/
















































































































































































































































































































































Author: Гагарина Л.Г. Киселев Д.В. Федотова Е.Л.
Tags: информационные технологии вычислительная техника обработка данных учебники и учебные пособия информатика
ISBN: 978-5-8199-0316-2
Year: 2007




Text
Л. Г. Гагарина, Д. В. Киселев,
Е. Л. Федотова
РАЗРАБОТКА И ЭКСПЛУАТАЦИЯ
АВТОМАТИЗИРОВАННЫХ
ИНФОРМАЦИОННЫХ СИСТЕМ
Под редакцией профессора Л. Г. Гагариной
Допущено Министерством образования Российской Федерации
в качестве учебного пособия для студентов учреждений среднего
профессионального образования, обучающихся по группе
специальностей 2200 «Информатика и вычислительная техника»
Москва
ИД «ФОРУМ» - ИНФРА-М
2007
УДК 004(075.32)
ББК 32.973я723
Г12
Издание выполнено в рамках реализации национального
проекта «Образование» по инновационной образовательной
программе «Современное профессиональное образование для российской
инновационной системы в области электроники»
Рецензенты:
доктор техн, наук, профессор кафедры информатики и программного
обеспечения вычислительных систем (МИЭТ) Е. М. Портнов',
кандидат техн, наук, доцент кафедры информационных технологий
(Институт искусства и информационных технологий) А. А. Петров
Гагарина Л. Г., Киселев Д. В., Федотова Е. Л.
Г12 Разработка и эксплуатация автоматизированных информационных
систем: учеб, пособие / Под ред. проф. Л. Г. Гагариной. — М.:
ИД «ФОРУМ»: ИНФРА-М, 2007. — 384 с.: ил. — (Профессиональное
образование).
ISBN 978-5-8199-0316-2 (ИД «ФОРУМ»)
ISBN 978-5-16-003008-1 (ИНФРА-М)
Приведены основные понятия и определения процесса проектирования ав-
томатизированных информационных систем на основе анализа предметной
области; освещены вопросы разработки программно-информационного ядра
АИС на основе систем управления базами данных. Рассмотрены системы ав-
томатизированного проектирования АИС, средства автоматизированного про-
ектирования структур баз данных, язык структурных запросов SQL, стандарт-
ные системы доступа к базам данных.
В качестве основополагающих факторов изучения автоматизированного
проектирования СУБД приведены клиенты удаленного доступа и дано по-
строение запросов к СУБД; разработка клиентского программного обеспече-
ния; основные элементы клиентских программ. Изложены также особенности
эксплуатации АИС, методы и средства сбора и передачи данных; обеспечение
достоверности информации в процессе ее хранения и обработки; экспортиро-
вание структур баз данных; восстановление информации в базах данных.
Для студентов средних специальных учебных заведений, обучающихся по
специальностям 2202 «Автоматизированные системы обработки информации и
управления», 2203 «Программное обеспечение вычислительной техники и ав-
томатизированных систем»; может быть использовано для самообразования в
области информационных технологий.
УДК 004(075.32)
ББК 32.973я723
ISBN 978-5-8199-0316-2 (ИД «ФОРУМ»)
ISBN 978-5-16-003008-1 (ИНФРА-М)
©Л. Г. Гагарина, Д. В. Киселев,
Е. Л. Федотова, 2007
© ИД «ФОРУМ», 2007
Предисловие
В настоящее время в условиях развивающегося информаци-
онного общества с учетом всеобщего применения и распростра-
нения телекоммуникационных и информационных технологий и
систем, а также в связи с реализацией национального проекта
«Образование» появление учебного пособия, освещающего не-
посредственно теоретические и практические вопросы разработ-
ки и эксплуатации автоматизированных информационных сис-
тем, более чем актуально.
Кроме того, поскольку Интернет в нашей стране доступен в
основном пользователям, проживающим в крупных городах, а
информатизация общества невозможна без хорошо развитой
коммуникационной инфраструктуры, наибольший спрос ожида-
ет научно-техническую литературу прикладного характера, к ка-
ковой и относится представленная книга. К тому же, системное
изложение материала в соответствии с требованиями государст-
венного стандарта профессионального образования и богатый
иллюстративный материал, несомненно, придают изданию осо-
бую ценность.
Согласно «Концепции информатизации сферы образования
Российской Федерации» и задачам реализации упомянутого
выше национального проекта, одной из особенностей перспек-
тивной системы образования в нашей стране является опережаю-
щее образование, в рамках которого изучаются средства, методы
и последние достижения в области информатизации, а также
перспективы дальнейшего ее развития и практического исполь-
зования. Анализ содержания представленного пособия позволяет
утверждать, что его следует рассматривать не только как важное
средство информационной поддержки учебного процесса, как
эффективный педагогический инструмент, но и как необходи-
мый инструментарий опережающего образования.
В учебном пособии достаточно полно представлены все ас-
пекты изучения автоматизированных информационных систем
(АИС): основные термины и определения, классификация, тех-
нология проектирования, методология описания предметной об-
4
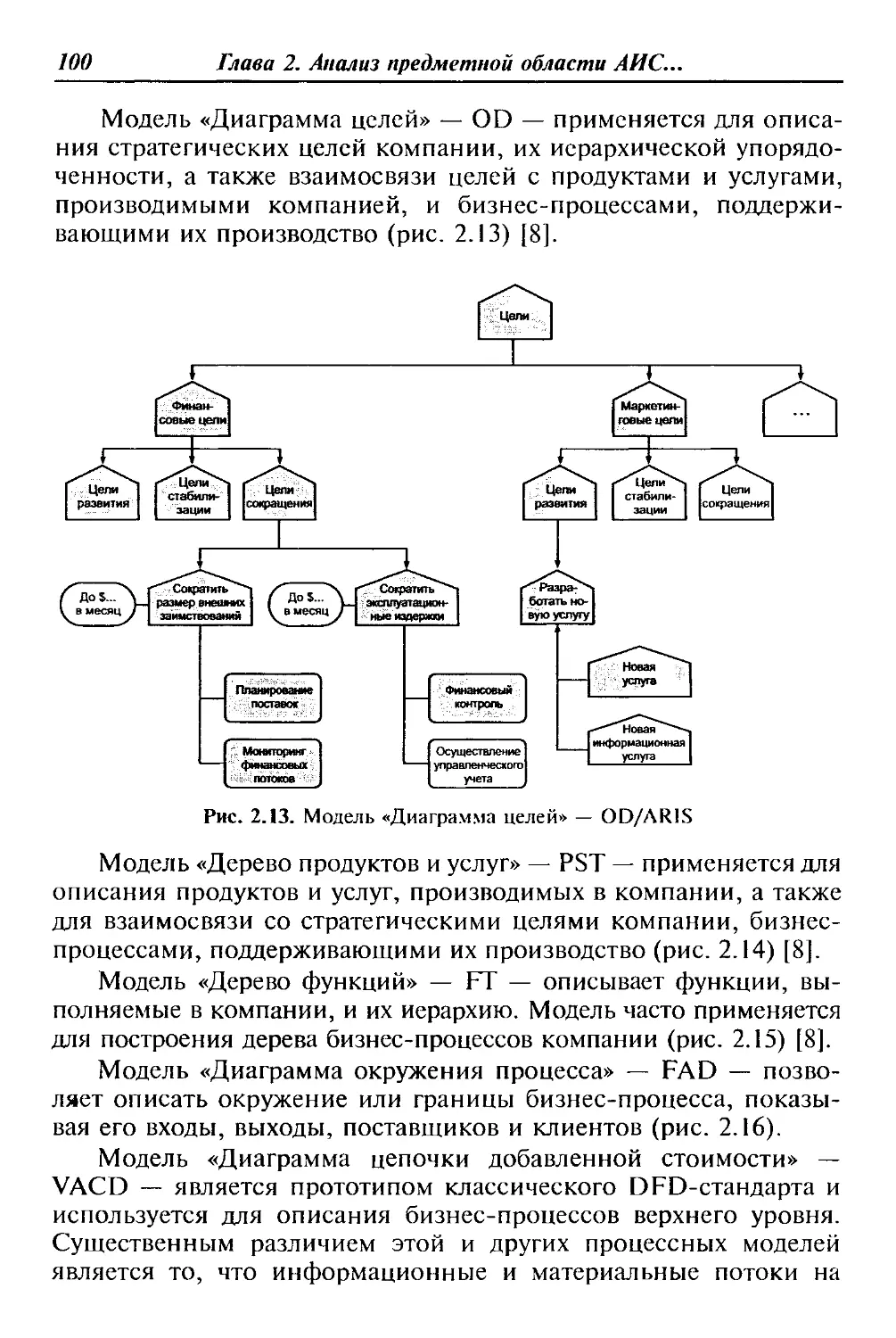
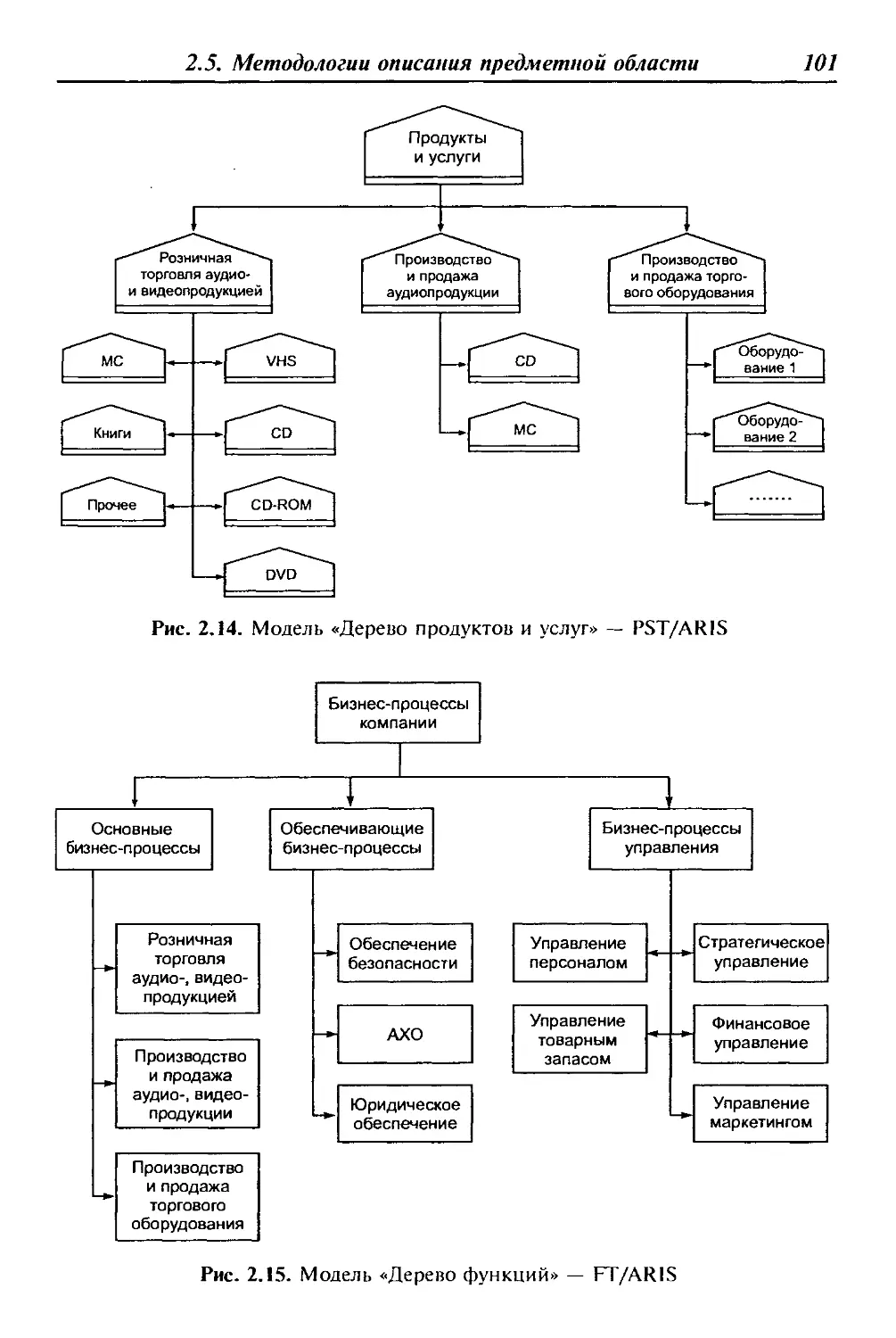
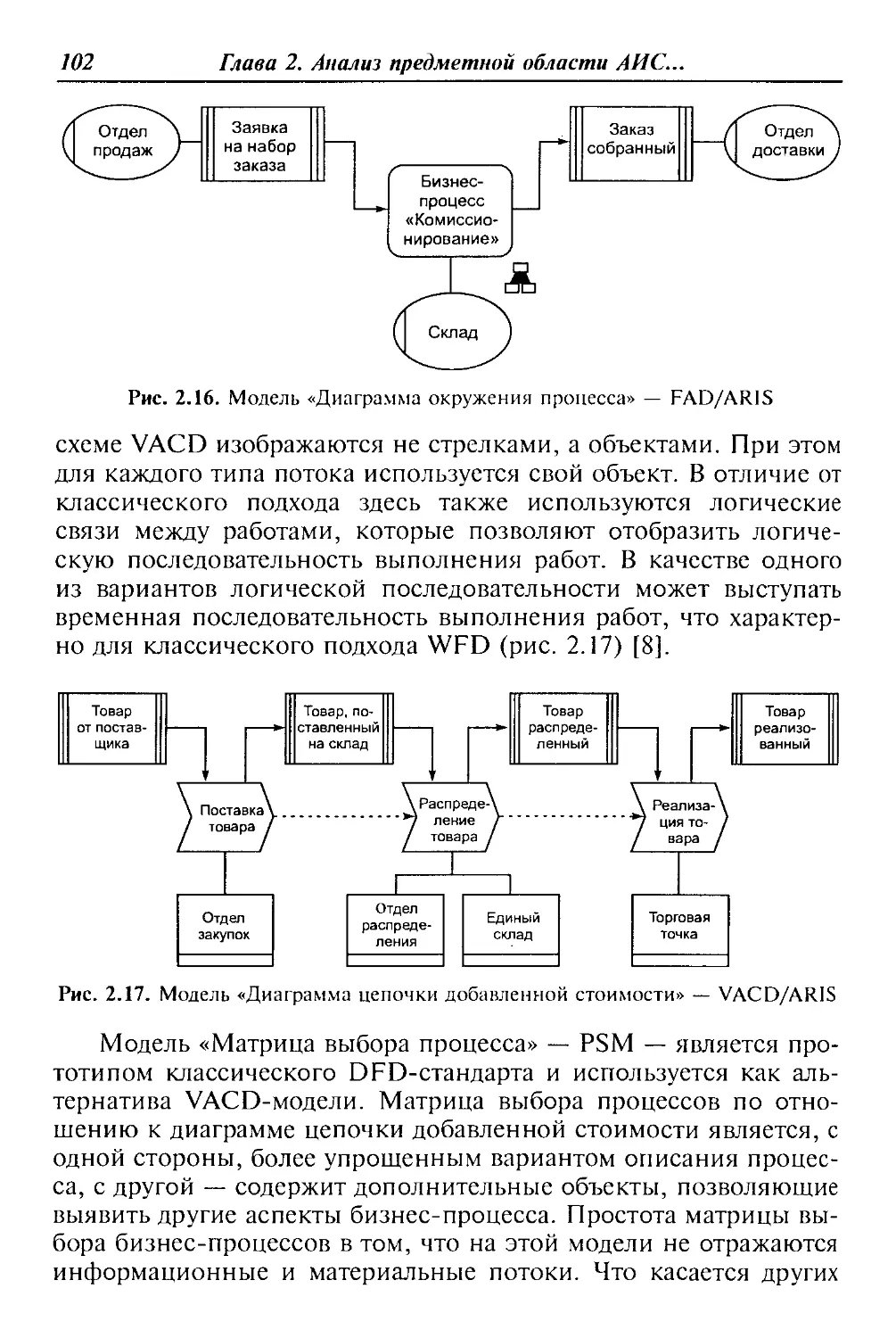
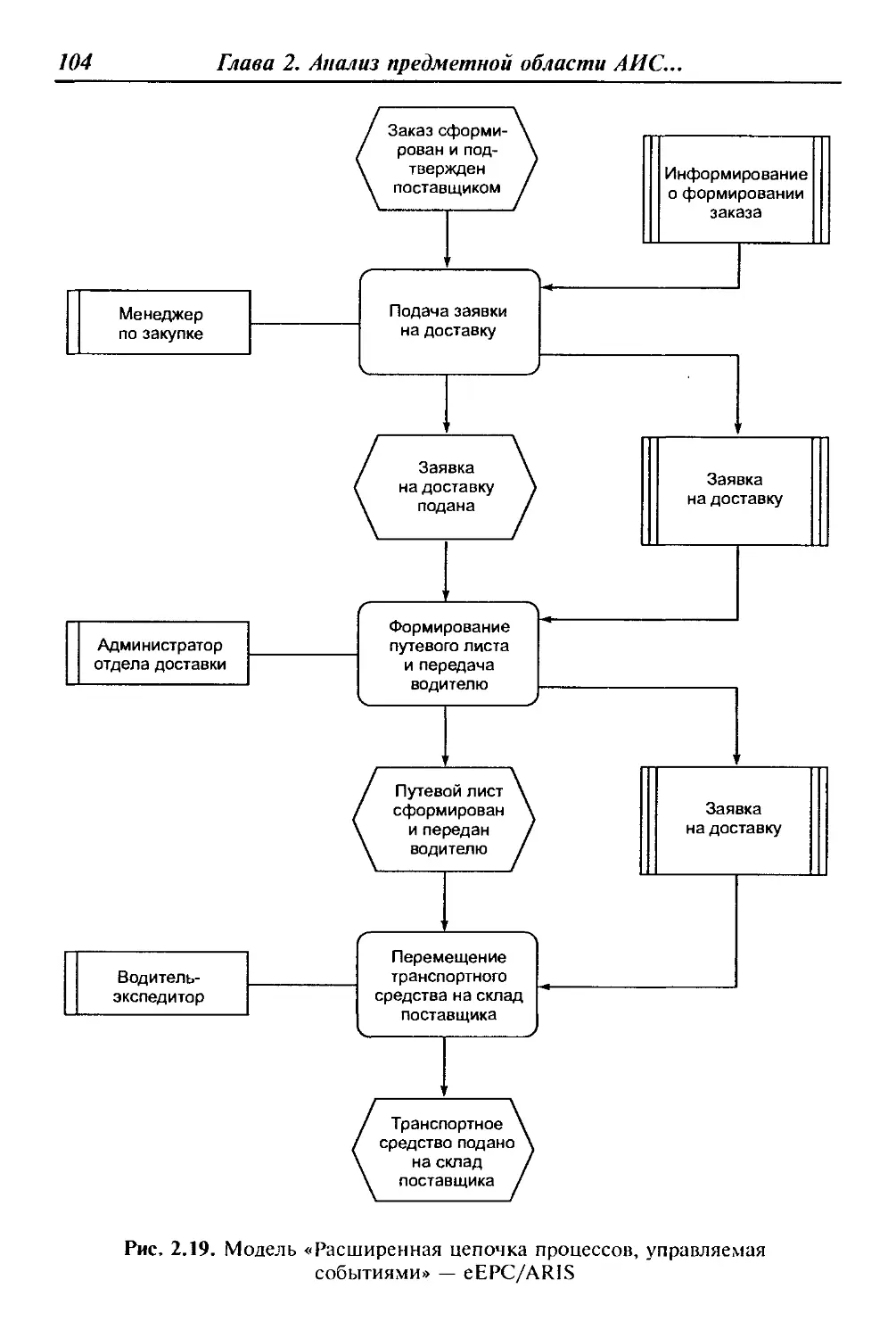
Предисловие
ласти и т. д. Отличие данного пособия от аналогичных изданий
заключается в освещении основных дидактических единиц дис-
циплины «Разработка и эксплуатация автоматизированных ин-
формационных систем» с учетом базовой подготовки потенци-
ального читателя — студента среднего профессионального учеб-
ного заведения. Именно поэтому только на базе основных
понятий и определений АИС возможно корректное освещение
проблем разработки программно-информационного ядра указан-
ных систем на основе систем управления базами данных (СУБД),
выбора СУБД, разработки клиентского программного обеспече-
ния и т. д. Весьма интересными и своевременными для будущих
специалистов современного глобального общества являются гла-
вы о выборе средств автоматизированного проектирования струк-
тур баз данных и организация сбора, размещения, хранения, на-
копления, преобразования и передачи данных в АИС.
Материал пособия прошел апробацию в Московском инсти-
туте электронной техники и используется в учебном процессе
различных факультетов.
Глава 1
ПРОЕКТИРОВАНИЕ
АВТОМАТИЗИРОВАННЫХ
ИНФОРМАЦИОННЫХ СИСТЕМ
1.1. Понятие и классификация автоматизированных
информационных систем
Автоматизированные информационные системы (АИС) от-
носятся к классу сложных систем, как правило, не столько в
связи с большой физической размерностью, сколько в связи с
многозначностью структурных отношений между их компонен-
тами [1]. В рамках системного анализа сложные системы изуча-
ются посредством разбиения на элементы: предполагается, что
сложная система есть целое, состоящее из взаимосвязанных час-
тей, которые не могут быть определены априорно, а строятся
или выбираются в процессе декомпозиции (физической или
концептуальной) исходной системы [2]. Поэтому, прежде чем
непосредственно перейти к изучению АИС, рассмотрим основ-
ные понятия и подходы к классификации информационных сис-
тем (ИС) вообще.
В настоящее время нет единого определения ИС и нет еди-
ной их классификации в связи с динамично протекающими про-
цессами накопления знаний в области информационных техно-
логий, поэтому приведем для сравнения наиболее существенные.
Информационная система [3] — совокупность информацион-
ных, экономико-математических методов и моделей, техниче-
ских, программных, технологических средств и специалистов,
предназначенная для сбора, хранения, обработки и выдачи ин-
формации и принятия управленческих решений.
Согласно [5] информационная система есть распространенное
обозначение человеческого коллектива и процедур, а также раз-
Глава 1. Проектирование АИС
работанного, построенного, используемого и обслуживаемого
оборудования для сбора, обработки, сохранения, извлечения и
отображения информации.
Актуальной задачей в информационном плане на сегодняш-
ний день для предприятий и корпораций всех организационных
форм и видов собственности и в любой предметной области явля-
ется обеспечение надежного управления всем объемом разнород-
ных данных, которые порождаются, хранятся и используются в
различных ИС, существующих на предприятии и связанных с ин-
формационной поддержкой продукции (услуг) в течение ее жиз-
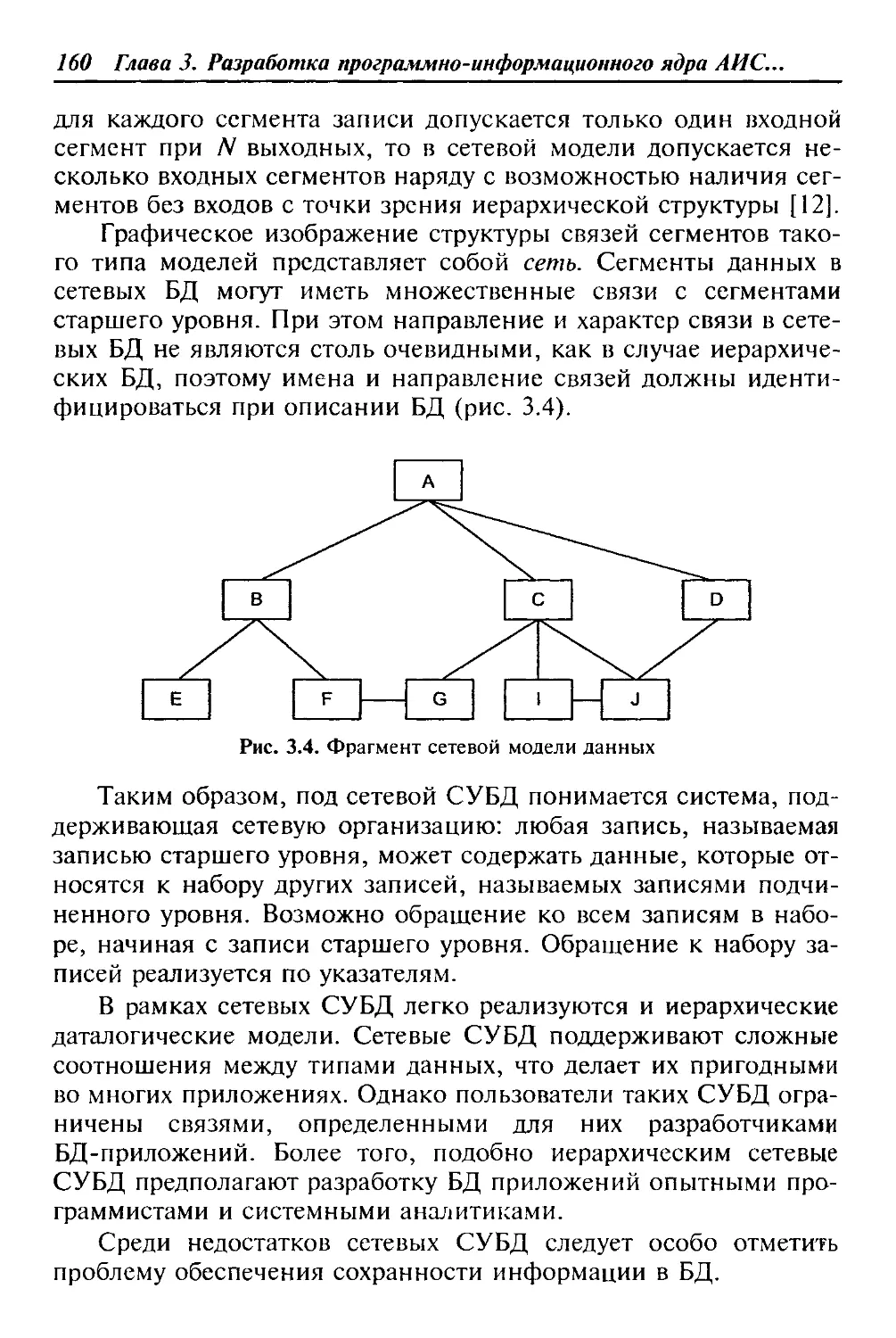
ненного цикла. Разнообразие проблем, решаемых с помощью
ИС, привело к появлению разнотипных систем, различающихся
принципами построения и заложенными в них правилами обра-
ботки информации.
ИС можно классифицировать по различным признакам. В ос-
нову нижеприведенной классификации [19] положен ряд сущест-
венных признаков, определяющих функциональные возможности
и особенности построения современных систем; также принима-
лись во внимание объем решаемых задач, используемых техниче-
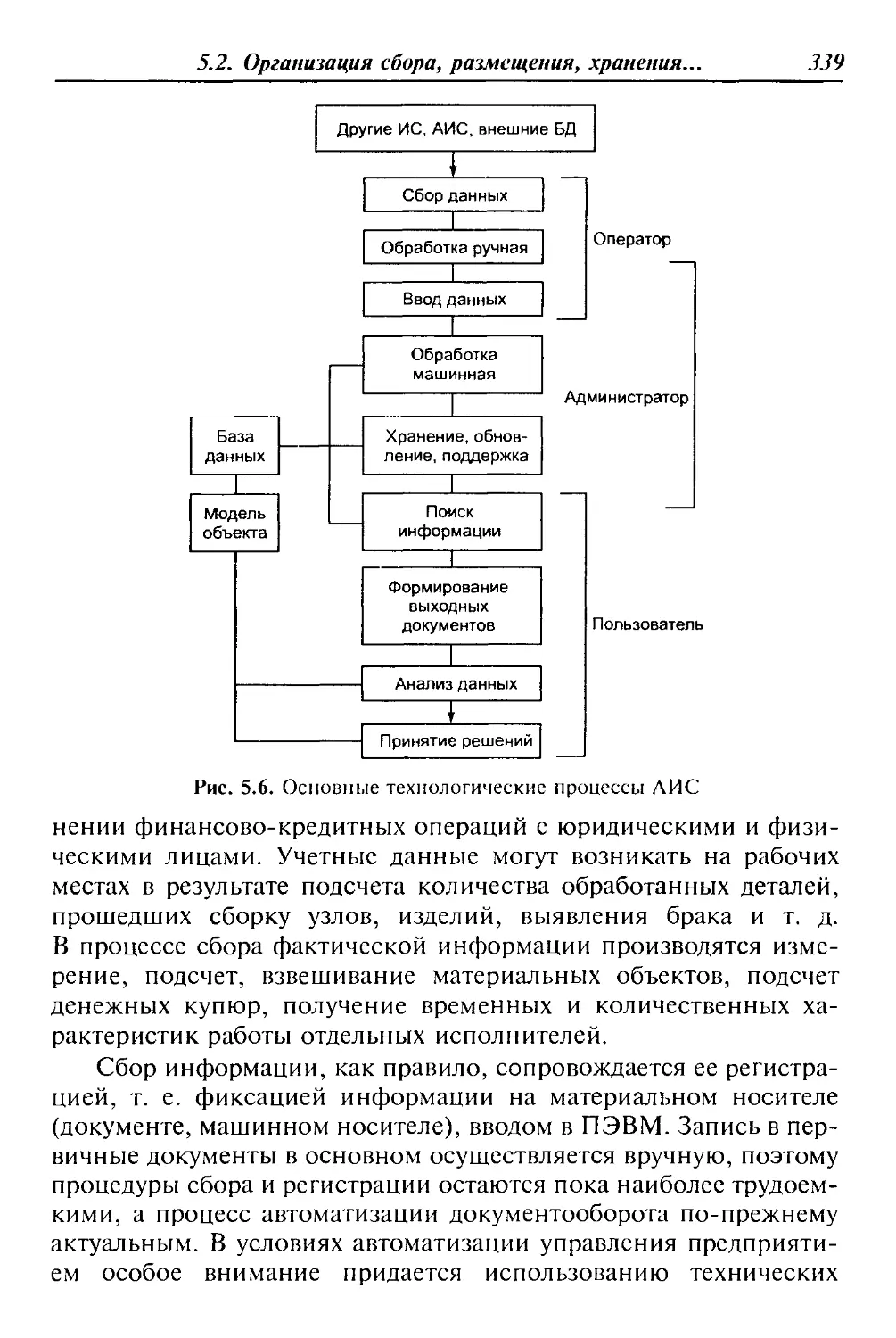
ских средств, организации функционирования и т. д. (рис. 1.1).
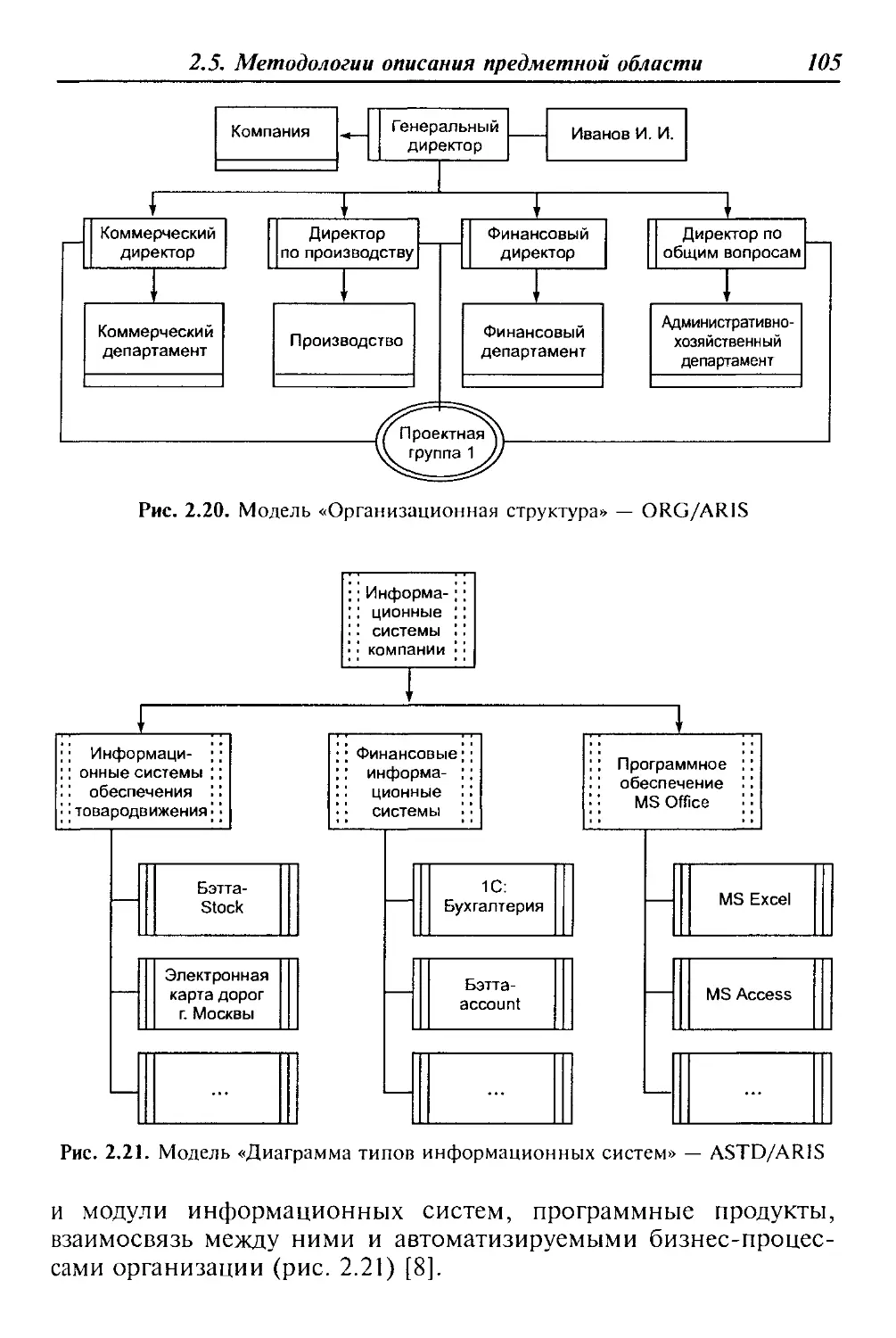
По типу хранимых данных ИС делятся на фактографические
и документальные. Фактографические системы предназначены
Рис. 1.1. Классификация информационных систем
1.1. Понятие и классификация АИС
7
для хранения и обработки структурированных данных в виде чи-
сел и текстов. Над такими данными можно выполнять различ-
ные операции.
В документальных системах информация представлена в виде
документов, состоящих из наименований, описаний, рефератов
и текстов. Поиск по неструктурированным данным осуществля-
ется с использованием семантических признаков. Отобранные
документы предоставляются пользователю, а обработка данных в
таких системах практически не производится.
Основываясь на степени автоматизации информационных про-
цессов в системе управления фирмой (организацией), ИС делят-
ся на ручные, автоматические и автоматизированные.
Ручные ИС характеризуются отсутствием современных тех-
нических средств переработки информации и выполнением всех
операций человеком.
В автоматических ИС все операции по переработке инфор-
мации выполняются без участия человека.
Автоматизированные ИС предполагают участие в процессе
обработки информации и человека, и технических средств, при-
чем главная роль в выполнении рутинных операций обработки
данных отводится компьютеру. Именно этот класс систем соот-
ветствует современному представлению понятий «информацион-
ная система» и «автоматизированная система».
Так, в ГОСТ 34.003—90 [4] приводится нижеследующее оп-
ределение.
Автоматизированная система (АС) — это система, состоящая
из персонала и комплекса средств автоматизации его деятельно-
сти, реализующая информационную технологию установленных
функций.
Комплекс средств автоматизации (КСА) — совокупность всех
компонентов АС, за исключением персонала.
Пользователь АС — лицо, участвующее в функционировании
АС или использующее результаты ее функционирования.
В зависимости от характера обработки данных АИС1 делятся
на информационно-поисковые и информационно-решающие.
1 Здесь и далее на основании вышеприведенных объяснений и во
избежание разночтений терминов «информационная система» и «авто-
матизированная система» используется термин «автоматизированная
информационная система, АИС».
8
Глава 1. Проектирование АИС
Информационно-поисковые системы производят ввод, систе-
матизацию, хранение, выдачу информации по запросу пользова-
теля без сложных преобразований данных. Например, ИС биб-
лиотечного обслуживания, резервирования и продажи билетов
на транспорте, бронирования мест в гостиницах и пр.
Информационно-решающие системы осуществляют, кроме того,
операции переработки информации по определенному алгоритму.
По характеру использования выходной информации такие системы
принято делить на управляющие и советующие. Результирующая
информация управляющих АИС непосредственно трансформиру-
ется в принимаемые человеком решения. Для этих систем свойст-
венны задачи расчетного характера и обработка больших объемов
данных, например АИС планирования производства или заказов,
бухгалтерского учета. Советующие АИС вырабатывают информа-
цию, которая принимается человеком к сведению и учитывается
при формировании управленческих решений, а не инициирует
конкретные действия. Эти системы имитируют интеллектуальные
процессы обработки знаний, а не данных (например, экспертные
системы).
В зависимости от сферы применения различают следующие
классы АИС [5].
Системы организационного управления предназначены для ав-
томатизации функций управленческого персонала как промыш-
ленных предприятий, так и непромышленных объектов (гости-
ниц, банков, магазинов и пр.). Основными функциями подоб-
ных систем являются: оперативный контроль и регулирование,
оперативный учет и анализ, перспективное и оперативное пла-
нирование, бухгалтерский учет, управление сбытом, снабжением
и другие экономические и организационные задачи.
Системы управления технологическими процессами (ТП) слу-
жат для автоматизации функций производственного персонала
по контролю и управлению производственными операциями.
В таких системах обычно предусматривается наличие развитых
средств измерения параметров технологических процессов (тем-
пературы, давления, химического состава и т. п.), процедур кон-
троля допустимости значений параметров и регулирования тех-
нологических процессов.
Системы автоматизированного проектирования (САПР) пред-
назначены для автоматизации функций инженеров-проектиров-
щиков, конструкторов, архитекторов, дизайнеров при создании
новой техники, сооружений или технологий. Основными функ-
1.1. Понятие и классификация АИС 9
циями подобных систем являются: инженерные расчеты, созда-
ние графической документации (чертежей, схем, планов), созда-
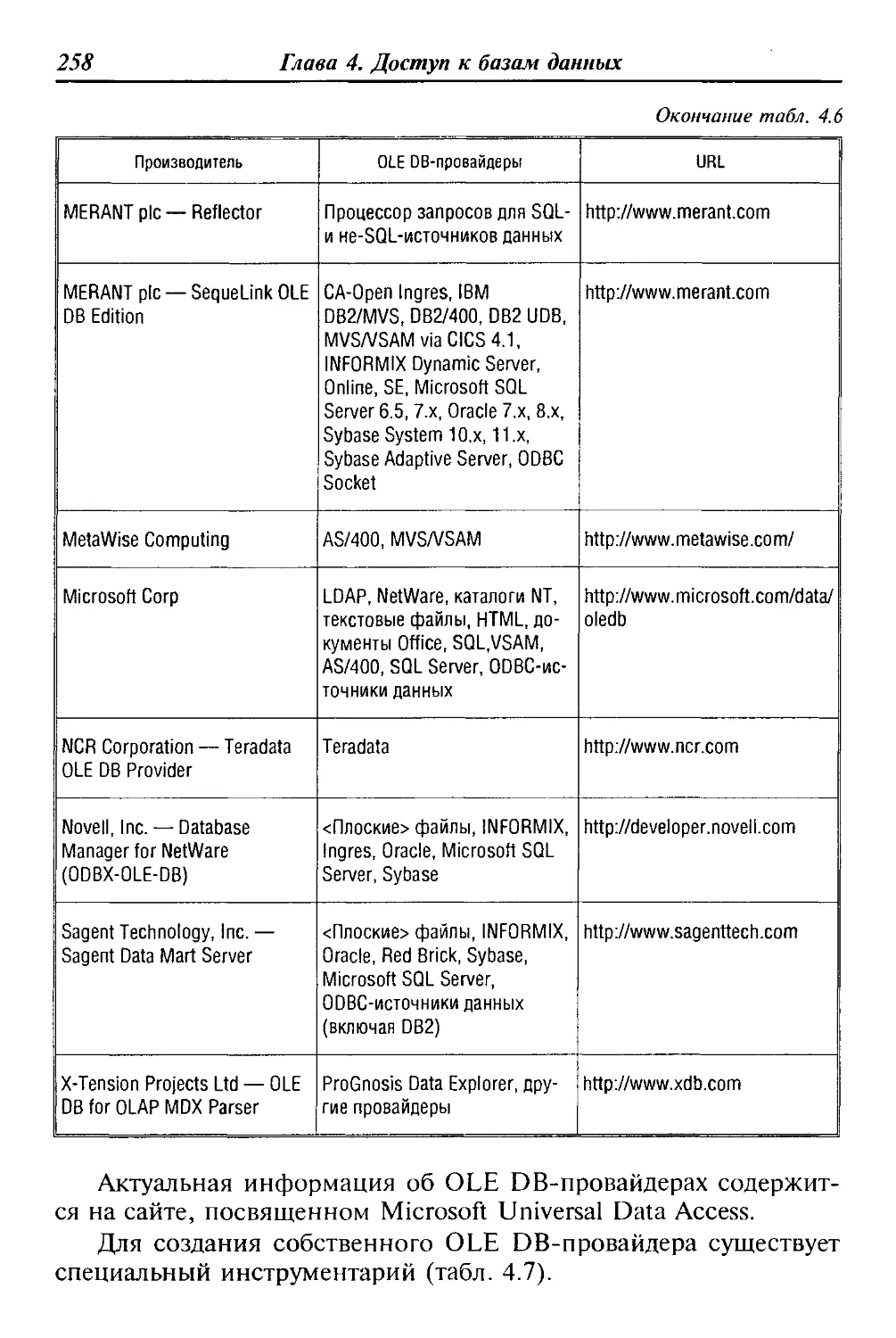
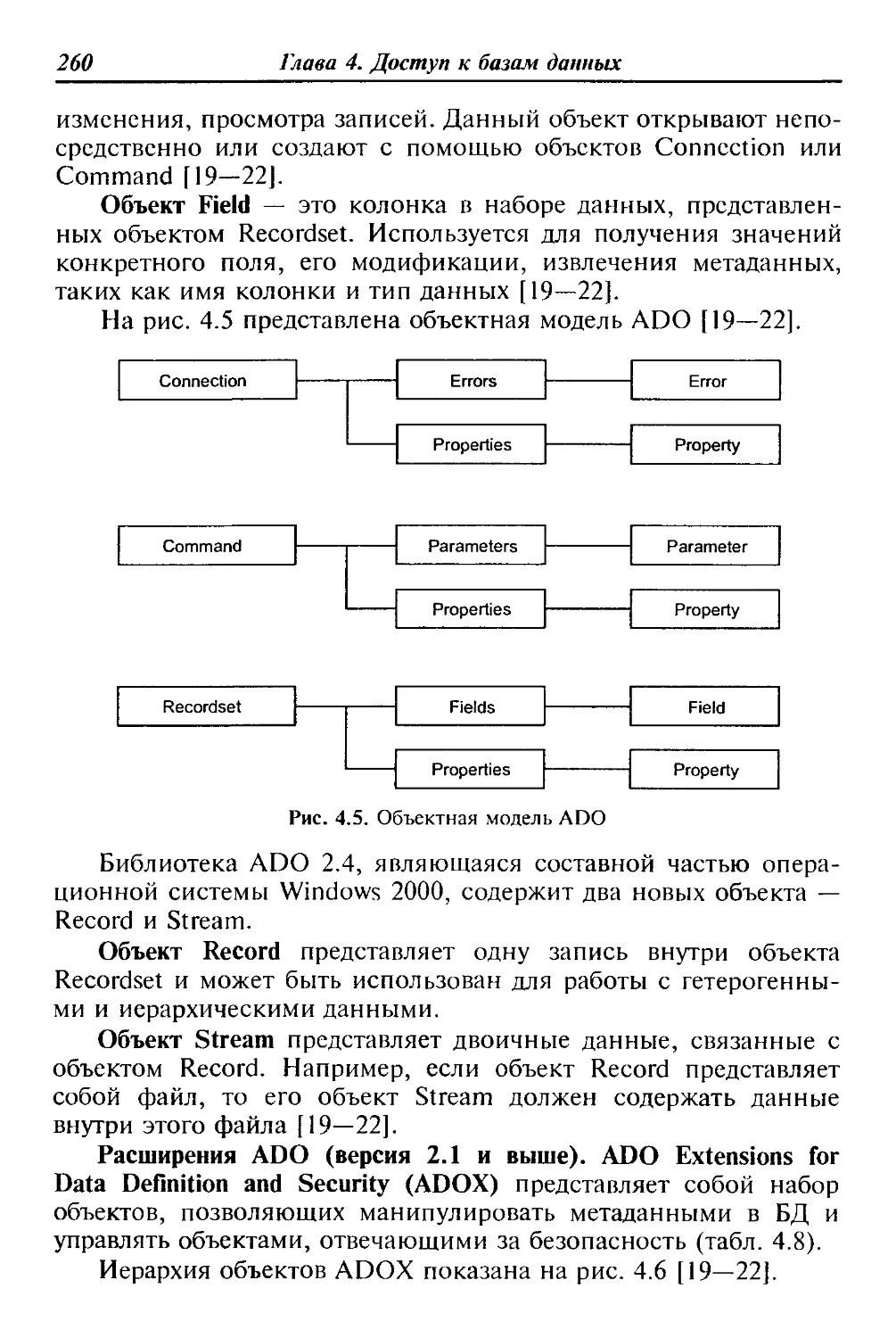
ние проектной документации, моделирование проектируемых
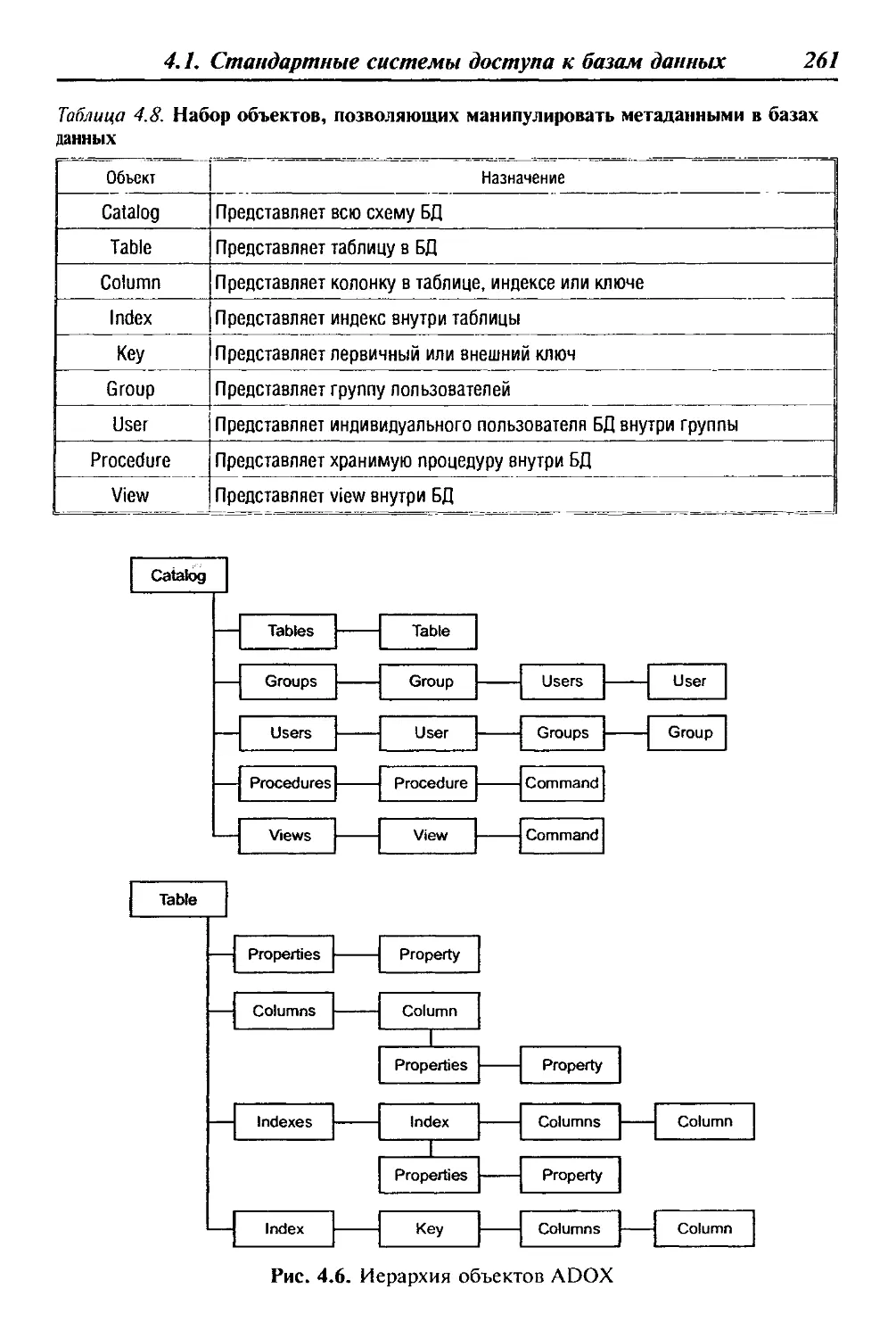
объектов.
Интегрированные (корпоративные) АИС используются для ав-
томатизации всех функций фирмы (корпорации) и охватывают
весь цикл работ — от планирования деятельности до сбыта про-
дукции. Они включают в себя ряд модулей (подсистем), работаю-
щих в едином информационном пространстве и выполняющих
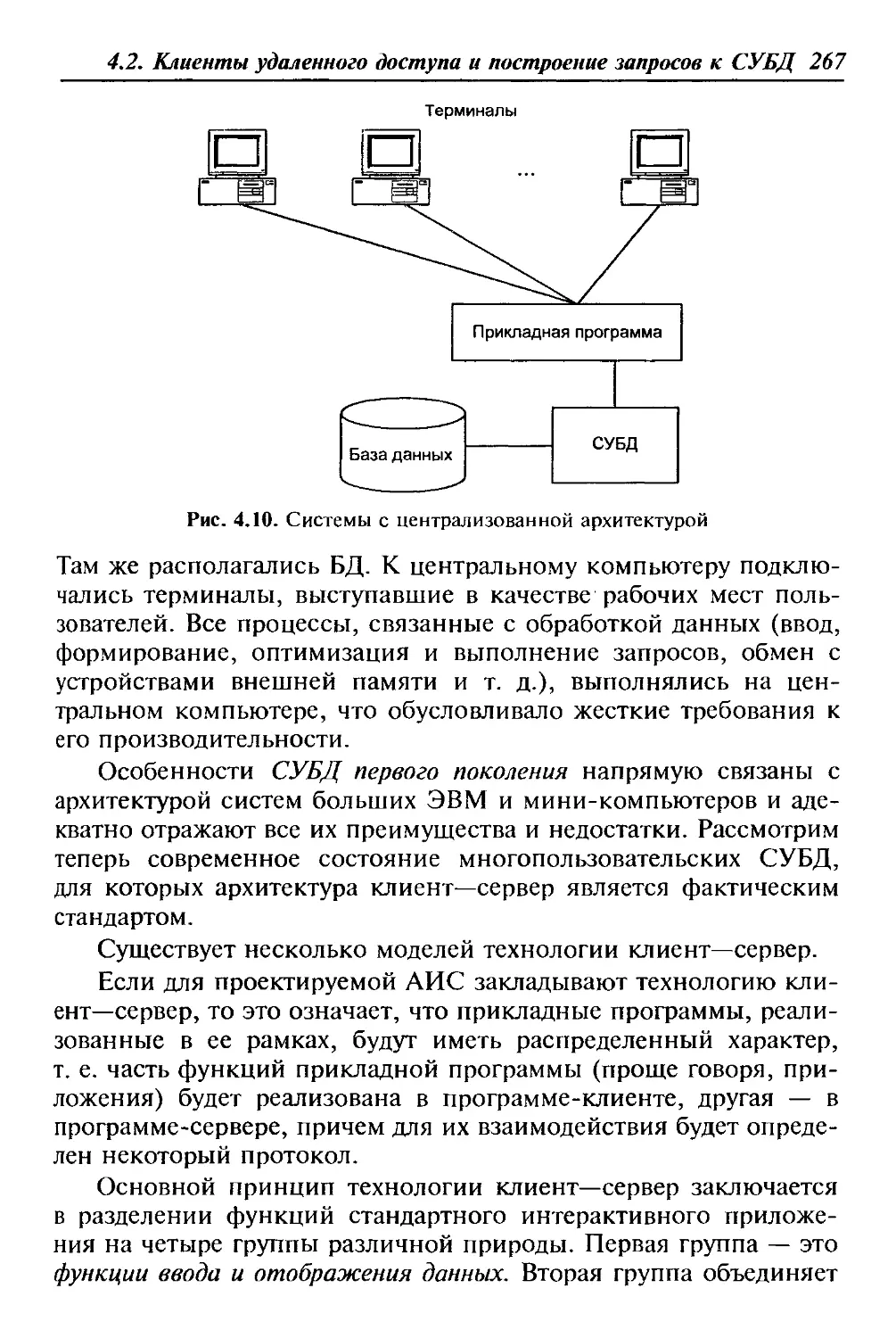
функции поддержки соответствующих направлений деятельности.
Анализ современного состояния рынка АИС показывает
устойчивую тенденцию роста спроса на информационные систе-
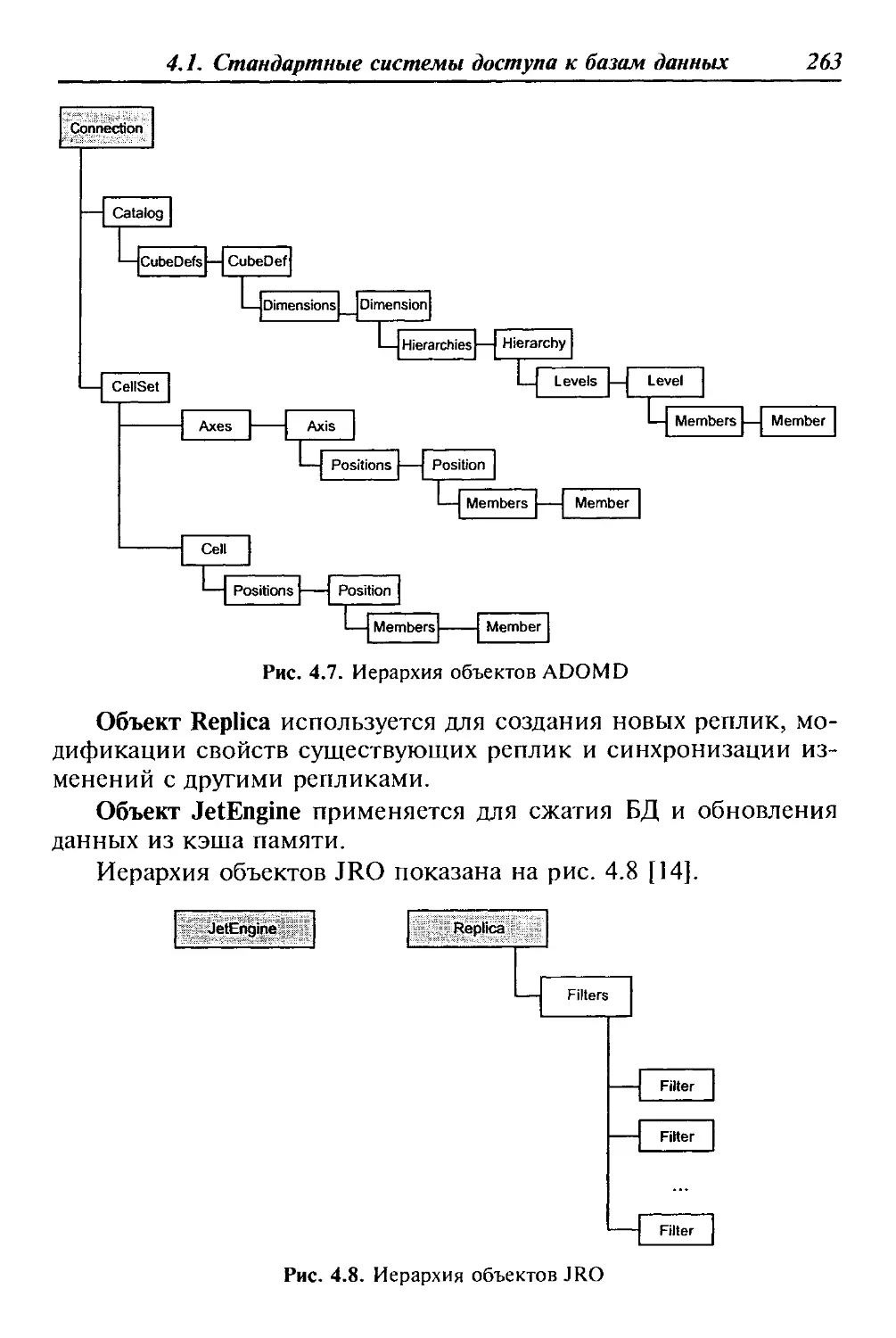
мы организационного управления. Причем продолжает расти
спрос именно на интегрированные системы. Автоматизация от-
дельной функции, например, бухгалтерского учета или сбыта го-
товой продукции, считается уже пройденным этапом для многих
предприятий [7].
В табл. 1.1 приведен перечень наиболее популярных в на-
стоящее время программных продуктов для реализации АИС ор-
ганизационного управления различных классов.
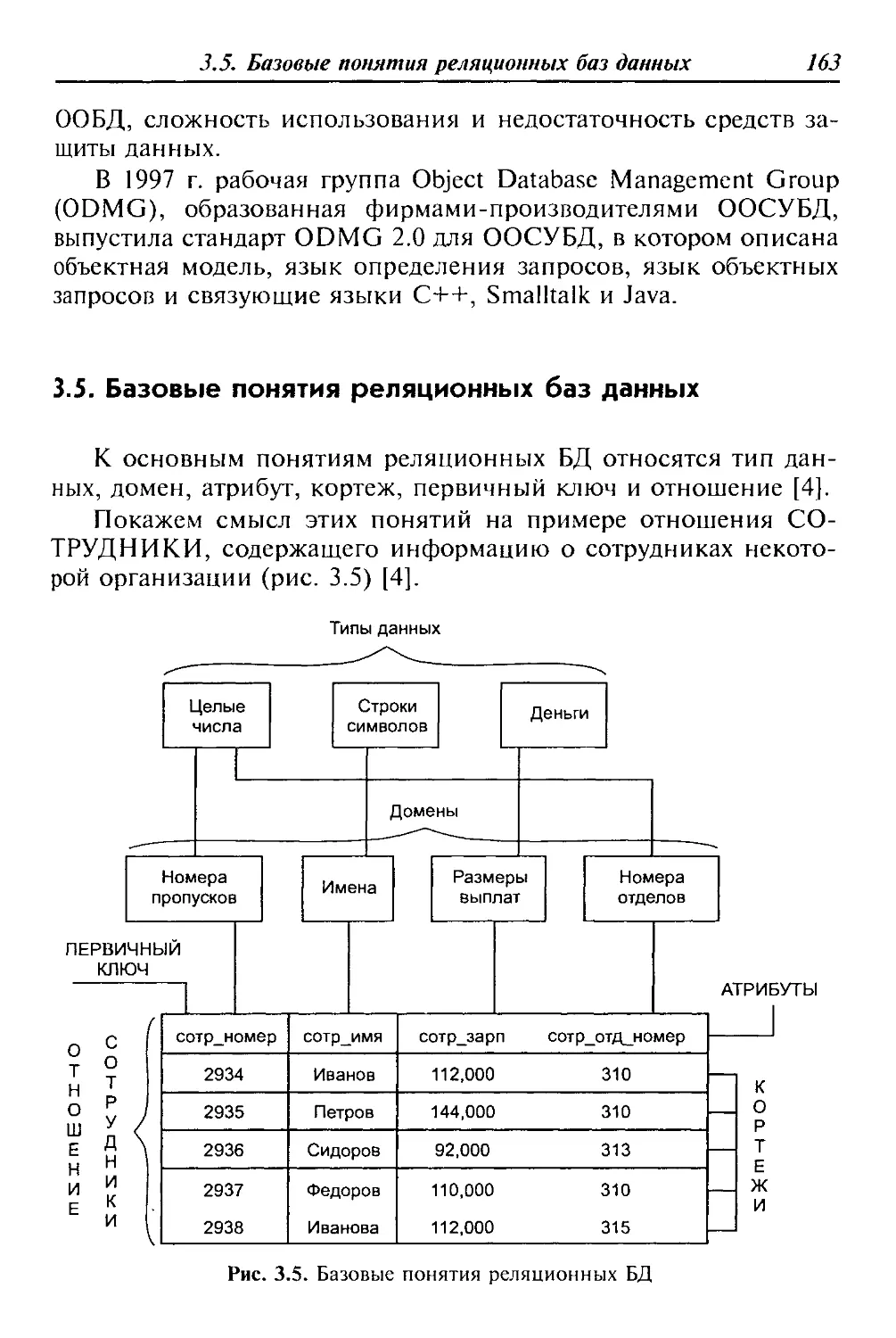
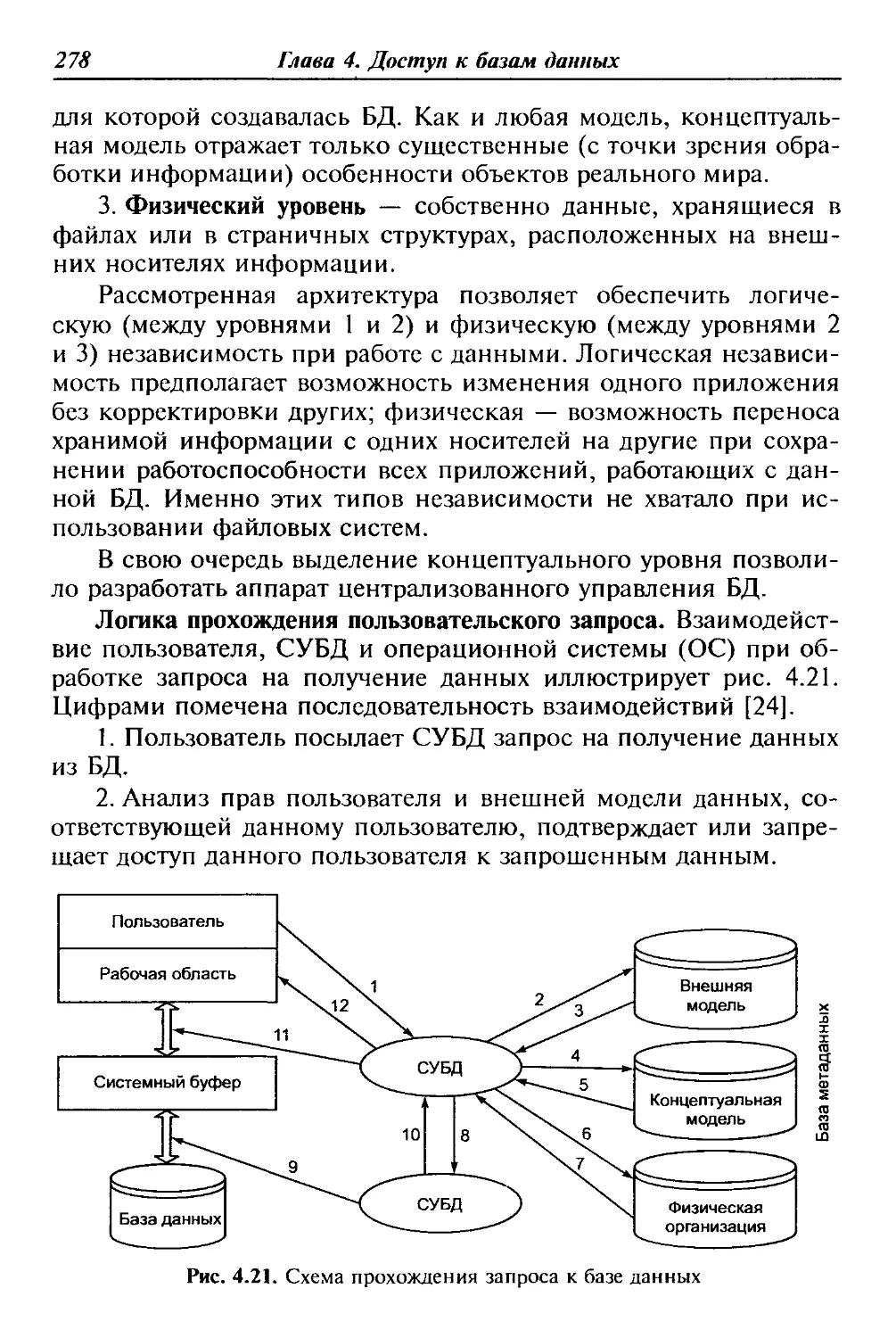
Таблица 1.1. Позиционирование на рынке АИС
Локальные Малые интегрированные Средние интегрированные Крупные интегрированные
Супер-Менеджер Инотек Инфософт БЭСТ Турбо-Бухгалтер Инфо-Бухгалтер Concorde XAL Exact NS-2000 Platinum PRO/MIS Scala SunSystems БЭСТ-ПРО 1С-Предприятие БОСС-Корпорация Галактика Парус Ресурс Эталон Microsoft-Business Solutions-Navision Microsoft-Business Solutions Axapta. MFG-Pro (QAD/BMS) SyteLine (СОКАП/SYMIX) SAP/R3 (SAP AG) Baan(Baan) BPCS (ITS/SSA) Oracle Applications (Oracle)
В интегрированных АИС выделяют функциональные и обес-
печивающие подсистемы. Функциональные подсистемы инфор-
мационно обслуживают определенные виды деятельности, ха-
рактерные для структурных подразделений предприятия или
функций управления. Интеграция функциональных подсистем
10
Глава 1. Проектирование АИС
в единую систему достигается за счет создания и функциониро-
вания обеспечивающих подсистем.
Функциональная подсистема представляет собой комплекс за-
дач с высокой степенью информационных обменов (связей) ме-
жду задачами. При этом под задачей понимается некоторый
процесс обработки информации с четко определенным множест-
вом входной и выходной информации. Состав функциональных
подсистем определяется характером и особенностями автомати-
зируемой деятельности, отраслевой принадлежностью, формой
собственности, размером предприятия. Деление АИС на функ-
циональные подсистемы может строиться по различным прин-
ципам:
• предметному;
• функциональному;
• проблемному;
• смешанному (предметно-функциональному).
При использовании предметного принципа [5] выделяют под-
системы, отвечающие за управление отдельными ресурсами:
управление сбытом, управление производством, управление фи-
нансами, управление персоналом и т. д. При этом в подсистемах
рассматривается решение задач на всех уровнях управления,
обеспечивая интеграцию информационных потоков по вертика-
ли (табл. 1.2).
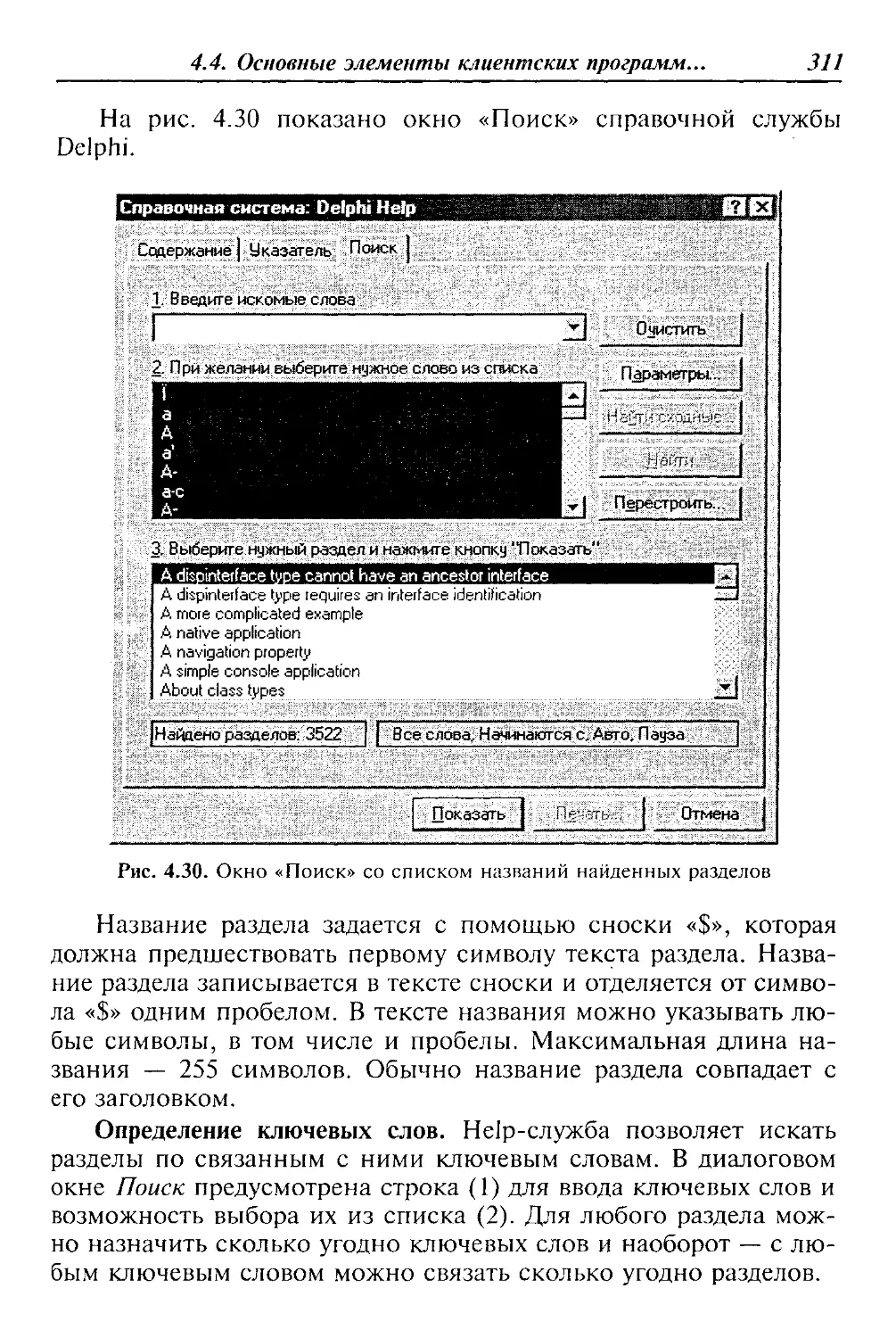
Таблица 1.2. Функциональные подсистемы, выделенные по предметному принципу
Уровни управления Функциональные подсистемы
Сбыт Производство Снабжение Финансы
Стратегиче- ский уровень Новые продукты и услуги. Исследования и разработки Производственные мощности. Выбор технологий технологии Материальные ис- точники. Товарный прогноз Финансовые ис- точники. Выбор модели уплаты налогов
Тактический уровень Анализ и плани- рование объ- емов сбыта Анализ и планирова- ние производствен- ных программ Анализ и планиро- вание объемов за- купок Анализ и плани- рование денеж- ных потоков
Оперативный уровень Обработка зака- зов клиентов. Выписка счетов и накладных Обработка производ- ственных заказов Складские операции. Заказы на закупку Ведение бухгал- терских книг
1.1. Понятие и классификация АИС 11
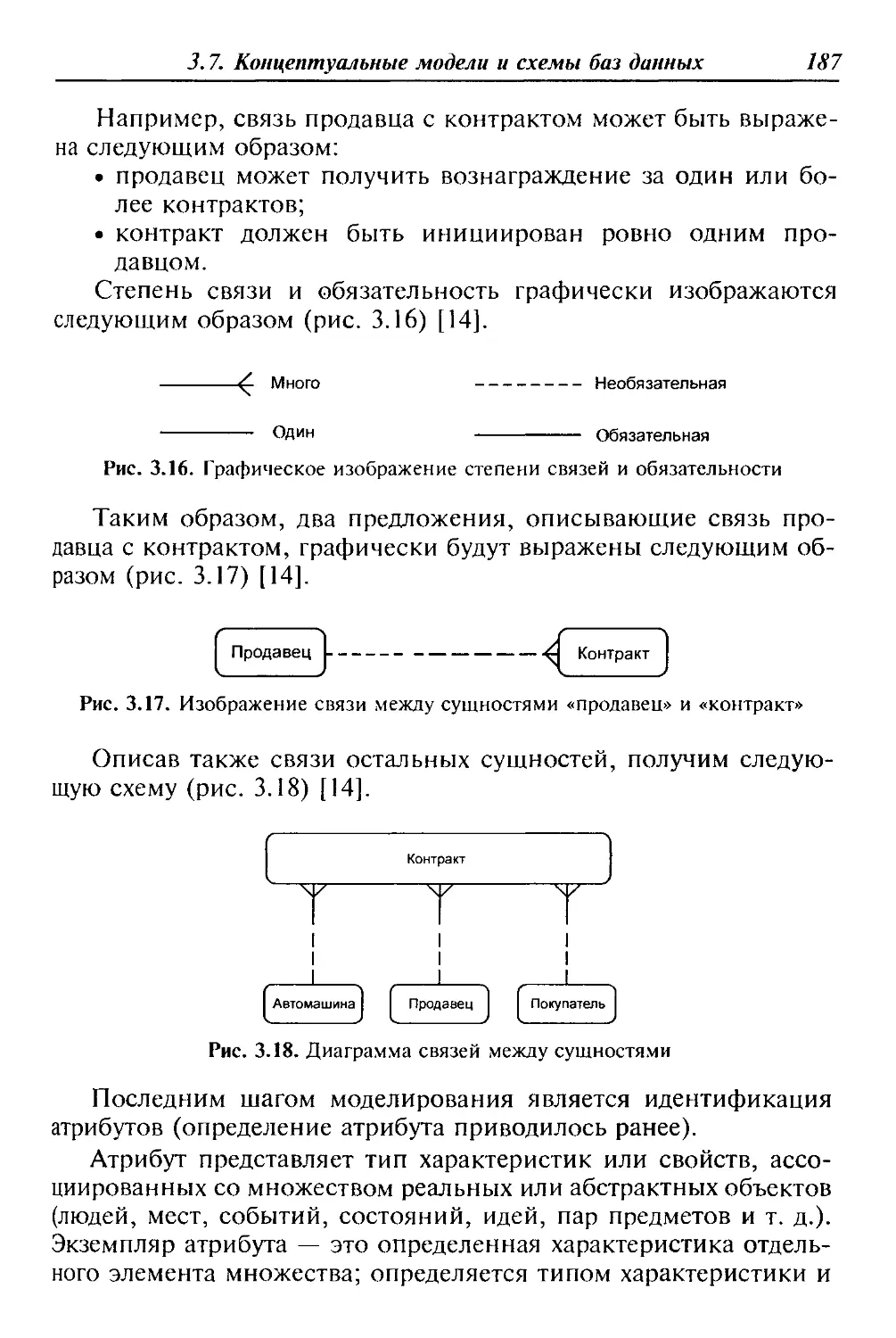
Применение функционального принципа [5] предполагает вы-
деление подсистем по направлениям деятельности: технико-эко-
номическое планирование, бухгалтерский учет, анализ хозяйст-
венной деятельности, перспективное развитие (рис. 1.2).
Рис. 1.2. Структура функциональных подсистем АИС согласно
функциональному принципу
Состав обеспечивающих подсистем не зависит от конкретных
функциональных подсистем и предметной области и рассматри-
вается в п. 1.2.
Рассмотренная классификация АИС с указанными выше
классификационными признаками не является единственной.
Приведем пример классификации, где в качестве основного клас-
сификационного признака рассматриваются особенности авто-
матизируемой профессиональной деятельности — процесса пере-
работки входной информации для получения требуемой выход-
ной [9].
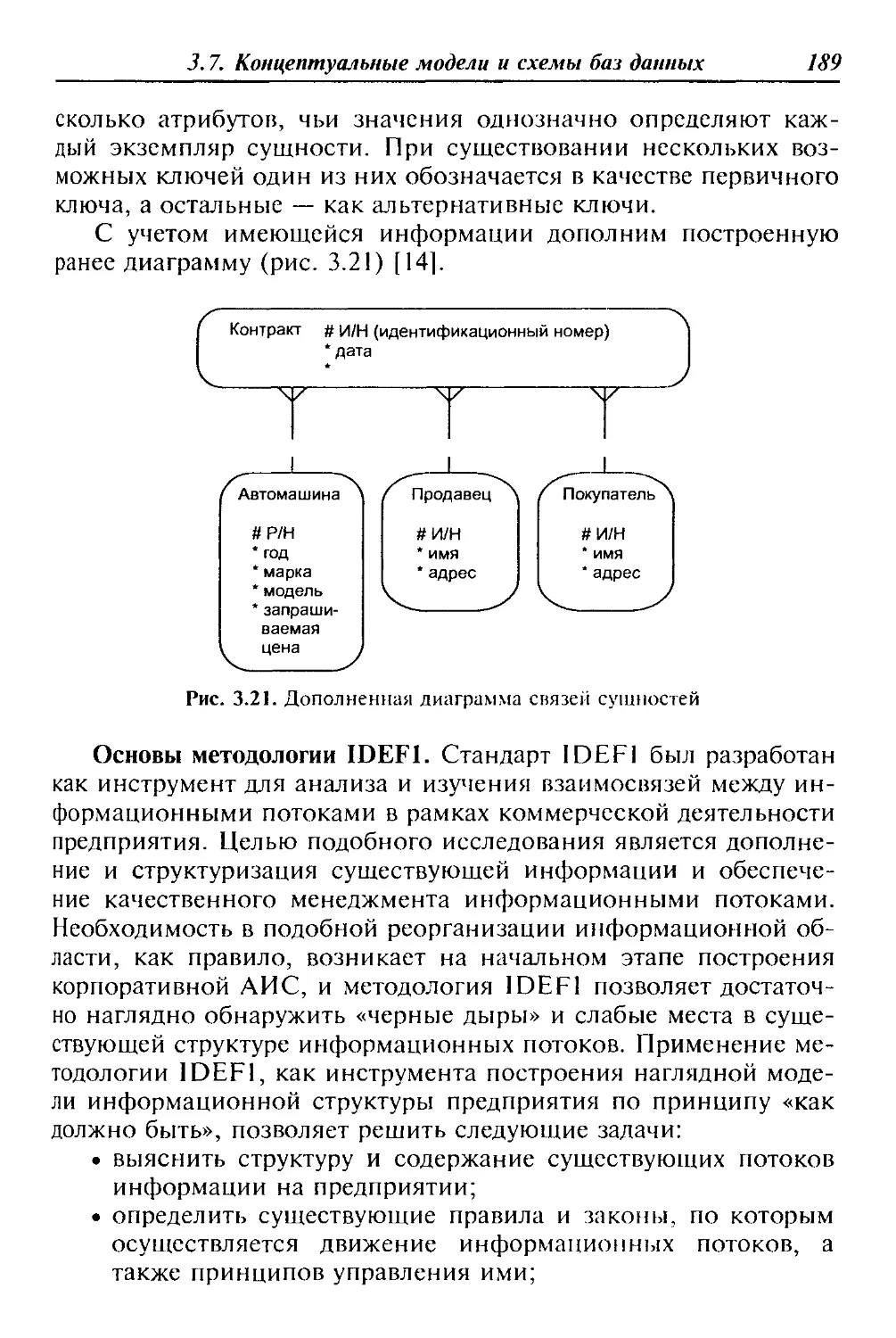
В соответствии с названиями приведенных на рис. 1.3 систем
(аббревиатуры общеприняты среди специалистов по информа-
12
Глава 1. Проектирование АИС
Рис. 1.3. Классификация АИС с учетом особенностей автоматизируемой профес-
сиональной деятельности:
АСУ — автоматизированные системы управления (П — персоналом, ТС — тех-
ническими средствами); СППР — системы поддержки принятия решения (Р —
руководителя, О — должностного лица органа управления, Д — оперативного де-
журного, Оп — оператора); АИВС — автоматизированные информационно-вы-
числительные системы; ИРС — информационно-расчетная система; САПР —
система автоматизированного проектирования; МЦ — моделирующий центр;
ПОИС — проблемно-ориентированная имитационная система; АИИС — авто-
матизированные информационно-справочные системы; АА — автоматизирован-
ные архивы; АСД — автоматизированные системы делопроизводства; АС — ав-
томатизированные справочники и АК — автоматизированные картотеки;
АСВЭК — автоматизированные системы ведения электронных карт; АСО — ав-
томатизированные системы обучения; АСОДИ — автоматизированные системы
обеспечения деловых игр; Т и ТК — тренажеры и тренажерные комплексы
ционным технологиям и системам) нетрудно определить назна-
чение и особенности каждой из них.
1.2. Обеспечение АИС
Различают девять обеспечивающих подсистем или так назы-
ваемое обеспечение АИС, в частности [4]:
• информационное;
• лингвистическое;
* математическое;
• методическое;
• организационное;
J.2. Обеспечение АИС
13
• правовое;
• программное;
• техническое;
• эргономическое.
Ниже приведены тестированные определения каждого вида
обеспечения, его компоненты и особенности.
Информационное обеспечение — совокупность форм докумен-
тов, классификаторов, нормативной базы и реализованных ре-
шений по объемам, размещению и формам существования ин-
формации, применяемой в АИС при ее функционировании [4].
Информационное обеспечение включает:
• описание технологических процессов;
• описание организации информационной базы;
• описание входных потоков;
• описание выходных сообщений;
• описание систем классификации и кодирования;
• формы документов;
• описание структуры массивов.
Системы классификации [10] позволяют группировать объ-
екты, выделяя определенные классы, которые характеризуются
рядом общих свойств. Классификаторы представляют собой сис-
тематизированные своды, перечни классифицируемых объектов
и имеют определенное (обычно числовое) обозначение. Приме-
няются государственные, отраслевые, региональные классифи-
каторы. Например, классифицированы отрасли промышленно-
сти, оборудование, профессии, единицы измерения, статьи за-
трат и т. д.
Назначение классификаторов:
• систематизация наименований кодируемых объектов;
• однозначная интерпретация одних и тех же объектов в раз-
личных задачах;
• возможность обобщения информации по заданной сово-
купности признаков;
• возможность сопоставления одних и тех же показателей,
содержащихся в формах статистической отчетности;
• возможность поиска и обмена информацией между под-
системами и внешними АИС;
• оптимизация использования ресурсов вычислительной тех-
ники при работе с кодируемой информацией.
14
Глава 1. Проектирование АИС
Используются три метода классификации объектов, которые
различаются стратегией применения классификационных при-
знаков:
• иерархический;
• фасетный;
• дескрипторный.
Иерархический метод реализует достаточно жесткую процеду-
ру построения структуры классификации. Предварительно опре-
деляется цель — набор свойств, которыми должны обладать
классифицируемые объекты. Эти свойства полагают признаками
классификации. В иерархической системе классификации каж-
дый объект на любом уровне должен быть отнесен к одному
классу, характеризуемому конкретным значением выбранного
классификационного признака. Количество уровней классифи-
кации, соответствующее числу признаков, выбранных в качестве
основания деления, характеризует глубину классификации.
Достоинства иерархической системы классификации: про-
стота построения и использование независимых классификаци-
онных признаков в различных ветвях иерархической структуры.
Недостатками этой системы являются жесткая структура, ос-
ложняющая внесение изменений, так как это приводит к пере-
распределению классификатора, и невозможность группировать
объекты по заранее не предусмотренным сочетаниям признаков.
При использовании фасетного метода классификации до-
пустимо выбирать признаки классификации независимо как
друг от друга, так и от семантического содержания классифици-
руемого объекта. Признаки классификации называются фасета-
ми (facet — рамка). Каждый фасет содержит совокупность одно-
родных значений данного классификационного признака, при-
чем значения в фасете могут располагаться в произвольном
порядке, хотя предпочтительнее их упорядочение. Схема по-
строения фасетной системы классификации представляется в
виде таблицы. Названия столбцов соответствуют выделенным
классификационным признакам (фасетам). В каждой клетке таб-
лицы хранится конкретное значение фасета. Процедура класси-
фикации состоит в присвоении каждому объекту соответствую-
щих значений из фасетов [10].
Достоинства фасетной системы классификации: возмож-
ность создания большой емкости классификации, т. е. использо-
вания большого числа признаков классификации и их значений
для создания группировок; возможность простой модификации
1.2. Обеспечение АИС
15
всей системы классификации без изменения структуры сущест-
вующих группировок.
Недостатком системы является сложность ее построения, так
как необходимо учитывать все многообразие классификацион-
ных признаков.
Для организации поиска информации, для ведения тезауру-
сов (словарей) эффективно используется дескрипторная (описа-
тельная) система классификации, язык которой приближается к
естественному языку описания информационных объектов. Осо-
бенно широко она используется в библиотечной системе поиска.
Системы классификации принципиально отличаются от сис-
тем кодирования в соответствии с определением.
Система кодирования — совокупность правил кодового обо-
значения объектов. Код строится на базе алфавита, состоящего
из букв, цифр и других символов. Код характеризуется: дли-
ной — число позиций в коде, и структурой — порядок располо-
жения в коде символов, используемых для обозначения класси-
фикационного признака.
Кодирование применяется для замены названия объекта на
условное обозначение (код) в целях обеспечения удобной и бо-
лее эффективной обработки информации.
Унифицированные системы документации создаются на госу-
дарственном, отраслевом и региональном уровнях. Главная цель
их использования — обеспечение сопоставимости показателей
различных сфер общественного производства. Разработаны стан-
дарты, где устанавливаются требования к:
• унифицированным системам документации;
• унифицированным формам документов различных уровней
управления;
• составу и структуре реквизитов и показателей;
• порядку внедрения, ведения и регистрации унифицирован-
ных форм документов.
Однако, несмотря на существование унифицированной сис-
темы документации, при обследовании большинства организа-
ций постоянно выявляют типичные недостатки:
• чрезвычайно большой объем документов для ручной обра-
ботки;
• одни и те же показатели часто дублируются в разных доку-
ментах;
• работа с большим количеством документов отвлекает спе-
циалистов от решения непосредственных задач;
16
Глава 1. Проектирование АИС
• наличие показателей, которые создаются, но не использу-
ются, и др.
Устранение указанных недостатков является одной из задач,
стоящих при создании информационного обеспечения.
Схемы информационных потоков отражают маршруты движе-
ния информации, ее объемы, места возникновения и использо-
вания. Анализ таких схем позволяет выработать меры по совер-
шенствованию всей системы управления.
Для создания информационного обеспечения необходимо:
• ясное понимание целей, задач, функций всей системы
управления организацией;
• выявление движения информации от момента возникнове-
ния и до ее использования на различных уровнях управле-
ния, представленной для анализа в виде схем информаци-
онных потоков;
• совершенствование системы документооборота;
• наличие и использование системы классификации и коди-
рования;
• владение методологией создания концептуальных информа-
ционно-логических моделей, отражающих взаимосвязь ин-
формации;
• создание массивов информации на машинных носителях,
что требует наличия современного технического обеспе-
чения.
Лингвистическое обеспечение — совокупность средств и правил
для формализации естественного языка, используемых при обще-
нии пользователей и эксплуатационного персонала АИС с ком-
плексом средств автоматизации при функционировании АИС [4].
Языковые средства лингвистического обеспечения делятся
на две группы: традиционные языки (естественные, математиче-
ские, алгоритмические, моделирования) и языки, предназначен-
ные для диалога с ЭВМ.
Математическое обеспечение — совокупность математических
методов, моделей и алгоритмов, применяемых в АИС [4].
В состав математического обеспечения входят:
• средства математического обеспечения (средства моделиро-
вания типовых задач управления, методы многокритери-
альной оптимизации, математической статистики, теории
массового обслуживания и др.);
• техническая документация (описание задач, алгоритмы ре-
шения задач, экономико-математические модели);
1.2. Обеспечение АИС
17
• методы выбора математического обеспечения (методы
определения типов задач, методы оценки вычислительной
сложности алгоритмов, методы оценки достоверности ре-
зультатов).
Методическое обеспечение — совокупность документов, описы-
вающих технологию функционирования АИС, методы выбора и
применения пользователями технологических приемов для получе-
ния конкретных результатов при функционировании АИС [4].
Организационное обеспечение — совокупность документов,
устанавливающих организационную структуру, права и обязан-
ности пользователей и эксплуатационного персонала АИС в ус-
ловиях функционирования, проверки и обеспечения работоспо-
собности АИС [4].
Организационное обеспечение реализует следующие функ-
ции:
• анализ существующей системы управления предприятием
(организацией), где используется АИС, выявление задач,
подлежащих автоматизации;
• подготовку задач к автоматизации, включая разработку тех-
нических заданий и технико-экономических обоснований
эффективности;
• разработку управленческих решений по изменению струк-
туры организации и методологий решения задач, направ-
ленных на повышение эффективности системы управления.
Организационное обеспечение включает:
• методические материалы, регламентирующие процесс со-
здания и функционирования АИС;
• совокупность средств для эффективного проектирования и
функционирования АИС;
• техническую документацию, получаемую в процессе обсле-
дования предприятия, проектирования, внедрения и со-
провождения системы;
• персонал (организационно-штатные структуры предпри-
ятия), проектирующий, внедряющий, сопровождающий и
использующий ИС.
Правовое обеспечение — совокупность правовых норм, регла-
ментирующих правовые отношения при функционировании
АИС и юридический статус результатов ее функционирования.
Примечание: правовое обеспечение реализуется в организа-
ционном обеспечении АИС [4].
18
Глава 1. Проектирование АИС
В состав правового обеспечения входят законы, указы, по-
становления государственных органов власти; приказы, инструк-
ции и другие нормативные документы министерств, ведомств,
организаций, местных органов власти. В правовом обеспечении
можно выделить общую часть, регулирующую функционирова-
ние любой ИС, и локальную часть, регулирующую функциони-
рование конкретной системы.
Правовое обеспечение разработки АИС включает норматив-
ные акты, связанные с договорными отношениями разработчика
и заказчика и правовым регулированием отклонений от договора.
Правовое обеспечение функционирования АИС включает:
• статус АИС;
• права, обязанности и ответственность персонала;
• правовые положения отдельных видов процесса управле-
ния;
• порядок создания и использования информации.
Программное обеспечение — совокупность программ на но-
сителях данных и программных документов, предназначенная
для отладки, функционирования и проверки работоспособности
АИС [4].
К программному обеспечению АИС относят:
• программное обеспечение, специально разработанное в
рамках автоматизации, реализующее разработанные моде-
ли разной степени адекватности, отражающие функциони-
рование реального объекта;
• программное обеспечение общего назначения, предназна-
ченное для решения типовых задач обработки информации.
Техническая документация на разработку программных
средств должна содержать описание задач, задание на алгорит-
мизацию, экономико-математическую модель задачи, контроль-
ные примеры.
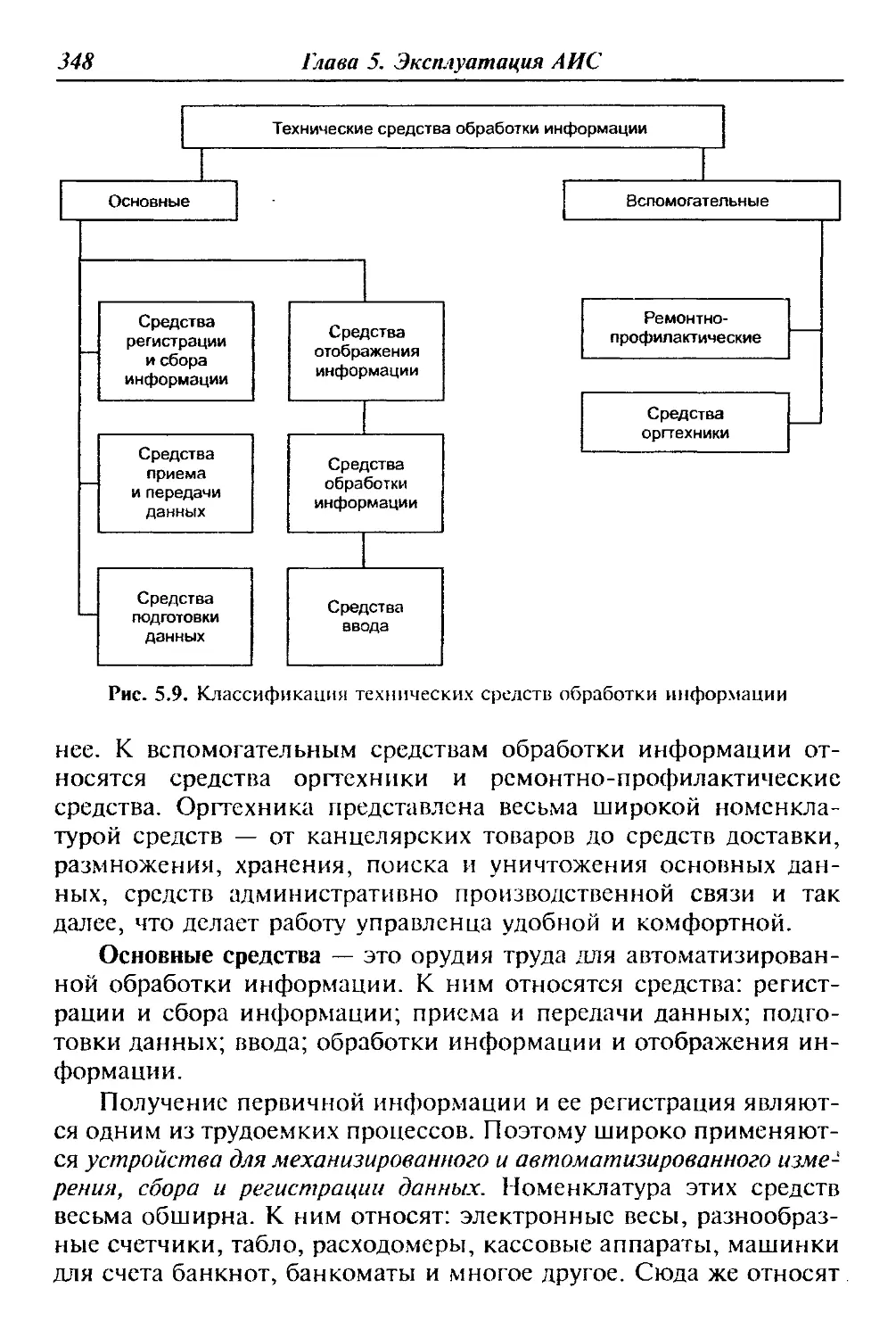
Техническое обеспечение — совокупность всех технических
средств, используемых при функционировании АИС [4].
К техническим средствам относят:
• используемую вычислительную технику разного назначе-
ния (серверы, рабочие станции);
• специальные устройства сбора, накопления, обработки, пе-
редачи и вывода информации;
• устройства передачи данных и линии связи;
• устройства автоматического съема информации;
• оргтехнику, эксплуатационные материалы и т. д.
1.3. Архитектура АИС
19
Выбор технических средств, организация их эксплуатации,
технологический процесс обработки данных, технологическое
оснащение документально оформляются.
Документацию технического обеспечения можно условно
разделить на группы:
• общесистемная документация, включающая государствен-
ные и отраслевые стандарты по техническому обеспече-
нию;
• специализированная документация, содержащая комплекс
методик по всем этапам разработки технического обеспе-
чения;
• нормативно-справочная документация, используемая при
выполнении расчетов по техническому обеспечению.
Эргономическое обеспечение — совокупность реализованных
решений в АИС по согласованию психологических, психофи-
зиологических, антропометрических, физиологических характе-
ристик и возможностей пользователей АИС с техническими ха-
рактеристиками комплекса средств автоматизации АИС и пара-
метрами рабочей среды на рабочих местах персонала АИС [4].
Охрана здоровья трудящихся, обеспечение безопасности ус-
ловий труда, ликвидация профессиональных заболеваний и про-
изводственного травматизма составляют одну из главных забот
человеческого общества. Обращается внимание на необходи-
мость широкого применения прогрессивных форм научной ор-
ганизации труда, сведения к минимуму ручного, малоквалифи-
цированного труда, на создание обстановки, исключающей про-
фессиональные заболевания и производственный травматизм.
1.3. Архитектура АИС
Термин «архитектура» применительно к вычислительным
системам появился задолго до создания первых АИС, тем не ме-
нее он является одним из основополагающих и в сфере инфор-
мационных технологий. Существуют различные подходы к опре-
делению архитектуры АИС, различные точки зрения и различная
степень детализации рассмотрения; приведем некоторые из них.
Согласно [11] архитектура — это организационная структура
автоматизированной системы. Известно и другое определение
[12]: архитектура — это концептуальное описание структуры
20
Глава 1. Проектирование АИС
системы, включающее описание элементов системы, их взаимо-
действия и внешних свойств. Выделяют два уровня архитектуры
АИС:
• бизнес-архитектуру (бизнес-уровень);
• уровень информационных технологий (технический уро-
вень).
Бизнес-архитектура обычно первична по отношению к тех-
ническому уровню; может существовать и реализуема вне зави-
симости от существования АИС. Бизнес-архитектура является
предметной областью для анализа и проведения автоматизации.
На бизнес-уровне определяется набор задач, требований, харак-
теристик, осуществляемых с помощью АИС. Соответствие ука-
занному уровню технического уровня является основой эффек-
тивности функционирования АИС.
С другой стороны, новые возможности, предоставляемые ис-
пользованием информационных технологий, стимулируют раз-
витие и корректировку бизнес-архитектуры, в связи с чем она
является неотъемлемой частью архитектуры АИС и всего пред-
приятия [13].
Уровень информационных технологий или технический уровень
представляет собой интегрированный комплекс технических
средств, используемых в АИС для реализации задач предпри-
ятия, и включает в себя как логические, так и технические (про-
граммные и аппаратные) компоненты. Компонентами этого
уровня, в свою очередь, являются следующие подуровни:
• архитектура программных систем;
• информационная архитектура;
• технологическая (инфраструктурная) архитектура.
Информационная архитектура представляет собой логическую
организацию данных, с которыми работает АИС, т. е. практиче-
ски структуры баз данных и баз знаний, а также принципы их
взаимодействия.
Под архитектурой программных систем понимают совокуп-
ность следующих технических решений:
• общий архитектурный стиль и общую организацию про-
граммной части АИС;
• деление программного комплекса на функциональные под-
системы и модули;
• свойства модулей, методы их взаимодействия и объедине-
ния, используемые интерфейсы.
1.4. Жизненный цикл АИС
21
Архитектура программной системы охватывает не только
структурные и поведенческие аспекты, но и правила ее использо-
вания и интеграции с другими системами, функциональность,
производительность, гибкость, надежность, эргономичность, тех-
нологические ограничения.
Технологическая архитектура описывает инфраструктуру, ис-
пользуемую для передачи данных. На этом уровне решаются во-
просы сетевой структуры, применяемых каналов связи и т. д.
По мере развития программных систем все большее значе-
ние приобретает их комплексная интеграция для построения
единого информационного пространства предприятия. Обеспе-
чение такой интеграции является важнейшим элементом архи-
тектуры, в противном случае АИС окажется неэффективной.
В современных стандартах четко определены процессы со-
здания архитектуры, способной к удовлетворению не только
сформулированных, но и потенциальных потребностей пользо-
вателей. К числу самых известных и авторитетных разработчи-
ков стандартов в области АИС относятся следующие междуна-
родные организации:
• SEI (Software Engineering Institute);
• WWW (консорциум World Wide Web);
• OMG (Object Management Group);
• организация разработчиков Java — JCP (Java Community
Process);
• IEEE (Institute of Electrical and Electronics Engineers) и т. д.
1.4. Жизненный цикл АИС
Одним из базовых понятий методологии проектирования
АИС является понятие жизненного цикла ее программного
обеспечения (ЖЦ ПО). ЖЦ ПО — это непрерывный процесс,
который начинается с момента принятия решения о необходи-
мости его создания и заканчивается в момент его полного изъя-
тия из эксплуатации [15].
По аналогии правомерно будет утверждать, что жизненный
цикл АИС есть непрерывный процесс с момента принятия ре-
шения о необходимости ее создания до полного завершения ее
эксплуатации. Продолжительность жизненного цикла современ-
ных АИС составляет около 10 лет, что значительно превышает
сроки морального и физического старения технических и сис-
22
Глава 1. Проектирование АИС
темных программных средств, используемых при реализации
АИС. Поэтому, как правило, в течение ЖЦ системы проводится
ее модернизация, после чего все функции системы должны вы-
полняться с не меньшей эффективностью.
Добиться этого на протяжении всего ЖЦ АИС — довольно
сложная по ряду объективных и субъективных причин задача, в
результате подавляющее большинство проектов АИС внедряется
с нарушениями качества, сроков или сметы; почти треть проек-
тов прекращают свое существование незавершенными. По дан-
ным Standish Group в 1996 г. 84 % проектов АИС не были завер-
шены в установленные сроки, в 1998 г. это число сократилась до
74 %, после 2000 г. оно не опускается ниже 50 % [19]. Главной
причиной такого положения является то, что уровень техноло-
гии анализа и проектирования систем, методов и средств управ-
ления проектами не соответствует сложности создаваемых сис-
тем, которая постоянно возрастает в связи с усложнением и бы-
стрыми изменениями бизнеса [19].
Из мировой практики известно, что затраты на сопровожде-
ние прикладного программного обеспечения АИС составляют не
менее 70 % его совокупной стоимости на протяжении ЖЦ, по-
этому крайне важно еще на проектной стадии предусмотреть не-
обходимые методы и средства сопровождения, включая методы
конфигурационного управления.
Процесс проектирования АИС регламентирован следующей
документацией (стандартами, методологиями, моделями) [18, 19]:
• ГОСТ 34.601—90 — стандарт на стадии и этапы создания
АИС, соответствующие каскадной модели ЖЦ ПО (рас-
сматривается ниже). Приводится описание содержания ра-
бот на каждом этапе;
• ISO/IEC 12207:1995 — стандарт на процессы и организа-
цию жизненного цикла; распространяется на все виды за-
казного программного обеспечения; не содержит описания
фаз, стадий и этапов;
• Custom Development Method (методология Oracle) — техно-
логический материал по разработке прикладных АИС, де-
тализированный до уровня заготовок проектных докумен-
тов в расчете на использование Oracle. Применяется для
классической модели ЖЦ (предусмотрены все работы, за-
дачи и этапы), а также для технологий «быстрой разработ-
ки» (Fast Track) или «облегченного подхода», рекомендуе-
мых в случае малых проектов;
1.4. Жизненный цикл АИС
23
• Rational Unified Process (методология RUP) — технологиче-
ский материал по реализации итеративной модели разра-
ботки, включающей четыре фазы (цикл разработки): нача-
ло, исследование, построение и внедрение. Каждая фаза
разбита на этапы (итерации), результатами которых явля-
ются версии для внутреннего или внешнего использова-
ния. Каждый цикл завершается генерацией очередной вер-
сии системы. Если после этого работа над проектом не
прекращается, то полученный продукт продолжает разви-
ваться и снова проходит те же фазы. Суть работы в рамках
RUP-методологии — создание и сопровождение моделей
на базе UML [14];
• Microsoft Solution Framework (методология MSF) — техно-
логический материал по реализации итеративной модели
разработки, аналогично RUP включает четыре фазы: ана-
лиз, проектирование, разработку, стабилизацию; предпола-
гает использование объектно-ориентированного моделиро-
вания. MSF в сравнении с RUP в большей степени ориен-
тирована на разработку бизнес-приложсний;
• Extreme Programming (ХР) — экстремальное программиро-
вание (самая новая среди рассматриваемых методологий);
сформировалось в 1996 г. Основой методологии является
работа в команде, эффективные коммуникации между за-
казчиком и исполнителем в течение всего проекта; разра-
ботка АИС ведется с использованием последовательно до-
рабатываемых прототипов.
В качестве определяющего документа на создание и испыта-
ния АИС целесообразно рассматривать международный стандарт
ISO/IEC 12207, так как ГОСТы серии 34 уже устарели, а ряд эта-
пов ЖЦ АИС представлены недостаточно полно. Стандарт
ISO/IEC 12207 в структуре жизненного цикла определяет про-
цессы, которые выполняются при создании ПО АИС. Эти про-
цессы подразделяют на три группы:
• основные (приобретение, поставка, разработка, эксплуата-
ция и сопровождение);
• вспомогательные (документирование, управление конфигу-
рацией, обеспечение качества, верификация, аттестация,
оценка, аудит и решение проблем);
• организационные (управление проектами, создание инфра-
структуры проекта, определение, оценка и улучшение са-
мого жизненного цикла, обучение).
24
Глава 1. Проектирование АИС
Среди основных процессов жизненного цикла самыми важ-
ными являются разработка, эксплуатация и сопровождение. Каж-
дый процесс характеризуется определенными задачами и мето-
дами их решения, исходными данными, полученными на преды-
дущем этапе, и результатами [8, 18, 19].
Разработка АИС включает все работы по созданию про-
граммного обеспечения и его компонентов в соответствии с за-
данными требованиями. Этот процесс также предусматривает:
• оформление проектной и эксплуатационной документа-
ции;
• подготовку материалов, необходимых для тестирования
разработанных программных продуктов;
• разработку материалов, необходимых для обучения персо-
нала.
Как правило, составляющими процесса разработки являются
стратегическое планирование, анализ, проектирование и реали-
зация (программирование).
К процессу эксплуатации относятся:
• конфигурирование базы данных и рабочих мест пользова-
телей;
• обеспечение пользователей эксплуатационной документа-
цией;
• обучение персонала.
Основные эксплуатационные работы включают:
• непосредственно эксплуатацию;
• локализацию проблем и устранение причин их возникно-
вения;
• модификацию программного обеспечения;
• подготовку предложений по совершенствованию системы;
• развитие и модернизацию системы.
Профессиональное, грамотное сопровождение — необходи-
мое условие решения задач, выполняемых АИС. Службы техни-
ческой поддержки играют весьма заметную роль в жизни любой
АИС. Ошибки на этом этапе могут привести к явным или скры-
тым финансовым потерям, сопоставимым со стоимостью самой
системы.
К предварительным действиям при организации техническо-
го обслуживания АИС относятся:
• выделение наиболее ответственных узлов системы и опре-
деление для них критичности простоя (это позволит выде-
лить наиболее критичные составляющие АИС и оптимизи-
1.4. Жизненный цикл АИС
25
ровать распределение ресурсов для технического обслужи-
вания);
• определение задач технического обслуживания и их разде-
ление на внутренние, решаемые силами обслуживающего
подразделения, и внешние, решаемые специализированны-
ми сервисными организациями (таким образом четко огра-
ничивается круг исполняемых функций и производится
распределение ответственности);
• проведение анализа имеющихся внутренних и внешних ре-
сурсов, необходимых для организации технического обслу-
живания в рамках описанных задач и разделения компе-
тенции (основные критерии для анализа: наличие гарантии
на оборудование, состояние ремонтного фонда, квалифи-
кация персонала);
• подготовка плана организации технического обслужива-
ния с определением этапов исполняемых действий, сроков
их исполнения, затрат на этапах, ответственности испол-
нителей.
Обеспечение качественного технического обслуживания
АИС требует привлечения специалистов высокой квалифика-
ции, которые в состоянии решать не только ежедневные задачи
администрирования, но и быстро восстанавливать работоспособ-
ность системы при сбоях и авариях.
В табл. 1.3 ориентировочно приведены описания основных
процессов ЖЦ АИС.
Среди вспомогательных процессов одним из главных является
управление конфигурацией, которое поддерживает основные про-
цессы жизненного цикла АИС, прежде всего процессы разработ-
ки и сопровождения.
Разработка сложных АИС предполагает независимую разра-
ботку компонентов системы, что приводит к появлению многих
вариантов и версий реализации как отдельных компонентов, так
и системы в целом. Таким образом, возникает проблема обеспе-
чения сохранения единой структуры в ходе разработки и модер-
низации АИС. Управление конфигурацией позволяет организо-
вывать, систематически учитывать и контролировать внесение
изменений в различные компоненты АИС на всех стадиях ее
ЖЦ [2, 5, 6].
Организационные процессы имеют очень большое значение,
так как современные АИС — это большие комплексы, в созда-
Таблица 1.3. Содержание основных процессов ЖЦ АИС (ISO/IEC 12207)
Процесс(испол- нитель процесса) Действия Вход Результат
Приобретение (заказчик) Инициирование. Подготовка заявочных предло- жений. Подготовка договора. Контроль деятельности постав- щика. Приемка АИС Решение о начале работ по внедре- нию АИС. Результаты обследования деятель- ности заказчика. Результаты анализа рынка АИС/тен- дера. План поставки/разработки. Комплексный тест АИС Технико-экономическое обоснование внедрения АИС. Техническое задание на АИС. Договор на поставку/разработку. Акты приемки этапов работы. Акт приемо-сдаточных испытаний
Поставка (разработчик АИС) Инициирование. Ответ на заявочные предложения. Подготовка договора. Планирование исполнения. Поставка АИС Техническое задание на АИС. Решение руководства об участии в разработке. Результаты тендера. Техническое задание на АИС. План управления проектом. Разработанная АИС и документация Решение об участии в разработке. Коммерческие предпожения/конкурсная заявка. Договор на поставку/разработку. План управления проектом. Реапизация/корректировка. Акт приемо-сдаточных испытаний
Разработка (разработчик АИС) Подготовка. Анализ требований к АИС. Проектирование архитектуры АИС. Разработка требований к ПО. Проектирование архитектуры ПО. Детальное проектирование ПО. Кодирование и тестирование ПО. Интеграция ПО и квалификацион- ное тестирование ПО. Интеграция ИС и квалификацион- ное тестирование АИС Техническое задание на АИС. Техническое задание на АИС, мо- дель ЖЦ. Техническое задание на АИС. Подсистемы АИС. Спецификации требования к компо- нентам ПО. Архитектура ПО. Материалы детального проектиро- вания ПО. План интеграции ПО, тесты. Архитектура ИС, ПО, документация на ИС, тесты Используемая модель ЖЦ, стандарты разработки. План работ. Состав подсистем, компоненты оборудования. Спецификации требования к компонентам ПО. Состав компонентов ПО, интерфейсы с БД, план ин- теграции ПО. Проект БД, спецификации интерфейсов между ком- понентами ПО, требования к тестам. Тесты модулей ПО, акты автономного тестирования. Оценка соответствия комплекса ПО требованиям ТЗ. Оценка соответствия ПО, БД, технического комплек- са и комплекта документации требованиям ТЗ
Глава 1. Проектирование АИС
1.4. Жизненный цикл АИС
27
нии и обслуживании которых занято много людей разных спе-
циальностей.
Управление проектом связано с вопросами планирования и
организации работ, создания коллективов разработчиков, кон-
троля сроков и качества выполнения работ. Техническое и орга-
низационное обеспечение проекта включает:
• выбор методов и инструментальных средств реализации
проекта;
• определение методов описания состояния процесса разра-
ботки;
• разработку методов и средств испытаний созданного про-
граммного обеспечения;
• обучение персонала.
Обеспечение качества проекта связано с проблемами вери-
фикации, проверки и тестирования компонентов АИС.
Верификация — процесс определения соответствия текущего
состояния разработки, достигнутого на данном этапе, требова-
ниям этого этапа.
Проверка — процесс определения соответствия параметров
разработки исходным требованиям. Проверка отчасти совпадает с
тестированием, которое проводится для определения различий
между действительными и ожидаемыми результатами, а также для
оценки соответствия характеристик АИС исходным требованиям.
Для поддержки практического применения стандарта
ISO/IEC 12207 разработаны технологические документы: Руко-
водство для ISO/IEC 12207 (ISO/IEC TR 15271:1998 Information
technology — Guide for ISO/IEC 12207) и Руководство по приме-
нению ISO/IEC 12207 к управлению проектами (ISO/IEC TR
16326:1999 Software engineering — Guide for the application of
ISO/IEC 12207 to project management).
В 2002 г. был опубликован стандарт на процессы ЖЦ автома-
тизированных систем (ISO/IEC 15288 System life cycle processes).
В разработке стандарта участвовали специалисты из различных
областей деятельности; учитывался практический опыт создания
систем в правительственных, коммерческих, военных и академи-
ческих организациях. Согласно стандарту ISO/IEC серии 15288 в
структуру ЖЦ включены следующие группы процессов.
1. Договорные процессы:
• приобретение (внутренние решения или решения внеш-
него поставщика);
28
Глава 1. Проектирование АИС
• поставка (внутренние решения или решения внешнего
поставщика).
2. Процессы предприятия:
• управление окружающей средой предприятия;
• инвестиционное управление;
• управление ЖЦ ИС;
• управление ресурсами;
• управление качеством.
3. Проектные процессы:
• планирование проекта;
• оценка проекта;
• контроль проекта;
• управление рисками;
• управление конфигурацией;
• управление информационными потоками;
• принятие решений.
4. Технические процессы:
• определение требований;
• анализ требований;
• разработка архитектуры;
• внедрение;
• интеграция;
• верификация;
• переход;
• аттестация;
• эксплуатация;
• сопровождение;
• утилизация.
5. Специальные процессы:
• определение и установка взаимосвязей исходя из задач и
целей.
В табл. 1.4 приведены перечень стадий и основные результа-
ты к моменту их завершения в соответствии с указанным стан-
дартом.
В 1970-х гг. корпорация IBM предложила методологию
Business System Planning (BSP) или методологию организацион-
ного планирования.
Метод структурирования информации с использованием
матриц пересечения бизнес-процессов, функциональных под-
1.4. Жизненный цикл АИС
29
Таблица 1.4. Стадии создания АИС (ISO/IEC 15288)
Стадия Описание
Формирование концепции Анализ потребностей, выбор концепции и проектных решений
Разработка Проектирование системы
Реализация Изготовление системы
Эксплуатация Ввод в эксплуатацию и использование системы
Поддержка Обеспечение функционирования системы
Снятие с эксплуатации Прекращение использования, демонтаж, архивирование системы
разделений, функций систем обработки данных (информацион-
ных систем), информационных объектов, документов и баз дан-
ных, предложенный в BSP, используется сегодня не только в
проектах создания АИС, но и в проектах реинжиниринга биз-
нес-процессов, изменения организационной структуры. Важней-
шие шаги процесса BSP, их последовательность (получить под-
держку высшего руководства, определить процессы предпри-
ятия, определить классы данных, провести интервью, обработать
и организовать данные интервью) можно встретить практически
во всех формальных методиках, а также в проектах, реализуемых
на практике [21].
По опубликованным данным [19, 21] каждый этап разработки
АИС требует определенных затрат времени. В основном
(45—50 %) время уходит на кодирование, комплексное и авто-
го %
Рнс. 1.4. Распределение времени при разработке АИС
30
Глава 1. Проектирование АИС
Сопровождение
67%
Анализ
требований
3%
Комплексное
тестирование
7%
Кодирование
7%
Автономное
тестирование
8%
Проектирование
5%
Рис. 1.5. Распределение времени при разработке, эксплуатации
и сопровождении АИС
Определение
спецификаций
номное тестирование (рис. 1.4). В среднем разработка АИС зани-
мает лишь одну треть всего жизненного цикла системы (рис. 1.5).
1.5. Модели жизненного цикла АИС
Согласно [8, 16—18] рассмотренные выше процессы характе-
ризуются определенными задачами и методами их решения, ис-
ходными данными, полученными на предыдущем этапе, результ
татами. Результатами анализа, в частности, являются функцио-
нальные модели, информационные модели и соответствующие
им диаграммы. При этом ЖЦ ПО носит итерационный характер:
результаты очередного этапа часто вызывают изменения в прот
ектных решениях, выработанных на более ранних этапах. Из-
вестные модели ЖЦ ПО (каскадная, итерационная, спиральная)
определяют порядок исполнения этапов в ходе разработки, а
также критерии перехода от этапа к этапу.
По аналогии с известным определением модели ЖЦ ПО и в
соответствии с устоявшейся среди специалистов терминологией,
[18] приведем определение модели ЖЦ АИС.
Модель жизненного цикла АИС — это структура, описываю-
щая процессы, действия и задачи, которые осуществляются в
ходе разработки, функционирования и сопровождения в течение
всего жизненного цикла системы.
Модель ЖЦ АИС отражает состояние системы с момента*
осознания необходимости создания данной АИС до полной ее
1.5. Модели жизненного цикла АИС
31
утилизации. Выбор модели жизненного цикла зависит от специ-
фики, масштаба, сложности проекта и набора условий, в кото-
рых АИС создается и функционирует. Модель ЖЦ АИС вклю-
чает:
• стадии;
• результаты выполнения работ на каждой стадии;
• ключевые события или точки завершения работ и приня-
тия решений.
В соответствии с известными моделями ЖЦ ПО определяют
модели ЖЦ АИС — каскадную, итерационную, спиральную.
Ниже подробно рассмотрена каждая из них.
Каскадная модель описывает классический подход к разра-
ботке систем в любых предметных областях; широко использо-
валась в 1970—80-х гг. Организация работ по каскадной схеме
официально рекомендовалась и широко применялась в различ-
ных отраслях в связи с наличием теоретического обоснования,
промышленных методик и стандартов, а также успешного ис-
пользования модели в течение десятилетий.
Каскадная модель предусматривает последовательную орга-
низацию работ, причем основной особенностью модели являет-
ся разбиение всей работы на этапы. Переход от предыдущего
этапа к последующему происходит только после полного завер-
шения всех работ предыдущего. Каждый этап завершается вы-
пуском полного комплекта документации для того, чтобы иметь
возможность при необходимости всегда продолжить разработку.
Периодически названия стадий разработки в каскадной мо-
дели менялись; кроме того, в каждый период времени регламент
приписывания определенных работ к конкретным этапам нико-
гда не являлся жестким и однозначным. Тем не менее выделяют
пять устойчивых этапов разработки, практически не зависящих
от предметной области (рис. 1.6).
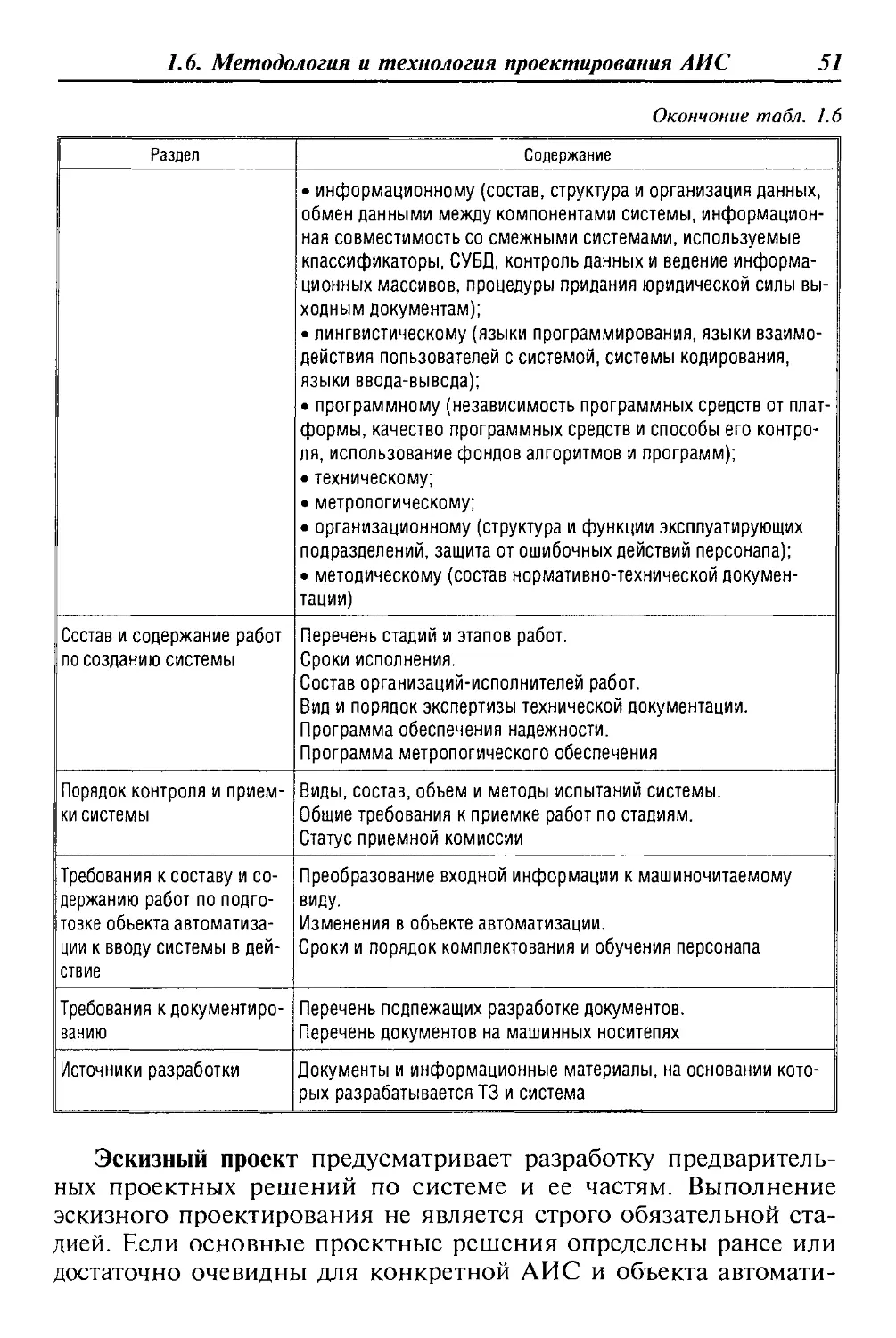
На первом этапе проводится исследование проблемной об-
ласти, формулируются требования заказчика. Результатом дан-
ного этапа является техническое задание (задание на разработ-
ку), согласованное со всеми заинтересованными сторонами.
В ходе второго этапа, согласно требованиям технического за-
дания, разрабатываются те или иные проектные решения. В ре-
зультате появляется комплект проектной документации.
Третий этап — реализация проекта; по существу, разработка
программного обеспечения (кодирование) в соответствии с про-
ектными решениями предыдущего этапа. Методы реализации
32
Глава 1. Проектирование АИС
Рис. 1.6. Каскадная модель ЖЦ АИС
при этом принципиального значения не имеют. Результатом вы-
полнения этапа является готовый программный продукт.
На четвертом этапе проводится проверка полученного про-
граммного обеспечения на предмет соответствия требованиям,
заявленным в техническом задании. Опытная эксплуатация по-
зволяет выявить различного рода скрытые недостатки, прояв-
ляющиеся в реальных условиях работы АИС.
Последний этап — сдача готового проекта, и главное здесь —
убедить заказчика в том, что все его требования выполнены в
полной мере.
Этапы работ в рамках каскадной модели часто называют час-
тями проектного цикла АИС, поскольку этапы состоят из мно-
гих итерационных процедур уточнения требований к системе и
вариантов проектных решений. ЖЦ АИС существенно сложнее
и длиннее: он может включать в себя произвольное число цик-
лов уточнения, изменения и дополнения уже принятых и реали-
зованных проектных решений. В этих циклах происходит разви-
тие АИС и модернизация отдельных ее компонентов.
Каскадная модель получила широкое распространение не
только среди специалистов, так как обладает достоинствами,
проявляющимися при выполнении различных разработок. Ниже
приведены основные:
1) на каждом этапе формируется законченный набор проект-
ной документации, отвечающий критериям полноты и согласо-
ванности. На заключительных этапах разрабатывается пользова-
тельская документация, охватывающая все предусмотренные
стандартами виды обеспечения АИС (организационное, инфор-
мационное, программное, техническое и т. д.);
1.5. Модели жизненного цикла АИС
33
2) последовательное выполнение этапов работ позволяет
планировать сроки завершения и соответствующие затраты.
Каскадная модель изначально разрабатывалась для решения
различного рода инженерных задач и не потеряла своего значе-
ния для прикладной области до настоящего времени. Кроме
того, каскадный подход идеально подходит для разработки АИС,
так как уже в самом начале разработки можно достаточно точно
и полно сформулировать все требования с тем, чтобы предоста-
вить разработчикам свободу технической реализации. К таким
АИС, в частности, относятся сложные расчетные системы и сис-
темы реального времени.
Тем не менее модель имеет ряд недостатков, ограничиваю-
щих ее применение:
• существенная задержка в получении результатов;
• ошибки и недоработки на любом из этапов проявляются,
как правило, на последующих этапах работ, что приводит к
необходимости возврата;
• сложность параллельного ведения работ по проекту;
• чрезмерная информационная перенасыщенность каждого
из этапов;
• сложность управления проектом;
• высокий уровень риска и ненадежность инвестиций.
Задержка в получении результатов проявляется в том, что
при последовательном подходе к разработке согласование ре-
зультатов с заинтересованными сторонами производится только
после завершения очередного этапа работ. В результате может
оказаться, что разрабатываемая АИС не соответствует требова-
ниям, и такие несоответствия могут возникать на любом этапе
разработки; кроме того, ошибки могут непреднамеренно вно-
ситься и проектировщиками-аналитиками, и программистами,
так как они не обязаны хорошо разбираться в тех предметных
областях, для которых разрабатывается АИС.
Кроме того, используемые при разработке АИС модели авто-
матизируемого объекта, отвечающие критериям внутренней со-
гласованности и полноты, в силу различных причин могут уста-
реть за время разработки (например, из-за внесения изменений
в законодательство).
Возврат на более ранние стадии. Этот недостаток является
одним из проявлений предыдущего: поэтапная последовательная
работа над проектом может привести к тому, что ошибки, допу-
щенные на более ранних этапах, обнаруживаются только на по-
34
Глава 1. Проектирование АИС
следующих стадиях. В результате проект возвращается на преды-
дущий этап, перерабатывается и только затем передается в по-
следующую работу. Это может послужить причиной срыва
графика и усложнения взаимоотношений между группами разра-
ботчиков, выполняющих отдельные этапы.
Самый плохой вариант, когда недоработки предыдущего эта-
па обнаруживаются не на следующем этапе, а позднее. Напри-
мер, на стадии опытной эксплуатации могут проявиться ошибки
в описании предметной области. Это означает, что часть проекта
должна быть возвращена на начальный этап работы. Вообще,
работа может быть возвращена с любого этапа на любой преды-
дущий, поэтому в реальности каскадная схема разработки выгля-
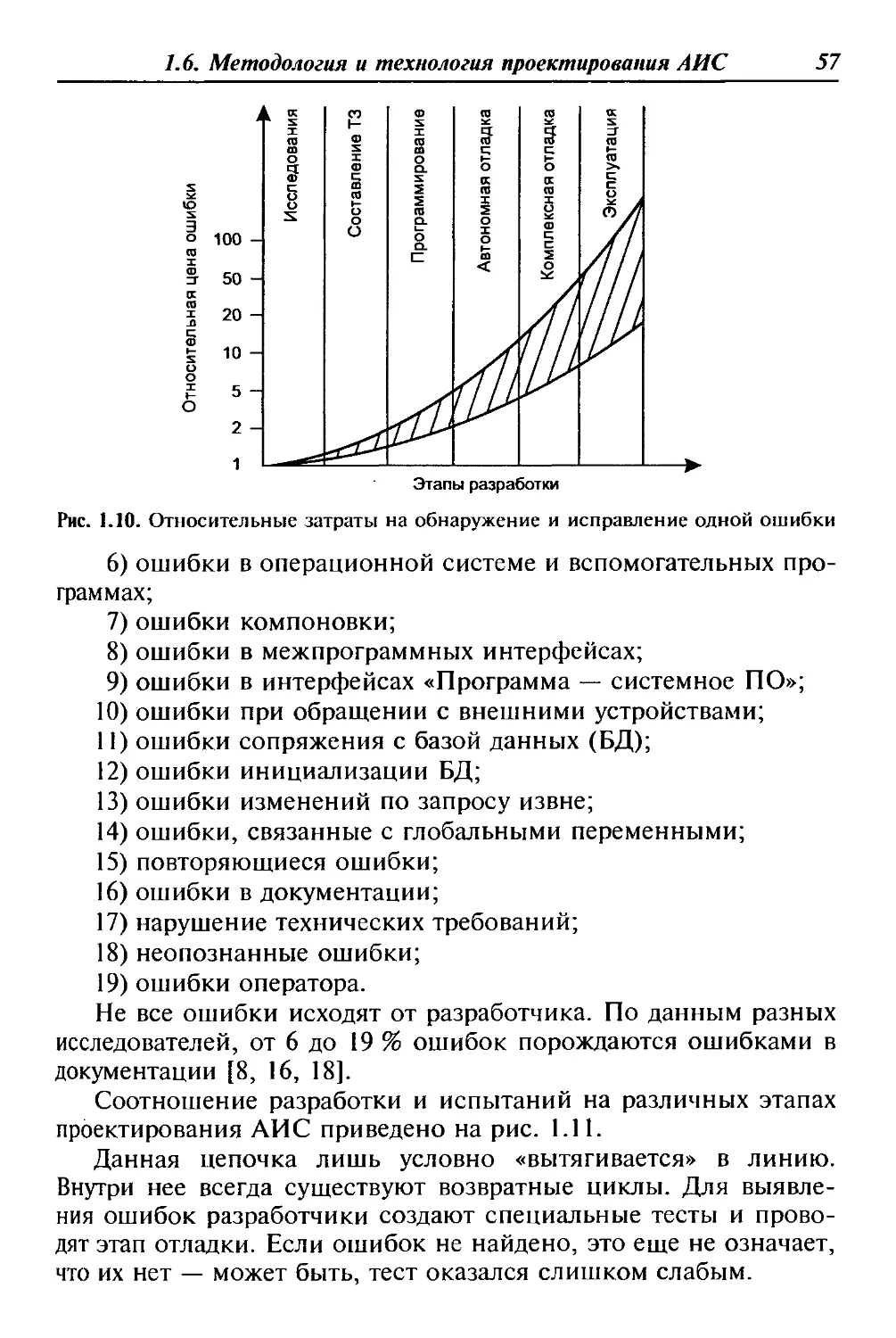
дит так, как показано на рис. 1.7 [16—18].
Рис. 1.7. Процесс разработки АИС по каскадной схеме
Одной из причин возникновения данной ситуации является
то, что в качестве экспертов, участвующих в описании предмет-
ной области, часто выступают будущие пользователи системы,
которые иногда не могут четко сформулировать требования к
АИС. Кроме того, заказчики и исполнители часто неправильно
понимают друг друга, так как заказчики далеки от программиро-
вания, а исполнители обычно не являются специалистами в
предметной области.
Сложность параллельного ведения работ связана с необходи-
мостью постоянного согласования различных частей проекта.
Чем сильнее взаимозависимость отдельных частей проекта, тем
чаще и тщательнее должна выполняться синхронизация, тем
сильнее зависят друг от друга группы разработчиков. В результа-
те преимущества параллельного ведения работ просто теряются-;
1.5. Модели жизненного цикла АИС
35
отсутствие параллелизма негативно сказывается и на организа-
ции работы всего коллектива.
В частности, пока производится анализ предметной области,
проектировщики, разработчики и те, кто занимается тестирова-
нием и администрированием, почти не загружены. Кроме того,
при последовательной разработке крайне сложно внести измене-
ния в проект после завершения этапа и передачи проекта на сле-
дующую стадию. Так, если после передачи проекта на следую-
щий этап группа разработчиков нашла более эффективное реше-
ние, оно не может быть реализовано, поскольку предыдущее
решение уже, возможно, реализовано и увязано с другими частя-
ми проекта [8, 16—18].
Проблема информационной перенасыщенности возникает
вследствие сильной зависимости между различными группами
разработчиков. Дело в том, что при внесении изменений в одну
из частей проекта, необходимо оповещать тех разработчиков,
которые использовали (могли использовать) ее в своей работе.
При наличии большого числа взаимосвязанных подсистем син-
хронизация внутренней документации становится отдельной
важнейшей задачей: разработчики должны постоянно знако-
миться с изменениями и оценивать, как скажутся (или уже ска-
зались) эти изменения на полученных результатах.
В итоге может потребоваться повторное тестирование и вне-
сение изменений в уже готовые части проекта. Причем эти из-
менения, в свою очередь, необходимо отразить во внутренней
документации и разослать другим группам разработчиков. Как
следствие, резко возрастет объем документации и, соответствен-
но, понадобится больше времени для ознакомления с ней.
Помимо изучения нового материала, не отпадает необходи-
мость и в изучении старой информации. Ведь вполне вероятно,
что в процессе разработки изменится кадровый состав и новым
разработчикам понадобится информация о сделанном ранее.
Причем, чем сложнее проект, тем больше времени требуется,
чтобы ввести нового разработчика в курс дела.
Сложность управления проектом в основном обусловлена
строгой последовательностью стадий разработки и наличием
сложных взаимосвязей между различными частями проекта. Рег-
ламентированная последовательность работ приводит к тому,
что одни группы разработчиков должны ожидать результатов ра-
боты других команд, поэтому требуется административное вме-
36
Глава 1. Проектирование АИС
шательство для согласования сроков и состава передаваемой до-
кументации.
В случае же обнаружения ошибок в работе необходим воз-
врат к предыдущим этапам; текущая работа тех, кто ошибся,
прерывается. Следствием этого обычно является срыв сроков
выполнения как исправляемого, так и нового проектов.
Упростить взаимодействие между разработчиками и умень-
шить информационную перенасыщенность документации мож-
но, сокращая количество связей между отдельными частями
проекта, но далеко не каждую АИС можно разделить на слабо
связанные подсистемы.
Высокий уровень риска. Чем сложнее проект, тем дольше длит-
ся каждый этап разработки и тем сложнее взаимосвязи между от-
дельными частями проекта, количество которых также увеличи-
вается. Причем результаты разработки можно реально увидеть и
оценить лишь на этапе тестирования, т. е. после завершения ана-
лиза, проектирования и разработки — этапов, выполнение кото-
рых требует значительного времени и средств [18].
Запоздалая оценка порождает серьезные проблемы при вы-
явлении ошибок анализа и проектирования — требуется возврат
на предыдущие стадии и повторение процесса разработки. Одна-
ко возврат на предыдущие стадии может быть связан не только с
ошибками, но и с изменениями, произошедшими в предметной
области или в требованиях заказчика за время разработки. При
этом никто не гарантирует, что предметная область снова не из-
менится к тому моменту, когда будет готова следующая версия
проекта. Фактически это означает, что существует вероятность
«зацикливания» процесса разработки: расходы на проект будут
постоянно расти, а сроки сдачи готового продукта постоянно от-
кладываться.
Таким образом, сложные проекты, разрабатываемые по кас-
кадной схеме, имеют повышенный уровень риска. Этот вывод
подтверждается практикой: по сведениям консалтинговой ком-
пании The Standish Group в США более 31 % проектов корпора-
тивных информационных систем (IT-проектов) заканчивается
неудачей; почти 53 % IT-проектов завершается с перерасходом
бюджета (в среднем на 189 %, т. е. почти в 2 раза); и толь-
ко 16,2 % проектов укладывается и в срок, и в бюджет [13].
Помимо приведенных недостатков каскадной модели есть
еще один. Он связан с возникновением конфликтов (не всегда
явных) между разработчиками, которые обусловлены тем, что
1.5. Модели жизненного цикла АИС
37
возврат части проекта на предыдущую стадию обычно сопрово-
ждается поиском виновных. Поскольку однозначно персонифи-
цировать виноватого не всегда возможно, отношения в коллек-
тиве усложняются.
Как следствие, в рабочей группе часто ценится не тот руко-
водитель, который имеет высокую квалификацию и больший
опыт, а тот, кто умеет «отстоять» своих подчиненных, обеспе-
чить им более удобные условия работы и т. п. В результате появ-
ляется опасность снижения и квалификации, и творческого по-
тенциала всей команды. Соответственно, техническое руково-
дство проектом начинает в большей степени подменяться
организационным, более детальной проработкой должностных
инструкций и более формальным их исполнением.
Тот, кто не умеет организовать работу, обречен бороться за
дисциплину. И здесь возникает проблема несовместимости дис-
циплины и творчества. Чем строже дисциплина, тем менее твор-
ческой становится атмосфера в коллективе. Такое положение ве-
щей может привести к тому, что наиболее одаренные кадры со
временем покинут коллектив [5, 6].
Построение итерационной модели заключается в серии корот-
ких циклов (шагов) по планированию, реализации, изучению,
действию.
Создание сложных АИС предполагает проведение согласова-
ний проектных решений, полученных при реализации отдельных
задач. Подход к проектированию «снизу — вверх» обусловливает
необходимость таких итераций возвратов, когда проектные ре-
шения по отдельным задачам объединяются в общие системные
решения. При этом возникает потребность в пересмотре ранее
сформировавшихся требований.
Преимущество итерационной модели в том, что межэтапные
корректировки обеспечивают меньшую трудоемкость разработки
по сравнению с каскадной моделью.
Недостатки итерационной модели:
• время жизни каждого этапа растягивается на весь период
разработки;
• вследствие большого числа итераций возникают рассогла-
сования выполнения проектных решений и документации;
• запутанность архитектуры;
• трудности использования проектной документации на ста-
диях внедрения и эксплуатации вызывают необходимость
перепроектирования всей системы.
38
Глава 1. Проектирование АИС
Спиральная модель, в отличие от каскадной, но аналогично
предыдущей предполагает итерационный процесс разработки
АИС. При этом возрастает значение начальных этапов, таких
как анализ и проектирование, на которых проверяется и обосно-
вывается реализуемость технических решений путем создания
прототипов.
Каждая итерация представляет собой законченный цикл раз-
работки, приводящий к выпуску внутренней или внешней вер-
сии изделия (или подмножества конечного продукта), которое
совершенствуется от итерации к итерации, чтобы стать закон-
ченной системой (рис. 1.8).
Проектирование
Реализация
Версия 2
Версия 3
Тестирование
Разработка
требований
Рис. 1.8. Спиральная модель ЖЦ АИС
Версия 1 Ввод в действие
прототипов системы
Таким образом, каждый виток спирали соответствует созда-
нию фрагмента или версии программного изделия, на нем уточ-
няются цели и характеристики проекта, определяется его качест-
во, планируются работы на следующем витке спирали. Каждая
итерация служит для углубления и последовательной конкрети-
зации деталей проекта, в результате этого выбирается обосно-
ванный вариант окончательной реализации.
Использование спиральной модели позволяет осуществлять
переход на следующий этап выполнения проекта, не дожидаясь
полного завершения текущего, — недоделанную работу можно
будет выполнить на следующей итерации. Главная задача каж-
дой итерации — как можно быстрее создать работоспособный
1.5. Модели жизненного цикла АИС
39
продукт для демонстрации пользователям. Таким образом, суще-
ственно упрощается процесс внесения уточнений и дополнений
в проект.
Спиральный подход к разработке программного обеспечения
позволяет преодолеть большинство недостатков каскадной моде-
ли и, кроме того, обеспечивает ряд дополнительных возможно-
стей, делая процесс разработки более гибким.
Преимущества итерационного подхода:
• итерационная разработка существенно упрощает внесение
изменений в проект при изменении требований заказчика;
• при использовании спиральной модели отдельные элемен-
ты АИС интегрируются в единое целое постепенно. По-
скольку интеграция начинается с меньшего количества
элементов, то возникает гораздо меньше проблем при ее
проведении (при использовании каскадной модели инте-
грация занимает до 40 % всех затрат в конце проекта);
• снижение уровня рисков (следствие предыдущего преиму-
щества, так как риски обнаруживаются именно во время ин-
теграции). Уровень рисков максимален в начале разработки
проекта, по мере продвижения разработки он снижается.
Данное утверждение справедливо при любой модели разра-
ботки, однако при использовании спиральной снижение
уровня рисков происходит с наибольшей скоростью, так как
интеграция выполняется уже на первой итерации. На на-
чальных итерациях выявляются многие аспекты проекта
(пригодность используемых инструментальных средств,
программного обеспечения, квалификация разработчиков
и т. п.). На рис. 1.9 приведено сравнение зависимостей рис-
ков от времени разработки для каскадного и итерационного
подходов [8, 16—18];
Рис. 1.9. Зависимость рисков от времени разработки
40
Глава 1. Проектирование АИС
• итерационная разработка обеспечивает большую гибкость в
управлении проектом, давая возможность внесения такти-
ческих изменений в разрабатываемое изделие. Так, можно
сократить сроки разработки за счет снижения функциональ-
ности системы или использовать в качестве составных час-
тей продукцию сторонних фирм вместо собственных разра-
боток (актуально при рыночной экономике, когда необхо-
димо противостоять продвижению изделия конкурентов);
• итерационный подход упрощает повторное использование
компонентов, поскольку гораздо проще выявить (иденти-
фицировать) общие части проекта, когда они уже частично
разработаны, чем пытаться выделить их в самом начале
проекта. Анализ проекта после нескольких начальных ите-
раций позволяет выявить общие многократно используе-
мые компоненты, которые на последующих итерациях бу-
дут совершенствоваться;
• спиральная модель позволяет получить более надежную и
устойчивую систему. Это связано с тем, что по мере разви-
тия системы ошибки и слабые места обнаруживаются и ис-
правляются на каждой итерации. Одновременно корректи-
руются критические параметры эффективности, что в слу-
чае каскадной модели доступно только перед внедрением
системы;
• итерационный подход позволяет совершенствовать процесс
разработки — в результате анализа в конце каждой итера-
ции проводится оценка изменений в организации разра-
ботки; на следующей итерации она улучшается.
Основная проблема спирального цикла — трудность опреде-
ления момента перехода на следующий этап. Для ее решения не-
обходимо ввести временные ограничения на каждый из этапов
жизненного цикла. Иначе процесс разработки может превра-
титься в бесконечное совершенствование уже сделанного.
При итерационном подходе полезно следовать принципу
«лучшее — враг хорошего». Поэтому завершение итерации долж-
но производиться строго в соответствии с планом, даже если не
вся запланированная работа закончена [5, 8, 16—18]. Планиро-
вание работ обычно проводится на основе статистических дан-
ных, полученных в предыдущих проектах, и личного опыта раз-
работчиков. В основе спиральной модели жизненного цикла ле-
жит применение прототипной — Rapid Application Development,
RAD-технологии [17, 18]. Эта технология обеспечивает создание
1.6. Методология и технология проектирования АИС 41
на ранней стадии реализации действующей интерактивной моде-
ли системы так называемой системы-прототипа, позволяющей
наглядно продемонстрировать пользователю будущую систему,
уточнить его требования, оперативно модифицировать интер-
фейсные элементы — формы ввода сообщений, меню, выходные
документы, структуру диалога, состав реализуемых функций.
В процессе работы с системой-прототипом пользователь ре-
ально осознает возможности будущей системы и определяет
наиболее удобный для него режим обработки данных, что значи-
тельно повышает качество создаваемых систем. Осуществляется
проверка принципиальных проектных решений по составу и
структуре АИС и оценка основных ее эксплуатационных харак-
теристик.
Вовлечение пользователей в процесс проектирования и кон-
струирования приложения позволяет получать замечания и до-
полнения к требованиям непосредственно в процессе проекти-
рования приложения, сокращая время разработки. Представите-
ли заказчика получают возможность контролировать процесс
создания системы и влиять на ее функциональное наполнение.
Результатом является сдача в эксплуатацию системы, учитываю-
щей большинство потребностей заказчиков.
1.6. Методология и технология проектирования АИС
Современные методологии и реализующие их технологии
проектирования АИС поставляются в электронном виде вместе
с CASE-средствами (рассмотрены далее) и включают библиоте-
ки процессов, шаблонов, методов, моделей и других компонен-
тов, предназначенных для построения ПО того класса систем,
на который ориентирована методология. Электронные методо-
логии и технологии составляют ядро комплекса согласованных
инструментальных средств разработки АИС [6, 8, 16—18]. Осо-
бенности современных методологических решений проектиро-
вания АИС невозможно реализовать без определенных техноло-
гий проектирования, соответствующих масштабу и специфике
проекта.
Технология проектирования АИС — это совокупность методов
и средств проектирования АИС, а также методов и средств орга-
низации проектирования (управление процессом создания и мо-
42
Глава 1. Проектирование АИС
дернизации проекта АИС) [8, 16—18]. В основе технологии про-
ектирования лежит технологический процесс (ТП), который оп-
ределяет действия, их последовательность, состав исполнителей,
средства и ресурсы, требуемые для выполнения этих действий.
Согласно [20] ТП проектирования АИС представляет собой
совокупность последовательно-параллельных, связанных и со-
подчиненных цепочек действий, каждое из которых может иметь
свой предмет. Действия, которые выполняются при проектирова-
нии АИС, могут быть определены как неделимые технологиче-
ские операции или как подпроцессы технологических операций.
Все действия могут быть собственно проектировочными, которые
формируют или модифицируют результаты проектирования, и
оценочными, которые вырабатывают по установленным критери-
ям оценки результатов проектирования.
Таким образом, технология проектирования задается регла-
ментированной последовательностью технологических опера-
ций, выполняемых в процессе создания проекта на основе того
или иного метода.
Предметом выбираемой технологии проектирования должно
служить отражение взаимосвязанных процессов проектирования
на всех стадиях жизненного цикла АИС.
Основные требования, предъявляемые к выбираемой техно-
логии проектирования, следующие:
• созданный с помощью этой технологии проект должен от-
вечать требованиям заказчика;
• технология должна максимально отражать все этапы цикла
жизни проекта;
• технология должна обеспечивать минимальные трудовые и
стоимостные затраты на проектирование и сопровождение
проекта;
• технология должна способствовать росту производительно-
сти труда проектировщиков;
• технология должна обеспечивать надежность процесса про-
ектирования и эксплуатации проекта;
• технология должна способствовать простому ведению про-
ектной документации.
Технология проектирования АИС реализует определенную
методологию проектирования. В свою очередь, методология про-
ектирования предполагает наличие некоторой концепции, прин-
ципов проектирования и реализуется набором методов и средств.
1.6. Методология и технология проектирования АИС
43
Методы проектирования АИС можно классифицировать по
степени использования средств автоматизации, типовых проект-
ных решений, адаптивности к предполагаемым изменениям.
По степени автоматизации различают:
• ручное проектирование, при котором проектирование ком-
понентов АИС осуществляется без использования специ-
альных инструментальных программных средств; програм-
мирование производится на алгоритмических языках;
• компьютерное проектирование, при котором генерация
или конфигурация (настройка) проектных решений произ-
водится с использованием специальных инструментальных
программных средств.
По степени использования типовых проектных решений разли-
чают:
• оригинальное (индивидуальное) проектирование, когда
проектные решения разрабатываются «с нуля» в соответст-
вии с требованиями к АИС;
• типовое проектирование, предполагающее конфигурацию
АИС из готовых типовых проектных решений (программ-
ных модулей).
Оригинальное проектирование АИС предполагает максималь-
ный учет особенностей автоматизированного объекта.
Типовое проектирование выполняется на основе готовых ре-
шений и является обобщением опыта, полученного ранее при
создании родственных проектов.
По степени адаптивности проектных решений различаются
следующие методы:
• реконструкция — адаптация проектных решений выполня-
ется путем переработки соответствующих компонентов
(перепрограммирования программных модулей);
• параметризация — проектные решения настраиваются в
соответствии с заданными и изменяемыми параметрами;
• реструктуризация модели — изменяется модель предметной
области, что приводит к автоматическому переформирова-
нию проектных решений.
Сочетание различных признаков классификации методов
проектирования обусловливает характер используемой техноло-
гии проектирования АИС. Выделяются два основных класса
технологии проектирования: каноническая и индустриальная
(табл. 1.5). Индустриальная технология проектирования в свою
очередь разбивается на два подкласса: автоматизированное (ис-
44
Глава 1. Проектирование АИС
пользование CASE-технологий) и типовое (параметриче-
ски-ориентированное или модельно-ориентированное) проекти-
рование. Использование индустриальных технологий проекти-
рования не исключает использования в отдельных случаях
канонической технологии [18, 19].
Таблица 1.5. Характеристики классов технологий проектирования
Класс технологии проек- тирования Степень автоматизации Степень типизации Степень адаптивности
Каноническое проек- тирование Ручное проектирова- ние Оригинальное проек- тирование Реконструкция
Индустриальное авто- матизированное про- ектирование Компьютерное проек- тирование То же Реструктуризация мо- дели
Индустриальное типо- вое проектирование То же Типовое сборочное проектирование Параметризация и ре- структуризация мо- дели
Каноническое проектирование АИС ориентировано на исполь-
зование главным образом каскадной модели жизненного цикла
АИС. Стадии и этапы работы такого проектирования описаны
в ГОСТ 34.601-90.
В зависимости от сложности объекта автоматизации и набо-
ра задач, требующих решения при создании конкретной АИС,
стадии и этапы работ могут иметь различную трудоемкость. До-
пускается объединять последовательные этапы и исключать не-
которые из них на любой стадии проекта. Допускается также на-
чинать выполнение работ следующей стадии до окончания пре-
дыдущей.
Стадии и этапы создания АИС, выполняемые организация-
ми-участниками, прописываются в договорах и технических за-
даниях на выполнение работ.
Стадия 1. Формирование требований к АИС:
• обследование объекта и обоснование необходимости созда-
ния АИС;
• формирование требований пользователей к АИС;
• оформление отчета о выполненной работе и тактико-тех-
нического задания на разработку.
Стадия 2. Разработка концепции АИС:
• изучение объекта автоматизации;
1.6. Методология и технология проектирования АИС 45
• проведение необходимых научно-исследовательских работ;
• разработка вариантов концепции АИС, удовлетворяющих
требованиям пользователей;
• оформление отчета и утверждение концепции.
Стадия 3. Техническое задание:
• разработка и утверждение технического задания на созда-
ние АИС.
Стадия 4. Эскизный проект:
• разработка предварительных проектных решений по систе-
ме и ее частям;
• разработка эскизной документации на АИС и ее части.
Стадия 5. Технический проект:
• разработка проектных решений по системе и ее частям;
• разработка документации на АИС и ее части;
• разработка и оформление документации на поставку ком-
плектующих изделий;
• разработка заданий на проектирование в смежных частях
проекта.
Стадия 6. Рабочая документация:
• разработка рабочей документации на АИС и ее части;
• разработка и адаптация программ.
Стадия 7. Ввод в действие:
• подготовка объекта автоматизации;
• подготовка персонала;
• комплектация АИС поставляемыми изделиями (программ-
ными и техническими средствами, программно-технически-
ми комплексами, информационными изделиями);
• строительно-монтажные работы;
• пусконаладочные работы;
• проведение предварительных испытаний;
• проведение опытной эксплуатации;
• проведение приемочных испытаний.
Стадия 8. Сопровождение АИС:
• выполнение работ в соответствии с гарантийными обяза-
тельствами;
• послегарантийное обслуживание.
Рассмотрим специфику составляющих некоторых стадий
подробнее.
46
Глава 1. Проектирование АИС
Обследование — это изучение и анализ организационной
структуры предприятия, его деятельности и существующей сис-
темы обработки информации [20]. Материалы, полученные в ре-
зультате обследования, используются для:
• обоснования разработки и поэтапного внедрения систем;
• составления технического задания на разработку систем;
• разработки технического и рабочего проектов систем.
На этапе обследования целесообразно выделить две состав-
ляющие: определение стратегии внедрения АИС и детальный
анализ деятельности организации.
Основная задача первого этапа обследования — оценка ре-
ального объема проекта, его целей и задач на основе выявлен-
ных функций и информационных элементов автоматизируемого
объекта высокого уровня. Эти задачи могут быть реализованы
или заказчиком АИС самостоятельно, или с привлечением кон-
салтинговых организаций. Этап предполагает тесное взаимодей-
ствие с основными потенциальными пользователями системы и
бизнес-экспертами. Основная задача взаимодействия — полу-
чить полное и однозначное понимание требований заказчика.
Как правило, нужная информация может быть получена в ре-
зультате интервью, бесед или семинаров с руководством, экспер-
тами и пользователями.
По завершении стадии обследования появляется возмож-
ность определить вероятные технические подходы к созданию
системы и оценить затраты на ее реализацию (на аппаратное
обеспечение, на закупаемое программное обеспечение и на раз-
работку нового программного обеспечения).
Результатом этапа определения стратегии является документ
(технико-экономическое обоснование — ТЭО — проекта), где
четко сформулировано, что получит заказчик, если согласится
финансировать проект, когда он получит готовый продукт (гра-
фик выполнения работ) и сколько это будет стоить (для крупных
проектов — это график финансирования на разных этапах ра-
бот). В документе желательно отразить не только затраты, но и
выгоду проекта, например время окупаемости проекта, ожидае-
мый экономический эффект (если его удается оценить).
Примерное содержание ТЭО:
• ограничения, риски, критические факторы, которые могут
повлиять на успешность проекта;
• совокупность условий, при которых предполагается экс-
плуатировать будущую систему, — архитектура системы, ап-
1.6. Методология и технология проектирования АИС
47
паратные и программные ресурсы, условия функционирова-
ния, обслуживающий персонал и пользователи системы;
• сроки завершения отдельных этапов, форма приемки/сдачи
работ, привлекаемые ресурсы, меры по защите информации;
• описание выполняемых системой функций;
• возможности развития и модернизации системы;
• интерфейсы и распределение функций между человеком и
системой;
• требования к ПО и системам управления базами данных
(СУБД).
На этапе детального анализа деятельности организации изу-
чаются деятельность, обеспечивающая реализацию функций
управления, организационная структура, штаты и содержание
работ по управлению предприятием, а также характер подчинен-
ности вышестоящим органам управления. Здесь следует наметить
инструктивно-методические и директивные материалы, на осно-
вании которых определяются состав подсистем и перечень задач,
а также возможности применения новых методов решения задач.
Аналитики собирают и фиксируют информацию в двух взаи-
мосвязанных формах:
• функции — информация о событиях и процессах, которые
происходят в автоматизируемой организации;
• сущности — информация о классах объектов, имеющих
значение для организации и о которых собираются данные.
При изучении каждой функциональной задачи управления
определяются:
• наименование задачи; сроки и периодичность ее решения;
• степень формализуемости задачи;
• источники информации, необходимые для решения задачи;
• показатели и их количественные характеристики;
• порядок корректировки информации;
• действующие алгоритмы расчета показателей и возможные
методы контроля;
• действующие средства сбора, передачи и обработки инфор-
мации;
• действующие средства связи;
• принятая точность решения задачи;
• трудоемкость решения задачи;
• действующие формы представления исходных данных и ре-
зультатов их обработки в виде документов;
• потребители результатной информации по задаче.
48
Глава 1. Проектирование АИС
Одной из наиболее трудоемких, хотя и хорошо формализуе-
мых, задач этого этапа является описание документооборота ор-
ганизации. При обследовании документооборота составляется
схема маршрута движения документов, которая должна отразить:
• количество документов;
• место формирования показателей документов;
• взаимосвязь документов при их формировании;
• маршрут и длительность движения документа;
• место использования и хранения данного документа;
• внутренние и внешние информационные связи;
• объем документа в знаках.
По результатам обследования устанавливают перечень задач
управления, подлежащих автоматизации, и очередность их раз-
работки.
На этапе обследования следует классифицировать планируе-
мые функции системы по степени важности. Один из возможных
форматов представления такой классификации — MuSCoW [22].
Эта аббревиатура расшифровывается так: Must have — необходи-
мые функции; Should have — желательные функции; Could have —
возможные функции; Won't have — отсутствующие функции.
Функции первой категории обеспечивают критичные для
успешной работы системы возможности. Реализация функций
второй и третьей категорий ограничивается временными и фи-
нансовыми рамками: разрабатывается необходимое, а также мак-
симально возможное в порядке приоритета число функций вто-
рой и третьей категорий. Последняя категория функций особен-
но важна, поскольку нужно четко представлять границы проекта
и набор функций, которые будут отсутствовать в системе.
Модели деятельности организации создаются в двух видах
[6, 16, 18]:
• модель «как есть» («as is») — отражает существующие в ор-
ганизации бизнес-процессы;
• модель «как должно быть» («to be») — отражает необходи-
мые изменения бизнес-процессов с учетом внедрения АИС.
Уже на этапе анализа необходимо привлекать к работе груп-
пы тестирования для решения следующих задач:
• получения сравнительных характеристик предполагаемых к
использованию аппаратных платформ, операционных сис-
тем, СУБД и т. п.;
1.6. Методология и технология проектирования АИС
49
• разработки плана работ по обеспечению надежности АИС
и се тестирования.
Привлечение тестировщиков на ранних этапах разработки
является целесообразным для любых проектов. Чем позже обна-
ружены ошибки в проектных решениях, тем дороже обходится
их исправление; худший вариант — их обнаружение на этапе
внедрения. Таким образом, чем раньше группы тестирования
начнут выявлять ошибки в АИС, тем ниже стоимость работы
над системой. Время на тестирование системы и на исправление
обнаруженных ошибок должно быть предусмотрено не только на
этапе разработки, но и на этапе проектирования.
Облегчить и увеличить эффективность тестирования призва-
ны специальные системы отслеживания ошибок. Их использова-
ние позволяет иметь единое хранилище ошибок, отслеживать их
повторное появление, контролировать скорость и эффектив-
ность исправления ошибок, видеть наиболее нестабильные ком-
поненты системы, а также поддерживать связь между группой
разработчиков и группой тестирования.
Результаты обследования представляют объективную основу
для формирования технического задания на АИС [16—18].
Техническое задание — это документ, определяющий цели,
требования и основные исходные данные, необходимые для раз-
работки автоматизированной системы управления.
При разработке технического задания (ТЗ) необходимо ре-
шить следующие задачи:
• установить общую цель создания АИС;
• установить общие требования к проектируемой системе;
• разработать и обосновать требования, предъявляемые к ин-
формационному, математическому, программному, техни-
ческому и технологическому обеспечению;
• определить состав подсистем и функциональных задач;
• разработать и обосновать требования, предъявляемые к
подсистемам;
• определить этапы создания системы и сроки их выполнения;
• провести предварительный расчет затрат на создание сис-
темы и определить уровень экономической эффективности
ее внедрения;
• определить состав исполнителей.
Типовые требования к составу и содержанию технического
задания приведены в табл. 1.6.
50
Глава 1. Проектирование АИС
Таблица 1.6. Состав и содержание технического задания (ГОСТ 34.602—89)
Раздел Содержание
Общие сведения Полное наименование системы и ее условное обозначение. Шифр темы или шифр (номер) договора. Наименование предприятий разработчика и заказчика системы, их реквизиты. Перечень документов, на основании которых создается ИС. Плановые сроки начала и окончания работ. Сведения об источниках и порядке финансирования работ. Порядок оформления и предъявления заказчику результатов работ по созданию системы, ее частей и отдельных средств
Назначение и цепи созда- ния (развития) системы Вид автоматизируемой деятельности. Перечень объектов, на которых предполагается использование системы. Наименования и требуемые значения технических, технологиче- ских, производственно-экономических и др. показателей объек- та, которые должны быть достигнуты при внедрении ИС
Характеристика объектов автоматизации Краткие сведения об объекте автоматизации. Сведения об условиях эксплуатации и характеристиках окру- жающей среды
Требования к системе Требования к системе в целом: • требования к структуре и функционированию системы (пере- чень подсистем, уровни иерархии, степень централизации, спо- собы информационного обмена, режимы функционирования, взаимодействие со смежными системами, перспективы разви- тия системы); • требования к персоналу (численность пользователей, квали- фикация, режим работы, порядок подготовки); • показатели назначения (степень приспособляемости системы к изменениям процессов управления и значений параметров) • требования к надежности, безопасности, эргономике, транс- портабельности, эксплуатации, техническому обслуживанию и ремонту, защите и сохранности информации, защите от внеш- них воздействий, к патентной чистоте, по стандартизации и уни- фикации. Требования к функциям (по подсистемам): • перечень подлежащих автоматизации задач; • временной регламент реализации каждой функции; • требования к качеству реализации каждой функции, к форме представления выходной информации, характеристики точно- сти, достоверности выдачи результатов; • перечень и критерии отказов. Требования к видам обеспечения: • математическому (состав и область применения математиче- ских моделей и методов, типовых и разрабатываемых алго- ритмов);
1.6. Методология и технология проектирования АИС
51
Окончание табл. 1.6
Раздел Содержание
• информационному (состав, структура и организация данных, обмен данными между компонентами системы, информацион- ная совместимость со смежными системами, используемые классификаторы, СУБД, контроль данных и ведение информа- ционных массивов, процедуры придания юридической силы вы- ходным документам); • лингвистическому (языки программирования, языки взаимо- действия пользователей с системой, системы кодирования, языки ввода-вывода); • программному (независимость программных средств от плат- формы, качество программных средств и способы его контро- ля, использование фондов алгоритмов и программ); • техническому; • метрологическому; • организационному (структура и функции эксплуатирующих подразделений, защита от ошибочных действий персонала); • методическому (состав нормативно-технической докумен- тации)
Состав и содержание работ по созданию системы Перечень стадий и этапов работ. Сроки исполнения. Состав организаций-исполнителей работ. Вид и порядок экспертизы технической документации. Программа обеспечения надежности. Программа метрологического обеспечения
Порядок контроля и прием- ки системы Виды, состав, объем и методы испытаний системы. Общие требования к приемке работ по стадиям. Статус приемной комиссии
Требования к составу и со- держанию работ по подго- товке объекта автоматиза- ции к вводу системы в дей- ствие Преобразование входной информации к машиночитаемому виду. Изменения в объекте автоматизации. Сроки и порядок комплектования и обучения персонала
Требования к документиро- ванию Перечень подлежащих разработке документов. Перечень документов на машинных носителях
Источники разработки Документы и информационные материалы, на основании кото- рых разрабатывается ТЗ и система
Эскизный проект предусматривает разработку предваритель-
ных проектных решений по системе и ее частям. Выполнение
эскизного проектирования не является строго обязательной ста-
дией. Если основные проектные решения определены ранее или
достаточно очевидны для конкретной АИС и объекта автомата-
52
Глава 1. Проектирование АИС
зации, то эта стадия может быть исключена из общей последова-
тельности работ.
Содержание эскизного проекта задается в ТЗ на систему.
Как правило, на этапе эскизного проектирования определяются:
• функции АИС;
• функции подсистем, их цели и ожидаемый эффект от вне-
дрения;
• состав комплексов задач и отдельных задач;
• концепция информационной базы и ее укрупненная струк-
тура;
• функции системы управления базой данных;
• состав вычислительной системы и других технических
средств;
• функции и параметры основных программных средств.
По результатам проделанной работы оформляется, согласо-
вывается и утверждается документация в объеме, необходимом
для описания полной совокупности принятых проектных реше-
ний и достаточном для дальнейшего выполнения работ по созда-
нию системы.
В соответствии с ГОСТ 19.102—77 стадия эскизного проек-
тирования содержит два этапа: разработку эскизного проекта;
утверждение эскизного проекта.
Первый этап разработки состоит из:
• предварительной разработки структуры входных и выход-
ных данных;
• уточнения методов решения задачи;
• разработки общего описания алгоритма решения задачи;
• разработки технико-экономического обоснования;
• разработки пояснительной записки.
При этом допускается объединение и исключение некоторых
работ.
Ниже приведен набор документов, который должен и может
быть подготовлен по окончании эскизного проектирования.
Обязательные документы:
1) уточненное техническое задание на проектирование и раз-
работку АИС;
2) спецификация квалификационных требований на АИС;
3) комплект спецификаций требований на функциональные
программные компоненты и описания данных;
4) спецификация требований на внутренние интерфейсы
компонент и интерфейсы с внешней средой;
1.6. Методология и технология проектирования АИС
53
5) описание системы управления базой данных, структуры и
распределения программных и информационных объектов в базе
данных;
6) проект руководства по защите информации и обеспече-
нию надежности функционирования АИС;
7) предварительный вариант руководства администратора
АИС;
8) предварительный вариант руководства пользователя АИС;
9) уточненный план реализации проекта;
10) уточненный план управления обеспечением качества АИС;
11) пояснительная записка предварительного проекта АИС;
12) уточненный контракт (договор) с заказчиком на деталь-
ное проектирование АИС.
Документы, оформляемые по согласованию с заказчиком:
1) предварительное описание функционирования АИС;
2) схема потоков данных между функциональными компо-
нентами АИС;
3) уточненная схема архитектуры АИС, взаимодействия
программных и информационных компонент, организации вы-
числительного процесса и распределения ресурсов;
4) описание показателей качества компонент и требований
к ним по этапам разработки АИС;
5) отчет о технико-экономических показателях, графике
реализации проекта, распределении ресурсов и бюджета;
6) таблица распределения специалистов по компонентам и
по этапам работ;
7) аттестаты разработчиков на право использования техно-
логии и средств автоматизации разработки АИС;
8) описание требований к составу и формам результирую-
щих документов по этапам работ;
9) план отладки программных компонент, обеспечения ее
методами и средствами автоматизации тестирования;
10) предварительное руководство для детального проектиро-
вания, программирования и отладки компонент АИС;
11) предварительный план продажи и внедрения;
12) описание предварительной структуры базы данных.
На основе технического задания и эскизного проекта разра-
батывается технический проект АИС.
Технический проект системы — это техническая документа-
ция, содержащая общесистемные проектные решения, алгорит-
мы решения задач, а также оценку экономической эффективно-
54
Глава 1. Проектирование АИС
сти АИС и перечень мероприятий по подготовке объекта к вне-
дрению.
На этом этапе осуществляется комплекс научно-исследова-
тельских и экспериментальных работ для выбора основных про-
ектных решений и расчет экономической эффективности систе-
мы. Состав и содержание технического проекта приведены в
табл. 1.7.
Таблица 1.7. Содержание технического проекта
Раздел Содержание
Пояснительная записка Основания для разработки системы. Перечень организаций разработчиков. Краткая характеристика объекта с указанием основных техни- ко-экономических показателей его функционирования и связей с другими объектами. Краткие сведения об основных проектных решениях по функцио- нальной и обеспечивающим частям системы
Функциональная и органи- зационная структура сис- темы Обоснование выделяемых подсистем, их перечень и назначение. Перечень задач, решаемых в каждой подсистеме, с краткой ха- рактеристикой их содержания. Схема информационных связей между подсистемами и между задачами в рамках каждой подсистемы
Постановка задач и алго- ритмы решения Организационно-экономическая сущность задачи (наименование, цель решения, краткое содержание, метод, периодичность и вре- мя решения задачи, способы сбора и передачи данных, связь за- дачи с другими задачами, характер использования результатов решения, в которых они используются). Экономико-математическая модель задачи (структурная и раз- вернутая форма представления). Входная оперативная информация (характеристика показателей, диапазон изменения, формы представления). Нормативно-справочная информация (НСИ) (содержание и фор- мы представления). Информация, хранимая для связи с другими задачами. Информация, накапливаемая для последующих решений данной задачи. Информация по внесению изменений (система внесения измене- ний и перечень информации, подвергающейся изменениям). Алгоритм решения задачи (последовательность этапов расчета, схема, расчетные формулы). Контрольный пример (набор заполненных данными форм вход- ных документов, условные документы с накапливаемой и храни- мой информацией, формы выходных документов, заполненные по результатам решения экономико-технической задачи и в соот- ветствии с разработанным алгоритмом расчета)
1.6. Методология и технология проектирования АИС
55
Окончание табл. 1.7
Раздел Содержание
Организация информаци- онной базы Источники поступления информации и способы ее передачи. Совокупность показателей, используемых в системе. Состав документов, сроки и периодичность их поступления. Основные проектные решения по организации фонда НСИ. Состав НСИ, включая перечень реквизитов, их определение, диа- пазон изменения и перечень документов НСИ. Перечень массивов НСИ, их объем, порядок и частота корректи- ровки информации. Структура фонда НСИ с описанием связи между его элементами; требования к технологии создания и ведения фонда. Методы хранения, поиска, внесения изменений и контроля. Определение объемов и потоков информации НСИ. Контрольный пример по внесению изменений в НСИ. Предложения по унификации документации
Альбом форм документов Отсутствует
Система математического обеспечения Обоснование структуры математического обеспечения. Обоснование выбора системы программирования. Перечень стандартных программ
Принцип построения ком- плекса технических средств Описание и обоснование схемы технологического процесса обра- ботки данных. Обоснование и выбор структуры комплекса технических средств и его функциональных групп. Обоснование требований к разработке нестандартного оборудо- вания. Комплекс мероприятий по обеспечению надежности функциони- рования технических средств
Расчет экономической эффективности системы Сводная смета затрат, связанных с эксплуатацией систем. Расчет годовой экономической эффективности, источниками ко- торой являются оптимизация производственной структуры хо- зяйства (объединения), снижение себестоимости продукции за счет рационального использования производственных ресурсов и уменьшения потерь, улучшения принимаемых управленческих решений
Мероприятия по подготов- ке объекта к внедрению системы Перечень организационных мероприятий по совершенствованию бизнес-процессов. Перечень работ по внедрению системы, которые необходимо вы- полнить на стадии рабочего проектирования, с указанием сроков и ответственных лиц
Ведомость документов Отсутствует
56
Глава 1. Проектирование АИС
На стадии «Рабочая документация» осуществляется создание
программного продукта и разработка всей сопровождающей до-
кументации. Документация должна содержать все необходимые
и достаточные сведения для обеспечения выполнения работ по
вводу АИС в действие и ее эксплуатации, а также для поддержа-
ния уровня эксплуатационных характеристик (качества) систе-
мы. Разработанная документация должна быть соответствующим
образом оформлена, согласована и утверждена.
На стадии «Ввод в действие» для АИС устанавливают сле-
дующие основные виды испытаний: предварительные испытания,
опытная эксплуатация и приемочные испытания. При необходи-
мости допускается дополнительно проведение других видов ис-
пытаний системы и ее частей.
В зависимости от взаимосвязей компонентов АИС и объекта
автоматизации испытания могут быть автономные и комплекс-
ные. В автономных испытаниях участвуют компоненты системы.
Их проводят по мере готовности частей системы к сдаче в опыт-
ную эксплуатацию. Комплексные испытания проводят для групп
взаимосвязанных компонентов (подсистем) или для системы в
целом.
Для планирования проведения всех видов испытаний разра-
батывается документ «Программа и методика испытаний». Раз-
работчик документа устанавливается в договоре или ТЗ. В каче-
стве приложения в документ могут включаться тесты или кон-
трольные примеры.
Отладка — наиболее трудоемкий процесс проектирования.
Скрытые ошибки иногда проявляются после многолетней экс-
плуатации системы. Полностью избежать ошибок невозможно,
что обусловлено астрономическим числом вариантов работы
системы. Проверить их все на правильность работы в обозримые
сроки практически невозможно.
Затраты на выявление и устранение ошибок на более позд-
них этапах проектирования возрастают примерно экспоненци-
ально (рис. 1.10) [8, 16, 18].
Исследователи насчитывают 169 типов ошибок, сведенных в
19 больших классов:
1) логические;
2) ошибки манипулирования данными;
3) ошибки ввода-вывода;
4) ошибки в вычислениях;
5) ошибки в пользовательских интерфейсах;
1.6. Методология и технология проектирования АИС
57
Рис. 1.10. Относительные затраты на обнаружение и исправление одной ошибки
6) ошибки в операционной системе и вспомогательных про-
граммах;
7) ошибки компоновки;
8) ошибки в межпрограммных интерфейсах;
9) ошибки в интерфейсах «Программа — системное ПО»;
10) ошибки при обращении с внешними устройствами;
11) ошибки сопряжения с базой данных (БД);
12) ошибки инициализации БД;
13) ошибки изменений по запросу извне;
14) ошибки, связанные с глобальными переменными;
15) повторяющиеся ошибки;
16) ошибки в документации;
17) нарушение технических требований;
18) неопознанные ошибки;
19) ошибки оператора.
Не все ошибки исходят от разработчика. По данным разных
исследователей, от 6 до 19 % ошибок порождаются ошибками в
документации [8, 16, 18].
Соотношение разработки и испытаний на различных этапах
проектирования АИС приведено на рис. 1.11.
Данная цепочка лишь условно «вытягивается» в линию.
Внутри нее всегда существуют возвратные циклы. Для выявле-
ния ошибок разработчики создают специальные тесты и прово-
дят этап отладки. Если ошибок не найдено, это еще не означает,
что их нет — может быть, тест оказался слишком слабым.
58
Глава 1. Проектирование АИС
Техническое задание и требования к АИС
Разработка
Испытание
Разработка требований к АИС
Разработка
программных модулей
Комплексная отладка АИС
Доработка по результатам
испытаний главного
конструктора
Комплексирование модулей,
разработка групп
программ
Разработка технического
проекта АИС
Проверка совместимости
требований
к системе в целом
Проверка соответствия
технологического проекта
требованиям
Испытание
программных модулей
Испытание качества
решения функциональных
задач
Комплексные испытания
по требованиям
главного конструктора
Заключительные
приемо-сдаточные
испытания АИС
Эксплуатация АИС
Рис. 1.11. Соотношение разработки и испытаний по этапам
проектирования АИС
Методика отладки учитывает симптомы возможных ошибок:
• неверная обработка (неправильный ответ, результат) —
до 30 %;
• неверная передача управления — 16 %;
• несовместимость программ с используемыми данными —
15 %;
• несовместимость программ по пересылаемым данным —
до 9 %.
При разработке отладочных заданий решаются следующие
задачи:
• составление тестов;
• выбор точек, зон и маршрутов контроля;
• определение перечня контролируемых величин и порядка
фиксации их значений;
1.6. Методология и технология проектирования АИС
59
• задание порядка тестирования;
• оценка достоверности и трудоемкости отладки.
Отлаживаемая программа должна хотя бы один раз прорабо-
тать по каждой ветви алгоритма и при этом присвоить перемен-
ным ряд значений, захватывая границы диапазона, несколько
значений внутри него, нулевые значения и особые точки (если
есть). Для специализированных систем разрабатывают специаль-
ные языки отладки. Они могут содержать относительно неболь-
шое число команд (20—30) с дополнительными настроечными
параметрами для решения следующих задач:
• управления выводом;
• моделирования процесса исполнения отлаживаемой про-
граммы;
• выдачи состояния компонент памяти в процессе исполне-
ния программ;
• проверки условий достижения определенных состояний в
процессе исполнения программы;
• установления тестовых значений исходных данных;
• осуществления условных переходов в тестировании в зави-
симости от результатов исполнения других макрокоманд
или различных тестов;
• выполнения служебных операций по подготовке програм-
мы к тестированию.
Процесс отладки нельзя отнести к полностью формализован-
ному, поэтому существуют эмпирические рекомендации по его
проведению, которые приведены ниже.
1. Используйте семантический, заранее продуманный подход
к отладке, планируйте процесс отладки и тщательно проекти-
руйте тестовые наборы данных с наиболее простых вариантов,
исключая наиболее вероятные источники ошибок.
2. Для упорядочения процесса тестирования собирайте и
анализируйте информацию:
• об особенностях и статистике ошибок;
• о специфике исходных данных и последовательности из-
менения переменных в программе и их взаимном влиянии;
• о структуре алгоритма и особенностях его программной
реализации.
3. В каждый момент времени определяйте местоположение
только одной ошибки.
4. Используйте средства регистрации и отображения инфор-
мации об ошибках, включая в программу специальный отладоч-
60
Глава 1. Проектирование АИС
ный код для распечатки выборочных значений переменных, со-
общений об окончании отдельных участков программы, трасси-
ровки, логических условий и т. п.
5. Внимательно изучайте полученные выходные данные и
сравнивайте их с ожидаемыми, заранее рассчитанными результа-
тами.
6. Обращайте внимание на данные, тщательно анализируйте
работу программы при использовании граничных значений и
при неправильном вводе; контролируйте типы данных, диапазо-
ны, размеры полей и точность.
7. Используйте анализ потоков данных и потоков управле-
ния для проверки корректности и установления областей опре-
деления данных для разных маршрутов выполнения программы.
8. Используйте одновременно различные средства отладки,
не останавливаясь на одной возможности. Привлекайте автома-
тизированные средства и одновременно ручную отладку и тести-
рование, проверяя текст программы с точки зрения функциони-
рования с учетом наиболее вероятных ошибок.
9. Документируйте все обнаруженные и исправленные
ошибки, их отличия, местоположение и тип. Эта информация
будет полезна для предупреждения будущих ошибок.
10. Измеряйте сложность программ. В программах с высокой
сложностью высока вероятность ошибок спецификаций и про-
ектирования, а с низкой сложностью — кодирования и канце-
лярских ошибок.
11. Для повышения опыта и тренировки в отладке искусст-
венно помещайте в программы ошибки. После определенного
периода отладки программисту следует указать на оставшиеся и
не обнаруженные им ошибки. Подобное «засевание» широко ис-
пользуют для оценки числа необнаруженных ошибок (если рав-
номерно обнаруживаются и исправляются и искусственные, и
реальные ошибки, то по процентному соотношению обнаружен-
ных внесенных и реальных ошибок можно предположить, сколь-
ко еще их осталось).
Предварительные испытания проводят для определения рабо-
тоспособности системы и решения вопроса о возможности ее
приемки в опытную эксплуатацию. Предварительные испытания
следует выполнять после проведения разработчиком отладки и
тестирования поставляемых программных и технических средств
системы и представления соответствующих документов об их го-
1.7. Типовое проектирование АИС
61
товности к испытаниям, а также после ознакомления персонала
АИС с эксплуатационной документацией.
Опытную эксплуатацию системы проводят с целью определе-
ния фактических значений количественных и качественных ха-
рактеристик системы и готовности персонала к работе в условиях
ее функционирования, а также определения фактической эффек-
тивности и корректировки, при необходимости, документации.
Приемочные испытания проводят для определения соответст-
вия системы техническому заданию, оценки качества опытной
эксплуатации и решения вопроса о возможности приемки систе-
мы в постоянную эксплуатацию.
1.7. Типовое проектирование АИС
Методы типового проектирования АИС достаточно подроб-
но рассмотрены в литературе [8, 16—18]. Здесь приведены ос-
новные определения и представлено задание для разработки
проекта АИС методом типового проектирования.
Как было отмечено выше, типовое проектирование АИС пред-
полагает создание системы из готовых типовых элементов. При
этом основным требованием метода является возможность де-
композиции проектируемой АИС на множество составляющих
компонентов (подсистем, комплексов задач, программных моду-
лей и т. д.). Для реализации выделенных компонентов выбира-
ются имеющиеся на рынке типовые проектные решения, кото-
рые настраиваются на особенности конкретного предприятия.
Типовое проектное решение (ТПР) — это тиражируемое (при-
годное к многократному использованию) проектное решение.
ТПР классифицируются по уровням декомпозиции системы.
Приняты следующие классы:
• элементные ТПР. Типовое решение задачи или отдельного
вида обеспечения задачи (информационного, программно-
го, технического, технологического, математического, ор-
ганизационного);
• подсистемные ТПР. Решение является отдельной функцио-
нально полной подсистемой;
• объектные ТПР. Типовой проект, включающий полный
набор функциональных и обеспечивающих подсистем АИС
(для вида деятельности, отрасли и т. п.).
62
Глава 1. Проектирование АИС
ТПР должно содержать не только функциональные элементы
(программные или аппаратные), но и документацию с деталь-
ным описанием состава компонентов и процедуры настройки в
соответствии с задачами проекта.
В табл. 1.8 приведены особенности различных классов ТПР.
Таблица 1.8. Достоинства н недостатки ТПР
Класс ТПР. реализация ТПР Достоинства Недостатки
Элементные ТПР. Библиотеки методоори- ентированных программ Обеспечивается применение мо- дульного подхода к проектирова- нию и документированию АИС Большие затраты времени на сопряжение разнородных эле- ментов вследствие информа- ционной, программной и тех- нической несовместимости. Большие затраты времени на доработку ТПР отдельных эле- ментов
Подсистемные ТПР. Пакеты прикладных программ Достигается высокая степень ин- теграции элементов АИС. Позволяют осуществлять модуль- ное проектирование; параметри- ческую настройку программных компонентов на различные объ- екты управления. Обеспечивают сокращение затрат на проектирование и программи- рование взаимосвязанных компо- нентов; хорошее документирова- ние отображаемых процессов об- работки информации Адаптивность ТПР недостаточ- на с позиции непрерывного ин- жиниринга деловых процессов. Возникают проблемы в ком- плексировании разных функ- циональных подсистем, особенно в случае использова- ния решений нескольких произ- водителей программного обес- печения
Объектные ТПР. Отраслевые проекты ИС Комплексирование всех компо- нентов АИС за счет методологи- ческого единства и информаци- онной, программной и техниче- ской совместимости. Открытость архитектуры позволяет устанавливать ТПР на разных программно-технических платформах. Масштабируемость допускает конфигурацию ИС для перемен- ного числа рабочих мест. Конфигурируемость позволяет выбирать необходимое подмно- жество компонентов Проблемы привязки типового проекта к конкретному объекту управления, что вызывает в не- которых случаях даже необхо- димость изменения организа- ционно-экономической струк- туры объекта автоматизации
1.7. Типовое проектирование АИС
63
Для реализации типового проектирования могут использо-
ваться два подхода: параметрически-ориентированное и модель-
но-ориентированное проектирование.
Параметрически-ориентированное проектирование включает
следующие этапы:
• определение критериев оценки пригодности пакетов при-
кладных программ (ППП) для решения поставленных
задач;
• анализ и оценка доступных ППП по сформулированным
критериям;
• выбор и закупка наиболее подходящих пакетов;
• настройка параметров (доработка) закупленных ППП.
Ниже приведены группы, на которые делятся критерии
оценки ППП:
• назначение и возможности пакета;
• характеристики и свойства пакета;
• требования к аппаратным и программным средствам;
• документация пакета;
• финансовые факторы;
• особенности установки и настройки пакета;
• особенности эксплуатации пакета;
• обязательства поставщика по внедрению и сопровождению
пакета;
• оценка качества пакета и опыт его использования;
• перспективы развития пакета.
Внутри каждой группы критериев выделяется некоторое под-
множество частных показателей, детализирующих каждый из
приведенных аспектов анализа выбираемых ППП [8, 16—18].
Числовые значения показателей для конкретных ППП устанав-
ливаются экспертами по выбранной шкале оценок. На их основе
формируются групповые оценки и комплексная оценка пакета
(путем вычисления средневзвешенных значений). Нормирован-
ные взвешивающие коэффициенты также получаются эксперт-
ным путем.
Модельно-ориентированное проектирование заключается в
адаптации состава и характеристик типовой АИС в соответствии
с моделью объекта автоматизации.
Технология проектирования в этом случае должна обеспечи-
вать единые средства для работы с моделями типовой АИС и ав-
томатизируемого объекта (предприятия).
64
Глава 1. Проектирование АИС
На рис. 1.12 приведена конфигурация АИС, проектируемая
на основе модельно-ориентированной технологии [18].
Специальная база метаданных — репозиторий — содержит
модель объекта автоматизации, на основе которой осуществляет-
ся конфигурирование программного обеспечения. Модель объ-
екта автоматизации строится с помощью специального про-
граммного инструментария (например, SAP Business Engineering
Workbench — BEW, BAAN Enterprise Modeler).
Альтернативный способ — создание системы на базе типо-
вой модели из репозитория, который поставляется вместе с про-
граммным продуктом и расширяется по мере накопления опыта
проектирования АИС для различных отраслей и типов произ-
водства.
Репозиторий содержит базовую (ссылочную) модель АИС,
типовые (референтные) модели определенных классов АИС, мо-
дели конкретных АИС предприятий.
Типовая \
модель: \
Типовая '
модель:
Типовая
модель:
Объекты
Функции
Процессы
Орг, структура
Рис. 1.12. Конфигурация АИС на основе модельно-ориентированной технологии
1.7. Типовое проектирование АИС
65
Базовая модель АИС содержит описание бизнсс-функций,
бизнес-процессов, бизнес-объсктов, бизнес-правил, организаци-
онной структуры, которые поддерживаются программными мо-
дулями типовой АИС.
Типовые модели описывают конфигурации АИС для опреде-
ленных отраслей или типов производства.
Модель конкретного предприятия строится либо путем вы-
бора фрагментов основной или типовой модели в соответствии
со специфическими особенностями предприятия (BAAN Enter-
prise Modeler), либо путем автоматизированной адаптации этих
моделей в результате экспертного опроса (SAP Business Engi-
neering Workbench).
Построенная модель предприятия в виде метаописания хра-
нится в репозитории и при необходимости может быть откор-
ректирована. На основе этой модели автоматически осуществля-
ются конфигурирование и настройка АИС.
Бизнес-правила определяют условия корректности совместно-
го применения различных компонентов АИС и используются
для поддержания целостности создаваемой системы.
Модель бизнес-функций представляет собой иерархическую
декомпозицию функциональной деятельности предприятия.
Модель бизнес-процессов отражает выполнение работ для
функций самого нижнего уровня модели бизнсс-функций. Для
отображения процессов используется модель управления собы-
тиями. Модель бизнес-процессов позволяет выполнить настрой-
ку программных модулей — приложений АИС в соответствии с
характерными особенностями конкретного предприятия.
Модели бизнес-объектов используются для интеграции при-
ложений, поддерживающих исполнение различных бизнес-про-
цессов.
Модель организационной структуры предприятия представля-
ет собой традиционную иерархическую структуру подчинения
подразделений и персонала.
Внедрение типовой АИС начинается с анализа требований,
которые выявляются на основе результатов предпроектного об-
следования объекта автоматизации. Для оценки соответствия
этим требованиям программных продуктов может использоваться
описанная выше методика оценки ППП. После выбора про-
граммного продукта на базе имеющихся в нем референтных моде-
лей строится предварительная модель АИС, в которой отражают-
ся все особенности реализации АИС для конкретного предпри-
66
Глава 1. Проектирование АИС
ятия. Предварительная модель является основой для выбора
типовой модели системы и определения перечня компонентов,
которые будут реализованы с использованием других программ-
ных средств или потребуют разработки с помощью имеющихся в
составе типовой АИС инструментальных средств [18, 19].
Реализация типового проекта предусматривает выполнение
следующих операций:
• установку глобальных параметров системы;
• задание структуры объекта автоматизации;
• определение структуры основных данных;
• задание перечня реализуемых функций и процессов;
• описание интерфейсов;
• описание отчетов;
• настройку авторизации доступа;
• настройку системы архивирования.
Контрольные вопросы
1. Дайте определение информационной и автоматизированной инфор-
мационной систем.
2. Приведите примеры классификационных признаков и классификаций
АИС.
3. Перечислите виды обеспечения (обеспечивающих подсистем) АИС.
4. Дайте определение архитектуры АИС.
5. Перечислите этапы и стадии жизненного цикла АИС.
6. Перечислите модели жизненного цикла АИС.
7. Перечислите требования технологии проектирования АИС.
8. Объясните разницу в терминологии «методология» и «технология»
проектирования.
9. Назовите этапы типового проектирования.
10. Перечислите достоинства и недостатки типового проектного решения.
Литература
1. Попов И. И. Автоматизированные информационные системы (по об-
ластям применения): учеб, пособие / под ред. К. И. Курбакова. М.: Изд-во
Рос. экон, акад., 1998. 103 с.
2. Месарович М., Мако Д., Такахара Ю. Теория иерархических много-
уровневых систем. М.: Мир, 1974.
3. Информационные технологии: толковый словарь аббревиатур /
Э. Наян; пер. с англ. К. Г. Финогенова. М.: БИНОМ; Лаборатория знаний,
2003. 646 с.
1.7. Типовое проектирование АИС
67
4. ГОСТ 34-003—90. Автоматизированные системы. Термины и опреде-
ления. Комплекс стандартов на автоматизированные системы. ИПК «Изда-
тельство стандартов», 1997.
5. Избачков Ю. С., Петров В. Н. Информационные системы. СПб.:
Питер, 2005. 656 с.
6. Ковалев С. М., Ковалев В. М. Современные методологии описания
бизнес-процессов: просто о сложном. Ч. 6. // Консультант директора.
2004. № 12.
7. Кузнецов С. Д. Основы современных баз данных. Информацион-
но-аналитические материалы Центра Информационных технологий,
www/citmgu.ru.
8. Проектирование экономических информационных систем / Г. Н. Смир-
нова и др. М.: Финансы и статистика, 2003. 512 с.
9. Балдин К. В., Уткин В. Б. Информационные системы в экономике:
учебник. 2-е изд. М.: Дашков и К°, 2006. 395 с.
10. Информационные технологии управления: учеб, пособие для ву-
зов / под ред. проф. Г. А. Титоренко. 2-е изд., доп. М.: ЮНИТИ-ДАНА,
2004. 439 с.
11. IEEE Std. 610.12—1990.
12. ГОСТ 34.601—90. Автоматизированные системы. Стадии создания.
Комплекс стандартов на автоматизированные системы. ИПК «Издательство
стандартов», 1997.
13. Грабауров В. А. Информационные технологии для менеджеров. 2-е
изд., перераб. и доп. М.: Финансы и статистика, 2005. 512 с.
14. Буч Г., Рамбо Д., Джекобсон А. Язык UML: Руководство пользова-
теля. Пер. с англ. М.: ДМК, 2000. 142 с.
15. Балдин К. В. Моделирование жизненного цикла сложных систем.
Ч. I и II. М.: Издательство РДЛ, 2000.
16. Трояновский В. М. Проектирование информационных систем. М.:
МИЭТ, 2002. 108 с.
17. Вендров А. М. Проектирование программного обеспечения эконо-
мических информационных систем. 2-е изд., перераб. и доп. М.: Финансы
и статистика, 2005. 180 с.
18. Грекул В. И. Проектирование информационных систем,
http://www.intuit.ru.
19. Модели и методологии разработки информационных систем,
http://www.stormsystemst.ru.
20. Верников Г. Н. Основы методологии обследования организаций,
http: //www.vernikov.ru.
21. Емельянов А. А., Власов Е. А. Информационное моделирование в
экономических системах: учеб, пособие. М.: МЭСИ, 2003.
22. Clegg, Dai, and Richard Barker. CASE-Method Fast-track. A RAD
Approach. Adison-Wesley, 1994.
Глава 2
АНАЛИЗ ПРЕДМЕТНОЙ ОБЛАСТИ АИС
С ПРИМЕНЕНИЕМ СИСТЕМ
АВТОМАТИЗИРОВАННОГО
ПРОЕКТИРОВАНИЯ
2.1. Этапы анализа предметной области
Проект разработки АИС для любой предметной области и
любого предприятия следует рассматривать как крупные инве-
стиции, которые должны окупиться за счет повышения эффек-
тивности деятельности, поэтому сначала необходимо определить,
какие именно функциональные области и какие типы производ-
ства нужно охватить, т. е. провести анализ предметной области
АИС [ 1]. В свою очередь, для эффективного анализа предметной
области необходимо:
1) разработать стратегию комплексной автоматизации;
2) провести анализ деятельности предприятия;
3) рассмотреть вопросы реорганизации деятельности.
Рассмотрим каждый из пунктов подробнее. Понятие страте-
гии автоматизации основывается на базовых принципах автома-
тизации предприятия, которая включает в себя следующие ком-
поненты:
• цели — области деятельности предприятия и последова-
тельность, в которой они будут автоматизированы;
• способ автоматизации — по участкам, направлениям, ком-
плексная автоматизация;
• долгосрочная техническая политика — комплекс внутрен-
них стандартов, поддерживаемых на предприятии;
• ограничения;
• процедура управления изменениями плана.
2.1. Этапы анализа предметной области 69
Стратегия автоматизации в первую очередь должна соответст-
вовать приоритетам и стратегии (задачам) бизнеса и определять
пути достижения этого соответствия. Стратегический план авто-
матизации составляется с учетом:
• среднего периода между сменой технологий основного
производства;
• среднего времени жизни выпускаемых предприятием про-
дуктов и их модификаций;
• анонсированных долгосрочных планов поставщиков техни-
ческих решений в плане их развития;
• сроков амортизации используемых систем;
• стратегического плана развития предприятия, включая пла-
ны слияния и разделения, изменения численности и но-
менклатуры выпускаемой продукции;
• планируемых изменений функций персонала.
Автоматизация — один из способов достижения стратегиче-
ских бизнес-целей, а не процесс, развивающийся по своим
внутренним законам. Во главе стратегии автоматизации должна
лежать стратегия бизнеса предприятия: миссия предприятия,
направления и модель бизнеса. Таким образом, стратегия авто-
матизации представляет собой план, согласованный по срокам
и целям со стратегией организации.
Второй важной особенностью автоматизации является сте-
пень соответствия приоритетов автоматизации стратегии бизне-
са, т. е. достижению поставленных целей, к которым можно от-
нести:
• снижение стоимости продукции;
• увеличение количества или ассортимента;
• сокращение цикла: разработка новых товаров и услуг, вы-
ход на рынок;
• переход от производства «на склад» к производству «под
конкретного заказчика» с учетом индивидуальных требова-
ний и т. д.
Стратегические цели бизнеса с учетом ограничений (финан-
совых, временных и технологических) конвертируются в страте-
гический план автоматизации предприятия.
Автоматизация предприятия является инвестиционной дея-
тельностью и к ней применимы все подходы оценки эффектив-
ности инвестиций.
К основным ограничениям, которые необходимо учитывать
при выборе стратегии автоматизации, относятся: финансовые;
70
Глава 2. Анализ предметной области АИС...
временные; ограничения, связанные с влиянием человеческого
фактора; технические.
Финансовые ограничения определяются величиной инвести-
ций, которые предприятие способно вложить в развитие автома-
тизации. Этот тип ограничений наиболее универсален, так как
остальные три вида могут быть частично конвертированы в фи-
нансовые.
Временные ограничения обычно связаны со сменой техноло-
гий основного производства, рыночной стратегией предприятия,
государственным регулированием экономики.
К ограничениям, связанным с влиянием человеческого факто-
ра, относятся корпоративная культура или отношение персонала
к автоматизации и особенности рынка труда в части трудового
законодательства.
Технические ограничения определяются степенью материаль-
ного и морального износа технического парка предприятия (ор-
ганизации).
Кроме рассмотренных выше ограничений, существуют ти-
пичные проблемы, возникающие при разработке стратегии авто-
матизации и, как правило, связанные со следующими факторами:
• состоянием рынка информационных технологий;
• определением эффективности инвестиций в информацион-
ные технологии;
• необходимостью реорганизации деятельности предприятия
при внедрении информационных технологий.
Под анализом деятельности предприятия здесь понимается сбор
и представление информации о деятельности предприятия в фор-
мализованном виде, пригодном для принятия решения о разра-
ботке определенного класса АИС. В зависимости от выбранной
стратегии автоматизации предприятия технологии сбора и пред-
ставления информации могут быть различными. Итоговое пред-
ставление информации на этапе анализа деятельности играет одну
из ключевых ролей во всей дальнейшей работе. Желательно, что-
бы анализ предприятия закончился построением набора моделей,
соответствующих стандартам IDEF (будут рассмотрены далее).
Реорганизация деятельности преследует, как правило, цель
повышения эффективности деятельности предприятия в целом
и может предусматривать применение методологий BSP, TQM
или BPR.
2.1. Этапы анализа предметной области
71
Методология BSP (см. также гл. 1) определяется как «подход,
помогающий предприятию определить план создания информа-
ционных систем, удовлетворяющих его ближайшим и перспек-
тивным информационным потребностям». Информация является
одним из основных ресурсов и должна планироваться в масшта-
бах всего предприятия, АИС должна проектироваться независимо
от текущего состояния и структуры предприятия. BSP основыва-
ется на нисходящем анализе информационных объектов и регла-
ментирует 13 этапов выполнения работ.
Подход TQM (Total Quality Management) успешно применял-
ся при реорганизации предприятий еще в середине XX в. В ос-
нове подхода лежит очевидная концепция управления качеством
выпускаемой продукции. Качество должно быть направлено на
удовлетворение текущих и будущих потребностей потребителя
как самого важного звена производственной линии. Достижение
соответствующего уровня качества требует постоянного совер-
шенствования производственных процессов. Для решения этой
задачи Э. Демингом было предложено 14 принципов, в совокуп-
ности составляющих теорию управления качеством и примени-
мых для предприятий произвольных типов и различных масшта-
бов. Безусловно, этих принципов недостаточно для полного ре-
шения стоящих перед современными предприятиями проблем,
тем не менее они являются основой трансформации промыш-
ленности Японии и США.
BPR (Business Process Reengineering) — реинжиниринг биз-
нес-процессов — определяется как фундаментальное переосмыс-
ление и радикальное перепланирование бизнес-процессов ком-
паний, имеющее целью резкое улучшение показателей их дея-
тельности, таких как затраты, качество, сервис и скорость. При
этом используются следующие положения.
1. Несколько работ объединяются в одну.
2. Исполнителям делегируется право по принятию решений.
3. Этапы процесса выполняются в естественном порядке.
4. Реализуются различные версии процесса.
5. Работа выполняется там, где ее целесообразно делать (вы-
ход работы за границы организационных структур).
6. Снижаются доли работ по проверке и контролю.
7. Минимизируется количество согласований.
72
Глава 2. Анализ предметной области АИС...
8. Ответственный менеджер является единственной точкой
контакта с клиентом процесса.
9. Используются и централизованные и децентрализованные
операции.
Для того чтобы выполнить пп. 1—9, необходимо использо-
вать так называемый «инжиниринговый подход» [2].
2.2. Реинжиниринг бизнес-процессов
Организационный анализ компании при таком подходе про-
водится по определенной схеме с помощью полной бизнес-модели
компании. Компания рассматривается как целевая, открытая,
социально-экономическая система, принадлежащая иерархиче-
ской совокупности открытых внешних надсистем (рынок, госу-
дарственные учреждения и пр.) и внутренних подсистем (отде-
лы, цеха, бригады и пр.). Возможности компании определяются
характеристиками ее структурных подразделений и организаци-
ей их взаимодействия. На рис. 2.1 представлена обобщенная схе-
ма организационной бизнес-модели [3].
Рис. 2.1. Обобщенная схема организационного бизнес-моделирования
2.2. Реинжиниринг бизнес-процессов
73
Построение бизнес-модели компании начинается с модели-
рования ее взаимодействия с внешней средой, т. е. с определе-
ния миссии компании.
Миссия согласно стандарту ISO 15704 — это:
1) деятельность, осуществляемая предприятием для того, что-
бы выполнить функцию, для которой оно было учреждено, —
предоставление заказчикам продукта или услуги;
2) механизм, с помощью которого предприятие реализует
свои цели и задачи.
Миссия компании по удовлетворению социально значимых
потребностей рынка определяется как компромисс интересов
рынка и компании. При этом миссия как атрибут открытой сис-
темы разрабатывается, с одной стороны, исходя из рыночной
конъюнктуры и позиционирования компании относительно дру-
гих участников внешней среды, а с другой — исходя из объек-
тивных возможностей компании и ее субъективных ценностей,
ожиданий и принципов. Миссия является своеобразной мерой
устремлений компании и, в частности, определяет рыночные
претензии компании (предмет конкурентной борьбы). Определе-
ние миссии позволяет сформировать дерево целей компании —
иерархические списки уточнения и детализации миссии.
Дерево целей формирует дерево стратегий — иерархические
списки уточнения и детализации целей. При этом на корпора-
тивном уровне разрабатываются стратегии роста, интеграции и
инвестиции бизнесов. Блок бизнес-стратегий определяет продук-
товые и конкурентные стратегии, а также стратегии сегментации
и продвижения. Ресурсные стратегии определяют стратегии при-
влечения материальных, финансовых, человеческих и информа-
ционных ресурсов. Функциональные стратегии определяют стра-
тегии в организации компонентов управления и этапов жизнен-
ного цикла продукции. Одновременно выясняется потребность и
предмет партнерских отношений (субподряд, сервисные услуги,
продвижение и пр.). Это позволяет обеспечить заказчикам необ-
ходимый продукт требуемого качества, в нужном количестве, в
нужном месте, в нужное время и по приемлемой цене. При этом
компания может занять в партнерской цепочке создаваемых цен-
ностей оптимальное место, где ее возможности и потенциал бу-
дут использоваться наилучшим образом. Это дает возможность
сформировать бизнес-потенциал компании — набор видов ком-
мерческой деятельности, направленный на удовлетворение по-
требностей конкретных сегментов рынка.
74
Глава 2. Анализ предметной области АИС...
Далее, исходя из специфики каналов сбыта, формируется
первоначальное представление об организационной структуре
(определяются центры коммерческой ответственности). Возни-
кает понимание основных ресурсов, необходимых для воспроиз-
водства товарной номенклатуры.
Бизнес-потенциал, в свою очередь, определяет функционал
компании — перечень бизнес-функций, функций менеджмента и
функций обеспечения, требуемых для поддержания на регуляр-
ной основе указанных видов коммерческой деятельности. Кроме
того, уточняются необходимые для этого ресурсы (материаль-
ные, человеческие, информационные) и структура компании.
Построение бизнес-потенциала и функционала компании
позволяет с помощью матрицы проекций определить зоны от-
ветственности менеджмента.
Матрица проекций — модель, представленная в виде матри-
цы, задающей систему отношений между классификаторами в
любой их комбинации.
Матрица коммерческой ответственности закрепляет ответст-
венность структурных подразделений за получение дохода в ком-
пании от реализации коммерческой деятельности. Ее дальнейшая
детализация (путем выделения центров финансовой ответствен-
ности) обеспечивает построение финансовой модели компании,
что, в свою очередь, позволяет внедрить систему бюджетного
управления.
Матрица функциональной ответственности закрепляет ответст-
венность структурных звеньев (и отдельных специалистов) за вы-
полнение бизнес-функций при реализации процессов коммерче-
ской деятельности (закупка, производство, сбыт и пр.), а также
функций менеджмента, связанных с управлением этими процес-
сами (планирование, учет, контроль в области маркетинга, фи-
нансов, управления персоналом и пр.). Дальнейшая детализация
матрицы (до уровня ответственности отдельных сотрудников)
позволит получить функциональные обязанности персонала, что
в совокупности с описанием прав, обязанностей, полномочий
обеспечит разработку пакета должностных инструкций.
Описание бизнес-потенциала, функционала и соответствую-
щих матриц ответственности представляет собой статическое
описание компании. При этом процессы, протекающие в компа-
нии, идентифицируются, классифицируются и закрепляются за
исполнителями (будущими хозяевами этих процессов) [2].
2.2. Реинжиниринг бизнес-процессов 75
На этом этапе бизнес-моделирования формируется обще-
признанный набор основополагающих внутрифирменных регла-
ментов [3|:
• базовое Положение об организационно-функциональной
структуре компании;
• пакет Положений об отдельных видах деятельности (фи-
нансовой, маркетинговой и т. д.);
• пакет Положений о структурных подразделениях (цехах,
отделах, секторах, группах и т. п.);
• должностные инструкции.
Это вносит прозрачность в деятельность компании за счет
четкого разграничения и документального закрепления зон от-
ветственности менеджеров.
Дальнейшее развитие (детализация) бизнес-модели происхо-
дит на этапе динамического описания компании на уровне процесс-
ных потоковых моделей.
Процессная потоковая модель [3] — это модель, описывающая
процесс последовательного во времени преобразования матери-
альных и информационных потоков компании в ходе реализации
какой-либо бизнес-функции или функции менеджмента. Снача-
ла (на верхнем уровне) описывается логика взаимодействия уча-
стников процесса, а затем (на нижнем уровне) — технология ра-
боты отдельных специалистов на своих рабочих местах (рис. 2.2).
Рис. 2.2. П отоковая процессная модель
76
Глава 2. Анализ предметной области АИС...
Завершается организационное бизнес-моделирование разра-
боткой модели структур данных, которая определяет перечень и
форматы документов, сопровождающих процессы в компании, а
также задает форматы описания объектов внешней среды, ком-
понентов и регламентов самой компании. При этом создается
система справочников, на основании которых получают пакеты
необходимых документов и отчетов.
Такой подход позволяет описать деятельность компании с
помощью универсального множества управленческих регистров
(цели, стратегии, продукты, функции, организационные звенья
и т. д.).
Управленческие регистры по своей структуре представляют
собой иерархические классификаторы. Объединяя классифика-
торы в функциональные группы и закрепляя между собой эле-
менты различных классификаторов с помощью матричных про-
екций, можно получить полную бизнес-модель компании.
При этом происходит процессно-целевое описание компании,
позволяющее получить взаимосвязанные ответы на следующие
вопросы: зачем, что, где, кто, как, когда, кому, сколько (рис. 2.3).
Рис. 2.3. Основные этапы процессно-целевого описания компании
Следовательно, полная бизнес-модель компании [3] — это со-
вокупность функционально ориентированных информационных
моделей, обеспечивающая взаимосвязанные ответы на перечис-
ленные выше вопросы (рис. 2.4).
2.2. Реинжиниринг бизнес-процессов
77
Рис. 2.4. Полная бизнсс-молель компании
Таким образом, организационный анализ предполагает по-
строение комплекса взаимосвязанных информационных моде-
лей компании, который включает:
• стратегическую модель целеполагания (отвечает на вопро-
сы: зачем компания занимается именно этим бизнесом,
почему предполагает быть конкурентоспособной, какие
цели и стратегии для этого необходимо реализовать);
• организационно-функциональную модель (отвечает на во-
прос: кто — что делает в компании и кто за что отвечает);
• функционально-технологическую модель (отвечает на во-
прос: что — как реализуется в компании);
• процессно-ролевую модель (отвечает на вопрос: кто —
что — как — кому);
• количественную модель (отвечает на вопрос: сколько необ-
ходимо ресурсов);
• модель структуры данных (отвечает на вопрос: в каком
виде описываются регламенты компании и объекты внеш-
него окружения).
78
Глава 2. Анализ предметной области АИС...
Представленная совокупность моделей обеспечивает необхо-
димую полноту и точность описания компании и позволяет вы-
рабатывать понятные требования к проектируемой информаци-
онной системе.
2.3. Методы сбора материалов обследования
Для построения рассмотренных выше моделей необходимо
получить и проанализировать соответствующую информацию и
здесь существуют разнообразные методы сбора данных (материа-
лов) обследования [2—5].
Метод бесед и консультаций с руководителями чаще всего про-
водится в форме обычной беседы с руководителями предприятий
и подразделений или в форме деловой консультации со специа-
листами по вопросам, носящим глобальный характер и относя-
щимся к определению проблем и стратегий развития и управле-
ния предприятием.
Метод опроса исполнителей на рабочих местах используется в
процессе сбора сведений непосредственно у специалистов путем
бесед, которые требуют тщательной подготовки. Заранее состав-
ляют список сотрудников, с которыми намереваются беседовать,
разрабатывают перечень вопросов о роли и назначении работ в
деятельности объекта автоматизации, порядке их выполнения.
Метод анализа операций заключается в расчленении рассмат-
риваемого делового процесса и работы на составные части, зада-
чи, расчеты, операции и даже элементы. После этого анализиру-
ется каждая часть в отдельности, выявляется повторяемость от-
дельных операций, многократное обращение к одной и той же
операции, степень зависимости друг от друга.
Метод анализа представленного материала применим, в основ-
ном, при выяснении таких вопросов, на которые нельзя получить
ответ от исполнителей. Как было сказано ранее (см. п. 1.4), «об-
следование — это изучение и анализ оргструктуры предприятия»,
и процедура эта является обязательной при анализе предметной
области АИС, причем проводить ее можно различными метода-
ми. Рассмотрим наиболее употребительные.
Метод фотографии рабочего дня исполнителя работ предпола-
гает непосредственное участие проектировщиков и применение
рассчитанного для регистрации данных наблюдения специаль-
2.3. Методы сбора материалов обследования 79
ного листа фотографии рабочего дня и распределения его между
работами.
Метод выборочного хронометража отдельных работ требует
предварительной подготовки, известных навыков и наличия спе-
циального секундомера. Данные хронометража позволяют уста-
новить нормативы на выполнение отдельных операций и собрать
подробный материал о технике осуществления некоторых работ.
Метод личного наблюдения применим, если изучаемый во-
прос понятен по существу и необходимо лишь уточнение дета-
лей без существенного отрыва исполнителей от работы.
Метод документальной инвентаризации управленческих работ
заключается в том, что на каждую работу в отдельности откры-
вается специальная карта обследования, в которой приводятся
все основные данные о регистрируемой работе или составляе-
мых документах.
Метод ведения индивидуальных тетрадей — дневников. Записи
в дневнике производятся исполнителем в течение месяца еже-
дневно, сразу же после выполнения очередной работы.
Метод самофотографии рабочего дня заключается в том, что
наблюдение носит более детальный характер и происходит в ко-
роткий срок. Этот метод дает сведения о наиболее трудоемких
или типичных отдельных работах, которые используются для оп-
ределения общей трудоемкости выполнения всех работ.
Расчетный метод применяется для определения трудоемкости
и стоимости работ, подлежащих переводу на выполнение с по-
мощью ЭВМ, а также для установления объемов работ по от-
дельным операциям.
Метод аналогии основан на отказе от детального обследова-
ния какого-либо подразделения или какой-либо работы. Ис-
пользование метода требует наличия тождественности и не ис-
ключает общего обследования и выяснения таких аспектов, на
которые аналогия не распространяется.
На рис. 2.5 представлен вариант формы плана-графика вы-
полнения работ [4].
№ п/п Наименова- ние работы Код работы Исполнитель Дата начала Длительность выполнения Дата окончания
Рис. 2.5. «Шапка» формы плана-графика выполнения работ по сбору
материма обследования
80
Глава 2. Анализ предметной области АИС...
2.4. Формализация материалов обследования
Сбор материалов обследования проводится с помощью стан-
дартных форм и таблиц (рис. 2.6) |5].
Результатом прсдпроектного обследования является «Отчет
об экспресс-обслсдовании предприятия». Его типовая структура
приведена ниже.
1. Краткое схематичное описание бизнес-процессов:
• управление закупками и запасами;
• управление производством;
• управление продажами;
• управление финансовыми ресурсами.
2. Основные требования и приоритеты автоматизации.
3. Оценка необходимых для обеспечения проекта ресурсов
заказчика.
4. Оценка возможности автоматизации, предложения по со-
зданию автоматизированной системы с оценкой примерных сро-
ков и стоимости.
Рис. 2.6. Формализация материалов обследования
2.5. Методологии описания предметной области
81
Проведение предпроектного обследования решает следую-
щие задачи:
• предварительное выявление требований к будущей системе;
• определение перечня целевых функций организации;
• определение структуры организации;
• анализ распределения функций по подразделениям и со-
трудникам;
• выявление функциональных взаимодействий между под-
разделениями, информационных потоков внутри подразде-
лений и между ними, внешних информационных воздейст-
вий;
• анализ существующих средств автоматизации организации.
Информация, полученная в результате предпроектного об-
следования, анализируется с помощью методов структурного
и/или объектного анализа и используется для построения моде-
лей деятельности организации.
Модель организации предполагает построение двух видов мо-
делей:
1) модели «как есть» («as is»), отражающей существующее на
момент обследования положение дел в организации и описы-
вающей, каким образом функционирует данная организация.
Использование такой модели позволяет выявить узкие места и
сформулировать предложения по улучшению;
2) модели «как должно быть» («to be»), отражающей пред-
ставление о новых, преобразованных технологиях работы орга-
низации.
Каждая из моделей включает в себя полную функциональ-
ную и информационную модель деятельности организации, а
также модель, описывающую динамику поведения организации
(в случае необходимости).
2.5. Методологии описания предметной области
Бизнес-моделирование может быть реализовано с помощью
различных методик, отличающихся подходами к моделированию
организации. В соответствии с различными представлениями об
организации принято различать методики объектные и функ-
циональные (структурные) [5].
Сущность функционального подхода к моделированию биз-
нес-процессов сводится к построению схемы технологического
82
Глава 2. Анализ предметной области АИС...
процесса в виде последовательности операций, на входе и выхо-
де которых отражаются объекты различной природы: материаль-
ные и информационные объекты, используемые ресурсы, орга-
низационные единицы.
Достоинство функционального подхода заключается в на-
глядности и понятности представления бизнес-процессов на раз-
личных уровнях абстракции, что особенно важно на стадии вне-
дрения разработанных бизнес-процессов в подразделениях пред-
приятия. Существенным недостатком функционального подхода
является некоторая субъективность детализации операций и, как
следствие, большая трудоемкость в адекватном построении биз-
нес-процессов.
Объектно-ориентированный подход предполагает выделение
классов объектов и определение действий, в которых участвуют
объекты. При этом различают пассивные объекты (материалы,
документы, оборудование), над которыми выполняются дейст-
вия, и активные объекты (организационные единицы, конкрет-
ные исполнители, информационные подсистемы), которые со-
вершают эти действия.
Такой подход позволяет выделять операции над объектами и
решать задачи целесообразности существования самих объектов.
Недостаток объектно-ориентированного подхода заключает-
ся в меньшей наглядности конкретных процессов для лиц, при-
нимающих решения. Вместе с тем выявленные операции в даль-
нейшем могут быть представлены для наглядности в виде функ-
циональных диаграмм.
В настоящее время для проведения моделирования деловых
и информационных процессов разработаны различные методо-
логии и соответствующие инструментальные средства, большин-
ство из которых имеют узкую направленность применения.
Методологии функционального моделирования (диаграммы
потоков данных, структурные диаграммы процессов) ориенти-
рованы на отображение последовательности функций. При их
использовании трудно определить конкретные альтернативы
процессов, не видна схема взаимодействия объектов. Объектные
модели, наоборот, отражают только обобщенную схему взаимо-
действия объектов без детализации последовательности выпол-
нения функций. Методологии объектно-ориентированного под-
хода отражают объекты, функции и события, при которых объ-
екты инициируют выполнение конкретных процессов; при этом
теряется общая наглядность модели [2|.
2.5. Методологии описания предметной области
83
2.5.1. Функциональное моделирование
бизнес-процессов с использованием стандарта IDEFO
Методология 1DEF0 является развитием хорошо известного
графического языка описания функциональных систем SADT
(Structured Analysis and Design Teqnique).
IDEFO как стандарт был разработан в 1981 г. в рамках об-
ширной программы автоматизации промышленных предприятий
Integrated Computer Aided Manufacturing (ICAM) предложенной
департаментом военно-воздушных сил США. Семейство стан-
дартов унаследовало свое обозначение от названия этой про-
граммы — ICAM DEFinition — IDEF. В процессе практической
реализации участники программы ICAM столкнулись с необхо-
димостью разработки новых методов анализа процессов взаимо-
действия в промышленных системах. При этом, кроме усовер-
шенствованного набора функций для описания бизнес-процес-
сов, одним из требований к новому стандарту было наличие эф-
фективной методологии взаимодействия в рамках «аналитик —
специалист». Другими словами, новый метод должен был обес-
печить групповую работу над созданием модели с непосредст-
венным участием всех аналитиков и специалистов, занятых в
рамках проекта [2, 5, 8, 11, 13].
Со времени появления стандарт IDEFO претерпел несколько
незначительных изменений, в основном, ограничивающего ха-
рактера; последняя его редакция была выпущена в декабре
1993 г. Национальным институтом по стандартам и технологиям
США (NIST).
Графический язык IDEFO прост и гармоничен. В основе ме-
тодологии лежат четыре основных понятия, первым из которых
является понятие функционального блока (Activity Box). Функ-
циональный блок графически изображается в виде прямоуголь-
ника (рис. 2.7) и представляет собой некоторую конкретную
функцию в рамках рассматриваемой системы [5, 8, 11, 13]. По
требованиям стандарта название каждого функционального бло-
ка должно быть сформулировано в глагольном наклонении (на-
пример, «производить услуги», а не «производство услуг»).
Каждая из четырех сторон функционального блока имеет
свое определенное значение (играет свою роль):
• верхняя сторона имеет значение «Управление» (Control);
• левая сторона имеет значение «Вход» (Input);
84
Глава 2. Анализ предметной области АИС...
Управление
Механизм
Рис. 2.7. Функциональный блок
• правая сторона имеет значение «Выход» (Output);
• нижняя сторона имеет значение «Механизм» (Mechanism).
Каждый функциональный блок в рамках единой рассматри-
ваемой системы должен иметь свой уникальный идентификаци-
онный номер.
Второе основное понятие методологии IDEF0 — интерфейс-
ная дуга (Arrow). Интерфейсные дуги также называют потоками
или стрелками. Интерфейсная дуга отображает элемент системы,
который обрабатывается функциональным блоком или оказыва-
ет иное влияние на функцию, отображенную данным функцио-
нальным блоком.
Графическим отображением интерфейсной дуги является од-
нонаправленная стрелка. Каждая интерфейсная дуга должна
иметь свое уникальное наименование (Arrow Label). По требова-
нию стандарта, наименование должно быть оборотом существи-
тельного.
С помощью интерфейсных дуг отображают различные объек-
ты, в той или иной степени определяющие процессы, происхо-
дящие в системе. Такими объектами могут быть элементы реаль-
ного мира (детали, вагоны, сотрудники и т. д.) или потоки дан-
ных и информации (документы, данные, инструкции и т. д.).
Интерфейсные дуги бывают «входящими», «исходящими» и
«управляющими» в зависимости от стороны блока, к которой
они подходят.
«Источником» (началом) и «приемником» (концом) функ-
циональной дуги могут быть только функциональные блоки.
При этом «источником» может быть только выходная сторона
блока, а «приемником» — любая из трех остальных.
Каждый функциональный блок должен иметь, по крайней
мере, одну управляющую интерфейсную дугу (т. е. каждый про-
2.5. Методологии описания предметной области
85
цесс протекает по каким-то правилам) и одну исходящую (выда-
ча некоторого результата).
При построении диаграмм по стандарту IDEF0 необходимо
правильно разделять входящие и управляющие интерфейсные
дуги, что не всегда просто.
На рис. 2.8 приведен пример диаграммы, изображающий
функциональный блок «Обработать заготовку» [5, 8, II, 13]. Для
получения детали рабочему выдают заготовку и технологические
указания. Неверно считать, что технологические указания (ка-
кой-то документ или документы) и заготовка являются входящими
объектами. На самом деле в этом процессе заготовка обрабатыва-
ется по правилам, отраженным в технологических указаниях, кото-
рые должны изображаться управляющей интерфейсной дугой.
Другой пример [5, 8, II, 13] приведен на рис. 2.9, где описы-
вается процесс обработки и изменения главным технологом тех-
нологических указаний. Здесь технологические указания отобра-
Технологические
указания
Рабочий
Рис. 2.8. Функциональный блок «Обработать заготовку»
Новые
промышленные
стандарты
Технологические
указания
Корректировать
технологические
указания
АО
Новые
технологические
указания
Главный
технолог
Рис. 2.9. Функциональный блок «Корректировать технологические указания»
86
Глава 2. Анализ предметной области АИС...
жаются входящей интерфейсной дугой, а управляющим объектом
являются, например, новые промышленные стандарты, учитывая
которые производятся изменения.
Теперь понятно, что входящие и управляющие интерфейс-
ные дуги имеют схожую природу. Тем не менее для систем одно-
го класса всегда есть определенные разграничения. Так, напри-
мер, в случае рассмотрения предприятий и организаций сущест-
вуют пять основных видов объектов:
• материальные потоки (детали, товары, сырье и т. д.);
• финансовые потоки (наличные и безналичные, инвестиции
и т. д.);
• потоки документов (коммерческие, финансовые и органи-
зационные);
• потоки информации (информация, данные о намерениях,
устные распоряжения и т. д.);
• ресурсы (сотрудники, станки, машины и т. д.).
При этом в разных случаях входящими и исходящими интер-
фейсными дугами могут отображаться все виды объектов, управ-
ляющими — только относящиеся к потокам документов и инфор-
мации, а дугами-механизмами — только ресурсы [5, 7, 10, II, 13].
Одно из главных отличий стандарта 1DEF0 от других ме-
тодологий классов DFD (Data Flow Diagram) и WFD (Work
Flow Diagram) — обязательное наличие управляющих интер-
фейсных дуг.
Третье основное понятие стандарта 1DEF0 — это декомпози-
ция (Decomposition). Декомпозиция применяется при разбиении
сложного процесса на составляющие его функции. При этом
уровень детализации процесса определяется непосредственно
разработчиком модели.
Декомпозиция дает возможность представлять модель систе-
мы в виде иерархической структуры отдельных диаграмм. Это
делает диаграммы менее перегруженными и легко читаемыми.
Модель 1DEF0 всегда начинается с представления системы
как единого целого — одного функционального блока с интер-
фейсными дугами, входящими и выходящими за пределы рас-
сматриваемой области. Такая диаграмма с одним функциональ-
ным блоком называется контекстной диаграммой и обозначается
идентификатором «АО». В пояснительном тексте к контекстной
диаграмме должна быть указана цель (Purpose) построения диа-
граммы в виде краткого описания и зафиксирована точка зрения
(Viewpoint).
2.5. Методологии описания предметной области
87
Определение и формализация цели разработки модели
IDEF0 — важнейшие аспекты функционального моделирова-
ния. Цель, прежде всего, определяет первоочередные области
исследования. Так, моделирование деятельности одного и того
же предприятия с целью разработки АИС или, например, опти-
мизации логистических цепочек даст в результате различные
модели.
Точка зрения определяет основное направление развития мо-
дели и уровень необходимой детализации. Четкая фиксация точ-
ки зрения позволяет разгрузить модель, отказаться от детализа-
ции и исследования второстепенных элементов для разрабаты-
ваемой АИС. Например, функциональные модели одного и того
же предприятия, построенные главным технологом и финансо-
вым директором, будут существенно различаться по направлен-
ности их детализации. Финансового директора в меньшей степе-
ни интересуют аспекты обработки сырья на производственных
станках, а главному технологу не нужны детализированные схе-
мы финансовых потоков. Правильный выбор точки зрения суще-
ственно сокращает временные затраты на построение конечной
модели.
В процессе декомпозиции функциональный блок, который в
контекстной диаграмме отображает систему как единое целое,
подвергается детализации на другой диаграмме.
Диаграмма второго уровня содержит функциональные блоки,
отображающие главные подфункции функционального блока
контекстной диаграммы, и называется дочерней (Child diagram)
по отношению к нему. Каждый из функциональных блоков,
принадлежащих дочерней диаграмме, соответственно называется
дочерним блоком — Child Box.
В свою очередь, функциональный блок «предок» называется
родительским блоком (Parent Box) по отношению к дочерней диа-
грамме, а диаграмма, к которой он принадлежит, — родитель-
ской диаграммой (Parent Diagram).
Каждая из подфункций дочерней диаграммы может затем де-
тализироваться с помощью аналогичной декомпозиции соответ-
ствующего ей функционального блока. В каждом случае деком-
позиции функционального блока все интерфейсные дуги, входя-
щие в данный блок или исходящие из него, фиксируются на
дочерней диаграмме. Этим достигается структурная целостность
IDEFO-модели. Наглядно принцип декомпозиции представлен
на рис. 2.10 [3, 5, 7, 8, II, 13]. Следует обратить внимание на
88
Глава 2. Анализ предметной области АИС...
Рис. 2.10. Декомпозиция функциональных блоков
2.5. Методологии описания предметной области
89
взаимосвязь нумерации функциональных блоков и диаграмм —
каждый блок имеет свой уникальный порядковый номер на диа-
грамме (цифра в правом нижнем углу прямоугольника), а обо-
значение под ним указывает на номер дочерней для этого блока
диаграммы. Отсутствие этого обозначения говорит о том, что де-
композиция для данного блока не существует.
Возможны ситуации, когда отдельные интерфейсные дуги
нет смысла рассматривать в дочерних диаграммах ниже како-
го-то определенного уровня в иерархии, или наоборот, отдель-
ные дуги не имеют практического смысла выше какого-то уров-
ня. Например, интерфейсную дугу, изображающую «деталь» на
входе функционального блока «Обработать на токарном станке»,
не имеет смысла отражать на диаграммах более высоких уров-
ней — это будет только перегружать диаграммы и делать их
сложными для восприятия. С другой стороны, бывает необходи-
мо избавиться от отдельных «концептуальных» интерфейсных
дуг и не детализировать их глубже некоторого уровня.
Для решения подобных задач в стандарте IDEFO предусмот-
рено понятие туннелирования. Обозначение «туннеля» (Arrow
Tunnel) в виде двух круглых скобок у начала интерфейсной дуги
означает, что эта дуга не была унаследована от функционального
родительского блока и появилась (из «туннеля») только на этой
диаграмме. В свою очередь, такое же обозначение у конца
(стрелки) интерфейсной дуги рядом с блоком-приемником озна-
чает, что в дочерней по отношению к этому блоку диаграмме эта
дуга не будет отображаться и рассматриваться. Чаще всего от-
дельные объекты и соответствующие им интерфейсные дуги не
рассматриваются на некоторых промежуточных уровнях иерар-
хии, т. е. они сначала «погружаются в туннель», а затем при не-
обходимости «возвращаются из туннеля».
Четвертое базовое понятие стандарта IDEFO — глоссарий
(Glossary). Для каждого из элементов IDEFO (диаграмм, функ-
циональных блоков, интерфейсных дуг) существующий стандарт
подразумевает создание и поддержание набора соответствующих
определений, ключевых слов, повествовательных изложений
и т. д., которые характеризуют объект, отображенный данным
элементом. Такой набор называется глоссарием и является опи-
санием сущности данного элемента. Например, для управляю-
щей интерфейсной дуги «распоряжение об оплате» глоссарий
может содержать перечень полей соответствующего дуге доку-
мента, необходимый набор виз и т. д. Глоссарий гармонично до-
90
Глава 2. Анализ предметной области АИС...
полняет наглядный графический язык, снабжая диаграммы не-
обходимой поясняющей информацией.
Обычно IDEFO-модели несут в себе сложную и концентри-
рованную информацию, и для того, чтобы не перегружать их и
сделать удобочитаемыми, в соответствующем стандарте приняты
следующие принципиальные ограничения сложности'.
• ограничение числа функциональных блоков на диаграмме
тремя и шестью. Верхний предел (шесть) заставляет разра-
ботчика использовать иерархии при описании сложных
предметов, а нижний предел (три) гарантирует, что на со-
ответствующей диаграмме достаточно деталей, чтобы оп-
равдать ее создание;
• ограничение числа подходящих к одному функционально-
му блоку (выходящих из одного функционального блока)
интерфейсных дуг четырьмя.
Следовать этим ограничениям необязательно, однако их ис-
пользование весьма целесообразно в практической работе.
Стандарт IDEF0 содержит набор процедур, позволяющих
разрабатывать и согласовывать модель большим коллективом
специалистов — профессионалов в разных областях деятельно-
сти. Обычно процесс разработки является итерационным и со-
стоит из следующих условных этапов [3, 5, 7, 8, II, 13].
1. Создание модели группой специалистов из разных сфер
деятельности предприятия. Эта группа в терминах IDEF0 назы-
вается авторами (Authors). Построение первоначальной модели
является динамическим процессом, в течение которого авторы
опрашивают компетентных лиц о структуре различных процес-
сов. На основе имеющихся положений, документов и результа-
тов опросов создается черновик (Model Draft) модели.
2. Распространение черновика для рассмотрения, согласова-
ний и комментариев. На этой стадии происходит обсуждение
черновика модели с широким спектром компетентных лиц (в
терминах IDEF0 — читателей) на предприятии. При этом каж-
дая из диаграмм черновой модели письменно критикуется и
комментируется, а затем передается автору. Автор, в свою оче-
редь, также письменно соглашается с критикой или отвергает ее
с изложением логики принятия решения и вновь возвращает от-
корректированный черновик на дальнейшее рассмотрение. Этот
цикл продолжается до тех пор, пока авторы и читатели не при-
дут к единому мнению.
2.5. Методологии описания предметной области
91
3. Официальное утверждение модели. Утверждение согласо-
ванной модели происходит руководителем рабочей группы в том
случае, если у авторов модели и читателей отсутствуют разногла-
сия по поводу ее адекватности. Окончательная модель представ-
ляет собой согласованное представление о предприятии (систе-
ме) с заданной точки зрения и для заданной цели.
Наглядность графического языка IDEF0 делает модель впол-
не читаемой и для лиц, не принимавших участия в ее создании,
и эффективной для проведения показов и презентаций. В даль-
нейшем, на базе построенной модели могут быть организованы
новые проекты, нацеленные на производство изменений на
предприятии (в системе) [5].
2.5.2. Моделирование потоков данных
(процессов) — DFD
Диаграммы потоков данных — основные средства моделиро-
вания функциональных требований проектируемой системы.
С их помощью эти требования разбиваются на функциональные
компоненты (процессы) и представляются в виде сети, связан-
ной потоками данных. Главная цель таких средств — продемон-
стрировать, как каждый процесс преобразует свои входные дан-
ные в выходные, а также выявить отношения между этими про-
цессами [ 10].
В соответствии с методологией модель системы определя-
ется как иерархия диаграмм потоков данных (DFD — Data
Flow Diagram), описывающих асинхронный процесс преобра-
зования информации от ее ввода в систему до выдачи пользо-
вателю. Диаграммы верхних уровней иерархии (контекстные
диаграммы) определяют основные процессы или подсистемы
АИС с внешними входами и выходами. Они детализируются с
помощью диаграмм нижнего уровня. Декомпозиция, создавая
многоуровневую иерархию диаграмм, продолжается до тех
пор, пока не будет достигнут такой уровень, на котором про-
цессы становятся элементарными и детализировать их далее
невозможно [14].
При построении DFD можно использовать различные нота-
ции (табл. 2.1). Эти нотации незначительно отличаются друг от
друга графическим изображением символов.
92
Глава 2. Анализ предметной области АИС...
Таблица 2.1. Графическое отображение объектов DFD
Объект Методика
Йодана Гейна — Сарсона SADT SAG
1. Процесс । Имя, ) к № J № № Имя
Имя Имя
2. Поток данных Имя Имя Имя Имя
3. Хранилище данных Имя БД Имя Нет Имя
4. Источник/прием- ник информации Имя ~^Им^^|| Текстовая метка Имя
5. Сущность Нет Нет Нет Имя
Атрибуты
6. Чтение/запись Нет Нет Нет Чтение Чтение/Запись Запись
7. Группировка (сцеп- ление) потоков 1 Групповой узел J J J J у D Надо делать дополнительный процесс
8. Разгруппировка Нет
9. Неиспользуемый узел Нет ►
10. Узлы-предки (на- следование узлов) Серого цвета Серого - цвета 1С0М-метки Автоматическое наследование не происходит
Для построения DFD используются следующие понятия.
Потоки данных — механизмы, которые отображают передачу
информации от одного процесса другому. На схеме они обычно
изображаются направленной стрелкой, которая показывает на-
правление движения информации или материалов (если рас-
сматриваются материальные потоки).
Информация может двигаться в одном направлении, обраба-
тываться и возвращаться назад, в источник. Такая ситуация мо-
жет моделироваться либо двумя различными потоками, либо од-
ним — двунаправленным.
2.5. Методологии описания предметной области
93
Процесс преобразует значения данных. Назначение процес-
са — генерация выходных потоков из входных в соответствии с
действием, задаваемым именем процесса. Это имя должно со-
держать глагол в неопределенной форме с последующим допол-
нением (например, «вычислить максимальную высоту»). Каж-
дый процесс должен иметь уникальный номер для ссылок на
него внутри диаграммы. Этот номер может использоваться со-
вместно с номером диаграммы для получения уникального ин-
декса процесса во всей модели.
Хранилище (накопитель) данных — пассивный объект в соста-
ве DFD, в котором данные сохраняются для последующего до-
ступа. Такой объект позволяет на определенных участках опре-
делять данные, которые будут сохраняться в памяти между про-
цессами [10].
Фактически хранилище представляет «срезы» потоков дан-
ных во времени. Информация, которую оно содержит, может
использоваться в любое время после ее определения, при этом
данные могут выбираться в любом порядке. Имя хранилища
должно идентифицировать его содержимое и быть существи-
тельным. В случае, когда поток данных входит или выходит в/из
хранилища и его структура соответствует структуре хранилища,
он должен иметь то же самое имя, которое нет необходимости
отражать на диаграмме.
Внешняя сущность (источник/приемник информации) — сущ-
ность вне контекста системы, являющаяся источником или при-
емником системных данных. Ее имя должно содержать сущест-
вительное, например, «склад». Предполагается, что объекты,
представленные такими узлами, не должны участвовать ни в ка-
кой обработке.
Декомпозиция DFD осуществляется на основе процессов:
каждый процесс может раскрываться с помощью DFD нижнего
уровня [10].
Важную специфическую роль в модели играет специальный
вид DFD — контекстная диаграмма, моделирующая систему
наиболее общим образом. Контекстная диаграмма отражает
взаимодействие системы с внешним миром, а именно, информа-
ционные потоки между системой и внешними сущностями, с
которыми она должна быть связана. Она идентифицирует эти
внешние сущности и, как правило, единственный процесс, отра-
жающий главную цель или природу системы, насколько это воз-
можно. Каждый проект должен иметь только одну контекстную
94
Глава 2. Анализ предметной области АИС...
диаграмму, при этом нет необходимости в нумерации ее единст-
венного процесса.
Диаграмма первого уровня строится как декомпозиция про-
цесса, который присутствует на контекстной диаграмме. По-
строенная диаграмма первого уровня также имеет множество
процессов, которые в свою очередь могу быть декомпозированы
в диаграмму нижнего уровня. Таким образом строится иерархия
DFD с контекстной диаграммой в корне дерева. Декомпозиция
продолжается до тех пор, пока процессы эффективно описыва-
ются с помощью коротких (до одной страницы) мини-специфи-
каций обработки (спецификаций процессов).
При таком построении иерархии DFD каждый процесс более
низкого уровня необходимо соотнести с процессом верхнего
уровня. Обычно для этой цели используются структурированные
номера процессов. Например, если детализируется процесс но-
мер 2 на диаграмме первого уровня, раскрывая его с помощью
DFD, содержащей три процесса, то их номера будут иметь сле-
дующую нумерацию: 2.1, 2.2 и 2.3. При необходимости можно
перейти на следующий уровень, т. с. для процесса 2.2 получим
2.2.1, 2.2.2 и т. д.
Потоки могут группироваться с помощью введения нового
потока. Такой поток называется потоком-предком или групповым
потоком и состоит из потоков-потомков.
Обратная операция (расщепление потоков на подпотоки)
осуществляется с использованием группового узла (рис. 2.11)
[7, 10]. Поток может быть расщеплен на любое число подпото-
ков. При расщеплении подпотоки также должны быть фор-
мально определены в словаре данных.
Аналогичным образом осуществляется и декомпозиция пото-
ков через границы диаграмм, позволяющая упростить детализи-
Рис. 2.11. Расширения диаграммы потоков данных
2.5. Методологии описания предметной области
95
рующую DFD. Пусть имеется поток ЗАГОТОВКИ, входящий в
детализируемый процесс. На диаграмме, детализирующей этот
процесс, декомпозируемого потока может не быть совсем, но
вместо него могут быть детализирующие потоки (как будто бы
переданные из детализируемого процесса). Применение таких
операций над данными позволяет обеспечить структуризацию
данных, увеличивает наглядность и читабельность диаграмм.
Для обеспечения декомпозиции данных и некоторых других
сервисных возможностей к DFD добавляются следующие типы
объектов [7, 10].
Групповой узел. Объект предназначен для расщепления и
объединения потоков. В некоторых случаях может отсутствовать
(фактически вырождаться в точку слияния/расщепления пото-
ков на диаграмме).
Узел-предок. Объект позволяет увязывать входящие и выхо-
дящие потоки между детализируемым процессом и детализирую-
щей диаграммой.
Неиспользуемый узел. Объект применяется в случае, когда
декомпозиция данных производится в групповом узле, при этом
требуются не все элементы входящего в узел потока.
Узел изменения имени. Объект позволяет неоднозначно име-
новать потоки, при этом их содержимое эквивалентно. Напри-
мер, если при проектировании разных частей системы один и
тот же фрагмент данных получил различные имена, то эквива-
лентность соответствующих потоков данных обеспечивается уз-
лом изменения имени. При этом один из потоков данных явля-
ется входным для данного узла, а другой — выходным.
Также можно использовать текст в свободном формате в лю-
бом месте диаграммы.
Главная цель построения иерархического множества DFD
заключается в том, чтобы сделать требования ясными и понят-
ными на каждом уровне детализации, а также разбить эти требо-
вания на части с однозначно определенными отношениями ме-
жду ними. При этом целесообразно пользоваться следующими
рекомендациями [7, 10]:
• размещать на каждой диаграмме от 3 до 6—7 процессов.
Верхняя граница соответствует человеческим возможно-
стям одновременного восприятия и понимания структуры
сложной системы с множеством внутренних связей, ниж-
няя граница выбрана исходя из соображений здравого
96
Глава 2. Анализ предметной области АИС...
смысла: нет необходимости детализировать процесс диа-
граммой, содержащей всего один или два процесса;
• не загромождать диаграммы несущественными на данном
уровне деталями;
• декомпозицию потоков данных осуществлять параллельно
с декомпозицией процессов; эти две работы должны вы-
полняться одновременно, а не последовательно;
• выбирать ясные, отражающие суть дела, имена процессов и
потоков для обеспечения читабельности диаграмм, при
этом стараться не использовать аббревиатуры;
• однократно определять функционально идентичные про-
цессы на самом верхнем уровне (где они необходимы) и
ссылаться на них на нижних уровнях;
• пользоваться простейшими диаграммными техниками: по
возможности описывать что-либо с помощью DFD, а не с
помощью более сложных объектов;
• отделять управляющие структуры от обрабатывающих
структур (процессов), локализовывать управляющие струк-
туры.
В соответствии с рекомендациями моделирование включает
следующие этапы [7,10].
1. Расчленение множества требований и организация их в
основные функциональные группы.
2. Идентификация внешних объектов, с которыми должна
быть связана система.
3. Идентификация основных видов информации, циркули-
рующей между системой и внешними объектами.
4. Предварительная разработка контекстной диаграммы, на
которой основные функциональные группы представляются
процессами, внешние объекты — внешними сущностями, основ-
ные виды информации — потоками данных между процессами и
внешними сущностями.
5. Изучение предварительной контекстной диаграммы и вне-
сение в нее изменений по результатам ответов на возникающие
вопросы по всем се частям.
6. Построение контекстной диаграммы путем объединения
всех процессов предварительной диаграммы в один процесс, а
также диаграммы сгруппированых потоков.
7. Формирование DFD первого уровня на базе процессов
предварительной контекстной диаграммы.
8. Проверка основных требований по DFD первого уровня.
2.5. Методологии описания предметной области
97
9. Декомпозиция каждого процесса текущей DFD с помо-
щью детализирующей диаграммы или спецификации процесса.
10. Проверка основных требований по DFD соответствующе-
го уровня.
11. Добавление определений новых потоков в словарь дан-
ных при каждом их появлении на диаграммах.
12. Параллельное процессу декомпозиции изучение требова-
ний (в том числе и вновь поступающих), разбиение их на эле-
ментарные и идентификация процессов или спецификаций про-
цессов, соответствующих этим требованиям.
13. После построения двух-трех уровней проведение ревизии
с целью коррекции и улучшения читабельности модели.
14. Построение спецификации процесса (а не простейшей
диаграммы) в случае, если некоторую функцию сложно или не-
возможно выразить комбинацией процессов.
2.5.3. Методология ARIS
Одной из современных методологий бизнес-моделирования,
получившей широкое распространение в России, является мето-
дология ARIS (Architecture of Integrated Information Systems) —
проектирование интегрированных АИС [2, 8]. В настоящий мо-
мент методология ARIS является наиболее объемной и содержит
около 100 различных бизнес-моделей, используемых для описа-
ния, анализа и оптимизации различных аспектов деятельности
организации. Часть моделей используется в настроечном модуле
интегрированной АИС SAP/R3, который применяется при вне-
дрении системы и ее настройки в соответствии с деятельностью
компании.
Методология ARIS предусматривает четыре группы биз-
нес-моделей (рис. 2.12).
1. «Оргструктура» состоит из моделей, с помощью которых
описывается организационная структура компании, а также эле-
менты внутренней инфраструктуры организации.
2. «Функции» состоят из моделей, используемых для описа-
ния стратегических целей компании, функций и прочих элемен-
тов функциональной деятельности организации.
3. «Информация» состоит из моделей, с помощью которых
описывается информация, используемая в деятельности органи-
зации.
98
Глава 2. Анализ предметной области АИС...
Рис. 2.12. Группы моделей методологии ARIS
4. «Процессы» состоят из моделей, используемых для описа-
ния бизнес-процессов, а также различных взаимосвязей между
структурой, функциями и информацией.
Большим преимуществом методологии ARIS является эрго-
номичность и высокая степень визуализации бизнес-моделей,
что делает методологию удобной и доступной в использовании
всеми сотрудниками компании, начиная от топ-менеджеров и
заканчивая рядовыми сотрудниками. В методологии ARIS смы-
словое значение имеет цвет, что повышает восприимчивость и
читабельность схем бизнес-моделей. Например, структурные
подразделения по умолчанию изображаются желтым цветом,
бизнес-процессы и операции — зеленым.
Помимо большего числа моделей по сравнению с другими
методологиями, методология ARIS имеет наибольшее число раз-
личных объектов, используемых при построении бизнес-моде-
лей, что увеличивает их аналитичность. Например, материаль-
ные и информационные потоки на процессных схемах обознача-
ются разными по форме и цвету объектами, что позволяет
быстро определить тип потока.
Несмотря на большое число моделей в методологии ARIS, в
проектах по описанию и оптимизации деятельности в общем
случае их используется не более десяти. Методология AR1S по-
зиционирует себя как конструктор, из которого под конкретный
проект в зависимости от его целей и задач разрабатывается ло-
2.5. Методологии описания предметной области
99
кальная методология, состоящая из небольшого количества тре-
буемых бизнес-модслей и объектов. Наиболее часто используе-
мые в проектах модели приведены в табл. 2.2 [8].
Таблица 2.2. Наиболее часто используемые на практике модели методологии ARIS
Название модели Описание и предназначение модели
Английский вариант Русский вариант
0D — Objective diagram Диаграмма целей Модель описывает стратегические цели компании и их взаимосвязь с другими элементами организации
PST — Product/Service tree Дерево продуктов и услуг Модель описывает продукты и услуги, производимые компанией, и их взаи- мосвязь с другими элементами орга- низации
FT — Function tree Дерево функций Модель описывает функции, выпол- няемые в компании, и их иерархию
FAD — Function allocation diagram Диаграмма окружения процесса Процессная модель описывает окруже- ние бизнес-процесса
VACD — Value added chain diagram Диаграмма цепочки до- бавленной стоимости Процессная модель — прототип клас- сического стандарта DFD; применяется для описания бизнес-процессов верх- него уровня
PSM — Process selection matrix Матрица выбора процесса Процессная модель — прототип клас- сического стандарта DFD; является аль- тернативой модели VACD и применяет- ся для описания бизнес-процессов верхнего уровня
eEPC — Extended event driven Process Chain Расширенная цепочка про- цессов, управляемая со- бытиями Процессная модель — прототип клас- сического стандарта WFD; применяется дня описания бизнес-процессов ниж- него уровня.
ORG — Organizational chart Модель организационной структуры Модель описывает организационную структуру компании
ASTD — Application system type diagram Диаграмма типов инфор- мационных систем Модель описывает структуру информа- ционных систем, используемых в ком- пании
100
Глава 2. Анализ предметной области АИС...
Модель «Диаграмма целей» — OD — применяется для описа-
ния стратегических целей компании, их иерархической упорядо-
ченности, а также взаимосвязи целей с продуктами и услугами,
производимыми компанией, и бизнес-процессами, поддержи-
вающими их производство (рис. 2.13) [8].
Рис. 2.13. Модель «Диаграмма целей» — OD/AR1S
Модель «Дерево продуктов и услуг» — PST — применяется для
описания продуктов и услуг, производимых в компании, а также
для взаимосвязи со стратегическими целями компании, бизнес-
процессами, поддерживающими их производство (рис. 2.14) [8].
Модель «Дерево функций» — FT — описывает функции, вы-
полняемые в компании, и их иерархию. Модель часто применяется
для построения дерева бизнес-процессов компании (рис. 2.15) [8].
Модель «Диаграмма окружения процесса» — FAD — позво-
ляет описать окружение или границы бизнес-процесса, показы-
вая его входы, выходы, поставщиков и клиентов (рис. 2.16).
Модель «Диаграмма цепочки добавленной стоимости» —
VACD — является прототипом классического DFD-стандарта и
используется для описания бизнес-процессов верхнего уровня.
Существенным различием этой и других процессных моделей
является то, что информационные и материальные потоки на
Рис. 2.14. Модель «Дерево продуктов и услуг» — PST/AR1S
Рис. 2.15. Модель «Дерево функций» — FT/ARIS
102
Глава 2. Анализ предметной области АИС...
Рис. 2.16. Модель «Диаграмма окружения процесса» — FAD/ARIS
схеме VACD изображаются не стрелками, а объектами. При этом
для каждого типа потока используется свой объект. В отличие от
классического подхода здесь также используются логические
связи между работами, которые позволяют отобразить логиче-
скую последовательность выполнения работ. В качестве одного
из вариантов логической последовательности может выступать
временная последовательность выполнения работ, что характер-
но для классического подхода WFD (рис. 2.17) [8].
Рис. 2.17. Модель «Диаграмма цепочки добавленной стоимости» — VACD/ARIS
Модель «Матрица выбора процесса» — PSM — является про-
тотипом классического DFD-стандарта и используется как аль-
тернатива VACD-модели. Матрица выбора процессов по отно-
шению к диаграмме цепочки добавленной стоимости является, с
одной стороны, более упрощенным вариантом описания процес-
са, с другой — содержит дополнительные объекты, позволяющие
выявить другие аспекты бизнес-процесса. Простота матрицы вы-
бора бизнес-процессов в том, что на этой модели не отражаются
информационные и материальные потоки. Что касается других
2.5. Методологии описания предметной области
103
аспектов, то данная модель позволяет на одной схеме компактно
и наглядно показать различные варианты выполнения описывае-
мого бизнес-процесса.
Матрицу выбора процессов целесообразно применять вместо
диаграммы цепочки добавленной стоимости в случаях, когда
описываемый бизнес-процесс имеет несколько вариантов ис-
полнения, каждый из которых ложится на базовую схему. При-
мер применения матрицы выбора процессов для описания дея-
тельности компании, имеющей функциональную организацион-
ную структуру, показан на рис. 2.18 [8].
Рис. 2.18. Модель «Матрица выбора процессов» — PSM/AR1S
Модель «Расширенная цепочка процессов, управляемая собы-
тиями» — еЕРС — является прототипом классического WFD-стан-
дарта и используется для описания бизнес-процессов нижнего
уровня. Существенным отличием еЕРС-модели от классической
WFD-схемы является наличие в модели объекта, который называ-
ется событием. С помощью событий изображается факт, время или
событие, инициирующие начало выполнения работ процесса, а
также факт или время их завершения (рис. 2.19) [8].
Модель «Организационная структура» — ORG — использует-
ся для описания организационной структуры компании; отобра-
жает структурные подразделения, группы, должности, роли и
прочие элементы организационной структуры и связи между
ними (рис. 2.20) [8].
Модель «Диаграмма типов информационных систем» —
ASTD — используется для описания структуры информационных
систем, применяемых в компании. Здесь отображаются типы
104
Глава 2. Анализ предметной области АИС...
Рис. 2.19. Модель «Расширенная цепочка процессов, управляемая
событиями» — eEPC/ARIS
2.5. Методологии описания предметной области
105
Рис. 2.20. Модель «Организационная структура» — ORG/AR1S
Информа-
ционные
системы
компании
Рис. 2.21. Модель «Диаграмма типов информационных систем» — ASTD/AR1S
и модули информационных систем, программные продукты,
взаимосвязь между ними и автоматизируемыми бизнес-процес-
сами организации (рис. 2.21) [8].
106
Глава 2. Анализ предметной области АИС...
2.5.4. Объектно-ориентированный подход. Язык
унифицированного моделирования UML
Использование языка ИМЬдля моделирования организации
и се бизнес-процессов позволяет в полной мере отобразить
структурное, статическое и динамическое представление. Полу-
чаемая в ходе объектно-ориентированного анализа и проектиро-
вания UML-модель организации представляет собой совокуп-
ность взаимосвязанных диаграмм, идентифицирующих биз-
нес-процессы, описывающих их жизненный цикл, структуру
организации и взаимодействие процессов функционирования во
времени и пространстве с привязкой к используемым ресурсам и
получаемым результатам [9].
UML-модель применительно к бизнес-моделированию мо-
жет включать в себя следующие диаграммы.
[.Структурный аспект: Use-Casc-диаграммы, идентифици-
рующие бизнес-процессы и бизнес-транзакции, их взаимосвязь,
соподчинснность и взаимодействие; Package-диаграммы, струк-
турно организующие предметную область и иерархически упоря-
доченную структуру организации.
2. Динамический аспект: Behavior-диаграммы (Activity, State-
chart, Collaboration, Sequence), описывающие поведение (жиз-
ненный цикл) бизнес-процессов в их взаимодействии во време-
ни и в пространстве с привязкой к используемым ресурсам и по-
лучаемым результатам.
3. Статический аспект: Class-диаграммы, отражающие сово-
купность взаимосвязанных объектов. В этих диаграммах рас-
сматриваются логическая структура предметной области, ее
внутренние концепции, иерархия объектов и статические связи
между ними, структуры данных и объектов; Deployment-диа-
граммы, отражающие технологические ресурсы организации.
Не обязательно строить все диаграммы: аналитик или разра-
ботчик сам определит нужные ему уровень детализации, полноту
описания и точку зрения.
UML-модель позволяет получить подробные ответы на стан-
дартные вопросы о деятельности организации, в частности:
• каковы виды деятельности организации и предметные об-
ласти управления (предметно-структурный аспект);
• каковы бизнес-процессы организации (функциональный
аспект);
2.5. Методологии описания предметной области
107
• кто и где выполняет бизнсс-процессы (организационный
аспект);
• как выполняются бизнес-процсссы (методический аспект);
• когда выполняются бизнес-процессы (динамический ас-
пект);
• что, откуда и куда перемешается, обрабатывается, получа-
ется в материальных и в связанных с ними информацион-
ных потоках (сущностно-элементный аспект);
• с помощью чего (какими инструментами) выполняются
бизнес-процсссы (ресурсный и технологический аспекты).
В табл. 2.3 представлена связь между различными аспектами
моделирования деятельности организации и их отражение на
UML-диаграммах [9].
Таблица 2.3. Связь между аспектами моделирования и UML-диаграммами
Аспект моделирования UML-диаграмма
Предметно-структурный Package-диаграммы
Функциональный Use-Case-диаграммы
Организационный Package-диаграммы, Class-диаграммы
Методический Activity-диаграммы
Динамический Statechart-, Collaboration-, Sequence-диаграммы
Сущностно-элементный Class-диаграммы
Технологический Deployment-диаграммы
Ядро UML поддерживает использование расширений стан-
дартных элементов в виде стереотипов, именованных значений,
графических обозначений, позволяющих уточнить синтаксис и
семантику модели и таким образом лучше понять моделируемую
предметную область. Для бизнес-моделирования деятельности
организации используют следующие расширения (табл. 2.4) [9].
Activity-диаграммы раскрывают методический аспект биз-
нес-процессов. Каждая бизнес-транзакция есть полная или час-
тичная реализация некоторой управленческой функции, итогом
выполнения которой является значимый на том или ином уров-
не управления результат. Для достижения данного результата
108
Глава 2. Анализ предметной области АИС...
Таблица 2.4. Расширения UML
Элемент UML Расширение Обозначение
Package Пакеты предметных областей управления или видов деятельности. Стереотип — «Business System» На «Bus именован!/ iness Systt е т»
Пакеты организационных единиц (структурных под- разделений). Стереотип — «Organization Unit» н Наймет «Organiza о ti вание эп Unit »
Class Бизнес-сущности, обозначающие владельцев биз- нес-процессов. Стереотип — «Business Actor» Наименование «Business Actor»
Бизнес-сущности, обозначающие деловых работни- ков (исполнителей). Стереотип — «Business Worker» Наименование «Business Worker»
Бизнес-сущности, обозначающие объект учета. Сте- реотип — «Business Object» е Ct»
Наименовани «Business Obje
Бизнес-сущности, обозначающие субъекты учета. Стереотип — «Business Subject» е Ct»
Наименовани «Business Subjr
Бизнес-сущности, обозначающие первичные доку- менты. Стереотип — «Document» На « именова Documen ние t»
2.5. Методологии описания предметной области
109
при выполнении бизнес-транзакции используются некоторые
материальные, информационные и иные объекты (бизнес-сущ-
ности), идентифицированные на Class-диаграммах. Выполнение
бизнес-транзакции закрепляется за определенным исполните-
лем, также идентифицированным на Class-диаграмме со стерео-
типом «Organization Unit». Бизнес-сущности в ходе выполнения
бизнес-транзакции могут менять свое внутреннее состояние, что
также находит отражение на Activity-диаграммах, а полная карта
состояний и переходов между ними — на соответствующих
Statechart-диаграммах [9].
Кроме того, каждая бизнес-транзакция или состояние могут
быть детализованы на вложенных Activity- и Statechart-диаграм-
мах соответственно.
Таким образом, Activity-диаграммы, отражая реализацию
бизнес-процесса, выступают как связующее звено между други-
ми диаграммами и элементами UML-модели.
по
Глава 2. Анализ предметной области АИС...
Идентифицированный однажды элемент модели может быть
использован на других диаграммах, отражая многообразие его
связей, взаимодействий и особенностей. Использование такого
подхода — серьезное преимущество UML-моделей.
Таким образом, UML-модсль выступает как средство доку-
ментирования и анализа существующих бизнес-процессов, их
оптимизации или перепроектирования, моделирования новых
бизнес-процессов во взаимосвязи с организационной структу-
рой, предметными областями и функциями управления органи-
зацией, а также выступает как фундаментальная основа для фор-
мирования требований к построению АИС, автоматизирующей
деятельность организации.
2.6. Системы автоматизированного
проектирования АИС
2.6.1. Этапы развития CASE-систем
За последнее десятилетие сформировалось новое направле-
ние в проектировании информационных систем — автоматизи-
рованное проектирование с помощью CASE-средств. Термин
CASE (Computer Aided System/Software Engineering) первона-
чально относился только к автоматизации разработки программ-
ного обеспечения; сейчас он охватывает процесс разработки
сложных АИС в целом [11, 15, 16].
Изначально CASE-технологии развивались с целью преодо-
ления недостатков структурной методологии проектирования
(сложности понимания, высокой трудоемкости и стоимости ис-
пользования, трудности внесения изменений в проектные спе-
цификации и т. д.) за счет автоматизации и интеграции поддер-
живающих средств.
CASE-технологии не существуют сами по себе, не являются
самостоятельными. Они автоматизируют и оптимизируют ис-
пользование соответствующей методологии, дают возможность
повысить эффективность ее применения.
Другими словами, CASE-технологии представляют собой со-
вокупность методологий анализа, проектирования, разработки и
сопровождения сложных систем программного обеспечения,
2.6. Системы автоматизированного проектирования АИС
111
поддержанную комплексом взаимосвязанных средств автомати-
зации, которые позволяют в наглядной форме моделировать
предметную область, анализировать эту модель на всех стадиях
разработки и сопровождения АИС и разрабатывать приложения
в соответствии с информационными потребностями пользовате-
лей [2].
Современные CASE-средства охватывают обширную область
поддержки многочисленных технологий проектирования АИС —
от простых средств анализа и документирования до полномас-
штабных средств автоматизации, покрывающих весь жизненный
цикл АИС. Наибольшая потребность в использовании CASE-сис-
тем испытывается на начальных этапах разработки — на этапах
анализа и спецификации требований к АИС. Допущенные здесь
ошибки практически фатальны, их цена значительно превышает
цену ошибок поздних этапов разработки.
Основные задачи CASE-средств состоят в том, чтобы отде-
лить начальные этапы (анализ и проектирование) от последую-
щих и не обременять разработчиков деталями среды разработки
и функционирования системы.
В большинстве современных CASE-систем применяются ме-
тодологии структурного и/или объектно-ориентированного анали-
за и проектирования, основанные на использовании наглядных
диаграмм, графов, таблиц и схем.
При грамотном применении CASE-инструментария достига-
ется значительный рост производительности труда, составляю-
щий (по оценкам зарубежных фирм пользователей CASE-техно-
логий) от 100 до 600 % в зависимости от объема, сложности ра-
бот и опыта работы с CASE. При этом изменяются все фазы
жизненного цикла АИС, но наибольшие изменения касаются
фаз анализа и проектирования (табл. 2.5, 2.6) [11, 15, 16].
Таблица 2.5. Оценки трудозатрат по фазам жизненного цикла АИС
Способ разработки Анализ, % Проектирование, % Кодирование, % Тестирование,%
Традиционная разработка 20 15 20 45
Использование структурной методологии 30 30 15 25
Использование CASE-техно- логий 40 40 5 15
112
Глава 2. Анализ предметной области АИС...
Таблица 2.6. Сравнение использования CASE и традиционной разработки
Традиционная разработка Разработка с CASE-средствами
Основные усилия — на кодирование и тестирование Основные усилия — на анализ и проектирование
«Бумажные» спецификации Быстрое итеративное прототипирование
Ручное кодирование Автоматическая кодогенерация
Ручное документирование Автоматическая генерация документации
Тестирование кодов Автоматический контроль проекта
Сопровождение кодов Сопровождение спецификаций проектирования
Применение CASE-средств не только автоматизирует струк-
турную методологию и дает возможность использовать совре-
менные методы системной и программной инженерии, но и пре-
доставляет другие преимущества (рис. 2.22), в частности:
• улучшает качество разрабатываемого программного обес-
печения за счет средств автоматической генерации и кон-
троля;
• позволяет уменьшить время создания прототипа АИС, что
дает возможность на ранних этапах оценить качество и эф-
фективность проекта;
• ускоряет процесс проектирования и разработки;
• позволяет многократно использовать разработанные ком-
поненты;
• поддерживает сопровождение АИС;
• освобождает от рутинной работы по документированию
проекта, так как использует встроенный документатор;
• облегчает коллективную работу над проектом.
Рис. 2.22. Преимущества разработки АИС с использованием CASE-технологий:
а — коэффициент уменьшения стоимости проекта; б — коэффициент уменьше-
ния временных затрат на разработку
2.6. Системы автоматизированного проектирования АИС 113
В основе большинства CASE-средств лежат четыре главных
понятия: методология, метод, нотация, средство (И, 15, 16].
Методология определяет руководящие указания для оценки и
выбора решений при проектировании и разработке АИС, этапы
работы, их последовательность, правила распределения и назна-
чения методов.
Методы — процедуры генерации компонентов и их описа-
ний.
Нотации предназначены для описания общей структуры сис-
темы, элементов данных, этапов обработки, могут включать гра-
фы, диаграммы, таблицы, блок-схемы, формальные и естествен-
ные языки.
Средства — инструментарий для поддержки и усиления ме-
тодов; поддерживает работу пользователей при создании и ре-
дактировании проекта в интерактивном режиме, помогает орга-
низовать проект в виде иерархии уровней абстракции, осуществ-
ляет проверки соответствия компонентов.
2.6.2. Классификация CASE-средств
До сих пор не существует устойчивой классификации
CASE-средств, определены только подходы к классификации в
зависимости от различных классификационных признаков. Ниже
приведены некоторые из них [II, 12].
Ориентация на технологические этапы и процессы жизненного
цикла АИС:
• средства анализа и проектирования. Используются для со-
здания спецификаций системы и ее проектирования. Они
поддерживают широко известные методологии проектиро-
вания;
• средства проектирования баз данных. Обеспечивают логи-
ческое моделирование данных, генерацию структур БД;
• средства управления требованиями;
• средства управления конфигурацией программного обеспе-
чения. Поддерживают программирование, тестирование,
автоматическую генерацию ПО из спецификаций;
• средства документирования;
• средства тестирования;
• средства управления проектом. Поддерживают планирова-
ние, контроль, взаимодействие;
114
Глава 2. Анализ предметной области АИС...
• средства реверсного инжиниринга, предназначенные для
переноса существующей системы в новую среду.
Поддерживаемые методологии проектирования [11, 12, 15, 16]:
• функционально-ориентированные (структурно-ориентиро-
ванные);
• объектно-ориентированные;
• комплексно-ориентированные (набор методологий проек-
тирования).
Поддерживаемые графические нотации построения диаграмм:
• с фиксированной нотацией;
• с отдельными нотациями;
• с наиболее распространенными нотациями.
Степень интегрированности:
• вспомогательные программы (Tools), самостоятельно ре-
шающие автономную задачу;
• пакеты разработки (Toolkit), представляющие собой сово-
купность средств, обеспечивающих помощь для одного из
классов программных задач;
• наборы интегрированных средств, связанных общей базой
проектных данных — репозиторием, автоматизирующие
все или часть работ разных этапов создания АИС
(Workbench).
Коллективная разработка проекта:
• без поддержки коллективной разработки;
• ориентированные на разработку проекта в режиме реально-
го времени;
• ориентированные на режим объединения подпроектов.
Типы CASE-средств:
• средства анализа (Upper CASE); среди специалистов назы-
ваются средствами компьютерного планирования. С помо-
щью этих CASE-средств строят модель, отражающую всю
существующую специфику. Она направлена на понимание
общего и частного механизмов функционирования, имею-
щихся возможностей, ресурсов, целей проекта в соответст-
вии с назначением фирмы. Эти средства позволяют прово-
дить анализ различных сценариев, накапливая информа-
цию для принятия оптимальных решений;
• средства анализа и проектирования (Middle CASE); счита-
ются средствами поддержки этапов анализа требований и
проектирования спецификаций и структуры АИС. Основ-
ной результат использования среднего CASE-срсдства со-
2.6. Системы автоматизированного проектирования АИС 115
стоит в значительном упрощении проектирования систе-
мы, так как проектирование превращается в итеративный
процесс работы с требованиями к АИС. Кроме того, сред-
ние CASE-средства обеспечивают быстрое документирова-
ние требований;
• средства разработки ПО (Lower); поддерживают системы
разработки программного обеспечения АИС. Содержат
системные словари и графические средства, исключающие
необходимость разработки физических спецификаций —
имеются системные спецификации, которые непосредст-
венно переводятся в программные коды разрабатываемой
системы (при этом автоматически генерируется до 80 % ко-
дов). Главными преимуществами нижних CASE-средств
являются значительное уменьшение времени на разработ-
ку, облегчение модификаций, поддержка возможностей ра-
боты с прототипами.
CASE-средства, кроме того, классифицируют по типу и архи-
тектуре вычислительной техники, а также по типу операционной
системы [11, 12, 16].
В настоящее время рынок программных продуктов представ-
лен самым разнообразным ПО, в том числе и CASE-средствами
практически любого из перечисленных классов.
2.6.3. Характеристики CASE-средств
Silverrun. CASE-средство Silverrun американской фирмы
Computer Systems Advisers, Inc. (CSA) используется для анализа и
проектирования АИС бизнес-класса и ориентировано в большей
степени на спиральную модель ЖЦ. Оно применимо для под-
держки любой методологии, основанной на раздельном построе-
нии функциональной и информационной моделей (диаграмм
потоков данных и диаграмм «сущность—связь») [7, 11, 16].
Настройка на конкретную методологию обеспечивается вы-
бором требуемой графической нотации моделей и набора правил
проверки проектных спецификаций. В системе имеются готовые
настройки для наиболее распространенных методологий:
DATARUN (основная методология, поддерживаемая Silverrun),
Gane/Sarson, Yourdon/DeMarco, Merise, Ward/Mellor, Information
Engineering. Для каждого понятия, введенного в проекте, имеет-
ся возможность добавления собственных описателей. Архитекту-
116
Глава 2. Анализ предметной области АИС...
pa Silverrun позволяет наращивать среду разработки по мере не-
обходимости.
Silverrun имеет модульную структуру и состоит из четырех
модулей, каждый из которых является самостоятельным продук-
том и может приобретаться и использоваться отдельно.
1. Модуль построения моделей бизнес-процессов в форме диа-
грамм потоков данных Business Process Modeler (BPM) позволяет
моделировать функционирование автоматизируемой организа-
ции или создаваемой АИС. Возможность работы с моделями
большой сложности обеспечена функциями автоматической пе-
ренумерации, работы с деревом процессов (включая визуальное
перетаскивание ветвей), отсоединения и присоединения частей
модели для коллективной разработки. Диаграммы могут изобра-
жаться в нескольких предопределенных нотациях, включая
Yourdon/DeMarco и Gane/Sarson. Имеется также возможность
создавать собственные нотации, например в число изображае-
мых на схеме дескрипторов добавлять определенные пользовате-
лем поля.
2. Модуль концептуального моделирования данных Entity-Rela-
tionship eXpert (ERX) обеспечивает построение моделей данных
«сущность—связь», не привязанных к конкретной реализации.
Встроенная экспертная система позволяет создавать корректную
нормализованную модель данных посредством ответов на содер-
жательные вопросы о взаимосвязи данных. Предусмотрено авто-
матическое построение модели данных из описаний структур
данных. Анализ функциональных зависимостей атрибутов дает
возможность проверить соответствие модели требованиям треть-
ей нормальной формы и обеспечить их выполнение. Проверен-
ная модель передается в модуль Relational Data Modeler.
3. Модуль реляционного моделирования Relational Data Modeler
(RDM) позволяет создавать детализированные модели «сущ-
ность-связь», предназначенные для реализации в реляционной
БД. В этом модуле документируются все конструкции, связан-
ные с построением базы данных: индексы, триггеры, хранимые
процедуры и т. д. Гибкая изменяемая нотация и расширяемость
репозитория позволяют работать по любой методологии. Воз-
можность создавать подсхемы соответствует подходу ANSI
SPARC к представлению схемы БД. На языке подсхем модели-
руются как узлы распределенной обработки, так и пользователь-
ские представления. Этот модуль обеспечивает проектирование
и полное документирование реляционных БД.
2.6. Системы автоматизированного проектирования АИС
117
4. Менеджер репозитория рабочей группы Workgroup Repository
Manager (WRM) применяется как словарь данных для хранения
общей для всех моделей информации, а также обеспечивает ин-
теграцию модулей Silverrun в единую среду проектирования.
Достоинством CASE-срсдства Silverrun являются высокая
гибкость и разнообразие изобразительных средств построения
моделей, а недостатком — отсутствие жесткого взаимного кон-
троля между компонентами различных моделей (например, воз-
можности автоматического распространения изменений между
DFD различных уровней декомпозиции). Следует, однако, отме-
тить, что этот недостаток может иметь существенное значение
только в случае использования каскадной модели жизненного
цикла [7, 11, 16].
В Silverrun включены средства:
• автоматической генерации схем баз данных для наиболее
распространенных СУБД: Oracle, Informix, DB2, Ingres,
Progress, SQL Server, SQLBase, Sybase;
• передачи данных средствам разработки приложений: JAM,
PowerBuilder, SQL Windows, Uniface, NewEra, Delphi.
Таким образом, можно полностью определить ядро БД с ис-
пользованием всех возможностей конкретной СУБД: триггеров,
хранимых процедур, ограничений ссылочной целостности. При
создании приложения данные, перенесенные из репозитория
Silverrun, используются либо для автоматической генерации ин-
терфейсных объектов, либо для быстрого их создания вручную.
Для обмена данными с другими средствами автоматизации
проектирования, создания специализированных процедур ана-
лиза и проверки проектных спецификаций, составления специа-
лизированных отчетов в соответствии с различными стандартами
в системе Silverrun предусмотрено три способа выдачи проект-
ной информации во внешние файлы.
1. Система отчетов. Отчеты выводятся в текстовые файлы.
2. Система экспорта/импорта. Задается не только содержи-
мое экспортного файла, но и разделители записей, полей в запи-
сях, маркеры начала и конца текстовых полей. Такие экспорт-
ные файлы можно формировать и загружать в репозиторий. Это
дает возможность обмениваться данными с различными систе-
мами: другими CASE-средствами, СУБД, текстовыми редактора-
ми и электронными таблицами.
3. Хранение репозитория во внешних файлах с доступом с
помощью ODBC-драйверов. Для доступа к данным репозитория
118
Глава 2. Анализ предметной области АИС...
из наиболее распространенных СУБД обеспечена возможность
хранить всю проектную информацию непосредственно в форма-
те этих СУБД.
Silverrun поддерживает два способа групповой работы:
1) в стандартной однопользовательской версии имеется меха-
низм контролируемого разделения и слияния моделей. Модель
может быть разделена на части и распределена между несколь-
кими разработчиками. После детальной проработки части снова
собираются в единую модель;
2) сетевая версия Silverrun позволяет вести параллельную
групповую работу с моделями, хранящимися в сетевом репози-
тории на базе СУБД Oracle, Sybase или Informix. При этом не-
сколько разработчиков могут работать с одной и той же моде-
лью, так как блокировка объектов происходит на уровне отдель-
ных элементов модели.
JAM. Средство разработки приложений JYACC's Application
Manager (JAM) — продукт фирмы JYACC. Главной особенностью
является соответствие методологии RAD, так как JAM позволяет
достаточно быстро реализовать цикл разработки приложения, за-
ключающийся в формировании очередной версии прототипа
приложения с учетом требований, выявленных на предыдущем
шаге, и предъявить его пользователю [7, 11, 16].
JAM имеет модульную структуру и состоит из следующих
компонентов:
• ядра системы;
• JAM/DBi — специализированных модулей интерфейса к
СУБД (JAM/DBi-Oracle, JAM/DBi-Informix, JAM/DBi-ODBC
и т. д.);
• JAM/RW — модуля генератора отчетов;
• JAM/CASEi — специализированных модулей интерфейса к
CASE-средствам (JAM/CASE-TeamWork, JAM/CASE-Inno-
vator и т. д.);
• JAM/TPi — специализированных модулей интерфейса к ме-
неджерам транзакций (например, JAM/TPi-Server TUXEDO
и т. д.);
• Jterm — специализированного эмулятора Х-терминала.
Ядро системы является законченным продуктом и может са-
мостоятельно использоваться для разработки приложений. Все
остальные модули — дополнительные и самостоятельно исполь-
зоваться не могут.
2.6. Системы автоматизированного проектирования АИС
119
Ядро системы включает в себя следующие основные ком-
поненты:
• редактор экранов. В состав редактора экранов входят среда
разработки экранов, визуальный репозиторий объектов,
собственная СУБД JAM — JDB, менеджер транзакций, от-
ладчик, редактор стилей;
• редактор меню;
• набор вспомогательных утилит;
• средства изготовления промышленной версии приложения.
При использовании JAM разработка внешнего интерфейса
приложения представляет собой визуальное проектирование и
сводится к созданию экранных форм путем размещения на них
интерфейсных конструкций и определению экранных полей
ввода/вывода информации. Проектирование интерфейса в JAM
осуществляется с помощью редактора экранов. Приложения,
разработанные в JAM, имеют многооконный интерфейс. Разра-
ботка экрана заключается в размещении на нем интерфейсных
элементов, их группировке, задании значений их свойств.
Редактор меню позволяет разрабатывать и отлаживать систе-
мы меню. Реализована возможность построения пиктографиче-
ских меню. Назначение пунктов меню объектам приложения
осуществляется в редакторе экранов.
В ядро JAM встроена однопользовательская реляционная
СУБД JDB. Основным назначением JDB является прототипиро-
вание приложений в тех случаях, когда работа со штатной СУБД
невозможна или нецелесообразна. В JDB реализован необходи-
мый минимум возможностей реляционных СУБД, в который не
входят индексы, хранимые процедуры, триггеры и представле-
ния. С помощью JDB можно построить БД, идентичную целевой
БД (с точностью до отсутствующих в JDB возможностей), и раз-
работать значительную часть приложения.
Отладчик позволяет проводить комплексную отладку разра-
батываемого приложения. Осуществляется трассировка всех со-
бытий, возникающих в процессе исполнения приложения.
Утилиты JAM включают три группы:
1) конверторы файлов экранов JAM в текстовые. JAM сохра-
няет экраны в виде двоичных файлов собственного формата;
2) конфигурирование устройств ввода-вывода. JAM и прило-
жения, построенные с его помощью, не работают непосредст-
венно с устройствами ввода-вывода. Вместо этого JAM обраща-
120
Глава 2. Анализ предметной области ЛИС...
ется к логическим устройствам ввода-вывода (клавиатура, тер-
минал, отчет);
3) обслуживание библиотек экранов.
Одним из дополнительных модулей JAM является генератор
отчетов. Компоновка отчета осуществляется в редакторе экра-
нов JAM. Описание работы отчета осуществляется с помощью
специального языка. Генератор отчетов позволяет определить
данные, выводимые в отчет, группировку выводимой информа-
ции, форматирование вывода и т. д.
Приложения, разработанные с использованием JAM, могут
быть изготовлены в виде исполняемых модулей. Для этого раз-
работчики должны иметь компилятор С и редактор связей.
JAM содержит встроенный язык программирования JPL (JAM
Procedural Language), с помощью которого в случае необходимо-
сти могут быть написаны модули, реализующие специфические
действия. Данный язык является интерпретируемым. Существу-
ет возможность обмена информацией между средой визуально
построенного приложения и такими модулями. Кроме того, в
JAM реализована возможность подключения внешних модулей,
написанных на языках, совместимых по вызовам функций с
языком С.
JAM является событийно-ориентированной системой, состоя-
щей из набора событий — открытие и закрытие окон, нажатие
клавиши клавиатуры, срабатывание системного таймера, получе-
ние и передача управления каждым элементом экрана. Разработ-
чик реализует логику приложения путем определения обработ-
чика каждого события.
Обработчиками событий в JAM могут быть как встроенные
функции JAM, так и функции, написанные разработчиком на С
или JPL. Набор встроенных функций включает более 200 функ-
ций различного назначения; они доступны для вызовов из функ-
ций, написанных как на JPL, так и на С.
Промышленная версия приложения, разработанного с помо-
щью JAM, состоит из следующих компонентов:
• исполняемого модуля интерпретатора приложения;
• экранов, составляющих приложение (поставляются в виде
отдельных файлов, в составе библиотек экранов или
встраиваются в тело интерпретатора);
• внешних JPL-модулсй (поставляются в виде текстовых
файлов или в прекомпилированном виде; прекомпилиро-
2.6. Системы автоматизированного проектирования АИС
121
ванные внешние JPL-модули — в виде отдельных файлов и
в составе библиотек экранов);
• файлов конфигурации приложения — файлов конфигура-
ции клавиатуры и терминала, файла системных сообще-
ний, файла обшей конфигурации.
Непосредственное взаимодействие с СУБД реализуют моду-
ли JAM/DBi (Database interface). Способы реализации взаимо-
действия в JAM разделяются на два класса: ручные и автомати-
ческие.
При ручном способе разработчик самостоятельно пишет запро-
сы на SQL, в которых источниками и адресатами приема резуль-
татов выполнения запроса могут быть как интерфейсные элемен-
ты визуально спроектированного внешнего уровня, так и внут-
ренние, невидимые для конечного пользователя переменные.
Автоматический режим реализуется менеджером транзакций
JAM. Он осуществим для типовых распространенных видов опе-
раций с БД, так называемых QBE (Query By Example — запросы
по образцу), с учетом достаточно сложных взаимосвязей между
таблицами БД и автоматическим управлением атрибутами эк-
ранных полей ввода-вывода в зависимости от вида транзакции
(чтение, запись и т. д.), в которой участвует сгенерированный
запрос.
JAM позволяет строить приложения для работы с более чем
20 СУБД: ORACLE, Informix, Sybase, Ingres, InterBase, NetWare
SQL Server, Rdb, DB2, ODBC-совместимые СУБД и др.
Отличительной чертой JAM является высокий уровень пере-
носимости приложений между различными платформами (MS
DOS/MS Windows, SunOS, Solaris (i80x86, SPARC), HP-UX,
AIX, VMS/Opcn VMS и др.); возможно требование «перерисо-
вать» статические текстовые поля на экранах с русским текстом
при переносе между средами DOS—Windows—UNIX. Кроме
того, переносимость облегчается тем, что в JAM приложения
разрабатываются для виртуальных устройств ввода-вывода, а не
для физических. Таким образом, при переносе приложения с
платформы на платформу, как правило, требуется лишь опреде-
лить соответствие между физическими устройствами ввода-вы-
вода и их логическими представлениями для приложения.
Использование SQL в качестве средства взаимодействия с
СУБД также помогает обеспечивать переносимость между
СУБД. В случае переноса структуры БД приложения могут не
требовать никакой модификации, за исключением инициализа-
122
Глава 2. Анализ предметной области АИС...
ции сеанса работы. Это возможно, если р приложении не ис-
пользовались специфические для СУБД расширения SQL.
При росте нагрузки на систему и сложности решаемых задач
(распределенность и гетерогенность используемых ресурсов, ко-
личество одновременно подключенных пользователей, сложность
логики приложения) применяется трехзвенная модель архитекту-
ры «клиент — сервер» с использованием менеджеров транзакций.
Компоненты JAM/TPi-Client и JAM/TPi-Scrver позволяют доста-
точно просто перейти на трехзвенную модель. При этом ключе-
вую роль играет модуль JAM/TPi-Servcr, так как основная труд-
ность внедрения трехзвенной модели заключается в реализации
логики приложения в сервисах менеджеров транзакций.
Интерфейс JAM/CASE позволяет осуществлять обмен ин-
формацией между репозиторием объектов JAM и репозиторием
CASE-средства. Обмен происходит аналогично тому, как струк-
тура БД импортируется в репозиторий JAM непосредственно из
БД. Отличие заключается в том, что обмен между репозитория-
ми является двунаправленным.
Кроме модулей JAM/CASEi, существует также модуль JAM/
CASEi Developer's Kit. С помощью этого модуля можно само-
стоятельно разработать интерфейс (т. е. специализированный
модуль JAM/CASEi) для конкретного CASE-средства, если гото-
вого модуля JAM/CASEi для него не существует.
Существует интерфейс, реализующий взаимодействие между
CASE-средством Silverrun и JAM. Он производит перенос схемы
БД и экранных форм приложения между CASE-средством
Silverrun-RDM и JAM версии 7.0; имеет два режима работы:
1) прямой режим (Silverrun-RDM->JAM) предназначен для
создания объектов CASE-словаря и элементов репозитория JAM
на основе представления схем в Silverrun-RDM. Исходя из пред-
ставления моделей данных интерфейса в Silverrun-RDM произ-
водится генерация экранов и элементов репозитория JAM. Мост
преобразует таблицы и отношения реляционных схем RDM в
последовательность объектов JAM соответствующих типов. Ме-
тодика построения моделей данных интерфейса в Silverrun-RDM
предполагает применение механизма подсхем для прототипиро-
вания экранов приложения. По описанию каждой из подсхем
RDM мост генерирует экранную форму JAM;
2) обратный режим (JAM->Silverrun-RDM) предназначен для
переноса модификаций объектов CASE-словаря в реляционную
модель Silverrun-RDM.
2.6. Системы автоматизированного проектирования АИС 123
Режим реинжиниринга позволяет переносить модификации
всех свойств экранов JAM, импортированных ранее из RDM, в
схему Silverrun. Для контроля целостности БД не допускаются
изменения схемы в виде добавления или удаления таблиц и по-
лей таблиц.
Ядро JAM имеет встроенный интерфейс к средствам конфи-
гурационного управления (PVCS на платформе Windows и SCCS
на платформе UNIX). Под управлением этих систем передаются
библиотеки экранов и/или репозитории. При отсутствии таких
систем JAM самостоятельно реализует часть функций поддержки
групповой разработки.
На платформе MS-Windows JAM имеет встроенный интер-
фейс к PVCS, и действия по выборке/возврату производятся не-
посредственно из среды JAM.
Vantage Team Builder (Westmount I-CASE). Vantage Team
Builder представляет собой интегрированный программный про-
дукт, ориентированный на реализацию и полную поддержку кас-
кадной модели жизненного цикла [7, И, 16].
Vantage Team Builder обеспечивает выполнение следующих
функций:
• проектирование диаграмм потоков данных, диаграмм
«сущность—связь», структур данных, структурных схем
программ и последовательностей экранных форм;
• проектирование диаграмм архитектуры системы — SAD
(проектирование состава и связи вычислительных средств,
распределения задач системы между вычислительными
средствами, моделирование отношений типа «клиент — сер-
вер», анализ использования менеджеров транзакций и осо-
бенностей функционирования систем в реальном времени);
• генерация кода программ на языке целевой СУБД с пол-
ным обеспечением программной среды и генерация
SQL-кода для создания таблиц БД, индексов, ограничений
целостности и хранимых процедур;
• программирование на языке С со встроенным SQL;
• управление версиями и конфигурацией проекта;
• многопользовательский доступ к репозиторию проекта;
• генерация проектной документации по стандартным и ин-
дивидуальным шаблонам;
• экспорт и импорт данных проекта в формате CDIF (CASE
Data Interchange Format).
124
Глава 2. Анализ предметной области АИС...
Vantage Team Builder поставляется в различных конфигура-
циях в зависимости от используемых СУБД (ORACLE, Informix,
Sybase или Ingres) или средств разработки приложений (Uniface).
Конфигурация Vantage Team Builder for Uniface отличается от
остальных частичной ориентацией на спиральную модель жиз-
ненного цикла за счет возможностей быстрого прототипирова-
ния. Для описания проекта АИС используется большой набор
диаграмм.
При построении всех типов диаграмм обеспечивается кон-
троль соответствия моделей синтаксису используемых методов, а
также контроль соответствия одноименных элементов и их ти-
пов для различных типов диаграмм.
При построении диаграмм потоков данных DFD обеспечива-
ется контроль соответствия диаграмм различных уровней деком-
позиции. Контроль за правильностью верхнего уровня DFD осу-
ществляется с помощью матрицы списков событий ELM. Для
контроля за декомпозицией составных потоков данных исполь-
зуется несколько вариантов их описания: в виде диаграмм струк-
тур данных DSD или в нотации БНФ (форма Бэкуса — Наура).
Для построения SAD используется расширенная нотация
DFD, дающая возможность вводить понятия процессоров, задач
и периферийных устройств, что обеспечивает наглядность про-
ектных решений [16].
При построении модели данных в виде ERD выполняется ее
нормализация и вводится определение физических имен элемен-
тов данных и таблиц, которые будут использоваться в процессе
генерации физической схемы данных конкретной СУБД. Обес-
печивается возможность определения альтернативных ключей
сущностей и полей, составляющих дополнительные точки входа
в таблицу (поля индексов), и мощности отношений между сущ-
ностями.
Наличие универсальной системы генерации кода, основан-
ной на специфицированных средствах доступа к репозиторию
проекта, позволяет поддерживать высокий уровень исполнения
проектной дисциплины разработчиками: жесткий порядок фор-
мирования моделей; жесткую структуру и содержимое докумен-
тации; автоматическую генерацию исходных кодов программ
и т. д.; все это обеспечивает повышение качества и надежности
разрабатываемых ИС.
Для подготовки проектной документации могут использо-
ваться издательские системы FrameMaker, Interleaf или Word
2.6. Системы автоматизированного проектирования АИС 125
Perfect. Структура и состав проектной документации настраива-
ются в соответствии с заданными стандартами. Настройка вы-
полняется без изменения проектных решений.
При разработке крупных АИС вся система в целом соответст-
вует одному проекту как категории Vantage Team Builder. Проект
может быть декомпозирован на ряд систем, каждая из которых
соответствует некоторой относительно автономной подсистеме
АИС и разрабатывается независимо от других. В дальнейшем
системы проекта могут быть интегрированы.
Процесс проектирования АИС с использованием Vantage
Team Builder реализуется в виде четырех последовательных фаз
(стадий) — анализа, архитектуры, проектирования и реализации,
при этом законченные результаты каждой стадии полностью или
частично переносятся (импортируются) в следующую фазу. Все
диаграммы, кроме ERD, преобразуются в другой тип или изме-
няют вид в соответствии с особенностями текущей фазы. Так,
DFD преобразуются в фазе архитектуры в SAD, DSD — в DTD.
После завершения импорта логическая связь с предыдущей фа-
зой разрывается, т. е. в диаграммы можно вносить все необходи-
мые изменения.
Конфигурация Vantage Team Builder for Uniface обеспечивает
совместное использование двух систем в рамках единой техноло-
гической среды проектирования, при этом схемы БД (SQL-модс-
ли) переносятся в репозиторий Uniface, и наоборот, прикладные
модели, сформированные средствами Unifacc, могут быть пере-
несены в репозиторий Vantage Team Builder. Возможные рассо-
гласования между репозиториями двух систем устраняются с по-
мощью специальной утилиты. Разработка экранных форм в среде
Uniface выполняется на базе диаграмм последовательностей
форм FSD после импорта SQL-модели. Технология разработки
АИС на базе данной конфигурации показана на рис. 2.23 [7].
Структура репозитория, хранящегося в целевой СУБД, и ин-
терфейсы Vantage Team Builder являются открытыми, что в
принципе обеспечивает возможность интеграции с любыми дру-
гими средствами.
Uniface. Продукт фирмы Compuware представляет собой сре-
ду разработки крупномасштабных приложений в архитектуре
«клиент—сервер» и имеет следующую компонентную архитекту-
ру 17, 11, 16]:
• Application Objects Repository (репозиторий объектов при-
ложений) содержит метаданные, автоматически используе-
126
Глава 2. Анализ предметной области АИС...
Разработчик приложений
Рис. 2.23. Взаимодействие Vantage Team Builder и Uniface
мыс всеми остальными компонентами на протяжении жиз-
ненного цикла АИС (прикладные модели, описания дан-
ных, бизнес-правил, экранных форм, глобальных объектов
и шаблонов). Репозиторий может храниться в любой из
БД, поддерживаемых Uniface;
• Application Model Manager поддерживает прикладные моде-
ли (E-R-модели), каждая из которых представляет собой
подмножество общей схемы БД с точки зрения данного
приложения, и включает соответствующий графический
редактор;
2.6. Системы автоматизированного проектирования АИС 127
• Rapid Application Builder — средство быстрого создания эк-
ранных форм и отчетов на базе объектов прикладной моде-
ли. Включает графический редактор форм, средства прото-
типирования, отладки, тестирования и документирования.
Реализован интерфейс с разнообразными типами оконных
элементов управления Open Widget Interface для существую-
щих графических интерфейсов — MS Windows (включая
VBX), Motif, OS/2. Универсальный интерфейс представле-
ния Universal Presentation Interface позволяет использовать
одну и ту же версию приложения в среде различных графи-
ческих интерфейсов без изменения программного кода;
• Developer Services (службы разработчика) используются для
поддержки крупных проектов и реализуют контроль версий
(Uniface Version Control System), права доступа (разграниче-
ние полномочий), глобальные модификации и т. д. Это
обеспечивает разработчиков средствами параллельного про-
ектирования, входного и выходного контроля, поиска, про-
смотра, поддержки и выдачи отчетов по данным системы
контроля версий;
• Deployment Manager (управление распространением прило-
жений) — средства, позволяющие готовить созданное при-
ложение для распространения, устанавливать и сопровож-
дать его (при этом платформа пользователя может отли-
чаться от платформы разработчика). В их состав входят
сетевые драйверы и драйверы СУБД, сервер приложений
(полисервер), средства распространения приложений и
управления БД. Unifacc поддерживает интерфейс практиче-
ски со всеми известными программно-аппаратными плат-
формами, СУБД, CASE-средствами, сетевыми протокола-
ми и менеджерами транзакций;
• Personal Series (персональные средства) используются для
создания сложных запросов и отчетов в графической фор-
ме (Personal Query и Personal Access — PQ/PA), а также для
переноса данных в такие системы, как WinWord и Excel;
• Distributed Computing Manager — средство интеграции с
менеджерами транзакций Tuxedo, Encina, CICS, OSF DCE.
Версия Uniface 7 полностью поддерживает распределенную
модель вычислений и трехзвенную архитектуру «клиент—сервер»
(с возможностью изменения схемы декомпозиции приложений
на этапе исполнения). Приложения, создаваемые с помощью
Uniface 7, могут исполняться в гетерогенных операционных сре-
128
Глава 2. Анализ предметной области АИС...
дах, использующих различные сетевые протоколы, одновремен-
но на нескольких разнородных платформах (в том числе и в*
Internet).
В состав компонент Uniface 7 входят:
• Uniface Application Server — сервер приложений для рас-
пределенных систем;
• WebEnabler — серверное ПО для эксплуатации приложе-
ний в Internet и intranet;
• Name Server — серверное ПО, обеспечивающее использо-
вание распределенных прикладных ресурсов;
• PolyServer — средство доступа к данным и интеграции раз-
личных систем.
В список поддерживаемых СУБД входят DB2, VSAM и IMS;
PolyServer обеспечивает также взаимодействие с ОС MVS.
Designer/2000 + DeveIoper/2000. Designer/2000 2.0 фирмы
ORACLE является интегрированным CASE-средством, обеспе-
чивающим в совокупности со средствами разработки приложе-
ний Developer/2000 поддержку полного ЖЦ ПО для систем, ис-
пользующих СУБД ORACLE [7, 11, 16].
Designer/2000 представляет собой семейство методологий и
поддерживающих их программных продуктов. Базовая методоло-
гия Designer/2000 (CASE*Method) — структурная методология
проектирования систем, полностью охватывающая все этапы
жизненного цикла АИС. На этапе планирования определяются
цели создания системы, приоритеты и ограничения, разрабаты-
вается системная архитектура и план разработки АИС. В процес-
се анализа строятся: модель информационных потребностей
(диаграмма «сущность—связь»), диаграмма функциональной
иерархии (на основе функциональной декомпозиции АИС), мат-
рица перекрестных ссылок и диаграмма потоков данных.
На этапе проектирования разрабатывается подробная архи-
тектура АИС, проектируется схема реляционной БД и про-
граммные модули, устанавливаются перекрестные ссылки между
компонентами АИС для анализа их взаимного влияния и кон-
троля за изменениями.
На этапе реализации создается БД, строятся прикладные
системы, производится их тестирование, проверка качества и со-
ответствия требованиям пользователей. Создается системная до-
кументация, материалы для обучения и руководства пользовате-
лей. На этапах эксплуатации и сопровождения анализируются
2.6. Системы автоматизированного проектирования АИС 129
производительность и целостность системы, выполняется под-
держка и, при необходимости, модификация АИС.
Designer/2000 обеспечивает графический интерфейс при раз-
работке различных моделей (диаграмм) предметной области.
В процессе построения моделей информация о них заносится в
репозиторий. В состав Designer/2000 входят следующие компо-
ненты:
• Repository Administrator — средства управления репозито-
рием (создание и удаление приложений, управление досту-
пом к данным со стороны различных пользователей, экс-
порт и импорт данных);
• Repository Object Navigator — средства доступа к репозито-
рию, обеспечивающие многооконный объектно-ориентиро-
ванный интерфейс доступа ко всем элементам репозитория;
• Process Modeller — средство анализа и моделирования де-
ловой деятельности, основывающееся на концепциях реин-
жиниринга бизнес-процессов BPR и глобальной системы
управления качеством TQM (см. гл. 2);
• Systems Modeller — набор средств построения функцио-
нальных и информационных моделей проектируемой АИС,
включающий средства для построения диаграмм «сущ-
ность-связь» (Entity-Relationship Diagrammer), диаграмм
функциональных иерархий (Function Hierarchy Diagram-
mer), диаграмм потоков данных (Data Flow Diagrammer) и
средство анализа и модификации связей объектов репози-
тория различных типов (Matrix Diagrammer);
• Systems Designer — набор средств проектирования АИС,
включающий средство построения структуры реляционной
БД (Data Diagrammer), а также средства построения диа-
грамм, отображающих взаимодействие с данными, иерар-
хию, структуру и логику приложений, реализуемую храни-
мыми процедурами на языке PL/SQL (Module Data
Diagrammer, Module Structure Diagrammer и Module Logic
Navigator);
• Server Generator — генератор описаний объектов БД
ORACLE (таблиц, индексов, ключей, последовательностей
и т. д.). Помимо продуктов ORACLE, генерация и реинжи-
ниринг БД могут выполняться для СУБД Informix, DB/2,
Microsoft SQL Server, Sybase, а также для стандарта ANSI
SQL DDL и баз данных, доступ к которым реализуется по-
средством ODBC;
130
Глава 2. Анализ предметной области АИС...
• Forms Generator — генератор приложений для ORACLE
Forms. Генерируемые приложения включают в себя различ-
ные экранные формы, средства контроля данных, провер-
ки ограничений целостности и автоматические подсказки.
Дальнейшая работа с приложением выполняется в среде
Developer/2000;
• Repository Reports — генератор стандартных отчетов, и итог-
рированный с ORACLE Reports и позволяющий русифици-
ровать отчеты, а также изменять структурное представле-
ние информации.
Репозиторий Designer/2000 представляет собой хранилище
всех проектных данных и может работать в многопользователь-
ском режиме, обеспечивая параллельное обновление информа-
ции несколькими разработчиками. В процессе проектирования
автоматически поддерживаются перекрестные ссылки между
объектами словаря; генераторы более 70 стандартных отчетов о
моделируемой предметной области. Физическая среда хранения
репозитория — база данных ORACLE. Генерация приложений,
помимо продуктов ORACLE, выполняется также для Visual Basic.
Designer/2000 можно интегрировать с другими средствами,
используя открытый интерфейс приложений API (Application
Programming Interface). Средство ORACLE CASE Exchange под-
держивает экспорт/импорт объектов репозитория с целью обме-
на информацией с другими CASE-средствами. Developer/2000
обеспечивает разработку переносимых приложений, работающих
в графической среде Windows, Macintosh или Motif. В среде
Windows интеграция приложений Developer/2000 с другими сред-
ствами реализуется через механизм OLE и управляющие элемен-
ты VBX. Взаимодействие приложений с другими СУБД (DB/2,
DB2/400, Rdb) реализуется с помощью средств ORACLE Client
Adapter для ODBC, ORACLE Open Gateway и API.
S-Designor. S-Designor 4.2 представляет собой CASE-средство
для проектирования реляционных БД. По своим функциональ-
ным возможностям и стоимости аналогично средству ErWin,
отличаясь внешне используемой на диаграммах нотацией.
S-Designor реализует стандартную методологию моделирования
данных и генерирует описание БД для таких СУБД, как
ORACLE, Informix, Ingres, Sybase, DB/2, Microsoft SQL Server и
др. Для существующих систем выполняется реинжиниринг БД.
S-Designor совместимо со средствами разработки приложе-
ний (PowerBuilder, Uniface, TeamWindows и др.) и позволяет экс-
2.6. Системы автоматизированного проектирования АИС 131
портировать описание БД в репозитории данных средств. Для
PowerBuilder выполняется также прямая генерация шаблонов
приложений.
CASE-Аналитик. CASE-Аналитик 1.1 является практически
единственным в настоящее время конкурентоспособным отече-
ственным CASE-средством функционального моделирования и
реализует построение диаграмм потоков данных [7, 11, 16].
Его основные функции:
• построение и редактирование DFD;
• анализ диаграмм и проектных спецификаций на полноту и
непротиворечивость;
• получение разнообразных отчетов по проекту;
• генерация макетов документов в соответствии с требова-
ниями ГОСТ серий 19 и 34.
БД проекта реализована в формате СУБД Paradox и открыта
для доступа.
С помощью отдельного программного продукта (Catherine)
выполняется обмен данными с CASE-средством ErWin. При
этом из проекта, выполненного в CASE-Аналитике, экспортиру-
ется описание структур данных и накопителей данных, которое
по определенным правилам формирует описание сущностей и
их атрибутов.
Rational Rose. CASE-средство фирмы Rational Software
Corporation (США), предназначено для автоматизации этапов
анализа и проектирования ПО, а также для генерации кодов на
различных языках и выпуска проектной документации. Rational
Rose использует синтез-методологию объектно-ориентированно-
го анализа и проектирования, основанную на подходах трех веду-
щих специалистов в данной области — Г. Буча, Д. Рамбо и А. Дже-
кобсона. Разработанная ими универсальная нотация для модели-
рования объектов (UML — Unified Modeling Language) претендует
на роль стандарта в области объектно-ориентированного анализа
и проектирования. Конкретный вариант Rational Rose определя-
ется языком, на котором генерируются коды программ (C++,
Smalltalk, PowerBuilder, Ada, SQLWindows и ObjectPro). Основной
вариант — Rational Rose/C++ — позволяет разрабатывать проект-
ную документацию в виде диаграмм и спецификаций, а также ге-
нерировать программные коды на C++. Кроме того, Rational
Rose содержит средства реинжиниринга программ, обеспечиваю-
щие повторное использование программных компонент в новых
проектах.
132
Глава 2. Анализ предметной области АИС...
В основе работы Rational Rose лежит построение различного
рода диаграмм и спецификаций, определяющих логическую и
физическую структуры модели, ее статические и динамические
аспекты. В их число входят диаграммы классов, состояний, сце-
нариев, модулей, процессов [7, 11, 16].
В составе Rational Rose можно выделить шесть основных
структурных компонентов: репозиторий, графический интерфейс
пользователя, средства просмотра проекта (browser), средства
контроля проекта, средства сбора статистики и генератор доку-
ментов. К ним добавляются генератор кодов (индивидуальный
для каждого языка) и анализатор для C++, обеспечивающий ре-
инжиниринг — восстановление модели проекта по исходным
текстам программ.
Репозиторий представляет собой объектно-ориентированную
БД. Средства просмотра обеспечивают «навигацию» по проекту,
в том числе перемещение по иерархиям классов и подсистем,
переключение от одного вида диаграмм к другому и т. д. Средст-
ва контроля и сбора статистики дают возможность находить и
устранять ошибки по мере развития проекта, а не после завер-
шения его описания. Генератор отчетов формирует тексты вы-
ходных документов на основе содержащейся в репозитории ин-
формации.
Средства автоматической генерации кодов программ на языке
C++, используя информацию, содержащуюся в логической и
физической моделях проекта, формируют файлы заголовков и
файлы описаний классов и объектов. Создаваемый таким обра-
зом скелет программы может быть уточнен путем прямого про-
граммирования на языке C++. Анализатор кодов C++ реализо-
ван в виде отдельного программного модуля. Его назначение со-
стоит в том, чтобы создавать модули проектов в форме Rational
Rose на основе информации, содержащейся в определяемых
пользователем исходных текстах на C++. В процессе работы
анализатор осуществляет контроль правильности исходных тек-
стов и диагностику ошибок. В результате полученная модель мо-
жет целиком или фрагментарно использоваться в различных
проектах. Анализатор обладает широкими возможностями на-
стройки по входу и выходу (определение типов исходных фай-
лов, базового компилятора, задание требований к информации
для формируемой модели и т. д.). Таким образом, Rational
Rose/C++ обеспечивает возможность повторного использования
программных компонентов.
2.6. Системы автоматизированного проектирования АИС 133
В результате разработки проекта АИС с помощью Rational
Rose формируются следующие документы:
• диаграммы классов;
• диаграммы состояний;
• диаграммы сценариев;
• диаграммы модулей;
• диаграммы процессов;
• спецификации классов, объектов, атрибутов и операций;
• заготовки текстов программ;
• модель разрабатываемой программной системы.
Последний из перечисленных документов является тексто-
вым файлом, содержащим всю необходимую информацию о
проекте.
Тексты программ являются заготовками для последующей
работы программистов. Они формируются в рабочем каталоге в
виде файлов типов .h (заголовки, содержащие описания классов)
и .срр (заголовки программ для методов). Система включает в
программные файлы собственные комментарии, которые начи-
наются с последовательности символов //##. Состав информа-
ции, включаемой в программные файлы, определяется либо по
умолчанию, либо по усмотрению пользователя. В дальнейшем
эти исходные тексты развиваются программистами в полноцен-
ные программы.
Rational Rose интегрируется со средством PVCS для органи-
зации групповой работы и управления проектом и со средством
SoDA — для документирования проектов. Интеграция Rational
Rose и SoDA обеспечивается средствами SoDA.
Для организации групповой работы в Rational Rose возмож-
но разбиение модели на управляемые подмодели. Каждая из них
независимо сохраняется на диске или загружается в модель.
В качестве подмодели может выступать категория классов или
подсистема.
Для управляемой подмодели предусмотрены операции:
• загрузка подмодели в память;
• выгрузка подмодели из памяти;
• сохранение подмодели на диске в виде отдельного файла;
• установка защиты от модификации;
• замена подмодели в памяти на новую.
Наиболее эффективно групповая работа организуется при
интеграции Rational Rose со специальными средствами управле-
ния конфигурацией и контроля версий (PVCS). В этом случае
134
Глава 2. Анализ предметной области АИС...
защита от модификации устанавливается на все управляемые
подмодели, кроме тех, которые выделены конкретному разра-
ботчику. В этом случае признак защиты от записи устанавлива-
ется для файлов, которые содержат подмодели, поэтому при
считывании «чужих» подмоделей защита их от модификации со-
храняется, и случайные воздействия окажутся невозможными.
ErWin, BpWin. Разработаны фирмой Logic Works; с 1998 г.
выпускаются под логотипом PLATINUM technology и включены
в состав комплекса продуктов и технологий разработки приклад-
ного ПО PLATINUM Advantage [7, 11, 16].
BpWin — средство моделирования бизнес-процессов, реали-
зующее метод IDEF0 (см. гл. 2). Текущая версия поддерживает
также диаграммы потоков данных и потоков работ. В процессе
моделирования BpWin позволяет переключиться с нотации
IDEF0 на любой ветви модели на нотацию IDEF3 или DFD и
создать смешанную модель.
Семейство продуктов ErWin представляет собой набор
средств концептуального моделирования данных, использующих
метод IDEF1X (новая версия метода IDEF1, позволяющего по-
строить модель данных, эквивалентную реляционной модели в
третьей нормальной форме). ErWin реализует проектирование
схемы БД, генерацию ее описания на языке целевой СУБД и ре-
версный инжиниринг существующей БД. Интегрируется с попу-
лярными средствами разработки клиентской части приложений
PowerBuilder, Visual Basic, Delphi, что позволяет автоматически
генерировать код приложений. Для разных сред разработки реа-
лизована различная техника генерации кода. Семейство ErWin
не поддерживает непосредственно генерацию кода для Delphi.
Его можно сгенерировать с помощью продукта MetaBASE.
Для управления групповой разработкой используется средст-
во Model Mart, обеспечивающее многопользовательский доступ
к моделям, созданным с помощью ErWin и BpWin. Модели хра-
нятся на центральном сервере и доступны для всех участников
группы проектирования.
Модель Model Mart удовлетворяет ряду требований, предъяв-
ляемых к средствам управления разработкой крупных АИС,
а именно:
• совместное моделирование;
• создание библиотек решений;
• управление доступом.
2.6. Системы автоматизированного проектирования АИС 135
Model Mart включает специальную утилиту — Model Mart
Synchronizer, позволяющую проводить синхронизацию моделей
процессов (BpWin) и данных (ErWin), хранящихся в библиотеках
Model Mart.
ErWin поддерживает взаимодействие с Rational Rose: модуль
ErWin Translation Wizard позволяет конвертировать объектную
модель Rational Rose в модель данных ErWin и обратно и затем с
помощью ErWin генерировать схему БД для любой из поддержи-
ваемых в ErWin СУБД.
Для связывания объектной модели, созданной средствами Pa-
radigm Plus, с моделью данных не требуется дополнительных ути-
лит. Версия Paradigm Plus 3.6 полностью интегрирована с ErWin.
Существует также возможность импорта/экспорта данных
из/в репозиторий ErWin и из репозиториев BpWin и Oracle
Designer.
Oracle Designer. Интегрированное CASE-средство фирмы
Oracle, обеспечивающее в совокупности со средствами разработки
приложений Oracle Developer и Oracle Application Server поддерж-
ку полного ЖЦ ПО для систем, использующих СУБД Oracle.
Oracle Designer представляет собой семейство методов и под-
держивающих их программных продуктов. Базовый метод Oracle
Designer — структурный метод проектирования систем, охваты-
вающий полностью все стадии ЖЦ ПО. В настоящее время дан-
ный метод продолжает развиваться и поставляется корпорацией
Oracle как самостоятельный продукт под названием Custom
Development Method (CDM) в совокупности с методами и средст-
вами управления проектом Project Management Method (РММ).
Версия Oracle Designer для объектно-реляционной СУБД
Oracle8i содержит также расширение в виде средств объектного
моделирования, базирующихся на стандарте UML.
Oracle Designer обеспечивает графический интерфейс при
разработке различных моделей предметной области. В процессе
построения моделей информация о них заносится в репозито-
рий. В состав Oracle Designer входят компоненты:
• Repository Administrator — средства управления репозито-
рием;
• Repository Object Navigator — средство доступа к репозито-
рию, обеспечивающее многооконный объектно-ориентиро-
ванный интерфейс доступа ко всем элементам репозитория;
• Process Modeler — средство анализа и моделирования дея-
тельности организации, основывающееся на концепциях
136
Глава 2. Анализ предметной области АИС...
реинжиниринга бизнес-процессов и глобальной системы
управления качеством;
• Systems Modeler — набор средств построения функцио-
нальных и информационных моделей проектируемой АИС,
включающий средства для построения диаграмм «сущ-
ность-связь», диаграмм функциональных иерархий, диа-
грамм потоков данных и средство анализа и модификации
связей объектов репозитория различных типов;
• Systems Designer — набор средств проектирования ПО,
включающий средство построения структуры реляционной
базы данных, а также средства построения диаграмм, ото-
бражающих взаимодействие с данными, иерархию, струк-
туру и логику приложений, реализуемых хранимыми про-
цедурами на языке PL/SQL;
• Server Generator — генератор описаний объектов БД Oracle;
• Forms Generator — генератор приложений для Oracle Forms.
Генерируемые приложения включают в себя различные эк-
ранные формы, средства контроля данных, проверки огра-
ничений целостности и автоматические подсказки;
• Repository Reports — генератор стандартных отчетов, интег-
рированный с Oracle Reports и позволяющий русифициро-
вать отчеты, а также изменять структурное представление
информации;
• репозиторий Oracle Designer представляет собой хранилище
всех проектных данных и может работать в многопользова-
тельском режиме, обеспечивая параллельное обновление
информации несколькими разработчиками. В процессе
проектирования автоматически могут генерироваться бо-
лее 70 стандартных отчетов о моделируемой предметной
области. Физическая среда хранения репозитория — база
данных Oracle.
Oracle Designer интегрируется с другими средствами с помо-
щью открытого интерфейса приложений API. Кроме того, мож-
но использовать средство Oracle CASE Exchange для экспор-
та/импорта объектов репозитория в целях обмена информацией
с другими CASE-средствами.
Oracle Developer обеспечивает разработку переносимых при-
ложений, работающих в графической среде Windows, Macintosh,
Motif. В среде Windows интеграция приложения Oracle Developer
с другими средствами реализуется через механизм OLE и управ-
ляющие элементы VBX. Взаимодействие приложений с другими
2.6. Системы автоматизированного проектирования АИС
137
СУБД реализуется с помощью средств Oracle Client Adapter для
ODCB, Oracle Open Gateway и API.
Sybase PowerDesigner 9.0. Полнофункциональный инстру-
мент для моделирования бизнес-приложений, включающий в
себя средства моделирования бизнес-процессов, сочетающий
возможности моделирования UML-объектов с возможностями
традиционного проектирования БД и анализа и предоставляю-
щий централизованный репозиторий объектов масштаба пред-
приятия [7, 11, 16].
В зависимости от требований к проектированию и разработке,
можно выбрать только необходимые модули PowerDesigner 9.0.
PhysicalArchitect (PDM). Физическое проектирование и гене-
рация БД, включая моделирование хранилищ данных. Этот мо-
дуль, входящий в состав минимальной конфигурации, обеспечи-
вает инструментальные средства, необходимые для создания фи-
зических моделей БД (как OLTP, так и OLAP), генерации
SQL-кода и реинжиниринга существующих БД из гетерогенных
источников.
DataArchitect (PDM, CDM). Двухуровневое, итерационное
проектирование БД и генерация операторов описания БД
(DLL). Поддерживает интегрированное физическое и концепту-
альное моделирование данных (включая моделирование храни-
лищ данных), позволяя проектировать и генерировать БД для
более чем 30 РСУБД и настольных платформ.
ObjectArchitect (PDM, CDM, OOM). Объектно-ориентирован-
ный анализ и проектирование в комбинации с двухуровневым,
итерационным проектированием БД и языком описания БД
(DLL). С расширенной поддержкой UML (use case, activity,
sequence, диаграммы классов и компонентов), интегрированной
с возможностями моделирования данных от DataArchitect, этот
модуль делает максимально эффективной работу проектировщи-
ков БД и приложений.
Developer (PDM, OOM). Объектное моделирование и физиче-
ское проектирование БД. Это идеальный инструмент для разра-
ботчика. Физическое моделирование данных, интегрированное с
UML-моделированием (use case, activity, sequence, диаграммы
классов и компонентов), включающее возможности генерации
сложного объектного кода и реинжиниринг.
Studio (BPM, PDM, CDM, OOM). Поставляемый в редакциях
Personal и Enterprise, модуль Studio объединяет в себе технологии
моделирования бизнес-процессов с возможностями расширен-
138
Глава 2. Анализ предметной области АИС...
ного UML-моделирования и моделирования данных. Комбини-
руя все необходимые методы моделирования в одной среде, эти
модули дают возможность бизнес- и IT-менеджерам с их коман-
дами разработчиков совместно строить бизнес-системы, эффек-
тивно поддерживающие работу предприятия.
Viewer. Обеспечивает всем IT-специалистам организации
единое представление информации о моделировании. Этот мо-
дуль, работающий только в режиме чтения (read-only), обеспечи-
вает графическое представление информации обо всех смодели-
рованных компонентах системы и включает генератор отчетов с
расширенной функциональностью.
Репозиторий объектов масштаба предприятия обеспечивает:
• возможность одновременной работы над одной моделью
многих аналитиков и проектировщиков;
• хранение, управление и создание версий моделей Power-
Designer и других документов;
• поиск объектов в модели и их повторное использование в
других моделях;
• эффективное управление взаимосвязями между моделями.
Основные особенности:
• моделирование бизнес-процессов на основе диаграмм по-
токов управления;
• технологии моделирования данных (концептуальная и фи-
зическая модель), основанные на индустриальном стандар-
те «сущность—связь» (entity—relationship), включая техно-
логии моделирования хранилищ данных (схемы «звезда»,
«снежинка», многомерное моделирование, привязка к кон-
кретному источнику данных);
• стандартные диаграммы UML: use case, activity, sequence,
диаграммы классов и компонентов;
• генерация на основе диаграмм классов исходных текстов
для Java, C++, PowerBuilder и Visual Basic;
• генерация операторов DDL (Data Definition Language) бо-
лее чем для 30 РСУБД;
• поддержка EJB 2.0;
• отображение «сущность—связь»;
• определение сложных пользовательских типов данных,
включая Java-классы и хранимые Java-процедуры, содержа-
щиеся в БД;
• обратное проектирование схемы базы данных в концепту-
альную и физическую модель;
2.6. Системы автоматизированного проектирования АИС 139
• обратное проектирование существующей бизнес-логики в
диаграммы классов (Java и PowerBuilder);
• прямое и обратное проектирование XML-приложений в
диаграммы классов. Поддержка XML-DTD, XML-схемы и
XML-данных;
• интеграция с популярными средствами разработки на Java
и с ведущими, сертифицированными под J2EE/EJB 2.0
серверами приложений;
• современный, графический, настраиваемый пользователь-
ский интерфейс, содержащий общую оболочку, обозрева-
тель объектов, область редактирования диаграмм и область
состояния;
• улучшенное управление моделями, включая синхрониза-
цию объектов, моделей и баз данных;
• расширенный, независимый от модели генератор отчетов,
позволяющий получить документ, включающий в себя ин-
формацию по нескольким моделям.
Web-службы в Sybase PowerDesigner. Описывая все элементы
Web-служб совместно со всеми другими элементами организа-
ции, PowerDesigner позволяет управлять сложной информацион-
ной архитектурой предприятия.
Встроенная в среду PowerDesigner, поддержка многочислен-
ных языков программирования дает возможность легко доку-
ментировать взаимозависимости программных компонентов и
Web-служб в гетерогенных средах, используя языки Java с под-
держкой J2EE и EJB, PowerBuilder, С, С#, VB, VB.NET и т. д.
Используя генерацию объектного кода на основе шаблона,
PowerDesigner 9.0 автоматизирует создание кода компонента на
выбранном языке программирования, а также WSDL (языка
описания Web-служб), требуемого для разработки Web-служб.
2.6.4. Функциональный анализ популярных в России
CASE-средств
Кроме рассмотренных выше CASE-средств, на российском
рынке ПО постоянно появляются их новые версии и модифика-
ции, а также еще не локализованные отечественными пользова-
телями системы — CASE/4/0, PRO-IV, System Architect,
VisibleAnalyst Workbench, EasyCASE [12].
140
Глава 2. Анализ предметной области АИС...
Тем не менее наиболее популярными до сих пор остаются
средства BpWin/ErWin (Platinum Technology), Rational Rose
(Rational Software Corporation) и ARIS (Scheer AG), сравнитель-
ный анализ которых представлен в табл. 2.7 [7].
Таблица 2.7. Сравнительный функциональный анализ
№ Функции, свойства ARIS ErWin/ BpWin Rational Rose
1 Моделирование организационных функ- ций и процессов + + +
2 Разработка технического задания + +/- +/-
3 Функционально-стоимостной анализ + + +/-
4 Оптимизация бизнес-процессов + -
5 Имитационное моделирование, собы- тийно-управляемое моделирование + +/- -
6 Генерация кода приложения - + +/-
7 Оформление проектной документации; генерация технологических инструкций для рабочих мест + +/- +
8 Хранение моделей деятельности пред- приятий + +/- +/-
9 Создание концептуальных и физических моделей структуры базы данных +/- + +
10 Генерация программного кода, SQL-сценариев для создания структуры базы данных - + +/-
11 Стандартное представление основных бизнес-процессов (более 100 типов) + __ -
12 Ведение библиотеки типовых биз- нес-моделей + +/- +/-
13 Групповая работа над проектом + + +
14 Выдача встроенных отчетов по стандар- ту IS09000 + - -
Ценовые различия $31 740 (+$14 610) $23 685 (+ $4245) $40 520 (+$?)
«+» — да.
«+/-»— частичная реализация, требующая доработки иными инструментальными средствами.
«-» — нет.
2.6. Системы автоматизированного проектирования АИС 141
Контрольные вопросы
1. Каковы этапы анализа предметной области АИС?
2. Что такое миссия компании?
3. Зачем проводится предпроектное обследование?
4. Назовите методологии моделирования деятельности организации при
разработке АИС.
5. Что такое функциональный блок в методологии IDEF?
6. Какие основные понятия используются при построении диаграмм по-
токов данных?
7. Перечислите основные связи между аспектами моделирования и
UML-диаграммами.
8. Перечислите методы сбора материалов обследования.
9. На какие группы методология ARIS делит бизнес-модели?
10. На какие стандартные вопросы о деятельности организации дает отве-
ты UML-модель?
11. Охарактеризуйте системы автоматизированного проектирования АИС.
12. Что такое CASE-технологии?
13. Какие основные задачи решают CASE-средства?
14. Какие способы классификации CASE-средств существуют?
15. Что лежит в основе работы Rational Rose?
16. Каким образом и какие документы формируются в результате раз-
работки проекта с помощью CASE-средства Rational Rose?
17. Объясните, как происходит взаимодействие Vantage Team Builder и
Uniface.
Литература к главе 2
1. Гагарина Л. Г. Автоматизированные информационные системы:
учеб, пособие. М.: МИЭТ, 2003. 114 с.
2. Тельнов Ю. Ф. Реинжиниринг бизнес-процессов: учеб, пособие. М.:
МЭСИ, 2002. 99 с.
3. Гренул В. И. Проектирование информационных систем, http//
www.intuit.ru.
4. Проектирование экономических информационных систем: учебник /
под ред. Ю. Ф. Тельнова / Г. Н. Смирнова и др. М.: Финансы и статистика,
2005. 512 с.
5. Вернинов Г. X. Основные методологии обследования организаций.
Стандарт IDEF. http://www.vernikov.ru.
6. Петров Ю. А., Шлимович Е. Л., Ирюпин И. В. Комплексная авто-
матизация управления предприятием: информационные технологии — тео-
рия и практика. М.: Финансы и статистика, 2001. 128 с.
142
Глава 2. Анализ предметной области АИС...
7. Каляное Г. Н. Консалтинг при автоматизации предприятий: подходы,
методы, средства. http//www.interface.ru.
8. Ковалев С. М., Ковалев В. М. Современные методологии описания
бизнес-процессов — просто о сложном. Ч. 6. // Консультант директора.
2004. № 12.
9. Якобсон А., Буч Г., Рамбо Дж. Унифицированный процесс разра-
ботки программного обеспечения. Пер. с англ. СПб.: Питер, 2002. 496 с.
10. Калашян А. Н. Структурные модели бизнеса: DFD-анализ. М.: Фи-
нансы и статистика, 2003. 512 с.
11. Вендров А. 44. CASE-технологии. Современные методы и средства
проектирования информационных систем, http://citforum.ru.
12. Балдин К. В., Уткин В. Б. Информационные системы в экономике:
учебник. 2-е изд. М.: Дашков и К°, 2006. 395 с.
13. Черемных С. В. Структурный анализ систем: IDEF-технологии. М.:
Финансы и статистика, 2005. 512 с.
14. Материалы кафедры информатики и математического обеспечения
Петрозаводского государственного университета, http://cs.karelia.ru/
~sigovtse/study_pr/inf_sys/inf_s_book/lecture/15b.html.
15. Clegg, Dai, and Richard Barker. CASE-Method Fast-track. A RAD
Approach. on-Wesley, 1994.
16. Вендров A. 44. Проектирование программного обеспечения эконо-
мических информационных систем. 2-е изд., перераб. и доп. М.: Финансы
и статистика, 2005. 180 с.
Глава 3
РАЗРАБОТКА
ПРОГРАММНО-ИНФОРМАЦИОННОГО
ЯДРА АИС НА ОСНОВЕ СИСТЕМ
УПРАВЛЕНИЯ БАЗАМИ ДАННЫХ
3.1. Основы современных систем управления базами
данных
Для понимания принципов построения систем управления
базами данных напомним ряд известных определений.
База данных — это набор структурированной информации,
предназначенной для совместного употребления несколькими
пользователями одновременно. Отдельные элементы данных свя-
заны между собой логически. Структурированность означает, что
данные имеют некоторую логическую структуру, некоторую схе-
му, модель, которая связывает между собой отдельные данные.
БД предполагает наличие некоторого программного обеспечения,
позволяющего пользователю работать с ней (рис. 3.1) [1, 2].
Рис. 3.1. Компоненты системы баз данных
144 Глава 3. Разработка программно-информационного ядра АИС...
Система управления базами данных (СУБД) позволяет созда-
вать БД, модифицировать в них данные, разрабатывать пользо-
вательские приложения без учета физического представления
данных.
Прикладные программы относятся к категории приложений.
Банк данных — обычно БД или несколько БД, связанных ме-
жду собой логически.
Схема базы данных описывает взаимоотношения между дан-
ными, структуру отдельных компонентов, правила модификации
и взаимозависимость между данными.
Модель данных — описание принципов, на основе которых
построена БД. При разработке БД используют инструменталь-
ные программные средства СУБД [3].
Известно, что к числу основных функций СУБД принято от-
носить следующие [4].
Непосредственное управление данными во внешней памяти. Эта
функция включает обеспечение необходимых структур внешней
памяти как для хранения данных, непосредственно входящих в
БД, так и для служебных целей, например, для повышения ско-
рости доступа к данным в некоторых случаях (индексирование).
В некоторых реализациях СУБД активно используются возмож-
ности существующих файловых систем, в других работа произ-
водится вплоть до уровня устройств внешней памяти. В разви-
тых СУБД пользователи в любом случае не обязаны знать, ис-
пользует ли СУБД файловую систему, и если использует, то не
обязаны знать, как организованы файлы. В частности, СУБД
поддерживает собственную систему именования объектов БД [5].
Управление буферами оперативной памяти. СУБД обычно ра-
ботают с БД значительного размера (много больше доступного
объема оперативной памяти). Если при обращении к любому
элементу данных производится обмен с внешней памятью, то
вся система будет работать со скоростью устройства внешней па-
мяти. Практически единственным способом реального увеличе-
ния этой скорости является буферизация данных в оперативной
памяти. При этом, даже если операционная система производит
общесистемную буферизацию (как в случае ОС UNIX), этого
недостаточно для целей СУБД, которая располагает гораздо
большей информацией о полезности буферизации той или иной
части БД. Поэтому в развитых СУБД поддерживается собствен-
ный набор буферов оперативной памяти с собственной дисцип-
линой замены буферов.
3.1. Основы современных систем управления базами данных 145
Существует отдельное направление СУБД, которое ориенти-
ровано на постоянное присутствие в оперативной памяти всей
БД. Это направление основано на предположении, что в буду-
щем объем оперативной памяти компьютеров будет настолько
велик, что позволит не беспокоиться о буферизации. Пока эти
работы находятся в стадии исследований.
Управление транзакциями. Транзакция — это последователь-
ность операций над БД, рассматриваемых СУБД как единое це-
лое. Либо транзакция успешно выполняется, и СУБД фиксирует
(COMMIT) изменения БД, произведенные этой транзакцией, во
внешней памяти, либо ни одно из этих изменений никак не от-
ражается ща состоянии БД. Понятие транзакции необходимо для
поддержания логической целостности БД |3].
Таким образом, поддержание механизма транзакций являет-
ся обязательным условием даже однопользовательских СУБД, в
многопользовательских СУБД он строго обязателен.
То свойство, что каждая транзакция начинается при целост-
ном состоянии БД и оставляет это состояние целостным после
своего завершения, делает очень удобным использование поня-
тия транзакции как единицы активности пользователя по отно-
шению к БД. При соответствующем управлении параллельно
выполняющимися транзакциями со стороны СУБД каждый из
пользователей может в принципе ощущать себя единственным
пользователем СУБД (на самом деле, иногда в многопользова-
тельских СУБД заметно наличие нескольких пользователей).
С управлением транзакциями в многопользовательской
СУБД связаны важные понятия сериализации транзакций и сери-
ального плана выполнения смеси транзакций. Под сериализацией
параллельно выполняющихся транзакций понимается такой по-
рядок планирования их работы, при котором суммарный эффект
смеси транзакций эквивалентен эффекту их некоторого последо-
вательного выполнения. Сериальный план выполнения смеси
транзакций — это такой план, который приводит к сериализа-
ции транзакций. Понятно, что если удается добиться действи-
тельно сериального выполнения смеси транзакций, то для каж-
дого пользователя, по инициативе которого образована транзак-
ция, присутствие других транзакций будет незаметно (если не
считать некоторого замедления работы по сравнению с одно-
пользовательским режимом).
Существует несколько базовых алгоритмов сериализации
транзакций. В централизованных СУБД наиболее распростране-
146 Глава 3. Разработка программно-информационного ядра АИС...
ны алгоритмы, основанные на синхронизационных захватах объ-
ектов БД. При использовании любого алгоритма сериализации
возможны конфликты между двумя или более транзакциями по
доступу к объектам БД. В этом случае для поддержания сериали-
зации необходимо выполнить откат (ликвидировать все измене-
ния, произведенные в БД) одной или более транзакций. Это один
из случаев, когда пользователь многопользовательской СУБД мо-
жет реально ощутить присутствие в системе транзакций других
пользователей [4].
Журнализация и восстановление БД после сбоев. Одним из ос-
новных требований к СУБД является надежность хранения дан-
ных во внешней памяти. Под надежностью хранения понимают
то, что СУБД в состоянии восстановить последнее согласован-
ное состояние БД после любого аппаратного или программного
сбоя. Обычно рассматривают два возможных вида аппаратных
сбоев: так называемые мягкие сбои, которые можно трактовать
как внезапную остановку работы компьютера (например, ава-
рийное выключение питания), и жесткие сбои, характеризуемые
потерей информации на носителях внешней памяти. Примерами
программных сбоев являются аварийное завершение работы
СУБД (по причине ошибки в программе или в результате неко-
торого аппаратного сбоя) или аварийное завершение пользова-
тельской программы, в результате чего некоторая транзакция ос-
тается незавершенной. Первую ситуацию можно рассматривать
как особый вид мягкого аппаратного сбоя; при возникновении
последней требуется ликвидировать последствия только одной
транзакции.
В любом случае для восстановления БД нужно располагать
некоторой дополнительной информацией. Другими словами,
поддержание надежности хранения данных в БД требует избы-
точности хранения данных, причем та часть данных, которая ис-
пользуется для восстановления, должна храниться особо надеж-
но. Наиболее распространенным методом поддержания такой из-
быточной информации является ведение журнала изменений БД.
Журнал — это особая часть БД, недоступная пользователям
СУБД и поддерживаемая с особой тщательностью (иногда под-
держиваются две копии журнала, располагаемые на разных физи-
ческих дисках), в которую поступают записи обо всех изменениях
основной части БД. В разных СУБД изменения БД журнализуют-
ся на разных уровнях: иногда запись в журнале соответствует не-
которой логической операции изменения БД (например, опера-
3.1. Основы современных систем управления базами данных 147
ции удаления строки из таблицы реляционной БД), иногда — ми-
нимальной внутренней операции модификации страницы
внешней памяти; в некоторых системах одновременно использу-
ются оба подхода.
Во всех случаях придерживаются стратегии «упреждающей»
записи в журнал (так называемого протокола Write Ahead Log —
WAL). Эта стратегия заключается в том, что запись об измене-
нии любого объекта БД должна попасть во внешнюю память
журнала раньше, чем измененный объект попадет во внешнюю
память основной части БД. Известно, что если в СУБД коррект-
но соблюдается протокол WAL, то с помощью журнала можно
решить все проблемы восстановления БД после любого сбоя.
Самая простая ситуация восстановления — индивидуальный
откат транзакции. Строго говоря, для этого не требуется обще-
системный журнал изменений БД. Достаточно для каждой тран-
закции поддерживать локальный журнал операций модификации
БД, выполненных в этой транзакции, и производить откат тран-
закции путем выполнения обратных операций, следуя от конца
локального журнала. В некоторых СУБД так и делают, но в
большинстве систем локальные журналы не поддерживают, а
индивидуальный откат транзакции выполняют по общесистем-
ному журналу, для этого все записи от одной транзакции связы-
вают обратным списком (от конца к началу).
При мягком сбое во внешней памяти основной части БД мо-
гут находиться объекты, модифицированные транзакциями, не
закончившимися к моменту сбоя, и могут отсутствовать объек-
ты, модифицированные транзакциями, которые к моменту сбоя
успешно завершились (по причине использования буферов опе-
ративной памяти, содержимое которых при мягком сбое пропа-
дает). При соблюдении протокола WAL во внешней памяти жур-
нала должны гарантированно находиться записи, относящиеся к
операциям модификации обоих видов объектов. Целью процесса
восстановления после мягкого сбоя является состояние внешней
памяти основной части БД, которое возникло бы при фиксации
во внешней памяти изменений всех завершившихся транзакций
и которое не содержало бы никаких следов незаконченных тран-
закций. Для того чтобы этого добиться, сначала производят от-
кат незавершенных транзакций (undo), а потом повторно вос-
производят (redo) те операции завершенных транзакций, резуль-
таты которых не отображены во внешней памяти. Этот процесс
148 Глава 3. Разработка программно-информационного ядра АИС...
содержит много тонкостей, связанных с общей организацией
управления буферами и журналом.
Для восстановления БД после жесткого сбоя используют
журнал и архивную копию БД. Грубо говоря, архивная копия —
это полная копия БД к моменту начала заполнения журнала (из-
вестно несколько вариантов более гибкой трактовки смысла ар-
хивной копии). Конечно, для нормального восстановления БД
после жесткого сбоя необходимо, чтобы журнал не пропал. Как
уже отмечалось, к сохранности журнала во внешней памяти в
СУБД предъявляются особо повышенные требования. Тогда вос-
становление БД состоит в том, что исходя из архивной копии по
журналу воспроизводится работа всех транзакций, которые за-
кончились к моменту сбоя. В принципе, можно даже воспроиз-
вести работу незавершенных транзакций и продолжить их работу
после завершения восстановления. Однако в реальных системах
это обычно не делается, поскольку процесс восстановления по-
сле жесткого сбоя является достаточно длительным.
Поддержка языков БД. Для работы с БД используются специ-
альные языки, в целом называемые языками баз данных. В ран-
них СУБД поддерживалось несколько специализированных по
своим функциям языков; чаще всего выделялись два — язык
описания данных Schema Definition Language (SDL) и язык мани-
пулирования данными Data Manipulation Language (DML). SDL
служил главным образом для определения логической структуры
БД, т. е. той структуры БД, какой она представляется пользовате-
лям. DML содержал набор операторов манипулирования данны-
ми, т. е. операторов, позволяющих заносить/удалять данные в/из
БД, модифицировать или выбирать существующие данные.
В современных СУБД обычно поддерживается единый интег-
рированный язык, содержащий все необходимые средства для ра-
боты с БД (начиная от ее создания) и обеспечивающий базовый
пользовательский интерфейс с БД. Стандартным языком наибо-
лее распространенных в настоящее время реляционных СУБД
является язык Structured Query Language (SQL).
Язык SQL, прежде всего, сочетает средства SDL и DML, т. е.
позволяет определять структуру реляционной БД и манипулиро-
вать данными. При этом именование объектов БД (для реляци-
онной БД — именование таблиц и их столбцов) поддерживается
на языковом уровне в том смысле, что компилятор языка SQL
производит преобразование имен объектов в их внутренние
идентификаторы на основании специально поддерживаемых
3.1. Основы современных систем управления базами данных 149
служебных таблиц-каталогов. Внутренняя часть СУБД (ядро) во-
обще не работает с именами таблиц и их столбцов.
Язык SQL содержит специальные средства определения ог-
раничений целостности БД. Ограничения целостности хранятся
в специальных таблицах-каталогах, и обеспечение контроля це-
лостности БД производится на языковом уровне, т. е. при ком-
пиляции операторов модификации БД компилятор SQL на ос-
новании имеющихся в БД ограничений целостности генерирует
соответствующий программный код.
Специальные операторы языка SQL позволяют определять
так называемые представления БД, фактически являющиеся
хранимыми в БД запросами (результатом любого запроса к реля-
ционной БД является таблица) с именованными столбцами. Для
пользователя представление является такой же таблицей, как
любая базовая таблица, хранимая в БД, но с помощью представ-
лений можно ограничить или, наоборот, расширить видимость
БД для конкретного пользователя. Поддержание представлений
производится также на языковом уровне.
Наконец, авторизация доступа к объектам БД производится
также на основе специального набора операторов SQL. Суть со-
стоит в том, что для выполнения операторов SQL разного вида
пользователь должен обладать различными полномочиями. Пользо-
ватель, создавший таблицу БД, обладает полным набором пол-
номочий для работы с этой таблицей, в число которых входит
право на передачу всех или части полномочий другим пользова-
телям, включая право на передачу полномочий. Полномочия
пользователей описываются в специальных таблицах-каталогах,
контроль полномочий поддерживается на языковом уровне.
Организация типичной СУБД и состав ее компонентов соот-
ветствует рассмотренному набору функций (управление данны-
ми во внешней памяти; управление буферами оперативной па-
мяти; управление транзакциями; журнализация и восстановле-
ние БД после сбоев; поддержание языков БД).
Логически в современной реляционной СУБД выделяют
внутреннюю часть — ядро СУБД (часто его называют Data Base
Engine), компилятор языка БД (обычно SQL), подсистему под-
держки времени выполнения, набор утилит. В некоторых систе-
мах эти части выделяются явно, в других — нет, но логически
такое разделение можно провести во всех СУБД.
Ядро СУБД отвечает за управление данными во внешней па-
мяти, управление буферами оперативной памяти, управление
150 Глава 3. Разработка программно-информационного ядра АИС...
транзакциями и журнализацию. Соответственно, выделяют та-
кие компоненты ядра (по крайней мере, логически, хотя в неко-
торых системах эти компоненты выделяются явно), как менед-
жер данных, менеджер буферов, менеджер транзакций и менед-
жер журнала. Функции этих компонентов взаимосвязаны, и для
обеспечения корректной работы СУБД все компоненты должны
взаимодействовать по тщательно продуманным и проверенным
протоколам. Ядро СУБД обладает собственным интерфейсом, не
доступным пользователям напрямую и используемым в програм-
мах, производимых компилятором SQL (или в подсистеме под-
держки выполнения таких программ), и утилитах БД. Ядро СУБД
является основной резидентной частью СУБД. При использова-
нии архитектуры «клиент — сервер» ядро является основной со-
ставляющей серверной части системы.
Основная функция компилятора языка БД — компиляция
операторов языка в некоторую выполняемую программу. Как
правило, языки реляционных СУБД, в частности SQL, являются
непроцедурными, т. е. в операторе такого языка специфицирует-
ся некоторое действие над БД, но эта спецификация лишь опи-
сывает в некоторой форме условия совершения желаемого дей-
ствия. Поэтому компилятор должен определить, каким образом
выполнять оператор языка, прежде чем произвести программу.
Результат компиляции — выполняемая программа, представлен-
ная в некоторых системах в машинном коде (чаще в выполняе-
мом внутреннем машинно-независимом коде). В последнем слу-
чае реальное выполнение оператора производится с привлечени-
ем подсистемы поддержки времени выполнения, т. е., по сути дела,
интерпретатора этого внутреннего языка.
В отдельные утилиты БД обычно выделяют такие процеду-
ры, которые слишком накладно выполнять с использованием
языка БД, например загрузка и выгрузка БД, сбор статистики,
глобальная проверка целостности БД и т. д. Утилиты програм-
мируются с использованием интерфейса ядра СУБД, а иногда
даже с проникновением внутрь ядра [4].
3.2. Архитектурные решения баз данных
Архитектура БД на основе разделяемых файлов. Применяется
для создания локальных сетей на основе файлового сервера. На
каждом из персональных компьютеров запускается приложе-
3.2. Архитектурные решения баз данных
151
ние, использующее общие файлы, которые находятся на фай-
ловом сервере. В результате можно быстро и дешево запустить
однопользовательское приложение в многопользовательском
режиме [4].
Среди недостатков архитектуры следует отметить:
• низкую пропускную способность сети, большое время ре-
акции;
• зависимость целостности данных от прикладной програм-
мы, а в ней возможны ошибки;
• отсутствие механизма для обеспечения одновременного
доступа к данным нескольких пользователей;
• зависимость от администратора системы в случае аппарат-
ного сбоя (отключение питания); проверку и восстановле-
ние в течение нескольких часов должен делать только он;
• вопрос незакрытых транзакций при аппаратном сбое.
Проблемы низкой производительности при интенсивной ра-
боте нескольких пользователей и обеспечения целостности —
принципиальные и непреодолимые. Такую архитектуру можно
использовать для небольшой БД при одновременной работе
5—10 пользователей.
Архитектура «хост—терминал». Применяется на рабочем мес-
те пользователя (на терминале); производит только физическое
отображение и ввод информации. Вся логика приложений и все
данные хранятся на центральном компьютере (хосте).
Недостатки:
• алфавитно-цифровой монохромный интерфейс;
• сложность администрирования;
• масштабируемость — увеличение числа пользователей при-
водит к необходимости аппаратной и программной моди-
фикации.
Архитектура «клиент—сервер». Предусматривает наличие двух
типов программ: программы-клиента (активная) и програм-
мы-сервера (пассивная).
К функциям сервера БД относят:
• выполнение клиентских запросов по извлечению и моди-
фикации данных;
• предоставление механизма одновременного доступа к дан-
ным нескольких пользователей;
• обеспечение идентификации и разграничения прав доступа
разных пользователей к разным данным;
152 Глава 3. Разработка программно-информационного ядра ЛИС...
• обеспечение целостности и непротиворечивости данных в
случае аппаратных и программных сбоев;
• защиту данных от несанкционированного доступа;
• предоставление средств администрирования АИС.
Среди функций клиента основными являются:
• взаимодействие с пользователем;
• выполнение некоторых системных задач, не связанных с
внутренним представлением и хранением данных.
Архитектура с использованием сервера приложений. В случае,
если клиентское приложение достаточно велико, то часть его це-
лесообразно выполнять на сервере, особенно при использовании
изменяющихся параметров (размер налога и т. п.). Суть реализа-
ции сервера приложений заключается в разбиении приложения
на две части — собственно клиента и сервера данного приложе-
ния. Сервер приложений может быть один для нескольких прило-
жений. В отличие от рассмотренных выше архитектурных реше-
ний, здесь наличествуют три типа взаимодействующих компонен-
тов — сервер БД, приложение (клиент) и сервер приложений [3].
3.3. Критерии выбора СУБД при создании АИС
Выбор СУБД представляет собой сложную многопараметри-
ческую задачу и является одним из важных этапов при разработ-
ке приложений БД. Программный продукт должен удовлетво-
рять как текущим, так и будущим потребностям пользователя,
при этом следует учитывать финансовые затраты на приобрете-
ние необходимого оборудования, самой системы, разработку
программного обеспечения на ее основе, а также обучение пер-
сонала. Кроме того, необходимо убедиться, что новая СУБД
способна принести предприятию реальные выгоды.
В данной книге по результатам анализа доступных источни-
ков [1] сформулированы требования или критерии выбора
СУБД, приводится их классификация. Очевидно, самый простой
подход при этом — оценка того, в какой мере существующие
системы удовлетворяют основным требованиям создаваемого
проекта АИС. Более сложным и дорогостоящим вариантом яв-
ляется создание пилотного проекта на основе нескольких СУБД
и последующий выбор наиболее подходящей. Вообще говоря,
перечень требований к СУБД, используемых при создании той
3.3. Критерии выбора СУБД при создании АИС
153
или иной АИС, может изменяться в зависимости от поставлен-
ных целей. Известны следующие группы критериев:
• моделирование данных;
• особенности архитектуры и функциональные возможности;
• контроль работы системы;
• особенности разработки приложений;
• производительность;
• надежность;
• требования к рабочей среде;
• смешанные критерии.
Рассмотрим каждую группу в отдельности, при этом следует
заметить, что в состав группы входит несколько компонентов.
Моделирование данных. Существует множество моделей дан-
ных [7], поэтому вопрос о применении той или иной модели
должен решаться на начальном этапе проектирования АИС.
К наиболее распространенным среди используемых моделей дан-
ных относятся иерархическая, сетевая, реляционная, объект-
но-реляционная и объектно-ориентированная.
Триггеры и хранимые процедуры. Триггер — программа базы
данных, вызываемая всякий раз при вставке, изменении или
удалении строки таблицы. Триггеры обеспечивают проверку лю-
бых изменений на корректность, прежде чем эти изменения бу-
дут приняты. Хранимая процедура — программа, которая хра-
нится на сервере и может вызываться клиентом. Поскольку хра-
нимые процедуры выполняются непосредственно на сервере БД,
обеспечивается более высокое быстродействие, нежели при вы-
полнении тех же операций средствами клиента БД. В различных
программных продуктах для реализации триггеров и хранимых
процедур используются различные инструменты.
Средства поиска. Ряд современных систем имеет встроенные
дополнительные средства контекстного поиска.
Предусмотренные типы данных. Здесь необходимо учесть два
фактически независимых критерия: какие типы данных заложе-
ны в систему — базовые или основные, и возможны ли расши-
рения типов. В то время как отклонения базовых наборов типов
данных у современных систем от некоего стандартного, обычно,
невелики, механизмы расширения типов данных в системах того
или иного производителя существенно различаются.
Реализация языка запросов. Все современные системы совмес-
тимы со стандартным языком доступа к данным SQL-92, однако
реализуют различные расширения данного стандарта.
154 Глава 3. Разработка программно-информационного ядра ЛИС...
Особенности архитектуры и функциональные возможности пе-
речислены ниже. Мобильность — независимость системы от сре-
ды, в которой она работает. Средой в данном случае является
как аппаратура, так и программное обеспечение (операционная
система).
Масштабируемость. При выборе СУБД необходимо учиты-
вать, сможет ли данная система обеспечивать развитие АИС, ко-
торое может проявляться в увеличении числа пользователей, объ-
ема хранимых данных и объема обрабатываемой информации.
Распределенность. Основной причиной применения АИС на
основе БД является стремление создать единое информационное
пространство организации. Самый простой и надежный под-
ход — централизация хранения и обработки данных на одном
сервере. К сожалению, это не всегда возможно и приходится
применять распределенные БД. Различные системы имеют раз-
ные возможности управления распределенными БД.
Сетевые возможности. Многие системы позволяют исполь-
зовать широкий диапазон сетевых протоколов и служб для рабо-
ты и администрирования.
Контроль работы системы подразумевает наличие нижепере-
численных видов контроля.
Контроль использования памяти компьютера. В системе пре-
дусматривается возможность управления как оперативной памя-
тью, так и дисковым пространством. В последнем случае к вы-
шесказанному относятся, например, функции сжатия БД или
удаления избыточных файлов.
Автонастройка. Многие современные системы предусматри-
вают самоконфигурирование, которое, как правило, опирается
на результаты работы сервисов самодиагностики производитель-
ности. При этом выявляются слабые места конфигурации систе-
мы, и она автоматически настраивается на максимальную про-
изводительность.
Особенности разработки приложений. Ряд производителей
СУБД выпускает также средства разработки приложений, кото-
рые, как правило, позволяют наилучшим образом реализовать
все возможности сервера. Поэтому при анализе СУБД следует
обратить внимание на особенности средств разработки приложе-
ний [4].
Средства проектирования. Некоторые системы имеют средст-
ва автоматического проектирования как БД, так и прикладных
3.3. Критерии выбора СУБД при создании АИС
155
программ. Средства проектирования различных производителей
могут существенно различаться.
Многоязыковая поддержка. Поддержка большого количества
национальных языков расширяет область применения системы и
приложений, построенных на ее основе.
Возможности разработки Web-приложений. При разработке
различных приложений зачастую возникает необходимость ис-
пользовать возможности среды Internet. Средства разработки не-
которых производителей имеют большой набор инструментов
для построения приложений под Web.
Поддерживаемые языки программирования. Широкий спектр
используемых языков программирования может повысить дос-
тупность системы для разработчиков, а также существенно по-
влиять на быстродействие и функциональность создаваемых при-
ложений.
Производительность. Для тестирования производительности
применяются различные средства и существует множество тесто-
вых рейтингов.
Рейтинг ТРС (Transactions per Cent) является одним из самых
популярных и объективных. Фактически ТРС-анализ произво-
дительности систем рассматривает композицию СУБД и аппара-
туры, на которой эта СУБД работает. Показатель ТРС — это от-
ношение количества запросов, обрабатываемых за некий проме-
жуток времени, к стоимости всей системы.
Возможности параллельной архитектуры. Для обеспечения
параллельной обработки данных существуют как минимум два
подхода: распараллеливание обработки последовательности за-
просов на несколько процессоров; использование нескольких
компьютеров-клиентов, работающих с одной БД, которые объ-
единяют в так называемый параллельный сервер.
Возможности оптимизирования запросов. При использовании
непроцедурных языков запросов их выполнение бывает неопти-
мальным. Поэтому необходимо произвести процесс оптимиза-
ции, т. е. выбрать такой способ выполнения, когда по начально-
му представлению запроса путем его синтаксических и семанти-
ческих преобразований вырабатывается процедурный план
выполнения запроса, наиболее оптимальный при существующих
в БД управляющих структурах.
Надежность. Понятие надежности системы трактуется неод-
нозначно — это и сохранность информации при любом сбое, и
безотказность работы системы в любых условиях, и обеспечение
156 Глава 3. Разработка программно-информационного ядра АИС...
защиты данных от несанкционированного доступа [8|. Рассмот-
рим некоторые из них.
Восстановление после сбоев. При возникновении программных
или аппаратных сбоев целостность, да и работоспособность всей
системы могут быть нарушены. От того, насколько эффективен
механизм восстановления, зависит жизнеспособность системы.
Резервное копирование. В результате аппаратного сбоя зачас-
тую частично повреждается или выводится из строя носитель
информации и тогда восстановление данных невозможно.
В этом случае и в ситуациях, когда происходит логический сбой
системы (например, при ошибочном удалении таблиц), спасает
резервное копирование. Существует множество механизмов ре-
зервирования данных (хранение одной или более копий всей
БД, хранение копии ее части, копирование логической структу-
ры и т. д.). Зачастую в систему закладывается возможность ис-
пользования нескольких таких механизмов.
Откат изменений. При выполнении транзакции применяется
простое правило — либо транзакция выполняется полностью,
либо не выполняется вообще. Это означает, что в случае сбоев
все результаты недоведенных до конца транзакций должны быть
аннулированы. Механизм отката может иметь различное быст-
родействие и эффективность.
Многоуровневая система защиты. АИС организации почти
всегда содержит секретную информацию, поэтому для предотвра-
щения несанкционированного доступа используется служба иден-
тификации пользователей. Уровень защиты может быть различ-
ным. Кроме непосредственной идентификации пользователей,
при входе в систему предусматривается также механизм шифрова-
ния данных при передаче по линиям связи.
Требования к рабочей среде. В качестве требований рассмат-
ривают:
• поддерживаемые аппаратные платформы;
• минимальные требования к оборудованию;
• максимальный размер адресуемой памяти. Поскольку почти
все современные системы используют свою файловую сис-
тему, немаловажным фактором является то, какой макси-
мальный объем физической памяти они могут использо-
вать.
Смешанные критерии. При анализе данной группы очевидна
принадлежность существующих критериев к различным пред-
метным областям, в связи с чем они и называются смешанными.
3.4. Концептуальные модели данных
157
Качество и полнота документации. Не все системы и не все-
гда имеют полную и подробную документацию.
Локализованность — возможность использования националь-
ных языков; не во всех системах она реализована полностью.
Модель формирования стоимости. Как правило, производите-
ли СУБД используют определенные модели формирования стои-
мости. Так, стоимость одного и того же продукта может сущест-
венно изменяться в зависимости от того, сколько пользователей
будут с ним работать.
Стабильность производителя. Обычно имеют в виду много-
летнее (стабильное) присутствие производителя на рыке.
Распространенность СУБД. Согласно существующей практи-
ке решение об использовании той или иной СУБД принимает
один человек — обычно, руководитель предприятия, а он зачас-
тую опирается отнюдь не на технические критерии. Здесь свою
роль могут сыграть такие незначительные факторы, как реклам-
ная раскрутка компании-производителя СУБД, использование
конкретных систем на других предприятиях, стоимость. При
этом последний фактор может трактоваться и в зависимости от
финансового состояния, и в зависимости от политики предпри-
ятия. С одной стороны, используется принцип: «Чем дороже,
тем лучше», с другой — возможность бесплатной эксплуатации
продукта («взлома» лицензионной защиты). [9].
3.4. Концептуальные модели данных
Ядром любой БД является модель данных (МД), которая
представляет собой множество структур данных, ограничений
целостности и операций манипулирования данными. С помо-
щью МД могут быть представлены объекты предметной области
и взаимосвязи между ними [10].
Наиболее распространенные МД уже были перечислены
ранее. По способу установления связей между данными СУБД
основывается на использовании трех основных видов модели:
иерархической, сетевой, реляционной. Однако различия между
этими моделями постепенно стираются, что обусловлено, преж-
де всего, интенсивными работами в области баз знаний (БЗ) и
объектно-ориентированной информационной технологией.
158 Глава 3. Разработка программно-информационного ядра АИС...
Каждая из указанных моделей обладает характеристиками,
делающими ее наиболее удобной для конкретных приложений.
В частности, структура иерархических и сетевых СУБД часто не
может быть изменена после ввода данных, тогда как структура
реляционных СУБД изменяема в любое время. С другой сторо-
ны, для больших БД, структура которых остается длительное
время неизменной, и постоянно работающих с ними приложе-
ний с интенсивными потоками запросов на БД-обслуживание,
именно иерархические и сетевые СУБД являются самыми эф-
фективными, так как обеспечивают более быстрый доступ к ин-
формации БД, чем реляционные [1, 2].
Иерархическая модель данных. Иерархическая структура
представляет совокупность элементов, связанных между собой
по определенным правилам. Объекты, связанные иерархически-
ми отношениями, образуют ориентированный граф (переверну-
тое дерево). К основным понятиям иерархической структуры от-
носятся: уровень, элемент (узел), связь.
Узел — это совокупность атрибутов данных, описывающих
некоторый объект. На схеме иерархического дерева узлы пред-
ставляются вершинами графа.
Каждый узел на более низком уровне связан только с одним
узлом, находящимся на более высоком уровне. Иерархическое
дерево имеет только одну вершину (корень дерева), не подчи-
ненную никакой другой вершине и находящуюся на самом верх-
нем (первом) уровне. Зависимые (подчиненные) узлы находятся
на втором, третьем и т. д. уровнях. Количество деревьев в БД оп-
ределяется числом корневых записей. К каждой записи БД су-
ществует только один (иерархический) путь от корневой записи.
Каждому узлу структуры соответствует один сегмент, представ-
ляющий собой поименованный линейный кортеж полей данных.
Каждому сегменту (кроме S1-корневого) соответствует один
входной и несколько выходных сегментов. Каждый сегмент
структуры лежит на единственном иерархическом пути, начи-
нающемся от корневого сегмента (рис. 3.2).
В настоящее время СУБД, поддерживающие на концептуаль-
ном уровне только иерархические модели, не разрабатываются.
Как правило, системы, использующие иерархический подход,
допускают связывание древовидных структур между собой и/или
установление связей внутри них. Это приводит к сетевым дата1-
логическим моделям СУБД.
3.4. Концептуальные модели данных
159
Рис. 3.2. Иерархическая модель данных
К основным недостаткам иерархических моделей следует от-
нести:
• неэффективность реализации отношений типа N:N;
• медленный доступ к сегментам данных нижних уровней
иерархии;
• четкую ориентацию на определенные типы запросов и др.
В связи с этими недостатками ранее созданные иерархиче-
ские СУБД подвергаются существенным модификациям, позво-
ляющим поддерживать более сложные типы структур, в первую
очередь, сетевые и их модификации (рис. 3.3) [11].
Рис. 3.3. Фрагмент иерархической модели данных
Сетевая модель данных. В сетевой структуре при тех же ос-
новных понятиях (уровень, узел, связь) каждый элемент может
быть связан с любым другим элементом. Сетевая модель СУБД
во многом подобна иерархической: если в иерархической модели
160 Глава 3. Разработка программно-информационного ядра АИС...
для каждого сегмента записи допускается только один входной
сегмент при N выходных, то в сетевой модели допускается не-
сколько входных сегментов наряду с возможностью наличия сег-
ментов без входов с точки зрения иерархической структуры [12].
Графическое изображение структуры связей сегментов тако-
го типа моделей представляет собой сеть. Сегменты данных в
сетевых БД могут иметь множественные связи с сегментами
старшего уровня. При этом направление и характер связи в сете-
вых БД не являются столь очевидными, как в случае иерархиче-
ских БД, поэтому имена и направление связей должны иденти-
фицироваться при описании БД (рис. 3.4).
Рис. 3.4. Фрагмент сетевой модели данных
Таким образом, под сетевой СУБД понимается система, под-
держивающая сетевую организацию: любая запись, называемая
записью старшего уровня, может содержать данные, которые от-
носятся к набору других записей, называемых записями подчи-
ненного уровня. Возможно обращение ко всем записям в набо-
ре, начиная с записи старшего уровня. Обращение к набору за-
писей реализуется по указателям.
В рамках сетевых СУБД легко реализуются и иерархические
даталогические модели. Сетевые СУБД поддерживают сложные
соотношения между типами данных, что делает их пригодными
во многих приложениях. Однако пользователи таких СУБД огра-
ничены связями, определенными для них разработчиками
БД-приложений. Более того, подобно иерархическим сетевые
СУБД предполагают разработку БД приложений опытными про-
граммистами и системными аналитиками.
Среди недостатков сетевых СУБД следует особо отметить
проблему обеспечения сохранности информации в БД.
3.4. Концептуальные модели данных
161
Реляционная модель данных. Понятие реляционный (от англ.
relation — отношение) связано с разработками известного амери-
канского специалиста в области систем баз данных, сотрудника
фирмы IBM доктора Е. Кодда (Codd E.F., A Relational Model of
Data for Large Shared Data Banks. CACM 13: 6, June 1970), кото-
рый впервые употребил термин «реляционная модель данных».
В течение долгого времени реляционный подход рассматри-
вался как удобный формальный аппарат анализа БД, не имею-
щий практических перспектив, так как его реализация требовала
слишком больших машинных ресурсов. Только с появлением
персональных ЭВМ реляционные и близкие к ним системы ста-
ли самыми распространенными.
Реляционная модель данных (РМД) представляет собой на-
бор сведений, сгруппированных в одну или несколько таблиц.
Таблицу можно представить как двумерный массив или набор
записей одинаковой структуры. Записи называют рядами. Таб-
лица состоит из рядов и столбцов. Число столбцов и записей
для каждой таблицы теоретически не ограничено. Каждый стол-
бец имеет определенный тип, неизменный для каждой записи
внутри таблицы. Множество возможных значений конкретного
столбца называется доменом. Значение каждого атрибута должно
быть атомарным, неделимым. Каждый ряд таблицы описывает
некий отдельный объект. Связь между таблицами существует на
логическом уровне и определяется предметной областью за счет
логических связей.
Достоинства РМД:
• нефункциональное^ языка запроса (SQL) — «что» найти, а
не «как» найти. Реляционные СУБД поддерживают Structured
Query Language (SQL) — язык структурированных запросов;
• высокая стандартизованность;
• наличие четких математических основ для работы с дан-
ными.
Недостаток — ограниченность набора возможных типов
данных.
Объектно-реляционные модели данных (ОРМД). Расширению
возможностей реляционных БД способствует применение в кон-
цепции БД понятия объекта, аналогичного понятию объекта в
объектно-ориентированном программировании. Это расширение
достигается за счет использования таких объектно-ориентиро-
ванных компонентов, как пользовательские типы данных, ин-
162 Глава 3. Разработка программно-информационного ядра АИС...
капсуляция, полиморфизм, наследование, переопределение ме-
тодов и т. п.
К сожалению, до настоящего времени разработчики не при-
шли к единому мнению о том, как следует определять ОРМД [2].
Модели, поддерживаемые различными производителями СУБД,
существенно отличаются по своим функциональным характери-
стикам, поэтому о включении объектов в РМД можно говорить
только как об общем направлении развития БД. О перспективах
этого направления свидетельствует тот факт, что ведущие фир-
мы-производители СУБД, в числе которых Oracle, Informix и
INGRES, расширили возможности своих продуктов до объект-
но-реляционной СУБД (ОРСУБД).
В большинстве реализаций ОРМД объектами признаются аг-
регат и таблица (отношение), которая может входить в состав
другой таблицы. Методы обработки данных представлены в виде
хранимых процедур и триггеров, которые являются процедурны-
ми объектами БД, и связаны с таблицами. На внутреннем (фи-
зическом) уровне все данные ОРБД хранятся в виде отношений,
и ОРСУБД поддерживают язык SQL.
Объектно-ориентированные модели данных. Еще один подход
к построению БД — использование объектно-ориентированных
моделей данных (ООМД). Моделирование данных в ООМД ба-
зируется на понятии объекта. Для ООМД, как и в случае с
ОРМД, не существует общепризнанной модели данных [2].
При создании объектно-ориентированных СУБД (ООСУБД)
используются разные методы, а именно: встраивание в объект-
но-ориентированный язык средств для работы с БД; создание
объектно-ориентированных библиотек функций для работы с
СУБД; расширение существующего языка работы с БД объект-
но-ориентированными функциями; создание нового языка и но-
вой объектно-ориентированной модели данных.
К достоинствам ООМД относят широкие возможности моде-
лирования предметной области, выразительный язык запросов и
повышенную производительность. Эти модели обычно применя-
ются для сложных предметных областей, для моделирования ко-
торых не хватает функциональности реляционной модели (на-
пример, систем автоматизации проектирования, издательских
систем и т. п.).
Среди недостатков ООМД следует отметить отсутствие уни-
версальной модели, недостаток опыта создания и эксплуатации
3.5. Базовые понятия реляционных баз данных 163
ООБД, сложность использования и недостаточность средств за-
щиты данных.
В 1997 г. рабочая группа Object Database Management Group
(ODMG), образованная фирмами-производителями ООСУБД,
выпустила стандарт ODMG 2.0 для ООСУБД, в котором описана
объектная модель, язык определения запросов, язык объектных
запросов и связующие языки C++, Smalltalk и Java.
3.5. Базовые понятия реляционных баз данных
К основным понятиям реляционных БД относятся тип дан-
ных, домен, атрибут, кортеж, первичный ключ и отношение [4].
Покажем смысл этих понятий на примере отношения СО-
ТРУДНИКИ, содержащего информацию о сотрудниках некото-
рой организации (рис. 3.5) [4].
Типы данных
Рис. 3.5. Базовые понятия реляционных БД
164 Глава 3. Разработка программно-информационного ядра АИС...
Тип данных. Понятие тип данных в реляционной модели дан-
ных полностью адекватно понятию типа данных в языках про-
граммирования. Обычно в современных реляционных БД допус-
кается хранение символьных, числовых данных, битовых строк,
специализированных числовых данных (таких, как «деньги»), а
также специальных «темпоральных» данных (дата, время, вре-
менной интервал). Достаточно активно развивается подход к
расширению возможностей реляционных систем абстрактными
типами данных (соответствующими возможностями обладают,
например, системы семейства Ingres/Postgres). В нашем примере
мы имеем дело с данными трех типов: строки символов, целые
числа и «деньги» [1, 4].
Домен. Понятие домена более специфично для БД, хотя и
имеет некоторые аналогии с подтипами в некоторых языках
программирования. В самом общем виде домен определяется за-
данием некоторого базового типа данных, к которому относятся
элементы домена, и произвольного логического выражения,
применяемого к элементу типа данных. Если вычисление этого
логического выражения дает результат «истина», то элемент дан-
ных является элементом домена [1, 4].
Наиболее правильной интуитивной трактовкой понятия до-
мена является понимание домена как допустимого потенциаль-
ного множества значений данного типа. Например, домен «Име-
на» в нашем примере определен на базовом типе строк симво-
лов, но в число его значений могут входить только те строки,
которые отображают имя (в частности, такие строки не могут
начинаться с мягкого знака).
Следует отметить также семантическую нагрузку понятия до-
мена: данные считаются сравнимыми только в том случае, когда
они относятся к одному домену. В нашем примере значения до-
менов «Номера пропусков» и «Номера отделов» относятся к типу
целых чисел, но не являются сравнимыми.
Схема отношения, схема базы данных. Схема отношения —
это именованное множество пар [имя атрибута, имя домена (или
типа, если понятие домена не поддерживается)]. Степень или
«арность» схемы отношения — мощность этого множества. Сте-
пень отношения СОТРУДНИКИ равна четырем, т. е. оно явля-
ется 4-арным. Если все атрибуты одного отношения определены
на разных доменах, осмысленно использовать для именования
атрибутов имена соответствующих доменов (не забывая, конеч-
но, о том, что это является всего лишь удобным способом име-
3.5. Базовые понятия реляционных баз данных
165
нования и не устраняет различия между понятиями домена и ат-
рибута). В структурном смысле схема БД — это набор именован-
ных схем отношений.
Ключи. Для идентификации записей используются ключи.
Ключ — набор атрибутов, который позволяет идентифицировать
запись внутри таблицы, при этом никакие подмножества этих
атрибутов не будут ключом. Простой ключ состоит из одного ат-
рибута, составной ключ — из двух и более. Атрибут, входящий в
тот или иной ключ, называется ключевым атрибутом. Атрибут,
который не входит ни в один из ключей, называется неключе-
вым атрибутом. Ключ должен гарантировать уникальную иден-
тификацию записи для всех возможных комбинаций записей в
отношении. Некоторый ключ, который выделяют разработчики
или проектировщики БД, называется первичным. Первичным
может считаться любой ключ. Ключи бывают естественными и
искусственными. Естественный ключ состоит из реальных атри-
бутов. Искусственный ключ вводится специально fl, 4].
Кортеж, отношение. Кортеж, соответствующий данной схеме
отношения, — это множество пар [имя атрибута, значение], ко-
торое содержит одно вхождение каждого имени атрибута, при-
надлежащего схеме отношения. «Значение» является допусти-
мым значением домена данного атрибута (или типа данных, если
понятие домена не поддерживается). Тем самым, степень или
«арность» кортежа, т. е. число элементов в нем, совпадает с «ар-
ностью» соответствующей схемы отношения. Попросту говоря,
кортеж — это набор именованных значений заданного типа.
Отношение — это множество кортежей, соответствующих од-
ной схеме отношения. Иногда, чтобы не путаться, говорят «от-
ношение-схема» и «отношение-экземпляр», или схему отноше-
ния называют заголовком отношения, а отношение как набор
кортежей — телом отношения. На самом деле, понятие схемы
отношения ближе всего к понятию структурного типа данных в
языках программирования. Удобно и логично было бы отдельно
определять схему отношения, а затем одно или несколько отно-
шений с данной схемой. Однако в реляционных БД это не при-
нято. Имя схемы отношения в таких БД всегда совпадает с име-
нем соответствующего отношения-экземпляра. В классических
реляционных БД после определения схемы БД изменяются толь-
ко отношения-экземпляры. В них могут появляться новые и уда-
ляться или модифицироваться существующие кортежи. Однако
во многих реализациях допускается и изменение схемы БД:
166 Глава 3. Разработка программно-информационного ядра АИС...
определение новых и изменение существующих схем отноше-
ния. Такой процесс называют эволюцией схемы базы данных.
Обычным представлением отношения является таблица, за-
головком которой является схема отношения, а строками — кор-
тежи отношения-экземпляра; в этом случае имена атрибутов
именуют столбцы этой таблицы. Поэтому иногда говорят «стол-
бец таблицы», имея в виду «атрибут отношения» (эта терминоло-
гия используется при рассмотрении практических вопросов ор-
ганизации реляционных БД и средств управления, а также в
большинстве коммерческих реляционных СУБД).
Реляционная база данных — это набор отношений, имена ко-
торых совпадают с именами схем отношений в схеме БД. Основ-
ные структурные понятия реляционной модели данных (не счи-
тая понятия «домен») имеют очень простую интуитивную интер-
претацию, хотя в теории реляционных БД все они определяются
абсолютно формально и точно.
3.6. Проектирование реляционных баз. данных
с использованием нормализации
Сначала рассмотрим классический подход, при котором про-
цесс проектирования сводится (с применением терминологии
реляционной модели данных методом последовательных прибли-
жений) к удовлетворительному набору схем отношений. Исход-
ной точкой является представление предметной области в виде
одного или нескольких отношений, и на каждом шаге проекти-
рования производится некоторый набор схем отношений, обла-
дающих лучшими свойствами. Процесс проектирования пред-
ставляет собой процесс нормализации схем отношений, причем
каждая следующая нормальная форма обладает лучшими свойст-
вами, чем предыдущая [13].
Каждой нормальной форме соответствует некоторый опреде-
ленный набор ограничений, и отношение находится в некоторой
нормальной форме, если удовлетворяет свойственному ей набо-
ру ограничений. Примером набора ограничений является огра-
ничение первой нормальной формы — значения всех атрибутов
отношения атомарны. Поскольку требование первой нормаль-
ной формы является базовым требованием классической реля-
ционной модели данных, будем считать, что исходный набор от-
ношений уже соответствует этому требованию.
3.6. Проектирование реляционных баз данных...
167
В теории реляционных БД обычно выделяют следующую по-
следовательность нормальных форм [4]:
• первая нормальная форма (1NF);
• вторая нормальная форма (2NF);
• третья нормальная форма (3NF);
• нормальная форма Бойса — Кодда (BCNF);
• четвертая нормальная форма (4NF);
• пятая нормальная форма, или нормальная форма проек-
ции-соединения (5NF или PJ/NF).
Основные свойства нормальных форм:
• каждая следующая нормальная форма в некотором смысле
лучше предыдущей;
• при переходе к следующей нормальной форме свойства
предыдущих нормальных свойств сохраняются.
В основе проектирования РБД лежит метод нормализации,
декомпозиция отношения, находящегося в предыдущей нор-
мальной форме, в два или более отношения, удовлетворяющих
требованиям следующей нормальной формы.
Наиболее важные на практике нормальные формы отноше-
ний основываются на фундаментальном в теории реляционных
БД понятии функциональной зависимости. Для дальнейшего из-
ложения нам потребуется несколько определений.
1. Функциональная зависимость. В отношении R атрибут Y
функционально зависит от атрибута X (X и Y могут быть состав-
ными) в том и только в том случае, если каждому значению X
соответствует в точности одно значение Y: R.X (г) R.Y.
2. Полная функциональная зависимость. Функциональная за-
висимость R.X (г) R.Y называется полной, если атрибут Y не за-
висит функционально от любого точного подмножества X.
3. Транзитивная функциональная зависимость. Функциональ-
ная зависимость R.X R.Y называется транзитивной, если су-
ществует такой атрибут Z, что имеются функциональные зависи-
мости R.X R.Z и R.Z -> R.Y, и отсутствует функциональная
зависимость R.Z -> R.X. (При отсутствии последнего требования
мы имели бы «неинтересные» транзитивные зависимости в лю-
бом отношении, обладающем несколькими ключами.)
4. Неключевой атрибут. Неключевым атрибутом называется
любой атрибут отношения, не входящий в состав первичного
ключа (в частности, первичного).
168 Глава 3. Разработка программно-информационного ядра АИС...
5. Взаимно независимые атрибуты. Два атрибута или более
взаимно независимы, если ни один из этих атрибутов не являет-
ся функционально зависимым от других.
6. Вторая нормальная форма. Рассмотрим следующий пример
схемы отношения:
СОТРУДНИКИ-ОТДЕЛ Ы-ПРОЕКТЫ
(СОТРНОМЕР, СОТРЗАРП, ОТД_НОМЕР, ПРО НОМЕР,
СОТРЗАДАН)
Первичный ключ:
СОТР НОМЕР, ПРО НОМЕР
Функциональные зависимости:
СОТР НОМЕР -> СОТР ЗАРП
СОТР НОМЕР -> ОТДНОМЕР
ОТДНОМЕР -> СОТР ЗАРП
СОТР НОМЕР, ПРО НОМЕР^ СОТР_ЗАДАН
Понятно, что хотя первичным ключом является составной
атрибут СОТР НОМЕР, ПРО_НОМЕР, атрибуты СОТР_ЗАРП
и ОТД НОМЕР функционально зависят от части первичного
ключа, атрибута СОТР НОМЕР. В результате невозможно вста-
вить в отношение СОТРУДНИКИ-ОТДЕЛЫ-ПРОЕКТЫ кор-
теж, описывающий сотрудника, который еще не выполняет ни-
какого проекта (первичный ключ не может содержать неопреде-
ленное значение). При удалении кортежа не только разрушается
связь данного сотрудника с данным проектом, но и утрачивает-
ся информация о том, что он работает в некотором отделе. При
переводе сотрудника в другой отдел необходимо модифициро-
вать все кортежи, описывающие этого сотрудника, иначе полу-
чится несогласованный результат. Подобные явления называют-
ся аномалиями схемы отношения. Они устраняются путем нор-
мализации.
Дадим теперь определение второй нормальной формы
(в этом определении предполагается, что единственным ключом
отношения является первичный ключ).
Отношение R находится во второй нормальной форме (2NF) в
том и только в том случае, когда находится в 1NF, и каждый не-
ключевой атрибут полностью зависит от первичного ключа.
3.6. Проектирование реляционных баз данных...
169
Произведем следующую декомпозицию отношения СО-
ТРУДНИКИ-ОТДЕЛЫ-ПРОЕКТЫ в два отношения СОТРУД-
НИКИ-ОТДЕЛЫ и СОТРУДНИКИ-ПРОЕКТЫ:
СОТРУДНИКИ-ОТДЕЛЫ (СОТР НОМЕР, СОТР_ЗАРП,
ОТД_НОМЕР)
Первичный ключ:
СОТРНОМЕР
Функциональные зависимости:
СОТР НОМЕР -> СОТРЗАРП
СОТР НОМЕР ОТДНОМЕР
ОТДНОМЕР СОТРЗАРП
СОТРУДНИКИ-ПРОЕКТЫ (СОТР НОМЕР, ПРО НОМЕР,
СОТР_ ЗАДАН)
Первичный ключ:
СОТР НОМЕР, ПРО_НОМЕР
Функциональные зависимости:
СОТР НОМЕР, ПРО НОМЕР -у СОТР__ЗАДАН
Каждое из этих двух отношений находится в 2NF, и в них
устранены отмеченные выше аномалии (легко проверить, что
все указанные операции выполняются без проблем).
Если допустить наличие нескольких ключей, то определе-
ние 6 примет следующий вид. Отношение R находится во второй
нормальной форме (2NF) в том и только в том случае, когда оно
находится в 1NF, и каждый неключевой атрибут полностью за-
висит от каждого ключа R.
Здесь и далее мы не будем приводить примеры для отноше-
ний с несколькими ключами. Они слишком громоздки и отно-
сятся к ситуациям, редко встречающимся на практике.
7. Третья нормальная форма. Рассмотрим еще раз отношение
СОТРУДНИКИ-ОТДЕЛЫ, находящееся в 2NF. Заметим, что
функциональная зависимость СОТР НОМЕР -> СОТР ЗАРП
является транзитивной; она является следствием функциональ-
ных зависимостей СОТР НОМЕР -> ОТД НОМЕР и ОТД НО-
МЕР -> СОТР ЗАРП. Другими словами, заработная плата со-
170 Глава 3. Разработка программно-информационного ядра АИС...
трудника на самом деле является характеристикой не сотрудни-
ка, а отдела, в котором он работает (это нс очень естественное
предположение, но достаточное для примера).
В результате невозможно занести в базу данных информа-
цию, характеризующую заработную плату отдела, до тех пор,
пока в этом отделе не появится хотя бы один сотрудник (первич-
ный ключ не может содержать неопределенное значение). При
удалении кортежа, описывающего последнего сотрудника данно-
го отдела, исчезает информация о заработной плате отдела. Для
того чтобы согласованным образом изменить заработную плату
отдела, необходимо предварительно найти все кортежи, описы-
вающие сотрудников этого отдела, т. е. в отношении СОТРУД-
НИКИ-ОТДЕЛЫ по-прежнему существуют аномалии. Их можно
устранить путем дальнейшей нормализации.
Дадим теперь определение третьей нормальной формы (сно-
ва определение дается в предположении существования единст-
венного ключа.)
Отношение R находится в третьей нормальной форме (3NF) в
том и только в том случае, если находится в 2NF и каждый не-
ключевой атрибут нетранзитивно зависит от первичного ключа.
Произведем декомпозицию отношения СОТРУДНИКИ-ОТ-
ДЕЛЫ в два отношения СОТРУДНИКИ и ОТДЕЛЫ:
СОТРУДНИКИ (СОТРНОМЕР, ОТДНОМЕР)
Первичный ключ:
СОТРНОМЕР
Функциональные зависимости:
СОТР НОМЕР -> ОТД НОМЕР
ОТДЕЛЫ (ОТД НОМЕР, СОТР_ЗАРП)
Первичный ключ:
ОТДНОМЕР
Функциональные зависимости:
ОТД НОМЕР -т СОТР_ЗАРП
Каждое из этих двух отношений находится в 3NF и свободно
от отмеченных аномалий. Если отказаться от того ограничения,
3.6. Проектирование реляционных баз данных...
171
что отношение обладает единственным ключом, то определение
3NF примет следующий вид.
Отношение R находится в третьей нормальной форме (3NF) в
том и только в том случае, если находится в 1NF, и каждый не-
ключевой атрибут не является транзитивно зависимым от како-
го-либо ключа R.
На практике третья нормальная форма схем отношений дос-
таточна в большинстве случаев, и приведением к третьей нор-
мальной форме процесс проектирования реляционной базы дан-
ных обычно заканчивается. Однако иногда полезно продолжить
процесс нормализации.
8. Нормальная форма Бойса — Кодда. Рассмотрим следующий
пример схемы отношения
СОТРУДНИКИ-ПРОЕКТЫ (СОТР НОМЕР, СОТР_ИМЯ,
ПРОНОМ ЕР, СОТРЗАДАН)
Возможные ключи:
СОТР_НОМЕР, ПРО НОМЕР
СОТР-ИМЯ, ПРО НОМЕР
Функциональные зависимости:
СОТР НОМЕР -> СОТР_ИМЯ
СОТР НОМЕР -> ПРО НОМЕР
СОТРИМЯ -> СОТР НОМЕР
СОТРИМЯ -> ПРО НОМЕР
СОТР НОМЕР, ПРО НОМЕР -> СОТР ЗАДАН
СОТР ИМЯ, ПРО НОМЕР -> СОТР ЗАДАН
В этом примере предполагается, что личность сотрудника
полностью определяется как его номером, так и именем (не
очень жизненно, но облегчает понимание).
В соответствии с определением 7 отношение СОТРУДНИ-
КИ-ПРОЕКТЫ находится в 3NF. Однако тот факт, что имеются
функциональные зависимости атрибутов отношения от атрибута,
являющегося частью первичного ключа, приводит к аномалиям
(для того чтобы изменить имя сотрудника с данным номером со-
гласованным образом, потребуется модифицировать все корте-
жи, включающие его номер). Для дальнейших рассуждений не-
обходимо дать определение детерминанта.
172 Глава 3. Разработка программно-информационного ядра АИС...
Детерминант — любой атрибут, от которого полностью функ-
ционально зависит некоторый другой атрибут.
Отношение R находится в нормальной форме Бойса — Кодда
(BCNF) в том и только в том случае, если каждый детерминант
является возможным ключом.
Очевидно, что это требование не выполнено для отношения
СОТРУДНИКИ-ПРОЕКТЫ. Произведем его декомпозицию к
отношениям СОТРУДНИКИ и СОТРУДНИК И-ПРОЕКТЫ:
СОТРУДНИКИ (СОТР НОМЕР, СОТР_ИМЯ)
Возможные ключи:
СОТРНОМЕР
СОТРИМЯ
Функциональные зависимости:
СОТР НОМЕР -> СОТР_ИМЯ
СОТР-ИМЯ -> СОТР_НОМЕР
СОТРУДНИКИ-ПРОЕКТЫ (СОТР_НОМЕР, ПРО НОМЕР,
СОТР ЗАДАН)
Возможный ключ:
СОТР НОМЕР, ПРО НОМЕР
Функциональные зависимости:
СОТР НОМЕР, ПРО НОМЕР -> СОТР_ЗАДАН
Возможна альтернативная декомпозиция, если выбрать за
основу СОТР ИМЯ. В обоих случаях получаемые отношения
СОТРУДНИКИ и СОТРУДНИКИ-ПРОЕКТЫ находятся в
BCNF, и им нс свойственны отмеченные аномалии.
9. Четвертая нормальная форма. Рассмотрим пример следую-
щей схемы отношения.
ПРОЕКТЫ (ПРО НОМЕР, ПРО_СОТР, ПРО_ЗАДАН)
Отношение ПРОЕКТЫ содержит номера проектов, для каж-
дого проекта список сотрудников, которые могут выполнять
проект, и список заданий, предусматриваемых проектом. Со-
трудники могут участвовать в нескольких проектах, и разные
проекты могут включать одинаковые задания.
3.6. Проектирование реляционных баз данных...
173
Каждый кортеж отношения связывает некоторый проекте со-
трудником, участвующим в этом проекте, и заданием, которое со-
трудник выполняет в рамках данного проекта (полагаем, что лю-
бой сотрудник, участвующий в проекте, выполняет все задания,
предусмотренные этим проектом). По причине сформулирован-
ных выше условий единственным возможным ключом отноше-
ния является составной атрибут ПРО НОМЕР, ПРО СОТР,
ПРОЗАДАН, и нет никаких других детерминантов. Следователь-
но, отношение ПРОЕКТЫ находится в BCNF, но при этом оно
обладает недостатками: если, например, некоторый сотрудник
присоединяется к данному проекту, необходимо вставить в отно-
шение ПРОЕКТЫ столько кортежей, сколько заданий в нем пре-
дусмотрено.
В отношении R (А, В, С) существует многозначная зависи-
мость R.A -> -> R.B в том и только в том случае, если множество
значений В, соответствующее паре значений А и С, зависит
только от А и нс зависит от С.
В отношении ПРОЕКТЫ существует две многозначные за-
висимости:
ПРО НОМЕР -> -> ПРО_СОТР
ПРОНОМЕР -> -> ПРО ЗАДАН
Легко показать, что в общем случае в отношении R (А, В, С)
существует многозначная зависимость R.A > -> R.B в том и
только в том случае, если существует многозначная зависи-
мость R.A -э- -э- R.C.
Дальнейшая нормализация отношений, подобных отноше-
нию ПРОЕКТЫ, основывается на теореме Фейджина.
Отношение R(A, В, С) можно спроецировать без потерь в от-
ношения R1(A, В) и R2(A, С) в том и только в том случае, если
существует MVD А -> -> В | С.
Под проецированием без потерь понимается такой способ
декомпозиции отношения, при котором исходное отношение
полностью и без избыточности восстанавливается путем естест-
венного соединения полученных отношений.
Отношение R находится в четвертой нормальной форме (4NF)
в том и только в том случае, если в случае существования много-
значной зависимости А -э- -э- В все остальные атрибуты R функ-
ционально зависят от А.
174 Глава 3. Разработка программно-информационного ядра АИС...
Произведем декомпозицию отношения ПРОЕКТЫ в два от-
ношения ПРОЕКТЫ-СОТРУДНИКИ и ПРОЕКТЫ-ЗАДАНИЯ:
ПРОЕКТЫ-СОТРУДНИКИ (ПРО НОМЕР, ПРО_СОТР)
ПРОЕКТЫ-ЗАДАНИЯ (ПРО_НОМЕР, ПРО_ЗАДАН)
Оба эти отношения находятся в 4NF и свободны от отмечен-
ных аномалий.
10. Пятая нормальная форма. Во всех рассмотренных норма-
лизациях производилась декомпозиция одного отношения в два.
Иногда это сделать не удается, но возможна декомпозиция в
большее число отношений, каждое из которых обладает лучши-
ми свойствами.
Рассмотрим, например, отношение:
СОТРУДНИКИ-ОТДЕЛЫ-ПРОЕКТЫ (СОТР_НОМЕР,
ОТД НОМЕР, ПРО НОМЕР)
Предположим, что один и тот же сотрудник работает в не-
скольких отделах и в каждом отделе работает над несколькими
проектами. Первичным ключом этого отношения является пол-
ная совокупность его атрибутов, отсутствуют функциональные и
многозначные зависимости, поэтому отношение находится в
4NF. Однако в нем могут существовать аномалии, которые уст-
ранимы путем декомпозиции в три отношения.
Отношение R(X, Y, ..., Z) удовлетворяет зависимости соеди-
нения * (X, Y, ..., Z) в том и только в том случае, если R восста-
навливается без потерь путем соединения своих проекций на X,
Y, ..., Z.
Отношение R находится в пятой нормальной форме (нормаль-
ной форме проекции-соединения — PJ/NF) в том и только в том
случае, если любая зависимость соединения в R следует из суще-
ствования некоторого возможного ключа в R.
Введем следующие имена составных атрибутов:
СО = {СОТР_НОМЕР, ОТД НОМЕР}
СП = {СОТР НОМЕР, ПРО НОМЕР}
ОП = {ОТД НОМЕР, ПРО_НОМЕР}
Предположим, что в отношении СОТРУДНИКИ-ОТДЕ-
ЛЫ-ПРОЕКТЫ существует зависимость соединения:
* (СО, СП, ОП)
3.7. Концептуальные модели и схемы баз данных
175
На примерах легко показать, что при вставках и удалениях
кортежей возникают проблемы. Их можно устранить путем де-
композиции исходного отношения в три новых отношения:
СОТРУДНИКИ-ОТДЕЛЫ (СОТР НОМЕР, ОТДНОМЕР)
СОТРУДНИКИ-ПРОЕКТЫ (СОТР_НОМЕР, ПРО_НОМЕР)
ОТДЕЛЫ-ПРОЕКТЫ (ОТД_НОМЕР, ПРО_НОМЕР)
Пятая нормальная форма — это последняя нормальная фор-
ма, которую можно получить путем декомпозиции. Ее условия
достаточно нетривиальны, и на практике 5NF не используется.
Заметим, что зависимость соединения является обобщением как
многозначной, так и функциональной зависимости.
3.7. Концептуальные модели и схемы баз данных
Широкое распространение реляционных СУБД и их использо-
вание в самых разнообразных приложениях показывает, что реля-
ционная модель данных достаточна для моделирования предмет-
ных областей. Однако проектирование реляционной базы данных
в терминах отношений на основе кратко рассмотренного выше ме-
ханизма нормализации зачастую представляет собой очень слож-
ный и неудобный для проектировщика процесс [4]. При этом про-
является ограниченность РМД в следующих аспектах.
Модель не предоставляет достаточных средств для передачи
смысла данных. Семантика реальной предметной области долж-
на в независимости от модели представляться в голове проекти-
ровщика. В частности, это относится к упомянутой выше про-
блеме представления ограничений целостности.
Для многих приложений трудно моделировать предметную
область на основе плоских таблиц. В ряде случаев на самой на-
чальной стадии проектирования разработчику приходится при-
лагать массу усилий, чтобы описать предметную область в виде
одной (возможно, даже ненормализованной) таблицы.
Несмотря на то, что весь процесс проектирования происхо-
дит с учетом зависимостей, реляционная модель не предусмат-
ривает средств для их представления. Процесс проектирования
начинается с выделения некоторых существенных для приложе-
ния объектов предметной области («сущностей») и выявления
связей между этими сущностями, тем нс менее РМД не предла-
гает какого-либо аппарата для разделения сущностей и связей.
176 Глава 3. Разработка программно-информационного ядра АИС...
Потребности проектировщиков БД в более удобных и мощ-
ных средствах моделирования предметной области вызвали к
жизни направление семантических моделей данных (СМД). При
том, что любая развитая семантическая модель данных, как и
РМД, включает структурную, манипуляционную и целостную
части, главным назначением семантических моделей является
обеспечение возможности выражения семантики данных.
Чаше всего на практике семантическое моделирование ис-
пользуется на первой стадии проектирования БД. При этом в
терминах СМД производится концептуальная схема БД, которая
затем вручную преобразуется к реляционной (или какой-либо
другой) схеме согласно методикам, где достаточно четко огово-
рены все этапы преобразования.
Реже реализуется автоматизированная компиляция концепту-
альной схемы в реляционную. При этом известны два подхода: на
основе явного представления концептуальной схемы как исходной
информации для компилятора и построения интегрированных
систем проектирования с автоматизированным созданием концеп-
туальной схемы на основе интервью с экспертами предметной об-
ласти. И в том, и в другом случае в результате производится реля-
ционная схема БД в третьей нормальной форме.
Наконец, третья возможность, реализуемая пока только в
рамках исследовательских и экспериментальных проектов, — это
работа с БД в семантической модели, т. е. СУБД, основанные на
СМД. При этом снова рассматриваются два варианта: обеспече-
ние пользовательского интерфейса на основе СМД с автомати-
ческим отображением конструкций в РМД (задача примерно
того же уровня сложности, что и автоматическая компиляция
концептуальной схемы БД в реляционную схему) и прямая реа-
лизация СУБД, основанная на какой-либо СМД. Второй вари-
ант наиболее приемлем для современных объектно-ориентиро-
ванных СУБД, модели данных которых по многим параметрам
близки к семантическим моделям.
3.7.1. Диаграммное представление
Рассмотрим особенности одной из наиболее популярных
СМД — модели «сущность—связи» (часто ее называют кратко
ER-моделью, ER-диаграммой; предложена П. Ченом (Chen) в
1976 г.).
3.7. Концептуальные модели и схемы баз данных 177
Использование разновидностей ER-модели лежит в основе
большинства современных подходов к проектированию БД (глав-
ным образом, реляционных). Моделирование предметной облас-
ти базируется на использовании графических диаграмм, вклю-
чающих небольшое число разнородных компонентов. В связи с
наглядностью представления концептуальных схем БД ER-моде-
ли получили широкое распространение в CASE-системах, под-
держивающих автоматизированное проектирование реляционных
БД. Рассмотрим структурную часть такой модели в CASE-системе
фирмы ORACLE.
Основные понятия ER-модели. Сущность — это реальный или
представляемый объект, информация о котором должна сохра-
няться и быть доступна. В диаграммах ER-модели сущность
представляется в виде прямоугольника, содержащего имя сущ-
ности. При этом имя сущности — имя типа, а не некоторого
конкретного экземпляра этого типа. Для большей выразительно-
сти и лучшего понимания имя сущности может сопровождаться
примерами конкретных объектов этого типа.
На рис. 3.6 изображена сущность АЭРОПОРТ с примерными
объектами Шереметьево и Хитроу [4].
АЭРОПОРТ
Шереметьево,
Хитроу
Рис. 3.6. Сущность АЭРОПОРТ
Каждый экземпляр сущности необходимо отличать от любо-
го другого экземпляра той же сущности (это требование в неко-
тором роде аналогично требованию отсутствия кортежей-дубли-
катов в реляционных таблицах).
Связь — это графически изображаемая ассоциация, устанав-
ливаемая между двумя сущностями. Эта ассоциация всегда явля-
ется бинарной и может существовать между двумя разными сущ-
ностями или между сущностью и ей же самой (рекурсивная
связь). В любой связи выделяются два конца (в соответствии с
существующей парой связываемых сущностей), на каждом из ко-
торых указывается имя конца связи, степень конца связи (сколь-
ко экземпляров данной сущности связывается), обязательность
связи (т. е. любой ли экземпляр данной сущности должен участ-
вовать в данной связи).
178 Глава 3. Разработка программно-информационного ядра АИС...
Связь представляется в виде линии, связывающей две сущ-
ности или ведущей от сущности к ней же самой. При этом в
месте «стыковки» связи с сущностью используется трехточеч-
ный вход в прямоугольник сущности, если для этой сущности в
связи могут использоваться много (many) экземпляров сущно-
сти, и одноточечный вход, если в связи может участвовать толь-
ко один экземпляр сущности. Обязательный конец связи изо-
бражается сплошной линией, а необязательный — прерывистой
линией.
Как и сущность, связь — это типовое понятие, все экземпля-
ры обеих пар связываемых сущностей подчиняются правилам
связывания.
В примере на рис. 3.7 изображена связь между сущностями
БИЛЕТ и ПАССАЖИР. Конец сущности с именем «для» позво-
ляет связывать с одним пассажиром более одного билета (связь
поэтому называется «один ко многим»), причем каждый билет
должен быть связан с каким-либо пассажиром; конец сущности
с именем «имеет» означает, что каждый билет может принадле-
жать только одному пассажиру, причем пассажир не обязан
иметь хотя бы один билет [4].
БИЛЕТ
ПАССАЖИР
Для
Имеет
Рис. 3.7. Изображение связи «один ко многим».
Лаконичной устной трактовкой изображенной диаграммы
является следующая:
• каждый БИЛЕТ предназначен для одного и только одного
ПАССАЖИРА;
• каждый ПАССАЖИР может иметь один или более БИЛЕ-
ТОВ.
В следующем примере изображена рекурсивная связь, связы-
вающая сущность ЧЕЛОВЕК с ней же самой. Конец связи с име-
нем «сын» определяет тот факт, что у одного отца может быть бо-
лее одного сына. Конец связи с именем «отец» означает, что не у
каждого человека могут быть сыновья (рис. 3.8) [4].
Лаконичной устной трактовкой изображенной диаграммы
является следующая:
• каждый ЧЕЛОВЕК является сыном одного и только одного
ЧЕЛОВЕКА;
3.7. Концептуальные модели и схемы баз данных
179
Рис. 3.8. Пример рекурсивной связи
• каждый ЧЕЛОВЕК может являться отцом для одного или
более ЛЮДЕЙ («ЧЕЛОВЕКОВ»),
Атрибутом сущности является любая деталь, которая служит
для уточнения, идентификации, классификации, числовой ха-
рактеристики или выражения состояния сущности (рис. 3.9).
Имена атрибутов заносятся в прямоугольник, изображающий
сущность, под именем сущности и изображаются малыми буква-
ми (можно с примерами) [4].
Рис. 3.9. Изображение сущности с атрибутами
Уникальным идентификатором сущности является атрибут,
комбинация атрибутов, комбинация связей или комбинация
связей и атрибутов, уникально отличающая любой экземпляр
сущности от других экземпляров сущности того же типа.
Нормальные формы ER-схем. Как и в реляционных схемах
БД, в ER-схемах вводится понятие нормальных форм, причем по
смыслу они очень близки. Заметим, что формулировки нормаль-
ных форм ER-схем делают более понятным смысл нормализации
реляционных схем. Ниже приведены очень краткие и нефор-
мальные определения трех первых нормальных форм.
В первой нормальной форме ER-схемы устраняются повто-
ряющиеся атрибуты или группы атрибутов, т. е. производится
выявление неявных сущностей, «замаскированных» под атри-
буты.
Во второй нормальной форме устраняются атрибуты, завися-
щие только от части уникального идентификатора. Эта часть
уникального идентификатора определяет отдельную сущность.
180 Глава 3. Разработка программно-информационного ядра АИС...
В третьей нормальной форме устраняются атрибуты, завися-
щие от атрибутов, нс входящих в уникальный идентификатор.
Эти атрибуты являются основой отдельной сущности.
Более сложные элементы ER-модели рассмотрим на примере
самых основных и наиболее очевидных понятиях ER-модели
данных [4].
Подтипы и супертипы сущностей. В языках программирова-
ния с развитыми типовыми системами (в языках объектно-ори-
ентированного программирования) вводится возможность на-
следования типа сущности, исходя из одного или нескольких су-
пертипов.
Связи «тапу-Ю-тапу». Иногда необходимо связать сущности
таким образом, что с обоих концов связи могут присутствовать
несколько экземпляров сущности (например, все члены коопе-
ратива сообща владеют имуществом кооператива). Для этого
вводится разновидность связи «многие-ко-многим».
Уточняемые степени связи. Иногда необходимо определить
возможное количество экземпляров сущности, участвующих в
данной связи (например, разработчику запрещено участвовать
более чем в тре,х проектах одновременно). Для выражения этого
семантического ограничения на конце связи указывают ее мак-
симальную или обязательную степень.
Каскадные удаления экземпляров сущностей. Некоторые связи
бывают настолько сильными (конечно, в случае связи
«один-ко-многим»), что при удалении опорного экземпляра сущ-
ности (соответствующего концу связи «один») нужно удалить и
все экземпляры сущности, соответствующие концу связи «мно-
гие». Соответствующее требование «каскадного удаления» можно
сформулировать при определении сущности.
Домены. Как и в случае реляционной модели данных, бывает
полезно определить потенциально допустимое множество значе-
ний атрибута сущности (домена).
Вышеперечисленные и другие более сложные элементы
ER-диаграммы «сущность—связи» делают ее существенно более
мощной, но одновременно несколько усложняют ее использова-
ние. Естественно, при реальном использовании ER-диаграмм
для проектирования БД необходимо ознакомиться со всеми воз-
можностями.
Рассмотрим теперь подробнее один из упомянутых элемен-
тов — подтип сущности.
3.7. Концептуальные модели и схемы баз данных
181
Сущность может быть расщеплена на два или более взаимно
исключающих подтипа, каждый из которых включает общие ат-
рибуты и/или связи, явно определяемые один раз на более вы-
соком уровне. В подтипах могут определяться собственные ат-
рибуты и/или связи. В принципе подтипизацию продолжают и
на более низких уровнях, но в большинстве случаев достаточно
двух-трех уровней.
Сущность, на основе которой определяются подтипы, назы-
вается супертипом. Подтипы должны образовывать полное мно-
жество, т. е. любой экземпляр супертипа должен относиться к
некоторому подтипу. Иногда для полноты приходится опреде-
лять дополнительный подтип ПРОЧИЕ (рис. 3.10) [4].
Летательный аппарат
Аэроплан
Планер Моторный самолет
Вертолет
Птицелет
Прочие
Рис. 3.10. Пример сущности супертипа
Дадим словесную интерпретацию графического изображе-
ния. От супертипа: ЛЕТАТЕЛЬНЫЙ АППАРАТ, который дол-
жен быть АЭРОПЛАНОМ, ВЕРТОЛЕТОМ, ПТИЦЕЛЕТОМ или
ДРУГИМ ЛЕТАТЕЛЬНЫМ АППАРАТОМ. От подтипа: ВЕРТО-
ЛЕТ, который относится к типу ЛЕТАТЕЛЬНОГО АППАРАТА.
От подтипа, который является одновременно супертипом: АЭ-
РОПЛАН, который относится к типу ЛЕТАТЕЛЬНОГО АППА-
РАТА и должен быть ПЛАНЕРОМ или МОТОРНЫМ САМО-
ЛЕТОМ.
Иногда удобно иметь два или более разных разбиения сущ-
ности на подтипы. Например, сущность ЧЕЛОВЕК можно раз-
бить на подтипы по профессиональному признаку (ПРОГРАМ-
МИСТ, ДОЯРКА и т. д.); по половому признаку (МУЖЧИНА,
182 Глава 3. Разработка программно-информационного ядра АИС...
ЖЕНЩИНА); по квалификационному (ТЕХНИК, ИНЖЕНЕР,
МАГИСТР и т. д.)
Получение реляционной схемы из ER-диаграммы. Для реаль-
ного использования вышеприведенного материала необходима,
кроме прочего, методика создания таблицы из ER-диаграммы.
Шаг 1. Каждая простая сущность превращается в таблицу.
Простая сущность — сущность, не являющаяся подтипом и не
имеющая подтипов. Имя сущности становится именем таблицы.
Шаг 2. Каждый атрибут становится возможным столбцом с
тем же именем; может выбираться более точный формат. Столб-
цы, соответствующие необязательным атрибутам, могут содер-
жать неопределенные значения; столбцы, соответствующие обя-
зательным атрибутам, — не могут.
Шаг 3. Компоненты уникального идентификатора сущности
превращаются в первичный ключ таблицы. Если имеется не-
сколько возможных уникальных идентификаторов, выбирается
наиболее используемый. Если в состав уникального идентифи-
катора входят связи, к числу столбцов первичного ключа добав-
ляется копия уникального идентификатора сущности, находя-
щейся на дальнем конце связи (этот процесс может продолжать-
ся рекурсивно). Для именования этих столбцов используются
имена концов связей и/или имена сущностей.
Шаг 4. Связи «один-ко-многим» (и «один-к-одному») стано-
вятся внешними ключами, т. е. делается копия уникального
идентификатора с конца связи «один», и соответствующие
столбцы составляют внешний ключ. Необязательные связи соот-
ветствуют столбцам, допускающим неопределенные значения;
обязательные связи — столбцам, не допускающим неопределен-
ные значения.
Шаг 5. Индексы создаются для первичного ключа (уникаль-
ный индекс), внешних ключей и тех атрибутов, на которых
предполагается в основном базировать запросы.
Шаг 6. Если в концептуальной схеме присутствовали подти-
пы, то возможны два способа (табл. 3.1):
а) все подтипы в одной таблице;
б) для каждого подтипа — отдельная таблица.
При применении способа а) таблица создается для наиболее
внешнего супертипа, а для подтипов могут создаваться пред-
ставления. В таблицу добавляется, по крайней мере, один стол-
бец, содержащий код ТИПА; он становится частью первичного
ключа.
3.7. Концептуальные модели и схемы баз данных
183
При использовании метода о) для каждого подтипа первого
уровня (для более нижних — представления) супертип воссозда-
ется с помощью представления UNION (из всех таблиц подти-
пов выбираются общие столбцы — столбцы супертипа).
Таблица 3./. Преимущества и недостатки способов создания таблицы
Все в одной таблице Таблица — на подтип
Преимущества
Все хранится вместе Легкий доступ к супертипу и подтипам Требуется меньше таблиц Более ясны правила подтипов Программы работают только с нужными таб- лицами
Недостатки
Слишком общее решение Требуется дополнительная логика работы с разными наборами столбцов и разными огра- ничениями Потенциальное узкое место (в связи с блоки- ровками) Столбцы подтипов должны быть необязатель- ными В некоторых СУБД для хранения неопределен- ных значений требуется дополнительная память Слишком много таблиц Смущающие столбцы в представлении UNION Потенциальная потеря производительности при работе через UNION Над супертипом невозможны модификации
Шаг 7. Имеется два способа работы при наличии исключаю-
щих связей (табл. 3.2):
а) общий домен;
б) явные внешние ключи.
Если остающиеся внешние ключи все в одном домене, т. е.
имеют общий формат (способ а), то создаются два столбца:
идентификатор связи и идентификатор сущности. Столбец иден-
тификатора связи используется для различения связей, покры-
ваемых дугой исключения. Столбец идентификатора сущности
используется для хранения значений уникального идентифика-
тора сущности на дальнем конце соответствующей связи.
Если результирующие внешние ключи не относятся к одно-
му домену, то для каждой связи, покрываемой дугой исключе-
ния, создаются явные столбцы внешних ключей; все эти столб-
цы могут содержать неопределенные значения.
184 Глава 3. Разработка программно-информационного ядра АИС...
Таблица 3.2. Преимущества и недостатки способов работы при наличии исключаю-
щих связей
Общий домен Явные внешние ключи
Преимущества
Нужно только два столбца Условия соединения — явные
Недостатки
Оба дополнительных атрибута должны ис- Слишком много столбцов
пользоваться в соединениях
Альтернативные модели сущностей [4] приведены на
рис. 3.11—3.13. Вариант 2 гораздо лучше варианта 1, если подти-
пы действительно существуют. В свою очередь, вариант 3 намно-
го лучше варианта 3 при наличии осмысленного супертипа D.
Рис. 3.11. Вариант I. Связи сущностей
Рис. 3.12. Вариант 2. Связи сущностей при существовании подтипов
Рис. 3.13. Вариант 3. Связь сущностей при наличии супертипа D
3.7. Концептуальные модели и схемы баз данных
185
3.7.2. Виды нотаций
Кроме вышеприведенного способа представления ER-диа-
грамм, существуют и другие. Рассмотрим их подробнее.
Case-метод Баркера. Нотация ER-диаграммы была впервые
введена П. Ченом и получила дальнейшее развитие в работах
Р. Баркера'. Метод Баркера изложен на примере предметной об-
ласти компании по торговле автомобилями по результатам опро-
са персонала компании.
Главный менеджер. Одна из основных обязанностей — содер-
жание автомобильного парка, т. е. ему известно, сколько запла-
чено за машины и каковы накладные расходы. Обладая этой ин-
формацией, он устанавливает минимальную цену, за которую
можно продать конкретный экземпляр. Кроме того, он несет от-
ветственность за продавцов и обязан знать, кто что продает и
сколько уже продал.
Продавец. Он обязан знать, какую цену запрашивать и какова
нижняя граница сделки. Кроме того, он должен владеть инфор-
мацией о машинах: год выпуска, марка, модель и т. п.
Администратор. Его задача сводится к составлению контрак-
тов, для этого нужна информация о покупателе, автомашине и
продавце, поскольку именно контракты приносят продавцам
вознаграждения за продажи.
Первый шаг моделирования — анализ информации в резуль-
тате опроса и выделение сущностей (рис. 3.14). Определение
сущности было приведено ранее.
<имя сущности»
Рис. 3.14. Графическое изображение сущности
Каждая сущность должна обладать уникальным идентифика-
тором [14]. Каждый экземпляр сущности должен однозначно
идентифицироваться и отличаться от всех других экземпляров
данного типа сущности. Каждая сущность должна обладать не-
которыми свойствами:
• иметь уникальное имя, и к одному и тому же имени долж-
на всегда применяться одна и та же интерпретация. Одна и
1 Barker R. CASE*Method. Entity-Relationship Modelling. Copyright
Oracle Corporation UK Limited, Addison-Wesley Publishing Co., 1990.
186 Глава 3. Разработка программно-информационного ядра АИС...
та же интерпретация не может применяться к различным
именам, если только они не являются псевдонимами;
• обладать одним или несколькими атрибутами, которые
либо принадлежат сущности, либо наследуются через связь;
• обладать одним или несколькими атрибутами, которые од-
нозначно идентифицируют каждый экземпляр сущности;
• может обладать любым количеством связей с другими сущ-
ностями.
Из приведенных выше сведений следует, что сущности, ко-
торые могут быть идентифицированы с главным менеджером —
это автомашины и продавцы. Продавцу важны автомашины и
связанные с их продажей данные. Для администратора важны
покупатели, автомашины, продавцы и контракты. Исходя из
этого, выделяются четыре сущности (автомашина, продавец, по-
купатель, контракт), которые изображаются на диаграмме сле-
дующим образом (рис. 3.15).
Автомашина
Продавец
Покупатель
Контракт
Рис. 3.15. Выделенные сущности
Следующим шагом моделирования является идентификация
связей. Уточним понятие связи, приведенное ранее.
Связь — это ассоциация между сущностями, при которой,
как правило, каждый экземпляр одной сущности, называемой
родительской сущностью, ассоциирован с произвольным (в том
числе нулевым) количеством экземпляров второй сущности, на-
зываемой сущностью-потомком, а каждый экземпляр сущно-
сти-потомка ассоциирован в точности с одним экземпляром
сущности-родителя. Таким образом, экземпляр сущность-пото-
мок может существовать только при существовании сущно-
сти-родителя.
Связи может даваться имя, выражаемое грамматическим
оборотом глагола и помещаемое возле линии связи. Имя каждой
связи между двумя данными сущностями должно быть уникаль-
ным, но имена связей в модели не обязаны быть уникальными.
Имя связи всегда формируется с точки зрения родителя, так что
предложение может быть образовано соединением, имени сущ-
ности-родителя, имени связи, выражения степени и имени сущ-
ности-потомка.
3.7. Концептуальные модели и схемы баз данных 187
Например, связь продавца с контрактом может быть выраже-
на следующим образом:
• продавец может получить вознаграждение за один или бо-
лее контрактов;
• контракт должен быть инициирован ровно одним про-
давцом.
Степень связи и обязательность графически изображаются
следующим образом (рис. 3.16) [14].
------Много ---------Необязательная
-------- Один --------- Обязательная
Рис. 3.16. Графическое изображение степени связей и обязательности
Таким образом, два предложения, описывающие связь про-
давца с контрактом, графически будут выражены следующим об-
разом (рис. 3.17) [14].
Продавец
Контракт
Рис. 3.17. Изображение связи между сущностями «продавец» и «контракт»
Описав также связи остальных сущностей, получим следую-
щую схему (рис. 3.18) [14].
Контракт
Рис. 3.18. Диаграмма связей между сущностями
Последним шагом моделирования является идентификация
атрибутов (определение атрибута приводилось ранее).
Атрибут представляет тип характеристик или свойств, ассо-
циированных со множеством реальных или абстрактных объектов
(людей, мест, событий, состояний, идей, пар предметов и т. д.).
Экземпляр атрибута — это определенная характеристика отдель-
ного элемента множества; определяется типом характеристики и
188 Глава 3. Разработка программно-информационного ядра АИС...
ее значением, называемым значением атрибута. В ER-модели ат-
рибуты ассоциируются с конкретными сущностями. Таким обра-
зом, экземпляр сущности должен обладать единственным опреде-
ленным значением для ассоциированного атрибута.
Атрибут может быть либо обязательным, либо необязатель-
ным (рис. 3.19) [14]. Обязательность означает, что атрибут не мо-
жет принимать неопределенных значений (null values). Атрибут
может быть либо описательным (т. е. обычным дескриптором
сущности), либо входить в состав уникального идентификатора
(первичного ключа). Уникальный идентификатор — это атрибут
или совокупность атрибутов и/или связей, предназначенная для
уникальной идентификации каждого экземпляра данного типа
сущности. В случае полной идентификации каждый экземпляр
данного типа сущности полностью идентифицируется своими
собственными ключевыми атрибутами, в противном случае в его
идентификации участвуют также атрибуты другой сущности-ро-
дителя (рис. 3.20) [14].
<имя сущности>
*<атрибут-1>
* — обязательный атрибут;
о — необязательный атрибут
Рис. 3.19. Изображение атрибутов сущности
Полная идентификация Идентификация посредством
другой сущности
Рис. 3.20. Изображение вида идентификации сущности
Каждый атрибут идентифицируется уникальным именем,
выражаемым грамматическим оборотом существительного, опи-
сывающим представляемую атрибутом характеристику. Атрибу-
ты изображаются в виде списка имен внутри блока ассоцииро-
ванной сущности, причем каждый атрибут занимает отдельную
строку. Атрибуты, определяющие первичный ключ, размещают-
ся наверху списка и выделяются знаком «#».
Каждая сущность должна обладать хотя бы одним возмож-
ным ключом. Возможный ключ сущности — это один или не-
3.7. Концептуальные модели и схемы баз данных
189
сколько атрибутов, чьи значения однозначно определяют каж-
дый экземпляр сущности. При существовании нескольких воз-
можных ключей один из них обозначается в качестве первичного
ключа, а остальные — как альтернативные ключи.
С учетом имеющейся информации дополним построенную
ранее диаграмму (рис. 3.21) [14].
цена
। Контракт # и/Н (идентификационный номер)
* Дата
I
''Автомашина
#Р/Н
‘ год
* марка
* модель
* запраши-
ваемая
Рис. 3.21. Дополненная диаграмма связей сущностей
Основы методологии IDEF1. Стандарт IDEF1 был разработан
как инструмент для анализа и изучения взаимосвязей между ин-
формационными потоками в рамках коммерческой деятельности
предприятия. Целью подобного исследования является дополне-
ние и структуризация существующей информации и обеспече-
ние качественного менеджмента информационными потоками.
Необходимость в подобной реорганизации информационной об-
ласти, как правило, возникает на начальном этапе построения
корпоративной АИС, и методология 1DEF1 позволяет достаточ-
но наглядно обнаружить «черные дыры» и слабые места в суще-
ствующей структуре информационных потоков. Применение ме-
тодологии IDEF1, как инструмента построения наглядной моде-
ли информационной структуры предприятия по принципу «как
должно быть», позволяет решить следующие задачи:
• выяснить структуру и содержание существующих потоков
информации на предприятии;
• определить существующие правила и законы, по которым
осуществляется движение информационных потоков, а
также принципов управления ими;
190 Глава 3. Разработка программно-информационного ядра АИС...
• определить, какие проблемы, выявленные в результате
функционального анализа и анализа потребностей, вызваны
недостатком управления соответствующей информацией;
• выявить информационные потоки, требующие дополни-
тельного управления для эффективной реализации модели.
Характерно, что с помощью IDEF1-модели рассматривают
не только автоматизированные компоненты, БД и соответствую-
щую им информацию, но и реальные объекты, такие как сами
сотрудники, кабинеты, телефоны и т. д. В отличие от методов
разработки структур БД (IDEF1X), IDEF1 является аналитиче-
ским методом. Результаты анализа информационных потоков
могут быть использованы для стратегического и тактического
планирования деятельности предприятия и улучшения информа-
ционного менеджмента.
Основные преимущества IDEFI. Методология IDEF1 позволя-
ет на основе простых графических изображений моделировать
информационные взаимосвязи и различия между:
• реальными объектами;
• физическими и абстрактными зависимостями, существую-
щими среди реальных объектов;
• информацией, относящейся к реальным объектам;
• структурой данных, используемой для приобретения, нако-
пления, применения и управления информацией.
Концепции моделирования IDEF1. При построении информа-
ционной модели разработчик всегда оперирует двумя основны-
ми глобальными областями, каждой из которых соответствует
множество характерных объектов. Первой из этих областей яв-
ляется реальный мир, или же совокупность физических и интел-
лектуальных объектов, таких, как люди, места, вещи, идеи
и т. д., а также все свойства этих объектов и зависимости между
ними. Второй же является информационная область. Она вклю-
чает в себя существующие информационные отображения объ-
ектов первой области и их свойств. Информационное отображе-
ние, по существу, не является объектом реального мира, однако
изменение его, как правило, является следствием некоторого из-
менения соответствующего ему объекта реального мира. Мето-
дология IDEF1 разработана как инструмент для исследования
статического соответствия вышеуказанных областей и установ-
ления строгих правил и механизмов изменения объектов инфор-
мационной области при изменении соответствующих им объек-
тов реального мира.
3.7. Концептуальные модели и схемы баз данных
191
Терминология и семантика 1DEFI. Методология IDEF1 разде-
ляет элементы структуры информационной области, их свойства
и взаимосвязи на классы. Центральным понятием методологии
1DEF1 является понятие сущности. Класс сущностей представ-
ляет собой совокупность информации, накопленной и храня-
щейся в рамках предприятия и соответствующей определенному
объекту или группе объектов реального мира. Основными кон-
цептуальными свойствами сущностей в IDEF1 являются:
1) устойчивость. Информация, имеющая отношение к той
или иной сущности, постоянно накапливается;
2) уникальность. Любая сущность может быть однозначно
идентифицирована из другой сущности.
Каждая сущность имеет свое имя и атрибуты. Класс атрибу-
тов представляет собой набор пар, состоящих из имени атрибута
и его значения для определенной сущности. Каждая сущность
может характеризоваться несколькими ключевыми атрибутами.
Класс взаимосвязей в IDEF1 представляет собой совокупность
взаимосвязей между сущностями. Взаимосвязь между двумя от-
дельными сущностями считается существующей в том случае,
когда класс атрибутов одной сущности содержит ключевые атри-
буты другой сущности. Каждый из вышеописанных классов име-
ет свое условное графическое отображение.
На рис. 3.22 приведен пример IDEF1-диаграммы [15]. На ней
представлены две сущности с именами «Отдел» и «Сотрудник» и
взаимозвязь между ними с именем «работает в». Имя взаимосвязи
Взаимосвязь
Имя сущности
Рис. 3.22. Пример 1DEF1-диаграммы
192 Глава 3. Разработка программно-информационного ядра АИС...
всегда выражается в глагольной форме. Если же между двумя или
несколькими объектами реального мира не существует установ-
ленной зависимости, то с точки зрения IDEF1 между соответст-
вующими им сущностями взаимосвязь также отсутствует [ 15].
Основы методологии IDEF1X. IDEF1X является методом раз-
работки реляционных БД и использует условный синтаксис,
специально созданный для удобства построения концептуальной
схемы. Концептуальной схемой называют универсальное пред-
ставление структуры данных в рамках коммерческого предпри-
ятия, независимое от конечной реализации БД и аппаратной
платформы. Будучи статическим методом разработки, IDEF1X
изначально не предназначен для динамического анализа по
принципу «as is» («как есть»), тем не менее он иногда применя-
ется в этом качестве, как альтернатива методу IDEF1. Использо-
вание метода IDEF1X наиболее целесообразно для построения
логической структуры БД после того, как все информационные
ресурсы исследованы (например, с помощью метода IDEF1) и
решение о внедрении реляционной БД, как части корпоратив-
ной АИС, принято. Следует заметить, что средства моделирова-
ния IDEF1X специально разработаны для построения реляцион-
ных информационных систем, и если необходимо разработать
другую систему (например, объектно-ориентированную), то луч-
ше избрать другие методы моделирования.
Существует несколько очевидных причин, по которым
IDEF1X не следует применять в случае построения нереляцион-
ных систем. Во-первых, IDEF1X требует от проектировщика оп-
ределения ключевых атрибутов, для того чтобы отличить одну
сущность от другой, в то время как объектно-ориентированные
системы не требуют задания ключей в целях идентифицирова-
ния объектов. Во-вторых, в тех случаях, когда более чем один ат-
рибут является однозначно идентифицирующим сущность, раз-
работчик должен определить один из этих атрибутов первичным
ключом, а все остальные — вторичными. Таким образом постро-
енная и переданная для окончательной реализации программи-
сту IDEFlX-модель является некорректной для применения ме-
тодов объектно-ориентированной реализации; она предназначе-
на для построения реляционной системы.
Концепция и семантика IDEFIX. Несмотря на то, что терми-
нология IDEF1X практически совпадает с терминологией IDEF1,
существует ряд фундаментальных отличий в теоретических кон-
цепциях этих методологий. Сущность в IDEF1X описывает сово-
3.7. Концептуальные модели и схемы баз данных
193
купность или набор экземпляров похожих по свойствам, но од-
нозначно отличаемых друг от друга по одному или нескольким
признакам. Каждый экземпляр является реализацией сущности.
Таким образом, сущность в IDEF1X описывает конкретный набор
экземпляров реального мира в отличие от сущности в IDEF1, ко-
торая представляет собой абстрактный набор информационных
отображений реального мира. Примером сущности IDEF1X мо-
жет быть сущность «СОТРУДНИК», которая представляет собой
всех сотрудников предприятия, а один из них, скажем, Иванов
Петр Сергеевич, является конкретной реализацией этой сущно-
сти. На рис. 3.22 каждый экземпляр сущности СОТРУДНИК со-
держит следующую информацию: ID сотрудника, имя сотрудни-
ка, адрес сотрудника и т. п. В IDEFlX-модели эти свойства назы-
ваются атрибутами сущности. Каждый атрибут содержит только
часть информации о сущности.
Связи между сущностями в IDEF1X представляют собой
ссылки, соединения и ассоциации между сущностями. Фактиче-
ски, связи — суть глаголы, которые показывают, как соотносят-
ся сущности между собой, что демонстрирует ряд нижеприве-
денных примеров.
Отдел <состоит из> нескольких Сотрудников.
Самолет <перевозит> нескольких Пассажиров.
Сотрудник <пишет> разные Отчеты.
Здесь взаимосвязи между сущностями соответствуют схеме
«один-ко-многим», т. е. один экземпляр первой сущности связан с
месколькими экземплярами второй сущности. Причем первая сущ-
ность является родительской, а вторая — дочерней. В приведенных
примерах глаголы заключены в угловые скобки. Связи отобража-
ются в виде линии между двумя сущностями с точкой на одном
конце и глагольной фразой, отображаемой над линией. Диаграмма
связи между Сотрудником и Отделом приведена на рис. 3.22.
Отношения «многие-ко-многим» обычно используются на
начальной стадии разработки диаграммы, например, в диаграм-
ме зависимости сущностей и отображаются в IDEF1X в виде
сплошной линии с точками на обоих концах. Поскольку отно-
шения «многие-ко-многим» могут скрыть другие бизнес-правила
•или ограничения, они должны быть полностью исследованы на
одном из этапов моделирования. Например, иногда отношение
«многие-ко-многим» на ранних стадиях моделирования иденти-
фицируется неправильно, на самом деле представляя два или не-
194 Глава 3. Разработка программно-информационного ядра АИС...
сколько случаев отношений «один-ко-многим» между связанны-
ми сущностями. Или в случае необходимости хранения допол-
нительных сведений о связи «многие-ко-многим», например,
даты или комментария, такая связь должна быть заменена до-
полнительной сущностью, содержащей эти сведения. При моде-
лировании необходимо иметь в виду, что все отношения «мно-
гие-ко-многим» следует подробно обсудить на более поздних
стадиях моделирования в целях правильного моделирования от-
ношений.
Идентификация сущностей. Представление о ключах. Сущ-
ность в диаграмме IDEF1X описывается графическим объектом
в виде прямоугольника. На рис. 3.23 приведен пример IDEF1X-
диаграммы [16]. Каждый прямоугольник, отображающий сущ-
ность, разделяется горизонтальной линией на части. Верхняя
часть называется ключевой областью (в ней расположены клю-
чевые поля), а нижняя часть — областью данных (в ней располо-
жены неключевые поля). Ключевая область объекта СОТРУД-
НИК содержит поле «Уникальный идентификатор сотрудника»,
в области данных находятся поля «Имя сотрудника», «Адрес со-
трудника», «Телефон сотрудника» и т. д.
Ключевая область содержит первичный ключ для сущности
или набор атрибутов, выбранных для идентификации уникаль-
ных экземпляров сущности. Атрибуты первичного ключа распо-
Рис. 3.23. Пример IDEFlX-диаграммы
3.7. Концептуальные модели и схемы баз данных
195
лагаются над линией в ключевой области. Неключевые атрибуты
располагаются в области данных.
При создании сущности в IDEFlX-модели одним из главных
вопросов является вопрос: «Как идентифицировать уникальную
запись?». Требуется уникальная идентификация каждой записи в
сущности для того, чтобы правильно создать логическую модель
данных. Напомним, что сущности в IDEF1X всегда имеют клю-
чевую область, поэтому в каждой сущности должны быть опре-
делены ключевые атрибуты.
Выбор первичного ключа для сущности очень важен и требу-
ет особого внимания. В качестве первичных ключей используют
несколько атрибутов или групп атрибутов. Атрибуты, которые
могут быть выбраны первичными ключами, называются канди-
датами в ключевые атрибуты (потенциальные атрибуты); они
должны уникально идентифицировать каждую запись сущности.
В соответствии с этим, ни одна из частей ключа не может быть
NULL, не заполненной или отсутствующей.
Например, для того чтобы корректно использовать сущность
СОТРУДНИК в IDEFlX-модели данных (и далее, в базе дан-
ных), необходимо уникально идентифицировать записи. Прави-
ла, по которым выбирается первичный ключ из списка предпо-
лагаемых ключей, очень жесткие, тем не менее их применяют ко
всем типам баз данных и информации. Согласно правилам, ат-
рибуты и группы атрибутов должны:
• уникальным образом идентифицировать экземпляр сущ-
ности;
• не использовать NULL-значений;
• не изменяться со временем. Экземпляр идентифицируется
с помощью ключа. При изменении ключа, экземпляр соот-
ветственно меняется;
• быть как можно короче для индексирования и получения
данных. При использовании ключа, являющегося комби-
нацией ключей из других сущностей, необходимо убедить-
ся в том, что каждая часть ключа соответствует правилам.
Для наглядного представления о том, как следует подходить
к выбору первичных ключей, найдем первичный ключ для сущ-
ности СОТРУДНИК:
• Атрибут «ID сотрудника» является потенциальным ключом,
так как он уникален для всех экземпляров сущности СОТРУД-
НИК.
196 Глава 3. Разработка программно-информационного ядра АИС...
• Атрибут «Имя сотрудника» не очень хорош для потенци-
ального ключа, так как среди служащих на предприятии может
быть, к примеру, двое Иванов Петровых.
• Атрибут «Номер страхового полиса сотрудника» является
уникальным, но проблема в том, что СОТРУДНИК может не
иметь такового.
• Комбинация атрибутов «Имя сотрудника» и «Дата рожде-
ния сотрудника» может оказаться удачной для наших целей и
стать искомым потенциальным ключом.
После проведенного анализа назовем два потенциальных
ключа: первый — «Номер сотрудника», второй — комбинация,
включающая поля «Имя сотрудника» и «Дата рождения сотруд-
ника». Поскольку атрибут «Номер сотрудника» имеет самые ко-
роткие и уникальные значения, то он больше других подходит
для первичного ключа.
При выборе первичного ключа для сущности разработчики
модели часто используют дополнительный (суррогатный) ключ,
т. е. произвольный номер, который уникальным образом опре-
деляет запись в сущности. Атрибут «Номер сотрудника» является
примером суррогатного ключа. Суррогатный ключ лучше всего
подходит на роль первичного ключа потому, что является корот-
ким и быстрее всего идентифицирует экземпляры в объекте.
К тому же, система способна генерировать суррогатные ключи
так, чтобы нумерация была сплошной, т. е. без пропусков.
Потенциальные ключи, которые не выбраны первичными,
могут использоваться в качестве вторичных или альтернативных
ключей. С помощью альтернативных ключей часто отображают
различные индексы доступа к данным в конечной реализации
реляционной базы.
Если сущности в IDEFlX-диаграмме связаны, связь передает
ключ (или набор ключевых атрибутов) дочерней сущности. Эти
атрибуты называются внешними ключами. Внешние ключи опре-
деляются как атрибуты первичных ключей родительского объек-
та, переданные дочернему объекту через их связь. Передаваемые
атрибуты называются мигрирующими.
Классификация сущностей в IDEF1X. Зависимые и независимые
сущности. При разработке модели зачастую приходится сталки-
ваться с сущностями, уникальность которых зависит от значе-
ний атрибута внешнего ключа. Для этих сущностей (для уни-
3.7. Концептуальные модели и схемы баз данных
197
кального определения каждой сущности) внешний ключ должен
быть частью первичного ключа дочернего объекта.
Дочерняя сущность, уникальность которой зависит от атри-
бута внешнего ключа, называется зависимой сущностью. Сущ-
ность СОТРУДНИК является зависимой сущностью потому, что
его идентификация зависит от сущности ОТДЕЛ. В обозначени-
ях IDEFIX зависимые сущности представлены в виде закруглен-
ных прямоугольников.
Зависимые сущности далее классифицируются как сущно-
сти, которые не могут существовать без родительской сущности
и сущности, которые не идентифицируются без использования
ключа родителя (сущности, зависящие от идентификации).
Сущность СОТРУДНИК принадлежит ко второму типу зависи-
мых сущностей, так как сотрудники могут существовать и без
отдела.
Напротив, существуют ситуации, в которых сущность зависит
от существования другой сущности. Рассмотрим две сущности:
ЗАПРОС, используемый для отслеживания запросов покупате-
лей, и ПОЗИЦИЯ ЗАПРОСА, которая отслеживает отдельные
элементы в ЗАПРОСЕ. Связь между этими сущностями можно
выразить в виде ЗАПРОС <содержит> одну или несколько ПО-
ЗИЦИЙ ЗАПРОСА. В этом случае, ПОЗИЦИЯ ЗАПРОСА зави-
сит от существования ЗАКАЗА.
Сущности, независящие при идентификации от других объ-
ектов в модели, называются независимыми сущностями. В выше-
описанном примере сущность ОТДЕЛ — независимая. В IDEF1X
независимые сущности представлены в виде прямоугольников.
Типы связей между сущностями. Идентифицирующие и неиден-
тифицирующие связи. В IDEF1X концепция зависимых и незави-
симых сущностей усиливается типом взаимосвязей. Пусть необ-
ходимо, чтобы внешний ключ передавался в дочернюю сущность
(и, в результате, создавал зависимую сущность), тогда следует
создать идентифицирующую связь между родительской и дочер-
ней сущностью. Идентифицирующие взаимосвязи между сущно-
стями обозначаются сплошной линией.
Неидентифицирующие связи, являющиеся уникальными для
IDEF1X, также связывают родительскую сущность с дочерней.
Эти связи используются для отображения другого типа передачи
атрибутов внешних ключей — передачи в область данных дочер-
ней сущности (под линией).
198 Глава 3. Разработка программно-информационного ядра АИС...
Неидентифицирующие связи отображаются пунктирной ли-
нией между объектами. Поскольку переданные ключи в неиден-
тифицирующей связи не являются составной частью первичного
ключа дочерней сущности, то этот вид связи не проявляется ни в
одной идентифицирующей зависимости. В этом случае и ОТДЕЛ,
и СОТРУДНИК рассматриваются как независимые сущности.
Тем не менее взаимосвязь отражает зависимость существова-
ния, если бизнес-правило для взаимосвязи определяет, что
внешний ключ не может принимать значение NULL. Если су-
ществует внешний ключ, то это означает, что запись в дочерней
сущности может существовать только при наличии ассоцииро-
ванной с ним родительской записи.
Преимущества 1DEF1X. Основным преимуществом IDEF1X
[16] по сравнению с другими методами разработки реляцион-
ных БД является жесткая и строгая стандартизация моделирова-
ния. Установленные стандарты позволяют избежать различной
трактовки построенной модели, которая, несомненно, является
значительным недостатком ER-диаграмм.
3.8. Средства автоматизированного проектирования
структур баз данных
Ранее (гл. 2) был представлен обзор CASE-инструментария
для анализа и проектирования АИС, рассмотрены и охарактери-
зованы наиболее популярные на отечественном рынке интегри-
рованные CASE-средства. Остановимся теперь на особенностях
CASE-средств, применяемых для проектирования структур БД,
как программно-информационного ядра АИС, перечень кото-
рых с указанием фирмы-производителя и адреса сайта в глобаль-
ной сети приведен в табл. 3.3. Следует отметить, что многие из
этих продуктов предназначены не только для проектирования
БД, но и для решения других задач, таких, как моделирование
потоков данных или бизнес-процессов, функциональное моде-
лирование, прототипирование приложений, их документирова-
ние, управление проектами и т. д.
ER/Studio фирмы Embarcadero Technologies по своему назна-
чению сходен с ErWin представляет собой специализированное
средство проектирования данных и не содержит в своем составе
инструментов для объектно-ориентированного моделирования
3.8. Средства автоматизированного проектирования...
199
Таблица 3.3. Средства проектирования структур баз данных
CASE-средство Производитель URL
Designer 2000 Oracle http://www.oracle.com/
ErWin Computer Associates http://www.cai.com/
PowerDesigner Sybase http://www.sybase.com/
ER/Studio Embarcadero http://www.embarcadero.com/
System Architect Popkin Software http://www.popkin.com/
Visible Analyst Visible Systems http://www.visible.com
Visio Enterprise Microsoft http://www.microsoft.com/
или моделирования бизнес-процессов [17]. Список поддерживае-
мых СУБД у этого продукта достаточно широк и включает все
наиболее популярные серверные и настольные СУБД. В отличие
от ErWin, последняя версия ER/Studio поддерживает новые типы
данных SQL Server 7.
К особенностям пакета относится написание макросов на
SAX Basic (клон Visual Basic for Applications) для выполнения од-
нотипных операций, например добавления стандартных полей к
вновь создаваемым сущностям. Этот же язык позволяет генери-
ровать стандартные триггеры и хранимые процедуры для встав-
ки, удаления, изменения записей. Можно даже отлаживать код
на этом языке и обращаться к свойствам сущностей для конст-
руирования серверного кода. Однако, в отличие от ErWin,
ER/Studio не позволяет добавлять к каждой таблице свои шабло-
ны триггеров или просматривать код конкретного триггера в
процессе разработки модели; чтобы получить код одного тригге-
ра, нужно сгенерировать скрипт для всей модели.
Модели ER/Studio сохраняют не только в виде DDL-скрип-
та, но и в формате XML. Предусмотрена возможность создания
репозитария для их хранения в любой серверной СУБД.
ER/Studio позволяет импортировать модели ErWin, но при им-
порте теряются связи шаблонов серверного кода с конкретными
таблицами, и не все макросы ErWin корректно преобразуются в
макросы SAX Basic.
Программный пакет также предусматривает генерацию
Java-классов для клиентских приложений.
200 Глава 3. Разработка программно-информационного ядра АИС...
Кроме того, ER/Studio является COM-сервером, т. е. приго-
ден для использования в других приложениях с возможностью
просмотра и редактирования моделей данных, а также для созда-
ния других решений на его основе [17].
System Architect 2001 фирмы Popkin Software представляет со-
бой универсальное CASE-средство, позволяющее осуществить
не только проектирование данных, но и структурное моделиро-
вание [18]. Средство создания ER-диаграмм является одной из
составных частей этого продукта.
System Architect 2001 поддерживает СУБД практически всех
ведущих производителей, включая Oracle (Oracle 8), Sybase, DB2,
SQL Server, IBM (AS400, DB2), Informix, Sybase, Access, dBASE,
Paradox и др. В процессе логического моделирования позволяет
проверять модель на соответствие правилам проектирования БД
(на соответствие ее первой, второй или третьей нормальным
формам). При генерации DDL-скрипта можно сгенерировать
триггеры (в том числе и нестандартные).
Все компоненты System Architect позволяют документиро-
вать процесс работы над проектом, включая техническое зада-
ние, план тестирования и др.
Модели System Architect 2001 при необходимости сохраняют в
репозитарии, однако в отличие от традиционных репозитариев с
более или менее стандартной структурой хранимых данных, этот
является настраиваемым — к сохраняемым объектам можно до-
бавлять дополнительные свойства, определенные пользователем.
System Architect обладает встроенным языком Visual Basic for
Application, что позволяет создавать разнообразные решения на
базе этого продукта, включая автоматическую генерацию моде-
лей и проектной документации.
System Architect 2001 при необходимости генерирует код кли-
ентских приложений для Visual Basic, Delphi и PowerBuilder (на
сегодняшний день это практически единственное CASE-средст-
во, поддерживающее генерацию кода Delphi), классы C++, а так-
же код и текстовые экранные формы COBOL [18].
Visible Analyst фирмы Visible Systems Corporation — весьма
популярный продукт; широко известны также ранее производи-
мые компанией CASE-средства EasyER и EasyCASE — предше-
ственники Visible Analyst [19].
Продукт выпускается в трех модификациях. Первая — Visible
Analyst DB Engineer, включает средства проектирования данных;
Visible Analyst Standard, кроме проектирования БД, позволяет
3.8. Средства автоматизированного проектирования...
201
осуществлять структурное моделирование; третья модифика-
ция — Visible Analyst Corporate, помимо указанных выше функ-
ций, осуществляет также объектно-ориентированное моделиро-
вание.
Visible Analyst поддерживает довольно широкий спектр
СУБД с точки зрения генерации серверного кода, включая
Oracle 7, Sybase SQL Server (System 10 и 4.x); Informix, DB2,
Ingres. Последние версии многих серверных СУБД (Oracle 8,
Microsoft SQL Server 6.5/7/2000, последние версии серверов
Sybase) в этом списке пока отсутствуют.
Для Informix и DB2 указанный продукт позволяет генериро-
вать DDL-скрипты, учитывающие специфические особенности
организации физической памяти наиболее популярных сервер-
ных СУБД, такие как управление табличным пространством,
размером экстентов, режимами блокировки данных, степенью
заполнения данными (fill factor), а также создавать кластеризо-
ванные индексы и генерировать триггеры для выполнения стан-
дартных операций. Из этих же СУБД можно производить непо-
средственно обратное проектирование. Помимо этих двух СУБД
обратное проектирование производится из DDL-скриптов, сге-
нерированных для других СУБД, а также на основе кода
COBOL.
Модели Visible Analyst можно сохранять в многопользова-
тельском репозитарии, созданном в одной из серверных СУБД.
Кроме того, Visible Analyst позволяет на основе созданных моде-
лей генерировать код для Visual Basic, C++ и COBOL [19].
Visio Enterprise фирмы Microsoft. Продукт под названием
Visio, приобретенный в январе 2000 г. корпорацией Microsoft
вместе с его разработчиком — компанией Visio Corporation, пози-
ционировался на рынке как одно из самых популярных средств
создания схем и диаграмм. Модификация Microsoft Visio 2000 —
Visio 2000 Enterprise — содержит в своем составе полноценное
CASE-средство [20].
Visio Enterprise позволяет производить прямое и обратное
проектирование БД, преобразовывать логическую модель в фи-
зическую. Этим средством поддерживаются все ODBC- и OLE
DB-источники данных. С его помощью создаются триггеры для
стандартной обработки нарушений ссылочной целостности в
случае, если DDL-скрипт создается для Microsoft SQL Server, и
серверные ограничения, если скрипт создается для другой СУБД.
Отметим, что Visio при генерации скриптов позволяет указывать
202 Глава 3. Разработка программно-информационного ядра АИС...
параметры организации физической памяти Oracle, Informix,
Microsoft SQL Server, DB2 и некоторых других СУБД.
Помимо средств проектирования баз данных Visio включает
средства объектно-ориентированного моделирования и генера-
ции кода приложений Visual Basic 6, а также классов C++ и Java.
Модели Visio можно сохранять в Microsoft Repository.
В отличие от специализированных средств проектирования
данных, Visio нс обладает скриптовым языком, позволяющим
создавать серверный код, не связанный с конкретной СУБД.
При использовании этого продукта такой код нужно создавать
на этапе физического проектирования в уже созданном скрипте,
однако и стоимость Visio Enterprise по сравнению с ErWin или
PowerDesigner DataArchitect невысока, тем более что Visio в це-
лом представляет собой продукт более широкого назначения.
К тому же продукт является сервером автоматизации, обладает
весьма обширной объектной моделью и встроенным средством
разработки — Visual Basic for Applications, что позволяет, в част-
ности, создавать на его базе разнообразные решения, в том чис-
ле и автоматизировать разработку моделей данных [20].
Vantage Team Builder фирмы Westmount I-CASE. Согласно [4]
характерной особенностью этого программного продукта являет-
ся использование одного из вариантов нотации П. Чена. На
ER-диаграммах сущность обозначается прямоугольником, содер-
жащим ее имя (рис. 3.24), а связь — ромбом, связанным линией
с каждой из взаимодействующих сущностей. Числа над линиями
означают степень связи.
Рис. 3.24. Обозначение сущностей и связей
Связи являются многонаправленными и могут иметь атрибу-
ты (за исключением ключевых). Кроме того, выделяют следую-
щие виды связей.
В необязательной связи (рис. 3.25) могут участвовать не все
экземпляры сущности.
В отличие от необязательной в полной (total) связи участвуют
все экземпляры хотя бы одной из сущностей, т. е. экземпляры
такой связи существуют только при условии существования эк-
земпляров другой сущности. Полная связь может иметь один из
3.8. Средства автоматизированного проектирования...
203
Рис. 3.25. Необязательная связь
четырех видов: обязательная связь, слабая связь, связь «супер-
тип—подтип» и ассоциативная связь.
Обязательная (mandatory) связь описывает связь между неза-
висимой и зависимой сущностями. Все экземпляры зависимой
(обязательной) сущности существуют только при наличии эк-
земпляров независимой (необязательной) сущности, т. е. экзем-
пляр обязательной сущности существует только при условии су-
ществования определенного экземпляра необязательной сущно-
сти. Так, на рис. 3.26 показано, что каждый автомобиль имеет,
по крайней мере, одного водителя, но не каждый служащий
управляет машиной.
Рис. 3.26. Обязательная связь
В слабой связи существование одной из сущностей (слабой),
принадлежащей некоторому множеству, зависит от существования
определенной сущности (сильной), принадлежащей другому мно-
жеству, т. е. экземпляр слабой сущности идентифицируется толь-
ко посредством экземпляра сильной сущности. Ключ сильной
сущности является частью составного ключа слабой сущности.
Слабая связь всегда является бинарной и подразумевает обя-
зательную связь для слабой сущности. Сущность бывает слабой
в одной связи и сильной в другой, но не может быть слабой бо-
лее чем в одной связи. Слабая связь может не иметь атрибутов.
Как показано на рис. 3.27, ключ (номер) строки в документе
может не быть уникальным и должен быть дополнен ключом до-
кумента.
Рис. 3.27. Слабая связь
Связь «супертип—подтип» изображена на рис. 3.28. Общие
характеристики (атрибуты) типа определяются в сущности-су-
204 Глава 3. Разработка программно-информационного ядра АИС...
Рис. 3.28. Связь «супертип—подтип»
пертипе, сущность-подтип наследует все характеристики супер-
типа. Экземпляр подтипа существует только при условии сущест-
вования определенного экземпляра супертипа. Подтип не может
иметь ключ (он импортирует ключ из супертипа). Сущность, яв-
ляющаяся супертипом в одной связи, может быть подтипом в
другой. Связь супертипа не может иметь атрибутов.
В ассоциативной связи каждый экземпляр связи (ассоциатив-
ный объект) существует только при условии существования оп-
ределенных экземпляров каждой из взаимосвязанных сущно-
стей. Ассоциативный объект — объект, являющийся одновре-
менно сущностью и связью. Ассоциативная связь — это связь
между несколькими независимыми сущностями и одной зависи-
мой сущностью. Связь между независимыми сущностями имеет
атрибуты, которые определяются в зависимой сущности. Таким
образом, зависимая сущность определяется в терминах атрибу-
тов связи между остальными сущностями.
Иллюстрация указанной связи приведена на рис. 3.29: само-
лет выполняет посадку на взлетную полосу в заданное время при
определенной скорости и направлении ветра. Поскольку эти ха-
рактеристики применимы только к конкретной посадке, они яв-
ляются атрибутами посадки, а не самолета или взлетной полосы.
Пилот, выполняющий посадку, связан гораздо сильнее с кон-
кретной посадкой, чем с самолетом или взлетной полосой.
Рис. 3.29. Ассоциативная связь
Первичный ключ каждого типа сущности помечается звез-
дочкой (*).
3.8. Средства автоматизированного проектирования...
205
В свою очередь ER-диаграмма строится по следующим пра-
вилам [4]:
• каждая сущность, каждый атрибут и каждая связь должны
иметь имя (связь супертипа или ассоциативная связь может
не иметь имени);
• имя сущности должно быть уникально в рамках модели
данных;
• имя атрибута должно быть уникально в рамках сущности;
• имя связи должно быть уникально, если для нее генериру-
ется таблица БД;
• каждый атрибут должен иметь определение типа данных;
• сущность в необязательной связи должна иметь ключевой
атрибут. То же самое относится к сильной сущности в сла-
бой связи, супертипу в связи «супсртип—подтип» и необя-
зательной сущности в обязательной (полной) связи;
• подтип в связи «супертип—подтип» не может иметь ключе-
вой атрибут;
• в ассоциативной или слабой связи может быть только одна
ассоциативная (слабая) сущность;
• связь не может быть одновременно обязательной, «супер-
типом—подтипом» или ассоциативной.
Общие характеристики CASE-средств. В результате анализа
функциональных возможностей вышеперечисленных продуктов
можно сделать вывод о том, что несмотря на некоторую специ-
фику и различные сферы применения, все они характеризуются
рядом одних и тех же функций, к которым относятся [4]:
• создание логических моделей, не зависящих от СУБД, и ге-
нерации физических моделей на их основе;
• поддержка нескольких типов СУБД, включая не только
серверные, но и настольные;
• поддержка специфических особенностей тех или иных
СУБД ведущих производителей (генерация триггеров,
управление физическим хранением данных);
• реализация обратного проектирования на основе либо
имеющейся базы данных, либо имеющегося DDL-скрипта;
• генерация отчетов и проектной документации на основе
созданной модели;
• сохранение модели в репозитарии, который во многих слу-
чаях может быть разделяемым;
• поддержка генерации кода для одного или нескольких
средств разработки или языков программирования.
206 Глава 3. Разработка программно-информационного ядра АИС...
3.9. Язык структурных запросов SQL
Стандарт и реализация языка SQL. Увеличение объемов ин-
формации, необходимость хранения огромных массивов данных
и их обработки привели к тому, что возникла потребность в соз-
дании стандартного языка БД, который мог бы использоваться в
многочисленных компьютерных системах различных видов (на
персональном компьютере, сетевой рабочей станции, универ-
сальной ЭВМ и т. д.). Таким языком, согласно известным сведе-
ниям [1, 21, 22], стал язык SQL (Structured Query Language).
В настоящее время он получил очень широкое распространение
и фактически превратился в стандартный язык реляционных БД.
В 1986 г. Американский национальный институт стандартов
(ANSI) выпустил стандарт на язык SQL, а в 1987 г. Международ-
ная организация стандартов (ISO) приняла его в качестве между-
народного; сейчас это SQL/92.
Однако использование любых стандартов наряду с очевид-
ными преимуществами, порождает определенные недостатки.
Прежде всего, стандарты направляют в определенное русло раз-
витие соответствующей индустрии; в случае языка SQL наличие
твердых основополагающих принципов приводит, в конечном
счете, к совместимости его различных реализаций и способству-
ет как повышению переносимости программного обеспечения и
БД в целом, так и универсальности работы администраторов БД.
С другой стороны, стандарты ограничивают гибкость и функ-
циональные возможности конкретной реализации. Под реализа-
цией языка SQL понимается программный продукт SQL соответ-
ствующего производителя. Для расширения функциональных
возможностей добавляют к стандартному языку SQL различные
расширения. Следует отметить, что стандарты требуют от любой
законченной реализации языка SQL наличия определенных ха-
рактеристик и в общих чертах отражают основные тенденции,
которые не только приводят к совместимости между всеми кон-
курирующими реализациями, но и способствуют повышению
значимости программистов SQL и пользователей реляционных
БД на современном рынке программного обеспечения.
Все конкретные реализации языка несколько отличаются
друг от друга, и в то же время соответствуют современным
стандартам ANSI в части переносимости и удобства работы
пользователей. Отличия в реализациях заключаются в усовер-
3.9. Язык структурных запросов SQL
207
шенствовании или расширении языка SQL, которые представ-
ляют собой дополнительные команды и опции, являющиеся
добавлениями к стандартному пакету, доступные в данной кон-
кретной реализации.
В настоящее время язык SQL поддерживают десятки СУБД
различных типов, разработанных для самых разнообразных вы-
числительных платформ.
Языки манипулирования данными, созданные для СУБД до
появления реляционных БД, были ориентированы на операции
с данными, представленными в виде логических записей фай-
лов. Поэтому пользователь должен был детально знать организа-
цию хранения данных и предпринимать серьезные усилия для
указания типов и структур данных, их размещения и способа по-
лучения.
Язык SQL ориентирован на операции с данными, представ-
ленными в виде логически взаимосвязанных совокупностей таб-
лиц-отношений. Важнейшая особенность его структур — ориен-
тация на конечный результат обработки данных, а не на проце-
дуру этой обработки. Язык SQL сам определяет, где находятся
данные, индексы и даже то, какие наиболее эффективные по-
следовательности операций следует использовать для получения
результата, а потому указывать эти детали в запросе к БД не
требуется.
Формы языка SQL. Структурированный язык запросов SQL
реализуется в следующих формах:
• интерактивной;
• статической;
• динамической;
• встроенной.
Интерактивный SQL позволяет конечному пользователю в
интерактивном режиме выполнять SQL-операторы. Все СУБД
предоставляют инструментальные средства для работы с БД в
интерактивном режиме. Например, СУБД Oracle включает ути-
литу SQL*Plus, позволяющую в строчном режиме выполнять
большинство SQL-операторов.
Статический SQL может реализовываться как встроенный
SQL или модульный SQL. Операторы статического SQL опреде-
лены уже в момент компиляции программы.
Динамический SQL позволяет формировать операторы SQL
во время выполнения программы.
208 Глава 3. Разработка программно-информационного ядра АИС...
Встроенный SQL позволяет включать операторы SQL в код
программы на другом языке программирования (например,
C++).
Типы данных SQL. Данные, хранящиеся в столбцах таблиц
SQL-ориентированной БД, являются типизированными, т. е.
представляют собой значения одного из типов данных, предо-
пределенных в языке SQL или определяемых пользователями
путем применения соответствующих средств языка. Для этого
при определении таблицы каждому ее столбцу назначается неко-
торый тип данных (или домен), и в дальнейшем СУБД должна
следить, чтобы в каждом столбце каждой строки каждой табли-
цы присутствовали только допустимые значения. В этом разделе
мы обсудим систему типов языка SQL.
Все допустимые в SQL типы данных, которые можно ис-
пользовать при определении столбцов, разбиваются на следую-
щие категории [22]:
• точные числовые типы;
• приближенные числовые типы;
• типы символьных строк;
• типы битовых строк;
• типы даты и времени;
• типы временных интервалов;
• булевский тип;
• типы коллекций;
• анонимные строчные типы;
• типы, определяемые пользователем;
• ссылочные типы.
В столбцах таблиц, определенных на любых типах данных,
наряду со значениями этих типов, допускается сохранение неоп-
ределенного значения, которое обозначается ключевым словом
NULL.
Подробная информация о типах данных языка содержится в
специальной литературе.
Понятие домена. Домен — это набор допустимых значений
для одного или нескольких атрибутов. Если в таблице БД или в
нескольких таблицах присутствуют столбцы, обладающие одни-
ми и теми же характеристиками, можно описать тип такого
столбца и его поведение через домен, а затем поставить в соот-
ветствие каждому из одинаковых столбцов имя домена. Домен
определяет все потенциальные значения, которые могут быть
присвоены атрибуту [21].
3.9. Язык структурных запросов SQL
209
Стандарт SQL позволяет определить домен с помощью сле-
дующего оператора:
<определение_домена>::=
CREATE DOMAIN имя_домена [AS]
типданных
[ DEFAULT значение]
[ CHECK (допустимые значения)]
Каждому создаваемому домену присваивается имя, тип дан-
ных, значение по умолчанию и набор допустимых значений.
Следует отметить, что приведенный формат оператора является
неполным. Теперь при создании таблицы можно указать вместо
типа данных имя домена.
Удаление доменов из БД выполняется с помощью оператора:
DROP DOMAIN имя домена | RESTRICT |
CASCADE]
Альтернативой доменам в среде SQL Server являются пользо-
вательские типы данных.
Подробная информация о доменах содержится в специаль-
ной литературе.
Группы операторов SQL. Язык SQL определяет:
• операторы языка, называемые иногда командами языка SQL;
• типы данных;
• набор встроенных функций.
По своему логическому назначению операторы языка SQL
часто разбиваются на следующие группы [23]:
• язык определения данных DDL (Data Definition Language);
• язык манипулирования данными DML (Data Manipulation
Language).
Язык определения данных включает операторы, управляющие
объектами БД. К последним относятся таблицы, индексы, пред-
ставления. Для каждой конкретной БД существует свой набор
объектов БД, который может значительно расширять набор объ-
ектов, предусмотренный стандартом. В некоторых СУБД, таких
как Oracle, все объекты БД, принадлежащие одному пользовате-
лю, образуют схему БД. С другой стороны, в стандарте SQL92 тер-
мином «схема» стали называть группу взаимосвязанных таблиц
CREATE SCHEMA — создать схему БД;
DROP SHEMA — удалить схему БД;
CREATE TABLE — создать таблицу;
210 Глава 3. Разработка программно-информационного ядра АИС...
ALTER TABLE — изменить таблицу;
DROP TABLE — удалить таблицу;
CREATE DOMAIN — создать домен;
ALTER DOMAIN — изменить домен;
DROP DOMAIN — удалить домен;
CREATE COLLATION — создать последовательность;
DROP COLLATION — удалить последовательность;
CREATE VIEW — создать представление;
DROP VIEW — удалить представление.
Язык манипулирования данными включает операторы, управ-
ляющие содержанием таблиц БД и извлекающие информацию
из этих таблиц. К таким операторам относятся:
SELECT — извлечение данных из одной или нескольких
таблиц;
INSERT — добавление строк в таблицу;
DELETE — удаление строк из таблицы;
UPDATE — изменение значений полей в таблице.
Оператор INSERT вставляет в таблицу новую запись:
INSERT INTO <имя таблицы>(<поле1>,<поле2>,...)
VALUE (<значение1>,<значение2>,...).
Число значений должно соответствовать числу указанных
полей. Полям, не перечисленным в списке, присваивается зна-
чение NULL. Полю SERIAL, если его нет в списке или указано
значение 0, присваивается новое уникальное значение. Если
значение указано явно, то оно и присваивается.
Кроме констант для задания значений можно использовать
выражения: строковые, арифметические, дату и др., и функции:
USER — имя пользователя, выполняющего данный опе-
ратор;
TODAY — дата выполнения оператора;
CURRENT — момент времени выполнения оператора.
Для удаления ненужных записей в таблице используется опе-
ратор DELETE:
DELETE FROM <имя таблицы> [WHERE <условие>].
Фазы выполнения SQL-оператора приведены в табл. 3.4.
Понятие транзакции. Транзакцией называется последователь-
ность действий, которая или полностью фиксируется в БД, или
полностью отменяется. Иногда под транзакцией также подразу-
3.9. Язык структурных запросов SQL
211
Таблица 3.4. Фазы выполнения SQL-оператора
SELECT A,B,C, FROM X, Y WHERE A<500 AND C='ASF'
parse Синтаксический разбор оператора
Validate Проверка привилегий пользователя, проверка действительности имен системных каталогов, таблиц и названий полей
access plan Генерация плана доступа к ресурсам. План доступа — это двоичное представление выполнимого кода по отношению к данным, сохра- няемым в БД
Optimize Оптимизация плана доступа. Дпя увеличения скорости поиска дан- ных могут применяться индексы. Оптимизация использования взаи- мосвязанных таблиц
Execute Выполнение оператора
мевают не группу SQL-операторов, а интервал времени, выпол-
няемые в течение которого SQL-операторы можно или все за-
фиксировать или все отменить [24].
Так, операция перевода денег с одного счета на другой долж-
на составлять единую транзакцию. Иначе может возникнуть си-
туация, когда первый SQL-оператор переведет деньги на другой
счет, а второй, выполняющий снятие их со счета, не доведет
дело до конца из-за непредвиденного сбоя.
Фиксация транзакции может производиться принудительно по
SQL-оператору или неявно после завершения каждого SQL-опе-
ратора. Во втором случае применяется режим автокоммита. Как
правило, выполнение SQL-операторов в интерактивном режиме
всегда использует автокоммит. Очень часто в интегрированных
средах разработки классы, инкапсулирующие работу с базой дан-
ных, по умолчанию предполагают режим автокоммита [24].
Новая транзакция начинается с начала каждого сеанса рабо-
ты с базой данных. Далее все выполняемые SQL-операторы бу-
дут входить в одну транзакцию до тех пор, пока не будет выпол-
нен оператор COMMIT WORK или ROLLBACK WORK.
Оператор COMMIT WORK завершает текущую транзакцию,
выполняя фиксацию сделанных изменений в базе данных. Иногда
говорят, что оператор COMMIT WORK фиксирует транзакцию.
Оператор ROLLBACK WORK выполняет откат транзакции,
отменяя действие всех SQL-операторов, выполненных в текущей
транзакции.
Логически транзакция должна объединять только выполне-
ние взаимосвязанных операций. Так, если делать транзакции
212 Глава 3. Разработка программно-информационного ядра АИС...
«очень большими», состоящими из последовательности не свя-
занных между собой операторов, то любой сбой, автоматически
выполняющий откат транзакции, повлияет на отмену действий,
которые могли бы быть успешно завершены при более «корот-
ких» транзакциях [24].
3.10. Создание объектов баз данных
Логическая структура БД [21] определяет структуру таблиц,
взаимоотношения между ними, список пользователей, хранимые
процедуры, правила, умолчания и другие объекты БД.
Логически данные в SQL организованы в виде объектов; в
табл. 3.5 представлены основные объекты.
Рассмотрим теперь каждый объект подробнее.
Таблица — основной объект для хранения информации в ре-
ляционной БД. Она состоит из содержащих данные строк и
столбцов, занимает в БД физическое пространство и может быть
постоянной или временной [1, 21].
Поле, также называемое в реляционной БД столбцом, явля-
ется частью таблицы, за которой закреплен определенный тип
данных. Каждая таблица БД должна содержать хотя бы один
столбец. Строка данных — это запись в таблице БД, она включа-
ет поля, содержащие данные из одной записи таблицы. Прежде
чем создавать таблицу, разработчик должен задаться следующи-
ми вопросами:
• Как будет называться таблица?
• Как будут называться столбцы (поля) таблицы?
• Какие типы данных будут закреплены за каждым столбцом?
• Какой размер памяти необходимо выделить для хранения
каждого столбца?
• Какие столбцы таблицы требуют обязательного ввода?
• Из каких столбцов будет состоять первичный ключ?
Базовый синтаксис оператора создания таблицы (упрощен-
ная версия) имеет следующий вид:
<определение_таблицы> ::=
CREATE TABLE имя таблицы
(имя_столбца тип данных
[NULL | NOT NULL ] [,...n])
3.10. Создание объектов баз данных
213
Таблица 3.5. Основные объекты базы данных SQL
Термин Расшифровка термина
Tables Таблицы базы данных, в которых хранятся собственно данные
Views Представления (виртуальные таблицы) для отображения дан- ных из таблиц
Stored Procedures Хранимые процедуры
Triggers Триггеры — специальные хранимые процедуры, вызываемые при изменении данных в таблице
User Defined function Создаваемые пользователем функции
Indexes Индексы — дополнительные структуры, призванные повы- сить производительность работы с данными
User Defined Data Types Определяемые пользователем типы данных
Keys Ключи — один из видов ограничений целостности данных
Constraints Ограничение целостности — объекты для обеспечения логи- ческой целостности данных
Users Пользователи, обладающие доступом к базе данных
Roles Роли, позволяющие объединять пользователей в группы
Rules Правила базы данных, позволяющие контролировать логиче- скую целостность данных
Defaults Умолчания или стандартные установки базы данных
Приведенный стандарт совпадает с реализацией оператора
создания таблицы в среде MS SQL Server.
Главное в команде создания таблицы — определение имени
таблицы и описание набора имен полей, которые указываются в
соответствующем порядке. Кроме того, этой командой оговари-
ваются типы данных и размеры полей таблицы.
Ключевое слово NULL используется для указания того, что в
данном столбце могут содержаться значения NULL. Значение
NULL отличается от пробела или нуля — к нему прибегают, ко-
гда необходимо указать, что данные недоступны, опущены или
недопустимы. Если указано ключевое слово NOT NULL, то бу-
дут отклонены любые попытки поместить значение NULL в
данный столбец. Если указан параметр NULL, помещение зна-
214 Глава 3. Разработка программно-информационного ядра АИС...
чений NULL в столбец разрешено. По умолчанию стандарт SQL
предполагает наличие ключевого слова NULL.
Представления, или просмотры (VIEW) представляют собой
временные производные (иначе — виртуальные) таблицы и яв-
ляются объектами БД, информация в которых не хранится по-
стоянно, а формируется динамически при обращении к ним.
Обычные таблицы — это базовые таблицы, т. е. такие, которые
содержат данные и постоянно находятся на устройстве хранения
информации. Представление не существует само по себе, а опре-
деляется только в терминах одной или нескольких таблиц. При-
менение представлений позволяет разработчику БД обеспечить
каждому пользователю или группе пользователей наиболее под-
ходящие способы работы с данными, в целях удобства и безо-
пасности. Содержимое представлений выбирается из других таб-
лиц с помощью запроса, причем изменение значений в таблицах
данных приводит к изменению В представлении. Представле-
ние — фактически тот же запрос, который выполняется всякий
раз с какой-либо командой. Результат выполнения запроса в лю-
бой момент времени становится содержанием представления.
У пользователя создается впечатление, что он работает с настоя-
щей, реально существующей таблицей.
В СУБД есть две возможности реализации представлений.
В простейшем случае система формирует каждую запись пред-
ставления по мере необходимости, постепенно считывая исход-
ные данные из базовых таблиц. В более сложных случаях СУБД
сначала выполняет операцию, как материализации представле-
ния, т. е. сохраняет информацию, из которой состоит представ-
ление, во временной таблице, а затем приступает к выполнению
пользовательской команды и формированию ее результатов. По-
сле этого временная таблица удаляется.
Фактически, представление — это предопределенный запрос,
хранящийся в БД, который выглядит подобно обычной таблице
и не требует для хранения дисковой памяти (используется толь-
ко оперативная память). Создания и изменения представлений в
стандарте языка и реализации в MS SQL Server совпадают и
представлены следующей командой:
{ CREATE] ALTER} VIEW имя_просмотра
[(имя_столбца [,...п])]
[WITH ENCRYPTION]
AS SELECT_onepaTop
[WITH CHECK OPTION]
3.10. Создание объектов баз данных
215
Обращение к представлению осуществляется с помощью
оператора SELECT как к обычной таблице.
Представление используют так же, как и любую другую таб-
лицу: представление можно запрашивать, модифицировать (если
оно отвечает определенным требованиям), соединять с другими
таблицами. Содержание представления не фиксировано и об-
новляется каждый раз, по ссылке в команде. Представления зна-
чительно расширяют возможности управления данными. В част-
ности, это прекрасный способ разрешить доступ к информации
в таблице, скрыв часть данных.
Преимущества и недостатки представлений. Механизм пред-
ставления — мощное средство СУБД, позволяющее скрыть ре-
альную структуру БД от некоторых пользователей за счет опреде-
ления представлений. Любая реализация представления должна
точно соответствовать состоянию данных, которые определяют
это представление. Обычно вычисление представления произво-
дится каждый раз при его использовании. Уже в процессе созда-
ния представления информация о нем записывается в каталог БД
под собственным именем. Любые изменения в данных адекватно
отобразятся в представлении — что отличает его от очень похо-
жего на него запроса к БД. В то же время запрос представляет со-
бой как бы «мгновенную фотографию» данных и при изменении
последних запрос к БД необходимо повторить. Наличие пред-
ставлений в БД необходимо для обеспечения логической незави-
симости данных, т. е. изменение логической структуры данных
не приводит к изменению пользовательских программ. Очевид-
но, что с увеличением количества данных, хранимых в БД, воз-
никает необходимость ее расширения за счет добавления новых
атрибутов или отношений (рост БД). При реструктуризации дан-
ных информация сохраняется, но изменяется ее расположение,
например за счет перегруппировки атрибутов в отношениях.
В случае применения СУБД на отдельном персональном компь-
ютере использование представлений обычно имеет целью лишь
упрощение структуры запросов к БД. В случае многопользова-
тельской сетевой СУБД представления играют ключевую роль в
определении структуры БД и организации защиты информации.
Рассмотрим основные преимущества применения представлений
в подобной среде.
Независимость от данных. С помощью представлений можно
создать согласованную, неизменную картину структуры БД, ко-
торая будет оставаться стабильной даже в случае изменения фор-
216 Глава 3. Разработка программно-информационного ядра АИС...
мата исходных таблиц (например, добавления или удаления
столбцов, изменения связей, разделения таблиц, их реструктури-
зации или переименования). Если в таблицу добавляются или из
нее удаляются не используемые в представлении столбцы, то из-
менять определение этого представления не потребуется. Если
структура исходной таблицы переупорядочивается или таблица
разделяется, можно создать представление, позволяющее рабо-
тать с виртуальной таблицей прежнего формата.
Актуальность. Изменения данных в любой из таблиц базы
данных, указанных в определяющем запросе, немедленно ото-
бражаются на содержимом представления.
Повышение защищенности данных. Права доступа к данным
могут быть предоставлены исключительно через ограниченный
набор представлений, содержащих только то подмножество дан-
ных, которое необходимо пользователю. Подобный подход по-
зволяет существенно ужесточить контроль за доступом отдель-
ных категорий пользователей к информации в базе данных.
Снижение стоимости. Представления позволяют упростить
структуру запросов за счет объединения данных из нескольких
таблиц в единственную виртуальную таблицу. В результате мно-
готабличные запросы сводятся к простым запросам к одному
представлению.
Дополнительные удобства. Создание представлений может
обеспечивать пользователей дополнительными удобствами, на-
пример возможностью работы только с действительно нужной
частью данных. В результате можно добиться максимального
упрощения той модели данных, которая понадобится каждому
конечному пользователю.
Возможность настройки. Представления являются удобным
средством настройки индивидуального образа базы данных. В ре-
зультате одни и те же таблицы могут быть предъявлены пользова-
телям в совершенно разном виде.
Обеспечение целостности данных. Если оператор CREATE
VIEW дополнить фразой WITH CHECK OPTION, то СУБД ста-
нет осуществлять контроль за тем, чтобы в исходных табли-
цах БД не появилась ни одна строка, не удовлетворяющая пред-
ложению WHERE в определяющем запросе. Этот механизм га-
рантирует целостность данных в представлении, что является
одним из значимых преимуществ специализированных представ-
лений в среде SQL.
3.10. Создание объектов баз данных
217
Несмотря на довольно внушительный перечень преиму-
ществ, представления не лишены недостатков. Отметим лишь
основные.
Ограниченные возможности обновления. В некоторых случаях
представления не позволяют вносить изменения в содержащиеся
в них данные.
Структурные ограничения. Структура представления устанав-
ливается в момент его создания. Если определяющий запрос
представлен в форме SELECT * FROM_, то символ * ссылается
на все столбцы, существующие в исходной таблице на момент
создания представления. Если впоследствии в исходную таблицу
базы данных добавятся новые столбцы, то они не появятся в
данном представлении до тех пор, пока это представление не бу-
дет удалено и вновь создано.
Снижение производительности. Использование представле-
ний связано с определенным снижением производительности.
В одних случаях влияние этого фактора совершенно незначи-
тельно, тогда как в других оно может послужить источником су-
щественных проблем. Например, представление, определенное с
помощью сложного многотабличного запроса, может потребо-
вать значительных затрат времени на обработку, поскольку при
его разрешении потребуется выполнять соединение таблиц вся-
кий раз, когда понадобится доступ к данному представлению.
Выполнение разрешения представлений связано с использова-
нием дополнительных вычислительных ресурсов.
Хранимые процедуры представляют собой группы связанных
между собой операторов SQL, предусмотренных для облегчения
работы программиста. Хранимые процедуры — это набор ко-
манд, состоящий из одного или нескольких операторов SQL или
функций и сохраняемый в БД в откомпилированном виде. Вы-
полнение в БД хранимых процедур вместо отдельных операторов
SQL дает пользователю следующие преимущества [21]:
• необходимые операторы уже содержатся в БД;
• все они прошли этап синтаксического анализа и находятся
в исполняемом формате; перед выполнением хранимой
процедуры SQL-сервер генерирует для нее план исполне-
ния, выполняет ее оптимизацию и компиляцию;
• хранимые процедуры поддерживают модульное программи-
рование, так как позволяют разбивать большие задачи на
самостоятельные, более мелкие и удобные в управлении
части;
218 Глава 3. Разработка программно-информационного ядра АИС...
• хранимые процедуры могут вызывать другие хранимые
процедуры и функции; <
• хранимые процедуры могут быть вызваны из прикладных
программ других типов;
• как правило, хранимые процедуры выполняются быстрее,
чем последовательность отдельных операторов;
• хранимые процедуры проще использовать: они могут со-
стоять из десятков и сотен команд, но для их запуска до-
статочно указать всего лишь имя нужной хранимой проце-
дуры. Это позволяет уменьшить размер запроса, посылае-
мого от клиента на сервер, а значит, и нагрузку на сеть.
Хранение процедур в том же месте, где они исполняются,
уменьшает объем передаваемых по сети данных и повышает об-
щую производительность системы. Применение хранимых про-
цедур упрощает сопровождение программных комплексов и вне-
сение изменений в них. Обычно все ограничения целостности в
виде правил и алгоритмов обработки данных реализуются на
сервере БД и доступны конечному приложению в виде набора
хранимых процедур, которые и представляют интерфейс обра-
ботки данных. Для обеспечения целостности данных, а также в
целях безопасности приложение обычно не получает прямого
доступа к данным — вся работа с ними ведется путем вызова тех
или иных хранимых процедур.
Подобный подход значительно упрощает модификацию ал-
горитмов обработки данных и обеспечивает возможность расши-
рения системы без внесения изменений в само приложение: до-
статочно только изменить хранимую процедуру на сервере БД.
Разработчику не нужно перекомпилировать приложение, созда-
вать его копии, а также инструктировать пользователей о необ-
ходимости работы с новой версией. Пользователи вообще могут
не подозревать о том, что в систему внесены изменения.
Хранимые процедуры существуют независимо от таблиц или
каких-либо других объектов БД. Они вызываются клиентской
программой, другой хранимой процедурой или триггером. Раз-
работчик может управлять правами доступа к хранимой проце-
дуре, разрешая или запрещая ее выполнение. Изменять код хра-
нимой процедуры вправе только ее владелец; при необходимо-
сти можно передать права владения ею от одного пользователя
к другому.
При работе с SQL [21] пользователи могут создавать собст-
венные процедуры, реализующие те или иные действия. Храни-
3.10. Создание объектов баз данных
219
мне процедуры являются полноценными объектами БД, а пото-
му каждая из них хранится в конкретной БД. Непосредственный
вызов хранимой процедуры возможен, только если он осуществ-
ляется в контексте той БД, где находится процедура.
В SQL предусмотрено несколько типов хранимых процедур.
Системные хранимые процедуры предназначены для выполне-
ния различных административных действий (практически все,
что касается администрирования сервера). Проще говоря, сис-
темные хранимые процедуры являются интерфейсом, обеспечи-
вающим работу с системными таблицами, которая в конечном
счете сводится к изменению, добавлению, удалению и выборке
данных из системных таблиц как пользовательских, так и сис-
темных БД. Системные хранимые процедуры имеют префикс
sp_, хранятся в системной БД и могут быть вызваны в контексте
любой другой БД.
Пользовательские хранимые процедуры реализуют те или иные
действия. Хранимые процедуры — полноценный объект БД.
Вследствие этого каждая хранимая процедура располагается в
конкретной БД, где и выполняется.
Временные хранимые процедуры существуют лишь некоторое
время, после этого автоматически уничтожаются сервером. Они
делятся на локальные и глобальные. Локальные временные храни-
мые процедуры могут быть вызваны только из того соединения, в
котором созданы. При создании такой процедуры ей необходи-
мо дать имя, начинающееся с символа #. Как и все временные
объекты, хранимые процедуры этого типа автоматически удаля-
ются при отключении пользователя, перезапуске или остановке
сервера. Глобальные временные хранимые процедуры доступны для
любых соединений сервера, на котором имеется такая же проце-
дура. Для ее определения достаточно дать ей имя, начинающееся
с символов ##. Удаляются эти процедуры при перезапуске или
остановке сервера, а также при закрытии соединения, в контек-
сте которого они были созданы.
Создание хранимой процедуры предполагает решение сле-
дующих задач [21]:
• определение типа создаваемой хранимой процедуры — вре-
менная или пользовательская. Кроме этого, можно создать
свою собственную системную хранимую процедуру, назна-
чив ей имя с префиксом sp_ и поместив ее в системную
БД. Такая процедура будет доступна в контексте любой БД
локального сервера;
220 Глава 3. Разработка программно-информационного ядра АИС...
• планирование прав доступа. При создании хранимой про-
цедуры следует учитывать, что она будет иметь те же права
доступа к объектам БД, что и создавший се пользователь;
• определение параметров хранимой процедуры. Подобно
процедурам, входящим в состав большинства языков про-
граммирования, хранимые процедуры могут обладать вход-
ными и выходными параметрами;
• разработку кода хранимой процедуры. Код процедуры мо-
жет содержать последовательность любых команд SQL,
включая вызов других хранимых процедур.
Триггеры являются одной из разновидностей хранимых про-
цедур; они исполняются при выполнении для таблицы како-
го-либо оператора языка манипулирования данными (DML).
Триггеры используются для проверки целостности данных, а
также для отката транзакций. Другими словами, триггер — это
откомпилированная SQL-процедура, исполнение которой обу-
словлено наступлением определенных событий внутри реляци-
онной БД. Применение триггеров весьма удобно для пользовате-
лей БД, но связано зачастую с дополнительными затратами ре-
сурсов на операции ввода/вывода. В том случае, когда тех же
результатов (с гораздо меньшими непроизводительными затрата-
ми ресурсов) можно добиться с помощью хранимых процедур
или прикладных программ, применение триггеров нецелесооб-
разно.
Триггеры — особый инструмент SQL, используемый для
поддержания целостности данных в БД. С помощью ограниче-
ний целостности, правил и значений по умолчанию не всегда
можно добиться нужного уровня функциональности — часто
требуется реализовать сложные алгоритмы проверки данных, га-
рантирующие их достоверность и реальность. Кроме того, ино-
гда необходимо отслеживать изменения значений таблицы, что-
бы нужным образом изменить связанные данные. Триггеры
можно рассматривать как своего рода фильтры, вступающие в
действие после выполнения всех операций в соответствии с пра-
вилами, стандартными значениями и т. д.
Триггер представляет собой специальный тип хранимых про-
цедур, запускаемых сервером автоматически при попытке изме-
нения данных в таблицах, с которыми связаны триггеры. Каж-
дый триггер привязывается к конкретной таблице. Все произво-
димые им модификации данных рассматриваются как одна
транзакция. В случае обнаружения ошибки или нарушения це-
3.10. Создание объектов баз данных
221
лостности данных происходит откат этой транзакции, тем самым
внесение изменений запрещается. Отменяются также вес изме-
нения, уже сделанные триггером.
Создает триггер только владелец БД. Это ограничение позво-
ляет избежать случайного изменения структуры таблиц, спосо-
бов связи с ними других объектов и т. п.
Триггер представляет собой весьма полезное и в то же время
опасное средство. Так, при неправильной логике работы легко
уничтожить целую БД, поэтому триггеры необходимо очень тща-
тельно отлаживать.
В отличие от обычной подпрограммы, триггер выполняется
неявно в каждом случае возникновения триггерного события, к
тому же он не имеет аргументов. Приведение его в действие
иногда называют запуском триггера. С помощью триггеров вы-
полняются следующие функции:
• проверка корректности введенных данных и выполнение
сложных ограничений целостности данных, которые труд-
но, если вообще возможно, поддерживать с помощью огра-
ничений целостности, установленных для таблицы;
• выдача предупреждений, напоминающих о необходимости
выполнения некоторых действий при обновлении таблицы,
реализованном определенным образом;
• накопление аудиторской информации посредством фикса-
ции сведений о внесенных изменениях и тех лицах, кото-
рые их выполнили;
• поддержка репликации.
Функции пользователя. При реализации на языке SQL слож-
ных алгоритмов, которые могут потребоваться более одного
раза, встает вопрос о сохранении разработанного кода для даль-
нейшего применения. Эта задача просто решается с помощью
хранимых процедур, однако их архитектура не позволяет ис-
пользовать процедуры непосредственно в выражениях, так как
они требуют промежуточного присвоения возвращенного значе-
ния переменной, которая затем и указывается в выражении [21].
Возможность создания пользовательских функций предо-
ставлена в среде MS SQL Server 2000. В других реализациях SQL
в распоряжении пользователя имеются только встроенные функ-
ции, которые обеспечивают выполнение наиболее распростра-
ненных алгоритмов: поиск максимального или минимального
значения и др.
222 Глава 3. Разработка программно-информационного ядра АИС...
Функции пользователя представляют собой самостоятельные
объекты БД, такие, например, как хранимые процедуры или
триггеры. Функция пользователя располагается в определен-
ной БД и доступна только в ее контексте.
В SQL Server имеются следующие классы функций пользо-
вателя:
• Scalar — функции возвращают обычное скалярное значение,
каждая может включать множество команд, объединяемых в
один блок с помощью конструкции BEGIN...END;
• Inline — функции содержат всего одну команду SELECT и
возвращают пользователю набор данных в виде значения
типа данных TABLE;
• Multi-statement — функции также возвращают пользователю
значение типа данных TABLE, содержащее набор данных,
однако в теле функции находится множество команд SQL
(INSERT, UPDATE и т. д.). Именно с их помощью и фор-
мируется набор данных, который должен быть возвращен
после выполнения функции.
Пользовательские функции сходны с хранимыми процедура-
ми, но, в отличие от них, могут применяться в запросах так же,
как и системные встроенные функции. Пользовательские функ-
ции, возвращающие таблицы, являются альтернативой представ-
лениям. Последние ограничены одним выражением SELECT, а
пользовательские функции способны включать дополнительные
выражения, что позволяет создавать более сложные и мощные
конструкции.
Встроенные функции SQL, условно разбивают на следующие
группы:
• математические функции;
• строковые функции;
• функции для работы с датой и временем;
• функции конфигурирования;
• функции системы безопасности;
• функции управления метаданными;
• статистические функции.
Подробная информация об особенностях каждой группы
функций с примерами и заданиями для самопроверки содержит-
ся в специальной литературе.
Индексы представляют собой структуру, позволяющую вы-
полнять ускоренный доступ к строкам таблицы на основе значе-
ний одного или более ее столбцов. Наличие индекса существен-
3.10. Создание объектов баз данных
223
но повышает скорость выполнения некоторых запросов и сокра-
щает время поиска необходимых данных за счет физического
или логического их упорядочивания. Индекс — это набор ссы-
лок, упорядоченных по определенному столбцу таблицы, кото-
рый в данном случае называется индексированным столбцом.
Хотя индекс и связан с конкретным столбцом (или столбцами)
таблицы, все же он является самостоятельным объектом БД.
Физически индекс — всего лишь упорядоченный набор зна-
чений из индексированного столбца с указателями на места фи-
зического размещения исходных строк в структуре БД. Когда
пользователь выполняет обращающийся к индексированному
столбцу запрос, СУБД автоматически анализирует индекс для
поиска требуемых значений.
Однако, поскольку индексы должны обновляться системой
при каждом внесении изменений в их базовую таблицу, они соз-
дают дополнительную нагрузку на систему.
Индексы обычно создаются с целью удовлетворения опреде-
ленных критериев поиска после того, как таблица уже находи-
лась некоторое время в работе и увеличилась в размерах. Созда-
ние индексов не предусмотрено стандартом SQL, однако боль-
шинство диалектов поддерживают как минимум следующий
оператор:
CREATE [ UNIQUE ] INDEX имя_индекса
ON имя_таблицы(имя_столбца[А8С|ОЕ5С][,...п])
Указанные в операторе столбцы составляют ключ индекса.
Индексы могут создаваться только для базовых таблиц, но не
для представлений. Если в операторе указано ключевое слово
UNIQUE, уникальность значений ключа индекса будет автома-
тически поддерживаться системой. Требование уникальности
значений обязательно для первичных ключей, а также возможно
и для других столбцов таблицы (например, для альтернативных
ключей). Хотя создание индекса допускается в любой момент,
при его построении для уже заполненной данными таблицы мо-
гут возникнуть проблемы, связанные с дублированием данных в
различных строках. Следовательно, уникальные индексы (по
крайней мере, для первичного ключа) имеет смысл создавать не-
посредственно при формировании таблицы. В результате систе-
ма сразу возьмет на себя контроль за уникальностью значений
данных в соответствующих столбцах.
224 Глава 3. Разработка программно-информационного ядра АИС...
Если созданный индекс впоследствии окажется ненужным,
его можно удалить с помощью оператора:
DROP INDEX имя индскса
В среде MS SQL Server индексы расположены в самой таблице
и являются удобным внутренним механизмом системы SQL-сер-
вера, с помощью которого осуществляется доступ к данным наи-
более оптимальным способом. В среде SQL Server реализованы
эффективные алгоритмы поиска нужного значения в строго опре-
деленной последовательности данных. Ускорение поиска дости-
гается именно за счет того, что данные представляются упорядо-
ченными (хотя физически, в зависимости от типа индекса, они
могут храниться в соответствии с очередностью их добавления в
таблицу). К настоящему времени разработаны эффективные ма-
тематические алгоритмы поиска данных в упорядоченной после-
довательности. Наиболее эффективной структурой для поиска
данных в машинном представлении являются В-деревья — мно-
гоуровневая иерархическая структура с переменным количеством
элементов в каждом узле.
Создание индекса. Если выборка данных из таблицы требует
значительного времени, это означает, что для нее необходимо
создать индекс. Индексы существенно повышают производи-
тельность выполнения операций поиска и выборки данных. При
выборе столбца для индекса следует проанализировать, какие
типы запросов чаще всего выполняются пользователями и какие
столбцы являются ключевыми, т. е. задающими критерии выбор-
ки данных (например, порядок сортировки). В среде SQL Server
реализовано несколько типов индексов:
• некластерные ;
• кластерные;
• уникальные.
Некластерные индексы. В отличие от кластерных, не пере-
страивают физическую структуру таблицы, а лишь организуют
ссылки на соответствующие строки.
Для идентификации нужной строки в таблице некластерный
индекс организует специальные указатели, включающие:
• информацию об идентификационном номере файла, в ко-
тором хранится строка;
• идентификационный номер страницы соответствующих
данных;
3.10. Создание объектов баз данных
225
• номер искомой строки на соответствующей странице;
• содержимое столбца.
В большинстве случаев следует ограничиваться 4—5 индек-
сами.
Кластерный индекс. Принципиальным отличием кластерного
индекса от индексов других типов является то, что при его опре-
делении в таблице физическое расположение данных перестраи-
вается в соответствии со структурой индекса. Логическая струк-
тура таблицы в этом случае представляет собой, скорее, словарь,
чем индекс. Данные в словаре физически упорядочены (напри-
мер, по алфавиту).
Кластерные индексы приводят к существенному увеличению
производительности поиска данных даже по сравнению с обыч-
ными индексами (это особенно заметно при работе с последова-
тельными данными). Если в таблице определен некластерный
индекс, то сервер сначала должен обратиться к индексу, а затем
найти нужную строку в таблице. При использовании кластерных
индексов следующая запись данных располагается сразу после
найденных ранее данных. В результате отпадают лишние опера-
ции, связанные с обращением к индексу и новым поиском нуж-
ной строки в таблице.
Естественно, в таблице определяют только один кластерный
индекс. В качестве такового следует выбирать наиболее часто
используемые столбцы. При этом необходимо выполнять общие
рекомендации создания индексов и не индексировать слишком
длинные столбцы.
Кластерный индекс может включать несколько столбцов, од-
нако количество таких столбцов рекомендуется по возможности
свести к минимуму.
Необходимо избегать создания кластерного индекса для час-
то изменяемых столбцов, поскольку серверу придется физиче-
ски перемещать все данные в таблице с целью их упорядочения.
Для часто изменяемых столбцов больше подходит некластерный
индекс.
При создании в таблице первичного ключа (PRIMARY KEY)
сервер автоматически создает для него кластерный индекс, если
его не существовало ранее или если при определении ключа не
был явно указан другой тип индекса.
В случае, когда в таблице определен и некластерный индекс,
его указатель ссылается не на физическое положение строки в
БД, а на соответствующий элемент кластерного индекса, описы-
226 Глава 3. Разработка программно-информационного ядра АИС...
вающего эту строку, что позволяет не перестраивать структуру
некластерных индексов всякий раз, когда кластерный индекс
меняет физический порядок строк в таблице.
Уникальный индекс гарантирует уникальность значений в ин-
дексируемом столбце. При наличии уникальных индексов сервер
не разрешит вставить новое или изменить существующее значе-
ние так, чтобы в результате этой операции в столбце появились
два одинаковых значения.
Уникальный индекс является своеобразной надстройкой и
реализуется как для кластерного, так и для некластерного индек-
са. В одной таблице может существовать один уникальный кла-
стерный и множество уникальных некластерных индексов. Уни-
кальные индексы следует определять только тогда, когда это
действительно необходимо. Для обеспечения целостности дан-
ных в столбце можно определить ограничение целостности
UNIQUE или PRIMARY KEY, а не прибегать к уникальным ин-
дексам. Их использование только для обеспечения целостности
данных является неоправданной тратой пространства в БД. Кро-
ме того, на их поддержание тратится и процессорное время.
Средства языка SQL предлагают несколько способов опреде-
ления индекса:
• автоматическое создание индекса при создании первичного
ключа;
• автоматическое создание индекса при определении ограни-
чения целостности unique;
• создание индекса с помощью команды CREATE INDEX.
Удаление индекса выполняется командой
DROP INDEX ’имя_индекса'[, -п]
Пользовательские типы данных — это типы данных, которые
создает пользователь на основе системных типов данных, когда в
нескольких таблицах необходимо хранить однотипные значения;
причем столбцы в таблице должны иметь одинаковый размер,
тип данных и чувствительность к значениям NULL.
Создание пользовательского типа данных осуществляется
выполнением системной процедуры:
sp_addtype [@typename=]type,[@phystype=]
syste mdatatype
[ ,|@nuiltype== I’nulltype']
3.10. Создание объектов баз данных
227
Тип данных system data type выбирается из табл. 3.6.
Таблица 3.6. Типы данных
Виды данных
image smalldatetime decimal bit
text real ’decimal[(p[,s])]’ 'binary(n)'
uniqueidentifier datetime numeric 'char(n)'
smallint float 'numeric[(p[,s])]' 'nvarchar(n)'
int 'float(n)' 'varbinary(n)’,
ntext 'varchar(n)' 'nchar(n)'
Ограничения целостности — механизм обеспечения автомати-
ческого контроля соответствия данных установленным условиям
(или ограничениям). Ограничения целостности имеют приори-
тет над триггерами, правилами и значениями по умолчанию.
К ограничениям целостности относятся: ограничение на значе-
ние NULL, проверочные ограничения, ограничение уникально-
сти (уникальный ключ), ограничение первичного ключа и огра-
ничение внешнего ключа. Последние три ограничения тесно
связаны с понятием ключей.
Обязательные данные. Для некоторых столбцов требуется на-
личие в каждой строке таблицы конкретного и допустимого зна-
чения, отличного от опущенного значения или значения NULL.
Для заданий ограничений подобного типа стандарт SQL преду-
сматривает использование спецификации NOT NULL.
Требования конкретного предприятия. Обновления данных в
таблицах могут быть ограничены существующими в организации
требованиями (бизнес-правилами). Стандарт SQL позволяет реа-
лизовать бизнес-правила предприятий с помощью предложения
CHECK и ключевого слова UNIQUE.
Ограничения для доменов полей. Каждый столбец имеет собст-
венный домен — некоторый набор допустимых значений. Стан-
дарт SQL предусматривает два различных механизма определе-
ния доменов. Первый состоит в использовании предложения
CHECK, позволяющего задать требуемые ограничения для
столбца или таблицы в целом, а второй предполагает примене-
ние оператора CREATE DOMAIN.
228 Глава 3. Разработка программно-информационного ядра АИС...
Целостность сущностей. Первичный ключ таблицы должен
иметь уникальное непустое значение в каждой строке. Стандарт
SQL позволяет задавать подобные требования поддержки целостно-
сти данных с помощью фразы PRIMARY KEY. В пределах таблицы
сс можно указывать только один раз. Тем не менее для любых аль-
тернативных ключей таблицы существует возможность гарантиро-
вать уникальность значений, что с успехом обеспечивает ключевое
слово UNIQUE. Кроме того, при определении альтернативных
ключей рекомендуется использовать спецификаторы NOT NULL.
Ссылочная целостность. Внешние ключи представляют собой
столбцы (или наборы столбцов), предназначенные для связыва-
ния каждой из строк дочерней таблицы, содержащей этот внеш-
ний ключ, со строкой родительской таблицы, содержащей соот-
ветствующее значение потенциального ключа. Стандарт SQL
предусматривает механизм определения внешних ключей с по-
мощью предложения FOREIGN KEY, а ссылка REFERENCES
определяет имя родительской таблицы, (там находится соответ-
ствующий потенциальный ключ). При использовании этого
предложения система отклонит выполнение любых операторов
INSERT или UPDATE, с помощью которых будет предпринята
попытка создать в дочерней таблице значение внешнего ключа,
нс соответствующее одному из уже существующих значений по-
тенциального ключа родительской таблицы. Когда действия сис-
темы выполняются при поступлении операторов UPDATE и
DELETE, содержащих попытку обновить или удалить значение
потенциального ключа в родительской таблице, которому соот-
ветствует одна или более строк дочерней таблицы, то они зави-
сят от правил поддержки ссылочной целостности, указанных во
фразах ON UPDATE и ON DELETE предложения FOREIGN
KEY. При попытке удалить из родительской таблицы строку, на
которую ссылается одна или более строк дочерней таблицы,
язык SQL предоставляет следующие возможности:
• CASCADE — выполняется удаление строки из родитель-
ской таблицы и автоматическое удаление всех ссылающих-
ся на нее строк дочерней таблицы;
• SET NULL — выполняется удаление строки из родитель-
ской таблицы, а во внешние ключи всех ссылающихся на
нее строк дочерней таблицы записывается значение NULL;
• SET DEFAULT — выполняется удаление строки из роди-
тельской таблицы, а во внешние ключи всех ссылающихся
3.10. Создание объектов баз данных
229
на нее строк дочерней таблицы заносится значение, при-
нимаемое по умолчанию;
• NO ACTION — операция удаления строки из родительской
таблицы отменяется. Именно это значение используется по
умолчанию в тех случаях, когда в описании внешнего клю-
ча фраза ON DELETE опушена.
Те же самые правила применяются в языке SQL и тогда, ко-
гда значение потенциального ключа родительской таблицы об-
новляется.
Определитель MATCH позволяет уточнить способ обработки
значения NULL во внешнем ключе.
При определении таблицы предложение FOREIGN KEY
можно применять произвольное количество раз.
В операторе CREATE TABLE используется необязательная
фраза DEFAULT, которая предназначена для задания принимае-
мого по умолчанию значения, когда в операторе INSERT значе-
ние в данном столбце будет отсутствовать.
Фраза CONSTRAINT позволяет задать имя ограничению,
что позволит впоследствии отменить то или иное ограничение с
помощью оператора ALTER TABLE.
Умолчание — самостоятельный объект БД, представляющий
значение, которое будет присвоено элементу таблицы при встав-
ке строки, если в команде вставки явно не указано значение для
этого столбца.
Умолчания создаются и удаляются в любой момент времени,
до или после введения данных в таблицу. Значения по умолча-
нию создаются командой create default (создать умолчание), а
удаляются с командой drop default (удалить умолчание).
Умолчание может быть связано с определенным столбцом
таблицы, с несколькими столбцами или со всеми столбцами таб-
лиц БД, имеющими заданный пользователем тип данных. Для
связывания умолчания со столбцом или типом данных использу-
ется системная процедура sp_bindefault (присоединить умолча-
ние); в противном случае — процедура sp_unbindefault (отсоеди-
нить умолчание).
Создание правил. Правила создаются с помощью команды
create rule (создать правило), а затем присоединяются к столбцу
или пользовательскому типу данных с помощью системной про-
цедуры sp_binderule (присоединить правило). Отсоединение пра-
вила от столбца или пользовательских типа данных проводится с
помощью системной процедуры sp unbindrule (отсоединить пра-
230 Глава 3. Разработка программно-информационного ядра АИС...
вило) или путем присоединения нового правила к столбцу или
пользовательскому типу [25].
Названия правил должны соответствовать правилам, уста-
новленным для идентификаторов. Правила можно создавать
только в текущей базе данных.
Названия правил должны быть уникальными для каждого
пользователя внутри одной базы данных. Например, один поль-
зователь не может создать два правила с названием socsecrule.
Однако два различных пользователя могут создать правила с на-
званием socsecrule, поскольку имена пользователей позволяют их
различить.
Правила, связанные со столбцами, всегда сильнее правил,
связанных с типами данных. Присоединение правила к столбцу
заменяет правило, которое связано с типом данных этого столб-
ца, но присоединение правила к типу данных не заменяет пра-
вила, связанного со столбцом этого типа.
Правило, связанное с типом данных, начинает действовать
только при попытке обновить или вставить значения в столбец
данных этого типа. Поскольку правила не проверяют значения
переменных, то пользователь должен стараться не присваивать
переменной пользовательского типа значения, которое не допус-
кается правилом для этого типа данных.
Контрольные вопросы
1. Изложите основы современных СУБД.
2. Перечислите виды архитектурных решений баз данных.
3. Каковы критерии выбора СУБД при создании АИС?
4. Назовите концептуальные модели данных.
5. Какие понятия реляционных баз данных относятся к базовым?
6. Что такое нормализация?
7. Что значит диаграммное представление баз данных?
8. Перечислите известные виды нотаций.
9. Какие средства относятся к средствам автоматизированного проекти-
рования структур баз данных?
10. Каковы основные действия для создания таблиц?
11. Что означают представления?
12. Что означают умолчания?
13. Что представляют собой внешние ключи?
14. Что такое кластерный и некластерный индексы?
15. Перечислите основные функции для работы с датой и временем.
3.10. Создание объектов баз данных
231
Литература
1. Диго С. М. Базы данных: проектирование и использование. М.: Фи-
нансы и статистика. 2005. 592 с.
2. Карпова И. П. Введение в базы данных. Ч. 1. М.: МЭСИ, 2003.
3. Головина О. С. Программирование в корпоративных СУБД. Москов-
ский международный институт эконометрики, информатики, финансов и
права. М., 2002. 125 с.
4. Кузнецов С. Д. Основы современных баз данных, информацион-
но-аналитические материалы ЦИТ. http//www.citmgu.ru.
5. Каратыгин С. И. Базы данных: простейшие средства обработки ин-
формации: системы управления базами данных. ABF, 1995.
6. Аносо А. Критерии выбора СУБД при создании информационных
систем, http://www.nwsta.com.
7. Емельянов А. А., Власов Е. А. Информационное моделирование в
экономических системах: учеб, пособие. М.: МЭСИ, 1996.
8. Сычев Ю. Н. Информационная безопасность: учеб, пособие / Мос-
ковский государственный университет экономики, статистики и информати-
ки. М., 2004. 240 с.
9. Мельников В. И. Защита информации в компьютерных системах.
М.: Финансы и статистика, 1997.
10. Павловский Ю. Н. Имитационные модели и системы. М.: Фазис,
2000.
11. Малыхина М. П. Базы данных: основы, проектирование, использо-
вание. СПб.: БХВ-Петербург, 2004. 512 с.
12. Кузнецов С. Д. Введение в модель данных SQL. htpp://intuit.ru.
13. Смирнова Г. Н., Тельнов Ю. Ф. Проектирование экономических
информационных систем. М.: Финансы и статистика, 2004.
14. Вендров А. М. CASE-технологии. Современные методы и средства
проектирования информационных систем, http:// citforum.ru.
15. Верников Г. Основы методологии IDEF1. http://www.itrealty.ru.
16. Верников Г. Основы методологии IDEF1X. http://www.itrealty.ru.
17. http://www.embarcadero.com/products/Design/erdatasheet.htm.
18. http://www.popkin.com/products/sa2001 /data/data.htm.
19. http://www.visible.com/dataapp/daprods.html.
20. http://www.microsoft.com/office/visio/.
21. Полякова Л. H. Основы SQL. http://www.intuit.ru.
22. Кузнецов С. Д. Введение в модель данных SQL. http://www.intuit.ru.
23. Карпова И. П. Введение в базы данных. Ч. 1. М.: МЭСИ, 2003.
24. Баженова И. Ю. SQL и процедурно-ориентированные языки, http://
www.intuit.ru.
25. http://palien.narod.ru.
Глава 4
ДОСТУП К БАЗАМ ДАННЫХ
4.1. Стандартные системы доступа к базам данных
Существует несколько способов доступа к данным из средств
разработки и клиентских приложений [I, 2, 3]. Подавляющее
большинство систем управления БД содержит в своем составе
библиотеки, предоставляющие специальный прикладной про-
граммный интерфейс (Application Programming Interface — API) для
доступа к данным этой СУБД. Обычно такой интерфейс пред-
ставляет собой набор функций, вызываемых из клиентского при-
ложения. В случае настольных СУБД эти функции обеспечивают
чтение/запись файлов БД, а в случае серверных СУБД иниции-
руют передачу запросов серверу БД и получение от сервера ре-
зультатов выполнения запросов или кодов ошибок, интерпрети-
руемых клиентским приложением. Библиотеки, содержащие API
для доступа к данным серверной СУБД, обычно входят в состав
ее клиентского программного обеспечения, устанавливаемого на
компьютерах, где функционируют клиентские приложения.
В последнее время Windows-версии клиентского программ-
ного обеспечения наиболее популярных серверных СУБД, в ча-
стности Microsoft SQL Server, Oracle, Informix, содержат также
COM-серверы, предоставляющие объекты для доступа к данным
и метаданным.
Использование клиентского API (или клиентских СОМ-объ-
ектов) является наиболее очевидным (и нередко самым эффек-
тивным с точки зрения производительности) способом манипу-
ляции данными в приложении. Однако в этом случае созданное
приложение сможет использовать данные только СУБД этого
производителя, и замена ее на другую (например, с целью рас-
ширения хранилища данных или перехода в архитектуру «кли-
ент — сервер») повлечет за собой переписывание значительной
4.1. Стандартные системы доступа к базам данных
233
части кода клиентского приложения — клиентские API и объ-
ектные модели не подчиняются никаким стандартам и различны
для разных СУБД.
Другой способ манипуляции данными в приложении базиру-
ется на применении универсальных механизмов доступа к данным.
Указанный механизм обычно реализован в виде библиотек и до-
полнительных модулей, называемых драйверами или провайдера-
ми. Библиотеки содержат некий стандартный набор функций
или классов, укомплектованный согласно той или иной специ-
фикации. Дополнительные модули, специфичные для различных
СУБД, реализуют непосредственное обращение к функциям
клиентского API конкретных СУБД.
Отметим, что достоинством универсальных механизмов яв-
ляется возможность применения одного и того же абстрактного
API, а во многих случаях — COM-серверов, компонентов, клас-
сов для доступа к разным типам СУБД. Поэтому приложения,
использующие универсальные механизмы доступа к данным,
легко модифицировать при необходимости замены СУБД. При-
чем модификация, как правило, затрагивает не код приложения
как таковой, а настройки доступа к данным, содержащиеся в
реестре или внешних файлах. Недостатками универсальности яв-
ляются невозможность доступа к уникальной функциональности
конкретной СУБД, снижение производительности приложений,
а также усложнение процедуры поставки приложения — ведь в
его состав нужно включать библиотеки, ответственные за реали-
зацию универсальных механизмов, драйверы для конкретных
СУБД, а также обеспечивать настройки, необходимые для их
правильного функционирования.
Ниже приведены наиболее популярные среди универсальных
механизмов доступа к данным:
• Borland Database Engine (BDE);
• Open Database Connectivity (ODBC);
. OLE DB;
• ActiveX Data Objects (ADO).
Универсальные механизмы ODBC, OLE DB и ADO фирмы
Microsoft представляют собой по существу промышленные стан-
дарты. BDE фирмы Borland так и не стал промышленным стан-
дартом, однако до недавнего времени применялся довольно ши-
роко, так как до выхода Delphi 5 был практически единственным
универсальным механизмом доступа к данным, поддерживаемым
средствами разработки Borland на уровне компонентов и классов.
234
Глава 4. Доступ к базам данных
Графическая интерпретация механизмов доступа к данным
из приложений приведена на рис. 4.1.
Рис. 4.1. Возможные механизмы доступа к данным из приложений
В общем случае приложение, использующее БД, может при-
менять следующие механизмы доступа:
• непосредственный вызов функций клиентского API (или
обращение к СОМ-объектам клиентских библиотек);
• вызов функций ODBC API (или применение классов, ин-
капсулирующих подобные вызовы);
• непосредственное обращение к интерфейсам OLE DB;
• применение ADO (или применение классов, инкапсули-
рующих обращение к объектам ADO);
• применение ADO + OLE DB + ODBC;
• применение BDE + SQL Links (или применение классов,
инкапсулирующих обращение к функциям BDE);
• применение BDE + ODBC Link + ODBC.
Кроме вышеуказанных, существуют и другие способы досту-
па к данным, использующие перечисленные универсальные ме-
ханизмы или непосредственно клиентские API.
4.1.1. Технология BDE
Borland Database Engine (BDE) — универсальный механизм
доступа к данным, применяемый в средствах разработки фирмы
Borland (а именно — Delphi и C++ Builder), а также в некоторых
4.1. Стандартные системы доступа к базам данных
235
других продуктах, например Corel Paradox, Corel Quattro Pro,
Seagate Software Crystal Reports.
BDE создан на основе библиотеки Paradox Engine, предна-
значенной для Borland Pascal и Borland C++. Приложения, разра-
ботанные с помощью последних, обеспечивали доступ к табли-
цам СУБД Paradox. После создания Paradox Engine компания
Borland разработала несколько библиотек-драйверов под общим
названием SQL Links. Эти библиотеки расширили функциональ-
ность BDE, позволив применять имевшийся в Paradox Engine на-
бор функций для доступа к данным dBase, ODBC-источников, а
также наиболее популярных серверных СУБД. Позже к этому на-
бору были добавлены библиотеки для доступа к Access и FoxPro.
Механизм BDE широко использовался при создании прило-
жений с помощью Borland Pascal 7.0 и Borland C++ 4.5 и 5. За-
тем средства разработки Borland были преобразованы в средства
быстрой разработки приложений (Rapid Application Develop-
ment — RAD), и большинство вызовов BDE API оказалось ин-
капсулировано в компонентах доступа к данным библиотеки
Visual Components Library (VCL). BDE был фактически единст-
венным механизмом доступа к данным в Delphi и C++ Builder,
поддерживаемым на уровне компонентов, классов, а также визу-
альных компонентов для редактирования данных, вплоть до по-
явления 5-й версии обоих продуктов.
Физически BDE представляет собой набор библиотек досту-
па к данным, реализующих BDE API — набор функций для ма-
нипуляции данными, вызываемых из приложения. Эти функ-
ции, в свою очередь, могут обращаться к функциям клиентско-
го API (в случае, например, Oracle, Informix, IB Database) или
ODBC API (Access 2000, Microsoft SQL Server 7.0, любые
ODBC-источники), а также непосредственно манипулировать
файлами некоторых СУБД (dBase, Paradox).
Для доступа к БД с помощью BDE на компьютере с клиент-
ским приложением следует установить библиотеки BDE общего
назначения, а также BDE-драйвер для данной СУБД. В случае
серверных СУБД такие драйверы носят название SQL Links. Эти
драйверы содержат BDE API — стандартный набор функций,
созданных на основе функций клиентских API соответствующих
СУБД.
Среди BDE-драйверов есть драйвер, созданный с использова-
нием ODBC API, — так называемый ODBC Link, который при-
меняется вместе с ODBC-драйвером для выбранной СУБД.
236
Глава 4. Доступ к базам данных
В отличие от ODBC-драйверов и OLE DB-провайдеров, вы-
пускаемых как производителями СУБД, так и многими сторон-
ними производителями, BDE-драйверы производятся только са-
мой компанией Inprise. Число СУБД, для которых имеются
BDE-драйверы, ограничено пятью наиболее популярными сер-
верными СУБД, несколькими форматами данных настольных
СУБД (в основном ранних версий СУБД) и сервером IB
Database, входящим в комплект поставки средств разработки
Borland. Для доступа к данным остальных СУБД с помощью
BDE можно использовать только ODBC-драйвер и ODBC Link.
Рассмотрим теперь конкретные СУБД, доступные с помо-
щью BDE-драйверов, причем настольных СУБД.
Paradox, dBase, текстовые файлы. Для доступа к данным
Paradox, dBase и текстовым файлам существуют BDE-драйверы
прямого доступа, осуществляющие считывание и запись файлов
этих СУБД. Более того, фирма Microsoft прямо указывает, что
для записи данных в файлы этих СУБД с помощью ODBC или
OLE DB (в частности, из приложений Visual Basic или VBA, при
использовании этих файлов в качестве присоединенных баз дан-
ных Access или Microsoft SQL Server) на компьютере, где исполь-
зуется подобное приложение, следует установить BDE соответст-
вующей версии, так как только эти драйверы осуществляют за-
пись в такие файлы. Таким образом, применяя указанные
форматы данных в приложениях, созданных с помощью таких
средств разработки, не только для чтения, но и для записи, не-
обходимо установить BDE на компьютеры как было сказано
выше. В табл. 4.1 приведены сведения о том, какие версии BDE
требуются для доступа к данным Paradox и dBase различных вер-
сий с помощью ODBC или OLE DB.
Из вышеизложенного следует, что не имеет особого смысла
использовать ODBC-драйверы этих СУБД и ODBC Link, по
крайней мере, в средствах разработки, поддерживающих BDE
(Delphi, C++ Builder), и в созданных с их помощью приложени-
ях. Несмотря на то, что такой доступ к данным технически впол-
не осуществим, реально в приложении все равно используется
BDE-драйвер прямого доступа. В этом случае между приложени-
ем и драйвером оказываются две «лишние» библиотеки, не до-
бавляющие никакой дополнительной функциональности, а лишь
создающие неудобства при поставке приложения и настройке
доступа к данным, к тому же нередко еще и снижающие произ-
водительность приложения.
4.1. Стандартные системы доступа к базам данных
237
Таблица 4.1. Версии BDE
Доступ к данным Paradox или поздних версий dBase непо-
средственно с помощью BDE в Visual Basic, Visual C++ и иных
средств разработки, не ориентированных на поддержку BDE на
уровне визуальных компонентов и классов, возможен только на
уровне вызовов BDE APL
Microsoft Access. BDE-драйвер прямого доступа в настоящее
время доступен для Access 95 и Access 97. Оба эти драйвера рабо-
тают только в том случае, когда на компьютере, где эксплуатиру-
ется использующее их приложение, установлена соответствую-
щая версия библиотек Microsoft Jet Engine (она входит в ком-
плект поставки Microsoft Access и Microsoft Visual FoxPro). Эти
драйверы не способны работать с данными Access 2000.
Для доступа с помощью BDE к Access 2000 используют соот-
ветствующий ODBC-драйвер и ODBC Link, при этом на компью-
тере, где эксплуатируется использующее их приложение, требует-
ся наличие Microsoft Jet Engine 4.0. Продукт входит в состав
Microsoft Access 2000, а также в состав Microsoft Data Access
Components (MDAC) (доступны на Web-сайте корпорации
Microsoft). Следует отметить, что не все типы данных, используе-
мые этой версией Access, поддерживаются BDE, поэтому ка-
кие-то из таблиц или их столбцов могут оказаться недоступными.
238
Глава 4. Доступ к базам данных
Однако, использование BDE — не самый эффективный спо-
соб доступа к данным Access. Применение его целесообразно
для старых версий средств разработки Borland (Delphi 1.0—4.0,
C++ Builder 1.0—4.0), ориентированных на применение BDE как
единственного механизма доступа к данным на уровне компо-
нентов и классов. В случае применения других средств разработ-
ки, а также последних версий Delphi и C++ Builder гораздо эф-
фективнее осуществлять доступ к данным Access с помощью
ADO и OLE DB, так как эти механизмы предоставляют по срав-
нению с BDE гораздо больше функциональных возможностей.
Microsoft FoxPro и Visual FoxPro. Доступ к данным FoxPro
осуществим в первую очередь с помощью BDE-драйвера прямо-
го доступа, позволяющего производить запись в файлы этой
СУБД. Возможен также доступ через ODBC Link и соответст-
вующий ODBC-драйвер. Доступ к данным Visual FoxPro осуще-
ствим только с помощью ODBC Link и соответствующего
ODBC-драйвера, поскольку BDE-драйвер для БД Visual FoxPro
(*.vfp) в настоящее время отсутствует.
Microsoft SQL Server и MSDE. BDE-драйвер прямого досту-
па существует сегодня для Microsoft SQL Server версий 4.x и 6.x.
Он не всегда работает с Microsoft SQL Server 7.0 и MSDE, так
как некоторые особенности Microsoft SQL Server 7.0, отсутство-
вавшие в прежних версиях этой СУБД, например ряд типов дан-
ных, не поддерживаются BDE.
Следует подчеркнуть, что, как и в случае с Access, несмотря
на существование теоретической возможности доступа к данным
этой СУБД с помощью ODBC Link и соответствующего ODBC-
драйвера, практически это осуществимо не всегда по той же са-
мой причине. Доступ к данным этой СУБД необходимо осуще-
ствлять с помощью ADO/OLE DB (либо с помощью объектной
модели клиентской части этой СУБД).
Oracle, Sybase, IBM DB2, Informix, InterBase. Для всех пере-
численных СУБД существуют BDE-драйверы прямого доступа
(SQL Links). Кроме того, СУБД доступны с помощью ODBC
Link и ODBC-драйверов в случае, когда в качестве средства раз-
работки используется Delphi Professional или C++ Builder Pro-
fessional, не имеющие SQL Links в своем составе. Для этих ука-
занных СУБД нередко имеется по нескольку ODBC-драйверов
разных производителей, иногда поддерживающих разную функ-
циональность.
4.1. Стандартные системы доступа к базам данных
239
В случае использования объектно-ориентированных возмож-
ностей Oracle 8 на данный момент более предпочтительно при-
менение BDE механизма доступа к данным, так как объектные
типы данных этой СУБД поддерживаются ее BDE-драйвером
прямого доступа (и не поддерживаются имеющимися версиями
OLE DB-провайдеров). Однако поддержка этих возможностей на
уровне компонентов и классов в Delphi и C++ Builder возможна
только начиная с версии 4.0.
4.1.2. Механизм ODBC
Open Database Connectivity (ODBC) — широко распростра-
ненный программный интерфейс фирмы Microsoft, удовлетво-
ряющий стандартам ANSI и ISO для интерфейсов обращений к
БД (Call Level Interface — CLI). Для доступа к данным конкрет-
ной СУБД с помощью ODBC, кроме собственно клиентской
части этой СУБД, нужен ODBC Administrator (приложение, по-
зволяющее определить, какие источники данных доступны для
данного компьютера с помощью ODBC, и описать новые источ-
ники данных) и ODBC-драйвер для доступа к этой СУБД.
ODBC-драйвер представляет собой динамически загружаемую
библиотеку (DLL), которую клиентское приложение может за-
грузить в свое адресное пространство и использовать для доступа
к источнику данных. Для каждой используемой СУБД нужен
собственный ODBC-драйвер, так как ODBC-драйверы использу-
ют разные функции клиентских API для различных СУБД.
ODBC позволяет манипулировать данными любой СУБД (и
даже данными, не имеющими прямого отношения к БД, напри-
мер данными в файлах электронных таблиц или в текстовых фай-
лах), если для них имеется ODBC-драйвер. Для манипуляции
данными используют как непосредственные вызовы ODBC API,
так и другие универсальные механизмы доступа к данным, на-
пример OLE DB, ADO, BDE, реализующие стандартные функ-
ции или классы на основе вызовов ODBC API в драйверах или
провайдерах, специально предназначенных для работы с любы-
ми ODBC-источниками.
Спецификация ODBC подразумевает несколько стандартов
на ODBC-драйверы (в этом случае употребляются термины
Level 1, Level 2 и т. д.). Эти стандарты отличаются различной
функциональностью, которая должна быть реализована в таком
240
Глава 4. Доступ к базам данных
драйвере. Например, драйверы, соответствующие стандарту
Level 1, нс обязаны поддерживать работу с хранимыми процеду-
рами, а некоторые ODBC-драйверы не поддерживают двухфаз-
ное завершение транзакций (применяемое в том случае, когда
требуется согласованное изменение данных в нескольких раз-
личных серверных СУБД).
ODBC-источники. Для доступа с помощью BDE к источни-
кам данных следует использовать ODBC-драйвер и ODBC Link.
В табл. 4.2 приведен список ODBC-драйверов, сертифициро-
ванных для использования с Delphi 5/С++ Builder 5 и BDE. В це-
лом доступ к наиболее популярным СУБД может быть осуществ-
лен с помощью BDE способами, перечисленными в табл. 4.3.
Таблица 4.2. Список ODBC-драйверов, сертифицированных для использования
с Delphi 5/С++ Builder 5 и BDE
Сертификация при- менимости с BDE Полностью серти- фицированные драйверы Драйверы, серти- фицированные как реализующие ос- новную функцио- нальность Версия ODBC Driver Manager 3.5 СУБД Access 95/97 FoxPro Производитель ODBC-драйвера Microsoft Версия ODBC-драйвера 3.40 3.40
Microsoft SQL Server 6.5 3.00
Microsoft SQL Server 6.5 Intersolv 3.01
Oracle 7.3 3.01
3.51 Access 95/97 Microsoft 3.51
FoxPro 3.51
Microsoft SQL Server 6.5 3.6
Microsoft SQL Server 6.5, 7.0 Intersolv 3.11
Oracle 7.3 3.11
3.5 Informix 7.20 и 9.11 3.01
DB2 (IBM v5 client 6/98); протестирован с серверами 2.12 и 5.0 (UDB) Нет сведений об ODBC-драйверах
Sybase 11.02 Intersolv 3.01
3.51 DB2 (IBM v5 client 6/98; протестирован с серверами 2.12 и 5.0 (UDB) Нет сведений об ODBC-драйверах
Sybase 11.02 Intersolv 3.11
Oracle 7.3 и 8.0.4 3.11
4.1. Стандартные системы доступа к базам данных
241
Таблица 4.3. Способы осуществления доступа с помощью BDE к наиболее
популярным СУБД
СУБД ODBC-драйвер + ODBC Link BDE-драйвер
Paradox + +
dBase + +
Microsoft Access 95 + (требуется Microsoft Jet Engine 3.0) + (требуется Microsoft Jet Engine 3.0)
Microsoft Access 97 + (требуется Microsoft Jet Engine 3.5) + (требуется Microsoft Jet Engine 3.5)
Microsoft Access 2000 Частично (требуется Microsoft Jet Engine 4.0) —
Microsoft FoxPro Microsoft Visual FoxPro + + +
Microsoft SQL Server 6.5 + +
Microsoft SQL Server 7.0 + —
Microsoft Data Engine + —
Oracle 7 + +
Oracle 8 + + (начиная с версии 8.0.4)
Sybase 4.0 (с интерфейсом DB-Lib) + +
Sybase System 10 и бопее поздние версии с интерфейсом CT-Lib Interface + + (начиная с версии 10.0.4 EBF7264)
Informix + +
IBM DB2 + +
IB Database 4.0, 5.x + +
Резюмируя сказанное выше, отметим, что по сравнению с
другими универсальными механизмами доступа к данным при-
менение BDE оправданно, если:
• для хранения данных используются СУБД, ранее принад-
лежавшие фирме Borland (Paradox, dBase);
• для создания приложений используются ранние версии
средств разработки Borland вместе с Informix, IB Database,
DB2, Sybase, а также ранними версиями Access и Microsoft
SQL Server;
• используются объектные расширения Oracle и средства
разработки Borland двух последних версий.
242
Глава 4. Доступ к базам данных
4.1.3. Компоненты для доступа к ODBC-источникам
Поскольку на данный момент ODBC является самым ис-
пользуемым универсальным механизмом доступа к данным, пер-
спективы применения подобных компонентов очевидны. Произ-
водительность приложений, использующих компоненты для до-
ступа к ODBC-источникам, обычно выше производительности
приложений, которые используют BDE и ODBC Link, за счет
отказа от использования дополнительных библиотек BDE. По
этой же причине упрощена поставка таких приложений, по-
скольку не требуется включать BDE в дистрибутив и обеспечи-
вать его настройку на компьютере пользователя.
ODBCExpress (Korbitec) [4] представляет собой набор компо-
нентов и классов для Delphi и C++ Builder, применяемых для
доступа к ODBC-источникам данных и инкапсулирующих вызо-
вы ODBC API. Для работы приложений, использующих эти ком-
поненты и классы, требуются библиотеки ODBC (доступные на
Web-сервере Microsoft) и ODBC-драйвер для выбранной СУБД.
Сами компоненты и классы ODBCExpress располагаются внугри
исполняемого файла приложения.
ODBCExpress совместим со стандартными компонентами
отображения данных и генераторами отчетов, наиболее часто
применяемыми с этими средствами разработки, а также с наибо-
лее популярными коммерческими компонентами отображения
данных, такими, как InfoPower (Woll2Woll Software) и Orpheus
(TurboPower).
Эксперты, тестировавшие продукт, отмечают его отличную
работу вместе с ODBC-драйверами для Microsoft SQL Server и
Microsoft Access и неудовлетворительную работу с ODBC-драй-
верами для Sybase SQL Anywhere и IB Database.
ODBC98 (Kosta Corriveau), как и ODBCExpress, представляет
собой набор компонентов и классов для Delphi и C++ Builder,
обеспечивающих доступ к ODBC-источникам и использующих
для этой цели ODBC API [5]. Применение этих библиотек также
требует библиотек ODBC и ODBC-драйвер для выбранной
СУБД. Сами компоненты и классы ODBC98 также располагают-
ся внутри исполняемого файла приложения.
ODBC98 совместим со стандартными компонентами ото-
бражения данных и генераторами отчетов, наиболее часто при-
меняемыми с этими средствами разработки, а также с наибо-
лее популярными коммерческими компонентами отображения
4.1. Стандартные системы доступа к базам данных
243
данных, такими, как InfoPower (Woll2Woll Software) и Orpheus
(Turbo Powe г).
ODBC98 — относительно новый продукт; он, по мнению
экспертов, имеет высококачественную техническую поддержку.
Достоинством продукта также считают и регулярные публика-
ции результатов его тестирования совместно с вновь выходящи-
ми ODBC-драйверами.
4.1.4. Компоненты прямого доступа к Oracle
Несмотря на достойную поддержку Oracle в BDE, компонен-
ты прямого доступа к Oracle имеют хорошие перспективы приме-
нения, так как не требуют приобретения дорогих Enterprise-вер-
сий Delphi или C++ Builder и предоставляют дополнительную
функциональность, специфичную для данной СУБД.
Производительность приложений с компонентами прямого
доступа к Oracle (как и к любым другим серверным СУБД),
обычно выше, чем приложений с BDE, поскольку отпадает не-
обходимость пользования дополнительными библиотеками BDE.
Поставка приложений с такими компонентами не представляет
трудностей — в состав дистрибутива приложений не нужно
включать ни BDE, ни ODBC. Однако клиентская часть Oracle на
компьютере пользователя, безусловно, должна присутствовать —
эти компоненты используют функции или объекты из ее биб-
лиотек.
Oracle Data Access Components (ODAC) фирмы CoRe Lab
Software Development представляет собой набор невизуальных
компонентов для Delphi и C++ Builder, позволяющих осущест-
вить доступ к Oracle без использования универсальных механиз-
мов доступа к данным. Для доступа к объектам Oracle ODAC ис-
пользует непосредственно API клиентской части Oracle — Oracle
Call Interface (OCI). В результате повышается производитель-
ность приложений и, кроме того, при создании приложений
Delphi Professional или C++ Builder Professional продукты более
дешевые, чем Enterprise-версии [6].
ODAC используют совместно со стандартными компонента-
ми отображения данных — QuickReport, ReportBuildcr Pro —
а также с наиболее популярными коммерческими компонентами
отображения данных, такими, как InfoPower (Woll2Woll Software)
и Orpheus (TurboPower).
244
Глава 4. Доступ к базам данных
Компоненты ODAC могут быть использованы с Oracle 7.3,
Oracle 8, Oracle 8i, включая Personal Oracle и Personal Oracle Lite.
Direct Oracle Access (Allround Automations) представляет собой
еще один набор компонентов, использующий клиентский API
для доступа к данным Oracle. Эти компоненты не требуют при-
менения каких-либо универсальных механизмов доступа к дан-
ным, тем самым повышая производительность создаваемых при-
ложений, а также позволяют использовать Professional-версии
средств разработки Borland для создания приложений с Oracle.
Кроме того, Direct Oracle Access позволяет выполнять блоки
PL/SQL и использовать объектные расширения Oracle 8 [7].
Direct Oracle Access применим совместно со стандартными
компонентами отображения данных, генераторами отчетов типа
QuickRcport, ReportBuildcr Pro, а также с наиболее популярными
коммерческими компонентами отображения данных, такими,
как InfoPower (Woll2Woll Software) и Orpheus (TurboPower).
Данный набор компонентов совместим со всеми версиями
клиентов Oracle и со всеми версиями Oracle — от Personal Oracle
Lite до Oracle 8i.
4.1.5. Компоненты прямого доступа
к InterBase Database
Компоненты прямого доступа к InterBase (IB) Database (как и
аналогичные компоненты для Oracle) имеют неплохие перспекти-
вы применения, так как нс требуют приобретения Enterprise-вер-
сий Delphi или C++ Builder, предоставляя дополнительную функ-
циональность, специфичную для IB Database. Один из таких на-
боров уже входит в комплект поставки Enterprise-версий Delphi 5
и C++ Builder 5, но при наличии Professional-версий этих продук-
тов (или более ранних их версий) лучше обратить внимание на
продукты сторонних фирм, реализующие аналогичную функцио-
нальность.
Производительность приложений, использующих компонен-
ты прямого доступа к IB Database, обычно выше производитель-
ности приложений, которые используют BDE. При поставке та-
ких приложений на компьютере пользователя следует установить
клиентскую часть IB Database — эти компоненты используют
клиентский API, содержащийся в ее библиотеке.
4.1. Стандартные системы доступа к базам данных
245
InterBase Objects (Jason Wharton) — IB Objects представляет
собой набор из более чем 40 компонентов прямого доступа к 1В
Database для Delphi (начиная с версии 2.0) и C++ Builder (начи-
ная с версии 3.0), использующих клиентский API этой СУБД.
Этот набор совместим со стандартными компонентами отобра-
жения данных и генераторами отчетов, наиболее часто приме-
няемыми с этими средствами разработки, а также с наиболее по-
пулярными коммерческими компонентами отображения дан-
ных, такими как InfoPower (Woll2Woll Software) и Orpheus
(TurboPower), однако содержит и собственные визуальные ком-
поненты, в том числе реализующие поиск данных в таблицах и
результатах запросов. IB Objects позволяет использовать специ-
фические особенности IB Database, в частности связанные с об-
работкой транзакций в этой СУБД [8|.
В комплект поставки IB Objects входит также сервер прило-
жений, позволяющий создавать Web-приложения с применени-
ем этих компонентов, а также средство просмотра SQL-запро-
сов, генерируемых приложением.
FreelBComponents (Gregory Deatz) — набор VCL-компонен-
тов прямого доступа к IB Database 4.2 и 5 для Delphi (начиная с
Delphi 3). Кроме собственно компонентов доступа к данным, со-
держит Pascal-версию заголовочного файла API клиентской час-
ти IB Database [9].
Продукт распространяется бесплатно, тем не менее следует
отметить быстрое исправление ошибок и недостатков.
4.1.6. Компоненты Titan для доступа
к различным СУБД
Компоненты Titan фирмы Reggatta Systems для доступа к
Btrieve, Microsoft Access, Sybase SQL Anywhere используют кли-
ентский API этих СУБД, что исключает необходимость исполь-
зования других библиотек доступа к данным (BDE, ODBC и др.)
и позволяет достичь приемлемой производительности [10].
Titan Btrieve (Reggatta Systems) представляет собой набор
компонентов прямого доступа к данным Btrieve 6.x и выше, а
также Pervasive.SQL. Эти компоненты используют непосредст-
венно Btrieve API и требуют наличия соответствующих библио-
тек на клиентском компьютере, где используется такое прило-
жение.
246
Глава 4. Доступ к базам данных
Компоненты Titan Btrieve совместимы со всеми компонента-
ми отображения данных Delphi и C++ Builder.
Среди особенностей Titan Btrieve следует отметить возмож-
ность добавлять в исполняемый файл сведения о метаданных ис-
пользуемой этим приложением БД (имена таблиц, наименования
и типы полей и др.). В результате снижается число обращений к
БД и тем самым уменьшается сетевой трафик. При использова-
нии Titan Btrieve можно также вызывать процедуры сжатия БД
и восстановления се после сбоев [10].
Titan Access (Reggatta Systems) представляет собой набор
компонентов прямого доступа к данным Access. Эти компонен-
ты используют библиотеки Microsoft Jet, которые следует уста-
новить на компьютере пользователя [10].
Компоненты Titan Access совместимы со всеми компонента-
ми отображения данных Delphi и C++ Builder.
Titan SQL Anywhere (Reggatta Systems) представляет собой
набор компонентов прямого доступа к данным Sybase SQL
Anywhere. Эти компоненты используют API клиентской части
SQL Anywhere, в том числе недокументированные функции.
Компоненты Titan SQL Anywhere совместимы со всеми ком-
понентами отображения данных Delphi и C++ Builder.
По мнению экспертов, данный продукт обладает высокой
производительностью [10].
4.1.7. Компоненты управления данными dBase
и dBase-подобных СУБД
Компоненты доступа к dBase весьма перспективны к приме-
нению, так как на протяжении многих лет dBase и его версии
были самыми популярными в мире форматами данных. Количе-
ство данных, хранящихся в этом формате, а также информаци-
онных систем, базирующихся на применении формата данных
dBase, по-прежнему очень велико, особенно в нашей стране.
TOPAZ (Software Science, Inc.) представляет собой набор
компонентов, классов и функций для Delphi и C++ Builder, по-
зволяющих осуществить прямой доступ к данным ранних версий
формата dBase, а также применять в приложениях, созданных с
помощью Delphi, функции, характерные для xBase-языков (они
реализованы в библиотеках TOPAZ) [11].
4.1. Стандартные системы доступа к базам данных
247
TOPAZ совместим со стандартными компонентами отображе-
ния данных (QuickReport), а также с наиболее популярными ком-
мерческими компонентами отображения данных, — InfoPower
(Woll2Woll Software) и Orpheus (TurboPower) — однако содержит и
собственные визуальные компоненты, предназначенные для пе-
чати некоторых специализированных отчетов (типа почтовых и
других этикеток) и редактирования данных в стиле «старых»
dBase-приложений.
Поставка приложений, использующих TOPAZ, не представ-
ляет трудностей — в состав дистрибутива приложений не нужно
включать ни BDE, ни ODBC. Сами же компоненты находятся
внутри исполняемого файла, использующего их приложения, и
не требуют никаких дополнительных библиотек.
Кроме библиотек компонентов и функций для манипуляции
данными, в комплект поставки TOPAZ входит ряд полезных
утилит, например для редактирования dBase-таблиц и их струк-
туры и др. [11].
Apollo (Vista Software) представляет собой набор VCL-компо-
нентов к Delphi и C++ Builder для осуществления прямого дос-
тупа к таблицам и индексам FoxPro и Clipper (файлы с расшире-
ниями .DBF, .DBT, .NTX, .FPT, .IDX, .CDX), а также к собст-
венному формату данных Vista Software (файл с расширением
.NSX). При поставке приложений, кроме исполняемого файла,
требуются две динамически загружаемые библиотеки размером
350 Кбайт [12].
Особенностью Apollo является поддержка режима блокиро-
вок, характерного для DOS-приложений, созданных с помощью
FoxPro и Clipper. Это позволяет совместно использовать одну и
ту же БД приложениями, созданными с помощью Apollo, и при-
ложениями, созданными с помощью FoxPro и Clipper. Помимо
этого Apollo поддерживает оптимизацию запросов наподобие
применяемой в FoxPro, шифрование данных, использование
функций, определяемых пользователем, в запросах и индексах
(что широко применялось в dBase, Clipper, FoxPro, но сейчас
практически не используется в универсальных механизмах до-
ступа к данным; с этой точки зрения Apollo — практически един-
ственный инструмент, позволяющий манипулировать dBase-таб-
лицами с индексами, основанными на выражениях).
Apollo совместим со стандартными компонентами отображе-
ния данных, с популярными генераторами отчетов, используе-
мыми с этими средствами разработки, а также с наиболее попу-
248
Глава 4. Доступ к базам данных
лярными коммерческими компонентами отображения данных
InfoPower (Woll2Woll Software) и Orpheus (TurboPower) [12].
Advantage Database Server (Extended Systems, Inc.) является
одним из некогда «модных» решений — надстройкой над
dBase-данными, в виде отдельного процесса, функционирующе-
го наподобие сервера БД и управляющего dBase-таблицами.
Клиентские приложения обращаются к этому серверу, а не не-
посредственно к таблицам, т. е. в результате получаем некоторые
преимущества архитектуры «клиент — сервер» (например, обра-
ботку запросов на сервере, увеличение объема хранимых дан-
ных) при сохранении устаревшего формата данных; следует от-
метить, что это решение пока еще довольно популярно, по край-
ней мере в США [13].
Advantage Database Server содержит компоненты и классы
для Delphi и C++ Builder, позволяющие использовать стандарт-
ные компоненты отображения данных, самые популярные гене-
раторы отчетов, используемые с этими средствами разработки, а
также наиболее популярные коммерческие компоненты отобра-
жения данных InfoPower (Woll2Woll Software) и Orpheus
(TurboPower).
Для использования Advantage Database Server с другими сред-
ствами разработки в комплект поставки продукта входит
ODBC-драйвер.
Серверная часть Advantage Database Server (без клиентских
утилит) входит в комплект поставки Visual dBase начиная с вер-
сии 7.5.
На компьютере, где эксплуатируются приложения, исполь-
зующие Advantage Database Server, требуется наличие его клиент-
ской части.
4.1.8. Универсальный механизм доступа к данным
Universal Data Access
Универсальный механизм доступа к данным — Universal Data
Access (Microsoft) [15] представляет собой стратегию предостав-
ления доступа к любому типу информации. В результате обеспе-
чен высокопроизводительный доступ к различным источникам
информации (включая реляционные и нереляционные данные),
в том числе к данным, хранящимся на серверах, данным элек-
тронной почты и файловой системы, текстовым, графическим и
4.1. Стандартные системы доступа к базам данных
249
географическим данным и др. Вполне очевидно, что могут появ-
ляться новые форматы данных и способы их хранения, поэтому
разумным требованием к универсальному механизму доступа к
данным будет организация поддержки нс только существующих
в настоящее время форматов и источников данных, но и форма-
тов данных в будущем.
Назначение универсального механизма доступа к данным
фирмы Microsoft — предоставить доступ к перечисленным ис-
точникам данных с помощью единой модели доступа к данным.
В настоящее время универсальный механизм доступа к дан-
ным фирмы Microsoft поддерживает все наиболее популярные
настольные и серверные СУБД.
Рассмотрим основные компоненты архитектуры универсаль-
ного механизма доступа к данным Microsoft и обсудим их более
детально.
• Microsoft ActiveX Data Objects (ADO) — программный ин-
терфейс для доступа к данным из приложений. С точки
зрения программирования, ADO и его расширения явля-
ются упрощенным высокоуровневым объектно-ориентиро-
ванным интерфейсом к OLE DB;
• OLE DB — низкоуровневый интерфейс для доступа к дан-
ным. ADO использует OLE DB, но можно использовать
OLE DB и напрямую, минуя ADO;
• Open Database Connectivity (ODBC) — стандартный способ
доступа к реляционным данным, уже обсуждавшийся ра-
нее. Этот компонент универсального механизма доступа к
данным оставлен с целью обеспечения совместимости с
прежними версиями программного обеспечения. В совре-
менных приложениях применению ODBC-драйверов пред-
почитают использование OLE DB-провайдеров.
Архитектура универсального механизма доступа к данным
Microsoft схематически представлена на рис. 4.2 [14, 15].
Поскольку OLE DB является низкоуровневым интерфейсом
доступа к данным, рассмотрение составных частей универсаль-
ного механизма доступа к данным фирмы Microsoft начнем
именно с него: обсудим архитектуру и интерфейсы OLE DB,
а затем остановимся на взаимодейсивии с ADO.
OLE DB и ADO — часть универсального механизма доступа к
данным Microsoft, позволяющая осуществить доступ как к реля-
ционным, так и к нереляционным источникам данных, таким
250
Глава 4. Доступ к базам данных
Рис. 4.2. Архитектура универсального механизма доступа к данным Microsoft
как файловая система, данные электронной почты, многомер-
ные хранилища данных и др. [15—18].
Microsoft ActiveX Data Objects (ADO) — это набор библиотек,
содержащих COM-объекты, реализующие прикладной про-
граммный интерфейс для доступа к таким данным и используе-
мые в клиентских приложениях. ADO использует библиотеки
OLE DB, предоставляющие низкоуровневый интерфейс для до-
ступа к данным. OLE DB предоставляет доступ к данным с по-
мощью COM-интерфейсов. Можно также использовать OLE DB
непосредственно, минуя ADO.
Для доступа к источнику данных с помощью OLE DB на
компьютере, где используется клиентское приложение, необхо-
димо установить OLE DB-провайдер для данной СУБД. Он
представляет собой DLL, загружаемую в адресное пространство
клиентского приложения и используемую для доступа к источ-
нику данных. Для каждого типа СУБД нужен собственный OLE
DB-провайдер, так как эти провайдеры базируются на функциях
клиентских API, разных для различных СУБД.
Среди OLE DB-провайдеров для разных источников данных
имеется специальный провайдер Microsoft OLE DB Provider for
ODBC Drivers, который использует интерфейс ODBC API, поэто-
му он применяется вместе с ODBC-драйвером для выбранной
СУБД.
4.1. Стандартные системы доступа к базам данных
251
Следует отметить, что ADO становится все более популяр-
ным способом доступа к данным, так как входит в состав широ-
ко используемых продуктов Microsoft Office 2000 и Microsoft
Internet Explorer 5.0, а также включен в ядро операционных сис-
тем семейства Windows 2000.
OLE DB представляет собой программный интерфейс для
доступа к различным источникам данных (реляционные и нере-
ляционные данные, текстовые, графические и географические
данные, архивы электронных писем, файловая система, биз-
нес-объекты). В спецификации OLE DB определен набор
COM-интерфейсов (СОМ — Component Object Model — компо-
нентная модель объектов Microsoft, являющаяся составной ча-
стью 32-разрядных версий Windows), инкапсулирующих различ-
ные сервисы управления данными и предоставляющих однотип-
ный доступ к перечисленным выше данным.
Компоненты OLE DB. На самом верхнем уровне различают
три главных компонента OLE DB: потребители (consumers), про-
вайдеры данных (data providers) и сервисные компоненты (service
components) [15—18].
Любой компонент программного обеспечения, применяю-
щий интерфейсы OLE DB, является потребителем (например,
любое офисное приложение или иное бизнес-приложение, сред-
ство разработки типа Visual Basic или Delphi либо даже СОМ-объ-
екты для доступа к данным). Потребители могут обращаться к
данным посредством ActiveX Data Objects, в виде высокоуровне-
вого интерфейса к OLE DB, или применять OLE DB непосредст-
венно, используя OLE DB-провайдер.
Провайдер — это часть программного обеспечения, в которой
реализованы интерфейсы OLE DB. Здесь определяют два типа
OLE DB-провайдеров — провайдеры данных и сервисные ком-
поненты.
Провайдер данных — это компонент программного обеспече-
ния, манипулирующий данными, который располагается между
потребителем данных и БД. В OLE DB все провайдеры пред-
ставляют данные в табличном формате (аналогичном тому, в ко-
тором хранятся данные в реляционных СУБД и файлах элек-
тронных таблиц), в виде виртуальных таблиц. Провайдер данных
выполняет функции:
• приема от потребителя запросов на получение или моди-
фикацию данных;
• получения данных из БД или их модификацию в БД;
252 Глава 4. Доступ к базам данных
• возвращения данных потребителю.
К провайдерам данных относится провайдер Microsoft Jet 4.0
OLE DB Provider, который используется для доступа к данным
Microsoft Access, I-1SAM (Installable Indexed Sequential Access
Method); файлам рабочих книг Excel, хранилищ данных Micro-
soft Outlook и Microsoft Exchange, таблиц dBase и Paradox, тек-
стовым файлам, файлам в формате HTML и др. Таким же про-
вайдером является Microsoft OLE DB Provider for SQL Server,
применяемый для доступа к БД Microsoft SQL Server 6.5 и 7.0.
Провайдер сервисов (или сервисный компонент) реализует
расширенную функциональность, не поддерживаемую обычны-
ми провайдерами данных (сортировку и фильтрацию данных,
обработку транзакций и SQL-запросов, управление курсором и
др.) Сервисный компонент может обращаться к хранилищу дан-
ных непосредственно или с помощью соответствующего провай-
дера данных — в этом случае провайдер сервисов является одно-
временно и провайдером, и потребителем. Так, сервисные ком-
поненты Microsoft Cursor Service for OLE DB и Microsoft Data
Shaping Service for OLE DB могут использоваться совместно с
провайдерами данных OLE DB для расширения их функцио-
нальности. На рис. 4.3 показано, как компоненты OLE DB взаи-
модействуют между собой [14—18]: потребитель может получать
данные непосредственно с помощью провайдера данных или с
использованием сервисов, предоставляемых сервисными компо-
нентами.
Рис. 4.3. Взаимодействие компонентов OLE DB
4.1. Стандартные системы доступа к базам данных
253
В табл. 4.4 приведен список провайдеров в составе набора
MDAC (Microsoft Data Access Components), поставляемого с
продуктами Microsoft.
Таблица 4.4. Список провайдеров, доступных в составе набора MDAC
Провайдер Описание
Microsoft OLE DB Provider for ODBC Drivers Позволяет осуществить доступ к любому ODBC-источнику
Microsoft Jet 4.0 OLE DB Provider Применяется для доступа к данным Microsoft Access и некоторых других СУБД
Microsoft OLE DB Provider for SQL Server Используется для доступа к данным Microsoft SQL Server
Microsoft OLE DB Provider for Oracle Используется для доступа к данным Oracle
Microsoft OLE DB Provider for Internet Publishing Используется для доступа к Web-серверам и ресурсам, обслуживаемым Microsoft Frontpage или Microsoft Internet Information Server
OLE DB Provider for Microsoft Directory Services Применяется для доступа к гетерогенным службам каталогов с помощью Microsoft Active Directory Service Interfaces (ADSI)
Microsoft OLE DB Provider for Microsoft Index Server Предоставляет доступ «только для чтения» к файловой системе и данным Web, индексиро- ванным с помощью Microsoft Indexing Service
Microsoft OLE DB Simple Provider Используется для доступа к текстовым файлам
Cursor Service for OLE DB Расширяет функциональность курсора
Data Shaping Service for OLE DB Применяется для создания связей между на- борами данных и получения иерархических наборов данных
OLE DB Persistence Provider Используется для сохранения наборов данных в форматах ADTG (Advanced Data Table Gram) или XML (extensible Markup Language)
OLE DB Remoting Provider Позволяет обращаться к провайдерам данных на удаленных компьютерах
Microsoft OLE DB Provider for OLAP Services Применяется с расширением ADO Multi-Dimensional (ADO MD) для доступа к многомерным данным, созданным с помо- щью Microsoft SQL Servei 7.0 OLAP Services
254
Глава 4. Доступ к базам данных
OLE DB представляет собой набор СОМ-интсрфейсов. На
рис. 4.4 схематически представлено четыре основных объекта и
их интерфейсы, а также методы их взаимодействия [14—18]. От-
метим, что каждый OLE DB-провайдер должен содержать реали-
зацию основных объектов DataSource, Session и Rowset.
Рис. 4.4. Основные объекта и их интерфейсы
Рассмотрим эти объекты подробнее.
Объекты OLE DB. Объектная модель OLE DB содержит че-
тыре ключевых объекта [15—18]:
• DataSource;
• Session;
• Command;
• Rowset.
Объект DataSource, применяемый потребителями данных для
соединения с провайдером, создается различными способами,
включая вызов функции CoCreateInstance с идентификатором
класса (CLSID, Class Identifier) OLE DB-провайдера, использо-
вание объекта Enumerator (см. далее), который занимается поис-
ком источников данных, и пр. Объект DataSource инкапсулирует
информацию, связанную с соединением (включая имя пользова-
теля и пароль). Основное назначение этого объекта — предо-
ставлять данные из источника данных потребителю [15—18].
Создание новой сессии (объект Session) производится методом
CreateSession интерфейса IDBCreateSession объекта DataSource.
4.1. Стандартные системы доступа к базам данных
255
Объект Session предоставляет контекст для транзакций, спо-
собен генерировать наборы данных (rowsets) из источников дан-
ных, а также команды для запросов к источнику данных. Кроме
того, он может выполнять роль фабрики классов для объектов
Command и Rowset (см. далее) и объекта Transaction, применяе-
мого для управления вложенными транзакциями. Объекты
Command и Rowset используются для создания или модификации
таблиц и индексов, интерфейс lOpenRowset — для работы с от-
дельными таблицами и индексами в хранилище данных [15—18].
С одним объектом DataSource может быть связано несколько
объектов Session.
Если OLE DB-провайдер поддерживает команды или запро-
сы, он должен порождать объект Command. С одним объектом
DataSource может быть связано несколько объектов Command.
Для создания нового объекта Command применяется опция
CreateCommand интерфейса IDBCreateCommand.
Объект Command используется для выполнения команд в
виде строк, передаваемых для выполнения от потребителя дан-
ных объекту DataSource. В большинстве случаев такая команда
представляет собой SQL-предложение SELECT; однако в общем
случае — любое другое SQL-предложение (например, DDL-пред-
ложение). Команды могут содержать параметры — в этом случае
применяется интерфейс ICommandWithParameters. Одна сессия
может порождать несколько команд. Результатом выполнения
команды (с помощью опции Execute интерфейса ICommand)
обычно является новый объект Rowset [15—18].
Объект Rowset (набор данных) позволяет OLE DB-провайде-
ру данных представлять данные из источников данных в таблич-
ном формате, т. е. в виде набора строк, содержащих одну или
несколько колонок. Объект появляется в результате выполнения
команды или может быть сгенерирован непосредственно про-
вайдером данных, если провайдер не поддерживает команд. Все
провайдеры данных обеспечивают создание наборов данных на-
прямую. Объект Rowset можно использовть для обновления, до-
бавления или удаления строк в зависимости от функционально-
сти провайдера данных.
Интерфейс I Rowset позволяет перемещаться по набору дан-
ных вперед из объекта Rowset и, если набор данных позволяет,
назад. Некоторые провайдеры предоставляют дополнительные
функции наподобие непосредственного доступа или определе-
ния примерной позиции данной строки в наборе.
256
Глава 4. Доступ к базам данных
Частным случаем объекта Rowset является объект Index
(в виде набора строк), использующий соответствующий индекс
для получения набора данных в упорядоченном виде.
Существуют также специальные объекты типа Rowset —
schema rowsets, содержащие метаданные (т. е. сведения о струк-
туре данных), и view rowsets, содержащие подмножество строк и
столбцов объекта Rowset.
Кроме объектов, перечисленных выше, существуют и дру-
гие — для перечисления источников данных, управления тран-
закциями, обработки ошибок и др. [15—18|.
Объект Enumerator необходим для получения списка доступ-
ных объектов, обеспечивающих доступ к источникам данных
(OLE DB-провайдеров); используется для поиска соответствую-
щих объектов. В большинстве случаев сведения, возвращаемые
объектом Enumerator, извлекаются из системного реестра. Объ-
ект реализует интерфейс ISourceRowset и возвращает объект
Rowset с описанием всех источников данных и других доступных
с его помошью объектов Enumerator. Для этой цели использует-
ся метод GetSourcesRowset интерфейса ISourceRowset [15—18].
Объект Transaction поддерживает транзакции в источнике
данных. Транзакции позволяют определить группу операций,
которые либо выполняются все вместе, либо все вместе отменя-
ются.
Транзакции бывают локальными и распределенными. Ло-
кальные транзакции — это транзакции, выполняемые в контек-
сте единого провайдера данных. Такой провайдер должен реали-
зовать интерфейс ITransactionLocal. Транзакция начинается с
вызова метода StartTransaction, завершается с помощью метода
Commit или откатывается с помощью Abort. Способность про-
вайдера поддерживать транзакции определяют с помощью ин-
терфейса IDBProperties [15].
Распределенные транзакции выполняются в контексте не-
скольких провайдеров данных. В этом случае используют интер-
фейс TtransactionJoin. Для регистрации сессии в распределенной
транзакции вызывается метод JoinTransaction. После присоеди-
нения к распределенной транзакции потребитель использует ин-
терфейс ITransaction для завершения или отката транзакции
[15-18].
Объект Error. В дополнение к кедам возврата и информации
о состоянии (успсх/неуспех вызова любого из методов OLE DB)
OLE DB-провайдеры могут предоставлять расширенную инфор-
4.1. Стандартные системы доступа к базам данных
257
мацию об ошибках с помощью объекта Error. Интерфейс
ISupportErrorlnfo сообщает, может ли данный объект возвратить
объект Error, и если да, то каким образом [15—18].
Поставщики OLE DB-провайдеров. Многие производители
СУБД поставляют OLE DB-провайдеры в составе своих продук-
тов (табл. 4.5).
Таблица 4.5. Список производителей серверных СУБД
Производитель OLE ОВ-провайдеры URL
Computer Associates, Inc. Jasmine OLE DB Provider http://www.cai.com/
Informix Softwares. INFORMIX OLE DB Provider http://www.informix.com
Object Design, Inc. OtStore OLE DB Provider http://www.odi.com
SAS Institute SAD В http://www.sas.com
Sequiter Softwarnc. CodeBase OLE DB Provider http://www.sequiter.com
Помимо этого существуют компании, производящие OLE
DB-провайдеры для различных источников данных (табл. 4.6).
Таблица 4.6. Компании, производящие OLE DB-провайдеры для различных
источников данных
Производитель OLE ОВ-провайдеры URL
Applied Information Services — UniAccess AIS UniAccess http://www.uniaccess.com
ASNA Acceler8-DB and DateGate/400 http://www.asna.com/
B2 Systems — SQL Integratorr Oracle, Sybase, Informix, Microsoft SQL Server, RDB, DB2, <плоские> файлы http://www.b2systems.com/
HiT Software, Inc. HiT OLE DB Server/400 http://www.hit.com/
ISG — ISG Navigator C-ISAM, DB2, IMS, INFORMIX, Jasmine, Openlngres, Oracle, SQL Server, Sybase, ADABAS, Rdb, RMS, VSAM http://www.isgsoft.com/
MERANT pic —CONNECT OLE DB INFORMIX 7.x и 9.x, Lotus Notes 4.11a, 4.5, Microsoft SQL Server 6.5, 7.x, Oracle 7.x, 8.0.x, Sybase System 10,11, Adaptive Server 11.x http://www.merant.com
258
Глава 4. Доступ к базам данных
Окончание табл. 4.6
Производитель OLE ОВ-провайдеры URL
MERANT pic — Reflector Процессор запросов для SQL- и He-SQL-источников данных http://www.merant.com
MERANT pic — SequeLink OLE DB Edition СА-Ореп Ingres, IBM DB2/MVS, DB2/400, DB2 UDB, MVSA/SAM via CICS 4.1, INFORMIX Dynamic Server, Online, SE, Microsoft SQL Server 6.5,7.x, Oracle 7.x, 8.x, Sybase System 10.x, 11.x, Sybase Adaptive Server, ODBC Socket http://www.merant.com
MetaWise Computing AS/400, MVS/VSAM http://www.metawise.com/
Microsoft Corp LDAP, NetWare, каталоги NT, текстовые файлы, HTML, до- кументы Office, SQL.VSAM, AS/400, SQL Server, ODBC-ис- точники данных http://www.microsoft.com/data/ oledb
NCR Corporation — Teradata OLE DB Provider Teradata http://www.ncr.com
Novell, Inc. — Database Manager for NetWare (ODBX-OLE-DB) <Плоские> файлы, INFORMIX, Ingres, Oracle, Microsoft SQL Server, Sybase http://developer.novell.com
Sagent Technology, Inc. — Sagent Data Mart Server <Плоские> файлы, INFORMIX, Oracle, Red Brick, Sybase, Microsoft SQL Server, ODBC-источники данных (включая DB2) http://www.sagenttech.com
X-Tension Projects Ltd — OLE DB for OLAP MDX Parser ProGnosis Data Explorer, дру- гие провайдеры http://www.xdb.com
Актуальная информация об OLE DB-провайдерах содержит-
ся на сайте, посвященном Microsoft Universal Data Access.
Для создания собственного OLE DB-провайдера существует
специальный инструментарий (табл. 4.7).
4.1. Стандартные системы доступа к базам данных
259
Таблица 4.7. Инструменты для создания OLE DB-провайдеров
Производитель Инструментарий URL
Simba Technologies SimbaProviderSimbaProvider for OLAP SDK http://www.simba.com/
Automation Technoloompany OpenAccess OLE DB SDK http://www.odbcsdk.com/
Geppetto's Workshop AntMDX http://www.geppetto.com/
X-Tension MDX Parser for OLE DB for OLAP http://www.x-tension.com/
IBM Client Access for Windows 9x/NT SDK http://www.as400.ibm.com/
Binh Ly OLE DB Provider Toollkit for Delphi 5 http://www.techvanguards.com
4.1.9. Технология Microsoft ActiveX Data Objects (ADO)
ADO представляет собой высокоуровневый программный
интерфейс для доступа к OLE DB-интерфейсам. Он позволяет
манипулировать данными с помощью любых OLE DB-провайде-
ров в составе Microsoft Data Access Components, некоторых дру-
гих продуктов Microsoft, так и в составе продуктов других произ-
водителей. Набор объектов ADO приведен ниже [19—22].
Объект ADO Connection применяется для установки связи с
источником данных и представляет единственную сессию. Он
предусматривает изменение параметров соединения с БД, а так-
же начало или завершение транзакции. С помощью Connection
можно выполнять команды (например, SQL-запросы) посредст-
вом опции Execute. Если команда возвращает набор данных, ав-
томатически создается объект Recordset, который возвращается в
результате выполнения этого метода [19—22].
Объект Error используется для получения сведений об ошиб-
ках, возникающих в процессе выполнения.
Объект Command представляет собой команду, которую вы-
полняем в источнике данных. Команда может содержать
SQL-предложение или вызов хранимой процедуры. В последнем
случае для определения параметров процедуры можно использо-
вать коллекцию Parameters объекта Command [19—22].
Объект Recordset — это набор записей, полученных из источ-
ника данных; может использоваться для добавления, удаления,
260
Глава 4. Доступ к базам данных
изменения, просмотра записей. Данный объект открывают непо-
средственно или создают с помощью объектов Connection или
Command [19—22].
Объект Field — это колонка в наборе данных, представлен-
ных объектом Recordset. Используется для получения значений
конкретного поля, его модификации, извлечения метаданных,
таких как имя колонки и тип данных [19—22].
На рис. 4.5 представлена объектная модель ADO [19—22].
Библиотека ADO 2.4, являющаяся составной частью опера-
ционной системы Windows 2000, содержит два новых объекта —
Record и Stream.
Объект Record представляет одну запись внутри объекта
Recordset и может быть использован для работы с гетерогенны-
ми и иерархическими данными.
Объект Stream представляет двоичные данные, связанные с
объектом Record. Например, если объект Record представляет
собой файл, то его объект Stream должен содержать данные
внутри этого файла [19—22].
Расширения ADO (версия 2.1 и выше). ADO Extensions for
Data Definition and Security (ADOX) представляет собой набор
объектов, позволяющих манипулировать метаданными в БД и
управлять объектами, отвечающими за безопасность (табл. 4.8).
Иерархия объектов ADOX показана на рис. 4.6 [19—22].
4.1. Стандартные системы доступа к базам данных
261
Таблица 4.8. Набор объектов, позволяющих манипулировать метаданными в базах
данных
Объект Назначение
Catalog Представляет всю схему БД
Table Представляет таблицу в БД
Column Представляет колонку в таблице, индексе или ключе
Index Представляет индекс внутри таблицы
Key Представляет первичный или внешний ключ
Group Представляет группу пользователей
User Представляет индивидуального пользователя БД внутри группы
Procedure Представляет хранимую процедуру внутри БД
View Представляет view внутри БД
Рис. 4.6. Иерархия объектов ADOX
262
Глава 4. Доступ к базам данных
Согласно диаграммам на рис. 4.6 объекты Table, Column и
Index имеют стандартную коллекцию Properties. Объекты ADOX
представляют большинство основных объектов в типичных реля-
ционных СУБД, и их свойства и методы могут быть использова-
ны для создания этих объектов и манипуляции ими [19—22].
ADO Multi-Dimensional Extensions (ADOMD) — это набор
объектов, позволяющих использовать многомерные данные в
ADO-приложениях. Эти данные управляются OLAP-серверами
(Online Analytical Processing — OLAP), такими как Microsoft
OLAP Server, входящий в комплект поставки Microsoft SQL
Server 7.0 (или Analytical Services в Microsoft SQL Server 2000).
OLAP-серверы широко применяются в системах принятия реше-
ний для статистического анализа больших объемов данных. Объ-
екты ADOMD кратко описаны в табл. 4.9 [19—22].
Таблица 4.9. Объекты ADOMD
Объект Назначение
Catalog Представляет всю схему многомерной БД
CubeDef Представляет многомерный куб в БД
Dimension Представляет размерность внутри куба
Hierarchy Представляет иерархию внутри размерности
Level Представляет уровень иерархии
Cellset Представляет результат запроса к кубу
Cell Представляет ячейку в объекте CellSet
Axis Представляет одну из осей в объекте CellSet
Position Представляет позицию в объектах Cell или Axis
Member Представляет конкретное значение вдоль оси или уровня иерархии
Иерархия объектов ADOMD показана на рис. 4.7 [14].
Jet and Replication Objects (JRO) — набор специальных объ-
ектов, предназначенных для использования совместно с
Microsoft Jet OLE DB Provider. Его свойства позволяют созда-
вать, модифицировать и синхронизировать реплики. Реплика —
это копия БД, изменения в которой синхронизируются с глав-
ной БД (master database) [14].
4.1. Стандартные системы доступа к базам данных
263
Connection
j Cell |
I—| PositionsHPosition"!
I—| Members^
Level
Member
Рис. 4.7. Иерархия объектов ADOMD
Объект Replica используется для создания новых реплик, мо-
дификации свойств существующих реплик и синхронизации из-
менений с другими репликами.
Объект JetEngine применяется для сжатия БД и обновления
данных из кэша памяти.
Иерархия объектов JRO показана на рис. 4.8 [14].
JetEngine
Рис. 4.8. Иерархия объектов JRO
264
Глава 4. Доступ к базам данных
4.2. Клиенты удаленного доступа и построение
запросов к СУБД
4.2.1. Классификация приложений для работы
с базами данных
Традиционно такие приложения делятся на локальные прило-
жения и приложения в архитектуре клиент—сервер, которые в
свою очередь подразделяются на клиентские и серверные со-
ставляющие.
Локальными называются программы, расположенные на од-
ном компьютере с БД. При этом БД управляется сравнительно
маломощной СУБД, а язык SQL не является определяющим при
создании запросов и обмене данными. Иногда БД может распо-
лагаться на фиксированном сетевом диске в локальной сети.
Программа называется соответствующей архитектуре кли-
ент—сервер, если она имеет мощный сервер БД, отвечающий за
обработку поступающих запросов и передачу результата клиен-
там. В качестве СУБД используются мощные промышленные
серверы, для создания запросов и управления данными — SQL.
Также обязательной составляющей являются клиентские прило-
жения, обеспечивающие отображение данных и интерфейс с ко-
нечным пользователем. Клиентское ПО располагается на уда-
ленных рабочих местах, в сетях, требующих отдельного админи-
стрирования.
По мере развития локальных и глобальных компьютерных
коммуникаций и распространения персональных компьютеров
такая классификация стала утрачивать актуальность.
Одновременно с усложнением решаемых задач усложнялись
и совершенствовались программы для работы с БД. Появились
деления на однопользовательские и многопользовательские локаль-
ные СУБД, соответственно локальные программы стали делиться
на однопользовательские и сетевые. Возникла дополнительная
классификация клиентских приложений на «слабые» («тонкие»)
и «сильные» («толстые»), появились разнообразные способы
связи между клиентом и сервером, алгоритмы обслуживания
очередей клиентов и способы управления транзакциями.
Согласно новой классификации все приложения для работы
с БД делятся на группы в зависимости от числа уровней обра-
ботки данных.
4.2. Клиенты удаленного доступа и построение запросов к СУБД 265
Те программы, которые раньше назывались локальными (не-
зависимо от способа связи с СУБД), сейчас входят в число одно-
уровневых приложений, так как обработка данных в них ведется
в единственном месте. Клиент-серверные приложения стали де-
лится на двухуровневые.
Технология клиент—сервер. Клиент—сервер — это модель
взаимодействия компьютеров в сети, так как они, в общем, рав-
ноправны. Часть компьютеров в сети владеет и распоряжается
информационно-вычислительными ресурсами (такими как про-
цессоры, файловая система, почтовая служба, служба печати,
база данных); другая часть имеет возможность обращаться к
этим службам, пользуясь услугами первых. Компьютер, управ-
ляющий тем или иным ресурсом, принято называть сервером
этого ресурса, а компьютер, желающий им воспользоваться —
клиентом. Конкретный сервер определяется видом ресурса, ко-
торым он владеет. Так, если ресурсом являются БД, то речь идет
о сервере баз данных, назначение которого — обслуживать запро-
сы клиентов, связанные с обработкой данных; если ресурс — это
файловая система, то говорят о файловом сервере, или файл-сер-
вере, и т. д.
В сети один и тот же компьютер может выполнять и роль
клиента, и роль сервера. Например, в АИС, включающей персо-
нальные компьютеры, большую ЭВМ и мини-компьютер под
управлением UNIX, последний может выступать как в качестве
сервера БД, обслуживая запросы от клиентов — персональных
компьютеров, так и в качестве клиента, направляя запросы
большой ЭВМ [1, 3, 14, 23].
Этот же принцип распространяется и на взаимодействие
программ. Если одна из них выполняет некоторые функции,
предоставляя соответствующий набор услуг другим, то такая
программа выступает в качестве сервера. Программы-пользова-
тели услуг называют клиентами. Так, ядро реляционной
SQL-ориентированной СУБД часто называют сервером БД, или
SQL-сервером, а программу, обращающуюся к нему за услугами
по обработке данных, — SQL-клиентом.
В реализованной по архитектуре клиент—сервер информаци-
онной сети клиенту предоставлен широкий спектр приложений
и инструментов разработки, которые ориентированы на макси-
мальное использование вычислительных возможностей клиент-
ских рабочих мест, используя ресурсы сервера в основном для
хранения и обмена документами, а также для выхода во внеш-
266
Глава 4. Доступ к базам данных
нюю среду. Для программных систем с разделением на клиент-
скую и серверную части, применение данной архитектуры по-
зволяет надежнее защитить серверную часть приложений, при
этом предоставляя возможность приложениям либо непосредст-
венно адресоваться к другим серверным приложениям, либо
маршрутизировать запросы к ним. Средством (инструментари-
ем) для реализации клиентских модулей для ОС Windows в дан-
ном случае является, как правило, Delphi.
Однако при этом частые обращения клиента к серверу сни-
жают производительность работы сети, кроме того, приходится
решать вопросы информационной безопасности, так как прило-
жения и данные распределены между различными клиентами.
Распределенный характер построения системы обусловливает
сложность ее настройки и сопровождения. Чем сложнее структу-
ра сети с архитектурой клиент—сервер, тем выше вероятность
отказа любого из ее компонентов (рис. 4.9) [23].
Модели клиент—сервер. Первоначально СУБД имели центра-
лизованную архитектуру (рис. 4.10). Это значит, что СУБД и
прикладные программы для работы с БД функционировали на
центральном компьютере (большая ЭВМ или мини-компьютер).
Клиент
Сервер Сервер
приложений баз данных
Прикладная
программа,
часть № 1
Интерфейс
вызова
удаленных
приложений
Недостатки:
приложения должны быть рас-
пределенными и поддерживать-
ся каждым из клиентов, что обхо-
дится дорого и требует больших
затрат времени. Кроме этого,
сложно настроить систему с боль-
шим числом клиентов
Сложность развертывания и тестиро-
вания за счет распределенного харак-
тера приложений
Прикладная
программа,
часть № 2
Прикладная
программа,
часть № 3
Вызовы
хранимых
процедур
Операционная
система
Драйвер
базы
данных
Драйвер
баз данных
Преимущества:
1) большой выбор приложений и инструментов разработки;
2) наличие солидного опыта разработки и эксплуатации;
3) высокая степень автономности клиента;
4) уменьшение нагрузки на сервер за счет распределенных
приложений;
5) высокая степень защиты серверной части приложений
Чем сложнее архитектура сети, тем
выше вероятность отказа ее компо-
нентов, что затрудняет локализацию
и устранение неисправностей
Рис. 4.9. Компоненты архитектуры клиент—сервер и их свойства
4.2. Клиенты удаленного доступа и построение запросов к СУБД 267
Рис. 4.10. Системы с централизованной архитектурой
Там же располагались БД. К центральному компьютеру подклю-
чались терминалы, выступавшие в качестве рабочих мест поль-
зователей. Все процессы, связанные с обработкой данных (ввод,
формирование, оптимизация и выполнение запросов, обмен с
устройствами внешней памяти и т. д.), выполнялись на цен-
тральном компьютере, что обусловливало жесткие требования к
его производительности.
Особенности СУБД первого поколения напрямую связаны с
архитектурой систем больших ЭВМ и мини-компьютеров и аде-
кватно отражают все их преимущества и недостатки. Рассмотрим
теперь современное состояние многопользовательских СУБД,
для которых архитектура клиент—сервер является фактическим
стандартом.
Существует несколько моделей технологии клиент—сервер.
Если для проектируемой АИС закладывают технологию кли-
ент-сервер, то это означает, что прикладные программы, реали-
зованные в ее рамках, будут иметь распределенный характер,
т. е. часть функций прикладной программы (проще говоря, при-
ложения) будет реализована в программе-клиенте, другая — в
программе-сервере, причем для их взаимодействия будет опреде-
лен некоторый протокол.
Основной принцип технологии клиент—сервер заключается
в разделении функций стандартного интерактивного приложе-
ния на четыре группы различной природы. Первая группа — это
функции ввода и отображения данных. Вторая группа объединяет
268
Глава 4. Доступ к базам данных
чисто прикладные функции, характерные для данной предметной
области (например, для банковской системы — открытие счета,
перевод денег с одного счета на другой и т. д.)- К третьей группе
относятся фундаментальные функции хранения и управления ин-
формационными ресурсами (БД, файловыми системами и т. д.).
Наконец, функции четвертой группы — это служебные функции
(играют роль связок между функциями первых трех групп).
В соответствии с вышесказанным в любом приложении вы-
деляются следующие логические компоненты:
• компонент представления, реализующий функции первой
группы;
• прикладной компонент, поддерживающий функции второй
группы;
• компонент доступа к информационным ресурсам, поддер-
живающий функции третьей группы, а также вводятся и
уточняются соглашения о способах их взаимодействия
(протокол взаимодействия).
Различия в реализациях технологии клиент—сервер опреде-
ляются четырьмя факторами. Во-первых, тем, в какие виды про-
граммного обеспечения интегрированы каждый из этих компо-
нентов. Во-вторых, тем, какие механизмы программного обеспе-
чения используются для реализации функций всех трех групп.
В-третьих, как логические компоненты распределяются между
компьютерами в сети. В-четвертых, какие механизмы использу-
ются для связи компонентов между собой.
Выделяются четыре подхода, реализованные в моделях:
• модель файлового сервера (File Server — FS);
• модель доступа к удаленным данным (Remote Data Access —
RDA);
• модель севера базы данных (DataBase Server — DBS);
• модель сервера приложений (Application Server — AS).
FS-модель является базовой для локальных сетей персональ-
ных компьютеров. Не так давно она была очень популярна среди
отечественных разработчиков в средах FoxPRO, Clipper, Clarion,
Paradox и т. д. Суть модели невероятно проста: один из компью-
теров в сети считается файловым сервером и предоставляет услу-
ги по обработке файлов другим компьютерам. Файловый сервер
работает под управлением сетевой операционной системы (на-
пример, Novell NetWare) и играет роль компонента доступа к
информационным ресурсам (т. е. к файлам). На других компью-
терах сети функционирует приложение, в кодах которого совме-
4.2. Клиенты удаленного доступа и построение запросов к СУБД 269
щены компонент представления и прикладной компонент
(рис. 4.11). Протокол обмена представляет собой набор низко-
уровневых вызовов, обеспечивающих приложению доступ к
файловой системе на файл-сервере.
Рис. 4.11. Модель файлового сервера
FS-модсль послужила фундаментом для расширения возмож-
ностей персональных СУБД в направлении поддержки много-
пользовательского режима. В таких системах на нескольких пер-
сональных компьютерах выполняется как прикладная программа,
так и копия СУБД, а БД содержатся в разделяемых файлах, кото-
рые находятся на файловом сервере. Когда прикладная програм-
ма обращается к БД, СУБД направляет запрос на файловый сер-
вер. В этом запросе указаны файлы, где находятся запрашивае-
мые данные. В ответ на запрос файловый сервер направляет по
сети требуемый блок данных. СУБД, получив его, выполняет дей-
ствия, которые были декларированы в прикладной программе.
К технологическим недостаткам модели относят интенсив-
ный сетевой трафик (передача множества файлов, необходимых
приложению), узкий спектр операций манипуляции с данными
(«данные — это файлы»), отсутствие адекватных средств безо-
пасности доступа к данным (защита только на уровне файловой
системы) и т. д. Собственно, перечисленное не есть недостатки,
но — следствие внутренне присущих FS-модели ограничений,
определяемых ее характером. Недоразумения возникают, когда
FS-модель используют не по назначению, например, пытаются
интерпретировать как модель сервера БД. Место FS-модели в
иерархии моделей клиент—сервер — это всего лишь место моде-
ли файлового сервера. Именно поэтому невозможно создание на
основе FS-модели крупных корпоративных систем, что нередко
делалось в прошлом и предпринимается сейчас.
RDA-модель (более технологичная) существенно отличается
от FS-модели характером компонента доступа к информацион-
ным ресурсам. Это, как правило, SQL-сервер. В RDA-модели
270
Глава 4. Доступ к базам данных
коды компонента представления и прикладного компонента со-
вмещены и выполняются на компьютере-клиенте. Он поддержи-
вает как функции ввода и отображения данных, так и чисто при-
кладные функции. Доступ к информационным ресурсам обеспе-
чивается либо операторами специального языка (языка SQL,
если речь идет о БД), либо вызовами функций специальной биб-
лиотеки (если имеется соответствующий интерфейс прикладного
программирования — API).
Клиент направляет запросы к информационным ресурсам
(например, к БД) по сети удаленному компьютеру. На нем
функционирует ядро СУБД, которое обрабатывает запросы и
возвращает клиенту результат, оформленный как блок данных
(рис. 4.12).
Рис. 4.12. Модель доступа к удаленным данным
При этом инициатором манипуляций с данными выступают
программы, выполняющиеся на компьютерах-клиентах, в то
время как ядру СУБД отводится пассивная роль — обслужива-
ние запросов и обработка данных.
RDA-модель не имеет недостатков, присущих системам с
централизованной архитектурой и системам с файловым серве-
ром. Прежде всего, перенос компонента представления и при-
кладного компонента на компьютеры-клиенты существенно раз-
гружает сервер БД, сводя к минимуму общее число процессов
операционной системы. Сервер БД освобождается от несвойст-
венных ему функций; процессор или процессоры сервера цели-
ком загружаются операциями обработки данных, запросов и
транзакций (благодаря отсутствию терминалов и автоматизиро-
ванных рабочих мест собственными локальными вычислитель-
ными ресурсами). С другой стороны, резко уменьшается загруз-
ка сети, так как по ней передаются от клиента к серверу не за-
просы на ввод-вывод (как в системах с файловым сервером), а
запросы на языке SQL, их объем существенно меньше.
Основное достоинство RDA-модели — унификация интер-
фейса клиент—сервер в виде языка SQL. Действительно, взаимо-
4.2. Клиенты удаленного доступа и построение запросов к СУБД 271
действие прикладного компонента с ядром СУБД невозможно
без стандартизованного средства общения, таким средством и
является язык SQL
Тем не менее, необходимо отметить недостатки RDA-модели.
Во-первых, взаимодействие клиента и сервера посредством
SQL-запросов существенно загружает сеть. Во-вторых, удовле-
творительное администрирование приложений в RDA-модели
практически невозможно из-за совмещения в одной программе
различных по своей природе функций (функции представления и
прикладные).
DBS-модель реализована в некоторых реляционных СУБД
(Informix, Ingres, Sybase, Oracle); в настоящее время приобретает
все большую популярность. Ее основу составляет механизм хра-
нимых процедур— средство программирования SQL-сервера. Про-
цедуры хранятся в словаре БД, разделяются между несколькими
клиентами и выполняются на том же компьютере, где функцио-
нирует SQL-сервер. Язык, на котором разрабатываются хранимые
процедуры, представляет собой процедурное расширение языка
запросов SQL и уникален для каждой конкретной СУБД.
В DBS-модели (рис. 4.13) компонент представления выпол-
няется на компьютере-клиенте, в то время как прикладной ком-
понент оформлен как набор хранимых процедур и функциони-
рует на компьютере-сервере БД.
Рис. 4.13. Модель сервера базы данных
Там же выполняется компонент доступа к данным, т. е. ядро
СУБД. Среди достоинств DBS-модели следует отметить: воз-
можность централизованного администрирования прикладных
функций и снижение трафика (вместо SQL-запросов по сети на-
правляются вызовы хранимых процедур); возможность разделе-
ния процедуры между несколькими приложениями; экономию
ресурсов компьютера за счет использования единожды создан-
ного плана выполнения процедуры. К недостаткам модели отно-
сят ограниченность средств написания хранимых процедур, ко-
272
Глава 4. Доступ к базам данных
торые представляют собой разнообразные процедурные расши-
рения SQL, не выдерживающие сравнения по изобразительным
средствам и функциональным возможностям с языками третьего
поколения, такими как С или Pascal. Сфера их использования
ограничена конкретной СУБД, в большинстве СУБД отсутству-
ют возможности отладки и тестирования разработанных храни-
мых процедур.
На практике часто используют смешанные модели, когда це-
лостность БД и некоторые простейшие прикладные функции
поддерживаются хранимыми процедурами (DBS-модель), а бо-
лее сложные функции реализуются непосредственно в приклад-
ной программе, которая выполняется на компьютере-клиенте
(RDA-модель). Так или иначе, современные многопользователь-
ские СУБД опираются на RDA- и DBS-модели и при создании
АИС, предполагающем использование только СУБД, выбирают
одну из этих двух моделей либо их разумное сочетание.
В AS-модели (рис. 4.14) процесс, выполняющийся на компь-
ютере-клиенте, отвечает, как обычно, за интерфейс с пользова-
телем (т. е. осуществляет функции первой группы). Обращаясь
за выполнением услуг к прикладному компоненту, этот процесс
играет роль клиента приложения {Application Client — АС). При-
кладной компонент реализован как группа процессов, выпол-
няющих прикладные функции, и называется сервером приложе-
ния {Application Server — AS). Все операции над информационны-
ми ресурсами выполняются соответствующим компонентом, по
отношению к которому AS играет роль клиента. Из прикладных
компонентов доступны ресурсы различных типов — БД, очере-
ди, почтовые службы и др.
Рис. 4.14. Модель сервера приложений
RDA- и DBS-модели опираются на двухзвенную схему разде-
ления функций. В RDA-модели прикладные функции приданы
программе-клиенту, в DBS-модели ответственность за их выпол-
нение берет на себя ядро СУБД. В первом случае прикладной
компонент сливается с компонентом представления, во вто-
4.2. Клиенты удаленного доступа и построение запросов к СУБД 273
ром — интегрируется в компонент доступа к информационным
ресурсам. В AS-модели реализована трехзвенная схема разделе-
ния функций, где прикладной компонент выделен как важней-
ший изолированный элемент приложения, для его определения
используются универсальные механизмы многозадачной опера-
ционной системы и стандартизованы интерфейсы с двумя други-
ми компонентами. AS-модель является фундаментом для мони-
торов обработки транзакций (Transaction Processing Monitors —
TPM), или, проще, мониторов транзакций, которые выделяют-
ся как особый вид программного обеспечения.
4.2.2. Этапы развития серверов баз данных
В период создания первых СУБД в архитектуре систем не
было адекватного механизма организации взаимодействия типа
клиент—сервер, в современных же системах он жизненно необ-
ходим. Первое время доминировала модель, которая совмещала
управление данными (функция сервера) и взаимодействие с
пользователем в одной программе (рис. 4.15, а).
Затем функции управления данными были выделены в само-
стоятельную группу — сервер, однако модель взаимодействия
пользователя с сервером соответствовала парадигме «один-к-од-
ному» (рис. 4.15, б), т. е. сервер обслуживал запросы ровно одно-
го пользователя (клиента). Для обслуживания нескольких клиен-
тов нужно было запустить эквивалентное число серверов. Выде-
а б
Рис. 4.15. Централизованная архитектура (а) и архитектура «один-к-одному» (6)
274
Глава 4. Доступ к базам данных
ление сервера в отдельную программу — революционный шаг,
позволяющий, в частности, поместить сервер на одну машину, а
программный интерфейс с пользователем — на другую, осущест-
вляя взаимодействие между ними по сети (рис. 4.16). Однако не-
обходимость запуска большого числа серверов для обслуживания
множества пользователей сильно ограничивала возможности та-
кой системы.
Рис. 4.16. Размещение клиента и сервера на различных машинах
Проблемы, возникающие в модели «один-к-одному», реша-
ются в архитектуре систем с выделенным сервером, способным об-
рабатывать запросы от многих клиентов. Сервер — единствен-
ный, обладает монополией на управление данными и взаимодей-
ствует одновременно со многими клиентами. Логически каждый
клиент связан с сервером отдельной нитью (thread) или потоком,
по которому пересылаются запросы. Такая архитектура получила
название многопотоковой (multi-threaded) (рис. 4.17).
Благодаря ей, значительно уменьшается нагрузка на операци-
онную систему при работе большого числа пользователей. С дру-
гой стороны, возможность взаимодействия многих клиентов с
одним сервером позволяет в полной мере использовать разделяе-
мые объекты (начиная с открытых файлов и кончая данными из
системных каталогов), что значительно уменьшает потребности в
памяти и общее число процессов операционной системы. Так,
система с архитектурой «один-к-одному» для 50 пользователей
создаст 50 копий процессов СУБД, тогда как системе с многопо-
токовой архитектурой для этого понадобится только один сервер.
4.2. Клиенты удаленного доступа и построение запросов к СУБД 275
Рис. 4.17. Многопотоковая архитектура
Однако, такое решение порождает новую проблему. По-
скольку сервер реализуем только на одном процессоре, возника-
ет естественное ограничение на применение СУБД для мульти-
процессорных платформ. Если компьютер имеет, например, че-
тыре процессора, то СУБД с одним сервером используют только
один из них, не загружая оставшиеся три.
В некоторых системах эта проблема решается заменой выде-
ленного сервера на диспетчер или виртуальный сервер (virtual
server) (рис. 4.18), который теряет право монопольно распоря-
жаться данными, выполняя только функции диспетчеризации
запросов к актуальным серверам. Таким образом, в архитектуру
системы добавляется новый слой, который размещается между
клиентом и сервером, что увеличивает затраты ресурсов на под-
держку баланса загрузки и ограничивает возможности управле-
ния взаимодействием клиент—сервер. Во-первых, становится
невозможным направить запрос от конкретного клиента кон-
кретному серверу, во-вторых, серверы становятся равноправны-
ми — нет возможности устанавливать приоритеты для обслужи-
вания запросов.
Подобная организация взаимодействия клиент—сервер явля-
ется аналогом банка, где имеется несколько окон кассиров, и
Рис. 4.18. Архитектура с виртуальным сервером
276
Глава 4. Доступ к базам данных
банковский служащий (диспетчер) направляет каждого вновь
пришедшего посетителя (клиента) к свободному кассиру (акту-
альному серверу). Система работает нормально, пока все посети-
тели равноправны (имеют равные приоритеты), но стоит по-
явиться посетителям с высшим приоритетом (обслуживаются в
специальном окне), как возникают проблемы.
Учет приоритета клиентов особенно важен в системах опера-
тивной обработки транзакций, однако именно эту возможность
архитектура систем с диспетчеризацией предоставить не может.
Современное решение проблемы СУБД для мультипроцес-
сорных платформ заключается в возможности запуска несколь-
ких серверов БД, в том числе и на различных процессорах. При
этом каждый из серверов должен быть многопотоковым. Если
эти два условия выполнены, то есть основание говорить о много-
потоковой архитектуре с несколькими серверами (рис. 4.19).
Рис. 4.19. Многопотоковая мультисерверная архитектура
Активный сервер. Настоящие профессиональные СУБД обла-
дают мощным активным сервером БД, который коренным обра-
зом изменяет представление о роли, масштабах и принципах ис-
пользования СУБД, а в чисто практическом плане позволяет
выбрать современные, эффективные методы построения гло-
бальных АИС.
Идея активного интеллектуального сервера БД возникла не
сама по себе — она стала ответом на задачи реальной жизни.
Объекты реального мира, помимо непосредственных, прямых
связей, имеют друг с другом более сложные причинно-следст-
венные связи; они динамичны, постоянно изменяются. Эти свя-
зи и процессы должны каким-то образом отражаться и в базе
данных, если мы имеем в виду не статичное хранилище данных,
а информационную модель маленькой части реального мира.
Иными словами, в БД, помимо собственно данных и непосред-
ственных связей между ними, должны храниться знания о дан-
4.2. Клиенты удаленного доступа и построение запросов к СУБД 277
ных, а сама БД должна адекватно отражать процессы реального
мира. Значит, необходимо иметь средства хранения и управле-
ния такой информацией.
4.2.3. Архитектура базы данных
В процессе научных исследований [24] относительно архитек-
туры СУБД предлагались различные способы реализации. Самым
жизнеспособным из них оказалась предложенная американским
комитетом по стандартизации ANSI (American National Standards
Institute) трехуровневая система организации БД (рис. 4.20).
1. Уровень внешних моделей — самый верхний уровень, где
каждая модель имеет свое «видение» данных. Этот уровень опре-
деляет точку зрения на БД отдельных приложений. Каждое при-
ложение «видит» и обрабатывает только те данные, которые не-
обходимы именно ему; так, система распределения работ ис-
пользует сведения о квалификации сотрудника, но не требует
информации об окладе, домашнем адресе и телефоне сотрудни-
ка; и наоборот, именно эти сведения используются в подсистеме
отдела кадров.
2. Концептуальный уровень — центральное управляющее зве-
но; здесь БД представлена в наиболее общем виде, который объе-
диняет данные, используемые всеми приложениями, работаю-
щими с БД. Фактически концептуальный уровень отражает обоб-
щенную модель предметной области (объектов реального мира),
Рис. 4.20. Трехуровневая модель системы управления базой данных
278
Глава 4. Доступ к базам данных
для которой создавалась БД. Как и любая модель, концептуаль-
ная модель отражает только существенные (с точки зрения обра-
ботки информации) особенности объектов реального мира.
3. Физический уровень — собственно данные, хранящиеся в
файлах или в страничных структурах, расположенных на внеш-
них носителях информации.
Рассмотренная архитектура позволяет обеспечить логиче-
скую (между уровнями 1 и 2) и физическую (между уровнями 2
и 3) независимость при работе с данными. Логическая независи-
мость предполагает возможность изменения одного приложения
без корректировки других; физическая — возможность переноса
хранимой информации с одних носителей на другие при сохра-
нении работоспособности всех приложений, работающих с дан-
ной БД. Именно этих типов независимости не хватало при ис-
пользовании файловых систем.
В свою очередь выделение концептуального уровня позволи-
ло разработать аппарат централизованного управления БД.
Логика прохождения пользовательского запроса. Взаимодейст-
вие пользователя, СУБД и операционной системы (ОС) при об-
работке запроса на получение данных иллюстрирует рис. 4.21.
Цифрами помечена последовательность взаимодействий [24].
1. Пользователь посылает СУБД запрос на получение данных
из БД.
2. Анализ прав пользователя и внешней модели данных, со-
ответствующей данному пользователю, подтверждает или запре-
щает доступ данного пользователя к запрошенным данным.
4.2. Клиенты удаленного доступа и построение запросов к СУБД 279
3. В случае запрета на доступ к данным СУБД сообщает об
этом пользователю (стрелка 12) и прекращает дальнейший про-
цесс обработки данных. В противном случае СУБД определяет
часть концептуальной модели, которая затрагивается запросом
пользователя.
4. СУБД получает информацию о запрошенной части кон-
цептуальной модели.
5. СУБД запрашивает информацию о местоположении дан-
ных на физическом уровне (файлы или физические адреса).
6. В СУБД возвращается информация о местоположении
данных в терминах ОС.
7. СУБД запрашивает ОС предоставить необходимые дан-
ные, используя средства ОС.
8. ОС осуществляет перекачку информации из устройств
хранения и пересылает ее в системный буфер.
9. ОС оповещает СУБД об окончании пересылки.
10. СУБД из доставленной информации, находящейся в сис-
темном буфере, выбирает только то, что нужно пользователю, и
пересылает эти данные в рабочую область пользователя.
Для хранения всей информации об используемых структурах
данных, логической организации данных, правах доступа поль-
зователей и, наконец, физическом расположении данных преду-
смотрена так называемая База метаданных' (БМД). Для управле-
ния БМД существует специальное программное обеспечение ад-
министрирования БД, которое предназначено для корректного
использования единого информационного пространства многи-
ми пользователями.
Однако запрос не всегда проходит полный цикл, так как
СУБД обладает достаточным интеллектом, чтобы не повторять
бессмысленных действий. Так, если один и тот же пользователь
повторно обратится к СУБД с новым запросом, то для него уже
не будут проверяться внешняя модель и права доступа, а если
дальнейший анализ запроса покажет, что данные могут нахо-
диться в системном буфере, то СУБД осуществит только 11- и
12-й шаги в обработке запроса.
В заключение следует отметить, что механизм прохождения
запроса в реальных СУБД гораздо сложнее.
Анализ структуры СУБД. Рассмотрим теперь структурную
схему типичной СУБД (рис. 4.22) [3].
1 Metadata — «данные о данных».
280
Глава 4. Доступ к базам данных
Пользователь/Приложение
Администратор базы данных
Рис. 4.22. Компоненты системы управления базами данных
Прямоугольниками из одинарных линий обозначены компо-
ненты системы, а фигурами из двойных линий — структуры дан-
ных, организованные в памяти. Непрерывные отрезки со стрел-
ками указывают направление потоков управляющих инструкций
и данных, а пунктирными линиями отмечены только потоки
4.2. Клиенты удаленного доступа и построение запросов к СУБД 281
данных. Наверху изображено два различных источника управ-
ляющих инструкций: рядовые пользователи и прикладные про-
граммы, запрашивающие или изменяющие данные; администра-
тор базы данных — лицо или группа лиц, ответственных за под-
держку и развитие структуры или схемы БД.
Команды языка определения данных. Относительно более
простым является множество команд, поступающих от админи-
стратора БД (их поток изображен в правой верхней части). В ка-
честве примера рассмотрим БД факультета университета. Адми-
нистратор может включить в ее состав таблицу (отношение),
строки (кортежи) которой представляют информацию о студен-
тах — их имена и фамилии, номера курсов и курсовые отметки.
Администратор вправе ограничить множество допустимых отме-
ток, выставляемых студентам по окончании курса, скажем, зна-
чениями А, В, С, D и F. Структура создаваемой таблицы и вво-
димая информация об ограничениях становятся частью схемы
БД. Для реализации этого администратор должен обладать спе-
циальными полномочиями по выполнению команд, затрагиваю-
щих схему БД, поскольку от этого зависит структура хране-
ния информации. Такие команды, как уже говорилось выше в
гл. 3, — команды языка DDL1, подвергаются лексической обра-
ботке с помощью компилятора DDL и передаются для выполне-
ния исполняющей машине, которая при посредничестве менедже-
ра ресурсов изменяет метаданные, т. е. информацию, описываю-
щую схему БД.
Обработка запросов. Большая часть обращений к БД ини-
циируется пользователями и приложениями (см. рис. 4.22),что
не оказывает влияния на схему БД, но затрагивает ее содержи-
мое (если команда предусматривает внесение изменений) либо
предполагает чтение данных (если команда содержит запрос).
Такие команды оформляются с помощью языка управления дан-
ными DML (см. гл. 3), или, проще говоря, языка запросов (query
language). Существует множество различных языков управления
данными, но самым распространенным и мощным из них явля-
ется SQL. Инструкции языка DML обрабатываются двумя от-
дельными подсистемами СУБД, описываемыми ниже.
Получение ответа на запрос. Запрос анализируется и оптими-
зируется компилятором запросов. Сформированный компилято-
ром план запроса, или последовательность действий, подлежа-
1 Data Definition Language — язык определения данных.
282
Глава 4. Доступ к базам данных
щих выполнению системой с целью получения ответа на запрос,
передается исполняющей машине. Машина направляет группу
запросов на получение небольших порций данных — как прави-
ло, строк (кортежей) таблицы (отношения) — менеджеру ресур-
сов, который «осведомлен» об особенностях размещения инфор-
мации в файлах данных, содержащих таблицы, о форматах и
размерах записей в этих файлах и о структурах индексных фай-
лов, обеспечивающих существенное ускорение процессов поиска
запрошенных данных.
Запросы на получение данных транслируются в адреса стра-
ниц и пересылаются менеджеру буферов. Его задачей является
обращение к соответствующим порциям данных на носителях
вторичных устройств хранения (дисках) с последующим перено-
сом данных в буферы оперативной памяти, и наоборот. Едини-
цами потоков обмена данными между буферами в памяти и дис-
ком является страница или «дисковый блок».
Для получения информации с диска менеджеру буферов
приходится обращаться к услугам менеджера хранения данных,
который, решая возложенные на него задачи, может вызывать
команды операционной системы, но чаще всего непосредствен-
но инициирует инструкции дискового контроллера.
Менеджеры буферов и хранения данных. Информация, храни-
мая в БД, обычно располагается на носителях вторичных уст-
ройств хранения, т. е. на магнитных дисках. Но для выполнения
любой полезной операции над данными необходимо перенести
их в оперативную память. Задача управления размещением ин-
формации на диске и обмена ею между диском и оперативной
памятью возлагается на менеджера хранения данных.
В простой системе БД роль менеджера хранения выполняется
непосредственно файловой системой, обслуживаемой соответст-
вующей операционной системой. Для обеспечения эффективно-
сти вычислений СУБД обычно (при определенных обстоятельст-
вах) самостоятельно управляет размещением данных на дисках.
В ответ на запрос со стороны менеджера буферов менеджер хра-
нения данных определяет положение файлов на диске и получает
набор блоков диска, содержащих требуемый файл или его часть.
Известно, что поверхность диска обычно разделена на дисковые
блоки — непрерывные участки, способные сохранять большое
число байтов информации, до 212 или 214 (4096 или 16 384).
Менеджер буферов ответственен за разбиение доступной
оперативной памяти на буферы — участки-страницы, куда мож-
4.2. Клиенты удаленного доступа и построение запросов к СУБД 283
но поместить содержимое дисковых блоков. Все компоненты
СУБД, обращающиеся к диску, взаимодействуют с буферами и
менеджером буферов либо непосредственно, либо с помощью
исполняющей машины. Данные, затрагиваемые компонентами
системы, относятся к одной из следующих категорий:
1) собственно данные — содержимое БД как таковой;
2) метаданные — описание схемы, или логической структу-
ры, БД, введенных ограничений и т. д.;
3) статистика — информация о свойствах данных, таких как
размеры различных отношений, о вероятностных распределени-
ях хранящихся значений и т. п., собранная СУБД;
4) индексы — структуры данных, обеспечивающие эффек-
тивный доступ к информации в БД.
Транзакции (см. также гл. 3). Запросы и другие команды язы-
ка управления данными группируются в транзакции — процес-
сы, которые должны выполняться атомарным образом и изоли-
рованно друг от друга. Зачастую каждый отдельный запрос или
операция по изменению данных является самостоятельной тран-
закцией. Транзакция должна обладать свойством устойчивости,
т. е. результат каждой завершенной транзакции должен быть за-
фиксирован в БД даже в тех ситуациях, когда после окончания
транзакции по той или иной причине происходит сбой системы.
На рис. 4.22 процессор транзакций представлен в виде двух ос-
новных компонентов:
1) планировщика заданий, или менеджера параллельных зада-
ний, ответственного за обеспечение атомарности и изолирован-
ности транзакций;
2) менеджера протоколирования и восстановления, гаранти-
рующего выполнение требования устойчивости транзакций.
Обработка транзакций. Менеджер транзакций получает от
приложения команды транзакций, которые свидетельствуют о
начале и завершении транзакции, а также передают информа-
цию о предпочтениях приложения в отношении параметров
транзакции (приложение, например, может отказаться от свой-
ства атомарности транзакции). Процессор транзакций выполня-
ет функции, рассмотренные ниже.
Протоколирование. Для удовлетворения требованию устойчи-
вости транзакций каждое изменение в БД фиксируется в специ-
альных дисковых файлах. Менеджер протоколирования в своей
работе руководствуется одной из нескольких стратегий, при-
званных исключить вредные последствия системных сбоев во
284
Глава 4. Доступ к базам данных
время выполнения транзакции, а менеджер восстановления в
случае возникновения подобных ситуаций способен считать
протокол изменений и привести БД в некоторое сообразное со-
стояние. Информация протокола изначально сохраняется в бу-
ферах; затем менеджер протоколирования в определенные мо-
менты времени взаимодействует с менеджером буферов, чтобы
проверить сохранность содержимого буферов на диске (где дан-
ные находятся под надежной зашитой в момент возможного
краха системы).
Управление параллельными заданиями. Транзакции должны
выполняться в полной изоляции друг от друга. Однако в реаль-
ных системах одновременно могут действовать несколько про-
цессов-транзакций. Планировщик заданий, или менеджер па-
раллельных заданий, должен обеспечить такой режим работы
системы, чтобы результат выполнения отдельных перемежаю-
щихся во времени операций многочисленных транзакций ока-
зался таким, как если бы транзакции в действительности ини-
циировались, протекали и полностью завершались в строгой
очередности. Типичный планировщик заданий добивается по-
ставленной перед ним цели, устанавливая признаки блокировки
на соответствующие фрагменты содержимого БД. Блокировки
препятствуют возможности единовременного обращения не-
скольких транзакций к порции данных такими способами, кото-
рые плохо согласуются друг с другом. Признаки блокировки
обычно хранятся в таблице блокировок, размещаемой в опера-
тивной памяти, как показано на рис. 4.22. Планировщик зада-
ний воздействует на процесс выполнения запросов и других опе-
раций, запрещая исполняющей машине обращаться к блокиро-
ванным порциям данных.
Поскольку транзакции состязаются за ресурсы, которые могут
быть блокированы планировщиком заданий, возможно возник-
новение такой структуры, когда ни одна из транзакций не в со-
стоянии продолжить работу ввиду того, что ей необходим ресурс,
находящийся в ведении другой. Менеджер транзакций обладает
правом прерывать (откатывать) одну или несколько транзакций,
чтобы остальные могли продолжить работу (см. также гл. 4).
ACID: свойства транзакций. Известно, что правильно реали-
зованные транзакции удовлетворяют «условиям АСЮ»:
• А представляет свойство «atomicity» (атомарность) — тран-
закция осуществляется в соответствии с принципом «все
4.2. Клиенты удаленного доступа и построение запросов к СУБД 285
или ничего», т. е. должна быть выполнена либо вся цели-
ком, либо не выполнена вовсе;
• С обозначает свойство «consistency» (согласованность).
• I служит сокращением термина «isolation» (изолирован-
ность) — процесс протекает таким образом, словно в тот
же период времени других транзакций не существует;
• D определяет требование под названием «durability» (устой-
чивость) — результат выполнения завершенной транзакции
должен сохраняться при любых условиях;
Все БД вводят те или иные ограничения, учитывающие осо-
бенности различных элементов данных и их взаимную согласо-
ванность (так, сумма бухгалтерской проводки не может быть от-
рицательной). Транзакции должны сохранять согласованность
данных.
Процессор запросов — это подсистема, в наибольшей степени
определяющая показатели производительности СУБД. На
рис. 4.22 процессор запросов представлен двумя компонентами,
рассмотренными ниже.
1. Компилятор запросов транслирует запрос во внутренний
формат системы — план запроса, который описывает последова-
тельность выполняемых инструкций. Компилятор запросов со-
стоит из трех основных частей:
• синтаксического анализатора запросов, создающего на ос-
нове текста запроса древовидную структуру данных;
• препроцессора запросов, выполняющего семантический
анализ запроса (проверку отношений и их атрибутов, упо-
мянутых в тексте запроса, на существование) и функции
преобразования дерева, построенного анализатором, в де-
рево алгебраических операторов, отвечающих исходному
плану запроса;
• оптимизатора запросов, осуществляющего трансформацию
плана запроса в наиболее эффективную последователь-
ность фактических операций над данными.
Компилятор запросов для принятия решений относительно
оптимальной по быстродействию последовательности операций
использует метаданные и статистическую информацию, накоп-
ленную СУБД. Так, наличие индекса способно существенным
образом повлиять на выбор наиболее эффективного плана хра-
нения определенных значений, которые соответствуют порциям
содержимого отношения.
286
Глава 4. Доступ к базам данных
2. Исполняющая машина отвечает за осуществление каждой
из операций, согласно плану запроса. В процессе работы она
взаимодействует с большинством других компонентов СУБД
либо напрямую, либо при посредничестве буферов данных. Для
обработки данных исполняющая машина, прежде всего, считы-
вает их с носителя и переносит в буферы. При этом она взаимо-
действует с планировщиком заданий, чтобы избежать обращения
к блокированным порциям информации, а также взаимодейст-
вует с менеджером протоколирования (фиксирует все изменения
в БД, в протоколе).
Оптимизация запросов. Теперь рассмотрим фазы обработки
запроса в современных реляционных СУБД (рис. 4.23).
Рис. 4.23. Этапы обработки запроса в реляционной СУБД
На первой фазе запрос, представленный на языке запросов
(SQL, QUEL), подвергается лексическому и синтаксическому
анализу. При этом вырабатывается его внутреннее представле-
ние, отражающее структуру запроса и содержащее информацию,
которая характеризует объекты БД (отношения, поля и констан-
ты). Информация о хранимых в БД объектах выбирается из ка-
талогов БД. Внутреннее представление запроса используется и
преобразуется на следующих стадиях обработки запроса.
На второй фазе запрос в своем внутреннем представлении
подвергается логической оптимизации. При этом могут приме-
няться различные преобразования, «улучшающие» начальное
представление запроса. Среди них различают эквивалентные
преобразования, после проведения которых получают внутрен-
нее представление, семантически эквивалентное начальному
(например, приведение запроса к некоторой канонической фор-
ме); различают и преобразования семантические, когда получае-
4.2. Клиенты удаленного доступа и построение запросов к СУБД 287
мое представление не является семантически эквивалентным на-
чальному, но результат выполнения преобразованного запроса
совпадает с результатом начального запроса при соблюдении ог-
раничений целостности, существующих в БД. В любом случае
после выполнения второй фазы обработки запроса его внутрен-
нее представление остается непроцедурным, хотя и является в
некотором смысле белее эффективным, чем начальное.
Третий этап обработки запроса состоит в выборе набора аль-
тернативных процедурных планов выполнения запроса в соответ-
ствии с его внутренним представлением, полученным на второй
фазе. Кроме того, для каждого плана оценивается предполагаемая
стоимость выполнения запроса. При оценках используется стати-
стическая информация о состоянии БД, доступная оптимизатору.
Из полученных альтернативных планов выбирается самый деше-
вый: именно его внутреннее представление теперь соответствует
обрабатываемому запросу.
На четвертом этапе по внутреннему представлению опти-
мального плана выполнения запроса формируется выполняемое
представление плана. Это либо программа в машинных кодах,
если система ориентирована на компиляцию запросов в машин-
ные коды, либо машинно-независимое, но более удобное для
интерпретации представление, если система ориентирована на
интерпретацию запросов.
Наконец, на последнем, пятом, этапе обработки происходит
реальное выполнение запроса в соответствии с выполняемым
планом. Это либо выполнение соответствующей подпрограммы,
либо вызов интерпретатора с передачей ему для интерпретации
выполняемого плана.
Эффективные алгоритмы выполнения запросов. Оптимизация
запросов состоит в выборе оптимального (или близкого к тако-
вому) способа выполнения запроса на основе:
• особенностей физической структуры БД и поддерживаемых
в ней управляющих структур;
• заложенных в систему знаний о допустимых стратегиях вы-
полнения элементарных составляющих запроса;
• той или иной статистической информации, позволяющей
оценить эффективность выбранного плана выполнения за-
проса.
Для оптимизатора запроса все эти данные являются внешни-
ми, т. е. оптимизация ограничена внешними факторами. При
этом, если оценки планов выполнения запросов близки к реаль-
288
Глава 4. Доступ к базам данных
ным, то вероятность выбора неоптимального плана уменьшается,
в связи с чем работы по выработке более эффективных структур
хранения БД, новых управляющих структур и новых алгоритмов
выполнения реляционных операций непосредственно связаны
с оптимизацией запросов.
Рассмотрим предложения, направленные на более эффектив-
ное выполнение операций соединения, вычисление агрегатных
функций, а также повышение эффективности выполнения выде-
ленных наборов запросов.
Алгоритмы реляционных соединений. Работы, связанные с
созданием эффективных структур данных и алгоритмов выпол-
нения реляционных операций, касаются реляционных соедине-
ний в связи с распространенностью и важностью операции со-
единения. Тем не менее надо повышать эффективность и прочих
операций. Рассмотрим сначала предложения по части эффектив-
ного вычисления агрегатных функций.
Известно, что возможности агрегатных запросов наиболее
полно поддерживаются на языке SQL. В списке выборки опера-
тора SELECT этого языка наряду с арифметическими выраже-
ниями, построенными из имен полей отношений (указанных в
списке FROM) и констант, встречаются арифметические выра-
жения, включающие агрегатные функции COUNT, AVG, MIN и
МАХ, параметрами которых могут быть арифметические выра-
жения первого типа. Выполнение запросов с агрегатными функ-
циями, как правило, требует сортировок. В этом случае сначала
выполняется сортировка, а затем над отсортированным отноше-
нием или группами его кортежей вычисляются агрегатные функ-
ции. Предлагаемая оптимизация этой процедуры проста — со-
вместить, если это возможно, процесс сортировки и вычисления
агрегатных функций. Тогда отпадет необходимость повторного
сканирования отсортированного отношения.
Оптимизация в распределенных СУБД. С развитием сетевого
оборудования и программного обеспечения ЭВМ проблема ин-
теграции разобщенных БД становится все более актуальной. Су-
ществует много подходов к решению этой проблемы, начиная от
обеспечения удаленного сетевого доступа к локальным БД и
кончая построением сложных распределенных СУБД, обеспечи-
вающих пользователя прозрачностью местоположения интере-
сующих его данных. В последнем случае пользователи взаимо-
действуют с глобальной распределенной базой данных на основе
ее глобальной схемы.
4.3. Разработка клиентского программного обеспечения
289
К классу распределенных систем БД относятся распределен-
ные СУБД, основанные на однородных локальных СУБД.
Логические уровни оптимизации’запросов, включая семан-
тическую оптимизацию, фактически не связаны с распределен-
ной или локальной природой БД (не считая некоторой специ-
фики обработки запросов через представления). Распределенный
характер БД затрагивает главным образом «физические» уровни
оптимизации, связанные с выбором и оценкой планов выполне-
ния запроса.
Другая проблема распределенных систем БД касается алго-
ритмов выполнения двухместных реляционных операций над от-
ношениями, хранящимися в разных узлах распределенной сис-
темы. Проблема существует и при традиционном хранении каж-
дого отношения целиком в одной локальной БД и в случае так
называемых разделенных и раскопированных БД.
В самой обшей постановке задачей компонента распределен-
ной СУБД, оптимизирующего выполнение глобального запроса,
является генерация множества альтернативных планов выполне-
ния запроса и выбора из этого множества на основе некоторых
критериев одного плана, на основе которого и производится вы-
полнение запроса. Как видно, в такой общей постановке задача
оптимизации глобальных запросов формулируется точно так же,
как и в случае локальной СУБД. Однако решение этой задачи
для распределенных систем с локальной автономностью узлов
существенно более сложное, чем для локальных СУБД.
В заключение следует отметить, что все вышеизложенные
проблемы очень активно и широко обсуждаются в специальной
литературе.
4.3. Разработка клиентского программного
обеспечения
4 .3.1. Классификация средств разработки приложений
До сих пор не существует единого подхода к классификации
средств разработки клиентского программного обеспечения или
приложений (что одно и то же, как было сказано выше), опреде-
лены только подходы к ней и то в зависимости от критериев.
Так, возможна классификация исходя из поддерживаемого язы-
290
Глава 4. Доступ к базам данных
ка программирования; работоспособности созданных приложе-
ний на той или иной платформе; наличия в средствах разработ-
ки тех или иных библиотек и визуальных средств. Известна
классификация средств разработки приложений с учетом удобст-
ва их применения для создания продуктов, представляющих со-
бой пользовательский интерфейс к БД.
Фактически любое средство разработки, претендующее на
универсальность, может работать с любой БД — достаточно под-
держки применения в нем сторонних библиотек и наличия у
этой БД набора клиентских интерфейсов (API) для платформы,
на которой должны функционировать созданные приложения.
Но не любая пара продуктов «средство разработки плюс СУБД»
оправдывает трудозатраты, связанные с созданием подобных
приложений. Так, абсолютно несоизмеримы с полученным ре-
зультатом затраты на создание полноценного приложения, вы-
зывающего функции клиентского API и реализующего удобный
пользовательский интерфейс с помощью компилятора языка С и
простейшей графической библиотеки (например, позволяющей
изменять цвет пикселов на экране) для той операционной систе-
мы, в которой будет работать данное приложение. Дело в том,
что разработчикам придется реализовывать функции, которые
уже содержатся в библиотеках классов и компонентов средств
разработки, более глубоко ориентированных на создание прило-
жений с БД или включающих поддержку создания таких прило-
жений.
Средства разработки, ориентированные на конкретные СУБД.
Ранее во многих приложениях, использующих БД, функции кли-
ентского API вызывались с помощью кода, написанного на одном
из языков программирования, чаще всего на С. В настоящее вре-
мя стало ясно, что трудозатраты по написанию подобного кода
существенно сократятся, если собрать в библиотеки наиболее ти-
пичные фрагменты кода и наиболее часто встречающиеся эле-
менты пользовательского интерфейса. Далее, надо оформить эти
библиотеки в виде отдельного продукта и добавить к нему среду
разработки и утилиты проектирования пользовательских форм
для просмотра и редактирования данных, а также отчетов. Имен-
но так и появились первые средства разработки, ориентирован-
ные на конкретные СУБД, такие, например, как Oracle*Forms
(предшественник нынешнего Oracle Forms Developer).
Современный рынок широко представляет продукты этого
класса и сегодня: почти все производители серверных СУБД
4.3. Разработка клиентского программного обеспечения
291
производят и средства разработки приложений. Причем совре-
менные версии этих средств разработки поддерживают доступ
к СУБД других производителей как минимум с помощью одного
из универсальных механизмов доступа к данным (ODBC, OLE
DB, BDE). Однако доступ к «своей» СУБД обычно осуществля-
ется максимально эффективным способом, т. е. с помощью кли-
ентских API, объектов, содержащихся в библиотеках клиентской
части серверных СУБД, специальных классов для доступа к дан-
ным этой СУБД либо за счет реализации драйверов для универ-
сальных механизмов доступа к данным, способной учитывать
специфические особенности данной СУБД.
Среды разработки настольных СУБД выделяют в отдельную
категорию. Большинство настольных СУБД, таких как Microsoft
Visual FoxPro, Microsoft Access, Corel Paradox, Visual dBase, под-
держивают доступ к серверным СУБД с помощью универсаль-
ных механизмов доступа к данным, что позволяет условно отне-
сти их и к категории средств разработки. Исключение составля-
ют пары Microsoft Access — MSDE, Microsoft Access — Microsoft
SQL Server и Microsoft Visual FoxPro — Microsoft SQL Server. Как
известно, Microsoft стремится к максимальной совместимости
своих продуктов и обеспечивает наиболее безболезненную для
пользователей замену своих настольных СУБД собственными
серверами БД.
Средства разработки, универсальные по отношению к СУБД.
Универсальные (по отношению к СУБД) средства разработки
«выросли» из обычных средств разработки приложений, не
имеющих прямого отношения к БД. К ним относятся Borland
Pascal, Borland C++, Microsoft QuickC. При использовании биб-
лиотеки сторонних производителей эти средства позволяют об-
ращаться к функциям клиентских API, а с развитием универ-
сальных механизмов доступа к данным (например, ODBC) — и к
функциям API библиотек. С помощью этих средств разработки
создавались также среды настольных СУБД dBase, FoxBase или
псевдокомпиляторы для языков семейства xBase (Clipper).
Более поздние версии указанных средств разработки приоб-
рели библиотеки функций и классов, предназначенные для до-
ступа к данным с помощью тех или иных универсальных меха-
низмов. Дальнейшее развитие средств разработки привело к по-
явлению двух категорий продуктов подобного назначения.
К первой категории относятся средства разработки, обладаю-
щие обширными библиотеками классов, большим количеством
292
Глава 4. Доступ к базам данных
«мастеров» и кодогенераторов, но ориентированные на «ручное»
создание кода и довольно редко применяемые для создания
«стандартных»1 приложений для работы с БД. К таким продук-
там относятся Microsoft Visual C++. С помощью Microsoft Visual
C++ и библиотеки MFC (Microsoft Foundation Classes) можно
создавать любые приложения при наличии навыков, знаний,
умений и времени. Тем не менее приложения, обладающие
сложным пользовательским интерфейсом (например, исполь-
зующие БД), разрабатывают не часто. В основном этот продукт
применяется для создания клиентских приложений в случае
предъявления к ним особых требований, таких, например, как
высокая производительность, способность осуществлять ка-
кие-либо нестандартные операции и пр.
Ко второй категории относятся средства разработки с разви-
тыми визуальными инструментами, позволяющие буквально
«рисовать» пользовательский интерфейс. В результате частично
стираются различия между работой программиста и пользовате-
ля и удешевляется конечный продукт за счет привлечения к про-
ектированию интерфейса разработчиков, обладающих не самой
высокой квалификацией.
Указанная категория средств разработки чаще всего применя-
ется при создании клиентских приложений. К самым распростра-
ненным продуктам подобного класса следует отнести Microsoft
Visual Basic, Borland Delphi, Sybase PowerBuilder и Borland
C++ Builder. Как правило, среда разработки такого продукта со-
держит «заготовку» проектируемой формы (аналога окна), от-
дельную панель с пиктограммами элементов пользовательского
интерфейса и других объектов, которые можно выбирать и поме-
щать на форму-окно, в котором отображаются и редактируются
свойства одного из выбранных элементов, окно редактора кода,
где можно вводить фрагменты кода, связанные с обработкой тех
или иных событий, а также код, реализующий логику работы дан-
ного приложения. Как правило, современные средства разработ-
ки такого класса позволяют создавать простейшие приложения
для редактирования данных практически без написания кода.
Весьма популярным делом в настоящее время стало также
создание приложений, использующих доступ к БД, но располо-
1 «Стандартное приложение» здесь — приложение, имеющее непо-
средственный доступ к БД, с которым взаимодействует пользователь,
т. е. являющееся «классическим» клиентом серверной СУБД.
4.3. Разработка клиентского программного обеспечения
293
женных внутри обычных документов. В качестве основы средств
разработки таких приложений здесь приняты макроязыки соот-
ветствующих редакторов. К этой категории относится Visual
Basic for Applications, сходный с перечисленными выше визуаль-
ными средствами разработки и отличающийся от них тем, что
созданные с его помощью приложения содержатся внутри доку-
ментов Microsoft Office и не отчуждаются от них.
В заключение отметим, что приведенная классификация
средств разработки весьма условна. Как уже говорилось выше,
практически все средства разработки приложений с БД, в том
числе и ориентированные на конкретные СУБД, поддерживают
как минимум один из универсальных механизмов доступа к дан-
ным. И практически все «универсальные» средства разработки
приложений, если они принадлежат производителю каких-либо
серверных СУБД, поддерживают «свои» СУБД лучше, чем СУБД
сторонних производителей (наличие особых библиотек классов
или компонентов для доступа к серверу, наличие общих репози-
тариев объектов и моделей данных, а иногда и общих с клиент-
ской частью серверной СУБД редакторов параметров доступа к
данным или схем данных).
Borland Delphi. Автоматизация самых разнообразных сфер
человеческой деятельности накладывает определенные требова-
ния к создаваемым АИС. Причем связаны они не только со
сложностью, многообразием и большим объемом обрабатывае-
мых данных, но и с тем, что большинство пользователей таких
систем не являются специалистами в области компьютерных
технологий, а имеют совершенно другие профессии. Поэтому,
наряду с определенными требованиями доступа к используемым
данным, интерфейс приложений для пользователя должен быть
максимально простым, интуитивно понятным, и в то же время
соответствующим определенным стандартам, так, чтобы пользо-
ватель легко мог освоить очередное приложение. Таким обра-
зом, созданное приложение должно, как правило, в своем со-
ставе иметь:
• меню, аналогичное стандартному, с разделами «Файл»,
«Редактирование», «Сервис», «Справка» и «горячие» клави-
ши быстрого доступа;
• инструментальную панель, содержащую кнопки, дубли-
рующие наиболее часто используемые пункты меню;
• полосы прокрутки, группы радиокнопок, списки, выклю-
чатели, строки редактирования и другие интерфейсные
294
Глава 4. Доступ к базам данных
элементы, традиционно используемые в современных при-
ложениях;
• функцию правой клавиши мыши для вызова контекст-
но-зависимых меню;
• контекстно-зависимую справочную систему, подсказки для
интерфейсных элементов, панель для отражения текущего
состояния приложения и комментариев.
Кроме этого, при создании АИС следует учитывать необхо-
димость ее модернизации в дальнейшем, например, потенциаль-
ную возможность переноса ее в архитектуру клиент—сервер или
замену одного сервера БД другим. Такая модернизация должна
требовать разумных трудозатрат и происходить безболезненно
для пользователя.
Помимо прочего приложение должно обладать высокой про-
изводительностью и это тоже следует помнить при выборе сред-
ства разработки, так как задержки при выполнении тех или
иных операций являются одной из главных причин недовольства
пользователей.
Современные средства быстрой разработки Windows-прило-
жений, или так называемые RAD-средства (Rapid Application
Development), обладают в той или иной степени почти всеми
возможностями создания в приложениях подобных интерфейс-
ных элементов. Многие из них позволяют осуществлять доступ к
БД, в том числе и к серверным БД, однако Borland Delphi явля-
ется наиболее простым и удобным, что объясняется следующи-
ми причинами:
• создание пользовательского интерфейса происходит прак-
тически без написания кода;
• поддерживаются все стандартные интерфейсные элемен-
ты — окна просмотра, списки, выключатели, радиокнопки
и радиогруппы, полосы прокрутки, меню (как оконные,
так и привязанные к конкретным элементам), а также мно-
жество других полезных интерфейсных элементов — блок-
нотов, прогресс-баров и т. д.;
• легко создаются контекстно-зависимая справка, ярлычки с
подсказками, панели состояний, инструментальные панели;
• имеется большая библиотека шаблонов форм и приложе-
ний, которую можно пополнять своими шаблонами;
• доступ к данным (плоским таблицам или серверным БД)
совершенно однотипен, а описание конкретных источни-
ков данных можно вынести за пределы приложения в спе-
4.3. Разработка клиентского программного обеспечения
295
циальный файл конфигурации библиотеки BDE, обеспечи-
вающей универсальную работу с разнородными данными,
вплоть до гетерогенных запросов (таким свойством облада-
ют не все RAD-средства);
• в процессе разработки можно пользоваться реальными
данными, отображаемыми в соответствующих интерфейс-
ных элементах;
• приложения отличаются высокой производительностью, так
как являются полностью скомпилированными выполняе-
мыми модулями (большинство используемых RAD-средств
использует интерпретируемый код). Кроме того, язык про-
граммирования Object Pascal, используемый в Delphi, отли-
чается жесткой типизацией переменных, что также положи-
тельно сказывается на производительности;
• отладка приложений очень удобна за счет того, что, во-пер-
вых, компилятор Pascal является очень быстрым, во-вто-
рых, поддерживается инкрементная компиляция, в-третьих,
в среду разработки встроен удобный и гибкий отладчик;
• средства работы с графикой так же удобны, как и в Pascal
(для средств разработки приложений по работе с БД это
большая редкость);
• поддерживаются элементы VBX (в первой версии) и OCX
(во второй версии); на сегодняшний день на рынке имеет-
ся также большое число дополнительных компонентов для
Delphi, созданных на самой Delphi, и их создание является
несложным процессом;
• есть интерфейс со средством контроля версий Intersolv
PVCS, облегчающий групповую разработку крупных про-
ектов;
• имеются удобные средства генерации отчетов, при этом
можно использовать и генераторы отчетов сторонних раз-
работчиков (например, Crystal Reports);
• среда разработки создана с учетом последних достижений в
области эргономики — никаких лишних движений мышью,
или лишних нажатий на клавиши.
Borland Delphi — одно из самых популярных средств визуаль-
ной разработки приложений, использующих БД. Этот продукт
является логическим развитием Borland Pascal и соответственно
использует Object Pascal в качестве языка для написания кода.
Доступ к данным в текущей версии Delphi осуществляется с
помощью двух основных универсальных механизмов: BDE, кото-
296
Глава 4. Доступ к базам данных
рый изначально являлся единственным универсальным механиз-
мом доступа к данным, поддерживаемым на уровне компонентов
данного средства разработки (компонентами в Delphi называется
особая разновидность классов, реализующих какую-либо стан-
дартную функциональность и позволяющих существенно облег-
чить создание приложений), и ADO/OLE DB (на уровне компо-
нентов — начиная с версии 5.0, на уровне СОМ-объектов — с
версии 3.0). Доступ к данным с помощью ODBC в Delphi реали-
зован с помощью специально созданного BDE-драйвера, в кото-
ром стандартные функции BDE реализованы с помощью функ-
ций ODBC API либо с помощью OLE DB-провайдера для
ODBC-драйверов. Отметим также, что на рынке компонентов
Delphi, созданных сторонними производителями, имеется широ-
кий выбор компонентов доступа к данным, которые реализуют
иные механизмы доступа к данным (вызовы ODBC API или
функций API клиентской части соответствующих серверных
СУБД). В частности, такой набор компонентов, предназначен-
ный для осуществления доступа к IB Database и использующий
вызовы API клиентской части этой СУБД, входит в комплект по-
ставки Delphi.
Следующая версия Delphi содержит компоненты, реализую-
щие еще один механизм доступа к данным — dbExpress. Меха-
низм разработан компанией Borland (как и BDE) и предполагает
создание драйверов БД переносимых между Windows и Linux на
уровне исходного кода. Он призван стать основным методом
доступа к данным в Linux-версии Delphi (Kylix).
Borland Delphi также обладает мощными возможностями
создания распределенных приложений. С их помощью создают
Web-приложения, ASP-компоненты, а также распределенные
приложения с «тонкими» Windows-клиентами.
4.4. Основные элементы клиентских программ доступа
к базам данных
К основным элементам клиентских программ доступа к БД
относится интерфейс пользователя (с элементами управления),
справочная система, инсталляционный пакет, действия и свя-
занные с ними компоненты, файлы и устройства ввода-вывода
и т. д. Рассмотрим некоторые из них на примере MS Windows.
4.4. Основные элементы клиентских программ...
297
4.4.1. Интерфейс пользователя
Элементы управления. Суть пользовательского интерфейса
составляют элементы управления. Всеми программами нужно
управлять более или менее единообразно, поэтому в составе ОС
имеется набор типовых кнопок, редактирующих элементов,
списков выбора и т. п., перечень этот постоянно пополняется;
содержатся они в библиотеке ComCtl32.dll. Во-первых, с новы-
ми версиями продуктов фирмы Microsoft поставляются новые
элементы управления; во-вторых, на ниве их создания подвиза-
ются многочисленные сторонние фирмы, оформляющие свои
элементы управления в виде элементов ActiveX (файлов OCX).
И, в-третьих, достаточное количество элементов написано пря-
мо в Delphi — как в фирме Borland, так и независимыми
разработчиками.
Элементам управления, пришедшим из состава Windows,
начиная с Delphi 3, отведена отдельная страница в Палитре
компонентов под названием Win32. Эти элементы управления
не являются ActiveX. Это — обычные специализированные раз-
новидности окон Windows, установка свойств которых проис-
ходит посредством посылки специализированных сообщений.
Полная документация по всем сообщениям и применяемым в
них константам и структурам есть в MSDN. Для большинства
сообщений предусмотрены специальные функции оболочки,
которые описаны в специальном модуле (CommCtrl.pas). Сами
«дельфийские» классы компонентов работают с их использо-
ванием.
В Палитре компонентов имеется два элемента (компонента)
управления, обеспечивающих создание многостраничных блок-
нотов — TTabControl и TPageControl. Переключение между стра-
ницами осуществляется с помощью закладок. Закладки могут
выглядеть как «настоящие» в бумажном блокноте, а могут быть
похожи на стандартные кнопки Windows. Кстати, сама Палитра
компонентов Delphi является примером использования такого
элемента управления. Механизмы работы отдельных страниц у
каждого компонента свои.
В свою очередь, панель инструментов получила развитие с
появлением стандартного элемента управления TToolBar, кото-
рый объединяет расположенные на нем кнопки и другие эле-
менты управления и централизованно управляет ими.
298
Глава 4. Доступ к базам данных
С ростом возможностей пользовательского интерфейса
Windows все больше и больше элементов управления стали осна-
щаться значками и картинками. И вот для централизованного
управления этими картинками появился элемент управления
TlmageList. Он представляет собой оболочку для создания и ис-
пользования коллекции одинаковых по размеру и свойствам
изображений. На этапе разработки ее «начиняют» картинками
(с Delphi для этих целей поставляется подборка, находящаяся в
каталоге \Images). Компонент TlmageList обладает двумя свойст-
вами — Images и Imageindex. Первое указывает на список (ком-
понент TlmageList), второе — на конкретную картинку в этом
списке.
На базе компонентов TTreeView и TListView создано ядро
пользовательского интерфейса — оболочка Explorer, да и боль-
шинство других утилит Windows 98 или Windows 2000. Они вклю-
чены в библиотеку ComCtl32.dll и доступны программистам.
Компонент TTreeView называют деревом (рис. 4.24). Компо-
нент TTreeView — правопреемник компонента TOutiine, разра-
ботанного Borland еще для Delphi 1; предназначен для отображе-
ния иерархической информации. Его «сердцем» является свой-
ство property Items: TTreeNodes или это список всех вершин
дерева, причем список, обладающий дополнительными полез-
ными свойствами. Каждый из элементов списка — это объект
типа TTreeNode.
S-& HKEY_LOCAL_MACHINE
В-В HARDWARE
B-В SAM
SECURITY
Й-D Controls etOOl
i В-В Controlset002
В В MountedD evices
i ЙВ Select
Й-Ч.Е23
j a-а wpa
[3 a Controls etOOl
Й-B Controls etOOl
| ; Й-B Controlset002
r Й-B MountedDevices
В В Select
В-В Setup
I B-В WPA
BB CurrentControlSet
Рис. 4.24. Внешний вид компонента TTreeView
4.4. Основные элементы клиентских программ...
299
Для работы с системным реестром используется объект VCL
TRegistry, удачно инкапсулирующий все предназначенные для
этого функции Windows API. В обработчике события OnCreate
главной формы создается объект Reg, а также к списку Listview 1
добавляются два заголовка (свойство Columns).
Календарь. Выбор даты — одна из часто используемых опе-
раций при вводе данных. Для облегчения этого действия разра-
ботчики Borland создали два новых элемента управления. Ком-
понент TMonthCaiendar инкапсулирует календарь, панель кото-
рого содержит типовую таблицу на один месяц. Компонент
TDateTimePicker совмещает календарь с однострочным тексто-
вым редактором, позволяя вводить даты путем выбора из кален-
даря.
Компонент TMonthCaiendar представляет собой панель с ка-
лендарем на один месяц (рис. 4.25). Назначение свойств компо-
нента, отвечающих за внешний вид и управление календарем,
достаточно прозрачно и не требует особенных комментариев.
Q Февраль 2003 г.
□
Пн Вт Ср Чт Пт Сб Вс
,:;8 >8 38 3 1 2
3 4 5 6 7 8 9
10 11 12 13 14 15
17 18 18 20 21 22 23
24 25 26 27 28 >
Э Сегодня:
16.02.2003
Рис. 4.25. Компонент TMonthCaiendar
Сам календарь содержит в верхней части месяц и год, а рас-
положенные слева и справа кнопки позволяют переходить к сле-
дующему и предыдущему месяцу. Красная окружность определя-
ет текущую дату. Синий круг означает выбранную пользователем
дату. При увеличении размеров в элементе управления отобра-
жается целое число календарей для месяцев, ближайших к теку-
щему.
Панель состояния предназначена для отображения справоч-
ной информации различного рода. Панель состояния инкапсули-
рована в компоненте TStatusBar. Обычно панель состояния раз-
мещается в нижней части окна. Поэтому при переносе на форму
свойство Align всегда имеет значение al Bottom. Панель состояния
300
Глава 4. Доступ к базам данных
можно разделить на произвольное число самостоятельных час-
тей. Каждая часть описывается объектом TStatusPanel.
Выпадающий список (расширенный комбинированный спи-
сок TComboBoxEx) знаком пользователям со времен Windows 95
(например, список всех элементов оболочки Shell: папки Му
Computer, Му Documents и т. п.). Соответствующий элемент
управления появился в библиотеке ComCtl32 несколько позже, а
в компонент он превратился только в Delphi 7.
Создание нового компонента на базе элементов управления из
библиотеки ComCtl32. Мастер создания новых компонентов
(рис. 4.26) создаст шаблон. Поскольку элементы из состава биб-
лиотеки ComCtl32 есть не что иное, как окна со специфически-
ми свойствами, новый компонент «имеет свое происхождение»
от TWinControl. IP-редактор представляет собой окно класса
WCIPADDRESS. Название нового компонента выбрано
TCustomiPEdit. Такая схема принята разработчиками Delphi для
большинства компонентов VCL. Непосредственным предком,
допустим, TEdit является компонент TCustomEdit.
New Component
X
New Component |
iTActionMainMenuBat [ActnMenu:
Ancestor type: ||
Class N ame: |TActionM ainMenuBarl
Palette Page: [Samples T]
Unit file name: |d:\piogram files\borland\delphi7\LitAActionMain ...|
Search path: |$(DELPH^Lib;$(DELPHI)\Bin;$(DELPHI)4mpor .[
Install...
Cancel
Help
Рис. 4.26. Мастер создания новых компонентов Delphi 7
При создании компонента сначала следует опубликовать ти-
повые свойства и события, которые есть у большинства визуаль-
ных компонентов. Далее приступим к описанию свойств, кото-
рыми будет отличаться новый компонент от других. Возможно-
4.4. Основные элементы клиентских программ...
301
сти, предоставляемые 1Р-редактором, описаны в справочной
системе MSDN. Визуально он состоит из четырех полей, разде-
ленных точками (рис. 4.27).
Рис. 4.27. Тестовое приложение, содержащее IP-редактор (внизу)
Для каждого из полей можно задать отдельно верхнюю и
нижнюю границы допустимых значений. Это удобно, если идет
работа с адресами какой-либо конкретной IP-сети. По умолча-
нию границы равны 0—255.
Визуальные стили, интегрированные в Windows ХР, управля-
ют внешним видом и поведением элементов управления. При
этом визуальный стиль использует настройки параметров поль-
зовательского интерфейса, заданные текущей темой. Для управ-
ления темами визуального стиля операционная система исполь-
зует менеджер тем.
Визуальный стиль позволяет настраивать внешний вид эле-
ментов управления в целом и его составных частей. Правила и
методы рисования сохраняются в файле с расширением mst, ко-
торый входит в состав визуального стиля.
Совместно с Windows ХР поставляется только один визуаль-
ный стиль.
Визуальные стили в Delphi. По умолчанию среда разработки
Delphi предлагает к использованию два стиля:
• Standard — приложение использует системную библиотеку
ComCtl32.dll версии 5;
• Windows ХР — приложение использует системную библио-
теку ComCtl32.dll версии 6 и единственный стандартный
визуальный стиль Windows ХР.
302
Глава 4. Доступ к базам данных
Эти стили применимы только к элементам управления, раз-
мещенным на панелях инструментов (TActionToolBar), создан-
ных в компоненте TActionManager. Также есть возможность соз-
дания собственного стиля, но для этого на основе базовых клас-
сов элементов управления требуется создать собственные классы
с нужным разработчику поведением и внешним видом.
Компоненты настройки цветовой палитры. Вид пользователь-
ского интерфейса приложения можно изменить более простым
способом: в составе Палитры компонентов Delphi 7 есть специа-
лизированные компоненты (на странице Additional), позволяю-
щие настраивать цветовую палитру всех возможных деталей
пользовательского интерфейса одновременно.
Все они представляют собой контейнер, содержащий цвета
для раскраски различных деталей элементов управления. Разра-
ботчику необходимо лишь настроить эту цветовую палитру и по
мере необходимости подключать к пользовательскому интер-
фейсу приложения. Для этого снова используется компонент
TActionManager.
Списки и коллекции. Практически любое приложение должно
выполнять ряд стандартных операций по обработке данных, в
частности: загрузку данных при открытии приложения, пред-
ставление данных в удобном виде для использования внутри
приложения, сохранение данных при завершении работы. Пере-
численные действия необходимы и приложениям баз данных, и
играм, и научным программам.
В принципе хранение и использование наборов значений
можно обеспечить с помощью хорошо всем известных массивов.
Однако их прямое использование требует от разработчика допол-
нительных усилий. Ведь при реализации программной логики не-
обходимо добавлять в массив новые элементы, изменять сущест-
вующие и удалять ненужные. Кроме этого, часто бывает необхо-
димо найти элемент массива по значению. Все эти операции
стандартны и повторяются для наборов любых типов данных.
Для решения перечисленных задач в Delphi доступны для ис-
пользования специальные классы. Помимо хранения наборов
значений в них реализованы свойства, позволяющие контроли-
ровать состояние списка и методы, обеспечивающие редактиро-
вание списка и поиск в нем отдельных элементов.
Для загрузки и сохранения данных используются потоки —
классы, инкапсулирующие механизмы доступа к различным хра-
4.4. Основные элементы клиентских программ...
303
нилищам информации — файлам, памяти и т. д. Их общим
предком является класс Tstream.
Для работы со строковыми списками предназначены классы
TStrings и TStringList. Любые типы данных можно заносить в
список указателей, который реализован в классе TList. Использо-
вание наборов объектов (широко применяются в классах VCL),
которые называются коллекциями, осуществляется с помощью
классов TCollection И TCollectionltem.
Список строк. Строковый тип данных широко используется
программистами. Во-первых, многие данные действительно не-
обходимо представлять с помощью этого типа. Во-вторых, мно-
жество функций преобразования типов позволяет представлять
числовые типы в виде строк, избегая тем самым проблем с несо-
вместимостью типов. Класс TStrings является базовым классом,
который обеспечивает потомков основными свойствами и мето-
дами, позволяющими создавать работоспособные списки строк.
Его прямым предком является класс TPersistent.
Класс TStrings реализует все вспомогательные свойства и ме-
тоды, которые обеспечивают управление списком. При этом ме-
тоды, непосредственно добавляющие и удаляющие элементы
списка, не реализованы и объявлены как абстрактные.
Коллекция представляет собой разновидность списка указа-
телей, оптимизированную для работы с объектами определенно-
го вида. Сама коллекция инкапсулирована в классе Tcollection.
Элемент коллекции должен быть экземпляром класса, унаследо-
ванного от класса TCollectionitem. Это облегчает программиро-
вание и позволяет обращаться к свойствам и методам объектов
напрямую.
Коллекции объектов широко используются в компонентах
VCL (например, панели компонента TCoolBar объединены в
коллекцию). Для работы с коллекцией независимо от инкапсу-
лирующего ее компонента применяется специализированный
Редактор коллекции (рис. 4.28), набор элементов управления ко-
торого может немного изменяться для разных компонентов.
Список Редактора объединяет элементы коллекции. При выборе
одной строки из списка свойства объекта коллекции становятся
доступны в Инспекторе объектов. В список можно добавлять
новые элементы и удалять существующие, а также менять их
взаимное положение.
304
Глава 4. Доступ к базам данных
Рис. 4.28. Редактор коллекции
Класс TCollectionltem инкапсулирует основные свойства и
методы элемента коллекции. Свойства класса обеспечивают хра-
нение информации о расположении элемента в коллекции.
4.4.2. Действия (Actions) и связанные с ними
компоненты
Пользовательский интерфейс современных приложений
весьма многообразен, и зачастую один и тот же результат можно
получить разными способами — щелчком на кнопке на панели
инструментов, выбором пункта меню, нажатием комбинации
клавиш и т. п. Можно решить проблему «в лоб» и повторить
один и тот же код два, три раза и т. д. Недостатки такого подхо-
да очевидны. Можно воспользоваться Инспектором объектов и
назначить пункту меню тот же обработчик события, что и кноп-
ке; этот способ неплох, но при большом количестве взаимных
ссылок легко запутаться.
Наконец, современный способ — воспользоваться компо-
нентом TActionList и разом решить все проблемы. Как следует
из названия, это — централизованное хранилище, где воздейст-
вия со стороны пользователя связываются с реакциями на них.
Действием называется операция, которую пользователь хо-
чет произвести, воздействуя на элементы интерфейса. Тот ком-
понент, на который он хочет воздействовать, называется целью
4.4. Основные элементы клиентских программ... 305
действия (Action target). Компонент, посредством которого дей-
ствие инициировано (кнопка, пункт меню), — клиент действия
(Action client). Таким образом, в иерархии классов Delphi дейст-
вие TAction — это невизуальный компонент, который играет
роль «черного ящика», получающего сигнал от одного или не-
скольких клиентов, выполняющих действия над одной (или раз-
ными) целями.
Действия функционируют только будучи объединенными в
список компонентов TActionList или TActionManager. Вне этих
компонентов применение действий невозможно. Спроектировав
на бумаге пользовательский интерфейс, начните работу с поме-
щения на форму компонента TActionList. Он находится в Палитре
компонентов на первой странице Standard. После этого следует
запустить редактор списка действий двойным щелчком мышью
на компоненте или с помощью контекстного меню (рис. 4.29).
Теперь можно начинать добавление действий. Для программиста
предусмотрен набор типовых, наиболее часто встречающихся
действий.
Рис. 4.29. Внешний вид редактора действий компонента TActionList
События, связанные с действиями. Компонент TAction реаги-
рует на три события: OnExecute, OnUpdate и OnHint. Первое
(самое главное) должно быть реакцией на данное действие. Это
событие возникает в момент нажатия кнопки, пункта меню, т. е.
при поступлении сигнала от клиента действия. Здесь, как прави-
ло, пишется обработчик.
306
Глава 4. Доступ к базам данных
Свойства, распространяемые на клиентов действия. Если у не-
скольких кнопок или пунктов меню общий обработчик, разумно
потребовать, чтобы у них были и другие общие свойства. Так
оно и реализовано в Delphi.
Стандартные действия. Шаблоны и заготовки для типовых
меню и кнопок появились еще в самой первой версии Delphi.
Но в шестой версии действия действительно стали действиями.
Это значит, что раньше заготовка содержала только подходящий
заголовок. Теперь они содержат в себе все субкомпоненты, весь
программный код и делают всю необходимую работу сами.
4.4.3. Файлы и устройства ввода-вывода
Большинство приложений создаются для того, чтобы обра-
батывать данные. С развитием программных технологий появи-
лась возможность получать и посылать все более крупные и
сложные массивы данных; однако до сих пор 90 % из них хра-
нятся в файлах.
Для использования файлов в приложении разработчику при-
ходится решать множество задач. Главные из них — поиск необ-
ходимого файла и выполнение с ним операций ввода-вывода.
Основные принципы и структура файловой системы мало
изменились со времен MS-DOS. Файловые системы (FAT32,
NTFS), появившаяся в Windows 2000 служба Active Directory не
изменяют главного — понятия файла и способов обращения к
нему.
Среда Delphi дает возможность выбрать один из четырех ва-
риантов работы:
• использование традиционного набора функций работы с
файлами, унаследованного от Turbo Pascal;
• использование функций ввода-вывода из Windows API;
• использование потоков (rstream и его потомки);
• использование отображаемых файлов.
Использование файловых переменных. Типы файлов. Зачастую
современный программный код Delphi для чтения данных из
файла удивительно похож на аналогичный, написанный, к при-
меру, в Turbo Pascal 4.0. Это возможно потому, что программи-
сты Borland сохранили неизменным «старый добрый» набор
файловых функций, работающих через файловые переменные.
При организации операций файлового ввода-вывода в приложе-
4.4. Основные элементы клиентских программ...
307
нии большое значение имеет, какого рола информация содер-
жится в файле. Чаше всего это строки, но встречаются двоичные
данные или структурированная информация, например массивы
или записи.
Естественно, что сведения о типе хранящихся в файле дан-
ных важно задать изначально. Для этого используются специаль-
ные файловые переменные, определяющие тип файла. Они де-
лятся на нетипизированные и типизированные.
Перед началом работы с любым файлом необходимо описать
файловую переменную, соответствующую типу данных этого
файла. В дальнейшем эта переменная используется при обраще-
нии к файлу.
В Delphi имеется возможность создавать нетипизированные
файлы. Для их обозначения используется ключевое слово file: var
UntypedFile: file;
Такие файловые переменные используются для организации
быстрого и эффективного ввода-вывода безотносительно к типу
данных. При этом подразумевается, что данные читаются или
записываются в виде двоичного массива. Для этого применяют-
ся специальные процедуры блочного чтения и записи.
Ввод-вывод с использованием функций Windows API. Для тех,
кто переходит на Delphi не с прежних версий Turbo Pascal, а с С,
других языков или начинает освоение с «нуля», более привыч-
ными будут стандартные функции работы с файлами Windows.
Тем более, что возможности ввода-вывода в них расширены. Ка-
ждый файл в этом наборе функций описывается не переменной,
а дескриптором (Handle) — 32-разрядной величиной, которая
идентифицирует файл в операционной системе.
Отложенный (асинхронный) ввод-вывод. Эта принципиально
новая возможность введена впервые в Win32 с появлением ре-
альной многозадачности. Вызывая функции чтения и записи
данных, на самом деле исходные данные передаются одному из
потоков (threads) операционной системы, который и осуществ-
ляет фактические обязанности по работе с устройством. Время
доступа всех периферийных устройств гораздо больше доступа к
ОЗУ, и программа, вызвавшая Read или write, будет дожидаться
окончания операции ввода-вывода. Замедление работы програм-
мы налицо. Выход был найден в использовании отложенного
(overlapped) ввода-вывода. До начала отложенного ввода-вывода
инициализируется дескриптор объекта типа события (функция
createEvent) и структура типа TOveriapped. Вызывается функция
308
Глава 4. Доступ к базам данных
RcadFile или writeFile, в которой последним параметром указы-
ваете на TOveriapped. Эта структура содержит дескриптор собы-
тия Windows (event). ОС начинает операцию (ее выполняет от-
дельный программный поток, скрытый от программиста) и не-
медленно возвращает управление; можно не тратить время на
ожидание.
Контроль ошибок ввода-вывода. При работе с файлами разра-
ботчик обязательно должен предусмотреть обработку возможных
ошибок. Практика показывает, что именно операции ввода-вы-
вода вызывают большую часть ошибок, возникающих в прило-
жении из-за воздействия окружающей программной среды.
Контроль за ошибками ввода-вывода зависит от применяе-
мых функций. При использовании доступа через Win32 API все
функции возвращают код ошибки Windows, который и нужно
проанализировать.
При возникновении ошибок ввода-вывода в функциях, ис-
пользующих файловые переменные, генерируется исключитель-
ная ситуация класса EinOutError. Но гак происходит только в
том случае, если включен контроль ошибок ввода-вывода. Для
этого используются соответствующие директивы компилятора.
Использование графики. В Delphi с самого начала появились
развитые средства для работы с графическими возможностями
Windows. В стандартном графическом интерфейсе Windows
(GDI) основой для рисования служит дескриптор контекста уст-
ройства (нос) и связанные с ним шрифт, перо и кисть. В состав
VCL входят объектно-ориентированные надстройки над послед-
ними, назначением которых является удобный доступ к свойст-
вам инструментов и прозрачная для пользователя обработка всех
их изменений.
Обязательным для любого объекта, связанного с графикой в
Delphi, является событие property OnChange: TNotifyEvent. Его
обработчик вызывается всякий раз, когда меняются какие-то ха-
рактеристики объекта, влияющие на его внешний вид.
4.4.4. Встроенная справочная система
Ни одна серьезная программная разработка не обходится без
создания контекстно-чувствительной справочной службы (да-
лее — Help-службы).
4.4. Основные элементы клиентских программ...
309
Разработка Help-службы требует решения следующих основ-
ных задач:
• планирования системы справок. На этом этапе составляет-
ся перечень разделов справочной службы и необходимых
перекрестных ссылок;
• создания текстовых файлов, содержащих описания спра-
вочных разделов. Текстовые файлы готовятся с помощью
любого текстового редактора, поддерживающего расширен-
ный текстовый формат RTF. В них включаются специаль-
ные управляющие символы для создания перекрестных
ссылок и подключения растровых изображений;
• разработки проектного файла, содержащего специальные
команды для Help-компилятора. Проектный файл описы-
вает структуру справочной службы в целом, в нем каждому
разделу присваивается уникальный целочисленный иден-
тификатор;
• разработки файла содержания. Содержание активизируется
при запуске HLP-файла, а также после щелчка по кнопке
содержание в окне справочной службы;
• компиляции Help-файлов;
• тестирования и отладки Help-службы;
• связи программы с разделами Help-службы.
На этапе планирования системы справок, в свою очередь,
необходимо составить перечень разделов справочной службы и
нужных перекрестных ссылок. Структура разделов и количество
перекрестных ссылок зависят от сложности программы, для ко-
торой создается Help-служба, опыта (и вкуса) разработчика. По-
лезно учесть следующие рекомендации:
• любой раздел может содержать список подчиненных или
связанных разделов, т. е. разрешается произвольная иерар-
хия справочной службы;
• полезно структурировать разделы по роду предоставляемой
ими информации. Например, предусмотреть разделы для
начинающего пользователя с пошаговыми инструкциями,
выделить примеры использования программы, предоста-
вить информацию опытным пользователям с точным и де-
тальным описанием каждой программной функции, а так-
же информацию о «продвинутых» возможностях програм-
мы и т. п.;
• каждый раздел должен по возможности отображаться в од-
ном распахнутом окне. Следует избегать слишком длинных
310
Глава 4. Доступ к базам данных
пояснений, лучше разбить комментарий на несколько раз-
делов;
• справочная информация должна быть изложена простым и
ясным языком, без профессионального жаргона;
• текст необходимо структурировать, выделять важную ин-
формацию шрифтами и цветом.
На этапе создания текстовых файлов следует иметь в виду:
• вся справочная информация помещается в один или не-
сколько текстовых файлов в формате RTF. Для их создания
может использоваться любой текстовый редактор, поддер-
живающий этот формат;
• любой раздел, доступный с помощью перекрестных ссылок
или индексных указателей, должен иметь связанный с ним
идентификатор — уникальную текстовую строку;
• раздел может иметь название и связанный с ним список
ключевых слов.
Задание идентифицирующей строки и организация перекрест-
ных ссылок. Для задания перекрестных ссылок, реализующих
скачок от одного раздела к другому, разделы помечаются уни-
кальными идентифицирующими строками (идентификаторами).
Только помеченные идентификаторами разделы можно просмат-
ривать в рамках гипертекстовой системы (непомеченные разде-
лы могут быть доступны для просмотра по ключевым словам и в
порядке просмотра связанных разделов).
Идентифицирующая строка может содержать любые симво-
лы, кроме #, @, !, *, =, >, % и пробелов. Разница в высоте ла-
тинских букв (но не кириллицы!) игнорируется. Длина строки —
до 255 символов.
В качестве идентификаторов имеет смысл использовать текст
заголовка раздела, в котором пробелы заменены символами под-
черкивания, — в этом случае вам не придется вспоминать иден-
тификатор при ссылке на него.
Идентификатор задается с помощью сноски «#» в самом на-
чале раздела.
Задание названия раздела. Название раздела используется в
Help-службе следующим образом:
• появляется после активизации опции закладка в главном
меню Help-службы;
• указывается в списке разделов диалоговых окон, связанных
с кнопками поиск и хронология инструментальной панели
справочного окна.
4.4. Основные элементы клиентских программ...
311
На рис. 4.30 показано окно «Поиск» справочной службы
Delphi.
Справочная система: Delphi Help • BQ!
Содержание] Указатель Поиск
1. Введите искомые слова
I 3
3. Выберите нужный раздел и нажмите кнопку "Показать"
A dispinterface type cannot have an ancestor interface
A dispinterface type requires an interface identification
A more complicated example
A native application
A navigation property
A simple console application
About class types
[Найдено разделов: 3522 | | Всеслова, Начинаются с. Авто. Пауза
Показать I Печати.. Отмена
Рис. 4.30. Окно «Поиск» со списком названий найденных разделов
Название раздела задается с помощью сноски «$», которая
должна предшествовать первому символу текста раздела. Назва-
ние раздела записывается в тексте сноски и отделяется от симво-
ла «$» одним пробелом. В тексте названия можно указывать лю-
бые символы, в том числе и пробелы. Максимальная длина на-
звания — 255 символов. Обычно название раздела совпадает с
его заголовком.
Определение ключевых слов. Help-служба позволяет искать
разделы по связанным с ними ключевым словам. В диалоговом
окне Поиск предусмотрена строка (1) для ввода ключевых слов и
возможность выбора их из списка (2). Для любого раздела мож-
но назначить сколько угодно ключевых слов и наоборот — с лю-
бым ключевым словом можно связать сколько угодно разделов.
312
Глава 4. Доступ к базам данных
Для определения ключевого слова в начале раздела (до пер-
вого символа текста раздела) ставится сноска, помеченная ла-
тинской буквой «К» или «к». Например:
к открыть;текст файл;ASCII;текст
Все связанные с разделом ключевые слова помешаются в
текст сноски и отделяются от «К» одним пробелом, а друг от
друга символом «;». Группы связанных по смыслу ключевых
слов объединяются во фразы, которые отделяются друг от друга
пробелами. Help-служба ищет и отображает в списке выбора на-
звания всех разделов, ключевые слова которых перечислены в
одной фразе. Например, если для приведенной выше сноски
пользователь ввел слово файл, будут представлены названия раз-
делов, связанных со словами файл, ASCII и текст.
Помимо основной таблицы ключевых слов в Help-службе
может быть определена дополнительная таблица. Слова из до-
полнительной таблицы не показываются в окне Поиск. Их ис-
пользование возможно только в макрокомандах ALink и
TestALink.
Определение условий компиляции. Подобно директивам
условной компиляции Delphi в RTF-файл можно вставлять ука-
зания Help-компилятору помещать или не помешать в результи-
рующий файл тот или иной раздел. Такие указания могут пона-
добиться на этапе отладки справочной службы, а также при соз-
дании нескольких версий приложения (например, справочная
служба демонстрационной версии может не содержать некото-
рых разделов, определенных для основной версии). Они вставля-
ются в текст с помощью сноски, помеченной символом «*». Что-
бы включить условный раздел в Help-файл или исключить его из
файла, ключевое слово, определяемое сноской «*», должно ука-
зываться в секции соответственно include или Exclude файла
проекта справочной службы.
Выполнение макрокоманд. При открытии того или иного разде-
ла можно выполнить одну или несколько макрокоманд. С помо-
щью макрокоманд можно гибко воздействовать на состояние окна
справочной службы: его положение, размеры, цвет, содержимое
меню и инструментальных кнопок, отображать другие Help-фай-
лы, выполнять внешние программы и т. д. Для указания макроко-
манды, исполняющейся в момент открытия раздела, се имя задает-
ся в тексте сноски «!». Сноска указывается вместе с другими сно-
сками в самом начале раздела (до первого символа текста).
4.4. Основные элементы клиентских программ...
313
4.4.5. Инсталляционный пакет
Этапы инсталляции. Windows записывает ненужную в данный
момент системе информацию на диск. Это правильно, но это
касается данных. Программы никогда на диск не записываются,
поскольку в Windows сегмент кода программы не может быть из-
менен.
Программа инсталляции копирует себя и все необходимые
файлы во временный каталог на жесткий диск и перезапускает
себя с жесткого диска. Это и есть первый этап инсталляции.
В зарубежных программах он обычно называется «Prepare to
install». Следует отметить, что совсем не обязательно выполнять
этот этап, если вы инсталлируетесь не с дискет, или если ваша
инсталляция умещается на одну дискету.
На втором этапе программа инсталляции обычно показыва-
ет пользователю несколько предупреждений. Реализация этого
этапа проста, поэтому не будем на нем останавливаться по-
дробно.
Следующий этап — третий. Здесь программа установки
выспрашивает у пользователя важные данные: имя пользова-
теля и его организацию, тип установки, куда будем ставить,
как будет называться группа программ и т. д. На этом этапе
встречаются некоторые технические трудности, но их неслож-
но обойти.
Четвертый этап — копирование. Это сложно, и некоторые
проблемы возникнут. Во-первых, надо проверить наличие сво-
бодного места на целевом диске. Во-вторых, надо удостоверить-
ся, что есть доступ к нужному каталогу. В-третьих, надо прове-
рять, нет ли уже такого файла.
Следующий, пятый, этап — настройка системного реестра.
Шестой этап заключается в создании группы программ в
меню «Пуск» или, если вы захотите вынести ярлык на рабо-
чий стол.
Финальная часть включает демонстрацию нескольких фай-
лов (например, readme), затем online-регистрацию и последнее
сообщение «Инсталляция успешно завершена».
Во время инсталляции программы иногда запрашивают имя
пользователя и его организацию. Как правило, программа ин-
сталляции берет эти данные из Windows (поскольку при установ-
ке Windows пользователь их уже вводил) и просит всего лишь
изменить их, если это необходимо.
314
Глава 4. Доступ к базам данных
Копирование программы. Некоторые инсталляции считают,
что это C:\Program Files. В действительности, конечно, это мо-
жет быть другой диск, поэтому следует найти его в реестре:
Н KEYLOCALM АСН1N E\Software\Microsoft\Windows\
CurrentVersion\ProgramFilcsDir= 'D:\Program Files’
Можно воспользоваться функцией SHGetSpecialFolder-
Location (это более корректно с точки зрения Microsoft). Для из-
менения каталога вы можете вызывать функции SelectDirectory
или SHBrowseForFoIder. Можно также создать собственное окно
диалога «Выбор каталога» с помощью компонента Directory -
ListBox.
Программа инсталляции перед копированием файлов обяза-
на проверить, сколько на целевом диске осталось свободного
дискового пространства. Это делается с помощью функции
GetDiskFreeSpace (из модуля Windows) или функции DiskFree (из
модуля SysUtils). Вторая функция — это надстройка Delphi над
Win АР! (в смысле, она вызывает GetDiskFreeSpace), но у нее
значительно меньше параметров.
Группы программ. Обычно программа инсталляции создает
для новой программы новую группу. Как правило, когда вводит-
ся название группы, рядом присутствует список, в котором пе-
речислены все существующие группы. Получить такой список
можно двумя способами. Один из них — работа с DDE-серве-
ром, который называется Program Manager. Второй способ осно-
ван на том, что все меню «Программы» находятся в одном из ка-
талогов диска. Все подменю являются на самом деле подкатало-
гами, а пункты — обычными ссылками (файлами с расширением
.Ink).
Путь к папке, содержащей меню «Программы», можно найти
в реестре:
HKEY_CURRENT_USER\Software\Microsoft\Windows\
CurrentVersion\Explorer\Shell Foldcrs\
Programs = 'D:\WlNNT\Profiles\mark\EnaBHoe мсню\ Программы'
He очень сложно прочитать содержимое этого каталога с по-
мощью функций FindFirst/FindNext.
Копирование. Как это ни странно, нет другого такого процес-
са в программе инсталляции, который выглядел бы столь про-
4.4. Основные элементы клиентских программ...
315
стым и был бы в реализации столь сложным, как копирование.
Рассмотрим процесс подробнее.
Для того чтобы скопировать один файл, можно вызвать функ-
цию Windows, которая называется CopyFile:
function CopyFile(lpExistingFileName, IpNewFileName: PChar;
bFaillfExists: BOOL): BOOL; stdcall;
Функции необходимо передать имена двух файлов — исход-
ного и целевого. Третий параметр отвечает за то, как функция
будет поступать, если целевой файл уже существует. Значение
True говорит о том, что функция не будет копировать файл, зна-
чение False — о том, что целевой файл будет перезаписан.
Функция возвращает True, если операция копирования была
успешно выполнена. Значение False подсказывает нам, что необ-
ходимо вызвать функцию GetLastError для того, чтобы узнать
код произошедшей ошибки.
Эта функция работает очень надежно, поскольку является
частью операционной системы, и практически наверняка имен-
но она тестировалась огромное количество раз. Тем не менее:
if CopyFile(PChar(SourcePath), PChar(TargetPath), False) then
// Выполнилась успешно.
else
// Ошибка. Код ошибки можно получить, вызвав GetLastError.
У этой функции один недостаток, но он способен перекрыть
все ее достоинства, — нет доступа к процессу копирования. Это
означает, что невидим индикатор процесса копирования и не-
возможно прервать функцию CopyFile, если пользователь нажал
кнопку «Отмена» или клавишу Escape.
Если требуется копировать большое количество маленьких
файлов, то этот недостаток неважен; если требуется копировать
файлы размером в несколько мегабайт, то у пользователя про-
граммы могут возникнуть определенные проблемы.
В Delphi для копирования файлов можно воспользоваться
объектами класса TFileStream.
Корректное копирование предполагает, что у целевого файла
обязательно устанавливается флаг Archive (если необходимо реа-
лизовать полноценную операцию копирования, следует об этом
помнить).
316
Глава 4. Доступ к базам данных
Копирование нескольких файлов представляется достаточно
простым, тем более если файлы поставляются в одном архиве
(.САВ или .RAR). Сложным может показаться копирование фай-
лов по маске (*.*) и копирование вложенных подкаталогов.
Сжатие. На дискеты необходимо помешать сжатую информа-
цию. Существуют три метода сжатия данных.
Первый метод — это сжатие файлов стандартными утилита-
ми, разработанными фирмой Microsoft.
Второй метод — сжатие файлов с помощью библиотеки
ZLib, которая поставляется вместе с Delphi. Она предоставляет
два класса, которые являются наследниками TStream. Можно
воспользоваться кодом функции копирования с помощью
TFileStream для того, чтобы реализовать как сжатие, так и рас-
паковку произвольного потока (в том числе и файла).
Третий метод — использование различных динамических
библиотек, которые можно найти в Интернете.
Системный реестр — это древовидная структура данных, в ко-
торой хранятся настройки программы. В реестре также содер-
жатся данные других программ, в том числе и операционной
системы. Реестр является не только важным этапом во время
инсталляции, но и прекрасным источником самой различной
информации. Реестр состоит из нескольких крупных деревьев,
каждое из которых имеет уникальное название.
Дерево HKEY LOCAL MACHINE (часто сокращаемое до
HK.LM) может содержать настройки программы для текущей ма-
шины безотносительно к тому, кто за ней работает. В Windows
пользователи, не обладающие правами администратора, нс могут
записывать данные в это дерево. Из этого следует вывод — если
программа имеет общепользовательскис настройки, то устанав-
ливать ее на компьютер (и изменять эти настройки впоследст-
вии) может только администратор.
HKEYCURRENTUSER (HKCU) содержит настройки про-
граммы для текущего пользователя. Это дерево для каждого
пользователя компьютера свое. Оно может храниться не только
на локальной машине, но и на сервере; в результате пользова-
тель на каждом компьютере сети может иметь одни и те же на-
стройки (обои, клавиши переключения раскладки и др.).
Для того чтобы просматривать и редактировать реестр, надо
запустить редактор реестра (программа regedit.exe).
Деревья реестра состоят из разделов (keys, в редакторе реест-
ра они выглядят, как папки). У каждого раздела могут быть раз-
4.4. Основные элементы клиентских программ...
317
личные параметры (values). По крайней мере, один параметр
есть у каждого раздела — в редакторе реестра он называется «по
умолчанию» (в английской версии, естественно, «Default»).
Выбрать дерево можно, используя свойство RootKey; для
чтения/записи данных потребуется открыть раздел (метод
ОрепКеу); чтобы данные сохранились, не забудьте раздел за-
крыть (метод CloseKey). Название параметра по умолчанию —
пустая строка.
В Windows регламентированы правила записи параметров
программы в реестр. Вы, конечно, можете помещать данные
куда угодно, однако знать эти правила вам не помешает.
В соответствии с правилами, параметры программы должны
находиться в \5оПлуаге\<Название фирмы>\<Название програм-
мы>\<Версия>. Реальное же расположение поддерева програм-
мы зависит только от пользователя.
В реестре хранится масса полезной информации; большая
часть данных Windows находится в ветках HKLM\Software\
Microsoft\Windows\CurrentVersion и HKCU\Software\Microsoft\
Windows\CurrentVersion.
Для того чтобы поместить свою программу на рабочий стол,
или в меню Автозагрузка, или сохранить результаты работы в
папке Мои документы, требуется знать, где расположены соот-
ветствующие каталоги. Всеми этими процессами заведует Про-
водник, поэтому нужную информацию можно найти в нем.
Для того чтобы программа деинсталляции появилась в стан-
дартном списке деинсталляторов (Панель управления/Установка
и удаление программ/Закладка «Установка/Удаление»), надо
прописать ее в реестре, т. е. создать в ветке HKLM\...\Uninstall
раздел с произвольным именем (чаще всего используют назва-
ние программы) и добавить к нему два строковых параметра:
DisplayName (то, что будет показано в списке готовых к деин-
сталляции программ) и UninstallString (командная строка запус-
ка деинсталлятора — можно использовать параметры).
Для инсталляции на компьютер разделяемых файлов (кото-
рыми могут пользоваться два или более приложений) надо про-
писать их в HKLM\...\SharedDLLs. Названием параметра служит
имя разделяемого файла, а значением (целого типа) — количест-
во ссылок на него. При инсталляции файла следует проверить,
существует ли он в реестре, и если да, просто увеличить количе-
ство ссылок на единицу. Если разделяемого файла в реестре нет,
следует его создать и установить количество ссылок равным еди-
318
Глава 4. Доступ к базам данных
ницс. При деинсталляции файла надо уменьшить количество
ссылок на I, и если оно стало равным нулю — удалить его.
В ветках реестра HKCU\...\Run, HKLM\...\Run, HKLM\...\
RunOnce и HKLM\...\RunServiceOnce можно прописывать про-
граммы, которые надо запускать при включении компьютера
или входе в систему. Названием параметра может служить про-
извольная строка, а значением (строковым) будет путь к запус-
каемой программе.
Раздел Run просто запускает указанную программу всякий
раз, когда пользователь входит в систему (действует аналогично
папке Автозагрузка). Раздел RunOnce работает так же, как и
Run, однако после выполнения программы ее параметр из
RunOnce удаляется — это приводит к тому, что программа запус-
кается только один раз. Наконец, RunServiccOnce действует точ-
но так же, как и RunOnce, но выполняется при включении ком-
пьютера, т. е. еще до того, как пользователь вошел в систему.
Излишне, наверное, говорить, что HKCU\...\Run выполняет-
ся только для одного конкретного пользователя, a HKLM\...\
Run — для любого пользователя компьютера.
С помощью реестра можно осуществить следующее. Провод-
ник будет ассоциировать иконку с типом файлов пользователя
и запускать программу пользователя при двойном щелчке на
файле. Для этого необходимо использовать ветку реестра
HKEYCLASSESROOT (HKCR).
Для создания нового файла используется раздел HKEY_
CLASSES_ROOT\.ext\ShellNew. В этом разделе может находить-
ся один из трех параметров: FileName, Command и Data.
В FileName записывается имя файла, который должен находить-
ся в каталоге с шаблонами документов (там лежат пустые файлы
зарегистрированных типов) — он будет скопирован в указанный
каталог с новым именем DocumentName.ext.
Создание группы программ. Сейчас, когда в Windows появился
Проводник, менеджер программ ушел на второй план и исполь-
зуется, в основном, с одной-единствснной целью — создавать
группы программ во время инсталляции.
Менеджер программ может быть сервером DDE-соединения.
Для работы с DDE-серверами будем использовать компонент
DdeClientConv, который находится на закладке System панели
компонентов. Итак, DDE (Dynamic Data Excahnge) — это уста-
ревшая технология, которая использовалась ранее для передачи
данных между программами (сейчас для этих целей используется
4.4. Основные элементы клиентских программ...
319
OLE). Передача данных в DDE производится через соединения.
Программа-клиент устанавливает соединение с программой-сер-
вером, псрсдаст/принимает данные и разрывает соединение.
Применительно к поставленной задаче менеджер программ
будет выступать в роли DDE-сервера, а программа инсталля-
ции — в роли DDE-клиента. DDE предоставляет двухуровневую
схему связи с сервером; для ее установки клиенту необходимо
указать имя сервера и имя сервиса (topic), который клиент хочет
у сервера запросить.
Теперь подробнее остановимся на создании группы про-
грамм средствами Проводника. Дело в том, что меню, которое вы
видите, нажав на кнопку Пуск, хранится на диске в виде обыч-
ных каталогов и файлов.
Для того чтобы создать группу, надо всего лишь создать ка-
талог; для того чтобы создать элемент — скопировать файл в ка-
талог или создать ярлык на существующую программу. Ярлык —
это файл с расширением .LNK, в котором хранится информация
о каком-либо другом файле. Для операционной системы ярлык
олицетворяет собой файл, на который он ссылается. Ярлыки
применяют для того, чтобы вам не нужно было хранить на своем
диске несколько одинаковых файлов. Например, программа
WinZip во время инсталляции помещает себя на рабочий стол, в
меню Пуск и в меню Программы. При этом файл winzip.exe вовсе
не хранится на диске в трех экземплярах. Ярлык занимает на
диске где-то 250—400 байт, поэтому для файлов меньшего раз-
мера ярлыки создавать бессмысленно.
Группы менеджера программ доступны нам через кнопку
Пуск подменю Программы. В действительности, все они являют-
ся подкаталогами, одного из каталогов Windows (это может
быть, например, C:\Windows\EiaBHoe меню\Программы). Путь к
этому каталогу Проводник хранит в реестре.
procedure ReadGroups(Strings: TStrings);
var
ARegistry: TRegistry;
Programs: String;
SearchRec: TSearchRec;
FindResult: Integer;
begin
Strings.Clear;
320
Глава 4. Доступ к базам данных
// Находим каталог
ARegistry := TRegistry.Create;
with ARegistry do
begin
RootKey := HKEY CURRENT USER;
if OpenKey('\Software\Microsoft\Windows\CurrentVersion\Explorer\
Shell Folders’, False) then
begin
Programs := ReadString('Programs');
Close Key;
end
else
Programs := ”;
Free;
end;
if (Length(Programs) > 0) and (Programs[Length(Programs)| <> ’\’) then
Programs := Programs + '\';
11 Читаем содержимое каталога
FindResult := FindFirst(Programs + faDirectory, SearchRec);
while FindResult = 0 do
begin
with SearchRec do
if (Name <> and (Name <> and (Attr and faDirectory <> 0) then
Strings.Add(Name);
FindResult := FindNext(SearchRec);
end;
FindClose(SearchRec);
end;
Точно таким же способом можно прочитать содержимое лю-
бой группы. Достаточно просто создать группу, удалить ее, пере-
именовать группу и т. д.
Деинсталляция. В идеале деинсталляция должна привести
компьютер к виду, в котором он был до инсталляции. На прак-
тике это возможно не для всех приложений, особенно если они
разделяют ресурсы с другими программами.
Программа инсталляции должна вести журнал инсталляции,
в который занесены все действия, производимые этой програм-
4.4. Основные элементы клиентских программ...
321
мой: создание разделов в реестре, секций в .INI-файлах, копиро-
вание, переименование, регистрация ActiveX-компонентов и
многое другое.
Программа деинсталляции может, основываясь на этом жур-
нале, произвести деинсталляцию продукта. В табл. 4.10 перечис-
лены действия, происходящие во время процессов инсталляции
и деинсталляции.
Таблица 4.10. Перечень процессов инсталляции и деинсталляции
Процесс инсталляции Процесс деинсталляции
Создать каталог Directory Удалить каталог Directory
Копировать файл Sourer в Target Удалить файл Target
Копировать разделяемый файл Sourer в Target. Увеличить счетчик инсталляций на 1, если он уже существует или присвоить ему 1 в противном случае Уменьшить счетчик инсталляций на 1. Если он равен 0, то удалить файл Target
Создать раздел Key в реестре Удалить раздел Key в реестре
Создать параметр Value в реестре Удалить параметр Value в реестре
Изменить значение параметра Value с Did на New Записать в Value значение Old
Создать новый INI-файл Удалить INI-файл
Создать секцию в INI-файле Удалить секцию в INI-файле
Записать параметр в секцию INI-файла. Если параметр уже существует, сохранить его со- держимое Если в журнале сохранено предыдущее содер- жимое параметра, то записываем его. В про- тивном случае удаляем параметр из секции
Следует отметить, что при деинсталляции журнал должен об-
рабатываться в обратном порядке. Например, если при инстал-
ляции сначала был создан каталог, а потом в него скопированы
несколько файлов, то при деинсталляции сначала удаляются эти
файлы, а затем каталог.
Самое трудное — удаление самой программы деинсталляции
с жеткого диска. Дело в том, что программу невозможно удалить
до тех пор, пока она запущена — Windows закрывает к ней до-
ступ. В таких случаях наиболее распространенные инсталляторы
(например, InstallShield и Wise) просто оставляют программу де-
инсталляции на диске. Она становится разделяемым ресурсом,
частью операционной системы (помещается в каталог Windows).
322
Глава 4. Доступ к базам данных
Можно также скопировать программу деинсталляции во вре-
менный каталог и запустить ее оттуда. Она, конечно, не будет
уничтожена, однако при следующей чистке временного каталога
пользователь ее удалит.
Наконец, можно удалить единственный ЕХЕ-файл автомати-
чески. Для того чтобы понять, как это делается, достаточно
вспомнить о разделе RunOnce системного реестра.
[ Н К EY_LOCAL_M АСН IN E\SOFTWARE\M icrosoft\Windows\
CurrentVersion\RunOnce]
SomeName=»C:\WINDOWS\COMMAND.COM /С DEL
C:\TEMP\DEINST.EXE»
При следующей перезагрузке компьютера будет вызван ко-
мандный процессор, который и удалит ненужный ЕХЕ-файл.
Затем параметр SomeName будет автоматически удален из разде-
ла RunOnce.
Контрольные вопросы
1. Назовите современные стандартные системы доступа к базам данных.
2. В чем суть технологии BDE?
3. Изложите принцип действия механизма ODBC.
4. Перечислите компоненты для доступа к ODBC-источникам.
5. Охарактеризуйте компоненты прямого доступа к Oracle.
6. Охарактеризуйте Компоненты прямого доступа к InterBase Database.
7. Охарактеризуйте Компоненты Titan для доступа к различным СУБД.
8. Охарактеризуйте Компоненты управления данными dBase и dBase-по-
добных СУБД.
9. В чем заключается универсальность механизм доступа к данным
Universal Data Access?
10. Изложите особенности технологии Microsoft ActiveX Data Objects
(ADO).
11. Изложите принципы классификации приложений для работы с базами
данных.
12. Назовите этапы развития серверов баз данных.
13. Какова суть понятия «архитектура базы данных»?
14. В чем особенности клиентского программного обеспечения?
15. Как классифицируются средства разработки приложений?
16. Охарактеризуйте основные элементы клиентских программ доступа к
базам данных.
17. Перечислите особенности инсталляционных пакетов.
4.4. Основные элементы клиентских программ...
323
Литература
].ГрекулВ.И. Проектирование информационных систем, http://
www.intuit.ru.
2. Вендров А. М. CASE-технологии. Современные методы и средства
проектирования информационных систем, http://citforum.ru.
3. Гарсиа-Молина Г., Умдом Дж., Ульман Дж. Системы баз данных.
Полный курс. М.: Вильямс, 2003. 1088 с.
4. http://www.odbcexpress.com.
5. http://www.odbc98.com.
6. http://www.crlab.com.
7. http://www.allroundautomations.nl.
8. http://www.ibobjects.com/.
9. http://www.interbase.com/downloads/summaries/47.html.
10. http://www.regatta.com.
11. http://www.softsi.com/.
12. http://www.vistasoftware.com/.
13. http://www.advantagedatabase.com/.
14. Федоров А. X., Елманова Н. У. Введение в базы данных, http://
msnews.microsoft.com.
17. microsoft.public.oledb.
18. microsoft.public.oledb.sdk.
19. http://www.microsoft.com/data/ado.
20. http://msnews.microsoft.com:.
21. microsoft.public.data.ado.
22. microsoft.public.data.ado.rds.
23. Власов А. И., Лыткин С. Л. Краткое практическое руководство
разработчика информационных систем на базе СУБД ORACLE, htpp://
www.interface.ru.
24. Курс лекций по управлению данными, htpp://ipm.kstu.ru.
Глава 5
ЭКСПЛУАТАЦИЯ АИС
5.1. Этапы и виды технологических процессов
обработки информации
5.1.1. Технологический процесс преобразования
информации
Согласно [1] технологический процесс (ТП) обработки ин-
формации представляет собой комплекс взаимосвязанных опе-
раций по преобразованию информации в соответствии с постав-
ленной целью с момента ее возникновения (входа в систему) до
момента потребления пользователями. Сложность и многообра-
зие вариантов ТП обусловливают необходимость их деления на
этапы и операции.
Этапы ТП — это его укрупненные части: относительно само-
стоятельные, характеризующиеся логической законченностью,
пространственной или временной обособленностью [1]. Этапы
делятся на технологические операции, различаются их составом
и последовательностью выполнения. ТП принято делить на пер-
вичный, подготовительный и основной этапы. На первичном этапе
обеспечиваются сбор первичной информации, ее регистрация и
передача на обработку. На подготовительном этапе осуществля-
ется перенос первичной информации на машинные носители для
автоматизации ее последующего ввода в технические средства.
Реализация основного этапа позволяет выполнять обработку ин-
формации и получать необходимые результаты.
На всех этапах выполняется максимум операций для дости-
жения достоверности и полноты преобразования информации.
Технологическая операция — это взаимосвязанная совокупность
действий, выполняемых над информацией на одном рабочем
5.1. Этапы и виды технологических процессов...
325
месте в процессе ее преобразования для достижения общей цели
ТП. При этом объектами особого внимания являются время
преобразования и качество результатной информации. По со-
держанию и последовательности преобразования информации
различают следующие технологические операции: сбор и регист-
рация информации, ее передача, прием, запись на машинные
носители, арифметическая и логическая обработка, получение
результатной информации, выпуск выходных документов, пере-
дача их пользователям [2].
По степени механизации и автоматизации операции бывают
ручные (выписка первичного документа), механизированные — с
использованием технических средств, но преимущественно вы-
полняемые человеком (регистрация на пишущей машинке), ав-
томатизированные — в большей степени выполняются техниче-
скими средствами, но предполагается и участие человека (запись
данных на магнитные носители с помощью средств, в которых
автоматизирован контроль), автоматические — без участия че-
ловека (передача информации по линиям связи).
По роли в ТП различают рабочие и контрольные операции. Ра-
бочие обеспечивают получение конечного результата, а кон-
трольные — надежность рабочих.
Технологический процесс преобразования информации в общем
случае включает в себя такие процедуры (стадии), как получе-
ние, сбор и регистрация информации, передача, хранение, обра-
ботка, выдача обработанной (результатной) информации, при-
нятие решения для выработки управляющих воздействий [3].
На всех стадиях ТП, кроме первой и последней, преобразо-
вание информации осуществляется по существу лишь на синтак-
сическом уровне. Даже на стадии обработки, когда выполняются
совокупности арифметических и логических операций над ин-
формацией, с формальной точки зрения выполняются операции
над данными. Хотя состав и последовательность этих операций
(алгоритм преобразования) обусловлены семантическими или
прагматическими свойствами информации, после разработки ал-
горитма реализации смысловое содержание информации не име-
ет значения. Таким образом, информация, полученная после
анализа состояния объекта управления и внешней (по отноше-
нию к системе управления) среды и зафиксированная на носите-
ле для дальнейшего преобразования, превращается в данные, а
результирующие данные в момент их использования (при выра-
ботке решения) снова становятся информацией. Поэтому ТП
326
Глава 5. Эксплуатация АИС
преобразования информации без первой и последней стадий,
названных выше, обычно называют технологическим процессом
обработки данных, а систему, реализующую указанный про-
цесс, — системой обработки данных [3].
Как отмечено в [4] обработка информации представляет собой
переработку информации определенного типа (текстовой, звуко-
вой, графической и др.) и преобразование ее в информацию дру-
гого определенного типа. Так, принято различать обработку тек-
стовой информации, изображений (графики, фото, видео и
мультипликация), звуковой информации (речь, музыка, другие
звуковые сигналы). Однако, использование современных инфор-
мационных технологий обеспечивает комплексное представле-
ние и одновременную обработку информации любого вида
(текст, графика, аудио-, видео-, мультипликация), ее преобразо-
вание и вывод в текстовом, видео-, аудио- и мультипликацион-
ном формате.
Способы сбора, анализа и обработки структурированных и
неструктурированных данных существенно различаются. Наибо-
лее развитыми в настоящее время (с точки зрения задач обра-
ботки и анализа информации) являются программные средства
обработки структурированных данных, так как структуризацию
можно считать первичной и наиболее трудно формализуемой и
алгоритмизируемой обработкой [3].
При оперировании информацией в процессах ее создания
(порождения), сбора, выдачи и потребления огромное значение
имеет понятие документированной информации или просто доку-
мента. Справедливо будет заметить, что в большинстве случаев
информация предстает и фигурирует в образе документа, исклю-
чая ту часть информационных процессов, в которых используют-
ся только данные, в автоматизированных системах управления
технологическими процессами (АСУТП) информация появляет-
ся в виде показаний датчиков (входные данные), обрабатывается,
выдается и потребляется в виде управляющих сигналов (выход-
ные данные) на технологическое оборудование.
Рассмотрим существующие трактовки термина документ —
историческую, организационно-управленческую и нормативно-пра-
вовую трактовки.
• Исторически под документом понимался (и в определен-
ных случаях понимается сейчас) объект, средство, способ
удостоверения личности, прав собственности и т. д.
5.1. Этапы и виды технологических процессов...
327
• В организационно-управленческом смысле документ пони-
мается как служебный или организационно-распоряди-
тельный документ, т. е. как форма и способ выражения ор-
ганизационно-управленческих решений и воздействий.
• В нормативно-правовом аспекте документ определяется как
зафиксированная на материальном носителе информация с
реквизитами, позволяющими се идентифицировать [3].
Для традиционного «бумажного» документа совокупность ре-
квизитов, идентифицирующих конкретный документ, определя-
ется соответствующими ГОСТами (ГОСТ Р 6.30—97. Унифици-
рованная система организационно-распорядительной документа-
ции. Требования к оформлению документов. М.: Госстандарт
России, 1997) и руководящими документами по делопроизводст-
ву или отраслям технологической документации (ЕСКД — Еди-
ная система конструкторской документации; ЕСПД — Единая
система программной документации и т. д.). Отметим, что важ-
нейшим реквизитом, идентифицирующим традиционные доку-
менты, является подпись ответственного должностного лица. По-
добный подход для компьютерной информации в настоящее вре-
мя развит в виде техники «электронных цифровых подписей»,
основанных на криптографических методах, также закреплен со-
ответствующими ГОСТами (ГОСТ Р 34.10—94. Информационная
технология. Криптографическая защита информации. Процеду-
ры выработки и проверки электронной цифровой подписи на
базе асимметричного криптографического алгоритма. М.: Гос-
стандарт России, 1994) и применяется в телекоммуникационных
системах передачи данных.
Вместе с тем такая особенность компьютерной информации,
как возможность ее эталонного копирования (т. е. получение
практически мгновенного и в любых количествах полностью
идентичных копий, экземпляров), делает процесс идентифика-
ции электронных документов и определение их юридического
статуса в вычислительной среде сложной и до конца еще нере-
шенной проблемой.
Под документированием информации в широком смысле слова
понимают выделение единичной смысловой части информации
(данных) по некоторой предметной области в общей ее массе,
обособление этой части с приданием ей самостоятельной роли
(имя, статус, реквизиты и т. п.).
Процесс документирования превращает информацию в ин-
формационные ресурсы. Согласно нормативно-правовой трак-
328
Глава 5. Эксплуатация АИС
товке, информационные ресурсы определяются, как «отдельные
документы и отдельные массивы документов, документы и мас-
сивы документов в информационных системах (библиотеках, ар-
хивах, фондах, банках данных, других видах информационных
систем)» (Закон РФ «Об участии в международном информаци-
онном обмене» от 04.07.1996 г. № 85-ФЗ).
Таким образом, документирование информации подводит к
одному из самых фундаментальных понятий в сфере информаци-
онного обеспечения — информационной системе. Так же как и для
понятий информации и документа, понятие ИС многогранно и
имеет несколько определений и подходов. В гл. 1 уже рассматрива-
лось несколько определений ИС и АИС; теперь посмотрим на
предмет исследования иначе. В нормативно-правовом смысле ИС
определяется как «организационно упорядоченная совокупность
документов (массивов документов) и информационных техноло-
гий, в том числе и с использованием средств вычислительной тех-
ники и связи, реализующих информационные процессы».
В технологическом плане факт использования средств вычис-
лительной техники в ИС и обеспечение на этой основе автома-
тизации решения каких-либо задач отражается близким терми-
ном автоматизированная система — система, состоящая из пер-
сонала и комплекса средств автоматизации его деятельности,
реализующая информационную технологию выполнения уста-
новленных функций [3].
Опыт, практика создания и использования автоматизирован-
ных информационных систем (АИС) в различных сферах дея-
тельности позволяют дать более широкое и универсальное опре-
деление, которое отражает все аспекты их сущности.
Под информационной системой будем понимать прикладную
программную подсистему, ориентированную на сбор, хранение,
поиск и обработку текстовой и/или фактографической информа-
ции.
Исторически первыми видами ИС являются архивы и библио-
теки, которым присуши все ИС-атрибуты. Они обеспечивают в
какой-либо предметной области сбор данных, их представление и
хранение в определенной форме (книго-, архивохранилища, ката-
логи и т. д.), в них определяется порядок использования инфор-
мационных фондов (т. е. определены абоненты, режимы и спосо-
бы выдачи информации — абонементы, читальные залы и т. п.).
ИС, в которых представление, хранение и обработка инфор-
мации осуществляются с помощью вычислительной техники,
5.1. Этапы и виды технологических процессов... 329
называются автоматизированными', в настоящее время АИС яв-
ляются неотъемлемой частью современного инструментария ин-
формационного обеспечения различных видов деятельности и
наиболее бурно развивающейся отраслью индустрии информа-
ционных технологий.
В самом общем случае типовые программные компоненты,
входящие в состав АИС, включают:
• диалоговый ввод-вывод;
• логику диалога;
• прикладную логику обработки данных;
• логику управления данными;
• операции манипулирования файлами и (или) базами данных.
Таким образом, ИС являются основным средством, инстру-
ментарием решения задач информационного обеспечения, а со-
отношение понятий, связанных с информационным обеспече-
нием, правомерно отобразить графически (рис. 5.1) [3].
Упорядоченную последовательность взаимосвязанных дейст-
вий, выполняемых в строго определенной последовательности с
момента возникновения информации до получения заданных
результатов, называют технологическим процессом обработки ин-
формации.
Технологический процесс обработки информации зависит от
характера решаемых задач, используемых технических средств,
Рис. 5.1. Технологический процесс обработки информации
330
Глава 5. Эксплуатация АИС
систем контроля, числа пользователей и т. д. Для дальнейшего
исследования процесса обработки информации необходимо дать
определение информационной технологии [4].
5.1.2. Понятие информационной технологии
Вообще говоря, технология при переводе с греческого
(techne) означает искусство, мастерство, умение, а это не что
иное, как процессы. Под процессом следует понимать определен-
ную совокупность действий, направленных на достижение по-
ставленной цели. Процесс должен определяться выбранной че-
ловеком стратегией и реализовываться с помощью совокупности
различных средств и методов.
Под технологией материального производства понимают про-
цесс, определяемый совокупностью средств и методов обработ-
ки, изготовления, изменения состояния, свойств, формы сырья
или материала. Технология изменяет качество или первоначаль-
ное состояние материи в целях получения материального про-
дукта (рис. 5.2) [5].
Рис. 5.2. Информационная технология как аналог технологии переработки
материальных ресурсов
Информация является одним из ценнейших ресурсов обще-
ства наряду с такими традиционными материальными видами
ресурсов, как нефть, газ, полезные ископаемые и др., а значит,
процесс ее переработки по аналогии с процессами переработки
материальных ресурсов можно воспринимать как технологию.
Тогда справедливо следующее определение.
Информационная технология — процесс, использующий сово-
купность средств и методов сбора, обработки и передачи данных
(первичной информации) для получения информации нового
качества о состоянии объекта, процесса или явления (информа-
ционного продукта).
Цель технологии материального производства — выпуск про-
дукции, удовлетворяющей потребности человека или системы.
Цель информационной технологии — производство информа-
ции для ее анализа человеком и принятия на его основе реше-
ния по выполнению какого-либо действия.
5.1. Этапы и виды технологических процессов...
331
Известно, что, применяя разные технологии к одному и тому
же материальному ресурсу, можно получить разные изделия,
продукты. То же самое будет справедливо и для технологии пе-
реработки информации [5].
В связи с тем, что информационные технологии могут суще-
ственно различаться в различных предметных областях и компь-
ютерных средах, выделяют такие понятия, как обеспечивающие и
функциональные технологии.
Обеспечивающие информационные технологии — это информа-
ционные технологии, которые могут использоваться как инстру-
менты в различных предметных областях для решения различ-
ных задач.
Функциональная информационная технология — программный
продукт (или часть его), предназначенный для автоматизации
задач в определенной предметной области и заданной техниче-
ской среде.
Преобразование (модификация) обеспечивающей информа-
ционной технологии в функциональную может быть выполнено
не только специалистом-разработчиком систем, но и самим
пользователем. Это зависит от квалификации пользователя и от
сложности необходимой модификации.
В зависимости от вида обрабатываемой информации, инфор-
мационные технологии могут быть ориентированы на:
• обработку данных (системы управления БД, электронные
таблицы, алгоритмические языки, системы программиро-
вания и т. д.);
• обработку тестовой информации (текстовые процессоры,
гипертекстовые системы и т. д.);
• обработку графики (средства для работы с растровой гра-
фикой, средства для работы с векторной графикой);
• обработку анимации, видеоизображения, звука (инстру-
ментарий для создания мультимедийных приложений);
• обработку знаний (экспертные системы).
Следует помнить, что современные информационные техно-
логии могут образовывать интегрированные системы, включаю-
щие обработку различных видов информации.
Технология обработки информации на компьютере может
заключаться в заранее определенной последовательности опера-
ций и не требовать вмешательства пользователя в процесс обра-
ботки. В этом случае диалог с пользователем отсутствует, и ин-
формация обрабатывается в пакетном режиме.
332
Глава 5. Эксплуатация АИС
Экономические задачи, решаемые в пакетном режиме, ха-
рактеризуются следующими свойствами:
• алгоритм решения задачи формализован, процесс ее реше-
ния не требует вмешательства человека;
• имеется большой объем входных и выходных данных, значи-
тельная часть которых содержится на магнитных носителях;
• расчет выполняется для большинства записей входных
файлов;
• большое время решения задачи обусловлено большими
объемами данных;
• задается периодичность решения задачи — регламент.
В том случае, если необходимо непосредственное взаимодей-
ствие пользователя с компьютером, при котором на каждое свое
действие пользователь получает немедленные действия компью-
тера, используется диалоговый режим обработки информации.
Диалоговый режим является не альтернативой пакетному, а его
развитием. Если применение пакетного режима позволяет умень-
шить вмешательство пользователя в процесс решения задачи, то
диалоговый режим предполагает отсутствие жестко закрепленной
последовательности операций обработки данных (если она не
обусловлена предметной технологией).
Таким образом, с точки зрения участия или неучастия поль-
зователя в процессе выполнения функциональных информаци-
онных технологий все они могут быть разделены на пакетные и
диалоговые.
С точки зрения структурной организации информационная
технология может быть представлена в виде совокупности эта-
пов, действий, операций (рис. 5.3) [4]:
• 1-й уровень — этапы, где реализуются сравнительно дли-
тельные технологические процессы, состоящие из опера-
ций и действий последующих уровней;
• 2-й уровень — операции, в результате выполнения которых
будет создан конкретный объект в выбранной на 1-м уров-
не программной среде;
• 3-й уровень — действия — совокупность стандартных для
каждой программной среды приемов работы, приводящих
к выполнению поставленной в соответствующей операции
цели.
Таким образом, освоение информационной технологии и
дальнейшее ее использование сводятся к тому, что сначала сле-
дует хорошо овладеть набором элементарных операций, число
5.1. Этапы и виды технологических процессов...
333
Рис. 5.3. Представление информационной технологии в виде иерархической
структуры, состоящей из этапов, действий, операций
которых ограничено. Из этого ограниченного числа элементар-
ных операций в разных комбинациях составляется действие, а из
действий (также в разных комбинациях) составляются операции,
которые определяют тот или иной технологический этап. Сово-
купность технологических этапов образует технологический про-
цесс (технологию).
Следует отметить, что технологический процесс необязатель-
но должен состоять из всех уровней, представленных на рис. 5.3.
Он может начинаться с любого уровня и не включать, например,
этапы или операции, а состоять только из действий. Для реали-
зации этапов технологического процесса могут использоваться
разные программные среды.
Информационная технология, как и любая другая, должна
отвечать следующим требованиям:
• обеспечивать высокую степень расчленения всего процес-
са обработки информации на этапы (фазы), операции,
действия;
• включать весь набор элементов, необходимых для достиже-
ния поставленной цели;
334
Глава 5. Эксплуатация АИС
• иметь регулярный характер. Этапы, действия, операции
технологического процесса могут быть стандартизированы
и унифицированы, что позволит более эффективно осуще-
ствлять целенаправленное управление информационными
процессами.
С точки зрения методологической различают централизован-
ную и децентрализованную информационные технологии.
Централизованная обработка информации была первой исто-
рически сложившейся информационной технологией. Создава-
лись крупные вычислительные центры коллективного пользова-
ния, оснащенные большими ЭВМ (в нашей стране — ЕС ЭВМ).
Применение таких ЭВМ позволяло обрабатывать большие мас-
сивы входной информации и получать на этой основе различные
виды информационной продукции, которая затем передавалась
пользователям. Такой технологический процесс был обусловлен
недостаточным оснащением вычислительной техникой предпри-
ятий и организаций в 1960—1970-е гг.
Достоинства методологии централизованной информацион-
ной технологии:
• возможность обращения пользователя к большим массивам
информации в виде БД и к информационной продукции
широкой номенклатуры;
• сравнительная легкость внедрения методологических реше-
ний по развитию и совершенствованию информационной
технологии благодаря их централизованному принятию.
Недостатки методологии:
• ограниченная ответственность низшего персонала, кото-
рый не способствует оперативному получению информа-
ции пользователем, тем самым препятствуя правильности
выработки управленческих решений;
• ограничение возможностей пользователя в процессе полу-
чения и использования информации.
Децентрализованная обработка информации связана с появле-
нием в 1980-х гг. персональных компьютеров и развитием средств
телекоммуникаций. Она весьма существенно потеснила центра-
лизованную ИТ, поскольку дала пользователю широкие возмож-
ности в работе с информацией и не ограничивала его инициатив.
Достоинства методологии:
• гибкость структуры, обеспечивающая простор инициати-
вам пользователя;
• усиление ответственности низшего звена сотрудников;
5.1. Этапы и виды технологических процессов...
335
• уменьшение потребности в пользовании центральным ком-
пьютером и соответственно контроле со стороны вычисли-
тельного центра;
• более полная реализация творческого потенциала пользо-
вателя благодаря использованию средств компьютерной
связи.
Недостатки методологии:
• сложность стандартизации из-за большого числа уникаль-
ных разработок;
• психологическое неприятие пользователями рекомендуе-
мых вычислительным центром стандартов и готовых про-
граммных продуктов;
• неравномерность развития ИТ на местах, что в первую оче-
редь определяется квалификаций конкретного работника.
Описанные недостатки централизованной и децентрализо-
ванной ИТ привели к необходимости создания так называемой
рациональной методологии, которая объединила достоинства того
и другого подхода.
В этом случае:
• вычислительный центр (ВЦ) должен отвечать за выработку
общей стратегии использования ИТ, помогать пользовате-
лям как в работе, так и в обучении, устанавливать стандар-
ты и определять политику применения программных и тех-
нических средств;
• персонал, использующий ИТ, должен придерживаться ука-
заний вычислительного центра, осуществлять разработку
своих локальных систем и технологий в соответствии с об-
щим планом организации.
Рациональная методология использования ИТ способствует
достижению большей гибкости, поддержке общих стандартов,
обеспечению совместимости информационных локальных про-
дуктов, уменьшению дублирования деятельности и др. [6].
5.1.3. Информационная технология обработки данных
В последнее время с развитием теории менеджмента и опре-
делением так называемой управленческой пирамиды (рис. 5.4)
термин «обработка данных» применяют в очень широком смыс-
ле. С этой точки зрения информационная технология обработки
данных предназначена для решения хорошо структурированных
336
Глава 5. Эксплуатация АИС
Рис. 5.4. Квалификация персонала по уровням управления
задач, для которых имеются необходимые входные данные и из-
вестны алгоритмы и другие стандартные процедуры их обработ-
ки. Эта технология применяется на уровне операционной (испол-
нительской) деятельности персонала невысокой квалификации,
где решаются следующие задачи:
• обработка данных об операциях, производимых фирмой;
• создание периодических контрольных отчетов о состоянии
дел в фирме;
• получение ответов на всевозможные текущие запросы и
оформление их в виде бумажных документов или отчетов.
В результате автоматизации рутинных постоянно повторяю-
щихся операций управленческого труда существенно повышает-
ся производительность труда персонала.
Существует несколько особенностей, связанных с обработ-
кой данных, отличающих данную технологию от всех прочих:
• выполнение необходимых фирме задач по обработке дан-
ных. Каждой фирме предписано законом хранить данные о
своей деятельности, которые можно использовать как сред-
ство обеспечения и поддержания контроля на фирме. По-
этому в любой фирме обязательно должна быть информа-
ционная система обработки данных и разработана соответ-
ствующая информационная технология;
• решение только хорошо структурированных задач, для ко-
торых можно разработать алгоритм;
• выполнение стандартных процедур обработки. Существую-
щие стандарты определяют типовые процедуры обработки
данных и предписывают их соблюдение организациями
всех видов;
5.1. Этапы и виды технологических процессов...
337
• выполнение основного объема работ в автоматическом ре-
жиме с минимальным участием человека;
• использование детализированных данных. Записи о дея-
тельности фирмы имеют детальный (подробный) характер,
допускающий проведение ревизий. В процессе ревизии
деятельность фирмы проверяется хронологически от нача-
ла периода к его концу и от конца к началу;
• акцент на хронологию событий;
• требование минимальной помощи в решении проблем со
стороны специалистов других уровней [7].
Основные компоненты информационной технологии обработки
данных приведены на рис. 5.5 [8].
Сбор данных. По мере того как фирма производит продукцию
или услуги, каждое ее действие сопровождается соответствую-
щими записями данных. Обычно действия фирмы, затрагиваю-
щие внешнее окружение, выделяются особо как операции, про-
изводимые фирмой.
Обработка данных. Для создания из поступающих данных
информации, отражающей деятельность фирмы, используются
следующие типовые операции:
• классификация или группировка. Первичные данные обыч-
но имеют вид кодов, состоящих из одного или нескольких
символов. Эти коды, выражающие определенные признаки
объектов, используются для идентификации и группировки
записей;
• сортировка, с помощью которой упорядочивается последо-
вательность записей;
Данные Информация
из внешней среды для внутреннего
и внешнего
использования
Рис. 5.5. Основные компоненты информационной технологии обработки данных
338
Глава 5. Эксплуатация АИС
• вычисления, включающие арифметические и логические
операции. Эти операции, выполняемые над данными, дают
возможность получать новые данные;
• укрупнение или агрегирование, служащее для уменьшения
количества данных и реализуемое в форме расчетов итого-
вых или средних значений.
Хранение данных. Многие данные на уровне операционной
деятельности необходимо сохранять для последующего исполь-
зования либо здесь же, либо на другом уровне. Для их хранения
создаются базы данных.
Создание отчетов (документов). В информационной техно-
логии обработки данных необходимо создавать документы для
руководства и работников фирмы, а также для внешних партне-
ров. При этом документы создаются как в связи с проведенной
фирмой операцией, так и периодически в конце каждого меся-
ца, квартала или года.
5.2. Организация сбора, размещения, хранения,
накопления, преобразования и передачи данных в АИС
5.2.1. Процессы в АИС, компоненты н структуры
Для того чтобы получить представление об организации сбо-
ра, размещения, хранения, накопления, преобразования и пере-
дачи данных в АИС, рассмотрим графическое представление ТП,
протекающего в автоматизированной системе (рис. 5.6) [9, 10].
Сбор и регистрация информации происходят по-разному на
различных экономических объектах. Наиболее сложна эта про-
цедура в автоматизированных управленческих процессах про-
мышленных предприятий, фирм, где производятся сбор и реги-
страция первичной учетной информации, отражающей произ-
водственно-хозяйственную деятельность объекта. Не менее
сложна эта процедура и в финансовых органах, где происходит
оформление движения денежных ресурсов.
Особое значение при этом придается достоверности, полноте
и своевременности первичной информации. На предприятии
сбор и регистрация информации происходят при выполнении
различных хозяйственных операций (прием готовой продукции,
получение и отпуск материалов и т. п.), в банках — при выпол-
5.2. Организация сбора, размещения, хранения...
339
Рис. 5.6. Основные технологические процессы АИС
нении финансово-кредитных операций с юридическими и физи-
ческими лицами. Учетные данные могут возникать на рабочих
местах в результате подсчета количества обработанных деталей,
прошедших сборку узлов, изделий, выявления брака и т. д.
В процессе сбора фактической информации производятся изме-
рение, подсчет, взвешивание материальных объектов, подсчет
денежных купюр, получение временных и количественных ха-
рактеристик работы отдельных исполнителей.
Сбор информации, как правило, сопровождается ее регистра-
цией, т. е. фиксацией информации на материальном носителе
(документе, машинном носителе), вводом в ПЭВМ. Запись в пер-
вичные документы в основном осуществляется вручную, поэтому
процедуры сбора и регистрации остаются пока наиболее трудоем-
кими, а процесс автоматизации документооборота по-прежнему
актуальным. В условиях автоматизации управления предприяти-
ем особое внимание придается использованию технических
340
Глава 5. Эксплуатация АИС
средств сбора и регистрации информации, совмещающих опера-
ции количественного измерения, регистрации, накопления и пе-
редачи информации по каналам связи, ввод непосредственно в
ЭВМ для формирования нужных документов или накопления по-
лученных данных в системе.
Передача информации осуществляется различными способа-
ми: с помощью курьера; пересылка по почте; доставка транс-
портными средствами; дистанционная передача по каналам свя-
зи с помощью других средств коммуникаций. Дистанционная
передача по каналам связи сокращает время передачи данных,
однако для ее осуществления необходимы специальные техниче-
ские средства, что удорожает процесс передачи. Предпочтитель-
ным является использование технических средств сбора и реги-
страции, которые, собирая автоматически информацию с уста-
новленных на рабочих местах датчиков, передают ее в ЭВМ для
последующей обработки, что повышает ее достоверность и сни-
жает трудоемкость.
Дистанционно может передаваться как первичная информа-
ция с мест ее возникновения, так и результатная в обратном на-
правлении. В этом случае результатная информация фиксируется
различными устройствами: дисплеями, табло, печатающими уст-
ройствами. Поступление информации по каналам связи в центр
обработки в основном осуществляется двумя способами: на ма-
шинном носителе или непосредственно вводом в ЭВМ с по-
мощью специальных программных и аппаратных средств [11].
Дистанционная передача информации с помощью современ-
ных коммуникационных средств постоянно развивается и совер-
шенствуется. Особое значение этот способ передачи информации
имеет в многоуровневых межотраслевых системах, где примене-
ние дистанционной передачи значительно ускоряет прохождение
информации с одного уровня управления на другой и сокращает
общее время обработки данных.
Машинное кодирование — процедура машинного представле-
ния (записи) информации на машинных носителях в кодах, при-
нятых в ПЭВМ. Такое кодирование информации производится
путем переноса данных первичных документов на магнитные
диски, информация с которых затем вводится в ПЭВМ для об-
работки.
Запись информации на машинные носители осуществляется
на ПЭВМ как самостоятельная процедура или как результат об-
работки.
5.2. Организация сбора, размещения, хранения...
341
Хранение и накопление информации вызвано многократным ее
использованием, применением условно-постоянной, справочной
и других видов информации, необходимостью комплектации пер-
вичных данных до их обработки. Хранение и накопление инфор-
мации осуществляется в информационных базах, на машинных
носителях в виде информационных массивов, где данные распо-
лагаются по установленному в процессе проектирования порядку.
Кроме того, существуют так называемые очень большие базы
данных. В то время как в 1980-е гг. к этой категории относили
базы данных объема, измеряемого в лучшем случае сотнями ги-
габайтов, в 1990-е гг. речь шла уже о десятках и сотнях терабай-
тов [16].
Терабайтовые системы стали реальностью. Информацион-
ные ресурсы такого объема уже накоплены в хранилищах дан-
ных ряда крупных корпораций. Данными терабайтового объема
оперируют системы хранения и обработки результатов спутни-
ковой цифровой фотосъемки поверхности Земли. Вскоре к кате-
гории систем очень больших баз данных можно будет отнести
ряд электронных библиотек, поддерживающих крупные коллек-
ции цифровых аудио- и видеоданных, изображений, полнотек-
стовых информационных ресурсов, детализированные цифровые
модели Земли и др.
Более того, в настоящее время уже осуществляются некото-
рые уникальные проекты, ориентированные на объемы данных,
измеряемые петабайтами. Один из них — система EOS/D1S
(Earth Observation System/Data Information System), разрабаты-
ваемая агентством NASA в США (10,58). С 1998 г. в системе ре-
гистрируется ежедневно до 5 Тбайт спутниковых данных о со-
стоянии атмосферы, океанов, земной поверхности. Предполага-
ется, что к 2007 г. общий объем поддерживаемых в системе
данных составит 15 Пбайт.
С хранением и накоплением непосредственно связан поиск
данных, т. е. выборка нужных данных из хранимой информации,
включая поиск информации, подлежащей корректировке или за-
мене. Процедура поиска информации выполняется автоматиче-
ски на основе составленного пользователем или ПЭВМ запроса
на нужную информацию.
Обработка информации производится на ПЭВМ, как прави-
ло, децентрализованно, в местах возникновения первичной ин-
формации, где организуются автоматизированные рабочие места
специалистов той или иной управленческой службы (отдела ма-
342
Глава 5. Эксплуатация ЛИС
тсриально-технического снабжения и сбыта, отдела главного
технолога, конструкторского отдела, бухгалтерии, планового от-
дела и т. п.). Обработка, однако, может производиться не только
автономно, но и в вычислительных сетях с использованием на-
бора ПЭВМ программных средств и информационных массивов
для решения функциональных задач.
В ходе решения задач на ЭВМ в соответствии с машинной
программой формируются результатные сводки, которые печата-
ются машиной на бумаге или отображаются на экране.
Печать сводок может сопровождаться процедурой тиражиро-
вания, если документ с результатной информацией необходимо
предоставить нескольким пользователям.
5.2.2. Режимы обработки данных
При проектировании технологических процессов ориентиру-
ются на режимы их реализации. Режим реализации технологии
зависит от объемно-временных особенностей решаемых задач:
периодичности и срочности, требований к быстроте обработки
сообщений, а также от режимных возможностей технических
средств, и в первую очередь ЭВМ. Существуют следующие ре-
жимы: пакетный; реального масштаба времени; разделения вре-
мени; регламентный; запросный; диалоговый; телеобработки;
интерактивный; однопрограммный; многопрограммный (муль-
тиобработка). Ранее (см. п. 5.1) уже были представлены характе-
ристики пакетного и диалогового режимов выполнения функ-
циональных информационных технологий; в этом разделе упот-
ребляется та же самая терминология, но применительно к
другому процессу — к обработке данных, что в общем случае не
одно и то же.
Пакетный режим. При использовании этого режима пользо-
ватель не имеет непосредственного общения с ЭВМ. Сбор и ре-
гистрация информации, ввод и обработка не совпадают по вре-
мени. Вначале пользователь собирает информацию, формируя ее
в пакеты в соответствии с видом задач или каким-то др. призна-
ком. (Как правило, это задачи неоперативного характера, с дол-
говременным сроком действия результатов решения.) После за-
вершения приема информации производится ее ввод и обработ-
ка, таким образом, происходит задержка обработки. Этот режим
используется, как правило, при централизованном способе обра-
5.2. Организация сбора, размещения, хранения...
343
ботки информации (см. п. 4.1). Например, в течение первой по-
ловины операционного дня производится прием документов,
система работает на прием данных. Во второй половине дня соб-
ранная и организованная в пакеты информация направляется в
вычислительный центр для обработки. Передача может осущест-
вляться как в виде документов или машинных носителей, так и
по каналам связи.
Диалоговый режим (запросный) — режим, при котором суще-
ствует возможность пользователя непосредственно взаимодейст-
вовать с вычислительной системой в процессе работы пользова-
теля. Программы обработки данных находятся в памяти ЭВМ
постоянно, если ЭВМ доступна в любое время, или в течение
определенного промежутка времени, когда ЭВМ доступна поль-
зователю. Взаимодействие пользователя с вычислительной сис-
темой в виде диалога может быть многоаспектным и определять-
ся различными факторами: языком общения, активной или пас-
сивной ролью пользователя; кто является инициатором
диалога — пользователь или ЭВМ; временем ответа; структурой
диалога и т. д. Если инициатором диалога является пользова-
тель, то он должен обладать знаниями по работе с процедурами,
форматами данных и т. п. Если инициатор — ЭВМ, то машина
сама сообщает на каждом шаге, что нужно делать с разнообраз-
ными возможностями выбора. Этот метод работы называется
«выбором меню». Он обеспечивает поддержку действий пользо-
вателя и предписывает их последовательность. При этом от
пользователя Требуется меньшая подготовленность.
Режим меню часто используется при вводе информации на
рабочем месте, для него на экране дисплея высвечивается гото-
вый документ со свободными графами, которые заполняются
исходными данными из документов. Процесс ввода стандарти-
зируется и упрощается.
Диалоговый режим требует определенного уровня техниче-
ской оснащенности пользователя, т. е. наличие терминала или
ПЭВМ, связанных с центральной вычислительной системой ка-
налами связи. Этот режим используется для доступа к информа-
ции, вычислительным или программным ресурсам. Возможность
работы в диалоговом режиме может быть ограничена во времени
(начало и конец работы), а может быть и неограниченной.
Иногда различают диалоговый и запросный режимы, тогда под
запросным понимается одноразовое обращение к системе, после
которого она выдает ответ и отключается, а под диалоговым —
344
Глава 5. Эксплуатация АИС
режим, при которым система после запроса выдает ответ и ждет
дальнейших действий пользователя.
Режим реального масштаба времени — способность вычисли-
тельной системы взаимодействовать с контролируемыми или
управляемыми процессами в темпе протекания этих процессов.
Время реакции ЭВМ должно удовлетворять темпу контролируе-
мого процесса или требованиям пользователей и иметь мини-
мальную задержку. Как правило, этот режим используется при
децентрализованной и распределенной обработке данных. На-
пример, с помощью персонального компьютера (ПК) на рабо-
чем месте служащего вся информация по операциям вводится в
ЭВМ по мере ее поступления.
Режим телеобработки дает возможность удаленному пользо-
вателю взаимодействовать с вычислительной системой.
Интерактивный режим предполагает возможность двусторон-
него взаимодействия пользователя с системой, т. е. у пользовате-
ля есть возможность воздействия на процесс обработки данных.
Режим разделения времени предполагает способность систе-
мы выделять свои ресурсы группе пользователей поочередно.
Вычислительная система настолько быстро обслуживает каждого
пользователя, что создается впечатление одновременной работы
нескольких пользователей. Такая возможность достигается за
счет соответствующего программного обеспечения.
Однопрограммный и многопрограммный режимы характеризу-
ют возможность системы работать одновременно по одной или
нескольким программам.
Регламентный режим характеризуется определенностью во
времени отдельных задач пользователя. Например, получение
результатных сводок по окончании месяца, расчет ведомостей
начисления зарплаты к определенным датам и т. д. Сроки реше-
ния устанавливаются заранее по регламенту в противополож-
ность к произвольным запросам.
5.2.3. Способы обработки данных
Современное производство требует высоких скоростей обра-
ботки информации, удобных форм ее хранения и передачи. Необ-
ходимо также иметь динамичные способы обращения к информа-
ции, способы поиска данных в заданные временные интервалы;
возможность реализовывать сложную математическую и логиче-
5.2. Организация сбора, размещения, хранения... 345
скую обработку данных. Управление крупными предприятиями,
экономикой на уровне страны требует участия в этом процессе
достаточно крупных коллективов. Такие коллективы могут распо-
лагаться в различных районах города, в различных регионах стра-
ны и даже в различных странах. Для решения задач управления,
обеспечивающих реализацию экономической стратегии, стано-
вится важной и актуальной скорость и удобство обмена информа-
цией, а также возможность тесного взаимодействия всех участ-
вующих в процессе выработки управленческих решений.
Различаются следующие способы обработки данных: цен-
трализованная, децентрализованная, распределенная и интегриро-
ванная.
Ранее (см. п. 5.1) уже были изложены преимущества и недос-
татки методологий централизованной и децентрализованной ин-
формационных технологий. Все вышесказанное справедливо и
для аналогичных способов обработки данных; представим лишь
некоторые дополнительные сведения.
Принцип централизованной обработки данных не отвечал вы-
соким требованиям к надежности процесса обработки, затруднял
развитие систем и не мог обеспечить необходимые временные
параметры при диалоговой обработке данных в многопользова-
тельском режиме. Кратковременный выход из строя централь-
ной ЭВМ приводил к роковым последствиям для системы в це-
лом, так как приходилось дублировать функции центральной
ЭВМ, значительно увеличивая затраты на создание и эксплуата-
цию систем обработки данных (рис. 5.7).
Рис. 5.7. Централизованная обработка данных
Централизованная обработка данных предполагает наличие
ВЦ. При этом способе пользователь доставляет на ВЦ исходную
информацию и получает результаты обработки в виде результат-
ных документов. Особенностью такого способа обработки явля-
ются сложность и трудоемкость налаживания быстрой, беспере-
346
Глава 5. Эксплуатация АИС
бойной связи, большая загруженность ВЦ информацией (так как
велик ее объем), регламентацией сроков выполнения операций,
организация безопасности системы от возможного несанкцио-
нированного доступа.
Что касается децентрализованной обработки данных, то в на-
стоящее время в банковской сфере существует три вида техноло-
гий децентрализованной обработки данных:
• ПК нс объединены в локальную сеть (данные хранятся в
отдельных файлах и на отдельных дисках). Для получения
показателей производится перезапись информации на ком-
пьютер. Недостатки: отсутствие взаимосвязанности задач,
невозможность обработки больших объемов информации,
ненадежная защита от несанкционированного доступа;
• ПК объединены в локальную сеть, что ведет к созданию
единых файлов данных. Недостаток: ПК не рассчитан на
большие объемы информации;
• ПК объединены в локальную сеть, в которую включаются
специальные серверы (в режиме «клиент—банк»).
Распределенная обработка данных — обработка данных, вы-
полняемая на независимых, но связанных между собой компью-
терах, представляющих распределенную систему.
Для реализации распределенной обработки данных были
созданы многомашинные ассоциации, структура которых разра-
батывается по одному из следующих направлений:
• многомашинные вычислительные комплексы (МВК);
• компьютерные (вычислительные) сети.
Многомашинный вычислительный комплекс — группа установ-
ленных рядом вычислительных машин, объединенных с помо-
щью специальных средств сопряжения и выполняющих совмест-
но единый информационно-вычислительный процесс.
Распределенный способ обработки данных основан на рас-
пределении функций обработки между различными ЭВМ, вклю-
ченными в сеть. Этот способ может быть реализован двумя путя-
ми: первый предполагает установку ЭВМ в каждом узле сети
(или на каждом уровне системы), при этом обработка данных
осуществляется одной или несколькими ЭВМ в зависимости от
реальных возможностей системы и ее потребностей на текущий
момент времени (рис. 5.8). Второй путь — размещение большого
числа различных процессоров внутри одной системы. Такой
путь применяется в системах обработки банковской и финансо-
5.2. Организация сбора, размещения, хранения...
347
Рис. 5.8. Распределенная обработка данных
вой информации, там, где необходима сеть обработки данных
(филиалы, отделения и т. д.).
Преимущества распределенного способа: возможность обра-
батывать в заданные сроки любой объем данных; высокая сте-
пень надежности, так как при отказе одного технического сред-
ства есть возможность моментальной замены его на другой; со-
кращение времени и затрат на передачу данных; повышение
гибкости систем, упрощение разработки и эксплуатации про-
граммного обеспечения и т. д.
Распределенный способ основывается на комплексе специа-
лизированных процессоров, т. е. каждая ЭВМ предназначена для
решения определенных задач, или задач своего уровня.
Интегрированный способ обработки информации предусматри-
вает создание информационной модели управляемого объекта,
т. е. создание распределенной БД. Такой способ обеспечивает
максимальное удобство для пользователя. С одной стороны,
базы данных предусматривают коллективное пользование и цен-
трализованное управление. С другой, объем информации, разно-
образие решаемых задач требуют распределения БД. Технология
интегрированной обработки информации позволяет улучшить
качество, достоверность и скорость обработки, так как обработ-
ка производится на основе единого информационного массива,
однократно введенного в ЭВМ. Особенностью этого способа яв-
ляется отделение технологически и по времени процедуры обра-
ботки от процедур сбора, подготовки и ввода данных.
Рассмотрим теперь технические средства обработки информа-
ции; они делятся на две большие группы — средства основные и
вспомогательные (рис. 5.9).
Вспомогательные средства — это оборудование, обеспечи-
вающее работоспособность основных средств, а также оборудо-
вание, облегчающее и делающее управленческий труд комфорт-
348
Глава 5. Эксплуатация АИС
Рис. 5.9. Классификация технических средств обработки информации
нее. К вспомогательным средствам обработки информации от-
носятся средства оргтехники и ремонтно-профилактические
средства. Оргтехника представлена весьма широкой номенкла-
турой средств — от канцелярских товаров до средств доставки,
размножения, хранения, поиска и уничтожения основных дан-
ных, средств административно производственной связи и так
далее, что делает работу управленца удобной и комфортной.
Основные средства — это орудия труда для автоматизирован-
ной обработки информации. К ним относятся средства: регист-
рации и сбора информации; приема и передачи данных; подго-
товки данных; ввода; обработки информации и отображения ин-
формации.
Получение первичной информации и ее регистрация являют-
ся одним из трудоемких процессов. Поэтому широко применяют-
ся устройства для механизированного и автоматизированного изме-
рения, сбора и регистрации данных. Номенклатура этих средств
весьма обширна. К ним относят: электронные весы, разнообраз-
ные счетчики, табло, расходомеры, кассовые аппараты, машинки
для счета банкнот, банкоматы и многое другое. Сюда же относят
5.3. Методы и средства сбора и передачи данных
349
различные регистраторы производства, предназначенные для
оформления и фиксации сведений о хозяйственных операциях на
машинных носителях.
Средства приема и передачи информации. Под передачей ин-
формации понимается процесс пересылки данных (сообщений)
от одного устройства к другому. Взаимодействующая совокуп-
ность объектов, устройств передачи и обработки данных называ-
ется сетью. Объединяют устройства, предназначенные для пере-
дачи и приема информации. Они обеспечивают обмен информа-
цией между местом ее возникновения и местом ее обработки.
Структура средств и методов передачи данных определяется рас-
положением источников информации и средств обработки дан-
ных, объемами и временем на передачу данных, типами линий
связи и другими факторами. Средства передачи данных пред-
ставлены абонентскими пунктами (АП), аппаратурой передачи,
модемами, мультиплексорами.
Средства подготовки данных представлены устройствами под-
готовки информации на машинных носителях, устройствами для
передачи информации с документов на носители, включающие
устройства ЭВМ. Эти устройства могут осуществлять сортировку
и корректирование.
Средства ввода служат для восприятия данных с машинных
носителей и ввода информации в компьютерные системы.
Средства обработки информации играют важнейшую роль в
комплексе технических средств обработки информации. К сред-
ствам обработки относят компьютеры, которые в свою очередь
подразделяют на четыре класса: микро, малые (мини); большие
и суперЭВМ.
Средства отображения информации используют для вывода
результатов вычисления, справочных данных и программ на ма-
шинные носители, печать, экран и т. д. К устройствам вывода
относят мониторы, принтеры и плоттеры.
5.3. Методы и средства сбора и передачи данных
В зависимости от используемых технических средств и тре-
бований к технологии обработки информации изменяется и со-
став операций ТП.
350
Глава 5. Эксплуатация АИС
Операции сбора и регистрации данных осуществляются с по-
мощью различных методов и средств. Различают следующие ме-
тоды сбора и регистрации данных: механизированный; автома-
тизированный; автоматический.
Механизированный — сбор и регистрация информации осу-
ществляются непосредственно человеком с использованием про-
стейших приборов (весы, счетчики, мерная тара, приборы учета
времени и т. д.).
Автоматизированный предполагает использование машиночи-
таемых документов, регистрирующих автоматов, универсальных
систем сбора и регистрации, обеспечивающих совмещение опе-
раций формирования первичных документов и получения ма-
шинных носителей.
Автоматический используется в основном при обработке дан-
ных в режиме реального времени. Информация с датчиков, учи-
тывающих ход производства — выпуск продукции, затраты сы-
рья, простои оборудования и т. д. — поступает непосредственно
в ЭВМ.
Технические средства передачи данных включают:
• аппаратуру передачи данных (АПД), которая соединяет
средства обработки и подготовки данных с телеграфными,
телефонными и широкополосными каналами связи;
• устройства сопряжения ЭВМ с АПД, которые управляют
обменом информации — мультиплексоры передачи данных.
Запись и передача информации по каналам связи в ЭВМ
имеют следующие преимущества:
• упрощается процесс формирования и контроля инфор-
мации;
• соблюдается принцип однократной регистрации информа-
ции в первичном документе и машинном носителе;
• обеспечивается высокая достоверность информации, по-
ступающей в ЭВМ.
Дистанционная передача данных, основанная на использова-
нии каналов связи, представляет собой передачу данных в виде
электрических сигналов, которые могут быть непрерывными во
времени и дискретными, т. е. носить прерывный во времени ха-
рактер. Наиболее широко используются телеграфные и телефон-
ные каналы связи. Электрические сигналы, передаваемые по те-
леграфному каналу связи являются дискретными, а по телефон-
ному — непрерывными.
5.3. Методы и средства сбора и передачи данных
351
В зависимости от направлений, по которым пересылается
информация, различают каналы связи:
• симплексный (передача идет только в одном направлении);
• полудуплексный (в каждый момент времени производится
либо передача, либо прием информации);
• дуплексный (передача и прием информации осуществля-
ются одновременно в двух встречных направлениях).
Каналы характеризуются скоростью передачи данных, досто-
верностью, надежностью передачи.
Скорость передачи определяется количеством информации,
передаваемой в единицу времени, и измеряется в бодах (бод =
= 1 бит/с). Различают:
• телеграфные каналы низкоскоростные — К= 50—200 бод;
• телефонные среднескоростные — К= 200—2400 бод;
• широкополосные высокоскоростные — И=4800 бод и более.
При выборе наилучшего способа передачи информации учи-
тываются объемные и временные параметры доставки, требова-
ния к качеству передаваемой информации, трудовые и стоимост-
ные затраты на передачу информации.
Говоря о технологических операциях сбора, регистрации, пере-
дачи информации с помощью различных технических средств не-
обходимо сказать несколько слов и о сканирующих устройствах.
Ввод информации, особенно графической, с помощью кла-
виатуры в ЭВМ очень трудоемок. В последнее время намети-
лись тенденции применения деловой графики — одного из ос-
новных видов информации, что требует оперативности ввода
информации в ЭВМ и предоставления пользователям возмож-
ности формирования гибридных документов и БД, объединяю-
щих графику с текстом. Все эти функции в ПЭВМ выполняют
сканирующие устройства. Они реализуют оптический ввод ин-
формации и преобразование ее в цифровую форму с последую-
щей обработкой.
Для ПЭВМ IBM PC разработана система PC Image/Graphix,
предназначенная для сканирования различных документов и их
передачи по коммуникациям. К документальным носителям, ко-
торые могут сканироваться камерой системы, относятся текст,
штриховые чертежи, фотографии, микрофильмы. Сканирующие
устройства на базе ПЭВМ применяются не только для ввода тек-
стовой и графической информации, но и в системах контроля,
обработки писем, выполнения различных учетных функций.
352
Глава 5. Эксплуатация АИС
5.4. Обеспечение достоверности информации
в процессе хранения и обработки
5.4.1. Резервное копирование базы данных
и последующее восстановление
Резервное копирование — один из самых надежных способов
сохранить данные от потери или порчи и обеспечить достовер-
ность информации в процессе хранения. Процесс резервного ко-
пирования также делается в профилактических целях для увели-
чения производительности БД — это достигается за счет того,
что в момент копирования происходит считывание последних
версий всех записей, старые же версии в копию никогда не по-
падают. Отметим, что одного лишь резервного копирования не-
достаточно — надо иногда проверять восстанавливаемость БД из
резервной копии [12, 13].
Для минимизации потери данных и восстановления утерян-
ных данных необходимо иметь стратегию резервного копирова-
ния. Потеря данных может быть связана с ошибками в аппарат-
ном или программном обеспечении или:
• при случайном или злоумышленном использовании опера-
тора DELETE;
• при случайном или злоумышленном использовании опера-
тора UPDATE — например, без использования WHERE
оператора вместе с оператором UPDATE (все записи будут
обновлены вместо одной строки определенной таблицы);
• с деструктивными вирусами;
• при стихийном бедствии, таком как пожар, наводнение и т. д.;
• с воровством.
Если существует стратегия резервного копирования, то можно
восстановить данные с минимальными потерями рабочего време-
ни и минимизировать вероятность безвозвратной потери данных.
Стратегия резервного копирования должна вернуть систему об-
ратно в то состояние, которое было до наступления проблемы.
Стоимость, связанная с развертыванием стратегии резервно-
го копирования, включает количество времени, истраченное на
разработку, установку, автоматизирование и тестирование про-
цедур резервного копирования. Невозможно предотвратить по-
терю данных полностью, поэтому надо разработать стратегию
так, чтобы минимизировать размер вреда. При планировании
5.4. Обеспечение достоверности информации...
353
стратегии резервного копирования рассматривается приемлемое
количество времени, которое система может быть недоступна, а
также приемлемое количество данных, которые могут быть поте-
ряны в момент ошибки системы.
Частота резервирования данных зависит от количества дан-
ных, которые можно потерять, и величины активности базы
данных. Когда резервируется пользовательская БД, рассматрива-
ются следующие факты и рекомендации:
• резервировать БД чаще, если система работает в окруже-
нии OLTP;
• резервировать данные реже, если система имеет маленькую
активность или используется для принятия решений;
• запланировать резервное копирование, когда SQL Server
бездействует или сильно обновлен;
• автоматизировать процесс, используя Database Maintenance
Plan Wizard.
5.4.2. Модели восстановления базы данных
Изменить модель восстановления БД можно в любое время,
но нужно планировать модель восстановления при создании БД.
Сервер SQL имеет три модели восстановления БД; каждая из
них сохраняет данные в момент ошибки сервера, различие толь-
ко в том, как SQL Server восстанавливает данные, как хранит и
сколько требуется затрат производительности в момент ошибки
диска.
Full Recovery Model — полная модель восстановления. Модель
полного восстановления следует использовать, когда необходимо
полное восстановление с поврежденного носителя. Эта модель ис-
пользует копию БД и всей информации журнала для восстановле-
ния БД. Сервер SQL журнализирует (см. гл.1) все изменения в БД,
включая массивные операции и создание индексов. Если журнал
транзакций не испорчен, то можно восстановить все данные, ис-
ключая транзакции, которые были активны в момент ошибки.
Поскольку все транзакции журнализируются, восстановле-
ние можно выполнить в любой момент времени. Сервер SQL
поддерживает вставку именованных меток в журнал транзакций,
что позволяет восстанавливать данные до указанной метки.
Так как метки журнала транзакций отнимают пространство
журнала, необходимо использовать их только если транзакция
354
Глава 5. Эксплуатация АИС
играет важную роль в стратегии восстановления. Основное огра-
ничение этой модели — большой размер файлов журнала и ре-
зультирующего хранилища и цена производительности.
Bulk Logged-модель восстановления. Подобно полной модели
восстановления, Bulk Logged-модель использует одновременно
зарезервированную БД и журнал для воссоздания БД, при этом
требуется гораздо меньшее пространство журнала для следую-
щих операций: CREATE INDEX, операции массовой загрузки,
SELECT INTO, WRITETEXT и UPDATETEXT. Журнал записы-
вает только факт происшествия операции без записи детальной
информации.
Для сохранения изменения целых массовых операций загруз-
ки сохраняется только окончательный результат множественных
операций. В результате журнал получается меньше и операции
выполняются быстрее.
Используя эту модель, можно восстановить все данные, но
неудобство состоит в том, что невозможно восстановить только
часть зарезервированного, так как это делается при метках.
Простая модель восстановления применяется для небольших
БД и в тех базах, где изменения происходят редко. Эта модель
использует полную или дифференцированную копию БД и вос-
становление ограничено только восстановлением БД на момент
последнего резервного копирования. Все изменения, внесенные
после резервного копирования, теряются и требуют повторного
создания. Главное преимущество этой модели — меньший раз-
мер носителя и простота внедрения этой модели.
Создание модели восстановления базы данных. По умолчанию
SQL Server Standard Edition и SQL Server Enterprise Edition ис-
пользуют полную модель восстановления. Можно изменить мо-
дель в любой момент времени, но необходимо произвести до-
полнительное резервное копирование на момент изменения. Для
определения того, какую модель использует БД, применяется
функция DATABASEPROPERTYEX [12].
5.4.3. Резервирование SQL Server
Во время выполнения операции резервного копирования
SQL Server:
• позволяет выполнять резервирования БД в то время как
пользователи продолжают работать с этой базой;
5.4. Обеспечение достоверности информации...
355
• резервирует оригинальные файлы БД и хранящиеся в ней
записи.
Резервирование содержит:
• структуру файла и схемы;
• данные;
• порции файла журнала транзакций, которые содержат ак-
тивность БД после старта процесса резервирования.
Сервер SQL использует резервные копии для воссоздания
файлов в их оригинальном расположении полностью с объекта-
ми и данными на момент резервирования БД. Процесс резерви-
рования SQL Server динамический, он выполняется, когда с по-
мощью SQL Server:
• записываются все страницы на носитель с помощью пря-
мого чтения диска;
• фиксируются все записи журнала транзакций, появившие-
ся во время выполнения процесса резервирования.
Для выполнения резервирования БД в SQL Server необходимо
определить, кому разрешено выполнять резервирование и где бу-
дет храниться результат. Для резервирования используется опера-
тор Transact-SQL или SQL Server Enterprise Manager.
Сервер SQL может резервировать на жесткий диск, ленточ-
ный носитель (должен быть локально подключен к компьютеру)
и именованный канал.
Наиболее часто носителем для хранения резервных копий
являются дисковые файлы (локальные или сетевые).
Резервирование системных баз данных. Системные БД содер-
жат важную информацию о SQL Server и всех пользовательских
БД, поэтому необходимо регулярно их резервировать.
Информацию о всех БД SQL Server содержит БД master. Оче-
видно, что при создании любой пользовательской БД следует сра-
зу же эту БД резервировать, тогда в случае порчи БД master поль-
зовательские БД легко восстановить с резервной копии. После
этого можно восстанавливать другие системные таблицы и ссыл-
ки на существующие пользовательские БД. Для перестроения не-
обходимо воспользоваться утилитой \Program Files\Microsoft SQL
Server\80\Tools\Binn\ Rebuildm.exe
Резервирование пользовательских баз данных. Необходимо
планировать регулярное резервное копирование пользователь-
ских БД. Также необходимо выполнять резервирование после:
1) создания БД;
2)создания индекса;
356
Глава 5. Эксплуатация АИС
3) выполнения определенных операторов, которые не журна-
лизм руются.
В первом случае без полного резервного копирования невоз-
можно восстановить резервирование журнала транзакций.
Во втором случае резервирование БД после создания индек-
са гарантирует, что зарезервированная БД содержит данные и
структуру индексов. Если после создания индекса резервируется
только журнал транзакций, и в дальнейшем восстанавливается
журнал транзакций, то SQL Server должен перестроить индексы.
В результате на перестроение индексов может быть затрачено
больше времени, чем на полное резервное копирование БД.
После очистки журнала транзакций следует резервировать
БД с помощью операторов BACKUP WITH TRUNCATEONLY
или BUCKUP LOG WITH NO LOG. После этого журнал тран-
закций больше не содержит записей об активности и не может
использоваться для восстановления изменений в БД. Операции,
которые не записываются в журнал транзакций, называются не-
журналируемыми операторами.
Применение некоторых моделей восстановления нс преду-
сматривает восстановление изменений, сделанных нежурнали-
руемыми операторами:
. операторы BUCKUP LOG WITH TRUNCATE ONLY или
BUCKUP LOG WITH NO LOG. Сервер SQL удаляет неак-
тивную часть журнала транзакций без создания резервной
копии;
• операторы WRIRETEXT и UPDATETEXT. Сервер SQL из-
меняет данные в текстовых колонках и по умолчанию не
записывает эту активность в журнал транзакций. Однако
можно указать опцию WITH LOG для записи этой актив-
ности в журнал транзакций;
• оператор SELECT ... INTO, когда создаются постоянные
таблицы или полные копии программ.
Желательно резервировать БД после выполнения нежурна-
лируемых операторов, так как если система даст сбой, то в жур-
нале транзакций может отсутствовать информация, необходимая
для восстановления БД [13].
Ограничения активности во время резервирования. Резервиро-
вание БД выполнимо, когда она активна и доступна. Однако
следует иметь в виду, что во время резервирования невозможно:
• создание и изменение базы данных CREATE DATABASE,
ALTER DATABASE;
• выполнение операций автоприращения БД;
5.4. Обеспечение достоверности информации...
357
• создание индексов;
• выполнение любых нежурнализируемых операторов;
• обрезание БД [13].
5.4.4. Выполнение резервирования
При выполнении резервирования сначала следует создать
файлы для резервного копирования (постоянные или времен-
ные), для хранения резервных данных. Созданный заранее файл
для резервирования данных и используемый для операций ре-
зервирования называется «устройством резервирования».
Для повторного использования файлов резервных копий, ко-
торые были созданы для автоматизации задач резервирования
БД, необходимо создать постоянные устройства резервирования
(например, с помощью SQL Server Enterprise Manager или с по-
мощью выполнения встроенной системной процедуры).
Создание файлов резервирования на непостоянных устройст-
вах. Создание постоянных устройств резервирования предпочти-
тельнее, но с помощью оператора BACKUP DATABASE можно
создать временные файлы резервирования без указания опреде-
ленного устройства резервирования (если нет необходимости в
регулярном использовании резервных файлов) Так, если выпол-
няется только единственное резервирование БД, которое не по-
вторится в будущем, или происходит тестирование операции ре-
зервирования с целью дальнейшей автоматизации, то целесооб-
разно создавать временный файл резервирования.
При создании временного файла необходимо указать тип но-
сителя (диск, ленточный носитель или именованный канал),
полный путь и имя файла.
Использование нескольких файлов резервирования для хране-
ния резервных копий. Сервер SQL может производить запись в
несколько резервных файлов одновременно (параллельно). При
этом данные распределяются между всеми файлами, которые ис-
пользуются при создании резервной копии. Эти файлы хранят
набор разделенных данных.
Рекомендуется резервировать на несколько ленточных носи-
телей или дисковых контроллеров, чтобы уменьшить общее вре-
мя на резервирование БД (резервирование на один ленточный
носитель занимает 4 часа, добавление второго носителя умень-
шает время резервирования до 2 часов).
358
Глава 5. Эксплуатация АИС
Резервирование на ленточное устройство. Ленточный носи-
тель — это удобное средство для резервирования в силу своей
дешевизны, большого объема памяти и наличия средств защи-
ты данных. При резервировании на ленточный носитель SQL
Server записывает информацию о резервировании на ленточную
этикетку, которая включает имя БД, время, дату, тип резерви-
рования.
Сервер SQL использует стандарт формата резервирования
Microsoft Таре Format для записи резервирования на ленту. В ре-
зультате данные SQL Server могут сосуществовать на одном но-
сителе с другими наборами резервирования или наборами резер-
вирования, созданными другими клиентами. Например, SQL
Server и MS Windows 2000 могут хранить свои резервные копии
на одном ленточном носителе.
5.4.5. Типы методов резервирования
Сервер SQL предоставляет разные методы резервирования
для удовлетворения потребностей широкого круга бизнес-окру-
жения и активности БД.
Полное резервирование БД. При использовании БД в основ-
ном только для чтения полное резервирование может быть наи-
лучшим решением для предотвращения потери данных. Во время
выполнения полного резервного копирования SQL Server:
• резервирует любую активность, которая происходит во вре-
мя резервирования;
• резервирует любые незавершенные транзакции в журнале
транзакций. Сервер SQL использует части журнала тран-
закций, которые были захвачены в файл резервирования
для того, чтобы убедиться в целостности во время восста-
новления.
Дифференцированное резервирование БД выполняется для со-
кращения времени, необходимого для восстановления часто из-
меняемой БД. Метод рекомендуется использовать в случае, если
выполнено полное резервирование. При дифференцированном
резервировании SQL Server:
• резервирует часть БД, которая изменилась с момента по-
следнего полного резервирования. Для определения изме-
ненных страниц SQL Server сравнивает LSN на странице
для синхронизации с LSN последнего резервирования;
5.4. Обеспечение достоверности информации...
359
• резервирует всю активность, которая появилась во время
дифференцированного резервирования, и любые незавер-
шенные транзакции в журнале транзакций.
Резервирование журнала транзакций применяется для записи
любых изменений в БД. Метод рекомендуется использовать при
выполнении полного резервирования БД. При этом журнал
транзакций нельзя восстановить без соответствующего резерви-
рования БД; журнал транзакций невозможно резервировать с
помощью простой модели резервирования.
Резервирование файлов БД и файловых групп. Метод исполь-
зуется в случае нецелесообразности полного резервного копиро-
вания на очень больших БД. При резервировании файлов БД
или файловых групп с помощью SQL Server:
• резервируются только те файлы, которые указаны в опции
FILE или FILEGROUP;
• резервируются только определенные файлы, а не вся БД.
Ограничения при резервировании файлов и файловых групп БД.
При резервировании БД, которая состоит из нескольких файлов
или файловых групп, бывает необходимо резервировать различ-
ные файлы БД как целый модуль, если созданы индексы. Сервер
SQL автоматически определяет время создания индексов с мо-
мента последнего резервирования БД и требует резервирования
полного набора измененных файлов в один целый модуль.
При создании индекса в простой модели восстановления
журнал транзакций фиксирует факт создания индекса и список
страниц, которые использовались при этом. Использование это-
го журнала транзакций во время восстановления БД приводит к
тому, что SQL Server выполняет оператор CREATE INDEX и ис-
пользует оригинальные страницы индекса.
Для того чтобы SQL Server пересоздал индексы, все файлы
БД, содержащие базовые таблицы, и все файлы БД, измененные
во время создания индекса, должны находиться в том состоя-
нии, в котором и находились при создании индекса [12, 131.
5.4.6. Планирование стратегии резервирования
При планировании стратегии резервирования с учетом осо-
бенностей производственного окружения сначала определяют
метод резервирования или комбинацию методов. Далее рассмат-
ривается процесс восстановления.
360
Глава 5. Эксплуатация АИС
Стратегия полного резервирования базы данных. Время и ре-
сурсы, необходимые для выполнения этой стратегии, определя-
ют размер БД и частоту изменения данных. Полное резервирова-
ние выполняют в случае:
• небольшого объема БД, так как время резервирования ог-
раничено соображениями целесообразности;
• небольшого количества модификаций БД или использова-
ния БД только для чтения.
В результате применения этой стратегии в конечном счете
заполнится журнал транзакций. При переполнении журнала SQL
Server может не допустить дальнейшую активность с БД, пока
журнал не будет очищен.
С помощью этой стратегии можно полностью восстановить
БД до момента возникновения ошибки, если журнал транзакций
остался цел. При хранении журнала транзакций и БД на разных
дисках вероятность разрешения обоих дисков очень мала, поэто-
му такая стратегия работает очень хорошо. Если данные в БД
слишком важны и в случае ошибки восстанавливать вручную за-
труднительно, необходимо регулярно резервировать журнал тран-
закций [12].
Стратегия полного резервирования БД и журнала транзакций —
наиболее часто выполняемая стратегия. В дополнение к выпол-
нению полного резервирования БД необходимо надлежащим об-
разом резервировать журнал для записи всей активности БД, ко-
торая происходит между полными резервированиями.
Стратегия позволяет восстановить БД из наиболее полного
последнего резервирования, после этого следует применить все
зарезервированные журналы транзакций, которые выполнят из-
менения, происшедшие с момента последнего полного резерви-
рования БД.
Стратегию полного резервирования БД и журнала транзак-
ций выполняют для часто обновляемых БД, причем необходимо
следить за тем, чтобы БД и журнал резервировались в доступное
время.
Для восстановления БД необходимо:
• по возможности зарезервировать журнал транзакций с ис-
пользованием опции WITH NOTRUNCATE;
• восстановить БД из последнего полного резервирования;
• восстановить журналы двух предпоследних транзакций;
5.5. Экспортирование структур баз данных
361
• восстановить журнал транзакций, который был создан на
момент разрушения с опцией WITH NO TRUNCATE [12].
Стратегия дифференцированного резервирования подразумева-
ет резервирование только части БД, которая была изменена с
момента последнего полного резервирования. При дифференци-
рованном резервировании SQL Server:
• не записывает изменения журнала транзакций, поэтому не-
обходимо периодически резервировать журнал транзакций;
• требует восстановления только последней дифференциро-
ванной копии для восстановления БД. Последняя диффе-
ренцированная копия содержит все изменения, которые
были выполнены с момента последнего полного резерви-
рования БД.
Эта стратегия применяется для оптимизации времени вос-
становления, если БД была разрушена (дифференцированное
резервирование предпочтительнее, чем восстановление множест-
ва больших журналов транзакций) [12].
Стратегия резервирования файлов и файловых групп. При ис-
пользовании этой стратегии, как правило, резервируется журнал
транзакций как часть стратегии.
В комбинации с регулярным резервированием журнала тран-
закций эта технология является распределенной во времени аль-
тернативой полного резервирования БД. Например, если время
резервирования ограничено одним часом (при полном резерви-
ровании это отнимает 4 часа), следует резервировать отдельные
файлы каждый день в ночное время и при этом обеспечивать за-
щиту данных [12].
5.5. Экспортирование структур баз даннь’х
5.5.1. Экспорт и импорт данных
При работе с АИС часто возникают задачи, для решения ко-
торых необходимо производить перенос данных между БД. Су-
ществуют две формы переноса данных:
• экспортирование — процесс, при котором данные переда-
ются внешнему источнику;
• импортирование — процесс, при котором данные извлека-
ются из внешнего источника.
362
Глава 5. Эксплуатация АИС
Таким образом, один и тот же процесс переноса данных, в
зависимости от точки зрения на него, является одновременно и
экспортом и импортом данных.
В зависимости от поставленных целей процесс экспортиро-
вания данных может быть как разовым (по запросу), так и перио-
дически выполняемым (по расписанию).
Экспортирование данных требуется в следующих случаях:
• перевод БД на другой физический носитель или сервер;
• создание копии БД;
• архивирование БД;
• перенос данных между разными информационными систе-
мами;
• перенос данных от унаследованных систем.
Необходимость переноса БД на другой физический носитель
или сервер возникает, например, в случае модернизации аппа-
ратного обеспечения АИС, перехода на другую версию про-
граммного обеспечения или переезда организации, работающей
с АИС.
Создание копии БД (репликация) — один из способов разгруз-
ки основного сервера АИС. В этом случае часть функций АИС,
связанных с чтением данных, может выполняться на копии ос-
новной БД. Если в АИС большое число пользователей, то это
позволяет ускорить работу с данными.
Также можно поддерживать информационную деятельность
географически удаленных пользователей, если нет возможности
обеспечить их работу через глобальную сеть. В удаленном под-
разделении устанавливается сервер, на который с заданной пе-
риодичностью экспортируются требуемые данные.
Архивирование БД — обязательная периодическая процедура,
помогающая избежать или, по крайней мере, уменьшить ущерб
от утраты данных в результате программных и аппаратных сбоев,
ошибок или злого умысла пользователей.
Задачи переноса данных между АИС возникают при пересе-
чении предметных областей систем, что приводит к их парал-
лельной согласованной работе с одними и теми же данными.
Например, это могут быть ИС, автоматизирующие организации
разного уровня иерархии: АИС министерства и подчиненного
учреждения, центрального офиса и торговой точки. В этих слу-
чаях по запросу или по расписанию производится экспорт дан-
ных в ту или иную сторону.
5.5. Экспортирование структур баз данных
363
Проведение переноса данных между АИС может выполнять-
ся и внутри одного объекта (организации) при так называемой
«лоскутной» автоматизации, когда организация использует не-
скольких слабоинтсгрированных ИС. Например, экспорт дан-
ных из АИС отдела продаж в АИС бухгалтерии.
На сегодняшний день, когда эволюция АИС насчитывает де-
сятилетия, трудно найти проект, который создается на пустом
месте. Как правило, к моменту внедрения разработанной АИС
существует одна или несколько уже действующих, так называе-
мых унаследованных систем.
Несмотря на то, что эти системы уже нс в состоянии решать
поставленные задачи на современном уровне, данные, накоп-
ленные в них, представляют большую ценность для автоматизи-
руемой организации — создание новой АИС не означает, что ор-
ганизация только начинает свое становление.
После внедрения необходимо исключить или максимально
сократить период параллельной работы унаследованной и новой
АИС. Поддержка двух или более систем вместо одной требует
больших усилий и от администраторов и от пользователей; со-
здается впечатление, что внедряемая АИС не реализует всех
функций унаследованной системы.
Экспорт данных из унаследованных систем следует прово-
дить таким образом, чтобы новая АИС могла полноценно рабо-
тать и со старыми данными (полученными от унаследованных
систем), и с новыми, и с их комбинациями.
Для проведения экспортирования данных необходимо:
• указать источник данных;
• указать получатель (приемник) данных;
• задать набор преобразований данных из формата источни-
ка в формат получателя (если требуется).
5.5.2. Преобразование данных при экспортировании
Сложность экспорта данных сильно зависит от характери-
стик источника и получателя данных, их соответствия друг дру-
гу. Исходя из этого, экспорт данных может заключаться в про-
стом переносе данных или в выполнении ряда преобразований
переносимых данных.
Простой перенос данных — это создание копий структур дан-
ных (таблиц, представлений и т. д.) источника в БД получателя.
364
Глава 5. Эксплуатация АИС
Значительно сложнее проведение экспорта, когда в БД полу-
чателя данных существуют соответствующие структуры. Экспор-
тируемые данные в этом случае должны быть преобразованы та-
ким образом, чтобы полностью соответствовать организации
данных в БД получателя.
Существуют нижеследующие виды преобразований данных.
Переименование. Объекты данных (таблицы, поля и т. п.) ис-
точника получают имена в соответствии с организацией данных
получателя.
Реструктуризация. Общая предметная область в БД-источни-
ке и БД-получателе может быть разделена на таблицы и поля
разными способами. В этом случае переносимые данные долж-
ны быть реструктуризированы. При этом одна таблица может
состоять из нескольких таблиц или, наоборот, несколько таблиц
объединяется в одну. То же самое касается и полей — в соответ-
ствии со структурой БД-получателя экспортируемые поля могут
объединяться или разделяться.
Агрегирование. БД-получатель предусматривает не просто
импорт данных, а получение некоторого сводного или итогового
отчета. Для этого данные преобразуются агрегирующими запро-
сами. Например, в офис фирмы передаются не таблицы с запи-
сями обо всех продажах, а итоговый отчет, агрегированный по
датам и типам товаров.
Кодирование и декодирование. Если БД-источник и БД-полу-
чатель используют разные системы кодирования атрибутов дан-
ных или в одной из них атрибут кодируется, а в другой — нет, то
при экспортировании с помощью декодирования и кодирования
данные изменяются так, чтобы они соответствовали системе ко-
дирования атрибутов в БД-получателе.
Конвертирование. В случае использования разных форматов
для хранения соответствующих атрибутов (числовых, текстовых
или логических) в процессе экспортирования данные необходи-
мо конвертировать — привести к формату атрибута в БД-получа-
теле.
Согласование. При экспортировании данных необходимо
обеспечить их согласование с данными, хранимыми в БД-полу-
чателе. В разных БД могут использоваться разные способы ото-
бражения одной и той же информации. Например, какой-то па-
раметр оценивается по пяти- или десятибалльной системе; рас-
стояние измеряется в метрах, километрах и т. п.
5.5. Экспортирование структур баз данных
365
Проверка. В БД могут использоваться разные ограничения на
допустимость значений полей, поэтому экспортируемые данные
должны проверяться и соответственно преобразовываться. При
этом записи, не прошедшие проверку, могут помечаться в слу-
жебных полях или сохраняться в специальных таблицах, что по-
зволит в дальнейшем подвергнуть их анализу и корректировке.
Таким образом, преобразование данных при экспортирова-
нии может являться большой сложной задачей. Алгоритм выпол-
нения экспорта с преобразованиями реализуется в виде последо-
вательности запросов. Такая последовательность называется
скриптом (сценарием).
5.5.3. Технологии экспортирования данных
Существует множество технологий экспорта и импорта дан-
ных. Современные СУБД содержат специальные инструменты
(утилиты), реализующие такие технологии.
Выбор технологии при решении конкретной задачи зависит
от многих факторов: формата данных, характеристик БД, в кото-
рых они хранятся, частоты выполнения и т. п.
В современных продуктах Microsoft для переноса данных ис-
пользуется технология OLE DB, построенная на основе СОМ.
Эта технология позволяет работать с данными в любом формате,
для которых существуют провайдеры (специальные интерфейс-
ные компоненты).
СУБД Microsoft SQL Server включает в себя Data Trans-
formation Services (DTS) — программное обеспечение, позволяю-
щее экспортировать, импортировать и преобразовывать данные.
DTS может работать не только с данными СУБД, но и с элек-
тронными таблицами и текстовыми файлами. Работая с DTS,
можно сохранять и неоднократно выполнять специальные паке-
ты DTS, реализующие процесс перевода данных.
В СУБД Oracle утилиты экспортирования и импорта вызыва-
ются командами ЕХР и IMP. Утилита экспорта выводит данные
в файлы двоичного формата. Экспорт в ORACLE может произ-
водиться в трех режимах:
• режим таблицы. Экспортируются указанные таблицы;
• режим пользователя. Экспортируются все объекты, при-
надлежащие пользователю;
• режим полной базы. Экспортируются все объекты БД.
366
Глава 5. Эксплуатация АИС
5.6. Восстановление информации в базах данных
5.6.1. Журнализация и восстановление
Проблемы восстановления информации в БД частично были
рассмотрены ранее (см. п. 5.4) в контексте вопросов резервиро-
вания и последующего восстановления данных. Информация,
кроме того, подлежит восстановлению после различных сбоев
транзакций, типология которых (индивидуальные, жесткие, мяг-
кие) подробно изложена в гл. 3 при освещении процессов жур-
нализации.
Алгоритмы восстановления основаны на двух базовых сред-
ствах — ведении журнала и поддержке теневых состояний сегмен-
тов [12]. Нет смысла повторяться и останавливаться на принци-
пах механизма журнализации и правила WAL; рассмотрим под-
робнее вопросы, нс затронутые ранее.
При окончании любой транзакции производится выталкива-
ние недозаполненного буфера журнала и тем самым гарантиру-
ется наличие в журнале полной информации обо всех изменени-
ях, произведенных данной транзакцией. Насильственное вы-
талкивание страниц буфера БД не производится (слишком
накладно было бы производить такие выталкивания при оконча-
нии любой транзакции). В результате после мягкого сбоя неко-
торые страницы на внешней памяти могут не содержать инфор-
мации, помешенной в них уже закончившимися транзакциями,
а другие страницы могут содержать информацию, помещен-
ную транзакциями, которые к моменту сбоя не закончились.
При восстановлении необходимо добавить информацию в стра-
ницах первого типа и удалить информацию в страницах второго
типа [14].
Периодически устанавливаются системные контрольные точ-
ки. При установлении такой контрольной точки производится
насильственное выталкивание во внешнюю память буфера жур-
нала и всех буферов страниц. Это дорогостоящая операция и вы-
полняется достаточно редко. При каждой системной контроль-
ной точке в журнал помешается специальная запись.
Предположим, что последняя системная контрольная точка
устанавливалась в момент времени /с, а мягкий сбой произошел
в некоторый более поздний момент времени tf. Тогда все тран-
закции системы можно разбить на пять категорий. Транзакции
5.6. Восстановление информации в базах данных
367
категории Т, начались и кончились до момента /с. Следователь-
но, все произведенные ими изменения БД надежно находятся на
внешней памяти, и по отношению к ним никаких действий при
восстановлении производить не нужно. Транзакции категории Т,
начались до момента но успели кончиться к моменту мягкого
сбоя tf. Изменения, произведенные такими транзакциями после
момента /с, могли не попасть на внешнюю память, и при восста-
новлении должны быть повторно произведены. Транзакции ка-
тегории Т3 начались до момента Гс, но не кончились к моменту
сбоя. Все их изменения, произведенные до момента /с, и, воз-
можно, некоторые изменения, произведенные после момента /с,
содержатся на внешней памяти. При восстановлении их необхо-
димо удалить. Транзакции категории Т4 начались после момента
установки системной контрольной точки и успели закончиться
до момента сбоя. Их изменения могли не отобразиться на внеш-
нюю память; при восстановлении необходимо выполнить их по-
вторно. Наконец, транзакции категории Т5 начались после мо-
мента /с и не закончились к моменту сбоя. Их изменения долж-
ны быть удалены из страниц на внешней памяти.
В принципе можно было бы выполнить все необходимые
восстановительные действия после мягкого сбоя, основываясь
только на информации из журнала. Однако ситуация несколько
упрощается за счет применения техники теневых страниц.
Принцип теневых страниц давно использовался в файловых сис-
темах, поддерживающих файлы со страничной организацией.
В соответствии с этим принципом после открытия файла на из-
менение модифицированные страницы записываются на новое
место внешней памяти (т. е. под них выделяются свободные бло-
ки внешней памяти). При этом во внешней памяти сохраняется
старая (теневая) таблица отображения страниц файла во внеш-
нюю память, а в оперативной памяти по ходу изменения файла
формируется новая таблица. При закрытии файла заново сфор-
мированная таблица записывается во внешнюю память, образуя
новую теневую таблицу, а блоки внешней памяти, содержащие
предыдущие образы страниц файла, освобождаются. При сбое
процессора автоматически сохраняется состояние файла, в кото-
ром он находился перед последним открытием (конечно, с воз-
можной потерей некоторых блоков внешней памяти, которые
затем собираются с помощью специальной утилиты). Допуска-
ются операции явной фиксации текущего состояния файла и яв-
ного отката состояния файла к точке последней фиксации.
368
Глава 5. Эксплуатация АИС
Развитие идей теневого механизма применяется в контексте
мультидоступных БД. Сегменты БД представляют собой файлы
со страничной организацией. Соответственно, существуют и
таблицы приписки этих файлов на блоки внешней памяти. При
выполнении операции установки системной контрольной точки
после выталкивания буферов страниц на внешнюю память таб-
лицы отображения всех сегментов также фиксируются на внеш-
ней памяти, т. е. становятся теневыми. Далее, до следующей
контрольной точки доступ к страницам сегментов производится
через таблицы отображения, располагаемые в оперативной па-
мяти, и каждая изменяемая страница любого сегмента записыва-
ется на новое место внешней памяти с коррекцией соответст-
вующей текущей таблицы отображения.
Тогда, если происходит мягкий сбой, все сегменты автомати-
чески переходят в состояние, соответствующее последней сис-
темной контрольной точке, т. е. изменения, произведенные поз-
же момента установления этой контрольной точки, в них просто
не содержатся.
Это достаточно сильно упрощает процедуру восстановления
после мягкого сбоя. Система вообще не должна предпринимать
никаких действий по отношению к изменениям транзакций типа
Т5 — этих изменений нет на внешней памяти. При восстановле-
нии достаточно выполнить обратные изменения транзакций
типа Т3, повторно выполнить изменения транзакций типа Т2.
Кроме того, нужно просто повторить изменения транзакций
типа Т4. Естественно, что начинать действия по журналу следует
с записи о последней контрольной точке.
Следует отметить, что на самом деле теневой механизм ис-
пользуется не для упрощения процедуры восстановления после
мягкого сбоя, а в связи с тем, что восстановление БД можно на-
чинать только от ее физически согласованного состояния. Дело
в том, что в журнал помешается информация об изменении объ-
ектов БД, а не страниц. Например, в журнале может находиться
информация о модификации кортежа в виде триплета <tid, ста-
рое состояние кортежа, новое состояние кортежа>. Реально же
при выполнении операции модификации изменяются несколько
страниц: исходная страница; возможно, страница замены, если
кортеж не поместился в исходную страницу; страницы индексов.
И так происходит при выполнении любой операции изменения
БД. Поскольку буфера страниц выталкиваются во внешнюю па-
мять по отдельности, то к моменту мягкого сбоя во внешней па-
5.6. Восстановление информации в базах данных
369
мяти может возникнуть набор физически рассогласованных
страниц, не соответствующий никакой журнализуемой опера-
ции. При таком состоянии внешней памяти восстановление по
журналу невозможно.
Когда выполняется операция установки системной кон-
трольной точки, то до насильственного выталкивания буферов
страниц система дожидается завершения всех операций всех
транзакций и до окончания выталкивания не допускает выпол-
нения новых операций. Поэтому теневое состояние всех сегмен-
тов БД физически согласовано и может служить основой восста-
новления по журналу.
При жестких сбоях утрачивается содержимое всех или части
сегментов БД. Для восстановления БД используется журнал и
ранее произведенная копия БД. Допускается посегментное вос-
становление. Для этого копия сегмента переписывается с архив-
ного носителя на заново выделенный рабочий носитель, а затем
по журналу повторяются все изменения, производившиеся в
объектах этого сегмента после момента копирования. Поскольку
в момент жесткого сбоя содержимое оперативной памяти не ут-
рачивается, то возможно продолжение выполнения транзакций
после завершения восстановления. Более того, если авария кос-
нулась только части сегментов БД, то транзакции могут продол-
жать работу на фоне процесса восстановления с объектами БД,
расположенными в неповрежденных сегментах.
Единственным требованием к архивной копии сегмента яв-
ляется то, что страницы в ней должны находиться в физически
согласованном состоянии (поскольку восстановление ведется в
терминах записей журнала). Поэтому для создания архивной ко-
пии сегмента достаточно лишь дождаться конца выполнения
операций над объектами данного сегмента и запретить начало
новых операций до конца копирования. Тем самым выполнение
архивной копии не требует перевода системы в какой-либо осо-
бый режим работы и только незначительно тормозит нормаль-
ную работу транзакций.
В заключение, заметим, что журнал располагается в файле
большого, но постоянного размера и используется он в цикличе-
ском режиме. Когда записи журнала достигают конца файла, они
начинают помещаться в его начало. Поскольку переход на начало
файла можно считать утратой предыдущего журнала, этот переход
сопровождается копированием сегментов БД. В некоторых систе-
мах используется подход с архивизацией самого журнала [13].
370
Глава 5. Эксплуатация АИС
5.6.2. Восстановление данных и информации
Постоянный рост объемов информации увеличивает риск по-
тери данных. Это происходит из-за постоянно увеличивающейся
плотности записи данных на цифровых носителях, некорректной
работы пользователей и операционных систем, аппаратных сбоев
оборудования, перебоев в питании, вирусных атак, случаев сабо-
тажа и обстоятельств непреодолимой силы, таких как пожары,
наводнения и т. п.
Данные и информацию восстанавливают в случаях, когда
происходят следующие сбои:
• логические ошибки (ошибки структуры файловой системы);
• ошибки чтения служебной информации (устройство рабо-
тает исправно, но не может корректно функционировать,
так как не знает своих параметров);
• выход из строя платы электроники;
• выход из строя коммутатора или головок чтения/записи;
• неисправность или заклинивание электродвигателя;
• физическое разрушение магнитного слоя на поверхности
магнитных пластин.
Восстанавливают данные как с простейших носителей ин-
формации (flash-диски и карты памяти, дискеты и т. п.), так и с
серверов и RAID-массивов [14] любого уровня (RAID О, RAID 1,
RAID 5) и любого объема (от нескольких гигабайт до десятков
терабайт).
Восстановление RAID. RAID — Redundant Array of Inexpensive
[or Independent] Disks — избыточный массив независимых (недо-
рогих, дешевых) дисков.
По сути своей RAID — это система хранения данных, орга-
низованная с помощью нескольких одинаковых дисков, запись
данных на которые производится определенными частями; т. е.
данные разбиваются на части (блоки) и пишутся на параллельно
соединенные диски (рис. 5.10) [14].
Количество и размер блоков, а также метод их записи зави-
сит от способа организации RAID-массива (его уровня). Также
RAID-массивы различаются по степени надежности.
Изначально RAID-массивы задумывались, как системы хра-
нения данных с избыточным запасом надежности от потери дан-
ных. Однако и эти супернадежные системы не застрахованы от
сбоев и ошибок. Наиболее распространенные сбои — это ошиб-
ки работы файловой системы, пользователей и системных адми-
5.6. Восстановление информации в базах данных
371
Рис. 5.10. Пример RAID-массивов
нистраторов, аппаратные сбои контроллеров RAID-массивов и
перебои в питании.
Восстановление RAID-массивов. Высокая степень подготовки
и богатейший опыт позволяют восстанавливать RAID-массивы,
организованные при использовании таких файловых систем, как
Novell Netware, Unix, Linux, MacOs и др.
При восстановлении данных с RAID-массивов любого уров-
ня и объема работают исключительно с копиями данных. Для
этого производится посекторное копирование каждого из дисков
массива.
Несмотря на практически нулевую надежность RAID 0-мас-
сива случаи восстановления данных массива такого типа не еди-
ничны. Такой массив требует параллельного соединения как ми-
нимум двух дисков.
Данные в RAID 0-массиве разбиваются на блоки, и каждый
блок записывается на последующий диск, как показано на
рис. 5.11 [14].
Рис. 5.11. Блоки RAID-массива 0-го уровня
372
Глава 5. Эксплуатация АИС
В результате приобретаются заметные преимущества: ско-
рость чтения/записи сильно увеличивается за счет того, что опе-
рации чтения/записи производятся посредством нескольких ка-
налов/дисков. За счет передачи данных с помощью многока-
нальных контроллеров, где на каждый из каналов контроллера
приходится отдельный диск, достигается максимальная произво-
дительность при передаче данных. Тем более, что вычисление
контрольной суммы не используется.
К сожалению, RAID 0-массив нельзя называть RAID-м из-за
отсутствия отказоустойчивости, поскольку выход из строя одно-
го из дисков массива может послужить причиной потери данных
всего массива. В связи с этим не рекомендуется использовать
RAID 0-массив там, где требуется отказоустойчивая система хра-
нения стратегически важных данных.
Восстановление RAID 1-массивов. RAID-массив 1-го уровня
требует параллельного соединения как минимум двух дисков.
Данные в RAID 1 разбиваются на блоки, и каждый блок записы-
вается на зеркально соединенные диски (рис. 5.12). На каждую
пару зеркально соединенных дисков одновременно возможна
одна операция записи или две операции чтения данных.
При этом используется 100%-ная избыточность данных, т. е.
при отказе одного из дисков в зеркале нужно только заменить
диск и скопировать данные с зеркала на него, операция rebuild
нс требуется. В ходе процесса восстановления вычисление кон-
трольной суммы не производится.
Недостатком технологии является то, что типичные функции
RAID выполняются программным путем, загружая при этом
процессор и систему и снижая пропускную способность при вы-
сокой нагрузке. Поэтому рекомендуется использовать аппарат-
MIRROR MIRROR
(зеркало) (зеркало)
Рис. 5.12. Характеристики RAID-массива 1-го уровня
MIRROR
(зеркало)
5.6. Восстановление информации в базах данных
373
ный RAID. Также при использовании программного RAID 1-го
уровня может нс поддерживаться функция горячей замены дис-
ков (hot swap) [14].
5.6.3. Восстановление резервных копий и полное
восстановление БД
Рассмотрим теперь методику восстановления БД на примере
SQL 2000 [15].
Восстановление с помощью резервной копии. Для полного вос-
становления БД необходимо выполнить следующую последова-
тельность действий.
1. По возможности выполнить резервное копирование теку-
щего журнала транзакций; это позволит полностью восстановить
базу данных на момент аварии.
2. Восстановить наиболее свежую полную резервную копию
без полного восстановления БД.
3. Если есть дифференциальная резервная копия, следует
восстановить наиболее свежую без полного восстановления БД.
4. Восстановить все резервные копии журналов транзакций
по порядку, начиная с последней полной резервной копии (или
дифференциальной копии, если таковые имеются) без восста-
новления БД.
5. Восстановить резервную копию файла журнала, которая
создана в п. I, и выполнить полное восстановление БД.
Если нельзя выполнить резервное копирование журнала
(п. I), то нужно выполнить полное восстановление БД после п. 4.
При этом можно восстановить БД только на состояние, совпа-
дающее с окончанием последней резервной копии журнала тран-
закций.
Рассмотренная методика предусматривает два способа вы-
полнения: посредством функциональности Диспетчера Предпри-
ятия (SQL Server Enterprise Manager) или с помощью команды
Restore.
В дереве Диспетчера Предприятия следует нажать правой
кнопкой мыши на требуемой БД и в появившемся меню выбрать
опцию All Tasks, а затем Restore Database... (рис. 5.13) [15].
Далее необходимо выбрать соответствующие настройки на
вкладке General окна Restore Database (рис. 5.14) [7].
374
Глава 5. Эксплуатация АИС
SQL Server Enterprise Manager* (Console RootWicrosoft SQL Serv...
File Action . View Toofc Window Help
'^тёW x ep ©Швкq её
f 1 Conscfe Root
IS-^I Microsoft 5QL Servers
?; & 5dtss Feder^ton
SQiASRvi (widows nt)
О Database*
• Ехваскир Ю Rems
Diagrams
Tables
New Database.
U m«i ...
(J mod:
У msdl jl
Hott
‘J pefcj View
Lj terr^ New Window from Here
New
AJ Tasks
J Import Data..
I Export Data...
£j Manager
Qj Repficati
G] Security;
GJ Suppwt;
Delete
Refresh
Export list.
Properties
^8)SQL\SAV2^ Help
$QI\SRV3 O^dwsKfT)'
SQL, Server Group
Nahtonaxe Plan...
Generate SQL Script.
Backup Database..,
> - Restore O&base. «>
Shrink Database...
Detach Database...
Take Offlne
Copy Subscription Database...
View Replkatkxr Conflicts...
"'User'befmed "yscrDefned'
Datatypes Functions
Рис. 5.13. Диспетчер Предприятия
Restore database
General | Options |
Restore as database; [&Ф<ккир
Restore: (• IjSabasd Ffegioups or files From device
-Parameters-------------------------------------------------------------------
Show backups of database: |EXBack<^>
First backup to restore: [5Z27Z2002 AM • EXBackup bad:up
Г“ Pjjirfl in lime resloiec I ____|
Restore j Type Backup Set Dale jSfee -BestoceFrom Backup Set Name
® Й 5/27/20026:02... 72... E:\Backups... EXBackupbackup
gi ® 5/27/2002 6 04... 80 Kb E:\Backups... EXBackup backup
Vi @ 5/27/2002 6.05... 15 Kb E.XBackups... EXBackup backup
OK | Cancel | Hdb
Рис. 5.14. Интерфейсное окно Restore Database
5.6. Восстановление информации в базах данных
375
Restore as database (восстановить как базу данных) определяет
имя БД, в которую проводится восстановление. Если имя БД уже
существует, БД будет перезаписана в ходе восстановления.
Restore позволяет выбрать тип восстановления. Сервер SQL
сохраняет записи обо всех резервных копиях; их можно восста-
новить, используя опции Database или Filegroups or files. При
восстановлении резервной копии, сделанной на другом компью-
тере, а также в случае утраты информации об истории резервно-
го копирования используется опция From device и каждая из ре-
зервных копий выбирается вручную.
Database (база данных) обеспечивает восстановление всех
файлов, образующих БД.
Filegroups or files (группы файлов или файлы) обеспечивает
восстановление некоторых или всех файлов, образующих БД.
From device (с устройства) обеспечивает восстановление ре-
зервной копии, которая не найдена при использовании преды-
дущих двух опций.
Использование опции Database предусматривает доступ к
следующим параметрам:
• Show Backup Of Database (показать резервные копии БД);
обеспечивает выбор БД, которой доступны существующие
резервные копии;
• First Backup to restore (восстановить первую резервную ко-
пию); обеспечивает выбор старейшей резервной копии
(копий);
• Point in time restore (восстановление в определенный момент
времени); обеспечивает выбор времени и даты восстановле-
ния БД, например, как раз до того, как произошла ошибка
или были удалены критические данные (рис. 5.15) [7].
Полное восстановление в определенное время возможно
только для БД, которые используют полную или Bulk_Logged (за-
писи групповых операций) модель восстановления (до тех пор,
пока не имели места групповые операции после последнего пол-
ного резервного копирования).
Рассмотрим теперь настройки вкладки Options окна Restore
Database (рис. 5.16).
Restore database files as (восстановить файлы БД как) обес-
печивает переименование любых восстанавливаемых файлов
или их перемещение из мест хранения после резервного копи-
рования.
376
Глава 5. Эксплуатация АИС
Point In Time Restore
Port in time restore wfll halt the restoration of transaction
log' entries recorded after the specified date and time.
Date: | 5/27/2002 3
6:05:20 AM ТЙЁйШйЙЙВЙ
If.?. ... ;l Canc,j| I
Рис. 5.15. Интерфейсное окно Point in time restore
Рис. 5.16. Вкладка Options
Leave database operational... (оставить БД работающей) запус-
кает процесс полного восстановления после восстановления ре-
зервных копий. Если выбрано несколько резервных копий на
вкладке General, процесс полного восстановления не начнется до
тех пор, пока все резервные копии не будут восстановлены.
Leave database nonoperational... (оставить БД неработаю-
щей) — процесс полного восстановления не запускается, поль-
зователи не имеют доступа к БД.
5.6. Восстановление информации в базах данных
377
Leave database read-only... (оставить БД доступной только для
чтения) — процесс полного восстановления нс запускается, но
пользователи имеют доступ к БД с разрешением read (без права
записи/редактирования данных).
После выполнения всех настроек и нажатия кнопки ОК про-
изойдет полное восстановление БД.
В среде SQL 2000 предусмотрены дополнительные настройки
резервного копирования. Прежде всего, сервер позволяет выпол-
нять резервное копирование сразу на несколько устройств одно-
временно, что значительно уменьшает время выполнения ре-
зервного копирования/восстановления с/на магнитную ленту.
Кроме того, есть опции выбора носителя резервного копирова-
ния, опции обеспечения защиты от случайного перезаписывания
и т. д.
В заключение следует еще раз подчеркнуть важность резерв-
ного копирования системных БД. В случае полного выхода сер-
вера из строя, имея только резервные копии пользовательских
БД, нельзя рассчитывать на быстрое восстановление данных —
придется проделать огромную работу по внесению утраченной
информации.
Контрольные вопросы
1. Назовите этапы и виды технологических процессов обработки инфор-
мации.
2. В чем заключается технологический процесс преобразования инфор-
мации?
3. Объясните понятие «информационная технология» и назовите этапы
ее развития.
4. В чем суть информационной технологии обработки данных?
5. Охарактеризуйте процессы, компоненты и структуры АИС.
6. Перечислите известные режимы обработки данных.
7. Перечислите известные способы обработки данных.
8. Назовите методы и средства сбора и передачи данных.
9. Каким образом обеспечивается достоверность информации в процес-
се хранения и обработки?
10. Как производится резервное копирование БД?
11. Назовите основные модели восстановления базы данных.
1 2. В чем суть технологии резервирования SQL Server?
13. Перечислите типы методов резервирования.
14. Каким образом осуществляется планирование стратегии резервиро-
вания?
378
Глава 5. Эксплуатация АИС
15. Охарактеризуйте процессы экспорта и импорта данных.
16. Каким образом происходит преобразование данных при экспортиро-
вании?
17. назовите известные технологии экспортирования данных.
18. В чем суть журнализации и восстановления данных?
19. Чем восстановление резервных копий отличается от полного восста-
новления БД?
Литература
1. Гобарева Я. Л. Автоматизированные системы обработки экономиче-
ской информации, http://www.history.ru/index.php?option=com_ewriting&
ltemid=117&func=chapterinfo&chapter=18068&story=13827.
2. Каратыгин С. И. Базы данных: простейшие средства обработки ин-
формации: системы управления базами данных. ABF, 1995.
3. ИС-Букварь. http://www.stormsystems.ru/downloads/part01.pdf.
4. http://info.territory.ru/univer/info.htm.
5. Рабочая программа Бийского технологического института, http://
do.bti.secna.ru/lib/book_it/it.html.
6. Рабочая программа Бийского технологического института, http://
do.bti.secna.ru/lib/book_it/sostav_it.html.
7. Информатика: учебник. 3-е изд. / под ред. Н. В. Макаровой. М.:
Финансы и статистика, 1999.
8. Основы информационной культуры, http//www.stu.ru.
9. Попов И. И. Автоматизированные информационные системы (по об-
ластям применения): учеб, пособие / под общ. ред. К. И. Курбакова. М.:
Роюэкон. акад., 1998. 103 с.
10. Гагарина Л. Г. Автоматизированные информационные системы:
учеб, пособие. М.: МИЭТ, 2003. 103 с.
11. Титоренко Г. А. Автоматизированные информационные технологии
в экономике. М.: ЮНИТИ, 1998. http://eusi.narod.ru/lib/ait/text/2_1.htm.
12. http://zeus.sai.msu.ru:7000/database/interbase/backup/.
13. www.megalib.com/books/1332/5.pdf.
14. Восстановление RAID, http://datarc.narod.ru/.
15. Восстановление резервных копий и полное восстановление баз дан-
ных SQL 2000. http://doc.mpv.ru/Win2k_server/article10-3.htm.
16. Когаловский М. Р. Энциклопедия баз данных. 3-е изд. М.: Финансы
и статистика, 2002. 800 с.
Оглавление
Предисловие ......................................... 3
Глава 1. ПРОЕКТИРОВАНИЕ АВТОМАТИЗИРОВАННЫХ
ИНФОРМАЦИОННЫХ СИСТЕМ ................................ 5
1.1. Понятие и классификация автоматизированных
информационных систем.......................... 5
1.2. Обеспечение АИС ......................... 12
1.3. Архитектура АИС........................... 19
1.4. Жизненный цикл АИС ....................... 21
1.5. Модели жизненного цикла АИС .. 30
1.6. Методология и технология проектирования АИС ... 41
1.7. Типовое проектирование АИС................ 61
Глава 2. АНАЛИЗ ПРЕДМЕТНОЙ ОБЛАСТИ АИС
С ПРИМЕНЕНИЕМ СИСТЕМ АВТОМАТИЗИРОВАННОГО
ПРОЕКТИРОВАНИЯ............................... 68
2.1. Этапы анализа предметной области.......... 68
2.2. Реинжиниринг бизнес-процессов............. 72
2.3. Методы сбора материалов обследования ..... 78
2.4. Формализация материалов обследования...... 80
380
Оглавление
2.5. Методологии описания предметной области ....81
2.5.1. Функциональное моделирование
бизнес-процессов с использованием
стандарта 1DEF0 ............................ 83
2.5.2. Моделирование потоков данных
(процессов) — DFD........................... 91
2.5.3. Методология ARIS.................... 97
2.5.4. Объектно-ориентированный подход.
Язык унифицированного
моделирования UML ......................... 106
2.6. Системы автоматизированного
проектирования АИС............................. НО
2.6.1. Этапы развития CASE-систем.......... НО
2.6.2. Классификация CASE-средств........ 113
2.6.3. Характеристики CASE-средств........ 115
2.6.4. Функциональный анализ популярных
в России CASE-средств ..................... 139
Глава 3. РАЗРАБОТКА ПРОГРАММНО-ИНФОРМАЦИОННОГО
ЯДРА АИС НА ОСНОВЕ СИСТЕМ УПРАВЛЕНИЯ
БАЗАМИ ДАННЫХ....................................... 143
3.1. Основы современных систем управления
базами данных................................. 143
3.2. Архитектурные решения баз данных.......... 150
3.3. Критерии выбора СУБД при создании АИС...... 152
3.4. Концептуальные модели данных ............. 157
3.5. Базовые понятия реляционных баз данных..... 163
3.6. Проектирование реляционных баз данных
с использованием нормализации ................ 166
3.7. Концептуальные модели и схемы баз данных... 175
3.7.1. Диаграммное представление.......... 176
3.7.2. Виды нотаций ...................... 185
Оглавление
381
3.8. Средства автоматизированного проектирования
структур баз данных......................... 198
3.9. Язык структурных запросов SQL ............. 206
3.10. Создание объектов баз данных.............. 212
Глава 4. ДОСТУП К БАЗАМ ДАННЫХ ...................... 232
4.1. Стандартные системы доступа к базам данных .... 232
4.1.1. Технология BDE....................... 234
4.1.2. Механизм ODBC ....................... 239
4.1.3. Компоненты для доступа
к ODBC-источникам ......................... 242
4.1.4. Компоненты прямого доступа к Oracle ..243
4.1.5. Компоненты прямого доступа
к InterBase Database ...................... 244
4.1.6. Компоненты Titan для доступа
к различным СУБД .......................... 245
4.1.7. Компоненты управления данными dBase
и dBase-подобных СУБД ..................... 246
4.1.8. Универсальный механизм доступа
к данным Universal Data Access..............248
4.1.9. Технология Microsoft AciveX Data
Objects (ADO).............................. 259
4.2. Клиенты удаленного доступа и построение
запросов к СУБД................................. 264
4.2.1. Классификация приложений для работы
с базами данных............................ 264
4.2.2. Этапы развития серверов баз данных ...273
4.2.3. Архитектура базы данных.............. 277
4.3. Разработка клиентского программного
обеспечения..................................... 289
4.3.1. Классификация средств разработки
приложений ................................ 289
382
Оглавление
4.4. Основные элементы клиентских программ
доступа к базам данных .......................... 296
4.4.1. Интерфейс пользователя............... 297
4.4.2. Действия (Actions) и связанные с ними
компоненты .................................. 304
4.4.3. Файлы и устройства ввода-вывода ..... 306
4.4.4. Встроенная справочная система........ 308
4.4.5. Инсталляционный пакет ............... 313
Глава 5. ЭКСПЛУАТАЦИЯ АИС ............................ 324
5.1. Этапы и виды технологических процессов
обработки информации ............................ 324
5.1.1. Технологический процесс преобразования
информации................................... 324
5.1.2. Понятие информационной технологии.... 330
5.1.3. Информационная технология обработки
данных....................................... 335
5.2. Организация сбора, размещения, хранения,
накопления, преобразования и передачи
данных в АИС .................................... 338
5.2.1. Процессы в АИС, компоненты
и структуры ................................. 338
5.2.2. Режимы обработки данных.............. 342
5.2.3. Способы обработки данных ............ 344
5.3. Методы и средства сбора и передачи данных...349
5.4. Обеспечение достоверности информации
в процессе хранения и обработки.................. 352
5.4.1. Резервное копирование базы данных
и последующее восстановление ................ 352
5.4.2. Модели восстановления базы данных..... 353
5.4.3. Резервирование SQL Server............ 354
5.4.4. Выполнение резервирования ........... 357
Оглавление
383
5.4.5. Типы методов резервирования .......... 358
5.4.6. Планирование стратегии резервирования . . . 359
5.5. Экспортирование структур баз данных..........361
5.5.1. Экспорт и импорт данных .............. 361
5.5.2. Преобразование данных при
экспортировании ............................. 363
5.5.3. Технологии экспортирования данных...... 365
5.6. Восстановление информации в базах данных.....366
5.6.1. Журнализация и восстановление ........ 366
5.6.2. Восстановление данных и информации .... 370
5.6.3. Восстановление резервных копий
и полное восстановление БД .................. 373
Гагарина Лариса Геннадьевна
Киселев Денис Викторович
Федотова Елена Леонидовна
Разработка и эксплуатация
автоматизированных информационных систем
Учебное пособие
Редактор Е. Г. Соболевская
Корректор А. В. Волковицкая
Компьютерная верстка И. В. Кондратьевой
Оформление серии Б. А. Гомона
Сдано в набор 02.11.2006. Подписано в печать 20.12.2006. Формат 60x90/16.
Печать офсетная. Гарнитура «Таймс». Усл. печ. л. 24,0. Уч.-изд. л. 24,5.
Бумага типографская. Тираж 3000 экз. Заказ № 5052
ЛР № 071629 от 20.04.98
Издательский Дом «ФОРУМ»
101000, Москва — Центр, Колпачный пер., д. 9а
Тел./факс: (495) 625-39-27
E-mail: forum-books@mail.ru
ЛР № 070824 от 21.01.93
Издательский Дом «ИНФРА-М»
127282, Москва, Полярная ул., д. 31 в
Тел.: (495) 380-05-40
Факс: (495) 363-92-12
E-mail: books@infra-m.ru
Http://www.infra-m.ru
Отпечатано с предоставленных диапозитивов
в ОАО “Тульская типография”. 300600, г. Тула, пр. Ленина,109.