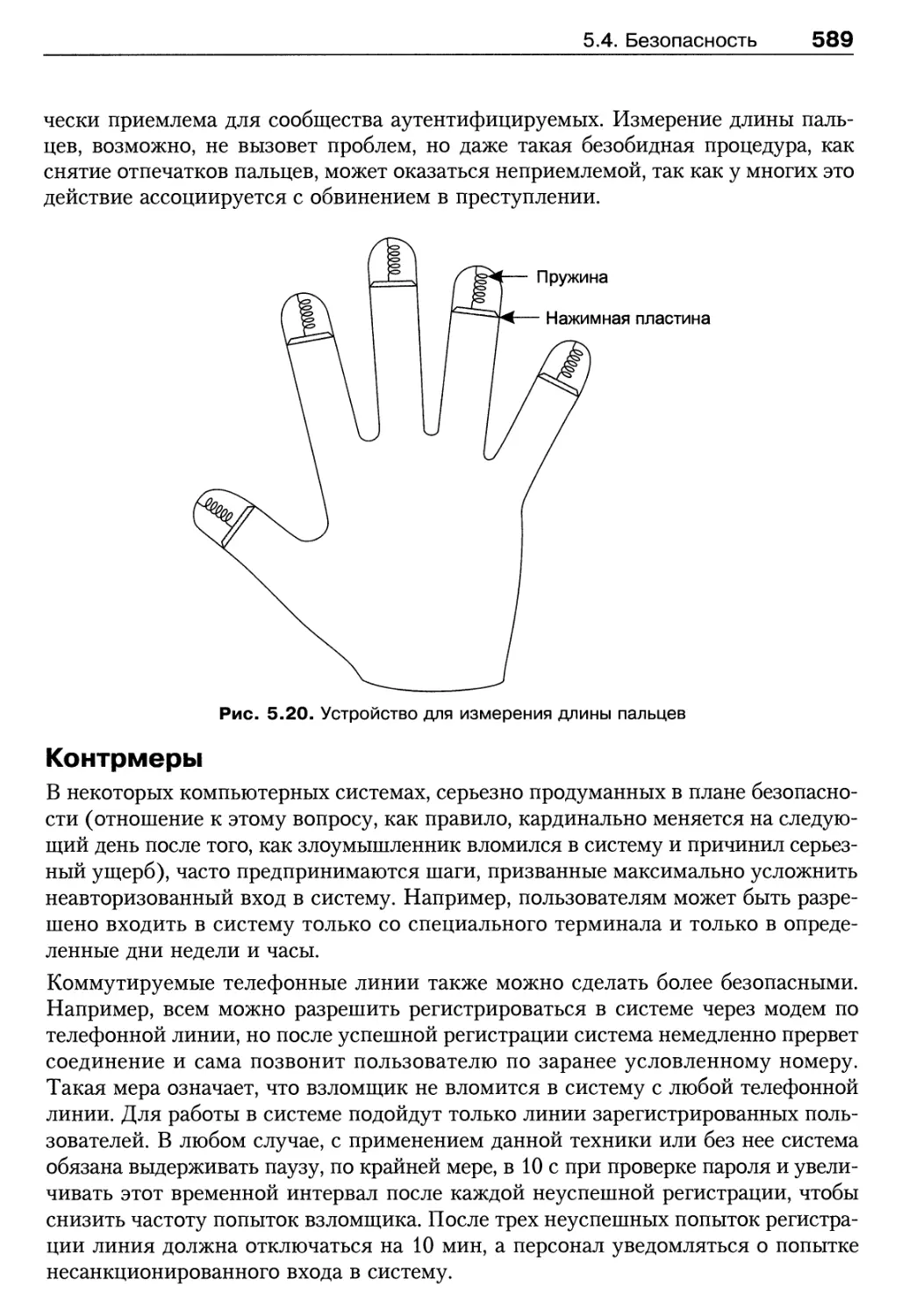
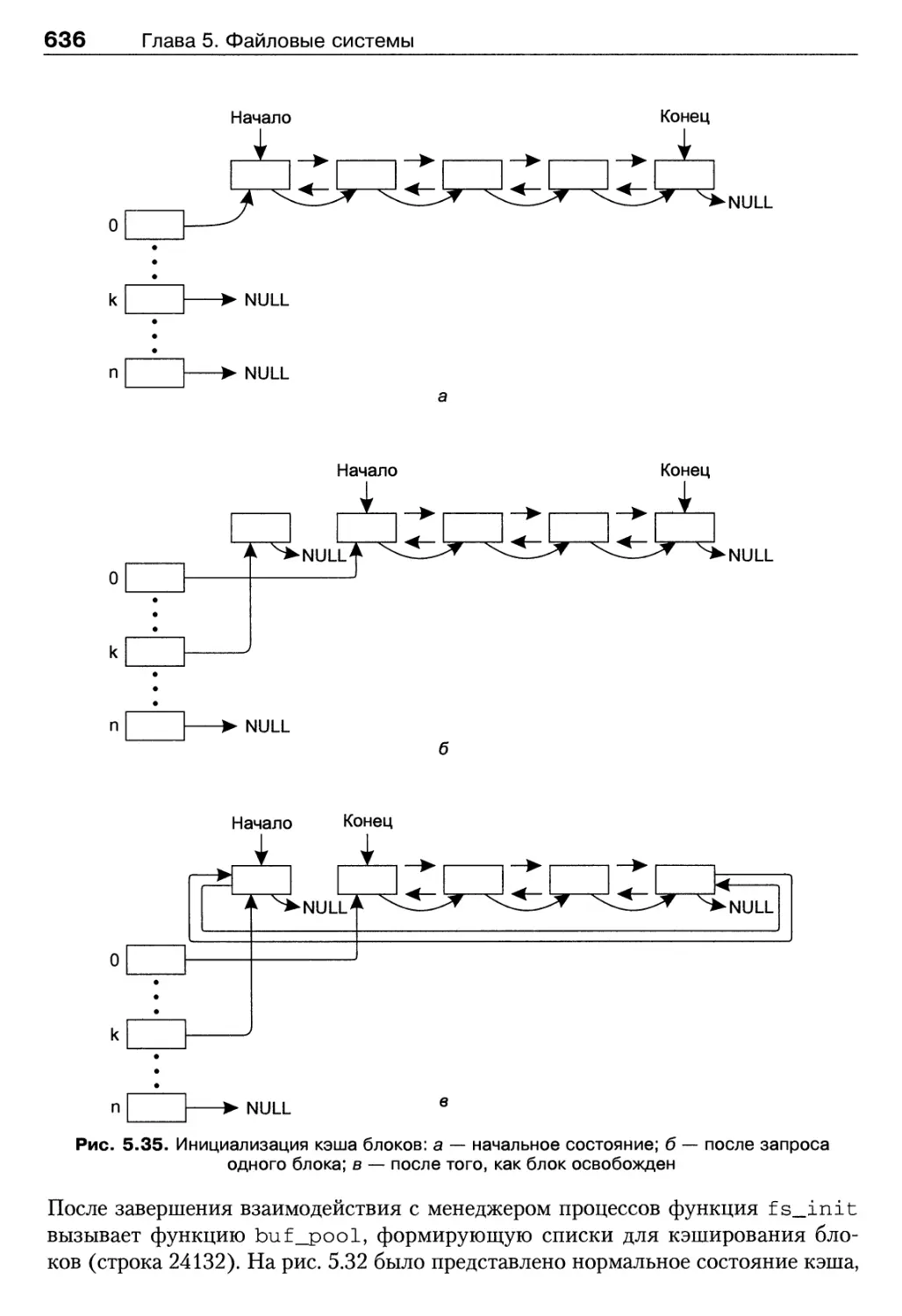
/






















































































































































































































































































































































































































































































































































































































































































































Author: Таненбаум Э. Вудхалл А.
Tags: системное программное обеспечение программирование операционные системы
ISBN: 978-5-469-01403-4
Year: 2007




Text
СЕРИЯ
OPERATING SYSTEMS
DESIGN AND IMPLEMENTATION
Third Edition
ANDREW S.TANENBAUM
Vrije Universiteit
Amsterdam, The Netherlands
ALBERT S.WOODHULL
Amherst, Massachusetts
Upper Saddle River, New Jersey 07458
Э. ТАНЕНБАУМ, А. ВУДХАЛЛ
ОПЕРАЦИОННЫЕ
СИСТЕМЫ
Разработка и реализация
3-е издание
Москва - Санкт-Петербург - Нижний Новгород - Воронеж
Новосибирск - Ростов-на-Дону - Екатеринбург - Самара
Киев - Харьков - Минск
2007
ББК 32.973-018.2
УДК 004.451
Т18
Таненбаум Э., Вудхалл А.
Т18 Операционные системы. Разработка и реализация (+CD). Классика CS. 3-е изд.
— СПб.: Питер, 2007. — 704 с: ил.
ISBN 978-5-469-01403-4
5-469-01403-7
Третье издание классического труда Эндрю Таненбаума «Operating Systems: Design and
Implementation» — это единственный в своем роде учебник, в котором успешно сочетаются теория
и практика построения операционных систем. В книге подробно описываются процессы и
межпроцессное взаимодействие, семафоры, мониторы, передача сообщений, алгоритмы работы
планировщика, ввод/вывод, разрешение тупиковых ситуаций, драйверы устройств, алгоритмы
управления памятью, разработка файловых систем, а также затрагиваются вопросы
безопасности и защиты данных. В то же время обсуждается конкретная UNIX-совместимая
операционная система MINIX и приводится ее исходный код (вы найдете его на компакт-диске).
Это позволяет не только изучать основополагающие принципы, но и наблюдать их применение
в реальных операционных системах.
ББК 32.973-018.2
УДК 004.451
Права на издание получены по соглашению с Pearson Education Inc
Все права защищены Никакая часть данной книги не может быть воспроизведена в какой бы то ни было форме без письменного
разрешения владельцев авторских прав.
Информация, содержащаяся в данной книге, получена из источников, рассматриваемых издательством как надежные Тем не менее,
имея в виду возможные человеческие или технические ошибки, издательство не может гарантировать абсолютную точность и полноту
приводимых сведений и не несет ответственности за возможные ошибки, связанные с использованием книги
©2006, 1997, 1987 by Pearson Education, Inc.
ISBN 0-13-0-13-142938-8 (англ.) © Перевод на русский язык ООО «Питер Пресс», 2007
ISBN 978-5-469-01403-4 © Издание на русском языке, оформление ООО «Питер Пресс», 2007
Краткое содержание
Об авторах 11
Предисловие 14
Глава 1. Введение 18
Глава 2. Процессы 78
Глава 3. Ввод-вывод 252
Глава 4. Управление памятью 414
Глава 5. Файловые системы 530
Глава 6. Библиография 669
Приложение А. Установка MINIX 3 683
Приложение Б. Список файлов MINIX 3 на компакт-диске 691
Алфавитный указатель 694
Компакт-диск MINIX 3 703
Содержание
Об авторах 11
Предисловие 14
От издателя перевода 17
Глава 1. Введение 18
1.1. Понятие операционной системы 21
1.1.1. Операционная система как расширенная машина 21
1.1.2. Операционная система как менеджер ресурсов 22
1.2. История развития операционных систем 24
1.2.1. Первое поколение A945-1955): электронные лампы и коммутационные панели 24
1.2.2. Второе поколение A955-1965): транзисторы и системы пакетной обработки . . 25
1.2.3. Третье поколение A965-1980): интегральные схемы и многозадачность .... 27
1.2.4. Четвертое поколение (с 1980 года по наши дни): персональные компьютеры . . 33
1.2.5. История MINIX 3 35
1.3. Основные концепции 39
1.3.1. Процессы 40
1.3.2. Файлы 42
1.3.3. Оболочка 46
1.4. Системные вызовы 47
1.4.1. Системные вызовы для управления процессами 50
1.4.2. Системные вызовы для управления сигналами 53
1.4.3. Системные вызовы для управления файлами 55
1.4.4. Системные вызовы для управления каталогами 60
1.4.5. Системные вызовы для защиты 63
1.4.6. Системные вызовы для управления временем 64
1.5. Структура операционной системы 65
1.5.1. Монолитные системы 65
1.5.2. Многоуровневые системы 67
1.5.3. Виртуальные машины 69
1.5.4. Экзоядра 72
1.5.5. Модель клиент-сервер 72
1.6. Краткий обзор остальных глав 74
Резюме 75
Вопросы и задания 75
Глава 2. Процессы 78
2.1. Знакомство с процессами 78
2.1.1. Модель процессов 78
2.1.2. Создание процессов 80
2.1.3. Завершение процессов 82
2.1.4. Иерархии процессов 83
2.1.5. Состояния процессов 84
2.1.6. Реализация процессов 86
2.1.7. Программные потоки 88
2.2. Взаимодействие между процессами 92
2.2.1. Гонки 93
2.2.2. Критические секции 94
2.2.3. Взаимное исключение с активным ожиданием 95
2.2.4. Примитивы взаимодействия между процессами 100
2.2.5. Семафоры 103
2.2.6. Мьютексы 105
2.2.7. Мониторы 106
2.2.8. Передача сообщений 110
2.3. Классические проблемы взаимодействия между процессами 113
2.3.1. Проблема обедающих философов 113
2.3.2. Проблема читателей и писателей 116
2.4. Планирование 118
2.4.1. Основы планирования 118
2.4.2. Планирование в системах пакетной обработки 124
2.4.3. Планирование в интерактивных системах 127
2.4.4. Планирование в системах реального времени 134
2.4.5. Политика и механизм планирования 135
2.4.6. Планирование программных потоков 135
2.5. Процессы в MINIX 3 137
2.5.1. Внутренняя структура системы MINIX 3 138
2.5.2. Управление процессами в MINIX 3 141
2.5.3. Взаимодействие между процессами в MINIX 146
2.5.4. Планирование процессов в MINIX 3 148
2.6. Реализация процессов в MINIX 3 151
2.6.1. Структура исходного кода MINIX 3 151
2.6.2. Компиляция и запуск MINIX 3 155
2.6.3. Общие заголовочные файлы 157
2.6.4. Заголовочные файлы MINIX 3 164
2.6.5. Структуры данных процессов и заголовочные файлы 173
2.6.6. Начальная загрузка MINIX 3 184
2.6.7. Инициализация системы 188
2.6.8. Обработка прерываний в MINIX 195
2.6.9. Взаимодействие между процессами в MINIX 3 206
2.6.10. Планирование процессов в MINIX 3 210
2.6.11. Аппаратная поддержка ядра 214
2.6.12. Утилиты и библиотека ядра 219
2.7. Системное задание в MINIX 3 221
2.7.1. Обзор системного задания 223
2.7.2. Реализация системного задания 227
2.7.3. Реализация системной библиотеки 230
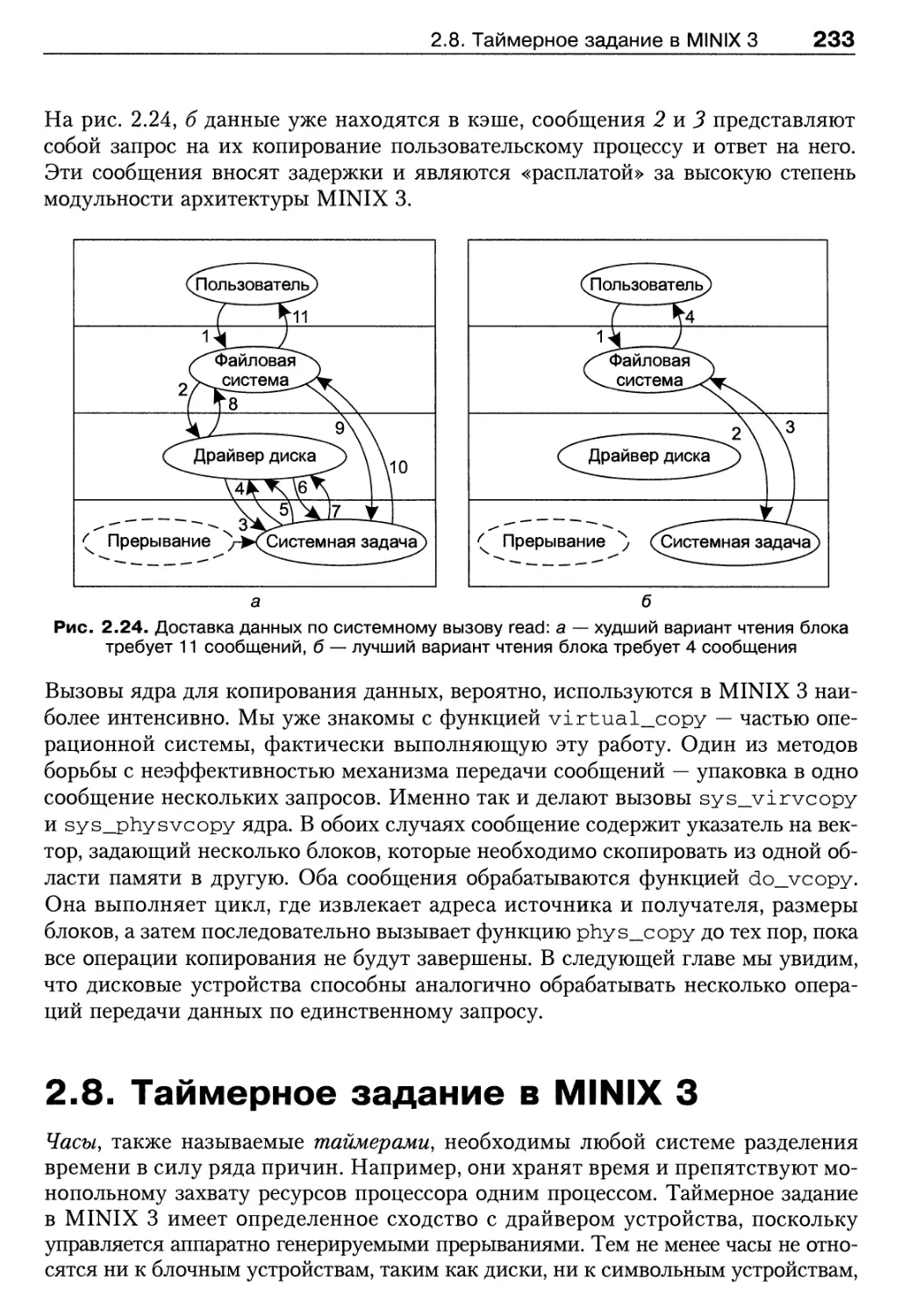
2.8. Таймерное задание в MINIX 3 233
2.8.1. Аппаратное обеспечение часов 234
2.8.2. Программное обеспечение часов 235
2.8.3. Обзор драйвера часов в MINIX 3 238
2.8.4. Реализация драйвера часов в MINIX 3 243
Резюме 245
Вопросы и задания 246
Глава 3. Ввод-вывод 252
3.1. Аппаратное обеспечение ввода-вывода 252
3.1.1. Устройства ввода-вы вода 253
3.1.2. Контроллеры устройств 254
3.1.3. Ввод-вывод с отображением на память 256
3.1.4. Прерывания 257
3.1.5. Прямой доступ к памяти 258
3.2. Программное обеспечение ввода-вывода 261
3.2.1. Назначение программного обеспечения ввода-вывода 261
3.2.2. Обработчики прерываний 263
3.2.3. Драйверы устройств 263
3.2.4. Независимое от устройств программное обеспечение ввода-вывода 265
3.2.5. Программное обеспечение ввода-вывода пользовательского пространства . . 268
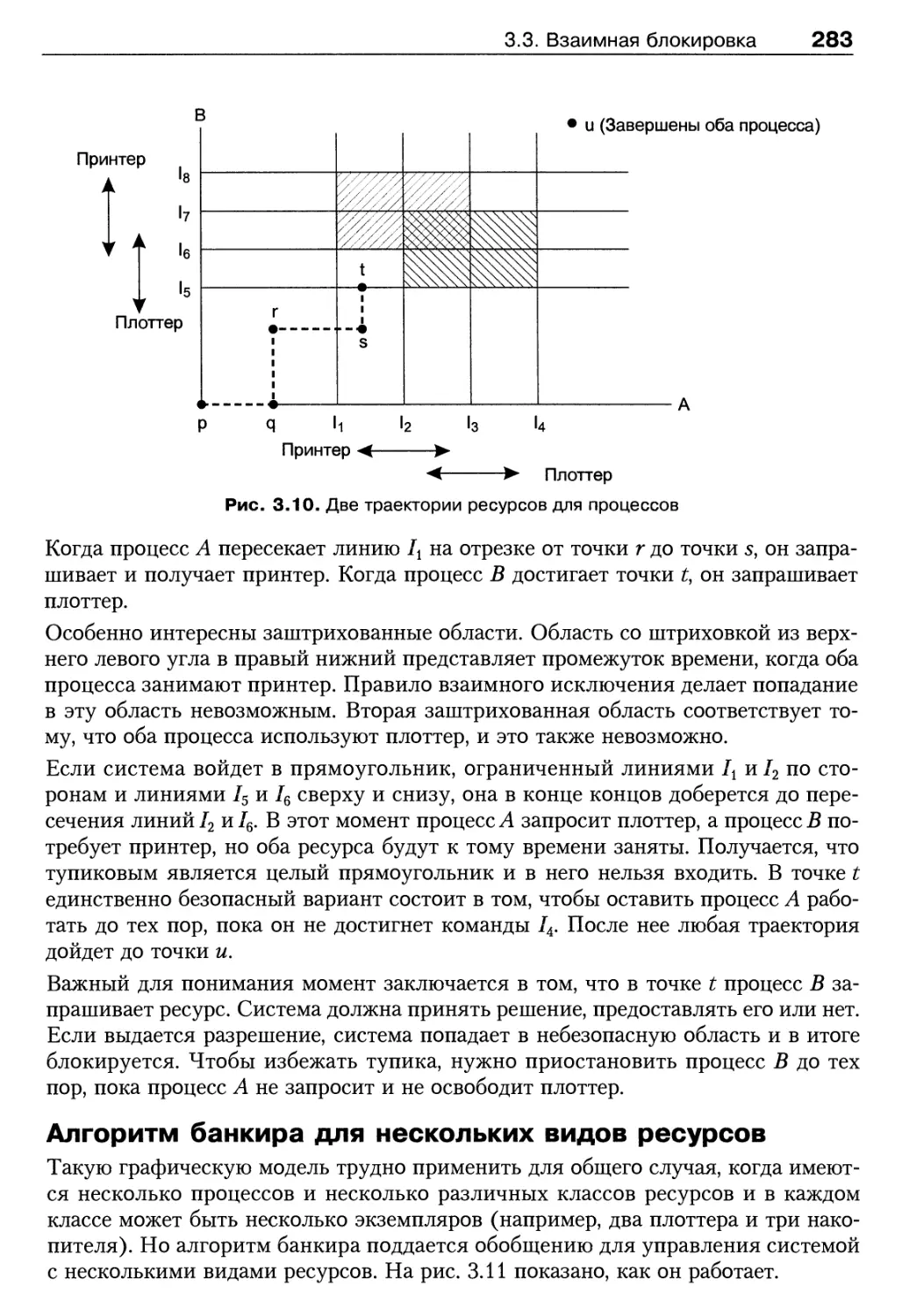
3.3. Взаимная блокировка 270
3.3.1. Ресурсы 270
3.3.2. Механизм взаимной блокировки 272
3.3.3. Алгоритм страуса 276
3.3.4. Обнаружение и устранение взаимных блокировок 277
3.3.5. Предотвращение взаимных блокировок 278
3.3.6. Избежание взаимных блокировок 280
3.4. Ввод-вывод в MINIX 3 286
3.4.1. Обработчики прерываний и доступ к вводу-выводу в MINIX 3 286
3.4.2. Драйверы устройств в MINIX 3 290
3.4.3. Аппаратно-независимый код ввода-вывода в MINIX 294
3.4.4. Программы ввода-вывода пользовательского уровня в MINIX 294
3.4.5. Взаимная блокировка в MINIX 295
3.5. Блочные устройства в MINIX 3 296
3.5.1. Обзор драйверов блочных устройств MINIX 3 296
3.5.2. Общие программы для драйверов блочных устройств 299
3.5.3. Библиотека поддержки драйверов 303
3.6. Виртуальные диски 305
3.6.1. Аппаратное и программное обеспечение виртуального диска 306
3.6.2. Драйвер виртуального диска в MINIX 3 307
3.6.3. Реализация драйвера виртуального диска в MINIX 3 309
3.7. Реальные диски 313
3.7.1. Аппаратное обеспечение диска 313
3.7.2. RAID 315
3.7.3. Программное обеспечение жестких дисков 316
3.7.4. Драйвер жестких дисков в MINIX 3 323
3.7.5. Реализация драйвера жесткого диска в MINIX 3 327
3.7.6. Дисковод гибких дисков 337
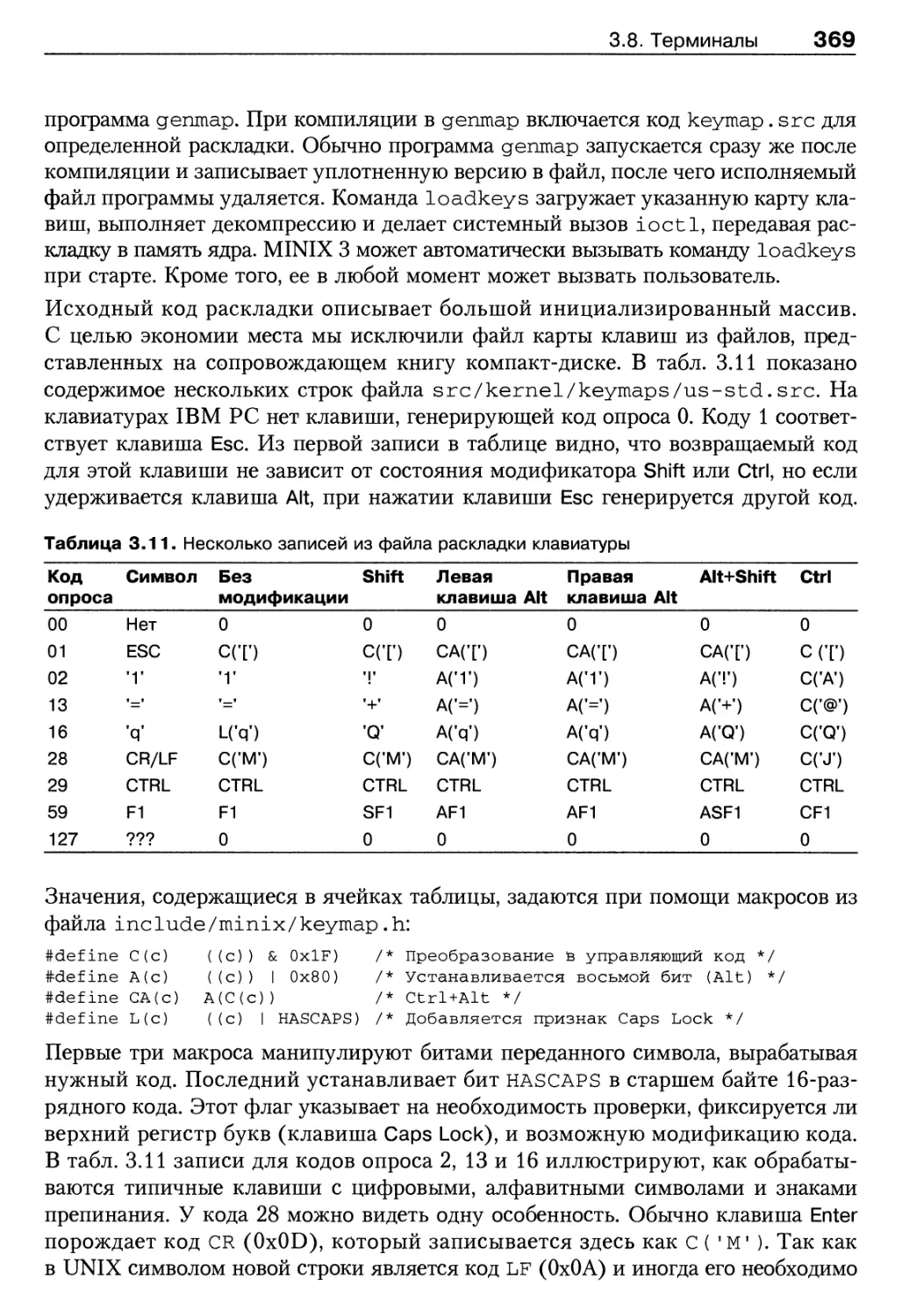
3.8. Терминалы 339
3.8.1. Аппаратное обеспечение терминала 340
3.8.2. Программное обеспечение терминала 345
3.8.3. Драйвер терминала в MINIX 3 354
3.8.4. Реализация аппаратно-независимого драйвера терминала 370
3.8.5. Реализация драйвера клавиатуры 390
3.8.6. Реализация драйвера экрана 398
Резюме 407
Вопросы и задания 408
Глава 4. Управление памятью 414
4.1. Базовые механизмы управления памятью 415
4.1.1. Однозадачная система без подкачки и замещения страниц 415
4.1.2. Многозадачная система с фиксированными разделами 416
4.1.3. Переадресация и защита 418
4.2. Подкачка 419
4.2.1. Управление памятью с помощью битовых карт 422
4.2.2. Управление памятью с помощью связанных списков 423
4.3. Виртуальная память 426
4.3.1. Замещение страниц 427
4.3.2. Таблицы страниц 431
4.3.3. Буферы быстрого преобразования адресов 435
4.3.4. Инвертированные таблицы страниц 438
4.4. Алгоритмы замещения страниц 440
4.4.1. Оптимальный алгоритм замещения страниц 441
4.4.2. Алгоритм NRU 442
4.4.3. Алгоритм FIFO 443
4.4.4. Алгоритм второго шанса 443
4.4.5. Алгоритм часов 444
4.4.6. Алгоритм LRU 445
4.4.7. Программное моделирование алгоритма LRU 446
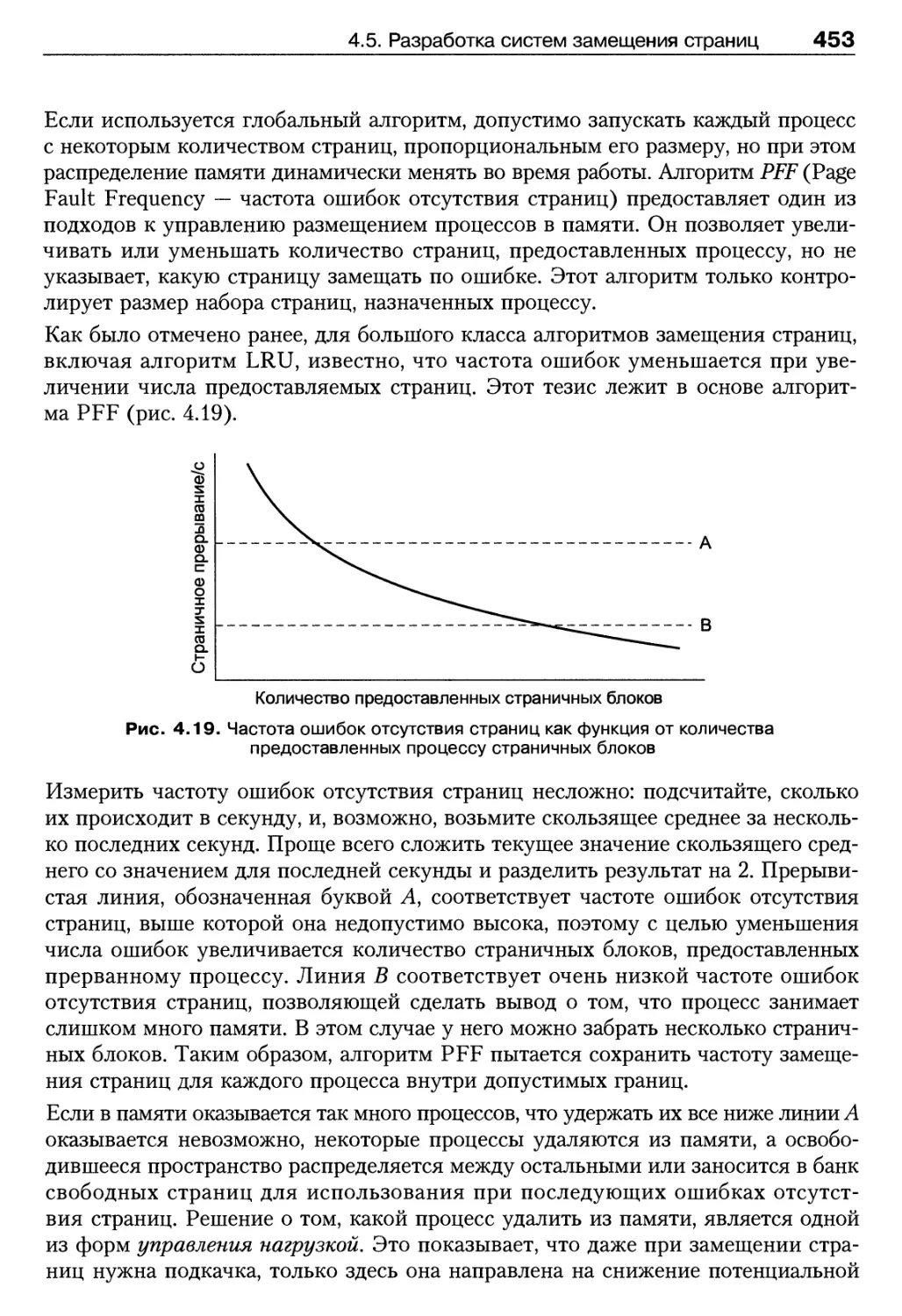
4.5. Разработка систем замещения страниц 448
4.5.1. Модель рабочего набора 449
4.5.2. Локальная и глобальная политики распределения памяти 451
4.5.3. Размер страницы 454
4.5.4. Интерфейс виртуальной памяти 455
4.6. Сегментация 456
4.6.1. Реализация сегментации 460
4.6.2. Сегментация с замещением страниц в Intel Pentium 460
4.7. Знакомство с менеджером процессов в MINIX 3 466
4.7.1. Распределение памяти 468
4.7.2. Обработка сообщений 471
4.7.3. Структуры данных и алгоритмы менеджера процессов 474
4.7.4. Системные вызовы fork, exit и wait 478
4.7.5. Системный вызов exec 480
4.7.6. Системный вызов brk 484
4.7.7. Обработка сигналов 484
4.7.8. Прочие системные вызовы 493
4.8. Управление памятью в MINIX 494
4.8.1. Заголовочные файлы и структуры данных 494
4.8.2. Главная программа 497
4.8.3. Реализация системных вызовов fork, exit и wait 503
4.8.4. Реализация системного вызова exec 505
4.8.5. Реализация системного вызова brk 509
4.8.6. Реализация сигналов 510
4.8.7. Реализация других системных вызовов 519
4.8.8. Утилиты управления памятью 522
Резюме 524
Вопросы и задания 525
Глава 5. Файловые системы 530
5.1. Файлы 531
5.1.1. Именование файлов 531
5.1.2. Структура файла 533
5.1.3. Типы файлов 535
5.1.4. Доступ к файлам 537
5.1.5. Атрибуты файлов 538
5.1.6. Операции с файлами 539
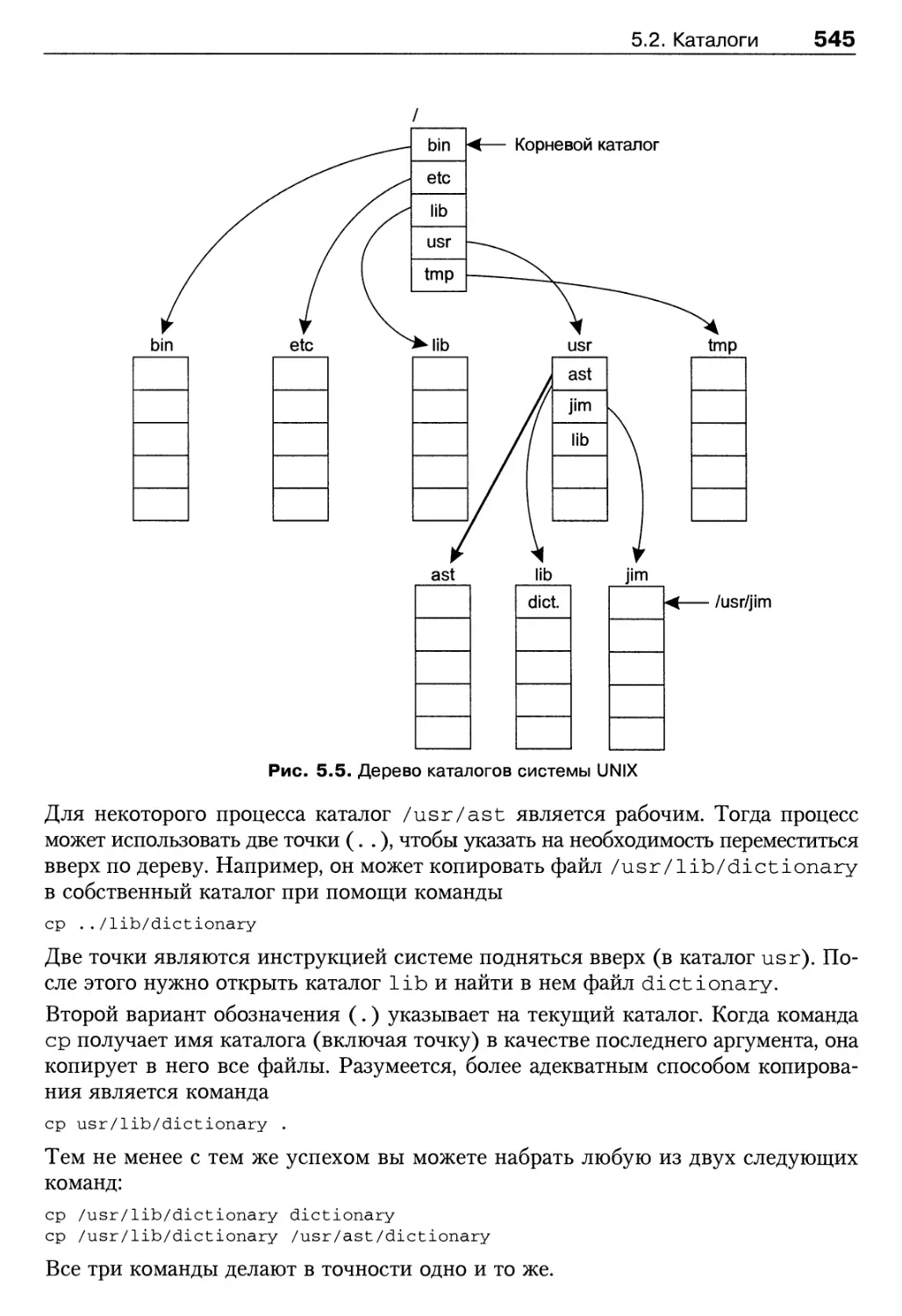
5.2. Каталоги 541
5.2.1. Простые каталоги 541
5.2.2. Иерархические системы каталогов 542
5.2.3. Пути 543
5.2.4. Операции с каталогами 546
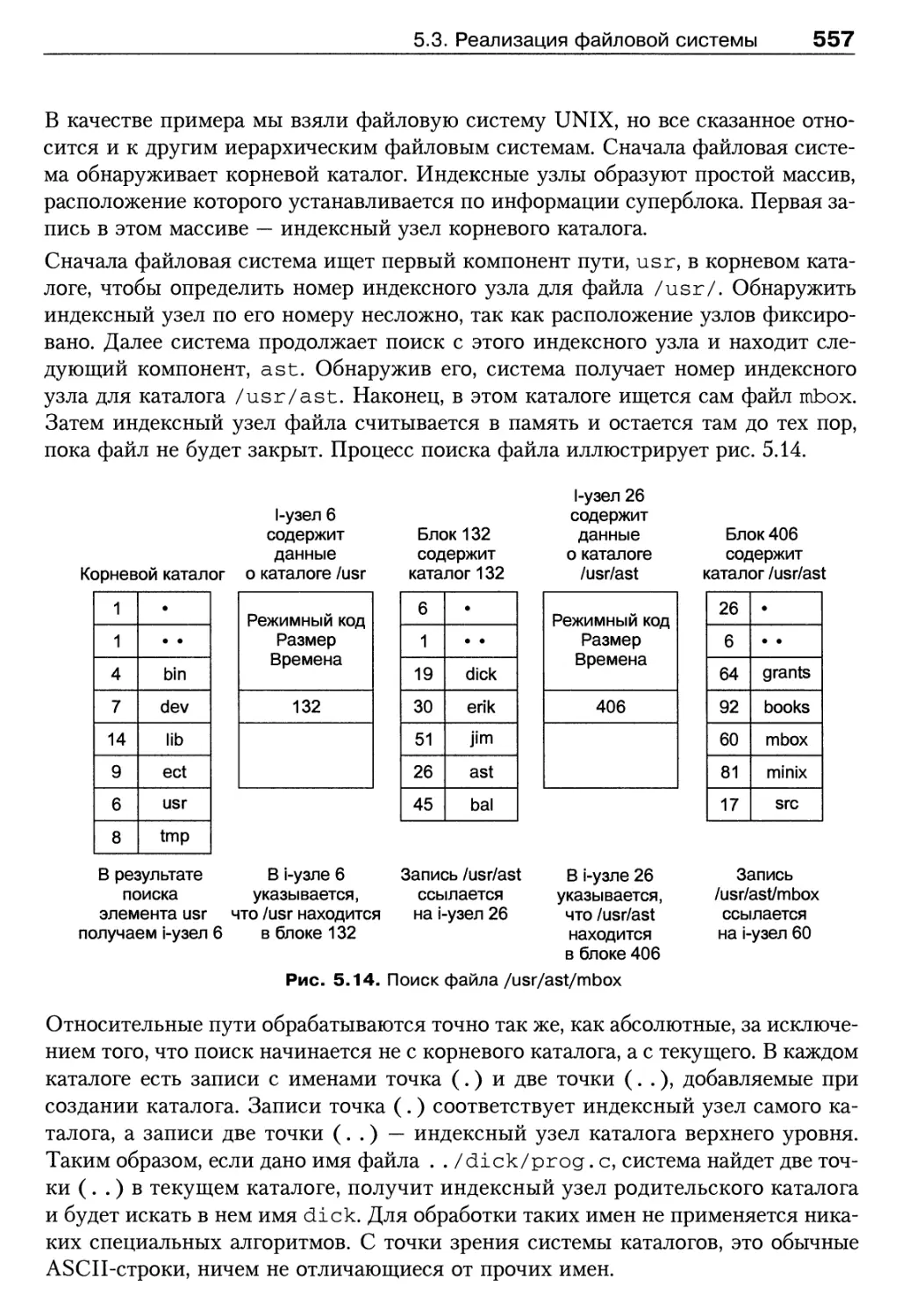
5.3. Реализация файловой системы 547
5.3.1. Структура файловой системы 547
5.3.2. Реализация файлов 549
5.3.3. Реализация каталогов 553
5.3.4. Организация дискового пространства 559
5.3.5. Надежность файловой системы 563
5.3.6. Производительность файловой системы 571
5.3.7. Файловые системы с журнальной структурой 576
5.4. Безопасность 578
5.4.1. Безопасное окружение 578
5.4.2. Общие виды атак на систему безопасности 584
5.4.3. Принципы разработки механизмов безопасности 585
5.4.4. Аутентификация пользователей 586
5.5. Механизмы защиты 590
5.5.1. Домены защиты 590
5.5.2. Списки управления доступом 593
5.5.3. Мандаты 595
5.5.4. Секретные каналы 598
5.6. Обзор файловой системы MINIX 3 601
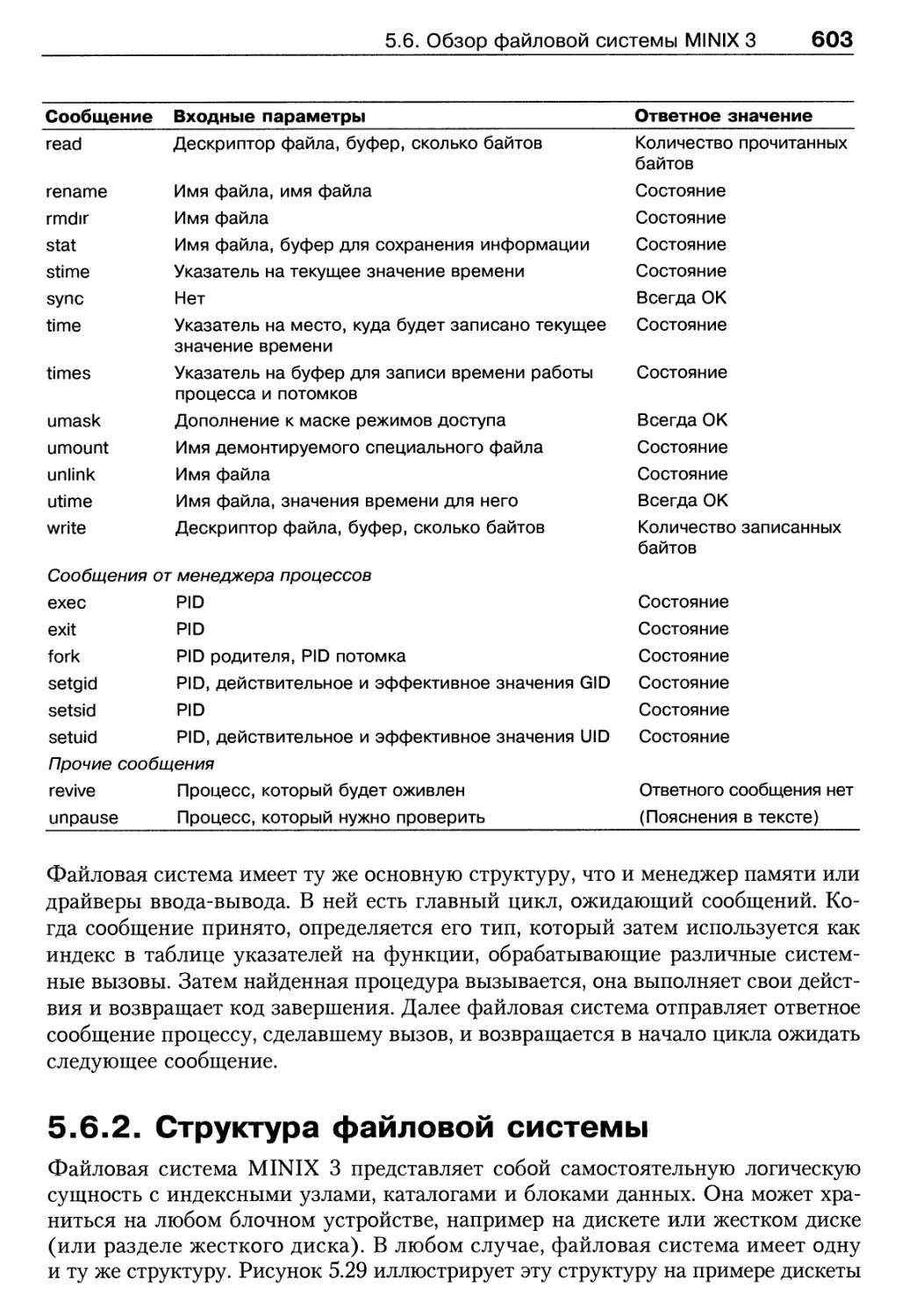
5.6.1. Сообщения 602
5.6.2. Структура файловой системы 603
5.6.3. Битовые карты 607
5.6.4. Индексные узлы 609
5.6.5. Кэш блоков 611
5.6.6. Каталоги и пути 613
5.6.7. Дескрипторы файлов 616
5.6.8. Блокировка файлов 617
5.6.9. Каналы ввода-вывода и специальные файлы 618
5.6.10. Пример системного вызова read 620
5.7. Реализация файловой системы MINIX 3 621
5.7.1. Заголовочные файлы и глобальные структуры данных 621
5.7.2. Таблицы 625
5.7.3. Главная программа 634
5.7.4. Операции с отдельными файлами 638
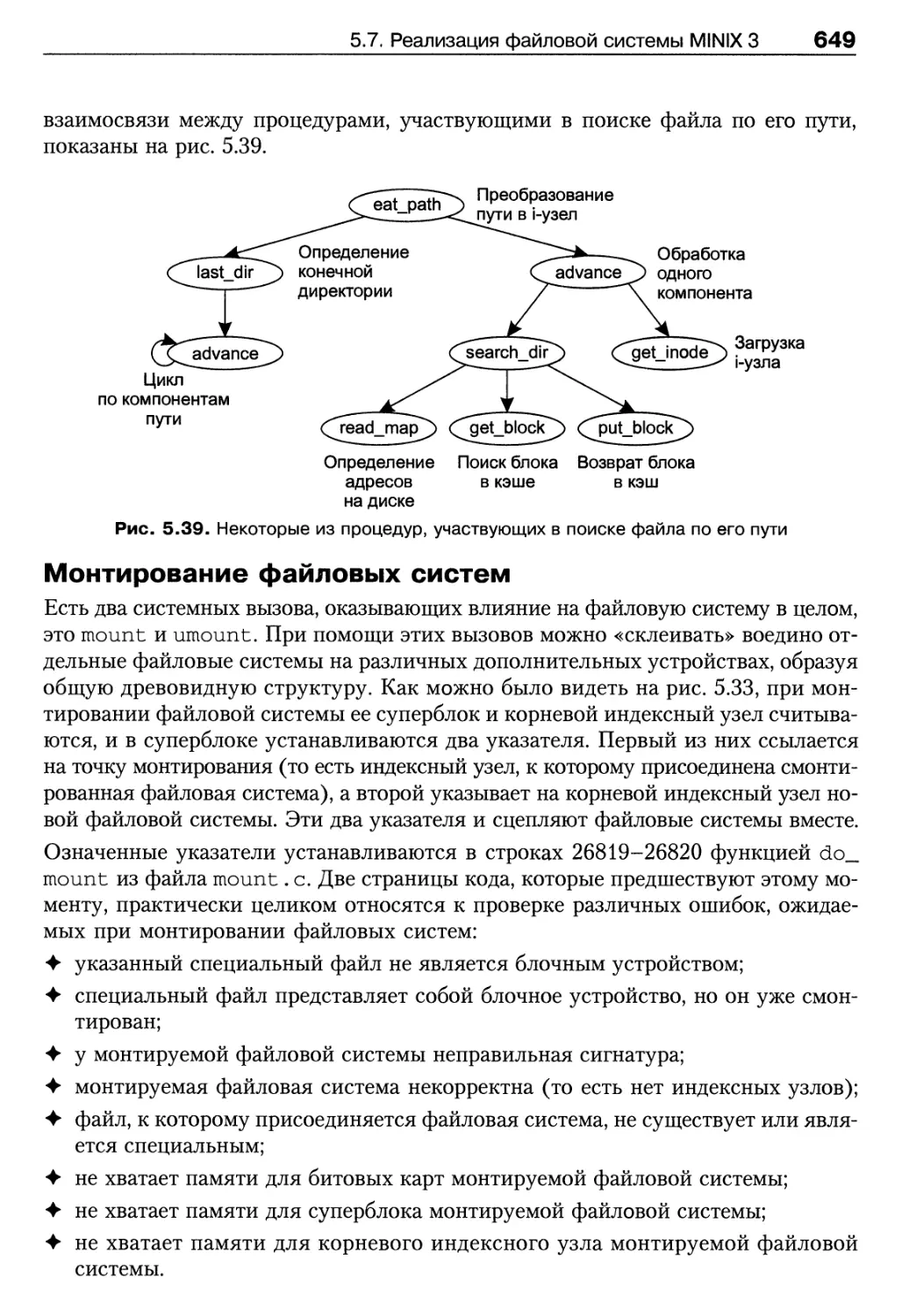
5.7.5. Каталоги и пути 648
5.7.6. Прочие вызовы файловой системы 652
5.7.7. Интерфейс устройств ввода-вывода 654
5.7.8. Поддержка дополнительных системных вызовов 660
5.7.9. Утилиты файловой системы 662
5.7.10. Прочие компоненты MINIX 3 662
Резюме 663
Вопросы и задания 664
Глава 6. Библиография 669
6.1. Рекомендуемая литература 669
6.1.1. Вводные и общие публикации 669
6.1.2. Процессы 671
6.1.3. Ввод-вывод 672
6.1.4. Управление памятью 673
6.1.5. Файловые системы 674
6.2. Алфавитный список литературы 675
Приложение А. Установка MINIX 3 683
А. 1. Подготовка к установке 683
А.2. Загрузка 685
А.З. Установка на жесткий диск 686
А.4. Тестирование 688
А.5. Использование симулятора 689
Приложение Б. Список файлов MINIX 3 на компакт-диске 691
Заголовочные файлы 691
Драйверы 691
Ядро 692
Файловая система 692
Менеджер процессов 693
Алфавитный указатель 694
Компакт-диск MINIX 3 703
Системные требования 703
Аппаратное обеспечение 703
Программное обеспечение 703
Установка 703
Поддержка продукта 703
Об авторах
Эндрю Таненбаум (Andrew S. Tanenbaum) получил степень бакалавра в Масса-
Массачусетсском технологическом институте и степень доктора наук в Калифорнийском
университете в Беркли. Он является профессором кибернетики в университете
Врийе (Vrije) в Амстердаме, где возглавляет Группу компьютерных систем. Кроме
того, вплоть до 2005 года автор в течение 12 лет являлся деканом межуниверситет-
межуниверситетской школы аспирантов по кибернетике и обработке изображений (Advanced School
for Computing and Imaging), занимающейся исследованиями в области современных
параллельных систем, распределенных систем и систем обработки изображений.
В прошлом автор занимался исследованиями компиляторов, операционных сис-
систем, компьютерных сетей и локальных распределенных систем. В настоящее время
его усилия в основном направлены на разработку систем безопасности, особенно
для операционных систем, компьютерных сетей и глобальных распределенных
систем. Результатом этих исследовательских проектов стали более 100 статей
в журналах и отчетах конференций. Э. Таненбаум является автором пяти книг.
Профессор Таненбаум написал множество программ. Под его руководством
разрабатывалась архитектура проекта Amsterdam Compiler Kit — инструмента,
предназначенного для создания кросс-платформенных компиляторов. Кроме то-
того, он руководил созданием учебной операционной системы MINIX — упрощен-
упрощенной версии системы UNIX, на базе которой была впоследствии разработана
система Linux. Вместе со своими аспирантами и программистами он участвовал
в разработке высокопроизводительной локальной распределенной операционной
системы Amoeba. Также профессор является одним из разработчиков высоко-
высокопроизводительной распределенной системы Globe, ориентированной на миллио-
миллионы пользователей. В настоящее время все эти программные продукты свободно
распространяются через Интернет.
Его аспиранты, многие из которых сами стали докторами наук, достигли боль-
больших успехов. Профессор Таненбаум очень гордится своими учениками. В этом
смысле он напоминает курицу-наседку.
Профессор Таненбаум является членом Ассоциации по вычислительной технике
(Association for Computing Machinery, ACM), почетным членом Института ин-
инженеров по электротехнике и электронике (Institute of Electrical and Electronics
Engineers, IEEE), членом Голландской королевской академии искусств и наук.
В 1994 году ему была присуждена премия АСМ Карла В. Карлстрома (Karl
V. Karlstrom) как выдающемуся преподавателю, в 1997 году — премия АСМ/
SIGCSE за выдающийся вклад в обучение кибернетике, в 2004 году — премия
Texty за лучший учебник. А в 2005 году Э. Таненбаум стал одним из пяти новых
профессоров Королевской Академии (Royal Academy). Его домашняя страница
в Интернете расположена по адресу http://www.cs.vu.nl/~ast/.
Альберт Вудхалл (Albert S. Woodhull) получил степень бакалавра в Массачу-
Массачусетсском технологическом университете и степень доктора в университете Ва-
Вашингтона. Поступив в Массачусетсский институт, чтобы стать электротехником,
он окончил его как биолог. Сам себя он называет «ученым, неплохо разбираю-
разбирающимся в технике». Более 20 лет он был преподавателем Школы естественных
наук Хэмпширского колледжа, Массачусетс, преподавая параллельно в несколь-
нескольких других колледжах и университетах. Как биолог, пользующийся электрон-
электронным оборудованием, он начал работать с микрокомпьютерами, когда они стали
доступными. Его технические курсы для студентов развились в лекции, посвя-
посвященные взаимодействию и программированию задач реального времени.
Доктор Вудхалл всегда испытывал большой интерес к преподаванию и к вопро-
вопросам влияния науки и технологии на производство. Перед поступлением в аспи-
аспирантуру он в течение двух лет преподавал естественные науки в Нигерии. Позже
он потратил несколько своих отпусков на обучение студентов вычислительной
технике в Никарагуа, в Universidad Nacional de Ingenieria и Universidad Nacional
Autonoma de Nicaragua.
В сферу его интересов входят компьютеры как электронные системы и взаимо-
взаимодействие компьютеров с другими электронными системами. Он особенно насла-
наслаждается преподаванием архитектуры вычислительной техники, операционных
систем и компьютерных коммуникаций, программирования на языке ассемблер.
А. Вудхалл также работал консультантом по разработке электронного оборудо-
оборудования и связанного с ним программного обеспечения, а также системным адми-
администратором.
Помимо этого у него немало других, не академических интересов, включая спор-
спортивные игры на открытом воздухе, радиолюбительство и чтение. Он любит путеше-
путешествовать и изучать другие языки помимо родного английского. Вудхалл являет-
является пользователем и горячим сторонником системы MINIX. Его страничка в Сети
управляется MINIX и располагается по адресу http://minix1.hampshire.edu/asw/.
Сюзанне, Барбаре, Марвину, памяти моих дорогих п и Брэма.
Э. Таненбаум
Барбаре и Гордону.
А. Вудхалл
Предисловие
Большинство книг, посвященных операционным системам, в основном касаются
теории, а не практики. Та же, которую вы держите в руках, в этом смысле более
сбалансирована. В ней скрупулезно рассматриваются все теоретические основы,
в том числе процессы, взаимодействие между процессами, семафоры, мониторы,
передача сообщений, планирование, ввод-вывод, взаимные блокировки, драйве-
драйверы устройств, управление памятью, замещение страниц, разработка файловых
систем, безопасность и защита данных. В то же время обсуждается конкретная
UNIX-совместимая операционная система MINIX и приводится копия ее исход-
исходных кодов (на компакт-диске). Это позволяет не только изучать основополагаю-
основополагающие принципы, но и видеть, как эти принципы применяются в реальных опера-
операционных системах.
Появившись в 1987 году, первая редакция этой книги в определенной степени
произвела революцию в понимании того, как нужно изучать операционные сис-
системы. До того большинство книг посвящалось только теоретической части. С по-
появлением MINIX во многих школах стали проводить лабораторные занятия, на
которых ученики могли «изнутри» увидеть, как работают операционные систе-
системы. Мы сочли эту тенденцию весьма желательной и надеемся, что она сохранит-
сохранится и в третьей редакции.
За первые десять лет операционная система MINIX претерпела множество из-
изменений. Первоначальный код был рассчитан на IBM PC с процессором 8088
и 256 Кбайт памяти с двумя дисководами, но без жестких дисков. В основе
MINIX лежала система UNIX версии 7. С течением времени система MINIX
развивалась в различных направлениях: появилась поддержка компьютеров с 32-
разрядным защищенным режимом, оснащенных оперативной памятью и жесткими
дисками большого объема. Кроме того, система теперь базируется не на UNIX
версии 7, а на международном стандарте POSIX (IEEE 1003.1 и ISO 9945-1).
Добавлено множество новых возможностей — на наш взгляд, пожалуй, даже
слишком много. (Впрочем, некоторым и этого мало, что в конце концов и привело
к появлению Linux.) В дополнение, система MINIX была перенесена на множе-
множество других платформ, включая Macintosh, Amiga, Atari и SPARC. Вторая редак-
редакция данной книги, в которой рассматривалась именно эта версия MINIX, вышла
в свет в 1997 году и широко использовалась в университетах.
Операционная система MINIX сохраняет свою популярность, о чем свидетельст-
свидетельствует количество запросов по слову MINIX в поисковой системе Google.
В третью редакцию книги внесено множество изменений. Практически весь
материал переработан; кроме того, к нему добавлен значительный объем новой
информации. Главными нововведениями являются рассмотрение новой версии
операционной системы MINIX под названием MINIX 3. Хотя MINIX 3 является
продолжением MINIX 2, многие ключевые аспекты новой операционной систе-
системы принципиально иные.
К созданию MINIX 3 разработчиков подтолкнули громоздкость, низкое быстро-
быстродействие и ненадежность существующих операционных систем. Операционные
системы выходят из строя значительно чаще, чем электронные устройства —
телеприемники, сотовые телефоны и DVD-плееры, а кроме того, имеют столь
огромное количество функций и параметров, что практически ни один человек
не способен эффективно управлять ими и освоить их полностью. Разумеется,
существенную роль в этом играют и разнообразные виды вредоносных программ
(вирусы, черви, шпионские программы, спам и др.), что приняло масштабы самой
настоящей эпидемии.
Многие перечисленные проблемы в значительной степени обусловлены фунда-
фундаментальным недостатком существующих операционных систем — отсутствием
модульности. Современная операционная система — это одна огромная испол-
исполняемая программа, скомпилированная из миллионов строк кода, написанного на
языках С и C++, и функционирующая в режиме ядра. Ошибка хотя бы в одной
строке может стать причиной выхода операционной системы из строя. Обеспе-
Обеспечить корректность всего кода невозможно: 70 % его объема составляют драйверы
устройств, написанные сторонними разработчиками, которые находятся вне по-
поля зрения специалистов, занятых поддержкой операционной системы.
Посредством MINIX 3 мы демонстрируем, что монолитная архитектура опера-
операционной системы не является единственно возможной. Ядро MINIX 3 включает
всего лишь 4000 строк исполняемого кода, в противовес «миллионным» ядрам
Windows, Linux, Mac OS X и FreeBSD. Остальная часть операционной системы,
в том числе драйверы всех устройств (за исключением таймера), представляет
собой совокупность компактных модульных процессов, работающих в пользова-
пользовательском режиме. Деятельность каждого процесса четко ограничена; кроме того,
жестко регламентировано и взаимодействие между процессами.
Несмотря на то что работа над MINIX 3 еще далека от завершения, мы полага-
полагаем, что архитектура на основе совокупности пользовательских процессов с высо-
высокой степенью инкапсуляции в будущем приведет к созданию более надежных
операционных систем. Система MINIX 3 предназначена главным образом для
небольших компьютеров, распространенных в странах «третьего мира», и встраи-
встраиваемых систем, всегда резко ограниченных в ресурсах. Как бы то ни было, сту-
студентам значительно проще ознакомиться с принципами работы операционной
системы на примере модульной архитектуры, нежели изучать монолитную и гро-
громоздкую структуру.
Данная книга снабжена компакт-диском. Вставьте его в дисковод, перезагрузите
компьютер, и через несколько секунд на экране появится экран входа MINIX 3.
Вы можете войти под именем root и опробовать систему, не устанавливая ее на
жесткий диск. Разумеется, установка на жесткий диск также предусмотрена. Под-
Подробные указания по установке вы найдете в приложении А.
Как уже отмечалось, над MINIX 3 ведется постоянная работа, результатом которой
является периодическое появление новых версий операционной системы. Вы
можете загрузить наиболее свежий образ установочного компакт-диска с офици-
официального веб-сайта www.minix3.org. На сайте вы также найдете большое количество
нового программного обеспечения, документации и новостей, касающихся раз-
разработки MINIX 3. Дискуссиям и вопросам о MNIX 3 посвящена группа новостей
comp.os.minix. Пользователи, лишенные возможности работать с группами ново-
новостей, могут следить за обсуждениями по адресу http://groups.google.com/group/
comp.os.minix.
Вы можете работать с MINIX 3 при помощи одного из симуляторов ПК, пере-
перечисленных на главной странице официального веб-сайта MINIX. Использование
симулятора избавит вас от необходимости устанавливать операционную систему
на жесткий диск компьютера.
Преподаватели, применяющие данную книгу в качестве пособия в рамках уни-
университетского курса, могут получить решения задач у местного представителя
издательства Prentice Hall. Книге посвящен отдельный веб-сайт; вы можете по-
посетить его, указав оригинальное название книги (Operating Systems Design and
Implementation) на странице http://www.prenhall.com/tanenbaum.
В процессе работы над книгой нам посчастливилось сотрудничать с людьми,
оказавшими неоценимую помощь. В первую очередь, следует отметить вклад Бе-
Бена Граса (Ben Gras) и Джоррит Хердер (Jorrit Herder), написавших большинство
программ для новой редакции. Им пришлось работать в условиях жестко ограни-
ограниченных сроков и зачастую отвечать на электронные сообщения глубоко за пол-
полночь. Кроме того, они ознакомились с содержанием рукописи и внесли немало
полезных замечаний. Мы выражаем Бену и Джоррит свою глубокую призна-
признательность.
Кис Бот (Kees Bot) принял деятельное участие в работе над предыдущими ре-
редакциями книги, создав нам хороший задел для текущей работы. Он написал
объемные фрагменты кода для версий до 2.0.4, исправил ошибки и ответил на
многочисленные вопросы. Филипп Хомбург (Philip Homburg) написал большую
часть программного кода для работы с компьютерной сетью, а также сделал еще
много полезного, особенно в части комментариев к рукописи.
Следует упомянуть людей, принимавших участие в кодировании самых первых
версий MINIX и «поставивших» эту операционную систему «на ноги». Число их
столь велико, а результаты их работы подверглись столь значительным измене-
изменениям, что мы сочли разумным выразить им общую благодарность.
Некоторые из читавших рукопись книги предоставили нам свои замечания. Осо-
Особую благодарность за помощь мы выражаем Джойко Бабику (Goiko Babic), Майк-
Майклу Кроули (Michael Crowley), Джозефу М. Кицца (Joseph M. Kizza), Сэму Кону
(Sam Kohn), Александру Манову (Alexander Manov) и Ду Цангу (Du Zhang).
Наконец, мы ничего не добились бы без наших семей. Сьюзан прошла через
все это уже шестнадцать раз, Барбара — пятнадцать, а Марвин — четырнадцать.
Я (Эндрю С. Таненбаум) всегда признателен за вашу любовь и поддержку.
Что же до Барбары Альберта, то это ее второе испытание. Без ее помощи, терпе-
терпения и хорошего чувства юмора вообще ничего бы не получилось. Гордон стал
для нас терпеливым слушателем. Это счастье — иметь сына, которого интересу-
интересуют и заботят те же вещи, что восторгают меня (Альберта С. Вудхалла). Наконец,
первый день рождения внука Зайна совпал с выходом в свет операционной сис-
системы MINIX 3. Когда-нибудь он по достоинству оценит это.
Эндрю С. Таненбаум
Альберт С. Вудхалл
От издателя перевода
Ваши замечания, предложения и вопросы отправляйте по адресу электронной
почты comp@piter.com (издательство «Питер», компьютерная редакция).
Мы будем рады узнать ваше мнение!
Все исходные тексты, приведенные в книге, вы можете найти по адресу http://
www.piter.com/download.
Подробную информацию о наших книгах вы найдете на веб-сайте издательства:
http://www.piter.com.
Глава 1
Введение
Без программного обеспечения любой компьютер — просто бесполезная груда
железа. Именно благодаря программам компьютер может хранить, обрабатывать
и искать информацию, воспроизводить музыку и видео, отсылать сообщения
электронной почты, вести поиск в Интернете и решать множество других важных
задач, для которых он и предназначен. Программное обеспечение можно грубо
разбить на две большие группы: системные программы, управляющие работой
самого компьютера, и прикладные программы, предназначенные для решения поль-
пользовательских задач. Самая главная системная программа — это операционная
система, она управляет всеми системными ресурсами и обеспечивает основу для
работы прикладных программ. Именно операционные системы являются пред-
предметом рассмотрения в данной книге. В качестве примера, демонстрирующего
принципы архитектуры и их практическую реализацию, приведена ОС MINIX 3.
Современный компьютер состоит из одного или нескольких процессоров, опера-
оперативной памяти, дисков, клавиатуры, монитора, принтеров, сетевых интерфейсов
и других устройств ввода-вывода, то есть является сложной системой. Написание
программ, которые отслеживают все компоненты, корректно используют их и при
этом оптимально работают, представляет собой крайне трудную задачу. Если бы
каждому программисту приходилось задумываться о том, как работают жесткие
диски, помнить о множестве нюансов, которые могут произойти при чтении блока
данных, то многие программы, скорее всего, вообще не были бы написаны.
Еще много лет назад стало очевидно, что нужно как-то оградить программистов
от тонкостей, связанных с аппаратным обеспечением. Постепенно был вырабо-
выработан следующий путь: поверх аппаратуры работает дополнительная программная
прослойка, которая управляет всем оборудованием и предоставляет пользова-
пользователю интерфейс, или виртуальную машину, более простую для понимания и про-
программирования, чем аппаратура. Операционная система и является этой про-
программной прослойкой.
Место операционной системы в общей структуре компьютера показано на ри-
рисунке 1.1. Внизу находится аппаратное обеспечение, которое во многих случаях
само состоит из двух или более уровней (или слоев). Самый нижний уровень
содержит физические устройства, состоящие из интегральных микросхем, про-
проводников, источников питания, электронно-лучевых трубок и т. п. То, как они
устроены и как работают, относится к сфере деятельности инженеров, специали-
специалистов по электронике.
Рис. 1.1. Компьютер состоит из аппаратного обеспечения, а также
системных и прикладных программ
Далее следует микроархитектурный уровень, на котором физические устройства
группируются в функциональные блоки. Как правило, на микроархитектурном
уровне находятся внутренние регистры ЦПУ (центральное процессорное устрой-
устройство) и тракт данных, включающий арифметико-логическое устройство. На каждом
такте процессора данные извлекаются из регистров и обрабатываются арифме-
арифметико-логическим устройством (к примеру, участвуют в операции арифметического
или логического суммирования). Результат сохраняется в одном или нескольких
регистрах. В некоторых компьютерах функционирование тракта данных находит-
находится под управлением особой программы, называемой микропрограммой. В осталь-
остальных случаях управление обеспечивают аппаратные схемы.
Тракт данных предназначен для выполнения наборов команд. Некоторые на-
наборы могут быть выполнены в одном цикле тракта данных, другие же требуют
нескольких тактов. В распоряжении команд находятся различные аппаратные
средства, в том числе регистры. Аппаратное обеспечение и команды, доступ-
доступные программисту на языке ассемблера, образуют архитектуру набора команд
(Instruction Set Architecture, ISA). Зачастую данный уровень называют машин-
машинным языком.
Обычно машинный язык содержит от 50 до 300 команд, служащих преимуще-
преимущественно для перемещения данных в пределах компьютера, выполнения ариф-
арифметических операций и сравнения величин. Управление устройствами на этом
уровне осуществляется путем загрузки определенных величин в специальные
регистры устройств. Например, диску можно дать команду чтения, записав в его
регистры адрес места на диске, адрес в основной памяти, число байтов для
чтения и направление действия (чтение или запись). На практике нужно переда-
передавать больше параметров, а информация о статусе операции, возвращаемая дис-
диском, достаточно сложна. Кроме того, при программировании многих устройств
ввода-вывода (Input/Output, I/O) очень важную роль играют временные соот-
соотношения.
Основное предназначение операционной системы — скрыть все эти сложности
и предоставить программисту более удобную систему команд. Чтение блока из
файла в этом случае представляется намного более простым действием, чем в слу-
случае, когда программисту приходится думать о перемещении головок диска, о за-
задержках, связанных с их установкой в нужное место и т. д.
Поверх операционной системы на нашем рисунке расположены остальные сис-
системные программы. Здесь находятся интерпретатор команд (оболочка), ком-
компиляторы, редакторы и т. д. Важно понимать, что подобные программы не яв-
являются частью операционной системы, хотя обычно поставщики компьютеров
устанавливают их на машины. Это очень важное, хотя и тонкое, замечание. Под
операционной системой обычно понимается то программное обеспечение, кото-
которое запускается в режиме ядра или, как его еще называют, режиме супервизора.
Операционная система защищена от вмешательства пользователя с помощью
аппаратных средств (мы не рассматриваем в данный момент некоторые старые
микропроцессоры, которые вообще не имеют аппаратной защиты). Компилято-
Компиляторы и редакторы запускаются в пользовательском режиме. Если пользователю не
нравится какой-либо компилятор, он при желании может написать собственный,
но ему не удастся написать собственный обработчик прерываний от системных
часов, являющийся частью операционной системы и обычно защищенный аппа-
ратно от попыток его модифицировать.
Подобная классификация имеет весьма размытые границы во встраиваемых сис-
системах, допускающих отсутствие ядра, и в интерпретируемых системах (к приме-
примеру, в Java-системах, где компоненты разделяются путем интерпретации, а не ап-
паратно). Тем не менее в традиционных компьютерах операционная система
является элементом, исполняемым в режиме ядра.
Во многих системах применяются программы, хотя и исполняемые в пользо-
пользовательском режиме, но призванные помогать операционной системе или ре-
решать привилегированные задачи. Распространенный пример — программа сме-
смены пароля пользователями. Она не является частью операционной системы и не
работает в режиме ядра, однако несет важную функцию и, очевидно, требует осо-
особой защиты.
В некоторых системах, включая MINIX 3, описанный подход реализован столь
утрированно, что компоненты, традиционно относимые к операционной системе
(к примеру, файловая система), функционируют в пользовательском режиме. Гра-
Граница между системным и прикладным программным обеспечением размывается.
Очевидно, что компоненты, исполняемые в режиме ядра, относятся к операцион-
операционной системе, однако многие «пользовательские» программы также несут систем-
системные функции либо, как минимум, тесно связаны с ними. К примеру, в MINIX 3
файловая система представляет собой не что иное, как большую С-программу,
исполняемую в пользовательском режиме.
Подведем итог вышесказанному: поверх системных программ выполняются при-
прикладные программы. Обычно они покупаются пользователем (или пишутся им)
для решения собственных проблем — обработки текста, электронных таблиц,
технических расчетов или хранения информации в базе данных.
1.1. Понятие операционной системы
Большинство пользователей компьютеров имеют некоторый опыт общения с опе-
операционной системой, но обычно они испытывают затруднения при попытке дать
ей определение. В известной степени проблема связана с тем, что операционные
системы выполняют две основные, но практически не связанные между собой
функции: расширение возможностей машины и управление ее ресурсами. И в за-
зависимости от того, какому пользователю вы зададите вопрос, вы услышите в ответ
больше или об одной функции, или о другой. Давайте рассмотрим обе.
1.1.1. Операционная система
как расширенная машина
Как было упомянуто ранее, архитектура (система команд, организация памяти,
ввод-вывод данных и структура шин) большинства компьютеров на уровне
машинного языка примитивна й неудобна для работы с программами, особенно
в отношении ввода-вывода данных. Чтобы это утверждение не показалось го-
голословным, кратко рассмотрим пример того, как происходит ввод-вывод данных
с гибкого диска через совместимые микросхемы контроллера NEC PD765, ис-
используемые на большинстве персональных компьютеров с процессором Intel.
(В этой книге мы будем использовать термины «гибкий диск» и «дискета» как
синонимы.) Контроллер PD765 поддерживает 16 команд, каждая требует пере-
передачи от 1 до 9 байт в регистр устройства. Это — команды для чтения и записи
данных, перемещения головки диска и форматирования дорожек, а также для
инициализации, распознавания, установки в исходное положение и калибровки
контроллера и приводов.
Основными командами являются команды read (чтение) и write (запись). Ка-
Каждая из них требует 13 параметров, упакованных в 9 байт. Эти параметры опре-
определяют такие вещи, как адрес блока на диске, который нужно прочитать, количе-
количество секторов на дорожке, физический режим записи, расстановку промежутков
между секторами. Они же сообщают, что делать с метками адресов удаленных
данных. Если вы не можете сразу все осмыслить, не волнуйтесь — полностью это
могут понять лишь несколько посвященных. Когда выполнение операции завер-
завершается, чип контроллера возвращает упакованные в 7 байт 23 параметра, отра-
отражающие наличие и типы ошибок. Но и этого недостаточно; программист при ра-
работе с гибким диском должен также постоянно знать, включен двигатель или
нет. Если двигатель выключен, его следует включить (с длительным ожиданием
запуска) прежде, чем данные будут прочитаны или записаны. Двигатель не может
оставаться включенным слишком долго, так как гибкий диск изнашивается. Про-
Программист вынужден выбирать между длинными задержками во время загрузки
и изнашивающимися гибкими дисками (с вероятностью потери данных на них).
Даже если не вдаваться в подробности этого процесса, становится ясно, что
обыкновенный программист вряд ли захочет столкнуться с такими деталями при
работе с гибким диском (или жестким диском, работа с ним не менее сложна, но
происходит совершенно иначе). Вместо этого программисту нужны простые вы-
высокоуровневые абстракции. В случае работы с дисками типичной абстракцией
является коллекция именованных файлов, содержащихся на диске. Каждый файл
может быть открыт для чтения или записи, прочитан или записан, а потом за-
закрыт. А такие детали, как текущее состояние двигателя или механизм модифи-
модифицированной частотной модуляции, используемый при записи, не должны отра-
отражаться в абстракции, предстающей перед пользователем.
Конечно же, программа, скрывающая истину об аппаратном обеспечении и пред-
представляющая простой список поименованных файлов, которые можно читать и за-
записывать, — это и есть операционная система. Операционная система не только
устраняет необходимость непосредственного взаимодействия дисками, не только
предоставляет простой ориентированный на работу с файлами интерфейс, но
и скрывает множество проблем, связанных с прерываниями, счетчиками време-
времени, организацией памяти и другими низкоуровневыми элементами. В каждом слу-
случае абстракция, предлагаемая операционной системой, намного проще и удобнее
в обращении, чем-то, что может предложить непосредственно основное обору-
оборудование.
С точки зрения пользователя операционная система выполняет функцию расши-
расширенной машины или виртуальной машины, для которой проще программировать
и с которой легче работать, чем непосредственно с аппаратным обеспечением.
История о том, каким образом операционная система достигает своей цели, —
получается долгой, и мы подробно опишем ее в нашей книге. Подведем итог вы-
вышесказанному: операционная система предоставляет нам ряд средств, которые
могут использовать программы с помощью специальных команд, называемых
системными вызовами. Мы приведем примеры наиболее общих системных вызо-
вызовов далее в этой главе.
1.1.2. Операционная система
как менеджер ресурсов
Концепция, в которой операционная система, прежде всего, рассматривается как
удобный интерфейс пользователя, — это взгляд сверху вниз. Альтернативный
взгляд, снизу вверх, дает представление об операционной системе как о механиз-
механизме, предназначенном для управления всеми частями компьютера. Современные
компьютеры состоят из процессоров, памяти, таймеров, дисков, мыши, сетевых
интерфейсов, принтеров и огромного количества других устройств. В соответ-
соответствии со вторым подходом назначение операционной системы — обеспечение
организованного и контролируемого распределения процессоров, памяти и уст-
устройств ввода-вывода между различными программами, состязающимися за пра-
право их использовать.
Представьте, что случилось бы, если бы три программы, работающие на одном
компьютере, одновременно попытались напечатать свои выходные данные на од-
одном и том же принтере. Возможно, первые несколько строк на листе появились
бы в результате работы первой программы, следующие несколько — в результате
работы второй, затем последовало бы несколько строк третьей программы и т. д.
В результате получилась бы полная неразбериха. Операционная система наводит
порядок в подобных ситуациях, буферизируя на диске все данные, предназначен-
предназначенные для печати. В процессе работы программы операционная система сохраняет ее
выходные данные на диске во временном файле. Затем, по окончании работы этой
программы, система отправляет данные на принтер, в то время как другая програм-
программа может продолжать формировать свои выходные данные, не обращая внимания
на то, что они пока еще фактически не посылаются на печатающее устройство.
Когда с компьютером (или сетью) работают несколько пользователей, сложность
управления памятью, устройствами ввода-вывода, другими ресурсами и их за-
защиты значительно возрастает, поскольку пользователи могут обращаться к ним
в абсолютно непредсказуемом порядке. К тому же часто приходится распреде-
распределять между пользователями не только оборудование, но и информацию (файлы,
базы данных и т. д.). С этой точки зрения основная задача операционной систе-
системы заключается в отслеживании того, кто и какой ресурс использует, в обработ-
обработке запросов на ресурсы, в подсчете степени загрузки и разрешении проблем кон-
конфликтующих запросов от различных программ и пользователей.
В рамках управления ресурсами различают два варианта их мультиплексирования
(совместного использования): временной и пространственный. При временном
мультиплексировании программы или пользователи задействуют ресурс по оче-
очереди. Примером является исполнение нескольких программ в однопроцессор-
однопроцессорной среде. Сначала операционная система предоставляет центральный процес-
процессор одной программе, затем, по прошествии достаточного временного интерва-
интервала, — другой и так далее, до тех пор пока очередь снова не дойдет до первой
программы. Определение алгоритма мультиплексирования (порядок и длитель-
длительность доступа к ресурсу) является задачей операционной системы. Еще один при-
пример временного мультиплексирования — совместное использование принтера.
При постановке нескольких заданий печати в очередь необходимо решить, какое
задание будет выполнено следующим.
Второй вид мультиплексирования — пространственный. Компоненты, желающие
использовать ресурс, не выстраиваются в очередь; вместо этого каждый из них
получает долю ресурса в свое распоряжение. Пространство оперативной памяти,
как правило, расходуется одновременно несколькими программами. Это позво-
позволяет им оставаться резидентными, например, для того, чтобы по очереди полу-
получать доступ к центральному процессору. При достаточном объеме оперативной
памяти компьютера эффективнее держать в ней сразу несколько программ, не-
нежели предоставлять одной программе всю память целиком (особенно если про-
программе требуется лишь небольшая ее доля). Разумеется, такой подход ставит во-
вопросы равноправия при выделении ресурса, защиты и т. д., и разрешение этих
вопросов возлагается на операционную систему. Еще одним примером ресур-
ресурса с пространственным мультиплексированием является жесткий диск. Во мно-
многих компьютерах несколько пользователей одновременно хранят свои файлы на
единственном жестком диске. Типичная задача управления ресурсами, решаемая
операционной системой, — выделение областей на жестком диске и наблюдение
за теми, кто ими пользуется.
1.2. История развития
операционных систем
История развития операционных систем насчитывает уже много лет. В следую-
следующих разделах книги мы кратко рассмотрим некоторые основные моменты. Так
как операционные системы появились и развивались в процессе конструирова-
конструирования компьютеров, то эти события исторически тесно связаны. Поэтому чтобы
представить, как выглядели операционные системы, мы обсудим следующие друг
за другом поколения компьютеров. Такая схема взаимосвязи поколений опера-
операционных систем и компьютеров довольно груба, но она обеспечивает некоторую
структуру, без которой ничего не было бы понятно.
Первый настоящий цифровой компьютер был изобретен английским математи-
математиком Чарльзом Бэббиджем (Charles Babbage, 1792-1871). Хотя большую часть жиз-
жизни Бэббидж посвятил попыткам создания своей «аналитической машины», он
так и не смог заставить ее работать должным образом. Это была чисто механиче-
механическая машина, а технологии того времени не были достаточно развиты. Не стоит
и говорить, что аналитическая машина Бэббиджа не имела операционной системы.
Интересный исторический факт: Бэббидж понимал, что для аналитической ма-
машины ему необходимо программное обеспечение, поэтому он нанял молодую
женщину по имени Ада Лавлейс (Ada Lovelace), дочь знаменитого британского
поэта Лорда Байрона. Она и стала первым в мире программистом, а язык про-
программирования Ada назван в ее честь.
1.2.1. Первое поколение A945-1955):
электронные лампы и коммутационные панели
После неудачных попыток Бэббиджа вплоть до Второй мировой войны в конст-
конструировании цифровых компьютеров не было практически никакого прогресса.
Примерно в середине 1940-х Говард Айкен (Howard Aiken) в Гарварде, Джон
фон Нейман (John von Neumann) в Принстонском институте, Дж. Преспер Эк-
керт (J. Presper Eckert), Вильям Мочли (William Mauchley) в Пенсильванском
университете, Конрад Цузе (Konrad Zuse) в Германии и многие другие продолжи-
продолжили работу в направлении создания вычислительных машин. На первых машинах
использовались механические реле, но они были очень медлительны, длитель-
длительность такта составляла несколько секунд. Позже реле заменили электронными
лампами. Машины получались громоздкими, занимающими целые комнаты, с де-
десятками тысяч электронных ламп, но все равно они были в миллионы раз мед-
медленнее, чем даже самый дешевый современный персональный компьютер.
В те времена каждую машину и разрабатывала, и строила, и программировала,
и эксплуатировала, и поддерживала в рабочем состоянии одна команда. Все
программирование выполнялось на абсолютном машинном языке, управление
основными функциями машины осуществлялось просто путем соединения ком-
коммутационных панелей проводами. Тогда еще не были известны языки програм-
мирования (даже ассемблера не было). Об операционных системах никто и не
слышал. Обычный режим работы программиста был таков: записаться на опре-
определенное время на специальном стенде, затем спуститься в машинную комнату,
вставить свою коммутационную панель в компьютер и провести несколько следую-
следующих часов в надежде, что во время работы ни одна из двадцати тысяч электрон-
электронных ламп не выйдет из строя. Фактически, тогда на компьютерах занимались
только прямыми числовыми вычислениями, например расчетами таблиц сину-
синусов, косинусов и логарифмов.
К началу 50-х, с выпуском перфокарт, установившееся положение несколько
улучшилось. Стало возможно вместо использования коммутационных панелей
записывать программы на карты и считывать их с карт, но во всем остальном
процедура вычислений оставалась прежней.
1.2.2. Второе поколение A955-1965):
транзисторы и системы пакетной обработки
В середине 50-х изобретение и применение транзисторов радикально изменило
всю картину. Компьютеры стали достаточно надежными, машины с высокой ве-
вероятностью могли работать довольно долго, выполняя при этом полезные функ-
функции. Впервые сложилось четкое разделение между проектировщиками, сборщи-
сборщиками, операторами, программистами и обслуживающим персоналом.
Машины, теперь называемые мэйнфреймами, располагались в специальных комна-
комнатах с кондиционированным воздухом, где ими управлял целый штат профессио-
профессиональных операторов. Только большие корпорации, правительственные учрежде-
учреждения или университеты могли позволить себе технику, цена которой исчислялась
миллионами долларов. Чтобы выполнить задание (то есть программу или комплект
программ), программист сначала должен был записать его на бумаге (на языке
FORTRAN или на ассемблере), а затем перенести на перфокарты. После этого
требовалось принести колоду перфокарт в комнату ввода данных, передать од-
одному из операторов и идти пить кофе в ожидании, когда будет готов результат.
Когда компьютер заканчивал выполнение какого-либо из текущих заданий, опе-
оператор подходил к принтеру, отрывал лист с полученными данными и относил
его в комнату для распечаток, где программист позже мог его забрать. Затем опе-
оператор брал одну из колод перфокарт, принесенных из комнаты ввода данных,
и помещал в механизм считывания. Если в процессе расчетов был необходим
компилятор языка FORTRAN, то оператору приходилось брать его из картотечного
шкафа и загружать в машину отдельно. Из-за одного только хождения операторов
по машинному залу впустую терялась масса драгоценного компьютерного времени.
Если учитывать высокую стоимость оборудования, не удивительно, что люди до-
довольно скоро занялись поиском оптимизации использования машинного времени.
Общепринятым решением стала система пакетной обработки. Первоначально
замысел состоял в том, чтобы собрать все задания (колоды перфокарт) в комнате
входных данных и затем переписать их на магнитную ленту, используя неболь-
небольшой и (относительно) недорогой компьютер, например IBM 1401, который был
очень хорош для считывания карт, копирования лент и печати выходных дан-
данных, но не подходил для числовых вычислений.
Другие, более дорогостоящие машины, такие как IBM 7094, использовались для
настоящих вычислений (рис. 1.2).
Рис. 1.2. Ранняя система пакетной обработки: а — программист приносит карты для IBM 1401;
б — IBM 1401 записывает пакет заданий на магнитную ленту; в — оператор приносит входные
данные на ленте к IBM 7094; г — IBM 7094 выполняет вычисления; д — оператор переносит
ленту с выходными данными на IBM 1401; е — IBM 1401 печатает выходные данные
Примерно после часа, затрачиваемого на сбор пакета заданий, лента перематыва-
перематывалась и ее относили в машинную комнату, где устанавливали на лентопротяжном
устройстве. Затем оператор загружал специальную программу (прообраз се-
сегодняшней операционной системы), которая считывала первое задание с ленты
и запускала его. Выходные данные записывались на вторую ленту вместо того,
чтобы идти на печать. Завершив очередное задание, операционная система авто-
автоматически считывала с ленты следующее и начинала обрабатывать его. После
обработки всего пакета оператор снимал ленты с входной и выходной инфор-
информацией, ставил новую ленту со следующим заданием, а готовые данные поме-
помещал на IBM 1401 для печати в автономном режиме (то есть без связи с главным
компьютером).
Структура типичного входного задания показана на рис. 1.3. Оно начиналось
с карты $ЗАДАНИЕ, на которой указывалось максимальное время выполне-
выполнения задания в минутах, загружаемый учетный номер и имя программиста. Затем
поступала карта SFORTRAN, дающая операционной системе указание загру-
загрузить компилятор языка FORTRAN с системной магнитной ленты. Эта карта
следовала за программой, которую нужно было компилировать, а после нее шла
карта $ЗАГРУЗИТЬ, указывающая операционной системе загрузить только что
скомпилированную объектную программу. (Скомпилированные программы час-
часто записывались на временных лентах, данные с которых могли стираться сразу
после использования, и их загрузка должна была выполняться явно.) Следом
шла карта $ЗАПУСТИТЬ с данными, дающая операционной системе команду
выполнять программу. Наконец, карта завершения $КОНЕЦ отмечала конец за-
задания. Эти примитивные управляющие перфокарты были предшественниками
современных языков управления и интерпретаторов команд.
Рис. 1.3. Структура типичного FMS-задания
Большие компьютеры второго поколения использовались главным образом для
научных и технических вычислений, таких как решение дифференциальных
уравнений в частных производных, часто встречающихся в физике и инженер-
инженерных расчетах. В основном на них программировали на языке FORTRAN и ас-
ассемблере, а типичными операционными системами были FMS (Fortran Monitor
System) и IBSYS (операционная система, созданная корпорацией IBM для ком-
компьютера IBM 7094).
1.2.3. Третье поколение A965-1980):
интегральные схемы и многозадачность
К началу 60-х годов большинство производителей выпускало две полностью не-
несовместимые линейки компьютеров. С одной стороны, существовали большие
компьютеры с пословной обработкой текста типа IBM 7094, использовавшиеся для
числовых вычислений в науке и технике. С другой стороны, выпускались коммер-
коммерческие компьютеры с посимвольной обработкой, такие как IBM 1401, широко
применявшиеся в банках и страховых компаниях для сортировки и печати данных.
Развитие, поддержка и маркетинг двух совершенно разных линеек компьютеров
для изготовителей были достаточно дорогим удовольствием. Кроме того, многим
покупателям изначально требовалась небольшая машина, однако позже ее воз-
возможностей становилось недостаточно, и требовался более мощный компьютер,
который имел бы ту же архитектуру и работал бы с теми же самыми программа-
программами, но быстрее.
Корпорация IBM попыталась решить эти проблемы разом, выпустив линейку
машин IBM/360. Это была серия программно совместимых машин, начиная от
компьютеров размером с IBM 1401 и заканчивая машинами, значительно более
мощными, чем IBM 7094. Они различались только ценой и производительностью
(максимальным объемом памяти, быстродействием процессора, количеством
устройств ввода-вывода и т. д.). Так как все машины имели одинаковую архитек-
архитектуру и набор команд, программы, написанные для одного компьютера, могли
работать на всех других (по крайней мере, в теории). Кроме того, семейство ма-
машин 360 было разработано для поддержки как научных (то есть численных), так
и коммерческих вычислений. Одно семейство машин могло удовлетворить нужды
всех покупателей. В последующие годы, используя более современные техноло-
технологии, корпорация IBM выпустила компьютеры, совместимые с 360, эти машины
известны под номерами 370, 4300, 3080, 3090 и Z.
Семейство машин 360 стало первой основной линейкой компьютеров, на кото-
которой использовались малые интегральные схемы, дававшие преимущество в цене
и качестве по сравнению с машинами второго поколения, созданными на базе от-
отдельных транзисторов. Корпорация IBM добилась мгновенного успеха, а идею
семейства совместимых компьютеров скоро приняли и все остальные основные
производители. В компьютерных центрах до сих пор можно встретить потомков
этих машин. Они еще используются для управления огромными базами дан-
данных (например, для систем бронирования и продажи билетов на авиалиниях)
или как серверы узлов Интернета, которые должны обрабатывать тысячи за-
запросов в секунду.
Основное преимущество «одного семейства» оказалось одновременно и вели-
величайшей его слабостью. По замыслу его создателей все программное обеспечение,
включая операционную систему OS/360, должно было одинаково хорошо рабо-
работать на всех моделях компьютеров: и в небольших системах, которые часто заме-
заменяли машины 1401 и применялись для копирования перфокарт на магнитные
ленты, и на огромных системах, заменяющих машины 7094 и использовавшихся
для расчета прогноза погоды и других сложных вычислений. Кроме того, пред-
предполагалось, что одну операционную систему можно будет использовать как с не-
несколькими внешними устройствами, так и с большим их количеством; а также
как в коммерческих, так и в научных областях. Но самым важным было, чтобы
это семейство машин давало результаты независимо от того, кто и как его ис-
использует.
Однако ни IBM, ни кому-либо другому пока не удалось написать программного
обеспечения, удовлетворяющего всем этим противоречивым требованиям. В ре-
результате появилась огромная и необычайно сложная операционная система, при-
примерно на два или три порядка превышающая по сложности FMS. Она состояла
из миллионов строк, написанных на ассемблере тысячами программистов, содер-
содержала тысячи и тысячи ошибок, что повлекло за собой непрерывный поток новых
версий, в которых устранялась часть ошибок, но вместо них появлялись новые,
так что общее их число, вероятно, оставалось постоянным.
Один из разработчиков OS/360, Фред Брукс (Fred Brooks), впоследствии написал
остроумную и язвительную книгу с описанием своего опыта работы с OS/360
[14]. Мы не можем здесь дать полную оценку этой книги, но достаточно будет
сказать, что на ее обложке изображено стадо доисторических животных, увяз-
увязших в яме с дегтем. Обложка книги [107] демонстрирует похожую точку зрения
на операционные системы, бывшие динозаврами в мире компьютеров.
Несмотря на свои огромные размеры и недостатки, система OS/360 и подобные
ей операционные системы третьего поколения, созданные другими произво-
производителями компьютеров, на самом деле достаточно неплохо удовлетворяли тре-
требованиям большинства клиентов. Они даже сделали популярными несколько
ключевых технических приемов, не поддерживаемых в операционных системах
второго поколения. Самым важным достижением явилась многозадачность. На
компьютере IBM 7094, когда текущая работа приостанавливалась в ожидании
операций ввода-вывода с магнитной ленты или других устройств, центральный
процессор просто бездействовал до окончания операции ввода-вывода. В слож-
сложных научных вычислениях и при ограниченных возможностях процессора уст-
устройства ввода-вывода задействовались довольно редко, так что это потраченное
впустую время не играло существенной роли. Но при коммерческой обработке
данных время ожидания устройства ввода-вывода могло занимать 80 или 90 %
всего рабочего времени, поэтому необходимо было что-нибудь сделать во избе-
избежание длительного простоя весьма дорогостоящего процессора.
Решение этой проблемы заключалось в разбиении памяти на несколько частей,
называемых разделами, каждому из которых давалось отдельное задание, как по-
показано на рис. 1.4. Пока одно задание ожидало завершения работы устройства
ввода-вывода, другое могло использовать центральный процессор. Если в опе-
оперативной памяти содержалось достаточное количество заданий, центральный
процессор мог быть загружен почти на все 100 % по времени. Множество одно-
одновременно хранящихся в памяти заданий требовало наличия специального обору-
оборудования для защиты каждого задания от возможного любопытства и ущерба со
стороны остальных заданий. Машина 360 и другие системы третьего поколения
были снабжены подобными аппаратными средствами.
Рис. 1.4. Многозадачная система с тремя заданиями в памяти
Другим важным достоинством операционных систем третьего поколения стала
способность считывать задание с перфокарт на диск по мере того, как их прино-
приносили в машинный зал. Всякий раз, когда текущее задание заканчивалось, опе-
операционная система могла загрузить новое задание с диска в освободившийся
раздел памяти и запустить его. Этот технический прием называется подкачкой
данных, или спулингом (английское слово spooling произошло от аббревиатуры
SPOOL, которая расшифровывается как Simultaneous Peripheral Operation On
Line — совместные периферийные операции в режиме подключения), и его также
используют для выдачи полученных данных. С появлением механизма подкачки
машины 1401 стали более не нужными, а многократные перемещения магнитных
лент сошли «на нет».
Хотя операционные системы третьего поколения вполне подходили для слож-
сложных научных вычислений и справлялись с крупными коммерческими задачами,
они все еще, по существу, представляли собой разновидности систем пакетной
обработки. Многие программисты тосковали по первому поколению машин, ко-
когда они могли распоряжаться всей машиной в течение нескольких часов и имели
возможность быстро отлаживать свои программы. В системах третьего поколе-
поколения временной промежуток между передачей задания и возвращением результа-
результатов часто составлял несколько часов, так что одна лишняя запятая могла стать
причиной сбоя при компиляции, и получалось, что программист тратил впустую
половину дня.
Желание сократить время ожидания ответа привело к разработке системы раз-
разделения времени, варианту многозадачной системы, в которой у каждого пользо-
пользователя есть свой диалоговый терминал. Если двадцать пользователей зарегист-
зарегистрированы в системе, работающей в режиме разделения времени, и семнадцать из
них думают, беседуют или пьют кофе, то центральный процессор по очереди
предоставляется трем пользователям, желающим работать на машине. Так как
люди, отлаживая программы, обычно выполняют короткие команды (например,
компилировать процедуру на пяти страницах) чаще, чем длинные (например,
упорядочить файл с миллионами записей), то компьютер может обеспечивать
быстрое интерактивное обслуживание нескольких пользователей. При этом он
может работать с большими пакетами в фоновом режиме, когда центральный
процессор не занят другими заданиями. Первая серьезная система разделения
времени под названием CTSS (Compatible Time Sharing System — совместимая
система разделения времени) была разработана в Массачусетсском технологиче-
технологическом институте (M.I.T.) на специально переделанном компьютере IBM 7094 [23].
Однако разделение времени не стало действительно популярным до тех пор, по-
пока среди машин третьего поколения не получили широкого распространения не-
необходимые технические средства защиты.
После успеха системы CTSS Массачусетсский технологический институт, иссле-
исследовательские лаборатории Bell Labs и корпорация General Electric (тогда — глав-
главный изготовитель компьютеров) решили начать разработку «компьютерного
приложения» — машины, которая должна была поддерживать одновременную
работу сотен пользователей в режиме разделения времени. Образцом для новой
машины послужила система распределения электроэнергии. Когда вам нужна
электроэнергия, вы просто вставляете вилку в розетку и получаете энергии столь-
столько, сколько вам нужно. Проектировщики этой системы, известной как MULTICS
(MULTiplexed Information and Computing Service — мультиплексная информаци-
информационная и вычислительная служба), представляли себе одну огромную вычислитель-
вычислительную машину, воспользоваться которой мог каждый человек в районе Бостона.
Мысль о том, что машины, гораздо более мощные, чем их мэйнфрейм GE-645,
будут продаваться миллионами по цене тысяча долларов за штуку всего лишь
через тридцать лет, казалась чистейшей научной фантастикой, как если бы сего-
сегодня кто-либо вздумал проектировать сверхзвуковые трансатлантические подвод-
подводные поезда.
Успех MULTICS не был полным. Предполагалось, что система сможет обслужи-
обслуживать сотни пользователей, будучи лишь немногим мощнее персональных компь-
компьютеров на базе Intel 80386 (хотя система MULTICS значительно превосходила
их в объеме ввода-вывода). Идея была не столь безумна, как кажется, поскольку
в то время люди умели писать компактные и эффективные программы (похоже,
впоследствии это умение было утрачено). Системе MULTICS не удалось поко-
покорить мир в силу целого ряда причин, весьма важной из которых является ис-
использование языка PL/I для ее создания. Компилятор PL/I появился с опозда-
опозданием на несколько лет и оказался практически нефункциональным. Кроме того,
для своего времени система MULTICS была чересчур амбициозной, подобно
аналитической машине Бэббиджа в XIX веке.
В итоге система MULTICS стала источником многих конструктивных идей для
компьютерных теоретиков, но превратить ее в серьезный продукт и добиться
коммерческого успеха оказалось намного труднее, чем ожидалось. Группа иссле-
исследовательских лабораторий Bell Labs выбыла из проекта, а компания General
Electric совсем оставила компьютерный бизнес. Однако Массачусетсский техно-
технологический институт проявил упорство и со временем получил вполне работо-
работоспособную систему. В конце концов, она была продана как коммерческое из-
изделие компанией Honeywell, купившей компьютерный бизнес General Electric,
и установлена примерно в восьмидесяти больших компаниях и университетах по
всему миру. Несмотря на небольшой тираж системы MULTICS, ее пользователи
проявили исключительную лояльность к своему приобретению. Компании General
Motors, Ford и Национальное агентство безопасности США свернули системы
MULTICS лишь в конце 90-х, а последняя машина MULTICS, работавшая в Ми-
Министерстве обороны Канады, была снята с эксплуатации в октябре 2000 г. Не-
Несмотря на неудачу с точки зрения коммерции, система MULTICS значительно
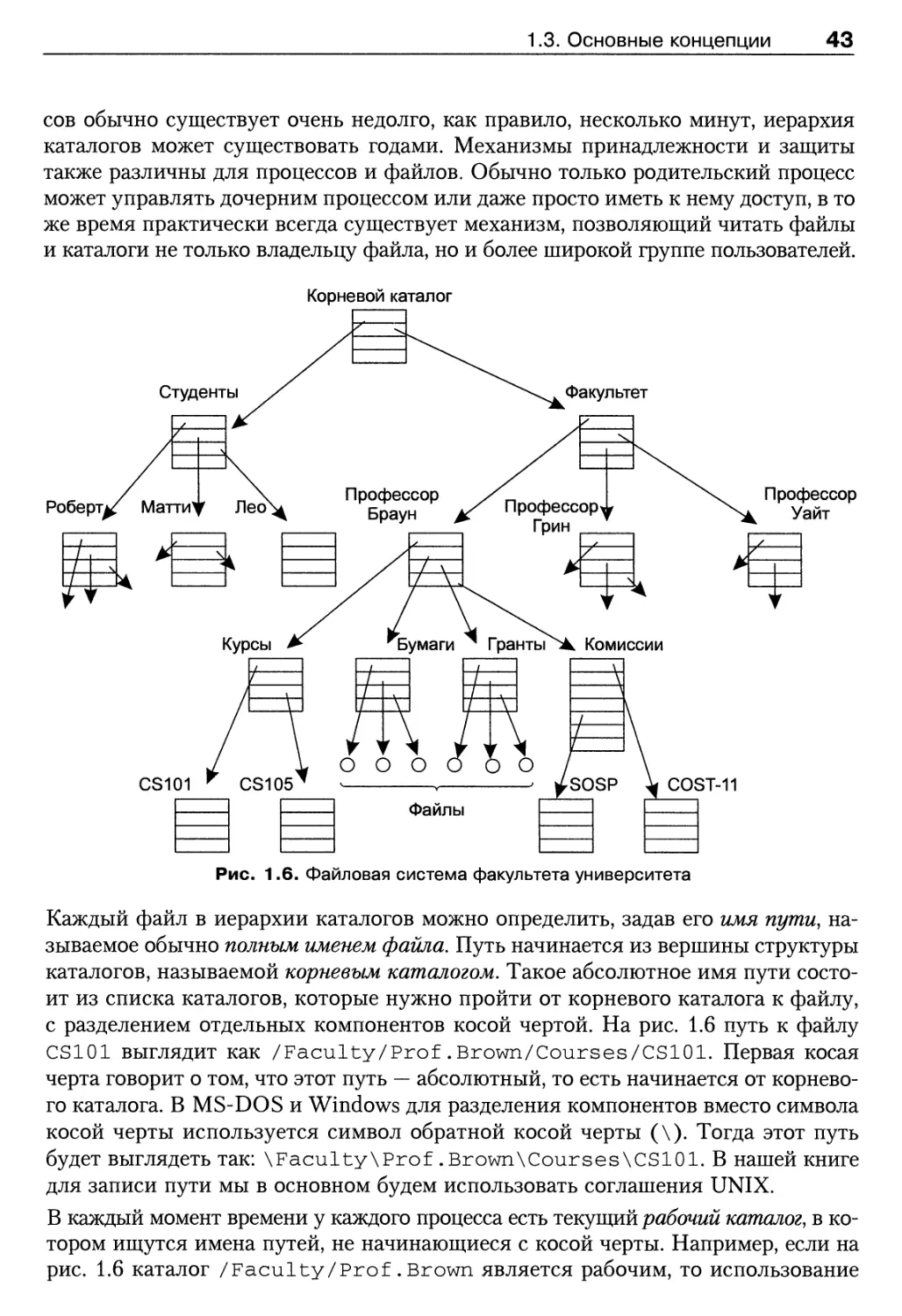
повлияла на последующие операционные системы [24, 25, 28, 94, 101]. В Интерне-
Интернете имеется веб-сайт, на котором представлена обширная информация о системе
MULTICS, ее разработчиках и пользователях (www.multicians.org).
Словосочетание «компьютерное приложение» вышло из употребления, однако
в последние годы его идея получила «вторую жизнь». В простейшем случае компь-
компьютеры, или рабочие станции (персональные компьютеры большой мощности),
расположенные в компании или классной комнате, посредством локальной сети
подключаются к файловому серверу, хранящему все программы и данные. При
такой топологии системный администратор устанавливает и обеспечивает защиту
единственного набора программ и данных. Администратору не нужно заботить-
заботиться об извлечении и сохранении локальных данных неисправного компьютера;
он может без проблем переустановить его программное обеспечение. В неодно-
неоднородном окружении появляется дополнительный класс программ, называемых
промежуточным, или связующим, программным обеспечением и заполняющих про-
пробел между локальными пользователями и файлами, программами и базами дан-
данных, расположенными на удаленных серверах. Благодаря связующим програм-
программам пользователи воспринимают сетевые персональные компьютеры и рабочие
станции как локальные. Связующие программы создают единый пользователь-
пользовательский интерфейс в условиях неоднородности серверов, компьютеров и рабочих
станций. Хорошим примером является веб-браузер. Он отображает пользовате-
пользователю документы в едином виде, при этом текст документа может находиться на од-
одном сервере, графика — на другом, а таблица стилей, определяющая формат до-
документа, — на третьем. Как правило, веб-интерфейс используется компаниями и
университетами для доступа к базам данных и запуска программ на компьютере,
расположенном в другом здании или даже в другом городе. Может показаться,
что связующие программы образуют операционную систему для распределенной
системы, однако, на самом деле, они вообще не являются операционной систе-
системой и их рассмотрение выходит за рамки темы этой книги. Более подробную
информацию о распределенных системах вы найдете в [117].
Еще одним важным моментом развития третьего поколения машин был феноме-
феноменальный рост числа мини-компьютеров после выпуска машины PDP-1 корпораци-
корпорацией DEC в 1961 году. Компьютеры PDP-1 обладали оперативной памятью, состоя-
состоящей всего лишь из 4 К 18-разрядных слов, но стоили они по 120 тысяч долларов
за штуку (это меньше 5 % цены IBM 7094) и поэтому расхватывались как горячие
пирожки. На некоторых видах нечисловой работы они работали почти с такой
же скоростью, как IBM 7094, что стало толчком к рождению новой индустрии.
За этой машиной последовала целая серия других машин семейства PDP (в отли-
отличие от семейства IBM, полностью несовместимых), и как кульминация — PDP-11.
Кен Томпсон (Ken Thompson), один из специалистов по компьютерам в Bell Labs,
работавший над проектом MULTICS, впоследствии нашел мини-компьютер
PDP-7, которым никто не пользовался, и решил написать усеченную однопользо-
однопользовательскую версию системы MULTICS. Эта работа позже развилась в операцион-
операционную систему UNIX, ставшую популярной в академическом мире, в правительст-
правительственных управлениях и во многих компаниях.
История развития UNIX уже многократно описывалась в самых различных кни-
книгах (см., например, [103]). По причине широкой доступности исходного кода
различные организации создавали собственные (несовместимые) версии, что при-
привело к хаосу. Были разработаны две главные версии UNIX: System V корпорации
AT&T и BSD (Berkeley Software Distribution) Калифорнийского университета
Беркли. Эти системы, в свою очередь, распадаются на отдельные разновидности,
среди которых в настоящее время известны FreeBSD, OpenBSD и NetBSD. Чтобы
можно было писать программы, работающие в любой системе UNIX, Институт
инженеров по электротехнике и электронике (Institute of Electrical and Electronic
Engineers, IEEE) разработал стандарт системы UNIX, называемый POSIX, кото-
который теперь поддерживают большинство версий UNIX. Стандарт POSIX опреде-
определяет минимальный интерфейс системного вызова, который должны поддержи-
поддерживать совместимые с UNIX системы. Некоторые другие операционные системы
теперь тоже поддерживают интерфейс POSIX. Информация, необходимая для
написания программ в стандарте POSIX, вполне доступна [64, 79]. Далее в этой
книге под именем UNIX мы будем понимать все POSIX-совместимые опера-
операционные системы, за исключением особо оговоренных случаев. Несмотря на
внутренние отличия, эти системы следуют стандарту POSIX и весьма схожи
друг с другом с точки зрения программиста.
1.2.4. Четвертое поколение (с 1980 года
по наши дни): персональные компьютеры
Следующий период эволюции операционных систем связан с появлением боль-
больших интегральных схем (Large Scale Integration, LSI) — кремниевых микросхем,
содержащих тысячи транзисторов на одном квадратном сантиметре. Это поколе-
поколение стало поколением персональных компьютеров на базе микропроцессоров.
С точки зрения архитектуры персональные компьютеры (первоначально назы-
называемые микрокомпьютерами) были во многом похожи на мини-компьютеры
класса PDP-11, но, конечно, отличались по цене. Если появление мини-компью-
мини-компьютеров позволило отделам компаний и факультетам университетов иметь собст-
собственный компьютер, то с появлением микропроцессоров каждый человек полу-
получил возможность купить собственный персональный компьютер.
Было создано несколько семейств микрокомпьютеров. В 1974 году фирма Intel
представила первый 8-разрядный микропроцессор общего назначения 8080. Ряд
компаний производил полноценные компьютерные системы, оснащенные про-
процессором 8080 (или совместимым Zilog Z80) и операционной системой СР/М
(Control Program for Microcomputers — программа управления микрокомпью-
микрокомпьютерами) компании Digital Research. Такие системы получили широкое распро-
распространение. Для СР/М было написано множество программ, а сама операционная
система удерживала лидерство в мире персональных компьютеров на протяже-
протяжении приблизительно 5 лет.
Фирма Motorola также представила 8-разрядный микропроцессор — 6800. После
того как группа инженеров внесла ряд предложений по его усовершенствованию,
которые были отвергнуты, она выделилась в компанию MOS Technology и раз-
разработала центральное процессорное устройство 6502. Этим устройством были
оснащены некоторые первые персональные компьютеры. Одна из их разновид-
разновидностей, Apple II, стала главным конкурентом СР/М на рынке домашних и об-
образовательных компьютеров. Тем не менее популярность СР/М была столь
высока, что многие владельцы Apple II приобретали сопроцессорные платы рас-
расширения Z-80 для получения возможности работать с системой СР/М (процес-
(процессор 6502 несовместим с этой ОС). Платы СР/М выпускала небольшая компания
Microsoft, заодно являвшаяся поставщиком интерпретаторов BASIC для ряда
микрокомпьютеров под управлением СР/М.
Следующее поколение микропроцессоров было 16-разрядным. Фирма Intel пред-
предложила процессор 8086, а в начале 1980-х компанией IBM был выпущен пер-
персональный компьютер IBM PC на основе процессора Intel 8088 (внутренний
процессор 8086 с внешним 8-разрядным трактом данных). Компания Microsoft
предложила IBM пакет, включавший собственный интерпретатор BASIC и опера-
операционную систему DOS (Disk Operating System — дисковая операционная система).
Система DOS была разработана другой компанией, однако компания Microsoft
приобрела продукт и заключила с автором договор об усовершенствовании опера-
операционной системы. В результате появилась операционная система MS-DOS (Micro-
(Microsoft DOS), быстро завоевавшая рынок IBM PC.
Операционные системы СР/М, MS-DOS и APPLE DOS имели интерфейс ко-
командной строки, с помощью которого пользователи вводили команды с кла-
клавиатуры. Несколькими годами ранее сотрудник исследовательского института
Стэнфорда Дуг Энгельбарт (Doug Elgelbart) изобрел графический интерфейс
пользователя (Graphical User Interface, GUI), включавший окна, значки, меню
и мышь. Стив Джобе (Steve Jobs) из компании Apple увидел возможность со-
создания системы с дружественным интерфейсом (для пользователей, не только
ничего не знающих о компьютерах, но и не желающих заниматься их изучени-
изучением), и в начале 1984 было объявлено о создании компьютера Apple Macintosh.
Компьютер был оснащен 16-разрядным центральным процессором Motorola
68000 и 64 Кбайт постоянной памяти (Read Only Memory, ROM) для поддерж-
поддержки графического интерфейса. В последующие годы компьютер Macintosh был
усовершенствован: процессоры стали 32-разрядными, а затем фирма Apple пере-
перешла к использованию процессоров IBM PowerPC с RISC-архитектурой, сначала
32-, позднее — 64-разрядной. В 2001 году Apple кардинально изменила операци-
операционную систему, выпустив Mac OS X с новой версией графического интерфейса
Macintosh на основе Berkley UNIX. В 2005 году компания заявила о намерении
перейти к использованию процессоров Intel.
Чтобы составить конкуренцию Macintosh, компания Microsoft разработала опе-
операционную систему Windows. Изначально Windows представляла собой лишь
графическую среду, работающую поверх 16-разрядной ОС MS-DOS; другими
словами, она являлась скорее оболочкой, нежели настоящей операционной сис-
системой. Что же касается текущих версий Windows, это — потомки ОС Windows
NT, написанной «с нуля».
Другой значимый претендент на лидерство в мире персональных компьютеров —
операционная система UNIX и различные ее ответвления. Она доминирует на
рабочих станциях и других мощных компьютерах, таких как сетевые серверы.
Особенно распространена эта ОС среди высокопроизводительных систем на RISC-
процессорах. На компьютерах с процессором Pentium популярной альтернати-
альтернативой Windows является ОС Linux, все чаще используемая студентами и корпора-
корпоративными клиентами (в данной книге термином «Pentium» мы будем обозначать
все семейство одноименных процессоров, включая маломощные Celeron, высо-
высокопроизводительные Хеоп и совместимые микропроцессоры AMD).
Хотя многие пользователи UNIX, особенно опытные в программировании, пред-
предпочитают командную строку графическому интерфейсу, практически все систе-
системы UNIX поддерживают оконную среду X Windows, разработанную M.I.T. Эта
среда позволяет пользователю создавать, удалять, перемещать и изменять размеры
окон при помощи мыши. Зачастую существует возможность использования пол-
полноценного графического интерфейса пользователя на базе X Window, к примеру,
интерфейса Motif. Это позволяет любителям графического режима придать
UNIX внешний вид, напоминающий Macintosh и Microsoft Windows.
С середины 80-х годов начали расти и развиваться сети персональных компьюте-
компьютеров, управляемых сетевыми и распределенными операционными системами [117].
В сетевой операционной системе пользователи знают о существовании много-
многочисленных компьютеров, могут регистрироваться на удаленных машинах и ко-
копировать файлы с одной машины на другую. Каждый компьютер работает под
управлением локальной операционной системы и имеет собственного локально-
локального пользователя (или пользователей). Как правило, компьютеры работают неза-
независимо друг от друга.
Сетевые операционные системы мало отличаются от однопроцессорных опера-
операционных систем. Ясно, что они нуждаются в сетевом интерфейсном контроллере
и специальном низкоуровневом программном обеспечении, поддерживающем
работу контроллера, а также в программах, разрешающих пользователям удален-
удаленную регистрацию в системе и доступ к удаленным файлам. Но эти дополнения,
по сути, не изменяют структуру операционной системы.
Распределенная операционная система, напротив, представляется пользователям
традиционной однопроцессорной системой, хотя она и функционирует на мно-
множестве процессоров. При этом пользователи не должны беспокоиться о том, где
работают их программы или где расположены файлы; все это должно автомати-
автоматически и эффективно обрабатываться самой операционной системой.
Чтобы создать настоящую распределенную операционную систему, недостаточ-
недостаточно просто добавить несколько страниц кода к однопроцессорной операционной
системе, так как распределенные и централизованные системы имеют сущест-
существенные различия. Распределенные системы, например, часто позволяют при-
прикладным заданиям одновременно обрабатываться на нескольких процессорах,
поэтому требуется более сложный алгоритм загрузки процессоров для оптими-
оптимизации распараллеливания.
Наличие задержек при передаче данных в сетях означает, что эти алгоритмы
должны справляться с неполной, устаревшей или даже неправильной информа-
информацией. Эта ситуация радикально отличается от однопроцессорной системы, в ко-
которой операционная система обладает полной информацией относительно со-
состояния системы.
1.2.5. История MINIX 3
Во времена молодости UNIX (версии 6) ее исходные коды были широко дос-
доступны по лицензии AT&T и активно изучались. Джон Лайонс (John Lions) из
университета Нового Южного Уэльса в Австралии даже написал небольшую
брошюру, шаг за шагом описывающую работу UNIX [82]. С разрешения AT&T
эта брошюра использовалась во многих университетских курсах по операцион-
операционным системам.
С выходом версии 7 стало ясно, что система UNIX превратилась в дорогостоя-
дорогостоящий коммерческий продукт, поэтому лицензия, под которой распространялась
версия 7, запрещала преподавание исходного кода на учебных курсах, чтобы не
подвергать риску его статус коммерческого секрета. Поэтому многие универси-
университеты просто прекратили изучение UNIX, довольствуясь одной теорией.
К сожалению, изучение одной только теории формирует у студентов однобо-
однобокий взгляд на то, какой в действительности может быть операционная система.
В книгах и курсах, посвященных операционным системам, в подробностях рас-
рассматриваются чисто теоретические вопросы, например алгоритмы планирова-
планирования, которые на практике не столь важны. Действительно важные вещи, такие
как ввод-вывод и файловые системы, зачастую опускаются, так как им не посвя-
посвящено достаточно теории.
Чтобы исправить ситуацию, один из авторов этой книги (Э. Таненбаум) решил
написать собственную операционную систему, которая с точки зрения пользова-
пользователя совместима с UNIX, но внутри совершенно самостоятельна. Так как в этой
системе не используется ни строчки кода AT&T, она не попадает под действие
лицензионных ограничений и может свободно использоваться при обучении.
Таким образом, студенты могут «вскрывать» реальную операционную систему,
чтобы увидеть, как она устроена изнутри, точно так же, как студенты-медики
вскрывают лягушек. Название MINIX происходит от mini-UNIX, так как эта
система достаточно мала, чтобы даже начинающий мог понять, как она работает.
У MINIX есть и еще одно преимущество перед UNIX. Она на десять лет моложе
UNIX, поэтому ее код в большей степени обладает модульной структурой. На-
Например, начиная с первой версии MINIX, файловая система и менеджер памяти
вообще не являются частью операционной системы, а работают как отдельные
пользовательские программы. В текущем выпуске ОС (MINIX 3) такая модуль-
модульность распространилась и на драйверы устройств ввода-вывода — все они, за ис-
исключением драйвера часов, выполняются в пользовательском режиме. Другое от-
отличие в том, что система UNIX создавалась, чтобы быть эффективной, а MINIX —
чтобы быть понятной (насколько может быть понятным текст любой программы
из тысяч страниц). Поэтому, например, в коде системы MINIX имеются множе-
множество комментариев.
ОС MINIX разрабатывалась в расчете на совместимость с UNIX версии 7. Эта
версия была выбрана за основу благодаря ее простоте и элегантности. Иногда го-
говорят, что версия 7 лучше не только по сравнению с предыдущими версиями, но
и по сравнению с последующими. С пришествием POSIX, развитие MINIX нача-
начало стремиться к новому стандарту, поддерживая в то же время обратную совмес-
совместимость с существующими программами. Это — обычный для компьютерной ин-
индустрии путь развития, так как никакой производитель не захочет поставлять
систему, которой никто не может пользоваться. Рассматриваемая в этой книге
система MINIX версии 3 базируется на стандарте POSIX.
Как и UNIX, ОС MINIX написана на языке программирования С, чтобы упро-
упростить ее перенос на различные компьютеры. Первая реализация предназначалась
для IBM PC, а затем система была перенесена на целый ряд других платформ.
Придерживаясь философии «меньше да лучше», MINIX изначально не требо-
требовала для работы жесткого диска, тем самым вписываясь в студенческий бюд-
бюджет (сейчас это может показаться удивительным, но в середине 80-х, когда ОС
MINIX впервые увидела свет, жесткие диски все еще были дорогостоящей дико-
диковинкой). Со временем и функциональность, и объем системы росли, и в итоге
потребовался жесткий диск. Но философия MINIX не была забыта, и для рабо-
работы вполне достаточно раздела объемом 200 Мбайт. В противоположность этому,
даже небольшая система Linux на сегодняшний день требует 500 Мбайт диско-
дискового пространства, а для установки основных приложений необходимо несколь-
несколько гигабайтов.
Для среднего пользователя, сидящего за IBM PC, MINIX мало отличается от
UNIX. Имеются стандартные программы, такие как cat, grep, Is, make, выпол-
выполняющие те же действия, что и их аналоги в UNIX. Как и сама операционная сис-
система, эти программы были полностью переписаны автором, студентами и неко-
некоторыми другими посвященными людьми, чтобы избежать использования кода,
являющегося собственностью AT&T или других компаний. В настоящее время
существует большое количество бесплатно распространяемых программ, и во
многих случаях их удалось перенести (рекомпилировать) на MINIX.
Развитие MINIX продолжалось в течение 10 лет. В результате в 1997 году по-
появилась система MINIX версии 2, а с ней — и вторая редакция этой книги, описы-
описывавшая новую операционную систему. Изменения были значительными, но эво-
эволюционными, к примеру, от 16-разрядного процессора 8088 в реальном режиме
и гибких дисков был сделан переход к 32-разрядному процессору 386 в защи-
защищенном режиме и использованию жесткого диска.
Неторопливая и систематичная работа продолжалась до 2004 года, когда Та-
ненбаум пришел к выводу о том, что программное обеспечение стало слишком
громоздким и утратило надежность. Он решил вдохнуть в MINIX новую жизнь
и совместно с программистами и студентами Университета Врие (Vrije Universiteit)
в Амстердаме создал операционную систему MINIX 3. Она получилась в результа-
результате значительной переработки предыдущих версий: структура ядра была изменена,
его объем сокращен, а акцент сделан на модульности и надежности. Новая вер-
версия предназначена как для персональных компьютеров, так и для встроенных
систем, где компактность, модульность и надежность являются первостепенными
факторами. Несмотря на настойчивое желание некоторых разработчиков полно-
полностью переименовать операционную систему, в конечном счете было решено на-
назвать ее MINIX 3, поскольку имя MINIX уже получило достаточную извест-
известность. Аналогичным образом поступила и фирма Apple, оставляя свою прежнюю
операционную систему Mac OS 9 и заменяя ее вариантом Berkley Unix. Новая
ОС получила имя Mac OS X, а не APPLIX или нечто подобное. Фундаменталь-
Фундаментальные изменения имели место и в семействе Windows, тем не менее операционные
системы сохранили первоначальное имя.
Объем ядра MINIX 3 составляет менее 4000 строк исполняемого кода, в то время
как объем Windows, Linux, FreeBSD или любой другой операционной системы
составляет миллионы строк. Компактность ядра важна, поскольку ошибки в нем
имеют значительно более деструктивный эффект, нежели ошибки в пользова-
пользовательских программах, а с ростом объема кода растет и число ошибок. В результате
скрупулезного исследования [6] было установлено, что число выявленных оши-
ошибок на 1000 строк исполняемого программного кода составляет от 6 до 16. Сле-
Следует ожидать, что фактическое число ошибок в коде гораздо выше, поскольку
исследователям известны лишь ошибки, которые удалось обнаружить. Согласно
другому исследованию [95], даже после 12 выпусков программного обеспечения
в нем остается примерно 6 % файлов, содержащих ошибки, обнаруживаемые
впоследствии. Кроме того, в определенный момент уровень ошибок стабили-
стабилизируется, а не продолжает асимптотически стремиться к нулю. Этот результат
подтверждается исследованием надежных версий Linux и OpenBSD с помощью
простого автоматического инструмента проверки. В ядре обнаруживаются сот-
сотни ошибок, преимущественно в драйверах устройств [20, 42]. По этой причине
в MINIX 3 драйверы были исключены из ядра. В пользовательском режиме вре-
вредоносный эффект от содержащихся в них ошибок значительно меньше.
Операционная система MINIX 3 будет использоваться во всех примерах, пред-
представленных в этой книге. Тем не менее большинство комментариев, касающихся
системных вызовов MINIX 3 (в противоположность комментариям о непосред-
непосредственном коде), актуально для других систем UNIX. Следует иметь эту ремарку
в виду при чтении текста.
Отступая от темы, можно сказать несколько слов о LINUX и связи LINUX
с MINIX. Вскоре после создания MINIX для обсуждения этой операционной
системы была сформирована группа новостей. За несколько недель на нее под-
подписалось более сорока тысяч человек, и большинство из них хотели добавить
в систему множество новых возможностей, чтобы сделать ее лучше и больше (или
просто больше). Каждый день несколько сотен человек давали советы, предлагали
идеи и фрагменты кода. Создатель системы несколько лет успешно сопротивлял-
сопротивлялся этому напору, чтобы система оставалась достаточно компактной и понятной
для студентов. Некоторые пользователи, недовольные MS-DOS, рассматривали
существующую альтернативу в виде MINIX (с исходным кодом) как побудитель-
побудительный мотив для приобретения персонального компьютера.
Одним из таких пользователей стал финский студент по имени Линус Торвальдс
(Linus Torvalds). Он установил MINIX на свой новый компьютер и тщательно
изучил исходный код. Торвальдс хотел иметь возможность читать группы ново-
новостей (в частности — comp.os.minix) не только в университете, но и у себя дома,
однако в MINIX отсутствовали необходимые для этого средства. Он написал недос-
недостающую программу, но обнаружил, что нужный ему драйвер терминала также
отсутствует. Тогда он своими силами решил и эту проблему. Когда он столкнулся
с задачей загрузки и сохранения корреспонденции, он написал дисковый драй-
драйвер и создал файловую систему. В августе 1991 года в распоряжении Торвальдса
было собственное примитивное ядро операционной системы. 25 августа 1991 года
он обнародовал свои достижения в группе comp.os.minix. Другие люди заинтере-
заинтересовались его работой и стали принимать в ней участие. В результате 13 марта
1994 года свет увидела операционная система LINUX версии 1.0. С этой даты
и начинается отсчет существования LINUX.
LINUX является ярким достижением движения открытого исходного кода, в ста-
становлении которого свою роль сыграла и операционная система MINIX. Во
многих средах LINUX конкурирует с UNIX и Windows. Отчасти это обусловле-
обусловлено тем, что производительность персональных компьютеров, поддерживающих
LINUX, сравнима с производительностью специализированных RISC-систем,
требуемых некоторыми реализациями UNIX. Другие программы с открытым
исходным кодом, в особенности веб-сервер Apache и база данных MySQL, удач-
удачно взаимодействуют с LINUX в коммерческих приложениях. LINUX, Apache,
MySQL, а также языки программирования Perl и РНР с открытыми кодами
зачастую совместно используются на веб-серверах. Иногда их в совокупности
обозначают акронимом LAMP. Более подробную информацию об истории LINUX
и программного обеспечения с открытыми исходными кодами вы найдете в ли-
литературе [37, 89, 92].
1.3. Основные концепции
Интерфейс между операционной системой и пользовательскими программами
определяется набором «расширенных инструкций», предоставляемых системой.
По традиции эти расширенные инструкции называют системными вызовами, хо-
хотя сейчас для их реализации используются несколько разных способов. Чтобы
действительно понять, что может делать операционная система, нужно тщатель-
тщательно изучить этот интерфейс. Поддерживаемые вызовы у разных операционных
систем могут значительно различаться (хотя скрывающиеся за ними концепции
оказываются схожими).
Таким образом, при описании основных концепций, относящихся к операци-
операционным системам, нам пришлось делать выбор между размытыми обобщения-
обобщениями («операционные системы поддерживают системные вызовы для чтения фай-
файлов») и спецификой конкретной системы («MINIX 3 поддерживает системный
вызов READ с тремя параметрами: один указывает, какой файл будет считы-
ваться, другой — куда поместить считанные данные, а третий задает количество
считываемых байтов»).
Мы выбрали второй подход. Он сложнее, но дает гораздо больше в плане по-
понимания того, как работают операционные системы. В пункте 1.4 представлен
более подробный обзор основных системных вызовов, поддерживаемых UNIX
(включая различные версии BSD), LINUX и MINIX 3. Для простоты мы будем
рассматривать только MINIX 3, но в большинстве случаев соответствующие
вызовы UNIX и LINUX тоже основаны на стандарте POSIX. Однако перед рас-
рассмотрением реальных системных вызовов имеет смысл дать общий обзор MINIX 3,
чтобы почувствовать, что это за система. Этот обзор в равной степени применим
и к UNIX и LINUX.
Системные вызовы MINIX 3 можно грубо разделить на две категории: вызовы
для работы с процессами и вызовы для работы с файловой системой. Рассмот-
Рассмотрим каждую из этих групп.
1.3.1. Процессы
Ключевое понятие MINIX 3 и любой другой операционной системы — процесс.
Процессом, по существу, называют программу в момент ее выполнения. С каж-
каждым процессом связывается его адресное пространство — список адресов в па-
памяти от некоторого минимума (обычно нуля) до некоторого максимума, которые
процесс может прочесть и в которые он может писать. Адресное пространство
содержит саму программу, данные к ней и ее стек. Со всяким процессом связы-
связывается некий набор регистров, включая счетчик команд, указатель стека и другие
аппаратные регистры, плюс вся остальная информация, необходимая для запус-
запуска программы.
Мы более детально рассмотрим понятие процесса в главе 2, но сейчас для того,
чтобы интуитивно осознать, что это такое, вспомним о многозадачных системах.
Предположим, что операционная система периодически решает остановить ра-
работу одного процесса и запустить другой, потому что первый израсходовал отве-
отведенную для него часть рабочего времени центрального процессора в прошедшую
секунду.
Если процесс был приостановлен подобным образом, позже он должен быть за-
запущен заново из того же состояния, в каком его остановили. Следовательно, всю
относящуюся к процессу информацию нужно где-либо явно хранить на время
его приостановки. Например, процесс может одновременно открыть для чтения
несколько файлов. Связанный с каждым файлом указатель дает текущую пози-
позицию (то есть номер байта или записи, которые будут прочитаны следующими).
При приостановке процесса все указатели нужно сохранить так, чтобы команда
чтения, выполненная после возобновления выполнения процесса, прочла пра-
правильные данные. Во многих операционных системах вся информация каждого
процесса, дополняющая содержимое его собственного адресного пространства,
хранится в таблице операционной системы. Эта таблица называется таблицей
процессов и представляет собой массив (или связанный список) структур, по од-
одной на каждый существующий в данный момент процесс.
Таким образом, приостановленный процесс состоит из собственного адресного
пространства, обычно называемого образом памяти (core image1), и компонентов
таблицы процесса, содержащей, помимо других величин, значения его регистров.
Главными системными вызовами, управляющими процессами, являются вызовы,
связанные с созданием и завершением процессов. Рассмотрим типичный при-
пример. Процесс, называемый интерпретатором команд, или оболочкой (shell), чи-
читает команды с терминала. Пользователь только что напечатал команду, содер-
содержащую запрос на компиляцию программы. После этого оболочка должна создать
новый процесс, который запустит компилятор. Когда процесс закончит компи-
компиляцию, он выполнит системный вызов, завершающий его собственную работу.
1 Слово «core», которое можно перевести как «сердечник», напоминает об использовавшейся дав-
давным-давно памяти на магнитных сердечниках.
В Windows и других операционных системах, оснащенных графическим интер-
интерфейсом пользователя, двойной щелчок мышью на значке, расположенном на
рабочем столе, запускает программу почти так же, как если бы вы ввели ее имя
в командной строке. Хотя мы и не будем уделять много внимания графическим
интерфейсам пользователя, они, на самом деле, представляют собой простые ин-
интерпретаторы команд.
Если процесс может создавать несколько других процессов (называющихся
дочерними), а эти процессы, в свою очередь, тоже могут создать дочерние про-
процессы, перед нами предстает дерево процессов (рис. 1.5). Связанные процессы —
это процессы, которые объединены для решения некоторой задачи, и им нуж-
нужно часто передавать данные от одного к другому и синхронизировать свою дея-
деятельность. Такое взаимодействие называется межпроцессным и будет обсуж-
обсуждаться в главе 2.
Рис. 1.5. Дерево процессов. Процесс А создал два дочерних процесса В и С.
Процесс В создал три дочерних процесса D, Е и F
Другие системные вызовы предназначаются для запросов о предоставлении
дополнительной памяти (или освобождении не использующейся памяти), ожи-
ожидании завершения дочерних процессов и оверлейном выполнении программы
вместе с другой.
Время от времени необходимо передавать информацию работающему процессу
так, чтобы он не простаивал в ожидании получения этой информации. Напри-
Например, процесс, связанный с другим процессом на удаленном компьютере, делает
это, посылая сообщения по сети. Чтобы предотвратить возможность потери со-
сообщения или ответа на него, отправитель может потребовать от собственной опе-
операционной системы уведомления, если по истечении определенного интервала
ожидания не будет получено подтверждение о получении сообщения. В этом
случае он сможет повторить отправку сообщения. После установки таймера про-
программа продолжит выполнение другой работы.
Если по истечении определенного количества секунд ответа нет, операционная
система посылает процессу аварийный сигнал, который вызывает временную
остановку работы процесса независимо от того, что процесс делает в данный
момент; сохраняет его регистры в стеке и запускает специальную процедуру об-
обработки сигнала (например, передающую повторно предположительно поте-
потерянное сообщение). После завершения обработки сигнала работающий процесс
запускается заново в том состоянии, в котором он находился до сигнала. Сигна-
Сигналы являются программными аналогами аппаратных прерываний и могут быть
сгенерированы по различным причинам, а не только из-за истечения какого-ли-
какого-либо интервала времени. Многие аппаратные прерывания (например, вызванные
выполнением недопустимой команды или использованием неправильного адре-
адреса) также преобразуются в сигналы, направляемые процессу, являющемуся ис-
источником ошибки.
Каждому пользователю, которому разрешено работать с системой MINIX 3, систем-
системный администратор присваивает идентификатор пользователя (User IDentification,
UID). У каждого работающего процесса есть идентификатор пользователя, запус-
запустившего процесс. Дочерний процесс получает тот же самый идентификатор поль-
пользователя, что и его родитель. Пользователи могут являться членами групп, каждой
из которых присваивается идентификатор группы (Group IDentification, GID).
Пользователь с особым идентификатором пользователя, называемый в UNIX су-
суперпользователем (superuser), имеет особые полномочия и может игнорировать
множество правил защиты. В больших системах только системный администра-
администратор знает пароль, необходимый для того, чтобы стать суперпользователем. Одна-
Однако множество обыкновенных пользователей (особенно студентов) тратят массу
времени и сил на поиски брешей в системе защиты, которые позволили бы им
стать суперпользователями без пароля.
Процессы, межпроцессное взаимодействие и сопутствующие вопросы рассмат-
рассматриваются в главе 2.
1.3.2. Файлы
Другая обширная группа системных вызовов относится к файловой системе. Как
было замечено ранее, основной функцией операционной системы является скры-
скрытие особенностей устройства дисков и других устройств ввода-вывода и предо-
предоставление пользователю понятной и удобной абстрактной модели независимых
от устройств файлов. Системные вызовы очевидно необходимы для создания,
удаления, чтения или записи файлов. Перед тем как прочитать файл, его нужно
разместить на диске и открыть, а после прочтения его нужно закрыть. Все эти
функции осуществляют системные вызовы.
Предоставляя место для хранения файлов, операционные системы используют
понятие каталога (directory) как средства объединения файлов в группы. На-
Например, студент может иметь по одному каталогу для каждого изучаемого им
курса (для программ, необходимых в рамках этого курса), каталог для элек-
электронной почты и еще один — для своей домашней веб-страницы. Для создания
и удаления каталогов также необходимы системные вызовы. Они же обеспечива-
обеспечивают перемещение существующего файла в каталог и удаление файла из каталога.
Содержимое каталогов могут составлять файлы или другие каталоги. Эта мо-
модель образует иерархию — файловую систему (рис. 1.6).
Иерархии и процессов, и файлов организованы в виде деревьев, однако на этом
их сходство заканчивается. Иерархия процессов обычно не очень глубока (в ней
редко бывает больше трех уровней), тогда как файловая структура достаточно
часто имеет четыре, пять или даже больше уровней в глубину. Иерархия процес-
сов обычно существует очень недолго, как правило, несколько минут, иерархия
каталогов может существовать годами. Механизмы принадлежности и защиты
также различны для процессов и файлов. Обычно только родительский процесс
может управлять дочерним процессом или даже просто иметь к нему доступ, в то
же время практически всегда существует механизм, позволяющий читать файлы
и каталоги не только владельцу файла, но и более широкой группе пользователей.
Рис. 1.6. Файловая система факультета университета
Каждый файл в иерархии каталогов можно определить, задав его имя пути, на-
называемое обычно полным именем файла. Путь начинается из вершины структуры
каталогов, называемой корневым каталогом. Такое абсолютное имя пути состо-
состоит из списка каталогов, которые нужно пройти от корневого каталога к файлу,
с разделением отдельных компонентов косой чертой. На рис. 1.6 путь к файлу
CS101 выглядит как /Faculty/Prof . Brown/Courses/CSlOl. Первая косая
черта говорит о том, что этот путь — абсолютный, то есть начинается от корнево-
корневого каталога. В MS-DOS и Windows для разделения компонентов вместо символа
косой черты используется символ обратной косой черты (\). Тогда этот путь
будет выглядеть так: \Faculty\Prof .Brown\Courses\CS101. В нашей книге
для записи пути мы в основном будем использовать соглашения UNIX.
В каждый момент времени у каждого процесса есть текущий рабочий каталог, в ко-
котором ищутся имена путей, не начинающиеся с косой черты. Например, если на
рис. 1.6 каталог /Faculty/Prof .Brown является рабочим, то использование
пути Courses/CS101 даст тот же самый файл, что и показанный ранее абсолют-
абсолютный путь. Процессы могут изменять свой рабочий каталог, используя системные
вызовы.
В операционной системе MINIX 3 каждому файлу и каталогу присваивается
И-разрядный двоичный код защиты. Код защиты включает три 3-разрядных поля:
одно — для владельца, одно — для прочих членов группы владельца (разбиение
пользователей на группы осуществляется системным администратором) и од-
одно — для всех остальных пользователей. Два оставшихся бита мы рассмотрим
позднее. В каждом поле имеется бит доступа по чтению, бит доступа по записи и
бит доступа по исполнению. Эти три бита в совокупности называют rwx-бита-
ми1. К примеру, код защиты rwxr-x--x означает, что владелец файла может
читать, записывать и запускать файл, другие члены группы владельца — только
читать и запускать файл (без права записи), и, наконец, все прочие пользовате-
пользователи — только исполнять файл (без права чтения и записи). Для каталога, в от-
отличие от файла, доступ по исполнению означает возможность поиска. Прочерк
указывает на отсутствие разрешения (значение соответствующего бита равно 0).
Перед тем как прочесть или записать файл, его нужно открыть, в это же время
проверяется разрешение доступа. Если доступ разрешен, система возвращает не-
небольшое целое число, называемое дескриптором файла и используемое в после-
последующих операциях. Если доступ запрещен, то возвращается код ошибки (-1).
Другое важное понятие в MINIX 3 — это смонтированная файловая система.
Почти все персональные компьютеры имеют один или несколько дисководов
для компакт-дисков, куда можно вставить и откуда можно вынуть диск. Что-
Чтобы предоставить возможность общения со сменными носителями (CD-дисками,
DVD-дисками, дискетами, Zip-дисками), MINIX 3 позволяет присоединять фай-
файловую систему сменного диска к главному дереву. Рассмотрим ситуацию, пока-
показанную на рис. 1.7, а. Перед вызовом системной процедуры mount корневая фай-
файловая система на жестком диске и вторая файловая система на компакт-диске
существуют раздельно и никак не связаны между собой.
Однако файлы на компакт-диске нельзя использовать, потому что для них не-
невозможно определить путь. MINIX 3 не позволяет присоединять к началу пути
название диска или его номер, так как это привело бы к жесткой зависимости
от устройств, которой операционная система должна избегать. Вместо этого
системный вызов mount позволяет присоединять файловую систему на гибком
диске к корневой файловой системе в том месте, где этого захочет программа.
На рис. 1.7, б файловая система диска 0 установлена в каталог Ь, таким обра-
образом, обеспечен доступ к файлам по путям /b/х/ и /b/у. Если каталог b со-
содержал какие-либо файлы, они будут недоступны, пока смонтирован гибкий
диск, так как теперь имя /Ь ссылается на корневой каталог диска 0. (Невоз-
(Невозможность доступа к этим файлам не так страшна, как кажется с первого взгля-
взгляда: файловые системы почти всегда устанавливаются в пустые каталоги.) Если
1 Аббревиатура rwx образована тремя английскими словами: read — чтение, write — запись, execution —
исполнение — Примеч. пер.
система содержит несколько жестких дисков, они все могут быть встроены в од-
одно дерево таким же образом.
Рис. 1.7. Монтирование файловой системы: а — перед монтированием файлы на диске О
недоступны; б — после монтирования они становятся частью общей файловой структуры
Еще одно важное понятие в MINIX 3 — это специальный файл. Специальные
файлы служат для того, чтобы устройства ввода-вывода выглядели как файлы.
При этом можно прочесть информацию из специальных файлов или записать ее
туда с помощью тех же самых системных вызовов, что используются для чтения
и записи файлов. Существует два вида специальных файлов: блочные специ-
специальные файлы и символьные специальные файлы. Блочные специальные файлы
используются для моделирования устройств, состоящих из набора произволь-
произвольно адресуемых блоков, таких как диски. Открывая блочный специальный файл
и читая, скажем, блок 4, программа может напрямую получить доступ к блоку 4
на устройстве без обращения к содержащейся на нем файловой системе. Таким
же образом символьные специальные файлы используются для моделирования
принтеров, модемов и других устройств, которые принимают или выдают поток
символов. По соглашению специальные файлы хранятся в каталоге /dev. На-
Например, файл /dev/lp может быть строковым принтером.
И последнее понятие, которое мы здесь обсудим, — это каналы (pipe), имеющие
отношение и к процессам, и к файлам. Канал (также иногда называемый трубой)
представляет собой псевдофайл, который можно использовать для связывания
двух процессов, как показано на рис. 1.8. Если процессы А и В захотят пооб-
пообщаться с помощью канала, они должны установить его заранее. Когда процесс А
решает отправить данные процессу В, он пишет их в канал, как если бы это был
выходной файл. Процесс В может прочесть данные, читая их из канала, как если
бы он был файлом с входными данными. Таким образом, взаимодействие между
процессами в UNIX очень похоже на обычные чтение и запись файлов. Более того,
только сделав специальный системный вызов, процесс может обнаружить, что
выходной файл, в который он пишет данные, — это не реальный файл, а канал.
Рис. 1.8. Два процесса, соединенные каналом
1.3.3. Оболочка
Операционная система представляет собой программу, выполняющую систем-
системные вызовы. Редакторы, компиляторы, ассемблеры, компоновщики и командные
интерпретаторы не являются частью операционной системы, несмотря на их
большую важность и полезность. Поскольку есть риск запутаться в этих поняти-
понятиях, мы кратко рассмотрим только командный интерпретатор MINIX 3, называе-
называемый оболочкой (shell). Хотя оболочка не входит в операционную систему, но во
всю пользуется многими функциями операционной системы и поэтому является
хорошим примером того, как могут применяться системные вызовы. Кроме это-
этого, оболочка предоставляет основной интерфейс между пользователем, сидящим
за своим терминалом, и операционной системой, если, конечно, пользователь не
использует графический интерфейс. Существуют целый ряд оболочек, включая
csh, ksh, zsh и bash. Все они поддерживают описываемую здесь функциональ-
функциональность исходной оболочки (sh).
Когда какой-либо пользователь входит в систему, запускается оболочка. Стан-
Стандартным входным и выходным устройством для оболочки является терминал.
Оболочка начинает работу с печати приглашения (prompt) — знака доллара,
говорящего пользователю, что оболочка ожидает ввода команды. После этого
пользователь может вводить команды, например:
date
В этом случае оболочка создает дочерний процесс и запускает программу date.
Пока дочерний процесс работает, оболочка ожидает его завершения. После за-
завершения дочернего процесса оболочка опять печатает приглашение и пытается
прочесть следующую введенную строку. Пользователь может перенаправить стан-
стандартный вывод данных в файл:
date >file
Таким же образом можно переопределить устройство, с которого читаются вход-
входные данные:
sort <filel >file2
Эта команда предписывает программе сортировки считать данные из файла f ilel
и вывести результат в файл f ile2.
Выходные данные одной программы можно использовать в качестве входных
данных для другой, соединив их каналом, например:
cat filel file2 file3 I sort >/dev/lp
Эта команда предписывает программе cat объединить (concatenate) три файла
и послать выходные данные программе sort, которая расставит все строки в ал-
алфавитном порядке. Результат работы программы sort перенаправляется в файл
/dev/lp, обычно обозначающий принтер.
Если пользователь вводит после команды знак &, оболочка не ждет окончания
выполнения команды. В этом случае она немедленно выводит новое приглаше-
приглашение. Например:
cat filel file2 file3 I sort >/dev/lp &
В результате выполнения этой команды сортировка запустится как фоновое
задание, разрешая пользователю в ходе сортировки продолжать нормальную ра-
работу. Оболочка имеет множество других интересных особенностей, для обсуж-
обсуждения которых у нас здесь, к сожалению, недостаточно места. Тем, кто хочет
освоить операционную систему MINIX более детально, можно порекомендовать
большинство книг для начинающих пользователей UNIX [58, 98].
1.4. Системные вызовы
Вооружившись общим пониманием того, как MINIX 3 работает с процессами
и файлами, можно приступить к изучению интерфейса между операционной
системой и пользовательскими программами, то есть системных вызовов. Хотя
это обсуждение затрагивает конкретно стандарт POSIX (международный стан-
стандарт 9945-1), а следовательно, MINIX 3, UNIX и LINUX, большинство других
современных операционных систем поддерживает системные вызовы, выполняю-
выполняющие те же самые функции, хотя детали могут различаться. Так как фактический
механизм обращения к системным функциям является в высокой степени ма-
машинно-зависимым и часто должен реализовываться на ассемблере, существуют
библиотеки процедур, делающие возможным обращение к системным процеду-
процедурам из программ на С и на других языках с тем же успехом.
Следует помнить о том, что любой однопроцессорный компьютер способен вы-
выполнять лишь одну команду за раз. Если процесс выполняет программу в поль-
пользовательском режиме и требует поддержки со стороны операционной системы
(к примеру, при чтении данных из файла), необходимо прерывание или систем-
системный вызов для того, чтобы передать операционной системе управление. Опера-
Операционная система определяет запрошенное процессом действие по переданным
параметрам, выполняет системный вызов и возвращает управление команде,
следующей за вызовом. В этом смысле системный вызов похож на вызов проце-
процедуры, однако в отличие от процедуры системный вызов осуществляет вход в яд-
ядро или другие привилегированные компоненты операционной системы.
Для того чтобы прояснить механизм системных вызовов, кратко рассмотрим сис-
системный вызов read. Как упоминалось ранее, у него есть три параметра: первый
служит для задания файла, второй указывает на буфер, третий определяет ко-
количество байтов, которое нужно прочитать. Вызов из программы на С может
выглядеть так:
count = read(fd, buffer, nbytes);
Системный вызов (и библиотечная процедура) возвращает количество действи-
действительно прочитанных байтов в переменной count. Обычно эта величина совпада-
совпадает с параметром nbytes, но может быть меньше, если, например, в процессе чте-
чтения процедуре встретился символ конца файла.
Если системный вызов не может быть выполнен или из-за неправильных пара-
параметров или из-за дисковой ошибки, значение счетчика count устанавливает-
устанавливается равным -1, а номер ошибки помещается в глобальную переменную errno.
Программы всегда должны проверять результат системного вызова, чтобы от-
отслеживать появление ошибки.
В общей сложности операционная система MINIX 3 поддерживает 53 системных
вызова. Они перечислены в табл. 1.1 и для удобства разбиты на шесть групп.
Помимо упомянутых, существует еще несколько системных вызовов, однако они
имеют столь специальное назначение, что мы решили опустить их. В последую-
последующих разделах мы кратко рассмотрим каждый вызов, чтобы понять, что он делает.
В целом, выполняемые этими системными вызовами функции определяют боль-
большую часть возможностей операционной системы, так как возможности управле-
управления ресурсами на персональных компьютерах сведены к минимуму (по крайней
мере, по сравнению с большими машинами, обслуживающими множество поль-
пользователей).
Таблица 1.1. Основные системные вызовы MINIX (fd обозначает дескриптор
файла, п — число байтов)
Вызов Описание
Управление процессами
pid = fork( ) Создает дочерний процесс, идентичный родительскому
pid = waitpid(pid, &statloc, options) Ожидает завершения дочернего процесса
s = wait(&status) Старая версия waitpid
s = execve(name, argv, envp) Перемещает образ памяти процесса
exit(status) Завершает выполнение процесса и возвращает статус
size = brk(addr) Устанавливает размер сегмента данных
pid = getpid() Возвращает идентификатор процесса, сделавшего вызов
pid = getpgrp() Возвращает идентификатор группы процессов для
сделавшего вызов процесса
pid = setsid() Открывает новый сеанс и возвращает для него
идентификатор группы процессов
I = ptrace(req, pid, addr, data) Используется для отладки
Сигналы
s = sigaction(sig, &act, &oldact) Устанавливает реакцию на сигнал
s = sigreturn(&context) Возвращается из обработчика сигнала
s = sigprocmask(how, &set, &old) Определяет или устанавливает маску сигналов для процесса
s = sigpending(set) Определяет набор блокированных сигналов
s = sigsuspend(sigmask) Устанавливает маску сигналов для процесса
и приостанавливает его
s = kill(pid, sig) Посылает сигнал процессу
residual = alarm(seconds) Устанавливает сигнальный таймер
s = pause() Приостанавливает процесс до прихода следующего сигнала
Управление файлами
fd = creat(name, mode) Устаревший способ создать файл
fd =mknod(name, mode, addr) Создает обычный, специальный или относящийся
к каталогу индексный узел
fd=open(file, how, ...) Открывает файл для чтения, записи или того и другого
s = close(fd) Закрывает открытый файл
Вызов Описание
n = read(fd, buffer, nbytes) Читает данные из файла в буфер
n = write(fd, buffer, nbytes) Пишет данные из буфера в файл
pos = lseek(fd, offset, whence) Передвигает указатель файла
s = stat(name, &buf) Получает информацию о состоянии файла
s = fstat(fd, &buf) Получает информацию о состоянии файла
fd = dup(fd) Закрепляет за открытым файлом новый дескриптор
s = pipe(&fd[O]) Создает канал
s = ioctl(fd, request, argp) Специальные действия с файлом
s = access(name, amode) Проверяет доступность файла
s = rename(old, new) Переименовывает файл
s = fcntl(fd, cmd, ...) Захватывает файл и выполняет другие действия
Управление каталогами и файловой системой
s = mkdir(name, mode) Создает новый каталог
s = rmdir(name) Удаляет пустой каталог
s = Iink(name1, name2) Создает новый элемент с именем пагле2, указывающий
на namel
s = unlink(name) Удаляет элемент каталога
s = mount(special, name, flag) Монтирует файловую систему
s = umount(special) Демонтирует файловую систему
s = sync() Сбрасывает все кэшированные блоки на диск
s = chdir(dirname) Изменяет рабочий каталог
s = chroot(dirname) Изменяет корневой каталог
Защита
s = chmod(name, mode) Изменяет биты защиты файла
uid = getuid() Определяет идентификатор пользователя для вызвавшего
gid = getgid() Определяет идентификатор группы для вызвавшего
s = setuid(uid) Устанавливает идентификатор пользователя для вызвавшего
s = setgid(gid) Устанавливает идентификатор группы для вызвавшего
s = chown(name, owner, group) Меняет идентификатор владельца файла
oldmask = umask(complmode) Меняет режим маскирования
Управление временем
seconds = time(&seconds) Получает время, прошедшее с 1 января 1970 года
s = stime(tp) Устанавливает время, прошедшее с 1 января 1970 года
s = utime(file, timep) Устанавливает время последнего доступа к файлу
s = times(buffer) Определяет время работы пользовательского процесса
и системы
Особое внимание следует обратить на то, что преобразование вызовов POSIX-
процедур в системные вызовы не является взаимно однозначным. Стандарт
POSIX определяет ряд процедур, которые должны поддерживать совместимые
системы, но он не указывает, являются ли они системными вызовами, библио-
библиотечными вызовами или чем-нибудь еще. В некоторых случаях POSIX-процеду-
ры поддерживаются в MINIX 3 библиотечными функциями. Иногда требуемые
процедуры являются всего лишь разновидностями друг друга, и один системный
вызов обрабатывает сразу несколько библиотечных вызовов.
1.4.1. Системные вызовы
для управления процессами
Первая группа вызовов в табл. 1.1 управляет процессами. Начнем рассмотре-
рассмотрение с вызова fork. Системный вызов fork (разветвление) является единствен-
единственным способом создания нового процесса в MINIX 3. Он создает точную копию
исходного процесса, включая дескрипторы файла, регистры и т. п. После вызова
fork исходный процесс и его копия (родительский и дочерний процессы) раз-
развиваются отдельно друг от друга. Все переменные имеют одинаковые величины
во время вызова fork, но как только родительские данные скопированы для со-
создания дочернего процесса, последующие изменения в одном из них уже не влияют
на другой. (Текст программы, который не изменяется, распределяется между роди-
родительским и дочерним процессами.) Вызов fork возвращает величину, равную ну-
нулю в дочернем процессе и равную идентификатору дочернего процесса в родитель-
родительском. Используя возвращенный идентификатор процесса (Process IDentifier, PID),
два процесса могут выяснить, какой из них родительский, а какой — дочерний.
В большинстве случаев после вызова fork дочернему процессу необходимо вы-
выполнить программный код, отличный от кода родительского процесса. Рассмотрим
пример оболочки. Она читает команды с терминала, запускает дочерний процесс,
ждет, пока дочерний процесс выполнит команду, и читает следующую команду
после завершения работы дочернего процесса. Ожидая, пока дочерний процесс
закончит работу, родительский процесс выполняет системный вызов waitpid,
который ожидает завершения дочернего процесса (или всех дочерних процессов,
если их на данный момент несколько). Вызов waitpid может ждать окончания
какого-либо определенного дочернего процесса или любого дочернего процес-
процесса, для этого нужно задать первый параметр вызова равным -1. Когда вызов
waitpid выполнен, указатель, задаваемый вторым параметром statloc, пока-
покажет статус завершения дочернего процесса (нормальное или аварийное заверше-
завершение и выходное значение). Третий параметр определяет различные необязатель-
необязательные настройки. Вызов waitpid заменяет ранее использовавшийся вызов wait,
который на данный момент устарел и поддерживается лишь для обратной со-
совместимости.
Теперь рассмотрим, как вызов fork используется оболочкой. Когда печатается
команда, оболочка создает дочерний процесс, который должен выполнить коман-
команду пользователя. Он делает это с помощью системного вызова execve, заме-
заменяющего весь его образ памяти файлом, указанным в первом параметре. (Фак-
(Фактически самим системным вызовом является exec, но несколько различных
библиотечных процедур вызывают его с разными параметрами и незначительно
отличающимися именами. Мы здесь воспользуемся ими как системными вызо-
вызовами.) Весьма упрощенная оболочка, иллюстрирующая использование команд
fork, waitpid и exec, показана в листинге 1.1.
Листинг 1.1. Усеченная оболочка. Здесь и далее в книге предполагается,
что значение TRUE равно 1
#define TRUE I
while (TRUE) { /* вечный цикл */
type_prompt( ); /* печать приглашения на экране */
read_command(command, parameters); /* читать входные данные с терминала */
if (fork( ) 1= 0) { /* запускает дочерний процесс */
/* код родительского процесса */
waitpid(-l, &status, 0); /* ждать окончания дочернего процесса */
} else {
/* код дочернего процесса */
execve(command, parameters, 0); /* выполнение command */
}
}
В самом общем случае у команды exec есть три параметра: имя выполняемого
файла, указатель на массив аргументов и указатель на массив переменных окруже-
окружения. Эти параметры мы кратко обсудим в дальнейшем. Различные библиотечные
программы, включая execl, execv, execle и execve, разрешают опускать па-
параметры или определять их другими способами. В книге мы воспользуемся на-
названием exec для того, чтобы представить системный вызов, вызываемый всеми
этими процедурами.
Рассмотрим следующую команду:
ср filel file2
Эта команда используется для копирования файла filel в файл f ile2. После
создания оболочкой дочернего процесса последний находит и исполняет файл
ср и передает ему имена исходного и целевого файлов.
Основной модуль программы ср (как и большинство других головных программ
на языке С) содержит определение:
main(argc, argv, envp)
В этом определении в параметр argc входит количество записей в командной
строке, включая имя программы. Например, для показанной строки параметр
argc равен 3.
Второй параметр argv является указателем на массив указателей. Элемент г
массива указывает на г-ю запись в командной строке. В нашем примере параметр
argv [ 0 ] должен указывать на строку ср, a argv [ 1 ] и argv [ 2 ] — на строки
filel и file2 соответственно.
Третий параметр функции main с именем envp является указателем на массив
строковых переменных окружения вида имя = величина, которые используются
для передачи программе такой информации, как тип терминала или имя домаш-
домашнего каталога. В листинге 1.1 третий параметр равен нулю, поскольку дочернему
процессу ничего не передается.
Если команда exec кажется сложной, не огорчайтесь, потому что это — один из
наиболее сложных системных вызовов в POSIX. Все остальные намного про-
проще. В качестве еще одного примера рассмотрим вызов exit, процессы должны
использовать его при завершении работы. У него есть всего один параметр, статус
выхода, изменяющийся от 0 до 255. Он возвращается родительскому процессу
через переменную statloc в системном вызове waitpid. Младший байт этой
переменной содержит значение статуса выхода, который равен 0 при нормальном
завершении работы и ненулевому значению при завершении по ошибке. Старший
байт содержит статус завершения дочернего процесса (от 0 до 255). Например:
n = waitpid(-l, &status, options);
Если родительский процесс выполнит эту команду, то его работа будет приоста-
приостановлена до завершения дочернего процесса. Если дочерний процесс завершится,
скажем, через вызов exit с параметром 4, то когда родительский процесс про-
продолжит работу, п будет содержать PID дочернего процесса, a statloc — значе-
значение 0x0400 (в языке С принято писать символы Ох перед шестнадцатеричными
числами, это соглашение постоянно используется в книге).
В MINIX 3 под процессы отводится часть памяти, которая, в свою очередь, де-
делится на три сегмента: текста (код программы), данных (переменные) и стека.
Сегмент данных растет снизу вверх, а стек увеличивается сверху вниз, как пока-
показано на рис. 1.9. Между ними существует часть неиспользованного адресного
пространства. Стек автоматически занимает такую часть этого участка памяти,
какую необходимо, но расширение сегмента данных выполняется явным обра-
образом. Для этого используется специальный системный вызов brk, задающий новый
адрес для границы сегмента данных. Этот адрес может быть как больше текуще-
текущего значения (сегмент растет), так и меньше (сегмент уменьшается). Но, конечно
же, этот адрес должен быть меньше, чем указатель стека, так как в противном
случае данные и стек могут перекрываться, что недопустимо.
Рис. 1.9. Под процессы отводится три сегмента: текст, данные и стек. В данном примере
все три расположены в едином адресном пространстве, однако также поддерживаются
раздельные пространства сегментов команд и данных
Для удобства программиста предлагается библиотечная процедура sbrk, так-
также меняющая размер сегмента данных. Ее единственный параметр указывает, на
сколько должен быть увеличен размер сегмента (чтобы уменьшить сегмент, нуж-
нужно передавать отрицательные значения). Процедура работает так: вызовом brk
определяется текущий размер сегмента, затем вычисляется новый размер, после
чего делается еще один системный вызов, запрашивающий требуемое количест-
количество байтов. Оба вызова (brk и sbrk) не относятся к стандарту POSIX. Для дина-
динамического выделения памяти программисты могут использовать библиотечную
процедуру malloc. Поскольку впрямую эту процедуру применяют очень редко,
ее стандартизацию посчитали нецелесообразной.
Следующий системный вызов для работы с процессами, getpid, является заодно
и простейшим из них. Этот вызов просто возвращает идентификатор вызвавшего
его процесса. Обратите внимание на то, что при вызове fork значение идентифи-
идентификатора дочернего процесса получает только родительский процесс. Если дочерне-
дочернему процессу потребуется узнать собственный идентификатор процесса, ему придет-
придется использовать вызов getpid. Вызов getgrp возвращает идентификатор группы
процессов, в которую входит процесс, сделавший вызов. Вызов sets id открывает
новый сеанс и устанавливает идентификатор группы процессов равным иден-
идентификатору процесса, сделавшего вызов. Сеансы относятся к необязательной
функции POSIX, называемой управлением заданиями и в MINIX 3 не реализо-
реализованной, поэтому данная функция в дальнейшем не упоминается.
Последний системный вызов из этой группы, ptrace, используется отладчиками
для управления отлаживаемой программой. Он позволяет отладчику обращаться
к памяти отлаживаемого процесса, а также управлять им другими способами.
1.4.2. Системные вызовы
для управления сигналами
Хотя обычно все взаимодействие между процессами запланировано, существуют
ситуации, когда требуется незапланированное взаимодействие. Например, если
пользователь случайно потребовал от текстового редактора показать содержи-
содержимое очень большого файла и заметил свою ошибку, должен существовать способ
прервать работу редактора. В MINIX 3 пользователь может нажать клавиши
Ctrl+C; это сочетание посылает текстовому редактору соответствующий сигнал.
Получив его, редактор прекращает распечатку. Сигналы могут использоваться
и для того, чтобы перехватывать некоторые аппаратные исключения, например
недопустимые инструкции или переполнение при операциях с плавающей точ-
точкой. Задержки также реализуются через сигналы.
Если процесс никак не анонсировал свое желание отвечать на сигналы, то, по-
получив сигнал, он просто принудительно завершается. Чтобы избежать подобной
судьбы и рассказать о своем желании отвечать на сигналы определенного типа,
процесс может использовать системный вызов sigaction, который позволяет
указать новый адрес процедуры для обработки сигнала и узнать адрес прежней
процедуры. После того как такой вызов сделан, при получении сигнала соот-
соответствующего типа (например, при нажатии клавиш Ctrl+C) состояние процесса
будет сохранено в стеке и вызван обработчик сигнала. Обработчик может ра-
работать сколь угодно долго и делать при этом любые системные вызовы. Но на
практике обработчики сигналов обычно весьма коротки. Завершив свою работу,
обработчик делает вызов sigreturn, чтобы продолжить работу процесса с того
места, где он был прерван. Вызов sigaction заменяет прежний системный вы-
вызов signal, который теперь для обратной совместимости реализован в виде
библиотечной процедуры.
В MINIX 3 сигналы можно блокировать. Блокированный сигнал задерживается
до тех пор, пока не будет разблокирован. То есть сигнал не передается, но и не
теряется. Вызов sigprocmask позволяет процессу задать набор блокируемых
сигналов, передавая ядру битовую карту. Кроме того, процесс может узнать, ка-
какие сигналы имели место, но были заблокированы. Для этого служит системный
вызов sigpending, возвращающий набор сигналов в виде битовой маски. Нако-
Наконец, системный вызов sigsuspend позволяет процессу атомарно задать бито-
битовую карту блокированных сигналов и приостановить свое выполнение.
Вместо того чтобы передавать в качестве обработчика сигнала указатель на функ-
функцию, программа может использовать константу SIG_IGN, чтобы все последую-
последующие сигналы определенного типа игнорировались. Передав константу SIG_DFL,
можно восстановить обработку сигнала по умолчанию. По умолчанию процесс
либо принудительно завершается по сигналу, либо сигнал просто игнорируется.
Это зависит от конкретного сигнала. В качестве примера того, как используется
константа SIG_IGN, рассмотрим работу оболочки при запуске фонового процес-
процесса с помощью такой команды:
command &
В этом случае сигнал от нажатия клавиш Ctrl+C не должен влиять на работу фо-
фонового процесса, поэтому после вызова fore, но перед вызовом exec оболочка
делает следующие вызовы:
sigaction(SIGINT, SIG_IGN, NULL);
sigaction(SIGQUIT, SIG_IGN, NULL);
Эти вызовы отключают обработку сигналов SIGINT и SIGQUIT (сигнал SIGQUIT
генерируется нажатием клавиш Ctrl+\ и делает то же самое, что и Ctrl+C, но, если
его не обрабатывать или не блокировать, позволяет получить дамп памяти завер-
завершенного процесса). Для обычных процессов, выполняющихся не в фоновом ре-
режиме, игнорировать сигналы не нужно.
Нажатие клавиш Ctrl+C — не единственный способ послать процессу сигнал. Сис-
Системный вызов kill позволяет одному процессу послать сигнал другому (у обоих
процессов должен быть одинаковый идентификатор пользователя, так как не-
несвязанные процессы не могут послать друг другу сигналы). Возвращаясь к рас-
рассматриваемому примеру, предположим, что запущенный фоновый процесс по-
потребовалось завершить. Сигналы SIGQUIT и SIGINT этот процесс игнорируют,
так что требуется что-то другое. Решение дает программа kill, которая с помо-
помощью системного вызова KILL может послать сигнал любому процессу. Процесс
можно принудительно завершить, послав ему сигнал 9 (SIGKILL). Этот сигнал
нельзя обработать или игнорировать.
Во многих приложениях реального времени процесс нужно прерывать по исте-
истечении некоторого интервала времени, за который он должен успеть выполнить
свою работу, например повторно передать пакет данных по ненадежной линии
связи. Для этой ситуации предназначен системный вызов alarm. Параметр это-
этого вызова описывает интервал времени, по истечении которого процессу переда-
передается сигнал SIGALARM. В любой момент времени процесс может запланировать
только один сигнал. Если сделать вызов alarm, указав задержку 10 секунд, а за-
затем, по истечении 3 секунд, еще раз выполнить вызов alarm с параметром 20 се-
секунд, придет сигнал только от того вызова, который сделан последним. Первый
вызов отменяется. Чтобы отменить сделанный ранее вызов alarm, нужно еще
раз сделать вызов alarm, передав в качестве аргумента 0. Если пришедший сиг-
сигнал SIGALARM не обрабатывать, то выполняется действие по умолчанию, и про-
процесс завершается.
Иногда возникают ситуации, когда процессу нечем заняться до прибытия сигнала.
Например, рассмотрим компьютерную программу для проверки скорости чтения
и внимательности. Эта программа выводит некоторый текст, а затем делает вы-
вызов alarm с параметром 30 секунд. Пока ученик читает текст, программа ничего
не должна делать. Программа может выполнять пустой цикл, но это будет бес-
бессмысленной тратой процессорного времени, которое может потребоваться дру-
другому процессу. Гораздо лучше использовать системный вызов pause, который
заставляет MINIX 3 приостановить выполнение процесса до прихода сигнала.
1.4.3. Системные вызовы
для управления файлами
Многие системные вызовы имеют отношение к файловой системе. В этом разде-
разделе мы рассмотрим вызовы, работающие с отдельными файлами, а в следующем
разделе обратимся к вызовам, которые оперируют каталогами или файловой
системой в целом. Для создания нового файла служит вызов creat (ответ на во-
вопрос, почему именно creat, а не create, затерялся в тумане времен). Его пара-
параметры — имя файла и права доступа, например:
fd = creat("abc", 0751);
Эта команда создаст файл с именем abc и установит для него права доступа 0751
(в С числа с ведущим нулем считаются восьмеричными). Младшие 9 бит этого
числа показывают, что владелец файла имеет права доступа rwx G означает
права на чтение, запись и исполнение), члены группы владельца имеют права
на чтение и исполнение E), а прочие пользователи — только на исполнение A).
Вызов creat не только создает новый файл, но и открывает его для записи неза-
независимо от указанного режима. Дальнейшая запись в файл производится через
его дескриптор f d, значение которого возвращается вызовом. Если выполнить
вызов creat для существующего файла, то файл усекается до нулевой длины
(если, конечно, права доступа позволяют это). Сейчас вызов creat устарел и под-
поддерживается для обратной совместимости, вместо него нужно использовать
вызов open.
Чтобы создать специальный файл, нужно вместо creat выполнить вызов mknod.
Вот типичный пример:
fd = mknod("/dev/ttyc2", 020744, 0x0402);
Эта команда создает файл с именем /dev/ttyc2 (обычно это имя соответствует
второй консоли) и задает для него права доступа 020744 (специальный символьный
файл с правами rwxr--r--). Третий параметр составлен из пары байтов, из
которых старший задает основное устройство D), а младший — вторичное уст-
устройство B). Основное устройство может быть любым, а вторичное для файла
/dev/ttyc2 должно быть равно 2. Делать вызов mknod может только супер-
суперпользователь, в противном случае возникает ошибка.
Чтобы прочитать или записать файл, его сначала нужно открыть при помощи
вызова open. Для этого вызова указывается имя открываемого файла (задается
или абсолютный путь файла, или ссылка на рабочий каталог) и код O_RDONLY,
O_WRONLY или O_RDWR, означающий, что файл открывается для чтения, записи
или того и другого. Для создания нового файла служит код O_CREAT. Возвра-
Возвращаемый дескриптор файла затем можно употребить при чтении или записи. По-
Потом файл закрывается с помощью вызова close, который делает дескриптор
файла доступным для последующего вызова creat или open.
Наиболее часто используемыми вызовами, без сомнения, являются read и write.
Вызов read мы уже обсуждали, write имеет те же самые параметры.
Несмотря на то что большинство программ читает и записывает файлы путем
последовательного доступа, некоторым прикладным программам необходима
возможность доступа к любой случайно выбранной части файла. Связанный с ка-
каждым файлом указатель содержит текущую позицию в файле. Когда чтение (за-
(запись) осуществляется последовательно, он обычно указывает на байт, который
должен быть прочитан (записан) следующим. Вызов lseek может изменить зна-
значение позиции указателя, так что следующий вызов read или write начнет опе-
операцию где-либо в другой части файла.
У вызова lseek есть три параметра: первый — это идентификатор файла, вто-
второй — позиция в файле, а третий говорит, является ли второй параметр позицией
в файле относительно начала файла (абсолютная позиция), относительно теку-
текущей позиции или относительно конца файла. Вызов lseek возвращает абсолют-
абсолютную позицию в файле после изменения указателя.
Для каждого файла MINIX хранит следующие данные: тип файла (обычный,
специальный, каталог и т. д.), размер, время последнего изменения и другую ин-
информацию. Программа может запросить эту информацию через системные вызо-
вызовы statnfstat. Они различаются только тем, что первый из них требует име-
имени файла, а второй полагается на дескриптор файла и полезен для открытых
файлов, особенно для файлов стандартного ввода и вывода, имена которых не
всегда известны. У обоих вызовов второй параметр указывает на структуру, куда
нужно поместить информацию. Эта структура показана в листинге 1.2.
Листинг 1.2. Структура, используемая для получения информации от системных вызовов STAT
и FSTAT. В фактическом коде для некоторых типов используются символические имена
struct stat {
short st_dev; /* устройство, которому принадлежит i-узел */
unsigned short st_ino; /* номер inode */
unsigned short st_mode; /* режим доступа */
short st_nlink; /* число ссылок на файл */
short st_uid; /* идентификатор пользователя */
short st_gid; /* идентификатор группы */
short st_rdev; /* основное и вторичное */
/* устройство для специальных файлов */
long st_size; /* размер файла */
long st_atime; /* время последнего обращения */
long st_mtime; /* время последнего изменения */
long st_ctime; /* время последнего изменения для i-узла */
};
При работе с дескрипторами файлов иногда может оказаться полезным систем-
системный вызов dup. Например, рассмотрим программу, которая закрывает стандарт-
стандартный вывод (дескриптор 1), подставляет в качестве стандартного вывода другой
файл, вызывает функцию, которая что-то пишет в этот файл, а затем восстанав-
восстанавливает исходное состояние. Если просто закрыть стандартный вывод и открыть
новый файл, то новый файл станет стандартным выводом (если используется
стандартный ввод, дескриптор которого равен 0), но восстановить состояние
будет невозможно. Решение дает следующая команда, в которой используется
системный вызов dup:
fd = dupA);
При выполнении этой команды в переменную f d помещается новый дескриптор,
который будет соответствовать тому же файлу, что и стандартный вывод A).
Затем стандартный вывод можно закрыть, после чего открыть новый файл и ис-
использовать его. Когда понадобится восстановить исходное состояние, нужно за-
закрыть дескриптор 1 и выполнить код:
n = dup(fd);
В результате самый меньший из дескрипторов файлов, а именно 1, станет соот-
соответствовать тому же файлу, что и f d. Наконец, f d можно закрыть, в результате
мы вернемся к той же ситуации, с которой начали.
У системного вызова dup есть второй вариант, с помощью которого можно связать
неиспользованный дескриптор с уже открытым файлом. Он записывается так:
dup2(fd, fd2);
Здесь f d — это дескриптор открытого файла, a f d2 — не связанный ни с каким
файлом дескриптор, который после выполнения вызова будет ссылаться на тот
же файл. Таким образом, если f d ссылается на стандартный ввод (дескриптор
равен 0), а дескриптор f d2 равен 4, то после выполнения вызова и 0 и 4 будут
соответствовать стандартному вводу.
Как уже отмечалось, для обеспечения взаимодействия между процессами в MINIX 3
можно использовать каналы. Например:
cat filel file2 I sort
Когда пользователь дает оболочке эту команду, то оболочка создает канал и со-
соединяет стандартный вывод первого процесса с входом канала, а стандартный
ввод второго процесса с выходом канала. Чтобы создать канал, применяется сис-
системный вызов pipe, возвращающий два дескриптора файлов: один для чтения
из канала, другой для записи в него:
pipe(&fd[O]);
Здесь f d — массив двух целых чисел, f d [ 0 ] — дескриптор для чтения, a f d [ 1 ] —
дескриптор для записи. Как правило, после этого делается вызов fork, роди-
родительский процесс закрывает дескриптор для чтения, а дочерний процесс — де-
дескриптор для записи (или наоборот), чтобы один процесс мог писать в канал,
а другой — читать из него.
В листинге 1.3 приведен каркас процедуры, создающей два процесса таким обра-
образом, что выход первого из них передается через канал во второй (более реали-
реалистичный пример обеспечивал бы проверку ошибок и обработку аргументов).
Сначала создается поток, затем делается вызов fork, и родительский процесс
становится первым процессом в канале, а дочерний процесс — вторым. Так как
запускаемые файлы, processl и process2, ничего не знают о том, что они
соединяются каналом, для работы программы необходимо, чтобы стандартный
вывод первого процесса был соединен со стандартным вводом второго процесса
каналом. Сначала родительский процесс закрывает дескриптор для чтения из ка-
канала. Затем он закрывает стандартный вывод и делает вызов dup, после которого
стандартным выводом становится вход канала. Важно понимать, что вызов dup
всегда возвращает наименьший допустимый дескриптор, в данном случае — 1.
Наконец, исходный дескриптор для записи в канал закрывается.
Листинг 1.3. Каркас процедуры, создающей конвейер из двух процессов
#define STD_INPUT 0 /* Дескриптор файла для стандартного ввода */
#define STD_OUTPUT I /* Дескриптор файла для стандартного вывода*/
pipeline(processl, process2) /* Указатели на имена программ */
char *processl, *process2;
{
int fd[2];
pipe(&fd[0]); /* создать конвейер */
if(fork() !=0) {
/* Эти выражения исполняются родительским процессом */
close(fd[0]); /* Процесс 1 не нуждается в чтении с конвейера */
close(STD_OUTPUT); /* Подготовка нового стандартного вывода */
dup(fd[l]); /* Сделать стандартным выводом устройство fd[l] */
close(fd[1]); /* Этот дескриптор файла больше не нужен */
execl(processl,processl, 0);
} else {
/* Эти выражения исполняются процессом-наследником */
close(fd[l]); /* Процесс 2 не нуждается в записи в конвейер */
close(STD_INPUT); /* Подготовка нового стандартного ввода */
dup(fd[0]); /* Сделать стандартным вводом устройство fd[O] */
close(fd[0]); /* Этот дескриптор файла больше не нужен */
execl(process2,process2, 0);
}
}
После вызова exec стартует процесс, у которого дескрипторы 0 и 2 остались без
изменений, а дескриптор 1 соответствует записи в канал. Код дочернего про-
процесса аналогичен. Значение параметра функции execl повторяется потому, что
первым ее параметром должно быть имя программы, а вторым — значение перво-
первого аргумента запускаемой программы, которое для большинства программ долж-
должно совпадать с именем.
Следующий системный вызов, ioctl, потенциально применим ко всем специаль-
специальным файлам. Например, он используется драйверами блочных устройств, таких
как SCSI-драйверы для работы с ленточными накопителями и CD-ROM. Тем не
менее он в основном применяется к символьным специальным файлам, особен-
особенно к терминалам. В стандарте POSIX определено несколько функций, которые
транслируются библиотекой в вызовы ioctl. С помощью функций tcgetattr
и t с set at t r можно изменить характеристики терминала, такие как коррекция
ошибок, режим и т. д. Эти функции используют вызов ioctl.
Режим с обработкой (cooked mode) — это нормальный режим работы терминала,
в котором возможно удаление символов, клавиши Ctrl+S и Ctrl+Q соответствен-
соответственно останавливают и запускают вывод информации на терминал, клавиши Ctrl+D
задают конец файла, а клавиши Ctrl+C генерируют сигнал прерывания. Нажатие
клавиш Ctrl +\ в этом режиме генерирует сигнал, по которому процесс принуди-
принудительно прерывается, и выводится дамп памяти.
В режиме без обработки (raw mode) вся эта дополнительная обработка не вы-
выполняется, и символы передаются программе напрямую. Более того, в этом ре-
режиме терминал не ждет окончания ввода строки, а передает символы программе
сразу. В таком режиме зачастую работают экранные редакторы.
Режим с прерыванием (cbreak mode) — промежуточный между двумя предыдущи-
предыдущими. В этом режиме при редактировании не работают клавиши стирания и удале-
удаления, а также комбинация Ctrl+D, но клавиши Ctrl+S, Ctrl+Q, Ctrl+C и Ctrl+\ работа-
работают. Как и в режиме без обработки, символы передаются программам сразу, не
дожидаясь окончания ввода строки (так как редактирование строк не работает,
не обязательно дожидаться окончания ввода, потому что пользователь не сможет
передумать и удалить введенные символы, как в режиме с обработкой).
Режимы с обработкой, без обработки и с прерыванием в стандарте POSIX не
описаны. Вместо этого POSIX определяет канонический режим (canonical mode),
соответствующий режиму с обработкой. В нем определено одиннадцать специаль-
специальных символов, и ввод ведется построчно. В неканоническом режиме (noncanonical
mode) ввод данных определяется минимальным воспринимаемым количеством
символов и временем (в десятых долях секунды). Стандарт POSIX очень гибок
и определяет множество различных флагов, управляя которыми можно прибли-
приблизить неканонический режим как к режиму без обработки, так и к режиму с пре-
прерыванием. Старые термины более содержательны, поэтому мы неформально бу-
будем их придерживаться.
У вызова ioctl есть три параметра. Например, вызов функции tcsetattr,
устанавливающей параметры терминала, выглядит так:
ioctl(fd, TCSETS, &termios);
Первый параметр задает файл, второй — выполняемую операцию, а третий —
адрес POSIX-структуры, содержащей флаги и массив управляющих символов.
Другие коды операций позволяют отложить изменения до завершения выво-
вывода, считать текущие значения параметров и отбросить не полностью считанные
данные.
Системный вызов access позволяет узнать, разрешено ли системой ограни-
ограничения доступа обращение к определенному файлу. Этот вызов необходим по-
потому, что некоторые программы могут работать под другим идентификатором
пользователя. Для этого программами используется механизм SETUID, кото-
который описан далее.
Чтобы присвоить файлу новое имя, применяется системный вызов rename. Его
параметры задают старое и новое имя файла.
Наконец, для управления файлами служит вызов f cntl, в чем-то подобный
вызову ioctl (и оба этих вызова — так называемые грязные хаки). У этого вы-
вызова есть несколько параметров, самые важные из которых служат для управ-
управления захватом файла. Вызовом fcntl можно захватывать и освобождать от-
отдельные части файлов, а также определять, захвачен ли нужный участок. Этот
вызов никак не определяет семантику захвата файла. Программы должны сами
решать, что делать.
1.4.4. Системные вызовы
для управления каталогами
В этом разделе мы рассмотрим некоторые системные вызовы, относящиеся ско-
скорее к каталогам и файловой системе в целом, нежели просто к тому или иному
файлу. Первые два вызова, mkdir и rmdir, соответственно создают и удаля-
удаляют пустые каталоги. Следующий вызов — link. Он разрешает одному файлу
появляться под двумя или более именами, часто в разных каталогах. Этот вы-
вызов обычно применяется, когда несколько программистов, работающих в одной
команде, должны совместно использовать один общий файл. Тогда этот файл
может появиться в каталоге у каждого из программистов, возможно, под дру-
другим именем. Разделение (совместное использование) файла — это не то же самое,
что копирование файла для каждого члена команды. При совместном исполь-
использовании файла изменения, производимые одним программистом, немедленно
становятся видимыми для остальных — все происходит в одном файле. А при
создании копии файла последующие изменения не влияют на другие копии
этого файла.
Чтобы понять, как работает вызов link, рассмотрим рис. 1.10, а. Два пользо-
пользователя, Ast и Jim, имеют собственные каталоги ast и j im с файлами. Предпо-
Предположим, что пользователь Ast запускает программу, содержащую системный
вызов:
link(Vusr/jim/memo", "/usr/ast/note");
Тогда файл memo из каталога j im появится в каталоге ast под названием note.
Соответственно, имена /usr/jim/memo и /usr/ast/note после этого будут
ссылаться на один и тот же файл.
Рис. 1.10. Механизм выполнения вызова link: a — два каталога до присоединения
/usr/jim/memo к каталогу ast; б — те же каталоги после вызова link
Возможно, станет понятнее, что делает системный вызов link, если разобраться
в том, как он работает. Каждый файл в UNIX имеет уникальный номер, который
идентифицирует файл. Этот номер представляет собой индекс в таблице индекс-
пых узлов (index nodes), или i-узлов (i-nodes), содержащей по одному индексному
узлу на файл. Каждый индексный узел включает в себя информацию о владель-
владельце файла, о том, какие блоки на диске он занимает и т. д. Каталог представляет
собой просто файл, содержащий набор пар из номера индексного узла и ASCII-
имени. В первых версиях UNIX каждый элемент каталога занимал 16 байт: 2 на
номер индексного узла и 14 на имя. Для поддержки длинных имен файлов
требуется более сложная структура, однако концептуально каталог представля-
представляет собой файл с парами номеров индексных узлов и ASCII-имен. На рис. 1.10
файл mail имеет номер индексного узла 16 и т. д. Действие вызова link заклю-
заключается в создании нового элемента каталога, имя которого, возможно, является
новым, а номер индексного узла равен номеру индексного узла существующе-
существующего файла. На рис. 1.10, б два элемента имеют одинаковый номер индексного
узла G0) и, таким образом, ссылаются на один и тот же файл. Если впоследст-
впоследствии один из них будет удален с помощью системного вызова unlink, другой
элемент останется. Если будут удалены оба файла, UNIX обнаружит, что больше
нет записей, соответствующих этому файлу (поле в таблице индексных узлов
хранит данные с номером элемента каталога, указывающего на файл), и удалит
файл с диска.
Как упоминалось ранее, системный вызов mount позволяет две файловых систе-
системы объединить в одну. Обычная ситуация такова: на жестком диске находится
корневая файловая система, содержащая двоичные (исполняемые) версии об-
общих команд и наиболее часто использующиеся файлы. При этом пользователь
может вставить в дисковод компакт-диск с файлами для чтения.
При помощи системного вызова mount файловую систему с гибкого диска можно
присоединить к корневой файловой системе, как показано на рис. 1.11. Типич-
Типичная команда на языке С, выполняющая монтирование, выглядит так:
mount("/dev/cdromO", "/mnt", 0);
Здесь первым параметром является имя специального блочного файла на дис-
диске 0, второй параметр — это место в дереве, куда будет вмонтирована файловая
система, а третий параметр говорит о том, монтируется ли встроенная файловая
система для чтения и записи или только для чтения.
Рис. 1.11. Файловая система: а — до вызова mount; б — после вызова mount
После вызова mount доступ к файлу на диске 0 можно получить, просто указав
его путь из корневого или рабочего каталога, независимо от того, на каком диске
он находится. В действительности второй, третий и четвертый диски тоже мож-
можно встроить в любое удобное место в дереве. Вызов mount позволяет объединить
съемные носители в единую интегрированную файловую структуру, не заботясь
о том, на каком из устройств фактически находится файл. Хотя в нашем примере
рассматривались компакт-диски, жесткие диски или их части, часто называемые
разделами (partition), или второстепенными устройствами (minor devices), мон-
монтируются аналогично. Когда файловая система более не нужна, ее можно демон-
демонтировать с помощью системного вызова umount.
MINIX 3 поддерживает блочное кэширование, то есть система кэширует в памяти
последние блоки, к которым были совершены обращения, чтобы избежать слиш-
слишком частых обращений к диску. Если блок в кэше модифицирован (например,
вызовом write) и система рухнет до того, как обновленный блок будет записан
на диск, и файловая подсистема окажется поврежденной. Чтобы снизить риск
повреждения, важно периодически сбрасывать содержимое кэша на диск, чтобы
в случае сбоя системы терялось только небольшое количество данных. Систем-
Системный вызов sync заставляет MINIX 3 сбросить на диск все кэшированные блоки,
измененные с момента считывания. Обычно при старте MINIX вместе с систе-
системой запускается фоновая программа update, каждые 30 секунд выполняющая
вызов sync.
Для работы с каталогами служат еще два вызова, chdir и enroot. Первый из
них меняет текущий каталог, а второй корневой. Например:
chdir("/usr/ast/test");
После этого вызова открытие файла xyz приведет к открытию файла /usг/
ast/test/xyz. Вызов enroot работает аналогично. Как только процесс изме-
изменяет корневой каталог системы, все абсолютные пути (те, которые начинают-
начинаются с символа /), начинают указывать на другой корень. Вы спросите, для чего
это нужно? С целью безопасности: серверные программы протоколов FTP (File
Transfer Protocol — протокол передачи файлов) и HTTP (HyperText Transfer
Protocol — протокол передачи гипертекста) меняют корневой каталог, чтобы
сделать недоступными все файлы, находящиеся в иерархии выше. Правом за-
запуска вызова enroot обладают только суперпользователи, но и они выполня-
выполняют его нечасто.
1.4.5. Системные вызовы для защиты
В MINIX 3 для каждого файла определен используемый для его защиты 11-раз-
11-разрядный код режима, иногда также называемый модой (mode). Код режима вклю-
включает 9 бит, по три (чтение, запись и выполнение) для владельца, для членов
группы владельца и для других пользователей. Системный вызов chmod предо-
предоставляет возможность изменения кода режима для файла. Например, следующий
вызов предоставит всем, кроме владельца, доступ к файлу только для чтения;
владелец же сможет еще и выполнять файл:
chmodC'file" , 0644) ;
Другие два бита зашиты, 02000 и 04000, называются соответственно битами
SETGID (Set-Group-Id — установить идентификатор группы) и SETUID (Set-
User-Id — установить идентификатор пользователя). Когда пользователь запус-
запускает программу, для которой установлен бит SETUID, то на время выполнения
процесса идентификатор пользователя заменяется идентификатором владельца
программы. Эта специальная возможность широко применяется для того, чтобы
позволить пользователям выполнять функции, доступные только суперпользо-
суперпользователям, такие как создание каталогов. Именно для создания каталога требуется
вызов mknod, доступный только суперпользователю. Если же владельцем про-
программы mkdir окажется суперпользователь и для нее будут установлены права
доступа 04755, обычные пользователи смогут запускать ее и тем самым делать
вызов mknod, но весьма ограниченным образом.
Когда процесс исполняет файл, в разрешениях которого выставлен бит SETUID
или SETGID, эффективный идентификатор пользователя или группы отличает-
отличается от реального значения. Но иногда для процесса важно знать, чему равны эф-
эффективные и реальные значения идентификаторов пользователя и группы. Что-
Чтобы получить эту информацию, процесс может делать системные вызовы getuid
и getgid. Оба этих вызова возвращают одновременно и эффективный, и реаль-
реальный идентификаторы, а чтобы получать эти значения по отдельности, служат че-
четыре библиотечные процедуры: getuid, getgid, geteuid, getegid. Первые
две возвращают реальные значения, вторые две — эффективные.
Для обычных пользователей единственный способ изменить свой идентифика-
идентификатор — запустить программу, у которой установлен бит SETUID. Но для супер-
суперпользователей существует и другая возможность, предоставляемая системным
вызовом setuid, устанавливающим одновременно реальное и эффективное зна-
значения идентификатора пользователя. Вызов setgid, соответственно, устанав-
устанавливает реальное и эффективное значения идентификатора группы. Кроме того,
суперпользователь может менять владельца файла при помощи системного вы-
вызова chown. Другими словами, у суперпольователя есть множество возможно-
возможностей нарушать все возможные правила защиты. Это объясняет, почему многие
студенты посвящают столь много времени попыткам стать суперпользователем.
Два последних системных вызова из данной категории могут делаться и обыч-
обычными процессами. Первый из них, umask, устанавливает системную битовую
маску, применяемую для маскирования битов прав доступа к файлу при его со-
создании. Например:
umask@22);
Если сделать такой вызов, то при вызовах creat или mknod в правах доступа
к создаваемому объекту будут маскироваться биты 022. Иначе говоря, следую-
следующий вызов создаст файл с правами доступа 0755, а не 0777:
creat("file", 0777) ;
Кроме того, битовая маска наследуется дочерними процессами, поэтому если
оболочка сразу после входа сделает вызов umask, ни одной из запущенных поль-
пользователем в этом сеансе программ не удастся создать файл, в который смогут за-
записывать данные другие пользователи.
Когда владельцем программы является суперпользователь и у нее установлен бит
SETUID, то она может обращаться к любому файлу. Но часто программе нужно
знать, имеет ли вызвавший ее пользователь разрешение обращаться к данному
файлу. Простая попытка обращения к файлу ничего не даст, так как она всегда
завершится успехом.
Следовательно, необходимо иметь возможность узнать, разрешен ли доступ для
реального (а не эффективного) идентификатора пользователя. Это можно сделать
с помощью системного вызова access. Чтобы проверить возможность чтения,
код режима должен быть равен 4, параметр записи — 2 и параметр исполнения — 1.
Эти значения можно комбинировать. Например, если код режима равен 6, то вы-
вызов вернет 0, если разрешены и запись, и чтение. В противном случае вызов вер-
вернет -1. Если код режима равен 0, проверяется, что файл существует и возможен
поиск в ведущих к нему каталогах.
Хотя механизмы защиты UNIX-подобных операционных систем, в общем, яв-
являются схожими, имеются и различия, которые приводят к ошибкам, а следо-
следовательно, к уязвимости системы безопасности. Более подробную информацию
см. в [16].
1.4.6. Системные вызовы
для управления временем
Для работы с системными часами MINIX 3 поддерживает четыре системных вы-
вызова. Вызов time возвращает текущее время в секундах, причем нулем считается
полночь 1 января 1970 года (имеется в виду начало дня, а не его конец). Кроме
того, чтобы считывать значение системного таймера, нужно иметь возможность
сначала это значение установить. Возможность установить часы дает вызов
stime, доступный только суперпользователю. Третий вызов — utime, он позво-
позволяет владельцу файла изменить значение времени, записанное в индексном узле
файла. У этого вызова довольно ограниченная область применения, но некото-
некоторым программам он нужен, например, программа touch устанавливает время
в индексном узле файла в соответствие с текущим временем.
Наконец, вызов times позволяет узнать, сколько времени процессор провел, ис-
исполняя процесс, и сколько времени потрачено на систему (то есть на обработку
системных вызовов). Кроме того, суммируется и возвращается общее время сис-
системы и процесса для всех дочерних процессов.
1.5. Структура операционной системы
Теперь, когда мы узнали, как выглядят операционные системы снаружи (то есть
мы познакомились с программным интерфейсом), самое время заглянуть внутрь.
Чтобы получить представление обо всем спектре возможных вариантов, в следую-
следующих разделах мы исследуем пять существующих (или использовавшихся ранее)
структур. Исследование это нельзя назвать всесторонним, здесь лишь рассмат-
рассматриваются несколько моделей, применявшихся на практике в разных системах.
Их пять — монолитные системы, многоуровневые системы, виртуальные маши-
машины, экзоядра и модель клиент-сервер.
1.5.1. Монолитные системы
В общем случае организация монолитной системы представляет собой «большой
хаос». То есть структура как таковая отсутствует. Операционная система пишет-
пишется в виде набора процедур, каждая из которых может вызывать другие, когда ей
это нужно. При использовании такой техники каждая процедура системы имеет
строго определенный интерфейс в терминах параметров и результатов и каждая
имеет возможность вызвать любую другую процедуру для выполнения некото-
некоторой необходимой для нее работы.
Для построения монолитной системы необходимо скомпилировать все отдель-
отдельные процедуры, а затем связать их в единый объектный файл с помощью ком-
компоновщика. Здесь, по существу, совсем не скрываются детали реализации —
каждая процедура видит любую другую процедуру (в отличие от структуры, со-
содержащей модули, в которых большая часть информации является локальной
для модуля, и процедуры модуля можно вызвать только через специально опре-
определенные точки входа).
Однако даже такие монолитные системы могут иметь некоторую структуру. При
системных вызовах, поддерживаемых операционной системой, параметры по-
помещаются в строго определенные места — регистры или стек, после чего выпол-
выполняется специальная инструкция перехвата, известная как вызов ядра, или вызов
супервизора.
Эта инструкция переключает машину из режима пользователя в режим ядра
и передает управление операционной системе. У большинства процессоров
есть два режима работы: режим ядра, предназначенный для ОС, и пользова-
пользовательский режим, в котором запрещен ввод-вывод и некоторые другие инст-
инструкции.
Теперь самое время посмотреть на то, как выполняются системные вызовы.
Вспомним, что вызов read выглядит следующим образом:
count = read(fd, buffer, nbytes);
Перед вызовом библиотечной процедуры read, фактически осуществляющей
системный вызов read, вызывающая программа сначала помещает параметры
в стек (шаги 1-3 на рис. 1.12). В силу исторических причин компиляторы язы-
языков С и C++ размещают параметры в обратном порядке (дело в том, что при пере-
передаче параметров функции print f первой в стеке должна располагаться формат-
форматная строка). Первый и третий параметры передаются по значению, а второй — по
ссылке. Это означает, что процедура read получает адрес буфера (указываемый
знаком &), а не его содержимое. Далее (на шаге 4) осуществляется фактический
вызов библиотечной процедуры. Данная инструкция ничем не отличается от
обычных вызовов процедур.
Рис. 1.12. Выполнение системного вызова read(fd, buffer, nbytes) за 11 шагов
Библиотечная процедура, возможно, написанная на языке ассемблера, обычно по-
помещает номер системного вызова туда, куда требует операционная система (напри-
(например, в регистр, как показано на шаге 5). Затем процедура исполняет инструкцию
trap, чтобы переключиться из пользовательского режима в режим ядра и начать
исполнение с определенного адреса внутри ядра (шаг б). Запущенный код ядра
анализирует номер системного вызова и выбирает для него соответствующий об-
обработчик, как правило, с помощью таблицы указателей на обработчики систем-
системных вызовов, индексируемой по номеру системного вызова (шаг 7). Затем вы-
выбранный обработчик запускается (шаг 8). По завершении его работы управление
может быть возвращено библиотечной процедуре и передано инструкции, сле-
следующей за trap (шаг 9). Процедура, в свою очередь, возвращает управление
программе пользователя так же, как любая другая процедура (шаг 10).
В завершение программа пользователя должна очистить стек: это действие все-
всегда выполняется после возврата из процедуры (шаг 11). Предполагая, что стек
растет сверху вниз, как это обычно бывает, скомпилированный код увеличивает
указатель стека (Stack Pointer, SP) ровно настолько, чтобы удалить из него пара-
параметры, помещенные перед вызовом read. После этого программа может смело
приступать к выполнению следующих действий.
Описывая шаг 9, мы намеренно сказали, что управление «может быть возвраще-
возвращено библиотечной процедуре». Дело в том, что системный вызов способен блоки-
блокировать выполнение вызвавшего процесса. Например, если вызов должен считать
ввод с клавиатуры, но пользователь ничего не вводит, вызвавший процесс под-
подлежит блокированию. В этом случае операционная система попытается найти
процесс, который можно выполнить в образовавшейся паузе. Когда ожидаемый
ввод, наконец, произойдет, система вернется к обработке блокированного про-
процесса и выполнит шаги 9-11.
Такая организация операционной системы предполагает следующую структуру:
♦ Главная программа, которая вызывает требуемую служебную процедуру.
♦ Набор служебных процедур, выполняющих системные вызовы.
♦ Набор утилит, обслуживающих служебные процедуры.
В этой модели для каждого системного вызова имеется одна служебная процеду-
процедура. Утилиты выполняют функции, которые нужны нескольким служебным про-
процедурам. Деление процедур на три уровня иллюстрирует рис. 1.13.
Рис. 1.13. Простая структурная модель монолитной системы
1.5.2. Многоуровневые системы
Обобщением этого подхода является организация операционной системы в виде
иерархии уровней. Первой системой, построенной таким образом, была система
THE, созданная Э. Дейкстрой (Е. W. Dijkstra) и его студентами в 1968 году. Она
была простой пакетной системой для голландского компьютера Electrologica X8,
память которого состояла из 32 К 27-разрядных слов.
Система включала 6 уровней, как показано в табл. 1.2. Уровень 0 отвечал за
распределение времени процессора, переключая процессы при возникновении
прерывания или при срабатывании таймера. Над уровнем 0 система состояла из
последовательных процессов, каждый из которых можно было запрограммиро-
запрограммировать, не заботясь о том, что на одном процессоре запущено несколько процессов.
Другими словами, уровень 0 обеспечивал базовую многозадачность процессора.
Таблица 1.2. Структура операционной системы THE
Уровень Функция
5 Оператор
4 Пользовательские программы
3 Управление вводом-выводом
2 Взаимодействие оператор-процесс
1 Управление памятью и барабаном
О Выделение процессора и многозадачность
Уровень 1 управлял памятью. Он выделял процессам пространство в оператив-
оперативной памяти и на магнитном барабане объемом 512 К слов для тех частей процес-
процессов (страниц), которые не помещались в оперативной памяти. Процессы более
высоких уровней не заботились о том, находятся ли они в данный момент в па-
памяти или на барабане. Программы уровня 1 обеспечивали попадание страниц
в оперативную память по мере необходимости.
Уровень 2 управлял взаимодействием между консолью оператора и процессами.
Таким образом, все процессы выше этого уровня имели собственную консоль
оператора. Уровень 3 управлял устройствами ввода-вывода и буферизовал пото-
потоки информации к ним и от них. Любой процесс выше уровня 3 вместо того, что-
чтобы работать с конкретными устройствами, учитывая разнообразные нюансы их
конструкции, мог обращаться к абстрактным устройствам ввода-вывода, обла-
обладающим удобными для пользователя характеристиками. На уровне 4 работали
пользовательские программы, которым не надо было заботиться ни о процессах,
ни о памяти, ни о консоли, ни об управлении устройствами ввода-вывода. Про-
Процесс системного оператора размещался на уровне 5.
Дальнейшее обобщение многоуровневой концепции было сделано в операцион-
операционной системе MULTICS. В ней уровни представляли собой серию концентриче-
концентрических колец, где внутренние кольца являлись более привилегированными, чем
внешние. Когда процедура внешнего кольца хотела вызвать процедуру внут-
внутреннего, она должна была выполнить эквивалент системного вызова, то есть
команду trap, параметры которой тщательно проверяются перед тем, как вы-
выполняется вызов. Хотя операционная система MULTICS являлась частью адрес-
адресного пространства каждого пользовательского процесса, аппаратура обеспечива-
обеспечивала защиту данных на уровне сегментов памяти, разрешая или запрещая доступ
к отдельным процедурам (в действительности — к сегментам памяти) для записи,
чтения или выполнения.
Стоит отметить, что в системе THE многоуровневая схема представляла собой
исключительно конструктивное решение и все части системы были, в конечном
счете, связаны в один объектный файл, а в MULTICS механизм разделения
колец действовал во время исполнения на аппаратном уровне. Преимущество
подхода MULTICS заключается в том, что его можно расширить и на структуру
пользовательских подсистем. Например, профессор может написать программу
для тестирования и оценки студенческих программ и запустить ее в кольце гг,
в то время как студенческие программы будут работать в кольце п + 1, так что
они не смогут изменить свои оценки. Аппаратное обеспечение Pentium поддер-
поддерживает кольцевую структуру MULTICS, однако в настоящий момент ее не ис-
использует ни одна из распространенных операционных систем.
1.5.3. Виртуальные машины
Исходная версия OS/360 была системой исключительно пакетной обработки.
Однако множество пользователей OS/360 желали работать в системе с разделени-
разделением времени, поэтому различные группы программистов как в самой корпорации
IBM, так и вне ее решили написать для этой машины системы разделения времени.
Официальная система разделения времени от IBM, которая называлась TSS/360,
поздно вышла в свет и оказалась настолько громоздкой и медленной, что на нее
перешли немногие. В конечном счете от нее отказались, но уже после того, как ее
разработка потребовала около 50 млн долларов [106]. Группа из научного цен-
центра IBM в Кембридже, штат Массачусетс, разработала в корне отличающуюся от
нее систему, которую компания IBM в результате приняла как законченный
продукт. Сейчас она широко используется на еще оставшихся мэйнфреймах.
Эта система, в оригинале называвшаяся CP/CMS, а позже переименованная в VM/
370VM/370, была основана на следующем проницательном наблюдении: систе-
система разделения времени обеспечивает, во-первых, многозадачность, во-вторых,
расширенную машину с более удобным интерфейсом, чем тот, что предоставля-
предоставляется оборудованием напрямую. Система VM/370 основана на полном разделе-
разделении этих двух функций.
Сердце системы, называемое монитором виртуальной машины, работает с обору-
оборудованием и обеспечивает многозадачность, предоставляя верхнему уровню не
одну, а несколько виртуальных машин, как показано на рис. 1.14. Но, в отли-
отличие от всех других операционных систем, эти виртуальные машины не являются
расширенными. Они не поддерживают файлы и прочие удобства, а предоставля-
предоставляют точные аппаратные копии, включая режимы ядра и пользователя, ввод-вывод
данных, прерывания и все остальное, характерное для реального компьютера.
Поскольку каждая виртуальная машина идентична настоящему оборудованию,
на каждой из них может работать любая операционная система, которая запуска-
запускается прямо на аппаратуре. На разных виртуальных машинах могут (а зачастую
так и происходит) функционировать различные операционные системы. На не-
некоторых из них для обработки пакетов и транзакций работают потомки OS/360,
а на других для интерактивного разделения времени пользователей работает
однопользовательская интерактивная система CMS (Conversational Monitor Sys-
System — система диалоговой обработки).
Рис. 1.14. Структура VM/370 с системой CMS
Когда программа операционной системы CMS выполняет системный вызов, он
перехватывается операционной системой на собственной виртуальной машине,
а не на VM/370, как произошло бы, если бы он работал на реальной машине вме-
вместо виртуальной. Затем CMS выдает обычные команды ввода-вывода для чтения
своего виртуального диска или другие команды, которые могут понадобиться
системе для выполнения вызова. Эти команды ввода-вывода перехватываются
ОС VM/370, которая выполняет их в рамках моделирования реального оборудо-
оборудования. При полном разделении функций многозадачности и предоставления рас-
расширенной машины каждая часть может быть намного проще, гибче и удобней
для обслуживания.
Идея виртуальной машины очень часто используется в наши дни, но в несколько
другом контексте: для работы на Pentium (или на других 32-разрядных процессо-
процессорах от Intel) старых программ, написанных для MS-DOS. При разработке компь-
компьютера Pentium и его программного обеспечения обе компании, Intel и Microsoft,
понимали, что возникнет острая потребность в поддержании работы старых про-
программ на новом оборудовании. Поэтому корпорация Intel создала на процессоре
Pentium режим виртуального процессора 8086. В этом режиме машина действует
как 8086 (с точки зрения программного обеспечения она идентична 8088), вклю-
включая 16-разрядную адресацию памяти с ограничением объема памяти в 1 Мбайт.
Такой режим используется системой Windows и другими операционными сис-
системами для запуска программ MS-DOS. Программы запускаются в режиме вир-
виртуального процессора 8086. Пока они выполняют обычные команды, эти про-
программы работают напрямую с оборудованием. Но когда программа пытается
обратиться по прерыванию к операционной системе, чтобы сделать системный
вызов, или пытается напрямую осуществить ввод-вывод данных, происходит
прерывание с переключением на монитор виртуальной машины.
Возможны два варианта устройства. Первый: сама система MS-DOS загружена
в адресное пространство виртуальной машины 8086, так что монитор виртуаль-
виртуальной машины только отсылает прерывания назад к MS-DOS, как это происхо-
происходит на реальной машине 8086. Когда затем MS-DOS пытается самостоятельно
осуществить ввод-вывод, операция перехватывается и выполняется монитором
виртуальной машины.
В другом варианте монитор виртуальной машины перехватывает первое преры-
прерывание и сам выполняет ввод-вывод, так как он знает все системные вызовы MS-
DOS и имеет представление о том, что должно делать каждое прерывание. Этот
вариант не столь безупречен, как первый, потому что, в отличие от первого вари-
варианта, он корректно моделирует только MS-DOS и никакие другие операционные
системы. С другой стороны, он намного быстрее работает, так как не требует за-
запуска MS-DOS для выполнения ввода-вывода. Существует еще один недостаток
фактического запуска MS-DOS в режиме виртуальной машины 8086: MS-DOS
очень часто оперирует флагом разрешения/запрещения прерываний, а модели-
моделирование этого требует больших затрат.
Стоит отметить, что ни один из двух описанных методов в действительности не
обеспечивает то, чем была система VM/370, потому что смоделированная машина
представляет собой только машину 8086, а не полноценный процессор Pentium.
В системе VM/370 можно было запустить на виртуальной машине саму систему
VM/370. Даже для самых старых версий Windows необходим как минимум про-
процессор 286, а, значит, их невозможно запустить на виртуальной машине 8086.
Некоторые реализации виртуальных машин предлагаются рынку как коммерче-
коммерческие. Для компаний, предоставляющих услуги веб-хостинга, экономически вы-
выгоднее использовать несколько виртуальных машин на одном мощном сервере
(возможно, многопроцессорном), нежели несколько компьютеров, обслуживаю-
обслуживающих отдельные сайты. Именно для такого применения предназначены машины
VMWare и Microsoft Virtual PC. В качестве имитируемых дисков для гостевых
систем (guest systems) эти программы используют большие файлы на физиче-
физической системе. Для эффективности они анализируют двоичный код программ
гостевой системы и разрешают выполнение безопасного кода непосредственно
на физическом аппаратном обеспечении, перехватывая инструкции, осуществ-
осуществляющие системные вызовы. Подобные системы также полезны в сфере обучения.
Например, студенты, изучающие ОС MINIX 3, могут работать с ней как с госте-
гостевой операционной системой при помощи виртуальной машины VMWare на фи-
физическом компьютере с Windows, Linux или UNIX без риска повредить другое
установленное программное обеспечение. Многие преподаватели с опаской отно-
относятся к совмещению своих занятий с курсом операционных систем на одних и тех
же компьютерах, поскольку ошибки, совершаемые студентами при работе с ОС,
способны повредить или вовсе уничтожить данные на дисках.
Еще одна область применения виртуальных машин, хотя и несколько специ-
специфичная, — это исполнение Java-программ. Вместе с языком Java компания Sun
Microsystems изобрела виртуальную машину (то есть компьютерную архитекту-
архитектуру) JVM (Java Virtual Machine — виртуальная машина Java). Компилятор Java
создает код для JVM, который, как правило, исполняется программным JVM-
интерпретатором. Преимущество такого подхода заключается в том, что JVM-
код может быть передан через Интернет и исполнен на любом компьютере, осна-
оснащенном JVM-интерпретатором. Двоичный код, созданный компилятором, к приме-
примеру, для SPARC или Pentium, нельзя использовать где угодно с такой же просто-
простотой. Разумеется, фирма Sun могла бы сначала предложить компилятор двоичного
кода для SPARC, а затем его интерпретатор, однако интерпретировать JVM-ap-
хитектуру значительно легче. У JVM есть и другое важное преимущество: если
интерпретатор реализован корректно (что отнюдь не является нетривиальным),
входящие JVM-программы можно проверять на безопасность и затем испол-
исполнять в безопасной среде, чтобы избежать похищения данных и деструктивных
последствий.
1.5.4. Экзоядра
В системе VM/370 каждый процесс пользователя получает точную копию настоя-
настоящей машины. На Pentium, в режиме виртуальной машины 8086, каждый пользо-
пользовательский процесс получает точную копию другой машины. Шагнув несколько
дальше, исследователи из Массачусетсского технологического института изобре-
изобрели систему, которая обеспечивает каждого пользователя абсолютной копией ре-
реального компьютера, но со своим подмножеством ресурсов [43, 75]. Например,
одна виртуальная машина может получить блоки на диске с номерами от 0 до
1023, следующая — от 1024 до 2047 и т. д.
На нижнем уровне в режиме ядра работает программа, которая называется экзо-
ядро (exokernel). В ее задачу входит распределение ресурсов для виртуальных
машин, а после этого проверка их использования (то есть отслеживание попыток
машин задействовать чужой ресурс). Каждая виртуальная машина на уровне
пользователя может работать с собственной операционной системой, как на
VM/370 или виртуальных машинах 8086 для Pentium, с той разницей, что каж-
каждая машина ограничена набором ресурсов, которые она запросила и которые ей
были предоставлены.
Преимущество схемы экзоядра заключается в том, что она позволяет обойтись
без уровня отображения. При других методах работы каждая виртуальная маши-
машина считает, что она использует собственный диск с нумерацией блоков от 0 до
некоторого максимума. Поэтому монитор виртуальной машины должен поддер-
поддерживать таблицы преобразования адресов на диске (и всех других ресурсов). Не-
Необходимость преобразования отпадает при наличии экзоядра, которому нужно
только хранить запись о том, какой виртуальной машине выделен данный ре-
ресурс. Подобный подход имеет еще одно преимущество: он отделяет многозадач-
многозадачность (в экзоядре) от операционной системы пользователя (в пользовательском
пространстве) с меньшими затратами, так как для этого ему необходимо всего
лишь не допускать вмешательства одной виртуальной машины в работу другой.
1.5.5. Модель клиент-сервер
Система VM/370 сильно выигрывает в простоте благодаря переносу значитель-
значительной части кода (обеспечивающего расширенную машину) традиционной опера-
операционной системы на верхний уровень, в систему CMS. Однако VM/370 и при
этом останется сложной комплексной программой, потому что моделирование
нескольких виртуальных машин 370 само по себе не так просто (особенно если
вы хотите сделать это достаточно эффективно).
В развитии современных операционных систем наблюдается тенденция в сторо-
сторону дальнейшего переноса кода на верхние уровни и удалении при этом всего, что
только возможно, из операционной системы, оставляя минимальное ядро. Обыч-
Обычно для этого решение большинства задач операционной системы перекладывает-
перекладывается на пользовательские процессы. Получая запрос на обслуживание, например
чтение блока файла, пользовательский процесс (теперь называемый клиент-
клиентским) посылает запрос серверному процессу, который его обрабатывает и высы-
высылает назад ответ.
В модели, показанной на рис. 1.15, в задачу ядра входит только управление взаи-
взаимодействием между клиентами и серверами. Благодаря разделению операци-
операционной системы на части, каждая из которых управляет всего одним элементом
системы (файловой подсистемой, процессами, терминалом или памятью), все
части становятся небольшими и легко управляемыми. К тому же, поскольку все
серверы работают как процессы в пользовательском режиме, а не в режиме ядра,
они не имеют прямого доступа к оборудованию. Поэтому если происходит ошиб-
ошибка на файловом сервере, может оказаться неработоспособной служба обработки
файловых запросов, но это обычно не приводит к остановке машины в целом.
Рис. 1.15. Модель клиент-сервер
Другое преимущество модели клиент-сервер заключается в ее простой адапта-
адаптации к использованию в распределенных системах (рис. 1.16). Если клиент обща-
общается с сервером, посылая ему сообщения, клиенту не нужно знать, обрабатывает-
обрабатывается его сообщение локально на его собственной машине или оно посылается по
сети серверу на удаленной машине. С точки зрения клиента в обоих случаях про-
происходит одно и то же: запрос посылается и на него приходит ответ.
Рис. 1.16. Модель клиент-сервер в распределенной системе
Рассказанная история о ядре, управляющем передачей сообщений от клиентов
к серверам и обратно, не совсем реалистична. Некоторые функции операционной
системы, такие как загрузка команд в регистры физических устройств ввода-вы-
ввода-вывода, трудно, если вообще возможно, выполнить из программ в пользователь-
пользовательском пространстве. Есть два способа разрешения этой проблемы. Первый заклю-
заключается в том, что некоторые критически важные серверные процессы (например,
драйверы устройств ввода-вывода) действительно запускаются в режиме ядра
с полным доступом к аппаратуре, но при этом взаимодействуют с другими про-
процессами по обычной схеме передачи сообщений. Вариант такого механизма ис-
использовался в ранних версиях MINIX, где драйверы компилировались в ядро,
однако выполнялись как отдельные процессы.
Второй способ состоит в том, чтобы встроить минимальный механизм обработки
информации в ядро, но оставить принятие политических решений за серверами
в пользовательском пространстве. Например, ядро может опознавать сообщения,
посланные по определенным адресам. Для ядра это означает, что нужно взять со-
содержимое сообщения и загрузить его, скажем, в регистры ввода-вывода некото-
некоторого диска для запуска операции чтения диска. В этом примере ядро даже может
не обследовать байты сообщения, если они оказались допустимы или осмыслен-
осмысленны; оно может вслепую копировать их в регистры диска. (Очевидно, должна ис-
использоваться некоторая схема, ограничивающая круг процессов, имеющих право
отправлять подобные сообщения.) Именно так работает операционная система
MINIX 3. Драйверы находятся в пользовательском пространстве и посылают яд-
ядру специальные вызовы, запрашивающие чтение и запись регистров ввода-выво-
ввода-вывода или доступ к информации, содержащейся в ядре. Разделение между механиз-
механизмом и политикой является очень важной концепцией, постоянно используемой
в различных контекстах в операционных системах.
1.6. Краткий обзор остальных глав
Типичные операционные системы состоят из четырех основных компонентов,
обеспечивающих управление процессами, устройствами ввода-вывода, памятью
и файлами. MINIX 3 в этом отношении не является исключением. Следующие
четыре главы будут посвящены указанным четырем компонентам, по одной гла-
главе на каждый. В главе 6 содержится перечень рекомендуемой литературы и биб-
библиографии.
Главы о процессах, вводе-выводе, управлении памятью и файловых системах име-
имеют одну и ту же общую структуру. Сначала излагаются общие принципы. Затем
идет обзор соответствующего элемента MINIX 3 (эта информация применима
и к UNIX). Наконец, подробно рассматривается реализация в MINIX 3. Раздел,
посвященный реализации, можно без потери целостности изложения пропустить
или коснуться вскользь. Те же читатели, которые заинтересованы в изучении ра-
работы реальной ОС (MINIX 3), должны прочитать все разделы.
Резюме
Операционную систему можно рассматривать с двух точек зрения: как менеджер
ресурсов и как расширенную машину. Как менеджер ресурсов операционная
система рационально управляет различными частями системы. С точки зрения
расширенной машины, работа операционной системы состоит в предоставлении
пользователям виртуальной машины, более удобной, чем настоящий компьютер.
Операционные системы имеют достаточно долгую историю развития, которая на-
начинается с тех дней, когда операционные системы заменили оператора, и про-
продолжается до современных многозадачных систем.
Сердцем любой операционной системы является набор системных вызовов, ко-
которые она может обработать. Они говорят о том, что реально делает операцион-
операционная система. Мы рассмотрели шесть групп системных вызовов для MINIX 3.
Первая группа обеспечивает создание и завершение процессов. Вторая группа
предназначена для работы с сигналами. Третья — для чтения и записи файлов.
Четвертая нужна для управления каталогами. Пятая включила в себя управле-
управление защитой, а шестая — управление временем.
Операционные системы могут быть структурированы по-разному. В наиболее
общем случае структурирование может быть таким: монолитные системы, иерар-
иерархические многоуровневые системы, виртуальные машины, экзоядра, модель кли-
клиент-сервер.
Вопросы и задания
1. Каковы две главные функции операционной системы?
2. В чем различие между режимом ядра и пользовательским режимом? Почему
это различие представляет важность для операционной системы?
3. Что такое многозадачность?
4. Что такое подкачка? Как вы считаете, будут ли передовые персональные ком-
компьютеры будущего поддерживать подкачку данных в качестве стандартной
функции?
5. На ранних компьютерах чтение или запись каждого байта данных управля-
управлялись напрямую центральным процессором (то есть тогда не было прямого
доступа к памяти). Какой смысл имеет это понятие для многозадачности?
6. Почему системы разделения времени не были широко распространены на
компьютерах второго поколения?
7. Какая из следующих команд должна быть разрешена только в режиме ядра:
1) отключение всех прерываний;
2) чтение счетчика даты/времени;
3) изменения счетчика даты/времени;
4) изменение схемы распределения памяти.
8. Перечислите основные различия между операционной системой для персо-
персонального компьютера и для мэйнфрейма.
9. Приведите причину, по которой фирменная операционная система с закры-
закрытым исходным кодом (к примеру, Windows) должна быть лучше по качеству
по сравнению с операционной системой, имеющей открытый исходный код
(например, Linux). Приведите причину, по которой, напротив, операционная
система с открытым исходным кодом должна быть лучше по качеству, чем
фирменная операционная система с закрытым исходным кодом.
10. У файла в MINIX идентификатор владельца равен 12 и идентификатор груп-
группы равен 1. Файлу присвоены следующие разрешения: rwxr-x--. К этому
файлу пытается обратиться другой пользователь, у которого идентификатор
пользователя равен 6, а идентификатор группы — 1. Что произойдет?
11. Как в свете того, что существование суперпользователя может привести к мно-
множеству проблем безопасности, объяснить сам факт существования концепции
суперпользователя?
12. Все версии UNIX поддерживают именование файлов с использованием двух
типов путей — абсолютных (относительно корня) и относительных (относи-
(относительно рабочего каталога). Можно ли отказаться от одного из типов, сохра-
сохранив лишь другой? Если да, какой из них следует сохранить?
13. Почему таблица процессов необходима в системах разделения времени? Нуж-
Нужна ли она в системах, где в каждый момент времени существует единствен-
единственный процесс, занимающий все ресурсы компьютера до окончания своего вы-
выполнения?
14. В чем заключается существенная разница между блочным специальным фай-
файлом и символьным специальным файлом?
15. Что случится, если в MINIX 3 пользователь 2 создаст ссылку на файл, кото-
которым владеет пользователь 1, затем пользователь 1 удалит файл, и, наконец,
пользователь 2 попытается прочитать файл?
16. Являются ли каналы необходимой функцией операционной системы? Какая
основная функциональность утрачивается при отсутствии каналов?
17. Современные потребительские товары, такие как цифровые камеры и стерео-
стереосистемы, зачастую оснащены дисплеем, с помощью которого можно вводить
команды и просматривать результаты их выполнения. Обычно в такие това-
товары встроена простейшая операционная система. Какой области программного
обеспечения персонального компьютера соответствует обработка команд че-
через дисплей стереосистемы и камеры?
18. В операционной системе Windows не поддерживается системный вызов fork,
однако это не лишает ее возможности создания новых процессов. Сформули-
Сформулируйте научную догадку о том, какова семантика системного вызова Windows,
создающего новый процесс.
19. Почему системный вызов chroot разрешено выполнять только суперпользо-
суперпользователю (подсказка: не забывайте о безопасности)?
20. Рассмотрите список системных вызовов, приведенный в табл. 1.1. Какие,
по вашему мнению, вызовы используются наиболее часто? Поясните ответ.
21. Предположим, что компьютер исполняет 1 млрд инструкций в секунду, а сис-
системный вызов включает 1000 инструкций, считая прерывание и переключе-
переключение контекста. Сколько системных вызовов в секунду способен обработать
компьютер при условии, что половина ресурсов процессора тратится на ис-
исполнение кода приложений?
22. Мы рассматривали системный вызов mknod, но не рассматривали вызов rmnod.
Означает ли это, что вы должны очень вдумчиво подходить к созданию узлов
подобным образом, поскольку нет способа их удаления?
23. Зачем в MINIX 3 все время работает фоновая программа update?
24. Имеет ли смысл игнорировать сигнал sigalarm?
25. Модель клиент-сервер популярна в распределенных системах. Может ли она
использоваться в системах из одного компьютера?
26. Первые версии процессора Pentium не могли поддерживать монитор вирту-
виртуальной машины. Какая основополагающая характеристика машины позволя-
позволяет виртуализировать ее?
27. Напишите программу (или набор программ), чтобы протестировать все сис-
системные вызовы MINIX 3. Произведите каждый вызов с разными параметрами,
в том числе и с некорректными, чтобы увидеть реакцию системы на ошибки.
28. Напишите оболочку, напоминающую показанную в листинге 1.1, но достаточ-
достаточно работоспособную, чтобы ее можно было протестировать. Желательно так-
также наделить ее некоторыми дополнительными функциями, включая перена-
перенаправление ввода и вывода, поддержку каналов, обработку фоновых заданий.
Глава 2
Процессы
С этой главы мы начнем детальное изучение устройства и работы операцион-
операционных систем, в основном MINIX 3. Основополагающей концепцией для любой
операционной системы является процесс — абстракция запущенной программы.
Все остальное базируется на концепции процесса, поэтому представляется край-
крайне важным, чтобы разработчики операционных систем (а также студенты) хоро-
хорошо поняли эту концепцию.
2.1. Знакомство с процессами
Все современные компьютеры могут одновременно делать несколько вещей. На-
Например, параллельно с запущенной пользователем программой может выполнять-
выполняться чтение с диска и вывод текста на экран монитора или на принтер. В многозадач-
многозадачной системе процессор переключается между программами, предоставляя каждой
от десятков до сотен миллисекунд персонального времени. При этом в каждый
конкретный момент времени процессор занят только одной программой, но за
секунду он успевает поработать с несколькими, создавая у пользователей ил-
иллюзию одновременной работы со всеми программами. Иногда в этом контексте
говорят о псевдопараллелизме, в отличие от настоящего параллелизма в много-
многопроцессорных системах (в которых установлено два и более процессора, имею-
имеющих общую физическую память). Отслеживать работу параллельно протекающих
процессов достаточно трудно, поэтому со временем разработчики операционных
систем придумали концептуальную модель логически упорядоченных процессов.
В данной главе мы опишем применение этой модели, а также некоторые резуль-
результаты ее использования.
2.1.1. Модель процессов
В модели процесса все функционирующее на компьютере программное обеспе-
обеспечение, иногда включая собственно операционную систему, организовано в виде
набора логически упорядоченных процессов, или, для краткости, просто процессов.
Процессом является выполняемая программа, вместе с текущими значениями
счетчика команд, регистров и переменных. С позиций данной абстрактной модели
у каждого процесса есть собственный виртуальный центральный процессор.
На самом деле, разумеется, реальный процессор переключается с процесса на про-
процесс, но для лучшего понимания системы значительно проще рассматривать на-
набор процессов, выполняемых параллельно (псевдопараллельно), чем пытаться
представить себе процессор, переключающийся от программы к программе. Как
мы уже знаем из первой главы, это переключение называется многозадачностью.
На рис. 2.1, а представлена схема многозадачного компьютера с четырьмя про-
программами в памяти. На рис. 2.1, б мы видим четыре независимых друг от друга
процесса, каждый со своей управляющей логикой (то есть логическим счетчи-
счетчиком команд). Конечно, на самом деле существует только один физический счет-
счетчик команд, подменяемый логическим счетчиком команд текущего процесса. Ко-
Когда время, отведенное текущему процессу, заканчивается, значение физического
счетчика сохраняется в логическом счетчике команд, то есть в памяти процесса.
На рис. 2.1, в видно, что за достаточно большой промежуток времени изменилось
состояние всех четырех процессов, но в каждый конкретный момент в действи-
действительности работает только один процесс.
Рис. 2.1. Иллюстрация многозадачности: а — четыре программы в многозадачном режиме;
б — принципиальная модель четырех независимых логически упорядоченных процессов;
в — в каждый момент времени активна только одна программа
Поскольку процессор переключается между программами, скорость, с которой
он производит свои вычисления, оказывается непостоянной и, возможно, даже
иной при каждом новом запуске процесса. Поэтому не следует программировать
процессы, исходя из каких-либо жестко заданных временных предположений.
Представьте себе, например, процесс ввода-вывода, запускающий накопитель на
магнитной ленте для восстановления упакованных файлов. Процесс выполняет
холостой цикл задержки из 10 000 итераций, чтобы предоставить накопителю
время разогнаться, а затем дает команду считать первый сектор. Если во время
холостого цикла процессор решит переключиться на другую задачу, может слу-
случиться так, что работающий с магнитофоном процесс запустится снова уже по-
после того, как считывающая головка пройдет первую запись. Если у процесса есть
критические временные ограничения, то есть отдельные события должны укла-
укладываться в заданное количество миллисекунд, необходимы специальные меры,
позволяющие удостовериться в завершении события. Однако обычно многоза-
многозадачный режим, а также относительные скорости различных процессов не влияют
на работу большинства отдельных процессов.
Различие между процессом и программой трудноуловимо, но тем не менее оно
имеет принципиальное значение. Воспользуемся следующей аналогией: пред-
представьте себе программиста, имеющего познания в кулинарии и своими руками
выпекающего торт на день рождения собственной дочери. В его распоряжении
есть рецепт торта, кухня, оборудованная всем необходимым, и ингредиенты для
торта: мука, яйца, сахар, ванилин и т. п. Согласно этой аналогии, рецепт — это
программа (то есть алгоритм), программист исполняет роль процессора, а ингре-
ингредиенты торта представляют собой входные данные. Процессом является следую-
следующая последовательность действий: программист читает рецепт, смешивает про-
продукты и печет торт.
Теперь представьте, что на кухню прибегает плачущий сын программиста и кри-
кричит, что его ужалила пчела. Программист отмечает, на чем он остановился (со-
(сохраняет текущее состояние процесса), находит справочник по оказанию первой
помощи и действует в соответствии с инструкцией. Таким образом, наш процес-
процессор переключается с одного процесса (выпечка торта) на другой, с более высо-
высоким приоритетом (оказание первой помощи), и каждый процесс связан со своей
программой (рецепт торта и справочник по оказанию первой помощи). После
проведения всех необходимых процедур по борьбе с укусом пчелы программист
возвращается к торту, продолжая с той операции, на которой он прервался.
Мы привели такую аналогию с целью показать, что процесс — это некоторого ро-
рода деятельность. У него есть программа, входные и выходные данные, а также со-
состояние. Один процессор может переключаться между различными процессами,
опираясь на некий алгоритм планирования для определения момента перехода
от одного процесса к другому.
2.1.2. Создание процессов
Операционной системе нужен способ, позволяющий удостовериться в существо-
существовании всех обслуживаемых процессов. В простейших системах, а также в систе-
системах, разработанных для выполнения единственного приложения (таких как кон-
контроллер микроволновой печи), нетрудно реализовать ситуацию, в которой все
требуемые процессы уже присутствуют в системе при ее запуске. Однако в мно-
многоцелевых системах требуется способ создания и завершения процессов по мере
необходимости. Сейчас мы рассмотрим несколько связанных с этим вопросов.
Существуют четыре основных события, приводящие к созданию процессов:
1. Инициализация системы.
2. Исполнение запущенным процессом системного вызова создания процесса.
3. Запрос пользователя на создание процесса.
4. Инициализация пакетного задания.
При загрузке операционной системы зачастую создаются несколько процессов.
Некоторые из них являются приоритетными, то есть процессами, взаимодейст-
взаимодействующими с пользователями (людьми) и выполняющими для них определенную
работу. Другие процессы являются фоновыми: они не связаны с конкретными
пользователями, однако имеют определенное функциональное назначение. На-
Например, фоновый процесс может принимать входящие запросы на открытие веб-
вебстраниц, размещенных на компьютере, «просыпаясь» каждый раз при получении
запроса и обслуживая его. Процессы, выполняемые в фоновом режиме и осуще-
осуществляющие определенную деятельность, такую как обслуживание веб-страниц,
печать и т. д., часто называют демонами, В больших системах обычно работают
десятки демонов. В MINIX 3 список выполняемых процессов можно получить
при помощи программы ps.
Процессы могут создаваться не только при загрузке операционной системы, но
и во время ее работы. Зачастую запущенный процесс создает один или несколь-
несколько новых процессов, которые помогают ему выполнять свои функции. Создание
новых процессов особенно полезно в случаях, когда работу можно представить
как совокупность взаимодействующих, но в остальном независимых друг от дру-
друга процессов. Так, при компиляции большой программы утилита make сначала
вызывает компилятор языка С, чтобы преобразовать исходные файлы в объект-
объектный код, а затем обращается к программе install, чтобы скопировать программу
в целевой каталог, задать владельца, разрешения и прочие атрибуты. В MINIX 3
сам компилятор языка С представляет собой набор отдельных совместно рабо-
работающих программ: препроцессор, синтаксический анализатор, генератор кода на
языке ассемблера, ассемблер и редактор связей.
В интерактивных системах пользователи могут запустить программу путем вво-
ввода команды. В MINIX 3 виртуальные консоли позволяют пользователю запус-
запустить программу (скажем, компилятор), затем переключиться на другую консоль
и запустить еще одну программу, например редактор документов, в то время как
компилятор выполняет свою работу.
Последнее событие, приводящее к созданию процессов, поддерживается только
в системах пакетной обработки, устанавливаемых на больших мэйнфреймах.
В таких системах пользователи могут вводить в систему пакетные задания (в том
числе удаленно). Когда операционная система обнаруживает, что для запуска
еще одного задания достаточно ресурсов, она создает новый процесс и запускает
задание, извлекаемое из входной очереди.
Во всех описанных случаях новый процесс создается путем выполнения соответ-
соответствующего системного вызова существующим процессом. В качестве последнего
может выступать пользовательский процесс, системный процесс, активизируе-
активизируемый клавиатурой или мышью, а также менеджер пакетной обработки. Процесс
исполняет системный вызов, запрашивающий у операционной системы создание
нового процесса, и указывает (прямо или косвенно), какая программа должна
быть запущена в этом процессе.
Для создания нового процесса в MINIX 3 существует единственный системный
вызов fork. Он создает точную копию вызывающего процесса. По завершении
вызова два процесса, родительский и дочерний, имеют одинаковые образы памя-
памяти, строки окружения и открытые файлы. Как правило, затем дочерний процесс
исполняет вызов execve или аналогичный системный вызов, чтобы изменить
свой образ памяти и запустить новую программу. К примеру, когда пользователь
вводит в оболочку команду sort, оболочка создает дочерний процесс, который
и исполняет команду. Смысл такого двухэтапного действия заключается в том,
что дочерний процесс получает возможность манипулировать своими дескрип-
дескрипторами файлов между вызовами fork и exec, чтобы перенаправить стандарт-
стандартные потоки ввода, вывода и ошибок.
Как в UNIX, так и в MINIX 3 родительский и дочерний процессы имеют собст-
собственные адресные пространства. Если какой-либо процесс изменит слово в своем
адресном пространстве, это не затронет другой процесс. Адресное пространство
дочернего процесса является копией адресного пространства родителя, однако не
совпадает с ним; у двух процессов нет общей памяти для записи (как и некоторые
реализации UNIX, MINIX 3 поддерживает возможность использования процес-
процессами общего кода, поскольку его невозможно модифицировать). Тем не менее
процесс-потомок может совместно с родителем использовать другие ресурсы, на-
например открытые файлы.
2.1.3. Завершение процессов
После создания процесса он запускается и начинает выполнять свою работу. Од-
Однако ничто не вечно, и это в полной мере справедливо в отношении процессов.
Рано или поздно процесс завершается одним из следующих четырех способов:
1. Нормальное завершение (добровольное).
2. Завершение вследствие ошибки (добровольное).
3. Завершение вследствие фатальной ошибки (принудительное).
4. Уничтожение другим процессом (принудительное).
Большинство процессов завершаются по причине окончания своей работы. После
компиляции переданной ему программы компилятор исполняет системный вызов,
чтобы уведомить операционную систему о том, что работа завершена. В операци-
операционной системе MINIX 3 таким вызовом является exit. Программы с экранным
интерфейсом также поддерживают внешнее завершение. Например, все редакто-
редакторы имеют комбинацию клавиш, нажатие которой пользователем приводит к со-
сохранению рабочего файла, удалению временных файлов и завершению работы.
Вторая причина завершения процесса — обнаружение неисправимой ошибки.
Например:
ее foo.c
Если пользователь введет эту команду, но файла foo.c не существует, компиля-
компилятор просто закончит работу.
Третья причина завершения — ошибка, вызванная процессом, например, из-за не-
неправильно написанной программы. Возможно, программа содержит недопустимую
инструкцию, ссылку на несуществующую область памяти или пытается выпол-
выполнить деление на ноль. В MINIX 3 процесс может сообщить операционной системе
о намерении обрабатывать некоторые ошибки самостоятельно. В этом случае при
появлении ошибки процесс получает сигнал (прерывается), а не завершается.
Четвертая причина завершения процесса — исполнение одним процессом сис-
системного вызова, требующего у операционной системы завершения другого про-
процесса. В ОС MINIX 3 таким вызовом является kill. Разумеется, запрашиваю-
запрашивающий процесс должен иметь соответствующие права. В некоторых операционных
системах при завершении процесса, независимо от причины, все созданные им
процессы также подлежать немедленному завершению. Это замечание не каса-
касается MINIX 3.
2.1.4. Иерархии процессов
В некоторых системах после порождения одного процесса другим между дочер-
дочерним и родительским процессами продолжает существовать определенная связь.
Дочерний процесс может также создавать новые процессы, тем самым порождая
иерархию. В отличие от растений и животных, размножающихся половым путем
и имеющих двух родителей, процессы имеют единственного родителя. В то же
время число дочерних процессов может быть любым — 0, 1, 2 или более.
В операционной системе MINIX 3 процесс, его детей и прочих потомков можно
объединить в группу. Сигнал, посланный пользователем с клавиатуры, может
быть передан всем членам группы процессов, в данный момент связанной с клавиа-
клавиатурой (как правило, это все процессы, созданные в текущем окне). Это — сигналь-
сигнальная зависимость. Каждый член группы процессов может по-своему отреагировать
на переданный группе сигнал: перехватить, проигнорировать или выполнить
действие по умолчанию (завершиться).
В качестве простого примера использования деревьев процессов рассмотрим ини-
инициализацию операционной системы MINIX 3. В ее загрузочном образе имеются
два специальных процесса — сервер реинкарнации (reincarnation server) и init.
В функции сервера реинкарнации входит запуск и перезапуск драйверов и дру-
других серверов. Первое, что он делает, — блокируется и ожидает сообщения, указы-
указывающему ему, что нужно создать.
Процесс init запускает сценарий /etc/rc, с помощью которого передает сер-
серверу реинкарнации команды запуска драйверов и серверов, отсутствующих в за-
загрузочном образе. В результате все драйверы и серверы, запущенные подобным
образом, являются потомками сервера реинкарнации. Это означает, что если кто-
либо из них завершит выполнение, сервер реинкарнации получит об этом уве-
уведомление и сможет перезапустить (реинкарнировать) драйвер или сервер. Такой
механизм позволяет MINIX 3 справляться с авариями драйверов и серверов, по-
поскольку в этом случае перезапуск осуществляется автоматически. На практике
переустановить драйвер значительно проще, чем сервер, поскольку влияние драй-
драйвера на систему меньше. Мы не утверждаем, что наше решение работает идеаль-
идеально, и ведем работу над его улучшением.
Далее процесс init считывает конфигурационный файл /etc/ttytab, чтобы
получить информацию о существующих реальных и виртуальных терминалах.
Для каждого терминала init создает новый процесс getty с помощью системно-
системного вызова fork, отображает приглашение для входа в систему и ожидает ввода.
После ввода имени getty запускает системным вызовом exec процесс login,
передав ему имя в качестве аргумента. Если вход пользователя в систему оказал-
оказался удачным, login также при помощи вызова exec запускает оболочку поль-
пользователя. Таким образом, оболочка является дочерним процессом по отношению
к init. Команды пользователя порождают дочерние процессы для оболочки,
являющиеся «внуками» init. Описанная последовательность событий демон-
демонстрирует использование деревьев процессов. Коды сервера реинкарнации, про-
процесса init и оболочки не представлены в данной книге, поскольку продолжать
обсуждение до бесконечности невозможно. Тем не менее теперь у вас есть базо-
базовое представление о концепции.
2.1.5. Состояния процессов
Несмотря на то что процесс является независимым объектом со своим счетчи-
счетчиком команд, регистрами, стеком, открытыми файлами, аварийными сигналами
и прочими атрибутами внутреннего состояния, существует необходимость его
взаимодействия и синхронизации с другими процессами. Например, выходные
данные одного процесса могут служить входными данными для другого процес-
процесса. В этом случае необходимо обеспечить передачу данных между процессами.
Например:
cat chapterl chapter2 chapter3 I grep tree
В этой команде оболочки первый процесс cat объединяет и распечатывает три
файла. Второй процесс grep отбирает все строки, содержащие слово tree. В за-
зависимости от относительных скоростей процессов (скорости зависят от относи-
относительной сложности программ и процессорного времени, предоставляемого каж-
каждому процессу) может получиться, что процесс grep уже готов к запуску, но
входных данных для него еще нет. В этом случае процесс блокируется до поступ-
поступления входных данных.
Процесс блокируется потому, что с точки зрения логики он не в состоянии продол-
продолжать свою работу (обычно это связано с отсутствием входных данных, ожидае-
ожидаемых процессом). Также возможна ситуация, когда активный и работоспособный
процесс останавливается, так как операционная система решила предоставить
на время процессор другому процессу. Эти ситуации принципиально различны.
В первом случае приостановка выполнения является внутренней проблемой
(например, невозможно обработать командную строку пользователя до того, как
она введена). Во втором случае проблема является технической (нехватка про-
процессоров для каждого процесса). На рис. 2.2 представлена диаграмма состояний,
показывающая три возможных состояния процесса:
1. Выполнение (процесс использует процессор).
2. Готовность (процесс временно приостановлен, чтобы позволить выполняться
другому процессу).
3. Блокировка (процесс не может быть запущен прежде, чем произойдет некое
внешнее событие).
Рис. 2.2. Процесс может находиться в состоянии выполнения, готовности или блокировки.
Стрелками показаны возможные переходы между состояниями
С позиций логики первые два состояния схожи. В обоих вариантах процесс мо-
может быть запущен, только во втором случае процессор недоступен. Третье со-
состояние отличается тем, что запустить процесс невозможно, какой бы ни была
загруженность процессора.
Как показано на рисунке, между этими тремя состояниями допустимы четыре
перехода. Переход 1 происходит, когда процесс обнаруживает, что продолжение
работы невозможно. В некоторых системах процесс должен выполнить систем-
системный запрос, например block или pause, чтобы оказаться в состоянии блоки-
блокировки. В других системах, например в MINIX 3, процесс автоматически блоки-
блокируется, если при считывании из канала или специального файла (предположим,
терминала) входные данные не обнаружены.
Переходы 2 и 3 вызываются частью операционной системы, называемой пла-
планировщиком процессов, так что сами процессы даже не знают о существовании
этих переходов. Переход 2 происходит, когда планировщик решает, что пора
предоставить процессор следующему процессу. Переход 3 имеет место, когда
все остальные процессы уже исчерпали предоставленное им время, и процессор
снова возвращается к первому процессу. Вопрос планирования (когда следует
запустить очередной процесс и на какое время) сам по себе достаточно важен.
Было разработано множество алгоритмов, призванных сбалансировать требо-
требования по эффективности системы в целом и каждого процесса в отдельно-
отдельности. Мы рассмотрим планирование и изучим некоторые его алгоритмы позднее
в этой главе.
Переход 4 происходит с появлением внешнего события, ожидавшегося процес-
процессом (например, поступления входных данных). Если в этот момент не запущен
какой-либо другой процесс, происходит переход 5, и процесс запускается. В про-
противном случае процессу придется некоторое время находиться в состоянии го-
готовности, пока не освободится процессор.
Модель процессов упрощает представление о внутреннем поведении системы.
Некоторые процессы запускают программы, выполняющие команды, введенные
с клавиатуры пользователем. Другие процессы являются частью системы и об-
обслуживают такие задания, как выполнение запросов файловой подсистемы,
управление запуском диска или магнитного накопителя. В случае дискового пре-
прерывания система может остановить текущий процесс и запустить дисковый про-
процесс, который был заблокирован в ожидании этого прерывания. Слово «может»
использовано потому, что выполнение или невыполнение системой указанных
действий зависит от приоритета текущего процесса по отношению к приоритету
дискового драйвера. Тем не менее важнее здесь то, что вместо прерываний мы
можем представлять себе дисковые процессы, процессы пользователя, термина-
терминала и т. п., блокирующиеся на время ожидания событий. Когда событие происхо-
происходит (информация считывается с диска или клавиатуры), блокировка снимается,
после чего процесс может быть запущен.
Рассмотренный подход описывается моделью, представленной на рис. 2.3. Ниж-
Нижний уровень операционной системы — это планировщик, выше него — все мно-
множество процессов. За обработку прерываний и детали, связанные с остановкой
и запуском процессов, отвечает планировщик, который является, по сути, совсем
небольшой программой. Вся остальная часть операционной системы упорядо-
упорядочена в виде набора процессов. Модель, изображенная на рисунке, используется
в операционной системе MINIX 3. Разумеется, нижний уровень состоит не толь-
только из планировщика: он также обеспечивает обработку прерываний и взаимо-
взаимодействие между процессами. Тем не менее представленная модель «в первом
приближении» адекватно демонстрирует основную структуру.
Рис. 2.3. Нижний уровень операционной системы отвечает за прерывания
и планирование. Выше расположены логически упорядоченные процессы
2.1.6. Реализация процессов
Для реализации модели процессов операционная система поддерживает таб-
таблицу (массив структур), называемую таблицей процессов, в которой для каждого
процесса имеется по одной записи. (Некоторые авторы называют эти записи
блоками управления процессом.) Записи таблицы содержат информацию о со-
состоянии процесса, счетчике команд, указателе стека, распределении памяти,
состоянии открытых файлов, использовании и распределении ресурсов, ава-
аварийных и прочих сигналах, а также всю остальную информацию, которую не-
необходимо сохранять при переключении из состояния выполнения в состояние
готовности, чтобы позже процесс мог быть запущен снова так, как будто он ни-
никогда не останавливался.
В MINIX 3 за взаимодействие между процессами, управление памятью и фай-
файлами ответственны различные модули из состава системы, поэтому таблица
разбита на разделы, где каждый модуль поддерживает относящиеся к нему
поля. В табл. 2.1 представлены некоторые наиболее важные поля типичной
системы. К теме данной главы относятся только поля первой колонки; осталь-
остальные колонки лишь демонстрируют информацию, используемую в других об-
областях системы.
Таблица 2.1. Некоторые поля типовой записи таблицы процессов MINIX 3. Поля
сгруппированы для ядра, модулей управления процессами и файловой системой
Ядро Управление процессами Управление файлами
Регистры Указатель на текстовый сегмент Маска UMASK
Счетчик команд Указатель на сегмент данных Корневой каталог
Слово состояния Указатель на сегмент стека Рабочий каталог
программы Статус завершения Дескрипторы файлов
Указатель стека Состояние сигналов Реальный идентификатор
Состояние процесса Идентификатор процесса пользователя
Текущий приоритет Родительский процесс Эффективный
Максимальный приоритет Группа процесса поГов^0"
Оставшееся число тактов Процессорное время дочернего Реальный идентификатор
Размер кванта процесса группы
Использованное Реальный идентификатор Эффективный
процессорное время пользователя (UID) идентификатор группы
Указатели очереди Эффективный идентификатор Управление
сообщений пользователя
,- ^ /Л1Г^Ч Область сохранения для
Биты действующих Реальный идентификатор группы (GID) чтения/записи
сигналов Эффективный идентификатор группы параметры системного
Различные флаги Файловая информация о совместном вызова
Имя процесса использовании текста Различные битовые флаги
Битовые маски для сигналов
Различные битовые флаги
Имя процесса
Теперь, после знакомства с таблицей процессов, настало время сказать несколь-
несколько слов о том, как создается иллюзия параллельного исполнения процессов на
машине с одним процессором и несколькими устройствами ввода-вывода. Затем
мы познакомимся с работой планировщика в MINIX 3 (см. рис. 2.3), но все ска-
сказанное относится и к большинству других современных ОС. С каждым классом
устройств ввода-вывода (гибкий диск, жесткий диск, таймер, терминал) связана
структура данных, называемая таблицей дескрипторов прерываний. Самой важ-
важной частью каждой записи этой таблицы является вектор прерываний. Вектор
прерываний содержит адрес процедуры обработки прерываний. Представьте, что
в момент дискового прерывания работал пользовательский процесс 23. Содер-
Содержимое счетчика команд процесса, слово состояния программы и, возможно, один
или несколько регистров записываются в (текущий) стек аппаратными средства-
средствами. Затем происходит переход по адресу, указанному в векторе прерывания дис-
диска. Вот и все, что делают аппаратные средства. С этого момента вся остальная
обработка прерывания производится программно, обычно стандартной процеду-
процедурой-обработчиком.
Обработка любого прерывания начинается с сохранения регистров, часто в блоке
управления текущим процессом в таблице процессов. Затем информация, поме-
помещенная в стек прерыванием, удаляется, и указатель стека переставляется на вре-
временный стек, используемый программой обработки процесса. Такие действия,
как сохранение регистров и установка указателя стека, невозможно даже выра-
выразить на языке высокого уровня (например, на С). Поэтому они выполняются не-
небольшой ассемблерной программой, обычно одинаковой для всех прерываний,
поскольку процедура сохранения регистров не зависит от причины прерывания.
Взаимодействие между процессами в MINIX 3 организуется при помощи сооб-
сообщений, таким образом, следующий шаг — формирование сообщения дисковому
процессу, который ожидает информации от системы в заблокированном состоя-
состоянии. В сообщении указывается, что произошло именно прерывание, чтобы его
можно было отличить от сообщений других пользовательских процессов, запраши-
запрашивающих чтение дисковых блоков и т. п. После этого состояние процесса меняет-
меняется с блокировки на готовность, и выполняется вызов планировщика. В MINIX 3
у процессов могут быть разные приоритеты, с целью дать обработчикам ввода-
вывода преимущество перед обычными пользовательскими программами. Соот-
Соответственно, если в данный момент у дискового процесса наибольший приоритет,
для запуска будет выбран этот процесс. Если же приоритет прерванного процес-
процесса не меньше, то будет запущен он, а дисковому придется немного подождать.
По завершении своей работы эта программа вызывает процедуру на языке С, ко-
которая выполняет все остальные действия, связанные с конкретным прерывани-
прерыванием. (Мы предполагаем, что операционная система написана на С, что является
стандартным решением для всех существующих ОС.) Схема обработки прерыва-
прерывания нижним уровнем операционной системы и действия планировщика рассмат-
рассматриваются далее. Следует отметить, что частности могут несколько варьировать-
варьироваться от системы к системе.
1. Аппаратное обеспечение сохраняет в стеке счетчик команд и т. и.
2. Аппаратное обеспечение загружает новый счетчик команд из вектора преры-
прерываний.
3. Ассемблерная процедура сохраняет регистры.
4. Ассемблерная процедура устанавливает новый стек.
5. Запускается программа обработки прерываний на С.
6. Код передачи сообщений отмечает готовность получателя сообщений.
7. Планировщик выбирает следующий процесс.
8. Программа на С передает управление ассемблерной процедуре.
9. Ассемблерная процедура запускает новый процесс.
2.1.7. Программные потоки
В традиционных операционных системах у каждого процесса есть адресное
пространство и один поток управления. В сущности, это почти полностью оп-
определяет процесс. Тем не менее нередко возникают ситуации, в которых же-
желательно иметь несколько потоков управления, квазипараллельно выполняю-
выполняющихся в одном адресном пространстве так, как будто они представляют собой
отдельные процессы (за исключением общности адресного пространства). Такие
потоки управления обычно называются программными потоками, или легковес-
легковесными процессами.
С одной стороны, процесс можно рассматривать как сгруппированные, связан-
связанные между собой ресурсы. Процесс имеет адресное пространство, содержащее
текст программы и данные, а также другие ресурсы, например открытые файлы,
дочерние процессы, действующие аварийные сигналы, обработчики сигналов,
учетную информацию и др. Группировка ресурсов в виде процесса упрощает
управление ими.
С другой стороны, с процессом связано понятие программного потока. Программ-
Программный поток имеет счетчик команд, указывающий на следующую исполняемую
команду, регистры, содержащие рабочие переменные, а также стек, в котором
хранится последовательность исполнения. Хотя программный поток и должен
исполняться в рамках какого-либо процесса, программный поток и его про-
процесс — не одно и то же, и их следует рассматривать отдельно. Процессы — это
механизм группировки ресурсов, а программные потоки — элементы, исполняе-
исполняемые центральным процессором по определенному плану.
Программные потоки дополняют модель процесса возможностью параллельного
исполнения в рамках одного процессного окружения с высокой степенью неза-
независимости. На рис. 2.4, а представлены три обычных процесса, у каждого из
которых есть собственное адресное пространство и единственный поток управ-
управления. На рис. 2.4, б представлен один процесс с тремя потоками управления.
В обоих случаях присутствуют три программных потока, но на рис. 2.4, а каж-
каждый из них имеет собственное адресное пространство, а на рис. 2.4, б программ-
программные потоки имеют общую память.
Рис. 2.4. Модель программных потоков: а — три процесса с собственным программным
потоком каждый; б — один процесс с тремя программными потоками
В качестве примера приложения, рассчитанного на многопоточность, рассмот-
рассмотрим веб-браузер. Веб-страницы зачастую содержат множество картинок неболь-
небольшого размера. Для воспроизведения каждой картинки браузер должен устано-
установить отдельное соединение с сайтом, которому принадлежит страница, и послать
запрос на ее получение. Установка и разрыв соединений отнимают много вре-
времени. При поддержке браузером многопоточности можно загружать несколько
картинок одновременно, что значительно ускоряет загрузку страницы, посколь-
поскольку при небольшом размере большинства изображений установка соединений от-
отнимает больше времени, чем передача данных.
Когда в одном адресном пространстве имеется несколько программных пото-
потоков, то некоторые из полей, показанных в табл. 2.1, относятся уже не к процессам,
а к отдельным программным потокам. Поэтому необходима дополнительная таб-
таблица, каждая запись в которой будет описывать отдельный поток. Среди прочих
в этой таблице должны быть поля для счетчика команд, регистров и состояния
потока. Счетчик команд нужен потому, что программные потоки, как и про-
процессы, могут приостанавливаться и возобновлять свою работу. Поля регистров
необходимы по той причине, что значения регистров приостановленного про-
программного потока необходимо сохранять. Наконец, программные потоки, как
и процессы, могут находиться в состоянии выполнения, готовности и блокировки.
В табл. 2.2 перечислены некоторые поля, относящиеся к процессам и программ-
программным потокам.
Таблица 2.2. В первой колонке перечислены поля, совместно используемые всеми
программными потоками процесса, а во второй колонке — поля, относящиеся
к отдельным программным потокам
Процесс Программный поток
Адресное пространство Счетчик команд
Глобальные переменные Регистры
Открытые файлы Стек
Дочерние процессы Состояние
Действующие аварийные сигналы
Сигналы и их обработчики
Учетная информация
Иногда операционная система не заботится о программных потоках. Другими
словами, управление программными потоками происходит целиком в пользова-
пользовательском режиме. Например, когда программный поток блокируется, то, перед
тем как остановиться, он решает, какой программный поток должен выполнять-
выполняться следующим, и запускает его. Существуют и широко используются несколько
библиотек для поддержки пользовательских программных потоков, в том числе
пакеты P-Threads от POSIX и C-Threads от Mach.
В других случаях ОС учитывает существование множества потоков, и когда
один программный поток переходит в состояние блокировки, система выбирает
для запуска следующий поток в том же самом процессе или в другом. Чтобы
поддерживать такую функциональность, ядро системы должно хранить таблицу
всех программных потоков в системе, наподобие таблицы процессов.
Хотя, на первый взгляд, оба варианта могут показаться равносильными, между
ними есть заметная разница в производительности. Переключение потоков про-
происходит гораздо быстрее, если оно происходит без участия ядра. Этот факт —
серьезный аргумент за пользовательские программные потоки. В то же время,
когда один из пользовательских программных потоков блокируется системой
(например, он ожидает завершения операции ввода-вывода или должен обрабо-
обработать ошибку отсутствия страницы), то блокируется весь процесс, поскольку ядро
не подозревает о существовании нескольких последовательностей команд. Это —
сильный аргумент за потоки, управляемые ядром [10]. Как следствие, использу-
используются оба механизма, существует также множество гибридных схем [1].
Хотя программные потоки часто бывают полезными, они существенно усложня-
усложняют программную модель. Представьте себе системный вызов fork. Если роди-
родительский процесс состоял из множества программных потоков, должно ли это
свойство распространяться на дочерний процесс? Если нет, то возможно непра-
неправильное функционирование процесса, поскольку все программные потоки могут
оказаться необходимыми.
Но что произойдет, если поток родительского процесса будет блокирован вызо-
вызовом read с клавиатуры, а у дочернего процесса столько же программных потоков,
сколько у родительского? Будут ли в этом случае блокированы два программных
потока — один из родительского процесса, другой из дочернего? И если с кла-
клавиатуры поступит строка, получат ли оба программных потока ее копию? Или
только один — тогда какой? Та же проблема возникает при работе с открытыми
сетевыми соединениями.
Другой класс проблем связан с тем, что программные потоки совместно использу-
используют большое количество структур данных. Что произойдет, если один программ-
программный поток закроет файл в то время, когда другой считывает из него данные?
Представьте себе, что одному программному потоку перестало хватать памяти, и он
просит выделить дополнительную. На полпути происходит переключение потоков,
и уже новый программный поток обнаруживает, что ему не хватает памяти, и за-
запрашивает ее для себя. В этой ситуации память может быть выделена дважды.
Еще одна проблема связана с сообщениями об ошибках. В UNIX после систем-
системного вызова система помещает информацию о состоянии операции в глобальную
переменную errno. А что произойдет, если сразу после того, как первый про-
программный поток сделает системный вызов, управление будет передано другому
потоку, который также сделает системный вызов и затрет значение глобальной
переменной?
Теперь рассмотрим сигналы. Одни из них замыкаются на программные потоки,
тогда как другие — нет. Например, если программный поток выполняет запрос
alarm, результирующий сигнал по логике должен вернуться к этому программ-
программному потоку. Однако когда программные потоки реализованы в пространстве
пользователя, ядро ничего не знает об их существовании и вряд ли направит сиг-
сигнал по назначению. Ситуация еще больше усложняется, если у процесса может
быть только один необработанный аварийный сигнал, а несколько программных
потоков выполняют запрос alarm независимо друг от друга.
Другие сигналы, такие как прерывания с клавиатуры, не связаны с программ-
программными потоками. Кто должен их перехватывать? Один специально выделенный
для этого программный поток? Все программные потоки? Просто очередной
программный поток? Что случится, если один программный поток изменит обг
работчик сигнала, не предупредив об этом остальные программные потоки?
Последняя проблема, порождаемая программными потоками, — управление сте-
стеками. Во многих системах при переполнении стека процесса ядро автоматически
увеличивает его. Если у процесса несколько программных потоков, стеков тоже
должно быть несколько. Если ядро не знает о существовании этих стеков, оно не
может их автоматически наращивать при переполнении. Ядро может даже не
связать ошибки памяти с переполнением стеков.
Разумеется, эти проблемы преодолимы, но на их примере хорошо видно, что
введение программных потоков в существующую систему без тщательной и про-
продуманной реконструкции всей системы не имеет смысла. По крайней мере, при-
придется изменить семантику системных запросов и переписать библиотеки. И ре-
результат ваших трудов должен быть совместим с существующими программами
для процессов с одним программным потоком. Дополнительную информацию
о программных потоках см. в [56, 83].
2.2. Взаимодействие между процессами
Процессам часто бывает необходимо взаимодействовать между собой. Напри-
Например, в конвейере ядра выходные данные первого процесса должны передаваться
второму процессу и далее по цепочке. Поэтому на первый план выходит задача
правильно организовать взаимодействие между процессами, по возможности не
используя прерывания. В этом разделе мы рассмотрим некоторые аспекты взаи-
взаимодействия между процессами (InterProcess Communication, IPC).
Если не вдаваться в подробности, проблема имеет три аспекта. О первом мы уже
упомянули — это передача информации от одного процесса к другому. Второй
связан с контролем над деятельностью процессов: как гарантировать, что два
процесса не «пересекутся» в критических ситуациях (представьте себе два про-
процесса, каждый из которых пытается завладеть последним мегабайтом памяти).
Третий касается согласования действий процессов: если процесс А отвечает за
поставку данных, а процесс В за их вывод на печать, то процесс В должен ждать,
не начиная печатать, пока не поступят данные от процесса А. Все три аспекта
рассматриваются в этом разделе.
Нельзя не упомянуть о том, что два из перечисленных аспектов проблемы взаимо-
взаимодействия в равной степени относятся к программным потокам. Первый — пере-
передача информации — не представляет большой сложности, если все программные
потоки находятся в едином адресном пространстве (в случае если программные
потоки принадлежат разным адресным пространствам, их взаимодействие попа-
попадает в категорию взаимодействия между процессами). Тем не менее обеспечение
«непересекаемости» и согласованности действий программных потоков столь же
актуально: те же проблемы, те же решения. Далее мы будем вести рассуждения
применительно к процессам, однако эти рассуждения в равной степени можно
отнести к программным потокам.
2.2.1. Гонки
В некоторых операционных системах процессы, работающие совместно, сообща
используют некое общее хранилище данных. Каждый из процессов может счи-
считывать что-либо из общего хранилища данных и записывать туда информацию.
Это хранилище представляет собой область в основной памяти (возможно, в струк-
структуре данных ядра) или файл общего доступа. Местоположение разделяемой па-
памяти не влияет на суть взаимодействия и возникающие проблемы. Рассмотрим
взаимодействие между процессами на простом, но очень распространенном при-
примере системы буферизации (спулере) печати. Если процессу требуется вывести
на печать файл, он помещает имя файла в специальный каталог спулера. Другой
процесс, демон печати, периодически проверяет наличие отправленных на пе-
печать файлов, печатает их и удаляет их имена из каталога.
Представьте, что каталог спулера состоит из большого числа сегментов, прону-
пронумерованных последовательно @, 1, 2, ...), в каждом их которых может храниться
имя файла. Также есть две совместно используемые переменные: out, указываю-
указывающая на следующий файл для печати, и in, указывающая на следующий свобод-
свободный сегмент. Эти две переменные можно хранить в одном файле (состоящем из
двух слов), доступном всем процессам. Пусть в данный момент сегменты с 0 по 3
пусты (соответствующие файлы уже напечатаны), а сегменты с 4 по 6 заняты
(файлы ждут своей очереди на печать). Пусть более или менее одновременно
процессы А и В решают поставить файл в очередь на печать. Описанную ситуа-
ситуацию схематически иллюстрирует рис. 2.5.
Рис. 2.5. Два процесса хотят одновременно получить доступ к совместно
используемой памяти
В соответствии с законом Мерфи (который звучит примерно так: «Если что-то
плохое может случиться, оно непременно случится»), возможна следующая си-
ситуация. Процесс А считывает значение G) переменной in и сохраняет его в ло-
локальной переменной next_f ree_slot. После этого происходит прерывание по
таймеру, и процессор переключается на процесс В. Процесс Б, в свою очередь,
считывает значение переменной in (опять 7) и сохраняет его в своей локальной
переменной next_f ree_slot. В данный момент оба процесса считают, что сле-
следующий свободный сегмент — седьмой. Процесс В сохраняет в каталоге спулера
имя файла и заменяет значение in на 8, затем продолжает заниматься своими
задачами, не связанными с печатью.
Наконец, управление переходит к процессу А, и он продолжает с того места, на
котором остановился. Он обращается к переменной next__f ree_slot, считыва-
считывает ее значение и записывает в сегмент 7 имя файла (разумеется, удаляя при этом
имя файла, помещенное туда процессом В). Затем он заменяет значение in на 8
(next_f ree_slot + 1=8). Структура каталога спулера не нарушена, поэтому
демон печати не заподозрит ничего плохого, но файл процесса В не будет напе-
напечатан. Пользователь, связанный с процессом JS, может в этой ситуации полдня
описывать круги вокруг принтера, ожидая результата. Ситуации, в которых два
(и более) процесса считывают или записывают данные одновременно, а конеч-
конечный результат зависит от того, какой из них был первым, называются гонками.
Отладка программы, в которой вероятно возникновение условий гонок, вряд ли
может доставить удовольствие. Результаты большинства тестов будут хороши-
хорошими, но изредка будет происходить нечто странное и необъяснимое.
2.2.2. Критические секции
Как избежать гонок? Основным способом предотвращения проблем в этой и лю-
любой другой ситуации, связанной с конкурентным использованием памяти, фай-
файлов и чего-либо еще, является запрет одновременной записи и чтения данных
более чем одним процессом. Говоря иными словами, необходимо взаимное ис-
исключение. То есть в тот момент, когда один процесс использует общие данные,
другому процессу это должно быть запрещено. Проблема, описанная в предыду-
предыдущем разделе, возникла из-за того, что процесс В начал работу с одной из общих
переменных до того, как процесс А ее закончил. Выбор подходящей простейшей
операции, реализующей взаимное исключение, является серьезным моментом
разработки операционной системы, и сейчас мы рассмотрим его подробно.
Проблему исключения условий гонок можно сформулировать на абстрактном
уровне. Некоторый промежуток времени (слот) процесс занят внутренними рас-
расчетами и другими задачами, не приводящими к условиям гонок. В другие момен-
моменты времени процесс обращается к совместно используемым файлам или памяти.
Часть программы, в которой происходит обращение к общей памяти, называется
критической секцией. Если нам удастся избежать одновременного нахождения
двух процессов в критических секциях, мы сможем избежать гонок.
Несмотря на то что поставленное требование исключает гонки, его недостаточно
для правильной совместной работы параллельных процессов и эффективного ис-
использования общих данных. Для этого необходимо выполнение четырех условий.
1. Два процесса не должны одновременно находиться в критических секциях.
2. Нельзя делать никаких предположений относительно скорости или количест-
количестве процессоров.
3. Процесс, выполняющийся вне критической секции, не может блокировать
другие процессы.
4. Недопустима ситуация, в которой процесс бесконечно ожидает попадания
в критическую секцию.
Нужное нам поведение иллюстрирует рис. 2.6. Процесс А входит в свою крити-
критическую секцию в момент времени Tt. Чуть позднее, в момент времени Г2, про-
процесс В также пытается войти в свою критическую секцию, однако попытка окан-
оканчивается неудачей, поскольку один процесс уже находится в критической сек-
секции, а мы не позволяем это делать двум и более процессам одновременно. Таким
образом, процесс В временно приостанавливается до тех пор, пока А не покинет
критическую секцию (момент Г3). Далее процесс В немедленно войдет в свою
критическую секцию и выйдет из нее в момент времени Г4, после чего мы вернем-
вернемся в исходную ситуацию, когда оба процесса находятся вне критических секций.
Рис. 2.6. Взаимное исключение с использованием критических секций
2.2.3. Взаимное исключение
с активным ожиданием
В этом разделе мы рассмотрим различные варианты реализации взаимного ис-
исключения. Благодаря такой реализации никакой процесс не может войти в свою
критическую секцию и стать источником проблем, пока один из процессов занят
обновлением общей памяти в своей критический секции.
Запрет на прерывания
Самое простое решение состоит в запрете всех прерываний при входе процесса
в критическую секцию и разрешение прерываний по выходу из нее. Если преры-
прерывания запрещены, невозможно прерывание по таймеру. Запрет на прерывания
исключает передачу процессора другому процессу. Таким образом, запретив пре-
прерывания, процесс может спокойно считывать и сохранять общие данные, не опа-
опасаясь вмешательства конкурентов.
И все же было бы неразумно давать пользовательскому процессу полномочия
для запрета прерываний. Представьте себе, что процесс отключил все прерывания
и в результате какого-либо сбоя не включил их обратно. Операционная система
на этом может закончить свое существование. К тому же, в многопроцессорной
системе запрет прерываний влияет только на тот процессор, который выполняет
инструкцию disable. Остальные процессоры продолжат работу и сохранят дос-
доступ к общим данным.
В то же время для ядра блокировка прерываний для некоторых команд может
быть полезной при работе с переменными или списками. Возникновение прерыва-
прерывания в момент, когда, например, список готовых процессов находится в неопреде-
неопределенном состоянии, могло бы привести к условиям гонок. Итак, запрет прерыва-
прерываний бывает полезным в самой операционной системе, но для пользовательских
процессов это решение в качестве механизма взаимного исключения неприемлемо.
Переменные блокировки
Теперь попробуем найти программное решение. Рассмотрим одну совместно ис-
используемую переменную блокировки, изначально равную 0. Если процесс хочет
попасть в критическую секцию, он предварительно считывает значение пере-
переменной блокировки. Если переменная равна 0, процесс изменяет ее на 1 и входит
в критическую секцию. Если же переменная равна 1, то процесс ждет, пока ее
значение сменится на 0. Таким образом, 0 означает, что ни одного процесса в кри-
критической секции нет, а 1 свидетельствует, что какой-либо процесс уже находится
в критической секции.
К сожалению, у предложенного метода те же проблемы, что и в примере с ката-
каталогом буферизации печати. Представьте, что один процесс считывает перемен-
переменную блокировки, обнаруживает, что она равна 0, но прежде чем он успевает из-
изменить ее на 1, управление получает другой процесс, успешно изменяющий ее
на 1. Когда первый процесс снова получит управление, он тоже установит пере-
переменную блокировки в 1, и два процесса одновременно окажутся в критических
секциях.
Можно подумать, что проблема решается повторной проверкой значения пере-
переменной до ее замены, но это не так. Второй процесс может получить управление
как раз после того, как первый процесс закончит вторую проверку, но еще не
успеет изменить значение переменной блокировки.
Строгое чередование
Третий метод реализации взаимного исключения иллюстрирует листинг. 2.1.
Этот фрагмент программного кода, как и многие другие в данной книге, написан
на С. Язык С был выбран, поскольку практически все существующие операцион-
операционные системы написаны на С (или C++), а не на языках, подобных Java. Язык С
обладает всеми необходимыми свойствами для написания операционных систем,
это — мощный, эффективный и предсказуемый язык программирования. А язык
Java, например, не является предсказуемым, поскольку у программы, написан-
написанной на нем, может в критический момент закончиться свободная память, и она
вызовет «сборщик мусора» в исключительно неподходящее время. В случае С
это невозможно, поскольку в С процедура сборки мусора в принципе отсутствует.
Сравнительный анализ С, C++, Java и четырех других языков программирова-
программирования представлен в [97].
Листинг 2.1. Предлагаемое решение проблемы критической секции (для обоих процессов
необходимо удостовериться в наличии точки с запятой после цикла while)
/* Процесс 1 */
while(TRUE) {
while(turn!=0) /* ожидание */;
critical_region();
turn=l;
noncritical_region();
}
/* Процесс 2 */
while(TRUE) {
while(turn 1=1) /* ожидание */;
critical_region();
turn=0;
noncritical_region();
}
В листинге 2.1 целая переменная turn, изначально равная 0, фиксирует, чья оче-
очередь входить в критическую секцию. Вначале процесс 0 проверяет значение turn,
считывает 0 и входит в критическую секцию. Процесс 1 также проверяет значе-
значение turn, считывает 0 и после этого в цикле непрерывно проверяет, когда же
значение turn будет равно 1. Постоянная проверка значения переменной в ожи-
ожидании некоторого значения называется активным ожиданием. Однако подобного
подхода следует избегать, поскольку он является причиной бесцельного расхо-
расходования ресурсов процессора. Активное ожидание может быть приемлемым толь-
только в случае, когда есть уверенность в коротком времени ожидания.
Когда процесс 0 покидает критическую секцию, он изменяет значение turn на 1,
позволяя процессу 1 завершить цикл. Предположим, что процесс 1 быстро поки-
покидает свою критическую секцию, так что оба процесса находятся в обычном со-
состоянии, и значение turn равно 0. После этого процесс 0 быстро выполняет весь
цикл, выходит из критической секции и устанавливает значение turn равным 1.
В итоге в этот момент значение turn оказывается равным 1, и оба процесса на-
находятся вне критической секции.
Неожиданно процесс 0 завершает работу вне критической секции и возвращается
к началу цикла. Но на большее он не способен, поскольку значение turn равно 1,
и процесс 1 находится вне критической секции. Процесс 0 «зависает» в своем
цикле while, ожидая, пока процесс 1 изменит значение turn на 0. Получается,
что метод поочередного доступа к критической секции не слишком удачен, если
один процесс существенно медленнее другого.
Эта ситуация нарушает третье из сформулированных нами условий: один про-
процесс блокируется другим, не находящимся в критической секции. Возвратимся
к примеру с каталогом спулера: если заменить критическую секцию процедурой
считывания из каталога и записи в каталог, процесс 0 не сможет послать файл на
печать, поскольку процесс 1 занят чем-то другим.
Фактически этот метод требует, чтобы два процесса попадали в критические
секции строго по очереди. Ни один из них не сможет войти в критическую сек-
секцию (например, послать файл на печать) два раза подряд. Хотя этот алгоритм
и исключает условия гонок, его нельзя рассматривать всерьез, поскольку он на-
нарушает третье правило успешной работы двух параллельных процессов с общи-
общими данными.
Алгоритм Петерсона
Датский математик Деккер (Т. Dekker) был первым, кто разработал программ-
программное решение проблемы взаимного исключения, не требующее строгого чередова-
чередования. Подробное изложение алгоритма можно найти в [38].
В 1981 году Петерсон (G. L. Peterson) придумал существенно более простой
алгоритм взаимного исключения. С этого момента вариант Деккера считается
устаревшим. Алгоритм Петерсона, представленный в листинге 2.2, состоит из
двух процедур, написанных на языке С, соответствующем стандарту ANSI, что
предполагает необходимость прототипов для всех определяемых и используе-
используемых функций. В целях экономии места мы не будем приводить прототипы для
этого и последующих примеров.
Листинг 2.2. Решение Петерсона для взаимного исключения
#define FALSE О
#define TRUE 1
#define N 2 /* Количество процессов */
int turn; /* Чья сейчас очередь? */
int interested[N]; /* Все переменные изначально
/* равны О (FALSE) */
void enter_region(int process); /* Процесс 0 или 1 */
{
int other; /* Номер второго процесса */
other = 1 - process; /* "Противоположный" процесс */
interested[process] = TRUE; /* Индикатор интереса */
turn = process; /* Установка флага */
while (turn == process && interested[other] == TRUE) /* Пустой цикл */;
}
void leave_region(int process) /* Процесс, покидающий
/* критическую секцию */
{
interested[process] = FALSE; /* Индикатор выхода из
/* критической секции */
}
Прежде чем обратиться к общим переменным (то есть перед тем, как войти в кри-
критическую секцию), процесс вызывает процедуру enter_region со своим но-
номером @ или 1) в качестве аргумента. Поэтому процессу при необходимости
приходится ждать, прежде чем входить в критическую секцию. После выхода из
критической секции процесс вызывает процедуру leave_region, чтобы обо-
обозначить свой выход и тем самым разрешить другому процессу вход в критиче-
критическую секцию.
Рассмотрим алгоритм более подробно. Изначально оба процесса находятся вне
критических секций. Процесс 0 вызывает процедуру enter_region, задает эле-
элементы массива и устанавливает переменную turn равной 0. Поскольку про-
процесс 1 не заинтересован в попадании в критическую секцию, происходит возврат
из процедуры. Теперь, если процесс 1 вызовет процедуру enter_region, ему
придется подождать, пока interested [0] примет значение FALSE, а это про-
произойдет только в тот момент, когда процесс 0 вызовет процедуру leave_region,
покидая критическую секцию.
Представьте, что оба процесса вызвали процедуру enter_region практически
одновременно. Оба запомнят свои номера в turn. Но сохранится номер того про-
процесса, который был вторым, а предыдущий номер будет утерян. Предположим,
что вторым был процесс 1, отсюда значение turn равно 1. Когда оба процесса
дойдут до конструкции while, процесс 0 войдет в критическую секцию, а про-
процесс 1 останется в цикле и будет ждать, пока процесс 0 выйдет из нее.
Команда TSL
Рассмотрим решение, поддерживаемое аппаратно. Многие компьютеры, особен-
особенно разработанные с расчетом на несколько процессоров, имеют в составе коман-
команду TSL (Test and Set Lock — проверить и заблокировать):
TSL RX,LOCK
Эта команда действует следующим образом. Она считывает содержимое слова
памяти LOCK в регистр RX, а затем сохраняет по адресу LOCK ненулевое значе-
значение. Операция чтения слова и сохранения в него значения гарантированно явля-
является неделимой — ни один другой процесс не может получить доступ к слову до
окончания исполнения команды. Процессор, исполняющий команду TSL, блоки-
блокирует для этой цели шину памяти.
Чтобы применить команду TSL, мы воспользуемся общедоступной переменной
LOCK, координирующей доступ к общей памяти. Когда значение LOCK равно 0,
любой процесс может установить ее в 1 с помощью TSL, а затем выполнить чте-
чтение или запись общей памяти. Закончив действие, процесс снова устанавливает
LOCK в 0 при помощи обычной команды MOVE.
Итак, как же использовать команду TSL для реализации взаимного исключения?
Решение приведено в листинге 2.3. Здесь представлена подпрограмма из четы-
четырех команд, написанная на некотором обобщенном (но типичном) ассемблере.
Первая команда копирует старое значение LOCK в регистр и затем устанавливает
значение переменной в 1. Потом старое значение сравнивается с нулем. Если оно
ненулевое, значит, блокировка уже была произведена, и проверка начинается
сначала. Рано или поздно значение окажется нулевым (это означает, что про-
процесс, находившийся в критической секции, покинул ее), и подпрограмма вернет
управление в вызвавшую программу, установив блокировку. Сброс блокировки
не представляет собой ничего сложного — просто в переменную LOCK помещает-
помещается 0. Специальной команды процессора не требуется.
Листинг 2.3. Вход и выход из критической секции с помощью команды TSL
enter_region;
TSL REGISTER,LOCK /* Значение LOCK копируется в регистр */
/* Значение переменной устанавливается равным 1 */
CMP REGISTER,#0 /* Старое значение LOCK сравнивается с нулем */
JNE ENTER_REGION /* Если оно ненулевое, значит, блокировка уже была */
/* установлена, поэтому цикл */
RET /* Возврат в вызывающую программу */
/* Процесс вошел в критическую секцию */
leave_region;
MOVE LOCK,#0 /* Сохранение 0 в переменной LOCK */
RET /* Возврат в вызывающую программу */
Одно из решений проблемы критических секций теперь очевидно. Прежде чем
попасть в критическую секцию, процесс вызывает процедуру enter_region,
которая выполняет активное ожидание вплоть до снятия блокировки, затем она
устанавливает блокировку и возвращает управление. По выходу из критической
секции процесс вызывает процедуру leave_region, помещающую 0 в перемен-
переменную LOCK. Как и во всех остальных решениях проблемы критической секции,
для корректной работы процесс должен вызывать эти процедуры своевременно,
в противном случае обойти взаимное исключение не удастся.
2.2.4. Примитивы взаимодействия
между процессами
Оба решения — Петерсона и с использованием команды TSL — корректны, но
они обладают одним и тем же недостатком: наличием активного ожидания. В сущ-
сущности, оба они реализуют следующий алгоритм: перед входом в критическую
секцию процесс проверяет, можно ли это сделать. Если нельзя, процесс ожидает
разрешения на вход в критическую секцию в бесконечном цикле.
Этот алгоритм не только бесцельно расходует ресурсы процессора, но и может
иметь некоторые неожиданные последствия. Рассмотрим два процесса: Н с вы-
высоким приоритетом и £ с низким приоритетом. Правила планирования в этом
случае таковы, что процесс Н запускается немедленно, как только он оказывает-
оказывается в состоянии ожидания. В какой-то момент, когда процесс L находится в кри-
критической секции, процесс Н оказывается в состоянии ожидания (например, он
закончил операцию ввода-вывода). Процесс Н попадает в состояние активного
ожидания, но поскольку процессу L при условии работающего процесса Н про-
процессорное время предоставлено быть не может, у процесса L не будет возможно-
возможности выйти из критической секции, и процесс Н навсегда останется в цикле. Эту
ситуацию иногда называют проблемой инверсии приоритета.
Теперь рассмотрим некоторые примитивы взаимодействия между процессами,
применяемые вместо циклов ожидания (в которых лишь напрасно расходуется
процессорное время). Эти примитивы блокируют процессы в случае запрета на
вход в критическую секцию. Одной из простейших является пара примитивов
sleep и wakeup. Примитив sleep — системный вызов, в результате которого
вызывающий процесс блокируется, пока его не запустит другой процесс. Вызов
wakeup имеет один аргумент — идентификатор запускаемого процесса. Также
возможно наличие одного аргумента у обоих вызовов (ожидания и запуска) —
адреса ячейки памяти, предназначенной для их согласования.
Проблема производителя и потребителя
В качестве примера использования этих примитивов рассмотрим проблему про-
производителя и потребителя, также известную как проблема ограниченности буфе-
буфера. Два процесса совместно используют буфер ограниченного размера. Один из
них, производитель, помещает данные в этот буфер, а другой, потребитель, счи-
считывает их оттуда. (Можно обобщить задачу на случай т производителей и п по-
потребителей, но мы разберем случай с одним производителем и одним потребите-
потребителем, поскольку это существенно упрощает решение.)
Трудности начинаются в тот момент, когда производитель желает поместить
в буфер очередную порцию данных и обнаруживает, что тот полон. Для произ-
производителя решением является ожидание, пока потребитель полностью или час-
частично не очистит буфер. Аналогично, если потребитель хочет забрать данные
из буфера, а буфер пуст, потребитель переключается в состояние ожидания и вы-
выходит из него, как только производитель положит что-нибудь в буфер и разбу-
разбудит спящего.
Это решение кажется достаточно простым, но оно приводит к условиям гонок,
как и пример с каталогом спулера. Нам нужна переменная count для отслежи-
отслеживания количества элементов в буфере. Если максимальное число элементов, хра-
хранящихся в буфере, равно N, программа производителя должна проверить, не рав-
равно ли N значение count, прежде чем поместить в буфер следующую порцию
данных. Если значение count равно N, производитель переключается в состоя-
состояние ожидания; в противном случае он помещает данные в буфер и увеличивает
значение count.
Код программы потребителя прост: сначала проверить, не равно ли значение count
нулю. Если равно, то уйти в состояние ожидания; иначе забрать порцию данных
из буфера и уменьшить значение count. Каждый из процессов также должен
проверять, не следует ли активизировать другой процесс, и в случае необходимо-
необходимости делать это. Программы обоих процессов представлены в листинге 2.4.
Для описания на языке С системных вызовов sleep и wakeup мы представили
их в виде вызовов библиотечных процедур. В стандартной библиотеке С их нет,
но они будут доступны в любой системе, в которой поддерживаются такие сис-
системные вызовы. Процедуры insert_item и remove_item помещают элементы
в буфер и извлекают их оттуда.
Теперь давайте вернемся к условиям гонок. Их возникновение вероятно, по-
поскольку доступ к переменной count не ограничен. Может возникнуть следую-
следующая ситуация: буфер пуст, и потребитель только что считал значение перемен-
переменной count, чтобы проверить, равно ли оно нулю. В этот момент планировщик
передал управление производителю, производитель поместил элемент в буфер
и увеличил значение count, убедившись, что теперь оно стало равно 1. Зная, что
ранее значение было равно 0, а потребитель находился в состоянии ожидания,
производитель активизирует потребителя вызовом wakeup.
Листинг 2.4. Проблема производителя и потребителя с неустранимыми условиями гонок
#define N 100 /* Максимальное количество элементов
/* в буфере */
int count =0; /* Текущее количество элементов в буфере */
void producer(void)
{
int item;
while (TRUE) { /* Повторять непрерывно */
item = produce_item(); /* Сформировать следующий элемент */
if (count == N) sleep(); /* Если буфер полон, уйти в состояние
/* ожидания */
insert_item(item); /* Поместить элемент в буфер */
count = count + 1; /* Увеличить количество элементов в буфере */
if (count == 1) wakeup(consumer); /* Был ли буфер пуст? */
}
}
void consumer(void)
{
int item;
while (TRUE) { /* Повторять непрерывно */
if (count == 0) sleepO; /* Если буфер пуст, уйти в состояние
/* ожидания */
item = remove_item( ); /* Забрать элемент из буфера */
count = count - 1; /* Уменьшить счетчик элементов в буфере */
if (count == N - 1) wakeup(producer); /* Был ли буфер полон? */
consume_item(item); /* Отправить элемент на печать */
}
}
Но потребитель не был в состоянии ожидания, следовательно, сигнал активиза-
активизации пропал впустую. Когда управление перейдет к потребителю, он вернется
к считанному когда-то значению count, обнаружит, что оно равно 0, и уйдет в со-
состояние ожидания. Рано или поздно производитель наполнит буфер и также пе-
перейдет в состояние ожидания. Оба процесса так и будут ждать.
Суть проблемы в данном случае состоит в том, что сигнал активизации, поступив-
поступивший процессу, не находящемуся в состоянии ожидания, уходит в никуда. Если
бы не это, проблемы бы не было. Быстрым решением может быть введение бита
ожидания активизации. Если сигнал активизации послан процессу, не находящему-
находящемуся в состоянии ожидания, этот бит устанавливается. Позже, когда процесс пытается
перейти в состояние ожидания, бит ожидания активизации сбрасывается, но про-
процесс остается активным. Этот бит исполняет роль копилки сигналов активизации.
Хотя введение бита ожидания запуска в нашем примере спасло положение,
легко представить ситуацию с несколькими процессами, в которой одного бита
окажется недостаточно. Мы можем добавить еще один бит, или 8, или 32, но это
не решит проблему.
2.2.5. Семафоры
В 1965 году Дейкстра (Е. W. Dijkstra) показал, как использовать целую перемен-
переменную для подсчета сигналов запуска, сохраненных на будущее. Им был предло-
предложен новый тип переменных, так называемых семафоров, значение которых мо-
может быть нулем (в случае отсутствия сохраненных сигналов активизации) или
некоторым положительным числом, соответствующим количеству отложенных
сигналов.
Дейкстра предложил две операции, down и up (обобщения примитивов sleep
и wakeup). Операция down сравнивает значение семафора с нулем. Если значе-
значение семафора больше нуля, операция down уменьшает его (то есть расходует один
из сохраненных сигналов активизации) и просто возвращает управление. Если
значение семафора равно нулю, процедура down не возвращает управление про-
процессу, а процесс переводится в состояние ожидания. Все операции проверки
значения семафора, его изменения и перевода процесса в состояние ожидания
выполняются как единое и неделимое атомарное действие. Тем самым гаран-
гарантируется, что после начала операции ни один процесс не получит доступа к се-
семафору до окончания или блокирования операции. Атомарность операции чрез-
чрезвычайно важна для разрешения проблемы синхронизации и предотвращения
условий гонок.
Операция up увеличивает значение семафора. Если с этим семафором связаны
один или несколько ожидающих процессов, которые не могут завершить более
раннюю операцию down, один из них выбирается системой (например, случай-
случайным образом) и ему разрешается завершить свою операцию down. Таким обра-
образом, после операции up, примененной к семафору, связанному с несколькими
ожидающими процессами, значение семафора так и остается равным 0, но число
ожидающих процессов уменьшается на единицу. Операция увеличения значения
семафора и активизации процесса тоже неделима. Ни один процесс не может
быть блокирован во время выполнения операции up, как ни один процесс не мог
быть блокирован во время выполнения операции wakeup в предыдущей модели.
В оригинале Дейкстра употреблял вместо down и up обозначения Р и V соответ-
соответственно. Мы не будем в дальнейшем использовать оригинальные обозначе-
обозначения, поскольку тем, кто не знает голландского языка, эти обозначения ничего не
скажут (да и тем, кто знает язык, говорят немного). Впервые обозначения down
и up появились в языке Алгол 68.
Решение проблемы производителя и потребителя
с помощью семафоров
Как показано в листинге 2.5, проблему потерянных сигналов запуска можно ре-
решить с помощью семафоров. Очень важно, чтобы они были реализованы недели-
неделимым образом. Стандартным способом является реализация операций down и up
в виде системных вызовов с запретом операционной системой всех прерываний
на период проверки семафора, изменения его значения и возможного перевода
процесса в состояние ожидания. Поскольку для выполнения всех этих действий
требуется всего лишь несколько команд процессора, запрет прерываний не при-
приносит никакого вреда. Если используются несколько процессоров, каждый сема-
семафор необходимо защитить переменной блокировки посредством команды tsl,
чтобы гарантировать одновременное обращение к семафору только одного про-
процессора. Необходимо понимать, что использование команды tsl принципиаль-
принципиально отличается от активного ожидания, при котором производитель или потреби-
потребитель ждут наполнения или опустошения буфера. Операция с семафором занимает
несколько микросекунд, тогда как активное ожидание может затянуться на суще-
существенно больший промежуток времени.
Листинг 2.5. Решение проблемы производителя и потребителя с помощью семафоров
#define N 100 /* Количество сегментов в буфере */
typedef int semaphore; /* Семафоры — особый вид целочисленных
/* переменных */
semaphore mutex = 1; /* Контроль доступа в критическую секцию */
semaphore empty = N; /* Число пустых сегментов буфера */
semaphore full =0; /* Число полных сегментов буфера */
void producer(void)
{
int item;
while (TRUE) { /* TRUE - константа, равная 1*/
item = produce_item(); /* Создать данные, помещаемые в буфер */
down(&empty); /* Уменьшить счетчик пустых сегментов буфера */
down(&mutex); /* Вход в критическую секцию */
insert_item(item); /* Поместить в буфер новый элемент */
up(&mutex); /* Выход из критической секции */
up(&full); /* Увеличить счетчик полных сегментов буфера */
}
}
void consumer(void)
{
int item;
while (TRUE) { /* Бесконечный цикл */
down(&full); /* Уменьшить число полных сегментов буфера */
down(&mutex); /* Вход в критическую секцию */
item= remove_item(); /* Удалить элемент из буфера */
up(&mutex); /* Выход из критической секции */
up(&empty); /* Увеличить счетчик пустых сегментов буфера */
consume_item(item); /* Обработка элемента */
}
}
В представленном решении используются три семафора: один для подсчета
заполненных сегментов буфера (full), другой для подсчета пустых сегментов
(empty), а третий предназначен для исключения одновременного доступа про-
производителя и потребителя (mutex) к буферу. Значение счетчика full изначаль-
изначально равно нулю, счетчик empty равен числу сегментов в буфере, а счетчик mutex
равен 1. Семафоры, исходное значение которых установлено в 1, предназначен-
предназначенные для исключения одновременного нахождения в критической секции двух
процессов, называются двоичными семафорами. Взаимное исключение обеспечи-
обеспечивается, если каждый процесс выполняет операцию down перед входом в крити-
критическую секцию и up — после выхода из нее.
Теперь, когда у нас есть примитивы взаимодействия между процессами, вернемся
к очередности обработки прерываний (см. список в конце п. 2.1.6). В системах,
использующих семафоры, естественным способом скрыть прерывание является
связывание с каждым устройством ввода-вывода семафора, изначально равного
нулю. Сразу после включения устройства ввода-вывода управляющий процесс
выполняет операцию down на соответствующем семафоре, тем самым входя в со-
состояние блокировки. В случае прерывания обработчик прерывания выполняет
операцию up на соответствующем семафоре, переводя процесс в состояние го-
готовности. В такой модели шаг 5 в алгоритме из пункта 2.1.6 заключается в вы-
выполнении операции up на семафоре устройства, чтобы следующим шагом плани-
планировщик смог запустить программу, управляющую устройством. Разумеется, если
в этот момент несколько процессов находятся в состоянии готовности, плани-
планировщик вправе выбрать другой, более значимый процесс. Мы рассмотрим неко-
некоторые алгоритмы планирования позже в этой главе.
В примере, представленном в листинге 2.5, семафоры используются двояко. Это
различие достаточно ощутимо, чтобы сказать о нем особо. Семафор mutex пред-
предназначен для реализации взаимного исключения, то есть для исключения одно-
одновременного обращения к буферу и к связанным переменным двух процессов.
Мы рассмотрим взаимное исключение и методы его реализации в следующем
разделе.
Остальные семафоры введены с целью синхронизации. Семафоры full и empty
позволяют удостовериться в том, что происходят (или не происходят) опреде-
определенные последовательности событий. В нашем случае они дают гарантию, что
производитель прекращает работу, когда буфер полон, а потребитель прекраща-
прекращает ее, когда буфер пуст. Такое применение отличается от взаимного исключения.
2.2.6. Мьютексы
Иногда, если не нужно применять семафор как счетчик, используется его упро-
упрощенный вариант, называемый мьютексом (mutex). Мьютексы способны лишь
обеспечивать взаимное исключение для общего ресурса или фрагмента кода.
Их реализация отличается простотой и эффективностью, что делает мьютексы
исключительно полезными в программных потоках, реализуемых исключитель-
исключительно в пространстве пользователя.
Мьютекс представляет собой переменную, способную находиться в одном из двух
состояний: блокированном и разблокированном. Для хранения такой перемен-
переменной достаточно одного бита, хотя на практике мьютекс имеет целочисленный тип:
нулевое значение соответствует разблокированному состоянию, а любое ненуле-
ненулевое — блокированному. Мьютексы управляются двумя процедурами. Когда про-
процессу (или программному потоку) необходимо войти в критическую секцию, он
вызывает процедуру mutex_lock. Если мьютекс в этот момент разблокирован
(то есть критическая область свободна), вызов завершается успешно и вызы-
вызывающий поток получает возможность входа в критическую секцию.
Если же мьютекс находится в блокированном состоянии, вызвавший процесс
блокируется до тех пор, пока процесс, находящийся в критической секции, не за-
завершит работу с ней и не вызовет процедуру mutex_unlock. В случае блокиро-
блокирования мьютексом нескольких процессов из них случайным образом выбирается
один, которому разрешается вход в критическую секцию.
2.2.7. Мониторы
Взаимодействие между процессами с применением семафоров выглядит доволь-
довольно просто, не правда ли? Но эта простота кажущаяся. Взгляните внимательнее
на порядок выполнения процедур down перед помещением элементов в буфер
или удалением их из буфера в листинге 2.5. Представьте себе, что две процедуры
down в программе производителя поменялись местами, так что значение mutex
было уменьшено раньше, чем empty. Если буфер был заполнен, производитель
блокируется, сбросив mutex в 0. Соответственно, в следующий раз, когда потре-
потребитель обратится к буферу, он выполнит операцию down с переменной mutex,
равной 0, и тоже заблокируется. Оба процесса навсегда оказываются заблокиро-
заблокированными. Эта неприятная ситуация называется взаимной блокировкой (deadlock),
и мы вернемся к ней в главе 3.
Описанная ситуация показывает, с какой аккуратностью нужно обращаться с се-
семафорами. Одна маленькая ошибка, и все останавливается. Это напоминает про-
программирование на ассемблере, но на самом деле еще сложнее, поскольку такие
ошибки приводят к абсолютно невоспроизводимым и непредсказуемым услови-
условиям гонок, взаимным блокировкам и т. п.
Чтобы упростить написание программ, Бринч Хансен (Brinch Hansen) в 1973 го-
году и Хоар (Ноаге) в 1974 году предложили примитив синхронизации более вы-
высокого уровня, называемый монитором. Их предложения несколько отличались
друг от друга, как мы увидим дальше. Монитор — это набор процедур, пере-
переменных и других структур данных, объединенных в особый модуль, или пакет.
Процессы могут вызывать процедуры монитора, но у процедур, объявленных вне
монитора, нет прямого доступа к внутренним структурам данных монитора. По-
Подобное правило, обычное для современных объектно-ориентированных языков,
таких как Java, было нестандартным в то время, хотя объекты поддерживались
уже в языке Simula 67. В листинге 2.6 представлен монитор, написанный на во-
воображаемом языке, некоем «местечковом диалекте» — «пиджин» Pascal.
Реализации взаимных исключений способствует важное свойство монитора: при
обращении к монитору в любой момент времени активным может быть только
один процесс. Мониторы являются структурным компонентом языка програм-
программирования, поэтому компилятор знает, что обрабатывать вызовы процедур мони-
монитора следует иначе, чем вызовы остальных процедур. Обычно при вызове процеду-
процедуры монитора первые несколько команд процедуры проверяют, нет ли в мониторе
активного процесса. Если таковой есть, вызывающему процессу придется подо-
подождать, в противном случае запрос удовлетворяется.
Листинг 2.6. Монитор
monitor example
integer i;
condition с;
procedure producer(x) ;
end;
procedure consumer(x);
end;
end monitor;
Реализация взаимного исключения зависит от компилятора, но обычно использу-
используется мьютекс или двоичный семафор. Поскольку взаимное исключение обеспечи-
обеспечивает компилятор, а не программист, вероятность ошибки гораздо меньше. В любом
случае программист, пишущий код монитора, не должен задумываться о том, как
компилятор организует взаимное исключение. Достаточно знать, что обеспечив
попадание в критические секции через процедуры монитора, можно не бояться
нахождения в критических секциях двух процессов одновременно.
Хотя мониторы предоставляют простой механизм реализации взаимного ис-
исключения, этого недостаточно. Необходим также способ блокировки процессов,
которые не могут продолжать свою деятельность. В случае проблемы производи-
производителя и потребителя достаточно просто поместить все проверки буфера (пуст —
не пуст) в процедуры монитора, но как процесс заблокируется, обнаружив пол-
полный буфер?
Решение заключается в условных переменных и двух операциях, wait и signal.
Когда процедура монитора обнаруживает, что она не в состоянии продолжать
работу (например, производитель выясняет, что буфер заполнен), она выполняет
операцию wait для какой-либо условной переменной, скажем, full. Это при-
приводит к блокировке вызывающего процесса и позволяет другому процессу войти
в монитор.
Другой процесс, в нашем примере потребитель может активизировать ожидаю-
ожидающего напарника, например, выполнив операцию signal для той условной пере-
переменной, для которой он был заблокирован. Чтобы в мониторе не оказалось двух
активных процессов одновременно, нам необходимо правило, определяющее по-
последствия операции signal. Xoap предложил запуск «разбуженного» процесса
и остановку второго. Бринч Хансен придумал другое решение: процесс, выпол-
выполнивший операцию signal, должен немедленно покинуть монитор. Иными слова-
словами, операция signal выполняется только в самом конце процедуры монитора.
Мы будем использовать это решение, поскольку оно в принципе проще и к тому
же легче в реализации. Если операция signal выполнена для переменной, с ко-
которой связаны несколько заблокированных процессов, планировщик выбирает
и «оживляет» только один из них.
Кроме этого, существует третье решение, не основывающееся на предположени-
предположениях Хоара и Хансена: позволить процессу, выполнившему операцию signal,
продолжать работу и запустить ожидающий процесс только после того, как пер-
первый процесс покинет монитор.
Условные переменные не являются счетчиками. В отличие от семафоров они не
аккумулируют сигналы, чтобы впоследствии воспользоваться ими. Это означает,
что в случае выполнения операции signal для условной переменной, с которой
не связано ни одного блокированного процесса, сигнал будет утерян. Проще го-
говоря, операция wait должна выполняться прежде, чем signal. Последнее пра-
правило существенно упрощает реализацию. На практике оно не создает проблем,
поскольку отслеживать состояния процессов при необходимости не очень труд-
трудно. Процесс, который собирается выполнить операцию signal, может оценить
необходимость этого действия по значениям переменных.
В листинге 2.7 представлена схема решения проблемы производителя и потреби-
потребителя с применением мониторов, написанная на языке «пиджин» Pascal. В данной
ситуации этот суррогат языка удобен своей простотой, а также тем, что он позво-
позволяет в точности следовать моделям Хоара и Хансена. В каждый момент времени
активна только одна процедура монитора. Буфер состоит из N сегментов.
Можно подумать, что операции wait и signal похожи на sleep и wakeup, ко-
которые приводили к неустранимым условиям гонок. Они действительно похожи,
но с одним существенным отличием: неудачи при применении операций sleep
и wakeup были связаны с тем, что один процесс пытался уйти в состояние ожи-
ожидания, в то время как другой процесс предпринимал попытки активизировать
его. С мониторами такого произойти не может. Автоматическое достижение
взаимного исключения, реализуемое процедурами монитора, гарантирует: если
производитель, находящийся в мониторе, обнаружит полный буфер и решит вы-
выполнить операцию wait, можно не опасаться, что планировщик передаст управ-
управление потребителю раньше, чем операция wait будет завершена. Потребитель
даже не сумеет попасть в монитор, пока операция wait не будет выполнена и про-
производитель не прекратит работу.
Хотя «пиджин» Pascal является вымышленным языком, некоторые «настоящие»
языки программирования поддерживают мониторы, пусть и не всегда в форме
Хоара и Хансена. Одним из таких языков является Java. Java представляет собой
объектно-ориентированный язык, дающий пользователю возможность работать
с программными потоками и поддерживающий группировку методов (процедур)
в классы. Добавление в объявление метода ключевого слова synchronized
гарантирует, что если какой-либо программный поток вызовет этот метод, то ни-
никакой другой поток не вызовет любой другой метод этого же класса, также объ-
объявленный с ключевым словом synchronized.
Листинг 2.7. Схема решения проблемы производителя и потребителя
с применением мониторов
monitor ProducerConsumer
condition full, empty;
integer count;
procedure insert(item: integer);
begin
if count = N then wait(full);
insert_item(item);
count := count+1;
if count = 1 then signal(empty)
end;
function remove: integer;
begin
if count = 0 then wait(empty);
remove = remove_item;
count := count—1;
if count = N-l then signal(full)
end;
count := 0;
end monitor;
procedure producer;
begin
while true do
begin
item = produce_item;
ProducerConsumer.insert(item)
end
end;
procedure consumer;
begin
while true do
begin
item = ProducerConsumer.remove;
consume_item(item)
end
end;
Между синхронизированными методами Java и классическими мониторами су-
существует принципиальное отличие: в Java отсутствуют условные переменные.
Вместо этого имеются две процедуры, wait и notify, представляющие собой
эквиваленты sleep и wakeup за одним исключением. Когда эти процедуры ис-
используются внутри синхронизированных методов, между ними исключены усло-
условия гонок.
Благодаря автоматизации взаимного исключения при применении мониторов
в программах ошибки встречаются значительно реже, чем при применении сема-
семафоров. Но и у мониторов есть свои недостатки. Недаром монитор, представлен-
представленный в листинге 2.7, написан на «пиджин» Pascal, а не на С, как все остальные
примеры этой книги. Как мы уже говорили, мониторы являются структурным
компонентом языка программирования, и компилятор должен их распознавать
и организовывать взаимное исключение. Языки Pascal, С и многие другие не
поддерживают мониторов, поэтому странно было бы ожидать от их компилято-
компиляторов выполнения правил взаимного исключения. И в самом деле, как компилято-
компилятору отличить процедуры монитора от остальных?
Эти языки не поддерживают и семафоров, хотя решить эту проблему несложно:
добавьте в библиотеку две короткие процедуры на ассемблере, выполняющие те
же действия, что и системные вызовы up и down. Компиляторам даже не обяза-
обязательно знать о них. Разумеется, операционная система должна знать о семафо-
семафорах, но если операционная система поддерживает семафоры, вы можете писать
для нее программы на С, C++ или даже (при мазохистских наклонностях) на
FORTRAN. Что же касается мониторов, язык должен обеспечивать их встроен-
встроенную поддержку.
Другая проблема, связанная с мониторами и семафорами, состоит в том, что они
были разработаны для решения задачи взаимного исключения в системе с одним
или несколькими процессорами, имеющими доступ к общей памяти. Помещение
семафоров в совместно используемую память с защитой в виде команд TSL
может исключить условия гонок. Однако эти примитивы неприменимы в рас-
распределенной системе, состоящей из нескольких процессоров с собственной па-
памятью у каждого, связанных локальной сетью. Вывод из всего вышесказанного
следующий: семафоры являются примитивами слишком низкого уровня, а мо-
мониторы применимы только в некоторых языках программирования. Примитивы
не подходят и для обмена информацией между компьютерами — в этом случае
нужно что-то другое.
2.2.8. Передача сообщений
В роли чего-то другого выступает механизм передачи сообщений. Взаимодействие
между процессами такого рода строится на двух примитивах: send и receive,
которые являются скорее системными вызовами, нежели структурными компо-
компонентами языка (что отличает их от мониторов и делает похожим на семафоры).
Поэтому их легко можно инкапсулировать в библиотечные процедуры, например:
send(destination, &message);
receive(source, &message);
Первый запрос посылает сообщение заданному приемнику, а второй получает
сообщение от указанного источника (или от любого источника, если это не име-
имеет значения). Если сообщения нет, второй запрос блокируется до поступления
сообщения либо немедленно возвращает код ошибки.
Разработка систем передачи сообщений
С системами передачи сообщений связано множество сложных проблем и конст-
конструктивных вопросов, которых не возникает в случае семафоров и мониторов.
Особенно много сложностей появляется в случае взаимодействия процессов,
проистекающих на различных компьютерах, соединенных сетью. Так, сообщение
может затеряться в сети. Чтобы избежать потери сообщений, отправитель и по-
получатель договариваются, что при получении сообщения получатель посылает
обратно подтверждение приема. Если отправитель не получает подтверждение
через некоторое время, он отсылает сообщение еще раз.
Теперь представим, что сообщение получено, но подтверждение до отправителя
не дошло. Отправитель направит сообщение еще раз, и до получателя оно дойдет
дважды. Крайне важно, чтобы получатель мог отличить копию предыдущего со-
сообщения от нового сообщения. Обычно проблема решается введением порядко-
порядкового номера сообщения в тело самого сообщения. Если к получателю приходит
сообщение с номером, совпадающим с номером предыдущего сообщения, оно
классифицируется как копия и игнорируется. Решение проблемы успешного об-
обмена информацией в условиях ненадежного механизма передачи сообщений со-
составляет основу компьютерных сетей.
Для систем обмена сообщениями также важен вопрос названий процессов. Необ-
Необходимо однозначно определять процесс, указанный в вызове send или receive.
Кроме того, встает вопрос аутентификации: каким образом клиент может опре-
определить, что он взаимодействует с настоящим файловым сервером, а не с само-
самозванцем?
Помимо этого существуют конструктивные проблемы, существенные при распо-
расположении отправителя и получателя на одном компьютере. Одной из таких про-
проблем является производительность. Копирование сообщений из одного процесса
в другой происходит гораздо медленнее, чем операция над семафором или вход
в монитор. Было проведено множество исследований с целью повышения эф-
эффективности передачи сообщений. В [18], например, предлагалось ограничивать
размер сообщения размерами регистров и передавать сообщения через регистры.
Решение проблемы производителя и потребителя
путем передачи сообщений
Теперь рассмотрим решение проблемы производителя и потребителя посредст-
посредством передачи сообщений и без использования общей памяти. Решение представ-
представлено в листинге 2.8. Мы предполагаем, что все сообщения имеют одинаковый
размер, и сообщения, которые посланы, но еще не получены, автоматически по-
помещаются операционной системой в буфер. В этом решении передается N со-
сообщений, по аналогии с N сегментами в буфере. Потребитель начинает с того,
что посылает производителю N пустых сообщений. Как только у производителя
оказывается элемент данных, который он может предоставить потребителю, он
берет пустое сообщение и отсылает назад полное. Таким образом, общее число
сообщений в системе постоянно и их можно хранить в заранее отведенной об-
области памяти.
Если производитель работает быстрее, чем потребитель, все сообщения будут
ожидать потребителя в цельном виде. При этом производитель блокируется
в ожидании пустого сообщения. Если потребитель работает быстрее, ситуация
обратная: все сообщения будут пустыми, а потребитель блокируется в ожидании
полного сообщения.
Листинг 2.8. Решение проблемы производителя и потребителя
с использованием N сообщений
#define N 100 /* Количество сегментов в буфере */
void producer(void)
{
int item;
message m; /* Буфер для сообщений */
while (TRUE) {
item = produce_item(); /* Сформировать нечто, чтобы заполнить
/* буфер */
receive(consumer., &m); /* Ожидание прибытия пустого сообщения */
build_message(&m, item); /* Сформировать сообщение для отправки */
send(consumer, &m); /* Отослать элемент потребителю */
}
}
void consumer(void)
{
int item, i;
message m;
for (i = 0; i < N; i++)
{
send(producer, &m) ;
} /* Отослать N пустых сообщений */
while (TRUE) {
receive(producer, &m); /* Получить сообщение с элементом */
item = extract_item(&m); /* Извлечь элемент из сообщения */
send(producer, &m); /* Отослать пустое сообщение */
consume_item(item); /* Обработка элемента */
}
}
Передача сообщений реализуется по-разному. Рассмотрим способ адресации
сообщений. Можно присвоить каждому из процессов уникальный адрес и адре-
адресовать сообщение непосредственно процессам. Другой подход состоит в исполь-
использовании новой структуры данных, называемой почтовым ящиком. Почтовый
ящик — это буфер для определенного количества сообщений, тип которых зада-
задается при создании ящика. При использовании почтовых ящиков адресуемыми
параметрами в вызовах send и receive являются почтовые ящики, а не процес-
процессы. Если процесс пытается послать сообщение в переполненный почтовый ящик,
ему приходится ждать, пока хотя бы одно сообщение не будет оттуда удалено.
В задаче производителя и потребителя оба они создадут почтовые ящики, доста-
достаточно большие, чтобы хранить N сообщений. Производитель будет посылать со-
сообщения с данными в почтовый ящик потребителя, а потребитель отправлять
пустые сообщения в почтовый ящик производителя. В случае почтовых ящиков
способ буферизации очевиден: в почтовом ящике получателя хранятся сообще-
сообщения, которые были посланы процессу-получателю, но еще не получены.
Другой крайностью при использовании почтовых ящиков является принци-
принципиальное отсутствие буферизации. При таком подходе, если вызов send вы-
выполняется раньше, чем receive, процесс-отправитель блокируется до вызова
receive, когда сообщение может быть напрямую скопировано от отправителя
к получателю без промежуточной буферизации. Если вызов receive выполня-
выполняется раньше, чем send, процесс-получатель блокируется до вызова send. Этот
метод часто называют рандеву, он легче реализуется, чем схема буферизации со-
сообщений, но менее гибок, поскольку отправитель и получатель должны работать
в режиме жесткой синхронизации.
Процессы, формирующие операционную систему MINIX 3, для взаимодейст-
взаимодействия между собой используют метод рандеву с сообщениями фиксированного
размера. Таким же способом пользовательские процессы взаимодействуют с ком-
компонентами операционной системы, хотя с точки зрения программиста это неза-
незаметно: системные вызовы «скрыты» библиотечными процедурами. Взаимодейст-
Взаимодействие между пользовательскими процессами в MINIX 3 происходит посредством
каналов, которые по своей сути являются почтовыми ящиками. Единственная
разница между механизмом каналов и настоящими почтовыми ящиками состоит
в том, что в каналах нет разграничения сообщений. Другими словами, если ис-
источник поместит в канал 10 сообщений по 100 байт, а приемник прочитает
1000 байт, то он сразу прочитает все 10 сообщений. В реальной системе обмена
сообщениями каждая операция read возвращает единственное сообщение. Ко-
Конечно, если существует договоренность всегда использовать сообщения одного
и того же размера, то подобных проблем не возникает. Кроме того, можно ввести
специальный символ для разделения сообщений (скажем, перевод строки).
Передача сообщений, как правило, применяется в системах параллельного про-
программирования. Широкую известность получила система MPI (Message-Passing
Interface — интерфейс передачи сообщений), используемая в научных расчетах.
2.3. Классические проблемы
взаимодействия между процессами
В литературе по операционным системам описываются множество интересных
проблем, которые широко обсуждались и анализировались с применением раз-
различных методов синхронизации. В этом разделе мы рассмотрим две наиболее из-
известные проблемы.
2.3.1. Проблема обедающих философов
В 1965 году Дейкстра сформулировал и решил проблему синхронизации, на-
названную им проблемой обедающих философов. С тех пор каждый, кто изобре-
изобретал еще один новый примитив синхронизации, считал своим долгом проде-
продемонстрировать достоинства нового примитива на примере решения проблемы
обедающих философов. Задачу можно сформулировать следующим образом:
пять философов сидят за круглым столом и у каждого есть тарелка со спагетти.
Спагетти настолько скользкие, что каждому философу нужны две вилки, чтобы
управиться с яством. Но между каждыми двумя тарелками лежит только одна
вилка (рис. 2.7).
Рис. 2.7. Время обеда на факультете философии
Жизнь философа состоит из чередующихся периодов поглощения пищи и раз-
размышлений. (Разумеется, это абстракция, даже применительно к философам, но
остальные процессы жизнедеятельности для нашей задачи несущественны.) Ко-
Когда философ голоден, он пытается получить две вилки, левую и правую, в любом
порядке. Если ему удается завладеть двумя вилками, он некоторое время ест, за-
затем кладет вилки обратно и продолжает размышления. Вопрос состоит в сле-
следующем: можно ли написать алгоритм, который моделирует эти действия для
каждого философа и никогда не оказывается заблокированным? (Кое-кто счита-
считает, что требование наличия двух вилок выглядит несколько искусственно. Воз-
Возможно, нам следует заменить итальянскую пищу блюдами китайской кухни: спа-
спагетти — рисом, а вилки — палочками.)
В листинге 2.9 представлено очевидное решение проблемы. Процедура take_
fork ждет, пока указанная вилка не освободится, и берет ее. К сожалению, это
решение неверно — представьте себе, что все пять философов возьмут одно-
одновременно свои левые вилки. Каждый останется без правой вилки, то есть будет
иметь место взаимная блокировка.
Листинг 2.9. Неверное решение проблемы обедающих философов
#define N 5 /* Количество философов */
void philosospher(int i) /* i — номер философа, от 0 до 4 */
{
while(TRUE) {
think(); /* Философ размышляет */
take_fork(i); /* Берет левую вилку */
take_fork((i+1) % N); /* Берет правую вилку */
eat(); /* Спагети, ням-ням */
put_fork(i); /* Кладет на стол левую вилку */
put_fork((i+1) % N); /* Кладет на стол правую вилку */
}
}
Можно изменить программу так, чтобы после получения левой вилки проверя-
проверялась доступность правой. Если правая вилка недоступна, философ кладет левую
обратно, ждет некоторое время и повторяет весь процесс. Этот подход также не
будет работать, хотя и по другой причине. Если не повезет, все пять философов
могут начать процесс одновременно, взять левую вилку, обнаружить отсутст-
отсутствие правой, положить левую обратно на стол, одновременно взять левую вилку,
и так до бесконечности. Ситуация, в которой все программы продолжают рабо-
работать сколь угодно долго, но не могут добиться хоть какого-то прогресса, называ-
называется зависанием (starvation).
Вы можете подумать: «Если философы будут размышлять в течение некото-
некоторого случайно выбранного промежутка времени после неудачной попытки взять
правую вилку, вероятность того, что все процессы будут продолжать топтать-
топтаться на месте хотя бы в течение часа, невелика». Это правильно, и для большинст-
большинства приложений повторение попытки спустя некоторое время снимает проблему.
Например, в локальной сети Ethernet в ситуации, когда два компьютера посы-
посылают пакеты одновременно, каждый должен подождать случайно заданное вре-
время и повторить попытку — на практике это решение хорошо работает. Тем не
менее в некоторых приложениях предпочтительным является другое решение,
работающее всегда и не зависящее от случайных чисел (например, в прило-
приложении, предназначенном для обеспечения безопасности на атомных электро-
электростанциях).
Листинг 2.9 можно улучшить, исключив взаимные блокировки и зависания процес-
процессов; для этого достаточно защитить пять команд, следующих за запросом think,
бинарным семафором. Тогда философ должен будет выполнить операцию down
для переменной mutex прежде, чем тянуться к вилкам. А после возврата вилок
на место ему следует выполнить для переменной mutex операцию up. С теорети-
теоретической точки зрения решение вполне подходит. С позиций практики возникают
проблемы эффективности: в каждый момент времени может есть спагетти только
один философ. Но вилок пять, поэтому логичней было бы разрешить есть в каж-
каждый момент времени двум философам.
Решение, представленное в листинге 2.10, исключает взаимные блокировки и по-
позволяет реализовать максимально возможный параллелизм для любого числа
философов. Здесь используется массив state для отслеживания душевного со-
состояния каждого философа: он либо ест, либо размышляет, либо голодает (пы-
(пытаясь получить вилки). Философ может начать есть, только если ни один из его
соседей не ест. Соседи философа i определяются макросами LEFT и RIGHT (то
есть если i = 2, то LEFT = 1 и RIGHT = 3).
В программе используется массив семафоров, по одному на философа, чтобы бло-
блокировать голодных философов, если их вилки заняты. Обратите внимание, что
каждый процесс запускает процедуру philosopher в качестве своей основной
программы, но остальные процедуры take_f orks, put_f orks и test являют-
являются обычными процедурами, а не отдельными процессами.
Листинг 2.10. Решение проблемы обедающих философов
#define N 5 /* Количество философов */
#define LEFT (i+N.l)%N /* Номер левого соседа философа с номером i */
#define RIGHT (i+l)%N /* Номер правого соседа философа с номером i */
#define THINKING 0 /* Философ размышляет */
#define HUNGRY I /* Философ пытается получить вилки */
#define EATING 2 /* Философ ест */
typedef int semaphore; /* Семафоры — особый вид целочисленных
/* переменных */
int state[N]; /* Массив для отслеживания состояния каждого
/* философа */
semaphore mutex = 1; /* Взаимоисключение для критических секций */
semaphore s[N]; /* Каждому философу - по семафору */
void philosopher(int i) /* i — номер философа, от 0 до N-1 */
{
while (TRUE) { /* Повторять постоянно */
think(); /* Философ размышляет */
take_forks(i); /* Получает две вилки или блокируется */
eat(); /* Спагетти, ням-ням */
put_forks(i); /* Кладет на стол обе вилки */
}
}
void take_forks(int i) /* i — номер философа, от 0 до N-1*/
{
down(&mutex); /* Вход в критическую секцию */
state[i] = HUNGRY; /* Выявление голодного философа */
test(i); /* Попытка получить две вилки */
up(&mutex); /* Выход из критической секции */
down(&s[i]); /* Блокировка, если вилок не досталось */
}
void put_forks(i) /* i — номер философа, от 0 до N-1*/
{
down(&mutex); /* Вход в критическую секцию */
state[i] = THINKING; /* Философ перестал есть */
test(LEFT); /* Проверить, может ли есть сосед слева */
test(RIGHT); /* Проверить, может ли есть сосед справа */
up(&mutex); /* Выход из критической секции */
}
void test(i) /* i — номер философа, от 0 до N-1*/
{
if (state[i]
== HUNGRY && state[LEFT] 1= EATING && state[RIGHT] != EATING) {
state[i] = EATING;
up(&s[i]);
}
}
2.3.2. Проблема читателей и писателей
Проблема обедающих философов полезна для моделирования процессов, сорев-
соревнующихся за монопольный доступ к ограниченному количеству ресурсов, напри-
например к устройствам ввода-вывода. Другой известной проблемой является проблема
читателей и писателей, моделирующая доступ к базе данных [27]. Представьте
себе базу данных для бронирования билетов на самолет, к которой пытается полу-
получить доступ множество клиентов. Можно разрешить одновременное считывание
данных из базы, но если процесс записывает информацию в базу, доступ осталь-
остальных процессов должен быть прекращен, даже доступ на чтение. Как запрограм-
запрограммировать читателей и писателей? Одно из решений представлено в листинге 2.11.
Листинг 2.11. Решение проблемы читателей и писателей
typedef int semaphore; /* Воспользуйтесь своим воображением */
semaphore mutex =1; /* Контроль доступа к гс */
semaphore db = 1; /* Контроль доступа к базе данных */
int re = 0; /* Количество процессов, читающих или */
/* желающих читать */
void reader(void)
{
while (TRUE) { /* Повторять до бесконечности */
down(&mutex); /* Получение монопольного доступа к гс V
гс = гс+1; /* Одним читающим процессом больше */
if (гс == 1) down(&db); /* Если этот читающий процесс — */
/* первый... */
up(&mutex); /* Отказ от монопольного доступа к гс */
read_data_base(); /* Доступ к данным */
down(&mutex); /* Получение монопольного доступа к гс */
гс = гс-1; /* Одним читающим процессом меньше */
if (гс == 0) up(&db); /* Если этот читающий процесс — /*
/* последний... */
up(&mutex); /* Отказ от монопольного доступа к гс V
use_data_read(); /* Вне критической секции */
}
}
void writer(void)
{
while (TRUE) { /* Повторять до бесконечности */
think_up_data(); /* Вне критической секции */
down(&db); /* Получение монопольного доступа */
write_data_base(); /* Запись данных */
up(&db); /* Отказ от монопольного доступа */
}
}
Первый читающий процесс выполняет операцию down для семафора db, чтобы
получить доступ к базе. Последующие читатели просто увеличивают значение
счетчика гс. По мере уменьшения числа читающих из базы значение счетчика
уменьшается, и последний читающий процесс выполняет для семафора db опера-
операцию up, позволяя блокированному пишущему процессу получить доступ к базе.
В этом решении один момент требует комментариев. Представьте, что в то время
как один читатель уже пользуется базой, другой читатель запрашивает к ней
доступ. Доступ разрешается, поскольку читающие процессы друг другу не меша-
мешают. Доступ разрешается и третьему, и последующим читателям.
Затем доступ запрашивает пишущий процесс. Запрос отклоняется, поскольку
пишущим процессам необходим монопольный доступ, и пишущий процесс при-
приостанавливается. Пока в базе есть хотя бы один активный читающий процесс,
доступ остальным читателям разрешается, а они все приходят и приходят. Если
предположить, что новый читающий процесс запрашивает доступ каждые 2 с,
а для работы с базой ему надо 5 с, то пишущий процесс никогда в базу не попадет.
Чтобы избежать такой ситуации, нужно немного изменить программу: если
пишущий процесс ждет доступа к базе, новый читающий процесс доступа не по-
получает, а становится в очередь за пишущим процессом. Теперь пишущему про-
процессу нужно подождать, пока базу покинут уже находящиеся в ней читающие
процессы, но не нужно пропускать вперед читающие процессы, пришедшие к ба-
базе после него. Недостаток этого решения заключается в снижении производи-
производительности, вызванном ослаблением конкуренции. В [27] представлено реше-
решение, в котором пишущим процессам предоставляется более высокий приоритет.
2.4. Планирование
Когда компьютер работает в многозадачном режиме, на нем могут быть активны-
активными несколько процессов, пытающихся одновременно получить доступ к процес-
процессору. Эта ситуация возникает, когда два и более процессов находятся в состоя-
состоянии готовности. Если доступен только один процессор, необходимо выбирать
между процессами. Отвечающая за это часть операционной системы называется
планировщиком, а используемый алгоритм — алгоритмом планирования.
Многие вопросы планирования в одинаковой степени касаются процессов и про-
программных потоков. Сначала мы акцентируем внимание на планировании про-
процессов, а затем коснемся специфических вопросов планирования программных
потоков.
2.4.1. Основы планирования
Давным-давно, во времена систем пакетной обработки, перфокарт и магнитных
лент в качестве устройств ввода, алгоритм планирования был прост: запустить
следующую задачу. С появлением систем разделения времени алгоритм пла-
планирования усложнился, поскольку теперь несколько задач одновременно могли
ожидать обслуживания. На некоторых мэйнфреймах до сих пор совмещаются
системы пакетной обработки и службы разделения времени. Может показаться,
что на персональных компьютерах активным является только один процесс: в са-
самом деле, пользователь, работающий с документом в текстовом редакторе, едва
ли станет компилировать программу в фоновом режиме. В то же время фоновые
задания отнюдь не являются редкостью. Примером является демон электронной
почты, осуществляющий прием и передачу сообщений. Вы также можете поду-
подумать, что в последние годы быстродействие компьютеров возросло настолько, что
о нехватке ресурсов процессора можно забыть. Однако и требования современных
приложений к ресурсам совсем не те, что раньше: вспомните хотя бы обработку
цифровых фотографий или просмотр видео в реальном времени.
Поведение процесса
Почти все процессы чередуют периоды интенсивной вычислительной работы
с вводом-выводом (в том числе дисковым), как показано на рис. 2.8. Как прави-
правило, в течение некоторого времени процессор работает без остановки, а затем
выполняется системный вызов на запись или чтение файла. По завершении сис-
системного вызова процессор вновь продолжает вычисления до тех пор, пока не воз-
возникнет потребность получения или записи данных и т. д. Обратите внимание, что
некоторые действия по вводу-выводу считаются вычислительными. Примером
служит копирование процессором битов в видеопамять для обновления экрана.
Здесь мы имеем дело именно с вычислениями, поскольку в данной операции за-
задействован центральный процессор. Под вводом-выводом в таком контексте сле-
следует понимать ситуацию, когда процесс блокируется и ожидает окончания работы
внешнего устройства.
Рис. 2.8. Чередование периодов использования процессора и ожидания ввода-вывода:
а — процесс ограничен вычислительными возможностями; б — процесс ограничен
возможностями ввода-вывода
Рисунок 2.8 иллюстрирует одну важную вещь. Некоторые процессы (рис. 2.8, а)
большую часть своего времени тратят на вычисления, другие же процессы
(рис. 2.8, б) в основном ожидают ввода-вывода. Первые ограничены вычисли-
вычислительными возможностями, вторые — возможностями ввода-вывода. Процессы,
ограниченные вычислительными возможностями процессора, имеют длительные
периоды вычислений, а ожидания ввода-вывода происходят редко. Процессы,
ограниченные возможностями ввода-вывода, напротив, регулярно тратят время
на ожидание ввода-вывода, а их вычислительные циклы невелики. Обратите
внимание на то, что ключевым фактором является продолжительность вычисли-
вычислительного цикла, а не цикла ввода-вывода. Ограниченность процессов возможно-
возможностями ввода-вывода возникает не потому, что они выполняют мало вычислений
между запросами на ввод-вывод, а потому, что обслуживание этих запросов яв-
является длительным. Время считывания дискового блока не зависит от скорости
обработки считанных данных.
Следует заметить, что с повышением быстродействия процессоров узким ме-
местом для процессов становится ввод-вывод. Это объясняется тем, что прогресс
в производстве процессоров значительно опережает прогресс в производстве
дисков. Таким образом, планирование процессов, ограниченных возможностями
ввода-вывода, в будущем станет более важным. Основная задача — как можно
скорее обслуживать дисковые запросы таких процессов и предоставлять им ре-
ресурсы процессора.
Когда требуется планирование
Планирование требуется в самых разных ситуациях. Оно, безусловно, необходи-
необходимо в двух случаях.
1. При завершении процесса.
2. При блокировании процесса семафором или вводом-выводом.
Обе ситуации приводят к тому, что выполнение текущего процесса прекращает-
прекращается, а значит, требуется выбрать следующий процесс для запуска.
Планирование обычно осуществляется еще в трех случаях, хотя и без жесткой
логической необходимости.
1. При создании нового процесса.
2. При прерывании ввода-вывода.
3. При прерывании от таймера.
Когда появляется новый процесс, имеет смысл заново оценить приоритеты.
Иногда родительский процесс может запросить другой уровень приоритета для
дочернего процесса.
Прерывание ввода-вывода, как правило, означает окончание работы устройства
ввода-вывода. В этом случае существует вероятность, что блокированный ранее
процесс может быть запущен.
Прерывание от таймера дает возможность проверить, не выполняется ли теку-
текущий процесс слишком долго. С точки зрения реакции на прерывания от таймера
алгоритмы планирования делятся на два класса. При невытесняющем алгоритме
планирования процесс выбирается и выполняется до блокирования (вызванного
вводом-выводом либо ожиданием другого процесса) или добровольного завер-
завершения. При вытесняющем алгоритме планирования процесс выбирается и вы-
выполняется в течение некоторого временного интервала. Если по окончании ин-
интервала процесс не завершил работу, он приостанавливается, а планировщик
выбирает другое задание (при его наличии). При вытесняющем планирова-
планировании необходимо прерывание от таймера в конце каждого временного интервала
с последующей передачей процессора под управление планировщика. В отсут-
отсутствие таймера невытесняющий алгоритм является единственным вариантом
планирования.
Категории алгоритмов планирования
Неудивительно, что в зависимости от особенностей окружения возникает потреб-
потребность в различных алгоритмах планирования. Различные области применения
и виды операционных систем преследуют разные цели, а, значит, планировщик
по-разному должен оптимизировать управление процессами. Отметим три вари-
варианта окружения.
1. Системы пакетной обработки.
2. Интерактивные системы.
3. Системы реального времени.
В системах пакетной обработки не существует проблемы пользователей, ожи-
ожидающих у своих терминалов как можно более скорой реакции системы. Таким
образом, вполне приемлемым является применение невытесняющих алгоритмов
планирования или вытесняющих алгоритмов с длительным временным интерва-
интервалом. Эти алгоритмы позволяют повысить производительность за счет уменьше-
уменьшения количества переключений между процессами.
В окружении с интерактивными пользователями необходимо вытеснение, позво-
позволяющее избежать захвата процессора одним процессом и отказа в обслуживании
всем остальным. Даже если ни один из процессов не «зациклится» из-за ошибки
в программе, возможны ситуации, в которых процесс парализует работу систе-
системы. Вытеснение предотвращает подобное поведение.
Как ни странно, в системах реального времени вытеснение не всегда оказывается
необходимым. Дело в том, что процессы в таких системах должны работать бы-
быстро, а значит, и блокирование не бывает долгим. Системы реального времени
содержат только те программы, которые требуются для решения конкретных задач.
Интерактивные системы, напротив, являются универсальными и могут включать
самые разные программы, в том числе бесполезные и даже вредоносные.
Цели алгоритма планирования
Чтобы разработать алгоритм планирования, необходимо определить, что от него
требуется. Некоторые цели алгоритма планирования зависят от окружения, в ко-
котором он будет применяться, однако есть и общие характеристики, наличие кото-
которых желательно всегда. Мы перечислим и рассмотрим некоторые из них.
+ Все системы:
♦ равноправие — предоставление каждому процессу справедливой доли про-
процессорного времени;
♦ применение политик — наблюдение за соблюдением установленной поли-
политики;
♦ баланс — обеспечение работой всех компонентов системы.
+ Системы пакетной обработки:
♦ пропускная способность — выполнение максимального количества зада-
заданий в единицу времени;
♦ время оборота — минимизация времени, затрачиваемого на ожидание об-
обслуживания и обработку задания;
♦ коэффициент использования процессора — обеспечение постоянной заня-
занятости процессора.
+ Интерактивные системы:
♦ время отклика — быстрая реакция на запросы;
♦ пропорциональность — соответствие ожиданиям пользователей.
+ Системы реального времени:
♦ соответствие временным ограничениям — избежание потерь данных;
♦ предсказуемость — избежание потери качества в мультимедиа-системах.
При всех обстоятельствах необходимо справедливое распределение процессор-
процессорного времени. Сопоставимые процессы должны получать сопоставимое обслу-
обслуживание. Выделять одному процессу намного больше ресурсов процессора, чем
другому, эквивалентному, несправедливо. Разумеется, с различными категория-
категориями процессов следует обращаться совершенно по-разному. Сравните, например,
задачи обеспечения безопасности атомной электростанции и начисления зара-
заработной платы в компьютерном центре.
Применение системных политик связано со справедливым распределением ре-
ресурсов. Если, к примеру, локальная политика требует, чтобы процессы управле-
управления безопасностью могли быть запущены в любой момент даже при условии, что
программа выдачи платежных ведомостей будет задержана на 30 секунд, плани-
планировщик должен обеспечить выполнение таких условий работы.
Еще одна общая цель планировщика — по возможности загружать все части сис-
системы работой. Если процессор и все устройства ввода-вывода работают непре-
непрерывно, их производительность выше, чем при простое каких-либо компонентов.
Например, в системе пакетной обработки планировщик решает, какие процессы
загружать в память для выполнения. Предпочтительнее иметь в памяти несколь-
несколько из процессов, ограниченных возможностями процессора и ввода-вывода, чем
сначала загрузить и выполнить только первые, а затем — только вторые. Процес-
Процессы, ограниченные вычислительными возможностями, начнут конкурировать за
вычислительный ресурс, а диск в это время будет простаивать. Когда очередь
дойдет до процессов, ограниченных возможностями ввода-вывода, будет про-
простаивать процессор, поскольку основная борьба развернется за устройства вво-
ввода-вывода. Лучше всего поддерживать в работе всю систему, тщательно отбирая
процессы для обработки.
Как правило, менеджеры корпоративных компьютерных центров с интенсивной
пакетной обработкой оценивают производительность подведомственных систем
по трем показателям: пропускной способности, времени оборота и коэффициенту
использования процессора. Пропускной способностью называется число зада-
заданий, выполняемых системой в секунду. Ясно, что 50 заданий в секунду лучше,
чем 40. Время оборота — это среднее время с момента ввода задания до его вы-
выполнения. Оно показывает, сколько в среднем пользователь вынужден ждать
результатов обработки. Нетрудно сформулировать правило: чем меньше время
оборота, тем лучше.
Алгоритм планирования, максимизирующий пропускную способность, совсем не
обязательно сводит к минимуму время оборота. Например, если планировщик
выбирает из группы заданий в первую очередь самые короткие, а затем — самые
длинные, пропускная способность системы оказывается очень высокой (большое
число коротких заданий, выполняемых в секунду). Расплатой за это является
увеличение времени оборота длительных заданий. При высокой интенсивности
поступления коротких заданий длительные задания не будут обрабатываться во-
вовсе. В результате среднее время оборота окажется бесконечным, но система при
этом покажет высокие величины пропускной способности.
Использование процессора имеет значение для систем пакетной обработки, по-
поскольку в больших мэйнфреймах, на которых работают такие системы, ресурс
центрального процессора является наиболее дорогостоящим. По этой причине
менеджеры компьютерных центров чувствуют себя виноватыми, если им не удает-
удается полностью загрузить процессор работой. Тем не менее коэффициент исполь-
использования процессора — не самый лучший показатель. Более важными являют-
являются число заданий, выполняемых системой в секунду (пропускная способность)
и время ожидания результатов (время оборота). Оценивать функционирование
системы по коэффициенту использования процессора — приблизительно то же,
что оценивать качество автомобиля по числу оборотов двигателя в секунду.
В интерактивных системах, особенно в серверах с разделением времени, цели яв-
являются совершенно иными. Наиболее важная из них — минимизировать время
отклика — время с момента ввода команды до получения результата. На персо-
персональном компьютере с выполняющимся фоновым процессом (к примеру, считы-
считывающим и сохраняющим сообщения электронной почты, полученные из сети)
запрос пользователя об открытии файла или запуске программы должен иметь
более высокий приоритет. Обслуживание может считаться хорошим, если все
интерактивные запросы обрабатываются системой в первую очередь.
С обслуживанием связано понятие пропорциональности. Пользователи имеют рас-
распространенные (хотя зачастую неверные) представления о том, сколько времени
должно занимать то или иное действие. Если принято считать, что действие яв-
является длительным, пользователи принимают это, однако если действие считает-
считается быстрым, но система тратит на него много времени, пользователи выражают
недовольство. Пусть, к примеру, компьютер подключен к Интернету с помощью
простого аналогового модема. Если с момента щелчка на значке до установки со-
соединения проходит 45 секунд, пользователь воспримет это как должное. Однако
если столько же времени потребуется на разъединение, то через полминуты поль-
пользователь начнет ворчать, а пятнадцатью секундами позже разразится бранью с пе-
пеной у рта. Все это объясняется общепринятым мнением о том, что набор номера
и подключение к сети требуют значительно больше времени, чем разрыв соеди-
соединения. Иногда (как в этом примере) планировщик не может повлиять на время
отклика, хотя в других случаях он способен на это (особенно если задержка вы-
вызвана неудачным выбором процесса для обработки).
Системы реального времени по характеристикам отличаются от интерактивных
систем, а следовательно, цели планирования в них также иные. Особенностью
систем реального времени является наличие ограничения по времени обработки.
Например, если компьютер управляет устройством, генерирующим данные с опре-
определенной частотой, опоздание при запуске процесса сбора данных может привести
к их потере. Таким образом, главным требованием систем реального времени явля-
является соблюдение всех или большинства установленных временных ограничений.
В некоторых системах реального времени (особенно связанных с использованием
мультимедиа) важна предсказуемость. Единичное опоздание при обработке аудио-
аудиоданных не является катастрофой, однако неравномерность выполнения процесса
быстро приведет к падению качества звука. То же касается и видеоданных, одна-
однако ухо значительно чувствительнее к джиттеру, чем глаз. Во избежание проблем
планирование процессов должно быть регулярным и хорошо предсказуемым.
2.4.2. Планирование в системах
пакетной обработки
Теперь самое время перейти от общих вопросов планирования к изучению кон-
конкретных алгоритмов. В этом разделе мы рассмотрим алгоритмы, применяемые
в системах пакетной обработки, а в следующих — алгоритмы интерактивных сис-
систем и систем реального времени. Некоторые алгоритмы используются как в пакет-
пакетных, так и интерактивных системах, однако мы расскажем о них позже. Сейчас
наше внимание будет сосредоточено на алгоритмах, характерных исключительно
для систем пакетной обработки.
Первым пришел — первым обслужен
Пожалуй, самым простым алгоритмом планирования является алгоритм под на-
названием первым пришел — первым обслужен. Согласно этому алгоритму, процессы
обрабатываются в порядке поступления запросов на использование процессора.
Упрощенно говоря, мы имеем дело с единственной очередью готовых процессов.
Первое задание, поступившее в систему в начале рабочего дня, немедленно при-
принимается и обрабатывается столько, сколько требуется. По мере поступления
других заданий они помещаются в конец очереди, и когда текущий процесс бло-
блокируется, из очереди на выполнение выбирается первый процесс. После снятия
блокировки предыдущий процесс обрабатывается как новый, то есть помещается
в конец очереди.
Главное преимущество такого алгоритма планирования заключается в простоте
и легкости программирования. Кроме того, он является справедливым в том же
смысле, в каком справедливой считается продажа дефицитных билетов на концерт
или спортивное состязание людям, стоящим в очереди с 2 часов ночи. В алгоритме
«первым пришел — первым обслужен» все готовые процессы помещаются в един-
единственный связанный список. Выбор процесса на выполнение равносилен удале-
удалению из списка первого элемента, а ввод в очередь нового или разблокированного
процесса — добавлению элемента в конец списка. Что может быть проще?
К сожалению, у алгоритма «первым пришел — первым обслужен» есть и не менее
важный недостаток. Представьте, что вы имеете дело с процессом, ограниченным
вычислительными возможностями и запускаемым раз в секунду, и множеством
процессов, ограниченных возможностями ввода-вывода, тратящих мало време-
времени на процессорную обработку, но требующих для завершения 1000 операций
считывания с диска. Процесс, ограниченный вычислительными возможностями
процессора, выполняется одну секунду, а затем считывает блок с диска; Далее вы-
выполняются все процессы, ограниченные возможностями ввода-вывода, и также
читают данные с диска. Получив информацию, процесс, ограниченный вычисли-
вычислительными возможностями, снова выполняется одну секунду, а за ним следуют
все остальные процессы.
В результате оказывается, что каждый процесс, ограниченный возможностями
ввода-вывода, считывает блок данных раз в секунду, а, следовательно, для завер-
завершения ему потребуется 1000 секунд. Если бы алгоритм планирования прерывал
процесс, ограниченный вычислительными возможностями, каждые 10 мс, про-
процесс, ограниченный возможностями ввода-вывода, завершился бы за 10, а не за
1000 секунд. При этом процесс, ограниченный вычислительными возможностя-
возможностями, не оказался бы слишком задержанным.
Самое короткое задание — первое
Теперь рассмотрим еще один пакетный невытесняющий алгоритм, основанный
на предположении о том, что время выполнения процессов известно заранее.
Например, в страховых компаниях специалисты, используя повседневный опыт,
могут весьма точно сказать, сколько времени займет обработка пакета из 1000 по-
полисов. Если в очереди есть несколько одинаково важных заданий, планиров-
планировщик выбирает самое короткое задание первым. Посмотрите на рис. 2.9, а. У нас
есть четыре задания: Л, Б, С и D с временем выполнения 8, 4, 4 и 4 мин соответ-
соответственно. Если мы запустим их в данном порядке, время оборота задания А будет
8 мин, В — 12 мин, С — 16 мин, D — 20 мин, а среднее время составит 14 мин.
Рис. 2.9. Пример планирования по алгоритму «самое короткое задание — первое»: а — запуск
четырех заданий в исходном порядке; б — запуск в соответствии с алгоритмом
А теперь запустим задания в соответствии с алгоритмом «самое короткое зада-
задание — первое», как показано на рис. 2.10, б. Значения времени оборота составят
4, 8, 12 и 20 мин соответственно, а среднее время будет равно И мин. Алгоритм
оптимизирует задачу. Рассмотрим четыре процесса с временем выполнения а, Ъ,
end. Первое задание выполняется за время а> второе — за время а + Ъ и т. д.
Среднее время оборота будет равно Dа + ЗЬ + 2с + d)/A. Очевидно, что вклад
времени а в среднее время больше, чем всех остальных интервалов времени,
поэтому первым должно выполняться самое короткое задание, а последним —
самое длительное, вносящее вклад, равный собственному времени оборота. Точ-
Точно так же рассматривается система с любым количеством заданий.
Следует отметить, что алгоритм «самое короткое задание — первое» является
оптимальным лишь при наличии сразу всех заданий. В качестве контрпримера
можно рассмотреть пять заданий, Л, J5, С, D и Еу причем первые два доступны
сразу же, а три оставшиеся — через три минуты. Время выполнения этих за-
заданий составляет 2, 4, 1, 1 и 1 мин соответственно, а время оборота — 0, 0, 3, 3
и 3 мин. Вначале можно выбрать только А или J5, поскольку остальные недос-
недоступны. Если руководствоваться алгоритмом «самое короткое задание — первое»,
задания будут запущены на обработку в следующем порядке: A, J5, С, Д Е и сред-
среднее время оборота составит 4,6 мин. Если же запустить их в порядке J5, С, Д Е, Л,
оно будет равно 4,4 мин.
Задание с наименьшим временем завершения —
следующее
Версией предыдущего алгоритма с использованием вытеснения является алго-
алгоритм задание с наименьшим временем завершения — следующее. Согласно ему,
планировщик всегда выбирает процесс, время завершения которого является
наименьшим. Как и в случае алгоритма «самое короткое задание — первое», вре-
время выполнения процессов должно быть известно заранее. При появлении нового
задания общее время его выполнения сравнивается с длительностью заверше-
завершения текущего задания. Если новое задание можно выполнить быстрее, чем за-
закончить текущее, текущее задание приостанавливается, а новое задание при-
принимается к обработке. Подобная схема обеспечивает хорошее обслуживание
коротких заданий.
Трехуровневое планирование
С определенной точки зрения системы пакетной обработки позволяют осуще-
осуществлять планирование на трех разных уровнях, как показано на рис. 2.10. После
поступления в систему новые задания сначала помещаются в очередь, храни-
хранимую на жестком диске. Далее планировщик допуска решает, какие задания при-
принять в систему. Остальные ожидают во входной очереди, пока не будут выбра-
выбраны планировщиком. Как правило, контроль допуска обеспечивает желательное
сочетание заданий, ограниченных возможностями процессора и ввода-вывода.
Возможен и другой подход — короткие задания выбираются быстрее, чем дли-
длительные. Планировщик допуска может выбирать задания из очереди по собст-
собственному усмотрению, независимо от того, какие из них пришли раньше, а какие —
позже.
Рис. 2.10. Трехуровневое планирование
После того как задание допущено в систему, для него может быть создан про-
процесс, способный претендовать на ресурсы процессора. Тем не менее возможна
ситуация, в которой процессов окажется так много, что в имеющейся памяти их
не удастся разместить. В этом случае часть процессов будет вытеснена на жест-
жесткий диск. Какие процессы вытеснить, а какие оставить в памяти, решает второй
уровень планирования, а соответствующий планировщик называется планиров-
планировщиком памяти.
Планирование памяти должно осуществляться регулярно, поскольку процессы,
находящиеся на диске, нуждаются в обслуживании. Однако перенос процесса
с диска в оперативную память является затратным, а потому планирование имеет
смысл выполнять не чаще одного раза в секунду. Постоянное «жонглирование»
содержимым памяти приведет к тому, что значительная часть пропускной спо-
способности диска будет потеряна, замедлив ввод-вывод файлов.
Чтобы оптимизировать производительность системы в целом, планировщику па-
памяти имеет смысл рассчитать желаемое число и типы процессов в памяти. Число
процессов называется степенью многозадачности. Зная, какие процессы ограни-
ограничены вычислительными возможностями, а какие — возможностями ввода-вывода,
планировщик может нацелить усилия на поддержку в памяти нужного сочета-
сочетания процессов. В качестве очень грубого приближения можно привести следую-
следующий пример: если некоторый класс процессов тратит 20 % времени на вычисле-
вычисления, то наличие в памяти 5 таких процессов обеспечит 100-процентную загрузку
процессора.
Планировщик памяти периодически анализирует каждый процесс на жестком
диске, чтобы решить, следует ли перенести его в основную память. Решение мо-
может основываться на следующих критериях.
♦ Сколько времени прошло с последнего переноса процесса в оперативную па-
память или на жесткий диск?
♦ Сколько процессорного времени получил данный процесс за последнее время?
♦ Каков объем процесса? (Небольшие процессы вряд ли переполнят память.)
♦ Насколько важным является процесс?
На третьем уровне планирования из находящихся в оперативной памяти процес-
процессов выбирается тот, который будет запущен следующим. Как правило, плани-
планировщика этого уровня называют планировщиком процессора и именно его чаще
всего имеют в виду, говоря о планировании. Планировщик процессора может
использовать любой подходящий алгоритм с вытеснением или без вытесне-
вытеснения. Часть алгоритмов уже нами рассмотрена; другие мы рассмотрим в следую-
следующем разделе.
2.4.3. Планирование в интерактивных системах
Теперь мы сосредоточим внимание на некоторых алгоритмах, которые можно
использовать в интерактивных системах. Все эти алгоритмы также подходят
для планировщика процессора пакетных систем. В интерактивных системах нет
трехуровневого планирования, однако планировщики памяти и процессора су-
существуют и широко распространены. Далее мы изучим планировщик процессора
и некоторые общие алгоритмы планирования.
Циклическое планирование
Одним из наиболее старых, простых, справедливых и часто используемых явля-
является алгоритм циклического, или карусельного, планирования. Каждому процес-
процессу предоставляется некоторый интервал времени процессора, так называемый
квантом. Если к концу кванта процесс все еще работает, он прерывается, а управ-
управление передается другому процессу. Разумеется, если процесс блокируется или
прекращает работу раньше, переход управления происходит в этот момент. Реа-
Реализация циклического планирования проста. Планировщику нужно всего лишь
согласно поддерживать список процессов в состоянии готовности (рис. 2.11, а).
Исчерпав свой лимит времени, процесс отправляется в конец списка (рис. 2.11, б).
Рис. 2.11. Циклическое планирование: а — список процессов в состоянии готовности;
б — список процессов в состоянии готовности после того, как процесс В
исчерпал свой квант
Единственным интересным моментом этого алгоритма является величина кван-
кванта. Переключение с одного процесса на другой занимает некоторое время —
необходимо сохранить и загрузить регистры и карты памяти, обновить таблицы
и списки, сохранить и перезагрузить кэш памяти и т. п. Представим, что переклю-
переключение процессов, или переключение контекста, как его иногда называют, занимает
1 мс, включая переключение карт памяти, перезагрузку кэша и т. п. Пусть вели-
величина кванта установлена равной 4 мс. В таком случае 20 % процессорного време-
времени уйдет на администрирование — это слишком много.
Для повышения эффективности назначим размер кванта, скажем, 100 мс. Теперь
пропадает только 1 % времени. Но представьте, что будет в системе разделения
времени, если 10 пользователей одновременно нажмут клавишу возврата карет-
каретки. В список будет занесено 10 процессов. Если процессор был свободен, первый
процесс будет запущен немедленно, второму придется ждать 100 мс и т. д. По-
Последнему процессу, возможно, придется ждать целую секунду, если все осталь-
остальные не блокируются за время кванта. Большинству пользователей секундная за-
задержка вряд ли понравится.
Важен и тот фактор, что если установленное значение кванта больше среднего
интервала работы процессора, переключение процессов будет происходить ред-
редко. Напротив, большинство процессов окажутся заблокированными прежде, чем
истечет квант, сто потребует переключение процессов. Устранение принудитель-
принудительных переключений процессов повышает производительность системы, так как
переключения будут происходить только тогда, когда это логически необходимо,
то есть когда процесс заблокирован и не может продолжать работу.
Вывод можно сформулировать следующим образом: слишком малый квант ведет
к частому переключению процессов и небольшой эффективности, но слишком
большой квант может привести к замедленной реакции на короткие интерактивные
запросы. Разумным компромиссом обычно является значение кванта в 20-50 мс.
Приоритетное планирование
Алгоритм карусельного планирования базируется на важном допущении о том,
что все процессы равнозначны. В случае компьютера с большим числом пользо-
пользователей это может быть не так. Например, в университете первыми должны об-
обслуживаться деканы, затем профессора, секретари, уборщицы, сторожа и лишь
потом студенты. Необходимость принимать во внимание подобные внешние фак-
факторы приводит к приоритетному планированию. Основная идея проста: каждому
процессу присваивается свой приоритет в «табеле о рангах» и управление пере-
передается готовому к работе процессу с самым высоким приоритетом.
Даже на персональном компьютере с одним пользователем могут выполняться
несколько процессов, отдельные из которых являются более важными, чем дру-
другие. Демон, отвечающий за пересылку электронной почты в фоновом режиме,
имеет более низкий приоритет, чем процесс, отображающий на экране видео-
видеофильм в реальном времени.
Чтобы предотвратить бесконечное выполнение высокоприоритетных процессов,
планировщик может уменьшать приоритет выполняемого процесса с каждым
тактом (то есть по каждому прерыванию от таймера). Если в результате приори-
приоритет текущего процесса окажется ниже приоритета следующего процесса, про-
произойдет переключение. Возможно также предоставление каждому процессу мак-
максимального отрезка времени работы. Как только время кончается, управление
передается следующему по значимости процессу.
Приоритеты процессам могут присваиваться статически или динамически. На во-
военной базе процессу, запущенному генералом, присваивается приоритет 100, пол-
полковником — 90, майором — 80, капитаном — 70, лейтенантом — 60 и т. д. А в ком-
коммерческом компьютерном центре выполнение заданий с высоким приоритетом
может стоить 100 долларов в час, со средним — 75, с низким — 50. Команда nice
в системе UNIX позволяет пользователю добровольно снизить приоритет своих
процессов, проявляя любезность по отношению к остальным пользователям.
Справедливости ради следует отметить, что этой командой никто никогда не
пользуется.
Система вправе динамически назначать приоритеты для достижения своих целей.
Например, некоторые процессы настолько ограничены возможностями устройств
ввода-вывода, что большую часть времени проводят в ожидании завершения
соответствующих операций. Когда бы ни потребовался процессор такому про-
процессу, его следует немедленно предоставить, чтобы процесс мог начать обраба-
обрабатывать следующий запрос ввода-вывода, который будет выполняться параллель-
параллельно с вычислениями другого процесса. Если заставить процесс, ограниченный
возможностями устройств ввода-вывода, длительное время ждать доступа к про-
процессору, он будет неоправданно долго находиться в памяти. Простой алгоритм
обслуживания процессов, сдерживаемых возможностями устройств ввода-выво-
ввода-вывода, состоит в установке приоритета, равного 1//, где / — часть использованного
в последний раз кванта. Процесс, утилизировавший всего 1 мс из 50-миллисе-
кундного кванта, получит приоритет 50, процесс, использовавший 25 мс, полу-
получит приоритет 2, а процесс, задействовавший весь квант, получит приоритет 1.
Часто бывает удобно сгруппировать процессы в классы по приоритетам и ис-
использовать приоритетное планирование среди классов и циклическое планиро-
планирование внутри каждого класса. На рис. 2.12 представлена система с четырьмя
классами приоритетов. Алгоритм планирования выглядит следующим образом:
пока в классе 4 есть готовые к запуску процессы, они запускаются один за
другим согласно алгоритму циклического планирования и каждому отводится
квант времени. При этом классы с более низким приоритетом не будут их беспо-
беспокоить. Если в классе 4 нет готовых к запуску процессов, запускаются процессы
класса 3 и т. д. Если приоритеты постоянны, до процессов класса 1 процессор
может не дойти никогда.
Рис. 2.12. Алгоритм планирования с четырьмя классами приоритетов
Операционная система MINIX 3 использует похожий алгоритм, однако по умол-
умолчанию в ней поддерживаются 16 классов приоритетов. В MINIX 3 компоненты
операционной системы выполняются как процессы. Задания (драйверы ввода-
вывода) и серверы (менеджер памяти, файловая система и сеть) имеют наиболее
высокие приоритеты. Начальный приоритет каждого задания или службы опре-
определяется во время компиляции. Драйверу медленного устройства ввода-вывода
можно задать более низкий приоритет, чем драйверу быстрого устройства или
сервера. Как правило, приоритеты процессов пользователя ниже, чем систем-
системных компонентов, однако во время выполнения все приоритеты могут меняться.
Планирование с несколькими очередями
Один из первых «приоритетных» планировщиков был реализован в системе
CTSS [23]. Основной проблемой системы CTSS стало слишком медленное пере-
переключение процессов, поскольку в памяти компьютера IBM 7094 мог находиться
только один процесс. Каждое переключение означало выгрузку текущего про-
процесса на диск и считывание нового процесса с диска. Разработчики CTSS быст-
быстро сообразили, что эффективность будет выше, если процессам, ограниченным
возможностями процессора, лучше выделять большие кванты времени, чем не-
небольшие кванты, но часто. С одной стороны, это уменьшит количество подкачек
с диска в память, но с другой, как мы уже видели, приведет к увеличению времени
отклика. В результате было разработано решение с классами приоритетов. Про-
Процессам класса с максимальным приоритетом выделялся один квант, процессам
следующего класса — два кванта, следующего — четыре кванта и т. д. Когда про-
процесс использовал все отведенное ему время, он переходил на класс ниже.
В качестве примера рассмотрим процесс, которому необходимо производить вы-
вычисления в течение 100 квантов. Вначале ему будет предоставлен один квант, за-
затем процесс будет сброшен на диск. В следующий раз ему достанется 2 кванта,
затем 4, 8, 16, 32, 64, хотя из 64 он использует только 37. В этом случае понадо-
понадобятся всего 7 подкачек (включая первоначальную загрузку) вместо 100, которые
понадобились бы в случае циклического алгоритма. Помимо того, по мере погру-
погружения в очередь приоритетов процесс будет запускаться все реже, в пользу более
коротких процессов.
Чтобы дать погибнуть процессу, который при запуске считался «долгоиграю-
«долгоиграющим», но позже стал интерактивным, была разработана следующая стратегия.
Как только с терминала приходит сигнал возврата каретки, процесс, соответст-
соответствующий этому терминалу, переносится в класс максимального приоритета, по-
поскольку предполагается, что он становится интерактивным. Однако однажды
пользователь, запустивший процесс, значительно ограниченный вычислитель-
вычислительными возможностями, обнаружил, что простое нажатие клавиши Enter сущест-
существенно сокращает время отклика, и рассказал об этом друзьям. Мораль этой исто-
истории такова: осуществить задуманное на практике гораздо сложней, чем в теории.
Для разделения процессов по классам используются многие другие алгоритмы.
Например, в системе XDS 940, разработанной в Беркли [71], было четыре класса
приоритетов: терминал, ввод-вывод, короткий квант и длинный квант. Когда
запускался процесс, ожидающий вывода на терминал, он перемещался в класс
высшего приоритета (терминал). Когда снималась блокировка процесса, ожидав-
ожидавшего доступа к диску, он переходил во второй класс. Если к концу отведенного
времени процесс все еще работал, он сначала зачислялся в третий класс. Если про-
процесс слишком много раз полностью задействовал свой квант времени, не бло-
блокируясь на терминале или другом устройстве ввода-вывода, он перемещался в по-
последний класс. Этот метод практикуется во многих системах для предоставления
преимущества интерактивным процессам по сравнению с фоновыми.
Самый короткий процесс — следующий
Поскольку в пакетных системах выполнение самых коротких заданий первыми
обеспечивает минимальное среднее время отклика, было бы весьма желательно
добиться подобного результата и при интерактивной обработке. Как правило,
функционирование интерактивного процесса состоит из циклической последова-
последовательности ожиданий исполнения и исполнения команд. Если уподобить исполне-
исполнение команды «заданию», то, выполняя самые короткие процессы первыми, мы мог-
могли бы свести общее время отклика к минимуму. Единственной проблемой является
определение кратчайшего среди текущих, готовых к выполнению процессов.
Один из подходов — оценить время окончания процессов на основе их поведе-
поведения в прошлом и выбрать тот процесс, чья оценка минимальна. Предположим,
что для некоторого терминала оценка длительности обработки одной команды
при первом запуске составила Го, а при втором запуске — Тх. Мы можем обновить
первичную оценку, взяв взвешенную сумму двух результатов: аТ0 + A - a)Tt. От
значения а зависит скорость убывания влияния старых запусков на общую оцен-
оценку. Например, если а = 1/2, ряд оценок будет следующим:
Го, Г0/2 + 7V2, Г0/4 + Тх/А + Г2/2, Г0/8 + Т{/8 + Г2/4 + Г3/2.
После трех запусков весовой коэффициент Го снизился до 1/8.
Метод оценки путем взвешивания текущего и предыдущих результатов иногда
называют старением. Он применим во многих ситуациях, где необходимо выпол-
выполнить прогноз на основе множества измерений. Метод старения особенно легко
реализовать для а = 1/2. Все, что требуется сделать, — сложить новое значение
с текущей оценкой и разделить сумму пополам (сдвигом вправо на один бит).
Гарантированное планирование
Принципиально другим подходом к планированию является предоставление поль-
пользователям реальных обещаний и затем их исполнение. Вот обещание, которое
легко произнести и легко выполнить: если вместе с вами с процессором работа-
работают п пользователей, вам будет предоставлено \/п мощности процессора. И в сис-
системе с одним пользователем и п запущенными процессорами каждому достанет-
достанется 1/п циклов процессора.
Чтобы сдержать это обещание, система должна отслеживать распределение про-
процессора между процессами с момента создания каждого процесса. Затем система
рассчитывает количество ресурсов процессора, на которое процесс имеет право,
например, время с момента создания, деленное на п. После этого можно сосчи-
сосчитать отношение времени, предоставленного процессу, к времени, на которое он
имеет право. Полученное значение 0,5 означает, что процессу выделили только
половину положенного, а 2,0 говорит о том, что процессу досталось в два раза
больше его нормы. Далее запускается процесс, у которого это отношение наи-
наименьшее, пока оно не станет больше, чем у его ближайшего соседа.
Лотерейное планирование
Хотя идея обещаний пользователям и их выполнения хороша, но ее трудно реа-
реализовать. Для получения предсказуемых результатов применяется другой алго-
алгоритм, называемый лотерейным планированием [126].
В его основе лежит раздача процессам «лотерейных билетов» на доступ к раз-
различным ресурсам, в том числе к процессору. Когда планировщику необходимо
принять решение, выбирается случайным образом лотерейный билет, и его обла-
обладатель получает доступ к ресурсу. Что касается доступа к процессору, «лотерея»
может разыгрываться 50 раз в секунду, и победитель получает 20 мс времени
процессора.
Если перефразировать Джорджа Оруэлла, можно сказать, что все процессы
равны, но некоторые равнее других. Более важным процессам можно раздать
дополнительные билеты, чтобы повысить вероятность выигрыша. Если тираж
всего 100 билетов и 20 из них находятся у одного процесса, то ему достанется
20 % времени процессора. В отличие от приоритетного планирования, где очень
трудно оценить, что означает, скажем, приоритет 40, в лотерейном планировании
все очевидно. Каждый процесс получит процент ресурсов, примерно равный про-
проценту имеющихся у него билетов.
Лотерейное планирование характеризуется несколькими интересными свойства-
свойствами. Например, если при создании процессу достается несколько билетов, то уже
в следующем розыгрыше его шансы на выигрыш пропорциональны количеству
билетов. Другими словами, лотерейное планирование обладает высокой «отзыв-
«отзывчивостью».
Взаимодействующие процессы могут при необходимости обмениваться биле-
билетами. Так, если клиентский процесс посылает сообщение серверному процессу
и затем блокируется, он вправе передать все свои билеты серверному процессу,
чтобы увеличить шанс запуска сервера. Когда серверный процесс заканчивает
работу, ему ничего не стоит вернуть все билеты обратно. Действительно, если
клиентов нет, то и билеты серверу не нужны.
Лотерейное планирование позволяет решать задачи, которые не решить с помо-
помощью других алгоритмов. В качестве примера приведем видеосервер, на котором
несколько процессов передают своим клиентам потоки видеоинформации с раз-
различной частотой кадров. Предположим, что процессы используют частоты 10, 20
и 25 кадров в секунду. Предоставив процессам соответственно 10, 20 и 25 биле-
билетов, можно реализовать загрузку процессора в желаемой пропорции 10:20:25.
Справедливое планирование
До настоящего момента мы планировали процессы, игнорируя вопрос о том, кто
является их владельцами. Если, к примеру, пользователь 1 запустит 9 процессов,
а пользователь 2 — 1 процесс, то, согласно циклическому или приоритетному
планированию, пользователь 1 получит 90 % процессорного времени, а пользо-
пользователь 2 — 10 %.
Чтобы избежать подобного «неравенства», некоторые системы используют в пла-
планировании информацию о владельцах процессов. Каждому пользователю пре-
предоставляется определенная доля ресурсов процессора, и процессы выбираются
на исполнение таким образом, чтобы обеспечить принятый вариант разделения.
Например, если двум пользователям обещана половина процессорного времени,
система обеспечит этот показатель независимо от запущенных ими процессов.
Пусть пользователь 1 запустил четыре процесса — А, В, С и Д а пользователь
2 — единственный процесс Е. Если в системе принято циклическое планирова-
планирование, то всем требованиям удовлетворит следующая последовательность выпол-
выполнения процессов:
AEBECEDEAEBECEDE...
Если пользователю 1 предоставлено вдвое больше процессорного времени, чем
пользователю 2, последовательность примет вид:
ABECDEABECDE...
Разумеется, справедливое планирование может быть реализовано и множеством
других способов, в зависимости от принятого толкования справедливости.
2.4.4. Планирование в системах
реального времени
В системах реального времени, как и следовало ожидать, существенную роль
играет время. Чаще всего одно или несколько внешних физических устройств
генерируют входные сигналы, и компьютер должен адекватно на них реагировать
в течение заданного временного интервала. Например, компьютер в проигрыва-
проигрывателе компакт-дисков получает биты от дисковода и должен за очень маленький
промежуток времени преобразовать их в музыку. Если процесс преобразования
будет слишком долгим, звук окажется искаженным. Подобные системы исполь-
используются для наблюдения за пациентами в палатах интенсивной терапии, для ав-
автоматического пилотирования самолета, для управления роботами на автомати-
автоматизированном производстве. В любом из этих случаев запоздалая реакция ничуть
не лучше, чем отсутствие реакции.
Системы реального времени делятся на жесткие системы реального времени, что
означает наличие жестких сроков для каждого задания (в них обязательно надо
укладываться), и гибкие системы реального времени, в которых нарушения вре-
временного графика нежелательны, но допустимы. В обоих случаях реализуется
разделение программы на несколько процессов, каждый из которых предсказу-
предсказуем. Эти процессы чаще всего бывают короткими и завершают свою работу в те-
течение секунды. Когда появляется внешний сигнал, именно планировщик должен
обеспечить соблюдение графика.
Внешние события, на которые система должна реагировать, можно разделить на
периодические (возникающие через регулярные интервалы времени) и неперио-
непериодические (возникающие непредсказуемо). Возможно наличие нескольких потоков
периодических событий, которые система должна обрабатывать. В зависимости
от времени, затрачиваемого на обработку каждого из событий, может оказаться,
что система не в состоянии своевременно обработать их все. Если в систему по-
поступает т периодических событий, событие с номером i поступает с периодом Р{
и на его обработку уходит С{ секунд работы процессора, то своевременную обра-
обработку всех потоков обеспечивает выполнение следующего условия:
Системы реального времени, удовлетворяющие этому условию, называются пла-
планируемыми.
В качестве примера рассмотрим гибкую систему реального времени с тремя пе-
периодическими сигналами с периодами в 100, 200 и 500 мс соответственно. Если
на обработку этих сигналов уходит, в том же порядке, 50, 30 и 100 мс, система
является планируемой, поскольку 0,5 + 0,15 + 0,2 < 1. Даже при добавлении чет-
четвертого сигнала с периодом в 1 с системой все равно можно будет управлять пу-
путем планирования, пока время обработки сигнала не превысит 150 мс. В этих
расчетах существенным является предположение, что время переключения меж-
между процессами пренебрежимо мало.
Алгоритмы планирования для систем реального времени бывают как статиче-
статическими, так и динамическими. В первом случае все решения по планированию
принимаются заранее, еще до запуска системы. Во втором случае решения выно-
выносятся по ходу дела. Статическое планирование применимо лишь при наличии
априори точной информации о работе, которую необходимо выполнить, и огра-
ограничениях, которые должны быть соблюдены. Алгоритмы динамического плани-
планирования не выдвигают подобных требований.
2.4.5. Политика и механизм планирования
Вплоть до настоящего момента мы подразумевали, что процессы в системе при-
принадлежат разным пользователям и конкурируют за доступ к процессору. Чаще
всего именно так все и происходит, но возможна ситуация, в которой под управле-
управлением одного процесса выполняются множество дочерних процессов. Например,
у процесса, управляющего базой данных, может быть много дочерних процес-
процессов, обрабатывающих отдельные запросы или выполняющих конкретные функции
(анализ запроса, доступ к диску и т. п.). Вполне вероятно, что родительский про-
процесс лучше представляет, какой из его дочерних процессов более важен (или для
которого фактор времени более критичен), а какой — менее. К сожалению, ни
один из рассмотренных нами планировщиков не в силах получать информацию
от пользовательских процессов и учитывать ее при принятии решений по пла-
планированию. В результате планировщики редко выносят оптимальное решение.
Преодолеть проблему можно, отделив механизм планирования от политики пла-
планирования. Таким образом, мы реализуем ситуацию, в которой алгоритм плани-
планирования будет каким-либо образом параметризован, но параметры могут быть
заданы пользовательским процессом. Обратимся еще раз к примеру базы дан-
данных. Пусть ядро поддерживает алгоритм приоритетного планирования, но суще-
существует системный запрос, посредством которого процесс может устанавливать
(и менять) приоритеты своих дочерних процессов. В этом случае родительский
процесс имеет право управления планированием дочерних процессов, хотя сам
он планирования не осуществляет. Механизм определяется ядром, но политику
задает пользовательский процесс.
2.4.6. Планирование программных потоков
Если некоторые процессы системы используют несколько программных пото-
потоков, мы сталкиваемся с двумя уровнями параллелизма: процессами и программ-
программными потоками. В таких системах планирование выполняется принципиально
другим способом, в зависимости от уровней программных потоков, поддержи-
поддерживаемых системой: пользовательского, ядра или обоих одновременно.
Сначала рассмотрим пользовательский уровень. Поскольку ядро не всегда знает
о существовании программных потоков, оно обращается с процессами стандарт-
стандартным образом, выбирая, к примеру, процесс А и предоставляя ему управление
в течение заданного кванта. Планировщик программных потоков внутри процес-
процесса Л решает, какой программный поток запустить — предположим, А1. Поскольку
не существует прерываний от таймера, поддерживающих потоковую многозадач-
многозадачность, выполнение программного потока А1 будет продолжаться столько, сколь-
сколько необходимо самому потоку. А если он займет весь квант, выделенный процес-
процессу А, ядро попросту выберет следующий процесс для обслуживания.
Когда процесс А будет запущен снова, программный поток А1 возобновит вы-
выполнение и будет занимать время процесса А до тех пор, пока не завершится.
Однако такое поведение никак не затронет другие процессы. Они будут полу-
получать свою долю процессорного времени независимо от того, что происходит
в процессе А.
Теперь представим, что время выполнения программных потоков процесса А су-
существенно меньше, чем квант выделяемого ему времени: скажем, каждый поток
выполняется в течение 5 мс, в то время как квант длится 50 мс. В этом случае
в течение кванта планировщик программных потоков несколько раз передаст
управление различным программным потокам. Например, это может привести
к такой последовательности обслуживания потоков: А1, А2, A3, А1, А2, A3, А1,
А2, A3, А1, после чего ядро переключится на процесс В. Данную ситуацию иллю-
иллюстрирует рис. 2.13, а.
Рис. 2.13. Планирование программных потоков: а — планирование программных
потоков уровня пользователя при времени выполнения потока 5 мс и кванте 50 мс;
б — планирование программных потоков уровня ядра в тех же условиях
Система реального времени может использовать любой из алгоритмов плани-
планирования, описанных ранее. На практике чаще всего прибегают к циклическому
и приоритетному алгоритмам. Единственным ограничением является отсутствие
таймера, прерывающего программный поток, который выполняется слишком долго.
Теперь рассмотрим ситуацию с программными потоками уровня ядра. Ядро само
выбирает программный поток для выполнения, при этом оно решает, учитывать
или не учитывать процесс, которому принадлежит программный поток. Каждому
потоку выделяется квант времени, и, если он не успевает завершиться к оконча-
окончанию кванта, выполнение потока приостанавливается. Если квант процесса равен
50 мс, а квант программного потока — 5 мс, то в случайно взятые 30 мс процес-
процессорного времени возможна следующая последовательность исполнения про-
программных потоков: А1, В1, А2, В2, ВЗ. В аналогичных условиях такая ситуация
исключена с программными потоками уровня пользователя. Иллюстрация пла-
планирования программных потоков уровня ядра приведена на рис. 2.13, б.
Основное отличие между программными потоками уровней пользователя и ядра
заключается в производительности. Для переключения между пользовательски-
пользовательскими программными потоками требуется всего несколько машинных команд, в то
время как на уровне ядра осуществляется полное переключение контекста, вклю-
включая смену карты памяти и очистку кэша. Это отнимает на несколько порядков
больше времени. С другой стороны, блокирование программного потока по вводу-
выводу на уровне ядра не останавливает весь процесс, как это происходит на
уровне пользователя.
Поскольку ядро знает о том, что переключение между потоком процесса А и по-
потоком процесса В является более затратным, чем запуск следующего программ-
программного потока процесса А (из-за изменения карты памяти и потери актуальности
кэша), эту информацию можно использовать при принятии решения. К примеру,
при прочих равных условиях планировщик может отдать предпочтение про-
программному потоку, принадлежащему тому же процессу, что и только что забло-
заблокированный поток, а не потоку, принадлежащему другому процессу.
Еще один важный фактор заключается в том, что программные потоки уровня
пользователя могут использовать планировщик потоков, предоставляемый прило-
приложением. К примеру, веб-сервер имеет специальный программный поток диспет-
диспетчеризации, принимающий и распределяющий входящие запросы рабочим про-
программным потокам. Если рабочий поток оказывается заблокированным, какой
поток должен выполняться следующим? Приложение, знающее назначение всех
программных потоков, безусловно, выберет диспетчера, который получит возмож-
возможность запустить еще один рабочий поток. Подобная стратегия максимизирует
степень параллелизма в среде, где рабочие программные потоки часто блокиру-
блокируются дисковым вводом-выводом. Ядро же никогда не узнает, для чего использует-
используется тот или иной поток, хотя существует возможность присвоения программным
потокам различных приоритетов. В целом, внутренние планировщики заданий
управляют работой приложения более эффективно, чем ядро.
2.5. Процессы в MINIX 3
Сейчас, завершив изучение принципов управления процессами, взаимодействия
между ними и алгоритмы планирования, мы можем приступить непосредствен-
непосредственно к их реализации в MINIX 3. В отличие от UNIX, где ядро представляет собой
монолитную программу, не разбитую на модули, ядро MINIX само является на-
набором процессов, взаимодействующих с пользователем и между собой при помо-
помощи единственного примитива — механизма передачи сообщений. Такой подход
дает более гибкую и модульную структуру, позволяя, например, легко заменить
всю файловую систему, не прибегая к перекомпиляции ядра.
2.5.1. Внутренняя структура системы MINIX 3
Начнем наше изучение MINIX с общего обзора системы. Структурно система
разбита на четыре уровня, каждый из которых выполняет строго определенные
функции. Эти уровни показаны на рис. 2.14.
Рис. 2.14. Четыре уровня структуры MINIX 3. Только процессы нижнего уровня могут
использовать привилегированные команды (команды режима ядра)
Ядро, находящееся на нижнем уровне, осуществляет обработку и управление со-
состояниями готовности, выполнения и блокировки (см. рис. 2.2). Кроме того, яд-
ядро обрабатывает все сообщения, передаваемые между процессами, — проверяет
допустимость адресата, обнаруживает в физической памяти буферы приема и пе-
передачи и копирует байты от отправителя к получателю. Частью ядра является
механизм доступа к портам ввода-вывода и прерываниям, в современных про-
процессорах требующий использования привилегированных команд режима ядра,
которые недоступны обычным процессам.
Помимо ядра, нижний уровень содержит два модуля, функционирующих по-
подобно драйверам устройств. Таймерное задание представляет собой драйвер вво-
ввода-вывода в том смысле, что оно взаимодействует с аппаратным обеспечением,
генерирующим тактовые сигналы. Тем не менее, в отличие от драйвера диска
или линии связи, оно недоступно пользователю, поскольку имеет интерфейс
только с ядром.
Одной из главных функций уровня 1 является предоставление вышестоящим
драйверам и серверам набора вызовов ядра. С помощью этих вызовов осуществ-
осуществляется чтение и запись портов ввода-вывода, копирование данных между адрес-
адресными пространствами и т. д. Реализация вызовов ядра возложена на системное
задание. Хотя системное и таймерное задания находятся в адресном пространстве
ядра, их планирование осуществляется раздельно, а сами процессы имеют собст-
собственные стеки вызовов.
Большая часть ядра и все задания ядра и системы написаны на языке С. Однако
в некоторых небольших фрагментах ядра используется ассемблер — в тех, кото-
которые отвечают за обработку прерываний, низкоуровневые механизмы управления
переключением контекста между процессами (сохранение и восстановление ре-
регистров и т. п.) и устройствами управления памятью. В общем, ассемблер приме-
применялся там, где ядру было необходимо непосредственное низкоуровневое взаимо-
взаимодействие с аппаратным обеспечением, недоступное для языка С. При переносе
MINIX 3 на новую архитектуру ассемблерный код должен быть соответствую-
соответствующим образом переписан.
Три уровня, находящихся над ядром, могут рассматриваться как один, поскольку
ядро, в сущности, взаимодействует с ними одинаково. Уровни ограничены коман-
командами пользовательского режима, а ядро планирует запуск каждого из них. Уров-
Уровни не имеют прямого доступа к портам ввода-вывода и, более того, ни один из
них не способен обращаться к памяти за пределами выделенного ему сегмента.
Тем не менее привилегии процессов (к примеру, возможность вызывать ядро)
могут различаться. На этом и построено разделение по уровням 2, 3 и 4. Процессы
уровня 2 имеют самые широкие привилегии, процессы уровня 3 — более ограни-
ограниченные, и, наконец, процессы уровня 4 совсем лишены привилегий. К примеру,
драйверы устройств, находящиеся на уровне 2, могут без ограничений требо-
требовать, чтобы системное задание выполнило чтение или запись данных в порты
ввода-вывода. Драйвер необходим каждому типу устройств — дискам, принте-
принтерам, терминалам, сетевым интерфейсам и др. Драйверы устройств могут выпол-
выполнять и другие вызовы ядра, например копирование считанных данных в адрес-
адресное пространство другого процесса.
Третий уровень включает серверы — процессы, предоставляющие полезные услу-
услуги пользовательским процессам. Два сервера являются обязательными. Менеджер
процессов (Process Manager, PM) выполняет все системные вызовы MINIX 3,
связанные с запуском и остановкой процессов (например, fork, exec и exit),
а также сигналами (например, alarm и kill, то есть вызовами, способными из-
изменить состояние процесса). Кроме того, менеджер процессов ответственен за
управление памятью, в частности, с помощью системного вызова brk. Файловая
система (File System, FS) выполняет все файловые системные запросы, такие
как read, mount и chdir.
Важно понимать различие между вызовами ядра и системными POSIX-вызова-
ми. Вызовы ядра представляют собой низкоуровневые функции, предоставляе-
предоставляемые системным заданием драйверам и серверам для выполнения необходимых
действий. Типичный вызов ядра — чтение данных из аппаратного порта ввода-
вывода. Системные POSIX-вызовы, такие как read, fork и unlink, напротив,
являются высокоуровневыми и доступны программам, расположенным на уров-
уровне 4. Пользовательские программы выполняют большое количество систем-
системных вызовов, однако не выполняют вызовов ядра. Конечно, если разрешить себе
«жонглирование» терминами, вызов ядра можно было бы назвать системным
вызовом. Механизмы выполнения обоих типов вызовов схожи, и вызовы ядра
допустимо рассматривать как особый частный случай системных вызовов.
В дополнение к менеджеру процессов и файловой системе, уровень 3 включает
и другие серверы, выполняющие функции, специфичные для MINIX 3. Можно
с уверенностью утверждать, что функциональность менеджера процессов и фай-
файловой системы поддерживается в любой операционной системе. Информацион-
Информационный сервер (Information Server, IS) предоставляет отладочную и статусную ин-
информацию о других драйверах и серверах. Подобная возможность необходима
скорее в экспериментальной системе, подобной MINIX 3, нежели в коммерче-
коммерческой операционной системе, которую пользователи изменять не могут. Сервер
реинкарнации (Reincarnation Server, RS) стартует одновременно с ядром; его на-
назначение — запускать и при необходимости перезапускать драйверы устройств,
отсутствующие в памяти. В частности, при сбое драйвера в процессе работы сер-
сервер реинкарнации обнаруживает неполадку, завершает работу драйвера, если она
не была завершена, и запускает его новую копию, обеспечивая высокую степень
отказоустойчивости системы. Аналогичная возможность в большинстве опера-
операционных систем не поддерживается. В сетевой системе на уровне 3 имеется не-
необязательный сетевой сервер (network server). Серверы не могут осуществлять
ввод-вывод напрямую — вместо этого они обращаются с запросами ввода-выво-
ввода-вывода к драйверам. Серверы также способны взаимодействовать с ядром при по-
посредничестве системного задания.
Как было отмечено в начале главы 1, операционные системы решают две основ-
основные задачи: управляют ресурсами и реализуют при помощи системных вызовов
интерфейс расширенной машины. В MINIX 3 распределением ресурсов в основ-
основном занимаются драйверы уровня 2, а ядро помогает им в доступе к портам вво-
ввода-вывода и работе с прерываниями. Интерпретация системных вызовов осуще-
осуществляется менеджером процессов и серверами файловой системы на уровне 3.
Файловая система была тщательно разработана в виде сервера и ее легко с не-
небольшими изменениями переместить на удаленный компьютер.
Для того чтобы включить в систему дополнительные серверы, ее не требуется
перекомпилировать. Серверы могут быть установлены в любое время — как при
запуске MINIX 3, так и позднее. Хотя драйверы устройств, как правило, запус-
запускаются при старте системы, их можно запустить и позже. Драйверы устройств
и серверы компилируются и хранятся на диске одинаково — как обычные испол-
исполняемые файлы. После запуска им назначаются необходимые привилегии. Поль-
Пользовательская программа, называемая службой, предоставляет интерфейс к серверу
реинкарнации, ответственному за это действие. Хотя драйверы и серверы явля-
являются независимыми процессами, они отличаются от пользовательских процес-
процессов тем, что в ходе работы системы они, как правило, никогда не завершаются.
Мы будем зачастую объединять драйверы и серверы уровней 2 и 3 под общим
названием системных процессов. Безусловно, системные процессы являются частью
операционной системы. Они не принадлежат никакому пользователю, и многие,
если не все, из них стартуют раньше, чем первый пользователь входит в систему.
Еще одно отличие между системными и пользовательскими процессами состоит
в том, что системные процессы имеют более высокий приоритет выполнения.
Обычно приоритет драйверов выше, чем процессов, однако такой режим работы
автоматически не поддерживается. Приоритет выполнения в MINIX 3 назнача-
назначается каждому процессу в отдельности. Это позволяет задать драйверу, обслужи-
обслуживающему медленное устройство, более низкий приоритет, чем серверу, реакция
которого должна быть быстрой.
Наконец, уровень 4 содержит все пользовательские процессы: оболочки, редак-
редакторы, компиляторы и творения самого пользователя. Пока пользователи входят
в систему, работают в ней и выходят из нее, многочисленные пользовательские
процессы запускаются и завершаются. Как правило, в системе выполняется так-
также несколько процессов, запускаемых сразу после ее загрузки и работающих все
время функционирования системы. Примером такого процесса является процесс
init; мы рассмотрим его в следующем разделе. Кроме того, вероятно присутст-
присутствие нескольких демонов. Демон представляет собой фоновый процесс, периоди-
периодически запускающийся или работающий в ожидании какого-либо события (на-
(например, прихода пакета по сети). В определенном смысле демон — это сервер,
запускаемый независимо и функционирующий как пользовательский процесс.
Однако в отличие от «настоящих» серверов, устанавливаемых при запуске, де-
демон допускает назначение себе более высокого приоритета, чем у обыкновенных
пользовательских процессов.
Следует уделить особое внимание терминам «задание» и «драйвер устройст-
устройства». В предыдущих версиях MINIX все драйверы устройств были объединены
с ядром, что давало им возможность доступа к структурам данных ядра и друг
друга. Кроме того, драйверы могли впрямую использовать порты ввода-вывода.
Они назывались заданиями, что позволяло не путать их с полностью независи-
независимыми пользовательскими процессами. В операционной системе MINIX 3 драй-
драйверы устройств реализованы исключительно в пользовательском пространстве.
Единственным исключением является таймерное задание, однако оно не является
типичным драйвером устройства, так как пользовательские процессы не имеют
к нему доступа через файл устройства. В данной книге мы старались применять
термин «задание» только к таймерному и системному заданиям, которые встрое-
встроены в ядро. В остальных случаях мы по возможности тщательно вместо термина
«задание» использовали термин «драйвер устройства». Тем не менее имена
функций, переменных, а также комментарии в программном коде, возможно, не
были обновлены с той же скрупулезностью. Это означает следующее: встретив
в исходном коде MINIX 3 слово «task» (задание), воспринимайте его как «device
driver» (драйвер устройства).
2.5.2. Управление процессами в MINIX 3
В MINIX 3 процессы соответствуют описанной несколько ранее обобщенной мо-
модели процесса. Процессы могут запускать процессы-потомки, те, в свою очередь,
могут делать то же самое, образуя, таким образом, дерево процессов. По сути, все
пользовательские процессы в системе — листы одного дерева, в корне которого
находится процесс init (см. рис. 2.14). Разумеется, особый случай представля-
представляют серверы и драйверы, поскольку часть из них должна быть запущена раньше
любого пользовательского процесса, включая init.
Запуск MINIX 3
Каким же образом запускается операционная система? Этому вкратце посвяще-
посвящены несколько следующих страниц. О загрузке некоторых других операционных
систем вы можете узнать в [41].
В большинстве компьютеров, оснащенных дисковыми устройствами, имеется
иерархия загрузочных дисков. Как правило, если в дисководе обнаруживается
дискета, она используется в качестве загрузочного диска. Если дискеты нет, но
в устройство CD-ROM вставлен компакт-диск, система пытается загрузиться
с него. Если же ни дискета, ни компакт-диск не вставлены, в качестве загрузоч-
загрузочного выбирается первый жесткий диск. Порядок иерархии можно задать в BIOS
сразу после подачи питания на компьютер. Иногда поддерживается возможность
загрузки с других устройств, в основном сменных.
Аппаратное обеспечение считывает первый сектор первой дорожки загрузочного
диска в память и исполняет записанный на нем код. В случае дискеты этот сек-
сектор содержит программу начальной загрузки. Она очень мала — не более одного
сектора E12 байт). Программа начальной загрузки MINIX 3 загружает дру-
другую, большую программу boot, а та, в свою очередь, — операционную систему.
В случае загрузки с жесткого диска требуется дополнительный промежуточный
этап. Жесткие диски разбиваются на разделы, и первый сектор жесткого диска
содержит небольшую программу и таблицу разделов, вместе они называются глав-
главной загрузочной записью (Master Boot Record, MBR). Программная часть считы-
считывает таблицу разделов и выбирает активный раздел. В первом секторе активного
раздела расположена программа начальной загрузки, которая загружается, после
чего действует так же, как при загрузке с дискеты, запуская программу boot.
Устройства CD-ROM появились позже, чем дискеты и жесткие диски. При под-
поддержке загрузки с компакт-диска существует возможность копирования в память
более чем одного сектора. Компьютер, поддерживающий загрузку с CD-ROM,
может единовременно разместить в оперативной памяти блок данных большого
объема. Как правило, в этом случае с компакт-диска загружается точная копия
загрузочной дискеты, которая используется в качестве виртуального диска. Да-
Далее управление передается виртуальному диску и загрузка продолжается так,
как будто в качестве физического загрузочного устройства используется диске-
дискета. Устаревшие компьютеры, оснащенные устройством CD-ROM, но не поддер-
поддерживающие загрузку с компакт-диска, позволяют скопировать на дискету загру-
загрузочный образ, посредством которого можно запустить систему (разумеется, при
вставленном в устройство чтения компакт-диске).
В любом случае после запуска программа boot ищет на диске различные компо-
компоненты системы и размещает их по нужным адресам — создает загрузочный образ.
Ключевыми составляющими загрузочного образа являются ядро (включающее
таймерное и системное задания), менеджер процессов и файловая система. В за-
загрузочный образ должен входить как минимум один драйвер диска. Кроме того,
в загрузочном образе имеется ряд других программ — сервер реинкарнации, вир-
виртуальный диск, консоль, драйверы журналов и процесс init.
Следует особо подчеркнуть, что все части загрузочного образа являются отдель-
отдельными программами. После загрузки необходимых компонентов — ядра, ме-
менеджера процессов и файловой системы — можно отдельно загрузить множество
других частей. Исключение составляет сервер реинкарнации, который должен
являться частью загрузочного образа. После инициализации он назначает обыч-
обычным загруженным процессам приоритеты, делающие их системными. Сервер ре-
реинкарнации также перезапускает драйверы в случае аварии (именно этим объ-
объясняется его название). Как было отмечено ранее, загрузочный образ должен
содержать как минимум один дисковый драйвер. Если корневая файловая систе-
система подлежит копированию на виртуальный диск, также потребуется драйвер па-
памяти (в противном случае его можно загрузить позднее). Драйверы tty и log
являются на загрузочном образе необязательными. Они загружаются как можно
раньше потому, что на начальной стадии запуска системы желательно иметь воз-
возможность отображать сообщения на консоли и записывать информацию в жур-
журнал. Разумеется, процесс init тоже можно загрузить позднее, однако он управ-
управляет начальным конфигурированием системы, и включение его в загрузочный
образ упрощает работу.
Запуск системы — не простая операция. Программа boot вынуждена брать на
себя действия, выполняемые дисковым драйвером и файловой системой до того,
как эти компоненты будут готовы взять управление на себя. В следующем разделе
мы подробнее рассмотрим вопросы запуска MINIX 3, а сейчас достаточно сказать,
что как только процесс загрузки завершается, ядро начинает работу.
В процессе инициализации ядро запускает сначала таймерное и системное за-
задания, затем — менеджер процессов и файловую систему. Менеджер процессов
и файловая система совместными усилиями запускают остальные серверы и драй-
драйверы, входящие в загрузочный образ. После запуска и инициализации все эти
компоненты блокируются и ожидают действий. Планировщик MINIX 3 назнача-
назначает процессам приоритеты. Первый пользовательский процесс, init, запускается
лишь после того, как все задания, драйверы и серверы, загруженные из образа,
оказываются в состоянии блокировки. Системные компоненты, загружаемые
из загрузочного образа или в ходе инициализации, перечислены в табл. 2.3.
Таблица 2.3. Некоторые важные системные компоненты MINIX 3 (помимо них могут
присутствовать и другие, например драйвер Ethernet или сетевой сервер)
Компонент Описание Источник загрузки
kernel Ядро плюс таймерное и системное задания Загрузочный образ
рт Менеджер процессов Загрузочный образ
fs Файловая система Загрузочный образ
rs (Пере)запуск серверов и драйверов Загрузочный образ
memory Драйвер виртуального диска Загрузочный образ
log Буферизация вывода в журнал Загрузочный образ
tty Драйвер консоли и клавиатуры Загрузочный образ
driver Драйвер (bios или дискеты) Загрузочный образ
продолжение-^
Таблица 2.3 {продолжение)
Компонент Описание Источник загрузки
init Предок всех пользовательских процессов Загрузочный образ
floppy Драйвер дискеты (если загрузка идет с жесткого диска) /etc/rc
is Информационный сервер (для отладочных данных) /etc/rc
cmos Чтение CMOS-часов для установки времени /etc/rc
random Генератор случайных чисел /etc/rc
printer Драйвер принтера /etc/rc
Инициализация дерева процессов
Процесс init является первым пользовательским процессом и одновременно по-
последним процессом, загружаемым как часть загрузочного образа. Глядя на рис. 1.5,
можно подумать, что рост дерева процессов начинается с процесса init, однако
это не совсем так. Такое утверждение было бы верным в традиционной операци-
операционной системе, однако MINIX 3 работает несколько иначе. Во-первых, несколько
системных процессов запускаются раньше, чем init. Задания CLOCK (таймер-
ное задание) и SYSTEM (системное задание) — уникальные процессы, невидимые
за пределами ядра. У них нет идентификаторов, и они не входят в дерево процес-
процессов. Первым процессом, выполняемым в пользовательском пространстве, явля-
является менеджер процессов. Он имеет нулевой идентификатор процесса и не явля-
является ни предком, ни потомком по отношению к каким-либо другим процессам.
Предком всех прочих процессов, запущенных из загрузочного образа (например,
драйверов и серверов), является сервер реинкарнации. Смысл такой структуры
заключается в том, что сервер реинкарнации должен получать уведомления при
необходимости перезапуска этих компонентов.
Как мы увидим далее, даже после запуска процесса init различия между по-
построением дерева процессов в MINIX 3 и традиционных операционных системах
остаются. В UNIX-подобных системах процессу init присваивается идентифи-
идентификатор 1, и хотя в MINIX 3 процесс init запускается не первым, для него тоже
зарезервирован традиционный идентификатор 1. Как и все пользовательские про-
процессы загрузочного образа (за исключением менеджера процессов), init являет-
является одним из потомков сервера реинкарнации. Первое, что делает процесс init, —
запускает сценарий оболочки /etc/rc (это же характерно и для стандартных
UNIX-подобных систем). Этот сценарий, в свою очередь, запускает дополни-
дополнительные драйверы и серверы, не являющиеся частью загрузочного образа. Любая
программа, запущенная сценарием г с, является дочерней по отношению к init.
Одной из первых запускается утилита service. Она тоже является потомком
init, однако здесь снова начинаются отступления от традиционной схемы.
Утилита service предоставляет пользовательский интерфейс для сервера ре-
реинкарнации. Сервер реинкарнации запускает обычную программу и превращает
ее в системный процесс. В частности, он запускает такие программы, как floppy
(если она не использовалась ранее для загрузки системы), cmos (необходима
для чтения часов реального времени) His (информационный сервер, управляю-
управляющий отладочной информацией, генерируемой по нажатию функциональных кла-
виш F1, F2 и др. на клавиатуре консоли). Одна из задач сервера реинкарнации —
сделать все системные процессы, кроме менеджера процессов, своими потомками.
После запуска драйвера устройства cmos сценарий г с может инициализировать
часы реального времени. К этому моменту все необходимые файлы должны при-
присутствовать на корневом устройстве. Серверы и драйверы находятся в каталоге
/sbin, а остальные команды, нужные для запуска, — в каталоге /bin. По завер-
завершении начальных шагов запуска выполняется монтирование других файловых
систем, таких как /usr. Важной функцией сценария гс является проверка
наличия повреждений файловых систем, которые могли появиться в результате
последней аварии системы. Тест прост — если система завершает свою работу
корректно, посредством команды shutdown, в журнал истории загрузки /usr/
adm/wtmp добавляется запись. Команда shutdown -С проверяет, является ли
последняя запись wtmp записью завершения работы. Если нет, предполагается,
что система закончила работу аварийно, и для проверки всех файловых систем
запускается утилита f sck. Последняя функция сценария /etc/rc — запуск де-
демонов. Эта функция может выполняться при помощи вспомогательных сценари-
сценариев. Если вы изучите данные, выводимые командой ps axl, предназначенной для
вывода идентификаторов PID (Process IDentifier — идентификатор процесса)
и PPID (Parent Process IDentifier — идентификатор родительского процесса), вы
увидите, что демоны update и usyslogd обычно находятся среди первых по-
постоянных процессов, являющихся потомками init.
Наконец, init считывает файл /etc/ttytab, в котором перечислены все воз-
возможные терминальные устройства. Если какое-либо устройство может быть ис-
использовано как терминал для входа в систему (в стандартной поставке это толь-
только консоль и не более трех виртуальных консолей, хотя вы можете добавлять
последовательные линии и сетевые псевдотерминалы), то в файле /etc/ttytab
у него присутствует запись в поле getty. Для каждого такого терминала init
запускает дочерний процесс. Обычно каждый из этих дочерних процессов запус-
запускает программу /usr/bin/getty, которая выводит приглашение и ждет, ко-
когда пользователь введет свое имя. Если же для определенного терминала требу-
требуются какие-то специальные действия (например, телефонное подключение), то
в /etc/ttytab можно указать команду (например, /usr/bin/stty), кото-
которая будет выполнена перед запуском getty.
Когда пользователь вводит свое имя для входа в систему, запускается процесс
/bin/ login, которому в качестве аргумента передается имя пользователя. Про-
Процесс login определяет наличие пароля, при необходимости запрашивает и све-
сверяет его. После успешного входа процесс login запускает пользовательскую
оболочку. По умолчанию используется оболочка /bin/sh, однако в файле /etc/
passwd можно указать другую оболочку. Оболочка воспринимает и интерпрети-
интерпретирует вводимые пользователем команды, запуская для их исполнения новые про-
процессы. Таким образом, оболочки являются прямыми потомками процесса init,
пользовательские процессы являются его «внуками», а все процессы вместе об-
образуют единое дерево. Фактически, в дерево входят все процессы (пользователь-
(пользовательские и системные), кроме внутренних заданий ядра и менеджера процессов. Тем
не менее, в отличие от традиционных операционных систем семейства UNIX,
init не является корнем дерева процессов, а структура дерева не позволяет
определить порядок запуска процессов.
Для управления процессами в MINIX 3 предназначены два основных системных
вызова: fork и exec. Сделать вызов fork — это единственный способ создать
новый процесс. Вызов exec позволяет процессу запустить указанную програм-
программу. При запуске программы ей выделяется объем памяти, указанный в ее заго-
заголовке. Этот объем памяти удерживается за программой все время работы, хотя
распределение памяти между сегментом данных, сегментом стека и неиспользо-
неиспользованным пространством может меняться динамически.
Вся информация о процессах хранится в таблице процессов, поля которой поде-
поделены между ядром, менеджером памяти и файловой системой. Когда появляется
новый процесс (благодаря вызову fork) или же когда процесс завершается (по
системному вызову exit или по сигналу), то прежде всего свои поля в таблице
процессов обновляет менеджер процессов. Затем он посылает ядру и файловой
системе сообщения с указаниями поступить таким же образом.
2.5.3. Взаимодействие между
процессами в MINIX
Для отправки и приема сообщений предусмотрено три примитива. Им соответ-
соответствуют следующие библиотечные процедуры языка С:
♦ Отправление сообщения процессу dest:
send(dest, &message);
+ Получение сообщения от процесса source (или от любого процесса):
receive(source, &message);
+ Отправление сообщения и ожидание ответа от процесса:
send_rec(src_dst, &message);
У всех трех вызовов во втором аргументе передается локальный адрес данных
сообщения. Механизм передачи сообщений в ядре копирует эти данные из буфе-
буфера отправителя в буфер приемника. При использовании процедуры send_rec
ответ записывается поверх исходного сообщения. В принципе, механизм переда-
передачи сообщений в ядре можно было бы переделать так, чтобы обмениваться ими
через сеть и тем самым реализовать распределенную систему. Однако на практи-
практике все осложняется тем, что сообщения обычно содержат указатели на большие
структуры данных и в распределенной системе требуется как-то реализовать ме-
механизм копирования этих данных через сеть.
Процесс, задание или сервер может вести обмен сообщениями только с определен-
определенным кругом других процессов. Более детально этот вопрос рассматривается нами
позднее. Как правило, передача сообщений ведется сверху вниз (см. рис. 2.14).
Обмен сообщениями допустим между процессами, расположенными на одном
уровне либо на смежных уровнях. Пользовательские процессы не могут посы-
лать сообщения друг другу. Вместо этого пользовательские процессы уровня 4
передают сообщения серверам уровня 3, а те, в свою очередь, передают сообще-
сообщения драйверам уровня 2.
Когда процесс отправляет сообщение другому процессу, который в этот момент
его не ждет, отправитель блокируется до тех пор, пока адресат не выполнит вызов
receive. Другими словами, в MINIX 3 во избежание проблем с буферизацией
отправленных, но еще не принятых сообщений применяется метод рандеву. Дос-
Достоинства такого подхода — простота и отсутствие необходимости управления бу-
буферами (включая ситуацию переполнения буферов). Кроме того, все сообщения
в момент сборки имеют фиксированную длину, а следовательно, структурно ис-
исключается самый распространенный источник ошибок — переполнение буферов.
Причина ограничений на обмен сообщениями следующая. Предположим, что про-
процессу А разрешается сделать вызов send или sendrec непосредственно к про-
процессу В, а затем процессу В разрешается сделать вызов receive с процессом А,
указанным в качестве отправителя, но запрещается выполнять вызов send к про-
процессу А. Предположим, А пытается отправить В сообщение и блокируется; если В
тоже попытается отправить сообщение А и заблокируется, возникнет взаимная
блокировка. Ресурсом, необходимым каждому из процессов для завершения
операции, является не физический компонент, подобный порту ввода-вывода,
а вызов receive адресатом. Более подробно взаимная блокировка рассматрива-
рассматривается в главе 3.
Иногда необходимо действие, не вызывающее блокировку сообщений. Сущест-
Существует еще один важный примитив передачи сообщений, вызываемый библиотеч-
библиотечной процедурой языка С:
notify(dest);
Эта процедура используется в случае, когда одному процессу необходимо уведо-
уведомить другой о наступлении важного события. Процедура notify не является
блокирующей; то есть отправитель продолжает выполнение независимо от того,
ждет адресат или нет. Подобная схема уведомления позволяет исключить воз-
возможность взаимной блокировки процессов.
Передача уведомлений осуществляется через механизм сообщений, однако пере-
передаваемая информация весьма ограниченна. В общем случае сообщение содержит
только данные, идентифицирующие отправителя, и временную метку, устанав-
устанавливаемую ядром. Иногда этого оказывается достаточно. К примеру, клавиатура
вызывает процедуру notify при нажатии одной из функциональных клавиш
(F1-F12) либо комбинации функциональной клавиши с клавишей Shift. В опера-
операционной системе MINIX 3 функциональные клавиши используются для сброса
отладочной информации. Драйвер Ethernet — пример процесса, генерирующего
единственный вид отладочного дампа и не нуждающегося в ином взаимодейст-
взаимодействии с драйвером консоли. В такой ситуации уведомление, посылаемое драйве-
драйвером консоли драйверу Ethernet при нажатии клавиши, сбрасывающей отладоч-
отладочные данные, воспринимается однозначно. В других случаях само уведомление не
несет большого смысла, однако получивший его процесс может послать отправи-
отправителю сообщение, запрашивающее дополнительную информацию.
Уведомления упрощены не случайно. Поскольку вызов notify не приводит к бло-
блокировке, его можно посылать раньше, чем получатель завершит вызов receive.
Однако простота сообщения означает, что неполученное уведомление можно
с легкостью сохранить до следующего вызова receive адресатом. В такой ситуа-
ситуации буквально каждый бит является существенным. Уведомления предназначе-
предназначены для использования немногочисленными системными процессами. У каждого
системного процесса имеется битовая карта активных уведомлений, в которой
каждый бит соответствует определенному системному процессу. Поэтому, если
процесс А желает послать уведомление процессу В в то время, когда последний
не блокирован вызовом receive, механизм доставки сообщений устанавливает
в битовой карте активных уведомлений процесса В бит, соответствующий про-
процессу А. При вызове receive процессом В первым шагом является проверка би-
битовой карты. Проверка позволяет обнаружить наличие активных уведомлений
от нескольких источников сразу. Единственного бита достаточно, чтобы восста-
восстановить информационное содержимое уведомления — идентификационные дан-
данные отправителя и временную метку, устанавливаемую ядром при доставке. Как
правило, при помощи временных меток определяют истечение времени, поэтому
если метка указывает на более позднее время, чем время первой попытки от-
отправителя послать уведомление, это не приводит к негативным последствиям.
В механизме уведомлений имеется еще одно усовершенствование. В некоторых
случаях используется дополнительное поле сообщений-уведомлений. Если уведом-
уведомление информирует получателя о прерывании, в сообщение включается битовая
карта всех возможных источников прерываний, а если уведомление сгенерирова-
сгенерировано системным заданием, его частью является битовая карта всех активных сигна-
сигналов получателя. Возникает естественный вопрос: каким образом хранится допол-
дополнительная информация, если уведомление посылается процессу, не ожидающему
сообщений? Дело в том, что упомянутые битовые карты находятся в структурах
данных ядра и их не нужно копировать. Если получение уведомления отклады-
откладывается, уведомление превращается в один бит. Когда получатель делает вызов
receive, уведомление восстанавливается. При этом определяется его источник,
а по источнику можно обнаружить местонахождение дополнительной инфор-
информации сообщения. Зная источник уведомления, адресат определяет не только
наличие в нем дополнительной информации, но и способ ее интерпретации.
Взаимодействие между процессами поддерживается еще несколькими примити-
примитивами, о которых мы поговорим в следующем разделе, но они не столь важны, как
send, sendrec и notify.
2.5.4. Планирование процессов в MINIX 3
Мультипрограммную операционную систему движет система прерываний. Сде-
Сделав запрос на ввод данных, процесс блокируется, позволяя выполняться другим
процессам. Когда запрошенные данные становятся доступными, процесс преры-
прерывается диском, клавиатурой или другим оборудованием. Кроме того, прерывания
генерируются и таймером, это гарантирует, что процесс, не требующий ввода, не
будет работать слишком долго. Задача нижнего уровня MINIX 3 — скрыть пре-
прерывания, преобразовав их в сообщения. С точки зрения процессов, завершение
операции устройством ввода-вывода — это сообщение, передаваемое устройст-
устройством определенному процессу, пробуждающее его и приводящее его в состояние
готовности.
Прерывания также генерируются программно; в этом случае их иногда называют
исключениями. Описанные ранее операции send и receive транслируются сис-
системной библиотекой в команды программного прерывания, эффект от которого
ничем не отличается от аппаратного прерывания. Процесс, исполняющий про-
программное прерывание, немедленно блокируется, а ядро активизируется для об-
обработки прерывания. Пользовательские программы не обращаются к операциям
send и receive впрямую, однако каждый раз при использовании одного из
системных вызовов, перечисленных в табл. 1.1 (непосредственно или через биб-
библиотечную процедуру), происходит внутренний вызов sendrec и генерируется
программное прерывание.
Каждый раз, когда происходит прерывание процесса, независимо от источни-
источника прерывания (таймер или периферийное устройство), у системы появляется
возможность принять решение, какому процессу больше требуется процессор.
Конечно, это обязательно нужно делать и при завершении процесса, но в систе-
системах, подобных MINIX 3, переключения должны происходить чаще, чем заверше-
завершения процессов.
Планировщик MINIX использует многоуровневую систему очередей. Определе-
Определены шестнадцать очередей, хотя при повторной компиляции число очередей мож-
можно без труда увеличить или уменьшить. Самый низкий приоритет назначается
только процессу IDLE, который выполняется исключительно во время простоя.
По умолчанию пользовательские процессы запускаются с приоритетом на не-
несколько уровней выше наименьшего.
Как правило, серверы в очереди имеют более высокий приоритет, чем пользова-
пользовательские процессы, драйверы — более высокий приоритет, чем серверы, а тай-
мерное и системное задания — самый высокий приоритет. Обычно в отдельно
взятый момент времени используются не все 16 возможных очередей, а лишь не-
несколько. Процесс может быть перемещен из одной очереди в другую системой
или (с оговорками) пользователем при помощи команды nice. «Дополнитель-
«Дополнительные» уровни открывают возможности для экспериментов и по мере добавления
в систему новых драйверов позволяют изменить предлагаемые по умолчанию
параметры для оптимизации производительности. Например, если вы захотите
добавить сервер, передающий в сеть потоковые аудио- и видеоданные, вы сможе-
сможете назначить ему более высокий стартовый приоритет, чем у других серверов.
Вы также можете снизить приоритет текущего сервера или драйвера, чтобы обес-
обеспечить более высокую производительность нового сервера.
Помимо очередей с разными приоритетами, существует еще один механизм,
обеспечивающий одним процессам преимущество над другими. Квант, то есть
временной интервал, выделяемый процессу для работы, имеет разную длитель-
длительность для разных процессов. Квант пользовательских процессов относительно
короткий; драйверы и серверы же, как правило, выполняются до тех пор, пока не
входят в состояние блокировки. Квант применяется к драйверам и серверам для
того, чтобы избежать сбоев в работе системы (зависаний), однако он значи-
значительно длиннее, чем у пользовательских процессов. Если процесс исчерпал свой
квант, он считается готовым к работе и помещается в конец очереди. Если же
выясняется, что исчерпавший текущий квант процесс выполнялся и в предыду-
предыдущем кванте, это трактуется как признак «зацикливания», препятствующего ра-
работе процессов с более низким приоритетом. В этом случае процесс помещается
в конец более низкоприоритетной очереди. Если ситуация повторяется, приори-
приоритет процесса снова снижается тем же способом. В конечном счете система рано
или поздно выберет другой процесс для запуска.
Процесс, приоритет которого был снижен, может снова его повысить. Если про-
процесс расходует свои кванты времени, но не препятствует выполнению других про-
процессов, он помещается в очередь с более высоким приоритетом и может подобным
образом достичь наивысшего доступного ему уровня. Очевидно, что такой про-
процесс нуждается в процессорном времени, но не захватывает его в ущерб другим.
В рамках очереди планирование процессов осуществляется при помощи цикли-
циклического алгоритма с небольшим изменением. Если процесс не исчерпал свой
квант, но вышел из состояния готовности, это воспринимается как блокирование
по вводу-выводу. Когда процесс вновь готов к выполнению, он помещается в на-
начало очереди, но ему выделяется не целый квант, а лишь неиспользованная часть
кванта, в ходе которого он был заблокирован. Такой подход обеспечивает опера-
оперативность реакции пользовательских процессов на ввод-вывод. Процесс, исчер-
исчерпавший выделенный ему квант, помещается в конец очереди согласно классиче-
классическому циклическому алгоритму.
Поскольку задания, как правило, имеют наивысший приоритет, за ними следуют
драйверы, затем серверы и лишь затем пользовательские процессы, последние
выполняются только в случае, если все системные процессы бездействуют. Сис-
Системные же процессы ради обслуживания пользовательских процессов отложены
быть не могут.
Выбирая процесс для запуска, планировщик обращается к очереди с наивысшим
приоритетом. Если один или несколько ее процессов готовы, из их числа выби-
выбирается первый. В противном случае аналогично проверяется очередь с более
низким приоритетом и т. д. Поскольку драйверы отвечают на запросы серверов,
а серверы — на запросы пользовательских процессов, в какой-то момент все вы-
высокоприоритетные процессы заканчивают свою работу и переходят в состояние
ожидания, а пользовательские процессы получают возможность выполняться и
генерируют новые запросы. Если же система обнаружит, что ни один процесс не
готов, она выберет процесс IDLE, переводящий процессор в состояние низкого
энергопотребления до появления прерывания.
По каждому сигналу таймера проверяется, не истек ли квант текущего процесса.
Если квант истек, планировщик перемещает процесс в конец очереди (для этого
не требуется никаких действий, если очередь состоит из единственного процесса).
Затем выбирается следующий процесс. Предыдущий процесс может получить
второй квант времени подряд при двух условиях: очереди с более высокими при-
приоритетами отсутствуют, а в своей очереди он является единственным. В против-
противном случае процессорное время получает процесс, находящийся в начале первой
по приоритету непустой очереди. Важные драйверы и серверы получают настоль-
настолько длинный квант, что, как правило, не прерываются таймером. Тем не менее их
приоритет может быть временно снижен в случае неполадок, чтобы предотвра-
предотвратить полную остановку системы. Возможно, сбой важного драйвера не позволит
системе выполнять полезные действия, однако, как минимум, есть шанс завер-
завершить ее работу корректно, без потери данных, и даже собрать отладочную ин-
информацию для устранения неполадки.
2.6. Реализация процессов в MINIX 3
Мы уже почти добрались для изучения реального кода, но предварительно следует
сказать несколько слов о терминах, которые вы встретите в ходе изложения. Тер-
Термины «процедура» и «функция» означают то же самое, что «подпрограмма». Имена
переменных, процедур и файлов записываются моноширинным шрифтом (на-
(например: rw_f lag) и состоят только из строчных букв. Исключениями являются
три встроенных в ядро задания — они пишутся прописными буквами: CLOCK,
SYSTEM и IDLE. Системные вызовы пишутся строчными буквами, например, read.
Книга не попадает в печать в первый же день после того, как авторы ставят по-
последнюю точку, и книга, и программное обеспечение постоянно развиваются.
Поэтому между приведенными в книге листингами и версиями кода на компакт-
диске могут быть небольшие различия. Но обычно различия незначительны, не
более одной или двух строк. Приведенный исходный код упрощен: из него удале-
удалены не обсуждаемые в книге фрагменты. Полную версию вы найдете на компакт-
диске. Кроме того, текущая редакция, включая новые средства, дополнительное
программное обеспечение и документацию, представлена на веб-сайте операци-
операционной системы MINIX 3 (http://www.minix3.org).
2.6.1. Структура исходного кода MINIX 3
Как уже отмечалось, реализация операционной системы MINIX 3 предназначена
для персонального компьютера, совместимого с IBM PC, оснащенного с расши-
расширенным набором микросхем и 32-разрядными словами (например, 80386, 80486,
Pentium, Pentium Pro, II, III, 4, M и D). Мы объединим все перечисленные про-
процессоры под общим названием «32-разрядные процессоры Intel». Полный путь
к исходному коду С на стандартной платформе Intel выглядит так: /usr/src/
(символ / в конце означает, что путь указывает на каталог). Каталог исходных
кодов на других платформах может быть иным. В книге ссылки на файлы с ис-
исходным кодом MINIX 3 будут даваться относительно каталога src/. Важным
подкаталогом дерева исходных кодов является каталог src /include/, содер-
содержащий главные копии заголовочных С-файлов. Мы будем называть этот каталог
include/.
Каждый каталог дерева исходных кодов содержит файл с именем Makefile,
управляющий выполнением стандартной UNIX-утилиты make. Файл Makefile
задает режим компиляции файлов, находящихся в одном каталоге с ним, а также
способен управлять компиляцией в одном или нескольких подкаталогах. Меха-
Механизм функционирования утилиты make отличается сложностью, и его полное
описание выходит за рамки темы этой книги. Тем не менее, в общем, функциони-
функционирование сводится к эффективной компиляции программ, исходный код которых
находится в нескольких файлах. Утилита make гарантирует, что все необходимые
файлы участвуют в компиляции. Она проверяет актуальность скомпилированных
ранее модулей и при необходимости перекомпилирует те, чьи исходные файлы
были изменены с момента последней компиляции. Модули, оставшиеся неизмен-
неизменными, не перекомпилируются, что дает экономию времени. Наконец, утилита make
преобразует несколько независимо скомпилированных модулей в исполняемую
программу, а также может принимать участие в установке готовой программы.
При желании местоположение дерева src/ можно изменить, поскольку в фай-
файлах Makefile всех каталогов пути к файлам исходного С-кода являются отно-
относительными. К примеру, вы можете поместить исходные коды в корневую фай-
файловую систему, /src/ — это ускорит компиляцию, если корневым устройством
является виртуальный диск. Если вы разрабатываете собственную версию опе-
операционной системы, можете сделать копию каталога src/ с другим именем.
Особый случай представляет путь к заголовочным С-файлам. В процессе компиля-
компиляции подразумевается, что исходные файлы находятся в каталоге /usr/include
(либо в соответствующем каталоге платформы, отличной от Intel). Тем не менее
файл Makefile из каталога src/tools/, используемый для перекомпиляции
системы, ориентирован на то, что главная копия заголовочных файлов размеще-
размещена в каталоге /usr/src/include (в системе Intel). Тем не менее перед пере-
перекомпиляцией системы дерево /usr/include/ стирается и туда копируется содер-
содержимое /usr/src/include. Это делается для того, чтобы получить возможность
хранить все файлы, необходимые для разработки MINIX 3, в одном месте. Кроме
того, так проще поддерживать несколько копий дерева исходных и заголовочных
кодов во время экспериментов с различными конфигурациями операционной
системы. Тем не менее, если вы захотите отредактировать заголовочный файл
при таком эксперименте, вы должны использовать его копию в каталоге src/
include, а не в каталоге /usr/include/.
Для новичков в языке С самое время познакомиться с особенностями заключе-
заключения имен файлов в кавычки при использовании команды #include. Каждый
компилятор С имеет каталог заголовочных файлов, предлагаемый по умолча-
умолчанию, в котором он ищет файлы, указанные в команде #include. Зачастую этим
каталогом является /usr/include/. Когда имя включаемого файла заключено
между символами операций сравнения (<. . . >), компилятор ищет файл в ката-
каталоге заголовочных файлов, предлагаемом по умолчанию, либо в указанном под-
подкаталоге. К примеру:
#include <имя файла>
Эта команда включает файл из каталога /usr/include/.
Многие программы также требуют в локальных заголовочных файлах определе-
определений, не действующих в масштабе всей системы. Имена таких заголовочных файлов
могут совпадать с именами стандартных файлов, а первые файлы — заменять со-
собой вторые. Если имя заключено в обычные кавычки ("..."), поиск файла сна-
сначала выполняется в каталоге, где находится файл исходного кода (или в указан-
указанном подкаталоге), и лишь затем при его отсутствии — в каталоге, предлагаемом
по умолчанию. Например, следующая команда считывает локальный файл:
#include "имя файла"
Каталог include/ содержит набор заголовочных файлов в стандарте POSIX,
а также три подкаталога:
+ sys/ — дополнительные заголовочные POSIX-файлы;
+ minix/ — заголовочные файлы операционной системы MINIX 3;
+ ibm/ — заголовочные файлы с определениями, специфичными для IBM PC.
Для поддержки MINIX-расширений и программ, работающих в среде MINIX 3,
в каталог include/ включены и другие подкаталоги и файлы; это касается как
компакт-диска, так и веб-сайта MINIX 3. Например, для поддержки сетевых рас-
расширений предусмотрены каталоги include/arpa/, include/net и подката-
подкаталог include/net/gen/.
Помимо подкаталога src/include/, каталог src/ содержит три других важ-
важных подкаталога с исходным кодом операционной системы:
+ kernel/ — уровень 1 (планирование, сообщения, часы и системные задачи);
+ drivers/ — уровень 2 (драйверы диска, консоли, принтера и других уст-
устройств);
+ servers/ — уровень 3 (менеджер процессов, файловая система, другие сер-
серверы).
Кроме того, есть еще три каталога, содержимое которых в книге не рассматрива-
рассматривается, но которые нужны для получения работоспособной среды:
+ src /lib/ — исходные коды библиотечных процедур (например, open, read);
+ src/tools/ — файлы Makefile и сценарии сборки системы MINIX 3;
+ src /boot/ — коды загрузки и установки MINIX 3.
В стандартной комплектации MINIX 3 вы найдете еще множество исходных
файлов, не упомянутых в книге. Помимо исходных кодов менеджера процессов
и файловой системы, каталог src /servers/ включает код программы init
и сервера реинкарнации, rs. Оба эти компонента обеспечивают работоспособ-
работоспособность операционной системы. Исходный код сетевого сервера находится в ка-
каталоге src/ servers /inet/. Каталог src/drivers/ содержит исходный код
драйверов устройств, не рассматриваемых в книге, в частности альтернативные
дисковые драйверы, драйверы звуковой платы и сетевых адаптеров. Поскольку
MINIX 3 — экспериментальная операционная система, предназначенная для мо-
модификации, в нее включен каталог src /test/ с программами, обеспечиваю-
обеспечивающими тщательное тестирование скомпилированной системы. Безусловно, любая
операционная система существует для поддержки команд (программ), работаю-
работающих под ее управлением, поэтому в MINIX 3 включен объемный каталог src/
commands/ с исходными кодами утилит, таких как cat, cp, date, Is, pwd —
всего более 200 команд. В нем же вы найдете нескольких важных приложений
с открытым кодом, разработанных в рамках проектов GNU и BSD.
В «книжной» версии MINIX 3 опущены многие необязательные компоненты
операционной системы. Поверьте, включить все в одну книгу для нас так же не-
невозможно, как для вас — изучить ее за один семестр. При компиляции «книж-
«книжной» версии из файлов Makefile были удалены ссылки на все ненужные файлы.
В стандартном файле Makefile необходимо указывать дополнительные компо-
компоненты, даже если они не участвуют в компиляции, однако удаление неиспользуе-
неиспользуемых файлов и условных операторов упрощает чтение кода.
Для удобства мы упоминаем только имена файлов в случаях, когда путь к ним
очевиден из контекста. Тем не менее имейте в виду, что в различных каталогах
имеются файлы с совпадающими именами, например const.h. Файл src/
kernel/const .h определяет константы, используемые ядром, файл src/
servers/pm/const. h — константы менеджера процессов и т. д.
Файлы, расположенные в одном каталоге, рассматриваются совместно, поэтому
наличие повторяющихся имен в разных каталогах не вызовет путаницы. На со-
сопровождающем книгу компакт-диске файлы представлены в порядке их обсу-
обсуждения в книге, что позволяет сделать чтение упорядоченным. Имеет смысл
обзавестись парой закладок, чтобы с легкостью чередовать изучение текста и лис-
листингов.
Приложение Б содержит упорядоченный по алфавиту список всех файлов, пред-
представленных на компакт-диске. Список разбит на разделы, соответствующие заго-
заголовочным файлам, драйверам, ядру, файловой системе и менеджеру процессов.
Индексы в этом приложении, на веб-сайте и компакт-диске ссылаются на пере-
перечисленные объекты по номеру строки в исходном коде.
Код уровня 1 системы находится в каталоге src /kernel/. Файлы этого катало-
каталога обеспечивают управление процессами — нижнего уровня структуры опера-
операционной системы MINIX 3, как было показано на рис. 2.14. Этот уровень вклю-
включает функции, обслуживающие инициализацию системы, прерывания, передачу
сообщений и планирование процессов. Два тесно связанных между собой моду-
модуля компилируются в один двоичный код, однако выполняются как отдельные
процессы. Эти два модуля — системное задание, предоставляющее интерфейс
между службами ядра и процессами более высоких уровней, и таймерное за-
задание, поддерживающее тактовые сигналы для ядра. В главе 3 мы обратимся к фай-
файлам некоторых подкаталогов каталога src /drivers, предназначенных для под-
поддержки драйверов устройств — уровень 2 на рис. 2.14. Далее, в главе 4, наше
внимание будет сконцентрировано на файлах менеджера процессов, располо-
расположенных в каталоге src/servers/pm. Наконец, в главе 5 предметом рассмот-
рассмотрения станет файловая система, исходный код которой размещен в каталоге
src/servers/fs/.
2.6.2. Компиляция и запуск MINIX 3
Чтобы скомпилировать операционную систему MINIX 3, запустите команду
make в каталоге src/tools. Команда имеет ряд параметров, управляющих ре-
режимами установки. Эти параметры можно просмотреть, запустив команду make
без параметров. Простейшим методом установки является выполнение команды
make image.
При использовании команды make image последняя копия заголовочных фай-
файлов каталога src /include/ копируется в каталог usr/ include/. Затем ис-
исходные коды каталога src /kernel/ и некоторых подкаталогов src /servers/
и src /drivers/ компилируются в объектные файлы. Все объектные файлы
src /kernel/ компонуются в единственную исполняемую программу, kernel,
объектные файлы src/servers/pm — в программу pm, а объектные файлы
src/servers/fs/ — в программу fs. Дополнительные программы, являю-
являющиеся в табл. 2.3 частью загрузочного образа, также подвергаются компиляции
и компоновке в своих каталогах. В частности, программы rs и init создают-
создаются в подкаталогах src/drivers/, a memory, log и tty — в подкаталогах src/
drivers/. Компонент, упомянутый в табл. 2.3 как «драйвер», может быть од-
одним из нескольких дисковых драйверов. Мы будем считать, что операционная
система MINIX 3 сконфигурирована под загрузку с жесткого диска с использова-
использованием стандартного драйвера at_wini, компилируемого в каталоге src/drivers/
at_wini/. Можно добавить и множество других драйверов, однако большинст-
большинство из них не обязательно включать в загрузочный образ. Это же касается и сете-
сетевой поддержки; компиляция базовой системы MINIX 3 не зависит от наличия
или отсутствия сети.
Для того чтобы готовая к работе система MINIX 3 могла загружаться, програм-
программа installboot (ее исходный код находится в каталоге src/boot/) именует
kernel, pm, f s, init и прочие ее компоненты, дополняет их так, чтобы размер
каждого компонента был кратен размеру сектора диска (для упрощения незави-
независимой загрузки программ), и объединяет их в единый файл. Это файл является
загрузочным образом; вы можете скопировать его в каталог /boot/ или под-
подкаталог /boot/image/ дискеты или раздела жесткого диска. Позже программа
монитора загрузки поместит загрузочный образ в память и передаст управление
операционной системе.
На рис. 2.15 показана структура памяти после того, как программы загрузочно-
загрузочного образа отделены друг от друга и загружены. Ядро располагается в нижней час-
части адресного пространства, в то время как все остальные компоненты — выше
1 Мбайт. Сначала пользовательским программам выделяется свободное место
над ядром. Когда очередную программу не удается разместить там, ее поме-
помещают выше, над программой init. Разумеется, детали зависят от конфигурации
системы. Например, на рис. 2.15 система MINIX 3 содержит кэш блоков, способ-
способный хранить 512 блоков размером по 4 Кбайт. Это весьма скромная конфигурация;
при достаточном объеме памяти размер кэша следует увеличить. В то же вре-
время, если размер кэша блоков сократить, всю систему можно разместить в памяти
ниже отметки 640 К, при этом в оставшуюся память можно загрузить несколько
пользовательских процессов.
Рис. 2.15. Структура памяти после загрузки MINIX 3 с диска. Ядро, серверы и драйверы
компилируются и компонуются независимо друг от друга. Названия соответствующих
программ перечислены слева. Размеры указаны приблизительно и не соответствуют
масштабам рисунка
Важно понимать, что MINIX 3 состоит из нескольких полностью независимых
друг от друга программ, взаимодействующих друг с другом посредством сообще-
сообщений. Процедура panic из каталога src/servers/f s/ не конфликтует с одно-
одноименной процедурой из каталога src/ servers /pm/, поскольку при компонов-
компоновке они помещаются в разные исполняемые файлы. Единственные процедуры,
совместно используемые тремя компонентами операционной системы, находят-
находятся в библиотеке src /lib/. Модульная структура позволяет с легкостью моди-
модифицировать, скажем, файловую систему, не затронув менеджер процессов. Более
того, не составляет труда полностью удалить файловую систему и поместить ее
на другой компьютер, играющий роль файлового сервера и взаимодействующий
с пользовательскими машинами, обмениваясь сообщениями по сети.
Еще один пример модульности MINIX 3 — абсолютное безразличие менеджера
процессов, файловой системы и ядра к поддержке или отсутствию поддержки
сети. Драйвер Ethernet и сервер inet могут быть активированы после загрузки
загрузочного образа. Они будут запущены сценарием /etc/гси размещены в об-
области памяти, доступной пользовательским программам. Система MINIX 3 с се-
сетевой поддержкой может быть задействована как удаленный терминал либо как
FTP- или веб-сервер. Изменение базовых компонентов MINIX 3 потребуется
лишь в одном случае — если вы захотите добавить возможность входа в систему
через сеть. В этом случае необходимо перекомпилировать драйвер консоли, tty,
предварительно сконфигурировав в нем псевдотерминалы.
2.6.3. Общие заголовочные файлы
В каталоге include/ и его подкаталогах содержится набор файлов с общими
константами, типами данных и макроопределениями. Большинство этих опреде-
определений обусловлены стандартом POSIX, который указывает, какое определение
в каком файле каталога include/ или его подкаталоге include/sys/ находит-
находится. Файлы, которые присутствуют в этих каталогах, называются заголовочны-
заголовочными, или включаемыми, и имеют расширение .h. Подключаются они директивой
#include языка С. Благодаря заголовочным файлам упрощается поддержка
большой системы.
Для компиляции пользовательских программ требуются по большей части заго-
заголовочные файлы из каталога include/, а файлы из каталога include/sys/
традиционно нужны для компиляции системных утилит. Но это — не слишком
важное ограничение, и в типичной программе, будь то пользовательская програм-
программа или часть системы, задействуются файлы из обоих каталогов. Здесь мы обсу-
обсудим файлы, необходимые для компиляции MINIX 3, сначала те из них, которые
находятся в каталоге include/, а затем — из каталога include/sys/. В следую-
следующем разделе мы рассмотрим файлы в каталогах include/minix/ и include/
ibm/, которые соответственно содержат код, специфичный для системы MINIX 3
и ее реализации на IBM-совместимых компьютерах.
Файлы в каталоге include/ в действительности предназначены для решения
общих задач, поэтому в большинство модулей с исходным кодом системы они не
включаются. Вместо этого они добавляются в другие заголовочные файлы, напри-
например в главный заголовочный файл src/kernel/kernel .h, файлы src/mm/mm.h
и src/fs/fs.h, подключаемые при каждой сборке системы. Главные заголо-
заголовочные файлы каждой из трех составных частей системы служат каждый для
своих целей, но начало у всех них одинаковое, оно приведено в листинге 2.12.
Главные заголовочные файлы еще будут обсуждаться в этой книге, цель данного
обзора — только подчеркнуть, что заголовочные файлы из различных каталогов
используются совместно. В этом и следующем разделах мы упомянем каждый из
перечисленных в листинге 2.12 файлов.
Листинг 2.12. Часть основного заголовка, подключающая все заголовочные файлы, нужные
в коде. Обратите внимание на два файла const.h, один из которых находится
в каталоге include/, второй — в локальном каталоге
#include <minix/config.h> /* Этот файл ДОЛЖЕН включаться первым */
#include <ansi.h> /* Этот файл ДОЛЖЕН включаться вторым */
#include <limits.h>
#include <errno.h>
#include <sys/types,h>
#include <minix/const,h>
#include <minix/type,h>
#include <minix.syslib.h>
#include "const.h"
Начнем с первого из файлов в каталоге include/ — ansi.h (строка 0000).
Это — второй заголовочный файл, обрабатываемый при компиляции любой из
частей MINIX 3 — лишь файл include/minix/сonf ig.h обрабатывается
раньше. Назначение ansi.h — удостовериться, что компилятор соответствует
требованиям стандарта языка С, который определяется Международной органи-
организацией по стандартизации. Этот стандарт иногда называется также ANSI С,
поскольку изначально, до международного признания, он разрабатывался Аме-
Американским национальным институтом стандартов (American National Standard
Institute, ANSI). Соответствующий стандарту компилятор должен определять
несколько макросов, пригодных к использованию в компилируемых программах.
Например, макрос STDC у «правильного» компилятора должен иметь зна-
значение 1, как если бы препроцессор С получил строку
#define STDC 1
Сейчас поставляемый с MINIX 3 компилятор удовлетворяет стандарту, но более
старые версии MINIX были разработаны до его принятия, поэтому MINIX 3 все
еще можно скомпилировать классическим компилятором С Кернигана и Ритчи.
MINIX создавалась как легко переносимая система, и возможность привлекать
старые компиляторы — важная составная часть задуманного. Следующая коман-
команда в строках 0023 и 0025 обрабатывается в том случае, если применяется стан-
стандартный компилятор:
#define _ANSI
В ansi.h определяются несколько макросов, причем способ зависит от того,
определен ли макрос _ANSI. Это пример макроса проверки поддерживаемых
функций.
Еще один определенный здесь макрос проверки поддерживаемых функций —
_POSIX_SOURCE (строка 0065). Его наличие требуется согласно стандарту
POSIX. Мы проверяем определение макроса _POSIX_SOURCE в случае, если оп-
определены другие макросы стандарта POSIX.
При компиляции программ на языке С типы данных аргументов функций и воз-
возвращаемых ими значений должны быть известны до генерации использующего
их кода. В сложной системе выдерживать такой порядок определения функций
затруднительно, поэтому в С можно указывать прототипы функций, позволяющие
объявлять типы аргументов и возвращаемых значений до определения функции.
Наиболее важным макросом в файле ansi .h является „PROTOTYPE. Он позво-
позволяет записывать прототип функции в таком виде:
_PROTOTYPE(тип-результата, имя-функции, (тип-аргумента аргумент, ...))
Если компилятор соответствует стандарту, препроцессор приводит эту запись
к следующему виду:
тип-результата имя-функции (тип-аргумента аргумент, ...)
Если же компилятор более старый, макрос транслируется так:
тип-результата имя-функции ()
Прежде чем переходить от ansi .h к другим файлам, обратим внимание еще на
один момент. Все содержимое файла (кроме начальных комментариев) обрамле-
обрамлено следующими строками:
#ifndef _ANSI_H
#endif /*_ANSI_H*/
Сразу после строки #ifndef _ANSI_H определяется сам макрос _ANSI_H. На-
Назначение этой конструкции состоит в том, чтобы убедиться, что заголовочный
файл будет включен только один раз. При повторном включении все его содер-
содержимое игнорируется. Подобная техника используется во всех файлах из катало-
каталога include/.
Здесь нужно пояснить два момента. Во-первых, во всех последовательностях
#ifndef . . . #def ine в главных заголовочных каталогах имена файлов предва-
предваряются подчеркиванием. В каталогах исходных С-кодов может присутствовать
другой заголовочный файл с тем же именем; к нему будет применен тот же ме-
механизм, однако без подчеркивания. Таким образом, включение файла из глав-
главного заголовочного каталога не воспрепятствует обработке одноименного за-
заголовочного файла цз локального каталога. Во-вторых, обратите внимание на
комментарий /*_ANSI_H*/ после #ifndef. Он не является обязательным, а все-
всего лишь помогает отслеживать вложенные конструкции #ifndef . . . #endif
и #ifdef. . . #endif. Тем не менее при написании комментариев следует со-
соблюдать осторожность: отсутствие комментариев лучше, чем ошибки в них.
Второй файл из include/, косвенно включаемый в большинство исходных
файлов MINIX 3, — это limits.h (строка 0100). В нем объявлены основные
размеры, относящиеся как к типам языка (разрядность целого числа), так и к опе-
операционной системе (максимальная длина имени файла).
Обратите внимание на то, что номера строк в исходных текстах на сопровождаю-
сопровождающем книгу компакт-диске начинаются с новой сотни с каждым новым фай-
файлом. Другими словами, не следует думать, что файл ansi . h содержит 100 строк,
с 00000 по 00099. По этой причине небольшие изменения, вносимые в один файл,
скорее всего (хотя и не гарантированно), не подействуют на последующие фай-
файлы. Кроме того, когда в листинге появляется новый файл, указывается особый
заголовок, включающий ряд символов +, имя файла и еще один ряд символов +
(без нумерации строк). Пример такого заголовка вы можете видеть между стро-
строками 00068 и 00100.
Большинство главных заголовочных файлов также включает файл errno.h
(строка 0200). Здесь содержатся коды ошибок, возвращаемые пользователю в гло-
глобальной переменной errno после системных вызовов. Эта переменная также
индицирует некоторые внутренние ошибки, например попытку переслать со-
сообщение несуществующему процессу. Внутри системы было бы неэффективно
проверять значение глобальной переменной после вызова функции, способного
привести к ошибке, однако функции зачастую возвращают другие целые чис-
числа, например количество байтов, переданных во время операции ввода-вывода.
В MINIX 3 коды ошибок отрицательны, благодаря чему система может распо-
распознать их. Перед тем как возвращенное функцией значение передается программе
пользователя, оно преобразуется в положительное. Такой эффект достигается за
счет того, что каждый код ошибки задается строкой вида (строка 0236):
#define EPERM (_SIGN 1)
При компиляции системных файлов в главных заголовочных файлах определя-
определяется макрос _SYSTEM, в результате чего _SIGN транслируется в «-», а при ком-
компиляции пользовательских программ _SYSTEM никогда не определяется, и _SIGN
просто игнорируется.
Следующая рассматриваемая группа файлов не включается в главные заголо-
заголовочные файлы, хотя и повсеместно используется в коде MINIX 3. Главный из
них — unistd. h (строка 0400). В нем перечислены константы, большая часть из
которых обязательна в стандарте POSIX. Кроме того, в нем описаны прототипы
многих функций, в том числе всех функций для доступа к системным вызовам
MINIX 3. Второй файл — string. h (строка 0600); он содержит прототипы мно-
многочисленных функций, работающих со строками. Файл signal .h (строка 0700)
задает стандартные имена сигналов. В нем же определено несколько специаль-
специальных сигналов для внутреннего использования операционной системы MINIX 3.
Поскольку функции операционной системы выполняются независимыми процес-
процессами, а не единым ядром, системным компонентам необходим особый способ взаи-
взаимодействия друг с другом, подобный обмену сигналами. В файле signal .h оп-
определены прототипы некоторых функций для работы с сигналами. Как мы позд-
позднее увидим, использование сигналов характерно для всех компонентов MINIX 3.
В файле f cntl .h (строка 0900) указываются различные параметры, используе-
используемые при управлении файлами. Например, благодаря задаваемым здесь констан-
константам для открытия файла в режиме чтения можно указывать макрос O_RDONLY
вместо того, чтобы напрямую передавать значение 0. Этот файл нужен в основ-
основном файловой системе, но он же применяется в нескольких местах внутри ядра
и менеджера памяти.
Как мы увидим при рассмотрении уровня драйверов устройств MINIX в главе 3,
консольный и терминальный интерфейсы операционной системы сложны, по-
поскольку большое количество различного оборудования должно взаимодейство-
взаимодействовать с операционной системой и пользовательскими программами стандартным
образом. Для управления устройствами ввода-вывода терминального типа исполь-
используются константы, макросы и функции, прототипы которых приведены в файле
termios .h (строка 1000). Самая главная структура здесь — структура termios.
В нее входят различные флаги, управляющие режимами работы, переменные
для задания скоростей ввода и вывода данных, а также массив специальных сим-
символов, таких как INTR и KILL. Эта структура, как и многие макросы и функции
в файле termios .h, регламентирована стандартом POSIX.
Тем не менее, каким бы всеобъемлющим ни был стандарт POSIX, он не может
включить в себя все, что может понадобиться. Поэтому вторая часть файла, на-
начиная со строки 1140, относится к расширениям POSIX. Некоторые из них
вполне очевидны, например определение стандартных скоростей передачи дан-
данных E7 600 бод и выше) и поддержка отображения окон терминалами. По-
Подобные расширения не запрещены POSIX, поскольку стандарт не может объять
необъятное. Но при разработке в MINIX 3 программ, которые рассчитаны на пе-
перенос в другое окружение, следует избегать специфичных для MINIX 3 опреде-
определений. Сделать это несложно. Если в файле имеются специфичные для MINIX
расширения, то их использование контролируется макрокомандой
#ifdef _MINIX
Если макрос _MINIX не определен, расширения игнорируются.
Поддержка «сторожевых» таймеров задается файлом timers.h (строка 1300),
включенным в главный заголовочный файл ядра. Этот файл определяет струк-
структуру struct timer и прототипы функций, работающих со списками таймеров.
В строке 1321 появляется определение типа tmr_func_t. Это — указатель на
функцию, применение которого продемонстрировано в строке 1332: в структуре
timer, используемой в качестве элемента списка таймеров, один элемент имеет
тип tmr_f unc_t и определяет функцию, вызываемую при истечении таймера.
Упомянем еще четыре файла, находящихся в каталоге include/. Файл stdlib.h
определяет типы, макросы и прототипы функций, как правило, необходимые для
компиляции С-программ, по сложности превосходящих самые примитивные.
Файл stdlib.h — один из наиболее часто применяемых заголовочных файлов
при компиляции пользовательских программ, хотя лишь немногие исходные
тексты ядра MINIX 3 ссылаются на него. Файл stdio.h знаком любому, кто
начинал осваивать язык С с написания известной программы «Hello, World!».
Его вряд ли можно встретить в системных файлах, хотя он используется почти
в каждой пользовательской программе. Файл а. out. h определяет формат фай-
файлов, в которых исполняемые программы хранятся на диске. В нем определе-
определена структура exec, информация которой используется менеджером процес-
процессов для загрузки нового образа программы при системном вызове exec. Файл
stddef .h задает несколько употребительных макросов.
Теперь переместимся в подкаталог include/sys/. Как видно из листинга 2.12,
все главные заголовочные файлы основных составных частей MINIX 3 включают
в себя файл sys/types .h (строка 1400) сразу после ansi .h. В types .h опреде-
определяются различные типы данных, встречающиеся в MINIX 3. Благодаря ему можно
избежать различных ошибок, связанных с неправильным использованием базо-
базовых типов. Размеры некоторых типов данных (в битах) для 16- и 32-разрядных
систем указаны в табл. 2.4. Кроме того, обратите внимание, что имена всех типов
данных заканчиваются символами «_t». Это — больше чем договоренность,
это — требование стандарта POSIX. Согласно последнему, суффикс «_t» явля-
является зарезервированным и не должен использоваться в идентификаторах, не яв-
являющихся именами типов.
Таблица 2.4. Размеры (в битах) некоторых типов данных на 16- и 32-разрядных системах
Тип 16-разрядная система MINIX 32-разрядная система MINIX
gid_t 8 8
dev_t 16 16
pid_t 16 32
ino_t 16 32
В настоящее время операционная система MINIX 3 полностью поддерживает
32-разрядные микропроцессоры, однако с течением времени 64-разрядные процес-
процессоры будут приобретать все большую значимость. При необходимости существу-
существует возможность создания типа данных, не поддерживаемого аппаратно. В строке
1471 определен тип u64_t в виде структуры struct {u32_t [2] }. В текущей
реализации он используется нечасто, однако иногда может быть полезен — к при-
примеру, все данные о дисках и разделах (смещения и размеры) хранятся в виде
64-разрядных чисел, что позволяет задействовать диски очень большого объема.
В MINIX 3 используются множество определений типов данных, которые, в конеч-
конечном счете, сводятся компилятором к относительно небольшому числу базовых
типов. Это делает код более удобочитаемым; например, переменная, объявлен-
объявленная с типом dev_t, содержит главный и вспомогательный номера, определяю-
определяющие устройство ввода-вывода. С точки зрения компилятора, ничего бы не изме-
изменилось, если бы вы указали тип short в качестве типа переменной. Отметим
еще одну особенность: многие типы объявлены «парами», где два имени разли-
различаются только регистром первой буквы, к примеру, dev_t и Dev_t. Все типы,
начинающиеся с прописной буквы, эквивалентны int. Они предназначены для
прототипов функций, которые должны использовать типы данных, совместимые
с int, с целью поддержки классических С-компиляторов. Более подробные объ-
объяснения вы найдете в комментариях файла types .h.
Внимания заслуживает еще один фрагмент условного кода (строки 1502-1516),
начинающийся с директивы
#if _EM_WSIZE ==2
Как было отмечено ранее, большая часть условного кода удалена из текста, однако
мы сохранили этот пример, чтобы продемонстрировать механизм использования
условных определений. Макрос _EM_WSIZE — еще один макрос проверки поддер-
поддерживаемых функций, определенный компилятором. Он задает размер слова дан-
данных целевой системы в байтах. Последовательность #if. . . #else. . .#endif
создает определения «раз и навсегда», чтобы обеспечить корректную компиля-
компиляцию кода независимо от разрядности системы — 16 или 32 бит.
В операционной системе MINIX 3 широко используются несколько других файлов
из каталога include/sys/. Файл sys/sigcontext .h (строка 1600) определяет
структуры для сохранения и восстановления нормального состояния системы до
и после исполнения процедуры обработки сигнала и используется ядром и ме-
менеджером процессов. Файл sys/stat .h (строка 1700) определяет структуру,
представленную в листинге 1.2 и возвращаемую системными вызовами stat
и f stat, прототипы функций stat и f stat, а также других функций, работаю-
работающих со свойствами файлов. Ссылки на файл sys / stat. h имеются в нескольких
местах файловой системы и менеджера процессов.
Остальные файлы, которые мы рассмотрим в этом разделе, используются не так
широко. Файлы sys/dir .h (строка 1800) определяют структуру записи катало-
каталога MINIX 3. Существует лишь одна прямая ссылка на данный файл, однако она
включает файл sys/dir .h в другой заголовочный файл, широко используемый
в файловой системе. Важным параметром, определяемым в sys/dir .h, являет-
является максимальная длина имени файла F0 символов). Файл sys /wait .h (строка
1900) содержит макросы, используемые системными вызовами wait и waitpid,
реализованными в диспетчере процессов.
Стоит упомянуть несколько файлов каталога include/sys/. Операционная
система MINIX 3 поддерживает трассировку исполняемых файлов и анализ
ключевых дампов в программе отладки. Файл sys /ptrace .h определяет различ-
различные операции, выполняемые по системному вызову ptrace. Файл sys/svrctl .h
включает структуры данных и макросы, используемые в svrctl — неком подо-
подобии системного вызова, предназначенным для координирования процессов сер-
серверного уровня в ходе запуска системы. Системный вызов select организует
ожидание ввода по нескольким каналам, например, для псевдотерминалов, ожи-
ожидающих сетевых подключений. Определения, необходимые вызову select, на-
находятся в файле sys /select .h.
Мы намеренно отложили обсуждение файла sys/ioctl.h и связанных с ним
файлов, поскольку их назначение невозможно полностью понять, не разобравшись
с файлом minix/ioctl .h. Системный вызов ioctl используется для управле-
управления устройствами. Число устройств, подключаемых к современным компьюте-
компьютерам, неуклонно растет, и каждое из них нуждается в управлении. В данной книге
мы описываем операционную систему MINIX 3 с относительно небольшим ко-
количеством устройств ввода-вывода. Многие из них, включая сетевые интер-
интерфейсы, SCSI-контроллеры и звуковые карты, могут быть добавлены в систему.
Для того чтобы облегчить управление, нужные объявления разбиты на группы
и размещены в отдельных небольших файлах. Все эти файлы включены в файл
sys/ioctl .h (строка 2000), действующий подобно главному заголовочному
файлу в листинге 2.12. На компакт-диске имеется лишь один из файлов, sys/
ioc_disk.h (строка 2100). Он, а также все прочие файлы, включенные в sys/
ioctl.h, расположены в каталоге include/sys/. Они являются частью «от-
«открытого интерфейса»; другими словами, программист может использовать их
для написания любой программы, предназначенной для работы в среде MINIX 3.
Тем не менее все указанные файлы зависят от дополнительных макроопределений
из файла minix/ioctl .h (строка 2200), являющегося для них заголовочным.
Сам файл minix/ioctl .h не следует использовать при программировании, имен-
именно поэтому он расположен в каталоге include/minix/, а не include/sys/.
Макросы, заданные в упомянутых файлах, определяют, каким образом различ-
различные элементы, необходимые всем допустимым функциям, представляются 32-раз-
32-разрядным целым числом, передаваемым системному вызову ioctl. К примеру,
дисковые устройства требуют 5 видов операций, как видно из строк 2110-2114
файла sys/ioc_disk.h. Символьный параметр 'd' указывает вызову ioctl,
что операция относится к дисковому устройству, число от 3 до 7 задает код опе-
операции, а третий параметр операции чтения или записи определяет размер струк-
структуры, в которую осуществляется передача данных. В файле minix/ioctl .h
строки 2225-2231 показывают, что 8 бит символьного кода сдвигаются на 8 бит
влево, 13 бит размера структуры (младших) сдвигаются на 16 бит влево, а затем
к полученным значениям применяется логическая операция И, где вторым опе-
операндом является код операции. В старших трех разрядах 32-разрядного числа за-
записан код, определяющий тип возвращаемого значения.
Хотя может показаться, что все описанное требует большого объема работы, эта
работа выполняется на этапе компиляции и создает более эффективный интер-
интерфейс с системным вызовом на этапе выполнения, поскольку фактически пере-
переданный параметр — наиболее естественный тип данных для процессора. Тем не
менее здесь вспоминается известный комментарий Кена Томпсона, помещенный
в исходный код одной из ранних версий UNIX:
/* предполагается, что вы это не поймете */
В строке 2241 файла minix/ioctl .h содержится прототип системного вызова
ioctl. Как правило, программисты не совершают этот вызов впрямую, посколь-
поскольку во многих POSIX-функциях с прототипами в файле include/termios .h
устаревшая библиотечная функция ioctl больше не используется для работы
с терминалами, консолями и другими подобными устройствами. Тем не менее
она по-прежнему нужна. Фактически, библиотека превращает POSIX-функции,
управляющие терминальными устройствами, в системные вызовы ioctl.
2.6.4. Заголовочные файлы MINIX 3
Файлы, специфичные для MINIX 3, расположены в каталогах include/minix/
и include/ibm/. Первый каталог содержит файлы, общие для реализаций
MINIX на всех платформах, хотя в некоторых из файлов есть альтернативные
определения, зависящие от платформы. Один из таких файлов, ioctl.h, был
рассмотрен нами в предыдущем подразделе. Второй каталог включает структуры
и макросы, специфичные для реализации MINIX 3 на платформе IBM.
Мы начнем изучение с каталога minix/. Ранее был упомянут файл conf ig.h
(строка 2300), включаемый во все главные заголовочные файлы основных ком-
компонентов системы и фактически являющийся первым файлом, обрабатываемым
компилятором. Во многих случаях, когда в системе меняется оборудование или
же нужно изменить способ работы MINIX 3, нужно лишь отредактировать этот
файл и перекомпилировать систему. Если вы редактируете файл, то, по всей
вероятности, вам следует также изменить комментарий к строке 2303, отразив
в нем суть нововведений.
Параметры, задаваемые пользователем, находятся в первой части файла, хотя
некоторые из них не предназначены для редактирования в нем. В строке 2326
происходит включение заголовочного файла minix/sys_conf ig.h и опреде-
определение нескольких унаследованых от него параметров. Программисты сочли это
целесообразным, поскольку некоторым системным файлам нужны лишь базовые
определения файла minix/ sys_conf ig. h, а остальные определения conf ig. h
являются излишними. В файле conf ig.h имеется множество имен файлов,
не начинающихся с символа подчеркивания и способных вызывать конфликты
с обычными именами, например именами CHIP или INTEL, которые вполне мо-
могут встретиться в программах, перенесенных в MINIX 3 из другой операционной
системы. Все имена в sys_config.h начинаются с подчеркивания, и вероят-
вероятность конфликтов значительно ниже.
Параметру MACHINE в файле sys_config.h задается значение _MACHINE_
1ВМ_РС. В строках 2330-2334 определены альтернативные значения для MACHINE.
Предыдущие версии MINIX переносились на платформы Sun, Atari и Macintosh,
а полный исходный код содержит варианты для альтернативного аппаратного
обеспечения. Большая часть исходного кода MINIX 3 не зависит от типа компь-
компьютера, однако операционная система всегда включает в себя зависимые от плат-
платформы фрагменты. Поскольку MINIX 3 — новая система, на момент написания
этой книги работа над ее переносом на платформы, отличные от Intel, еще не бы-
была завершена.
Другие определения файла conf ig.h позволяют настроить операционную сис-
систему под конкретные нужды. Например, количество буферов, хранимых в дис-
дисковом кэше файловой системы, следует задавать как можно большим, хотя это
и приводит к значительному потреблению памяти. В строке 2345 определено
кэширование 128 блоков — это число считается минимальным и приемлемо толь-
только в случае, если система располагает менее 16 Мбайт оперативной памяти. Если
объем оперативной памяти больше, число кэшируемых блоков можно значитель-
значительно увеличить. Если желательно использовать модем или входить в систему через
сетевое подключение, значения параметров NR_RS_LINES и NR_PTYS (строки
2379 и 2380) следует увеличить, а затем перекомпилировать систему. Заключи-
Заключительная часть файла conf ig.h содержит необходимые определения, изменять
которые, однако, не рекомендуется. Многие из них задают альтернативные име-
имена для констант, определенных в файле sys_conf ig.h.
Файл sys_config.h (строка 2500) включает определения констант, которые
могут понадобиться системному программисту, например, пишущему новый
драйвер устройства. Вам вряд ли понадобится изменять содержимое этого фай-
файла, за исключением параметра _NR_PROCS (строка 2522), задающего размер таб-
таблицы процессов. Если вы хотите использовать систему MINIX 3 в качестве сете-
сетевого сервера с большим числом удаленных пользователей или одновременно
выполняемых процессов, может возникнуть необходимость увеличить значение
этой константы.
Следующий файл, const .h (строка 2600), иллюстрирует еще один распростра-
распространенный вариант применения заголовочных файлов. В нем находится большое
количество определений используемых в нескольких местах одновременно кон-
констант, значения которых обычно не меняют при перекомпиляции ядра. Однократ-
Однократное определение констант в заголовочном файле позволяет избежать ошибок,
вызываемых противоречивыми определениями в различных фрагментах кода,
использующих эти константы. Дерево исходных кодов MINIX 3 содержит ряд
других файлов с именем const .h, однако они имеют более ограниченное при-
применение. Например, определения, требующиеся только в ядре, помещены в файл
src/kernel/const .h, определения файловой системы — в файл src/servers/
f s/const .h, менеджер процессов использует для локальных определений файл
src/servers/pm/const .h. Файл include/minix/const .h содержит толь-
только определения, применяемые как минимум двумя компонентами операционной
системы.
Несколько определений из файла const .h стоит рассмотреть подробнее. Макрос
EXTERN позволяет объявлять переменные как внешние (строка 2608). Глобаль-
Глобальные переменные, объявленные в заголовочных файлах и включаемые в два или
более файлов, объявляются с ключевым словом EXTERN, например:
EXTERN int who;
Можно попытаться объявить переменную без ключевого слова EXTERN:
int who;
Однако если бы переменная была объявлена таким образом и включена в не-
несколько файлов, некоторые редакторы связей указали бы на ошибку — много-
многократное определение переменной. Более того, справочное руководство по языку
С явно запрещает подобные конструкции [67].
Во избежание проблем необходимо, чтобы объявление было прочитано так:
extern int who;
Но есть одно исключение. Использование макроса EXTERN решает проблему, по-
поскольку макрос преобразуется в слово extern во всех файлах, включающих за-
заголовочный файл const .h и не переопределяющих EXTERN как пустую строку
после включения const .h. Последнее делается в каждой части MINIX 3 по-
посредством размещения глобальных определений в специальном файле glo .h
(к примеру, src/kernel/glo.h), который неявно включается при компиляции.
В любом файле glo .h присутствует фрагмент
#ifdef _TABLE
#undef EXTERN
#define EXTERN
#endif
А в каждом файле table. с имеется предшествующая #include директива
#define _TABLE
Таким образом, когда заголовочный файл включается при компиляции table. с,
ключевое слово extern перед объявлениями переменных не ставится (так как
в файле table. с макрос EXTERN определен как пустая строка), поэтому все гло-
глобальные переменные размещаются в одном месте, в объектном файле table.о.
Если вы новичок в программировании на С и не совсем понимаете, к чему при-
приводят описанные действия, не пугайтесь — эти детали в действительности не так
важны. Это всего лишь деликатное перефразирование приведенного ранее ком-
комментария Кена Томпсона. У некоторых компоновщиков многократное включе-
включение одного файла может вызвать проблему, так как приводит к многократному
объявлению одних и тех же переменных. Макрос EXTERN используется для того,
чтобы сделать систему более переносимой между различными платформами с по-
потенциально проблематичными компоновщиками.
Макрос PRIVATE определяется в качестве синонима для ключевого слова static.
Этот макрос всегда применяется для объявления процедур и данных, на которые
не будут ссылаться другие компоненты системы, чтобы имена этих объектов не
были видимы за пределами того файла, где они объявлены. Как правило, пере-
переменные и процедуры необходимо по возможности размещать в локальной облас-
области видимости. Макрос PUBLIC определен как пустая строка. Например:
PUBLIC void lock_dequeue(rp)
Это объявление преобразуется препроцессором в следующий код:
void lock_dequeue(rp)
В соответствии с синтаксическими правилами языка С этот фрагмент означает,
что функция с именем lock_dequeue экспортируется и может быть использо-
использована в других файлах, компонуемых в один двоичный код — в данном случае,
в любом месте ядра. Еще пример:
PRIVATE void dequeue(rp)
Это объявление функции в том же файле будет обработано препроцессором сле-
следующим образом:
static void dequeue(rp)
Такая функция может быть вызвана только кодом, расположенным в том же ис-
исходном файле. Использовать макросы PRIVATE и PUBLIC необязательно, это —
только попытка исправить проблемы, вносимые соглашениями С (где по умол-
умолчанию имена размещаются в глобальной области видимости, а должно быть
наоборот).
В оставшейся части файла const .h определяются константы, повсеместно ис-
используемые в системе. Так, например, везде и всюду в коде фигурирует величина
базового блока памяти, зависящая от архитектуры системы. Для платформ Intel
она равна 1024 байт. В строках 2673-2681 определены другие ее значения, соот-
соответствующие платформам Intel, Motorola 68000 и Sun SPARC. Кроме того, в этом
файле определяются удобные макросы МАХ и MIN. Например, для вычисления
большего из двух значений можно применить следующую запись:
z = МАХ(х, у);
Еще один файл, косвенно включаемый при каждой компиляции в главные заго-
заголовочные файлы, — это type. h (строка 2800). В нем содержится ряд описаний
ключевых типов и связанных с ними числовых констант.
Первые две структуры определяют два различных типа карт памяти (строки
2828-2840): одна из них соответствует локальным областям (внутри пространств
ва данных процесса), а другая — удаленным областям памяти (к примеру, вирту-
виртуальному диску). Здесь самое время рассказать о концепциях обращения к памя-
памяти. Как мы уже упомянули, размер базового блока памяти в MINIX 3 составляет
1024 байт. Существует две ссылки на память: ссылка phys_clicks использует-
используется ядром для доступа к любому элементу памяти системы, а ссылка vir_
clicks предназначена для всех процессов, отличных от ядра. Ссылка vir_
clicks всегда указывается относительно начала сегмента памяти, выделенной
определенному процессу, и ядру зачастую приходится осуществлять преобразо-
преобразования между виртуальными (относящимися к процессам) и физическими (отно-
(относящимися к оперативной памяти) адресами. Подобное неудобство компенсиру-
компенсируется тем, что процесс может самостоятельно выполнять внутренние обращения
к памяти, используя ссылку vir_c licks.
Вы могли бы предположить, что для задания размера памяти обоих типов доста-
достаточно одной ссылки. Тем не менее указание выделенной процессу памяти с по-
помощью ссылки vir_clicks имеет одно преимущество: vir_clicks гарантирует,
что ни одно обращение к памяти не выйдет за границы пространства, выделенного
процессу. Такая возможность присуща современным процессорам Intel, в част-
частности семейству Pentium, и называется защищенным режимом. Отсутствие за-
защищенного режима в ранних процессорах 8086 и 8088 вызывало проблемы при
разработке первых версий MINIX.
Еще одна важная структура, определенная в файле type.h, — sigmsg (строки
2866-2872). При перехвате сигнала ядро должно гарантировать, что процесс,
которому был послан сигнал, при следующем своем запуске начнет выполнять
процедуру обработки сигнала, а не продолжит работу в обычном порядке. Боль-
Большая часть работы по управлению сигналами выполняется менеджером процес-
процессов. В случае перехвата сигнала менеджер процессов передает ядру структуру,
подобную sigmsg.
Структура kinf о (строки 2875-2893) используется для распространения инфор-
информации о ядре среди других компонентов системы. Менеджер процессов задейст-
задействует эту информацию, формируя свою часть таблицы процессов.
Структуры данных и прототипы функций взаимодействия между процессами оп-
определены в заголовочном файле ipc .h (строка 3000). Наиболее важным опреде-
определением в этом файле является тип message (строки 3020-3032). Его можно бы-
было бы задать как массив определенного количества байтов, но для поддержания
хорошего стиля программирования он описан как структура, содержащая объ-
объединение различных типов сообщений. Всего имеется семь форматов сообще-
сообщений, с именами от mess_l до mess_8 (формат mess_6 больше не использует-
используется). В структуре message есть поле m_source, представляющее собой структуру
с информацией об отправителе сообщения, поле m_type, определяющее формат
сообщения (для системного задания — SYS_EXEC), и поля с данными сообщения.
Структуры семи типов сообщений показаны на рис. 2.16. Первые две и послед-
последние две структуры кажутся одинаковыми. С точки зрения размеров элементов
данных это действительно так, однако в типах данных имеется множество разли-
различий. Если на 32-разрядном процессоре Intel типы int, long и указатели на дан-
данные имеют одинаковую разрядность 32 бита, это отнюдь не означает, что на другой
аппаратной платформе картина будет той же. Семь различных форматов введены
именно для упрощения перекомпиляции MINIX 3 под различные архитектуры.
Рис. 2.16. Семь типов сообщений MINIX 3. Размеры элементов сообщений зависят
от архитектуры компьютера; здесь показаны размеры для процессоров
с 32-разрядными указателями, например семейства Pentium
Когда необходимо передать сообщение, содержащее, к примеру, три целочислен-
целочисленных значения и три указателя, задействуется первая структура. Подобным же
образом используются и другие форматы. Как же можно присвоить нужное зна-
значение первому целочисленному полю в первой структуре? Предположим, что сооб-
сообщение имеет имя х. Тогда объединение (union), содержащее параметры сообщения,
будет иметь имя х. m_u. Чтобы обратиться к первой структуре этого объедине-
объединения, подставляется имя x.m_u.m_ml. Наконец, чтобы обратиться к первому це-
целочисленному полю в этой структуре, следует применять запись: x.m_u.m_
ml .mlil. Она довольно длинная, поэтому после описания самого типа message
описываются несколько макроопределений, слегка укорачивающих запись. Так,
x.m_u.m_ml .mlil можно заменить на x.ml_il. Укороченные имена имеют
следующий формат: они начинаются с буквы «т», затем следует номер структу-
структуры, знак подчеркивания, один или два символа, обозначающие тип значения (це-
(целое число, указатель, длинное целое, символ, массив символов, функция), после
чего записывается число, позволяющее локализовать нужное поле в структуре.
При обсуждении форматов сообщений имеет смысл обратить внимание на то,
что операционная система и компилятор зачастую «понимают» такие вещи, как
размещение структур, что может упростить жизнь программисту. В MINIX 3 по-
поля с типом int зачастую используются для хранения беззнаковых целых значе-
значений. В некоторых случаях это чревато ошибками переполнения, но система на-
написана в расчете на то, что компилятор без потерь может присваивать значения
типа unsigned переменным типа int и наоборот без изменения данных и без
переполнения. При более строгом подходе нужно было бы заменить каждую такую
целочисленную переменную объединением, состоящим из полей int и unsigned.
То же самое относится и к полям типа long, которые иногда используются для
передачи данных типа unsigned long. Кто-то может сказать, что мы поступаем
неправильно, но если вы собираетесь перенести MINIX 3 на новую платформу,
то вам почти наверняка придется некоторое время поработать над точным фор-
форматом сообщений, теперь же вы предупреждены, что поведению компилятора
также нужно уделить немало внимания.
В файле ipc. h также определены прототипы ранее описанных примитивов пе-
передачи сообщений (строки 3095-3101). Наряду с основными примитивами send
receive, sendrec и notify, определен и ряд других. Последние применяются
редко и являются скорее пережитками ранних этапов разработки MINIX 3. Ста-
Старые компьютерные программы являются источником интересных «археологиче-
«археологических находок» и в последующих выпусках операционной системы вполне могут
«вымереть». Тем не менее без пояснений с нашей стороны некоторые читате-
читатели наверняка засомневаются. Неблокирующие вызовы nb_send и nb_receive
в основном заменены вызовом notify, появившимся позднее и лучше разре-
разрешавшим проблему передачи и проверки неблокирующих сообщений. Прототип
примитива echo не имеет полей источника и приемника. Вызов echo бессмыс-
бессмыслен в рабочем коде, однако полезен в процессе разработки, поскольку позволяет
определять время передачи и приема сообщений.
Один из файлов каталога include/minix, syslib.h (строка 3200) использу-
используется практически повсеместно и включен в главные заголовочные файлы всех
компонентов MINIX 3, относящихся к пользовательскому пространству. Для
доступа к самому себе ядру не нужны библиотечные функции, поэтому в заголо-
заголовочном файле ядра, src/kernel/kernel .h, ссылка на syslib.h отсутствует.
Файл syslib.h содержит прототипы библиотечных С-функций, вызываемых
из операционной системы для доступа к другим системным службам.
Мы не будем описывать детали, касающиеся библиотек С, однако многие биб-
библиотечные функции являются стандартными и доступны в любом компиляторе
языка. Тем не менее функции, на которые ссылается файл syslib.h, специ-
специфичны для MINIX 3, и перенос MINIX 3 в систему с другим компилятором потре-
потребует переноса указанных функций. К счастью, это не составляет труда, посколь-
поскольку большинство функций попросту извлекают параметры, указанные в вызове,
и вставляют их в структуру сообщения, а затем отсылают сообщение и извлека-
извлекают результаты из ответа. Многие из таких библиотечных функций укладывают-
укладываются в дюжину строк С-кода.
Отдельного внимания в файле syslib. h заслуживают четыре макроса досту-
доступа к портам ввода-вывода по чтению и записи с использованием байтов и слов,
а также прототип функции sys_sdevio, на которую ссылаются все макросы
(строки 3241-3250). Важнейшим механизмом, используемым в MINIX 3 и по-
позволяющим переместить все драйверы устройств в пользовательское простран-
пространство, является передача запросов на чтение и запись портов ввода-вывода от драй-
драйверов устройств к ядру.
Несколько функций, которые могли бы быть включены в файл syslib.h, вынесе-
вынесены в другой файл, sysut il. h (строка 3400), поскольку их объектный код компи-
компилируется в отдельную библиотеку. Две функции нуждаются в более тщательном
рассмотрении. Первая из них — print f (строка 3442). Если вы имеете опыт
программирования на С, вы знаете printf как стандартную библиотечную
функцию, которую можно встретить почти во всех программах.
Тем не менее здесь вы имеете дело не с тем, к чему, вероятно, привыкли. Версию
print f из стандартной библиотеки нельзя использовать внутри системных ком-
компонентов. Кроме того, стандартная функция printf предназначена для генера-
генерации стандартного вывода и должна «уметь» форматировать вещественные числа.
Наличие стандартного вывода требует взаимодействия с файловой системой,
однако в случаях неполадок проблемному компоненту желательно иметь воз-
возможность отображать сообщения без помощи каких-либо других компонентов.
Кроме того, поддержка всех спецификаций формата стандартной версии print f
сделает код громоздким без веских на то причин. Таким образом, в библиотеку
системных утилит включена упрощенная версия функции printf, выполняю-
выполняющая лишь действия, нужные операционной системе. Местоположение библиоте-
библиотеки системных утилит зависит от платформы; в 32-разрядных системах Intel она
находится в файле /usr/lib/i386/libsysutil .а. Если файловая система,
менеджер процессов или другая часть операционной системы связывается с биб-
библиотечными функциями, сначала выполняется поиск в библиотеке системных
утилит и лишь затем — в стандартной библиотеке.
В следующей строке находится прототип функции kputc. Она вызывается сис-
системной версией printf и отображает символы на консоли. Однако здесь есть
некоторая тонкость. Функция kputc определена в нескольких местах; ее копия
имеется в библиотеке системных утилит и используется по умолчанию. Тем не
менее другие компоненты системы определяют собственные версии kputc. Мы
рассмотрим одну из них при изучении консольного интерфейса в следующей
главе. Версия kputc есть и у драйвера журнала (здесь мы не описываем его в де-
деталях). Более того, ядро поддерживает свою версию функции kputc, но это —
особый случай. Ядро не пользуется функцией print f; вместо нее для печати
внутри ядра определяется и применяется специальная функция kprintf.
Когда процессу в MINIX 3 нужно сделать системный вызов, он посылает сооб-
сообщение менеджеру процессов или файловой системе. Каждое сообщение включает
номер желаемого системного вызова. Номера системных вызовов хранятся в фай-
файле callnr. h (строка 3500). Некоторые числа не используются — они зарезерви-
зарезервированы для еще нереализованных вызовов или соответствуют вызовам предше-
предшествующих версий MINIX и в настоящее время обрабатываемым библиотечными
функциями. В конце файла определены номера, не относящиеся к вызовам, пе-
перечисленным в табл. 1.1. Например, вызов svrctl (упомянутый ранее), а также
вызовы ksig, unpause, revive и task_reply используются только внутри
операционной системы. Механизм системных вызовов удобен для реализации
этих вызовов. Поскольку перечисленные вызовы не могут быть задействованы
внешними программами, в последующих версиях MINIX 3 их можно модифици-
модифицировать, не опасаясь за совместимость с пользовательскими программами.
Далее следует файл com.h (строка 3600). Одна интерпретация его названия —
«общий» (common), другая — «взаимодействие» (communication). В реальности
же файл содержит общие определения для обеспечения взаимодействия между
серверами и драйверами устройств. В строках 3623-3626 определены номера за-
заданий. Чтобы отличать их от номеров процессов, номера заданий отрицательны.
В строках 3633-3640 заданы номера процессов загрузочного образа. Обратите
внимание на то, что номера процессов — это номера элементов таблицы процес-
процессов. Их не следует путать с идентификаторами процессов (PID).
Следующий раздел файла com.h определяет механизм формирования сообще-
сообщений, используемых для выполнения операции notify. Номера процессов участ^
вуют в генерации величины, записываемой в поле сообщения m_type. Типы для
уведомлений и прочих сообщений, определяемые в данном файле, формиру-
формируются сочетанием категории типа и числа, идентифицирующего тип. В конце
com.h перечислены макросы, преобразующие осмысленные идентификаторы
в числовые шифры, задающие типы сообщений и имена полей.
В каталоге include/minix/ на сопровождающем книгу компакт-диске имеют-
имеются несколько файлов. Файл devio .h (строка 4100) определяет типы и констан-
константы, поддерживающие доступ к портам ввода-вывода из пользовательского про-
пространства, а также несколько макросов, упрощающих написание кода, в котором
описываются порты и значения. Файл dmap. h (строка 4200) задает структуру
dmap и массив элементов типа dmap. Структура представляет собой таблицу,
связывающую главные номера устройств с поддерживающими их функциями.
В этом же файле определяются главный и вспомогательный номера для драйве-
драйвера memory и главные номера для других важных драйверов устройств.
Каталог include /minix/ содержит несколько дополнительных специализиро-
специализированных заголовочных файлов, необходимых для компиляции системы. Один из
них, u64.h, обеспечивает поддержку арифметических операций над 64-раз-
64-разрядными целыми числами, требуемую для обработки адресов дисков большого
объема. При появлении системы UNIX, языка С, процессоров класса Pentuim
и операционной системы MINIX об этом было невозможно даже помыслить.
Возможно, следующая версия MINIX 3 будет написана на языке, оснащенном
встроенной поддержкой 64-разрядных целых чисел и процессоров с 64-разряд-
64-разрядными регистрами. До этого времени определения файла u64 .h сыграют роль
временного решения.
Итак, нам осталось рассмотреть еще три файла. Файл keymap. h определяет
структуры, которые используются в реализации раскладок клавиатуры, рассчи-
рассчитанных на символы различных языков. Кроме того, данный файл необходим
программам, которые намерены генерировать и загружать таблицы нестандартных
символов. В файле bitmap.h представлено несколько макросов, упрощающих
битовые операции, такие как установка, сброс и тестирование. Файл part it ion. h
определяет информацию, необходимую MINIX 3 для задания дискового разде-
раздела, — по абсолютному смещению в байтах и размеру либо по адресу в формате
(цилиндр, головка, сектор). Размер и смещение указываются в виде числа типа
u64_t, позволяя использовать диски большого объема. В этом файле не описы-
описывается расположение разделов на диске; файл с подобным описанием находится
в следующем каталоге.
Последний каталог со специализированными заголовочными файлами, который
мы затронем, — include/ibm. В нем располагаются несколько файлов с опре-
определениями, специфическими для компьютеров семейства IBM PC. Поскольку
язык С «знает» лишь адреса памяти и не предоставляет доступа к портам ввода-
вывода, библиотека содержит процедуры чтения и записи портов на языке ассемб-
ассемблера. Различные процедуры объявлены в файле ibm/portio.h (строка 4300).
Доступны все возможные процедуры ввода и вывода для байтов, целых и расши-
расширенных целых данных, причем как отдельных, так и в виде строк: от inb (ввод
байта) до out si (вывод строки чисел long). Низкоуровневым процедурам ядра
может потребоваться возможность включать и отключать прерывания процессо-
процессора, также не поддерживаемая языком С. Для этой цели в библиотеку помещен
ассемблерный код, а функции intr_disable и intr_enable объявлены в стро-
строках 4325 и 4326.
Следующий файл в каталоге — interrupt .h (строка 4400), определяющий адре-
адреса портов и областей памяти, используемых контроллером прерываний и BIOS
PC-совместимых компьютеров. Дополнительные определения портов ввода-вы-
ввода-вывода содержатся в файле ports.h (строка 4500). Последний включает адреса,
необходимые для доступа к интерфейсу клавиатуры и микросхеме таймера, ис-
используемой микросхемой часов.
Некоторые файлы каталога include /ibm являются обязательными и должны
быть упомянуты. Файлы bios .h, memory .h и part it ion. h снабжены объем-
объемными комментариями, и вы можете прочесть их, чтобы подробнее изучить меха-
механизм использования памяти и таблицы разделов диска. Файлы cmos .h, cpu.h
и int86 .h предоставляют дополнительную информацию о портах, битовых фла-
флагах процессора, вызовах служб BIOS и DOS в 16-разрядном режиме. Наконец,
файл diskparm.h определяет структуру данных для форматирования дискет.
2.6.5. Структуры данных процессов
и заголовочные файлы
Теперь мы познакомимся с MINIX поближе и посмотрим, на что похож код в ка-
каталоге src/kernel. Сперва мы изучим настоящий системный заголовочный
файл kernel. h (строка 4600). Он начинается с объявления трех макросов. Пер-
Первый из них — _POSIX_SOURCE, макрос проверки поддерживаемых функций, оп-
определяется стандартом POSIX. Все подобные макросы начинаются с символа
подчеркивания. Этот макрос включается для того, чтобы были видимы все сим-
символы, как требуемые стандартом, так и разрешенные, но не обязательные, а не-
неофициальные расширения были бы скрыты. Следующие два макроопределения
уже упоминались — это макрос _MINIX, переопределяющий действие макроса
_POSIX_SOURCE для расширений MINIX 3, и макрос _SYSTEM, наличие которого
проверяется там, где при компиляции необходимо учитывать разницу между сис-
системным и пользовательским кодом (например, может меняться знак кода возврата).
Затем в kernel. h включаются другие заголовочные файлы из каталога include/
и его подкаталогов include/sys/, include/minix/ и include/ibm/, в том
числе перечисленные в листинге 2.12. Все эти файлы уже были нами рассмот-
рассмотрены в двух предыдущих разделах. Затем присоединяются еще шесть заголовоч-
заголовочных файлов из локального каталога src/kernel/, имена которых заключены
в кавычки.
Файл kernel .h позволяет легко включить в исходные файлы большое количе-
количество необходимых определений при помощи одной команды:
#include "kernel.h"
Иногда имеет значение то, в каком порядке включаются заголовочные файлы.
Именно использование файла kernel .h позволяет раз и навсегда гарантировать
соблюдение требуемой последовательности. Это поднимает концепцию «сделал
и забыл», реализуемую заголовочными файлами, на более высокий уровень. Ана-
Аналогичные главные заголовочные файлы имеются в каталогах с кодами других
системных компонентов, в частности файловой системы и менеджера процессов.
Теперь давайте перейдем к локальным файлам, включаемым в kernel. h. В пер-
первую очередь мы встретим файл conf ig.h, который, подобно своему «тезке» сис-
системного уровня include/minix/ conf ig.h, должен включаться в файл исходно-
исходного кода раньше локальных заголовочных файлов. Как и каталог include/
minix/, каталог src/kernel/ включает файлы const .h и type.h. В include/
minix/ помещены файлы, используемые несколькими компонентами, в том чис-
числе программами, работающими под управлением MINIX 3. Файлы, находящиеся
в каталоге src/kernel/, содержат определения, необходимые только для ком-
компиляции ядра. Каталоги файловой системы, менеджера процессов и других ком-
компонентов системы также включают файлы const.h и type.h, определяющие
константы и типы для локального использования. В главный заголовочный файл
включены еще два файла, proto. h и glo. h; их аналогов нет в главных катало-
каталогах include/, однако они присутствуют в файловой системе и менеджере про-
процессов. Последним локальным заголовочным файлом, включенным в kernel .h,
является ipc . h.
Обратите внимание на начало файла kernel /conf ig.h. В нем вы найдете после-
последовательность #ifndef. . .#define, предотвращающую проблемы при попыт-
попытке неоднократного включения файла. Мы рассматривали это решение раньше,
однако обратите внимание, что на этот раз имя макроса, CONFIG_H, не начинает-
начинается с символа подчеркивания. Это означает, что макрос CONFIG_H отличается от
макроса _CONFIG_H, определенного в файле include/minix/conf ig.h.
Локальная версия файла conf ig.h ядра объединяет определения, которые вам
вряд ли нужно изменять, если вы собираетесь использовать MINIX 3 для изуче-
изучения операционной системы или просто в качестве операционной системы компь-
компьютера общего назначения. Тем не менее представим себе, что вам необходимо
сделать систему MINIX 3 очень компактной, чтобы с ее помощью вести управле-
управление научным инструментом или самодельным мобильным телефоном. Опре-
Определения, расположенные в строках 4717-4743, позволяют исключить ненужные
вызовы ядра. Избавление от ненужной функциональности также снижает требо-
требования к памяти, поскольку код, осуществляющий обработку каждого вызова ядра,
условно компилируется при помощи упомянутых определений. При отключении
функции соответствующий код просто не включается в системный двоичный
файл. К примеру, мобильный телефон не нуждается в запуске новых процессов,
поэтому код данной функции можно исключить и уменьшить объем потребляемой
памяти. Большая часть остальных констант, определенных в файле config.h,
управляет базовыми параметрами. Например, при обработке прерываний ис-
используется специальный стек размером K_STACK_BYTES. Значение этой кон-
константы задается в строке 4772. Память под стек резервируется в ассемблерном
файле mpx3 86 . s.
В файле const.h (строка 4800) определен макрос, преобразующий виртуаль-
виртуальные адреса, заданные относительно базы пространства ядра, в физические адреса
(строка 4814). С-функция umap_local определена в другом месте кода ядра;
ядро может выполнять такое преобразование от имени других компонентов сис-
системы, однако внутри ядра использование макроса более эффективно. В файле
const.h определено несколько других полезных макросов, включая макросы,
предназначенные для работы с битовыми картами. Два определения макросов
активируют важный механизм безопасности, встроенный в аппаратное обеспече-
обеспечение Intel. Слово состояния процессора (Processor Status Word, PSW) представля-
представляет собой регистр процессора, а биты уровня защиты ввода-вывода (I/O Protection
Level, IOPL) в нем определяют разрешение или запрет доступа к системе преры-
прерываний и портам ввода-вывода. В строках 4859 и 4851 заданы различные значения
слова состояния процессора, определяющие режимы указанного доступа для
обычных и привилегированных процессов. Эти значения помещаются в стек при
подготовке процесса к запуску.
В следующем файле, который мы рассмотрим, type.h (строка 4900), структура
memory (строки 4925-4928) использует два значения, базовый адрес и размер,
однозначным образом определяющие область памяти.
Файл type. h содержит ряд других прототипов и структур, используемых в лю-
любой реализации операционной системы MINIX 3. Например, в нем определены
две структуры: kmessages для передачи ядром диагностических сообщений и
randomness для генератора случайных чисел. В type .h также имеется ряд ма-
машинно-зависимых определений типов. Чтобы сократить код и сделать его более
удобочитаемым, мы удалили из файла условные фрагменты и определения дру-
других типов процессоров. Тем не менее вы должны понимать, что определения, по-
подобные структуре stackframe_s (строки 4955-4974), задающей сохранение
машинных регистров в стеке, являются специфичными для 32-разрядных про-
процессоров Intel. В случае другой платформы структура stackf rame_s будет оп-
определена согласно конструкции регистров используемого процессора. Еще один
пример — структура segdesc_s (строки 4976-4983). Она является частью за-
защитного механизма, предотвращающего доступ процессов к не принадлежащим
им областям памяти. Для другого процессора такая структура вообще может ока-
оказаться ненужной — это зависит от применяемого им механизма защиты памяти.
Еще один аспект, касающийся подобных структур: наличие всех нужных данных
является необходимым, однако недостаточным для оптимальной производитель-
производительности. Структура stackf rame_s должна обрабатываться ассемблерным кодом.
Чем более простые чтение и запись на языке ассемблера обеспечивает определе-
определение этой структуры, тем меньше время переключения контекста.
Следующий файл, proto.h (строка 5100), содержит прототипы всех функций,
которые должны быть видимы за пределами тех файлов, где они объявлены. Все
прототипы описаны при помощи макроса „PROTOTYPE, о котором говорилось
в предыдущем разделе. Таким образом, ядро MINIX 3 может быть скомпилиро-
скомпилировано как классическим компилятором С Кернигана и Ритчи, так и более совре-
современным, соответствующим стандарту ANSI С (такой компилятор входит в ком-
комплектацию MINIX 3). Некоторые прототипы являются системно-зависимыми,
включая обработчики прерываний и исключений, а также функции, написанные
на языке ассемблера.
В файле glo.h (строка 5300) находятся глобальные переменные ядра. Макрос
EXTERN уже обсуждался при рассмотрении файла include/minix/const .h.
Обычно он преобразуется в ключевое слово extern. Обратите внимание на то,
что макрос EXTERN предваряет многие определения файла glo .h. Макрос EXTERN
переопределяется, если этот файл включается в файл table. с, где определяется
макрос _TABLE. To есть место для хранения переменных, определенных подоб-
подобным образом, фактически резервируется, когда glo.h включается в компиля-
компиляцию table, с. Включение glo.h в другие исходные С-файлы делает перемен-
переменные файла table. с видимыми в других модулях ядра.
Некоторые структуры данных ядра, определенные в файле glo. h, используются
при запуске операционной системы. Структура aout (строка 5321) содержит ад-
адрес массива заголовков всех компонентов системного образа MINIX 3. Обратите
внимание на то, что эти адреса являются физическими, то есть адресами, отно-
относительными всего адресного пространства процессора. Как мы увидим позже,
физический адрес структуры aout передается от монитора загрузки ядру при за-
запуске MINIX 3, чтобы процедуры запуска ядра могли получить адреса всех ком-
компонентов операционной системы из пространства памяти монитора. Структура
kinf о (строка 5322) также несет в себе важную информацию. Вспомните, что
одноименная структура была определена в файле include/minix/type.h.
Как только монитор загрузки передает ядру информацию обо всех процессах
в загрузочном образе при помощи структуры aout, ядро заполняет поля струк-
структуры kinf о данными о себе, которые могут оказаться нужными другим систем-
системным компонентам.
Следующий раздел файла glo .h содержит переменные, относящиеся к управле-
управлению исполнением процессов и ядра. Переменные prev_ptr, proc_ptr и next_
ptr указывают на записи таблицы процессов, соответствующие предыдущему,
текущему и следующему исполняемым процессам. Переменная bill_ptr ука-
указывает на процесс, ответственный за процессор. Когда пользовательский процесс
вызывает файловую систему и она выполняется, proc_ptr указывает на про-
процесс файловой системы. Вместе с тем bill_ptr будет указывать на пользова-
пользовательский процесс, и время, которое работала файловая система, учитывается во
времени работы пользовательского процесса. Нам не известны случаи, когда владе-
владелец системы MINIX взимает с пользователей плату за израсходованное процес-
сорное время, однако это можно сделать. Следующая переменная, k_reentler,
требуется для подсчета вложенных запусков кода ядра. Вложенный запуск имеет
место, например, если в момент прерывания процессором исполнялось ядро, а не
пользовательский процесс. Это важно, поскольку переключение контекста между
пользовательским процессором и ядром (а также наоборот) отличается от по-
повторного входа в ядро. По завершении процедуры обслуживания прерывания
необходимо определить, оставить управление ядру либо передать его пользова-
пользовательскому процессу. Переменная k_reentler также проверяется некоторыми
функциями, включающими и отключающими прерывания, например lock_
enqueue. Если такая функция выполняется, когда прерывания уже запрещены,
они не должны быть снова разрешены, если это является нежелательным. Нако-
Наконец, в данном разделе имеется счетчик потерянных тактовых сигналов. Вопросы
причины потери тактовых сигналов и реакции на нее рассматриваются при изу-
изучении таймерного задания.
Последние переменные, определенные в файле glo.h, были включены в него
потому, что доступ к ним необходим во всем коде ядра. Эти переменные объявле-
объявлены с ключевым словом extern вместо EXTERN потому, что являются инициали-
инициализируемыми. Язык С поддерживает такую возможность. Использование макроса
EXTERN несовместимо с инициализацией в стиле С, поскольку инициализация
допустима лишь однократно.
Задания, выполняемые в пространстве ядра (в настоящий момент их две — тай-
мерное и системное), обладают собственными стеками внутри t_stack. При об-
обработке прерывания ядро работает с отдельным стеком, который здесь не объяв-
объявлен, так как к нему обращается только код в языке ассемблера и глобального
доступа к этому стеку не требуется. Последний файл, включенный в kernel .h
и, тем самым, используемый в любом варианте компиляции, — ipc .h (стро-
(строка 5400). Он определяет различные константы для взаимодействия между про-
процессами. Мы рассмотрим их позже, когда приступим к изучению содержащего
их файла, kernel /proc . с.
Ядро содержит еще несколько заголовочных файлов, используемых широко, хо-
хотя и не настолько, чтобы включать их в файл kernel. h. Первый из них, proc . h
(строка 5500), описывает таблицу процессов ядра. Состояние процесса полно-
полностью описывается его данными, находящимися в памяти, и информацией в со-
соответствующей ему записи таблицы процессов. Последняя содержит данные
регистров процессора во время приостановки процесса. При возобновлении ис-
исполнения процесса содержимое регистров восстанавливается. Именно таким
образом создается представление о «параллельном» выполнении и взаимодейст-
взаимодействии процессов, хотя, на самом деле, в любой момент времени процессор обраба-
обрабатывает команды только одного процесса. Ядру необходимо затрачивать время на
сохранение и восстановление состояния процесса при каждом переключении кон-
контекста, хотя, очевидно, что в это время работа процесса прерывается. По этой
причине структуры определяются так, чтобы обеспечить максимальную эффек-
эффективность. Как отмечено при рассмотрении файла proc.h, многие процедуры,
написанные на языке ассемблера, имеют доступ к этим структурам, и в файле
sconst.h заданы смещения полей в таблице процессов для использования
ассемблерным кодом. Таким образом, изменение определения в proc.h может
потребовать редактирования файла sconst .h.
Перед тем как двигаться дальше, заметим, что из-за микроядерной структуры
MINIX 3 таблица процессов, которую мы будем рассматривать, имеет аналоги
в менеджере процессов и файловой системе. Последние используют таблицы, за-
записи которых характеризуют процессы, а содержащаяся в них информация отно-
относится к функциональности соответствующего системного компонента MINIX 3.
В совокупности все три таблицы эквивалентны таблице процессов операцион-
операционной системы с монолитной структурой, однако обсуждая таблицу процессов здесь,
мы будем иметь в виду таблицу ядра. Остальные таблицы рассматриваются в со-
соответствующих главах.
Каждая запись в таблице процессов определена как структура pro с (строки
5516-5545). Каждый элемент таблицы процессов хранит регистры процесса,
указатель стека, состояние процесса, карту памяти, предельный размер стека,
идентификатор процесса, информацию о времени срабатывания таймера, сооб-
сообщениях и прочие сведения о процессе. Первая часть каждого элемента таблицы —
это структура stackf rame_s. Когда процесс переходит в состояние выполне-
выполнения, его указатель стека восстанавливается по адресу из записи в таблице про-
процессов, и все регистры процессора восстанавливаются из этой структуры.
Тем не менее состояние процесса — это больше, чем регистры процессора и дан-
данные памяти. В MINIX 3 каждый процесс имеет указатель на структуру привиле-
привилегий в своей записи в таблице процессов (строка 5522). Эта структура определяет
допустимых отправителей и получателей сообщений для данного процесса, а так-
также множество привилегий. Мы рассмотрим детали позднее, а сейчас просто
обратите внимание на следующее: каждый системный процесс содержит указа-
указатель на уникальную копию этой структуры, однако привилегии пользователей
одинаковы, поскольку указатели пользовательских процессов ссылаются на од-
одну и ту же копию. Кроме того, имеется поле размером 1 байт, содержащее набор
битовых флагов, p_rts_f lags (строка 5523). Назначения битов описаны далее.
Установка любого бита в 1 означает, что процесс не может быть запущен; таким
образом, нулевое значение поля указывает на готовность процесса.
Каждая запись в таблице процессов предоставляет место для информации, ко-
которая может быть необходима ядру. Например, поле p_max_priority (стро-
(строка 5526) указывает, в какую очередь следует поместить процесс, когда он будет
готов к выполнению в первый раз. Поскольку приоритет процесса может быть
понижен при условии, что он препятствует выполнению других процессов, имеет-
имеется поле p_priority, значение которого изначально совпадает с полем р_тах_
priority. Поле p_priority определяет очередь, в которую процесс помеща-
помещается при готовности.
Время, затраченное процессом, регистрируется в двух переменных clock_t (стро-
(строки 5532 и 5533). Ядро должно иметь доступ к этой информации, поэтому ее хра-
хранение в пространстве памяти процесса было бы неэффективно, хотя и возможно
логически. Структура p_next ready (строка 5535) используется для связыва-
связывания процессов в очередях планировщика.
Следующие несколько полей содержат информацию, связанную с сообщениями,
которыми обмениваются процессы. Если процесс не может завершить вызов
send потому, что получатель не находится в состоянии ожидания, отправитель
помещается в очередь, на которую ссылается указатель p_caller_q получате-
получателя (строка 5536). Таким образом, когда получатель наконец выполняет вызов
receive, легко определить все процессы, желающие передать ему сообщение.
Поле p_q_link (строка 5537) используется для связывания процессов, находя-
находящихся в очереди.
Применение для передачи сообщений метода рандеву становится возможным
благодаря резервированию памяти для хранения в строках 5538-5540. Если про-
процесс выполняет вызов receive, но не обнаруживает входящего сообщения, он
блокируется, а число процессов, от которых он желает получить сообщения, хра-
хранится в переменной p__getf rom. Аналогично, переменная p_sendto содержит
число получателей, не ожидающих сообщения, когда процесс выполняет вызов
send. Адрес буфера сообщений хранится в переменной p_messbuf. Предпослед-
Предпоследним полем в каждом элементе таблицы процессов является p__pending (стро-
(строка 5542) — битовая карта, служащая для наблюдения за сигналами, не передан-
переданными менеджеру процессов из-за того, что он не ожидает сообщения.
Последнее поле элемента таблицы процессов представляет собой массив симво-
символов p_name и содержит имя процесса. Это поле не является обязательным для
управления процессом со стороны ядра. MINIX 3 поддерживает разнообразные
отладочные дампы, генерируемые по нажатию специальной клавиши на кла-
клавиатуре консоли. Некоторые дампы содержат информацию обо всех процессах,
включая их имена. Назначение процессам осмысленных имен упрощает понима-
понимание и отладку ядра.
За определением элемента таблицы процессов следуют определения констант,
используемых в его полях. В строках 5548-5555 приведены и описаны значения,
задающие различные комбинации битовых флагов в p_rts_f lags. Если элемент
не используется, устанавливается значение SLOT_FREE. После вызова fork уста-
устанавливается значение NCL.MAP, препятствующее запуску дочернего процесса до
установки карты памяти. Значения SENDING и RECEIVING указывают на то, что
процесс заблокирован при попытке передать или принять сообщение. Значения
SIGNALED и SIG_PENDING устанавливаются, когда сигналы приняты, a P_STOP
обеспечивает поддержку трассировки. Значение NO__PRIV служит для задержки
запуска нового системного процесса до момента его окончательной установки.
Далее (строки 5562-5567) определено число очередей и допустимые значения
поля p_priority. В данной версии файла допускается назначение процессам
максимального приоритета; вероятно, это пережиток времен тестирования рабо-
работы драйверов в пользовательском пространстве, и константе MAX_USER_Q следу-
следует присвоить большее значение (соответствующее меньшему приоритету).
Затем следует несколько макросов, позволяющих определять адреса важных эле-
элементов таблицы процессов как константы во время компиляции — это ускоряет
доступ к ним при выполнении. Следующие макросы предназначены для вычисле-
вычислений и проверок на этапе исполнения. Макрос proc_addr (строка 5577) необходим
потому, что в С не поддерживаются отрицательные индексы. С логической точки
зрения, элементы массива ргос должны нумероваться от -NR_TASKS до +NR_
PROCS. К сожалению, язык С позволяет нумеровать элементы лишь с нуля, поэто-
поэтому ргос [ 0 ] указывает на самую «отрицательную» задачу. Чтобы упростить со-
сопоставление процессов и элементов таблицы процессов, мы используем команду
rp = proc_addr(п);
Она присваивает переменной гр адрес элемента, соответствующего процессу п,
где п может иметь как положительное, так и отрицательное значения.
Сама таблица процессов определена как массив структур ргос, ргос [NR_TASKS
+ NR_PROCS] (строка 5593). Обратите внимание на то, что величина NR_TASKS
определена в файле include/minix/com.h (строка 3630), a NR_PROCS — в файле
include/minix/config.h (строка 2522). Сумма этих значений задет размер
таблицы процессов. При необходимости NR_PROCS можно изменить, чтобы сис-
система (к примеру, большой сервер) могла обрабатывать большее число процессов.
Наконец, несколько макросов предназначены для ускорения доступа к таблице
процессов. Обращения к таблице процессов осуществляются часто, а вычисле-
вычисление адреса в массиве требует выполнения медленной операции умножения. По
этой причине введен массив указателей на элементы таблицы процессов рргос_
addr (строка 5594). Два массива, rdy_head и rdy_tail, поддерживают очере-
очереди процессов. Например, указатель rdy_head[USER_Q] ссылается на первый
процесс в очереди пользовательских процессов, предлагаемых по умолчанию.
Как мы упомянули в начале рассмотрения файла ргос. h, имеется файл sconst. h
(строка 5600), который необходимо приводить в соответствие с ргос. h при вне-
внесении изменений в структуру таблицы процессов. Файл sconst. h содержит оп-
определения констант, используемых ассемблерным кодом, в форме, доступной ас-
ассемблеру. Все константы задают смещения внутри структуры stackframe_s,
составляющей часть записи таблицы процессов. Поскольку ассемблерный код не
обрабатывается компилятором С, подобные определения лучше вынести в от-
отдельный файл. Кроме того, эти определения являются машинно-зависимыми,
а, значит, их обособление упрощает перенос MINIX 3 в систему с другим процес-
процессором (требуется создать новую версию файла sconst .h). Обратите внимание
на то, что многие смещения определены как сумма предшествующего смещения
и W — величины, равной длине слова (строка 5601). Это позволяет компилиро-
компилировать 16- и 32-разрядные версии MINIX 3, используя один и тот же файл.
Потенциальным источником проблем могут стать повторяющиеся определения.
Изначально предполагалось, что заголовочные файлы будут содержать единст-
единственный набор определений, который будет использоваться различными фрагмен-
фрагментами системы без скрупулезного вникания в детали. Очевидно, что повторяю-
повторяющиеся определения, присутствующие в файлах ргос .h и sconst .h, нарушают
этот принцип. Разумеется, здесь мы имеем дело с исключением, однако, изменяя
один файл, мы должны тщательно проверить другой, чтобы обеспечить их вза-
взаимную непротиворечивость.
Структура системных привилегий, кратко упомянутая при обсуждении таблицы
процессов, полностью определена в файле priv.h (строки 5718-5735). Она со-
содержит набор битовых флагов s_f lags, а также поля s_trap_mask, s_ipc_
from, s_ipc_to и s_call_mask, определяющие, какие системные вызовы могут
быть инициированы, какие сообщения могут быть приняты и переданы, какие
вызовы ядра разрешены.
Структура привилегий не является частью таблицы процессов, но каждый эле-
элемент таблицы процессов содержит указатель на ее экземпляр. Различные копии
имеются лишь у системных процессов; все пользовательские процессы задейст-
задействуют один и тот же экземпляр. Таким образом, остальные поля структуры для
пользовательского процесса не играют роли, поскольку их совместное использо-
использование не имеет смысла. Эти поля содержат битовые карты активных уведомле-
уведомлений и аппаратных прерываний, а также сигналы и таймер. Разумеется, эти поля
имеет смысл указывать для системных процессов; управление уведомлениями,
сигналами и таймерами пользовательских процессов осуществляется от имени
последних менеджером процессов.
Файлы priv. h и proc . h организованы по схожему принципу. За определением
структуры привилегий следуют определения битовых флагов, несколько важных
адресов, необходимых на этапе компиляции, а также макросы для вычисления
адресов во время выполнения. Далее определяется таблица структур привиле-
привилегий, priv[NR_SYS_PROCS], а затем — массив указателей ppriv_addr [NR_
SYS_PROCS] (строки 5762 и 5763). Массив указателей обеспечивает быстрый
доступ к структуре. О значении константы STACK_GUARD (строка 5738) нетруд-
нетрудно догадаться; мы используем ее позднее. Мы предлагаем читателю поискать
в Интернете информацию об истории появления этой константы.
Оставшаяся часть файла priv.h — это проверка, является ли значение NR_
SYS_PROCS большим, чем число процессов в загрузочном образе. Если это так,
будет выведено сообщение об ошибке, указанное в строке terror. После этого
стандартный компилятор MINIX 3 прекратит компиляцию, хотя поведение дру-
других компиляторов С может быть иным.
Клавиша F4 вызывает генерацию отладочного дампа, содержащего некоторую
информацию из таблицы привилегий. В листинге 2.13 показаны несколько ее
строк, соответствующих «представительным» процессам. Для флагов использо-
использованы следующие обозначения: Р — выгружаемый, в — с учетом времени, S —
системный. Ловушки обозначены так: Е — echo, S — send, R — receive, в — оба,
N — уведомление. Битовая карта содержит биты для каждого из разрешенных
системных процессов NR_SYS_PROCS C2) в порядке согласно идентификатору
(в листинге представлены только 16 бит). Все пользовательские процессы имеют
идентификатор 0 (крайний левый столбец). Согласно битовой карте, пользова-
пользовательские процессы, такие как init, могут передавать сообщения только менед-
менеджеру процессов, файловой системе и серверу реинкарнации и, кроме того, долж-
должны задействовать вызов sendrec. Серверы и драйверы, указанные в листинге,
могут пользоваться любыми примитивами взаимодействия между процессами,
а все, кроме memory, имеют возможность передачи сообщений любым процессам.
Листинг 2.13. Фрагмент отладочного дампа таблицы привилегий. Таймерное задание,
файловая система, процессы tty и init имеют привилегии, типичные для заданий,
серверов, драйверов устройств и пользовательских процессов соответственно.
Битовая карта сокращена до 16 бит
--пг- -id- -name- -flags- -traps- -ipc_to mask
(-4) @1) IDLE P-BS- 00000000 00001111
[-3 ] @2) CLOCK —S- --R-- 00000000 00001111
[-2 ] @3) SYSTEM S- --R-- 00000000 00001111
[-1 ] @4) KERNEL S- 00000000 00001111
0 @5) pm P--S- ESRBN 11111111 11111111
1 @6) fs P--S- ESRBN 11111111 11111111
2 @7) rs P--S- ESRBN 11111111 11111111
3 @9) memory P--S- ESRBN 00110111 01101111
4 A0) log P--S- ESRBN 11111111 11111111
5 @8) tty P--S- ESRBN 11111111 11111111
6 A1) driver P--S- ESRBN 11111111 11111111
7 @0) init P-B-- E--B- 00000111 00000000
Теперь рассмотрим другой заголовочный файл, который также включается в боль-
большое число различных файлов с исходными кодами, protect.h (строка 5800).
Почти все, что есть в этом файле, относится к архитектуре процессоров Intel с под-
поддержкой защищенного режима (это процессоры 80286, 80386, 80486 и семейство
Pentium). Детальное рассмотрение процессоров Intel не входит в круг задач этой
книги. Достаточно только сказать, что у них есть ряд внутренних регистров, ука-
указывающих на таблицу дескрипторов в памяти. Информация из таблицы деск-
дескрипторов позволяет узнать, как используются ресурсы системы, предотвращать
доступ процесса к памяти, принадлежащей другому процессу и др.
Архитектура 32-разрядных процессоров Intel предлагает четыре уровня приви-
привилегий, из которых в MINIX 3 поддерживаются три. Они определены в строках
5843-5845. Центральная часть ядра, то есть код, относящийся к прерываниям
и переключению контекста, работает с полномочиями уровня INTR_PRIVILEGE.
Процесс с таким уровнем доступа вправе обращаться к любым регистрам и лю-
любым ячейкам памяти. Задания работают с уровнем привилегий TASK_PRIVILEGE,
который позволяет им обращаться к устройствам ввода-вывода, но не дает изме-
изменять значения некоторых специальных регистров, например указатели на табли-
таблицы дескрипторов. Серверы и пользовательские процессы выполняются на уров-
уровне USER_PRIVILEGE. Этот уровень запрещает процессам выполнять некоторые
инструкции, например инструкции ввода-вывода, управления распределением
памяти и смены привилегий.
Для тех, кто изучал современные процессоры, концепция нескольких уровней
защиты по привилегиям наверняка понятна, но те, кто знакомился с архитекту-
архитектурой компьютеров по маломощным микропроцессорам, могли не сталкиваться
с подобными ограничениями.
В каталоге kernel/ имеется один заголовочный файл, который мы еще не рас-
рассматривали — system, h. Мы и сейчас отложим знакомство с ним до изучения
системного задания (далее в этой главе), выполняющегося как независимый про-
процесс, хотя и внутри ядра. Пока же будем считать изучение заголовочных файлов
оконченным и перейдем к рассмотрению файлов с расширением .с, содержащих
исходный код на языке С. Первый из них называется table.с (строка 6000).
Его компиляция не приводит к генерации исполняемого кода, однако объектный
файл table. о содержит все структуры данных ядра. Определения многих из этих
структур мы встречали в файле glo. h и других заголовочных файлах. В строке
6028 перед директивами #include определен макрос _TABLE. Как было отмече-
отмечено ранее, это определение делает EXTERN пустой строкой и выделяет память для
всех данных, предшествующих EXTERN.
Помимо переменных, объявленных в заголовочных файлах, имеются два других
хранилища глобальных данных. Некоторые определения заданы прямо в файле
table. с. В строках 6037-6041 определен стек, необходимый компонентам ядра,
а общий стек для заданий зарезервирован как массив t_stack[TOT_STACK_
SPACE] (строка 6045).
Остальная часть файла table. с содержит определения большого числа констант,
относящихся к свойствам процессов, например, комбинаций битовых флагов,
ловушек вызовов и масок, задающих допустимых адресатов сообщений и уве-
уведомлений (строки 6048-6071), которых мы видели в листинге 2.13. Далее следу-
следуют маски, определяющие разрешенные вызовы ядра для различных процессов.
Менеджеру процессов и файловой системе разрешены все вызовы, серверу реин-
реинкарнации — тоже, но не для собственного использования, а потому, что он явля-
является родителем всех остальных системных процессов, а его потомки могут насле-
наследовать лишь подмножества его привилегий. Драйверам назначены одинаковые
маски системных вызовов; исключение составляет лишь драйвер виртуального
диска, которому требуется особый доступ к памяти (в комментарии к строке
6075 упоминается термин «менеджер системных служб»; это следует читать как
«сервер реинкарнации» — в процессе разработки имя компонента было измене-
изменено, но некоторые устаревшие комментарии сохранились).
Наконец, в строках 6095-6109 определена таблица image. Она помещена в файл
table. с, а не в заголовочный файл потому, что метод предотвращения множе-
множественных объявлений с помощью макроса EXTERN неприменим к инициали-
инициализируемым переменным. Другими словами, вы не можете где угодно написать
extern int х = 3;
Таблица image содержит детальную информацию, необходимую для инициа-
инициализации всех процессов, загружаемых из загрузочного образа. Эта информация
используется системой при запуске. Например, поле, «озаглавленное» в коммен-
комментарии как qs (строка 6096), определяет размер кванта для каждого процесса.
Обычные пользовательские процессы, как потомки init, получают в свое рас-
распоряжение 8 тактов таймера, а задания CLOCK и SYSTEM — по 64 такта. Считает-
Считается, что последние обычно блокируются до истечения своего кванта, однако в от-
отличие от пользовательских серверов и драйверов, системные задания не могут
быть перемещены в очередь с более низким приоритетом, если они препятству-
препятствуют выполнению других процессов.
Если в загрузочный образ необходимо включить новый процесс, в таблицу image
следует ввести дополнительную строку. Несоответствие размера image значениям
других констант недопустимо. В конце файла table, с размещены команды
проверки ошибок, причем массив dummy объявлен здесь дважды. В каждом объ-
объявлении размер массива недопустим и приводит к ошибке компилятора. По-
Поскольку массив dummy объявлен как extern, память под него не выделяется ни
в этом, ни в других файлах. Более того, этот массив больше нигде не фигурирует,
а следовательно, не беспокоит компилятор.
В конце ассемблерного файла mpx3 86 . s выделяется дополнительная глобаль-
глобальная память. Несмотря на то что мы «перепрыгнули» на несколько страниц кода
вперед, это целесообразно, так как знакомство с глобальными переменными сей-
сейчас весьма актуально. В строке 6822 директива ассемблера . sect . rom записы-
записывает сигнатуру, идентифицирующую работоспособное ядро MINIX 3, в нача-
начало сегмента данных ядра. Директива . sect bss и псевдокоманда . space ре-
резервируют место под стек ядра. Псевдокоманда . comm именует несколько слов
вершины стека, чтобы дать возможность прямого обращения к ним. Мы вер-
вернемся к файлу трхЗ 8 б . s немного позже, завершив изучение начальной за-
загрузки MINIX 3.
2.6.6. Начальная загрузка MINIX 3
Уже почти настало время перейти к рассмотрению исполняемого кода, но пе-
перед тем как мы им займемся, попытаемся разобраться, как MINIX 3 загружается
в память. Загрузка, конечно же, производится с диска, однако эту процедуру
нельзя назвать элементарной, а последовательность действий зависит от типа
диска. На рис. 2.17 показано, как устроены дискеты и жесткие диски, разбитые
на разделы.
Рис. 2.17. Дисковые структуры, используемые при начальной загрузке: а — диск
без разбиения на разделы, первый сектор является загрузочным блоком; б — диск,
разбитый на разделы, в первом секторе находится главная загрузочная запись
При старте системы аппаратное обеспечение (а в действительности программа
из ПЗУ) считывает первый сектор загрузочного диска и исполняет считанный
код. На дискете, не разбитой на разделы, первый сектор содержит загрузоч-
загрузочный блок, который, в свою очередь, загружает программу boot, как показано на
рис. 2.17, а. В отличие от дискет жесткие диски разбиты на разделы, и в первом
секторе находится программа, которая считывает таблицу разделов (из того же
первого сектора), а затем загружает и исполняет программу из первого сектора
активного раздела, как это показано на рис. 2.17, б (один и только один сектор
должен быть помечен как активный). Раздел, из которого загружается MINIX 3,
имеет такую же структуру, как и загрузочная дискета MINIX 3, и в первом сек-
секторе находится загрузочный блок.
Реальная ситуация может быть сложнее, чем показано на рисунке, так как от-
отдельные разделы могут быть разбиты на подразделы. В этом случае в первом
секторе раздела будет находиться еще одна загрузочная запись со своей табли-
таблицей подразделов. Как бы то ни было, в конце концов, управление получит про-
программа из загрузочного сектора на устройстве, которое разделено на разделы. На
дискетах, например, загрузочным сектором всегда является первый. MINIX 3
допускает разбиение дискеты на разделы, но в этом случае для загрузки можно
использовать только первый раздел, остальные недоступны. Такое поведение уп-
упрощает монтирование дискет, так как и обычные дискеты, и поделенные на раз-
разделы монтируются одинаково. Разбиение на разделы применяется, например, на
установочных дискетах, чтобы разделить образ, копируемый в ОЗУ, и монтируе-
монтируемый раздел, который при необходимости может быть размонтирован, с целью
освобождения привода для продолжения процесса установки.
Изменение загрузочного сектора MINIX 3 осуществляется при его записи на диск
специальной программой installboot. Она вписывает в загрузочный сектор
адрес файла с именем boot. В MINIX 3 стандартным местоположением програм-
программы boot является каталог /boot/, однако он может находиться где угодно — до
загрузки операционной системы невозможно найти местоположение нужного
файла по его имени. Именно поэтому в загрузочный сектор записывается адрес
файла, который будет использован для дальнейшей загрузки.
Программа boot является вторичным загрузчиком MINIX 3. Она не только за-
загружает саму операционную систему, но и сама является монитором загрузки,
позволяя пользователю устанавливать, менять и сохранять различные парамет-
параметры загрузки. Их boot ищет во втором секторе загрузочного раздела. Как требу-
требуют стандарты UNIX, MINIX 3 резервирует первый килобайт каждого диска под
загрузочный блок, но под загрузчик используется только 512 байт, поэтому еще
512 байт остается для сохранения параметров. Эти параметры управляют про-
процессом загрузки, кроме того, они передаются самой операционной системе. На-
Настройка по умолчанию предлагает пользователю только один вариант — загрузку
MINIX 3, но можно сделать и более сложное меню, при помощи которого поль-
пользователь сможет загрузить, например, другие операционные системы (передав
управление загрузочному блоку на другом разделе) или же загрузить MINIX 3,
но с другими параметрами. Кроме того, можно настроить загрузчик так, чтобы
он пропускал меню и немедленно начинал загрузку MINIX 3.
Программа boot не является частью операционной системы, но способна оты-
отыскать на диске образ операционной системы, опираясь на структуры файловой
системы. По умолчанию ищется файл /boot/image, в противном случае —
файл, указанный в параметре загрузки image =. Если задано имя файла, то он
подлежит загрузке; если же указано имя каталога, загружается самый новый со-
содержащийся в нем файл. Во многих операционных системах имя файла загру-
загрузочного образа жестко определено, однако пользователи MINIX 3 могут созда-
создавать собственные образы и присваивать им другие имена. Выбор из нескольких
версий удобен, так как в случае неудачного эксперимента есть возможность вер-
вернуться к более раннему варианту.
Ограниченный объем книги не позволяет нам углубиться в детальное изучение
монитора загрузки. Это сложная программа, почти миниатюрная операционная
система. Она функционирует совместно с MINIX 3, и когда последняя корректно
завершает работу, управление передается монитору загрузки. Ссылка на подроб-
подробное описание исходного кода монитора загрузки имеется на веб-сайте MINIX 3.
Загрузочный, или системный, образ операционной системы MINIX 3 представля-
представляет собой совокупность файлов ряда программ: ядра, менеджера процессов, фай-
файловой системы, сервера реинкарнации, нескольких драйверов устройств и про-
программы init, как показано в табл. 2.3. Загрузочный образ версии MINIX 3,
описываемый в этой книге, включает единственный дисковый драйвер, хотя до-
допускается наличие нескольких драйверов, один из которых активный. Как и все
двоичные программы, файлы загрузочного образа включают заголовок, содержа-
содержащий объем памяти, которая резервируется после загрузки под неинициализиро-
неинициализированные данные и стек. Это позволяет правильно определять адрес, по которому
будет загружена следующая программа.
Области памяти, в которые можно загружать монитор загрузки и компоненты
MINIX 3, зависят от аппаратного обеспечения. В некоторых архитектурах требу-
требуется выравнивание внутренних адресов исходного кода согласно фактическому
адресу, по которому загружена программа. Сегментная организация памяти про-
процессоров Intel избавляет от такой необходимости.
Детали загрузки зависят от типа компьютера. Важным является то, что в любом
случае операционная система так или иначе оказывается в памяти. Перед тем
как MINIX 3 сможет начать работу, требуется выполнить несколько подготови-
подготовительных действий. Сначала при загрузке образа программа boot считывает из
него несколько байтов, содержащих свойства образа. Главное из этих свойств —
разрядность, для которой скомпилирован образ — 16 или 32. Затем ядру предо-
предоставляется дополнительная информация, необходимая для запуска системы. За-
Заголовки компонентов а. out извлекаются в массив внутри пространства памяти
программы boot, а базовый адрес массива передается ядру. По завершении
работы MINIX 3 может вернуть управление монитору загрузки, поэтому место,
с которого выполнение должно возобновиться, также подлежит передаче. Как
мы увидим позже, все эти параметры помещаются в стек.
Монитор загрузки должен передать операционной системе еще несколько важных
сведений — параметров загрузки. Некоторые из них необходимы ядру, другие
передаются как справочная информация, например имя загрузочного образа.
Параметры загрузки можно представить в виде пар имя = значение, а адрес
таблицы, содержащей такие пары, размещается в стеке. В листинге 2.14 показан
типичный набор параметров загрузки, выведенный командой sysenv операци-
операционной системы MINIX 3.
Листинг 2.14. Параметры загрузки, передаваемые ядру в типичной системе MINIX 3
rootdev=904
гamimagedev=904
ramsize=0
processor=686
bus=at
video=vga
chrome=color
memory=800:92540,100000:3DF0000
label=AT
controller=c0
image=boot/image
В этом примере особую важность представляет параметр memory, с которым мы
вскоре столкнемся. Здесь он указывает, что монитор загрузки определил в памя-
памяти два сегмента, доступных для использования MINIX 3. Один из них начина-
начинается по шестнадцатеричному адресу 800 B048 в десятичной системе счисления)
и имеет размер 0x92540 байт E99 360 в десятичной системе). Второй сегмент
начинается по адресу 100000 A 048 576), а его длина составляет 0x3DF00000
F4 946 176) байт. Такая конфигурация типична для всех PC-совместимых ком-
компьютеров, за исключением самых старых. В архитектуре IBM PC память только
для чтения размещается в начале доступного диапазона адресов — для процессо-
процессора 8088 последний ограничен значением 1 Мбайт. Современные РС-совмести-
мые компьютеры оснащены значительно большим объемом памяти, однако для
совместимости они имеют такую же область памяти для чтения, как и их пред-
предшественники. В результате память, доступная и для чтения, и для записи, разде-
разделена на две части, одна из которых находится ниже 640 Кбайт, а другая — выше
1 Мбайт. По возможности монитор загрузки помещает ядро в нижнюю область,
а серверы, драйверы и процесс init — в верхнюю. В основном это делается для
удобства файловой системы, поскольку дает возможность определять кэш бло-
блоков большего объема, не разделяемый памятью для чтения надвое.
Обратим ваше внимание на то, что операционные системы не всегда загружают-
загружаются с диска. Бездисковые рабочие станции могут загружаться с удаленной системы
через сетевое соединение. Конечно, это требует наличия в ПЗУ программного
обеспечения для работы с сетью. В таком случае процесс загрузки будет аналоги-
аналогичен описанному, хотя детали могут быть другими. Программа в ПЗУ должна
уметь получить через сеть исполняемый код, который, в свою очередь, загрузил
бы всю систему. При таком способе загрузки MINIX 3 процесс инициализации,
начинающийся сразу после размещения системы в памяти, изменился бы очень
незначительно: потребовался бы сетевой сервер и модифицированная файловая
система, способная обращаться к файлам по сети.
2.6.7. Инициализация системы
Ранние версии операционной системы MINIX могли компилироваться в 16-разряд-
16-разрядном режиме для совместимости со старыми процессорами, и в MINIX 3 сохране-
сохранена часть кода для 16-разрядных процессоров. Однако версия, описанная в книге
и записанная на компакт-диск, совместима только с 32-разрядными компьютера-
компьютерами, оснащенными процессором не ниже 80386. Она не работает в 16-разрядном
режиме, а в случае создания 16-разрядной версии некоторые возможности опе-
операционной системы могут оказаться недоступными. Кроме того, 32-разрядные
двоичные файлы имеют больший объем, чем 16-разрядные, и независимые поль-
пользовательские драйверы не могут совместно использовать код, как при компиля-
компиляции драйверов в одну двоичную библиотеку. Тем не менее задействуется общая
база исходного кода на С, и компилятор генерирует надлежащие выходные дан-
данные в зависимости от собственной разрядности. Компилятор самостоятельно оп-
определяет макрос _WORD_SIZE из файла include/minix/conf ig.h.
Первая часть исполняемого кода MINIX написана на языке ассемблера, поэтому
для 16- и 32-разрядных версий компилятора должен использоваться разный код.
В частности, 32-разрядная версия начального кода системы находится в файле
mpx3 86 . s. Альтернативная версия для 16-разрядных систем — в файле mpx88 . s.
Обе эти версии поддерживают различные низкоуровневые операции для ядра.
Выбор того, какой из файлов будет использоваться, производится автоматиче-
автоматически в файле mpx. s. Этот файл состоит всего из нескольких строк кода и цели-
целиком приведен в листинге 2.15.
Листинг 2.15. Выбор одной из двух альтернативных версий ассемблерного кода
#include <minix/config.h>
#if _WORD_SIZE == 2
#include "mpx3 86.s"
#else
#include "mpx88.s"
#endif
Здесь показано необычное использование директивы препроцессора #include.
Обычно эта директива применяется для подсоединения заголовочных файлов,
но, как показано на листинге, годится и для выбора одной из альтернативных
секций исходного кода. Оперируя лишь директивами #if, весь код, как для 32-
разрядной, так и для 16-разрядной версий, пришлось бы поместить в один файл.
Это не только громоздко, но и приводит к расточению дискового пространства,
так как в конкретных установочных пакетах может потребоваться только одна
из версий, в то время как вторая могла бы быть помещена в архив или удалена.
В последующем обсуждении мы будем рассматривать в качестве примера только
32-разрядную версию (mpx3 86 . s).
Так мы приступаем к рассмотрению исполняемого кода впервые, начнем с того,
что скажем несколько слов о порядке подобного рассмотрения в оставшейся части
книги. Большие программы на языке С состоят из множества файлов, которые
трудно выстроить в какой-то последовательности. Как правило, мы будем рас-
рассматривать файлы поочередно. Порядок размещения файлов на компакт-диске
соответствует порядку их изучения в книге. Мы будем начинать с точки входа
каждого из компонентов MINIX 3 и, как правило, двигаться в порядке испол-
исполнения кода. Когда нам будет встречаться вызов вспомогательной функции, мы
скажем о ней несколько слов, но подробное разбирательство отложим до того
времени, когда начнем знакомство с соответствующим файлом. Важнейшие вспо-
вспомогательные функции обычно объявляются в том же файле, в котором они
используются, но небольшие или многоцелевые функции чаще сгруппированы
в отдельных файлах. Мы не пытаемся описать внутреннее устройство каждой
функции, поэтому файлы, содержащие подобные функции, на компакт-диске мо-
могут отсутствовать.
Кроме того, чтобы упростить перенос системы на другие платформы, машинно-
зависимый и машинно-независимый фрагменты кода зачастую помещены в от-
отдельные файлы. Чтобы сократить размер листингов и сделать исходный код бо-
более понятным, большая часть условного кода для платформ, отличных от 32-раз-
32-разрядных систем Intel, в компакт-диск не включена. Полные версии всех файлов
находятся на веб-сайте MINIX 3.
Немало усилий было затрачено на то, чтобы сделать код понятным. Тем не ме-
менее в больших программах всегда имеется множество ответвлений, и зачастую,
чтобы понять работу основной программы, требуется рассмотреть те функции,
которые она вызывает. По этой причине вам может быть полезно сделать не-
несколько закладок и временами отклоняться от порядка повествования книги.
Изложив общий порядок обсуждения кода, обратим внимание на важное ис-
исключение. Процесс запуска MINIX 3 требует нескольких передач управления
между ассемблерными процедурами файла mpx3 86.s и С-функциями из фай-
файлов start, с и main, с, поэтому рассмотрение будет вестись в той последова-
последовательности, в которой вызываются функции.
После того как процесс начальной загрузки помещает в память код операцион-
операционной системы, управление передается по метке MINIX (файл mpx3 86 . s). Первая
инструкция выполняет переход вперед на несколько байтов, чтобы обойти об-
область, занимаемую флагами, которые монитор загрузки использует для получе-
получения информации о ядре (строка 6423). К этому моменту флаги уже выполняют
свои функции — они считываются монитором в процессе загрузки ядра в па-
память. Флаги расположены так потому, что их адрес легко задать. Они позволяют
монитору загрузки определить различные характеристики ядра, самая главная
из которых — его разрядность A6 или 32). Монитор загрузки всегда стартует
в 16-разрядном режиме, но при необходимости перед передачей управления на
метку MINIX переключается в 32-разрядный.
Чтобы понять следующий далее код, нужно разобраться с состоянием стека. Мо-
Монитор передает MINIX 3 через стек ряд параметров. Сначала он размещает в стеке
адрес переменной aout, содержащей адрес массива с заголовочной информацией
компонентов загрузочного образа, затем — размер и адрес таблицы параметров
загрузки. Все указанные значения являются 32-разрядными. Далее следует адрес
сегмента кода монитора и адрес возврата после завершения работы MINIX 3.
Эти значения 16-разрядные, поскольку монитор функционирует в 16-разрядном
защищенном режиме. Первые несколько команд файла трхЗ 8 6 . s преобразуют
16-разрядный указатель стека монитора в 32-разрядную величину для исполь-
использования в защищенном режиме. Затем следующая команда копирует указатель
стека в регистр ebp (строка 6436):
mov ebp, esp
Это позволяет со смещениями использовать регистр для извлечения из стека
значений, помещенных туда монитором (строки 6464-6467). Поскольку в про-
процессорах Intel рост стека происходит вниз, значение 8 (ebp) указывает на вели-
величину, помещенную вслед за величиной 12 (ebp).
Значительная часть работы должна делаться ассемблерным кодом: настройка
кадра стека, чтобы создать необходимую среду для С-кода, копирование таблиц,
описывающих сегменты памяти, и установка различных регистров процессора.
Когда эта работа завершается, управление передается процессу инициализации
вызовом С-функции cstart (строка 6481). Обратите внимание на то, что в ас-
ассемблерном коде ссылка на нее выглядит как _с start, поскольку компилятор
каждое имя функции в таблице символов предваряет знаком подчеркивания,
и компоновщику при компоновке различных файлов требуются именно такие
имена. Так как при использовании ассемблера никаких дополнительных знаков
к именам не приписывается, здесь к именам всех С-функций необходимо явно
добавлять знак подчеркивания, иначе компоновщик не сможет правильно ском-
скомпоновать объектные файлы.
В свою очередь, функция cstart вызывает функцию для инициализации гло-
глобальной таблицы дескрипторов (Global Descriptor Table, GDT) — центральной
структуры данных, используемой 32-разрядными процессорами Intel для защиты
памяти, и таблицы дескрипторов прерываний (Interrupt Descriptor Table, IDT),
с помощью которой выбирается обработчик для каждого конкретного прерыва-
прерывания. После возврата из cstart сформированные таблицы активизируются при
помощи команд lgdt и lidt (строки 6487 и 6488), загружающих выделенные
регистры. Следующая команда на первый взгляд выглядит как пустая операция,
так как она передает управление точно в ту же точку, куда оно бы попало после
серии инструкций пор:
jmpbf СS_SELECTOR:csinit
Но в действительности это — важный элемент инициализации, поскольку пере-
переход принуждает к использованию только что инициализированных структур
данных. Далее следует ряд манипуляций с регистрами процессора, после чего
MINIX переходит к строке 6503 (без вызова), являющейся точкой входа функции
main ядра (в файле main. с). К этому моменту код инициализации в трхЗ 86 . s
завершает свою работу. Остальная часть ассемблерного кода ответственна за за-
запуск или перезапуск процессов и заданий, обработку прерываний и прочие дей-
действия, которые для эффективности должны быть написаны на языке ассемблера.
Мы вернемся к этим процедурам в следующем разделе.
Теперь перейдем к рассмотрению высокоуровневых С-функций инициализации.
Общая стратегия такова, чтобы как можно больше использовать высокоуровневый
код на языке С. Практически первое, что делается в функции cstart (файл
start. с, строка 6920), вызывается процедура prot_init, инициализирующая
механизмы защиты памяти и таблицы прерываний. Затем на очереди выпол-
выполняются перенос параметров загрузки в область памяти ядра и их сканирование
с использованием функции get_value (строка 6997). Сканирование представ-
представляет собой определение имен параметров и возврат соответствующих численных
значений в виде строк. В файле start. с определяется тип дисплея, шины и про-
процессора, а в 16-разрядном режиме — режим работы процессора (реальный или
защищенный). Вся эта информация помещается в соответствующие глобальные
переменные, чтобы ее можно было при необходимости задействовать в других
частях ядра.
Функция main (файл main.с, строка 7130) завершает инициализацию и пере-
переводит систему в режим нормальной работы. Для этого сначала настраиваются
средства управления прерываниями с помощью функции intr_init. Данный
вызов помещен здесь потому, что он зависит от аппаратного обеспечения и не
может быть сделан до того, как определен тип машины. Значение передаваемого
функции intr_init аргумента, равное 1, указывает, что инициализация выпол-
выполняется для MINIX 3. Если передать 0, параметры возвратятся в исходное состоя-
состояние, когда операционная система завершит выполнение и передаст управление
монитору загрузки. Функция intr_init гарантирует, что любые прерывания
до окончания инициализации игнорируются. О том, как этого добиться, мы по-
поговорим позже.
Большая часть кода функции main служит для создания таблиц процессов и при-
привилегий, чтобы к началу планирования первых заданий и процессов их карты
памяти, регистры и данные о привилегиях были установлены правильно. Все
ячейки таблицы процессов помечаются как свободные, а массив pproc_addr,
введенный для ускорения доступа к таблице процессов, заполняется в цикле
(строки 7150-7154). Цикл в строках 7155-7159 очищает таблицу привилегий
и массив pproc_addr, а также таблицу процессов и массив доступа к ней. При
записи значения в поле таблицы процессов или привилегий соответствующий
элемент помечается как неиспользуемый. Тем не менее любой элемент таблицы,
независимо от того, используется он или нет, должен быть инициализирован
номером индекса.
Строка 7153:
(pproc_addr + NR_TASKS)[i] = rp;
Поскольку в С запись а [ i ] в точности эквивалентна записи * (a+i), то есть нет
большой разницы, прибавлять смещение к адресу массива или к индексу, эту
строку можно записать проще:
pproc_addr[i + NR_TASKS] = rp;
Однако некоторые компиляторы генерируют лучший код, если постоянное сме-
смещение прибавляется к адресу массива.
Самый большой фрагмент кода функции main в рамках длинного цикла (строки
7172-7242) заполняет таблицу процессов информацией, необходимой для запуска
всех процессов загрузочного образа (обратите внимание, что в устаревшем коммен-
комментарии к строке 7161 упоминаются только задания и серверы). Все эти процессы
обязаны существовать к моменту запуска системы, и ни один из них при нор-
нормальной работе не должен завершаться. В начале цикла в ip помещается адрес
элемента таблицы image (строка 7173). Это — указатель на структуру, поэтому
к полям самой структуры можно обратиться с помощью записи вида 1р->имя_
поля, как в строке 7174. Подобная запись широко используется в коде MINIX 3.
Аналогично, гр представляет собой указатель на элемент таблицы процессов,
a priv (гр) указывает на элемент таблицы привилегий. Значительная часть ко-
кода инициализации таблиц процессов и привилегий в цикле включает чтение зна-
значения из таблицы image и сохранения его в таблице процессов или привилегий.
В строке 7185 проверяется, является ли процесс частью ядра, и в случае, если
это так, в базе области стека задания сохраняется последовательность STACK_
GUARD. Позднее с ее помощью можно убедиться в том, что стек не переполнен.
Далее для каждого задания инициализируется указатель стека. Каждому зада-
заданию необходим собственный указатель стека. Поскольку рост стека происходит
в сторону меньших адресов, начальное значение указателя рассчитывается как
сумма базового адреса стека и его размера (строки 7190 и 7191). Существует од-
одно исключение: процесс KERNEL (в некоторых местах идентифицируемый как
HARDWARE) никогда не считается готовым, никогда не выполняется как обычный
процесс, а следовательно, не нуждается в указателе стека.
Двоичные коды компонентов загрузочного ядра компилируются так же, как и
любые другие программы MINIX 3, а компилятор создает в начале каждого фай-
файла заголовок согласно определению в include/a. out .h. Загрузчик копирует
заголовки в собственное пространство памяти до запуска операционной системы,
а когда монитор передает управление на метку MINIX файла трхЗ 8 б . s, физиче-
физический адрес заголовочной области передается ассемблерному коду в стеке, как мы
уже видели. В строке 7202 один из этих заголовков копируется в локальную
exec-структуру, ehdr, где hdrindex используется в качестве индекса массива
заголовков. Затем адреса сегментов данных и кода преобразуются в базовые еди-
единицы и вводятся в карту памяти процесса (строки 7205-7214).
Перед тем как продолжить, следует подробнее рассмотреть несколько моментов.
Во-первых, для процессов ядра значение hdr index всегда устанавливается равным
нулю (строка 7178). Все процессы ядра компилируются в один файл с самим
ядром, а информация об их стеках находится в таблице image. Поскольку задание
ядра способно вызывать любой его код и использовать внутренние данные, объем
отдельного задания становится неважным. Таким образом, ядру и его заданиям
соответствует один и тот же элемент массива aout, а поля, определяющие объе-
объемы заданий, заполняются значениями размеров самого ядра. Задания получают
информацию о своих стеках из таблицы image, инициализируемой в процессе
компиляции файла table. с. После того как все процессы ядра обработаны, зна-
значение переменной hdrindex инкрементируется на каждой итерации цикла (стро-
(строка 7196), поэтому все системные процессы, выполняемые в пользовательском
пространстве, получают надлежащие данные из своих собственных заголовков.
Еще один аспект: в функциях, осуществляющих копирование данных, не обяза-
обязательно соблюден привычный порядок указания источника и приемника. Изучая
описанный цикл, постарайтесь не запутаться. Порядок указания аргументов
стандартной библиотечной С-функции strncpy таков, что приемник задается
первым:
strncpy(куда, откуда, счетчик)
Это аналогично операции присваивания, в левой части которой находится пе-
переменная, а в правой — выражение, значение которого записывается. Функция
strncpy копирует имена процессов в элементы таблицы процессов для отла-
отладочных и других целей (строка 7179). Обратное преобразование выполняет
функция phys_copy:
hys_cору(откуда, куда, счетчик)
Она используется в строке 7202 для копирования заголовков пользовательских
процессов.
Продолжая изчение инициализации таблицы процессов, в строках 7220 и 7221
мы видим установку начальных значений счетчика команд и слова состояния
процессора. Слово состояния процессора для заданий отличается от драйверов
устройств и серверов, поскольку привилегии заданий выше, чтобы обеспечить
им доступ к портам ввода-вывода. Далее, если процесс является пользователь-
пользовательским, выполняется инициализация указателя его стека.
Один из элементов таблицы процессов не должен и не может планироваться.
Процесс HARDWARE существует только для учетных целей: считается, что он вы-
выполняется лишь во время обслуживания прерываний. Все остальные процессы
помещаются в соответствующие очереди кодом строк 7234 и 7235. Функция
lock_enqueue запрещает прерывания перед изменением очередей, а затем, по
завершении изменения, включает их. Разумеется, пока ни один из процессов
не запущен, этого не требуется, однако подобный метод является стандартным,
и писать другой код, чтобы воспользоваться им лишь единожды, нецелесообразно.
Последний этап инициализации элемента таблицы процессов — вызов функции
alloc_segments (строка 7241). Это машинно-зависимая процедура, размещаю-
размещающая в соответствующих полях местоположение, размеры и уровни разрешений
сегментов памяти процесса. Для более старых процессоров Intel, не поддержи-
поддерживающих защищенный режим, определяется только положение сегмента. Если
систему нужно будет перенести на процессор, выделяющий память иначе, проце-
процедура alloc_segments должна быть переписана.
После инициализации в таблице процессов элементов всех заданий, серверов
и процесса init система почти готова к работе. В переменной bill_ptr хра-
хранится ссылка на процесс, которому в текущий момент передается процессор. Эту
переменную необходимо инициализировать, для чего подходит ссылка на про-
процесс IDLE (строка 7250). После этого ядро готово к обычной работе — управле-
управлению и планированию процессов, как показано на рис. 2.2.
Еще не все компоненты системы готовы к нормальному функционированию, одна-
однако они выполняются как независимые процессы, считаются готовыми и поставлены
в очередь. Процессы инициализируют себя во время выполнения. Все, что оста-
осталось сделать ядру, — вызвать функцию announce, чтобы уведомить всех о своей
готовности, а затем — функцию restart (строки 7251 и 7252). Во многих С-про-
граммах функция main представляет собой цикл, однако в MINIX 3 ядро за-
завершается, как только заканчивается инициализация. Вызов функции restart
в строке 7252 запускает первый процесс, стоящий в очереди. Управление больше
никогда не возвращается функции main.
Функция _restart представляет собой ассемблерную подпрограмму, код кото-
которой находится в файле трхЗ 86 . s. Фактически _restart не является самостоя-
самостоятельной функцией. Это промежуточная точка входа в более сложную процеду-
процедуру. Подробно мы рассмотрим ее в следующем разделе, а пока скажем лишь, что
_restart вызывает переключение контекста и управление получает процесс, на
который указывает переменная proc_ptr. В первый раз _restart запускает
процесс. Затем эта функция вызывается снова и снова, по мере того как пользова-
пользовательские процессы, задания и серверы по очереди получают и теряют управление,
либо приостанавливаясь в ожидании ввода, либо по истечении кванта времени.
Разумеется, когда _restart запускается впервые, завершенной оказывается
только инициализация ядра. Вспомним, что в таблице процессов MINIX 3 име-
имеется три части. Вы можете спросить: каким же образом можно начинать выпол-
выполнение процессов, когда основные компоненты таблицы процессов не установле-
установлены? Исчерпывающий ответ на этот вопрос вы получите в следующих главах
книги. Пока для краткости можно привести такое объяснение: счетчики команд
всех процессов загрузочного образа изначально указывают на код инициализа-
инициализации процессов, поэтому все процессы вскоре блокируются. В конечном счете,
управление получают менеджер процессов и файловая система, которые запус-
запускают коды инициализации и заполняют свои области в таблице процессов. Да-
Далее управление получает процесс init, который запускает несколько дочерних
процессов getty, по одному на каждый терминал. Эти процессы до ввода какой-
либо информации на терминал также остаются заблокированными. После этого
первый пользователь получает возможность войти в систему.
Мы рассмотрели процесс запуска MINIX 3, управляемый кодом из трех файлов,
два из которых написаны на С, один — на ассемблере. В ассемблерном файле,
mpx3 86 . s, есть дополнительный код, связанный с обработкой прерываний, об-
обсуждение которого мы отложим до следующего раздела. А пока давайте завер-
завершим тему инициализации системы кратким описанием оставшихся функций из
С-файлов. В файле start. с это — функция get_value (строка 6997), обнару-
обнаруживающая копии параметров загрузки в окружении ядра. Она представляет со-
собой упрощенную версию стандартной библиотечной функции, переписанную во
избежание излишнего загромождения ядра.
В файле main, с остались нерассмотренными три процедуры. Процедура announce
отображает сообщение об авторских правах и указывает режим работы MINIX 3 —
реальный, 16-разрядный или защищенный 32-разрядный. Пример:
MINIX 3.1 Copyright 2006 Vrije Universiteit, Amsterdam, The Netherlands
Executing in 3 2-bit protected mode
Если вы получили такое сообщение, это означает, что инициализация ядра за-
завершена. Функция prepare_shutdown (строка 7272) посылает всем процессам
сигнал SIGKSTOP (системным процессам нельзя посылать сигналы так же, как
пользовательским), а затем устанавливает таймер, выделяя всем системным про-
процессам время на «уборку» до вызова последней процедуры, shutdown. Процеду-
Процедура shutdown, как правило, возвращает управление монитору загрузки MINIX 3.
Для этого к контроллерам прерываний применяются параметры, восстанавли-
восстанавливаемые из BIOS с помощью функции intr_init @) (строка 7338).
2.6.8. Обработка прерываний в MINIX
Особенности обработки прерываний во многом зависят от аппаратной платфор-
платформы, но у любой системы должны быть элементы с подобной функционально-
функциональностью. В 32-разрядных процессорах Intel прерывания генерируются аппаратным
обеспечением и в виде электрических сигналов передаются сначала на контрол-
контроллер прерываний. Это — интегральная схема, которая умеет различать несколько
подобных сигналов и для каждого из них генерировать уникальный идентифи-
идентификатор на шине данных процессора. Сам же процессор имеет лишь один вход для
всех устройств, а следовательно, не может определить, какое именно устройство
нуждается в обслуживании. У компьютеров с 32-разрядными процессорами Intel
обычно имеются два контроллера прерываний, каждый из которых обслуживает
8 устройств. Но один контроллер подчинен (slave) другому, то есть сигналы с его
выхода передаются на вход главного (master) контроллера. Таким образом, эта
комбинация контроллеров способна обслуживать 15 различных устройств, как
показано на рис. 2.18. Некоторые из 15 входов являются выделенными; напри-
например, вход таймера, IRQ 0, не подключен к какому-либо разъему, предназначенному
для адаптеров. Остальные же входы подключены к разъемам и могут использо-
использоваться так же, как и обычные устройства.
Рис. 2.18. Обработка прерываний в 32-разрядных процессорах Intel
Здесь прерывания приходят по одной из линий IRQ n, нарисованных в правой
части схемы. Процессор получает сигнал о том, что произошло прерывание, по
контакту INT. В ответ на это сообщение процессор посылает по контакту INTA
(INTerrupt Acknowledge — подтверждение прерывания) сигнал, по которому
контроллер помещает на шину данных информацию, говорящую системе о том,
какой из обработчиков вызывать. Программируются контроллеры прерываний
при инициализации системы в момент, когда функция main вызывает функцию
intr_init. При программировании определяется, какие данные контроллер
сформирует на шине данных процессора при поступлении сигнала по каждой из
входных линий контроллера, а также устанавливается ряд других параметров
контроллера. Передаваемые на шину данные представляют собой 8-разрядное
число, используемое далее как индекс в массиве максимум из 256 элементов.
В MINIX этот массив содержит 56 элементов, из которых реально задействуют-
ся 35. Остальные зарезервированы для будущих версий процессоров Intel или
расширений в MINIX 3. В 32-разрядной версии системы в записях таблицы со-
содержатся дескрипторы шлюзов прерываний (interrupt gate descriptor). Каждый
дескриптор является 8-байтовой структурой с несколькими полями.
Есть несколько режимов обработки прерываний. В том, который принят в MINIX 3,
из нескольких полей дескриптора наибольшее значение для нас будут иметь ад-
адрес сегмента памяти, где размещена функция-обработчик, и адрес этой функции
внутри сегмента. Получив сигнал прерывания, процессор выполняет код, на ко-
который ссылается запись в таблице. Результат полностью эквивалентен ассемб-
ассемблерному вызову
int <nnn>
Разница только в том, что при аппаратном прерывании адрес процедуры берется
не из памяти, а из регистра контроллера.
Механизм переключения задач в 32-разрядных процессорах Intel, как ответ на
прерывание, довольно сложен, и изменение значения счетчика команд — только
часть этого процесса. Когда процессор, уже обрабатывающий некоторый процесс,
получает прерывание, он сначала выделяет новый стек, который будет использо-
использоваться для выполнения обработчика. Положение стека определяется значением
записи в сегменте состояния задания (Task State Segment, TSS). Эта структура
едина для всей системы, инициализируется при вызове prot_init и модифи-
модифицируется при запуске каждого процесса. В результате каждый новый стек, со-
создаваемый прерыванием, всегда начинается от конца структуры stackf rame_s
в записи в таблице процессов прерванного процесса. Затем процессор автомати-
автоматически помещает в новый стек значения нескольких регистров, включая нужные
для восстановления стека и счетчика команд прерванного процесса. Обработчик
прерывания заносит в стек значения дополнительных регистров, заполняя кадр
стека, после чего переключается на другой стек, предоставляемый ядром. Этот
стек и используется для всех действий по обработке прерывания.
Завершив свою работу, обработчик прерывания переключается обратно на кадр
стека в таблице процессов (не обязательно на тот, который использовался для
предыдущего прерывания), затем самостоятельно извлекает из стека значения
дополнительных регистров и выполняет инструкцию iretd (возврат из преры-
прерывания). Эта инструкция восстанавливает значения регистров, помещенные в стек
процессором, и переключается на исходный (до прерывания) стек. Таким образом,
прерывание останавливает текущий процесс, а по завершении обработки процесс
запускается, причем не обязательно тот, который был приостановлен. Данная схема
отличается от более простых алгоритмов, часто встречающихся во многих ассемб-
ассемблерных программах, тем, что в стеке прерванного процесса не сохраняется никаких
данных. Более того, так как стек пересоздается в заранее заданном месте (которое
определяется записью в TSS), упрощается управление несколькими параллельно
работающими процессами. Все, что нужно для запуска нового процесса, — по-
поместить в указатель стека адрес нового кадра стека, извлечь из стека значения
регистров, помещаемые туда программно, и выполнить инструкцию iretd.
Получив прерывание, процессор блокирует все остальные прерывания. Это га-
гарантирует, что с кадром стека во время выполнения обработчика не произойдет
ничего, что может вызвать переполнение жестко ограниченного кадра стека.
Блокировка происходит автоматически, хотя существуют и ассемблерные инст-
инструкции, которые могут запрещать или разрешать обработку прерываний. Преры-
Прерывания остаются блокированными, пока используется стек ядра, расположенный
за пределами таблицы процессов. Существует механизм, позволяющий запустить
в это время обработчик исключений (с помощью которого процессор реагирует
на обнаружение ошибок). Исключения аналогичны прерываниям, однако их не-
невозможно блокировать. Таким образом, исключения делают возможной обработ-
обработку вложенных прерываний. В подобной ситуации новый стек не создается — не-
необходимые регистры сохраняются в существующем стеке. Предполагается, что
во время работы ядра исключение не может возникнуть; это вызвало бы хаос.
Когда при выполнении ядра процессор встречает команду iretd, он использует
более простой механизм возврата, нежели в случае прерванного процесса. С помо-
помощью селектора сегмента кода, извлекаемого из стека при обработке инструкции
iretd, процессор может определить, какой из ее вариантов следует выполнить.
Различные варианты реакции процессора на прерывания при выполнении кода
ядра определяются упомянутыми ранее уровнями привилегий. Когда уровень при-
привилегий прерванного кода совпадает с уровнем обработчика, действует упрощен-
упрощенный механизм. Тем не менее прерванный код чаще всего имеет более низкий
уровень привилегий, чем код обработки прерывания. В этом случае используется
механизм, ориентированный на TSS и создание нового стека. Уровень привиле-
привилегий сегмента кода запоминается в его селекторе, который сохраняется в стеке,
что и позволяет при возврате из прерывания определить, какой механизм будет
применяться.
При создании нового стека аппаратно решается еще одна задача. Проверяется,
достаточно ли новый стек велик для того, чтобы вместить необходимый минимум
информации. Это предотвращает случайный (или намеренный) крах ядра в слу-
случае, когда пользовательский процесс делает системный вызов при несоответст-
несоответствующем размере стека. Такая функциональность встроена в процессор специаль-
специально для того, чтобы реализовывать мультипрограммные операционные системы.
Описанное поведение может показаться непонятным непосвященным в архитек-
архитектуру 32-разрядных процессоров Intel. Обычно мы будем стараться избегать по-
подобных деталей, но чтобы понять, что происходит при возникновении прерыва-
прерывания и исполнении команды iretd, нужно разобраться в том, как ядро управляет
переходом процесса в состояние выполнения и выходом из него (см. рис. 2.2).
То, что значительная часть работы выполняется аппаратно, упрощает жизнь про-
программиста и, по видимости, делает систему более эффективной. В то же время
такая помощь со стороны аппаратного обеспечения усложняет понимание кода.
Познакомившись с механизмом прерываний, вернемся к файлу mpx3 86 . s. В нем
содержится крохотная часть ядра MINIX 3, непосредственно взаимодействую-
взаимодействующая с прерываниями. Для каждого прерывания в этом файле имеется точка входа.
Так, обработчики от _hwintOO до _hwintO7 (строки 6531-6560) делают вызов
hwint_master (строка 6515), а обработчики от _hwintO8 до _hwintl5 (стро-
(строки 6583-6612) — вызов hwint_slave (строка 6566). Каждая точка входа пере-
передает вызову аргумент, указывающий, какое из устройств требует обслуживания.
Фактически эти «вызовы» являются не вызовами, а макросами: имеется восемь
копий макроопределения hwint_master, различающихся только параметром
irq. Аналогично дело обстоит и с макросом hwint_slave. Возможно, идея ка-
кажется экстравагантной, однако в результате ассемблированный код оказывается
очень компактным. Объектный код каждого из макросов занимает менее 40 байт.
При обслуживании прерывания важна скорость, а использование макросов из-
избавляет от трех действий — загрузки параметра, вызова подпрограммы и извле-
извлечения переданного параметра.
Далее в обсуждении мы будем рассматривать вызов hwint_master так, как буд-
будто это функция, а не восемь отдельных макросов. Вспомним, что перед исполне-
исполнением hwint_master процессор создает новый стек в структуре stackf rame_s
прерванного процесса внутри его элемента в таблице процессов. В нем уже со-
сохранены семь ключевых регистров, а все прерывания запрещены. Первое дейст-
действие, выполняемое hwint_master, — вызов save (строка 6516). Эта подпрограм-
подпрограмма помещает в стек значения вех регистров, необходимых для восстановления
прерванного процесса. Ее можно было бы переписать как часть макроса, чтобы
повысить скорость, но это увеличило бы размер макроса более чем в два раза,
и, кроме того, подпрограмма save необходима для вызовов, осуществляемых дру-
другими функциями. Как мы увидим, save занимается тем, что хитро манипулиру-
манипулирует со стеком. После возврата из hwint_master используется стек, выделенный
ядром, а не кадр стека в таблице процессов.
Теперь подошла очередь использования двух таблиц, объявленных в файле glo .h.
Таблица _irq_handlers содержит информацию об обработчиках прерывания,
включая их адреса. Номер обрабатываемого прерывания подлежит преобразова-
преобразованию в адрес, определяемый таблицей _irq_handlers. Этот адрес передается
в стек как аргумент функции _intr_handle, которая затем и вызывается. Мы
рассмотрим код этой функции позднее. Пока мы лишь скажем, что она вызывает
процедуру обработки прерывания, а кроме того, устанавливает или сбрасывает
флаг в массиве _irq_actids в зависимости от того, была ли обработка преры-
вания успешной, и дает другим записям очереди возможность выполниться. В за-
зависимости от конкретного обработчика, после возврата из вызова _intr_handle
контроллер прерываний может быть как готовым, так и не готовым к приему
следующего прерывания. Это определяется соответствующей записью в массиве
_irq_actids.
Ненулевое значение в _irq_actids указывает на то, что процедура обработки
данного прерывания не завершена. Если это так, контроллеру запрещается реа-
реагировать на прерывания, поступающие по той же линии (строки 67722-6724).
Приведенные команды маскируют возможность контроллера прерываний отве-
отвечать на определенные входные данные; процессор имеет внутренний запрет реа-
реагировать на все прерывания с момента первого появления сигнала прерывания,
и этот запрет продолжает действовать.
Скажем несколько слов для читателей, не знакомых с программированием на
языке ассемблера. Следующая команда в строке 6521 не задает количество бай-
байтов, на которое нужно совершить скачок:
jz Of
Значение Of не является ни шестнадцатеричным числом, ни меткой (имена
обычных меток не могут начинаться с цифры). Мы имеем дело с определением
локальной метки, принятым в ассемблере MINIX 3. Аргумент Of означает пере-
переход вперед на первую численную метку 0 в строке 6525. Байт, записанный в этой
строке, позволяет контроллеру прерываний возобновить нормальное функцио-
функционирование, возможно, с запретом прерываний текущей линии.
Интересное и, вероятно, странное наблюдение относительно метки 0 в строке
6525: такая же метка присутствует в том же файле в строке 6576 внутри макроса
hwint_slave. Ситуация осложняется еще и тем, что обе метки расположены
в макросах, а подстановка последних выполняется до того, как ассемблер про-
просматривает код. В результате ассемблер обнаруживает в одном коде шестнадцать
меток 0! Подобное тиражирование меток при их использовании в макросах ста-
стало причиной ввода механизма локальных меток. При разрешении последних ас-
ассемблер ищет первую метку в указанном направлении, игнорируя все остальные.
Процедура _intr_handle является аппаратно-зависимой, и детали, касающие-
касающиеся ее кода, будут рассмотрены нами при изучении файла i8259 . с. Тем не менее
несколько общих слов о ее функционировании здесь вполне уместны. Процеду-
Процедура _intr_handle сканирует связанный список структур, содержащих адреса
функций, обрабатывающих прерывания устройств, и номера процессов, соответ-
соответствующих драйверам устройств. Связанный список требуется потому, что одна
линия прерываний может совместно использоваться несколькими устройствами.
Обработчик прерывания сначала проверяет, нуждается ли, на самом деле, в об-
обслуживании его устройство. Разумеется, в случае таймера (прерывание 0) такая
проверка не нужна, поскольку линия прерывания физически связана с микро-
микросхемой, генерирующей тактовые сигналы, и она является единственным устрой-
устройством, способным вызвать прерывание.
Код обработчика должен быть написан так, чтобы его выполнение занимало как
можно меньше времени. Если не требуется выполнять какие-либо действия
либо обслуживание прерывания завершается немедленно, обработчик возвращает
значение TRUE. Обработчик может выполнять такие действия, как чтение данных
входного устройства и передача их в буфер для последующего доступа к ним со
стороны соответствующего драйвера. Обработчик может послать драйверу сообще-
сообщение, заставляющее планировать его как обычный процесс. Если работа не завер-
завершена, обработчик возвращает значение FALSE. Элемент массива _irq_act_ids
представляет собой битовую карту, регистрирующую результаты работы всех
обработчиков списка так, что нулевое значение имеет место в том и только в том
случае, если все обработчики вернули TRUE. Иначе команды строк 6522-6524
запрещают прерывание до повторного включения контроллера в строке 6536.
Данный механизм гарантирует, что ни один из обработчиков в цепочке, принад-
принадлежащей прерыванию, не будет активирован до того, как все соответствующие
драйверы устройств закончат свою работу. Очевидно, что необходим альтерна-
альтернативный способ разрешения прерываний; такой способ предоставляет функция
enable_irq, рассмотрением которой мы займемся позднее. Пока достаточно
сказать, что эта функция должна вызываться по завершении работы каждого
драйвера устройства. Кроме того, очевидно, что функция enable_irq должна
сначала сбросить собственный бит в элементе _irq_act_ids, соответствующий
прерыванию драйвера, а затем проверить, все ли биты сброшены. Лишь после
этого прерывание можно заново разрешить на контроллере.
Приведенное описание в его простейшей форме можно применить лишь к драй-
драйверу часов, поскольку часы — единственное устройство, генерирующее прерыва-
прерывания и являющееся частью библиотеки ядра. Адрес обработчика прерываний дру-
другого процесса не важен в контексте ядра, и функция enable_irq ядра не может
быть вызвана отдельным процессом в собственном пространстве памяти. Для всех
драйверов устройств, находящихся в пользовательском пространстве (то есть
всех драйверов, реагирующих на аппаратные прерывания, за исключением драй-
драйвера часов), адрес общего обработчика generic_handler хранится в связанном
списке обработчиков. Исходный код generic_handler размещен среди файлов
системного задания, однако, поскольку последнее компилируется вместе с ядром
и полученный код выполняется в ответ на прерывание, функцию generic_
handler нельзя считать частью системного задания. Помимо адреса общего об-
обработчика, в каждом элементе связанного списка хранится номер процесса со-
соответствующего драйвера устройства. При вызове функция generic_handler
посылает драйверу сообщение, запускающее определенные его функции. Сис-
Системное задание поддерживает другой конец описанной выше цепочки событий.
Когда драйвер устройства завершает работу, он выполняет вызов sys_irqctl
ядра, в ответ на который системное задание вызывает функцию enable_irq от
имени драйвера, чтобы подготовиться к следующему прерыванию.
Возвращаясь к функции hwint_master, обратим внимание на то, что она завер-
завершается командой ret (строка 6527). Здесь происходит нечто не вполне очевид-
очевидное. Если процесс был прерван, то активным является стек ядра, а не стек, со-
созданный аппаратно в таблице процессов перед запуском hwint_master. В этом
случае обработка стека подпрограммой save оставит адрес функции _restart
в стеке ядра, что вызовет повторный запуск задания, драйвера, сервера или поль-
пользовательского процесса. С большой вероятностью это будет процесс, отличный
от того, который выполнялся в момент прерывания. Все зависит от того, привело
ли к изменению планирования процессов обслуживание сообщения, созданного
процедурой обработки прерывания. Как правило, в случае аппаратного прерыва-
прерывания очереди процессов изменяются. Обработчики прерываний чаще всего пере-
передают драйверам устройств сообщения, а драйверы размещаются в очередях с бо-
более высоким приоритетом, чем пользовательские процессы. Таким образом, мы
видим самое сердце механизма, обеспечивающего иллюзию нескольких одновре-
одновременно выполняющихся процессов.
Для полноты упомянем, что в том случае, когда прерывание происходит в мо-
момент выполнения кода ядра, стек ядра уже используется. Поэтому функция save
помещает в стек адрес restartl. Тогда после завершения hwint_master ко-
командой ret работа ядра восстанавливается. Это позволяет делать вложенные
прерывания, которые запрещены в MINIX 3, поскольку прерывания недопусти-
недопустимы во время исполнения кода ядра. Тем не менее, как было отмечено, данный
механизм необходим для обработки прерываний. Когда выполнение низкоуров-
низкоуровневых процедур завершается, вызывается _restart. В результате реакции на
исключение при исполнении кода ядра с высокой вероятностью следующим
будет запущен процесс, отличный от прерванного. Исключение в ядре приведет
к сбою, после которого система попытается завершить свою работу с минималь-
минимальными повреждениями.
Процедура hwint_slave отличается от hwint_master только тем, что в ней
необходимо восстанавливать два контроллера, и подчиненный, и главный, так
как они оба блокируются при приеме сигнала подчиненным контроллером.
Теперь двинемся дальше и рассмотрим процедуру save (строка 6622), уже не-
несколько раз упомянутую. Ее имя описывает ее предназначение, заключающееся
в том, чтобы сохранить контекст прерванного процесса в выделенном процессо-
процессором стеке (в кадре стека внутри таблицы процессов). Кроме того, для поддержки
вложенных прерываний save использует переменную _k_reenter, чтобы под-
подсчитать число вложений и определить их наличие. Если процесс был прерван,
следующая инструкция (строка 6635) переключается на стек в ядре:
mov esp, k_stktop
Следующая же за ней инструкция помещает в стек адрес подпрограммы _ге-
start. В противном случае, если уже используется стек ядра, в него заносится
адрес restartl (строка 6642). Разумеется, прерывания здесь запрещены, одна-
однако данный механизм предназначен для обработки исключений. Независимо от
того, какая ветвь алгоритма была выполнена, для возврата из процедуры не
годится обычная инструкция return, так как положение стека могло быть из-
изменено, а адрес возврата «похоронен» под помещенными в стек регистрами. По-
Поэтому для возврата применяется инструкция
jmp RETADR-P_STACKBASE(eax)
Ее вы можете увидеть в двух точках выхода процедуры (строки 6638 и 6643).
Эта инструкция восстанавливает тот адрес, который был помещен в стек перед
вызовом save, и осуществляет переход по нему.
Повторный вход в ядро вызывает множество проблем, и избавление от него
упростило некоторые фрагменты кода. В MINIX 3 переменная _k_reenter не
теряет смысла: хотя обычные прерывания во время исполнения ядра недопусти-
недопустимы, исключения возможны. При нормальном функционировании команда пере-
перехода в строке 6634 никогда не выполняется, однако она необходима для обработ-
обработки исключений.
В качестве отступления заметим, что при разработке MINIX 3 в процессе избав-
избавления от повторного входа в ядро программирование опередило документирова-
документирование. Документирование в некоторых аспектах сложнее, чем написание программ.
Если ошибки в программе можно выявить во время ее выполнения или с помо-
помощью компилятора, то обнаружить некорректные комментарии аналогичным об-
образом невозможно. Так, в начале файла mpx3 86 . s приведен длинный коммен-
комментарий, который, к сожалению, неверен. В его части, расположенной в строках
6310-6315, должно быть сказано, что повторный вход в ядро возможен лишь
при появлении исключения.
Далее в файле mpx3 86.s следует процедура _s_call (строка 6649). Прежде
чем вдаваться в детали, посмотрим, как она заканчивается. Здесь вы не увидите
в конце инструкции ret или jmp. Фактически, выполнение продолжается с метки
_restart (строка 6681). Процедура _s_call является двойником механизма
обработки прерываний из числа системных вызовов. Она получает управление
при возникновении программного прерывания, то есть в результате срабатыва-
срабатывания инструкции int <nnn>. Программные прерывания обрабатываются так же,
как и аппаратные, за исключением того, что индекс записи в таблице дескрипто-
дескрипторов прерываний берется из инструкции, а не передается контроллером. Таким
образом, когда _s_call получает управление, процессор уже переключен на стек
в таблице процессов и в него помещены значения нескольких регистров. Так как
у подпрограммы _s_call нет в конце команды выхода, выполняется процедура
_restart, после чего подпрограмма окончательно завершается инструкцией
iretd. В результате, как и в случае с аппаратным прерыванием, запускается про-
процесс, на который в данный момент ссылается указатель proc_ptr. На рис. 2.19
сравниваются механизмы обработки аппаратного прерывания и системного вы-
вызова, использующего программные прерывания.
Рассмотрим процедуру _s_call более подробно. Еще одна метка, _p_s_call, —
специфика 16-разрядной версии MINIX 3, в которой имеются раздельные проце-
процедуры для защищенного и реального режимов. В 32-разрядной версии обращение
по любой из меток приводит к одному результату. Когда программист на С про-
программирует системный вызов, он пишет код, выглядящий как обычный вызов
функции, локальной или библиотечной. Поддерживающая системные вызовы биб-
библиотечная подпрограмма подготавливает соответствующее сообщение, помещает
идентификатор процесса и адрес сообщения в регистры процессора и вызывает
инструкцию int SYS3 86_VECTOR. Как было отмечено ранее, такая инструкция
инициирует программное прерывание и управление передается подпрограмме
_s_call, перед вызовом которой в стек (в таблице процессов) помещается ряд
регистров.
Рис. 2.19. Сравнение механизмов обработки аппаратного прерывания и системного вызова:
а — обработка аппаратного прерывания; б — так происходит системный вызов
Первая часть процедуры _s_call напоминает код save с раскрытыми макросами.
Как и в коде save, процессор переключается на стек в ядре инструкцией
mov esp, k_stktop
Аналогично разрешаются прерывания. (Сходство программных и аппаратных пре-
прерываний проявляется и в том, что в обоих случаях прерывания перед входом в об-
обработчик запрещаются.) Далее следует вызов процедуры _sys_call (строка 6672),
которую мы рассмотрим разделом позже. Сейчас мы скажем только то, что она при-
приводит к доставке сообщения и, следовательно, запускает планировщик. Таким обра-
образом, когда _sys_call выполняет возврат, указатель proc_ptr может не указывать
на процесс, сделавший системный вызов. Затем управление передается restart.
Мы видим, что вызов _restart (строка 6681) происходит в трех случаях:
1. В функции main при запуске системы.
2. При выполнении перехода в функции hwint_master или hwint_slave по-
после аппаратного прерывания.
3. После выполнения системного вызова, за счет того, что _s_call не содержит
завершающей инструкции.
На рис. 2.20 показана упрощенная схема передачи управления между процессами
и ядром через вызов _restart.
Рис. 2.20. Restart — код, исполняемый как после запуска системы, так и после прерываний
и системных вызовов. После него запускается следующий запланированный процесс
(как правило, отличный от прерванного). На диаграмме не показаны прерывания,
происходящие во время выполнения ядра
В любом из трех случаев прерывания перед вызовом _restart запрещаются.
К моменту, когда выполнение кода достигает строки 6690, следующий процесс
уже выбран и не может быть изменен, поскольку прерывания запрещены. Табли-
Таблица процессов разработана так, чтобы начинаться с кадра стека, поэтому следую-
следующая инструкция заносит в регистр указателя стека ссылку на кадр стека в табли-
таблице процессов:
mov esp, (_proc_ptr)
Далее выполняется инструкция
lldt P_LDT_SEL(esp)
Эта инструкция загружает значение регистра локальной таблицы дескрипторов
из кадра стека, заставляя процессор использовать сегменты памяти, принадлежа-
принадлежащие тому процессу, который будет запущен. Следующая инструкция загружает
из записи очередного процесса адрес кадра стека, который будет задействован
при возникновении следующего прерывания, и помещает этот адрес в сегмент
состояния задания (TSS).
Первая часть подпрограммы „restart не нужна в том случае, если прерывание
произошло в момент работы кода ядра, поскольку стек ядра уже используется,
и после завершения обработки выполнение кода должно продолжиться с пре-
прерванного места. Тем не менее в MINIX 3 повторное вхождение в ядро не допус-
допускается, и обычные прерывания не могут происходить во время его работы. Метка
restartl (строка 6694) отмечает инструкцию, с которой в данном случае необ-
необходимо продолжить выполнение при появлении исключения во время работы
ядра (будем надеятся, что это никогда не произойдет). В этом месте декременти-
руется значение переменной k_reenter, обозначая тем самым новый уровень
вложения прерываний, а последующие команды восстанавливают состояние про-
процессора. Завершающие инструкции модифицируют стек так, чтобы игнорировался
адрес возврата, помещенный в стек при вызове save. Если прерывание произош-
произошло во время выполнения пользовательского процесса, завершающая инструкция
iretd передает управление следующему процессу в очереди планировщика, при
этом восстанавливаются его оставшиеся регистры, в том числе указатель и адрес
сегмента стека. Но если управление было передано через restartl, то есть за-
задействован не кадр стека, а стек ядра, это означает, что после завершения совсем
не нужно переходить к новому процессу, а требуется завершить выполнение пре-
прерванного кода ядра. Процессор отслеживает подобную ситуацию, когда извлека-
извлекает дескриптор сегмента кода из стека при выполнении iretd, и, обнаружив ее,
оставляет использоваться стек ядра.
Теперь самое время сказать несколько слов об исключениях. Исключения вы-
вызываются различными ошибками выполнения, однако это не всегда плохо. Ис-
Исключения полезны, чтобы побудить систему предоставить некоторые допол-
дополнительные услуги, например выделить программе дополнительную память или
загрузить в оперативную память страницу, перемещенную в область подкачки
(хотя в MINIX 3 подобные услуги не предусмотрены). Иногда исключения обу-
обусловлены ошибками в программах. Когда исключение возникает внутри ядра,
это вызывает серьезный сбой системы. Если исключение происходит в поль-
пользовательской программе, ее можно завершить, но такой подход неприменим
к операционной системе — она должна выполняться постоянно. Обрабаты-
Обрабатывают исключения так же, как и прерывания, то есть через дескрипторы в таб-
таблице дескрипторов прерываний. В этой таблице имеется шестнадцать запи-
записей, содержащих указатели на точки входа обработчиков исключений, начиная
с _divide_error и заканчивая _copr_error, которые можно увидеть в кон-
конце файла mpx3 86 . s (строки 6707-6769). Каждая из этих точек входа передает
управление процедуре exception (строка 6774) или errexception (стро-
(строка 6785) в зависимости от того, помещается ли при исключении в стек код
ошибки или нет. Обработка выполняется командами ассемблера и во многом на-
напоминает уже рассмотренный нами код: значения регистров сохраняются в сте-
стеке, и вызывается С-функция _exception (обратите внимание на знак под-
подчеркивания перед именем). Последствия исключений могут быть различными:
некоторые игнорируются, некоторые вызывают сообщение о сбое ядра, другие
посылают сигналы процессам. Самой функцией _exception мы займемся в сле-
следующем разделе.
Существует еще одна точка входа, которая обрабатывается как прерывание, —
это _levelO_call (строка 6714). Она используется, когда код необходимо ис-
исполнить с нулевым (максимальным) уровнем привилегий. Эта точка входа нахо-
находится в файле трхЗ 8 б . s вместе с прерываниями и исключениями потому, что
она также вызывается при помощи инструкции int <nnn>. Как и обработчики
исключений, она выполняет вызов save, а завершается инструкцией ret, веду-
ведущей к _restart. Ее мы рассмотрим в следующем разделе, когда мы познако-
познакомимся с кодом, нуждающемся в обычно недоступных (даже ядру) привилегиях.
Наконец, в конце ассемблерного файла выделяется место для хранения некото-
некоторых данных. Определяются два различных сегмента данных.
.sect.rom
Это объявление в строке 6822 гарантирует, что указанная область памяти нахо-
находится в самом начале сегмента данных ядра. Сюда компилятор помещает сигна-
сигнатуру (магическое число), чтобы программа boot могла убедиться, что загружает
действительно ядро. При компиляции всей системы за магическим числом будут
размещены различные строковые константы. Еще одна область данных задается
следующей директивой (строка 6825):
.sect.bss
Эта директива резервирует в неинициализированном пространстве ядра место
для стека, а выше него — память для переменных, применяемых обработчиками
прерываний. Место под стек пользовательских процессов и серверов резервиру-
резервируется на этапе компоновки, а ядро устанавливает нужное значение дескриптора
сегмента стека при их выполнении. О себе ядро должно позаботиться само.
2.6.9. Взаимодействие между
процессами в MINIX 3
В MINIX 3 процессы взаимодействуют друг с другом при помощи сообщений по
принципу рандеву. Когда процесс делает системный вызов send (отправка сооб-
сообщения), нижний уровень ядра проверяет, ожидает ли получатель сообщение от
отправителя (или от любого процесса — неопределенный отправитель имеет спе-
специальное имя ANY). Если это так, сообщение копируется из буфера отправителя
в буфер получателя, и оба процесса помечаются как готовые к выполнению. Если
получатель не ждет сообщений, отправитель блокируется и помещается в оче-
очередь процессов, ожидающих отправки сообщения.
Когда процесс делает системный вызов receive, ядро проверяет, есть ли в очере-
очереди ожидающих отправки процессов процессы, пытающиеся отправить сообщение
текущему процессу. Если таковые есть, сообщение передается из буфера отпра-
отправителя в буфер получателя, и оба процесса выходят из состояния блокировки.
Если ожидающих отправителей нет, процесс-получатель приостанавливается до
прибытия сообщения.
В операционной системе MINIX 3, где компоненты выполняются как полностью
независимые процессы, метод рандеву не всегда хорош. Именно для таких ситуа-
ситуаций предназначен примитив notify, рассылающий «базовые» сообщения. От-
Отправитель не блокируется, если адресат такого сообщения не находится в ожида-
ожидании приема, но при этом сообщение не теряется. При ближайшем совершении
получателем вызова receive активные уведомления доставляются прежде обыч-
обычных сообщений. Уведомления применяются в ситуациях, где использование обыч-
обычных сообщений привело бы к взаимным блокировкам. Ранее мы указывали на
то, что необходимо избежать ситуации, когда процесс А блокируется при попыт-
попытке передать сообщение процессу J5, а процесс В блокируется при попытке пере-
передать сообщение процессу А. Если одно из сообщений является неблокирующим
уведомлением, проблема исчезает.
В большинстве случаев отправитель с помощью уведомления информирует ад-
адресата о чем-либо. Есть две особые ситуации, когда уведомление несет в себе до-
дополнительные сведения, однако адресат всегда может послать отправителю сооб-
сообщение, чтобы запросить подробности.
Высокоуровневый код для обмена информацией между процессами находится
в файле ргос. с. Задача ядра состоит в том, чтобы преобразовать аппаратное
или программное прерывание в сообщение. Первые генерируются аппаратным
обеспечением компьютера, а вторые служат для передачи ядру запросов, в дан-
данном случае — системных вызовов. Оба варианта достаточно похожи, и для их об-
обработки можно было бы использовать одну функцию, но более эффективно со-
создать две специализированные.
В начале файла находятся два макроопределения и один комментарий, заслужи-
заслуживающие отдельного рассмотрения. Для управления списками интенсивно исполь-
используются указатели на указатели, и в строках 7420-7436 описаны их преимущества
и применение. Макрос BuildMess (строки 7458-7471) требуется при формиро-
формировании сообщений для примитива notify. Единственной вызываемой функцией
является get_uptime, которая считывает переменную, поддерживаемую таймер-
ным заданием для установки временных меток. «Вызовы» другой «функции»,
priv, являются подстановками макроса, определенного в файле priv.h:
#define priv(rp) ((rp)->p_priv)
Второй макрос, CopyMess, предоставляет дружественный интерфейс к ассемб-
ассемблерной процедуре cp_mess, расположенной в файле klib386 . s.
На макросе BuildMess стоит остановиться подробнее. Макрос priv использу-
используется в двух особых случаях. Если отправителем является HARDWARE, уведомле-
уведомление содержит дополнительную информацию — копию битовой карты активных
прерываний процесса-получателя. Если отправителем является SYSTEM, уве-
уведомление включает битовую карту активных сигналов. Обе карты размещены
в элементах таблицы привилегий получателя и доступны в любой момент. Если
получатель не блокирован в ожидании уведомления на момент его отправки,
уведомление может быть доставлено позднее. В случае обычных сообщений это
потребовало бы буфера для размещения недоставленных сообщений. Для хране-
хранения уведомлений же достаточно битовой карты, в которой биты соответствуют
процессам, способным отсылать уведомления. Если уведомление не было достав-
доставлено, в битовой карте адресата устанавливается бит, соответствующий процессу-
отправителю. При вызове receive получателем битовая карта анализируется,
и при обнаружении установленного бита уведомление восстанавливается. Бит
позволяет установить отправителя, и если им является HARDWARE или SYSTEM,
к уведомлению добавляется дополнительная информация. Кроме того, при вос-
восстановлении сообщения в него добавляется временная метка. Временные метки
не нужны при первой попытке доставки уведомления, поскольку важным явля-
является время успешной доставки.
Первой функцией в файле ргос. с является sys_call (строка 7480). Она преоб-
преобразует программное прерывание (инструкция int SYS3 86_VECTOR инициирует
системный вызов) в сообщение. Существует большое количество возможных
источников и приемников, и вызов может потребовать отправки сообщения или
приема либо того и другого. Необходимо выполнить ряд проверок. В строках
7480 и 7481 извлекается код функции (SEND, RECEIVE и др.) и флаги из первого
аргумента вызова. Первая проверка устанавливает, разрешено ли вызывающему
процессу совершать вызов. Вызов iskernel (строка 7501) является макросом,
определенным в файле proc.h (строка 5584). Следующая проверка позволяет
убедиться в том, что указанный отправитель или получатель является допусти-
допустимым процессом. Далее проверяется, что указатель сообщения ссылается на до-
допустимую область памяти. Привилегии MINIX 3 определяют, каким процессам
может посылать сообщения данный процесс, и именно эта проверка выполняет-
выполняется следующей (строки 7537-7541). Наконец, последний тест позволяет убедить-
убедиться в том, что процесс-получатель выполняется, а не инициировал завершение
(строки 7543-7547). Если все проверки успешно пройдены, начинается выпол-
выполнение реальной работы с помощью одной из трех функций: — mini_send, mini_
receive и mini_notify. Если переменная function имеет значение ECHO,
используется макрос CopyMess с одинаковыми источником и приемником. Как
было отмечено ранее, ECHO применяется исключительно с целью тестирования.
Ошибки, проверяемые тестами в функции sys_call, маловероятны, однако
соответствующие проверки выполнить не сложно, поскольку, в конечном счете,
они сводятся к сравнению небольших целых чисел. На самом базовом уровне
операционной системы желательно проверять даже самые невероятные ошибки.
В периоды активности системы ее код выполняется многократно.
Функции mini_send, mini_rec и mini_notify составляют основу стандартно-
стандартного механизма передачи сообщений MINIX 3 и должны быть тщательно изучены.
У mini_send (строка 7591) имеется три входных параметра: отправитель, полу-
получатель и указатель на буфер, в котором расположено сообщение. После много-
многочисленных тестов, проводимых в функции sys_call, в mini_send выполня-
выполняется лишь один, призванный предотвратить взаимную блокировку по записи.
В строках 7606-7610 проверяется, что отправитель и получатель не пытаются
отправить сообщения друг другу. Ключевая проверка в mini_send реализована
в строках 7615-7616. Она устанавливает, не находится ли адресат в состоянии
блокировки после вызова receive. Для этого анализируется значение бита
RECEIVING в поле p_rts_f lags элемента таблицы процессов получателя. Если
получатель ждет сообщение, то на следующем шаге выясняется, от кого. Если
выясняется, что ожидаемым источником является процесс-отправитель или про-
процесс ANY, срабатывает макрос CopyMess, копирующий данные в буфер получа-
получателя и разблокирующий его сбросом бита RECEIVING. Далее, чтобы дать полу-
получателю возможность выполниться, совершается вызов enqueue (строка 7620).
Если же адресат не блокирован или блокирован, но ждет сообщение от другого
процесса, выполняется код, расположенный в строках 7623-7632 и переводящий
уже отправителя в состояние блокировки и вывода из очереди. Все процессы,
ожидающие отправки сообщения одному и тому же получателю, связываются
вместе в список, на начало которого указывает поле p_callerq получателя.
Пример на рис. 2.21, а показывает, что произойдет, если процесс 3 не сможет
отправить сообщение процессу 0. Если при этом процесс 4 также не сможет от-
отправить сообщение процессу 0, возникает ситуация, продемонстрированная на
рис. 2.21, б.
Рис. 2.21. Очереди процессов, ожидающих отправления сообщения процессу 0
Функция mini_receive (строка 7642) вызывается функцией sys_call в случае,
если значение переменной function равно RECEIVE или BOTH. Как мы упомяну-
упомянули ранее, уведомления имеют более высокий приоритет, чем обычные сообщения.
Тем не менее уведомление никогда не передается в ответ на вызов send, поэтому
битовые карты проверяются на наличие активных уведомлений лишь в случае,
если флаг SENDREC_BUSY сброшен. При обнаружении уведомления оно помеча-
помечается как неактивное и доставляется (строки 7670-7685). При доставке использу-
используются макросы BuildMess и CopyMess, определенные в начале файла ргос.с.
На первый взгляд может показаться, что, поскольку временная метка является
частью уведомления, он несет в себе полезную информацию. Например, если ад-
адресат не мог выполнить вызов receive в течение какого-то времени, временная
метка поможет определить, как долго сообщение ожидало доставки. Однако
временная метка устанавливается при генерации уведомления, а именно — в мо-
момент его доставки, а не отправки. Для этого есть причина. Дело в том, что для
сохранения уведомлений, которые не могут быть доставлены немедленно, не
нужно никаких специальных действий. Все, что требуется, — это установить бит,
указывающий на необходимость восстановления уведомления в момент, когда
доставка станет возможной. Таким путем достигается максимально экономичное
хранение уведомлений — 1 бит на одно активное уведомление.
Есть и еще одно основание записывать в качестве временной метки момент дос-
доставки. Пусть, к примеру, с помощью уведомления менеджеру процессов переда-
передается сообщение SYN_ALARM. Если бы временная метка была проставлена при от-
отправке, менеджеру процессов пришлось бы запросить у ядра правильное время
перед проверкой очереди таймера.
Обратим внимание на то, что уведомления доставляются по одному за раз, после
чего функция mini_send завершается (строка 7684). Тем не менее отправи-
отправитель не блокируется и сразу после получения уведомления может выполнить
еще один вызов receive. Если уведомлений не обнаруживается, очереди от-
отправителя проверяются на наличие активных сообщений любых других типов
(строки 7690-7699). Если сообщение присутствует, оно доставляется макросом
CopyMess, а источник разблокируется вызовом enqueue (строка 7694). В этом
случае отправитель не блокируется.
Если ни уведомлений, ни других сообщений нет, отправитель блокируется вызо-
вызовом dequeue (строка 7708).
Функция mini_notify (строка 7719) используется для выполнения уведомле-
уведомлений. Она аналогична mini_send, и нам не потребуется долго изучать ее. Если
получатель блокирован и ожидает сообщения, уведомление генерируется мак-
макросом BuildMess и доставляется. Флаг RECEIVING получателя сбрасывается,
и функция enqueue ставит его в очередь (строки 7738-7743). Если получатель
не находится в состоянии ожидания, в его карте s_notify_pending устанавли-
устанавливается бит, указывающий на наличие активного уведомления и определяющий
отправителя. Далее отправитель продолжает свою работу, и, если необходимо
отправить получателю еще одно уведомление раньше, чем он получит предыду-
предыдущее, указанный бит попросту переписывается. Фактически, все уведомления од-
одного источника объединяются в одно сообщение, что избавляет от необходимости
управления буферами и в то же время обеспечивает возможность асинхронной
передачи сообщений.
Когда функция mini_notify вызывается из-за программного прерывания и по-
последующего вызова sys_call, прерывания запрещаются. Тем не менее тай-
мерному, системному или другому заданию, поддержка которого может быть
реализована в MINIX 3 в будущем, может потребоваться передача уведомления
в момент, когда прерывания разрешены. Функция lock_notify (строка 7758)
является безопасным проводником к mini_notify. Она проверяет переменную
k_reenter, чтобы убедиться, что прерывания уже запрещены, и если это так,
просто вызывает mini_not if у. Если прерывания разрешены, то сначала они за-
запрещаются вызовом lock, затем вызывается mini_notify, а после этого пре-
прерывания вновь разрешаются вызовом unlock.
2.6.10. Планирование процессов в MINIX 3
В MINIX 3 применяется многоуровневый алгоритм планирования. Процессам
назначаются начальные приоритеты, однако, как показано на рис. 2.14, число
уровней больше, и приоритет процесса может меняться по ходу его выполнения.
Таймерные и системные задания выполняются на уровне 1 и имеют наивысший
приоритет. Драйверы устройств на уровне 2 имеют более низкие, но не равные
между собой приоритеты. Приоритет серверов уровня 3 ниже, чем у драйверов,
но выше, чем у некоторых других процессов. Пользовательские процессы запус-
запускаются с одинаковым приоритетом, уступающим всем системным процессам, од-
однако приоритет отдельного процесса может быть понижен или повышен при по-
помощи команды nice.
Планировщик поддерживает 16 очередей готовых процессов, хотя не все из них
могут использоваться в конкретный момент времени. На рис. 2.22 показаны
очереди и помещенные в них процессы сразу после того, как ядро закончило
инициализацию и запустилось, то есть при вызове restart в файле main. с (стро-
(строка 7252). Массив rdy_head содержит по одному элементу для каждой очереди,
указывающему на первый процесс в очереди. Аналогично, элементы массива
rdy_tail указывают на последние процессы в каждой очереди. Оба массива оп-
определены с макросом EXTERN в файле proc. h (строки 5595 и 5596). Начальное
формирование очередей процессов при запуске системы определяется таблицей
image в файле table . с (строки 6095-6109).
Рис. 2.22. Планировщик поддерживает 16 очередей, по одной на каждый уровень приоритета.
Здесь показано начальное планирование процессов при запуске MINIX 3
Планирование внутри каждой очереди происходит по циклическому алгоритму.
Если текущий процесс исчерпал свой квант времени, он перемещается в хвост
очереди и получает очередной квант. Однако при разблокировании процесс по-
поступает в начало очереди, если на момент блокирования его квант не истек. Ко-
Когда такой процесс выбирается на исполнение, вместо нового кванта ему выделя-
выделяется время, оставшееся в кванте, который он не израсходовал. Массив rdy_tail
делает постановку процессов в конец очереди более эффективной. При блокиро-
блокировании текущего процесса или завершении готового процесса по сигналу такой
процесс удаляется из очередей планировщика. Очереди состоят только из про-
процессов, готовых к исполнению.
Алгоритм планирования с описанной структурой очередей прост. Берется непус-
непустая очередь с наивысшим приоритетом, в которой выбирается первый процесс.
Процесс IDLE всегда готов и находится в очереди с самым низким приоритетом.
Если все «вышестоящие» очереди пусты, система запускает процесс IDLE.
В предыдущем разделе мы неоднократно упоминали функции enqueue и dequeue.
Теперь самое время познакомиться с ними подробнее. Функция enqueue вызы-
вызывается с указателем на элемент таблицы процессов в качестве аргумента (стро-
(строка 7787). Она вызывает другую функцию, sched, с указателями на перемен-
переменные, определяющие, в какую очередь следует поместить процесс и куда именно —
в конец или начало. Открываются три возможности. Если выбранная очередь
пуста, то в оба массива, rdy_head и rdy_tail, записывается указатель на добав-
добавляемый массив, а полю связи p_nextready присваивается специальное значе-
значение NIL_PROC, означающее, что данный элемент списка является последним (за
ним не следует никакой другой процесс). Если процесс добавляется в начало суще-
существующей очереди, ее указателю p_nextready присваивается текущее значение
rdy_head, а затем массиву rdy_head присваивается адрес, указывающий на
новый процесс. Если процесс добавляется в конец очереди, полю p_nextready
текущего хвостового процесса, а также указателю rdy_tail присваивается ад-
адрес нового процесса. Полю p_nextready нового процесса присваивается значе-
значение NIL_PROC. Далее вызывается функция pick_proc, определяющая следую-
следующий процесс для запуска.
Если процесс необходимо вывести из состояния готовности, вызывается функ-
функция dequeue (строка 7823). Для того чтобы процесс перешел в состояние бло-
блокировки, необходимо, чтобы он выполнялся, поэтому с большой вероятностью
он будет находиться в начале очереди. Тем не менее сигнал может быть послан
и невыполняемому процессу. Тогда для поиска «жертвы» выполняется обход
очереди, причем с большой вероятностью искомый процесс находится в ее нача-
начале. Затем значения указателей изменяются так, что процесс удаляется, а если
процесс находился в состоянии выполнения, дополнительно вызывается функ-
функция pick_proc.
Касательно функции dequeue есть еще один интересный момент. Поскольку за-
задания, выполняемые в ядре, используют общий аппаратный стек, рекомендуется
время от времени проверять целостность их стековых областей. В начале тела
dequeue выясняется, находится ли удаляемый процесс внутри ядра. Если это
так, то далее проверяется, была ли перезаписана характерная последовательность,
помещенная в конец стека (строки 7835-7838).
Затем следует функция sched, выбирающая очередь, в которую следует по-
поместить новый готовый к выполнению процесс, а также место в ней — начало
или конец. В таблице процессов для каждого процесса определена длительность
кванта, время, оставшееся до истечения кванта, текущий и максимальный прио-
приоритеты. В строках 7880-7885 проверяется, полностью ли израсходован квант.
Если нет, то процесс перезапускается с количеством времени, оставшимся до
окончания кванта. Если же квант исчерпан, то проверяется, был ли процесс
запущен дважды подряд. Положительный ответ расценивается как возможное
зацикливание или, как минимум, слишком долгое выполнение процесса, и уро-
уровень его приоритета увеличивается на единицу. Если же у других процессов бы-
была возможность получить ресурсы процессора, уровень приоритета, напротив,
уменьшается на единицу. Разумеется, такая мера бессмысленна, если в системе
циклически выполняются два процесса, сменяющие друг друга. Выявление по-
подобных ситуаций — актуальная проблема.
Далее выбирается очередь для обработки. Очередь 0 имеет наивысший приори-
приоритет, а очередь 15 — самый низкий. Кто-то может возразить и сказать, что должно
быть наоборот, однако такая интерпретация соответствует UNIX, где повышение
уровня приоритета означает снижение самого приоритета. Процессы ядра (тай-
мерное и системное задания) неприкосновенны, а вот приоритет всех остальных
процессов может быть понижен помещением их в очередь с большим номером.
В момент запуска все процессы имеют наивысший возможный для них приори-
приоритет, поэтому попытка уменьшения уровня приоритета ни к чему не приводит.
Приоритет процесса может стать выше лишь в случае, если он был хотя бы едино-
единожды понижен после запуска. У приоритетов обычных процессов есть и нижняя
граница — они никогда не попадают в одну очередь с процессом IDLE.
Вернемся к функции pick_proc (строка 7910). Главное ее назначение — уста-
установить указатель next_ptr. Любое изменение в очередях, способное повлиять
на выбор следующего процесса для выполнения, требует нового вызова pick_
proc. Если текущий процесс блокируется, pick_proc вызывается для перепла-
перепланирования процессора. Фактически, функция pick_proc и есть планировщик.
Функция pick_proc проста. Она проверяет каждую очередь, причем очередь
TASK_Q проверяется первой. Если в этой очереди имеется готовый процесс,
pick_proc сразу устанавливает указатель proc_ptr и завершается. В против-
противном случае проверяется соседняя очередь с более низким приоритетом и т. д. —
вплоть до очереди IDLE_Q. Указатель bill_ptr изменяется и задает пользова-
пользовательский процесс, время которого расходуется системой (строка 7694). В качест-
качестве такого процесса используется последний процесс, выполнявшийся системой.
В файле ргос . с имеются еще три процедуры — lock_send, lock^enqueue
и lock_dequeue. Все они обеспечивают доступ к своим основным функциям
при помощи вызовов lock и unlock по аналогии с рассмотренной нами проце-
процедурой lock_notify.
Итак, подведем итоги. В алгоритме планирования поддерживаются несколько
очередей с различными приоритетами. На выполнение всегда выбирается пер-
первый процесс очереди с наивысшим приоритетом. Таймерное задание ведет учет
времени, расходуемого всеми процессами. Если пользовательский процесс из-
израсходовал свой квант, он помещается в конец своей очереди. Таким образом,
планирование равноправных процессов осуществляется по классическому цикли-
циклическому алгоритму. Предполагается, что выполнение заданий, драйверов и сер-
серверов обычно прерывается блокировками, поэтому им предоставляются более
длинные кванты. Тем не менее они могут быть вытеснены, если занимают ресур-
ресурсы процессора слишком долго. При нормальной работе системы это происходит
редко, однако квантование высокоприоритетных процессов предотвращает за-
зависание системы по их вине. Процесс, препятствующий выполнению других
процессов, также может быть временно перемещен в очередь с более низким
приоритетом.
2.6.11. Аппаратная поддержка ядра
В системе есть несколько С-функций, которые очень существенно зависят от ап-
аппаратной платформы. Чтобы способствовать переносу MINIX 3 на разные плат-
платформы, такие функции выделены в отдельные файлы: exception.с, i8259 .с
и protect. с, а не помещены в тех же файлах с высокоуровневым кодом, в кото-
которых они используются.
Файл exception, с содержит обработчик исключений, функцию exception
(строка 8012), которая вызывается из ассемблерной программы обработки ис-
исключений в mpx3 86 . s (вызывается как _exception). Когда источником ис-
исключения является пользователь, оно преобразуется в сигнал, так как ошибки
в пользовательских программах ожидаемы. Но когда источником исключения
является операционная система — это признак того, что произошло нечто дейст-
действительно серьезное. Такое исключение приводит к сообщению о сбое ядра. Сооб-
Сообщение, которое при этом появляется на экране, или сигнал, отправляемый при-
приложению, задаются массивом ex_data (строки 8022-8040). Третье поле задает
минимальный номер модели процессора, поддерживающего данное исключение,
поскольку круг исключений в ранних моделях процессоров Intel довольно узок.
Этот массив является интересным индикатором развития семейства процессоров
Intel, на которых развертывается система MINIX 3. В строке 8065 печатается аль-
альтернативное сообщение, если сбой вызван неожиданным прерыванием процессора.
Аппаратная поддержка прерываний
Три функции файла i8259 . с вызываются при запуске системы для инициали-
инициализации контроллеров прерываний на микросхемах Intel 8259. Макрос в строке 8119
определяет пустую функцию (настоящая нужна лишь в 16-разрядной версии
MINIX 3). Функция intr_init (строка 8124) инициализирует контроллеры.
Два шага гарантируют отсутствие прерываний до полного завершения инициа-
инициализации. Первый — вызов функции intr_disable (строка 8134). Это С-вызов
ассемблерной библиотечной функции, выполняющей единственную команду cli,
которая запрещает процессору реагировать на прерывания. Далее в регистры ка-
каждого контроллера прерываний записывается последовательность байтов, отклю-
отключающая реакцию контроллеров на внешние воздействия. Байт, записываемый
в строке 8145, состоит из единиц и одного нуля, соответствующего каскадному
входу главного контроллера, связывающего его с подчиненным контроллером
(см. рис. 2.18). Нулевое значение бита включает вход, единичное — отключает
его. Байт, записываемый во вторичный контроллер в строке 8151, состоит цели-
целиком из единиц.
Таблица, хранимая в контроллере прерываний i8259, генерирует 8-разрядный
индекс, используемый процессором с целью поиска соответствующего дескрип-
дескриптора шлюза прерываний для каждого возможного входа (сигналы в правой части
рис. 2.18). Таблица инициализируется BIOS при запуске компьютера, и почти
все ее значения можно оставить неизменными. По мере запуска драйверов,
нуждающихся в прерываниях, в таблицу могут быть внесены необходимые изме-
изменения. Каждый драйвер может запросить сброс бита контроллера, включающий
требуемый вход прерываний. Параметр mine функции intr_init использу-
используется для того, чтобы определить, завершает MINIX 3 работу или запускается.
Функция intr_init может быть использована как для инициализации на за-
запуске, так и для сохранения параметров BIOS при завершении работы операци-
операционной системы.
После инициализации аппаратного обеспечения функция intr_init выполня-
выполняет последнее действие — копирует векторы прерываний BIOS в таблицу векто-
векторов прерываний MINIX 3.
Вторая функция в файле i8259.c — put_irq_handler (строка 8162). При
инициализации она вызывается для каждого процесса, который должен реаги-
реагировать на прерывания. Она помещает адрес процедуры-обработчика в таблицу
прерываний irq_handlers, определенную со словом EXTERN в файле glo.h.
В современных компьютерах пятнадцати линий прерываний не всегда достаточ-
достаточно, поскольку устройств ввода-вывода может быть больше. Это означает, что не-
некоторые линии прерывания совместно используются двумя устройствами. Такая
ситуация недопустима для базовых устройств, поддерживаемых рассматривае-
рассматриваемой версией MINIX 3, однако совместное использование линии прерывания мо-
может потребоваться при оснащении системы сетевыми интерфейсами, звуковыми
платами или более экзотическими устройствами. Чтобы обеспечить подобную
поддержку, таблица векторов не должна состоять из одних лишь адресов. Мас-
Массив irq_handlers [NR_IRQ_VECTORS] представляет собой массив указателей
на структуры irq_hook — тип, определенный в файле kernel/type.h. Эти
структуры содержат поле, в котором хранится указатель на другую структуру того
же типа. Таким образом, строится связанный список с началом в одном из эле-
элементов массива irq_handlers. Функция put_irq_handler добавляет элемент
подобных списков. Самое важное поле такого элемента — указатель на обработ-
обработчик прерываний, представляющий собой функцию, выполняемую при возникно-
возникновении прерывания, например при завершении запрошенного ввода-вывода.
Некоторые детали функции put_irq_handler заслуживают внимания. Пере-
Переменная id устанавливается в значение 1 перед началом цикла while, сканирую-
сканирующего связанный список (строки 8176-8180). Каждый раз при прохождении цикла
значение id сдвигается на один бит влево. Проверка в строке 8181 ограничивает
длину цепочки разрядностью id — 32 обработчиками в случае 32-разрядной сис-
системы. Нормальным результатом сканирования является обнаружение конца
цепочки, с которым можно связать новый обработчик. После этого значение id
сохраняется в одноименном поле нового элемента цепочки. Функция put_irq_
handler также устанавливает бит в глобальной переменной irq_use, указы-
указывая, что для соответствующего прерывания имеется обработчик.
Если вы усвоили основную цель разработки MINIX 3 — перенос драйверов уст-
устройств в пользовательское пространство, — то предшествующая дискуссия о вызове
обработчиков прерываний должна была несколько спутать ваши представления.
Адреса обработчиков прерываний, хранимые в структурах в irq_hook, бесполез-
бесполезны, если они не указывают на функции, находящиеся внутри адресного простран-
пространства ядра. Единственным устройством, использующим прерывания и заключенным
внутри области ядра, являются часы. А как же обстоит дело с драйверами уст-
устройств, располагающих собственными адресными пространствами?
Ответ на данный вопрос состоит в том, что их обработкой занимается системное
задание. На самом деле, системное задание занимается практически всем, что ка-
касается взаимодействия между ядром и процессами, находящимися в пользова-
пользовательском пространстве. При необходимости регистрации обработчика прерыва-
прерываний «пользовательский» драйвер устройства обращается к системному заданию
с вызовом sys_irqctl. Системное задание вызывает функцию put_irq_
handler, однако в поле обработчика прерываний вместо адреса, принадлежаще-
принадлежащего пространству драйвера, сохраняется адрес процедуры generic_handler, яв-
являющейся частью системного задания. Поле номера процесса в структуре irq_
hook используется процедурой generic_handler для доступа к записи драй-
драйвера в таблице привилегий и установки соответствующего бита в карте актив-
активных прерываний. Затем generic_handler посылает драйверу уведомление от
имени HARDWARE, в которое включается битовая карта активных уведомлений
драйвера. Таким образом, если драйверу необходимо отвечать на прерывания бо-
более чем одного источника, он может определить, какое из прерываний вызвало
передачу уведомления. Фактически установка битовой карты предоставляет
драйверу информацию обо всех активных прерываниях. Еще одно поле в струк-
структуре irq_hook — поле политики, определяющее, следует разрешить прерывание
немедленно или оставить его запрещенным. Во втором случае драйвер сам дол-
должен будет выполнить вызов ядра sys_irqenable по завершении обработки
прерывания.
Одна из целей создания операционной системы MINIX 3 — поддержка реконфи-
гурирования устройств ввода-вывода в процессе выполнения. Следующая функ-
функция, rm_irq_handler, удаляет обработчик, что является необходимым при
удалении и замене драйвера устройства. Фактически rm_irq_handler выпол-
выполняет действия, противоположные put_irq_handler.
Последняя функция файла i82 59.c — функция intr_handle (строка 8221);
она вызывается из макросов hwint_master и hwint_slave, знакомых нам по
файлу mpx386.s. Элемент массива irq_actids битовых карт, соответствую-
соответствующих обслуживаемому прерыванию, используется для регистрации текущего со-
состояния каждого обработчика в списке. Для каждой функции списка intr_
handle устанавливает соответствующий бит irq_actids и вызывает обработ-
обработчик. Если обработчик не выполняет каких-либо действий либо завершает обслу-
обслуживание прерывания немедленно, он возвращает значение TRUE, и бит в irq_
actids очищается. В конце макросов hwint_master и hwint_slave битовая
карта прерывания, рассматриваемая как целое число, проверяется, чтобы опре-
определить, можно ли разрешить прерывание перед запуском следующего процесса.
Поддержка защищенного режима процессоров Intel
В файле protect.с находятся несколько функций, необходимых для работы
защищенного режима процессоров Intel. В памяти выделяются глобальная таблица
дескрипторов (Global Descriptor Table, GDT), локальная таблица дескрипторов
(Local Descriptor Table, LDT) и таблица дескрипторов прерываний (Interrupt
Descriptor Table, IDT), необходимые для предоставления защищенного доступа
к системным ресурсам. GDT- и IDT-адреса хранятся в специальных регистрах
процессора, а GDT-записи содержат ссылки на отдельные локальные таблицы
дескрипторов. Таблица GDT должна быть доступна для всех процессов и содер-
содержит дескрипторы сегментов для областей памяти, используемые операционной
системой. Как правило, каждому процессу соответствует одна таблица LDT, со-
содержащая дескрипторы сегментов его памяти. Дескрипторы представляют собой
структуры объемом 8 байт, состоящие из нескольких компонентов. Важнейшие
из полей хранят базовый адрес и размер области памяти. Таблица дескрипторов
прерываний также состоит из 8-байтовых дескрипторов, в которых важнейшее
поле хранит адрес кода, который будет выполнен при возникновении прерывания.
Файл start. с содержит функцию prot_init (строка 8368), устанавливающую
GDT (строки 8421-8438). Система BIOS IBM PC требует, чтобы эта таблица
была упорядочена определенным образом, для чего в файле protect .h описаны
необходимые значения индексов. Область памяти для LDT выделяется в таблице
процессов. Каждая такая таблица содержит два дескриптора: один для сегмента
кода и один для сегмента данных. Заметьте: сегменты, которые мы обсуждаем,
это сегменты, как их воспринимает аппаратное обеспечение системы. Это — не
те сегменты, с которыми работает операционная система. Так, заданный аппарат-
но сегмент данных далее разбивается на сегменты данных и стека. В строках
8444-8450 для каждой из таблиц LDT создаются дескрипторы, помещаемые
в GDT. За это ответственны функции init_dataseg и init_codeseg. Записи
в самой таблице LDT инициализируются в тот момент, когда меняется карта па-
памяти процесса (то есть когда делается системный вызов exec).
Еще одна системная структура данных, которую необходимо инициализировать, —
это сегмент состояния задания (Task State Segment, TSS). Его структура опреде-
определяется в начале файла (строки 8325-8354) и включает в себя области для хране-
хранения регистров процессора, а также другой информации, которую необходимо за-
запоминать при переключении заданий. В MINIX 3 используются только те поля,
которые определяют, где будет создан новый стек в момент возникновения пре-
прерывания. Вызов init_dataseg (строка 8460) гарантирует, что этот стек может
быть найден через GDT.
Чтобы понять, как MINIX 3 работает на нижнем уровне, важнее всего разобраться,
как прерывания, исключения и инструкции int <nnn> приводят к исполнению
различных процедур, написанных для их обработки. Для этого необходима табли-
таблица дескрипторов шлюзов прерываний. Массив gate_table (строки 8383-8418)
заполняется компилятором адресами процедур, которые обрабатывают исключе-
исключения и аппаратные прерывания. Затем значительная часть этого массива в цикле
(строки 8464-8468) инициируется, вызывая функцию int_gate.
Существует несколько причин, в силу которых данные определенным образом
структурированы в виде дескрипторов. Основная мотивация — особенности
аппаратного обеспечения и необходимость поддерживать совместимость между
современными и старыми 16-разрядными процессорами. К счастью, детали мы
можем оставить разработчикам процессоров Intel. Язык программирования С
позволяет по большей части избегать таких мелочей. Тем не менее при разработ-
разработке операционной системы так или иначе придется с ними столкнуться. Внут-
Внутренняя структура одного дескриптора сегмента приведена на рис. 2.23. Обратите
внимание на то, что базовый адрес, к которому С-программы обращаются как
к простому 32-разрядному целому числу, разбит на три части, две из которых
разделены 1-, 2- и 4-разрядными блоками. Размер области является 20-раз-
20-разрядным числом, которое хранится в виде пары блоков из 16 и 4 бит. Этот размер
может интерпретироваться либо как количество байтов, либо как количество
страниц объемом 4096 байт, в зависимости от значения бита G. У других деск-
дескрипторов другая структура, не менее сложная. Более подробно мы обсудим эти
структуры в главе 4.
Рис. 2.23. Формат дескриптора сегмента Intel
Большинство остальных функций из файла protect. с предназначены для пре-
преобразования данных между переменными в С-программах и тем сложным пред-
представлением, которое принято в дескрипторах. Функции init_codeseg (строка
8477) и init_dataseg (строка 8493) работают сходным образом. Их назначе-
назначение в том, чтобы преобразовать переданные им данные в дескрипторы сегментов.
Обе они, чтобы завершить свою работу, в свою очередь, вызывают другую функ-
функцию, sdesc (строка 8508). Именно она имеет дело с запутанной структурой, кото-
которая показана на рис. 2.23. Функции init_codeseg и init_ dataseg вызы-
вызываются не только при инициализации системы. Помимо этого они вызываются
системой каждый раз, когда запускается новый процесс, чтобы выделить новому
процессу необходимые сегменты памяти. Вызов функции seg2phys (строка 8533)
выполняется только из файла start. с, ее действие обратно действию sdesc —
извлечение базового адреса сегмента из дескриптора. Функция phys2seg (стро-
(строка 8556) больше не нужна, поскольку доступ к удаленным сегментам памяти (на-
(например, к зарезервированной памяти в пространстве между 640 Кбайт и 1 Мбайт)
обеспечивает вызов sys_segctl ядра. Функция int_gate (строка 8571), ана-
аналогичная init_codeseg и init_dataseg, заполняет ячейки таблицы дескрип-
дескрипторов прерываний.
Функция enable_iop (строка 8589) файла protect. с необходима для одного
«грязного хака». Она изменяет уровень привилегий операций ввода-вывода, позво-
позволяя текущему процессу исполнять команды считывания и записи портов ввода-
вывода. Объяснить назначение этой функции сложнее, чем описать саму функ-
функцию — она всего лишь устанавливает два бита в слове записи кадра стека вызы-
вызывающего процесса, которое будет загружено в регистр состояния процессора при
следующем выполнении процесса. Эта функция в настоящее время не применя-
применяется, и способов запустить ее из пользовательского пространства не существует.
Последняя функция в файле protect. с — функция alloc_segments (строка
8603), которая вызывается do_newmap, а также процедурой ядра main во время
инициализации. Ее определение в значительной степени зависит от аппаратной
платформы. Она работает с регистрами и дескрипторами, предназначенными для
поддержки защищенных сегментов на аппаратном уровне процессором Pentium,
используя для этого назначения сегментов в элементах таблицы процессов. Мно-
Множественные присваивания (строки 8629-8633) характерны для языка С.
2.6.12. Утилиты и библиотека ядра
У ядра есть библиотека вспомогательных функций, написанных на языке ассемб-
ассемблера. Эти функции подключаются при компиляции файла klib. s. Также имеет-
имеется несколько вспомогательных программ на языке С, которые находятся в файле
misc . с. Сначала мы рассмотрим ассемблерные файлы. Файл klib. s (стро-
(строка 8700) представляет собой короткий ассемблерный файл, сходный с mpx. s.
В нем в зависимости от значения WORD_SIZE выбирается одна из версий кода.
Код, который мы будем обсуждать, расположен в файле klib3 86.s. В этом
файле содержится около двух дюжин вспомогательных функций, которые напи-
написаны на ассемблере либо по соображениям эффективности, либо потому, что они
вообще не могут быть реализованы на С.
Функция _monitor (строки 8844) позволяет вернуться из системы в монитор
загрузки. С точки зрения монитора загрузки, вся операционная система — не более,
чем подпрограмма, и когда MINIX 3 запускается, адрес монитора остается в сте-
стеке. Функции _monitor необходимо только восстановить значения селекторов
сегментов и указателя стека, после чего выполнить возврат из подпрограммы.
Функция int8 6 (строка 8864) поддерживает вызовы BIOS. BIOS используется
для предоставления альтернативных дисковых драйверов, которые в книге не
описываются. Эта функция передает управление монитору загрузки, который
управляет переходом из защищенного режима в реальный для выполнения вы-
вызова BIOS, а затем возвращается в защищенный режим для передачи управления
32-разрядной системе MINIX 3. Монитор загрузки также возвращает длитель-
длительность вызова BIOS в виде числа тактов таймера. Зачем это нужно, мы узнаем
при изучении таймерного задания.
Хотя функция _phys_copy (см. далее) могла бы использоваться для копиро-
копирования сообщений, для этого есть более быстрая специализированная функция
_cp_mess. Она вызывается следующим образом:
cp_mess(source, src_clicks, src_dest, dest_clicks, dest_offset);
Здесь source — это номер процесса отправителя, который копируется в поле т_
source буфера получателя. Адреса буферов получателя и отправителя пред-
представлены в виде заданного «числа кликов», обычно базового адреса сегмента, со-
содержащего буфер, и смещения. Это — более эффективная форма представления
адресов, чем 32-разрядные целые числа, как в _phys_copy.
Функции _exit, exit и exit (строки 9006-9008) необходимы потому,
что некоторые из библиотечных процедур, которые могут использоваться при
компиляции MINIX 3, способны делать вызовы стандартной С-функции exit.
Она вызывается, когда необходимо выйти из программы, но выход из ядра не
имеет смысла, здесь просто некуда выходить. Эта проблема решена так: функция
разрешает прерывания и входит в бесконечный цикл. В определенный момент
возникает прерывание от таймера или операции ввода-вывода, и система возвра-
возвращается к нормальной работе. Точка входа с именем main (строка 9012) —
еще один пример борьбы с таким режимом работы компилятора, который имеет
смысл при компиляции пользовательской программы, но бесполезен для ядра.
Эта точка входа указывает на ассемблерную инструкцию ret (возвращение из
подпрограммы).
Функции _phys_insw (строка 9022), _phys__insb (строка 9047), _phys_outsw
(строка 9072) и _phys_outsb (строка 9098) предоставляют доступ к портам
ввода-вывода, которые в архитектуре процессоров Intel занимают отдельное адрес-
адресное пространство, поэтому для работы с ними требуются инструкции, отличные
от обычных инструкций работы с памятью (ins, insb, outs и outsb). Послед-
Последние специально предназначены для эффективной обработки массивов (строк),
16-разрядных слов и 8-разрядных байтов. Дополнительные инструкции в каж-
каждой функции устанавливают все параметры, необходимые для перемещения за-
заданного числа байтов или слов между физически адресуемыми буфером и пор-
портом. Такой метод обеспечивает скорость, достаточную для обслуживания дисков,
а диски должны обслуживаться быстрее, чем выполняются обычные операции
ввода-вывода над отдельными байтами или словами.
Разрешение и запрещение откликов процессора на все прерывания можно выпол-
выполнить одной командой. Функции _enable_irq (строка 9126) и _disable_irq
(строка 9162) устроены несколько сложнее. Они работают на уровне контролле-
контроллера прерываний и разрешают или запрещают отдельные аппаратные прерывания.
Функция _phys_copy (строка 9204) вызывается на С следующим образом:
_phys_copy(source_address, destination_address, bytes);
Она копирует блок данных из одной области физической памяти в любое другое
место. Оба передаваемых этой функции адреса абсолютные, то есть 0 означает
первый байт адресного пространства. Все три аргумента функции являются по
типу беззнаковыми длинными целыми.
В целях безопасности вся используемая программой память должна быть очищена
от любых данных, оставленных в ней предыдущей программой. В MINIX 3 эта за-
задача решается с помощью системного вызова exec, в конечном счете, обращаю-
обращающегося к функции phys_memset (строка 9248) — следующей в файле klib386 . s.
Две следующие короткие функции специфичны для процессоров Intel. Функция
_mem_rdw (строка 9291) возвращает 16-разрядное слово из произвольного места
памяти. Результат дополняется нулями и помещается в 32-разрядный регистр
еах. Функция _reset (строка 9307) сбрасывает процессор. Для этого в деск-
дескриптор прерываний процессора загружается нулевой указатель, после чего вы-
вызывается программное прерывание. Результирующий эффект равносилен аппа-
аппаратному сбросу.
Функция idle_task (строка 9318) вызывается в случае отсутствия какой-либо
работы. Эта функция содержит бесконечный цикл, однако она не просто нагру-
нагружает процессор (хотя и это подошло бы для данной цели), а использует команду
hit, переводящую процессор в экономичный режим до появления прерывания.
Однако hit является привилегированной командой, и ее исполнение при ненуле-
ненулевом уровне привилегий вызовет исключение. По этой причине функция idle_
task помещает в стек адрес подпрограммы, содержащей hit, и делает вызов
level0 (строка 9322). Функция получает адрес подпрограммы halt и копирует
его в зарезервированную область памяти (объявленную в файле glo. h и факти-
фактически зарезервированную в table. с).
Функция _levelO воспринимает загруженный в указанную область адрес как
функциональную часть процедуры обработки прерываний, которую нужно за-
запустить с максимальным (нулевым) уровнем привилегий.
Последние две функции в файле klib3 86 . s — read_tsc и read_f lags. Пер-
Первая считывает регистр процессора, исполняющего команду rdtsc (считать счет-
счетчик временной метки). Этот счетчик подсчитывает циклы процессора и приме-
применяется для определения производительности и отладки. Указанная команда не
поддерживается ассемблером MINIX 3 — ее код операции записан как шестна-
дцатеричное число. Функция read_f lags считывает флаги процессора и воз-
возвращает их как С-переменную. К сожалению, программный комментарий о пред-
предназначении этой функции ошибочен.
Последний файл, который мы рассмотрим в этой главе, — utility. с. В нем на-
находятся три важные функции. Если в ядре происходят серьезные неполадки, вы-
вызывается функция panic (строка 9429). Она печатает сообщение и вызывает
функцию prepare_shutdown. Когда ядру необходимо напечатать сообщение,
оно не может использовать функцию стандартной библиотеки printf; по этой
причине в файле utility. с определена специальная функция kprintf (стро-
(строка 9450). Полный набор возможностей форматирования не нужен ядру, однако
большая часть функциональности printf поддерживается в kprintf. Посколь-
Поскольку для доступа к файлу или устройству ядро не может воспользоваться файловой
системой, оно передает каждый символ другой функции, kputc (строка 9525),
которая добавляет символы в буфер. Получив код END_OF_KMESS, функция
kputc информирует процесс, ответственный за обработку сообщений. Этот про-
процесс определяется в файле include/minix/config.h и может быть драйве-
драйвером журнала или драйвером консоли. В случае драйвера журнала сообщение пе-
передается и в журнал, и на консоль.
2.7. Системное задание в MINIX 3
В результате перемещения за пределы ядра и разделения на независимые про-
процессы основные системные компоненты лишились возможности самостоятель-
самостоятельно осуществлять ввод-вывод, манипулировать таблицами ядра и выполнять
другие действия, присущие операционной системе. К примеру, системный вызов
fork обрабатывается менеджером процессов. Когда новый процесс создается,
ядро должно узнать о его существовании, чтобы запланировать его выполнение.
Как же менеджеру процессов сообщить ядру о новом процессе?
Решение заключается в следующем. Ядро предоставляет драйверам и серверам
набор служб, недоступных обычным пользовательским процессам. Эти службы
позволяют драйверам и серверам осуществлять ввод-вывод, получать доступ
к содержимому таблиц ядра и выполнять другие действия, находясь вне ядра.
Управление перечисленными службами осуществляет системное задание. На
рис. 2.14 оно показано на уровне 1. Хотя его двоичный код объединен с ядром,
системное задание является отдельным процессом и планируется соответствую-
соответствующим образом. Назначение системного задания — прием от драйверов и серверов
запросов на особые услуги ядра и предоставление этих услуг. Поскольку систем-
системное задание находится в адресном пространстве ядра, имеет смысл заняться его
изучением именно сейчас.
В этой главе мы уже сталкивались с примером услуг, предоставляемых системным
заданием. Описывая обработку прерываний, мы видели, как драйвер устройства
использовал вызов sys_irqctl для передачи сообщения системному заданию,
запрашивающего установку обработчика прерываний. Драйвер не имеет доступа
к структуре данных ядра, хранящей адреса процедур обработки, однако системное
задание может выполнить нужную работу. Кроме того, поскольку процедура об-
обработки прерывания должна находиться в адресном пространстве ядра, адрес об-
обработчика указывает на функцию generic_handler системного задания. Эта
функция реагирует на прерывание, посылая уведомление драйверу устройства.
Сейчас самое время дать несколько терминологических пояснений. В обычной
операционной системе с монолитным ядром термин системный вызов относится
ко всем вызовам служб ядра. В современных операционных системах семейства
UNIX системные вызовы доступны всем процессам и следуют стандарту POSIX.
Тем не менее иногда имеют место расширения, выходящие за рамки POSIX,
и пользующийся системным вызовом программист, как правило, обращается к биб-
библиотечной С-функции, предоставляющей простой программный интерфейс. Кро-
Кроме того, некоторые библиотечные функции, кажущиеся программисту систем-
системными вызовами, на самом деле используют такой же механизм доступа к ядру.
Система MINIX 3 устроена иначе: компоненты операционной системы выполня-
выполняются в пользовательском пространстве, хотя и имеют некоторые привилегии.
Под словосочетанием «системный вызов» мы будем понимать все стандартные
системные вызовы POSIX (а также несколько расширений MINIX), перечислен-
перечисленные в табл. 1.1, однако пользовательские процессы не обращаются к службам
ядра впрямую. В MINIX 3 системные вызовы пользовательских процессов пре-
преобразуются в сообщения, адресуемые серверам. Серверы, в свою очередь, при
помощи сообщений взаимодействуют друг с другом, с драйверами устройств
и с ядром. Предмет обсуждения этого раздела, системное задание, принимает все
запросы на предоставление услуг ядра. В первом приближении мы можем на-
назвать такие запросы системными вызовами, но более точным является термин
вызовы ядра. Вызовы ядра не могут совершаться пользовательскими процессами.
Во многих случаях системный вызов пользовательского процесса от имени сер-
сервера инициирует вызов ядра с тем же именем. Это объясняется тем, что запро-
запрошенная услуга предоставляется только ядром. К примеру, системный вызов
fork поступает от пользовательского процесса менеджеру процессов, который
выполняет часть необходимой работы. Однако вызов fork требует изменений
в области ядра таблицы процессов. Для завершения действия менеджер процес-
процессов обращается с вызовом sys_f ork к системному заданию, которое и осущест-
осуществляет нужные манипуляции с таблицей. Не все вызовы ядра имеют столь оче-
очевидную связь с единственным системным вызовом. Например, вызов sys_
devio ядра предназначен для чтения и записи портов ввода-вывода и поступает
от драйвера устройства. Больше половины системных вызовов, перечисленных
в табл. 1.1, способны активизировать драйвер устройства для выполнения одно-
одного или нескольких вызовов sys_devio.
С технической точки зрения, в дополнение к системным вызовам и вызовам
ядра следует выделить еще одну категорию вызовов — примитивы сообщений.
Примитивы сообщений, применяемые для взаимодействия между процессами,
такие как send, receive и notify, напоминают системные вызовы, и именно
так мы неоднократно называли их в книге — эти вызовы действительно обраще-
обращены к системе. Тем не менее они отличаются как от системных вызовов, так и от
вызовов ядра, и было бы более корректным использовать для них другие терми-
термины. Иногда можно встретить словосочетание примитив взаимодействия между
процессами, или же термин ловушка, причем оба упоминаются в комментариях
к исходному коду. Примитив сообщений подобен радиоволне в системе бес-
беспроводной связи. Чтобы радиоволна стала полезной, как правило, необходима
модуляция; тип сообщения и другие компоненты его структуры позволяют на-
наполнить вызов информационным содержанием. Иногда полезен и немодули-
рованный радиосигнал, к примеру, в радиомаяках аэропортов. По аналогии,
примитив notify практически не содержит никакой другой информации, кроме
своего источника.
2.7.1. Обзор системного задания
Системное задание принимает 28 типов сообщений, перечисленных в табл. 2.5.
Каждый из них воспринимается как результат вызова ядра, однако позже мы
увидим, что в некоторых случаях несколько макросов, определенных под разны-
разными именами, приводят к созданию сообщения одного и того же типа. Иногда об-
обработка сообщений нескольких типов выполняется одной и той же процедурой.
Структура главной программы системного задания подобна другим заданиям —
после необходимой инициализации следует цикл, принимающий сообщение, вы-
вызывающий надлежащую процедуру обслуживания и отсылающий результат. Не-
Некоторые функции общей поддержки находятся в файле system.с, однако для
обработки каждого из вызовов ядра основной цикл вызывает процедуру в отдель-
отдельном файле каталога kernel /system. Причину организации такой структуры
и ее работу мы разберем позже, при рассмотрении реализации системного задания.
Таблица 2.5. Типы сообщений, принимаемых системным заданием. Тип Any означает
любой системный процесс. Пользовательские процессы не могут обращаться
к системному заданию напрямую
Тип сообщений Источник Описание
sys_fork pm Процесс запущен
sys_exec pm Установить указатель стека после вызова exec
sys_exit pm Процесс завершен
sys_nice pm Задать приоритет планирования
sys_privctl rs Задать или изменить привилегии
sys_trace pm Выполнить операцию вызова ptrace
sys_kill pm, fs, tty Послать сигнал процессу после вызова kill
sys_getksig pm Проверка активных сигналов менеджером процессов
sys_endksig pm Завершение обработки сигнала менеджером процессов
sys_sigsend pm Послать сигнал процессу
sys_sigreturn pm Очистка после завершения сигнала
sys_irqctl Драйверы Разрешить, запретить или сконфигурировать
прерывание
sys_devio Драйверы Выполнить операцию чтения или записи над портом
sys_sdevio Драйверы Выполнить над портом операцию чтения или записи
строки
sys_vdevio Драйверы Выполнить вектор запросов ввода-вывода
sys_int86 Драйверы Выполнить вызов BIOS в реальном режиме
sys_newmap pm Установить карту памяти процесса
sys_segctl Драйверы Добавить сегмент и получить его селектор (доступ
к удаленным данным)
sysjnemset pm Записать символ в область памяти
sys_umap Драйверы Преобразовать виртуальный адрес в физический
sys_vircopy fs, драйверы Выполнить копирование с использованием
виртуальной адресации
sys_physcopy Драйверы Выполнить копирование с использованием
физической адресации
sys_virvcopy Any Вектор запросов vcopy
sys_physvcopy Any Вектор запросов physcopy
sys_times pm Получить время работы системы и процессов
sys_setalarm pm, fs, драйверы Запланировать сигнал синхронизации
sys_abort pm, tty Сбой: MINIX не может продолжать работу
sys_getinfo Any Запросить системную информацию
Для начала опишем назначение каждого вызова ядра. Типы сообщений в табл. 2.5
можно разделить на категории. Первые несколько сообщений относятся к управле-
управлению процессами. Очевидно, что вызовы sys_f ork, sys_exec, sys_exit и sys_
trace тесно связаны с системными вызовами стандарта POSIX. Хотя nice не
относится к числу обязательных вызовов POSIX, изменение приоритета процес-
процесса, в конечном счете, приводит к вызову sys_nice ядра. Единственным незна-
незнакомым вам вызовом из данной группы может быть лишь вызов sys_privctl.
Он используется сервером реинкарнации (rs) — компонентом MINIX 3, ответ-
ответственным за перевод обычных пользовательских процессов в разряд системных.
Вызов sys_privctl изменяет привилегии процесса, позволяя ему, к примеру,
обращаться с вызовами к ядру. Вызов sys_privctl используется, если драйве-
драйверы и серверы, не являющиеся частью загрузочного образа, запускаются сцена-
сценарием /etc/гс. Драйверы MINIX 3 также могут запускаться и перезапускаться
в любое время; во всех этих случаях необходимо изменять их привилегии.
Следующая группа вызовов ядра относится к сигналам. Вызов sys_kill связан
с доступным пользователю (и неправильно называемым) системным вызовом
kill. Остальные вызовы группы, sys_getksig, sys_endksig, sys_sigsend
и sys_sigreturn, используются менеджером процессов для обработки сигна-
сигналов с поддержкой ядра.
Вызовы sys_irqctl, sys_devio, sys_sdevio и sys_vdevio ядра являются
специфичными для MINIX 3. Они обеспечивают поддержку драйверам устройств,
находящимся в пользовательском пространстве. В начале этого раздела мы уже
упомянули вызов sys_irqctl; одна из его задач состоит в установке обработ-
обработчика аппаратных прерываний и разрешения прерываний от имени драйвера.
С помощью вызова sys_devio драйвер может попросить систему считать или
записать байт в порт ввода-вывода. Это действие, очевидно, необходимо; очевид-
очевидно также, что, если бы драйверы выполнялись в пространстве ядра, а не пользо-
пользователя, сопутствующие задержки были бы меньше. Следующие два вызова ядра
обеспечивают более высокоуровневую поддержку устройств ввода-вывода. Вы-
Вызов sys_sdevio позволяет считать или записать последовательность байтов
или слов (например, строку) по одному адресу ввода-вывода (например, через
последовательный порт). Вызов sys_vdevio пересылает системному заданию
вектор запросов ввода-вывода. Под вектором понимается набор пар (порт-значе-
(порт-значение). Ранее в этой главе мы описали функцию intr_init, инициализирующую
контроллеры прерываний Intel i8259. В строках 8140-8152 последовательность
команд выполняет запись нескольких байтовых значений. В каждом контролле-
контроллере i8259 имеется порт управления, задающий режим, и еще один порт, прини-
принимающий 4-байтовую инициализирующую последовательность. Разумеется, этот
код выполняется внутри ядра и, следовательно, не требует никакой поддержки
со стороны системного задания. Однако если бы это делал пользовательский
процесс, то передача одного сообщения, содержащего адрес буфера с 10 парами
(порт-значение), была бы значительно эффективнее, чем передача 10 сообще-
сообщений, содержащих по одному адресу порта и одному значению, которое нужно
в него записать.
Следующие три вызова ядра из табл. 2.5 явно задействуют память. Вызов sys_
newmap делается менеджером процессов при изменении памяти, используе-
используемой процессом. В этом случае требуется обновить область ядра таблицы про-
процессов. Вызовы sys_segctl и sys_memset обеспечивают безопасный доступ
процесса к памяти за пределами его пространства данных. Как отмечалось при
рассмотрении вопросов запуска MINIX 3, область памяти с адресами ОхаОООО-ОхптТ
зарезервирована для устройств ввода-вывода. Некоторые устройства использу-
используют эту память для ввода и вывода данных, например, чтобы вывести изображе-
изображение на видеокарту, нужно записать данные в определенную область, располо-
расположенную в указанном диапазоне адресов. Вызов sys_segctl предоставляет
драйверу устройства селектор сегмента, позволяющий обращаться к зарезер-
зарезервированной памяти, a sys_memset используется сервером для записи данных
в память за пределами его адресного пространства. С помощью вызова sys_
memset менеджер процессов обнуляет память при запуске нового процесса, что-
чтобы предотвратить возможную попытку чтения данных, оставленных предыду-
предыдущим процессом.
Следующая группа вызовов ядра предназначена для копирования памяти. Вызов
sys_umap преобразует виртуальные адреса в физические, a sys_vircopy и sys_
physcopy копируют области памяти с использованием виртуальных и физиче-
физических адресов соответственно. Вызовы sys_virvcopy и sys_physvcopy пред-
представляют собой векторные версии предыдущих двух. Подобно векторам запро-
запросов ввода-вывода, векторные вызовы позволяют с помощью системного задания
выполнить последовательность операций копирования памяти.
Как следует из названия, вызов sys_times ядра работает с временем и свя-
связан с системным вызовом times стандарта POSIX. Аналогично, вызов sys_
setalarm связан с системным вызовом alarm стандарта POSIX, однако связь
относительно слабая. Большая часть действий по обслуживанию POSIX-вызова
выполняется менеджером процессов, поддерживающим очередь таймеров от
имени пользовательских процессов. Менеджер процессов задействует вызов
sys_setalarm ядра тогда, когда ему нужно установить таймер от имени ядра.
Как правило, это необходимо лишь при изменении начала очереди таймеров,
и не каждый вызов alarm от пользовательского процесса сопровождается вызо-
вызовом sys_setalarm ядра.
Последние два вызова табл. 2.5 предназначены для управления системой. Вызов
sys_abort инициируется менеджером процессов после нормального запроса
на завершение работы системы или после сбоя либо драйвером устройства tty
в ответ на нажатие пользователем комбинации клавиш Ctrl+Alt+Del.
Наконец, вызов sys_getinf о обслуживает множество разнообразных запро-
запросов информации, содержащейся в ядре. Если вы поищете в исходном С-коде
MINIX 3 этот вызов непосредственно по его имени, вы наверняка найдете всего
лишь несколько. Совсем другие результаты подобный поиск принесет в заголо-
заголовочных файлах: так, в include/minix/ syslib. h имеется не меньше 13 макро-
макросов, задающих sys_getinf о альтернативные имена. Например:
sys_getkinfo(dst) sys_getinfo(GET_KINFO, dst, 0, 0, 0)
Этот макрос используется для возврата менеджеру процессов структуры kinf о,
определенной в файле include/minix/type.h (строки 2875-2893), во время
запуска системы. Та же информация может потребоваться и в другие моменты.
Например, пользовательской команде ps нужно знать местоположение области
ядра таблицы процессов, чтобы отобразить сведения о состоянии всех процессов
системы. Команда посылает запрос менеджеру процессов, который, в свою оче-
очередь, получает информацию с помощью варианта sys_getkinfо вызова sys_
getinfo.
Перед тем как закончить обзор типов вызовов ядра, мы хотели бы обратить вни-
внимание на то, что вызов sys_getinfo является не единственным вызовом, для
которого в файле include/minix/syslib.h определен набор макросов, задаю-
задающих альтернативные имена. К примеру, обращение к вызову sys_sdevio, как
правило, выполняется через макросы sys_insb, sys_insw, sys_outsb и sys_
outsw. С этими именами проще понять, что делает операция (читает или записы-
записывает) и с чем она это делает (байт или слово). Аналогично, вызов sys_irqctl
обычно выполняется макросами sys_irqenable, sys_irqdisable и рядом
других. Подобные макросы упрощают чтение кода, а также облегчают работу про-
программистам, автоматически подставляя в вызовы постоянные аргументы.
2.7.2. Реализация системного задания
Системное задание компилируется из заголовочного файла system.h и файла
system.с с исходным С-кодом; оба файла расположены в каталоге kernel/.
Кроме того, исходные файлы подкаталога kernel /system/ компилируются
в специальную дополнительную библиотеку. Такая структура вполне обоснован-
обоснованна. Несмотря на то что рассматриваемая в книге версия MINIX 3 является уни-
универсальной, данная операционная система может иметь и специальное примене-
применение, к примеру, обеспечивать встроенную поддержку портативного устройства.
В этом случае имеет смысл урезать операционную систему. Так, если в устройст-
устройстве отсутствует жесткий диск, необходимость в файловой системе отпадает. Как
мы видели при рассмотрении файла kernel/conf ig.h, компиляция ядра может
быть выборочной. Подключение кода, поддерживающего вызовы ядра, на по-
последнем шаге компиляции при компоновке с библиотекой упрощает создание за-
заказной системы.
Реализация поддержки каждого вызова ядра в отдельном файле упрощает рабо-
работу с программным обеспечением. Однако эти файлы в определенной степени из-
избыточны, и включение их в книгу потребовало бы не менее 40 дополнительных
страниц. Все файлы из каталога /kernel/system вы можете найти на компакт-
диске и веб-сайте MINIX 3.
Мы начнем с изучения файла kernel/system.h (строка 9600). В нем находят-
находятся прототипы функций, соответствующих большинству вызовов ядра из табл. 2.5.
Кроме того, имеется прототип do_unused — это прототип функции, выполняе-
выполняемой при обращении к вызову, не поддерживаемому ядром. Некоторые типы сооб-
сообщений, перечисленные в табл. 2.5, относятся к определенным в файле макросам
(строки 9625-9630). Это примеры функций, обслуживающих несколько вызовов.
Перед тем как переходить к коду файла system, с, обратите внимание на век-
вектор вызовов call_vec и определение макроса тар в строках 9745-9749. Вектор
call_vec представляет собой массив указателей на функции. Из него выбира-
выбирается функция, обслуживающая сообщение, с использованием в качестве индекса
целого числа, соответствующего типу сообщения. Подобный механизм неодно-
неоднократно применяется в MINIX 3. Макрос тар — удобный инструмент инициали-
инициализации такого массива. Определение тар выполнено так, что попытка раскрытия
макроса с некорректным значением аргумента приводит к объявлению массива
отрицательного размера. Разумеется, это является недопустимым и вызывает
ошибку компилятора.
Верхним уровнем системного задания является процедура sys_task. После вы-
вызова, инициализирующего массив указателей на функции, процедура sys_task
выполняется циклически. Она ожидает сообщения, выполняет несколько прове-
проверок его корректности, выбирает функцию, обслуживающую вызов в зависимости
от типа сообщения, возможно, генерирует ответное сообщение и повторяет цикл
до тех пор, пока работает MINIX 3 (строки 9768-9796). Проверка включает две
части: сначала функция просматривает запись в таблице привилегий и убежда-
убеждается в том, что вызывающему процессу разрешено использовать данный вызов,
а затем определяет допустимость типа вызова. Выбор обслуживающей функции
выполняется в строке 9783. В качестве индекса массива call_vec используется
номер вызова, вызываемая функция определяется адресом, содержащимся в соот-
соответствующей ячейке массива, аргументом функции является указатель на сооб-
сообщение, а возвращаемое значение представляет собой код состояния. Код со-
состояния EDONTREPLY указывает на отсутствие необходимости генерировать
ответное сообщение, в противном случае отправка ответного сообщения выпол-
выполняется в строке 9792.
Как видно из рис. 2.22, при запуске MINIX 3 системное задание находится в на-
начале очереди с самым высоким приоритетом. По этой причине имеет смысл ини-
инициализировать массив обработчиков прерываний и список таймеров сигналов
с помощью функции initialize системного задания (строки 9808-9815).
Поскольку системное задание, как было отмечено ранее, используется для разре-
разрешения прерываний от имени драйверов, расположенных в пользовательском
пространстве и нуждающихся в реагировании на прерывания, подготовка табли-
таблицы будет вполне уместной. Кроме того, системное задание устанавливает тай-
таймеры, если другим системным процессам необходимы сигналы синхрониза-
синхронизации. По этой причине инициализировать списки таймеров здесь так же логично.
В продолжение инициализации в строках 9822-9824 все элементы массива call_
vec заполняются адресами процедуры do_unused, используемой при неподдер-
неподдерживаемом вызове ядра. Строки 9827-9867 включают несколько расширений
макроса тар, каждое из которых записывает адрес функции в соответствующий
элемент массива call_vec.
В оставшейся части файла system, с находятся функции, объявленные откры-
открытыми (public) и доступные для различных подпрограмм, обслуживающих вы-
вызовы ядра, а также для других областей ядра. Например, первая такая функция,
get_priv (строка 9872), используется функцией do_privctl, поддерживаю-
поддерживающей вызов sys_privctl ядра. Кроме того, get_priv вызывается самим ядром
при формировании элементов таблицы процессов для процессов загрузочного об-
образа. Возможно, имя get_priv несколько сбивает с толку: функция не получает
информацию об уже назначенных привилегиях, а находит доступную структуру
привилегий и присваивает ее вызывающему процессу. Возможны два варианта.
Первый — каждый системный процесс получает собственную запись в табли-
таблице привилегий. Второй — если таблица недоступна, процесс не может стать сис-
системным. Всем пользовательским процессам соответствует одна общая запись
в таблице.
Функция get_randomness (строка 9899) используется для получения исход-
исходных чисел для генератора случайных чисел, реализованного в MINIX 3 в виде
символьного устройства. Новейшие процессоры Pentium включают внутренний
счетчик циклов и поддерживают команду ассемблера, считывающую его значе-
значение. По возможности применяется эта команда, в противном случае вызывается
функция, считывающая регистр микросхемы часов.
Функция send_sig генерирует уведомление системному процессу после уста-
установки бита в битовой карте s_sig_pending процесса-получателя сигнала. Бит
устанавливается в строке 9942. Поскольку s_sig_pending является частью
структуры привилегий, этот механизм может применяться только для уведомле-
уведомления системных процессов. Все пользовательские процессы имеют общую запись
в таблице привилегий, а, следовательно, поля, подобные s_sig_pending, не мо-
могут быть совместными и не используются. Перед вызовом send_sig выполняет-
выполняется проверка, что адресат является системным процессом. Обращение к функции
send_sig возможно лишь в результате вызова sys_kill либо при передаче
символьной строки функцией kprintf ядра. В первом случае отправитель оп-
определяет, является ли получатель системным процессом, во втором ядро просто
передает данные для печати одному из процессов — драйверу консоли или драй-
драйверу журнала; оба процесса являются системными.
Функция cause_sig (строка 9949) посылает сигнал пользовательскому процессу.
Она выполняется, когда пользовательский процесс является получателем сис-
системного вызова sys_kill. Функция cause_sig помещена в файл system.с
потому, что она может быть вызвана непосредственно ядром в ответ на исключе-
исключение, вызванное пользовательским процессом. Как и в случае с send_sig, в бито-
битовой карте получателя должен быть установлен бит активного сигнала, однако
для пользовательского процесса эта карта находится не в таблице привилегий,
а в таблице процессов. Кроме того, следует вывести получателя из состояния
готовности с помощью вызова lock_dequeue, а его флаги (в том числе и в таб-
таблице процессов) должны быть обновлены и указывать на то, что процессу будет
подан сигнал. Затем посылается сообщение, однако не пользовательскому про-
процессу, а менеджеру процессов, в ведении которого находится все, что касается
сигнализации, связанной с пользовательскими процессами.
Далее следуют три функции, поддерживающие вызов sys_umap ядра. Процессы
обычно оперируют виртуальными адресами, относительными базового адреса оп-
определенного сегмента. Тем не менее иногда возникает необходимость использо-
использования абсолютных (физических) адресов, например, при копировании областей
памяти, принадлежащих различным сегментам. Виртуальный адрес можно задать
тремя способами. Наиболее употребительный — в виде смещения относительно
одного из сегментов памяти (текста, данных или стека), выделенных процессу
и записанных в таблице процессов. Преобразование такой формы виртуального
адреса в физический выполняется функцией umap_local (строка 9983).
Второй вид адресации памяти — обращение к области, находящейся за предела-
пределами сегментов процесса, однако за которую процесс несет определенную ответст-
ответственность. Примеры — видеодрайвер и драйвер Ethernet, с которыми связывается
область памяти в диапазоне OxaOOOO-Oxffff, зарезервированном для устройств
ввода-вывода. Еще один пример — драйвер памяти, управляющий виртуальным
диском и обеспечивающий доступ к любой области памяти через устройства
/dev/mem и dev/kmem. Преобразование описанных адресов в физические вы-
выполняется функцией umap_remote (строка 10025).
Наконец, адрес может указывать на память BIOS, которая включает область
ниже значения 2 Кбайт (под областью, куда загружается MINIX 3) и диапазон
0x90000—Oxfffff (над областью MINIX 3) плюс зарезервированное пространство
ввода-вывода. Преобразование такого адреса может, как и в предыдущем слу-
случае, выполняться функцией umap_remote, однако функция umap_bios (стро-
(строка 10047) проверяет, принадлежит ли на самом деле адрес диапазону BIOS.
Последняя функция, определенная в файле system, с, — virtual_copy (стро-
(строка 10071). Большую часть ее тела составляет инструкция switch, использующая
описанные функции шпар_* для преобразования виртуальных адресов в физи-
физические. Преобразование выполняется как адреса источника, так и адреса прием-
приемника. Фактическое копирование осуществляется вызовом ассемблерной функ-
функции phys_copy (строка 10121) из файла klib386 . s.
2.7.3. Реализация системной библиотеки
Исходный код функции с именем вида do_xyz находится в файле kernel/
system/do_xyz . с. Файл Makefile из каталога kernel/ содержит строку
cd system && $(МАКЕ) -$(MAKEFLAGS) $@
Эта строка компилирует все файлы каталога kernel /system/ в библиотеку
system.а каталога kernel/. Когда управление передается в главный каталог
ядра, следующая строка Makefile ищет эту локальную библиотеку первой при
компоновке объектных файлов ядра.
На компакт-диске мы привели два файла из каталога kernel /system/. Они
были выбраны потому, что соответствуют двум основным видам поддержки,
предоставляемым системным заданием. Первый вид — это доступ к структурам
данных ядра от имени системного процесса, выполняемого в пользовательском
пространстве. В качестве примера такой поддержки мы рассматриваем файл
system/do_setalarm. с. Второй вид — обслуживание системных вызовов, в ос-
основном обрабатываемых процессами пользовательского пространства, однако
нуждающихся в выполнении некоторых действий внутри ядра. Примером для
нас служит файл system/do_exec . с.
Вызов sys_setalarm ядра аналогичен вызову sys_irqenable, который упоми-
упоминался нами при обсуждении обработки прерываний ядром. Вызов sys_irqenable
устанавливает адрес обработчика, который вызывается при появлении соответ-
соответствующего прерывания. В роли обработчика выступает функция generic_
handler системного задания, генерирующая уведомление драйверу устройства,
который должен отреагировать на прерывание. Файл system/do_setalarm.c
(строка 10200) содержит код, управляющий таймерами по принципу, аналогич-
аналогичному прерываниям. Вызов sys_setalarm ядра инициализирует таймер для
системного процесса в пользовательском пространстве, которому необходимо
получать сигналы синхронизации, и предоставляет функцию, уведомляющую
пользовательский процесс при истечении таймера. Вызов также может отменить
ранее запланированную передачу сигнала, указав ноль в поле сообщения, соот-
соответствующему времени истечения. Операция проста — в строках 10230-10232
извлекается информация, переданная в сообщении. Наиболее важными ее эле-
элементами являются время срабатывания таймера и процесс, который должен
узнать об этом. У каждого системного процесса имеется собственная структура
таймера в таблице привилегий. В строках 10237-10239 осуществляется доступ
к структуре данных, и в нее вводится номер процесса и адрес функции, которая
будет запущена по истечении таймера.
Если таймер уже запущен, вызов sys_setalarm возвращает в ответном сооб-
сообщении оставшееся до истечения время. Если возвращенное значение равно ну-
нулю, таймер неактивен. Допустимо несколько вариантов. Первый — таймер может
быть деактивирован: для этого в его поле exp_time необходимо записать специ-
специальное значение, TMR_NEVER. С точки зрения С-кода оно представляет собой
большое целое число, поэтому его проверка выполняется во время проверки ис-
истечения таймера. Таймер может указывать прошедшее время; это маловероятно,
но легко проверяется. Таймер может также указывать время в будущем. В любом
случае ответ содержит нулевое значение, иначе возвращается оставшееся до ис-
истечения время (строки 10242-10247).
Наконец, выполняется запуск или перезапуск таймера. На данном уровне для
этого в нужное поле структуры таймера записывается желаемое время истечения
и вызывается другая функция. Разумеется, для перезапуска таймера записывать
значение не нужно. Скоро мы познакомимся с функциями set и reset; они
расположены в файле исходного кода таймерного задания. Поскольку и систем-
системное, и таймерное задания находятся внутри образа ядра, доступны все функции,
объявленные в них открытыми (public).
В файле do_setalarm.c определена еще одна функция — cause_alarm. Это
сторожевая подпрограмма, адрес которой хранится в каждом таймере. При исте-
истечении таймера сторожевая функция вызывается. Все, что она делает — генериру-
генерирует уведомление процессу, номер которого хранится в структуре таймера. Таким
образом, сигнал синхронизации внутри ядра преобразуется в сообщение систем-
системному процессу, нуждающемуся в этом сигнале.
Немного отвлечемся и вспомним, что несколькими страницами ранее (в том числе
и в этом разделе) мы говорили о сигналах синхронизации, необходимых про-
процессам. Если сейчас это не вполне ясно и вы не понимаете, что такое сигнал
синхронизации и как обстоит дело с таймерами несистемных процессов, вам
поможет следующий раздел, посвященный таймерному заданию. В операционной
системе так много взаимосвязанных компонентов, что практически невозможно
выстроить их описание, избежав ссылок на еще неизученные части. Особенно
это относится к реализации. Если бы мы не имели дело с реальной операционной
системой, мы бы, вероятно, не стали вдаваться в такие детали. В чисто теоретиче-
теоретическом описании вы едва ли столкнулись бы с таким понятием, как системное зада-
задание. Об ограничении доступа системных компонентов, расположенных в пользо-
пользовательском пространстве, к привилегированным ресурсам, таким как прерывания
и порты ввода-вывода, можно было бы попросту забыть.
Последним файлом каталога kernel /system/, который мы рассмотрим под-
подробно, является do_exec. с (строка 10300). Большая часть работы системного
вызова exec выполняется менеджером процессов. Сначала менеджер процессов
устанавливает для новой программы стек, содержащий аргументы и окружение,
а затем передает указатель стека ядру при помощи вызова sys_exec ядра, кото-
который обрабатывается функцией do_exec (строка 10618). Указатель стека записы-
записывается в область таблицы процессов, принадлежащую ядру, и, если новый процесс
использует дополнительный сегмент, вызывается ассемблерная функция phys_
memset из файла klib386 . s, затирающая все данные, которые могли сохранить-
сохраниться в памяти после предыдущего процесса (строка 10330).
С вызовом exec связана одна необычная деталь. Процесс, выполнивший этот
вызов, передает сообщение менеджеру процессов и блокируется. Другой систем-
системный вызов мог бы снять блокировку с процесса, послав ему ответ, однако вызов
exec этого не делает, поскольку загруженный образ не ожидает ответа. В ре-
результате разблокирование процесса выполняется самой функцией do_exec
(строка 10333). В следующей строке функция lock_enqueue готовит новый об-
образ к запуску, предотвращая возможные условия гонок. Наконец, выполняется
сохранение командной строки, чтобы пользователь смог увидеть процесс, вос-
воспользовавшись командой ps или нажав функциональную клавишу для отобра-
отображения данных таблицы процессов.
Завершая обсуждение системного задания, рассмотрим его роль в типичной ус-
услуге, предоставляемой операционной системой, — доставке данных по системно-
системному вызову read. Когда пользователь выполняет вызов read, файловая система
проверяет свой кэш на наличие требуемого блока. Если блок обнаружить не
удается, она посылает сообщение драйверу диска, чтобы загрузить его в кэш,
а затем — сообщение системному заданию, чтобы скопировать блок пользова-
пользовательскому процессу. В худшем случае для чтения блока понадобится 11 сообще-
сообщений, в лучшем случае — 4, как показано на рис. 2.24. На рис. 2.24, а сообще-
сообщение 3 запрашивает у системного задания исполнить инструкции ввода-вывода,
сообщение 4 является подтверждением. При появлении аппаратного прерыва-
прерывания системное задание уведомляет об этом ожидающий драйвер сообщением 5.
Сообщения 6 и 7 — это запрос на копирование данных в кэш файловой системы
и ответ на него. Сообщение 8 говорит файловой системе о готовности данных,
сообщения 9 и 10 — это запрос на копирование данных из кэша в пользователь-
пользовательский процесс и ответ на него. Наконец, сообщение 11 — это ответ пользователю.
На рис. 2.24, б данные уже находятся в кэше, сообщения 2 и 3 представляют
собой запрос на их копирование пользовательскому процессу и ответ на него.
Эти сообщения вносят задержки и являются «расплатой» за высокую степень
модульности архитектуры MINIX 3.
Рис. 2.24. Доставка данных по системному вызову read: a — худший вариант чтения блока
требует 11 сообщений, б — лучший вариант чтения блока требует 4 сообщения
Вызовы ядра для копирования данных, вероятно, используются в MINIX 3 наи-
наиболее интенсивно. Мы уже знакомы с функцией virtual_copy — частью опе-
операционной системы, фактически выполняющую эту работу. Один из методов
борьбы с неэффективностью механизма передачи сообщений — упаковка в одно
сообщение нескольких запросов. Именно так и делают вызовы sys_virvcopy
и sys_physvcopy ядра. В обоих случаях сообщение содержит указатель на век-
вектор, задающий несколько блоков, которые необходимо скопировать из одной об-
области памяти в другую. Оба сообщения обрабатываются функцией do_vcopy.
Она выполняет цикл, где извлекает адреса источника и получателя, размеры
блоков, а затем последовательно вызывает функцию phys_copy до тех пор, пока
все операции копирования не будут завершены. В следующей главе мы увидим,
что дисковые устройства способны аналогично обрабатывать несколько опера-
операций передачи данных по единственному запросу.
2.8. Таймерное задание в MINIX 3
Часы, также называемые таймерами, необходимы любой системе разделения
времени в силу ряда причин. Например, они хранят время и препятствуют мо-
монопольному захвату ресурсов процессора одним процессом. Таймерное задание
в MINIX 3 имеет определенное сходство с драйвером устройства, поскольку
управляется аппаратно генерируемыми прерываниями. Тем не менее часы не отно-
относятся ни к блочным устройствам, таким как диски, ни к символьным устройствам,
таким как терминалы. В каталоге /dev/ MINIX 3 не предлагает интерфейса для
часов; более того, таймерное задание исполняется в пространстве ядра, и пользова-
пользовательские процессы не имеют к нему прямого доступа. Таймерное задание может
работать с любыми функциями и данными ядра, а пользовательским процессам
для этого необходимо прибегать к услугам системного задания. В этом разделе
мы сначала рассмотрим аппаратное и программное обеспечение часов с общей
точки зрения, а затем перейдем к воплощению описанных концепций в MINIX 3.
2.8.1. Аппаратное обеспечение часов
В компьютерах применяют два типа часов. Оба радикально отличаются от привыч-
привычных нам наручных или настенных часов. Простейшие часы подключены к элек-
электрической линии с напряжением 110 или 220 В и генерируют прерывание в каждом
цикле изменения напряжения (с частотой 50 или 60 Гц). Такие часы практиче-
практически невозможно встретить в современном компьютере.
Другой тип часов состоит из трех компонентов — кварцевого осциллятора, счет-
счетчика и регистра временного хранения (рис. 2.25). Кварцевый кристалл, разрезан-
разрезанный надлежащим образом и помещенный под напряжение, способен генериро-
генерировать периодический сигнал с очень высокой точностью, как правило, в диапазоне
5-200 МГц (это зависит от самого кристалла). Как минимум один такой осцил-
осциллятор присутствует в каждом компьютере. С его помощью генерируются сигна-
сигналы синхронизации для различных схем компьютера. Этот сигнал поступает на
счетчик, заставляя его значение уменьшаться. При достижении нулевого значе-
значения генерируется прерывание процессора. Если заявлено, что частота часов ком-
компьютера превышает 200 МГц, то, чаще всего, в нем используются более медлен-
медленные часы с умножителем частоты.
Рис. 2.25. Программируемые часы
Программируемые часы, как правило, имеют несколько режимов работы. В режи-
режиме однократного срабатывания при запуске часов значение регистра временного
хранения копируется в счетчик, а затем счетчик уменьшается на 1 при каждом
импульсе от кристалла. Когда значение счетчика становится нулевым, генерируется
прерывание, и часы останавливаются до тех пор, пока снова не будут запущены
программно. В режиме тактового меандра после генерации прерывания значение
регистра временного хранения автоматически копируется в счетчик, и процесс
циклически повторяется до бесконечности. Периодические прерывания называ-
называются тактами часов, или тиками.
Преимущество программируемых часов заключается в том, что частотой генери-
генерируемых ими прерываний можно управлять программно. При использовании
кристалла с частотой 1 МГц импульсы подаются на счетчик с периодом 1 мкс.
Если разрядность регистров часов равна 16, прерывания могут генерироваться
с интервалом от 1 до 65 536 мкс. Микросхемы программируемых часов, как пра-
правило, содержат двое или трое часов с возможностью независимого программиро-
программирования, а также поддерживают множество других возможностей (например, уве-
увеличение значения счетчика вместо уменьшения, отключение прерываний и т. д.).
Чтобы текущее время не стиралось при отключении питания, большинство ком-
компьютеров оснащено резервными часами, питающимися от аккумулятора. Резерв-
Резервные часы используют схемы с низким питанием, типичные для цифровых часов.
Данные резервных часов считываются во время запуска компьютера. При отсут-
отсутствии резервных часов система может попросить пользователя ввести текущее
время. Кроме того, существует стандартный протокол считывания времени с уда-
удаленного сервера. Каким бы способом время ни было введено в систему, оно пе-
переводится в число секунд, прошедших с момента всеобщего скоординированного
времени (Universal Coordinated Time, UTC) — полуночи 1 января 1970 года (рань-
(раньше употреблялся термин время по Гринвичу — Greenwich Mean Time) или с како-
какого-либо другого начала отсчета. В UNIX и MINIX используется всеобщее скоор-
скоординированное время. Такты часов генерируются самой системой, и по истечении
секунды реальное время увеличивается на единицу. В MINIX 3 и большинстве
UNIX-подобных систем не принимаются в расчет 23 секундных скачка, произо-
произошедших с 1970 года. Эта неточность не считается существенной. Как правило,
системы оснащены прикладными программами, позволяющими устанавливать
часы вручную, считывать время резервных часов и синхронизировать системные
часы с другими.
Отметим, что во всех IBM-совместимых компьютерах, за исключением самых
ранних, имеется отдельная схема часов, обеспечивающая тактовыми сигналами
процессор, внутренние шины данных и прочие компоненты. Частоту именно
этих сигналов имеют в виду люди, когда говорят о быстродействии процессора,
измеряя его в мегагерцах для устаревших компьютеров и в гигагерцах для со-
современных систем. Базовая схемотехника кварцевых кристаллов, осцилляторов
и счетчиков осталась неизменной, однако требования изменились настолько, что
современные компьютеры оснащают независимыми часами для управления про-
процессором и учета времени.
2.8.2. Программное обеспечение часов
Все, что делает аппаратное обеспечение часов, — генерирует прерывания через
известные промежутки времени. Остальные действия, связанные со временем,
должны выполняться программно драйвером часов. Конкретные обязанности
драйвера часов зависят от системы, однако чаще всего включают следующее:
+ хранение даты и времени;
+ прекращение выполнения процессов при истечении отведенного им времени;
+ учет коэффициента использования процессора;
+ обработка системного вызова alarm от пользовательских процессов;
+ предоставление сторожевых таймеров компонентам системы;
+ профилирование, наблюдение и сбор статистики.
Первая функция часов, хранение даты и времени (также называемых реальным
временем), проста. Все, что она делает, — увеличивает счетчик на единицу каж-
каждый такт часов, как было сказано ранее. Единственная проблема кроется в раз-
разрядности счетчика. Если тактовая частота часов составляет 60 Гц, переполнение
32-разрядного счетчика наступит уже через два года. Таким образом, 32-раз-
32-разрядного значения недостаточно для хранения числа тактов с 1 января 1970 года.
К разрешению этой проблемы имеется три подхода. Первый — воспользоваться
64-разрядным счетчиком. Это увеличивает накладные расходы на поддержку
таймера, поскольку его обслуживание выполняется много раз в секунду. Второй
подход — использование вспомогательного счетчика. Время хранится в виде чис-
числа секунд, а не тактов часов и увеличивается только тогда, когда вспомогатель-
вспомогательный счетчик насчитывает полную секунду. Поскольку 232 секунд — это больше,
чем 136 лет, такой метод будет исправно работать до 22 века.
Третий подход предлагает считать такты не с фиксированной точки отчета, а с мо-
момента загрузки системы. После чтения резервных часов или ввода текущего време-
времени пользователем время загрузки подсчитывается и сохраняется в любой подхо-
подходящей форме. Чтобы получить текущее время, достаточно сложить сохраненное
время со значением счетчика. Все три подхода иллюстрирует рис. 2.26.
Рис. 2.26. Три варианта поддержки текущего времени
Вторая функция часов — прекращение выполнения процессов по истечении от-
отведенного им времени. Каждый раз при запуске процесса планировщик должен
инициализировать счетчик значением, равным кванту и выраженным в тактах
часов. При каждом прерывании от часов их драйвер уменьшает текущее значение
счетчика на единицу. Как только счетчик становится нулевым, драйвер часов об-
обращается к планировщику с тем, чтобы тот выбрал другой процесс.
Третья функция часов — учет коэффициента использования процессора. Самый
точный способ сделать это — запустить вместе с процессом второй таймер, от-
отличный от основного таймера системы. При остановке процесса значение тайме-
таймера можно считать и определить, как долго выполнялся процесс. Во избежание
искажений, значение второго таймера должно сохраняться каждый раз при пре-
прерывании и восстанавливаться с возобновлением работы процесса.
Менее точный, но гораздо более простой способ наблюдения за использованием
процессора — ввести глобальную переменную, содержащую указатель на запись
текущего процесса в таблице процессов. С каждым тактом часов поле записи теку-
текущего процесса увеличивается на единицу и такт «присваивается» использовавшему
его процессу. У такого подхода есть небольшой недостаток: если во время вы-
выполнения процесса произойдет большое количество прерываний, они будут за-
засчитаны как такты использованного процессорного времени, хотя в момент пре-
прерывания процесс, по сути, не делает полезной работы. Точный учет потребления
процессора при прерываниях слишком накладен и применяется редко.
В MINIX 3 и многих других операционных системах процесс может попросить
систему послать ему предупреждение через определенный интервал времени.
Как правило, предупреждение имеет форму сигнала, прерывания, сообщения
и т. д. Пример приложения, нуждающегося в предупреждениях, — программы,
ведущие передачу данных по сети: если подтверждение о приеме пакета удален-
удаленной стороной не получено в течение заданного времени, следует повторить пере-
передачу пакета. Еще один пример — электронные системы обучения: если студент
не отвечает на вопрос, через определенный интервал времени правильный ответ
появляется на экране.
Если бы в распоряжении драйвера часов было достаточно таймеров, он мог бы
использовать отдельный таймер для каждого запроса. Однако это невозможно
на практике. В результате драйверу приходится поддерживать множество вир-
виртуальных таймеров на основе единственных физических часов. Один из спо-
способов такой поддержки — ведение таблицы, содержащей время срабатывания
всех активных таймеров, и переменной, хранящей время «ближайшего» таймера.
Каждый раз при обновлении реального времени драйвер проверяет, истекло ли
время у «ближайшего» таймера. Если да, из таблицы выбирается следующий
«ближайший» таймер.
Если число активных сигналов велико, эффективнее объединить все активные
запросы таймера в связанный список, упорядоченный по времени, как показано
на рис. 2.27. Каждый элемент списка определяет, через сколько тактов часов
после срабатывания предыдущего таймера должен сработать текущий таймер.
В приведенном примере сигналы должны быть сгенерировать в моменты вре-
времени 4203, 4207, 4213, 4215 и 4216.
Рис. 2.27. Имитация нескольких таймеров с помощью единственных часов
В момент, изображенный на рис. 2.27, только что сработал один из таймеров.
Следующее прерывание произойдет через 3 тика, поэтому в поле следующего
сигнала загружено число 3. С каждым тиком значение этого поля уменьшается
на единицу. Когда оно становится равным нулю, генерируется сигнал, соответст-
соответствующий первому элементу списка, после чего элемент удаляется. Затем в по-
поле следующего сигнала загружается значение нового первого элемента списка —
в данном случае 4. Во многих случаях использовать абсолютное время удобнее,
чем относительное, и именно такой поход применяется в MINIX 3.
Обратите внимание на то, что при прерывании от часов драйвер выполняет це-
целый ряд действий — увеличение реального времени, уменьшение кванта и его
проверка на равенство нулю, учет коэффициента использования процессора,
уменьшение счетчика сигналов. Каждая из этих операций должна быть тщатель-
тщательно продуманна и выполняться очень быстро, поскольку все они повторяются
много раз в секунду.
Компонентам операционной системы также нужны таймеры, называемые сторо-
сторожевыми. При изучении жесткого диска мы увидим, что пробуждающий вызов
планируется каждый раз, когда контроллеру диска подается команда — в случае
сбоя это позволяет сделать попытку восстановления. Дисковые драйверы дискет
используют таймеры для ожидания разгона и остановки механизма. Некоторые
принтеры с перемещаемой печатающей головкой способны печатать со скоро-
скоростью 120 символов в секунду (8,3 миллисекунды на символ), однако не всегда
успевают возвратить головку к левой границе за 8,3 миллисекунды, поэтому
драйвер терминала вынужден ждать после ввода символа возврата каретки.
Механизм, используемый драйвером часов для поддержки сторожевых таймеров,
тот же, что и для пользовательских сигналов. Единственное различие состоит
в том, что при срабатывании таймера драйвер часов не генерирует сигнал, а об-
обращается к процедуре, поддерживаемой вызывающим процессом и являющейся
частью его кода. При разработке MINIX 3 это стало проблемой, поскольку целью
операционной системы было изъятие драйверов из адресного пространства ядра.
Проблему решили, возложив на системное задание, находящееся внутри ядра,
функции по установке сигналов от имени некоторых процессов пользователь-
пользовательского пространства и уведомлению этих процессов. В будущем мы планируем
усовершенствовать этот механизм.
Последняя функция часов в нашем списке — профилирование. Некоторые опе-
операционные системы предоставляют пользовательским программам возможность
построения гистограммы счетчика команд, позволяющей определить расход вре-
времени. Если поддержка профилирования присутствует, на каждом тике драйвер
проверяет, ведется ли профилирование текущего процесса, и если да, подсчиты-
подсчитывает двоичное число (диапазон адресов), соответствующий счетчику команд. За-
Затем двоичное число увеличивается на единицу. Подобный механизм можно при-
применять и для профилирования самой системы.
2.8.3. Обзор драйвера часов в MINIX 3
Драйвер часов MINIX 3 находится в файле kernel/clock. с. В нем можно вы-
выделить три функциональные части. Во-первых, как и драйверы устройств, кото-
которые будут рассмотрены нами в следующей главе, драйвер часов имеет циклически
выполняемый механизм заданий, ожидающий сообщения и вызывающий под-
подпрограммы, выполняющие запрашиваемые в сообщениях действия. Однако в тай-
мерном задании участие этого механизма сведено к минимуму. Использование
сообщений приводит к значительным задержкам, вклад в которые вносит пере-
переключение контекста. По этой причине к сообщениям прибегают лишь в случаях,
когда необходимо выполнить большой объем работы. Таймерное задание прини-
принимает лишь один вид сообщений, имеет одну подпрограмму их обработки, а по за-
завершении обслуживания ответное сообщение не генерируется.
Вторая существенная часть драйвера часов — обработчик прерывания, активи-
активируемый 60 раз в секунду и обеспечивающий базовую поддержку времени. Он об-
обновляет значение счетчика тактов часов с момента загрузки системы и сравнива-
сравнивает его со временем следующего истечения таймера. Кроме того, обработчик
обновляет счетчики израсходованного процессом времени — общего и в текущем
кванте. Если процесс израсходовал свой квант или сработал таймер, обработчик
генерирует сообщение, поступающее в главный цикл задания. В противном слу-
случае никакого сообщения не передается. Цель стратегии обработчика — в каждом
тике выполнять минимум действий и завершаться как можно быстрее. Затратное
основное задание активизируется только при большом объеме работы.
Третья часть драйвера часов представляет собой набор подпрограмм, осуществ-
осуществляющих общую поддержку, однако не вызываемых в ответ на прерывания от
таймера ни обработчиком, ни главным циклом задания. Одна из этих подпро-
подпрограмм объявлена закрытой (private) и вызывается перед входом в главный
цикл. Она инициализирует часы — записывает в микросхему данные, обеспечи-
обеспечивающие генерацию прерываний через желаемые промежутки времени. Под-
Подпрограмма инициализации также помещает адрес обработчика прерываний так,
чтобы воспользоваться им при срабатывании прерывания от таймера по линии 8,
и включает эту линию.
Остальные подпрограммы файла clock. с объявлены открытыми (public) и мо-
могут вызываться любым кодом ядра. Файл clock. с не содержит обращений к этим
подпрограммам; в основном их использует системное задание для обслуживания
системных вызовов, связанных с временем. Подпрограммы выполняют такие дей-
действия, как чтение счетчика тактов часов с момента загрузки системы, синхрониза-
синхронизация по каждому тику, чтение регистра микросхемы часов, синхронизация с мик-
микросекундным разрешением. Имеются подпрограммы для сброса и переустановки
таймеров. Кроме того, одна из подпрограмм вызывается при завершении работы
MINIX 3. Она устанавливает параметры аппаратного таймера, требуемые BIOS.
Таймерное задание
Главный цикл таймерного задания принимает единственный тип сообщений,
HARD_INT, поступающих от обработчика прерываний. Все остальные сообщения
считаются ошибочными. Более того, главный цикл принимает сообщения не для
всех прерываний от таймера, хотя подпрограмма приема сообщений называется
do_clocktick. Последняя вызывается только при необходимости планирова-
планирования процесса или при истечении таймера.
Обработчик прерываний от таймера
Обработчик прерываний от таймера запускается каждый раз, когда счетчик мик-
микросхемы часов достигает нулевого значения и генерирует прерывание. Именно
обработчик выполняет основную работу по поддержке времени. В MINIX 3 вре-
время хранится так, как показано на рис. 2.26, в. Тем не менее в файле clock.с
используется лишь счетчик тиков, прошедших со времени последней загрузки
системы; время загрузки хранится в другом месте. Программное обеспечение ча-
часов пользуется только текущим счетчиком и поддерживает системный вызов,
запрашивающий реальное время. Дальнейшая обработка выполняется одним из
серверов. Такой подход соответствует стратегии MINIX 3, направленной на пе-
перенос функциональности в пользовательское пространство.
Обработчик прерываний обновляет значение локального счетчика при каждом
прерывании. Если прерывания запрещены, такты теряются. В некоторых случа-
случаях этот эффект можно компенсировать. Подсчет потерянных тактов возможен
с использованием глобальной переменной, значение которой складывается с ло-
локальным счетчиком, а при наступлении прерывания и активации обработчика
счетчик сбрасывается в ноль. Мы увидим, как это делается, во время изучения
реализации.
Обработчик также изменяет значения переменных, расположенных в таблице
процессов, с целью учета времени процессов и управления ими. Он посылает со-
сообщение таймерному заданию лишь в случае, если в текущий момент следую-
следующий запланированный таймер истек либо закончился квант процесса. Все, что
делает обработчик, — выполняет простые целочисленные операции: арифмети-
арифметические, сравнения, логические (И/ИЛИ), присваивания. Такие операции с лег-
легкостью переводятся компилятором в машинный код. В худшем случае соверша-
совершается 5 сложений или вычитаний, 6 сравнений и несколько логических операций
и присваиваний в конце процедуры. Задержки, связанные с вызовами подпро-
подпрограмм, равны нулю.
Сторожевые таймеры
Несколько страниц назад мы оставили открытым вопрос о том, как обеспечить
пользовательские процессы сторожевыми таймерами, которые обычно представ-
представляют как пользовательские процедуры, исполняемые по истечении таймера.
Очевидно, в MINIX 3 это попросту невозможно. Тем не менее мы можем постро-
построить мост между ядром и пользовательским пространством с помощью сигналов
синхронизации.
Сейчас самое время разобраться в том, что представляет собой сигнал синхрони-
синхронизации. Сигнал может генерироваться вне зависимости от того, какой процесс ис-
исполняется в текущий момент. То же касается и активации обычного сторожевого
таймера. Говорят, что такие события происходят асинхронно. Сигнал синхрони-
синхронизации доставляется в виде сообщения и может быть получен при выполнении
адресатом вызова receive. Мы говорим о синхронности потому, что адресат ожи-
ожидает сигнал. Когда отправитель уведомляет адресата о сигнале с помощью проце-
процедуры notify, отправителю не нужно блокироваться, а адресату — беспокоиться
о том, что сигнал будет пропущен. Если адресат не находится в ожидании, сооб-
сообщения процедуры notify сохраняются. Для этой цели используется битовая
карта, где каждый бит соответствует возможному отправителю.
Сторожевые таймеры используют поле s_alarm_timer типа timer_t, имею-
имеющееся в каждом элементе таблицы привилегий. Каждому системному процессу
в этой таблице соответствует свой элемент. Чтобы установить таймер, систем-
системный процесс, находящийся в пользовательском пространстве, выполняет вызов
sys_setalarm, обрабатываемый системным заданием. Системное задание на-
находится в пространстве ядра и, таким образом, может инициализировать таймер
от имени вызывающего процесса. Инициализация включает размещение в нуж-
нужном поле адреса процедуры, запускаемой при истечении таймера, и ввод таймера
в список таймеров, как показано на рис. 2.27.
Разумеется, исполняемая процедура также должна находиться в пространстве
ядра. Это не является проблемой. Системное задание располагает сторожевой
функцией, cause_alarm, генерирующей пользователю синхронное уведомле-
уведомление в момент срабатывания с помощью процедуры notify. Данный сигнал мо-
может вызвать сторожевую функцию в пользовательском пространстве. «Настоя-
«Настоящая» сторожевая функция находится внутри ядра, а пользовательский процесс
всего лишь получает сигнал синхронизации. Подобный алгоритм отличается от
исполнения пользовательской функции таймером. Он сопровождается больши-
большими накладными расходами, однако проще, чем механизм прерываний.
Мы намеренно указали на то, что системное задание устанавливает сигналы от
имени некоторых процессов пользовательского пространства. Описанный меха-
механизм применяется лишь к системным процессам. У каждого системного процес-
процесса есть собственная запись в таблице привилегий, а все несистемные процессы
используют единственную общую запись. Области таблицы привилегий, кото-
которые не могут использоваться совместно, например битовая карта активных уве-
уведомлений и таймер, недоступны пользовательским процессам вообще. Выход из
ситуации следующий: менеджер процессов управляет таймерами от имени поль-
пользовательских процессов. Аналогичным образом системное задание управляет
таймерами от имени системных процессов.
Когда пользовательский процесс выполняет системный вызов alarm, чтобы
установить сигнал, он обрабатывается менеджером процессов, конфигурирую-
конфигурирующим таймер и помещающим его в список таймеров. Менеджер процессов просит
системное задание послать ему уведомление, когда для первого таймера в списке
будет назначено время истечения. Помощь менеджеру процессов требуется лишь
при изменении начального элемента списка таймеров — из-за того, что первый
таймер истек или был выключен, либо из-за нового вызова, таймер которого дол-
должен оказаться в списке первым. Все это делается для поддержки системного
вызова alarm, определенного стандартом POSIX. Подлежащая исполнению
процедура находится в адресном пространстве менеджера процессов. Во время
выполнения инициировавшему вызов пользовательскому процессу передается
сигнал, а не уведомление.
Миллисекундные задержки
В файле clock.с имеется процедура, обеспечивающая микросекундное разре-
разрешение. Различным устройствам ввода-вывода требуются задержки длительно-
длительностью всего лишь несколько микросекунд, которые невозможно обеспечить на
практике при помощи сигналов и интерфейса передачи сообщений. Счетчик,
используемый для генерации прерываний от таймера, может быть считан впрямую.
Его уменьшение выполняется с интервалом, приблизительно равным 0,8 мкс,
а значение достигает нуля 60 раз в секунду (один раз за 16,67 мс). Для того
чтобы использовать значение счетчика для задержек устройств ввода-вывода,
его необходимо опрашивать процедурой, находящейся в пространстве ядра, од-
однако драйверы устройств размещены за его пределами. В настоящее время эта
функция используется только в качестве источника исходных данных для ге-
генератора случайных чисел. Возможно, она окажется более полезной в системе
с высоким быстродействием, но это — вопрос будущего.
Службы времени
В табл. 2.6 перечислены службы файла clock.с, прямо или косвенно предостав-
предоставляющие различные услуги. Несколько функций объявлены открытыми (public),
что дает возможность вызывать их из ядра или системного задания. Все остальные
службы доступны только косвенно — с помощью системных вызовов, в конеч-
конечном счете, обрабатываемых системным заданием. Остальные системные процес-
процессы могут косвенно обращаться к системному заданию. Пользовательские про-
процессы должны взаимодействовать с менеджером задач, который также прибегает
к службам системного задания.
Таблица 2.6. Службы времени, поддерживаемые драйвером часов
Служба Доступ Ответ Клиенты
get_uptjme Вызов функции Такты Ядро или системное задание
set_timer Вызов функции Нет Ядро или системное задание
reset_tjmer Вызов функции Нет Ядро или системное задание
read_clock Вызов функции Счетчик Ядро или системное задание
clock_stop Вызов функции Нет Ядро или системное задание
Сигнал синхронизации Системный вызов Уведомление Сервер или драйвер, через
системное задание
Сигнал POSIX Системный вызов Сигнал Пользовательский процесс,
через менеджер процессов
Время Системный вызов Сообщение Любой процесс, через
менеджер процессов
Ядро и системное задание могут получить текущее время работы системы, уста-
установить или сбросить таймер, не прибегая к затратному обмену сообщениями.
Ядро и системное задание также вызывают функцию read_clock, считываю-
считывающую счетчик из микросхемы таймера для получения времени, выраженного в еди-
единицах длительностью приблизительно 0,8 мкс. Функция clock_stop вызывает-
вызывается при завершении работы MINIX 3 и восстанавливает тактовую частоту BIOS.
Системный процесс (драйвер или сервер) может запросить сигнал синхрониза-
синхронизации, активирующий сторожевую функцию в пространстве ядра, и уведомление,
передаваемое вызывающему процессу. Сигнал POSIX запрашивается пользова-
пользовательским процессом у менеджера процессов, который, в свою очередь, просит
системное задание активировать сторожевую функцию. По истечении таймера
системное задание уведомляет менеджер процессов, а тот доставляет сигнал поль-
пользовательскому процессу.
2.8.4. Реализация драйвера часов в MINIX 3
Таймерное задание не использует основные структуры данных; для работы со
временем предназначены несколько переменных. Переменная realtime (стро-
(строка 10462) является главной — она считает такты часов. Глобальная переменная
lost_ticks определена в файле glo.h (строка 5333). Она предназначена для
использования всеми функциями, выполняемыми в пространстве ядра и способ-
способными запретить прерывания, которые достаточно длинны для того, чтобы один
или более тиков оказались потерянными. В настоящее время переменную lost_
ticks использует функция int86, расположенная в файле klib386 . s. Функ-
Функция int86 задействует монитор загрузки для передачи управления в BIOS, и пе-
перед возвращением в ядро монитор возвращает в регистре есх число тиков, затра-
затраченных на обслуживание вызова BIOS. Хотя микросхема таймера не приводит
к выполнению обработчика прерывания при обслуживании запроса BIOS, мони-
монитор загрузки может поддерживать время с помощью BIOS.
Драйвер часов осуществляет доступ к ряду других глобальных переменных. Он
использует переменную proc__ptr — указатель на запись таблицы процессов,
соответствующую текущему процессу, prev_ptr — указатель на предыдущий
процесс и bill_ptr — указатель на процесс, которому начисляется процессор-
процессорное время. С помощью этих переменных драйвер часов оперирует различными
полями записей, в частности p_user_time и p_sys_time, для учета и для
уменьшения оставшегося времени кванта соответственно.
При запуске MINIX 3 выполняется вызов всех драйверов. Большинство из них
совершают действия по инициализации, пытаются получить сообщение и бло-
блокируются. Драйвер часов, clock_task (строка 10648), не является исключени-
исключением. Сначала он обращается к функции init_clock, чтобы установить частоту
часов равной 60 Гц. После получения сообщения драйвер вызывает функцию
do_clockticks при условии, что типом сообщения является HARD_INT (стро-
(строка 10486). Все остальные сообщения считаются ошибками.
Функция do_clockticks (строка 10497), противореча собственному назва-
названию, не вызывается в каждом такте часов. Она вызывается в случае, если об-
обработчик прерывания определил наличие важной работы. Одно из условий
запуска do_c lock ticks — окончание кванта текущего процесса. Если процесс
может быть вытеснен (системное и таймерное задания не входят в их число), вы-
вызывается функция lock_dequeue, а затем — функция lock_enqueue (стро-
(строки 10510-10512). В результате процесс удаляется из очереди, снова переводится
в состояние готовности и перепланируется. Еще одна причина запуска do_
clockticks — истечение сторожевого таймера. Таймеры и их связанные спи-
списки используются в MINIX 3 столь интенсивно, что для их поддержки создана
целая библиотека функций. Библиотечная функция tmrs_exptimers, вызы-
вызываемая в строке 10517, запускает сторожевые функции для всех истекших тайме-
таймеров и деактивирует их.
Функция init_clock (строка 10529) вызывается только один раз — при вызо-
вызове таймерного задания. В коде можно найти несколько мест и сказать: «выполне-
«выполнение MINIX 3 начинается отсюда!» Это — одно из них; часы являются обязатель-
обязательным компонентом любой системы с вытесняющей многозадачностью. Функция
init_clock сначала записывает 3 байта в микросхему часов, задавая ее режим
и нужное значение счетчика в главном регистре, а затем регистрирует свой но-
номер процесса, номер прерывания и адрес обработчика для надлежащего об-
обслуживания. Наконец, функция разрешает контроллеру прерываний принимать
прерывания от таймера.
Следующая функция, clock_stop, отменяет результаты инициализации мик-
микросхемы часов. Она объявлена открытой (public) и не вызывается из файла
clock.с. Она помещена сюда из-за очевидного сходства с init_clock. Един-
Единственный ее вызов выполняется системным заданием при завершении работы
MINIX 3 для передачи управления монитору загрузки.
Одновременно с запуском функции init_clock (а точнее, через 16,67 мс)
происходит первое прерывание от таймера, и далее прерывания генерируются
с частотой 60 раз в секунду до тех пор, пока работает MINIX 3. Вероятно, код
функции clock_handler (строка 10556) выполняется чаще, чем любой дру-
другой в MINIX 3. По этой причине разработчики сделали так, чтобы он завер-
завершался как можно быстрее. Единственная ситуация, в которой необходим вы-
вызов подпрограмм, — использование устаревшего компьютера IBM PS/2 (строка
10586). Обновление текущего времени (в тактах часов) выполняется в стро-
строках 10589-10591. После этого обновлению подлежат учетное время и время
пользователя.
Внутри обработчика принимается несколько не вполне очевидных решений.
В строке 10610 выполняются две проверки, и если хотя бы одна из них оказыва-
оказывается успешной, таймерному заданию посылается уведомление. Функция do_
clocktick, вызываемая таймерным заданием, повторяет проверки с целью оп-
определения необходимых действий. Этот шаг нужен потому, что уведомление не
способно нести информацию о различных условиях. Рассмотреть и оценить аль-
альтернативы мы предлагаем читателю самостоятельно.
Оставшаяся часть файла clock, с содержит уже упомянутые функции. Функ-
Функция get_uptime (строка 10620) возвращает значение realtime, видимое только
функциями файла clock, с. Функции set_timer и reset_timer используют
другие функции библиотеки, ответственные за детали манипуляции с цепочкой
таймеров. Наконец, функция read_clock считывает и возвращает текущее зна-
значение регистра счетчика микросхемы часов.
Резюме
Чтобы скрыть эффект прерываний, операционная система предоставляет кон-
концептуальную модель, в которой параллельно выполняются логически упорядо-
упорядоченные процессы. Процессы могут взаимодействовать друг с другом при помощи
примитивов, таких как семафоры, мониторы и сообщения. Назначение примити-
примитивов в том, чтобы гарантировать, что никакие два процесса не окажутся в крити-
критической секции единовременно. Процессы могут находиться в состоянии вы-
выполнения, готовности и приостановки, а также переходить из одного состояния
в другое, когда тот или иной процесс исполняет один из примитивов взаимодей-
взаимодействия между процессами.
Примитивы необходимы для решения таких проблем, как проблема производи-
производителя и потребителя, проблема обедающих философов, проблема писателей и чи-
читателей. Но даже при использовании примитивов необходимо быть осторожным,
во избежание ошибок и взаимных блокировок. Известно много различных алго-
алгоритмов планирования, таких как циклический алгоритм, приоритетный алго-
алгоритм, алгоритм с многоуровневыми очередями, алгоритм управления политика-
политиками планирования.
Операционная система MINIX 3 поддерживает концепцию процесса и предо-
предоставляет примитивы для взаимодействия между процессами. Сообщения не бу-
буферизуются, поэтому вызов send завершается успехом только после того, как
адресат получит сообщение. Аналогично, вызов receive завершается лишь
тогда, когда сообщение уже отправлено. В противном случае сделавший вызов
процесс переходит в состояние ожидания. MINIX 3 также поддерживает небло-
неблокирующую разновидность сообщений — уведомления, передаваемые с помощью
примитива notify. Попытка послать уведомление адресату, не находящемуся
в состоянии ожидания, приводит к установке бита, вызывающего восстановле-
восстановление уведомления при вызове receive в будущем.
В качестве примера потока сообщений рассмотрим вызов read, выполняемый
пользовательским процессом. Процесс посылает запрос на чтение в виде сообще-
сообщения, адресованного файловой системе. Если данные не удалось обнаружить в кэше,
файловая система запрашивает их чтение с диска у драйвера, а сама переходит
в состояние блокировки. При дисковом прерывании системное задание получает
уведомление, позволяющее ему передать ответ драйверу диска, а тому, в свою
очередь, — файловой системе. После этого файловая система запрашивает систем-
системное задание скопировать данные из кэша, в который был помещен требуемый
блок, пользовательскому процессу. Перечисленные шаги иллюстрирует рис. 2.24.
За прерыванием может последовать переключение процессов. В случае прерывания
в элементе таблицы процессов, соответствующем прерванному процессу, созда-
создается стек, в который помещается вся информация, необходимая для его переза-
перезапуска. При перезапуске процесса указателю стека присваивается адрес элемента
таблицы процессов, далее выполняются команды, восстанавливающие регистры
процессора, а затем — команда iretd. Выбор элемента таблицы процессов, адрес
которого помещается в указатель стека, возлагается на планировщика.
Прерывания во время исполнения ядра невозможны. Если при выполнении ядра
возникло исключение, вместо стека таблицы процессов используется стек ядра.
По завершении обслуживания прерывания процесс перезапускается.
Алгоритм планирования в MINIX 3 использует множество очередей с различны-
различными приоритетами. Системные процессы, как правило, имеют наивысший при-
приоритет, а приоритет пользовательских процессов, чаще всего, невысок. Тем не
менее приоритет каждого процесса может задаваться отдельно. Зациклившийся
процесс может быть временно понижен в приоритете и восстановлен после того,
как другие процессы получат возможность выполниться. Для изменения уровня
приоритета процесса внутри заданных границ используется команда nice. Вы-
Выбор процессов на исполнение происходит по циклическому алгоритму, а кванты
задаются для каждого процесса индивидуально. Тем не менее процесс, сначала
блокированный в середине кванта, а затем ставший готовым, помещается в на-
начало очереди и выполняется все время, оставшееся до окончания прерванного
кванта. Это сокращает время отклика для процессов, требующих ввода-вывода.
Драйверам устройств и серверам предоставлен больший квант, поскольку пред-
предполагается, что их исполнение обычно прерывается блокированием. Тем не ме-
менее даже системные процессы вытесняются в случае, если их выполнение ока-
оказывается слишком долгим.
Образ ядра включает системное задание, обеспечивающее взаимодействие про-
процессов, которые выполняются в пользовательском пространстве. Системное
задание поддерживает серверы и драйверы устройств, совершая от их имени
привилегированные операции. В состав ядра MINIX 3 также входит таймер-
ное задание. Оно не является драйвером устройства в обычном смысле: поль-
пользовательские процессы не могут обращаться с часами так же, как с другими
устройствами.
Вопросы и задания
1. Почему многозадачность является основным требованием для современных
операционных систем?
2. Каковы три основных состояния процесса? Кратко опишите смысл каждого
из них.
3. Представьте, что вы разрабатываете усовершенствованную компьютерную
архитектуру, в которой процессы переключаются аппаратно, а не с помощью
прерываний. Какая информация потребуется процессору? Опишите возмож-
возможную реализацию аппаратного переключения процессов.
4. На всех существующих компьютерах как минимум часть обработчиков пре-
прерываний написана на ассемблере. Почему?
5. Измените рис. 2.2, добавив в него два состояния процесса — «новый» и «за-
«завершенный». Процесс находится в состоянии «новый» после создания, а в со-
состоянии «завершенный» — после окончания своей работы.
6. В тексте утверждалось, что модель, представленная на рис. 2.4, а, не подходит
для файлового сервера с кэшем в памяти. Почему? Может ли каждый про-
процесс иметь собственный кэш?
7. В чем заключается фундаментальное различие между процессом и программ-
программным потоком?
8. Если в системе используются программные потоки, выделяется ли каждо-
каждому из них собственный стек или стеки имеются лишь у процессов? Поясните
ответ.
9. Что такое условия гонок?
10. Приведите пример условия гонок, которое возможно при покупке двумя пас-
пассажирами билетов на один и тот же самолет.
11. Напишите сценарий оболочки, которая создает файл, содержащий после-
последовательные числа, путем считывания последнего числа, прибавления к нему
единицы и записывания результата в конец файла. Запустите одну копию
сценария в качестве фонового процесса и одну — в качестве приоритетного
процесса. Сколько времени пройдет, прежде чем возникнут условия гонок?
Что в данной модели является критической секцией? Измените сценарий,
чтобы избежать условий гонок. Подсказка: воспользуйтесь следующим сцена-
сценарием, чтобы заблокировать файл данных
In file file.lock
12. Имеется инструкция
In file file.lock
Реализует ли эта инструкция эффективный механизм разделения доступа
для таких пользовательских программ, как сценарий в предыдущем задании?
Почему?
13. Будет ли работать решение для активного ожидания с применением перемен-
переменной turn (см. листинг 2.1) в случае двух процессоров, совместно использую-
использующих общую память?
14. Рассмотрим компьютер, в котором не поддерживается инструкция tsl, но
есть инструкция для обмена содержимого регистра и слова памяти за одну
неделимую операцию. Можно ли применить эту инструкцию для написания
программы enter_region, аналогичной показанной в листинге 2.3?
15. Опишите коротко, как реализовать семафоры в операционной системе, умею-
умеющей блокировать прерывания.
16. Покажите, как молено реализовать «считающие» семафоры (то есть способ-
способные хранить произвольные значения) при помощи только бинарных семафо-
семафоров и обычных машинных команд.
17. В п. 2.2.4 была описана ситуация с высокоприоритетным процессом Н и низко-
низкоприоритетным процессом L, которая приводила к зацикливанию процесса Я.
Может ли возникнуть подобная проблема, если вместо приоритетного плани-
планирования использовать циклическое? Поясните.
18. Синхронизация в мониторах происходит с использованием переменных со-
состояния и двух специальных операций, wait и signal. Более общая форма
синхронизации предполагает один примитив waituntil с произвольным бу-
булевым предикатом в качестве параметра. Например:
waituntil x<0 or y+z<n
В данном случае примитив signal больше не нужен. Эта схема существенно
более общая, чем схемы Хоара и Хансена, и тем не менее она не используется.
Почему? Подсказка: подумайте о реализации.
19. В ресторане быстрого питания есть четыре категории обслуживающего пер-
персонала:
1) работники, принимающие заказы;
2) повара, готовящие пищу;
3) специалисты по упаковке блюд;
4) кассиры, принимающие у клиентов деньги и выдающие еду.
Каждой из категорий можно сопоставить последовательный процесс взаимо-
взаимодействия. Какой формой взаимодействия между процессами они пользуют-
пользуются? Свяжите эту модель с процессами в MINIX 3.
20. Рассмотрим систему передачи сообщений через почтовые ящики. При попыт-
попытке послать сообщение в полный ящик или получить сообщение из пустого
ящика процесс не блокируется, а получает код ошибки. Затем процесс повто-
повторяет попытку, пока она не окажется успешной. Приведет ли подобная схема
к условиям гонок?
21. Почему в процедуре take_f orks решения задачи обедающих философов
(см. листинг 2.10) переменной состояния присваивается значение HUNGRY?
22. Рассмотрим процедуру put_f orks в листинге 2.10. Пусть переменной state [ i ]
присваивается значение THINKING после двух вызовов процедуры test, а не
до. Как это повлияет на решение для трех философов? Для 100 философов?
23. Проблему читателей и писателей можно формулировать по-разному, в зави-
зависимости от того, какие процессы и в какое время могут быть запущены. Тща-
Тщательно опишите три варианта проблемы, в каждом из которых предоставляет-
предоставляется (или не предоставляется) преимущество одной из категорий. В каждом
варианте укажите, что происходит, когда читающий или пишущий процесс
готов обратиться к базе данных, и что происходит, когда процесс заканчивает
работу с базой.
24. Компьютеры CDC 6600 в состоянии обрабатывать до 10 процессов ввода-вы-
ввода-вывода одновременно благодаря интересной форме циклического планирова-
планирования, называемой разделением процессора. Переключение между процессами
происходит после каждой команды, поэтому команда 1 поступает от первого
процесса, команда 2 — от второго и т. д. Переключение процессов произво-
производится аппаратно, и издержки равны нулю. Если в отсутствие других процес-
процессов процессу для выполнения работы нужно Т секунд, сколько ему потребу-
потребуется времени в случае п процессов?
25. Обычно планировщики с циклическим алгоритмом поддерживают список про-
процессов, готовых к работе, причем каждый процесс находится в списке в единст-
единственном экземпляре. Что произойдет, если процесс окажется в списке дважды?
Существует ли причина, по которой подобное изменение может оказаться по-
полезным?
26. Измерения показали, что время выполнения среднестатистического процесса
до блокировки ввода-вывода равно Г. На переключение между процессами
уходит время S, которое теряется впустую. Напишите формулу расчета эф-
эффективности для циклического планирования с квантом Q, принимающим
следующие значения:
1) Q = oo;
2) Q>T;
3) S < Q < Г;
4) Q = S;
5) Q около 0.
27. Запуска ожидают пять заданий. Предполагаемое время выполнения заданий
составляет 9, 6, 3, 5 и X В каком порядке их следует запустить, чтобы мини-
минимизировать среднее время отклика? (Ответ должен зависеть от X)
28. Пять пакетных заданий, Л, В, С, Д £, поступают в компьютерный центр прак-
практически одновременно. Ожидается, что время их выполнения составит 10, 6,
2, 4 и 8 мин. Их установленные приоритеты равны 3, 5, 2, 1 и 4, причем 5 —
высший приоритет. Определите среднее время оборота для каждого из сле-
следующих алгоритмов планирования, пренебрегая потерями на переключение
между процессами:
1) циклическое планирование;
2) приоритетное планирование;
3) первым пришел — первым обслужен (в порядке 10, 6, 2, 4, 8);
4) самое короткое задание — первое.
В первом случае предполагается, что система многозадачная и каждому за-
заданию достается справедливая доля процессорного времени. В остальных
случаях считается, что в каждый момент времени выполняется одно задание,
работающее вплоть до завершения. Все задания ограничены исключительно
возможностями процессора.
29. Процессу, запущенному в CTSS-системе, для завершения необходимо 30 кван-
квантов. Сколько раз он будет выгружен на диск, учитывая самый первый раз
(прежде, чем он был запущен)?
30. Для предсказания времени выполнения используется алгоритм старения
с а = 1/2. Предыдущие четыре значения времени составляли 40, 20, 40 и 15 мс
(первое значение — самое давнее). Оцените следующее время выполнения.
31. На рис. 2.10 изображена схема трехуровневого планирования в системе па-
пакетной обработки. Можно ли использовать его в интерактивной системе без
новых поступающих заданий? Как?
32. Предположим, что программные потоки, изображенные на рис. 2.13, а, вы-
выполняются в следующем порядке: один поток процесса А, один поток процес-
процесса В и т. д. Сколько последовательностей программных потоков возможно
для первых четырех вариантов планирования?
33. В гибкой системе реального времени поддерживаются четыре события с пе-
периодами 50, 100, 200 и 250 мс. Предположим, что эти события требуют 35, 20,
10 и х мс процессорного времени соответственно. Найдите максимальное зна-
значение х, при котором система является планируемой.
34. В процессе работы MINIX 3 использует переменную proc_ptr, содержащую
указатель на ячейку текущего процесса в таблице процессов. Зачем?
35. В MINIX 3 сообщения не буферизуются. Поясните, почему это приводит к про-
проблемам с прерываниями от таймера и клавиатуры.
36. Когда в MINIX приостановленному процессу отправляется сообщение, вызы-
вызывается подпрограмма ready, которая помещает процесс в одну из очередей
планировщика. Эта подпрограмма начинается с блокирования прерываний.
Почему?
37. В MINIX функция mini_rec содержит цикл. Зачем?
38. Схема планирования в MINIX в целом соответствует рис. 2.22 с различными
приоритетами для разных классов. Нижний класс (пользовательские процес-
процессы) планируется по циклической схеме, но задания и серверы выполняются
всегда, пока не попадут в состояние блокировки. Могут ли низкоуровневые
процессы зависать? Почему да (или почему нет)?
39. Подходит ли MINIX для решения задач реального времени (таких как сбор
данных)? Если нет, то что можно сделать для исправления ситуации?
40. Предположим, у вас имеется операционная система, предоставляющая сема-
семафоры. Реализуйте систему обмена сообщениями. Напишите подпрограммы
для отправки и приема сообщений.
41. Студент, изучающий антропологию и посещающий занятия по информатике,
занялся исследовательским проектом, цель которого — выяснить, можно ли
научить африканских бабуинов избегать взаимной блокировки. Он нашел
глубокий каньон и протянул через него веревку, чтобы бабуины могли пере-
перебраться на другую сторону на руках. За один раз могут перебраться несколь-
несколько бабуинов, если все они движутся в одном направлении. Если на веревке
одновременно оказываются бабуины, двигающиеся на восток и на запад, воз-
возникнет взаимная блокировка (бабуины зависают посреди веревки), так как
один бабуин не может перебраться через другого. Поэтому если бабуин хочет
перебраться, он сначала должен проверить, что на веревке нет тех, кто дви-
движется в обратном направлении. Напишите программу с использованием се-
семафоров, которая не допускала бы блокировки. Не беспокойтесь о том, что
группа бабуинов, движущихся на восток, может бесконечно удерживать тех,
кто хочет двигаться на запад.
42. Решите предыдущую задачу, но теперь постарайтесь избежать зависаний.
Для этого, когда бабуин хочет перебраться на восток и при этом на веревке
уже висят несколько обезьян, движущихся на запад, бабуин ждет, когда ве-
веревка освободится. Другое условие: нужно запретить для остальных движе-
движение на запад, пока бабуин не перейдет на восток.
43. Решите задачу обедающих философов с помощью мониторов, а не семафоров.
44. Добавьте в ядро MINIX 3 код, который бы подсчитывал, сколько раз процесс
(или задание) г обратится к процессу (или заданию) j. Сделайте так, чтобы
полученная матрица печаталась по нажатию клавиши F4.
45. Измените планировщик MINIX 3 так, чтобы он отслеживал, сколько времени
каждый процесс занимал процессор последний раз. Когда все задания и сер-
серверы освобождают процессор для пользовательских процессов, выбирайте
тот из них, который меньше всех тревожил процессор.
46. Измените MINIX 3 так, чтобы каждый процесс мог явно задавать приори-
приоритет своих дочерних процессов с использованием нового системного вызова
setpriority с параметрами pid и priority.
47. Перепишите макросы hwint_master и hwint_slave из файла mpxx386 . s
так, чтобы действия, выполняемые функцией save, были встроены в код. На-
Насколько увеличился объем кода? Можете ли вы измерить прирост производи-
производительности?
48. Поясните все выводимые элементы команды sysenv системы MINIX 3. Если
в вашем распоряжении нет работающей копии операционной системы, вос-
воспользуйтесь листингом 2.14.
49. Обсуждая инициализацию таблицы процессов, мы упомянули, что некоторые
компиляторы С могут генерировать несколько лучший код при сложении ад-
адреса массива с константой, нежели при индексировании. Напишите пару ко-
коротких С-программ, чтобы проверить это.
50. Измените систему MINIX 3 так, чтобы в ней осуществлялся сбор сведений
о передаче сообщений с указанием отправителей и получателей. Напишите
программу, выполняющую подобный сбор и печатающую статистику в удоб-
удобном для восприятия виде.
Глава 3
Ввод-вывод
Одна из важнейших функций операционной системы состоит в управлении
всеми устройствами ввода-вывода компьютера. Операционная система должна
давать этим устройствам команды, перехватывать прерывания и обрабатывать
ошибки. Она должна также предоставить простой и удобный интерфейс между
устройствами и остальной частью системы. Интерфейс, насколько это возможно,
должен быть одинаковым для всех устройств (он не должен зависеть от при-
применяемого оборудования). Программное обеспечение ввода-вывода составляет
существенную часть операционной системы. Тому, как операционная система
управляет устройствами ввода-вывода, и посвящена эта глава.
Глава организована следующим образом. Сначала мы рассмотрим некоторые
базовые понятия, касающиеся устройств ввода-вывода, а затем в общих чертах
познакомимся с соответствующим программным обеспечением. Программное
обеспечение ввода-вывода может быть структурировано в виде уровней, каждо-
каждому из которых отведен строго очерченный круг задач. Мы рассмотрим все уров-
уровни, чтобы понять, что они делают и как согласуются друг с другом.
Далее следует раздел, посвященный взаимной блокировке. Мы дадим строгое
определение этому понятию, покажем, как возникают взаимные блокировки,
представим две модели для их анализа и обсудим некоторые алгоритмы их пре-
предотвращения.
Затем мы сделаем общий обзор механизма ввода-вывода в MINIX 3, в том числе
прерываний, драйверов устройств, зависимого и независимого от оборудования
ввода-вывода. Далее мы детально изучим различные устройства ввода-вывода:
диски, клавиатуры и дисплеи. Каждое устройство будет рассмотрено как с аппа-
аппаратной, так и с программной точки зрения.
3.1. Аппаратное обеспечение
ввода-вывода
Разные специалисты рассматривают аппаратное обеспечение ввода-вывода по-
разному. Инженеры-электронщики видят микросхемы, проводники, источники
питания, двигатели и прочие физические компоненты. Программисты, в первую
очередь, обращают внимание на интерфейс, предоставляемый программному
обеспечению, — команды, воспринимаемые аппаратурой, выполняемые ею функ-
функции, ошибки, о которых аппаратура может сообщить. В этой книге нас интересу-
интересует именно программирование устройств ввода-вывода, а не их проектирование,
разработка или поддержка. Поэтому сфера наших интересов будет ограничена
тем, как программировать аппаратуру, а физические принципы работы аппарату-
аппаратуры останутся «за кадром». В то же время программирование многих устройств
ввода-вывода часто оказывается тесно связанным с их внутренним функциони-
функционированием. В следующих трех разделах будут кратко затронуты общие основы
знаний из области аппаратуры ввода-вывода, касающиеся программирования.
3.1.1. Устройства ввода-вывода
Устройства ввода-вывода можно грубо разделить на две категории: блочные
и символьные. Блочными называются устройства, хранящие информацию в виде
адресуемых блоков фиксированного размера. Обычно размеры блоков варьиру-
варьируются от 512 до 32 768 байт. Важное свойство блочного устройства состоит в том,
что каждый блок может быть прочитан независимо от остальных блоков. Наибо-
Наиболее распространенными блочными устройствами являются диски.
Если приглядеться внимательнее, то окажется, что граница между устройствами,
адресуемыми поблочно, и устройствами, к отдельным составляющим которых
нельзя адресоваться напрямую, строго не определена. Все согласны с тем, что
диск является поблочно адресуемым устройством, так как вне зависимости от
текущего положения головки дисковода всегда можно переместить ее на опреде-
определенный цилиндр и затем считать или записать отдельный блок с нужной дорож-
дорожки. Рассмотрим теперь накопитель на магнитной ленте (магнитофон), применяе-
применяемый для хранения резервных копий диска. На ленте хранится последовательность
блоков. Если магнитофону дать команду прочитать некоторый блок, ему потре-
потребуется перемотать ленту и начать читать данные, пока процесс не дойдет до за-
запрашиваемого блока. Эта операция подобна поиску блока на диске с той лишь
разницей, что она занимает значительно больше времени. Кроме того, в зависи-
зависимости от накопителя и формата хранящихся на нем данных запись отдельного
произвольного блока в середине ленты не гарантирована. Попытка использовать
магнитные ленты в качестве блочных устройств произвольного доступа явилась
бы в какой-то степени натяжкой: никто их не использует таким образом.
Другой тип устройств ввода-вывода — символьные устройства. Символьное уст-
устройство принимает или предоставляет поток символов без какой-либо блочной
структуры. Символьное устройство не является адресуемым и не выполняет
операцию поиска. Принтеры, сетевые интерфейсные адаптеры, мыши (для ука-
указания позиции на экране), крысы (для лабораторных экспериментов по психоло-
психологии) и большинство других устройств, не похожих на диски, можно рассматри-
рассматривать как символьные устройства.
Такая схема классификации несовершенна. Некоторые устройства просто не по-
попадают ни в одну из категорий. Например, часы не являются поблочно адресуе-
адресуемыми. Они также не формируют и не принимают символьных потоков. Вся их
деятельность сводится к инициированию прерываний в строго определенные
моменты времени. И все же разделение на блочные и символьные устройства
является достаточно всеобъемлющим и неплохо подходит в качестве основы,
позволяющей добиться, чтобы программное обеспечение операционных систем
не зависело от устройств ввода-вывода. Так, файловая система общается с абст-
абстрактными блочными устройствами, а зависимую от устройств часть оставляет
низкоуровневому программному обеспечению — драйверам устройств.
Диапазон скорости работы устройств ввода-вывода очень широк (табл. 3.1). Это
значительно усложняет программы, призванные обеспечивать качественное об-
обслуживание устройств со скоростями передачи данных, отличающимися на по-
порядки. Нельзя не отметить и год от года растущее быстродействие большинства
устройств ввода-вывода.
Таблица 3.1. Скорости передачи данных некоторых типичных устройств, шин и сетей
Устройство Скорость
Клавиатура 10 байт/с
Мышь 100 байт/с
Модем 56 Кбайт 7 Кбайт/с
Сканер 400 Кбайт/с
Цифровая камера 4 Мбайт/с
CD-ROM 52x 8 Мбайт/с
Firewire (IEEE 1394) 50 Мбайт/с
USB 2.0 60 Мбайт/с
Монитор XGA 60 Мбайт/с
Сеть SONET OC-12 78 Мбайт/с
Gigabit Ethernet 125 Мбайт/с
Диск Serial ATA 200 Мбайт/с
Диск SCSI Ultrawide 320 Мбайт/с
Шина PCI 528 Мбайт/с
3.1.2. Контроллеры устройств
Устройства ввода-вывода, как правило, состоят из механических и электронных
компонентов. В большинстве случаев эти компоненты можно логически разделить,
чтобы получить максимально модульную и обобщенную модель. Электронный
компонент называется контроллером устройства, или адаптером. В персональ-
персональных компьютерах он обычно имеет вид печатной платы, вставляемой в слот рас-
расширения. Механический компонент — это само устройство. Данная структура
представлена на рис. 3.1.
Плата контроллера обычно снабжается разъемом, к которому может быть под-
подключен кабель, ведущий к самому устройству. Многие контроллеры способны
управлять двумя, четырьмя или даже восемью идентичными устройствами. Если
интерфейс между контроллером и устройством является стандартным, то есть
определен официальным стандартом ANSI, IEEE или ISO, либо фактическим
стандартом, это упрощает выпуск по отдельности контроллеров и устройств, со-
соответствующих данному интерфейсу. Так, многие компании производят жесткие
диски, соответствующие интерфейсу IDE или SCSI.
Рис. 3.1. Модель подключения процессора, памяти, контроллеров и устройств ввода-вывода
Мы упоминаем о различии между контроллером и устройством потому, что опе-
операционная система практически всегда имеет дело с контроллером, а не с самим
устройством. У большинства небольших компьютеров взаимодействие с устрой-
устройствами организуется по модели единой шины (см. рис. 3.1). У больших машин,
мэйнфреймов, применяется другая модель с несколькими шинами, которые об-
обслуживаются специализированными компьютерами ввода-вывода, называемыми
каналами ввода-вывода. Такая организация позволяет снизить нагрузку на основ-
основной процессор.
Интерфейс между устройством и контроллером часто является интерфейсом
очень низкого уровня. Например, какой-нибудь жесткий диск может быть от-
отформатирован по 1024 сектора на дорожку, с размером секторов по 512 байт.
В действительности с диска в контроллер поступает последовательный поток би-
битов, начинающийся с заголовка сектора {преамбулы), за которым следует 4096 бит
в секторе, и, наконец, контрольная сумма, также называемая кодом исправления
ошибок (Error-Correcting Code, ECC). Заголовок сектора записывается на диск
во время форматирования. Он содержит номера цилиндров и секторов, размер
сектора, информацию синхронизации и т. п.
Работа контроллера заключается в преобразовании последовательного потока
битов в блок байтов и в коррекции ошибок, если это необходимо. Обычно блок
байтов собирается бит за битом в буфере контроллера. Затем проверяется кон-
контрольная сумма блока, и если она совпадает с указанной в заголовке сектора,
блок полагается считанным без ошибок, после чего он копируется в оператив-
оперативную память.
Контроллер монитора (видеоконтроллер) также работает как последовательное
побитовое устройство на таком же низком уровне. Он считывает из памяти байты,
содержащие символы, которые следует отобразить, и формирует сигналы, исполь-
используемые для модуляции луча электронной трубки, заставляющие ее выводить
изображение на экран. Кроме того, видеоконтроллер формирует сигналы, управ-
управляющие горизонтальным и вертикальным перемещениями электронного луча. На
жидкокристаллическом экране эти сигналы указывают на отдельные пикселы и за-
задают их яркость, имитируя электронный луч. Если бы не контроллер, программи-
программисту пришлось бы делать это самому. В действительности же операционная система
всего-навсего инициализирует контроллер, задавая небольшое число параметров,
таких как количество символов или пикселов в строке и число строк на экране,
а основную работу по управлению разверткой берет на себя контроллер.
Контроллеры некоторых устройств, особенно дисков, постепенно становятся очень
сложными. Например, современные дисковые контроллеры оснащены многими
мегабайтами внутренней памяти. В результате при выполнении операции чте-
чтения контроллер начинает считывать и сохранять данные сразу после того, как
головка оказывается на нужном цилиндре (не дожидаясь доступа к сектору).
Такое кэширование эффективно при последовательных запросах данных. Более
того, после получения требуемых данных контроллер может продолжить кэши-
кэширование последующих секторов, поскольку вероятность доступа к ним в буду-
будущем велика. Подобный механизм позволяет обслуживать множество запросов на
чтение без обращения к диску.
3.1.3. Ввод-вывод с отображением на память
У каждого контроллера есть несколько регистров, с помощью которых с ним мо-
может общаться центральный процессор. Записывая в эти регистры определенные
значения, операционная система посылает устройству команды передачи и прие-
приема данных, включения, отключения и др. Считывание регистров устройства по-
позволяет определить его состояние, готовность принять команду и т. д.
В дополнение к регистрам управления, многие устройства имеют буфер данных,
доступный для чтения и записи со стороны операционной системы. Например,
отображение пикселов на экране в большинстве компьютеров осуществляется
с помощью видеопамяти. В сущности, видеопамять представляет собой буфер,
в который программы операционной системы записывают отображаемые данные.
Возникает вопрос, каким образом процессор взаимодействует с регистрами управ-
управления и буферами данных устройств. Существует две альтернативы. Первая
предполагает назначение каждому регистру номера порта ввода-вывода — 8- или
16-разрядного числа. Процессор может считать регистр управления PORT и со-
сохранить результат в своем регистре REG, используя специальную команду ввода-
вывода, например, такую:
IN REG,PORT
Аналогично, следующая команда записывает содержимое регистра REG процес-
процессора в регистр управления PORT устройства:
OUT PORT,REG
Так работало большинство первых компьютеров, включая практически все мэйн-
мэйнфреймы (в частности, IBM 360 и всех его предков). В этом случае память и область
ввода-вывода имеют разные адресные пространства, как показано на рис. 3.2, а.
Рис. 3.2. Варианты расположения пространства памяти и ввода-вывода: а — раздельные
пространства памяти и ввода-вывода; б — ввод-вывод с отображением на память;
в — смешанный вариант
В других компьютерах регистры ввода-вывода являются частью обычного адрес-
адресного пространства памяти (рис. 3.2, б). Такая организация называется вводом-
выводом с отображением на память. Она была впервые применена в мини-ком-
мини-компьютере PDP-11. Каждому регистру управления назначается уникальный адрес
памяти, с которым обычная память не связана. Как правило, для регистров управ-
управления выделяются адреса из верхней части адресного пространства. На рис. 3.2, в
представлена смешанная схема, использующая отображенные на память буферы
данных и отдельные порты ввода-вывода для регистров управления. Подобная
архитектура применяется в системах на основе процессора Pentium, где диапазон
адресов от 640 Кбайт до 1 Мбайт зарезервирован под буферы данных устройств,
а область портов ввода-вывода занимает первые 64 Кбайт.
Как же функционируют описанные схемы? Во всех случаях процессор, желаю-
желающий считать слово, выставляет его адрес на адресные линии шины, а затем вы-
выдает сигнал чтения по линии управления. Для того чтобы отличить обращение
к пространству ввода-вывода от обращения к памяти, требуется вторая сиг-
сигнальная линия. В случае обращения к памяти ответить на запрос должна память,
а в случае обращения к пространству ввода-вывода — соответствующее устройст-
устройство. При наличии единого адресного пространства (см. рис. 3.2, б) каждый модуль
памяти и каждое устройство ввода-вывода сопоставляют адрес, выставленный
на шину, с диапазоном обслуживаемых адресов. Если адрес попал в диапазон,
устройство отвечает на запрос. Поскольку адреса не присваиваются ни памяти,
ни устройствам ввода-вывода, двусмысленность и конфликты исключены.
3.1.4. Прерывания
Как правило, регистры контроллеров содержат один или несколько битов состоя-
состояния. Их можно проверить и определить, завершена ли операция вывода и имеются
ли новые данные в устройстве ввода. Цикл, выполняемый процессором и прове-
проверяющий бит состояния до готовности устройства принять или передать данные,
называется опросом, или активным ожиданием. Мы познакомились с этой кон-
концепцией в пункте 2.2.3 в контексте работы с критическими секциями (впрочем,
в большинстве случаев активное ожидание нежелательно). Поскольку ожидание
готовности внешнего устройства к приему или передаче данных может оказаться
очень долгим, активное ожидание допустимо лишь в небольших выделенных од-
однозадачных системах.
В дополнение к битам состояния, многие контроллеры часто используют преры-
прерывания, которые позволяют сообщить процессору, что регистры готовы для запи-
записи или чтения. Мы рассмотрели обработку прерываний процессором в пунк-
пункте 2.1.6. В контексте ввода-вывода вам нужно знать лишь одно: большинство
интерфейсных устройств генерирует вывод, означающий завершение операции
или готовность данных (то есть по смыслу совпадающий с соответствующими
битами состояния), однако возбуждающий определенную линию (линию запро-
запроса прерывания) системной шины. В результате завершение операции, вызы-
вызывающей прерывание, останавливает процессор и запускает процедуру обработки
прерывания. Процедура обработки прерывания информирует операционную
систему о том, что ввод-вывод завершен. После этого операционная система мо-
может проверить биты состояния и убедиться в отсутствии ошибок, считать полу-
полученные данные или инициировать повторную передачу.
Количество входов контроллера прерываний ограничено. Например, у персональ-
персональных компьютеров Pentium только 15 линий прерывания доступны для устройств
ввода-вывода. Некоторые из контроллеров устаревших компьютеров встроены
в материнскую плату, как, например, контроллер клавиатуры на IBM PC. У тех
контроллеров, что вставляются в разъем на объединительной плате, установить
соответствие между IRQ-сигналом и устройством иногда можно при помощи пе-
перемычек или переключателей. Если пользователь приобретал новую карту, он
был вынужден вручную устанавливать линию прерывания, чтобы избежать ее
конфликта с существующими устройствами. Большинство пользователей со-
совершало в этом ошибки, что, в конечном счете, привело к появлению механизма
автоконфигурирования (Plug and Play), благодаря которому BIOS самостоя-
самостоятельно назначает устройствам корректные линии прерывания на этапе загрузки
системы.
3.1.5. Прямой доступ к памяти
Независимо от того, поддерживается ли отображение ввода-вывода системы на
память, центральному процессору необходимо адресовать контроллеры уст-
устройств, чтобы обмениваться с ними данными. Процессор может запрашивать
данные у контроллера побайтно, но если требуется получать от устройства боль-
большие блоки (например, при считывании с диска), значительная часть времени
будет потрачена впустую. По этой причине для взаимодействия с памятью при-
применяют другой метод, называемый прямым доступом к памяти (Direct Memory
Access, DMA). Операционная система может использовать DMA только при
наличии контроллера прямого доступа к памяти (DMA-контроллера). Боль-
Большинство компьютеров оснащено таким контроллером. Иногда DMA-контрол-
DMA-контроллер встраивают в другие контроллеры (например, дисковые), но в этом случае
он требуется каждому устройству. Чаще системы оснащают единственным DMA-
контроллером, который обычно размещается на материнской плате. Он управля-
управляет обменом данными с множеством устройств ввода-вывода, причем зачастую
параллельно.
Где бы физически ни располагался DMA-контроллер, он имеет независимый от
процессора доступ к системной шине (рис. 3.3). DMA-контроллер имеет несколь-
несколько регистров, доступных процессору для чтения и записи: регистр адреса, счет-
счетчик байтов и ряд регистров управления. Последние определяют используемый
порт ввода-вывода, направление обмена данными (чтение или запись), единицу
обмена (байт или слово) и число байтов, передаваемых в одном цикле.
Рис. 3.3. Работа DMA-контроллера
Чтобы объяснить принципы функционирования DMA, сначала разберемся, как
осуществляется чтение с диска в отсутствие прямого доступа к памяти. Сначала
контроллер последовательно, бит за битом, считывает блок (один или несколько
секторов), пока он не окажется во внутреннем буфере контроллера. Далее под-
считывается контрольная сумма и проверяется наличие ошибок. Затем генери-
генерируется прерывание. Когда операционная система запущена, она может считать
переданный блок из буфера контроллера. Считывание осуществляется цикличе-
циклически, побайтно или пословно. После считывания байта (слова) он сохраняется
в основной памяти, адрес памяти инкрементируется, а счетчик оставшихся эле-
элементов декрементируется. Цикл прекращается, когда значение счетчика стано-
становится равным нулю.
Прямой доступ к памяти изменяет описанную процедуру. Сначала процессор
программирует DMA-контроллер, записывая в его регистры значения, указываю-
указывающие контроллеру, что и куда передавать (шаг 1 на рис. 3.3). Затем контроллеру
посылается команда считать данные с диска в свой внутренний буфер и сверить
контрольную сумму. После появления в буфере контроллера корректных дан-
данных DMA может приступать к работе.
DMA-контроллер начинает перенос данных, посылая дисковому контроллеру по
шине запрос на чтение (шаг 2). Этот запрос выглядит как обычный запрос на
чтение, потому контроллер диска даже не знает, поступил он от центрального
процессора или от DMA-контроллера. Обычно адрес памяти уже находится на
адресной шине, соответственно, контроллер диска всегда в курсе, куда нужно
переслать следующее слово из своего внутреннего буфера. Запись в память яв-
является еще одним стандартным циклом шины (шаг 3). Когда запись закончена,
контроллер диска также по шине посылает сигнал подтверждения DMA-кон-
DMA-контроллеру (шаг 4). Затем DMA-контроллер инкрементирует используемый адрес
памяти и декрементирует значение счетчика байтов. После этого шаги 2—4 по-
повторяются, пока значение счетчика не станет равным нулю. По завершении
цикла копирования DMA-контроллер инициирует прерывание процессора. Опе-
Операционной системе не нужно копировать блок с диска в память. Он уже нахо-
находится там.
Возможно, вы задаетесь вопросом, почему контроллер не помещает данные пря-
прямо в оперативную память по мере получения их с диска. Другими словами, зачем
ему нужен внутренний буфер? Тому есть две причины. Во-первых, за счет внут-
внутренней буферизации контроллер диска может проверить контрольную сумму до
начала переноса данных в память. Если значения не совпадают, формируется
сигнал об ошибке и передача данных не производится.
Во-вторых, дело в том, что как только стартует операция чтения с диска, биты
начинают поступать с постоянной скоростью, независимо от того, готов контрол-
контроллер диска их принимать или нет. Если контроллер диска попытается писать эти
данные напрямую в память, ему придется делать это по системной шине. Если
при передаче очередного слова шина окажется занятой каким-либо другим уст-
устройством, контроллеру диска придется ждать. Если следующее слово с диска
прибудет раньше, чем контроллер успеет сохранить отложенное, контроллер ли-
либо потеряет предыдущее слово, либо ему придется запоминать его где-либо еще.
Если шина используется интенсивно, контроллер будет вынужден сохранять
сразу несколько слов и выполнять немало служебных действий. При наличии
внутреннего буфера шина не нужна до тех пор, пока не начнется операция пря-
прямого доступа к памяти. В результате устройство контроллера диска оказывается
проще, так как при операции прямого доступа к памяти временные параметры не
являются критичными.
Не все компьютеры поддерживают DMA. Главный аргумент против прямого
доступа к памяти состоит в том, что по скорости центральный процессор обычно
значительно превосходит DMA-контроллер и в состоянии выполнить ту же ра-
работу значительно быстрее (если только сдерживающим фактором не является
быстродействие устройства ввода-вывода). При отсутствии другой нагрузки на
быстрый центральный процессор заставлять его ждать, пока медленный DMA-
контроллер выполнит свою работу, бессмысленно. Кроме того, компьютер без
DMA-контроллера, но с центральным процессором, выполняющим все программ-
программно, оказывается дешевле, что крайне важно в производстве компьютеров нижней
ценовой категории, а также встроенных систем.
3.2. Программное обеспечение
ввода-вывода
Перейдем теперь от аппаратуры ввода-вывода к программному обеспечению
ввода-вывода. Сначала мы познакомимся с назначением программного обеспече-
обеспечения ввода-вывода, а затем изучим различные способы выполнения операций
ввода-вывода с точки зрения операционной системы.
3.2.1. Назначение программного
обеспечения ввода-вывода
Ключевая концепция разработки программного обеспечения ввода-вывода из-
известна как независимость от устройств. Эта концепция означает возможность
написания программ, способных получать доступ к любому устройству ввода-
вывода без предварительного указания конкретного устройства. Соответственно,
программа, читающая данные из входного файла, должна с одинаковым успехом
работать с файлом на дискете, жестком диске или компакт-диске. Причем без
каких-либо изменений в программе. Например, должна иметься возможность
выполнить команду вроде
sort <input >output
Эта команда должна работать, невзирая на то, что именно указано в качестве
входного устройства — гибкий диск, IDE-диск, SCSI-диск или клавиатура. В ка-
качестве выходного устройства также с равным успехом может быть указан экран,
файл на любом диске или принтер. Все проблемы, связанные с отличиями этих
устройств, должна разрешать операционная система.
Тесно связан с идеей независимости от устройств принцип единообразного име-
именования. Имя файла или устройства должно быть просто текстовой строкой
или целым числом и никоим образом не зависеть от физического устройства.
В UNIX и MINIX 3 все диски могут быть произвольным образом интегрированы
в иерархию файловой системы, поэтому пользователю не обязательно знать,
какое имя какому устройству соответствует. Например, гибкий диск не запреща-
запрещается монтировать поверх каталога /usr/ast/backup, вследствие чего копи-
копирование файла в каталог /usr/ast/backup/monday автоматически приведет
к копированию файлов на гибкий диск. Таким образом, все файлы и устройства
адресуются одним и тем же способом — по пути к ним.
Другим важным аспектом программного обеспечения ввода-вывода является
обработка ошибок. Ошибки должны обрабатываться как можно ближе к аппа-
аппаратуре. Если контроллер обнаружил ошибку чтения, он должен попытаться по
возможности исправить эту ошибку сам. Если он не в силах это сделать, тогда
ошибку обязан обработать драйвер устройства, допустим, попытавшись прочи-
прочитать этот блок еще раз. Многие ошибки бывают временными, например ошибки
чтения, вызванные пылинками на читающих головках. Такие ошибки часто не
воспроизводятся при повторной попытке чтения блока. Только если нижний
уровень пасует перед проблемой, о ней следует информировать верхний уро-
уровень. Во многих случаях восстановление после ошибок предпочтительно делать
на нижнем уровне, прозрачно для верхних уровней, то есть так, чтобы вышестоя-
вышестоящие уровни даже не подозревали о наличии сбоев.
Еще один ключевой вопрос — способ передачи данных: синхронный (блокирую-
(блокирующий) против асинхронного (управляемого прерываниями). Большинство опера-
операций ввода-вывода на физическом уровне являются асинхронными — централь-
центральный процессор начинает передачу данных и забывает о ней, пока не появится
прерывание. Пользовательские программы значительно легче писать, применяя
блокирующие операции ввода-вывода, — после обращения к системному вызову
receive программа автоматически приостанавливается до тех пор, пока данные
не появятся в буфере. Тем, чтобы операции ввода-вывода, в действительности
являющиеся асинхронными, в пользовательских программах выглядели как бло-
блокирующие, занимается операционная система.
Говоря о программном обеспечении ввода-вывода, нельзя обойти вниманием буфе-
буферизацию. Часто данные, поступающие с устройства, не могут быть сохранены сра-
сразу там, куда они в конечном итоге направляются. Например, когда пакет прихо-
приходит по сети, операционная система не знает, куда его поместить, пока не изучит
его содержимое, для чего этот пакет нужно где-то временно пристроить. Кроме
того, для многих устройств реального времени крайне важными оказываются па-
параметры сроков поступления данных (например, для устройств воспроизведения
оцифрованного звука), поэтому полученные данные должны быть помещены
в выходной буфер заранее, чтобы скорость, с которой они извлекаются из буфера
проигрывателем, не зависела от скорости заполнения буфера. Буферизация под-
подразумевает копирование данных в значительных количествах, что часто являет-
является основным фактором снижения производительности операций ввода-вывода.
И последнее — это понятие выделенных устройств и разделяемых устройств. С не-
некоторыми устройствами ввода-вывода, такими как диски, может одновременно
работать большое количество пользователей. При этом не должно возникать
проблем, когда несколько пользователей одновременно откроют файлы на одном
и том же диске. Другие устройства, такие как накопители на магнитной ленте,
должны предоставляться в монопольное владение одному пользователю, пока он
не завершит свою работу с этим устройством. Если два или более пользователей
одновременно станут писать вперемешку блоки на одну ленту, ничего хорошего
не получится. Введение понятия выделенных (монопольно используемых) уст-
устройств также привносит целый спектр проблем, таких как взаимные блокиров-
блокировки. Тем не менее операционная система обязана управлять как разделяемыми,
так и выделенными устройствами и преодолевать различные потенциальные про-
проблемы самостоятельно.
Эти задачи решаются путем разбиения программного обеспечения ввода-вывода
на четыре уровня.
1. Обработчики прерываний (нижний уровень).
2. Драйверы устройств.
3. Независимый от аппаратуры код операционной системы.
4. Пользовательские программы (верхний уровень).
В следующих подразделах мы последовательно рассмотрим каждый из них. В этой
главе акцент смещен на драйверы устройств (уровень 2), но мы изучим и другие
виды программного обеспечения ввода-вывода, а также покажем их взаимосвязь.
3.2.2. Обработчики прерываний
Хотя программный ввод-вывод иногда бывает полезен, для большинства опера-
операций ввода-вывода приходится прибегать к прерываниям. Прерывания должны
быть упрятаны как можно глубже во внутренностях операционной системы, что-
чтобы о них знала как можно меньшая ее часть. Лучший способ завуалировать их
заключается в блокировке драйвера, начавшего операцию ввода-вывода, вплоть
до окончания этой операции и получения прерывания. Драйвер может заблоки-
заблокировать себя сам, выполнив на семафоре процедуру down, процедуру wait на пе-
переменной состояния, процедуру receive на сообщении или что-либо подобное.
Когда происходит прерывание, начинает работу обработчик прерываний. По ее
окончании он может разблокировать драйвер-инициатор. В некоторых случаях
это реализуется через процедуру up на семафоре. В других ситуациях обработ-
обработчик прерываний вызывает процедуру монитора signal с переменной состояния.
Или же он посылает заблокированному драйверу сообщение. В любом случае ре-
результат один — драйвер разблокируется и продолжает работу. Эта схема лучше
всего работает в драйверах, являющихся процессами с собственными состояни-
состоянием, стеком и счетчиком команд.
3.2.3. Драйверы устройств
Ранее в этой главе мы узнали, что у каждого контроллера устройства есть реги-
регистры, в которые можно записывать команды, считывать состояние устройства
или делать и то и другое. Число регистров и смысл команд значительно изменя-
изменяются от устройства к устройству. Например, драйвер мыши принимает инфор-
информацию о ее перемещении и нажатых кнопках. В то же время драйверу диска
нужно знать о секторах, дорожках, цилиндрах, головках, их перемещении и вре-
времени установки, двигателях и тому подобных вещах.
Поэтому для управления каждым устройством ввода-вывода, подключенным
к компьютеру, требуется специальная программа. Эта программа, называемая
драйвером устройства, часто пишется производителем устройства и распростра-
распространяется на компакт-дисках вместе с самим устройством. Поскольку для каждой
операционной системы требуются специализированные драйверы, производите-
производители обычно поставляют драйверы для нескольких наиболее популярных операци-
операционных систем.
Каждый драйвер обслуживает один тип устройств или более крупный класс сход-
сходных устройств. Например, было неплохо иметь один драйвер мыши, несмотря на
то, что система поддерживает несколько типов мышей. Дисковый драйвер мог бы
поддерживать несколько типов дисков, различающихся объемами и скоростями,
а также, возможно, компакт-диски. С другой стороны, диск настолько непохож
на мышь, что им, безусловно, нужны разные драйверы.
Чтобы драйвер имел доступ к аппаратной части устройства, то есть к регистрам
контроллера, его традиционно интегрируют в ядро операционной системы. Та-
Такой подход обеспечивает максимальную производительность, но минимальную
надежность, поскольку ошибка в любом драйвере устройства способна вывести
из строя всю систему. В MINIX 3 используется другая, более надежная модель.
Как мы увидим, в этой операционной системе каждый драйвер устройства явля-
является отдельным процессом, выполняющимся в пользовательском пространстве.
Как мы говорили ранее, с точки зрения операционной системы бывают драйверы
для блочных устройств (например, диски) и символьных устройств (например,
клавиатуры и принтеры). Большинство операционных систем определяет два
стандартных интерфейса, которые должны поддерживаться всеми блочными
и всеми символьными устройствами компьютера соответственно. Интерфейсы
включают совокупность процедур, вызываемых операционной системой, чтобы
обеспечить драйверам возможность выполнять свою работу.
Вообще говоря, назначение драйвера в том, чтобы воспринимать абстрактные за-
запросы от аппаратно-независимых программ верхнего уровня и сообщать им, что
запрос выполнен. Типичный запрос, поступающий драйверу диска, — считать за-
заданный блок данных. При этом если в момент передачи запроса драйвер бездей-
бездействует, он сразу начинает работу. Если же драйвер занят, запрос обычно помеща-
помещается в очередь и обслуживается по мере возможности.
Первым шагом в обслуживании запроса ввода-вывода является проверка кор-
корректности переданных параметров и при необходимости возврат ошибки. Если
запрос верен, следующий шаг — его преобразование из абстрактного представле-
представления в конкретную форму. Скажем, драйвер диска должен выяснить, где находит-
находится запрошенный блок данных, проверить, работает ли привод диска, находится
ли головка над нужной дорожкой и т. д. Говоря коротко, драйвер должен сам оп-
определить свою последовательность действий.
После того как необходимые команды определены, драйвер начинает передавать
их устройству через регистры контроллера. Простые контроллеры способны вос-
воспринимать только по одной команде за раз, а более сложные поддерживают свя-
связанный список команд, выполняемых далее без вмешательства операционной
системы.
Когда все команды переданы, ситуация развивается по одному из двух сценари-
сценариев. Во многих случаях драйвер устройства должен ждать, пока контроллер вы-
выполняет для него определенную работу, поэтому он блокируется до поступления
прерывания от устройства. В других вариантах операция завершается без за-
задержек, и драйверу не нужно блокироваться. Например, для прокрутки экрана
в символьном режиме требуется записать лишь несколько байтов в регистры
контроллера. Каких-либо физических перемещений нет, и вся операция занима-
занимает несколько микросекунд.
Если драйвер блокируется, то выход из блокировки происходит по прерыванию.
В других случаях драйвер не блокируется вообще. Как бы то ни было, по завер-
завершении операции драйвер обязан убедиться, что операция прошла без ошибок.
Если все в порядке, драйверу, возможно, придется передать данные (например,
только что прочитанный блок) независимому от устройств программному обес-
обеспечению. Наконец, драйвер возвращает некоторую информацию вызывающей
программе для уведомления о статусе завершения операции. Если в очереди на-
находились другие запросы, один из них теперь может быть выбран и запущен,
иначе драйвер блокируется в ожидании следующего запроса.
Основное назначение драйвера — обрабатывать запросы на чтение и запись, одна-
однако иногда ему приходится выполнять и другую работу. Например, иногда требу-
требуется инициализировать устройство при запуске системы или первом использо-
использовании. Кроме того, для обслуживания электропитания, автоконфигурирования,
ведения журналов событий также служат драйверы.
3.2.4. Независимое от устройств
программное обеспечение ввода-вывода
Хотя некоторая часть программного обеспечения предназначена для работы с кон-
конкретными устройствами, значительная его часть не зависит от устройств. Точ-
Точную границу между драйверами и независимым от устройств программным
обеспечением проводит система, так как некоторые функции, которые можно реа-
реализовать независимо от устройств, часто выполняются прямо в драйверах из
различных соображений, в том числе с позиций эффективности. Следующие функ-
функции обычно реализуются независимым от устройств программным обеспечением:
4- единообразный интерфейс для драйверов устройств;
+ буферизация;
+ сообщения об ошибках;
+ захват и освобождение выделенных устройств;
4- обеспечение аппаратно-независимого размера блока.
В MINIX 3 большинство независимых от устройств программ является частью
файловой системы. Файловую систему мы будем изучать в главе 5, а здесь дадим
только краткий обзор, чтобы продемонстрировать некоторые перспективы и луч-
лучше объяснить, как работают драйверы.
Главная цель независимого от устройств программного обеспечения — выполне-
выполнение функций ввода-вывода, общих для всех устройств, и предоставление едино-
единообразного интерфейса для программ пользовательского уровня. Далее мы рас-
рассмотрим эти вопросы более подробно.
Единообразный интерфейс для драйверов устройств
Основное назначение операционной системы — более или менее унифициро-
унифицированное представление устройств ввода-вывода и драйверов. Если бы диски,
принтеры, мониторы, клавиатуры и другие устройства имели разные интерфейсы,
подключение к компьютеру каждого нового устройства требовало бы модифи-
модификации операционной системы. На рис. 3.4, а схематично показана ситуация, в ко-
которой каждый драйвер устройства имеет собственный интерфейс с операци-
операционной системой, а на рис. 3.4, б все драйверы имеют один и тот же интерфейс.
Рис. 3.4. Взаимодействие драйверов с операционной системой: а — в отсутствие стандартного
интерфейса драйверов; б — при наличии стандартного интерфейса драйверов
Стандартный интерфейс значительно упрощает ввод в систему нового драйвера
устройства, если последний его поддерживает. Следование стандарту предпола-
предполагает, что авторы драйвера знают, какие функции должны быть реализованы и ка-
какие вызовы ядра находятся в их распоряжении. На практике устройства разли-
различаются, однако число их типов невелико, и между разными типами зачастую
имеется много общего. Даже блочные и символьные устройства выполняют не-
немало одинаковых функций.
Один из аспектов унификации интерфейса — способ именования устройств вво-
ввода-вывода. Отображением символических имен устройств на соответствующие
драйверы занимаются аппаратно-независимые программы. Например, в UNIX
и MINIX 3 имя устройства /dev/diskO однозначно указывает индексный узел
специального файла, а подходящий драйвер определяется по главному номеру
устройства. Этот индексный узел также содержит вспомогательный номер уст-
устройства, передаваемый в виде параметра драйверу для указания конкретного
диска или раздела диска, к которому относится операция чтения или записи. Все
устройства в системе UNIX имеют главный и вспомогательный номера, по кото-
которым они однозначно идентифицируются. Выбор всех драйверов осуществляется
по главному номеру устройства.
С именованием устройств тесно связан вопрос защиты. Как операционная систе-
система предотвращает доступ пользователей к устройствам, на который у них нет
прав? В UNIX, MINIX 3 и поздних версиях Windows (например, 2000 и ХР) уст-
устройства представляются в файловой системе в виде именованных объектов, что да-
дает возможность применять обычные правила защиты файлов к устройствам ввода-
вывода. Таким образом, системному администратору легко установить нужные
разрешения для каждого устройства (например, при помощи битов rwx в UNIX).
Буферизация
Буферизация также является важной как для блочных, так и для символьных
устройств. Для блочных устройств аппаратное обеспечение обычно требует, чтобы
чтение или запись производились большими блоками. Однако для пользователь-
пользовательских программ такого ограничения нет, и они вправе передавать любые объемы
информации. Поэтому если пользователь передает только половину блока, опе-
операционная система обычно не сразу записывает эти данные на диск, а дожидает-
дожидается передачи оставшейся части блока. Что же касается символьных устройств, то
пользователь может передавать данные быстрее, чем устройство в состоянии их
воспринять, таким образом, и здесь нужна буферизация. Не исключено также,
что данные, поступающие, например, от клавиатуры, могут опережать считыва-
считывание, и в этом случае также не обойтись без буфера.
Сообщения об ошибках
В контексте ввода-вывода ошибки — как нигде частое явление. Операционная
система должна приложить максимальные усилия к их обработке. Многие ошибки
являются специфичными для конкретного устройства и должны обрабатываться
драйвером, так как только он знает, что делать (например, повторить попытку,
игнорировать ошибку или инициировать сбой системы). Типичная ошибка — по-
повреждение или недоступность блока на диске. Драйвер диска пытается несколь-
несколько раз повторить чтение и, если оно не удается, информирует вышестоящую про-
программу. С этого момента обработка ошибки является аппаратно-независимой.
Если ошибка имела место при чтении пользовательского файла, достаточно про-
просто передать сообщение программе, сделавшей вызов. Если же невозможно про-
прочитать критически важную системную структуру, не исключено, что системе
придется вывести информацию об ошибке и завершить свою работу.
Захват и освобождение выделенных устройств
Некоторые устройства, например привод CD-RW, рассчитаны на монопольное
владение процессом в каждый момент времени. Операционная система должна
рассмотреть запросы на использование такого устройства и либо принять их, либо
отказать в выполнении запроса, в зависимости от доступности запрашиваемого
устройства. Простой способ обработки этих запросов заключается в соответст-
соответствующей реализации системного вызова open по отношению к специальным фай-
файлам. Если устройство недоступно, вызов open завершится неуспешно. Обраще-
Обращение к системному вызову close освобождает устройство.
Обеспечение аппаратно-независимого размера блока
У различных дисков могут быть разные размеры сектора. Независимое от уст-
устройств программное обеспечение должно скрывать этот факт от верхних уровней
и предоставлять им единообразный размер блока, например, объединяя несколь-
несколько физических сегментов в одну логическую сущность. При этом более высокие
уровни имеют дело только с абстрактными устройствами, с одним и тем же
размером логического блока, не зависящим от размера физического сектора.
Некоторые символьные устройства предоставляют свои данные побайтно (на-
(например, модемы), тогда как другие выдают их большими порциями (сетевые
интерфейсы). Эти различия также могут быть скрыты.
3.2.5. Программное обеспечение ввода-вывода
пользовательского пространства
Хотя большая часть программного обеспечения ввода-вывода относится к опера-
операционной системе, небольшие его порции состоят из библиотек, скомпонованных
с пользовательскими программами, или даже целых программ, работающих вне
ядра. Системные вызовы, включая системные вызовы ввода-вывода, обычно соб-
собраны из библиотечных процедур, например:
count = write(fd, buffer, nbytes);
Если С-программа содержит такой вызов, библиотечная процедура write будет
скомпонована с программой и, таким образом, окажется в двоичном коде, загру-
загружаемом в память во время выполнения программы. Набор всех этих библиотеч-
библиотечных процедур, несомненно, является частью системы ввода-вывода.
Хотя многие такие процедуры мало что делают, помимо выполнения системного
вызова с соответствующими аргументами, есть ряд процедур ввода-вывода, произ-
производящих определенную работу. В частности, библиотечными процедурами выпол-
выполняются форматные операции ввода и вывода. Например, С-процедура print f,
принимающая на входе текстовую строку и, возможно, несколько переменных,
создает из нее ASCII-строку, после чего делает системный вызов write для не-
непосредственного вывода. Рассмотрим следующую команду:
printf("Квадрат %3d равен %6d\n", i, i*i);
Эта команда формирует строку, состоящую из слова «Квадрат», значения i в ви-
виде трехсимвольной строки, «слова равен», значения квадрата i в виде строки из
6 символов и символа конца строки.
Примером сходной процедуры ввода служит процедура scanf, читающая тексто-
текстовую строку и преобразующая ее в значения переменных в соответствии с форма-
форматом, напоминающим используемый процедурой print f. Стандартная библиотека
ввода-вывода содержит большое количество процедур, включающих операции
ввода-вывода и работающих как часть пользовательской программы.
Не все программное обеспечение ввода-вывода пользовательского пространства
состоит из библиотечных процедур. Другая важная категория — это система
спулинга. Спулинг (spooling) представляет собой способ работы с выделенными
устройствами в многозадачной системе. Типичным устройством, на котором ис-
используется спулинг, является принтер. В принципе, можно разрешить каждому
пользователю открывать специальный символьный файл принтера, однако пред-
представьте себе, что процесс, открыв его, не обращается к принтеру в течение несколь-
нескольких часов. Ни один другой процесс в это время не сможет ничего напечатать.
Вместо этого создается специальный процесс, называемый демоном, и специаль-
специальный каталог, называемый каталогом спулинга. Чтобы распечатать файл, процесс
сначала создает специальный файл, предназначенный для печати, который по-
помещает в каталог спулинга. Этот файл печатает демон, единственный процесс,
которому разрешается пользоваться специальным файлом принтера. Таким об-
образом, потенциальная проблема, связанная с тем, что какой-либо процесс на
слишком долгий срок захватит принтер, решается защитой специального файла
принтера от прямого доступа пользователей.
Спулинг используется не только для принтеров. Например, программное обес-
обеспечение электронной почты, как правило, включает демона. Письмо, которое не-
необходимо послать, помещается в каталог спулинга. Затем демон электронной
почты извлекает его оттуда и пытается отправить. В любой момент времени
существует вероятность, что получатель недоступен; в этом случае демон остав-
оставляет письмо в каталоге спулинга и фиксирует информацию о том, что попытку
передачи следует повторить позднее. Демон также может уведомить отправите-
отправителя о задержке, а если письмо не удается отправить в течение нескольких часов
или дней, — послать сообщение о том, что доставка письма невозможна.
На рис. 3.5 показана структура системы ввода-вывода со всеми уровнями и основ-
основными функциями каждого уровня.
Рис. 3.5. Уровни и основные функции системы ввода-вывода
Стрелки на рис. 3.5 изображают потоки управления. Например, когда пользо-
пользовательская программа пытается прочитать блок из файла, для обработки вызова
запускается операционная система. Независимое от устройств программное обес-
обеспечение ищет этот блок в кэше. Если требуемого блока там нет, оно вызывает
драйвер устройства, чтобы обратиться к аппаратуре и получить этот блок с диска.
Процесс же блокируется до завершения дисковой операции.
Когда диск завершает операцию, аппаратура инициирует прерывание. Обработчик
прерываний запускается с целью определить, что случилось, то есть выяснить,
какое устройство требует внимания. Затем он получает информацию о состоя-
состоянии устройства и активизирует «спящий» процесс, чтобы завершить обработку
запроса ввода-вывода и предоставить пользовательскому процессу возможность
продолжения работы.
3.3. Взаимная блокировка
В компьютерных системах есть такие ресурсы, каждый из которых в конкретный
момент времени может использоваться только одним процессом. В качестве при-
примеров можно привести принтеры, накопители на магнитной ленте и элементы
внутренних таблиц системы. Наличие двух процессов, одновременно передаю-
передающих данные на принтер, приведет к печати бессмысленного набора символов.
Наличие двух процессов, использующих один и тот же элемент таблицы файло-
файловой системы, обязательно станет причиной краха файловой структуры. Поэтому
все операционные системы обладают способностью предоставлять процессу экс-
эксклюзивный доступ (по крайней мере, временный) к определенным ресурсам, как
программным, так и аппаратным.
Часто прикладной процесс нуждается в исключительном доступе не к одному,
а к нескольким ресурсам. Предположим, например, что каждый из двух процессов
хочет записать отсканированный документ на компакт-диск. Процесс А запра-
запрашивает разрешение на использование сканера и получает его. Процесс В запро-
запрограммирован по-другому, поэтому сначала запрашивает устройство для записи
компакт-дисков и также получает его. Затем процесс А обращается к устройству
для записи компакт-дисков, но запрос отклоняется до тех пор, пока это устрой-
устройство занято процессом В. К сожалению, вместо того чтобы освободить устройст-
устройство для записи компакт-дисков, В запрашивает сканер. Процессы оказываются за-
заблокированными и будут вечно оставаться в «подвешенном» состоянии. Такая
ситуация называется взаимной блокировкой, или тупиком.
Взаимные блокировки характерны не только для запросов выделенных устройств
ввода-вывода, но и для множества других ситуаций. В системах баз данных про-
программа может оказаться вынужденной заблокировать несколько записей, чтобы
избежать гонок. Если процесс А заблокирует запись R1, процесс В заблокирует
запись R2, а затем каждый процесс попытается заблокировать чужую запись, мы
также окажемся в тупике. Таким образом, взаимные блокировки появляются при
работе как с аппаратными, так и с программными ресурсами.
В этой главе мы рассмотрим тупиковые ситуации более подробно, увидим, как
они возникают, и изучим некоторые способы, позволяющие предупредить вза-
взаимные блокировки или избежать их. Хотя информация о взаимных блокировках
представлена в контексте операционной системы, они также могут встретиться
в системах баз данных и во множестве других систем, поэтому рассматриваемый
материал на самом деле применим к широкому кругу систем, работающих с не-
несколькими процессами.
3.3.1. Ресурсы
Система может оказаться в ситуации взаимной блокировки, когда процессам
предоставляются исключительные права доступа к устройствам, файлам и т. д.
Чтобы максимально обобщить рассказ о взаимных блокировках, мы будем назы-
называть объекты доступа ресурсами. Ресурсом может быть устройство (например,
накопитель на магнитной ленте) или порция информации (закрытая запись в базе
данных). В компьютере существует масса различных ресурсов, к которым могут
происходить обращения. Кроме того, в системе может оказаться несколько иден-
идентичных экземпляров какого-либо ресурса, например три накопителя на магнит-
магнитных лентах. Если в системе есть несколько взаимозаменяемых копий ресурса,
называемых однородными1, то в ответ на обращение к ресурсу может предостав-
предоставляться любая из доступных копий. Короче говоря, ресурс — это все то, что впра-
вправе использоваться только одним процессом в любой момент времени.
Ресурсы бывают двух типов: выгружаемые и невыгружаемые. Выгружаемый ре-
ресурс позволяется безболезненно забирать у владеющего им процесса. Образцом
такого ресурса является память. Рассмотрим, например, систему с пользователь-
пользовательской памятью размером 64 Мбайт, одним принтером и двумя процессами по
64 Кбайт, каждый из которых хочет что-то напечатать. Процесс А запрашивает
и получает принтер, затем начинает вычислять данные для печати. Еще не за-
закончив расчеты, он превышает свой квант времени и выгружается на диск в об-
область подкачки.
После этого работает процесс В и безуспешно пытается обратиться к принтеру.
В данный момент мы получили потенциальную тупиковую ситуацию, поскольку
процесс А оккупирует принтер, процесс В занимает память, и ни один из них
не может продолжать работу без ресурса, удерживаемого другим. К счастью,
не запрещено выгрузить (забрать) память у процесса В, переместив его на диск
в область подкачки и загрузив с диска в память процесс А. После этого процесс А
может закончить вычисления, выполнить печать и затем освободить принтер.
Взаимной блокировки не происходит.
Невыгружаемый ресурс, в противоположность выгружаемому, — это такой ре-
ресурс, который нельзя забрать от текущего владельца, не уничтожив результаты
вычислений. Если в момент записи компакт-диска внезапно отнять у процесса
устройство для записи и передать его другому процессу, то в результате мы по-
получим испорченный компакт-диск. Устройство для записи компакт-дисков яв-
является невыгружаемым в произвольный момент времени ресурсом.
Вообще говоря, взаимные блокировки касаются невыгружаемых ресурсов. По-
Потенциальные тупиковые ситуации, в которые вовлечен противоположный вид
ресурсов, обычно разрешаются путем перераспределения ресурсов от одного
процесса другому. Поэтому мы сконцентрируем свое внимание на невыгружае-
невыгружаемых ресурсах.
Последовательность событий, необходимых для использования ресурса, в абст-
абстрактной форме выглядит следующим образом.
1. Запрос ресурса.
2. Использование ресурса.
3. Возврат ресурса.
1 Это юридический и экономический термин. Например, взаимозаменяемым является золото: один
его грамм эквивалентен любому другому.
Если ресурс недоступен, запрашивающий его процесс вынужден ждать. В неко-
некоторых операционных системах при неудачном обращении к ресурсу процесс ав-
автоматически блокируется и возобновляется только после того, как ресурс стано-
становится доступным. В других системах при запросе ресурса и получении отказа
возвращается код ошибки, тогда вызывающий процесс может подождать немно-
немного и повторить попытку.
3.3.2. Механизм взаимной блокировки
Определение взаимной блокировки формально можно озвучить так: Группа
процессов находится в ситуации взаимной блокировки, если каждый процесс из
группы ожидает события, которое может вызвать только другой процесс из
той же группы.
Так как все процессы находятся в состоянии ожидания, ни один из них не мо-
может стать причиной события, которое могло бы активизировать любой другой
процесс в группе, и все процессы продолжают ждать до бесконечности. В этой
модели мы предполагаем, что каждый процесс имеет только один программ-
программный поток, и нет прерываний, способных активизировать заблокированный про-
процесс. Условие отсутствия прерываний необходимо, чтобы предотвратить ситуа-
ситуацию, когда тот или иной заблокированный процесс активизируется, скажем, по
сигналу тревоги и затем приводит к событию, которое освобождает другие про-
процессы в группе.
В большинстве случаев событием, которого ждет каждый процесс, является
возврат какого-либо ресурса, в данный момент занятого другим процессом груп-
группы. Другими словами, каждый участник в группе процессов, оказавшихся в ту-
тупике, ожидает доступа к ресурсу, принадлежащему заблокированному процессу.
Ни один из процессов не может работать, ни один из них не может освободить
какой-либо ресурс и ни один из них не может возобновиться. Количество про-
процессов и количество и вид ресурсов, имеющихся и запрашиваемых, здесь не
важны. Результат остается тем же самым для любого вида ресурсов, аппаратных
и программных.
Условия взаимной блокировки
В [21] перечислены 4 условия взаимной блокировки.
1. Взаимное исключение. Каждый ресурс в данный момент либо отдан ровно
одному процессу, либо доступен.
2. Удержание и ожидание. Процессы, в данный момент удерживающие полу-
полученные ранее ресурсы, вправе запрашивать новые ресурсы.
3. Отсутствие принудительной выгрузки ресурса. У процесса нельзя принуди-
принудительным образом забрать ранее полученные ресурсы. Процесс, владеющий
ими, должен сам освободить ресурсы.
4. Циклическое ожидание. Должна существовать циклическая последователь-
последовательность из двух и более процессов, каждый из которых ждет доступа к ресурсу,
удерживаемому следующим членом последовательности.
Для того чтобы произошла взаимная блокировка, должны выполниться все эти
четыре условия. Если хоть одно из них не выполняется, тупиковая ситуация не-
невозможна.
В серии публикаций Левина [76—78] указывается на то, что в литературе тер-
термином «взаимная блокировка» называют целый ряд ситуаций и перечисленные
в [21] условия относятся лишь к взаимной блокировке ресурсов. Известны приме-
примеры взаимных блокировок, не удовлетворяющих всем четырем сформулирован-
сформулированным условиям. Например, если четыре автомобиля одновременно встретятся на
перекрестке, то, согласно правилам, ни один из них не вправе продолжить дви-
движение, однако здесь ни один из «процессов» (автомобилей) не является владель-
владельцем уникального ресурса. Данная проблема называется взаимной блокировкой
планирования и разрешается внешним участником — полицейским, принимаю-
принимающим решение о приоритетах машин.
Следует заметить, что каждое из условий относится к политике, которая может
быть принята или не принята в системе. Может ли определенный ресурс едино-
единовременно использоваться более чем одним устройством? Выгружаемы ли ресур-
ресурсы? Возможно ли циклическое ожидание? Позже мы увидим, как справиться
с взаимными блокировками, нарушая некоторые из этих условий.
Моделирование взаимных блокировок
В [61] показано, как можно смоделировать четыре условия взаимной блокиров-
блокировки, используя направленные графы. Графы имеют два вида узлов: процессы, по-
показанные кружочками, и ресурсы, нарисованные квадратиками. Ребро, направ-
направленное от узла ресурса (квадрат) к узлу процесса (круг), означает, что ресурс
ранее был запрошен процессом, получен и в данный момент используется этим
процессом. На рис. 3.6, а ресурс R в настоящее время отдан процессу А
Рис. 3.6. Графы распределения ресурсов: а — ресурс занят; б — запрос ресурса;
б — взаимная блокировка
Ребро, направленное от процесса к ресурсу, означает, что процесс в данный
момент блокирован и находится в состоянии ожидания доступа к этому ресур-
ресурсу. На рис. 3.6, б процесс В ждет ресурс S. На рис. 3.6, в мы видим взаимную
блокировку: процесс С ожидает ресурс Т, удерживаемый процессом D. Про-
Процесс D вовсе не намеревается освобождать ресурс Г, потому что он ждет ре-
ресурс U, используемый процессом С. Оба процесса будут ждать до бесконечности.
Цикл в графе означает наличие взаимной блокировки, циклично включающей
процессы и ресурсы (предполагается, что в системе есть по одному ресурсу ка-
каждого вида). В этом примере циклом является последовательность C-T-D-U-C.
Теперь рассмотрим пример того, как извлечь пользу из графов ресурсов. Пред-
Представим, что у нас есть три процесса: А, В и С, и три ресурса: R, S и Т. Последо-
Последовательность запросов и возвратов ресурсов для трех процессов показана на
рис. 3.7, а-в. Операционная система может запустить любой незаблокированный
процесс в любой момент времени, значит, таковым может оказаться процесс А
Процесс А будет выполняться до тех пор, пока не закончит всю свою работу, за-
затем запустится процесс В, а по его завершении — процесс С.
Такой порядок не приводит к взаимной блокировке (не возникает соперничества
за использование ресурсов), но здесь также по сути нет параллельной работы.
Помимо запроса и возврата ресурсов, процессы выполняют вычисления и ввод-
вывод данных. Когда процессы работают последовательно, нереальна ситуация,
при которой один процесс использует процессор, в то время как другой ждет за-
завершения операции ввода-вывода. Таким образом, строго последовательная ра-
работа процессов не бывает оптимальной. С другой стороны, если вообще ни один
процесс не выполняет операций ввода-вывода, алгоритм «самое короткое за-
задание — первое» работает эффективнее, чем циклический, поэтому в некото-
некоторых ситуациях последовательный запуск всех процессов может быть наилучшим.
Теперь предположим, что процессы выполняют как вычисления, так и ввод-вы-
ввод-вывод, соответственно циклический алгоритм планирования является рациональ-
рациональным. Запросы ресурсов могут происходить в порядке, указанном на рис. 3.7, г.
Если эти шесть запросов будут осуществлены в такой последовательности, в ре-
результате мы получим шесть графов, показанных на рис. 3.7, д-к. После запроса 4
процесс А блокируется в ожидании ресурса S (см. рис. 3.7, з). На двух следую-
следующих шагах также блокируются процессы В и С, в конечном счете приводя к цик-
циклу и взаимной блокировке на рис. 3.7, к.
Однако как мы упоминали ранее, операционная система не обязана запускать
процессы в каком-то особом порядке. В частности, если выполнение отдельного
запроса приводит к тупику, операционная система вправе просто приостановить
процесс без удовлетворения запроса (то есть не выполняя план процесса) до тех
пор, пока это безопасно. На рис. 3.7 операционная система могла бы приостановить
процесс В вместо того, чтобы отдавать ему ресурс S, если бы она знала о пред-
предстоящей взаимной блокировке. Работая только с процессами Аи С, мы могли бы
получить такой порядок запросов ресурсов и их возвратов, который представлен
на рис. 3.7, л, вместо показанного на рис. 3.7, г. Такая последовательность дейст-
действий отражена графами на рис. 3.7, м-с, и она не приводит к тупику.
После шага с процесс В может получить ресурс S, потому что процесс А уже за-
закончил свою работу, а процесс С имеет в своем распоряжении все необходимые
ему ресурсы. Даже если затем процесс В, когда он запросит ресурс Г, будет за-
заблокирован, система не зависнет. Процесс В всего лишь будет ждать завершения
процесса С.
Рис. 3.7. Пример возникновения взаимной блокировки и способ избежать ее
Позже в этой главе мы изучим подробный алгоритм для принятия решений
о распределении ресурсов, которые не приведут к взаимной блокировке. В дан-
данный момент важно понять, что графы ресурсов являются инструментом, позво-
позволяющим увидеть, станет ли заданная последовательность запросов и возвратов
ресурсов причиной тупиковой ситуации. Мы всего лишь шаг за шагом осуществ-
осуществляем запросы и возвраты ресурсов и после каждого шага проверяем граф на со-
содержание циклов. Если они есть, мы оказались в тупике; если нет, значит, взаим-
взаимной блокировки тоже нет. Хотя мы рассматривали графы ресурсов для случая,
когда в системе присутствует по одному ресурсу каждого типа, графы также
можно построить для обработки ситуации с несколькими одинаковыми ресурса-
ресурсами [61]. Тем не менее в [76, 77] указано на то, что в случае однородных ресурсов
графы оказываются очень сложными. Если хотя бы одна ветвь графа не входит
в цикл, то есть один неблокированный процесс захватывает одну из копий одно-
одного из ресурсов, взаимной блокировки не происходит.
Вообще говоря, для борьбы с взаимными блокировками практикуются четыре
стратегии.
1. Полное игнорирование проблемы. Если вы проигнорируете проблему, воз-
возможно, затем она проигнорирует вас.
2. Обнаружение и устранение. Взаимной блокировке позволяется произойти,
затем она обнаруживается и предпринимаются те или иные действия для ре-
решения проблемы.
3. Предотвращение путем структурного избежания одного из четырех условий
взаимной блокировки.
4. Динамическое избежание тупиковых ситуаций путем аккуратного распреде-
распределения ресурсов.
Мы по очереди изучим каждый из этих методов в следующих четырех разделах.
3.3.3. Алгоритм страуса
Самым простым подходом является «алгоритм страуса»: воткните голову в пе-
песок и притворитесь, что проблемы вообще не существует. Различные люди от-
отзываются об этой стратегии по-разному. Математики считают ее полностью не-
неприемлемой и говорят, что взаимные блокировки нужно предотвращать любой
ценой. Инженеры спрашивают, как часто встает подобная проблема, как часто
система попадает в аварийные ситуации по другим причинам и насколько серь-
езны последствия взаимных блокировок. Если взаимные блокировки случа-
случаются в среднем один раз в пять лет, а сбои операционной системы, ошибки ком-
компилятора и поломки компьютера из-за неисправности аппаратуры происходят
раз в неделю, то большинство инженеров не захотят добровольно терять в произ-
производительности и удобстве для того, чтобы ликвидировать возможность взаим-
взаимных блокировок.
Чтобы подчеркнуть контраст между этими подходами, добавим, что UNIX и
MINIX 3 потенциально страдают от взаимных блокировок, которые даже не
обнаруживаются, не говоря уже об автоматическом выходе из тупика. Суммар-
Суммарное количество процессов в системе определяется количеством записей в таблице
процессов. Таким образом, ячейки таблицы процессов являются ограниченным
ресурсом. Если системный вызов fork получает отказ, в силу того, что таблица
целиком заполнена, разумно будет, чтобы программа, вызывающая fork, подож-
подождала какое-то время и повторила попытку.
Теперь предположим, что система MINIX 3 имеет 100 ячеек процессов. Работа-
Работают десять программ, каждой необходимо создать 12 (под)процессов. После обра-
образования каждым процессом девяти процессов 10 исходных и 90 новых процессов
заполнят таблицу до конца. После этого каждый из десяти исходных процессов
попадает в бесконечный цикл, состоящий из попыток разветвления и отказов, то
есть возникает взаимная блокировка. Вероятность того, что произойдет по-
подобное, минимальна, но она ненулевая. Нужно ли нам отказываться от процессов
и вызова fork, чтобы решить проблему?
Максимальное количество открытых файлов также ограничено размером табли-
таблицы индексных узлов, следовательно, когда таблица заполняется целиком, возни-
возникает та же самая проблема. Пространство для подкачки файлов на диск является
еще одним ограниченным ресурсом. Фактически, почти каждая таблица в опера-
операционной системе представляет собой ограниченный ресурс. Должны ли мы уп-
упразднить их все из-за того, что теоретически возможна ситуация, когда в группе
из п процессов каждый может потребовать 1/п от целого, а затем попытаться по-
получить еще часть?
Большая часть операционных систем, включая UNIX, MINIX 3 и Windows,
игнорируют эту проблему. Разработчики исходят из предположения, что боль-
большинство пользователей скорее предпочтут иметь дело со случающимися время
от времени взаимными блокировками, чем с правилом, по которому всем поль-
пользователям разрешается иметь только один процесс, только один открытый файл
и т. д. Если бы можно было легко устранить взаимные блокировки, не возникло
бы столько разговоров на эту тему. Сложность заключается в том, что цена
достаточно высока, и в основном она, как мы вскоре увидим, исчисляется в на-
наложении неудобных ограничений на процессы. Таким образом, мы столкнулись
с неприятным выбором между удобством и корректностью и множеством дис-
дискуссий о том, что более важно и для кого. В таких условиях трудно найти вер-
верное решение.
3.3.4. Обнаружение и устранение
взаимных блокировок
Второй подход предполагает обнаружение и устранение. Здесь система лишь
следит за запросом и освобождением ресурсов. Каждый раз, когда запрашивает-
запрашивается или освобождается новый ресурс, то есть когда обновляется граф ресурсов,
система проверяет, имеются ли в нем циклы. Если цикл есть, один из входящих
в него процессов принудительно завершается. Это повторяется до тех пор, пока
циклов не останется.
Более грубый метод не анализирует граф ресурсов, а просто проверяет наличие
процессов, которые оказались заблокированными надолго, скажем, не менее ча-
часа. Если такие процессы обнаруживаются, они завершаются.
Стратегия обнаружения и устранения применяется в больших компьютерных сис-
системах, особенно в системах пакетной обработки, где принудительное завершение
и повторный запуск процессов обычно вполне приемлемы. Тем не менее необхо-
необходимо с осторожностью производить восстановление любых модифицированных
файлов и устранение любых побочных эффектов, которые могли произойти.
3.3.5. Предотвращение взаимных блокировок
Третья стратегия предполагает наложение на процессы допустимых ограничений,
делающих взаимные блокировки конструктивно невозможными. Четыре усло-
условия, сформулированные в [21], являются предпосылками для некоторых подоб-
подобных решений.
Сначала попробуем атаковать условие взаимного исключения. Если в системе
нет ресурсов, отданных в единоличное пользование одному процессу, мы нико-
никогда не попадем в состояние взаимной блокировки. Но в равной степени понятно,
что если позволить двум процессам одновременно печатать данные на принтере,
воцарится хаос. Используя механизм спулинга, несколько процессов могут гене-
генерировать свои выходные данные одновременно. В такой модели только один
процесс, который фактически запрашивает физический принтер, является демо-
демоном принтера. Так как демон не запрашивает никакие другие ресурсы, для прин-
принтера тупики исключаются.
К сожалению, не все устройства поддерживают спулинг (таблица процессов —
дело резидентное). Кроме того, конкуренция за дисковое пространство для спулин-
спулинга сама по себе чревата тупиком. Что получится, если два процесса заполнят свои-
своими выходными данными каждый по половине диска, отведенного под спулинг,
и ни один из них не заканчивает вычисления? Демон может быть запрограммиро-
запрограммирован так, что начнет печать, не дожидаясь спулинга всех выходных данных, и прин-
принтер тогда простоит впустую в том случае, если вычисляющий процесс решил по-
подождать несколько часов после первого пакета выходных данных. По этой при-
причине обычно демоны программируют так, что они начинают печать только после
того, как файл выходных данных целиком станет доступен. В этом же случае мы
получаем два процесса, каждый из которых обработал часть выходных данных, но
не все и не в состоянии продолжать вычисления дальше. Ни один из двух процес-
процессов никогда не завершится, то есть имеет место взаимная блокировка на диске.
Второе из условий, сформулированных в [21], кажется, все же подает надежду.
Если у нас получится уберечь процессы, занимающие некоторые ресурсы, от ожи-
ожидания остальных ресурсов, мы устраним тупиковую ситуацию. Один из способов
достижения этой цели состоит в требовании, следуя которому любой процесс дол-
должен запрашивать все необходимые ресурсы до начала работы. Если все ресурсы
доступны, процесс получит все, что ему нужно, и сможет работать до успешного
завершения. Если один или несколько ресурсов заняты, процессу ничего не пре-
предоставляется, и он просто переводится в состояние ожидания.
Первая проблема, вносимая этим подходом, заключается в том, что многие про-
процессы не знают, сколько ресурсов им понадобится, до тех пор, пока не начнут ра-
работу. Другая проблема состоит в том, что ресурсы не будут расходоваться опти-
оптимально. Возьмем, например, процесс, который читает данные с входной ленты,
анализирует их в течение часа и затем пишет выходную ленту, а заодно и чертит
результаты на плоттере. Если все ресурсы нужно запрашивать заранее, то про-
процесс целый час не позволит работать накопителю на магнитной ленте и принтеру.
Слегка отличающийся метод, позволяющий нарушить условие удержания и ожи-
ожидания, вытекает из наложения следующего требования на процесс, запрашиваю-
запрашивающий ресурс: процесс сначала должен временно освободить все используемые им
в данный момент ресурсы. Затем этому процессу разрешается попытаться сразу
получить все необходимое.
Попытка исключить третье условие (нет принудительной выгрузки ресурса)
вселяет еще меньше надежд, чем устранение второго условия. Если процесс по-
получил принтер и в данный момент печатает выходные данные, насильственное
изъятие принтера по причине недоступности требуемого плоттера в лучшем слу-
случае сложно, а в худшем — невозможно.
Остается только одно условие. Циклическое ожидание можно устранить несколь-
несколькими путями. Один их них — просто следовать правилу, гласящему, что процессу
дано право только на один ресурс в конкретный момент времени. Если нужен вто-
второй ресурс, процесс обязан освободить первый. Но подобное ограничение непри-
неприемлемо для процесса, копирующего огромный файл с магнитной ленты на принтер.
Другой способ обойти циклическое ожидание заключается в поддержке общей
нумерации всех ресурсов, как показано на рис. 3.8, а. В этом случае действует
следующее правило: процессы могут запрашивать ресурс, когда хотят этого, но
все запросы должны быть сделаны в соответствии с нумерацией ресурсов. Про-
Процесс может запросить сначала сканер, затем накопитель на магнитной ленте, но
не вправе сначала потребовать плоттер, а затем сканер.
Рис. 3.8. Общая нумерация ресурсов: а — пронумерованные ресурсы; б — граф ресурсов
При выполнении такого соглашения граф распределения ресурсов никогда не
будет иметь циклов. Покажем, что это так, в случае двух процессов (рис. 3.8, б).
Мы попадем в ситуацию взаимной блокировки, только если процесс А запросит
ресурсу, а процесс В обратится к ресурсу г. Предположим, что ресурсы г nj раз-
различны, значит, они имеют разные номера. Если i >j, тогда процессу А не позво-
позволяется запрашивать ресурсу, потому что его номер меньше, чем номер уже имею-
имеющегося у него ресурса. Если же i < j, процесс В не может запрашивать ресурс i,
так как этот номер меньше номера уже занятого им ресурса. Так или иначе, вза-
взаимная блокировка исключена.
При работе с несколькими процессами сохраняется та же самая логика. В каж-
каждый момент времени один из предоставленных ресурсов будет иметь наивысший
номер. Процесс, использующий этот ресурс, уже никогда не запросит другие
занятые ресурсы. Он либо закончит свою работу, либо, в худшем случае, запро-
запросит ресурс с еще большим номером, а любой такой ресурс является доступным.
В итоге процесс завершит работу и освободит свои ресурсы. На этот момент сло-
сложится ситуация, когда ресурс с высшим номером уже занят каким-то другим
процессом, который также сможет нормально завершиться. То есть существует
алгоритм, по которому все процессы отрапортуют о выполнении без взаимной
блокировки.
Вариантом этого алгоритма является схема, в которой исключается требование
приобретения ресурсов в строго возрастающем порядке, но сохраняется условие,
что процесс не может запросить ресурсы с меньшим номером, чем уже у него
имеющиеся. Если процесс на начальной стадии запрашивает ресурсы 9 и 10, за-
затем освобождает их, то это равнозначно тому, как если бы он начал работу зано-
заново, поэтому нет причины запрещать ему запрос ресурса 1.
Хотя систематизация ресурсов путем их нумерации устраняет проблему взаимных
блокировок, бывают ситуации, когда невозможно найти порядок, удовлетворяю-
удовлетворяющий всех. Когда ресурсы включают в себя области таблицы процессов, дисковое
пространство для спулинга, закрытые записи базы данных и другие абстрактные
ресурсы, число потенциальных объектов интереса и вариантов их применения
может быть настолько огромным, что никакая систематизация не спасет. Кроме
того, согласно [78], упорядочивание ресурсов сводит «на нет» взаимозаменяе-
взаимозаменяемость — копия ресурса при таких правилах может оказаться недоступной.
В табл. 3.2 обобщены различные методы предотвращения взаимных блокировок.
Таблица 3.2. Методы предотвращения взаимных блокировок
Условие Метод
Взаимное исключение Организовывать спулинг
Удержание и ожидание Запрашивать все ресурсы на начальной стадии
Отсутствие принудительной выгрузки ресурса Отобрать ресурсы
Циклическое ожидание Упорядочить ресурсы по номерам
3.3.6. Избежание взаимных блокировок
На рис. 3.7 мы видели, что избежать взаимных блокировок можно не с помо-
помощью строгих правил, применяемых к процессам, а путем тщательного анализа
каждого запроса на ресурсы и его удовлетворения только в случае, если запрос
признан безопасным. Неизбежен новый вопрос: существует ли алгоритм, кото-
который никогда не приведет к взаимной блокировке, то есть все время делающий
правильный выбор? Ответом является условное «да» — мы можем избежать
тупиков, но только если заранее будет доступна определенная информация. В сле-
следующем разделе мы изучим способы избежания взаимных блокировок за счет
аккуратного предоставления ресурсов.
Алгоритм банкира для одного вида ресурсов
Алгоритм планирования, позволяющий избегать взаимных блокировок, был пред-
предложен в [38] и носит название алгоритма банкира. Алгоритм моделирует банки-
банкира в маленьком городке, имеющего дело с группой клиентов, которым он выдал
ряд кредитов. У банкира не обязательно имеется на руках достаточно средств,
чтобы выдать каждому клиенту полную сумму кредита. На рис. 3.9, а мы видим
четырех клиентов, Л, В, С и Д каждый из которых получил определенное коли-
количество единиц кредита (пусть единица равна 1000 долларов). Банкир знает, что
не всем клиентам понадобится вся сумма немедленно, поэтому он зарезервиро-
зарезервировал только 10 единиц, а не все 22, которые требуются клиентам. Он рассчитыва-
рассчитывает на то, что каждый из клиентов будет способен погасить кредит вскоре после
его получения. В этом случае банкир сможет обслужить все запросы (чтобы про-
провести аналогию с компьютерной системой, считаем, что клиенты — это процес-
процессы, единицами, скажем, являются накопители на магнитной ленте, а банкир —
это операционная система).
Рис. 3.9. Три состояния распределения ресурсов: a — безопасное;
б — безопасное; в — небезопасное
Каждая часть рисунка демонстрирует состояние системы, соответствующее выде-
выделенным ресурсам, то есть список клиентов с указанием ссуженных сумм (выде-
(выделенных ленточных накопителей) и максимальных доступных им кредитов (наи-
(наибольшее число накопителей, одновременно необходимых в будущем). Состояние
системы считается безопасным, если существует последовательность других со-
состояний, ведущих к тому, что все клиенты до исчерпания кредита могут взять
максимально доступный для них заем (все процессы получают требуемые ресур-
ресурсы и завершаются).
Клиенты вращаются в соответствующем бизнесе, время от времени прося у бан-
банка ссуды (то есть запрашивая ресурсы). В некоторый момент возникает ситуа-
ситуация, показанная на рис. 3.9, б. Это состояние безопасно, поскольку остались две
свободные единицы и банкир может задержать все обращения, кроме запро-
запросов клиента, или процесса, С, таким образом, позволяя процессу С завершиться
и вернуть все четыре отданных ему ресурса. Имея на руках четыре единицы,
банкир может отдать их или клиенту D или В, обеспечивая их необходимыми
единицами и т. д.
Посмотрим, что могло бы произойти, если бы в ситуации на рис. 3.9, б был
удовлетворен запрос еще одной единицы для клиента В. Мы попали бы в состоя-
состояние (рис. 3.9, в), не являющееся безопасным. Если бы все клиенты вдруг запро-
запросили максимальные ссуды, то банкир не сумел бы их обеспечить, и мы попали
бы в ситуацию взаимной блокировки. И хотя небезопасное состояние не обяза-
обязательно приводит к взаимной блокировке, так как клиентам может не потребо-
потребоваться весь доступный кредит, рассчитывать на такую ситуацию банкиру не
следует.
В алгоритме банкира каждый запрос по мере поступления изучается на пред-
предмет того, приведет ли его удовлетворение к безопасному состоянию. Если да,
процесс получает ресурс, иначе запрос откладывается на более позднее время.
Чтобы понять, является ли состояние безопасным, банкир оценивает, доста-
достаточно ли ресурсов для завершения работы какого-либо клиента. Если да, эти
ссуды считаются погашенными, после чего проверяется следующий ближайший
к верхнему пределу займа клиент и т. д. Если, в конце концов, все ссуды могут
быть погашены, состояние является безопасным, и исходный запрос можно
удовлетворить.
Траектории ресурсов
Предыдущий алгоритм описан в терминах одного класса ресурсов (то есть в на-
нашем распоряжении имеются только принтеры или только ленточные накопители,
но не то и другое вместе). На рис. 3.10 представлена модель системы с двумя про-
процессами и двумя классами ресурсов, например принтером и плоттером. По гори-
горизонтальной оси выводятся номера команд, выполняемых процессом А По верти-
вертикальной оси отложены номера команд, выполняемых процессом В. В команде It
процесс А запрашивает принтер, в команде 12 ему требуется плоттер. Принтер
и плоттер освобождаются командами /3 и /4 соответственно. Процессу В необхо-
необходим плоттер с команды /5 по команду 17 и принтер с команды /6 по команду /8.
Каждая точка на диаграмме представляет совместное состояние двух процес-
процессов. Изначально система находится в точке р, когда ни один из процессов еще
не выполнил ни одной инструкции. Если планировщик запустит процесс А пер-
первым, мы попадем в точку q, в которой процесс А выполнил какое-то количество
команд, а процесс В еще ничего не сделал. В точке q траектория становится
вертикальной, показывая, что планировщик решил запустить процесс В. При
наличии одного процессора все отрезки траектории могут быть только верти-
вертикальными или только горизонтальными, но не наклонными. Кроме того, движе-
движение всегда происходит на «север» или «восток» (вверх или вправо) и никогда
на «юг» или «запад» (вниз или влево), так как процессы не могут течь в обрат-
обратном направлении.
Рис. 3.10. Две траектории ресурсов для процессов
Когда процесс А пересекает линию 1Х на отрезке от точки г до точки s, он запра-
запрашивает и получает принтер. Когда процесс В достигает точки t, он запрашивает
плоттер.
Особенно интересны заштрихованные области. Область со штриховкой из верх-
верхнего левого угла в правый нижний представляет промежуток времени, когда оба
процесса занимают принтер. Правило взаимного исключения делает попадание
в эту область невозможным. Вторая заштрихованная область соответствует то-
тому, что оба процесса используют плоттер, и это также невозможно.
Если система войдет в прямоугольник, ограниченный линиями 1Х и 12 по сто-
сторонам и линиями /5 и /6 сверху и снизу, она в конце концов доберется до пере-
пересечения линий 12 и /6. В этот момент процесс А запросит плоттер, а процесс В по-
потребует принтер, но оба ресурса будут к тому времени заняты. Получается, что
тупиковым является целый прямоугольник и в него нельзя входить. В точке t
единственно безопасный вариант состоит в том, чтобы оставить процесс А рабо-
работать до тех пор, пока он не достигнет команды /4. После нее любая траектория
дойдет до точки и.
Важный для понимания момент заключается в том, что в точке t процесс В за-
запрашивает ресурс. Система должна принять решение, предоставлять его или нет.
Если выдается разрешение, система попадает в небезопасную область и в итоге
блокируется. Чтобы избежать тупика, нужно приостановить процесс В до тех
пор, пока процесс А не запросит и не освободит плоттер.
Алгоритм банкира для нескольких видов ресурсов
Такую графическую модель трудно применить для общего случая, когда имеют-
имеются несколько процессов и несколько различных классов ресурсов и в каждом
классе может быть несколько экземпляров (например, два плоттера и три нако-
накопителя). Но алгоритм банкира поддается обобщению для управления системой
с несколькими видами ресурсов. На рис. 3.11 показано, как он работает.
Рис. 3.11. Алгоритм банкира в системе с несколькими видами ресурсов
На рисунке изображены две матрицы. Матрица слева показывает, сколько ресурсов
каждого вида занимает в настоящее время каждый из пяти процессов. Матрица
справа объединяет ресурсы, которые нужно добавить каждому процессу для успеш-
успешного завершения. Как и в случае одного вида ресурсов, процессы должны точно
определять необходимое суммарное количество ресурсов до начала работы для
того, чтобы система могла рассчитать правую матрицу в каждый момент времени.
Три вектора, изображенные справа от матриц, показывают соответственно суще-
существующие (вектор £), занятые (вектор Р) и доступные ресурсы (вектор А). Из
вектора Е мы видим, что система имеет шесть накопителей на магнитной ленте,
три плоттера, четыре принтера и два устройства чтения компакт-дисков. Из них
заняты в данный момент пять ленточных накопителей, три плоттера, два принте-
принтера и два привода компакт-дисков. Чтобы увидеть это, нужно просуммировать че-
четыре столбца, соответствующие ресурсам, в левой матрице. Вектор доступных
ресурсов является разницей между тем, что доступно в системе, и тем, что ис-
используется.
Теперь можно изложить алгоритм, проверяющий, безопасно ли состояние системы.
1. Ищем в матрице R строку, соответствующую процессу, чьи неудовлетво-
неудовлетворенные потребности ресурсов меньше или равны вектору Л. Если такой стро-
строки не существует, система в конце концов попадет в состояние взаимной
блокировки, так как ни один процесс не сможет проработать до успешного за-
завершения.
2. Допускаем, что процесс, строку которого мы выбрали на шаге 1, запрашивает
все необходимые ресурсы (гарантируется, что это возможно) и заканчивает
работу. Отмечаем этот процесс как завершенный и прибавляем все его ресур-
ресурсы к вектору А
3. Повторяем шаги 1 и 2 до тех пор, пока либо все процессы будут помечены как
завершенные (состояние в этом случае является безопасным), либо произой-
произойдет взаимная блокировка (тогда состояние небезопасно).
Если на шаге 1 можно выбрать несколько процессов, не имеет значения, какой
из них будет взят: общий резерв доступных ресурсов увеличится или, в худшем
случае, останется неизменным.
Вернемся к примеру на рис. 3.11. Текущее состояние является безопасным. Пред-
Предположим, процесс В в данный момент запрашивает принтер. На этот запрос мож-
можно ответить положительно, потому что получающееся в результате состояние все
еще будет безопасным (процесс D может доработать до конца, затем процесс А
или J?, затем остальные).
Теперь представим, что после того, как процесс В получает один из двух остав-
оставшихся принтеров, процесс Е требует последний принтер. Удовлетворение этого
запроса сократит вектор доступных ресурсов до A 0 0 0), что приведет к взаимной
блокировке процессов. Ясно, что следует отложить на время запрос процесса Е.
Алгоритм банкира впервые был предложен в 1965 году [38]. С тех пор практиче-
практически каждая книга по операционным системам описывает его в деталях. Различ-
Различным аспектам этого алгоритма было посвящено бессчетное количество статей.
К сожалению, мало у кого из авторов хватило смелости показать, что хотя алго-
алгоритм замечателен в теории, на практике он, по существу, бесполезен, поскольку
нечасто можно определить заранее, сколько ресурсов потребуется процессам
в будущем. Кроме того, количество процессов не фиксировано, оно динамически
изменяется по мере входа пользователей в систему и выхода из нее. И, более
того, считавшиеся доступными ресурсы могут внезапно исчезнуть (например,
накопитель на магнитной ленте может сломаться). Таким образом, на практике
немногие системы (если такие вообще есть) используют алгоритм банкира, что-
чтобы избежать взаимных блокировок.
Обобщая, скажем, что описанные алгоритмы, объединенные термином «предот-
«предотвращение взаимных блокировок», накладывают чересчур сильные ограничения.
В то же время алгоритмы, входящие в группу «избежание взаимных блокиро-
блокировок», требуют для своей работы информацию, которая не всегда имеется. Если
вам удастся придумать обобщенный алгоритм, который в реалии работает так же
хорошо, как и в теории, непременно сообщите об этом в ближайший научный
компьютерный журнал.
Несмотря на практическую несостоятельность обобщенных алгоритмов избе-
избежания и предотвращения взаимных блокировок, для некоторых частных при-
применений разработаны превосходные специализированные алгоритмы. Например,
в системах управления базами данных часто встречается ситуация, когда сначала
запрашивается блокировка нескольких записей, а затем эти записи обновляются.
Если же одновременно работают несколько процессов, возникает реальная опас-
опасность тупика. Для решения этой проблемы существуют специальные методы.
Ч&сто используемый подход называется двухфазной блокировкой. В первой фазе,
то есть на первом этапе, процесс пытается заблокировать все требуемые записи,
по одной за раз. Если операция успешна, процесс переходит ко второму этапу,
выполняя обновление заблокированных записей и освобождение ресурсов. Ни-
Никакой полезной работы на первом этапе не совершается.
Если во время первой фазы какая-либо необходимая запись оказывается уже за-
заблокированной, процесс просто сбрасывает все свои блокировки и начинает пер-
первую фазу заново. В некотором смысле этот метод похож на схему, в которой за-
запрос всех необходимых ресурсов происходит загодя или, по крайней мере, перед
тем, как произойдет что-то необратимое. В некоторых вариациях двухфазной
блокировки, если блокировка встретилась во время первой фазы, не происходит
возврата ресурсов и возобновления работы процесса. В таких вариациях может
возникнуть тупиковая ситуация.
Но эту стратегию нельзя обобщить. Например, в системах реального времени
и системах контроля процессов недопустимо частично завершить процесс из-за
того, что ресурс недоступен, а потом начинать все заново. Также недопустимо
перезапускать процесс, если он прочел сообщение из сети или написал его, обно-
обновил файлы и сделал что-нибудь еще, что не может быть безопасно повторено.
Алгоритм работает только в тех ситуациях, когда программист очень тщательно
подготовил все таким образом, что программу нетрудно остановить в любой точ-
точке первой фазы и запустить заново. Многие программы не могут быть структу-
структурированы таким образом.
3.4. Ввод-вывод в MINIX 3
Структура системы ввода-вывода в MINIX 3 показана на рис. 3.5. Четыре верхних
уровня этой структуры соответствуют четырем уровням на рис. 2.14. В следую-
следующих разделах мы вкратце рассмотрим каждый из этих уровней, делая акцент на
драйверах устройств. Механизм обработки прерываний MINIX 3 был рассмот-
рассмотрен в предыдущей главе, а аппаратно-зависимый ввод-вывод будет обсуждаться
в главе 5 при изучении файловой системы.
3.4.1. Обработчики прерываний и доступ
к вводу-выводу в MINIX 3
Большинство драйверов инициируют ввод-вывод и переходят в состояние блоки-
блокировки, ожидая, когда прибудет сообщение. Обычно это сообщение генерируется
обработчиком прерываний устройства. Существуют другие драйверы, которые
не запускают физических процессов ввода-вывода (пример — чтение с вирту-
виртуального диска или вывод текста в видеопамять, представляющую собой, по сути,
экран, отображаемый на память), не опираются на прерывания и не ждут сооб-
сообщений от устройств. Механизм генерации сообщений и переключения заданий,
управляемый прерываниями, в предыдущей главе обсуждался очень подробно.
Здесь же мы рассмотрим его применение в общем, а детально вернемся к этой
теме, когда будем демонстрировать код для различных устройств.
Для дисков ввод и вывод в основном сводятся к передаче устройству соответст-
соответствующей команды и ожиданию ее завершения. Большую часть работы выполняет
контроллер диска, поэтому обработчик прерывания весьма прост. Если бы все
прерывания обрабатывались так просто, наша жизнь была бы намного легче.
Однако иногда обработчику приходится выполнять более сложные действия.
Механизм передачи сообщений имеет свою цену. Когда прерывания происходят
часто, а объем передаваемых данных невелик, имеет смысл усложнить обра-
обработчик и отложить передачу сообщения до следующего прерывания, чтобы дать
обслуживающему устройство заданию больше времени. В MINIX 3 это невоз-
невозможно для большинства устройств ввода-вывода, поскольку низкоуровневый
обработчик, находящийся в ядре, представляет собой подпрограмму общего на-
назначения, пригодную почти для всех устройств.
Из предыдущей главы вы знаете, что часы в этом отношении являются исключе-
исключением. Часы входят в ядро и могут иметь собственный обработчик прерываний,
выполняющий дополнительную работу. Многие такты часов не требуют большо-
большого числа действий — обычно необходимо лишь обновлять время. Это делается
без передачи сообщений таймерному заданию. Обработчик прерываний от тай-
таймера инкрементирует переменную реального времени realtime, возможно, до-
добавляя такты, пропущенные при вызове BIOS. Обработчик выполняет простые
арифметические действия — увеличивает счетчики времени пользователя и про-
процесса, уменьшает счетчик ticks_lef t текущего процесса и проверяет, истек ли
таймер. Сообщение посылается таймерному заданию лишь в случае, если теку-
текущий процесс исчерпал свой квант или таймер истек.
Обработчик прерываний от таймера является уникальным компонентом MINIX 3,
поскольку часы — единственное устройство, генерирующее прерывания и выпол-
выполняемое в пространстве ядра. Аппаратная часть часов интегрирована в компьютер:
фактически, линия прерываний от таймера не подключается к контакту какого-
либо разъема, предназначенного для дополнительных контроллеров ввода-выво-
ввода-вывода. Таким образом, часы невозможно модернизировать, подключив их новую мо-
модель и установив драйвер от производителя, а, значит, резонно сделать драйвер
частью ядра и предоставить ему полный доступ к внутренним данным. Тем не
менее основной целью разработки MINIX 3 является устранение необходимости
подобного доступа для всех остальных устройств.
Драйверы устройств, выполняемые в пользовательском пространстве, не имеют
прямого доступа к памяти ядра и портам ввода-вывода. Хотя процедура обслужи-
обслуживания прерываний могла бы совершить дальний вызов для запуска подпрограм-
подпрограммы, обрабатывающей прерывание и находящейся в сегменте кода пользователь-
пользовательского процесса, это нарушило бы принципы организации архитектуры MINIX 3.
Такой подход был бы более опасным, чем возможность вызова функции ядра
пользовательским процессом. В последнем случае мы, как минимум, можем быть
уверены в том, что функция написана компетентным системным разработчиком,
сведущим в вопросах безопасности и даже, возможно, читавшим эту книгу. Но
в любом случае ядро не должно доверять коду пользовательской программы.
Драйверу, находящемуся в пользовательском пространстве, могут понадобиться
различные уровни доступа к вводу-выводу.
1. Доступ к памяти за пределами области данных драйвера. Пример — драйвер
оперативной памяти, управляющий виртуальным диском. Подобный доступ
является для него единственным необходимым.
2. Чтение и запись портов ввода-вывода. Инструкции машинного кода, выпол-
выполняющего эти операции, доступны только в режиме ядра. Как мы скоро уви-
увидим, такой доступ необходим драйверу жесткого диска.
3. Реакция на ожидаемые прерывания. Например, драйвер жесткого диска запи-
записывает команды в дисковый контроллер, а тот генерирует прерывания по за-
завершении операций.
4. Реакция на непрогнозируемые прерывания. Такая возможность необходима
драйверу клавиатуры. Данный уровень доступа можно рассматривать как
подмножество предыдущего, однако непредсказуемость усложняет проблемы
доступа.
Все перечисленные уровни доступа поддерживаются вызовами ядра, обрабаты-
обрабатываемыми системным заданием.
На первом уровне, уровне доступа к внешним сегментам памяти, используется
аппаратная сегментация процессоров Intel. Несмотря на то что обычный про-
процесс может обращаться только к собственным сегментам кода, данных и стека,
системное задание позволяет пользовательским процессам определять другие
сегменты и получать к ним доступ. Так драйвер памяти обращается к областям
памяти, зарезервированным под виртуальный диск, и к другим областям специ-
специального применения. Аналогичным образом драйвер консоли имеет доступ к па-
памяти дисплейного адаптера.
На втором уровне MINIX 3 предоставляет вызовы ядра для использования ко-
команд ввода-вывода. Системное задание выполняет ввод-вывод от имени менее
привилегированных процессов. Позже в этой главе мы познакомимся с тем, как
эту возможность задействует жесткий диск. Пока скажем лишь несколько слов.
Драйвер диска записывает значение в выходной порт, чтобы выбрать диск, а за-
затем считывает другой порт, чтобы убедиться в готовности устройства. Если от-
ответ, как обычно, приходит быстро, можно воспользоваться механизмом опроса.
Ядро предоставляет вызовы, позволяющие выполнять запись и чтение. При за-
записи указывается номер порта и данные, а при чтении — номер порта и место
под считанные данные. Требуется, чтобы вызов чтения из порта был неблокирую-
неблокирующим; в действительности, вызовы ядра вообще не вызывают блокировку.
Полезно каким-либо образом страховаться от сбоев устройств. Например, в оп-
опрашивающий цикл можно включить счетчик, завершающий его при отсутствии
ответа от устройства в течение определенного числа итераций. Это — не очень
хороший метод, поскольку время ожидания зависит от быстродействия процес-
процессора. Можно соотнести число итераций с используемым процессором, к приме-
примеру, устанавливая его на основе значения глобальной переменной, инициализи-
инициализируемой при запуске системы. Более удачный способ предоставляет системная
библиотека MINIX 3, содержащая функцию getuptime. Последняя обращается
к ядру для получения числа тактов часов с момента запуска системы, содержа-
содержащегося в счетчике, который поддерживает таймерное задание. Этот способ опре-
определения времени нахождения в цикле имеет свою цену — дополнительный вызов
ядра в каждой итерации. Еще один выход из положения — запросить у системного
задания установку сторожевого таймера, однако для получения уведомления от
таймера требуется блокирующая операция receive. Это решение не подходит,
если ответ необходимо получить быстро.
Жесткий диск также использует варианты вызовов ядра, позволяющие посылать
системному заданию списки портов и данных для записи или переменных для
присваивания. Это очень полезная возможность: драйверу жесткого диска, кото-
который мы рассмотрим позже, для инициализации действия требуется записывать
последовательность байтов в семь выходных портов. Последний байт содержит
команду, и дисковый контроллер генерирует прерывание по ее выполнении. Все
это можно сделать одним вызовом ядра, значительно уменьшив число требуе-
требуемых сообщений.
Мы подошли к третьему уровню — реакции на ожидаемые прерывания. Как бы-
было отмечено при рассмотрении системного задания, обработчиком прерывания,
инициализируемого от имени пользовательской программы вызовом ядра sys_
irqctl, всегда является внутренняя функция системного задания generic_
handler. Она преобразует прерывание в уведомление процессу, от имени кото-
которого было установлено прерывание. Таким образом, после вызова ядра, подающего
команду контроллеру, драйвер устройства должен вызвать операцию receive.
После получения уведомления драйвер может продолжить выполнение дейст-
действий по обслуживанию прерывания.
Описанный механизм предполагает наличие прерывания. Несмотря на это, сле-
следует учесть возможность сбоя. Чтобы подготовиться к возможному отсутствию
прерывания, процесс может запросить системное задание установить стороже-
сторожевой таймер. Сторожевые таймеры генерируют уведомления, а, значит, посредст-
посредством операции receive можно получить два вида уведомлений — о появлении
прерывания и об истечении таймера. Это не является проблемой, поскольку по
уведомлению можно установить его источник. Хотя оба уведомления генериру-
генерируются системным заданием, отправителем уведомления о прерывании является
HARDWARE, а отправителем уведомления об истечении таймера — CLOCK.
Есть еще одна проблема. Если прерывание получено вовремя и сторожевой тай-
таймер не успел истечь, то его истечение будет обнаружено позднее очередной опе-
операцией receive, возможно, в главном цикле драйвера. Одно из решений — от-
отключить таймер системным вызовом при получении уведомления от HARDWARE.
Альтернативная ситуация: если при следующем вызове receive сообщение от
CLOCK маловероятно, уведомление можно проигнорировать. Следует иметь в ви-
виду и еще один редкий сценарий: завершение дисковой операции после истечения
сторожевого таймера. Решения те же — запретить прерывание вызовом ядра при
истечении таймера либо игнорировать при операции receive неожидаемые
сообщения ОТ HARDWARE.
Самое время сказать о том, что при первом разрешении прерывания вызовом яд-
ядра для него можно задать «политику». «Политика» представляет собой обычный
флаг, определяющий, следует разрешать прерывание автоматически или остав-
оставлять его запрещенным до тех пор, пока драйвер устройства сам не разрешит его
вызовом ядра. Драйверу диска после прерывания может потребоваться выпол-
выполнить большое количество работы, поэтому ему лучше разрешить прерывание
самостоятельно по окончании копирования данных.
Самым проблематичным в списке является четвертый пункт. Поддержка клавиату-
клавиатуры осуществляется драйвером tty, обслуживающим как ввод, так и вывод. Кроме
того, возможна поддержка нескольких устройств. Это означает, что вывод может
приходить как с локальной клавиатуры, так и от удаленного пользователя, подклю-
подключенного через сеть или последовательный порт. Допустимо также выполнение
нескольких процессов, каждый из которых генерирует вывод для своего локального
или удаленного терминала. Если вы не знаете, когда может произойти (и может
ли вообще) прерывание, недопустимо использовать блокирующий вызов receive
для получения ввода от одного источника в то время, как этому же процессу
требуется реагировать на ввод других источников и выводить данные самому.
В MINIX 3 предусмотрено несколько методов разрешения этой проблемы. Основ-
Основной метод, используемый драйвером терминала для обработки клавиатурного
ввода, состоит в максимально быстром отклике на прерывание, исключающем
потерю символов. Перенос данных из аппаратной части клавиатуры в буфер
производится как можно меньшим количеством действий. Кроме того, после
буферизации перед завершением обработки прерывания считывание клавиатуры
осуществляется еще раз. Прерывания генерируют уведомления, не блокирую-
блокирующие отправителя, что помогает предотвратить потери ввода. Доступна и опера-
операция receive, также не вызывающая блокировку, хотя она и используется лишь
для обработки сообщений в случае аварии системы. Сторожевые таймеры вызы-
вызывают подпрограмму, проверяющую клавиатуру.
3.4.2. Драйверы устройств в MINIX 3
Для каждого из классов устройств ввода-вывода в MINIX существует отдельный
драйвер. Эти драйверы являются полноценными процессами, каждый со своим
состоянием, регистрами, стеком и т. д. Драйверы взаимодействуют с файловой
системой при помощи механизма передачи сообщений, как и любые другие про-
процессы MINIX 3. Код простого драйвера можно уместить в одном файле. Драйверы
виртуального диска, жесткого диска и дисковода для дискет расположены каждый
в своем файле; кроме того, они используют общие функции работы с блочными
устройствами, вынесенными в файлы driver.с и drvlib.c. Подобное разделе-
разделение программного обеспечения на части, зависимые и независимые от аппарат-
аппаратного обеспечения, позволяет с легкостью приспосабливать его к самым разным
конфигурациям оборудования. Хотя дисковые драйверы пользуются некоторы-
некоторыми фрагментами общего кода, каждый из них работает как отдельный процесс.
Это изолирует драйверы друг от друга и ускоряет передачу данных.
Подобным же образом организован и исходный код драйвера терминала, где ап-
паратно-независимый код помещен в файле tty. с, а в отдельных файлах нахо-
находится код для поддержки различных типов устройств, таких как отображаемые
на память консоли, клавиатура, последовательные интерфейсы и псевдотерми-
псевдотерминалы. Однако в этом случае все типы устройств обслуживает один процесс.
Кроме того, для групп сходных устройств, например для дисков и терминалов,
есть еще и заголовочные файлы. Файл driver.h поддерживает все драйверы
блочных устройств, а файл tty.h предоставляет общие определения для всех
типов терминалов.
Поскольку система MINIX 3 построена на исполнении компонентов операционной
системы в пользовательском пространстве как полностью независимых процессов,
для нее характерны высокая степень модульности и приемлемая эффективность.
Это — одно из кардинальных отличий MINIX 3 от UNIX. В MINIX процесс, для того
чтобы прочитать файл, посылает сообщение файловой системе. В свою очередь,
файловая система может послать сообщение драйверу диска, запрашивая чтение не-
необходимого блока. Драйвер диска использует вызовы ядра для фактического ввода-
вывода и копирования данных между процессами. Эта последовательность (не-
(несколько упрощенная по сравнению с реальностью) изображена на рис. 3.12, а.
За счет того, что взаимодействие происходит через механизм сообщений, обеспе-
обеспечивается стандартный коммуникационный интерфейс между частями системы.
Рис. 3.12. Два варианта взаимодействия пользователя и системы: а — сообщения с запросами
и ответами между четырьмя независимыми процессами; б — передача управления
в адресное пространство ядра из пользовательского пространства по прерыванию
В UNIX у каждого процесса есть две части: одна в пользовательском пространст-
пространстве и другая в пространстве ядра (рис. 3.12, б). Когда процесс делает системный
вызов, операционная система некоторым волшебным образом переключается из
пользовательской области в область ядра. Такой механизм является пережитком
MULTICS, где переключение было простым вызовом процедуры, а не ловушкой
с сохранением состояния пользовательской части процесса, как в UNIX.
В UNIX драйверы устройств являются простыми подпрограммами ядра, которые
может вызывать часть процесса, загруженная в пространстве ядра. Когда драйверу
надо дождаться прерывания, он вызывает процедуру, и процесс засыпает до тех
пор, пока прерывание его не разбудит. Заметьте, что пользовательский процесс
при этом также приостанавливается, так как это — две части одного процесса.
Можно бесконечно приводить доводы в пользу преимущества монолитных сис-
систем (таких как UNIX) над структурированными с помощью процессов (наподо-
(наподобие MINIX 3), и наоборот. Используемый в MINIX 3 подход обеспечивает более
высокую степень модульности, более прозрачный интерфейс между компонента-
компонентами и легко расширяется на распределенные системы, где разные процессы могут
выполняться на разных машинах. Подход UNIX более эффективен, так как вызов
подпрограммы выполняется гораздо быстрее, чем передача сообщения. Система
MINIX 3 структурирована в виде множества процессов, так как мы убеждены,
что по мере роста производительности компьютерных систем ясная структура
программного обеспечения окажется важнее, чем небольшая потеря в произ-
производительности. Для большинства операционных систем плата за переход к ис-
исполнению компонентов в пользовательском пространстве составила бы 5-10 %.
Тем не менее многие системные разработчики не разделяют это убеждение.
В этой главе обсуждаются драйверы виртуального диска, жесткого диска, таймера
и терминала. Стандартная комплектация MINIX 3 включает в себя также драй-
драйверы для дисковода гибких дисков и принтера, которые мы подробно не рассмат-
рассматриваем. Кроме того, имеются драйверы для последовательного интерфейса RS-
232, приводов CD-ROM, адаптера Ethernet и звуковой карты. Они могут быть
скомпилированы отдельно и задействованы «на лету» в любой момент времени.
Все драйверы взаимодействуют с другими частями MINIX 3 единообразно: путем
отправки сообщений. Сообщения с запросами содержат различные поля, в кото-
которые помещаются код операции (чтение или запись) и ее параметры. Получив со-
сообщение, драйвер пытается выполнить запрос и отправляет ответное сообщение.
Поля сообщений запроса и ответа для блочного устройства приведены в табл. 3.3.
Сообщение с запросом содержит адрес буфера для обмена данными. Ответ вклю-
включает в себя информацию о состоянии, которую вызвавший процесс может ис-
использовать для проверки правильности выполнения запроса. Для символьных
устройств поля сообщений могут несколько отличаться от драйвера к драйверу,
но в целом имеют сходную структуру. Например, сообщения для драйвера терми-
терминала — это адрес структуры данных, описывающей все возможные параметры,
такие как символы, используемые функциями построчного редактирования.
Назначение драйверов — воспринимать и выполнять запросы от других процес-
процессов (обычно от файловой системы). Все драйверы блочных устройств написаны
так, чтобы получить запрос, выполнить его и послать ответ. Такая структура
означает простоту — драйверы выполняются строго последовательно, в них нет
внутренней многозадачности. Когда обслуживание аппаратного запроса заверше-
завершено, драйвер вызывает операцию receive, чтобы указать, что далее он ожидает
только сообщений прерываний, но не новых запросов на обслуживание. Новые
запросы при этом откладываются до тех пор, пока не будет обслужен текущий
запрос (принцип рандеву). Драйвер терминала работает несколько по-другому,
так как обслуживает несколько устройств. Поэтому он может воспринимать
задание на ввод с клавиатуры и тогда, когда еще не завершено чтение с последо-
последовательного интерфейса. Тем не менее для каждого отдельного устройства новый
запрос начинает обрабатываться только после обработки предыдущего.
Таблица 3.3. Поля запросов от файловой системы к драйверам блочных устройств
и ответов, отправляемых файловой системе
Поле Тип Значение
Запрос
m.mjype int Запрошенное действие
m.DEVICE int Вспомогательный номер устройства
m.PROC_NR int Процесс, запрашивающий ввод-вывод
m.COUNT int Количество байтов или код ioctl
m.POSITION long Позиция устройства
m.ADDRESS char* Адрес в пределах процесса, сделавшего запрос
Ответ
m.m_type int Всегда имеет значение DRIVER_REPLY
m.REP_PROC_NR int To же, что и PROC_NR в запросе
m.REP_STATUS int Количество переданных байтов или код ошибки
Структура основной части кода у каждого драйвера одинакова и в общих чертах
приведена в листинге 3.1. При запуске системы управление передается каждому из
драйверов с целью дать им возможность инициализировать внутренние таблицы
и тому подобные данные. Завершив инициализацию, каждый из драйверов делает
вызов receive, чтобы получить сообщение, и переходит в состояние блокировки.
Когда сообщение приходит, запоминается, какой процесс его отправил, после чего
вызывается подпрограмма для выполнения необходимых действий. После того как
обработка запроса завершена, вызвавшему процессу отправляется сообщение
с результатами, а драйвер переходит к началу цикла и ожидает новых сообщений.
Листинг 3.1. Общая структура основной процедуры драйвера ввода-вывода
message mess; /* Буфер сообщений */
void io_driver() {
initialize(); /* Вызывается только один раз при инициализации */
while (TRUE) {
receive(ANY, &mess); /* Ожидаем запрос */
caller = mess.source; /* Процесс, сделавший запрос */
switch(mess.type) {
case READ: rcode = dev_read(&mess); break;
case WRITE: rcode = dev_write(&mess); break;
/* Тут находится код для выполнения других операций,
таких как OPEN, CLOSE и IOCTL */
default: rcode = ERROR;
}
mess.type = DRIVER_REPLY;
mess.status = rcode; /* Код возврата */
send(caller, &mess); /* Отправляем ответ */
}
}
За выполнение различных действий, поддерживаемых драйвером, ответственны
подпрограммы с именами dev_xxx. Код завершения помещается в поле REP_
STATUS ответа, он равен количеству переданных байтов (ноль или положитель-
положительное число), если операция закончилась успехом, или номер ошибки (отрицатель-
(отрицательное число) в противном случае. Количество переданных байтов может отличаться
от запрошенного, например, когда достигнут конец файла. В случае терминалов
за один запрос возвращается не больше одной строки, даже если запрошено боль-
больше информации.
3.4.3. Аппаратно-независимый код
ввода-вывода в MINIX
Весь аппаратно-независимый код ввода-вывода в MINIX 3 является частью фай-
файловой системы. Система ввода-вывода так тесно связана с файловой системой,
что они обе объединены в один процесс. Функции файловой системы перечисле-
перечислены в пункте 3.2.4, за исключением функций захвата и освобождения отдельных
устройств, которых в существующей конфигурации MINIX 3 нет. Тем не менее,
если такая потребность возникнет, эти функции могут быть легко добавлены
в код соответствующих драйверов.
В дополнение к взаимодействию с драйверами, к буферизации и выделению бло-
блоков, файловая система также решает задачи защиты и управления индексными
узлами, каталогами и монтированными файловыми системами. Подробно эта те-
тема рассмотрена в главе 5.
3.4.4. Программы ввода-вывода
пользовательского уровня в MINIX
В программах ввода-вывода пользовательского уровня также применяется обоб-
обобщенная модель, описанная ранее в этой главе. Для выполнения системных
вызовов и стандартных С-функций, требуемых стандартом POSIX (напри-
(например, функций форматного ввода-вывода printf и scanf), предоставляются
библиотечные процедуры. В стандартной конфигурации MINIX имеется так-
также демон lpd, который занимается поддержкой очереди печати документов,
отправленных на печать командой 1р. В стандартной комплектации MINIX
имеется еще ряд демонов, ответственных за различные сетевые функции. Опи-
Описываемая в этой книге комплектация MINIX 3 поддерживает большинство се-
сетевых операций. Все, что требуется, — это включить во время запуска сетевой
сервер и драйверы адаптеров Ethernet. Перекомпиляция драйвера терминала
с поддержкой псевдотерминалов и последовательного порта позволит входить
в систему с удаленных терминалов и иметь доступ к сети через последова-
последовательные интерфейсы (включая модемы). Сетевой сервер имеет тот же приори-
приоритет, что менеджер памяти и файловая система. Все они выполняются как пользо-
пользовательские процессы.
3.4.5. Взаимная блокировка в MINIX
Как UNIX, так и MINIX 3 относятся к взаимной блокировке одинаково — они
полностью игнорируют проблему. В MINIX 3 нет выделенных устройств ввода-
вывода, хотя, если кто-то хочет «подвесить» стандартный промышленный лен-
ленточный DAT-привод на персональный компьютер, написать к нему программное
обеспечение не составит особенного труда. Говоря коротко, единственное место,
в котором могут возникнуть взаимные блокировки, это общие ресурсы, такие
как ячейки таблицы процессов, ячейки таблицы индексных узлов и т. д., исполь-
используемые неявно. Ни один из известных алгоритмов борьбы с взаимными блоки-
блокировками не подходит для подобных ресурсов, которые явно не запрашиваются.
В действительности, сказанное — не совсем правда. Помимо того что пользова-
пользовательский процесс может оказаться в тупиковой ситуации, в самой операционной
системе есть несколько мест, где необходимы особые меры предосторожности,
позволяющие избежать проблем. Главное — это взаимодействие между процес-
процессами посредством передачи сообщений. Например, для обмена сообщениями поль-
пользовательским процессам разрешено задействовать единственный метод sendrec.
По этой причине пользовательский процесс никогда не будет заблокирован вызо-
вызовом receive при отсутствии других процессов, желающих вступать с ним в кон-
контакт при помощи вызова send. Серверы пользуются вызовами send и sendrec
только для взаимодействия с драйверами устройств, а те, в свою очередь, — толь-
только для взаимодействия с системным заданием, находящимся на уровне ядра. Для
тех редких случаев, когда серверам необходимо общаться между собой (напри-
(например, менеджеру процессов вести обмен с файловой системой во время инициа-
инициализации своих фрагментов таблицы процессов), порядок взаимодействия во из-
избежание блокировок тщательно продуман. Кроме того, на самом низком уровне
системы обмена сообщениями выполняется проверка, позволяющая гарантиро-
гарантировать, что при попытке одного процесса отправить сообщение другому получа-
получатель не попытается сделать то же самое.
Помимо упомянутых ограничений, в MINIX 3 введен новый примитив notify
для обработки ситуаций, когда необходимо передавать сообщения «снизу вверх».
Примитив notify не приводит к блокировке, и уведомления сохраняются в слу-
случае, если их получатель недоступен. По мере изучения реализации драйверов
устройств MINIX 3 мы увидим, насколько интенсивно используется механизм
уведомлений.
Еще один способ предотвращения взаимных блокировок — разграничение досту-
доступа. Разграничивать доступ к устройствам можно и без поддержки операционной
системы. В качестве по-настоящему глобальной переменной, доступной всем про-
процессам, изумительно подходит имя файла. Наличие или отсутствие определенного
файла может быть легко замечено любым процессом. В MINIX 3, как и в UNIX-
подобных системах, существует специальный каталог, /usr/ spool /locks/, где
процессы, чтобы обозначить занятость определенного ресурса, могут создавать
подобные файлы блокировки (lock file), которые иногда называют файловыми се-
семафорами. Файловая система MINIX также поддерживает блокировку файлов,
предписанную стандартом POSIX. Но ни один из этих механизмов не является
принудительным. Все зависит от того, обращает ли программа внимание на эти
механизмы или нет; не существует способа запретить программе задействовать
ресурс, уже занятый другой программой. Это — не то же самое, что и выгрузка
(preemption) ресурса, так как ничто не мешает первому процессу делать по-
повторные попытки его использования. Другими словами, взаимное исключение
не обеспечивается. В результате, хотя неправильно работающий процесс может
получить некорректные результаты, взаимной блокировки не возникнет.
3.5. Блочные устройства в MINIX 3
В MINIX 3 поддерживается несколько типов блочных устройств, поэтому мы
начнем с обсуждения общих аспектов, затем изучим виртуальный диск, жесткий
диск и дисковод для дискет. Каждое из этих устройств по-своему интересно.
Виртуальный диск необычен тем, что это устройство обладает всеми атрибутами
обычного блочного устройства, за исключением того, что при его работе ника-
никакого реального ввода-вывода не происходит. Этот «диск» целиком находится
в оперативной памяти. Поэтому драйвер устроен просто и является хорошей от-
отправной точкой для изучения. Жесткий диск позволяет понять, на что похож
драйвер реального диска. Некоторым может показаться, что привод для дискет
(накопитель на гибких дисках) проще, чем жесткий диск, но это не так. Мы не
будем обсуждать драйвер гибкого диска в подробностях, но укажем на некото-
некоторые связанные с ним сложности.
Закончив с драйверами блочных устройств, мы приступим к драйверу термина-
терминала (клавиатуры и дисплея), который важен для любой системы и, к тому же, яв-
является удачным примером драйвера символьного устройства.
Каждый из разделов содержит описание соответствующего оборудования и прин-
принципов построения программы драйвера, а также обзор реализации и сам код.
Такая организация делает информацию полезной еще и тем, кто не заинтересо-
заинтересован в деталях.
3.5.1. Обзор драйверов
блочных устройств MINIX 3
Ранее мы упомянули, что основной код большинства драйверов ввода-вывода
имеет единую структуру. У MINIX 3 в ядре всегда в наличии, как минимум, два
встроенных блочных драйвера ввода-вывода: драйвер виртуального диска и с ним
драйвер жесткого диска или дисковода для дискет. Как правило, присутствуют
три блочных драйвера, поскольку в системе есть и дисковод для дискет, и жест-
жесткий диск стандарта IDE (Integrated Drive Electronics — встроенный интерфейс
дисковых накопителей). Драйверы всех блочных устройств компилируются не-
независимо, однако используют общую библиотеку исходного кода.
В состав предыдущих версий MINIX иногда включался отдельный драйвер
CD-ROM, который при необходимости можно было добавить. В настоящий
момент такие драйверы считаются устаревшими. Они были нужны для поддерж-
поддержки собственных интерфейсов различных производителей дисководов. Современ-
Современные накопители, как правило, подключаются к IDE-контроллеру, хотя на пор-
портативных компьютерах дисководы часто используют интерфейс с шиной USB
(Universal Serial Bus — универсальная последовательная шина). Полная версия
драйвера жесткого диска MINIX 3 включает поддержку CD-ROM, однако в дан-
данной книге она не рассматривается.
Конечно, каждому драйверу нужно выполнить некоторые действия для инициа-
инициализации. Драйвер виртуального диска должен зарезервировать необходимый объ-
объем памяти, драйвер жесткого диска — определить параметры устройства и т. д.
Все драйверы дисков вызываются, инициализируются и, завершив инициализа-
инициализацию, входят в бесконечный цикл. Этот цикл никогда не завершается, в нем нет
команды выхода. В цикле драйвер получает сообщение, вызывается одна из функ-
функций обработки и генерируется ответное сообщение.
Основной цикл, вызываемый каждым из драйверов, компилируется из файлов
каталога драйвера, в том числе drivers/libdriver/driver. с, а затем копия
объектного файла driver.о компонуется в исполняемый файл драйвера. Бла-
Благодаря такому подходу каждый драйвер имеет возможность передать в основной
цикл параметр — указатель на таблицу адресов функций, которые драйвер дол-
должен косвенно вызывать для выполнения требуемых действий.
Если бы драйверы компилировались в единый исполняемый файл, то потребова-
потребовалась бы всего одна копия главного цикла. На самом деле, главный цикл был на-
написан для более ранней версии MINIX, в которой драйверы компилировались
вместе. В MINIX 3 акцент сделан на максимальную индивидуализацию компо-
компонентов операционной системы, однако использование общего исходного кода
разными программами остается хорошим способом повышения надежности.
Создав свободный от ошибок фрагмент кода, вы обеспечиваете им все драйверы,
а если в драйвере обнаружилась ошибка, то с большой вероятностью она присут-
присутствует и в других драйверах. В результате тестирование общего кода можно про-
провести более тщательно.
В файле drivers/libdriver/drvlib.c определен набор функций, потенци-
потенциально полезных для различных дисковых драйверов. Эти функции скомпилирова-
скомпилированы в объектный файл drvlib. о. Их можно было бы включить в файл driver. о,
однако полный функциональный набор нужен далеко не всем драйверам. Напри-
Например, самый простой драйвер memory компилируется исключительно с файлом
driver.о. Драйвер at_wini, напротив, при компиляции использует и файл
driver. о, и файл drvlib. о.
Главный цикл приведен в листинге 3.2. Команды, подобные следующей, являют-
являются косвенными вызовами функций:
code = (*entry_points->dev_read) (&mess);
Каждый драйвер вызывает свою функцию dev_read, хотя главный цикл един
для всех драйверов. Но некоторые операции, например close, достаточно про-
просты, чтобы для всех устройств можно было использовать одну и ту же функцию.
Листинг 3.2. Основная процедура драйверов устройств ввода-вывода
message mess; /* Буфер сообщений */
void shared_io_driver(struct driver_table *entry_points) {
/* Перед входом в эту функцию каждый из драйверов инициализируется */
while (TRUE) {
receive (ANY, &mess);
caller = mess.source;
switch(mess.type) {
case READ: rcode = (*entry_points->dev_read) (&mess); break;
case WRITE rcode = (*entry_points->dev_write)(&mess); break;
/* Тут находится код для выполнения других операций,
таких как OPEN, CLOSE и IOCTL */
default: rcode = ERROR;
}
mess.type = DRIVER_REPLY;
mess.status = rcode; /* Код возврата */
send(caller, &mess);
}
}
Есть шесть различных операций, которые могут быть запрошены у каждого
драйвера устройства. Им соответствуют значения в поле m.m_type сообщения
(СМ. табл. 3.3). Вот они: OPEN, CLOSE, READ, WRITE, IOCTL, SCATTERED__IO.
Большая часть этих операций, вероятно, знакома читателям, имеющим опыт
программирования. На уровне драйвера устройства они сводятся к системным
вызовам с соответствующими именами. Смысл операций READ и WRITE, на-
например, вполне понятен. Эти операции передают блок данных из памяти вы-
вызвавшего процесса в устройство или наоборот. Обычно операция READ не пере-
передает управление в вызвавший процесс до тех пор, пока не завершена передача
данных. Но операционная система может буферизовать передаваемые данные,
тогда вызов может завершиться сразу, а данные переданы позже. Это никак не
сказывается на сделавшей вызов программе, сразу после него она вправе исполь-
использовать буфер, так как операционная система уже скопировала нужные ей дан-
данные. Операции OPEN и CLOSE для устройства означают то же, что и системные
вызовы open и close для файлов. Операция OPEN проверяет, что устройство
доступно, и возвращает код ошибки, если это не так. Операция CLOSE должна
гарантировать, что все буферизованные данные переданы до полного заверше-
завершения обмена информацией с устройством.
Возможно, назначение операции IOCTL не столь очевидно. У многих устройств
ввода-вывода есть параметры, значение которых иногда нужно проверять и, пред-
предположительно, менять. Выполнение этих действий обеспечивает операция IOCTL.
Хороший пример использования этой операции — управление быстродействием
последовательного интерфейса или настройка механизма контроля четности.
Для блочных устройств IOCTL применяется реже. В частности, в MINIX 3 при
помощи IOCTL можно определять и управлять разбиением диска на разделы
(хотя это можно было бы сделать просто при помощи операции чтения и записи
блока данных).
Операция SCATTERED_IO, без сомнений, известна менее всех других. Дело в том,
что трудно достигнуть приемлемой производительности блочного устройства,
если запрашивать данные последовательно, отдельными порциями. Исключение
составляют лишь очень быстрые устройства, такие как виртуальный диск. Опе-
Операция SCATTERED_IO позволяет системе сделать запрос на чтение или запись
нескольких блоков. В случае операции read система пытается предугадать,
какие блоки может запросить процесс, и считывает их заранее. В таком запросе
не все затребованные данные обязательны. Каждый из запросов блока данных,
передаваемых драйверу устройства, можно модифицировать, установив бит, со-
сообщающий, что запрос не обязателен. В результате файловая система может соз-
создать запрос, который в переводе на человеческий язык звучал бы так: «Было бы
неплохо прочитать все эти данные, но все они вовсе не нужны мне прямо сей-
сейчас». Далее устройство само решает, что лучше делать. Например, гибкий диск
может прочитать все данные в пределах одной дорожки, говоря тем самым: «Эти
данные я для тебя прочитаю, а остальные попроси потом, мне слишком долго
переходить на другую дорожку».
Когда необходимо записать данные, не возникает вопроса, обязательно ли запи-
записывать каждый отдельный блок — все, что запрошено, обязательно для выполне-
выполнения. Однако система вправе буферизовать несколько запросов на запись в наде-
надежде на то, что сразу их удастся обработать быстрее, чем по отдельности. При
запросе SCATTERED__IO, будь то для чтения или для записи, список запрошен-
запрошенных блоков сортируется, что позволяет считывать данные более эффективно,
чем если бы они считывались в порядке поступления. Кроме того, передача не-
нескольких блоков за один раз уменьшает количество сообщений, пересылаемых
внутри MINIX 3.
3.5.2. Общие программы для драйверов
блочных устройств
Определения для всех драйверов блочных устройств находятся в файле drivers/
libdriver/driver .h. Самая главная часть этого файла — структура driver
(строки 10829-10845), посредством которой в главный цикл передается список
адресов функций, выполняющих запросы. Дополнительно здесь определяется
структура device (строки 10856-10859), в которой хранится наиболее важная
информация о разделах, базовый адрес и размер в байтах. Формат этой структу-
структуры был выбран так, чтобы устройства, основой которых является оперативная
память, могли задействовать данные без преобразования, обеспечивая высокую
скорость отклика. Для реальных дисков характерно такое количество разнооб-
разнообразных факторов, влияющих на время отклика, что преобразование байтовых ад-
адресов в секторы не играет принципиальной роли.
Код главного цикла и общих для всех драйверов блочных устройств функций
находится в файле driver. с. Выполнив все действия по инициализации, зави-
зависящие от конкретных устройств, каждый драйвер вызывает процедуру driver_
task, передавая в качестве аргумента вызова заполненную структуру driver.
Далее определяется адрес буфера DMA-устройства, и управление переходит в глав-
главный цикл (строки 11071-11120).
В инструкции switch главного цикла выполняются косвенные вызовы функ-
функций, адреса которых содержатся в структуре driver. Вызовы функций являют-
являются реакцией на получение сообщений первых пяти типов — DEV_OPEN, DEV_
CLOSE, DEV_IOCTL, DEV_CANCEL И DEV_SELECT. Сообщения DEV_READ И DEV_
WRITE приводят к непосредственному вызову функции do_rwdt, а сообщения
DEV_GATHER и DEV_SCATTER — функции do_vrdwt. Заметьте, что структура
driver передается как аргумент во все вызовы, как косвенные, так и непо-
непосредственные, поэтому все вызываемые подпрограммы могут к ней обращаться.
Функции do_rwdt и do_vrdwt выполняют некоторую предварительную об-
обработку, однако затем также косвенно обращаются к зависящим от устройств
подпрограммам.
Другие выходы инструкции switch, включая HARD_INT, SYS_SIG и SYN_
ALARM, относятся к уведомлениям. В них также используются косвенные вызо-
вызовы, однако по завершении каждого из них исполняется инструкция continue,
возвращающая управление в начало цикла, минуя очистку и генерацию ответно-
ответного сообщения.
После выполнения запрошенных в сообщении действий может потребоваться
определенная подготовка перед переходом к следующей операции. Например,
в случае гибкого диска можно запустить таймер, который по истечении некото-
некоторого времени отключит привод, если за это время не будет других запросов. Для
выполнения подобных действий также используется косвенный вызов. После
очистки генерируется сообщение, которое отправляется в ответ процессу, сде-
сделавшему вызов (строки 11113-11119). Подпрограммы, обслуживающие сообще-
сообщения, могут отменять создание ответа, возвращая значение EDONTREPLY, однако
ни один из существующих драйверов не прибегает к такой возможности.
Первое действие, которое выполняет каждый драйвер при входе в главный цикл, —
вызов функции init_buf fer (строка 11126), задающей буфер для операций
прямого доступа к памяти. Причина, по которой эта инициализация вообще
нужна, кроется в странностях работы первых компьютеров IBM PC, для кото-
которых было необходимо, чтобы буфер не пересекал границу в 64 Кбайт. Другими
словами, если размер буфера 1 Кбайт, он может начинаться по адресу 64510, но
не по адресу 64514, так как в последнем случае будет превышена граница, нахо-
находящаяся по адресу 65536.
Это неприятное требование проистекает из того, что в IBM PC применялся старый
чип контроллера прерываний Intel 8237А с 16-разрядным счетчиком. Так как для
DMA используются абсолютные, а не относительные сегментные адреса, требовал-
требовался счетчик большей емкости. На старых машинах, способных адресовать только
1 Мбайт памяти, младшие 16 бит адреса DMA загружались в 8237А, а оставшиеся
старшие 4 бита помещались в 4-разрядный регистр-переключатель. У более совре-
современных машин применяется 8-разрядный переключатель, что позволяет адресо-
адресовать 16 Мбайт. Но когда адрес в 8237А переходит от OxFFFF к 0x0000, не фор-
формируется признак переноса, и адрес DMA внезапно прыгает вниз на 64 Кбайт.
Переносимая С-программа не может оперировать абсолютными адресами, по-
поэтому не в силах предотвратить недопустимого положения буфера. Эта пробле-
проблема решается так: выделяется буфер вдвое большего размера, чем нужно (строка
11044), а специальный указатель tmp_buf (строка 11045) содержит адрес реаль-
реально используемого буфера. Функция init_buf f er сначала пробует установить
этот указатель так, чтобы он ссылался на начало выделенного буфера, а затем
проводит проверку, допустимо ли такое положение. Если нет, то значение ука-
указателя tmp_buf увеличивается на количество реально затребованных байтов.
Таким образом, всегда остается неиспользованный блок памяти, но граница
64 Кбайт никогда не попадает внутрь буфера.
У новых компьютеров семейства IBM PC более совершенные контроллеры DMA,
поэтому код мог бы быть упрощен, а количество запрашиваемой памяти — умень-
уменьшено. Но нет гарантии, что проблема никогда не проявится. Если же вы рассчи-
рассчитываете на это, то должны знать, как действовать в случае ошибки. Если требует-
требуется буфер объемом 1 Кбайт, то с вероятностью 1/64 выделенный буфер окажется
непригоден для компьютера со старым контроллером DMA. Каждый раз, если
изменение кода ядра приводит к изменению размера его исполняемых файлов,
ошибка может проявить себя с той же вероятностью. Ошибка может не прояв-
проявлять себя, поэтому, когда в следующем месяце или году она возникнет, ее свя-
свяжут с последними изменениями в коде, а не с реальной причиной. Подобные
«особенности» аппаратного обеспечения чреваты длительным поиском ошибок,
особенно если в технической документации о них ни слова не говорится (как
в этом случае).
Следующая функция в файле driver. с — это do_rdwt (строка 11148). Она,
в свою очередь, косвенным вызовом запускает одну из двух функций dr_prepare
или dr_transf er, опираясь на переданные адреса из структуры driver. В даль-
дальнейшем, чтобы обозначить функцию, вызываемую через указатель, мы будем ис-
использовать запись вида *функция__указатель, напоминающую язык С.
Далее проверяется, что количество переданных байтов больше нуля, после чего
функция do_rdwt вызывает *dr_prepare. Эта операция вводит в структуру
device базовый адрес и размер диска, раздела или подраздела, к которому осу-
осуществляется доступ. Для драйвера памяти, не поддерживающего разделы, лишь
проверяется корректность вспомогательного номера устройства. Для жесткого
диска функция использует вспомогательный номер устройства, чтобы получить
размер соответствующего раздела или подраздела. Данный вызов не должен за-
закончиться неудачно, так как единственная причина, по которой это возможно —
неправильно указанное в операции open устройство. Далее заполняется стан-
стандартная структура iovecl типа iovec_t, описание которой находится в файле
include/minix/type. h (строки 2856-2859). Эта структура определяет вирту-
виртуальный адрес и размер локального буфера, которым системное задание вос-
воспользуется для копирования данных. Она же применяется как элемент массива
запросов в случае, если вызов требует считать несколько блоков. Адрес перемен-
переменной и первого элемента массива такого же типа может быть обработан аналогич-
аналогичным образом. Затем следует еще один косвенный вызов, на этот раз функции
*dr_transf er, которая копирует данные и выполняет другие действия, необхо-
необходимые для ввода-вывода. Все подпрограммы, обрабатывающие передачу, ожида-
ожидают в качестве аргумента массив запросов. В функции do_rdwt последним аргу-
аргументом является 1, что указывает массив из одного элемента.
Как мы увидим при обсуждении программного обеспечения диска в следующем
разделе, обслуживание дисковых запросов в порядке поступления может быть
неэффективным, и данная подпрограмма позволяет конкретному устройству
обслуживать запросы в оптимальном для себя порядке. Косвенный вызов по
максимуму маскирует различия конкретных устройств. Для виртуального дис-
диска dr_transf er указывает на подпрограмму, совершающую вызов ядра, чтобы
скопировать данные из одной области физической памяти в другую посредством
системного задания, если вспомогательным устройством является /dev/ram,
/dev/mem, /dev/kmem, /dev/boot или /dev/zero. Разумеется, при доступе
к /dev/null никакого копирования не требуется. В случае реального диска
функция dr_transf er тоже должна запросить у системного задания передачу
данных. Тем не менее перед копированием (при чтении) или после него (при за-
записи) нужно дополнительно вызвать ядро, чтобы системное задание выполнило
фактический ввод-вывод, записав в регистры дискового контроллера байты, оп-
определяющие место на диске, объем и направление передачи.
В подпрограмме передачи значение счетчика iov_size структуры iovecl изме-
изменяется и содержит либо отрицательное значение (код ошибки), либо положитель-
положительное значение, равное числу переданных байтов. Если число переданных байтов
равно нулю, это не обязательно означает ошибку; возможно, в процессе ввода-
вывода был достигнут конец устройства. При возвращении в главный цикл код
ошибки или число байтов записывается в поле REP__STATUS ответного сообще-
сообщения процедуры driver_task.
Следующая функция, do_vrdwt (строка 11182), обрабатывает разрозненные
запросы ввода-вывода. В сообщении драйверу, содержащем подобный запрос,
в поле ADDRESS помещается адрес массива структур типа iovec_t. Каждая из
этих структур хранит информацию для выполнения одного запроса: адрес буфе-
буфера и число передаваемых байтов. В MINIX 3 подобный запрос может быть сде-
сделан только для смежных блоков диска; начальное смещение на устройстве и вид
операции (чтение или запись) указаны в сообщении. Таким образом, все опера-
операции одного запроса являются либо чтением, либо записью и отсортированы со-
согласно следованию блоков в устройстве. В строке 11198 проверяется, сделан ли
запрос от имени задания ввода-вывода внутри ядра. Эта проверка унаследована
из ранних редакций MINIX 3, в которых драйверы еще не были полностью пере-
переписаны для выполнения в пользовательском пространстве.
Код данной операции очень похож на чтение и запись в процедуре do_rdwt.
Делаются те же косвенные вызовы аппаратно-зависимых подпрограмм *dr_
prepare и *dr_transf er. Цикл для обработки множественных запросов вы-
выполняется внутри функции, на которую указывает *dr_transf er. Последний
аргумент в этом случае не 1, а размер массива элементов iovec_t. После заверше-
завершения цикла массив запросов копируется в обратном направлении. Поле io_size
каждого элемента массива показывает число байтов, переданных по соответст-
соответствующему запросу, и хотя общая сумма не посылается в сообщении, генерируе-
генерируемом driver_task, вызывающая сторона может извлечь ее из массива.
Следующие несколько функций из файла driver. с поддерживают выполнение
описанных ранее операций. Вызов *dr_name возвращает имя устройства. Если
у устройства нет фиксированного имени, функция no_name возвращает строку
noname. Некоторым устройствам не нужен ряд функций. Например, виртуаль-
виртуальный диск не должен ничего делать по запросу DEV_CLOSE. В качестве пустой
функции используется функция do_nop, возвращаемое ею значение зависит от
типа запроса. Дополнительные функции nop_signal, nop_alarm, nop_prepare,
nop_cleanup и nop_cancel также являются пустыми и предназначены для
устройств, которым не требуется предоставлять подобное обслуживание.
Наконец, функция do_diocntl (строка 11216) выполняет для блочных устройств
запросы DEV_IOCTL. Она сообщает об ошибке, если затребована любая другая
операция помимо считывания (DIOGETP) или записи (DIOSETP) информации
о разделе. Чтобы удостовериться, что устройство задано корректно, и получить
указатель на структуру device с информацией о базовом адресе и размере разде-
раздела, do_dioct 1 вызывает *dr_prepare. При обработке запроса на чтение вызы-
вызывается специфичная для устройства функция *dr_geometry, с целью получить
информацию о цилиндрах, головках и секторах, относящихся к разделу диска.
В каждом случае выполняется вызов ядра sys_datacopy, чтобы системное за-
задание скопировало данные из пространства памяти драйвера в пространство по-
пославшего запрос процесса.
3.5.3. Библиотека поддержки драйверов
Файлы drvlib.h и drvlib.c содержат системно-зависимый код, поддержи-
поддерживающий работу с разделами дисков на IBM PC-совместимых компьютерах.
Разбиение диска на разделы позволяет получить на одном накопителе несколько
логических дисков. Обычно на разделы дробятся жесткие диски, хотя MINIX 3
поддерживает и разбиение дискет. Вот несколько причин в пользу разбиения на
разделы.
1. Стоимость мегабайта меньше для больших дисков. Если используются две
или более операционные системы с различными файловыми подсистемами,
дешевле иметь один большой диск, поделенный на несколько частей, чем не-
несколько маленьких.
2. У операционной системы могут иметься ограничения на максимальный размер
устройства. Обсуждаемая здесь версия MINIX 3 поддерживает максималь-
максимальный размер файловой системы 4 Гбайт, а у более старых версий было ограни-
ограничение до 256 Мбайт. В результате оставшееся дисковое пространство расхо-
расходовалось впустую.
3. Операционная система может использовать две или более файловые подсис-
подсистемы. Например, для обыкновенных файлов — стандартная файловая подсис-
подсистема, а для области подкачки — подсистема с совершенно другой структурой.
4. Бывает удобно поместить часть операционной системы на отдельное устрой-
устройство. Например, для упрощения создания резервных копий можно записать
корневую файловую систему MINIX в отдельный маленький раздел. Это так-
также позволяет скопировать ее на виртуальный диск во время загрузки.
Механизм поддержки разделов зависит от платформы, причем эта зависимость
не относится к аппаратному обеспечению. К накопителям поддержка разделов
не привязана. Но если на одном и том же наборе устройств работают несколько
операционных систем, они должны иметь одинаковое представление о формате
таблицы разделов. Для IBM PC стандарт задает DOS-команда f disk, и другие
операционные системы, такие как MINIX 3, Windows и Linux, поддерживают этот
формат и могут сосуществовать с MS-DOS. Когда MINIX 3 переносится на дру-
другую платформу, имеет смысл использовать формат таблицы разделов, совмести-
совместимый с другими операционными системами, работающими на данной платформе.
Код для поддержки таблицы разделов на IBM PC-совместимых системах поме-
помещен в отдельный файл drvlib.c, а не включен в файл driver.с. Этому есть
две причины. Во-первых, не все типы дисков поддерживают разделы. Как было
отмечено ранее, драйвер памяти компонуется с объектным файлом driver.о,
однако не использует функции, скомпилированные в drvlib.o. Во-вторых, пе-
перенос MINIX 3 на другие платформы упрощается. Заменить один небольшой
файл легче, чем редактировать большой, включающий код условной компиля-
компиляции для различных вариантов окружения.
Основная структура данных, унаследованная от разработчиков программно-ап-
программно-аппаратных средств, определена в файле include/ ibm/part it ion. h, включае-
включаемом при помощи директивы #include (строка 10900) в файл drvlib.h. Сюда
входит информация о геометрии всех разделов (цилиндры, головки, секторы),
а также код, идентифицирующий тип файловой системы раздела, и флаг, указы-
указывающий, является ли раздел загрузочным. После проверки файловой системы
большая часть этой информации MINIX 3 не нужна.
Функция partition в файле drvlib.h (строка 11426) вызывается, когда в пер-
первый раз открывается блочное устройство. В аргументы этой функции входит струк-
структура driver, поэтому первая в состоянии вызывать специфичные для данного
устройства функции. Также в функцию передаются вспомогательный номер уст-
устройства и параметр, задающий вариант разбиения на разделы (существуют различ-
различные варианты разбиения для гибкого диска, основного раздела и подраздела).
Чтобы проверить работоспособность устройства и поместить в структуру device
базовый адрес и размер раздела, вызывается функция *dr_prepare. Затем, чтобы
определить факт наличия таблицы разделов и считать ее, вызывается get_part_
table. Если таблицы разделов не оказалось, работа завершается. В противном
случае вычисляется вспомогательный номер устройства для первого раздела (пра-
(правила нумерации устройств определяются упомянутым ранее вариантов разбие-
разбиения на разделы). Для случая основных разделов таблица сортируется так, чтобы
порядок следования разделов соответствовал другим операционным системам.
В этом месте делается другой вызов *dr_prepare, на этот раз ему в качест-
качестве параметров передается только что вычисленный для первого раздела номер
устройства. Если устройство корректное, в цикле проверяются все записи в таблице
на этом устройстве с целью удостовериться, что хранящиеся в таблице ссылки не
выходят за пределы, отведенные устройству. Если все данные корректны, таблица
в памяти соответствующим образом изменяется. Может показаться, что такие
проверки сродни маниакальной идее, но таблицы разделов могут создаваться раз-
различными операционными системами. Программист, работавший с другой системой,
мог бы попытаться каким-то необычным образом использовать таблицу разделов,
или же таблица может быть просто испорчена. Мы с большим доверием относим-
относимся к значениям, вычисляемым в MINIX. Лучше подстраховаться, чем сожалеть.
В том же самом цикле для всех разделов, идентифицированных как разделы
MINIX 3, рекурсивно вызывается функция partition, чтобы получить инфор-
информацию о подразделах. Если раздел идентифицирован как расширенный, вместо
нее вызывается функция extpartition (строка 11501).
Последняя в действительности не имеет никакого отношения к собственно опера-
операционной системе MINIX 3, поэтому мы не будем вдаваться в детали. Некоторые
другие операционные системы (например, Windows) используют расширенные
разделы (extended partition). Такие разделы хранят подразделы в виде связанного
списка, а не массива фиксированного размера. Для простоты в MINIX 3 использу-
используется один и тот же механизм и для основных разделов, и для подразделов. Тем не
менее минимальная поддержка расширенных разделов присутствует, чтобы дать
возможность MINIX 3 считывать и записывать файлы и каталоги других операци-
операционных систем. Эти операции просты; организовать полноценную поддержку мон-
монтирования и расширенных разделов в качестве основных значительно труднее.
Функция get_part_table (строка 11549) вызывает do_rdwt, чтобы получить
тот сектор устройства (или вложенного устройства), в котором расположена табли-
таблица разделов. Передаваемое функции смещение должно быть равно 0, если функ-
функция вызывается для основного раздела, а для подразделов смещение принимает
отличное от нуля значение. Функция проверяет наличие сигнатуры @хАА55)
и возвращает результат проверки (истина или ложь). Кроме того, если таблица най-
найдена, функция копирует таблицу по адресу, переданному ей через другой аргумент.
Наконец, функция sort (строка 11582) сортирует по нижнему сектору все запи-
записи в таблице разделов. Записи, помеченные как не имеющие раздела, исключа-
исключаются из сортировки и идут последними, даже если в поле, по которому велась
сортировка, у них записано нулевое значение. Для сортировки применяется про-
простой пузырьковый алгоритм. Более сложные способы сортировки для таблицы
из четырех записей ни к чему.
3.6. Виртуальные диски
Теперь мы вернемся к изучению отдельных блочных устройств и подробно рас-
рассмотрим некоторые из них. Сначала мы обратимся к драйверу памяти, обеспечи-
обеспечивающему доступ к произвольным областям памяти. Его типовая область приме-
применения — резервирование части памяти для использования в качестве обычного
диска. Драйвер памяти мы также будем называть драйвером виртуального диска.
Виртуальный диск не обеспечивает долговременного хранения данных, но рабо-
работает со скопированными в него файлами исключительно быстро.
Виртуальный диск полезен при начальной установке операционной системы на
компьютер с единственным устройством, обслуживающим сменные носители
данных — дисководом для дискет, компакт-дисков и др. Если поместить корневую
файловую систему на виртуальный диск, сохранение файлов на дискету станет
невозможным, так как корневое устройство (единственный дисковод для дискет)
не подлежит демонтированию. Виртуальные диски используются также с демон-
демонстрационными компакт-дисками, позволяющими оценить и опробовать работу
операционной системы, не копируя ее файлы на жесткий диск. Кроме того, раз-
размещение корневого устройства на виртуальном диске придает системе большую
гибкость: к ней можно монтировать любую комбинацию дисководов для дискет
и жестких дисков. MINIX 3 и множество других операционных систем распростра-
распространяются на компакт-дисках с описанными «демонстрационными» возможностями.
Мы увидим, что возможности драйвера памяти выходят за рамки поддержки
виртуального диска. Драйвер позволяет осуществлять прямой случайный доступ
к любой области памяти, побайтно или блоками произвольного размера. Функ-
Функционируя подобным образом, драйвер ведет себя скорее как символьное, нежели
блочное, устройство. Драйвер памяти также поддерживает два символьных уст-
устройства — /dev/zero и/dev/null.
3.6.1. Аппаратное и программное обеспечение
виртуального диска
Идея устройства виртуального диска проста. Любое блочное устройство — это
накопитель, поддерживающий две команды: прочитать блок и записать блок.
Обычно блоки находятся на вращающихся дисках, таких как дискеты или пла-
пластины жестких дисков. Виртуальный диск проще. Он хранит данные в предва-
предварительно выделенной области оперативной памяти. Преимущество такого диска
в том, что он обеспечивает высокую скорость доступа (так как не требуется пере-
перемещать головки и вращать носитель) и может быть использован для хранения
данных, к которым часто происходят обращения.
Отступая в сторону, нужно вкратце рассказать о различии между операционны-
операционными системами, поддерживающими монтирование файловых подсистем (UNIX,
MINIX), и системами, не имеющими такой поддержки (MS-DOS, Windows). Когда
файловые системы монтируются, корневая файловая система всегда находится
в фиксированном месте, а прочие (например, диски) встраиваются в указанное
место в дереве файлов, образуя единую файловую структуру. Смонтировав неко-
некоторую файловую систему, пользователь может больше не задумываться, на ка-
каком устройстве расположен файл.
В противовес такому подходу в других операционных системах пользователь дол-
должен указывать положение каждого файла либо явно (например: В: \DIR\FILE),
либо пользуясь различными умолчаниями (текущее устройство, текущий каталог
и т. д.). В небольших системах, с одним или двумя дисками, это можно вытер-
вытерпеть, но на мощных компьютерах с несколькими десятками устройств постоянно
следить за всеми дисками невыносимо. Заметьте, что UNIX работает на компью-
компьютерах от IBM PC до рабочих станций и суперкомпьютеров, подобных IBM Blue
Gene/L, a MS-DOS используется только в малых системах.
На рис. 3.13 показано устройство виртуального диска. Диск разбивается на п бло-
блоков, в зависимости от того, сколько памяти для него выделено. Размер каждого
блока равен размеру блока реального диска. Когда драйвер получает запрос на
чтение или запись блока, он просто вычисляет адрес и производит чтение или
запись по этому адресу, вместо того чтобы обслуживать дискету или жесткий
диск. Обмен данными выполняется системным заданием. Ассемблерная проце-
процедура ядра phys__copy копирует информацию в пользовательскую программу или
из нее с максимальной скоростью, поддерживаемой аппаратным обеспечением.
Рис. 3.13. Виртуальный диск
Драйвер виртуального диска может поддерживать несколько виртуальных дис-
дисков, которые различаются присвоенным им вспомогательным номером устройст-
устройства. Обычно эти области полностью разделены, но иногда бывает удобно, чтобы
они перекрывались, как мы увидим в следующем разделе.
3.6.2. Драйвер виртуального диска в MINIX 3
Драйвер виртуального диска в MINIX 3 в действительности представляет собой
шесть тесно связанных между собой драйверов. Каждое сообщение для этого
драйвера указывает одно из следующих устройств:
0: /dev/ram 2: /dev/kmem 4: /dev/boot
1: /dev/mem 3: /dev/null 5: /dev/zero
Первый из специальных файлов, /dev/ram, является «настоящим» виртуаль-
виртуальным диском. Ни размер, ни положение занимаемой им области памяти в драйвере
не прописаны. Они определяются файловой системой при загрузке MINIX 3. По
умолчанию размер виртуального диска равен размеру образа корневой файловой
системы, чтобы можно было скопировать на него корневую систем}^. Варьирова-
Варьирование параметрами загрузки позволяет установить больший размер виртуального
диска, а если не копировать на него образ корневой системы, то можно назна-
назначить диску произвольный размер, который и в памяти умещается, и оставляет
достаточно места для работы MINIX 3. Определив размер диска, система выде-
выделяет в памяти область достаточно большого размера, до того как начнет работу
менеджер процессов. Такая стратегия позволяет увеличивать или уменьшать
размер виртуального диска без перекомпиляции системы.
Следующие два устройства применяются для доступа к оперативной памяти или
к памяти ядра соответственно. Открыв устройство /dev/mem и считывая из него
данные, можно обратиться к любой области памяти, начиная с абсолютного ну-
нулевого адреса (где расположены векторы прерываний реального режима). Обыч-
Обычные пользовательские программы не имеют такой потребности, но системным
программам, служащим для отладки операционной системы, это может оказать-
оказаться полезным. Записывая данные в /dev/mem, можно изменять векторы преры-
прерываний. Не стоит и говорить, что делать это должен только опытный пользова-
пользователь, твердо знающий, что он делает.
Файл /dev/kmem полностью подобен файлу /dev/mem за тем исключением, что
нулевой адрес в файле соответствует нулевому адресу в пространстве ядра, поло-
положение последнего зависит от размера сегмента кода MINIX 3. Этот файл также
по большей части привлекается для целей отладки рядом специальных программ.
Обратите внимание на то, что области виртуального диска, соответствующие ука-
указанным двум устройствам, перекрываются. Если вы точно знаете, где в памяти
находится ядро, то если прочитать из /dev/mem данные по означенному адресу,
можно увидеть точно те же данные, которые находятся в начале файла /dev/kmem.
При перекомпиляции системы размер и положение ядра в памяти могут изме-
измениться, но файл /dev/kmem все равно будет содержать область памяти ядра.
Следующий файл в группе, /dev/null, служит специально для ненужных дан-
данных. Он часто используется в программах оболочки, чтобы скрыть вывод про-
программы, когда он не нужен. Например:
a.out >/dev/null
Эта команда запустит программу а. out, но все, что она выводит, будет игнориро-
игнорироваться. Драйвер виртуального диска считает, что размер этого устройства равен О,
поэтому никаких данных на него не записывается и с него не считывается. При
попытке считывания вы сразу же получите символ конца файла (End of File, EOF).
Освоив назначения файлов каталога /dev/, вы, возможно, обратили внимание
на то, что единственным блочным устройством среди них является /dev/ram,
все остальные устройства — символьные. Драйвер памяти поддерживает еще
одно блочное устройство — /dev/boot. С точки зрения драйвера это блочное
устройство находится в памяти, как и /dev/ ram. Тем не менее для его инициа-
инициализации требуется скопировать в память файл, присоединенный к загрузочному
образу, а не начать с пустого блока, как в случае /dev/ram. Это устройство заре-
зарезервировано на будущее и не используется в текущей версии MINIX 3, которой
посвящена книга.
Наконец, последним устройством, поддерживаемым драйвером памяти, является
символьный файл /dev/zero. Иногда бывает удобно иметь источник нулевых
значений. Запись в /dev/zero эквивалентна записи в /dev/null, однако при
чтении из /dev/zero вы получаете нули в любом нужном количестве — от од-
одного символа до целого диска.
На уровне драйвера код, обслуживающий устройства /dev/ram, /dev/mem,
/dev/kmem и /dev/boot, идентичен. Единственное различие между этими че-
четырьмя устройствами состоит в том, что они работают с разными областями па-
памяти, задаваемыми массивами ram_origin и ram_limit, каждый из которых
индексируется вспомогательным номером устройства. Файловая система управ-
управляет устройствами на более высоком уровне. Она различает символьные и блочные
устройства, а следовательно, способна монтировать /dev/ram и /dev/boot,
читать и записывать потоки данных (хотя чтение потока из /dev/null всегда
возвращает символ конца файла).
3.6.3. Реализация драйвера
виртуального диска в MINIX 3
Как и у других дисковых драйверов, главный цикл драйвера виртуального диска
находится в файле driver, с. Поддержка специальных функций виртуального
диска обеспечивается файлом memory. с (строка 10800). При компиляции драй-
драйвера памяти копия объектного файла drivers/libdriver/driver.о, по-
получаемого из файла drivers/libdriver/driver. с, компонуется с объект-
объектным файлом drivers /memory /memory .о — результатом компиляции файла
drivers /memory /memory, с.
Компиляции основного цикла следует уделить особое внимание. Объявление
структуры driver в файле driver.h (строки 10829-10845) лишь описывает,
но не создает ее. Объявление m_dtab (строки 11645-11660) создает экземпляр
структуры driver и заполняет его указателями на функции. Некоторые из этих
функций являются общими и компилируются из файла driver.с (например,
все функции пор), другие компилируются из файла memory. с (например, щ_
do_open). Обратите внимание на то, что для драйвера памяти семь подпрограмм
делают мало или вообще ничего, а последние два указателя являются нулевыми
(NULL). Это означает, что соответствующие функции никогда не вызываются
(смысла нет даже в do_nop). Таким образом, нетрудно видеть, что функциони-
функционирование виртуального диска не отличается замысловатостью.
Работа с памятью не требует большого количества структур данных. В массиве
m_geom [NRJDEVS] (строка 11627) хранятся базовые адреса и размеры всех
шести специальных устройств. Для них используется 64-разрядный беззнаковый
тип данных, что на сегодняшний день исключает возможность нехватки объема
виртуального диска. В следующей строке определена интересная структура
ni_seg [NR_DEVS], недоступная другим драйверам. Внешне она представляет со-
собой массив целых чисел, однако эти числа используются как индексы, позволяю-
позволяющие отыскивать дескрипторы сегментов. Отличие драйвера памяти от других
процессов пользовательского пространства заключается в возможности доступа
к памяти, находящейся за пределами сегментов данных, кода и стека. Этот мас-
массив содержит информацию, необходимую для доступа к выделенным дополни-
дополнительным областям памяти. Переменная же m_device хранит индекс текущего
активного вспомогательного устройства.
Чтобы воспользоваться устройством /dev/ram как корневым, драйверу па-
памяти необходимо инициализироваться на очень ранней стадии запуска MINIX 3.
Структуры kinf о и machine, определения которых следуют далее, хранят дан-
данные, полученные из ядра при запуске. Эти данные необходимы для инициализа-
инициализации драйвера памяти.
Одна структура данных, dev_zero, определяется раньше исполняемого кода.
Она представляет собой массив размером 1024 байт, данные которого предостав-
предоставляются при обслуживании обращения read к устройству /dev/zero.
Главная процедура main (строка 11672) сначала вызывает функцию локальной
инициализации, а затем переходит в цикл, принимающий сообщения, вызываю-
вызывающий соответствующие процедуры и отсылающий ответы. До завершения работы
драйвера управление никогда не передается назад в main.
Следующая функция, m_name, исключительно проста — она всего лишь возвра-
возвращает строку memory.
Выполняя операцию чтения или записи, главный цикл драйвера делает три вы-
вызова: один для подготовки устройства, один, чтобы запланировать операцию вво-
ввода-вывода, и еще один, чтобы завершить операцию. В данном случае первому
вызову соответствует функция m_prepare. Она убеждается, что было выбрано
правильное вспомогательное устройство, и возвращает адрес структуры, содер-
содержащей базовый адрес и размер запрошенной области памяти. Второй вызов об-
обслуживает функция m_transfer (строка 11706), которая и выполняет всю ра-
работу. Как мы видели в файле driver.с, все вызовы чтения и записи данных
преобразуются в вызовы чтения и записи множественных смежных блоков дан-
данных. Если требуется считать только один блок данных, вызов все равно преобра-
преобразуется в запрос нескольких блоков данных, где параметр количества блоков ра-
равен 1. В результате драйверу передается всего два вида запросов — DEV_GATHER
(чтение одного или нескольких блоков) и DEV_SCATTER (запись одного или не-
нескольких блоков). Таким образом, получив номер вспомогательного устройства,
m_transf ег запускает цикл, число итераций которого равно числу затребован-
затребованных передач. Цикл содержит ветви по типу устройства.
Первая ветвь — /dev/null. Для запроса DEV_GATHER происходит немедлен-
немедленный возврат из функции, а для запроса DEV_SCATTER — переход в конец ветви
(это позволяет вернуть число переданных байтов, как в любой операции записи,
хотя для устройства /dev/null оно всегда равно нулю).
Для всех типов устройств, обращающихся к физической памяти, выполняется
аналогичная обработка. Сначала проверяется, не приводит ли переданное сме-
щение к выходу за пределы памяти, выделенной устройству, а затем совершается
вызов ядра, копирующий данные из памяти или в память устройства. Тем не ме-
менее для выполнения последнего действия применяются два разных фрагмента
кода. Устройства /dev/ram, /dev/kmem и /dev/boot используют виртуаль-
виртуальные адреса, поэтому требуется получить из массива m_seg сегмент адреса облас-
области памяти, к которой осуществляется доступ, а затем совершить вызов sys_
vircopy ядра (строки 11640-11652). Устройство /dev/mem использует физи-
физический адрес, обрабатываемый вызовом sys_physcopy.
Оставшаяся операция выполняет чтение и запись в устройство /dev/zero. При
чтении данные извлекаются из упомянутого ранее массива dev_zero. Вы спро-
спросите, зачем копировать нули в буфер, если их можно просто генерировать? По-
Поскольку копирование данных выполняется вызовом ядра, такой метод потребует
неэффективного копирования отдельных байтов из драйвера памяти в систем-
системное задание либо создания кода, генерирующего для системного задания нуле-
нулевые значения. Последнее решение усложнило бы код ядра — то, чего мы стара-
старались избежать при создании MINIX 3.
Для завершения операции чтения или записи памяти не нужен третий шаг, по-
поэтому соответствующий элемент m_dtab указывает на функцию nop_f inish.
За открытие виртуального диска отвечает функция m_do_open (строка 11801).
Самые главные действия в ней выполняет вызов m_prepare, который проверя-
проверяет, что устройство указано корректно. Любопытная деталь: комментарий внутри
функции относится к коду, который был в ней в предыдущих версиях MINIX.
Раньше в этом месте был реализован некий программный трюк. Вызов, от-
открывающий устройство /dev/rnem или /dev/kmem, волшебным образом дает
совершившему его пользовательскому процессу возможность исполнять коман-
команды доступа к портам ввода-вывода. У процессоров Pentium есть четыре уровня
привилегий, при этом пользовательские программы работают на последнем уров-
уровне. Если процесс пытается исполнить команду, недопустимую на его уровне при-
привилегий, процессор генерирует исключение общей защиты. Способ преодоления
этого ограничения был признан безопасным, поскольку доступ к устройствам
памяти имел лишь пользователь с максимальными привилегиями. В любом случае
подобная сомнительная «возможность» исключена в MINIX 3 — операционная
система предоставляет вызовы ядра, обеспечивающие доступ к портам ввода-вы-
ввода-вывода посредством системного задания. Комментарий сохранен в коде, чтобы ука-
указать на необходимость возвращения описанного «трюка» в MINIX 3 при переносе
на аппаратную платформу с вводом-выводом, отображаемым на память. Соот-
Соответствующая функция, enable_iop, сохранена в коде ядра и демонстрирует
реализацию «трюка», хотя сейчас в ней нет необходимости.
Следующая функция, m__init (строка 11817), вызывается только один раз, когда
в первый раз делается вызов mem_task. Эта подпрограмма использует множество
вызовов ядра, и на ее основе можно выполнить целое исследование на тему взаимо-
взаимодействия драйверов с ядром посредством служб системного задания в MINIX 3.
Сначала вызов sys__getkinfо получает из ядра копию структуры kinfо. Из
нее функция копирует базовый адрес и размер /dev/kmem в соответствующие
поля структуры m_geom. Вызов sys_segctl преобразует физический адрес
и размер устройства /dev/kmem в дескриптор сегмента, чтобы память ядра вос-
воспринималась как виртуальная. Если образ загрузочного устройства включен в за-
загрузочный образ системы, поле базового адреса /dev/boot будет ненулевым.
В этом случае информация для доступа к области памяти данного устройства ус-
устанавливается так же, как и для /dev/kmem. Затем массив, используемый для
предоставления данных при доступе к устройству /dev/zero, явно заполняется
нулями. Возможно, это является излишним, так как большинство компиляторов С
инициализируют создаваемые статические переменные нулевыми значениями.
Наконец, функция m_init с помощью системного вызова sys_machine полу-
получает из ядра еще одну структуру, machine, содержащую различные атрибуты
аппаратного обеспечения. В данном случае необходимо узнать, поддерживает ли
процессор защищенный режим. В зависимости от этой информации и режима
работы MINIX 3 (8088 или 80386) размер устройства /dev/mem устанавлива-
устанавливается равным 1 Мбайт D Гбайт - 1). Эти размеры являются максимальными,
поддерживаемыми MINIX 3, и не зависят от объема оперативной памяти, уста-
установленной на компьютере. Заданию подлежит только размер устройства; пред-
предполагается, что компилятор корректно установит базовый адрес равным нулю.
Поскольку доступ к /dev/mem осуществляется как к физическому, а не вирту-
виртуальному устройству, нет необходимости совершать системный вызов sys_
segctl для задания дескриптора сегмента.
Перед тем как завершить рассмотрение функции m_init, следует упомянуть
еще один неочевидный вызов ядра. Многие действия, выполняемые при ини-
инициализации драйвера памяти, необходимы для корректного функционирования
MINIX 3. По этой причине выполняется несколько тестов, и в случае неудачного
исхода вызывается подпрограмма panic — в данном случае это библиотечная
функция, инициирующая вызов ядра sys_exit. Ядро, менеджер процессов (как
мы увидим) и файловая система используют собственные подпрограммы panic.
Драйверам устройств и прочим небольшим системным компонентам предостав-
предоставляется библиотечная функция с таким именем.
Интересная деталь: функция m_init не инициализирует важнейшее устрой-
устройство памяти /dev/ram. Этим занимается следующая функция, m_ioctl (стро-
(строка 11863). Фактически, для виртуального диска определена одна операция
ioctl — MIOCRAMSIZE, используемая файловой системой для установки вирту-
виртуального диска. Большая часть работы делается без служб ядра. Вызов allocmem
(строка 11187) является системным, но он не обращен к ядру, а обрабатывается
менеджером процессов, поддерживающим всю информацию, необходимую для
поиска доступных областей памяти. Тем не менее в конце без вызова ядра все
же не обойтись. Вызов sys_segctl (строка 11894) преобразует физический
адрес и размер, возвращаемый вызовом allocmem, в сегментную информацию,
необходимую для будущего доступа.
Последняя функция в файле memory.с — это m_geometry. Для виртуального
диска понятия цилиндра, дорожки и сектора не имеют смысла, но если система
запросит эту информацию, он должен притвориться, что у него есть 64 дорожки
и 32 сектора в каждой дорожке. Исходя из этого, данная функция подсчитывает
число «цилиндров» виртуального диска.
3.7. Реальные диски
Все современные компьютеры, за исключением встроенных, оснащены жест-
жесткими дисками. По этой причине мы займемся их изучением. Мы начнем с аппа-
аппаратной части, затем скажем несколько общих слов о дисковом программном
обеспечении, и, наконец, перейдем к рассмотрению вопросов управления диска-
дисками в операционной системе MINIX 3.
3.7.1. Аппаратное обеспечение диска
Все реальные диски организованы в цилиндры, каждый из которых содержит
столько дорожек, сколько вертикально установленных головок есть у устройст-
устройства. Дорожки делятся на секторы, их количество обычно варьируется от 8 до 32
у гибких дисков и до нескольких сотен у жестких дисков. В простейших случаях
число секторов на всех дорожках одинаково. Все секторы содержат одинаковое
количество байтов, хотя нетрудно понять, что физическая длина секторов растет
с удалением от центра диска. Тем не менее время чтения и записи любого сектора
неизменно. Плотность данных возрастает от краев диска к центру, что вынужда-
вынуждает изменять ток выборки, подаваемый на головки при чтении близких к центру
дорожек. Об этом заботится аппаратная часть дискового контроллера. Ни поль-
пользователь, ни разработчик операционной системы не имеют к этому отношения.
Увеличение плотности данных по мере приближения дорожек к центру накла-
накладывает ограничения на емкость диска и делает системы более сложными. Была
попытка создать гибкие диски, скорость вращения которых растет при переме-
перемещении считывающих головок на дорожки, удаленные от центра. Это позволило
бы разместить на таких дорожках больше секторов и увеличить объем диска. По-
Подобные диски не поддерживаются ни одной из платформ, для которых предна-
предназначена система MINIX 3. Современные жесткие диски большого объема также
имеют на внешних дорожках больше секторов, чем на внутренних. Эти диски от-
относятся к типу IDE (Integrated Drive Electronics — встроенный интерфейс диско-
дисковых накопителей). Они оснащены встроенной электроникой, ведущей с диском
сложную работу и скрывающую ее детали. С точки зрения операционной систе-
системы IDE-диски имеют простую физическую структуру с одинаковым числом сек-
секторов на каждой дорожке.
Диск и электронные компоненты важны не меньше, чем механические. Главным
элементом дискового контроллера является специальная интегральная схема,
фактически представляющая собой микрокомпьютер. Раньше она располагалась
на плате, вставляемой в объединительную панель компьютера, однако в совре-
современных компьютерах дисковый контроллер размещается на материнской плате.
Контроллер современного жесткого диска может оказаться проще, чем контрол-
контроллер гибких дисков, если жесткий диск оснащен мощным встроенным электрон-
электронным контроллером.
Важным свойством дисков, влияющим на дисковый драйвер, является возмож-
возможность одновременного поиска на двух или более дисках, так называемого поиска
с перекрытием. В то время как контроллер и программное обеспечение ожидают
окончания операции поиска на одном устройстве, контроллер может иницииро-
инициировать поиск на другом устройстве. Многие контроллеры жестких дисков также
умеют совмещать операцию чтения или записи на одном диске с поиском на дру-
другом или даже нескольких дисках. Однако контроллеры гибких дисков не могут
одновременно читать и писать на двух дисководах. (Чтение или запись требуют
от контроллера перемещения битов с максимальной скоростью, на которую он
рассчитан, поэтому операция чтения или записи отнимает большую часть его
вычислительных возможностей.) В случае IDE-дисков с их встроенными мик-
микроконтроллерами ситуация радикально меняется, поэтому в одной системе спо-
способны одновременно работать несколько жестких дисков, по крайней мере, пе-
переносить данные между диском и буфером контроллера. Вместе с тем, между
контроллером и оперативной памятью в каждый момент времени происходит
только одна операция по переносу данных. Способность параллельного выпол-
выполнения двух или более дисковых операций может существенно сократить среднее
время доступа.
Глядя на спецификации современных жестких дисков, следует помнить, что ука-
указанная геометрия, используемая программным обеспечением драйвера, может
отличаться от физического формата. Если вы прочтете рекомендуемые парамет-
параметры установки для жесткого диска большого объема, то, скорее всего, обнаружите
следующее: 16 383 цилиндра, 16 головок и 63 сектора на одну дорожку (при лю-
любом объеме диска). Эти цифры — для диска размером 8 Гбайт, однако они те же
для любого диска большего объема. Разработчики оригинальных машин IBM PC
выделили в ПЗУ BIOS только 6 бит под счетчик секторов, 4 бита под головку
и 14 бит под цилиндр. При размере сектора 512 байт получаем объем 8 Гбайт.
По этой причине установка жесткого диска на очень старый компьютер может
обернуться тем, что доступными окажутся лишь 8 Гбайт при значительно боль-
большем объеме диска. Обычный способ преодоления этого ограничения — логиче-
логическая адресация блоков, согласно которой секторы диска попросту нумеруются,
начиная с нуля. Нумерация никак не связана с физическими особенностями диска.
В контексте современных жестких дисков описанная геометрия, на самом деле, —
не более чем фантастика. Поверхность современного диска разбита на 20 или бо-
более зон. Чем ближе зоны расположены к центру, тем меньше в них секторов на
одной дорожке. По этой причине физическая длина сектора остается приблизи-
приблизительно одинаковой вне зависимости от его расположения на диске. Это повыша-
повышает эффективность использования дисковой поверхности. Внутренняя адресация
контроллера диска включает четыре компонента: зону, цилиндр, головку и сек-
сектор. Тем не менее все это скрыто от пользователя, и подробности редко можно
найти в публикуемых спецификациях. Вывод такой: адресация по цилиндру,
головке и сектору (Cylinder-Head-Sector, CHS) имеет смысл лишь в случае, если
вы имеете дело с устаревшим компьютером, не поддерживающим логическую
адресацию блоков. Кроме того, нет смысла приобретать новый диск размером
400 Гбайт для компьютера РС-ХТ, купленного в 1983 году: он не позволит вам
использовать более 8 Гбайт дискового пространства.
Здесь самое время рассказать о путанице, касающейся спецификаций дисков. Спе-
Специалисты в области вычислительной техники привыкли измерять емкость диска
в степенях с основанием 2. Так, килобайтом (Кбайт) считается 210 = 1024 байт,
мегабайтом (Мбайт) — 220 = 10242 байт и т. д. По такой логике 1 Гбайт равен
10243, или 230 байт. Однако производители дисков под гигабайтом понимают
109 байт, что означает заметное увеличение объема их продукции, но только на
бумаге. Таким образом, упомянутый ранее предел в 8 Гбайт на языке продавца
компьютерного магазина превращается в 8,4 Гбайт. В последнее время намети-
наметилась тенденция к использованию термина «гибибайт» (GiBibyte), обозначающе-
обозначающего 230 байт. Однако в этой книге авторы пользуются принятыми толкованиями
мега- и гигабайта, отдавая дань традиции и протестуя против искажения терми-
терминов в угоду рекламе.
3.7.2. RAID
Несмотря на то что современные диски значительно быстрее своих предшест-
предшественников, производительность процессоров растет гораздо быстрее, чем дисков.
С течением времени специалистам неоднократно приходила в голову идея о том,
что параллельный дисковый ввод-вывод способен изменить ситуацию. Так по-
появился новый класс устройств ввода-вывода, обозначаемый аббревиатурой RAID
(Redundant Array of Independent Disks — избыточный массив независимых дис-
дисков). Разработчики RAID (университет Беркли) изначально понимали эту аб-
аббревиатуру иначе: Redundant Array of Inexpensive Disks (избыточный массив
дешевых дисков), позиционируя ее как противоположность другой архитектуре,
SLED (Single Expensive Large Disk — единственный дорогой большой диск). Тем
не менее, когда технология RAID стала пользоваться коммерческой популярно-
популярностью, производители изменили расшифровку аббревиатуры, поскольку дорого
продавать продукт, в названии которого стояло слово «дешевый», было затруд-
затруднительно. Первоначальная идея RAID состояла в установке рядом с компьюте-
компьютером (как правило, большим сервером) коробки, наполненной дисками, замене
дискового контроллера RAID-контроллером, копировании данных в RAID-мас-
RAID-массив и продолжении обычной работы.
Независимые диски можно совместно использовать целым рядом способов. Из-за
ограничений объема книги мы не можем исчерпывающе описать их все, к тому
же MINIX 3 пока не поддерживает RAID-массивы. Тем не менее при знакомстве
с операционными системами нельзя обойтись без упоминания хотя бы некото-
некоторых из них. RAID позволяет одновременно повысить скорость дискового досту-
доступа и безопасность данных.
Рассмотрим, к примеру, простейший RAID-массив, состоящий из двух дисков.
Когда требуется записать на «диск» несколько секторов данных, RAID-контроллер
посылает секторы 0, 2, 4 и т. д. на диск 1, а секторы 1, 3, 5 и т. д. — на диск 2. Кон-
Контроллер разделяет данные и ведет независимую запись на оба диска одновременно,
тем самым удваивая скорость записи. При чтении обращение к обоим дискам
осуществляется также одновременно, но теперь контроллер собирает данные в над-
надлежащем порядке, а с точки зрения остальной системы чтение просто происходит
с удвоенной скоростью. Этот метод называется расщеплением данных (stripping).
Данный пример демонстрирует простейший RAID-массив уровня 0. На практи-
практике используются не два, а четыре или более устройств. RAID-массив полезен
в случаях, когда данные в основном считываются или записываются большими
блоками. Очевидно, что при запросах на чтение одного сектора никакой выгоды
от использования RAID-массива нет.
Предыдущий пример показывает, как можно увеличить скорость доступа с по-
помощью нескольких дисков. А как же обстоит дело с надежностью? RAID уровня 1
работает так же, как и RAID уровня 0, за исключением дублирования данных.
Можно снова прибегнуть к простейшему массиву из двух дисков, но записывать
на них одни и те же данные. В этом случае прироста скорости не будет, однако
мы получим 100-процентную избыточность. Если при чтении произойдет ошиб-
ошибка, необходимости в повторной попытке не возникнет, если данные безошибочно
считаны со второго диска. Все, что нужно контроллеру, — убедиться в коррект-
корректности данных, передаваемых системе. Тем не менее отказываться от повторных
попыток при неудачной записи, вероятно, не следует. Если ошибки происхо-
происходят настолько часто, что отказ от повторного чтения значительно увеличивает
скорость считывания, можно уверенно говорить о неминуемости полного краха.
Как правило, дисководы RAID-массивов допускают «горячую» замену, то есть
замену, не требующую отключения питания системы.
Более сложные дисковые массивы позволяют увеличивать скорость и надеж-
надежность одновременно. Рассмотрим, к примеру, массив, состоящий из семи дисков.
Байты могут быть разбиты на 4 группы по 2 бита в каждой. Каждая группа за-
записывается на соответствующий диск, а на три оставшихся диска помещается
3-разрядный код коррекции ошибок. Если один из дисков выйдет из строя и по-
потребует «горячей» замены, отсутствующий диск будет эквивалентен одному ис-
искаженному биту, поэтому система сможет продолжить работу в процессе уста-
установки другого диска. Ценой семи дисков вы обеспечите бесперебойную работу
системы с четырехкратным увеличением производительности.
3.7.3. Программное обеспечение
жестких дисков
В этом разделе мы изучим некоторые общие вопросы работы драйверов жестких
дисков. Прежде всего, выясним, сколько времени требуется для считывания дис-
дискового блока. Это время складывается из трех слагаемых.
1. Время поиска (перемещение головки на нужный цилиндр).
2. Задержка вращения (время, через которое нужный сектор пройдет под головкой).
3. Время передачи данных.
Для большинства дисковых накопителей наибольший вклад в задержку имеет
первый показатель, поэтому снижение среднего времени поиска принципиально
важно для роста производительности системы.
Работа дисковых накопителей чревата ошибками. В силу этого в каждый сек-
сектор диска всегда записывается та или иная проверочная информация, в виде
контрольной суммы или кода для циклического контроля избыточности (Cyclic
Redundancy Check, CRC). Даже адреса секторов, которые записываются на диск
при форматировании, содержат проверочные данные. Контроллер гибкого диска,
обнаружив ошибку, сообщает о ней системе, которая должна решить, как посту-
поступить. Контроллеры жестких дисков часто берут на себя значительную часть дей-
действий по обработке ошибки.
Для жестких дисков последовательное чтение секторов в пределах одной дорожки
происходит очень быстро. Поэтому для повышения эффективности работы системы
имеет смысл считывать больше секторов, чем запрошено, и кэшировать их в памяти.
Алгоритмы планирования перемещения головки
Если драйвер диска принимает и выполняет запросы по одному в порядке их по-
получения, то есть по принципу FCFS (First Come, First Served — первым пришел,
первым обслужен), тогда мало что можно сделать для оптимизации времени по-
поиска. Однако при высокой загрузке диска допустимо применение другой страте-
стратегии. В этом случае высока вероятность поступления новых запросов от других
процессов во время перемещения головки для обработки предыдущего запроса.
Многие дисковые драйверы содержат таблицу, индексированную по номерам
цилиндров, в которой в единый связанный список собираются все поступившие
и ждущие обработки обращения к цилиндрам.
С помощью подобной структуры данных можно создать более совершенный алго-
алгоритм планирования, чем простое обслуживание в очередности поступления запро-
запросов. Рассмотрим, например, диск с 40 цилиндрами. Поступает запрос на чтение
блока с цилиндра И. Во время перемещения головки на этот цилиндр происхо-
происходят запросы на чтение блоков с цилиндров 1, 36, 16, 34, 9 и 12. Новые запросы
помещаются в таблицу, составленную из отдельных списков для каждого цилин-
цилиндра. На рис. 3.14 поступившие запросы помечены крестиками.
Рис. 3.14. Алгоритм планирования SSF
Выполнив первый запрос (обращение к цилиндру 11), драйвер диска должен вы-
выбрать на обслуживание следующий запрос. Если обслуживать запросы в порядке
поступления, то драйвер должен переместить головку на цилиндр 1, затем на
цилиндр 36 и т. д. В результате выполнение этого алгоритма потребует переме-
перемещения блока головок на 10, 35, 20, 18, 25 и 3 цилиндра, что в сумме составит
111 цилиндров.
Время перемещения головки можно уменьшить, выбирая каждый раз ближай-
ближайший цилиндр. При той же серии запросов (см. рис. 3.14), последовательность их
обработки выглядит как ломаная кривая, представленная в нижней части рисунка.
При такой последовательности выполнения запросов потребуются перемещения
блока головок на 1, 3, 7, 15, 33 и 2 цилиндра, что суммарно равно 61 цилиндр.
Применение данного алгоритма, названного SSF (Shortest Seek First — бли-
ближайший запрос обслуживается первым), минимизирует суммарные перемещения
головок почти вдвое.
К сожалению, у данного алгоритма есть недостатки. Предположим, во время
обработки запросов, показанных на рис. 3.14, поступили новые запросы. На-
Например, после обработки обращения к цилиндру 16 приходит новый запрос
к цилиндру 8. Этот запрос будет иметь приоритет над обращением к цилиндру 1.
Затем, если поступит запрос к цилиндру 13, головка опять начнет перемещаться
к цилиндру 13 для обработки нового запроса, а запрос к цилиндру 1 останется
необработанным. При сильной загрузке диска головка диска будет большую часть
времени находиться где-то в районе средних цилиндров, а запросам к крайним
цилиндрам диска придется ждать, пока нагрузка снизится и обращений к середи-
середине диска станет меньше. В результате качество обслуживания запросов к цилинд-
цилиндрам, удаленным от срединной части, может оказаться низким. То есть в конфликт
вступают принцип минимизации времени отклика и принцип справедливости.
В высотных зданиях также приходится иметь дело с данной проблемой планиро-
планирования обслуживания запросов лифта. Вызовы лифта постоянно поступают с раз-
разных этажей. Компьютер, управляющий лифтом, должен следить за последова-
последовательностью поступления запросов и удовлетворять их либо в порядке подачи
заявок, либо обслуживая первым ближайший запрос.
В большинстве лифтов применяют различные алгоритмы, пытаясь примирить
конфликтующие цели эффективности и справедливости. Обычно лифт продол-
продолжает двигаться в одном направлении до тех пор, пока на этом направлении более
не остается запросов. Затем лифт меняет направление движения. Этот алгоритм,
называющийся элеваторным, требует от программного обеспечения отслежива-
отслеживания всего одного бита, хранящего информацию о текущем направлении движе-
движения, вверх или вниз. Выполнив очередной запрос, диск или лифт проверяет зна-
значение бита. Если он требует движения вверх, кабина лифта (или блок головок)
перемещается в соответствующую сторону к следующему запросу. Если желаю-
желающих подняться больше нет, состояние бита инвертируется.
Рисунок 3.15 иллюстрирует выполнение элеваторного алгоритма с теми же се-
семью запросами, показанными в качестве примера на рис. 3.14. Предполагается,
что изначально бит направления движения указывал вверх. При этом цилиндры
обслуживаются в порядке 12, 16, 34, 36, 9 и 1, что соответствует перемещению
блока головок на 1, 4, 18, 2, 27 и 8 цилиндров и в сумме составляет 60 цилинд-
цилиндров. В данном случае элеваторный алгоритм оказался даже чуть лучше, чем алго-
алгоритм SSF, однако на практике он обычно работает несколько хуже. Достоинство
элеваторного алгоритма состоит в том, что при любом заданном наборе запросов
верхняя граница необходимых перемещений блока головок для выполнения всех
запросов фиксирована и ограничена удвоенным числом цилиндров.
Рис. 3.15. Элеваторный алгоритм планирования обращений к диску
Незначительная модификация этого алгоритма с меньшим разбросом времени
отклика состоит в том, чтобы сканировать цилиндры всегда в одном направле-
направлении [118]. После обслуживания обращения к цилиндру с самым большим номе-
номером блок головок перемещается к самому нижнему запрашиваемому цилиндру
и далее продолжает движение вверх. Таким образом, самый нижний цилиндр как
бы считается расположенным выше самого верхнего.
Некоторые контроллеры дисков предоставляют программному обеспечению спо-
способ узнавать номер текущего сектора под головкой. Такие контроллеры позволя-
позволяют использовать дополнительный метод оптимизации. Если есть два или более
запросов к одному и тому же цилиндру, драйвер может выбрать из них тот, сек-
сектор которого пройдет под головкой первым. Обратите внимание, что при нали-
наличии нескольких головок у диска последовательные запросы могут обращаться
к различным дорожкам на одном цилиндре. Контроллер может практически
мгновенно переключаться с головки на головку, так как такое переключение не
требует ни перемещения блока головок, ни ожидания поворота диска.
По скорости передачи данных современные жесткие диски настолько превосходят
дисководы для дискет, что требуется автоматическое кэширование. Как правило,
при любом запросе на считывание сектора считываются все секторы до конца
текущей дорожки (включая требуемый) в зависимости от доступного свободного
места в кэше. В настоящее время размер кэша зачастую составляет 8 Мбайт и более.
При наличии нескольких дисководов необходимо поддерживать отдельные оче-
очереди активных запросов для каждого из них. При простое диска следует выпол-
выполнить поиск и перевести его головку на цилиндр, который будет использоваться
для следующего считывания (при условии, что контроллер поддерживает пере-
перекрывающийся поиск). По завершении текущей передачи данных можно про-
проверить, имеются ли диски, головки которых установлены на нужный цилиндр.
Если хотя бы один такой диск найден, следующую передачу можно осуществить
с него. Если ни одна головка не находится в требуемом положении, то драйверу
следует выполнить поиск на диске, только что завершившем передачу, и подо-
подождать следующего прерывания, чтобы определить, какая головка достигнет нуж-
нужного цилиндра первой.
Обработка ошибок
Драйверу виртуального диска не нужно заботиться об оптимизации поиска сек-
сектора, так как в любой момент можно прочитать или записать любой блок без ка-
каких бы то ни было механических движений. Обработка ошибок — еще одна об-
область, в которой виртуальный диск намного проще. Виртуальный диск работает
всегда, в то время как реальный диск нет. Реальные дисковые накопители под-
подвержены самым разнообразным ошибкам. Вот самые распространенные из них:
+ программные ошибки (например, запрос несуществующего сектора);
+ временная ошибка контрольной суммы (например, вызванная пылью, попав-
попавшей на головку);
+ постоянная ошибка контрольной суммы (физическое повреждение блока);
+ ошибка поиска (допустим, головка была отправлена на цилиндр 6, но оказа-
оказалась на цилиндре 7);
+ ошибка контроллера (например, контроллер отказался принимать команду).
Обрабатывать все эти ошибки наилучшим образом — задача драйвера диска.
Программные ошибки возникают, когда драйвер передает контроллеру команду
на переход к несуществующему цилиндру, на чтение несуществующего сектора,
использование несуществующей головки или на передачу данных в несущест-
несуществующую область памяти. Большинство контроллеров проверяют передаваемые
им параметры и уведомляют о неполадках. Теоретически таких ошибок возни-
возникать не должно, но что делать, если контроллер все же сообщит об этом? Для
«доморощенной» системы лучше всего было бы вывести на экран текст «свяжи-
«свяжитесь с разработчиком», чтобы ошибку можно было найти или исправить. Для
коммерческой системы, работающей на многих тысячах компьютеров по всему
миру, такое поведение менее привлекательно. Вероятно, лучшее, что можно сде-
сделать в данном случае, это завершить текущий запрос с кодом ошибки и надеять-
надеяться, что она не будет случаться слишком часто.
Временные ошибки контрольной суммы вызываются пылинками, которые оста-
остаются в воздухе между головкой и поверхностью диска. С ними можно бороться,
повторив несколько раз операцию. Если же повторным чтением ошибка не уст-
устраняется, блок помечается как поврежденный (bad block). Такой блок в дальней-
дальнейшем не используется.
Один из способов избежать работы с поврежденными блоками требует специаль-
специальной программы, которая получает на входе список поврежденных блоков и по
этим данным создает файл, состоящий целиком из таких блоков. Они помечают-
помечаются как занятые, и в результате ни одна программа не будет пытаться обращаться
к ним. В результате ни одна из программ не попытается прочитать файл сбой-
сбойных блоков, и ошибка не возникает.
Не читать поврежденные блоки — это проще сказать, чем сделать. Часто резерв-
резервные копии дисков создаются путем подорожечного копирования содержимого
диска на ленту или другой диск. Если следовать этой процедуре, избежать повре-
поврежденных блоков невозможно. Пофайловое резервное копирование медленнее, но
может помочь решить проблему, если программа, зная имя файла поврежденных
блоков, не пытается его копировать.
Другая проблема, не решаемая при помощи файла поврежденных блоков, — это
нарушение системной структуры, которая должна занимать фиксированное поло-
положение на диске. Практически у любой файловой системы есть структура, поло-
положение которой должно быть одним и тем же с целью облегчения ее поиска. Если
файловая система разбита на разделы, то можно заново разбить ее и попробовать
обойти сбойный блок, но если повреждены первые несколько секторов диске-
дискеты или жесткого диска, накопитель становится непригодным к использованию.
«Умные» контроллеры резервируют несколько дорожек, делая их недоступными
пользовательским программам. При форматировании диска контроллер опреде-
определяет, какие из секторов содержат ошибки, и автоматически замещает их одним
из запасных. Таблица, отображающая поврежденные блоки на запасные, хранит-
хранится во внутренней памяти контроллера и на диске. Подмена происходит незамет-
незаметно для драйвера, за исключением того, что не исключена потеря эффективности
тщательно отработанного элеваторного алгоритма, если контроллер будет «тайно»
использовать цилиндр 800 вместо запрошенного цилиндра 3. Технология произ-
производства магнитных поверхностей исключительно точна, но все равно не идеаль-
идеальна. Поэтому механизм скрытия таких дефектов от пользователя имеет большое
значение. Для жестких дисков контроллер отслеживает появление новых сбой-
сбойных блоков и, если ошибка неустранима, заменяет их запасными блоками. Рабо-
Работая с таким диском, драйвер практически никогда не будет видеть плохие блоки.
Дефектные секторы не являются единственным источником ошибок. Также воз-
возникают ошибки поиска цилиндра, вызванные механическими проблемами блока
головок. Контроллер следит за положением блока головок. При установке голов-
головки на заданный цилиндр он выдает серию импульсов двигателю блока головок,
по одному импульсу на цилиндр. Когда блок головок устанавливается в требуе-
требуемое положение, контроллер считывает истинное значение цилиндра из заголовка
первого попавшегося сектора. Если блок головок оказывается не на той дорожке,
на которой нужно, возникает ошибка поиска и предпринимается некоторое кор-
корректирующее действие.
Практически все контроллеры жестких дисков автоматически исправляют ошиб-
ошибки поиска, но большинство контроллеров гибких дисков (включая установленные
на компьютерах IBM PC) просто выставляют бит ошибки и оставляют все осталь-
остальное драйверу. Драйвер обрабатывает ошибку, выдавая команду recalibrate.
При этом блок головок отодвигается на самую внешнюю дорожку диска до упора.
Это положение принимается контроллером за нулевую дорожку, таким образом,
контроллер снова начинает понимать, где находится блок головок. Обычно это
решает проблему. Если же нет, то либо нужно сменить диск, либо починить дис-
дисковод.
Как мы видели, контроллер в действительности представляет собой небольшой
специализированный компьютер с полным комплектом программного обеспе-
обеспечения, переменных, буферов и, по всей видимости, ошибок. Иногда необычное
стечение обстоятельств, например приход прерывания с одного устройства, в то
время как другое устройство выполняет команду recalibrate, может разбу-
разбудить «спящую» до тех пор ошибку, в результате контроллер войдет в бесконеч-
бесконечный цикл или забудет, что он делал. Разработчики контроллеров обычно гото-
готовятся к худшему и предоставляют на всякий случай специальный контакт на
микросхеме, обращение к которому вызывает сброс контроллера. Если ника-
никакие другие меры не помогают, драйвер может установить бит, отвечающий за
подачу сигнала на такой контакт, и сбросить контроллер. Если и это не реши-
решило вопроса, все, что драйверу остается сделать, — вывести сообщение об ошибке
и сдаться.
Кэширование дорожек
Время, требующееся на переход к новому цилиндру, обычно много больше, чем
время поворота диска, и всегда больше времени чтения или записи сектора. Дру-
Другими словами, если драйвер решил перевести куда-либо головку, многое зависит
от того, будет ли читаться только один сектор или вся дорожка. Эффект в осо-
особенности заметен, если контроллер позволяет определить, над каким сектором
находится дорожка, чтобы драйвер мог отдать ему команду на чтение следующе-
следующего сектора, тем самым считывая дорожку целиком за один оборот диска. (Обыч-
(Обычно в среднем на чтение отдельного сектора требуется половина оборота диска
плюс время на чтение одного сектора.)
Некоторые драйверы поддерживают специальный кэш дорожки, невидимый для
программ. Если запрошенный у контроллера сектор находится в этом кэше, об-
обмениваться данными с диском не нужно. Недостаток такого подхода (помимо
усложнения драйвера и необходимости выделения памяти для буфера) состоит
в том, что передача данных пользовательской программе из кэша должна про-
производиться процессором в программном цикле, а не путем прямого доступа к па-
памяти (DMA).
По данной причине многие современные контроллеры поддерживают кэш до-
дорожки самостоятельно, в своей внутренней памяти. В этом случае кэширование
происходит прозрачно для драйвера и передачу данных можно производить пу-
путем прямого доступа к памяти. Если контроллер поддерживает подобную функ-
функцию, не имеет большого смысла дублировать ее в драйвере. Заметьте, что обеспе-
обеспечить чтение одной дорожки целиком могут как контроллер, так и драйвер диска,
но не пользовательская программа, так как для пользовательских программ диск
представляется линейной последовательностью блоков без разбиения на дорожки
и цилиндры. Точная геометрия диска известна лишь его контроллеру.
3.7.4. Драйвер жестких дисков в MINIX 3
Драйвер жесткого диска — это первая рассмотренная нами составная часть
MINIX 3, которая работает с широким диапазоном оборудования различных ти-
типов. Поэтому, прежде чем обсуждать детали драйвера, мы познакомимся с неко-
некоторыми проблемами, порождаемые различиями в аппаратном обеспечении.
Под обозначением «PC» в действительности скрывается семейство различных
компьютеров. Члены семейства имеют не только разные процессоры — весьма
существенные расхождения есть также в базовом аппаратном обеспечении. Опе-
Операционная система MINIX 3 разрабатывалась для компьютеров, оснащенных
процессорами Pentium, однако даже между этими компьютерами имеются раз-
различия. Так, к примеру, первые системы Pentium использовали 16-разрядную
шину AT, изначально разработанную для процессоров 80286. Преимущество
шины AT заключалось в том, что она поддерживала более старые 8-разрядные
периферийные устройства. Позднее для периферийных устройств появилась
шина PCI, однако разъем шины AT все еще присутствовал в компьютерах. В но-
новых системах от поддержки AT отказались, сохранив только PCI. Тем не менее
можно предположить, что пользователи компьютеров «определенного возраста»
будут устанавливать MINIX 3 вместе с периферийными устройствами различ-
различных разрядностей — 8, 16 и 32.
Для каждой шины имеется отдельное семейство адаптеров ввода-вывода. В уста-
устаревших системах адаптеры ввода-вывода представляют собой отдельные печатные
платы, вставляемые в материнскую плату компьютера. В более новых компьюте-
компьютерах многие стандартные адаптеры, особенно дисковые контроллеры, интегриро-
интегрированы в набор микросхем материнской платы. Для программиста это не является
проблемой, поскольку интегрированные адаптеры, как правило, обладают про-
программным интерфейсом, идентичным интерфейсу съемных устройств. Кроме то-
того, чаще всего имеется возможность отключать интегрированные контроллеры,
устанавливая взамен более совершенные дополнительные устройства, например
SCSI-контроллеры. Чтобы воспользоваться подобной гибкостью, операционной
системе необходимо поддерживать более одного типа адаптеров.
В семействе IBM PC, как и в большинстве других компьютерных систем, каждая
шина сопровождается программно-аппаратной поддержкой в виде постоянной
памяти (Read Only Memory, ROM) с базовой системой ввода-вывода (Basic
Input/Output System, BIOS). Так преодолевается разрыв между операционной
системой и спецификой оборудования. Некоторые периферийные устройства
даже оснащены микросхемой памяти, содержащей расширение BIOS. Эта мик-
микросхема расположена на плате устройства. Сложность, с которой приходится
сталкиваться разработчику операционной системы, заключается в том, что мик-
микросхема BIOS в IBM-совместимых компьютерах (разумеется, в ранних) разраба-
разрабатывалась в расчете на MS-DOS — операционную систему, не поддерживающую
многозадачность и работающую в реальном режиме с разрядностью 16 бит. Имен-
Именно таковы характеристики «общего знаменателя» различных режимов, поддер-
поддерживаемых процессорами семейства 80x86,
Таким образом, перед создателем новой операционной системы для IBM PC
встает несколько вопросов. Первый из них: использовать ли для поддержки обо-
оборудования BIOS или писать новые драйверы «с нуля». Для разработчиков ран-
ранних версий MINIX выбор был несложен, так как возможности BIOS во многом
не соответствовали потребностям MINIX. Конечно, для того чтобы выполнить
начальную загрузку MINIX 3 с дискеты, жесткого диска или CD-ROM, монитор
загрузки пользуется функциями BIOS, так как здесь практически нет другой
альтернативы. Но загруженная система с собственными драйверами ввода-выво-
ввода-вывода способна на гораздо больше, чем BIOS.
Второй вопрос звучит так: как без поддержки BIOS обеспечить работу драйверов
с различным оборудованием? Чтобы сделать вопрос более конкретным, рассмот-
рассмотрим два принципиально различных типа контроллеров жестких дисков, исполь-
используемых в современных 32-разрядных процессорах Pentium, для которых и разра-
разрабатывалась операционная система MINIX 3: интегрированный IDE-контроллер
и контроллеры SCSI-расширения для шины PCI. Если вы хотите воспользовать-
воспользоваться устаревшим аппаратным обеспечением и приспособить MINIX 3 к оборудова-
оборудованию, на которое были рассчитаны предыдущие версии MINIX, могут быть при-
применены четыре типа контроллеров жесткого диска: оригинальный 8-разрядный
контроллер XT, 16-разрядный контроллер AT и два различных контроллера для
компьютеров серий PS/2. Есть несколько возможных путей решения данной
проблемы.
1. Для каждого типа дискового контроллера компилировать свою версию опера-
операционной системы.
2. Встроить в ядро несколько различных драйверов и дать системе возможность
автоматически выбирать нужный во время загрузки.
3. Встроить в ядро несколько различных драйверов и предоставить пользовате-
пользователю право выбрать подходящий.
Как мы увидим, эти решения не являются взаимоисключающими.
Первый вариант оптимален при долговременной работе. Если операционная сис-
система работает на конкретной машине, нет необходимости хранить в памяти код
драйверов, которые никогда не будут использованы. С другой стороны, такой
вариант очень неудобен для распространителя системы. Предоставлять несколь-
несколько загрузочных дисков и инструктировать пользователя, какой из них в каком
случае использовать, — сложно и дорого. Таким образом, более предпочтитель-
предпочтительны два других решения, по крайней мере, для начальной установки.
При втором подходе ОС должна выяснить, какое оборудование имеется в нали-
наличии, считывая ПЗУ на периферийных картах или обмениваясь с ними данными
через порты ввода-вывода. На некоторых системах это выполнимо, но для IBM
такое решение не всегда работает, так как для этих систем выпущено слишком
много нестандартного оборудования. Попытка передать данные в порт ввода-вы-
ввода-вывода, чтобы определиться с одним устройством, может активизировать другое уст-
устройство, которое захватит управление и заблокирует систему. Подобный подход
усложняет начальный код для каждого из устройств и к тому же работает не
слишком хорошо. Поэтому операционные системы, опирающиеся на него, должны
предоставлять возможность вручную корректировать результаты автоматиче-
автоматического детектирования оборудования. Обычно это механизмы, подобные исполь-
используемым в MINIX 3.
В третьем подходе, присущем MINIX 3, компилируются несколько драйверов,
один из которых выбирается по умолчанию. Монитор начальной загрузки считы-
считывает различные параметры загрузки. Эти параметры могут быть введены вручную
либо храниться на диске. Пусть, например, при загрузке ищется такой параметр:
label = AT
Тогда используется драйвер IDE-контроллера (at_wini). Все зависит от драй-
драйвера at_wini, связанного с меткой. Метки назначаются при компиляции загру-
загрузочного образа.
В MINIX 3 есть еще два инструмента, позволяющие снизить остроту проблем,
связанных с различиями в драйверах жестких дисков. Прежде всего, это специ-
специальный драйвер, который в своей работе использует функции BIOS. Этот драй-
драйвер гарантированно работает практически с любой системой. Чтобы выбрать его,
необходимо задать следующий параметр загрузки:
label = bios
Однако этот драйвер стоит рассматривать лишь как крайнее средство. В систе-
системах с процессором 80386 и выше MINIX 3 работает в защищенном режиме, а код
BIOS всегда выполняется в реальном режиме (режим 8086). Переключение ре-
режимов при каждом вызове функции BIOS требует очень много времени.
Кроме того, еще одна стратегия, которая используется в MINIX 3 при работе
с драйверами, сводится к тому, чтобы отложить инициализацию до самого по-
последнего момента. Таким образом, если ни один из драйверов жестких дисков не
работает с некоторой конфигурацией, мы все равно можем запустить MINIX 3
с дискеты и выполнить некоторые полезные действия. Это не выглядит особо
дружественным пользователю, но примите во внимание то, что если бы все драй-
драйверы пытались инициализироваться непосредственно при запуске системы, то
неправильная установка некоторых устройств, которые все равно лежат балла-
балластом, могла бы полностью парализовать ОС. Отложив инициализацию драйверов,
система может работать только с тем, что реально функционирует, давая пользо-
пользователю возможность исправить ситуацию.
Отступая в сторону, заметим, что этот урок тяжело нам дался. Ранние версии
MINIX пытались инициализировать жесткий диск при загрузке системы. Если
жесткого диска не было, система зависала. Такое поведение было особенно не-
неприятным потому, что система MINIX рассчитана также на машины без жестко-
жесткого диска, хотя это снижает и доступный объем памяти, и производительность.
В этом и следующем разделах мы будем рассматривать драйвер жесткого диска
в стиле AT, устанавливаемый в MINIX 3 по умолчанию. Это — многоцелевой
драйвер, обеспечивающий поддержку широкого диапазона контроллеров, как
ранних, применявшихся в системах 286, так и современных с усовершенство-
усовершенствованным интерфейсом жестких дисков с интегрированной электроникой (Extended
Integrated Drive Electronics, EIDE), работающих с дисками гигабайтного объема.
Современные EIDE-контроллеры также поддерживают стандартные дисководы
CD-ROM. Тем не менее, чтобы упростить обсуждение, расширения, обеспечиваю-
обеспечивающие поддержку CD-ROM, были исключены из кода, представленного на сопро-
сопровождающем книгу компакт-диске. Общие аспекты работы жесткого диска, кото-
которые мы включим в рассмотрение, относятся и к остальным драйверам.
Главным циклом драйвера жесткого диска служит уже изученный нами единый
код, поддерживающий девять стандартных запросов. Запрос DEV_OPEN непри-
неприятен потенциальным немалым количеством работы, так как на жестком диске
всегда есть разделы и с высокой вероятностью подразделы. При открытии уст-
устройства (то есть при первом обращении к нему) эта информация должна быть
прочитана. В случае поддержки CD-ROM при обработке запроса DEV_OPEN
должно проверяться наличие носителя в приводе. Для CD-ROM имеет значение
и операция DEV_CLOSE: она приводит к отпиранию дверцы привода и выбросу
диска. В случае сменного носителя есть и другие сложности, в большей степени
имеющие отношение к гибким дискам, поэтому мы рассмотрим их позже. В данном
случае, чтобы «выбросить» диск, используется операция DEV_IOCTL, устанавли-
устанавливающая значение флага, который анализируется при обработке запроса DEV_
CLOSE. Кроме того, DEV_IOCTL применяется для записи и чтения таблиц разделов.
Как мы видели ранее, обработка каждого из запросов DEV_READ, DEV_WRITE,
DEV_GATHER и DEV_SCATTER состоит из двух фаз — подготовки и передачи. В слу-
случае жесткого диска вызовы DEV_CANCEL и DEV_SELECT игнорируются.
Драйвер жесткого диска не выполняет планирования — это делает файловая сис-
система, формирующая векторы запросов для объединенного и разрозненного вво-
ввода-вывода. Кэш файловой системы передает драйверу запросы DEV_GATHER или
DEV_SCATTER на множество блоков (в MINIX 3 по умолчанию 4 Кбайт), однако
драйвер обрабатывает запросы по секторам E12 байт), хотя и в любом количе-
количестве. Как бы то ни было, главный цикл всех дисковых драйверов преобразует
совокупность запросов на отдельные блоки данных в единый вектор запросов.
Запросы на чтение и запись не объединяются в один вектор. Кроме того, запросы
не могут быть помечены как необязательные. Элементы вектора запросов соот-
соответствуют непрерывной последовательности секторов диска. Файловая система
сортирует вектор перед его передачей драйверу, чтобы указать лишь начальную
позицию на диске для совокупности запросов.
Предполагается, что драйвер успешно выполнит как минимум первый запрос
вектора и совершит возврат в случае неудачной обработки. Решение о дальней-
дальнейших действиях принимается файловой системой; запись она попытается завер-
завершить, а при чтении вернет столько данных, сколько удалось получить.
Сама файловая система за счет разрозненного ввода-вывода могла бы реализо-
реализовать что-либо наподобие элеватора [118] (в запросе разрозненного ввода-вывода
запросы сначала сортируются по номеру блока). Второй этап планирования
выполняется в контроллере современного диска. Подобные контроллеры дос-
достаточно «умные» и умеют хранить в буфере большой объем данных, тем самым
безотносительно к порядку поступления запросов обеспечивая максимальную
эффективность передачи больших объемов данных при помощи внутренних
алгоритмов.
3.7.5. Реализация драйвера
жесткого диска в MINIX 3
Жесткие диски часто называют «винчестерами». Существует несколько историй
о том, как родилось это название. Оно было у проекта компании IBM, разраба-
разрабатывавшей технологию, в которой магнитные головки «парят» над поверхностью
вращающегося диска, опираясь на тонкую воздушную прослойку. Одно из тол-
толкований названия в том, что у первых моделей было два герметически закрытых
корпуса: фиксированный C0 Мбайт) и сменный (тоже 30 Мбайт). Предполо-
Предположительно, это напомнило разработчикам винчестер «30-30», ставший «героем»
многих вестернов. Каково бы ни было происхождение названия, основа техно-
технологии остается той же самой, хотя типичные жесткие диски современных мик-
микрокомпьютеров гораздо миниатюрнее и хранят гораздо больше данных, чем их
14-дюймовый прототип начала 1970-х.
Драйвер жесткого диска, рассчитанного на шину AT, находится в файле at_
wini.c (строка 12100). Драйвер предназначен для сложного устройства и со-
содержит несколько страниц макроопределений, задающих регистры контроллера,
биты состояния, команды, структуры данных и прототипы. Как и в случае с драй-
драйверами других блочных устройств, в драйвере винчестера создается структура
типа driver, хранящаяся в переменной w_dtab (строки 12316-12331). Эта струк-
структура заполняется адресами функций, которые и выполняют все основные функ-
функции драйвера. Код большинства функций находится в файле at_wini . с, но так
как для жесткого диска не нужны специальные действия для завершения работы,
поле dr_cleanup структуры содержит ссылку на функцию nop_cleanup в фай-
файле driver. с. Последняя используется всеми драйверами, которые не нуждаются
в особых действиях для завершения. Данный драйвер не нуждается еще в не-
нескольких функциях; соответствующие указатели ссылаются на функции семей-
семейства пор_. Точка входа в драйвер — это функция at_winchester_task (стро-
(строка 12336), которая выполняет аппаратно-зависимую инициализацию и вызывает
главный цикл (файл driver, с), передавая ему адрес w_dtab. Главный цикл
(функция driver_task файла libdriver/driver.с) исполняется бесконеч-
бесконечно, обслуживая поступающие запросы и вызывая функции, адреса которых запи-
записаны в полях структуры w_dtab.
Поскольку в настоящее время мы имеем дело с электромеханическими устройст-
устройствами хранения информации, функции init_params (строка 12347) необходимо
сделать немало работы для инициализации драйвера жесткого диска. Различные
параметры жесткого диска хранятся в таблице wini (строки 12254-12276). Таб-
Таблица включает элемент для каждого из восьми (MAX_DRIVES) поддерживаемых
дисков — до четырех обычных дисков и до четырех дисков на шине PCI с IDE-
и SATA-контроллерами (аббревиатура SAT А расшифровывается как Serial AT
Attachment — последовательное АТ-подключение).
Следуя политике откладывания тех шагов инициализации, которые могут вы-
вызвать сбой, до момента их действительной необходимости, функция init_
params не выполняет никаких действий, требующих доступа к дисковым устрой-
устройствам. Основное ее предназначение — скопировать информацию о логической
конфигурации жесткого диска в массив wini. ROM BIOS компьютера Pentium
получает базовую конфигурационную информацию из CMOS-памяти при вклю-
включении компьютера раньше, чем начинается процесс загрузки MINIX 3. Копиро-
Копирование информации из BIOS осуществляется в строках 12366-12392. Многие
используемые здесь константы определены в файле include/ ibm/bios .h. Его
код вы можете найти на компакт-диске MINIX 3. Неудачная попытка получения
этой информации не обязательно приводит к аварии. Современные жесткие дис-
диски позволяют считывать конфигурационные данные при первом обращении. Сле-
Следом за вводом информации, полученной из BIOS, вызывается функция init_
drive, заполняющая дополнительные данные для каждого диска.
На старых системах с IDE-контроллерами диск функционирует так, как будто
он является периферийной АТ-платой, хотя он может быть интегрирован в мате-
материнскую плату. Современные дисковые контроллеры, как правило, работают как
PCI-устройства и используют 32-разрядный тракт данных к процессору вместо
16-разрядной шиной AT. К счастью, после завершения инициализации интер-
интерфейс к обоим поколениям дисковых контроллеров одинаков с точки зрения про-
программиста. Если необходимо, функция init_params_pci (строка 12437) вызыва-
вызывается для получения параметров PCI-устройств. Мы не будем вдаваться в ее детали,
но отметим несколько аспектов. Во-первых, параметр загрузки ata_instance,
используемый в строке 12361, задает значение переменной w_instance. Если
параметр загрузки не задан явно, по умолчанию выбирается нулевое значение.
Если параметр задан и положителен, тест в строке 12365 пропускает опрос BIOS
и инициализацию стандартных IDE-дисководов. В этом случае зарегистрирован-
зарегистрированными окажутся только диски, обнаруженные на шине PCI.
Второй аспект состоит в том, что контроллер, обнаруженный на шине PCI, иден-
идентифицируется как устройства управления с идентификаторами c0d4-c0d7.
При ненулевом значении w_instance идентификаторы c0d0-c0d3 пропуска-
пропускаются, если только контроллер шины PCI не идентифицирует себя как «совмести-
«совместимый». Эти идентификаторы назначаются дискам, подключенным к совместимому
контроллеру шины PCI. Скорее всего, пользователи MINIX 3 могут проигнори-
проигнорировать все эти сложности. Компьютер, оснащенный менее чем четырьмя дисками
(включая дисковод CD-ROM), с большой вероятностью будет иметь классическую
конфигурацию, в которой устройствам назначаются идентификаторы c0d0-c0d3
независимо от контроллера, к которому они подключены (IDE или PCI), и типа
соединителя — классического 40-контактного или более нового последователь-
последовательного. Тем не менее программное обеспечение, создающее всю эту иллюзию, от-
отличается высокой сложностью.
После вызова общего основного цикла никаких событий до первой попытки дос-
доступа к диску может не происходить. При попытке доступа основной цикл полу-
получает сообщение, запрашивающее операцию DEV_OPEN, и происходит косвенный
вызов функции w_do_open (строка 12521). В свою очередь, она вызывает w_
prepare, чтобы определить, корректно ли указано устройство, а далее, чтобы
выяснить тип устройства и инициализировать некоторые дополнительные пара-
параметры в массиве wini, вызывает w_identify. Счетчик в массиве wini нужен
для того, чтобы определить, является ли текущий вызов первым после запуска
MINIX 3. После каждого вызова значение счетчика увеличивается. Если обнару-
обнаружено, что это — первая операция DEV_OPEN, вызывается функция partition
из файла drvlib. с.
Следующая функция, w_prepare (строка 12577), принимает один целочислен-
целочисленный аргумент device, равный вспомогательному номеру устройства, и возвра-
возвращает указатель на структуру device, которая содержит информацию о базовом
адресе и размере устройства. (В языке С идентификатор, означающий имя струк-
структуры, разрешено использовать в качестве имени переменной.) Тип устройства
(является ли оно диском, разделом или подразделом) можно определить по его
вспомогательному номеру. После того как w_prepare завершает свою работу,
нет необходимости вызывать какие-либо связанные с разбиением на разделы
функции, записывающие или считывающие данные. Как вы могли увидеть, w_
prepare вызывается в ответ на запрос DEV_OPEN. Это также является одной из
частей трехэтапного цикла подготовки, планирования и завершения, применяе-
применяемого во всех операциях обмена данными.
Программно совместимые со стандартом AT диски находятся в употреблении
довольно давно, и функция w_identify (строка 12603) должна определить,
какой из появившихся за эти годы вариантов жесткого диска используется. На
первом шаге выясняется, доступны ли для чтения и записи порты ввода-вывода,
которые должны существовать для всех дисковых контроллеров одного семейст-
семейства. Здесь мы впервые имеем дело с доступом пользовательского драйвера к пор-
портам ввода-вывода, поэтому данная операция заслуживает описания. Дисковый
ввод-вывод реализуется с помощью структуры command, определенной в стро-
строках 12201-12208. Эта структура заполняется последовательностью байтовых ве-
величин. Более детально мы опишем их чуть позже. Пока имейте в виду, что из
двух присваиваемых значений одним является ATA_IDENTIFY — команда за-
запроса идентификации АТА-диска (аббревиатура AT А расшифровывается как AT
Attachment — АТ-подключение), а вторым — битовая комбинация, выбирающая
диск. Затем вызывается функция com_simple.
Эта функция выполняет всю работу по формированию вектора из семи адресов
портов ввода-вывода и байтов, которые необходимо записать в них, передаче этой
информации системному заданию, ожиданию прерывания и проверки возвра-
возвращенного состояния. Она проверяет работоспособность диска и считывает строку
16-разрядных значений посредством вызова ядра sys_insw в строке 12629.
Декодирование информации — весьма запутанный процесс, и мы не станем рас-
рассматривать его в подробностях. Достаточно сказать, что объем извлекаемых дан-
данных весьма велик, и среди них — модель диска и предпочтительные физические
параметры цилиндра, головки и сектора. (Заметьте, что «физическая» конфигура-
конфигурация в действительности может не совпадать с реальной физической структурой,
но у нас нет другой альтернативы, кроме как верить в то, что заявляет диск.)
Кроме того, эти сведения содержат информацию о том, поддерживает ли диск
линейную адресацию блоков (Linear Block Addressing, LBA). Если данная функция
поддерживается, драйвер вправе игнорировать цилиндры, дорожки и секторы и ад-
адресовать секторы диска просто по их абсолютным номерам, что намного проще.
Как уже отмечалось, не исключена ситуация, когда функция init_params
окажется не в состоянии получить информацию о конфигурации диска из BIOS.
Если такое случилось, код в строках 12666—12674 делает попытку сформиро-
сформировать подходящий набор параметров, основанных на тех данных, которые удалось
прочитать с самого диска. Основная идея состоит в том, что номера цилиндра,
дорожки и сектора не должны превышать соответственно 1023, 255 и 63, то есть
учитывается заложенное в структуры данных BIOS ограничение на количество
битов, выделяемых под эти параметры.
Если команда ATA_IDENTIFY возвращает отрицательный результат, это может
просто означать, что вы столкнулись со старой моделью диска, который не под-
поддерживает саму команду. В таком случае все, что мы имеем, — это параметры ло-
логической конфигурации, ранее прочитанные функцией init_params. Если они
корректны, то они и записываются в поля структуры wini, в противном случае
сообщается об ошибке, и система отказывается работать с диском.
Наконец, чтобы считать адреса в байтах, в MINIX 3 используется переменная
u32_t. Максимальный объем раздела, с которым умеет работать драйвер, огра-
ограничен значением в 4 Гбайт. Тем не менее структура device, используемая для
хранения базового адреса и размера раздела и определенная в файле drivers/
libdriver/driver. h (строки 10856-10858), содержит числа типа u64_t. Для
подсчета объема диска применяется операция 64-разрядного умножения (стро-
(строка 12688). Далее базовый адрес и размер диска вводятся в массив wini и вызы-
вызывается (дважды при необходимости) функция w_specify, передающая обратно
контроллеру его рабочие параметры (строка 12691). Затем выполняются вызовы
ядра. Вызов sys_irqsetpolicy (строка 12699) гарантирует, что по окончании
обслуживания прерывания от контроллера диска прерывания будут разрешены
автоматически. После этого вызов sys_irqenable фактически разрешает пре-
прерывание.
Функция w_name (строка 12711) возвращает указатель на строку, содержащую
имя устройства: «AT-DO», «AT-D1», «AT-D2» или «AT-D3». При необходимо-
необходимости генерации сообщения об ошибке данная функция указывает, какой из дис-
дисков является ее источником.
Не исключено, что в силу какой-либо причины диск окажется несовместимым
с MINIX 3. Функция w_io_test (строка 12723) проверяет каждый из дисков
при первой попытке получения доступа к нему. Она пытается считать первый
блок диска с более коротким временем ожидания, чем при обычном функциони-
функционировании. Если попытка не удается, диск помечается как недоступный.
Функция w_specify (строка 12775) в дополнение к передаче параметров кон-
контроллеру выполняет повторную калибровку устройства (для старых моделей),
передавая команду поиска нулевого цилиндра.
Функция do_transf er (строка 12814) заполняет структуру command байтовы-
байтовыми значениями, необходимыми для передачи фрагмента данных (до 255 секто-
секторов), а затем вызывает функцию com_out, посылающую команду контроллеру
диска. Формат данных зависит от способа адресации диска — по цилиндру,
головке и сектору или посредством линейной адресации блоков. Внутри MINIX 3
адресация дисковых блоков линейна. Таким образом, при линейной адресации
блоков первые три байтовых поля заполняются сдвигом счетчика сектора на со-
соответствующее число битов вправо и маскирования для получения 8-разрядного
значения. Счетчик сектора является 28-разрядным, поэтому последняя операция
маскирования использует 4-разрядную маску (строка 12830). Если диск не под-
поддерживает линейную адресацию блоков, значения цилиндра, головки и сектора
вычисляются согласно параметрам диска (строки 12833-12835).
Данный код рассчитан на будущее расширение. Линейная адресация блоков с 28-
разрядным счетчиком сектора ограничивает объем жесткого диска, доступный
операционной системе MINIX 3, значением 128 Гбайт (вы можете использо-
использовать жесткие диски большего объема, но для MINIX 3 будет доступно лишь
128 Гбайт). Программисты работают над новым режимом LBA48, хотя готовой
его реализации пока нет. В LBA48 для адресации дисковых блоков используется
48 бит. В строке 12824 проверяется, применяется ли режим LBA48. В описывае-
описываемой здесь версии MINIX 3 результат этого теста всегда отрицателен, поскольку
для противного случая еще нет кода. Имейте в виду, что если вы захотите вос-
воспользоваться режимом LBA48 самостоятельно, просто добавить сюда недостаю-
недостающие команды недостаточно. Чтобы обеспечить обработку 48-разрядных адресов,
вам придется изменить множество фрагментов программного кода. Проще дож-
дождаться, пока MINIX 3 будет перенесена на платформу с 64-разрядным процессо-
процессором. Если диска объемом 128 Гбайт для вас недостаточно, LBA48 позволит вам
расширить объем дискового пространства до 128 Пбайт (петабайт).
Теперь мы кратко рассмотрим передачу данных на более высоком уровне. Сна-
Сначала вызывается уже описанная нами функция w_prepare. Если запрошенная
операция касается множества блоков (запрос DEV_GATHER или DEV_SCATTER),
сразу после этого вызывается функция w_transf er (строка 12848). Если же опе-
операция относится к одному блоку (запрос DEV_READ или DEV_WRITE), то сначала
создается одноэлементный вектор запроса, а затем вызывается w_transf er.
Функция w_transf er ожидает вектор запросов iovec_t. Каждый элемент век-
вектора включает адрес и размер буфера с ограничением, что размер буфера должен
быть кратен размеру дискового сектора. Вся остальная информация передается
в качестве аргумента при вызове и применяется к вектору запросов целиком.
Первое, что делает функция w_transf er, — проверяет, выровнен ли начальный
адрес, затребованный для передачи, по границе сектора (строка 12863). Далее
следует внешний цикл функции, повторяемый для каждого элемента вектора за-
запросов. Как мы многократно видели, в этом цикле совершаются многочисленные
предварительные проверки, и лишь затем начинается фактическая работа. Снача-
Сначала поля iov_size каждого элемента вектора запросов суммируются, чтобы
получить общее число запрашиваемых байтов. Результат проверяется на крат-
кратность размеру сектора. Далее проверяется, что начальный адрес находится стро-
строго внутри адресного пространства устройства. Если запрос выходит за рамки
устройства, его размер округляется. До этого момента все расчеты производятся
в байтах, однако в строке 12876 позиция блока на диске вычисляется с исполь-
использованием 64-разрядной арифметики. Хотя переменная и имеет название block,
в ней хранится число блоков диска, то есть 512-байтных секторов, а не внутренних
«блоков» операционной системы MINIX 3 по 4096 байт каждый. Затем выпол-
выполняется еще одна «подстройка». У каждого диска имеется ограничение на число
байтов, которые можно запросить одновременно, и при необходимости объем
запроса соответственно уменьшается. После проверки инициализации диска
и, возможно, ее повторения запрос фрагмента данных посылается вызовом функ-
функции do_transf ег (строка 12887).
После запроса на передачу осуществляется вход во внутренний цикл, повторяе-
повторяемый для каждого сектора. При чтении и записи каждый сектор вызывает преры-
прерывание. При чтении прерывание означает, что данные готовы к передаче. Вызов
ядра sys_insw (строка 12913) запрашивает системное задание периодически
считывать порт ввода-вывода, передавая данные по виртуальному адресу в про-
пространстве данных указанного процесса. В случае записи порядок меняется на
противоположный. Вызов sys_outsw несколькими строчками ниже записывает
строку данных в контроллер, а контроллер генерирует прерывание после завер-
завершения передачи. Прием прерывания и при чтении, и при записи осуществляет
функция at_intr_wait, к примеру, в строке 12920 — после операции записи.
Несмотря на то что в нормальном режиме прерывание должно быть, функция
at_intr_wait способна обработать ситуацию сбоя, и прерывание никогда не
генерируется. Функция также считывает регистр состояния контроллера диска
и возвращает различные коды, проверяемые в строке 12933. Если при чтении
или записи происходит ошибка, команда break предотвращает выполнение сек-
секции, в которой записываются результаты, а указатели и счетчики готовят операцию
над следующим сектором. По этой причине в следующей итерации внутреннего
цикла предпринимается попытка повторно обработать неудачный сектор, если
это разрешено. Если контроллер диска указал, что сектор неисправен, функция
w_transf ег немедленно завершает работу. Для других ошибок значение счет-
счетчика увеличивается, и функции разрешается продолжить свою работу, если чис-
число ошибок не достигло max_errors.
Следующая функция, которую мы рассмотрим — com_out. Она посылает коман-
команду контроллеру диска, однако прежде чем разбираться в том, как она это делает,
давайте поймем, как контроллер выглядит с точки зрения программы. Управле-
Управление контроллером диска осуществляется с помощью набора регистров. В некото-
некоторых системах эти регистры отображаются на память, однако в IBM-совместимых
компьютерах они представлены как порты ввода-вывода. Мы рассмотрим эти реги-
регистры и обсудим некоторые аспекты их применения (а также регистров управления
вводом-выводом в целом). В MINIX 3 имеет место дополнительная сложность,
связанная с тем, что драйверы выполняются в пользовательском пространстве
и не могут исполнять команды чтения и записи регистров. Это означает, что сле-
следует изучить вызовы ядра, снимающие данное ограничение.
Регистры, используемые стандартным контроллером жесткого диска, совмести-
совместимым с IBM-AT, показаны в табл. 3.4.
♦ LBA — для режима адресации по цилиндре, головке и сектору (CHS) — 0, для
режима линейной адресации блоков (LBA) — 1;
♦ D — для главного диска (master) — 0, для подчиненного (slave) — 1;
♦ HSn — для режима CHS — выбор головки, для режима LBA биты 24-27 вы-
выбора блока.
Таблица 3.4. Регистры управления IDE-контроллером жесткого диска. Номера в скобках
означают биты логического адреса блока, соответствующие каждому регистру в режиме LBA
Регистр Чтение Запись
0 Данные Данные
1 Ошибка Предварительная компенсация записи
2 Количество секторов Количество секторов
3 Номер сектора @-7) Номер сектора @-7)
4 Цилиндр (младшие биты) (8-15) Цилиндр (младшие биты) (8-15)
5 Цилиндр (старшие биты) A6-23) Цилиндр (старшие биты) A6-23)
6 Выбор привода/головки B4-27) Выбор привода/головки B4-27)
7 Состояние Команда
Мы уже неоднократно упоминали чтение и запись в порты ввода-вывода, ото-
отождествляя их с адресами памяти. Однако порты ввода-вывода зачастую ведут се-
себя совершенно иначе, чем адреса памяти. Вообще говоря, входные и выходные
регистры, которым соответствует один и тот же порт ввода-вывода, не обязатель-
обязательно совпадают. То есть данные, записанные в некоторый порт, нельзя считать из
него последующей операцией чтения. Например, последний регистр в табл. 3.4
показывает состояние контроллера диска, если считывать из него данные, а при
записи в него данных передает команду контроллеру. Кроме того, часто сам факт
записи данных в порт ввода-вывода приводит к выполнению некоторых дей-
действий независимо от характера передаваемых данных (например, для регистра
команд АТ-совместимого контроллера). При работе с ним параметры заносятся
в младшие регистры, а в регистр команд помещается код операции. Сигналом на-
начала операции является факт записи данных в регистр команд.
Этот случай является иллюстрацией ситуации, когда назначение регистров зави-
зависит от режима работы. В приведенном в табл. 3.4 примере режим выбирается
шестым битом шестого регистра, как показано в табл. 3.5. Данные, записывае-
записываемые или считываемые в регистры 3-5, а также младшие четыре бита регистра 6
по-разному интерпретируются в зависимости от значения бита LBA.
Таблица 3.5. Поля регистра выбора привода/головки
7 6 5 4 3 2 10
J LBA 1 D HS3 HS2 HS1 HS0
Теперь рассмотрим, как при помощи функции com_out (строка 12947) команда
передается контроллеру. Эта функция вызывается после заполнения структуры
cmd уже изученной нами функцией do_transfer. Прежде чем менять какие-
либо регистры, программа узнает, занят ли контроллер, считывая бит STATUS_
BSY. Здесь важна скорость, и так как контроллер обычно должен быть свободен
или скоро освободится, здесь используется активное ожидание. В строке 12960
вызывается команда w_waitf or, тестирующая значение бита STATUS_BSY. Чтобы
проверить бит в регистре состояния, w_waitfor делает вызов ядра, осуществ-
осуществляющий чтение порта ввода-вывода. Цикл активного ожидания продолжается до
тех пор, пока бит не установится в значение готовности либо не истечет интервал
ожидания. Как только диск готов, цикл быстро прекращается. В качестве возвра-
возвращаемого значения будет указана истина, если контроллер готов сразу, истина, ес-
если контроллер оказывается готов с некоторой задержкой, и ложь, если контрол-
контроллер не приходит в состояние готовности в течение интервала ожидания. Более
подробно интервал ожидания рассматривается при описании функции w_waitf or.
Контроллер способен обслуживать более одного диска, поэтому когда он освобо-
освобождается, в регистры записывается байт, выбирающий привод, головку и режим
работы (строка 12966), и функция w_waitf or вызывается снова. Иногда приво-
приводу не удается выполнить команду или правильно вернуть код ошибки; в конце
концов, это — механическое устройство, которое может заесть или просто сломать-
сломаться, и для страховки совершается вызов sys_setalarm ядра, чтобы системное
задание запланировало вызов подпрограммы, разблокирующей драйвер. Следом
за этим команда передается контроллеру, для чего сначала все параметры за-
записываются в разные регистры, а затем в регистр команд кладется код самой
команды. Это делает вызов sys_voutb ядра, посылающий вектор пар (значение,
адрес) системному заданию. Системное задание записывает каждое значение
в порт ввода-вывода, задаваемый адресом. Вектор данных для вызова sys_voutb
формируется с помощью макроса pv_set, определенного в файле include/
mimix/devio.h. Обработка начинается, когда в регистр команд записывается
код операции. По завершении генерируется прерывание и отправляется уведом-
уведомление. Если при выполнении команды истечет интервал ожидания, синхронное
уведомление активирует дисковый драйвер.
Следующие несколько функций, которые мы рассмотрим, меньше по объему.
Функция w_need_reset (строка 12999) вызывается при истечении интервала
ожидания прерывания или готовности диска. Все, что делает w_need_reset, —
задает значение переменной state для каждого диска в массиве wini, чтобы
вызвать инициализацию при следующей попытке доступа.
Функция w_do_close (строка 13016) в отношении обычного жесткого диска не
делает почти ничего. Если необходима поддержка CD-ROM, следует включить
в нее дополнительный код.
Функция com_simple отправляет команду контроллеру и немедленно заверша-
завершается без обмена данными. В данную категорию попадают команды, которые слу-
служат для идентификации диска, установки некоторых параметров и повторной
калибровки привода. Пример использования этой функции мы видели в функции
w_identify. Перед ее вызовом структура command должна быть корректно ини-
инициализирована. Обратите внимание на то, что сразу же после вызова com_out
вызывается функция at_intr_wait. В конечном счете, она совершает вызов
receive, который обеспечивает блокировку до тех пор, пока не будет получено
уведомление о прерывании.
Мы упомянули о том, что функция com_out выполняет вызов sys_setalarm
ядра перед тем, как обратиться к системному заданию за записью регистров,
устанавливающих и исполняющих команду. Как уже отмечалось, следующая опе-
операция receive должна получить уведомление о прерывании. Если уведомление
было активизировано, а прерывания не случилось, следующим сообщением бу-
будет SYN_ALARM. В этом случае вызывается функция w_timeout (строка 13046).
Конкретные действия, которые нужно выполнить, зависят от текущей команды
в w_command. Возможно, от предыдущей команды остался истекший интервал
ожидания, и значение w_command равно CMD_IDLE, что указывает на заверше-
завершение работы диска. В этом случае никаких действий выполнять не нужно. Если
работа не завершена и операция является чтением или записью, размер запросов
ввода-вывода можно сократить. Это делается в два этапа: количество запра-
запрашиваемых секторов уменьшается сначала до 8, затем — до 1. Во всех случаях
истечения времени ожидания на экран выводится сообщение и для повторной
инициализации всех приводов при следующей попытке доступа вызывается
функция w_need_reset.
Когда требуется сброс, вызывается функция w_reset (строка 13076). Эта под-
подпрограмма использует библиотечную функцию tickdelay, устанавливающую
сторожевой таймер и ожидающую его истечения. Сначала w_reset делает на-
начальную задержку, чтобы дать приводу время вернуться в исходное состояние
после предыдущих действий. Затем стробируется бит регистра управления кон-
контроллера диска, то есть сначала на заданное время бит устанавливается в 1, а за-
затем возвращается в 0. Далее вызывается w_waitfor, чтобы позволить диску
прийти в состояние готовности. Если сброс не завершился успехом, на экран вы-
выводится сообщение и возвращается код ошибки.
Команды, затрагивающие обмен данными с диском, обычно завершаются генера-
генерацией прерывания, которое отправляет сообщение обратно драйверу. Фактически
прерывание генерируется каждый раз, когда считывается или записывается
сектор. Функция w_intr_wait (строка 13123) циклически вызывает receive,
и если получено сообщение SYN_ALARM, вызывается w_timeout. Помимо со-
сообщения SYN_ALARM, функция w_intr_wait воспринимает лишь один тип
сообщений — HARD_INT. При его получении выполняется считывание регистра
состояния, и прерывание инициализируется заново вызовом ack_args.
Функция w_intr_wait не вызывается впрямую; при ожидании прерывания вы-
вызывается следующая функция, at_intr_wait (строка 13152). После получения
ею прерывания выполняется быстрая проверка битов состояния диска. Штатным
считается состояние, в котором сброшены биты занятости, сбоя записи и ошиб-
ошибки. В противном случае выполняется более тщательный анализ. Если регистр
вовсе не удалось прочитать, это считается сбоем системы. Если неполадка вызвана
неисправным сектором и возвращен определенный код ошибки, передается код
общей ошибки. Во всех случаях устанавливается бит STATUS_ADMBSY, который
позднее должен быть сброшен источником вызова.
Имеется несколько мест, где для активного ожидания бита регистра состояния
контроллера диска вызывается функция w_waitf or (строка 13177). Она исполь-
используется в ситуациях, когда предполагается, что при первой проверке бит может
быть сброшен и желательно протестировать его быстро. Для скорости в ранних
версиях MINIX задействовали макрос, впрямую считывавший порт ввода-вывода.
Разумеется, это невозможно в MINIX 3, где драйверы выполняются в пользова-
пользовательском пространстве. Выходом является применение цикла do...while с ми-
минимумом накладных расходов перед первой проверкой. Если проверяемый бит
сброшен, выход из цикла производится немедленно. Чтобы принять в расчет воз-
возможный сбой, в цикле предусмотрен интервал ожидания с учетом числа тактов
часов. При истечении интервала ожидания вызывается функция w_need_reset.
Параметр timeout, используемый функцией w_waitfor, определен констан-
константой DEF_TIMEOUT_TICKS, равной 300 тактам или 5 секундам (строка 12228).
Аналогичный параметр WAKEUP (строка 12216), применяемый при планирова-
планировании «пробуждения» драйвера по сигналу таймерного задания, равен 31с. Это —
очень большие периоды времени для активного ожидания, если сравнивать их
с обычным процессом, которому на работу дается 100 мс. Такие большие за-
задержки обусловлены существующими стандартами для АТ-совместимых дисков.
Согласно этим стандартам, диску может потребоваться до 31 с, чтобы разо-
разогнаться. Конечно, на практике такое время требуется только в самом худшем
случае, а разгон диска в большинстве систем происходит при включении питания
или после длительных периодов бездействия. Возможно, когда будет добавлена
поддержка CD-ROM (или других устройств, у которых раскрутка происходит
часто), данный вопрос станет более актуальным.
В файле at_wini.c есть еще несколько функций. Функция w_geometry воз-
возвращает максимальное значение номеров цилиндров, дорожек и секторов для
выбранного жесткого диска. В отличие от виртуального диска, где эти значения
имитировались, здесь в числа вложен реальный смысл. Функция w_other выпол-
выполняется для всех нераспознанных команд и вызовов управления вводом-выводом.
В текущем выпуске MINIX 3 она не используется, поэтому, вероятно, следовало
бы исключить ее из кода, представленного на сопровождающем книгу компакт-
диске. Функция w_hw_int вызывается при неожидаемом аппаратном прерыва-
прерывании. В обзоре мы упомянули, что подобная ситуация может произойти из-за того,
что прерывание генерируется после истечения интервала ожидания. «Опоздав-
«Опоздавшее» прерывание разблокирует операцию receive, блокированную его ожида-
ожиданием, однако уведомление о прерывании может быть обнаружено следующим
вызовом receive. Единственное, что нужно сделать, — это снова разрешить пре-
прерывания. Для этого вызывается функция ack_irqs (строка 13297). Она обраба-
обрабатывает все обнаруженные диски в цикле, выполняя для каждого из них вызов
sys_irqenable ядра, который гарантированно разрешает прерывания. Наконец,
в файле at_wini .с имеются две странные маленькие функции, strstatus
и strerr. Они объединяют коды ошибок со строками при помощи указанных
перед ними макросов (строки 13313 и 13314). Эти функции в описываемой вер-
версии MINIX 3 не используются.
3.7.6. Дисковод гибких дисков
Драйвер дисковода гибких дисков сложнее, чем драйвер жесткого диска, а объем
его кода больше. Это на первый взгляд парадоксально, так как механизмы диско-
дисковода гибких дисков должны быть проще, чем механизмы винчестера, но кон-
контроллер первого сложнее и требует к себе больше внимания от операционной
системы. К тому же, дополнительные сложности вносит сменный носитель. В теку-
текущем разделе мы рассмотрим некоторые вопросы, которые могут оказаться полез-
полезными для программиста, имеющего дело с гибкими дисками. В основных дета-
деталях код драйвера дисковода сходен с кодом драйвера жесткого диска. Детально
же разбирать код, ввиду его сложности, мы не будем.
Одна из проблем, с которыми мы не столкнемся, работая с приводами дискет, —
это необходимость поддерживать много типов контроллеров, что было обяза-
обязательно для жестких дисков. Хотя использующиеся сейчас гибкие диски с высо-
высокой плотностью записи не поддерживались оригинальными машинами IBM PC,
все контроллеры гибких дисков обслуживаются одним драйвером. Такое от-
отличие от жестких дисков произошло, видимо, потому, что на дисководы гибких
дисков не оказывалось то давление, которое заставляло разработчиков повышать
производительность жестких дисков. Дискеты редко используются как рабочее
хранилище в компьютерной системе, их скорость и емкость слишком ограничены
по сравнению с винчестерами. Дискеты продолжают использоваться, но только
для переноса небольших файлов, поэтому такими дисководами все еще оснаще-
оснащено большинство компьютеров.
Драйвер дисковода гибких дисков не включает в себя сложных алгоритмов пла-
планирования, таких как SSF или элеваторный алгоритм. Запросы выполняются
строго последовательно, причем следующий запрос не принимается, пока не вы-
выполнен текущий. Изначально при разработке MINIX предполагалось, что эта
система предназначена для персональных компьютеров, где большую часть вре-
времени будет активен только один процесс, и вероятность появления одного запро-
запроса во время обработки другого мала. Таким образом, поддержка очередей запро-
запросов не дала бы заметного увеличения производительности, зато потребовала бы
значительного усложнения кода. Сейчас это тем более не имеет смысла, так как
дискеты по большей части применяют для переноса отдельных файлов с одной
системы на другую.
Драйвер дисковода гибких дисков, как и любое блочное устройство, способен об-
обрабатывать запросы разрозненного ввода-вывода. Тем не менее массив запросов
у него меньшего объема, чем у драйвера жесткого диска. Количество запросов
в массиве ограничено максимальным числом секторов на одной дорожке дискеты.
Простота устройства аппаратной части дисковода гибких дисков приводит к услож-
усложнению его драйвера. Использовать в дешевых, медленных и обладающих малой
емкостью дисководах сложные контроллеры, входящие в современные жесткие
диски, неоправданно. Поэтому программному обеспечению приходится явно учи-
учитывать все аспекты взаимодействия с диском. В качестве примера, показываю-
показывающего сложность работы с дисководом, рассмотрим процесс позиционирования
магнитной головки на нужную дорожку при выполнении операции SEEK. Для
жесткого диска драйверу вообще никогда не требуется явно вызывать операцию
SEEK. Номера цилиндров, головок и секторов, видимые программисту, могут не
совпадать с реальным физическим устройством жесткого диска. Реальная гео-
геометрия может быть весьма запутанной, например, на внешних цилиндрах может
быть больше секторов, чем на внутренних. Тем не менее пользователь этого не
замечает. Жесткие диски способны поддерживать логическую адресацию блоков
(LBA), когда сектор указывается его абсолютным номером на диске, как альтерна-
альтернативу традиционной адресации по цилиндру, головке и сектору (CHS). Но даже
при традиционной адресации можно использовать любую геометрию, раз кон-
контроллер сам вычисляет, куда переместить головку, и при необходимости выпол-
выполняет операцию поиска.
Что же касается дискет, для них операция SEEK требует явного программирова-
программирования. Если команда SEEK завершается неудачей, требуется вызвать подпрограм-
подпрограмму, выполняющую операцию RECALBRATE, которая принудительно перемещает
головку на нулевой цилиндр. Это позволяет контроллеру заново найти нужную
дорожку, по шагам перемещая головку на известное количество дорожек. Конеч-
Конечно же, подобные действия необходимы и для жесткого диска, но контроллер же-
жесткого диска обходится без детальных инструкций драйвера.
Вот некоторые из особенностей дисководов для гибких дисков, которые услож-
усложняют драйвер.
1. Сменный носитель.
2. Различные форматы дисков.
3. Необходимость управления мотором.
Некоторые контроллеры жестких дисков предусматривают работу со сменным
носителем (например, контроллер CD-ROM), и обычно контроллер справляется
с большинством сложностей без помощи драйвера. В случае привода дискет встро-
встроенной поддержки нет, и это при том, что нужна она здесь еще больше. Дискеты
используются для переноса файлов и установки программ, и часто бывает, что
нужно менять дискеты, извлекая одну и вставляя следующую. Если данные, ко-
которые должны быть записаны на один диск, оказались на другом, неприятностей
не избежать. Драйвер обязан пойти на все во избежание таких проблем, хотя это
не всегда возможно, так как не все приводы позволяют определить, открывалась
ли дверца с момента последнего обращения. Другая проблема, к которой приво-
приводит использование сменного носителя, — это обращение к приводу без дискеты,
что опасно зависанием системы. Такой проблемы можно избежать, если сущест-
существует возможность определить, открыта ли дверца привода, но так как это не все-
всегда гарантируется, необходимо предусмотреть прерывание операции по истече-
истечении интервала времени.
Сменный носитель по определению заменяется другим, причем в случае дискет
носители могут иметь множество различных форматов. MINIX поддерживает
как 3,5-дюймовые, так и 5,25-дюймовые диски, отформатированные с различной
плотностью записи, от 360 Кбайт до 1,2 Мбайт (для 5-дюймовых дискет) или
1,44 Мбайт (для 3-дюймовых).
MINIX 3 работает с семью различными форматами. Существует два способа ре-
решения проблемы множества форматов. При первом подходе каждому формату
соответствует отдельное устройство с собственным вспомогательным номером.
Он использовался в ранних версиях MINIX. Были определены 14 различных
устройств, начиная с устройства /dev/pcO, которому сопоставлен 5-дюймовый
диск объемом 360 Кбайт, и заканчивая устройством /dev/PSl, то есть 3-дюймо-
3-дюймовой дискетой на 1,44 Мбайт. Такое решение громоздко, и в MINIX 3 применяется
альтернативный подход. Когда к дисководу обращаются через файл /dev/fdO
или /dev/ f dl (второй дисковод), драйвер тестирует дискету, чтобы определить
ее формат. У разных форматов разное число цилиндров и секторов, и чтобы оп-
определить формат, делается попытка прочитать последние секторы и дорожки.
Нужный вариант определяется путем исключения. Конечно, для этого требуется
некоторое время, однако на современных компьютерах, как правило, установле-
установлены 3,5-дюймовые дискеты объемом 1,44 Мбайт, поэтому такой формат проверя-
проверяется первым. Кроме того, диск, имеющий сбойные секторы или защиту от копи-
копирования, может быть идентифицирован неправильно. Для тестирования дисков
имеется специальная утилита; средствами операционной системы это делается
слишком медленно.
Последняя сложность при работе с дисководом гибких дисков — это управление
двигателем. Считывать или записывать данные на дискету невозможно, если она
не вращается. Жесткие диски разрабатываются так, чтобы работать тысячи часов
без износа, но если мотор дисковода все время оставлять в движении, дискета
быстро придет в негодность. Если при обращении к диску мотор оказывается
выключенным, то прежде чем пытаться считывать данные, необходимо подать
команду для его включения, после чего подождать примерно полсекунды. На
включение и выключение двигателя уходит много времени, поэтому MINIX
оставляет двигатель работающим в течение еще нескольких секунд после обра-
обращения. Если за это время к диску происходят новые обращения, таймер запуска-
запускается заново. В противном случае мотор отключается.
3.8. Терминалы
В течение десятилетий пользователи взаимодействуют с компьютерами при по-
помощи устройств, состоящих из клавиатуры и дисплея. Посредством клавиатуры
пользователь вводит в компьютер данные, а компьютер отображает результаты
на дисплее. Долгое время клавиатура и дисплей объединялись в отдельное уст-
устройство, подключаемое к компьютеру проводом. Большие мэйнфреймы, используе-
используемые в финансовой и туристической отраслях, до сих пор имеют такие терминалы.
Как правило, терминал соединяется с мэйнфреймом при помощи модема, особенно
если расстояние между ними велико. С появлением персональных компьютеров
клавиатура и дисплей стали отдельными периферийными устройствами, однако
они по-прежнему тесно взаимосвязаны, и мы будем рассматривать их совместно
под общим названием «терминал».
На протяжении своей истории терминалы имели множество различных форм.
Скрытие этих различий ложится на драйвер терминала, чтобы не переписывать
аппаратно-независимую часть системы и пользовательские программы для каж-
каждого нового типа терминала. В этом разделе мы последуем нашему стандартному
подходу к подаче материала и сначала обсудим аппаратное и программное обес-
обеспечение терминалов в общем и целом, а затем перейдем к подробностям их реа-
реализации в MINIX 3.
3.8.1. Аппаратное обеспечение терминала
С точки зрения операционной системы, терминалы можно разбить на три катего-
категории, в зависимости от того, как ОС взаимодействует с ними. Первую категорию
представляют терминалы, отображаемые на память и состоящие из клавиатуры
и дисплея, которые подключаются к компьютеру. Такая модель применяется во
всех персональных компьютерах. Во вторую группу входят терминалы, подклю-
подключаемые через последовательную линию передачи данных стандарта RS-232, чаще
всего через модем. Такая модель до сих пор используется в некоторых мэйнфрей-
мэйнфреймах, однако имеются и персональные компьютеры с последовательным интер-
интерфейсом. Третью группу образуют терминалы, подключаемые через сеть. Разно-
Разнообразие терминалов иллюстрирует рис. 3.16.
Рис. 3.16. Типы терминалов
Отображаемые на память терминалы
Первая широкая категория терминалов (см. рис. 3.16) — это отображаемые на
память терминалы. Такие терминалы представляют собой составную часть самого
компьютера, в особенности персонального. Они состоят из клавиатуры и мони-
тора. Доступ к такому терминалу происходит посредством специальной области
памяти» называемой видеопамятью, которая входит в общее адресное простран-
пространство компьютера и адресуется так же, как и остальная память (рис. 3.17).
Рис. 3.17. Отображаемые на память терминалы, доступ через видеопамять
На видеокарте имеется также микросхема, называемая видеоконтроллером. На ее
вход подаются коды символов, а на выходе она генерирует видеосигнал, который
воспринимается монитором. Электронно-лучевая трубка монитора генерирует
электронный луч, горизонтально сканирующий экран, рисуя на нем линии. Обыч-
Обычно экран имеет разрешение от 480 до 1200 линий по вертикали и от 640 до
1920 точек в линии. Эти точки называют пикселами. Сигнал от видеоконтролле-
видеоконтроллера модулирует электронный луч и определяет, будет ли пиксел светлым или тем-
темным. У цветных мониторов есть три независимо модулируемых луча, отдельно
для красного, зеленого и синего цветов.
Жидкокристаллический дисплей имеет кардинально иное внутреннее устройство,
однако существуют жидкокристаллические дисплеи, воспринимающие те же ви-
видео- и синхронизирующие сигналы, что и электронно-лучевые мониторы. Эти
сигналы используются для управления жидким кристаллом каждого пиксела.
У простого монохромного монитора каждый символ (включая межсимвольный
промежуток) помещается в прямоугольник размером 9 пикселов в ширину и 14
в высоту, всего на экране получается 25 строк по 80 символов в каждой. При
этом дисплей должен иметь разрешение 350 строк по 720 пикселов в каждой. Ка-
Каждый кадр обновляется от 45 до 70 раз в секунду. Видеоконтроллер при этом
мог бы считывать из видеопамяти первые 80 символов, генерировать для них
14 строк растра, затем считывать следующую строку символов, генерировать для
них растр и т. д. Фактически же, большинство контроллеров считывают символ
из видеопамяти один раз на строку растра, чтобы не было необходимости в буфе-
буферизации. Рисунки символов размером 9 х 14 хранятся в ПЗУ видеоконтролле-
видеоконтроллера (или ОЗУ, чтобы отображать пользовательские шрифты). Эта область памя-
памяти адресуется 12-разрядным адресом, в котором 8 бит определяют код символа,
а 4 бита задают номер строки. 8 бит каждого байта памяти определяют 8 пиксе-
пикселов, а девятый пиксел всегда пустой. Таким образом, для отображения на экране
одной строки текста требуется 14 х 8 = 1120 обращений к видеопамяти. То же
количество обращений делается к ПЗУ генератора символов.
В IBM PC поддерживаются несколько режимов работы экрана. Простейший из
них представляет собой символьный дисплей для консоли. На рис. 3.18, а мы
видим область видеопамяти. Каждый символ на рис. 3.18, б представлен в видео-
видеопамяти двумя байтами. Младший байт — это ASCII-код символа, а старший —
байт атрибутов, который может определять цвет, инверсию, мигание и прочие
атрибуты символа. В этом режиме весь экран размером 25 х 80 символов занима-
занимает 4000 байт видеопамяти. Такой режим поддерживается всеми современными
дисплеями.
Рис. 3.18. Область видеопамяти: а — содержимое видеопамяти для монохромного
дисплея IBM; б — соответствующее изображение на экране
Современные растровые дисплеи основаны на том же принципе, за исключением
того, что позволяют управлять цветом каждого пиксела на экране по отдельно-
отдельности. В простейшем варианте для монохромного дисплея каждому пикселу соот-
соответствует один бит видеопамяти. В другом предельном случае цвет пиксела опи-
описывается 24-разрядным словом, в котором по 8 бит выделяется на красный,
зеленый и синий компоненты. Чтобы просто хранить содержимое экрана раз-
разрешением 768 х 1024 пикселов и глубиной цветности 24 бит/пиксел, требуется
2 Мбайт видеопамяти.
У отображаемого на память терминала клавиатура полностью отделена от экра-
экрана. Она может подключаться через последовательный или параллельный порт.
При каждом срабатывании клавиши генерируется прерывание, и драйвер кла-
клавиатуры считывает из порта ввода-вывода код нажатого символа.
У персонального компьютера клавиатура содержит встроенный микропроцессор,
который через специальный последовательный порт взаимодействует с чипом
контроллера на материнской плате. Прерывание генерируется каждый раз, когда
клавиша нажимается или отпускается. Все, что сообщает клавиатура, — это но-
номер нажатой клавиши, а не ее ASCII-код. Например, когда нажимается клавиша А,
в регистр ввода-вывода помещается код 30. А означает ли это символ верхнего
регистра, нижнего регистра, комбинацию Ctrl+A, Alt+A, Ctrl+Alt+A или другую
комбинацию, должен знать драйвер клавиатуры. У него имеется достаточно ин-
информации для выполнения этой работы, так как он в курсе, какие клавиши были
нажаты, но не были отпущены (например, Shift). Так как клавиатурный интер-
фейс перекладывает все сложности на программное обеспечение, он очень гибок.
Например, программе может потребоваться информация о том, была ли цифра
набрана на цифровой клавиатуре или на основной. В принципе, драйвер клавиа-
клавиатуры может предоставить эту информацию.
Терминалы RS-232
Терминалы RS-232 представляют собой устройства, состоящие из клавиатуры
и экрана, которые взаимодействуют через последовательный интерфейс. Такой
интерфейс позволяет передавать по одному биту за раз (рис. 3.19). Эти термина-
терминалы подключаются через 9- или 25-контактный разъем, в котором один контакт
служит для передачи данных, один для приема и один для заземления. Осталь-
Остальные контакты отвечают за разного рода управляющие функции, и большинство
из них не используется. Чтобы передать символ, терминал RS-232 должен от-
отправлять по одному биту, предварив передачу стартовым битом и завершив ее
одним или двумя стоповыми битами. Также может быть добавлен бит контроля
четности, который позволяет организовать простейшую проверку правильности
передачи, хотя обычно он требуется только для взаимодействия с мэйнфреймами.
Этот бит может находиться перед стоповыми битами. Стандартно применяются
скорости передачи 14 400 и 56 000 бит/с: первая для факсимильной информа-
информации, вторая — для данных. Терминалы RS-232 обычно подключаются к удален-
удаленной системе при помощи модема и телефонной линии.
Рис. 3.19. Терминал RS-232 взаимодействует с компьютером через последовательную
линию передачи данных, передавая по одному биту за раз. Терминал и компьютер
полностью независимы
Так как на внутреннем уровне как терминал, так и компьютер представляют
информацию в виде символов, а передают по последовательной линии, были
разработаны микросхемы, осуществляющие преобразование символа в последова-
последовательность битов, и наоборот. Эти чипы называются UART (Universal Asynchronous
Receiver Transmitter — универсальный асинхронный приемопередатчик). UART
подключаются к компьютеру при помощи интерфейсных карт RS-232, соединен-
соединенных с шиной, как показано на рис. 3.19. На современных компьютерах интерфей-
интерфейсы RS-232 и UART зачастую являются частью набора микросхем материнской
платы. Не исключена возможность отключения встроенной микросхемы UART
и использования вместо нее модемной интерфейсной платы либо сосуществова-
сосуществования двух устройств. Модем осуществляет передачу по телефонной линии вместо
последовательного кабеля и может быть оснащен устройством UART (возмож-
(возможно, встроенным в состав многофункциональной микросхемы наряду с другими).
С точки зрения компьютера, UART выглядит неизменно при любой среде пере-
передачи — будь то последовательный кабель или телефонный провод.
Терминалы RS-232 постепенно вымирают, и на смену им приходят персональ-
персональные компьютеры, однако их все еще можно встретить в старых мэйнфреймах,
особенно в банковской сфере, системах предварительного заказа авиабилетов и т. д.
Чтобы вывести символ на экран, драйвер терминала записывает этот символ в ин-
интерфейсную карту, в которой она буферизируется, после чего поразрядно выдви-
выдвигается в последовательную линию универсальным асинхронным приемопередат-
приемопередатчиком. Например, для аналогового модема, работающего со скоростью 56 000 бит/с,
для передачи одного символа требуется немного более 140 мкс. Поскольку эта
скорость невелика, драйвер обычно передает в интерфейсную карту RS-232 один
символ. Затем драйвер блокируется и ждет прерывания, которое инициирует ин-
интерфейс, передав символ и перейдя в состояние готовности к приему следующе-
следующего символа. Микросхема UART способна одновременно передавать и принимать
символы. Прерывание также генерируется при получении символа, и обычно не-
несколько принятых символов могут сохраняться в буфере. Получив прерывание,
драйвер терминала должен проверить регистр, чтобы определить причину пре-
прерывания. Некоторые интерфейсные карты имеют собственный процессор и па-
память и способны одновременно поддерживать несколько линий, разгружая тем
самым центральный процессор.
Терминалы с интерфейсом RS-232 подразделяются на три категории. Наиболее
простыми являются печатающие терминалы, или телетайпы. Символы, набирае-
набираемые на клавиатуре, посылаются компьютеру. Символы, посланные компьютером,
печатаются на бумаге. Такие терминалы уже давно считаются устаревшими и поч-
почти не встречаются.
Простейшие электронно-лучевые терминалы работают похожим образом, но
вместо бумаги они выводят символы на экран. Такой терминал также называют
«стеклянным телетайпом» (glass tty), поскольку функционально он аналогичен
печатающему телетайпу. Термин «tty» является сокращением имени компании
Teletype, бывшей пионером в области компьютерных терминалов. Теперь сокра-
сокращение «tty» используется для обозначения любого терминала. «Стеклянные» те-
телетайпы также устарели.
«Умные» электронно-лучевые терминалы на самом деле представляют собой не-
небольшие специализированные компьютеры. У них есть процессор и память. Они
также содержат программное обеспечение, хранящееся, как правило, в ПЗУ.
С точки зрения операционной системы, основное различие между «стеклянным»
телетайпом и «умным» терминалом состоит в том, что последний понимает
управляющие последовательности символов, называемые ESC-последователь-
ностями. Передав такому терминалу ASCII-символ ESC @33) и следом несколь-
несколько других символов, можно управлять выводом на экран терминала. Напри-
Например, с помощью ESC-последовательности можно переместить курсор на новую
позицию, вывести текст в любое заданное место экрана, очистить экран и т. д.
3.8.2. Программное обеспечение терминала
Клавиатура и экран являются почти независимыми устройствами, поэтому мы
будем рассматривать их здесь по отдельности. Однако они не совсем незави-
независимы, так как вводимый с клавиатуры символ обычно эхом выводится на экран.
В MINIX 3 клавиатура и экран являются частью одного процесса, в других сис-
системах за них могут отвечать разные драйверы.
Программное обеспечение ввода
Основная работа клавиатурного драйвера состоит в сборе вводимых с клавиату-
клавиатуры символов и передаче их программам, читающим с терминала. Существует две
концепции, описывающие работу драйвера. Согласно первой, задача драйвера
заключается в сборе ввода и передаче его программам без всяких изменений.
Программа, читающая с терминала, получает необработанные последовательно-
последовательности ASCII-символов. (Передавать пользовательским программам коды нажатых
клавиш нельзя, так как они в большой степени зависят от конкретной машины.)
Эта философия хорошо удовлетворяет потребности таких сложных текстовых
редакторов, как emacs, который позволяет пользователю связать любое дейст-
действие с любым символом или последовательностью символов. Однако это озна-
означает, что если пользователь вместо date наберет на клавиатуре команду dste,
а затем исправит ошибку, удалив три последние символа, допечатав символы
ate и нажав клавишу Enter, пользовательская программа получит одиннадцать
ASCII-символов.
Не все программы способны разобраться в этих сложностях. Чаще всего им нуж-
нужна уже исправленная строка, а не вся последовательность введенных символов.
Таким образом, формируется вторая концепция: драйвер выполняет все редак-
редактирование внутри строки, а пользовательской программе передает уже готовый
результат. Первая концепция ориентирована на символы, вторая — на строки.
Изначально эти режимы работы драйвера назывались режимом без обработки
и режимом с обработкой. В стандарте POSIX режим с обработкой называется
каноническим режимом. Неканонический режим соответствует режиму без обра-
обработки, хотя многие детали поведения терминала могут различаться. Совмести-
Совместимые со стандартом POSIX системы предоставляют несколько библиотечных
функций, обеспечивающих выбор любого из этих двух режимов, а также измене-
изменение многих аспектов конфигурации терминала. В операционной системе MINIX 3
данные функции поддерживает системный вызов ioctl.
Итак, основная задача клавиатурного драйвера состоит в сборе символов. Если ка-
каждое нажатие клавиши вызывает прерывание, драйвер может получать введенный
символ во время обработки прерывания. Если прерывания преобразуются низ-
низкоуровневым программным обеспечением в сообщения, каждый полученный сим-
символ может включаться в сообщение. В качестве альтернативы символ может
помещаться в небольшой буфер в памяти, а сообщение использоваться только
для извещения драйвера о том, что что-то прибыло. Второй подход более надежен,
особенно если сообщение посылается только ожидающему его процессу, а драйвер
клавиатуры занят обработкой предыдущего символа.
Получив символ, драйвер должен начать его обработку. Если клавиатура переда-
передает информацию о номере нажатой клавиши, а не о коде символа, который нужен
для прикладных программ, драйверу требуется преобразовать номер в код сим-
символа при помощи таблицы. Не все IBM-совместимые клавиатуры имеют одина-
одинаковую нумерацию клавиш, поэтому драйвер, чтобы обеспечить поддержку раз-
различных клавиатур, должен иметь разные таблицы перекодировки для разных
клавиатур. Простейший подход — скомпилировать драйвер с таблицей, предна-
предназначенной для преобразования кодов клавиш в кодировку ASCII (American
Standard Code for Information Interchange — американский стандартный код об-
обмена информацией). К сожалению, такое решение неудовлетворительно для не-
неанглоязычных пользователей. В разных странах приняты разные раскладки кла-
клавиатур, и стандартного набора ASCII-символов недостаточно для большинства
людей, населяющих восточное полушарие. Например, тем, кто разговаривает на
французском, португальском и испанском языках, требуются буквы с надстроч-
надстрочными знаками и знаки препинания, которых нет в английском. Чтобы обеспечить
гибкую работу с клавиатурными раскладками для различных языков, во многих
операционных системах имеется возможность загружать различные кодовые
страницы. Они позволяют выбирать (при загрузке или позже), как клавиатур-
клавиатурные коды должны преобразовываться в коды символов.
Если терминал работает в каноническом режиме (режиме с обработкой), введен-
введенные символы должны храниться в буфере до тех пор, пока не будет завершена
вся строка, поскольку пользователь может решить удалить ее часть. Даже если
переключить терминал в неканонический режим, может оказаться, что програм-
программа еще не запрашивала входные данные, поэтому введенные символы все равно
должны буферизироваться, чтобы позволить пользователю производить упреж-
упреждающий ввод. (Разработчиков систем, не позволяющих пользователям вводить
символы с клавиатуры без возможности исправления, следует обмазывать дег-
дегтем и вываливать в перьях, ибо заставить их пользоваться собственной системой
было бы слишком жестоким наказанием.)
Для буферизации символов обычно применяются два метода. В первом случае
в драйвере содержится центральный пул буферов, в каждом из которых хра-
хранится около 10 символов. С каждым терминалом связана структура данных, со-
содержащая, среди прочего, указатель на цепочку буферов, в которых находятся
символы, введенные с данного терминала. Чем больше символов введено, тем
больше выделяется буферов, соединенных в цепь. Когда символ передается
пользовательской программе, буферы удаляются и память возвращается цен-
центральному пулу.
Другой подход заключается в том, что буферизация производится прямо в струк-
структуре данных терминала, без центрального пула буферов. Поскольку пользовате-
пользователи часто печатают команду, обработка которой требует некоторого времени (на-
(например, на перекомпиляцию и сборку большой программы), а затем печатают
еще несколько строк, буфер драйвера должен вмещать не меньше 200 символов
для каждого терминала. В большой системе разделения времени с сотней терми-
терминалов выделение по 20 Кбайт на буфер ввода с каждой клавиатуры кажется
чрезмерным, поэтому центрального пула буферов размером около 5 Кбайт будет,
видимо, достаточно. В то же время при выделенном буфере для отдельного тер-
терминала драйвер становится проще (не требуется управления связанным спи-
списком). Такой подход является предпочтительным на персональном компьютере
с единственной клавиатурой. Рисунок 3.20 иллюстрирует разницу между этими
двумя подходами.
Рис. 3.20. Варианты буферизации ввода: а — центральный пул буферов;
б — выделенный буфер для каждого терминала
Хотя клавиатура и экран являются логически разделенными устройствами, мно-
многие пользователи привыкли сразу же видеть на экране вводимые с клавиатуры
символы. Некоторые (старые) терминалы должны были автоматически (аппа-
ратно) отображать все, что вводилось с клавиатуры, что не только крайне не-
неудобно при вводе паролей, но также значительно ограничивает гибкость слож-
сложных редакторов и других программ. К счастью, на большинстве терминалов при
нажатии клавиши ничего автоматически не отображается. Отображением симво-
символов на экране занимается исключительно программное обеспечение. Этот про-
процесс называется эхопечатъю.
Эхопечать неудобна тем, что во время нажатия пользователем клавиши програм-
программа может выполнять вывод на экран. По меньшей мере, драйвер должен решить,
где поместить «эхо» так, чтобы оно не исчезло под выходным потоком программы.
Кроме того, если пользователь вводит более 80 символов в одной строке, вывод
«эха» на 80-символьном экране может выглядеть по-разному. В зависимости от
приложения переход на следующую строку может оказаться приемлемым либо
неприемлемым. Некоторые драйверы просто усекают все введенные строки до
80 символов, игнорируя все после колонки 80.
Еще одна проблема заключается в обработке символов табуляции. Обычно драй-
драйвер вычисляет текущую позицию курсора, учитывая как вывод программы, так
и «эхо», после чего вычисляет число отображаемых до позиции табулятора
пробелов.
Наконец, существует проблема эквивалентности устройств. Логически в конце
строки текста требуется символ возврата каретки, чтобы переместить курсор
обратно к колонке 1, и символ перевода строки для перемещения курсора на
следующую строку. Требовать от пользователя вводить оба символа — вряд ли
удачная мысль, хотя на некоторых терминалах имеется специальная клавиша,
посылающая оба символа с 50-процентной вероятностью в том порядке, в кото-
котором их ожидает программа. Преобразование всего, что поступает с клавиатуры
в стандартный внутренний формат, используемый операционной системой, яв-
является одной из задач драйвера.
Если стандартом регламентируется хранение только символов перевода строки
(соглашение UNIX), тогда символы возврата каретки должны преобразовывать-
преобразовываться в символы перевода строки. Если внутренний формат предусматривает хране-
хранение обоих символов (соглашение Windows), тогда драйвер должен формировать
символ перевода строки при получении символа возврата каретки, и наоборот.
Независимо от внутренних правил, терминал может требовать наличия обоих
символов для корректного управления выводом на экран. Поскольку к большо-
большому компьютеру могут оказаться подключенными терминалы различных типов,
драйвер клавиатуры должен обеспечивать преобразование всех комбинаций сим-
символов возврата каретки и перевода строки во внутренний стандарт, а также сле-
следить за правильностью эхопечати.
И это еще не все. Есть еще одна проблема, связанная с перемещением на но-
новую строку. Некоторым терминалам на вывод специальных символов требуется
больше времени, чем на отображение «нормальных» символов (то есть букв или
цифр). К примеру, если микропроцессору в терминале, чтобы выполнить про-
прокрутку экрана, нужно скопировать большой блок текста, то перевод строки
может выполняться медленно. Если механической печатающей головке надо
вернуться к левому полю документа, на вывод символа возврата каретки потре-
потребуется больше времени. В обоих случаях драйвер терминала может вставлять
в выходной поток символы заполнения (пустые символы) или же просто приоста-
приостанавливать вывод на некоторое время, чтобы терминал успел за потоком симво-
символов. Необходимая задержка часто связана с быстродействием терминала. На-
Например, на скорости 4800 бит/с и ниже задержка вряд ли нужна, а на 9600 бит/с
и выше может понадобиться один символ заполнения. Терминалам с аппаратной
поддержкой табуляции, особенно тем, которые выдают печатный документ, до-
дополнительная задержка может потребоваться после символа табуляции.
При работе в каноническом режиме некоторые вводимые символы имеют особое
значение. В табл. 3.6 показаны все специальные символы, определенные стан-
стандартом POSIX, а также дополнительные, распознаваемые системой MINIX 3. По
умолчанию все они являются управляющими символами, которые не должны
конфликтовать с вводимым текстом или кодами, используемыми программами.
Однако все символы, кроме последних двух, допустимо изменять с помощью ко-
команды stty. Многие специальные символы, принятые по умолчанию в UNIX,
отличаются от приведенных здесь.
Таблица 3.6. Специальные символы канонического режима
Клавиши Имя в POSIX Комментарий
Ctrl+D EOF Конец файла
EOL Конец строки (не определен)
Ctrl+H ERASE Удалить один символ слева
Ctrl+C INTR Прервать процесс (SIGINT)
Ctrl+U KILL Удалить всю введенную строку
Ctrl+\ QUIT Принудительный дамп памяти (SIGQUIT)
Ctrl+Z SUSP Приостановить (игнорируется MINIX)
Ctrl+Q START Начать вывод
Ctrl+S STOP Остановить вывод
Ctrl+R REPRINT Заново отобразить ввод (расширение MINIX)
Ctrl+V LNEXT Интерпретировать следующий символ буквально
(расширение MINIX)
Ctrl+O DISCARD Отмена вывода (расширение MINIX)
Ctrl+M CR Возврат каретки (неизменный символ)
Ctrl+J NL Перевод строки (неизменный символ)
Символ ERASE позволяет пользователю удалить один только что введенный
символ. В MINIX 3 этому символу соответствует клавиша забоя (Ctrl+H). Этот
символ не добавляется к очереди символов, а, наоборот, удаляет предыдущий
символ из очереди. Печать эха для такого символа должна выглядеть как после-
последовательность трех символов: перемещение курсора на позицию влево, пробел
и еще раз возврат на позицию, чтобы удалить с экрана предыдущий символ. Если
же предыдущим символом был символ табуляции, требуется определить, какой
символ предшествует ему. В большинстве систем забой удаляет символы только
текущей строки. Символы возврата каретки и перевода строки не удаляются.
Во многих старых системах, не позволяющих перемещать курсор влево и вправо,
если пользователь обнаруживал ошибку в начале введенной строки, единствен-
единственным способом ее исправления являлось удаление всей строки. Для удаления
строки целиком используется специальный символ KILL (Ctrl+U в MINIX 3).
В MINIX 3 строка стирается с экрана, хотя в некоторых системах удаленная стро-
строка выводится с символами возврата каретки и конца строки, поскольку некото-
некоторые пользователи хотят ее видеть. Таким образом, способ отображения символа
KILL — дело вкуса. Как и в случае с ERASE, действие KILL не распространяется
дальше текущей строки. При удалении блока символов драйвер может как воз-
возвращать, так и не возвращать буферы в пул (если он используется).
Иногда символы ERASE или KILL должны быть введены в строку как обычные
данные. Для этого служит символ LNEXT, действующий в качестве префиксного
символа. В MINIX 3 ему по умолчанию соответствует сочетание клавиш Ctrl+V.
В более старых версиях UNIX для ввода символа KILL часто использовалась
клавиша @, но впоследствии этот символ стал составной частью адресов элек-
электронной почты Интернета (например, linda@cs.washington.edu). Те, кому привычнее
старые соглашения, могут переопределить символ KILL как @, но тогда при набо-
наборе адреса электронной почты им придется вводить символ @, нажимая сочетание
клавиш Ctrl+V, <§>. Сам символ LNEXT может быть введен, если дважды нажать
клавиши Ctrl+V. Встретив символ LNEXT, драйвер установит флаг, означающий,
что следующий символ не следует подвергать специальной обработке. Сам сим-
символ LNEXT не помещается в очередь символов.
Чтобы приостановить и продолжить вывод на экран, также предоставляются спе-
специальные управляющие коды. В MINIX 3 это символы STOP (Ctrl+S) и START
(Ctrl+Q). Они не хранятся в буфере, но используются для установки и сброса
флага в структуре данных терминала. При каждой операции вывода на экран
проверяется значение этого флага. Если флаг установлен, вывод не производит-
производится. Эхопечать при этом, как правило, также подавляется.
Часто возникает необходимость прервать выполнение отлаживаемой програм-
программы. Для этой цели могут использоваться символы INTR (Ctrl+C) и QUIT (Ctrl+\).
В MINIX 3 сочетание Ctrl+C посылает сигнал прерывания SIGINT всем процес-
процессам, запущенным с этого терминала. Реализация может быть непростой. Наи-
Наиболее сложной является передача информации от драйвера в ту часть системы,
которая занимается обработкой сигналов, поскольку она не ожидает получения
подобной информации. Результат нажатия клавиш Ctrl+\ аналогичен нажатию
клавиш Ctrl+C, с той разницей, что процессам посылается сигнал SIGQUIT, вы-
вызывающий прекращение работы процесса с сохранением дампа ядра, если этот
сигнал специально не перехватывается процессом или не игнорируется.
При нажатии любого из этих сочетаний клавиш драйвер должен вывести эхо
в виде символов перевода строки и возврата каретки, а также очистить свой бу-
буфер с накопленными символами, чтобы позволить начать новый ввод. Во многих
UNIX-системах символ INTR по умолчанию генерируется клавишей Del. Посколь-
Поскольку программы зачастую используют Del наравне с клавишей забоя при редакти-
редактировании, в настоящее время предпочтение отдается комбинации Ctrl+C.
Специальный символ EOF (Ctrl+D) в MINIX 3 удовлетворяет активный запрос на
чтение и передает все содержимое буфера, даже если он пуст. Нажатие клавиш
Ctrl+D в начале строки приводит к тому, что программа считывает 0 байт. При
считывании файла это обычно воспринимается и обрабатывается как конец файла.
Некоторые драйверы терминала предоставляют возможность более сложного ре-
редактирования строки, чем было описано здесь. Они имеют специальные управ-
управляющие символы, позволяющие удалять целиком слова, перемещать курсор впе-
вперед и назад по символам и по словам, вставлять текст в середину уже набранной
строки и т. д. Добавление подобных функций к драйверу значительно увели-
увеличивает его. Кроме того, эти функции чаще всего оказываются неиспользуемыми
экранными редакторами, предпочитающими работать с драйверами клавиатуры
в режиме без обработки.
Стандарт POSIX требует того, чтобы в стандартной библиотеке были доступны
несколько функций, позволяющих программам управлять параметрами терми-
нала. Самые важные из них — tcgetattr и tcsetattr. Первая получает от
системы копию структуры termios, показанной в листинге 3.3. Эта структу-
структура содержит всю информацию, необходимую для задания режимов работы, на-
настройки специальных символов и управления характеристиками терминала.
Программа может узнать текущие значения параметров и изменить их на свой
вкус. Функция tcsetattr позволяет передать эту структуру обратно драйверу
терминала.
Листинг 3.3. Структура termios. В MINIX3 3 тип c_flag_t эквивалентен типу short,
тип speed_t — типу int, а тип cc_t — типу char
struct termios {
tcflag_t c_iflag; /* Режимы ввода */
tcflag_t c_oflag; /* Режимы вывода */
tcflag_t c_cflag; /* Режимы управления */
tcflag_t c_lflag; /* Локальные режимы */
speed_t c_ispeed; /* Скорость ввода */
speed_t c_ospeed; /* Скорость вывода */
cc_t c_cc[NCCS]; /* Управляющие символы */
};
Стандарт POSIX не определяет, как реализовывать свои требования — при по-
помощи системных вызовов или библиотечных подпрограмм. В MINIX имеется
системный вызов ioctl, записываемый следующим образом:
ioctl(file_descriptor, request, argp);
Этот вызов позволяет определять и изменять конфигурацию многих устройств
ввода-вывода. Функции tcgetattr и tcgetattr реализованы на его основе.
Здесь переменная request указывает, считывать или записывать структуру
termios (для записи также указывается, нужно ли выполнять действие немед-
немедленно или отложить до завершения текущей очереди запросов). Переменная argp
содержит указатель на структуру termios вызывающей программы. Такой под-
подход к взаимодействию драйвера с программой был выбран по большей мере для
совместимости с UNIX, чем из соображений удобства.
Следует сделать несколько замечаний о структуре termios. Четыре управляю-
управляющих слова в ней обеспечивают большую гибкость. Отдельные биты поля с_
if lag отвечают за то, как обрабатываются входные данные. Например, бит ICRNL
управляет преобразованием символов CR в NL при вводе. В MINIX 3 этот флаг
установлен по умолчанию. Поле с_оflags содержит флаги, управляющие выво-
выводом. Например, флаг OPOST разрешает обработку выводимых данных. Этот бит,
как и бит ONLCR, который обеспечивает преобразование символов NL в последо-
последовательность CR NL, в MINIX 3 устанавливается по умолчанию. Поле c_cf lag
содержит флаги управления. Параметры MINIX 3, установленные по умолчанию,
разрешают передачу 8-разрядных символов, кроме того, модем должен «класть
трубку» при отключении пользователя. Поле c_lf lag — это флаги локального
режима. Бит ECHO управляет выводом эха (при входе пользователя в систему
эту функцию можно отключить, чтобы обезопасить ввод пароля). Один из самых
важных битов — бит I CANON, разрешающий канонический режим. Когда бит
I CANON сброшен, существует несколько возможностей. Если сохранить значе-
значения по умолчанию для всех остальных параметров, терминал переходит в режим,
идентичный традиционному режиму с прерыванием. В этом режиме символы
передаются программе, не дожидаясь ввода всей строки, но управляющие коды
INTR, QUIT, START и STOP сохраняют свое действие. Этот режим можно отклю-
отключить, сбросив значения других флагов, и получить эквивалент обычного режима
без обработки.
Различные специальные символы, значения которых можно изменить (включая
расширения MINIX 3), хранятся в массиве с_сс. Кроме того, в нем хранятся два
параметра, используемые в неканоническом режиме. Значение MIN, помещаемое
в с_сс [VMIN], задает минимальное количество символов, достаточное для вы-
вызова read. Величина TIME, хранящаяся в с_сс [VTIME], задает лимит времени
для этого вызова. К какому результату приводят разные комбинации значе-
значений, показано в табл. 3.7, иллюстрирующей обработку вызова, запрашивающего
N байт. Если значение TIME равно 0, a MIN — 1, поведение аналогично режиму
без обработки.
Таблица 3.7. Параметры MIN и TIME определяют, как выполняется чтение в неканоническом
режиме. N — число запрошенных байтов
TIME = О TIME > О
MIN = 0 Вызов завершается немедленно, Сразу же запускается таймер. Возвращается
возвращая имеющееся число первый полученный байт или ни одного,
байтов, от 0 до N если истекло время
MIN > 0 Вызов возвращает от MIN После первого байта запускается
до N байт. Возможна межбайтовый таймер. Возвращается
бесконечная блокировка N байт, если они уложились во временной
интервал, но не меньше 1 байта. Возможна
бесконечная блокировка
Программное обеспечение вывода
Терминальный вывод несколько проще ввода, однако драйверы терминалов RS-
232 радикально отличаются от драйверов терминалов, отображаемых на память.
Как правило, метод, используемый для терминалов с интерфейсом RS-232, со-
состоит в том, что для каждого терминала выделяется выходной буфер. Эти буфе-
буферы могут входить в тот же пул буферов, что и входные буферы, или представ-
представлять собой выделенные буферы. Когда программы выводят данные в терминал,
вывод сначала копируется в буфер. После того как символы оказываются в вы-
выходном буфере, первый символ выводится на терминал, а затем драйвер блоки-
блокируется. Когда происходит прерывание, извещающее драйвер о готовности терми-
терминала принять следующий символ, посылается этот символ и т. д.
Отображаемые на память терминалы позволяют применять еще более простую
схему. Символы, которые должны быть напечатаны, один за другим извлекаются
из пользовательского пространства и записываются непосредственно в видеопа-
видеопамять. В случае с терминалами RS-232 символ просто передается в последова-
тельную линию передачи данных. При отображении на память некоторые симво-
символы нуждаются в дополнительной обработке. Среди них символы забоя, возврата
каретки, перевода строки и звукового сигнала (Ctrl+G). Драйвер отображаемого
на память терминала должен программно отслеживать текущее положение кур-
курсора, обновляя его после вывода печатного символа. При выводе специальных
символов он должен соответствующим образом менять положение курсора.
В частности, переводя строку внизу экрана, необходимо выполнять прокрут-
прокрутку его содержимого. Работу прокрутки иллюстрирует рис. 3.18. Если видео-
видеоконтроллер всегда располагает начало видеопамяти по адресу ОхВОООО, единст-
единственный способ сдвинуть содержимое — скопировать 24 х 80 символов (каждый
символ представляется двумя байтами) из области, начинающейся по адресу
ОхВООАО, в область ОхВОООО. На это требуется время. В растровом режиме си-
ситуация еще хуже.
К счастью, обычно аппаратное обеспечение несколько упрощает эту операцию.
У большинства видеоконтроллеров имеется регистр, указывающий, какому адре-
адресу в видеопамяти соответствует первая строка экрана. Поэтому чтобы прокру-
прокрутить экран вверх на одну строку, достаточно изменить значение этого регистра
так, чтобы видимая область начиналась по адресу ОхВООАО, а не ОхВОООО. Тогда
единственное, что должен сделать драйвер, — просто записать новые символы
в следующую строку в видеопамяти. Когда видеоконтроллер достигает верхней
границы видеопамяти, он переходит в ее конец, начиная вновь с нижнего адреса.
Подобная аппаратная поддержка предоставляется и в растровом режиме.
Еще одна вещь, о которой должен заботиться драйвер отображаемого на память
терминала, — позиционирование курсора. Опять же, упрощает дело наличие ап-
аппаратного регистра, указывающего, куда должен переместиться курсор. Наконец,
остается проблема обработки звукового сигнала, который получается путем по-
подачи прямоугольной или синусоидальной волны на внутренний динамик, имею-
имеющий мало общего с видеопамятью.
Перед экранными редакторами и другими сложными программами иногда воз-
возникают более трудные задачи перерисовки экрана, нежели обычная прокрутка
текста в конец дисплея. Для этого многие драйверы терминала поддерживают
различные управляющие последовательности. Хотя некоторые терминалы поль-
пользуются уникальными наборами управляющих последовательностей, желатель-
желательно иметь стандарт, который позволил бы переносить программное обеспечение
с одной системы на другую. Американский национальный институт стандартов
(American National Standard Institute, ANSI) разработал набор стандартных
управляющих последовательностей. MINIX 3 поддерживает подмножество этого
набора, представленное в табл. 3.8 и достаточное для многих распространенных
операций. Когда драйвер встречает символ начала управляющей последователь-
последовательности, он устанавливает флаг и дожидается ее окончания, а затем передает соот-
соответствующий символ программе. Вставка и удаление текста требуют перемеще-
перемещения блоков символов в видеопамяти. Здесь аппаратная поддержка практически
отсутствует, за исключением прокрутки и отображения курсора.
Таблица 3.8. Управляющие последовательности, воспринимаемые драйвером терминала
при выводе. ESC означает символ начала управляющей последовательности @x1 В), a n, m
и s — дополнительные численные параметры
ESC-последовательность Значение
ESC [пА Переместить курсор вверх на п строк
ESC [пВ Переместить курсор вниз на п строк
ESC [пС Переместить курсор вправо на п позиций
ESC [nD Переместить курсор влево на п позиций
ESC [m;nH Переместить курсор в позицию (т, п)
ESC [sJ Очистить экран от позиции курсора @ — до конца,
1 — до начала, 2 — весь)
ESC [sK Очистить строку от позиции курсора @ — до конца,
1 — до начала, 2 — всю)
ESC [nl_ Вставить п строк в позицию курсора
ESC [пМ Удалить п строк в позиции курсора
ESC [пР Удалить п символов в позиции курсора
ESC [п@ Вставить п символов в позицию курсора
ESC [nm Разрешить выделение текста @ — нормальный текст,
4 — полужирный текст, 5 — мерцающий текст,
7 — инверсный текст)
ESC M Прокрутка экрана в обратную сторону, если курсор
находится в верхней строке
3.8.3. Драйвер терминала в MINIX 3
Код драйвера терминала в MINIX находится в четырех С-файлах (если включе-
включена поддержка псевдотерминалов RS-232, то в шести). Вместе они образуют са-
самый большой и сложный драйвер в MINIX 3. Большой размер частично объяс-
объясняется тем, что драйвер должен обслуживать одновременно клавиатуру и экран,
которые сами по себе являются сложными устройствами, а также два других до-
дополнительных типа терминалов. Но многих все равно удивляет, что обслужива-
обслуживание терминального ввода-вывода требует в тридцать раз больше кода, чем зани-
занимает планировщик. (Это удивление подкрепляется многочисленными книгами,
в которых обсуждению работы планировщика отводится в тридцать раз больше
места, чем обсуждению ввода-вывода.)
Драйвер терминала принимает около полутора десятков типов сообщений. Пере-
Перечислим наиболее важные.
1. Чтение с терминала (от файловой системы по поручению пользовательского
процесса).
2. Вывод на терминал (от файловой системы по поручению пользовательского
процесса).
3. Установка параметров терминала для ioctl (от файловой системы по пору-
поручению пользовательского процесса).
4. Прерывание от клавиатуры (нажатие или отпускание клавиши).
5. Отмена предыдущего запроса (от файловой системы, когда возникает сигнал).
6. Открытие устройства.
7. Закрытие устройства.
Остальные типы сообщений используются для специальных целей, например
для отображения диагностических данных по нажатию функциональных клавиш
или для генерации дампов при сбоях.
Сообщения с командами на запись и чтение имеют тот же формат, что и сообще-
сообщения, показанные в табл. 3.3, за тем небольшим исключением, что не требуется
поле POSITION. Работая с диском, программа должна указывать, какой блок не-
необходимо считать. При работе с терминалом такого выбора нет: всегда считыва-
ется следующий введенный пользователем символ. Клавиатуры не поддержива-
поддерживают произвольную запись (позиционирование).
Функции стандарта POSIX, tcsetattr и tcgetattr, необходимые для опре-
определения и изменения параметров (атрибутов) терминала, поддерживаются при
помощи системного вызова ioctl. Хороший стиль программирования требует,
чтобы для управления терминалом использовались эти и другие функции из
файла include/termios .h, а преобразование этих вызовов в системный вы-
вызов ioctl было бы оставлено стандартной библиотеке языка С. Тем не менее
MINIX 3 необходимы некоторые управляющие операции, которые не охватыва-
охватываются стандартом POSIX, например загрузка альтернативной раскладки клавиа-
клавиатуры. Для таких операций программисту не остается ничего другого, как явно
выполнять вызов ioctl.
Сообщение, которое ioctl отправляет драйверу терминала, содержит код за-
запрашиваемой функции и указатель. Библиотечной функции tcsetattr соот-
соответствуют коды функций TCSETS, TCSETSW и TCSETSF, а указатель должен ссы-
ссылаться на структуру termios (см. листинг 3.3). В данном случае вызов замещает
текущие значения атрибутов новыми, различие между тремя функциями в том,
что запрос TCSETS приводит к немедленному изменению атрибутов, TCSETW вы-
выполняется только после того, как завершается вывод, a TCSETSF сначала до-
дожидается окончания вывода, а затем очищает все еще не считанные входные
данные. Функция tcgetattr транслируется в вызов ioctl с кодом операции
TCGETS и возвращает сделавшей вызов программе заполненную атрибутами
структуру termios, позволяя определить параметры устройства. Те вызовы
ioctl, у которых нет аналогов в стандарте POSIX, могут требовать ссылки на
другие структуры. Например, для операции KIOCSMAP, загружающей новую рас-
раскладку клавиатуры, требуется ссылка на 1536-байтовую структуру keymap_t
A6-разрядные коды для 128 клавиш х 6 модификаторов). То, как вызовы стан-
стандарта POSIX преобразуются в системные вызовы ioctl, показано в табл. 3.9.
У драйвера терминала имеется одна центральная структура данных, tty_table,
представляющая собой массив структур tty, по одной на терминал. У стан-
стандартного персонального компьютера есть только одна клавиатура и экран, но
MINIX 3 поддерживает до восьми виртуальных терминалов, в зависимости от
объема памяти у контроллера. Это позволяет с одной консоли входить в систему
несколько раз, переключая клавиатуру между разными «пользователями». Если
есть две виртуальные консоли, то нажав клавиши Alt+F2, можно переключиться
на вторую, а нажатие клавиш Alt+F1 активизирует первую консоль. Для пере-
переключения можно также использовать комбинацию клавиши Alt и клавиш управ-
управления курсором. Кроме того, последовательные линии обеспечивают поддерж-
поддержку двух удаленных пользователей, подключающихся через модем или кабель
RS-232, а псевдотерминалы позволяют пользователям подключаться через сеть,
Драйвер написан так, чтобы можно было легко добавлять новые терминалы.
Таблица 3.9. POSIX-вызовы и операции системного вызова ioctl
POSIX-функция POSIX-операция Тип ioctl Параметр ioctl
Tcdrain (нет) TCDRAIN (нет)
Tcflow TCOOFF TCFLOW int=TCOOFF
Tcflow TCOON TCFLOW int=TCOON
Tcflow TCIOFF TCFLOW int=TCIOFF
Tcflow TCION TCFLOW int=TCION
Tcflush TCIFLUSH TCFLSH int=TCIFLUSH
Tcflush TCOFLUSH TCFLSH int=TCOFLUSH
Tcflush TCIOFLUSH TCFLSH int=TCIOFLUSH
Tcgetattr (нет) TCGETS termios
Tcsetattr TCSANOW TCSETS termios
Tcsetattr TCSADRAIN TCSETSW termios
Tcsetattr TCSAFLUSH TCSETSF termios
Tcsendbreak (нет) TCSBRK int=duration
Каждая из структур tty в массиве tty_table отслеживает как ввод, так и вы-
вывод. При вводе она поддерживает очередь символов, которые были введены
пользователем, но еще не считаны, информацию о запросе на чтение символов
и об интервалах таймера, чтобы драйвер не блокировался, если не нажато ни од-
одного символа. При выводе она хранит параметры запросов на вывод, которые
еще не были выполнены. Также есть другие поля с различной общей информа-
информацией, например с описанной ранее структурой termios, от которой зависят
многие характеристики ввода и вывода. Кроме того, в структуре tty есть указа-
указатель, который ссылается на информацию, необходимую для конкретного класса
устройств, но не требуемую для всех терминалов. Так, завязанной на аппаратное
обеспечение части кода драйвера терминала требуется информация о текущем
положении вывода в видеопамяти, но при работе с линией RS-232 эта информа-
информация не нужна. Дополнительно для каждого типа устройств имеются собственные
структуры данных, содержащие информацию о расположении буферов, в кото-
которые помещают свои данные обработчики прерываний. Медленным устройствам,
таким как клавиатуры, не нужны такие большие буферы, как быстрым.
Терминальный ввод
Чтобы лучше понять, как работает драйвер терминала, сначала рассмотрим, как
напечатанный пользователем символ прокладывает себе путь к ожидающей его
программе. Хотя этот раздел является обзорным, мы дадим читателю ссылки на
строки исходного кода с используемыми функциями. Возможно, изучение кода
покажется вам излишне динамичным, поскольку файлы tty.с, keyboard.с
и console. с слишком велики для детального изучения.
Когда пользователь входит с системной консоли, для него создается оболочка,
которая для ввода, вывода и ошибок использует файл /dev/console. Запус-
Запустившись, оболочка пытается считать данные стандартного ввода при помощи
библиотечного вызова read. Эта процедура отправляет файловой системе сооб-
сообщение, содержащее дескриптор файла, адрес буфера и количество считываемых
байтов. На рис. 3.21 это сообщение обозначено цифрой 1. Отправив сообще-
сообщение, оболочка блокируется, ожидая ответа. (Пользовательские процессы испол-
исполняют только примитив sendrec, который комбинирует вызов send с вызовом
receive от того процесса, которому было послано сообщение.)
Рис. 3.21. Запрос на чтение с терминала в отсутствие введенных символов. Драйвер
терминала получает сообщение при каждом нажатии клавиши и ставит в очередь коды
опроса по мере их ввода; затем коды опроса интерпретируются, полученные ASCII-
коды помещаются в буфер, который копируется в пользовательский процесс
Файловая система получает сообщение и определяет местонахождение индекс-
индексного узла, соответствующего указанному дескриптору файла. В данном случае
это индексный узел для специального символьного файла /dev/console, со-
содержащий вспомогательный и основной номера устройства терминала. Основ-
Основной номер для терминалов равен 4, вспомогательный номер для консоли равен 0.
Файловая система при помощи карты устройств, dmap, определяет номер драй-
драйвера терминала. Затем она отправляет ему сообщение, которое на рис. 3.21 поме-
помечено цифрой 2. Обычно к этому моменту пользователь еще ничего не напеча-
напечатал, и драйвер терминала не в состоянии выполнить запрос. Поэтому драйвер
немедленно отправляет файловой системе ответ, чтобы разблокировать ее и со-
сообщить, что ни одного символа пока не введено (цифра 3 на рисунке). Файловая
система фиксирует в таблице tty_table тот факт, что процесс ожидает ввода
с терминала, и переходит к следующему запросу. Пользовательская оболочка при
этом остается заблокированной, пока не прибудут введенные символы.
Когда, наконец, с клавиатуры вводится символ, генерируются два прерывания,
одно — когда клавиша нажимается, и одно — когда отпускается. Важным является
то, что клавиатура персонального компьютера при нажатии клавиши генерирует
не ASCII-код, а код опроса. При отпускании генерируется еще один код, семь
младших разрядов которого совпадают с кодом опроса. Таким образом, единст-
единственное отличие заключается в старшем бите: при нажатии клавиши он равен О,
а при отпускании — 1. Это же правило относится и к клавишам-модификаторам,
таким как Shift и Ctrl, которые сами по себе не приводят к получению ASCII-ко-
ASCII-кодов, но все равно генерируют два кода опроса, идентифицирующих клавишу
(при желании драйвер может отличить правую клавишу от левой), и вызывают
два прерывания.
Клавиатуре соответствует прерывание IRQ1. Эта линия прерывания недоступна
через системную шину и не может использоваться другим адаптером ввода-
вывода. Когда функция _hwint01 (строка 6535) вызывает функцию intr_
handle (строка 8221), проход по списку обработчиков прерываний быстро вы-
выявляет, что уведомление должно быть послано драйверу терминала. На рис. 3.21
показано, что источником уведомления 4 является системное задание, посколь-
поскольку его генерирует функция generic_handler из файла system/do_irqctl. с
(не представлен). Тем не менее прямой вызов этой функции осуществляют
низкоуровневые процедуры обработки прерывания, а системное задание не акти-
активизируется. После получения сообщения HARD_INT функция tty_task (стро-
(строка 13740) вызывает функцию kbd_interrupt (строка 15335), а та, в свою
очередь, — функцию scan_keyboard (строка 15800). Функция scan_keyboard
совершает три вызова ядра E, 6 и 7), чтобы системное задание выполнило чте-
чтение и запись в несколько портов ввода-вывода. В результате возвращается код
опроса и помещается в циклический буфер. Затем устанавливается флаг tty_
events, показывающий, что буфер не пуст и содержит символы.
Здесь необходимости в использовании сообщений нет. Каждый раз главный
цикл tty_task запускает другой цикл, анализирующий флаг tty_events каж-
каждого терминала и вызывающий функцию handle_events (строка 14358) для
всех терминалов, флаг которых установлен. Флаг tty_events может указывать
на разные ситуации (хотя наличие ввода — наиболее вероятная из них), поэтому
функция handle_events всегда вызывает специфичные для устройства функции
как в случае ввода, так и в случае вывода. При вводе с клавиатуры вызывается
функция kb_read (строка 15360), которая отслеживает наличие кодов управ-
управляющих клавиш Ctrl, Shift и Alt и преобразует коды опроса в ASCII-коды. Функ-
Функция kb_read, в свою очередь, вызывает функцию in_process (строка 14486),
которая обрабатывает ASCII-коды, учитывает специальные символы и значения
различных флагов, включая флаги, задающие канонический режим. В результате
символ, как правило, просто добавляется во входную очередь клавиатуры в tty_
table, хотя некоторые коды, например BACKSPACE, могут приводить к другому
эффекту. Кроме того, обычно функция in_proccess осуществляет эхопечать
вводимых ASCII-символов на дисплее.
Получив достаточно символов, драйвер терминала выполняет вызов ядра (8), за-
запрашивающий у системного задания копирование данных по адресу, затребован-
затребованному оболочкой. Эта операция также не является передачей сообщения, поэтому
обозначена на рис. 3.21 многоточием (9). На рисунке изображено несколько
линий с цифрой 9, поскольку до того, как пользовательский запрос будет полно-
полностью выполнен, данные могут быть переданы несколько раз. Когда операция
полностью завершится, драйвер терминала отправляет файловой системе со-
сообщение о том, что работа выполнена {10), а файловая система в результате от-
отправляет сообщение оболочке и выводит ее из состояния блокировки A1).
Определение количества обрабатываемых символов зависит от режима термина-
терминала. В каноническом режиме запрос считается выполненным, когда поступает
символ перевода строки, конца строки или конца файла. Также длина строки не
может превышать величину входной очереди, чтобы входные данные могли пра-
правильно обрабатываться. В неканоническом режиме может запрашиваться гораз-
гораздо большее количество символов, и функции in_process может потребоваться
передавать данные несколько раз перед тем, как файловой системе будет возвра-
возвращено сообщение, означающее завершение работы.
Обратите внимание на то, что системное задание копирует данные напрямую из
своего адресного пространства в адресное пространство оболочки. Данные не пе-
передаются через файловую систему. При блочных операциях ввода-вывода ин-
информация сначала поступает файловой системе, чтобы та могла поддерживать
кэш недавно запрошенных блоков. Если запрошенный блок оказывается в кэше,
файловая система может самостоятельно выполнить пользовательский запрос
без реального обращения к диску.
При работе с клавиатурой кэширование не имеет смысла. Кроме того, запрос фай-
файловой системы к драйверу диска всегда может быть обслужен максимум за не-
несколько сотен миллисекунд, поэтому нет большой проблемы в том, что файловой
системе приходится немного подождать. Операции с клавиатурой могут длиться
часами или вообще могут не завершаться (в каноническом режиме драйвер ждет
ввода полной строки, а в неканоническом ждет достаточно длинной строки, в за-
зависимости от параметров MIN и TIME). Поэтому файловая система не должна
блокироваться, ожидая выполнения запросов терминального ввода-вывода.
Вполне вероятно, что пользователь введет какой-либо текст заранее, и символы
благодаря предыдущим прерываниям и событию 4 окажутся доступными до то-
того, как они будут запрошены. В этом случае все события 1, 2 и 5-11 происходят
сразу же после запроса, а события 3 вообще не происходит.
Читатели, знакомые с ранними версиями операционной системы MINIX, возмож-
возможно, помнят, что в них драйвер терминала и все прочие драйверы были объединены
с ядром. У каждого драйвера был собственный обработчик прерываний в про-
пространстве ядра. Обработчик прерываний драйвера клавиатуры осуществлял бу-
буферизацию определенного количества кодов опроса и выполнял предваритель-
предварительную обработку (большую часть кодов, полученных при отпускании клавиши,
можно отбросить, поскольку их буферизация необходима только при нажатии
управляющих клавиш). Сам обработчик не посылал сообщения драйверу тер-
терминала, поскольку с большой вероятностью терминал не блокировался вызовом
receive и не мог получать сообщения в любой момент времени. Вместо этого
обработчик прерывания от таймера периодически активизировал драйвер терми-
терминала. Эти методы требовались для того, чтобы избежать потери вводимых с кла-
клавиатуры данных.
Ранее мы упоминали о различиях в обработке ожидаемых прерываний (напри-
(например, от дискового контроллера) и неожидаемых прерываний (например, от кла-
клавиатуры). Тем не менее складывается ощущение, что в MINIX 3 не предпринято
особых мер для разрешения проблем с неожидаемыми прерываниями. В чем же
дело? Первое, что следует иметь в виду, — огромная разница в производительно-
производительности между компьютерами, для которых создавались первые версии MINIX, и со-
современными системами. Тактовая частота процессоров выросла, а число тактов
на одну команду сократилось. Минимальная рекомендация для процессора при
использовании MINIX 3 — 80386. Даже медленный компьютер 80386 выполняет
команды приблизительно в 20 раз быстрее, чем первые машины IBM PC. Процес-
Процессор Pentium с тактовой частотой 100 МГц работает в 25 раз быстрее, чем 80386.
Таким образом, скорости современных процессоров вполне достаточно.
Следующий аспект заключается в том, что по компьютерным меркам ввод с кла-
клавиатуры осуществляется очень медленно. Печатая 100 слов в минуту, машини-
машинистка вводит менее 10 символов в секунду. Даже при высокой скорости печати
драйвер терминала, скорее всего, будет успевать посылать сообщения о прерыва-
прерывании для каждого введенного символа. Другие устройства способны вводить дан-
данные с гораздо большей скоростью. Так, последовательный порт, подключенный
к модему скоростью 56 Кбит/с, предоставляет данные в 1000, а возможно, и бо-
более раз интенсивнее, нежели машинистка. В течение такта часов может быть по-
получено приблизительно 120 символов, однако чтобы обеспечить сжатие данных
в модемной линии, последовательный порт должен поддерживать обработку как
минимум вдвое большего их числа.
Следует иметь в виду, что по последовательному порту передаются не коды опро-
опроса, а символы, поэтому каждое нажатие клавиши вызывает одно, а не два, прерыва-
прерывания даже при устаревшем UART-устройстве, не поддерживающем буферизацию.
Более новые компьютеры оснащены приемопередатчиками с буферизацией 16,
а иногда и 128 символов. Таким образом, прерывание для каждого нажатия кла-
клавиши на самом деле не требуется. К примеру, UART с 16-символьным буфером
можно настроить так, что прерывание будет генерироваться при наличии в буфе-
буфере 14 символов. Сети Ethernet способны доставлять символы с гораздо большей
скоростью, чем последовательная линия, однако Ethernet-адаптеры буферизуют
целые пакеты, и генерация прерывания требуется лишь для всего пакета.
В завершение нашего обсуждения терминального ввода подведем итог и рассмот-
рассмотрим все события, которые происходят, когда драйвер терминала впервые активи-
активизируется по запросу на чтение или когда он повторно получает управление после
клавиатурного ввода (рис. 3.22). В первом случае, когда драйвер терминала полу-
получает сообщение, запрашивающее вводимые с клавиатуры символы, главная про-
процедура, tty_task (строка 13740), вызывает процедуру do_read (строка 13953),
которая и выполняет запрос. Если имеющейся в буфере информации недостаточно
для выполнения запроса, процедура сохраняет параметры запроса в tty_table.
Рис. 3.22. Обработка ввода драйвером терминала. Левая часть дерева соответствует
обработке запроса на чтение символов, а правая — передаче сообщения от клавиатуры
драйверу раньше, чем пользователь затребовал ввод
После этого, чтобы получить уже введенные данные, вызывается функция in_
transfer (строка 14416), а затем — функция handle_events (строка 14358), ко-
которая, в свою очередь, вызывает функцию kb_read через указатель *tp->tty_
devread (строка 15360) и еще раз функцию in_transf ег, чтобы получить из
входного потока еще несколько символов. Функция kb_read несколько раз вы-
вызывает другие подпрограммы, не показанные на рис. 3.22. В результате пользова-
пользователю копируются все доступные данные. Если доступных данных нет, ничего не
копируется. Когда вызов in_transf ег или handle_events полностью выпол-
выполняет запрос, файловой системе отправляется сообщение, чтобы она могла раз-
разблокировать запросивший данные процесс. Если чтение не завершено (не введе-
введено ни одного символа или введено недостаточное количество), функция do_
report информирует об этом файловую систему, чтобы та могла либо заблоки-
заблокировать вызвавший процесс, либо, если было запрошено неблокирующее чтение,
отменить запрос.
На правой части рис. 3.22 воспроизведены все события, возникающие, когда
драйвер терминала «просыпается» вследствие прерывания от клавиатуры. Когда
напечатан символ, «обработчик» прерываний kbd_interrupt (строка 15335) вы-
вызывает функцию scan_keyboard, которая обращается к системному заданию за
выполнением ввода-вывода (мы заключили слово «обработчик» в кавычки пото-
потому, что функция kbd_interrupt фактически обработчиком не является. Она вы-
вызывается, когда tty_task получает сообщение от функции generic_handler
системного задания). Функция kbd_interrupt помещает код опроса в клавиа-
клавиатурный буфер ibuf и устанавливает флаг, позволяющий определить, какому из
устройств направлен ввод. Когда kbd_interrupt возвращает управление tty_
task, команда continue инициирует новую итерацию главного цикла. Флаги
событий всех терминалов проверяются, и для терминалов с установленным фла-
флагом вызывается функция handle_event. Последняя для клавиатуры вызывает
функции kb_read и in_transfer, как это делается и при получении исход-
исходного запроса на чтение. Отраженные в правой части рис. 3.22 события могут
происходить несколько раз, до тех пор пока не поступит достаточное для выпол-
выполнения запроса количество символов. Этот запрос поступает к do_read после
первого сообщения от файловой системы. Если файловая система пытается ини-
инициировать новый запрос до того, как устройство обслужило предыдущий, воз-
возвращается ошибка. Естественно, все устройства независимы; запрос на чтение
с удаленного терминала обрабатывается отдельно от запроса чтения с клавиатуры.
На рис. 3.22 не показаны функции, вызываемые функцией kb_read: функция
map_key (строка 15303) преобразует в ASCII-коды коды клавиш (коды опроса),
генерируемые аппаратным обеспечением; функция make_break (строка 15431)
отслеживает состояние клавиш-модификаторов (таких как Shift); функция in_
process (строка 14486) ответственна за такие возможности, как удаление не-
неправильно введенного символа, обработка различных специальных символов
и управление параметрами терминала. Кроме того, in_process вызывает функ-
функцию tty_echo (строка 14647), чтобы вводимые символы отображались на тер-
терминале.
Терминальный вывод
Вообще говоря, консольный вывод проще ввода, так как здесь действиями управ-
управляет операционная система, и не нужно бояться, что события произойдут в не-
неподходящее время. Более того, процесс еще больше упрощается за счет того, что
в MINIX 3 консолью является отображаемый на память экран. Прерывания
не нужны, вывод производится путем копирования данных из одной области
памяти в другую. Однако в этом случае все операции по управлению экраном,
включая обработку управляющих последовательностей, ложатся на программ-
программное обеспечение драйвера. Как и при изучении ввода в предыдущем разделе,
мы проследим, какие действия происходят при выводе символа на консольный
дисплей. В этом примере предполагается, что вывод производится на актив-
активный дисплей. Небольшое усложнение, вносимое виртуальными консолями, мы
обсудим позже.
Обычно, когда процесс хочет что-нибудь напечатать, он вызывает функцию
printf. Эта функция делает системный вызов write, который отправляет фай-
файловой системе сообщение с указателем на выводимые символы (но не сами
символы). Затем файловая система посылает сообщение драйверу терминала,
а тот извлекает указанные ему символы и копирует их в видеопамять. Основ-
Основные подпрограммы, из которых складывается терминальный вывод, показаны
на рис. 3.23.
Рис. 3.23. Основные подпрограммы терминального вывода. Штриховой линией обозначено
прямое копирование символов в буфер ramqueue подпрограммой cons_write
Когда драйвер терминала получает сообщение, требующее от него вывести что-
либо на экран, вызывается подпрограмма do_write (строка 14029), которая со-
сохраняет параметры в массиве tty_table структуры tty, соответствующей вы-
выбранной консоли. Затем вызывается функция handle_event (та же функция,
которая вызывается при обнаружении установленного флага tty_events). Эта
подпрограмма при каждом вызове выполняет для указанного устройства как за-
запись, так и чтение. В случае с консолью это означает, что сначала будут обрабо-
обработаны еще не принятые клавиатурные данные. Если необработанного ввода нет,
переданные символы добавляются к другим символам, ожидающим вывода.
Затем вызывается процедура cons_write (строка 16036), выполняющая вывод
для отображаемых на память экранов. Последняя использует подпрограмму
phys_copy, чтобы скопировать блок символов от пользовательского процесса
в локальный буфер, причем, возможно, это действие будет повторено несколько
раз, так как локальный буфер вмещает только 64 байта. Когда буфер укомплек-
укомплектовывается, каждый 8-разрядный байт переносится в другой буфер, ramqueue,
представляющий собой массив 16-разрядных слов. Дополнительные байты за-
заполняются текущим значением байта атрибутов, который определяет цвет сим-
символов, цвет фона и некоторые другие параметры текста. Когда это возможно,
символы копируются напрямую в буфер ramqueue, но некоторые символы, на-
например управляющие символы, образующие ESC-последовательности, необходимо
обрабатывать особо. Кроме того, специальная обработка требуется тогда, когда
позиция символа превышает ширину экрана или буфер ramqueue заполнен.
В этом случае, чтобы передать символы и выполнить необходимые дополнитель-
дополнительные действия, вызывается функция out_char (строка 16119). Так, каждый раз
когда на последней строке экрана принимается символ перевода строки, делается
вызов подпрограммы scroll_screen (строка 16205), a parse_escape при-
принимает символы, образующие ESC-последовательность. Обычно out_char вы-
вызывает подпрограмму flush (строка 16259), которая копирует ramqueue в ви-
видеопамять при помощи ассемблерной подпрограммы mem_vid_copy. Функция
flush также вызывается после того, как в ramqueue передается последний
символ, чтобы гарантировать, что отображены все символы. Конечный результат
работы flush — команда, предаваемая микросхеме видеоконтроллера 6845 с це-
целью отобразить в нужном месте курсор.
Байты, поступающие от пользовательского процесса, было бы логично выводить
по одному, в цикле. Тем не менее для систем класса Pentium с защитой памяти
более эффективно предварительно накапливать их в буфере ramqueue, а затем
копировать весь блок вызовом mem_vid_copy. Интересно, что этот прием при-
применялся в ранних версиях MINIX еще тогда, когда использовались более старые
процессоры, не поддерживающие защищенного режима. Предшественник mem_
vid_copy решал другую проблему — проблему синхронизации. Дело в том, что
у старых экранов запись в видеопамять необходимо было производить при очист-
очистке экрана, во время вертикального обратного хода луча, чтобы избежать появления
на экране «мусора». Сейчас такое устаревшее оборудование не поддерживается
MINIX 3, так как это приводит к слишком большим потерям производительно-
производительности. Тем не менее сама техника копирования целого блока из ramqueue приме-
применяется и поныне, хотя и для другой цели.
Доступная консоли область видеопамяти задается полями c_start и c_limit
структуры console. Текущее положение курсора хранится в полях c_column
и c_row. Координатам @,0) соответствует верхний левый угол экрана, с это-
этого места аппаратное обеспечение начинает заполнять экран. Изображение на-
начинается с адреса, задаваемого значением c_org, и занимает 80 х 25 символов
D000 байт). Другими словами, микросхема 6845 извлекает из видеопамяти сло-
слово по адресу со смещением c_org и отображает в левом верхнем углу байт сим-
символа, а второй байт использует для задания цветов, мигания и прочих атрибутов.
Затем чип извлекает из памяти следующее двухбайтовое слово и отображает
символ в позиции A, 0). Этот процесс продолжается до тех пор, пока не дос-
достигнута позиция G9, 0), после чего начинается рисование второй строки экрана,
начиная с координат @, 1).
При включении компьютера экран очищается, и данные записываются в видео-
видеопамять, начиная с положения c_start, a c_org присваивается то же значение,
что и c_start. Таким образом, первая строка текста выводится в верхней строке
экрана. Когда вывод переходит на следующую строку в результате либо прихода
символа перевода строки, либо заполнения верхней строки экрана, новые симво-
символы помещаются по адресу, равному c_start плюс 80. Со временем все 25 строк
экрана оказываются заполненными и требуется прокрутка экрана. Некоторым
программам, например текстовым редакторам, требуется возможность прокручи-
прокручивать экран и в обратном направлении, когда курсор находится в верхней строке
экрана и нужно перейти выше по тексту.
Существует два подхода к решению задачи прокрутки экрана. Когда применяет-
применяется программная прокрутка, символу с координатами @, 0) всегда соответствует
один и тот же адрес видеопамяти, с нулевым смещением относительно c_start.
Видеоконтроллер всегда выводит этот символ на одном месте благодаря тому,
что в c_org хранится один и тот же адрес. Когда необходимо выполнить про-
прокрутку, область видеопамяти, начинающаяся со второй строки экрана (смеще-
(смещение 80 относительно c_start), копируется в начало занимаемой консолью облас-
области (смещение 0). Положение самой занимаемой экраном области памяти не ме-
меняется. В результате содержимое экрана перемещается на одну строку вверх. Эта
операция занимает время, необходимое процессору для сдвига 80 х 24 = 1920 слов
памяти. При аппаратной прокрутке данные никуда не перемещаются. Вместо
этого контроллер получает команду выводить данные с другого адреса, например
со слова 80. Для этого новое значение записывается в c_org, чтобы его можно
было использовать в дальнейшем, а также копируется в нужный регистр видео-
видеоконтроллера. Такая схема работает, если контроллер достаточно интеллектуален
и при достижении конца видеопамяти (адрес в c_limit) переходит на ее начало
(адрес в c_start), или же при такой емкости видеопамяти, когда в ней помеща-
помещается более одного экрана, то есть 80 х 2000 слов.
У старых адаптеров дисплея обычно была небольшая память, зато они умели
переходить на начало памяти, достигнув конца, и благодаря этому поддерживали
аппаратную прокрутку. У современных контроллеров памяти обычно больше,
чем необходимо для хранения одного экрана, но перескакивать на начало они не
научены. Так, контроллер с видеопамятью объемом 32 768 байт может хранить
в памяти 204 полные строки по 160 байт каждая и 179 раз выполнить аппарат-
аппаратную прокрутку, прежде чем невозможность перехода в начало станет проблемой.
Затем потребуется копирование области памяти с целью переместить данные
с последних 24 строк в начало видеобуфера. При любом методе нижняя строка
экрана заполняется пробелами, чтобы гарантировать ее очистку.
При конфигурировании виртуальных консолей доступная видеопамять поровну
делится между всеми консолями, для чего соответствующим образом инициали-
инициализируются поля c_start и c_limit каждой консоли. Это оказывает влияние на
прокрутку. Любому видеоконтроллеру, обладающему достаточно большой для
поддержки нескольких виртуальных консолей памятью, время от времени необ-
необходима программная прокрутка, хотя номинально поддерживается аппаратная.
Чем меньший объем памяти доступен каждому виртуальному дисплею, тем чаще
требуется программная прокрутка. Предел достигается, когда создается макси-
максимально возможное количество виртуальных консолей. При этом каждая про-
прокрутка оказывается программной.
Положение курсора относительно начала видеопамяти можно вычислить, исхо-
исходя из значения в полях c_column и c_row, но быстрее хранить его в явном виде
(c_cur). Когда на экран выводится символ, он записывается в память по адресу
c_cur, который после вывода обновляется, как и значение в поле c_column.
Все поля структуры console, оказывающие влияние на текущее положение вы-
вывода и начало экрана в памяти, перечислены в табл. 3.10.
Таблица 3.10. Поля структуры console, связанные с текущей позицией на экране
Поле Значение
c_start Начало видеопамяти для консоли
cjimit Предел видеопамяти для консоли
c_column Номер текущего столбца @-79), считая слева
c_row Номер текущей строки @-24), считая сверху
c_cur Смещение курсора в видеопамяти
c_org Область памяти, отводимая под экран. В микросхеме 6845 эта область
адресуется регистром базы
При обработке символов, изменяющих текущую позицию (то есть символов
перевода строки, забоя и т. д.), соответственным образом изменяются значения
полей c_column, c_row и c_cur. Это делается в конце кода процедуры flush,
где вызывается функция set_6 84 5, которая устанавливает регистры видео-
видеоконтроллера.
Драйвер терминала поддерживает ESC-последовательности, то есть гибкие воз-
возможности управления экраном для редакторов и прочих интерактивных про-
программ. Поддерживаемые последовательности являются подмножеством стандарта
ANSI и достаточны для простого переноса на MINIX 3 большинства программ,
написанных для другого аппаратного обеспечения и других операционных систем.
Есть две категории ESC-последовательностей: те, которые никогда не имеют па-
параметров, и те, которые могут содержать варьируемые данные. Единственный
представитель первой категории, реализованный в MINIX 3, это последователь-
последовательность ESC M, выполняющая обратный перевод строки. При этом курсор подни-
поднимается на одну строку вверх, а если курсор уже находится на верхней строке,
экран прокручивается на строку вниз. У последовательностей второй категории
могут быть один или два численных параметра. Все такие цепочки символов на-
начинаются с символов ESC [. Символ [ является преамбулой управляющей после-
последовательности. Список последовательностей, описываемых стандартом ANSI
и поддерживаемых MINIX 3, приведен в таблице 3.8.
Анализ управляющих последовательностей не так прост. В MINIX 3 корректные
последовательности могут содержать от двух символов, как ESC M, до 8, как
последовательности с двумя двухразрядными параметрами. Например, последо-
последовательность ESC [2 0; 6ОН перемещает курсор на строку 20, в столбце 60. Если
параметр один, его можно опускать, при наличии двух параметров позволено
опустить оба. Когда параметр не указывается или указывается значение, превы-
превышающее граничное, используется значение по умолчанию, которое равно наи-
наименьшему допустимому значению.
Посмотрим, какие ESC-последовательности позволяют переместить курсор в верх-
верхний левый угол экрана.
♦ Последовательность ESC [H. Так как оба параметра опущены, берутся наи-
наименьшие значения.
♦ Последовательность ESC [I; 1H переместит курсор в строку 1, столбец 1
(в ANSI нумерация столбцов и строк начинается с единицы).
♦ Опустив только один из параметров, можно получить последовательности
ESC [1;Н и ESC [; 1Н. Отсутствующий параметр по умолчанию будет счи-
считаться равным 1.
♦ К тому же результату приведет последовательность ESC [ 0; ОН, так как в ней
оба параметра меньше минимально допустимой величины. Они будут замене-
заменены значениями по умолчанию.
Эти примеры не нужно рассматривать как рекомендацию специально использо-
использовать некорректные значения параметров; их следует расценивать как иллюстра-
иллюстрацию того, что интерпретирующий эти последовательности код нетривиален.
Для разбора ESC-последовательностей в MINIX 3 реализован конечный авто-
автомат. Переменная состояния этого автомата c_esc_state в структуре console
обычно имеет значение 0. Когда функция out_char обнаруживает символ ESC,
она устанавливает переменную состояния c_esc_state в 1, и последующие
символы интерпретируются функцией parse_escape (строка 16293). Если сле-
следующий полученный символ является преамбулой ESC-последовательности,
выполняется переход в состояние 2; в противном случае последовательность
считается завершенной и вызывается функция do_escape (строка 16352). В со-
состоянии 2, пока на вход поступают цифровые символы, вычисляется значение
числовых параметров. А именно: предыдущее значение (которое изначально рав-
равно 0) умножается на 10, и к нему добавляется значение полученного числового
символа. Значения параметров хранятся в массиве, и когда поступает символ
точки с запятой, осуществляется переход к следующей ячейке массива. В MINIX 3
этот массив содержит всего два элемента, но принцип тот же. Когда полученный
символ оказывается нечисловым и не точкой с запятой, последовательность счи-
считается завершенной и снова вызывается do_e scape. Символ, являющийся теку-
текущим на момент обращения к do_escape, используется для того, чтобы опреде-
определить, какое именно действие необходимо выполнить и как интерпретировать
параметры, будь то значения по умолчанию или считанные из потока симво-
символов данные. Подробнее этот конечный автомат рассматривается в пункте 3.8.6.
Подгружаемые раскладки клавиатуры
Клавиатура IBM PC не генерирует ASCII-коды напрямую. Клавиши иденти-
идентифицируются по их номерам, начиная с клавиш в верхнем ряду оригинальной
клавиатуры IBM PC. Соответственно, клавиша Esc имеет номер 1, клавиша 1 —
номер 2 и т. д. Номера присвоены всем клавишам, включая клавиши-модифика-
клавиши-модификаторы, такие как левая и правая клавиши Shift, которые соответственно имеют но-
номера 42 и 54. Когда нажимается клавиша, MINIX 3 извлекает ее номер из кода
опроса клавиатуры. Код опроса генерируется и в том случае, когда клавиша
отпускается, но здесь устанавливается старший значащий бит кода (что эквива-
эквивалентно добавлению числа 128 к номеру) Благодаря этому операционная система
может различать, была клавиша нажата или отпущена Поскольку система от-
отслеживает состояние клавиш-модификаторов, возможно множество комбина-
комбинаций Для большинства целей достаточно двухклавишных сочетаний, таких как
Shift+A или Ctrl+D, удобных для тех, кто при печати привык пользоваться обеими
руками, но в некоторых специальных случаях могут применяться комбинации из
трех (и более) клавиш, например Ctrl+Shift+A или Ctrl+Alt+Del (последняя ис-
используется в PC для сброса системы)
Сложность клавиатуры PC обеспечивает гибкость ее использования В стандарт-
стандартном наборе присутствуют 47 клавиш с типовыми символами B6 алфавитных
символов, 10 цифр и И знаков препинания) Если мы будем поддерживать ком-
комбинации из трех клавиш-модификаторов, таких как Ctrl+Alt+Shift, получается 376
(8 х 47) вариантов Это ни коим образом не предел возможного, но сейчас мы
не будем акцентировать внимание на различиях между левыми и правыми кла-
клавишами-модификаторами, а также учитывать функциональные клавиши или
клавиши цифровой клавиатуры Конечно, никто не заставляет нас использовать
в качестве модификаторов только клавиши Ctrl, Shift и Alt Мы вправе исключить
какую-либо клавишу из стандартного набора и использовать ее в качестве моди-
модификатора, для чего нужно написать драйвер, поддерживающий такую систему
Чтобы определить, какой код передать программе при нажатии определенной
клавиши, операционные системы, работающие с подобными клавиатурами, при-
применяют раскладки клавиатуры, или карты клавиш В MINIX 3 типичная карта
клавиш логически является массивом, имеющим 128 строк для каждого кода
опроса (такой размер был выбран для поддержания японских клавиатур, у евро-
европейских и американских клавиатур нет такого числа клавиш) и 6 столбцов
Столбцы сопоставлены следующим состояниям нет модификаторов, нажата
клавиша Shift, нажата клавиша Ctrl, нажата левая клавиша Alt, нажата правая кла-
клавиша Alt, нажата комбинация Alt+Shift Такая схема при соответствующей кла-
клавиатуре позволяет генерировать A28 - 6) х 6 = 720 различных кодов символов
Конечно, каждая запись в таблице должна содержать 16-разрядное значение
У американских клавиатур столбцы для левой и правой клавиш Alt идентичны
Для других языков правая клавиша Alt называется Altgr, и на клавишах многих из
подобных клавиатур нарисован третий символ, для ввода которого и использу-
используется этот модификатор
Стандартная карта клавиш встроена в ядро MINIX 3 и в файле keyboard с оп-
определяется строкой
#include keymaps/us-std src
Для загрузки альтернативной раскладки по адресу keymap используется систем-
системный вызов ioctl следующего вида
ioctl@, KIOCSMAP, keymap)
Полная раскладка занимает 1536 байт A28 х 6 х 2) Дополнительные расклад-
раскладки хранятся в сжатой форме Чтобы создать новую сжатую карту, запускается
программа genmap. При компиляции в genmap включается код keymap. src для
определенной раскладки. Обычно программа genmap запускается сразу же после
компиляции и записывает уплотненную версию в файл, после чего исполняемый
файл программы удаляется. Команда loadkeys загружает указанную карту кла-
клавиш, выполняет декомпрессию и делает системный вызов ioctl, передавая рас-
раскладку в память ядра. MINIX 3 может автоматически вызывать команду loadkeys
при старте. Кроме того, ее в любой момент может вызвать пользователь.
Исходный код раскладки описывает большой инициализированный массив.
С целью экономии места мы исключили файл карты клавиш из файлов, пред-
представленных на сопровождающем книгу компакт-диске. В табл. 3.11 показано
содержимое нескольких строк файла src/kernel/keymaps/us-std.src. На
клавиатурах IBM PC нет клавиши, генерирующей код опроса 0. Коду 1 соответ-
соответствует клавиша Esc. Из первой записи в таблице видно, что возвращаемый код
для этой клавиши не зависит от состояния модификатора Shift или Ctrl, но если
удерживается клавиша Alt, при нажатии клавиши Esc генерируется другой код.
Таблица 3.11. Несколько записей из файла раскладки клавиатуры
Код Символ Без Shift Левая Правая Alt+Shift Ctrl
опроса модификации клавиша Alt клавиша Alt
~00 Нет 0 0 0 0 0 0
01 ESC С(Т) С(Т) СА(Т) СА(Т) СА(Т) С ('[')
02 Т Т Т А(Т) А(Т) А(Т) С('А')
13 '=' '=' '+' A('=f) A('=f) A('+f) C('@f)
16 fqf L('q') fQf A('q') A('q') A('Q') C('Q')
28 CR/LF С('М') С('М') СА('М') СА('М') СА('М') C('Jf)
29 CTRL CTRL CTRL CTRL CTRL CTRL CTRL
59 F1 F1 SF1 AF1 AF1 ASF1 CF1
127 ??? 0 0 0 0 0 0
Значения, содержащиеся в ячейках таблицы, задаются при помощи макросов из
файла include/minix/keymap.h:
#define С(с) ((с)) & OxlF) /* Преобразование в управляющий код */
#define А(с) ((с)) I 0x80) /* Устанавливается восьмой бит (Alt) */
#define СА(с) А(С(с)) /* Ctrl+Alt */
#define L(c) ((с) I HASCAPS) /* Добавляется признак Caps Lock */
Первые три макроса манипулируют битами переданного символа, вырабатывая
нужный код. Последний устанавливает бит HASCAPS в старшем байте 16-раз-
16-разрядного кода. Этот флаг указывает на необходимость проверки, фиксируется ли
верхний регистр букв (клавиша Caps Lock), и возможную модификацию кода.
В табл. 3.11 записи для кодов опроса 2, 13 и 16 иллюстрируют, как обрабаты-
обрабатываются типичные клавиши с цифровыми, алфавитными символами и знаками
препинания. У кода 28 можно видеть одну особенность. Обычно клавиша Enter
порождает код CR (OxOD), который записывается здесь как С ( 'М1 ). Так как
в UNIX символом новой строки является код LF (ОхОА) и иногда его необходимо
вводить напрямую, комбинация Ctrl+Enter обрабатывается особым образом и про-
производит код С( ' J1 ).
Код опроса 29 — это один из кодов модификаторов, который должен распознавать-
распознаваться всегда, поэтому независимо от состояния прочих модификаторов возвращается
значение CTRL. Функциональные клавиши не генерируют обычных ASCII-сим-
ASCII-символов, и строка таблицы для кода опроса 59 содержит символьную запись значе-
значений, возвращаемых при нажатии клавиши F1 в комбинации с различными мо-
модификаторами. Это следующие коды: F1 @x0110), SF1 @x1010), AF1 @x0810),
ASF1 (ОхОСЮ), CF1 @x0210). Последняя запись в таблице соответствует коду
опроса 127 — типичному для конца массива маркеру. У большинства клавиатур,
используемых в Европе и Америке, недостаточно клавиш, чтобы генерировать
такие коды, поэтому соответствующие записи в таблице заполняются нулями.
Загружаемые шрифты
В ранних персональных компьютерах шаблоны, по которым генерировались изо-
изображения символов на экране, хранились только в ПЗУ. Теперь у контроллеров,
которыми оснащаются современные системы, образы символов можно загружать
в оперативную память. В MINIX 3 эта возможность поддерживается с помощью
системного вызова ioctl следующего вида:
ioctl@, TIOCFON, font)
MINIX 3 поддерживает видеорежим 80 столбцов на 25 строк, и файлы со шриф-
шрифтами содержат 4096 байт. Каждый байт такого файла управляет отрезком из
восьми пикселов, при этом подсвеченному пикселу соответствует 1, погашен-
погашенному — 0. Для генерации символа необходимо 16 таких отрезков. Тем не ме-
менее контроллер дисплея для хранения изображения каждого символа отводит
32 байта, чтобы работать при более высоком разрешении, не поддерживаемом
сейчас MINIX 3. Для того чтобы преобразовать такой файл в 8192-байтовую
структуру font, адрес которой передается в системный вызов ioctl, предна-
предназначена команда loadfont. Как и карты клавиш, шрифты могут загружаться
при запуске системы или же позднее, в любой момент нормальной работы. Одна-
Однако загружать шрифт не обязательно, у каждого видеоадаптера в ПЗУ имеется
встроенный шрифт, доступный по умолчанию. Встраивать шрифт в саму систе-
систему нет необходимости, поэтому единственное, что присутствует в ядре для под-
поддержки загружаемых шрифтов, — это код, выполняющий операцию TIOCSFON
системного вызова ioctl.
3.8.4. Реализация аппаратно-независимого
драйвера терминала
В этом разделе мы начнем подробное изучение кода драйвера терминала. Рассмат-
Рассматривая блочные устройства, мы видели, что драйверы, обслуживающие несколько
различных устройств, могут иметь общий базовый код. В случае драйвера тер-
терминала ситуация примерно та же, с той разницей, что один драйвер поддержи-
поддерживает несколько типов терминальных устройств. Мы начнем изучение с кода, не
зависящего от конкретных устройств. Позже мы перейдем к коду, работающему
с клавиатурой и отображаемым на память экраном.
Структуры данных драйвера терминала
В файле tty. h содержатся определения, используемые в коде драйверов терми-
терминала. Так как драйвер поддерживает большое число различных устройств, при
вызове необходимо различать эти устройства. Для этого используются вспомога-
вспомогательные номера устройств, определенные в строках 13405-13409.
Определения макросов O_NOCTTY и CL.NONBLOCK (значения необязательных
флагов для системного вызова open) в файле tty.h повторяют определения,
имеющиеся в файле include/ f cntl. h. Это сделано с той целью, чтобы не при-
присоединять другие заголовочные файлы. Типы devf un__t и devf unarg_t (стро-
(строки 13423 и 13424) применяются для передачи указателей на функции, которые
используются в механизмах косвенного вызова для главного цикла дисковых
драйверов, аналогичных рассмотренным нами ранее.
Большую часть объявленных в этом файле переменных можно идентифициро-
идентифицировать по префиксу tty_. Самое главное описание в файле tty. h — это структура
tty (строки 13426-13488). Для каждого терминального устройства, рассматри-
рассматриваемого в целом (консольный дисплей и клавиатура образуют один терминал),
существует одна такая структура. Первое ее поле, tty_events, представляет со-
собой флаг, который устанавливается в результате прерывания по факту измене-
изменений, требующих от драйвера терминала уделить внимание устройству.
Остальные поля структуры tty объединены в группы, связанные с операциями
ввода и вывода, состоянием устройства и информацией о незавершенных опера-
операциях. В секции операций ввода первая пара переменных, tty_inhead и tty_
intail, задают очередь, в которой буферизуются принимаемые символы. Поле
tty_incount является счетчиком количества символов в этой очереди, а в поле
tty_eotct подсчитываются строки символов. Все вызовы, зависящие от кон-
конкретного устройства, являются косвенными, за исключением вызовов процедур
инициализации терминала, которые и устанавливают указатели для косвенных
вызовов. Указатели на специфичный для данного терминала код хранятся в по-
полях tty_devread и tty_icancel. Это — соответственно указатели на функ-
функцию чтения данных и функцию отмены чтения. Значение поля tty_min сравни-
сравнивается с tty_eotct. Когда значение tty_eotct становится равно значению
tty_min, операция чтения считается завершенной. При каноническом вводе
tty_min равно 1, а в tty_eotct подсчитываются введенные строки. При нека-
неканоническом вводе в tty_eotct подсчитываются символы, a tty_min присваи-
присваивается значение из поля MIN структуры termios. Таким образом, сравнение
этих двух полей позволяет определить, когда завершен ввод строки или получе-
получено минимально необходимое количество символов (в зависимости от режима).
Поле tty_tmr является таймером данного терминального устройства, исполь-
используемым для поля TIME структуры termios.
Поскольку постановка данных в очередь вывода выполняется по-разному для раз-
разных устройств, секция вывода структуры tty не содержит переменных, а состоит
исключительно из указателей на специфичные для устройств функции, слу-
служащие для вывода, эхопечати, отправки сигнала прерывания и отмены вывода.
В секции состояния поля tty_reprint, tty_escaped и tty_inhibited слу-
служат флагами, индицирующими, что последний полученный символ несет специ-
специальную нагрузку. Так, когда получен символ LNEXT (Ctrl+V), флаг tty_escaped
устанавливается в 1, чтобы обозначить, что любое особое значение следующего
полученного символа необходимо игнорировать.
Следующая часть структуры хранит информацию о текущих операциях DEV_
READ, DEV_WRITE и DEV_IOCTL. Каждая из этих операций затрагивает два про-
процесса. Обслуживающий системный вызов сервер (обычно — файловая система)
идентифицируется полем tty_incaller (строка 13458). Сервер вызывает драй-
драйвер терминала от лица другого процесса, заинтересованного в операции ввода-
вывода, и этот процесс идентифицируется полем tty_inproc (строка 13459).
Как показано на рис. 3.21, при выполнении вызова read символы копируются
напрямую в приемный буфер в адресном пространстве сделавшего вызов про-
процесса. Положение буфера задается полями tty_inproc и tty_in_vir. Две
следующие переменные, tty_inlef t и tty_incum, фиксируют число симво-
символов, которое еще нужно и которое уже получено. Аналогичный набор перемен-
переменных предусмотрен и для системного вызова write. При выполнении вызова
ioctl может потребоваться немедленная передача данных между запрашиваю-
запрашивающим процессом и драйвером, для чего нужен виртуальный адрес, но информа-
информацию о состоянии этой операции сохранять не надо. К примеру, возможна задерж-
задержка обслуживания ioctl до окончания текущего вывода, однако затем запрос
выполняется за одну операцию.
Наконец, структура tty содержит еще несколько переменных, которые не попа-
попадают ни в какую другую категорию. Это — указатели на функции, выполняющие
операции DEV_IOCTL и DEV_CLOSE на уровне устройства, структура termios,
описанная в POSIX, и структура winsize, обеспечивающая поддержку экранов
с оконным интерфейсом. В последней части структуры зарезервировано место
для самой входной очереди в массиве tty_inbuf. Обратите внимание, что
это массив значений типа ul6_t, а не 8-разрядных символов char. Хотя при-
приложения и устройства используют для представления символов 8-разрядные
коды, язык С ужесточает требования, считая, что функция get char должна воз-
возвращать данные более длинного типа, чтобы помимо 256 допустимых значений
байта она могла возвращать код EOF.
Массив tty_table, состоящий из структур tty, объявлен со спецификатором
extern (строка 13491). Для каждого терминала в этом массиве резервируется
по одному элементу, а количество элементов определяется константами NR_
CONS, NR_RS_LINES и NR_PTYS, заданными в файле include/minix/conf ig.h.
В обсуждаемую в книге конфигурацию включены две консоли, но MINIX можно
перекомпилировать, обеспечив поддержку до двух последовательных интерфей-
интерфейсов и до 64 псевдотерминалов.
В файле tty. h есть еще одно внешнее (extern) определение. Переменная tty_
timers (строка 13516) представляет собой указатель, который используется
таймером для поддержания связанного списка полей timer_t. Файл tty.h
включается во многие другие файлы, и область памяти для tty_table и tty_
timers резервируется при компиляции tty .с.
В конце файла находится текст двух макросов, buf len и buf end (строки 13520
и 13521). Эти макроопределения многократно используются в коде драйвера
терминала, выполняющего много операций копирования в буферы и из них.
Независимый от устройств драйвер терминала
Основные функции драйвера терминала и все аппаратно-независимые вспомога-
вспомогательные функции сконцентрированы в файле tty.с. Далее следуют еще не-
несколько макроопределений. Если устройство не инициализировано, указатели
на специфические для данного устройства функции содержат нулевые значения,
которые записываются компилятором. То есть можно создать макрос tty_
active (строка 13687), который возвращает FALSE в случае, когда обнаружи-
обнаруживается нулевой указатель. Естественно, код инициализации устройства нельзя
вызвать косвенно, собственно, одна из задач такого кода — инициализация ука-
указателей, которые своим присутствием делают возможными косвенные вызовы.
Строки 13690-13696 содержат условные макроопределения, заменяющие адреса
функций инициализации терминала RS-232 или псевдотерминала нулевыми
адресами, если соответствующие устройства не включены в конфигурацию. Это
позволяет полностью пропустить код для означенных устройств, когда в дейст-
действительности он не нужен.
Так как терминал настраивается множеством параметров, а в сетевой системе
терминалов несколько, декларируется и заполняется значениями по умолчанию
структура termios_defaults (строки 13720-13727). Сами значения задаются
в файле /include/termios .h. Эта структура копируется в запись tty_table
при инициализации или повторной инициализации терминала. Значения по умол-
умолчанию для специальных символов были показаны в табл. 3.6. В табл. 3.12 пред-
представлены значения по умолчанию для различных флагов. Далее в коде следуют
строки, где аналогичным образом объявляется структура winsize_defaults.
Ее поля инициализируются нулями компилятором С; это подразумевает, что раз-
размер окна неизвестен и нужно использовать файл /etc/termcap.
Таблица 3.12. Значения по умолчанию для флагов структуры termios
Поле Значение по умолчанию
cjflag BRKINT ICRNL IXON IXANY
c_oflag OPOST ONLCR
c_cflag CREAD CS8 HUPCL
cjflag ISIG lEXTERN ICANON ECHO ECHOE
Последним набором определений перед началом исходного кода являются об-
общедоступные (public) глобальные переменные, ранее объявленные внешними
(extern) в файле tty.h (строки 13731-13735).
Точкой входа для драйвера терминала является функция tty_task (строка 13740).
Перед тем как начать свой главный цикл, она вызывает функцию tty_init
(строка 13752). Информация о главном компьютере, необходимая для инициа-
инициализации клавиатуры и консоли, предоставляется вызовом sys_getmachine
ядра, а затем выполняется сама инициализация при помощи подпрограммы kb_
init_once. Такое имя было выбрано, чтобы отличить эту подпрограмму от дру-
другой подпрограммы инициализации, вызываемой позднее для каждой виртуаль-
виртуальной консоли. Наконец, на вывод посылается один символ 0, чтобы проверить вывод
и исключить неинициализированные устройства раньше, чем будут предприня-
предприняты первые попытки их использования. В коде вызывается функция printf, но
она отличается от одноименной функции, вызываемой обычными программами.
Она вызывает локальную функцию putk драйвера консоли.
Главный цикл (строки 13764-13876) почти аналогичен главному циклу любого
другого драйвера. Принимается сообщение, при помощи инструкции switch
для каждого типа сообщения вызывается соответствующая функция обработки,
после чего генерируется ответное сообщение. Однако есть и отличия. Первое со-
состоит в том, что с момента последнего прерывания могут накопиться считанные
или выведенные на запись символы. Поэтому, прежде чем пытаться получить со-
сообщение, главный цикл проверяет флаги tp->tty_events для всех термина-
терминалов. Если необходимо позаботиться о незавершенных делах, вызывается функ-
функция handle_events, и только если не найдено ни одного требующего внимания
терминала, делается вызов receive.
Диаграмма с типами сообщений, представленная в комментариях в начале файла
tty. с, содержит лишь наиболее распространенные типы. В ней отсутствуют мно-
многие типы, требующие особой обработки драйвером терминала. Те же, которые на
ней изображены, не являются специфичными для какого-либо конкретного уст-
устройства. Главный цикл tty_task проверяет общие сообщения и обрабатывает
их раньше, чем специфичные. Первая проверка относится к типу SYN_ALARM,
и если сообщение относится к нему, выполняется вызов expire_timers, запус-
запускающий подпрограмму сторожевого таймера. Затем следует команда continue.
Фактически, все следующие варианты, которые мы рассмотрим, расположены
после этой команды. Скоро мы скажем об этом более подробно.
Следующий тип, соответствие которому проверяется для сообщения, — HARD_
INT. Сообщения такого типа чаще всего обусловлены нажатием или отпускани-
отпусканием клавиши на локальной клавиатуре. Сообщения HARD_INT также генерируются
при получении байтов по последовательному порту в случае, если он включен.
В конфигурации, описываемой в книге, последовательные порты не используют-
используются, однако мы сохранили в файле условный код, чтобы продемонстрировать, как
система функционировала бы при поддержке последовательных портов. Битовое
поле сообщения позволяет определить источник прерывания.
Затем проверяется тип SYS_SIG. Системные процессы (драйверы и серверы),
как правило, блокируются и ожидают сообщений. Обычные сигналы способны
получать лишь активные процессы, поэтому стандартный метод использова-
использования сигналов UNIX неприменим к системным процессам. Для передачи сигнала
системному процессу и служит сообщение типа SYS_SIG. Сигнал, посылае-
посылаемый драйверу терминала, может означать, что ядро собирается завершить ра-
работу (SIGKSTOP), выполнение драйвера терминала должно быть прекращено
(SIGTERM) либо ядру необходимо вывести сообщение на консоль (SIGKMESS).
В каждом из случаев вызываются соответствующие подпрограммы.
Последняя группа сообщений, не зависящих от устройств, включает сообщения
PANIC_DUMPS, DIAGNOSTICS и FKEY_CONTROL. Мы расскажем о них более под-
подробно при изучении функций, предназначенных для их обслуживания.
Теперь несколько слов об инструкции continue. В языке С команда continue
выполняет «короткое замыкание» цикла и возвращает управление в его начало.
Как только для сообщения устанавливается один из перечисленных типов, оно
обрабатывается соответствующим образом, после чего управление передается
в начало главного цикла (строка 13764). Снова выполняется проверка событий,
а затем вызов receive приводит к ожиданию нового сообщения. Быстрое вос-
восстановление готовности отклика важно, причем особенно — в случае ввода. Кро-
Кроме того, если любая из проверок типа в первой части цикла дает положительный
результат, смысл в проверках, следующих после первой в инструкции switch,
теряется.
Ранее мы говорили о сложностях, с которыми приходится иметь дело драйверу
терминала. Еще одна сложность состоит в том, что драйвер обслуживает не-
несколько устройств. Если прерывание не аппаратное, то чтобы определить, какое
устройство должно ответить на сообщение, используется поле сообщения TTY_
LINE. Младший номер устройства декодируется при помощи серии сравнений,
ив tp помещается адрес корректной записи в таблице терминалов tty_table
(строки 13834-13847). Если устройство является псевдотерминалом, вызывает-
вызывается функция do_pty (из файла pty. с), после чего главный цикл перезапускает-
перезапускается. В этом случае ответное сообщение генерируется функцией do_pty. Конечно,
если в конфигурации нет псевдотерминалов, данный вызов при помощи макроса
заменяется пустым, как было описано ранее. Можно было бы понадеяться на от-
отсутствие попыток обращения к несуществующим устройствам, но всегда проще
добавить еще одну упреждающую проверку, чем при ошибке разбираться со всей
остальной системой. В ситуации, когда устройство не существует или не скон-
сконфигурировано, генерируется ответное сообщение с кодом ENXIO, и управление
опять передается в начало цикла.
Оставшуюся часть драйвера составляет то, что мы уже видели в главной функ-
функции других драйверов, — инструкция switch, проверяющая значение типа сооб-
сообщения (строки 13862-13875). Для запроса каждого типа вызывается соответст-
соответствующая функция, do_read, do_write и т. д. В каждом из случаев функции
сами создают ответное сообщение, вместо того чтобы возвращать необходимую
информацию обратно в главный цикл. Ответное сообщение генерируется в кон-
конце цикла только при условии, что было получено сообщение неправильного ти-
типа. В этом случае оно содержит код ошибки EINVAL. Так как отправлять сооб-
сообщения требуется во многих местах кода, реализована общая подпрограмма tty_
reply, которая отвечает за детали создания ответного послания.
Если полученное функцией tty_task сообщение имеет корректный тип, а также
не является результатом прерывания и не пришло от псевдотерминала, инструк-
инструкция switch в конце главного цикла перенаправляет его одной из функций do_
read, do_write, do_ioctl, do_open, do_close do_select или do_cancel.
У этих функций есть два аргумента: указатель tp на структуру tty и адрес сооб-
сообщения. Прежде чем рассматривать эти функции по отдельности, отметим то,
что у них общего. Так как драйвер терминала обслуживает несколько устройств,
все функции должны срабатывать быстро, чтобы главный цикл мог продол-
продолжить работу.
Однако функции do_read, do_write и do_ioctl не всегда могут обеспечить
выполнение всех запрошенных действий сразу. Чтобы позволить файловой сис-
системе обслуживать другие вызовы, от функций требуется немедленный ответ. По-
Поэтому, если запрос не может быть удовлетворен немедленно, в поле состояния
ответного сообщения доставляется код SUSPEND. На рис. 3.21 это соответствует
сообщению C) и приводит к приостановке процесса-инициатора вызова, в то
время как файловая система вь!ходит из блокировки. Сообщения под номера-
номерами 7 и 8 отправляются позже, после завершения операции. Если операция может
быть выполнена полностью или произошла ошибка, то в поле состояния ответ-
ответного сообщения возвращается либо количество переданных байтов, либо код
ошибки. В последнем случае файловая система немедленно отправляет сделав-
сделавшему вызов процессу ответное сообщение, пробуждая его.
Чтение с терминала фундаментально отличается от чтения с диска. Драйвер дис-
диска отдает команды аппаратному обеспечению, и в итоге тоже возвращаются дан-
данные, если не случился механический или электрический сбой. В случае термина-
терминала компьютер может вывести на экран приглашение, но не существует способа
принудить сидящего за клавиатурой человека начать печатать хотя бы потому,
что нет никакой гарантии, что за клавиатурой кто-то сидит. Чтобы обеспечить
быстрый возврат, функция do_read (строка 13593) начинает с того, что сохра-
сохраняет информацию о запросе. Благодаря этому запрос можно выполнить позже,
когда прибудет недостающая информация. Сначала должен быть проведен кон-
контроль ошибок. Ошибка возникает в случае, если устройство все еще ожидает
ввод, чтобы выполнить предыдущий запрос, или если переданные в сообщении
параметры неправильны (строки 13964-13972). После окончания проверки ин-
информация готова к записи в поля записи tp->tty_table, соответствующей уст-
устройству (строки 13975-13979). Последним шагом в переменную tp->inlef t
записывается количество полученных символов. Это — важный шаг, так как
переменная tp->inlef t необходима для определения момента завершения
чтения. В каноническом режиме значение tp->inlef t декрементируется с ка-
каждым возвращенным символом до тех пор, пока не будет получен символ новой
строки, после чего эта переменная сразу обнуляется. В неканоническом режиме
она изменяется по-другому, но так или иначе, когда запрос выполнен, по тайм-
ауту или после получения минимального необходимого количества символов,
в эту переменную записывается нуль. Когда значение tp->tty_inlef t достига-
достигает нуля, отправляется ответное сообщение. Как мы увидим, ответное сообщение
может генерироваться в нескольких местах кода. Кроме того, иногда необходимо
удостовериться, что выполняющий чтение процесс ожидает ответа. Здесь инди-
индикатором служит ненулевое значение tp->tty_inlef t.
В каноническом режиме терминал ожидает ввода до тех пор, пока не введено за-
запрошенное количество символов или не получен символ конца строки или кон-
конца файла. Чтобы проверить, находится ли терминал в каноническом режиме, тес-
тестируется значение бита ICANON структуры termios (строка 13981). Если бит не
установлен, проверяется значение переменных MIN и TIME с целью определить-
определиться в дальнейших действиях.
Как мы видели в табл. 3.7, при чтении с терминала поведение определяют раз-
различные комбинации параметров MIN и TIME. Сначала проверяется значение па-
параметра TIME (строка 13983). Нулевое значение соответствует левому столбцу
таблицы, и в этом случае других проверок в текущий момент не нужно. Если
значение TIME не равно нулю, проверяется параметр MIN. Если это — нуль, дела-
делается вызов settimer для запуска таймера, который по истечении заданного ин-
интервала времени прервет запрос DEV_READ, даже если не будет прочитано ни од-
одного байта. В переменную tp->tty_min в этом случае записывается 1, чтобы
вызов завершился немедленно после того, как до истечения тайм-аута будет по-
получен хотя бы один симзол. В этой точке не проверяется, имеются ли уже вве-
введенные символы, поэтому может оказаться, чтр запроса уже ожидают несколько
символов. Как только обнаруживаются уже введенные символы, они возвраща-
возвращаются процессу, но не больше, чем задано при вызове read. В том случае, если
оба значения, MIN и TIME, не равны нулю, таймер ведет себя по-другому — отсчи-
отсчитывает время между символами. Он запускается только после того, как введен
первый символ, и перезапускается с каждым новым. В переменной tp->tty_
eotct в неканоническом режиме подсчитываются введенные символы. Ее зна-
значение проверяется, и при равенстве нулю (ни одного символа еще не получено)
таймер останавливается (строка 13993).
В любом случае после этого блока условных операторов вызывается функция
in_transfer, чтобы напрямую передать уже имеющиеся во входной очереди
символы на чтение процессу (строка 14001). Затем следует вызов handle_
events, который, в свою очередь, может поместить новые данные во входную
очередь и который снова вызывает функцию in_transfer. Такое кажущееся
дублирование вызовов требует дополнительных пояснений. Хотя до сих пор об-
обсуждение велось в терминах клавиатурного ввода, функция do_read не зависит
от конкретных устройств и обслуживает, в том числе, удаленные терминалы,
подключаемые по последовательной линии. Возможна ситуация, когда предыду-
предыдущий поток ввода заполняет буфер, и ввод приостанавливается. Первый вызов
in_transf ег не запускает поток, но вызов handle_events может это сделать.
То, что он при этом еще раз вызывает функцию in_transf ег, — всего лишь не-
небольшой «довесок». Нам важно, что удаленный терминал снова получает разре-
разрешение отправлять данные. Оба вызова способны привести к тому, что запрос
окажется выполненным, и файловой системе будет отправлено ответное сообще-
сообщение. В качестве флага-индикатора отправки ответного сообщения используется
переменная tp->tty_inlef t. Если ее значение не равно нулю (строка 14004),
do_read самостоятельно генерирует и отправляет ответ (строки 14013-14021).
В данном случае мы предполагаем, что системный вызов select не использо-
использовался, а, следовательно, вызова select_retry в строке 14006 также нет.
Если в исходном запросе требовалось неблокирующее чтение, файловой системе
дается указание вернуть код ошибки EAGAIN сделавшему вызов процессу. Если
в запросе было затребовано обыкновенное блокирующее чтение, файловая сис-
система получает код SUSPEND, который разблокирует ее, но дает указание оставить
процесс-инициатор вызова заблокированным. В данном случае в поле tp->tty_
inrepcode записывается значение REVIVE. Когда позднее делается вызов read,
этот код помещается в ответное сообщение файловой системе с целью информи-
информировать ее о том, что запросивший чтение процесс был приостановлен и должен
быть активизирован.
Функция do_write (строка 14029) подобна do_read, но проще, так как при
обработке системного вызова write нужно учитывать меньшее количество раз-
разнообразных параметров. Сначала делается ряд проверок, подобных проверкам
в do_read, из которых выясняется, что предыдущий запрос уже обработан и пе-
переданные параметры корректны. Затем параметры сообщения копируются в струк-
структуру tty. После этого вызывается функция handle_events и проверяется
значение переменной tp->tty_outlef t, чтобы узнать, завершена ли работа
(строки 14058-14060). Если да, значит, ответное сообщение уже отправлено
функцией handle_events, и делать больше нечего. Если нет, генерируется от-
ответ, параметры которого зависят от того, был исходный вызов write блокирую-
блокирующим или нет.
Далее следует довольно большая, но не сложная для понимания функция do_
ioctl (строка 14079). Тело этой функции состоит из двух инструкций switch.
Первая определяет размер параметра, на который ссылается указатель в сообще-
сообщении (строки 14094-14125). Если размер параметра не равен нулю, проверяется
его корректность. В этом месте нельзя контролировать содержимое, но можно
удостовериться, что структура имеет требуемый размер, начинается по указанно-
указанному адресу и умещается в том сегменте, где она должна находиться. Остаток
функции составляет еще одна инструкция switch, проверяющая тип запрошен-
запрошенной операции ioctl (строки 14148-14225).
К несчастью, поддержка требуемых стандартом POSIX операций подразумевает,
что для операций ioctl необходимо придумывать имена, которые напоминают,
но не дублируют POSIX-имена. Соответствие между именами POSIX-запро-
сов и параметрами вызова ioctl в MINIX 3 иллюстрирует табл. 3.9. Операция
TCGETS обслуживает пользовательский вызов tcgetattr и просто возвращает
копию структуры tp->tty_termios для терминального устройства. Следую-
Следующие четыре типа запросов разделяют общий код. Типы запросов TCSETSW,
TCSETSF и TCSETS соответствуют вызовам POSIX-функции tcsetattr, и ос-
основное действие в этом случае общее: структура termios копируется в струк-
структуру tty терминала. Для вызова TCSETS копирование происходит немедлен-
немедленно, а для TCSETSW и TCSETSF выполняется после того, как завершен вывод.
Копирование производится вызовом phys_copy, следующим за вызовом setattr
(строки 14153-14156). Если вызов tcsetattr был сделан с модификатором,
требующим отложить выполнение до момента, пока не будет завершен текущий
вывод, а проверка переменной tp->tty_outlef t показывает, что вывод дейст-
действительно еще не завершен (строка 14139), параметры запроса помещаются в струк-
структуру tty терминала для последующей обработки. Вызов tcdrain приостанав-
приостанавливает программу до тех пор, пока не будет завершен вывод. Он транслируется
в вызов ioctl типа TCDRAIN. Если вывод уже завершен, дальнейшей обработки
не требуется. Иначе информация также записывается в структуру tty.
POSIX-функция tcf lush отменяет незавершенный ввод и (или) вывод в за-
зависимости от переданного аргумента. Соответствующая операция ioctl состо-
состоит из вызова tty_icancel, который обслуживает все терминалы, и (или) вы-
вызова зависящей от устройства функции, адрес которой хранится в переменной
tp->tty_ocancel (строки 14159-14167). Вызов tcf low аналогичным образом
транслируется в вызов ioctl. Чтобы приостановить или вновь разрешить вы-
вывод, в переменную tp-> tty_inhibited записывается значение TRUE или
FALSE, а затем устанавливается флаг tp->tty_events. Чтобы приостановить
или вновь разрешить ввод, удаленному терминалу отправляется, соответственно,
код STOP (обычно Ctrl+S) или START (Ctrl+Q). Для этого используется специ-
специфичная для устройства подпрограмма, адрес которой хранится в переменной
tp->tty_echo (строки 14181-14186).
Большая часть остальных операций, обрабатываемых вызовом do_ioctl, выпол-
выполняются одной строчкой кода, то есть просто вызовом соответствующей функции.
В случае операций KIOCSMAP (загрузка раскладки клавиатуры) и TIOCSFON (за-
(загрузка шрифта) делается проверка того, что устройство действительно является
консолью, так как эти операции неприменимы к другим типам терминалов. Если
используются виртуальные терминалы, на всех консолях будет одна раскладка
клавиатуры и шрифт. Аппаратное обеспечение не позволяет легко изменить та-
такой режим работы. Операции, работающие с размером окна, переносят данные
структуры winsize между пользовательским процессом и драйвером терминала.
Обратите особое внимание на комментарий под кодом для операции TIOCSWINSZ.
Когда процесс меняет размер окна, в некоторых версиях UNIX от ядра ожидает-
ожидается, что оно отправит сигнал SIGWINCH всем процессам из той же группы процес-
процессов. По стандарту POSIX сигнал не требуется и в MINIX 3 не используется. Тем
не менее любой, кто хочет задействовать эти структуры, должен добавить сюда
код, инициирующий этот сигнал.
Последние два варианта из do_ioctl поддерживают POSIX-функции tcgetpgrp
и tcsetpgrp. С этими типами не связано никаких действий, и они всегда воз-
возвращают ошибку. И здесь нет ничего неправильного. Эти функции необходимы
для управления заданиями, для возможности приостанавливать и перезапускать
процесс с клавиатуры. Управление заданиями POSIX не требует, и оно не под-
поддерживается в MINIX 3. Тем не менее по стандарту POSIX эти функции должны
иметься даже в отсутствие управления заданиями с целью гарантировать пере-
переносимость программ.
Основная задача функции do_open (строка 14234) проста — она увеличивает
значение переменной tp->tty_openct для устройства, чтобы впоследствии
можно было судить, открыто оно или нет. Вместе с тем сначала нужно провести
несколько проверок. Согласно стандарту POSIX, первый процесс, открывающий
терминал, должен быть лидером сеанса, и когда этот процесс завершается, у дру-
других процессов из той же группы отбирается доступ к терминалу. Демонам необ-
необходимо иметь возможность выводить сообщения об ошибках, и если вывод демо-
демонов не перенаправлен в файл, он должен поступать на экран, который нельзя
закрыть.
Для этой цели в MINIX 3 существует устройство /dev/log. Физически это то
же устройство, что и /dev/console, но оно адресуется отдельным вспомога-
вспомогательным номером и обрабатывается иначе. Это устройство только для записи,
поэтому do_open возвращает ошибку EACCESS, если сделана попытка открыть
его для чтения (строка 14246). Еще одна проверка, которую делает do_open, —
проверка флага O_NOCTTY. Если флаг не установлен, а устройство не является
устройством /dev/log, терминал становится управляющим для данной груп-
группы процессов. Для этого номер процесса, сделавшего вызов, заносится в поле
tp->tty_pgrp записи таблицы tty_table. Затем инкрементируется перемен-
переменная tp-> tty_openct и отправляется ответное сообщение.
Терминальное устройство может быть открыто несколько раз, и потом функ-
функции do_close (строка 14260) нечего делать, кроме как уменьшить значение
tp->tty_openct на единицу. Следующая проверка (строка 14266) препятству-
препятствует закрытию устройства, если это устройство /dev/log. Если обнаруживает-
обнаруживается, что устройство закрыто в последний раз, для отмены ввода делается вызов
tp->tty_icancel. Также вызываются специфические для устройства функ-
функции tp->tty_ocancel и tp->tty_close. Различным полям структуры tty
закрытого устройства присваиваются значения по умолчанию и отправляется
ответное сообщение.
Последним из обработчиков сообщений является функция do_cancel (стро-
(строка 14281). Она вызывается, когда для блокированного процесса, пытающегося
выполнить чтение иди запись, получен сигнал. Возможны три различных со-
состояния, подлежащие контролю.
1. Когда процесс был завершен, он мог выполнять чтение.
2. Когда процесс был завершен, он мог выполнять запись.
3. Процесс мог быть приостановлен вызовом tcdrain до тех пор, пока его вы-
вывод не будет завершен.
Для каждого из этих случаев делается проверка и вызывается основная функция
tp->icancel или специфическая для устройства функция, адрес которой хра-
хранится в поле tp->ooancel. В последнем случае единственное, что требуется, —
сбросить флаг tp->tty_ioreq, тем самым обозначив, что операция ioctl за-
завершена. В завершение устанавливается флаг tp->tty_events и отправляется
ответное сообщение.
Код поддержки драйвера терминала
Мы рассмотрели функции верхнего уровня, вызываемые в главном цикле tty_
task, а сейчас настала пора обратиться к коду, обеспечивающему их работу. Мы
начнем с функции handle_events (строка 14358). Как упоминалось ранее, при
каждом проходе главного цикла драйвера терминала для каждого терминального
устройства проверяется флаг tp->tty_events, и если терминалу требуется вни-
внимание, вызывается функция handle_events. Подпрограммы do_read и do_
write также вызывают функцию handle_events. Эта подпрограмма должна
выполняться быстро. Она сбрасывает флаг tp->tty_events и обращается к спе-
специфическим для устройства функциям записи или чтения, опираясь на указатели
tp->tty_devread и tp->tty_devwrite (строки 14382-14385).
Функции вызываются без проверки условий, так как нет возможности выяснить,
что вызвало установку флага, чтение или запись. При разработке было решено,
что( проверять для каждого устройства два флага — более затратная операция,
чем вызывать две функции в том случае, если устройство активно. Кроме того,
большую часть времени обеспечивается эхопечать вводимых символов, то есть
полученный от терминала символ выводится на экран, поэтому необходимы
оба вызова. Как упоминалось при обсуждении вызова tcsetattr функцией
do_ioctl, POSIX не запрещает откладывать выполнение управляющих опе-
операций до тех пор, пока не будет завершен текущий вывод, поэтому сразу после
вызова tty_devwrite имеет смысл позаботиться об операциях ioctl. Это де-
делается в строке 14388, где, если имеются текущие управляющие запросы, вызы-
вызывается функция dev_ioctl.
Так как флаг tp->tty_events устанавливается прерываниями и от быстрого
устройства символы могут поступать с большой скоростью, существует вероят-
вероятность, что за время выполнения функций чтения и записи, а также вызова dev_
ioctl произойдет другое прерывание, и флаг снова окажется установленным.
Извлечению данных из буфера, куда они помещаются обработчиком прерыва-
прерываний, придается более высокий приоритет. Поэтому функция handle_events
повторяет вызов функций чтения и записи, если в конце цикла обнаруживается,
что флаг снова установлен (строка 14389). Когда входной поток останавливается
(это может быть и выходной поток, но для входа более характерны подобные
повторяющиеся запросы), чтобы передать символы из входной очереди в буфер
сделавшего вызов процесса, вызывается функция in_transfer. Эта функция
сама отправляет ответное сообщение, если переданные символы завершают за-
запрос (в каноническом режиме такое может произойти в том случае, если получе-
получено запрошенное количество символов, либо получен символ конца строки, либо
достигнут конец файла). Когда это происходит, переменная tp->tty_lef t по-
после возврата в handle_events будет равна нулю. Если при соответствующей
проверке оказывается, что количество переданных символов достигло необхо-
необходимого минимума, отправляется ответное сообщение. Проверка tp->tty_lef t
предотвращает повторную генерацию сообщения.
Далее перейдем к функции in_transfer (строка 14416), которая отвечает за
передачу данных из входной очереди в адресном пространстве драйвера в буфер
пользовательского процесса, запросившего ввод. Напрямую копировать блок
данных в этом случае невозможно. Входная очередь представляет собой кру-
круговой буфер, символы в которой необходимо проверять на признак конца фай-
файла или, если действует канонический режим, проверять, что ввод продолжается
с новой строки. Кроме того, символы во входной очереди 16-разрядные, а буфер
принимающего процесса является массивом 8-разрядных символов. Поэтому ис-
используется промежуточный локальный буфер. Символы один за одним проверя-
проверяются и помещаются в буфер, и когда тот заполняется, вызывается функция sys_
vircopy, которая переносит содержимое промежуточного буфера в приемный
буфер пользовательского процесса (строки 14432-14459).
Для того чтобы определить, есть ли работа для функции in_transf ег, задейст-
вуются три поля структуры tty: tp->tty_inleft, tp->tty_eotct и tp->
tty_min. Первые две управляют главным циклом процедуры. Ранее упомина-
упоминалось, что в tp->tty_inleft изначально помещается количество символов,
запрошенных в вызове read. Обычно эта переменная уменьшается на единицу
с каждым новым полученным символом, но она может быть внезапно сброшена
в ноль, если достигается состояние, сигнализирующее о завершении ввода. Когда
переменная становится равной нулю, генерируется ответное сообщение процессу,
запросившему чтение. Поэтому она также используется как индикатор отправки
сообщения. В результате, когда в строке 14429 выясняется, что переменная tp->
tty_inlef t уже равна нулю, это — вполне веская причина, чтобы прервать вы-
выполнение функции in_transfer без ответного сообщения.
Во второй части условия сравниваются переменные tp->tty_eotct и tp->
tty_min. В каноническом режиме обе переменные относятся к количеству пол-
полных введенных строк, а в неканоническом режиме они относятся к символам.
Переменная tp->tty__eotct увеличивается на единицу с каждым занесенным
во входную очередь «разрывом строки» или байтом и уменьшается подпрограм-
подпрограммой in_transfer, когда строки или байты удаляются из очереди. Таким обра-
образом, эта переменная подсчитывает количество строк или символов, полученных
драйвером терминала, но еще не переданных процессу. Поле tp->tty_min хра-
хранит значение минимального числа строк (в каноническом режиме) или симво-
символов (в неканоническом), которое должно быть передано для удовлетворения за-
запроса. В каноническом режиме это значение всегда равно 1, а в неканоническом
оно может принадлежать интервалу от 0 до MAX_INPUT (в MINIX 3 эта констан-
константа равна 255). Тем самым вторая половина проверки (строка 14429) приводит
в каноническом режиме к тому, что подпрограмма завершается сразу же, если
еще не получена хотя бы одна целая строка. Передача производится после получе-
получения всей строки, потому содержимое очереди можно изменить, если, например,
пользователь ввел символ KILL или ERASE до нажатия клавиши Enter. В некано-
неканоническом режиме немедленный возврат имеет место, если запрошенное количе-
количество символов еще недоступно.
Несколькими строками далее переменные tp->tty_inlef t и tp->tty_eotct
управляют главным циклом процедуры. В каноническом режиме передача про-
производится до тех пор, пока в очереди не останется больше полностью введенных
строк. В неканоническом режиме в поле tp->tty_eotct подсчитывается коли-
количество ожидающих передачи символов. Переменная tp->tty_min необходима,
чтобы определить, нужно ли входить в цикл, но в определении условия завер-
завершения цикла не участвует. После того как цикл начался, передаются либо все
полученные символы, либо запрошенное их количество в зависимости от того,
что меньше.
Во входной очереди символы представлены в виде 16-разрядных величин. Поль-
Пользовательскому процессу передается только сам код символа — младшие 8 бит.
Назначение старших битов кода иллюстрирует рис. 3.24. Здесь есть флаги, по-
показывающие, входит ли символ в ESC-последовательность (Ctrl+V), означает ли
он конец файла или содержит один из кодов, сопоставленных концу строки.
Рис. 3.24. Поля кода символа, находящегося во входной очереди
Четыре бита используются для подсчета символов, чтобы знать, сколько места
осталось для эхопечати. Условная инструкция в строке 14435 проверяет, уста-
установлен ли признак конца файла (D на рисунке). Эта проверка делается в начале
потому, что символ конца файла не должен ни передаваться программе, ни
использоваться при подсчете символов. При передаче каждого символа у него
маскируется 8 старших бит, и в локальный буфер записывается только ASCII-
значение (строка 14437).
Существуют несколько способов сигнализировать об окончании ввода, но от спе-
специфической для устройства функции ввода ожидается, что она распознает, когда
вводимый символ является переносом строки, концом файла (Ctrl+D) или одним
из подобных символов, и соответствующим образом пометит их. Функции in_
transfer остается только проверить эту отметку, бит IN_EOT (N на рис. 3.24)
в строке 14454. Если символ опознан, значение tp->tty_eotct уменьшается
на единицу. В неканоническом режиме подобным образом подсчитываются все
символы, и все они помечаются битом IN_EOT, поэтому tp->tty_eotct содер-
содержит число символов, не удаленных из очереди. Единственное различие в работе
главного цикла процедуры в двух разных режимах работы терминала определя-
определяется строкой 14457. Там обнуляется переменная tp->tty_eotct, когда полу-
получен символ, помеченный как разрыв строки, но делается это лишь тогда, когда
действует канонический режим. Таким образом, когда управление вновь переда-
передается в начало цикла, тот корректно завершается после символа разрыва строки.
Но сказанное верно только для канонического режима — в неканоническом раз-
разрывы строк игнорируются.
Когда цикл завершается, локальный буфер символов для передачи обычно час-
частично полон (строки 14461-14468). В том случае, если значение tp->tty_
inlef t достигло нуля, генерируется и отправляется ответное сообщение. В кано-
каноническом режиме это делается всегда, а в неканоническом число символов в бу-
буфере сравнивается с минимальным передаваемым количеством, и если символов
недостаточно, ответное сообщение не отправляется. Если у вас достаточно хорошая
память, чтобы запомнить вызовы in_transf ег (в do_read и handle_events),
вы, наверно, будете удивлены. Там код, следующий за вызовом, отправлял ответ-
ответное сообщение, когда функция in_transf ег передавала больше символов, чем
указано в tp->tty_min. И здесь именно этот случай. Причина, по которой от-
ответное сообщение не отправляется непосредственно из in_transf ег, раскрыва-
раскрывается чуть позже при обсуждении следующей функции, вызывающей функцию
in_transf ег при других обстоятельствах.
Эта следующая функция носит имя in_process (строка 14486). Она вызывается
из аппаратно-зависимого кода для выполнения общих действий, необходимых
всегда. Ее аргументами являются указатель на структуру tty для исходного
устройства, указатель на массив 8-разрядных символов, подлежащих обработке,
и счетчик. Новое значение счетчика возвращается в вызвавшую программу.
Функция in_process весьма велика, но ее работа не сложна. Она добавляет
16-разрядные символы во входную очередь, откуда их в дальнейшем извлекает
функция in_transfer.
Функцией in_transf er символы разделяются на несколько категорий.
1. Обычные символы, расширенные до 16 бит, которые добавляются в очередь.
2. Символы, управляющие дальнейшей обработкой, модифицируют флаги, но
сами в очередь не помещаются.
3. Символы для эхопечати применяются немедленно, без занесения в очередь.
4. Символы, имеющие специальное значение, заносятся в очередь с установлен-
установленными в старшем байте специальными битами, например, такими как бит EOT.
Сначала рассмотрим совершенно стандартную ситуацию, когда обычный символ,
такой как х (ASCII-код 0x78), вводится в середине короткой строки без воздей-
воздействия ESC-кодов на терминале, «настроенном» по умолчанию. Полученный
от устройства ввода, этот символ занимает биты от 0 до 7 (см. рис. 3.24). В строке
14504 старший значащий бит сбрасывается в ноль, если установлен бит I STRIP.
Но по умолчанию MINIX 3 не обнуляет старший бит, позволяя вводить 8-раз-
8-разрядные символы. В любом случае символ х это не затронет. Расширенная обра-
обработка ввода по умолчанию в MINIX 3 не разрешена, поэтому проверка бита
IEXTERN в переменной tp->tty_termios . c_l flags (строка 14507) дает поло-
положительный результат, но для всех последующих проверок результат отрицателен
вследствие установленных нами условий: не действует ESC-код (строка 14510),
сам символ не является ESC-кодом (строка 14517) и это — не символ REPRINT
(строка 14524).
Проверки в следующих нескольких строках обнаруживают, что символ не явля-
является специальным символом _POSIX_VDISABLE, ни CR, ни NL. Наконец, одна
проверка успешна: действует канонический режим, и символ не является специ-
специальным (строка 14324). Рассматриваемая нами буква х не является ни символом
ERASE, ни KILL, ни EOF (Ctrl+D), ни NL, ни EOL, поэтому до строки 14576 с ним
ничего не происходит. Здесь выясняется, что бит IXON установлен (по умол-
умолчанию). Этот бит разрешает использование символов START (Ctrl+S) и STOP
(Ctrl+Q), но х к таковым, очевидно, не относится. В строке 14597 обнаруживает-
обнаруживается, что установлен бит ISIG, разрешающий обработку INTR и QUIT, но, опять
же, совпадения в данном случае не обнаруживается.
Фактически первое интересное событие для обычного символа происходит в стро-
строке 14610, где выясняется, заполнена уже входная очередь или нет. В этом случае
символ игнорируется, и так как активен канонический режим, пользователь не
увидит эха символа на экране. Игнорирование символа обеспечивает инструк-
инструкция continue, которая вызывает переход в начало цикла. В данном случае рас-
рассматриваем рядовые условия выполнения, поэтому предположим, что буфер еще
не полон. Не проходит и следующий тест, выделяющий специальный неканони-
неканонический режим работы (строка 14616). Поэтому управление передается на стро-
строку 14629, содержащую вызов функции echo, которая показывает пользователю
введенный символ, так как по умолчанию флаг tp-> tty_termios .c_lf lag
установлен.
Наконец, в строках 14632-14636 символ подготавливается к занесению во входную
очередь. В этот момент увеличивается значение tp->tty_incount, a tp->tty_
eotct не изменяется, так как это — обычный символ, не отмеченный битом EOT.
Последняя строка в цикле вызывает функцию in_transf ег в том случае, если
только что помещенный в очередь символ привел к ее заподнению. В обычных
условиях, в которых протекает действие, функция in_transf ег ничего бы не
сделала, поскольку значение tp->tty_eotct равно нулю, tp->tty_min — еди-
единице (предполагается, что очередь обслуживалась нормально и предшествую-
предшествующий ввод был принят после завершения строки), и тест в начале функции in_
transfer (строка 14429) привел бы к немедленному возврату.
Итак, рассмотрев вызов in_transf ег для обычного символа в стандартных ус-
условиях, мы вновь вернемся к началу, но теперь взглянем, что происходит в менее
привычной ситуации. Первым будет на рассмотрении символ escape, который
позволяет символам, в обычной ситуации имеющим специальное значение, пере-
передаваться пользовательскому процессу. Действие этого символа включается уста-
установкой флага tp->tty_escaped. Когда ESC-режим активен, флаг сбрасывает-
сбрасывается, а к текущему символу добавляется бит IN_ESC, на рис. 3.24 обозначенный
как V. Это вызывает дополнительную обработку при эхопечати; чтобы сделать
такие символы видимыми, они отображаются с префиксом Л. Кроме того, бит
IN_ESC предотвращает интерпретацию символа как специального.
Следующие несколько строк проверяют сам ESC-символ, LNEXT (по умолчанию
Ctrl+V). При его обнаружении устанавливается флаг tp->tty_escaped и дваж-
дважды вызывается функция rawecho, чтобы вывести префикс л с примыкающим
символом забоя. Это напоминает пользователю, что действует ESC-режим, а после-
последующий ввод затирает префикс л. Символ LNEXT — пример символа, влияющего
на обработку последующего ввода (в данном случае затрагивается только один
последующий символ). Такой символ не заносится в очередь, и после двух вызо-
вызовов rawecho цикл переходит в начало. Порядок указанных двух проверок ва-
важен, так как им обеспечивается возможность передать LNEXT пользовательскому
процессу. Для этого символ необходимо ввести дважды.
Следующий специальный символ, обрабатываемый in_process, — REPRINT
(Ctrl+R). Обнаружение этого символа инициирует вызов reprint (строка 14525),
что приводит к повторному отображению выведенного эха. В дальнейшем сам
символ REPRINT игнорируется и не оказывает влияния на входную очередь.
Изучать, как обрабатываются все остальные специальные символы, было бы уто-
утомительно, а исходные коды функции in_process достаточно прямолинейны.
Поэтому мы упомянем лишь еще несколько деталей. Во-первых, использование
специальных битов из старшего байта 16-разрядного значения во входной очере-
очереди позволяет легко разбивать символы на классы, имеющие сходный эффект.
Так, все символы EOT (Ctrl+D), LF и альтернативный символ EOL (по умолчанию
не задан) отмечаются битом EOT (на рис. 3.24 это бит D (строки 14566-14573)),
что позволяет легко их распознавать.
Наконец, объясним отмеченное ранее странное поведение функции in_transf ег.
Ответное сообщение не генерируется каждый раз при завершении функции, хо-
хотя, казалось бы, после вызова in_transf er всегда следует код, генерирующий
ответ. Вспомните, что вызов in_transfer в функции in_process, когда оче-
очередь полна, не имеет эффекта в каноническом режиме (строка 14639). Но если
требуется неканоническая обработка, каждый символ помечается битом EOT,
и, таким образом, tp->tty_eotct подсчитывает все символы (строка 14636).
В свою очередь, это приводит к переходу в главный цикл функции in_transf ег
при ее вызове, когда вызов делается по причине заполнения очереди в неканони-
неканоническом режиме. В таком случае не нужно после возврата из in_transf ег пере-
передавать драйверу терминала никаких сообщений, ведь после этого наверняка бу-
будут считаны еще символы. Конечно, хотя в неканоническом режиме отдельный
вызов read ограничен размером входной очереди (в MINIX 3 — 255 символов),
в неканоническом режиме функция read должна быть способна передать коли-
количество символов по стандарту POSIX, задаваемое константой _POSIX_ SSIZE_
МАХ. В MINIX 3 это значение равно 32767.
Несколько следующих функций из файла tty.c обеспечивают ввод символов.
Функция tty_echo (строка 14647) особым образом обрабатывает некоторые
символы, но большинство из них просто отображаются ею в выводе того терми-
терминала, который используется для ввода. Когда вывод от пользовательского про-
процесса направлен на устройство, может оказаться, что в этот момент на устройст-
устройство производится эхопечать. Когда пользователь попытается удалить последний
введенный символ, это усложняет дело. Чтобы решить проблему, когда произво-
производится обычный вывод, флаг tp->tty_reprint всегда устанавливается аппа-
ратно-зависимыми функциями вывода. Поэтому функция, которая вызывается
для обработки символа забоя, может сообщить, что к экрану применен смешанный
вывод. Поскольку в echo для вывода символов также привлекаются аппаратные
процедуры вывода, текущее значение флага tp->tty_reprint сохраняется в ло-
локальной переменной гр и восстанавливается после вывода (строки 14668-14701).
Исключение составляет случай, когда только что начался ввод новой строки.
Здесь переменной гр присваивается значение FALSE, тем самым обеспечивается,
что флаг tp->tty_reprint будет сброшен по завершении функции echo.
Вы могли заметить, что функция echo возвращает значение. Например, вы мог-
могли встретить такую запись в коде in_process (строка 14629):
ch = tty_echo(tp, ch) ;
Возвращаемое значение говорит о том, сколько знакомест занял на экране вы-
вывод, и в случае символа TAB может достигать восьми. Эти символы подсчитыва-
ются в поле, которое на рис. 3.24 обозначено как с ее с. Обычные символы зани-
занимают одно знакоместо, но специальные, за исключением TAB, CR, NL или DEL
@x7F), требуют два, они отображаются с префиксом Л перед печатным ASCII-
символом. С другой стороны, NL или CR «занимают» ноль знакомест. Конечно
же, сам вывод эха должен осуществляться при помощи аппаратно-зависимых
подпрограмм, и когда устройству нужно передать символ, делается косвенный
вызов подпрограммы, адрес которой хранится в tp->tty_echo, как происхо-
происходит, например, для обычных символов в строке 14696.
Следующая функция, rawecho, вызывается тогда, когда необходимо обойти спе-
специальную обработку, присущую функции echo. Функция rawecho проверяет,
установлен ли флаг ECHO, и если да, отправляет введенный символ аппаратно-
зависимой подпрограмме tp->tty_echo без всякой дополнительной обработ-
обработки. Локальная переменная гр используется для того, чтобы сохранить значение
флага tp->tty_reprint.
Когда in_process обнаруживает символ забоя, вызывается функция backover
(строка 14721). Она манипулирует содержимым входной очереди, пытаясь по
возможности удалить из нее последний введенный символ, то есть если очередь
не пуста и последний символ не является переносом строки. Здесь проверяется
значение флага tp->tty_reprint, упоминавшегося при обсуждении функций
echo и rawecho. Когда этот флаг равен TRUE, происходит вызов reprint
(строка 14732), чтобы показать на экране чистую копию редактируемой строки.
Чтобы узнать, сколько знакомест необходимо очистить, проверяется значение
поля 1еп у последнего введенного символа (поле ее ее на рис. 3.24), и для каж-
каждого знакоместа при помощи rawecho выводится последовательность «забой-
пробел-забой», стирающая символ с экрана.
Следующая функция имеет имя reprint. В дополнение к тому, что ее вызывает
backover, она может вызываться, когда пользователь нажимает клавиши Ctr!+R
(REPRINT). Цикл в коде этой функции (строки 14764-14769) сканирует вход-
входную очередь в обратном направлении до последнего «разрыва строки». Если раз-
разрыв строки является последним введенным символом, значит, для функции нет
поля деятельности, и она заканчивает работу. Если это не так, сначала функция
выводит на экран символ REPRINT, который отображается как пара AR, перехо-
переходит на следующую строку и повторно показывает содержимое очереди, начиная
с последнего символа разрыва строки до конца.
Вот теперь мы добрались до функции out_process (строка 14789). Как и in_
process, она вызывается аппаратно-зависимыми функциями вывода, но устрое-
устроена проще. Сама эта функция вызывается не подпрограммами консоли, а специфи-
специфическими подпрограммами вывода, действующими при работе последовательного
интерфейса RS-232 и псевдотерминала. Эта функция обрабатывает кольцевой
байтовый буфер, но не удаляет из него символы. Единственное, что она меняет
в массиве, — вставляет перед символами NL символы CR, если установлены биты
OPOST (разрешение обработки вывода) и ONLCR (преобразование NL в CRLF)
в поле tp->tty_termios .of lag. В MINIX 3 по умолчанию эти биты уста-
установлены. Работа функции заключается в поддержании значения переменной
tp->tty_position в структуре tty устройства. Усложняют жизнь символы
табуляции и забоя.
Далее следует подпрограмма dev_ioctl (строка 14874). Она поддерживает do_
ioctl, выполняя функции tcdrain и tcf lush, когда do_ioctl вызывается
с аргументом TCSADRAIN или TCSAFLUSH. Вызов do_ioctl не может начать
обрабатываться немедленно, если вывод еще не завершен, поэтому информация
о запросе сохраняется в полях структуры tty, зарезервированных для этой цели.
Когда запускается функция handle_events, она после вызова аппаратно-зави-
симой подпрограммы проверяет значение флага tp->tty_ioreq, и если имеется
отложенная операция, вызывает dev_ioctl. Сама функция dev_ioctl прове-
проверяет tp->tty_outlef t, чтобы узнать, завершен ли вывод. Если это так, выпол-
выполняются те же действия, которые функция do_ioctl выполнила бы в варианте
без задержки. При работе tcdrain единственное, что нужно сделать, — это сбро-
сбросить поле tp->tty_ioreq и отправить ответное сообщение файловой системе
с просьбой разбудить приостановленный процесс, сделавший вызов. Вариант
TCSAFLUSH вызова tcsetaddr прибегает к вызову tty_icancel, чтобы пре-
прервать ввод. В обоих вариантах tcseatddr структура termios, адрес которой
передается при вызове ioctl, копируется в поле tp->tty_termios. Затем вы-
вызывается setattr и посылается ответное сообщение, как и в случае с tcdrain,
с целью разблокировать процесс-инициатор вызова.
Следующая на очереди — процедура setattr (строка 14899). Как вы могли
видеть, она вызывается из do_ioctl и dev_ioctl, чтобы изменить атрибуты
терминального устройства, а также из do_close, когда нужно сбросить атрибуты
в значения по умолчанию. Эта функция всегда вызывается после того, как за-
записываются новые данные в структуру termios, поскольку лишь изменения
значений недостаточно. Если управляемое устройство переведено в неканониче-
неканонический режим, необходимо установить бит IN_EOT у всех символов во входной
очереди, как если бы они изначально были напечатаны в неканоническом ре-
режиме. Так как нельзя узнать, какой атрибут только что был изменен, невоз-
невозможно и определить, следует ли устанавливать бит у символов в очереди. Поэто-
Поэтому проще все свести к одному случаю, нежели проверять содержимое очереди
(строки 14913-14919).
Далее нас интересуют значения параметров MIN и TIME. В каноническом режиме
значение tp->tty_min всегда равно 1 и установлено в строке 14926. В некано-
ническом режиме различные комбинации этих параметров позволяют реализо-
реализовать четыре разных режима работы, показанных в табл. 3.7. В tp->tty_min
(строки 14931-14934) сначала записывается значение, переданное через tp->
tty_termiso. ее [VMIN], а после при равенстве его нулю и при нулевом значе-
значении в tp->tty_termiso. ее [VTIME] оно изменяется.
Наконец, благодаря setattr вывод не останавливается, если отключено управ-
управление XON/XOFF; функция setattr отправляет сигнал SIGHUP, если скорость
передачи установлена в ноль, и делает косвенный вызов подпрограммы, адрес
которой хранится в tp->tty_ioctl, чтобы выполнить действия, доступные
только на уровне устройства.
Функция tty_reply (строка 14952) уже много раз упоминалась в предшест-
предшествующих обсуждениях. Ее алгоритм прост, она формирует сообщение и отправля-
отправляет его. Если по какой-то причине отправить сообщение не удалось, происходит
сбой системы. Оставшиеся функции столь же просты. Функция sigchar (стро-
(строка 14973) заставляет менеджера памяти отправить сигнал. Если установлен флаг
NOFLSH, очищается входная очередь — обнуляется счетчик полученных строк или
символов, а указатели на конец и начало очереди становятся равными. Это —
действие по умолчанию. Флаг может быть также установлен, когда ожидается
сигнал SIGHUP, чтобы продолжить ввод и вывод после получения сигнала. Функ-
Функция tty_icancel (строка 15000) очищает входную очередь, как это делает
sigchar, а в дополнение вызывает аппаратно-зависимую функцию tp->tty_
i cane el с целью очистить буфер самого устройства при наличии такого буфера.
Функция tty_init (строка 15013) вызывается один раз на каждое устройство
при запуске tty_task. Она устанавливает значения по умолчанию. Изначально
в поля tp->tty_icancel, tp->tty_ocancel, tp->tty_ioctl и tp->tty_
close записывается указатель на заглушку, tty_devnop. Затем tty_init вы-
вызывает одну из специфичных для устройства функций инициализации в зависи-
зависимости от того, к какой категории относится терминал: консоль, последовательная
линия или псевдотерминал. Эта функция сохраняет в полях структуры ссылки
на реальные функции, специфичные для данного устройства. (Вспомните, что
если в определенной категории не инициализировано ни одного устройства, со-
соответствующий макрос трубит немедленный отбой, в результате не компилиру-
компилируется ни одна из частей кода неиспользуемых устройств.) Затем вызов init_scr
инициализирует драйвер консоли и обращается к процедуре инициализации
клавиатуры.
Следующие три функции поддерживают таймеры. Сторожевой таймер инициали-
инициализируется указателем на функцию, запускаемую при его истечении. Для большин-
большинства таймеров, устанавливаемых драйвером терминала, такой функцией является
tty_timed_out. Она устанавливает флаги событий, форсирующие обработку
ввода и вывода. Функция expire_timers поддерживает очередь таймера драй-
драйвера терминала. Вспомните, что она вызывается из главного цикла функции
tty_task при получении сообщения SYN_ALARM. Библиотечная подпрограмма
tmrs_exptimers выполняет обход связанного списка таймеров, вызывая сторо-
сторожевые функции для тех, которые истекли. Если по возвращении из библиотечной
функции очередь все еще активна, выполняется вызов ядра sys_setalarm, за-
запрашивающий очередное сообщение SYN_ALARM. Наконец, функция settimer
(строка 15089) устанавливает таймеры, определяющие срок возврата из вызова
read в неканоническом режиме. Она вызывается с двумя параметрами: tty_jptr,
указателем на структуру tty, и enable, целым числом, обозначающим истину
или ложь. Библиотечные функции tmrs_settimer и tmrs_clrtimer исполь-
используются для включения и отключения таймера в соответствии со значением аргу-
аргумента enable. Если таймер включен, то в качестве сторожевой функции всегда
используется описанная ранее функция tty_timed_out.
Описание функции tty_devnop (строка 15125) длиннее, чем ее код, поскольку
последний попросту отсутствует. Это — пустая функция, косвенно вызываемая
в случае, если обслуживание устройству не требуется. Мы видели, что в tty_
init многие указатели функций по умолчанию указывают на tty_devnop до
тех пор, пока не выполнена процедура инициализации устройства.
Последняя функция в файле tty. с заслуживает особого внимания — это функ-
функция select. Она представляет собой системный вызов, используемый, когда
одному процессу необходимо асинхронно обслуживать несколько устройств
ввода-вывода. Классическим примером является программа связи, работающая
с локальной клавиатурой и удаленной системой, возможно, соединенными при
помощи модема. Вызов select дает возможность открыть несколько файлов
устройств и наблюдать за их считыванием или записью без блокирования. В от-
отсутствие select для двусторонней связи необходимо использовать два отдель-
отдельных процесса, один из которых является главным и обеспечивает связь в одном
направлении, а другой является подчиненным и обеспечивает связь в другом на-
направлении. Вызов select является примером удобной возможности, значитель-
значительно усложняющей систему. Одной из целей разработки MINIX 3 является про-
простота, достаточная для освоения операционной системы с разумными усилиями
за разумное время. По этой причине мы несколько ограничимся в повествовании
и не станем рассматривать здесь функцию do_select (строка 15135), а также
поддерживающие подпрограммы select_try (строка 14313) и select_retry
(строка 14348).
3.8.5. Реализация драйвера клавиатуры
Теперь мы обратимся к аппаратно-зависимому коду, обеспечивающему работу
консоли. В MINIX 3 консоль состоит из клавиатуры IBM PC и отображаемого
на память экрана. Физические устройства консоли полностью различны, у стан-
стандартных настольных систем экран поддерживается при помощи контроллера
(одного из дюжины типов), а работу клавиатуры обеспечивают схемы на ма-
материнской плате, взаимодействующие с однокристальным 8-разрядным компью-
компьютером клавиатуры. Для поддержания двух различных устройств требуются два
варианта программного обеспечения, которые в MINIX находятся в файлах
keyboard.с и console.с.
С точки зрения операционной системы клавиатура и экран являются частями
одного устройства, /dev/console. Если у видеоконтроллера достаточно памяти,
то в систему может быть включена поддержка виртуальной консоли, тогда, по-
помимо устройства /dev/console, могут существовать дополнительные логиче-
логические устройства, /dev/ttycl, /dev/ttyc2 и т. д. В любой момент времени на
экране видна только одна из этих консолей, эта же консоль получает ввод с един-
единственной клавиатуры. Логически клавиатура подчинена консоли, хотя подтвер-
подтверждается это только двумя достаточно незначительными фактами. Во-первых,
в структуре консоли tty, хранящейся в tty_table, есть отдельные заполняемые
при запуске поля для ввода и вывода, например tty_devread и tty_devwrite,
являющиеся указателями на функции в файлах keyboard.с и console.с. Одна-
Однако есть только одно поле tty_priv, ссылающееся исключительно на структуры
данных консоли. Во-вторых, перед входом в главный цикл tty_task проводит
инициализацию всех логических устройств. Для /dev/console процедура ини-
инициализации расположена в файле с on sole.с,и код для инициализации клавиа-
клавиатуры вызывается из нее. В то же время иерархия может быть перевернута. Имея
дело с устройствами ввода-вывода, мы всегда сначала рассматривали ввод, а затем
вывод, и сейчас мы продолжим эту традицию, рассмотрев код в файле keyboard. с
в текущем разделе и отложив файл console. с до следующего.
Файл keyboard, с, как и многие другие, начинается с нескольких директив
#include. Но одна из них необычна. Файл keymaps/us-std. src, включен-
включенный в строке 15218, не является заголовочным С-файлом, это — файл исходных
кодов, который при компиляции определяет раскладку клавиатуры по умол-
умолчанию, попадающую в keyboard. о в виде инициализированного массива. Сам
этот файл довольно велик, и в табл. 3.11 мы привели лишь несколько типичных
записей из него. После директив #include следуют макросы, задающие разнооб-
разнообразные константы. Первая группа привлекается для низкоуровневого взаимодей-
взаимодействия с контроллером клавиатуры. Большая часть из них задают адреса портов
ввода-вывода или битовые комбинации, используемые при таком взаимодейст-
взаимодействии. Следующая группа макросов описывает символические имена для специ-
специальных клавиш. Константа KB_IN_BYTES (строка 15249), имеющая значение 32,
определяет размер циклического клавиатурного буфера. Следующие переменные
хранят различные параметры, необходимые для правильной интерпретации нажа-
нажатия клавиши. Поскольку буфер только один, необходимо гарантировать полную
обработку его содержимого перед сменой виртуальной консоли.
Следующая группа переменных обеспечивает хранение различных состояний,
что необходимо для корректной интерпретации нажатия клавиши. Они имеют
разное назначение. Например, флаг caps_down (строка 15266) переключается
с TRUE на FALSE, и наоборот, при нажатии клавиши Caps Lock. Флаг shift (стро-
(строка 15264) устанавливается в TRUE, когда нажимается клавиша Shift, и сбрасыва-
сбрасывается, когда она отпускается. Переменная esc устанавливается, когда получен
код опроса escape. Она всегда сбрасывается после получения одного символа.
Макрос map_keyO (строка15297) возвращает ASCII-код, соответствующий дан-
данному коду опроса без учета модификаторов, то есть попадающий в первую ко-
колонку карты клавиш. «Старший брат» этого макроса, макрос map_key (строка
15303), выполняет преобразование кода опроса в ASCII-код с учетом всех моди-
модификаторов, действующих при вводе символа.
Когда нажимается или отпускается клавиша, вызывается обработчик прерыва-
прерываний клавиатуры, подпрограмма kbd_interrupt (строка 15335). Чтобы узнать
от контроллера клавиатуры код опроса, она вызывает scode. Когда прерывание
инициировано отпусканием клавиши, у кода опроса устанавливается старший
значащий бит, и в этом случае нажатие игнорируется, если это — не одна из кла-
клавиш-модификаторов. Чтобы обслужить прерывание как можно быстрее, все не-
необработанные коды опроса помещаются в кольцевой буфер, и для текущей кон-
консоли устанавливается флаг tp-> tty_events (строка 15350). Как и ранее, мы
будем считать, что вызовов select не производилось, и выход из обработчика
kbd_interrupt выполняется немедленно после этого. На рис. 3.25 представлен
пример содержимого кольцевого буфера для короткой строки, содержащей два
символа в верхнем регистре, каждый из которых предваряется кодом опроса, соот-
соответствующим нажатию клавиши Shift, а следом за кодом символа идет код отпус-
отпускания клавиши Shift.
Рис. 3.25. Содержимое входного буфера для строки текста, введенной с клавиатуры. Вторая
строка таблицы описывает нажатия клавиш. Символы L+, L-, R+ и R- означают соответственно
нажатие и отпускание правой и левой клавиши Shift. Код отпускания клавиши
на 128 больше кода нажатия
Функция kb_read извлекает из циклического буфера коды опроса и помещает
в свой локальный буфер ASCII-коды. Этот локальный буфер должен быть дос-
достаточно емким, чтобы вместить ESC-последовательности, генерируемые в ответ
на нажатия некоторых клавиш на цифровой клавиатуре. Затем, чтобы поместить
символы во входную очередь, вызывается функция in_process. В строке 15379
значение icount инкрементируется. Вызов make_break возвращает ASCII-код
в виде целого числа. В этой точке специальные клавиши, например клавиши циф-
цифровой клавиатуры и функциональные клавиши, имеют коды большие, чем OxFF.
Коды в диапазоне от НОМЕ до INSRT (от 0x101 до ОхЮС, эти константы задаются
в файле include/minix/keymap.h) при помощи массива numpad_map пре-
преобразуются в трехсимвольные ESC-последовательности, показанные в табл. 3.13.
Эти последовательности затем передаются в функцию in_process (строки
15392-15397). Большие по величине коды в функцию in_process не пере-
передаются, среди них ищутся коды, соответствующие комбинациям клавиш Alt+<—,
Alt+-> и от Alt+F1 до Alt+F12. Если обнаруживается одна из таких комбинаций,
вызывается функция select_console, переключающая виртуальные консоли.
Сочетания от Ctrl+F1 до Ctrl+F12 также обрабатываются особо. Сочетание Ctrl+F1
показывает текущие назначения функциональных клавиш (более подробно об
этом мы скажем позже), а сочетание Ctrl+F3 обеспечивает переключение между
программной и аппаратной прокруткой на экране консоли. Сочетания Ctrl+F7,
Ctrl+F8 и Ctrl+F9 генерируют те же сигналы, что Ctrl+\, Ctrl+C и Ctrl+U соответ-
соответственно, с тем исключением, что они не могут быть изменены командой stty.
Таблица 3.13. ESC-последовательности, генерируемые для клавиш цифровой клавиатуры.
Когда коды опроса преобразуются в ASCII-коды, специальным клавишам присваиваются
«псевдоАБСП-коды», большие OxFF
Клавиша Код опроса «ASCII» ESC-последовательность
Home 71 0x101 ESC [ Н
Up 72 0x103 ESC [A
PgUp 73 0x107 ESC [ V
74 0x10A ESC[S
Left 75 0x105 ESC [ D
5 76 0x109 ESC[G
Right 77 0x106 ESC [ С
+ 78 0x10B ESC[T
End 79 0x102 ESC [ Y
Down 80 0x104 ESC[B
PgDn 81 0x108 ESC [ U
jns 82 0x1 ОС ESC[@
Функция make_break преобразует коды опроса в ASCII-коды и обновляет зна-
значение переменных, отслеживающих значения модификаторов. Но перед этим она
ищет «волшебную» комбинацию клавиш Ctrl+Alt+Del, которую все пользователи
PC знают как способ принудительной перезагрузки MS-DOS. Обратите внима-
внимание на комментарий о том, что это действие было бы лучше выполнить на более
низком уровне. Тем не менее простота обработки прерываний в MINIX 3 в про-
пространстве ядра делает обнаружение нажатия этого сочетания невозможным, когда
уведомление о прерывании послано, но код опроса клавиатуры еще не считан.
Желательным является штатное завершение работы системы, поэтому вместо
обращения к подпрограммам PC BIOS выполняется вызов ядра sys_kill, ини-
инициирующий передачу сигнала SIGKILL процессу init — родителю всех ос-
остальных процессов (строка 15448). Ожидается, что init обработает этот сигнал
и в нормальном порядке завершит работу системы, прежде чем вернуться в мо-
монитор начальной загрузки, из которого можно управлять либо полным переза-
перезапуском системы, либо перезагрузкой MINIX 3.
Конечно, было бы неправильно ожидать, что этот механизм будет работать все-
всегда. Большинство пользователей понимают опасность внезапной перезагрузки
и не прибегают к клавишам Ctrl+Alt+Del до тех пор, пока не произойдет что-то
действительно серьезное, после чего управлять системой будет невозможно.
К этому моменту может сложиться ситуация, когда правильно отправить сигнал
другому процессу уже невозможно. Именно потому в make_break есть статиче-
статическая переменная CAD_count. При большинстве сбоев система обработки преры-
прерываний продолжает работать, значит, клавиатурный ввод продолжает поступать,
и таймерное задание остается работоспособным. MINIX 3 учитывает поведение
пользователей, которые, когда система не реагирует на нажатия клавиш, начина-
начинают в сердцах нажимать все подряд. Если попытка отправить сигнал SIGABRT
процессу in it не удается, и пользователь обращаетсяся к магической комбина-
комбинации Ctrl+Alt+Del во второй раз, делается прямой вызов функции wreboot, кото-
которая принудительно возвращает управление монитору начальной загрузки.
Основная часть make_break устроена не сложно. В переменную make запи-
записывается признак, было ли прерывание вызвано нажатием или отпусканием кла-
клавиши, после чего в переменную ch помещается ASCII-код, возвращаемый функ-
функцией map_key. Далее следует инструкция switch, проверяющая значение ch
(строки 15460-15499). Рассмотрим два случая: случай обычной клавиши и слу-
случай специальной клавиши. Если нажата обычная клавиша, ни одно из условий
в switch не будет выполнено, в варианте по умолчанию также ничего не про-
произойдет, поскольку обычные символы принимаются только при нажатии клави-
клавиши. Если каким-то образом обычная клавиша была воспринята при отпускании,
ее код заменяется значением -1, которое игнорируется вызывающей функцией
kb_read. Специальная клавиша, например Ctrl, обнаруживается в соответствую-
соответствующем месте инструкции switch, в данном случае — в строке 15461. Состояние
make фиксируется в надлежащей переменной (ctrl), а в качестве кода символа
возвращается (и игнорируется) -1. Обработка колов ALT, CALOCK, NLOCK и SLOCK
сложнее, но во всех этих вариантах действия похожи: в переменную записывает-
записывается либо новое состояние модификатора (если модификатор действует только то-
тогда, когда удерживается клавиша), либо инвертированное старое состояние (для
клавиш наподобие Caps Lock).
Нужно рассмотреть еще один вариант, код EXTKEY и переменную esc. He пу-
путайте этот случай с клавишей Esc на клавиатуре, которой соответствует код оп-
опроса 0x1 В. Код EXTKEY нельзя сгенерировать, нажав какую-либо клавишу или
их комбинацию. Это префикс расширенных клавиш для клавиатур PC, первый
байт двухбайтового кода опроса, означающего, что передаваемый далее код оп-
опроса не является частью обычного набора клавиш PC. Во многих случаях про-
программное обеспечение интерпретирует обычный и расширенный коды одинаково.
Например, это почти всегда так для обычной клавиши / и клавиши / на цифро-
цифровой клавиатуре. В других случаях может потребоваться различать их нажатия.
Так, во многих раскладках клавиатур для языков, отличных от английского, ле-
левая и правая клавиши Alt интерпретируются по-разному, позволяя вводить три
разных символа с помощью одной клавиши. Код опроса у обеих клавиш одина-
одинаков и равен 56, но при нажатии правой клавиши Alt код опроса предваряется ко-
кодом EXTKEY. Когда получен код EXTKEY, устанавливается флаг esc, и в этом
случае функция make_break выполняет возврат прямо из инструкции switch,
тем самым обходя операторы в конце функции, записывающие в переменную esc
нулевое значение. В результате esc действует только на один символ, который
должен быть получен следующим. Если вы знакомы с особенностями обычного
программирования ввода с клавиатур PC, то это также будет вам понятно, хотя
и немного странно, так как BIOS PC не позволяет считывать код опроса для кла-
клавиши Alt и возвращает другое значение для расширенного кода, нежели MINIX 3.
Функция set_leds (строка 15508) управляет светодиодами на клавиатуре, ин-
индицирующими состояние клавиш Num Lock, Caps Lock и Scroll Lock. Чтобы ука-
указать клавиатуре, что следующий записанный в порт байт управляет индикато-
индикаторами, в порт записывается управляющий байт, LED_CODE. Состояние всех трех
светодиодов кодируется тремя битами этого байта. Разумеется, данные операции
выполняются вызовами ядра, обращающимися к системному заданию для за-
записи в выходные порты. Поддержка осуществляется с помощью двух функций.
Функция kb_wait (строка 15530) вызывается тогда, когда необходимо опреде-
определить момент готовности клавиатуры к получению управляющей последователь-
последовательности, a kb_ack (строка 15552) проверяет, что команда подтверждена. Обе эти
команды используют механизм активного ожидания, непрерывно считывая со-
состояние до тех пор, пока не получено нужное значение. Такая методика не реко-
рекомендуется для операций ввода-вывода, но переключение индикаторов не должно
происходить часто, поэтому временные издержки не так велики. Заметьте, что
и kb_wait, и kb_ack могут завершиться неудачей, что видно из кода возврата
функций. Число повторных попыток ограничено счетчиком цикла. Правда, пере-
переключение индикаторов на клавиатуре — не самая важная задача, поэтому возвра-
возвращаемое значение не проверяется и set_leds выполняется «вслепую».
Так как клавиатура является составной частью консоли, ее подпрограмма инициа-
инициализации, kb_init (строка 15572), вызывается из scr_init в файле console.с,
а не напрямую из tty_init в tty.c. Если включены виртуальные консоли
(то есть константа NR_CONS в include/minix/conf ig.h больше 1), kb_init
вызывается для каждой логической консоли. Следующая функция, kb_init_
once (строка 15583), вызывается всего один раз, что и отражено в ее названии.
Она задает состояние индикаторов на клавиатуре и сканирует клавиатуру, чтобы
удостовериться, что не считано никаких остаточных нажатий клавиш. Затем
инициализируются два массива, f key_obs и sf key_obs, предназначенные для
связывания функциональных клавиш с процессами, которые должны на них реа-
реагировать. Когда все готово, выполняются два вызова ядра, sys_irqsetpolicy
и sys_irqenable, задающие запросы на прерывание от клавиатуры и автома-
автоматическое разрешение прерываний. Таким образом, tty_task будет получать
уведомление при каждом нажатии и отпускании клавиши.
Хотя рассмотрением работы функциональных клавиш мы займемся чуть позже,
сейчас вполне целесообразно изучить массивы fkey_obs и sfkey_obs. Каждый
из них содержит 12 элементов, соответствующих 12 функциональным клавишам,
которыми оснащены современные персональные компьютеры. Первый массив
предназначен для немодифицированных функциональных клавиш, а второй —
для функциональных клавиш, нажатых одновременно с Shift. Массивы включают
элементы типа obs_t, представляющего собой структуру, хранящую номер про-
процесса и целое число. Структура и сами массивы объявлены в файле keyboard. с
в строках 15279-15281. При инициализации структуры ее полю proc_nr при-
присваивается значение, определенное как NONE и указывающее на то, что она не
используется. Значение NONE лежит за пределами, допустимыми для номеров
процессов. Обратите внимание на то, что номер процесса — это не его иденти-
идентификатор, а индекс в таблице процессов. Возможно, терминология несколько
запутанна, однако для передачи уведомления используется именно номер, а не
идентификатор процесса, поскольку номера процессов индексируют таблицу priv,
разрешающую процессам принимать уведомления. Целочисленная переменная
events также имеет нулевое начальное значение и применяется для подсчета
количества событий.
Следующие три функции довольно просты. Подпрограмма kbd_loadmap (стро-
(строка 15610) почти тривиальна. Она вызывается из do_ioctl файла tty.c с це-
целью скопировать карту клавиш из пользовательского адресного пространства.
При этом новая раскладка записывается поверх раскладки по умолчанию, сгене-
сгенерированной благодаря тому, что исходный файл раскладки включен в начало
файла keyboard. с.
С первого выпуска операционная система MINIX обеспечивала генерацию дам-
дампов различной системной информации и другие специальные действия по нажа-
нажатию функциональных клавиш на консоли. Другие операционные системы, как
правило, не делают этого, однако система MINIX всегда была средством обучения,
стимулируя пользователей к экспериментам и предоставляя им дополнительные
возможности отладки. Во многих случаях вывод информации по нажатию функ-
функциональных клавиш поддерживается даже при крахе системы. В табл. 3.14 пред-
представлены функциональные клавиши и выполняемые ими действия.
Таблица 3.14. Функциональные клавиши, обнаруживаемые функцией func_key
Клавиша Действие
F1 Вывод таблицы процессов ядра
F2 Вывод информации о занятой процессом памяти
F3 Вывод загрузочного образа
F4 Вывод привилегий процессов
F5 Вывод параметров монитора загрузки
F6 Вывод информации о прерываниях
F7 Вывод сообщений ядра
F10 Вывод параметров ядра
F11 Вывод таймерной информации
F12 Вывод информации об очередях
SF1 Вывод таблицы процессов менеджера процессов
SF2 Вывод сигналов
SF3 Вывод таблицы процессов файловой системы
SF4 Отображение устройства/драйвера
SF5 Отображение клавиш печати
SF9 Вывод Ethernet-статистики (только для RTL8139)
CF1 Отображение клавиш вывода
CF3 Переключение между программной и аппаратной прокруткой
CF7 Отправка сигнала SIGQUIT, тот же эффект дает нажатие клавиш Ctrl+\
CF8 Отправка сигнала SIGINT, тот же эффект дает нажатие клавиши Del
CF9 Отправка сигнала SIGKILL, тот же эффект дает нажатие клавиш Ctrl+U
Нажатие функциональных клавиш поодиночке или совместно с клавишей Shift
приводит к появлению событий, которые невозможно обработать с помощью
драйвера терминала. Эти события приводят к передаче уведомлений драйверам
и серверам. Поскольку загрузка, включение и выключение драйверов в MINIX 3
возможны в процессе работы операционной системы, статическая привязка к ним
клавиш во время компиляции вряд ли является удачным решением. Для поддерж-
поддержки изменений в реальном времени подпрограмма tty_task принимает сообще-
сообщения типа FKEY_CONTROL, а обработкой запросов занимается функция do_f key_
ctl (строка 15624). Существует три типа запросов: FKEY_MAP, FKEY_UNMAP
и FKEY_EVENTS. Первые два соответственно назначают и отменяют функцио-
функциональную клавишу процессу, указанному в битовой карте сообщения. Третий
запрос возвращает битовую карту нажатых клавиш, связанную с вызывающим
процессом, и очищает поле events для этих событий. Информационный сервер
(Information Server, IS) инициализирует параметры процессов в загрузочном обра-
образе, а также участвует в генерации откликов. Тем не менее драйверы также могут
быть связаны с функциональной клавишей и реагировать на нее. Как правило,
это имеет место для Ethernet-драйверов, сбрасывающих дампы со статистикой
пакетов, которые полезны при разрешении сетевых проблем.
Функция f unc_key (строка 15715) вызывается из kb_read для того, чтобы оп-
определить, имеются ли нажатые клавиши для локальной обработки. Это действие
выполняется каждый раз и в первую очередь при получении кода опроса. Если
клавиша не является функциональной, то как минимум три сравнения выполня-
выполняются прежде, чем управление возвращается kb_read. Если же клавиша являет-
является функциональной и связана с процессом, последнему посылается уведомление.
В случае когда процесс связан с единственной клавишей, само уведомление ука-
указывает ему, что делать. Если же процесс связал себя с несколькими функцио-
функциональными клавишами, требуется диалог: процесс посылает запрос FKEY_EVENTS
драйверу терминала, который обрабатывает его с помощью подпрограммы do_
f key_ctl и информирует источник о том, какие клавиши являются активными.
Затем процесс может вызвать процедуру обработки для каждой нажатой клавиши.
Функция scan_keyboard (строка 15800) взаимодействует с аппаратным ин-
интерфейсом клавиатуры, считывая и записывая байты из портов ввода-вывода.
Контроллер клавиатуры информируется о том, что символ был считан последо-
последовательностью команд в строках 15809-15810. Эти команды считывают байт, за-
затем записывают его обратно с установленным старшим битом, а затем перезапи-
перезаписывают его еще раз со сброшенным битом. В результате те же самые данные при
следующем чтении не встречаются. В этой функции не делается никаких прове-
проверок, что не важно, так как функция scan_keyboard вызывается только из обра-
обработчика прерываний.
Завершает файл keyboard.с функция do_panic_dumps (строка 15819). Вы-
Вызываемая в результате краха системы, она дает пользователю возможность про-
просмотреть отладочную информацию при помощи функциональных клавиш. Цикл
в строках 15830-15854 — еще один пример активного ожидания. Клавиатура
непрерывно опрашивается до тех пор, пока не нажата клавиша Esc. Безусловно,
никто не может заявить, что после сбоя, когда ожидается команда на перезагруз-
перезагрузку, имеет смысл применять более эффективные методики. Внутри цикла редко
используемая неблокирующая операция приема nb_receive служит для прие-
приема сообщений и проверки ввода с клавиатуры одного из вариантов, предложен-
предложенных в сообщении:
Hit ESC to reboot, DEL to shutdown, F-keys for debug dumps
В следующем разделе мы рассмотрим код функций do_newkmess и do_
diagnostics.
3.8.6. Реализация драйвера экрана
Если имеется достаточно видеопамяти, экран IBM PC можно сконфигурировать
как несколько виртуальных терминалов. В этом разделе рассматривается аппа-
ратно-зависимый код консоли. Кроме того, описываются подпрограммы вывода
отладочной информации, взаимодействующие с клавиатурой и дисплеем на низ-
низком уровне. Эти средства предоставляют ограниченные возможности для взаи-
взаимодействия с пользователем, но работают даже тогда, когда другие компоненты
системы не функционируют и могут дать полезную информацию даже после
практически тотального краха системы.
Специфичный для отображаемого на память экрана PC код расположен в файле
console. с. Здесь объявляется структура console (строки 15981-15998), кото-
которая по своему смыслу является расширением структуры tty из файла tty.c.
При инициализации в поле tp->tty_priv структуры tty для консоли записы-
записывается указатель на принадлежащую этой консоли структуру console. Первое
поле структуры является указателем, содержащим обратную ссылку на структу-
структуру tty. Остальные компоненты структуры содержат вполне ожидаемую для ви-
видеоустройства информацию: переменные, хранящие текущие координаты курсо-
курсора, адрес начала области памяти, отведенной для дисплея, и ее размер, адрес, на
который ссылается регистр базы чипа контроллера, текущий адрес курсора.
Другие переменные требуются для работы с ESC-последовательностями. Так
как символы принимаются в виде 8-разрядных байтов и перед выводом в видео-
видеопамять должны быть скомбинированы с байтом атрибутов, блок данных подго-
подготавливается к передаче в массиве c_ramqueue, объема которого достаточно для
хранения 80 16-разрядных пар «символ-атрибут». Каждой виртуальной консоли
требуется собственная структура console, для хранения которой выделяется
область памяти в cons_table (строка 16001). Как и в случае tty и других
структур, мы обычно будем ссылаться на поля console через указатель, на-
например: cons->c_tty.
Для каждой консоли в поле tp->tty_devwrite хранится адрес функции cons_
write (строка 16036). Она вызывается только из одного места — обработчика
handle_events в файле tty. с. Большая часть остальных функций в console. с
призвана обеспечивать работу функции cons_write. Когда она вызывается
впервые после того, как процесс-клиент сделал вызов write, выводимые данные
располагаются в буфере в адресном пространстве этого процесса. Определить
положение буфера можно при помощи полей tp->tty_outproc и tp->out_
vir структуры tty. Поле tp->tty_outleft говорит о том, сколько символов
должно быть передано, а поле tp->tty_outcum изначально равно нулю, сооб-
сообщая о том, что ни одного символа еще не выведено. Это — обычная ситуация
для функции cons_write, так как она выводит все данные, указанные в вызове.
Но если пользователь хочет замедлить процесс вывода, он может ввести с кла-
клавиатуры символ STOP (Ctrl+S), который приводит к тому, что устанавливается
флаг tp->tty_inhibited. Когда этот флаг установлен, cons_write немед-
немедленно возвращает управление, даже если вызов write еще не выполнен пол-
полностью. Причем handle_events продолжит вызывать cons_write и когда
флаг tp->tty_inhibited будет сброшен, а для этого необходимо ввести сим-
символ START (Ctrl+Q), прерванная передача данных возобновится.
Первым аргументом cons_write является указатель на структуру tty для дан-
данной консоли, поэтому первым действием инициализируется указатель cons, со-
содержащий адрес структуры console (строка 16049). Затем необходимо прове-
проверить, действительно ли есть какая-либо работа, так как handle_events всегда
вызывает cons_write. Если нет, функция быстро завершается (строка 16056).
После этого она входит в свой главный цикл (строки 16061-16089). Этот цикл
очень похож на цикл функции in_transf ег в файле tty. с. При помощи вы-
вызовов sys_vircopy ядра локальный буфер объемом 64 символа заполняется
данными из пользовательского буфера, обновляются указатель на начало буфера
и счетчик символов, после чего все символы из локального буфера переносятся
в массив cons->c_ramqueue, дополненные байтом атрибутов. Позже эти дан-
данные выводятся на экран с помощью функции flush.
Как вы могли видеть на рис. 3.23, существуют несколько способов осущест-
осуществить эту передачу. Можно вызывать out_char для каждого символа, но лишь
в расчете на то, что при выводе символов не потребуется ни одна из специаль-
специальных функций out_char, не выводится ESC-последовательность, ширина экрана
не превышена и массив cons->c_ramqueue не заполнен. Если все функции
out_char не требуются, символ можно поместить в массив cons->c_ramqueue
напрямую, вместе с байтом атрибутов (поле cons->c_attr), а все переменные
cons->c_rwords (индекс в очереди), cons->c_column (отслеживает текущий
столбец на экране) и tbuf (указатель на буфер) инкрементируются. Прямой пе-
перенос символов в cons->c_ramqueue соответствует штриховой линии с левой
стороны рис. 3.23. При необходимости вызывается функция out_char (стро-
(строка 16082). В этом вызове выполняются все подсчеты и по мере надобности
вызывается функция flush, которая обеспечивает окончательную передачу дан-
данных в видеопамять.
Перекачка данных из пользовательского буфера в локальный производится до
тех пор, пока значение в поле tp->tty_outlef t говорит о наличии символов
и не установлен флаг tp->tty_inhibited. Если передача останавливается, в ре-
результате завершения вызова write или потому, что установлен флаг tp->tty_
inhibited, то чтобы передать последние символы из очереди в память экрана,
опять вызывается функция flush. Когда операция завершена (то есть проверка
показывает, что поле tp->tty_outleft содержит нулевое значение), при по-
помощи tty_reply отправляется ответное сообщение (строки 16096-16097).
В дополнение к вызовам cons_write из handle_events, символы на консоль
могут выводить функции echo и rawecho в аппаратно-независимой части драй-
драйвера терминала. Если текущим устройством вывода является консоль, косвен-
косвенные вызовы через указатель tp->tty_echo перенаправляются функции cons_
echo (строка 16105). Она делает свою работу, вызывая out_char и затем flush.
Пользователь вводит данные символ за символом, и ему предпочтительно, чтобы
эхо отображалось сразу же, без видимой задержки, поэтому помещать символы
в очередь было бы неправильно.
Итак, теперь мы добрались до функции out_char (строка 16119). Сначала она
проверяет, вводится ли ESC-последовательность, вызывая parse_escape, и ес-
если это так, немедленно завершается (строки 16124-16126). В противном случае
управление передается в конструкцию switch, которая проверяет различные
особые случаи: нулевой символ, символ забоя, символ звонка и т. п. Несложно
проследить, как обрабатывается большая часть этих ситуаций. Самые сложные
варианты — символы перевода строки и табуляции, поскольку они сложным об-
образом меняют координаты курсора на экране и могут вызвать прокрутку. По-
Последняя проверка выполняется на код ESC. Если он обнаруживается, устанавли-
устанавливается флаг cons->c_esc_state (строка 16181) и последующие вызовы out_
char перенаправляются в parse_escape до тех пор, пока последовательность
не завершится. Вариант по умолчанию выполняется для печатных символов.
Если превышена ширина экрана, при необходимости делается прокрутка экрана
и вызывается flush. Прежде чем поместить символ в выходную очередь, прове-
проверяется, заполнена ли она, и если заполнена, вызывается flush. Как мы видели
ранее при описании функции cons_write, в случае занесения символа в оче-
очередь необходимо учесть это, обновив значения нескольких переменных.
Далее следует функция scroll_screen (строка 16205). Она выполняет как про-
прокрутку вверх, то есть нормальную прокрутку, ожидаемую при заполнении нижней
строки экрана, так и прокрутку вниз, которая необходима при попытке устано-
установить курсор выше верхней границы экрана. Для каждого направления прокрутки
возможны три метода. Это проистекает из требования поддержки различных
типов видеокарт.
Мы рассмотрим случай прокрутки вверх. Сначала переменной chars присваивает-
присваивается значение, равное размеру экрана минус 1. Когда прокрутка делается программ-
программно, для ее выполнения достаточно одного вызова функции vid_vid_copy, ко-
которая копирует chars символов на одну строку ниже в памяти. Эта функция
умеет переходить в начало области при достижении ее конца, и наоборот. Так,
если ей указано скопировать блок памяти, начало которого выходит за верхнюю
границу памяти, то не укладывающиеся в область видеопамяти данные берутся
из ее нижней части, то есть видеопамять рассматривается как циклический мас-
массив. Простота этого вызова не компенсирует низкую скорость операции. Несмот-
Несмотря на то что подпрограмма vid_vid_copy написана на языке ассемблера (ее
код хранится в файле drivers /tty/vidcopy. s), для ее выполнения необхо-
необходимо скопировать 3840 байт, что довольно много даже для ассемблерного кода.
Программная прокрутка никогда не выбирается по умолчанию. Пользователь мо-
может включить ее, если аппаратная не работает или по каким-то причинам неже-
нежелательна. Одна из таких причин — желание использовать команду screendump,
чтобы иметь возможность сохранить экранную память в файле или просматри-
просматривать дисплей главной консоли при работе с удаленного терминала. При аппарат-
аппаратной прокрутке эта команда не дает ожидаемого результата, так как начало видео-
видеопамяти наверняка не совпадает с началом видимой на экране области.
В первой части составного условия (строка 16226) проверяется значение пере-
переменной wrap. Эта переменная содержит TRUE для старых экранов, поддержи-
поддерживающих аппаратную прокрутку, и если проверка не выполняется, в ветви else
производится простая аппаратная прокрутка (строка 16230). Соответственно,
значение указателя на начало экранной области, используемого видеоконтролле-
видеоконтроллером, cons->c_orig, изменяется так, чтобы указывать на первый символ той
строки, которая окажется наверху экрана. Если значение wrap равно FALSE,
проверка составного условия продолжается. В этом случае проверяется, помес-
поместится ли перемещаемый блок памяти в области памяти, отведенной для консоли.
Если нет, то вызовом vid_vid_copy содержимое копируется физически в на-
начало области видеопамяти. Если же адреса не перекрываются, делается простая
аппаратная прокрутка, всегда практикуемая в более старых видеоконтроллерах.
Для этого изменяется значение cons->c_org, и новое значение указателя на
начало области заносится в нужный управляющий регистр контроллера. Соот-
Соответствующий вызов делается позднее, как и вызов, очищающий нижнюю строку
экрана для достижения эффекта «прокрутки».
Код прокрутки вниз очень похож на тот, что прокручивает экран вверх. В конце
нижняя (или верхняя) строка экрана, на которую указывает переменная new_
line, очищается вызовом mem_vid_copy, обновляются значения некоторых пе-
переменных и делается проверка того, что координаты курсора имеют приемлемые
значения. При необходимости, если, например, ESC-последовательность перемес-
переместила курсор на столбец с отрицательным номером, координаты корректируются.
В завершение вычисляется, где должен быть курсор, и это значение сравнивает-
сравнивается с cons->c_cur. Если значения не совпадают, а обрабатываемая память при-
принадлежит текущей виртуальной консоли, то чтобы записать корректные значе-
значения в регистр курсора контроллера, делается вызов подпрограммы set_6845.
На рис. 3.26 показано, как можно представить анализ ESC-последовательностей
при помощи конечного автомата. Этот автомат реализуется подпрограммой
parse_escape (строка 16293), вызываемой в начале кода out_char, если поле
cons->c_esc_state не равно нулю. Сам символ ESC обнаруживается в out_
char, и переменная cons->c_esc_state переводится в состояние 1. Когда
получен следующий символ, функция parse_escape подготавливается к обра-
обработке дальнейшей информации: значение ' \0 ' заносится в поле cons->c_esc_
intro, указатель на начало массива параметров, cons->c_esc_paramv [ 0 ], за-
заносится в cons->c_esc_paramp, а сам массив параметров заполняется нуля-
нулями. Затем проверяется первый символ, следующий за ESC. Допустимыми зна-
значениями являются [ и м. В первом случае символ [ копируется в переменную
cons->c_esc_intro, и автомат переходит в состояние 2. Во втором случае вы-
вызывается функция do_e scape, которая выполняет действие, и автомат возвра-
возвращается в состояние 0. Если же за ESC следует недопустимый символ, он игнори-
игнорируется, а дальше все обрабатывается, как обычно.
Рис. 3.26. Конечный автомат для обработки ESC-последовательностей
Когда автомат получает последовательность ESC [, следующий полученный
символ обрабатывается в состоянии 2. В этой точке возможны три варианта.
Если на входе числовой символ, его значение добавляется к увеличенному в де-
десять раз значению параметра, на который в текущий момент указывает cons->
c_esc_paramp (сначала этот указатель ссылается на cons->c_esc_paramv [ 0 ],
и все параметры равны нулю). Здесь состояние автомата не меняется. Это по-
позволяет передавать параметры в виде последовательности чисел, накапливая их
итог, хотя максимальное значение, в текущий момент распознаваемое MINIX,
равно 80. Оно может быть использовано в последовательности, перемещающей
курсор в указанную позицию на экране (строки 16335-16337). Если получено не
число, а точка с запятой, тогда указатель на текущий параметр перемещается
к следующему параметру, чтобы начать считывание в нечисловых значений (стро-
(строки 16339-16341). Благодаря такому подходу, если изменить константу МАХ_
ESC_PARMS в сторону массива большего объема, код менять не придется. Нако-
Наконец, в третьем случае, когда получен символ, не являющийся ни числом, ни точ-
точкой с запятой, вызывается do_e scape.
Функция do_escape (строка 16352) весьма объемна, несмотря на относительно
скромную поддержку ESC-последовательностей в MINIX 3. Но при любом объе-
объеме код должен быть достаточно простым. После того как делается вызов flush,
нужно убедиться, что содержимое экрана полностью обновлено. Инструкция i f
выполняет простую проверку, является ли следующий за ESC символ преамбу-
преамбулой ESC-последовательности или нет. Если нет, допустимо только одно дейст-
действие — перемещение курсора на строку вверх, этому соответствует ESC-последо-
вательность ESC M. Обратите внимание, что проверка значения осуществляется
в инструкции switch в расчете на появление новых вариантов, то есть новых
последовательностей, не соответствующих формату ESC [. Поэтому обрабатывает-
обрабатывается вариант без преамбулы типичным для многих последовательностей образом:
по значению переменной cons->c_row определяется, необходима ли прокрут-
прокрутка. Если курсор находится в нулевой строке, делается вызов scroll_screen
с параметром SCROLL_DOWN. Если нет, курсор просто сдвигается на одну строку
вверх, для чего переменная cons->c_row уменьшается на 1 и вызывается flush.
Если обнаружена преамбула ESC-последовательности, срабатывает другая ветвь
инструкции if (строка 16377). Сначала проверяется, не символ [ ли это, то есть
единственная возможная преамбула, обрабатываемая в текущий момент в MINIX 3.
Если символ корректен, в переменную value записывается значение первого
полученного параметра, или ноль, если параметров нет (строка 16380). Если по-
последовательность некорректна, ничего не происходит, за исключением того, что
switch с большим телом (строки 16381-16586) пропускается, а состояние авто-
автомата сбрасывается в 0 перед вызовом do_escape. В более интересном случае,
когда последовательность правильна, выполняется инструкция switch. Все воз-
возможные варианты мы рассматривать не будем. Вместо этого обсудим только
наиболее характерные типы действий, управляемых ESC-последовательностями.
Первые пять последовательностей без числовых аргументов на клавиатурах IBM
PC генерируются клавишами со стрелками и клавишей Ноте. Две последователь-
последовательности, ESC [А и ESC [В, сходны с ESC M, с той разницей, что числовой параметр
позволяет перемещаться более чем на одну строку, а при достижении границ эк-
экрана содержимое не прокручивается. Функция flush в этом случае обнаружи-
обнаруживает попытки передвинуть курсор за границы экрана и ограничивает его переме-
перемещение. Две другие последовательности, ESC [С и ESC [D, перемещающие курсор
вправо и влево, аналогичным образом ограничены функцией flush. Когда они
генерируются клавишами управления курсором, числовой аргумент не передает-
передается, поэтому происходит перемещение на одну строку или один столбец.
Далее, последовательность ESC [H может иметь два числовых параметра, на-
например ESC [2 0; 60Н. Эти параметры задают положение курсора в абсолютных
координатах, а не относительно предыдущего места расположения, и для пра-
правильной интерпретации преобразуются из координат, отсчитываемых с 1, в ко-
координаты с началом в 0. Клавиша Ноте на клавиатуре генерирует последова-
последовательность без параметров (с параметрами по умолчанию), которая перемещает
курсор в положение A;1).
Две следующие последовательности, ESC [sJ и ESC [sK, очищают либо часть
строки, либо часть всего экрана, в зависимости от переданного параметра. В обоих
случаях подсчитывается количество символов. Например, для последовательно-
последовательности ESC [1J в count заносится количество символов от начала экрана до теку-
текущего положения курсора, и это количество и параметр положения, dst, который
может быть равен началу экрана, cons->c_org, используются как аргументы
для вызова mem_vid_copy. Аргументы процедуры таковы, что она заполняет
указанную область экрана текущим цветом фона.
Четыре следующие последовательности вставляют новые строки и удаляют стро-
строки и пробелы в текущем местоположении курсора, и их работа не нуждается в де-
детальном рассмотрении. Последний вариант, последовательность ESC [та (обратите
внимание, что п — это числовой аргумент, am — литера, часть последовательности),
оказывает влияние на параметр cons->c_attr. Это — байт атрибутов, который
при записи символов в видеопамять чередуется с кодами символов.
Функция set_6 84 5 (строка 16594) вызывается тогда, когда необходимо об-
обновить информацию видеоконтроллера. У контроллера 6845 есть внутренние
16-разрядные регистры, которые программируются по 8 бит за раз. Поэтому для
записи одного регистра требуются четыре операции с портами ввода-вывода.
В каждой из них создается массив (вектор) пар (порт, значение) и осуществляется
вызов ядра sys_voutb, обращающийся к системному заданию для выполнения
ввода-вывода. Некоторые регистры микросхемы видеоконтроллера 6845 пере-
перечислены в табл. 3.15.
Таблица 3.15. Некоторые из регистров микросхемы 6845
Регистры Назначение
10-11 Размер курсора
12-13 Начальный адрес видимой части экрана
14-15 Положение курсора
Следующая функция, get_6845 (строка 16613), возвращает значения доступных
для считывания регистров видеоконтроллера. Для этого она пользуется вызова-
вызовами ядра. В текущем коде MINIX 3 эта функция не вызывается, однако может
быть полезна для расширений в будущем (например, для добавления графиче-
графической поддержки).
Функция beep (строка 16629) вызывается при нажатии клавиш Ctrl+G. Она по-
подает на внутренний динамик прямоугольный сигнал, опираясь на встроенные
аппаратные возможности PC. Звук появляется путем некоторых магических ма-
манипуляций с портами ввода-вывода, которые интересны только программистам
на ассемблере. Более интересно то, что сигнал выключается при помощи уведом-
уведомления. Будучи процессом с системными привилегиями (такими как запись в таб-
таблице priv), драйвер терминала может установить таймер с помощью библиотеч-
библиотечной функции tmrs_settimers. Это делается в строке 16655, а следующая
функция, stop_beep, вызывается после истечения таймера. Этот таймер ста-
ставится в собственную очередь драйвера терминала. Вызов ядра sys_setalarm,
следующий далее, обращается к системному заданию для установки таймера в яд-
ядре. По его истечении главный цикл драйвера терминала, tty_task, обнаружива-
обнаруживает сообщение SYN_ALARM и вызывает функцию expire_timers. Последняя об-
обрабатывает все таймеры, принадлежащие драйверу терминала, один из которых
установлен функцией beep.
Адрес следующей подпрограммы, stop_beep (строка 16666), помещен функ-
функцией beep в поле tmr_f unc таймера. Она выключает сигнал после истечения
заданного интервала времени и сбрасывает флаг beeping. Это предотвращает
обработку лишних обращений к функции генерации сигнала.
Подпрограмма scr_init вызывается из tty_init столько раз, сколько указано
в NR_CONS. При каждом вызове аргументом подпрограммы является указатель
на структуру, один из элементов массива tty_table. В строках 16693 и 16694
вычисляется значение line, будущий индекс в массиве cons_table, это значе-
значение проверяется на корректность, и если все правильно, оно используется для
инициализации указателя cons, ссылающегося на текущую запись в массиве
cons_table. К этому моменту поле cons->c_tty может быть инициализиро-
инициализировано указателем на главную структуру tty для устройства, а в tp->tty_priv,
в свою очередь, может быть записан указатель на структуру console_t устрой-
устройства. Затем для инициализации клавиатуры вызывается подпрограмма kb_init
и устанавливаются указатели на специфичные для данного устройства подпро-
подпрограммы. После этого tp->tty_devwrite ссылается на cons_write, a tp->
tty_echo содержит указатель на cons_echo. Далее из BIOS извлекается адрес
ввода-вывода регистра базы видеоконтроллера и в соответствии с типом ви-
видеоконтроллера устанавливается флаг wrap, определяющий способ прокрутки
(строки 16708-16731). Затем в глобальной таблице дескрипторов запоминается
дескриптор сегмента области видеопамяти (строка 16735).
В дальнейшем происходит инициализация виртуальных консолей. При инициа-
инициализации каждой консоли с разным значением tp вызывается scr_init, и таким
образом, для каждой консоли в scr_init используются собственные значения
line и cons (строки 16750-16753), и каждая консоль «арендует» собственную
область видеопамяти. Затем каждый экран очищается, и, наконец, консоль с ну-
нулевым номером становится активной.
Ряд подпрограмм отображает вывод от имени драйвера терминала, ядра или дру-
другого системного компонента. Первая, kputc (строка 16775), просто вызывает
функцию putk, которая побайтно выводит текст. Она применяется здесь потому,
что библиотечная подпрограмма, предоставляющая возможность использования
printf системным компонентам, связывается с одноименной подпрограммой
символьной печати, однако другие функции драйвера терминала рассчитаны на
подпрограмму с именем putk.
Функция do_new_kmess (строка 16784) применяется для печати сообщений из
ядра. Здесь термин «сообщения» не самый удачный; он не имеет отношения к со-
сообщениям, обеспечивающим взаимодействие между процессами. Данная функ-
функция отображает на консоли текст, содержащий информацию, предупреждения
и сведения об ошибках.
Ядру необходим особый механизм отображения данных. Этот механизм должен
быть достаточно самостоятельным, чтобы работать во время загрузки, когда ком-
компоненты операционной системы еще не функционируют, и во время сбоев, когда
основные компоненты могут быть недоступными. Ядро помещает текст в цик-
циклический символьный буфер, входящий в структуру, содержащую указатели на
следующий записываемый байт и размер еще не обработанного текста. При по-
появлении нового текста ядро посылает драйверу терминала сообщение SYS_SIG,
и если главный цикл в процедуре tty_task функционирует, вызывается функ-
функция do_new_kmess. При внештатной ситуации (например, в случае краха сис-
системы) сообщение SYS_SIG обнаруживается циклом процедуры do_panic_
dumps с помощью операции неблокирующего чтения, которую мы видели в фай-
файле keyboard, с, и функция do_new_kmess вызывается оттуда. В обоих случаях
вызов ядра sys_getkmessages получает копию структуры ядра, байты ото-
отображаются по одному с помощью функции put к, а последний вызов put к с ну-
нулевым символом приводит к сбросу вывода. Хранение позиции в буфере для
различных сообщений осуществляется с помощью локальной статической пере-
переменной.
Функция do_diagnostics (строка 16823) имеет назначение, схожее с do_
new_kmess, однако обеспечивает вывод сообщений не для ядра, а для систем-
системных процессов. Сообщение типа DIAGNOSTICS может быть получено главным
циклом функции tty_task либо циклом в функции do_panic_dumps. В обоих
случаях производится вызов do_diagnostics. Сообщение содержит указатель
на буфер вызывающего процесса и его размер. Локальная буферизация не ис-
используется; вместо этого текст побайтно доставляется путем многократных вы-
вызовов sys_vircopy ядра. Это защищает драйвер терминала; в случае если про-
произойдет сбой и процесс начнет генерировать большие объемы данных, проблема
переполнения буфера не сможет возникнуть. Вывод символов осуществляется
по одному функцией putk и завершается нулевым байтом.
Функция putk (строка 16850) печатает символы от имени кода драйвера терми-
терминала и используется описанными функциями для вывода текста от лица ядра
или других системных компонентов. Она просто вызывает функцию out_char
для каждого полученного ненулевого символа и функцию flush для нулевого
символа, которым заканчивается строка.
Остальные процедуры в файле console.с просты и невелики, поэтому мы не
потратим на них много времени. Функция toggle_scroll (строка 16869)
делает именно то, что означает ее название, она изменяет значение флага типа
прокрутки: аппаратная или программная. Помимо этого, она выводит текст в те-
текущей позиции курсора, сообщая, какой режим выбран. Функция cons_stop
(строка 16869) инициализирует консоль, переводя ее в состояние, которое ожи-
ожидает монитор начальной загрузки. Это делается перед выходом из системы или
перезагрузкой. Функция cons_orgO (строка 16893) используется только тогда,
когда нажатием клавиши F3 изменяется режим прокрутки или идет подготовка
к выходу из системы. Функция select_console (строка 16917) выбирает (ак-
(активизирует) виртуальную консоль. При вызове ей передается индекс новой
консоли, и она дважды вызывает функцию set_6845, чтобы показать на экране
данные из соответствующей части видеопамяти.
Две последние подпрограммы в значительной степени зависят от особенностей
программного обеспечения. Функция con_loadf ont (строка 16931) загружает
в видеоконтроллер шрифт, обеспечивая выполнение операции TIOCSFON вызова
ioctl. Эта функция серией вызовов ga_program (строка 16971) делает так, что
становится видимой память шрифтов контроллера, которая в обычной ситуации
не адресуема. Затем, чтобы скопировать шрифт в ставшую доступной область
памяти, вызывается функция phys_copy, а после этого другая последователь-
последовательность команд возвращает устройство в нормальный режим работы.
Последняя функция, cons_ioctl (строка 16987), совершает лишь одно дейст-
действие: задает размер экрана. Она вызывается функцией scr_init, используя зна-
чения, полученные из BIOS. Если бы возникла необходимость вызова ioctl для
изменения размеров экрана, в MINIX 3 пришлось бы добавить код для работы
с новыми параметрами.
Резюме
Вводом-выводом часто пренебрегают, хотя он заслуживает более серьезного от-
отношения. Значительная доля кода любой операционной системы связана с вво-
вводом-выводом. Тем не менее драйверы устройств ввода-вывода часто становятся
причиной проблем. Как правило, драйверы создают программисты, работающие
в компаниях-производителях устройств. Традиционные операционные системы
предоставляют драйверам доступ к критически важным ресурсам, таким как пре-
прерывания, порты ввода-вывода и память других процессов. В MINIX 3 драйверы
являются независимыми процессами с ограниченными привилегиями. По этой
причине ошибка в одном драйвере не приводит к краху всей системы.
Мы начали с рассмотрения аппаратного обеспечения ввода-вывода и связи уст-
устройств ввода-вывода с контроллерами. Именно такую связь создает программ-
программное обеспечение. Затем мы рассмотрели четыре уровня программного обеспече-
обеспечения ввода-вывода: обработчики прерываний, драйверы устройств, независимое
от устройств программное обеспечение и библиотеки плюс спулеры, работаю-
работающие в пользовательском пространстве.
Далее мы изучили проблему взаимной блокировки и инструментарий для борь-
борьбы с ней, Взаимная блокировка возникает, когда имеется группа процессов,
получивших монопольный доступ к некоторым ресурсам, и каждому процессу
в группе необходим помимо этого другой ресурс, принадлежащий другому процес-
процессу. В таком случае все процессы блокируются и не могут выполняться. Взаимную
блокировку можно исключить, если система построена в расчете на упреждение
подобной ситуации. Например, можно разрешить каждому процессу удерживать
не более одного ресурса в каждый момент времени. Другой способ избежать бло-
блокировки — проверять каждый запрос, определяя, ведет ли он к опасной ситуации
(в которой возможно возникновение блокировки) и отменять или откладывать
опасные запросы.
В MINIX 3 драйверы устройств реализованы в виде процессов, встроенных в яд-
ядро. Мы рассмотрели драйверы виртуального диска, жесткого диска и терминала.
У каждого из этих драйверов есть главный цикл, в котором принимаются и об-
обрабатываются запросы, в конечном итоге формируется и отправляется ответное
сообщение о результатах. Исходный код главных циклов и общих функций драй-
драйверов помещен в единую библиотеку драйверов, хотя каждый драйвер компили-
компилируется и связывается с собственными копиями библиотечных процедур. Адресные
пространства драйверов индивидуальны. Множество различных терминалов, ис-
использующих системную консоль, последовательные линии и сетевые соединения,
поддерживаются одним и тем же процессом драйвера терминала.
Драйверы устройств по-разному взаимодействуют с системой прерываний. Уст-
Устройства, которые могут выполнить свою работу быстро, например виртуальный
диск или отображаемый на память экран, вообще не прибегают к прерываниям.
У жесткого диска большая часть работы выполняется в самом коде драйвера, а об-
обработчики прерываний возвращают информацию о состоянии. Прерывания всегда
ожидаемы, для чего можно прибегать к вызову receive. Прерывание от кла-
клавиатуры может произойти в любой момент. Сообщения, сгенерированные всеми
прерываниями для драйвера терминала, принимаются и обрабатываются в глав-
главном цикле драйвера. При появлении прерывания от клавиатуры первый шаг
обработки ввода должен быть как можно более быстрым, чтобы подготовиться
к приему последующих прерываний.
Драйверы MINIX 3 обладают ограниченными привилегиями: они не могут обра-
обрабатывать прерывания и самостоятельно пользоваться портами ввода-вывода. Пре-
Прерывания обрабатывает системное задание; оно посылает сообщение драйверу,
чтобы уведомить его о том, что прерывание произошло. Аналогичным образом
системное задание выступает в роли посредника при доступе к портам ввода-вы-
ввода-вывода. Сами драйверы не могут читать из них и писать в них напрямую.
Вопросы и задания
1. Устройство для чтения DVD со скоростью 1х способно предоставлять 1,32 Мбайт
данных в секунду. Какова максимальная скорость устройства, которое мож-
можно подключить к компьютеру с помощью интерфейса USB 2.0 без потери
данных?
2. Многие диски содержат коды исправления ошибок (ЕСС) в конце каждого
сектора. Какие действия следует предпринять, если сам код ошибочен? Какой
программный или аппаратный компонент должен это делать?
3. Что такое ввод-вывод, отображаемый на память? Для чего он используется?
4. Объясните, что такое прямой доступ к памяти (DMA) и для чего он исполь-
используется.
5. Хотя DMA не использует процессор, максимальная скорость передачи дан-
данных остается ограниченной. Предположим, вы считываете блок с диска. На-
Назовите три фактора, ограничивающие скорость его передачи.
6. Музыка с качеством, соответствующим компакт-диску, должна иметь частоту
дискретизации сигнала 44 100 Гц. Предположим, что таймер генерирует пре-
прерывания с такой частотой, а обработка прерывания занимает 1 мс на про-
процессоре со скоростью 1 ГГц. Какова наименьшая частота таймера, обеспе-
обеспечивающая сохранение всех данных? Положим, что число команд обработки
прерывания постоянно, следовательно, удвоение частоты таймера удваивает
время обработки прерывания.
7. Альтернативой прерываниям является опрос. Существуют ли ситуации, в ко-
которых опрос предпочтительней?
8. Дисковые контроллеры снабжены внутренними буферами, объем которых
растет с каждой новой моделью. Почему?
9. У каждого драйвера устройства имеются два различных интерфейса с опе-
операционной системой. Один интерфейс представляет собой набор функций
драйвера, вызываемых операционной системой, а второй интерфейс — набор
функций операционной системы, вызываемой драйвером. Назовите вызов,
с высокой вероятностью имеющийся в каждом из этих интерфейсов.
10. Почему разработчики операционных систем стараются по возможности обес-
обеспечивать ввод-вывод, независимый от устройств?
11. На каком из четырех уровней программного обеспечения ввода-вывода вы-
выполняются следующие действия:
1) вычисление номеров дорожки, сектора и головки для чтения диска;
2) поддержание кэша последних блоков;
3) запись команд в регистры устройства;
4) проверка разрешения доступа пользователя к устройству;
5) преобразование двоичного целого числа в ASCII-символы для вывода
на печать.
12. Почему файлы, посылаемые на принтер, обычно перед печатью накапливают-
накапливаются на диске?
13. Приведите пример взаимной блокировки, которая может иметь место в ре-
реальном мире.
14. Рассмотрим рис. 3.7. Предположим, что на шаге п процесс С вместо ресурса R
запрашивает ресурс S. Приведет ли это к взаимной блокировке? А если он за-
запросит оба ресурса, то есть и S и Ю
15. Внимательно посмотрите на рис. 3.9, б. Если процесс D запросит еще одну
единицу, приведет это к безопасному состоянию или к небезопасному? Что
будет, если запрос поступит от процесса С, а не D?
16. Все траектории на рис. 3.10 горизонтальны или вертикальны. Можете ли вы
представить себе условия, при которых имелись бы также наклонные траек-
траектории?
17. Предположим, процесс А на рис. 3.11 запросил последний ленточный накопи-
накопитель. Приведет ли это к взаимной блокировке?
18. У компьютера есть шесть накопителей на магнитной ленте и п процессов, со-
соревнующихся за право их использовать. Каждому процессу может потребо-
потребоваться два накопителя. При каких значениях п в системе не будет взаимных
блокировок?
19. Может ли система находиться в состоянии, не являющимся ни состоянием
взаимной блокировки, ни безопасным состоянием? Если да, приведите при-
пример. Если нет, докажите, что все состояния либо являются тупиками, либо
они безопасны.
20. Распределенная система, использующая почтовые ящики, имеет два прими-
примитива для взаимодействия между процессами: SEND (послать) и RECEIVE (по-
(получить). Второй примитив указывает процесс, от которого следует получить
сообщение, и блокируется, если сообщения от процесса недоступны, даже не-
несмотря на то, что могут ожидаться сообщения от других процессов. Здесь нет
общих ресурсов, но процессам необходимо часто связываться друг с другом
относительно других вопросов. Возможна ли взаимная блокировка? Аргу-
Аргументируйте ответ.
21. Сотни одинаковых процессов в электронных системах межбанковского пере-
перевода денежных средств работают следующим образом. Каждый процесс читает
входную строку, определяющую количество денег для перевода, кредитовый
и дебетовый счета. Затем процесс блокирует оба счета и выполняет транзак-
транзакцию, а после завершения перевода снимает блокировку. При параллельно ра-
работающем большом количестве процессов существует опасность, что имея
заблокированным счет х, процесс будет неспособен заблокировать счет г/, по-
поскольку счет у уже окажется заблокированным процессом, в данный момент
ожидающим счет х. Разработайте схему взаимодействия, позволяющую избе-
избежать взаимных блокировок. Не освобождайте запись счета до тех пор, пока
вы не закончите транзакцию. (Иначе говоря, не позволяются решения, в ко-
которых один счет блокируется и затем немедленно освобождается, если другие
счета заблокированы.)
22. Алгоритм банкира работает в системе, где есть т классов ресурсов и п процес-
процессов. При стремящихся к бесконечности тип количество операций, которые
нужно выполнить для проверки безопасности состояния, пропорционально
manb. Что представляют собой величины аи Ь?
23. Рассмотрим алгоритм банкира на рис. 3.11. Предположим, что процессы Аи D
изменяют свои запросы на дополнительные ресурсы A,2, 1, 0) и A, 2, 1,0)
соответственно. Могут ли эти запросы быть удовлетворены с сохранением
безопасного состояния системы?
24. Золушка и Принц расторгают брак. Чтобы разделить свое имущество, они со-
согласились на следующий алгоритм. Каждое утро любой из них может послать
письмо адвокату другого, в котором запрашивает один предмет имущества.
Поскольку день уходит на доставку писем, они пришли к соглашению, что ес-
если оба обнаруживают, что запросили один и тот же предмет в один и тот же
день, на следующий день они посылают письмо с отменой запроса. Среди
прочего имущества у них есть собака Буфер, конура Буфера, их канарейка
Твитер и клетка Твитера. Животные любят свои жилища, поэтому было при-
принято соглашение, что любой вариант раздела имущества, отделяющий живот-
животное от его дома, является недействительным, после которого весь раздел
имущества требуется начать заново. И Золушка, и Принц отчаянно хотят запо-
заполучить Буфера. Поскольку они могут уехать (отдельно друг от друга) в отпуск,
каждый супруг запрограммировал персональный компьютер для обработки
переговоров. Когда они возвращаются из отпусков, компьютеры все еще ве-
ведут переговоры. Почему? Возможна ли взаимная блокировка? Возможно ли
зависание? Аргументируйте ответ.
25. Рассмотрим диск, содержащий 10 000 цилиндров, 1000 секторов/дорожек
размером 512 байт с 8 дорожками на цилиндре. Период вращения составляет
10 мс, а время поиска дорожки — 1 мс. Какова максимально доступная часто-
частота цикла передачи? Длительность цикла передачи?
26. Локальная сеть используется следующим образом. Пользователь делает сис-
системный вызов, чтобы записать пакеты данных через сеть. Затем операцион-
операционная система копирует данные в буфер ядра. После этого данные копируются
в схему сетевого адаптера. После того как все байты попадают в контроллер,
они посылаются по сети со скоростью 10 Мбит/с. Получающий данные сетевой
контроллер сохраняет каждый бит, спустя 1 мкс после его отправки. Когда
последний бит получен, центральный процессор компьютера-получателя пре-
прерывается, и ядро копирует прибывший пакет в свой буфер, чтобы исследо-
исследовать его. Поняв, какому пользователю предназначается пакет, ядро копирует
данные в пространство этого пользователя. Если предположить, что каждое
прерывание и его обработка занимают 1 мс, размер пакетов равен 1024 байт
(не считая заголовков), а копирование одного байта составляет 1 мкс, чему
равна максимальная скорость, с которой один процесс может передавать дан-
данные другому процессу? Предположите, что отправитель блокируется, пока по-
получатель не закончит работу и не отправит обратно подтверждение. Для про-
простоты допустим, что временем получения подтверждения можно пренебречь.
27. Сообщение, формат которого показан в табл. 3.3, используется для того, чтобы
отправлять запросы драйверам блочных устройств. Какие поля можно было
бы опустить в сообщении для символьных устройств и есть ли такие поля?
28. Драйвер диска получает запросы на чтение/запись к цилиндрам 10, 22, 20, 2,
40, 6 и 38. Перемещение блока головок с одного цилиндра на соседний зани-
занимает 6 мс. Сколько потребуется времени на перемещение головок при исполь-
использовании алгоритма:
1) обслуживания в порядке поступления запросов;
2) обслуживания в первую очередь ближайшего цилиндра;
3) элеваторного алгоритма (сначала блок головок двигается вверх);
Во всех случаях начальное положение блока головок на цилиндре 20.
29. Продавец персональных компьютеров, посещая университет на юго-западе
Амстердама для продажи партии компьютеров, заявляет, что его компания
приложила существенные усилия по развитию их версии UNIX. В качестве
примера он отмечает, что в их драйвере диска применяется элеваторный алго-
алгоритм, а обслуживание очереди запросов к одному цилиндру происходит в по-
порядке размещения секторов. На студента Гарри Хакера его речь производит
настолько сильное впечатление, что он покупает один компьютер. Гарри при-
приносит компьютер домой и пишет программу, читающую случайные 10 000 бло-
блоков диска. К его изумлению, замеренная им производительность идентична
той, которой можно было ожидать при использовании алгоритма обслужива-
обслуживания запросов в порядке поступления. Означает ли это, что продавец лгал?
30. В UNIX каждый процесс состоит из двух частей, работающих в адресном поль-
пользовательском пространстве и в пространстве ядра. Является ли часть в про-
пространстве ядра подпрограммой или сопрограммой?
31. На некотором компьютере обработчик прерываний от таймера выполняет
свои действия за 2 мс (включая накладные расходы по переключению про-
процессов). Прерывания от таймера поступают с частотой 60 Гц. Какая часть вре-
времени работы центрального процессора расходуется на таймер?
32. В тексте описано два варианта применения сторожевых таймеров: ожидание
запуска двигателя дисковода и выполнение возврата каретки на печатных тер-
терминалах. Приведите еще один пример.
33. Почему терминалы, использующие интерфейс RS-232, управляются прерыва-
прерываниями, а терминалы с отображением на память — нет?
34. Рассмотрим работу терминала. Драйвер посылает один символ, после чего
блокируется. За передачей символа в линию следует прерывание, затем драй-
драйвер разблокируется и посылает следующий символ и т. д. Какую часть време-
времени центрального процессора занимает управление модемом, если обработка
прерывания, вывод одного символа и каждая блокировка требуют 4 мс? Бу-
Будет ли этот метод работать с линиями ПО бод? А что насчет линий 4800 бод?
35. Вообразите терминал, содержащий 1200 х 800 пикселов. Для прокрутки окна
центральный процессор (или контроллер) должен переместить все строки
текста вверх, копируя их биты из одной части видеопамяти в другую. Допус-
Допустим, в окне 66 строк по 80 символов в строке (всего 5280 символов), а каждый
символ имеет 8 пикселов в ширину и 16 пикселов в высоту. Сколько времени
займет прокрутка всего окна, если для копирования одного байта требуется
500 не? Если все строки имеют по 80 символов в длину, чему будет равна эк-
эквивалентная скорость терминала в бодах? Помещение одного символа на
экран занимает 50 мкс. Подсчитайте скорость, если терминал цветной и имеет
4 бит/пиксел (в этом случае помещение символа на экран занимает 200 мкс).
36. Для чего в операционных системах нужны ESC-последовательности, напри-
например Ctrl+V в MINIX?
37. Получив символ SIGINT (Ctrl+C), драйвер экрана MINIX очищает всю оче-
очередь на вывод для этого экрана. Почему?
38. У многих терминалов, использующих интерфейс RS-232, есть ESC-последо-
ESC-последовательности для удаления текущей строки и перемещения всех нижних строк
на одну строку вверх. Как, по-вашему, реализована эта операция внутри тер-
терминала?
39. На оригинальном компьютере IBM PC с цветным дисплеем запись в видеопа-
видеопамять в любое время, кроме того интервала, когда электронный луч совершал
вертикальный обратный ход, вызывала появление уродливых пятен по всему
экрану. На экран выводятся 25 строк по 80 символов, каждый из которых по-
помещается в квадрат 8x8 пикселов. Каждый ряд из 640 пикселов рисуется за
один горизонтальный проход луча, что занимает 63,6 мкс, включая горизон-
горизонтальное обратное движение луча. Экран перерисовывается 60 раз в секунду.
При каждом выводе экрана требуется период времени на вертикальный об-
обратный ход луча. Какую часть времени видеопамять оказывается доступной
для записи?
40. Напишите графический драйвер для цветного дисплея IBM или любого друго-
другого подходящего растрового дисплея. Драйвер должен воспринимать команды,
устанавливающие цвет отдельных пикселов, перемещающие прямоугольные
блоки по экрану и любые другие, какие вы сочтете интересными. Пользова-
Пользовательские программы должны взаимодействовать с драйвером, открывая файл
/dev/graphics и записывая туда команды.
41. Модифицируйте драйвер дисковода гибких дисков в MINIX, реализовав кэ-
кэширование дорожек.
42. Напишите драйвер дисковода гибких дисков, который работает как символь-
символьное, а не блочное устройство, чтобы обойти системный кэш блоков. Таким об-
образом, пользователи смогут считывать большие блоки данных, которые при
помощи DMA копируются непосредственно в адресное пространство пользо-
пользователя, что значительно повышает производительность. Такой драйвер прежде
всего был бы интересен программам, считывающим необработанное содержи-
содержимое диска, не используя файловую систему. В эту категорию программ попа-
попадают программы, проверяющие структуру файловой системы.
43. Реализуйте системный UNIX-вызов PROFIL, который не поддерживается
в MINIX.
44. Измените драйвер терминала так, чтобы в дополнение к специальной клави-
клавише, удаляющей последний введенный символ, была клавиша, удаляющая по-
последнее слово.
45. В систему MINIX 3 был добавлен новый диск со сменным носителем. Этому
устройству необходимо раскручивать диск после каждой смены носителя,
и время раскрутки довольно велико. Ожидается, что в процессе работы сис-
системы носитель будет часто меняться. Подпрограмма wait for из файла at_
wini. с перестала удовлетворять пользователей. Разработайте новый вари-
вариант процедуры wait for, которая после одной секунды активного ожидания
нужного значения работает так: драйвер диска ждет одну секунду, затем про-
проверяет значение порта, до тех пор пока не будет обнаружено нужное значение
или не истечет заданный параметром TIMEOUT интервал времени.
Глава 4
Управление памятью
Память представляет собой важный ресурс, требующий точного управления.
Хотя в наши дни память среднего домашнего компьютера в 2000 раз превышает
ресурсы IBM 7094 — машины, бывшей в начале 60-х годов самой мощной в ми-
мире, — программы все равно превосходят в объеме компьютерную память. Пе-
Перефразируя закон Паркинсона, можно сказать, что программное обеспечение
имеет свойство непрерывно разрастаться, заполняя всю доступную на данный
момент память.
В этой главе мы узнаем, как операционная система управляет памятью. В идеале
каждый программист хотел бы иметь неограниченную по объему и быстродейст-
быстродействию память, при этом также являющуюся энергонезависимой, то есть сохраняю-
сохраняющую свое содержимое при выключении питания. Раз уж мы взялись за эту тему,
то почему бы заодно не помечтать о дешевой памяти? К сожалению, существую-
существующие технологии пока не способны удовлетворить все подобные пожелания.
Вследствие этого память в компьютерах имеет иерархическую структуру. Не-
Небольшая часть ее представляет собой очень быструю, дорогую, энергозависимую
(то есть теряющую информацию при выключении питания) кэш-память. Кроме
того, компьютеры обладают десятками мегабайтов средней по быстродействию
и цене энергозависимой оперативной памяти (Random Access Memory, RAM),
а также десятками или сотнями гигабайтов медленной, дешевой и энергонезави-
энергонезависимой постоянной памяти (Read Only Memory, ROM) на жестком диске. Одной
из задач операционной системы является координация всех этих видов памяти.
Часть операционной системы, отвечающая за управление памятью, называется
менеджером памяти. Он следит за тем, какая часть памяти используется в дан-
данный момент, а какая — свободна; при необходимости выделяет память процессам
и по их завершении освобождает ресурсы; управляет обменом данными между
оперативной памятью и диском, если та слишком мала для того, чтобы вместить
все процессы. В большинстве операционных систем менеджер памяти является
частью ядра; MINIX 3 тем не менее в этом отношении является исключением.
В этой главе мы изучим несколько различных схем управления памятью, от са-
самой простой до весьма сложной и запутанной. Сначала мы рассмотрим наиболее
элементарную систему управления памятью, а затем постепенно будем перехо-
переходить к все более и более совершенным системам.
В главе 1 мы обращали внимание на то, что в компьютерном мире история имеет
тенденцию повторяться: программное обеспечение мини-компьютеров изначаль-
изначально было похожим на программное обеспечение мэйнфреймов, а программное
обеспечение персональных компьютеров — на программное обеспечение мини-
компьютеров. Теперь этот цикл повторяется для наладонных компьютеров (палм-
топов), персональных электронных секретарей и встраиваемых систем. В них до
сих пор применяются простые механизмы управления памятью, а следовательно,
они удобны для изучения.
4.1. Базовые механизмы
управления памятью
Системы управления памятью можно разделить на два класса: те, в которых про-
процессы при выполнении перемещаются между оперативной памятью и диском,
и те, в которых этого не происходит. Второй вариант проще, поэтому начнем с не-
него, а обменом с диском, требующим либо подкачки, либо замещения страниц, мы
займемся потом. Читая главу 4, следует помнить, что варианты с подкачкой и за-
замещением страниц в значительной степени являются искусственными, вызван-
вызванными отсутствием достаточного объема оперативной памяти для одновременного
хранения всех программ. Если когда-нибудь оперативная память настолько уве-
увеличится в объеме, что ее будет достаточно для любых целей, аргументы в пользу
той или иной схемы управления перестанут быть актуальными.
Однако не стоит забывать, что объем программ растет так же стремительно, как
и объем памяти, поэтому не исключено, что необходимость в эффективном
управлении памятью будет требоваться всегда. В 1980-е годы во многих универ-
университетах использовались компьютеры VAX, оснащенные системами разделения
времени и памятью объемом 4 Мбайт. С одним таким компьютером работали
десятки пользователей, получая более или менее удовлетворительное качество
обслуживания. Теперь для однопользовательского компьютера с операционной
системой Windows XP компания Microsoft рекомендует не менее 128 Мбайт па-
памяти. Повсеместное распространение мультимедиа еще более повышает требова-
требования к памяти, так что эффективное управление памятью будет востребовано еще
как минимум лет 10.
4.1.1. Однозадачная система без подкачки
и замещения страниц
В самой простой однозадачной системе управления памятью из всех возможных
в каждый конкретный момент времени работает только одна программа, при
этом память разделяется между программами и операционной системой. Есть
три варианта такой схемы. Как показано на рис. 4.1, а, операционная система
может находиться в нижней части памяти — в оперативной памяти (RAM), или
в ОЗУ (оперативное запоминающее устройство).
Рис. 4.1. Три простейшие модели организации памяти при наличии операционной системы
и одного пользовательского процесса. Существуют и другие варианты
Кроме того, операционная система может располагаться в самой верхней части
памяти (рис. 4.1, б) — в постоянной памяти (ROM), или в ПЗУ (постоянное за-
запоминающее устройство). В третьей модели драйверы устройств могут разме-
размещаться в ПЗУ, а остальная часть системы — ниже в ОЗУ (рис. 4.1, в). Первая мо-
модель раньше применялась на мэйнфреймах и мини-компьютерах, но в настоящее
время практически не употребляется. Вторая модель сейчас используется в не-
некоторых палмтопах и встраиваемых системах, а третья модель была характерна
для ранних персональных компьютеров (например, работающих под управлением
MS-DOS), при этом часть системы, которая располагалась в ПЗУ, носила назва-
название BIOS (Basic Input Output System — базовая система ввода-вывода).
Когда система организована таким образом, в каждый конкретный момент вре-
времени может работать только один процесс. Как только пользователь набирает
команду, операционная система копирует запрашиваемую программу с диска
в память и выполняет ее, а после окончания процесса выводит на экран пригла-
приглашение и ждет новой команды. Получив инструкции, она загружает другую про-
программу в память, записывая ее поверх предыдущей.
4.1.2. Многозадачная система
с фиксированными разделами
Однозадачные системы сложно использовать где-либо еще, кроме простейших
встроенных систем. Большинство современных систем поддерживает одновре-
одновременную работу нескольких процессов. Это означает, что когда один процесс
приостановлен в ожидании завершения операции ввода-вывода, другой вправе
использовать центральный процессор. Таким образом, многозадачность увели-
увеличивает загрузку процессора. Сетевые серверы всегда обеспечивают возможность
одновременной работы нескольких процессов (для разных клиентов), но и боль-
большинство клиентских машин (то есть настольных компьютеров) в наши дни не
уступают им в этом смысле.
Самый легкий способ достижения многозадачности представляет собой простое
разделение памяти на п (возможно не равных) разделов. Такое разбиение можно
выполнить, например, вручную при запуске системы.
Когда задание поступает в память, его можно расположить во входной очереди
к наименьшему разделу, достаточно большому для того, чтобы вместить это
задание. Так как в данной схеме размер разделов одинаков, все неиспользуемое
работающим процессом пространство в разделе пропадает. На рис. 4.2, а показано,
как выглядит система с фиксированными разделами и отдельными очередями
входных заданий.
Рис. 4.2. Многозадачность с фиксированными разделами памяти: а — фиксированные
разделы с отдельными входными очередями для каждого раздела; б — фиксированные
разделы с одной общей входной очередью
Недостаток размещения входящих заданий по отдельным очередям становится
очевидным, когда к большому разделу очередь отсутствует, в то время как к ма-
маленькому выстраивается довольно много заданий (в примере на рис. 4.2, а — это
разделы 1 и 3). Небольшим заданиям приходится ждать своей очереди, чтобы
попасть в память, и это при том, что память в основном свободна. Альтернатив-
Альтернативная схема заключается в организации одной общей очереди для всех разделов
(рис. 4.2, б): как только раздел освобождается, задание, ближайшее к началу оче-
очереди и подходящее для выполнения в этом разделе, можно загрузить и присту-
приступить к его выполнению. Поскольку нежелательно тратить большие разделы на
маленькие задания, существует другая стратегия. Она состоит в том, что каждый
раз после освобождения раздела происходит поиск в очереди наибольшего из
приемлемых по размерам для этого раздела заданий, и именно это задание выби-
выбирается для выполнения. Заметим, что последний алгоритм означает дискрими-
дискриминацию мелких заданий, как недостойных того, чтобы под них отводился целый
раздел, в то время как обычно небольшим программам (часто интерактивным)
крайне важно предоставлять привилегированное обслуживание.
Один из выходов из положения — создание хотя бы одного маленького раздела
памяти, который позволит выполнять маленькие задания без долгого ожидания
освобождения больших разделов.
Еще одни вариант — ввести правило, по которому задание, предназначенное для
обработки, можно держать в кандидатах на обслуживание не более k раз. Каждый
раз, когда его выполнение откладывается, к счетчику добавляется единица. Ко-
Когда значение счетчика становится равным k, игнорировать задание более нельзя.
Схема, в которой утром оператор задает фиксированные разделы и после этого
они не изменяются, в течение многих лет практиковалась в системах OS/360 на
больших мэйнфреймах компании IBM и носила название OS/MFT, или просто
MFT (Multiprogramming with a Fixed number of Tasks — мультипрограммирова-
мультипрограммирование с фиксированным количеством заданий). Она легка для понимания и проста
в реализации: входящее задание стоит в очереди до тех пор, пока не станет дос-
доступным соответствующий раздел, затем оно загружается в этот раздел памяти
и там работает до завершения процесса. Однако сейчас очень мало (если они во-
вообще сохранились) операционных систем, поддерживающих такую модель (это
относится даже к пакетным системам мэйнфреймов).
4.1.3. Переадресация и защита
Многозадачность вносит две существенные проблемы, требующие решения, —
это переадресация для перемещения программы в памяти и защита. Из рис. 4.2 яс-
ясно, что разные задания выполняются по разным адресам. Когда программа компо-
компонуется (то есть в едином адресном пространстве объединяются основной модуль,
написанные пользователем процедуры и библиотечные подпрограммы), компо-
компоновщик должен знать, с какого адреса будет начинаться программа в памяти.
Например, предположим, что первая команда представляет собой вызов проце-
процедуры с абсолютным адресом 100 внутри двоичного файла, создаваемого компо-
компоновщиком. Если эта программа загрузится в раздел 1 (по адресу 100 К), команда
обратится к абсолютному адресу 100, принадлежащему операционной системе.
А нужно вызвать процедуру по адресу 100 К + 100. Если же программа загрузит-
загрузится в раздел 2, команду нужно переадресовать по адресу 200 К + 100 и т. д. Эта
проблема известна как проблема переадресации.
Одним из возможных решений является модификация команд во время загруз-
загрузки программы в память. В программе, загружаемой в раздел 1, к каждому адресу
прибавляется значение 100 К, в программе, которая попадает в раздел 2, к адре-
адресам добавляется значение 200 К и т. д. Чтобы выполнить подобную переадреса-
переадресацию во время загрузки, компоновщик должен включить в двоичную программу
список или битовую карту с информацией о том, какие слова в программе яв-
являются адресами (и их нужно перераспределить), а какие — кодами машинных
команд, постоянными или другими частями программы, которые не нужно изме-
изменять. Так работает операционная система OS/MFT.
Переадресация во время загрузки не решает проблемы защиты. Вредоносные
программы всегда могут организовать какую-нибудь новую команду перехода
и с ее помощью проникнуть в память. Поскольку в такой системе использует-
используется абсолютная адресация памяти, а не смещение относительно того или иного
регистра, не существует способа, который позволил бы запретить программе
обращаться к любому слову в памяти для его чтения или записи. В многопользо-
вательских системах крайне нежелательно разрешать процессам доступ к облас-
области памяти, принадлежащей другим пользователям.
Для защиты компьютера IBM 360 разработчики приняли следующее решение:
они разделили память на блоки по 2 Кбайт и назначили каждому блоку 4-раз-
4-разрядный код защиты. Этот 4-разрядный ключ содержал слово состояния про-
программы (Program Status Word, PSW). Аппаратура IBM 360 перехватывала все
попытки работающих процессов обратиться к любой части памяти, код защиты
которой отличался от содержимого слова состояния программы. Поскольку
только операционная система была вправе изменять коды защиты и ключи,
предотвращалось вмешательство пользовательских процессов в дела друг друга
и в работу операционной системы.
Альтернативное решение сразу обеих проблем (защиты и переадресации) заклю-
заключается в оснащении машины двумя специальными аппаратными регистрами, на-
называемыми базовым и ограничительным. При планировании процесса в базо-
базовый регистр загружается адрес начала раздела памяти, а в ограничивающий
регистр — длина раздела. К каждому автоматически формируемому адресу перед
его передачей в память прибавляется содержимое базового регистра. Таким об-
образом, если базовый регистр содержит величину 100 К, команда CALL 100 будет
превращена в команду CALL 10 0К + 100 без изменения самой команды. Кроме
того, адреса проверяются по отношению к ограничительному регистру для га-
гарантии, что они не используются для адресации памяти вне текущего раздела.
Базовый и ограничительный регистры защищаются аппаратно, чтобы не допус-
допустить их изменений пользовательскими программами.
Неудобство, присущее этой схеме, — необходимость выполнять операции сложе-
сложения и сравнения при каждом обращении к памяти. Операция сравнения может
быть выполнена быстро, но сложение относительно нее — медленная операция
(за исключением тех случаев, когда применяется специальная микросхема сло-
сложения), что обусловлено временем распространения сигнала.
Такая система адресации использовалась в CDC 6600 — первом в мире супер-
суперкомпьютере. В центральном процессоре Intel 8088 для первых машин IBM PC
применялась ее упрощенная версия: были базовые регистры, но отсутствовали ог-
ограничительные. Сейчас эту схему можно встретить лишь в немногих компьютерах.
4.2. Подкачка
В случае пакетных систем память с фиксированными разделами действует про-
просто и эффективно. Каждое задание после ожидания в очереди загружается в раз-
раздел памяти и остается там до своего завершения. До тех пор пока в памяти мо-
может храниться достаточное количество заданий для обеспечения постоянной
занятости центрального процессора, нет причин что-либо усложнять.
Но совершенно другая ситуация имеет место в системах разделения времени и пер-
персональных компьютерах, ориентированных на работу с графикой. Оперативной
памяти иногда оказывается недостаточно для того, чтобы вместить все текущие
активные процессы, и тогда избыток процессов приходится хранить на диске,
а для обработки динамически переносить в память.
Существует два основных подхода к управлению памятью, зависящие (отчасти)
от доступного аппаратного обеспечения. Самая простая стратегия, называемая
подкачкой (swapping), заключается в том, что каждый процесс полностью копи-
копируется в память, работает некоторое время и затем полностью же возвращается
на диск. Другая стратегия, носящая название виртуальной памяти, позволяет про-
программам работать даже тогда, когда они только частично находятся в оперативной
памяти. Здесь мы изучим подкачку, а вторую стратегию рассмотрим в пункте 4.3.
Работа системы с подкачкой иллюстрирует рис. 4.3. На начальной стадии в па-
памяти находится только процесс А (рис. 4.3, а). Затем создаются или загружаются
с диска процессы В и С (рис. 4.3, б и в). На рис. 4.3, г процесс А выгружается на
диск. Затем появляется процесс Д а процесс В завершается (рис. 4.3, д и ё). Нако-
Наконец, процесс А снова возвращается в память (рис. 4.3, ж). Так как теперь про-
процесс А расположен в другом месте, его адреса должны быть перенастроены либо
программно во время загрузки в память, либо (более заманчивый вариант) аппа-
ратно во время выполнения программы.
Основная разница между фиксированными разделами на рис. 4.2 и непостоян-
непостоянными разделами на рис. 4.3 заключается в том, что во втором случае количество,
размещение и размер разделов изменяются динамически по ходу поступления
и завершения процессов, тогда как в первом варианте все эти параметры фикси-
фиксированы. Гибкость схемы, в которой нет ограничений, связанных с определенным
количеством разделов, и в которой каждый из разделов может быть очень боль-
большим или совсем маленьким, оптимизирует использование памяти, но и услож-
усложняет операции выделения и освобождения памяти, а также отслеживание проис-
происходящих изменений.
Когда в результате подкачки в памяти появляется множество неиспользованных
фрагментов, их можно объединить в один большой блок, передвинув все процес-
процессы в сторону младших адресов настолько, насколько это возможно. Такая опера-
операция называется уплотнением, или сжатием, памяти. Обычно ее не выполняют
по причине экономии времени работы процессора. Например, на машине с опе-
оперативной памятью объемом 1 Гбайт, которая может копировать 2 Гбайт в секун-
секунду A байт за 0,5 не), уплотнение всей памяти займет около 0,5 с. Конечно, время
не очень велико, но станет заметной помехой для пользователя, просматриваю-
просматривающего потоковое видео.
Еще один момент, на который стоит обратить внимание: сколько памяти должно
быть предоставлено процессу, когда он создается или копируется с диска? Если
процесс имеет фиксированный размер, размещение происходит просто: операци-
операционная система предоставляет точно необходимое количество памяти, ни больше,
ни меньше, чем нужно.
Однако если область данных процесса может расти, например, в результате ди-
динамического распределения памяти из кучи (heap), что позволяют многие языки
программирования, проблема предоставления памяти возникает каждый раз,
когда процесс пытается увеличиться. Если область неиспользованной памяти рас-
расположена рядом с процессом, ее можно отдать процессу, позволив ему вырасти
на величину этой области. Если же процесс соседствует с другим процессом, для
его увеличения нужно либо переместить достаточно большой свободный фраг-
фрагмент памяти, или перегрузить на диск один или больше процессов с целью со-
создать незанятый фрагмент достаточного размера. Если процесс не может расти
в памяти, а область на диске, предоставленная для подкачки, переполнена, про-
процесс будет вынужден завершиться или ждать освобождения памяти.
Рис. 4.3. Перераспределение памяти по мере того, как процессы поступают в память
и покидают ее. Заштрихованы неиспользуемые области памяти
Если предположить, что большинство процессов растет во время работы, вероятно,
сразу стоит предоставлять им несколько больше памяти, чем требуется, а всякий
раз, когда процесс копируется на диск или перемещается в памяти, придется обра-
обрабатывать служебные данные, связанные с перемещением или подкачкой процессов,
больше не умещающихся в предоставленной им памяти. Но когда процесс выгружа-
выгружается на диск, вместе с ним должно сохраняться содержимое только действительно
используемого адресного пространства, так как очень расточительно перемещать
также и придерживаемую им «про запас» память. На рис. 4.4, а показана конфи-
конфигурация памяти с предоставлением пространства для роста двух процессов.
Рис. 4.4. Распределение памяти в случае расширения процессов: а — предоставление
пространства для роста области данных; б — предоставление пространства
для роста стека и области данных
Если процесс имеет два наращиваемых сегмента, например сегмент данных,
используемый как куча для динамически назначаемых и освобождаемых пере-
переменных, и сегмент стека для обычных локальных переменных и адресов воз-
возврата, предлагается альтернативная схема распределения памяти, показанная на
рис. 4.4, б. Здесь мы видим, что у каждого процесса вверху предоставленной ему
области памяти находится стек, который расширяется вниз, и сегмент данных,
расположенный отдельно от текста программы и растущий вверх. Область памя-
памяти между ними является ничейной и может выделяться для любого из сегмен-
сегментов. Если ее становится недостаточно, процесс нужно либо перенести на другое,
большее по размерам свободное место, либо выгрузить на диск до появления
свободного пространства необходимого размера, либо завершить.
4.2.1. Управление памятью
с помощью битовых карт
Если память выделяется динамически, этим процессом должна управлять операци-
операционная система. Существует два подхода к учету использования памяти: битовые
карты и списки свободных областей. В этом и следующем разделах мы по очереди
рассмотрим оба метода.
При работе с битовой картой память разделяется на блоки размером от несколь-
нескольких слов до нескольких килобайтов. В битовой карте каждому свободному блоку
соответствует один нулевой бит, а каждому занятому блоку — бит, установлен-
установленный в 1 (или наоборот). На рис. 4.5, а показана область памяти, а на рис. 4.5, б —
соответствующая ей битовая карта.
Рис. 4.5. Учет использования памяти: а — область памяти с пятью процессами и тремя
свободными фрагментами; б — соответствующая битовая карта; в — та же информация
в виде списка
Размер минимального выделяемого блока — весьма важный параметр системы.
Чем он меньше, тем больше битовая карта. В случае если минимальный выде-
выделяемый блок памяти имеет размер 4 байта, то есть 32 бит, для него нужно 1 бит
в карте. Тогда область размером в 32и потребует п бит карты, таким образом, би-
битовая карта займет всего лишь 1/33 часть памяти. Если же отдать предпочтение
большим блокам, битовая карта станет меньше, но при этом может оказаться не-
неиспользуемой существенная часть последнего блока каждого процесса (если раз-
размер процесса не кратен размеру минимального блока).
Битовая карта предоставляет простой механизм отслеживания слов в памяти
фиксированного объема, поскольку ее размер зависит только от объема памяти
и размера минимального блока. Для этой схемы характерна проблема — при ре-
решении переместить процесс из k блоков в память менеджер памяти должен найти
в битовой карте последовательность из k смежных нулевых битов. Поиск после-
последовательности заданной длины в битовой карте является медленной операцией
(так как искомая последовательность битов может пересекать границы слов в бито-
битовом массиве). Это — главный аргумент противников битовых карт.
4.2.2. Управление памятью с помощью
связанных списков
Другой подход к отслеживанию состояния памяти предоставляют связанные спи-
списки занятых и свободных фрагментов памяти, где фрагментом является либо про-
процесс, либо участок между двумя процессами. Память, показанная на рис. 4.5, я,
представлена в виде однонаправленного списка сегментов на рис. 4.5, в. Каждая
запись в списке указывает, является ли область памяти свободной Н (от hole —
дыра) или занятой процессом Р (process), а также содержит адрес, с которого на-
начинается эта область, ее длину и указатель на следующую запись.
В нашем примере список упорядочен по адресам. Такая сортировка имеет следую-
следующее преимущество: когда процесс завершается или выгружается на диск, измене-
изменение списка представляет собой тривиальную операцию. Процесс обычно имеет
двух соседей (кроме случаев, когда он находится на самом «верху» или на самом
«низу» памяти). Соседями могут быть процессы или свободные фрагменты, что
приводит к четырем комбинациям, показанным на рис. 4.6. На рис. 4.6, а коррек-
корректировка списка требует замены Р на Н. На рис. 4.6, б и 4.6, в две записи объе-
объединяются в одну, а список становится на запись короче. На рис. 4.6, г объединя-
объединяются три записи, а из списка удаляются два элемента. Так как ячейка таблицы
процессов для завершившегося процесса обычно непосредственно указывает на
запись в списке для этого процесса, возможно, удобнее иметь список с двумя
связями, чем с одной (последний показан на рис. 4.5, в). Такая двунаправлен-
двунаправленная структура упрощает поиск предыдущей записи и оценку возможности кон-
конкатенации.
Рис. 4.6. Четыре варианта завершения процесса X
Если процессы и свободные участки хранятся в списке, отсортированном по
адресам, существуют несколько алгоритмов предоставления памяти процессу,
создаваемому заново (или существующему процессу после подкачки с диска).
Допустим, менеджер памяти знает, сколько памяти нужно предоставить. Про-
Простейший алгоритм представляет собой поиск первого соответствия. Менеджер
памяти просматривает список областей до тех пор, пока не находит достаточно
большой свободный участок. Затем этот участок делится на два: одна часть отда-
отдается процессу, а другая остается неиспользуемой. Так происходит всегда, кроме
статистически нереального случая точного соответствия свободного участка и по-
пожеланий процесса. Это быстрый алгоритм, поскольку поиск минимизирован на-
настолько, насколько это возможно.
Алгоритм следующего соответствия мало отличается от предыдущего. Он рабо-
работает так же, как и первый алгоритм, но всякий раз, когда находится нужный сво-
свободный фрагмент, запоминается его адрес. И когда алгоритм в следующий раз
вызывается для поиска, он стартует с того самого места, где остановился в про-
прошлый раз, вместо того чтобы снова и снова начинать поиск от головы списка, как
это делает алгоритм первого соответствия. Моделирование работы этого алго-
алгоритма показало, что его производительность несколько хуже, чем первого [7].
Другой хорошо известный алгоритм называется алгоритмом наилучшего соот-
соответствия. Здесь выполняется поиск по всему списку и выбирается наименьший
по размеру подходящий свободный фрагмент. Вместо того чтобы делить боль-
большую незанятую область, которая может понадобиться позже, этот алгоритм пре-
предоставляет возможность найти участок, наиболее приближенный по размерам
к реально необходимому.
За примерами работы алгоритмов первого соответствия и наилучшего соответст-
соответствия снова обратимся к рис. 4.5. Если необходим блок размером 2, правило первого
соответствия предоставит область по адресу 5, а схема наилучшего соответствия
разместит процесс в свободном фрагменте по адресу 18.
Алгоритм наилучшего соответствия медленнее алгоритма первого соответствия,
так как каждый раз требуется поиск во всем списке. Однако, что немного удиви-
удивительно, его результаты еще хуже, чем у алгоритмов первого соответствия и сле-
следующего первого соответствия, поскольку он стремится заполнить память очень
маленькими, практически бесполезными свободными областями, то есть фраг-
ментирует память. Для варианта первого соответствия в среднем характерны
большие свободные фрагменты.
Раз алгоритмы «соответствия» не всегда спасают, можно попытаться решить
проблему разделения памяти на практически точно совпадающие с процессом
области и маленькие свободные фрагменты, то есть использовать алгоритм наи-
наихудшего соответствия. Он всегда выбирает самый большой свободный фраг-
фрагмент, размер которого после дробления еще остается достаточным для даль-
дальнейшего применения. Однако моделирование показало, что это также не очень
подходящая идея.
Все четыре алгоритма можно ускорить, если поддерживать отдельные списки
для процессов и свободных областей. Тогда поиск будет производиться только
среди незанятых фрагментов. Неизбежная цена, которую придется заплатить за
повышение скорости размещения процесса в памяти, заключается в дополни-
дополнительной сложности и замедлении работы при освобождении областей памяти,
так как ставший свободным фрагмент необходимо удалить из списка процессов
и вставить в список незанятых участков.
Если для процессов и свободных фрагментов поддерживаются отдельные спи-
списки, то последний можно отсортировать по размеру, тогда алгоритм наилучшего
соответствия будет работать быстрее. Когда он выполняет поиск в списке сво-
свободных фрагментов от самого маленького к самому большому, то, как только на-
находит приемлемую незанятую область, алгоритм уже знает, что она — наимень-
наименьшая из тех, в которых может поместиться задание, то есть наилучшая. В отличие
от схемы с одним списком, дальнейший поиск не требуется. Таким образом, если
список свободных фрагментов отсортирован по размерам, схемы первого соот-
соответствия и наилучшего соответствия одинаково быстры, а алгоритм следующего
соответствия не имеет смысла.
При поддержке отдельных списков для процессов и свободных фрагментов воз-
возможна небольшая оптимизация. Вместо создания отдельного набора структур дан-
данных для списка свободных участков (рис. 4.5, в) можно использовать сами сво-
свободные участки. Первое слово каждого незанятого фрагмента может содержать
его размер, а второе — указывать на следующую запись. Узлы списка на рис. 4.5, в,
для которых требовались три слова и один бит (Р/Я), больше не нужны.
Еще один алгоритм распределения называется алгоритмом быстрого соответ-
соответствия] при использовании этого алгоритма поддерживаются отдельные списки
для некоторых из наиболее часто запрашиваемых размеров. Например, можно
представить таблицу с п записями, в которой первая запись указывает на начало
списка свободных фрагментов размером 4 Кбайт, вторая запись является указа-
указателем на список незанятых областей размером 8 Кбайт, третья — 12 Кбайт и т. д.
Свободный фрагмент размером, скажем, 21 байт мог бы располагаться в списке
областей по 20 Кбайт или в специальном списке участков дополнительных раз-
размеров. Поиск фрагмента требуемого размера происходит чрезвычайно быстро.
Но этот алгоритм имеет тот же недостаток, что и прочие схемы, которые сорти-
сортируют свободные области по размеру, а именно: если процесс завершается или
выгружается на диск, поиск его соседей с целью узнать, возможно ли их объеди-
объединение, является затратной операцией. А если не производить слияния областей,
память очень скоро окажется разбитой на множество маленьких свободных фраг-
фрагментов, в которые не поместится ни один процесс.
4.3. Виртуальная память
Уже достаточно давно люди столкнулись с проблемой размещения программ,
оказавшихся слишком большими и поэтому не помещавшихся в доступной фи-
физической памяти. Обычно принималось решение о разделении программы на
части, называемые оверлеями (overlays). Нулевой оверлей обычно запускался
первым. По завершении своего выполнения он вызывал следующий оверлей.
Некоторые оверлейные системы были очень сложными, позволяя одновременно
находиться в памяти нескольким оверлеям. Оверлеи хранились на диске и по
мере необходимости динамически перемещались между памятью и диском сред-
средствами операционной системы.
Хотя фактическая работа по загрузке оверлеев с диска и выгрузке на диск вы-
выполнялась системой, делить программы на части должен был программист. Раз-
Разбиение больших программ на маленькие модули поглощало много времени и бы-
было не слишком интересным занятием. Однако такая ситуация длилась недолго,
так как вскоре удалось поручить всю работу компьютеру.
Разработанный подход стал известен как виртуальная память [47]. Основная
идея этого подхода состоит в том, что хотя общий размер программы, данных
и стека может превышать объем доступной физической памяти, операционная
система хранит части программы, использующиеся в настоящий момент, в опера-
оперативной памяти, остальные — на диске. Например, программа размером 512 Мбайт
сможет работать на машине с объемом памяти 256 Мбайт, если тщательно про-
продумать, какие 256 Мбайт должны находиться в памяти в каждый момент време-
времени. При этом по мере необходимости части программы, находящиеся на диске,
будут меняться местами с частями в памяти.
Виртуальная память вполне работоспособна и в многозадачной системе при
наличии множества одновременно загруженных в память программ. Когда про-
программа ждет перемещения в память очередной ее части, она находится в состоя-
состоянии ожидания ввода-вывода и не работает, поэтому центральный процессор
может быть отдан другому процессу тем же самым способом, как в любой другой
многозадачной системе.
4.3.1. Замещение страниц
Большинство систем виртуальной памяти опираются на прием, называемый
замещение страниц (paging). На любом компьютере существует множество адре-
адресов в памяти, к которым может обратиться программа. Когда программа исполь-
использует следующую инструкцию, она делает это для того, чтобы скопировать содер-
содержимое памяти по адресу 1000 в регистр REG (или наоборот, в зависимости от
компьютера):
MOVE REG,1000
Адреса могут формироваться с использованием индексации, базовых регистров,
сегментных регистров и другими путями.
Эти программно формируемые адреса, называемые виртуальными, образуют
виртуальное адресное пространство. На компьютерах без виртуальной памяти
виртуальные адреса подаются непосредственно на шину памяти и при чтении
или записи читается или записывается слово в физической памяти с тем же
самым адресом. При применении виртуальной памяти виртуальные адреса не
передаются напрямую шиной памяти. Вместо этого они направляются в блок
управления памятью (Memory Management Unit, MMU), который отображает
виртуальные адреса на физические адреса (рис. 4.7).
Рис. 4.7. Расположение и функции блока управления памятью (MMU)
Очень простой пример того, как выполняется такого рода отображение, при-
приведен на рис. 4.8. Мы рассматриваем компьютер, который может формировать
16-разрядные адреса, от 0 до 64 К. Это — виртуальные адреса. У данного компью-
компьютера есть только 32 Кбайт физической памяти, поэтому, хотя программы разме-
размером 64 Кбайт писать можно, их нельзя целиком загрузить в память и запустить
на выполнение. Полная копия образа памяти программы размером до 64 Кбайт
должна присутствовать на диске, но в таком виде, чтобы ее можно было по мере
надобности переносить в память по частям.
Рис. 4.8. Связь между виртуальными и физическими адресами,
поддерживаемая с помощью таблицы страниц
Пространство виртуальных адресов разделено на единичные блоки, называе-
называемые страницами. Соответствующие блоки в физической памяти называются
страничными блоками (page frame). Размер страниц и их блоков всегда одинаков.
В этом примере они равны 4 Кбайт, но в реальных системах использовались раз-
размеры от 512 байт до 64 Кбайт. Имея 64 Кбайт виртуального адресного про-
пространства и 32 Кбайт физической памяти, мы получаем 16 виртуальных страниц
и 8 страничных блоков. Передача данных между ОЗУ и диском всегда происхо-
происходит постранично.
Пусть программа пытается получить доступ к адресу 0, например, с помощью
следующей команды:
MOVE REG,О
Тогда виртуальный адрес 0 передается в блок управления памятью (MMU). Блок
управления памятью видит, что этот виртуальный адрес попадает на страницу О
(от 0 до 4095), а та отображается на страничный блок 2 (адреса от 8192 до 12287).
MMU преобразует виртуальный адрес 0 в физический адрес 8192 и выставляет
последний на шину. Память ничего не знает о блоке управления памятью, а видит
просто запрос на чтение или запись слова по адресу 8192 и выполняет запрос.
Таким образом, блок управления памятью эффективно отображает все виртуаль-
виртуальные адреса между 0 и 4095 на физические адреса от 8192 до 12287.
Еще пример:
MOVE REG,8192
Поскольку виртуальный адрес 8192 находится на виртуальной странице 2, а эта
страница отображается на физический страничный блок 6 (физические адреса
от 24576 до 28671), эта инструкция точно так же преобразуется в команду
MOVE REG,24576
В качестве третьего примера рассмотрим виртуальный адрес 20500, который ад-
адресует байт 20 от начала виртуальной страницы 5 (виртуальные адреса от 20480
до 24575) и отображается на физический адрес 12288 + 20 = 12308.
Сама по себе возможность отображения 16 виртуальных страниц на любой из
восьми страничных блоков с помощью соответствующей карты отображения
в блоке управления памятью не решает проблемы, заключающейся в том, что
объем виртуального адресного пространства больше физической памяти. Так как
у нас есть только 8 физических страничных блоков, лишь 8 виртуальных страниц
на рис. 4.8 воспроизводятся в физической памяти. Другие страницы, обозначенные
на рисунке крестиками, не отображаются. В аппаратном обеспечении страницы,
физически присутствующие в памяти, отслеживаются с помощью бита присут-
присутствия/отсутствия.
Что произойдет, если программа попытается воспользоваться неотображаемой
страницей? Например:
MOVE REG,32780
Эта инструкции обращается к байту 12 на виртуальной странице 8 (отклады-
(откладываемой с адреса 32768). Блок управления памятью замечает, что страница не
отображается (обозначена крестиком на рисунке), и инициирует прерывание
центрального процессора, передающее управление операционной системе. Такое
прерывание называется ошибкой отсутствия страницы (page fault). Операцион-
Операционная система выбирает редко используемый страничный блок и записывает его
содержимое на диск. Затем она считывает с диска страницу, вызвавшую преры-
прерывание, в только что освободившийся блок, изменяет карту отображения и запус-
запускает прерванную команду заново.
Например, если операционная система решает удалить из оперативной памяти
страничный блок 1, она загружает виртуальную страницу 8 по физическому
адресу 4 К и производит два изменения в карте блока управления памятью.
Во-первых, содержимое виртуальной страницы 1 отмечается как неотображае-
мое, чтобы перехватывать в будущем любые попытки обращения к виртуальным
адресам между 4 К и 8 К. Затем заменяется крест в записи для виртуальной
страницы 8 номером 1, следовательно, когда прерванная команда будет выпол-
выполняться заново, она отобразит виртуальный адрес 32 780 на физический адрес 4108.
Теперь рассмотрим блок управления памятью изнутри, чтобы увидеть, как он
работает, и понять, почему мы выбрали размер страницы, являющийся степенью
числа 2. На рис. 4.9 представлен пример отображения виртуального адреса 8196
@010000000000100 в двоичном виде) согласно карте на рис. 4.8. Входной 16-раз-
16-разрядный виртуальный адрес разделяется на 4-разрядный номер страницы и 12-раз-
12-разрядное смещение. При выделении 4 бит под номер страницы в нашей системе
может существовать 16 страниц, а 12 бит смещения позволяют адресовать все
4096 байт внутри страницы.
Рис. 4.9. Внутренняя операция блока управления памятью в системе из 16 страниц по 4 Кбайт
Номер страницы используется в качестве индекса в таблице страниц, позволяю-
позволяющей получить номер страничного блока, соответствующего виртуальной стра-
странице. Если бит присутствия/отсутствия равен 0, управление переходит к опе-
операционной системе. Если этот бит равен 1, номер страничного блока, найденный
в таблице страниц, записывается в 3 старших бита выходного регистра, а 12 бит
смещения копируются без изменения из входного виртуального адреса. Все
вместе они составляют 15-разрядный физический адрес. Затем содержимое вы-
выходного регистра выставляется на шину памяти как адрес физической памяти.
4.3.2. Таблицы страниц
В теории отображение виртуальных адресов на физические происходит так, как
мы только что описали. Виртуальный адрес делится на номер виртуальной стра-
страницы (старшие биты) и смещение (младшие биты). Номер виртуальной страни-
страницы используется как индекс в таблице страниц для поиска записи этой страни-
страницы. По записи в таблице страниц находится номер физического блока страницы.
Данный номер присоединяется к старшим разрядам числа смещения, замещая
собой номер виртуальной страницы и тем самым формируя физический адрес,
который может быть послан в память.
Назначение таблицы страниц заключается в отображении виртуальных страниц
на страничные блоки. Говоря математически, таблица страниц — это функция,
имеющая в качестве аргумента номер виртуальной страницы и вырабатывающая
в результате номер физического блока. На основе полученного результата поле
виртуальной страницы в виртуальном адресе может быть заменено полем стра-
страничного блока, таким образом, формируется физический адрес.
При столь простом описании нам придется столкнуться с двумя важными аспек-
аспектами применения таблицы страниц.
1. Таблица страниц может оказаться слишком большой.
2. Отображение должно выполняться быстро.
Первое утверждение следует из того факта, что современные компьютеры ис-
используют, по крайней мере, 32-разрядные виртуальные адреса. При размере стра-
страницы, скажем, 4 Кбайт, 32-разрядное адресное пространство будет состоять из
1 млн страниц, а 64-разрядное адресное пространство потребует намного больше
страниц, чем то количество, с которым можно иметь дело. Один миллион страниц
в виртуальном адресном пространстве требует 1 млн записей в таблице стра-
страниц. И это при том, что каждый процесс нуждается в собственной таблице страниц
(так как у него есть свое собственное виртуальное адресное пространство).
Второе положение вытекает из того, что преобразование виртуальных адресов
в физические должно выполняться при каждом обращении к ячейке памяти.
Типичная команда процессора часто включает в себя, помимо кода операции,
операнд(ы) памяти. В результате необходимо сделать 1, 2 или иногда больше об-
обращений к таблице страниц в рамках отработки одной команды. Если выполне-
выполнение команды занимает, скажем, 1 не, то поиск в таблице страниц должен за-
завершиться до истечения 250 пс, чтобы преобразование виртуальных адресов не
стало главным узким местом системы.
Потребность в массовом, но при этом быстром страничном отображении накла-
накладывает существенные ограничения на устройство компьютеров. Хотя проблема
наиболее серьезна для машин вершины модельного ряда, она также проявляется
и для машин его нижней части, когда стоимость и соотношение цена/производи-
цена/производительность имеют критические значения. В этом и следующих разделах мы рас-
рассмотрим структуру таблицы страниц в деталях и покажем несколько аппаратных
решений, которые использовались в реальных компьютерах.
Простейшее (по крайней мере, концептуально) конструкторское решение заклю-
заключается в поддержании таблицы страниц, состоящей из массива быстрых аппарат-
аппаратных регистров (по одной записи для каждой виртуальной страницы), индекси-
индексированного по номерам виртуальных страниц, как показано на рис. 4.9. Когда
процесс запускается, операционная система загружает в регистры таблицу страниц
процесса, данные берутся из копии, хранящейся в оперативной памяти. В ходе
обработки процесса таблице страниц больше не нужно обращаться к памяти.
Преимущество этого метода заключается в его простоте и отсутствии необходи-
необходимости обращений к памяти в ходе отображения адресов. Недостатком является
его потенциально высокая стоимость (если таблица страниц велика). Необходи-
Необходимость загрузки всей таблицы в регистры при каждом переключении контекста
крайне негативно сказывается на производительности.
Другая крайность состоит в том, что таблица страниц целиком располагается
в оперативной памяти. Тогда все необходимое оборудование — это единствен-
единственный регистр, указывающий на начало таблицы страниц. Такая схема позволя-
позволяет изменять карту памяти при переключении контекста путем перезагрузки только
одного регистра. Конечно, она имеет свой минус: во время выполнения каждой
инструкции программы требуется одно или несколько обращений к памяти для
чтения записей таблицы страниц. По этой причине данный метод редко исполь-
используется в своем оригинальном виде, но далее мы изучим несколько его разновид-
разновидностей, обеспечивающих намного более высокую производительность.
Многоуровневые таблицы страниц
Чтобы обойти проблему необходимости постоянного хранения в памяти ог-
огромных таблиц страниц, на многих компьютерах применяются многоуровневые
таблицы страниц. Простой пример представлен на рис. 4.10 а, где изображен
32-разрядный виртуальный адрес, разделенный на 10-разрядное поле РТ1, 10-раз-
10-разрядное поле РТ2 и 12-разрядное поле смещения. Так как под смещение отведено
12 бит, страницы имеют размер 4 Кбайт и их всего 220.
Секрет метода многоуровневой организации заключается в том, чтобы не дер-
держать постоянно в памяти все таблицы страниц. В частности, те части, которые не
нужны в данный момент, не должны находиться в памяти. Предположим, напри-
например, что процессу нужно 12 Мбайт: младшие 4 Мбайт памяти для текста про-
программы, следующие 4 Мбайт для данных и старшие 4 Мбайт для стека. Между
верхней границей данных и нижней границей стека образуется гигантский сво-
свободный фрагмент, который не используется.
На рис. 4.10, б мы видим, как в данном примере работает двухуровневая таб-
таблица страниц. Слева находится таблица страниц верхнего уровня с 1024 запи-
записями, соответствующими 10-разрядному полю РТ1. Когда виртуальный адрес
предстает перед блоком управления памятью, тот сначала выделяет поле РТ1
и использует его значение как индекс таблицы верхнего уровня. Каждая из этих
1024 записей представляет 4 Мбайт, поскольку целое 4-гигабайтное (то есть
32-разрядное) виртуальное адресное пространство было нарезано на куски по
1024 байта.
Рис. 4.10. Структура двухуровневой таблицы страниц: а — 32-разрядный адрес с полями
двух таблиц страниц; б — таблицы страниц
Запись, место которой определяется по индексу в таблице страниц верхнего
уровня, позволяет получить адрес, или номер, страничного блока таблицы стра-
страниц второго уровня. Запись 0 в таблице страниц первого уровня указывает на
таблицу страниц для текста программы, запись 1 — на таблицу страниц для дан-
данных, запись 1023 — на таблицу страниц для стека. Другие (заштрихованные) за-
записи не задействованы. Поле РТ2 используется как индекс в выбранной таблице
второго уровня для поиска номера страничного блока самой страницы.
В качестве примера рассмотрим 32-разрядный адрес 0x00403004 D 206 596 в деся-
десятичном виде), который соответствует байту 12292 в данных. У этого виртуального
адреса РТ1 = 1, РТ2 = 2 и смещение = 4. Менеджер памяти сначала по полю РГ7,
то есть по индексу в таблице страниц верхнего уровня, получает запись 1, кото-
которая соответствует адресам от 4 до 8 М. Затем по индексу из только что найден-
найденной таблицы второго уровня из поля РТ2 извлекается запись 3, которая соответ-
соответствует адресам от 12 288 до 16 383 внутри своего участка размером 4 М (то есть
абсолютным адресам от 4 206 592 до 4 210 687). Эта запись содержит номер
физического блока страницы, содержащей виртуальный адрес 0x00403004. Если
данная страница не находится в памяти, бит присутствия/отсутствия в записи
таблицы страниц будет равен нулю, что приведет к ошибке отсутствия страни-
страницы. Если страница в памяти, номер страничного блока, взятый из таблицы стра-
страниц второго уровня, присоединяется к смещению D), образуя физический адрес.
Этот адрес выставляется на шину и передается памяти.
Следует отметить одну интересную деталь на рис. 4.10. Хотя адресное пространст-
пространство содержит больше миллиона страниц, фактически нужны только четыре табли-
таблицы: таблица верхнего уровня и таблицы нижнего уровня для памяти от 0 до 4 М,
от 4 до 8 М и свыше 8 М. Битам присутствия/отсутствия для 1021 записи табли-
таблицы страниц верхнего уровня присвоено значение 0, что вызовет ошибку отсутст-
отсутствия страницы при любом обращении к ним. Если это произойдет, операционная
система заметит, что процесс пытается обратиться к области памяти, не предпо-
предполагающей ссылок на нее, и предпримет соответствующее действие, например, по-
пошлет ему сигнал или уничтожит его. В описанном примере мы выбрали круглые
значения для различных величин и размер поля РТ1, равный размеру поля РТ2,
но в реальной практике, конечно, возможны другие цифры.
Система двухуровневой иерархии (см. рис. 4.10) может быть расширена для трех,
четырех и более уровней. Дополнительные уровни дают большую гибкость, од-
однако сомнительно, что следует усложнять систему, слишком увеличивая число
уровней.
Структура записи таблицы страниц
Теперь от структуры таблицы страниц в целом перейдем к описанию отдельной
записи таблицы. Формат конкретной записи в значительной мере зависит от ма-
машины, но виды представленной информации примерно одни и те же. На рис. 4.11
мы привели образец записи таблицы страниц. Ее длина варьируется от компью-
компьютера к компьютеру, но 32 бита — это наиболее распространенный размер. Самым
важным полем является поле номера страничного блока. При отображении стра-
страниц основной задачей является определение данной величины. За этим полем
следует бит присутствия/отсутствия. Если этот бит равен 1, запись имеет силу
и может использоваться. Если он равен 0, виртуальная страница, которой соответ-
соответствует эта запись, в данный момент отсутствует в памяти. Обращение к записи
в таблице страниц, где биту присутствия/отсутствия присвоено нулевое значение,
приводит к ошибке отсутствия страницы.
Биты защиты говорят о том, какие виды доступа разрешены к этой странице.
В простейшей форме это поле содержит один бит, равный 1 для чтения/записи
и 0 только для чтения. Более сложные схемы имеют три бита, по одному для
допуска каждой из операций чтения, записи и выполнения страницы.
Рис. 4.11. Типичная запись таблицы страниц
Биты изменения и обращения отслеживают использование страницы. Когда стра-
страница записывается, аппаратура автоматически устанавливает бит изменения.
Этот бит учитывается, когда операционная система решает освободить странич-
страничный блок. Если страница в нем была изменена (то есть она «грязная»), ее новая
версия должна быть переписана на диск. Если она не была модифицирована (то
есть страница «чистая»), ее можно просто удалить из памяти, так как все еще
действительна копия на диске. Этот бит иногда называют грязным битом, так
как он отражает состояние страницы.
Бит обращения устанавливается всякий раз, когда происходит обращение к стра-
странице для чтения или записи. Его значение помогает операционной системе при
выборе страницы для удаления из памяти, когда случается ошибка отсутствия
страницы. Страницы, не использующиеся в данный момент, являются лучшими
кандидатами, чем находящиеся в работе. Этот бит играет важную роль в несколь-
нескольких алгоритмах перемещения страниц, которые мы изучим позже в текущей главе.
Наконец, последний бит позволяет запретить кэширование страницы. Данное
свойство важно для страниц, отображающихся не на память, а на регистры
устройств. Если операционная система находится в цикле ожидания ответа от
некоторого устройства ввода-вывода, которому была только что отдана команда,
существенно, чтобы аппаратура продолжала получать слово из устройства, а не
использовало старую копию из кэш-памяти. При помощи этого бита кэширова-
кэширование можно отключить. В нем не нуждаются компьютеры, имеющие отдельное
пространство адресов ввода-вывода и не использующие отображение регистров
ввода-вывода на память.
Заметим, что адрес места на диске, где хранится страница тогда, когда она не на-
находится в памяти, не является частью таблицы страниц. Причина очень проста.
Таблица страниц содержит только ту информацию, которая нужна аппаратуре
для преобразования виртуального адреса в физический. Информация, необходи-
необходимая операционной системе для обработки ошибок отсутствия страниц, хранится
в программных таблицах внутри самой ОС. Аппаратуре она не нужна.
4.3.3. Буферы быстрого преобразования адресов
В большинстве схем замещения страниц таблицы страниц хранятся в памяти из-за
их значительного размера. Потенциально такое устройство оказывает колоссаль-
колоссальное влияние на производительность. Рассмотрим, например, команду процессора,
копирующую содержимое одного регистра в другой. Без замещения страниц эта
команда приводит только к одному обращению к памяти для выборки самой ко-
команды. В случае же замещения страниц потребуются дополнительные ссылки
для доступа к таблице страниц. Так как скорость выполнения команд в основном
ограничена скоростью, с которой центральный процессор выбирает команды
и данные из памяти, необходимость двух обращений к таблице страниц на каж-
каждую ссылку к памяти снижает производительность на 2/3. При таких условиях
никто не стал бы внедрять этот метод.
Разработчики компьютеров многие годы размышляли об означенной проблеме
и в результате придумали решение. Оно основано на наблюдении, что боль-
большинство программ выполняет огромное количество обращений к небольшому
количеству страниц, а не наоборот. То есть в таблице страниц лишь малая толи-
толика записей читается интенсивно, остальная часть может быть вообще не востре-
востребована. Это — пример концепции локальности обращений, к которой мы еще вер-
вернемся в этой главе.
В результате принятого решения компьютер снабжается небольшим аппаратным
устройством, служащим для отображения виртуальных адресов на физические
без обращения к таблице страниц. Параметры этого устройства, называемого бу-
буфером быстрого преобразования адресов (Translation Lookaside Buffer, TLB), или
ассоциативной памятью, представлены в табл. 4.1. Оно обычно находится внут-
внутри блока управления памятью и обрабатывает несколько записей. В нашем при-
примере их восемь, но фактически записей редко бывает больше 64. Каждая запись
содержит информацию об одной странице, а именно: номер виртуальной страницы,
бит изменения, код защиты (разрешения на чтение/запись/выполнение) и но-
номер физического страничного блока, в котором расположена страница. Эти поля
однозначно соответствуют полям в таблице страниц. Еще один бит служит при-
признаком действительности записи (используется она в данный момент или нет).
Таблица 4.1. Параметры буфера быстрого преобразования адресов
Действительность Виртуальная страница Изменение Защита Страничный блок
~1 140 1 RW 31
1 20 0 RX 38
1 130 1 RW 29
1 129 1 RW 62
1 19 0 RX 50
1 21 0 RX 45
1 860 1 RW 14
J 861 1 RW 75
TLB-буфер, представленный в таблице, мог бы сформировать циклический про-
процесс, располагающийся на виртуальных страницах 19—21. Соответственно, эти
записи в табл. 4.1 имеют коды защиты для чтения и выполнения. Основные
данные, используемые в текущий момент (скажем, обрабатываемый массив),
находятся на страницах 129 и 130. Страница 140 содержит индексы, требуемые
для вычислений массива. И наконец, на страницах 860 и 861 находится стек.
Теперь посмотрим, как функционирует буфер быстрого преобразования адресов.
Когда виртуальный адрес представляется блоком управления памятью для ото-
отображения, аппаратура путем сравнения адреса одновременно со всеми записями
(то есть параллельно) сначала убеждается, что номер его виртуальной страницы
присутствует в TLB. Если найдено совпадение и обращение не нарушает биты
защиты, страничный блок берется прямо из TLB, без перехода к таблице стра-
страниц. Если номер виртуальной страницы присутствует в TLB-буфере, но инст-
инструкция требует записи на страницу, доступную только для чтения, формируется
ошибка защиты точно так же, как это происходило бы при использовании самой
таблицы страниц.
Интересная ситуация получается, если номер виртуальной страницы не находит-
находится в буфере быстрого преобразования адресов. Блок управления памятью обна-
обнаруживает этот факт и выполняет обычный поиск в таблице страниц. Затем он
удаляет одну из записей из буфера и заменяет ее только что найденной записью
из таблицы страниц. Таким образом, если страница вскоре будет затребована снова,
поиск окажется успешным. Когда запись удаляется из TLB-буфера, бит изменения
копируется в запись таблицы страниц в памяти. Другие значения уже находятся
там. Когда буфер загружается из таблицы страниц, все поля берутся из памяти.
Программное управление TLB-буфером
До сих пор мы предполагали, что каждая машина со страничной виртуальной
памятью имеет таблицы страниц, распознаваемые аппаратным обеспечением
и буфером быстрого преобразования адресов. При таком устройстве за управле-
управление TLB-буфером и обработку ошибок отсутствия страниц в нем полностью отве-
отвечает аппаратура блока управления памятью (MMU). Передача управления опера-
операционной системе происходит только тогда, когда страница отсутствует в памяти.
В прошлом это допущение было справедливо. Однако многие современные RISC-
компьютеры, включая SPARC, MIPS, Alpha, HP PA и PowerPC, почти полно-
полностью управляют страницами программно. На этих машинах записи TLB-буфера
явно загружаются операционной системой. Когда поиск в ассоциативной памяти
заканчивается неудачей (промах), блок управления памятью, вместо того чтобы
переключаться на таблицу страниц для поиска и выбора необходимой страницы,
формирует ошибку TLB-буфера и передает ее решение операционной системе.
Система должна найти страницу, удалить запись из буфера, ввести новую запись
и перезапустить прерванную инструкцию. И конечно, все это должно быть сде-
сделано при помощи небольшого числа команд, поскольку промахи в TLB-буфере
случаются намного чаще, чем ошибки отсутствия страниц.
Удивительно то, что если буфер достаточно велик (размером, скажем, 64 запи-
записи), чтобы минимизировать число промахов, программное управление буфером,
оказывается, является достаточно эффективным. Главная выгода здесь заклю-
заключается в намного более простом устройстве блока управления памятью, что ос-
освобождает достаточный объем пространства в микросхеме процессора для кэша
и других устройств, способных повысить производительность. Программное
управление буфером быстрого преобразования адресов обсуждается в [122].
Для повышения производительности на компьютерах, программно управляющих
TLB-буфером, разработаны различные стратегии. Один из подходов состоит
в попытке уменьшить как частоту промахов в буфере, так и издержки промаха,
когда он все-таки случается [5]. Чтобы снизить вероятность промаха, иногда опе-
операционная система может «интуитивно» вычислить, какие страницы, возможно,
будут использоваться следующими, и предварительно загрузить записи для них
в буфер. Например, когда клиентский процесс посылает сообщение серверному
процессу на той же самой машине, очень вероятно, что сервер вскоре запустится.
Зная это, система, пока обрабатывается прерывание, чтобы осуществить вызов
send, может также проверить, где находятся страницы серверного кода, данных
и стека, и преобразовать их адреса из виртуальных в физические до того, как они
смогут стать причиной ошибки TLB-буфера.
Обычный путь аппаратной или программной обработки промахов в буфере —
это переход в таблицу страниц и выполнение операции индексации с целью
определить положение страницы, к которой происходит обращение. При про-
программной реализации возникает проблема, суть которой в том, что страницы,
содержащиеся в таблице страниц, могут отсутствовать в TLB-буфере, что вызо-
вызовет дополнительные ошибки TLB-буфера во время обработки. Количество таких
ошибок можно уменьшить, поддерживая большой (например, размером 4 Кбайт)
программный кэш TLB-записей с фиксированным расположением в памяти. Если
сначала проверять программный кэш, операционная система способна в значи-
значительной степени снизить количество промахов в TLB-буфере.
4.3.4. Инвертированные таблицы страниц
Традиционные таблицы страниц, которые мы описывали до сих пор, требуют по
одной записи на каждую виртуальную страницу, так как они индексируются по
номеру этой страницы. Если адресное пространство состоит из 232 байт с разме-
размером страницы 4096 байт, тогда в таблице страниц должно быть больше миллиона
записей. То есть такая таблица страниц должна занимать минимум 4 Мбайт.
В достаточно больших системах это, вероятно, осуществимо.
Однако поскольку 64-разрядные компьютеры встречаются все чаще, ситуация ра-
радикально меняется. Если адресное пространство увеличивается до 264 байт с раз-
размером страницы 4 Кбайт, нам требуется таблица страниц с числом записей 252.
Если каждая запись равна 8 байт, таблица займет больше 30 Тбайт. Выделение
30 Тбайт только для таблицы страниц не реально уже сейчас и не будет реаль-
реальным когда-либо в будущем. Следовательно, для 64-разрядного страничного вир-
виртуального пространства необходимо другое решение.
Одним из таких решений является инвертированная таблица страниц. В этой
модели таблица содержит по одной записи на страничный блок в реальной памяти,
а не на страницу в виртуальном адресном пространстве. Например, при 64-раз-
64-разрядных виртуальных адресах, размере страниц 4 Кбайт и оперативной памяти
объемом 256 Мбайт инвертированная таблица страниц потребует всего лишь
65 536 записей. Каждая запись позволяет отслеживать, что (процесс, виртуаль-
виртуальная страница) расположено в данном страничном блоке.
Хотя инвертированные таблицы страниц экономят много места, по крайней мере,
когда виртуальное адресное пространство намного превышает физическую память,
они имеют серьезный недостаток: преобразование виртуального адреса в физи-
физический значительно усложняется. Когда процесс п обращается к виртуальной
странице р, аппаратное обеспечение не может больше найти физическую страни-
страницу, отталкиваясь от номера р как от индекса в таблице страниц. Вместо этого оно
должно производить поиск записи (я, р) во всей инвертированной таблице стра-
страниц. Более того, этот поиск должен выполняться при каждом обращении к памя-
памяти, а не только при ошибке отсутствия страницы. Операция поиска в таблице
размером 64 К записей при каждом обращении к памяти вовсе не повысит быст-
быстродействие вашей машины.
Выйти из этого затруднительного положения позволяет буфер быстрого преоб-
преобразования адресов (TLB). Если в TLB-буфер удастся включить все часто ис-
используемые страницы, трансляция адреса будет происходить так же быстро, как
и в случае обычных таблиц страниц. Но при промахе в TLB-буфере поиск в ин-
инвертированной таблице страниц должен выполняться программно. Один из
возможных способов усовершенствовать поиск — поддерживать хеширование
виртуальных адресов. Все виртуальные страницы, находящиеся в данный момент
в памяти и имеющие одинаковое значение хеш-функции, сцепляются друг с дру-
другом (рис. 4.12). Если хеш-таблица состоит из такого же количества ячеек, сколь-
сколько есть в машине физических страниц, средняя цепочка будет длиной только
в одну запись, что значительно повысит скорость отображения адресов. Как толь-
только обнаруживается номер страничного блока, новая пара (виртуальная, физиче-
физическая) помещается в TLB-буфер, а вызвавшая ошибку команда перезапускается.
Рис. 4.12. Сравнение обычной и инвертированной таблиц страниц
Инвертированные таблицы страниц в настоящее время используются на некото-
некоторых рабочих станциях компаний IBM, Sun и Hewlett-Packard и будут встречаться
все чаще, так как 64-разрядные машины получают все большее распространение.
О других методах управления виртуальной памятью большого размера можно
узнать в [62, ИЗ, 114]. Некоторые проблемы реализации виртуальной памяти,
связанные с аппаратным обеспечением, рассмотрены в [65].
4.4. Алгоритмы замещения страниц
Когда происходит ошибка отсутствия страницы, операционная система должна
выбрать страницу для удаления из памяти, чтобы освободить место для затребо-
затребованной страницы. Если удаляемая страница была изменена за время своего при-
присутствия в памяти, ее необходимо переписать на диск, обновив хранящуюся там
копию. Однако если страница не была модифицирована (например, страница
с текстом программы), копия на диске и так оказывается свежей, поэтому пере-
переписывать ее не надо. В этом случае затребованная страница просто считывается
на место выгружаемой.
Хотя, в принципе, при каждой ошибке отсутствия страницы для удаления мож-
можно выбирать случайную страницу, производительность системы заметно повы-
повышается, когда предпочтение отдается редко используемой странице. Если выгру-
выгружается страница, обращения к которой происходят часто, велика вероятность,
что вскоре опять потребуется вернуть ее в память, что даст в результате допол-
дополнительные издержки. Теме разработки алгоритмов замещения страниц было по-
посвящено много работ, как теоретических, так и экспериментальных. Здесь мы
опишем некоторые из наиболее важных алгоритмов.
Следует заметить, что проблема замещения страниц характерна и для других
компонентов компьютера. Например, большинство современных компьютеров
оснащено одним или несколькими кэшами памяти, хранящими недавно исполь-
использованные блоки памяти размером 32 или 64 байт. Когда кэш заполнен, возникает
задача выбора блока для удаления. Она аналогична удалению страницы, хотя
и должна решаться быстрее (если удаление страницы можно выполнить за не-
несколько миллисекунд, то при удалении блока из кэш-памяти требуется уложить-
уложиться в несколько наносекунд). Причина состоит в том, что при кэш-промахах полу-
получение данных осуществляется из основной памяти с нулевыми задержками на
перемещение головок и вращение диска.
Второй пример — веб-браузер, хранящий на диске копии страниц, к которым ра-
ранее имелся доступ. Обычно максимальный размер кэша фиксирован, поэтому
при интенсивном использовании браузера он с большой вероятностью заполнит-
заполнится. Когда к веб-странице обращаются по ссылке, сначала проверяется ее наличие
в кэше, а затем копия в кэше сравнивается с оригиналом на сервере. Если копия
актуальна, она предлагается пользователю, в противном случае страница загру-
загружается с веб-сервера. При отсутствии копии страница загружается сразу. В случае
если кэш содержит устаревшую версию страницы, она заменяется новой, только
что загруженной версией. Если оказывается, что страница (новая или обновляе-
обновляемая) не умещается в кэш, должно быть принято решение об удалении какой-ли-
какой-либо другой страницы из кэша. Методы выбора здесь аналогичны выбору страниц
в виртуальной памяти, за тем исключением, что веб-страницы никогда не моди-
модифицируются и не записываются обратно на веб-сервер. В системе с виртуальной
памятью страницы, находящиеся в основной памяти, могут быть «чистыми» или
«грязными».
4.4.1. Оптимальный алгоритм замещения страниц
Наилучший из алгоритмов замещения страниц легко описать, но невозможно
реализовать. Он действует так. В тот момент, когда происходит ошибка отсутст-
отсутствия страницы, в памяти находится некоторый набор страниц. К одной из этих
страниц будет обращаться следующая команда процессора (к странице, содер-
содержащей требуемую команду). Вполне вероятно, что на другие страницы ссылок
в течение следующих 10, 100 или даже 1000 команд не будет. Каждая страница
может быть помечена количеством команд, которые будут выполнены перед пер-
первым к ней обращением.
Оптимальный алгоритм замещения страниц просто сообщает, что должна быть
выгружена страница с наибольшей меткой. Если одна страница не будет исполь-
использоваться в течение 8 млн команд, а другая — в течение 6 млн команд, ошибка от-
отсутствия страницы отодвинет в будущее удаление первой на возможно макси-
максимальный срок. Компьютеры, подобно людям, пытаются отложить неприятные
события настолько, насколько это возможно.
С этим алгоритмом связана только одна проблема — он невыполним. В момент
ошибки отсутствия страницы операционная система не имеет возможности узнать,
когда произойдут следующие обращения к каждой из страниц. (Мы рассматривали
аналогичную ситуацию раньше, когда обсуждали алгоритм планирования «самое
короткое задание — первое»: откуда системе знать, какое задание самое корот-
короткое?) Тем не менее выполняя программу на модели и следя за всеми обращениями
к страницам, оптимальную замену можно осуществить при втором запуске, опира-
опираясь на информацию о ссылках на страницы, собранную во время первого запуска.
В этом случае можно сравнивать производительность реализуемых алгоритмов
с наилучшим. Если от операционной системы нужно добиться производительно-
производительности, скажем, всего на 1 % ниже, чем в случае оптимального алгоритма, усилия,
потраченные на поиск лучшего алгоритма, повысят продуктивность схемы мак-
максимум на 1 %.
Чтобы избежать возможных недоразумений, следует прояснить, что полученный
протокол обращений к страницам относится только к одной хорошо спланирован-
спланированной программе и, кроме того, к определенным входным данным. Таким образом,
алгоритм замещения страниц, выведенный из него, может быть хорош только для
этой программы с именно этими входными данными. Хотя такой метод полезен
для оценки алгоритмов замещения страниц, он не используется в реальных сис-
системах. Далее мы изучим алгоритмы, которые применимы в реальных ситуациях.
4.4.2. Алгоритм NRU
Чтобы дать операционной системе возможность собирать полезные статистиче-
статистические данные о том, какие страницы используются, а какие — нет, большинство
компьютеров с виртуальной памятью поддерживают два статусных бита, связан-
связанных с каждой страницей. Бит R (от Referenced — обращение) устанавливается
всякий раз, когда происходит обращение к странице (чтение или запись). Бит М
(от Modified — изменение) устанавливается, когда страница записывается (то есть
изменяется). Биты содержатся в каждом элементе таблицы страниц (см. рис. 4.11).
Важно реализовать обновление этих битов при каждом обращении к памяти,
поэтому необходимо, чтобы они задавались аппаратно. Если однажды бит был
установлен, то он остается равным 1 до тех пор, пока операционная система про-
программно не вернет его в состояние 0.
Если аппаратное обеспечение не поддерживает эти биты, их можно смоделиро-
смоделировать следующим образом. Когда процесс запускается, все его записи в таблице
страниц помечаются как отсутствующие в памяти. Как только происходит обра-
обращение к странице, происходит ошибка отсутствия страницы. Затем операционная
система устанавливает бит R (в своих внутренних таблицах); изменяет запись
в таблице страниц так, чтобы она указывала на корректную страницу с режимом
«только чтение», и перезапускает команду. Если страница позднее записывается,
происходит другая ошибка отсутствия страницы, позволяющая операционной
системе установить бит М и изменить режим на «чтение/запись».
Биты RnM могут использоваться для построения простого алгоритма замещения
страниц. Когда процесс запускается, оба страничных бита для всех его страниц
операционной системой сброшены в 0. Периодически (например, при каждом
прерывании от таймера) бит R очищается с целью отличить страницы, к кото-
которым давно не было обращений, от тех, к которым обращения были.
При возникновении ошибки отсутствия страницы операционная система прове-
проверяет все страницы и делит их на четыре категории на основании текущих значе-
значений битов йиМ:
♦ класс 0 — обращения и изменения не было;
♦ класс 1 — обращения не было, страница изменена;
♦ класс 2 — обращение было, страница не изменена;
♦ класс 3 — были и обращение, и изменение.
Хотя класс 1 на первый взгляд кажется невозможным, описываемая им ситуация
случается, когда у страницы из класса 3 бит R сбрасывается во время прерыва-
прерывания от таймера. Прерывания от таймера не затирают бит М, поскольку информа-
информация, которую он несет, необходима, чтобы понять, нужно переписывать страницу
на диске или нет. Поэтому если бит R сбрасывается, а М остается установлен-
установленным, страница попадает в класс 1.
Алгоритм NRU (Not Recently Used — не использовавшаяся в последнее время
страница) удаляет страницу после случайного поиска в непустом классе с наи-
меньшем номером. Подразумевается, что лучше выгрузить измененную страницу,
к которой не было обращений, по крайней мере, в течение одного такта систем-
системных часов (обычно 20 мс), чем стереть часто используемую страницу. Привле-
Привлекательность алгоритма NRU заключается в том, что он прост для понимания,
умеренно сложен в реализации и дает производительность, которая, хотя и не
оптимальна, обычно вполне достаточна.
4.4.3. Алгоритм FIFO
Другим требующим небольших издержек алгоритмом является FIFO (First-In,
First-Out — первым пришел, первым ушел). Чтобы проиллюстрировать его рабо-
работу, рассмотрим универсам, на полках которого можно выставить ровно k различ-
различных продуктов. Пусть в продажу поступил новый удобный пищевой продукт:
растворимый, «глубоко замороженный», экологически чистый йогурт, кото-
который можно мгновенно приготовить в микроволновой печи. Покупатели тут же
обратили внимание на этот продукт, и наш ограниченный в размерах супер-
супермаркет, для того чтобы продавать новинку, должен избавиться от одного из зале-
залежалых товаров.
Один из вариантов решения проблемы состоит в том, чтобы найти продукт,
который супермаркет продает дольше всего (то есть что-нибудь, что завезли на
реализацию не менее сотни лет назад), и освободить от него магазин на том
основании, что им никто больше не интересуется. На самом деле сохраняется но-
номенклатура всех продаваемых в данный момент в супермаркете товаров, упоря-
упорядоченная по времени их появления. Каждый новый продукт помещается в конец
перечня, а из начала списка удаляется самый старый товар.
Та же самая идея срабатывает в алгоритме замещения страниц. Операционная
система поддерживает список всех страниц, находящихся в данный момент в па-
памяти; первая страница в списке является старейшей, а страницы в хвосте спи-
списка попали в него совсем недавно. Когда происходит ошибка отсутствия стра-
страницы, выгружается из памяти страница в голове списка, а новая страница
добавляется в его конец. Применительно к тому же магазину: если согласно ал-
алгоритму FIFO воск для усов действительно стоит удалить, вряд ли то же самое
можно сказать в отношении муки, соли или масла. Та же проблема встает и в от-
отношении компьютеров. По этой причине алгоритм FIFO редко используется
в своей исходной форме.
4.4.4. Алгоритм второго шанса
В простейшем варианте алгоритма FIFO, который позволяет избежать проблемы
вытеснения из памяти часто используемых страниц, у самой старейшей страницы
изучается бит R. Если он равен 0, значит, страница не только находится в памяти
долго, она вдобавок еще и не используется, поэтому немедленно заменяется но-
новой. Если же бит R равен 1, ему присваивается значение 0, страница переносится
в конец списка, а время ее загрузки обновляется, то есть считается, что страница
только что попала в память. Затем процедура продолжается.
Работу этого алгоритма, называемого алгоритмом второго шанса (second chance),
иллюстрирует рис. 4.13, а. Здесь изображены страницы от А до Н, хранящиеся
в связанном списке и отсортированные по времени их поступления в память.
Числа над страницами обозначают время их загрузки в память.
Рис. 4.13. Иллюстрация работы алгоритма второго шанса: а — страницы, отсортированные
в порядке FIFO; б — список страниц, если ошибка отсутствия страницы произошла
в момент 20, а страница А имеет бит R, равный,0
Предположим, что в момент времени 20 происходит ошибка отсутствия страни-
страницы. Самой старшей страницей является страница Л, она была загружена в па-
память в момент 0, когда начал работу процесс. Если бит R страницы Л равен 0, она
выгружается из памяти либо с записью на диск (если страница «грязная»), либо
без записи (если она «чистая»). Если же бит R равен 1, страница Л передвигается
в конец списка, а ее «загрузочное время» принимает текущее значение B0). При
этом бит R сбрасывается. Поиск подходящей страницы продолжается; следую-
следующей проверяется страница В.
Алгоритм второго шанса ищет в списке самую старую страницу, к которой не
было обращений в предыдущем временном интервале. Если же происходили
ссылки на все страницы, то алгоритм второго шанса превращается в обычный
алгоритм FIFO. Представьте, что у всех страниц на рис. 4.13, а бит R равен 1.
Одну за другой передвигает операционная система страницы в конец списка,
очищая бит R каждый раз, когда она перемещает страницу в хвост. Наконец, она
вернется к странице Л, но теперь уже ее биту R присвоено значение 0. В этот
момент страница А выгружается из памяти. Таким образом, алгоритм всегда
успешно завершает свою работу.
4.4.5. Алгоритм часов
Хотя алгоритм второго шанса является корректным, он слишком неэффективен,
так как постоянно тасует страницы по списку. Поэтому лучше хранить все стра-
страничные блоки в кольцевом списке в форме часов (рис. 4.14, стрелка указывает на
старейшую страницу).
Рис. 4.14. Алгоритм часов
Когда происходит ошибка отсутствия страницы, проверяется та страница, на ко-
которую направлена стрелка. Если ее бит R равен 0, страница выгружается, на ее
место в часовой круг встает новая страница, а стрелка сдвигается вперед на одну
позицию. Если бит R равен 1, он сбрасывается, стрелка перемещается к следующей
странице. Этот процесс повторяется до тех пор, пока не обнаруживается та стра-
страница, у которой бит R = 0. Не удивительно, что алгоритм называется алгорит-
алгоритмом часов. Он отличается от алгоритма второго шанса только своей реализацией.
4.4.6. Алгоритм LRU
В основе этой неплохой аппроксимации оптимального алгоритма лежит на-
наблюдение, что страницы, к которым наблюдалось многократное обращение в не-
нескольких последних командах, вероятно, также будут часто востребованы в сле-
следующих. И наоборот, можно полагать, что страницы, к которым ранее не было
обращений, не потребуются в течение долгого времени. Эта идея привела к сле-
следующему реализуемому алгоритму: когда происходит ошибка отсутствия стра-
страницы, выгружается из памяти страница, которая не использовалась дольше все-
всего. Такая стратегия замещения страниц называется LRU (Least Recently Used —
дольше всего не использовавшаяся страница).
Хотя алгоритм LRU теоретически реализуем, он не дешев. Для полной реализации
алгоритма LRU необходимо поддерживать список всех содержащихся в памяти
страниц, такой, где последняя использовавшаяся страница находится в начале
списка, а та, к которой дольше всего не было обращений, — в конце. Сложность
заключается в том, что список должен обновляться при каждом обращении к па-
памяти. Поиск страницы, ее удаление, а затем вставка в начало списка — это опера-
операции, поглощающие очень много времени, даже если они выполняются аппаратно
(предположим, что необходимое оборудование можно сконструировать).
Существуют и другие способы реализации алгоритма LRU с помощью специ-
специального оборудования. Для первого метода требуется оснащение компьютера
64-разрядным аппаратным счетчиком С, который автоматически инкрементируется
после каждой команды. Кроме того, каждая запись в таблице страниц должна
иметь поле, достаточно большое для хранения значения счетчика. После каждого
обращения к памяти текущая величина счетчика С запоминается в записи табли-
таблицы, соответствующей той странице, к которой произошла ссылка. А если возни-
возникает ошибка отсутствия страницы, операционная система проверяет все значе-
значения счетчиков в таблице страниц и ищет наименьшее. Эта страница и является
дольше всего не использовавшейся.
Рассмотрим второй вариант аппаратной реализации алгоритма LRU. На машине
с п страничными блоками оборудование LRU может поддерживать матрицу разме-
размером п х п бит, изначально равных нулю. Всякий раз при доступе к страничному
блоку k аппаратура сначала присваивает всем битам строки k единицу, а затем
приравнивает нулю все биты столбца к В любой момент времени строка, двоич-
двоичное значение которой наименьшее, является дольше всего не использовавшейся.
Работа этого алгоритма продемонстрирована на рис. 4.15, где рассматриваются
четыре страничных блока и следующий порядок обращения к страницам:
О 1232 1 0323
После ссылки на страницу 0 мы получаем ситуацию, показанную на рис. 4.15, а;
после обращения к странице 1 — на рис. 4.15, б и т. д.
Рис. 4.15. Алгоритм LRU с привлечением матрицы. Обращения к страницам происходят
в последовательности: 0, 1, 2, 3, 2, 1, 0, 3, 2, 3
4.4.7. Программное моделирование
алгоритма LRU
Хотя оба описанных алгоритма LRU в принципе реализуемы, очень мало (если
вообще такие есть) машин оснащено подобным оборудованием, поэтому разра-
разработчики операционных систем для компьютеров, не имеющих такой аппаратуры,
редко используют эти алгоритмы. Вместо них применяется решение, программ-
программно реализуемое. Одна из разновидностей алгоритма LRU называется NFU (Not
Frequently Used — редко использовавшаяся страница). Для него необходим про-
программный счетчик, связанный с каждой страницей в памяти, изначально равный
нулю. Во время каждого прерывания от таймера операционная система исследует
все страницы в памяти. Бит R каждой страницы (он равен 0 или 1) прибавляется
к счетчику. В сущности, счетчики пытаются отследить, как часто происходят об-
обращения к каждой странице. При ошибке отсутствия страницы для замещения
выбирается страница с наименьшим значением счетчика.
Основная проблема, возникающая при работе алгоритма NFU, заключается в том,
что он никогда ничего не забывает. Например, в многопроходном компиляторе
страницы, которые часто обрабатывались во время первого прохода, могут иметь
высокое значение счетчика при дальнейших проходах. Фактически, если случа-
случается так, что первый проход выполняется дольше всех, страницы, содержащие
программный код для следующих проходов, могут всегда иметь более низкое зна-
значение счетчика, чем страницы первого прохода. Следовательно, операционная
система удалит полезные страницы вместо тех, которые больше не нужны.
К счастью, небольшая доработка алгоритма NFU наделяет его способностью моде-
моделировать алгоритм LRU достаточно хорошо. Изменение сводится к двум моди-
модификациям. Во-первых, каждый счетчик перед прибавлением бита R сдвигается
вправо на один разряд. Во-вторых, бит R вдвигается в крайний слева, а не в край-
крайний справа разряд счетчика.
На рис. 4.16 продемонстрировано, как работает видоизмененный алгоритм, из-
известный под названием алгоритма старения (aging). Предположим, после перво-
первого такта часов биты R для страниц от 0 до 5 имеют значения 1, 0, 1,0, 1, 1 соот-
соответственно (у страницы 0 бит R равен 1, у страницы 1 — 0, у страницы 2 — 1
и т. д.). Другими словами, между тактом 0 и тактом 1 произошло обращение к стра-
страницам 0, 2, 4 и 5, их биты R приняли значение 1, остальные сохранили значе-
значение 0. После того как шесть соответствующих счетчиков сдвинулись на разряд
и бит R занял крайнюю слева позицию, счетчики получили значения, показан-
показанные на рис. 4.16, а. Остальные четыре колонки рисунка изображают шесть счет-
счетчиков после следующих четырех тактов часов.
Когда происходит ошибка отсутствия страницы, удаляется та страница, счетчик
которой имеет наименьшую величину. Ясно, что счетчик страницы, к которой не
было обращений, скажем, за четыре такта, будет начинаться с четырех нулей
и, таким образом, иметь более низкое значение, чем счетчик страницы, на кото-
которую не ссылались в течение только трех тактов часов.
Эта схема отличается от алгоритма LRU в двух отношениях. Рассмотрим страни-
страницы 3 и 5 на рис. 4.16, д. Ни к одной из них не было обращений за последние
два такта, к обеим было обращение за предшествующий такт. Следуя алгоритму
LRU, при удалении страницы из памяти мы должны выбрать одну из двух. Пробле-
Проблема в том, что мы не знаем, к какой из них позже имелось обращение в интервале
между тактами 1 и 2. Записывая только один бит за промежуток времени, мы те-
теряем возможность отличить более ранние от более поздних обращений в этом
интервале времени. Все, что мы можем сделать, — это выгрузить страницу 3, так
как к странице 5 также обращались двумя тактами раньше, а к странице 3 — нет.
Рис. 4.16. Алгоритм старения программно моделирует алгоритм LRU. Показаны шесть
страниц после пяти тактов часов
Второе отличие между алгоритмом LRU и алгоритмом старения заключается
в том, что в последнем счетчик имеет конечное число разрядов, например 8.
Предположим, что каждая из двух страниц получила нулевое значение счетчика.
8 данной ситуации мы лишь случайным образом можем выбрать одну из них.
На самом деле не исключено, что к одной странице в последний раз обращались
9 тактов назад, а к другой — 1000 тактов назад. И мы не имеем возможности уви-
увидеть это. На практике, однако, обычно достаточно 8 бит при такте системных ча-
часов около 20 мс. Если к странице не обращались в течение 160 мс, очень вероят-
вероятно, что она не нужна.
4.5. Разработка систем замещения страниц
В предыдущих разделах мы объяснили, как работает механизм замещения стра-
страниц, представили несколько основных алгоритмов замещения страниц и показа-
показали, как моделировать такие системы. Но просто знания механизма недостаточно.
Чтобы разработать хорошую систему, нужно вникнуть во все детали намного
глубже. Разница такая же, как между человеком, который знает, как ходят ладья,
конь, слон и другие шахматные фигуры, и хорошим шахматистом. Здесь мы рас-
рассмотрим все то, что должны принимать во внимание разработчики операцион-
операционных систем, чтобы добиться от системы замещения страниц достойной произво-
производительности.
4.5.1. Модель рабочего набора
В простейшей схеме замещения страниц в момент запуска процессов нужные им
страницы отсутствуют в памяти. Как только центральный процессор пытается
выбрать первую команду, он получает ошибку отсутствия страницы, побуждаю-
побуждающую операционную систему перенести в память страницу, содержащую первую
команду. Обычно следом быстро происходят ошибки отсутствия страниц для
глобальных переменных и стека. Через некоторое время в памяти скапливается
большинство необходимых процессу страниц, и он приступает к работе с относи-
относительно незначительным количеством ошибок отсутствия страниц. Этот метод
называется замещением страниц по запросу (demand paging), так как страницы
загружаются в память по требованию, а не заранее.
Конечно, достаточно легко написать тестовую программу, систематически чи-
читающую все страницы в огромном адресном пространстве, что сопровождается
таким количеством ошибок отсутствия страниц, что для их обработки не хватает
памяти. К счастью, большинство процессов не работают таким образом. Они ха-
характеризуются локальностью обращений, означающей, что во время выполнения
любой своей фазы процесс обращается только к сравнительно небольшой части
собственных страниц. Многопроходный компилятор, например, на каждом про-
проходе обращается только к части страниц.
Множество страниц, которое процесс использует в данный момент, называется
рабочим набором [31, 32]. Если рабочий набор целиком находится в памяти, про-
процесс выполняется, не вызывая большого количества ошибок, пока он не перей-
перейдет к другой фазе выполнения (к следующему проходу в случае компилятора).
Если доступная память слишком мала, чтобы содержать полный рабочий набор,
процесс инициирует множество ошибок отсутствия страниц и замедляется, так
как выполнение среднестатистической команды занимает несколько наносекунд,
а чтение страницы с диска обычно требует 10 мс. При скорости одна или две ко-
команды на 10 мс для завершения программы понадобятся века. Говорят, что про-
программа пробуксовывает (thrashing), когда она вызывает ошибку отсутствия стра-
страницы каждые несколько команд [32].
В системах разделения времени процессы часто сбрасываются на диск (то есть
все их страницы удаляются из памяти) с целью позволить другим процессам по-
получить доступ к центральному процессору. Возникает вопрос, что делать, когда
процесс снова загружается в память. С формальной точки зрения делать ничего
не нужно. Процесс будет вызывать одну за другой ошибки отсутствия страниц
до тех пор, пока в память не загрузится весь его рабочий набор. Проблема в том,
что наличие 20, 100 или даже 1000 ошибок отсутствия страниц при каждой за-
загрузке процесса значительно замедляет систему, кроме того, впустую тратится
много времени центрального процессора, до нескольких миллисекунд, столько,
сколько требуется операционной системе для обработки каждой ошибки отсут-
отсутствия страницы.
Поэтому многие системы замещения страниц пытаются отслеживать рабочий
набор каждого процесса и обеспечивают его нахождение в памяти еще до запуска
процесса. Такой подход носит название модели рабочего набора [33]. Эта модель
призвана значительно снизить процент ошибок отсутствия страниц. Загрузка
страниц перед тем, как разрешить процессу работать, также называется опере-
опережающим замещением страниц (prepaging). Заметьте, что рабочий набор с тече-
течением времени изменяется.
Давно известно, что большинство программ обращается к различным областям
своего адресного пространства не в случайном порядке. Напротив, обращения
группируются на небольшом количестве страниц. При обращении к памяти мо-
может выполняться чтение данных, чтение команды или запись данных. В любой
момент времени t существует набор, включающий все страницы к последних об-
обращений к памяти. Этот набор, w(k, t), является рабочим. Поскольку с увеличе-
увеличением к мы все дальше «заглядываем в прошлое», число страниц рабочего набора
не может уменьшаться. Другими словами, функция w(k, t) представляет собой
монотонно неубывающую функцию от к. Кроме того, у этой функции есть конеч-
конечный предел, поскольку программа не может обратиться к большему числу стра-
страниц, чем есть в ее адресном пространстве. Случаи, когда программа обращается
ко всем страницам своей памяти, очень редки. График зависимости размера ра-
рабочего набора от числа последних обращений к памяти представлен на рис. 4.17.
Рис. 4.17. Рабочий набор — это множество страниц, использованных при последних
к обращениях к памяти. Функция w(k, t) представляет собой размер рабочего
набора в момент времени t
Быстрый рост кривой вначале и его последующее резкое замедление говорят
о том, что программы, как правило, имеют доступ к большинству своих страниц,
однако рабочий набор не подвержен значительным изменениям во времени. На-
Например, если программа исполняет цикл, занимающий 2 страницы памяти, и ис-
использует данные, расположенные на 4 других страницах, то, возможно, за 1000 ко-
команд осуществляется обращение ко всем 6 страницам, а последнее обращение,
например, к странице 7 случилось миллион команд назад на этапе инициализа-
инициализации программы. Из-за такого асимптотического поведения содержимое рабочего
набора нечувствительно к выбранному значению к. Другими словами, существу-
существует большое количество значений к, для которых рабочие наборы одинаковы. Это
позволяет, на основе знаний о страницах, использованных при последнем завер-
завершении программы, разумно спрогнозировать множество страниц, которые по-
потребуются на начальной стадии работы программы при следующем ее запуске.
Благодаря опережающему замещению страниц эти страницы загружают в память
перед тем, как процесс получает разрешение на запуск.
Для реализации модели рабочего набора необходимо, чтобы операционная сис-
система отслеживала, какие страницы в нем находятся. Один из способов получить
такую информацию — использовать описанный ранее алгоритм старения. Пусть
установленный старший бит счетчика у страницы означает, что она входит в ра-
рабочий набор. Если в течение п последовательных тактов часов к такой странице
не было сделано обращений, она удаляется из рабочего набора. Параметр п при-
придется определить экспериментальным путем, но производительность системы
обычно не слишком чувствительна к его точному значению.
При помощи информации рабочего набора можно повысить производительность
алгоритма часов. Обычно, когда «стрелка часов» показывает на страницу, у кото-
которой бит R равен нулю, эта страница удаляется. Чтобы улучшить алгоритм, мож-
можно дополнительно проверять, входит ли страница в рабочий набор текущего про-
процесса, и если да, оставлять ее. Такой алгоритм называется wsclock.
4.5.2. Локальная и глобальная политики
распределения памяти
В предыдущих разделах мы обсудили несколько алгоритмов, выполняющих в слу-
случае ошибки поиск страницы для замещения. Основной вопрос, связанный с этим
выбором (который мы тщательно обходили до сих пор): как должна быть рас-
распределена память между параллельными конкурирующими работоспособными
процессами?
Обратим внимание на рис. 4.18, а. Здесь три процесса, А, В и С, составляют набор
работоспособных процессов. Предположим, процесс А вызвал ошибку отсутствия
страницы. Должен ли алгоритм замещения страниц пытаться найти дольше
всех не использовавшуюся страницу, учитывая только 6 страниц, предоставлен-
предоставленных в данный момент процессу Д или же он должен рассматривать все страницы
памяти? Если алгоритм производит поиск только среди страниц процесса Л, наи-
наименьший возраст имеет страница Л5, и мы получаем ситуацию, изображенную
на рис. 4.18, б.
В то же время, если удаляется страница с наименьшим возрастом, независимо от
того, к какому процессу она относится, то будет выбрана страница ВЗ, и система
попадет в состояние, показанное на рис. 4.18, в. Алгоритм на рис. 4.18, б называет-
называется локальным, а на рис. 4.18, в — глобальным. Локальные алгоритмы соответствуют
размещению каждого процесса в фиксированной области памяти. Глобальные
алгоритмы динамически распределяют страничные блоки между выполняющи-
выполняющимися процессами. Таким образом, количество страничных блоков, предоставлен-
предоставленных каждому процессу, изменяется со временем.
В целом глобальные алгоритмы работают лучше, особенно если размер рабочего
набора может изменяться за время жизни процесса. Если используется локаль-
локальный алгоритм и рабочий набор увеличивается в размере, мы получим пробуксов-
пробуксовку, даже если в системе имеется достаточное количество свободных страничных
блоков. Когда рабочий набор уменьшается, в случае локального алгоритма часть
памяти тратится впустую. Если же задействован глобальный алгоритм, система
должна непрерывно решать, сколько страничных блоков предоставить каждому
процессу. Можно наблюдать за размером рабочего набора с помощью битов воз-
возраста страниц, но этот метод не всегда позволяет избежать пробуксовки. Рабо-
Рабочий набор может изменяться в размере за микросекунды, тогда как биты возрас-
возраста являются грубым усреднением тактов часов.
Рис. 4.18. Локальный алгоритм замещения страниц в сравнении с глобальным:
а — исходная конфигурация; б — локальное замещение страниц;
в —• глобальное замещение страниц
Другой подход состоит в том, чтобы реализовать в системе алгоритм распределе-
распределения страничных блоков между процессами. Например, можно периодически оп-
определять количество работающих процессов и предоставлять каждому равную
часть памяти. Соответственно, при наличии доступных (то есть не принадлежа-
принадлежащих операционной системе) 12 416 страничных блоков и 10 процессов каждый
процесс получает 1241 блок. Оставшиеся 6 блоков поступают в резерв для ис-
использования в тот момент, когда происходит ошибка отсутствия страницы.
Хотя этот метод кажется справедливым, существует вероятность, что процессы
размером 10 и 300 Кбайт получат равные области памяти. Вместо этого можно
предоставлять страницы пропорционально абсолютному размеру каждого про-
процесса, тогда больший из этих двух процессов получит долю памяти в 30 раз
большую, чем меньший процесс. Разумно отдавать каждому процессу некоторый
минимум, чтобы он мог работать независимо от своего размера. На некоторых
машинах, например, одиночная команда процессора, включающая в себя два
операнда, может нуждаться в целых шести страницах, поскольку сама команда,
операнд-источник и операнд-приемник могут располагаться на разных страни-
страницах. Если предоставить только пять страниц, программа, содержащая подобную
инструкцию, вообще не сумеет выполниться.
Если используется глобальный алгоритм, допустимо запускать каждый процесс
с некоторым количеством страниц, пропорциональным его размеру, но при этом
распределение памяти динамически менять во время работы. Алгоритм PFF (Page
Fault Frequency — частота ошибок отсутствия страниц) предоставляет один из
подходов к управлению размещением процессов в памяти. Он позволяет увели-
увеличивать или уменьшать количество страниц, предоставленных процессу, но не
указывает, какую страницу замещать по ошибке. Этот алгоритм только контро-
контролирует размер набора страниц, назначенных процессу.
Как было отмечено ранее, для большого класса алгоритмов замещения страниц,
включая алгоритм LRU, известно, что частота ошибок уменьшается при уве-
увеличении числа предоставляемых страниц. Этот тезис лежит в основе алгорит-
алгоритма PFF (рис. 4.19).
Рис. 4.19. Частота ошибок отсутствия страниц как функция от количества
предоставленных процессу страничных блоков
Измерить частоту ошибок отсутствия страниц несложно: подсчитайте, сколько
их происходит в секунду, и, возможно, возьмите скользящее среднее за несколь-
несколько последних секунд. Проще всего сложить текущее значение скользящего сред-
среднего со значением для последней секунды и разделить результат на 2. Прерыви-
Прерывистая линия, обозначенная буквой Л, соответствует частоте ошибок отсутствия
страниц, выше которой она недопустимо высока, поэтому с целью уменьшения
числа ошибок увеличивается количество страничных блоков, предоставленных
прерванному процессу. Линия В соответствует очень низкой частоте ошибок
отсутствия страниц, позволяющей сделать вывод о том, что процесс занимает
слишком много памяти. В этом случае у него можно забрать несколько странич-
страничных блоков. Таким образом, алгоритм PFF пытается сохранить частоту замеще-
замещения страниц для каждого процесса внутри допустимых границ.
Если в памяти оказывается так много процессов, что удержать их все ниже линии А
оказывается невозможно, некоторые процессы удаляются из памяти, а освобо-
освободившееся пространство распределяется между остальными или заносится в банк
свободных страниц для использования при последующих ошибках отсутст-
отсутствия страниц. Решение о том, какой процесс удалить из памяти, является одной
из форм управления нагрузкой. Это показывает, что даже при замещении стра-
страниц нужна подкачка, только здесь она направлена на снижение потенциальной
потребности в памяти, а не для возвращения и немедленного использования
блоков. Выгрузка процессов для снижения нагрузки на память является насле-
наследием двухуровневого планирования, при котором часть процессов сбрасывается
на диск, а остальными управляет упрощенный планировщик. Разумеется, два под-
подхода можно совместить, обеспечив наличие в памяти такого количества процес-
процессов, при котором частота ошибок отсутствия страниц будет приемлемой.
4.5.3. Размер страницы
Зачастую размер страницы является параметром, выбираемым операционной
системой. Даже если аппаратное обеспечение предусматривает, например, раз-
размер страницы в 512 байт, операционная система может просто рассматривать
страницы 0 и 1, 2 и 3, 4 и 5 и т. д. как страницы размером 1 Кбайт, всегда предо-
предоставляя для них два смежных страничных блока.
Определение оптимального размера страницы требует учета нескольких взаимо-
взаимосвязанных факторов. Поэтому не существует абсолютного лучшего решения.
Прежде всего, есть два довода в пользу маленького размера страниц. Случайно
выбранный текст, данные или сегмент стека не заполняют страницы целиком.
В среднем половина последней страницы оказывается пустой, и это дополнитель-
дополнительное пространство пропадает. Такие потери называют внутренней фрагментаци-
фрагментацией. Если в памяти п сегментов, а размер страницы равен р байт, то в результате
внутренней фрагментации пр/2 байт будет потрачено впустую. Это — разумный
аргумент в пользу страниц небольшого размера.
Другой довод становится очевидным, если мы представим себе программу, вы-
выполняемую за 8 шагов, по 4 Кбайт каждый. При размере страницы 32 Кбайт про-
программе должно быть постоянно выделено 32 Кбайт. При размере страницы
16 Кбайт ей необходимо только 16 Кбайт. При размере страницы 4 Кбайт или
меньше программа требует всего лишь 4 Кбайт в любой момент времени. То есть
большой размер страницы скорее, чем маленький, станет причиной того, что в па-
памяти окажется неиспользуемая часть страницы.
Однако небольшой размер страницы означает, что программам потребуется мно-
много страниц, для которых нужна огромная таблица страниц. Программа размером
32 Кбайт требует всего 4 страницы по 8 Кбайт или целых 64 страницы по 512 байт.
Как правило, страница за раз переносится на диск и с него, при этом большая
часть времени уходит на поиск цилиндра и задержку вращения, так что переме-
перемещение маленькой страницы занимает почти столько же времени, сколько и боль-
большой. То есть нужно 64 х 10 мс, чтобы загрузить 64 страницы размером 512 байт,
и всего лишь 4 х 10,1 мс для загрузки четырех страниц по 8 Кбайт.
На некоторых машинах таблица страниц должна записываться в аппаратные ре-
регистры каждый раз, когда процессор переключается с одного процесса на другой.
Если на таком компьютере страница имеет маленький размер, то время, требуе-
требуемое для загрузки таблицы, растет пропорционально уменьшению размера стра-
страницы. Более того, пространство, занятое таблицей страниц, также возрастает
с уменьшением страницы.
Этот последний момент можно проанализировать математически. Пусть средний
размер процесса равен s байт, а страницы — р байт. Кроме того, предположим,
что запись для каждой страницы требует е байт. Тогда приблизительное количе-
количество страниц, необходимое для процесса, равно s/p, что соответствует se/p байт
для таблицы страниц. Потеря памяти в последней странице процесса вследствие
внутренней фрагментации равна р/2. Таким образом, общие накладные расходы
вследствие поддержки таблицы страниц и потери от внутренней фрагментации
равны сумме этих двух составляющих:
Расход = se/p + р/2.
Первое слагаемое (размер таблицы страниц) растет при уменьшении размера
страницы. И наоборот, при увеличении размера страницы возрастает второе сла-
слагаемое (внутренняя фрагментация). Оптимальный вариант следует искать где-то
посередине. Если взять первую производную по переменной р и приравнять ее
нулю, мы получим равенство:
-se/p2 + 1/2 = 0.
Из этого равенства мы можем вывести формулу, дающую оптимально сбаланси-
сбалансированный размер страниц (принимая во внимание только потери памяти на
фрагментацию, а также величину таблицы страниц). В результате получится:
Для среднего размера процесса 5=1 Мбайт и длины записи в таблице страниц
е = 8 байт оптимальный размер страницы равен 4 Кбайт. В серийно выпускае-
выпускаемых компьютерах были приняты значения в диапазоне от 512 байт до 1 Мбайт.
По мере увеличения объемов памяти размер страницы также имеет тенденцию к
росту (хотя и нелинейному): при возведении объема памяти в квадрат размер
страницы удваивается.
4.5.4. Интерфейс виртуальной памяти
До сих пор в наших рассуждениях предполагалось, что виртуальная память про-
прозрачна для процессов и программистов, то есть все, что они видят, — это огром-
огромное виртуальное адресное пространство на компьютере с небольшой (по крайней
мере, меньшей, чем виртуальная) физической памятью. Обычно это соответству-
соответствует истине, но в некоторых усовершенствованных системах программистам пре-
предоставлена определенная свобода управления картой памяти, которую они могут
направить на улучшение поведения программы нетрадиционными способами.
Рассмотрим кратко некоторые из них.
Одной из причин предоставления программистам контроля над картой памяти
является желание позволить двум и более процессам совместно использовать
одну и ту же память. Если программисты сами будут давать названия областям
памяти, один процесс сможет сообщить другому процессу имя области памяти,
и этот второй процесс также сможет ей пользоваться. Если два (или больше) про-
процессов имеют общие страницы памяти, становится реальной высокая пропускная
способность совместного доступа: один процесс сможет просто писать в общую
память, а другой — читать из нее.
Совместное использование страниц находит также применение в высокопроизво-
высокопроизводительных системах передачи сообщений. Когда передается сообщение, данные
обычно копируются из одного адресного пространства в другое, а это означает
значительные издержки. Если процессы будут управлять своей картой страниц,
можно передавать сообщения внутри общего адресного пространства: процесс-
отправитель будет убирать из карты страницу (страницы) с сообщением, а про-
процесс-получатель помещать ее (их) в карту. При этом достаточно копировать
только имена страниц вместо всех данных.
Еще один современный подход к управлению памятью носит название распреде-
распределенной общей памяти [45, 80, 131]. Распределенная общая память позволяет не-
нескольким процессам в сети совместно использовать набор страниц, возможно
(но не обязательно) как единое разделяемое линейное адресное пространство.
Когда процесс обращается к странице, не отображаемой в данный момент, он ини-
инициирует ошибку отсутствия страницы. Обработчик ошибок отсутствия страниц,
находящийся в ядре или в пользовательском пространстве, находит машину, со-
содержащую страницу, и посылает ей сообщение с запросом на выгрузку страницы
и ее отправку по сети. Когда страница прибывает, она попадает в карту, и пре-
прерванная команда перезапускается.
4.6. Сегментация
Обсуждавшаяся до сих пор виртуальная память представляла собой одномерное
пространство, в котором виртуальные адреса идут один за другим от 0 до некото-
некоторого максимума. Для решения многих задач наличие двух и более отдельных
виртуальных адресных пространств может быть лучше, чем одно. Например, по
мере трансляции формируются несколько структур данных компилятора.
1. Исходный текст, сохраненный для печати листинга (в пакетных системах).
2. Символьная таблица с именами и атрибутами переменных.
3. Таблица со всеми используемыми константами: целыми и с плавающей точкой.
4. Дерево грамматического разбора с результатами синтаксического анализа про-
программы.
5. Стек, используемый для процедурных вызовов внутри компилятора.
Во время компиляции каждая из первых четырех структур непрерывно растет.
Стек при компиляции непредсказуемо увеличивается или уменьшается. В одно-
одномерной памяти эти пять структур должны размещаться в смежных частях вирту-
виртуального адресного пространства (рис. 4.20).
Рассмотрим, что происходит, если программа имеет исключительно большое
число переменных и обычное количество всего остального. Область адресного
пространства, предоставленная для символьной таблицы, может заполниться, но
в других структурах, скорее всего, останется пустым множество ячеек. Конечно,
компилятор может просто послать сообщение о том, что компиляция не может
продолжаться вследствие слишком большого количества переменных, но нам
кажется, что это вряд ли можно назвать хорошим решение проблемы, поскольку
в других структурах осталась уйма неиспользованного места.
Рис, 4.20, В одномерном адресном пространстве при росте таблиц
одна может упереться в другую
При другом подходе можно поиграть в Робин Гуда, забирая пространство у струк-
структур с излишками места и передавая их структурам с их недостатком. Такая пере-
перетасовка реализуема, но она аналогична управлению собственными оверлеями, что
в лучшем случае неудобно, а в худшем случае требует большого объема скучной
и непродуктивной работы.
На самом деле нужно найти подход, освобождающий программиста от управле-
управления расширяющимися и сокращающимися структурами данных, так же как вир-
виртуальная память избавляет программы от возни с оверлеями.
Простое и предельно обобщенное решение заключается в том, чтобы обеспечить
машину множеством полностью независимых адресных пространств, называемых
сегментами. Каждый сегмент содержит линейную последовательность адресов
от 0 до некоторого максимума. Длина каждого сегмента может быть любой от
нуля до разрешенного максимума. Различные сегменты могут быть различной
длины. Более того, длины сегментов могут меняться во время выполнения про-
программы. Длина сегмента стека может увеличиваться всякий раз, когда что-либо
помещается в стек, и уменьшаться при выборке данных из стека.
Поскольку каждый сегмент образует отдельное адресное пространство, разные
сегменты могут расти или сокращаться независимо друг от друга. Если стек,
находящийся в определенном сегменте, нуждается в увеличении адресного про-
пространства, он может получить его, потому что в его адресном пространстве нет
больше ничего, что может стать препятствием для роста. Конечно, сегмент мо-
может заполниться, но сегменты обычно очень большие, поэтому такие инциденты
редки. Чтобы определить адрес в такой сегментированной, или двухмерной,
памяти, программа должна указать адрес, состоящий из двух частей: номера сег-
сегмента и адреса внутри сегмента. Рисунок 4.21 иллюстрирует сегментированную
память, использующуюся для обсуждавшихся ранее структур данных компиля-
компилятора. Здесь показаны 5 независимых сегментов.
Рис, 4.21. Сегментированная память позволяет каждой структуре расти
или уменьшаться независимо от других
Стоит подчеркнуть, что сегмент — это логический объект, о чем программист
знает и поэтому использует его как логический объект. Сегмент может иметь
в составе процедуру, массив, стек или набор скалярных переменных, хотя обыч-
обычно разных типов он не содержит.
Помимо простоты управления увеличивающимися или сокращающимися струк-
структурами данных, сегментированная память обладает и другими преимуществами.
Если каждая процедура занимает отдельный сегмент и имеет нулевой начальный
адрес, компоновка отдельно скомпилированных процедур происходит намно-
намного проще. После того как все процедуры, составляющие программу, скомпи-
скомпилированы и скомпонованы, для адресации слова 0 (начальной точки) при об-
обращении к процедуре в сегменте п будет использоваться адрес, состоящий из
двух частей (п, 0).
Если потом процедура в сегменте п модифицируется и компилируется заново,
другие процедуры изменять не потребуется (потому что начальный адрес остает-
остается тем же), даже если новая версия больше предыдущей. В одномерной памяти
процедуры «упакованы» одна к одной, и между ними нет свободного адресного
пространства. В результате изменение размера одной процедуры может повли-
повлиять на начальный адрес другой, не имеющей отношения к первой. Это, в свою
очередь, требует модификации всех процедур, вызывающих любую из передви-
передвинутых процедур, чтобы поместить в них новые начальные адреса. Если програм-
программа содержит сотни процедур, такой процесс оказывается очень затратным.
Сегментация также облегчает совместное использование процедур и данных
несколькими процессами. Хорошим примером является библиотека совместного
доступа. Современные рабочие станции, работающие с современными оконны-
оконными системами, часто имеют крайне большие графические библиотеки, входящие
практически в каждую программу. В сегментированных системах графические
библиотеки могут располагаться в отдельном сегменте и совместно использо-
использоваться несколькими процессами, что устраняет необходимость их присутствия
в адресном пространстве каждого процесса. В принципе, в «чистых» системах
замещения страниц также можно иметь совместно используемые библиотеки,
но это намного сложнее в реализации. Поэтому такие системы предоставляют
совместный доступ путем моделирования сегментации.
Поскольку каждый сегмент формирует логический объект (такой как процедура,
массив или стек), с которым общается программист, у различных сегментов мо-
могут быть разные виды защиты. Сегмент процедуры может быть определен, как
только исполняемый, что запрещает попытки чтения из него или сохранения
в него. Для массива чисел с плавающей точкой можно разрешить режим чтения
и записи, но не исполнения, чтобы перехватывать попытки передачи управления
по адресам, на которых располагается массив. Такая защита полезна при пере-
перехвате программных ошибок.
Нужно попытаться понять, почему защита имеет смысл в сегментированной па-
памяти, а не в одномерной страничной памяти. В сегментированной памяти поль-
пользователь знает о том, что представляет собой каждый сегмент. В обычном случае
сегмент не может содержать, например, и процедуру и стек, а только либо пер-
первое, либо второе. Так как каждый сегмент содержит только один тип объектов,
он может иметь защиту, соответствующую этому конкретному типу. Замещение
страниц и сегментация сравниваются в табл. 4.2.
Таблица 4.2. Сравнение замещения страниц и сегментации
Вопрос Замещение страниц Сегментация
Нужно ли программисту знать о том, Нет Да
что используется эта техника?
Сколько в системе линейных 1 Много
адресных пространств?
Может ли суммарное адресное Да Да
пространство превышать
размеры физической памяти?
Возможно ли разделение процедур Нет Да
и данных, а также их раздельная
защита?
Легко ли размещать в памяти структуры Нет Да
данных с непостоянными размерами?
Таблица 4.2 (продолжение)
Вопрос Замещение страниц Сегментация
Облегчен ли совместный доступ Нет Да
пользователей к процедурам?
Зачем была придумана эта техника? Чтобы получить Чтобы иметь возможность
большое линейное разбивать программы
адресное пространство и данные на логически
без дополнительных независимые адресные
затрат на физическую пространства, а также
память упростить совместный
доступ и защиту
Содержимое страниц в известной степени случайно. Программист не осведомлен
даже о том факте, что происходит замещение страниц. Хотя добавление несколь-
нескольких битов в каждую запись таблицы страниц для определения режима доступа
в принципе возможно, однако, чтобы использовать такой подход, программисту
пришлось бы отслеживать, где находятся границы страниц в его адресном про-
пространстве. Это представляет собой в точности тот вид администрирования, для
устранения которого была придумана технология замещения страниц. Посколь-
Поскольку пользователь сегментированной памяти имеет дело с иллюзией постоянного
нахождения всех сегментов в оперативной памяти (то есть он может адресовать-
адресоваться к ним так, как будто они существуют), он может защищать сегменты по от-
отдельности, не заботясь об управлении их загрузкой в память.
4.6.1. Реализация сегментации
Реализация сегментации и замещения страниц существенно различаются: стра-
страницы имеют фиксированный размер, а сегменты — нет. На рис. 4.22, а показан
пример физической памяти, изначально содержащей пять сегментов. Рассмот-
Рассмотрим ситуацию, когда удаляется сегмент 1, а на его место помещается сегмент 7
меньшего размера. В результате мы получаем конфигурацию памяти, изображен-
изображенную на рис. 4.22, б. Между сегментом 7 и сегментом 2 оказывается неиспользуе-
неиспользуемая область, или дыра. Затем сегмент 4 замещается сегментом 5 (рис. 4.22, в),
а сегмент 3 — сегментом 6 (рис. 4.22, г). После того как система поработает ка-
какое-то время, память разделится на некоторое количество фрагментов, часть ко-
которых содержит сегменты, а часть — нет. Этот феномен разделения памяти на
маленькие свободные фрагменты называется внешней фрагментацией. С внеш-
внешней фрагментацией можно бороться путем уплотнения (рис. 4.22, д).
4.6.2. Сегментация с замещением
страниц в Intel Pentium
Pentium поддерживает 16 К независимых сегментов по 232 байт виртуальной памя-
памяти каждый. Операционная система может настроить Pentium на использование
сегментации, замещения страниц, либо того и другого вместе. Большинство опе-
операционных систем, включая Windows XP и все семейство UNIX, поддерживают
только замещение страниц, при котором каждому процессу выделяется единст-
единственный сегмент размером 232 байт. Поскольку Pentium обеспечивает выделение
процессам больших адресных пространств и одна из существующих операцион-
операционных систем (OS/2) на практике задействует все эти возможности адресации, мы
подробно рассмотрим виртуальную память Pentium.
Основой виртуальной памяти Pentium являются две таблицы: локальная (Local
Descriptor Table, LDT) и глобальная таблицы дескрипторов (Global Descriptor
Table, GDT). У каждой программы есть собственная локальная таблица дескрип-
дескрипторов, но глобальная таблица дескрипторов одна, ее совместно используют все
программы в компьютере. Локальная таблица дескрипторов описывает сегмен-
сегменты, локальные для каждой программы, — ее код, данные, стек и т. д., тогда как
глобальная таблица дескрипторов несет информацию о системных сегментах,
включая саму операционную систему.
Рис. 4.22. Решение проблемы фрагментации: a-r— развитие внешней фрагментации;
д — устранение фрагментации путем уплотнения
Чтобы получить доступ к сегменту, программа процессора Pentium сначала за-
загружает селектор этого сегмента в один из шести сегментных регистров машины.
Во время выполнения регистр CS содержит селектор сегмента кода, а регистр
DS — селектор сегмента данных. Каждый селектор представляет собой 16-раз-
16-разрядный номер (рис. 4.23).
Рис. 4.23. Селектор в системе Pentium
Один из битов селектора говорит, является ли данный сегмент локальным или
глобальным (то есть находится он в локальной или глобальной таблице дескрип-
дескрипторов). Следующие 13 бит — это номер записи в таблице дескрипторов, поэтому
размер этих таблиц ограничен: каждая содержит 8 К сегментных дескрипторов.
Остальные два бита относятся к защите и рассматриваются позже. Дескрип-
Дескриптор 0 запрещен — его можно безопасно загрузить в сегментный регистр, чтобы
показать, что сегментный регистр в данный момент недоступен, но при попытке
его использовать вырабатывается прерывание.
Во время загрузки селектора в сегментный регистр, соответствующий элемент
извлекается из локальной или глобальной таблицы дескрипторов и сохраняется
в микропрограммных регистрах, что обеспечивает к нему быстрый доступ. Деск-
Дескриптор состоит из 8 байт, в которые входят базовый адрес сегмента, размер
и другая информация (рис. 4.24).
Рис. 4.24. Дескриптор программного сегмента в системе Pentium. Сегменты данных
немного отличаются
Формат селектора сознательно продуман так, чтобы упростить определение ме-
местоположения дескриптора. Сначала выбирается локальная или глобальная таб-
таблица дескрипторов, основываясь на бите 2 селектора. Затем селектор копируется
во внутренний рабочий регистр и 3 младших бита сбрасываются в нули. Нако-
Наконец, к нему прибавляется адрес одной из таблиц, с целью получить прямой ука-
указатель на дескриптор. Например, селектор 72 ссылается на запись 9 в глобальной
таблице дескрипторов, расположенную по адресу GDT + 72.
Теперь проследим, как пара селектор-смещение преобразуется в физический ад-
адрес. Как только микропрограмма узнает, какой сегментный регистр использует-
используется, она может найти в своих внутренних регистрах полный дескриптор, соответ-
соответствующий этому селектору. Если сегмент не существует (селектор равен 0) или
в данный момент выгружен, происходит прерывание.
Затем микропрограмма проверяет, выходит ли смещение за пределы сегмента,
в этом случае также возникает прерывание. Логически, в дескрипторе просто
должно существовать 32-разрядное поле размера сегмента, но там доступны толь-
только 20 бит, поэтому действует другая схема. Если поле G (Granularity — глубина
детализации) равно 0, то поле лимита содержит точный размер сегмента, до
1 Мбайт. Если поле G равно 1, поле лимита дает размер сегмента в страницах,
а не в байтах. Размер страницы в системе Pentium фиксирован и равен 4 Кбайт,
поэтому 20 бит достаточно для сегментов размером до 232 байт.
Предположим, что сегмент находится в памяти, а смещение попало в нужный ин-
интервал. Тогда Pentium прибавляет 32-разрядное поле базы в дескрипторе к смеще-
смещению, формируя то, что называется линейным адресом, как показано на рис. 4.25.
Поле базы разбито на три части, которые разбросаны по дескриптору для совмес-
совместимости с процессором Intel 80286, где размер этого поля равен только 24 бита.
В сущности, поле базы позволяет каждому сегменту начинаться в произвольном
месте внутри 32-разрядного линейного адресного пространства.
Рис. 4.25. Преобразование пары селектор-смещение в физический адрес
Если режим замещения страниц отключен (за счет бита в глобальном управляю-
управляющем регистре), линейный адрес интерпретируется как физический адрес и посы-
посылается в память для чтения или записи. Таким образом, при отключении режима
замещения страниц мы получаем чистую схему сегментации с базовым адресом
каждого сегмента, выдаваемым его дескриптором. Сегментам разрешено пере-
перекрываться случайным образом, возможно потому, что реализация контроля за
тем, чтобы они не пересекались, была бы слишком трудоемкой и заняла бы слиш-
слишком много времени.
В то же время в режиме замещения страниц линейный адрес интерпретируется
как виртуальный адрес и отображается на физический адрес с помощью таблицы
страниц практически так же, как в наших предыдущих примерах. Единственная
серьезная трудность заключается в том, что при 32-разрядном виртуальном адресе
и странице размером 4 Кбайт сегмент может содержать 1 млн страниц, поэтому
имеет место двухуровневое отображение с целью уменьшения размера таблицы
страниц для маленьких сегментов.
У каждой работающей программы есть страничный каталог, состоящий из 32-раз-
32-разрядных записей в количестве 1024. Он расположен по адресу, хранящемуся в гло-
глобальном регистре. Каждая запись в каталоге ссылается на таблицу страниц, так-
также содержащую 1024 записей (тоже 32-разрядных). Записи в таблицах страниц,
в свою очередь, указывают на страничные блоки. Эта организация продемонст-
продемонстрирована на рис. 4.26.
Рис. 4.26. Отображение линейного адреса на физический
На рис. 4.26, а мы видим линейный адрес, разделенный на три поля: каталога,
страницы и смещения. Поле каталога используется как индекс в страничном
каталоге, определяющий расположение указателя на правильную таблицу стра-
страниц. Затем обрабатывается поле страницы в качестве индекса в таблице страниц,
с целью найти физический адрес страничного блока. И наконец, чтобы получить
физический адрес требуемого байта или слова, к адресу страничного блока при-
прибавляется последнее поле — поле смещения.
Каждая запись в таблице имеет размер 32 бита, двадцать из которых содержат
номер страничного блока. Остальные биты — это биты доступа и «грязный» бит,
задаваемые аппаратно для операционной системы, биты защиты и другие полез-
полезные биты.
Каждая таблица страниц включает в себя записи для 1024 страничных блоков
размером по 4 Кбайт, таким образом, одна таблица страниц обеспечивает управ-
управление памятью размером 4 Мбайт. Сегмент, размер которого меньше 4 Мбайт,
будет иметь страничный каталог с единственной записью — указателем на его
единственную таблицу страниц. Следовательно, в случае короткого сегмента на
поддержку таблиц страниц расходуется только две страницы вместо миллиона
в случае одноуровневой таблицы страниц.
Чтобы избежать повторных обращений к памяти, система Pentium имеет неболь-
небольшой буфер быстрого преобразования адреса (TLB), который напрямую отобра-
отображает наиболее часто используемые комбинации полей каталога и страницы на
физический адрес страничного блока. Только когда текущая комбинация от-
отсутствует в TLB, действительно выполняется процедура, которую иллюстрирует
рис. 4.26, после чего TLB обновляется. Система обладает хорошей производи-
производительностью до тех пор, пока обращения к отсутствующим в TLB страницам про-
происходят относительно редко.
Если немного поразмыслить над механизмом замещения страниц, можно прий-
прийти к выводу о том, что смысла в использовании нулевого значения поля базы
нет. Единственное, для чего нужно это поле, — обеспечить смещение, позволяющее
использовать записи, находящиеся в середине, а не в начале страничного катало-
каталога. Фактически база требуется лишь для поддержки «чистой» (без замещения
страниц) сегментации, а также для совместимости с процессором 286, в котором
режим замещения страниц всегда отключен.
Также следует отметить, что даже если приложение не требует сегментации, а до-
довольствуется единым разбитым на страницы 32-разрядным адресным простран-
пространством, эта модель все равно работает. Все сегментные регистры могут быть на-
настроены тем же самым селектором, в дескрипторе которого поле базы равно О,
а поле лимита установлено на максимум. Тогда при использовании единого ад-
адресного пространства смещение команды будет линейным адресом — в сущно-
сущности, это обычное замещение страниц. Фактически все современные операцион-
операционные системы для компьютера Pentium работают таким образом. Система OS/2
была единственной, в которой были задействованы все возможности архитекту-
архитектуры блока управления памятью (MMU) компании Intel.
В конце концов, кто-то должен похвалить разработчиков Pentium. При постав-
поставленных перед ними противоречивых задачах — реализовать «чистое» замещение
страниц памяти, «чистую» сегментацию и страничные сегменты и в то же время
обеспечить совместимость с процессором 286, а кроме того, сделать все это эф-
эффективно — то, что у них получилось, на удивление просто и понятно.
Мы, хотя и кратко, но целиком описали архитектуру виртуальной памяти про-
процессоров Pentium и теперь следует сказать несколько слов о защите, так как эта
тема тесно связана с виртуальной памятью. Pentium поддерживает четыре уров-
уровня защиты, где уровень 0 является наиболее привилегированным, а уровень 3 —
наименее привилегированным (рис. 4.27). В каждый момент времени работаю-
работающая программа находится на определенном уровне, что отмечается 2-разрядным
полем в его слове состояния программы (PSW). Каждый сегмент в системе так-
также имеет свой уровень.
До тех пор пока программа сама ограничивает использование сегментов на своем
собственном уровне, система прекрасно работает. Разрешаются попытки получе-
получения доступа к данным более высокого уровня. Попытки доступа к данным более
низкого уровня запрещены и вызывают прерывания. Попытки вызвать процеду-
процедуры различного уровня (более высокого или низкого) позволяются, но тщательно
контролируются. Чтобы сделать межуровневый вызов, инструкция CALL должна
содержать селектор вместо адреса. Этот селектор определяет дескриптор, назы-
называемый шлюзом вызова (call gate) и передающий адрес вызываемой процедуры.
Таким образом, попасть в середину произвольного сегмента кода другого уровня
невозможно, открыты лишь официальные точки входа.
Рис. 4.27. Защита в системе Pentium
Рисунок 4.27 иллюстрирует типичное применение этого механизма. На уровне 0 мы
находим ядро операционной системы, занимающееся обработкой операций ввода-
вывода, управлением памятью и другими первоочередными задачами. На уров-
уровне 1 находится обработчик системных вызовов. Пользовательские программы
этого уровня могут обращаться к процедурам для выполнения системных вызовов,
но только к определенному и защищенному списку процедур. Уровень 2 содер-
содержит библиотечные процедуры, возможно, совместно используемые несколькими
работающими программами. Пользовательские программы вправе вызывать эти
процедуры и читать их данные, но не могут их изменять. И наконец, пользова-
пользовательские программы работают на наименее защищенном уровне 3.
В программные и аппаратные прерывания заложен механизм, аналогичный шлю-
шлюзам вызовов. Они тоже обращаются к дескрипторам, а не к абсолютным адресам,
а эти дескрипторы указывают на определенные процедуры. Поле типа на рис. 4.24
позволяет различать программные сегменты, сегменты данных и шлюзы вызовов
различных видов.
4.7. Знакомство с менеджером
процессов в MINIX 3
В MINIX 3 управление памятью реализовано элементарно: ни замещение стра-
страниц, ни подкачка попросту не используются. Тем не менее код поддержки под-
подкачки входит в полную версию операционной системы и позволяет применять
MINIX 3 в условиях нехватки физической памяти. На практике объемы памяти
таковы, что к подкачке приходится прибегать достаточно редко.
В этой главе мы изучим сервер, работающий в пользовательском пространстве
и называемый менеджером процессов (Process Manager, PM). Менеджер про-
процессов обрабатывает системные вызовы, связанные с управлением процессами.
Среди этих вызовов есть и те, которые тесно связаны с управлением памятью,
в частности fork, exec и brk. Управление процессами также включает обработ-
обработку системных вызовов, имеющих отношение к сигналам, установке и считыва-
считыванию свойств процессов (к примеру, пользователя и группы, владеющих процес-
процессом), времени работы процессора. Кроме того, менеджер процессов в MINIX 3
устанавливает и опрашивает часы реального времени.
Иногда мы называем часть менеджера процессов, осуществляющую управление
памятью, менеджером памяти. Возможно, в будущих версиях функции управле-
управления процессами и памятью будут полностью разделены, однако в MINIX 3 они
интегрированы в один процесс.
Менеджер процессов поддерживает список свободных участков памяти («дыр»),
отсортированный по адресам. Когда процессу вследствие вызова fork или exec
требуется память, элементы списка перебираются до тех пор, пока не обнаружи-
обнаруживается первая достаточно большая дыра. В отсутствие подкачки процесс, распо-
расположившись в памяти, всегда остается на прежнем месте до своего завершения.
Он никогда не выгружается на диск и не перемещается по другому адресу. Кроме
того, он никогда не увеличивает и не уменьшает выделенную ему область памяти.
Такая стратегия требует некоторых пояснений. Ее определяют три фактора.
1. Желание сделать систему максимально простой для понимания.
2. Архитектура оригинального процессора IBM PC (Intel 8088).
3. Желание обеспечить простоту переноса MINIX 3 на другие аппаратные плат-
платформы.
Поскольку MINIX 3 представляет собой обучающую систему, было крайне жела-
желательно не усложнять ее. Размер исходного кода в 250 страниц был сочтен доста-
достаточным. Так как система разрабатывалась для оригинального компьютера IBM
PC, у которого не было даже блока управления памятью, на начальном этапе
обеспечить поддержку замещения страниц было невозможно. Другие компьюте-
компьютеры в то время также были лишены блока управления памятью, а, следовательно,
выбранная стратегия управления памятью упрощала задачу переноса системы на
платформы Macintosh, Atari, Amiga и др.
Разумеется, правомерным является вопрос: а имеет ли смысл описанная страте-
стратегия на сегодняшний день? Первый пункт до сих пор актуален, хотя система зна-
значительно расширилась с течением времени. Тем не менее появились и несколь-
несколько новых важных факторов. Память современных компьютеров по объему в 1000
с лишним раз превышает память первых машин IBM PC. Хотя и программы ста-
стали больше, памяти большинства систем достаточно для того, чтобы не прибегать
к подкачке и замещению страниц. Наконец, система MINIX 3 в определенной
степени рассчитана на низкопроизводительные и встроенные системы. Цифровые
камеры, DVD-плееры, аудиоаппаратура, сотовые телефоны и прочее оборудование
зачастую имеют операционную систему, однако, очевидно, не поддерживающую
подкачку и замещение страниц. Поскольку система MINIX 3 рассчитана на при-
прикладное применение, ни подкачка, ни замещение страниц не являются для нее
высокоприоритетными задачами. Тем не менее в настоящее время анализируется
возможность реализации в MINIX 3 простейших механизмов виртуальной памяти.
Сведения о текущих разработках можно получить на веб-сайте MINIX.
Следует обратить внимание на еще одну особенность управления памятью в
MINIX 3, отличающую ее от большинства других операционных систем. Менед-
Менеджер процессов является не частью ядра, а процессом, выполняющимся в пользо-
пользовательском пространстве и взаимодействующим с ядром при помощи стандарт-
стандартного механизма сообщений. Местоположение менеджера процессов в структуре
операционной системы иллюстрирует рис. 2.14.
Исключение менеджера процессов из ядра — пример разделения политики и ме-
механизма. Решение о том, какая область памяти будет отведена каждому из процес-
процессов (политика), принимается менеджером процессов. Реальное же обслуживание
карт памяти для процессов (то есть механизм) выполняется системным заданием
ядра. Подобное разделение позволяет легко изменить политику управления па-
памятью (алгоритмы и т. д.), не затрагивая нижние уровни операционной системы.
Большая часть кода менеджера процессов в MINIX 3 относится к обработке сис-
системных вызовов, связанных с созданием процессов (в основном это fork и exec),
а не манипулированию списками процессов и свободных блоков памяти. В сле-
следующем разделе мы изучим распределение памяти, а еще дальше последует об-
обзор процедур обработки системных вызовов менеджером процессов.
4.7.1. Распределение памяти
Программы в MINIX 3 могут быть скомпилированы так, чтобы использовать
объединенное пространство данных и кода. В этом случае под все составные час-
части процесса (текст, данные и стек) выделяется единый блок памяти. Этот блок
используется ими совместно и освобождается единовременно. Такая схема распре-
распределения памяти применялась по умолчанию в исходной версии MINIX. В MINIX 3,
напротив, по умолчанию принято компилировать программы с раздельными про-
пространствами данных и кода. Для ясности мы сначала рассмотрим более простую
модель с общей памятью. Процессы с раздельными пространствами данных и ко-
кода позволяют расходовать память эффективнее, но при этом возникают сложно-
сложности, которые мы изучим позднее.
В обычном режиме выделение памяти в MINIX 3 происходит в двух ситуациях.
Во-первых, когда процесс разветвляется, дочернему процессу предоставляется
необходимая ему память. Во-вторых, когда процесс при помощи системного
вызова exec заменяет свой образ, старый образ памяти процесса возвращается
в список свободных блоков памяти, а новая память выделяется на новом месте.
Положение нового образа процесса в памяти зависит от того, где найден первый
подходящий по размеру блок. Кроме того, когда процесс завершается (самостоя-
(самостоятельно или принудительно, по сигналу), занятая им память освобождается. Име-
Имеет место и третий случай, в котором системный процесс запрашивает память под
собственные нужды. Например, драйвер памяти может запросит память под вир-
виртуальный диск. Это возможно лишь на этапе инициализации системы.
На рис. 4.28 показаны оба варианта выделения памяти. На рис. 4.28, а мы ви-
видим в памяти два процесса, А и В. Если процесс А разветвляется, мы попадаем
в ситуацию, представленную на рис. 4.28, б. Дочерний процесс является точной
копией процесса А. Если теперь дочерний процесс выполнит файл С, память
придет в состояние, показанное на рис. 4.28, в. Образ дочернего процесса был
заменен образом С.
Рис. 4.28. Выделение памяти: а — исходное состояние; б — состояние после
вызова fork; б — дочерний процесс сделал вызов exec. Неиспользованные
области памяти отмечены штриховкой. Код и данные процесса находятся
в одном адресном пространстве
Обратите внимание, что область памяти, занимаемая потомком, освобождается
перед тем, как выделить память для нового образа, поэтому С может занять па-
память, в которой раньше располагался потомок. Таким образом, после выпол-
выполнения нескольких пар вызовов fork и exec все процессы будут соседствовать
в памяти впритирку друг к другу. Если бы память для нового образа выделялась
первой, между процессами обязательно зияли бы дыры.
Добиться такого результата непросто. Представим себе возможное состояние
ошибки, когда памяти для выполнения вызова exec оказывается недостаточно.
Чтобы дочерний процесс мог каким-либо образом среагировать на ошибку, опре-
определение объема памяти, необходимой для выполнения операции, должно выпол-
выполняться до освобождения памяти дочерним процессом. Это означает, что память
дочернего процесса нужно рассматривать как свободную, в то время как она еще
используется.
Когда память распределяется по вызову fork или exec, некоторая ее часть от-
отдается новому процессу. В первом случае запросы дочернего и родительского
процессов удовлетворяются в равной мере. Во втором — менеджер процессов
оперирует значением из заголовка исполняемого файла. После того как память
однажды выделена, ни при каких условиях процесс не может посягнуть на до-
дополнительную память.
Сказанное относится к программам, которые были скомпилированы с объеди-
объединенными адресными пространствами кода и данных. Программы, у которых эти
пространства разделены, получают улучшенный механизм управления памятью,
который называется общим кодом (shared text). Когда подобный процесс делает
вызов fork, память выделяется только под стек и данные дочернего процесса.
Потомок получает в наследство исполняемый код, который используется роди-
родительским процессом. Когда делается вызов exec, в таблице процессов ищется
процесс, уже применяющий требуемый код. Если такой процесс обнаруживает-
обнаруживается, память, опять же, выделяется только для данных и стека. Однако разделение
кода усложняет завершение процесса. При завершении процесса всегда осво-
освобождается память, занимаемая его данными и стеком. Память же, занимаемая
сегментом текста, освобождается только тогда, когда поиск в таблице процессов
показал, что ни один другой процесс этот код больше не интересует. Может по-
получиться так, что процессу при запуске выделяется больше памяти, чем освобо-
освобождается при его завершении. Мы говорим про случай, когда при запуске процесс
загружает собственный код, а по окончании оказывается, что этот код уже ис-
используется другими процессами.
На рис. 4.29 показано, как программа хранится в виде файла на диске и как она
располагается в памяти, когда MINIX 3 запускает процесс. Информация о раз-
размерах различных частей образа процесса находится в заголовке файла, так же
как и сведения о его полном размере. Для программы с объединенными адресны-
адресными пространствами кода и данных в заголовке указывается суммарный размер
двух частей, они копируются напрямую в образ в памяти. Для сегмента данных
образа при копировании в память выделяется больший объем. Размер дополни-
дополнительной области памяти в байтах хранится в поле bss заголовка. Эта область
заполняется нулями и используется для неинициализированных статических
данных. Общий объем памяти, который будет выделен процессу, задается по-
полем общего размера в заголовке. Если, например, у программы код имеет размер
4 Кбайт, данные плюс дополнительный объем занимают 2 Кбайт, стек — 1 Кбайт,
а в заголовке указано выделить всего 40 Кбайт, то неиспользуемый промежуток
памяти между сегментами данных и стека будет иметь размер 33 Кбайт. Кроме
того, программа на диске может содержать символьную таблицу. Она требуется
для отладки и не загружается в память.
Рис. 4.29. Распределение памяти для программы: а — программа хранится на диске в виде
файла; б — внутреннее распределение памяти для одного процесса. На обеих частях
рисунка в нижней части расположены нижние адреса
Если программист знает, что общий объем памяти, необходимый для стека и дан-
данных программы в файле а. out, не превышает 10 Кбайт, то при помощи следую-
следующей команды он может изменить поле заголовка исполняемого файла:
chmem = 10240 a.out
После этого вызов exec будет выделять только 10 240 байт дополнительной па-
памяти. Так, для описанного примера будет выделено 16 Кбайт памяти. Из этой
памяти верхний килобайт отводится под стек, а 9 Кбайт образуют свободную об-
область для будущего роста стека и (или) области данных.
Для программ с раздельными адресными пространствами кода и данных (у кото-
которых компоновщик устанавливает специальный бит в заголовке программы) по-
поле общего размера в заголовке относится только к стеку и данным. Так, при за-
загрузке программы с 4 Кбайт кода, 2 Кбайт данных, 1 Кбайт стека и суммарным
размером 64 Кбайт будет выделено 68 Кбайт памяти D Кбайт на код, 64 Кбайт
образуют адресное пространство данных, а 61 Кбайт останется для роста стека
и данных). Граница сегмента данных может быть изменена только при помощи
системного вызова brk. При выполнении этого вызова проверяется, не упирает-
упирается ли новая граница сегмента данных в нижнюю границу стека, и соответствую-
соответствующие изменения вносятся во внутренние таблицы. Это делается исключительно
внутри памяти, выделенной процессу, поскольку у операционной системы не за-
запрашивается никаких новых блоков. Если же после изменения границы сегмент
данных будет пересекаться со стеком, вызов завершается ошибкой.
Тут нужно упомянуть небольшую семантическую сложность. Когда мы говорим
«сегмент», мы имеем в виду область памяти, определяемую операционной систе-
системой. Но у процессоров Intel 80x86 есть специальные внутренние сегментные ре-
регистры и (у более новых из них) таблицы дескрипторов сегментов, обеспечи-
обеспечивающие аппаратную поддержку «сегментов». Концепция сегмента в архитектуре
Intel сходна с тем, как сегменты определяются в MINIX 3, но это — не одно и то
же. Все ссылки на сегменты в этом тексте следует рассматривать в контексте их
определения в MINIX 3. Когда мы будем говорить об аппаратных сегментах, мы
явно укажем сегментные регистры и дескрипторы сегментов.
Это предупреждение может быть обобщено. Разработчики аппаратного обеспече-
обеспечения часто целенаправленно стараются реализовать поддержку на своем оборудова-
оборудовании конкретных операционных систем. Поэтому терминология описания регистров
и других аспектов архитектуры процессора обычно отражает то, как все это будет
использоваться. Подобные возможности часто полезны для разработчиков опера-
операционной системы, но практика не обязательно соответствует идеям производителя
оборудования. В результате термины, звучащие одинаково, но имеющие разное зна-
значение для операционной системы и оборудования, могут привести к непониманию.
4.7.2. Обработка сообщений
Как и все остальные компоненты ОС MINIX 3, менеджер памяти управляется
с помощью сообщений. После инициализации системы менеджер памяти входит
в свой главный цикл, в котором сообщение принимается, выполняется содержа-
содержащийся в сообщении запрос и отправляется ответное сообщение.
Менеджер процессов может получать две категории сообщений. Для высокопри-
высокоприоритетного взаимодействия между ядром и системными серверами служат сис-
системные уведомления. Это особые сообщения, которые рассмотрены в части этой
главы, посвященной реализации. Большинство сообщений, получаемых менед-
менеджером процессов, создаются в результате системных вызовов, выполняемых
пользовательским процессом. Допустимые типы сообщений этой категории, вход-
входные параметры и возвращаемые значения перечислены в табл. 4.3.
Таблица 4.3. Типы и параметры сообщений для менеджера памяти и ответные значения
Тип сообщения Параметры Ответное значение
fork Нет PID потомка
exit Код возврата При успехе без ответа
wait Нет Состояние
waitpid Нет Состояние
brk Новый размер Новый размер
exec Указатель на исходный стек При успехе без ответа
kill Идентификатор процесса и сигнал Состояние
alarm Время ожидания в секундах Оставшееся время
pause Нет При успехе без ответа
sigaction Номер сигнала, код операции, старый код Состояние
операции
sigsuspend Маска сигналов При успехе без ответа
sigpending Нет Состояние
sigprocmask Способ изменения, новый набор, старый набор Состояние
sigreturn Контекст Состояние
getuid Нет Идентификатор UID и его
действующее значение
getgid Нет Идентификатор GID и его
действующее значение
getpid Нет Идентификатор PID и его
действующее значение
setuid Новый идентификатор UID Состояние
setgid Новый идентификатор GID Состояние
setsid Новый идентификатор SID Группа процессов
getpgrp Новый идентификатор GID Группа процессов
ptrace Запрос, PID, адрес, данные Состояние
reboot Действие (останов, перезагрузка, сбой) При успехе без ответа
svrctl Запрос, данные (в зависимости от функции) Состояние
getsysinfo Запрос, данные (в зависимости от функции) Состояние
getprocnr Нет Номер процедуры
memalloc Размер, указатель на адрес Состояние
memfree Размер, адрес Состояние
getpriority PID, тип, значение Приоритет
setpriority PID, тип, значение Приоритет
gettimeofday Нет Время, время работы
Вызовы fork, exit, wait, waitpid, brk и exec тесно связаны с выделением
и освобождением памяти. Вызовы kill, alarm и pause связаны с сигналами,
такими как sigaction, sigsuspend, sigpending, sigmask и sigreturn.
Они оказывают влияние и на память, так как при завершении процесса по сигна-
сигналу занимаемая этим процессом память высвобождается. Семь вызовов get/set
не имеют никакого отношения к управлению памятью, но, очевидно, связаны
с управлением процессами. Остальные вызовы с одинаковым успехом могли бы
обрабатываться и менеджером процессов, и файловой системой, поскольку дру-
других компонентов, которые могли бы их обслужить, нет. Они были помещены в код
менеджера процессов просто потому, что код файловой системы и без того доста-
достаточно объемен. Вызов ptrace, применяемый при отладке, а также вызовы time,
stime и times попали сюда по той же причине.
Вызов reboot действует в масштабе всей системы, однако его главным назначени-
назначением является передача сигналов для контролируемого завершения всех процессов,
поэтому было логично поместить его в менеджер процессов. То же касается и вызо-
вызова svrctl, основное применение которого — включение и отключение подкачки.
Возможно, вы заметили, что последние два упомянутых вызова, reboot и svrctl,
не приведены в табл. 1.1. То же касается и других системных вызовов, представ-
представленных в табл. 4.3: getsysinfo, getprocnr, memalloc, memfree и get set-
priority. Все они не предназначены для обычных пользовательских процес-
процессов и не являются частью стандарта POSIX. Они нужны лишь операционным
системам, подобным MINIX 3. В системах с монолитным ядром действия, вы-
выполняемые этими вызовами, могли бы осуществляться функциями, встроенны-
встроенными в ядро. Однако в MINIX 3 традиционные компоненты операционной системы
выполняются в пользовательском пространстве, что и требует дополнительных
системных вызовов. Некоторые системные вызовы несут чуть больше функций,
чем обеспечение интерфейсов с вызовами ядра (имеются в виду вызовы, запра-
запрашивающие различные службы ядра у системного задания).
Как отмечалось в главе 1, несмотря на наличие библиотечной подпрограммы
sbrk, одноименного системного вызова не существует. Подпрограмма вычисля-
вычисляет объем необходимой памяти, инкрементируя или декрементируя текущий раз-
размер согласно передаваемому параметру, и выполняет вызов brk для установки
нового размера. Аналогично, не существует отдельных системных вызовов для
функций geteuid и getegid. Вызовы getuid и getpid возвращают соответ-
соответственно эффективный и реальный идентификаторы. Аналогично, getpid воз-
возвращает идентификаторы вызывающего процесса и его родителя.
Ключевой структурой данных для обработки сообщений является call_vec,
определяемая в файле table. с. Она содержит указатели на подпрограммы, об-
обрабатывающие все типы сообщений. Когда сообщение попадает в менеджер про-
процессов, команды в главном цикле извлекают из него тип сообщения и записыва-
записывают его в глобальную переменную call_nr. Позже это значение используется
как индекс в таблице call_vec, и по нему находится адрес подпрограммы для
обработки прибывшего сообщения. Затем эта подпрограмма отрабатывает, выпол-
выполняя системный вызов. Значение, которое возвращает обработчик, отправляется
обратно, чтобы сообщить о выполнении или ошибке. Этот механизм подобен ме-
механизму обработки системных вызовов (шаг 7 на рис. 1.12), но только в адрес-
адресном пользовательском пространстве, а не в пространстве ядра.
4.7.3. Структуры данных и алгоритмы
менеджера процессов
У менеджера процессов есть две ключевые структуры данных: таблица процес-
процессов и таблица свободных блоков памяти.
Из табл. 2.1 видно, что одни поля таблицы процессов необходимы ядру, дру-
другие нужны для управления процессами, а третьи требуются файловой системе.
В MINIX 3 каждая из трех частей операционной системы поддерживает собст-
собственную таблицу процессов, содержащую только те поля, которые интересны ей.
Записи всех трех таблиц соответствуют друг другу, чтобы не усложнять дело.
Так, ячейка k таблицы процессов менеджера процессов соответствует тому же
процессу, что и ячейка k таблицы процессов файловой системы. При создании
или уничтожении процесса необходимо обновлять записи во всех трех таблицах,
чтобы поддерживать их в согласованном состоянии.
Исключения составляют процессы, не видимые за пределами ядра. К ним от-
относятся встроенные в ядро таймерное и системное задания (CLOCK и SYSTEM),
а также «заполнители» IDLE и KERNEL. В таблице процессов ядра их номера отри-
отрицательны, а в таблицах менеджера процессов и файловой системы соответствую-
соответствующих им записей вообще нет. Таким образом, строго говоря, утверждение о ячейках
таблиц с номером k справедливо лишь при значении ky большем или равном 0.
Процессы в памяти
Таблица процессов менеджера процессов называется mproc, она определена
в файле src/ servers /pm/mproc .h. В этой таблице содержатся поля, связанные
с выделением памяти, а также некоторые дополнительные сведения. Самым важ-
важным полем является массив mp_seg, у которого есть три записи, для сегмента
текста (кода), данных и стека. Все его элементы представляют собой структуры,
содержащие виртуальный и физический адреса, а также длину сегмента, причем
эти величины измеряются не в байтах, а в кликах. Размер клика (минимального
блока памяти) зависит от реализации. В ранних версиях MINIX используется
значение 256 байт, а в MINIX 3 — 1024 байта. Все сегменты начинаются на гра-
границе клика и содержат целое число кликов.
Способ записи информации о выделении памяти иллюстрирует рис. 4.30. На ри-
рисунке показан процесс с такой структурой: 3 Кбайт кода, 4 Кбайт данных, зазор
имеет величину 1 Кбайт, а после него следует стек объемом 2 Кбайт. Всего вы-
выделено 10 Кбайт памяти. На рис. 4.30, б показано, что хранится в полях длины
и виртуального и физического адресов для этих сегментов при условии, что
процесс не разделяет адресные пространства кода и данных. В этой модели
размер сегмента кода всегда считается равным нулю, а сегмент данных содержит
и данные, и код. Когда показанный на рисунке процесс обращается к виртуаль-
ному адресу 0 или совершает переход по этому адресу, происходит обращение
к физическому адресу 0x32000 (в десятичной записи — 200 К). В кликах этот
адрес записывается как 0хс8.
Рис. 4.30. Способ записи информации о выделении памяти: а — процесс в памяти;
б — представление процесса с единым адресным пространством данных и кода;
в — представление процесса с раздельными пространствами данных и кода
Нужно отметить, что виртуальный адрес, с которого начинается стек, зависит от
общего объема памяти, выделенной процессу. Так, если при помощи команды
chmem модифицировать заголовок исполняемого файла, чтобы при запуске для
программы резервировалось больше динамически распределяемой памяти (проме-
(промежуток между сегментами стека и данных), то при следующем запуске программы
начало стека будет расположено выше. Если стек вырастет на один клик, его запись
должна измениться с тройки @x8, OxdO, 0x2) на тройку @x7, Oxcf, 0x3). Обратите
внимание на то, что в этом примере рост стека на один клик привел бы к исчез-
исчезновению промежутка, если бы общий объем выделенной памяти не увеличился.
Аппаратное обеспечение процессоров 8088 не поддерживает прерывание пере-
переполнения стека, и в MINIX стек задается так, чтобы на 32-разрядных процес-
процессорах не инициировать прерывание до тех пор, пока сегмент стека не пересечется
с сегментом данных. Таким образом, информация о стеке будет обновлена толь-
только при следующем системном вызове brk, при этом операционная система явно
считывает значение SP (указатель стека) и пересчитывает параметры стека. На
машинах, поддерживающих аппаратный контроль переполнения стека, инфор-
информация о стеке должна обновляться, как только стек переполнит свой сегмент.
По причинам, которые мы далее обсудим, в 32-разрядной версии MINIX 3 для
процессоров Intel этого не делается.
Ранее мы уже упоминали, что усилия разработчиков аппаратного обеспечения
не всегда приводят к тем результатам, которые нужны программистам. Даже ра-
работая в защищенном режиме Pentium, MINIX 3 не отслеживает ситуацию, когда
стек переполняет свой сегмент. Хотя в этом режиме MINIX 3 обрабатывает попыт-
попытки обратиться к памяти за пределами сегмента, параметры которого определены
дескриптором сегмента (см. рис. 4.24), в MINIX 3 дескрипторы сегмента данных
и стека всегда идентичны. В MINIX 3 стек и данные находятся в едином адрес-
адресном пространстве, и благодаря этому они могут расширяться за счет межсегмент-
межсегментного зазора. Но это не более чем внутреннее представление MINIX 3. С точки
зрения процессора при обращении к памяти между сегментами нет никакой
ошибки, так как она является частью общего сегмента данных и стека. Аппарат-
Аппаратное обеспечение помогает отслеживать серьезные ошибки, например попытки
обращения к памяти за пределами комбинированной области из данных, зазора
и стека, благодаря чему один процесс можно защитить от ошибок другого про-
процесса, но уберечь процесс самого от себя таким образом нельзя.
MINIX 3 это делает сознательно. Если у вас есть аргументы за то, чтобы отка-
отказаться от разделяемого аппаратного сегмента и зазора, мы не будем спорить. Аль-
Альтернативой могут быть два раздельных аппаратных сегмента для стека и данных.
Такой подход обеспечивает большую безопасность в отношении некоторых оши-
ошибок, но превращает MINIX 3 в чудовище, пожирающее память. Исходные коды
системы открыты для всех, кто желает поэкспериментировать с таким подходом.
На рис. 4.30, в показано, как будут определены сегменты в случае раздельных ад-
адресных пространств кода и данных. Здесь уже и сегмент стека, и сегмент данных
имеют ненулевую длину. Показанный на рис. 4.30, бив массив mp_seg большей
частью применяется для преобразования виртуальных адресов в физические.
Зная виртуальный адрес и адресное пространство, которому он принадлежит,
несложно проверить, является этот адрес допустимым (то есть попадает ли он
в сегмент), и рассчитать, какому физическому адресу он соответствует. Напри-
Например, такое преобразование осуществляет вспомогательная подпрограмма шпар_
local, которую задания ввода-вывода привлекают для обмена данными с поль-
пользовательскими процессами.
Общий код
При выполнении процесса содержимое его областей данных и стека может ме-
меняться, но код не меняется никогда. Часто случается, что несколько процессов
выполняют одну и ту же программу, например, несколько пользователей могут
работать с одной оболочкой. Поэтому общий код повышает эффективность памя-
памяти. Когда системный вызов exec собирается загрузить процесс, он открывает
файл с образом этого процесса и считывает заголовок. Если у процесса раздель-
раздельные адресные пространства кода и данных, среди всех ячеек таблицы mproc осу-
осуществляется поиск по полям mp_dev, mp_ino, mp_ctime. Эти поля содержат
информацию о номере индексного узла и времени модификации образов, испол-
исполняемых другими процессами. Если обнаруживается процесс, который уже вы-
выполняет нужную программу, то выделять память под еще одну копию кода не
нужно. Вместо этого в карту памяти нового процесса в поле mp_seg [T] записы-
записывается указатель на ту область памяти, где уже хранится код, а память выделяет-
выделяется только под данные и стек (рис. 4.31). Если загруженного образа найдено не
было или адресные пространства кода и данных объединены, память выделяется
согласно рис. 4.30 и заполняется данными с диска.
Рис. 4.31. Использование общего кода: а — карта памяти для раздельных адресных
пространств кода и данных, как на предыдущем рисунке; б — распределение памяти после
запуска второго процесса, выполняющего тот же код; в — карта памяти второго процесса
Помимо информации о сегментах, mproc хранит идентификатор самого процес-
процесса и его родителя, идентификаторы пользователя и группы (реальное и эффек-
эффективное значения), информацию о сигналах и код возврата, если процесс уже за-
завершился, но его родитель еще не завершил вызов wait. В mproc есть поля
таймера для si gal arm, а также накопленного времени пользователя и системы
для дочерних процессов. В ранних версиях MINIX за эти поля отвечало ядро,
однако в MINIX 3 это делает менеджер процессов.
Список свободных участков
Таблица свободных участков памяти, hole, заданная в файле src/servers/
pm/alloc.c, является другой важнейшей таблицей менеджера процессов. За-
Записи в этой таблице расположены в порядке возрастания адресов памяти. Про-
Промежутки между сегментами стека и данных зарезервированы для определенного
процесса и не считаются незанятыми участками памяти, поэтому они не входят
в эту таблицу. Каждая запись таблицы «дыр» содержит три поля: базовый адрес
свободного блока памяти в кликах, длину блока тоже в кликах и указатель на
следующую запись в списке. Список является односвязным, другими словами,
зная одну запись, легко найти любую следующую, но если необходимо найти
предшествующую запись, придется перебирать список с самого начала. Из-за ог-
ограниченности объема книги текст файла alloc. с в ней не приведен. Вы можете
найти этот файл на компакт-диске. Тем не менее код, определяющий список
свободных участков, прост и приведен в листинге 4.1.
Листинг 4.1. Список свободных участков представляет собой массив структур hole
PRIVATE struct hole {
struct hole *h_next; /* Указатель на следующий элемент списка дыр */
phys_clicks h_base; /* Начало списка */
phys_clicks h_len; /* Размер списка*/
} hole[NR_HOLES];
Причина, по которой положение сегментов и свободных блоков измеряется
в кликах, а не в байтах, проста — это более эффективно. В 16-разрядном режиме
для записи адресов памяти используются 16-разрядные целые числа, что позво-
позволяет при размере клика 1024 байт поддерживать до 64 Мбайт памяти. В 32-раз-
32-разрядном режиме таким образом может адресоваться до 242 байт B32 х 210), что со-
составляет 4096 Гбайт.
Основными действиями над списком свободных участков являются выделение
блока заданного размера и освобождение ранее выделенного блока. При выделении
блока список просматривается в порядке возрастания адресов, пока не обнару-
обнаруживается достаточно большой свободный блок. Затем свободный участок умень-
уменьшается на величину выделенного сегмента или же, в том редком случае когда
размер «дыры» равен затребованному размеру блока, свободный участок вовсе
исключается из списка. Это — быстрый и простой механизм, но он подвержен
как внутренней (при выделении блока может быть впустую израсходовано до
1023 байт, так как всегда выделяется целое число кликов), так и внешней фраг-
фрагментации.
Когда процесс завершается и удаляется из памяти, память, выделенная под дан-
данные и стек, возвращается в список свободных блоков. Если адресные простран-
пространства кода и данных процесса объединены, это означает, что возвращается вся за-
занятая процессом память, поскольку выделение отдельного блока под код здесь
не предусмотрено. Если адресные пространства разделены и обнаруживается,
что код процесса больше никем не используется, то занятая кодом память также
высвобождается. При возврате блока в список свободных участков он, если
это возможно, объединяется с соседними свободными блоками, соответственно,
двух смежных свободных участков никогда не возникает. Таким образом, при
работе системы постоянно меняются количество, положение и размеры свобод-
свободных участков памяти. Когда все пользовательские процессы завершаются, вся
свободная память вновь готова к распределению. Она не обязательно образует
один сплошной блок, так как физическая память может прерываться областями,
недоступными даже операционной системе. Например, в IBM PC-совместимых
системах доступна память ниже 640 Кбайт и выше 1 Мбайт, а промежуток между
этими адресами занят постоянной памятью и памятью, зарезервированной для
операций ввода-вывода.
4.7.4. Системные вызовы fork, exit и waif
Когда создаются или уничтожаются процессы, необходимо выделять и освобож-
освобождать память. Кроме того, нужно обновлять таблицу процессов, в том числе и те
ее части, которые поддерживаются ядром и файловой системой. Эту деятельность
координирует менеджер процессов. За создание процесса отвечает вызов fork,
выполняющийся за несколько шагов. Эта последовательность такова.
1. Проверить, заполнена ли таблица процессов.
2. Попытаться выделить память для данных и стека дочернего процесса.
3. Скопировать содержимое данных и стека родительского процесса в память
потомка.
4. Найти свободную ячейку в таблице процессов и скопировать в нее запись ро-
родительского процесса.
5. Поставить на учет карту памяти дочернего процесса в таблице процессов.
6. Выбрать идентификатор (PID) для дочернего процесса.
7. Передать информацию о потомке ядру и файловой системе.
8. Сообщить ядру сведения о карте памяти потомка.
9. Отправить дочернему и родительскому процессам ответные сообщения.
Остановить вызов fork на полпути сложно и неудобно, поэтому менеджер про-
процессов, чтобы всегда знать, есть ли свободные ячейки в таблице процессов, под-
поддерживает счетчик существующих процессов. Если таблица еще не заполнена,
делается попытка выделить память под данные и стек дочернего процесса. Для
процессов с разделенными пространствами кода и данных запрашивается только
память, достаточная для размещения стека и данных. Если этот шаг пройден
успешно, fork гарантированно выполняется. Затем выделенная область памя-
памяти заполняется, в таблице процессов находится и заполняется ячейка нового
процесса, для него выбирается PID и другие части системы информируются
о создании нового процесса.
Процесс полностью завершается только по факту наступления двух следующих
событий:
♦ Процесс закончил выполняться (самостоятельно или по сигналу).
♦ Родительский процесс, чтобы выяснить, чем все закончилось, выполнил сис-
системный вызов wait.
Процесс, прекративший выполняться или завершенный по сигналу, при условии,
что его родитель еще не выполнил вызов wait, попадает в своего рода состояние
зомби. Он исключается из планирования, сигнальный таймер у него отключается
(если он был включен), но процесс остается в таблице процессов. Память про-
процесса при этом освобождается. В состоянии зомби процесс находится временно,
и оно редко длится долго. Когда родительский процесс наконец выполняет вы-
вызов wait, занятая ячейка в таблице процессов освобождается, и файловая систе-
система и ядро уведомляются об этом.
Проблема возникает в случае, если родитель завершающегося процесса сам уже
завершен. Если не предпринять никаких действий, потомок станет полноправным
зомби. Поэтому таблицы загодя меняются так, чтобы процесс стал потомком про-
процесса init. При запуске системы процесс in it считывает файл /etc/ttytab
с информацией обо всех терминалах и для обслуживания каждого терминала
ответвляет от себя дочерний процесс. Затем он входит в состояние блокировки,
ожидая уведомлений о завершении. Таким образом, осиротевшие зомби быстро
добиваются.
4.7.5. Системный вызов exec
Когда с терминала поступает команда, оболочка ответвляет новый процесс, который
выполняет запрошенную команду. Этим мог бы заняться один системный вызов,
который бы одновременно решал задачи вызовов fork и exec, но они разделены
по одной очень веской причине: чтобы упростить реализацию перенаправления
ввода-вывода. Если стандартный ввод перенаправлен и оболочка выполняет ветв-
ветвление, то потомок, перед тем как выполнить команду, закрывает стандартный
ввод, а затем открывает новый. Таким образом, запущенный процесс наследует
перенаправление стандартного ввода. То же относится и к стандартному выводу.
Системный вызов exec является самым сложным в MINIX 3. Он должен за-
заменить текущий образ процесса новым и, в том числе, установить новый стек.
Разумеется, образ должен быть исполняемым двоичным файлом. Допустимо,
чтобы исполняемый файл представлял собой сценарий, интерпретируемый дру-
другой программой, например оболочкой или программой perl. В этом случае в об-
образ помещается двоичный код интерпретатора, а имя сценария передается ему
в качестве аргумента. В данном разделе мы рассмотрим простой пример вызова
exec для бинарного исполняемого файла, а при обсуждении реализации выяс-
выясним, что ему нужно дополнительно сделать для исполнения сценария.
Этапы выполнения этого системного вызова.
1. Проверить, является ли файл исполняемым.
2. Считать из заголовка файла размеры сегментов и общий требуемый объем
памяти.
3. Узнать у выполнившего запуск процесса аргументы и переменные окружения.
4. Выделить область памяти и освободить старую область.
5. Копировать в новый образ стек.
6. Записать в новый образ в памяти данные (и, возможно, код).
7. Проверить и, если они установлены, обработать биты setuid, setgid.
8. Подправить запись в таблице процессов.
9. Сообщить ядру, что процесс готов к запуску.
Каждый из шагов сам, в свою очередь, состоит из серии более мелких шагов, неко-
некоторые из них могут завершиться неудачей. Например, доступной памяти может
не хватить для запуска процесса. Порядок, в котором производятся проверки,
продуман так, чтобы гарантировать, что старый образ процесса в памяти остает-
остается до тех пор, пока не будет уверенности, что вызов exec завершится успехом.
Это делается во избежание ситуации, когда новый образ сформировать невозмож-
невозможно, а к старому уже не вернуться. Как правило, вызов exec не передает управле-
управление обратно, но если вызов «провалился», процесс вновь получает управление
и уведомляется об ошибке.
Некоторые из перечисленных шагов нуждаются в небольшом пояснении. Преж-
Прежде всего, это вопрос о том, достаточно ли для нового процесса места. После того
как выяснена потребность в памяти (с возможными проверками, есть ли уже за-
запущенные процессы с тем же кодом), то, чтобы узнать, достаточно ли памяти,
просматривается список свободных блоков. Это делается до освобождения ста-
старой памяти, так как в противном случае, если памяти не хватит, вернуть старый
образ будет проблематично.
Однако такая проверка чересчур строга. Иногда отклоняется вызов exec, кото-
который, фактически, мог бы быть выполнен. Например, предположим, что выпол-
выполняющий вызов exec процесс занимает 20 Кбайт и другие процессы его код не
разделяют. Далее, представим, что есть свободный блок объемом 30 Кбайт, а но-
новый образ требует 50 Кбайт памяти. Выполняя проверку до освобождения памя-
памяти, мы обнаружим, что доступно только 30 Кбайт памяти, и вызов будет откло-
отклонен. Если бы память сначала высвобождалась, то вызов мог бы быть выполнен,
в зависимости от того, объединятся ли при освобождении памяти имеющийся
свободный блок размером 30 Кбайт с новым, размером 20 Кбайт. Более сложный
алгоритм мог бы лучше обрабатывать подобные ситуации.
Еще одно потенциальное улучшение — искать два свободных блока, один для
сегмента кода и один для сегмента данных, если адресные пространства запус-
запускаемого процесса разделены. Сегменты не обязательно располагать непрерывно.
Более тонкий нюанс — умещается ли новый процесс в виртуальном адресном
пространстве. Суть проблемы в том, что память выделяется не байтами, а 1024-
байтовыми кликами. Каждый клик должен целиком принадлежать одному сегмен-
сегменту и не может, например, быть наполовину занят данными, наполовину стеком,
так как все управление памятью производится в кликах.
Чтобы стало очевиднее, почему это приводит к проблемам, заметим, что на
16-разрядных системах (8086 и 80286) адресное пространство ограничено вели-
величиной 64 Кбайт, что составляет 64 клика A024-байтовых). Представим теперь,
что программе с раздельными адресными пространствами кода и данных требу-
требуется 40 000 байт под код, 32 770 байт под данные и 32 760 байт под стек. Тогда
сегмент данных займет 33 клика, причем в последнем клике будут использованы
лишь 2 байта, хотя он будет принадлежать сегменту целиком. Под стек потребу-
потребуется 32 клика. Для данных и стека вместе нужно более 64 кликов, таким образом,
они не смогут сосуществовать, хотя необходимое количество байтов умещается
в виртуальной памяти (едва-едва). В теории эта проблема относится ко всем ма-
машинам, у которых размер клика более одного байта, но на практике для процес-
процессоров класса Pentium она возникает исключительно редко, так как на таких ма-
машинах допустимы большие сегменты (более 4 Гбайт). К сожалению, код должен
выявлять подобные ситуации. Система, не проверяющая маловероятные, но воз-
возможные ошибки, находится под угрозой неожидаемой аварии в случае, если хоть
одна из ошибок произойдет.
Другой важный вопрос — начальная установка стека. Библиотечный вызов, обыч-
обычно используемый для выполнения exec, выглядит так:
execve(name, argv, envp);
Здесь name — указатель на имя загружаемого файла, argv ссылается на массив
указателей на аргументы, а указатель envp содержит адрес массива указателей,
ссылающихся на строки переменных окружения.
Достаточно просто реализовать вызов exec, передав эти три указателя в сооб-
сообщении менеджеру процессов и позволив ему самостоятельно извлечь имя файла
и адреса двух массивов. Но тогда для каждого аргумента потребовалось бы отправ-
отправлять системному заданию как минимум одно сообщение, а возможно, и больше,
так как менеджер процессов не знает, какого размера каждая последующая порция.
Чтобы снизить накладные расходы, связанные со считыванием всех этих кусоч-
кусочков, была выбрана совершенно иная стратегия. Библиотечная процедура execve
сама строит новый стек и передает менеджеру процессов его базовый адрес и раз-
размер. Создавать новый стек в пользовательском пространстве гораздо эффектив-
эффективнее, поскольку указатели на аргументы окажутся локальными и не будут ссы-
ссылаться на другое адресное пространство.
Чтобы яснее понять этот механизм, рассмотрим пример. Пусть пользователь
вводит в оболочке следующую команду:
Is -I f.c g.c
В этом случае оболочка интерпретирует ее, вызывая библиотечную процедуру:
execve("/bin/Is", argv, envp);
Содержимое двух массивов указателей показано на рис. 4.32, а. Затем процедура
execve, работая в пользовательском пространстве, строит новый стек (рис. 4.32, б).
В конечном итоге стек при выполнении менеджером памяти системного вызова
exec копируется без изменений.
Когда стек, в конце концов, попадает в пользовательский процесс, он не помещает-
помещается по нулевому виртуальному адресу. Вместо этого он записывается в конец выде-
выделенной области памяти, размер которой определяется по заголовку исполняемо-
исполняемого файла. Для примера предположим, что общий размер составляет 8192 байт, то
есть последний доступный программе байт имеет адрес 8191. Тогда менеджер
процессов располагает в стеке указатели так, как показано на рис. 4.32, в.
Когда системный вызов exec завершится и программа начнет работу, стек при-
придет в состояние, показанное на рис. 4.32, в, а указатель стека станет содержать
значение 8136. Однако еще одна проблема остается нерешенной. Главная проце-
процедура исполняемого файла, скорее всего, объявлена примерно так:
main (argc, argv, envp);
Поскольку рассматривается компилятор С, main является всего лишь одной из
функций. Компилятор не знает о ее особой роли, поэтому строит ее код так, как
если бы аргументы передавались ей по стандартному соглашению вызова языка С,
когда последний аргумент идет в стеке первым. Поскольку значениями аргумен-
аргументов являются одно целое число и два указателя, ожидается, что они займут три
слова, предшествующие адресу возврата. Естественно, показанный на рис. 4.32, в
стек выглядит совершенно иначе.
Решение в том, чтобы выполнение программы не начиналось с функции main.
Вместо нее управление сначала получает маленькая стартовая ассемблерная
подпрограмма crtso, которую компоновщик помещает в сегмент кода по «нуле-
«нулевому» адресу. Эта подпрограмма называется runtime, и ее назначение в том,
чтобы поместить в стек три требующихся слова и вызвать функцию main, пользу-
пользуясь стандартным соглашением о вызове. Благодаря этой хитрости функция main
может думать, что она вызвана обычным образом (хотя в действительности это
не трюк, она действительно вызывается совершенно обычно).
Рис. 4.32. Создание стека в пользовательском пространстве: а — массивы, передаваемые
подпрограмме execve; б — созданный стек; в — стек после перемещения менеджером
памяти; г — стек, который процедура видит в начале выполнения
Если программист в конце кода функции main не сделал вызов exit, то после
ее завершения управление передается обратно в подпрограмму runtime. Опять
же, с точки зрения компилятора, main — обычная функция, и для возврата из
нее компилятор генерирует стандартный код. Большая часть кода 32-разрядной
версии crtso приведена в листинге 4.2. Комментарии поясняют выполняемые
действия. Не вошли в этот листинг лишь фрагменты кода, инициализирующие
окружение (на случай, если это не сделает программист), загружающие из стека
помещенные туда регистры, а также несколько строк, устанавливающие флаг на-
наличия/отсутствия математического сопроцессора. Весь код вы можете просмот-
просмотреть, открыв файл src/lib/i386/rts/crtso.s.
Листинг 4.2. Ключевая часть стартовой подпрограммы runtime
push ecx ; push environ
push edx ; push argv
push eax ; push argc
call _main ; main(argc, argv, envp)
push eax ; push exit_status
call _exit
hit ; если вызов exit не удался, вызывается прерывание
4.7.6. Системный вызов brk
При помощи библиотечных подпрограмм brk и sbrk изменяется положение
верхней границы сегмента данных. Первая из них берет абсолютное значение но-
нового адреса (в байтах) и передает его системному вызову brk. Вторая вычисляет
положительное или отрицательное приращение текущего положения, вычисляет
новый размер и вызывает brk. Отдельного системного вызова sbrk в действи-
действительности нет.
Интересен вопрос: как sbrk определяет текущий размер, чтобы вычислить но-
новый? Ответом на него является переменная brksize, в которой всегда хранится
размер и откуда brk и sbrk всегда могут его считать. Эта переменная инициали-
инициализируется генерируемым компилятором символом, определяющим либо суммар-
суммарный размер кода и данных (общее адресное пространство), либо только размер
данных (раздельные адресные пространства). Имя и даже само существование
такого символа привязаны к компилятору, поэтому вы не найдете его обозначе-
обозначение ни в одном из заголовочных файлов исходных кодов. Символ задается в биб-
библиотеке, в файле brksize . s. Где именно он расположен, зависит от системы, но
он будет в том же каталоге, что и с г to. s.
Для менеджера процессов несложно выполнить вызов brk. Все, что ему нужно
сделать, — это проверить, что сегмент умещается в адресном пространстве, обно-
обновить таблицы и уведомить ядро.
4.7.7. Обработка сигналов
В главе 1 сигналы были определены как средство передачи информации процес-
процессу, который не обязательно ждет ввода. Задается набор сигналов, и у каждого
сигнала есть действие по умолчанию: либо завершить процесс, которому сигнал
адресован, либо игнорировать сигнал. Если бы других альтернатив не было, обра-
обработку сигналов было бы просто понять и реализовать. Но при помощи системных
вызовов процессы способны менять это поведение. Процесс может потребовать,
чтобы любой сигнал (за исключением особого сигнала sigkill) игнорировался.
Более того, процесс может перехватить сигнал, предписав, чтобы вместо дейст-
действия по умолчанию был вызван указанный им обработчик сигнала (опять же, это
не относится к сигналу sigkill). Таким образом, с точки зрения программиста
есть два этапа работы с сигналами: подготовительная фаза, когда определяется
ответная реакция на будущий сигнал, и ответная, когда сигнал генерируется и об-
обрабатывается. Ответным действием может быть выполнение собственной подпро-
подпрограммы-обработчика. В действительности есть и третья фаза. Когда пользова-
пользовательский обработчик завершается, специальный системный вызов восстанавли-
восстанавливает нормальную работу получившего сигнал процесса. Программисту об этой
третьей фазе знать не нужно, он пишет обработчики сигналов как обычные
функции, а заботу о вызове и завершении обработчиков и управлении стеком
берет на себя операционная система.
Таким образом, три фазы обработки сигналов выглядят следующим образом.
1. Подготовка — программный код готовится к возможному сигналу.
2. Реакция — сигнал принимается и в ответ выполняется действие.
3. Очистка — восстанавливается нормальное функционирование процесса.
В подготовительной фазе программа вправе в любой момент изменить реакцию
на сигнал при помощи нескольких системных вызовов. Самый общий из них —
вызов sigaction, посредством которого можно указать, чтобы сигнал игнори-
игнорировался, обрабатывался (при этом вместо действия по умолчанию для такого
сигнала выполняется некоторый заданный пользователем код из самого процес-
процесса), или же восставить ответную реакцию, предлагаемую по умолчанию. При по-
помощи другого системного вызова, sigprocmask, сигнал можно заблокировать,
тогда он будет поставлен в очередь и обработан только тогда, когда процесс раз-
разблокирует сигналы этого типа. Эти вызовы можно делать в любой момент даже
из самой функции-обработчика. В MINIX 3 действия подготовительной стадии
осуществляются исключительно в менеджере процессов, так как все необходи-
необходимые структуры данных расположены в его части таблицы процессов. Для каж-
каждого процесса в этой таблице имеется несколько переменных типа sigset_t,
в которых за каждый сигнал отвечает определенный бит. Одна из переменных
хранит информацию о том, какие сигналы необходимо игнорировать, другая —
какие сигналы обрабатывать и т. д. Кроме того, у каждого процесса есть массив
структур sigaction, по одной на каждый сигнал, как показано в листинге 4.3.
В этой структуре присутствует переменная, хранящая адрес пользовательского
обработчика сигнала, а также дополнительное поле типа sigset_t, где запоми-
запоминается информация о сигналах, заблокированных во время исполнения другого
обработчика. В поле адреса обработчика вместо адреса пользовательской функ-
функции могут храниться специальные данные, означающие, что данный сигнал дол-
должен быть игнорирован или обработан по умолчанию.
Листинг 4.3. Структура sigaction
struct sigaction {
sighandler_t sa_handler; /* SIG_DFL, SIG_IGN, SIG_MESS
или указатель на функцию */
sigset_t sa_mask; /* сигналы, которые должны быть
блокированы в обработчике */
int sa_flags; /* специальные флаги */
}
Здесь следует отметить, что системные процессы, в частности менеджер процес-
процессов, не могут перехватывать сигналы. Системные процессы используют новый
тип обработчика, SIG_MESS, указывающий менеджеру процессов передать сиг-
сигнал с помощью уведомления SYS_SIG. Для уведомлений типа SYS_SIG не тре-
требуется очистка.
В генерации сигнала участвуют многие компоненты операционной системы
MINIX 3. Начинается все с менеджера процессов, который решает, какой про-
процесс должен при помощи упомянутых выше структур получить сигнал. Если
данный сигнал обрабатывается, его необходимо доставить процессу. Для этого
требуется сначала сохранить информацию о процессе, чтобы после обработки вос-
восстановить его нормальное состояние. Эта информация сохраняется в стеке про-
процесса, причем предварительно делается проверка, достаточно ли места в стеке.
Стеком заведует менеджер процессов, который и выполняет этот контроль, а за-
затем, чтобы поместить информацию в стек, вызывает системное задание, которое
также изменяет значение счетчика команд процесса, чтобы выполнился код обра-
обработчика. Когда обработчик завершается, делается системный вызов sigreturn.
Посредством этого вызова менеджер процессов и ядро участвуют в восстановлении
контекста — сигналов и регистров процесса, возвращая его к обычному режиму
работы. Если сигнал не обрабатывается, выполняется действие по умолчанию.
При этом если необходимо получить дамп ядра (то есть записать образ процесса
в файл для последующего анализа под управлением отладчика), может быть затро-
затронута файловая система, а если процесс должен быть прекращен, затрагивается
как менеджер процессов, так и файловая система и ядро. Наконец, если сигнал
адресован группе процессов, менеджер памяти может предписать повторить эти
действия несколько раз.
Сигналы, о которых известно MINIX 3, определяются в файле include/
signal .h, согласно стандарту POSIX. Они перечислены в табл. 4.4. В MINIX 3
объявлены все требуемые POSIX сигналы, но пока что не все они поддержива-
поддерживаются. Например, стандартом определен набор сигналов для управления задания-
заданиями, позволяющих перевести задание в фоновый режим и вернуть его обратно.
В MINIX 3 управление заданиями не поддерживается, но программы, которые
генерируют такие сигналы, могут быть перенесены для работы под управлением
MINIX 3. Неподдерживаемые сигналы в этом случае просто игнорируются. Под-
Поддержка управления заданиями отсутствует потому, что при разработке пред-
предполагалось реализовать возможность запуска программы с ее последующим
переводом в фоновый режим, что позволяет пользователю совершать другие
действия. В MINIX 3 по нажатию комбинации клавиш Alt+F2 открывается но-
новый виртуальный терминал, дающий такую возможность. Виртуальные терми-
терминалы представляют собой примитивное подобие оконной системы, однако их на-
наличие освобождает от необходимости управления заданиями и их сигналами, по
крайней мере, при работе на локальной консоли. Кроме того, MINIX определяет
ряд сигналов, не описанных в POSIX, а также несколько синонимов для POSIX-
имен с целью обеспечить совместимость с более старым исходным кодом.
Таблица 4.4. Сигналы MINIX 3, регламентированные POSIX. Знак (*) означает, что сигнал
зависит от аппаратной поддержки, сигналы с пометкой (М) не описаны в POSIX и введены
в MINIX 3 для поддержания совместимости с устаревшим кодом. Сигналы ядра являются
специфичными для MINIX 3 и предназначены для информирования системных процессов
о событиях системы. В таблицу не попали несколько устаревших имен и синонимов
Сигнал Описание Источник
SIGHUP Отбой Системный вызов kill
SIGINT Прерывание Ядро
SIGQUIT Завершение Ядро
SIGILL Недопустимая инструкция Ядро (*)
Сигнал Описание Источник
SIGTRAP Прерывание трассировки Ядро (М)
SIGABRT Аномальное завершение Ядро
SIGFPE Ошибка при вычислениях с плавающей точкой Ядро (*)
SIGKILL Принудительное завершение (сигнал не может Системный вызов kill
быть игнорирован или обработан)
SIGUSR1 Задаваемый пользователем сигнал номер 1 Не поддерживается
SIGSEGV Нарушение целостности памяти Ядро (*)
SIGUSR2 Задаваемый пользователем сигнал номер 2 Не поддерживается
SIGPIPE Запись в канал, из которого никто не читает Файловая система
SIGALRM Сигнал таймера, истечение тайм-аута Менеджер процессов
SIGTERM Сигнал завершения программы Системный вызов kill
SIGCHLD Дочерний процесс завершил работу или остановился Не поддерживается
SIGCONT Продолжить работу после останова Не поддерживается
SIGSTOP Остановить выполнение процесса Не поддерживается
SIGTSTP Интерактивный сигнал останова Не поддерживается
SIGTTIN Фоновый процесс пытается выполнить ввод Не поддерживается
SIGTTOU Фоновый процесс пытается выполнить вывод Не поддерживается
SIGKMESS Сообщение ядра Ядро
SIGKSIG Ожидание сигнала ядра Ядро
SIGKSTOP Завершение работы ядра Ядро
В традиционной UNIX-подобной системе сигналы генерируются либо ядром, либо
при помощи системного вызова kill. В MINIX 3 некоторые процессы, функ-
функционирующие в пользовательском пространстве, выполняют действия, которые
в других операционных системах делало бы ядро. В табл. 4.4 показаны все сигна-
сигналы, известные MINIX 3, и их источники. Сигналы sigint, sigquit и sigkill
можно инициировать нажатием специальных сочетаний клавиш. Сигнал sigalarm
управляется менеджером процессов, a sigpipe генерируется файловой систе-
системой. Для того чтобы послать любой сигнал любому процессу, можно воспользо-
воспользоваться вызовом kill. Некоторые сигналы ядра зависят от аппаратной поддерж-
поддержки. Например, процессоры 8086 и 8088 не умеют обнаруживать недопустимые
инструкции, а процессоры 286 и выше при попытке выполнить такую инструкцию
вызывают прерывание. Это обусловлено аппаратными возможностями. Чтобы
в ответ на прерывание генерировать сигнал, разработчики операционной систе-
системы должны заготовить для этого код. В главе 2 мы видели, что в файле kernel/
exception. с как раз содержится нужный код для разных условий. Таким обра-
образом, когда MINIX 3 работает на машине с процессором 286 или выше, недо-
недопустимая инструкция приведет к появлению сигнала sigkill, но на компьютере
с процессором 8088 такого никогда не произойдет.
То, что оборудование способно генерировать аппаратное прерывание при возник-
возникновении некоторой ситуации, не означает, что разработчики операционной сис-
системы могут во всем понадеяться на эту возможность. Так, все процессоры Intel,
начиная с 286, распознают несколько типов нарушений целостности памяти,
вызывающих исключения. Код в файле kernel /except ion. с преобразует эти
исключения в сигналы sigsegv. Нарушениям аппаратных границ стека и границ
других сегментов соответствуют разные типы исключений в расчете на различную
их обработку. Тем не менее, в силу особенностей работы MINIX 3 с памятью, не
все возникающие нарушения могут быть обнаружены. Аппаратные регистры за-
задают базовый адрес сегмента и его длину. В MINIX 3 базовый адрес аппаратного
сегмента стека совпадает с базовым адресом аппаратного сегмента данных, но
аппаратно заданный размер сегмента данных превышает контролируемую про-
программно границу. Другими словами, контролируемый аппаратно размер сегмен-
сегмента данных соответствует ситуации, когда стек уменьшился до нуля. Аналогично,
заданный аппаратно объем стека соответствует нулевому объему данных. Таким
образом, хотя некоторые из нарушений и поддаются аппаратному обнаружению,
наиболее вероятная ошибка — повреждение области данных из-за переполнения
стека — не выявляется. Это следствие того, что с точки зрения аппаратных реги-
регистров и таблиц дескрипторов сегменты данных и стека перекрываются.
Имеется потенциальная возможность добавить в ядро код, который бы прове-
проверял регистры процесса всякий раз после того, как процесс получает управление,
и в случае нарушения программно заданных границ сегментов данных или стека
генерировал бы сигнал sigsegv. Но не совсем понятно, стоит ли это делать, ведь
аппаратные ловушки в силах обнаружить сбой по доступу сразу же после того,
как он произошел. Программная же проверка может случиться спустя много ты-
тысяч инструкций после момента переполнения, когда обработчик прерывания уже
мало на что годится и восстановление неосуществимо.
Где бы ни брали свое начало сигналы, менеджер процессов обрабатывает их оди-
одинаково. Сначала для каждого процесса-получателя делается набор проверок с це-
целью убедиться, можно ли передать ему сигнал. Один процесс может передавать
другому сигнал в том случае, если первый принадлежит суперпользователю ли-
либо если его эффективный идентификатор пользователя (UID) равен реальному
или эффективному идентификатору второго. Но существует еще несколько усло-
условий, вмешивающихся в отправку сигнала. Например, нельзя передавать сигнал
процессу, находящемуся в состоянии зомби. Также процессу нельзя передавать
сигнал, если он явно сделал вызов sigaction, чтобы игнорировать возможный
сигнал, или вызов sigprocmask, чтобы его блокировать. Блокировка сигнала
и пренебрежение им — разные вещи. Заблокированный сигнал запоминается и пе-
передается процессу, когда тот снимает блокировку (если он ее вообще снимает).
Наконец, если у процесса-получателя недостаточно места в стеке, этот процесс
принудительно завершается.
Когда все тесты пройдены, сигнал можно отправлять. Если процесс не сделал
ничего, чтобы обработать сигнал, то и никакой информации передавать ему не
требуется. В таком случае менеджер процессов выполняет обработку сигнала,
предлагаемую по умолчанию; обычно это означает либо завершение процесса,
либо сброс дампа памяти в файл. Несколько сигналов по умолчанию игнориру-
игнорируются. Сигналы, которые в табл. 4.4 обозначены как неподдерживаемые, рекомен-
рекомендованы стандартом POSIX, но в MINIX 3 игнорируются.
Обработка сигнала процессом заключается в исполнении заданного пользователем
кода обработчика, адрес обработчика сохранен в структуре sigaction в таблице
процессов. В главе 2 мы видели, как в кадр стека в пределах таблицы процессов
записывается информация, необходимая для восстановления процесса после его
прерывания. Путем модификации кадра стека процесса-получателя сигнала можно
добиться того, чтобы в следующий раз, когда процесс получит управление, он на-
начал исполнять код обработчика сигнала. Посредством манипуляций с собственным
стеком процесса в пользовательском пространстве делается так, чтобы по заверше-
завершении обработчика произошел системный вызов sigreturn. Явно эта подпрограм-
подпрограмма из пользовательского кода никогда не вызывается. Вызов исполняется за счет
того, что ядро помещает его адрес в стек, то есть здесь это — адрес возврата, на ко-
который осуществляется переход после завершения обработчика. Вызов sigreturn
восстанавливает исходный кадр стека получившего сигнал процесса, чтобы тот
мог продолжить свое выполнение с момента, на котором его застал сигнал.
Хотя финальная стадия отправки сигнала происходит в системном задании, пора
подытожить все то, что мы уже узнали. Когда сигнал должен быть обработан, не-
необходимо действие, во многом сходное с обычным переключением контекстов,
которое происходит, когда один процесс переводится в ожидание, а вместо него
начинает выполняться другой. Но в таблице процессов есть только одно место,
где можно сохранить все регистры процессора, необходимые для восстановле-
восстановления исходного состояния процесса. Достаточно ли этого? Для ответа на вопрос
посмотрим на рис. 4.33, а. Здесь изображен в упрощенном виде стек процесса
и часть его записи в таблице процессов в тот момент, когда процесс только что
был приостановлен по факту прерывания. На время бездействия содержимое всех
регистров копируется в запись stack frame этого процесса в части таблицы
процессов, принадлежащей ядру. Данная ситуация соответствует времени гене-
генерации сигнала. Источник и приемник сигнала — разные процессы, поэтому при-
приемник при этом не может выполняться.
В ходе подготовки к обработке сигнала содержимое кадра стека копируется из
таблицы процессов в собственный стек процесса в виде структуры sigcontext,
тем самым сохраняется информация о состоянии. Затем в стек помещается
структура sigf rame, содержащая информацию, которая потребуется вызову
sigreturn после завершения обработчика. Кроме того, в ней хранится и адрес
самой библиотечной подпрограммы sigreturn — ret addrl, и еще один адрес
возврата, ret addr2, то есть адрес, с которого необходимо продолжить выполне-
выполнение прерванной программы. Как мы увидим в дальнейшем, при нормальной ра-
работе второй адрес использоваться не должен.
Хотя обработчик и пишется программистом как обычная функция, он не вызы-
вызывается инструкцией call. Чтобы началось исполнение кода обработчика, изме-
изменяется значение поля счетчика команд в кадре стека в таблице процессов, в ре-
результате, когда restart переводит процесс в состояние исполнения, начинает
выполняться обработчик. На рис. 4.33, б показана ситуация, когда все эти приго-
приготовления завершены и обработчик уже занимается своим делом. Ну, а поскольку
обработчик все-таки является обычной процедурой, когда он завершает работу,
из стека извлекается адрес ret addrl и запускается sigreturn.
Рис. 4.33. Стек процесса (сверху) и кадр стека (снизу), соответствующие различным фазам
обработки сигнала: а — состояние, в котором процесс приостанавливается; б — состояние
на начало исполнения обработчика; в — состояние во время исполнения вызова sigretum;
г — состояние после завершения вызова sigretum
Ситуация, когда исполняется sigretum, показана на рисунке 4.33, в. Оставшая-
Оставшаяся часть структуры sigf rame используется как локальные переменные вызова
sigretum. Одно из действий этого системного вызова направлено на такое из-
изменение собственного указателя стека, когда при обычном возврате осуществля-
осуществляется переход на адрес ret addr2. Но в действительности вызов sigretum не
завершается как вызов обычной функции. Он, как и другие системные вызовы,
передает право решать, какой процесс станет активным, планировщику в ядре.
В конечном итоге, в какой-то момент времени получивший сигнал процесс вы-
выбирается для выполнения. Выполнение продолжается с этого адреса, продуб-
продублированного в оригинальном кадре стека процесса. Данный адрес помещается
в стек для того, чтобы отладчик, проходя по программе, не испытывал проблем
со стеком при трассировке обработчика сигнала. Благодаря таким манипуляциям
на каждом этапе выполнения стек выглядит как обычный стек процесса с собст-
собственными локальными переменными после адреса возврата.
Главное, что должен сделать вызов sigreturn, — это вернуть все в исходное со-
состояние, то есть к моменту получения сигнала. Важнее всего восстановить кадр
стека процесса, для чего и используется его копия, сохраненная в собственном
стеке процесса. В результате после завершения sigreturn процесс возвращает-
возвращается в исходное состояние (рис. 4.33, г).
По умолчанию большинство сигналов приводят к завершению процесса. Забо-
Заботится об этом менеджер процессов, завершающий процесс, когда сигнал не игно-
игнорируется по умолчанию или процесс-приемник не требует его блокировать, об-
обрабатывать или игнорировать. Если завершения процесса ожидает его родитель,
процесс завершается, и соответствующая информация удаляется из таблицы
процессов. Если родитель пренебрегает своим долгом, процесс превращается в зом-
зомби. Кроме того, для некоторых типов сигналов (например, sigquit) менеджер
процессов записывает в текущий каталог дамп памяти процесса.
Легко может случиться так, что получивший сигнал процесс находится в состоя-
состоянии блокировки, скажем, читает с терминала при помощи вызова read, когда на
терминал не поступает данных. Если процесс не указал, что сигнал должен обра-
обрабатываться, он просто завершается обычным образом. Но если сигнал обрабаты-
обрабатывается, закономерен вопрос: что должен делать процесс после того, как обработано
прерывание сигнала. Должен ли он вернуться в состояние ожидания или про-
продолжить работу со следующей инструкции?
В MINIX 3 делается следующее: системный вызов завершается с кодом возвра-
возврата EINTR, поэтому процесс может понять, что он был прерван сигналом. Узнать
о том, что процесс заблокирован на системном вызове, не так просто. Менеджеру
процессов придется спрашивать об этом файловую систему.
Такое поведение предполагается стандартом POSIX, который позволяет вызову
read возвращать байты, считанные до прихода сигнала, хотя и не жестко пред-
предписано. Кроме того, возврат с кодом EINTR позволяет легко реализовать таймер
и обработать сигнал sigalarm, например, чтобы завершить операцию login и по-
повесить трубку модема, если пользователь некоторое время (тайм-аут) не отвечает.
Таймеры пользовательского пространства
Генерация оповещения для активизации процесса через заданный интервал време-
времени — одно из наиболее распространенных применений сигналов. В традиционных
операционных системах работа с оповещениями полностью выполняется ядром
или драйвером часов в пространстве ядра. В операционной системе MINIX 3 ответ-
ответственность за оповещения пользовательских процессов возлагается на менеджер
процессов. Это сделано для того, чтобы снизить нагрузку на ядро и упростить
код, выполняемый в пространстве ядра. Если заданному объему кода соответст-
соответствует определенное число неизбежных ошибок, то логично сделать вывод о том,
что с уменьшением ядра число ошибок также сокращается. Однако даже если ко-
количество ошибок останется неизменным, их последствия окажутся менее серьез-
серьезными, если они будут происходить в пользовательском пространстве, а не в ядре.
Можно ли обеспечить обработку оповещений вообще без участия ядра? Разуме-
Разумеется, в MINIX 3 ответ на этот вопрос отрицательный. В первую очередь, обработ-
обработкой оповещений занимается таймерное задание, которое выполняется в про-
пространстве ядра. Оно управляет связанным списком, или очередью, таймеров, как
показано на рис. 2.27. При каждом прерывании от микросхемы часов время исте-
истечения таймера, находящегося в начале очереди, сравнивается с текущим време-
временем, и если таймер истек, таймерное задание входит в главный цикл и посылает
оповещение запросившему его процессу.
В MINIX 3 нововведение заключается в том, что в пространстве ядра поддержива-
поддерживаются лишь таймеры системных процессов. Менеджер процессов управляет другой
очередью таймеров, которые запущены пользовательскими процессами, запросив-
запросившими оповещения. Менеджер процессов запрашивает оповещение от часов только
для таймера, находящегося в начале своей очереди. Если очередь пуста, то и необ-
необходимости обращаться к часам с запросом нет (разумеется, на самом деле запрос
посылается через системное задание, поскольку таймерное задание не взаимодей-
взаимодействует с какими-либо процессами напрямую). Когда после прерывания от часов
определяется истечение таймера, менеджеру процессов передается уведомление.
Менеджер процессов проверяет собственную очередь таймеров, посылает сигнал
пользовательскому процессу и подает новый запрос, если его очередь не пуста.
В изложенных идеях не видно значительного снижения нагрузки на ядро, здесь
имеет место ряд других соображений. Во-первых, существует вероятность исте-
истечения нескольких таймеров в одном такте часов. То, что два процесса могут за-
затребовать оповещения одновременно, кажется неправдоподобным, однако не все
так просто. Хотя проверка таймеров на истечение выполняется при каждом пре-
прерывании от микросхемы часов, мы знаем, что иногда прерывания запрещены.
Обращение к BIOS может привести к пропуску столь большого числа прерыва-
прерываний, что предусмотрено средство «наверстывания», которое «переводит» время,
отсчитываемое таймерным заданием, на несколько тактов вперед. Следователь-
Следовательно, возможна ситуация, в которой необходимо обработать сразу несколько ис-
истекших таймеров. Менеджер процессов берет эту задачу на себя, освобождая яд-
ядро от поиска и очистки собственной очереди, а также от генерации множества
уведомлений.
Во-вторых, оповещения могут быть отменены. Не исключено, что пользователь-
пользовательский процесс завершится до истечения установленного им таймера, или таймер
будет использоваться для предотвращения бесконечного ожидания события, кото-
которое может никогда не произойти. Если событие происходит, оповещение можно
отменить. Очевидно, нагрузка на код ядра снижается, если отмена выполняется
в очереди менеджера процессов, находящегося за пределами ядра. Очередь ядра
требует внимания лишь при истечении таймера, находящегося в ее начале, а также
при изменении процесса, находящегося в начале очереди менеджера процессов.
Реализацию таймеров проще понять, кратко рассмотрев функции, обрабатываю-
обрабатывающие оповещения. В обработке принимает участие множество функций менедже-
менеджера процессов и ядра, поэтому их последовательное и подробное изучение затруд-
затруднит восприятие общей концепции.
Когда менеджер процессов устанавливает оповещение от имени пользователь-
пользовательского процесса, функция set_alarm инициализирует таймер. Структура тайме-
таймера содержит поля времени истечения, процесса, от имени которого установлено
оповещение, и указателя на исполняемую функцию. Для оповещений всегда вы-
вызывается функция cause_sigalarm. Далее происходит обращение к системному
заданию для установки оповещения в пространстве ядра. При истечении тайме-
таймера вызывается сторожевая функция cause_alarm, которая посылает уведомле-
уведомление менеджеру процессов. В этом участвуют различные функции и макросы, од-
однако в конечном счете уведомление принимает функция get_work менеджера
процессов. Главный цикл менеджера процессов определяет, что уведомление
имеет тип SYN_ALARM, и вызывает функцию pm_expire_timers. После этого
используется несколько функций, расположенных в пространстве менеджера про-
процессов. Библиотечная функция tmrs_exptimers вызывает сторожевую функцию
cause_sigalarm, та, в свою очередь, — функцию checksig, a checksig —
функцию sig_proc. В sig_proc принимается решение о том, следует ли унич-
уничтожить процесс или послать ему сигнал SIGALRM. Для передачи сигнала нужно
обратиться за помощью к системному заданию, выполняющемуся в пространст-
пространстве ядра, поскольку требуется манипуляция с данными таблицы процессов и сте-
стека адресата сигнала (см. рис. 4.33).
4.7.8. Прочие системные вызовы
Менеджер процессов отвечает еще за несколько простых системных вызовов. Вызо-
Вызовы time и stime предназначены для работы с часами реального времени. Вызов
times получает учетное время процесса. Все эти вызовы обрабатываются менед-
менеджером процессов в основном потому, что их удобно направлять ему. Еще один
системный вызов, utime, рассматривается в главе 5, посвященной файловой
системе, поскольку он хранит время модификации файлов в индексных узлах.
Две библиотечные функции, getuid и geteuid, пользуются одним и тем же
системным вызовом getuid, который в ответном сообщении возвращает оба
значения. Аналогично, системный вызов getgid возвращает как реальное, так
и действующее значения идентификаторов, нужные соответственно функциям
getgid и getegid. Подобно работает и вызов getpid, возвращающий идентифи-
идентификатор самого процесса и его родителя, а при помощи вызовов setuid и setgid
можно устанавливать как реальное, так и эффективное значения сразу, одним
вызовом. В этой группе есть два дополнительных системных вызова, getpgrp
и sets id. Первый возвращает идентификатор группы процессов, а второй уста-
устанавливает его равным текущему идентификатору процесса (PID). Эти семь
функций — самые простые системные вызовы в MINIX 3.
Вызовы ptrace и reboot также выполняются в менеджере процессов. Первый
из них помогает отлаживать программы. Второй оказывает влияние на многие
аспекты системы. В первую очередь этот вызов отправляет сигналы, чтобы за-
завершить все процессы, кроме init, поэтому его код помещен именно в менед-
менеджер процессов. Чтобы завершить работу после того, как отправлены сигналы,
в процесс выполнения вовлекаются файловая система и системное задание.
4.8. Управление памятью в MINIX
В общих чертах разобравшись в том, как работает менеджер процессов, давайте
обратимся к самому коду. Менеджер процессов полностью написан на языке С,
его код прост и снабжен множеством комментариев, поэтому мы, как правило, не
будем слишком глубоко вдаваться в детали. Сначала мы изучим заголовочные
файлы, затем — главную программу, а потом — файлы с кодом описанных ранее
системных вызовов.
4.8.1. Заголовочные файлы и структуры данных
В каталоге исходных файлов менеджера процессов есть несколько заголовочных
файлов, имена которых совпадают с именами файлов ядра. Эти же имена мы
встретим еще раз при изучении файловой системы. Такие файлы имеют «одно-
«одноименные» функции (в своем контексте). Параллельная структура была выбрана
для того, чтобы упростить понимание устройства MINIX 3 в целом. Помимо озна-
означенных, к менеджеру памяти относятся несколько заголовочных файлов с уникаль-
уникальными именами. Как и в других частях системы, место для хранения глобальных
переменных выделяется в файле table. с. Его рассмотрением, а также рассмот-
рассмотрением сопутствующих заголовочных файлов мы займемся в этом разделе.
Как и у всех остальных основополагающих компонентов MINIX 3, у менеджера
процессов есть свой главный заголовочный файл, pm.h (строка 17000). Он вклю-
включается в каждый файл с кодом и, в свою очередь, включает в себя все общесис-
общесистемные заголовочные файлы из каталога /usr/include и его подкаталогов,
нужные каждому объектному модулю. С ним присоединяется большая часть фай-
файлов, включаемых в kernel/kernrl .h, а также собственные версии файлов
const. h, type . h, proto . h и glo . h. Кроме того, менеджеру процессов необ-
необходимы некоторые определения из файлов include/fcntl .h и include/
unistd.h. Аналогичную структуру мы наблюдали при изучении ядра.
Файл const .h (строка 17100) задает ряд констант, необходимых менеджеру
процессов.
Файл type. h в текущей версии не используется и содержит только каркас, что-
чтобы структура менеджера процессов была такой же, как и прочих частей системы.
Файл proto.h (строка 17300) предназначен для того, чтобы в одном месте со-
собрать прототипы всех необходимых менеджеру процессов функций. В строках
17313 и 17314 содержатся определения пустых функций, необходимые при компи-
компиляции MINIX 3 с использованием подкачки. Данные макросы упрощают компи-
компиляцию без подкачки, поскольку в противном случае ненужные вызовы пришлось
бы удалять из многих файлов исходного кода.
Глобальные переменные менеджера процессов декларируются в файле glo.h
(строка 17500). Здесь применен тот же самый трюк с макросом EXTERN, что и в яд-
ядре. А именно, макрос EXTERN разворачивается в ключевое слово extern во всех
файлах, за исключением table. с, где он порождает пустую строку. В результате
в файле table.с резервируется память для хранения глобальных переменных.
Первая из глобальных переменных, тр, является указателем на структуру mproc.
Эта структура описывает ту часть таблицы процессов, которая принадлежит ме-
менеджеру процессов, а переменная тр ссылается на процесс, системный вызов ко-
которого обрабатывается в текущий момент. Вторая переменная, procs_in_use,
служит для подсчета имеющихся процессов, эта цифра помогает выяснить, вы-
выполним ли вызов fork.
Буфер сообщений m_in предназначен для запросов. Переменная who содержит
индекс текущего процесса. Она связана с переменой тр следующим соотношением:
mp=&mproc[who];
Когда получен системный вызов, его номер извлекается из сообщения и помеща-
помещается в переменную call_nr.
Если процесс завершается аварийно, MINIX 3 записывает его образ в файл дам-
дампа. Переменная core_name содержит имя этого файла, core_sset — это бито-
битовая карта, определяющая сигналы, которые должны генерировать дампы, a ign_
sset — битовая карта сигналов, которые следует игнорировать. Обратите вни-
внимание на то, что переменная core_name и массив call_vec определены с клю-
ключевым словом extern, а не EXTERN. Причину этому мы объясним при рассмот-
рассмотрении файла table. с.
Та часть таблицы процессов, которой заведует менеджер процессов, описана
в следующем файле, mproc .h (строка 17600). По большей части, назначение по-
полей этой таблицы объясняется комментариями. Несколько полей связаны с об-
обработкой сигналов. Поля mp_ignore, mp_catch, mp_sig2mess, mp_sigmask,
mp_sigmask2 и mp_sigpending представляют собой битовые карты, в кото-
которых каждый бит означает один из сигналов, разрешенный к отправке процессу.
Эти поля имеют тип sigset_t, являющийся 32-разрядным целым, следователь-
следовательно, MINIX 3 может поддерживать до 32 сигналов. Сейчас определено только
22 сигнала, а отсутствующие определения допускаются стандартом POSIX. Сиг-
Сигналу номер 1 соответствует наименее значимый (самый правый) бит карты.
Впрочем, согласно POSIX, требуются специальные функции для добавления
и удаления сигналов в эти наборы, поэтому при манипуляциях с битовыми кар-
картами программисту не нужно вдаваться в такие детали. А вот массив mp_sigact
важен для обработки сигналов. В нем имеется по одной структуре типа sigaction
(файл include/signal .h) на каждый возможный тип сигнала. Эта структура
составлена из трех полей:
+ sa_handler — признак, который определяет, будет ли для сигнала выполне-
выполнено действие по умолчанию, специальное действие по обработке или же сиг-
сигнал должен игнорироваться;
+ sa_mask — битовая карта, в которой отмечается, какие сигналы были забло-
заблокированы во время выполнения пользовательского обработчика;
+ sa_f lags — набор флагов сигнала.
Благодаря массиву mp_sigact обеспечивается большая гибкость при обра-
обработке сигналов.
Поле mp_f lags, как показано в конце файла, необходимо для хранения разно?
образных битовых сочетаний. В нем хранится беззнаковое целое, 16-разрядное
для самых старых процессоров и 32-разрядное для процессоров 386 и выше.
Последнее поле таблицы процессов называется mp_procargs. Когда запускается
новый процесс, строится стек, подобный показанному на рис. 4.32, и указатель
на массив argv нового процесса сохраняется в этой переменной. Например, на
рис. 4.32 в поле будет сохранено значение 8164, благодаря чему, цока выполняется
команда Is, команда ps может вывести содержимое командной строки:
Is -I f.с g.c
Благодаря данному массиву обеспечивается значительная гибкость при обработ-
обработке сигналов.
Поле mp_swapq не используется в рассматриваемой версии MINIX. Оно приме-
применяется при включенной подкачке и указывает на очередь ожидающих подкачки
процессов. Поле mp_reply предназначено для ответного сообщения. В более
ранних версиях MINIX такое поле было всего одно, определялось оно в файле
glo .h и компилировалось вместе с table. с. В MINIX 3 память под ответные
сообщения предоставляется каждому процессу. Это позволяет менеджеру про-
процессов приступать к обработке следующего входящего сообщения, если ответ на
предыдущее сообщение не может быть отправлен сразу по окончании его генера-
генерации. Менеджер процессов не способен обрабатывать два запроса одновременно,
но при необходимости может откладывать отправку ответов, пытаясь послать все
активные ответы каждый раз по завершении обработки запроса.
Последние два элемента таблицы процессов можно считать украшательствами.
Поле mp_nice содержит значение, позволяющее пользователям снизить приори-
приоритет процесса, например, для того, чтобы другой, более важный, процесс мог вы-
вытеснить его. Тем не менее MINIX 3 использует это поле для собственных нужд,
назначая различные приоритеты различным системным процессам (драйверам
и серверам) в зависимости от их потребностей. Поле mp_name удобно для отлад-
отладки, помогая программисту найти запись таблицы процессов в дампе памяти.
Имеется системный вызов, выполняющий поиск в таблице процессов по задан-
заданному имени и возвращающий соответствующий идентификатор.
Обратите внимание на то, что часть таблицы процессов, принадлежащая ме-
менеджеру процессов, объявлена как массив размером NR_PROCS (строка 17655).
Вспомните, что часть, принадлежащая ядру, имеет размер NR_TASKS + NR_
PROCS и объявлена в файле kernel/proc .h (строка 5593). Как было отмечено
ранее, процессы, являющиеся частью ядра, невидимы для компонентов операци-
операционной системы, находящихся в пользовательском пространстве, например, менед-
менеджеру процессов. На самом деле, эти процессы не играют ключевой роли.
Следующий файл, param.h (строка 17700), содержит макросы, помогающие
формировать сообщения для многих системных вызовов. Кроме того, здесь же
описаны четыре макроса для формирования ответных сообщений. В любом фай-
файле, куда включен файл param.h, может быть указано такое выражение:
k = m_in.pid;
В этом случае перед компиляцией препроцессор преобразует его следующим об-
образом (строка 17707):
k = m_in.ml_il;
Перед тем как продолжить, давайте обратимся к файлу table. с (строка 17800).
При его компиляции получается объектный файл, в котором выделяется место
для хранения глобальных переменных и структур, объявленных с директивой
EXTERN. Такие конструкции мы видели в файлах glo. h и mproc . h. Благодаря
тому, что в этом файле присутствует следующее выражение, макрос EXTERN раз-
разворачивается в пустую строку:
#define _TABLE
Это — тот же самый механизм, который мы могли наблюдать в коде ядра. Как
уже было отмечено, переменная core_name объявлена в файле glo .h с ключе-
ключевым словом extern, а не EXTERN. Теперь становится ясно, почему: core_name
объявляется со строкой инициализации, а инициализация в определении extern
невозможна.
Еще один важный элемент файла table. с — массив call_vec (строка 17815).
Он также инициализирован, а потому в glo .h его нельзя было бы объявлять
с ключевым словом EXTERN. С его помощью номер системного вызова преобра-
преобразуется в адрес выполняющей его функции, номер вызова играет роль индекса
в массиве. Если в сообщении указан несуществующий номер системного вызова,
управление передается функции no_sys, которая просто возвращает код ошиб-
ошибки. Несмотря на то что при объявлении массива call_vec применяется макрос
„PROTOTYPE, в действительности это — описание не прототипа, а инициализи-
инициализированного массива. Но так как он же массив указателей на функции, проще всего
получить код, компилируемый как классическим (Керниган и Ричи), так и стан-
стандартным компилятором С при помощи макроса „PROTOTYPE.
И наконец, последнее замечание о заголовочных файлах. Поскольку MINIX 3 до
сих пор находится в стадии активной разработки, некоторые «острые углы» до
сих пор не «сглажены». Один из них состоит в том, что некоторые исходные файлы
в каталоге рт/ включают заголовочные файлы из каталога ядра. Если не знать
об этом, можно столкнуться с проблемами при поиске некоторых важных опреде-
определений. Вероятно, определения, используемые более чем одним из основных компо-
компонентов MINIX 3, следует разместить в заголовочных файлах каталога include/.
4.8.2. Главная программа
Менеджер процессов компилируется и компонуется независимо от ядра и фай-
файловой системы. Следовательно, у него имеется собственная главная процедура,
которая запускается после того, как ядро заканчивает свою инициализацию. Она
расположена в файле main. с (строка 18041). В ней менеджер процессов сначала
выполняет собственную инициализацию (функция pm_init), а затем входит
в цикл (строка 18051). В этом цикле сначала, чтобы дождаться входящего сооб-
сообщения, делается вызов get_work. Затем вызывается одна из функций do_XXX,
адрес которой берется из массива call_vec, а далее, при необходимости, от-
отправляется ответное сообщение. Такая конструкция должна быть вам уже знако-
знакома, по тому же принципу работают задания ввода-вывода.
Данное описание несколько упрощено. Как было отмечено в главе 2, уведом-
уведомления могут быть посланы любому процессу. Уведомления идентифицируются
особыми значениями в поле call_nr. В строках 18055-18062 выполняется про-
проверка для двух типов уведомлений, которые может принимать менеджер про-
процессов, и для каждого из них выполняется специальное действие. Кроме того,
в строке 18064 проверяется корректность значения call_nr, а затем делается
попытка обслужить запрос (строка 18067). Хотя вероятность некорректного за-
запроса невелика, проверить его несложно, в то время как последствия некоррект-
некорректности будут весьма серьезными.
Еще один заслуживающий внимания момент — функция swap_in (строка 18073).
Рассматривая файл proto.h, мы отметили, что в описываемой версии MINIX
эта функция пустая. Тем не менее в полноценной версии функция swap_in
проверяет, возможна ли подкачка для процесса.
Комментарий в строке 18070 говорит о том, что здесь выполняется отправка от-
ответа, однако этот комментарий несколько упрощен. Вызов set reply формирует
ответное сообщение в записи таблицы процессов текущего процесса. В цикле
выполняется проверка всех записей таблицы процессов и отправка всех ожидаю-
ожидающих ответов, которые можно отправить (строки 18078-18091). Ответы, которые
не могут быть посланы, пропускаются.
Соответственно, две следующие функции, get_work (строка 18099) и setreply
(строка 18116), отвечают за реальные прием и отправку сообщений соответст-
соответственно. С помощью особого трюка функция get_work делает так, что сообщение,
посылаемое ядром, выглядит как отправленное менеджером процессов, посколь-
поскольку у ядра нет собственной записи в таблице процессов. Функция setreply фак-
фактически не отправляет ответ, а, как уже отмечалось, откладывает его для отправ-
отправки в будущем.
Инициализация менеджера процессов
Самая длинная процедура в main. с — pm_ini t, она инициализирует менеджер
процессов. После того как система заработала, эта процедура больше не нужна.
Хотя драйверы и серверы компилируются раздельно и выполняются как незави-
независимые процессы, некоторые из них помещаются в загрузочный образ монитором
загрузки. Весьма затруднительно представить себе запуск операционной системы
без менеджера процессов и файловой системы, поэтому эти компоненты, вероят-
вероятно, всегда будут загружаться в память монитором. В загрузочный образ также
входят некоторые драйверы устройств. Хотя в MINIX 3 поставлена цель обеспе-
обеспечить независимость загрузки как можно большего числа драйверов, без драйвера
диска едва ли удастся обойтись уже на ранней стадии работы системы.
Основное предназначение pm_init заключается в инициализации таблиц ме-
менеджера процессов с целью обеспечить возможность работы процессов, предва-
предварительно загруженных в память. Как было отмечено ранее, менеджер процессов
поддерживает две важные структуры данных — таблицу свободных участков (или
таблицу свободной памяти) и часть таблицы процессов. Сначала мы рассмотрим
таблицу свободных участков. Инициализация памяти — сложная задача. Приво-
Приводимое далее описание проще понять, сначала ознакомившись с организацией па-
памяти на момент активации менеджера процессов. MINIX 3 предоставляет для
этого всю необходимую информацию.
Перед тем как сам загрузочный образ MINIX 3 попадает в память, монитор за-
загрузки определяет структуру доступной памяти. Находясь в загрузочном меню
и нажав клавишу Esc, вы получите доступ к параметрам загрузки. Одна из
строк на экране показывает блоки неиспользуемой памяти и выглядит сле-
следующим образом:
memory = 800:923еО,100000:3df0000
После запуска MINIX 3 вы можете получить эту информацию при помощи ко-
команды sysenv или клавиши F5. Разумеется, числа, которые вы увидите, могут
отличаться от приведенных в этом примере.
Здесь мы видим два блока свободной памяти. Кроме того, два блока памяти
заняты: ниже адреса 0x800 находятся данные BIOS, главная загрузочная запись
и загрузочный блок. Не имеет значения, как используется эта память, важно, что
на момент запуска монитора загрузки она недоступна. Память, начинающаяся
с адреса 0x800, является «базовой памятью» для IBM-совместимых компьюте-
компьютеров. В данном примере свободный блок с началом по адресу 0x800 B048) имеет
размер 0х923е0 E99008) байт. Далее следует блок «верхней области памяти»
с 640 Кбайт до 1 Мбайт, который недоступен обычным программам. Он зарезер-
зарезервирован под память для чтения и выделенную память адаптеров ввода-вывода.
Начиная с адреса 0x100000 A Мбайт), свободно 0x3df0000 байт. Как правило,
этот участок называют расширенной памятью. В показанном примере компью-
компьютер оснащен в общей сложности 64 Мбайт оперативной памяти.
Если вы внимательно следили за числами, то заметили, что сумма свободной
базовой памяти составляет менее 638 Кбайт, как «должно бы быть». Загрузочный
монитор MINIX 3 загружает себя как можно выше в данном диапазоне и в рас-
рассматриваемом случае занимает около 52 Кбайт. Таким образом, свободными ока-
оказываются приблизительно 584 Кбайт памяти. Следует отметить, что механизм
использования памяти может быть сложнее, чем описано здесь. Например, один
из методов запуска MINIX, к моменту написания книги еще не перенесенный
в MINIX 3, предполагает применение DOS-файла для имитации диска MINIX.
Этот метод требует загрузки некоторых компонентов MS-DOS до запуска мо-
монитора загрузки MINIX 3. Если компоненты окажутся загруженными в области
памяти, несмежные с уже занятыми, число областей свободной памяти будет
больше двух.
Когда монитор загрузки помещает загрузочный образ в память, информация о его
компонентах отображается на экране консоли. Часть экрана показана на рис. 4.34.
В этом примере (типичном, но, вероятно, отличающемся от вашего экрана, по-
поскольку для его создания использовалась рабочая редакция MINIX 3) монитор
загрузки поместил ядро в свободную область памяти, начиная с адреса 0x800.
Менеджер процессов, файловая система, сервер реинкарнации и прочие компо-
компоненты, не показанные в листинге, устанавливаются в блок памяти, начинающий^
ся по адресу 1 Мбайт. Это было не единственным возможным решением — ниже
588 Кбайт нашлось бы достаточно места для некоторых из этих компонентов.
Тем не менее, когда MINIX 3 компилируется с кэшем блоков большого объема
(как в данном примере), файловая система не умещается в пространство, нахо-
находящееся над ядром. Загрузить все в верхнюю область памяти было бы проще, но
совсем не обязательно. Такой метод не приводит к каким-либо потерям, менед-
менеджер памяти способен использовать свободную память ниже 588 Кбайт уже после
того, как система запущена и начали работу пользовательские процессы.
Рис. 4.34. Использования памяти монитором загрузки для нескольких
первых компонентов загрузочного образа
Инициализация менеджера процессов начинается с циклического просмотра
таблицы процессов с целью отключить таймер каждой записи во избежание лож-
ложных срабатываний. Затем инициализируются глобальные переменные, опреде-
определяющие наборы сигналов, по умолчанию игнорируемые или вызывающие гене-
генерацию дампов. Далее обрабатывается информация об использовании памяти.
В строке 18182 системное задание считывает строку memory монитора загрузки,
которую мы уже видели. В нашем примере свободная память описывается двумя
парами базовый адресразмер. Вызов функции get_mem_chunks (строка 18184)
преобразует ASCII-строку в двоичные данные и вводит значения базового адре-
адреса и размера в массив mem_chunks (строка 18192), элементы которого определе-
определены следующим образом:
struct memory {phys_clicks base; phys_clicks size;}
Массив mem_chunks не является списком свободных участков. Это всего лишь
небольшой массив, в котором накапливается информация до инициализации
списка свободных участков.
После опроса ядра и преобразования информации об использовании ядром опе-
оперативной памяти в число кликов вызывается функция patch_mem_chunks для
исключения памяти ядра из массива mem_chunks. Теперь учтена и память, ко-
которая использовалась до запуска MINIX 3, и память, занятая ядром. Массив
mem_chunks содержит не всю информацию, однако память, требуемая обычным
процессам загрузочного образа, учитывается внутри цикла, инициализирующего
записи таблицы процессов (строки 18201-18239).
Информация об атрибутах всех процессов, входящих в состав загрузочного
образа, находится в таблице image, объявленной в файле kernel / table. с
(строки 6095-6109). Перед входом в основной цикл менеджер процессов по-
получает копию таблицы image вызовом sys_get image ядра (строка 18197).
Строго говоря, sys_get image является не вызовом ядра, а одним из более 10 мак-
макросов, определенных в файле include/minix/syslib.h и обеспечивающих
простой интерфейс к вызову ядра sys_getinfo. Процессы ядра невидимы из
пользовательского пространства, и части таблицы процессов, принадлежащие
менеджеру процессов и файловой системе, не нуждаются в инициализации со
стороны компонентов ядра. Фактически место под записи процессов ядра не ре-
резервируется. Каждый из них имеет отрицательный номер (индекс в таблице про-
процессов) и игнорируется при проверке в строке 18202. Кроме того, вызывать
функцию patch_mem_chunks для процессов ядра не обязательно; при выделе-
выделении памяти под ядро потребности его процессов учитываются.
Как системные, так и пользовательские процессы необходимо добавить в табли-
таблицу процессов, хотя работа с ними ведется по-разному (строки 18210-18219).
Единственным пользовательским процессом, включенным в состав загрузочного
образа, является init, поэтому в строке 18210 выполняется проверка для INIT_
PROC_NR. Все остальные процессы, входящие в загрузочный образ, — системные.
Системные процессы являются особыми: они не могут быть вытеснены, каждый
из них обладает собственной записью в таблице priv ядра и набором привиле-
привилегий, задаваемым флагами. Для каждого процесса определены надлежащие пара-
параметры обработки сигналов по умолчанию, при этом между системными про-
процессами и init имеются определенные различия. Далее карта памяти каждого
процесса извлекается из ядра при помощи функции get_mem_map, совершаю-
совершающей вызов ядра sys_getinfo, и patch_mem_map, соответствующим образом
изменяющей массив mem_chunks (строки 18225-18230).
Наконец, файловой системе передается сообщение, с помощью которого каждый
процесс инициализируется в принадлежащей ей части таблицы процессов (стро-
(строки 18233-18236). Сообщение содержит только номер и идентификатор процесса;
этого достаточно, чтобы инициализировать запись в таблице файловой системе,
поскольку все процессы загрузочного образа принадлежат суперпользователю
и могут получить одинаковые значения по умолчанию. Каждое сообщение от-
отправляется при помощи операции send, поэтому ответа на него не ожидается.
После передачи сообщения имя процесса отображается на консоли (строка 18237):
Building process table: pm fs rs tty memory log driver init
Здесь driver заменяет стандартный драйвер диска. В загрузочный образ можно
включить несколько драйверов диска, один из которых выбирается по умолча-
умолчанию в соответствии со значением параметра загрузки label.
Собственная запись менеджера процессов в таблице процессов представляет со-
собой особый случай. После завершения основного цикла менеджер процессов вы-
выполняет некоторые изменения в своей записи и посылает итоговое сообщение
файловой системе с символьным значением NONE в качестве номера процесса.
Передача сообщения осуществляется вызовом sendrec, поэтому менеджер процес-
процессов ждет ответа. Пока менеджер процессов выполняет цикл инициализирующего
кода, файловая система в строках 24189-24202 выполняет цикл receive (дан-
(данный код рассматривается в следующей главе). Получение сообщения со значением
NONE в качестве номера процесса указывает файловой системе на то, что все сис-
системные процессы инициализированы, можно выйти из цикла и послать синхрони-
синхронизирующее сообщение для снятия блокирования с менеджера процессов.
После этого файловая система может продолжить собственную инициализацию,
а инициализация менеджера процессов почти завершена. В строке 18253 вызы-
вызывается функция mem_init. Она инициализирует связанный список свободных
областей памяти и нужные переменные, которые будут использованы для управ-
управления памятью в процессе работы системы, на основе данных массива mem_
chunks. Управление памятью в обычном режиме начинается после того, как на
консоль выводится сообщение, содержащее общий объем памяти, память, заня-
занятую MINIX 3, и объем свободной памяти:
Physical memory: total 63996 KB, system 12834 KB, free 51162 KB
Следующая функция, get_nice_value (строка 18263), вызывается для опреде-
определения «уровня вежливости» каждого из процессов загрузочного образа. В таблице
image содержится значение, определяющее приоритет очереди, в которую процесс
будет помещен при планировании. Это значение варьируется от 0 для самых вы-
высокоприоритетных процессов, таких как CLOCK, до 15 для процесса IDLE. Одна-
Однако для UNIX-подобных систем традиционным является диапазон «уровней веж-
вежливости» с положительными и отрицательными значениями. По этой причине
функция get_nice_value переводит для пользовательских процессов значения
приоритетов ядра в шкалу с нулем посередине. Масштабирование производится
с использованием констант PRIO_MIN и PRIO_MAX (-20 и +20 соответственно),
определенных в виде макросов в файле include/sys/resource. h (отсутству-
(отсутствует в листинге). Они масштабируются между значениями MIN_USER_Q и МАХ_
USER_Q, определенными в файле kernel/proc . h. Таким образом, при увеличе-
увеличении и уменьшении числа приоритетных очередей команда nice продолжает ра-
работать. Процесс init, корень дерева пользовательских процессов, помещается
в очередь с приоритетом 7 и получает «уровень вежливости» 0, который насле-
наследуется дочерними процессами после вызова fork.
Последние две функции файла main.с уже упоминались. Функция get_mem_
chunks (строка 18280) вызывается лишь однажды. Она принимает информацию,
возвращаемую монитором загрузки в виде ASCII-строки с парами базовый ад-
рес -.размер, преобразует ее в клики и сохраняет в массиве mem_chunks. Функ-
Функция patch_mem_chunks (строка 18333) продолжает формирование списка сво-
свободных участков памяти и вызывается несколько раз — один раз для ядра, один
раз для процесса init и по одному разу для каждого системного процесса, ини-
инициализированного в главном цикле процедуры pm_init. Она корректирует пер-
первоначальную информацию, предоставленную монитором загрузки. Работа функ-
функции patch_mem_chunks проще, поскольку она оперирует данными в кликах.
Для каждого процесса она получает базовые адреса и размеры сегментов кода
и данных. Сначала к базовому адресу последнего элемента массива свободных
блоков памяти обрабатываемого процесса прибавляется сумма размеров сегмен-
сегментов кода и данных, а затем полученный размер блока уменьшается на ту же вели-
величину, чтобы соответствующая память была помечена как используемая.
4.8.3. Реализация системных
вызовов fork, exit и wait
Системные вызовы fork, exit и wait реализуются соответственно процеду-
процедурами do_fork, do_pm_exit и do_waitpid из файла forkexit .с. Процедура
do_f огк (строка 18430) руководствуется последовательностью действий, пере-
перечисленных в пункте 4.7.4. Обратите внимание, что второй вызов procs_in_use
(строка 18445) резервирует для суперпользователя несколько последних ячеек
в таблице процессов. При вычислении необходимой потомку памяти в сумму
включается промежуток между данными и стеком, но не сегмент кода. Так дела-
делается потому, что сегмент кода либо разделяемый, либо, если адресные простран-
пространства кода и данных процесса объединены, его размер равен нулю. После того как
нужный объем памяти подсчитан, чтобы получить ее, делается вызов alloc_
mem. Если память успешно выделена, базовые адреса родителя и потомка преоб-
преобразуются из кликов в байты, и чтобы выполнить копирование, вызывается функ-
функция sys__copy, которая отправляет сообщение системному заданию.
После того как память предоставлена, в таблице процессов ищется свободная
ячейка. Предыдущая проверка, затрагивающая переменную procs_in_use,
гарантирует, что такая ячейка найдется. Найденная ячейка заполняется, для это-
этого в нее сначала копируются данные родительского процесса, затем обновляют-
обновляются поля mp_parent, mp_f lags, mp_child_utime, mp_child_stime, mp_seg,
mp_exitstatus и mp_sigstatus. Некоторые из этих полей требуют специаль-
специальной подготовки. Так, в поле mp_f lags наследуется лишь часть битов. Поле тр_
seg является массивом, элементы которого соответствуют сегментам кода, дан-
данных и стека, и если обнаруживается, что у процесса адресные пространства раз-
разделены, ячейка, соответствующая сегменту кода, не меняется и продолжает ука-
указывать на код родительского процесса.
На следующем шаге дочернему процессу назначается идентификатор (PID). Вызов
функции get_f ree_pid получает свободное значение идентификатора. Это не
так просто, как может показаться, и мы рассмотрим данную функцию позднее.
Вызовы sys_f ork и tell_f s информируют ядро и файловую систему о рожде-
рождении нового процесса, чтобы они могли обновить свои структуры таблицы про-
процессов. (Все процедуры, имена которых начинаются с префикса sys_, служат
для отправки системному заданию сообщений, запрашивающих различные услу-
услуги согласно табл. 2.5). Создание или уничтожение процесса всегда инициируется
менеджером процессов и только потом в число участников этого таинства допус-
допускаются ядро и файловая система.
Ответное сообщение процессу-потомку отправляется точно в конце кода do_
fork. Ответ родителю, содержащий идентификатор нового процесса, посылает-
посылается из главного цикла в main, как обычный ответ на запрос.
Следующим системным вызовом, который выполняется менеджером процессов,
является exit. Вызов принимает процедура do_pm_exit (строка 18509), но
большую часть черновой работы делает pm_exit несколькими строками позже.
Причина такого разделения труда в том, что функция pm_exit требуется также
в ситуации, когда необходимо позаботиться о процессе, завершаемом по сигналу.
Действия в этом случае те же самые, но другие аргументы, и такое разделение
делается, по сути, для удобства.
Прежде всего, pm_exit останавливает таймер, если у процесса он активен. Затем
файловой системе и ядру сообщается, что процесс более не может быть запущен
на выполнение (строки 18550 и 18551). Вызов ядра sys__exit отправляет сис-
системному заданию сообщение, по получении которого оно очищает запись про-
процесса в своей таблице процессов. Затем освобождается память. Функция f ind_
share определяет, разделяется ли сегмент кода с другими программами. Если
нет, сегмент кода освобождается вызовом f ree_mem. Следом за этим аналогич-
аналогичный вызов освобождает память, занимаемую стеком и данными. Иногда всю па-
память можно освободить одним вызовом f ree_mem, но дело того не стоит. Если
родитель процесса ожидает, то чтобы освободить ячейку, вызывается функ-
функция cleanup. Если нет, процесс превращается в зомби, это индицируется битом
ZOMBIE в поле mp_f lags, и родителю отправляется сигнал SIGCHILD.
Полностью уничтожив процесс или превратив его в зомби, функция pm_exit
ищет в таблице процессов его потомков (строки 18582-18589). Если таковые об-
обнаруживаются, они делаются потомками процесса init. Когда init находится
в ожидании и один из его потомков становится зомби, для этого потомка вызы-
вызывается cleanup. Таким образом обрабатываются ситуации, подобные показан-
показанной на рис. 4.35, а. На этом рисунке мы видим процесс 12, который собирается
завершиться, и его родителя, процесс 7, находящегося в ожидании. Чтобы из-
избавиться от процесса 12, для него будет вызвана функция cleanup, процессы 52
и 53 станут потомками init (рис. 4.35, б). В результате оказывается, что про-
процесс 53, который уже завершился, является потомком процесса, выполняющего
вызов wait. Следовательно, записи о нем будут корректно очищены.
Рис. 4.35. Иллюстрация механизма завершения процесса: а — процесс 12 собирается
завершиться; б — ситуация после его завершения
Когда родитель делает вызов wait или waitpid, управление передается сле-
следующей функции, do_waitpid (строка 18598). Параметры этих двух систем-
системных вызовов различны, ожидаемые действия также различны, но благодаря
специальной настройке значений внутренних переменных (строки 18613-18615),
функция do_waitpid может выполнять оба вызова. После того как присвоены
значения внутренним переменным, стартует цикл, в котором просматривается
вся таблица процессов, с целью выяснить, есть ли вообще у процесса потомки
(строки 18623-18642). Если есть, проверяется, есть ли среди них зомби, кото-
которых теперь можно добить. Когда обнаруживается зомбированный процесс (стро-
(строка 18630), он уничтожается и функция do_waitpid возвращает код SUSPEND.
Если обнаруживается отслеживаемый процесс-потомок, do_waitpid передает
управление назад, отправив предварительно ответное сообщение, говорящее, что
процесс остановлен.
Если оказалось, что у вызвавшего wait процесса нет потомков, возвращается
код ошибки (строка 18653). Если потомки есть, но среди них нет ни зомби, ни
отслеживаемых процессов, проверяется, хотел ли сделавший вызов процесс
дожидаться завершения работы потомков. Если да (это — обычный случай),
устанавливается бит, означающий, что процесс находится в ожидании (строка
18648), и родитель приостанавливается до тех пор, пока один из его потомков не
завершится.
Когда процесс заканчивает выполняться, а родитель этого процесса ожидает его
завершения (в каком бы порядке это ни произошло), для исполнения последних
церемоний вызывается функция cleanup (строка 18660). У нее не слишком
много работы. Родительский процесс, прохлаждающийся в ожидании в резуль-
результате вызова wait или waitpid, пробуждается, ему передается PID завершивше-
завершившегося потомка, а также код выхода и состояние сигналов. В этот момент память
потомка уже освобождена файловой системой, а ядро исключило его из плани-
планирования, поэтому все, что осталось сделать для завершения ритуала, — очистить
занимаемую процессом ячейку в таблице процессов.
4.8.4. Реализация системного вызова exec
Код системного вызова exec соответствует пошаговой процедуре, представлен-
представленной в пункте 4.7.7. Этот код находится в функции do_exec (строка 18747) файла
exec. с. Сделав несколько простых проверок правильности данных, менеджер
процессов извлекает из пользовательского адресного пространства имя файла
программы, которая будет запущена как новый процесс (строки 18773-18776).
Вспомним, что библиотечные процедуры, реализующие вызов exec, создают стек
в старом образе памяти, как мы видели на рис. 4.32. Этот стек переносится в про-
пространство памяти менеджера процессов (строка 18782).
Следующие несколько шагов выполняются в цикле (строки 18789-18801). Од-
Однако для обычных двоичных исполняемых файлов цикл имеет одну итерацию,
и именно этот случай мы рассмотрим в первую очередь. В строке 18791 файло-
файловой системе отправляется специальное сообщение, меняющее текущий каталог,
чтобы полученный путь интерпретировался относительно рабочего каталога
пользователя, а не каталога менеджера процессов. Затем вызывается процедура
allowed, которая открывает файл в случае, если его исполнение разрешено.
Если же проверка оканчивается неудачей, вместо дескриптора файла возвращает-
возвращается отрицательное число, и процедура do_exec завершается с указанием ошибки.
Если же файл существует и является исполняемым, менеджер процессов вы-
вызывает функцию read_header и считывает размеры сегментов. Для обычного
двоичного файла выход из цикла по коду, возвращаемому функцией read_
header, выполняется в строке 18800.
Теперь рассмотрим, что происходит, если исполняемый файл является сценари-
сценарием. Как и большинство UNIX-подобных операционных систем, MINIX 3 поддер-
поддерживает исполняемые сценарии. Процедура read_header проверяет, составляют
ли первые два байта «волшебную» последовательность (# !), и если такая после-
последовательность обнаружена, возвращает специальный код, указывающий на сце-
сценарий. Первая строка помеченного таким образом сценария содержит интерпре-
интерпретатор для его исполнения и, возможно, флаги и параметры, передаваемые этому
интерпретатору. Например, сценарий, первая строка которого выглядит так,
будет обработан интерпретатором Bourne:
#! /bin/sh
В то же время сценарий, начинающийся со следующей строки, обработает интер-
интерпретатор Perl:
#! /usr/local/bin/perl -wT
В последнем случае флаги указывают интерпретатору выдавать предупреждения
о возможных проблемах. Однако поддержка сценариев усложняет вызов exec.
Если требуется запустить сценарий, функция do_exec должна загрузить в память
не сам сценарий, а двоичный файл его интерпретатора. После идентификации сце-
сценария в нижней части цикла вызывается функция patch_stack (строка 18801).
Действие функции patch_stack можно проиллюстрировать следующим при-
примером. Предположим, что Perl-сценарий вызывается из командной строки с не-
несколькими аргументами следующим образом:
perl_prog.pl filel file2
Если в сценарий была включена «волшебная» строка, аналогичная показанной
ранее, функция patch_stack создает стек для исполнения двоичного Perl-фай-
Perl-файла так, как будто бы командная строка имела вид
/usr/local/bin/perl -wT perl# prog.pl filel file2
Если это действие выполняется успешно, возвращается первая часть строки, то
есть путь к двоичному исполняемому файлу интерпретатора. Далее тело цикла
исполняется еще раз, при этом считывается заголовок файла и размеры сегмен-
сегментов файла, который необходимо выполнить. В первой строке сценария не разре-
разрешается указывать другой сценарий в качестве интерпретатора. Именно поэтому
используется переменная г: ее можно инкрементировать лишь однажды, дав воз-
возможность однократного вызова функции patch_stack. Если на второй ите-
итерации цикла обнаруживается код, указывающий на сценарий, проверка в стро-
строке 18800 прерывает цикл. Код, обозначающий сценарий, имеет символьное имя
ESCRIPT и является отрицательным числом, определенным в строке 18741. В этом
случае проверка в строке 18803 приведет к тому, что процедура do_exit завер-
завершится с кодом ошибки, который указывает на ее источник: файл, не подлежа-
подлежащий исполнению, или слишком длинную командную строку.
Чтобы завершить вызов exec, необходимо выполнить еще несколько действий.
Функция f inal_share проверяет, может ли новый процесс разделять код с уже
работающими (строка 18809), a new_mem выделяет память для нового образа
и освобождает память, отведенную под старый. Перед началом выполнения про-
программы, для которой совершен вызов exec, требуется обеспечить готовность
образа в памяти и таблицы процессов. В строках 18819-18821 в таблице про-
процессов сохраняются индексный узел, файловая система и время модификации
исполняемого файла. Затем стек устанавливается, как показано на рис. 4.32, в,
и копируется в новый образ памяти. Далее с помощью процедуры rw_seg (стро-
(строки 18834-18841) считываются в память сегменты кода (если код не является раз-
разделяемым) и данных. Если установлен бит setuid или setgid, файловой сис-
системе необходимо послать уведомление с тем, чтобы она поместила эффективный
идентификатор процесса в свою часть таблицы процессов (строки 18845-18852).
Указатель на аргументы новой программы сохраняется в таблице процессов ме-
менеджера процессов, что позволяет команде ps отобразить командную строку.
В таблице процессов менеджера процессов также инициализируются битовые
маски сигналов. Далее файловой системе передается уведомление, предписываю-
предписывающее закрыть все дескрипторы файлов, которые должны быть закрыты по завер-
завершении вызова exec, и сохраняется имя команды, выводимое утилитой ps или
при отладке (строки 18856-18877). Как правило, последним шагом является
информирование ядра, однако если трассировка включена, требуется послать
сигнал (строки 18878-18881).
Описывая функцию do_exec, мы упомянули множество действий, вынесенных
во вспомогательные процедуры в файле exec. с. Например, функция read_
header (строка 18889) не только считывает заголовок и возвращает размеры
сегментов, но и проверяет, является ли файл нормальным исполняемым файлом
MINIX 3 для данного типа процессора. Константа А_1803 86 в строке 18944 опре-
определяется в директивах #if def ...#endif на этапе компиляции. Двоичные исполняе-
исполняемые программы для 32-разрядной операционной системы MINIX 3 и платформы
Intel должны иметь эту константу в заголовке. Если же MINIX 3 компилиро-
компилировалась для 16-разрядного режима, вместо константы А_18 03 8б используется
А_1808б. Кроме того, функция read_header проверяет, умещаются ли сегмен-
сегменты в оперативной памяти. При желании вы можете ознакомиться со значениями
для других процессоров в файле include/a. out .h.
Процедура new_mem (строка 18980) выясняет, достаточно ли доступной памяти
для загрузки нового образа. Для этого она ищет свободный блок, достаточно
большой для размещения данных и стека в том случае, если код разделяется, а если
код не разделяется, ищется блок для размещения текста, данных и стека в совокуп-
совокупности. Этот алгоритм можно улучшить, если отдельно искать свободное место
для кода и для стека с данными, так как эти сегменты не обязательно распола-
располагать вместе. Данное требование было обязательным для ранних версий MINIX,
однако в MINIX 3 оно снято. Если нужная память найдена, ранее занятая память
освобождается и выделяется новый блок. Если памяти недостаточно, вызов exec
завершается неудачей. Выделив память, new_mem обновляет карту памяти (тр_
seg) и передает ее ядру вызовом sys_newmap ядра.
Оставшаяся часть кода new_mem связана с обнулением области неинициализи-
неинициализированных глобальных переменных (сегмент bss), области зазора и сегмента сте-
стека. Многие компиляторы сами генерируют обнуляющий код, но благодаря тому,
что очистка выполняется менеджером процессов, MINIX 3 может работать с ком-
компиляторами, которые так не поступают. Обнуляется и участок между сегмента-
сегментами данных и стека, чтобы при расширении области данных вызовом brk выде-
выделяемая память уже содержала нули. Это — не только дополнительное удобство
для программиста, который может рассчитывать на то, что новые переменные
инициализируются нулем, но еще и средство защиты информации в многополь-
многопользовательских системах, так как процесс, ранее занимавший память, мог содер-
содержать данные, которые нельзя показывать другим процессам.
Следующая процедура называется patch_ptr (строка 19074); ее цель — исправ-
исправление значений указателей, показанных на рис. 4.32, б, в форму на рис. 4.32, в.
Алгоритм ее работы прост: найти в стеке все указатели и добавить к ним значе-
значение базового адреса.
Следующие две функции работают совместно. Мы уже описывали их назначение.
Когда системный вызов exec выполняется над сценарием, в качестве исполняе-
исполняемого файла используется двоичный файл интерпретатора. Функция insert_
arg (строка 19106) вставляет строки в копию стека, принадлежащую менеджеру
процессов. Она работает под управлением функции patch_stack (строка 19162),
которая ищет все слова в «волшебной» строке сценария и вызывает insert_
arg. Разумеется, значения указателей также должны быть надлежащим образом
скорректированы. Функция insert_arg проста, однако для ее правильной ра-
работы требуется выполнить несколько проверок. Здесь стоит упомянуть о том,
что при обработке сценариев проверка проблем особенно важна. Сценарии могут
быть с успехом написаны пользователями, а всем компьютерным профессиона-
профессионалам известно, что пользователи по определению являются основным источни-
источником проблем. Если же говорить серьезно, то принципиальным отличием между
сценарием и скомпилированным двоичным файлом является то, что компилятор
отказывается преобразовывать в двоичную форму исходный код, содержащий
какие-либо из выявленных им ошибок. Сценарии подобную проверку не про-
проходят.
На рис. 4.36 показано, как будет обработан вызов сценария оболочки s. sh, опери-
оперирующий файлом f 1. Команда выглядит следующим образом:
s.sh fl
При этом «волшебная» строка сценария указывает, что его следует интерпрети-
интерпретировать с помощью оболочки Bourne:
#! /bin/sh
Рисунок 4.36, а иллюстрирует копирование стека из пространства вызываю-
вызывающего процесса, а рис. 4.36, б — преобразование стека функциями patch_stack
и insert_arg. Обе диаграммы соответствуют рис. 4.32, б.
Рис. 4.36. Обработка сценария: а — массивы, переданные вызову execve, и стек, созданный
при исполнении сценария; б — вид массивов и стека после обработки функцией patch_stack.
Имя сценария передается программе, интерпретирующей сценарий
Следующая функция, определенная в файле exec .с, — это функция rw_seg
(строка 19208). При каждом вызове exec она исполняется один или два раза.
Обязательный вызов выполняет загрузку сегмента данных, а необязательный
вызов — сегмента кода. Файловая система прибегает к специальному трюку, что-
чтобы поместить сразу весь сегмент в пользовательское пространство, а не считы-
считывать и копировать файл блок за блоком. Суть в том, что вызов особым образом
декодируется файловой системой и выглядит так, как будто сам пользователь-
пользовательский процесс считывает весь сегмент. Лишь несколько первых строк процедуры
считывания файловой системы знают о том, как в действительности обстоит де-
дело. Подобный маневр значительно ускоряет процесс загрузки сегмента.
Последняя подпрограмма в файле exec. с называется f ind_share (строка 19256).
Она по номеру индексного узла, номеру устройства и времени модификации ищет
в таблице процессов процесс, с которым можно разделить код. Это — простой
последовательный поиск подходящего поля в таблице mproc. Конечно, при про-
просмотре необходимо игнорировать сам процесс, для которого выполняется поиск.
4.8.5. Реализация системного вызова brk
Как мы видели, модель памяти в MINIX 3 довольно проста: каждому процессу
при его создании выделяется один непрерывный участок памяти для данных
и стека. Процесс никогда не перемещается в памяти, никогда из нее не выгружа-
выгружается, не растет и не уменьшается. Могут произойти только два важных события:
область данных может израсходовать резерв и достигнуть области стека, и, на-
наоборот, стек может разрастись на всю область зазора и попасть в область дан-
данных. С учетом этих обстоятельств, реализация системного вызова brk (файл
break, с) относительно проста. При его выполнении сначала просто проверяет-
проверяется, что указанные размеры допустимы, а затем в таблицы вносятся изменения.
Выполняет вызов подпрограмма do_brk (строка 19328), но большая часть рабо-
работы делается в процедуре adjust (строка 19361). Последняя проверяет, не пере-
пересеклись ли сегменты данных и стека. Если да, вызов brk завершается с ошибкой,
но процесс не уничтожается немедленно. При выполнении сравнения к верхней
границе области данных добавляется значение множителя безопасности, SAFETY_
BYTES, поэтому остается надежда на то, что в стеке есть немного места и процесс
может еще немного поработать. Управление возвращается процессу, чтобы он
хотя бы вывел соответствующее сообщение и правильно завершился.
Обратите внимание: значения SAFETY_BYTES и SAFETY_CLICKS заданы в сере-
середине процедуры при помощи директивы #define. Это довольно необычно, тра-
традиционно подобные объявления размещаются в начале файла или в отдельных
заголовочных файлах. Комментарий рядом поясняет, что программист нашел
сложным выбор значения множителя безопасности. Без сомнения, описание бы-
было расположено таким необычным образом для привлечения внимания и, воз-
возможно, чтобы стимулировать дальнейшие эксперименты.
Базовый адрес сегмента данных не меняется, поэтому вызову adjust требуется
обновлять только длину сегмента. Стек растет вниз с фиксированного конечного
адреса, поэтому если adjust обнаруживает, что указатель стека (он передается
в виде параметра) вышел за пределы области стека (то есть достиг более низких
адресов), обновляются как адрес начала сегмента стека, так и его длина.
4.8.6. Реализация сигналов
С сигналами связаны 8 системных вызовов, перечисленных в табл. 4.5. Как сами
сигналы, так и эти системные вызовы обрабатываются кодом из файла signal. с.
Таблица 4.5. Системные вызовы, относящиеся к сигналам
Системный вызов Назначение
sigaction Изменение реакции на будущий сигнал
sigprocmask Модификация набора блокируемых сигналов
kill Отправка сигнала другому процессу
alarm Отправка сигнала ALRM самому себе после задержки
pause Приостановка работы до следующего сигнала
sigsuspend Изменение набора блокируемых сигналов с последующим вызовом pause
sigpending Определение набора текущих (то есть заблокированных) сигналов
sigreturn Восстановление после завершения обработчика сигнала
Системный вызов sigaction поддерживает две функции, sigaction и signal,
позволяющие процессу изменять свою реакцию на сигнал. Функция sigaction
регламентирована стандартом POSIX и является в любом случае предпочти-
предпочтительной, однако библиотечная функция signal удовлетворяет стандарту ANSI С,
и если программа должна быть переносима на системы, не соответствующие
стандарту POSIX, необходимо использовать вторую функцию. Код do_sigaction
(строка 19544) начинается с проверок правильности номера сигнала и отсутст-
отсутствия попыток изменить реакцию на сигнал sigkill (строки 19550-19551). Сиг-
Сигнал sigkill нельзя ни игнорировать, ни блокировать, ни обрабатывать. Это то
исключительное средство, при помощи которого пользователь может контро-
контролировать собственные процессы, а системный оператор — пользователей. При
вызове sigaction передаются указатели на структуру типа sigaction, по ад-
адресу sig_osa помещаются старые значения атрибутов, а по адресу sig_nsa —
новый набор атрибутов.
На первом шаге, чтобы скопировать текущие значения атрибутов по указателю
sig_osa, вызывается системное задание. Далее, при вызове sigaction указа-
указатель sig_nsa может иметь значение NULL. Это означает, что требуется считать
текущие значения атрибутов, не меняя их. В таком случае sigaction немедлен-
немедленно возвращает управление (строка 19560). Если указатель sig_nsa не равен
NULL, в пространство менеджера процессов копируется новая структура, описы-
описывающая действие сигнала.
Код в строках 19567-19585 модифицирует битовые карты mp_catch, mp_ignore
и mp_sigpending, чтобы указанный сигнал либо игнорировался, либо обраба-
обрабатывался так, как предлагается по умолчанию, либо вызывал обработчик. Поле
sa_handler структуры sigaction используется для передачи указателя на про-
процедуру в исполняемую функцию, если сигнал вызывает обработчик, либо одного
из специальных кодов SIG_IGN и SIG_DFL, значения которых понятны, если вы
ориентируетесь в рассмотренных ранее стандартах обработки сигналов POSIX.
Кроме того, может использоваться код SIG_MESS, специфичный для MINIX 3;
мы рассмотрим его позже.
Библиотечные функции sigaddset и sigdelset модифицируют битовые кар-
карты сигналов, хотя те же действия можно реализовать и при помощи макроса, как
и другие простые манипуляции с битами. Тем не менее эти функции требуются
по стандарту POSIX с целью упростить перенос программ на другие системы,
в том числе те, в которых общее число сигналов превышает число битов в целом
значении. Использование библиотечных функций упрощает и перенос самой
системы MINIX 3 на различные платформы.
Ранее мы упомянули особый случай — код SIG_MESS. Этот код, проверяемый
в строке 19576, доступен только для привилегированных (системных) процессов.
Как правило, такие процессы блокируются, ожидая сообщений-запросов. Это оз-
означает, что обычный метод получения сигнала, при котором менеджер процессов
просит ядро выставить кадр сигнала на стек приемника, будет отложен до мо-
момента, когда сообщение активизирует приемник. Код SIG_MESS предписывает
менеджеру процессов доставить уведомление, имеющее более высокий приори-
приоритет, чем обычные сообщения. Уведомление содержит набор активных сигналов
в качестве аргумента, допуская передачу нескольких сигналов в одном сообщении.
В завершение заполняются другие относящиеся к сигналам поля той части
таблицы процессов, которая принадлежит менеджеру процессов. Для каждого
потенциального сигнала здесь есть битовая карта, sa_mask, определяющая,
какие сигналы будут блокироваться при обработке. Кроме того, для каждого сиг-
сигнала хранится указатель, sa_handler. Он может содержать либо указатель на
функцию обработки, либо специальное значение, означающее, что сигнал дол-
должен быть блокирован, обработан, как предписано по умолчанию, либо использо-
использован для генерации сообщения. Адрес библиотечной функции, по завершении об-
обработчика выполняющей системный вызов sigreturn, хранится в поле тр_
sigretrun. Этот адрес передается в одном из полей сообщения, которое полу-
получает менеджер процессов.
POSIX позволяет процессу изменять способ обработки получаемых им сигналов
даже внутри обработчика. Благодаря этому можно, например, изменить реакцию
на сигнал на время его обработки, а затем восстановить нормальный отклик.
Следующая группа системных вызовов и служит для подобных манипуляций
сигналами. Вызов sigpending выполняется функцией do_sigpending (стро-
(строка 19597), возвращающей битовую карту mp_sigpending, по которой процесс
может определить, имеются ли активные сигналы. Вызов sigprocmask, обслу-
обслуживаемый функцией do_sigprocmask, возвращает набор блокируемых сигна-
сигналов. Кроме того, с его помощью можно изменить блокировку либо одного сигна-
сигнала из набора, либо сразу установить новый набор. В тот момент, когда с сигнала
снимается блокировка, стоит проверить, есть ли задержанные сигналы, для этого
в конце вариантов SIG_SETMASK и SIG_UNBLOCK вызывается функция check_
pending (строки 19635 и 19641). Функция do_sigsuspend выполняет систем-
системный вызов sigsuspend. Этот вызов приостанавливает выполнение процесса до
тех пор, пока не будет получен сигнал. Как и другие обсуждаемые здесь функции,
do_sigsuspend манипулирует битовыми картами. Кроме того, она устанавли-
устанавливает в поле mp_f lags бит SIGSUSPENDED, что и предотвращает выполнение про-
процесса. Опять же, в завершение здесь стоит вызвать функцию check_pending.
Наконец, функция do_sigretrun обслуживает системный вызов sigreturn,
обеспечивающий возврат из пользовательского обработчика сигнала. Эта функ-
функция восстанавливает контекст сигналов, предшествующий входу в обработчик,
а также вызывает функцию check_pending в строке 19682.
Когда пользовательский процесс, такой как команда kill, совершает системный
вызов kill, происходит обращение к функции do_kill (строка 19689) менед-
менеджера процессов. Один вызов kill может привести к доставке сигналов группе
различных процессов, поэтому do_kill вызывает функцию check_sig, кото-
которая проверяет допустимых получателей во всей таблице процессов.
Некоторые сигналы, такие как SIGINT, исходят от самого ядра. Функция ksig_
pending (строка 19699) выполняется, когда ядро посылает менеджеру процес-
процессов сообщение об активных сигналах. Активные сигналы могут иметься у не-
нескольких процессов, поэтому цикл в строках 19714-19722 многократно запра-
запрашивает активный сигнал у системного задания, передает его процедуре handle_
sig и указывает системному заданию на то, что обработка завершена, если про-
процессов с активными сигналами больше нет. В сообщения включается битовая
карта, что позволяет ядру генерировать несколько сигналов одним сообщением.
Следующая функция, handle_sig, побитно обрабатывает битовую карту (стро-
(строки 19750-19763). Некоторые сигналы ядра требуют особого внимания: иногда
идентификатор процесса изменяется, чтобы сигнал был доставлен группе про-
процессов (строки 19753-19757). В противном случае для каждого установленного
бита вызывается функция check_sig, как в подпрограмме do_kill.
Оповещения и таймеры
Системный вызов alarm выполняется функцией do_alarm (строка 19769). Она
вызывает следующую функцию, set_alarm, указав нулевое время оповещения.
Код set_alarm вынесен в отдельную функцию потому, что он также использу-
используется для отключения таймера, когда процесс завершается, а таймер еще работает.
Функция sig_alarm работает с таймерами, поддерживаемыми внутри менед-
менеджера процессов. Сначала она определяет, установлен ли таймер от имени за-
запрашивающего процесса, и, если да, истек ли он. Такие проверки позволяют сис-
системному вызову вернуть оставшееся время предыдущего оповещения в секундах
или нуль, если таймер не установлен. Комментарий описывает некоторые про-
проблемы, связанные с большими тайм-аутами. В строке 19818 весьма неприятный
на вид код преобразует время в тики, умножая аргумент, переданный при вызове
(время в секундах), на константу HZ — число тактов таймера в секунду. Для того
чтобы привести результат к требуемому типу clock_t, нужно трижды преобра-
преобразовать его тип. В следующей строке тип clock_t переменной ticks преобразу-
преобразуется обратно в unsigned long. Затем результат сравнивается с преобразова-
преобразованием исходного значения аргумента в unsigned long. Если обнаруживается
несовпадение, то запрошенное время вызывает выход за пределы значений одно-
одного из используемых типов данных, и вместо него подставляется значение, указы-
указывающее бесконечное время. Наконец, вызывается одна из функций pm_set_
timer или pm_cancel_timer, соответственно добавляющая и удаляющая тай-
таймер из очереди менеджера процессов. Ключевым аргументом последнего вызова
является cause_sigalarm — сторожевая функция, которая должна быть вы-
выполнена по истечении таймера.
Взаимодействие с таймерами, поддерживаемое в пространстве ядра, скрыто в вы-
вызовах подпрограмм pm_XXX_timer. Любой запрос оповещения, в конечном сче-
счете, вызывающий его генерацию, обычно приводит к запросу установки таймера
в пространстве ядра. Единственным исключением является ситуация, в которой
несколько запросов оповещения возникают одновременно. Однако процессы
могут отменять оповещения или завершать работу до истечения установленных
ими таймеров. Вызов ядра, устанавливающий таймер в пространстве ядра, дол-
должен выполняться лишь при изменении таймера, находящегося во главе очереди
таймеров менеджера процессов.
Когда таймер, стоящий в очереди в пространстве ядра и установленный от имени
менеджера процессов, истекает, системное задание информирует об этом менедже-
менеджера процессов, посылая ему уведомление, а тот обнаруживает его в своем главном
цикле по типу SYN_ALARM. В результате запускается функция pm_expire_
timers, которая, в конечном счете, вызывает другую функцию, cause_sigalarm.
Функция cause_sigalarm (строка 19935) является упомянутой выше сто-
сторожевой функцией. Она получает номер процесса, которому требуется послать
сигнал, проверяет некоторые флаги, сбрасывает флаг ALARM_ON и вызывает
функцию check_sig, отправляющую сигнал SIGALRM.
По умолчанию сигнал SIGALRM уничтожает процесс. Если же выполняется его
обработка, то вызов sigaction должен установить функцию обработки. Вся по-
последовательность событий обработки сигнала SIGALRM показана на рис. 4.37.
Здесь представлены три последовательности сообщений. При помощи сообще-
сообщения 1 пользователь делает системный вызов alarm (сообщение менеджеру про-
процессов), менеджер процессов ставит таймер в очередь таймеров пользователь-
пользовательских процессов и в качестве подтверждения посылает сообщение 2. В течение
какого-то времени новые события могут не происходить. Когда таймер данного
запроса достигнет начала очереди из-за отмены или истечения стоящих впереди
таймеров, системному заданию отправляется сообщение 3, чтобы оно установи-
установило новый таймер для менеджера процессов в пространстве ядра. Сообщение 4
является подтверждением. После этого между событиями снова наступает пе-
перерыв. После того как этот таймер достигает начала очереди таймеров ядра, об-
обработчик прерываний от таймера узнает о его истечении. Передача оставшихся
сообщений выполняется быстро. Обработчик прерываний от таймера посылает
таймерному заданию сообщение HARD_INT E), по нему таймерное задание за-
запускается и обновляет свои таймеры. Сторожевая функция таймера, cause_
alarm, передает уведомление менеджеру процессов F), который также обновля-
обновляет свои таймеры. После того как он с помощью собственной таблицы процессов
определяет, что в целевом процессе установлен обработчик сигнала SIGALRM, он
посылает системному заданию сообщение 7, чтобы выполнить манипуляции со
стеком, нужные для передачи сигнала пользовательскому процессу. Сообще-
Сообщение 8 является подтверждением. Пользовательский процесс планируется и вы-
выполняет обработчик, после чего обращается к менеджеру процессов с вызовом
sigreturn (9). Менеджер процессов передает сообщение 10 системному зада-
заданию, чтобы завершить очистку, и получает сообщение 11 в качестве подтвержде-
подтверждения. На диаграмме не представлена еще одна пара сообщений между менедже-
менеджером процессов и системным заданием. С ее помощью передается время работы
системы. Обмен этими сообщениями осуществляется перед сообщением 3.
Следующая функция, do_pause, заботится о системном вызове pause (стро-
(строка 19853). На самом деле она не связана с оповещениями и таймерами, хотя ее
можно использовать для приостановки исполнения программы до получения
оповещения или какого-либо другого сигнала. Все, что ей нужно сделать, — это
установить бит и вернуть код SUSPEND. Это приведет к тому, что главный цикл
менеджера процессов не будет отвечать, сохраняя вызвавший процесс заблоки-
заблокированным. Не нужно даже информировать ядро, так как оно уже знает о блоки-
блокировании процесса.
Рис. 4.37. Сообщения при работе таймера. Самые главные из них: 7 — пользователь
делает вызов alarm; 3 — менеджер процессов обращается к системному заданию,
чтобы установить таймер; 6 — таймер информирует менеджер процессов
об истечении таймера; 7 — менеджер процессов запрашивает сигнал
для пользователя; 9 — обработчик завершается вызовом sigreturn
Функции поддержки сигналов
Ранее мы упоминали о нескольких вспомогательных функциях из файла signal. с.
Теперь рассмотрим их подробно. Важнейшей из них является sig_proc (строка
19864), которая и отвечает за отправку сигнала. Сначала она делает несколько
проверок. Попытка послать сигнал завершившемуся или зомбированному про-
процессу является признаком серьезной ошибки и приводит к панике в системе
(строки 19889-19893). Если процесс отслеживается, то при получении сигнала
он останавливается (строки 19894-19899). Если же сигнал должен игнорировать-
игнорироваться, работа функции sig_proc завершается в строке 19902. Это действие приня-
принято по умолчанию для ряда сигналов, например для тех, которые задает стандарт
POSIX, но не поддерживает MINIX 3. Если сигнал блокируется, нужно только
установить соответствующий бит в битовой карте mp_sigpending процесса.
Ключевое значение имеет проверка, отделяющая процессы, которым разрешено
перехватывать сигнал, от тех, которым это не разрешено (строка 19910). После
этого все особые случаи игнорируются, и процессы, не удостоившиеся права пе-
перехватывать сигнал, завершаются. Единственное исключение составляют сигна-
сигналы, преобразуемые в сообщения, адресованные системным службам.
Сначала мы рассмотрим обработку сигналов, которые процессу разрешено пе-
перехватывать (строки 19911-19950). Сначала формируется сообщение для ядра,
некоторые части сообщения заполняются копиями информации из принадле-
принадлежащей менеджеру процессов части таблицы процессов. Если ранее процесс был
приостановлен сигналом sigsuspend, в сообщение включается маска сигналов,
сохраненная в момент остановки, если нет, туда вставляется текущая маска
(строка 19914). Дополнительно в сообщение включаются некоторые адреса из
адресного пространства процесса-получателя сигнала: адрес обработчика, адрес
библиотечной подпрограммы sigreturn, подлежащей вызову после завершения
обработчика, и текущее значение указателя стека.
Затем выделяется место в стеке процесса. Структура, которая помещается в стек,
показана на рис. 4.38. Часть sigcontext сохраняется в стеке и позднее восста-
восстанавливается из него потому, что ее значение в таблице процессов меняется при
подготовке к запуску обработчика. Часть, названная sigframe, содержит адрес
возврата и данные, необходимые вызову sigreturn для восстановления состоя-
состояния процесса. Адрес возврата и указатель кадра стека в действительности не ис-
используются нигде в MINIX 3. Они нужны для того, чтобы обмануть отладчик
при трассировке обработчика событий.
Рис. 4.38. Чтобы подготовиться к запуску обработчика, в стек помещаются структуры
sigcontext и sigframe. Регистры процессора копируются из кадра стека на момент
переключения контекста
Структура, помещаемая в стек, довольно объемна. Для нее выделяется место
(строки 19923 и 19924), а затем, чтобы проверить, достаточно ли байтов в сте-
стеке, вызывается adjust. Если места не хватает, происходит переход по метке
determinate (здесь вы можете увидеть редко используемую в языке С команду
goto), и процесс завершается.
При вызове adjust возможна проблема. При обсуждении реализации системного
вызова brk говорилось, что adjust начинает сообщать об ошибке тогда, когда
стек приближается к области данных на расстояние SAFETY_BYTES. Дополни-
Дополнительный зазор вводится потому, что программно стек может проверяться лишь
время от времени. В данном случае, вероятно, такой запас прочности излишен,
так как достоверно известно, какая часть стека требуется для сигнала, а допол-
дополнительное место необходимо только обработчику, который предположительно
является относительно простой функцией. Поэтому возможно, что некоторые
процессы вследствие чересчур строгой проверки в adjust будут «заживо похо-
похоронены», но это все же лучше, чем наблюдать таинственные сбои в работе систе-
системы. Таким образом, указанные проверки можно улучшить.
Если в стеке достаточно места, проверяются значения еще двух флагов. Флаг
SA_NODEFER означает, что дальнейшие сигналы такого же типа должны быть бло-
блокированы на время выполнения обработчика. Флаг SA_RESETHAND — признак
того, что при получении сигнала обработчик должен быть возвращен в исходное
состояние. (В результате получается честная имитация устаревшего вызова
signal. Хотя такое поведение обычно рассматривалось как недостаток, при под-
поддержке устаревших функций приходится поддерживать и их недостатки.) Затем
вызовом sys_sendsig ядра отправляется уведомление ядру (строка 19940).
В завершение сбрасывается бит-индикатор задержанного сигнала и вызывается
функция unpause, которая прерывает любой системный вызов, остановивший
процесс. В следующий раз, когда процесс получит управление, начнет работу об-
обработчик. Если по каким-либо причинам все указанные тесты закончатся неудач-
неудачно, менеджер процессов вызовет сбой (строка 19949).
Упомянутое ранее исключение (преобразование сигналов в сообщения, адресо-
адресованные системным службам) проверяется в строке 19951 и выполняется после-
последующим вызовом sys_kill ядра. В результате системное задание посылает уве-
уведомление получателю сигнала. В отличие от большинства других уведомлений,
уведомление системного задания помимо основной содержит дополнительную
информацию — сведения об источнике и временную метку. Дополнительная
информация представляет собой битовую карту сигналов, с помощью которой
системный процесс, которому адресован сигнал, обнаруживает все активные
сигналы. Если вызов sys_kill завершается неудачно, менеджер процессов ге-
генерирует сбой. В противном случае происходит выход из функции sig_proc
(строка 19954). Если проверка в строке 19951 имеет отрицательный результат,
управление передается на метку determinate.
Теперь давайте взглянем на код завершения процесса под меткой determinate
(строка 19957). Инструкция goto и метка — самый простой механизм обработки
возможных отказов при вызове adjust. Итак, сюда передается управление, если
сигнал по тем или другим причинам не может или не должен быть обработан.
Возможно, перехваченный сигнал необходимо проигнорировать; в этом случае
sig_proc просто завершает работу. В противном случае завершиться должен
процесс. Единственный вопрос состоит в том, нужно ли генерировать при этом
дамп памяти. Наконец, процесс завершается вызовом pm_exit (строка 19967)
так, как будто он делает это сам.
В функции check_sig (строка 19973) менеджер процессов проверяет, может ли
быть послан сигнал. Например:
kill @,sig);
Этот вызов означает, что указанный сигнал должен быть отправлен всем процессам
в текущей группе (то есть всем процессам, запущенным с того же терминала).
Сигналы, исходящие от ядра и системного вызова reboot, также могут затраги-
затрагивать несколько процессов. По этой причине check_sig в цикле перебирает все
процессы из таблицы процессов, выбирая из них потенциальных получателей
(строки 19996-20026). В цикле содержится много тестов, и только если все они
пройдены, при помощи sig_proc отправляется сигнал (строка 20023).
Еще одна функция, которая несколько раз вызывается в рассмотренном нами ко-
коде, называется check_pending (строка 20036). Она перебирает все биты в би-
битовой карте mp_sigpending процесса, сверяясь с битовыми картами с помо-
помощью функций do_sigmask, do_sigretrun и do_sigsuspend, и смотрит, не
была ли снята блокировка с одного из задержанных сигналов. Обнаружив пер-
первый такой сигнал, она отправляет его. Так как все обработчики событий со вре-
временем вызывают функцию do_sigreturn, все разблокированные активные сиг-
сигналы в конце концов доставляются.
Процедура unpause (строка 20065) необходима для отправки сигналов про-
процессам, приостановленным на одном из вызовов pause, wait, read, write или
sigsuspend. Выяснить, обусловлена ли остановка вызовом pause, wait или
sigsuspend, можно, сверившись с таблицей процессов менеджера процессов.
Если выясняется, что ни один из этих вызовов не является причиной остановки,
запрос передается файловой системе, которая при помощи собственной функции
do_ unpause проверяет, был ли процесс приостановлен для чтения или записи.
В любом случае результат одинаков: незаконченный вызов завершается с ошиб-
ошибкой, а процесс вновь запускается и может обработать сигнал.
Последняя процедура в этом файле называется dump_core (строка 20093). Она
записывает на диск дампы памяти. Дамп состоит из заголовка, содержащего ин-
информацию о размере занимаемых процессом сегментов, всей информации состоя-
состояния процесса (это копия записи процесса из таблицы процессов ядра) и образов
всех сегментов. Отладчик может прочитать эту информацию, чтобы помочь про-
программисту определить, что пошло не так в работе программы.
Код записи в файл прост. Здесь снова возможна проблема, упомянутая в предыду-
предыдущем разделе, но теперь в несколько иной форме. Чтобы гарантировать, что записы-
записываемый в дамп сегмент стека содержит самую последнюю информацию, вызывает-
вызывается функция adjust (строка 20010). Из-за проверки границы безопасности этот
вызов может «провалиться». Правда, дамп записывается в любом случае, незави-
независимо от успеха вызова, но информация о стеке может оказаться неправильной.
Функции поддержки таймеров
Менеджер процессов в MINIX 3 обрабатывает запросы оповещений от пользова-
пользовательских процессов, которым не разрешен непосредственный самостоятельный
контакт с ядром и системным заданием. Такой интерфейс скрывает все подроб-
ности планирования оповещения в системном задании. Возможностью установ-
установки таймера в ядре обладают лишь системные процессы. Соответствующая под-
поддержка предоставлена в файле timers . с (строка 20200).
Менеджер процессов управляет списком оповещений и просит системное зада-
задание уведомлять его, когда для оповещения наступает время. Получив оповеще-
оповещение от ядра, менеджер процессов передает его процессу, сделавшему запрос.
Поддержка таймеров осуществляется тремя функциями. Функция pm_set_
timer устанавливает таймер и добавляет его в список менеджера процессов,
pm_expire_timer проверяет истекшие таймеры, a pm_cancel_timer удаляет
таймер из списка. Все три функции пользуются подпрограммами библиотеки тай-
таймеров, объявленными в файле include/timers.h. Функция pm_set_timer
вызывает функцию tmrs_settimer, pm_expire_timer — функцию tmrs_
exptimers, a pm_cancel_timer — функцию tmrs_clrtimers. Эти функции
соответственно выполняют поиск в связанном списке, добавление и удаление его
элемента. Вмешательство системного задания с целью корректировки очереди тай-
таймеров в пространстве ядра требуется лишь при операциях вставки и удаления пер-
первого элемента очереди. В подобных случаях каждая из функций pm_XXX_timer
использует вызов sys_setalarm ядра, чтобы запросить помощь уровня ядра.
4.8.7. Реализация других системных вызовов
Менеджер процессов обрабатывает три системных вызова, связанных со време-
временем — time, stime и times. Соответствующий код находится в файле time. с.
Описания системных вызовов приведены в табл. 4.6.
Таблица 4.6. Три системных вызова, связанных со временем
Вызов Функция
time Считывание текущего реального времени и времени работы системы в секундах
stime Установка часов реального времени
times Считывание учетного времени процесса
Реальное время поддерживается таймерным заданием внутри ядра, однако само
таймерное задание ведет обмен сообщениями лишь с одним процессом — сис-
системным заданием. Таким образом, единственный способ считать и установить
реальное время — послать сообщение системному заданию. Именно этим и зани-
занимаются функции do_time (строка 20320) и do_stime (строка 20341). Реальное
время измеряется в секундах, начиная от 1 января 1970 года.
Ядро поддерживает учетную информацию для каждого процесса. Каждый такт
часов записывается в счет какого-либо процесса. Ядро не располагает сведениями
о соотношениях «родитель-потомок», поэтому задача накопления информации
об учетном времени потомков процессов возлагается на менеджер процессов. Ко-
Когда выполнение дочернего процесса завершается, его учетное время добавляется
в запись родителя в таблице процессов менеджера процессов. Функция do_times
(строка 20366) считывает время родительского процесса с помощью вызова
sys_times ядра, адресованного системному заданию, а затем создает ответное
сообщение, помещая в него пользовательское и системное время, начисленное
дочерним процессам.
Файл getset.c содержит только одну процедуру, do_getset (строка 20415),
выполняющую семь системных вызовов, обязательных согласно стандарту POSIX.
Эти вызовы перечислены в табл. 4.7. Все они настолько просты, что выделять
для них отдельные процедуры не имеет смысла. Вызовы getuid и getgid воз-
возвращают как реальные, так и эффективные значения идентификаторов пользо-
пользователя (UID) и группы (GID).
Таблица 4.7. Системные вызовы, поддерживаемые в файле servers/pm/getset.c
Системный вызов Описание
getuid Возвращает реальный и эффективный идентификаторы пользователя
getgid Возвращает реальный и эффективный идентификаторы группы
getpid Возвращает идентификаторы процесса и его родителя
setuid Устанавливает реальный и эффективный идентификаторы пользователя
setgid Устанавливает реальный и эффективный идентификаторы группы
setsid Создает новый сеанс и возвращает идентификатор процесса
getpgrp Возвращает идентификатор группы процессов
Установить GID или UID несколько сложнее, чем просто прочитать. Сначала
нужно проверить, уполномочен ли процесс изменять эти значения. Если проверка
пройдена, об изменении GID или UID необходимо информировать файловую сис-
систему, так как эти значения влияют на защиту файлов. Вызов setsid создает новый
сеанс; этого нельзя делать процессу, который уже является лидером группы, и со-
соответствующая проверка делается в строке 20463. После проверки вызов завершает
файловая система, делая процесс лидером группы без управляющего терминала.
В противоположность системным вызовам, рассмотренным к настоящему моменту
в этой главе, вызовы в файле mis с. с не требуются стандартом POSIX. Их нали-
наличие обусловлено необходимостью обеспечить взаимодействие с ядром драйверов
устройств и серверов, находящихся в MINIX 3 в пользовательском пространст-
пространстве. Подобная необходимость отсутствует в монолитных операционных системах.
Вызовы перечислены в табл. 4.8.
Таблица 4.8. Специальные системные вызовы MINIX 3 в файле servers/pm/misc.c
Системный вызов Описание
do_allocmem Выделение фрагмента памяти
do_freemem Освобождение фрагмента памяти
do_getsysinfo Получение от ядра информации о менеджере процессов
do_getprocnr Получение индекса таблицы процессов по идентификатору
или по имени пользователя
do_reboot Уничтожение всех процессов, информирование файловой
системы и ядра
do_getsetpriority Считывание или установка системного приоритета
do_svrctrl Преобразование процесса в сервер
Два первых вызова обрабатываются полностью менеджером процессов. Функ-
Функция do_allocmem считывает запрос из полученного сообщения, преобразует его
в клики и вызывает функцию alloc_mem. Вызов do_allocmem используется,
например, драйвером памяти для выделения памяти под виртуальный диск.
Вызов do_f reemem выполняется аналогично, но вместо alloc_mem происходит
обращение к функции f ree_mem.
Остальные вызовы, как правило, требуют поддержки других частей операционной
системы. Их можно рассматривать в качестве интерфейсов с системным заданием.
Вызов do_getsysinf о (строка 20554) способен выполнять ряд операций в зави-
зависимости от запроса в полученном сообщении. Он обращается к системному зада-
заданию за информацией о ядре, содержащейся в структуре kinf о (ее определение
находится в файле include/minix/type.h), а также предоставляет другому
процессу по запросу адрес части таблицы процессов, принадлежащей менеджеру
процессов, либо копию всей таблицы. Последним действием является вызов функ-
функции sys_datacopy (строка 20582). Функция do_getprocnr самостоятельно
возвращает индекс в таблице процессов по заданному значению PID, а если ей
задано имя целевого процесса, обращается за помощью к системному заданию.
Следующие два вызова, хотя и не требуются стандартом POSIX, в какой-либо
форме поддерживаются в большинстве операционных систем, подобных UNIX.
Процедура do_reboot посылает сигнал KILL всем процессам и информирует
файловую систему о том, что нужно подготовиться к перезагрузке. Лишь после
синхронизации файловой системы уведомление передается ядру вызовом sys_
abort (строка 20667). Перезагрузка может быть обусловлена сбоем, а также за-
запросом суперпользователя на остановку или перезапуск системы, и ядру необхо-
необходимо знать, какой из случаев имеет место. Функция do_getsetpriority под-
поддерживает известную UNIX-утилиту nice, позволяющую пользователю снизить
приоритет своего процесса, чтобы уступить место другим процессам (возможно,
принадлежащим тому же пользователю). В MINIX 3 эта утилита решает более
важную задачу — она обеспечивает точное управление относительными приори-
приоритетами системных компонентов. Например, сетевому или дисковому устройству,
получающему быстрый поток данных, можно назначить более высокий приори-
приоритет, чем устройству, чья скорость приема ниже (скажем, клавиатуре). Если высо-
высокоприоритетный процесс зациклится и воспрепятствует обслуживанию других
процессов, его приоритет также можно временно снизить. Изменение приоритета
процесса осуществляется при планировании путем помещения процесса в очередь
с более высоким или низким приоритетом. Реализация механизма планирования
описана в главе 2. Если изменение приоритета инициируется планировщиком
в ядре, вовлекать в операцию менеджер процессов не требуется. Пользовательско-
Пользовательскому же процессу в подобной ситуации придется выполнить системный вызов. Все,
что требуется сделать на уровне менеджера процессов, — считать текущее значе-
значение, возвращенное в сообщении, либо сгенерировать сообщение с новым значе-
значением. Новое значение передается системному заданию вызовом sys_nice ядра.
Последняя подпрограмма в файле mis с. с — do_svrctl. В настоящее время она
используется для включения и отключения подкачки. Другие функции, обслу-
обслуживаемые этим вызовом, предполагается реализовать в сервере реинкарнации.
Последний системный вызов, который мы рассмотрим в этой главе, — это вызов
ptrace из файла trace. с. Код этого файла вы можете найти на компакт-диске
книги и веб-сайте MINIX 3. Вызов ptrace используется для отладки программ.
В качестве параметра он принимает одну из 11 команд, перечисленных в табл. 4.9.
В менеджере процессов функция do_trace обрабатывает четыре из них: Т_ОК,
T_RESUME, T_TEXT и T_STEP. Она выполняет запросы на включение режима
трассировки и выход из режима. Все остальные команды передаются системному
заданию, которое имеет доступ к части таблицы процессов, принадлежащей
ядру. Для этого вызывается библиотечная функция sys_trace. Трассировка
поддерживается двумя функциями: f ind_proc ищет трассируемый процесс
в таблице процессов, a stop_proc останавливает трассируемый процесс при по-
получении сигнала.
Таблица 4.9. Команды отладки, поддерживаемые в файле servers/pm/trace.c
Команда Описание
T_STOP Остановка процесса
Т_ОК Включение трассировки родительским процессом для данного процесса
T_GETINS Возврат значения из пространства кода
T_GETDATA Возврат значения из пространства данных
T_GETUSER Возврат значения из таблицы пользовательских процессов
T_SETINS Установка значения в пространстве кода
T_SETDATA Установка значения в пространстве данных
T_SETUSER Установка значения в таблице пользовательских процессов
T_RESUME Возобновление исполнения
Т_ЕХ1Т Выход
T_STEP Установка бита трассировки
4.8.8. Утилиты управления памятью
В завершение этой главы мы кратко рассмотрим два файла, содержащие функ-
функции поддержки менеджера процессов: alloc . с и utility. с. Вы можете найти
эти файлы на компакт-диске и веб-сайте MINIX 3.
Файл alloc. с позволяет системе отслеживать, какие области памяти заняты,
а какие свободны. В этом файле определены три точки входа:
+ alloc_mem — запрос блока памяти заданного размера;
+ f ree_mem — возврат блока памяти;
+ mem_init — инициализация списка свободных блоков при запуске менедже-
менеджера процессов.
Как уже отмечалось, функция alloc_mem просто ищет в списке первый блок
подходящего размера. Если она обнаруживает слишком большой блок, она от-
отрезает от него нужную часть, а лишнее оставляет в списке. Если требуется
весь блок, вызывается функция del_slot, которая полностью удаляет блок из
списка.
Функция f ree_mem должна проверять, можно ли объединить возвращенный
блок с соседними. Если да, вызывается функция merge, которая объединяет ука-
указанные блоки и обновляет список.
Начальный список, охватывающий всю доступную память, строится функцией
mem_init.
Процедуры из последнего файла, utility. с, используются в различных частях
менеджера процессов.
Процедура get_f ree_pid ищет свободный идентификатор для дочернего про-
процесса. Она предотвращает возникновение возможной проблемы. Максимальное
значение идентификатора процесса равно 30 000. На самом деле, оно должно оп-
определяться верхней границей диапазона PlD_t, однако указанное значение было
выбрано потому, что некоторые устаревшие программы используют более узкий
тип. К примеру, если процессу-«долгожителю» был назначен идентификатор 20,
то за время его жизни 30 000 процессов могут быть созданы и уничтожены. Каж-
Каждый раз при необходимости в новом идентификаторе переменная инкрементиру-
ется; в конечном счете она достигнет порогового значения, обнулится, а затем
увеличится до 20. Повторное назначение уже используемого идентификатора
приведет к катастрофе (представьте, что будет, если кто-нибудь пошлет процес-
процессу 20 сигнал). Переменная, хранящая последний назначенный идентификатор
процесса, инкрементируется, и если ее значение выходит за установленный мак-
максимум, отсчет начинается заново с PID 2 (идентификатор PID 1 всегда назначен
процессу init). Затем выполняется поиск по всей таблице процессов с тем, что-
чтобы убедиться, что назначаемый идентификатор процесса не используется. Если
идентификатор процесса занят, процедура повторяется до тех пор, пока не будет
обнаружен свободный идентификатор процесса.
Процедура allowed проверяет, предоставлен ли доступ к файлу. Эта функция не-
необходима, например, do_exec, чтобы проверить, является ли файл исполняемым.
Процедура no_sys не должна вызываться никогда. Она здесь только на тот
случай, если менеджер процессов получит системный вызов с недопустимым но-
номером или вызов, не обрабатываемый им.
Когда менеджер процессов обнаруживает ошибку, после которой невозможно
восстановление, он вызывает функцию panic. Она сообщает об ошибке систем-
системному заданию, которое «со скрежетом» останавливает «несущуюся в пропасть»
систему MINIX. Просто так эту функцию лучше не вызывать.
Следующая функция в файле utility.с называется tell_fs. Она подготав-
подготавливает сообщение и отправляет его файловой системе, когда последнюю необхо-
необходимо информировать об обработанных менеджером процессов событиях.
Функция f ind_param применяется для разбора параметров монитора. В на-
настоящее время с ее помощью извлекается информация об использовании памяти
перед загрузкой MINIX 3, однако при необходимости она может находить и дру-
другую информацию.
Следующие две функции файла utility.с предоставляют интерфейсы к биб-
библиотечной функции sys_getproc, которая вызывает системное задание для
получения информации из части таблицы процессов, принадлежащей ядру. Функг
ция sys_getproc является макросом, определенным в файле include/minix/
syslib.h и передающим параметры вызову sys_getinf о ядра. Функция get_
mem_map получает карту памяти процесса, a get_stack_ptr — указатель стека.
Обеим функциям нужен номер процесса (индекс в таблице процессов), отличаю-
отличающийся от идентификатора процесса. Последняя функция в файле utility.с,
которая называется proc_f rom_pid, обеспечивает такую поддержку — при вы-
вызове она принимает PID, а возвращает индекс таблицы процессов.
Резюме
В этой главе были проанализированы как общие принципы управления памя-
памятью, так и их реализация в MINIX 3. Мы увидели, что в простейших системах
вообще не поддерживается подкачка или замещение страниц. Программа, загру-
загруженная в память, остается там до своего завершения. Некоторые операционные
системы позволяют находиться в памяти одновременно только одному процессу,
в то время как другие поддерживают многозадачность.
Следующим шагом вперед является подкачка (то есть загрузка и выгрузка целых
процессов). Благодаря подкачке система может обрабатывать большее количест-
количество процессов, чем то, для которого достаточно пространства в памяти. Процессы,
для которых в ней нет места, целиком выгружаются на диск. Свободные области
в памяти и на диске можно отслеживать с помощью битового массива или спи-
списка свободных участков.
Современные компьютеры часто поддерживают некоторую форму виртуальной
памяти. В простейшем виде адресное пространство каждого процесса делится на
части постоянного размера, называемые страницами, которые могут размещаться
в любом доступном страничном блоке в памяти. Существует множество алгорит-
алгоритмов замещения страниц, два наилучших — это алгоритмы «старения» и «второго
шанса». Для хорошей работы систем замещения страниц выбрать хороший алго-
алгоритм недостаточно; необходимо также обратить внимание на такие вопросы, как
определение рабочего набора, стратегию предоставления памяти и размер страниц.
Сегментация помогает в управлении структурами данных, изменяющими свой
размер во время выполнения, и упрощает процессы компоновки и совместного
доступа. Она также облегчает предоставление различных видов защиты разным
сегментам. Иногда механизмы сегментации и замещения страниц комбинируют-
комбинируются, что позволяет организовать двухмерную виртуальную память. Системы Intel
Pentium поддерживают сегментацию и замещение страниц памяти.
Управление памятью в MINIX 3 реализовано просто. Процессу выделяется па-
память, когда он делает системный вызов fork или exec. После того как область
памяти выделена, она никогда не меняет своих размеров, пока работает процесс.
На машинах с процессорами Intel система MINIX 3 поддерживает для процессов
две модели памяти. У маленьких программ инструкции и данные могут разме-
размещаться в одном сегменте. В более сложных программах адресные пространства
данных и кода могут быть разными. Такие процессы могут иметь общий код,
поэтому при вызове fork им выделяется память лишь под данные и стек. Такое
не исключено и при вызове exec, если окажется, что в памяти уже находится
процесс, использующий тот же код, который нужен новой программе.
По большей части работа менеджера процессов связана не с отслеживанием памя-
памяти, что делается при помощи списка свободных блоков и алгоритма выбора первого
подходящего блока, а с обслуживанием системных вызовов, относящихся к управ-
управлению памятью. Некоторые из системных вызовов обеспечивают работу сигналов
в стиле POSIX, а поскольку по умолчанию большинство таких сигналов завершают
процесс, имеет смысл обрабатывать их в менеджере процессов, инициирующем за-
завершение всех процессов. Отдельные системные вызовы напрямую к работе с па-
памятью не относятся, но также обрабатываются менеджером процессов в основном
из-за того, что он меньше файловой системы по объему и поместить их здесь удобнее.
Вопросы и задания
1. Компьютерная система имеет достаточно места для того, чтобы содержать в опе-
оперативной памяти четыре программы. Эти программы простаивают в ожида-
ожидании ввода-вывода половину времени. Какая часть времени работы централь-
центрального процессора пропадает?
2. Рассмотрим систему подкачки, когда в памяти содержатся свободные участки
следующих размеров и в следующем порядке: 10 Кбайт, 4 Кбайт, 20 Кбайт,
18 Кбайт, 7 Кбайт, 9 Кбайт, 12 Кбайт и 15 Кбайт. Какой из них будет выбран
по алгоритму первого соответствия для успешного удовлетворения запроса
сегмента следующего размера:
1) 12 Кбайт;
2) 10 Кбайт;
3) 9 Кбайт.
Ответьте на тот же самый вопрос для алгоритмов наилучшего соответствия,
наихудшего соответствия и следующего соответствия.
3. У компьютера есть 1 Гбайт оперативной памяти, выделяемой блоками по
64 Кбайт. Сколько килобайтов занимает битовая карта, хранящая данные о сво-
свободных блоках?
4. Рассмотрите предыдущий вопрос для случая, когда вместо битовой карты ис-
используется список свободных блоков. Сколько памяти займет список в луч-
лучшем и худшем случаях? Считайте, что операционная система занимает пер-
первые 512 Кбайт памяти.
5. В чем разница между физическим адресом и виртуальным?
6. Опираясь на таблицу страниц на рис. 4.8, сосчитайте физический адрес, соот-
соответствующий каждому из следующих виртуальных адресов:
1J0;
2) 4100;
3) 8300.
7. На рис. 4.9 поле страницы виртуального адреса имеет разрядность 4 бита, а по-
поле страницы физического адреса — 3 бита. Может ли число страничных битов
виртуального адреса в общем случае быть больше, меньше и равно числу битов
физического адреса? Объясните ответ.
8. Процессор Intel 8086 не поддерживает виртуальную память. Тем не менее не-
некоторые компании ранее продавали системы, содержащие стандартный про-
процессор 8086 и выполняющие замещение страниц. Предположите, как они это
делали. Подсказка: подумайте о логическом расположении блока управления
памятью (MMU).
9. Считая, что команда выполняется за 1 мкс, а ошибка отсутствия страницы
требует дополнительно п мкс, напишите выражение для фактического време-
времени выполнения команды с учетом того, что ошибки происходят через каждые
k инструкций.
10. Компьютер имеет 32-разрядное адресное пространство и страницы размером
8 Кбайт. Таблица страниц целиком поддерживается аппаратно, на запись в ней
отводится одно 32-разрядное слово. При запуске процесса таблица страниц
копируется из памяти в аппаратуру, одно слово требует 100 не. Если каждый
процесс работает в течение 100 мс (включая время загрузки таблицы страниц),
какая доля времени процессора жертвуется на загрузку таблицы страниц?
11. Компьютер с 32-разрядным адресом использует двухуровневую таблицу стра-
страниц. Виртуальные адреса расщепляются на 9-разрядное поле таблицы верх-
верхнего уровня, И-разрядное поле таблицы страниц второго уровня и смещение.
Чему равен размер страниц и сколько их в адресном пространстве?
12. Далее представлен алгоритм фрагмента программы для компьютера с разме-
размером страницы 512 байт. Программа расположена по адресу 1020, указатель
стека равен 8192 (стек увеличивается по направлению к нулю). Напишите
последовательность страничных обращений, создаваемую этой программой.
Каждая инструкция занимает 4 байта A слово), включая непосредственные
константы. В последовательности обращений учитываются обращения как
к инструкциям, так и к данным.
Загрузить слово 6144 в регистр 0.
Поместить содержимое регистра 0 в стек.
Вызвать процедуру по адресу 5120, поместив в стек адрес возврата.
Вычесть константу 16 из указателя стека.
Сравнить полученный результат с константой 4.
При равенстве перейти на адрес 5152.
13. Предположим, что 32-разрядный виртуальный адрес разбивается на четыре
поля. Первые три используются для трехуровневой системы таблиц страниц.
Четвертое поле — это смещение. Зависит ли количество страниц от размера
всех четырех полей? Если нет, какие из полей имеют значение, а какие нет?
14. Компьютер, процессы которого имеют 1024 страницы в своем адресном про-
пространстве, хранит таблицы страниц в памяти. На чтение слова из таблицы
страниц требуется 5 не. Чтобы уменьшить издержки, в компьютере присутст-
присутствует буфер быстрого преобразования адреса (TLB), который содержит 32 пары
(виртуальная страница, физический страничный блок) и может выполнить
поиск за 100 не. При какой частоте обращений к памяти, успешно реализуе-
реализуемых в TLB, потери в среднем будут меньше 200 не?
15. Буфер быстрого преобразования адреса на VAX-машинах не содержит би-
бита R. Почему?
16. Машина поддерживает 48-разрядные виртуальные адреса и 32-разрядные фи-
физические адреса. Размер страницы равен 8 Кбайт. Сколько требуется записей
в таблице страниц?
17. RISK-процессор с 64-разрядными виртуальными адресами и 8 Гбайт опера-
оперативной памяти использует инвертированную таблицу страниц с 8-килобайт-
ными страницами. Каков минимальный размер TLB?
18. Компьютер имеет четыре страничных блока. Время загрузки, время послед-
последнего доступа и биты R и М для каждой страницы показаны в следующей таб-
таблице (время считается в тактах системных часов).
Страница Загружена Последнее обращение R М
0 126 279 0 0
1 230 260 1 0
2 120 272 11
3 160 280 1 1
1) Какую страницу выгрузит алгоритм NRU?
2) Какую страницу выгрузит алгоритм FIFO?
3) Какую страницу выгрузит алгоритм LRU?
4) Какую страницу выгрузит алгоритм второго шанса?
19. Если используется алгоритм замещения страниц FIFO в системе с четырьмя
страничными блоками и восемью страницами, сколько ошибок отсутствия
страниц произойдет для последовательности обращений 0172327103 при ус-
условии, что четыре страничных блока изначально пусты? Решите эту задачу
для алгоритма LRU.
20. Небольшой компьютер имеет 8 страничных кадров, в каждом из которых содер-
содержится по странице. Страничные кадры включают виртуальные адреса А, С, G,
Н, В, L, N, D и F в перечисленном порядке, а относительные значения времени
загрузки равны соответственно 18, 23, 5, 7, 32, 19, 3 и 8. Соответствующие би-
биты R равны 1, 0, 1, 1, 0, 1, 1 и 0, а биты М — 1, 1, 1, 0, 0, 0, 1 и 1. В каком порядке
алгоритм второго шанса рассматривает страницы и какую из них выбирает?
21. Имеются ли какие-либо обстоятельства, в которых алгоритмы часов и второ-
второго шанса выбирают для замещения различные страницы? Если да, то какие?
22. Предположим, что компьютер использует алгоритм замещения страниц PFF,
однако имеющейся памяти достаточно для того, чтобы обслуживать все про-
процессы без ошибок отсутствия страниц. Что происходит?
23. У маленького компьютера четыре страничных блока. Во время первого такта
часов биты R равны 0111 (у страницы 0 бит R равен 0, у остальных — 1). Во
время последующих тактов часов биты R принимают значения 1011, 1010,
1101, 0010, 1010, 1100 и 0001. Считая, что используется алгоритм старения
с 8-разрядным счетчиком, напишите четыре значения, которые примет счет-
счетчик после последнего такта.
24. Сколько времени займет загрузка с диска программы размером 64 Кбайт, ес-
если среднее время поиска равно 10 мс, время оборота — 8 мс, каждая дорожка
содержит 1 Мбайт:
1) для страницы размером 2 Кбайт;
2) для страницы размером 4 Кбайт;
3) для страницы размером 64 Кбайт.
Распределение страниц на диске является случайным.
25. Используя результаты предыдущего задания, объясните, почему страницы
имеют малые объемы. Укажите два недостатка 64-килобайтных страниц по
сравнению со страницами размером 4 Кбайт.
26. Одна из первых машин с системой разделения времени PDP-1 имела память
из 4 К 18-разрядных слов. В каждый конкретный момент времени она содер-
содержала в памяти один процесс. Когда планировщик решал запустить другой
процесс, процесс в памяти записывался на страничный барабан из 4 К 18-раз-
18-разрядных слов по окружности барабана. Барабан мог начать запись (или чте-
чтение) с любого слова, а не только с нулевого. Как вы полагаете, почему была
выбрана эта конструкция?
27. Встроенный компьютер обеспечивает для каждого процесса 65 536 байт ад-
адресного пространства, разделенного на страницы по 4096 байт. Некая про-
программа имеет размер текста 32 768 байт, размер данных 16 386 байт и размер
стека 15 870 байт. Поместится ли эта программа в адресном пространстве?
А если бы размер страницы был 512 байт, она поместилась бы? Помните, что
страница не может вмещать части двух разных сегментов.
28. Было замечено, что количество инструкций, выполненных между ошибками
отсутствия страниц, прямо пропорционально количеству страничных блоков,
предоставленных программе. Если доступная память увеличивается вдвое, то
средний интервал между ошибками отсутствия страниц также увеличивается
вдвое. Предположим, что нормальная инструкция занимает 1 мкс, но если про-
происходит ошибка отсутствия страницы, она выполняется за 2001 мкс (то есть
2 мс идут на обработку прерывания). Если программа требует для работы 60 с
и в ходе выполнения она вызывает 15 000 ошибок отсутствия страниц, сколько
времени она работала бы в условиях удвоенного количества доступной памяти?
29. Разработчики из компании «Экономные операционные системы» размышля-
размышляют о способе сокращения объема резервного пространства для хранения дан-
данных, необходимого их операционной системе. Ведущий специалист пред-
предложил вообще не беспокоиться о сохранении текста программы в области
подкачки, а просто загружать его страницами прямиком из двоичного файла
всякий раз, когда он требуется. Имеются ли проблемы при таком подходе?
30. Объясните разницу между внутренней и внешней фрагментацией. Какая из
них происходит в системах замещения страниц? А в системах с «чистой» сег-
сегментацией?
31. Если поддерживаются и сегментация, и замещение страниц (как в Pentium),
сначала должен быть найден дескриптор сегмента, затем — идентификатор
страницы. Может ли при таком двухуровневом поиске работать также буфер
быстрого преобразования адреса (TLB)?
32. Почему при принятой в MINIX 3 системе управления памятью необходимы
программы типа chmem?
33. На рис. 4.34 показано начальное потребление памяти первыми четырьмя ком-
компонентами системы MINIX 3. Каковым будет значение cs для следующего
компонента, загруженного после rs?
34. IBM-совместимые компьютеры оснащены областью памяти, недоступной для
программ. Эта область находится в диапазоне адресов от 640 Кбайт до 1 Мбайт.
После того как монитор загрузки MINIX 3 перемещается в область, располо-
расположенную ниже 640 Кбайт, объем памяти, доступной для загрузки программ,
становится еще меньше. Глядя на рис. 4.34, ответьте, сколько памяти доступ-
доступно для загрузки программ в области между ядром и недоступным фрагмен-
фрагментом, если под монитор загрузки выделено 52 256 байт?
35. Имеет ли в предыдущем задание значение то, сколько в точности байтов за-
занимает монитор загрузки? Или же происходит округление до целого числа
кликов?
36. В пункте 4.7.5 при описании системного вызова exec было упомянуто, что
реализация алгоритма поиска подходящего участка свободной памяти перед
освобождением памяти текущего процесса не является оптимальной. Усовер-
Усовершенствуйте данный алгоритм.
37. В пункте 4.8.4 было отмечено, что предпочтительнее искать свободные участ-
участки для сегментов данных и кода раздельно. Реализуйте эту рекомендацию.
38. Измените код функции adjust так, чтобы избежать ситуаций, когда полу-
получивший сигнал процесс из-за слишком строгой проверки доступности стека
завершается зря.
39. Чтобы определить текущий объем памяти процесса в MINIX 3, вы можете
воспользоваться командой
chmem +0 а.out
Однако эта команда имеет неприятный побочный эффект — файл перезапи-
перезаписывается, а следовательно, изменяются дата и время его создания. Измените
команду chmem, создав на ее основе команду showmem, которая отображает
память, выделенную в текущий момент под переданный ей аргумент.
Глава 5
Файловые системы
Всем компьютерным приложениям нужно хранить и получать информацию.
В собственном адресном пространстве работающий процесс может хранить не-
некоторые объемы данных, но вместимость такого хранилища ограничена разме-
размером виртуального адресного пространства. Для некоторых приложений этого
размера вполне достаточно, но для других, например систем резервирования
авиабилетов, систем банковского или корпоративного учета, одного только вир-
виртуального адресного пространства недостаточно.
Вторая проблема — потеря информации, хранящейся в адресном пространстве
процесса, после завершения его работы. Для большинства приложений (на-
(например, баз данных) эта информация должна храниться неделями, месяцами
или даже вечно. Потеря данных после завершения работы процесса для таких
программ неприемлема. Информация должна продолжать существовать даже
при аварийном завершении процесса в случае сбоя компьютера.
Третья проблема состоит в том, что часто возникает необходимость нескольким
процессам одновременно получить доступ к одним и тем же данным (или части
данных). Если интерактивный телефонный справочник хранится в адресном
пространстве одного процесса, то доступ к нему есть только у этого процесса.
Для решения проблемы необходимо отделить информацию от процесса.
Таким образом, к устройствам долговременного хранения информации предъяв-
предъявляются три важных требования:
+ устройства должны обеспечивать хранение очень больших объемов данных;
+ информация должна оставаться в сохранности после прекращения работы ис-
использующего ее процесса;
+ несколько процессов должны иметь возможность параллельного доступа к ин-
информации.
Обычное решение всех этих проблем состоит в размещении информации на
дисках и других внешних хранителях в модулях, называемых файлами. Процес-
Процессы могут по мере надобности читать их и создавать новые файлы. Информа-
Информация, хранящаяся в файлах, должна быть устойчивой (persistent), то есть на нее
не должно оказывать влияния создание или завершение какого-либо процес-
процесса. Файл должен исчезать только тогда, когда его владелец выполняет команду
его удаления.
Файлами управляет операционная система. Их структура, именование, исполь-
использование, защита и реализация, а также доступ к ним являются важными аспекта-
аспектами устройства операционной системы. Часть операционной системы, работаю-
работающая с файлами, называется файловой системой. Ей и посвящена данная глава.
С точки зрения пользователя, самое важное в файловой системе — это механизм
взаимодействия с ней, то есть пользователю важно знать, как обеспечить имено-
именование и защиту файлов, как выполнять операции с файлами и т. д. Детали внут-
внутреннего устройства, крайне важные для разработчиков файловой системы, пред-
представляют для пользователя гораздо меньший интерес. Например, пользователю
не важно, что применяется для отслеживания свободных и занятых блоков дис-
диска, списки или битовые карты, также ему совершенно не интересно, сколько фи-
физических секторов в логическом блоке. По этой причине мы разбили главу на не-
несколько частей. Первые два раздела посвящены пользовательскому интерфейсу
файлов и каталогов. В следующих разделах мы рассмотрим способы реализации
файловой системы. После ознакомления с механизмами безопасности и защиты
мы завершим главу описанием файловой системы MINIX 3.
5.1. Файлы
В следующих нескольких разделах файлы рассматриваются с точки зрения поль-
пользователя, то есть обсуждаются их использование и свойства.
5.1.1. Именование файлов
Файлы являются объектами абстрактного механизма. Они предоставляют сред-
средство сохранения информация на диске и ее последующего считывания. При этом
от пользователя должны скрываться такие подробности, как способ и место хра-
хранения информации, а также детали работы дисков.
Вероятно, наиболее важной характеристикой любого абстрактного механизма
является то, как именуются управляемые объекты, поэтому мы начнем изучение
файловой системы с именования файлов. При создании файла процесс дает фай-
файлу имя. Когда процесс завершает работу, файл продолжает свое существование,
и по его имени к нему могут получить доступ другие процессы.
Правила именования файлов варьируются от системы к системе, но все совре-
современные операционные системы поддерживают использование в качестве имен
файлов 8-символьных текстовых строк. То есть идентификаторы andrea, bruce
и cathy являются допустимыми именами файлов. Часто в именах файлов также
разрешается употребление цифр и специальных символов, поэтому допустимы
и такие имена, как 2, urgent! HFig.2-14. Многие файловые системы поддер-
поддерживают имена файлов длиной до 255 символов.
В некоторых файловых системах, например UNIX, различаются прописные
и строчные буквы, тогда как в других, таких как MS-DOS, нет. Таким образом,
имена maria, Maria и MARIA в системе UNIX указывают на три различных
файла, и в то же время в MS-DOS все три имени относятся к одному файлу.
Операционная система Windows находится где-то посередине между этими край-
крайностями. В основе файловых систем Windows 95 и Windows 98 лежала файловая
система MS-DOS; по этой причине были унаследованы многие свойства послед-
последней, в частности, принцип именования файлов. С каждой версией в файловую
систему добавлялись усовершенствования, однако мы в основном ограничимся
изучением возможностей, общих у MS-DOS и «классических» версий Windows.
Операционные системы Windows NT, Windows 2000 и Windows XP предостав-
предоставляют поддержку файловой системы MS-DOS, однако обладают и собственной
файловой системой NTFS (New Technology File System — файловая система
новой технологии), имеющей другие свойства (такие как именование файлов
в кодировке Unicode). В перечисленных версиях Windows система NTFS также
изменялась. В данной главе рассматривается файловая система более старых
версий Windows, таких как Windows 98. Если какая-либо описываемая черта от-
отсутствует в MS-DOS или Windows 95, мы особо отметим это. Говоря об NTFS,
мы имеем в виду файловую систему Windows XP, а если рассматриваемый ас-
аспект неприменим к файловым системам Windows NT и Windows 2000, это также
оговаривается. Термин «Windows» означает все операционные системы Win-
Windows, начиная с Windows 95.
Во многих операционных системах имя файла может состоять из двух частей,
разделенных точкой, например prog. с. Часть имени файла после точки называ-
называется расширением имени файла и обычно характеризует его тип. Так, в MS-DOS
имя файла может содержать от 1 до 8 символов плюс расширение от 1 до 3 сим-
символов. В UNIX величина расширения файла определяется пользователем. Кроме
того, файл может иметь несколько расширений, например prog. с . bz2, где рас-
расширение bz2 означает, что файл prog, с сжат при помощи алгоритма bzip2.
Некоторые часто встречающиеся расширения имен файлов и их смысловая на-
нагрузка представлены в табл. 5.1.
Таблица 5.1. Некоторые типичные расширения имен файлов
Расширение Значение
file.bak Резервная копия файла
file.с Исходный текст программы на языке С
file.gif Изображение в формате GIF
file.hip Файл справки
file.html Документ в формате HTML (веб-страница)
file.jpg Статическое изображение стандарта JPEG
file.iso Образ компакт-диска, предназначенный для его записи
file.mp3 Музыка в аудиоформате MPEG, уровень 3
file.mpg Фильм в формате MPEG
file.о Объектный файл (еще не скомпонованный выходной файл компилятора)
file.pdf Документ формата PDF (программы Adobe Acrobat)
file.ps Документ формата PostScript
file.tex Входной файл для программы форматирования ТЕХ
file.txt Текстовый файл общего назначения
file.zip Сжатый архив
В отдельных системах (например, в UNIX) расширения являются просто согла-
соглашениями, и операционная система не принуждает пользователя строго этих со-
соглашений придерживаться. Файл f ile. txt может быть текстовым, но это ско-
скорее напоминание пользователю, а не руководство к действию для операционной
системы. С другой стороны, не исключено, что компилятор языка С откажется
компилировать файлы с расширениями, отличными от с.
Подобные соглашения особенно полезны, когда одна и та же программа должна
управлять различными типами файлов. Например, интегрированному компиля-
компилятору языка С может быть предоставлен список файлов, которые он должен пре-
преобразовать в объектный код и затем скомпоновать, причем некоторые из файлов
могут содержать программы на языке С (к примеру, f оо. с), тогда как другие
могут быть ассемблерными (к примеру, bar . s) или объектными (к примеру,
other.о). В этом случае именно по расширениям компилятор отличает одни
файлы от других.
Windows, напротив, принимает расширения в расчет и придает им смысл. Поль-
Пользователи и процессы могут регистрировать расширения в операционной системе
и указывать, какая программа «берет шефство» над тем или иным расширением.
Когда пользователь совершает двойной щелчок мышью на файле, программа, со-
соответствующая его расширению, запускается, а имя файла передается ей в каче-
качестве параметра. Например, двойной щелчок на файле с именем f ile. doc запус-
запускает Microsoft Word, открывая указанный файл для редактирования.
Некоторым пользователям кажется странным, что компания Microsoft по умол-
умолчанию скрывает известные расширения файлов, если уж они играют такую важ-
важную роль. К счастью, большинство параметров Windows, по умолчанию «непра-
«неправильных», можно изменить, хотя для этого нужно быть опытным пользователем
и знать, где найти их.
5.1.2. Структура файла
Файлы могут быть структурированы несколькими способами. Три типа струк-
структур показаны на рис. 5.1. Файл на рис. 5.1, а представляет собой неструктуриро-
неструктурированную последовательность байтов. В данном случае операционная система не
интересуется содержимым файла. Все, что она видит, — это байты. Значения этим
байтам присваиваются программами пользовательского уровня. Такой подход
характерен как для UNIX, так и для Windows 98.
Трактовка операционной системой файлов как просто последовательностей бай-
байтов обеспечивает максимальную гибкость. Пользовательские программы могут
помещать в файлы все что угодно и именовать их любым удобным для них спо-
способом. Операционная система не вмешивается в этот процесс, что особенно цен-
ценно для пользователей, собирающихся сделать что-либо необычное.
Первый шаг по направлению к структуризации иллюстрирует рис. 5.1, б. В дан-
данной модели файл представляет собой последовательность записей фиксирован-
фиксированной длины, каждая со своей внутренней структурой. Для файлов, состоящих
из записей, важным является то, что операция чтения возвращает одну запись,
а операция записи обновляет или дополняет одну запись. Несколько десяти-
десятилетий назад, когда вовсю применялись перфокарты, состоящие из 80 колонок
отверстий, многие операционные системы (на мэйнфреймах) оперировали фай-
файлами, состоящими из 80-символьных записей — образов перфокарт. Этими опе-
операционными системами поддерживались также файлы, составленные из 132-
символьных записей, предназначенные для линейных принтеров (которые в те
дни печатали по 132 символа в строке). В результате программы читали из вход-
входных файлов 80-символьные блоки и тут же расширяли их до 132-символьных
блоков. Ни одна современная универсальная система не работает подобным
образом.
Рис. 5.1. Три типа файлов: а — последовательность байтов;
б — последовательность записей; в — дерево
Третий вариант файловой структуры показан на рис. 5.1, в. При такой органи-
организации файл представляет собой дерево записей, не обязательно одной и той
же длины. Каждая запись содержит ключевое поле в фиксированной позиции.
Дерево упорядочено по ключевому полю с целью быстрого поиска по заданному
ключу.
Основной файловой операцией здесь является не получение следующей записи,
хотя это также возможно, а получение записи с указанным значением ключа.
Для файла, показанного на рис. 5.1, в, можно, например, запросить у системы
запись с ключом «пони», не беспокоясь о точном положении записи в файле
(вольера в зоопарке). При добавлении новой записи операционная система, а не
пользователь должна решать, куда ее поместить. Такой тип файлов принципи-
принципиально отличается от неструктурированных потоков байтов, применяемых в UNIX
и Windows 98. Подобные файловые системы характерны для больших мэйнфрей-
мэйнфреймов, еще используемых для коммерческой обработки данных.
5.1.3. Типы файлов
Многие операционные системы поддерживают различные типы файлов. Напри-
Например, в системах UNIX и Windows проводится различие между обычными файла-
файлами и каталогами. Кроме того, в UNIX различают символьные и блочные специ-
специальные файлы. Windows XP также использует файлы метаданных, которые мы
рассмотрим позднее. К обычным (regular) файлам относятся все файлы, содер-
содержащие пользовательскую информацию. Все файлы на рис. 5.1 являются просто
файлами. Каталоги — это системные файлы, обеспечивающие структуризацию
файловой системы. Позже мы рассмотрим их подробнее. Символьные специаль-
специальные файлы имеют отношение к вводу-выводу и используются для моделирова-
моделирования последовательных устройств ввода-вывода, таких как терминалы, принтеры
и сети. Блочные специальные файлы находят применение при моделировании
дисков. В данной главе в основном рассматриваются обычные файлы.
Обычные файлы, как правило, являются либо ASCII-файлами, либо двоичны-
двоичными файлами. ASCII-файлы содержат текстовые строки. В некоторых системах
каждая ASCII-строка завершается символом возврата каретки. В других (на-
(например, UNIX) используется символ перевода строки. Есть системы (напри-
(например, Windows), где требуются оба символа. Строки не обязаны иметь одну и ту
же длину.
Главным преимуществом ASCII-файлов является то, что они могут отображать-
отображаться на экране и выводиться на печать «как есть», без какого-либо преобразования,
и редактироваться любым текстовым редактором. Более того, если несколько
программ использует ASCII-файлы для ввода и вывода, несложно соединить
вход одной программы с выходом другой, как это делается в конвейерах оболоч-
оболочки. (Обмен данными между процессами не становится проще, но интерпретация
информации облегчается, если ее представление стандартизировано.)
Помимо ASCII-файлов существуют двоичные файлы. При выводе их на принтер
получается невразумительный набор символов. Но в действительности у них
есть некая внутренняя структура, известная использующей их программе.
Например, на рис. 5.2, а показан простой исполняемый двоичный файл, входя-
входящий в одну из версий UNIX. Хотя технически любой файл представляет собой
всего лишь последовательность байтов, операционная система станет исполнять
его только в том случае, если он имеет соответствующий формат. Файл состоит
из пяти разделов: заголовка, текста, данных, данных переадресации и символь-
символьной таблицы. Заголовок начинается с так называемого магического числа, иден-
идентифицирующего файл как исполняемый (чтобы предотвратить случайный «за-
«запуск» файла другого формата). Следом за сигнатурой в заголовке располагаются
поля с размерами различных частей файла, адресом точки входа файла и некото-
некоторые флаги. За заголовком следуют текст программы и данные. Они загружаются
в оперативную память и настраиваются на работу по адресу загрузки при помо-
помощи битов переадресации. Символьная таблица используется для отладки.
Второй пример двоичного файла представляет собой архив в системе UNIX. Он
состоит из набора библиотечных процедур (модулей), откомпилированных, но
не скомпонованных. Каждой процедуре предшествует заголовок, содержащий ее
имя, дату создания, имя владельца, код защиты и размер. Как и в случае испол-
исполняемого файла, заголовки модулей хранят большое количество двоичных чисел.
Если в таком виде подать их на принтер, получится полная тарабарщина.
Рис. 5.2. Структура двоичного файла: а — исполняемый файл; б — архив
Все операционные системы должны распознавать, по крайней мере, один тип
файлов — собственные исполняемые файлы, но некоторые операционные систе-
системы различают и другие типы файлов. Старая система TOPS-20 (для компьютера
DECsystem 20) даже анализировала время создания каждого предоставляемого
ей на исполнение файла. Затем она находила исходный файл и проверяла, не
был ли он изменен, после того как был создан исполняемый файл. Если оказыва-
оказывалось, что исполняемый файл уже устарел, операционная система автоматически
перекомпилировала исходный файл. В переводе на язык UNIX — программа
make была встроена в оболочку. Расширения имен файлов были обязательными,
чтобы операционная система могла определить, какая двоичная программа от
какого исходного файла произошла.
Однако такая жесткая привязка типов файлов к содержимому может оказаться
неудобной для пользователя, пытающегося сделать что-нибудь, не предусмот-
предусмотренное разработчиками операционной системы. Представьте, например, систему,
в которой файлы программного вывода автоматически получают расширение
dat (файлы данных). Пусть пользователь написал программу, форматирующую
исходные тексты программ на языке С. Программа читает файл с расширением с,
обрабатывает его и затем сохраняет результат в файле со стандартным расшире-
расширением dat. Если пользователь затем попытается предложить этот файл компиля-
компилятору С, операционная система не позволит его скомпилировать, так как у файла
для данного действия неверное расширение. Попытка скопировать файл f ile. dat
в f ile. с также будет отвергнута операционной системой, чтобы защитить поль-
пользователя от ошибки.
Хотя такая «дружественность» по отношению к пользователю («защита от ду-
дурака») может быть полезна для новичков, она ставит опытных пользователей
в безвыходное положение, заставляя их тратить массу усилий на то, чтобы пере1
хитрить операционную систему.
5.1.4. Доступ к файлам
В старых операционных системах к файлам предоставлялся только один тип
доступа — последовательный. В этих системах процесс мог читать байты или за-
записи файла только по порядку от начала к концу. В то же время для последова-
последовательных файлов поддерживалась «перемотка», что позволяло считывать их так
часто, как это требовалось. Последовательные файлы были удобны во времена,
когда в качестве устройства хранения информации использовался не диск, а маг-
магнитная лента.
С появлением дисков стало возможным читать байты или записи файла в произ-
произвольном порядке или получать доступ к записям по ключу. Файлы, байты кото-
которых могут быть прочитаны в произвольном порядке, называются файлами про-
произвольного доступа. Такие файлы используются многими приложениями.
Файлы произвольного доступа очень важны для ряда приложений, например для
баз данных. Если клиент звонит в авиакомпанию с целью зарезервировать место
на конкретный рейс, программа резервирования авиабилетов должна иметь воз-
возможность получить доступ к нужной записи, не читая все тысячи предшествую-
предшествующих записей с информацией о других рейсах.
Место начала чтения указывается двумя способами. В первом случае каждая
операция read неявно устанавливает позицию в файле. Во втором варианте ис-
используется специальная операция seek, устанавливающая новую текущую по-
позицию. После выполнения операции seek файл можно читать последовательно
с текущей позиции.
В некоторых старых операционных системах, работающих на мэйнфреймах, способ
доступа к файлу (последовательный или произвольный) указывался в момент
создания файла. Это позволяло операционной системе применять различные ме-
методы хранения файлов разных классов. В современных операционных системах
такого различия не проводится. Все файлы автоматически являются файлами
произвольного доступа.
5.1.5. Атрибуты файлов
У каждого файла есть имя и данные. Помимо этого, все операционные системы
связывают с каждым файлом другую информацию, например дату и время со-
создания файла, а также его размер. Мы будем называть эти дополнительные све-
сведения атрибутами файлов, хотя их иногда обозначают термином метаданные.
Список атрибутов значительно варьируется от системы к системе. В табл. 5.2
показаны некоторые возможные атрибуты, однако существуют и другие. На
практике ни в одной операционной системе не используются сразу все приве-
приведенные в таблице атрибуты файлов, но каждый из них можно встретить в той
или иной системе.
Таблица 5.2. Некоторые возможные атрибуты файлов
Атрибут Значение
Защита Кто и каким образом может получить доступ к файлу
Пароль Пароль для получения доступа к файлу
Создатель Идентификатор пользователя, создавшего файл
Владелец Текущий владелец
Флаг только чтения 0 — для чтения/записи; 1 — только для чтения
Флаг скрытия 0 — нормальный; 1 — не показывать в перечне файлов каталога
Флаг «системный» 0 — нормальный; 1 — системный
Флаг архивации 0 — файл помещен в резервное хранилище; 1 — требуется
резервирование
Флаг ASCII/двоичный 0 — ASCII; 1 — двоичный
Флаг произвольного доступа 0 — только последовательный доступ; 1 — произвольный доступ
Флаг «временный» 0 — нормальный; 1 — удаление файла по окончании процесса
Флаги блокировки 0 — неблокированный; ненулевой в случае блокировки
Длина записи Количество байтов в записи
Позиция ключа Смещение до ключа в записи
Длина ключа Количество байтов в поле ключа
Время создания Дата и время создания файла
Время последнего доступа Дата и время последнего доступа к файлу
Время последнего Дата и время последнего изменения файла
изменения
Текущий размер Количество байтов в файле
Максимальный размер Количество байтов, до которого можно увеличивать размер файла
Первые четыре атрибута относятся к защите файла и содержат информацию о том,
кто вправе получить доступ к файлу, а кто нет. Возможны различные схемы за-
защиты файла, несколько из них мы рассмотрим позже. В некоторых системах
пользователь должен для получения доступа к файлу указать пароль. В этом слу-
случае пароль должен входить в атрибуты файла.
Флаги представляют собой отдельные биты или короткие битовые поля, управляю-
управляющие некоторыми специфическими свойствами. Например, скрытые файлы не по-
появляются в перечне файлов при распечатке каталога. Флаг архивации представляет
собой бит, следящий за тем, была ли создана для файла резервная копия. Этот
флаг очищается программой архивирования и устанавливается операционной
системой при изменении файла. Таким образом, программа архивирования мо-
может определить, какие файлы следует архивировать. Временный файл можно ав-
автоматически удалить по окончании работы создавшего файл процесса.
Атрибуты длины записи, позиции ключа и длины ключа присутствуют только
у тех файлов, записи которых могут искаться по ключу.
Различные атрибуты, хранящие значения времени, позволяют следить за тем,
когда файл был создан, когда в последний раз он был изменен, когда к нему в по-
последний раз предоставлялся доступ. Эти сведения можно использовать в различ-
различных целях. Например, если исходный файл программы был модифицирован по-
после создания соответствующего ему объектного файла, данный исходный файл
должен быть перекомпилирован.
В качестве текущего размера файла указывается количество байтов в файле в на-
настоящий момент. В некоторых старых операционных системах мэйнфреймов
при создании файла требовалось указать также максимальную длину файла, что
позволяло операционной системе зарезервировать достаточно места для его по-
последующего увеличения. Современные операционные системы, работающие на
персональных компьютерах, умеют обходиться без подобного резервирования.
5.1.6. Операции с файлами
Файлы позволяют сохранять информацию и получать ее позднее. В различных
операционных системах поддерживаются различные операции с файлами. Далее
перечислены наиболее часто встречаемые системные вызовы, имеющие отноше-
отношение к файлам.
create
Создание файла. Файл создается без данных. Этот системный вызов объявля-
объявляет о появлении нового файла и позволяет установить некоторые его атрибуты.
delete
Удаление файла. Когда файл уже более не нужен, его удаляют, чтобы освобо-
освободить пространство на диске. Этот системный вызов поддерживается во всех
операционных системах.
open
Открытие файла. Прежде чем использовать файл, процесс должен его открыть.
Системный вызов open позволяет системе считать в оперативную память ат-
атрибуты файла и список дисковых адресов для быстрого доступа к содержимо-
содержимому файла при последующих вызовах.
close
Закрытие файла. Когда все операции с файлом закончены, атрибуты и дисковые
адреса становятся не нужными, поэтому файл следует закрыть, чтобы освобо-
освободить пространство во внутренней таблице системы. Многие операционные сис-
системы позволяют одновременно открывать лишь ограниченное количество фай-
файлов. Запись на диск производится поблочно, а закрытие файла вызывает
запись последнего блока файла, даже если этот блок еще не заполнен до конца.
read
Чтение данных из файла. Обычно байты поступают с текущей позиции в фай-
файле. Считывающий процесс должен указать количество требуемых данных и пре-
предоставить для них буфер.
write
Запись в файл. Запись данных в файл также происходит в текущую позицию
в файле. Если текущая позиция находится в конце файла, размер файла авто-
автоматически увеличивается. В противном случае запись производится поверх
существующих данных, которые безвозвратно теряются.
append
Добавление данных в конец файла. Этот системный вызов представляет со-
собой усеченную версию вызова write. Он позволяет только добавлять данные
к концу файла. Данный вызов может не поддерживаться в операционных сис-
системах с минимальным набором системных вызовов.
seek
Позиционирование в файле. Для файлов произвольного доступа требуется
способ указать, где располагаются данные в файле. Эта операция устанавли-
устанавливает указатель текущей позиции на определенное место файла. Последующие
данные будут считаны из этой позиции и записаны в нее.
get attributes
Получение атрибутов файла. Процессам часто требуются атрибуты интересую-
интересующих их файлов. Например, для сборки программ, состоящих из большого числа
отдельных исходных модулей, в UNIX часто используется программа make.
Эта программа исследует время изменения всех исходных и объектных файлов,
благодаря чему система обходится обработкой минимального их количества.
Для выполнения своей работы программе требуется знать атрибуты файлов.
set attributes
Установка атрибутов файла. Некоторые атрибуты файла могут устанавливать-
устанавливаться пользователем после создания файла. Этот системный вызов предоставля-
предоставляет такую возможность. Например, для файла может быть установлен код за-
защиты доступа и большинство других флагов.
rename
Переименование файла. Этот вызов позволяет изменить имя файла. Поддерж-
Поддержка операционной системой вызова rename не является необходимой, так как
обычно файл можно скопировать с новым именем, а старый экземпляр удалить.
lock
Блокирование файла. Блокирование файла или его фрагмента предотвращает
одновременный доступ к нему со стороны нескольких процессов. Например,
блокирование базы данных в системе резервирования авиабилетов исключа-
исключает возможность резервирования одного и того же места двумя пассажирами.
5.2. Каталоги
В файловых системах файлы обычно организуются в каталоги, или папки, ко-
которые, в свою очередь, в большинстве операционных систем также являются
файлами. В данном разделе мы рассмотрим каталоги, их организацию, свойства
и действия, которые могут быть выполнены с ними.
5.2.1. Простые каталоги
Обычно каталог содержит некоторое число записей, по одной записи на файл.
Один из вариантов показан на рис. 5.3, а, где каждая запись каталога включает
в себя имя файла, его атрибуты и адрес данных файла на диске. Другой вариант
представлен на рис. 5.3, б. Здесь запись каталога хранит имя файла и указатель
на структуру данных с атрибутами и дисковыми адресами. Широко применяют-
применяются оба этих варианта.
Рис. 5.3. Организация каталогов: а — атрибуты хранятся в каталоге;
б — атрибуты хранятся отдельно
Когда открывается файл, операционная система ищет его запись в каталоге. Затем
она извлекает и загружает в память атрибуты и дисковые адреса либо из самой
записи, либо из структуры, на которую запись ссылается. При всех последую-
последующих обращениях к файлу используется информация из памяти.
Количество каталогов меняется от системы к системе. В простейшем варианте име-
имеется один каталог, в котором хранятся все файлы всех пользователей (рис. 5.4, а).
Подобные системы были распространены в ранних персональных компьютерах,
отчасти потому, что компьютеры были однопользовательскими.
Рис. 5.4. Три варианта устройства файловой системы: а — один каталог на всех пользователей;
б — отдельный каталог для каждого пользователя; в — дерево каталогов для каждого
из пользователей. Буквами обозначены владельцы каталога или файла
Системам с одним каталогом присуща проблема: если пользователей много, то
некоторые из них могут непреднамеренно создавать файлы с одинаковыми име-
именами. Например, если пользователь А создает файл mailbox, а затем то же дела-
делает пользователь В, то файл пользователя А будет перезаписан. По этой причине
описанная схема больше не применяется в многопользовательских системах, од-
однако ее можно встретить в малых встраиваемых системах, к примеру, в персо-
персональных электронных секретарях и сотовых телефонах.
Чтобы избежать конфликтов, связанных с присвоением различными пользо-
пользователями одинаковых имен своим файлам, был сделан шаг к выделению персо-
персонального каталога каждому пользователю. В этом случае имена, выбираемые
пользователями, не влияют друг на друга, и применение одного и того же имени
в нескольких каталогах не создает проблем. Подобный подход приводит к сис-
системе, изображенной на рис. 5.4, б. Такие системы могут применяться, к примеру,
в многопользовательском компьютере или несложной локальной сети персо-
персональных компьютеров, имеющих общий файловый сервер.
В описанной схеме операционная система должна знать, какой пользователь пы-
пытается открыть тот или иной файл, чтобы выполнить поиск в соответствующем
каталоге. Следовательно, возникает необходимость процедуры входа в систему,
где пользователь должен указать имя входа или идентификационные данные.
В системе с одноуровневой структурой каталогов такая процедура не нужна.
Если описанная система реализована в простейшей форме, пользователи имеют
доступ только к файлам, находящимся в их собственных каталогах.
5.2.2. Иерархические системы каталогов
Двухуровневая иерархия исключает конфликты имен между файлами различ-
различных пользователей. Тем не менее существует другая проблема: пользователям,
работающим с большим числом файлов, необходимо группировать их. К примеру,
профессору было бы удобно хранить рабочие материалы для студентов отдельно
от черновиков книги, которую он пишет. Следовательно, нужна некая общая иерар-
иерархия (то есть дерево каталогов). При таком подходе каждый пользователь может
сам создать себе столько каталогов, сколько ему нужно, группируя свои файлы
естественным образом. Этот подход иллюстрирует рис. 5.4, в. Здесь каталоги Л,
В и С, вложенные в корневой каталог, принадлежат различным пользователям,
два из которых создали подкаталоги для проектов, над которыми они работают.
Возможность создавать произвольное количество подкаталогов является мощ-
мощным стимулом к структуризации файлов, позволяя пользователям лучше орга-
организовать свою работу. По этой причине почти все современные файловые систе-
системы персональных компьютеров и серверов реализуются подобным образом.
Тем не менее, как мы отмечали ранее, в отношении технологий история часто
повторяется. Цифровым камерам необходимо записывать снимки на какой-либо
носитель, как правило, на карту флэш-памяти. Самые первые камеры имели
единственный каталог, а файлы именовались DSC0001. JPG, DSC0002 . JPG и т. д.
Однако вскоре производители создали файловые системы с несколькими ката-
каталогами (рис. 5.4, б). Имеет ли значение то, что владельцы камер не понимают,
как пользоваться такими каталогами? Встроенное программное обеспечение об-
обходится производителям практически даром, поэтому не будет ничего удивитель-
удивительного в том, что в недалеком будущем появятся цифровые камеры с полноценны-
полноценными иерархическими файловыми системами, несколькими входными именами
и именами файлов длиной до 255 символов.
5.2.3. Пути
При организации файловой системы в виде дерева каталогов требуется некий
способ указания файла. Для этого обычно используют два метода. В первом слу-
случае обращение к файлу выполняется по абсолютному пути, составленному из
имен всех каталогов от корневого до того, в котором содержится файл, и имени
самого файла. Например, путь /usr/ast/mailbox означает, что корневой ка-
каталог содержит подкаталог us г, в который, в свою очередь, вложен подкаталог
ast, где находится файл mailbox. Абсолютные пути всегда начинаются от кор-
корневого каталога и являются уникальными. В UNIX компоненты пути разделяют-
разделяются косой чертой (/). В Windows в качестве разделителя принята обратная косая
черта (\). Таким образом, одно и то же имя пути в этих операционных системах
будет выглядеть следующим образом:
+ Windows:
\usr\ast\mailbox
♦ UNIX:
/usr/ast/mailbox
Если первой буквой имени пути был разделитель, независимо от используемого
в качестве разделителя символа, это означало, что путь абсолютный.
Помимо абсолютного применяют и относительный путь. Относительный путь
непосредственно связан с концепцией рабочего, или текущего, каталога. Поль-
Пользователь может назначить один из каталогов текущим (рабочим) каталогом.
В этом случае все имена путей без начального символа разделителя считаются
относительными и отсчитываются относительно текущего каталога. Например,
если текущим каталогом является /usr/ast, тогда к файлу с абсолютным путем
/usr/ast/mailbox можно обратиться просто как к mailbox. Другими слова-
словами, если рабочим каталогом является /usr/ast, следующие UNIX-команды вы-
выполнят одно и то же:
ср /usr/ast/mailbox /usr/ast/mailbox.bak
ср mailbox mailbox.bak
Относительная форма задания пути часто оказывается более удобной, хотя она
подразумевает то же, что и абсолютная.
Некоторым программам требуется доступ к файлам независимо от того, какой
каталог является в данный момент текущим. В этом случае они всегда должны
указывать абсолютные имена. Например, программе проверки правописания может
понадобиться для выполнения работы прочитать файл /usr/lib/dictionary.
В этом случае она должна использовать абсолютное имя файла, поскольку за-
заранее неизвестно, каким будет рабочий каталог при ее вызове. Абсолютное
имя файла будет работать всегда, независимо от того, какой каталог является
текущим.
Если программе проверки правописания понадобится большое количество фай-
файлов из каталога /usr/lib, она может, обратившись к операционной системе, поме-
поменять рабочий каталог на /usr/lib, после чего указывать просто имя dictionary
в качестве первого аргумента системного вызова open. Явно указав свой рабо-
рабочий каталог, программа может использовать в дальнейшем относительные име-
имена, поскольку точно знает, где она находится в дереве каталогов.
У каждого процесса есть свой рабочий каталог, поэтому, когда процесс меняет
свой рабочий каталог и потом завершает работу, это не влияет на работу других
процессов, и в файловой системе не остается никаких следов от подобных изме-
изменений. Таким образом, процесс может без опасений менять свой рабочий ката-
каталог, когда это ему удобно. С другой стороны, если библиотечная процедура по-
поменяет свой рабочий каталог и не восстановит его при возврате управления,
программа, вызвавшая такую процедуру, может оказаться не в состоянии про-
продолжать свою работу, так как ее предположения о текущем каталоге окажутся
неверными. По этой причине библиотечные процедуры редко меняют рабочие
каталоги, а когда все-таки меняют, обязательно восстанавливают старое имя пе-
перед возвратом управления.
Большинство операционных систем, поддерживающих иерархические катало-
каталоги, имеют специальные записи в каждом каталоге, означающие текущий (.)
и родительский (. .) каталог. Чтобы продемонстрировать, как работает по-
подобная запись, обратимся к дереву каталогов системы UNIX, показанному на
рис. 5.5.
Рис. 5.5. Дерево каталогов системы UNIX
Для некоторого процесса каталог /usr/ast является рабочим. Тогда процесс
может использовать две точки (. .), чтобы указать на необходимость переместиться
вверх по дереву. Например, он может копировать файл /usr/lib/dictionary
в собственный каталог при помощи команды
ср ../lib/dictionary
Две точки являются инструкцией системе подняться вверх (в каталог usr). По-
После этого нужно открыть каталог lib и найти в нем файл dictionary.
Второй вариант обозначения (.) указывает на текущий каталог. Когда команда
ср получает имя каталога (включая точку) в качестве последнего аргумента, она
копирует в него все файлы. Разумеется, более адекватным способом копирова-
копирования является команда
ср usr/lib/dictionary .
Тем не менее с тем же успехом вы можете набрать любую из двух следующих
команд:
ср /usr/lib/dictionary dictionary
ср /usr/lib/dictionary /usr/ast/dictionary
Все три команды делают в точности одно и то же.
5.2.4. Операции с каталогами
Системные вызовы, управляющие каталогами, значительно отличаются от сис-
системы к системе (в отличие от системных вызовов для работы с файлами). Чтобы
дать представление о том, что они собой представляют и как выполняются, при-
приведем следующий пример (взятый из UNIX).
create
Создание каталога. Только что созданный каталог пуст и не содержит дру-
других записей, кроме точки (.) и двух точек ( . .), помещаемых в каталог опе-
операционной системой автоматически или в некоторых случаях программой
mkdir.
delete
Удаление каталога. Может быть удален только пустой каталог. Записи точка (.)
и две точки (. .) файлами не являются и удалены быть не могут.
opendir
Открытие каталога. После этой операции каталог может быть прочитан. На-
Например, для распечатки всех файлов каталога программа, создающая список,
открывает каталог, чтобы прочитать имена всех содержащихся в нем файлов.
Прежде чем каталог может быть прочитан, его следует открыть, подобно от-
открытию и чтению файла.
closedir
Закрытие каталога. Когда каталог прочитан, его следует закрыть, чтобы осво-
освободить место во внутренней таблице системы.
readdir
Чтение следующей записи открытого каталога. В прежние времена можно бы-
было читать каталоги с помощью обычного системного вызова read, но такой
подход был небезопасен, так как требовал от программиста умения работать
с внутренней структурой каталогов. Поэтому был создан отдельный систем-
системный вызов readdir, всегда возвращающий одну запись каталога стандартного
формата независимо от текущей структуры каталогов.
rename
Переименование каталога. Во многих отношениях каталоги аналогичны фай-
файлам и могут переименовываться так же, как и файлы.
link
Связывание файлов. Связывание представляет собой технику, позволяющую
файлу появляться сразу в нескольких каталогах. Этот системный вызов полу-
получает в качестве входных параметров имя файла и имя пути и создает связь
между ними. Таким образом, один и тот же файл может появляться сразу в не-
нескольких каталогах. Подобная связь, увеличивающая на единицу счетчик в ин-
индексном узле файла (для учета количества каталогов со ссылками на этот
файл), иногда называется жесткой связью.
unlink
Удаление связи с файлом. Если файл присутствует только в одном каталоге,
данный системный вызов удалит его из файловой системы. Если существуют
несколько связей с этим файлом, будет удалена только указанная связь, а ос-
остальные останутся. Этот системный вызов применяется для удаления файла
в операционной системе UNIX.
В приведенном списке перечислены наиболее важные системные вызовы, но
существует также множество других, например для защиты информации.
5.3. Реализация файловой системы
Теперь перейдем от рассмотрения файловой системы с точки зрения пользовате-
пользователя к рассмотрению с точки зрения разработчика. Пользователей интересует, как
называются файлы, какие операции с ними допустимы, как выглядит дерево
каталогов и тому подобные вопросы. Проектировщики файловых систем интере-
интересуются тем, как хранятся файлы и каталоги, как осуществляется управление
дисковым пространством и как добиться надежной и эффективной работы фай-
файловой системы. В следующих разделах мы познакомимся с этим взглядом на
файловую систему.
5.3.1. Структура файловой системы
Как правило, файловые системы хранятся на дисках. Базовая структура диска
была рассмотрена нами в главе 2. Кратко повторим изложенное: большинство
дисков можно разбить на разделы, каждый из которых имеет независимую фай-
файловую систему. Сектор 0 диска называется главной загрузочной записью (Master
Boot Record, MBR) и используется для загрузки компьютера. В конце главной
загрузочной записи находится таблица разделов, содержащая начальные и ко-
конечные адреса всех разделов. Один из разделов таблицы может быть помечен
как активный. При загрузке компьютера BIOS считывает и исполняет код, со-
содержащийся в MBR. Первое, что делает программа MBR, — определяет актив-
активный раздел, считывает его первый блок, называемый загрузочным, и исполняет
его. Программа загрузочного блока загружает операционную систему раздела.
Для единообразия все разделы начинаются с загрузочного блока, в том числе
и те, которые не содержат загружаемую операционную систему.
Независимо от используемой операционной системы, приведенное описание
справедливо для любой аппаратной платформы, система BIOS которой способна
загружать более одной операционной системы.
Терминология в разных операционных системах может быть разной. Например,
главная загрузочная запись иногда называется начальным загрузчиком программ
(Initial Program Loader, IPL), кодом загрузки тома (volume boot code), или про-
просто главным загрузчиком (masterboot). Некоторые операционные системы не тре-
требуют, чтобы для их загрузки раздел был помечен как активный, и предоставляют
пользователю меню, содержащее разделы, доступные для загрузки. Ожидание
выбора пользователя может длиться в течение какого-то интервала, по истече-
истечении которого загружается система, предлагаемая по умолчанию. После того как
BIOS загружает MBR или загрузочный сектор, дальнейшие действия могут раз-
различаться. Например, программа, загружающая операционную систему, может за-
занимать несколько блоков раздела. Система BIOS способна загрузить лишь один
блок, который загружает дополнительные блоки, если разработчики операцион-
операционной системы запрограммировали его соответствующим образом. Разработчик
также может предоставить собственную главную загрузочную запись, однако она
должна уметь работать со стандартной таблицей разделов, чтобы поддерживать
загрузку нескольких операционных систем.
Системы, совместимые с персональными компьютерами, могут иметь не более
четырех главных разделов, поскольку между главной загрузочной записью и гра-
границей первого 512-байтового сектора есть место под массив, включающий лишь
4 элемента. Некоторые операционные системы позволяют выделять в таблице
разделов один расширенный раздел, указывающий на связанный список логиче-
логических разделов. Такая структура позволяет иметь неограниченное количество до-
дополнительных разделов. BIOS не может запустить операционную систему с ло-
логического раздела, поэтому начальную загрузку требуется проводить с главного
раздела, чтобы загрузить код, управляющий логическими разделами.
В MINIX 3 применяется альтернативный подход к расширенным разделам. Раз-
Раздел может содержать таблицу подразделов. Преимущество этого подхода заклю-
заключается в том, что таблица подразделов имеет ту же структуру, что и главная таб-
таблица разделов, а, следовательно, обеими таблицами может управлять один и тот
же код. Потенциально можно выделить собственные подразделы под корневое
устройство, подкачку, двоичные системные файлы и пользовательские файлы.
В этом случае проблемы в одном подразделе не затронут другой, а новую версию
операционной системы можно будет установить, изменив содержимое лишь не-
некоторых, а не всех подразделов.
Существуют диски, разбиение которых на разделы невозможно. Гибкие диски,
как правило, содержат в первом секторе загрузочный блок. BIOS считывает его
и ищет магическое число, идентифицирующее корректный исполняемый код.
Магическое число предотвращает попытку выполнения кода для неформатиро-
неформатированного или поврежденного диска. Главная загрузочная запись и загрузочный
блок используют одно и то же магическое число, поэтому с равным успехом
могут применяться в качестве загрузочного кода. Сказанное относится не только
к электромеханическим дисковым устройствам. В устройствах, подобных каме-
камерам и персональным электронным секретарям, где используется энергонезави-
энергонезависимая память (к примеру, флэш-память), часть памяти обычно имитирует диск.
Помимо неизменного загрузочного блока, расположенного в начале раздела, ос-
остальная структура дискового раздела может меняться в зависимости от файло-
файловой системы. UNIX-подобная файловая система содержит некоторые элементы,
представленные на рис. 5.6. Первый из них, суперблок, включает все базовые
параметры файловой системы и считывается в память при загрузке компьютера
или первом использовании файловой системы.
Рис. 5.6. Вариант организации файловой системы
Далее представлена информация о свободных блоках в файловой системе. Затем
могут следовать индексные узлы — массив структур данных, каждая из которых
соответствует файлу, описывает его и задает расположение его блоков. После этого
может быть задан корневой каталог, выступающий в качестве вершины дерева
файловой системы. Остальная часть диска содержит все прочие каталоги и файлы.
5.3.2. Реализация файлов
Вероятно, наиболее важным моментом в реализации механизма хранения фай-
файлов является учет соответствия блоков диска файлам. Для определения того, ка-
какой блок какому файлу принадлежит, в различных операционных системах при-
применяются различные методы. Некоторые из них рассмотрены в данном разделе.
Неразрывные файлы
Простейшей схемой выделения файлам определенных блоков на диске являет-
является система, в которой файлы представляют собой наборы смежных блоков диска.
Тогда на диске с блоками по 1 Кбайт файл размером в 50 Кбайт будет занимать
50 последовательных блоков. У неразрывных файлов есть два существенных пре-
преимущества. Во-первых, такую модель легко реализовать, так как системе, чтобы
определить, какие блоки принадлежат тому или иному файлу, нужно следить всего
лишь за двумя числами: номером первого блока файла и числом блоков в файле.
Зная первый блок файла, любой другой его блок легко получить при помощи
простой операции сложения.
Во-вторых, при работе с неразрывными файлами производительность просто
превосходна, так как весь файл может быть прочитан с диска за одну операцию.
Требуется только одна операция позиционирования (для первого блока). После
этого более не нужно искать цилиндры и тратить время на ожидание поворота
диска, поэтому данные могут считываться с максимальной скоростью, на какую
способен диск. Таким образом, непрерывные файлы легко реализуются и для
них характерна высокая производительность.
К сожалению, неразрывные файлы имеют и серьезный недостаток: их использо-
использование ведет к фрагментации дисков. Поначалу фрагментация не является про-
проблемой, поскольку каждый новый файл можно записать сразу следом за преды-
предыдущим. Однако в конечном счете диск заполнится, и возникнет необходимость
сжать его (что непозволительно дорого) либо реорганизовать свободные фраг-
фрагменты. Последнее требует ведения списка свободных фрагментов, что вполне ре-
реально. К тому же, при создании нового файла необходимо знать его конечный
размер, чтобы разместить в блоке подходящего размера.
Как было отмечено в главе 1, по мере появления новых поколений технологий
в вычислительной технике история может повторяться. Много лет назад вы-
выделение памяти непрерывными блоками благодаря простоте и высокой произ-
производительности применялось в файловых системах магнитных лент (в то время
удобству пользователя не придавалось большого значения). Затем от него отка-
отказались, сочтя недопустимой необходимость указывать размер файла в момент
его создания. Однако с изобретением CD-ROM, DVD и прочих видов оптиче-
оптических носителей с однократной записью неразрывные файлы снова оказались
в фаворе. Подобные носители допускают выделение памяти непрерывными бло-
блоками, более того, оно широко распространено. Размеры всех файлов известны за-
заранее и неизменны на протяжении всего срока использования файловой систе-
системы CD-ROM. Вывод: важно изучать старые системы и удачные концептуально
простые идеи, поскольку в будущем они могут получить совершенно неожи-
неожиданное применение.
Связанные списки
Второй метод размещения файлов состоит в представлении каждого файла в ви-
виде связанного списка блоков диска (рис. 5.7). Первое слово каждого блока явля-
является указателем на следующий блок. В остальной части блока хранятся данные.
Рис. 5.7. Размещение файла в виде связанного списка блоков диска
В отличие от систем с неразрывными файлами, связанный список позволяет ис-
использовать каждый блок диска. Нет потерь дискового пространства на фрагмен-
фрагментацию (если не считать потери в последних блоках файла). Кроме того, в каталоге
нужно хранить только адрес первого блока файла. Всю остальную информацию
можно найти по указанному адресу.
В то же время, хотя последовательный доступ к такому файлу несложен, произ-
произвольный доступ оказывается очень медленным. Чтобы получить доступ к бло-
блоку п, операционная система должна сначала прочитать первые п - 1 блоков по
очереди. Очевидно, такая схема оказывается медленной.
Кроме того, объем данных, хранимых в блоке, больше не является степенью двой-
двойки, поскольку несколько байтов отведено под указатель. Хотя это и не критично,
нестандартный размер снижает эффективность, поскольку многие программы
считывают и записывают блоки размером, составляющим степень двойки. Так
как указатель на следующий блок расположен в начале текущего блока, чтение
блока полноценного размера требует получения и конкатенации двух блоков. Это
приводит к дополнительным накладным расходам на копирование.
Связанные списки с индексацией
Оба недостатка предыдущей схемы организации файлов в виде списков могут
быть устранены, если указатели на следующие блоки хранить не прямо в бло-
блоках, а в отдельной таблице, загружаемой в память. На рис. 5.8 показан внеш-
внешний вид такой таблицы для файлов с рис. 5.7. На обоих рисунках присутствуют
два файла. Файл А занимает блоки диска 4, 7, 2, 10 и 12, а файл В — блоки 6, 3,
И и 14. С помощью таблицы мы можем начать с блока 4 и следовать по цепочке
до конца файла. Те же действия применимы для второго файла, если начать с бло-
блока 6. Обе цепочки завершаются специальным маркером, не являющимся допусти-
допустимым номером блока (например, -1). Такая таблица, загружаемая в оперативную
память, называется таблицей размещения файлов (File Allocation Table, FAT).
Рис. 5.8. Таблица размещения файлов
При такой организации все блоки доступны для данных. Кроме того, значитель-
значительно упрощается произвольный доступ. Хотя для обращения к какому-либо блоку
файла все равно понадобится проследовать по цепочке всех ссылок вплоть до
требуемого блока, в данном случае вся цепочка ссылок уже хранится в памяти и
ее прохождение не требует дополнительных дисковых операций. Как и в преды-
предыдущем случае, для доступа ко всем частям файла в каталоге достаточно хранить
один целый индекс (номер начального блока файла).
Основной недостаток этого метода состоит в том, что вся таблица должна по-
постоянно находиться в памяти. Для 20-гигабайтного диска с блоками размером
1 Кбайт потребовалась бы таблица из 20 000 000 записей, по одной для каждого
из 20 000 000 блоков диска. Каждая запись должна состоять как минимум из
3 байт. Для ускорения поиска размер записей должен быть увеличен до 4 байт.
Таким образом, резидентная таблица будет занимать 60 или 80 Мбайт опера-
оперативной памяти. Таблица, конечно, может быть размещена в виртуальной памяти,
но и в этом случае она продолжит занимать большой объем виртуальной па-
памяти и дискового пространства, а кроме того, приведет к генерации страничного
трафика. Операционные системы MS-DOS и Windows 98 используют только
файловые системы FAT; более поздние версии Windows также предоставляют
их поддержку.
Индексные узлы
Последний метод соотнесения блоков диска файлам заключается в связывании
с каждым файлом структуры данных, называемой индексным узлом (index node),
или i-узлом (i-node), содержащей атрибуты файла и адреса блоков файла. Про-
Простой пример индексного узла показан на рис. 5.9. При наличии индексного узла
можно найти все блоки файла. Большое преимущество такой схемы перед хра-
хранящейся в памяти таблицей из списков состоит в том, что индексный узел ока-
оказывается в памяти только тогда, когда открыт соответствующий ему файл. Если
каждый индексный узел занимает п байт, а одновременно открыть можно k фай-
файлов, для массива индексных узлов в памяти потребуется всего kn байт.
Обычно эта величина значительно меньше, чем размер таблицы FAT. Это легко
объясняется. Размер таблицы, хранящей список всех блоков диска, пропорцио-
пропорционален емкости самого диска. Для диска из п блоков потребуется п записей в таб-
таблице. Таким образом, размер таблицы линейно растет с ростом размера диска.
Для схемы индексных узлов, напротив, требуется массив в памяти с разме-
размером, пропорциональным максимальному количеству файлов, которые можно
открыть одновременно. При этом не важно, какой именно размер диска, 1, 10
или 100 Гбайт.
С такой схемой связана проблема, суть которой в том, что при выделении каждо-
каждому файлу фиксированного количества дисковых адресов этого количества может
не хватить. Одно из решений заключается в резервировании последнего дис-
дискового адреса не для блока данных, а для адреса косвенного блока, содержащего
адреса блоков диска. Этот принцип можно расширить и ввести блоки с двойным
и тройным уровнем косвенности, как показано на рис. 5.9.
Рис. 5.9. Индексный узел с тремя уровнями косвенных блоков
5.3.3. Реализация каталогов
Прежде чем прочитать файл, его следует открыть. При открытии файла опера-
операционная система оперирует указанным пользователем путем, чтобы найти за-
запись в каталоге. Разумеется, чтобы найти запись в каталоге, сначала требуется
найти корневой каталог. Корневой каталог может иметь фиксированное место-
местоположение относительно начала раздела или определяться на основе другой ин-
информации. Например, в классической файловой системе UNIX суперблок содер-
содержит сведения о размерах структур данных файловой системы, предшествующих
области данных. С помощью суперблока можно определить местоположение
индексных узлов. Первый индексный узел указывает на корневой каталог, созда-
создаваемый одновременно с файловой системой UNIX. В Windows XP информация
загрузочного сектора (который, на самом деле, занимает значительно больше,
чем один сектор) задает расположение главной таблицы файлов (Master File Table,
MFT), с помощью которой определяется местоположение других объектов фай-
файловой системы.
После обнаружения корневого каталога выполняется поиск нужной записи в де-
дереве каталогов. Запись каталога предоставляет информацию, с помощью кото-
которой можно найти дисковые блоки. В зависимости от системы это может быть
дисковый адрес всего файла (для неразрывных файлов), номер первого блока
файла (обе схемы со связанными списками) или номер индексного узла. Во всех
случаях основная функция системы каталогов состоит в преобразовании ASCII-
имени в информацию, необходимую для поиска данных.
С этой проблемой тесно связан вопрос хранения атрибутов файла. Каждая фай-
файловая система поддерживает различные атрибуты файла, такие как дату созда-
создания файла, имя владельца и т. д., и всю эту информацию нужно где-то хранить.
Один из очевидных вариантов — поместить эти сведения непосредственно в за-
запись каталога. В простейшем случае каталог представляет собой список записей
фиксированного размера, по одной записи на файл, содержащих имя файла фик-
фиксированной длины, структуру атрибутов и один или несколько дисковых адре-
адресов (не более определенного максимума), определяющих расположение блоков,
как мы видели на рис. 5.3, а.
Системы с индексными узлами могут хранить атрибуты в индексных узлах, а не
в записях каталога, как на рис. 5.3, б. В этом случае запись каталога короче: она
содержит только имя файла и номер индексного узла.
Общие файлы
В главе 1 мы кратко упомянули о связях между файлами, например, одного проекта,
упрощающих совместную работу с ними нескольких пользователей. На рис. 5.10
показана файловая система с рис. 5.4, в, однако теперь один из файлов пользова-
пользователя С присутствует также в одном из каталогов пользователя В.
Рис. 5.10. Файловая система, содержащая общий файл
В UNIX атрибуты файлов хранятся в индексных узлах, что упрощает совместное
использование файлов: любое количество записей каталогов может указывать на
один и тот же индексный узел. Индексный узел имеет поле, увеличиваемое на
единицу каждый раз при добавлении новой связи и уменьшаемое на единицу
при удалении связи. Удаление самого индексного узла и данных файла происхо-
происходит только тогда, когда значение счетчика становится равным нулю.
Подобный вид связи иногда называют жесткой связью. Совместное использование
файлов при помощи жестких связей возможно не всегда. Основное ограничение
состоит в том, что каталоги и индексные узлы представляют собой структуры
данных одной файловой системы (раздела), поэтому каталог не может указывать
на индексный узел другой файловой системы. Кроме того, файл может иметь
только одного владельца и один набор разрешений. Если владелец совместно ис-
используемого файла удалит его запись из своего каталога, не исключено, что дру-
другой пользователь лишится возможности удалить этот файл из своего каталога
(при отсутствии соответствующего разрешения).
Альтернативным способом совместного использования файлов является созда-
создание нового типа файла, содержимое которое представляет собой путь к другому
файлу. Такой вид связи работает для монтируемых файловых систем. Более то-
того, если в путях существует возможность указывать сетевые адреса, можно орга-
организовать связь с файлом, расположенным на другом компьютере. В UNIX этот
вид связи называется символьной связью, в Windows — ярлыком, а в Mac OS фир-
фирмы Apple — псевдонимом. Символьные связи могут применяться в системах, где
атрибуты хранятся в записях каталогов. Несложно понять, что синхронизация
множества записей каталогов, которые содержат атрибуты, — непростая задача.
Любое изменение, внесенное в файл, затрагивает все соответствующие ему за-
записи каталогов. Недостатком символьных связей является то, что при удалении
и даже при переименовании целевого файла они становятся недействительными.
Каталоги в Windows 98
Файловая система в начальной редакции Windows 95 была идентична файловой
системе MS-DOS, однако уже во второй редакции была организована поддержка
длинных имен файлов и файлов большего объема. Мы будем ссылаться на вторую
версию файловой системы как на файловую систему Windows 98, хотя ее можно
найти и на некоторых компьютерах, работающих под управлением Windows 95.
В Windows 98 поддерживаются два типа записей каталогов; первую из них
(рис. 5.11) мы будем называть базовой записью.
Рис. 5.11. Базовая запись каталога в Windows 98
Базовая запись каталога содержит всю информацию, которая имелась в запи-
записях каталогов более ранних версий Windows, а также дополнительные данные.
10 байт, начинающиеся с поля NT, являются добавлениями к предшествующей
структуре Windows 95, которая, к счастью (или, вероятнее, сознательно, с пла-
планами усовершенствования в будущем), не использовалась. Наиболее важным
обновлением является поле, увеличивающее число битов для указания на на-
начальный блок с 16 до 32. В результате максимальный размер файловой системы
увеличен с 216 до 232 блоков.
Эта структура рассчитана только на старые имена файлов в формате 8 + 3, уна-
унаследованном от MS-DOS и СР/М. А что же делать с длинными именами? Чтобы
обеспечить возможность использования более длинных имен файлов, одновремен-
одновременно сохранив совместимость с более ранними системами, было решено ввести до-
дополнительные записи каталогов. На рис. 5.12 показана альтернативная форма
записи каталога, позволяющая задавать имя файла длиной до 13 символов. Для
файлов с длинными именами автоматически генерируется сокращенная форма
имени и помещается в поля базового имени и расширения базовой записи каталога
(см. рис. 5.11). Перед базовой записью размещается столько записей, изображен-
изображенных на рис. 5.12, сколько нужно для хранения длинного имени файла. Записи
располагаются в обратном порядке. Поле атрибутов всех записей длинного имени
содержит значение OxOF, недопустимое в предшествующих файловых системах
(MS-DOS и Windows 95). Таким образом, эти записи будут проигнорированы
при чтении каталога старой системой (например, если каталог находится на гибком
диске). Бит в поле последовательности указывает системе последнюю запись.
Рис. 5.12. Запись (частичная) для длинного имени файла в Windows 98
Если все это кажется сложным, мы, пожалуй, согласимся с вами. Обеспечение
обратной совместимости с более ранними и простыми системами в сочетании с
новыми возможностями приводит к хаосу. Несомненно, борцы за чистоту идей
выступят против хаоса, но едва ли смогут разбогатеть на новых версиях операци-
операционных систем.
Каталоги в UNIX
В UNIX применяется исключительно простая структура каталогов (рис. 5.13).
Здесь каждая запись состоит из имени файла и номера индексного узла. Вся ос-
остальная информация, о размере файла, его типе, владельцах, времени изменения
и занимаемых им дисковых блоках, хранится в индексном узле. В некоторых
UNIX-подобных системах применяется другая схема, но, в любом случае, за-
запись каталога состоит исключительно из ASCII-строки и номера индексного узла.
Рис. 5.13. Запись каталога в UNIX версии 7
Когда открывается файл, файловая система должна найти на диске указанное ей
имя файла. Рассмотрим, как будет происходить поиск файла /usr/ast/mbox.
В качестве примера мы взяли файловую систему UNIX, но все сказанное отно-
относится и к другим иерархическим файловым системам. Сначала файловая систе-
система обнаруживает корневой каталог. Индексные узлы образуют простой массив,
расположение которого устанавливается по информации суперблока. Первая за-
запись в этом массиве — индексный узел корневого каталога.
Сначала файловая система ищет первый компонент пути, us г, в корневом ката-
каталоге, чтобы определить номер индексного узла для файла /usr/. Обнаружить
индексный узел по его номеру несложно, так как расположение узлов фиксиро-
фиксировано. Далее система продолжает поиск с этого индексного узла и находит сле-
следующий компонент, ast. Обнаружив его, система получает номер индексного
узла для каталога /usr/ast. Наконец, в этом каталоге ищется сам файл mbox.
Затем индексный узел файла считывается в память и остается там до тех пор,
пока файл не будет закрыт. Процесс поиска файла иллюстрирует рис. 5.14.
Рис. 5.14. Поиск файла/usr/ast/mbox
Относительные пути обрабатываются точно так же, как абсолютные, за исключе-
исключением того, что поиск начинается не с корневого каталога, а с текущего. В каждом
каталоге есть записи с именами точка (.) и две точки (. .), добавляемые при
создании каталога. Записи точка (.) соответствует индексный узел самого ка-
каталога, а записи две точки (. .) — индексный узел каталога верхнего уровня.
Таким образом, если дано имя файла . . /dick/prog. с, система найдет две точ-
точки (..) в текущем каталоге, получит индексный узел родительского каталога
и будет искать в нем имя dick. Для обработки таких имен не применяется ника-
никаких специальных алгоритмов. С точки зрения системы каталогов, это обычные
ASCII-строки, ничем не отличающиеся от прочих имен.
Каталоги в NTFS
Текущей файловой системой для продуктов Microsoft на сегодняшний день явля-
является NTFS (New Technology File System — файловая система новой технологии).
Рамки этой книги не предусматривают ее детального описания, однако некото-
некоторые проблемы, с которыми сталкивается NTFS, и их решениями мы ознакомимся.
Одна из проблем — длинные имена файлов и путей. NTFS поддерживает длин-
длинные имена файлов (до 255 символов) и путей (до 32 767 символов). Поскольку
предшествующие версии Windows в любом случае не способны читать файло-
файловую систему NTFS, сложная структура каталогов с обратной совместимостью не
нужна, и поле имени имеет переменную длину. Также предоставляется поддерж-
поддержка второго имени в формате 8 + 3, позволяющая устаревшим системам получать
доступ к NTFS-файлам по сети.
NTFS предусматривает использование в именах файлов различных алфавитов
с помощью кодировки Unicode. В Unicode каждый символ занимает 16 бит; это-
этого достаточно для представления множества языков с очень большими алфави-
алфавитами (например, японского языка). Однако помимо представления алфавитов,
многоязычное™ присущи и другие проблемы. Даже среди языков, использующих
латиницу, имеются свои тонкости. Так, в некоторых языках (к примеру, в испан-
испанском) определенные комбинации двух символов при сортировке считаются од-
одним символом. Слова, начинающиеся с префиксов «ch» и «11», должны следовать
после слов, начинающихся соответственно с префиксов «cz» и «lz». Еще сложнее
проблема чувствительности к регистру. Если по умолчанию имена файлов чув-
чувствительны к регистру, иногда может возникать необходимость в организации
нечувствительного к регистру поиска. Для языков на основе латиницы решение
проблемы очевидно, по крайней мере, их носителям. Если поддерживается только
один язык, правила очевидны, однако Unicode позволяет смешивать различные
языки. В многонациональной организации один и тот же каталог может содер-
содержать имена файлов на греческом, русском и японском языках. В качестве реше-
решения проблемы в NTFS введен атрибут файла, определяющий соглашения о реги-
регистре для языка, на котором написано его имя файла.
С помощью дополнительных атрибутов в NTFS решено много задач. Если в UNIX
файл представляет собой последовательность байтов, то в NTFS — коллекцию
атрибутов, где каждый атрибут является потоком байтов. Базовая структура дан-
данных NTFS — главная таблица файлов (Master File Table, MFT). Она поддержи-
поддерживает 16 атрибутов, каждый из которых может иметь длину до 1 Кбайт. Если этого
недостаточно, атрибут можно использовать в качестве заголовка, указывающего
на дополнительный файл с расширенными значениями атрибута. Такой атрибут
называется нерезидентным. Сама таблица MFT представляет собой файл и со-
содержит запись для каждого файла и каталога файловой системы. Поскольку ее
объем может значительно вырасти, при создании NTFS около 12,5 % пространст-
пространства раздела резервируется под MFT. Благодаря резервированию MFT не фраг-
ментируется как минимум до тех пор, пока все зарезервированное пространст-
пространство не будет исчерпано. В последнем случае для MFT резервируется еще одна
область. Таким образом, даже если таблица MFT фрагментирована, она состоит
из очень небольшого числа крупных блоков.
Как же в NTFS обстоит дело с данными? Данные попросту представляют собой
один из атрибутов файла. На самом деле, NTFS-файл может содержать несколь-
несколько потоков данных. Изначально эта возможность позволяла Windows-серверам
обслуживать файлы клиентов Apple Macintosh. В исходной операционной систе-
системе Macintosh (до Mac OS 9) все файлы имели два потока данных. Эти потоки
назывались «ветвь ресурсов» и «ветвь данных». Множественные потоки данных
имеют и другие применения; например, для большого графического файла можно
хранить его уменьшенный эскиз. Максимальный объем потока составляет 264 бай-
байта. В то же время система NTFS способна хранить содержимое небольших файлов
(до нескольких сотен байтов) в заголовке атрибута. Такие файлы называются
непосредственными [91].
Мы лишь слегка затронули несколько подходов, позволяющих NTFS решать про-
проблемы, не решенные более старыми и простыми файловыми системами. NTFS
также предоставляет и другие возможности: сложную систему защиты, шифро-
шифрование и сжатие данных. Их описание, как и описание их реализации, занимает
гораздо больше места, чем мы можем позволить себе в этой книге. Более деталь-
детальное рассмотрение NTFS вы найдете в [115]. Кроме того, дополнительную инфор-
информацию можно поискать в Интернете.
5.3.4. Организация дискового пространства
Обычно файлы хранятся на диске, поэтому организация дискового пространства
является основной заботой разработчиков файловых систем. Для хранения фай-
файла из п байт можно использовать две стратегии: выделение на диске п последова-
последовательных байтов или разбиение файла на несколько непрерывных блоков. Та же
дилемма характерна и для систем управления памятью, где имеется выбор меж-
между «чистой» сегментацией и замещением страниц.
Как уже отмечалось, при хранении файла в виде непрерывной последовательно-
последовательности байтов возникает проблема, связанная с увеличением его размеров. Един-
Единственный способ увеличить неразрывный файл состоит в перемещении его на
новое место на диске. Проблема существенна и для управления сегментами па-
памяти, с той разницей, что перемещение сегмента в памяти является более быст-
быстрой операцией по сравнению с перемещением файла на диске. По этой причине
почти все файловые системы хранят файлы в виде блоков фиксированного раз-
размера, но не обязательно смежных.
Размер блока
После принятия решения о хранении файлов блоками фиксированного размера
возникает вопрос о размере блоков. Учитывая организацию дисков, очевидными
кандидатами на роль блоков являются сектор, дорожка и цилиндр диска (недос-
(недостатком такого выбора является зависимость этих параметров от устройств). В сис-
системе управления страницами памяти страницы также входят в число основных
кандидатов. Если выбрать большую единицу хранения, такую как цилиндр, это
будет означать, что любой файл, даже состоящий из одного байта, займет как ми-
минимум целый цилиндр.
В то же время при маленьких единицах хранения каждый файл будет состоять
из большого числа блоков. Для чтения каждого блока файла обычно требуется
операция поиска нужного цилиндра и ожидание поворота диска, поэтому чтение
файла, состоящего из большого числа блоков, окажется медленным.
Например, представьте себе диск, в котором каждая дорожка содержит 131 072 байт
A28 Кбайт), период вращения составляет 8,33 мс, а среднее время поиска — 10 мс.
При этом время, требующееся для чтения блока из k байт, равно сумме времен
поиска, поворота и переноса данных:
10 + 4,165 + F/131 072) х 8,33.
Сплошная кривая на рис. 5.15 показывает зависимость скорости передачи дан-
данных от размера блока.
Рис. 5.15. Зависимость скорости чтения/записи данных диска (сплошная линия, левая
шкала) и эффективности использования дискового пространства (штриховая линия,
правая шкала) от размера блоков. Все файлы по 2 Кбайт
Чтобы вычислить эффективность использования дискового пространства, нам
необходимо сделать предположение о среднем размере файла. Одно из старых
исследований показало, что средний размер файла в системе UNIX составляет
около 1 Кбайт [91]. В 2005 году в отделе, где работает один из авторов, был про-
произведен подсчет для более чем 1 млн дисковых UNIX-файлов и 1000 пользова-
пользователей. Медианный размер составил 2475 байт; это означает, что половина фай-
файлов имеет меньший размер, а половина — больший. Медианный размер является
лучшим показателем, чем средний, поскольку на среднее значение могут оказы-
оказывать влияние всего лишь несколько файлов (например, руководства для аппа-
аппаратных устройств размером по 100 Мбайт или демонстрационные видеоролики),
а на медианное — нет.
В [125] показано, что в Windows NT работа с файлами происходит значительно
сложнее, чем в UNIX. Вот короткий фрагмент из этого издания:
Когда мы вводим несколько символов в текстовом редакторе Блокнот (Note-
(Notepad), сохранение их в файле приводит к 26 системным вызовам, включая 3 не-
неудачные попытки открыть файл, одну перезаписать файл и 4 дополнительных
последовательности открытия и закрытия файла.
Тем не менее в [125] приводятся следующие медианные размеры файлов (взве-
(взвешенные): только прочитанные файлы — 1 Кбайт, только записанные файлы —
2,3 Кбайт, прочитанные и записанные файлы — 4,2 Кбайт. Учитывая различия
в технике измерений (статическая и динамическая), результаты достаточно близ-
близки к 2-килобайтному медианному размеру файла.
Для простоты предположим, что все файлы имеют размер 2 Кбайт. В этом слу-
случае эффективность использования дискового пространства изображается пунк-
пунктирной кривой на рис. 5.15.
Проанализируем две полученные кривые. Время доступа к блоку полностью за-
зависит от времен поиска и поворота; если известно, что для доступа к блоку тре-
требуется 14 мс, то чем больше данных будет считано из блока, тем лучше. Таким
образом, скорость обмена данными растет с ростом размера блока до тех пор, пока
время передачи не начинает преобладать. Если блоки имеют небольшой размер,
являющийся степенью двойки, а файлы занимают 2 Кбайт, потерь дискового про-
пространства не происходит. Однако если размер блока составляет 4 Кбайт, часть
памяти диска тратится впустую. На практике размер файла очень редко кратен
размеру блока, поэтому в последнем блоке файла всегда теряется часть места.
Кривые показывают, что эффективность использования диска и производитель-
производительность находятся в обратной зависимости. Маленькие блоки экономят дисковое
пространство, но снижают производительность. Необходимо выбрать компромисс-
компромиссный размер блока. Для рассматриваемого случая хорошим решением является
значение 4 Кбайт, однако в некоторых операционных системах выбор делался
тогда, когда параметры дисков и размеры файлов были иными. Размер блока
в MS-DOS может быть любой степенью двойки от 512 байт до 32 Кбайт, однако
по другой причине зависит от объема диска: максимальное число блоков диско-
дискового раздела составляет 216, что заставляет использовать большие блоки на дис-
дисках большого объема.
Учет свободных блоков
После того как мы выбрали размер блоков, следует определиться, как учитывать
свободные и занятые блоки. Широкое распространение получили два метода,
представленные на рис. 5.16. Первый метод — не что иное, как использование
связанного списка блоков диска. При этом в каждом блоке списка содержится
столько номеров свободных блоков, сколько может поместиться в один блок. При
размере блока, равном 1 Кбайт, и 32-разрядных номерах блоков каждый блок
списка свободных блоков может содержать номера 255 свободных блоков. (Од-
(Одно 32-разрядное слово нужно для указателя на следующий блок списка.) Для
256-гигабайтного диска потребуется список свободных блоков, состоящий из
1 052 689 блоков, чтобы охватить все 228 дисковых блока. Часто список свобод-
свободных блоков хранится в самих свободных блоках.
Рис. 5.16. Учет свободных блоков: а — хранение информации о свободных блоках в виде
связанного списка; б — битовая карта
Другой метод учета свободного дискового пространства заключается в хранении
этой информации в виде битового массива (битовой карты). Здесь на каждый
блок приходится всего по одному биту. Свободные блоки обозначаются в массиве
единицами, а занятые — нулями (или наоборот). 256-гигабайтный диск состоит
из 228 1-килобайтных блоков, таким образом, для него требуется массив размером
228 бит, то есть 32 768 блоков. Нет ничего удивительного в том, что битовая карта
требует меньше пространства, поскольку в ней одному блоку соответствует 1 бит,
а не 32, как в модели со связанным списком. Схема на основе списка более эффек-
эффективна только тогда, когда диск практически полон (то есть свободных блоков
очень мало). В то же время, если число свободных блоков велико, то часть из них
можно отвести под хранение списка без ощутимых потерь дискового пространства.
При использовании списка свободных блоков достаточно хранить в памяти все-
всего один блок указателей. Когда создается файл, нужные блоки извлекаются из
блока указателей. Когда текущий блок заканчивается, следующий блок считыва-
ется с диска. Аналогично, при удалении файла его блоки освобождаются и до-
добавляются к блоку указателей в основной памяти. Заполненный блок сбрасыва-
сбрасывается на диск.
5.3.5. Надежность файловой системы
Разрушение файловой системы часто приносит больше бед, чем поломка компь-
компьютера. Если компьютер приходит в негодность вследствие пожара, удара молнии
или пролитой на клавиатуру чашки кофе, это неприятно, ремонт требует денег,
но обычно не причиняет много хлопот. Недорогие персональные компьютеры
можно заменить в течение часа, обратившись в ближайший компьютерный мага-
магазин. (Исключение составляют университеты, где для приобретения персональ-
персональных компьютеров требуется согласование этого вопроса в трех инстанциях, по-
получение пяти подписей и 90 дней ожидания.)
В случае же краха файловой системы по вине аппаратного или программного
обеспечения (либо крыс, посчитавших, что одного отверстия на гибком диске
недостаточно), восстановление всей информации оказывается делом трудным,
длительным, а часто и невыполнимым. Для пользователей, чьи программы, доку-
документы, файлы клиентов, счета, базы данных, маркетинговые планы или другие
данные теряются навсегда, последствия могут оказаться катастрофическими.
Хотя операционная система не в силах защитить от физического уничтоже-
уничтожения оборудование или носитель, она в состоянии помочь сберечь информацию.
В данном разделе мы рассмотрим некоторые вопросы, касающиеся защиты фай-
файловой системы от уничтожения.
Когда гибкие диски покидают фабрику, их качество, как правило, превосходно,
но со временем на них могут появиться дефектные блоки. Можно утверждать,
что сегодня это более вероятно, чем во времена более широкого распространения
дискет. Благодаря сетям и съемным устройствам большой емкости, таким как
компакт-диски с возможностью перезаписи, дискеты стали использовать редко.
Кулеры вместе с воздухом гонят в дисководы пыль, и если дисковод не исполь-
используется в течение долгого времени, попытка поработать с гибким диском может
привести к его поломке. Вероятность повреждения диска часто используемым
дисководом меньше.
У жестких дисков дефектные блоки часто бывают врожденными, поскольку про-
производство жестких дисков абсолютно без дефектов обходится чересчур дорого.
Как мы видели в главе 3, дефектные блоки обычно заменяются исправными при
помощи контроллера. У таких дисков каждая дорожка имеет как минимум один
лишний сектор, поэтому как минимум один поврежденный сектор можно про-
пропустить, создав зазор между двумя последовательными секторами. На каждом
цилиндре имеется несколько запасных секторов, что позволяет контроллеру ав-
автоматически переназначать секторы, если чтение или запись какого-либо секто-
сектора требует больше установленного числа попыток. Таким образом, пользователь
обычно ничего не подозревает о поврежденных блоках и их учете. Однако если
происходит отказ современного IDE- или SCSI-диска, обычно это — признак
серьезной проблемы, когда у диска заканчиваются запасные секторы. SCSI-диски,
заменяя сбойный блок запасным, сообщают о восстановлении после сбоя (recovered
error). Заметив это, драйвер может вывести на экран сообщение. Если такие со-
сообщения появляются на экране часто, пришло время менять диски.
Существует простое и элегантное программное решение проблемы сбойных бло-
блоков. Это решение сводится к тому, что файловая система аккуратно составляет
файл, содержащий в себе все сбойные блоки. Благодаря такому подходу блоки
исключаются из списка свободных и никогда не задействуются для хранения
данных. Если не делать к данному файлу обращений, никаких проблем (за ис-
исключением особых случаев) не возникнет. Соответственно, во время резервного
копирования нужно избегать чтения этого файла.
Резервные копии
Большинство пользователей считают создание резервных копий файлов просто
потерей времени. Однако когда в один прекрасный день диск внезапно отказы-
отказывается работать, они диаметрально меняют свои привычки. Компании, напротив,
обычно хорошо осознают ценность своей информации и выполняют резервное
копирование один раз в сутки, чаще всего на магнитную ленту. Современные
магнитные ленты вмещают десятки и иногда даже сотни гигабайтов при стоимо-
стоимости в несколько центов за гигабайт. Однако создание резервных копий является
далеко не столь тривиальным делом, как это может показаться, поэтому мы кос-
коснемся некоторых аспектов данной темы.
Как правило, резервирование на магнитную ленту осуществляется для решения
одной из двух потенциальных проблем: восстановления после аварии и вос-
восстановления после глупой ошибки. В первом случае требуется вернуть компью-
компьютер в работоспособное состояние после отказа диска, пожара, потопа или другой
природной катастрофы. На практике такие вещи происходят довольно редко,
и именно поэтому многие пользователи не заботятся о резервировании. Как
правило, в силу той же причины они не страхуют свое имущество от пожара.
Второй случай наступает тогда, когда пользователи случайно удаляют нужные
им файлы. Это происходит настолько часто, что разработчики Windows придума-
придумали специальный каталог, называемый корзиной (recycle bin), куда на самом деле
перемещается удаляемый файл и где он впоследствии может быть легко обнаружен
и восстановлен. Резервные копии являются развитием этого принципа и позво-
позволяют восстанавливать файлы, удаленные несколько дней или даже недель назад.
Создание резервной копии отнимает много времени и требует большого про-
пространства, поэтому важно, чтобы этот процесс был эффективным и удобным.
Возникает ряд вопросов, и первый из них — следует резервировать файловую
систему целиком или лишь ее часть? Зачастую исполняемые (двоичные) про-
программы содержатся в ограниченной части дерева файловой системы; резервиро-
резервировать их не обязательно, поскольку такие файлы можно восстановить с компакт-
дисков производителей. Кроме того, большинство систем имеют каталог времен-
временных файлов, и резервировать его также не имеет смысла. В UNIX все специаль-
специальные файлы (устройства ввода-вывода) содержатся в каталоге /dev/. Резерви-
Резервирование этого каталога не только не обязательно, а попросту опасно, поскольку
программа резервирования при попытке считывания файлов зависнет. Короче
говоря, чаще всего предпочтительнее создавать резервные копии содержимого
отдельных каталогов, нежели копировать всю файловую систему.
Во-вторых, резервировать файлы, которые не менялись с момента предыдущего
резервирования, бессмысленно. Это приводит к идее инкрементных резервных
копий. Простейшая форма инкрементной архивации состоит в том, что полная
резервная копия создается, скажем, раз в неделю или раз в месяц, а ежедневно
сохраняются только те файлы, которые изменились с момента последней полной
архивации. Еще лучше архивировать только те файлы, которые изменились со
времени последней инкрементной архивации. Несмотря на то что подобная схема
минимизирует время резервирования, процесс восстановления усложняется, по-
поскольку сначала требуется восстановить самую свежую архивную копию, а затем
все остальные копии в обратном порядке. С целью упрощения восстановления,
как правило, используются более сложные методы инкрементного резервирования.
В-третьих, объемы резервируемых данных, чаще всего, огромны, а, следователь-
следовательно, перед записью на магнитную ленту данные предпочтительно сжать. Однако
для большинства алгоритмов сжатия единственное повреждение на ленте делает
восстановление невозможным и не позволяет считать содержимое файла или всей
ленты. Таким образом, решение о сжатии резервной копии следует принимать
с осторожностью.
В-четвертых, трудно создать резервную копию работающей файловой системы.
В процессе резервирования файлы и каталоги создаются, удаляются и изменя-
изменяются, что может привести к некорректности резервной копии. Поскольку архи-
архивация длится до нескольких часов, систему необходимо освободить от работы на
большую часть ночи, что не всегда приемлемо. По этой причине были разработа-
разработаны алгоритмы, делающие «моментальный снимок» состояния файловой системы
путем копирования наиболее важных структур данных. После этого изменения,
вносимые в файлы и каталоги, приводят к копированию блоков, а не их обновле-
обновлению [63]. Таким образом, при создании «моментального снимка» файловая систе-
система «замораживается», и ее архивацию можно без проблем выполнить в будущем.
Наконец, в-пятых, резервные копии являются для организаций источниками про-
проблем нетехнического характера. Лучшая в мире интерактивная система безопасно-
безопасности может оказаться бесполезной, если системный администратор держит архив-
архивные магнитные ленты в своем офисе и не закрывает его, выходя на пару минут,
чтобы забрать документы с корпоративного принтера. Все, что нужно сделать
злоумышленнику, — зайти на секунду, положить одну крохотную ленту себе в кар-
карман и с беспечным видом отправиться дальше. Прощай, безопасность! Кроме то-
того, ежедневная архивация файлов бесполезна, если пожар, который уничтожит
компьютеры, уничтожит и все магнитные ленты с резервными копиями. Таким
образом, архивные ленты следует хранить в другом месте, хотя это и более риско-
рискованно с точки зрения безопасности. Подробно эти и другие вопросы практическо-
практического администрирования рассмотрены в [93]. Далее мы займемся изучением лишь
технических аспектов, связанных с резервированием файловой системы.
Существует две стратегии резервирования диска на магнитную ленту: получе-
получение физического или логического дампа. При получении физического дампа ко-
копирование начинается с нулевого блока диска, все блоки записываются на ленту
в порядке следования, а заканчивается дамп последним блоком диска. Программа
получения физического дампа настолько проста, что ее можно написать абсолют-
абсолютно безошибочно, что практически недостижимо для других полезных программ.
Тем не менее относительно получения физического дампа следует сделать не-
несколько комментариев. Во-первых, копирование неиспользуемых дисковых бло-
блоков не имеет смысла. Этого можно избежать, если программа получения дампа
имеет доступ к структуре данных, описывающей свободные блоки. Однако в слу-
случае, если свободные блоки пропускаются, перед каждым архивируемым блоком
нужно помещать его номер, так как теперь блок k на ленте не обязательно явля-
является блоком k на диске.
Вторая проблема — резервирование дефектных блоков. Если все такие блоки
заменены контроллером диска и скрыты от операционной системы так, как опи-
описано в пункте 5.4.4, программа получения физического дампа работает хорошо.
Однако, если поврежденные блоки видны операционной системе и перечислены
в одном или нескольких файлах или битовых массивах, было бы совершенно
логично, если бы программа получения физического дампа имела доступ к этой
информации, чтобы избежать копирования дефектных блоков. В противном слу-
случае программа зависнет из-за бесконечных попыток чтения с диска.
Основными преимуществами получения физического дампа являются простота
и высокая скорость: резервирование может выполняться со скоростью работы
диска. Главные недостатки — невозможность пропуска выбранных каталогов,
создания инкрементных дампов и восстановления отдельных файлов по запросу.
В силу этих причин чаще используются логические дампы.
Программа получения логического дампа начинает копирование с одного или не-
нескольких указанных каталогов и рекурсивно копирует все находящиеся в них
файлы и каталоги, изменившиеся с заданной базовой даты (например, с послед-
последней архивации для инкрементной резервной копии или со времени установки
системы в случае полной резервной копии). Таким образом, в логическом дампе
присутствует последовательность тщательно идентифицируемых каталогов и фай-
файлов, что позволяет без труда восстановить нужный файл или каталог по запросу.
Для того чтобы корректно восстановить даже один файл, на архивный носитель
необходимо записать всю информацию его пути. Таким образом, первый шаг по-
получения логического дампа — анализ дерева каталогов. Очевидно, что архивации
подлежат все модифицированные файлы и каталоги. Однако для правильного
восстановления требуется сохранить все каталоги, находящиеся на пути к изменен-
измененному файлу, даже если они не менялись. Это означает, что необходимо сохранить
не только данные (имена файлов и указателей на индексные узлы), но и атрибу-
атрибуты всех каталогов, чтобы восстановить их с соответствующими разрешениями.
Сначала на ленту записываются каталоги и их атрибуты, а затем — модифици-
модифицированные файлы также со своими атрибутами. Это позволяет восстановить ар-
архивированные файлы и каталоги в качестве новой файловой системы другого
компьютера. Таким образом, дамп и программы восстановления дают возмож-
возможность межмашинного переноса целых файловых систем.
Вторая причина получения дампа немодифицированных каталогов, находящихся
на пути к измененным файлам, — возможность инкрементного восстановления
отдельного файла (возможно, после его случайного удаления). Предположим, что
полный дамп файловой системы создан вечером в воскресенье, а инкрементный
дамп — вечером в понедельник. Во вторник каталог /usr/ jhs/proj /nr3/ удали-
удалили вместе со всеми вложенными файлами и каталогами. Утром в среду пользова-
пользователь хочет на свежую голову восстановить файл /usr/jhs/proj/nr3/plans/
summary, однако это невозможно, поскольку его некуда поместить. Сначала тре-
требуется восстановить каталоги пгЗ / и plans/. To есть нужно получить коррект-
корректную информацию об их владельцах и режимах, временные данные и т. д. А для
этого они должны присутствовать на архивной магнитной ленте, даже если не
были изменены со времени получения полного дампа.
Восстановить файловую систему с архивной магнитной ленты несложно. Снача-
Сначала на диске создается пустая файловая система, а затем в нее восстанавливается
самый свежий полный дамп. Поскольку каталоги расположены в начале ленты,
они восстанавливаются первыми, формируя каркас файловой системы. Затем вос-
восстанавливаются сами файлы. Этот процесс повторяется сначала для первого ин-
крементного дампа, созданного после полного дампа, затем — для второго и т. д.
Хотя в получении логического дампа нет ничего сложного, без нескольких тон-
тонкостей не обойтись. Во-первых, список свободных блоков не является файлом,
а следовательно, не резервируется. Таким образом, его потребуется воссоздать
«с нуля» после того, как все дампы восстановлены. Это всегда возможно, так как
список свободных блоков — всего лишь дополнение по отношению ко всей сово-
совокупности блоков, занятых файлами.
Отдельный аспект касается связей. Если файл связан с двумя или более катало-
каталогами, важно, чтобы его восстановление было однократным, а все каталоги, с ко-
которыми он связан, указывали на него.
Еще одна проблема заключается в том, что файлы в системе UNIX могут содер-
содержать дыры. Вполне допустимо сначала открыть файл и записать з него несколь-
несколько байтов, а затем совершить дальний переход pi записать еще несколько байтов.
Блоки, расположенные между двумя последовательностями байтов, не являются
частью файла, а значит, их не нужно ни резервировать, ни восстанавливать.
Файлы дампов памяти зачастую имеют большие дыры между сегментами дан-
данных и стека. Если не обеспечить надлежащую обработку таких файлов, при вос-
восстановлении пустая область будет заполнена нулями, а размер восстановленного
файла дампа оказывается равным размеру виртуального адресного пространства
B32, а может быть, и 264 байт).
Наконец, специальные файлы, именованные каналы и тому подобное не должно
записываться в дамп, независимо от того, в каком каталоге все это находится
(специальные файлы не обязательно расположены в каталоге /dev/). Дополни-
Дополнительную информацию об архивировании файловой системы вы найдете в [19, 132].
Непротиворечивость файловой системы
Еще одним аспектом проблемы надежности является непротиворечивость фай-
файловой системы. Файловые системы обычно читают блоки данных, модифициру-
модифицируют их и записывают обратно. Если в системе произойдет сбой прежде, чем все
модифицированные блоки будут записаны на диск, файловая система может ока-
оказаться в противоречивом состоянии. Эта проблема становится особенно важной
в случае, если одним из модифицированных и не сохраненных блоков оказыва-
оказывается блок индексного узла, каталога или списка свободных блоков.
Для обеспечения непротиворечивости файловой системы большинство компью-
компьютеров оснащаются специальной обслуживающей программой, проверяющей
состояние файловой системы. Например, в UNIX используется утилита f sck,
в Windows — chkdsk (в ранних версиях — scandisk). Данную программу мож-
можно запустить при загрузке системы, обычно после аварии. В приведенном далее
описании рассмотрена работа утилиты f sck. Несколько отличается от нее утилита
chkdsk, поскольку предназначена для другой файловой системы, однако прин-
принцип избыточности при восстановлении остается общим. Все программы проверки
обрабатывают каждую файловую систему (раздел диска) независимо от других.
Обычно контролируется непротиворечивость объектов двух типов: блоков и фай-
файлов. При проверке непротиворечивости блоков программа создает две таблицы,
каждая из которых содержит счетчик для каждого блока, изначально установ-
установленный в 0. Счетчики в первой таблице фиксируют, в каком количестве каждый
блок присутствует в файле. Счетчики во второй таблице показывает, сколько раз
каждый блок учитывается в списке (или в битовой карте) свободных блоков.
Затем программа считывает все индексные узлы. Начиная с индексного узла,
можно построить список всех номеров блоков, занятых соответствующим фай-
файлом. При считывании каждого номера блока счетчик этого блока увеличивается
на единицу. Затем программа анализирует список или битовую карту свободных
блоков, чтобы обнаружить все неиспользуемые блоки. Каждый раз, встречая но-
номер блока в списке свободных блоков, программа инкрементирует соответствую-
соответствующий счетчик во второй таблице.
Если файловая система непротиворечива, каждый блок будет встречаться только
один раз либо в первой, либо во второй таблице (рис. 5.17, а). Однако в резуль-
результате сбоя эти таблицы могут принять вид, соответствующий рис. 5.17, б. В этом
случае блок 2 отсутствует в каждой таблице. О таком блоке программа сообщит
как о недостающем. Хотя недостающие блоки не причиняют вреда, они зани-
занимают место на диске, снижая его емкость. Учесть же недостающие блоки очень
просто: программа проверки файловой системы просто добавляет их к списку
свободных.
Другая возможная ситуация показана на рис. 5.17, в. Здесь мы видим блок но-
номер 4, дважды появляющийся в списке свободных. (Дубликаты свободных блоков
могут появиться лишь тогда, когда в файловой системе реально используются
списки свободных блоков; в случае битовой карты это невозможно.) Решить
проблему также несложно — надо построить список свободных блоков заново.
Гораздо хуже, если один и тот же блок оказывается сразу в двух файлах, как
показано на рис. 5.17, г для блока 5. При удалении любого из этих файлов блок 5
окажется в списке свободных блоков, что приведет к ситуации, в которой один
и тот же блок одновременно является и свободным, и занятым. Если удалить оба
файла, блок будет помещен в список свободных блоков дважды.
Рис. 5.17. Состояния файловой системы: а — непротиворечивое; б — недостающий блок;
в — дубликат блока в списке свободных блоков; г — дубликат блока данных
В такой ситуации программа проверки файловой системы должна взять свобод-
свободный блок, скопировать в него содержимое блока 5 и вставить эту копию в один
из файлов. Таким образом, содержимое файлов останется неизменным (хотя
почти наверняка один из файлов уже испорчен), но, по крайней мере, струк-
структура файловой системы после этой операции становится непротиворечивой.
Программа также должна выдать сообщение об ошибке, чтобы пользователь мог
изучить проблему.
Помимо контроля принадлежности блоков, программа проверки также анализи-
анализирует структуру каталогов. Для этого используется таблица счетчиков, но уже не
для блоков, а для файлов. Проверка начинается с корневого каталога с рекурсив-
рекурсивным заходом в каждый каталог. Для каждого файла в каждом каталоге програм-
программа увеличивает на единицу счетчик использования файла. Благодаря жестким
связям файл может присутствовать сразу в нескольких каталогах. Символьные
связи не учитываются и не оказывают влияния на счетчик.
Когда сканирование дерева каталогов завершается, программа получает список,
индексированный по номерам индексных узлов, с информацией о том, в сколь-
скольких каталогах присутствует каждый файл. Затем программа сравнивает полу-
полученные числа со счетчиками связей, хранящимися в самих индексных узлах. Эти
счетчики содержат единицу при создании файла и инкрементируются всякий
раз, когда создается связь (жесткая) с данным файлом. В непротиворечивой
файловой системе оба счетчика должны совпадать. Однако возможны два типа
ошибок: значение счетчика связи в индексном узле может оказаться слишком
велико или слишком мало.
Если счетчик связи больше, чем количество записей в каталоге, тогда даже при
удалении всех файлов из каталогов счетчик все равно не уменьшится до нуля,
и индексный узел удален не будет. Эта ошибка несерьезная, но она приводит
к расходованию дискового пространства файлом, находящимся вне всех катало-
каталогов. Чтобы исправить ее, следует установить значение счетчика равным числу
существующих записей каталога.
Вторая ошибка таит в себе катастрофические последствия. Если у файла есть
две связанные с ним записи каталогов, согласно информации индексного узла
такая запись только одна, тогда при удалении записи каталогов этого файла в лю-
любом каталоге счетчик индексного узла уменьшится до нуля. При этом файловая
система освободит все блоки, занимаемые файлом, в том числе и блок, в котором
помещается сам индексный узел. Таким образом, в одном из каталогов сохра-
сохранится дескриптор файла, указывающий на неиспользуемый индексный узел, чьи
блоки могут быть вскоре выделены другим файлам. Решение здесь также заклю-
заключается в присваивании счетчику связей индексного узла фактического количест-
количества записей каталога.
Часто эти две операции, проверки блоков и проверки каталогов, для увеличения
эффективности выполняют за один проход. Возможно также проведение и других
проверок. Например, формат каталогов должен соответствовать определенным
требованиям относительно индексных узлов и ASCII-имен. Если номер индекс-
индексного узла оказывается больше числа индексных узлов на диске, это означает, что
каталог поврежден.
Более того, у каждого индексного узла могут оказаться значения режима досту-
доступа, являющиеся допустимыми, но странными, например 0007. Такое значение
совсем отказывает в доступе владельцу и его группе, но зато разрешает всем по-
посторонним читать, писать и исполнять файл. Программа должна хотя бы сооб-
сообщать обо всех файлах, предоставляющих сторонним пользователям больше прав,
чем владельцам. Каталоги, содержащие, скажем, более 1000 записей, также подоз-
подозрительны. Расположенные в каталогах пользователей файлы, владельцем которых
является суперпользователь и у которых установлен бит SETUID, представляют
собой потенциальную угрозу безопасности, так как такие файлы при запуске
любым пользователем дают полномочия суперпользователя. Список технически
возможных, но необычных ситуаций, о которых программа должна информиро-
информировать, можно продолжать довольно долго.
До сих пор мы обсуждали проблему защиты пользователя от сбоев. Некоторые
файловые системы также пытаются защитить пользователя от самого себя. На-
Например, пусть пользователь решает удалить все файлы с расширением о (создан-
(созданные компилятором объектные файлы) и вводит такую команду:
rm * .о
Однако случайно вместо этого вводит следующее (обратите внимание на пробел
после звездочки):
rm * .о
Тогда программа rm удалит все файлы в текущем каталоге, после чего сообщит,
что не может найти файл с расширением о. В системе MS-DOS и некоторых дру-
других системах при удалении файла устанавливается всего лишь один бит в ката-
каталоге или индексном узле, отмечая, что файл удален. Блоки диска не возвращаются
в список свободных блоков до тех пор, пока они не понадобятся. Таким образом,
если пользователь быстро обнаружит ошибку, он сможет восстановить удален-
удаленные файлы. В Windows удаленные файлы обычно помещаются в корзину, откуда
их можно при необходимости извлечь. При этом свободное пространство на дис-
диске не увеличивается до тех пор, пока корзина не будет очищена.
Подобные механизмы не являются безопасными. В безопасной системе при уда-
удалении с диска блоки данных заполняются нулями или случайными числами,
чтобы не дать возможность другому пользователю восстановить информацию.
Многие пользователи даже не подозревают, насколько «живучими» могут быть
данные. Конфиденциальные или важные данные зачастую удается восстановить
даже с утилизированных дисков [48].
5.3.6. Производительность файловой системы
Доступ к диску значительно медленнее, чем к оперативной памяти. Чтение слова
из памяти может занять около 10 не. Чтение с жесткого диска может выполнять-
выполняться со скоростью 10 Мбайт/с, что в сорок раз медленнее для 32-разрядного слова,
но к этому следует добавить 5-10 мс на поиск нужного цилиндра и поворот диска.
Если требуется прочитать или записать всего одно слово, то оперативная память
оказывается примерно в миллион раз быстрее жесткого диска. Поэтому во многих
файловых системах применяются различные методы оптимизации, повышающие
производительность. В данном разделе мы рассмотрим три из них.
Кэширование
Для минимизации количества обращений к диску применяется блочный, или бу-
буферный, кэш. (Термин «кэш» происходит от французского слова cacher, что зна-
значит «скрывать».) В данном контексте кэшем называется набор блоков, логически
принадлежащих диску, но хранящихся в оперативной памяти по соображениям
производительности.
Существуют различные алгоритмы кэширования. Обычная практика заключается
в перехвате всех запросов чтения к диску и поиске требующихся блоков в кэше.
Если блок присутствует в кэше, то запрос чтения блока может быть удовлетворен
без обращения к диску. В противном случае блок сначала считывается с диска
в кэш, а оттуда копируется по нужному адресу памяти. Последующие обращения
к тому же блоку могут удовлетворяться из кэша.
Функционирование кэша иллюстрирует рис. 5.18. Поскольку в кэше содержится
большое количество (зачастую тысячи) блоков, необходим быстрый способ оп-
определения наличия в нем требуемого блока. Как правило, применяется хеширо-
хеширование дисковых адресов и адресов устройств с последующим поиском результата
в хеш-таблице. Все блоки с одинаковыми хеш-кодами объединяются в связан-
связанный список, позволяющий вести цепочку соответствий.
Рис. 5.18. Структуры данных буферного кэша
Когда требуется загрузить блок в заполненный до предела кэш, какой-либо дру-
другой блок должен быть из него удален (и записан на диск, если он был модифици-
модифицирован в кэше). Эта ситуация очень похожа на замещение страниц, и к ней приме-
применимы все обычные для этого алгоритмы, описанные в главе 4, такие как FIFO,
LRU, второго шанса и т. д. Одно приятное отличие кэширования от страничной
организации памяти состоит в том, что обращения к кэшу производятся относи-
относительно нечасто, что позволяет хранить все блоки в точном LRU-порядке с одно-
однонаправленными списками.
На рис. 5.18 мы видим, что в дополнение к цепочке соответствий, начинающейся
от хеш-таблицы, имеется двунаправленный список всех блоков в порядке ис-
использования. Блок с наиболее давним обслуживанием находится во главе списка,
а последний использованный блок — в его конце. При обращении к блоку он
удаляется из текущей позиции в списке и перемещается в его конец. Таким обра-
образом обеспечивается точное соответствие LRU-порядку.
К сожалению, здесь есть одна загвоздка. Хотя мы можем реализовать точное соблю-
соблюдение алгоритма LRU, оказывается, что алгоритм LRU является нежелательным.
Вызвано это тем, что его буквальное применение снижает надежность файловой
системы и угрожает ее непротиворечивости (обсуждавшейся в предыдущем разде-
разделе). Если критически важный блок, например блок индексного узла, считывается
в кэш и далее модифицируется, но не записывается сразу же на диск, то компью-
компьютерный сбой может привести к тому, что файловая система окажется в некор-
некорректном состоянии. Если блок индексного узла поместить в конец LRU-цепочки,
может пройти довольно много времени, прежде чем этот блок попадет в ее нача-
начало и будет записан на диск.
Более того, к некоторым блокам, таким как блоки индексных узлов, программы
редко обращаются дважды в течение короткого интервала времени. Исходя из
этих соображений, мы приходим к модифицированной схеме LRU, принимая во
внимание два вопроса.
1. Насколько велика вероятность того, что данный блок скоро снова понадобится?
2. Важен ли данный блок для непротиворечивости файловой системы?
Для ответа на каждый из поставленных вопросов блоки можно разделить на ка-
категории, такие как блоки индексных узлов, «косвенные» блоки (блоки косвен-
косвенной адресации), блоки каталогов, блоки, целиком заполненные данными, и бло-
блоки, частично заполненные данными. Блоки, которые, вероятно, не потребуются
снова в ближайшее время, помещаются в начало LRU-списка, чтобы занимаемые
ими буферы могли вскоре освободиться. Блоки, вероятность повторного исполь-
использования которых в ближайшее время высока (например, частично заполненные
записываемые блоки), заносятся в конец LRU-списка, что позволяет им дольше
оставаться в кэше.
Второй вопрос не связан с первым. Если блок представляет важность для непро-
непротиворечивости файловой системы (обычно это все блоки, кроме блоков данных)
и такой блок модифицируется, то его следует немедленно сохранить на диске,
независимо от его положения в LRU-списке. Своевременно записывая критиче-
критически важные блоки, мы значительно снижаем вероятность того, что сбой компью-
компьютера повредит файловую систему. Пользователь вряд ли будет рад потере одного
из своих файлов из-за какого-то сбоя. Еще сильнее он огорчится, если при этом
испорченной окажется вся файловая система.
Даже при принятии всех перечисленных мер предосторожности по поддержанию
в рабочем состоянии файловой системы слишком долгое хранение в кэше блоков
с данными является нежелательным. Представьте себе автора будущей книги,
подготавливаемой на персональном компьютере. Даже если наш писатель перио-
периодически велит текстовому редактору сохранять редактируемый файл на диске,
есть большая вероятность, что все блоки останутся в кэше. Если произойдет сбой,
структура файловой системы не пострадает, но труд целого дня будет потерян.
Эта ситуация случается не слишком часто, и если случается, то только с очень
невезучими пользователями. Для решения данной проблемы обычно применяет-
применяется два метода. В системе UNIX есть вызов sync, принуждающий сохранить все
модифицированные блоки кэша на диске. При загрузке операционной системы
запускается фоновая программа, обычно под названием update, вся работа
которой заключается в периодическом (обычно через каждые 30 с) обращении
к системному вызову sync. В результате при любом сбое будет потеряно не бо-
более полминуты работы.
В Windows практикуется другой подход, состоящий в том, что каждый модифи-
модифицированный блок записывается на диск сразу же. Кэш, в котором все модифици-
модифицированные блоки немедленно записываются на диск, называется сквозным кэшем,
или кэшем со сквозной записью. При использовании сквозного кэша количество
обращений ввода-вывода к диску больше, чем при применении обычного кэша.
Чтобы лучше понять разницу в этих двух подходах, представьте себе программу,
сохраняющую блок размером в 1 Кбайт по одному символу. Система UNIX будет
собирать все символы в кэше и записывать этот блок на диск каждые 30 с, а так-
также при удалении блока из кэша. Windows будет обращаться к диску для каждого
символа. Конечно, в большинстве программ применяется внутренняя буфериза-
буферизация, поэтому обычно эти программы обращаются к системному вызову write не
с одним символом, а с целыми строками или большими единицами данных.
Результатом различия стратегий кэширования оказывается то, что простое удале-
удаление (гибкого) диска из системы UNIX без выполнения системного вызова sync
почти всегда ведет к потере данных и часто также к повреждению файловой сис-
системы. В Windows такой проблемы не возникает. Подобное различие в стратегиях
связано с тем, что система UNIX разрабатывалась в среде, в которой все диски
были жесткими и постоянными, тогда как система Windows изначально предна-
предназначалась для работы со сменными носителями. Когда жесткие диски стали нор-
нормой, более эффективный метод, присущий UNIX, также стал нормой и теперь
используется в Windows для жестких дисков.
Упреждающее чтение блоков
Второй метод повышения производительности файловой системы — помещение
блоков в кэш до того, как они оказываются нужными. Это увеличивает процент
кэш-попаданий. В частности, многие файлы считываются последовательно. Когда
файловой системе поступает запрос на блок k файла, она удовлетворяет его, одна-
однако затем скрытно проверяет в кэше наличие блока k + 1. Если блок отсутствует,
он считывается в кэш в надежде на то, что, когда он понадобится, его присутствие
будет обеспечено. По крайней мере, файловая система заранее себя подготовит.
Разумеется, стратегия упреждающего чтения применима лишь к последователь-
последовательно считываемым файлам. Если доступ к файлу носит случайный характер, упре-
упреждающее чтение не поможет. Более того, оно будет мешать дисковому доступу,
считывая ненужные блоки и удаляя из кэша потенциально полезные (а возмож-
возможно, еще и сбрасывая блоки на диск, если они были изменены). Чтобы опреде-
определить, стоит ли выполнять упреждающее чтение, файловая система может отсле-
отслеживать способ доступа к каждому открытому файлу. Например, каждому файлу
сопоставляется бит, значение которого определяет режим доступа: последователь-
последовательный и случайный. В начальный момент выдвигается сомнение в пользу файла:
считается, что режим доступа к нему последовательный. При попытке поиска по
файлу бит сбрасывается, однако при последовательном чтении устанавливается
вновь. Таким способом файловая система делает обоснованный вывод о том,
следует ли читать блоки заранее. Если иногда этот вывод оказывается неверным,
результатом является не катастрофа, а всего лишь небольшая потеря пропуск-
пропускной способности диска.
Уменьшение количества перемещений головки диска
Кэширование и упреждающее чтение не являются единственными способами по-
повышения производительности системы. Другой важный метод состоит в уменьше-
уменьшении затрат времени на перемещение блока головок. Достигается это помещением
блоков, к которым высока вероятность доступа в течение короткого интервала
времени, близко друг к другу, желательно на одном цилиндре. Когда записывает-
записывается выходной файл, файловая система должна зарезервировать место для чтения
таких блоков за одну операцию. Если свободные блоки учитываются в битовой
карте, а вся битовая карта помещается в оперативной памяти, то довольно легко
выбрать свободный блок как можно ближе к предыдущему блоку. Когда свобод-
свободные блоки хранятся в списке, часть которого находится в оперативной памяти,
а часть на диске, сделать это значительно труднее.
Однако даже при использовании списка свободных блоков может быть выполне-
выполнена определенная кластеризация данных. Хитрость заключается в том, чтобы учи-
учитывать место на диске не в блоках, а в группах последовательных блоков. Если
сектор состоит из 512 байт, система может использовать блоки размером в 1 Кбайт
(два сектора), но выделять пространство на диске в единицах по два блока (че-
(четыре сектора). Это не то же самое, что использовать 2-килобайтные дисковые
блоки, так как кэш рассчитан на килобайтные блоки, и дисковые операции чтения
и записи будут по-прежнему требовать килобайтных блоков. Однако при после-
последовательном чтении файла количество операций поиска цилиндра уменьшится
вдвое, что значительно повысит производительность. Вариацией этой темы яв-
является попытка системы учесть позицию блока в цилиндре.
Производительность файловых систем снижается еще в силу того, что при опе-
оперировании индексными узлами или чем-либо эквивалентным им, особенно при
чтении коротких файлов, требуется два обращения к диску вместо одного: одно
для индексного узла и одно для блока данных. Обычный вариант размещения
индексных узлов на диске показан на рис. 5.19, а. Здесь все индексные узлы рас-
располагаются в начале диска, значит, среднее расстояние между индексным узлом
и его блоками составляет около половины количества цилиндров, то есть при
доступе практически к каждому файлу потребуются значительные перемещения
блока головок.
Рис. 5.19. Уменьшение количества перемещений головки диска: а — индексные узлы,
размещенные в начале диска; б — диск, разделенный на группы цилиндров, каждая
с собственными блоками и индексными узлами
Один из способов подъема производительности заключается в помещении ин-
индексных узлов в середину диска. Таким образом уменьшается средний путь бло-
блоков головок в два раза. Другая идея (рис. 5.19, б) заключается в разбиении диска
на группы цилиндров, каждая со своими индексными узлами, блоками и спи-
списком свободных блоков [85]. Когда создается новый файл, может быть выбран
любой индексный узел, но предпринимается попытка найти блок в той же груп-
группе цилиндров, что и индексный узел. Если эта попытка заканчивается неудачей,
используется блок в соседней группе цилиндров.
5.3.7. Файловые системы
с журнальной структурой
Изменения в технологии оказывают влияние на современные файловые систе-
системы. В частности, центральные процессоры становятся все быстрее, диски — все
вместительнее и дешевле (при этом скорость доступа хотя и растет, но мед-
медленно), а размеры оперативной памяти растут экспоненциально. Единственным
параметром, не меняющимся столь стремительно, является время поиска цилин-
цилиндра диска. В результате это становится узким местом многих файловых систем.
В университете Беркли были проведены исследования, направленные на сни-
снижение остроты проблемы. В результате родилась совершенно новая файловая
система с журнальной структурой (Log-structured File System, LFS). В этом
разделе мы кратко опишем, как она работает, а дополнительные сведения можно
получить в [99].
В основе файловой системы с журнальной структурой лежит идея, что по мере
ускорения центральных процессоров и экстенсивного расширения оперативной
памяти растет и выгода от кэширования дисков. Поэтому становится возмож-
возможным удовлетворить весьма существенную часть всех дисковых запросов прямо
из кэша файловой системы без обращения к диску. Из этого следует, что в буду-
будущем большинство обращений к диску будут составлять обращения записи, по-
поэтому алгоритм опережающего чтения, применявшийся в некоторых файловых
системах, уже не дает большого выигрыша производительности.
Ситуация усложняется тем, что в большинстве файловых систем операции запи-
записи выполняются над очень маленькими блоками данных. Такие операции оказы-
оказываются крайне неэффективными, поскольку самой физической записи, занимаю-
занимающей 50 мкс, часто предшествует поиск цилиндра в течение 10 мс и его поворот
в течение 4 мс. При таких параметрах эффективность диска падает до 1 %.
Чтобы понять, из чего складываются все эти мелкие операции записи, рассмот-
рассмотрим создание файла в операционной системе UNIX. Здесь необходимо произ-
произвести запись в индексный узел каталога, блок каталога, индексный узел файла
и, наконец, блок самого файла. В принципе, эти операции записи могут быть от-
отложены на некоторое время, но тем самым не исключаются серьезные проблемы
непротиворечивости файловой системы в случае сбоя компьютера прежде, чем
запись на диск будет выполнена. По этой причине индексные узлы обычно со-
сохранятся на диск без промедления.
Учитывая все это, разработчики файловой системы с журнальной структурой
решили реализовать файловую систему UNIX таким образом, чтобы добиться
максимально эффективного обращения к диску, несмотря на то, что в рабочем
режиме выполняется множество случайных мелких операций записи. Идея ос-
основана на использовании диска как журнала. Периодически, когда возникает не-
необходимость, все буферизированные в памяти блоки, подлежащие записи, соби-
собираются вместе в единый сегмент, и он сбрасывается на диск одним непрерывным
фрагментом в конец журнала. Записываемый сегмент может содержать индекс-
индексные узлы, блоки каталогов и блоки данных, перемешанные друг с другом. В на-
начале каждого сегмента создается его оглавление. Если довести средний размер
сегмента до 1 Мбайт, то можно задействовать почти всю пропускную способ-
способность диска.
При такой организации индексные узлы существуют и имеют ту же структуру,
что и в UNIX, но теперь они не располагаются в фиксированной позиции на дис-
диске, а рассредоточены по всему журналу. Тем не менее, когда программа находит
индексный узел, определение расположения блоков выполняется обычным спо-
способом. Конечно, здесь обнаружить индексный узел намного сложнее, так как
его адрес не определяется по его номеру, как это было в UNIX. Чтобы можно
было найти индексный узел, создается массив индексных узлов, индексирован-
индексированный по номерам узлов. Элемент г массива указывает на узел г на диске. Массив
хранится на диске, но также содержится и в кэше, а это означает, что наиболее
часто востребованные части этого массива постоянно находятся в оператив-
оперативной памяти.
Таким образом, все операции записи буферизируются в памяти и периодически
данные из буфера записываются на диск в виде единых сегментов в конец жур-
журнала. Чтобы открыть файл, используется массив, позволяющий обнаружить ин-
индексный узел в файле. Как только индексный узел обнаружен, могут быть опре-
определены номера блоков файла. Все эти блоки также располагаются в сегментах
где-то в журнале.
Если бы диски были бесконечного размера, на этом все бы и заканчивалось. Одна-
Однако существующие диски имеют ограниченный размер, поэтому рано или поздно
журнал разрастается на весь диск. К счастью, многие сегменты могут содержать
уже ненужные блоки. Например, если файл был перезаписан, его индексный узел
будет указывать на новые блоки, хотя старые блоки будут все также занимать
место в записанных ранее сегментах.
Для решения проблемы повторного использования блоков в старых сегментах
в файловой системе с журнальной структурой выполняется программный поток
чистильщика, в обязанности которого входит постоянное сканирование журнала
с целью сделать последний более компактным. Чистильщик начинает с того, что
считывает содержимое самого первого сегмента журнала, выясняя, какие индекс-
индексные узлы и файлы в нем находятся. Затем он смотрит в текущий массив ин-
индексных узлов, проверяя, являются ли индексные узлы все еще текущими и ис-
используются ли все еще блоки файлов. Если нет, эта информация отбрасывается,
а рабочие индексные узлы и блоки считываются в память, чтобы записать их
в следующий сегмент. Исходный сегмент помечается как свободный, поэтому
журнал может помещать в него новые данные. Таким образом, чистильщик дви-
двигается по журналу, удаляя старые сегменты с диска и помещая всю имеющую
ценность информацию в память для перезаписи в следующий сегмент. В резуль-
результате диск превращается в большой кольцевой буфер, в котором пишущий поток
добавляет новые сегменты с одного конца, а чистящий процесс удаляет старые
сегменты с другого.
Учет расположения блоков здесь весьма нетривиален, поскольку, когда блок фай-
файла записывается в новый сегмент, индексный узел файла (где-то в журнале) дол-
должен быть найден, обновлен и помещен в буфер для записи в следующий сегмент.
При этом массив индексных узлов также должен быть обновлен, чтобы элемент
массива указывал на новую копию. Тем не менее администрирование такой сис-
системы вполне возможно, а рост производительности показывает, что все эти
сложности не напрасны. Результаты измерений показали, что файловая система
с журнальной структурой (LFS) превосходит файловую систему UNIX при мно-
множестве небольших записей на порядок, а при чтении и больших записях облада-
обладает близкой или более высокой производительностью.
5.4. Безопасность
Многие компании располагают ценной информацией, которую они тщательно
охраняют. Таким образом, защита информации от несанкционированного досту-
доступа является главной заботой всех операционных систем. В следующих разделах
мы рассмотрим различные вопросы, связанные с безопасностью и защитой, рав-
равно относящиеся как к системам разделения времени, так и к персональным ком-
компьютерам, связанным локальной сетью.
5.4.1. Безопасное окружение
Термины «безопасность» и «защита» иногда смешивают. Однако часто полез-
полезно провести границу между техническими, административными, юридическими
и политическими аспектами безопасности, с одной стороны (то есть с гарантией
того, что файлы не читаются и не модифицируются неавторизованными лица-
лицами), и специфическими механизмами операционной системы, привлекаемыми
для обеспечения безопасности, с другой стороны. Чтобы избежать путаницы, мы
будем применять термин безопасность для обозначения общей проблемы и тер-
термин защита при описании специфических механизмов операционной системы,
используемых для обеспечения информационной безопасности в компьютерных
системах, хотя в реальности граница между этими двумя терминами достаточно
размыта. Сначала мы познакомимся с вопросами безопасности, чтобы понять
природу проблемы. Затем мы рассмотрим механизмы защиты и модели, способ-
способствующие обеспечению безопасности.
Проблема безопасности многогранна. Тремя ее наиболее важными аспектами яв-
являются природа угроз, природа злоумышленников и случайная потеря данных.
Все эти вопросы рассматриваются в данном разделе.
Угрозы
С точки зрения безопасности компьютерные системы ставят три общие цели, ка-
каждой из которых соответствует своя категория угроз (табл. 5.3). Первая, конфи-
конфиденциальность данных, подразумевает, что данные, не подлежащие разглашению,
остаются тайными. Говоря точнее, если владелец данных разрешил доступ к ним
лишь ограниченному кругу лиц, то система должна гарантировать невозможность
несанкционированного доступа к ней. Как минимум, пользователь должен иметь
возможность указывать, кому и что разрешено просматривать, а система обязана
претворять эти указания в жизнь.
Таблица 5.3. Цели и угрозы безопасности
Цель Угроза
Конфиденциальность данных Несанкционированный доступ к данным
Целостность данных Искажение данных
Доступность системы Отказ в обслуживании
Вторая цель, целостность данных, означает, что неавторизованные пользователи
не могут изменять какие-либо данные без разрешения владельца. Под изменени-
изменением данных в таком контексте понимается не только их редактирование, но также
удаление и добавление. Если компьютер не может гарантировать, что никто, кро-
кроме владельца, не способен изменить данные, то его ценность как информацион-
информационной системы становится ничтожной. Целостность данных, как правило, еще важ-
важнее, чем конфиденциальность.
Третья цель, доступность системы, означает, что никто не может вывести систе-
систему из строя. Атаки типа отказа в обслуживании становятся все более и более
частыми. Например, если компьютер представляет собой интернет-сервер, его
можно вывести из строя, послав столько запросов, что все процессорное время
будет тратиться на их анализ и отклонение. Если, скажем, обработка входящего
запроса на чтение веб-страницы занимает 100 мкс, то каждый, кто способен послать
10 000 запросов в секунду, может вызвать отказ системы. Для борьбы с атаками
на конфиденциальность и целостность существуют продуманные модели и техно-
технологии; противостоять атакам типа отказа в обслуживании значительно сложнее.
Еще одним аспектом безопасности является приватность, то есть защита поль-
пользователей от ненадлежащего использования сведений о них. Это приводит к мно-
множеству вопросов юридического и морального характера. Могут ли органы управ-
управления собирать досье на кого угодно с целью поимки граждан, скрывающихся от
уплаты налогов? Может ли полиция собирать любые сведения о пользователях,
чтобы остановить организованную преступность? Имеют ли какие-либо права
работодатели и страховые компании? Если да, то как быть в случае их противо-
противоречия частным правам? Все эти вопросы исключительно важны, однако выходят
за рамки темы этой книги.
Злоумышленники
Большинство людей совершенно безвредно и законопослушно. Так зачем же бес-
беспокоиться о безопасности? Затем, что есть небольшая группа людей, которая от-
отнюдь не безвредна и жаждет причинять неприятности другим (возможно, для
собственной коммерческой выгоды). В литературе по безопасности злоумышленни-
злоумышленником называют человека, сующего свой нос в чужие дела. Злоумышленники подраз-
подразделяются на два вида. Пассивные злоумышленники просто пытаются прочитать
файлы, которые им не разрешено читать. Активные злоумышленники пытаются
незаконно изменить данные. При разработке системы защиты от злоумышлен-
злоумышленников важно знать врага, против которого нужно возводить укрепления, в лицо.
Рассмотрим наиболее распространенные категории злоумышленников.
+ Случайные любопытные пользователи, не применяющие специальных тех-
технических средств. У многих людей есть компьютеры, соединенные с общим
файловым сервером. И если не установить специальной защиты, благодаря
естественному любопытству многие начнут читать чужую электронную почту
и другие файлы. Например, во многих системах UNIX новые только что со-
созданные файлы по умолчанию доступны для чтения всем желающим.
+ Любители совать нос в чужие дела. Студенты, системные программисты, опе-
операторы и другой технический персонал часто считают взлом системы без-
безопасности локальной компьютерной системы святым долгом. Как правило,
они имеют высокую квалификацию и готовы посвящать достижению постав-
поставленной перед собой цели массу времени.
+ Желающие делать деньги любыми средствами. Некоторые программисты, рабо-
работающие в банках, предпринимали попытки украсть деньги у банка, в котором
они работали. Их схемы варьировались от изменения способов округления
сумм в программах и сбора, таким образом, «с миру по нитке», до шантажа
(«заплатите мне, или я уничтожу всю банковскую информацию»).
+ Лица, занимающиеся коммерческим и военным шпионажем. Шпионаж пред-
представляет собой серьезную и хорошо финансированную попытку конкурента
или другой страны украсть программы, коммерческие тайны, ценные идеи
и технологии, чертежи микросхем, бизнес-планы и т. д. Часто такие попытки
подразумевают подключение к линиям связи или установку антенн, направ-
направленных на компьютер для улавливания его электромагнитного излучения.
Очевидно, что попытка предотвратить кражу военных секретов враждебным
иностранным государством отличается от противостояния шалостям студентов,
встраивающих забавные сообщения в систему. Необходимые для поддержания
безопасности и защиты усилия зависят от предполагаемого противника.
Вредоносные программы
Еще одну угрозу безопасности представляют собой вредоносные программы.
В определенном смысле автора программы следует считать злоумышленником,
зачастую обладающим хорошо развитыми техническими навыками. Различие ме-
между традиционным злоумышленником и вредоносной программой заключается
в том, что злоумышленник — это человек, своими силами пытающийся взломать
систему с целью нанесения ущерба, а вредоносная программа — это программа,
написанная и выведенная злоумышленником в жизнь. Одни вредоносные про-
программы предназначены для повреждения систем, в то время как другие имеют
более узкие цели. Злоумышленники представляют собой серьезную проблему,
о которой выпущено множество публикаций [3, 15, 74, 84, 120, 127].
Наиболее известным типом вредоносных программ являются вирусы. Обычно
вирус представляет собой фрагмент кода, способный воспроизводить себя, при-
прикрепляя собственные копии к другим программам (такое поведение аналогично
размножению биологических вирусов). Помимо размножения, вирусы способны
выполнять и другие действия. Например, они могут делать что-нибудь без-
безвредное: отображать сообщения или изображения на экране, проигрывать музы-
музыку и т. д. К сожалению, они также способны изменять, уничтожать и похищать
файлы, отправляя их по электронной почте неизвестному адресату.
Еще один вариант воздействия вируса на компьютер — выведение его из работо-
работоспособного состояния, известное как атака типа отказа в обслуживании (Denial
Of Service, DOS). Как правило, такой результат достигается за счет сверхинтен-
сверхинтенсивного потребления ресурсов, например, центрального процессора либо захлам-
захламления жесткого диска. Вирусы, а также прочие виды вредоносных программ,
рассматриваемые здесь, могут быть использованы и для атак типа распределен-
распределенного отказа в обслуживании (Distributed Denial Of Service, DDOS). В этом слу-
случае вирус не начинает свою деятельность на зараженном компьютере немедлен-
немедленно. В установленные заранее дату и время тысячи копий вируса на компьютерах,
расположенных по всему миру, начинают запрашивать веб-страницы или другие
сетевые ресурсы у цели атаки, например, у сайта политической партии или кор-
корпорации. В результате сервер (или обслуживающая его сеть) может оказаться
перегруженным.
Зачастую вредоносные программы создаются ради выгоды. Многие нежелатель-
нежелательные сообщения электронной почты (если не большинство), известные как спам,
передаются адресатам через сети компьютеров, зараженных вирусами или други-
другими видами вредоносных программ. Зараженный компьютер оказывается в под-
подчинении главного компьютера, расположенного где-то в Интернете, и передает
ему информацию о своем состоянии. Затем главный компьютер рассылает спам
по всем адресам электронной почты, которые удалось извлечь из адресных книг
и прочих файлов подчиненного компьютера. Еще один вид вредоносных программ,
создаваемых с целью наживы, — перехватчик клавиатурного ввода, фиксирующий
все, что вводится с клавиатуры. Полученные данные несложно проанализировать
и получить такую информацию, как сочетания имен пользователей и паролей,
номера кредитных карт и дат истечения. Информация затем передается главному
компьютеру, после чего может быть использована или продана в преступных целях.
Сходной вирусу программой является червь. Если вирус распространяется, при-
прикрепляя себя к другой программе, и исполняется вместе с ней, то червь является
самостоятельным. Он распространяется на другие компьютеры путем рассыл-
рассылки своих копий по сети. Компьютеры, оснащенные операционной системой
Windows, имеют каталог автозагрузки для каждого пользователя. Любая поме-
помещенная в него программа исполняется при входе пользователя в систему. Таким
образом, все, что нужно сделать червю, — это поместить себя или ярлык, ука-
указывающий на себя, в папку автозагрузки удаленного компьютера. Существуют
и другие способы запуска программы, скопированной в файловую систему уда-
удаленной машины; зачастую обнаружить их значительно труднее. Последствия дей-
действий червя могут быть такими же, как и вируса. На самом деле, четкой границы
между этими видами программ нет; нередко вредоносные программы использу-
используют оба метода для своего распространения.
Еще одна категория вредоносных программ — троянские программы, или троя-
ны. Внешне они кажутся полезными; например, троянская программа может
быть замаскирована под игру или усовершенствованную версию утилиты. Одна-
Однако во время исполнения троянская программа ведет совсем иную деятельность:
запускает червя, вирус или выполняет другие вредоносные действия. Как прави-
правило, подобная работа отличается тонкостью и скрытостью. В отличие от червей
и вирусов, троянские программы загружаются с согласия пользователей. Как
только правда о них выходит наружу, троянские программы удаляют с загрузоч-
загрузочных сайтов, на которых они размещены.
Следующий вид вредоносной программы — логическая бомба. Это фрагмент ко-
кода, который написан программистом, работающим в компании, и тайно внедрен
в рабочую операционную систему. Бомба не делает ничего до тех пор, пока про-
программист ежедневно вводит свой пароль. Как только его увольняют и физически
отстраняют от оборудования без предупреждения, бомба не получает пароль
и взрывается.
Результатом взрыва может быть удаление информации с жесткого диска, случай-
случайное стирание файлов, аккуратная и труднообнаруживаемая модификация ключе-
ключевых программ или шифрование важных файлов. В последнем случае компания
стоит перед сложной дилеммой: обратиться в полицию (при этом разбирательство
затянется на месяцы с неясным результатом) или нанять бывшего программиста
в качестве «консультанта» для решения проблемы за астрономическую сумму
в надежде, что при этом он не заложит следующую бомбу.
Еще одной формой вредоносной программы является шпионская программа. Как
правило, заражение ей происходит при посещении веб-сайтов. В простейшем слу-
случае шпионская программа представляет собой просто cookie — небольшой файл,
используемый для обмена между веб-браузерами и веб-серверами. У cookie-фай-
cookie-файлов вполне легальное предназначение: они содержат информацию, с помощью
которой веб-сайт может вас идентифицировать при следующем посещении. Они
подобны квитанции, которую сервисный центр выдает вам, когда вы сдаете неис-
неисправный велосипед в ремонт. По выполнении ремонта вы приносите свою часть
квитанции, данные которой сравниваются с маркировкой велосипеда и номером
выставленного счета. Веб-соединения непостоянны, поэтому, если вы захотите
приобрести книгу в интерактивном магазине, веб-сайт последнего попросит ваш
браузер предоставить cookie-файл. Когда вы закончите свою виртуальную про-
прогулку и будете готовы оплатить сделанные заказы, сервер попросит вернуть
cookie-файлы, сохраненные в текущем сеансе. Информация, содержащаяся в них,
будет использована для формирования итогового списка ваших покупок.
Обычно срок действия cookie-файлов, применяемых подобным образом, истекает
быстро. Cookie-файлы весьма полезны, и вся электронная коммерция построена
на их применении. Тем не менее некоторые веб-сайты используют cookie-файлы
отнюдь не так безобидно. Например, реклама на сайтах зачастую создается со-
совсем не теми компаниями, которым принадлежит информационное наполнение
сайта. Первые платят вторым за такую возможность. Не исключено, что реклама
на сайтах продажи велосипедов и одежды предоставлена одной и той же компа-
компанией; если вы посещаете эти сайты с сопутствующим обменом cookie-файлами,
указанная компания может собрать и проанализировать ваши cookie-файлы.
В результате не исключено, что вы будете видеть рекламу перчаток или курток,
предназначенных специально для велосипедистов. Подобным образом рекламо-
рекламодатели способны собрать множество сведений о ваших интересах. Возможно, вы
сочтете столь пристальный интерес к себе нежелательным.
Более серьезной проблемой является то, что веб-сайты могут загружать на ваш
компьютер исполняемый код целым рядом способов. Большинство браузеров
поддерживают встраиваемые модули, с помощью которых в них добавляются но-
новые функции, к примеру, возможность обработки новых типов файлов. Пользо-
Пользователи часто дают согласие на установку встраиваемых модулей, не вникая в де-
детали. Возможен и другой вариант, когда пользователь осознанно соглашается
с- предложением установить встраиваемый модуль, который, например, превра-
превращает указатель мыши в танцующего котенка. А иногда дефект веб-браузера
позволяет удаленному сайту установить нежелательную программу, возможно,
после того, как пользователь посетит страницу, созданную специально для экс-
эксплуатации уязвимости. Намеренная или случайная установка программы от сто-
стороннего источника создает риск заражения вредоносным кодом.
Случайная потеря данных
Важные данные могут быть потеряны не только из-за злоумышленников, но и слу-
случайно. Вот наиболее распространенные причины случайной потери данных:
+ «Форс-мажор»: пожары, наводнения, землетрясения, войны, восстания, кры-
крысы, пожирающие магнитные ленты или гибкие диски.
+ Аппаратные и программные ошибки: сбои центрального процессора, нечи-
нечитаемые диски или ленты, ошибки при передаче данных, ошибки в программах.
+ Человеческий фактор: неправильный ввод данных, неверные вставленный
диск или заправленная лента, запуск не той программы, потерянные диск или
лента и т. д.
Большая часть этих проблем может быть разрешена при условии своевременного
создания соответствующих резервных копий и хранения их вдали от оригиналь-
оригинальных данных. Несмотря на то что защита данных от случайного удаления может
показаться несерьезной по сравнению с защитой от интеллектуальных злоумыш-
злоумышленников, на практике случайное удаление приносит больше вреда, чем атаки.
5.4.2. Общие виды атак
на систему безопасности
Поиск уязвимостей в системе безопасности — непростая задача. Обычный способ
проверить надежность системы безопасности заключается в приглашении группы
экспертов, называемых командой тигров, или группой вторжения, чтобы посмот-
посмотреть, смогут ли они взломать защиту. Бывало, в качестве такой команды приглаша-
приглашались аспиранты [57]. За несколько лет подобные команды обнаружили множество
сфер, в которых операционные системы проявляют свои слабости. Мы рассмот-
рассмотрим наиболее распространенные методы атак, часто завершающиеся успехом.
При разработке систем убедитесь, что им под силу выдержать атаки этих типов.
+ Запросите страницы памяти, место на диске или на магнитной ленте и просто
считывайте информацию. Многие системы не очищают память при ее выде-
выделении пользователю, поэтому память и диски могут содержать много инте-
интересной информации, записанной предыдущим владельцем.
+ Попытайтесь выполнять несуществующие системные вызовы или существую-
существующие, но с неверными параметрами. Многие системы не выдерживают подоб-
подобного обращения с ними.
+ Начните регистрацию, а затем в ходе регистрации нажмите клавишу Del,
Rubout или Break. В некоторых системах подобным образом удается уничто-
уничтожить процесс, осуществляющий проверку пароля, и успешно пройти регист-
регистрацию без ввода пароля.
+ Попытайтесь модифицировать сложные структуры операционной системы
(если таковые имеются), хранящиеся в пользовательской области памяти.
В некоторых системах (особенно в мэйнфреймах), для того чтобы открыть
файл, программа формирует большую структуру, содержащую имя файла
и множество других параметров, которую передает операционной системе.
При чтении и записи файла операционная система иногда сама обновляет эту
структуру. Модификация некоторых полей может иметь разрушительное воз-
воздействие на систему безопасности.
+ Напишите программу, просто запрашивающую у пользователя идентифика-
идентификационные данные. Многие пользователи послушно введут их, а программа ак-
аккуратно сохранит их для злоумышленника.
+ Прочитайте руководство и попытайтесь найти фразы, гласящие: «Не делай-
делайте X». После этого попытайтесь проделать «X» в различных комбинациях.
+ Убедите системного администратора реализовать обход важных этапов про-
проверки безопасности для любого пользователя с вашим регистрационным име-
именем. Подобные атаки известны как атаки с черного хода.
+ Если ничего другого не получилось, попытайтесь найти секретаршу систем-
системного администратора и притвориться несчастным пользователем, забывшим
свой пароль. В качестве альтернативы можно попытаться подкупить секретар-
секретаршу. У секретарши, как правило, есть доступ к самой разнообразной и очень
интересной информации, а зарплата обычно невелика. Не следует недооцени-
недооценивать человеческий фактор.
Подобные и другие методы атак обсуждаются в [81]. Существует большое коли-
количество других источников информации о безопасности и ее тестировании, осо-
особенно в Интернете. Последней работой по данной теме, ориентированной на опе-
операционную систему Windows, является [66].
5.4.3. Принципы разработки
механизмов безопасности
В 1975 году исследователи определили несколько общих принципов, которых
необходимо придерживаться при разработке безопасных систем [102]. Приве-
Приведем краткий обзор некоторых из этих идей на основе опыта работы с систе-
системой MULTICS.
+ Устройство системы не должно быть секретом. Предположение, что взлом-
взломщики не знают, как работает система, — это лишь ненужные иллюзии разра-
разработчиков.
+ По умолчанию доступ не должен предоставляться. Об ошибках, в результате
которых пользователям было отказано в законном доступе, сообщат значи-
значительно быстрее, чем о случаях ошибочного предоставления несанкциониро-
несанкционированного доступа.
+ Необходимо проверять текущее состояние прав доступа. Система не должна,
проверив наличие прав доступа и убедившись, что доступ разрешен, затем со-
сохранять эту информацию для последующего использования. Многие системы
проверяют разрешение доступа при открытии файла, но не после открытия.
Это означает, что пользователь, открывший файл и держащий его открытым
неделями, будет продолжать обладать доступом к файлу, даже если владелец
файла с тех пор уже давно изменил права доступа файла.
+ Предоставляйте каждому процессу как можно меньше привилегий. Если у про-
программы-редактора есть доступ только к редактируемому файлу (указанному
при вызове), то редакторы в виде троянских коней с ахейцами в брюхе вряд
ли смогут причинить много вреда. Применение этого принципа предполагает
схему защиты высокой степени детализации. Подобные схемы рассматрива-
рассматриваются позднее в данной главе.
+ Механизм защиты должен быть простым, одинаковым для всех и встроенным
в самые нижние уровни системы. Попытка установить механизмы безопас-
безопасности на существующую небезопасную систему практически невыполнима.
Безопасность, как и правильность, не является свойством, которое можно до-
добавить потом.
+ Выбранная схема должна быть психологически приемлемой. Если пользова-
пользователи почувствуют, что для защиты файлов требуется тратить слишком много
усилий, они не станут их защищать. В то же время они будут громко жало-
жаловаться, если что-либо пойдет не так. Ответы типа «это ваша вина», как прави-
правило, восприниматься не будут.
5.4.4. Аутентификация пользователей
Многие схемы защиты основаны на предположении, что система знает пользова-
пользователя, работающего с ней. Задача идентификации пользователя при его подклю-
подключении к системе называется его аутентификацией. Большинство методов аутен-
аутентификации основаны на выяснении чего-то, известного пользователю, чего-то,
имеющегося у пользователя, или чего-то, чем является пользователь.
Пароли
В наиболее широко применяемой форме аутентификации пользователю предла-
предлагается ввести имя и пароль. Парольная защита легко реализуется. В UNIX это
происходит следующим образом: программа входа в систему просит пользовате-
пользователя ввести имя и пароль, который немедленно шифруется. Затем программа чита-
читает файл паролей, представляющий собой последовательность ASCII-строк, где
каждая строка соответствует одному пользователю. Когда нужный пользователь
найден, введенный шифрованный пароль сравнивается с шифрованным паролем
из файла. В зависимости от результата сопоставления пользователю выдается
разрешение или отказ в доступе.
Парольная аутентификация легко уязвима. Зачастую можно видеть публикации
о том, как школьники старших и даже средних классов с домашних компьютеров
взламывают сверхсекретные системы крупных корпораций и правительственных
организаций. Почти всегда взлом происходит вследствие угадывания комбина-
комбинации имени пользователя и пароля.
Несмотря на более свежие исследования, классический труд по вопросу безопас-
безопасности паролей был написан аж в 1979 году на основе исследований систем UNIX
[90]. Авторы скомпилировали список вероятных паролей: имена и фамилии, на-
названия улиц, городов, слова из словарей среднего размера (в частности, написан-
написанные задом наперед), автомобильные номера и короткие строки случайных сим-
символов. Затем они сравнили свой полученный таким образом список с системным
файлом паролей, чтобы посмотреть, есть ли совпадения. Как выяснилось, более
86 % от общего количества паролей в файле оказались в их списке.
Если бы все пароли состояли из 7 символов, случайным образом выбранных из
95 печатных символов набора ASCII, их количество было бы равно 957, что при-
примерно равно 7 х 1013. Если выполнять 2000 операций шифрования в секунду, на
построение списка для сверки пароля потребуется около 2000 лет. Более того,
под хранение такого списка ушло бы 20 млн магнитных лент. Даже требование
того, чтобы пароли содержали как минимум один символ нижнего регистра, один
символ верхнего регистра, один специальный символ и имели бы как минимум
семь или восемь символов в длину, заметно улучшает ситуацию по сравнению
с тем случаем, когда пароль выбирается пользователем без всяких ограничений.
Даже для случая, когда по политическим причинам невозможно заставить поль-
пользователей выбирать разумные пароли, в [90] описана технология, делающая пред-
предлагаемый авторами метод атаки (заранее зашифровать большое число паролей)
практически бесполезным. Идея состоит в том, чтобы ассоциировать с каждым
паролем гг-разрядное случайное число. Это случайное число меняется при каж-
каждом изменении пароля. Оно хранится в файле паролей в незашифрованном виде,
и каждый может его видеть. Пароль же сначала объединяется со случайным чис-
числом, а только затем шифруется и записывается в файл.
Рассмотрим, к каким последствиям приведет эта техника для злоумышленника,
пытающегося составить список вероятных паролей, зашифровать их и сохранить
в отсортированном виде в файле f, где их затем легко будет найти. Если злоумыш-
злоумышленник считает, что слово Marilyn может быть паролем, ему теперь недостаточно
закодировать только это слово и записать его в f. Он должен зашифровать и за-
записать 2п строк, MarilynOOOO, MarilynOOOl, Marilyn0002 и т. д. Благодаря
этой технике, называемой добавлением соли в файл паролей, размер файла f уве-
увеличивается в 2п раз. В UNIX применяется значение п, равное 12. В некоторых
версиях UNIX сам файл паролей сделан недоступным для чтения, а для работы
с ним предоставлена программа, которая просматривает запрошенные записи,
внося дополнительную задержку, достаточную, чтобы сильно замедлить атаку.
Добавление случайных чисел к файлу паролей защищает систему от взломщи-
взломщиков, пытающихся заранее составить большой список зашифрованных паролей
и таким образом взломать несколько паролей сразу. Однако данный метод бесси-
бессилен помочь в том случае, когда пароль легко отгадать, например, если пользователь
David использует пароль David. Взломщик может просто попытаться отгадать
пароли один за другим. Обучение пользователей в данной области помогает, но
оно редко проводится. Однако помимо обучения пользователей в вашем распо-
распоряжении помощь компьютера. На некоторых системах устанавливается програм-
программа, формирующая случайные, легко произносимые бессмысленные слова, такие
как fotally, garbungy или bipitty, подходящие в качестве паролей (жела-
(желательно с чередованием прописных и строчных букв и с разбавлением специаль-
специальными символами).
Некоторые операционные системы требуют от пользователей регулярной смены
паролей, чтобы ограничить ущерб в ситуации, когда пароль становится извест-
известным взломщику. Крайность здесь — одноразовые пароли. В этом случае пользо-
пользователь получает блокнот, содержащий список паролей. Для каждого входа в сис-
систему используется следующий пароль в списке. В итоге, если даже взломщику
удастся узнать уже отработавший пароль, он ему не пригодится. (Предполагает-
(Предполагается, что пользователь не потеряет выданный ему блокнот.)
Еще одна вариация на тему паролей предполагает, что для каждого нового поль-
пользователя создается длинный список вопросов и ответов, который хранится на
сервере в надежном виде (например, в зашифрованном). Вопросы должны выби-
выбираться так, чтобы пользователю не нужно было их записывать. Примеры:
+ Как зовут сестру Марджолин?
+ На какой улице расположена ваша начальная школа?
+ Что преподавала мисс Воробьофф?
При регистрации сервер задает один из этих вопросов, выбирая его в списке слу-
случайным образом, и проверяет ответ.
Другой вариант называется запрос-отзыв. Он работает следующим образом. Поль-
Пользователь выбирает алгоритм, например я2, идентифицирующий его как пользовате-
пользователя. Когда пользователь входит в систему, сервер посылает ему некое случайное
число, например 7. В ответ пользователь отправляет серверу число 49. Алгоритм
может отличаться утром и вечером, в различные дни недели, для различных тер-
терминалов и т. д.
Физическая идентификация
Совершенно иным подходом к авторизации является проверка наличия у поль-
пользователя некоторого предмета, как правило, пластиковой карты с нанесенной
магнитной полосой. Обычно пользователь должен не только вставить карту, но
и ввести пароль; таким образом, доступ к системе обеспечивается при соблюде-
соблюдении двух условий — наличия у пользователя карты и знания им пароля. Обычно
на этом принципе основана работа банкоматов.
Другой метод проверки подлинности пользователя основан на измерении его
физических характеристик, которые трудно подделать. Например, для иденти-
идентификации пользователя может применяться специальное устройство считывания
отпечатков пальцев или распознавания тембра голоса. Поиск можно значительно
ускорить, если пользователь при этом будет сообщать системе, кто он; в этом
случае системе будет достаточно выполнить сравнение для одного отпечатка паль-
пальцев, нежели искать предоставленный отпечаток во всей базе данных. Визуальная
идентификация пока не встречается, но со временем и она может появиться.
Еще один метод идентификации заключается в анализе подписи. Пользователь
ставит подпись специальным пером, соединенным с терминалом, и компьютер
сверяет ее с оригиналом. Еще лучше сравнивать не подпись, а движения, выпол-
выполняемые при ее написании. Хороший специалист по подделке подписей может на-
нарисовать довольно точную копию подписи, но не обязательно угадает, в каком
порядке выполняются движения.
На удивление часто на практике используется измерение длины пальцев. При
этом каждый терминал оснащается устройством вроде показанного на рис. 5.20.
Пользователь засовывает в него руку, и устройство измеряет длину его пальцев
и сравнивает с информацией, хранящейся в базе данных.
Подобные примеры измерения биометрических характеристик можно приводить
еще и еще, но мы остановимся только на двух, которые помогут отметить кое-что
важное. Кошки и другие животные мочой метят свои владения по периметру.
Очевидно, кошки могут идентифицировать друг друга подобным образом. Пред-
Представьте себе, что кому-нибудь удастся создать небольшое устройство, способное
производить мгновенный анализ мочи, обеспечивая, таким образом, надежную
идентификацию. Раз так, значит, каждый терминал можно снабдить подобным
устройством, вывесив табличку: «Для регистрации помочитесь сюда, пожалуй-
пожалуйста». Возможно, таким образом удалось бы создать абсолютно надежную систе-
систему, хотя она вряд ли понравилась бы пользователям. То же самое можно сказать
о системе, состоящей из иголки и небольшого спектрометра и предлагающей поль-
пользователю проколоть палец иголкой, предоставив таким образом каплю крови для
анализа. Дело в том, что любая схема аутентификации должна быть психологи-
чески приемлема для сообщества аутентифицируемых. Измерение длины паль-
пальцев, возможно, не вызовет проблем, но даже такая безобидная процедура, как
снятие отпечатков пальцев, может оказаться неприемлемой, так как у многих это
действие ассоциируется с обвинением в преступлении.
Рис. 5.20. Устройство для измерения длины пальцев
Контрмеры
В некоторых компьютерных системах, серьезно продуманных в плане безопасно-
безопасности (отношение к этому вопросу, как правило, кардинально меняется на следую-
следующий день после того, как злоумышленник вломился в систему и причинил серьез-
серьезный ущерб), часто предпринимаются шаги, призванные максимально усложнить
неавторизованный вход в систему. Например, пользователям может быть разре-
разрешено входить в систему только со специального терминала и только в опреде-
определенные дни недели и часы.
Коммутируемые телефонные линии также можно сделать более безопасными.
Например, всем можно разрешить регистрироваться в системе через модем по
телефонной линии, но после успешной регистрации система немедленно прервет
соединение и сама позвонит пользователю по заранее условленному номеру.
Такая мера означает, что взломщик не вломится в систему с любой телефонной
линии. Для работы в системе подойдут только линии зарегистрированных поль-
пользователей. В любом случае, с применением данной техники или без нее система
обязана выдерживать паузу, по крайней мере, в 10 с при проверке пароля и увели-
увеличивать этот временной интервал после каждой неуспешной регистрации, чтобы
снизить частоту попыток взломщика. После трех неуспешных попыток регистра-
регистрации линия должна отключаться на 10 мин, а персонал уведомляться о попытке
несанкционированного входа в систему.
Все попытки входа в систему должны регистрироваться. Когда пользователь реги-
регистрируется, система должна сообщать ему дату и время последней регистрации,
а также терминал, примененный для входа, чтобы пользователь мог заметить
взлом системы злоумышленником.
Еще один вариант защиты заключается в установке ловушки для взломщика.
Простая схема ловушки представляет собой специальное имя регистрации с про-
простым паролем (например, имя guest и пароль guest). При каждом входе в систе-
систему с таким именем системные специалисты в области безопасности немедленно
уведомляются. Все команды, вводимые взломщиком, немедленно отображаются
на мониторе руководителя службы безопасности, чтобы он мог видеть, что на-
намеревается сделать взломщик. Другие ловушки могут представлять собой легко
обнаруживаемые ошибки в операционной системе и тому подобные вещи, на-
намеренно встроенные с целью отлавливания злоумышленников на месте преступ-
преступления. В [110] опубликован занимательный доклад о ловушках, установленных
автором с целью поймать шпиона, вломившегося на университетский компьютер
в поисках военных секретов.
5.5. Механизмы защиты
В предыдущих разделах мы рассмотрели множество проблем, некоторые из них
были техническими, тогда как другие — нет. В следующих разделах мы скон-
сконцентрируемся на некоторых технических деталях методов защиты файлов, ис-
используемых в операционных системах. Во всех этих методах проводится четкое
разграничение между политикой (от кого и чьи данные должны защищаться)
и механизмом (как система проводит данную политику). Отделение политики от
механизма обсуждается в [104]. Мы уделим особое внимание именно механизму,
а не политике.
В некоторых системах защита реализуется при помощи программы, называю-
называющейся монитором обращений. При каждой попытке доступа к некоторому ресур-
ресурсу система сначала просит монитор обращений проверить законность данного
доступа. Монитор обращений смотрит в таблицы политик и принимает решение.
Рассмотрим окружение, в котором работает монитор обращений.
5.5.1. Домены защиты
Компьютерная система подразумевает множество «объектов», которые требует-
требуется защищать. Это может быть аппаратура (например, центральный процессор,
память, диски или принтеры) или программное обеспечение (процессы, файлы,
базы данных или семафоры).
У каждого объекта есть уникальное имя, по которому к нему позволено обра-
обращаться, и набор операций, которые вправе выполнять с объектом процессы. Так,
к файлу применимы операции read и write, к семафору — операции up и down.
Очевидно, что для ограничения доступа к объектам требуется определенный ме-
механизм. Более того, этот механизм должен предоставлять возможность не полного
запрета доступа, а ограничения в пределах подмножества разрешенных операций.
Например, процессу А может быть разрешено читать файл F, но не писать в него.
Чтобы обсудить различные механизмы защиты, полезно ввести концепцию домена.
Домен представляет собой множество пар (объект, права доступа). Каждая пара
указывает объект и некоторое подмножество операций, разрешенных с ним. Права
доступа означают в данном контексте разрешение выполнить одну из операций.
Домен может соответствовать одному пользователю или группе пользователей.
На рис. 5.21 показаны три домена, содержащие объекты и разрешения для каждо-
каждого объекта в формате RWX (Read, Write, eXecute — чтение, запись, исполнение).
Обратите внимание, что объект Принтер 1 одновременно присутствует в двух
доменах. Хотя это и не отражено в данном примере, один и тот же объект может
иметь в различных доменах разные разрешения.
Рис. 5.21. Три домена защиты
В каждый момент времени каждый процесс работает в каком-либо одном домене
защиты. Другими словами, имеется некоторая коллекция объектов, к которым
он вправе получить доступ, и для каждого объекта у него есть определенный
набор разрешений. Во время выполнения процессы имеют право переключаться
с одного домена на другой. Правила переключения между доменами в значитель-
значительной степени зависят от системы.
Чтобы идея домена защиты выглядела конкретнее, рассмотрим пример из систе-
системы UNIX. В UNIX домен процесса определяется идентификаторами UID и GID
процесса. По заданной комбинации (UID, GID) можно составить полный список
всех объектов (файлов, включая устройства ввода-вывода, представленные в ви-
виде специальных файлов и т. д.), к которым процесс может получить доступ с ука-
указанием типа доступа (чтение, запись, исполнение). Два процесса с одной и той
же комбинацией (UID, GID) будут иметь абсолютно одинаковый доступ к оди-
одинаковому набору объектов.
Более того, каждый процесс в UNIX состоит из двух частей: пользовательской
и системной. Когда процесс выполняет системный вызов, он переключается из
пользовательской части в системную. Пользовательская и системная части про-
процесса различаются по уровню доступа к различным множествам объектов. На-
Например, системная составляющая может иметь доступ ко всем страницам в фи-
физической памяти, ко всему диску и ко всем другим защищенным ресурсам. Таким
образом, системный вызов осуществляет переключение доменов защиты.
Когда процесс выполняет системный вызов exec с файлом, у которого установ-
установлен бит SETUID или SETGID, процесс может получить новые идентификаторы
UID и GID. При новой комбинации UID и GID процесс получает новый набор
доступных файлов и операций. Запуск программы с установленным битом SETUID
или SETGID также представляет собой переключение домена, так как права дос-
доступа при этом изменяются.
Важным вопросом является то, как система отслеживает, какой объект какому
домену принадлежит. Можно себе представить большую матрицу, в которой ря-
рядами являются домены, а колонками — объекты. На пересечении располагаются
ячейки, содержащие права доступа для данного домена к данному объекту. Мат-
Матрица для рис. 5.21 показана на рис. 5.22. При наличии подобной матрицы опера-
операционная система может для каждого домена определить разрешения к любому
заданному объекту.
Рис. 5.22. Матрица защиты
Переключение между доменами также легко реализуется при помощи все той же
матрицы, если считать домены объектами, над которыми разрешена операция enter
(вход). На рис. 5.23 снова изображена та же матрица, что и на предыдущем рисун-
рисунке, но с тремя доменами, выступающими и в роли объектов. Процессы в состоянии
переключаться с домена 1 на домен 2, но обратно вернуться уже не могут. Эта
ситуация моделирует выполнение программы с установленным битом SETUID
в UNIX. Другие переключения доменов в данном примере не разрешены.
Рис. 5.23. Матрица защиты с доменами в роли объектов
5.5.2. Списки управления доступом
На практике разрешения доступа редко оформляются в виде матрицы, показан-
показанной на рис. 5.23, поскольку такая матрица была бы очень большой и практически
пустой. В большинстве доменов доступа ко многим объектам нет, поэтому хра-
хранение объемной матрицы означает бесполезную трату дискового пространства.
На практике применяются два метода, предполагающие хранение матрицы по
рядам или столбцам, причем хранятся только непустые элементы. Эти два подхо-
подхода, как ни странно, различаются между собой. В данном разделе мы рассмотрим
матрицу защиты в варианте по столбцам, а в следующем разделе познакомимся
с ее построчной реализацией.
Согласно первому методу, с каждым объектом ассоциируется список (упорядо-
(упорядоченный), содержащий все домены, которым разрешен доступ к данному объекту,
а также тип доступа. Такие списки называются списками управления доступом
(Access Control List, ACL, рис. 5.24). На нем изображены три процесса, А, В и С,
принадлежащие разным доменам, и три файла, F1, F2 и F3. Для простоты предпо-
предположим, что каждый домен соответствует ровно одному пользователю, в данном
случае, А, В и С. В литературе, посвященной безопасности, пользователей назы-
называют субъектами, или принципалами, в отличие от объектов — вещей, которыми
они обладают (например, файлов).
Рис. 5.24. Использование списков управления доступом применительно к файлам
С каждым файлом связан список управления доступом. ACL файла F1 состоит
из двух записей, разделенных точкой с запятой. Первая запись указывает на то,
что любой процесс пользователя А может читать и писать в файл, а вторая — на
то, что пользователь В может читать файл. Другие виды доступа для этих поль-
пользователей, а также все виды доступа для остальных пользователей запрещены.
Обратите внимание на то, что права назначены не процессам, а пользователям.
С точки зрения системы защиты, любой процесс, владельцем которого является
пользователь А, имеет право читать и писать в файл F1. Не имеет значения,
сколько таких процессов — один или сто; учитывается не идентификатор про-
процесса, а его владелец.
У файла F2 в ACL три записи: пользователи А, В и С могут читать файл, а, кроме
того, В имеет право записи в него. Все прочие виды доступа запрещены. Файл
F3, очевидно, является исполняемой программой, поскольку пользователи В и С
могут читать и исполнять его. Процесс В также имеет разрешение на запись в F3.
Данный пример демонстрирует простейшую форму защиты посредством ACL.
Механизмы, используемые на практике, более сложны. Для начала мы показали
лишь три права: на чтение, на запись и на исполнение. Существуют и другие
права: например, широко распространены права на копирование и уничтожение
объекта. Они имеются у любого объекта независимо от его типа. Возможны права,
специфичные для конкретных объектов. Например, у объекта «почтовый ящик»
существует право на добавление сообщения, а у объекта «каталог» — право сор-
сортировки в алфавитном порядке.
До настоящего момента мы говорили о ACL-записях, соответствующих отдель-
отдельным пользователям. Многие системы поддерживают концепцию групп поль-
пользователей. Группы имеют имена и могут включаться в ACL. Для групп поддер-
поддерживаются два вида семантики. В некоторых системах у каждого процесса есть
идентификатор пользователя (UID) и идентификатор группы (GID). В этом слу-
случае ACL-запись выглядит следующим образом:
UID1, GID1: права1; UID2, GID2: права 2; ...
При получении запроса на доступ к объекту проверяется наличие UID и GID
процесса в ACL, и, если эти идентификаторы удается найти, применяются пере-
перечисленные права. В противном случае в доступе отказывается.
Подобное использование групп приводит к концепции роли. Рассмотрим систе-
систему, в которой пользователь tana является системным администратором, а сле-
следовательно, входит в группу sysadm. Пусть в компании имеется несколько клу-
клубов для сотрудников, и tana входит в сообщество любителей голубей. Члены
этого сообщества принадлежат группе pigf an и имеют возможность управлять
собственной базой данных с компьютеров компании. В табл. 5.4 приведен фраг-
фрагмент списка управления доступом.
Таблица 5.4. Два списка управления доступом
Файл Список управления доступом
Password tana, sysadm: RW
Pigeon_data bill, pigfan: RW; tana, pigfan: RW;
Если tana попытается получить доступ к одному из этих файлов, результат за-
зависит от того, к какой группе этот пользователь принадлежит в текущий момент.
Возможно, при входе система просит его указать группу, в которую он хотел бы
войти; не исключено, что для разделения групп каждой из них даже соответству-
соответствуют свои имена входа и (или) пароли. Цель такой схемы — лишить пользователя
tana возможности доступа к файлу паролей, если он вошел в систему как член
сообщества любителей голубей. Он может работать с файлом паролей только как
системный администратор.
В некоторых случаях пользователь получает доступ к определенным файлам не-
независимо от группы, к которой он принадлежит. Такой режим задается с помо-
помощью маски, обозначающей любую группу. Например:
tana, *: RW
Запись подобного вида дает пользователю tana доступ к файлу паролей незави-
независимо от того, в какой группе он находится в текущий момент.
Еще одна возможность заключается в предоставлении пользователю доступа
к объекту при условии, что надлежащим правом обладает хотя бы одна группа,
в которую он входит. В этом случае пользователю, состоящему в нескольких
группах, не нужно указывать текущую группу при входе в систему. В любой мо-
момент времени учитываются все группы, членом которых он является. Недоста-
Недостаток такого подхода — меньшая изолированность: tana имеет возможность ре-
редактировать файл паролей во время общения с любителями голубей.
Применение групп и масок позволяет выборочно блокировать доступ пользова-
пользователей к файлам. Например:
virgil, *: (none); *.*: RW
Эта запись дает возможность всем, кроме пользователя virgil, читать и писать
в файл. Такой эффект достигается потому, что записи сканируются в порядке
перечисления и применяется первая подходящая (остальные же записи даже не
проверяются). Для virgil такой записью является первая; в ней указано отсут-
отсутствие каких-либо прав (попе). На этом поиск заканчивается, и то, что все ос-
остальные пользователи имеют права доступа, остается «за кадром».
Другой способ работы с группами предполагает, что в ACL-записях задействова-
задействованы не пары (UID, GID), а один из этих идентификаторов. Например, для файла
pigeon_data запись может выглядеть следующим образом:
debbie: RW; phil: RW; pigfan: RW
Она означает, что пользователи debbie, phil и все члены группы pigfan име-
имеют право чтения и записи.
Иногда владелец файла хочет отметить разрешения, назначенные пользователю
или группе. Списки управления доступом позволяют относительно легко отме-
отменить назначенные ранее права. Все, что нужно сделать, — это отредактировать
их. Тем не менее если список проверяется лишь при открытии файла, то измене-
изменения возымеют действие лишь при следующем вызове open. К любому открыто-
открытому файлу применяются права, актуальные на момент открытия, даже если позд-
позднее доступ пользователю запрещается.
5.5.3. Мандаты
Матрица, показанная на рис. 5.23, может также храниться по рядам. Здесь с каж-
каждым процессом ассоциирован список разрешенных для доступа объектов вместе
с информацией о том, какие операции разрешены, другими словами, это — домен
защиты объекта. Такой список называется списком мандатов (Capability List,
C-list, рис. 5.25), а его элементы — мандатами [36, 44].
Рис. 5.25. У каждого процесса имеется список мандатов
Каждый мандат наделяет владельца определенными правами на определенном
объекте. На рис. 5.25, к примеру, процесс, владельцем которого является пользо-
пользователь А, может читать файлы F1 и F2. Как правило, мандат состоит из иденти-
идентификатора файла (или, в общем случае, объекта) и битовой карты для различных
прав. В UNIX-подобных системах в качестве идентификатора файла, вероятно,
выступает номер индексного узла. Списки мандатов сами по себе являются объ-
объектами, и на них могут указывать другие списки мандатов, что позволяет совме-
совместно использовать поддомены.
Очевидно, что списки мандатов должны быть защищены от искажения пользо-
пользователями. Известны три способа защиты. Для первого требуется теговая архи-
архитектура, то есть аппаратно реализованная структура памяти, в которой у каждо-
каждого слова памяти есть дополнительный (теговый) бит, сообщающий, содержит ли
данное слово памяти мандат или нет. Теговый бит не используется в обычных
командах процессора, таких как арифметические команды или команды сравне-
сравнения. Он может быть изменен только программой, работающей в режиме ядра (то
есть операционной системой). Машины с теговой архитектурой реализованы
и могут быть эффективными [46]. Примером такой машины, получившей широ-
широкое распространение, является IBM AS/400.
Особенность второго способа в том, что список хранится внутри операционной
системы. При этом к элементам списка можно обращаться по их позиции в списке.
Такая форма адресации напоминает использование дескрипторов файла в UNIX.
Именно таким образом работала система Hydra [129].
Третий способ заключается в хранении списка мандатов в пользовательском
пространстве, но в зашифрованном виде, так чтобы пользователь не сумел изме-
изменить эту информацию. Этот подход особенно полезен для распределенных систем
и работает следующим образом. Когда клиентский процесс посылает сообщение
удаленному серверу (например, файловому), чтобы создать для него объект, сер-
сервер создает объект и генерирует длинное случайное число — код проверки. Под
объект резервируется запись в файловой таблице сервера, в которой поле про-
проверки хранится вместе с адресами дисковых блоков и прочей информацией. Вы-
Выражаясь в терминах UNIX, поле проверки хранится на сервере в индексном узле.
Оно никогда не отправляется обратно пользователю и никогда не передается по
сети. Сервер генерирует и возвращает пользователю мандат в форме, представ-
представленной на рис. 5.26.
Рис. 5.26. Криптографически защищенный мандат
Мандат включает идентификатор сервера, номер объекта (индекс в таблицах
сервера, то есть, по существу, номер индексного узла) и права в виде битовой
карты. Последнее поле образовано путем преобразования объединения объекта,
прав и поля проверки.
Когда пользователь желает получить доступ к объекту, он отсылает серверу ман-
мандат, включая его в запрос. Сервер извлекает номер объекта и использует его в ка-
качестве индекса своих таблиц для поиска. Затем он вычисляет значение /(объект,
права, поле проверки), где первые два параметра взяты из мандата, а третий
извлечен из собственных таблиц. Если результат совпадает с четвертым полем
мандата, запрос удовлетворяется, в противном случае отклоняется. Если пользо-
пользователь пытается получить доступ к чужому объекту, ему не удастся подделать
четвертое поле, поскольку он не знает значения поля проверки.
Пользователь может запросить у сервера более ограниченный мандат, например
только на чтение. Сначала сервер проверит корректность мандата. Если провер-
проверка успешна, он вычислит значение /(объект, новые права, поле проверки) и сге-
сгенерирует новый мандат, поместив вычисленное значение в четвертое поле. Обра-
Обратите внимание на то, что используется первоначальное значение поля проверки;
это объясняется тем, что от него зависят другие важные мандаты.
Новый мандат возвращается запросившему его процессу. Теперь пользователь
может послать этот мандат другу, просто написав ему сообщение. Если друг ус-
установит биты прав, которые должны быть сброшены, сервер определит это, по-
поскольку значение / изменится с изменением прав. Поскольку другу неизвестно
правильное значение поля проверки, он не сможет сфальсифицировать мандат,
соответствующий новым правам. Описанная схема была разработана для рас-
распределенной операционной системы Amoeba и активно в ней применялась [116].
Помимо специфических разрешений, зависящих от конкретного объекта, напри-
например чтение и исполнение, мандаты (как системные, так и защищенные шифрова-
шифрованием) включают в себя, как правило, общие права, то есть разрешения выполне-
выполнения действий, применимых ко всем объектам. Примеры:
1. Копирование мандата: создание нового мандата для того же объекта.
2. Копирование объекта: создание дубликата объекта с новым мандатом.
3. Удаление мандата: удаление записи в списке мандатов, объект при этом не за-
затрагивается.
4. Удаление объекта: удаление объекта и мандата.
Напоследок стоит отметить, что аннулировать доступ к объекту в мандатных
системах, реализованных на уровне ядра, довольно сложно. Системе трудно най-
найти все мандаты для конкретного объекта, чтобы забрать их, так как они могут
храниться в любом месте диска. Один из методов заключается в том, что мандат
должен указывать на объект не непосредственно, а косвенно. Система может в лю-
любой момент разорвать связь между объектом, таким образом аннулируя все ман-
мандаты. (Когда мандат позднее появится в системе, пользователь обнаружит, что
косвенный объект теперь указывает на нулевой объект.)
В системе Amoeba аннулирование мандатов выполняется легко. Все, что для это-
этого требуется, — это изменить контрольное поле, хранимое с объектом. «Одним
щелчком» все существующие мандаты объявляются недействительными. Одна-
Однако ни одна схема не обеспечивает выборочного аннулирования мандатов, то есть
невозможно, например, отменить мандат Джона, не затронув всех остальных
пользователей. Этот недостаток присущ всем мандатным системам.
Еще одну проблему представляет борьба с ситуацией, когда владелец корректно-
корректного мандата передает его множеству своих лучших друзей. Средства управления
ядром, как в Hydra, позволяют решить этот вопрос, однако они не приносят хо-
хороших результатов в распределенных системах, подобных Amoeba.
В то же время мандаты с элегантностью устраняют проблему нарушения без-
безопасности мобильным кодом. При запуске чужой программы последняя получа-
получает список мандатов, содержащий лишь те мандаты, которыми ее хочет наделить
владелец машины. К примеру, программе может быть разрешено выводить данные
на экран, а также читать и писать в файлы единственного, специально выделен-
выделенного для нее каталога. Если мобильный код будет помещен в процесс с подобны-
подобными ограниченными возможностями, он не сможет получить доступ к другим ре-
ресурсам. Выполнение кода с максимально ограниченным набором прав доступа
называется принципом наименьшего уровня привилегий. Этот принцип является
основополагающим при разработке безопасных систем.
Подводя краткий итог, отметим, что возможности списков управления доступом
и списков мандатов дополняют друг друга. Мандаты обладают высокой эффек-
эффективностью, поскольку не требуют проверки запросов процессов типа «открыть
файл, ссылка на который имеется в мандате 3». Использование ACL в подобной
ситуации привело бы к поиску, и, возможно, долгому. В отсутствие поддержки
групп, для разрешения чтения файла всеми пользователями в ACL пришлось бы
полностью перечислить их. Кроме того, мандаты позволяют с легкостью изоли-
изолировать процесс, в то время как ACL не предоставляют такой возможности. Нако-
Наконец, если объект удаляется, а мандат остается, возникают проблемы. Списки
управления доступом лишены подобного недостатка.
5.5.4. Секретные каналы
Даже при наличии списков управления доступом и мандатов в системе безопасно-
безопасности могут существовать бреши. В данном разделе мы поговорим о существовании
утечек информации в системах, для которых строго математически доказано, что
подобные утечки невозможны. Изложенные здесь идеи впервые высказаны в [72].
Описываемая модель изначально была сформулирована в терминах единой сис-
системы разделения времени, но те же идеи применимы в локальной сети и в других
многопользовательских средах. В ее чистом виде в эту модель входят три про-
процесса, работающих на одной защищенной машине. Первый процесс представляет
собой клиента, который доверяет выполнить некоторое задание второму процес-
процессу, серверу. Клиент и сервер доверяют друг другу не полностью. Например, ра-
работа сервера заключается в том, чтобы помочь клиентам заполнить их налоговые
декларации. Клиенты беспокоятся, что сервер запишет в тайную тетрадь их фи-
финансовую информацию, а затем, например, продаст эти сведения. Сервер озабо-
озабочен тем, что клиенты украдут ценную программу подсчета налогов.
Третий процесс, являясь сообщником сервера, намеревается украсть конфиден-
конфиденциальные сведения клиента. Владельцем этого процесса, как и сервера, обыч-
обычно является один и тот же человек. Все три процесса показаны на рис. 5.27.
Цель данной модели — помочь разработать систему, в которой невозможна утеч-
утечка к сообщнику сервера информации, полученной сервером у клиента. В [72] это
названо проблемой изоляции.
Рис. 5.27. Проблема изоляции: а — клиент, сервер и сообщник сервера; б — даже от
изолированного сервера информация может попасть к сообщнику по секретному каналу
С точки зрения разработчика системы задача заключается в изоляции сервера
таким образом, чтобы он не мог передать информацию сообщнику. С помощью
матрицы защиты несложно гарантировать, что сервер не будет общаться с со-
сообщником, записывая данные в файл, к которому у сообщника есть доступ для
чтения. Вероятно, можно также гарантировать отсутствие взаимодействия меж-
между процессами сервера и сообщника при помощи системного механизма.
К сожалению, утечка информации может происходить по секретным каналам.
Например, сервер может передавать последовательность нулей и единиц, коди-
кодируя единицы интервалами высокой активности процессора, а нули — интервала-
интервалами бездействия.
Сообщник может принимать этот поток, тщательно отслеживая время отклика
сервера. Как правило, время отклика меньше у простаивающего сервера, то есть
меньшее время отклика означает ноль, большее — единицу. Этот канал связи на-
называется секретным. Он показан на рис. 5.27, б.
Конечно, секретный канал по определению зашумлен, но если применить по-
помехоустойчивое кодирование (например, код Хэмминга), информация может
приниматься сообщником с высокой степенью надежности. Пропускная способ-
способность такого канала будет невелика, но это не снижает его опасности. Очевидно,
что ни одна из моделей защиты, основанных на матрицах объектов и доменов, не
в силах предотвратить данный тип утечки информации.
Модуляция центрального процессора не является единственным вариантом сек-
секретного канала. Информация может также кодироваться ошибками отсутствия
страниц, например, много ошибок отсутствия страниц в течение определенного
интервала времени будет означать 1, а отсутствие ошибок — 0. В принципе для
этой цели подойдет любой способ снижения производительности системы в те-
течение определенного интервала времени. Если система позволяет блокировать
файлы, тогда сервер может блокировать некий файл, что будет означать, на-
например, 1, и разблокировать его, кодируя, таким образом, 0. Некоторые системы
позволяют процессу определить, что файл блокирован, даже если у него нет
доступа к этому файлу. Такой секретный канал представлен на рис. 5.28, где бло-
блокировка файла устанавливается и снимается через определенные интервалы вре-
времени, известные серверу и его сообщнику. В проиллюстрированном примере по
секретному битовому потоку передается последовательность 11010100.
Рис. 5.28. Секретный канал, основанный на блокировке файлов
Блокировка и разблокировка предопределенного файла 5 не является слишком
зашумленным каналом, однако требует точного согласования по времени, если
только передача не ведется очень медленно. Надежность и производительность
можно повысить, введя протокол с подтверждениями. В этом протоколе ис-
используются два дополнительных файла F1 и F2, блокируемых соответственно
сервером и его сообщником с целью синхронизации. После блокировки или раз-
разблокировки файла 5 сервер инвертирует состояние файла F1, показывая, что бит
передан. Считав бит, сообщник инвертирует состояние файла F2, информируя
сервер о том, что готов к приему следующего бита. Затем он ждет инвертирова-
инвертирования F1, которое укажет ему на присутствие очередного бита в 5. Поскольку со-
согласование по времени больше не нужно, протокол является абсолютно надеж-
надежным даже в загруженной системе. Скорость его работы определяется скоростью
планирования двух процессов. Чтобы повысить ее, можно использовать два файла
в одном битовом интервале или увеличить ширину канала до байта, введя 8 сиг-
сигнальных файлов S0-S7.
Для передачи скрытых сигналов также применимы захват и освобождение внеш-
внешних ресурсов (например, магнитофонов, плоттеров и т. д.). В системе UNIX сервер
может создавать файл, что будет означать 1, и удалять его, передавая 0. Сообщ-
Сообщник может проверять наличие файла при помощи системного вызова access.
Этот системный вызов будет работать, даже если у сообщника нет доступа к со-
создаваемому сервером файлу. К сожалению, помимо таких «семафоров» сущест-
существует множество других возможностей для создания секретного канала.
В [72] также упомянуто о еще одном возможном потайном канале связи, но уже
между сервером и человеком. Например, сервер может сообщать, сколько работы
он сделал для клиента, выставляя ему счет. Если такой счет составляет 100 дол-
долларов, а доход клиента равен 53 000 долларов, то сервер может сообщить об этом
в виде счета в 100,53 доллара.
Обнаружить все секретные каналы чрезвычайно трудно, не говоря уже об их бло-
блокировке. На практике в наших силах немногое. Добавление процесса, случайным
образом вызывающего ошибки отсутствия страниц или снижающего производи-
производительность системы другим способом, чтобы уменьшить пропускную способность
секретных каналов, в качестве варианта решения проблемы не импонирует.
5.6. Обзор файловой системы MINIX 3
Как и любая другая файловая система, файловая система MINIX 3 обязана решать
рассмотренные нами задачи. Она должна выделять и освобождать пространство
для файлов, следить за блоками на диске и за свободным местом, предоставлять
какие-либо средства защиты от несанкционированного доступа и т. д. В оставшейся
части главы мы более подробно коснемся того, как эти задачи решаются в MINIX 3.
В первой части главы мы, ради большей общности, часто ссылались на UNIX, а не
на MINIX 3, хотя интерфейс этих двух систем практически идентичен. Теперь
же мы сосредоточимся на внутреннем устройстве MINIX 3. Информацию о внут-
внутреннем устройстве UNIX вы можете найти в дополнительной литературе [4, 82,
119, 124].
В MINIX 3 файловая система — это просто большая С-программа, работающая
в пользовательском пространстве (см. рис. 2.14). Чтобы прочитать или записать
файл, пользовательские процессы отправляют файловой системе сообщения, гово-
говорящие, что нужно сделать. Файловая система выполняет свою работу и отправля-
отправляет обратно ответ. Фактически такая система представляет собой сетевой файловый
сервер, оказавшийся на той же машине, что и обращающийся к нему процесс.
Такое устройство имеет несколько важных следствий. Прежде всего, файловую
систему можно модифицировать, экспериментировать с ней и тестировать ее прак-
практически независимо от остальных частей MINIX 3. Далее, файловую систему
можно легко перенести на другой компьютер, где есть компилятор С, скомпили-
скомпилировать ее там и использовать как отдельный удаленный UNIX-подобный файло-
файловый сервер. Единственные изменения коснутся того, как отправляются и прини-
принимаются сообщения, поскольку это делается по-разному на разных платформах.
В последующих разделах мы представим обзор многих ключевых компонентов
файловой системы. Особое внимание будет уделено сообщениям, структуре фай-
файловой системы, битовым картам, индексным узлам, кэшированию блоков, путям
и каталогам, дескрипторам файлов, блокированию файлов и специальным фай-
файлам (а также каналам). Рассмотрев эти темы, мы покажем, как все работает вме-
вместе, проследив, что происходит, когда пользовательский процесс выполняет сис-
системный вызов read.
5.6.1. Сообщения
Файловая система понимает 39 типов сообщений, запрашивающих различные
действия. Все они, кроме двух, соответствуют системным вызовам MINIX 3. Ис-
Исключения составляют два сообщения, генерируемые другими компонентами
MINIX 3. Что касается системных вызовов, то 31 из них принимаются от пользо-
пользовательских процессов. 6 сообщений соответствуют системным вызовам, обраба-
обрабатываемым сначала менеджером памяти, который затем, чтобы завершить работу,
вызывает файловую систему. Еще 2 сообщения также обрабатываются файловой
системой. Все эти сообщения перечислены в табл. 5.5.
Таблица 5.5. Сообщения файловой системы. Имя файла всегда передается как указатель
на строку. Ответное значение, отмеченное как «состояние», равно ОК или ERROR
Сообщение Входные параметры Ответное значение
Сообщения от пользователя
access Имя файла, режим доступа Состояние
chdir Имя нового рабочего каталога Состояние
chmod Имя файла, новая спецификация доступа Состояние
chown Имя файла, новый владелец и группа Состояние
chroot Имя нового корневого каталога Состояние
close Дескриптор закрываемого файла Состояние
creat Имя создаваемого файла, режим Дескриптор файла
dup Дескриптор файла (DUP2 требует два дескриптора) Новый дескриптор файла
fcntl Дескриптор файла, код функции, аргументы Зависит от функции
fstat Имя файла, буфер Состояние
ioctl Имя файла, код функции, аргументы Состояние
link Имя файла, на который создается ссылка, имя Состояние
ссылки
Iseek Дескриптор файла, смещение, место, откуда Новое положение
считать смещение
mkdir Имя файла, спецификация доступа Состояние
mknod Имя каталога или признак специального файла, Состояние
режим доступа и адрес
mount Имя специального файла, точка монтирования, Состояние
флаг только для чтения
open Имя открываемого файла, флаг r/w Дескриптор файла
pipe Указатель на два файловых дескриптора Состояние
(модифицируются)
Сообщение Входные параметры Ответное значение
read Дескриптор файла, буфер, сколько байтов Количество прочитанных
байтов
rename Имя файла, имя файла Состояние
rmdir Имя файла Состояние
stat Имя файла, буфер для сохранения информации Состояние
stime Указатель на текущее значение времени Состояние
sync Нет Всегда ОК
time Указатель на место, куда будет записано текущее Состояние
значение времени
times Указатель на буфер для записи времени работы Состояние
процесса и потомков
umask Дополнение к маске режимов доступа Всегда ОК
umount Имя демонтируемого специального файла Состояние
unlink Имя файла Состояние
utime Имя файла, значения времени для него Всегда ОК
write Дескриптор файла, буфер, сколько байтов Количество записанных
байтов
Сообщения от менеджера процессов
exec PID Состояние
exit PID Состояние
fork PID родителя, PID потомка Состояние
setgid PID, действительное и эффективное значения GID Состояние
setsid PID Состояние
setuid PID, действительное и эффективное значения UID Состояние
Прочие сообщения
revive Процесс, который будет оживлен Ответного сообщения нет
unpause Процесс, который нужно проверить (Пояснения в тексте)
Файловая система имеет ту же основную структуру, что и менеджер памяти или
драйверы ввода-вывода. В ней есть главный цикл, ожидающий сообщений. Ко-
Когда сообщение принято, определяется его тип, который затем используется как
индекс в таблице указателей на функции, обрабатывающие различные систем-
системные вызовы. Затем найденная процедура вызывается, она выполняет свои дейст-
действия и возвращает код завершения. Далее файловая система отправляет ответное
сообщение процессу, сделавшему вызов, и возвращается в начало цикла ожидать
следующее сообщение.
5.6.2. Структура файловой системы
Файловая система MINIX 3 представляет собой самостоятельную логическую
сущность с индексными узлами, каталогами и блоками данных. Она может хра-
храниться на любом блочном устройстве, например на дискете или жестком диске
(или разделе жесткого диска). В любом случае, файловая система имеет одну
и ту же структуру. Рисунок 5.29 иллюстрирует эту структуру на примере дискеты
или небольшого жесткого диска с блоком размером 1 Кбайт и индексными узла-
узлами в количестве 64. В этом простом случае битовая карта зон занимает 1 Кбайт.
Она позволяет отслеживать не более 8192 8-килобайтных зон (блоков), а, следо-
следовательно, размер файловой системы составляет не более 8 Мбайт. Даже для гиб-
гибкого диска 64 индексных узла делают число файлов весьма ограниченным, по-
поэтому под индексные узлы обычно отводят не 4 блока, как на рисунке, а больше.
На практике 8 блоков было бы лучше, однако в этом случае наша диаграмма ут-
утратила бы наглядность. Разумеется, для современного жесткого диска и индекс-
индексные узлы, и битовые карты зон занимают значительно больше, чем один блок.
Относительный размер различных компонентов (рис. 5.29) варьируется от од-
одной файловой системы к другой и зависит от ее размера, максимального числа
файлов и других параметров. Тем не менее наличие всех компонентов и их поря-
порядок всегда неизменны.
Рис. 5.29. Структура дискеты или небольшого жесткого диска с 64 индексными узлами
и размером блока 1 Кбайт (то есть два подряд идущих сектора по 512 байт
рассматриваются как один блок)
Любая файловая система начинается с загрузочного блока. Этот блок содержит
исполняемый код. Размер загрузочного блока всегда составляет 1024 байта (два
сектора диска), хотя в других случаях в MINIX 3 могут использоваться блоки
большего размера (что и имеет место по умолчанию). При включении компьютера
его аппаратное обеспечение считывает содержимое загрузочного блока в память
и исполняет его. Код в загрузочном блоке инициирует процесс загрузки самой
операционной системы. После того как система загружена, загрузочный блок боль-
больше не используется. Для загрузки системы подходит не каждый дисковый накопи-
накопитель, но ради единообразия структуры на каждом блочном устройстве резерви-
резервируется загрузочный блок. Худшее, к чему может привести такая стратегия, — это
потеря одного блока. Чтобы аппаратное обеспечение не пыталось загрузиться с уст-
устройства, не предназначенного для загрузки, в известное заранее место загрузочно-
загрузочного блока записывается сигнатура {«магическое» число) в том и только том случае,
если блок содержит исполняемый код. Аппаратура (а в действительности, код
BIOS) откажется загружаться с устройства, если загрузочный блок не имеет такой
сигнатуры. Таким образом, случайный «мусор» в качестве программы не запустится.
Суперблок содержит информацию, описывающую структуру файловой системы.
Его размер, как и размер загрузочного блока, составляет 1024 байта независимо
от размера блоков, используемых в остальной части файловой системы. Струк-
Структура суперблока показана на рис. 5.30.
Рис. 5.30. Структура суперблока в MINIX
Основное назначение суперблока — сообщить файловой системе, насколько ве-
велики отдельные ее части. Зная размер блока и число индексных узлов, несложно
подсчитать размер битовой карты индексных узлов и количество блоков индекс-
индексных узлов. Например, если блок имеет размер 1 Кбайт, каждый блок битовой
карты будет содержать 1 Кбайт (8 Кбит), то есть может быть использован для
отслеживания состояния 8192 индексных узлов. (Строго говоря, первый блок
битовой карты описывает только 8191 индексный узел, так как 0-го индексного
узла нет, но бит в битовой карте для него все равно выделяется.) Если всего име-
имеется 10 000 индексных узлов, то потребуется два блока для хранения битовой
карты. Так как каждый индексный узел занимает 64 байта, блок размером 1 Кбайт
может содержать до 16 индексных узлов. При наличии 64 используемых индекс-
индексных узлов для их хранения потребуется 4 дисковых блока.
Позже мы подробно объясним различие между дисковыми блоками и зонами,
сейчас же достаточно сказать, что место на диске может выделяться частями (зона-
(зонами) из 1, 2, 4, 8 или, в общем случае, 2п блоков. Битовая карта зон позволяет от-
отслеживать свободное пространство в зонах, а не в блоках. Для стандартных гибких
дисков, используемых MINIX 3, размер зоны совпадает с размером блока A Кбайт),
поэтому для таких устройств в первом приближении можно считать, что зона —
это то же самое, что и блок. Пока мы позже в этой главе не приступим к обсужде-
обсуждению деталей выделения места, вы можете считать, что эти понятия эквивалентны.
Обратите внимание, что количество блоков в зоне не хранится в суперблоке, так
как оно нигде не требуется. Все, что нужно, — это логарифм по основанию два от
этого числа, который используется как значение сдвига при преобразовании
блоков в зоны, и наоборот. Например, если зона содержит 8 блоков, Iog28 = 3.
То есть, чтобы найти зону, содержащую блок 128, нужно сдвинуть 128 на три бита
вправо (получится зона 16).
Битовая карта зон содержит только зоны, занимаемые данными (то есть в нее не
попадают блоки, хранящие битовые карты и индексные узлы), причем первая зо-
зона данных соответствует биту 1 в битовой карте. Как и в случае с картой индекс-
индексных узлов, нулевой бит не используется, а значит, первый блок битовой карты
описывает 8191 зон, а последующие — 8192 каждый. Если вы посмотрите на бито-
битовые карты только что отформатированного диска, вы увидите, что в обеих бито-
битовых картах (зон и индексных узлов) установлено два бита. Первый из них соот-
соответствует несуществующей 0-й зоне или индексному узлу. Второй соответствует
индексному узлу и зоне корневого каталога устройства, которая создается при
создании файловой системы.
Информация, хранящаяся в суперблоке, избыточна, так как иногда она требует-
требуется в одной форме, а иногда в другой. Так как на размещение суперблока отводит-
отводится 1 Кбайт места, имеет смысл хранить информацию во всех необходимых пред-
представлениях, а не преобразовывать ее в ходе работы. Например, номер первой
зоны данных на диске можно вычислить, исходя из размера блока, размера зоны,
числа индексных узлов и числа зон, но удобнее просто хранить это значение в су-
суперблоке. Оставшаяся часть суперблока все равно не используется, потому вы-
выделение в нем одного лишнего слова ничего не стоит.
Когда загружается MINIX 3, суперблок с корневого устройства считывается в таб-
таблицу в памяти. Аналогичным образом, при монтировании других файловых сис-
систем их суперблоки также помещаются в память. В этой таблице есть несколько
полей, которых нет на диске. Среди них флаг, индицирующий, что разрешено
только чтение, флаг, позволяющий установить нестандартный порядок следова-
следования байтов, а также поля, предназначенные для ускорения доступа. Они указы-
указывают положение в битовых картах, ниже которого все биты установлены (то есть
заняты). Кроме того, здесь есть поле, описывающее устройство, с которого при-
пришел данный суперблок.
Прежде чем файловая система MINIX 3 сможет использовать диск, он должен
быть приведен в соответствие структуре, показанной на рис. 5.29. Для построе-
построения файловой системы имеется утилита mkf s. Она может быть вызвана, на-
например, так:
mkfs /dev/fdl 1440
Такая команда создаст файловую систему из 1440 блоков на гибком диске в при-
приводе 1. Ей можно указать файл-прототип с перечислением каталогов и файлов,
подлежащих включению в созданную файловую систему. Эта же команда запи-
записывает в суперблок необходимую сигнатуру, идентифицирующую файловую
систему как файловую систему MINIX. MINIX развивается, и в ранних версиях
некоторые атрибуты файловой системы (например, размер индексного узла) бы-
были другими. При попытке монтировать дискету, имеющую другой формат, на-
например дискету MS-DOS, системный вызов mount, проверяющий суперблок на
наличие сигнатуры, сообщит об ошибке.
5.6.3. Битовые карты
MINIX 3 следит за свободными и занятыми индексными узлами и зонами при
помощи двух битовых карт. Когда удаляется файл, несложно подсчитать, какой
бит в битовой карте соответствует освободившемуся индексному узлу, и найти
его при помощи обычного механизма кэширования. В найденном блоке бит, со-
соответствующий освободившемуся индексному узлу, сбрасывается. Зоны освобо-
освобождаются точно так же, только используется битовая карта зон.
Логически, при создании файла файловая система должна последовательно про-
просмотреть битовые карты, чтобы найти первый свободный индексный узел, кото-
который будет выделен новому файлу. Фактически же, хранящийся в памяти супер-
суперблок содержит поле, указывающее на следующий свободный индексный узел,
поэтому требуется искать свободный индексный узел, начиная с этого положе-
положения (зачастую свободным оказывается следующий узел). Аналогичным образом,
когда индексный узел освобождается, проверяется, есть ли перед ним другие
свободные, и при необходимости обновляется значение указателя. Если оказалось,
что все индексные узлы на диске заняты, процедура поиска указывает на 0-й эле-
элемент. Именно поэтому 0-й индексный узел не используется (другими словами,
он является индикатором заполнения диска). (Когда программа mkfs создает
новую файловую систему, она обнуляет индексный узел 0 и устанавливает млад-
младший бит в битовой карте, соответственно, файловая система никогда не пытается
выделить этот блок.) Все, что только что было сказано для индексных узлов, от-
относится и к зонам. Когда необходимо дисковое пространство, логически ищется
первая свободная зона, начиная с начала, а чтобы избежать ненужного последо-
последовательного поиска, поддерживается указатель на первую свободную зону.
Теперь мы можем объяснить разницу между зонами и блоками. В основе идеи
зон лежит попытка гарантировать, что блоки одного файла расположены на одном
цилиндре — это дает возможность повысить производительность за счет после-
последовательного чтения. Для этого за один раз выделяется несколько блоков. Если,
например, размер блока равен 1 Кбайт, а зоны — 4 Кбайт, битовая карта зон от-
отслеживает зоны, а не блоки. Диск объемом 20 Мбайт будет разбит на 5 К зон по
4 Кбайт, и в битовой карте зон, таким образом, будет 5 Кбит.
Большинство файловых систем работают с блоками. Обмен данными с диском
всегда производится целыми блоками, кэш также оперирует блоками. Только та
небольшая часть файловой системы, которая работает с физическим адресом
(то есть с битовой картой зон и индексными узлами), знает о зонах.
В процессе разработки файловой системы MINIX 3 необходимо было принять
некоторые решения о ее структуре. В 1985 году, когда была задумана операцион-
операционная система MINIX, диски имели небольшой объем, и ожидалось, что у многих
пользователей будет только дисковод. Поэтому было решено в первой версии
файловой системе ограничить дисковый адрес значением 16 бит, чтобы впоследст-
впоследствии хранить большую их часть в блоках косвенной адресации. При 16-разрядном
номере зоны и размере зоны в 1 Кбайт такая система позволяла работать с диска-
дисками объемом до 64 Мбайт. В те дни это был огромный объем, и казалось, что если
диски станут больше, будет несложно переключиться на зоны размером 2 Кбайт
или 4 Кбайт, не меняя размер блока. Благодаря 16-разрядному номеру зоны раз-
размер индексного узла был ограничен значением 32 байта.
Когда широко распространились диски значительно большей емкости, стало оче-
очевидно, что желательны изменения. Многие файлы имеют объем менее 1 Кбайт,
поэтому увеличение размера блока привело бы к бесполезному расходованию
объема диска из-за того, что записываются и считываются почти пустые блоки,
и к бесполезной трате драгоценной оперативной памяти на кэш. Можно было бы
увеличить размер зоны, но большие зоны означают менее эффективное использова-
использование свободного места на диске, при этом все равно желательно было бы сохранить
эффективность работы с дисками маленького объема. Другой разумной альтерна-
альтернативой было бы задание разного размера зоны для больших и маленьких дисков.
В конце концов, было принято решение увеличить разрядность дискового ука-
указателя до 32 бит. Благодаря этому файловая система MINIX 2 могла бы работать
с дисками объемом до 4 Тбайт при размере зоны и блока 1 Кбайт и с дисками
объемом до 16 Тбайт при размере блока и зоны 4 Кбайт (в настоящее время
принятом по умолчанию). Однако другие факторы заставили урезать этот раз-
размер (к примеру, 32-разрядные указатели не позволяют выйти за предел 4 Гбайт).
Вместе с увеличением размера индексных узлов требуется увеличивать разряд-
разрядность дисковых указателей. Это не обязательно плохо: индексный узел MINIX 2
(а теперь и MINIX 3) совместим со стандартными индексными узлами UNIX
и имеет пространство для хранения трех значений времени, дополнительных зон
с одинарным и двойным уровнем косвенности, а также место для будущего рас-
расширения зонами с тройным уровнем косвенности.
Зоны приводят еще к одной неожиданной проблеме, которую можно проиллюст-
проиллюстрировать следующим простым примером, опять же, с зонами размером 4 Кбайт
и блоками 1 Кбайт. Предположим, что имеется файл размером 1 Кбайт, для
которого выделена одна зона. Последние три блока зоны содержат случайный
«мусор», оставшийся от предыдущих файлов, но ничего плохого в этом нет, так
как в индексном узле четко указано, что размер файла равен 1 Кбайт. Фактиче-
Фактически, этот мусор не попадет даже в дисковый кэш, так как чтение производится
блоками, а не зонами. Попытки прочитать информацию после конца файла все-
всегда возвращают 0 вместо данных.
Предположим, что кто-то установил файловый указатель на 32 768 и дописал
1 байт. Теперь размер файла станет равным 32 769. Если после этого установить
файловый указатель на 1 К и выполнить чтение, удастся получить данные, кото-
которые были в данном блоке ранее, что является серьезной угрозой безопасности.
Решение состоит в том, чтобы в ситуации, когда производится запись после кон-
конца файла, явно обнулять все еще не выделенные блоки в зоне, которая ранее бы-
была последней. Хотя такая ситуация встречается достаточно редко, система долж-
должна ее отслеживать, в результате ее код несколько усложняется.
5.6.4. Индексные узлы
Схема индексного узла MINIX показана на рис. 5.31. Она практически совпадает
со строением индексного узла в UNIX. Имеются девять 32-разрядных указателей
на зоны диска, из которых семь прямых и два косвенных. В MINIX 3 индексный
узел занимает 64 байта, как и в стандартной системе UNIX, поэтому остается ме-
место для дополнительного десятого указателя (тройного уровня косвенности), хотя
в текущей версии файловой системы он не поддерживается. Время последнего
доступа, модификации и изменения индексного узла в MINIX 3 хранятся стан-
стандартным образом, как в UNIX. Последний из этих параметров обновляется прак-
практически при каждой операции, за исключением чтения файла.
Когда файл открывается, его индексный узел считывается в память и помещает-
помещается в таблицу индексных узлов, где остается до закрытия файла. Записи в этой
таблице имеют несколько дополнительных полей, которых нет на диске. Напри-
Например, благодаря номеру индексного узла и номеру устройства, откуда он считан,
файловая система знает, куда перезаписать индексный узел, если он изменен
в памяти. Кроме того, у каждого индексного узла имеется счетчик. Если файл
открывается дважды, вторая копия индексного узла в память не копируется,
вместо этого увеличивается на единицу значение счетчика. При закрытии файла
счетчик декрементируется, и только тогда, когда он достигает нуля, индексный
узел удаляется из таблицы в памяти. Если за время нахождения в памяти он был
изменен, он записывается на диск.
Главное предназначение индексного узла в том, чтобы хранить сведения о положе-
положении блоков файла на диске. Первые семь номеров зон записываются в индексный
узел напрямую. Таким образом, при стандартных параметрах, когда зоны и блоки
имеют размер 1 Кбайт, файлы размером до 7 Кбайт не требуют использования
блоков косвенной адресации. После 7 Кбайт применяются косвенные блоки при-
примерно так, как это показано на рис. 5.8, за тем исключением, что это только бло-
блоки первого и второго уровней косвенности. Если блоки и зоны имеют размер
1 Кбайт, блок первого уровня косвенности содержит 256 записей, что соответствует
четверти мегабайта. Блок второго уровня косвенности ссылается на 256 блоков
первого уровня, обеспечивая доступ к области в 64 Мбайт. При размере блока
в 4 Кбайт блок второго уровня косвенности ссылается на 1024 х 1024 блоков, что
составляет более миллиона, а, следовательно, размер файловой системы превы-
превышает 4 Гбайт. На практике использование 32-разрядных указателей в качестве
файловых смещений ограничивает максимальный размер файла до величины
232 - 1 байт. Таким образом, при блоках размером 4 Кбайт MINIX 3 не нужны
блоки третьего уровня косвенности. Предельный размер файла ограничен разряд-
разрядностью указателя, а не возможностью следить за достаточным количеством блоков.
Рис. 5.31. Структура индексного узла в MINIX
Кроме того, индексный узел хранит информацию о типе файла (обычный файл,
каталог, специальный блочный файл, специальный символьный файл, канал
ввода-вывода) и биты защиты, а также биты SETUID и SETGID. В поле link
фиксируется, сколько разных каталогов ссылаются на данный файл, чтобы фай-
файловая система могла знать, когда следует освободить занимаемое им место. Не
путайте этот счетчик со счетчиком количества открытий файла, обычно разными
процессами (этот счетчик есть только в памяти в таблице индексных узлов).
В заключение отметим, что структуру, представленную на рис. 5.31, можно из-
изменять для различных целей. Пример, используемый в MINIX 3, — индексные
узлы для блочных и символьных устройств, которым не нужны указатели зон,
так как не требуется ссылаться на области данных диска. Главный и вспомога-
вспомогательный номера устройств хранятся в пространстве нулевой зоны. Индексный
узел также можно использовать для хранения данных небольшого файла (непо-
(непосредственного файла), хотя эта возможность в MINIX 3 не реализована.
5.6.5. Кэш блоков
Для повышения производительности файловой системы в MINIX 3 применяет-
применяется кэширование блоков. Кэш реализован в виде массива буферов, каждый из ко-
которых состоит из заголовка, содержащего указатели, счетчики и флаги, и тела —
области памяти для хранения одного блока. Все свободные буферы связаны друг
с другом в двунаправленный список, отсортированный в направлении от послед-
последних использовавшихся (Most Recently Used, MRU) к дольше всего не использо-
использовавшимся (Least Recently Used, LRU). Это иллюстрирует рисунок 5.32.
Рис. 5.32. Связанный список кэша блоков
С целью быстрого выяснения, находится нужный блок в кэше или нет, приме-
применяется хеш-таблица. Все буферы, имеющие одинаковое хеш-значение k, связаны
в однонаправленный список, на который ссылается запись k хеш-таблицы. Сдела-
Сделано так по той причине, что применяемая хеш-функция просто извлекает п млад-
младших битов из номера блока, и хеш-значения могут совпадать. Каждый буфер
принадлежит одной из цепочек. Конечно, сразу после загрузки MINIX 3 все
буферы свободны, поэтому все они находятся в одной цепочке, на которую ссы-
ссылается нулевая запись хеш-таблицы. Все остальные записи таблицы в это время
содержат нулевые указатели. Но после того как система начинает работу, буфе-
буферы исключаются из нулевой цепочки и формируются новые цепочки.
Если файловой системе необходим блок, она вызывает функцию get_block.
Эта функция вычисляет хеш-код блока и ищет его в соответствующем списке.
При вызове get_block ей передается как номер блока, так и номер устройства,
и при поиске оба эти параметра сравниваются с соответствующими полями
буферов из цепочки. Если нужный блок найден, увеличивается на единицу зна-
значение счетчика в его заголовке и возвращается указатель на него. Если затребо-
затребованный буфер в кэше не обнаруживается, выбирается первый из LRU-списка; он
гарантированно не используется, и содержащийся в нем блок может быть удален
из оперативной памяти.
Когда удаляемый из памяти блок выбран, проверяется один из флагов в его заго-
заголовке, означающий, что блок был модифицирован после считывания. Если флаг
установлен, блок записывается на диск. Затем с диска считывается нужный блок,
для этого отправляется сообщение драйверу диска. До тех пор пока запрошен-
запрошенный блок не прочитан, файловая система приостанавливается, а после этого воз-
возвращает указатель на прочитанный блок.
По окончании работы запросившей блок процедуры, чтобы освободить блок, она
вызывает другую процедуру, put_block. Обычно блок используется сразу по-
после выделения и затем освобождается, но так как существует вероятность того,
что перед освобождением блока будут сделаны дополнительные запросы, функ-
функция put_block сначала уменьшает на единицу счетчик использования и поме-
помещает блок обратно в LRU-список в том и только том случае, если счетчик достиг
нуля. Если он имеет ненулевое значение, блок не освобождается.
Один из аргументов функции put_block описывает, к какому классу принадле-
принадлежит освобождаемый блок (индексные узлы, каталог, данные). В зависимости от
этого значения принимаются два ключевых решения.
1. Поместить блок в начало или в конец LRU-списка.
2. Записать блок на диск немедленно (если он был модифицирован).
Почти все блоки присоединяются в конец списка в полном соответствии с идеей
сортировки по частоте использования. Исключение составляют блоки виртуаль-
виртуального диска; поскольку они уже находятся в памяти, хранение их в кэше практи-
практически бессмысленно.
Модифицированный блок не записывается до тех пор, пока не произойдет одно
из двух следующих событий.
1. Блок достиг начала LRU-списка и удаляется из памяти.
2. Выполнен системный вызов sync.
Вызов sync не перебирает элементы LRU-списка. Вместо этого он обрабатывает
массив буферов и записывает модифицированные буферы на диск даже в том
случае, если они еще используются.
Однако есть одно исключение. В старой версии MINIX суперблок модифициро-
модифицировался при монтировании системы, поэтому, чтобы снизить вероятность повреж-
повреждения файловой системы по причине неожиданного сбоя, он сохранялся без про-
промедления. Сейчас суперблок модифицируется лишь в случае, если необходимо
изменить размер виртуального диска во время запуска системы потому, что он
оказался больше, чем размер устройства. Тем не менее чтение и запись супер-
суперблока отличаются от аналогичных операций для обычного блока, поскольку размер
суперблока всегда равен 1024 байт независимо от размера блоков, подлежащих
кэшированию. Еще одним неудачным экспериментом в предыдущих версиях
MINIX стал макрос ROBUST в конфигурационном файле include/minix/
conf ig. h системы. С его помощью можно сделать так, чтобы файловая система
помечала индексные узлы, каталоги, блоки косвенной адресации и блоки битовых
карт как записываемые незамедлительно. Это должно было сделать файловую
систему более устойчивой, но ценой устойчивости оказалась потеря производи-
производительности. В результате идея была признана неэффективной. К тому же сбой
питания, произошедший, когда еще не все блоки записаны на диск, будь то блоки
с данными или индексными узлами, в любом случае вызвал бы проблемы.
Заметьте, что флаг в заголовке, означающий, что блок был модифицирован, уста-
устанавливается процедурой в файловой системе, которая его запросила и использует.
Процедуры get_block и put_block занимаются только манипуляциями с од-
однонаправленными списками. Они не имеют представления о том, какой проце-
процедуре файловой системы какой блок нужен и зачем.
5.6.6. Каталоги и пути
Другим важным компонентом файловой системы является подсистема управле-
управления каталогами и путями. Многие системные вызовы, такие как open, в качестве
аргумента получают имя файла. Но в действительности им нужен номер индекс-
индексного узла этого файла, поэтому файловая система должна просмотреть дерево
каталогов и найти нужный индексный узел.
В предыдущих версиях MINIX каталог представлял собой файл, содержащий
16-байтовые записи, где первые два байта отводились под номер индексного
узла, а оставшиеся 14 — под имя файла. Такая структура ограничивала число
файлов раздела значением 216, а длину имени — 14 символами, как и в UNIX
версии 7. Вместе с объемом дисков имена файлов также выросли. В MINIX 3
новая версия файловой системы поддерживает записи каталога длиной 64 байта,
где 4 байта занимает номер индексного узла и 60 байт — имя файла. Четыре мил-
миллиарда файлов в одном разделе, по сути, является бесконечно большим числом,
а любого программиста, называющего файлы именами длиной более 60 симво-
символов, следует отправить на медицинское освидетельствование.
Обратите внимание на то, что пути не имеют 60-символьного ограничения на
длину:
/usr/ast/course" material" for" this" year/operating" systems/examination-1.ps
Ограничение распространяется лишь на отдельные компоненты пути. Использо-
Использование записей каталогов фиксированной длины (в данном случае, равной 64 сим-
символам) представляет пример компромисса между простотой, скоростью и требуе-
требуемым объемом памяти. Другие операционные системы, как правило, организуют
свои каталоги в виде структуры данных, называемой кучей. В ней для каждого
файла имеется фиксированный заголовок, указывающий на имя, находящееся
в куче в конце каталога. Схема, применяемая в MINIX 3, очень проста; для ее
создания практически не потребовалось изменять код предыдущей версии. Кроме
того, она оперативна в поиске существующих имен и сохранении новых, посколь-
поскольку куча не требует какого-либо управления. Расплатой за это является потеря
дискового пространства, так как большинство файлов имеют имена длиной го-
гораздо меньше 60 символов.
Наше твердое убеждение состоит в том, что оптимизация ради экономии диско-
дискового пространства (и оперативной памяти, поскольку каталоги время от времени
попадают в нее) нежелательна. На первом месте должны стоять простота и пра-
правильность, и лишь затем следует обращать внимание на скорость. В условиях,
когда современные жесткие диски обычно имеют емкость свыше 100 Гбайт, не-
небольшая экономия памяти за счет усложнения и замедления кода — не лучшая
идея. К сожалению, многие программисты начинали в то время, когда диски бы-
были крошечными, а оперативная память — еще меньше. С первого дня их учили
разрешать все компромиссы между сложностью кода, скоростью и требуемым объе-
объемом памяти в пользу минимизации потребностей в памяти. Такую скрытую «ус-
«установку», безусловно, необходимо пересмотреть с учетом современных реалий.
Рассмотрим, как осуществляется поиск пути /usr/ast/mbox/. Сначала систе-
система ищет каталог usr в корневом каталоге, затем каталог ast в каталоге /usг/,
и, наконец, каталог mbox в каталоге /usr/ast/. Фактически поиск осуществля-
осуществляется последовательно, по одному компоненту пути за шаг (см. рис. 5.14).
Единственная сложность возникает тогда, когда встречается смонтированная
файловая система. В обычной конфигурации MINIX 3, как и во многих других
UNIX-подобных операционных системах, имеется небольшая корневая файло-
файловая система, содержащая основные файлы, необходимые для запуска и обслужи-
обслуживания системы, а основное число файлов, включая пользовательские каталоги,
находятся на отдельном устройстве, монтируемом в /usг. Здесь самое время по-
познакомиться с механизмом монтирования. Допустим, пользователь вводит с тер-
терминала команду:
mount /dev/c0dlp2/usr
В этом случае файловая система, размещенная на втором разделе первого жест-
жесткого диска, монтируется в каталог /usr корневой файловой системы. Файловые
системы до и после монтирования показаны на рис. 5.33.
Ключевым моментом при монтировании является флаг, который устанавливает-
устанавливается в хранящейся в памяти копии индексного узла каталога /usr после успешно-
успешного подсоединения. Этот флаг означает, что в данный каталог вмонтирована фай-
файловая система. Кроме того, вызов mount загружает суперблок файловой системы
в таблицу super_block и устанавливает два указателя на него. Дополнительно
вызов записывает корневой индексный узел смонтированной файловой системы
в таблицу индексных узлов.
На рис. 5.30 можно видеть, что в копии суперблока в памяти есть два поля, от-
относящихся к монтированию файловых систем. В первое из них записывается
указатель на корневой индексный узел смонтированной файловой системы. Вто-
Второе поле (указатель на индексный узел, смонтированный выше) хранит номер
индексного узла точки монтирования файловой системы, например, в нашем
случае это будет индексный узел /usг. Два этих поля служат для соединения
смонтированной и корневой файловых систем и представляют собой тот самый
«клей», который удерживает их вместе (на рис. 5.33, в это соединение схематич-
схематично показано точками). Благодаря данным полям и работают смонтированные
файловые системы.
Рис. 5.33. Механизм монтирования: а — корневая файловая система; б — немонтированная
файловая система; в — результат монтирования файловой системы в каталог /usr
Когда файловой системе передается путь наподобие /usr/ast/f2, она уви-
увидит установленный в индексном узле каталога /usr флаг и поймет, что продол-
продолжать поиск файла нужно с индексного узла файловой системы, смонтированной
в каталоге /usr. Возникает вопрос, как же она найдет этот корневой индексный
узел?
Ответ прост. Система перебирает все хранящиеся в памяти суперблоки, пока не
встретит тот, у которого поле указателя на индексный узел, смонтированный вы-
выше, указывает на /usr. Это должен быть суперблок файловой системы, смонтиро-
смонтированный в каталог /usr. Обнаружив его, несложно определить корневой индекс-
индексный узел соответствующей файловой системы. После этого можно продолжить
поиск файла. В данном случае файловая система перейдет в каталог ast в кор-
корневом каталоге второго раздела жесткого диска.
5.6.7. Дескрипторы файлов
После того как файл открыт, пользователю возвращается дескриптор этого фай-
файла, который впоследствии может использоваться в системных вызовах read
или write. В данном разделе мы рассмотрим, как файловая система обращается
с дескрипторами.
Подобно ядру и менеджеру процессов, файловая система поддерживает в своем
адресном пространстве собственную часть таблицы процессов. Особенно интерес-
интересны три поля этой таблицы. Первые два из них содержат указатели на индексные
узлы корневого и рабочего каталогов. Поиск файла всегда начинается с одного
из указанных каталогов, в зависимости от того, задан абсолютный или относи-
относительный путь. Значения этих указателей можно обновить при помощи систем-
системных вызовов chroot и chdir, которые изменяют соответственно текущие кор-
корневой и рабочий каталоги.
Третье интересное нам сейчас поле представляет собой массив, индексами в ко-
котором являются номера файловых дескрипторов. Этот массив служит для того,
чтобы по данному дескриптору определить соответствующий ему файл. На
первый взгляд, достаточно, чтобы элементы этого массива представляли собой
указатели на индексный узел файла. В конце концов, индексный узел загружает-
загружается в память при открытии файла и хранится там до закрытия файла, то есть ин-
индексный узел гарантированно доступен.
К несчастью, этот простой план обречен на провал, так как в MINIX 3 (как
и в UNIX) можно совместно работать с файлом. Возникающая проблема связа-
связана с 32-разрядным числом, индицирующим, какой байт считывается следующим.
Это тот самый номер, называемый файловым указателем (или указателем по-
позиции в файле), который меняется системным вызовом lseek. Проблема выра-
выражается следующим вопросом: «Где должен храниться файловый указатель?»
Первый вариант — поместить его в индексный узел. Но, к сожалению, если два
(или более) процесса будут в одно и то же время держать файл открытым, им
придется завести собственные указатели, так как иначе вызов lseek, сделанный
одним процессом, будет влиять на следующую операцию чтения другого процес-
процесса. Вывод: файловый указатель нельзя хранить в индексном узле.
А что насчет того, чтобы поместить его в таблицу процессов? Почему бы не
взять второй массив, параллельный массиву файловых дескрипторов, и хранить
в нем файловый указатель для каждого файла? Эта идея также не работает, хотя
и по более тонкой причине. Основная подоплека проблемы кроется в семантике
системного вызова fork. Когда процесс ветвится, то и родительский, и дочерний
процессы должны использовать единый указатель для всех открытых файлов.
Чтобы лучше понять проблему, представим себе сценарий оболочки, в котором
стандартный вывод перенаправлен в файл. Когда оболочка ответвляет от себя
первую программу, позиция в файле стандартного вывода для нее равна 0. Это
значение наследуется потомком, который направляет в стандартный вывод,
предположим, 1 Кбайт данных. После завершения потомка значение указателя
должно быть равно 1 К.
Пусть теперь оболочка считывает следующую команду сценария и ответвляет
следующую программу. Важно, чтобы эта программа унаследовала от оболочки
текущее положение в файле, равное 1 К, чтобы начать вывод в файл с того места,
на котором остановилась предшественница. Если оболочка не будет совместно с до-
дочерними программами использовать значение указателя, вторая программа, вместо
того чтобы дописать свои данные в конец файла, перекроет ими вывод первой.
Таким образом, и в таблице процессов нельзя хранить файловые указатели.
Они действительно должны использоваться совместно. Для решения проблемы
в MINIX применяется новая разделяемая таблица, называемая f ilp. В ней
хранятся значения всех файловых указателей (рис. 5.34). Благодаря тому, что
файловые указатели действительно используются совместно, можно корректно
реализовать семантику вызова fork, и сценарии оболочки заработают правильно.
Рис. 5.34. Совместное использование файловых указателей родительским
и дочерним процессами
Единственным обязательным значением, которое необходимо хранить в таблице
f ilp, является значение файлового указателя, но для удобства туда же записы-
записывается и указатель на индексный узел. Массив файловых дескрипторов в табли-
таблице процессов при этом содержит указатели на записи в массиве f ilp. Кроме то-
того, в таблице f ilp находятся значения битов управления доступом, некоторые
флаги, которые могут указывать, что файл открыт в каком-либо специальном режи-
режиме, и счетчик количества процессов, использующих данный указатель. Счетчик
необходим для того, чтобы файловая система могла определить, когда завершит-
завершится последний процесс, обращающийся к данной ячейке, и освободить ее.
5.6.8. Блокировка файлов
Специальная таблица нужна для реализации еще одного аспекта управления
файловой системой — блокировки файлов. В MINIX 3 поддерживается описы-
описываемый POSIX механизм добровольной блокировки файлов (advisory file locking).
Данный механизм позволяет отметить весь файл, его часть или несколько его
частей как заблокированные. Операционная система не мешает получать доступ
к заблокированным данным, но ожидается, что процессы будут вести себя при-
прилежно и проверять наличие блокировки, прежде чем делать что-либо, что может
привести к конфликту с другим процессом.
Причина, по которой для этого выделена отдельная таблица, аналогична дово-
доводам, приведенным в предыдущем разделе для таблицы f ilp. Один процесс мо-
может одновременно блокировать несколько файлов, и в то же время несколько
частей одного файла может быть заблокировано разными процессами (хотя за-
заблокированные области, конечно же, не перекрываются). Поэтому ни таблица
процессов, ни таблица f ilp не подходят для хранения этих данных. Так как на
одном файле может быть установлено несколько блокировок, индексный узел
тоже не годится.
В MINIX 3 для хранения сведений обо всех блокировках вводится таблица
f ile_lock. В каждой ячейке этой таблицы есть поля, указывающие тип блоки-
блокировки (на чтение или на запись), идентификатор процесса-владельца, указатель
на индексный узел блокированного файла, а также смещения первого и послед-
последнего байтов заблокированной области.
5.6.9. Каналы ввода-вывода
и специальные файлы
Каналы и специальные файлы имеют важное отличие от обычных файлов. Когда
процесс пытается читать дисковый файл или писать в него, в худшем случае опе-
операция займет несколько сотен миллисекунд. Максимально может потребоваться
два или три доступа к диску, не больше. При чтении из канала ситуация иная:
если в канале данных нет, читающий из него процесс будет ждать до тех пор, по-
пока кто-то другой не поместит их туда, на что могут потребоваться часы. Анало-
Аналогично, при чтении с терминала процесс будет ждать до момента, пока пользова-
пользователь что-нибудь не введет с клавиатуры.
Как следствие, обычное правило обслуживать запрос до его полного выполнения
здесь не работает. Такие запросы нужно приостанавливать и запускать позже.
Когда процесс делает попытку чтения из канала ввода-вывода, операционная
система вправе немедленно проверить его состояние и выяснить, можно ли за-
завершить операцию. Если да, операция выполняется, если нет, файловая система
сохраняет аргументы системного вызова в таблице процессов, чтобы перезапус-
перезапустить его, когда придет время.
Заметьте, что файловая система не предпринимает никаких действий, чтобы
приостановить сделавший вызов процесс. Все, что она делает, — воздерживается
от отправки ответного сообщения, в результате процесс остается заблокирован-
заблокированным в ожидании ответа. Таким образом, после приостановки процесса файловая
система возвращается в основной цикл, ожидая следующего системного вызова.
Как только другой процесс приведет канал ввода-вывода в состояние, позволяю-
позволяющее выполняться операции, запрошенной приостановленным процессом, файло-
файловая система устанавливает флаг, чтобы при следующем проходе основного цикла
извлечь из таблицы процессов аргументы системного вызова и выполнить его.
С терминалами и прочими символьными устройствами ситуация немного иная.
У каждого специального файла в индексном узле хранятся два числа — главный
и вспомогательный номера устройств. Первое из этих чисел характеризует класс
устройства (то есть RAM-диск, жесткий диск, терминал). Оно используется как
индекс в одной из таблиц файловой системы, которая ставит в соответствие это-
этому номеру драйвер ввода-вывода. В результате главный номер определяет, какой
драйвер вызвать. Второе число передается драйверу как аргумент. Оно определя-
определяет, какое конкретно устройство использовать, например терминал 2 или диск 1.
В некоторых случаях, особенно это касается терминалов, во вспомогательном
номере закодирована информация о категории устройств, обслуживаемых драй-
драйвером. Например, основная консоль MINIX 3, /dev/console, имеет номера 4, 0.
Виртуальные консоли обслуживаются той же частью драйвера — это устройства
/dev/ttycl D, 1), /dev/ttys2 D, 2) и т. д. Для обслуживания терминалов на
последовательных линиях требуется другое низкоуровневое программное обеспече-
обеспечение, и этим устройствам присваиваются следующие номера: 4, 16 (/dev/ttyOO)
и 4, 17 (/dev/ttyOl). Аналогичным образом, для обслуживания сетевых псев-
псевдотерминалов нужен отдельный низкоуровневый код, и эти устройства (ttypOl
и ttypO2) получают номера 4, 128 и 4, 129. С каждым из псевдоустройств ассо-
ассоциировано устройство ptypl, ptyp2 и т. д. с номерами 4, 192 и 4, 193... Эти номера
выбираются так, чтобы драйверу устройства было проще вызывать низкоуровне-
низкоуровневые функции, необходимые для работы с каждой из групп объектов. Никто не
ожидает, что когда-нибудь кому-нибудь придет в голову оснастить машину с сис-
системой MINIX 3 более чем 192 терминалами.
Когда процесс читает специальный файл, файловая система извлекает из его ин-
индексного узла главный и вспомогательный номера и по главному номеру при по-
помощи таблицы в файловой системе определяет номер процесса соответствующе-
соответствующего драйвера устройства. Определив драйвер, файловая система отправляет ему
сообщение, параметрами которого являются вспомогательный номер, выполняе-
выполняемая операция, номер сделавшего вызов процесса, адрес буфера и количество
байтов. Формат совпадает с показанным в табл. 3.3, с той разницей, что поле по-
позиции устройства не используется.
Если драйвер устройства может выполнить работу немедленно (то есть строка
уже введена в терминал), он копирует данные из собственного внутреннего бу-
буфера в пользовательский и отправляет файловой системе сообщение об успеш-
успешном завершении работы. Затем файловая система посылает ответное сообщение
пользователю, и вызов завершается. Обратите внимание: драйвер устройства не
передает данные файловой системе. При работе блочных устройств данные пере-
передаются через кэш блоков, но со специальными символьными файлами это не так.
Если же драйвер не может сразу выполнить работу, он записывает параметры
сообщения в свои внутренние таблицы и рапортует файловой системе о своей
недееспособности. В этот момент файловая система попадает в ту же ситуацию, ко-
которая возникает, когда кто-либо пытается прочитать из пустого канала ввода-выво-
ввода-вывода. Она фиксирует факт приостановки процесса и ждет следующего сообщения.
Когда драйвер получает достаточно данных для выполнения запроса, он перено-
переносит их в буфер все еще приостановленного пользовательского процесса и инфор-
информирует файловую систему о сделанном. Все, что осталось сделать файловой сис-
системе, — отправить пользовательскому процессу ответ, чтобы разблокировать его
и сказать, сколько байтов передано.
5.6.10. Пример системного вызова read
Как мы скоро увидим, большая часть кода файловой системы предназначена для
обслуживания системных вызовов. Следовательно, естественно было бы заклю-
заключить данный обзор кратким примером того, как работает один из самых важных
системных вызовов, read.
Когда пользовательская программа, чтобы прочитать обычный файл, выполняет
следующую команду, вызывается библиотечная подпрограмма read с тремя ар-
аргументами:
n = read (fd, buffer, nbytes);
Она формирует из этих значений сообщение, помещает в него код операции
read и отправляет его файловой системе, блокируясь в ожидании ответа. Полу-
Получив сообщение, файловая система выбирает из таблицы адрес функции-обработ-
функции-обработчика, пользуясь типом сообщения как индексом. В данном случае будет выбрана
процедура, ответственная за чтение.
Процедура извлекает из сообщения дескриптор файла, определяет по нему соот-
соответствующую запись в таблице f ilp, а затем находит индексный узел считывае-
считываемого файла (см. рис. 5.34). Далее запрос разбивается на такие части, чтобы каж-
каждая из них уместилась в один блок. Например, если текущее значение файлового
указателя равно 600 и запрошен 1 Кбайт данных, запрос будет разбит на две час-
части, от 600 до 1023 и от 1024 до 1623 (если размер блока равен 1 Кбайт).
Затем проверяется наличие каждого из этих блоков в кэше. Если блок в кэше от-
отсутствует, файловая система выбирает последний из использовавшихся незаня-
незанятых буферов и передает драйверу диска запрос на его перезапись, если в нем есть
мусор. Затем драйверу диска передается запрос на считывание блока.
После того как блок оказался в кэше, файловая система посылает системному за-
заданию сообщение, требующее поместить данные в соответствующее место в поль-
пользовательском буфере (то есть байты от 600 до 1023 скопировать в начало буфера,
а байты от 1024 до 1623 — по смещению 424 от начала). Выполнив копирование,
системное задание отправляет пользователю сообщение, указывая в нем, сколь-
сколько байтов обработано.
Когда ответ достигает пользователя, библиотечная подпрограмма read извлека-
извлекает из него код возврата и передает его значение в вызвавший процесс.
Тут есть один дополнительный шаг, который в действительности не является ча-
частью самого системного вызова read. Файловая система, выполнив чтение й от-
отправив ответ, инициирует чтение следующего блока, если считывание произво-
производится с блочного устройства и удовлетворены некоторые условия. Так как чаще
всего производится последовательное чтение, разумно ожидать, что при следую-
следующем чтении будет запрошен следующий блок файла, который, таким образом,
заранее окажется в кэше.
5.7. Реализация файловой системы MINIX 3
Код файловой системы MINIX 3 относительно объемен (более 100 страниц
С-кода), но достаточно прост. В нем запрос на выполнение системного вызова
принимается, выполняется и отправляется ответ. В последующих разделах мы
файл за файлом рассмотрим этот код, указывая на основные моменты. В свою
очередь и код содержит немало комментариев, чтобы облегчить задачу читателя.
Рассматривая код остальных составляющих MINIX 3, мы обычно сначала изуча-
изучали главный цикл процесса, а затем процедуры, обслуживающие различные типы
сообщений. Здесь же мы возьмем за основу другой подход. Сначала мы изучим
основные подсистемы (работу с кэшем, индексными узлами и т. д.). Затем рас-
рассмотрим главный цикл и системные вызовы, работающие с файлами. Потом на-
настанет пора системных вызовов для управления каталогами, и далее мы обсудим
оставшиеся системные вызовы. В заключение мы научимся обращаться со спе-
специальными файлами устройств.
5.7.1. Заголовочные файлы и глобальные
структуры данных
В файловой системе, как и в ядре, как и менеджере процессов, применяется
большое количество структур и таблиц, определяемых заголовочными файлами.
Некоторые из этих структур помещены в общесистемные заголовочные фай-
файлы, расположенные в каталоге include/ и его подкаталогах. Например, файл
include/sys/stat .h описывает формат представления информации индекс-
индексного узла для других программ, а структура данных каталога определяется фай-
файлом include/sys/dir.h. Оба этих файла предписаны стандартом POSIX.
Управляют файловой системой множество глобальных определений, расположен-
расположенных в файле include/minix/conf ig.h. Например, макросы NR_BUFS и NR_
BUFS_HASH отвечают за размер кэша блоков.
Заголовочные файлы файловой системы
Собственные заголовочные файлы файловой системы расположены в катало-
каталоге src/f s/. Имена многих из них уже знакомы вам по другим компонентам
MINIX 3. Главный заголовочный файл, f s .h (строка 20900), очень напоминает
файлы src/kernel/kernel .h и src/pmm/pm.h. Он включает остальные заго-
заголовочные файлы, необходимые всем другим файлам С-кода файловой системы.
Как и везде, в главный заголовочный файл включаются локальные заголовочные
файлы const. h, type. h, proto. h и glo. h. Их мы и рассмотрим далее.
В файле const.h (строка 21000) определяются некоторые константы, такие
как размеры таблиц или флаги, используемые далее во всей файловой системе.
У MINIX 3 уже есть история. В предыдущих версиях применялись другие фай-
файловые системы. Хотя MINIX 3 не поддерживает их, некоторые определения со-
сохранены для справки и для того, чтобы желающие могли в будущем обеспечить
их поддержку. Подобная поддержка полезна не только тем, что позволяет полу-
получать доступ к файлам предшествующих версий файловой системы MINIX, но
и тем, что делает возможным обмен файлами.
Старые версии файловой системы MINIX поддерживаются другими операцион-
операционными системами. К примеру, система Linux с самого начала использовала и до
сих пор их использует (то, что MINIX 3 не предоставляет подобную поддерж-
поддержку, в таком свете выглядит несколько комичным). Существуют утилиты для
MS-DOS и Windows, обеспечивающие доступ к устаревшим файловым системам
MINIX. Суперблок файловой системы содержит магическое число, по которому
операционная система способна определить тип файловой системы. Три магиче-
магических числа, соответствующих трем версиям файловой системы MINIX, задаются
константами SUPER_MAGIC, SUPER_V2 и SUPER_V3. Кроме того, для двух пер-
первых версий определены константы с суффиксом _REV, которые содержат значе-
значения магических чисел с обратным порядком следования байтов. Они применя-
применялись в версиях MINIX, перенесенных на системы с другим порядком следования
байтов (не обратным, а прямым). Это позволяло идентифицировать сменный
диск, записанный на компьютере с противоположным порядком следования бай-
байтов. В MINIX версии 3.1.0 необходимости в константе SUPER_V3_REV не было,
однако, вероятно, ее определение будет добавлено в будущем.
В файле type.h (строка 21100) описаны как структуры предыдущей, так и но-
новой версии в том виде, в котором они записываются на диск. Размер нового ин-
индексного узла вдвое больше, чем в старой системе, которая разрабатывалась как
компактная система для машин без жесткого диска и дискетами по 360 Кбайт. В но-
новой версии выделено место для всех трех полей времени, которые есть в UNIX-
подобных системах. В индексном узле версии 1 было всего одно поле времени,
а вызовы stat и fstat, возвращающие структуру stat, содержащую все три
поля, имитировали их наличие. При поддержке двух версий файловых систем
есть небольшое затруднение (комментарий в строке 21116 описывает его). Старое
программное обеспечение MINIX 3 полагается на то, что тип gid_t 8-разряд-
8-разрядный, поэтому поле d2_gid необходимо явно объявлять как ul6_t.
В файле proto.h (строка 21200) в форме, приемлемой как для компилятора
стандартного (ANSI) языка С, так и для старых компиляторов «а ля Керниган
и Ричи», описаны прототипы функций. Это большой, но не очень интересный
файл. Тем не менее тут нужно указать на один момент: так как файловая система
обслуживает такое большое количество системных вызовов, код различных про-
процедур &о_ххх рассеян по нескольким файлам. Описания в файле proto. h орга-
организованы так, чтобы было удобно узнать, в каком из файлов находится функция,
обрабатывающая интересующий вас системный вызов.
Наконец, в файле glo.h (строка 21400) описываются глобальные переменные.
Здесь же находятся буферы входящих и исходящих сообщений. При описании
переменных применяется уже знакомый вам трюк с макросом EXTERN, поэтому
они доступны из всех частей файловой системы. Как и в других компонентах
MINIX 3, место в памяти для этих переменных выделяется при компиляции
файла table.с.
Принадлежащая файловой системе часть таблицы процессов содержится в фай-
файле fsproc.h (строка 21500). В нем при помощи макроса EXTERN объявляется
массив f sproc. В последнем хранятся маска режима доступа, указатели на ин-
индексные узлы текущих рабочего и корневого каталогов, массив файловых деск-
дескрипторов, UID, GID, и номер терминала для каждого процесса. Здесь же можно
найти идентификатор процесса и группы процессов, которые дублируют поля
таблицы процессов, принадлежащие ядру и менеджеру процессов.
Несколько полей отведены под хранение аргументов остановленных на полпути
системных вызовов, таких как вызов для чтения из пустого канала. Для полей
fp_suspended и fp_revived в действительности требуется только один бит,
но для символа компиляторы практически всегда генерируют лучший код. Кро-
Кроме того, есть поле для битов FD_CLOEXEC, требуемых стандартом POSIX. Их
назначение в том, чтобы указать, что файл должен быть закрыт, когда делается
системный вызов exec.
Теперь мы приступим к файлам, в которых описываются остальные таблицы, ис-
используемые файловой системой. Прежде всего, это файл buf .h (строка 21600),
где задается кэш блоков. Все структуры в нем описаны при помощи макроса
EXTERN. Все буферы хранятся в массиве buf s, и каждый из них содержит об-
область данных Ь, полный указателей заголовок и счетчики. Область данных объ-
объявлена как объединение пяти типов (строки 21618-21632), поскольку иногда
к блоку удобнее обращаться как к массиву символов, иногда как к каталогу и т. д.
Так, чтобы обратиться к области данных буфера 3 как к массиву символов, нуж-
нужно использовать запись buf [3] .b.b data, так как buf [3] .b ссылается на
всю область данных, из которой выделяется поле b data. Хотя такой синтаксис
и правилен, он неуклюж, поэтому далее создается макрос b_data, позволяющий
использовать запись buf [3] ,b.b_data. Обратите внимание: поле записывается
как b data, с двумя символами подчеркивания, а макрос b_data — с одним.
Далее задаются аналогичные макросы для других способов обращения к данным
блока (строки 21650-21655).
Далее, сразу после этих макросов задается хеш-таблица буфера, buf_hash (стро-
(строка 21657). Каждый из ее элементов ссылается на список буферов, которые снача-
сначала пусты. Макросы в конце файла buf .h определяют различные типы блоков.
Бит WRITE_IMMED сигнализирует о том, что измененный блок должен быть пере-
перезаписан на диск немедленно, а бит ONE_SHOT отмечает блок, вероятность исполь-
использования которого в ближайшем будущем низка. Ни один из этих битов в настоя-
настоящий момент не применяется, однако они определены на случай, если у кого-нибудь
возникнет идея о том, как повысить производительность или надежность систе-
системы путем внесения изменений в обслуживание очереди блоков в кэше.
Наконец, в последней строке определяется константа HASH_MASK, значение ко-
которой зависит от константы NR_BUF_HASH, заданной в файле include/minix/
config.h. С константой HASH_MASK и номером блока выполняется операция
логического И, чтобы определить, какая запись в buf_hash будет использована
в качестве отправной точки при поиске буфера блока.
Файл file.h (строка 21700) содержит промежуточную таблицу f ilp (описан-
(описанную с ключевым словом EXTERN), применяемую для хранения текущего положе-
положения в файле и указателя на его индексный узел (см. рис. 5.34). Эта же таблица
дает ответ на вопрос, был ли файл открыт на чтение и (или) на запись, а также
сколько файловых дескрипторов в текущий момент ссылаются на ее элемент.
Таблица f ile_lock (объявленная с ключевым словом EXTERN) из файла lock.h
хранит сведения о блокировке файлов (строка 21800). Размер этого массива зада-
задается параметром NR_LOCKS, который определяется в файле const .h и по умол-
умолчанию равен 8. Если когда-либо потребуется реализовать на основе MINIX 3
многопользовательскую базу данных, это значение необходимо будет увеличить.
В файле inode.h (строка 21900) объявляется (опять же, как EXTERN) массив
индексных узлов inode. В нем хранятся все используемые в текущий момент
индексные узлы. Как уже отмечалось, индексный узел файла загружается в па-
память при его открытии и хранится там до тех пор, пока файл не будет закрыт.
В структуре inode есть информация, присутствующая в памяти, но отсутствую-
отсутствующая на диске. Заметьте, что здесь описывается только одна версия и нет никаких
зависящих от версии файловой системы особенностей. Различия между фай-
файловыми системами версии 1 и версий 2/3 учитываются при считывании индекс-
индексного узла с диска, и остальной системе не приходится задумываться о формате
диска, по крайней мере до тех пор, пока не понадобится записать измененную
информацию обратно.
К этому моменту вам должно быть понятно назначение большинства полей. Не-
Небольшого пояснения заслуживает только поле i_seek. Ранее упоминалось, что
при последовательном чтении файловая система, в качестве оптимизации, пыта-
пытается заранее (до того как он запрошен) поместить следующий блок в кэш. При
произвольном доступе к файлу опережающее чтение не нужно. Поэтому, когда
делается вызов lseek, чтобы отключить опережающее чтение, устанавливается
поле i_seek.
Файл param. h (строка 22000) аналогичен файлу менеджера процессов с тем же
именем. В нем определяются имена для полей сообщений с параметрами, чтобы,
например, можно было писать m_in. buf f er вместо m_in. ml_pl, имени одного
из полей буфера сообщения m_in.
В файле super.h (строка 22100) находится определение таблицы суперблоков.
Она отвечает за загрузку суперблока корневой системы, сюда же записываются
суперблоки монтируемых файловых систем. Как и другие таблицы, super_
block объявлена с ключевым словом EXTERN.
Выделение памяти для данных файловой системы
Последний файл, который мы обсудим, table. с (строка 22200), не является за-
заголовочным. Но, как и при описании менеджера процессов, имеет смысл рас-
рассмотреть его сразу после заголовочных файлов, поскольку все они присоединя-
присоединяются при компиляции файла table. с. Большинство упомянутых нами структур
данных — кэш блоков, таблица f ilp и др. — объявлены при помощи ключевого
слова EXTERN. Это же касается глобальных переменных и локальной части табли-
таблицы процессов. Так же как и в других частях MINIX 3, память для таких перемен-
переменных в действительности выделяется при компиляции файла table. с. Кроме
того, в этом файле содержится важный неинициализированный массив. Массив
call_vector хранит указатели на функции, он нужен в главном цикле, чтобы
определить, какая функция какой системный вызов выполняет. Похожую табли-
таблицу мы видели и внутри менеджера процессов.
5.7.2. Таблицы
С каждой важной таблицей, будь то таблица блоков, индексных узлов, супербло-
суперблоков и т. д., связан файл, содержащий процедуры для работы с ней. Эти процеду-
процедуры широко используются в остальном коде и образуют основу интерфейса меж-
между таблицами и файловой системой. Поэтому наше изучение кода файловой
системы имеет смысл начать с этих файлов.
Управление блоками
С кэшем блоков работают подпрограммы из файла cache.с. Он содержит де-
девять процедур, перечисленных в табл. 5.6. Первая из них, get_block (строка
22426), реализует стандартный способ получения блока данных. Когда процеду-
процедуре файловой системы необходимо прочитать блок пользовательских данных, ка-
каталог, суперблок или блок любого другого типа, она вызывает функцию get_
block, указывая ей номер блока и устройство.
Таблица 5.6. Процедуры управления блоками
Процедура Действие
get_block Извлекает блок для чтения или записи
put_block Помещает обратно блок, ранее запрошенный вызовом get_block
alloc_zone Выделяет новую зону (чтобы увеличить файл)
free_zone Освобождает зону (когда файл удаляется)
rw_block Перемещает блок между диском и кэшем
invalidate Чистит все кэшированные блоки с одного из устройств
flushall Сбрасывает на диск все измененные блоки для некоторого устройства
rw_scattered Читает или записывает разрозненные данные с устройства
rmjru Удаляет блок из LRU-списка
Когда вызывается функция get_block, она прежде всего смотрит, есть ли запро-
запрошенный блок в кэше. Если да, возвращается указатель на него. Иначе запрошен-
запрошенный блок необходимо считать. Блоки в кэше объединены в списки, всего NR_
BUF_HASH списков. Этот параметр, NR_BUF_HASH, можно настраивать, как и па-
параметр NR_BUFS, определяющий размер кэша блоков. Оба они устанавливаются
в файле include/minix/config.h. В заключение скажем несколько слов об
оптимизации размера кэша блоков и хеш-таблицы. Параметр HASH_MASK равен
NR_BUF_HASH - 1. Если имеется 256 списков, маска равна 255, и все блоки, в но-
номерах которых совпадают последние 8 бит, попадают в один список. Получается
256 списков для номеров 00000000, 00000001, ..., 11111111.
При поиске блока на первом шаге выясняется, в какой из цепочек хеш-таблицы
блок находится, хотя есть один особый случай, когда считывается свободное ме-
место из разреженного файла и поиск пропускается. Это — причина проверки, вы-
выполняемой в строке 22454. Если данный особый случай не обнаружен, следую-
следующие две строки устанавливают указатель Ьр на начало той цепочки, в которой
оказался бы нужный блок, если бы он был в кэше, для чего на номер блока на-
накладывается маска HASH_MASK. В следующем далее цикле перебираются элемен-
элементы цепочки в поисках запрошенного блока. Если блок найден и в данный момент
не используется, он исключается из LRU-списка. Если он используется, то в LRU-
списке его уже нет. Затем вызывающей программе возвращается указатель на
найденный блок (строка 22463).
Если в списке нужный блок не обнаружен, то и в кэше его нет, потому из LRU-
списка выбирается дольше всех не использовавшийся блок. Выбранный блок ис-
исключается из хеш-цепочки, так как ему будет назначен новый номер, и он попа-
попадет в другую цепочку. Если информация в блоке изменена, она записывается на
диск (строка 22495). Если это делать при помощи вызова f lushall, будут со-
сохранены все измененные блоки с того же устройства. Большинство блоков запи-
записываются именно так. Применяемые в текущий момент блоки никогда не могут
быть отданы для другого запроса, так как они отсутствуют в LRU-списке. Одна-
Однако блоки почти никогда не находятся в работе, и процедура put_block обычно
освобождает блок сразу по окончании использования.
Как только получен новый буфер, во все его поля, включая поле b_dev, записы-
записываются новые значения (строки 22499-22504), и можно считывать данные блока
с диска. Есть только два случая, в которых считывать диск с блока необязатель-
необязательно. Функция get_block может быть вызвана с параметром only_search. Это
может означать, что выполняется упреждающее выделение блока. Упреждающее
выделение подразумевает, что содержимое обнаруженного буфера при необхо-
необходимости перезаписывается на диск и ему назначается новый номер, но в поле Ь_
dev заносится значение NO_DEV, как свидетельство того, что блок не содержит
данных. Пример мы увидим, когда станем обсуждать функцию rw_scattered.
Кроме того, параметр only_search может использоваться тогда, когда блок ну-
нужен файловой системе для полной перезаписи его содержимого. Тогда считыва-
считывание старых данных было бы пустым расточительством. В том и другом случа-
случаях параметры блока обновляются, но реальное чтение не выполняется (строки
22507-22513). Когда новый блок готов и при необходимости считан, get__block
возвращает указатель на него в вызывающую программу.
Предположим, что файловой системе временно, чтобы найти имя файла, нужен
блок каталога. Тогда, чтобы получить этот блок, она вызывает функцию get_
block. Обнаружив имя файла, она, чтобы вернуть блок в кэш, вызывает функ-
функцию put_block (строка 22520), освобождая буфер про запас, в расчете, что позд-
позднее он понадобится для другого блока.
Функция put_block отвечает за возврат блока в LRU-список, а также в некото-
некоторых случаях перезаписывает его содержимое на диск. В строке 22544 принима-
принимается решение о том, будет ли блок помещен в начало или конец списка. Блоки
виртуального диска всегда размещаются в начале очереди. Кэш блоков не представ-
представляет большой пользы для виртуального диска, так как его данные уже находятся
в памяти и доступны без операций ввода-вывода. По значению флага ONE_SHOT
определяется, будет ли блок нужен в скором времени, и если нет, то он помещается
в начало очереди, где в скором времени его ждет повторное использование. Тем
не менее это происходит крайне редко, если вообще происходит. Почти все бло-
блоки, за исключением блоков виртуального диска, помещаются в конец очереди.
После того как блок помещен в список, делается другая проверка, чтобы выяс-
выяснить, нужно ли записать его на диск немедленно. Как и предыдущий тест, про-
проверка WRITE_IMMED является последствием неудачного эксперимента; в настоя-
настоящее время блоки не помечаются для немедленной записи.
По мере роста файла необходимо время от времени выделять новые зоны для
хранения его данных. За выделение зон отвечает процедура alloc_zone (стро-
(строка 22580). Она ищет свободную зону по битовой карте зон. Если это — первая зо-
зона файла, то перебирать всю битовую карту не нужно, так как поле s_zsearch
в суперблоке всегда указывает на первую свободную зону на диске. В противном
случае, чтобы зоны располагались вместе, ищется ближайшая к последней зоне
файла свободная зона. Соответственно, поиск начинается с последней зоны файла
(строка 22603). В строке 22615 номер бита в битовой карте преобразуется в но-
номер зоны (таким образом, что бит 1 соответствует первой зоне данных).
При удалении файла его зоны следует вернуть в битовую карту. Это действие
находится в ведении функции f ree_zone (строка 22621). Вся ее работа сводится
к вызовам функции f ree_bit, которой передается номер зоны и битовая карта.
Функция f ree_bit применяется и для освобождения индексных узлов, конечно,
тогда ей в качестве первого аргумента передается битовая карта индексных узлов.
При работе с кэшем требуется записывать и считывать блоки. Простой интерфейс
для взаимодействия с диском обеспечивает функция rw_block (строка 22641).
Она записывает или считывает один блок. Аналогично, функция rw_inode за-
записывает или считывает один индексный узел.
Следующая процедура называется invalidate (строка 22680). Она вызывается,
например, при размонтировании диска, чтобы убрать из кэша все блоки, принад-
принадлежащие размонтируемой файловой системе. Если этого не сделать, при следую-
следующем использовании устройства (с другим гибким диском) система может уви-
увидеть старые блоки вместо новых.
Функцию f lushall (строка 22694) вызывает функция get_block, чтобы уда-
удалить измененный блок из LRU-списка. Именно она осуществляет запись боль-
большинства данных. К функции f lushall также обращается системный вызов sync,
чтобы сбросить на диск все измененные буферы определенного устройства. Он пе-
периодически используется демоном обновления и однократно вызывает f lushall
для каждого монтированного устройства. Эта функция работает с кэшем буфе-
буферов как с одномерным массивом, поэтому она может обнаруживать изменен-
измененные буферы даже в том случае, если их нет в LRU-списке. Весь массив буферов
сканируется, и указатели на те из них, что принадлежат указанному устройству
и содержат обновленные данные, добавляются в массив указателей dirty. По-
Последний массив, чтобы не выделять его в стеке, объявлен как static. Затем мас-
массив передается rw_scattered.
В MINIX 3 ответственность за планирование дисковой записи снята с драйверов
устройств и целиком переложена на функцию rw_scattered (строка 22711).
Она получает на входе идентификатор устройства, указатель на массив указате-
указателей на буферы, размер этого массива и флаг чтения/записи. Первым делом
функция сортирует переданный ей массив указателей по номерам блоков, чтобы
передача данных происходила в наиболее эффективном порядке. Затем она фор-
формирует векторы смежных блоков, чтобы передать их драйверу устройства вы-
вызовом dev_io. Драйверу не нужно выполнять дополнительное планирование.
Вполне вероятно, что электронные компоненты современного жесткого диска
оптимизируют порядок запросов, однако эти действия находятся за пределами
видимости MINIX 3. Функция rw_scattered вызывается с флагом WRITING
только описанной ранее функцией f lushall. В этом случае несложно понять
происхождение номеров блоков, так как передаваемые буферы содержат данные,
которые были ранее считаны, а теперь изменены. Для чтения функция rw_
scattered вызывается только из функции rahead в файле read. с. Сейчас мы
не будем углубляться в детали ее работы, скажем лишь, что перед вызовом rw_
scattered несколько раз в режиме подготовки вызывается get_block, тем
самым резервируется группа буферов. Буферам назначается номер блока, а но-
номер устройства — нет, но это не проблема, поскольку номер устройства передает-
передается в качестве одного из аргументов в rw_scattered.
Есть важное отличие между тем, как драйвер устройства реагирует на чтение
и запись из rw_scattered. Запрос на запись некоторого количества блоков
обязательно должен быть выполнен полностью, в то время как запрос на чтение
обрабатывается разными драйверами по-разному, в зависимости от того, что
эффективнее для конкретного драйвера. Функция rahead зачастую вызывает
функцию rw_scattered, передавая ей список буферов, которые в действитель-
действительности могут не требоваться. Поэтому лучше всего считать только те блоки, до
которых легко добраться, не выискивая их по всему устройству и теряя драго-
драгоценное время. Например, драйвер гибкого диска может остановиться на границе
дорожки, а другие драйверы будут читать только последовательные блоки. Вы-
Выполнив чтение, rw_scattered помечает прочитанные блоки, вписывая в содер-
содержащие их буферы номер устройства.
Последняя функция из табл. 5.6, rm_lru (строка 22809), предназначена для того,
чтобы удалять блоки из LRU-списка. Она используется только внутри функции
get_block, поэтому вместо PUBLIC объявлена как PRIVATE с целью скрыть ее
от процедур из других файлов.
Прежде чем закончить изучение кэша блоков, скажем несколько слов о его тон-
тонкой настройке. Значение параметра NR_BUF_HASH должно быть степенью двой-
двойки. Если оно больше, чем NR_BUFS, средняя длина хеш-цепочки будет меньше
единицы. Но когда хватает памяти для большого количества буферов, ее хватит
и для большого количества хеш-цепочек, поэтому значение этого параметра
обычно выбирается равным ближайшей степени двойки, большей NR_BUFS. В об-
обсуждаемом коде заведено 128 блоков и 128 хеш-цепочек. Оптимальный размер
зависит от характера эксплуатации системы, поскольку определяет, сколько ин-
информации будет кэшироваться. В исходном коде полной версии MINIX 3, пред-
представленной на компакт-диске, который сопровождает эту книгу, задано 1280 бу-
буферов и 2048 хеш-цепочек. Опытным путем было установлено, что дальнейшее
увеличение числа буферов не дает прироста производительности при переком-
перекомпиляции MINIX 3, видимо, потому, что этого достаточно, чтобы хранить проме-
промежуточные файлы для всех проходов компилятора. Для некоторых задач более
адекватной была бы меньшая емкость кэша, а другим может потребоваться уве-
увеличить кэш ради увеличения быстродействия.
Буферы стандартной версии MINIX 3, размещенной на компакт-диске, занима-
занимают более 5 Мбайт оперативной памяти. Кроме этого, имеется дополнительный
двоичный файл с именем image_small, который скомпилирован под использо-
использование кэша блоков с 128 буферами. Буферы такой системы занимают лишь чуть
более половины мегабайта, а вся система способна работать на компьютере, ос-
оснащенном оперативной памятью объемом 8 Мбайт. Стандартная версия нужда-
нуждается в 16 Мбайт памяти. Нет сомнений в том, что, проведя некоторую оптимиза-
оптимизацию, можно снизить требования к оперативной памяти до 4 Мбайт.
Управление индексными узлами
Не только кэшу блоков требуются управляющие подпрограммы. Они также нуж-
нужны для работы с таблицей индексных узлов. Многие из этих процедур аналогич-
аналогичны процедурам управления блоками. Сами процедуры перечислены в табл. 5.7.
Таблица 5.7. Процедуры управления индексными узлами
Процедура Назначение
getjnode Помещает индексный узел в память
putjnode Возвращает более не нужный индексный узел
allocjnode Выделяет новый индексный узел (для нового файла)
wipejnode Очищает некоторые поля индексного узла
freejnode Освобождает индексный узел (при удалении файла)
update_times Обновляет поля времени в индексном узле
rwjnode Передает индексный узел между памятью и диском
oldjcopy Преобразует данные индексного узла, чтобы записать его на диск
в формате версии 1
newjcopy Преобразует данные индексного узла, чтобы записать его на диск
в формате версии 2
dupjnode Указывает, что кто-то еще использует индексный узел
Функция get_inode (строка 22933) является аналогом функции get_block.
Когда какой-либо части системы требуется получить индексный узел, она вызы-
вызывает эту функцию. Сначала get_inode ищет узел в таблице, чтобы узнать, не
загружен ли он уже. Если да, счетчик использования индексного узла увеличивает-
увеличивается и возвращается указатель на него. Поиск производится в строках 22945-22955.
Если в памяти индексный узел не найден, он загружается вызовом rw_inode.
Когда процедура, которой потребовался индексный узел, завершает свои дейст-
действия с ним, то, чтобы возвратить индексный узел, она вызывает процедуру put_
inode (строка 22976), уменьшающую значение счетчика использования. Нуле-
Нулевое значение счетчика подразумевает, что файл больше никому не нужен и мо-
может быть удален из таблицы. Если при этом индексный узел был изменен, он пе-
перезаписывается на диск.
Если поле i_link равно нулю, значит, на файл не ссылается ни один из катало-
каталогов, поэтому все его зоны могут быть освобождены. Обратите внимание, что об-
обнуление счетчика ссылок i_link и счетчика использования — разные события,
они обусловлены разными причинами и приводят к разным последствиям. Если
индексный узел соответствует каналу ввода-вывода, все его зоны должны быть
освобождены, даже если число ссылок не равно нулю. Такое может произойти,
когда процесс, читающий из канала, освободит его. Нет никакого смысла поддер-
поддерживать канал для одного процесса.
Когда создается файл, для него должен быть выделен новый индексный узел при
помощи процедуры alloc_inode (строка 23003). В MINIX 3 устройства можно
монтировать в режиме только для чтения, поэтому функция сначала проверяет
в суперблоке, разрешена ли запись на устройство. В отличие от зон, которые вы-
выбираются в стремлении держать все зоны файла близко друг к другу, здесь по-
подойдет любой индексный узел. Чтобы сократить время поиска в битовой карте
индексных узлов, используются поля суперблока, в которых хранится положе-
положение первого свободного индексного узла.
После того как новый индексный узел получен, он загружается в таблицу в па-
памяти при помощи функции get_inode. Затем, частично прямо на месте (строки
23038-23044), а частично — при помощи процедуры wipe_inode (строка 23060),
его поля инициализируются. Такое «разделение труда» выбрано здесь потому,
что wipe_inode вызывается и в некоторых других частях системы для очистки
отдельных полей индексного узла.
При удалении файла его индексный узел освобождается посредством процедуры
f ree_inode (строка 23079). Эта подпрограмма просто сбрасывает соответст-
соответствующий бит в карте индексных узлов и обновляет ссылку на первый свободный
индексный узел в суперблоке.
Следующая функция, update_times (строка 23099), вызывается, чтобы полу-
получить от системных часов время и изменить нуждающиеся в обновлении значе-
значения полей времени. Она также вызывается из stat и f stat, поэтому объявлена
как PUBLIC.
Процедура rw_inode (строка 23125) аналогична процедуре rw_block. Ее назна-
назначение в том, чтобы считать индексный узел с диска. Это действие она выполняет
в четыре этапа.
1. Определение блока, в котором находится необходимый индексный узел.
2. Считывание блока при помощи функции get_block.
3. Извлечение индексного узла и копирование его в таблицу индексных узлов.
4. Возврат блока посредством функции put_block.
Код rw_inode несколько сложнее, чем подразумевает приведенная схема, так
как от него требуются некоторые дополнительные действия. Во-первых, поскольку
определение текущего времени требует вызова ядра, все поля индексного узла,
подлежащие обновлению значением времени, только помечаются путем установки
соответствующих битов в поле индексного узла в памяти i_update. Если это поле
будет иметь ненулевое значение, при записи вызывается функция update_times.
Во-вторых, дополнительную сложность вносит история MINIX. В старой версии
файловой системы (в версии 1) индексные узлы на диске имели структуру, от-
отличную от структуры в версии 2. Поэтому о преобразовании заботятся две функ-
функции, old_icopy (строка 23168) и new_icopy (строка 23214). Первая из них
преобразует представление индексного узла в памяти в формат версии 1. Вторая
делает то же самое для версий 2 и 3. Обе функции используются только в преде-
пределах этого файла, поэтому они объявлены как PRIVATE. Обе они выполняют пре-
преобразование в двух направлениях, как из памяти на диск, так и обратно.
Предшествующие версии MINIX были перенесены на системы, где расположе-
расположение байтов в слове отличается от такового в процессорах Intel. В будущем анало-
аналогичный перенос предполагается и для MINIX 3. В каждой реализации инфор-
информация на диске хранится в том порядке, какой принят в системе. А что это за
порядок, система узнает из поля sp->native в суперблоке. Поэтому функции
old_icopy и new_icopy при необходимости вызывают подпрограммы conv2
и conv4 с целью изменить порядок следования байтов. Разумеется, многое из
того, что мы описали, не используется в MINIX 3, поскольку эта система не под-
поддерживает файловую систему версии 1 в степени, достаточной для использования
дисков с этой файловой системой. На момент написания книги никто не перенес
MINIX 3 на платформу с другим порядком следования байтов. Тем не менее эти
биты и поля сохраняются на случай, если кто-нибудь захочет расширить область
применения операционной системы.
Процедура dup_inode (строка 23257) просто увеличивает на единицу счетчик
использования индексного узла. Она вызывается при повторном открытии фай-
файла, при этом индексный узел не нужно еще раз считывать с диска.
Управление суперблоками
В файле super. с находятся процедуры для работы с суперблоками и битовыми
картами. Эти шесть процедур перечислены в табл. 5.8.
Таблица 5.8. Процедуры для работы с суперблоками и битовыми картами
Процедура Назначение
alloc_bit «Выделяет» бит в битовой карте индексных узлов или зон
free_bit «Освобождает» бит в битовой карте индексных узлов или зон
get_super Ищет устройство в таблице суперблоков
get_block_size Ищет размер блока для использования
mounted Сообщает, принадлежит индексный узел монтированной или корневой
файловой системе
read_super Считывает суперблок
Как мы уже отмечали, когда требуется индексный узел или зона, вызывается
функция alloc_inode или alloc_zone. Каждая из них, в свою очередь, вызы-
вызывает функцию alloc_bit (строка 23324), чтобы найти неустановленный бит
в битовой карте. Поиск включает в себя три вложенных цикла, работающих сле-
следующим образом.
1. Внешний цикл перебирает все блоки битовой карты.
2. Промежуточный цикл перебирает все слова блока.
3. Внутренний цикл проверяет все биты в слове.
В промежуточном цикле выясняется, является ли текущее слово дополнением
нуля, то есть состоит ли оно целиком из единиц. Если да, значит, в этом слове
нет «свободных» битов, и проверяется следующее слово. Когда обнаруживается
другое значение, где по крайней мере один бит равен 0, запускается внутренний
цикл, который определяет его позицию в слове. Если оказалось, что проверены
все блоки, но нулевых битов не нашлось, значит, свободных индексных узлов
или зон на диске нет, и возвращается код NO_BIT @). Подобный поиск может
потребовать много процессорного времени, но благодаря указателям на первый
свободный индексный узел (или зону), передаваемый из суперблока в alloc_
bit в качестве начальной позиции для поиска, его удается сократить.
Обнулить «занятый» бит проще, чем установить, так как не требуется выполнять
поиск. Функция f ree_bit (строка 23400) вычисляет, какой блок битовой кар-
карты содержит сбрасываемый бит, и дальше вызывает функцию get_block, обну-
обнуляет бит и завершает операцию вызовом put_block.
При помощи следующей процедуры, get_super (строка 23445), в таблице су-
суперблоков ищется запись для заданного устройства. Например, когда монтиру-
монтируется файловая систем^, нужно проверить, не делается ли это повторно. Для этого
можно вызовом get_super попробовать найти устройство, на котором файло-
файловая система расположена. Если устройство не найдено, то и файловая система
еще не смонтирована.
В MINIX 3 сервер файловой системы способен работать с файловыми система-
системами, размеры блоков которых различны, хотя в каждом разделе диска использует-
используется один и тот же размер. Функция get_block_size (строка 23467) выясняет,
какой размер имеет блок в файловой системе. Она ищет заданное устройство в таб-
таблице суперблоков и возвращает размер блока, если устройство смонтировано.
В противном случае возвращается минимальный размер блока, MIN_BLOCK_SIZE.
Функция mounted (строка 23489) вызывается только при закрытии блочного
устройства. Обычно при закрытии такого устройства все данные, сохранен-
сохраненные в кэше, сбрасываются. Но если оказалось, что устройство смонтировано, это
нежелательно. Функции mounted передается указатель на индексный узел уст-
устройства. Она проверяет, является ли устройство корневым или смонтированным,
и если устройство смонтировано, возвращает TRUE.
Наконец, перейдем к функции read_super (строка 23509). Она отчасти похожа
на функции rw_block и rw_inode, но выполняет только чтение. Суперблок не
считывается в кэш; обращение к устройству происходит для прямого считыва-
считывания 1024 байт, расположенных со смещением 1024 байта от начала устройства.
Записывать суперблок при нормальной работе системы не требуется. Считав
суперблок, функция read_super узнает версию файловой системы и при необ-
необходимости выполняет форматное преобразование. Таким образом, копия су-
суперблока в памяти всегда имеет стандартный формат, даже если она прочитана
с диска с другой структурой или другим порядком следования байтов.
Следует сказать несколько слов об «умном» методе определения порядка следо-
следования байтов в системе, записавшей диск, хотя этот метод в MINIX 3 пока и не
используется. Магическое число суперблока записано в порядке, принятом исход-
исходной системой; по этой причине проверке подлежат не только сами магические
числа, но и их значения, записанные с обратным порядком следования байтов.
Управление файловыми дескрипторами
В MINIX 3 имеются специальные подпрограммы и для работы с дескрипторами
и таблицами f ilp (см. рис. 5.34). Эти процедуры находятся в файле f iledes. с.
Когда файл создается или открывается, с ним связываются свободный дескрип-
дескриптор и незанятая ячейка в таблице f ilp. Для поиска свободных ресурсов предна-
предназначена процедура get_f d (строка 23716). Она не помечает их как занятые, так
как успешному завершению вызовов creat или open предшествует еще множе-
множество различных проверок.
Функция get_f ilp (строка 23761) проверяет, находится ли файловый дескрип-
дескриптор в заданных пределах и возвращает его указатель, взятый из f ilp.
Последняя процедура в файле, f ind_f ilp (строка 23774), позволяет выяснить,
что процесс пытается писать в неработающий канал (то есть канал, не открытый
другим процессом на чтение). Она прямым перебором ищет в таблице f ilp про-
процессы-читатели на другом конце канала. Если такой процесс найти не удалось,
значит, канал разрушен, и попытка записи в него обречена на провал.
Блокировка файлов
Функции POSIX для блокировки файлов перечислены в табл. 5.9. Область фай-
файла можно заблокировать на запись и чтение или только на запись при помощи
системного вызова f cntl с запросом F_SETLK или F_SETLKW. Узнать, заблоки-
заблокирована ли та или иная область файла, можно с помощью запроса F_GETLK.
Таблица 5.9. Операции блокировки записей согласно POSIX. Они выполняются по запросу
с помощью системного вызова FCNTL
Операция Действие
F_SETLK Блокирует область на запись и чтение
F_SETLKW Блокирует область на запись
F_GETLK Проверяет, свободна ли область
В файле lock. с есть только две функции. К первой из них, lock_op (стро-
(строка 23820), обращается системный вызов fcntl при выполнении каждой из опе-
операций, перечисленных в таблице. Функция делает несколько тестов, гаранти-
гарантирующих, что область в файле задана корректно. Блокировка области не должна
конфликтовать с существующими блокировками и не должна выполняться дваж-
дважды. Для снятия блокировки вызывается другая процедура из этого файла, lock_
revive (строка 23964). Она разблокирует все процессы, ранее заблокированные
в ожидании освобождения данной области.
Это компромиссная стратегия, потому для точного решения, какой процесс по-
получит управление, потребовался дополнительный код. Те процессы, время кото-
которых еще не наступило, вновь блокируются после запуска. Подобная стратегия
выбрана, исходя из предположения, что блокировка файлов — операция редкая.
Если на основе MINIX 3 будет построена многопользовательская база данных,
не исключено, что потребуется изменить данный алгоритм.
Процедура lock_revive также вызывается при закрытии заблокированного
файла, это может произойти, например, если процесс был завершен принудитель-
принудительно до того, как закончил работать с блокируемым им файлом.
5.7.3. Главная программа
Код главного цикла файловой системы находится в файле main. с (строка 24040).
Вход в него осуществляется после обращения к функции f s_init за инициали-
инициализацией. По своей структуре он очень похож на главный цикл менеджера процес-
процессов и драйверов устройств ввода-вывода. В нем вызывается функция get_work,
ожидающая прибытия следующего запроса на обслуживание (если не может
быть обслужен процесс, ранее приостановленный на чтении из канала или с тер-
терминала). Она же устанавливает значение глобальной переменной who, куда за-
записывается номер ячейки в таблице процессов, принадлежащей вызывающему
процессу, а также заполняет другую глобальную переменную, call_nr, записы-
записывая в нее номер сделанного системного вызова.
Как только управление возвращается в главный цикл, устанавливаются следую-
следующие флаги: f p указывает на запись вызывающего процесса в таблице процессов,
a super_user говорит, принадлежит ли этот процесс суперпользователю. Уве-
Уведомления имеют наивысший приоритет, поэтому в первую очередь проверке
подлежит сообщение SYS_SIG, чтобы выяснить, собирается ли система завершить
работу. Вторым проверяется сообщение SYN_ALARM, указывающее на то, что ус-
установленный файловой системой таймер истек. Сообщение NOT IFY_MES SAGE
означает, что драйвер устройства готов к обслуживанию, и передается на обра-
обработку функции dev_status. Затем начинается главное действо: на передний
план выходит процедура, выполняющая системный вызов. Адрес процедуры вы-
выбирается в таблице call_vecs указателей на процедуры, где в качестве индекса
выступает значение call_nr.
При возврате управления в главный цикл проверяется значение флага dont_
reply. Если он установлен, значит, ответное сообщение не требуется (то есть
процесс заблокирован по причине чтения из пустого канала). Иначе отправляет-
отправляется ответное сообщение при помощи функции reply (строка 24087). Последняя
команда в цикле должна распознавать последовательное чтение файла и, соот-
соответственно, для повышения производительности пытаться загрузить следующий
блок до того, как в действительности придет запрос.
Две следующие функции файла играют важную роль в главном цикле файловой
системы. Функция get_work (строка 24099) проверяет, имеются ли ранее за-
заблокированные процедуры, которые могут продолжить работу. Если такие есть,
они считаются приоритетнее новых сообщений. Только тогда, когда у файловой
системы нет отложенных задач, она отправляет ядру запрос на получение сле-
следующего сообщения (строка 24124). Несколькими строками далее находится
функция reply (строка 24159), запускаемая после завершения системного вы-
вызова (успешного или неуспешного). Процесс может быть завершен по сигналу,
и код состояния, возвращаемый ядром, игнорируется. В этом случае все равно
ничего больше не сделаешь.
Инициализация файловой системы
Оставшуюся часть файла main, с составляют функции инициализации, выпол-
выполняемые при запуске системы. Основную роль здесь играет функция f s_init,
вызываемая файловой подсистемой на этапе запуска всей системы еще до входа
в главный цикл. Рассматривая в главе 2 планирование процессов, на рис. 2.22 мы
показали начальную очередь процессов при запуске MINIX 3. Файловая система
помещается в очередь с более низким приоритетом, чем менеджер процессов, по-
поэтому можно быть уверенными в том, что менеджер процессов будет запущен
раньше. Инициализация менеджера процессов была рассмотрена нами в главе 4.
Создавая собственную часть таблицы процессов, менеджер процессов добавляет
в загрузочный образ записи о себе и других процессах. При формировании каж-
каждой записи он посылает файловой системе сообщение, чтобы она могла инициа-
инициализировать соответствующую запись в своей таблице процессов. Теперь мы мо-
можем ознакомиться со второй частью этого взаимодействия.
Когда файловая система начинает работу, она незамедлительно запускает собст-
собственный цикл в f s_init (строки 24189-24202). Первой инструкцией цикла яв-
является вызов receive для получения сообщения, которое было отправлено
функцией инициализации менеджера процессов pm_init в строке 18235. Каждое
сообщение содержит номер и идентификатор процесса. Номер процесса использу-
используется в качестве индекса таблицы процессов файловой системы, а идентификатор
сохраняется в поле f p_pid каждой ее записи. Далее для каждой записи устанав-
устанавливаются реальные и эффективные идентификаторы пользователя и группы су-
суперпользователя, а в поле umask всем битам присваивается единичное значение.
При получении сообщения, содержащего символьное значение NONE в поле но-
номера процесса, выполнение цикла прекращается, а менеджеру процессов отправ-
отправляется сообщение о том, что все прошло успешно.
Затем завершается инициализация файловой системы. Сначала проверяется
корректность значений важных констант; далее вызывается ряд других функций
с целью подготовить кэш блоков и таблицу устройств, при необходимости загру-
загрузить виртуальный диск, а также загрузить суперблок корневого устройства. На
этом этапе имеется доступ к корневому устройству, и часть таблицы процессов,
принадлежащая файловой системе, считывается в цикле, чтобы каждый процесс
из загрузочного образа получил информацию о своем корневом каталоге и уста-
установил его в качестве текущего (строки 24228-24235).
Рис. 5.35. Инициализация кэша блоков: а — начальное состояние; б — после запроса
одного блока; в — после того, как блок освобожден
После завершения взаимодействия с менеджером процессов функция f s_init
вызывает функцию buf_pool, формирующую списки для кэширования бло-
блоков (строка 24132). На рис. 5.32 было представлено нормальное состояние кэша,
где все блоки связаны друг с другом в LRU-список и хешированы. Полезно ра-
разобраться в том, как возникла ситуация, показанная на рисунке. Сразу после
инициализации процедурой buf_pool все буферы находятся в списке и все они
связаны в нулевую хеш-цепочку (рис. 5.35, а). Когда запрашивается буфер,
структура приходит в состояние, показанное на рис. 5.35, б, и остается в нем, пока
буфер используется. На этом рисунке мы можем видеть, что блок исключен из
LRU-списка и помещен в отдельную хеш-цепочку.
Обычно же блок освобождается и возвращается в LRU-список немедленно
(рис. 5.35, в). Здесь блок, хотя и не используется более, все еще содержит инфор-
информацию и при необходимости может быть извлечен из хеш-цепочки. После того
как система поработает некоторое время, почти все блоки, скорее всего, окажут-
окажутся случайно распределенными между различными цепочками. LRU-список при
этом будет выглядеть так, как показано на рис. 5.32.
Следующую функцию, build_dmap, мы опишем позже, когда пойдет речь о функ-
функциях, работающих с файлами устройств. После этого вызывается функция load_
ram, которая, в свою очередь, использует функцию igetenv (строка 2641). По-
Последняя получает от ядра численный идентификатор, передавая ему в качестве
аргумента параметр загрузки. Если вы пользовались командой sysenv для про-
просмотра параметров загрузки работающей системы MINIX 3, вы видели, что ин-
информация отображалась в виде строк, подобных следующей:
rootdev=912
Файловая система использует числа для идентификации устройств. Эти числа
вычисляются по формуле:
256 х главный_помер + вспомогательный_номер.
Здесь главный_номер и вспомогательный_номер — соответственно главный и вспо-
вспомогательный номера устройств. В приведенном примере главный номер равен 3,
а вспомогательный — 144, что соответствует устройству /dev/cOdlpOsO, на ко-
которое обычно устанавливают MINIX 3 в системах с двумя дисками.
Функция load_ram (строка 24260) выделяет память для виртуального диска
и загружает в него корневую файловую систему, если этого требуют загрузочные
параметры. С помощью функции igetenv она считывает параметры rootdev,
ramimagedev и ramsize, установленные в окружении загрузки (строки 24278-
24280). Если в параметрах загрузки указана следующая строка, корневая файло-
файловая система блок за блоком, начиная с загрузочного блока, копируется с устрой-
устройства ramimagedev на виртуальный диск:
rootdev=ram
При этом различные структуры файловой системы не интерпретируются. Если
значение параметра ramsize меньше объема корневой файловой системы, вир-
виртуальный диск увеличивается, чтобы вместить ее. Если же виртуальный диск
вмещает всю корневую файловую систему и на нем еще остается место, произво-
производится подстройка с целью подогнать размер диска под объем файловой систе-
системы (строки 24404-24420). Это — единственный случай, когда файловая система
осуществляет запись в суперблок, однако, как и при чтении последнего, кэш бло-
блоков не используется и данные пишутся непосредственно на устройство с помо-
помощью функции dev_io.
Сейчас два момента заслуживают комментария. Первый — код в строках 24291-
24307, обрабатывающий вариант загрузки с компакт-диска. В нем используется
функция cdprobe, не рассматриваемая в этой книге. Заинтересованным читате-
читателям мы предлагаем обратиться к коду файла fs/cdprobe. с, который можно
найти на компакт-диске и веб-сайте MINIX 3. Второй момент: независимо от ис-
используемого MINIX 3 размера обычных блоков, размер загрузочного блока всегда
равен 1 Кбайт, а суперблок загружается из второго килобайта дискового устрой-
устройства. Любые другие варианты оказались бы сложными, поскольку размер блока
можно узнать, лишь загрузив суперблок.
Функция load_ram выделяет пространство под пустой виртуальный диск, если
указан ненулевой размер ramsize, при этом виртуальный диск не используется
в качестве корневой файловой системы. Виртуальный диск будет можно задей-
задействовать как файловую систему лишь после инициализации командой mkf s,
поскольку структуры файловой системы не скопированы в него. В качестве аль-
альтернативы такой виртуальный диск можно сделать вторичным кэшем, если соот-
соответствующая поддержка интегрирована в файловую систему.
Последняя функция файла main, с, функция load_super (строка 24426), ини-
инициализирует таблицу суперблоков и считывает в нее суперблок корневого уст-
устройства.
5.7.4. Операции с отдельными файлами
В этом разделе мы рассмотрим системные вызовы для операций с отдельными
файлами (в противоположность операциям, например, с каталогами). Начнем же
с того, как файлы создаются, открываются и закрываются. Затем мы более под-
подробно изучим механизм записи и чтения файлов. И «на десерт» мы рассмотрим
процедуры для работы с каналами и выясним, чем они отличаются от процедур
для работы с файлами.
Создание, открытие и закрытие файлов
Файл open, с содержит код шести системных вызовов: creat, open, mknod,
mkdir, close и lseek. Вызовы creat и open мы рассмотрим вместе, а затем
перейдем к остальным.
В старых версиях UNIX вызовы creat и open служили для разных целей. При
попытке открыть несуществующий файл возникала ошибка, а новый файл дол-
должен был создаваться вызовом creat, еще одной целью которого является уста-
установка размера файла в нулевое значение. Однако в современной системе, соот-
соответствующей стандарту POSIX, два отдельных вызова не требуются. Согласно
POSIX созданием файла или «обнулением» существующего файла должен зани-
заниматься вызов open, поэтому возможности вызова creat теперь составляют лишь
часть потенциала open, и нужен он только для совместимости со устаревшими
программами. Процедуры, выполняющие действия creat и open, называются
соответственно do_creat (строка 24537) и do_open (строка 24550), то есть, как
и в случае с менеджером процессов, здесь соблюдается соглашение именовать
обработчик системного вызова ххх как йо_ххх. Открытие или создание файла
включает три шага.
1. Поиск индексного узла (или выделение и инициализация нового индексного
узла, если файл создается).
2. Поиск или создание записи в каталоге.
3. Настройка дескриптора файла и его возврат.
Оба вызова, creat и open, лишь получают имя файла и перекладывают задачи,
общие для обоих вызовов, «на плечи» вызова common_open.
Процедура common_open (строка 24573) начинает с того, что проверяет наличие
свободных файловых дескрипторов и ячеек в таблице f ilp. Затем, если при вызове
было указано создать новый файл (то есть установлен бит O_CREAT), вызывает-
вызывается функция new_node (строка 24594). Если запись в каталоге уже присутствует,
эта функция возвращает указатель на существующий индексный узел, в против-
противном случае она создает новые запись и индексный узел. Если индексный узел не
может быть создан, функция записывает код ошибки в глобальную переменную
err_code. Наличие кода ошибки не обязательно означает сбой. Когда функция
new_node обнаруживает одноименный файл, она сигнализирует об этом через
код ошибки, но в действительности здесь нет ничего противоправного (стро-
(строка 24597). При неустановленном бите O_CREAT поиск индексного узла осущест-
осуществляется альтернативным методом — с помощью функции eat_path из файла
path, с, которую мы обсудим позже. На данном этапе важно лишь знать, что
если индексный узел не удалось ни найти, ни создать, вызов common_open за-
завершается с ошибкой прежде, чем достигается строка 24606. Иначе функция
продолжает работу, назначая файлу дескриптор и запрашивая запись в табли-
таблице f ilp. Следующий блок кода (строки 24612-24680) пропускается, если файл
создается именно сейчас.
Если же файл существовал ранее, файловая система должна определить, что это
за файл, какие разрешения выставлены у него и т. д., чтобы выяснить, может ли
он быть открыт. Проверку битов rwx (то есть битов, управляющих доступом)
выполняет вызов forbidden (строка 24614). Если файл представляет собой
обычный файл и при вызове был установлен бит O_TRUNC, длина файла прирав-
приравнивается нулю и снова вызывается функция forbidden (строка 24620), на этот
раз чтобы проверить доступность файла на запись. Когда запись разрешена,
вызываются функции wipe_inode и rw_inode, очищающие индексный узел
и сохраняющие его на диске. Для других типов файлов (каталогов, специальных
файлов и каналов ввода-вывода) делаются соответствующие проверки. Так, в слу-
случае устройства, при помощи структуры dmap выполняется вызов нужной проце-
процедуры, которая открывает его (строка 24640). За открытие именованного канала
отвечает функция pipe_open (строка 24646), для него выполняются различные
проверки, имеющие отношение к каналам.
В коде функции common_open, как и в тексте других процедур файловой систе-
системы, есть большое количество проверок различных ошибок и недопустимых ком-
комбинаций параметров. Хотя этот код и не изящен, он важен для получения надеж-
надежной и свободной от врожденных дефектов файловой системы. Если произошла
какая-либо ошибка, ранее выделенные файловый дескриптор и ячейка в таблице
f ilp освобождаются (строки 24683-24689). Функция common_open в этом
случае возвращает отрицательное значение, говорящее об ошибке. Если проблем
с файловым дескриптором не было, код возврата является положительным числом.
Отложим в сторону файлы и займемся каталогами. И для начала поглядим на
работу функции new_node (строка 24697), которая занимается выделением
индексного узла и вводом пути для вызовов с г eat и open. Она также использу-
используется системными вызовами mknod и mkdir, которые еще будут обсуждаться.
Сначала эта функция анализирует путь к файлу (строка 24711), то есть про-
просматривает его компонент за компонентом, пока не достигает конечного катало-
каталога. При помощи функции advance проверяется, может ли быть открыт послед-
последний компонент.
Например:
fd = creat("/usr/ast/foobar", 0755);
Если сделан этот вызов, то load_dir попытается загрузить в таблицы индекс-
индексный узел для пути /usr/ast и вернуть указатель на него. Если файл foobar
еще не существует, этот индексный узел скоро понадобится, чтобы добавить но-
новый файл в каталог. Другие системные вызовы, добавляющие или удаляющие
файлы, также используют last_dir.
Если функция new_node обнаруживает, что файл не существует, она вызывает
alloc_inode (строка 24717), тем самым выделяя новый индексный узел, и воз-
возвращает указатель на него. Если свободных индексных узлов не осталось, назад
вернется код NIL_INODE.
Если выделить индексный узел удалось, выполнение продолжается со строки
24727: его поля заполняются и он записывается обратно на диск, а в конечный
каталог заносится запись с именем файла (строка 24732). Опять же, здесь мы
видим, что файловая система обязана постоянно проверять, не произошло ли
ошибки. Если ошибка происходит, необходимо без паники аккуратно освобо-
освободить все ресурсы, такие как индексный узел и удерживаемый блок. Если вместо
того, чтобы, скажем, при нехватке индексных узлов мы позволили бы MINIX
просто завершиться с фатальной ошибкой вместо того, чтобы тщательно отме-
отменять все действия вызова и возвращать код ошибки, файловая система была бы
ощутимо проще, но и, сами понимаете...
Ранее упоминалось, что каналы ввода-вывода требуют особых действий. Когда
с каналом не связан хотя бы один процесс, читатель либо писатель, функция
pipe_open (строка 24758) приостанавливает процесс-инициатор вызова. В про-
противном случае она вызывает процедуру release, которая ищет в таблице процес-
процессов те, что ожидают данный канал. Если такие процессы найдены, они запускаются.
Системный вызов mknod выполняется функцией do_mknod (строка 24785)* Эта
процедура аналогична do_creat за исключением того, что она лишь создает
индексный узел и делает для него запись каталога. Фактически, большую часть
работы выполняет функция new_node (строка 24797). Если индексный узел уже
существует, возвращается код ошибки. Код ошибки тот же самый, который был
приемлемым при открытии файла. Однако в данном случае код возвращается
в вызывающую программу, которая, предположительно, подобающим образом его
интерпретирует. Подробный анализ отдельных случаев, проводимый в common_
open, здесь не нужен.
Функция do_mkdir (строка 24805) выполняет системный вызов mkdir. Как
и в случае с предыдущими системными вызовами, важную роль здесь играет
функция new_node. Каталоги в отличие от файлов никогда не бывают пустыми,
так как любой каталог содержит, по крайней мере, две записи, точку (.) и две
точки (. .), первая из которых ссылается на сам каталог, а вторая — на вышестоя-
вышестоящий. Количество ссылок на один файл ограничено константой LINK_MAX (в файле
include/limits.h для стандартной конфигурации MINIX 3, предназначенной
для платформы Intel, она определена как SHRT_MAX и ее значение равно 32767).
Поэтому, раз дочерний каталог содержит ссылку на родительский, функция do_
mkdir сначала проверяет, можно ли добавить новую ссылку на родительский ка-
каталог (строки 24819-24820). Когда эта проверка пройдена, вызывается функция
new_node. Если и этот вызов удался, для каталогов создаются записи . и . .
(строки 24841-24842). Описанный алгоритм прямолинеен, но учитывает возмож-
возможность сбоев (например, переполнение диска). Чтобы ничего не испортить, обес-
обеспечивается откат к исходному состоянию, если процесс не может быть завершен.
Закрыть файл всегда проще, чем открыть. Поэтому функции do_close (стро-
(строка 24865) для обычных файлов, фактически, требуется только уменьшить значе-
значение счетчика в f ilp и, если оно достигло нуля, возвратить индексный узел при
помощи функции put_inode. (Каналам же и специальным файлам требуется
особое внимание.) На последнем шаге аннулируются все блокировки, связанные
с этим файлом, и пробуждаются все процессы, приостановленные по факту бло-
блокировки.
Заметьте, что возврат индексного узла означает только, что уменьшается счетчик
в таблице индексных узлов, следовательно, в конце концов, он может быть уда-
удален из таблицы. Эта операция не имеет ничего общего с освобождением индекс-
индексного узла (то есть со сбросом бита в битовой карте индексных узлов). Объект
индексного узла освобождается только тогда, когда файл больше не находится
ни в одном из каталогов.
Последняя процедура в файле open.с — процедура do_lseek (строка 24939).
Она вызывается, когда осуществляется переход на заданную позицию в файле. При
этом блокируется упреждающее чтение (строка 24968), поскольку явное переме-
перемещение на заданную позицию в файле несовместимо с последовательным доступом.
Чтение файла
Открыв файл, его можно читать или записывать в него данные. Функций для
этого больше, чем достаточно, — все связанные с чтением функции можно найти
в файле read. с. Мы обсудим сначала их, а затем перейдем к следующему файлу,
write. с, чтобы взглянуть на код, предназначенный специально для записи. Ме-
Механизмы чтения и записи во многом различны, но у них довольно много обще-
общего, поэтому все, что требуется от do_read (строка 25030), — это вызвать общую
процедуру read_write с флагом READING. В следующем разделе мы увидим,
что функция do_write столь же проста.
Функция read_write начинается в строке 25038. Код в строках 25063-25066
используется менеджером процессов, чтобы файловая система загрузила для
него целые сегменты в пользовательском пространстве. Обработкой обыч-
обычных вызовов занимается код, начинающийся в строке 25068. В первую очередь
выполняется несколько проверок корректности операции (скажем, не делает-
делается ли попытка читать из файла, открытого только на запись) и инициализиру-
инициализируются некоторые глобальные переменные. Чтение из специальных символьных
файлов производится в обход кэша блоков, поэтому такие файлы фильтруются
в строке 25122.
Проверки в строках 25132-25145 имеют место только при записи и работают
с файлами, размер которых может превысить размер устройства, а также предот-
предотвращают попытки записи за пределы конца файла, вызывающие образование
«дыр». Как уже упоминалось в обзоре MINIX 3, наличие нескольких блоков в зо-
зоне приводит к некоторым проблемам, с которыми приходится бороться. Каналы
ввода-вывода также являются особым случаем.
Сердцем механизма чтения, по крайней мере, для обычных файлов, является
цикл, начинающийся в строке 25157. Он разбивает данные на фрагменты, каж-
каждый из которых умещается в один дисковый блок. Фрагмент начинается с теку-
текущей позиции и считается завершенным при выполнении одного из трех условий:
+ считаны все байты;
+ встретилась граница блока;
+ достигнут конец файла.
Эти правила означают, что один фрагмент не может занимать два блока. На ри-
рисунке 5.36 показано, как определяется квота размера, для фрагментов разме-
размером 6, 2 и 1 байт соответственно. Фактический расчет осуществляется в стро-
строках 25159-25169.
Считывание выполняется функцией rw_chunk. Когда эта функция возвращает
управление, увеличиваются значения различных счетчиков и продвигаются указа-
указатели, после чего начинается следующая итерация. Когда цикл завершается, теку-
текущая позиция в файле и другие переменные (например, указатели канала) могут
быть обновлены.
Наконец, если было запрошено упреждающее чтение, позиция и индексный узел,
откуда его нужно начинать, сохраняются в глобальных переменных, чтобы фай-
файловая система, отправив пользователю ответное сообщение, могла начать считы-
считывать следующий блок. Часто при этом файловая система блокируется, ожидая
считывания блока, и у пользовательского процесса есть время начать работать
с только что полученными данными. Такое чередование обработки и ввода-вы-
ввода-вывода может значительно повысить производительность.
Рис. 5.36. Три примера того, как для 10-байтового файла определяется размер первого
фрагмента данных. Размер блока равен 8 байт, запрашивается 6 байт.
Фрагмент отмечен штриховкой
Процедура rw_chunk (строка 25251) получает на входе индексный узел и пози-
позицию в файле, преобразует эти значения в физический номер блока на диске и за-
запрашивает передачу этого блока (или его части) в область пользовательских
данных. Преобразование относительной позиции в файле в физический адрес на
диске выполняется функцией read_map, которая осведомлена о структуре ин-
индексных узлов и блоков косвенной адресации. Для обычного файла переменные
b и dev в строках 25280 и 25281 содержат соответственно физический номер
блока и номер устройства. Вызов get_block (строка 25303) запрашивает у об-
обработчика кэша блоков нужный блок, считывая его при необходимости. Затем
вызов rahead (строка 25295) убеждается в том, что блок считан в кэш.
После того как указатель на блок получен, вызов sys_vircopy ядра в строке
25317 обеспечивает копирование данных в пользовательское пространство. За-
Затем блок освобождается, чтобы позже он мог быть удален из кэша. (После того
как вызов get_block находит нужный блок, тот исключается из LRU-списка
и пребывает вне его до тех пор, пока счетчик использования в заголовке буфера
не обнулится. Вызов put_block уменьшает значение этого счетчика и, если наста-
настало время, возвращает буфер в LRU-список.) Код в строке 25327 определяет, запол-
заполнился ли блок при записи. Правда, на данном этапе это уже не принципиально,
так как функция put_block теперь игнорирует значение, передаваемое ей во вто-
втором аргументе, и всегда добавляет освободившиеся блоки в конец LRU-списка.
Функция read_map (строка 25337) преобразует логическое смещение в файле
в физический номер блока, пользуясь для этого информацией индексного узла.
Те блоки, которые достаточно близки к началу файла, попадут в одну из первых
семи зон (то есть в одну из зон, хранящихся в самом индексном узле). При этом
чтобы узнать, какая из зон необходима, требуется только несложная арифметика.
Для блоков, расположенных дальше, может понадобиться считать один или боль-
больше блоков косвенной адресации.
Функция rd_indir (строка 25400) вызывается, когда необходимо считать кос-
косвенный блок. Комментарии к ней несколько устарели; во-первых, код поддержки
процессора 68000 удален, во-вторых, файловая система MINIX 1 больше не ис-
используется и соответствующий ей код также можно исключить. Тем не менее
следует отметить, что в случае организации поддержки других файловых систем
или платформ, проблемы иных форматов сохранения данных на диске, типов дан-
данных и порядка следования байтов можно решить в этом файле. Если без труд-
трудных для понимания преобразований данных не обойтись, то совершив их здесь,
вы обеспечите единую форму представления данных во всей файловой системе.
Функция read_ahead (строка 25432) преобразует логическое положение в фи-
физический адрес блока, вызывает функцию get_block, в результате чего блок
оказывается в кэше, и немедленно возвращает его. В конце концов, сделать с ним
она все равно ничего не может. Задача read_ahead лишь в том, чтобы повысить
вероятность найти данные в кэше, если они скоро понадобятся.
Обратите внимание, что функция read_ahead вызывается только из главного
цикла в main. Ее вызов не является частью вызова read. Важно понять, что эта
функция вызывается после того, как пользователю отправлен ответ, чтобы он
мог продолжать свою работу, пока файловая система дожидается завершения
упреждающего чтения.
Сама функция read_ahead написана так, чтобы запрашивать всего один блок.
Реально трудится вызываемая ею подпрограмма г ahead. В г ahead (строка 25451)
заложена та жизненная концепция, что если немного больше — хорошо, а намно-
намного больше — еще лучше. Так как дискам и прочим накопителям часто требуется
много времени, чтобы найти первый запрошенный блок, но зато они могут быст-
быстро считать несколько смежных блоков, делается ставка на то, что получится счи-
считать много последовательных блоков ценой небольших дополнительных затрат.
Запрос на упреждающую выборку передается функции get_block, подготавли-
подготавливающей кэш блоков к получению нескольких блоков за раз. Затем вызывается
функция rw_scattered, которой передается список блоков. Работу этой функции
мы уже обсуждали. Вспомните, что rw_scattered передает запрос драйверу
устройства, который в ответ имеет право обслужить столько запросов, сколько
он способен выполнить эффективно. Все это звучит довольно витиевато, но зато
позволяет на нужное «много» повысить быстродействие приложений, считываю-
считывающих с диска ожидаемое «больше» данных.
На рис. 5.37 показаны взаимосвязи между основными подпрограммами, участ-
участвующими в чтении файла. В том числе указано, кто кого вызывает.
Запись
Код, обеспечивающий запись, находится в файле write. с. Запись в файл в боль-
большинстве своем сходна с чтением, и функция do_write (строка 25625) просто
вызывает read_write с флагом WRITING. Основное отличие записи в том, что
здесь может потребоваться выделение дополнительных блоков. Функция write_
map (строка 25635) аналогична read_map с той разницей, что вместо поиска
физического адреса блока по индексному узлу и косвенным блокам она добавля-
добавляет номер новой зоны, а не блока.
Рис. 5.37. Некоторые из процедур, участвующих в чтении файла
Код функции write__map сложный и длинный, поскольку эта функция должна
учитывать несколько ситуаций. Если новая зона вставляется в начало файла, она
должна быть вставлена в его индексный узел (строка 25658).
Самый же худший случай, когда по мере роста файла простых косвенных блоков
перестает хватать и приходится применять блоки второго уровня косвенности.
После этого выделяется блок первого уровня косвенности, и его адрес заносится
в блок второго. Как и в случае с чтением, для этого предусмотрена отдельная
процедура, wr_indir. Если блок второго уровня косвенности удалось выделить,
но из-за этого диск переполнился, а на блок первого уровня косвенности места
уже не хватает, то блок второго уровня нужно вернуть, чтобы избежать повреж-
повреждения битовой карты.
Опять же, если бы в случае неудачи можно было просто сообщить о фатальной
ошибке ядра, код был бы намного компактнее. Однако с точки зрения пользовате-
пользователя, гораздо лучше, когда при переполнении диска write возвращает код ошибки
вместо того, чтобы провоцировать крах, к тому же с разрушением файловой системы.
Функция wr_indir (строка 25726) записывает новый номер зоны в косвенный
блок, а чтобы преобразовать данные в нужный формат (порядок следования бай-
байтов), она вызывает подпрограмму преобразования conv4. Здесь мы снова имеем
дело с устаревшим кодом, работающим с файловой системой версии 1; на самом
деле, используется лишь код, работающий с версией 2. Пусть имя этой функции
не вводит вас в заблуждение. Помните, что действительную запись данных на
диск выполняют функции, обслуживающие кэш блоков.
Далее в файле write.с следует функция clear_zone (строка 25747). Она за-
занимается очисткой блоков, оказавшихся в середине файла. Такое может слу-
случиться, если записать некоторый объем данных после конца файла. К счастью,
это случается не очень часто.
Функция new_block (строка 25787) вызывается из rw_chunk, когда требуется
новый блок. На рис. 5.38 показаны шесть последовательных этапов увеличения
файла. В этом примере размер блока равен 1 Кбайт, а зоны — 2 Кбайт.
Рис. 5.38. Последовательное выделение блоков размером 1 Кбайт при размере зоны 2 Кбайт
Здесь при первом своем вызове функция new_block выделяет зону 12 (блоки
24 и 25). Затем она задействует блок 25, который уже выделен, но еще не исполь-
использован. При третьем вызове выделяется зона 20 (блоки 40 и 41) и т. д.
Функция zero_block (строка 25839) очищает блок, стирая его предыдущее со-
содержимое. Честно говоря, это описание длиннее, чем сам код.
Каналы ввода-вывода
Каналы во многих отношениях подобны файлам. В этом разделе мы сконцен-
сконцентрируем внимание на отличиях. Код, который мы будем обсуждать, находится
в файле pipe . с.
Прежде всего, каналы создаются иначе — вызовом pipe, а не creat. Вызов
pipe выполняется функцией do_pipe (строка 25933). Вся работа do_pipe
сводится к выделению индексного узла для канала, после чего для него воз-
возвращаются два файловых дескриптора. Владельцем каналов является система,
а не пользователь, и располагаются они на устройстве, назначенном в файле
include/minix/conf ig.h. В качестве этого устройства наиболее удобен вир-
виртуальный диск, так как данные каналов не нуждаются в долговременном хра-
хранении.
Запись в канал и чтение из него отличаются от случая с файлом, поскольку
канал имеет ограниченную пропускную способность. Попытка записать данные
в переполненный канал приведет к приостановке пишущего процесса. Анало-
Аналогичным образом, к блокировке приведет попытка чтения из пустого канала.
Итак, канал должен иметь два указателя, текущую позицию (она нужна чита-
читателям) и размер (интересный писателям). Все это вместе определяет, откуда и ку-
куда следуют данные.
Функция pipe_check (строка 25986) делает различные проверки, выясняя, воз-
возможна ли работа с каналом. В дополнение к этим проверкам, которые могут при-
привести к приостановке вызывающего процесса, pipe_check вызывает release,
чтобы определить, может ли быть оживлен ранее приостановленный процесс,
пытавшийся прочитать отсутствующие данные или злоупотребляющий записью.
За возобновление пишущих процессов отвечает код в строке 26017, читающих —
код на строке 26052. Здесь же обнаруживаются некорректно проложенные или
«сломанные» (то есть без читателей) каналы.
За приостановку процесса отвечает функция suspend (строка 26073). Она про-
просто сохраняет в таблице процессов параметры вызова и устанавливает в TRUE
флаг dont_reply, чтобы файловая система не отправляла ответное сообщение.
Процедура release (строка 26099) вызывается для проверки, может ли быть
запущен ранее приостановленный на канале процесс. Если может, вызывается
функция revive, устанавливающая флаг, на который позже обратит внимание
главный цикл. Эта функция не относится к системным вызовам, но работает че-
через механизм передачи сообщений.
Последняя процедура в файле pipe. с называется do_unpause (строка 26189).
Когда менеджер памяти пытается передать процессу сигнал, он обязан узнать, не
приостановлен ли процесс на доступе к каналу или к специальному файлу (если
это так, процесс будет возобновлен с ошибкой EINTR). Так как менеджер памяти
о каналах и специальных файлах никто в известность не ставил, он просит сове-
совета у файловой системы, передавая ей сообщение. Это сообщение обрабатывается
функцией do_unpause, которая возобновляет работу процесса в том случае, ес-
если он заблокирован. Как и revive, функция do_unpause имеет сходство с сис-
системным вызовом, хотя и не является таковым.
Последние две функции файла pipe. с — select_request_pipe (строка 26247)
и select_match_pipe (строка 26278). Они поддерживают вызов select, здесь
не рассматриваемый.
5.7.5. Каталоги и пути
Итак, мы завершили обзор функций записи и чтения файлов. Наша следующая
задача — разобраться, как обрабатываются пути к файлам и каталоги.
Преобразование пути в индексный узел
Многие системные вызовы принимают в качестве входного аргумента путь (то есть
имя файла). Это, например, вызовы open, unlink, mount. Большинству из них,
перед тем как начать выполнять сам вызов, требуется определить индексный узел
для указанного файла. Поэтому теперь мы подробно изучим, как имя файла преоб-
преобразуется в индексный узел. Общие контуры уже были обрисованы на рис. 5.14.
Для анализа имен файлов служит код в файле path.с. Первая его процедура,
eat_path (строка 26327), получает на входе указатель на имя файла, анализи-
анализирует имя, загружает нужный индексный узел в память и возвращает указатель на
узел. Она решает свою задачу при помощи функции last_dir, возвращающей
индексный узел каталога, в котором непосредственно находится файл. Затем,
чтобы получить последний компонент пути, она вызывает функцию advance.
Если поиск объекта закончился неудачей, например, такое может произойти, ес-
если один из каталогов в пути не существует или существует, но недоступен для
поиска, вместо указателя на индексный узел возвращается значение NIL_INODE.
Имена файлов могут быть абсолютными или относительными и иметь произ-
произвольное число компонентов, разделенных символами косой черты. Распознава-
Распознаванием занимается функция last_dir. Сначала она проверяет первый символ пу-
пути с целью выяснить, абсолютный тот или относительный (строка 26371). Если
путь абсолютный, в rip записывается указатель на корневой индексный узел,
для относительных путей в эту переменную помещается указатель на индексный
узел рабочего каталога.
С этого момента у last_dir есть путь и указатель на каталог, в котором нужно
искать первый компонент. В строке 26382 начинается цикл, где путь анализиру-
анализируется компонент за компонентом. После конечной итерации возвращается указа-
указатель на конечный каталог.
Функция get_name (строка 26413) является вспомогательной процедурой, из-
извлекающей компоненты пути из строк. Более интересна функция advance (стро-
(строка 26454), которая получает на входе указатель на каталог и строку и ищет ука-
указанную строку в каталоге. Если ей удается обнаружить в каталоге объект с таким
именем, она возвращает указатель на его индексный узел. Эта же функция учи-
учитывает особенности смонтированных файловых систем.
Хотя функция advance и управляет процессом поиска строки, самим сравнением
строк с записями в каталоге занимается функция search_dir (строка 26535).
Это — единственный элемент во всей файловой системе, который непосредст-
непосредственно имеет дело с файлами каталогов. В функции есть два вложенных цикла,
во внешнем перебираются блоки каталогов, а во внутреннем просматриваются
записи внутри каждого из блоков. Функция search_dir также вызывается
для удаления записей из каталога или для внесения новых записей. Основные
взаимосвязи между процедурами, участвующими в поиске файла по его пути,
показаны на рис. 5.39.
Рис. 5.39. Некоторые из процедур, участвующих в поиске файла по его пути
Монтирование файловых систем
Есть два системных вызова, оказывающих влияние на файловую систему в целом,
это mount и umount. При помощи этих вызовов можно «склеивать» воедино от-
отдельные файловые системы на различных дополнительных устройствах, образуя
общую древовидную структуру. Как можно было видеть на рис. 5.33, при мон-
монтировании файловой системы ее суперблок и корневой индексный узел считыва-
ются, и в суперблоке устанавливаются два указателя. Первый из них ссылается
на точку монтирования (то есть индексный узел, к которому присоединена смонти-
смонтированная файловая система), а второй указывает на корневой индексный узел но-
новой файловой системы. Эти два указателя и сцепляют файловые системы вместе.
Означенные указатели устанавливаются в строках 26819-26820 функцией do_
mount из файла mount. с. Две страницы кода, которые предшествуют этому мо-
моменту, практически целиком относятся к проверке различных ошибок, ожидае-
ожидаемых при монтировании файловых систем:
+ указанный специальный файл не является блочным устройством;
+ специальный файл представляет собой блочное устройство, но он уже смон-
смонтирован;
+ у монтируемой файловой системы неправильная сигнатура;
+ монтируемая файловая система некорректна (то есть нет индексных узлов);
+ файл, к которому присоединяется файловая система, не существует или явля-
является специальным;
+ не хватает памяти для битовых карт монтируемой файловой системы;
+ не хватает памяти для суперблока монтируемой файловой системы;
+ не хватает памяти для корневого индексного узла монтируемой файловой
системы.
Хотя может показаться, что нет смысла бесконечно повторять проверки, практи-
практика показывает, что в реальных операционных системах значительная часть кода
выполняет рутинную работу, которая не слишком интересна, но имеет ключевое
значение для системы. Если пользователь иногда случайно будет пытаться мон-
монтировать поврежденную дискету, это приведет к тотальной порче файловой сис-
системы, и он решит, что система ненадежна, в чем виноватым, естественно, окажет-
окажется не пользователь, а разработчик.
Томас Эдисон сделал одно замечание, которое применимо и к нашему случаю.
Он сказал, что гений — это 1 % вдохновения и 99 % труда. Различие между хоро-
хорошей и посредственной системой состоит не в превосходном алгоритме планиро-
планирования, а в том внимании, которое уделено деталям.
Демонтировать файловую систему проще, чем монтировать. Эту задачу в два
этапа решает функция do_umount (строка 26828). Она убеждается, что вызов
был сделан суперпользователем, преобразует имя в номер устройства, а затем
обращается к подпрограмме unmount (строка 26846), завершающей операцию.
Единственная проблема в том, что все файлы на демонтируемой файловой сис-
системе должны быть закрыты, и ни у одного процесса не должно быть текущего
каталога на ней. Проверка осуществляется тривиально: сканируется вся табли-
таблица индексных узлов на предмет поиска в памяти хотя бы одного индексного
узла, принадлежащего демонтируемой файловой системе. Если да, umount рапор-
рапортует об ошибке.
Последняя подпрограмма в файле mount .с носит имя name_to_dev (строка
26893). Она определяет главный и вспомогательный номера устройства по пере-
передаваемому ей имени специального файла. Эти номера хранятся в самом индекс-
индексном узле, там, где у обычных файлов хранится информация о первой зоне. Это
место пустует, поскольку у специальных файлов нет зон.
Создание и уничтожение ссылок
Следующий файл, который мы рассмотрим, называется link. с. Процедура do_
link (строка 27034) очень напоминает do_mount в том смысле, что практиче-
практически весь ее код связан с проверкой ошибок. Обратите внимание на вызов:
link(file_name, link_name);
Вот некоторые из возможных ошибок, которые могут произойти при этом вызове:
+ файл f ile_name не существует или недоступен;
+ у файла f ile_name уже есть максимальное количество ссылок;
+ файл f ile_name является каталогом (создавать такие ссылки имеет право
только суперпользователь);
+ файл link_name уже существует;
+ файлы link_name и f ile_name расположены на разных устройствах.
Если все в порядке, в каталоге создается новая запись с именем link_name и но-
номером индексного узла file_name. В коде имя namel соответствует file._
name, a name2 — link_name. Вносит новую запись в каталог функция search_
dir, вызываемая из do_link в строке 27086.
Удаление файлов и каталогов происходит путем уничтожения ссылок на них.
Поэтому оба системных вызова unlink и rmdir обслуживаются единственной
функцией do_unlink (строка 27104). Опять же, в ней делается множество раз-
различных проверок, общий код убеждается, что файл существует и не является
точкой монтирования, после чего в зависимости от типа вызова управление пе-
передается либо процедуре remove_dir, либо unlink_f ile. Мы вскоре обсудим
эти две подпрограммы.
Код в файле link. с обеспечивает работу еще одного системного вызова, rename.
Пользователям UNIX должна быть знакома команда mv оболочки, которая рабо-
работает исключительно с этим вызовом. Ее название отражает еще один из аспектов
вызова, так как он способен не только менять имя файла, но и эффективно пере-
перемещать его из одного каталога в другой, причем операция перемещения атомар-
атомарная, что позволяет избежать условий гонок. Этот вызов обрабатывается функцией
do_rename (строка 27162). Перед выполнением команды проверяется множест-
множество условий, среди которых есть следующие:
+ исходный файл должен существовать (строка 27177);
+ новый путь не должен быть подкаталогом старого (строки 27217-27218);
+ новое имя не может быть ни записью точки (.), ни записью две точки (. .)
(строка 27221);
+ исходный и конечный каталоги должны находиться на одном устройстве
(строки 27224-27225);
+ как исходный, так и конечный каталоги должны быть доступны для записи
и поиска файла и располагаться на устройстве, доступном для записи (строки
27195-27212);
+ ни старое, ни новое имя не могут обозначать каталог, в который смонтирова-
смонтирована файловая система.
Если одноименный файл существует, нужно проверить еще ряд дополнительных
условий. Самое главное — должно быть разрешено удалить имеющийся файл.
Несколько приемов, реализованных в коде do_rename, служат для снижения
риска возникновения некоторых проблем. Если при переименовании файл с но-
новым именем уже существует, то при заполненном диске может произойти ошиб-
ошибка, невзирая на то, что в конечном итоге дополнительное место не используется.
Чтобы обойти эту проблему, старый файл сначала удаляется, за это отвечают
строки кода с 27260 по 27266. По тем же соображениям из каталога сначала уда-
удаляется старое имя файла (в строке 27280), а затем в него записывается новое во
избежание выделения для каталога нового блока. Это соображение неприменимо
к случаю, когда новый и старый файлы расположены в разных каталогах, поэто-
поэтому в строке 27285 сначала создается новое имя, а затем удаляется старое. Такой
подход должен снизить риск повреждения файловой системы, если произойдет
сбой, так как с точки зрения целостности гораздо лучше иметь две ссылки на
один индексный узел, чем индексный узел, на который нет ссылок ни в одном из
каталогов. Вероятность, что в процессе переименования кончится свободное ме-
место, невысока, а вероятность краха системы еще меньше, но в данном случае ни-
ничего не стоит приготовиться к худшему варианту.
Оставшиеся в файле link, с функции обеспечивают работу уже рассмотренных
функций. В дополнение к ним, функция truncate (строка 27316) вызывается
и из некоторых других мест в коде файловой системы. Она проходит по индекс-
индексному узлу зона за зоной, освобождая все найденные зоны, а также косвенные
блоки. Функция remove_dir (строка 27375) сначала делает ряд проверок, чтобы
удостовериться, что каталог можно удалить, а затем вызывает функцию unlink_
file (строка 27415). Если никаких ошибок не произошло, запись каталога очи-
очищается и счетчик в индексном узле декрементируется.
5.7.6. Прочие вызовы файловой системы
Оставшаяся группа вызовов представляют собой неоднородную смесь функций,
затрагивающих состояние, каталоги, механизмы ограничения доступа, время
и другие службы.
Управление состоянием каталогов и файлов
Файл stadir.c содержит код для шести системных вызовов: chdir, fchdir,
chroot, stat, f stat и f statf s. Изучая код last_dir, мы видели, что поиск
файла по имени начинается с проверки первого символа пути. Если первый сим-
символ оказывался косой чертой, брался указатель на корневой каталог, если нет —
на рабочий.
Чтобы сменить текущий рабочий (или текущий корневой) каталог, нужно всего
лишь изменить значения этих двух указателей в таблице процессов. То есть
обратиться к функциям do_chdir (строка 27542) и do_chroot (строка 27580)
соответственно. Обе они сначала выполняют необходимые проверки, а затем
вызывают функцию change (строка 27594), осуществляющую несколько до-
дополнительных проверок, и change_into (строка 27611) с целью открыть новый
каталог и заменить им старый.
Функция do_fchdir (строка 27529) поддерживает вызов fchdir, который
делает то же самое, что и chdir, однако в качестве аргумента получает не путь,
а дескриптор файла. Вызов fchdir проверяет допустимость дескриптора, и в слу-
случае положительного результата вызывает функцию change_into, фактически
выполняющую всю работу.
В функции do_chdir есть код, не исполняемый при вызове chdir пользова-
пользовательскими процессами (строки 27552-27570). Он предназначен специально для
менеджера процессов, чтобы менять каталог при выполнении вызова exec. Когда
пользователь запускает в своем рабочем каталоге файл, скажем, a.out, менед-
менеджеру процессов проще перейти в этот каталог, чем раздумывать, где он находится.
Оставшиеся два вызова, stat и f stat, одинаковы во всем, кроме способа зада-
задания файла. Первому требуется имя файла, в то время как второму — дескриптор
открытого файла — по аналогии с парой вызовов chdir и fchdir. Поэтому обе
процедуры верхнего уровня, do_stat и do_f stat, вызывают функцию stat_
inode, которая и выполняет все, что требуется. В функции do_stat перед вы-
вызовом stat_inode файл сначала открывается, с целью получить его дескрип-
дескриптор. Таким образом, обе эти функции передают в stat_inode дескриптор.
Вся работа функции stat_inode (строка 27673) сводится к сбору информации
о файле и записи ее в буфер. Затем этот буфер должен быть явным образом
скопирован в пользовательское адресное пространство, так как он слишком велик
и не помещается в сообщении. Это действие выполняет вызов sys_datacopy
ядра (строки 27713-27714).
Последняя функция, которую мы встречаем — do_f stats (строка 27721). Вы-
Вызов f statf s не относится к стандарту POSIX, однако в POSIX определен похо-
похожий вызов f statvf s, возвращающий значительно более объемную структуру
данных. В MINIX 3 вызов f statf s возвращает лишь одно значение — размер
блока файловой системы. Прототип вызова имеет следующий вид:
_PROTOTYPE( int fstatfs, (int fd, struct statfs *st));
Используемая им структура statfs проста и описывается одной строкой:
struct {off_t f_bsize; /* размер блока файловой системы */};
Эти определения находятся в файле include/ sys/ statfs .h.
Защита
Механизм защиты в MINIX 3 основан на битах rwx. Это три набора битов, каж-
каждый из которых определяет доступность файла для его владельца, группы и для
остальных. Значениями этих битов можно управлять при помощи системного
вызова chmod, инициируемого функцией do_chmod из файла protect .с (стро-
(строка 27824). Она сначала делает ряд проверок, а затем меняет режим доступа к фай-
файлу (строка 27850).
Вызов chown подобен вызову chmod в том, что он тоже меняет значения внут-
внутренних полей индексного узла некоторого файла. Поэтому их реализация тоже
достаточно схожа, хотя do_chown (строка 27862) позволяет менять владельца
файла только суперпользователю. Обычные пользователи вправе применять этот
вызов, чтобы менять принадлежность их собственных файлов к группе.
Вызов umask позволяет задать маску (хранящуюся в таблице процессов), которая
маскирует биты разрешений при последующих вызовах creat. Весь код уместил-
уместился бы в одну строку B7907), если бы не потребность в восстановлении старого
значения маски. Это дополнительное требование утраивает объем кода (стро-
(строки 27906-27908).
При помощи системного вызова access процесс может выяснить, разрешен ли
ему определенный способ доступа к файлу (например, на чтение). Этот вызов
реализуется функцией do_access (строка 27914), которая считывает индекс-
индексный узел файла, а затем вызывает вспомогательную функцию forbidden (стро-
(строка 27938). Та, в свою очередь, проверяет UID и GID процесса, а также инфор-
информацию в индексном узле и в зависимости от этих данных принимает решение
о том, разрешен доступ или запрещен.
Небольшая процедура read_only проверяет файловую систему, в которой распо-
расположен переданный ей индексный узел, и определяет, смонтирована ли она с дос-
доступом только на чтение. Эта функция необходима для предотвращения попыток
записи в такую файловую систему.
5.7.7. Интерфейс устройств ввода-вывода
Как уже неоднократно упоминалось в этой книге, целью разработки MINIX 3
было повышение надежности операционной системы за счет превращения драйве-
драйверов устройств в процессы, выполняемые в пользовательском пространстве и не
имеющие доступа к коду и структурам данных ядра. Основным преимуществом
такого подхода является то, что неисправность драйвера устройства не вызывает
краха всей системы, однако есть и другие достоинства. Так, драйверы устройств,
не нужные сразу после запуска системы, могут быть запущены в любой момент
после окончания загрузки. Это подразумевает, что драйверы можно останавли-
останавливать, перезапускать и заменять во время работы системы. Разумеется, за подоб-
подобную гибкость приходится расплачиваться ограничениями — вы не можете запус-
запустить несколько драйверов для одного устройства. В то же время, если драйвер
жесткого диска выйдет из строя, его можно перезапустить из копии, находящей-
находящейся на виртуальном диске.
В MINIX 3 доступ к драйверам устройств осуществляется из файловой системы.
В ответ на пользовательские запросы ввода-вывода файловая система посылает
сообщения драйверам устройств, находящимся в пользовательском пространст-
пространстве. В таблице dmap хранятся записи для всех возможных типов устройств; она
сопоставляет главные номера устройств с соответствующими драйверами. Сле-
Следующие два файла, которые мы рассмотрим, работают с таблицей dmap. Объяв-
Объявление таблицы находится в файле dmap. с. Этот файл также поддерживает ини-
инициализацию таблицы и новый системный вызов devctl, предназначенный для
запуска, остановки и перезапуска драйверов устройств. Далее мы изучим файл
device.с, поддерживающий обычные действия над устройствами в процессе
работы, такие как open, close, read, write и ioctl.
При открытии и закрытии устройства, записи и чтении из него таблица dmap
предоставляет имя процедуры, которая вызывается для обслуживания соответ-
соответствующей операции. Все эти процедуры расположены в адресном пространстве
файловой системы. Многие из них ничего не делают, однако некоторые вызывают
драйвер устройства, чтобы запросить фактический ввод-вывод. Таблица dmap так-
также содержит номера процессов, соответствующих каждому главному устройству.
При добавлении в MINIX 3 нового устройства в таблицу должна быть вклю-
включена новая строка, указывающая, какие действия нужно предпринять (если нуж-
нужно) при открытии, закрытии, чтении и записи устройства. Простой пример: если
в MINIX 3 добавляется накопитель на магнитных лентах, при открытии его файла
необходимо проверить, не используется ли он уже кем-либо.
Файл dmap.с начинается с макроопределения DT (строки 28115-28117), исполь-
используемого для инициализации таблицы dmap. Оно упрощает добавление нового
драйвера устройства при реконфигурировании MINIX 3. Элементы таблицы dmap
определены в файле include/minix/dmap .h; каждый элемент состоит из ука-
указателя на функцию, вызываемую при операциях open и close, указателя на
функцию, вызываемую при операциях read и write, номера процесса (индек-
(индекса в таблице процессов, а не PID) и набора флагов. Фактически таблица пред-
представляет собой массив перечисленных элементов, объявленный в строке 28132.
Глобальный доступ к ней осуществляется через файловый сервер. Размер табли-
таблицы определяется константой NR_DEVICES, равной 32 в описываемой здесь вер-
версии MINIX 3. Это почти вдвое превышает число устройств, поддерживаемых
операционной системой в текущий момент. К счастью, все неинициализирован-
неинициализированные переменные в языке С устанавливаются равными нулю, что гарантирует от-
отсутствие недостоверной информации в неиспользуемых элементах.
За объявлением dmap следует объявление init_dmap — массива макросов DT,
по одному на каждое главное устройство. Подстановка макроса инициализирует
запись в глобальном массиве на этапе компиляции. Чтобы понять, как использу-
используются макросы, следует рассмотреть несколько из них. Макрос init_dmap[l]
определяет запись драйвера памяти, главный номер которого равен 1. Макрос
имеет следующий вид:
DTA, gen_opcl, gen_io, MEM_PROC_NR, 0)
Драйвер памяти всегда присутствует и загружается вместе с загрузочным образом
системы. Первый параметр, равный 1, указывает на необходимость присутствия
драйвера. Второй и третий параметры определяют, что открытие и закрытие уст-
устройства осуществляет функция gen_opcl, а запись и чтение — функция gen_io.
Параметр MEM_PROC_NR задает запись в таблице процессов, используемую драй-
драйвером памяти, а 0 означает, что ни один флаг не установлен. Теперь рассмотрим
запись драйвера дисковода для дискет; она выглядит следующим образом:
DT@, no_dev, 0, 0, DMAP_MUTABLE)
Первое нулевое значение указывает на то, что запись относится к драйверу, ко-
который не обязан быть в загрузочном образе. По умолчанию при попытке откры-
открытия устройства первый указатель вызывает функцию no_dev, возвращающую
вызвавшему процессу ошибку ENODEV (нет такого драйвера). Следующие два
нулевых значения также используются по умолчанию: поскольку устройство
невозможно открыть, нет необходимости вызывать функцию для фактического
ввода-вывода. Нуль в элементе таблицы процессов интерпретируется как отсут-
отсутствие процесса. Значение DMAP_MUTABLE указывает на то, что изменения этой
записи разрешены (обратите внимание, что отсутствие такого флага в записи
драйвера памяти означает невозможность ее модификации после инициализа-
инициализации). Система MINIX 3 может быть сконфигурирована как на наличие, так и на
отсутствие драйвера дисковода для дискет в загрузочном образе. Если драйвер
присутствует и определен параметром загрузки label = FLOPPY как дисковое
устройство по умолчанию, при запуске файловой системы его запись изменяет-
изменяется. Если драйвера нет в загрузочном образе либо он не является драйвером по
умолчанию, его запись не изменяется с запуском файловой системы. Тем не ме-
менее возможность активации драйвера дискет позднее сохраняется. Как правило,
ее выполняет сценарий /etc/rc при запуске init.
Функция do_devctl (строка 28157) исполняется первой при обслуживании вы-
вызова devctl. Текущая ее версия очень проста: она распознает два запроса, DEV_
MAP и DEV_UNMAP, причем в последнем случае возвращается ошибка ENOSYS
(функция не реализована). Очевидно, эта мера временная; в случае запроса DEV_
MAP вызывается вторая функция, map_driver.
Полезно ознакомиться с текущим использованием вызова devctl и планами его
применения в будущем. В MINIX 3 поддержку запуска серверов и драйверов
в процессе функционирования операционной системы осуществляет серверный
процесс, называемый сервером реинкарнации (Reincarnation Server, RS). Ин-
Интерфейс к серверу реинкарнации предоставляет утилита service, а примеры ее
применения можно найти в файле /etc/rc. Вот один из них:
service up /sbin/floppy -dev /dev/fdO
По этой команде сервер реинкарнации совершает вызов devctl, чтобы запустить
двоичный файл /sbin/floppy в качестве драйвера для устройства с файлом
/dev/fdO. С этой целью сервер реинкарнации «запускает» указанный двоич-
двоичный файл посредством команды exec, однако также устанавливает специальный
флаг, откладывающий фактический запуск до тех пор, пока соответствующий
процесс не будет преобразован в системный. После того как процесс загружается
в память и выясняется его номер в таблице процессов, определяется главный но-
номер устройства. Затем эта информация включается в сообщение, адресованное
файловому серверу, который запросил операцию devctl DEV_MAP. С точки зре-
зрения инициализации интерфейса ввода-вывода эта часть работы сервера реин-
реинкарнации наиболее важна. Для полноты описания отметим, что в завершение
инициализации драйвера устройства сервер реинкарнации совершает еще вызов
sys_privctl, чтобы подготовить запись процесса драйвера в таблице priv
и дать ему возможность запуститься. В главе 2 мы уже говорили о том, что имен-
именно наличие собственной записи в таблице priv превращает обычный пользова-
пользовательский процесс в системный.
Сервер реинкарнации является нововведением и в описанной здесь версии MINIX 3
находится в «зачаточном» состоянии. В будущих выпусках операционной систе-
системы планируется сделать сервер реинкарнации мощным компонентом, способным
не только запускать драйверы, но также останавливать и перезапускать их. Кро-
Кроме того, сервер реинкарнации будет наблюдать за драйверами и автоматически
перезапускать их при появлении проблем. О текущем состоянии разработки вы
можете осведомиться на веб-сайте MINIX 3 (www.minix3.org) и группе новостей
comp.os.minix.
Продолжим рассмотрение файла dmap. с. Функция map_driver (строка 28178)
проста: если для записи в таблице dmap установлен флаг DMAP_MUTABLE, в каж-
каждую запись вносятся соответствующие значения. Для открытия и закрытия фай-
файла устройства существуют три варианта функции, один из которых выбирается
на основе значения параметра style, передаваемого в сообщении от сервера ре-
реинкарнации файловой системе (строки 28204-28206). Обратите внимание на то,
что поле dmap_f lags остается неизменным. Если запись содержит константу
DMAP_MUTABLE, она сохраняет свой статус после вызова devctl.
Третьей функцией файла dmap. с является build_map. Она вызывается функ-
функцией f s_init при первом запуске файловой системы до входа в основной цикл.
Первое, что она делает, — циклически перебирает все записи в локальной таб-
таблице init_dmap и копирует развернутые макросы в глобальную таблицу dmap
для каждой записи, у которой в качестве члена dmap_opcl не указана функция
no_dev. Это обеспечивает корректность инициализации записей. В противном
случае значения по умолчанию для неинициализированного драйвера задаются
в dmap. Оставшаяся часть функции build_map более интересна. В загрузочный
образ можно включать несколько драйверов дисковых устройств. По умолчанию
утилита makefile, расположенная в src/tools, помещает в него драйверы
at_wini, bios_wini и floppy. К каждому драйверу добавляется метка, и при-
присваивание label = в параметрах загрузки определяет, какой из них будет фак-
фактически загружен в образ и активирован как дисковый драйвер по умолчанию.
Обращения к env_get_param в строках 28248 и 28250 используют библиотеч-
библиотечные процедуры, которые, в конечном счете, получают строки параметров загруз-
загрузки label и controller при помощи вызова sys_getinfo ядра. Последней
вызывается функция build_map (строка 28267), которая изменяет в dmap за-
запись, соответствующую загрузочному устройству. Ключевым моментом здесь
является присваивание номеру процесса значения DRVR_PROC_NR, которое рав-
равно 6. Это магическое число; драйвер, запись которого имеет этот номер, является
драйвером по умолчанию.
Теперь мы займемся файлом device.с, содержащим процедуры, необходимые
для ввода-вывода на устройства в процессе работы.
Первая такая процедура — dev_open (строка 28334). Она вызывается другими
компонентами файловой системы (чаще всего функцией common_open из файла
main. с), когда выясняется, что операция open пытается получить доступ к спе-
специальному файлу устройства. Функции load_ram и do_mount также обра-
обращаются к процедуре dev_open. Ее действие аналогично действию ряда других
процедур, которые мы здесь рассмотрим. Она определяет главный номер уст-
устройства, проверяет его допустимость и использует для установки указателя в за-
записи таблицы dmap, а затем вызывает функцию, на которую указывает запись,
в строке 28349:
г = (*dp->dmap_opcl)(DEV_OPEN, dev, proc, flags)
В случае диска вызывается функция gen_opcl, а в случае.терминального устрой-
устройства — tty_opcl. Возврат кода SUSPEND говорит о серьезной проблеме; вызов
open не должен завершаться подобным образом.
Следующий вызов, dev_close (строка 28357), проще. Предполагается, что обра-
обращение к неисправному устройству невозможно, поэтому неудачное завершение
попытки открытия файла не причинит вреда. По этой причине сам код состоит
из единственной строки, в конце которой вызывается процедура *_орс1, так же
как при открытии устройства вызывалась процедура dev_open.
После получения файловой системой уведомления от драйвера устройства про-
происходит обращение к функции dev_status (строка 28366). Уведомление озна-
означает, что произошло какое-то событие, а указанная функция должна определить,
какое именно, и инициировать ответное действие. Источник уведомления опре-
определяется по номеру процесса, поэтому первое, что нужно сделать, — выполнить
поиск в таблице dmap и найти запись, соответствующую уведомляющему про-
процессу (строки 18371-18373). Не исключено, что уведомление ложное, поэтому
отсутствие искомой записи источника не является ошибкой. Если же источник
обнаружен, выполняется цикл в строках 28378-28398. На каждой итерации про-
процессу драйвера посылается сообщение, запрашивающее его состояние. Ожида-
Ожидаются три варианта ответа. Сообщение DEV_REVIVE может быть получено, если
процесс, запросивший ввод-вывод, был приостановлен. В этом случае происходит
обращение к функции revive (файл pipe, с, строка 26146). Сообщение DEV_
IO_READY приходит при обращении к устройству вызовом select, a DEV_NO_
STATUS ожидается в случае, если приходит одно или оба предыдущих сообще-
сообщения. По этой причине переменная get_more используется для повторения цик-
цикла до тех пор, пока не будет получено сообщение DEV_NO_STATUS.
Когда требуется выполнить фактический ввод-вывод на устройство, из функции
read_write (строка 25124) или rw_block (строка 22661) вызывается функция
dev_io (строка 28406); read_write обрабатывает символьные файлы, a rw_
block — блочные. Функция dev_io создает стандартное сообщение (см. табл. 3.3)
и посылает его указанному драйверу устройства, вызвав gen_io или ctty_io
согласно содержимому поля dp->dmap_driver таблицы dmap. Пока функция
dev_io ожидает ответ от драйвера, файловая система также ждет. В ней нет
внутренней многозадачности. Как правило, ожидание длится недолго (например,
50 мс), и доступ к данным может оказаться невозможным, особенно если они за-
запрошены с терминального устройства. В этом случае ответное сообщение может
содержать код SUSPEND; это позволит файловой системе продолжить работу,
приостановив лишь совершившее вызов приложение.
Процедура gen_opcl (строка 28455) вызывается для дисковых устройств —
дискет, жестких дисков и накопителей. Формируется сообщение, и, как для чте-
чтения/записи, с помощью таблицы dmap определяется функция, которая должна
отправить его драйверу — gen_io или ctty_io. Функция gen_opcl использу-
используется также для закрытия дисковых устройств.
Открытие терминального устройства осуществляет функция tty_opcl (стро-
(строка 28482). Возможно, изменив некоторые флаги, она вызывает gen_opcl, и если
вызов сделал терминал управляющим для активного процесса, этот факт фикси-
фиксируется в поле fp_tty таблицы процессов.
Устройство /dev/tty является фиктивным и не соответствует какому бы то ни
было реальному устройству. С его помощью пользователь обращается к собст-
собственному терминалу, при этом не важно, какой именно физический терминал
применяется. Чтобы открыть или закрыть /dev/tty, выполняется вызов функ-
функции ctty_opcl (строка 28518). Она определяет, изменял ли предыдущий вызов
ctty_opcl содержимое поля fp_tty записи таблицы процессов, чтобы указать
управляющий терминал.
Системный вызов sets id требует от файловой системы некоторой работы, ко-
которая выполняется функцией do_setsid (строка 28534). Она изменяет запись
текущего процесса в таблице процессов, указывая на то, что он является веду-
ведущим процессом сеанса и не имеет управляющего процесса.
Большая часть работы системного вызова ioctl выполняется в файле device. с.
Здесь же этот вызов появляется потому, что тесно связан с интерфейсом драйве-
ров устройств. При обращении к ioctl вызывается функция do_ioctl (строка
28554), которая создает сообщение и посылает его соответствующему драйверу.
Для управления терминальными устройствами программы, совместимые со
стандартом POSIX, должны использовать одну из функций, объявленных в фай-
файле include/termios .h. С-библиотека преобразует такие функции в вызовы
ioctl. Вызов ioctl широко применяется не только для терминальных уст-
устройств (см, главу 3).
Следующая функция, gen_io (строка 28575), является настоящей «рабочей
лошадкой» этого файла. Какое бы действие ни выполнялось с файлом — open,
close, read, write или ioctl, она всегда доводит его до завершения. По-
Поскольку устройство /dev/tty не является физическим, перед отправкой ему
сообщения необходимо найти правильные главный и вспомогательный номера
устройства и подставить их в сообщение. Именно это делает функция ctty_io
(строка 28652). Вызов выполняется с использованием записи фактического
устройства в таблице dmap. В текущей конфигурации MINIX 3 результатом яв-
является обращение к функции gen_io.
Функция no_dev (строка 28677) вызывается из записей таблицы, для которых
не существует устройства, например, для сетевого устройства на компьютере без
сетевой поддержки. Функция возвращает значение ENODEV и предотвращает ава-
аварийные ситуации при попытках доступа к несуществующим устройствам.
Последней функцией в файле device. с является clone_opcl (строка 28691).
После открытия некоторые устройства нуждаются в особой обработке. Они «кло-
«клонируются»: после успешного открытия происходит подмена устройства новым
с уникальным вспомогательным номером. Такая возможность не используется
в описываемой здесь версии MINIX 3. Тем не менее она применяется при сете-
сетевой поддержке. Устройство, нуждающееся в клонировании, обязательно имеет
запись в таблице dmap, в поле dmap_opcl которой указана функция clone_
opcl. К ней обращается сервер реинкарнации, задающий STYLE_CLONE. Когда
функция clone_opcl открывает устройство, она действует идентично gen_
opcl, однако новый вспомогательный номер устройства может быть возвращен
в поле REP_STATUS ответного сообщения. В этом случае, если возможно выде-
выделить новый индексный узел, создается временный файл. Видимой записи в ката-
каталоге не создается: в этом нет необходимости, так как файл уже открыт.
Время
Каждому файлу сопоставлены три 32-разрядных числа, связанные со временем.
Первые два хранят время последнего доступа к файлу и момент его последнего
изменения. В третьем фиксируется время последнего изменения состояния са-
самого индексного узла. Это время меняется практически при каждом обращении
к файлу, за исключением вызовов read и exec. Все значения хранятся в индекс-
индексном узле. При помощи системного вызова ut ime владелец файла или суперполь-
суперпользователь может изменить время доступа и изменения. Это делается процедурой
do_utime (строка 28818) из файла time. с, которая получает индексный узел
и записывает в него значения времени. Затем сбрасываются флаги, индицирующие,
что требуется обновить время (строка 28848), с целью избежать затратного и не-
ненужного здесь вызова clock_time.
Как мы знаем из предыдущей главы, реальное время рассчитывается как сумма
времени, отсчитанного от последнего запуска системы и поддерживаемого таймер-
ным заданием, и реального времени запуска. Возврат значения реального времени
осуществляет вызов stime. Большую часть его работы делает менеджер процессов,
однако глобальная переменная boot time, хранящая время запуска системы, под-
поддерживается файловой системой. Каждый раз при поступлении вызова stime
менеджер процессов посылает файловой системе сообщение, благодаря кото-
которому ее функция do_stime (строка 28859) обновляет переменную boot time.
5.7.8. Поддержка дополнительных
системных вызовов
В этом разделе мы рассмотрим некоторые файлы, поддерживающие дополнитель-
дополнительные системные вызовы. В следующем разделе будут упомянуты файлы и функ-
функции, обеспечивающие более обобщенную поддержку файловой системы.
Файл mis с. с содержит процедуры нескольких системных вызовов и вызовов
ядра, которые не включены в другие файлы.
Вызов do_getsysinfо предоставляет интерфейс вызова ядра sys_datacopy.
Он поддерживает информационный сервер (Information Server, IS) с целью от-
отладки. Вызов do_getsysinfo позволяет информационному серверу запраши-
запрашивать копии структур данных файловой системы, чтобы в дальнейшем отображать
их пользователю.
Системный вызов dup дублирует дескриптор файла. Другими словами, он созда-
создает новый дескриптор, указывающий на тот же файл, что передан ему в качестве
аргумента. Существует разновидность вызова dup — dup2. Обе версии обслужива-
обслуживаются одной функцией, do_dup. Она включена в MINIX 3 для поддержки старых
двоичных программ. На сегодняшний день оба вызова считаются устаревшими;
если какой-либо из них встречается в коде, написанном на языке С, С-библиоте-
ка текущей версии MINIX 3 выполняет системный вызов f cntl.
Вызов fcntl, обрабатываемый функцией do_fcntl, является предпочтитель-
предпочтительным методом запрашивания операций над открытым файлом. Запросы формиру-
формируются с использованием флагов, описанных в стандарте POSIX и перечисленных
в табл. 5.10. Вызов принимает дескриптор файла, код запроса и дополнительные
аргументы, требуемые конкретным запросом. Например:
dup2(fd, fd2);
Эквивалентом этого устаревшего запроса является такой запрос:
dup2(fd, F_DUPFD, fd2);
Некоторые запросы просто считывают или устанавливают флаг; их код состоит
всего лишь из нескольких строк. Например, запрос F_SETFD устанавливает бит,
принудительно закрывающий файл, когда процесс, являющийся его владельцем,
выполняет вызов exec. Запрос F_GETFD определяет, следует ли закрыть файл
при выполнении exec. Запросы F_SETFL и F_GETFL позволяют устанавливать
флаги, указывающие на доступность файла в неблокирующем режиме или для
операции добавления.
Таблица 5.10. Параметры запроса системного вызова FCNTL согласно стандарту POSIX
Действие Значение
F_DUPFD Дублирование дескриптора
F_GETFD Считывание флага закрытия файла при системном вызове exec
F_SETFD Установка флага закрытия файла при системном вызове exec
F_GETFL Считывание флагов состояния файла
F_SETFL Установка флагов состояния файла
F_GETLK Считывание состояния блокирования файла
F_SETLK Блокирование чтения и записи в файл
F_SETLKW Блокирование записи в файл
Функция do_f cntl также занимается обработкой блокирования файлов. Вызов
с командой F_GETLK, F_SETLK или F_SETLKW преобразуется в вызов lock_op,
рассмотренный в предыдущем разделе.
Следующий системный вызов, sync, копирует все блоки и индексные узлы, изме-
измененные со времени записи на диск. Его обработкой занимается функция do_sync.
Она просто выполняет поиск измененных записей во всех таблицах. Индексные
узлы должны быть обработаны первыми, поскольку функция rw_inode сохраня-
сохраняет свои результаты в кэше блоков. После записи в кэш блоков всех модифициро-
модифицированных индексных узлов все модифицированные блоки сбрасываются на диск.
Системные вызовы fork, exec, exit и set принадлежат менеджеру процессов,
однако их результаты должны быть доступны и здесь. При создании процесса
посредством fork необходимо, чтобы ядро, менеджер процессов и файловая сис-
система знали об этом. Эти «системные вызовы» поступают не от пользовательских
процессов, а от менеджера процессов. Процедуры do_f ork, do_exit и do_set
фиксируют соответствующую информацию в части таблицы процессов, принадле-
принадлежащей файловой системе. Процедура do_exec с помощью процедуры do_
close ищет и закрывает файлы, которые должны быть закрыты при вызове exec.
Последняя функция в файле mi s с. с не является системным вызовом, однако
обрабатывается похожим образом. Функция do_revive вызывается, когда драй-
драйвер устройства завершает работу, затребованную файловой системой, которую
он был не в состоянии выполнить ранее (например, предоставить пользова-
пользовательскому процессу введенные данные). Файловая система возобновляет про-
процесс и посылает ему ответное сообщение.
Существует системный вызов, поддержка которого осуществляется отдельными
заголовочным и исходным С-файлами. Это — вызов select, поддерживаемый
файлами select.hnselect.с. Вызов select используется тогда, когда одно-
одному процессу (к примеру, сетевому приложению или программе взаимодействия)
требуется работать с несколькими потоками ввода-вывода. Детальное его описа-
описание выходит за рамки темы данной книги.
5.7.9. Утилиты файловой системы
Файловая система содержит набор утилит — процедур общего назначения, ис-
используемых в различных ее областях. Они собраны в файле utility. с.
Функция clock_time посылает сообщения системному заданию, чтобы опреде-
определить текущее реальное время.
Функция f etch_name используется потому, что многие системные вызовы при-
принимают в качестве аргумента имя файла. Если имя короткое, оно включается
в сообщение, передаваемое от пользователя файловой системе. В противном слу-
случае сообщение содержит указатель на имя, находящееся в пользовательском
пространстве. Функция fetch_name обрабатывает оба варианта и возвращает
полученное имя файла.
Две функции предназначены для обработки общих классов ошибок. Функция
no_sys вызывается в случае, если файловая система получает вызов, не принадле-
принадлежащий ей. Функция panic выводит сообщение и информирует ядро о катастрофи-
катастрофическом событии. Аналогичные функции можно найти в файле pm/utility.c,
расположенном в исходном каталоге менеджера процессов.
Последние две функции, conv2 и conv4, помогают MINIX 3 справиться с про-
проблемой порядка следования байтов, различающегося между семействами про-
процессоров. Они вызываются при чтении и записи дисковых структур данных, на-
например индексных узлов и битовых карт. Порядок следования байтов в системе,
создавшей диск, записан в суперблоке. Если он отличается от порядка, исполь-
используемого локальным процессором, порядок следования меняется на противо-
противоположный. Остальная часть файловой системы не должна заботиться о том, как
байты расположены на диске.
Существует еще два файла, содержащие специальные утилиты для обслужива-
обслуживания файловой системы. Файловая система может обратиться к системному зада-
заданию, чтобы то установило для нее таймер, однако в случае, если требуется не-
несколько таймеров, файловая система может вести связанный список таймеров по
аналогии с тем, как это делает менеджер процессов (см. предшествующую гла-
главу). Это возможно благодаря поддержке файловой системы в файле timers. с.
Наконец, в MINIX 3 реализован уникальный способ использования CD-ROM,
позволяющий загружать с компакт-диска демонстрационную версию операцион-
операционной системы. Файлы MINIX 3 невидимы для операционных систем, поддержи-
поддерживающих только стандартные файловые форматы CD-ROM.
5.7.10. Прочие компоненты MINIX 3
Менеджер процессов, описанный в предыдущей главе, и файловая система, рас-
рассмотренная в этой главе, являются серверами пользовательского пространства,
предоставляющими поддержку, которая в традиционных операционных системах
интегрирована в ядро. Конечно же, в MINIX 3 существуют и другие серверные
процессы. Они находятся в пользовательском пространстве, имеют системные
привилегии и должны рассматриваться как компоненты операционной системы.
Ограниченный объем книги не позволяет рассмотреть их внутреннее устройст-
устройство, однако здесь мы как минимум упомянем несколько компонентов.
Один из них уже фигурировал в этой главе — это сервер реинкарнации, спо-
способный запускать обычные процессы и превращать их в системные. В текущей
версии MINIX 3 он применяется для запуска драйверов устройств, не входящих
в состав загрузочного образа. В будущих выпусках сервер реинкарнации сможет
останавливать и перезапускать драйверы, а также наблюдать за ними, чтобы
выполнять эти действия автоматически в случае выявления признаков сбоя.
Исходный код сервера реинкарнации находится в каталоге src/servers/rs/.
Вскользь был упомянут информационный сервер. Он используется для генера-
генерации отладочных дампов по нажатию соответствующих функциональных клавиш
традиционной клавиатуры персонального компьютера. Исходный код сервера
находится в каталоге src/servers/is/.
Информационный сервер и сервер реинкарнации являются программами отно-
относительно небольшого размера. Существует еще один дополнительный сервер —
сетевой сервер (INET) весьма внушительного объема. Его образ на диске сопос-
сопоставим с образом всей операционной системы MINIX 3. Он запускается сервером
реинкарнации аналогично драйверам устройств. Исходный код сетевого сервера
находится в каталоге src/servers/inet/.
Напоследок мы упомянем еще один компонент, который считается не сервером,
а драйвером устройства. Это — драйвер журнала. Поскольку операционная сис-
система содержит большое число компонентов, работающих как независимые про-
процессы, желательно иметь единый способ обработки диагностических сообщений,
предупреждений и сообщений об ошибках. Решение MINIX 3 состоит в созда-
создании драйвера псевдоустройства /dev/klog, способного получать сообщения
и обслуживать их запись в файл. Исходный код драйвера журнала находится
в каталоге src/drivers/log/.
Резюме
Со стороны файловая система представляется как коллекция файлов, каталогов
и инструментов для действий над ними. Можно считывать или записывать фай-
файлы, создавать и уничтожать каталоги и перемещать файлы из одного каталога
в другой. В большинстве современных файловых систем поддерживается иерар-
иерархическая структура каталогов, когда в один каталог может быть вложен второй
и т. д., до бесконечности.
Если же смотреть изнутри, открывается совершенно другая картина. Разработ-
Разработчики файловой системы должны заботиться о том, как выделяется место, и от-
отслеживать, какой блок какому файлу соответствует. Мы увидели, что в разных
файловых системах структуры каталогов различаются. Надежность и произво-
производительность файловой системы тоже имеют существенное значение.
Исключительно важны как для пользователей, так и для разработчиков системы
вопросы безопасности и защиты. Мы обсудили известные уязвимости старых
систем и общие проблемы, волне вероятные для многих других. Размышляя о за-
защите, мы рассмотрели аутентификацию, с паролем и без, списки управления
доступом, мандатные системы, а также матричную модель защиты.
Наконец, мы подробно изучили файловую систему MINIX 3. Ее код весьма объ-
объемен, но не очень сложен. Файловая система принимает запросы от пользователь-
пользовательских процессов, находит в таблице системных вызовов адреса процедур и вызы-
вызывает эти процедуры, чтобы обслуживать запросы. Благодаря модульной структуре
и тому, что файловая система вынесена из ядра, ее можно легко выделить из
MINIX 3, превратив в самостоятельный сетевой файловый сервер, внеся лишь
незначительные поправки.
При обращении к файлу MINIX 3 буферизует блоки в кэше и пытается делать
упреждающее чтение при последовательном режиме работы с файлом. Если кэш
достаточно велик, то при многократных обращениях к одному и тому же набору
программ (например, з процессе компиляции) нужный файл с высокой вероят-
вероятностью окажется в памяти.
Вопросы и задания
1. В файловой системе NTFS для именования файлов используется кодировка
Unicode, поддерживающая 16-разрядные символы. В чем преимущество име-
именования файлов в Unicode по сравнению с ASCII?
2. Некоторые файлы начинаются с «магического» числа. Для чего оно исполь-
используется?
3. В табл. 5.2 перечислены некоторые атрибуты файлов, однако в ней отсутству-
отсутствует атрибут четности. Является ли четность полезным атрибутом для файла?
Если да, то как ее можно использовать?
4. Создайте пять различных путей к файлу /etc/passwd. Подсказка: исполь-
используйте в каталоге записи точка (.) и две точки (. .).
5. В системах, поддерживающих последовательный доступ, всегда имеется опе-
операция «перемотки» файлов. Нужна ли такая операция в системах, поддержи-
поддерживающих файлы произвольного доступа?
6. В некоторых операционных системах предоставляется системный вызов rename,
позволяющий сменить имя файла. Есть ли разница между использованием
этого системного вызова и копированием файла с новым именем с последую-
последующим удалением старого файла?
7. Рассмотрите дерево каталогов на рис. 5.5. Если /usr/ j im является рабочим
каталогом, как будет выглядеть абсолютный путь для файла с относительным
путем ../ast/x?
8. Предположим, у файловой системы нет единого корневого каталога, а вместо
этого у каждого пользователя имеется собственный корневой каталог. Делает
ли это файловую систему более гибкой? Обоснуйте ответ.
9. В файловой системе UNIX имеется вызов chroot, делающий указанный ката-
каталог корневым. Оказывает ли это какое-либо влияние на безопасность? Если
да, то какое?
10. В системе UNIX имеется вызов, осуществляющий чтение записи каталога.
Поскольку каталоги представляют собой файлы, является ли создание подоб-
подобного вызова необходимостью?
11. Стандартный персональный компьютер способен работать не более чем с че-
четырьмя операционными системами одновременно. Существует ли возмож-
возможность увеличить это значение? Какие последствия вызовет ваше предло-
предложение?
12. Как говорилось в тексте, выделение непрерывных областей памяти под фай-
файлы приводит к фрагментации диска. Является эта фрагментация внутренней
или внешней? Проведите аналогию с предыдущей главой.
13. На рис. 5.8 показана структура файловой системы FAT, использовавшейся
в операционной системе MS-DOS. В исходной версии она имела всего 4096 бло-
блоков, поэтому таблица с 4096 A2 бит) записями была приемлема. Если это
решение перенести на системы с 232 блоками, сколько памяти заняла бы таб-
таблица FAT?
14. Операционная система поддерживает только один каталог, но позволяет хра-
хранить в нем произвольное количество файлов с именами любой длины. Мож-
Можно ли в такой системе имитировать иерархическую файловую систему? Как?
15. Учет свободного дискового пространства может осуществляться с помощью
списков или битовых карт. Дисковые адреса состоят из D бит. При каком
условии для диска из В блоков, F из которых свободны, список займет мень-
меньше места, чем битовая карта? Выразите ваш ответ в процентах от объема
диска для D = 16.
16. Было предложено хранить первую часть каждого файла системы UNIX в том
же дисковом блоке, что и его индексный узел. Каковы преимущества такого
подхода?
17. Производительность файловой системы зависит от процента блоков, которые
удается в нем найти. Напишите формулу для среднего времени удовлетво-
удовлетворения запроса блока при частоте успешных обращений, равной /г, если об-
обслуживание запроса с помощью кэша занимает 1 мс, а для считывания блока
с диска требуется 40 мс. Нарисуйте график этой зависимости для значений h
в интервале от 0 до 1,0.
18. В чем разница между жесткой связью и символической связью? Назовите
преимущества каждой из них.
19. Назовите три «ловушки», которых необходимо избегать при резервном копи-
копировании файловой системы.
20. У гибкого диска 4000 цилиндров, каждый из которых содержит 8 штук
512-блочных дорожек. Время установки составляет 1 мс на одно перемеще-
перемещение между цилиндрами. Если не пытаться разместить блоки файла впритирку,
среднее время установки при перемещении между двумя последовательными
блоками будет равно 5 мс. Если же файловая система предпримет попытку
объединить логически соседние блоки в кластеры, то среднее межблочное
расстояние может быть уменьшено до 2, а время установки — до 100 мкс.
Сколько времени потребуется для считывания 100-блочного файла в обоих
случаях, если задержка вращения составляет 10 мс, а время переноса одного
блока равно 20 мкс?
21. Полезно ли периодическое уплотнение дискового пространства? Поясните
ответ.
22. В чем разница между вирусом и червем? Как каждый из них размножается?
23. Закончив учебное заведение, вы получаете должность директора большого
университетского компьютерного центра, где только что отправили свою
древнюю операционную систему на заслуженный отдых и перешли на UNIX.
Вы начинаете работать. Через пятнадцать минут ваша ассистентка вбегает
в кабинет в панике: «Какие-то студенты обнаружили алгоритм, которым
мы шифруем наши пароли, и выложили его в Интернете». Какой будет ваша
реакция?
24. Две студентки с факультета кибернетики, Кэролин и Элинор, обсуждают ин-
индексные узлы. Кэролин утверждает, что память стала настолько дешевой, что
при открытии файла проще и быстрее считать новую копию индексного узла
в таблицу индексных узлов, чем искать этот индексный узел по всей таблице.
Элинор не согласна. Кто прав?
25. Схема защиты Морриса—Томпсона с n-разрядными случайными числами бы-
была разработана, чтобы затруднить взломщику отгадывание паролей при помо-
помощи подготовленного заранее словаря. Защищает ли такая схема от студентов,
пытающихся угадать пароль суперпользователя?
26. У факультета технической кибернетики есть локальная сеть с большим коли-
количеством машин, работающих под управлением операционной системы UNIX.
Пользователь на любой машине может ввести команду вида machine4 who,
и эта команда будет выполнена на компьютере machine4, для чего пользова-
пользователю не нужно регистрироваться на удаленном компьютере. Это свойство
реализовано следующим образом. Ядро системы машины пользователя по-
посылает команду и ее UID удаленной машине. Надежна ли такая схема, если
ядрам системы можно доверять (например, в случае крупных миникомпьюте-
ров с разделением времени, оснащенных защитным аппаратным обеспечени-
обеспечением)? Что, если одна из машин представляет собой персональный компьютер
студента, на который не установлена аппаратная защита?
27. При удалении файла его блоки, как правило, возвращаются в список свобод-
свободных блоков, но их содержимое не стирается. Как вы полагаете, хорошо ли, если
операционная система будет очищать каждый блок перед тем, как его осво-
освободит? Рассмотрите в вашем ответе факторы безопасности и производитель-
производительности, а также покажите, какой эффект окажет эта схема на каждый фактор.
28. В данной главе обсуждались различные механизмы защиты: списки манда-
мандатов, списки управления доступом и биты rwx. Какой из этих механизмов мо-
может быть применен для каждой из следующих проблем (рассматривая UNIX,
представьте, что группы соответствуют таким категориям, как факультет, сту-
студенты, секретари и т. д.):
1) Кен хочет, чтобы его файлы могли читать все, кроме его коллеги по офису;
2) Мич и Стив хотят вместе пользоваться некоторыми секретными файлами;
3) Линда хочет сделать открытыми некоторые из своих файлов.
29. Возможна ли атака с внедрением троянской программы в систему, защищен-
защищенную списками мандатов?
30. Размер таблицы f ilp сейчас задается константой NR_FILPS, определенной
в файле fs/const.h. Чтобы приспособить сетевую систему для работы
большего числа пользователей, может потребоваться увеличить константу
NR_PROCS в файле include/minix/config.h. Как в зависимости от NR_
PROCS нужно изменить NR_FILPS?
31. Предположим, произошел технологический прорыв и появилась энергонеза-
энергонезависимая память, сохраняющая свое содержимое при исчезновении питания,
а по цене и производительности не отличающаяся от традиционной опера-
оперативной памяти. Как это скажется на файловых системах?
32. Символические ссылки представляют собой файлы, косвенно указывающие
на другие файлы или каталоги. В отличие от обычных ссылок, реализованных
в MINIX 3, у символической ссылки есть собственные индексный узел и блок
данных. Блок данных содержит путь к объекту, на который направлена ссыл-
ссылка, а отдельный индексный узел позволяет ссылке принадлежать другому
пользователю и иметь другие разрешения доступа. Такая ссылка не обязана
находиться на том же устройстве, что и файл, на который она ссылается.
Символические ссылки не являются частью MINIX 3. Реализуйте их под-
поддержку в MINIX 3.
33. Хотя в настоящий момент размер файлов в MINIX 3 ограничен 32-разряд-
32-разрядным указателем, в будущем, с появлением 64-разрядных указателей, возник-
возникнет возможность работы с файлами объема больше 232 - 1 байт. В этом случае
могут понадобиться блоки с тройным уровнем косвенности. Включите в фай-
файловую систему их поддержку.
34. Покажите, как установка параметра ROBUST (в настоящий момент неисполь-
неиспользуемого) делает систему более или менее устойчивой в случае сбоя. Резуль-
Результат может быть любым, поскольку такое исследование для текущей версии
MINIX 3 не проводилось. Тщательно изучите, что происходит, когда изме-
измененный блок вытесняется из кэша. Учтите, что модификация блока может
быть дополнена модификацией индексного узла и битовой карты.
35. Разработайте механизм, позволяющий добавить поддержку «иноязычной»
файловой системы, чтобы, например, можно было смонтировать файловую
систему MS-DOS в каталог MINIX 3.
36. Напишите две программы на языке С или в виде сценария интерпретатора, пе-
передающие и принимающие сообщение по тайному каналу в системе MINIX 3.
Подсказки: во-первых, бит разрешения видим, даже если другие способы
доступа к файлу запрещены, во-вторых, команда или системный вызов sleep
гарантирует задержку фиксированной длительности, заданную аргументом.
Измерьте скорость обмена данными в простаивающей системе, затем создай-
создайте искусственную высокую нагрузку, запустив множество фоновых процес-
процессов, и снова измерьте скорость обмена данными.
37. Реализуйте в MINIX 3 непосредственные файлы (маленькие файлы, храни-
хранимые в индексном узле и экономящие время доступа к диску).
Глава 6
Библиография
В предыдущих пяти главах нами были затронуты разнообразные темы. Эта глава
призвана помочь читателям, желающим заняться углубленным изучением опе-
операционных систем. В пункте 6.1 приведен список рекомендуемой литературы,
а в пункте 6.2 — еще один список, в котором в алфавитном порядке перечислены
все публикации, цитаты из которых использованы в этой книге.
Полезными источниками публикаций об операционных системах являются сбор-
сборники докладов Симпозиума по принципам операционных систем (Symposium
on Operating Systems Principles), проводимого раз в два года, Международной
конференции по распределенным компьютерным системам (International Con-
Conference on Distributed Computing Systems), проводимой IEEE ежегодно, а также
Симпозиума USENIX по проектированию и реализации операционных сис-
систем. Кроме того, в журналах ACM Transactions on Computer Systems и Operating
Systems Review периодически публикуются статьи, имеющие отношение к дан-
данной тематике.
6.1. Рекомендуемая литература
Далее представлен список рекомендуемых публикаций по главам этой книги.
6.1.1. Вводные и общие публикации
+ Bovet and Cesati, Understanding the Linux Kernel, 3rd Ed.
Возможно, эта книга является лучшим выбором для тех, кто желает разобрать-
разобраться в принципах внутренней организации ядра операционной системы Linux.
+ Brinch Hansen, Classic Operating Systems.
Операционные системы существуют уже в течение достаточно долгого времени,
чтобы некоторые из них — те, которым удалось повлиять на место компьюте-
компьютеров в мире, — успели стать классическими. В данной книге собраны 24 статьи
о наиболее значимых операционных системах, разделенных на следующие кате-
категории: с открытым доступом, пакетные, многозадачные, разделения времени,
для персональных компьютеров, распределенные. Книга рекомендуется всем,
кто интересуется историей операционных систем.
♦ Brooks, The Mythical Man-Month: Essays on Software Engineering.
Остроумная, занимательная и содержательная книга на основе горького опы-
опыта ее автора рассказывает о том, как не нужно писать операционные системы.
Содержит множество полезных советов.
♦ Corbato, «On Building Systems That Will Fail».
В своей лекции, приуроченной к вручению премии Тьюринга, автор принци-
принципа разделения времени рассуждает о многих вопросах, затрагиваемых Брук-
Бруксом в The Mythical Man-Month. Он приходит к выводу о том, что все слож-
сложные системы обречены, а чтобы иметь хотя бы небольшой шанс на успех,
абсолютно необходимо избегать сложности в проектировании, стремясь к про-
простоте и изящности.
♦ Deitel et al, Operating Systems, 3rd Ed.
Общий учебник по операционным системам. В дополнение к стандартному
материалу он содержит подробные исследования операционных систем Linux
и Windows XP.
♦ Dijkstra, «My Recollections of Operating System Design».
Воспоминания одного из первых разработчиков операционных систем, нача-
начало которых уходит в те времена, когда термина «операционная система» еще
не существовало.
+ IEEE, Information Technology — Portable Operating System Interface (POSIX),
Part 1: System Application Program Interface (API) [C language].
Стандарт, некоторые разделы которого вполне доступны для понимания (на-
(например, приложение В, «Rationale and Notes», объясняющее причины принятых
решений). Преимуществом стандартов является то, что они по определению
не содержат ошибок. Если опечатка в имени макроса оказывается незамечен-
незамеченной в процессе редактуры, она перестает быть ошибкой и становится нормой.
♦ Lampson, «Hints for Computer System Design».
Автор — один из самых прогрессивных разработчиков инновационных операци-
операционных систем в мире. За свой многолетний опыт он собрал множество советов,
рекомендаций и руководств, а затем изложил их в занимательной и содержа-
содержательной статье. Как и книгу Брукса, эту статью настоятельно рекомендуется
прочитать каждому заинтересованному разработчику операционных систем.
♦ Lewine, POSIX Programmer's Guide.
Данная книга описывает стандарт POSIX в гораздо более доступной форме,
нежели официальный документ, а также включает обсуждения о преобразо-
преобразовании устаревших программ к стандарту POSIX и разработке новых программ
для POSIX-подобного окружения. Материал сопровождается многочислен-
многочисленными примерами кода, в том числе несколькими полноценными программа-
программами. В книге описаны все библиотечные функции и заголовочные файлы, тре-
требуемые стандартом POSIX.
♦ McKusick and Neville-Neil, The Design and Implementation of the FreeBSD
Operating System.
Эта книга описывает внутреннюю работу FreeBSD — современной операцион-
операционной системы семейства UNIX. Она охватывает процессы, ввод-вывод, управле-
управление памятью, сетевые и практически все прочие возможности FreeBSD.
+ Milojicic, «Operating Systems: Now and in the Future».
Представьте, что вы хотите задать шести ведущим мировым экспертам в об-
области операционных систем вопросы о сфере их деятельности и ее перспекти-
перспективах. Получите ли вы одни и те же ответы? Конечно, нет! Прочитайте, что они
рассказали автору этой книги.
♦ Ray and Ray, Visual Quickstart Guide: UNIX, 2nd Ed.
Примеры из нашей книги гораздо легче освоить, если вы чувствуете себя уве-
уверенно в обращении с операционными системами UNIX. Данная книга являет-
является одним из многочисленных руководств для начинающих пользователей
UNIX. Несмотря на различия в реализации, с точки зрения пользователя
MINIX и UNIX выглядят схоже, поэтому эта или другая аналогичная книга
поможет читателю в освоении MINIX.
+ Russinovich and Solomon, Microsoft Windows Internals, 4th Ed.
Если прежде внутренняя работа Windows была для вас «тайной за семью пе-
печатями», эта книга полностью раскроет тайну. В ней вы найдете исчерпываю-
исчерпывающие сведения о процессах, управлении памятью, вводе-выводе, сетевых воз-
возможностях, безопасности и других аспектах функционирования Windows.
+ Silberschatz et al, Operating System Concepts, 7th Ed.
Еще один учебник по операционным системам, в котором рассмотрены про-
процессы, управление памятью, файлы и распределенные системы. В качестве
примеров показаны операционные системы Linux и Windows XP.
+ Stallings, Operating Systems, 5th Ed.
Учебник по операционным системам, в котором, помимо всех основных тем,
рассмотрены распределенные системы; есть также приложение, посвященное
теории очередей.
♦ Stevens and Rago, Advanced Programming in the UNIX Environment, 2nd Ed.
В этой книге идет речь о написании на языке С программ, использующих интер-
интерфейс системных вызовов UNIX и стандартную библиотеку С. Представлен-
Представленные примеры протестированы на ядрах операционных систем FreeBSD 5.2.1
и Linux 2.4.22, Solaris 9, Darwin 7.4.0, а также на базе FreeBSD/Mach операци-
операционной системы Mac OS X 10.3. Имеется детальное описание соотношения
указанных реализаций со стандартом POSIX.
6.1.2. Процессы
+ Andrews and Schneider, «Concepts and Notations for Concurrent Programming».
Учебное пособие по процессам и взаимодействию между процессами, вклю-
включая активное ожидание, семафоры, мониторы, обмен сообщениями и прочие
методы. В данной статье также показано, как эти концепции поддерживаются
встроенными средствами различных языков программирования.
+ Ben-Ari, Principles of Concurrent and Distributed Programming.
Данная книга состоит из трех частей; первая включает главы, посвященные
взаимному исключению, семафорам, мониторам, проблеме обедающих фило-
философов, а также другим темам. Во второй части рассматривается распределен-
распределенное программирование и полезные языки для него. Третья часть посвящена
принципам реализации параллелизма.
♦ Bic and Shaw, Operating System Principles.
Этот учебник по операционным системам включает четыре главы, посвящен-
посвященные процессам, в которых не только рассматриваются общие принципы, но
и имеется немало материала о реализации.
♦ Milo et al., «Process Migration».
По мере вытеснения суперкомпьютеров кластерными системами вопрос пере-
переноса процессов с одних компьютеров на другие (например, с целью выравни-
выравнивания нагрузки) становится все более важным. В данном обзоре авторы рас-
рассматривают принципы переноса процессов, его достоинства и недостатки.
+ Silberschatz et al, Operating System Concepts, 7th Ed.
Главы 3-7 этой книги посвящены процессам и взаимодействию между ними,
включая планирование, критические секции, семафоры, мониторы и другие
классические проблемы взаимодействия между процессами.
6.1.3. Ввод-вывод
+ Chen et al., «RAID: High Performance Reliable Secondary Storage».
Параллельное использование нескольких жестких дисков для ускорения вво-
ввода-вывода характерно для высокопроизводительных систем. Авторы рас-
рассматривают эту концепцию и исследуют различные варианты ее организации
с точки зрения производительности, стоимости и надежности.
♦ Coffman et al., «System Deadlocks».
Краткий обзор взаимных блокировок, их причин, способов обнаружения и пре-
предотвращения.
+ Corbet et al., Linux Device Drivers, 3rd Ed.
Если вы действительно хотите понять, как работает ввод-вывод, попробуйте
написать драйвер устройства. Эта книга поможет вам сделать это для опера-
операционной системы Linux.
♦ Geist and Daniel, «A Continuum of Disk Scheduling Algorithms».
Описан обобщенный алгоритм планирования головки диска, а также пред-
представлены многочисленные экспериментальные данные и результаты модели-
моделирования.
+ Holt, «Some Deadlock Properties of Computer Systems».
Рассматриваются взаимные блокировки. Автор представляет модель на осно-
основе направленных графов, с помощью которой можно анализировать некото-
некоторые ситуации взаимных блокировок.
+ IEEE Computer Magazine, March 1994.
В этом номере опубликованы восемь статей о передовых технологиях ввода-
вывода, моделировании, высокопроизводительных накопителях данных, кэши-
кэшировании, вводе-выводе параллельных компьютеров и мультимедиа.
+ Levine, «Defining Deadlocks».
Автор этой небольшой статьи поднимает интересные вопросы, касающиеся
традиционных определений и примеров взаимных блокировок.
+ Swift et al., «Recovering Device Drivers».
Частота ошибок в драйверах устройств на порядок превышает этот показа-
показатель для прочих компонентов кода операционной системы. Существуют ли
возможности повышения надежности? В этой статье рассматривается реше-
решение этой задачи с помощью теневых драйверов.
+ Tsegaye and Foss, «A Comparison of the Linux and Windows Device Driver
Architecture».
Операционные системы Linux и Windows имеют принципиально различные
архитектуры драйверов устройств. Эти архитектуры, их сходства и различия
рассмотрены в данной публикации.
♦ Wilkes et al., «The HP AutoRAID Hierarchical Storage System».
Важной инновационной разработкой в области высокопроизводительных дис-
дисковых систем является RAID — массив небольших дисков, совместно обра-
образующих систему с высокой пропускной способностью. В данной публикации
авторы описывают систему, созданную ими в лабораториях HP Labs.
6.1.4. Управление памятью
+ Bic and Shaw, Operating System Principles.
Три главы этой книги посвящены управлению памятью, а также физической,
виртуальной и общей памяти.
♦ Denning, «Virtual Memory».
Классическая публикация по многим аспектам виртуальной памяти. Автор
был одним из пионеров в данной области и создателем концепции рабочего
множества.
♦ Denning, «Working Sets Past and Present».
Полезный обзор множества алгоритмов управления памятью и замещения
страниц. Сопровождается объемной библиографией.
♦ Denning, «The Locality Principle».
Новый взгляд на историю принципа локальности и обсуждение его примене-
применения к различным проблемам, не относящимся к замещению страниц.
+ Halpern, «VIM: Taming Software with Hardware».
В этой провокационной статье автор доказывает, что на создание, отладку
и поддержку программного обеспечения с оптимизированным использованием
памяти тратятся огромные денежные средства, причем это касается не только
системного программного обеспечения, но и компиляторов, а также прочих
программ. Автор приводит аргументы, согласно которым с макроэкономиче-
макроэкономической точки зрения выгоднее вкладывать деньги в приобретение дополнитель-
дополнительной памяти и работать с простыми и более надежными программами.
♦ Knuth, The Art of Computer Programming, Vol. 1.
В этой книге рассматриваются и сравниваются между собой различные алго-
алгоритмы управления памятью — первого соответствия, наилучшего соответст-
соответствия и др.
♦ Silberschatz et al, Operating System Concepts, 7th Ed.
Главы 8 и 9 данной книги посвящены управлению памятью, включая подкач-
подкачку, замещение страниц и сегментирование. Упоминается множество алгорит-
алгоритмов замещения страниц.
6.1.5. Файловые системы
♦ Denning, «The United States vs. Craig Neidorf».
Когда молодой хакер получил и опубликовал информацию о принципах ра-
работы системы телефонной связи, ему было предъявлено обвинение в компью-
компьютерном мошенничестве. Данная статья посвящена этому случаю, поднявшему
множество фундаментальных проблем, в том числе свободу слова. Статья
вызвала массу неоднозначных откликов, а сам автор впоследствии выступил
с опровержением.
♦ Ghemawat et al., «The Google File System».
Предположим, вы задались целью разместить дома весь Интернет, чтобы
всегда иметь любую информацию под рукой. Каким будет ваш первый шаг?
Вероятно, купить много персональных компьютеров, скажем, 200 000 штук.
Никаких особых возможностей от этих компьютеров не потребуется. Ваш
второй шаг — прочитать эту статью и узнать, как этот подход реализован в сис-
системе Google.
♦ Hafner and Markoff, Cyberpunk: Outlaws and Hackers on the Computer Frontier.
Три замечательные истории о молодых хакерах, взламывающих компьютеры
по всему миру, рассказанные компьютерным репортером газеты New York
Times и его соавтором. Ранее из-под пера этого репортера вышла история об
интернет-черве.
♦ Harbron, File Systems: Structures and Algorithms.
Книга, посвященная проектированию файловой системы, приложениям и про-
производительности. Содержит описания структур и алгоритмов.
♦ Harris et al., Gray Hat Hacking: The Ethical Hacker's Handbook.
В этой книге рассматриваются юридические и этические аспекты тестирова-
тестирования компьютерных систем на наличие уязвимостей, а также техническая ин-
информация об их возникновении и обнаружении.
♦ McKusick et al., «A Fast File System for UNIX».
В BSD 4.2 файловая система UNIX была реализована заново. В данной пуб-
публикации рассматривается архитектура новой файловой системы и ее произ-
производительность.
+ Satyanarayanan, «The Evolution of Coda».
С развитием мобильных компьютеров необходимость интеграции и синхрони-
синхронизации мобильных и фиксированных файловых систем становится все более
насущной. Первой системой, решающей данную задачу, стала Coda. Ее разви-
развитию и функционированию посвящена данная статья.
+ Silberschatz et al Operating System Concepts, 7th Ed.
Главы 10 и 11 этой книги посвящены файловым системам. В них рассмотре-
рассмотрены операции над файлами, методы доступа, семантика согласованности, ката-
каталоги, защита, реализация, а также ряд других вопросов.
+ Stallings, Operating Systems, 5th Ed.
Глава 16 этой книги содержит немало полезной информации о безопасной
среде. Особое внимание уделено хакерам, вирусам и прочим угрозам.
♦ Uppuluri et al., «Preventing Race Condition Attacks on File Systems».
В некоторых ситуациях предполагается, что две операции выполняются про-
процессом атомарно, то есть непрерывно. Если же другому процессу удается
вторгнуться и выполнить какие-либо действия между этими операциями, без-
безопасность системы может оказаться под угрозой. Данная статья рассматривает
эту проблему и предлагает решение.
+ Yang et al., «Using Model Checking to Find Serious File System Errors».
Ошибки в файловой системе могут привести к потере данных, поэтому ее от-
отладка представляет значительную важность. В этой статье описан формаль-
формальный метод, помогающий обнаружить ошибки в файловой системе раньше,
чем они нанесут вред, и представлены результаты его применения к реальной
файловой системе.
6.2. Алфавитный список литературы
1. Anderson, Т.Е., Bershad, B.N., Lazowska, E.D., and Levy, H.M.: «Scheduler Acti-
Activations: Effective Kernel Support for the User-Level Management of Parallelism,»
ACM Trans, on Computer Systems, vol. 10, pp. 53-79, Feb. 1992.
2. Andrews, G.R., and Schneider, F.B.: «Concepts and Notations for Concurrent
Programming,» Computing Surveys, vol. 15, pp. 3—43, March 1983.
3. Aycock, J., and Barker, K.: «Viruses 101,» Proc. Tech. Symp. on Сотр. Sci.
Education, ACM, pp. 152-156, 2005.
4. Bach, M.J.: The Design of the UNIX Operating System, Upper Saddle River, NJ:
Prentice Hall, 1987.
5. Bala, К., Kaashoek, M.F., and Weihl, W.: «Software Prefetching and Caching for
Translation Lookaside Buffers,» Proc. First Symp. on Oper, Syst. Design and Imp-
Implementation, USENIX, pp. 243-254, 1994.
6. Basili, V.R., and Perricone, B.T.: «Software errors and Complexity: An Empirical
Investigation,» Commun. of the ACM, vol. 27, pp. 43—52, Jan. 1984.
7. Bays, C: «A Comparison of Next-Fit, First-Fit, and Best-Fit,» Commun. of the
ACM, vol. 20, pp. 191-192, March 1977.
8. Ben-Ari, M: Principles of Concurrent and Distributed Programming, Upper Saddle
River, NJ: Prentice Hall, 1990.
9. Bic, L.F., and SHAW, A.C.: Operating System Principles, Upper Saddle River, NJ:
Prentice Hall, 2003.
10. Boehm, H.-J.: «Threads Cannot be Implemented as a Library,» Proc. 2004 ACM
SIGPLAN Conf. on Prog. Lang. Design and ImpL, ACM, pp. 261-268, 2005.
11. Bovet, D.P., and CESATI, M.: Understanding the Linux Kernel, 2nd Ed., Sebastopol,
CA, O'Reilly, 2002.
12. Brinch Hansen, P.: Operating System Principles Upper Saddle River, NJ: Prentice
Hall, 1973.
13. Brinch Hansen, P.: Classic Operating Systems, New York: Springer-Verlag, 2001.
14. Brooks, F. P., Jr.: The Mythical Man-Month: Essays on Software Engineering,
Anniversary Ed., Boston: Addison-Wesley, 1995.
15. Cerf, V.G.: «Spam, Spim, and Spit,» Commun. of the ACM, vol. 48, pp. 39—43,
April 2005.
16. Chen, H, Wagner, D., and Dean, D.: «Setuid Demystified,» Proc. 11th USENIX
Security Symposium, pp. 171-190, 2002.
17. Chen, P.M., Lee, E.K., Gibson, G.A., Katz, R.H., and Patterson, D.A.: «RAID: High
Performance Reliable Secondary Storage,» Computing Surveys, vol. 26, pp. 145—
185, June 1994.
18. Cheriton, D.R.: «An Experiment Using Registers for Fast Message-Based Inter-
Interprocess Communication,» Operating Systems Review, vol. 18, pp. 12—20, Oct. 1984.
19. Chervenak, A., Vellanski, V., and Kurmas, Z.: «Protecting File Systems: A Survey
of Backup Techniques,» Proc. 15th Symp. on Mass Storage Systems, IEEE, 1998.
20. Chou, A., Yang, J.-F., Chelf, В., and Hallem, S.: «An Empirical Study of Operating
System Errors,» Proc. 18th Symp. on Oper. Syst. Prin., ACM, pp. 73-88, 2001.
21. Coffman, E.G., Elphick, M.J., and Shoshani, A.: «System Deadlocks,» Computing
Surveys, vol. 3, pp. 67—78, June 1971.
22. Corbato', F.J.: «On Building Systems That Will Fail,» Commun. of the ACM, vol.
34, pp. 72-81, Sept. 1991.
23. Corbato', F.J., Merwin-Daggett, M., and Daley, R.C: «An Experimental Time-Sharing
System,» Proc. AFIPS Fall Joint Computer Conf., AFIPS, pp. 335-344, 1962.
24. Corbato', F.J., Saltzer, J.H., and Clingen, СТ.: «MULTICS - The First Seven
Years,» Proc. AFIPS Spring Joint Computer Conf., AFIPS, pp. 571-583, 1972.
25. Corbato', F.J., and Vyssotsky, V.A.: «Introduction and Overview of the MULTICS
System,» Proc. AFIPS Fall Joint Computer Conf., AFIPS, pp. 185-196, 1965.
26. Corbet, J., Rubini, A., and Kroah-Hartman, G.: Linux Device Drivers, 3rd Ed.
Sebastopol, CA: O'Reilly, 2005.
27. Courtois, P J., Heymans, F., and Parnas, D.L.: «Concurrent Control with Readers
and Writers,» Comimm. of the ACM, vol. 10, pp. 667-668, Oct. 1971.
28. Daley, R.C., and Dennis, J.B.: «Virtual Memory, Processes, and Sharing in
MULTICS,» Commun. of the ACM, vol. 11, pp. 306-312, May 1968.
29. Deitel, H.M., Deitel, P. J., and Choffnes, D. R.: Operating Systems, 3rd Ed., Upper
Saddle River, NJ: Prentice-Hall, 2004.
30. Denning, D.: «The United states vs. Craig Neidorf,» Commun. of the ACM, vol. 34,
pp. 22-43, March 1991.
31. Denning, P.J.: «The Working Set Model for Program Behavior,» Commun. of the
ACM, vol. 11, pp. 323-333, 1968a.
32. Denning, P.J.: «Thrashing: Its Causes and Prevention,» Proc. AFIPS National
Computer Conf., AFIPS, pp. 915-922, 1968b.
33. Denning, P.J.: «Virtual Memory,» Computing Surveys, vol. 2, pp. 153—189, Sept.
1970.
34. Denning, P.J.: «Working Sets Past and Present,» IEEE Trans, on Software Engi-
Engineering, vol. SE-6, pp. 64-84, Jan. 1980.
35. Denning, P.J.: «The Locality Principle,» Commun. of the ACM, vol. 48, pp. 19—24,
July 2005.
36. Dennis, J.B., and Van Horn, E.C.: «Programming Semantics for Multiprogrammed
Computations,» Commun. of the ACM, vol. 9, pp. 143—155, March 1966.
37. DiBona, C, Ockman, S., and Stone, M. eds.: Open Sources: Voices from the Open
Source Revolution, Sebastopol, CA: O'Reilly, 1999.
38. Dijkstra, E.W.: «Co-operating Sequential Processes,» in Programming Languages,
Genuys, F. (Ed.), London: Academic Press, 1965.
39. Dijkstra, E.W.: «The Structure of THE Multiprogramming System,» Commun. of
the ACM, vol. 11, pp. 341-346, May 1968.
40. Dijkstra, E.W.: «My Recollections of Operating System Design,» Operating Systems
Review, vol. 39, pp. 4-40, April 2005.
41. Dodge, C, Irvine, C, and Nguyen, Т.: «A Study of Initialization in Linux and
OpenBSD,» Operating Systems Review, vol. 39, pp. 79-93 April 2005.
42. Engler, D., Chen, D.Y., and Chou, A.: «Bugs as Inconsistent Behavior: A General
Approach to Inferring Errors in Systems Code,» Proc. 18th Symp. on Oper. Syst.
Prin., ACM, pp. 57-72, 2001.
43. Engler, D.R., Kaashoek, M.F., and O'Toole, J. Jr.: «Exokernel: An Operating System
Architecture for Application-Level Resource Management,» Proc. 15th Symp. on
Oper. Syst. Prin., ACM, pp. 251-266, 1995.
44. Fabry, R.S.: «Capability-Based Addressing,» Commun. of the ACM, vol. 17,
pp. 403-412, July 1974.
45. Feeley, M.J., Morgan, W.E., Pighin, F.H., Karlin, A.R., Levy, H.M., and Thekkath,
C.A.: «Implementing Global Memory Management in a Workstation CLuster,»
Proc. 15th Symp. on Oper. Syst. Prin., ACM, pp. 201-212, 1995.
46. Feustal, E.A.: «The Rice Research Computer — A Tagged Architecture,» Proc.
AFIPS Conf. 1972.
47. Fotheringham, J.: «Dynamic Storage Allocation in the Atlas Including an Automatic
Use of a Backing Store,» Commun. of the ACM, vol. 4, pp. 435-436, Oct. 1961.
48. Garfinkel, S.L., and Shelat, A.: «Remembrance of Data Passed: A Study of Disk
Sanitization Practices,» IEEE Security & Privacy, vol. 1, pp. 17-27, Jan.-Feb. 2003.
49. Geist, R., and Daniel, S.: «A Continuum of Disk Scheduling Algorithms,» ACM
Trans, on Computer Systems, vol. 5, pp. 77—92, Feb. 1987.
50. Ghemawat, S., Gobioff, H., and Leung., S.-T.: «The Google File System,» Proc.
19th Symp. on Oper. Syst. Prin., ACM, pp. 29-43, 2003.
51. Graham, R.: «Use of High-Level Languages for System Programming,» Project
MAC Report TM-13, M.I.T., Sept. 1970.
52. Hafner, K., and Markoff, J.: Cyberpunk: Outlaws and Hackers on the Computer
Frontier, New York: Simon and Schuster, 1991.
53. Halpern, M.: «VIM: Taming Software with Hardware,» IEEE Computer, vol. 36,
pp. 21-25, Oct. 2003.
54. Harbron, T.R.: File Systems: Structures and Algorithms, Upper Saddle River, NJ:
Pentice Hall, 1988.
55. Harris, S., Harper, A., Eagle, C, Ness, J., and Lester, M.: Gray Hat Hacking: The
Ethical Hacker's Handbook, New York: McGraw-Hill Osborne Media, 2004.
56. Hauser, C, Jacobi, C, Theimer, M., Welch, В., and Weiser, M.: «Using Threads in
Interactive Systems: A Case Study,» Proc. 14th Symp. on Oper. Syst. Prin., ACM,
pp. 94-105, 1993.
57. Hebbard, B. et al.: «A Penetration Analysis of the Michigan Terminal System»
Operating Systems Review, vol. 14, pp. 7—20, Jan. 1980.
58. Herborth, C: UNIX Advanced: Visual Quickpro Guide, Berkeley, CA: Peachpit
Press, 2005.
59. Herder, J.N.: «Towards a True Microkernel Operating System,» M.S. Thesis, Vrije
Universiteit, Amsterdam, Feb. 2005.
60. Hoare, C.A.R.: «Monitors, An Operating System Structuring Concept,» Commun.
of the ACM, vol. 17, pp. 549-557, Oct. 1974; Erratum in Commun. of the ACM,
vol. 18, p. 95, Feb. 1975.
61. Holt, R.C: «Some Deadlock Properties of Computer Systems,» Computing Surveys,
vol. 4, pp. 179-196, Sept. 1972.
62. Huck, J., and Hays, J.: «Architectural Support for Translation Table Management
in Large Address Space Machines,» Proc. 20th Annual Int'l Symp. on Computer
Arch., ACM, pp. 39-50, 1993.
63. Hutchinson, N.C., Manley, S., Federwisch, M., Harris, G., Hitz, D, Kleiman, S, and
O'Malley, S.: «Logical vs. Physical File System Backup,» Proc. Third USENIX
Symp. on Oper. Syst. Design and Implementation, USENIX, pp. 239-249, 1999.
64. IEEE: Information technology — Portable Operating System Interface (POSIX),
Part 1: System Application Program Interface (API) [C Language], New York:
IEEE, 1990.
65. Jacob, В., and Mudge, Т.: «Virtual Memory: Issues of Implementation,» IEEE
Computer, vol. 31, pp. 33-43, June 1998.
66. Johansson, J., and Riley, S: Protect Your Windows Network: From Perimeter to
Data, Boston: Addison-Wesley, 2005.
67. Kernighan, B.W., and Ritchie, D.M.: The С Programming Language, 2nd Ed.,
Upper Saddle River, NJ: Prentice Hall, 1988.
68. Klein, D.V.: «Foiling the Cracker: A Survey of, and Improvements to, Password
Security,» Proc. UNIX Security Workshop II, USENIX, Aug. 1990.
69. Kleinrock, L.: Queueing Systems, Vol. 1, New York: John Wiley, 1975.
70. Knuth, D.E.: The Art of Computer Programming, Volume 1: Fundamental Algo-
Algorithms, 3rd Ed., Boston: Addison-Wesley, 1997.
71. Lampson, B.W.: «A Scheduling Philosophy for Multiprogramming Systems,»
Commun. of the ACM, vol. 11, pp. 347-360, May 1968.
72. Lampson, B.W.: «A Note on the Confinement Problem,» Commun. of the ACM,
vol. 10, pp. 613-615, Oct. 1973.
73. Lampson, B.W.: «Hints for Computer System Design,» IEEE Software, vol. 1,
pp. 11-28, Jan. 1984.
74. Ledin, G., Jr.: «Not Teaching Viruses and Worms is Harmful,» Commun. of the
ACM, vol. 48, p. 144, Jan. 2005.
75. Leschke, Т.: «Achieving Speed and Flexibility by Separating Management from
Protection: Embracing the Exokernel Operating System,» Operating Systems
Review, vol. 38, pp. 5-19, Oct. 2004.
76. Levine, G.N.: «Defining Deadlocks,» Operating Systems Review vol. 37, pp. 54—64,
Jan. 2003a.
77. Levine, G.N.: «Defining Deadlock with Fungible Resources,» Operating Systems
Review, vol. 37, pp. 5-11, July 2003b.
78. Levine, G.N.: «The Classification of Deadlock Prevention and Avoidance is
Erroneous,» Operating Systems Review, vol. 39, 47—50, April 2005.
79. Lewine, D.: POSIX Programmer's Guide, Sebastopol, CA: O'Reilly & Associates,
1991.
80. Li, K., and Hudak, P.: «Memory Coherence in Shared Virtual Memory Systems,»
ACM Trans, on Computer Systems, vol. 7, pp. 321-359, Nov. 1989.
81. Linde, R.R.: «Operating System Penetration,» Proc. AFIPS National Computer
Conf., AFIPS, pp. 361-368, 1975.
82. Lions, J.: Lions' Commentary on Unix 6th Edition, with Source Code, San Jose,
С A: Peer-to-Peer Communications* 1996.
83. Marsh, B.D., Scott, M.L., Leblanc, T.J., and Markatos, E.P.: «First-Class User-
Level Threads,» Proc. 13th Symp. on Oper. Syst. Prin., ACM, pp. 110-121, 1991.
84. McHugh, J.A.M., and Deek, F.P.: «An Incentive System for Reducing Malware
Attacks,» Commun. of the ACM, vol. 48, pp. 94-99, June 2005.
85. McKusick, M.K., Joy, W.N., Leffler, S.J., and Fabry, R.S.: «A Fast File System for
UNIX,» ACM Trans, on Computer Systems, vol. 2, pp. 181-197, Aug. 1984.
86. McKusick, M.K., and Neville-Neil, G.V.: The Design and Implementation of the
FreeBSD Operating System, Addison-Wesley: Boston, 2005.
87. Milo, D., Douglis, F., Paindaveine, Y, Wheeler, R., and Zhou, S.: «Process
Migration,» ACM Computing Surveys, vol. 32, pp. 241-299, July-Sept. 2000.
88. Milojicic, D.: «Operating Systems: Now and in the Future,» IEEE Concurrency,
vol. 7, pp. 12-21, Jan.-March 1999.
89. Moody, G.: Rebel Code Cambridge, MA: Perseus, 2001.
90. Morris, R., and Thompson, K.: «Password Security: A Case History,» Commun. of
the ACM, vol. 22, pp. 594-597, Nov. 1979.
91. Mullender, S.J., and Tanenbaum, A.S.: «Immediate Files,» Software — Practice
and Experience, vol. 14, pp. 365—368, April 1984.
92. Naughton, J.: A Brief History of the Future, Woodstock, NY: Overlook Books,
2000.
93. Nemeth, E., Snyder, G., Seebass, S., and Hein, T. R.: UNIX System Administation,
3rd Ed., Upper Saddle River, NJ, Prentice Hall, 2000.
94. Organick, E.I.: The Multics System, Cambridge, MA: M.I.T. Press, 1972.
95. Ostrand, T.J., Weyuker, E.J., and Bell, R.M.: «Where the Bugs Are,» Proc. 2004
ACM Symp. on Softw. Testing and Analysis, ACM, 86-96, 2004.
96. Peterson, G.L.: «Myths about the Mutual Exclusion Problem,» Information Proces-
Processing Letters, vol. 12, pp. 115—116, June 1981.
97. Prechelt, L.: «An Empirical Comparison of Seven Programming Languages,» IEEE
Computer, vol. 33, pp. 23-29, Oct. 2000.
98. Ray, D.S., and Ray, E.J.: Visual Quickstart Guide: UNIX, 2nd Ed., Berkeley, CA:
Peachpit Press, 2003.
99. Rosenblum, M., and Ousterhout, J.K.: «The Design and Implementation of a Log-
Structured File System,» Proc. 13th Symp. on Oper. Syst. Prin., ACM, pp. 1—15,
1991.
100. Russinovich, M.E., and Solomon, D.A.: Microsoft Windows Internals, 4th Ed.,
Redmond, WA: Microsoft Press, 2005.
101. Saltzer, J.H.: «Protection and Control of Information Sharing in MULTICS,»
Commun. of the ACM, vol. 17, pp. 388-402, July 1974.
102. Saltzer, J.H., and Schroeder, M.D.: «The Protection of Information in Computer
Systems,» Proc. IEEE, vol. 63, pp. 1278-1308, Sept. 1975.
103. Salus, P.H.: A Quarter Century of UNIX, Boston: Addison-Wesley, 1994.
104. Sandhu, R.S.: «Lattice-Based Access Control Models,» Computer, vol. 26, pp. 9—19,
Nov. 1993.
105. Satyanarayanan, M.: «The Evolution of Coda,» ACM Trans, on Computer Systems,
vol. 20, pp. 85-124, May 2002.
106. Seawright, L.H., and MacKinnon, R.A.: «VM/370 - A Study of Multiplicity and
Usefulness,» IBM Systems Journal, vol. 18, pp. 4—17, 1979.
107. Silberschatz, A., Galvin, P.B., and Gagne, G.: Operating System Concepts, 7th Ed.,
New York: John Wiley, 2004.
108. Stallings, W.: Operating Systems, 5th Ed., Upper Saddle River, NJ: Prentice Hall,
2005.
109. Stevens, W.R., and Rago, S. A.: Advanced Programming in the UNIX Environment,
2nd Ed., Boston: Addison-Wesley, 2005.
110. Stoll, C: The Cuckoo's Egg: Tracking a Spy through the Maze of Computer
Espionage, New York: Doubleday, 1989.
111. Swift, M.M., Annamalai, M., Bershad, B.N., and Levy, H.M.: «Recovering Device
Drivers,» Proc. Sixth Symp. on Oper. Syst. Design and Implementation, USENIX,
pp. 1-16, 2004.
112. Tai, K.C., and Carver, R.H.: «VP: A New Operation for Semaphores,» Operating
Systems Review, vol. 30, pp. 5-11, July 1996.
113. Talluri, M., and Hill, M.D.: «Surpassing the TLB Performance of Superpages with
Less Operating System Support,» Proc. Sixth Int'l Conf. on Architectural Support
for Progr. Lang, and Operating Systems, ACM, pp. 171—182, 1994.
114. Talluri, M., Hill, M.D., and Khalidi, Y.A.: «A New Page Table for 64-bit Address
Spaces,» Proc. 15th Symp. on Oper. Syst. Prin., ACM, pp. 184-200, 1995.
115. Tanenbaum, A.S.: Modern Operating Systems, 2nd Ed., Upper Saddle River: NJ,
Prentice Hall, 2001.
116. Tanenbaum, A.S., Van Renesse, R., Staveren, H. Van, Sharp, G.J., Mullender, S.J.,
Jansen, J., and Rossum, G. Van: «Experiences with the Amoeba Distributed
Operating System,» Commun. of the ACM, vol. 33, pp. 46-63, Dec. 1990.
117. Tanenbaum, A.S., and Van Steen, M.R.: Distributed Systems: Principles and
Paradigms, Upper Saddle River, NJ, Prentice Hall, 2002.
118. Teory, T.J.: «Properties of Disk Scheduling Policies in Multiprogrammed Computer
Systems,» Proc. AFIPS Fall Joint Computer Conf., AFIPS, pp. 1-11, 1972.
119. Thompson, K.: «UNIX Implementation,» Bell System Technical Journal, vol. 57,
pp. 1931-1946, July-Aug. 1978.
120. Treese, W.: «The State of Security on the Internet,» NetWorker, vol. 8, pp. 13-15,
Sept. 2004.
121. Tsegaye, M., and FOSS, R.: «A Comparison of the Linux and Windows Device
Driver Architectures,» Operating Systems Review, vol. 38, pp. 8—33, April 2004.
122. Uhlig, R., Nagle, D., Stanley, T, Mudge, Т., Secrest, S., and Brown, R: «Design
Tradeoffs for Software-Managed TLBs,» ACM Trans, on Computer Systems, vol. 12,
pp. 175-205, Aug. 1994.
123. Uppuluri, P., Joshi, U., and Ray, A.: «Preventing Race Condition Attacks on File
Systems,» Proc. 2005 ACM Symp. on Applied Computing, ACM, pp. 346—353,
2005.
124. Vahalia, U.: UNIX Internals - The New Frontiers, 2nd Ed., Upper Saddle River,
NJ: Prentice Hall, 1996.
125. Vogels, W.: «File System Usage in Windows NT 4.0,» Proc. ACM Symp. on
Operating System Principles, ACM, pp. 93-109, 1999.
126. Waldspurger, C.A., and Weihl, W.E.: «Lottery Scheduling: Flexible Proportional-
Share Resource Management,» Proc. First Symp. on Oper. Syst. Design and
Implementation, USENIX, pp. 1-11, 1994.
127. Weiss, A.: «Spyware Be Gone,» NetWorker, vol. 9, pp. 18-25, March 2005.
128. Wilkes, J., Golding, R., Staelin, C, and Sullivan, Т.: «The HP AutoRAID Hierarchical
Storage System,» ACM Trans, on Computer Systems, vol. 14, pp. 108—136,
Feb. 1996.
129. Wulf, W.A., Cohen, E.S., Corwin, W.M, Jones, A.K., Levin, R., Pierson, C, and
Pollack, F J.: «HYDRA: The Kernel of a Multiprocessor Operating System,» Com-
mun. of the ACM, vol. 17, pp. 337-345, June 1974.
130. Yang, J., Twohey, P., Engler, D. and Musuvathi, M.: «Using Model Checking to
Find Serious File System Errors,» Proc. Sixth Symp. on Oper. Syst. Design and
Implementation, USENIX, 2004.
131. Zekauskas, M J., Sawdon, W.A., and Bershad, B.N.: «Software Write Detection for
a Distributed Shared Memory,» Proc. First Symp. on Oper. Syst. Design and
Implementation, USENIX, pp. 87-100, 1994.
132. Zwicky, E.D.: «Torture-Testing Backup and Archive Programs: Things You Ought
to Know but Probably Would Rather Not,» Prof. Fifth Conf. on Large Installation
Systems Admin., USENIX, pp. 181-190, 1991.
Приложение А
Установка MINIX 3
В данном приложении рассматриваются вопросы установки операционной систе-
системы MINX 3. Для полной установки требуются компьютер с процессором Pentium
(или совместимым), не менее 16 Мбайт оперативной памяти, 1 Гбайт свободного
дискового пространства, CD-ROM с интерфейсом IDE и жесткий диск с ин-
интерфейсом IDE. Минимальная установка (без исходных файлов команд) требует
8 Мбайт оперативной памяти и 50 Мбайт дискового пространства. Поддержка
Serial ATA, USB и SCSI-дисков в настоящий момент отсутствует. За информа-
информацией о CD-ROM с интерфейсом USB обращайтесь на сайт www.minix3.org.
А.1. Подготовка к установке
Если в вашем распоряжении имеется компакт-диск (например, приложенный
к этой книге), вы можете пропустить шаги 1 и 2, однако желательно осведомить-
осведомиться о наличии более новой версии операционной системы на сайте www.minix3.org.
Если вы хотите использовать MINIX 3 на симуляторе, сначала обратитесь к пунк-
пункту А.5. Если вы не располагаете IDE-устройством CD-ROM, получите специаль-
специальный загрузочный USB-образ CD-ROM или воспользуйтесь симулятором.
1. Загрузка образа компакт-диска MINIX 3 из Интернета.
Загрузите образ компакт-диска MINIX 3 с веб-сайта www.minix3.org.
2. Создание загрузочного компакт-диска MINIX 3.
Разархивируйте загруженный файл. Вы получите поразрядный файл образа
компакт-диска с расширением .iso и данное руководство. Запишите его на ком-
компакт-диск. Это и будет загрузочный компакт-диск.
Если вы пользуетесь программой Easy CD Creator 5, в меню File (Файл) выбе-
выберите команду Record CD from CD image (Записать CD из образа) и в появив-
появившемся диалоговом окне измените расширение файлов с cif на iso.
При использовании Nero Express 5 выберите команду Disk Image or Saved Project
(Образ диска или сохраненный проект) и измените тип на Image Files (Файлы
образов), далее выберите файл образа и щелкните на кнопке Open (Открыть).
Выберите устройство CD-RW и щелкните на кнопке Next (Далее).
Если вы используете Windows XP и не имеете программы для записи компакт-
дисков, вы можете найти бесплатную программу на сайте alexfeinman.brinkster.net/
isorecorder.htm и использовать ее для создания образа диска.
3. Определение типа имеющейся у вас Ethernet-платы.
MINIX 3 поддерживает несколько типов Ethernet-плат для работы в сети че-
через локальные сети, ADSL и кабель. Это Intel Pro/100, Realtek 8029 и 8139,
AMD LANCE и несколько микросхем 3 Com. Во время установки будет задан
вопрос, какие Ethernet-платы у вас имеются (если имеются); ответ можно уз-
узнать из документации. Есть и альтернативный способ — если вы используете
Windows, запустите диспетчер устройств следующим образом:
♦ в Windows 2000 перейдите по цепочке Пуск ► Настройка ► Панель управле-
управления ► Система ► Оборудование ► Диспетчер устройств (Start ► Settings ► Control
Panel ► System ► Hardware ► Device Manager);
♦ в Windows XP перейдите по цепочке Пуск ► Панель управления ► Система ►
Оборудование ► Диспетчер устройств (Start ► Control Panel ► System ► Hard-
Hardware ► Device Manager).
На значке Система в панели управления требуется щелкнуть дважды, во всех
остальных случаях достаточно одного щелчка. Раскройте список Сетевые
платы (Network Adapters), щелкнув на значке + (плюс) слева от списка, и запи-
запишите названия установленных сетевых плат. Если у вас нет сетевой платы,
поддерживаемой MINIX 3, вы все равно сможете запустить систему, но без
поддержки Ethernet.
4. Создание раздела на жестком диске.
Вы можете загружать компьютер с CD-ROM, если вам это нравится, и MINIX 3
будет работать, но чтобы делать что-либо полезное, вы должны создать раздел
на вашем жестком диске. Перед созданием раздела убедитесь, что не забыли
сделать резервные копии на внешних носителях (на CD-ROM или DVD) на
случай ошибок в процессе установки.
Если вы не являетесь экспертом по разбиению дисков на разделы, строго ре-
рекомендуется прочитать соответствующее интерактивное руководство по ад-
адресу www.minix3.org/doc/partitions.html. Узнав, как создавать разделы, создайте
раздел размером не менее 50 Мбайт (или 1 Гбайт, чтобы установить все ис-
исходные файлы). Если вы не знаете, как создавать разделы, но у вас установле-
установлена программа для управления разделами, например Partition Magic, исполь-
используйте ее для создания раздела. Также убедитесь, что хотя бы один основной
раздел (то есть главная загрузочная запись) свободен. Сценарий установки
MINIX 3 проведет вас через все этапы создания раздела для MINIX в свободном
пространстве, которое может быть как на первом, так и на втором ЩЕ-диске.
Если вы используете Windows 95, 98, ME или 2000 и ваш диск содержит один
FAT-раздел, вы можете использовать программу presz134.exe, имеющуюся на
CD-ROM (она также доступна на сайте zeleps.com) для уменьшения его размера,
чтобы оставить место под MINIX. Во всех остальных случаях читайте упомя-
упомянутое интерактивное руководство по адресу www.minix3.org/doc/partitions.html.
Если размер вашего диска превышает 128 Гбайт, раздел MINIX 3 должен
быть полностью размещен в первых 128 гигабайтах (из-за механизма адреса-
адресации дисковых блоков).
ВНИМАНИЕ
Если вы сделаете ошибку во время создания раздела, то можете потерять данные на диске,
поэтому сохраните их на CD или DVD перед началом установки. Разбиение на разделы тре-
требует большой осторожности по причине опасности потери данных.
А. 2. Загрузка
На данном этапе у вас должен иметься некоторый объем свободного пространст-
пространства на вашем диске. Если вы еще не освободили требуемого пространства, сделай-
сделайте это сейчас. Раздел, предназначенный для MINIX 3, должен существовать.
1. Загрузка с CD-ROM.
Вставьте CD-ROM в накопитель и загрузите с него компьютер. Если компью-
компьютер имеет не менее 16 Мбайт оперативной памяти, выберите вариант Regular
(Обычная загрузка), если есть только 8 Мбайт — вариант Small (Компактная
загрузка). Если компьютер загружается с жесткого диска вместо CD-ROM,
запустите его снова, войдите в программу настройки BIOS и установите та-
такой порядок загрузки, при котором сначала идет обращение к CD-ROM, а по-
потом к жесткому диску.
2. Вход в качестве пользователя root.
Когда появится запрос на вход в систему, войдите как пользователь root.
После успешного входа вы увидите приглашение оболочки (#). С этого мо-
момента вы работаете в полнофункциональной операционной системе MINIX 3.
Если вы введете следующую команду, то сможете увидеть, какое программ-
программное обеспечение доступно:
Is /usr/bin/ I more
Нажмите пробел для прокрутки списка. Чтобы узнать, что делает программа
f оо, наберите команду man f oo. Страницы руководств также доступны по
адресу http://www.minix3.org/manpages/.
3. Запуск сценария установки.
Для запуска сценария установки MINIX 3 на жесткий диск введите команду
setup. После этой и всех последующих команд не забудьте нажимать клавишу
Enter. Когда сценарий установки выведет на экран строки с текстом, нажмите
клавишу Enter для продолжения. Если экран внезапно погаснет, нажмите кла-
клавиши Ctrl+F3 для «программной прокрутки» (может понадобиться только на
очень старых компьютерах). Обозначение Ctrl+клавиша указывает на то, что
нужно нажать клавишу Ctrl и, удерживая ее, нажать указанную клавишу.
А.З. Установка на жесткий диск
Перечисленные в этом разделе шаги соответствуют приглашениям на экране.
1. Select keyboard type (Выберите тип клавиатуры).
Когда система попросит выбрать вашу национальную клавиатуру, укажите ее.
На этом и других шагах предлагаются значения по умолчанию, указанные
в квадратных скобках. Если вы согласны со значением по умолчанию, просто
нажмите клавишу Enter. В большинстве шагов стандартные значения — луч-
лучший выбор для начинающих. Тип клавиатуры us-swap меняет клавиши Caps
Lock и Ctrl, как принято в UNIX-системах.
2. Select your Ethernet chip (Выберите ваш тип Ethernet-платы).
На данном этапе нужно выбрать драйвер, который будет установлен для ва-
вашей сетевой платы (или его отсутствие).
3. Basic minimal or full distribution (Минимальная или полная установка).
Если дискового пространства не хватает, выберите вариант М для минималь-
минимальной установки, которая включает все бинарные файлы, но устанавливаются
только исходные тексты системы. Исходные тексты программ не устанавли-
устанавливаются. 50 Мбайт достаточно для системы с примитивной конфигурацией.
Если имеется 1 Гбайт или больше, выберите вариант F для полной установки.
4. Create or select a partition for MINIX 3 (Создание или выбор раздела для MINIX 3).
Вначале будет задан вопрос, являетесь ли вы экспертом по созданию разде-
разделов в MINIX 3. Если да, запустится программа part, чтобы дать вам полные
полномочия для редактирования главной загрузочной записи. Если вы не
эксперт, нажмите клавишу Enter для выбора варианта, предлагаемого по умол-
умолчанию — автоматической пошаговой процедуры форматирования раздела
диска под MINIX 3.
1) Select a disk to install MINIX 3 (Выбор диска для установки MINIX 3).
IDE-контроллер может иметь до 4 дисков. Сценарий установки просмат-
просматривает каждый из них. Игнорируйте любые сообщения об ошибках. Когда
появится список дисков, выберите один и подтвердите выбор. Если у вас
два жестких диска, вы решили установить MINIX 3 на второй из них и есть
проблемы с загрузкой с него, попробуйте найти решение по адресу http://
www.minix3.org/org/doc/using2disks.html.
2) Select a disk region (Выбор раздела диска).
Выберите раздел диска, в который будет установлена система MINIX 3.
У вас есть три варианта:
♦ Select a free region (Выбрать незанятое пространство);
♦ Select a partition to overwrite (Перезаписать существующий раздел);
♦ Delete a partition to free up space and merge with adjacent free space (Удалить
раздел для освобождения пространства и объединить с существующим сво-
свободным местом).
Для первых двух вариантов введите номер раздела. Для третьего варианта
введите команду delete, а при появлении запроса введите номер раздела.
Этот раздел запишется заново, а его предыдущее содержимое будет поте-
потеряно навсегда.
3) Confirm your choices (Подтвердите свой выбор).
В данный момент мы достигли того этапа, после выполнения которого
«пути назад» уже нет. Появится запрос о том, желаете ли продолжать.
Если да, то все данные в выбранной области будут потеряны. Если вы увере-
уверены, введите команду yes и нажмите клавишу Enter. Для выхода из сцена-
сценария установки без изменения таблицы разделов нажмите клавиши Ctrl+C.
5. Reinstall Choice (Переустановка).
Если вы выбрали существующий раздел MINIX 3, на этом шаге вам будет
предоставлен выбор между полной установкой (Full install), которая сотрет все
на разделе, и переустановкой (Reinstall), которая не затронет ваш существую-
существующий раздел /home. Это означает, что вы можете поместить свои персональ-
персональные файлы в /home и заменить старую систему новой версией MINIX 3 без
потери своих файлов.
6. Select the size of /home (Выберите размер/home).
Выбранный раздел будет разделен на три подраздела: root, /us r и /home.
Последний предназначен для ваших персональных файлов. Определитесь,
сколько дискового пространства должно быть выделено для ваших файлов.
Выбор нужно будет подтвердить.
7. Select a block size (Выбор размера блока).
Поддерживаются блоки размерами 1, 2, 4 и 8 Кбайт, но для использования
размера более 4 Кбайт нужно изменить константу и перекомпилировать систе-
систему. Если объем оперативной памяти составляет 16 Мбайт или более, выберите
стандартное значение D Кбайт); в противном случае задайте 1 Кбайт.
8. Wait for bad block detection (Проверка поврежденных блоков).
Сценарий установки будет сканировать каждый раздел для поиска повреж-
поврежденных блоков. Это может занять несколько минут, возможно 10 минут и бо-
более на больших разделах; проявите терпение. Если вы абсолютно уверены,
что неисправных блоков нет, можно прекратить сканирование любого из раз-
разделов, нажав клавиши Ctrl+C.
9. Wait for files to be copied (Копирование файлов).
Когда закончится сканирование, файлы будут автоматически скопированы
с CD-ROM на жесткий диск. Вы увидите каждый копируемый файл. Когда
копирование завершится, система MINIX 3 окажется установленной. Вы-
Выключите систему, набрав команду shutdown. Всегда останавливайте MINIX 3
этим способом для предотвращения потери данных, так как MINIX 3 хра-
хранит некоторые файлы на виртуальном диске и копирует их на жесткий диск
только при завершении работы.
А.4. Тестирование
В этом разделе рассказывается, как проверить установленную систему, заново
собрать систему после модификации и затем загрузить ее. Для начала загрузите
вашу новую систему MINIX 3. К примеру, если вы используете контроллер О,
диск 0, раздел 3, введите команду boot c0d0p3 и войдите как пользователь root.
По некоторым причинам номер диска, видимый BIOS (и используемый монито-
монитором загрузки), может не совпадать с применяемым MINIX 3. Сначала попробуйте
задействовать номер, предложенный сценарием установки. Это хороший момент
для создания пароля пользователя root (справку вы можете получить с помо-
помощью команды man passwd).
1. Компиляция набора тестов.
Для проверки MINIX 3 наберите в командной строке следующую пару команд:
cd /usr/src/test
make
Дождитесь, пока не завершатся все 40 компиляций, а затем выйдите из систе-
системы, нажав клавиши Ctrl+D.
2. Запуск набора тестов.
Для тестирования системы войдите как пользователь bin (обязательно) и по-
последовательно введите две команды для запуска тестовых программ:
cd /usr/src/test
. /run
Все они должны запуститься корректно, но могут выполняться 20 (и более)
минут на быстрой машине и не менее часа на медленной.
ПРИМЕЧАНИЕ
Если необходимо компилировать набор программ как root, а выполнять, как bin, проверьте,
что бит setuid установлен корректно.
3. Повторная сборка всей операционной системы.
Если все тесты работают правильно, вы можете собрать систему заново пря-
прямо сейчас. После установки новой системы это вряд ли необходимо, но если
вы планируете модифицировать систему, вам нужно знать, как собрать ее по-
повторно. Кроме того, это хороший способ ознакомиться с тем, как работает
система. Для просмотра доступных параметров введите две команды:
cd /usr/src/tools
make
Сделайте новый загрузочный образ следующими тремя командами:
SU
make clean
time make image
Вы только что собрали операционную систему, включая ядро и пользователь-
пользовательскую часть. Это было недолго, не правда ли? Если у вас имеется накопитель
для гибких дисков, вы можете создать загрузочную дискету для дальнейшего
использования, вставив отформатированную дискету и набрав команду
make fdboot
Когда система запросит у вас путь, наберите f dO. Такой подход в настоя-
настоящее время не работает с USB-накопителями для гибких дисков, поскольку
в MINIX 3 для них нет драйверов. Для обновления загрузочного образа, уста-
установленного на жесткий диск, введите команду
make hdboot
4. Остановка и перезагрузка новой системы.
Для загрузки новой системы сначала завершите работу с помощью команды
shutdown. Она сохранит некоторые файлы и возвратит вас в монитор загруз-
загрузки MINIX 3. Для получения информации о работе монитора загрузки набери-
наберите в нем команду help. За более подробными сведениями обратитесь на сайт
Ьйр://\ллллл/.т1п1х3.огд/тапраде8/тап8/Ьоо1.8.111т1. Теперь вы можете извлечь
компакт-диск или дискету и выключить компьютер.
5. Способы последующей загрузки.
Если ваш компьютер оснащен дисководом для гибких дисков, то простейший
путь загрузить MINIX 3 — вставить новую загрузочную дискету и включить
питание, что займет всего лишь несколько секунд. Альтернативный способ —
загрузиться с компакт-диска MINIX 3, войти как пользователь bin и ввести
команду shutdown, чтобы вернуться в монитор загрузки MINIX 3. Затем для
загрузки с файла образа операционной системы на контроллере 0, диске О,
в разделе 0 следует ввести следующую команду:
boot cOdOpO
Конечно, если вы установите MINIX 3 на диск 0 в раздел 1, команда должна
выглядеть так:
boot cOdOpl
Третий вариант загрузки — сделать раздел с MINIX 3 активным и исполь-
использовать монитор загрузки для запуска MINIX 3 или любой другой операци-
операционной системы. Подробности вы найдете по адресу www.minix3.org/manpages/
man8/boot.8.html.
Наконец, четвертый способ — установить мультизагрузчик, например LILO
или GRUB (www.gnu.org/software/grub). После этого с легкостью можно будет
загружать любую из ваших операционных систем. Обсуждение мультизагруз-
чиков выходит за рамки темы данного руководства; дополнительную инфор-
информацию можно получить по адресу http://www.minix3.org/doc.
А.5. Использование симулятора
Принципиально иным подходом к использованию системы MINIX 3 является ее
запуск поверх существующей операционной системы, а не непосредственно на
«голом» компьютере. Для этой цели имеется ряд виртуальных машин, симулято-
ров и эмуляторов. Вот наиболее популярные:
+ VMware (www.vmware.com);
+ Bochs (www.bochs.org);
+ QEMU (www.qemu.org).
Ознакомьтесь с соответствующей документацией. Запуск программы на симуля-
торе аналогичен ее запуску на реальном компьютере, поэтому следует вернуться
к пункту А.1, получить компакт-диск с последней версией операционной систе-
системы и продолжить работу согласно данному руководству.
Приложение Б
Список файлов MINIX 3
на компакт-диске
Заголовочные файлы
00000 include/ansi.h
00200 include/errno.h
00900 include/fcntl.h
00100 include/limits.h
00700 include/signal.h
00600 include/string.h
01000 include/termios.h
01300 include/timers.h
00400 include/unistd.h
04400 include/ibm/interrupt.h
04300 include/ibm/portio.h
04500 include/ibm/ports.h
03500 include/minix/callnr.h
03600 include/minix/com.h
02300 include/minix/config.h
02600 include/minix/const.h
04100 include/minix/devio.h
04200 include/minix/dmap.h
02200 include/minix/ioctl.h
03000 include/mmix/ipc .h
02500 include/minix/sys 1 config.h
03200 include/minix/syslib.h
03400 include/minix/sysutil.h
02800 include/minix/type.h
01800 mclude/sys/dir.h
02100 include/sys/ioc i disk.h
02000 include/sys/ioctl.h
01600 include/sys/sigcontext.h
01700 include/sys/stat.h
01400 include/sys/types.h
01900 include/sys/wait.h
Драйверы
10800 drivers/drivers.h
12100 drivers/at ! wini/at ! wini.с
12000 drivers/at ! wini/at ! wini.h
11000 drivers/libdriver/driver.с
10800 drivers/libdriver/driver.h
11400 drivers/libdriver/drvlib.c
10900 drivers/libdriver/drvlib.h
11600 drivers/memory/memory.с
15900 drivers/tty/console.c
15200 drivers/tty/keyboard.c
13600 drivers/tty/tty.c
13400 drivers/tty/tty.h
Ядро
10400 kernel/clock.с
04700 kernel/config.h
04800 kernel/const.h
08000 kernel/exception.с
05300 kernel/glo.h
08100 kernel/i8259.c
05400kernel/ipc.h
04600 kernel/kernel.h
08700 kernel/klib.s
08800 kernel/klib386.s
07100 kernel/main.с
06200 kernel/mpx.s
06300 kernel/mpx386.s
05700 kernel/priv.h
07400 kernel/proc.c
05500 kernel/proc.h
08300 kernel/protect.с
05800 kernel/protect.h
05100 kernel/proto.h
05600 kernel/sconst.h
06900 kernel/start.с
09700 kernel/system.с
09600 kernel/system.h
10300 kernel/system/do ! exec.с
10200 kernel/system/do ! setalarm.c
06000 kernel/table.с
04900 kernel/type.h
09400 kernel/utility.с
Файловая система
21600 servers/fs/buf.h
22400 servers/fs/cache.c
21000 servers/fs/const.h
28300 servers/fs/device.с
28100 servers/fs/dmap.с
21700 servers/fs/file.h
23700 servers/fs/filedes.с
21500 servers/fs/fproc.h
20900 servers/fs/fs.h
21400 servers/fs/glo.h
22900 servers/fs/inode.c
21900 servers/fs/inode.h
27000 servers/fs/link.c
23800 servers/fs/lock.c
21800 servers/fs/lock.h
24000 servers/fs/main.с
26700 servers/fs/mount.с
24500 servers/fs/open.с
22000 servers/fs/param.h
26300 servers/fs/path.c
25900 servers/fs/pipe.с
27800 servers/fs/protect.с
21200 servers/fs/proto.h
25000 servers/fs/read.c
27500 servers/fs/stadir.c
23300 servers/fs/super.с
22100 servers/fs/super.h
22200 servers/fs/table.c
28800 servers/fs/time.с
21100 servers/fs/type.h
25600 servers/fs/write.c
Менеджер процессов
19300 servers/pm/break.c
17100 servers/pm/const.h
18700 servers/pm/exec.c
18400 servers/pm/forkexit.с
20400 servers/pm/getset.с
17500 servers/pm/glo.h
18000 servers/pm/main.c
20500 servers/pm/misc.с
17 600 servers/pm/mproc.h
17700 servers/pm/param.h
17000 servers/pm/pm.h
17300 servers/pm/proto.h
19500 servers/pm/signal.с
17800 servers/pm/table.c
20300 servers/pm/time.c
20200 servers/pm/timers.c
17200 servers/pm/type.h
Алфавитный указатель
А Н
ACL, 593 HTTP, 62
ANSI, 158,353
ATA, 329 |
R I/O, 19
IDE, 313
BIOS, 323, 416 IDT> 190> 217
BSD, 32 IEEE) 32
IOPL, 175
С IPC, 92
C-list, 595 IPL, 547
CMS, 70 IS, 140,397,660
cookie, 582 ISA, 19
CP/M, 33 i-узел, 61
CRC, 317
C-Threads, 90 ■
CTSS, 30 °
JVM, 71
D
DDOS, 581 L
DMA, 258 LAMP, 39
DOS, 34,581 LBA, 330
LBA, 48, 331
E LDT, 217,461
ECC 255 LFS, 576
EIDE, 326 lock file, 295
EOF, 308 LRU, 445,611
LSI, 33
FAT, 551 M
FCFS, 317 M.I.T., 30
FIFO, 443 Mac OS X, 34
FMS, 27 MBR, 142,547
FORTRAN, 25 MFT, 418, 553, 558
FS. 139 MINIX, 36
FTP' 62 MMU, 427
Motif, 35
G MPI, 113
GDT, 190,216,461 MRU, 611
GID, 42 MS-DOS, 34
GUI, 34 MULTICS, 30
N А
NFU, 447 абсолютный путь, 543
NRU, 442 аварийный сигнал, 41
NTFS 532 558 автоконфигурирование, 258
автономный режим, 26
О адаптер
Ethernet, 292
OS/360, 28 ввода-вывода, 323
понятие, 254
р сетевой, 153
адрес
PFF, 453 виртуальный, 427
PID, 50, 145 линейный, 463
РМ, 139, 467 физический, 176
POSIX 32 адресация блоков
PPID 145 линейная, 330
PSW175 419 логическая, 314
' ' адресное пространство, 40
P-Threads, 90 активное ожидание, 97,257
активный раздел, 142
R алгоритм
RAID, 315 ™sclock' 451
RAM 414 банкира
' для нескольких видов ресурсов, 283
ROM, 34,323,414 для одного вида ресурсов, 281
RS, 140, 656 быстрого соответствия, 426
второго шанса, 444
§ замещения страниц, 440
q лтл 497 наилучшего соответствия, 425
' наихудшего соответствия, 425
ъ^ьи, 6iD первого соответствия, 424
SP, 67 планирования, 118
SPOOL, 30 вытесняющий, 120
SSF, 318 карусельного, 128
System V, 32 невытесняющий, 120
приоритетного, 129
*— циклического, 128
■ следующего соответствия, 424
TLB, 436 старения, 447
TSS, 196, 217 часов, 445
элеваторный, 318
U аппаратная прокрутка, 365
аппаратное прерывание, 149
UART, 343 архивация
UID, 42 инкрементная, 565
UNIX, 32 полная, 565
USB, 297 архитектура
0Qr компьютера, 21
U 1 y^i Zoo * . _.
набора команд, 19
теговая, 596
W асинхронная передача, 262
wsclock, 451 асинхронное событие, 240
ассоциативная память, 436
у атака
отказа в обслуживании, 579, 581
X Windows, 34 с черного хода, 584
атомарное действие, 103 взаимное исключение, 94
атрибут взаимодействие между процессами, 41, 92, 168
внутреннего состояния процесса, 84 видеоконтроллер, 341
нерезидентный, 558 видеопамять, 341
символа, 342 виртуальная консоль, 391
файла, 538 виртуальная машина, 18, 22, 69
аутентификация виртуальная память, 420, 426
пользователя, 586 виртуальное адресное пространство, 427
сервера, 111 виртуальный адрес, 427
виртуальный диск, 142
Б вирус, 581
, ,лс включаемый файл, 157
базовая система ввода-вывода, 416 •. .«Л ,_о
базовый регистр, 419 внешняя пигментация, 460 478
бездисковая рабочая станция, 187 внутренняя фрагментация 454, 478
безопасное состояние, 281 вредоносная программа, 580
безопасность, 578 временная метка, 207
библиотека совместного доступа, 459 время
библиотечная процедура, 544 всеобщее скоординированное, 235
бит оборота, 122
грязный, 435 отклика, 123
защиты, 434 реальное, 236
изменения 435 вспомогательный номер устройства, 266
обращения, 435 встраиваемый модуль, 583
ожидания активизации, 102 второстепенное устройство, 62
присутствия/отсутствия, 429 выгружаемый ресурс, 271
состояния, 257 выделенное устройство, 262
битовая карта, 422 вызов
блок системный, 39, 222
загрузочный, 185, 547, 604 супервизора, 65
косвенный, 552 ядра, 65, 138, 222
недостающий, 568 вытесняющее планирование, 120
страничный, 428
управления |"
памятью, 427
процессом 86 гарантированное планирование, 132
блокировка ' гибкая система реального времени, 134
двухфазная, 285 главная загрузочная запись, 142,547
процесса, 84 главная таблица файлов, 553, 558
файлов, 617 главный номер устройства, 266
блочное кэширование, 62 главный раздел, 548
блочное устройство ввода-вывода, 253 глобальная таблица дескрипторов, 190,216,461
блочный кэш, 571 глобальное замещение страниц, 451
блочный специальный файл, 45, 535 глобальный дескриптор, 190, 216
буферизация, 262 гонки, 94
буферный кэш, 571 графический интерфейс пользователя, 34
группа
g вторжения, 584
грязный бит, 435
ввод-вывод, 252
аппаратное обеспечение, 252 ц
отображаемый на память, 256, 257 "
программное обеспечение, 261 дамп
вектор прерываний, 87 логический, 566
взаимная блокировка, 106, 270 физический, 565
планирования, 273 двоичный семафор, 105
ресурсов, 273 двухфазная блокировка, 285
демон защита
печати, 93, 268 от дурака, 537
понятие, 81, 141 от несанкционированного доступа, 578
дескриптор понятие, 578
глобальный, 190,216 защищенный режим, 168
локальный, 216 злоумышленник, 580
прерывания, 87, 190 зомби, 479
сегмента, 471
файла, 44, 616 шм
шлюза прерывания, 196
джиттер, 124 идентификатор
диск группы, 42
виртуальный, 142 пользователя, 42
загрузочный, 142 процесса, 50
добавление соли, 587 иерархия памяти, 414
добровольная блокировка файлов, 617 имя
домен защиты, 591 пути, 43
Доступ файла, 43
последовательный, 537 инверсия приоритета, 100
произвольный, 537 инвертированная таблица страниц, 438
доступность системы, 579 индексный узел, 61,552
дочерний процесс, 41 инициализируемая переменная, 177
драйвер устройства, 139,254,263 инкрементная архивация, 565
дружественный интерфейс, 34 инкрементная резервная копия, 565
интерпретатор команд, 40
Е интерфейс
единообразное именование, 261 графический, 34
дружественный, 34
л|л жестких дисков с интегрированной
электроникой, 325
жесткая связь, 546,554 командной строки, 34
жесткая система реального времени, 134 передачи сообщений, ИЗ
жидкокристаллический дисплей, 341 системного вызова, 32
информационный сервер, 140, 397
3 исключение, 149, 205
зависание, 115
заголовок К
процедуры 536 ^^ 45
сектора 255 ввода-вывода, 255
файла, 192, 475, 535 „ спп
заголовочный файл, 157 секретный, 599
загрузочный блок, 185,547,604 канонический режим, 345
загрузочный диск, 142 карта
загрузочный образ, 142, 186, 498 активных сигналов, 148
задание активных уведомлений, 148
программное, 25 источников прерываний, 148
с наименьшим временем завершения, 126 клавиш, 368
системное, 138, 222 карусельное планирование, 128
таймерное, 138 каталог, 42,541
замещение страниц, 427 корневой, 43
глобальное, 451 рабочий, 43, 544
локальное, 451 спулера, 93
опережающее, 450 спулинга, 268
по запросу, 449 страничный, 463
запрос-отзыв, 588 текущий, 544
зарезервированный суффикс, 162 квант, 128
клиентский процесс, 73 мандат, 595
клик, 474 маска, 595
ключ, 534 машина
ключевое поле, 534 виртуальная, 18, 22, 69
код расширенная, 22
исправления ошибок, 255 машинный язык, 19
общий, 470, 476 меандр, 234
опроса, 358 межпроцессное взаимодействие, 41
кодовая страница, 346 менеджер
команда тигров, 584 памяти, 414
консоль процессов, 139
виртуальная, 391 метаданные, 535, 538
оператора, 68 метка
контекст, 177 адреса удаленных данных, 21
контроллер временная, 207
прерываний, 196 локальная, 199
устройства, 254 механизм планирования, 135
контрольная сумма, 255 микроархитектурный уровень, 19
конфиденциальность данных, 579 микрокомпьютер, 33
корзина, 564 микропрограмма, 19
корневая файловая система, 44 микропроцессор, 33
корневой каталог, 43 многозадачность, 29,79
косвенный блок, 552 многопроцессорная система, 78
коэффициент использования процессора, 122 многоуровневая операционная система, 67
критическая секция, 94 мода 63
КУ™' 420 модель
кэш процессов, 78
блочный, 571 рабочего набора, 449
буферный, 571 модуль
со сквозной записью, 573 встраиваемый, 583
кэширование, 62 программы, 51
монитор
Л виртуальной машины, 69
легковесный процесс, 89 загрузки, 185
лидер сеанса, 380 обращений, 590
линейная адресация блоков, 330 понятие, 106
линейный адрес, 463 монолитная операционная система, 65
ловушка, 223 монтирование, 261
логическая адресация блоков, 314 мьютекс, 105
логическая бомба, 582 мэйнфрейм, 25
логический дамп, 566
логический раздел, 548 Н
локальная метка, 199 невыгружаемый ресурс, 271
локальная таблица дескрипторов, 216,461 .пл
у !ел невытесняющее планирование, 120
локальное замещение страниц, 451 „ , ~ХО
* « /оЛ/п недостающий блок, 568
локальность обращении, 436,449 о о. -
г ' ,„ неканонический режим, 345
локальный дескриптор, 216 к ' ...
у о/' непериодические события, 134
локальный режим, 351 „ , „ rrrk
,оо непосредственный файл, 559
лотерейное планирование, 132 у „ %, ' го
нерезидентный атрибут, 558
-- номер
™ страничного блока, 434
магическое число, 535, 604, 622 устройства
макрос проверки поддерживаемых вспомогательный, 266
функций, 158, 173 главный, 266
Q переменная
инициализируемая, 177
оболочка, 46 условная, 107
обработка ошибок, 261 перехват
обработчик исключения, 53
прерываний, 215 клавиатурного ввода, 581
сигнала, 484 сигнала, 484
образ периодические события, 134
загрузочный, 142, 186, 498 пиксел, 341
памяти, 40 планирование
системный, 186 в системах реального времени, 134
общие права, 597 вытесняющее, 120
общий код, 470, 476 гарантированное, 132
объединение пространств данных и кода, 468 карусельное, 128
объект, 593 лотерейное, 132
объявление, 158 механизм, 135
оверлей, 426 невытесняющее, 120
ограничительный регистр, 419 политика, 135
одноразовый пароль, 587 приоритетное, 129
однородный ресурс, 271 справедливое, 133
операционная система, 18 циклическое, 128
многоуровневая, 67 планировщик, 118
монолитная, 65 допуска, 126
распределенная, 35 памяти, 127
сетевая, 35 процессора, 127
опережающее замещение страниц, 450 планируемая система реального времени, 134
определение функции, 158 поврежденный блок, 320
опрос, 257 подкачка, 29
отказ в обслуживании, 579, 581 подтверждение приема, 111
открытый исходный код, 39 поиск с перекрытием, 314
отладочный дамп, 179 поколения компьютеров
относительный путь, 544 второе, 25
ошибка отсутствия страницы, 429 первое, 24
четвертое, 33
|"| политика планирования, 135
полное имя файла, 43
пакетная обработка, 25 пользовательский режим, 20, 139
палмтоп, 415 порт ввода-вывода, 256
память последовательный доступ, 537
ассоциативная, 436 постоянная память, 34
виртуальная, 420,426 почтовый ящик, 112
иерархия, 414 право доступа, 591
постоянная, 34 преамбула
сжатие, 420 битового потока, 255
уплотнение, 420 управляющей последовательности, 366
папка, 541 прерывание, 195, 215
параметр загрузки, 186, 325 аппаратное, 149
пароль, 587 программное, 149
первым пришел — первым обслужен, 124 префикс расширенных клавиш, 394
переадресация, 418 префиксный символ, 349
передача приватность, 579
асинхронная, 262 примитив
синхронная, 262 взаимодействия между процессами, 223
сообщений, 110 сообщения, 223
переключение принцип наименьшего уровня привилегий, 598
контекста, 128, 177 принципал, 593
процессов, 128 приоритетное планирование, 129
проблема р
изоляции, 599
инверсии приоритета, 100 рабочая станция
обедающих философов, ИЗ бездисковая, 187
ограниченности буфера, 101 рабочий каталог, 43, 544
переадресации, 418 рабочий набор, 449
производителя и потребителя, 101 раздел
читателей и писателей, 117 активный, 142
пробуксовка, 449 главный, 548
программа диска, 62, 142
вредоносная, 580 логический, 548
начальной загрузки, 142 расширенный, 548
троянская, 582 фиксированный, 416
шпионская, 582 разделение
программная независимость от устройств, 261 времени, 30
программная прокрутка, 365 пространств данных и кода, 468
программное прерывание, 149 процессора, 248
программный поток, 89 разделяемое устройство, 262
произвольный доступ, 537 рандеву, 113,147
прокрутка, 365 раскладка клавиатуры, 368
аппаратная, 365 распределенная общая память, 456
программная, 365 распределенная операционная система, 35
промежуточное программное обеспечение, 32 распределенная система, 32
пропорциональность, 123 распределенный отказ в обслуживании, 581
пропускная способность, 122 расширение имени файла, 532
пространство расширенная машина, 22
адресное, 40 расширенный раздел, 548
дисковое, 37 расщепление данных, 316
оперативной памяти, 23 реальное время, 236
прототип функции, 158 регистр
nP°f?yPa e// базовый, 419
библиотечная, 544 ограничительный, 419
понятие 151 сегментный, 471
процесс, 40 устройства, 19
блокировка, 84 J v
дочерний, 41 режим „ ос
завершение, 82 автономный, 26
клиентский, 73 без обРабо™и' ^
концепция, 78 защищенный, 168
легковесный, 89 канонический 345
модель, 78 локальный, 351
ограниченный возможностями неканонический, 345
ввода-вывода, 119 однократного срабатывания, 234
ограниченный вычислительными пользовательский, 20, 139
возможностями, 119 с обработкой, 345
реализация, 86 с прерыванием, 352
серверный, 73 супервизора, 20
системный, 140 тактового меандра, 234
создание, 80 яДРа> 20
состояние, 84 резервная копия
прямой доступ к памяти, 258 инкрементная, 565
псевдоним, 555 полная, 565
псевдопараллелизм, 78 ресурс, 270
псевдотерминал, 356 выгружаемый, 271
путь, 613 невыгружаемый, 271
абсолютный, 543 однородный, 271
относительный, 544 роль, 594
Q системное уведомление, 472
системный вызов, 39, 222
самое короткое задание - первое, 125 системный образ, 186
связующее программное обеспечение, 32 системный процесс, 140
связь сквозной кэш, 573
жесткая, 546, 554 службЭ| ш
между файлами 554 событие асинхронное, 240
символьная, 555 состояние
сеанс, 380 безопасное, 281
сегмент, 457 зомб т
данных, 52 581
состояния задания, 196,217 специальный файл, 45
СТ6КЭ., DZ * « / с
текста, 52 блочный, 45
сегментация, 456 символьный, 45
/пл СПИСОК
сегментный регистр, 471 r. r
секретный канал, 599 мандатов, 595
семафор, 103 управления доступом, 593
двоичный, 105 справедливое планирование, 133
файловый, 295 спулинг, 29, 268
сервер, 139 старение, 132,447
информационный, 140, 397 стек' 52
реинкарнации, 83, 140, 656 стеклянный телетайп, 344
сетевой 140 степень многозадачности, 127
файловый, 31 сторожевой таймер, 238
серверный процесс, 73 страница
сетевая операционная система, 35 кодовая, 346
сетевой адаптер, 153 пространства виртуальных адресов, 428
сетевой сервер, 140 страничный блок, 428
сжатие памяти, 420 страничный каталог, 463
сигнал, 53 стробирование, 335
аварийный, 41 субъект, 593
перехват, 484 суперблок, 548, 604
синхронизации, 240 супервизор, 20
сигнатура суперпользователь, 42
загрузочного блока, 604 суффикс, 162
ядра, 184
символ 1"
заполнения, 348
префиксный, 349 таблица
символьная связь, 555 дескрипторов, 182
символьное устройство ввода-вывода, 253 глобальная, 190, 216, 461
символьный специальный файл, 45 локальная, 216, 461
синхронизация, 105 прерываний, 87, 190, 217
синхронная передача, 262 сегментов, 471
система индексных узлов, 61
многопроцессорная, 78 подразделов, 548
операционная, 18 процессов, 40, 86
пакетной обработки, 25 разделов, 142
разделения времени, 30 размещения файлов, 551
распределенная, 32 свободных участков, 499
реального времени, 134 страниц, 430
гибкая, 134 инвертированная, 438
жесткая, 134 многоуровневая, 432
планируемая, 134 таймер
файловая, 139, 531 понятие, 233
системное задание, 138, 222 сторожевой, 238
таймерное задание, 138 файл (продолжение)
такт часов, 234 произвольного доступа, 537
тактовый меандр, 234 специальный, 45
теговая архитектура, 596 файловая система, 42, 139, 530, 531
текущий каталог, 544 корневая, 44
телетайп, 344 с журнальной структурой, 576
терминал, 339, 345 файловый семафор, 295
тик, 234 файловый сервер, 31
траектория ресурсов, 282 файловый указатель, 616
троянская программа, 582 физический адрес, 176
тупик, 270 физический дамп, 565
фиксированный раздел, 416
У фрагментация
внешняя, 460, 478
уведомление внутренняя, 454,478
процесса, 498
системное, 472 - _
узел индексный, 552 4i
указатель позиции в файле, 616 целостность данных, 579
уплотнение памяти, 420 циклическое планирование, 128
управление
заданиями, 53, 379 L|
нагрузкой, 453
управляющая последовательность, 366 часы, 233
уровень чеРвь> 581
микроархитектурный, 19 число магическое, 535, 604
привилегий, 182 чистильщик, 577
условная переменная, 107
устойчивость, 530 Ш
устройство шлюз вызова, 465
ввода-вывода шпионская программа, 582
блочное, 253
символьное, 253 ^
второстепенное, 62 ^
выделенное, 262 элеваторный алгоритм, 318
разделяемое, 262 эхопечать, 347
Ф я
файл, 530 ядро
атрибуты, 538 MINIX, 138
блокировки, 295 минимальное, 73
блочный, 535 язык
включаемый, 157 ассемблера, 19, 25
заголовочный, 157 машинный, 19
непосредственный, 559 программирования, 24
последовательного доступа, 537 ярлык, 555
Компакт-диск MINIX 3
Системные требования
Далее представлен список минимальных системных требований для установки
программного обеспечения, находящегося на данном компакт-диске.
Аппаратное обеспечение
Операционная система MINIX 3 предъявляет следующие требования к аппарат-
аппаратному обеспечению:
♦ персональный компьютер с процессором Pentium или другим совместимым
с ним процессором;
♦ 16 Мбайт или более оперативной памяти;
♦ 200 Мбайт или более свободного пространства на жестком диске;
♦ драйвер CD-ROM с интерфейсом IDE;
♦ жесткий диск с интерфейсом IDE.
Диски с интерфейсами Serial ATA, USB и SCSI не поддерживаются. За альтер-
альтернативными конфигурациями обратитесь на сайт http://www.mJnJx3.org.
Программное обеспечение
MINIX 3 является операционной системой. Если вы желаете сохранить сущест-
существующую операционную систему и данные (рекомендуется), реализовав на ком-
компьютере возможность двойной загрузки, необходимо создать на жестком диске
раздел для MINIX 3. Вы можете воспользоваться следующими средствами:
♦ Partition Magic (http://www.powerquest.com/partitionmagic);
♦ Partition Resizer (http://www.zeleps.com).
Инструкции ищите на сайте http://www.minix3.org/partitions.html.
Установка
Установка может быть полностью выполнена без подключения к Интернету, однако
некоторые специальные документы доступны только на сайте http://www.minix3.org.
Исчерпывающие инструкции по установке имеются на компакт-диске в формате
Adobe Acrobat PDF.
Поддержка продукта
За дополнительной технической информацией о программном обеспечении MINIX,
содержащемся на данном диске, обратитесь на официальный веб-сайт MINIX по
адресу http://www.minix3.org.
Эндрю Таненбаум, Альберт Вудхалл
Операционные системы
Разработка и реализация (+CD)
Классика CS
3-е издание
Перевел с английского А. Кузнецов
Заведующий редакцией А. Кривцов
Руководитель проекта П. Маннинен
Ведущий редактор О. Некруткина
Научный редактор А. Жданов
Технический редактор Л. Родионова
Литературный редактор А. Жданов
Художник Л, Аду веская
Корректор В. Листова
Верстка Р. Гришанов
Подписано в печать 26.12.06. Формат 70x100/16. Усл. п. л. 56,76. Тираж 3000. Заказ 3625.
ООО «Питер Пресс», 198206, Санкт-Петербург, Петергофское шоссе, 73, лит. А29.
Налоговая льгота — общероссийский классификатор продукции ОК 005-93, том 2; 95 3005 — литература учебная.
Отпечатано по технологии CtP в ОАО «Печатный двор» им. А. М. Горького.
197110, Санкт-Петербург, Чкаловский пр., 15.