/















































































































































































Author: Житомирский В.Г. Заварыкин В.М. Лапчик М.П.
Tags: научно информационная деятельность информатика математика математический анализ
ISBN: 5-09-000599-0
Year: 1991




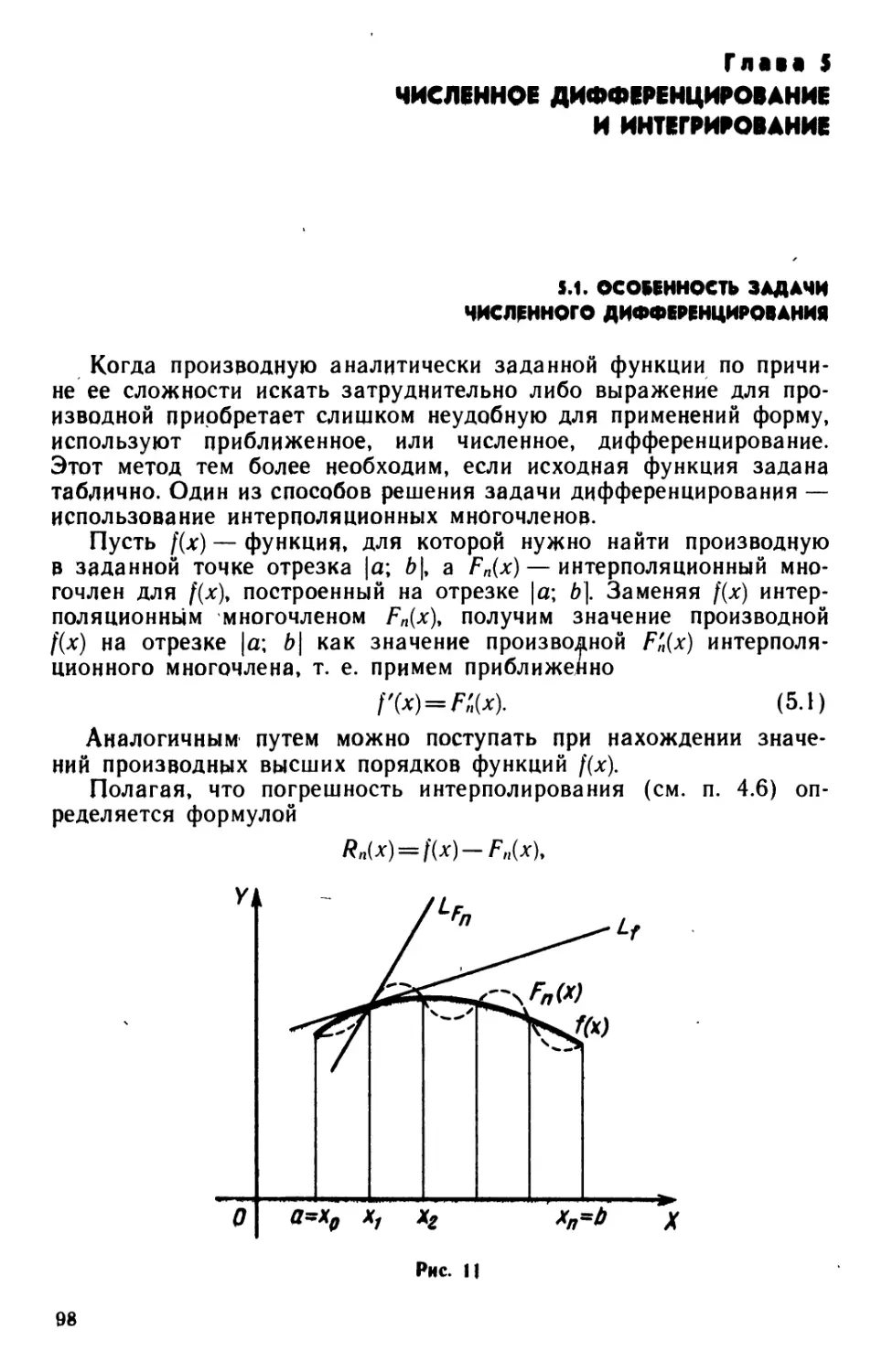
Text
В. М. Заварыкин
В. Г. Житомирский
М. П. Лапчик
ЧИСЛЕННЫЕ
МЕТОДЫ
Допущено Государственным
комитетом СССР
по народному образованию
в качестве учебного пособия для
студентов физико-математических
специальностей педагогических
институтов
Москва «Просвещение» 1991
ББК 73
3-13
Рецензенты:
кафедра математики и информатики Калужского педагогического института
им. К. Э. Циолковского (зав. кафедрой доцент, кандидат
физико-математических наук А. И. Панарин);
доцент, кандидат физико-математических наук А. Р. Есаян (Тульский
государственный педагогический институт им. Л. Н. Толстого)
Заварыкин В. М. и др.
3-13 Численные методы: Учеб. пособие для студентов физ.-мат.
спец. пед. ин-тов/Pv М. Заварыкин, В. Г. Житомирский,
М. П. Лапчик.— М.: Просвещение, 1990.—176 с: ил.—
ISBN 5-09-000599-0.
Пособие является составной частью единого учебно-методического
комплекса, подготавливающего будущих учителей к использованию
вычислительной техники в школе. Содержатся теоретические сведения по численным
методам алгебры и анализа,, элементам линейного программирования и
методам обработки экспериментальных данных. Имеются рекомендации к
проведению лабораторного практикума.
^ 4309000000—542
3 _1^У™" КБ_10_91-1990 ББК 73 + 32.973
103(03) —90
ISBN 5-09-000599-0
© Заварыкин В. М. и другие, 1990
ВВЕДЕНИЕ
Развитие новой технологии и широкое внедрение
математических методов в инженерные исследования, а также рост числа
выпускаемой вычислительной техники и повышение ее качества,
привели к широкому использованию электронно-вычислительных
машин (ЭВМ) во многих областях народного хозяйства. В
настоящее время успешное решение большинства научно-технических
задач в значительной степени зависит от умения оперативно
применять ЭВМ. Для этих целей существуют не только мощные и
удобные универсальные, персональные большие и малые ЭВМ, большой
набор инженерных программируемых калькуляторов, но и хорошо
разработанный арсенал соответствующих численных методов. Для
решения многих научно-технических задач разработан
удовлетворительный математический аппарат, позволяющий оценить точность
полученного решения и определить количество верных знаков
вычисленного на ЭВМ решения. И все же использование ЭВМ не
снимает всех проблем, которые возникают в ходе подготовки и
решения этих задач. Так или иначе процесс решения проходит целый
ряд стадий или этапов, каждый из которых имеет свои трудности и
оказывает свое влияние на достоверность окончательного
результата.
Решение практической задачи начинается с описания исходных
данных и целей задачи на языке строго определенных
математических понятий. Точная формулировка условий и целей решения —
это математическая постановка задачи. Выделяя наиболее
существенные свойства реального объекта, исследователь описывает их с
помощью математических соотношений. Этот этап решения
называется построением математической модели.
После этого осуществляется поиск метода решения задачи
в рамках математической модели и строится алгоритм. Этап
поиска и разработки алгоритма решения называют
алгоритмизацией. Здесь используются любые формы представления
алгоритмов: словесные описания, математические формулы и блок-схемы.
Во многих случаях вслед за построением алгоритма выполняют так
называемый контрольный просчет — грубую прикидку ожидаемых
результатов, которые используются затем для анализа
полученного решения. На следующем этапе алгоритм решения задачи
записывается на языке, понятном ЭВМ. Это — этап программирования.
В простейших случаях может оказаться, что на этом этапе вовсе и не
3
составляется новая программа для ЭВМ, а дело сводится, например,
к использованию имеющегося математического обеспечения ЭВМ.
Далее идет этап исполнения программы на ЭВМ и получение
результатов решения. Время, требуемое на прохождение этого этапа,
зависит от объема вычислений и быстродействия ЭВМ.
Завершающий этап решения задачи — анализ (или интерпретация)
результатов. Здесь происходит осмысливание полученных результатов,
сопоставление их с результатами контрольного просчета, а также с
данными, полученными экспериментальным путем (если таковые
имеются). При этом одни результаты могут оказаться приемлемыми,
а другие — противоречащими смыслу реальной задачи; такие
решения следует отбросить. Высшим критерием пригодности
полученных результатов в конечном счете является практика.
Таким образом, процесс решения задачи с использованием ЭВМ
в достаточно общем случае включает в себе следующие этапы:
1) постановка задачи и построение математической модели;
2) разработка алгоритма (алгоритмизация);
3) запись алгоритма на языке программирования;
4) исполнение программы на ЭВМ;
5) анализ полученных результатов.
Наиболее сложным и ответственным этапом решения является
построение математической модели. Если выбранная
математическая модель слишком грубо отражает взаимосвязи изучаемого
явления, то, какие бы изощренные методы решения вслед за этим
не применялись, найденные значения не будут отвечать условиям
реальной задачи и окажутся бесполезными. Математическая
модель может иметь вид уравнения, системы уравнений или быть
выраженной в форме иных, как угодно сложных, математических
структур или соотношений самой различной природы.
Математические модели, в частности, могут быть непрерывными или
дискретными, в зависимости от того, какими величинами — непрерывными
или дискретными — они описаны.
Своеобразные трудности вызывает также этап разработки
алгоритма, суть которых — в поиске метода решения задачи. Дело
в том, что уже даже для достаточно простых моделей иногда не
удается получить результат решения в аналитической форме. Пусть,
к примеру, задача свелась к решению уравнения с одной переменной:
2 л: — cos3x = 0.
При всей тривиальности этой задачи выразить корни уравнения
путем -аналитических преобразований не удается. Графический
метод большой точности не дает. В таких случаях приходится
использовать численные методы, позволяющие получать результаты
путем вычислений. По этой причине наиболее естественный путь
реализации численных методов — использование ЭВМ.
В условиях использования ЭВМ численные методы выступают
как мощное математическое средство решения практических
задач. При этом важно иметь в виду, что фактор использования
ЭВМ не упрощает, а в некотором смысле даже усложняет решение
4
вопросов оценки точности получаемых результатов (в виду резкого
возрастания количества выполняемых операций). Суть
возникающих здесь проблем подмечена в известном принципе Питера:
«ЭВМ многократно увеличивает некомпетентность вычислителя».
Из этого остроумного замечания следует, что, используя для
решения задачи ЭВМ, вычислитель не столько должен полагаться на
могущество вычислительной техники, сколько помнить о
необходимости понимания того, что в конечном итоге он получает на выходе.
На общую погрешность решения задачи, как это уже
отмечалось, влияет целый ряд факторов. Отметим основные из них,
пользуясь рассмотрением общего хода решения задачи — от построения
математической модели до производства вычислений.
Пусть R — точное значение результата решения некоторой
задачи. Из-за несоответствия построенной математической модели
реальной ситуации, а также по причине неточности исходных
данных вместо R будет получен результат, который обозначим /?|.
Образовавшаяся таким образом погрешность e\=R — R\ уже не
может быть устранена в ходе последующих вычислений (так
называемая неустранимая погрешность).
Приступив к решению задачи в рамках математической модели,
мы избираем приближенный (например, численный) метод и, еще
не приступив к вычислениям, допускаем новую погрешность,
приводящую к получению результата R2 (вместо R\). Погрешность
е2 = /?2 — R\ называют погрешностью метода.
И наконец, неизбежность округления приводит к получению
результата /?3> отличающегося от /?2 на величину вычислительной
погрешности ез = /?з — #2- Полная погрешность е, очевидно,
получается как сумма всех погрешностей:
8 = /?_/?3 = (/?-/?,) + (/?.-/?2) + (/?2-/?з) = е,+82 + 83.
Если вместо погрешностей ei, е2 и 83 удается лишь получить
их абсолютные верхние оценки Л|, Л2, Аз, то приходится
довольствоваться оценочным представлением общей погрешности:
в<Д|+Д2 + Аз.
При решении конкретных задач те или иные виды
погрешностей могут либо отсутствовать совсем, либо влиять на
окончательный результат незначительно. Тем не менее для
исчерпывающего представления о точности окончательного результата в
каждом случае необходим полный анализ погрешностей всех видов.
Это в полной мере относится и к неустранимой погрешности —
погрешности математической модели. Располагая несовершенной
математической моделью, вычислитель все-таки должен любым
способом составить представление о величине неустранимой
погрешности. Понятно, что в условиях слишком грубой модели не имело бы
смысла приводить уточненный анализ вычислительных ошибок.
Отсюда следует, что оценка величины неустранимой погрешности
может послужить удобным поводом для понижения требований к
точности последующих вычислений.
5
Глава 1
РЕШЕНИЕ УРАВНЕНИЙ
С ОДНОЙ ПЕРЕМЕННОЙ
1.1. ПОСТАНОВКА ЗАДАЧИ
Решение нелинейных уравнений с одной переменной
представляет одну из важных задач прикладного анализа, необходимость
в которой возникает в многочисленных и разнообразных разделах
физики, механики, техники и других областях.
В общем случае нелинейное уравнение можно записать в виде:
F(x) = 0, (1.1)
где функция F(x) определена и непрерывна на конечном или
бесконечном интервале [а, Ь\
Всякое число ее [а, Ь\ обращающее функцию F(x) в нуль, т. е.
такое, при котором /7(g) = 0, называется корнем уравнения (1.1).
Число q называется корнем k-й кратности, если при jc = g вместе
с функцией F(x) равны нулю ее производные до (ft— 1) порядка
включительно:
F(6) = H6) = ... = f<*-|)(6) = 0.
Однократный корень называется простым.
Два уравнения F(x) и G(x) называются равносильными
(эквивалентными), если всякое решение каждого из них является
решением и для другого, т. е. множества решений этих уравнений
совпадают.
Нелинейные уравнения с одним неизвестным подразделяются
на алгебраические и трансцендентные.
Уравнение (1.1) называется алгебраическим, если функция
является алгебраической функцией. Путем алгебраических
преобразований из всякого алгебраического уравнения можно получить
уравнение в канонической форме:
Рп(х) = а{)х" + а1хп-* + ...+ап=0,
где а0, а|, ..., ап — коэффициенты уравнения, а х — неизвестное.
Показатель п называют степенью алгебраического уравнения.
Известно [1J, что всякое алгебраическое уравнение имеет, по
крайней мере, один корень вещественный или комплексный.
При приведении алгебраического уравнения (1.1) к
канонической форме будем иметь те же корни, что и для исходного
уравнения. Однако при этом могут появиться некоторые лишние корни.
Например, уравнение
->/2х2-1 + х = Л[2хТ+~\-\
6
может быть приведено к канонической форме:
7х4+\2х* + 2х2 — 4л: —5 = 0.
Если функция F(x) не является алгебраической, то уравнение (1.1)
называется трансцендентным. Примерами трансцендентных
уравнений являются:
л:— 10sin л: = 0; 2* — 2cos л:=0; lg(jt + 5)=cosjt.
В некоторых случаях решение трансцендентных уравнений
можно свести к решению алгебраических уравнений.
Поскольку подавляющее большинство нелинейных уравнений
с одной переменной не решается путем аналитических
преобразований (точными методами), на практике их решают только
численными методами. Решить такое уравнение — это значит установить,
имеет ли оно корни, сколько корней, и найти значения корней с
заданной точностью. Задача численного нахождения
действительных и комплексных корней уравнения (1.1) обычно состоит из двух
этапов: отделение корней, т. е. нахождение достаточно малых
окрестностей рассматриваемой области, в которых содержится
одно значение корня, и уточнение корней, т. е. вычисление корней
с заданной степенью точности в некоторой окрестности.
В дальнейшем будем рассматривать численные методы
нахождения действительных корней уравнения (1.1). Наиболее
распространенными на практике численными методами решения
уравнения (1.1) являются: метод половинного деления, метод хорд,
метод касательных (Ньютона), комбинированный метод, метод
Рыбакова нахождения всех действительных корней, метод простой
итерации. Применение того или иного численного метода для
решения уравнения (1.1) зависит от числа корней, задания исходного
приближения и поведения функции F(x).
Остановимся подробно на наиболее часто используемых на
ЭВМ методе половинного деления и методе простой итерации.
1.2. ОТДЕЛЕНИЕ КОРНЕЙ
Первый этап численного решения уравнения (1.1) состоит в
отделении корней, т. е. в установлении «тесных»
промежутков, содержащих только один корень. Отделение корней во
многих случаях можно произвести графически. Принимая во
внимание, что действительные корни уравнения (1.1) —это точки
пересечения графика функции F(x) с осью абсцисс, достаточно
построить график F(x) и отметить на оси Ох отрезки, содержащие
по одному корню. Построение графиков часто удается сильно
упростить, заменив уравнение (1.1) равносильным ему уравнением
h(*)=h(x). (1-2)
В этом случае строятся графики функций f\(x) и f2{x)y а потом
на оси Ох отмечаются отрезки, локализующие абсциссы точек
пересечения этих графиков.
7
Рис. 1
Пример 1.2.1. Для графического отделения корней уравнения
sin 2л: — In л: = 0 выгодно отдельно построить графики функций
sin'2л: и In (л:) (рис. 1).
Из графика следует, что уравнение имеет корень,
принадлежащий отрезку [1; 1,5].
В сомнительных случаях графическое отделение корней
необходимо подкрепить вычислениями. При этом полезно использовать
следующие очевидные положения:
1) если непрерывная на отрезке \а\ Ь\ функция F(x) принимает
на его концах значения разных знаков (т. е. /7(a)-/7(ft)<0), то
уравнение (1.1) имеет на этом отрезке по меньшей мере один корень;
2) если функция F(x) к тому же еще и строго монотонна, то
корень на отрезке [а; Ь) единственный.
Вычислим для проверки с, помощью калькулятора значения
функции F(A:) = sin 2л: — In х на концах отрезка [1; 1,5]:
F(\) = 0,909298; f(lf5)= -0,264344.
Из рисунка 1 видно, что на отрезке [1; 1,5] имеется единственный
корень исходного уравнения.
Рассмотренный прием позволяет при желании сузить отрезок,
полученный графическим способом. Так, в нашем примере имеем
F( 1,3) = 0,253138 >0, так что отрезком отделения корней можно
считать [1,3; 1,5].
Для отделения корней можно эффективно использовать ЭВМ.
Пусть имеется уравнение /г(х) = 0, причем можно считать, что
все интересующие вычислителя корни находятся на отрезке [А\ В],
в котором функция F(x) определена, непрерывна и /7(Л)-/7(В)<0.
Требуется отделить корни уравнения, т. е. указать все отрезки
[а; /?]с=[Л; В], содержащие по одному корню.
Будем вычислять значения F(x\ начиная с точки л: = Л,
двигаясь вправо с некоторым шагом h (рис. 2). Как только
обнаружится пара соседних значений F(x\ имеющих разные знаки, и
функция F(x) монотонна на этом отрезке, так соответствующие
8
У = Г(х)
Рис. 2
С Отделение корней)
■ Т т
£&?£ ot, ft, h \
X, : = а
Х2:= Х/ + /Г
yt'--F(Xt)
да
Вы Sod xffx2
да
£
y2:=F(X2)
нет
нет
т
Хг:= Х,+//
z=j—
J—"
Рис. 3
vf
о
'x+h
8)
Рис. 4
значения аргумента х (предыдущее и последующее) можно
считать концами отрезка, содержащего корень. Схема
соответствующего алгоритма изображена на рисунке 3. Результатом решения
поставленной задачи будут выводимые на дисплей (или на печать)
в цикле значения параметров х\ и jc2 (концов выделенных отрезков).
Очевидно, что надежность рассмотренного подхода к
отделению корней уравнений зависит как от характера функции F(x)%
так и от выбранной величины шага /г. Действительно, если при
достаточно м^лом значении h на концах текущего отрезка \х\ x + h\
функция F(x) принимает значения одного знака, естественно
ожидать, что уравнение F(x) = 0 корней на этом отрезке не имеет. Это,
однако, не всегда так: при несоблюдении условия монотонности
функции F(x) на отрезке \х\ x + h\ могут оказаться корни уравнения
(рис. 4, а). Не один, а несколько корней могут оказаться на отрезке
[х\ x + h\ и при соблюдении условия F(x)*F(x + h)<0 (рис. 4, б).
Предвидя подобные случаи, следует выбирать при отделении
корней достаточно малые значения h.
По схеме алгоритма отделения корней, изображенной на
рисунке 3, легко составить программу для ЭВМ. Ниже приведена
программа отделения корней уравнения на языке Бейсик.
10 REM ОТДЕЛЕНИЕ КОРНЕЙ
20 DEPPN F(X)=G0S(X)-.1*X
30 INPUT A,B,H:K=0
40 Х*=А:Х2=ХТ+Н:Y*=FNF( XT)
50 IP Х2>В THEN 120
60 Y2=FNF (X2)
70 IP YTxY24) THEN 100
80 K=K+T
о
90 PRINT К;"-Й КОРЕНЬ";"[";XI;";"Х2;"]"
100 ХТ=Х2:Х2=Х1+Н:И=У2
ПО GOTO 50
120 END
RUN
1
2
3
4
5
6
7
-10, 10, .1
-Й КОРЕНЬ
-Й КОРЕНЬ
-Й КОРЕНЬ
-Й КОРЕНЬ
-Й КОРЕНЬ
-Й КОРЕНЬ
-Й КОРЕНЬ
[-9.7;
— 9.61
[-9; -8.9]
[-4.3; -4.2
[-1.8; —1.71
[1.4; 1.5]
[5.2; 5.3]
[7; 7.1]
Вслед за программой приведены результаты ее выполнения
для уравнения cosjc = 0,1x на отрезке [—10; 10| с шагом 0,1.
Для того чтобы эту программу использовать для отделения
корней другого уравнения, необходимо отредактировать строку 20:
после знака равенства вписать выражение новой функции.
1.3. МЕТОД ПОЛОВИННОГО ДЕЛЕНИЯ
Пусть уравнение (1.1) имеет на отрезке [а; Ь\ единственный
корень, причем функция F(x) на этом отрезке непрерывна.
Разделим отрезок \а\ Ь\ пополам точкой с = (а + Ь)/2. Если F(c)^0 (что
практически наиболее вероятно), то возможны два случая: либо
F(x) меняет знак на отрезке [а; с\ (рис. 5, а), либо на отрезке'(с; Ь\
(рис. 5, б). Выбирая в каждом случае тот из отрезков, на котором
функция меняет знак, и продолжая процесс половинного деления
дальше, можно дойти до сколь угодно малого отрезка,
содержащего корень уравнения.
Рис. 5
11
с
Метод половинного
деления
X
J
Ввод а,Ь,е
Г"
с = (а+6)/2
а. = с
НШ ^(a)F(c)^ да
Ь:=С
да
Х:=(а + Ь)/2
Ах:=(Ь-а)/2
X
Вывод х,Дх
Е
С Конец Л
Рис. 6
Рассмотренный метод можно использовать как метод решения
уравнения с заданной точностью. Действительно, если на каком-то
этапе процесса получен отрезок [а; р], содержащий корень, то,
приняв приближенно jc = (a+P)/2, получим ошибку, не превыша-,
ющую значения D = (P — a)/2. Метод связан с трудоемкими
вычислениями, однако он с успехом может использоваться на ЭВМ. На
рисунке 6 изображена схема алгоритма уточнения одного корня
уравнения (1.1) на отрезке [а; Ь] до заданной точности г методом
половинного деления. Из схемы видно, что, если даже на каком-то
этапе случится F(c)=Q> это не приведет к сбою алгоритма.
Пример 1.3.1. Уравнение sin 2х — In х = 0 имеет единственный
корень на отрезке [1,3; 1,5] (см. пример 1.2.1). Решим это уравнение
с точностью до Ю-4 методом половинного деления на ЭВМ.
В соответствии со схемой алгоритма половинного делений,
изображенного на рисунке 6, программа на языке Бейсик будет
иметь вид:
12
10 REM ПОЛОВИННОЕ ДЕЛЕНИЕ
20 DEFFN F(X)=SIN(2xX)-L0G(X)
30 INPUT A,B,E
40 C=(A+B)/2
50 IP FNF(A)*FNF(C)<0 THEN 70
,60 A=C:GOTO 80
70 B=C
80 IF B-A>E THEN 40
90 X=(A+B)/2:D=(B-A)/2
100 PRINT "X=f,;X, "D^D
110 END
В программе заданная точность обозначается Е, а граница
погрешности найденного корня D. Пустив программу для значения
А =1.3, В =1.5, Е = 0.0001, получим ответ:
X = 1.399462890625 D = 0.000048828125.
Округляя выведенные машиной результаты, окончательно получаем:
х= 1,3995 ±0,0001.
1.4. МЕТОД ПРОСТОЙ ИТЕРАЦИИ
Заменим уравнение (1.1) равносильным уравнением
x = f(x). (1.3)
Пусть I — корень уравнения (1.3), а х0 — полученное каким-либо
способом нулевое приближение к корню £. Подставляя х0 в правую
часть уравнения (1.3), получим некоторое число x\=f(xo).
Проделаем то же самое с Х\, получим jt2 = /(xi) и т. д. Применяя шаг за
шагом соотношение xn=f(xn-\) для я=1,2 образуем числовую
последовательность
Хо, хи ..., хп, ..., (1.4)
которую называют последовательностью
приближений или итерационной последовательностью (от
лат. iteratio — повторение).
Процесс построения итерационной последовательности имеет
простунр геометрическую интерпретацию.
13
Рис. 7
Последовательность приближений может быть как сходящейся,
так и расходящейся. На рисунке 7 изображен случай расходящейся
последовательности.
Если последовательность (1.4) сходится, а функция /
непрерывна, то предел последовательности (1.4) является корнем
уравнения (1.3).
Действительно, пусть £= lim хп. Перейдем к пределу в равенстве
П-+оо
хп =f(xn-\):
lim x„=lim f(*„_i)=/(lim *„_,) = /(£),
(1.5)
т. e. l = f(l).
Как видно из рисунка 7, применение метода итерации может и не
привести к уточнению корня. Достаточные условия сходимости
итерационного процесса выясняются следующей теоремой.
Теорема 1.1. Пусть уравнение x = f(x) имеет единственной
корень на отрезке [а; Ь\ и выполнены условия:
1) f(x) определена и дифференцируема на [а; Ь\\
2) /(jc)efa; Ь\ для всех jteja; b\\
3) существует такое вещественное qy что |/'(х)|<</<1 для
всех х^[а; Ь\.
Тогда итерационная последовательность xn = f(xn-\) (дг = 1, 2, ...)
сходится при любом начальном члене х0^\а\ Ь].
Доказательство. Построим итерационную
последовательность вида (1.4) с любым начальным значением *0е[а; Ь\. В силу
условия (2) все члены последовательности находятся в отрезке
fa; Ь\.
Рассмотрим два последовательных приближения xn = f{xn-\) и
хп + х =f(xn). По теореме Лагранжа о конечных приращениях имеем
х„ + |— Хп = ((хп)—1(хп-\)=}{с)(хп — Хп-\), с^[хп-\\ хп\. Перехо-
дя к модулям и принимая во внимание условие (3) теоремы,
14
Получим:
\x„ + \—x„\ = \f'(c)\- \хп— хп-\\ <,q\xn— х„_||,
Un-f.,— Xn\^q\xn— хп-\\.
При я = 1, 2, ... будем иметь:
1*2 —*il<<7j*i—-*ol, ч (1.6)
Iа:3 — х21 <<72|*i— х0|,
\хп + \—хп\ <<7"Ui— ATol-
Рассмотрим ряд
Х(, + (х,—Хо) + (Х2 —*,)+...+(*„—х„_, ) + •••• (1-7)
Составим частичные суммы этого ряда: S,=x0, S2 = x\, ..., S„ + i =
=х„.
Заметим, что (n-f 1)-я частичная сумма ряда (1.7) совпадает
с я-м членом итерационной последовательности (1.4), т. е.
Sn + \=xn. (1-8)
Сравним ряд (1.7) с рядом
l*i—*ol +q\x\—xu\ + q2\x\— х{)\ +.... (1.9)
Заметим, что в силу соотношений (1.6) абсолютные величины
членов ряда (1.7) (член х0 не берется во внимание) не превосходят
соответствующих членов ряда (1.9). Но ряд (1.9) сходится как
бесконечно убывающая геометрическая прогрессия (q<\ по
условию). Следовательно, и ряд (1.7) сходится, т. е. его частичная
сумма (1.8) имеет предел. Пусть lim *„ = £. В силу непрерывности
П-*- оо
функции f получаем (см. 1.5):
Б=/(6).
т. е. I — корень уравнения x = f(x).
В заключение заметим, что условия теоремы 1.1 не являются
необходимыми. Это означает, что итерационная
последовательность может оказаться сходящейся и при невыполнении этих
условий.
1.5. ОЦЕНКА ПОГРЕШНОСТИ МЕТОДА ИТЕРАЦИЙ
Как следует из теоремы 1.1, при выполнении ее условий
итерационная последовательность сходится при любом выборе
нулевого значения х0. Отсюда следует, что полученное в итерационном
процессе n-е приближение при желании можно считать начальным.
Это означает, что если в процессе вычисления приближений
допускались ошибки, то они не влияют на окончательный результат.
Указанное свойство метода итераций делает его одним из самых
надежных методов решения уравнений (разумеется, это
обстоятельство не исключает влияния на результат систематических вы-
15
числительных ошибок, например обусловленных возможностями
вычислительного прибора).
Между тем на практике построение итерационной
последовательности не может продолжаться бесконечно. Существование
предела итерационной последовательности не означает вовсе, что
его истинное значение может быть получено эмпирически путем
реализации бесконечного итерационного процесса. Приходится
обрывать этот процесс, допуская при этом погрешность метода.
Получим сейчас формулу, дающую способ определения погрешности
п-го приближения.
Пусть хп.— приближение к истинному значению корня
уравнения x = f(x). Абсолютная ошибка приближения хп оценивается
модулем
Л*„=|£ — хп\.
Принимая во внимание (1.7) и (1.8), имеем:
l — Xn = l — Sn+\=(Xn + \—Xn) + (xn + 2 — Xn + \)+... . (1.Ю)
Сравним (1.10) с остатком ряда (1.9):
<Л*.-*о1+<гл + ,|*.-*о1+.... (1.11)
Имеем, ввиду оценок (1.6),
)l-xn\^qn\xl^x0\+qn^1 \хх -х0|+... = j=j\xi-Xo\.
Таким образом, для оценки погрешности n-го приближения
получается формула
На практике удобнее использовать модификацию формулы (1.12).
Примем за нулевое приближение хп-\ (вместо лг0). Следующим
приближением будет хп (вместо х\). Учитывая также, что при
0<^<1 будет qn^.q (п = \, 2, ...), из (1.12) получаем:
A*n<y^l*«--*»-il- <1ЛЗ)
В оценочных формулах (1.12) и (1.13) используется вещественное q,
получаемое в процессе установления условия (3) теоремы 1.1.
Практически q можно получить как верхнюю грань модуля производной
|/'(х)| при jce[a; Ь]. Любопытно заметить, что, чем меньше
значение <7, тем быстрее сходится ряд (1.9) и, следовательно, тем быстрее
сходится итерационная последовательность.
Из оценки (1.13) можно получить важный практический вывод.
Пусть уравнение x = f(x) решается методом итераций, причем
результат должен быть получен с точностью е. Что может служить
критерием для прекращения вычислений при достижении заданной
точности?
Таким условием является, разумеется, Дхп<е. Учитывая оценку
16
(1.13), для этого достаточно потребовать
yZTj\Xn—Xn-l\<:Ey
ОТКУДа \xm-xn-t\<B(l-q)/q. (1.14)
Из неравенства (1.14) следует, что для нахождения корня
уравнения x = f(x) методом итераций с точностью е нужно продолжить
итерации до тех пор, пока модуль разности между последними
соседними приближениями остается больше числа e(\—q)/q.
1.6. ПРЕОБРАЗОВАНИЕ УРАВНЕНИЯ К ИТЕРАЦИОННОМУ ВИДУ
Уравнение F(x) = 0 может быть приведено к виду x = f(x) многими
способами, однако это требуется сделать так, чтобы для функции
f(x) выполнялись условия (1) — (3) теоремы 1.1. Как правило,
наибольшее беспокойство при этом вызывает условие (3). В
некоторых случаях, помимо обычных преобразований, полезно иметь
в виду следующие Ьпециальные приемы:
а) уравнение F(x) = 0 преобразуем к виду
х = х — т- F(x)y
где т — отличная от нуля константа. В этом случае можно принять:
f(x) = x—mF(x).
Дифференцируя, получим
f'(x)=l-mF'(x).
Для того чтобы было \f'(x)\ = 11 — mF'(x)\ ^q<C 1, достаточно
подобрать т так (если, конечно, это возможно), чтобы для
всех х отрезка [а; Ь] значение m^F(x)^l.
б) пусть уравнение F(x) = 0 записано в виде x = f(x)y однако при
исследовании функции f(x) на отрезке [а; Ь\ оказалось, что для всех х
из этого отрезка |/'(*)|>1. Тогда вместо функции (/ = /(х),рассмот-
рим функцию x = g(y\ обратную для f(x). Будем теперь решать
уравнение y = g(y) (или, в'старых обозначениях, x = g(x)). По свойству
производных обратных функций теперь на отрезке [а; Ь\ будет
иметь место:
так что для уравнения x = g(x)t равносильного исходному,.условие
(3) теоремы 1.1 оказывается выполненным.
Для ручных вычислений корня по методу итераций может
использоваться расчетная таблица, содержащая обычную
пооперационную запись формулы f(x) (табл. 1.1). Полученное в результате
одного «прохода» вычислений в правом столбце очередное
приближение корня сразу же переносится в следующую строку столбца хп
и процесс повторяется.
17
Таблица 1.1
Номера
приближений
0
1
Хп
Хо
Х\
Х„+\
Х\
Х2
ЧЫ
и т. д.
Пример 1.6.1. Уточнить с помощью калькулятора корень
уравнения sin 2л:—In х = 0 на отрезке [1,3; 1,5] методом итераций с
точностью до Ю-4 (см. пример 1.2.1).
Исходное уравнение можно привести к итерационному виду
несколькими способами, например:
1) jc = exp(sin 2х)\
2) * = ( — l)"0,5(arcsinlnx-f ял), /1 = 1, 2, ...;
3) лг = лг — m(sin 2х — In х\ тфЬ.
Исследуем возможность применения к полученным
представлениям метода итераций.
1. В первом случае /(jc) = exp(sin 2х). Функция f(x) определена
и дифференцируема на отрезке [1,3; 1,5], однако второе условие
теоремы 1.1 не выполняется: с помощью калькулятора получаем
/(1,3)= 1,674478, т. е. уже в левом конце отрезка значение функции
выходит за пределы отрезка.
2. Рассмотрим второе представление. Уравнение, равносильное
исходному на отрезке [1,3; 1,5], получается при
х = (л — arcsin In х)/2. (115)
Здесь f(x) = (n — arcsin In х)/2. Замечаем, что для всех х отрезка
[1,3; 1,5] будет ./'(*) = <;0Т следовательно, функция f{x)
2х-^\—\п2 х
монотонно убывает на этом отрезке. Вычислим ее значение в концах
отрезка [1,3; 1,5]:
/(l,3) = (ji-arcsinln 1,3)/2= 1,4380608,
/(1,5) = (я- arcsin In 1,5)/2 = 1,3620528.
Так как полученные значения входят в отрезок [1,3; 1,5|, а
функция f(x) монотонна, то отсюда следует, что второе условие
теоремы 1.1 выполняется.
Для проверки третьего условия исследуем модуль
производной функции f(x) на отрезке [1,3; 1,5]:
. ф(*)=1Г(*)1= . ' ■
2х-у]\-\п2х
Найдем производную функции (р(х):
*'{Х)= 4x^1-In*,) '
18
Заметим, что <|>'(лг) на отрезке |1,3; 1,5| всюду отрицательна. Это
значит, что ф(х)= \f'(x)\ на этом отрезке убывает и достигает
максимума на левом конце: |/'(1,3)1 =0,3846153.
Таким образом, условие (3) теоремы 1.1 будет выполнено,
если принять ^ = 0,39.
Уточнение корня уравнения (1.15) с нулевым значением jc(,= 1,4
на калькуляторе приведено в таблице 1.2.
Таблица 1.2
п х„ \„ + \ = — (arcsin In х„ — л)/2
0 1,4 1,3992123
1 1,3992123 1,3995113
2 1,3995113 1,3993978
Для удобства вычислений на МК формула (лт — arcsin In х)/2
представлена в виде —(arcsin In х —л)/2. Это позволяет
производить все вычисления без записи промежуточных результатов,
выполняя циклически следующую последовательность операций на
инженерном МК:
ШШШО^ШБЕЕЕ] 2 но
Используя оценочную формулу (1.14) и принимая во внимание
исходные значения е=|()~4 и (/ = 0,39, уже для третьего
приближения имеем: x;i — х2< 10~4(1 — 0,39)/0,39. Отсюда следует, что хл
является приближенным решением уравнения с заданной точностью
10~4. Округляя полученный результат, окончательно получаем:
а:=1,3994=ьЮ-4.
3. Посмотрим, как можно было бы воспользоваться третьим
представлением заданного уравнения:
х = х — m-(sin 2х — In х). (116)
В этом случае
f(x)=x — m(sm 2х — In х)у
/'(*) = 1 — т ( 2 cos 2jc — ~- ) .
Попробуем подобрать константу тфО так, чтобы для функции
f(x) были выполнены условия (2) и (3) теоремы 1.1. Обозначим
F(x) = s\n2x — \пх. Заметим, что производная F'(x) = 2cos2x — —
на отрезке [1,3; 1,5| отрицательна, следовательно, F(x) на этом
отрезке монотонно убывает. Ее значения на концах (см. пример 1.2.1):
/=■(1,3) = 0,253138; F( 1,5)= —0,264344. Функция f(x) также убывает
на отрезке |1,3; 1,5|, а ее значения на концах зависят от т\ /(1,3) =
= 1,3-т-0,253138; /(1,5)= 1,5 +/я-0,264344.
Учитывая монотонность функции /(х), из последних равенств
19
с
Метод Л
итераций J
7
36odx,8,q
t
a:=e(1-q)/q
да
легко заметить, что условие (2) теоремы 1.1
будет заведомо выполнено, если m —
правильная отрицательная дробь. Займемся
сейчас проверкой третьего условия
теоремы 1.1.
. Поскольку F'(x)=2cos2x на
отрезке [1,3; 1,5] отрицательна и монотонно
убывает, ее модуль имеет максимум на правом
конце отрезка:
|f'(1,5)|= | 2cos3 —у~| =2,6466526.
Понятно, если принять т-
нет
Вывод х
С Конец j
Рис. 8
1И1.5)|
« —0,37, то для всех х отрезка [1,3; 1,5]
значение выражения m(2cos2jt ) будет
правильной положительной дробью. Это
вполне обеспечивает выполнение условия (3)
теоремы 1.1 (так же как, впрочем, и
условия (2)). Учитывая, что
max | 1+0,37(2 cos 2jc— -±Л | «
« 0,0812868 < 0,1, 1,3<jc<1,5,
можно принять q = 0>\ (заметим, что малое значение q обещает
быструю сходимость).
Таким образом, уравнение (1.16) приобретает вид
jt = x + 0,37(sin2x — In jc). (1.17)
По методу простой итерации легко пишется программа для ЭВМ.
На рисунке 8 приведена схема алгоритма решения уравнения
x = f(x) методом итераций.
Если вывод очередных приближений включить в цикл, то
вычислителю предоставляется возможность по протоколу ЭВМ
следить за скоростью сходимости. Приведем программу на языке
Бейсик для решения уравнения sin 2х — In х = 0 (вместе с вводом
исходных данных и выводом результатов) методом простой итерации
с точностью до Ю-6 с использованием представления (1.17):
10 REM ИТЕРАЦИЯ
20 INPUT X,E,Q
30 A=Ek(!-Q)/Q
50 P=X-Y:X=Y
60 PRINT "X=";X
70 IF ABS(P)>A TNEN 40
40 Y=X+.37k(SIN(2kX)-L0G(X)) 80 END
20
При jt=1.4, £ = 0.000001 и Q = 0.1 результаты работы
программы будут такими:
RUN
? 1.4, .000001, .1
Х= 1.3994508880078
Х= 1.3994297174503
Х= 1.399428899378
Принимая во внимание величину затребованной точности 10~6,
округлим окончательный результат до шестого знака после запятой:
jc= 1,399429 ±10~6.
1.7. ПРАКТИЧЕСКАЯ СХЕМА РЕШЕНИЯ УРАВНЕНИЯ
С ОДНОЙ ПЕРЕМЕННОЙ НА ЭВМ
Процесс решения уравнения F(x) = 0 сводится к двум основным
этапам: 1) отделение корней; 2) уточнение корней с заданной
точностью. После того как корень уравнения отделен, т. е. указан
отрезок, содержащий лишь один корень уравнения, происходит
переход к уточнению этого корня тем или иным методом. Выше
были рассмотрены два метода уточнения: метод половинного
деления (п. 1.3) и метод простой итерации (п. 1.4—1.6). По каждому
из них была составлена программа для ЭВМ.
Процесс отделения корней и последующего их уточнения можно
совместить в одной программе. В этом случае в схеме алгоритма
отделения корней (рис. 3) вместо вывода концов отрезка,
локализующего корень, следует поместить обращение к подпрограмме
уточнения корня. В этом случае удобно использовать
рассмотренный в п. 1.2 метод половинного деления, так как он не требует
никаких предварительных исследований условий сходимости (в
отличие, скажем, от метода простой итерации). Ниже приведена
программа решения уравнения с одной переменной cos* — logjt = 0,
содержащая обращение к подпрограмме уточнения корней по
методу половинного деления. Значения концов А и В отрезка
(очевидно, что в данном случае достаточно исследовать, например,
отрезок [0,5; 10], величина шага отделения корней Я, а также
запрашиваемая точность корней Е определяются в процессе ввода в
основной программе.
10 REM РЕШЕНИЕ УРАВНЕНИЙ
20 DEFPN F(X)=C0S( )0-L0G(X)/L0G(10)
30 INPUT A,B,H,E:K=0
40 XI=A:X2=X*+H:YI=FNF(X2)
50 IP X2<=B THEN Y2=PNF(X2) ELSE 150
21
60 IF YIxY2<=0 THEN K=K+* ELSE 90
70 GOSUB 100
80 PRINT "X[";K;"]=";X;:PRINT FNF (X)
90 XI=X2:X2=XI+H:Y*=Y2:G0T0 50
TOO REM ПОДПРОГРАММА
110 C=(XI+X2)/2
120 IF FNF(XI)kFNF(C)<0 THEN X2=C ELSE XI=C
130 IF ABS(X*-X2)<E OR ABS(FNF(X2)-FNF(XI))<=E
THEN X=(X*+X2)/2 ELSE 110
140 RETURN
150 END
RUN
?. 5, 10, .1, .0001
X[l
X[2
X[3
= 1.418408203125 - 2.22255736E—06
= 5.552099609375 -7.3047227E—06
= 6.863037109375 2.750948721E—05
Контрольные вопросы
1. В чем заключается этап отделения корней при использовании
численных методов решения уравнений?
2. Каким образом графическое отделение корней уточняется
с помощью вычислений? Какие свойства функции одной
переменной при этом используются?
3. Каким способом в схеме алгоритма половинного деления
реализуется отбрасывание той половины отрезка, на которой
строго монотонная функция не меняет знака, т. е. не имеет корня?
4. Каковы достаточные условия сходимости итерационной
последовательности для уравнения x = f(x) на отрезке \а\ Ь\У содержащем
один корень?
5. Какое условие является критерием для достижения
заданной точности ? при решении уравнения x = f(x) методом простой
итерации?
ЛАБОРАТОРНАЯ РАБОТА 1
Тема. Решение уравнения с одной переменной.
Задание 1. С помощью ЭВМ отделить корни заданного
уравнения.
22
Задание 2. С помощью калькулятора вычислить один корень
уравнения с точностью 10~:\ используя метод простой итерации.
Задание 3. Составить программу для вычисления с помощью
ЭВМ всех корней заданного уравнения с точностью 10~6.
Варианты заданий приведены в таблице 1.3.
Пояснения к выполнению лабораторной работы 1. Для
заданного уравнения устанавливается отрезок, содержащий все корни
(если отрезок не задан особо). Эту задачу во многих случаях легко
решить графическим методом.
Для выполнения задания 1 составляется программа отделения
корней уравнения. Значение шага может варьироваться в
зависимости от величины отрезка и характера поведения функции.
Результатом выполнения задания должен быть перечень отрезков,
содержащих походному корню уравнения.
При выполнении задания 2 исходное уравнение приводится к
виду x = f(x) таким образом, чтобы на выбранном для выполнения
задания отрезке функция /(*) удовлетворяла условиям (1) — (3)
теоремы 1.1. Приемы преобразования уравнения к итерационному
виду и установление условий сходимости подробно рассмотрены
в п. 1.6.
При выполнении задания 3 самостоятельно составляется
программа вычисления всех корней уравнения. Программа может
быть получена путем объединения алгоритмов отделения и
последующего уточнения корней методом половинного деления (см.
пример на с. 12).
После выполнения заданий полезно сравнить полученные
результаты и сопоставить в них верные цифры.
Номер
варианта
1
2
3
4
5
6
7
8
9
10
.11
12
13
14
15
16
17
18
19
20
Уравнение
(0,2jt)3 = cosx
х — lOsin jc=0
2~* = sin x
2х — 2cosx=0
lg(*+5)=cosjt
■Jix+7=3cos x
x sin jc— 1 =0
8cos x — jc = 6
sin jc — 0,2* = 0
10cosjc-0,U2=0
2lg(*+7) — 5sinx =
4 cos jr + 0.3x = 0
5 sin 2jt=yi —x
l,2*4 + 2x3-24,l =
2x2-5 = 2*
2-jc=10-0,5jc2
4jc4—6,2=cos0,6jc
3sm8jt=0t7x—0,9
1,2 — In * = 4cos2jc
ln(x+6,l)=2sin (x
= 0
I3x2 + 14,2*
1.4)
Таблица 1.3
Пояснения
при jc<10
при x> — 10
при jc<5
на отрезке [ — 1; 1]
Глава 2
РЕШЕНИЕ СИСТЕМ
ЛИНЕЙНЫХ АЛГЕБРАИЧЕСКИХ УРАВНЕНИЙ
2.1. ОПРЕДЕЛЕНИЯ, ОБОЗНАЧЕНИЯ, ОБЩИЕ СВЕДЕНИЯ
Успешное решение большинства научно-технических задач в
значительной степени зависит от умения быстро и точно получать
решение систем линейных алгебраических уравнений. Многие
методы решения нелинейных задач также сводятся к решению
некоторой последовательности линейных систем. В настоящее время
хорошо разработан арсенал численных методов решения линейных
алгебраических уравнений на ЭВМ. Для многих методов разработан
математический аппарат, позволяющий оценить точность
полученного решения и определить количество верных знаков
вычисленного на ЭВМ решения. Многообразие численных методов решения
линейных алгебраических систем можно разделить на прямые
(точные) и итерационные.
Прямые методы характеризуются тем, что дают решение
системы за конечное число арифметических операций. Если все
операции выполняются точно (без ошибок округления), то решение
заданной системы также получается точным. К прямым методам
относятся: метод Крамера, методы последовательного исключения
неизвестных (метод Гаусса и его модификации: метод главного
элемента, метод квадратного корня, метод отражений и другие),
метод ортогонализации. Прямые методы применяются на практике
для решения систем на ЭВМ, как правило, с числами порядка
не выше 103.
Итерационные методы являются приближенными. Они дают
решение системы как* предел последовательных приближений,
вычисляемых по единообразной схеме. К итерационным методам
относятся: метод простой итерации, метод Зейделя, метод
релаксаций, градиентные методы и их модификации. На практике
итерационные методы применяются для решения систем с числами
порядка 106.
Рассмотрим систему т линейных алгебраических уравнений
с п неизвестными:
Щ\Х\ +а\2Х2 + ... + а\пХп = Ь\,
a2\x]-\-a22X2 + ...+a2nXn = b2,
(2.0)
которая может быть записана в матричном виде:
А -х = Ь\
24
здесь
laua\2...a\n
л I #21#22-..#2л
i GLm\CLm2...CL„
прямоугольная матрица размерности тХп, х=(х2) — вектор дг-го
Хц
ft,
порядка, а Ь= ( 2 ) — вектор m-го порядка/
Ьщ
Решением системы (2.0) называется такая упорядоченная
совокупность чисел *, =с,э х2 = с2, ..., хп = сп, которая обращает
все уравнения системы в верные равенства.
Система линейных уравнений называется совместной, если
она имеет хотя бы одно решение, и несовместной
(противоречивой), если она не имеет решений. Совместная система называется
определенной, если она имеет единственное решение, и
неопределенной, если более одного решения.
Две системы линейных уравнений называются равносильными
(эквивалентными), если каждое решение первой системы является
решением второй, и наоборот.
Матрица
1а\\а\2...а\пЬ\
g\a2\CL22...0>2nb)
\&т\0>т2'-.а>тпЬп
полученная из матрицы Л добавлением столбца свободных членов,
называется расширенной. Известно [1|, что система имеет
единственное решение, если ранг г матрицы А равен рангу
расширенной матрицы В: rangv4 = rangB. Система имеет единственное
решение, если ранг матрицы А равен числу неизвестных п, и
бесконечно много решений, если г<п. Если матрица А квадратная и ее
определитель не равен нулю det4=£0, то она называется
неособенной (невырожденной). Система линейных алгебраических
уравнений с п неизвестными, имеющая неособую матрицу Л, совместна
и имеет единственное решение.
Для неособенной матрицы важным является понятие обратной
матрицы. Обратной по отношению к данной называется матрица
А~\ которая, будучи умноженной как справа, так и слева на
указанную матрицу, дает единичную матрицу, т. е.
Л.Л-,=Л",.Л = £.
Матрица Л, полученная перестановкой в матрице Л строк со
столбцами, называется транспонированной матрицей
25
лг =
\
а\\а2\...аш\
a\2dn...ami
a\„CL2n-'.amn
Квадратная матрица А называется симметричной, если она
равна транспонированной (А=АТ), т. е. если a4=^alt.
Матрица называется ортогональной, если сумма квадратов
элементов каждого столбца равна единице, а сумма произведений
соответствующих элементов двух различных столбцов равна нулю,
т. е.
ЛГ.Л=£.
Характеристическим уравнением матрицы А называется
уравнение |Л — LE|=0, т. е.
0ц — 1а\2...а\п
#21022 — Я...02л |==0
#л2#л2...Япл "
Корни к, характеристического уравнения называются
собственными (характеристическими) числами матрицы. Собственным
вектором матрицы Л, отвечающим собственному значению к„ назы-
вается вектор v=(v'2), который удовлетворяет матричному урав-
нению Av = ktv.
Если в системе п линейных уравнений с п неизвестными
матрица А особая (deti4=0), то она будет иметь бесчисленное
множество решений при условии, когда вектор Ь ортогонален всем р
србственным значениям матрицы А\ отвечающим нулевому собт
ственному значению, т. е. (6, 1>*) = 0, где ATVk = 0 — частное
решение системы (с. 24), v = (v\v2...vp) — матрица, образованная из
собственных векторов v, матрицы Л, а с = {С\У с>> .... ^ —
произвольный постоянный вектор.
В дальнейшем будем рассматривать численные методы решения
систем линейных уравнений с квадратными матрицами.
2.2. МЕТОД ГАУССА
Рассмотрим систему линейных алгебраических уравнений:
011*1+ 012*2 + ...+а\пХп = Ь\,
021*1 +022*2 + . ..+02/.*/1=&2> (2.1)
а„\Х\ + 0„2*2 +... + 0«*« = Ьп
при условии, что ее матрица A=(atf) невырожденна. Метод Гаусса
26
решения системы (2.1) —это метод последовательного
исключения неизвестных. Суть его состоит в преобразовании системы (2.1)
к системе с треугольной матрицей, из которой затем
последовательно (обратным ходом) получаются значения всех неизвестных.
Сам по себе метод Гаусса относится к точным методам. Это
означает, что если точно выполнять все требуемые в нем действия, то
будет получено точное решение. Понятно, однако, что из-за
вычислительных ошибок (включая ошибки округления, а также
возможные ошибки исходных данных) этот идеал практически
недостижим.
Идея последовательного исключения неизвестных может быть
реализована различными вычислительными схемами ([1J, [2), [7J
и др.). Ниже рассматривается так называемая схема единственного
деления.
Подвергнем систему (2.1) следующему преобразованию. Считая,
что а\\ ФО (ведущий элемент), разделим на ам коэффициенты
первого уравнения. Выполнения условия аифО можно добиться
всегда путем перестановки уравнений системы:
X\+a\2X2 + ... + ainXn = $i. (2.2)
Пользуясь уравнением (2.2), легко исключить неизвестное х\ из
остальных уравнений системы (для этого достаточно из каждого
уравнения вычесть уравнение (2.2), предварительно умноженное
на соответствующий коэффициент при Х\.
Вслед за этим, оставив первое уравнение в покое, над
остальными уравнениями системы совершим аналогичное
преобразование: выберем из их числа уравнение с ведущим элементом и
исключим с его помощью из остальных уравнений неизвестное х2.
Повторяя этот процесс, вместо системы (2.1) получим равносильную
ей систему с треугольной матрицей:
*|+а|2*2 + а!з*з + ... + а|Я*я = Э|,
х2 + а2з*з +... + OL2nXn = р2, (2.3)
Хп — Рп
Из системы (2.3) последовательно находятся значения всех
неизвестных Хп, Хп-\у ..., Х\.
Таким образом, процесс решения системы (2.1) по методу
Гаусса распадается на два этапа. Первый этап, состоящий в
последовательном исключении неизвестных, называют прямым ходом.
Второй — нахождение значений неизвестных — принято называть
обратным ходом.
Ручные вычисления по схеме единственного деления удобно
оформлять в виде специальной расчетной таблицы (см. табл. 2.1).
Процесс решения системы линейных уравнений по схеме
единственного деления с контролем ручных вычислений рассмотрим на
примере.
27
Пример 2.2.1. Решим систему:
2,34х, -4,2U2- 11,61хз= 14,41,
8,04х, +5,22x2 + 0,27*3= -6,44,
3,92х, — 7,99х2 + 8,37хз = 55,56.
В раздел А таблицы 2.1 вносятся коэффициенты исходной
системы и свободные члены. Для исключения случайных ошибок в
схеме единственного деления предусматривается текущий контроль
правильности вычислений; с этой целью в схему вычислений
включены столбец контрольных сумм 2 и столбец строчных сумм S.
Таблица 2.1
Разделы
А
.
Л,
л2
В
Х\
2,34
8,04
3,92
1
1
*2
-4,21
5,22
-7,99
-1,7991
19,6848
-0,9375
1
1
Хз
-11,61
0,27
8,37
-4,9615
40,1605
27,8191
2,0402
29,7318
1
1
Свободные
члены
14,41
-6,44
55,56
6,1581
-55,9511
31,4202
-2,8424
?8,7555
0,9672
0,9672
-4,8157
2,2930
2
0,93
7,09
59,86
0,3974
3,8949
58,3022
0,1979
58,4877
1,9672
1,9672
-3,8256
3,2931
5
0,3975
3,8942
58,3018
0,1978
58,4873
Контроль в прямом ходе основывается на следующей идее.
После того как в раздел А внесены коэффициенты и свободные
члены исходной системы, находят контрольные суммы — суммы
коэффициентов и свободных членов по строкам и вносят их в
столбец 2 (в таблице 2.1 это числа 0,93; 7,09; 59,86). В дальнейшем,
.выполняя преобразования уравнений системы, над контрольными
суммами производятся те же операции, что и над свободными
членами. После выполнения каждого преобразования находят
строчную сумму результатов и помещают ее в столбец S. Понятно, что
при отсутствии случайных вычислительных ошибок числа в
столбцах 2 и 5 должны практически совпадать. Значительное
расхождение контрольных значений может указывать либо на
промахи в вычислениях, либо на неустойчивость алгоритма вычислений
по отношению к вычислительной погрешности.
После нахождения контрольных сумм первым преобразованием
в схеме единственного деления является деление элементов первой
строки (включая столбец 2) на ведущий элемент 2,34. Запись
результатов производится в четвертую строку раздела А. Здесь
же впервые вступает контроль: сравнивается результат обычного
текущего преобразования контрольной суммы первой строки. (Все
28
вычисления в таблице 2.1 для сокращения записей ведутся с
округлением до четырех знаков после запятой:
0,93:2,34 = 0,3974
и строчная сумма
1 - 1,7991 -4,9615 + 6,1581 =0,3975.)
Расхождение в четвертом знаке после запятой в данном случае
объясняется накоплением вычислительной ошибки в результате
округлений.
Используя четвертую строку раздела Л, можно приступить к
преобразованию второй и третьей строк этого раздела (исключение
неизвестного х\ во втором и третьем уравнениях системы).
Результаты этих преобразований образуют соответственно первую и
вторую строки раздела А\. Эти преобразования выполняются по
следующему правилу: каждый элемент первой строки раздела А\ равен
разности соответствующего элемента второй строки раздела А и
произведения его «проекций» на первый столбец и последнюю
строку раздела Л; аналогичным способом вторая строка раздела А\
получается из третьей строки раздела А.
Например, для вычисления первого элемента первой строки
раздела А\ берется элемент 5,22 из второй строки раздела Л и из
него вычитается произведение 8,04(—1,7991), т. е.
5,22 + 8,04.1,7991 = 19,684764 « 19,6848.
Точно так же второй элемент второй строки раздела А образуется
вычитанием из числа 8,37 произведения 3,92( —4,9615), т. е.
8,37 + 3,92 • 4,9615 = 27,81908 « 27,8191.
В общем случае, если Ь — вычисляемый элемент нового раздела,
а — соответствующий элемент предыдущего раздела, причем рв и
рг соответственно его вертикальная и горизонтальная «проекции»,
можно написать формулу
Ь = а — рврг.
Для вычислений с помощью калькулятора без иерархии операций
эту формулу удобнее использовать в виде:
Ь=— (рйХрг) + а.
После заполнения каждой строки нового раздела проводится
контроль.
Третья строка раздела А\ образуется делением первой строки
на ведущий элемент 19,6848, после чего аналогичным образом
заполняются строки раздела Л2.
Разделом Л2 заканчивается прямой ход. В столбце свободных
членов последней строки этого раздела уже получено значение
неизвестного х3 = 0,9672. Значения остальных неизвестных
последовательно находятся вычитанием из свободных членов
соответствующих строк прямого хода, начинающихся с единицы, суммы
29
произведений их коэффициентов на соответствующие значения
ранее найденных неизвестных. Так, для получения х^ проделываются
вычисления:
х2= -2,8424-2,0402-0,9672= -4,8256814» —4,8157.
Процесс нахождения неизвестных составляет обратный ход
(раздел В в таблице 2.1). Контроль в обратном ходе ведется путем
сравнения значений неизвестных, получаемых в столбце
свободных членов, с соответствующими числами из столбца 2 (они
образуются в результате действий, аналогичных действиям по
нахождению значений неизвестных, с той разницей, что вместо
свободных членов используются соответствующие числа из столбца 2).
Суть контроля состоит в том, что при безошибочном выполнении
вычислений числа в столбце 2 должны быть на единицу больше
соответствующих значений неизвестных из столбца свободных
членов. Этот эффект имеет простое обоснование. Введя в
вычисления столбец 2 и проделывая с его элементами те же действия,
что и с элементами столбца свободных членов, мы фактически
с самого начала наряду с решением исходной системы параллельно
решали вторую систему, у которой свободные члены образованы из
свободных членов исходной системы, сложенных с коэффициентами
соответствующих уравнений. Легко понять, что решениями этой
второй системы должны быть числа, на единицу больше значений
неизвестных исходной системы.
По причине округлений результат решения системы в
рассмотренном примере содержит вычислительную погрешность (наличие
такой погрешности в ходе вычислений подтвердилось контролем).
В этом можно убедиться, подставив найденные значения
неизвестных в исходную систему:
2,34*2,2930 —4,21( —4,8157)— 11,61 -0,9672 = 14,410525,
8,04 • 2,2930 + 5,22( - 4,8157) + 0,27.0,9672 = —6,44109,
3,92 • 2,2930 - 7,99( - 4,8157) + 8,37.0,9672 = 55,5615.
Значения разностей между свободными членами исходной системы
и результатами подстановки в уравнения системы найденных
значений неизвестных называют невязками. В рассмотренном примере
невязки имеют значения:
е, = 14,41 - 14,410525= -0,000525,
е2=-6,44-(-6,44109)=0,00Ю9,
е3 = 55,56 - 55,561467 = - 0,001467.
Используя невязки, можно уточнить решение системы, вычислив
поправки для найденных значений неизвестных. Для этого
достаточно решить систему с прежней матрицей коэффициентов, но с
новым столбцом свободных членов, составленным из невязок. При
этом можно восйользоваться той же схемой единственного
деления, в которой потребуется провести вычисления только для
дополнительно введенного столбца невязок. Полученные значения
поправок затем добавляются к найденным ранее значениям неизвестных.
30
2.3. ВЫЧИСЛЕНИЕ ОПРЕДЕЛИТЕЛЕЙ
Вычисление значения определителя квадратной матрицы
является важной задачей линейной алгебры. Так, численное решение
системы (2.1) имеет смысл лишь в том случае, когда матрица,
составленная из коэффициентов при неизвестных этой системы не-
вырожденна, т. е. когда ее определитель отличен от нуля. Однако и
в том случае, когда определитель системы отличен от нуля, но очень
мал по абсолютной величине, к полученным в ходе решения
значениям корней нужно относиться с осторожностью, поскольку они
могут значительно отличаться от истинного значения неизвестных.
Поэтому решение системы линейных уравнений полезно
сопровождать вычислением определителя этой системы. Вычисление
определителя может представлять и самостоятельный интерес. Так, при
получении множественного коэффициента корреляции и частных
коэффициентов корреляции (см. главу 7) приходится многократно
осуществлять вычисление различных определителей. Рассмотрим
два алгоритма вычисления определителей.
Начнем с решения системы уравнений методом Гаусса. Что
происходит на каждом шаге его реализации с определителем
исходной системы? Обозначим определитель системы (2.1) через
D. Ясно, что после того, как мы разделим левую и правую части
первого уравнения на ведущий элемент ап, определитель
преобразованной системы будет равен D/ац. Последующие
преобразования первого шага, связанные с исключением х\ из остальных
уравнений системы, величину определителя не изменяют.
На втором шаге, когда мы разделим обе части
(преобразованного) второго уравнения на второй ведущий элемент (обозначим
его для простоты через а22), определитель полученной^ системы
будет равен D/(au-a22).
Операции по исключению х2 из уравнения системы вновь не
изменяют величины определителя.
Осуществляя аналогичные действия, мы на дг-м шаге придем
к системе (2.1). Легко понять, что определитель этой системы будет
равен D/(aM-а22-. ••«««). Но матрица коэффициентов при
неизвестных системы (2.3) — треугольная; с единицами по главной
диагонали. Поэтому ее определитель равен 1. Получаем:
£>/(aii-a22-...-fl/i/i)=l.
Следовательно,
D = a\\ -а22-...-апп.
Таким образом, для вычисления определителя системы (2.1)
нужно получить произведение ведущих элементов, используемых
на каждом шаге метода Гаусса.
Рассмотрим еще один вариант алгоритма вычисления
определителя квадратной матрицы. Этот алгоритм основан на идее
представления исходной матрицы в виде произведения двух треугольных
матриц [6].
31
Пусть задана квадратная матрица X п-го порядка:
#П#12...Я1л
#2I#22.. .02п
х=\
#л1#л2..#пл.
Представим матрицу X в виде:
X=Y*Zy
где
К =
УпО -О \
^/2l«/22...0 \
Уп\Уп2-.Упп1
Z =
r"l2T12...^ih
01 ...z2„
00 ...1
Известно, что определитель произведения матриц равен
произведению определителей перемноженных матриц. Поэтому
\X\ = \Y\*\Z\.
Но определитель матрицы Z равен 1, а определитель матрицы Y
равен произведению ее диагональных элементов. Таким образам,
имеет место равенство
1*1 =!/|ГУ22'...'{//!
inn*
Как вычислить элементы матриц Y и Z? Перемножая матрицы
К и Z и приравнивая элементы матрицы-произведения
соответствующим элементам матрицы Х, получаем следующие вычислительные
формулы:
/-1
yi\=xi\\ уц = хц— 2 </<*•£*/ при />/>1,
1-1
Z\i = x\j/yu\ Zij = (Xij— 2 yik*Zkj)/yu при 1</</.
Упражнение. Возьмите в качестве .Y, У и Z матрицы третьего
порядка, выполните фактическое перемножение матриц К и Z и
убедитесь в правильности приведенных формул.
Алгоритм вычисления определителя, основанный на
описанной идее, прост. Обозначим величину определителя через D и
положим D=l. При каждом фиксированном /(/=1, ..., п) вычисляем по
имеющимся формулам элементы уц\\ Zij. Выполняем присваивание:
D = D..yu.
После завершения цикла по / переменная D будет иметь требуемое
значение.
При составлении соответствующей алгоритму программы
примем во внимание следующие соображения. Нет необходимости
32
использовать в программе матрицу Z. Элементы обеих матриц будем
«хранить» в матрице Y. Вычисленное значение определителя
представим в форме:
D=p-W, где 1<|р|<10.
Такое представление необходимо для того, чтобы при вычислении
определителей очень малых (или очень больших) по абсолютной
величине не происходило потери значащих цифр.
Приведем текст программы:
10 PRINT" ВЫЧИСЛЕНИЕ ОПРЕДЕЛИТЕЛЯ"
20 DIM X(20,20),Y(20,20)
30 INPUT "ВВЕДИТЕ ПОРЯДОК ОПРЕДЕЛИТЕЛЯ"^
40 PRINT "ВВЕДИТЕ ЭЛЕМЕНТЫ ОПРЕДЕЛИТЕЛЯ
ПО СТРОКАМ "
50 FOR 1=1 ТО N
60 FOR J=I ТО N
70 INPUT X(I,J)
80 NEXT J
90 NEXT I
100 P=I:C=0
110 FOR 1=1 TO N
120 Y(I,i)=X(l,T)
130 FOR J=2 TO N
140 IF I>=J THEN K=J-I ELSE K=I-I
150 S=0
160 FOR L=I TO К
170 S=S+Y(I,L)kY(L,J)
180 NEXT L
190 Y(I,J)=X(I,J)-S
33
200 IP J>I THEN Y(I,J)=Y(I,J)/Y(I,I)
210 NEXT J
220 Z=Y(I,I)
230 IP ABS(Z)>=I THEN 250
240 Z=I0*Z:C=C-T:G0T0 230
250 P=PxZ
260 IF ABS(P)<=I0 THEN 280
270 P=P/T0:C=C+T:G0T0 260
280 NEXT I
290 PRINT "ВЕЛИЧИНА ОПРЕДЕЛИТЕЛЯ D=PxTO С,ГДЕ"
300 PRINT "P=";P,"C=";C
310 END
Применим эту программу к вычислению определителя
1 2 3
2 3 1
3 1 2
Нетрудно сосчитать, что интересующее нас значение равно —18.
Программа выдаст результат в такой форме:
Величина определителя D = P>|<10AC, где Р = 1.8, С = 1.
Рассмотрим теперь определитель следующего вида:
I х а а ..
а х а ..
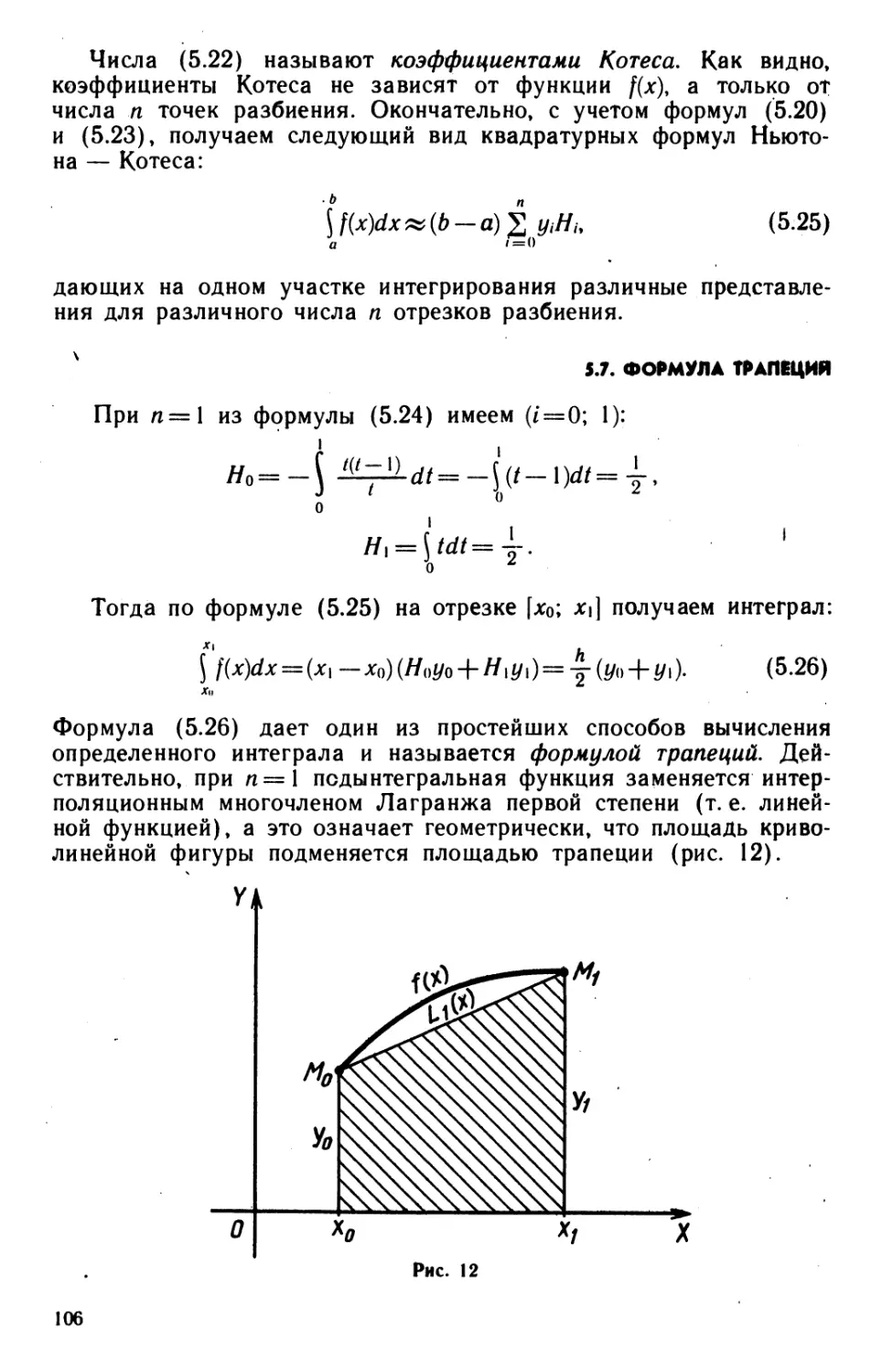
а а х ..
1 а а а ..
i и
а |
а
а
х 1
п раз
Точное значение такого определителя равно:
Вычисление по этой формуле при /г = 10, *=1, а = 0,97 дает
0,19151559-Ю-12. При тех же данных результат работы нашей
программы будет таким:
Вел у чина определителя D = P#10AC, где Р = 1.9151558999972,
С= —13.
34
Приведенный пример подтверждает целесообразность принятой
в программе формы представления результатов.
Упражнение. В том случае, когда исходная матрица X
является симметрической (т. е. выполняется соотношение хц = ху{
при всех /, /), элементы г-ц матрицы Z можно вычислять по формуле
гц = Уц/Уи ПРИ *'</•
Составьте программу вычисления определителя симметрической
матрицы. Предусмотрите ввод элементов лишь «правого угла»
матрицы X. Предусмотрите также размещение элементов уц и гц на
месте соответствующих элементов хц. Для контрольных расчетов
возьмите определитель симметрической матрицы из последнего
примера.
2.4. МЕТОД ПРОСТОЙ ИТЕРАЦИИ
Перепишем систему (2.1) в виде:
Х\=а\\Х\+а\2Х2 + .~ + а,\пХп + $\,
X2 = a,2\X\+<X22X2 + — + Ol2nXn + $2, (2.4)
Хп = OLn\X\ + а«2*2 + .-•. + OLnnXn + Р«,
или сокращенно:
Х{=УацХ1 + Ь (/=1, 2, ..., л).
Правая часть системы (2.4) определяет отображение F
F:yi= 2 «</*/ +Р< (/==1' 2* ••■• ")• (2-5)
преобразующее точку х(х\у х2, ..., хп) л-мерного векторного
пространства в точку у(у\, у2, ..., уп) того же пространства. Используя
систему (2.4) и выбрав начальную точку х{0)(х{°\ х2°\ ..., хп0)), можно
построить итерационную последовательность точек n-мерного
пространства (аналогично методу простой итерации для скалярного
уравнения x = f(x)):,
х(0), х(,),. ..., х(л), ... . (2.6)
Например, пусть дана система:
2х\— х2 — *з=1,
3x1—4^2+^3 = 2,
Х\—Х2 — #з==:3.
Перепишем эту систему в виде (2.4):
Х\ =3Xj— Х2 — Xz— 1,
jc2 = 3jc1—3JC2 + JC3 —2, (2.7)
Хз = Х\— Х2 — 3.
35
Примем теперь за начальное приближение, например, точку (0; 0; 0)
трехмерного пространства, подставим ее координаты в правую
часть системы (2.7) и произведем вычисления. Получим
координаты новой точки (—1; —2; —3). Используя теперь эту точку как
начальную, можно получить следующую точку (1; —2; —2) и т. д.
Тем самым будет получена последовательность точек:
(0; 0; 0), (-1; -2; -3), (1; -2; -2), ....
Оказывается, что при определенных условиях
последовательность (2.6) сходится и ее предел является решением системы (2.4),
т. е. системы (2.1). Напомним в этой связи отдельные сведения из
математического анализа ([7], [12]).
Функцию р(х, у), определяющую расстояние между точками х
и у множества X, назовем метрикой, если выполнены условия:
1) р(*. У)>0,
2) р(х, у) = 0 тогда и только тогда, когда х—у,
3) р(*, у) = р(у, *).
4) р(х, #)<р(х, z) + p(z, у).
(Множество с введенной в нем метрикой р становится
метрическим пространством.)
Последовательность точек метрического пространства
называется фундаментальной, если для любого е>0 существует такое
число N, что для всех ш, n>N выполняется неравенство р(хт, хп)<г.
Пространство называется полным, если в нем любая
фундаментальная последовательность сходится.
Пусть F — отображение, действующее в метрическом
пространстве Е с метрикой р; х и у — точки пространства Е, a Fx, Fy —
образы этих точек.
Отображение F пространства Е в себя называется сжимающим
отображением, если существует такое число а, 0<а<1, что для
любых двух точек х, у^Е выполняется неравенство
p(Fx; Л/)<а.р(х, у). (2.8)
Точка х называется неподвижной точкой отображения F, если*
Fx = x. Понятно, что применительно к системе (2.4) неподвижная
точка — это решение системы.
Для исследования вопроса о решении системы линейных
уравнений методом итераций (как, впрочем, и для многих других
приложений) исключительно важное значение имеет следующая
теорема.
Принцип сжимающих отображений. Если F — сжимающее
отображение, определенное в полном метрическом пространстве, то
существует единственная неподвижная точка х, такая, что x = Fx.
При этом итерационная последовательность, построенная для
отображения F с любым начальном членом х(0), сходится к х.
Оценка расстояния между неподвижной точкой отображения и
приближением х(Л) дается формулой. Оценка (2.9) появляется в
процессе доказательства принципа сжимающих отображений:
36
p(*> ^<Ti^ *°})' (2-9)
из которой, приняв (Л — 1 )-е приближение за нулевое {к = 1),
получаем еще одно полезное для приложений неравенство:
р(*. ^К^-р^*-'), *<*>). (2.10)
Здесь а — множитель из условия сжимаемости (2.8).
Таким образом, используя принцип сжимающих отображений,
можно заключить, что для решения системы (2.4) методом итераций
достаточно установить, что отображение F, заданное
соотношениями (2.5), является сжимающим. Если это так, то метод
итераций может быть применен к системе (2.4), причем ее решение
может быть получено с любой точностью при произвольном
начальном приближении.
2.5. ДОСТАТОЧНЫЕ УСЛОВИЯ СХОДИМОСТИ
ИТЕРАЦИОННОГО ПРОЦЕССА
Рассмотрим условия, при которых отображение (2.5) будет
сжимающим. Как следует из определения (2.8), решение этого
вопроса зависит от способа метризации пространства. Пусть
х(хи х2у ..., хп) и у(у\, у2, ..., уп) — две точки л-мерного пространства.
При практическом применении метода итерации удобно
рассматривать систему линейных уравнений в Пространстве с одной из
следующих трех метрик:
а) pi(*, у)= max \xi — yi\, (2.11)
б) р2(лг, у)=2 \х,-у,\, (2.12)
в) рз(*. У)=у£ (Xi-yif. (2.13)
Упражнение. Докажите, что пространство с каждой из
трех указанных метрик будет полным метрическим пространством.
Сформулируем сейчас условия сжимаемости отображения (2.5)
в пространствах с метриками рь р2 и р3. Эти условия выражаются
в конечном итоге; через коэффициенты при неизвестных
системы (2.4).
Итак, для того чтобы отображение F, заданное в метрическом
пространстве уравнениями (2.5), было сжимающим отображением
(см. неравенство (2.8)), достаточно выполнения одного из
следующих условий:
а) в пространстве с метрикой р{:
а = max У |а//|<1, (2.14)
37
т. е. максимальная из сумм модулей коэффициентов при
неизвестных в правой части системы (2.4), взятых по строкам, должна быть
меньше единицы;
б) в пространстве с метрикой р2:
а= max У |а/,|<1, (2.15)
т. е. максимальная из сумм модулей коэффициентов при
неизвестных в правой части системы (2.4), взятых по столбцам, должна
быть меньше единицы;
в) в пространстве с метрикой р3:
v /=1 /=1
(2.16)
т. е. сумма квадратов всех коэффициентов при неизвестных в
правой части системы (2.4) должна быть меньше единицы. Условия
(2.14) — (2.16) легко вывести. Рассмотрим для примера
условия (2.14).
Для двух точек *'(*(, *2, .., х'п) и х"(х", x'i, ..., х%) в соответствии
с (2.5) имеем: п
или по свойству абсолютной величины:
\У!-У?\< 21«</| \xj-rx?\9 i=l, 2, ..., п. (2.17)
Неравенства (2.17) усилятся, если заменить каждый модуль
\х\—х"\ значением р\(х\ х")\
\У(-У!'\< S 1а<у1-Р»(*'> *"). '=1. 2, — п-
Значение р\(х\ х"\ как постоянное число, можно вынести за знак
суммы, а сумму заменить ее максимальным значением:
\у!-уГ\<(тах У |а,7|).р,(х', *"). * = 1. 2, ..., п. (2.18)
Поскольку (2.18) справедливо при всех /=1, 2, ..., я, оно
справедливо и для того значения /, при котором \у[ — у"\ = р1(у\ у"):
PiQ/', </")<( max £ Ы-р1(х\ х"). (2.19)
Сравнивая (2.19) с (2.8), получаем условие (2.14).
Заметим, наконец, что каждое из условий (2.14) — (2.16)
является достаточным для того, чтобы отображение (2.5) было
сжимающим. Условие (2.15) является также и необходимым для
сжимаемости отображения (2.5) (в смысле метрики р2).
38
2.6. ПРАКТИЧЕСКАЯ СХЕМА РЕШЕНИЯ СИСТЕМ
ЛИНЕЙНЫХ УРАВНЕНИЙ МЕТОДОМ ПРОСТОЙ ИТЕРАЦИИ
Как следует из предыдущего, система (2.1) должна быть
сначала переписана в виде (2.4). При этом гарантией сходимости
итерационного процесса может служить выполнение хотя бы одного
из достаточных условий (2.14) —(2.16) при «погружении» системы
в пространство с одной из трех рассмотренных выше метрик.
Для обеспечения условий сходимости нужно получить систему
вида (2.4) из системы (2.1) так, чтобы коэффициенты при
неизвестных в правой части системы были существенно меньше
единицы. Этого можно достичь, если исходную систему вида (2.1) с
помощью равносильных преобразований привести к системе, у
которой абсолютные величины коэффициентов, стоящих на главной
диагонали, больше абсолютных величин каждого из других
коэффициентов при неизвестных в соответствующих уравнениях (такую
систему называют системой с преобладающими диагональными
коэффициентами). Если теперь разделить все уравнения на
соответствующие диагональные коэффициенты и выразить из каждого
уравнения неизвестное с коэффициентом, равным единице, будет
получена система вида (2.4), у которой все |а<;|<1. Выполнение
этого условия, разумеется, необходимо, но недостаточно для
удовлетворения условий сжимаемости (2.14) — (2.16). Если после
указанных выше преобразований ни одно из условий (2.14) —
(2.16) не выполняется, следует возвратиться к исходной системе
и попытаться выполнить преобразования так, чтобы добиться
лучшего эффекта. В общем случае на этот счет имеются специальные
приемы [2, 7].
Результатом установления хотя бы одного из условий (2.14) —
(2.16) является получение значения а, которое затем находит
применение в формуле оценки точности &-го приближения (2.10).
После того как сходимость установлена, можно приступить к
выполнению вычислений. Схема алгоритма метода итераций для
систем уравнений аналогична схеме метода итераций для одного
уравнения (рис. 8). За начальное приближение обычно берется
столбец свободных членов системы (2.4). На основе оценки (2.10)
получается формула, позволяющая устанавливать момент
прекращения итерационного процесса при достижении заданной точности
результата е:
р(^-1}, х*)<е(1 -а)/а. (2.20)
Здесь р — метрика, по которой была установлена сходимость
получено соответствующее значение а.
Пример 2.6.1. Решить систему (см. пример 2.2.1):
2,34а:, —4,21 х2 — 11,61*3= 14,41,
8,04х, +5,22х2 + 0,27л:з= —6,44,
3,92х, — 7,99jc2 + 8,37хз = 55,56
методом простой итерации с точностью е=10~4.
39
Получим сначала систему с преобладающими диагональными
коэффициентами. Для этого первым уравнением возьмем второе,
третьим — первое, а вторым — сумму первого с третьим:
8,04*,+ 5,22^2 + 0,27jc3 =—6,44, ,
6,26*1 — 12,20x2 — 3,24*3 = 69,97,
2,34х, -4,21x2- 11,61хз= 14,41.
Разделим теперь каждое уравнение на его диагональный
коэффициент и выразим из каждого уравнения диагональное
неизвестное:
х, = -0,6492537х2-0,033582хз-0,800995,
х2 = 0,5131147*| -0,2655737хз-5,7352459,
х3 = 0,2015503х,-0,3626184x2-1,2411714.
Теперь необходимо проверить одно из условий сходимости.
Попробуем установить сходимость по метрике р2 (см. условие (2.15)).
Замечаем, что максимальной суммой модулей коэффициентов по
столбцам будет сумма модулей коэффициентов при Х2- Однако
эта сумма не удовлетворяет условию (2.15):
0,6492537 + 0,3626184 > 1.
Невыполнение одного из условий еще не означает, что метод
итераций применить нельзя. Попробуем установить условие
сходимости в пространстве с евклидовой метрикой (см. (2.16)).
Имеем:
0,64925372 + 0,0335822 + 0,51311472 +
+ 0,26557372 +0,20155032 +0,36261842 =
= 0,4215303 + 0,0011277 + 0,2632866 +
+ 0,0705293 + 0,0412271 +0,1314921 =
=0,9291931 <: 1.
Итак, итерационный .процесс в евклидовом пространстве сходится,
причем коэффициент сжатия а = д/0,9291931 «0,96. Для
достижения точности е=10~4 приближения нужно находить до тех пор,
пока будет выполняться неравенство
р(^-,), х^)<е(1-а)/а,
где р(х(/г-,), х(/°) — расстояние между двумя последними соседними
приближениями в смысле евклидовой метрики, причем е=10~4,
а = 0,96.
Ниже приводятся программа и результаты решения заданной
системы на ЭВМ. В программе неизвестные обозначень! буквами
х, у, 2, их новые значения соответственно xl, у\% z\. Программа
печатает только искомый результат (для получения печати, всех
приближений следовало бы оператор проверки окончания
поставить вслед за оператором вывода). За начальное приближение
взята точка (0; 0; 0).
40
10 REM ИТЕРАЦИЯ
20 INPUT X,Y,Z9A,E
30 B-EXU/A)
40 X1—.6492337XY-. 033582*2-. 800993
30 Y1-.5131147XX-.26S5737XZ-5.73S2459
60 Z1-.201ЭЭ03ХХ-.3626184XY-1.2411714
70 P-8QR<(lH(>*2+<YlHr>*2+<Zl-Z>*2>
60 X-XliY-YliZ-Zl
90 IF РОВ THEN PRINTMX-M |Xi PRINTS-11 |Yi PRINT
"Z-M|Z ELSE 40
100 END
RUN
? 0, 0, 0, .96, .0001
X= 2.2930323733317
Y=-4.8154910930939
Z= .9672058621963
Полученный результат необходимо округлить в пределах
затребованной точности:
х = 2,2930; у= —4,8155; 2 = 0,9672.
При решении на ЭВМ систем с большим числом уравнений
в программе для хранения значений коэффициентов, свободных
членов, а также значений неизвестных следует использовать
массивы (для матрицы коэффициентов и свободных членов —
двумерный массив, для значений неизвестных — одномерные массивы).
В этом случае значения коэффициентов и свободных членов
естественно определять путем ввода.
Ниже приведена программа решения системы N линейных
уравнений с N неизвестными методом простой итерации. В
программе используются три массива: двумерный прямоугольный
массив A(N, N-j-1) значений коэффициентов и свободных членов
(исходная система имеет приведенный вид (2.4)), одномерные
массивы первичных и вторичных значений неизвестных — X(N) и
Y(N).
Исходными данными служат все параметры рассмотренной
выше задачи, что позволяет убедиться в совпадении полученных
результатов в пределах заданных границ погрешностей.
41
10 REM РЕШЕНИЕ СИСТЕМЫ УРАВНЕНИЙ
30 DIM A(20,2I),X(20),Y(20)
40 INPUT "ВВЕДИТЕ ЧИСЛО УРАВНЕНИЙ N ";N
50 PRINT "ВВЕДИТЕ МАТРИЦУ ПРИВЕДЕННОЙ СИСТЕМЫ"
60 PRINT "ПОСЛЕ КАЖДОГО КОЭФФИЦИЕНТА"
70 PRINT "НАЖИМАТЬ КЛАВИШУ [ВК]"
80 FOR I=£ ТО N
90 FOR J=t ТО N+I
100 INPUT A(I,J)
НО NEXT J: NEXT I
120 INPUT "ВВЕДИТЕ КОЭФФИЦИЕНТ СЖАТИЯ В";В
130 INPUT "ВВЕДИТЕ ТОЧНОСТЬ Е";Е
140 М=Ех(*-В)/В
150 FOR К=* ТО N
160 X(K)=A(K,N+I)
170 NEXT К
180 FOR 1=1 ТО N
190 Y(I)=A(I,N+*)
200 FOR J=* TO N
210 Y(I)=Y(l)+A(I,J)xX(J)
220 NEXT J: NEXT I
230 GOSUB 320
240 FOR K=C TO N
250 X(K)=Y(K)
260 NEXT К
270 IF R>M THEN 180 ELSE PRINT "РЕШЕНИЕ"
280 FOR I=* TO N
290 PRINT "X(";I;")=";X(i)
300 NEXT I
310 END
320 R=0
330 FOR K=* TO N
340 R=R+(X(K)-Y(K))A2
350 NEXT К
360 R=SOR(R)
370 RETURN
RUN
ВВЕДИТЕ ЧИСЛО УРАВНЕНИЙ N
? 3
ВВЕДИТЕ МАТРИЦУ ПРИВЕДЕННОЙ СИСТЕМЫ
ПОСЛТ£ КАЖДОГО КОЭФФИЦИЕНТА
НАЖИМАТЬ КЛАВИШУ [ВК]
? О
? —.6492537
? —.033582
? —.800995
? .5131147
? О
? —.2655737
43
? —5.7352459
? .2015503
? —.3626184
? 0
?—1.2411714
ВВЕДИТЕ КОЭФФИЦИЕНТ СЖАТИЯ В
? .96
ВВЕДИТЕ ТОЧНОСТЬ Е
? .0001
РЕШЕНИЕ
Х(1) =2.2930192044556
Х(2) = -4.8155227404776
Х(3)= .96718358705744
Метод простой итерации удобен для программирования на ЭВМ,
однако необходимость предварительного приведения системы
уравнений к специальному виду с доказательством условий сходимости
затрудняет его практическое использование. Учитывая, что условия
сходимости (2.14) — (2.16) не являются необходимыми (т. е. процесс
может сходиться и при несоблюдении этих условий), на практике
часто используют другой путь. В качестве условия достижения
решения принимается близость соседних приближений всех
неизвестных системы в пределах установленной точности:
Ы*+|)-*Р}|<е, /=1, 2, ..., п
(здесь k — номер приближения). Для того чтобы избежать
зацикливания программы (в случае, если итерационный процесс
расходится или сходится слишком медленно), с самого начала
вводится ограничение на количество итераций.
Кроме того, чтобы исключить подготовительную ручную работу
по приведению исходной системы к виду (2.4), эту часть процесса
решения целесообразно предусмотреть в программе, а систему
уравнений вводить в ЭВМ в естественном виде (2.1). Соблюдение
достаточных условий сходимости при этом не проверяется, но имеет
смысл постараться перестроить уравнения исходной системы вида
(2.1) так, чтобы диагональные коэффициенты были
преобладающими.
Пример 2.6.2. Решить систему уравнений на ЭВМ методом
простой итерации:
14,38*, — 2,41 х2 + 1,39*з = 5,86,
1 ,84л:, + 25,36*2 — 3,3 \х3 = — 2,28,
2,46jc;—3,49*2+16,37jc3 = 4,47.
Поскольку в системе уравнений диагональные коэффициеаты
являются преобладающими, то можно использовать для ее
решения программу:
44
10 REM РЕШЕНИЕ СИСТЕМЫ МЕТОДОМ ИТЕРАЦИЙ
20 REM ВЕЗ ДОКАЗАТЕЛЬСТВА СХОДИМОСТИ
30 DIM At20,21),X<20),Y<20>
40 РРШТ"ЧИСЛО УРАВНЕНИЙ"I INPUT N
50 PRINTHMATPHUA КОЭФФИЦИЕНТОВ'•
60 PRINT"H СВОБОДНЫХ ЧЛЕНОВ"
70 FOR 1-1 TO N
60 FOR J-l TO Ы+1
90 INPUT A(IpJ)
100 NEXT I1NEXT J
110 PRINT"ТОМНОСТЬ"I INPUT E
120 PRINTM4HCnO ИТЕРАЦИЙ"I INPUT R
130 REM ЗАДАНИЕ НАЧАЛЬНЫХ ЗНАЧЕНИЙ X(I)
140 FOR 1-1 TO N
150 X<I>-A<I9N+1>
160 NEXT I
170 8-0!REM S-СЧЕТЧИК ИТЕРАЦИЙ
180 REM ВЫЧИСЛЕНИЕ НОВЫХ ПРИБЛИЖЕНИЙ
190 FOR 1-1 TO N
200 T—A(I,N+1>
210 FOR J-l TO N
220 T-T«-A<If J)KX(J)
230 NEXT J
240 Y<I>-<-T+A<I,I>*X<I>>/A<IfI)
250 NEXT Ii S-S+l
260 REM ПРОВЕРКА БЛИЗОСТИ
270 FOR K-l TO N
280 IF AB8(X(K)-Y(K))>E THEN 350
290 NEXT KiPRINT-PEUIEHHE"
300 FOR 1-1 TO N
310 PRINT "X(H|I|")»,I|X(I>
320 NEXT I
330 PRINT"ПОЛУЧЕНО HA"|S|"-M ШАГЕ"
340 END
350 IF 8>R THEN 400
360 REM ПЕРЕДАЧА ЗНАЧЕНИЙ
370 FOR 1-1 TO N
380 X(I)-Y(I)
390 NEXT IiGOTO 180
400 PRINT "СХОДИМОСТЬ МЕДЛЕННАЯ"
410 END
45
Если запустить эту программу, введя матрицу заданной выше
системы, точность 0,0001 и число итераций 5, будет получен ответ:
СХОДИМОСТЬ МЕДЛЕННАЯ
Попробуем при той же точности увеличить границу числа
итераций до 10. ЭВМ выдаст результат:
РЕШЕНИЕ
Х(1) =.37308231354346
Х(2) = -.091173606535989
Х(3) =.19748300046689
ПОЛУЧЕНО НА 8-М ШАГЕ
Приведенную выше программу путем несложных
усовершенствований можно изменить так, чтобы после выдачи сообщения
СХОДИМОСТЬ МЕДЛЕННАЯ машина все же выдавала найденные к
тому времени значения переменных Х(1), а также делала проверку
этого решения методом подстановки в исходную систему. Это
даст возможность наглядно судить о ходе и перспективах
итерационного процесса.
2.7, РЕШЕНИЕ СИСТЕМ ЛИНЕЙНЫХ УРАВНЕНИЙ МЕТОДОМ ЗЕЙДЕЛЯ
Будем снова рассматривать исходную систему линейных
уравнений (2.1) и эквивалентную ей приведенную систему (2.4). При
решении системы (2.4) методом простой итерации каждый шаг
итерационного процесса состоит в переходе от уже имеющегося
приближения значений неизвестных к новому (очередному)
приближению. Обозначим элементы имеющегося приближения через
Х\, Х2, ..., хп, а элементы очередного (вычисляемого) приближения
через уь #2,'..., Уп. Вычислительные формулы имеют вид:
п
yi= 2 «</*/ +р,-; (/=1, 2, ..., п).
/=1
Основная идея метода Зейделя состоит в том, что на каждом
шаге итерационного процесса при вычислении значения у,
учитываются уже полученные значения у1у у2у ..., yi-\. Выпишем
соответствующие вычислительные формулы:
п
У\= 2 ai/X/ + Pi,
п
J/2 = a2i«/i+ 2 а2/-*/ + Ра. (2.21)
/ = 2
1-1 п
У<= 2 ЩУ1+ 2 СЫ/Xy + Pi.
/=1 /-'
п-\
Уп= 2 <Хя/|// + СХп/|'*п-ЬРя--
46
\ Справедливо следующее утверждение:
если для матрицы коэффициентов системы (2.4) выполняется
хотя бы одно из условий (2.14) — (2.16), то итерационный процесс
метода Зейделя сходится к единственному решению системы при
любом выборе начального приближения х\, *2, ..., хп [7].
Таким образом, каждое из условий (2.14) — (2.16) является
достаточным для сходимости итерационного процесса метода
Зейделя. Преимущество метода Зейделя состоит в том, что он
обычно обеспечивает более быструю сходимость, чем метод простой
итерации.
Мы уже отмечали, что «вручную» осуществлять переход от
системы (2.1) к системе (2.4), а затем производить проверку
выполнения достаточных условий сходимости неудобно. Опишем
практическую процедуру преобразования исходной системы (2.1),
гарантирующую сходимость итерационного процесса метода
Зейделя для соответствующей системы (2.4).
Запишем систему (2.1) в матричной форме:
А-Х = ВУ (2.22)
где А — матрица коэффициентов при неизвестных исходной
системы, В — вектор-столбец свободных членов, X — вектор-столбец
неизвестных. Обозначим, как принято в алгебре, через Ат результат
транспонирования матрицы А. Умножим левую и правую части
системы (2.22) слева на матрицу Ат:
Обозначим произведение Ат-А через С п Ат-В через D.
Преобразованная система теперь имеет вид:
C-X = D. (2.23)
Такого рода систему принято называть нормальной. Нормальные
системы обладают рядом «хороших» свойств, среди которых, в
частности, такие:
— матрица С коэффициентов при неизвестных норма-льной
системы является симметрической (т. е. ац = ац% /\ /=1, 2, ..., /г);
— все элементы главной диагонали матрицы С нормальной
системы положительны (т. е. ац>0% /=1, 2, ..., п).
Последний факт дает возможность «автоматически» приводить
нормальную систему (2.22) к виду:
Xi= 2 «//•*/ + ?/; (<=!> 2, ..., /г), (2.24)
где
а//=-7г(М0 и fr = ± (2.25)
С» Lit
Целесообразность осуществления описанных преобразований
вытекает из того, что имеет место
47
Теорема. Итерационный процесс Зейделя для приведенной
системы (2.24), эквивалентной нормальной системе (2.23), всегда
сходится к единственному решению этой системы при любом
выборе начального приближения [6].
Продемонстрируем описанные преобразования на примере
конкретной системы уравнений:
Xi+X2+X3 = 3,
2xi+x2 + x3 = 4,
Xi+X2 + X3 = 5.
Для заданной системы:
А= 2 1 1 В= 4 Лт= 1 1 3 )
V 3 Ч \Ч V » Ч
Вычислим:
Л 2 l\/l 1 l\ /б 6 А
С=АТ-А=\ 1 1 3 2 1 1=6 115
\1 1 1/\1 3 1/ \4 5 3/
"-^-(iiiKD-fg)
Таким образом, нормальная система, полученная из заданной
системы, имеет вид:
6Х| + 6х2 + 4х3 = 16,
6jci + 1U2 + 5a:3 = 22,
4х,+5х2 + 3х3=12.
Приведенная система, эквивалентная этой нормальной системе,
будет выглядеть так:
хх = — х2 — 0,6667хз + 2,6667,
х2 = — 0,5455х, — 0,4545хз + 2, '
х3 = — 1,3333х, — 1,6667х2 + 4.
Коэффициенты приведенной системы вычислены по формулам
(2.25) с точностью до четвертого знака после запятой. Отметим,
что точное решение исходной системы таково: Xi = l, х2=1, х3=1.
Расчетные формулы (2.21) итерационного процесса Зейделя
для данного конкретного случая будут иметь такой вид:
г/i = —аг2 — 0,6667хз + 2,6667,
1/2= — 0,5455у, —0,4545хз + 2,
уз =.- 1 >3333у, - 1,6667^2 + 4.
Составим, как это было сделано в предыдущем параграфе,
«индивидуальную» программу для выполнения итерационного
процесса Зейделя рассматриваемой системы. Предусмотрим ввод
значений начального приближения Х|, х2, х3 и заданной точности
вычислений Е. Окончанием итерационного процесса будем счи-
48
тать момен1\ когда для всех пар соответствующих значений в двух
последовательных приближениях будет выполняться соотношение:
|#—*,|<£; (/=1, 2, 3).
10 REM ИТЕРАЦИИ ЗЕЙДЕЛЯ
20 INRUT X*, Х2, ХЗ
30 INPUT Е
40 Yl=-X2-.6667хХЗ+2.6667
50 Y2=-.5455*Yi-.4545*X3+2
60 Y3=-T.3333kYI-I.6667kY2+4
70 A=ABS(Yi-XI):B=ABS(Y2-X2):C=ABS(Y3-X3)
80 IF A<B THEN A-B
90 IF A^C THEN A=C
100 XI=Y1:X2=Y2:X3=Y3
110 IF A>=E THEN 40
120 PRINT "Xl=";: PRINTUSING"* .♦,■«"; XI
130 PRINT ,fX2=";: PRINTUSING"*. IU S H; X2
140 PRINT "X3=";:PRINTUSING"* ЛШ " ;X3
150 END
Для начальных значений 2.7; 2; 4 (близких к свободным членам
системы) и £ = 0.00001 результат работы программы будет таким:
х\ =0.9999,
х2= 1.0000,
х3= 1.0002.
Теперь мы можем наметить основные шаги алгоритма решения
методом Зейделя произвольной системы линейных уравнений
вида (2.1):
1. Ввод матрицы А коэффициентов исходной системы и матрицы-
столбца В ее свободных членов.
2. Ввод точности вычислений Е.
3. Вычисление транспонированной матрицы Ат и матриц
С=АТА и D = ATB нормальной системы.
4. Приведение нормальной системы к виду, допускающему
49
осуществление итерационного процесса Зейделя (по
формулам (2.21)).
5. Циклическое осуществление итерационного процесса с
вычислением наибольшего значения разности между
соответствующими значениями неизвестных в последовательных
приближениях (обозначение этого наибольшего значения Af).
6. Выход из итерационного процесса при Л1<£ и печать
значений неизвестных, соответствующих последнему полученному
приближению.
2.8. РЕШЕНИЕ СИСТЕМ ЛИНЕЙНЫХ
УРАВНЕНИЙ МЕТОДОМ МОНТЕ-КАРЛО
Все вычислительные алгоритмы, которые мы рассматривали
до сих пор, являлись детерминированными. Это значит, что в
любом таком алгоритме результат, получаемый на очередном шаге,
точно (или с заданной погрешностью) определяется результатами,
полученными на предыдущих шагах (в частности, начальными
условиями). При многократной реализации детерминированного
алгоритма с одними и теми же исходными данными и при
отсутствии ошибок результаты, соответствующие одному и тому же
шагу алгоритма, будут совпадать.
Наряду с явлениями, протекающими детерминированно
(закономерно, предсказуемо), мы часто имеем дело с процессами и
событиями, характер проявления которых зависит от случая и
заранее непредсказуем. Такого рода события и связанные с ними
величины называют случайными. В качестве случайной величины
можно рассматривать, например, количество людей, ожидающих
автобус на остановке, продолжительность безотказной работы
некоторого прибора, число рыб, попавших в заброшенную
рыбаками сеть. Более подробно соответствующие понятия
рассматриваются в курсе теории вероятностей.
Алгоритмы, моделирующие случайные процессы и явления,
называют вероятностными. (Такие алгоритмы не являются
детерминированными.) Способы решения задач, использующие
случайные величины, получили общее название метода Монте-Карло.
Обычно этот метод предусматривает многократное воспроизведение
некоторого вероятностного алгоритма (говорят также о
многократном повторении случайных испытаний). Значение искомой
величины определяется в результате статистической обработки
данных, полученных при этих испытаниях. Характерной
особенностью метода Монте-Карло является использование случайных
чисел (числовых значений некоторой случайной величины).
Появление ЭВМ существенно расширило круг задач, доступных
для решения методом Монте-Карло, поскольку высокое
быстродействие компьютеров обеспечивает возможность многократного
повторения случайных испытаний и последующую обработку
полученных данных.
В алгоритмическом языке Бейсик имеется стандартная функция
50
RND(X), значениями которой являются случайные числа,
равномерно распределенные на отрезке [0; 1]. Сказанное означает, что
если разбить указанный отрезок на некоторое количество равных
интервалов и вычислить значение функции RND(X) большое число
раз, то в каждый интервал попадет приблизительно одинаковое
количество случайных чисел.
Опишем алгоритм решения методом Монте-Карло системы
линейных уравнений [6]. Пусть исходная система (2.1) записана
в виде:
а\\х{ +а\2х2 + ... + (1\пхп + а\п + ,=0,
#2I*| +a22*2 + ...4"a2„*,i + a2/! + l =0, (2 26)
ап\Х\ + ап2Х2 +... + аппхп + апп+х = 0.
Приведем систему (2.26) к виду, аналогичному (2.24), обычно
используемому для применения метода итераций:
Х\ =а\\Х\ + а 12*2 + ... -\-(Х\пХп-\-о*\п +1,
Х2 = 0621*2 + <Х22*2 + ••• + &2пХп + <Х2п + I,
Хп=-<Хп\Х\ +аЛ2*2 + --. + &ппХп + ССпп + I.
(2.27)
Будем предполагать, что для системы (2.27) имеют место
соотношения:
2 |а//|<1 (1=1, 2, ..., п). (2.28)
/=•
От системы (2.26) к системе (2.27), удовлетворяющей
соотношениям (2.28), можно перейти с помощью таких
преобразований.
Пусть для фиксированного /
/ = i
Если в /-м уравнении системы (2.26) коэффициент а,/>0, то
делим каждый член этого уравнения на — L, в противном случае
делим каждый член уравнения на L.
Обозначим
Полученные числа и будут коэффициентами системы (2.27).
Сопоставим теперь /-му уравнению этой системы разбиение
отрезка [0; 1] на я+1 отрезков точками s;, каждая из которых
имеет координату, определяемую соотношениями
*/= Д!,1а'*1 (/=1* 2 "У
Кроме того, положим s0 = 0 и sn + i = l.
51
Рассмотрим процесс «случайного блуждания» некоторой
частицы, которая в начальный момент находится в точке s/ /-го
разбиения отрезка [0; 1]. Воспользовавшись возможностью получения
случайных чисел, равномерно распределенных на отрезке [0; 1],
рассмотрим такое случайное число с. Если Ьно удовлетворяет
соотношению
S/_|<C<5/ (/=1, 2, ..., п)
для точек рассматриваемого /-го разбиения, то считаем, что
частица переходит из точки s, /-го разбиения в точку sy у-го разбиения.
Снова получаем случайное число и рассматриваем его положение
относительно точек у-го разбиения. Если в этом разбиении
полученное число лежит на отрезке \sk-\\ s*|, то считаем, что частица
переходит из точки s, у-го разбиения в точку s* /?-го разбиения. В том
случае, когда для некоторого разбиения очередное случайное число
попадет на отрезок \sn\ srt + i], считаем, что частица переходит в
точку sn + i и процесс случайного блуждания заканчивается.
Последовательность точек 5/, s/, Sk, ..., S/, 5m, s„ + i назовем траекторией
частицы. Свяжем с этой траекторией случайную величину yh
задаваемую соотношением
yi = VirVik-...-Vtm-Wnu
где
i/,, = SIGN (a;;), Vik = SlGti (aik), .... i>/m = SIGN(a,m),
а величина wm определяется равенством
п
Wm = OLmn+\/(l— X a"'/')-
Можно доказать, что математическое ожидание (смотри главу 7)
случайной величины у{ равно значению корня х( системы (2.27).
Этот факт дает способ практического отыскания jc/. Осуществим М
реализаций случайного блуждания частицы по траектории,
начинающейся в точке si. Обозначим через Y сумму значений
случайной величины yi% полученных во всех реализациях. Тогда будем
иметь приближенное равенство
xt~Y/M.
Следует иметь в виду, что при решении систем линейных
уравнений методом Монте-Карло точность получаемых результатов
сравнительно невысока. Повышение точности вычислений требует
значительного увеличения числа реализаций, а значит, и времени
решения системы. Вместе с тем ни один из известных методов
решения систем линейных уравнений (кроме метода Монте-Карло)
не позволяет вычислить значение одного корня системы, не
вычисляя значения других корней.
Составим программу для вычисления методом Монте-Карло
одного (любого) корня системы (2.27), для которой выполняются
соотношения (2.28).
52
Для осуществления процесса случайного блуждания нам
необходимо иметь в памяти ЭВМ точки сразу всех п разбиений
отрезка [0; 1]. Поэтому предусмотрим в программе ввод (по строкам)
коэффициентов системы (2.27) и одновременное заполнение
матрицы 5 размерности пХп, каждый элемент которой вычисляется
по формуле
sij= 2 1алИ (/, /=1, 2, ..., п).
й = 1
Значения всех величин до, также вычислим заранее и поместим
их в одномерный массив W. Номер определяемого корня и
количество реализаций случайного блуждания вводятся в ходе решения
системы. Решения задач методом Монте-Карло приведены в
следующей программе.
10 REM МЕТОД МОНТЕ-КАРЛО
20 REM ВЫЧИСЛЕНИЯ КОРНЯ СИСТЕМЫ ЛИНЕЙНЫХ
УРАВНЕНИЙ
30 DIM A(20,2I),B(20,20),W(20)
40 INPUT "ВВЕДИТЕ ПОРЯДОК РЕШАЕМОЙ СИСТЕМЫ";N
50 PRINT "ВВЕДИТЕ ПО СТРОКАМ КОЭФФИЦИЕНТЫ
СИСТЕМЫ"
60 FOR 1=1 ТО N
70 INPUT A(I,I):B(I,I)=ABS(.A(I,I))
80 FOR J=2 TO N
90 INPUT A(I,J):B(I,J)=B(I,J-I)+ABS(A(I,J))
100 NEXT J
110 INPUT A(I,N+I)
120 NEXT I
130 FOR 1=1 TO N
140 W(I)=A(I,N+I)/(I-B(I,N))
150 NEXT I
53
160 INPUT "ВВЕДИТЕ НОМЕР РЕШАЕМОГО УРАВНЕНИЯ -
В И КОЛИЧЕСТВО РЕАЛИЗАЦИИ СЛУЧАЙНОГО
ПРОЦЕССА - М ";В,М
170 T=I:Y=0
180 S=B:Y=1
190 IF T>MTHEN 260
200 C=RND(I)
210 FOR J=N TO I STEP -T
220 IF C<=B(S,J) THEN 240
230 IF J=N THEN T=T+T:Y=Y+V*W(S):GOTO 180
ELSE V=VkSNG(A(S,J+T)):S=J+I:G0T0 200
240 NEXT J
250 V=VxSGN(A(S,l)):S=I:GOTO 200
260 X=Y/M
270 PRINT "КОРЕНЬ ";B;" - ГО УРАВНЕНИЯ X=";X
280 END
Пусть требуется определить значение корня *2 системы
уравнений:
3*i + Хч — *3 — 2 = О,
*i+4*2 — 2*3 — 3 = 0,
2д:| — *2 + 5*з — 15 = 0.
(точное решение системы: *i = l, х2 = 2, *3=3).
Приведем заданную систему к виду (2.27) так, чтобы
выполнялись соотношения (2.28). Число L для первого уравнения равно 7,
для второго 10, для третьего 23. Коэффициенты преобразованной
системы запишем с точностью до четвертого знака после запятой:
*,= 0.571 4jc, -0.1429*2+0.1429*3 + 0.2857,
х2= — 0.1*,+ 0.6х2+ 0.2*3+0.3,
jc3= —0.0870*, +0.0435*2 + 0.7826*3 + 0.6522.
Для второго корня уравнения при числе реализаций, равном
54
100 (т. е, при В = 2 и Af=100), результаты работы программы
будут такими:
КОРЕНЬ 2-ГО УРАВНЕНИЯ Х = 2.17292672443
При В = 2 и Л1 = 500 программа даст следующие результаты:
КОРЕНЬ 2-ГО УРАВНЕНИЯ Х = 2.1259768867274
Упражнение. Дополните программу решения систем
линейных уравнений методом Монте-Карло так, чтобы она сама
осуществляла преобразование системы к виду (2.27). Предусмотрите
в программе возможность для пользователя выбирать: вычислять
ли значение единственного корня (с заданным номером), или
получать все корни системы?
2.9. РЕШЕНИЕ СИСТЕМ УРАВНЕНИЙ
МЕТОДОМ ОРТОГОНАЛИЗАЦИИ
Очень часто программа решения системы линейных уравнений
должна быть использована не для решения одной, отдельно взятой
системы, а как составная часть более общей программы. С такого
рода ситуацией мы столкнемся, например, в главе 7. Естественно,
что «встраиваемая» программа должна быть как можно компактнее,
не должна требовать никаких проверок сходимости или
значительных преобразований исходной системы. Рассмотренные в
предыдущих параграфах методы и соответствующие им программы
не обладают необходимыми свойствами. Поэтому опишем сейчас
еще один метод решения системы линейных уравнений — метод
ортогонализации [3].
Пусть исходная система (2.1) записана в виде:
anXi +ai2x2 + .- + ^in^«4-^i«H-i =0,
a2\xt+ а22Х2 + ... + а2пХп + а2п + \=0у (2.26)
ап\Х\+аП2Х2 + ... + аппХп + апп + \=0.
Левую часть каждого уравнения системы можно
рассматривать как скалярное произведение двух векторов:
Я/ = (а/1, Я/2, .-., Я/л, Я/л+l)
И
Х = (хи Х2, ..., *л, 1).
Таким образом, решение системы (2.26) сводится к построению
вектора, ортогонального к каждому вектору а,-. Добавим к системе
векторов а, линейно независимый от них вектор ап + \=(0у 0, ..., О, 1).
В векторном пространстве размерности п-\-\ будем строить такой
его ортонормированный базис b\y Ь2, ..., йл + i, чтобы при любом
й=1, 2, ..., az+1 векторы fc|, 62, ..., bk образовывали
ортонормированный базис подпространства Р*, порожденного
рассматриваемыми векторами аи Яг, .., я*. Для этого достаточно строить в
подпространстве Pk некоторый ортогональный базис ии и2 м*, а
затем нормировать его.
55
Вычисления будем вести в соответствии со следующим
алгоритмом.
Положим:
/я + 1 )'
Если для некоторого k^l уже построены векторы ti\y и2> ..., и* и
векторы Ь\% Ь2 Ьь то вектор Uk+i вычисляется с помощью
нескольких итераций по формулам
Здесь и(°+1 — начальное, а и£+1 — очередное приближение
вектора w*+i. Вектор bk+i по вектору и*+! определяется в
соответствии с формулой
ТпТ'\
bk+\=uk+\/'\ 2 "I+i/.
Через (i/Jf+i0, 6/) обозначено, как принято, скалярное произведение
векторов. Значения корней системы (2.26) связаны с координатами
вектора Ьп + ) так:
Xi = Ьп + I i/bn + I n + 1 •
Отметим, что.итерационные шаги при определении вектора
позволяют предотвратить возможную неустойчивость процесса орто-
гонализации. В простейшем случае можно воспользоваться
формулой
ч *
uk+i=ak+\— 2 (я* + 1> bj)-bj.
/=•
Применение итерационных шагов повышает точность
вычислений, особенно в случаях, когда исходная система имеет близкий
к нулю определитель. Обычно бывает достаточно трех-четырех
итераций.
Составим соответствующую описанному алгоритму программу.
Мы не будем в ней употреблять дополнительные массивы для
хранения векторов Uk и bk- Каждый из этих векторов строится на
месте соответствующего вектора а*. Одномерный массив с
используется для размещения в нем значений скалярных произведений:
c,={uUl\ Ь,).
10 REM МЕТОД 0РТ0Г0НАЛИЗА1ШИ
20 DIM А(20,20),С(20)
30 INPUT "ВВЕДИТЕ ПОРЯДОК СИСТЕМЫ" ;N
56.
40 PRINT "ВВЕДИТЕ ПО СТРОКАМ КОЭФФИЦИЕНТЫ
СИСТЕМЫ И ДОПОЛНИТЕЛЬНЫЙ ВЕКТОР"
50 FOR 1=1 ТО N+I
60 FOR J=I ТО N+I
70 INPUT A(I,T)
80KBXT I
90 NEXT J
100 FOR 1=1 TO N+I
110 IF I>I THEN 210
120 S=0
130 FOR K=I TO N+I
140 S=S+A(I,K)*2
150 NEXT К
160 S=SQR(S)
170 FOR J=I TO N+I
180 A(I,J)=A(I,J)+S
190 NEXT J
200 GOTO 380
210 K=0
220 FOR L=I TO I-I
230 C(L)=0
240 FOR M=I TO N+I
250 C(L)=C(L)+A(L,M)xA(I,M)
260 NEXT M
270 NEXT L
57
280 FOR J=I TO N+I
290 S=0
300 FOR L=I TO I+i
310 S=S+C(L)kA(L,J)
320 NEXT L
330 A(I,J)=A(I,J)-S
340 NEXT J
350 K=K+I
360 IF K<=3 THEN 220
370 GOTO 120
380 NEXT I
390 S=A(N+I,N+I)
400 FOR J=I TO N
410 X=A(N+T,J)/S:PRINT "X(";J;,,)=";X
420 NEXT J
430 END
Решим по этой программе систему, которую мы уже
рассматривали в предыдущем параграфе:
*1+*2 + *3 — 3 = 0,
2*1 4- *2 4- *з — 4=О,
х\ -(- Злг2+хз — 5 = 0.
Матрицу коэффициентов необходимо вводить в таком виде:
0 0 0 1/
Результат работы программы будет таким:
*(1) = . 99999999999988
х(2) = . 99999999999992
х(3)= 1.0000000000002
Контрольные вопросы
1. К какому типу методов — прямым или итерационным —
относится метод Гаусса?
2. В чем заключается прямой и обратный ход в схеме
единственного деления?
3. Как организуется контроль за вычислениями в прямом и
обратном ходе?
4. Как строится итерационная последовательность для
нахождения решения системы линейных уравнений с неизвестными?
5. Как формулируются достаточные условия сходимости
итерационного процесса? Как эти условия связаны выбором метрики
пространства?
6. В чём отличие итерационного процесса метода Зейделя от
аналогичного процесса метода простой итерации?
7. Какие преимущества дает применение метода ортогонали-
зации для решения системы линейных уравнений?
8. Какие процессы и явления называют случайными? Что такое
случайные числа?
9. Какова основная идея решения системы линейных
уравнений методом Монте-Карло? Какие достоинства и недостатки имеет
этот метод?
ЛАБОРАТОРНАЯ РАБОТА 2
Тема. Решение систем линейных уравнений.
Задание. Систему трех линейных уравнений с тремя неизвестными
а\\х{ + а12х2 + а13х3 = Ьи
а2\Х\+ а22Х2 + 023*3 = &2,
«31*1+ а32*2 + Дзз*з = Ьз j
решить различными способами:
1) методом Гаусса (по схеме единственного деления) с
применением калькулятора;
2) методом простой итерации на ЭВМ с точностью е= 10~~4;
3) методом ортогонализации (все корни системы) и методом
Монте-Карло (один из корней системы):
Коэффициенты и свободные члены заданной системы
уравнений по вариантам приведены в таблице 2.2.
Перед выполнением этой лабораторной работы необходимо
изучить материал главы 2.
Для решения системы уравнений методом Гаусса (задание 1)
составляется расчетная таблица (см. пример 2.1.1, табл. 2.1).
Вычисления на МК вести с сохранением четырех знаков после
запятой. В прямом и обратном ходе схемы единственного деления для
исключения случайных ошибок предусмотреть контроль.
Полученное решение подставить в исходную систему и произвести
вычисления. Вычислить определитель решаемой системы путем
перемножения ведущих элементов.
59
При выполнении задания 2 составляются две программы
решения заданной системы линейных уравнений по методу
итераций — с учетом достаточных условий сходимости и без учета этих
условий.
Для применения метода итераций с предварительным
доказательством условий сходимости исходная система преобразуется
к системе с преобладающими диагональными коэффициентами, а
затем к нормальному виду (2.4). Вслед за этим производится
проверка достаточных условий сходимости (в смысле одной из
метрик); в результате получается значение а (см. условия (2.14) —
(2.16), которое используется в программе для проверки окончания
цикла (см. (2.20)).
, При использовании другого подхода (см. пример 2.6.1) исходную
систему достаточно преобразовать в систему с преобладающими
диагональными коэффициентами. Затем с помощью ЭВМ, вводя
различные ограничения на число итераций, проводится эксперимент
по отысканию решения системы.
При выполнении задания 3 можно воспользоваться
программами, приведенными в п. 2.7 и 2.8. Можно также осуществить
модификацию указанных программ, например, так, как это
предусмотрено в соответствующих упражнениях.
Результаты, полученные при выполнении всех заданий, следует
сопоставить в пределах полученной точности, а также оценить
время, затраченное на решение одной и той же задачи разными
методами.
Таблица 2.2
Варианты
1
2
3
4
5
6
i
1
2
3
1
2
3
1
2
3
1
2
3
1
2
3
1
2
3
an
0,21
0,30
0,60
-3
0,5
0,5
0,45
-0,01
-0,35
0,63
0,15
0,03
-0,20
-0,30
1,20
0,30
-0,10
0,05
ai2
-0,45
0,25
-0,35
0,5
-6
0,5
-0,94
0,34
0,05
0,05
0,10
0,34
1,60
0,10
-0,20
1,20
-0,20
0,34
а/з
-0,20
0,43
-0,25
0,5
0,5
-3
-0,15
0,06
0,63
0,15
0,71
0,10
-0,10
-1,50
0,30
-0,20
1,60
0,10
b
1,91
0,32
1,83
-56,5
-100
-210
-0,15
0,31
0,37
0,34
0,42
0,32
0,30
0,40
-0,60
-0,60
0,30
0,32
60
Продолжение
Варианты
7
8
9
10 .
11
12
13
14
15
16
17
18
19
/
1
2
3
1
2
3
1
2
3
1
2
3
1
3
1
2
3
1
2
3
1
2
3
1
2
3
1
2
3
1
2
3
1
2
3
1
2
3
а,\
0,20
0,58
0,05
6,36
7,42
5,77
-9,11
7,61
— 4,64
-9,11
7,61
-4,64
1,02
6,25
1,13
0,06
0,99
1,01
0,10
0,04
0,91
0,62
0,03
0,97
0,63
0,90
0,13
0,98
0,16
9,74
0,21
0,98
0,87
3,43
74,4
3,34
0,66
1,54
1,42
Я/2
0,44
-0,29
0,34
11,75
19,03
7,48
1,02
6,25
1,13
1,02
6,25
1,13
-0,73
2,32
-8,88
0,92
0,01
0,02
-0,07
-0,99
1,04
0,81
-1,11
0,02
-0,37
0,99
-0,95
0,88
-0,44
-10,00
-0,94
-0,19
0,87
4,07
. 1,84
94,3
0,44
0,74
1,42
а/з
0,81
0,05
0,10
10
11,75
6,36
-0,73
-2,32
-8,88
-0,73
-2,32
-8,88
-9,11
7,62
4,64
0,03
0,07
0,99
-0,96
-0,85
0,19
0,77
-1,08
-1,08
1,76
0,05
0,69
-0,24
' -0,88
1.71
-0,94
0,93
-0,14
-106,00
-1,85
1,02
0,22
1,54
0,86
bt
0,74
0,02
0,32
-41,40
-49,49
-27,67
-1,25
2,33
-3,75
-1,25
2,33
-3,75 •
-1,25
2,33
-3,75
-0,82
0,66
-0,98
-2,04
-3,73
-1,67
-8,18
0,08
0,06
-9,29
0,12
0,69
1,36
-1,27
-5,31
-0,25
0,23
0,33
46,8
-26,5
92,3
-0,58
-0,32
0,83
1 0,78 -0,02 -0,12 0,56
20 2 0,02 -0,86 0,04 0,77
3 0,12 0,44 -0,72 1,01
Гулава 3
ЭЛЕМЕНТЫ ЛИНЕЙНОГО ПРОГРАММИРОВАНИЯ
3.1. ПОСТАНОВКА ЗАДАЧИ
Линейное программирование — раздел математики,
занимающийся решением таких задач на отыскание наибольших и
наименьших значений, для которых методы математического анализа
оказываются непригодными. К их числу относятся задачи на
рациональное использование сырья и оборудования, на составление
оптимального плана перевозок, работы транспорта и многие
другие, принадлежащие сфере оптимального планирования.
Задача 1. Для откорма животных на ферме в их ежедневный
рацион необходимо включить не менее 33 единиц питательного
вещества Л, 23 единицы вещества 5 и 12 единиц питательного
вещества С. Для откорма используется 3 вида кормов. Данные о
содержании питательных веществ и стоимости весовой единицы
каждого корма даны в таблице 3.1. Требуется составить наиболее
дешевый рацион, при котором каждое животное получило бы
необходимые количества питательных веществ Л, В и С.
Пусть х\у xL>, хз — количества кормов I, II и III видов,
включаемые в ежедневный рацион (понятно, что л:,^0, /=1, 2, 3). Тогда
должно быть:
4л:,+3л:2 + 2л:з>33,
?>xx+2x2+ Jt3>23,
*i+ Jt2+ 2*з > 12.
При этом линейная функция (стоимость рациона)
/ = 20*.+20*2+10*3
должна принимать наименьшее значение.
Таблица 3.1
Весовая единица корма I
Весовая единица корма II
Весовая единица корма III
А
4 ед.
3 ед.
2 ед.
В
3 ед.
2 ед.
1 ед.
С
1 ед.
1 ед.
2 ед.
Стоимость
20 к.
20 к.
10 к.
3 а д а ч а 2. На товарных станциях С\ и Сг имеется по 30
комплектов мебели. Известно, что перевозка одного комплекта со
станции С\ в магазины М\ч М2, М3 стоит соответственно 1 р., 3 р., 5 р.,
62
а стоимость перевозки со станции С2 в те же магазины — 2 р., 5 р.,
4 р. Необходимо доставить в каждый магазин по 20 комплектов
мебели.
Составить план перевозок так, чтобы затраты на
транспортировку мебели были наименьшими.
Таблица 3.2
Из Ci
Из С2
Всего получено
в М\
Ха
20'
в ЛЬ
Х2
хъ
20
в Мз
Хз
Хь
20
Всего
отправлено
30
30
60
Количество комплектов мебели, перевозимых со станции С\ в
магазины Mi, М2у М.и обозначим через *,, х2> х3, а со станции С2 —
через ^4, А^5, Х§. Схема перевозок приведена в таблице 3.2.
В соответствии с условием задачи Х/^О (/=1, 2, ..., 6). Задача
сводится к тому, чтобы найти такое неотрицательное решение
системы
Х\ + *2 + *3 = 30,
Xl+xA = 2Q,
х2 + х5 = 20,
х3 + х6 = 20,
при котором линейная функция (стоимость перевозок)
/ = х\ + Зх2 + 5х3 + 2хА + Ъхъ + 4х6
имеет наименьшее значение.
Можно привести немало других примеров, сводящихся к
аналогичным математическим моделям (в отдельных случаях условия
могут одновременно включать как равенства, так и неравенства, а
для линейной функции требуется отыскание не минимума, а
максимума). Приведем сейчас общую математическую формулировку
основной задачи линейного программирования.
Дана система т линейных уравнений с п неизвестными:
а\\Х\+а\2Х2-\-...-\-а\пхп = Ь\,
а2\Х\+а22х2 + ... + а2пхп = Ь2, (3.1)
0>т\Х\ + Я/и 2*2 + ••• -\-атпХп = Ьт *
и линейная функция
f = ClX]+C2X2 + ... + CnXn. (3.2)
Требуется найти такое неотрицательное решение системы (3.1)
*1>0, х2>0, ..., х„>0, (3.3)
при котором функция / принимает наименьшее значение.
63
Уравнения (3.1) называют системой ограничений данной
задачи; функцию / — целевой функцией (или линейной формой).
Следует заметить, что систему ограничений в виде неравенств
всегда можно свести к системе в виде равенств (способом введения
фиктивных добавочных неизвестных). Так, если имеется
ai\X\ + ... + ainxn^bi,
то, вводя неизвестное хп + !^0, получим
CLi\X\ -\~ ...-{-CLinXn — Xn+l=bi.
(Значением хп+\ в окончательном результате можно принебречь.)
Кроме того, так как min /= — max( — /), то любая задача на
максимизацию сводится к задаче минимизации (и наоборот). Так
что постановку задачи линейного программирования в форме
(3.1) — (3.3) вполне можно считать общей.
3.2. ПОДХОД К РЕШЕНИЮ ЗАДАЧИ
ЛИНЕЙНОГО ПРОГРАММИРОВАНИЯ
Пусть поставлена задача линейного программирования (3.1) —
(3.3). Требуется среди неотрицательных решений системы (3.1)
найти решение, минимизирующее целевую функцию (3.2).
Предположим, что заданная система ограничений преобразована
так, что какие-либо г ее неизвестных выражены через остальные.
(Вопрос о том, как привести систему к такому виду,
рассматривается позже (п. 3.4).)
Х\ =<Х|, г+ \Хг+\ +...+а\пХп + $\,
хг = аг. г+ \ХГ+1 -\-... -\-ccrnXn -{-рг,
причем
Pi>0, р2>0, ..., рг>0. (3.5)
Неизвестные х{у л:2, ..., хг называются базисными
неизвестными, остальные — небазисными (или свободными). Совокупность
неизвестных Б = {х\, х2, ..., Хг) будем называть базисом. Подставляя
в (3.2) вместо базисных неизвестных их выражения из (3.4), можно
целевую функцию f представить через свободные неизвестные:
f=vo+y;+\xr+\ + ^+ynxn. (3.6)
Примем теперь, что все свободные неизвестные аг/(/ = г —|- 1,
г + 2 п) равны нулю. Тогда из (3.4) имеем: *,=£,, х2 = р2, ..,
хг = Рг- Получили одно из решений системы (3.4):
(р,, р2, .... рг, 0, 0, ..., 0),
которое в силу (3.5) удовлетворяет условиям неотрицательности
(3.3). Это решение называют допустимым. Для этого решения,
соответствующего базису Б, значение целевой функции / = уо-
64
Основная идея метода решения задачи линейного
программирования состоит в переходе от базиса Б к новому базису Б' так,
чтобы новое значение / уменьшилось (или; по крайней мере, ье
увеличилось):
Б-+Б' при условии, что fB* ^/5.
Таким путем в конечном итоге можно либо прийти к базису,
дающему минимум функции /, либо выяснить, что задача не имеет
решения. Переход к новому базису Б происходит путем удаления
из исходного базиса Б одной из неизвестных и введения вместо
нее какой-либо свободной неизвестной. Эти преобразования
связаны, очевидно, с перестройкой системы (3.4). Результатом
каждого очередного этапа преобразований является новый базис,
соответствующее ему базисное решение, а также соответствующее этому
решению значение целевой функции.
Рассмотренный подход и составляет основное содержание
метода решения задачи линейного программирования, называемого
симплекс-методом (его называют также «методом
последовательного улучшения плана»). Познакомимся более подробно с идеей
этого метода на конкретном примере.
Пример 3.2.1. Даны системы ограничений в виде (3.4):
Х\=2-\-Х4—х5,
х2 = 7-2х4 — 3*5, (3.7)
хз=1— х4 + 2х5
и целевая функция
/ = 3 + х4 —2х5. (3.8)
Требуется найти неотрицательное решение системы (3.7),
минимизирующее функцию (3.8).
В системе (3.7) неизвестные х\, х2\ х3 образуют базис. Примем
jc4 == лг5 = 0 и получим соответствующее базисное решение: (2; 7;
1; 0; 0), для которого значение целевой функции / = 3.
Из (3.8) видно, что значение / может быть уменьшено либо
путем уменьшения значения х4у либо путем увеличения значения
хъ. Первое сразу отпадает, так как х4 = 0 и уменьшение его
значения привело бы к нарушению условий неотрицательности (3.3).
Будем увеличивать jc5, сохраняя х4 = 0. Однако при этом нам
придется следить за значениями базисных переменных х\у х2у л:3, ибо
бесконтрольное увеличение хъ может сделать их значения
отрицательными. Как видно из (3.7), значению jc3 это не угрожает, но из
первого и второго уравнений следует, что хъ можно увеличить не
более чем до 2.
Примем х5 = 2. Учитывая, что х4 = 0, и используя систему (3.7),
получаем новое решение: (0;. 1; 11; 0; 2), для которого значение
целевой функции /=--1 (уменьшилось по сравнению с прежним
значением / = 3).
Новый базис теперь составляют неизвестные х2у лг3. хъ
(неизвестное Х\ переходит вместо хъ в число свободных). Для соот-
65
зетствующей перестройки системы (3.7) из первого уравнения
выражаем хъ — 2 — х\+хА и подставляем в другие уравнения, а
также в выражение для целевой функции /. Получаем новую
систему ограничений:
х2= 1 +3*i —5л\ь
агз = 5 —2лг,+лг4, (3.9)
. *5 = 2 — Х|+Л-4
и целевую функцию
/= —1 Н-2л-!—лг4- (3.10)
На этом заканчивается один этап процесса. Дальше поступим
аналогично: будем пытаться уменьшить значение / путем увеличения
значения неизвестного х^.При этом из первого уравнения системы
(3.9) видно, что лг4 можно увеличить не более чем до 0,2. Итак,
сохраняя Jti=0, примем jc4 = 0,2. Получим новое решение:
(0; 0; 5,2; 0,2; 2,2), (3.11)
при котором /== — 1,2. Новый базис образуют неизвестные дг3, лг4,
хъ. Неизвестное х\ в выражении для целевой функции (3.10)
необходимо исключить, введя вместо него xL>. Из первого уравнения
системы (3.9) имеем:
.Vl==0,2 + 0,6x,— 0,2jc2,
что дает новое выражение для функции /:
/=-1,2+1,4л',4-0,2л'2.
Из полученного выражения легко сделать вывод, что значение /
более уже не может быть уменьшено, что сделать это можно было
бы только путем уменьшения значений неизвестных хх и х2. Однако,
как следует из (3.11), *, =лг2 = 0 и их уменьшение повлекло бы
нарушение условия неотрицательности.
Итак, задача peuteHa — получено решение (3.11),
минимизирующее значение целевой функции (при этом /= — 1,2).
Заметим, что рассмотренный выше процесс не всегда приводит
к получению оптимального решения: при решении отдельных задач
линейного программирования может сложиться ситуация, в которой
условия неотрицательности не препятствуют неограниченному
уменьшению значения целевой функции. Такой случай означает, что
функция / не имеет минимума и, следовательно, оптимального
решения не существует.
Для выяснения условий, приводящих к подобным случаям,
рассмотрим симплекс-метод в общем виде.
3.3. СИМПЛЕКС-МЕТОД
Исходя из формулировки задачи линейного программирования
(3.4) — (3.6) запишем систему ограничений и целевую функцию в
виде:
66
X\=b\—(a\.r+\Xr+\ + ... + a\nXn),
\ x2 = b2 — (a2. r + \Xr + \+... + a2HXn\ (3.12)
Xr = &л — (ar. г -f I*r + , + ... + OlrnXn),
f = C{) — (Cr+\Xr+\+...+CnX„). (3.13)
При этом в соответствии с (3.5) свободные члены Ь\% 62, ..., 6 г
неотрицательны, базис £ = {*,, jc2 *г), а соответствующее ему
базисное решение есть
(/>,, й2, .... 6„ 0, 0 0), (3.14)
ДЛЯ КОТОРОГО fB =Сц.
Как следует из (3.13), уменьшить значение / — это значит
путем увеличения одного из свободных неизвестных добиться того,
чтобы значение выражения в скобках стало положительным
(разумеется, при соблюдении условия неотрицательности для базисных
неизвестных). В зависимости от знаков коэффициентов cr+i, Сг+21
..., сп здесь могут быть два случая.
1. Все числа сЛ + |, с,+ 2. ...» сп неположительны. Тогда
значение / уже более не может быть уменьшено, ибо это могло быть
сделано только путем уменьшения значений свободных неизвестных,
что невозможно. Отсюда следует, что базисное решение (3.14) в
этом случае является оптимальным.
2. Среди чисел сг + ,э сЛ + 2 сп имеются положительные. Пусть,
например, г;>0 (r+l^/^я). Это позволяет уменьшить значение
Д путем увеличения ау, оставляя значения других свободных
неизвестных нулевыми. Считая, что значения всех неизвестных хЛ_н,
*г+2, ..., хПу кроме xjy равны нулю, на основании (3.12) и (3.13)
имеем:
X\=b\—a\jXj,
* = **-**. (3.l5)
xr = br — anxh
f = c{) — CjXh Cj>0. (3.16)
Из равенств (3.15) следует, однако, что, увеличивая значение
Xj, необходимо следить за сохранением условия
неотрицательности базисных переменных х\, х2, ..., хг. Легко видеть, что при
неотрицательности свободных членов Ь\% 62, ..., Ьг последнее полностью
зависит от знака коэффициентов при xf. Здесь, в свою очередь,
снова различаются два случая (2а и 26).
2а. Все числа aiy, a2/, ..., ar/ неположительны. Тогда значение
Xj может быть увеличено неограниченно, что приводит к
неограниченному уменьшению /. Таким образом,'в этом случае минимум
/ не достигается, т. е. min/= — оо.
26. Среди чисел a]h a2/, • , Дл/ имеются положительные. Пусть,
например, а*/>0 (1 </?</*); коэффициентов а*у, удовлетворяющих
этому условию, может быть несколько. Найдем для них значения
67
Ok л
частных вида — и выберем среди этих частных наименьшее —
пусть это будет — = К^0. Понятно (см. (3.15)), что для сохране-
ния неотрицательности всех базисных неизвестных Х\, л:2, ..., хг (и
прежде всего xi) значение х\ может быть увеличено не более чем
до К. Коэффициент atj в этих условиях называют разрешающим
элементом.
Итак, примем л:, = /С и найдем значения базисных неизвестных
(при условии, что все небазисные неизвестные, кроме х-]% равны
нулю):
Х\=Ь\—ачК,
Xi = bi — aijK = Q,
Xr = br — arjK.
Неизвестное х{ теперь должно перейти в состав свободных
неизвестных, а взамен него в базис следует ввести неизвестное хг
Новый базис будет иметь вид:
Значение целевой функции /, соответствующее базису />,, равно
(см. 3.16):
/я, =CQ — CjK^Co = fB> т. е. fBi </fi.
Последнее означает, .что в результате выполнения одного шага
процесса (для случая 26) происходит уменьшение (или, по крайней
мере, неувеличение) значения целевой функции.
Для перехода к следующему шагу симплекс-метода
необходимо преобразовать систему ограничений (3.12) и целевую функцию
(3.13) применительно к новому базису. С этой целью из уравнения
системы (3.12), отвечающего бывшему базисному неизвестному
Хы выражается новое базисное неизвестное х/, которое вслед за
этим исключается из остальных уравнений системы (подстановкой
в эти уравнения полученного выражения для *,•). Точно так же
неизвестное х\ исключается из выражения (3.13) для функции /.
Вслед за этим весь рассмотренный этап повторяется сначала.
Очевидно, что остановка процесса может произойти в случаях 1
или 2а. Гарантии результативности симплекс-метода
обеспечиваются следующей теоремой ([7), [16]).
Теорема 3.1 (о конечности алгоритма симплекс-метода).
Если существует оптимальное решение задачи линейного
программирования, то существует и базисное оптимальное решение. Это
решение может быть получено через конечное число шагов симплекс-
методом, причем начинать можно с любого исходного базиса.
68
3.4. СИМПЛЕКС-ТАБЛИЦЫ
Ручные вычисления по симплекс-методу удобно оформлять в
виде так называемых симплекс-таблиц. Для удобства составления
симплекс-таблицы будем считать, что система ограничений (3.12)
переписана в виде:
Х\ +01. г+1*г-Н +... -\-CL\nXn = b\,
х2 + а2, г +1 хг +1 +... + а2пХп = Ь2у (3.17)
Xr + #r, г+ [Хг+\ +... + arnXn = Ьг
и целеэая функция (3.13) определена равенством
f + Cr+\Xr+\+...+CnXn = Co. (3.18)
По исходным данным (3.17) —(3.18) заполняется начальная
симплекс-таблица, форма которой показана в таблице 3.3.
I Таблица 3.3
Базисные
неизвестные
Х\,
Свободные
члены
6,
Х\ .
1 .
... Xi .
... 0 .
.. хг
.. 0
Хг+1
Я|. г,+ 1
... X,
... а,/
Хп
... am
-+Xj
bi
0 .
.. 1 .
.. 0
Л/. '+I
... Оц
... СЦп
Хг
Форма /
Ьг
Со
0 .
0 .
.. 0 .
.. 0 .
.. 1
.. 0
Or. г+\
Cr+i
... а,/
... Cf
... dm
... Сп
Сформулируем сейчас алгоритм симплекс-метода
применительно к данным, внесенным в таблицу 3.3.
1. Выяснить, имеются ли в последней строке таблицы
положительные числа (со не принимается во внимание). Если все числа
отрицательны, то процесс закончен; базисное решение (b\y b2j ...,
Ьг% О, 0, ..., 0) является оптимальным; соответствующее значение
целевой функции / = с0.
ЧЕсли в последней строке имеются положительные числа, перейти
в п. 2.
2. Просмотреть столбец, соответствующий положительному
числу из последней строки, и выяснить, имеются ли в нем
положительные числа. Если щ в одном из таких столбцов нет
положительных чисел, то оптимального решения не существует.
Если найден столбец, содержащий хотя бы один
положительный элемент (если таких столбцов несколько, взять любой из них),
отметить этот столбец вертикальной стрелкой (см. табл. 3.3) и
перейти к п. 3.
3. Разделить свободные члены на соответствующие положи-
69
тельные числа из выделенного столбца и выбрать наименьшее
частное. Отметить строку таблицы, соответствующую наименьшему
частному, горизонтальной стрелкой. Выделить разрешающий
элемент ацУ стоящий на пересечении отмеченных строки и столбца.
Перейти к п. 4.
Комментарий. Задача теперь состоит в том, чтобы удалить
из базиса неизвестное, расположенное против разрешающего
элемента в строке (*,) и ввести вместо него свободное неизвестное,
расположенное напротив разрешающего элемента в столбце (*,).
В соответствии с алгоритмом симплекс-метода это означает
преобразование системы ограничений и целевой функции. В данном
случае это означает переход к новой симплекс-таблице, в первом
столбце которой вместо х,- вписывается обозначение *,, а
заполнение внутренних пустых клеток происходит по правилам,
изложенным ниже.
4. Разделить элементы выделенной строки исходной таблицы на
разрешающий элемент (на месте разрешающего элемента появится
единица). Полученная таким образом новая строка пишется на
месте прежней в новой таблице. Перейти к п. 5.
5. Каждая следующая строка новой таблицы образуется
сложением соответствующей строки исходной таблицы и строки,
записанной в п. 4, которая предварительно умножается на такое чисую,
чтобы в клетках выделенного столбца при сложении появились
нули. На этом заполнение новой таблицы заканчивается, и
происходит переход к п. 1.
Пример 3.4.1. Решим задачу линейного программирования
из примера 3.2.1 с помощью симплекс-таблиц.
Перед заполнением первой симплекс-таблицы (см. табл. 3.3)
перепишем систему ограничений (3.7) в соответствии с (3.17):
Х\ . — *4 + *5=2,
Х2 +2Х4+ЗХ5 = 7,
*3+ *4— 2*5=1
и линейную форму (3.8) в соответствии с (3.18):
/ — *4 + 2*5 = 3.
Воспользуемся алгоритмом симплекс-метода. Замечаем, что в
последней строке- таблицы 3.4 имеется положительный элемент,
* 2 7
выбираем наименьшее частное из -- и -у и выделяем разрешающий
элемент (на пересечении строки х\ к столбца хъ). В новый базис
вместо неизвестного *, войдет неизвестное хъ. Поскольку
разрешающий элемент уже равен единице, выделенную строку без
изменений переписываем на прежнее место в новую таблицу (см.
табл. 3.5). Остальные строки преобразовываем в соответствии с
алгоритмом так, чтобы в соответствующих клетках столбца хъ
появились нули (так, например, при преобразовании второй
строки она предварительно складывается с уже переписанной
первой, умноженной на —3).
70
Таблица 3.4
1
Базисные
Х\
х>
Хл
Форма /
неизвестные Свободные
2
7
1
3
члены
А'|
1
0
0
0-
Xi
0 '
1
0
0
хл
0
0
1
0
Х\
-1
2
1
-1
*5
ш
3
-2
2
К таблице 3.5 снова применяем симплекс-алгоритм, начиная
с п. 1. Поскольку в последней строке есть положительный элемент
(в столбце х4), процесс не заканчивается. В результате
преобразований получается таблица 3.6, в последней строке которой уже
нет положительных элементов. Это означает, что последнее
базисное решение (0; 0; 5,2; 0,2; 2,2) является оптимальным.
Соответствующее значение целевой функции /= — 1,2. Таким образом
задача решена.
Таблица 3.5
\
Базисные
хь
Х-2
Хл
Форма /
неизвестные
Свободные
2
1
5
-1
члены
Х\
1
-3
2
— 2
Х-2
0
1
0
0
Хл
0
0
1
0
хА
-1
Ш
-1
1
х&
1
0
0
0
Таблица 3.6
Базисные
хь
Х\
Хл
Форма /
неизвестные
Свободные
2,2
0,2
5,2
-1,2
члены
Х\
0.4
-0,6
1,4
-1,4
Xj
0,2
0,2
0,2
-0,2
Хл
0
0
1
0
Ха
0
1
0
0
Хь
1
0
0
0
3.5. ОТЫСКАНИЕ ИСХОДНОГО БАЗИСА
Начиная обсуждать алгоритм решения задачи линейного
программирования симплекс-методом (см. п. 3.2), мы предполагали,
что начальный базис системы ограничений уже известен. Укажем
71
некоторые приемы нахождения базиса системы т * линейных
уравнений с п неизвестными (m<in). t
В некоторых случаях базис усматривается непосредственно.
Пусть дана система:
2х\ + 1,4*3 — *4 = 6,8,
*2 + 5*з — 7,1 *4 = 4,3,
8*3 + 6,4*4 —4*5= —1,2.
Замечаем, что неизвестные *|, *2 и *5 можно выразить только через
неизвестные *3 и *4. С этой целью разделим первое уравнение на 2,
а третье — на —4 и перепишем для наглядности исходную систему
в виде (3.4):
*, =3,4 —0,7*3 + 0,5*4,
лг2 = 4,3 — 5*з + 7,1 *4,
хъ = 0,3 + 2*з +1,6*4.
Неизвестные *|, *2; *5 образуют базис. При этом существенно
заметить, что все свободные члены положительны, чем
обеспечивается выполнение необходимого условия (3.5).
Другой метод получения начального базиса — это метод
симплексного преобразования. Поскольку в преобразовании участвуют
только числа (коэффициенты и свободные члены), исходную
систему (3.1) удобно записывать в виде таблицы:
Таблица 3.7
Х\
an
«21
а,п\
х2
«12
022
am2
Хп
аХп
а>п
O-mn
Свободные
члены
Ьх
Ь-2
Ьт
При этом предполагается, что все свободные члены Ь{ (/=1, 2,
..., гп) — числа неотрицательные (этого легко добиться, умножая
уравнения с отрицательными свободными членами на —1).
Алгоритм симплексного преобразования основан на идее
последовательного исключения переменных методом, во многом схожим с
методом преобразования симплекс-таблиц.
Среди столбцов из коэффициентов при неизвестных выбирается
столбец, в котором имеется хотя бы один положительный
элемент. Если в таком столбце несколько положительных элементов,
то из них выбирается тот, который отвечает наименьшему числу
при делении соответствующих свободных членов на
положительные элементы выбранного столбца. Выделенный таким образом
элемент называется разрешающим (см. п. 3 алгоритма симплекс-
метода).
Элементы разрешающей строки делятся на разрешающий
элемент и переписываются в новую таблицу. Остальные элементы
72
таблицы получаются по правилу, описанному в п. 5 алгоритма
симплекс-метода.
Процесс продолжается до тех пор, пока не будет получено
неотрицательное базисное решение.
Пример 3.5.1. Найти неотрицательное базисное решение
системы
Х\— эх$ -\- 2xq =—3,
х2— 2хъ— х6 = 5,
Х;\ — 3*5 ~\г х6 = — 7,
хА+ хъ — Зх6= — 4.
Замечаем, что неизвестные х\, jc2, лг3, х4 могут быть легко
выражены через неизвестные хъ и хь (т. е. исходную систему формально
несложно переписать в виде (3.4)), однако при этом не будет
выполнено условие неотрицательности свободных членов (3.5).
Воспользуемся методом симплексного преобразования. Перед
составлением начальной таблицы вида 3.7 с целью получения
неотрицательных свободных членов третье уравнение умножим на (— 1)
и прибавим последовательно к первому и четвертому. Дальнейшие
преобразования по нахождению начального базиса приведены
в таблице 3.8. Уже на третьем этапе преобразований получается
одно из неотрицательных базисных решений (0; 53; 0; 63; 11; 26),
что при необходимости позволяет составить первую симплекс-
таблицу с начальным базисом
Б = [х2ч хА% Хы х6}.
Таблица 3.8
Этап
преобразований
1
2
3
•*■
1
0
0
0
1
1
1
4
3
5
1
8
Х-2
0
1
0
0
0
1
0
0
0
1
. 0
0
хл
-1
0
-1
-1
-1
-1
-2
-5
-5
-9
-2
-13
Хл
0
0
0
1
0
0
0
1
0
0
0
1
А'5
-2
-2
3
4
-2
— 4
ц
0
0
1
0
Хъ
щ
-1
-4
1
0
0
0
1
0
0
0
Свободные
члены
4
5
7
3
4
9
11
19
26
53
11
63
Метод симплексного преобразования составляет фактически
идейную основу и другого распространенного метода отыскания
начального базиса, особенно удобного для последующего
составления симплекс-таблиц, так называемого «метода искусственного
базиса».
73
Контрольные вопросы
1. Приведите математическую формулировку основной задачи
линейного программирования.
2. Какие неизвестные системы ограничения называются
базисными? , '
3. В чем заключается основная иде^ симплекс-метода? Как
в этой связи объясняется его другое название — «метод
последовательного улучшения плана»?
4. Каковы содержание и последовательность шагов симплекс-
алгоритма, реализуемого на симплекс-таблицах?
5. Назовите практические приемы нахождения исходного базиса
для заданной системы ограничений.
ЛАБОРАТОРНАЯ РАБОТА 3
Тема. Симплекс-метод решения задач линейного
программирования.
Задание. Среди всех неотрицательных решений системы
линейных уравнений с п неизвестными
ацХ\+а]2Х2 + ...+а]пХп = Ь\у
a2lxl+a22x2 + ...+a2nxn = b2, (3.20)
Я/н I Х\ -\- ат2Х2 -)-... + CimnXn = Ьп
найти такое, которое сообщает минимум целевой функции
f = C\X\+c2x2 + ... + cnxn. (3.21)
Задание выполнить двумя способами: а) преобразованием симплекс-
таблиц с применением калькулятора; б) обращением к программе
«симплекс-метод» на ЭВМ. Полученные решения сравнить.
Значения коэффициентов и свободных членов системы
ограничений вида (3.20) (в форме равенств) для двадцати вариантов
приведены в таблице 3.9, а значения коэффициентов целевой
функции — в таблице 3.10.
Пояснения к выполнению лабораторной работы 3. Выполнение
первой части задания следует начинать с отыскания
некоторого допустимого базисного решения (начального базиса). Если
начальный базис непосредственно не усматривается, для его
нахождения можно применить метод симплексного преобразования (см.
пример 3.5.1). После получения начального базиса система
ограничений приобретает вид (3.17) (разумеется, ъ каждом конкретном
случае базис могут составить г неизвестных, имеющих индексы не
обязательно от 1 до г), а целевая функция, выраженная через
свободные неизвестные,— вид (3.18). Вслед за этим решение
задачи сводится к последовательному заполнению симплекс-таблиц (см.
пример 3.4.1). Производя вычисления на МК, промежуточные
результаты следует округлять до четырех-пяти знаков после запятой.
Составление симплекс-таблиц продолжается до те^х пор, пока не
74
будет получено оптимальное решение, минимизирующее функцию /\
или будет установлено, что поставленная задача линейного
программирования решения не имеет.
Признаком достижения оптимального решения является
неположительность всех элементов последней строки симплекс-таблицы
(свободный член не принимается во внимание). Признаком
отсутствия оптимального решения является наличие в последней
строке положительных элементов, но таких, что все стоящие над
ними элементы таблицы неположительны.
Поскольку исходная система ограничений задана в таблице 3.9
в форме равенств, каждое равенство заменяется эквивалентными
ему двумя неравенствами. Полученный результат следует
сравнить с результатом «ручного» решения задачи по методу симплекс-
таблиц.
Таблица 3.9
Номера
вариантов
1
2
3
4
5
6
7
8
9
. /
1
2
3
1
2
3
1
2
3
1
2
3
1
2 ч
3
1
2
3
1
2
3
1
2
3
1
2
3
а<\
0
-8,704
8,654
5,067
0
0
-5,34
16,543
21,325
0
,71,053
0
0
0
-5,789
24,675
0
-54,675
-34,567
82,363
76,443
32,453
12,045
-56,214
. 93,785
56,344
-3,756
di-2 А
-5,871
7,453
-6,729
-25,396
6,375
-0,023
0
62,3
0
0
0
-3,1264
-14,894
39,995
4,001
45,308 -
1,453
32,408
0
0
i;056
-76,034
-65,432
43,511
0
0
11,591
6,543
8,962
8,453
0
0
7,277
2,1534
0
0
-98,345
21,£32
48,943
0
94,366
0
-67,432
6,432
1,345
38,564
'0
0
0
0
-4,329
0-1
38,456
0
<j,\
— 9,996
0,763
7,772
0
1,624
0
31,46
-11,101
25,6
-21,578
0
0
ащ
7,618
-8,654
5,432
5,637
2,454
-3765
0
0
36,081
49,378
34,589
12,435
36,8811 22,864
0 34,5812
о 88,9715
0
65,807
-54,111
49,583
53,642
— 28,341
8,654
-1,457
4,328
-13,234
0
0
2,807
2,005
2,876
б
12,567
0
45,026
54,443
5,432
48,401
38,988
77,345
bi
0,864
0
9f743
6,201
3,766
1,734
13,546
62,345
38,963
4,998
66,735
68,994
33,684
38,485
4,432
60,747
43,786
0
12,781
64,348
.88,443
0
0
6,439
10,554
9,341
7,576
75
Продолжение
Номера
вариантов
10
11
12
13
14
15
16
17
-
Номера
вариантов
i
1
2
3
1
2
3
1
,2
3
1
2
3
1
2
3
1
2
3
1
2
3
1
2
3
•■
С\
ац а,2
11,783
0
13,479
-32,032
0,347
9,496
2,346
0
-2,457
1,067
0
-4,085
6,861
-0,245
0
1,239
-34,127
0
20,304
, 32,531
0
0
51,345
-17,589
С2
-5,637
23,441
48,134
56,438
— 61,391
-64,581
5,431
1,895
6,589
2,492
-7,563
0
23,537
81,307
36,566
65,328
0
5,409
-4,502
0
34,567
13,567
0
0
Д/з
0
-56,789
3,345
0
0
53,464
1,356
21,048
0
-0,234
2,357
2,456
-7,866
0
15,703
-32,567
6,541
-4,583
3,305
60,439
5,804
-11,389
6,342
77,605
Сз
ац
4,456
66,349
-3,438
64,574
2,146
-7,652
-6,729
35,131
2,349
6,201
0
5,348
0
16,932
12,561
0
43,712
6,726
48,101
21,675
-5,689
33,456
88,997
31,401
С*
а»
87,333
13,567
0
0
7,651
-6,589
0
0
7,122
0
6,532
21,431
21,678
42,564
-0,276
45,231
4,328
3,417
52,423
6,789
37,567
66,448
38,945
64,387
Таб.
ь,
0,056
55,331
61,114
11,12
21,85
43,06
5,483
32,164
5,345
3,561
8,758
6,546
12,078
13,384
80,304
-4,568
2,089
2,091
0
4,567
5,673
0
34,565
6,054
лица 3.10
сь
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
7,541
0,213
12,523
-32,456
0
2,564
66,756
1,239
0 '
-90,814
2,152
1,216
1,452
13,862 *
1,324
3,052
6,015
-2,112
4,324
-6,308
0
-13,788,
0
70,813
-7,543
-37,404
13,456
-6,452
-4,517
2,342
-6,543
-6,525
5,036
70,678
7,655
-7,567
5,864
37,891
16,568
45,682
45,678
8,541
0
-7,894
0
6,218
-0,123
72,523
4,083
-5,6/2
-93,456
-9,218
42,679
-44,556
46,441
0
-30,037
9,101
-34,523
-16,789
6,664
1,801
-12,041
6,751
60,305
-6,541
21,372
0
7,649
-8,231
6,687
-23,441
13,405
4,562
-13,458
6,714
13,459
44,565
9,432
31,539
4,862
10,107
8,012
46,105
34,582
Глава 4
ИНТЕРПОЛИРОВАНИЕ ФУНКЦИЙ
4.1. ПОСТАНОВКА ЗАДАЧИ
Пусть известные значения некоторой функции / образуют
следующую таблицу:
Таблица 4.1
X
fix)
Х{)
Уо
Х\
У\
хп
Уп
При этом требуется получить значение функции / для такого
значения аргумента х, которое входит в отрезок [x(); хп\ но не
совпадает ни с одним из значений х( (/ = 0, 1, ..., /?).
Очевидный прием решения этой задачи — вычислить значение
f(x), воспользовавшись аналитическим выражением функции /.
Этот прием однако, можно применить лишь в случае, когда
аналитическое выражение / пригодно для вычислений. Более того,
часто аналитическое выражение функции / вовсе неизвестно.
В этих случаях применяется особый прием — построение по
исходной информации (табл. 4.1) приближающей функции /\ которая
в некотором смысле близка к функции / и аналитическим
выражением которой можно воспользоваться для вычислений, считая
приближенно, что
f(x)*=F(x). (4.1)
Классический подход к решению задачи построения
приближающей функции основывается на требовании строгого совпадения
значений f(x) и F(x) в точках *,(/ = (), 1, 2, ..., я), т. е.
F(x()) = yo, F(x\) = y\, ..., F(xn) = yn. (4.2)
В этом случае нахождение приближенной функции называют
интерполяцией (или интерполированием), а точки х()у х\, ...,
хп—узлами интерполяции.
Будем искать интерполирующую функцию F(x) в виде
многочлена степени п:
Рп{х) = а0хп + а[хп-] + ... + ап-]х + ап. (4.3)
Этот многочлен имеет п-\-1 коэффициент. Естественно
предполагать, что п-\-\ условия (4.2), наложенные на многочлен, позво-
11
лят однозначно определить его коэффициенты. Действительно,
требуя для Р„(х) выполнения условий (4.2), получаем систему
/z + 1 уравнений с я + 1 неизвестными:
V akxrk = yi (1 = 0, 1 л). (4.4)
Реишя эту систему относительно неизвестных а(), аь ..., а„, мы и
получим аналитическое выражение полинома (4.3). Система (4.4)
всегда имеет единственное решение, так как ее определитель
Х[) Х[) ... Х{) 1
х'[ х'Г1 ... *. I
^'хГ1'...'*,' 1
известный в алгебре как определитель Вандермонда, отличен от
нуля. Отсюда следует, что интерполяционный многочлен Рп(х)
для функции /, заданной таблицей 4.1, существует и единствен
, (может случиться, что какие-то коэффициенты в Р„{х), в том числе
и а0, равны нулю; поэтому интерполяционный полином при
рассмотренных условиях в общем случае имеет степень, не большую,
чем п).
Описанный прием в принципе можно было бы использовать и
для практического решения задачи интерполирования
многочленом, однако на практике используются другие, более удобные и
менее трудоемкие способы.
4.2. ИНТЕРПОЛЯЦИОННЫЙ МНОГОЧЛЕН ЛАГРАНЖА
Пусть функция / задана таблицей 4.1. Построим
интерполяционный многочлен L„(x), степень которого не больше п и для
которого выполнены условия (4.2). Будем искать L„(x) в виде
Ых) = Цх) + Цх) + ... + Цх\ (4.5)
где 1{х) — многочлен степени я, причем
''W-lO, если ьфк. <4-6)
Очевидно, что требование (4.6) с учетом (4.5) вполне
обеспечивает выполнение условий (4.2).
Многочлены li(x) составим следующим способом:
li(x) = Ci(x — *(>)(* —Х|)«.•..•(* — Xi-\)(x — *,+ ,)•...•(* — *„), (4.7)
где с,- — постоянный коэффициент, значение которого найдем из
первой части условия (4.6):
У/
0==;
(Xi — Xt))-...-(Xi — X/_|)(X/ — Xi+\)'...'{Xi — x„)
(замечаем, что ни один множитель в знаменателе не равен нулю).
78
Подставим d в (4.7) и далее с учетом (4.5) окончательно имеем:
Ux)= % !/i'77i—(х х их * \ (х х\' (>
i = 0 (Xi — X{))'...'(Xi—Xi-i)(Xi — */+| )•...•(*/ — Xn)
Это и есть интерполяционный многочлен Лагранжа. По таблице
исходной функции / формула (4.8) позволяет весьма просто
составить «внешний вид»/ многочлена.
Пример 4.2.1. Построить интерполяционный многочлен
Лагранжа для функции, заданной таблицей:
Из таблицы 4.2 следует, что п = 2 Таблица 4.2
(т. е. степень многочлена будет не выше, чем
вторая); здесь Jt0=l, *i=3, jc2 = 4.
Используя формулу (4.8), получаем:
w»i2<:-">(f"!)+4-u-i)u-4) ■
х 1 3
fix) 12 4
4
6
U-|)(.v-3)
О =
(1-3) (I-4) ' (3-1) (3-4) ' (4— 1)(4—3)
= 2(х2-7х+\2)-2(х2-5х + 4) + 2(х2-4х + 3) = 2х2-\2х + 22.
Используя обозначение П„ + |(лг) = (х — xu)(x — Xi)-...-(x — хп),
формуле Лагранжа можно придать более сжатый вид.
Продифференцируем П„+|(дг) по х:
П^+.,(*) = V (Jf — ДГп)-... -(ДС — Xi-\)(X — Xi+ |)-...- (х — х„).
/ = 0
При x = Xi имеем (/ = 0, 1, ..., п):
ПГ' + |(ДГ/) = (Л-/ — -Го)-...-(Х/ — ЛГ/_|)(ДГ/ — Л-/+|)-....-(ДС/ — дгя).
Тогда формула Лагранжа принимает вид:
4.3. ОРГАНИЗАЦИЯ РУЧНЫХ ВЫЧИСЛЕНИЯ
ПО ФОРМУЛЕ ЛАГРАНЖА
Непосредственное применение формулы Лагранжа приводит к
большому числу однотипных вычислений. Организация вычислений
существенно улучшится, если пользоваться специальной
вычислительной схемой.
В таблице 4.3 показано построение такой схемы для четырех
узлов (/=0, 1, 2, 3). Таблица составляется заново для кажкого
нового аргумента jc.
Заполнение таблицы начинается с того, что вычисляются и
заносятся в соответствующие клетки все элементарные
разности. Вслед за этим вычисляются произведения pt разностей по
строкам:
79
Ро = (х — Хо) (Х0 — Х\) (Хо — Х2) (Хо — *3),
Р\ =(Х\ — *о) (Х — Х\) (Xi —Х2) {Х\ —х3)
и т. д.
Таблица 4.3
X
Хо
Х\
Х2
Хз
Хо
Х — Хо
Х\ — Х[\
Х2 — Хо
Хз — Хп
Х\
Хо — Х\
Х — Х\
Х2 — Х\
Хз — Xi ■
Х-2
Хо — Х2
Х\—Х2
Х — Х2
Хз — х2
Хз
Хо — Хз
Х\—Хз
Х2 — Хз
х — Хз
Pi У> yi/Pi
S = Z(yi/Pi)
Легко видеть, что произведение, обозначенное в таблице через
/ р„—это знаменатель в формуле Лагранжа (4.9), т. е.
р/ = (х — *,)• ГЦ+ ,(*,) (/ = 0, 1, ..., п).
С учетом этого обозначения формула Лагранжа имеет вид:
Все необходимые значения последовательно получаются в таблице.
Сумма 5 образуется сложением элементов последнего столбца.
Для получения окончательного значения Ln(x) достаточно
умножить S на произведение Пп+\(х) (произведение диагональных
разностей таблицы).
Пример 4.3.1. Имеется таблица функции:
Таблица 4.4
X
0,41
1,55
2,67
3,84
Я*)
2,63
3,75
4,87
5,03
Требуется получить значение этой функции в точке х=1,91,
пользуясь интерполяционным многочленом Лагранжа. Вычисления
приведены, в таблице 4.5.
Для нахождения окончательного результата сумма значений
последнего столбца умножается на произведение Диагональных
разностей:
/(1,91)=0J9207.55422«4,15.
80
Таблица 4.5
JC =
хо
Х\
х2
*3
1,91
Хо
1,50
1,14
2,26
3,43
Х\
-1,14
0,36
1,12
2,29
х2
-2,26
-1,12
-0,76
1,17
Хл
-3,43
-2,29
-1,17
-1,93
Pi
-13,26
1,053
2,251
-17,74
У>
2,63
3,75
4,87
5,03
yi/Pi
-0,1983
3,561
2,163
-0,2835
5,2422
4.4. ПРОГРАММА ВЫЧИСЛЕНИЯ ЗНАЧЕНИЯ
ИНТЕРПОЛЯЦИОННОГО МНОГОЧЛЕНА ЛАГРАНЖА
Для составления программы вычисления одного значения
интерполяционного многочлена Лагранжа на ЭВМ воспользуемся
формулой (4.8). Основная рабочая часть искомого алгоритма состоит
из двойного цикла — во внутреннем цикле вычисляются п-\-\
значений многочленов-слагаемых вида (/ = 0, 1, ..., я):
(jc — x{))-...-(x — Xi-l)(x — xi+\)-...-{x — Xn)
i[X)~~yi(xi-x»).....(xi-xi-i)(x-xi+l).....(xi-xn)
(в числителе и знаменателе п сомножителей), а во внешнем —
накапливается общая сумма
Ln(x)=.£ 1{х).
/ = 0
Схема алгоритма изображена на рисунке 9.
Работа внутреннего цикла контролируется с помощью
индекса /. Изменяясь в пределах от 0 до п, индекс / принимает все-
таки ровно п значений, «проскакивая» текущее значение индекса /,
определяемого во внешнем цикле. Тем самым обеспечивается
правильное составление многочленов-слагаемых U{x) формулы Лагран-
-. жа. Носителем окончательного результата является переменная /.
Ниже приведена программа вычисления значения / с помощью
интерполяционной формулы Лагранжа на языке Бейсик для
функции, заданной таблицей из примера 4.3.1. Ввод исходной таблицы
происходит в цикле, причем массивы значений хну вводятся не
последовательно, а парами соответствующих элементов.
10 REM МНОГОЧЛЕН ЛАГРАНЖА
20 DIM X(3Q),Y(30)
30 INPUT "ВВЕДИТЕ КОЛИЧЕСТВО УЗЛОВ
ИНТЕРПОЛИРОВАНИЯ"^
40 PRINT "ВВЕДИТЕ ПАРАМИ ЗНАЧЕНИЯ X И Y"
81
Г ЛАГРАНЖ Л
B6odN
*
Ввод таблицы 1
х,У \
*
Ввод А
*
F=0
*
Начало цикла
по I
omldoN
*
L=1
i
Начало цикла
под
от I doN
да /й\
*^L i 'J ^^
*
1 Конец цикла
\ под
*
l=L*Y(I)
F=F + L
*
1 Конец цикла
\ по I
♦
| Вывод A, F
*
Г Конец
нет
\
г
\l=l*(a-x(j))/(x(i)-x(j))\
\
Рис. 9
50 FOR 1=1 TO N
60 INPUT X(I),Y(I)
70 NEXT I
80 INPUT "ВВЕДИТЕ ЗАДАННОЕ ЗНАЧЕНИЕ
АРГУМЕНТА";A:F=0
90 FOR 1=1 TO N
100 L=I
110 FOR J=I TO N
120 IF I=J THEN 140
130 L=LxA(-X(J))/(X(I)-X(J))
140 NEXT J
150 L=LxY(l):F=F+L
160 NEXT I
170 PRINT "ПРИ X=";A, "F(";A;")=";F
180 INPUT "ЕСЛИ ХОТИТЕ ПРОДОЛЖИТЬ ВЫЧИСЛЕНИЕ
-ВВЕДИТЕ 1,В ПРОТИВНОМ СЛУЧАЕ ВВЕДИТЕ 0";М
190 IF M=I THEN 80
200 END
Для набора исходных данных примера 4.3.1 будут получены
следующие результаты:
ПРИ Х= 1.91 F(1.91) =4.153908736123.
4.5. ИНТЕРПОЛЯЦИОННЫЕ МНОГОЧЛЕНЫ НЬЮТОНА
ДЛЯ РАВНООТСТОЯЩИХ УЗЛОВ
Часто интерполирование ведется для функций, заданных
таблицами с равноотстоящими значениями аргумента. В зггом случае
шаг таблицы li = xi+\ — х, (/ = 0, 1,2, ...) является величиной постоян-
83
ной. Для таких таблиц построение интерполяционных формул (как,
впрочем, и вычисление по этим формулам) заметно упрощается..
4.5.1. Конечные разности
Пусть функция задана таблицей 4.1 с постоянным шагом.
Разности между значениями функции в соседних узлах интерполяции
называются конечными разностями первого порядка:
A«// = №+i—*// (/ = 0, 1, 2, ...).
Из конечных разностей первого порядка образуются конечные
разности второго порядка:
Продолжая этот процесс, можно по заданной таблице функции
составить таблицу конечных разностей (см. таблицу 4.6). Конечные
разности любого порядка могут быть представлены через значения
функции. Действительно, для разностей первого порядка это
следует из определения. Для разностей второго порядка имеем:.
tfyi==Ayi+\—&yi = (yi+2--yi+\) — (yi+\—yi) = yi+2 — 2yi+i+yi.
Аналогично для разностей третьего порядка:
Д3*// = Л2</н-|— Д2(//=((/|+з —2t/i4-2 + ^4-i)—(j/i+2 — 2f//+,+ £//)=
= (// + :,— 3(// + 2 + 3i//+|— IJi
и т. д.
Методом математической индукции можно доказать, что
A^==/// + ,-^+,_,+^^///+._2-...+(-l)V (4.10)
Т а б л и ц а 4.6
X
Хи
Х\
Х'2
х-л
Ха
У
</<>
У\
Уг
У-а
У\
Ау,
А*/»
Аг/,
Л#2
А£/.,
Х'у,
А2*/<>
А2</,
А2«/2
AV/
A:Vo
AV.
4.5.2. Первая интерполяционная формула Ньютона
Пусть для функции, заданной таблицей с постоянным шагом,
составлена таблица конечных разностей 4.6. Будем искать
интерполяционный многочлен в виде:
Рп(х) = а() + а1(х — х{)) + а2(х — х{))(х — *,) + ...+
+ ап(х — jco)...(jc — хп-\). (4.11)
Это многочлен /2-й степени. Значения коэффициентов а0, а\, ..., ап
найдем из условия совпадения значений исходной функции и
многочлена в узлах. Полагая х = х0у из (4.11) находим (/0 = Рл(хо)'=ао,
откуда а0 = 1/о. Далее, придавая х значения х\ и х2, последовательно
84
получаем:
■у\=Рп{х\) = ао + а\(х{— хо), откуда ах=-—\
У 2 = Ря(х2) = а0 + а, (х2 — х) + а2(х2 — х0)(х2 — х1)>
т. е. у2 — 2Д(/0 —*/о = 2Л2а2, или y2 — 2yi+y0 = 2h2a2> откуда
<*2= olfc2
A2j/o
2!Л2
Далее, проведя аналогичные выкладки, можно получить:
A3j/o .
3!Л3
°з^- о..З
в общем случае выражение для а* будет иметь вид:
*=«?■■ (4л2)
Подставим теперь (4.12) в выражение для многочлена (4Л1):
Рп(х) = уо+^(х^Хо) + ^(х^Хо)(х^х1) + ... + ^(х--х0)Х
Х.:Х(х — Хп-\). (4.13)
Практически эта формула применяется в несколько ином виде.
Положим —— = t, т. е. x = xo + ht. Тогда:
Х — Х\ X — Xo — fl .
лг — х2 x — x0 — 2h
Т~= h ==/~~z
и т. д.
Окончательно имеем:
рп(х) = Рп(Хо + (Н) = уо + ^уо+1-^А2уо + ^+, '
+ ^l)-----(/--W + »)AV (4Л4)
Формула (4.14) называется первой интерполяционной формуг
лой Ньютона. Эта формула применяется для интерполирования в
начале отрезка интерполяции, когда / мало по абсолютной величине.
Первую интерполяционную формулу Ньютона называют по этой
причине формулой для интерполирования вперед. За начальное
значение х0 можно принимать любое табличное значение
аргумента х.
4.5.3. Вторая интерполяционная формула Ньютона
Когда значение аргумента находится ближе к концу отрезка
интерполяции, применять первую интерполяционную формулу ста-
85
новится невыгодно. В этом случае применяется формула для
интерполирования назад — вторая интерполяционная формула
Ньютона, которая отыскивается в виде:
Р„(х) = а{1 — а\(х — Хп) + а'Ах — хп)(х-:-хп-\) + ...+ап(х — х„)Х
X-.-XU-JCi). (4.15)
Как и для первой формулы Ньютона, коэффициенты а0, а\9 ..., ап
находятся из условия совпадения значений функции и
интерполяционного многочлена в узлах:
(подробный вывод см., например, в |2|). Подставляя (4.16) в (4.15)
и переходя к переменной /= ", получим окончательный вид
второй интерполяционной формулы Ньютона:
Рп(х) =*Р„(Л'„ + //!) = IJn + t\y* - . + ^Г^ А2^ -2 +
+<<+1к;Г"''^ (4.17)
4.6. ПОГРЕШНОСТЬ МНОГОЧЛЕННОЙ ИНТЕРПОЛЯЦИИ
Если известно аналитическое выражение интерполируемой
функции /, можно применять формулы для оценки погрешности
интерполирования (погрешности метода). Остаточный член
интерполяционного многочлена Fn(x) имеет вид:
. Rn(x) = f(x)-Fn(x).
В силу единственности интерполяционного многочлена для
фиксированного отрезка интерполирования изложение вопроса о
погрешности метода одинаково годится как для многочлена
Лагранжа, так и для многочлена Ньютона.
Предположим, что f(x) имеет все производные до (я + 1)-го
порядка включительно. Введем вспомогательную функцию
u(x) = j{x)-Fn(x)-k-Y\n + \{x\ (4.18)
где k — постоянный множитель. Как видно, функция и(х) имеет
я+1 корень (узлы интерполяции jc0, х{у ..., хп). Подберем
коэффициент k так, чтобы и(х) имела (я+2)-й корень в любой точке
х*Фх-, (/ = 0, 1 п). Действительно, чтобы было ы(х*) = 0, т. е.
/(дг) —F(jr*) —ft.nw + l(jr*) = 0.
достаточно принять
При этом значении k функция и(х) будет иметь п + 2 корня на
отрезке интерполирования и будет обращаться в нуль на концах
8#
каждого из (//-f-l)-ro отрезков:
» |л'„; х\\% \х\\ х->1 \xrt х*\ч \х*\ x/+i| |jrrt-i; х„\.
Применяя теорему Ролля к каждому из отрезков, убеждаемся в
том, что
и'(х) имеет не менее (п-\-1)-го корня;
и'\х) имеет не менее п корней;
и(п + х\х) имеет не менее одного корня.
Пусть g — та самая точка, в которой w(" fl)(£) = 0.
Продифференцируем (4.18) п + \ раз:
M(f, + I)(jc) = /C,, + I)(jc) — k(n+'l)l
откуда
а при х = $
к =
/<"+|>(Х)-|/<"+'>(*)
(п+\)\
"(л + I)! '
(4,20)
Сравнивая (4.19) и (4.20), имеем:
/(дг*)-^(дг*) = ^»Пя + ,(х*).
Но точка х* — произвольная (правда, £ от х* зависит!), поэтому
можно написать: . '
/(х)-^(х) = |^П/г + 1(х).
Если принять M„ + i= max |/Ч/, + |)(дг)|, то
Ли < X < Л„ '
\RrM\<^^\nn + l(x)\. ' (4.21)
Оценочная формула (4.21) непосредственно применима для
подсчета погрешности метода интерполирования по формуле Лаг-
ранжа. Используя подстановки / = и / = ' '" и заменяя
соответствующим образом выражение для Пп + \(х), можно получить из
(4.21) формулы оценки погрешностей интерполирования по
формулам Ньютона:
|/?.WI<^^.|/(/~l)(/-2).....(/-^)L (4.22)
|/?«(JC)| ^ ^JJ^l±-L |/(/_j_ ^(/-^З)....^^-!-^)!; (4.23)
(я + l)!
Анализ интерполяционных многочленов Лагранжа и Ньютона,
87
а также оценочных формул (4.21) — (4.23) позволяет сделать
полезные практические выводы ((1), [2], [7|, [18|).
Решающее влияние на значение погрешности оказывает
величина ПЛ + |(*)> которая минимизируется, когда х берется^ в сере
дине интервала узловых точек. При этом, когда х ближе к середине
между двумя узловыми значениями, выгодно взять четное число
п = 2т узлов (ш узлов слева и т справа от х). Если же х близко к
одному из узловых значений, следует использовать нечетное число
п = 2т + 1 узлов — узел, ближайший к jc, и по т узлов слева и
справа от него.
Очевидно, что при составлении интерполяционных формул
Ньютона на практике можно пренебречь членами, в которых
соответствующие конечные разности равны или близки к нулю. Поэтому
в практических вычислениях интерполяционные формулы Ньютона
обрывают на членах, содержащих такие разности, которые в
пределах заданной точности можно считать постоянными.
Связь между конечными разностями и точностью
интерполирования по формулам Ньютона подтверждается следующими
соображениями. Примем во внимание, что при малых значениях h и при
условии непрерывности /(" + |)(х) можно приближенно считать (|1|,
I2J):
АЛ А"+'#
где
Д"+^= тах |Дп+,ут|,
т. е. максимальная из модулей конечных разностей (я-|-1)-го
порядка. При этом условии оценки (4.22) и (4.23) остаточных членов
первой и второй интерполяционных формул Ньютона получают вид:
|ад|«и(,-,)(<-+2;;--(/-я)|д^-у. (4-24)
|/?nW|^l^ + l)(;+2);;-(/+")lA" + V. (4.25)
Формулы (4.24) и (4.25) удобны тем, что позволяют делать оценку
ошибки метода интерполирования без исследования (п + 1)-й
производной интерполируемой функции / (в частности, когда
аналитическое выражение / вовсе не известно).
На окончательную погрешность интерполирования, разумеется,
влияет и вычислительная погрешность. Полное исследование этих
вопросов доставляет немало трудностей, например, при
составлении надежных и многозначных вычислительных таблиц. С
применением ЭВМ, позволяющих вести счет с большим числом разрядов
и автоматизирующих печать таблиц, техническая работа
существенно облегчается, в то время как исследование вопросов точности
вряд ли становится менее актуальным.
88
4.7. УПЛОТНЕНИЕ ТАБЛИЦ ФУНКЦИЙ
Интерполирование может применяться для уплотнения
заданной таблицы функции/т. е. вычисления по исходной таблице новой
таблицы с большим числом значений аргумента на прежнем участке
его .изменения. Эту операцию называют иногда субтабулированием
функции. В случае, когда исходная таблица является таблицей
с постоянным шагом, естественно применять интерполяционный
многочлен Ньютона. При заданном числе узлов (т. е. при условии,
что конечные разности и степень полинома определены вручную)
для расчетов на ЭВМ формулы Ньютона удобно представлять по
схеме Горнера. Так, первая интерполяционная формула Ньютона
может быть представлена в виде:
pя(x) = ^ + /(Л^o + ^(A^o + ^(AVo + .•. + ,
+ Ч±1д<<^У..У (4'26)
Использование схемы Горнера позволяет вычислять значение
Рп(х) в цикле. Если же максимальный порядок используемых
конечных разностей невелик, для вычисления значений Рп(х) могут
использоваться формулы Ньютона в их стандартном виде (4.14)
и (4.17).
Пример 4.7.1.-Дана пятизначная таблица sin х на отрезке
(0,15; 0,18| с шагом k = 0,005. Требуется уплотнить эту таблицу с
шагом Я = 0,001 на участке |0,155; 0,165].
По исходной таблице сразу же составим таблицу- конечных
разностей (табл. 4.7). Для сокращения записей конечные
разности принято записывать только значащими цифрами. Замечаем,
что конечные разности второго порядка уже практически близки
к нулю в пределах точности таблицы. Поэтому при использовании
интерполяционной формулы Ньютона (4.14) ограничимся тремя
первыми слагаемыми:
Рп(х)« уи + /Д i/o + —2j— А V).
Таблица 4.7
X
0,150
0,155
0,160
0,165
0,170
0,175
0,180
sin х
0,14944
0,15438
0,15932
0,16425
0,16918
0,17411
0,17903
\у
494
494
493
493
493
Используем первую формулу Ньютона, в данном случае
естественно принять jt() = 0,155. Значение / для каждого значения х нахо-
89
да
Г- СУБТАБ Л
♦
Ввод данных
*
лг:= а
*\
(
t:=(x-x0)/h 1
у:=Рп(х0+Щ \
»
Печать х,у
*
Л:=гДГ+// 1
^^ у -+
f #£777
Г /Г0//6>4 J
дится по формуле
Рис. ю
/ =
X — х{)
Схема алгоритма субтабулирования
функции на отрезке [а; Ь\ по первой
интерполяционной формуле Ньютона при условии,
что конечные разности и порядок полинома
определены вручную, приведена на
рисунке 10.
Ниже приведена программа субтабу-
Лирования функции на языке Бейсик,
предусматривающая вь^вод на печать искомой
таблицы. В этой программе буквами А и В
обозначены концы субтабулирования, НО —
старый шаг таблицы, Н — новый шаг
таблицы, У0 — значение функции в
начальной точке субтабулирования (в формуле
Ньютона — это У0), У1 и У2 —
соответствующие (ненулевые) конечные разности
первого и второго порядка. Все эти
значения определяются в программе путем
ввода, так что эта же программа может
использоваться для субтабулирования на
других подходящих участках исходной
таблицы и с другой степенью плотности.
Буквой Д обозначена граница погрешности
метода интерполирования, вычисляемая в
соответствии с формулой (4.22).
10 REM СУБТАБ
20 INPUT A,B,H0,H,Y0,YT,Y2
30 PRINT "XV'YVD": PRINT
40 FOR X=A TO В STEP H
50 T=(X-A)/H0
60 Y=Y0+TkYI+Tk(T-T)kY2/2
70 D=IE-05kTk(T-I)k(T-2)/6
80 PRINT XЛ,:PRINTUSING"#£.£#$£#£**" ;D
90 NEXT X
100 END
90
RUN
? .155, .165, .005, .001, .15438, .00494, -.00001
X Y D
.155
.156
.157
.158
.159
.16
.161
.162
.163
.164
.165
.15438
.1553688
.1563572
.1573452
.1583328
.15932
.1603068
.1612932
.1622792
.1632648
.16425
0.00000000
0.00000048
0.00000064
0.00000056
0.00000032
0.00000000
— 0.00000032
— 0.00000056
— 0.00000064
— 0.00000048
0.00000000
Полученные результаты следует округлить до точности
исходной таблицы (в этой связи интересно отметить, что
вычислительные погрешности интерполяции вполне обеспечивают верность пяти
знаков после запятой во всех полученных значениях функции).
Путем незначительного усложнения программы можно достичь
большей надежности результатов интерполирования по формуле
Ньютона, если предусмотреть при переходе к новому узлу исходной
таблицы изменение значений х0, у{> и соответствующих конечных
разностей (т. е. каждый встречающийся в процессе
субтабулирования узел исходной таблицы автоматически принимать за
нулевой). Для субтабулирования на концевых участках исходной
таблицы нужное количество конечных разностей в формуле
обеспечивается применением второй интерполяционной формулы Ньютона.
Программа в этом случае составляется аналогично.
4.8. ИНТЕРПОЛЯЦИЯ СПЛАЙНАМИ
При большом количестве узлов интерполяции сильно возрастает
степень интерполяционных многочленов, что делает их неудобными
для вычислений. Высокой степени многочлена можно избежать,
разбив отрезок интерполяции на несколько частей с построением
на каждой части самостоятельного интерполяционного многочлена.
Однако такое интерполирование приобретает существенный
недостаток: в точках стыка разных интерполяционных многочленов будет
разрывной их первая производная.
В этом случае удобно пользоваться особым видом кусочно-
лолиноминальной интерполяции — интерполяции сплайнами (от
англ. spline — рейка).
Сплайн — это функция, которая на каждом частичном отрезке
интерполяции является алгебраическим многочленом, а на всем
заданном отрезке непрерывна вместе с несколькими своими
производными. Рассмотрим способ построения сплайнов третьей степени
(так называемых кубических сплайнов), наиболее широко
распространенных на практике.
91
Пусть интерполируемая функция / задана своими значениями
y-t в узлах jc/ (/ = 0, 1, 2, ..., /г). Длину частичного отрезка [x,_i, xi\
обозначим hi = Xi — Jt/_i (/=1, 2, ..., п). Будем искать кубический
сплайн на каждом из частичных отрезков [jc,_i, *,-] в виде:
S(x) = ai + bl{x-xi-l) + Ci(x-xi-l)2 + di(x-xi-l)\ (4.26)
где а/, 6„ с, d/ — четверка неизвестных коэффициентов (всего их,
следовательно, 4л). Можно доказать, что задача на нахождение
кубического сплайна имеет единственное решение (см. [14]).
Потребуем совпадения значений S(x) в узлах с табличными
значениями функции /:
S(Xi-i) = yt-i=Oi, (4.27)
S(xi)=yi=iai+bihi+cA?+dihl (4.28)
Число этих уравнений (2л) вдвое меньше числа неизвестных
коэффициентов; чтобы получить дополнительные условия, потребуем
также непрерывности S'(x) и S"(x) во всех точках, включая узлы.
Для этого следует приравнять левые и правые производные S'(x — 0),
S'(jt-f-O), S"(x — 0), S"(a:+0) во внутреннем узле *,-. Сначала
получим S'(jc) и S"(x), последовательно дифференцируя (4.26):
S'(x) = bi + 2ci(x-Xi-i) + 3di(x-xi-])\
Sf/(x) = 2ci + 6di(x — xi-ly
Имеем:
S'[Xi — 0)=bi+2cihi+3dihl S'(xi+0)=bi+u *=1, 2, ..., /г-1
(во втором случае прежде понадобилось в выражении S'(x)
заменить / на i-f-1)- Аналогично для второй производной:
S"(x)=2а+6di(x—х/_ i), S^jti - 0)=2с, + 6rfifti, $"(*/+0)=2с,+,.
Приравнивая левые' и правые производные, получим:
6/+1 =bi + 2dhi + 3dihl (4.29)
c/+i = c/+-3rfiAi (/=1, 2, ..., n-l). (4.30)
Уравнения (4.29) и (4.30) в совокупности дают еще 2(я — 1) условий.
Недостает еще два условия. Обычно в качестве этих условий берут
требования к поведению сплайна в граничных точках х0 и х„. Если
потребовать нулевой кривизны сплайна на концах (т. е. равенства
нулю второй производной), то получим:
с, =6, cn+3dnhn = 0. (4.31)
Перепишем теперь все уравнения (4.28) — (4.31), исключив п
неизвестных а,:
bihi — Cihf — dihf = yi — yi-\ (/=1, 2 л),
bi+l-bi-2cihi-3dih:t = 0 (i=l, 2, ..., я-1), (4.32)
C/+I— Ci — 3dihi = 0 (/=1, 2, ..., /i —1),
c,=0, ■
ся + 3£/яйя = 0.
92
Та
X
l(x)
б л и
2
4-
i ц а
3
-2
5
6
4.8
7
—3
Система (4.32) состоит из \п-\-2{п — 1) + 2| = Зя уравнений. Решив
ее, получим значения неизвестных 6,-, с и di, определяющих
совокупность всех формул для искомого интерполяционного сплайна.
S/(x) = ^_1+&/(jc~jc/_,)+c/(jc-jc/_,)2 + d/(jc--A:/_,)3, (4.33)
i=l, 2, ..., я.
Чтобы получить представление о характере и объеме
вычислительной работы по нахождению всех коэффициентов сплайна,
рассмотрим простой пример.
Пример 4.8.1. Интерполируемая функция задана таблицей,
состоящей из четырех узлов (/г = 3):
Здееь лго = 2, *i=3, л:2 = 5, *з = 7; уо = 4, у\ = —2,
(/2 = 6, уз=— 3; Л| = 1, Л2 = 2, Аз = 2. Требуется
найти значения коэффициентов 6|, Ьч, 63, С|, Сг,
£з, rfi, ^2, d3, определяющих кубический сплайн
на трех частичных отрезках:
Sl(x) = 4 + bl(x-5) + Ci(x-2)2 + dl(x-2)\ 2<jc<3;
S2(x)= -2 + ft2(^-3) + ^-3)2 + d2(x-3)3, 3<x<5;
S,(x) = 6 + b:i(x-5) + c3(x-5f + d3(x-5)\ 5<x<7.
Составим систему вида (4.32). Первая группа уравнений состоит
из трех уравнений (/=1, 2, 3):
26, + c.+di = -6,
2/b + 4c2 + 8d2 = 8,
263 + 4сз + 8Л=-9.
Следующая пара уравнений системы (4.32) дает еще четыре
уравнения (/= 1, 2):
Ь2 — Ьх—2с\— 3d,=0,
63 — 62 — 4с2 — 12rf2 = 0,
C2 — £i —3di =0,
Сз — С2 — 6d2 = 0.
И наконец, два уравнения, задающих граничные условия для
крайних сплайнов:
•ос
1
0
0
1
0
0
0
0
0
тоит
1
0
0
-2
0
-1
0
0
0
С\ =
=0,
c3 + 6d3 = 0.
из девяти
1
0
0
-3
0
— 3
0
1
0
0
2
0
1
-1
0
0
0
0
уравнений.
0 0
4 8
0 0
0 0
-4-12
1 0
-1 -6
0 0
0 0
0
0
2
0
1
0
0
0
0
Составим i
0
0
4
0
0
0
1
0
1
0 -6
0 8
8 -9
0 0
0 0
0 0
0 0
0 0
6 0
93
Система может быть решена на ЭВМ методом Гаусса
(результаты округлены до двух знаков после запятой):
Ьх = -11,60 с, =5,60 rf,=0
ft, = —0,40 /:2=6,60 d2= —1,70
6з=1,62 с3=-4,59 d3 = 0,76.
Полученные значения коэффициентов определяют искомый сплайн.
S,(jc) = 4-11,6(a:-2)+5,6(x-2)2,
S2(x) = — 2 —-0,4(л: — 3) + 5,6(х — З)2 — 1 J(x - 3)\
53(jc) = 6+K62(^-5)-4,59(jc-5)2 + 0,76(jc-5)3. .
Убедимся, что найденный сплайн удовлетворяет заданным
^свойствам (значения сплайна и его первых производных в
соответствующих узловых точках приведены в таблице 4.9):
Таблица 4.9
X
fix)
5,U)
S-Ax)
S,(x)
SUx)
S?>(x)
S!M
2
4
4
—
—
- 1 1.0
—
—
3
-2
_2
_2
—
-0,4
-0,4
— -
5
в
—
()
0
—
1,60
1,02
7
-3
—
—
-3.04
—
—
-7,02
Прежде всего отмечаем практическое совпадение значений
«соседних» выражений сплайна в узловых точках, а также
совпадение этих значений с табличными значениями функции f(x). Кроме
того, практически совпадают значения производных S[(x) и Si(x)
в узле х = 3, так же как и производных S'2(x) и Sfs(x) в узле х=5, что
обеспечивает гладкость совокупного кубического сплайна.
Рассмотренный пример показывает, что интерполяция
сплайнами сопряжена с немалым объемом вычислительной работы. Весьма
необычна и форма оконченного результата, ибо кубический сплайн
имеет различные представления на различных частичных отрезках
интерполяции. Это осложняет доступ к значениям сплайна в
каждой конкретной точке, так как предполагает прежде поиск
параметров, определяющих соответствующую формулу сплайна.
При использовании ЭВМ эти трудности легко предотвратимы,
так как упорядоченное хранение всех необходимых параметров
организовать нетрудно, а выполнение однотипных процедур по вы-'
числению параметров сплайна и его значений может быть
обеспечено специальными подпрограммами (см., например, подпрограммы
SPLINE и SEVAL в |17|). Кроме того, путем несложных
преобразований система вида (4.32) преобразуется к специальному виду,
для которого эффективно применяется так называемый метод
прогонки (|4|, |111 и др.).
94
Контрольные вопросы
1. В чем особенность приближения таблично заданной
функции методом^интерполирования?
2. Как обосновывается существование и единственность
интерполяционного многочлена? Как связана его степень с количеством
узлов интерполяции?
3. Как строятся интерполяционные многочлены Лагранжа и
Ньютона? В чем особенности этих двух способов интерполяции?
4. Как производится оценка погрешности метода интерполяции
в случае, когда: а) интерполируемая функция задана
аналитически; б) интерполируемая функция задана таблицей?
5. Как используется метод интерполирования для уточнения
таблиц функций?
ЛАБОРАТОРНАЯ РАБОТА 4
Тема. Интерполирование функций.
Задание 1. По заданной таблице значений функции
Таблица 4.10
Л'
У
-V,,
Уо
Х\
J/I
х>
Уг
составить формулу интерполяционного многочлена Лагранжа.
Построить его график и отметить на нем узловые точки M,{xt, у,),
1 = 0, I, 2.
Задание 2. Вычислить с помощью калькулятора одно значение
заданной функции для промежуточного значения аргумента с
помощью интерполяционного многочлена Лагранжа и оценить
погрешность интерполяции.
Задание 3. С помощью ЭВМ уплотнить часть таблицы
заданной функции, пользуясь интерполяционными формулами Ньютона и
Лагранжа.
Пояснения к выполнению лабораторной работы 4. При
выполнении задания 1 составляется многочлен Лагранжа по формуле
(4.8), производя1ч:я необходимые вычисления и приведение
подобных членов (см. пример 4.2.1). По полученной формуле строится
график интерполирующей функции, на котором отмечаются узловые
точки. Исходные данные для выполнения задания 1 берутся из
таблицы 4.11.
Задание 2 выполняется с помощью калькулятора по
специальной расчетной схеме (табл. 4.3). Для достижения наилучшей
точности берется максимально возможное четное или нечетное число
узлов, симметричных относительно заданного значения х. Оценка
погрешности интерполирования производится по формуле (4.21).
Результат интерполирования интересно сравнить с вычислением
значения функции по ее выражению, заданному в таблице.
Для отыскания варианта^ заданию 2 используется таблица 4.16.
95
Так, например, для варианта 7 задание 4 состоит в вычислении
значения функции, заданной таблицей 4.15 при л: = 4Д Использование
расчетной таблицы показано в примере 4.3.1.
Для выполнения первой части задания 3 по заданной таблице
функции с равноотстоящими значениями аргумента составляется
^таблица конечных разностей и определяется порядок
интерполяционного полинома Ньютона. В зависимости от расположения
участка субтабулирования относительно исходной таблицы и
потребности в конечных разностях избирается первая (4.14) или вторая
(4.17) интерполяционные формулы Ньютона. Исходные данные для
выполнения задания 3 (номер таблицы функции, концы отрезка
fa; Ь\ и шаг Н субтабулирования) берутся из таблицы 4.16. В
программе субтабулирования предусмотреть подсчет погрешности
метода по одной из формул (4.22), (4.24) или (4.23), (4.25). Перед
выполнением задания полезно рассмотреть пример 4.7.1.
Варна!
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
X
-3,2
-0,8
0,4
2,8
4,0
6,4
7,6
*т *0
1
2
0
7
-3
1
-2
2
— 4
-1
2
-9
0
-8
-7
1
7
-4
-3
* 0
Та
Х\
0
3
2
9
-1
2
-1
4
-2
1.5
4
-7
1
-5
-5
4
8
0
-1
3
Х-2
3
5
3
13
3
4
2
5
0
3
7
— 4
4
0
-4
9
10
2
1
8
[блица 4.14
/U) = 2,lsm 0,37л:
-1,9449
-0,6126
0,3097
1,8068
2,0913
1,4673
0,6797
\
Та
Уо
-3
4
— 1
2
7
-3
4
9
2
4
-1
3
7
9
4
-2
6
4
11
1
блица 4.1
У\
5
1
-4
-2
-1
— 7
9
— 3
8
-7
-6
-3
— 1
-2
-4
9
-2
8
— 1
5
'
</2
2
7
2
V 3
4
2
1
6
5
1
3
4
8
4
5
3
7
-2
6
-4
11
х .
2,6
3,3
4,7
6,1
7,5
8,2
9,6
X
1,3
2,1
3,7
4,5
6,1
7,7
8,5
X
1,2
1.9
3,3
4,7
5,4
6,8
7,5
/(*) =
Таблица 4.12
f(x)=\/x.\gx + x2
1,7777
4,5634
13,8436
20,3952
37,3387
59,4051
72,3593
Таблица 4.13
/(jc) = ln 2,3*-0,8/х
0,3486
1,0537
1,7844
2,2103
2,3712
2,6322
2,7411
Таблица 4.15
= l,7^x-cos(0,4-0,7x)
2,1874
2,8637
3,8161
3,8524
3,1905
2,8409
2,6137
96
§СЛСЛ4ь.4*СОСОЮГО—-»—
СЛОСЛОСЛОСЛОСЛО
ООООООООООО
сосо-чгослслсоооюю —
СЛ-Ч4*"^14*.->4СЛСОО->4Ю
sw<o- СЛ ГО О 00 4* О --
X
63
— о <
О СЛ !
■ р р р р р р р р
> "«О ~СО 00 ОС *->! "-1 О С*»
>слослослосяс?
р р р р р р р р р р р
00 00 00 00 V| Vj Vj "ф <J5 Oi СЛ
ФО)^-00СЛ-00*>СГ
— *v| — СО СО — -.1 — 4*. СЛ ..
КЭ^^^С*ЗК9 03ФЮ- О
~ ю^юсоооа54*юсс4*
р р р р р р р р р р р
О — *— tO tO СО СО V 4* 4*. СЛ
~v| Ю СТ> — О — О О СЛ СО 4*
4*04-OMCncOO*slO
н
09
2a
s
ооооооооооо
ооооооооооо
00 oo со со со со с
ел -ч о юсо ел <
ЮЧО- *0 СЛ 00 О 00 СЛ СО
СЛСЛ4*ОСОСОСОО-^10^3
ю оо ел а> ^j 4* •— ^*^осл
н
а»
OI
Sa
S
J=
О»
О СЛ 4* СО Ю — ОСОООЧО)СЛ4^С*ЛО-
СО00^1азсО00-^1О5СО00^4О>СО00->1СЛ
ФСЛМ**^*, СЛ Ю 4* 00 СО 4*. 4* О СО СО
00 КО СЛ *4w 05 — СО "сО О СО СО *— 00 СЛ СЛ 00
4* 4* 4* 4ь. 4* 4^ 4». 4* 4ь 4w 4* 4* 4^ 4*> 4* 4^
СО КЭ — 4* tO — 4*СО — 4^ СО Ю 4* СО Ю •—
— О О — о о-
• о —— оо
Ok
ъ
X
п
— оо — оо о о — — оо
oooooooooooooooo
о о о о о о о о о о о о о о о о
— Ю tO ~ Ю~ — Ю ЮЮ ГО — К> •— Ю —
СЛ СЛ СЛ СЛ СЛ
о»
о*
Sa
Глаша S
ЧИСЛЕННОЕ ДИФФЕРЕНЦИРОВАНИЕ
И ИНТЕГРИРОВАНИЕ
5.1. ОСОБЕННОСТЬ ЗАДАЧИ
ЧИСЛЕННОГО ДИФФЕРЕНЦИРОВАНИЯ
Когда производную аналитически заданной функции по
причине ее сложности искать затруднительно либо выражение для
производной приобретает слишком неудобную для применений форму,
используют приближенное, или численное, дифференцирование.
Этот метод тем более необходим, если исходная функция задана
таблично. Один из способов решения задачи дифференцирования —
использование интерполяционных многочленов.
Пусть f(x) — функция, для которой нужно найти производную
в заданной точке отрезка \а\ Ь\% а /^(х) — интерполяционный
многочлен для /(*), построенный на отрезке \а\ Ь\ Заменяя f(x)
интерполяционным многочленом Fn(x\ получим значение производной
f(x) на отрезке \а\ Ь\ как значение производной F'n(x)
интерполяционного многочлена, т. е. примем приближенно
/'(*) = F,',(*). (5.1)
Аналогичным путем можно поступать при нахождении
значений производных высших порядков функций f(x).
Полагая, что погрешность интерполирования (см. п. 4.6)
определяется формулой
Rn(x) = f(x)-Fn(x)%
98
получаем подход к оценке погрешности производной F'n(x):
rn(x) = f'(x)-F'n(x) = R'n(x), (5.2)
т. е. погрешность производной интерполирующей функции равна
производной от погрешности этой функции.
Заметим, однако, что задача численного дифференцирования
является некорректной. Дело в том, что погрешность производной
интерполяционного многочлена может существенно превышать
погрешность самой интерполяции. Из рисунка 11 хорошо видно,
что даже незначительное отличие (в том числе и совпадение)
значений f(x) и Fn(x) никак не гарантирует близости значений их
производных f'(x) и F'n(x) (Lj и LFn — касательные к кривым f(x) и
Fn(x) соответственно).
Рассмотрим методы численного дифференцирования на основе
интерполяционных многочленов Лагранжа и Ньютона (гл. 4).
5.2. ИНТЕРПОЛЯЦИОННАЯ ФОРМУЛА ЛАГРАНЖА
ДЛЯ РАВНООТСТОЯЩИХ УЗЛ01
Применяя для численного дифференцирования на отрезке [а, Ь]
интерполяционный полином, естественно строить на этом отрезке
систему равноотстоящих узлов а = л:0, Х\, х2, ..., хп = Ь, которыми
отрезок делится на п равных частей: xi+\ — jc, = A = const / (/ = 0, I,
2 лг — 1). В этом случае шаг интерполирования имеет значение
h = (b — a)/n> а интерполяционный многочлен Лагранжа (как и
интерполяционные многочлены Ньютона) строится на
равноотстоящих узлах и имеет более удобный вид. Примем подстановку:
с учетом представления (см. (4.9), с. 80):
Ln(x)=nn+l(x)i у_,
/=0 (X— Jf,)lln+| (*/)
получим новые выражения для П„ + |(лг/). Учитывая, что согласно
принятому обозначению
ПЯ + |(ДГ) = (.К — Xq)(x — */).....(* — Хп\
и используя (5.3), последовательно находим:
х — x0 = ht,
л: — JCi =л: — лг0 — А=Л(/— 1),
х—хг = х — Jto —2Л = Л(/ —2),
т. е. в общем случае:
х — Xi = x — хо — ih = h(t — /), / = 0, 1 п. (5.4)
Используя (5.4), получаем:
Пл + 1(х) = ЛЛ + ,/(/^1)(/-2)....Ч/~Аг).
99
С целью сокращения записей введем обозначение
/(/—1)(/ —2).....(/ —я)=/1я + 11,
тогда выражение Пп+\(х) принимает вид:
Пя + |(х)=й,, + ,/1|, + 11. (5.5)
Учитывая, что при постоянном шаге имеет место
Xi = xo + ih, i = 0, 1, ..., я,
последовательно находим:
а:/ — Х| =х/ — лго — Л = /г(/— 1), /cjgv
Xif — xn = jCi' — Xo — nh = h(i — n).
Заметим, что в (5.6) ровно п строк (/-я строка отсутствует), причем
значения разностей из первых / строк положительны, а
остальных— отрицательны. Используя (5.6), получаем:
П;1 + ,(х/) = (*, — *о)-...-(х/ — xr^i) (дг/ — х/+|)..... (*/ —*„) = АЯ|(*—1)Х
x...-i-(—1)--.-|—(л—01.
т. е.
.Пг + |(х/) = Ля.|!(л-/)!(-1Г-/. (5.7)
С учетом представлений (5.5) и (5.7) формула Лагранжа (4.9)
для равноотстоящих узлов принимает вид:
« / 1У'-'Л"-И1
Uxo + m-^L^-f. (5.8)
Пример 5.2.1. Составить интерполяционный многочлен
Лагранжа для функции, заданной своими значениями да
равноотстоящих узлах (я = 2, А = 1):
Таблица 5.1
2 3 4
fix) 4-2 6
Используя формулу (5.8), запишем:
/ /о | /у V(/-j>('-2) . / ^ (-1)/(/-Р(/-2) Л<-1)Н)
L3(2 + /)-4 217 +(^2) ГП +Ь 2W-2) ~~
= 2(/-1)(/-2) + 2/(/~2) + 3/(/-1) = 7/2-13/+4.
Узловые табличные значения функции (4; —2; 6) получаются по
этой формуле соответственно при / = 0; 1; 2.
100
5.3. ЧИСЛЕННОЕ ДИФФЕРЕНЦИРОВАНИЕ НА ОСНОВЕ
ИНТЕРПОЛЯЦИОННОЙ ФОРМУЛЫ ЛАГРАНЖА
Следуя (5.1), будем дифференцировать многочлен Лагранжа
(5.8) по х как функцию от /:
/(х)~М*).-_ДУ| —_._^_j.
dx
Учитывая, что согласно (5.3) x=Xo-\-th, а также jr = hy получим
окончательно:
Пх)=Г{х„ + 1Н)*±20у,^4\'—]. (5.9)
Пользуясь формулой (5.9), можно вычислять приближенные
значения производной функции f(x), если она задана на отрезке \а\ Ь\
значениями в равноотстоящих узлах а = х{), х\, ..., х„ = Ь (при этом
параметр / пробегает значения от 1 до л). Аналогично могут быть
найдены производные функции f(x) высших порядков.
Пример 5.3.1. Вычислить приближенное значение
производной функции, заданной таблицей в точке х = 4.
Таблица 5.2
4 5
fix) 2 -16
Применяя формулу (5.9), получим (здесь я = 2, Л=1):
Р/И~9 Х 4(/-0('-2)1 (-1) <*№-2)| , g I d\t(t-\)\
f W^2 2\ Jt i It—+6e2T—It—=
= (/—2 + /—l) + (/ —2 + /) + 3(/—1 -f-/) = 2/ —3 + 2/ —2 + 6/ —3 =
= 10/ —8.
Учитывая, что узел jc = 4 соответствует значению /=1 (т. е.
< = £=Л)э получаем /'(4)«2.
Если известно аналитическое выражение функции /(л:), то
формулу для оценки погрешности численного дифференцирования
можно при этом же условии получить на основе формулы
погрешности интерполирования (см. п. 4.6, с. 88):
/?n(x)=/W-Frt(x)=-^^nn+,(x), (5.10)
где I = 1(х) — значение из отрезка [а, Ь\9 отличное от узлов и х.
Учитывая (5.2) и допуская, что f(x) дифференцируема я + 1 раз,
запишем:
r„W = /?^)=^{/<''+,'(|).n/', + 1(i).£|/<» + l>(|)|); (5.11)
101
формула (5.11) значительно упрощается, если оценка находится
для значения производной f'(x) в узле лг, таблицы. В этом случае,
учитывая (5.7), получаем:
Гл(л:0 = /?А(^-)=(— 1Г "'. Л- ^jf • /("+! ^1)^ (5-12)
где I — промежуточное значение между jc0, х\% ..., хп. Обозначив
Af„ + i= max lrw+,)(jc)|» получим верхнюю оценку абсолютной
X о < X < X „
ошибки численного дифференцирования в узлах:
1^(^)1<(^Ая|!(/1-|)!. (5.13)
5.4. ЧИСЛЕННОЕ ДИФФЕРЕНЦИРОВАНИЕ НА ОСНОВЕ
ИНТЕРПОЛЯЦИОННОЙ ФОРМУЛЫ НЬЮТОНА
Запишем для функции /(х), заданной своими значениями в
равноотстоящих узлах jto, jci, ..., хп, первый интерполяционный
многочлен Ньютона (см. 4.14):
Ря(д)=Яя(дГ0 + /й) = ^
1 п\ "
Перепишем этот полином, производя перемножение скобок:
Pn(x0 + //i)=j/o + ^j/0 + ^f1A2f/o-<3~362+2<A3j/o +
+ '-«,+1"'-" *«* + •■■ ■
Дифференцируя Pn(x0-\-th) по /, получим аналогично формуле (5.9):
nx)«P^0 + //i)=|[Aj/o + ^A^o~3/2~f+2A3^ +
. 2/3-9/2+11/-3 а4 , 1 /с 1А.
Н г? А> + ... • (5.14)
Подобным путем можно получить и производные функции f(x)
более высоких порядков. Однако каждый раз, вычисляя значение
производной f(x) в фиксированной точке ху в качестве х0 следует
брать ближайшее слева узловое значение аргумента.
Формула (5.14) существенно упрощается, если исходным
значением х оказывается один из узлов таблицы. Так как в этом случае
каждый узел можно считать начальным, то, принимая х = х(),
/ = 0, получаем:
f(xo)-T{Ayo-— + ^ — + - •••)• (5.15)
Эта формула позволяет легко и достаточно точно получать значе-
102,
ния производных функций, заданных таблично. Воспользуемся
для иллюстрации функцией, производная которой (для
сопоставления) может быть легко вычислена обычным способом.
Пример 5.4.1. Найти значение производной функции f(x)=^[x
в точке jc=32, используя таблицу 5.3. В данном случае Л=1;
применяя формулу (5.15) к данным первой строки таблицы (до
разностей третьегб порядка включительно), получим:
Г(х)\ =0,088 + ^+^=0,089.
U—32-
Сопоставляя полученный ответ со значением
(V*)' I =Ц=-=о-™-=0,088,
2У32 2-5,657 *
I х=32
замечаем совпадение значений в пределах двух знаков после
запятой.
X
32
33
34
35
36
</=V*
5,657
5,745
5,831
5,916
6,000
*У
88
86
85
84
Т
ь2у
-2
-1
-1
абли ца
Л'</
1
0
А4 У
-1
5.3
Для вывода формулы погрешности дифференцирования
воспользуемся подходом, рассмотренным в п. 5.3. Используя формулу
(5.10) применительно к первому интерполяционному многочлену
Ньютона, запишем:
/?nW=/1^^^-|и;;+2);)^!^^•^-")r+■)Ш,
где I — некоторое промежуточное значение между узлами *0, х\,
..., хп и заданной точкой х. Предполагая, что f(x)
дифференцируема п+\ раз, получим для оценки погрешности
дифференцирования гп(х) (по аналогии с формулой (5.11)):
ф)=К{х)=^ {/(Л+,)(|). ~/[Л + ,Ч/[^,]-~Г+,)(1)]}. (5.16)
Для случая оценки погрешности в узле таблицы (когда х—х0 и
/ = 0) будем иметь удобный вид формулы (5.16):
ВД| =(-1Г^г/(Л+,)(1).
Х = Хо
Здесь учтено, что при / = 0 -т- t[n + i] = (— \)пп\.
103
На практике /('/-М)(|) оценивать непросто, поэтому при малых Л
приближенно полагают ([1|, [2|):
что позволяет использовать приближенную формулу
гп(х0)ъ h{n + l) . (5.17)
5.5. ПОСТАНОВКА ЗАДАЧИ ЧИСЛЕННОГО ИНТЕГРИРОВАНИЯ
При вычислении определенного интеграла
I\ = \f(x)dx,
а
где f(x) — непрерывная на отрезке fa; b] функция,'иногда удается
воспользоваться известной формулой Ньютона — Лейбница:
ь
\f(x)dx = F(b)-F(a). (5.18)
а
Здесь F(x) — одна из первообразных функций f(x) (т.е. такая
функция, что F'(x)=f(x). Однако даже в тех, практически редких,
случаях, когда первообразную удается явно найти в
аналитической форме, не всегда удается довести до числового ответа значение
определенного интеграла. Если к тому же учесть, что иногда
подынтегральная функция вовсе задается таблицей или графиком,
то становится понятным, почему интегрирование по формуле (5.18)
не получает широкого применения на практике.
В подобных случаях применяют различные методы
приближенного (численного) интегрирования. Формулы, используемые для
приближенного вычисления однократных интегралов, называют
квадратурными формулами. Простой прием построения
квадратурных формул состоит в том, что. подынтегральная функция }(х)
заменяется на отрезке \а\ Ь\ интерполяционным многочленом,
например многочленом Лагранжа L„(x\ и получается
приближенное равенство
Ь b
\f(x)dxtt\Ln(x)dx. (5.19)
а а
Подобный подход удобен тем, что он приводит к алгоритмам,
легко реализуемым на ЭВМ и позволяющим получать результат
с достаточной точностью. При этом, естественно, предполагается,
что отрезок [а; Ь\ разбит на п частей точками а = х{)у Х\у ..., х„ = &,
наличие которых подразумевается при построении мйогочлена Ln{x)
(см. п. 5.2).
Подставляя вместо Ln(x) его представление (4.9), получим:
104
П.+ |(д0
Таким образом:
где
V Ъ'=0 (дг—Х/)ГЦ+,(*,)
So Ja (* — Xi)Wa+i(Xi)
\f(x)dx&2 ytAu (5.20)
* "«+'(*> dx. (5.21)
По поводу полученных формул можно заметить, что:
1) коэффициенты Л, не зависят от функции f(x), так как они
составлены только с учетом узлов интерполяции;
2) если f(x) — полином степени пу то тогда формула (5.19)
точная, ибо в этом случае L„(jc)s=/(jt).
5.6. КВАДРАТУРНЫЕ ФОРМУЛЫ НЬЮТОНА — КОТЕСА
Как уже отмечалось выше, применение формулы (5.19)
предполагает построение на отрезке интегрирования [а; Ь\ системы
узлов интерполяции х0, *i, ••-, *п (здесь х0 = ау хп = Ь), которыми
отрезок делится на п частей. Длина лг,-+|-—*,■ = А (/=1, 2, ..., /г—-1)
называется при этом шагом интегрирования. Естественно считать,
что шаг h постоянен, т.е. h = (b — а)/п. В этом случае можно
применить интерполяционную формулу Лагранжа для
равноотстоящих узлов (см. п. 5.2). Итак, с учетом (5.5) и (5.7) формула
(5.21) для «весовых» коэффициентов Л, принимает вид:
Ai= j"(-')":;;^''^, ,«0. i «. (5.22)
J() i\(n — i)\{t — 1)
Перейдем в этом интеграле всюду к переменной /. Из
подстановки (5.3) получаем:
rf/=™, те- dx = hdt=-^—Z-dt.
h п
При jc==jco имеем / = 0, а при х = хп будет /= ", ° =п. Тогда
где
Ai= 1^^-^;+'!и(==(Ь-а)Н, (5.23)
Я,= -Ц (.„ и ' ., д», 1 = 0, 1, .... /1. (5.24)
105
Числа (5.22) называют коэффициентами Котеса. Как видно,
коэффициенты Котеса не зависят от функции /(*), а только от
числа л точек разбиения. Окончательно, с учетом формул (5.20)
и (5.23), получаем следующий вид квадратурных формул
Ньютона — Котеса:
\f{x)dx&{b-a)f> у№9
(5.25)
дающих на одном участке интегрирования различные
представления для различного числа п отрезков разбиения.
4 5.7. ФОРМУЛА ТРАПЕЦИЙ
При п=\ из формулы (5.24) имеем (/ = 0; 1):
Но=-\ «tz±dt=-\{t-\)dt=±,
о
H{ = \tdt=±- '
о *
Тогда по формуле (5.25) на отрезке |х0; х\\ получаем интеграл:
\i(x)dx = ^-Xb){H{)yb + Hxyi)=\{y{) + yi). (5.26)
Хи
Формула (5.26) дает один из простейших способов вычисления
определенного интеграла и называется формулой трапеций.
Действительно, при п=\ подынтегральная функция заменяется
интерполяционным многочленом Лагранжа первой степени (т. е.
линейной функцией), а это означает геометрически, что площадь
криволинейной фигуры подменяется площадью трапеции (рис. 12).
У,
~~о.
\,
)
1
<о
ШМ^:
)
•Л/,
У/
Ч
X
Рис. 12
106
Распространяя формулу (5.26) на все отрезки разбиения,
получим общую формулу трапеций для отрезка [а; Ь\.
\&х)йх = к(^+ух+у2 + ...+ул-х + ±). (5.27)
а '
Если аналитическое выражение подынтегральной функции
известно, может быть поставлен вопрос об оценке погрешности
численного интегрирования по формуле (5.27) (погрешность метода).
В этом случае имеется в виду, что
\f(x)dx=\Ln(x)dx + Rn(f\
а а
где /?„(/) — остаточный член квадратурной формулы (5.27).
Формулу остаточного члена получим вначале для отрезка [лс0; Х\]. Имеем:
R = \f(x)dx- |(</0 + </.) = Х) f(x)dx-
X» X»
откуда следует, что естественно рассматривать R как функцию
шага Л:/? = /?(А). Заметим, что /?(0) = 0.
Продифференцируем R(h) по А:
*ЧЛ)=(Тк*У*)'- 1[/(*о)+/(*о+Л)]- у[/'(*о+Л)]=
Хп
= Я*о + Л) - у Л*о + Л) - у f(xo) - у f (*о + Л) =
= ±.[f(Xo + h)-f(xo)}-j-f'(xo + h).
Заметим, что /?'(0)=0. Далее:
/?"(Л)- у/'(х„+Л)- -Lf'(Xo+h)- АГ(л:о+Л)==
= -|-Г'(-*:о + Л). (5.28)
Определим /?, последовательно интегрируя /?"(Л) на отрезке [0; Л]:
А
J/?"(z)rf2 = /?'(z)|?, = /?'(A)-/?'(0)=/?W
А
о
откуда с учетом (5.28) имеем:
/?'(/,) = f/?'>(2)d2= - Uzf"(x{) + z)dz. (5.29)
о z о
Применяя к (5.29) обобщенную теорему о среднем [4], получаем:
107
R'(h)=-±f"(h)\2dz=-■£}»&), (5.30)
* (I * . '
где £ie[jt0; лг0-+-Л| и £i зависит от Л. Далее
J R'(z)dz = R(z)\h0 = R(h)-R(0)=R(h\
о
откуда с учетом (5.30) и обобщенной теоремы о среднем имеем:
R(h)= \R'{z)dz= ±-\z2f"(h)dz= - £Н6). (5.31)
где £<=[хо; х0 + А].
Таким образом, погрешность метода при интегрировании
функции / на отрезке [х0; Х\\ по формуле (5.27) имеет величину:
*=-£/"(». Бе[дг0;х,|. (5.32)
Из формулы (5.32) видно, что при /"(£)>0 формула (5.27) дает
значение интеграла с избытком, а при ///(1)<0 — с недостатком.
Можно показать [2], что при распространении оценки (5.32)
на весь отрезок интегрирования [а; Ь\ (т. е. на все п частичных
отрезков) получается формула:
*«= ^ ПБ). где ge[a; 6|.
Учитывая, что hn = b — a, найден следующий окончательный вид
формулы для оценки погрешности метода интегрирования по
формуле трапеций:
|/?„1<М '*•"*'•*'. (5.33)
где
М= max 1П*)1-
Пример 5.7.1. Вычислить интеграл
i
/== $jt2sin xdx
i о
по формуле трапеций, разделив отрезок [0; 1| на 10 равных частей,
и оценить погрешность вычислений.
Оценим сначала ошибку метода. Для этого находим вторую
производную подынтегральной функции:
/г,/(лг)=(2 — x2)sin jc + 4jccos х.
На отрезке |0; 11 /"(*) всюду положительна, причем ее значение
ограничено сверху: /"(х)<3,3. Таким образом, используя
формулу (5.33) (а = 0, 6 = 1, Л = 0,1), имеем:
108
\R\
3,3-О, Г2
12
= 0,00275.
Итак, приняв на заданном участке интегрирования я=10, мы
сможем получить интеграл от заданной функции с погрешностью,
не превышающей 0,003, если только будем вести вычисления таким
образом, чтобы погрешность округления не исказила
окончательный результат в пределах точности метода. Понятно, что это условие
будет вполне соблюдено, если пользоваться для вычислений
калькулятором.
Значения подынтегральной функции в узловых точках
приведены в таблице 5.4.
Таблица 5.4
X/
0
0,1
0,2
0,3
0,4
0,5
0,6
0,7
0,8
0,9
1.0
*/,/2(/=0.10)
0
0,4207355
*//(/=!, 2 9)
0,0009983
0,0079467
0,0265968
0,0623068
0,1198562
0,2032711
0,3156668
0,4991078
0,6344948
0,4207355
1,8302453
Для последовательного вычисления по формуле x2sinjt
пригодна любая из программ для МК типа БЗ-18А:
В последней строке таблицы получены суммы значений у, по
столбцам. Используя значения этих сумм, в соответствии с
формулой трапеции (5.27) имеем:
/ = 0,1 (0,4207355 + 1,8302453) = 0,225098.
Учитывая вычисленную раньше ошибку /?, получаем окончательно:
/ = 0,225 ±0,003.
5.8. ФОРМУЛА СИМПСОНА
При я = 2 из формулы (5.24) последовательно имеем (/ = 0, !, 2):
1 г2 /(/-1)(/-2) , I
""--У], 2 rf/==T'
109
Ht = -Ut(t-2)dt=^,
H2=]-\t(t-\)dt=+r.
\ Ч 0
Тогда с учетом (5.25) получим на отрезке [х0\ х2\:
\f(x)dxtt(x2 — Xo) S H(yi = 2h [\уъ+ y</i + \у*)>
т. е.
\f{x)dx',
(Уо + 4у,+у2).
(5.34)
Геометрически, в соответствии со смыслом интерполяционной
формулы Лагранжа при п = 2, использование формулы (5.34) означает
замену подынтегральной функции f(x) параболой L2(x\ проходящей
через точки М,(х„ yi) (/ = 0, 1, 2) (рис. 13).
Если считать, что п — четное (п = 2т\ то, применяя формулу
(5.34) последовательно к каждой паре частичных отрезков [х2/_2, х2<\
(/=1, 2, ..., т), получим:
^хЦхЖЩ.(Л^+2у1+у, + ... + 2уат-1).
(5.35)
Формула (5.35) называется формул ой Симпсона.
Оценка остаточного члена формулы Симпсона дается форму-
лой ([1], [2], [7], [13]):
R„ =
(b-a)hA tiy,
180
П1\ Se|a; b\,
или
1Я„1<Л!
\b-a\-h*
(5.36)
хг X
по
где М= max \f (х)\. Как следует из оценки, формула Симпсона
и < х < b
оказывается точной для полиномов до третьей степени
включительно (ибо для этих случаев производная четвертого порядка
равна нулю). Формула Симпсона обладает повышенной точностью
по сравнению с формулой трапеций. Это означает, что для
достижения той же точности, что и по формуле трапеций, в ней можно
брать меньшее число п отрезков разбиения. Последнее
обстоятельство весьма важно для вычислений, поскольку основное время
затрачивается на нахождение значений функций в узлах.
Укажем в заключение весьма простой практический прием,
позволяющий прогнозировать требуемое число отрезков разбиения
по заданной точности е.
Пусть задана предельная допустимая погрешность
интегрирования г. Желая иметь |/?|<е с учетом оценки (5.36), достаточно
потребовать:
М щ <е,
откуда
Л4 < TT^hw. т. е. h < Vf-^^7- (5'37)
180° те /Ь<У 180*-
\Ь-а\.М • '*е- "^ V \b-a\-M
Формула (5.37) позволяет оценить величину шага, необходимую
для достижение заданной точности (из формулы виднс>, что h
имеет порядок -у/г).
• Пример 5.8.1. Вычислить интеграл из примера 5.7.1 по
формуле Симпсона при том же числе отрезков разбиения (я =10).
Для оценки остаточного члена найдем производную четвертого
порядка от подынтегральной функции f(x) = x2s\n х:
fw(x)=(x2— 12)sin х — 8л:cos х.
Значение |/iv(a:)| на отрезке [0; 1] ограничено числом 14. Используя
формулу (5.36), получаем оценку:
|/?|<-Ц|^-=0,0000077.
Значения подынтегральной функций в узлах, вычисленные с
максимальной точностью калькулятора БЗ-18А в соответствии с
формулой Симпсона (5.35), приведены в таблице 5.5. Используя значения
сумм из последней строки таблицы, имеем:
/ = -^- (0,4207355 + 0,7326324 + 2,1952255) = 0,2232395.
Округлим результат в соответствии с полученной оценкой:
/ = 0,223240 ±0,000008.
Сравнивая этот результат со значением интеграла, полученным
в примере 5.7.1, замечаем, что при одинаковом числе отрезков
разбиения формула Симпсона дает ответ с большим числом верных
знаков.
in
Таблица 5.5
Xi
0
0,1
0,2
0,3
0,4
0,5
0,6
0,7
0,8
0,9
1,0
yi/2 (/=0,10)
0
0,4207355
0,4207355
(/,(/ = 2,4.6.8)
0,0079467
0,0623068
0,2032711
0,4591078
0,7326324
2iji (i=l, 3. 5, 7, 9)
0,0019966
0,531936
0,2397124
0,6313333
0,2689896
2,1952255
Посмотрим, как можно было бы воспользоваться в данном
случае формулой (5.37). Пусть требуется найти значение
заданного интеграла с точностью е=10-6. Тогда по формуле (5.37)
получаем:
Л<
yso-io 6 =0<05981з8.
Отсюда следует, что при использовании формулы Симпсона для
достижения точности 10~6 достаточно было бы разбить отрезок
[0; 1] на 20 частей (с шагом h = 0,05).
5.9. ОБ ОЦЕНКЕ ТОЧНОСТИ КВАДРАТУРНЫХ ФОРМУЛ
Как следует из оценочных формул (5.31) и (5.36), оценка
погрешности метода интегрирования по формулам трапеций и
Симпсона возможна лишь тогда, когда подынтегральная функция
задана аналитически. Однако даже и в этом случае на практике
широко применяется следующий прием, пригодный для каждого из
рассмотренных методов интегрирования.
Искомый интеграл вычисляется дважды: при делении отрезка
[а; Ь\ на п частей и на 2п частей (разумеется, при интегрировании
по формуле Симпсона п к тому же должно быть четным). Вслед
за этим полученные значения интеграла (обозначим их 1„ и 12п)
сравниваются, и совпадающие первые десятичные знаки считаются
верными.
Для оценки погрешности метода Симпсона при этом может
использоваться простая формула. Пусть Rn и R2n — погрешности
интегрирования по формуле Симпсона, соответственно при п и
2/1 отрезках разбиения. Учитывая оценку (5.36), можно составить
равенство:
ТГ- = 4-. (5-38)
#2/, kin
где li„ и А2я — длина отрезков разбиения (шаг интегрирования)
112
hn/2. Тогда из (5.38)
(5.39)
In+Rn И I = l2n+R*n*
(5.40)
Формула (5.40) удобна для практической оценки погрешности
метода Симпсона, но требует двойного счета.
Из оценочных формул (5.33) и (5.36) следует, что ошибка
интегрирования по методу трапеций и методу Симпсона
уменьшается с уменьшением шага интегрирования (особенно это характерно
для формулы Симпсона, см. (5,39)). На основании этого хотелось
бы сделать вывод, что при последовательном увеличении числа
отрезков разбиения мы будем получать значение интеграла, все
более и более близкое к истинному. Однако этот вывод имеет
чисто теоретическое значение. Дело в том, что в процессе
практических вычислений при последовательном удвоении числа отрезков
разбиения начинает сильно прогрессировать удельный вес ошибки
округления, значение которой с некоторого момента ставит предел
достижимой точности результата интегрирования (подробное
исследование влияния указанных ошибок на результат интегрирования
содержится в [13]).
5.10. СОСТАВЛЕНИЕ ПРОГРАММ ДЛЯ ЭВМ
5.10.1. Формулы трапеций и Симпсона
Составим программу интегрирования по методу Симпсона.
Для организации циклического алгоритма формулу Симпсона
(5.35) удобно переписать в виде (прибавив и отняв у2т внутри
скобок):
\j(x)dx* |-[J^- +(2у, +У2) + (2у3 + у4) +
+ ... + (2у2т-\+уы)]. (5.41)
Выражение в квадратной скобке (кроме первого слагаемого) может
быть получено теперь циклическим суммированием двучленов вида
2у*+Уь + 1 при увеличении параметра k в каждом обороте цикла
на 2, причем верхней границей k должно служить лг — 1 (я=2т).
В случае, когда выбор шага интегрирования (т. е. задание
значения п) и оценка погрешности метода производятся «вручную»,
алгоритм вычисления интеграла по формуле (5.41) представляет
собой простой цикл (см. Схему алгоритма на рисунке 14). Ниже
приведена программа на языке Бейсик для выполнения заданий
из примера 5.8.1. При десяти отрезках индекс k в программе
изменяется от 1 до 11:
в первом и втором случае. Понятно, что h2n
получаем:
, /?л=16/?2л.
Если / — истинное значение интеграла, то /
откуда /rt+16/?2n = /2n + /?2n, т.е.
113
10 REM СИМПС0Н-1
20 DIM Y(1I)
30 X=0
40' FOR K=I TO 11
50 Y(K)=XA2*SIN(X):X=X+ Л
60 NEXT К
70 S^(Y(l)-Y(ll))/2
80 FOR K=2 TO 10 STEP 2
90 S=S+2kY(K)+Y(K+D
100 NEXT К
ПО I=2k.!kS/3
120 PRINT "1=и;1
130 END
Запустив программу, получим ответ: / = 22323962606178.
Используя вычисленную в примере. 5.8.1 оценку погрешности
метода, полученный результат следует округлить: /=0,223240 ±
±0,0008. Обращаем внимание на то, что значение интеграла в
точности совпадает с тем, что было получено в примере 5.8.1 с
помощью МК. Судя по величине погрешности метода и допуская,
что вычислительная погрешность в данном случае не превышает
погрешности метода (для вычислений на ЭВМ, ведущей счет более
чем с десятью знаками после запятой, такое предположение вполне
обоснованно), можно уверенно утверждать, что в полученном
значении интеграла по меньшей мере четыре знака после запятой
верны в строгом смысле.
Рассмотрим сейчас^ подход к программированию формулы
Симпсона по методу повторного счета с использованием оценки
(5.40). Если требуемая точность г не достигается (т.е. |/„ —
—/2л1>15е), в программе должен предусматриваться повторный
счет с шагом, уменьшенным вдвое. По этой причине формировать
заранее массив значений подынтегральной функции в узлах не
имеет смысла. Схема соответствующего алгоритма приведена на
рисунке 15.
Первоначальное значение интеграла (в схеме /„) принимается
равным 0. Вслед за этим тут же принимается л = 4 и ведется счет
значения интеграла /2„. Если проверка показывает, что требуемая
с
CMMTMJ
t
В б од а,д,п
х
Формирование
массибау[0-п]
*-(Уф-Уя)/*
X
к.= 1
.*«*-
S:=S+(2yK+yK+,)
f
/Г.'=АЧ- 2
Й7
I:=2(b-a)S/(3n)
Вы Sod I
I
CKoHeuij
Рис. 14
(^ симп-Г}
Ввод Q,b,e
x
I„:=0;n:=4
-*■*
S:=(f(a)-f(b))/2
X
S-=S + 2f(x) + f(x+/i)
x:= x + 2h
da
нет
/7:
= i>7
•=-Tg/7 |
&7
#6777
Выбод l2n
C^EED
Рис. 15
точность не достигнута, то после замены 1П на /2« и удвоения числа
отрезков разбиения п процесс повторяется сначала. Внешний Цикл
повторяется до тех пор, пока не будет достигнута требуемая
точность.
Практически при использовании описанного подхода следует
помнить о возможном влиянии на окончательный результат ошибок
округления (см. конец пункта 5.9). Применяя этот прием, необхо-
115
димо сопоставить величину запрашиваемой точности с возможным
диапазоном ошибки округления (это связано как с характером
производимых операций, так и с длиной разрядной сетки ЭВМ).
Приводим программу вычисления интеграла:
I = \ х2 sin xdx
о
с точностью 10_6 по формуле Симпсона в соответствии с
алгоритмом, изображенным на рисунке 15. В программе буквами А и В
обозначены концы отрезка интегрирования; Е — запрашиваемая
точность; N — число отрезков разбиения; Н — шаг интегрирования;
II и 12—соответственно первичное и вторичное значения
интеграла. При достижении заданной точности значение 12 выводится на
экран (или бумагу). Подынтегральная функция определяется с
помощью оператора DEFFN:
10 REM СИМПСОН-2
20 DEFFN F(X)=XA2xSIN(X)
30 INPUT А,В,Е
40 I1=0:N=4
50 h=(b-aVn
60 s=(fnf(a)-fnf(b))/2
70 X=A+H
80 S=S+2xFNF(X)+FNF(X+H)
90 X=X+2xH
100 IF X<B THEN 80
110 I2=2xHxS/3
120 N=2xN:M=ABS( И-12): 11=12
130 IF M>I5xE THEN 50
140 PRINT "I=";I2
150 END
I = .22324356715737.
Округляя полученный результат в соответствии с заданной точ-
116
ностью, получаем:
/ = 0,223244 ±10-6.
Сравнивая значения интеграла, вычисленные во всех
рассмотренных примерах, можно отметить полное согласование полученных
результатов с соответствующими оценками точности.
Действительно, из результата вычисления заданного интеграла по формуле
трапеций (пример 5.7.1) следовало, что верными являются лишь
два знака после запятой: 2, 2. Вычисления по формуле Симпсона
(пример 5.8.1) подтвердили правильность этих знаков и добавили
два новых знака: 2, 2, 3, 2. Дальнейшие вычисления по методу
повторного счета дали уже пять верных в строгом смысле знаков,
в число которых вошли все найденные раньше: 2, 2, 3, 2, 4.
Упражнение. Составьте программу вычисления интеграла
по формуле трапеций.
5.10.2. Вычисление интегралов методом Монте-Карло.
Мы видели, что программная реализация методов численного
интегрирования предусматривает получение суммы, количество
слагаемых в которой определяется числом точек разбиения
интервала интегрирования. В практических приложениях часто
приходится вычислять значение кратных интегралов. Кратный интеграл
вычисляется для функции многих переменных по замкнутой
ограниченной многомерной области. Вычислительная схема при этом
в основном сохраняется: интервал, соответствующий изменению
каждой переменной внутри области интегрирования, разбивается
на фиксированное число отрезков. Таким образом задается
разбиение области интегрирования на определенное число
элементарных многомерных объемов. Вычисляются значения
подынтегральной функции для точек, взятых по одной внутри каждого
элементарного объема, и полученные значения суммируются. Легко
понять, что при увеличении кратности интеграла число слагаемых
очень быстро возрастает. Пусть, например, мы разбиваем интервал
изменения каждой переменной на десять частей. Тогда для
вычисления тройного интеграла придется вычислять сумму примерно
тысячи слагаемых. Для вычисления же 10-кратного интеграла
потребуется сумма, количество слагаемых в которой определяется
числом 1010. Вычисление такой суммы затруднительно даже на
самых быстродействующих современных ЭВМ. В таких ситуациях
предпочтительнее использовать для получения значения интеграла
метод Монте-Карло, с основной идеей которого мы познакомились
в параграфе 2.7.
В основе оценки искомого значения интеграла / лежит
известное соотношение:
/ = |/ср-а, (5.42)
где уср — значение подынтегральной функции в некоторой
«средней» точке области интегрирования, а а—(многомерный) объем
области интегрирования. При этом, конечно, предполагается, что
подынтегральная функция (обозначим ее F) непрерывна в области
117
интегрирования. Выберем в этой области п случайных точек Af,.
При достаточно большом п приближенно можно считать:
Точность оценки значения интеграла методом Монте-Карло
пропорциональна корню квадратному из числа случайных
испытаний и не зависит от кратности интеграла. Именно поэтому
применение метода целесообразно для вычисления интегралов высокой
кратности. Мы, однако, ограничимся иллюстрацией рассматривае-
ь
мого метода для простейшего случая интеграла: I = \f(x)dx.
а
В этой ситуации о = Ь — а и равенство (5.42) принимает вид:
/=^2/(^Х (5.43)
где Xi (/=1, ..., п) — случайные точки, лежащие.в интервале [а; Ь\
Для получения таких точек на основе последовательности
случайных точек xiy равномерно распределенных в интервале [0; 1],
достаточно выполнить преобразование:
х, = а + (Ь — а)-х,.
Программа вычисления интеграла методом Монте-Карло по
формуле (5.43) будет совсем простой. Приведем эту программу
и осуществим по ней расчеты для интеграла из примера 5.7.1:
10 REM ВЫЧИСЛЕНИЕ ИНТЕГРАЛА МЕТОДОМ ПОНТЕ-КАРЛО
20 РВХМТ"ПОДЫНТЕГРАЛЬНАЯ ФУНКЦИЯ ЗАДАЕТСЯ
ОПЕРАТОРОМ 30м
30 DEFFN KX>-X~2X8IN<X>
40 INPUT-ВВЕДИТЕ ПРЕДЕЛЫ ИНТЕГРИРОВАНИЯ А И В"|А,В
90 INPUT-ВЕДИТЕ ЧИСЛО(СЛУЧАЙНЫХ ИСПЫТАНИЙ NN|N
60 8-0ID-B-A
70 FOR 1-1 ТО N
80 X-A+DXRND<l)lS-S+FNKX>
90 NEXT Z
100 I-SXD/N
110 PRINT "I-"|I
120 END
Для N= 100 получится следующий результат: / = .2191946537782.
118
Контрольные вопросы
1. В чем особенность задачи численного дифференцирования?
2. Как влияет на точность численного интегрирования величина
шага Л? Каким способом можно прогнозировать примерную
величину шага для достижения заданной точности интегрирования?
3. Можно ли добиться неограниченного уменьшения
погрешности интегрирования путем последовательного уменьшения шага?
ЛАБОРАТОРНАЯ РАБОТА 5
Тема. Численное дифференцирование и интегрирование.
Задание 1. Вычислить с помощью калькулятора значение
производной функции, заданной таблично, используя
интерполяционные формулы Лагранжа или Ньютона, и оценить погрешности
метода.
Задание 2. Составить программу и вычислить на ЭВМ одно
значение производной функции f(x\ заданной аналитически.
Задание 3. Вычислить с помощью калькулятора интеграл
заданной функции f(x) на отрезке [а\ Ь\ по формуле трапеции и Симпсо-
на при делении отрезка на 10 равных частей, произвести оценку
погрешности методов интегрирования и сравнить точность
полученных результатов.
Определить, какое число отрезков разбиения обеспечило бы
достижение точности 10~6 при вычислении заданного интеграла по
формуле Симпсона (в предположении, что.влияние вычислительной
погрешности заведомо меньше влияния погрешности метода).
Задание 4. Составить и пустить на ЭВМ программу вычисления
интеграла заданной функции на отрезке [а; Ь\ по формуле
Симпсона методом повторного счета с точностью 10~~6.
Пояснения к выполнению лабораторной работы 5. Для
выполнения задания 1 используются исходные данные таблиц 4.17—4.20,
которые выбираются в соответствии с номером варианта по
таблице 4.16 в разделе «задание 3» (см. предыдущую главу). Участок
таблицы для дифференцирования, значение аргумента ху а также
используемый метод задаются преподавателем. Перед выполнением
задания следует прочитать п. 5.1—5.4 главы 5, разобрать
примеры 5.2.1 и 5.3.1.
Задание 2 выполняется с использованием тех же исходных
данных, что и для задания 1, с той разницей, что из таблиц 4.17—4.20
берутся не табличные значения функции, а ее аналитическое
выражение. Полученное значение производной сопоставляется со
значением, найденным при выполнении задания 1, а также с
результатом вычисления производной заданной функции (например, на
калькуляторе) после непосредственного дифференцирования по
формуле.
Исходные данные для выполнения задания 3 берутся из
таблицы 5.5. Отрезок интегрирования разбивается на 10 равных частей
и производится вычисление интеграла по формулам трапеций и
119
Симпсона. С этой целью удобно составить единую таблицу
значений подынтегральной функции по схеме:
Таб л и ira 5.6
Z у ,/2 (/ = 0,10) £/,(/=!, 2, 3 9) 2</, (/=1, 3, 5, 7, 9) х
По каждому из трех столбцов таблицы находятся суммы
соответствующих значений подынтегральной функции (при этом по
столбцу ул для формулы трапеций находится сумма всех
элементов столбца, а для формулы Симпсона — только с четными
индексами). Вычисления ведутся с максимальной точностью.
Для оценки погрешности методов используются оценочные
формулы (5.33) и (5.36). Их применение предполагает исследование
модулей соответственно второй и четвертой производной
подынтегральной функции на отрезке [а; Ь\. В случае, когда исследование
общими методами оказывается слишком затруднительным, можно
воспользоваться табулированием указанных производных на
заданном отрезке с подходящим шагом на ЭВМ (цо необходимости такая
таблица может локально уплотняться на экстремальных участках
отрезка [а; Ь\).
Для выполнения заключительной части задания 1 используется
формула (5.37) (см. пример 5.8.1).
Перед выполнением задания 4 необходимо изучить п. 5.10 и
тщательно разобраться в сущности метода повторного счета.
Исходные данные для выполнения задания берутся из таблицы 5.7.
Варианты
1
2
3
4
5 ~
6
7
8
9
10
11
12
13
14
15
16
/(*)
0,37<?sinjr
0t5x+x\gx
(x+l,9)sin(*/3)
yln(*+2)
3cosjc
2*+1,7
(2х+0,6) cos (х/2)
2,6х2 In х
(j^+Osin^-O.S)
х2 cos (jc/4)
sin (0,2*—3)
3*+ln*
4*e*2
3*2 + tgj<:
Зле2 + sin*
X2
Зл*™8* .
**tgf
T;
a
0
1
1
2
0
1
1.2
0,5
2
3
1
-1
-0,5
0
0,2
1,5
i б л и ц a 5.7
b
1
2
2
3
1
2
2,2
1,5
3
4
2
0
0,5
1
1.2
2,5
Глава 6
РЕШЕНИЕ ОБЫКНОВЕННЫХ
ДИФФЕРЕНЦИАЛЬНЫХ УРАВНЕНИЙ
6.1. ПОСТАНОВКА ЗАДАЧИ
Простейшим обыкновенным дифференциальным уравнением
является уравнение первого порядка
y' = f(x, у). (6.1)
Основная задача, связанная с этим уравнением, известна как
задача Коши: найти решение уравнения (6.1) в виде функции у{х\
удовлетворяющей начальному условию:
</(*<>) = </,,. (6.2)
Геометрически это означает (рис. 16), что требуется найти
интегральную кривую у = у(х), проходящую через заданную точку
M{i(Xiu у{)) при выполнении равенства (6Л).
Существование и единственность решения уравнения (6.1)
обеспечиваются теоремой (см. [12]).
Теорема Пикара. Если функция / определена и непрерывна
в некоторой области G, определяемой неравенствами
U—*ol<a, \у—уо\<.Ь, (6.3)
и удовлетворяет в этой области условию Липшица по у:
|/(X, !/|)-/(ДГ, J/2)l <Л%,-021.
то на некотором отрезке |jc —Jtnl^ft, где А— положительное число,
существует, и притом только одно, решение у=у(х) уравнения (6.1),
удовлетворяющее начальному условию у() = у(х0).
Здесь М — постоянная (константа
Липшица), зависящая в общем случае
от а и Ь. Если /(jc, у) имеет
ограниченную в G производную fftx, у), то при
(х, (/)еС можно принять
М = тахШху у)\. (6.4)
В классическом анализе
разработано немало приемов нахождения
решений дифференциальных уравнений
через элементарные (или специальные)
функции. Между тем весьма часто при
решении практических задач эти
методы оказываются либо совсем беспо- ^ Рис. 16
у^у(х)
121
мощными, либо их решение связывается с недопустимыми
затратами усилий и времени.
По этой причине для решения задач практики созданы методы
приближенного решения дифференциальных уравнений. Весьма
условно, в зависимости от формы представления решения, эти
методы подразделяются на три основные группы.
1. Аналитические методы, применение которых дает решение
дифференциального уравнения в виде аналитического выражения.
2. Графические методы, дающие приближенное решение в виде
графика. '
3. Численные методы, когда искомая функция получается в
виде таблицы.
Ниже рассматриваются относящиеся к указанным группам
некоторые избранные методы решения обыкновенных
дифференциальных уравнений первого порядка вида (6.1). Что же касается
дифференциальных уравнений /г-го порядка:
У'1) = /(*, у% у\ ..., </"-'>),
для которых задача Коши состоит в нахождении решения у=у(х),
удовлетворяющего начальным условиям
У(*о) = Уо, </'Ы = </6 l/n-l)(xo) = y\>n-l\
где (/о, уб, ..., у№~п — заданные числа, то их можно свести к
системе дифференциальных уравнений первого порядка. Так,
например, уравнение второго порядка
</"=(*, У, У')
можно записать в виде системы двух уравнений первого порядка:
z'=f(xy у, Z).
Методы решения систем обыкновенных дифференциальных
уравнений осноэываются на соответствующих методах решения одного
уравнения (см. [1], [6]).
6.2. МЕТОД ПИКАРА
Этот метод позволяет получить приближенное решение
дифференциального уравнения (6.1) в виде функции, представленной
аналитически. Метод Пикара возник в связи с Доказательством
теоремы существования и единственности решения уравнения (6.1)
и является, по сути, одним из применений принципа сжимающих
отображений (см. п. 2.2).
Пусть в условиях теоремы существования требуется найти
решение уравнения (6.1) с начальным условием (6.2).
Проинтегрируем обе части уравнения (6.1) от х0 до х: ,
\dy= \f(x% y)dx,
122
или
х
У(х)=Уо + \ /(*; y)dx. ' (6.5)
Xq
Очевидно, решение интегрального уравнения (6.5) будет
удовлетворять дифференциальному уравнению (6.1) и начальному условию
(6.2). Действительно, при х=х0 получим:
Хо
у(х0) = у0 + \f(x, y)dx=y0.
x»
Вместе е тем интегральное уравнение (6.5) позволяет применить
метод последовательных приближений. Положим у = у0 и получим
из (6.5) первое приближение:
X
У\(х) = Уо+ $/(*, yo)dx.
Х(,
Интеграл в правой части содержит только переменную х\ после
нахождения этого интеграла будет получено аналитическое
выражение приближения у\(х) как функции переменной jc. Заменим
теперь в уравнении (6.5) у найденным значением у^х) и получим
второе приближение:
X
У2(х)=уо+ \f(x, y\)dx
х»
и т. д. В общем случае итерационная формула имеет вид:
X
У«(х)=у0+ \ f(x, yn-x)dx (п= 1, 2, ...). (66)
Циклическое применение формулы (6.6) дает последовательность
функций
УМ* У&\ -. Уп(х) (6.7)
Так как функция / непрерывна в области G, то она ограничена
в некоторой области G'czG, содержащей точку (лг0, уо)> т.е.
Wx,y)\<N. (6.8)
Применяя к уравнению (6.6) в условиях теоремы существования
принцип сжимающих отображений, нетрудно показать (см. [12]),
что последовательность (6.7) сходится (имеется в виДу сходимость
по метрике р(ф|, ф2)=тах |(pi(*) —(p2(x)| в пространстве
непрерывных функций ф, определенных на сегменте |jc—jc0Kd, таких, что
1ф(*)—yoKMi). Ее предел является решением интегрального
уравнения (6.6), а следовательно, и дифференциального
уравнения (6.1) с начальными условиями (6.2). Это означает, что Л-й член
последовательности (6.7) является приближением к точному
решению уравнения (6.1) с определенной степенью точности.
123
Оценка погрешности &-го приближения дается формулой:
M*)-yM\<MkN-£^, . (6.9)
где М—константа Липшица (6.4), N — верхняя грань модуля
функции f из неравенства (6.8), а величина d для определения
окрестности | jc — JCoKrf вычисляется по формуле
d = min(a,-£■). (6.10)
Пример 6.2.1. Методом последовательных приближений найти
приближенное решение дифференциального уравнения
(/' = х2 + 3#,
удовлетворяющее начальному условию у(0)=2.
Запишем для данного случая формулу вида (6.6):
X
yn(x) = 2+\(x2 + 3yn-\)dx(n=l, 2, ...).
о
Начальным приближением будем считать у{)(х) = 2. Имеем:
i/i(jc) = 2+jV + 6)rfjc = 2 + 6jc+T-
о •*
Далее получаем:
X
y2(x)=2-\-^x2 + 3(2 + 6x+Y)]dx=2 + 6x+9x'2+i + T-
о
Аналогично:
Уз(х) = 2 + 6х + 9х2 + 9х*+ i +~-ит.д.
Оценим погрешность третьего приближения. Для определения
области G, заданной неравенствами (6.3), примем, например, a=F=l,
ft = 2. В прямоугольнике G функция /(*, #)=л:2 + 3у определена и
непрерывна, причем (см. (6.4) и (6.8)):
М = тах |/£(*, #)|=3,
Л/ = тах |/(дг, */)| =7.
2
По формуле (6.10) находим d= у. Используя оценочную формулу
(6.9), получаем:
Ых)^ул(х)\<^ «0,053.
124
6.3. МЕТОД ЭЙЛЕРА
В основе метода ломаных Эйлера лежит идея графического
построения решения дифференциального уравнения, однако этот
метод дает одновременно и способ нахождения искомой функции
в численной (табличной) форме.
Пусть дано уравнение (6.1) с начальным условием (6.2). Выбрав
достаточно малый шаг Л, построим, начиная с точки jc0, систему
равностоящих точек х{ = х0 + Ш (/ = 0, 1, 2, ...). Вместо искомой
интегральной кривой на отрезке [лг0; Х\] рассмотрим отрезок
касательной к ней в точке М0(хо, уо) (обозначим ее Li, рис. 17) с
уравнением у=Уо + /(*о, Уо)-(х — х0).
При х=х\ из уравнения касательной L\ получаем: (/,=y0-f-
+ Л/(*о, Уо), откуда видно, что приращение значения функции на
первом шаге имеет вид: Д(/0 = Л/(л:о, уо).
Аналогично, проводя касательную L2 к некоторой интегральной
кривой семейства в точке М\(х\, у\\ получим:
У = У\+1(х\-У\)-(х — *i),
что при х = х> дает У2 = У\+М(Х\' У\)> т-е- У* получается из у\
добавлением приращения ky\=hf(x\, у\).
Таким образом, получение таблицы значений искомой функции
у(х) по методу Эйлера заключается в циклическом применении
пары формул:
\yk = hf(xky yk\
уА + |=у, + Ду,, й = 0, 1, 2 (6.11)
Метод Эйлера обладает малой точностью, к тому же
погрешность каждого нового шага, вообще говоря, систематически
возрастает. Наиболее приемлемым для практики методом оценки
точности является в данном случае способ двойного счета — с
шагом Лис шагом Л/2. Совпадение десятичных знаков в полученных
двумя способами результатах дает естественные основания считать
их верными.
Пример 6.3.1. Решить методом Эйлера дифференциальное
уравнение y' = cosy + 3jc с начальным условием у(0)=1,3 на
отрезке [0; 1], приняв шаг Л = 0,2.
Результаты вычислений с двумя знаками после запятой
приведены в таблице 6.1.
Таблица 6.1
к
0
1
2
3
4
5
Xk
0
0,2
0,4
0,6
0,8
1,0
Ук
1,30
1,35
1,52
1,77
2,09
2,47
A*/* = 0,2(cos f/ft + 3**)
0,05
0,16
0,25
0,32
0,38
125
(
Метод ЭЙЛЕРА Л
B6odx9y,h,b
Yl
Уз
У г
У г
У о
0
{
?
7
А
fe >
V
у ^
Ш
S^
ч >
-^-
h
L
—-<
X
г^Ц
и—
'* 5
Вы6одх,у
X
y:=y+hf(x,y)
Т
^ /fo//£*/ J
Рис. 17
Рис. 18
Программа для калькулятора типа «Электроника БЗ-18А» с
использованием регистра памяти в данном случае может иметь
вид (начальное значение & = 0):
Г
yk F cos F ЗАП **|Х 3 =
[ЕШЗШШШН 0,2 Щ \ yk 0j
Циклический переход по длинной стрелке означает одновременное
увеличение индекса k на единицу. Короткими вертикальными
стрелками в программе отмечены места занесения результата с
индикатора калькулятора в таблицу. Легко заметить, что значения Д#*
можно и не вносить в таблицу, т. е. последний столбец в ней можно
исключить.
Описанный алгоритм легко реализовать на ЭВМ. На рисунке 18
изображена схема алгоритма решения дифференциального
уравнения вида (6.1) методом Эйлера. Исходными данными в
алгоритме являются: начальные значения хну, шаг интегрирования А
и правая граница отрезка интегрирования Ь.
Ниже приведена программа решения заданного выше
дифференциального уравнения методом Эйлера на языке Бейсик с шагом Л=0,1,
уменьшенным вдвое по сравнению с вычислениями на МК. В
программе интегрирование ведется на отрезке [А\ В\ начальное
значение Y(A) обозначено У, шаг интегрирования Н. Результаты вычисле--
ния выводятся с округлением, до двух знаков после запятой:
126
10 REM МЕТОД ЭЙЛЕРА
20 INPUT A,Y,H,B
30 PRINT M XV Y-iPRINT
40 FOR X-A TO В 8TEP H
50 PRINT X,iPRINTU8ING "#•.##•• |Y
60 Y-Y+HX<COS<Y>+3XX)
70 NEXT X
X
0
0,1
0,2
0,3
0,4
0,5
0,6
0,7
0,8
0,9
1,0
yih
1,30
1,35
1,52
1,77
2,09
2,47
Уь
1,30
1,33
1,38
1,46
1,56
1,68
1,82
1,98
2,1.5
2,33
2,53
Результаты работы этой программы (шаг/i) Таблица 6.2
вместе с соответствующими узловыми
значениями из таблицы 6.1 (шаг 2Л) для удобства
сравнения сведены в таблицу 6.2.
Сопоставление приближений, полученных с различным
шагом, показывает, что при выбранном шаге
метод Эйлера дает невысокую точность — в
пределах одной-двух значащих цифр.
Существуют различные уточнения метода
Эйлера, повышающие его точность (см. [1],
[6], [7], [И], [13]). Модификации метода
обычно направлены на то, чтобы более точно
определить направление перехода из точки
(хи Уд в точку (*/+!,. y(+i). Метод Эйлера —
Коши, например, рекомендует следующий порядок вычислений:
yf+\=yi + h-f(Xi, yh
У(+\=У( + п 2 * (б-12)
Геометрически это означает, что мы определяем направление
интегральной кривой в исходной точке (лг„ yi) и во вспомогательной
точке (jt/+i, yf+i), а в качестве окончательного берем среднее этих,
направлений.
Составленная выше программа решения дифференциального
уравнения методом Эйлера легко преобразуется в программу для
метода Эйлера — Коши:
10 REM МЕТОД ЭЙЛЕРА-К0ШИ
20 DBF FNK(XJ)=C0S(y)-h3KX
30 INPUT A,Y,H,B
40 PRINT ff XV Г":PRINT
50 FOR X=A TO В STEP H
127
60 PRINT X,:PRINTUSIN<3 "ft.**";*
70 Z=Y+HxFNK(X,Y)
80 Y=Y+H*(FNK(X,Y)+FNK(X,Z))/2
90 NEXT X
100 END
6.4. МЕТОД РУНГЕ — КУТТА
Метод Эйлера и метод Эйлера — Коши относятся к семейству
методов Рунге — Кутта, имеющих следующий вид. Фиксируем
некоторые числа:
а2, .... a,; pi pq; р\/, 0<j<i^q;
последовательно вычисляем:
k,(h)=h-f(x, у),
k2(ti)=h-f(x+a2-h, y+P2ifti(A))t
'kq(h) = h-f(x + aqh, ^ + Э«|'*|(А) + - + Р«-1*,-|(А))
и полагаем:
y(x + h)&y(x) + 2 pMh) = z(h). (6.13)
1 = 1
Рассмотрим вопрос о выборе параметров а„ р„ р,:/. Обозначим
ф(Л)=</(*+Л)-*(/*).
Будем предполагать, что
ф(0) = ф'(0)=...=ф(л)(0) = 0
при любых функциях /(jc, (/), а ф(4" + |)(0)^=0 для некоторой функции
f(x, у). По формуле Тейлора справедливо равенство
ф^^+^^Ш^, (6.14).
где 0<8<Ь Величина ф(Л) называется погрешностью метода на
шаге, a s — порядком погрешности метода.
При q=\ будем иметь:
<((h) = y(x + li) — y(x) — p\-h-f(x, у)у
Ф(0) = 0,
«p'(0) = G/'(* + A)-Pi/(*. (у))|л=о = /(^ yXI-Pi).
Ф"(А)=«Г(* + А).
Ясно, что равенство ф'(0) = 0 выполняется для любых функ-
128
Ций /(*, у) лишь при условии, что pi = l. Легко видеть, что при
этом значении р\ из формулы (6.13) получается формула (6.11),
т. е. в этом случае мы получаем метод Эйлера. Для погрешности
этого метода на шаге согласно (6.14) будем иметь:
Рассмотрим случай q = 2, тогда
%q(h) = y(x + h) — y(x) — p\hf(x4 y)—p2hj(xy у\
где x = x + a2fi, y = y + $2\hf(x, у).
Согласно исходному дифференциальному уравнению
У = Г> У"=!х + Ы* У'" = 1хх + 2М + !юР + 1»У".1 (6.15)
(Здесь для краткости через у и f обозначены у(х) и f(x, у)
соответственно.)
Вычисляя производные функции ср(Д) и подставляя в
выражения для ф(Л), cp'(A) и ср"(А) значение /г = 0, получим (с учетом
соотношений (6.15)):
ф(0) = 0,
.<p'(0) = (\-Pi-p*)h
ф"(0) = (1 -2р2а2)/* + (1 -2p2fri)fyf-
Хорошо видно, что требование
ф(0) = ф'(0) = ф"(0) = 0
будет выполняться для всех f(x, у) лишь в том случае, если
одновременно будут справедливы следующие три равенства относительно
четырех параметров:
1 —Pi —р2 = 0,
1-2р2а2 = 0, (6.16)
l-2p2p2i=0.
Произвольно задавая значение одного из параметров и
определяя значения остальных из системы (6.16), мы будем получать
различные методы Рунге — Кутта с порядком погрешности 5 = 2.
Например, при р, = у из (6.16) получаем: р2= у, а2=1, р2, = 1.
Для этих значений параметров формула (6.13) принимает вид:
,i —иЛ-h К*" #) + /(*'+'. #и)
yi+\—yi-rn 2 '
(Здесь у, + | записано вместо y{x + h\ yt — вместо у(х\ а через yf+i
обозначено выражение */,.+Л •/(*,, yi).) Таким образом, в
рассматриваемом случае мы приходим к расчетным формулам (6.12),
соответствующим методу Эйлера — Коши. Из (6.14) следует, что при
этом главная часть погрешности на шаге есть ф ' /г3, т.е.
пропорциональна третьей степени шага h.
129
В вычислительной практике наиболее часто используется метод
Рунге — Кутта с q==4 и 5 = 4.
Приведем без вывода один из вариантов соответствующих
расчетных формул:
k\=h-f(x, у),
Л2 = А-/(*+у. У+т)*
*,=.*./(х+A, y+J.)f (6.17)
fe4 = A-/(x + A, у + Ы
by = z(h)-y(x)=±(ki+2k2 + 2kz + k4).
Отметим, что в этом случае погрешность на шаге
пропорциональна пятой степени шага (Л5). Отсюда, в частности, следует, что
при достаточно малом Л и малых погрешностях вычислений
решение уравнения (6.1), полученное методом Рунге — Кутта по
формулам (6.17), будет близким к точному.
Геометрический смысл использования метода Рунге — Кутта с
расчетными формулами (6.17) состоит в следующем. Из точки
(jc„ yi) сдвигаются в направлении, определяемом углом аь для
которого tga\=f{xiy yi). Ha этом направлении выбирается точка с
координатами (*/ + у* У'+Т")* Затем из точки (jc„ yi) сдвигаются
в направлении, определяемом углом <хг, для которого tg осг =
=/(*'+у» f/i + y)» и на этом направлении выбирается точка
с координатами (х/+у, #/+у)- Наконец, из точки (*,-, yi)
сдвигаются в направлении, определяемом углом аз, для которого
tga3 = / (xi+ у, <//+у) и на этом направлении выбирается точка
с координатами (х/ + Л, #/ + &з). Этим задается еще одно
направление, определяемое углом а4, для которого tga4=/(*/-(-Л, yi + k3).
Четыре полученные направления усредняются в соответствии, с
последней из формул (6.17). На этом окончательном направлении
и выбирается очередная точка (x,-+i, y/+i)=(jt/ + /i, у{ + \у).
Для того чтобы составить программу решения
дифференциального уравнения методом Рунге — Кутта, перечислим шаги
описанного алгоритма исходя из расчетных формул (6.17):
1. Ввести начальные условия, обозначив их соответственно А и Y.
2. Ввести шаг интегрирования Н и конечную точку В отрезка
интегрирования.
3. Цикл по х от А до В с шагом Н.
4. Вывести х и у.
5. Вычислить k\% *2, *3, *4-
6. Вычислить Ду.
7. Вычислить новое значение у=у + &у.
8. Конец цикла по х.
130
Для примера рассмотрим уравнение у'=у{1— х).
10 REM МЕТОД РУНГЕ-КУТТА
20 DEF FNR(X,Y)=Yx(YI-X)
30 INPUT "ВВЕДИТЕ НАЧАЛЬНЫЕ ЗНАЧЕНИЯ АРГУМЕНТА
И ФУНКЦИИ - А И Y";A,Y
40 INPUT "ВВЕДИТЕ ШАГ ИНТЕГРИРОВАНИЯ Н И КОНЕЦ
ОТРЕЗКА ИНТЕГРИРОВАНИЯ В";Н,В
50 PRINT " Хн," Y":PRINT
- 60 FOR Х=А ТО В STEP Н
70 PRINT X,:PRINTUSING "£#.±±#*";Y
80 Kl=HxFNR(X,Y)
90 K2=HkFNR(X+H/2,Y+K1/2)
100 K3=HxFNR(X+H/2,Y+K2/2)
110 K4=HxFNR(X+H/2,Y+K3/2)
120 fr=(М+2нК2+2хКЗ+К4)/ft
130 Y=Y+D
140 NEXT X
150 END
Результаты работы программы при Л=0, «/=1, Н=0.1, 5=1:
X
0
.1
.2
.3
.4
.5
.6
.7
.8
.9
1
Y
1.0000
1.0997
1.1972
1.2905
1.3771
1.4550
1.5220
1.5762
2.6161
2.6405
2.6487
131
Пример 6.4.1. Решим уравнение у' = у(1—х) с начальными
условиями у(0)=\ методом Эйлера — Коши и методом Рунге —
Кутта. Данное уравнение может быть решено аналитически. При
заданных начальных условиях это решение выглядит так:
Для сравнения сведем в одну таблицу результаты численного
решения уравнения указанными методами и значения точного
решения, вычисленные в соответствующих точках (с четырьмя
знаками после запятой).
T а б л и ц а 6.3
X
У
Метод Эйлера — Коши
Метод Рунге — Кутта
Точное решение
0
1.000
1.000
1.0000
0.1
1.1050
1.0997
1.0997
0.2
1.2089
1.1972
1.1972
0.3
1.3095
1.2905
1.2905
0.4
1.4044
1.3771
1.3771
0.5
1.4912
1.4550
1.4550
0.6 0.7 0.8 0.9 1
Метод Эйлера — Коши 1.5676 1.6316 1.6812 1.7152 1.7324
if Метод Рунге — Кутта 1.5220 1.5762 1.6161 1.6405 1.6487
Точное решение 1.5220 1.5762 1.6161 1.6405 1.6487
Мы видим, что метод Рунге — Кутта дает результаты,
практически совпадающие с точным решением.
Контрольные вопросы
1. На какие основные группы подразделяются приближенные
методы решения дифференциальных уравнений?
2. В какой форме получается приближенное решение
дифференциального уравнения по методу Пикара?
3. В какой форме можно получить решение
дифференциального уравнения по методу Эйлера?
4. Какой способ оценки точности используется при
приближенном интегрировании дифференциальных уравнений методами
Эйлера и Рунге — Кутта?
ЛАБОРАТОРНАЯ РАБОТА 6
Тема. Численное решение обыкновенного дифференциального
уравнения первого порядка.
Задание. Решить задачу Коши для дифференциального
уравнения y = f(x, у) на отрезке \а\ Ь\ при заданном начальном условии
у(а) = с и шаге интегрирования h:
1) методом Эйлера на МК с шагом 2/г и ЭВМ с шагом h (по
таблице, полученной на МК, сделать прикидку графика
интегральной кривой);
132
2) методом Рунге — Кутта на ЭВМ с шагом 2Л и шагом А;
3) обращением к библиотечной программе.
Исходные данные для 17 вариантов заданий содержатся в
таблице 6.4.
Пояснения к выполнению лабораторной работы 6. Первая часть
задания выполняется на калькуляторе и ЭВМ (см. пример 6.3.1).
Результаты ручных и машинных вычислений вносятся в одну
таблицу (см. табл. 6.2). Значения искомой функции в соответствующих
узлах сравниваются между собой и составляется представление
о точности полученного на МК результата. По вычисленной на МК
таблице функции строится точечный график и проводится плавная
кривая.
По второй части задания составляется программа на ЭВМ,
которая пускается дважды — для шага H = 2h и шага H = h (на
одном и том же отрезке интегрирования [а; Ь]. Сравнением
полученных значений устанавливается точность результата, которая
сопоставляется с точностью интегрирования по методу Эйлера.
Требуемая оценка осуществляется так. Пусть у2и —
вычисленное значение у(х) с шагом 2Л, а уп — соответствующее значение,
полученное с шагом А. Для ориентировочной оценки погрешности е
значения yh можно использовать формулу Л
I thh — Уь I
Таблица 6.4
а
4
2,6
-1
2
0
1
0,6
1,5
2,1
3
1
1
2
0,1
-2
0
1.5
Ь
5
4,6
1
3
0,5
2
2,6
2
3,1
5
3
2
3
0,5
-1
2
2,5
с
0,7
1.8
0,2
1,2
0,3
0,9
3,4
2,1
2,5
1,7
1,5
0,9
2,3
1,25
3
2,9
0,5
h
0,1
0,2
0,2
0,1
0,05
0,1
0,2
0,05
0,1
0,2
0,2
0,1
0,1
0,05
0,1
0,2
0,1
10
11
12
13
14
15
16
17
JOT—xl
-yj4x2+\-3y2
cps(l,5*-w2)-l,3
jc2 +xy-Vy*
cos(l,5(/ + x)2+l,4
4,l*-f/2 + 0,6
*+cos_y
if* -0,4
* + 4
2,5* + cos (y + 0,6)
jt + 2,5f/2 + 2
2-sin(x+«/)2
i У
* + cos-|-
Yjc2 + 0,5(/2 + 1
sin(x+f/)+l,5
Глава 7
МЕТОДЫ ОБРАБОТКИ
ЭКСПЕРИМЕНТАЛЬНЫХ ДАННЫХ
В этой главе будут рассмотрены некоторые методы анализа
и обработки, данных, получаемых в ходе эксперимента. Изложение
начинается с изучения простейших аналитических приемов
построения эмпирических зависимостей по методу наименьших
квадратов.
7.1. МЕТОД НАИМЕНЬШИХ КВАДРАТОВ
Пусть в результате измерений в процессе опыта получена
таблица некоторой зависимости /:
Таблица 7.1
X
/W
Х\
У\
х2
У*
Хп
Уп
Нужно найти формулу, выражающую эту зависимость
аналитически.
Можно, разумеется, применить метод интерполяции: построить
интерполяционный многочлен (например, Лагранжа или Ньютона),
значения которого в точках х\% х2, ..., хп будут совпадать с
соответствующими значениями f(x) из таблицы 7.1. Однако совпадение
значений в узлах иногда может вовсе не означать совпадения
характеров поведения исходной и интерполирующей функции.
Требование неукоснительного совпадения значений в узлах
выглядит тем более неоправданным, если значения функции f(x)
получены в результате измерений и являются сомнительными.
Поставим сейчас задачу так, чтобы с самого начала обязательно
учитывался характер исходной функции: найти функцию
заданного вида:
y=F(x)% (7.1)
которая в точках х\, х2, ..., хп принимает значения как можно
более близкие к табличным значениям уХч у2у ..., уп-
Практически вид приближающей функции F можно определить
следующим образом. По таблице 7.1 строится точечньГй график
функции /, а затем проводится плавная кривая, по возможности
наилучшим образом отражающая характер расположения точек
134
Х1 Х2
*3\
Рис. 19
(рис. 19). По полученной таким образом кривой устанавливается
вид приближающей функции (обычно из числа простых по виду
аналитических функций).
Следует заметить, что строгая функциональная зависимость
для экспериментально полученной таблицы 7.1 наблюдается
редко, ибо каждая из участвующих в ней величин может зависеть
от многих случайных факторов. Однако формула (7.1) (ее
называют эмпирической формулой или уравнением регрессии у на х)
интересна тем, что позволяет находить значения функции / для
нетабличных значений л\ «сглаживая» результаты измерений
величины у. Оправданность такого подхода определяется в конечном
счете практической полезностью полученной формулы.
Рассмотрим один из распространенных способов нахождения
формулы (7.1). Предположим, что приближающая функция F в
точках jt|, х2у ..., хп имеет значения
Уи #2, ..., Уп.
(7.2)
Требование близости табличных значений у{, у2, ..., уп и
значений (7.2) можно истолковать следующим образом. Будем
рассматривать совокупность значений функции / из таблицы 7.1 и
совокупность (7.2) как координаты двух точек /г-мерного пространства.
С учетом этого задача приближения функции может быть
переформулирована следующим образом: найти такую функцию F
заданного вида, чтобы расстояние между точками М(у]у у2, ...» Уп)
и М(у\, t/2, ..., Уп) было наименьшим. Воспользовавшись метрикой
евклидова пространства, приходим к требованию, чтобы величина
л1{Ух-^? + {У2-У2? + ^+{Уп-Уп)2 (7.3)
была наименьшей, что равносильно следующему: сумма квадратов
(У1-~У>?+(У2-~У2? + ...+(Уп-~Уп)2 . (7.4)
должна быть наименьшей.
135
Итак, задача приближения функции / теперь формулируется
следующим образом: для функции /, заданной таблицей 7.1, найти
функцию F определенного вида так, чтобы сумма квадратов (7.4)
была наименьшей.
Эта задача носит название приближения функции методом
наименьших квадратов,
В качестве приближающих функций в зависимости от
характера точечного графика функции / часто используют следующие
функции:
1) у = ах + Ь; . 5) у^—±—;
2) у = ах2 + Ьх + с\ 6) у = а-\пх + Ь-
3) у = ахт-% 7) у = а±+Ь;
4) у = а-ехр(тх); 8) у =
X
X
ах-\-Ь
Здесь а, Ь, с, т — параметры. Когда вид приближающей функции
установлен, задача сводится только к отысканию значений
параметров.
Рассмотрим метод нахождения параметров приближающей
функции в общем виде на примере приближающей, функции с тремя
параметрами:
y = F(x, a, ft, с). (7.5)
Итак, имеем: F(xt% a, ft, c) — yiy /=1, 2 п. Сумма квадратов
разностей соответствующих значений функций / и F будет иметь
вид:
2 [yi- F(xi4 a, ft, с)|2 = Ф(а, ft, с).
Эта сумма является функцией Ф(а, ft, с) трех переменных
(параметров a, ft и с). Задача сводится к отысканию ее минимума.
Используем необходимое условие экстремума:
да и' db и' дс и'
т. е.
jS [«// — F(xi% a, ft, c)].F'a(xiy а, ft, с) = 0,
2 \yi—F{xi% а, ft, c)\-Fi(xh a, ft, c) = 0,
i—\
%x[yi—F(xi% a, ft, c)]./^(*„ a, ft, 0 = 0. (7.6).
Решив эту систему трех уравнений с тремя неизвестными
относительно параметров a, ft и с, мы и получим конкретный вид
искомой функции F(x% a, ft, с). Как видно из рассмотренного примера,
136
изменение количества параметров не приведет к искажению
сущности самого подхода, а выразится лишь в изменении количества
уравнений в системе (7.6).
Естественно ожидать, что значения найденной функции
F(x, а, Ьу с) в точках х\у х2, ..., хп будут отличаться от табличных
значений у\у у2у ..., уп- Значения разностей
yi — F(xiy a, b, c) = ei (/=1, 2, ..., п) (7.7)
называются отклонениями (или уклонениями) измеренных
значений у от вычисленных по формуле (7.5). Для найденной
эмпирической формулы (7.5) в соответствии с исходной таблицей 7.1
можно, следовательно, найти сумму квадратов отклонений
а=2«ь (7.8)
которая в соответствии с принципом наименьших квадратов для
заданного вида приближающей функции (и найденных значений
хпараметров а, Ъ и с) должна быть наименьшей.
Из двух разных приближений одной и той же табличной
функции, следуя принципу наименьших квадратов, лучшим нужно
считать то, для которого сумма (7.8) имеет наименьшее
значение.
7.2. НАХОЖДЕНИЕ ПРИБЛИЖАЮЩЕЙ ФУНКЦИИ
В ВИДЕ ЛИНЕЙНОЙ ФУНКЦИИ И КВАДРАТНОГО ТРЕХЧЛЕНА
(ЛИНЕЙНАЯ И КВАДРАТИЧНАЯ РЕГРЕССИИ)
Будем искать приближающую функцию в виде:
F(x9 a, b) = ax + b. (7.9)
Найдем частные производные по параметрам
dF _ j^ , •
да -~Х> дЬ ~~1'
Составим теперь систему вида (7.6):
2 (у; — axi — b)xi = О,
V(y, — axi — Ь) = 0.
(Сумма здесь и дальше берется по параметру / в пределах от 1
до п.) Далее имеем:
2# — я2*'—л* = 0 (7.10)
или, деля каждое уравнение на п:
(£2*)-«+(т2*)-*-т2«1».
137
Введем обозначения:
Тогда последняя система будет иметь вид:
Мх*.а + М.Ь = Мх„у п 19х
Коэффициенты этой системы Afx, Муу Мх^ Мху — числа, которые
в каждой конкретной задаче приближения могут быть легко
вычислены по формулам (7.11), где х„ у{— значения из таблицы 7.1.
Решив систему (7.12), получим значения параметров а и 6, а
следовательно, и конкретный вид линейной функции (7.9).
В случае нахождения приближающей функции в виде
квадратного трехчлена имеем:
F{x% a, ft, c) = ax2 + bx + c. (7.13)
Находим частные производные: -|—=jt2, -|£-=л;, $L- = \m
Составим систему вида (7.6):
2 (j// — CLXi — ЬХ{
^(yi — axf — bx,
Yi(yi — axf — bxl
— c)xi = 04
— c) = 0.
После несложных преобразований получается система трех
линейных уравнений с неизвестными a, b и с. Коэффициенты
системы, так же как и в случае линейной функции, выражаются
только через известные данные из таблицы 7.1:
Мх<-а + Мх*-Ь-\-Мх*-с = Мх*у,
Мх>.а + Мх*.Ь + Мх.с = Мху, (7.14)
Мх>-а + Мх.Ь + с = Му.
Здесь использованы обозначения (7.11), а также
М* = 12 */, М^ = | V х?/ М*„ = 12 ж?#.
Решение системы (7.14) дает значения параметров а, 6 и с для
приближающей функции (7.13).
7.3. НАХОЖДЕНИЕ ПРИБЛИЖАЮЩЕЙ ФУНКЦИИ
В ВИДЕ ДРУГИХ ЭЛЕМЕНТАРНЫХ ФУНКЦИЙ
г
Покажем сейчас, как нахождение приближающей функции с
двумя параметрами F(xs a, Ь) в виде элементарных функций из
списка, приведенного на с. 136, может быть сведено к нахождению
параметров линейной функции.
138
7.3.1. Степенная функция (геометрическая регрессия)
Будем искать приближающую функцию в виде:
F(x, а, т)=ахт. (7.16)
Предполагая, что в исходной таблице 7.1 значения аргумента и
значения функции положительны, прологарифмируем равенство
(7.16) при условии а>0:
lnF = \na + mlnx. (7.17)
Так как функция F является приближающей для функции /,
функция In F будет приближающей для In /. Введем новую
переменную w = Injc; тогда, как следует из (7.17), In F будет функцией
от и: Ф(и).
Обозначим
т=Л, \х\а = В. (7.18)
Теперь равенство (7.17) принимает вид:
Ф(и, Л, В) = Л« + В, (7.19)
т. е. задача свелась к отысканию приближающей функции в виде
линейной.
Практически для нахождения приближающей функции в виде
степенной (при сделанных выше предположениях) необходимо
проделать следующее:
1) по данной таблице 7.1 составить новую таблицу,
прологарифмировав значения х и у я исходной таблице;
2) по новой таблице найти параметры А и В приближающей
функции вида (7.19) (см. п. 7.2);
3) используя обозначения (7.18), найти значения параметров
а и т и подставить их в выражение (7.16).
7.3.2. Показательная функция
Пусть исходная таблица 7.1 такова, что приближающую
функцию целесообразно искать в виде показательной функции:
F(x, а, т) = а«ехр(тл:), а>0. (7.20)
Прологарифмируем равенство (7.20):
\nF = \na + mx. (7.21)
Приняв обозначения (7.18), перепишем (7.21) в виде:
In F = Ax + B. (7.22)
Таким образом, для нахождения приближающей функции в
виде (7.20) нужно прологарифмировать значения функции в
исходной таблице 7.1 и, рассматривая их совместно с исходными
значениями аргумента, построить для новой таблицы приближающую
функцию вида (7.22). Вслед за этим в соответствии с
обозначениями (7.18) остается получить значения искомых параметров а
и Ь и подставить их в формулу (7.20).
139
7.3.3. Дробно-линейная функция
Будем искать приближающую функцию в виде:
**.«.*>-!Г|Т- (7-23)
Равенство (7.23) перепишем следующим образом:
1
Fix, а, Ь)
= ах-\-Ь.
Из последнего равенства следует, что для нахождения значений
параметров а и Ь по заданной таблице 7.1 нужно составить новую
таблицу, у которой значения аргумента оставить прежними, а
значения функции заменить обратными числами, после чего для
полученной таблицы найти приближенную функцию вида ах-\-Ь.
Найденные значения параметров а и Ь подставить в формулу (7.23).
7.3.4. Логарифмическая функция
Пусть приближающая функция имеет вид:
F(xy a, b) = a-\nx + b. (7.24)
Легко видеть, что для перехода к линейной функции достаточно
сделать подстановку \rix==u. Отсюда следует, что для нахождения
значений а и Ь нужно прологарифмировать значения аргумента
в исходной таблице 7.1 и, рассматривая полученные значения в
совокупности с исходными значениями функции, найти для
полученной таким образом новой таблицы приближающую функцию
в виде линейной. Коэффициенты а и Ь найденной функции
подставить в формулу (7.24).
7.3.5. Гипербола
Если точечный график, построенный по таблице 7.1, дает ветвь
гиперболы, приближающую функцию можно искать в виде:
F(x, a, Ь)=±+Ь. (7-25>
Для перехода к линейной функции сделаем подстановку u=l/jc.
Ф{иу а, b) = a-u + b. (7.26)
Практически перед нахождением приближающей функции вида
(7.26) значения аргумента в исходной таблице 7.1 следует
заменить обратными числами и найти для новой таблицы
приближающую функцию в виде линейной вида (7.26). Полученные значения
параметров а и b подставить в формулу (7.25).
7.3.6. Дробно-рациональная функция
Пусть приближающая функция находится в виде:
Имеем:
«*.**)= та- <7-27>
1 __ , ь_
Fix, а, Ь) ~~"а~г х '
140
У;
5
4
3
г
1
0
\
У
X
1 ™ iiiiii^
/ г 3 4 5 £ 7 лг
Рис. 20
так что задача сводится к случаю, рассмотренному в предыдущем
пункте. Действительно, если в исходной таблице заменить
значения х и у их обратными величинами по формулам z=\/x и и=\/у
и искать для новой таблицы приближающую функцию вида и =
= bz-\-ay то найденные значения а и Ь будут искомыми для
формулы (7.27).
Пример 7.3.1. Построим приближающую функцию методом
наименьших квадратов для зависимости, заданной следующей
таблицей:
Таблица 7.2
X 1,1
У 0,3
1.7
0,6
2,4
и
3,0
1,7
3,7
2,3
4,5
3,0
5,1
3,8
5,8
4,6
Точечный график изображен на рисунке 20. Для сравнения
качества приближений рассмотрим параллельно два способа
приближения заданной функции: в виде прямой у = ах + Ь и в виде
cteneHHofi функции у = схт. После нахождения значений параметров
а и Ь, с и т можно найти суммы квадратов уклонений (7.8) и
установить, какое из двух приближений лучше.
Значения параметров а и Ь линейной функции находятся из
системы вида (7.12), коэффициенты которой вычисляются по
данным из исходной таблицы 7.1 в соответствии с обозначениями
(7.11). Для вычисления коэффициентов системы по таблице 7.2
составим вспомогательную таблицу 7.3, в последней строке которой
получены суммы значений по соответствующим столбцам. Заметим,
что, используя регистр памяти калькулятора, суммирование
значений в столбцах можно производить параллельно с вычислениями
самих значений. Так, вычисления в столбце «ху» ведутся по
циклическому алгоритму:
141
(вертикальной стрелкой обозначен момент записи промежуточного
результата — произведения ху— в таблицу). После выполнения
действий с последней парой (5,8 и 4,6) значение суммы выводится
-щи.
на индикатор нажатием клавиш JF]
Точно так же вычисление значений х
лельным суммированием по алгоритму:
выполняется с парал-
Г
*МН1Ш1Д
Гт"
а затем производится извлечение суммы из регистра памяти
клавишами ПП |ИП|. Следует заметить, что, исключив фиксирование
промежуточных результатов (значений л:2), последний алгоритм
можно сделать еще более коротким: в
х\^П±?
При этом следует иметь в виду, что в каждом из
рассмотренных случаев перед началом вычислений должен быть очищен регистр
памяти:
С F ЗАП
X
1,1
1,7
2,4
3,0
3,7
4,5
5,1
5,8
У
0,3
0,6
1,1
1,7
2,3
3,0
3,8
4,6
Та
ху
0,33
1,02
2,64
5,10
8,51
13,50
1*9,38
26,68
блица 7.3
X2
1,21
2,89
5,76
9,00
13,69
20,25
26,01
33,64
27,3 17,4
77,16
112,45
Разделив полученные суммы на число элементов в столбцах,
имеем в соответствии с формулами (7.11):
М, = 3,412, М„ = 2,175,
Мхщ = 9,645, М* = 14,056.
Составим теперь систему вида (7.12):
14,056а + 3,4 \2Ь = 9,645,
3,412а + 6 = 2,175.
Решив систему, получаем: а = 0,921, 6 = — 0,968. Отсюда
следует, что приближающая функция y = F(xy а, Ь) имеет вид:
у = 0,921-0,968. . (7.28)
142
Для нахождения параметров сит степенной функции, как
следует из п. 7.3.1, по исходной таблице составляется новая
таблица — из логарифмов значений х и у. Обозначим значения новых
переменных соответственно и и г, т.е. w = lnx, г = 1пу. По
числовым данным из новой таблицы составляется система уравнений
вида (7.12):
Ми'А+МиВ=Миг, /7 9СП
MUA + B = M„ l'zy'
коэффициенты которой — числа, вычисляемые по данным из новой
таблицы по формулам вида (7.11), а неизвестные А и В связаны
с искомыми параметрами с и т соотношениями:
I А = т, В = 1п с.
Для нахождения коэффициентов системы (7.29) составляем
вспомогательную таблицу 7.4 (используем натуральный логарифм,
вычисления ведутся на МК с тремя знаками после запятой по
тем же алгоритмам, что и для таблицы 7.3). Разделив элементы
последней строки таблицы 7.4 на 8, получаем:
и
0,095
0,531
0,875
1,099
1,308
1,504
1,629
1,758
г
-1,204
-0,511
0,095
0,531
0,833
1,099
1,335
1,526
Таб
UZ
-0,114
-0,271
0,083
0,584
1,090
1,653
2,175
2.683
лица 7.4
и1
0,009
0,282
0,766
1,208
1,711
2,262
2,654
3,091
8,799 3,704 7,883 11,983
Л*м=1,1; М, = 0,463; Af„, = 0,985; Мц* = 1,498.
Составляем систему вида (7.29):
МЭМ+ 1,13 = 0,985,
1,14 + 5=0,463.
Ее решение:
А = 1,656, Я=-1,359.
Находим значения параметров с и т:
т = 1,656, с = ехр(—1,359)=0,257.
Следовательно, приближающая функция в виде степенной имеет
вид:
f/ = 0,257*'-656. (7.30)
Для сравнения качества приближений (7.28) и (7.30) вычислим
суммы квадратов уклонений (вычисления приведены в табл. 7.5).
143
Таблица 7.5
X
1,1
1,7
2,4
3,0
3,7
4,5
5,1
5,8
У
0,3
0,6
1,1
1,7
2,3
3,0
3,8
4,6
0,921а: —
— 0.968
0,0451
0,5977
1,2424
1,7950
2,4397
3,1765
3,7291
4,3738
2
ei ef
0,2459 0,0650
0,0023 0,0000
-0,1424 0,0203
-0,0950 0,0090
-0,1397 0,0195
-0,1765 0,0312
0,0709 0,0050
0,2262 0,0512
0,2012
0,257л-1'656
0,3009
0,6188
1,0954
1,5851
2,2432
3,1021
3,8165
4,7225
62 82
-0,0009 0,0000
-0,0188 0,0004
0,0046 0,0000
0,1149 0,0132
0,0568 0,0032
-0,1021 0,0104
-0,0165 0,0003
-0,1225 0,0150
0,0425
Как следует из таблицы 7.5, сумма квадратов уклонений для
линейной функции а = 0,2012, для степенной — а = 0,0425.
Сравнивая качество приближений (в смысле метода наименьших
квадратов), находим, что приближение в виде степенной функции в
данном случае предпочтительнее.
Рассмотренный пример показывает, что для решения задачи
приближения функции методом наименьших квадратов требуется
произвести немало вычислений с использованием значительного
количества числовых значений, порождаемых главным образом в
процессе самого счета (исходными данными здесь являются только
числа из таблицы 7.2). Очевидно, что наиболее подходящим
вычислительным инструментом в этом случае является ЭВМ.
Составим программу, которая по желанию пользователя
рассчитывает параметры уравнения регрессии одного из трех типов:
1) у = ах + 6, 2) у = ах"\ 3) у = аетх.
Исходными для работы программы должны служить данные,
представленные в виде таблицы 7.2.
Мы знаем, что несложными преобразованиями данных расчет
параметров уравнений типа 2 и 3 сводится к расчету параметров
уравнения первого типа, т.е. к решению системы вида (7.12).
Поэтому основные шаги подлежащего реализации алгоритма можно
сформулировать так:
1. Ввод исходных данных.
2. Выбор вида уравнения регрессии.
3. Преобразование данных к линейному типу зависимости.
4. Получение параметров уравнения регрессии.
5. Обратное преобразование данных и вычисление суммы
квадратов отклонений вычисленных значений функции от заданных.
6. Вывод результатов.
10 REM УРАВНЕНИЕ РЕГРЕССИИ
20 DIM X(50),Y(50),U(50),V(50)
30 INPUT "ВВЕДИТЕ N-КОМЧЕСТВО ПАР ЭЛЕМЕНТОВ
ТАБЛИЦЫ"^
144
40 PRINT "ВВЕДИТЕ ПОПАРНО ЧЕРЕЗ ЗАПЯТУЮ
СНАЧАЛА X, А ПОТОМ Y"
50 FOR 1=1 ТО N
60 INPUT X(I),Y(I)
70 NEXT I
80 PRINT "ВЫБЕРИТЕ ВИД УРАВНЕНИЯ РЕГРЕССИИ,
ПАРАМЕТРЫ КОТОРОГО ВЫ ХОТИТЕ РАСЧИТАТЬ"
90 PRINT"I) Y=A*X+B 2) Y=AxX М 3) Y=AxEXP(M*X)"
100 INPUT "ВВЕДИТЕ К-НОМЕР ВЫБРАННОГО
УРАВНЕНИЯ";
НО FOR 1=1 N
120 IF K=I THEN U(I)=X(I):V(I)=Y(I)
130 IF K=2 THEN U(I)=L0G(X(i)):U(I)=L0G(Y(D)
140 IF K=3 THEN U(I)=X(I):V(I)=L0G(Y(D)
150 SI=SI+U(I):S2=S2+V(I):S3=S3U(I)*U(I):
S4=S4+U(I)A2
160 NEXT I
170 D=NkS4-SIa2:A=(NkS3-SIxS2)/D:
B=(S4*S2-SIkS3)/D
180 FOR 1=1 TO N
190 V(l)=AxU(I)+B:IF K=2 OR K=3 THEN
V(I)=EXP(V(I))
200 5=3+(У(1)-У(1))л2 ,
210 NEXT I
220 PRINT "УРАВНЕНИЕ ЛИНИИ РЕГРЕССИИ"
145
230 IP K=I THEN PRINT ,,Y=";A;,,hX+,,;B:
PRINT "S=";S
240 IP K=2 THEN PRINT "Y=,,;EXP(B)+"kX ";A:
PRINT "S=";S
250 IF K=3 THEN PRINT "Г=";ЕХР(В);"кВХР(";А;
"aX)":PRINT "S=";S
260 INPUT "ЕСЛИ ХОТИТЕ ИСПОЛЬЗОВАТЬ ДРУГОЙ
ВИД УРАВНЕНИЯ РЕГРЕССИИ,
ВВЕДИТЕ ЦИФРУ I, ИНАЧЕ
ВВЕДИТЕ ЦИФРУ 2";М
270 IF M=I THEN 80
280 END
В программе для хранения исходных данных используются
одномерные массивы X и Y. Преобразованные данные заносятся
соответственно в массивы U и V.
Выполнив расчеты по этой программе для данных таблицы 7.2
в предложении о линейном типе зависимости (при k=l), получим
следующий результат:
УРАВНЕНИЕ ЛИНИИ РЕГРЕССИИ
Y = .92191044002332 * X + - .97101937657961
S = .20112760028512
Работа программы при k = 2 дает:
УРАВНЕНИЕ ЛИНИИ РЕГРЕССИИ
Y = .25804799057252 * Хл 1.6524291052773 ,
S = .039226937738423
Видно, что рассчитанные уравнения регрессии хорошо
согласуются с полученными ранее (см. (7.28) и (7.30)). Сравнение сумм
квадратов отклонений показывает, что для рассматриваемых
данных представление эмпирической зависимости в виде степенной
функции является более предпочтительным. ,
Для того чтобы убедиться, что наша программа хорошо работает
и при & = 3, рассмотрим такой набор данных (см. табл. 7.6):
146
Таблица 7.6
X
У
0,2
0,66
0,5
0,95
0,9
1,61
1,3
2,72
1,7
4,55
1,7
5,2
1,9
5,92
2,2
8,73
Вставим в рабочий вариант программы дополнительный
оператор 195 PRINT V(I), который выведет значения функции,
вычисленные в соответствии с полученным уравнением регрессии.
Результаты работы программы:
.6519879484939
.9620256245773
1.6160299398844
2.7146395063546
4.5601058913471
5.1914732224519
5.9102562224653
8.7207408464587
УРАВНЕНИЕ ЛИНИИ РЕГРЕССИИ
Y = .50304656399043 * ЕХР (1.2967166974499 * X)
S = 6.2941178316367Е- 04
Упражнение. Дополните программу «Уравнения регрессии»
так, чтобы она давала возможность вычислять параметры уравнения
вида у = а-\пх-\-Ь. Предусмотрите проверку исходных данных
на наличие неположительных значений в случае, когда требуется
их логарифмирование.
7.4. ЭЛЕМЕНТЫ МАТЕМАТИЧЕСКОЙ СТАТИСТИКИ
Пусть задача состоит в том, > чтобы исследовать заданный
качественный или количественный признак, характеризующий
элементы некоторой совокупности. Все множество объектов,
входящих в рассматриваемую совокупность, называют генеральной
совокупностью. Число элементов генеральной совокупности может
быть достаточно большим (в теоретических рассмотрениях
используются и совокупности, содержащие бесконечное множество
элементов). Часть генеральной совокупности, выбранную из нее
некоторым (случайным) образом, называют выборочной
совокупностью (выборкой).
Цель статистических расчетов, как правило, состоит в том, чтобы
по характеристикам выборочных совокупностей судить о свойствах
исходных генеральных совокупностей, об их сходстве или различии.
Пусть набор имеющихся в нашем распоряжении
экспериментальных данных состоит из п чисел х\, х2, ..., хп. Среднее арифметическое
(среднее значение) для этого набора определяется по формуле '
М = Ь!_. (7.31;
п
147
Если каждое значение х/(/=1, 2, ..., п) встречается в наборе
п
данных rii раз, а через N обозначена У т, то
<=i
М=^^. (7.32)
Элементы исследуемого набора (массива) чисел могут быть
по-разному расположены относительно своего среднего значения.
Так, два массива 14, 15, 16 и 2, 3, 40 имеют одинаковые средние
арифметические, равные 15. Но в первом массиве элементы «близко»
расположены к среднему значению, а во втором массиве элементы
значительно рассеяны вокруг среднего значения. Степень рассеяния
элементов массива вокруг среднего значения характеризует
выборочная дисперсия. Дисперсия вычисляется по формуле
| (Ъ-Mf
£='-', (7.33)
или по формуле
пХ xf-lZ xif-
D= жп-i) • (7.34)
Формуле (7.32) для среднего значения соответствуют следующие
формулы для дисперсии:
ZnJLxi-M?
Д= ^w=\ . (7.35)
N% niX2-(t rii-Xi)2
u- N(N-\) (7.36)
Корень квадратный из дисперсии называют средним квадра-
тическим отклонением (стандартным отклонением):
S=VZ>. (7,37)
Среднее квадратическое отклонение имеет ту же размерность,
что и элементы исходного массива. Это не дает возможности
сравнить между собой степень рассеяния (изменчивость)
разнородных величин. Поэтому необходима мера изменчивости, не
зависящая от единиц измерения изучаемых величин.
Такую меру изменчивости представляет собой коэффициент
вариации (коэффициент изменчивости) С, равный квадратному
отклонению, выраженному в процентах от среднего значения:
С=4.100. (7.38)
148
7.4.1. Распределения
Будем по-прежнему рассматривать массив исходных данных,
состоящий из п чисел х\, х2, ..., хп. Найдем наименьший А и
наибольший В элементы этого массива. Разобьем отрезок АВ на k равны*
интервалов (число k может быть вычислено по формуле 6=1-f
+ 3,31 lg/i[5]). Рассмотрим произвольный (j = n) интервал
.полученного разбиения. Обозначим через у\ число, соответствующее середине
этого интервала. Подсчитаем количество элементов исходного
массива, лежащих в рассматриваемом интервале, и обозначим
его через я,-.
Ясно, что 2 fij = n. Усредним элементы массива, лежащие
во взятом интервале, считая, что все они совпадают с у\. Число //,
определяемое по формуле
f _ ni
li— —.
будем называть частотой, соответствующей значению уг
Совокупность значений yt и соответствующих им частот
Уи #2, ..., Ук,
• /b /2, .-, h
называется эмпирическим распределением (или статистическим
распределением).
Теоретически мы можем рассматривать имеющиеся в нашем
распоряжении экспериментальные данные в качестве значений
некоторой случайной величины X. Если множество всех теоретически
возможных значений величины X конечно или счетно, ее называют
дискретной случайной величиной. Функция F(X)y которая для
каждого возможного значения х, дискретной случайной величины X
равна вероятности F(xi) появления этого значения, задает
распределение вероятностей случайной величины. Величину Е{Х),
определяемую формулой
E(X)=2xiF(xi\
i
называют математическим ожиданием случайной величины X.
Величину D(X), заданную формулой
i
называют дисперсией этой случайной величины. Математическое
ожидание характеризует центр распределения, а дисперсия —
степень рассеяния значений случайной величины вокруг центра.
Формулы 7.31—7.37 дают возможность получить оценку
математического ожидания и дисперсии (и среднего квадратического
отклонения) на основе опытных данных.
Из наиболее часто встречающихся дискретных распределений
можно назвать следующие.
Биноминальное распределение. Пусть случайная величина
может принимать целые значения 0, 1, 2 ..., . Будем говорить,
149
что эта величина распределена по биноминальному закону, если
функция, задающая ее распределение, имеет вид:
F(m) = CZ-pm(\-p)n-m. ' (7.39)
Здесь т<п и р— любое положительное чис^о, меньшее единицы.
Если вероятность появления некоторого события в каждом
из п , независимых опытов равна р, то общее число появлений
события во всех п опытах как раз и будет случайной величиной,
имеющей биноминальное распределение. Математическое ожидание
случайной величины, распределенной по биноминальному закону,
равнр пру а ее дисперсия равна /гр(1 —
Распределение Пуассона. Пусть случайная величина X может
принимать любое целое неотрицательное значение. Будем говорить,
что эта величина распределена по закону Пуассона, если функция,
задающая ее распределение, имеет вид:
F{m)=^e-a. (7.40)
Здесь а — некоторое положительное число, называемое
параметром закона Пуассона. Приведем пример случайной величины,
распределенной по закону Пуассона. Пусть на некоторой оси
случайным образом распределяются точки, причем выполняются
следующие условия.
1. Вероятность попадания того или иного числа точек на
отрезок зависит только от длины отрезка и не зависит от его
положения на оси, т. е. точки распределены на оси с одинаковой
средней плотностью, которую мы обозначим к.
2. Точки распределяются на оси независимо друг от друга.
3. Совпадение двух или большего числа точек практически,
невозможно. Если мы рассмотрим случайную величину,,
представляющую собой количество точек, попавших на некоторый отрезок
длины /, то эта случайная величина будет распределена по закону
Пуассона с параметром а=Х1. Для случайной величины,
распределенной по закону Пуассона, и математическое ожидание, и
дисперсия равны а.
Случайная величина X, множество теоретически возможных
значений которой несчетно, называется непрерывной. Для
непрерывной случайной величины не имеет смысла говорить о
вероятности появления ее отдельного значения. Мы можем, однако,
говорить о вероятности того, что случайная величина X примет
значение, лежащее в некотором достаточно малом интервале.
Если существует такая функция /(*), что при любом х произведение
f(x)&x (Ах достаточно мало) равно вероятности попадания значений
непрерывной случайной величины X на отрезке (х, х+Дх), то f(x)
называется плотностью распределения этой случайной величины.
Функция
Ф(Х)= \ f(x)dx
150
У
о,*
о,з
0,2
0,1
О
40 -3,0-2,04,0 0 1,0 2,0 3,0 4,0 X
/ Рис. 21
называется интегральной функцией распределения случайной
величины X, Ф(Х) представляет собой вероятность того, что случайная
величина X примет значение, не превосходящее х. Если нас
интересует вероятность того, что значение случайной величины попадает
в некоторый фиксированный интервал (а, Ь), то эта вероятность
будет равна
ь
\ f(x)dx = 0(b)-<P(a).
а
Понятие интегральной' функции распределения может быть
введено и для дискретной случайной величины. При этом
Математическое ожидание и дисперсия непрерывной случайной
величины определяется соответственно по формулам *
оо
Е(Х)= \ xf(x)dx,
— оо
ОД= ] {Х-Е{Х)Щх)йх.
— оо .
Оценка этих величин на основе экспериментальных данных
производится по формулам (7.31) — (7.37).
Рассмотрим некоторые примеры непрерывных распределений.
Нормальное распределение. Говорят, что непрерывная случайная
величина X. распределена по нормальному закону, еЬли плотность
распределения имеет вид:
/(*)=^ехр(-(-^). (7.41)
График этой функции представляет собой симметричную
колообразную кривую (рис. 21). Положение \ кривой зависит от
\6\
параметра \i (через точку с абсциссой |л проходит ось симметрии
кривой). Масштаб кривой зависит от параметра о (чем меньше а,
тем больше вытянута кривая вдоль оси симметрии и тем быстрее ее
ветви приближаются к оси абсцисс). Параметр |л равен
математическому ожиданию случайной величины X, а параметр о — ее
среднему квадратическому отклонению.
Если нормально распределенная случайная величина X имеет
математическое ожидание |i и среднее квадратическое отклонение а,
то случайная величина У, значения которой связаны со значениями
первой величины формулой~
будет тоже распределена нормально, причем ее математическое
ожидание будет равно 0, а среднее квадратическое отклонение
равно единице. Такую случайную величину называют
нормированной. Значения интегральной функции распределения нормированной
нормально распределенной случайной величины табулированы и
обычно печатаются в виде таблиц.
Нормальное распределение является одним из основных
теоретических распределений. Ошибки измерений, различные
свойства живых организмов и многие другие количественные
признаки распределены по нормальному закону.
Гамма-распределение. Говорят, что случайная величина имеет
гамма-распределение, если функция плотности для нее имеет вид:
JLxn-ie-x*_np|f х^о, к>0, г)>0,
Ал)
О — в остальных случаях. (7.42)
/(*)=
Здесь Г(г\) — гамма-функция: Г(г\)= \ хц l e~xdx (при
натуральном т|Г(т|) = (т) —1)!).
Форма кривой, являющейся графиком этой функции, изменяется
в зависимости от параметра ц (рис. 22). Масштаб кривой (при
фиксировании ц) определяется параметром I. Математическое
ожидание случайной величины, имеющей гамма-распределение,
равно -£-, а дисперсия равна -~. Отсюда следует, что оценки пара-
метров т] и К на основе опытных данных могут быть получены по
формулам
X=1L и Г1 = Ш, (7.43)
где М и D определяются по формуле 7.31—7.36.
Гамма-распределение описывает время, необходимое для
появления ровно г) независимых событий, если эти события
происходят с постоянной интенсивностью к. Так, например, если поставка
какой-нибудь детали производится партиями объемом г\ деталей
каждая, а заявки на отдельные детали поступают независимо
152
■Y,
W
0,6
0,6
0Л
0,2
\
lA=/
\ X=3
*
i
*~ ~ >
1,0
2,0
3,0 4,0
Рис. 22
5,0 6,0 X
друг от друга с постоянной интенсивностью К единиц, то промежуток
времени, за который будет израсходована вся партия, является
случайной величиной, имеющей гамма-распределение.
Перечислим теперь кратко непрерывные распределения,
связанные с нормальным распределением, и используемые при проверке
статистических гипотез.
Распределение X2. Распределение случайной величины X,
представляющей собой сумму квадратов k независимых
нормированных, нормально распределенных случайных величин, называется
распределением X2 с k степенями свободы. Функция плотности
распределения для этой случайной величины имеет вид:
«*)=
1
■(f)
при х>0,
(7.44)
2
\ z /
О при х^.0.
Если суммируемые случайные величины связаны между собой
некоторыми линейными соотношениями, причем количество этих
соотношений равно т, то число степеней свободы распределения X2
уменьшается на т.
По мере увеличения числа степеней свободы распределение X2
приближается к нормальному. '
Распределение Стьюдента. Пусть Y — нормированная, нормально
распределенная случайная величина, a Z — независимая от Y
случайная величина, распределенная по закону X2 с k степенями
свободы. Тогда случайная величина f, значения которой опреде-
Y
ляются формулой t=-
Т
153
имеет распределение, называемое распределением Стьюдента
(/-распределение) с к степенями свободы. Функция плотности
распределения для этой случайной величины имеет вид:
Я/)--Ц^- (1+f)" ' (7.45)
С увеличением числа степеней свободы распределение
Стьюдента быстро приближается к нормальному.
Распределение Фишера. Цусть Y и Z — независимые случайные
величины, распределенные по закону х2 по степеням свободы
соответственно к\ й къ. Тогда случайная величина, значения
которой определяются формулой
L
L
ь*
имеет распределение, называемое распределением Фишера (F-
распределением) с числом степеней свободы k\ и &2. Функция
плотности распределения этой случайной величины имеет вид:
№=
fe.+2
(*2 + *l/) 2
^7 при x>0, (746)
при jc<0.
7.4.2. Проверка статистических гипотез
Располагая каким-нибудь эмпирическим распределением, мы
можем ставить вопрос об отнесении этого распределения к
некоторому теоретическому типу или (если тип распределения известен)
вопрос о предполагаемой величине параметра такого распределения.
Нас может, также интересовать вопрос о равенстве параметров
нескольких распределений, о независимости произведения выборов
и т. п. Такого рода вопросы формулируются обычно в виде
статистических гипотез. Например: данная выборка произведена из
нормально распределенной генеральной совокупности; дисперсии двух
рассматриваемых нормальных генеральных совокупностей равны.
Нас интересует сейчас процедура, которая позволяет либо
отвергнуть проверяемую гипотезу как противоречащую имеющимся
данным, либо убедиться в том, что гипотеза этим данным не
противоречит.
Проверяемую гипотезу будем называть основной (нулевой)
гипотезой, а противоречащую ей гипотезу — альтернативой.
Поскольку мы имеем дело со статистическим материалом,
154
то, отвергая нулевую гипотезу или принимая ее, мы всегда рискуем
совершить ошибку. Ошибку, заключающуюся в том, что нулевая
гипотеза отвергается, тогда как она в действительности верна,
называют ошибкой первого рода. Ошибку, состоящую в том,
что нулевая гипотеза не отвергается, тогда как она в
действительности неверна, называют ошибкой второго рода.
Проверка статистических гипотез осуществляется с помощью
различных статистических критериев. В качестве критерия
используется некоторая случайная величина, значения которой могут
быть вычислены на основе имеющихся данных. В множестве
возможных значений критерия выбирают подмножество, называемое
критической областью. Если вычисленное значение критерия
принадлежит критической области, то нулевая гипотеза отвергается.
Критическая область выбирается таким образом, чтобы при этом
выборе вероятность совершить ошибку первого рода не превосходила
некоторого заранее определенного положительного числа а. Это
число а называют уровнем значимости и говорят: «нулевая гипотеза
отвергается на уровне значимости а». В качестве а обычно берут
одно из чисел: 0,05; 0,01; 0,001. Вероятность совершить ошибку
второго рода обозначается буквой р. Величина 1—р называется
мощностью критерия; она равна вероятности отвергнуть неверную
гипотезу. Чаще всего множество возможных значений критерия
принадлежит некоторому интервалу. Интервалом является и
критическая область. Граничные точки критической области называются
критическими точками. Критические точки выбираются таким
образом, чтобы при выбранном уровне значимости а мощность
критерия (1—Р) была наибольшей.
Наиболее распространенными являются критерии, в основе
которых лежат известные распределения: X2, Стьюдента, Фишера.
Для этих критериев составлены таблицы, в которых приведены
критические точки, соответствующие определенному уровню
значимости и определенному числу степеней свободы. Порядок
использования таких критериев будет описан ниже.
В качестве примера опишем процедуру проверки гипотезы о
принадлежности заданного эмпирического распределения к
некоторому теоретическому типу.
Пусть элементы выборки распределены по k интервалам,
причем /-му интервалу (/=1, 2, ..., k) соответствует частота /у.
Для проверки сформулированной гипотезы используется критерий
X2 (критерий Пирсона). Вычисленное значение критерия
определяется по формуле
Х\ыч=п-^^^. (7.47)
Здесь Ф — теоретическая частота, соответствующая /-му интервалу,
а лг — объем выборки. Правило вычисления Фу и определение числа
степеней свободы зависит от вида теоретического распределения
и способа оценки его параметров.
А. Сравнение эмпирического распределения с нормальным.
155
При таком сравнении в качестве значений параметров \i и а
теоретического распределения (см. формулу, (7.41)) обычно
используют среднее арифметическое рассматриваемой выборки и ее
среднее квадратическое отклонение. Для вычисления можно
использовать формулу
Ф/=$/(^| (7.48)
где а/, 0/ — границы /-го интервала, a f(x) — плотность нормального
распределения. Для упрощения вычислений можно заменить
интеграл в правой части этого равенства произведением длины
промежутка интегрирования и значения функции (7.38) в средней
точке интервала, т. е. использовать формулу
0/ = J^ ' ехр(-^Л <7'49>
^ k Т72л Pl 2S* J-
В таблице распределения X2 находим критическую точку,
соответствующую выбранному уровню значимости ос и числу
степеней свободы k — 3. (Заметим, что если параметры \i и 6
не определяются по имеющимся данным, а известны заранее,
то число степеней свободы равно k— 1.) Если вычисленное по
формуле (7.47) значение критерия больше табличного, то на уровне
значимости а проверяемая гипотеза должна быть отвергнута.
При.мер 7.4.1. Составим программу, позволяющую
осуществить сравнение эмпирического распределения с нормальным.
Пусть набор исходных данных состоит из п чисел х\9 х2, ..., хп.
Для построения на его основе соответствующего эмпирического
распределения используем часть алгоритма и программы примера
3.5.3 из [8]. Напомним основные шаги интересующей нас части
алгоритма:
1. Ввести элементы массива исходных данных.
2. Вычислить среднее значение Н и среднее квадратическое
отклонение S.
3. Упорядочить по возрастанию элементы исходного массива.
4. Взять в качестве А и В соответственно наименьший и наибольший
элементы упорядоченного массива.
5. Разбить интервал (АВ) на k интервалов и определить границы
каждого интервала.
Завершим описание алгоритма, добавив следующие шаги:
6. Вычислить для каждого интервала сЬответствующую ему
эмпирическую частоту F, теоретическую частоту Р и вывести
полученные, результаты.
7. Подсчитать по формуле (7.47) значение критерия и вывести его.
Программа может быть такой:
10 REM СРАВНЕНИЕ ЭМПИРИЧЕСКОГО РАСПРЕДЕЛЕНИЯ
С НОРМАЛЬНЫМ
156
20 DIM X(I00),R(20),F(20),P(20)
30 INPUT "ВВЕДИТЕ N-ЧИСЛО ЭЛЕМЕНТОВ ИСХОДНОГО
МАССИВА";N
40 PRINT "ВВЕДИТЕ ЭЛЕМЕНТЫ ИСХОДНОГО МАССИВА"
50 FOR 1=1 ТО N:INPUT X(I):NEXT I
60 M=0:S=0
70 FOR 1=1 TO N:M=M+X(I):S=S+X(I )A2:NEXT I
80 S=SQR((N*S-M*2)/(Nk(N-I))):M=M/N
90 FOR 1=1 TO N-*
100 Q=X(I):T=I:FOR J=I+1 TO N
110 IF 0>X(J) THEN Q=»X(J):T=J
120 NEXT J
130 X(T)=X(I):X(I)=Q
140 NEXT I
150 A=X(1):B=X(N):K=I+INT(3.3*L0G(N)/
L0G(I0)+.5:PRINT "K=";K
160 H=(B-A)/K
170 R(0)=A:FOR J=l TO K-I:R(J)=R(J-I)+H:
NEXT J:R(K)=B
180 1=1:FOR J=0 TO K-*
190 IF X(l)<=R(J+*) THEN F(J)=F(T)+1:1=1+1
ELSE 210
200 IF I<N THEN 190
210 NEXT J
220 Hl=H/2:D=I/(S*SQR(6.283186))
157
230 FOR J=0 TO K-C
240 F(J)=F(J)/N:C=R(J)+HI:P(J)=№«Dx ,
EXP(-(c-My>2/(2*s*2))
250 L=L+(F(J)-P(J))*2/P(;r)
260 NEXT J
270 PRINT "РЕЗУЛЬТАТЫ"
280 FOR J=0 TO K-*
290 PRINT "R("; J ;")=";: PRINTUSING"JMb $# ";
R(J);:PRINT "R(";J+£;")=";: '
PRINTUSING"#. {# " ;R( J+I);:
PRINT"F("; J ;")=";: PRINTUSING"&£. ^} ";
F(J);
300 PRINT ,,P(^;")=";:mimJSING"j$.H,,;P(J)
310 NEXT J
320 PRINT :PRINT"Bbl4HGnEHH0E ЗНАЧЕНИЕ КРИТЕРИЯ"
330 PRINT "L=";:PRINTUSING"H. НГ ;L*N
340 END
Пусть задан массив из 60 чисел:
4, 4.07, 4.05, 4.15, 4.18, 1.25, 4.21, 4.22, 4.30, 4.33, 4.35, 4.36. 4.55,
4.41, 4.40, 4.44, 4,51, 4.70, 4.80, 4.60, 5.00, 5.13, 5.15, 5.80, 5.20,
5.25, 5.34, 5.50, 7.00, 4.00, 3,90, 3.95, 3.83, 3.85, 3.81, 3.80, 3.70,
3.69, 3.68, 3.66, 3.65, 3.62, 3.60, 3.55, 3.50, 3.45, 3.40, 3.30, 3.20, 3.10,
3.00, 2.90, 2.85, 2.80, 2.75, 2.70, 2.50, 2.20, 1.
Результаты работы программы при этом будут такими:.
К=5
РЕЗУЛЬТАТЫ
/?(0)=1.00 /?(1)=1.86 F(0)=0.03 Р(0)=0.02
#(1)=1.86 /?(2) = 2.71 F(l)=0.05 Р(1)=0.09
Я(2)=2.71 /?(3) = 3.57 F(2)=0.20 Р(2)=0.25
fl(3)=3.57 /?(4)=4.43 F(3)=0.47 Р(3)=0.33
Я(4) = 4.43 Я(5) = 5.29 /?(4)=0.18 Р(4)=0.22
158
ВЫЧИСЛЕННОЕ ЗНАЧЕНИЕ КРИТЕРИЯ
L = 6:832
Вычисленное значение критерия X2 (обозначенное в программе
через L) равно 6.832. Табличное значение критерия,
соответствующее 95%-му уровню значимости и числу степеней свободы 4
(число степеней свободы равно k—3), равно 9.49. Поскольку
вычисленное значение критерия меньше табличного, то можно
считать,^ что имеющиеся данные не противоречат гипотезе о
принадлежности полученного эмпирического распределения к
нормальному типу.
Б. Сравнение эмпирического распределения с г^амма-распреде-
лением.
Для оценки значений параметров к и ц (см. формулу (7.42))
на основе выборочных данных удобно воспользоваться формулами
(7.43).
Значение Г(т]) можно вычислить, пользуясь рекуррентным
соотношением Г(т|)=(т| — 1)(Г(г| — 1). При 1<т]<2 значение Г(т|)
берется из таблиц или вычисляется по формуле из (7.39).
Теоретическую частоту Ф, можно вычислить по формуле (7.45),
подставив вместо f(x) функцию плотности гамма-распределения.
Правило применения критерия X2 остается тем же, что и в
пункте А. ч
Упражнение. Внесите изменения в предыдущую программу
так, чтобы она выполняла сравнение эмпирического распределения
с гамма-распределением.
7.4.3. Дальнейшие статистические характеристики выборочной
совокупности. Точечные и интервальные оценки
Как уже было сказано, математическое ожидание случайной
величины характеризует центр распределения. Другой
характеристикой центра распределения является срединная точка, или
медиана. Для непрерывной случайной величины ^имеющей плотность
распределения /(*), медианой является такая точка К, что
к
\ f(x)dx = 0,5.
— оо
Для дискретной величины медиана определяется аналогичным
образом, с той лишь разницей, что интеграл заменяется суммой
произведений значений случайной величины и соответствующих
вероятностей.
Оценка медианы на основе опытных данных происходит
следующим образом. Числа х{у х2, ..., хп упорядочиваются по величине.
Если п — нечетное число, то медиана равна тому члену
упорядоченной последовательности данных, который имеет номер "Т"< . Если
же п — четное, то медиана равна полусумме членов с номерами
п п I .
тит+1.
Для симметричных распределений медиана дает «лучшее
159
представление» о центре распределения, чем среднее значение, ибо
она менее чувствительна к небольшому числу крайних значений.
Третьей характеристикой центра распределения является
мода. Для дискретной случайной величины мода — это то ее
значение, которое имеет наибольшую вероятность. Мода
непрерывной случайной величины равна значению, соответствующему
максимуму плотности распределения (если имеется один максимум).
Для определения оценки моды на основе опытных данных
находим тот результат наблюдений, который встречается Наиболее
часто. Если данные сгруппированы по интервалам частот (как
это описано в п. 7.4.1), то в качестве моды берется середина
интервала, содержащего наибольшее число наблюдений.
Отметим, что для симметричного распределения с одним
максимумом все три показателя (математическое ожидание, мода
и медиана) совпадают.
Важную роль в математической статистике играют моменты
распределения случайной величины. Величину \ху определяемую
по формуле
называют k-м центральным моментом случайной величины X.
Мы уже видели, что второй центральный момент (дисперсия)
характеризует степень рассеяния значений случайной величины
вокруг центра распределения. Часто используются также третий
и четвертый центральные моменты.
Третий центральный момент связан с симметричностью (или,
точнее, с несимметричностью) распределения. Для симметричного
распределения (1з = 0. Если ^з<0, то распределение имеет «хвост»
слева, а при ^>0 — справа. Для сопоставления степени
несимметричности распределений, имеющих разные масштабы,
вводится специальный показатель — асимметрия, равный
отношению |ш3 к (м<2)3/2. Оценку асимметрии по результатам наблюдений
можно осуществить по формуле
2 (xi-Mf
Четвертый центральный момент используется для
характеристики островершинности распределения. Соответствующим
показателем является эксцесс, равный отношению \i2 » \il- Для нормального
распределения это отношение равно 3. Поэтому обычно при оценке
эксцесса по результатам наблюдений используют формулу
| (*2 -М)4
£=^^ 3- (7-51>
Все оценки статистических характеристик, которые мы
приводили до сих пор, были представлены одним числом, т. е. являлись
точенными оценками. Точечные оценки (особенно для выборок
малого объема) могут значительно отличаться от истинного
160
значения оцениваемого параметра. Для того чтобы дать
представление о точности и надежности точечной оценки, используют так
называемые доверительные интервалы и доверительные вероятности.
Проиллюстрируем эти понятия на примере случайной величины X.
Оценку математического ожидания Е(Х) по выборке объема п
дает среднее арифметическое М. Для различных выборок из одной
и той же генеральной совокупности средние арифметические
будут различны, т. е. само среднее арифметическое можно
рассматривать как случайную величину. Имеет смысл говорить
поэтому о среднем квадратическом отклонении этой случайной
величины. Обозначим его через т. Со средним квадратическим
отклонением S исходной случайной величины m связано формулой
m=fn. (7.52)
Рассмотрим интервал
(M-tm, M + tm). (7.53)
Множитель / можно подобрать таким образом, чтобы вероятность
того, что истинное значение Е(Х) лежит вне рассматриваемого
интервала, не превосходила некоторого достаточно малого уровня
значимости а. Возможность такого выбора основывается на том
. и М-Е(Х) . г
факте, что случайная величина L имеет распределение Стью-
дента с числом степеней свободы п— 1. Поэтому в качестве
требуемого / нужно взять из таблицы распределения Стьюдента
критическую тонку, соответствующую уровню значимости а и числу
степеней свободы п — \. Произведение tm дает нам точность
оценки интересующего нас параметра, а разность 1—а —
надежность этой оценки. Найденный интервал (7.53) называют
доверительным интервалом. Разность 1 —а называют также
доверительной вероятностью. Мы можем сказать, что с доверительной
вероятностью 1—а доверительный интервал (7.53) покрывает
истинное значение оцениваемого параметра Е(Х).
7.4.4. Критерии значимости
В п. 7.4.2 было написано, как используется критерий X2 для
проверки гипотезы о принадлежности эмпирического распределения
к некоторому теоретическому типу.
Рассмотрим несколько примеров проверки гипотез о значимости
различий оценок параметров распределений.
Различие между двумя выборочными средним^. Предположим,
что мы располагаем двумя выборками объемов тип
соответственно, взятыми из нормально распределенных генеральных
совокупностей с разными дисперсиями. Будем обозначать элементы
первой выборки буквой х, а элементы второй'выборки у.
Соответствующие средние значения обозначим Мх и Мч. Необходимо
выяснить, является ли различие между этими средними значимым.
Будем проверять гипотезу о равенстве математических ожиданий
исходных генеральных совокупностей.
Используем для этой цели критерий Стьюдента. Вычисленное
161
значение критерия будем определять по формуле
где ^ = —JLc—-V—;—» (7.54)
т п
m + л —2
Вычисленное значение критерия сравниваем с критической
точкой, взятой из таблицы распределения Стьюдента в
соответствии с выбранным уровнем значимости а и числом степеней
свободы т-\-п-^2. Если |/| больше табличного значения, то
гипотезу о равенстве средних следует отвергнуть. Это будет означать,
что различие средних нельзя считать случайным % (незначимым).
Различие между двумя выборочными дисперсиями. Пусть мы
снова имеем две йыборки объемов т и,п, взятые из нормальных
генеральных совокупностей. Обозначим дисперсию первой выборки
DXy а второй Dy. Значимо ли различие этих дисперсий? Проверим
гипотезу о равенстве дисперсий исходных генеральных
совокупностей. Воспользуемся для этого критерием Фишера. В качестве
вычисленного значения критерия возьмем отношение большей из
выборочных дисперсий к меньшей (пусть для определенности в
нашем случае большей будет дисперсия):
F=%-. (7.55)
Вычисленное значение критерия сравниваем с критическим
значением, взятым из таблицы распределения Фишера в
соответствии с уровнем значимости а и степенями свободы тип. Если
вычисленное значение критерия больше табличного, то различие
выборочных дисперсий следует признать значимым. .
Сравнение нескольких выборочных дисперсий. Предположим
теперь, что из нормально распределенных генеральных
совокупностей извлечены k выборок объемом п\ч п2> ..., пк соответственна
и с выборочными дисперсиями D!f D2, ..., Dk. Мы могли бы, как и
выше, исследовать по критерию Фишера значимость различий
каждой пары дисперсий. Для исследования «однородности» всего
набора дисперсий используется так называемый критерий Бартлета:
Введем обозначения:
к
^ = (2 л,-)-Л, D =
.2 (я/—!)• А
i=i
k
K = 2,3026(^lgD-2/n1-l)lgA),C=l + 1^((.Si-^r-l).
Проверим гипотезу равенства дисперсий генеральных совокупностей.
Вычисленное значение критерия определяется по формуле
В=~-. (7.56)
162
Вычисленное значение критерия сравниваем с критическим
значением, взятым из таблицы распределения X2 в соответствии
с выбранными уровнем значимости а и числом степеней свободы
k— 1. Если вычисленное значение больше табличного, то
проверяемая гипотеза должна быть отвергнута. Это значит, что
рассматриваемый набор дисперсий нельзя считать однородным.
Отметим, что для применимости критерия Бартлета необходимо,
чтобы объем каждой из выборок был не меньше четырех.
Если в предыдущем рассмотрении все выборки имеют один
и тот же объем п> то для проверки гипотезы о равенстве дисперсии
генеральных совокупностей может быть использован более простой
критерий значимости — критерий Кохрана.
В качестве критерия берется случайная величина,
представляющая собой отношение максимальной из имеющихся выборочных
дисперсий к сумме всех имеющихся дисперсий:
2 А
Для этрй случайной величины построены таблицы (таблица
распределения Кохрана), в которых помещены критические точки,
соответствующие уровню значимости а, числу сравниваемых
дисперсий k к числу степеней свободы п—\. Если вычисленное
по формуле (7.57) значение критерия окажется больше
соответствующего табличного значения, то проверяемая гипотеза должна
быть отвергнута. Это значит, что различия между имеющимися
выборочными дисперсиями нельзя считать незначимыми.
7.4.5. Корреляция и регрессия
Очень часто, результаты опыта описываются значениями не
одной случайной величины, а значениями двух или более случайных
величин X и Y. Результаты этого наблюдения можно рассматривать
как набор экспериментальных точек, абсциссами которых являются
значения Х> а ординатами—соответствующие им значения Y:
(*1, У\\ (*2, Ы> .-., (Хп, УпУ
Допустим, у нас есть основания предполагать, что между
переменными X и Y существует зависимость вида:
Y = f(X). (7.58)
(Обычно в таком случае X называют факториальным признаком,
a Y — результирующим признаком.) При этом выбор типа функции
f(x) может основываться на каких-либо теоретических предпосылках
или быть результатом анализа взаимного расположения
полученных экспериментальных точек.
Выше (см. п. 7.1) был рассмотрен порядок нахождения значений
параметров а и b по методу наименьших квадратов для случая,
когда предполагаемая зависимость является линейной, т. е.
f(x)=ax+b, , (7.59)
а также для ряда случаев, сводимых к линейной зависимости.
163
Значение параметров а и b называются коэффициентами регрессии,
а прямая с уравнением (7.59} называется линией регрессии
Y на X. Из системы (7.10) формулы для вычислений значений
а и b имеют вид:
п
« V п п п п п п .
. , Xtyi— 2 Xi % yi .2 $ S . У1— .2, Xt 2 X0/
-i^I f=1 l = l b = <=1 <=l lz!_EJ . (7.60)
a = -
«l^f-fbi)2 я |/?-(|,^2
Чем меньше при найденных значениях а и b величина z =
п
= 2 (yi — axi — bfy тем более обоснованно наше предположение
о том, что7 зависимость между Y и X близка к линейной. Расшифруем
это положение сейчас более подробно. Имеет место соотношение
(см. обозначения (7.11)):
2 (yt-Myf= 2 (yi-axi-bf+ 2 (axi + b-M„)2. (7.61)
Первое слагаемое в правой части обозначим через'г. (Отношение
z/(n — 2) называют остаточной дисперсией.) Второе слагаемое
представляет собой ту часть общего разброса значений переменной
Y относительно своего среднего Му, которая может быть объяснена
регрессией (т.е. дисперсия, обусловленная регрессией). Наше
предположение о линейности связи между Y и X тем обоснованнее^
чем меньше первое слагаемое по сравнению со вторым. Для
проверки значимости различий между этими дисперсиями может
быть использован критерий Фишера. Вычисление значения критерия
определяется по формуле
jt^axi + b-Mtf
; 2 (yi-axt-bf (7.62)
/ = 1
Значение F сравнивается со значением, взятым из таблицы
распределения Фишера в соответствии с уровнем значимости а и
степенями свободы 1 и п — 2. Если вычисленное значение больше
табличного, то различие дисперсий значимо и полученный нами
коэффициент а значимо отличен от нуля.
Существует еще один показатель, характеризующий тесноту
линейной .связи между X и' Y. Это (выборочный) коэффициент
корреляции. Он рассчитывается по формуле
ZjXi-MJ-iyi-M»)
Г =
'-■ (7.63)
у ^ = 1 / = 1
104
или по формуле
n%Xiyi— %Xi%^i
r =
/=i /=i < = i (7.64)
Сравнивая формулы (7.60) и (7.64), легко заметить, что
коэффициент корреляции г и коэффициент регрессии а связаны
соотношением
а^г9 (7.65)
где Sy и S*— средние квадратические отклонения рассматриваемых
значений Y и X соответственно.
Значения коэффициента корреляции всегда удовлетворяют
соотношению — l^r^l. Чем меньше отличается абсолютная
величина г от единицы, тем ближе к линии регрессии располагаются
экспериментальные точки. Если коэффициент корреляции равен
нулю, то переменные X и Y называют некоррелированными.
Для того чтобы проверить, значимо ли отличается от нуля
выборочный коэффициент корреляции, можно использовать критерий
Стьюдента. Вычисленное значение критерия определяется по
формуле
t=r^~* (7.66)
УСТ '.
Значение / сравнивается со значением, взятым из таблицы
распределения Стьюдента в соответствии с уровнем значимости а и
числом степеней свободы п — 2. Если вычисленное значение больше
табличного, то выборочный коэффициент корреляции значимо
отличен от нуля. Равенство коэффициента корреляции нулю, т. е.
некоррелированность Y и X, не означает, что между ними не может
существовать зависимость, отличная от линейной.
Пример 7.4.2. Пусть значения факториального признака
заданы элементами одномерного массива X: х\, х2> ..., хп, а
соответствующие значения результирующего признака — элементами массива Y:
У\, У2, ..., Уп- Составим программу вычисления коэффициента
корреляции между X и V, а также значения критерия Стьюдента
для определения значимости отличия полученного коэффициента
корреляции от нуля. Воспользуемся формулами (7.61) и (7.63).
Приведем эту простую программу без дополнительных пояснений:
10 REH КОЭФФИЦИЕНТ КОРРЕЛЯЦИИ
20 DIM X(50)PY(S0>
30 INPUT ВВЕДИТЕ N — ЧИСЛО ПАР ИСХОДНЫХ
ДАННЫХ ;N
40 PRINT ВВЕДИТЕ ПОПАРНО ИСХОДНЫЕ
ДАННЫЕ—СНАЧАЛА X, А ЗАТЕМ Y
165
50 FOR 1-1 TO NiINPUT ХШ ,Y(I> iNEXT I
60 FOR 1-1 TO N
70 81-81+X <I>IS2-S2+Y (I > 183-83+X < I) XY < I)
80 84«84+X<I)^2i85«8S+Y<I>'42iNEXT X
90 R-(№(83-81X82)/SOR(<NX84-B1~2>X(NX8S-82^2> >
100 T«RX8QR<N-2)/BQR<l-R^2>
110 PRINT-КОЭФФИЦИЕНТ КОРРЕЛЯЦИИ R-M|R
120 PRINTMBbWHCnEHHOE ЗНАЧЕНИЕ КРИТЕРИЯ T-"|T
130 END
Пусть массивы X и Y содержат по 20 чисел.
X: 3.4, 1.2, 2.2, 3.6, 2.8, 3.6, 2.4, 1.8, 1.4, 3.6, 1.6, 1.9, 2.1, 1.1, 1,. 1.5,
1.8, 2.3, 3;
Y: 295, 100, 190, 202, 357, 266, 381, 247, 193, 133, 333, 170, 202,
115, 93, 146, 194, 219, 303.
Результаты работы программы:
КОЭФФИЦИЕНТ КОРРЕЛЯЦИИ R = .98289587522615.
ВЫЧИСЛЕННОЕ ЗНАЧЕНИЕ КРИТЕРИЯ Т = 22.643490922289.
Поскольку вычисленное значение критерия 22.64 больше
табличного 2.55 (при числе степеней свободы 18 и 95%-ном уровне
значимости), то вычисленный коэффициент корреляции значимо
отличен от нуля.
Рассмотрим* теперь случай, когда значения результирующего
признака Y наблюдаются совместно со значениями целого набора
факториальных признаков *,, х2у ..., xk(k>\). Результат такого
наблюдения можно представить в виде следующего' массива
данных:
Уи </2, ..., Ук,
Х\\, Х\2> ..., Х\п, N /7 aj\
Xkl, XR2> .-., Xkn-
Снова ограничимся, рассмотрением лишь того случая, когда
имеются основания считать, что результирующий и факториальные
признаки связаны линейной зависимостью вида:
YF=a0 + a{x] +a2x2 + ...+akxk. (7.68)
Система нормальных уравнений метода наименьших квадратов
для определения неизвестных регрессионных коэффициентов а0,
а.|, а2, ..., ak будет теперь выглядеть так:
аоп + щ 2>i/+a22*2/+... + a*2**/= 2у<,
До 2 хи+щ 2 хЬ+ а2 2 xux2i + ... + ak 2 xuxv= 2 xuyiy (7.69)
a()2 ^i/ + ai2 xkiXu + a2y xkiX2i + ... + ak V 4/= 2 **'#>•
166 *
Если вместо системы (7.69) решать систему
'*2lPl+P2 + ...+''2*P/f===/'02, /7 70)
OSflPl +/*Л2Р2 + .-. + Рл = ^0Л,
то мы получим параметры так называемого стандартизованного
уравнения регрессии: / = Pi/i+P2*2 + ... + P*'*-
Коэффициенты этого уравнения показывают, на сколько
собственных средних квадратических отклонений изменится значение
результирующего признака при изменении факториального признака
на одно его среднее квадратическое отклонение и при неизменной
величине других факториальных признаков.
Стандартизованное уравнение регрессии соответствует
стандартизованным (нормированным) значениям переменных, переход
к которым от исходных значений совершается по формулам
yi-M„ хц-мХ{ (1 = 1', 2, ..., *),
tl-—sT%ii~ &,, (/=1, 2, .... п).
С регрессионными коэффициентами уравнения (7.68) р-коэффи-
s п
циенты связаны соотношениями сц= -~-р,; ао=Му— % aiMXi.
^Xi 1=1
Коэффициентами системы (7.70) являются коэффициенты
корреляции (будем называть их парными коэффициентами корреляции),
причем Гц представляет собой коэффициент корреляции /-й и /-й
строки массива (7.67) (/ = 0, 1, ..., k\ / = 0, 1, ..., k).
Часто для характеристики взаимной связи факториальных
признаков, входящих в рассматриваемый набор, и характеристики
их влияния на результирующий признак недостаточно знания
парных коэффициентов корреляции. В этом случае бывает полезно
вычислять частные коэффициенты корреляции.
Частный коэффициент корреляции /?,/ /-й и /-й переменной
(/-й и /-й строки массива (7.67)) характеризует тесноту связи
между этими переменными при условии, что влияние остальных
переменных исключается. Частные коэффициенты корреляции в
данном наборе переменных вычисляются исходя из матрицы
парных коэффициентов корреляции, вычисленной для этого набора.
Такую матрицу (размерности (£+1 )(& + !)) легко образовать из
коэффициентов системы (7.70):
1 Г01 г02 ... rok
... !.. (7.71)
\ ГкО Гк\ Г*2 ... 1
Частный коэффициент корреляции вычисляется по формуле
167
Здесь Aij обозначает алгебраическое дополнение элемента,
стоящего на пересечении /-й строки и /-го столбца матрицы (7.71).
Такой же смысл имеют обозначения Ац и Ац.
Величину /?, вычисляемую по формуле
где D — определитель матрицы (7.71), называют коэффициентом
множественной корреляции. Коэффициент R принимает значения
от0 до 1. Причем чем полнее рассматриваемый набор факториальных
признаков объясняет колеблемость результирующего признака,
тем ближе к единице будет значение этого показателя. Тагам
образом, по величине R мы можем судить о том, насколько
обоснованным было наше предположение о наличии зависимости вида (7.68).
Коэффициент множественной корреляции можно также вычислять
по формуле i
#=V''()iPi+'o2P2 + ... + /'o*Pa. (7.74)
п k
Пусть снова Z= У {У\ — До — У сцхц)2.
Величина т), определяемая по формуле
Ч=У
носит название множественное корреляционное отношение. Оно,
так же как и коэффициент множественной корреляции, принимает
значение от 0 до 1 и имеет такой же смысл. Однако множественное
корреляционное отношение может быть использовано и в том случае,
когда предполагаемая зависимость между факториальным и
результирующим признаками не является линейной. Величина Z в этом
случае должна быть равна сумме квадратов отклонений имеющихся
значений результирующего признака от соответствующих значений,
вычисленных по уравнению регрессии.
Контрольные вопросы
1. В чем суть приближения таблично заданной функции по
методу наименьших квадратов? Чем отличается этот метод от
метода интерполяции?
2. Каким образом сводится задача построения приближающих
функций в виде различных элементарных функций к случаю
линейной функции?
3. Что называется эмпирическим (статистическим)
распределением случайной величины?
4. Каковы основные виды статистических распределений и их
применение к проверке статистических гипотез?
5. Что такое парный коэффициент корреляции, частный
коэффициент корреляции, коэффициент множественной корреляции?
168
ЛАБОРАТОРНАЯ РАБОТА 7
Тема. Статистическая обработка опытных данных.
Задание. По заданной таблице значений результирующего
признака у и одного из факториальных признаков (например, #i)
построить методом наименьших квадратов две различные
эмпирические формулы и сравнить качество полученных приближений.
Пояснения к выполнению лабораторной работы 7.
Изучить материал п. 7.1—7.3 и рассмотреть пример 7.3.1.
По заданной таблице составляется точечный график, с помощью
которого выбираются два кажущихся наиболее предпочтительными
вида приближающей функции. Здесь невозможно указать какого-
либо общего метода угадывания наилучшего вида приближения,
во многих случаях удачное решение этой задачи зависит от
интуиции и опыта исследователя. При использовании ЭВМ появляется
возможность испытания разных способов без сколько-нибудь
значительных усилий.
Исследование точечного графика и выбор вида приближающей
функции облегчаются при умелом расположении графика в системе
координат и правильном сочетании масштабов на осях ОХ и О К,
подчеркивающих характер данной зависимости. Следует заметить,
что при построении эмпирической формулы всегда можно добиться,
чтобы исходные значения аргумента и функции были положительны.
Для этого достаточно сделать параллельный перенос в направлении
осей, т.е. фактически перейти к новым переменным; в записи
окончательного результата при этом необходимо вернуться к
прежним обозначениям.
После выбора вида приближающей функции следует приступить
к вычислениям. Если расчеты ведутся с помощью калькулятора,
то удобно использовать вспомогательные таблицы (см. табл. 7.4 и
7.5). При использовании ЭВМ составляется программа с выводом
значений параметров приближающих функций заданного вида
и соответствующих им сумм квадратов уклонений.
В некоторых случаях удается улучшить эмпирическую формулу.
Простейший прием состоит в следующем. Пусть y = F{x) — найденная
п
эмпирическая формула, а а + 28^—соответствующая ей сумма
квадратов уклонений (см. формулу (7.8)). Рассмотрим функцию
y = F(x) + c, где с — const. Нетрудно показать [6], что формуле
y = F(x)-\-c соответствует меньшее значение суммы квадратов
уклонений, чем формуле y = F(x\ если принять
1 п
При этом эффект уточнения будет тем ощутимее, чем сильнее
отличается от нуля значение с.
Исходные данные к работе помещены в таблице 7.7.
169
Т абл и ца 7.7
у 79,31 57,43 60,66 92,55 90,12 71,30 70,50 91,52 68,31 58,56
* xi 5,84 3,82 6,19 9,22 7,87 6,29 4,43 8,91 5,34 2,21
х2 6,04 6,33 : 4,86 5,91 4,96 5,58 6,15 6,13 4,65 5,49
*з 4,22 2,90 1,68 3,34 4,21 2^89 4J5 ЗД1 3137 4,41
I 82,16 61,02 44,56 82,52 99,17 70,24 63,23 66,48 48,35 40,24 '
xi 0,12 -3,48 —4,45 -6,19 1,81 —3,81 0,84 -2,08 -1,28 5,44
2 = ^
х2 2,91 2,94 6,35 6,58 3,80 6,43 0,57 5,96 3,40 4,55
хз 6,43 6,10 2,55 7,33 6,72 4,86 5,Й 3,87 3,27 4,02
у 113,84 119,66 106,28 120,68 107,43 114,88 115,53 117,40 120,24 118,74
xi 2,95 2,60 2,69 3,01 2,44 2,51 3,37 2,98 3,20 ,2,62
3
х2 6,06 7,20 5,62 7,01 5,73 6,98 6,06 6,52 6,90 7,21
хз 5,59 5,66 5,30 5,57 5,57 5,37 5,41 5,61 5,44 5,54'
у 65,72 58,05 60,05. 55,79 50,83 47,69 44,49 59,74 56,81- ■ 45,82
xi 5,14 5,59 4,33 4,59 4,21 3,78 4,23 5,61 4,87 3,87
4 :
jc2 4,23 1,40 4,07 2,93 3,44 1,09 1,82 2,43 3,85 0,97
хз 5,46 2,73 6,49 4,26 2,39 6,46 0,86 2,05 1,93 4,99
у 55,65 67,68 105,20 85,02 52,76 58,86 72,19 61,09 70,44 51,67
*\ 9,11 9,35 8,90 9,22 8,74 8,98 8,77 9,31 8,81 9,14
5 —
Х2 1,52 3,24 6,63 7,15 2,96 1,73 7,44 3,70 2,00 2,63
Продолжение
*з 2,51 3,74 8,70 5,36 1,89 3,01 ' 3,59 <Ш ' 4,77 1,60
у 22,81 28,42 24,95 26,96 8,78 36,55 15,77 22,89 " 27,99 14,45
хх 0,06 2,36 —3,14 2,10 -4,89 0,74 —0,22 1,63 -0,13 * -4,97
6 1
х2 6,82 7,03 7,08 7,08 7,97 8,66 6,98 6,41 8,32 7,31
хз 3,54 4,29 4,78 3,99 1,13 6,29 1,89 3,27 4,52 2,65
у 18,31 21,92 16,93 -8,23 10,90 24,18 38,45 24,11 36,62 30,42
Хх —1,96 —0,76 —1,06 -2,95 -4,36 0,16 -2,66 — 3,Т? -2,12 -0,96
7
Х2 —1,41 —1,44 4 0,45 -0,98 0,61 0,52 — 1,48ч —1,09 -1,60 0,15
*з 4,08 4,42 2,52 -0,08 2,14 3,36 7,35 5,00 7,04 4,76
у 80,93 109,10 87,80 83,95 '70,99 87,36 " 84,71 96,63 59,70 109,99
jc, 1,65 2,43 0,94 1,29 -0,61 -1,14 2,45' 2,80 -1,78 1,50
8 — " "
х2 5,11 7,26 5,54 4,39 5,92 7,22 4,83 6,30 3,90 8,23
х3 5,15 7,03 6,40 6,16 5,39 7,27, 5,10 5,61 5,88 7,46
у —19,23 —21,41 —9,90 -19,56 -0,30 -12,04 1,14 11,26 -24,64 4,90
хх 3,80 0,25 0,48' 5,78 4,91 1,56 0,91 5,73 1,98 1,23
9 1
jc2 —2,25 1,90 0,18 -0,50 -1,09 0,94 -0,13 -0,50 -4,38 -5,98
Хъ _4,95 -4,50 —2,29 —5,50 -1,50 —2,98 —0,23 0,57 -5,56 0,43
у 18,93 -22,13 -10,07 20,59 7,09 4,04 —20,78 —12,98 3,69 -11,43
10 хх 2,00 2,60 3,66 1,70 3,79 2,08 1,97 1,93 2,02 3,75
ч . Продолжение
х2 7,03 5,98 7,10 6,92 6,69 3,66 7,60 3,61 4,20 7,29
х3 0,82. -5,90 —4,42 1,19 -1,53 0,95 -5,86 -3,72 -1,11 -4,70
у 63,96 44,39 51,20 58,44 50,15 44,51 47,25 35,24 43,28 32,03
*i 3,05 2,20 0,65 1,65 1,92 1,92 0,89 0,75 2,79 0,44
11 ,
х2 7,92 4,71 8,09 8,35 6,24 4,39 6,95 3,67 2,88 3,71
*з 6,70 4,75 7,01 7,40 5,97 7,07 6,19 ' ^ 7,18 6,67 5,94
у 11,13 3,49 ~ 8,91 14,83 1,80 13,50 3,70 -2,40 10,00 16,04
х\ -0,05 —0,04 —0,88 0,32 —0,24 -1,05 0,57 0,01 0,40 0,79
12
х2 3,72 4,21 4,17 5,64 2,95 6,85 2,01 1,92 3,57 2,95
дгз 0,51 -2,26 f 0,63 0,07 —1,78 0,72 -1,67 -2,84 -0,35 1,45
у 58,46 36,05 31,17 16,17 11,16 69,23 58,08 43,13 73,24 42,86
jc, 0,22 -3,05 —1,76 —1,25 —0,45 —0,80 -0,26 -3,07 -1,27 —3,05
13
. х2 4,62 2,93 4,18 1,63 0,00 5,16 3,70 7,22 6,08 3,86
хъ 2,06 5,45 1,01 1,04 1,13 4,73 3,92 1,02 4,92 5,38
у 66,58 36,05 64,63 33,19 26,70 55,31 18,70 22,95 38,24 ^,18
хх 3,44 1,72 2,06 3,07 0,99 7,65 2,92 3,53 4,10 —0,47
14'—
х2 —0,78 —0,38 Й54 —0,93 —0,83 1,82 —2,14 0,49 1,29 —1,22
*з 7,90 4,00 7,94 2,68 3,13 2,16 0,74 0,24 2,12 1,42
(
ЛИТЕРАТУРА
1. Бахвалов Н. С. Численные' методы.—М.: Наука, 1973.
2. Березин И. С, Жидков Н. П. Методы вычислений.— М.:
Физматгиз, 1966.—Ч. I, II.
3. Воеводин В. В. Численные методы алгебры.— М.: Наука,
1966.
4. Волков Е. А. Численные методы.— М.: Наука, 1982.
5. Гренандер У., Фрайбергер В. Краткий курс вычислительной
вероятности и статистики.— М.: Наука, 1978.
6. Демидовин Б. Л., Марон И. А. Основы вычислительной
математики.— М.: Наука, 1970.
7. Демидовин Б. П., Марон И. А., Шувалова Э. 3. Численные
методы анализа.— М.: Наука, 1967.
8. Заварыкин В. М., Житомирский В. Г., Лапник М. П.
Техника вычислений и алгоритмизация.— М.: Просвещение, 1987.
9. Заварыкин В. М., Житомирский В. Г., Лапник М. П.
Основы информатики и вычислительной техники.— М.: Просвещение,
1989.
10! Иванова Т. П., Пухова Г. В. Программирование и
вычислительная математика.— М.: Просвещение, 1978.
11. Калиткин Н. П. Численные методы.— М.: Наука, 1978.
12. Колмогоров А. Н., Фомин С. В. Элементы теории функций
и функционального анализа.—М.: Наука, 1972.
13. Мак-Кракен Д., Дорн У. Численные методы и
программирование на Фортране.— М.: Мир, 1977.
14. Марнук Г. И. Методы вычислительной математики.— М.:
Наука, 1980.
15. Монахов В. М., Беляева Э. С, Краснер Н. Я. Методы
оптимизации.— М.: Просвещение, 1978.
16. Солодовников А. С. Введение в линейную алгебру и
линейное программирование.— М.: Просвещение, 1966.
17. Форсайт Дж., Малькольм М., Моллер /С. Машинные методы
математических вычислений.—М.: Мир, 1980.
18. Хемминг Р. В. Численные методы.— М.: Наука, 1968.
ОГЛАВЛЕНИЕ
Введение 3
Глава 1. Решение уравнений с одной переменной 6
1.1. Постановка задачи 6
1.2. Отделение корней . . 7
1.3. Метод половинного деления 11
1.4. Метод простой итерации 13
1.5. Оценка погрешности метода итераций 15
1.6. Преобразование уравнения к итерационному виду 17
1.7. Практическая схема решения уравнения с одной переменной на ЭВМ 21
Лабораторная работа 1 23
Глава 2. Решение систем линейных алгебраических уравнений 24
2.1. Определения, обозначения, общие сведения 24
2.2. Метод Гаусса 26
2.3. Вычисление определителей 31
2.4. Метод простой итерации 35
2.5. Достаточные условия сходимости итерационного процесса .... 37
2.6. Практическая схема решения систем линейных уравнений методом
простой итерации 39
2.7. Решение систем линейных уравнений методом Зейделя 46
2.8. Решение систем линейных уравнений методом Монте-Карло ... 50
2.9. Решение систем уравнений методом ортогонализации 55
Лабораторная работа 2 59
Глава 3. Элементы линейного программирования 62
3.1. Постановка задачи 62
3.2. Подход к решению задачи линейного программирования .... 64
3.3. Симплекс-метод 66
3.4. Симплекс-таблицы 69
3.5. Отыскание исходного базиса 71
Лабораторная работа 3 74
Глава 4. Интерполирование функций 77
4.1. Постановка задачи 77
4.2. Интерполяционный многочлен Лагранжа 78
4.3. Организация ручных вычислений по формуле Лагранжа .... 79
4.4. Программа вычисления значения интерполяционного многочлена
Лагранжа 81
4.5. Интерполяционные многочлены Ньютона для равноотстоящих узлов 83
4.5.1. Конечные разности 84
4.5.2. Первая интерполяционная формула Ньютона 84
4.5.3. Вторая интерполяционная формула Ньютона ...... 85
4.6. Погрешность многочленной интерполяции 86
4.7. Уплотнение таблиц функций 89
4.8. Интерполяция сплайнами 91
Лабораторная работа 4 95
Глава 5. Численное дифференцирование и интегрирование 98
5.1. Особенность задачи численного дифференцирования 98
5.2. Интерполяционная формула Лагранжа для равноотстоящих узлов 99
174
5.3. Численное дифференцирование на основе интерполяционной
формулы Лагранжа . . 101
5.4. Численное дифференцирование на основе интерполяционной
формулы Ньютона 102
5.5. Постановка задачи численного интегрирования 104
5.6. Квадратурные формулы Ньютона-Котеса 105
5.7. Формула трапеций 106
5.8. Формула Симпсона 109
5.9. Об оценке точности квадратурных формул 112
5.10. Составление программ для ЭВМ 113
5.10.1. Формулы трапеций и Симпсона 113
5.10.2. Вычисление интегралов методом Монте-Карло 117
Лабораторная работа 5 119
Глава в. Решение обыкновенных дифференциальных уравнений 121
6.1. Постановка задачи 121
6.2. Метод Пикара 122
6.3. Метод Эйлера 127
6.4. Метод Рунге — Кутта 128
Лабораторная работа 6 132
Глава 7. Методы обработки экспериментальных данных 134
7.1. Метод наименьших квадратов 134
7.2. Нахождение приближающей функции в виде линейной функции и
квадратного трехчлена (линейная и квадратичная регрессии) .... 137
7.3. Нахождение приближающей функции в виде других элементарных
функций 138
7.3.1. Степенная функция (геометрическая регрессия) 139
7.3.2. Показательная функция 139
7.3.3. Дробно-линейная функция 140
7.3.4. Логарифмическая функция 140
7.3.5. Гипербола 140
7.3.6. Дробно-рациональная функция 140
7.4. Элементы математической статистики 147
7.4.1. Распределения 149
7.4.2. Проверка статистических гипотез 154
7.4.3. Дальнейшие статистические характеристики выборочной
совокупности. Точечные и интервальные оценки 159
7.4.4. Критерии значимости 161
7.4.5. Корреляция и регрессия 163
Лабораторная работа 7 169
Литература 173
Учебное издание
Заварыкин Валерий Михайлович
Житомирский Владимир Габриэлович
Лапчик Михаил Павлович
ЧИСЛЕННЫЕ МЕТОДЫ
Зав. редакцией Т. А. Бурмистрова
Редакторы Н. А. Лесина, Н. А. Шагирова
Младшие редакторы Е. А. /Буюклян, Л. И. Заседателева
Художественный редактор Е. Р. Дашук
Художники Б. Л. Николаев, В. В. Костин
Технический редактор Г. В. Субочева
Корректор М. Ю. Сергеева
ИБ № 10952
Сдано в набор 11.05.89. Подписано к печати 28.04.90. Формат 60X90'/ie. Бум. офсетная М* 2. Гарнит.
литературная. Печать офсетная. Усл. печ. л. 11+форз. 0,25. Усл. кр.-отт. 11,69. Уч.-изд. л. 10,22-+-форз.
0,31. Тираж 47 000 экз. Заказ 2142. Цена 80 к.
Ордена Трудового Красного Знамени издательство «Просвещение» Государственного комитета РСФСР по
делам издательств, полиграфии и книжной торговли. 129846, Москва, 3-й проезд, Марьиной рощи, 41.
Смоленский полиграфкомбинат Министерства печати и массовой информации РСФСР. 214020, Смоленск,
ул. Смольянинова, 1.
Учебное пособие
для педагогических
институтов
В. М. Заварыкин
В. Г. Житомирский
М. П. Лапчик
ЧИСЛЕННЫЕ
МЕТОДЫ