «Interview with Seymour Cray», May 9, 1995, <americanhisto-
ry.si.edu/csr/comphist/cray.htm>.
30. Breckenridge, C., «Tribute to Seymour Cray,» November 19, 1996,
<www.cgl.ucsf.edu/home/tef/cray/tribute.html>.
31. Mitchell, R., «The Genius: Meet Seymour Cray, Father of the Supercomputer,»
BusinessWeek, April 30, 1990, <www.businessweek.com/1989-94/pre88/
b31571.htm>.
32. Allison, D., «Interview with Seymour Cray», May 9, 1995, <americanhisto;
ry.si.edu/csr/comphist/cray.htm>.
33. Breckenridge, C., «Tribute to Seymour Cray,» November 19, 1996,
<www.cgl.ucsf.edu/home/tef/cray/tribute.html>.
34. Mitchell, R., «The Genius: Meet Seymour Cray, Father of the Supercomputer,»
BusinessWeek, April 30, 1990, <www.businessweek.com/1989-94/pre88
b31571.htm>.
35. Allison, D., «Interview with Seymour Cray», May 9, 1995, <americanhisto-
ry.si.edu/csr/comphist/cray.htm>.
36. Mitchell, R., «The Genius: Meet Seymour Cray, Father of the Supercomputer,»
BusinessWeek, April 30, 1990, <www.businessweek.com/1989-94/pre88/
b31571.htm>.
37. Mitchell, R., «The Genius: Meet Seymour Cray, Father of the Supercomputer,»
BusinessWeek, April 30, 1990, <www.businessweek.com/1989-94/pre88/
b31571.htm>.
38. Cray Incorporated, «Historic Cray Systems,» <www.cray.com/company/h_sys
terns. html>.
39. Cray Incorporated, «Historic Cray Systems,» <www.cray.com/company/h_sys-
tems.html>.
40. Allison, D., «Interview with Seymour Cray», May 9, 1995,
<americanhistory.si.edu/csr/comphist/cray.htm>. .
41. Flynn, M., «Very High-Speed Computing Systems,» Proceedings of the IEEE,
Vol. 54, December 1966, pp. 1901-1909.
42. Flynn, M., and K. Rudd, «Parallel Architectures», ACM Computing Surveys,
Vol. 28, No. 1, March 1996, p. 67.
43. Accelerating Digital Multimedia Production with Hyper-Threading Technology»,
January 15, 2003. <http://cedar.intel.com/cgi-bin/ids.dll/content/con-
tent.jsp?cntKey=Generic+Editorial%3a%3ahyperthreading_digital_multime-
dia&cntType=IDS_EDITORIAL&catCode=CDN&path=5>.
44. Flynn, M., and K. Rudd, «Parallel Architectures», ACM Computing Surveys,
Vol. 28, No. 1, March 1996, p. 67.
45. Zhou, J., and K. Ross, «Research Sessions: Implementation Techniques: Imple-
menting Database Operations Using SIMD Instructions,» Proceedings of the 2002
ACM SIGMOD International Conference on Management of Data, June 2002,
p. 145.
46. Flynn, M., and K. Rudd, «Parallel Architectures», ACM Computing Surveys,
Vol. 28, No. 1, March 1996, p. 67.
47. Hennessy, J., and D. Patterson, Computer Organization and Design, San Fran-
cisco, CA: Morgan Kaufmann, 1998, pp. 751-752.
48. Flynn, M., and K. Rudd, «Parallel Architectures», ACM Computing Surveys,
Vol. 28, No. 1, March 1996, p. 67.
49. Gelenbe E., «Performance Analysis of the Connection Machine,» Proceedings of
the 1990 ACM SIGMETRICS Conference on Measurement and Modeling of Com
puter Systems, Vol. 18, No. 1, April 1990, pp. 183-191.
50. Flynn, M., and K. Rudd, «Parallel Architectures», ACM Computing Surveys,
Vol. 28, No. 1, March 1996, p. 67.
51. Crawley, D., «An Analysis of MIMD Processor Interconnection Networks for
Nanoelectronic Systems,» UCL Image Processing Group Report 98/3, 1998, p. 3.
52. Crawley, D., «An Analysis of MIMD Processor Interconnection Networks for
Nanoelectronic Systems,» UCL Image Processing Group Report 98/3,1998, p. 3.
53. Bhuyan, L.; Q. Yang; and D. Agrawal, «Performance of Multiprocessor Intercon-
nection Networks,» Computer, Vol. 20, No. 4, April 1987, pp. 50-60.
54. Rettberg, R., and R. Thomas, «Contention is No Obstacle to Shared Memory
Multiprocessors,» Communications of the ACM, Vol. 29, No. 12, December 1986,
pp. 1202-1212.
55. Crawley, D., «An Analysis of MIMD Processor Interconnection Networks for
Nanoelectronic Systems,» UCL Image Processing Group Report 98/3, 1998, p. 12.
56. Hennessy, J., and D. Patterson, Computer Organization and Design, San Fran-
cisco, CA: Morgan Kaufmann, 1998, pp. 718.
57. Crawley, D., «An Analysis of MIMD Processor Interconnection Networks for
Nanoelectronic Systems,» UCL Image Processing Group Report 98/3, 1998, p. 12.
58. Qin, X., and J. Baer, «А Performance Evaluation of Cluster Architectures,» Pro-
ceedings of the 1997 ACM SIGMETRICS Conference on Measurement and
Modeling of Computer Systems, p. 237.
59. Friedman, M., «Multiprocessor Scalability in Microsoft Windows NT/2000,»
Proceedings of the 26th Annual International Measurement Group Conference,
December 2000, pp. 645-656.
60. Enslow, P., «Multiprocessor Organization —- A Survey,» ACM Computing Sur-
veys, Vol. 9, No. 1, March 1977, pp. 103-129.
61. Bhuyan, L.; Q. Yang; and D. Agrawal, «Performance of Multiprocessor Intercon-
nection Networks,» Computer, Vol. 20, No. 4, April 1987, pp. 50-60.
62. Stenstrom, P., «Reducing Contention in Shared-Memory Multiprocessors,» Com
puter, Vol. 21, No. 11 November 1988, pp. 26-37.
63. Crawley, D., «An Analysis of MIMD Processor Interconnection Networks for
Nanoelectronic Systems,» UCL Image Processing Group Report 98/3, 1998, p. 19.
64. «UltraSPARC-Ш,» <www.sun.com/processors/UltraSPARC-III/USIIITech.html>.
65. Crawley, D., «An Analysis of MIMD Processor Interconnection Networks for
Nanoelectronic Systems,» UCL Image Processing Group Report 98/3, 1998, p- 8.
66. Seitz, C., «The Cosmic Cube,» Communications of the ACM, Vol. 28, No. 1, Janu-
ary 1985, pp. 22-33.
67. Padmanabhan, K., «Cube Structures for Multiprocessors», Communications of
the ACM, Vol. 33, No. 1, January 1990, pp. 43-52.
68. Hennessy, J., and D. Patterson, Computer Organization and Design, San Fran-
cisco, CA: Morgan Kaufmann, 1998, p. 738.
69. Crawley, D., «An Analysis of MIMD Processor Interconnection Networks for
Nanoelectronic Systems,» UCL Image Processing Group Report 98/3, 1998, p. 10.
70. «The nCUBE 2s,» Top 500 Supercomputer Sites, February 16, 1998
<www.top500.org/0RSC/1998/ncube.html>.
71. Bhuyan, L.; Q. Yang; and D. Agrawal, «Performance of Multiprocessor Intercon-
nection Networks,» Computer, Vol. 20, No. 4, April 1987, pp. 50-60.
72. Crawley, D., «An Analysis of MIMD Processor Interconnection Networks for
Nanoelectronic Systems,» UCL Image Processing Group Report 98/3, 1998, p. 15.
73. «USING ASCI White,» October 7, 2002, <www.llnl.gov/asci/platforms/white/>.
74. «IBM SP Hardware/Software Overview,» February 26, 2003, <www.llnl.gov/
computing/tutorials/ibmhwsw/#evolution>.
75. Skillicorn, D., «А Taxonomy for Computer Architectures,» Computer, Vol. 21,
No. 11, November 1988, pp. 46-57.
76. McKinley, D., «Loosely-Coupled Multiprocessing: Scalable, Available, Flexible
and Economical Computing Power,» RTC Europe, May 2001, pp. 22-24,
<www.rtceuropeonline.com/may2001 /specialreport.pdf >.
77. McKinley, D., «Loosely-Coupled Multiprocessing: Scalable, Available, Flexible
and Economical Computing Power,» RTC Europe, May 2001, pp. 22-24,
<www.rtceuropeonline.com/may2001/specialreport.pdf>.
78. Enslow, P., «Multiprocessor Organization — A Survey,» ACM Computing Sur-
veys, Vol. 9, No. 1, March 1977, pp. 103-129.
79. Van Lang, T., «Strictly On-Line: Parallel Algorithms for Calculating Under-
ground Water Quality,» Linux Journal, No. 63, July 1, 1999,
<www.linuxjournal.com/article.php?sid=3021>.
80. Enslow, P., «Multiprocessor Organization — A Survey,» ACM Computing Sur-
veys, Vol. 9, No. 1, March 1977, pp. 103-129.
81. Bartlett, J., «А NonStop Kernel,» Proceedings of the Eighth Symposium on Oper-
ating Systems Principles, December 1981, pp. 22-29.
82. Enslow, P., «Multiprocessor Organization - A Survey,» ACM Computing Sur
veys, Vol. 9, No. 1, March 1977, pp. 103-129.
83. Wilson, A., «More Power To You: Symmetrical Multiprocessing Gives
Large-Scale Computer Power at a Lower Cost with Higher Availability,»
Datamation, June 1980, pp. 216-223.
84. Rettberg, R., and R. Thomas, «Contention is No Obstacle to Shared Memory
Multiprocessors,» Communications of the ACM, Vol. 29, No. 12, December 1986,
pp. 1202-1212.
85. Mukherjee, В.; K. Schwan; and P. Gopinath, «А Survey of Multiprocessor Oper-
ating Systems», GIT-CC-92/05, November 5, 1993, p. 2.
86. Tripathi, A., and N. Karnik, «Trends in Multiprocessor and Distributed Oper-
ating Systems Design,» Journal of Supercomputing, Vol. 9, No 1/2, 1995, p. 4.
87 Mukherjee, В.; K. Schwan; and P. Gopinath, «А Survey of Multiprocessor Oper-
ating Systems», GIT-CC-92/05, November 5, 1993, p. 2.
88. Mukherjee, В.; K. Schwan; and P. Gopinath, «А Survey of Multiprocessor Oper-
ating Systems», GIT-CC 92/05, November 5, 1993, pp. 2-3.
Tripathi, A., and N. Karnik, «Trends in Multiprocessor and Distributed Oper-
ating Systems Design,» Journal of Supercomputing, Vol. 9, No 1/2, 1995, p. 3.
Многопроцессорность
7OJ
90. Joe, Т., and J. Hennessy, «Evaluating the Memory Overhead Required for COMA
Architectures», Proceedings of the 21st Annual Symposium on Computer Archi-
tecture, April 1994, p. 82.
91. Stenstrom, P.; T. Joe; and A. Gupta, «Computative Performance Evaluation of
Cache-Coherent NUMA and COMA Architectures,» Proceedings of the 19th An
nual Symposium on Computer Architecture, April 1992, p. 81.
92. Stenstrom, P.; T. Joe; and A. Gupta, «Computative Performance Evaluation of
Cache-Coherent NUMA and COMA Architectures,» Proceedings of the 19th An-
nual Symposium on Computer Architecture, April 1992, p. 81.
98. Tripathi, A., and N. Karnik, «Trends in Multiprocessor and Distributed Oper-
ating Systems Design,» Journal of Supercomputing, Vol. 9, No 1/2, 1995, p. 20.
94. Mukherjee, В.; K. Schwan; and P. Gopinath, «А Survey of Multiprocessor Oper-
ating Systems», GIT-CC-92/05, November 5, 1993, pp. 2-3.
95. Barroso, L. A.; J. Dean; and U. Hoelzle, «Web Search for a Planet: The Google
Cluster Architecture,» IEEE MICRO, March-April 2003, pp. 22-28.
96. Tripathi, A., and N. Karnik, «Trends in Multiprocessor and Distributed Oper-
ating Systems Design,» Journal of Supercomputing, Vol. 9, No 1/2, 1995, p. 3.
97. Tannenbaum, A., and R. Renesse, «Distributed Operating Systems,» Computing
Surveys, Vol. 17, No. 4, December 1985, p. 420.
98. Lai, K., and P. Hudak, «Memory Coherence in Shared Virtual Memory Systems,»
ACM Transactions on Computer Systems, Vol. 7, No. 4, November 1989, p. 325.
99. Lai, K., and P. Hudak, «Memory Coherence in Shared Virtual Memory Systems,»
ACM Transactions on Computer Systems, Vol. 7, No. 4, November 1989, p. 325.
100. «Cache Coherence,» Webopedia.com, <www.webopedia.com/TERM/C/cache_co-
herence.html>.
101. Stenstrom, P.; T. Joe; and A. Gupta, «Computative Performance Evaluation of
Cache-Coherent NUMA and COMA Architectures,» Proceedings of the 19th An-
nual Symposium on Computer Architecture, April 1992, p. 81.
102. Soundrarajan, V., et al., «Flexible Use of Memory for Replication/Migration in
Cache-Coherent DSM Multiprocessors,» Proceedings of the 25th Annual Sympo-
sium on Computer Architecture, June 1998, p. 342.
103. Lai, A., and B. Falsafi, «Comparing the Effectiveness of Fine-Grain Memory
Caching against Page Migration/Replication in Reducing Traffic in DSM Clus-
ters,» ACM Symposium on Parallel Algorithms and Architecture, 2000, p. 79.
104. Soundrarajan, V., et al., «Flexible Use of Memory for Replication/Migration in
Cache-Coherent DSM Multiprocessors,» Proceedings of the 25th Annual Sympo-
sium on Computer Architecture, June 1998, p. 342.
105. Baral, Y.; M. Carikar; and P. Indyk, «On Page Migration and Other Related Task
Systems,» ACM Symposium on Discrete Algorithms, 1997, p. 44.
106. Vergese, B., et al., «Operating System Support for Improving Data Locality on
CC-NUMA Computer Servers,» Proceedings of the 7th International Conference
on Architectural Support for Programming Languages and Operating Systems,
October 1996, p. 281.
107. Vergese, B., et al., «Operating System Support for Improving Data Locality on
CC-NUMA Computer Servers,» Proceedings of the 7th International Conference
on Architectural Support for Programming Languages and Operating Systems,
October 1996, p. 281.
108. LaRowe, R.; C. Ellis; and L. Kaplan, «The Robustness of NUMA Memory Man-
agement, » Proceedings of the 13th ACM Symposium on Operating System Princi-
ples, October 1991 pp. 137-138.
109. Lai, K., and P. Hudak, «Memory Coherence in Shared Virtual Memory Systems,»
ACM Transactions on Computer Systems, Vol. 7, No. 4, November 1989,
pp. 326-327.
110. Lai, К., and P. Hudak, «Memory Coherence in Shared Virtual Memory Systems,»
ACM Transactions on Computer Systems, Vol. 7, No. 4, November 1989,
pp. 327-328.
1. Tripathi, A., and N. Karnik, «Trends in Multiprocessor and Distributed Oper-
ating Systems Design,» Journal of Supercomputing, Vol. 9, No 1/2, 1995, p. 21.
112. Iftode, L., and J. Singh, «Shared Virtual Memory: Progress and Challenges,»
Proceedings of the IEEE Special Issue on Distributed Shared Memory, Vol. 87,
No. 3, March 1999, p. 498.
113. Iftode, L., and J. Singh, «Shared Virtual Memory: Progress and Challenges,»
Proceedings of the IEEE Special Issue on Distributed Shared Memory, Vol. 87,
No. 3, March 1999, p. 499.
114. Gharacharloo, K., et al., «Memory Consistency and Event Ordering in Scalable
Shared-Memory Multiprocessors,» Proceedings of the 17th Annual Symposium on
Computer Architecture, May 1990, pp. 17-19.
115. Carter, J.; J. Bennet; and J. Zwaenepoel, «Implementation and Performance of
Munin,» Proceedings of the 13th ACM Symposium on Operating System Princi-
ples, 1991, pp. 153-154.
116. Iftode, L., and J. Singh, «Shared Virtual Memory: Progress and Challenges,»
Proceedings of the IEEE Special Issue on Distributed Shared Memory, Vol. 87,
No. 3, March 1999, pp. 499-500.
117. Dudnicki, C., et al., «Improving Release-Consistent Shared Virtual Memory
Using Automatic Update,» Proceedings of the Second IEEE Symposium on
High-Performance Computer Architecture, February 1996, p. 18.
118. «Delayed Consistency and Its Effects on the Miss Rate of Parallel Programs,»
Proceedings of Supercomputing ‘91, 1991, pp. 197-206.
119. Iftode, L., and J. Singh, «Shared Virtual Memory: Progress and Challenges,»
Proceedings of the IEEE Special Issue on Distributed Shared Memory, Vol. 87,
No. 3, March 1999, p. 500.
120. Tripathi, A., and N. Karnik, «Trends in Multiprocessor and Distributed Oper-
ating Systems Design,» Journal of Supercomputing, Vol. 9, No 1/2, 1995, p. 14.
121. Tripathi, A., and N. Karnik, «Trends in Multiprocessor and Distributed Oper-
ating Systems Design,» Journal of Supercomputing, Vol. 9, No 1/2, 1995, p. 14.
122. Tripathi, A., and N. Karnik, «Trends in Multiprocessor and Distributed Oper-
ating Systems Design,» Journal of Supercomputing, Vol. 9, No 1/2,1995, p. 14.
123. Tannenbaum, A., and R. Renesse, «Distributed Operating Systems,» Computing
Surveys, Vol. 17, No. 4, December 1985, p. 436.
124. Bunt, R. B.; D. L. Eager; and S. Majumdar, «Scheduling in Multiprogrammed
Parallel Systems,» ACM SIGMETRICS, 1988, p. 106.
125. Bunt, R. B.; D. L. Eager; and S. Majumdar, «Scheduling in Multiprogrammed
Parallel Systems,» ACM SIGMETRICS, 1988, p. 105.
126. Bunt, R. B.; D. L. Eager; and S. Majumdar, «Scheduling in Multiprogrammed
Parallel Systems,» ACM SIGMETRICS, 1988, p. 106.
127. Gopinath, P., et aL, «А Survey of Multiprocessing Operating Systems (Draft),»
Georgia Institute of Technology, November 5, 1993, p. 15.
128. Mukherjee, В.; K. Schwan; and P. Gopinath, «А Survey of Multiprocessor Oper-
ating Systems», GIT-CC 92/05, November 5, 1993, p. 15.
129. Bunt, R. B.; D. L. Eager; and S. Majumdar, «Scheduling in Multiprogrammed
Parallel Systems,» ACM SIGMETRICS, 1988, p. 106.
130. Mukherjee, В.; K. Schwan; and P. Gopinath, «А Survey of Multiprocessor Oper-
ating Systems», GIT CC 92/05, November 5, 1993, p. 15.
131. Tripathi, A., and N. Karnik, «Trends in Multiprocessor and Distributed Oper-
ating Systems Design,» Journal of Supercomputing, Vol. 9, No 1 /2, 1995, p. 16.
132. Leutenegger, S. Т.» and M. K. Vernon, «The Performance of Multiprogrammed
Multiprocessor Scheduling Policies,» Proceedings of the ACM Conference on
Measurement and Modeling of Computer Systems, 1990, p. 227.
133. Leutenegger, S. T., and M. K. Vernon, «The Performance of Multiprogrammed
Multiprocessor Scheduling Policies,» Proceedings of the ACM Conference on
Measurement and Modeling of Computer Systems, 1990, p. 227.
134. Mukherjee, В.; K. Schwan; and P. Gopinath, «А Survey of Multiprocessor Oper-
ating Systems», GIT-CC-92/05, November 5, 1993, p. 17.
135. Tripathi, A., and N. Karnik, «Trends in Multiprocessor and Distributed Oper-
ating Systems Design,» Journal of Supercomputing, Vol. 9, No 1/2, 1995, p. 16.
136. Mukherjee, В.; K. Schwan; and P. Gopinath, «А Survey of Multiprocessor Oper-
ating Systems», GIT-CC-92/05, November 5, 1993, p. 16.
137. Mukherjee, В.; K. Schwan; and P. Gopinath, «А Survey of Multiprocessor Oper-
ating Systems», GIT-CC-92/05, November 5, 1993, p. 16.
138. Gupta, A., and A. Tucker, «Process Control and Scheduling Issues for
Multiprogrammed Shared-Memory Multiprocessors,» Proceedings of the 12th
ACM Symposium on Operating System Principles, 1989, p. 165.
139. Leutenegger, S. T., and M. K. Vernon, «The Performance of Multiprogrammed
Multiprocessor Scheduling Policies,» Proceedings of the ACM Conference on
Measurement and Modeling of Computer Systems, 1990, pp. 227-228.
140. Carlson, B.; L. Dowdy; K. Dussa; and K-H. Park, «Dynamic Partitioning in a
Transputer Environment,» Proceedings of the ACM, 1990, p. 204.
141. Carlson, B.; L. Dowdy; K. Dussa; and K-H. Park, «Dynamic Partitioning in a
Transputer Environment,» Proceedings of the ACM, 1990, p. 204.
142. Carlson, B-; L. Dowdy; K. Dussa; and K-H. Park, «Dynamic Partitioning in a
Transputer Environment,» Proceedings of the ACM, 1990, p. 204.
143. Tripathi, A., and N. Karnik, «Trends in Multiprocessor and Distributed Oper-
ating Systems Design,» Journal of Supercomputing, Vol. 9, No 1/2,1995, p. 17.
144. Milojicic, D., et al., «Process Migration,» ACM Computing Surveys, Vol. 32,
No. 3, September 2000, p. 246.
145. Milojicic, D., et al., «Process Migration,» ACM Computing Surveys, Vol. 32,
No. 3, September 2000, p. 246.
146. Langendorfer, H., and S. Petri, «Load Balancing and Fault Tolerance in Work-
station Clusters: Migrating Groups of Processes,» Operating Systems Review,
Vol. 29, No. 4, October 1995, p. 25.
147. Milojicic, D., et al., «Process Migration,» ACM Computing Surveys, Vol. 32,
No. 3, September 2000, p. 246.
148. Eskicioglu, M., «Design Issues of Process Migration Facilities in Distributed Sys-
tems, » IEEE Computer Society Technical Committee on Operating Systems News-
letter, Vol. 4, No. 2, 1990, pp. 5-6.
149. Steketee, С.; P. Socko; and B. Kiepuszewski, «Experiences with the Implementa-
tion of a Process Migration Mechanism for Amoeba,» Proceedings of the 19th
ACSC Conference, January-February 1996.
150. Eskicioglu, M., «Design Issues of Process Migration Facilities in Distributed Sys-
tems, » IEEE Computer Society Technical Committee on Operating Systems News-
letter, Vol. 4, No. 2, 1990, pp. 5-6.
151. Milojicic, D., et al., «Process Migration,» ACM Computing Surveys, Vol. 32,
No. 3, September 2000, p. 255.
152. Eskicioglu, M., «Design Issues of Process Migration Facilities in Distributed Sys-
tems, » IEEE Computer Society Technical Committee on Operating Systems News
letter, Vol. 4, No. 2, 1990, p. 10.
153. Milojicic, D., et al., «Process Migration,» ACM Computing Surveys, Vol. 32,
No. 3, September 2000, p. 256.
ГмВа 15
154. Mukherjee, В.; К. Schwan; and Р. Gopinath, «А Survey of Multiprocessor Oper-
ating Systems», GIT-CC 92/05, November 5, 1993, p. 21.
155. Steketee, С.; P. Socko; and B. Kiepuszewski, «Experiences with the Implementa
tion of a Process Migration Mechanism for Amoeba,» Proceedings of the 19th
ACSC Conference, January-February 1996.
Milojicic, D., et al., «Process Migration,» ACM Computing Surveys, Vol. 32,
No. 3, September 2000, p. 259.
157. Milojicic, D., et al., «Process Migration,» ACM Computing Surveys, Vol. 32,
No. 3, September 2000, p. 256.
158. Eskicioglu, M., «Design Issues of Process Migration Facilities in Distributed Sys-
tems,» IEEE Computer Society Technical Committee on Operating Systems News-
letter, Vol. 4, No. 2, 1990, p. 10.
159- Milojicic, D., et al., «Process Migration,» ACM Computing Surveys, Vol. 32,
No. 3, September 2000, p. 256.
160. Milojicic, D., et al., «Process Migration,» ACM Computing Surveys, Vol. 32,
No. 3, September 2000, p. 256.
161. Eskicioglu, M., «Design Issues of Process Migration Facilities in Distributed Sys-
tems,» IEEE Computer Society Technical Committee on Operating Systems News-
letter, Vol. 4, No. 2, 1990, p. 7.
162. Douglis, F., and J. Ousterhout, «Transparent Process Migration: Design Alter-
natives and the Sprite Implementation,» Software Practice and Experience,
Vol. 21, No. 8, p. 764.
163. Zayas, E., «Attacking the Process Migration Bottleneck,» Proceedings of the
Eleventh Annual ACM Symposium on Operating Systems Principles, 1987,
pp. 13-24.
164. Douglis, F., and J. Ousterhout, «Transparent Process Migration: Design Alter-
natives and the Sprite Implementation,» Software Practice and Experience,
Vol. 21, No. 8, p. 764.
165. Milojicic, D., et al., «Process Migration,» ACM Computing Surveys, Vol. 32,
No. 3, September 2000, p. 256.
166. Eskicioglu, M., «Design Issues of Process Migration Facilities in Distributed Sys-
tems, » IEEE Computer Society Technical Committee on Operating Systems News-
letter, Vol. 4, No. 2, 1990, p. 7.
167. Douglis, F., and J. Ousterhout, «Transparent Process Migration: Design Alter-
natives and the Sprite Implementation,» Software Practice and Experience,
Vol. 21, No. 8, p. 764.
168. Eskicioglu, M., «Design Issues of Process Migration Facilities in Distributed Sys-
tems,» IEEE Computer Society Technical Committee on Operating Systems News-
letter, Vol. 4, No. 2, 1990, pp. 6-7.
169. Mukherjee, В.; K. Schwan; and P. Gopinath, «А Survey of Multiprocessor Oper-
ating Systems», GIT CC 92/05, November 5, 1993, p. 14.
170. Mukherjee, В.; K. Schwan; and P. Gopinath, «А Survey of Multiprocessor Oper-
ating Systems», GIT CC-92/05, November 5, 1993, p. 14.
171. Mukherjee, В.; K. Schwan; and P. Gopinath, «А Survey of Multiprocessor Oper-
ating Systems», GIT-CC-92/05, November 5, 1993, pp. 14-15.
172. Diekmann, R.; B. Monien; and R. Preis, «Load Balancing Strategies for Distrib-
uted Memory Machines,» World Scientific, 1997, p. 3.
1 Tannenbaum, A., and R. Renesse, «Distributed Operating Systems,» Computing
Surveys, Vol. 17, No. 4, December 1985, p. 436.
. Diekmann, R.; B. Monien; and R. Preis, «Load Balancing Strategies for Distrib-
uted Memory Machines,» World Scientific, 1997, p. 5.
17 Diekmann, R.; B. Monien; and R. Preis, «Load Balancing Strategies for Distrib-
uted Memory Machines,» World Scientific, 1997, p. 7.
Многопроцессорность
176. Tannenbaum, A., and R. Renesse, «Distributed Operating Systems,» Computing
Surveys, Vol. 17, No. 4, December 1985, p. 438.
177. Milojicic, D., et al., «Process Migration,» ACM Computing Surveys, Vol. 32,
No. 3, September 2000, p. 250.
178. Milojicic, D., et al., «Process Migration,» ACM Computing Surveys, Vol. 32,
No. 3, September 2000, p. 251.
179. Shivarati, N.; P. Krueger; and M. Singhal, «Load Distributing for Locally Dis-
tributed Systems,» IEEE Computer, 1992, pp. 37-39.
180. Milojicic, D., et al., «Process Migration,» ACM Computing Surveys, Vol. 32,
No. 3, September 2000, p. 251.
181. Shivarati, N.; P. Krueger; and M. Singhal, «Load Distributing for Locally Dis-
tributed Systems,» IEEE Computer, 1992, pp. 37-39.
182. Milojicic, D., et al., «Process Migration,» ACM Computing Surveys, Vol. 32,
No. 3, September 2000, p. 251.
183. Shivarati, N.; P. Krueger; and M. Singhal, «Load Distributing for Locally Dis-
tributed Systems,» IEEE Computer, 1992, pp. 37-39.
184. Milojicic, D., et al., «Process Migration,» ACM Computing Surveys, Vol. 32,
No. 3, September 2000, p. 251.
185. Ahmad, I., and Y-K. Kwok, «Static Scheduling Algorithms for Allocating Di-
rected Task Graphs to Multiprocessors,» Communications of the ACM, 2000,
p. 462.
186. Luling, R., et al., «А Study on Dynamic Load Balancing Algorithms,» Proceed-
ings of the IEEE SPDP, 1991, p. 686-689.
187. Luling, R., et al., «А Study on Dynamic Load Balancing Algorithms,» Proceed-
ings of the IEEE SPDP, 1991, p. 686-689.
188. Tannenbaum, A., and R. Renesse, «Distributed Operating Systems,» Computing
Surveys, Vol. 17, No. 4, December 1985, p. 438.
189. Tannenbaum, A., and R. Renesse, «Distributed Operating Systems,» Computing
Surveys, Vol. 17, No. 4, December 1985, p. 438.
190. Barak, A., and A. Shiloh, «А Distributed Load Balancing Policy for a Microcom-
puter,» Software Practice and Experience, December 15, 1985, pp. 901-913.
191. Tripathi, A., and N. Karnik, «Trends in Multiprocessor and Distributed Oper-
ating Systems Design,» Journal of Supercomputing, Vol. 9, No 1/2, 1995, p. 11.
192. Mellor-Crummy, J. and M. Scott, «Algorithms for Scalable Synchronization on
Shared-Memory Multiprocessors,» ACM Transactions on Computer Systems,
Vol. 9, No. 1, February 1991, p. 22.
193. Mukherjee, В.; K. Schwan; and P. Gopinath, «А Survey of Multiprocessor Oper-
ating Systems», GIT-CC-92/05, November 5, 1993, p. 24.
194. Tripathi, A., and N. Karnik, «Trends in Multiprocessor and Distributed Oper-
ating Systems Design,» Journal of Supercomputing, Vol. 9, No 1/2, 1995,
pp. 11-12.
195. Tripathi, A., and N. Karnik, «Trends in Multiprocessor and Distributed Oper-
ating Systems Design,» Journal of Supercomputing, Vol. 9, No 1/2, 1995,
pp. 11-12.
196. Mukherjee, B., and K. Schwan, «Experiments with Configurable Locks for
Multiprocessors,» GIT-CC-93/05, January 10, 1993.
197. Tripathi, A., and N. Karnik, «Trends in Multiprocessor and Distributed Oper-
ating Systems Design,» Journal of Supercomputing, Vol. 9, No 1/2, 1995, p. 13.
198. Mellor-Crummy, J. and M. Scott, «Scalable Reader-Writer Synchronization on
Shared-Memory Multiprocessors,» Proceedings of the Third ACM SIGPLAN Sym-
posium on Principles and Practices of Parallel Programming, 1991, pp. 106-113.
199. Mukherjee, В.; K. Schwan; and P. Gopinath, «А Survey of Multiprocessor Oper-
ating Systems», GIT-CC-92/05, November 5, 1993, p. 24.
Глава 15
200. Flynn, М., «Very High-Speed Computing Systems,» Proceedings of the IEEE,
Vol. 54, December 1966, pp. 1901-1909.
201. Flynn, M., «Very High-Speed Computing Systems,» Proceedings of the IEEE,
Vol. 54, December 1966, pp. 1901-1909.
202. Mukherjee, В.; K. Schwan; and P. Gopinath, «А Survey of Multiprocessor Oper-
ating Systems», GITCC 92/05, November 5, 1993, p. 1
203. Tripathi, A., and N. Karnik, «Trends in Multiprocessor and Distributed Oper-
ating Systems Design,» Journal of Supercomputing, Vol. 9, No 1/2, 1995, p. 13.
204. Leutenegger, S. T., and M. K. Vernon, «The Performance of Multiprogrammed
Multiprocessor Scheduling Policies,» Proceedings of the ACM Conference on
Measurement and Modeling of Computer Systems, 1990, p. 227.
205. Bunt, R. B.; D. L. Eager; and S. Majumdar, «Scheduling in Multiprogrammed
Parallel Systems,» ACM SIGMETRICS, 1988, p. 106.
206. Lai, K., and P. Hudak, «Memory Coherence in Shared Virtual Memory Systems,»
ACM Transactions on Computer Systems, Vol. 7, No. 4, November 1989, p. 325
207. Iftode, L., and J. Singh, «Shared Virtual Memory: Progress and Challenges,»
Proceedings of the IEEE Special Issue on Distributed Shared Memory, Vol. 87,
No. 3, March 1999, p. 498
208. Milojicic, D., et al., «Process Migration,» ACM Computing Surveys, Vol. 32, No.
3, September 2000, p. 241
209 Langendorfer, H., and S. Petri, «Load Balancing and Fault Tolerance in Work-
station Clusters: Migrating Groups of Processes,» Operating Systems Review,
Vol. 29, No. 4, October 1995, p. 25.
I
I
Предметный указатель
2-D mesh network, 918, 971
4-connected 2-D mesh network, 918, 976
86-DOS, 801
A
A Frequently Redundant Array of
Independent Disks, 748, 758
abort, 197, 206, 208, 218
absolute loading, 158, 165
absolute path, 787, 831
absolute performance measure, 856, 890
accelerated Graphics Port, 128, 172
access Control List, 187, 221
--matrix, 807, 833
- - mode, 602, 627
- Isolation Mechanism, 187, 219
- methods, 783
- right, 627
- rights, 602
accessed bit, 658, 683
accessibility, 781, 832
acknowledgment protocol, 210
ACL, 187,221
ACPI, 140, 172, 430, 437, 440
acquire operation, 940, 973
action, 148
active states, 197
activity, 782, 831
actuator, 707, 763
Ada, 147, 173
adaptive lock, 970
— locks, 963
adaptive mechanism, 481, 497
add-on card, 117, 169
address binding, 158, 165
- bus, 127, 165
- space, 218
- translation map, 570, 628
admission scheduling, 459, 498
Advanced Configuration and Power
Interface, 140, 172, 430, 440
- Research Projects Agency, 98
- Technology Attachment, 132
advisable process lock, 963
Advisable Process Lock, 969
AFRAID, 748, 758
aging, 406, 439
- of priorities, 499
AGP, 128, 172
AIM, 187, 219
ALU, 118, 165
AM, 932, 975
American Standard Code for
Information Interchange, 779, 830
analytic model, 864, 890
anchor hash table, 588
anticipatory movement, 764
- buffering, 810, 835
- fetch, 523
--strategy, 550
- paging, 648, 683
API, 68, 92, 97, 149, 167
APL, 963, 969
append access, 602, 625
application base, 69, 93
- programming, 113, 170
--Interface, 68, 97, 149, 167
— vector, 862, 890
arithmetic and logic unit, 118, 165
ARPA, 56, 92, 98
ARPAnet, 57, 92
array processor, 914
— processors, 972
arrival rate, 872, 894
990
Операционные системы
artificial contiguity, 569, 626
ASCII, 779, 830
ASCI-White, 922
assembler, 144, 165
assembly language, 144, 173
associative mapping, 625
- memory, 580, 625
asynchronous cancellation, 271
- concurrent threads, 283, 335
- interrupt, 201
- processes, 488
- real-time process, 497
- signal, 251, 271
- threads, 283
- transmission, 142, 165
ATA. 132
Athlon, 877
Atlas, 564
atomic operation, 335
- transaction, 815, 831
Attraction Memory, 932, 975
attribute, 148, 165
authentication problem, 211
auxiliary storage, 125, 166
--management, 782, 836
avoidance, 397
awake thread, 240
В
backup, 783, 835
bandwidth, 57, 97, 124, 170
BAPCo, 865, 890
base address, 612
- register, 534, 548
baseline network, 920, 970
basic access method, 810, 835
- Input/Output System, 117, 165
batch process, 467, 498
- processing systems, 529
BBN Butterfly, 927
behavior, 148, 169
Belady s anomaly, 654
benchmark, 865, 891
Berkeley Software Distribution UNIX,
214, 218
best-fit, 523
- memory placement strategy, 550
— strategy, 541
bidding algorithm, 959, 970
billion instructions per second, 889
billions of instructions per second, 860
binary relation, 831
— relations, 822
- semaphore, 327, 336
BIOS, 117, 165
BIPS, 860, 889
bisection width, 915, 976
bit patterns, 779, 831
bitmap, 806, 831
block, 570, 625, 761, 796
- allocation, 796, 832
— device, 125, 172
block map table, 572, 628
-----origin register, 572, 627
block mapping, 571, 625
blocked list, 189, 221
- records, 782, 835
- state, 188, 220, 239, 273
blocking send, 209
boom, 763
boot sector, 138, 166
bootstrapping, 117, 168
born state, 239, 274
bottleneck, 727, 764, 871, 894
boundary register, 527, 549
bounded buffer, 359, 387
bounds register, 135, 169
branch penalty, 879, 891
— predication, 884, 892
broadcast 209
BSD UNIX, 214, 218
buffer, 141, 165
burping the memory, 550
bus, 117, 172
— mastering, 129, 167
- snooping, 936, 975
Business Application Performance
Corporation, 865, 890
--critical system, 70, 96
busy waiting, 298, 335
branch prediction, 882
byte, 779, 831
bytecode, 145, 165
Предметный указа тень
С
С#, 146
С, 49, 92, 146
C++, 146
C-LOOK disk scheduling, 758
C-SCAN disk scheduling, 758
cache, 521
- coherence, 972
- hit, 141, 168
- line, 141, 173
- memory, 548
- miss, 141, 168
- snooping, 936, 975
—coherent NUMA, 969
—miss latency, 931, 971
—Only Memory Architecture, 932, 969
cancel thread, 242
cancellation of a thread, 272
capacity, 858, 891
catch signal, 208
CC-NUMA, 936, 969
CD, 126, 168
CDC 6600, 911
CD-R, 126
CD-ROM, 126
CD-RW, 126
central processing unit, 118, 172
chaining, 588, 628, 797, 802, 836
character, 835
- device, 130, 172
— set, 779, 834
characters, 779
checkpoint, 431, 438, 815, 833
-/rollback, 431, 438
child process, 192, 194, 219
chipset, 117, 168
circular buffer, 359, 387
- SCAN, 717
- wait necessary condition for deadlock,
440
- wait, 401, 438
circular-wait condition, 409
CISC, 875, 890
class, 148, 168
client, 55, 95
clock page replacement strategy, 660,
683
clocktick, 120
clone, 258
C-LOOK, 721
close, 781
closing, 832
CMS Batch Facility, 616, 623
CMS, 616, 623
coalescing, 538
- the memory holes, 549
coarse-grained strip, 735, 765
COBOL, 146, 173
code generator, 152, 166
- /data bit, 613
collision, 588, 628
COMA, 932, 969
commit of transaction, 815
committed transaction, 832
Common Business Oriented Language,
146, 173
compact disk, 126, 168
Compatible Time-Sharing Systems, 187
compile, 151, 168
compiler, 145, 168
complex instruction set computing, 875,
890
compute-bound, 47, 96
concurrent, 336
- program execution, 219
- threads, 283
condition variable, 387
— variables, 356
configurable lock, 972
- locks, 963
Connection Machine, 914
consumer, 285, 337
- thread, 285, 337
contention, 916, 972
context switching, 199, 219
contiguous memory allocation, 524, 548
Control Program, 616, 624
controller, 117, 168
Conversational Monitor Subsystem, 616
---System, 623
cooperative multitasking, 191, 219
coprocessor, 171
copy, 781
| copying, 833
мно]/ацииппо1с чисшсмоГ
copy-on-reference migration, 954, 972
copy-on-write, 593,626
core file, 208
coscheduling, 947, 975
cost of an interconnection scheme, 915,
976
counting semaphore, 330, 337
CP, 616, 624
-/CMS, 49, 93, 98
-/M, 801
CPU, 118, 172
Cray-1, 911
Cray-4, 912
create, 781
creating, 836
critical region, 293, 336
- section, 293, 336
crossbar-switch matrix, 917, 974
C-SCAN, 717
CTSS, 48, 93, 98, 187
cycle stealing, 127, 167
cycle, 120, 171
cylinder, 707, 764
С-поток, 235
D
DARPA, 98
DASD, 793
DAT, 569, 624, 625
data bus, 127, 172
- compression, 731,764
— Definition Language, 821, 837
— hierarchy, 779, 833
- independence, 820, 834
— Manipulation Language, 821, 837
- regeneration, 739, 763
- region, 186, 219
- striping, 734, 763
database, 819, 831
- language, 820, 837
- management system, 819, 836
— system, 819, 836
data-dependent application, 832
DBMS, 819, 836
DDL, 821, 837
DDR, 127, 172
dead state, 239, 274
deadline rate-monotonic, 489
--scheduling, 430, 439, 485, 496, 498
deadlock, 303, 336, 397, 439
— avoidance, 410, 439
- detection, 410, 438, 425
— prevention, 410, 439
— recovery, 410, 437
deadly embrace, 401, 437
decryption, 784, 835
dedicated resource, 437
- resources, 401
dedicated, 411
default action, 208
Defense Advanced Research Projects
Agency, 98
deferred cancellation, 256, 272
defragmentation, 730, 761
degree of multiprogramming, 47, 48,
98, 459, 499
degree, 822, 836, 915
- of node, 975
Dekker‘s algorithm, 297, 335
delayed blocking, 963, 974
delayed branching, 878, 892
delayed consistency, 941, 974
delete, 781
deletion, 836
demand fetch, 523
--strategy, 550
— paging, 645, 683
derived speed, 121, 170
despooler, 362
destroy, 781
destruction, 836
detection, 397
device driver, 74, 94
— independence, 831
Dhrystone, 868, 889
digital signal processor, 118
Dijkstra's Algorithm, 326, 335
Dijkstra's Banker‘s Algorithm, 418, 437
Dining Philosophers, 404, 438
direct access storage device, 793
- file organization, 793, 835
- mapping, 578, 627
- Memory Access, 128, 170
directories, 784
Hpe^iviffinnvm ----- ------ ------
directory, 832
dirty bit, 650, 683
dirty eager migration, 954, 974
disable interrupt, 207
- interrupts, 336
- /mask interrupts, 219
disabled cancellation, 256, 271
disk arm, 707, 763
--anticipation, 732, 764
— array levels, 734
- cache buffer, 728, 761
- mirroring, 736, 762
- reorganization, 730, 763
— scheduler, 75, 97
- scheduling, 710, 761
dispatcher, 190, 218, 459, 497
dispatching, 190, 459, 497
dispersion, 857, 891
displacement, 572,627
distributed computing, 55, 97
— database, 821, 835
— file system, 818, 835
- operating system, 97
- system, 85, 98
distribution of response times, 857,
893
DMA, 128, 170
DML, 821, 837
domain, 822, 832
DOS, 614
double data rate, 127, 172
drafting algorithm, 959, 976
DRAM, 124, 166
DRM, 489
- , дисциплина планирования, 496
DSP, 118
DVD-R, 126
Dynamic Address Translation, 569,
625
— linking, 156, 166
- load balancing, 956, 971
- loading, 158, 166
— partitioning, 948, 971
- priorities, 463
- RAM, 124, 166
- real-time scheduling algorithm, 497,
489
E
eager migration, 953, 974
earliest-deadline-first, 489, 497
Earth Simulator, 910, 922
ease of use, 856, 894
EBCDIC, 779, 830
EDF, 489, 496
efficient operating system, 76, 98
EFI, 139, 171
elevator algorithm, 716, 761
embedded system, 70, 93
encryption, 783, 837
Enterprise System Architecture, 615
entry queue, 366, 387
- set, 366, 387
EPIC, 883, 893
ESA, 615
ESCON, 615
event-driven simulator, 869, 892
exception, 136, 167, 205, 219
exclusive access, 284
- OR, 762
execute access, 602, 625, 783, 832
- -only access, 602
execution context, 192
- mode, 133, 167
executive mode, 528, 549
expected value, 857, 891
Explicitly Parallel Instruction
Computing, 883, 893
ext 3, 816
Extended Binary-Coded Decimal
Interchange Code, 779
Extended Binafy-Coded Decimal
Interchange Code, 830
Extensible Firmware Interface, 139, 171
extensible operating system, 76, 98
extent, 796, 834
external fragmentation, 537, 548
- name, 153, 166
— reference, 153, 166
F
fair share group, 484, 497
--scheduling, 482, 498
fairness, 465, 499
false sharing, 940, 972
994
Операциенные системы
family of computers, 860, 893
far page-replacement strategy, 661, 684
fast instruction set computing, 881, 890
- mutual exclusion algorithm, 313, 335
FAT 32, 800, 831
fault, 206, 220
fault tolerance, 96
FCFS, 710, 713, 944, 969
- disk scheduling, 758
feedback loop, 872, 892
fetch strategies, 523
- strategy, 549
fiber, 261, 272
fiber local storage, 261, 272
field, 780, 834
FIFO anomaly, 654, 683
- page-replacement strategy, 684
I дисциплина планирования, 496
file, 837
- Allocation Table, 831, 836
- attribute, 831
- attributes, 790
- control block, 790, 832
I - descriptor, 790, 832
- integrity, 783
I— - mechanism, 834
- management, 782, 837
I- organization, 793, 834
- server, 818, 837
- system, 782, 837
--manager, 73, 94
--identifier, 789, 832
fine-grained stripe, 734
--strips, 764
FireWire, 131
firmware, 160, 166
first-come-first-served, 710, 944, 969
|first-fit, 523
- memory placement strategy, 550
- strategy, 541
first-in-first-out, 469, 496
- page replacement, 652
FISC, 881, 890
Ifixed-partition multiprogramming, 531,
549
hat directory structure, 834
- file system, 785
floating-point operations per second,
911
flops, 911
FLS, 261, 272
flushing, 650, 954, 976
- a page, 684
fork, 258
formatting of storage device, 837
Fortran, 146, 173
fragmentation, 534, 550, 730
fragmented disk, 764
free list, 805, 836
- memory list, 538, 549
frontside bus, 120, 171
FSB, 120, 171
FSCAN, 719
- disk scheduling, 758
FSS, 482, 496, 498
G5, 879, 881
gang scheduling, 947
garbage collection, 540, 549
GDT, 612, 624
GDTR, 612
general protection fault, 613, 624
- Public License, 96
- semaphore, 330, 336
general-purpose register, 120, 171
Global Descriptor Table, 612, 624
-----Register, 612
- run queue, 943, 971
gLRU, 676
। - page-replacement strategy, 684
GNU, 62, 93, 97
Google, 933
GPF, 613, 624
GPL, 62, 93, 96
granularity bit, 613, 625
graph reduction, 439
Graphical User Interface, 94
graphics coprocessor, 118
group, 809, 832
GUI, 51, 55, 93, 94
H
Hamming ECC, 741, 762
- error-correcting codes, 741, 762
hard affinity, 943, 971
Предметный указатель
7 7 S
— disk drive, 762
- link, 788, 832
— real-time scheduling, 487, 497
Hartstone, 868, 889
hash anchor table, 629
— code, 588
- function, 588, 629
- table, 588, 629
- value, 628
hbench, 861, 889
heavyweight process, 235, 274
heuristics, 141, 173
hierarchical page table, 585
- process structure, 194, 219
hierarchically structured file system,
832
highest-response-ratio-next, 476, 498
high-level language, 144, 173
high-level scheduling, 458, 498
hold-and-wait condition, 409
hole, 537, 548
home node, 936, 971
home-based consistency, 941, 971
hot spare disk, 739, 762
HRRN, 476, 496, 498
HTML, 58, 93, 94
HTTP, 58,93, 97
HWP, 235, 274
hybrid methodology, 863, 890
hypercube, 919, 971
HyperText Markup Language, 94
- Transfer Protocol, 97
I
I/O channel, 127, 167
- manager, 73, 94
--bound, 47, 96, 467, 499
- completion interrupt, 220
IA-32, 611
IBM 7030, 876
- PC,801
IBSYS, 614, 624
IDE, 132
IEEE 1394 port, 130, 170
ignore signal, 208
ILP, 884, 892
incremental backup, 813, 833
indefinite postponement, 303, 335, 397
Independent Software Vendor, 95
--Vendors, 68
index block, 801, 833
— node, 802
indexed sequential file organization,
793, 833
indirect block, 802, 833
indivisible operation, 336
indivisibly, 296
information hiding, 354, 387
initialized state, 262, 273
inode, 802, 833
- map, 833
— maps, 816
Input/Output Control System, 525, 548,
549
insert, 781
insertion, 832
instruction decode unit, 118, 166
- fetch unit, 118, 165
- length, 118, 166
- set, 874, 893
--architecture, 875, 890
instruction-level parallelism, 884, 892
Integrated Drive Electronics, 132
intensive resource management, 529
| - resources management, 548
I interactive operating system, 77, 94
- Problem Control System, 616, 624
— process, 467, 497
I - users, 48, 94
interconnection scheme, 915, 976
interfault time, 668, 683
Intermediate code generator, 152, 166
intermediate-level scheduling, 459, 498
internal fragmentation, 534, 548
Internet, 57, 95
interpreter, 145, 167
interprocess communication, 75
--manager, 73, 94
interrupt, 136, 170, 205, 220
I - handler, 200, 219
- vector, 203, 218
interrupting clock, 190, 221
I interval timer, 138, 167, 190, 221
I invalidation, 939, 974
f96
Онерац он ные системы
Averted page table, 587, 627
DCS, 525, 548
OStone, 868, 889
PC manager, 94
PC, 75
PCS, 616, 624
SA, 875, 890
SV, 68, 95
SV, 93
I
lava, 146
Virtual Machine, 71, 93
lava-монитор, 366
bb, 45, 94
I- control language, 529, 550
f- scheduling, 458, 498
r stream processor, 529, 549
ob-aware, 943
- scheduling, 971
ob-blind, 943
I scheduling, 971
ob-to-job transition, 529, 549
oin, 273, 822, 834
thread, 242
ournaling file system, 835
ournalizing file system, 816
TVM, 71, 93
I
kernel, 44, 98
r mode, 134, 171, 549
program, 863, 893
iernel-level thread, 245, 273
L
Lamport's Bakery Algorithm, 313, 335
Lan, 53
lane, 127, 167
atency, 497
laxity, 490, 499
layered, 81
operating system, 95
|azy copying, 954, 974
- data propagation, 941, 974
- migration, 952, 974
- release consistency, 940, 974
LDT, 612, 624
LDTR, 612
least-frequently-used page replacement,
657
least-recently-used page replacement,
655
level, 764
- of multiprogramming, 47
lexer, 151, 168
lexical analyzer, 151, 168
lexical scanner, 151
LFS, 816, 831
LFU page-replacement strategy, 685
library, 153
— module, 165
lightweight process, 272
lightweighted process, 235
limit register, 534, 549
linear address space, 611
- address space, 626
— ordering, 415, 438
link, 787, 836, 915
linking, 153, 171
linking loader, 156, 171
Linux, 802
list, 781, 835
Imbench, 861, 889
load, 710, 762
- balancing, 956, 970
— module, 153, 166
loader, 158, 166
Local Descriptor Table, 612, 624
-----Register, 612
locality, 626
location, 781
lock, 321
lockstep synchronization, 300, 336
Logged File System, 816
logical address space, 611, 626
— backup, 812, 833
- block, 782, 833
- record, 782, 833
- view, 783, 833
Log-structured File System, 831
long-term scheduling, 459, 497
LOOK, 720
— disk scheduling, 758
Предметные указатель
loosely coupled system, 922, 975
low-level scheduling, 459, 498
LRU page-replacement strategy, 685
LWP, 235, 272
M
Mach, 157
machine language, 143, 168
magnetic tape storage, 705, 762
main memory, 122, 169, 517
— thread of execution, 271
mainboard, 116, 168
many-to-many, 247
— (m-to-n ) thread mapping, 272
many-to-one, 243
- thread mapping, 272
mask a signal, 252, 272
— interrupt, 207
masking signal, 208
massive parallelism, 67, 95
massively parallel processor, 914, 975
master/slave multiprocessor
organization, 924, 973
maximum need, 418, 438
mean response time, 711, 764
Mean Time To Failure, 735
mean, 857, 893
mean-time-to-failure, 764
member, 794, 837
memory burping, 540
— coherence, 934, 972
- compaction, 540, 550
- dump, 208
- hierarchy, 121, 167, 521, 548
- line, 932, 976
— management strategies, 518
--strategy, 550
- - unit, 567, 624
— manager, 73, 94, 548
— mapped file, 834
- organization, 518, 549
— placement strategy, 541
— protection, 135, 167
--keys, 601
memory-mapped files, 810
message passing, 219
metadata, 789, 833
method, 148, 168
MFT, 614
microbenchmark, 861, 891
microbenchmark suite, 861, 891
microcode, 160, 168
microkernel operating system, 83, 96
micro-op, 883, 891
microprogramming, 160, 168
middleware, 66, 97
millions of instructions per second, 860,
889
MIMD, 914, 969
minimum-laxity-first, 490, 497
MIN-стратегия, 651
MIPS, 860, 879, 889
mirroring, 739
MISD, 913, 969
missing-page fault, 628
missing-segment fault, 598, 627
mission-critical system, 736
mission-critical systems, 70, 98
MMU, 567, 624
MobileMark, 866, 889
modified bit, 650, 658, 683
module, 152, 168
monitor entry routine, 354, 387
monitor, 354, 387
monolithic operating system, 79, 95
Moors law, 115, 167
most trusted user status, 168
motherboard, 116, 168
mount operation, 834
— point, 791, 836
- table, 792, 836
mounting, 791
MRDS, 218
MS-DOS, 801, 831
MTTF, 735, 764
Multics Relational Data Store, 187, 218
Multics, 49, 93, 187, 214
multilevel feedback queue, 478, 497
- page table, 585
- paging system, 626
multi-op instruction, 884, 891
multiple instruction stream, multiple
data stream, 914
-----, single data stream, 913
Операционные системы
— shared bus architecture, 916, 970
— Virtual Storages, 615, 624
MULTiplexed Information and
Computing Service, 187
multiprocessing system, 910
multiprocessor system, 972
multiprogramming, 95
multistage network, 920, 973
multithreading, 233, 272
mutual exclusion, 284, 336
--condition, 409
--lock, 336
--necessary condition for deadlock,
440
--primitive, 295
--primitives, 337
MVS, 615, 624
MVT, 614
N
namespace, 791, 835
n-ary relation, 831
— relations, 822
Native POSIX Thread Library, 256
nCUBE, 925
necessary condition fpr deadlock, 438
negative feedback, 873, 892
network diameter, 915, 971
Network File System, 818, 831
— link, 975
r- operating system, 85, 98
next-fit, 543
r memory placement strategy, 550
NFS, 85, 818, 831
NO Remote Memory Access, 933, 969
node, 915, 976
nonblocking send, 209
noncontiguous memory allocation, 524,
548
nonpreemptible, 407
- resource, 438
lonpreemptive, 460
- scheduling, 498
'Ion-Uniform Memory Access, 930, 969
lonuniform request distribution, 727,
762
lopreemption condition, 409
- necessary condition for deadlock, 440
NORMA, 933, 969
notify, 274, 386
— thread, 240
- All, 386
not-used recently page replacement, 657
NPTL, 256
N-step SCAN disk scheduling, 759
NTFS, 802
- Journaling File System, 816
NUMA, 930, 969
- с когерентным кэшем, 936, 969
NUR page-replacement strategy, 685
n-арное отношение, 822, 831
N-шаговый SCAN, 719, 759
О
object, 146, 168
- code, 151, 169
object-oriented operating systems, 61,
95
- programming, 146, 169
ODBC, 161, 169
offset, 572, 627
OLTP, 726, 763
on-board device, 117, 166
on-demand migration, 952, 972
one-to-one, 245
- mapping, 272
online, 48, 95
- spare, 739, 762
- - disk, 762
— transaction processing, 763
-----systems, 726
ООО, 881, 891
OOOS, 61, 95
OOP, 146, 169
open, 781
— DataBase Connectivity, 161, 169
- Software Foundation, 214, 221
- Source Initiative, 94
opening, 834
open-source software, 61, 97
operating system, 44, 96
OPT page-replacement strategy, 683
optimal page replacement strategy, 651
optimizer, 152, 169
Предметный указатель
ОРТ-стратегия, 651
OS, 624
-/360, 614, 624
-/390, 615
-/VS 1, 615
-/VS 2 MVS, 615
—/VS 2 SVS, 615
OSF, 214, 218, 221
OSI, 62, 93, 94
out-of-order execution, 881, 891
overlay, 549
overlays, 526
owner, 809, 832
P
P operation, 336
PAE, 614, 624
page, 571, 628
- Directory Entry, 613, 626
- fault, 577
— frame, 574, 626
- global directory, 625
— map table, 574, 628
— migration, 935, 972
- replication, 935, 975
- Size Extension, 614
- table, 574, 628
- - Entry, 577, 624
--origin register, 578, 627
page-fault-frequency, 668
page-replacement strategy, 643, 684
paging, 571
- systems, 628
parallel port, 130, 169
parent directory, 787, 835
— process, 192, 194, 220
parity, 741, 765
— logging, 748, 763
parser, 152, 171
partition, 518, 531, 549, 730
partitioned file, 835
--organization, 794
PASC, 255
Pascal, 147, 173
pathname, 785, 835
PCB, 116, 169, 192, 203, 218
PCI, 127
— bus, 172
PCP, 614
PDE, 613, 626
pending signal, 251, 272
Pentium, 611, 877
- 4, 881
performance monitoring, 855, 891
- projection, 855, 892
periodic processes, 487
- real-time process, 498
Peripheral Component Interconnect bus,
127, 172
per-node run queue, 943, 976
per-processor run queue, 943, 975
persistant storage, 125, 172
PFF, 668
— page-replacement strategy, 685
physical address, 172, 628
--Extension, 614, 624
--space, 628
— addresses, 567
— backup, 812, 837
- block, 782, 837
— device name, 837
- memory, 122, 172, 517
— names, 783
- record, 782, 837
- view, 783, 837
PID, 192, 219
PIO, 128, 170
pipe, 210, 219
placement strategies, 523
— strategy, 550
platter, 707, 763
plug-and-play, 113, 140, 165
PnP, 140
polling, 136, 169, 201, 220
port, 127, 170
portability, 95
Portable Application Standards
Committee, 255
— operating system, 76, 95
-----Interface, 67, 95
positive feedback, 873, 892
POSIX, 67, 93, 95, 255
POSIX-стандарты, 150
post-RISC, 881
woo
Операционные сиетемы
POWER З-П, 922
- 4, 921
precopy, 955, 976
predicate, 884, 892
predictability, 465, 499, 892
- of resource charges, 413
preemptible, 407
- resource, 439
preemptive, 460
- scheduling, 498
preferred direction, 716, 763
prefetching, 648, 683
prepaging, 648, 683
present bit, 612
prevention, 397
primary key, 822, 834
- memory, 517
- thread, 242, 260, 272
Principal Control Program, 614
principle of least privilege, 134, 170
printed circuit board, 116, 169
priority, 459, 499
- inversion, 465
- of a process, 97
privileged instruction, 134, 170
problem state, 166
procedural programming language, 170
— languages, 148
process, 49, 97, 185, 220
— control block, 192, 218
- descriptor, 218
— identification number, 192, 219
- migration, 950, 972
- priority, 220
- scheduler, 73, 97
- state, 185, 188, 221
- table, 193, 221, 628
processor, 118, 170
- affinity, 942, 975
- scheduling discipline, 497
--policy, 499
-----/discipline , 457
processor-bound, 47, 96, 467, 499
producer, 285, 337
- thread, 285, 337
-/consumer relationship, 336
production program, 865, 893
profile, 860, 893
program counter, 192, 220
program status word, 203
programmed I/O, 170
programmed input/output, 128
project, 809
projection, 822, 835
property, 148, 171
protected variable, 325, 336
protection, 77, 94
- bit, 598
PSE,614
PSW, 203
PTE, 577, 624
Pthread, 235, 271
Pthread-поток, 255
public, 809, 834
purchase priority, 463, 499
Q
QDOS, 801
quad pumping, 127, 172
quantum, 190, 219, 470, 497
query language, 821, 837
queued access methods, 810, 834
R
race condition, 964, 972
RAID, 75, 734, 759
- controller, 736, 759
- level 0, 759
- - 1, 759
- - 2, 759
- - 3, 759
- - 4, 760
- - 5, 760
--Уровня 0, 738, 759
RAID controller уровня 0+1, 749
----- 1, 739, 759
----- 10, 749
----- 2, 741, 759
----- 3, 744, 759
-----4, 746, 760
----- 5, 747, 760
-----6, 749
-----7, 749
RAID-контроллер, 736, 759
Предметный указатель
RAM, 123
RAMAC, 706, 760
RAND, 652
- page-replacement strategy, 685
random access memory, 123
--Method of Accounting and Control,
706, 760
- page replacement, 652
— policy, 958, 975
— seek pattern, 710, 764
- variable, 857, 893
rate-monotonic (RM ) scheduling, 496
read, 781
— access, 602, 625, 783, 832
—/execute access, 602
—/write access, 602
- /- bit, 593, 613
- /- head, 705, 761
- /- lock, 965, 970
reading, 837
read-modify-write, 321
— cycle, 743, 764
— memory operation, 337
read-only access, 602
ready list, 189, 221
- state, 188, 220, 239, 262, 273
real address, 136, 166, 628
--space, 567
real memory, 122, 169, 517
real-time scheduling, 487, 498
real-time system, 48, 98
receiver-initiated policy, 958, 971
record, 780, 832
recovery, 397, 783, 832
reduced, 427
- instruction set computing, 875, 877,
890, 911
redundancy, 734, 762
Redundant Array of Independent Disks,
75, 734, 759
reentrant, 408
— code, 439
referenced bit, 658, 683
register, 119, 171
relation, 821, 834
relational model, 835
relative address, 153, 169
relative path, 787, 834
relaxed consistency, 940, 973
release consistency, 940, 975
— operation, 940, 973
reliability, 762
relocatable loading, 158, 169
relocating, 153, 169
Remote Spooling Communications
Subsystem, 616, 624
rename, 781
renaming, 834
replacement strategies, 523
— strategy, 550
request rate, 710, 765
resident page set, 684
residual dependency, 952, 973
resource allocation graph, 401, 437
resource type, 439
resource types, 418
response time, 857, 890
resume, 218
— process, 198
RISC, 875, 877, 890, 911
RM, дисциплина планирования, 496
RMW, 321
robust operating system, 76, 94
rollback, 431, 815
rolling back a transaction, 834
root, 785, 833
— directory, 785, 833
rotational latency, 761
- latency time, 707
rotational optimization, 710, 763
round-robin, 470
- job scheduling, 946, 972
- process scheduling, 945, 972
- scheduling, 499
row, 821, 836
RR, 470, 499
RSCS, 616, 624
running state, 188, 220, 239, 262, 273
s
safe state, 419, 438
SAGE, 488
SAP, 867, 889
SATA, 132
1002
Операционные системы
SATF, 724
— disk scheduling, 760
saturation, 871, 891
— threshold, 402, 439
scalability, 465
scalability, 497
scalable operating system, 76, 95
SCAN disk scheduling, 760
scanner, 171
scheduler activation, 249, 271
script-driven simulator, 869, 893
SCSI, 130, 167
secondary storage, 125, 166
second-chance page-replacement
strategy, 685
- strategy, 660
sector, 763
- queuing, 722, 763
sectors, 708
secure operating system, 77, 94
seek operation, 707, 763
— optimization, 710, 763
- time, 709, 761
segment, 571, 594, 627
— descriptor, 612, 625
— limit, 613
- map table origin register, 597, 627
- register, 611
— selector, 611, 627
segmentation, 571, 594
segment-not-present exception, 612
segment-overflow exception, 598, 626
segment-protection exception, 599, 626
selection evaluation, 855, 892
selfish round-robin scheduling, 499
selfish round-robin, 471
semaphore, 325, 337
sender-initiated policy, 958, 971
separate-kernels multiprocessor
organization, 925, 973
sequential consistency, 940, 974
— file organization, 793, 835
SEQ-стратегия, 676
Serial ATA, 132
- port, 130, 170
serialize, 336
serializing, 284
serially reusable, 408
--code, 438
--resource, 401, 439
--shared resource, 387
server, 55, 98
- rate, 872, 891
setup time, 529, 548
shadow page, 815, 836
- paging, 815, 836
shadowing, 739
shared bus, 916, 973
shared library, 156, 171
shared resource, 439
Shared Virtual Memory, 933, 973
shared, 407
shell, 73, 95
shortest access time first, 724
— latency time first, 722
— positioning time first, 723
- seek time first, 714
shortest-process-first, 474, 945, 970
shortest-process-first scheduling, 497
shortest-remaining time, 476
shortest-remaining-time scheduling, 498
signal, 208, 220, 325, 337
- handler, 251, 272
— mask, 273
signal-and-continue, 356
— monitor, 387
signal-and-exit, 356
— monitor, 387
SIMD, 913, 969
simulation, 868, 891
simultaneous peripheral operations
on-line, 171
single instruction stream, multiple data
stream, 913
single instruction stream, single data
stream, 913
Single Virtual Storage, 615
single-level directory structure, 834
— file system, 785
single-stream batch processing system,
45, 95, 549
-----systems, 529
single-user contiguous memory
allocation system, 525, 549
SISD, 913, 969
Предметный ука отель
юоз
size, 781, 835
sleep interval, 240, 272
— state, 240
—/wakeup lock, 964, 970
sleeping state, 274
SLTF,722
- disk scheduling, 760
Small Computer Systems Interface, 130,
167
smallest-number-of-processes-first, 946,
969
SMP, 926, 929, 969
SNPF, 946, 969
soft affinity, 973
- link, 787, 834
soft real-time scheduling, 487, 498
software-generated interrupt, 205
Solaris, 214, 218
Solo, 357, 386
source code, 151, 167
space-partitioning scheduling
algorithms, 943
space-partitioning scheduling, 974
space-time product, 645, 684
spatial locality, 644, 684
spawn, 194
spawning a process, 220
SPEC, 865, 891
specified user, 809, 832
SPECmark, 866, 889
speculative loading, 884, 894
SPEC-тест, 889
SPEC-тесты, 866
SPF, 474, 496, 497, 945, 970
spin lock, 962, 975
spindle, 707, 765
spool, 171
spooler, 362
spooling, 142
SPTF disk scheduling, 760
SPTF, 723
SQL, 821, 831
SQL-запрос, 822
SRAM, 124, 171
SRR, 471, 497, 499
SRT, 476, 497, 498
SSTF, 714
— disk scheduling, 761
stability, 873, 894
stack region, 186, 219
Standard Application, 867, 889
- Performance Evaluation Corporation,
891
standby state, 262, 273
starvation, 397, 437
state transition, 190, 220
static load balancing, 956, 975
- priorities, 463
- RAM, 124, 171
- real-time scheduling algorithm, 499
-----algorithms, 489
STREAM, 868, 889
stream, 913, 974
Stretch, 876
strip, 734, 763
stripe, 762
structured programming, 147, 171
Structured Query Language, 821, 831
sufficient conditions for deadlock, 437
superblock, 789, 836
supercomputer, 911
superscalar architecture, 881, 893
supervisor call, 548
- calls, 528
supervisor state, 171
suspend/resume, 430, 439
suspended process, 196
— state, 220
— states, 197
suspended-blocked state, 197, 220
suspended-ready state, 197, 220
SVM, 933, 939, 973
swap, 323, 335, 549
swapping, 543
switch, 915, 972
symbol resolution, 154, 170
symbol table, 153, 171
symbolic name, 835
- names, 783
Symmetric MultiProcessor, 926, 929,
969
- policy, 975
symmetrical multiprocessor
organization, 926, 973
чм
One ционные системы
synchronization, 387
synchronized, 386
synchronous interrupt, 200
- signal, 251, 273
syntax analyzer, 152, 171
synthetic benchmark, 867, 893
synthetic program, 867, 893
SYSmark, 866, 889
SYSPLEX, 615
system call, 68, 98, 150, 171, 549
— Performance Evaluation Cooperative,
865
— programming, 113, 171
- reaction time, 857, 890
- tuning, 855, 891
- vector, 862, 893
-/360, 614
-/370, 615
-/390, 615
T
table fragmentation, 585, 628
Tandem, 926
Tape Operating System, 614
task, 186, 258, 271
— state segment, 203
TCP/IP, 57, 93, 97
teardown time, 529, 548
temporal locality, 522, 548
terminated state, 262, 273
termination housekeeping, 294, 337
ternary relation, 836
— relations, 822
test-and-set, 320, 335
text region, 186, 219
THE, 82
- multiprogramming system, 326, 335
thrashing, 664, 683
thread, 74, 97, 273
- local storage, 261, 272
- pooling, 247, 273
- state, 274
throughput, 97, 499, 711, 858, 893
thundering herd, 964, 973
tightly coupled system, 922, 976
time slice, 470, 497
time-of-day clock, 138, 172
Time-Sharing Option, 614
timeslicing, 491, 497
- scheduling, 942, 974
- system, 48, 98
Time-Sharing System, 614
timing, 860, 894
— constraint, 487, 497
TIPS, 860, 889
TLB, 581, 624
- hit, 583
— miss, 583
TLS, 261, 272
token, 152, 168
Top 50, 911
TOS, 614
TPC, 867, 889
trace, 117, 170, 859, 893
track, 761
Transaction Processing Performance
Council, 867, 889
transaction, 439
transactions, 431
transistor, 115, 172
transition state, 263, 274
Translation Lookaside Buffer, 581, 624
Transmission Control Protocol/Internet
Protocol, 97
transmission time, 709, 761
trap, 200, 206, 219
trillion instructions per second, 889
- of instructions per second, 860
TSO, 614
TSS, 49, 96, 203, 604, 614
tuple, 821
turnaround time, 49, 94, 857, 891
type, 613, 781, 836 .
u
UltraSPARC, 879
UMA, 929, 970
unblock, 220
unblocked records, 782, 834
undivided coscheduling algorithm, 947,
973
Unicode, 779, 831
Uniform Memory Access, 929, 970
UNIVAC 1, 705, 761
UNIVersal Automatic Computer, 761
Universal Serial Bus, 130, 172
UNIX, 49, 93
unknown state, 263, 273
unrestricted access, 603
unsafe state, 419, 438
upcall-механизм, 249
update, 781, 834
— image, 748, 763
usable operating system, 77, 97
USB, 130, 172
user class, 809
— classes, 833
—directories, 835
- directory, 785
— mode, 134, 169
user-level thread, 273
- threads, 243
utilization, 858, 893
V operation, 336
validate a model, 892
validation, 868
variable-partition multiprogramming,
537, 548
variance in response times, 892, 711
VAX, 879
vector processor, 914, 971
vector-based methodology, 862, 890
Very Long Instruction Word, 884, 890
virtual address, 625
--space, 212, 218, 567
- addresses, 566
virtual machine, 71, 93
--operating system, 616, 627
— memory, 50, 93, 563, 625
VLIW, 884, 890
VM operating system, 96
VM, 49, 71, 616
volatile media, 123
- storage, 173
volatility, 782, 833
volume, 780, 836
voluntary page release, 670, 683
w
W3C, 59
wait, 325, 336
- queue, 367, 387
- set, 367, 387
wait-for condition, 409, 440
waiting state, 240, 263, 274
wake, 273
wall clock time, 525, 548
web service, 66
— service, 93
WebMark, 866, 889
Whetstone, 868, 889
Win 32 API, 150
--thread, 273
WinBench 99, 868, 889
Windows API, 150, 167
word, 779, 836
worker thread, 248, 273
working directory, 786, 835
— set, 665, 684
--theory of program behavior, 662, 685
--window size, 665, 684
workload, 858, 893
World Wide Web, 93
WORM, 168
- disk, 126
worst-fit, 523
— memory placement strategy, 550
- strategy, 543
write, 781, 832
— access, 602, 625, 783, 832
— broadcast, 939, 976
write-back caching, 729, 762
Write-Once, Read-Many medium, 168
write-once/read-many disk, 126
write-through caching, 729, 762
WWW, 58, 93
X
XOR, 762
- ECC, 744
z
z/OS, 615
IVUO
Операционные системы
А
абсолютная загрузка, 158, 165
- показатели производительности, 856,
890
абсолютный путь, 787, 831
аварийное завершение, 197, 206, 208,
218
адаптивная блокировка, 963, 970
адаптивный механизм, 481, 497
адресная шина, 127, 165
адресное пространство, 218
- связывание, 158, 165
активация планировщика, 249, 271
активное ожидание, 298, 335
- управление ресурсами, 529, 548
активность, 831
- файла, 782
активные состояния, 197
алгоритм XOR-контроля и коррекции
ошибок, 744
- аукциона, 959, 970
- банкира, 418, 423
--, предложенный Дейкстрой, 437
- быстрого взаимоисключения, 313,
335
- Дейкстры, 326, 335
- Деккера, 297, 335
- диспетчеризации FCFS, 713
- кондитера, 313, 335
- лифта, 716, 761
- Лэмпорта, 312, 335
- Питерсона, 309
- планирования DRM, 489
- - EDF, 489
АЛУ, 118
аналитическая модель, 864, 890
аналитическое моделирование, 871
аномалия FIFO, 654, 683
- Белади, 654, 683
аппаратная независимость, 783, 831
арифметико-логическое устройство,
118, 165
архитектура СОМА, 932
— без доступа к удаленной памяти, 970
— компьютера с командными словами
сверхбольшой длины, 884, 890
архитектура с быстродействующим
набором команд, 881, 890
— с множеством потоков команд и
данных, 914, 970
- с несколькими общими шинами,
916, 970
— с одним потоком данных и
несколькими потоками команд, 970
— с одним потоком команд и
несколькими потоками данных, 970
------и одним потоком данных, 970
- с полным набором команд, 875, 890
— с сокращенным набором команд,
875, 890
- системы команд, 875, 890
архитектуры без доступа к удаленной
памяти, 933
— с одним потоком данных и
несколькими потоками команд, 913
------команд и несколькими потоками
данных, 913
------и одним потоком данных, 913
асинхронная отмена, 256, 271
- передача, 165
— связь, 209
асинхронное прерывание, 201
асинхронные параллельные потоки,
283, 335
— потоки, 283
— процессы, 488
асинхронный обмен, 141
- процесс реального времени, 497
- сигнал, 251, 271
ассемблер, 144, 165
ассоциативная память, 580, 625
ассоциативное отображение, 625
атомарная операция, 321
— операция, 335
— транзакция, 815, 831
атрибут, 148, 165
— файла, 831
атрибуты файла, 790
аукциона алгоритм, 959
Б
база данных, 819, 831
— приложений, 69, 93
базовая сеть, 920, 970
- система ввода/вывода, 117, 165
базовый адрес, 612
Предметный указатель
iWf
— регистр, 534, 548
байт, 779, 831
байт-код, 145, 165
балансировка нагрузки, 956, 970
банкира алгоритм, 418, 423
безопасная операционная система, 77
Бернерс-Ли Тим, 59
бесконечное откладывание, 303, 335,
397, 406
библиотека, 153
библиотечная организация файлов,
794
библиотечный модуль, 165
- файл, 831
бинарное отношение, 831
бинарные отношения, 822
бинарный семафор, 327
БИОС, 117, 165
бит грануляции, 613, 625
бит доступа, 658
- защиты, 598
- изменения, 650, 658, 683
бит кода/данных, 613
- обращения, 658, 683
- присутствия, 612
- чтения/записи, 593, 613
битовые последовательности, 831
битовый массив, 831
--занятости, 806
ближайший срок завершения первым,
489
ближайший срок завершения —
первым, планирование, 497
блок, 570, 625, 761, 796
- выборки команд, 118, 165
- управления процессом, 192, 203, 218
--файлами, 790
--файлом, 832
блокировка, 321
— взаимоисключения, 336
- с усыплением/пробуждением, 964,
970
- чтения/записи, 965, 970
блокирующая передача, 209
блочное размещение, 571, 625, 796,
832
бутылочное горлышко, 727
буфер, 141, 165
- быстрой трансляции, 581, 625
— кольцевой, 359
— ограниченный, 359
В
веб-служба, 66, 93
вектор прерываний, 203, 218
- приложения, 862, 890
векторная методология, 890
--оценки производительности, 862
векторный процессор, 914, 971
взаимное исключение, 962
взаимоблокировка, 303, 336, 397, 437
взаимоблокировки условия
возникновения, 409
взаимоблокировок восстановление
после, 410
- обнаружение, 410
— обход, 410
- предотвращение, 410
взаимоисключение, 284, 336
взаимоисключения условие, 409
Вирт Никлаус, 147
виртуализация, 565
виртуальная машина, 71, 93
--Java, 71, 93
виртуальная память, 50, 93, 563, 625
виртуальное адресное пространство,
212, 218, 567
виртуальный адрес, 566, 625
владелец, 809, 832
внешнее имя, 153, 166
внешние запоминающие устройства,
125
внешняя ссылка, 153, 166
- фрагментация, 537, 548
внутреннее устройство, 117, 166
внутренняя фрагментация, 534, 548
возобновление, 218
- процесса, 198
восстановление после
взаимоблокировки, 397, 430
восстановление после
взаимоблокировок, 410, 437
восстановление, 783, 832
вращательная задержка, 761
вращательное время задержки, 707
временная локальность, 521, 548
1008
Опврац онные системы
временные ограничения, 487, 497
временной квант, 470
время позиционирования, 709
- выключения задачи, 529
- выключения, 548
- отклика, 857, 890
- передачи, 709, 761
- по настенным часам, 548
- подготовки, 548
--задачи, 529
- позиционирования, 723, 761
- реакции системы, 857, 890
всемирная паутина, 58, 93
вспомогательная память, 166
вспомогательные запоминающие
устройства, 125
вставка, 832
вставлять данные, 781
встроенная система, 93
встроенное программное обеспечение,
160, 166
встроенные системы, 70
вторичное запоминающее устройство,
166
вторичные запоминающие устройства,
125
второе поколение RISC-процессоров,
881
выбор процесса для выполнения, 190
выделение непрерывных участков
памяти, 524, 548
выделение фрагментированных
участков памяти, 524, 548
выделенный ресурс, 401, 411, 437
вызов супервизора, 528, 548
выключения время, 548
вычисления с сокращенным набором
инструкций, 911
Г
генератор кода, 152, 166
- промежуточного кода, 152, 166
гибридная методология, 863, 890
гиперкуб, 919, 971
гипертекстовый язык разметки, 94
главный поток, 271
глобальная директория страниц, 625
- очередь выполнения, 943, 971
- стратегия LRU, 676
- таблица дескрипторов, 612, 625
глюк, 137
гнездо, 117
головка чтения/записи, 705, 761
горячая замена, 131
граница сегмента, 613
граф распределения ресурсов, 401,
427, 437
графический интерфейс пользователя,
51, 55, 94
— сопроцессор, 118
группа, 832
— по оценке производительности
бизнес-приложений, 865, 890
--системной производительности,
865, 891
- пользователей, 809
- справедливого раздела, 497
группы справедливого раздела, 483
д
дамп памяти, 208
двоичный семафор, 327, 336
двумерная ячеистая сеть, 918, 971
Дейкстра Эдсгер Вайба, 326
Дейкстры алгоритм, 326
действие, 148
— по умолчанию, 208
действительный адрес, 136, 166, 567
Деккера алгоритм, 297
Деннинг, 662
Деннинг Питер, 566
дескриптор процесса, 218
дескриптор сегмента, 612, 625
дескриптор файла, 790, 832
деспулер, 362
дефрагментация, 730, 761
дешифратор команд, 118, 166
дешифрование, 784
диаметр сети, 915, 971
динамическая балансировка нагрузки,
956, 971
— загрузка, 158, 166
- трансляция адресов, 569, 625
динамические алгоритмы
планирования реального времени, 489
— приоритеты, 463
Предметный указатель
динамический алгоритм планирования
реального времени, 497
динамическое ОЗУ, 124
- оперативное запоминающее
устройство, 124, 166
динамическое разделение, 948, 971
— связывание, 156, 166
директория, 784, 785, 832
дисковый буфер, 728, 761
дисперсия, 857, 891
диспетчер, 190, 218, 459, 497
диспетчер ввода/вывода, 73, 94
- межпроцессного взаимодействия, 73, 94
- памяти, 73, 94, 519, 548
— файловой системы, 73, 94
— диспетчеризация дисковых
операций, 710, 761
дисциплина планирования
первым-пришел-первым-ушел, 496
--процессора, 457, 497
длина команды, 118, 166
длительность жизненного цикла
задачи, 49, 94
добровольное освобождение страницы,
670, 683
долгосрочное планирование, 458, 497
домашний узел, 936, 971
домашняя состоятельность, 941, 971
домен, 822, 832
дорожка, 761
достаточные условия возникновения
взаимоблокировки, 437
доступ для выполнения, 783, 625
--записи, 602 , 625, 783, 832
--исполнения, 625,832
доступ для чтения, 602, 625, 783, 832
--чтения и записи, 602
-----и исполнения, 602
- только для чтения, 602
--на исполнение, 602
доступность, 832
доступом для дополнения, 602
дочерний процесс, 192, 194, 219
драйвер устройства, 74, 94
дублирование, 739
дублирование дисков, 736
дыра, 548
— в памяти, 537
птл
Ztv
ждущее состояние, 262
жесткая привязка, 943, 971
- синхронизация, 300, 336
- ссылка, 788, 832
жесткий диск, 706
жесткое планирование реального
времени, 487, 497
живучая операционная система, 76, 94
жизненно-важная система, 98, 736
журнальная файловая система, 816
3
зависание, 397
— процесса, 437
зависящее от данных приложение, 832
загрузочный модуль, 153, 166
загрузочный сектор, 138, 166
загрузчик, 158, 166
заданный пользователь, 832
задача, 45, 94, 186, 258, 271
задача ориентированная на
ввод/вывод, 47
--на вычисления, 47
задачно-независимое планирование,
943, 971
задачно-ориентированное
планирование, 943, 971
заданный режим, 134, 166
задержка, 497
- из-за промаха в кэше, 931
задержки при промахах в кэше, 971
закон Мерфи, 814
- Мура, 115, 167
закрывать файл, 781
закрытие, 832
записывать данные, 781
запись, 780, 832
запись в страничной директории, 626
- в таблице, 626
--директорий, 613
- страничной таблицы, 577
запрет отмены, 256
— прерываний, 319
запрещение прерываний, 207, 336
—/маскирование прерываний, 219
запрещенная отмена, 271
пли
Операционные системы
зафиксированная транзакция, 832
захват цикла, 127, 167
захват шины, 129, 167
защита, 77, 94
- памяти, 135, 167
защиты общая ошибка, 613
защищенная операционная система,
77, 94
- переменная, 325, 336
заявленная блокировка для процесса,
963, 971
зеркальное отображение, 739, 762
И
игнорирование сигнала, 208
идентификатор файловой системы,
789, 832
идентификационный номер процесса,
192, 219
иерархией данных, 779
иерархическая структура процессов,
194, 219
иерархически структурированная
файловая система, 832
иерархические страничные таблицы,
585
иерархия данных, 833
- памяти, 121, 167, 521, 548
избыточность, 733, 734, 737, 762
избыточный массив независимых
дисков, 734
издержки ветвлений, 879, 891
изменчивость, 833
— файла, 782
инверсия приоритетов, 465
индексированная последовательная
организация файла, 833
---- файлов, 793
индексные блоки, 801
индексный блок, 833
I- узел, 802, 833
инициативная группа по
распространению открытого
программного обеспечения, 62, 94
инициация отправителем, 958, 971
^инициация получателем, 958, 971
инкапсуляция информации, 354, 386
нкрементное резервное копирование,
I 813, 833
интенсивность обслуживания, 872, 891
интерактивная операционная система,
77, 94
интерактивный пользователь, 48, 94
интерактивный процесс, 467, 497
интервал промахов, 668, 683
- сна, 240, 272
интервальный таймер, 138, 167, 190,
219
интернет, 57, 95
интерпретатор, 145, 167
интерфейс малых компьютерных
систем, 130, 167
— переносимых операционных систем,
67, 95
интерфейс прикладного
программирования, 149, 167
-----Windows, 150, 167
исключающее ИЛИ, 762
исключение, 136, 167, 205, 219
исключение выхода за пределы
сегмента, 598, 626
- защиты сегмента, 599, 626
— отсутствия сегмента, 612
- искусственная целостность, 626
исполнение с изменением
последовательности, 881, 891
исполнительный режим, 133, 167
исходная программа, 151
исходный код, 167
К
кадр страницы, 574, 626
канал, 127, 167, 210, 219
- ввода/вывода, 127, 167
карта индексных узлов, 833
— трансляции адресов, 570, 626
карты индексных узлов, 816
квант, 219, 497
- времени, 190, 472
квантование времени, 491, 497
класс, 148, 168
— пользователей, 809
классы пользователей, 833
клиент, 55, 95
клинч,401, 437
ключ защиты памяти, 601
КОБОЛ, 146, 173
Предметный указатель
1011
когерентность кэша, 972
- памяти, 934, 972
код многократного использования, 408
— последовательного использования,
408
---повторного использования, 438
Кодд, 822
кодирование с коррекцией по
Хеммингу, 741
коды Хемминга, 762
кольцевой буфер, 359
---Java, 376, 387
команда swap, 324
— test-and-set, 320
коммутатор, 915, 972
компакт-диск с однократной записью и
многократным считыванием, 126,
168
компакт-диск, 126, 168
компилировать, 168
компилятор, 145, 168
компиляция, 151
компоновка, 168
кондитера алгоритм, 313
конкуренция, 972
консоль, 707
Консорциум Всемирной Паутины, 59
контекст выполнения, 192
контроллер, 117, 168
контрольная задача, 865, 891
- точка, 431, 438, 815, 833
контрольной точки/отката механизм,
438
контрольные задачи микроуровня,
861, 871, 891
контрольных точек/отката механизм,
431
конфигурируемая блокировка, 963,
972
конфликт на шине, 916
кооперативная многозадачность, 191,
219
копирование при записи, 593, 626
копирование, 833
копировать файл, 781
копланирование, 947, 972
Корбато Фернардо, 187
корень, 785, 833
корневая директория, 785, 833
косвенный блок, 802, 833
кратчайшая задержка сначала, 722
кратчайшее время доступа сначала,
724
--позиционирования сначала, 723
кратчайший процесс первым, 474, 945,
972
----, планирование, 497
Крей Сеймур, 911
критическая область, 293, 336
критический участок, 293, 336
круговая стратегия замены страниц,
683
круговое ожидание, 401, 415, 438
- планирование, 470
кругового ожидания условие, 409
круговой LOOK, 721
- SCAN, 717
- алгоритм планирования задач, 946,
972
----процессов, 945, 972
купить приоритет, 463
кэш, 124, 521
кэшевая архитектура памяти, 932, 972
кэширование, 124
- с отложенной записью, 729, 762
- со сквозной записью, 729, 762
кэш-память, 141, 548
—попадание, 141, 168
--промах, 141, 168
Л
легковесный процесс, 235, 272
лексема, 151, 168
лексер, 151, 168
лексический анализатор, 151, 168
лента, 734, 762
линейное адресное пространство, 611,
626
- упорядочивание, 415
--Хавендера, 438
ловушка, 200, 206, 219
логическая запись, 782, 833
логические гонки, 964, 972
логический блок, 782, 833
логическое адресное пространство,
611, 626
\tol2
]
1логическое представление, 783, 833
- резервное копирование, 812, 833
ложное совместное использование,
940, 972
локальная память нити, 261, 272
---потока, 261, 272
— сеть, 53
таблица дескрипторов, 612, 626
|локальность, 626
]- временная, 548
Лэмпорт Лесли, 314
Лэмпорта алгоритм, 312
м
максимальные потребности, 438
---процесса, 418
маскирование прерывания, 207
I— сигнала, 208, 252, 272
массово-параллельный процессор, 914,
972
массовый параллелизм, 67, 95, 238
масштабируемая операционная
система, 76, 95
масштабируемость, 465, 497
математическое ожидание, 857, 891
материнская плата, 116, 168
матрица контроля доступа, 807, 833
матричные процессоры, 914, 972
машинный язык, 143, 168
межпроцессное взаимодействие, 75
Мерфи закон, 814
Метаданные, 789, 833
Метания, 664, 683
метод, 148, 168
изоляции доступа, 219
|--AIM, 187
методы доступа к файлам, 783
।--с поддержкой очередей, 810, 834
механизм контрольных точек/отката,
“431
обеспечения целостности файла, 834
|- приостановки/возобновления, 430
Миграция по требованию, 972
Г процесса, 972
г процессов, 950
— по требованию, 952
- с копированием при обращении, 954,
972
Операционные системы
- страниц, 935, 937, 972
микрокод, 160, 168
микрооперация, 883, 891
микропрограммирование, 160, 168
миллиард операций в секунду, 860
миллион операций в секунду, 860
минимальное время позиционирования
сначала, 714
- растяжение во времени первым, 490
------, планирование, 497
многих-к-одному отношение между
потоками, 243
многих-ко-многим отношения между
потоками, 247
многозадачная система THE, 326
многократного использования код, 408
многопоточность, 233, 272
многопроцессорная система, 910, 912,
972
---ведущий/ведомый, 924
многопроцессорная система с
раздельными ядрами, 925, 973
---симметричной схемы, 926, 973
---схемы ведущий/ведомый, 973
многослойная операционная система,
95
многоуровневая операционная система,
95
— очередь с обратными связями, 497
многоуровневая сеть, 920, 921, 973
многоуровневая страничная система,
626
многоуровневые очереди с обратными
связями, 478
— страничные таблицы, 585
многоуровневый подход, 81
мобильная операционная система, 76,
95
мобильность, 95
моделирование, 868, 871, 891
модуль, 152, 168
монитор сигнализации-и-выхода, 356,
387
----и-продолжения, 356, 387
монитор, 354, 387
мониторинг производительности, 855,
870, 871, 891
монолитная операционная система, 79,
95
Предметный указатель
монопольный доступ, 284
монтирование, 834
— файловой системы, 791
мощность, 858,891
мультиоперационная команда, 884,
891
мультипрограммность, 95
мультипрограммный режим с
изменяемым распределением памяти,
548
--с фиксированным распределением
памяти, 531, 549
мультипрограммным с изменяемым
распределением памяти, 537
Мур Гордон, 115
мягкая привязка, 943, 973
мягкая ссылка, 787, 834
мягкое планирование реального
времени, 487, 498
н
набор контрольных задач, 871
----микроуровня, 861, 891
- микросхем, 117, 168
— символов, 779, 834
навесная плата, 117
нагрузка, 710, 762
надежное состояние, 438
--системы, 419
надежность, 762
наиболее полномочный
пользовательский уровень, 168
наименьшее количество процессов —
первым, 946, 973
накопители горячей замены, 762
— онлайн-замены, 762
накопитель горячей замены, 739
— на жестком диске, 706, 762
- на магнитной ленте, 705, 762
- онлайн-замены, 739
настраивающая загрузка, 158
настройка системы, 855, 891
насыщение, 871, 891
начальная загрузка, 117, 168
неблокированные записи, 782, 834
неблокирующая передача, 209
неделимая операция, 296, 336
независимость данных, 834
--в базах, 820
независимые поставщики ПО, 68
независимый поставщик программного
обеспечения, 95
ненадежное состояние, 438
--системы, 419
необходимое условие возникновения
взаимоблокировки, 438
неограниченный доступ, 602
неоднородный доступ к памяти, 930,
973
непераспределяемый ресурс, 407, 438
неперераспределяемости условие, 409,
414
непосредственный доступ, 706
непрерывное размещение файлов, 795
неравномерное распределение
запросов, 727, 762
неразделяющий алгоритм
копланирования, 947, 973
несущееся стадо, 964, 973
нить, 261, 272
О
обедающие философы, 404, 438
область, 834
- данных, 186, 219
- команд, 186, 219
— стека, 186, 219
обнаружение взаимоблокировки, 397,
410, 425, 438
обновление, 834
обновлять данные, 781
оболочка, 73, 95
оборотное время, 857, 891
обработчик прерываний, 200, 219
обработчик сигналов, 251, 272
образ обновления, 748, 763
обратная связь, 872, 892
обращенная страничная таблица, 587,
627
обход взаимоблокировок, 397, 410, 439
общая виртуальная память, 933, 939,
973
общая ошибка защиты, 613
- шина, 916, 973
общедоступный файл, 809, 834
общий семафор, 330, 336
1014
объединение, 822, 834
объект, 168
объектная программа, 151
объектно-ориентированная
операционная система, 61, 95
объектно-ориентированное
программирование, 146, 169
объектный код, 169
объекты, 146
оверлей, 526, 549
ограниченный буфер, 359
ограничительный регистр, 135, 169
один-к-одному отношения между
потоками, 245
однопользовательская система с
выделением непрерывных блоков,
525, 549
однопоточная пакетная система, 529,
549
— система пакетной обработки данных,
45, 95
однородный доступ к памяти, 929, 973
одноуровневая структура директорий,
834
- файловая система, 785
ожидания дополнительных ресурсов
условие, 409
- операцией, 325
ОЗУ, 123, 169
онлайн-обработка транзакций, 763
оперативная память, 122, 169, 517
оперативное запоминающее
устройство, 123, 169
оперативный режим, 48, 95
операцией ожидания, 325
операционная система, 44, 96
--Mach, 169
--Multics, 96
- - UNIX, 96
--виртуальной машины, 96, 616, 627
---на основе микроядра, 83, 96
--с разделением времени, 96
операция Р, 336
- V, 336
- захвата, 940, 973
- ожидания, 336
— оповещения, 325
- освобождения, 940, 973
Операционные системы
- позиционирования, 709, 763
- сигнализации, 325
оплата времени по настенным часам,
525
оповещение, 336, 354
опрос, 136, 169
оптимальная стратегия замены
страниц, 651, 683
оптимизатор, 152, 169
оптимизация по вращению, 710, 763
--позиционированию, 710, 763
организация памяти, 518, 549
- файлов, 793, 834
ориентированный на ввод/вывод, 96
--вычисления, 96
ослабленная состоятельность, 940, 973
основная память, 122, 169, 517
остаточная зависимость, 973
--процессов, 952
ответственная бизнес-ориентированная
система, 70, 96
отказоустойчивость, 96
отказоустойчивые системы, 737
откат, 431, 815
откат транзакции, 834
отклонение времени отклика, 892
открывать файл, 781
открытие, 834
открытое лицензионное соглашение,
62, 96
- ПО, 61
- программное обеспечение, 97
открытый интерфейс взаимодействия с
базами данных, 161, 169
отложенная отмена, 256, 272
- состоятельность, 974
отложенное блокирование, 963, 974
- выделение, 594
- обеспечение состоятельности при
освобождении, 940, 974
отложенное распространение данных,
941, 974
отложенной состоятельности, 941
отложенный сигнал, 251, 272
отмена потока, 242, 272
относительный адрес, 153, 169
- путь, 786,834
отношение, 821, 834
Предметный указатель
1015
— многих-к-одному, 272
— многих-ко-многим (т-к-п ), 272
— одного-к-одному, 272
- производитель-потребитель, 285, 336
отображаемые в память файлы, 810,
834
отображать файл, 781
отрицательная обратная связь, 873,
892
отсроченное ветвление, 878, 892
оценка относительно приложения, 871
- при выборе, 892
- производительности, 854
--при выборе, 855
очередь входа, 366, 387
- ожидания, 367, 387
п
пакетный модуль CMS, 623
- процесс, 467, 498
память с произвольной выборкой, 123,
169
параллелизм, 238
- уровня команд, 884, 892
параллельное выполнение, 185
--программ, 219
параллельные потоки, 283
параллельный порт, 130, 169
— процесс/поток, 336
Паскаль, 147
Патерсон Тим, 801
Пер Бринч Хансен, 357
первичная память, 517
первичный ключ, 822, 834
— поток, 242, 260, 272
первым пришел — первым обслужен,
944, 974
первым-пришелчпервым-ушел, 469,
496
передача сообщений, 219
переименование, 834
переименовывать файл, 781
переключающая матрица, 917, 974
переключение контекста, 199, 219
переменная-условие, 356, 387
перемещаемая загрузка, 158, 169
перемещение, 153, 169
переносимая операционная система, 97
переносимость, 97
перераспределяемый ресурс, 407, 439
перехват сигнала, 208
переход между задачами, 529, 549
переходное состояние, 263
периодически выполняющиеся
процессы реального времени, 498
периодические процессы, 487
печатная плата, 116, 169
Питерсона алгоритм, 309
плавное снижение эффективности, 928
планирование без приоритетного
вытеснения, 460, 498
— в многопроцессорных системах, 942
— допуска, 459, 498
планирование заданий, 458, 498
- на верхнем уровне, 458,498
--нижнем уровне, 459, 498
--промежуточном уровне, 459, 498
- по конечному сроку, 439
--наибольшему относительному
времени реакции, 476
--наименьшему остающемуся
времени, 476
--предельному сроку, 485
--принципу DRM, 498
----FIFO, 498
----RM, 498
----у справедливого раздела, 482
--сроку завершения, 485
- потоков Java, 491
— реального времени, 487, 498
- с временным разделением, 974
--приоритетным вытеснением, 460,
498
--пространственным разделением,
943, 974
— по конечному сроку, 430
— с временным разделением, 942
планировщик дисковых операций, 75,
97
- процессов, 73, 97
пластина, 707, 763
плата расширения, 117, 169
плоская структура директорий, 834
- файловая система, 785
по наибольшему относительному
времени реакции, планирование, 49£
1016
Операционные системы
— наименьшему остающемуся времени,
планирование, 498
— принципу справедливого раздела,
планирование, 498
- сроку завершения, планирование,
498
поведение, 148, 169
подготовки время, 548
подкачка, 543, 549
- по требованию, 645, 683
подтвердить достоверность модели, 892
подтверждение результатов
моделирования, 868
позднее выделение ресурсов, 594
- копирование, 954, 974
поздняя миграция процессов, 952
- миграция, 974
позиционирование головки, 707
покупка приоритетов, 499
поле, 780, 834
— типа, 613
политика планирования процессора,
457, 499
полная миграция, 974
--для активных страниц, 954, 974
--процессов, 953
положительная обратная связь, 873,
892
полоса, 734, 763
пользовательская директория, 785,
835
пользовательский режим, 134, 169
пометки о недействительности, 974
-----страниц, 939
попадание в TLB, 583
порог насыщения, 402, 439
порождение процесса, 194, 220
порт, 127, 170
- стандарта IEEE 1394, 130, 170
последовательная организация файла,
793, 835
— состоятельность, 940, 974
последовательно используемый
разделяемый ресурс, 387
последовательного использования код,
408
последовательный доступ, 284, 336
- опрос, 201, 220
- порт, 130, 170
посредническое программное
обеспечение, 66, 97
поток, 74, 97, 273, 913, 974
- POSIX 1003.1с, 271
- Win 32, 235
- потребителя, 285, 337
- производителя, 285, 337
- уровня пользователя, 273
-- ядра, 273
потоки C-threads, 273
- Win 32, 273
- уровня пользователя, 243
-- ядра, 245
поток-писатель, 363
поток-читатель, 363
потребитель, 285, 337
пошаговая синхронизация, 300, 336
права доступа, 602, 627
практичная операционная система, 77,
97
предварительная буферизация, 810,
835
- подкачка, 683, 648
предикат, 884, 892
предикация ветвления, 884, 892
предотвращение взаимоблокировок,
397, 410, 439
предпочитаемое направление, 716, 763
предсказуемость, 465, 499, 892
- платы за ресурсы, 413
прерывание, 136, 170, 205, 220
- завершения ввода/вывода, 220
приведение графа, 427, 439
привилегированная команда, 134, 170
привилегированный режим, 134, 170,
528, 549
привлеченная память, 932, 975
привод блока головок, 707, 763
привязка задач к процессорам, 942
— процесса к процессору, 975
прикладное программирование, 113,
170
приложения, 44
примитив взаимоисключения, 295, 337
принцип наименьшего уровня
привилегий, 134, 170
приоритет, 459, 499
Предметный указатель
101
— процесса, 97,220
приостановки/возобновления
механизм, 430, 439
приостановлен блокирован, состояние,
197
- готов, состояние, 197
приостановленный процесс, 196
присоединение, 273
- тпотока, 242
пробка, 398
проблема аутентификации, 211
— обедающих философов, 404
пробуждение, 273
проводник, 117
— на печатной плате, 170
прогноз производительности, 855, 892
прогнозирование ветвления, 882, 892
программа моделирования,
ориентированная на события, 892
------сценарий, 893
программа ядра, 863, 893
программируемый ввод/вывод, 128,
170
программное обеспечение,
распространяемое с исходным кодом,
61
- прерывание, 205
программный интерфейс приложений,
68, 97
программный счетчик, 192, 220
проект, 809
— свободного распространения
программного обеспечения, 62, 97
проецирование, 822, 835
производитель, 285, 337
производительность, 97, 499
производная частота, 121, 170
промах, 206, 220
- в TLB, 583
промежуточное хранение блоков
четности, 748, 763
пропускная способность, 57, 97, 124,
170, 711, 858, 893
просмотр, 835
пространственная локальность, 644,
684
пространственно-временной
показатель, 645, 684
пространство имен, 791, 835
простые методы доступа, 810, 835
протокол квитирования, 210
— передачи гипертекстов, 58
-----файлов, 97
- управления передачей/Протокол
Интернет, 57, 97
протоколирующая файловая система,
816, 835
профилирование, 860, 871
профиль, совокупность параметров,
893
процедура входа в монитор, 354, 387
процедурный язык программирования
148, 170
процесс, 49, 97, 185, 220
процесс, интенсивно использующий
ввод/вывод, 499
-----процессор, 499
процессор, 118, 170
— потока задач, 529, 549
— с полным распараллеливанием, 975
процессорная очередь выполнения,
943, 975
процессы, интенсивно использующие
ввод/вывод, 467
-----процессор, 467
прямая организация файлов, 793, 835
прямое отображение, 578, 627
прямой доступ, 706
--к памяти, 128, 170
пул потоков, 247, 262, 273
путь, 835
путь к файлу, 785
Р
рабочая директория, 786, 835
— нагрузка, 858, 893
— программа, 865, 893
рабочий набор, 665, 684
— поток, 248, 273
равноправие, 465, 499
разблокирование, 220
разброс времени реагирования, 711
разбудить поток, 240
раздел, 518, 549, 730
— фиксированного размера, 531
разделение данных, 734, 763
- ресурсов, 407
Операционные системы
разделенная организация файлов, 794
разделенный файл, 835
разделяемый ресурс, 439
размер окна рабочего набора, 665, 684
— страницы, 670
- файла, 781, 835
размещение в следующем подходящем
участке, 543
разрешение внешних ссылок, 154, 170
расположение файла, 781
распределение времени отклика, 857,
893
распределение ресурсов, 401
распределенная база данных, 821, 835
- обработка данных, 55, 97
- операционная система, 85, 97
- система, 98
- файловая система, 818, 835
распределенные системы, 85
растяжение во времени, 499
- процесса во времени, 490
расширение размеров страниц, 614
- физических адресов, 614
расширенный интерфейс встроенного
программного обеспечения, 139, 171
расширяемая операционная система,
76, 98
расшифровка, 835
реальное адресное пространство, 567
реальный адрес, 567, 627
регенерация данных, 739, 763
регистр, 171, 119
— адреса таблицы размещения блоков,
572, 627
- глобальной таблицы дескрипторов,
612
- границы, 527, 549
- локальной таблицы дескрипторов, 612
- начала сегментной таблицы, 597, 627
--страничной таблицы, 578, 627
- общего назначения, 120, 171
- предела, 534, 549
редукция графа, 427, 439
редуцирование графа, 427
реентерабельный код, 408, 439
режим доступа файла, 781
— контроля доступа, 602, 627
- пользователя, 134
- работы, 133
- ядра, 134, 171, 528, 549
резервное копирование, 783, 835
резидентный набор страниц, 684
реляционная база, 821
— модель, 821,835
реорганизация диска, 730, 763
репликация страниц, 935, 937, 975
ресурс последовательного повторного
использования, 401, 439
Ритчи Деннис, 52, 146
родительская директория, 787, 835
родительский процесс, 192, 194, 220
С
самоблокировка процесса, 190
сблокированные записи, 782, 835
сборка мусора, 540, 549
сброс, 650
— страницы, 684
свойство, 148, 171
связный список секторов, 796
связующее ПО, 161
связывание, 153, 171
связывающий загрузчик, 156, 171
связь, 915, 975
сегмент, 571, 594, 627
— состояния задачи, 203
сегментация памяти, 594
сегментная организация виртуальной
памяти, 571
сегментно-страничная система, 604
сегментный промах, 598, 627
- регистров, 611
сектор, 708, 763
секторное упорядочение, 722, 763
селектор сегмента, 611, 627
семафор, 325, 337
- бинарный, 327
— двоичный, 327
семейство вычислительных систем,
860, 893
сервер, 55, 98
сетевая операционная система, 85, 98
- файловая система, 818
сжатие данных, 731, 733, 764
сигнал, 208, 220
Предметный указатель
1019
сигнализации операция, 325
сигнализации-и-выхода монитор, 356
сигнализации-и-продолжения монитор,
356
сигнализация, 337, 354
сигнальная маска, 273
символ, 835
символы, 779
символьное имя, 783, 835
симметричная многопроцессорная
система, 929, 975
симметричный метод, 975
--балансировки, 958
синтаксический анализатор, 152, 171
синтезированная контрольная задача,
893
— программа, 893
синтетические контрольные задачи,
867
- программы, 867
синтетический тест, 871
синхронизация, 387
— потоков, 286
синхронная связь, 209
синхронное прерывание, 200
синхронный сигнал, 251, 273
система баз данных, 819, 836
- для решения критически важных
задач, 70, 98
система команд, 874, 893
- пакетной обработки, 529
- реального времени, 48,98
— с разделением времени, 48, 98, 614
- управления базой данных, 836
--вводом/ выводом, 549, 525
--базами данных, 819
системная шина, 120, 171
системное программирование, 113, 171
системный вектор, 862, 893
- вызов, 68, 98, 150, 171, 549
системы онлайн-обработки
транзакций, 726
сканер, 151, 171
слабосвязанная система, 922, 975
слежение за кэшами, 936, 975
слежение за шиной, 936, 975
слово, 779, 836
— состояния программы, 203
слот, 117
служебные операции завершения
потока, 294
----- потоков, 337
случайная переменная, 893
- последовательность выборки, 764
— стратегия, 975
--балансировки, 958
случайные переменные, 857
случайный порядок выборки, 710
смена состояний, 220
--процесса, 190
смещение, 572, 627
событие завершения операции
ввода/вывода, 188
совместимая система с разделением
времени, 98
совместно используемая библиотека,
156, 171
совместное планирование, 947, 975
создавать файл, 781
создание, 836
сокращенный набор команд, 877
сокрытие информации, 354, 387
сопроцессор, 171, 882
состояние b\i неизвестности, 263
- бездействия, 274
- блокировки, 220, 239, 273
- выполнения, 188, 220, 239, 262, 273
- готовности, 220, 273, 239, 262
- завершения, 262, 273
- зомби, 258
- инициализации, 262, 273
- неизвестности, 273
- ожидания, 240, 263, 273-274
- перехода, 274
- потока, 239, 274
- приостановки, 220
- приостановлен блокирован, 220
-- готов, 220
- процесса, 188, 221
- рождения, 239, 274
- системы надежное, 419
--ненадежное, 419
- смерти, 239, 274
- сна, 240, 274
состоянии блокировки, 188
1020
Операционные системы
— готовности, 188
состояний процесса, 185
состояния приостановки, 197
состоятельность при освобождении,
940, 975
сочетания битов, 779
спин-блокировка, 962, 975
списки контроля доступа ACL, 187
список готовых к выполнению
процессов, 189, 221
— заблокированных процессов, 189,
221
- контроля доступа, 221
— свободных блоков, 549, 805, 836
--областей, 538
спулер, 362
спулинг, 142, 171, 402
сращение, 538
— дыр в памяти, 549
среднее время реагирования, 711, 764
- значение, 857, 893
средняя наработка на отказ, 735, 764
средство разделения времени, 614
ссылка, 787, 836
стандарт POSIX, 255
старение, 439
I- приоритета, 499
- процесса, 406
статическая балансировка нагрузки,
975
статические алгоритмы планирования
реального времени, 489
статические приоритеты, 463
статический алгоритм планирования
реального времени, 499
статическое ОЗУ, 124
— оперативное запоминающее
устройство, 171
статической балансировкой нагрузки,
956
степень, 836
I— загрузки, 858
- использования, 858, 893
- многозадачности, 459, 499
- мультипрограммности, 47, 98
- отношения, 822
- узла, 915, 975
стоимость схемы соединений, 915, 976
столкновение, 588, 628
Столлмен Ричард, 65
страница, 571, 628
страничная организация виртуальной
памяти, 571
- таблица, 574, 628
- система, 628
страничный промах, 577, 628
стратегии загрузки, 523
--по требованию, 523
— замены, 523
- предварительной загрузки, 523
- размещения, 523
стратегии загрузки в наиболее
подходящих участках, 523
----наименее подходящих участках,
523
----первых подходящих участках,
523
— управления памятью, 518
- Хавендера, 411
стратегия второго шанса, 660
- загрузки, 549
--по требованию, 550
- замены, 550
--дальних страниц, 661, 684
--страниц, 684
----FIFO, 652, 684
----gLRU, 684
----LFU, 657, 685
----LRU, 655,685
----NUR, 657, 685
----PFF, 685
----RAND, 685
----второго шанса, 685
— круговой замены страниц, 660
— миграции с предварительным
копированием, 955
--со сбросом содержимого, 954
- предварительной загрузки, 550
— размещения, 550
--в наиболее подходящих участках
памяти, 541, 550
----наименее подходящих участках
памяти, 543, 550
---- памяти, 541
----первых подходящих участках
памяти, 541, 550
Предметный указатель
-----следующих подходящих
участках памяти, 550
— с предварительным копированием,
976
— случайной замены, 652
— со сбросом содержимого, 976
— управления памятью, 550
стратегиях замены страниц, 643
Страуструп Бъярне, 146
строка, 821, 836
— памяти, 932, 976
структурное программирование, 147,
171
СУБД, 819, 836
суперблок, 789, 836
супервизорный режим, 134, 171
суперкомпьютер, 911
суперскалярная архитектура, 881, 893
схема соединений, 976
--процессоров, 915
сцепление, 588, 628, 802, 836
— блоков, 797
счетчик команд, 192, 220
считающий семафор, 330, 337
т
таблица готовности, 189, 221
— имен, 153, 171
- монтирования, 792, 836
— процессов, 193, 221, 628
— размещения блоков, 572, 628
-- страниц, 574
--файлов, 836
- трансляции адресов, 570, 628
табличное фрагментированное
размещение, 798
таймер прерываний, 190, 221
такт, 120, 171
— синхронизации, 120
теневая страница, 815, 836
теневое копирование, 815, 836
теория рабочих наборов, 685
-----в поведении программ, 662
тернарное отношение, 822, 836
тесносвязанная система, 922, 976
тестирование работы программы, 353
технология EPIC, 893
- Plug-and-Play, 140
— параллельной обработки команд с
явным параллелизмом, 883, 893
тип ресурса, 439
тип файла, 781, 836
типы ресурсов, 418
том, 780, 836
Томпсон Кеннет, 52
тонкая полоса, 734
тонкие полосы, 764
Торвальдс Линус, 62, 64
точка монтирования, 791, 836
трамбовка памяти, 540, 550
транзакция, 431, 439
транзистор, 115, 172
транспортная пробка, 398
трассировка, 859, 871, 893
триллион операций в секунду, 860
тупик, 397
тупиковая ситуация, 397, 439
тупиковое состояние, 239, 274
тяжеловесный процесс, 235, 274
У
уведомление, 274
— потока, 240
удаление, 836
удалять данные, 781
удвоенная скорость обмена данными,
172
---передачи данных, 127
удобство использования, 856, 894
узел, 915, 976
узкое место, 727, 764, 871, 894
узловая очередь выполнения, 976, 943
указанный пользователь, 809
универсальная последовательная
шина, 130, 172
уничтожать файл, 781
уничтожение, 836
упаковка данных, 731
уплотнение памяти, 540, 550
упорядочивание линейное, 415
управление вспомогательными
устройствами хранения, 782, 836
— Перспективных Исследований и
Разработок Министерства Обороны
США, 98
Операционные системы
--исследовательских программ, 98
— файлами, 782, 837
управляемые событиями модели, 869
- сценариями модели, 869
управляющая программа/диалоговая
мониторная система, 98
упреждающая загрузка, 884, 894
упреждающее перемещение, 764
- позиционирование головки, 732
--головок, 764
уровень, 764
- мультипрограммирования, 47, 98
уровни дисковых массивов, 734
ускоренный графический порт, 128,
172
условие взаимоисключения, 409
--, необходимое для возникновения
взаимоблокировки, 440
- кругового ожидания, 409
----, необходимое для возникновения
взаимоблокировки, 440
условие неперераспределяемости, 409,
414
--, необходимое для возникновения
взаимоблокировки, 440
условие ожидания дополнительных
ресурсов, 409, 413
условия возникновения
взаимоблокировки, 409
усовершенствованный интерфейс
управления конфигурированием и
энергопотреблением, 140, 172, 440
устойчивость, 873, 894
устройства блочного ввода/вывода, 125
— долговременного хранения данных,
125
устройство блочного ввода/вывода, 172
— долговременного хранения данных,
172
- посимвольного ввода, 130
----/вывода, 172
— с произвольным доступом, 706
- управления памятью, 567
- хранения с прямым доступом, 793
учетверенная подкачка, 127, 172
Ф
файл, 837
- ядра, 208
файловая система журнальная, 816
-- одноуровневая, 785
файловая система, 782, 837
--плоская, 785
--протоколирующая, 816
файловый сервер, 818, 837
физическая запись, 782, 837
- память, 122, 172, 517
физический адрес, 136, 172, 566, 628
физический блок, 782, 837
физическое адресное пространство, 628
физическое имя, 783
--устройства, 837
физическое имя представление, 783,
837
- резервное копирование, 812, 837
фиксация транзакции, 815
флоп, 911
фонд открытого программного
обеспечения, 214, 221
форматирование накопителя, 837
ФОРТРАН, 146
фрагментация, 534, 550, 730
фрагментация внешняя, 548
- внутренняя, 548
- таблицы, 585, 628
фрагментированное размещение
файлов, 796
фрагментированный диск, 764
функция хэширования, 588
X
Хавендера стратегии, 4.11
Хансен Бринч, 357
хронометраж, 860, 871, 894
хэш-код, 588, 628
—таблица, 588, 629
—-функция, 629
ц
цели планирования, 464
целостность файлов, 783
центральный процессор, 118, 172
цепочка блоков, 797
цикл, 120
- чтение-изменение-запись, 743, 764
циклическое планирование, 470, 499
Предметный указатель
1023
цилиндр, 707, 764
цифровой процессор сигналов, 118
ч
частота запросов, 765
— поступления запросов, 710, 872, 894
— страничных промахов, 668
часы истинного времени, 138, 172
чертежный алгоритм, 959, 976
четность, 741, 765
четырехсвязная двумерная ячеистая
сеть, 918, 976
читать данные, 781
член файла, 794
чтение, 837
чтение-модификация-запись памяти,
337
— операции, 321
ш
шина, 117, 172
- PCI, 127
— данных, 127, 172
- соединения периферийных
устройств, 172
ширина сечения, 915, 976
широкая полоса, 735, 765
широковещательная запись, 939, 976
широковещательная передача, 209
шифрование, 837, 783
шпиндель, 707, 765
э
эвристика, 141, 173
эгоистичное циклическое
планирование, 471, 499
эксклюзивный доступ, 284
элеваторный алгоритмом, 716
элемент, 837
— кэша, 141, 173
Энгельбарт Дуглас, 56
энергозависимая запоминающая среда,
123
энергозависимое запоминающее
устройство, 173
эффективная операционная система,
76, 98
Я
ядро, 44, 73, 98
язык С, 173
- С+, 173
- HTML, 58
— Java, 173
- SQL, 822
- Ада, 173
- ассемблера, 144, 173
— баз данных, 837
- высокого уровня, 144
- запросов, 837
- обработки данных, 821, 837
- описания данных, 821, 837
- Паскаль, 173
— программирования высокого уровня.
173
--для промышленных и
правительственных учреждений, 173
— управления задачами, 529, 550
- ФОРТРАН, 173
— запросов, 821
языки баз данных, 820
якорная хэш-таблица, 588, 629
Научно-техническое издание
Харви Дейтел, Пол Дейтел, Дэвид Чофнес
Операционные системы Основы и принципы
Компьютерная верстка Л Г Свиридовой
Подписано в печать 22.10 2008. Формат 70х100/|6. Усл. печ. л 83,2. Гарнитура Школьная.
Бумага газетная. Печать офсетная Тираж 4000 экз Заказ 3515
Издательство «Бином-Пресс», 2009 г
141077, Королев, Московской обл., ул. 50 лет ВЛКСМ, 4-Г
Отпечатано в ГУП ИПК «Ульяновский дом печати»