/

































































































































































































































































































































Author: Федорова Г.Н.
Tags: информационные технологии вычислительная техника обработка данных программирование базы данных системное администрирование
ISBN: 978-5-4468-1584-5
Year: 2015




Text
Г. Н. Федорова
РАЗРАБОТКА
И АДМИНИСТРИРОВАНИЕ
БАЗ ДАННЫХ
Учебник
Профессиональный модуль
ПРОФЕССИОНАЛЬНОЕ ОБРАЗОВАНИЕ
Г. Н. ФЕДОРОВА
РАЗРАБОТКА
И АДМИНИСТРИРОВАНИЕ
БАЗ ДАННЫХ
Рекомендовано
Федеральным государственным автономным учреждением
«Федеральный институт развития образования»
в качестве учебника для использования в учебном процессе
образовательных учреждений, реализующих программы
среднего профессионального образования по специальности
«Программирование в компьютерных системах»
Регистрационный номер рецензии 122
от 09 апреля 2015 г. ФГ4 У «ФИРО»
УЧЕБНИК
Библиотека ГУАП
0000530377
ACADEMA
Москва
Издательский центр «Академма''
2015
УДК 004(075.32)
ББК 32.973-018.2я723
ФЗЗЗ
Ре цен з е пт —
преподаватель Уфимского авиационно['о техникума ФГБОУ ВПО «УГАТУ»,
канд. физ.-мат. наук Э.Р, Титшева
Федорова Г.Н.
ФЗЗЗ Разработка и администрирование баз данных : учеб, для
студ. учреждений сред. проф. образования. — М. : Издатель¬
ский центр «Академия», 2015. — 320 с.
ISBN 978-5-4468-1584-5
Учебник создан в соответствии с Федеральным государственным об¬
разовательным стандартом среднего профессионального образования по
специальности «Программирование в компьютерных системах», ПМ. 02
«Разработка и администрирование баз данных».
Рассмотрены типовые модели логической организации данных, меха¬
низмы проектирования баз данных, основные методы и средства защиты
данных, возможности языка SQL для работы с базами данных. Изложены
вопросы обеспечения целостности данных, принципы и технологии обмена
данными в компьютерных сетях.
Для студентов учреждений среднего профессионального образования.
УДК 004(075.32)
ББК 32.973-018.2я723
Оригинал-макет данного издания является собственностью
Издательского центра «Академия», и его воспроизведение любым способом
без согласия правообладателя запрещается
ISBN 978-5-4468-1584-5
© Федорова Г. Н., 2015
© Образовательно-издательский центр «Академия», 2015
© Оформление. Издательский центр «Академия», 2015
Уважаемый читатель!
Данный учебник является частью учебно-методического комп¬
лекта для специальности «Программирование в компьютерных
системах».
Учебник предназначен для изучения профессионального модуля
«Разработка и администрирование баз данных».
Учебно-методические комплекты нового поколения включают
в себя традиционные и инновационные учебные материалы, по¬
зволяющие обеспечить изучение общеобразовательных и общепро¬
фессиональных дисциплин и профессиональных модулей. Каждый
комплект содержит учебники и учебные пособия, средства обучения
и контроля, необходимые для освоения общих и профессиональных
компетенций, в том числе и с учетом требований работодателя.
Учебные издания дополняются электронными образовательными
ресурсами. Электронные ресурсы содержат теоретические и прак¬
тические модули с интерактивными упражнениями и тренажерами,
мультимедийные объекты, ссылки на дополнительные материалы и
ресурсы в Интернете. В них включены терминологический словарь
и электронный журнал, в котором фиксируются основные пара¬
метры учебного процесса: время работы, результат выполнения
контрольных и практических заданий. Электронные ресурсы легко
встраиваются в учебный процесс и могут быть адаптированы к раз¬
личным учебным программам.
Предисловие
Цель предлагаемого учебника — формирование у студентов
систематизированных знаний о моделях и структурах баз данных,
об основных принципах и технологиях разработки баз данных,
а также о современных технологиях обмена данными в компью¬
терных сетях.
В первом разделе учебника «Инфокоммуникационные системы
и сети», состоящим из шести глав, последовательно излагаются
основные аспекты архитектуры компьютерных сетей, технологии
сетевого взаимодействия — проводные, беспроводные локальные
и глобальные сети, их техническое и программное обеспечение,
описываются сетевые службы и сервисы.
В первой главе рассматриваются самые общие вопросы орга¬
низации компьютерных сетей, раскрываются основные понятия
и элементы, классификация сетей, топология сетевых решений.
Дается описание технических характеристик кабельных каналов
связи. Излагаются основные требования к компьютерным сетям.
Во второй главе раскрываются технологии передачи и обмена
данными в компьютерных сетях. Описываются протоколы и стан¬
дарты компьютерных сетей, разъясняются принципы адресации
узлов в сети.
В третьей главе описываются базовые технологии локальных
сетей, даются подробные описания практически всех основных
технологий — традиционных Ethernet, Tokin Ring, FDDI и высоко¬
скоростных Fast Ethernet, Gigabit Ethernet.
В четвертой главе описываются технические средства компью¬
терных сетей — структурированная кабельная система, сетевые
адаптеры, концентраторы, трансиверы, сетевые мосты, сетевые
коммутаторы, маршрутизаторы и сетевые шлюзы.
Пятая глава посвящена беспроводным технологиям, в ней
описываются сетевое оборудование и стандарты, позволяющие
создавать вычислительные сети без использования кабельной про¬
водки.
В шестой главе рассматриваются устройство и особенности се¬
тевых операционных систем, излагается концепция выделенного
4
сервера в сети. Раскрывается программная и техническая реализа¬
ция многоуровневой архитектуры «клиент-сервер». Описываются
понятия «сетевая служба», «сетевой сервис», «сетевое программное
обеспечение».
Во втором разделе «Технология разработки и защиты баз дан¬
ных» рассматриваются модели представления данных, раскрывают¬
ся теоретические основы проектирования баз данных, обсуждаются
вопросы обеспечения их целостности и применения языка SQL для
работы с данными. Раздел состоит из восьми глав.
В седьмой главе излагаются основные положения теории баз
данных, хранилищ данных, баз знаний. Здесь даются определения
основных понятий теории баз данных и информационных систем.
Приводятся характеристические черты систем управления данны¬
ми, описываются функции системы управления базами данных
(СУБД). Рассматриваются основные этапы развития технологий
обработки данных и перспективы их дальнейшего использования.
Обсуждаются вопросы формализованного представления информа¬
ции, вводится понятие многоуровневой модели данных, принципы
физической и логической независимости данных.
В восьмой главе вводятся понятия модели данных и структуры
данных. Приводится классификация моделей, используемых в си¬
стемах баз данных. Дается общая характеристика моделей представ¬
ления данных. Излагаются теоретические основы моделей данных,
поддерживаемых в СУБД. Описываются теоретико-графовые моде¬
ли данных, использовавшиеся в ранних системах управления баз
данных, а также современные, перспективные модели данных —
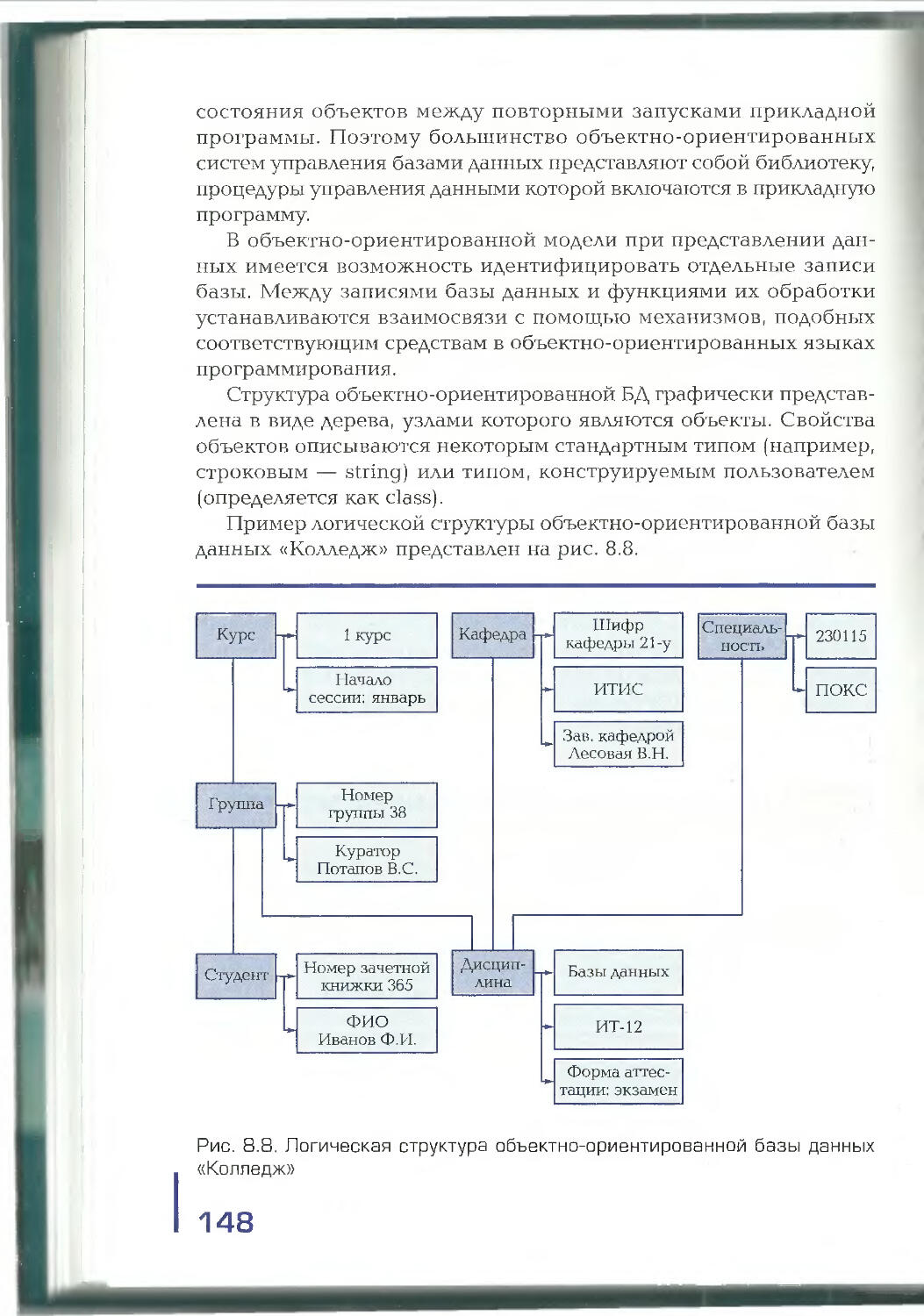
многомерные и объектно-ориентированные. Даются определения
основных компонентов реляционной модели.
В девятой главе рассматриваются основные понятия и компо¬
ненты широко распространенной реляционной модели данных.
С использованием большого количества примеров разъясняются
основы реляционной алгебры. Раскрываются механизмы индек¬
сирования, связывание таблиц, описывается понятие ссылочной
целостности. Разъясняются принципы поддержки целостности в
реляционной базе данных. Указываются достоинства и недостатки
реляционной модели данных.
В десятой главе разъясняются принципы построения концеп¬
туальной, логической и физической модели данных. Подробно
описываются основные этапы проектирования — от анализа пред¬
метной области до физической реализации базы данных. Приво¬
дятся примеры построения концептуальной и логической моделей.
Описывается процесс нормализации — разработки структуры базы
5
данных методом декомпозиции таблиц. Приводится пример проек¬
тирования базы данных на основе принципов нормализации. Обо¬
сновывается необходимость использования автоматизированных
средств проектирования баз данных. Даются определения основным
понятиям CASE-технологий, описываются характеристики различ¬
ных классов CASE-технологий.
В одиннадцатой главе рассматриваются достоинства и недостат¬
ки различных архитектур баз данных, описываются особенности
построения и использования модели многоуровневой архитектуры
«клиент-сервер». Даются определения основным объектам сервера
баз данных.
В двенадцатой главе рассматриваются основные приемы управ¬
ления базой данных с использованием структурированного языка
запросов SQL. Описываются основные категории команд языка
SQL, предназначенные для выполнения различных функций, вклю¬
чая выборку по условиям, модификацию данных и т. п. Большое
внимание уделяется проблеме обеспечения целостности данных —
от объявления ограничений на уровне таблицы, разработки триг¬
геров для поддержания базы данных в целостном состоянии до
создания транзакций. SQL на сегодняшний день — единственный
признанный стандарт языка баз данных, поддерживаемый всеми
основными поставщиками СУБД. Владение знаниями по SQL в
настоящее время является обязательным для профессиональных
разработчиков баз данных и приложений.
В тринадцатой главе нашли отражение вопросы обеспечения
целостности базы данных. В ней излагаются проблемы, возника¬
ющие при параллельном доступе к данным, и пути решения этих
проблем. Раскрываются механизм транзакций и способы обеспе¬
чения целостности данных с помощью управления блокировками.
Описывается процедура журнализации изменений.
Четырнадцатая глава раскрывает основные требования к со¬
временным системам управления базами данных и предлагает не¬
большой обзор наиболее популярных СУБД.
Весь материал содержит большое количество примеров, что
способствует более глубокому его освоению.
В каждую главу учебника включены контрольные вопросы для
самостоятельной работы, позволяющие студенту закрепить изучен¬
ный материал.
Учебник подготовлен в полном соответствии с Федеральным
государственным образовательным стандартом СПО специаль¬
ности 230115 «Программирование в компьютерных системах» по
профессиональному модулю «Разработка и администрирование
6
баз данных» и базируется на материалах, накопленных автором в
процессе практической деятельности. Разделы учебника соответ¬
ствуют требованиям МДК профессионального модуля «Разработка
и администрирование баз данных».
Учебник может использоваться преподавателями и студентами,
обучающимися по указанной специальности, не только в рамках
данного профессионального модуля, но и в других модулях и дис¬
циплинах, связанных с компьютерными сетями и проектированием
и эксплуатацией баз данных.
Предлагаемый материал может стать полезным также для ши¬
рокого круга специалистов, занимающихся разработкой и админи¬
стрированием баз данных на предприятиях, сетевым администриро¬
ванием, техническим и программным обеспечением компьютерных
сетей.
Содержание учебника предполагает, что читатель освоил курсы
информатики и информационных технологий и имеет общее пред¬
ставление об операционных системах и технических средствах
информатизации.
ИНФОКОММУНИКАЦИОННЫЕ
СИСТЕМЫ И СЕТИ
I
РАЗДЕЛ
V
Глава 1. Основные понятия, элементы
и структуры компьютерных сетей
Л
Глава 2. Технологии передачи и обмена
данными в компьютерных сетях
Глава 3. Базовые технологии локальных сетей
Глава 4. Технические средства компьютерных
сетей
Глава 5.
Глава 6.
Беспроводные технологии
Сетевое программное обеспечение.
Службы и сервисы
Глава 1
ОСНОВНЫЕ ПОНЯТИЯ, ЭЛЕМЕНТЫ
И СТРУКТУРЫ КОМПЬЮТЕРНЫХ
СЕТЕЙ
11
ОСНОВНЫЕ ПОНЯТИЯ И ОПРЕДЕЛЕНИЯ.
КЛАССИФИКАЦИЯ КОМПЬЮТЕРНЫХ
СЕТЕЙ
Под компьютерной сетью в широком смысле слова понимают
совокупность компьютеров, связанных между собой для обмена
данными. Передача информации между компьютерами позволяет
организовать совместную работу отдельных компьютеров, решать
одну задачу с помощью нескольких компьютеров, совместно ис¬
пользовать общие ресурсы и решать множество других проблем.
Компьютерные сети и телекоммуникационные технологии являют¬
ся результатом развития вычислительной техники, программного
обеспечения, средств коммуникации и связи. Компьютерные сети
и сетевые технологии обработки информации стали основой для
построения современных информационных систем.
Компьютерная сеть (network) — это совокупность компью¬
теров и телекоммуникационного оборудования, обеспечивающая
обмен информацией между компьютерами.
Таким образом, основное назначение компьютерных сетей —
обеспечение совместного доступа пользователей к информации
(базам данных, документам и т. д.) и аппаратным ресурсам (жесткие
диски, принтеры, накопители CD-ROM, модемы и т.д.).
Узел сети (node) — устройство, соединенное с другими устрой¬
ствами как часть компьютерной сети. Узлами могут быть компьюте¬
ры, мобильные телефоны, карманные компьютеры, а также специ¬
альные сетевые устройства, такие как маршрутизатор, коммутатор
или концентратор.
Коммутация — это технология организации передачи данных
в сетях. Скорость передачи данных по каналу связи измеряется ко¬
личеством единиц информации, передаваемых за единицу времени.
Единицы измерения — бит в секунду, килобит в секунду и т. п.
9
Объем информации, передаваемой через компьютерную сеть
за определенный период времени, называют сетевым трафиком.
Количество трафика измеряется как в пакетах, так и в битах, байтах
и их производных: килобайт (Кб), мегабайт (Мб) и т.д.
Трафик классифицируется:
■ как входящий (информация, поступающая в сеть);
■ исходящий (информация, поступающая из сети);
■ внутренний (в пределах определенной сети, чаще всего локаль¬
ной);
■ внешний (за пределами определенной сети, чаще всего интернет-
трафик) .
Канал связи (channel, data line) — система технических средств
и среда распространения сигналов для передачи данных от источ¬
ника к получателю.
Сетевой коммутатор (switch) — устройство, предназначенное
для соединения нескольких узлов компьютерной сети в пределах
одного или нескольких сегментов сети. Для соединения нескольких
сетей на основе сетевого уровня служат маршрутизаторы.
Маршрутизатор, или роутер (router) — специализирован¬
ный сетевой компьютер, имеющий как минимум один сетевой
интерфейс и пересылающий пакеты данных между различными
сегментами сети, связывающий разнородные сети различных
архитектур, принимающий решения о пересылке на основании
информации о топологии сети и определенных правил, заданных
администратором.
Сетевой концентратор, или хаб (hub) — устройство для объедине¬
ния компьютеров в сеть с применением кабельной инфраструктуры.
В настоящее время существует огромное количество различных
видов сетей, отличающихся друг от друга назначением, исполь¬
зуемыми компьютерными и коммуникационными технологиями,
сетевыми архитектурами.
По технологии передачи данных сети можно подразделить на
два типа: соединение «один ко многим» (вещание) и соединение
«точка — точка». В первом случае сообщение, отправленное од¬
ним компьютером, получают все компьютеры сети; в соединении
«точка — точка» используется индивидуальный канал связи для
обмена информацией компьютерами.
По принципу организации обмена данными между абонентами
различают сети, основанные на коммутации каналов, коммутации
сообщений и коммутации пакетов.
Сеть с коммутацией каналов — тип сети, в которой каждой
паре абонентов в течение сеанса их информационного взаимо¬
10
действия предоставляется физическое соединение. При этом на
время, в течение которого осуществляется сеанс связи между
абонентами, канал связи становится недоступным для других
абонентов. В сетях с коммутацией каналов по запросу пользова¬
теля создается непрерывный информационный канал, который
образуется путем резервирования «цепочки» линий связи, соеди¬
няющих абонентов на время передачи данных. На всем своем
протяжении канал передает данные с одной и той же скоростью.
Это означает, что через сеть с коммутацией каналов можно каче¬
ственно передавать данные, чувствительные к задержкам (голос,
видео). Однако невозможность динамического перераспределения
пропускной способности физического канала является принципи¬
альным недостатком сети с коммутацией каналов, который делает
ее неэффективной для передачи пульсирующего компьютерного
трафика.
При коммутации сообщений осуществляется передача инфор¬
мации между абонентами в виде логически завершенных порций
данных. Сеть с коммутацией сообщений работает аналогично
сети с коммутацией каналов, но каналы связи физически оста¬
ются заняты не на период всего сеанса связи, а только на период
передачи сообщения. В настоящее время сети с коммутацией
сообщений практически не используются. На их основе были
разработаны и применяются сети с коммутацией пакетов.
При коммутации пакетов передаваемые данные разбивают¬
ся на отдельные блоки небольших размеров — пакеты, которые
могут пересылаться из одной точки сети в другую по различным
маршрутам с промежуточным хранением этих пакетов в узлах
коммутации.
Пакет снабжается заголовком, в котором указывается адрес на¬
значения, поэтому он может быть обработан коммутатором неза¬
висимо от остальных данных. Пакеты могут разными маршрутами
достигать своего места назначения. После прибытия пакета в узел
приема производится сборка исходных данных в сообщение. Па¬
кеты передаются в сети независимо друг от друга. В таких сетях
по одной физической линии связи могут обмениваться данными
много узлов. Пакеты иногда называют дейтаграммами (datagram),
а режим индивидуальной коммутации пакетов — дейтаграммным
режимом.
Коммутация пакетов превышает производительность сети при
передаче пульсирующего трафика, так как при обслуживании
большого числа независимых потоков периоды их активности
не всегда совпадают во времени. Пакеты поступают в сеть без
11
предварительного резервирования ресурсов в том темпе, в ко¬
тором их генерирует источник. При перегрузе сети абоненты
не выбрасываются из сети, сеть просто снижает всем абонен¬
там скорость передачи. Абонент, использующий свой канал не
полностью, фактически отдает пропускную способность сети
остальным абонентам. Однако этот способ коммутации имеет
и отрицательные стороны: задержки передачи носят случайный
характер, поэтому возникают проблемы при передаче трафика
реального времени. Сеть с коммутацией пакетов имеет сложное
устройство, и часть пропускной способности расходуется на
технические данные.
По территориальному признаку, т. е. по величине территории,
что покрывает сеть, различают локальные, городские и глобальные
сети. Отличия технологий локальных и глобальных сетей очень
значительные, невзирая на их постоянное сближение.
Локальные сети (Local Area Networks — LAN) связывают пер¬
сональные компьютеры и периферийные устройства, обычно
находящиеся в одном здании (или комплексе зданий). Локальные
сети, представляющие собой самую элементарную форму сетей,
соединяют вместе группу персональных компьютеров или связыва¬
ют их с более мощным компьютером, выполняющим роль сетевого
сервера. Локальные сети позволяют отдельным пользователям легко
и быстро взаимодействовать друг с другом. Все персональные ком¬
пьютеры в локальной сети могут использовать специализированные
приложения, хранящиеся на сетевом сервере, и работать с общими
устройствами: принтерами, факсами и другой периферией. Каждый
персональный компьютер в локальной сети называется рабочей
станцией, или сетевым узлом.
Глобальные сети (Wide Area Networks — WAN) совмещают
компьютеры, рассредоточенные на расстоянии сотен и тысяч кило¬
метров, находящиеся в различных городах и странах. Для стойкой
передачи дискретных данных применяются более сложные методы
и оборудование, чем в локальных сетях.
Региональные, или городские, сети (Metropolitan Area Networks
MAN) занимают промежуточное положение между локальными
и глобальными сетями. Объединяют компьютеры на территории
городского района или города целиком. MAN имеют достоинства
локальных и глобальных сетей: они способны охватывать доста¬
точно большие расстояния между компьютерами (до нескольких
десятков километров) и при этом отличаются высокой скоростью
передачи данных, зачастую превышающей даже скорость в локаль¬
ных сетях.
12
В настоящее время уже невозможно четко классифицировать
сети, в частности, из-за того, что большинство локальных сетей име¬
ют выход в глобальные сети. Тем не менее принципы организации
обмена данными и доступа по-прежнему существенно отличаются
в разных типах сетей.
По принципу организации иерархии компьютеров вычисли¬
тельные сети подразделяются на два кардинально различающих¬
ся класса: одноранговые (одноуровневые) сети и иерархические
(многоуровневые).
Одноранговая сеть представляет собой сеть равноправных ком¬
пьютеров, каждый из которых имеет уникальное имя (имя компью¬
тера) и пароль для входа в него во время загрузки операционной си¬
стемы. Имя и пароль входа назначаются владельцем персонального
компьютера средствами операционной системы. Одноранговые сети
могут быть организованы с помощью различных разновидностей
операционных систем.
Иерархическая сеть включает в себя один или несколько специ¬
альных компьютеров (серверов), которые предоставляют другим
объектам некоторые услуги. На серверах хранится информация,
совместно используемая различными пользователями. Компьюте¬
ры, с которых осуществляется доступ к информации на сервере,
называются рабочими станциями, или клиентами.
Сервер — это компьютер, который предоставляет клиентам
доступ по сети к своим службам и ресурсам с целью хранения,
обмена и обработки информацией. Другими словами, сервер —
это постоянное хранилище разделяемых ресурсов. Сам сервер
может быть клиентом только сервера более высокого уровня ие¬
рархии. Поэтому иерархические сети иногда называются сетями
с выделенным сервером. Серверы обычно представляют собой
высокопроизводительные компьютеры, возможно, с несколькими
параллельно работающими процессорами, жесткими дисками
большой емкости, высокоскоростными сетевыми картами.
Различают две архитектуры использования сервера: «файл-
сервер» и «клиент-сервер». В архитектуре «файл-сервер» данные и
программы хранятся на сервере, а обработка их и выполнение задач
осуществляются на компьютерах клиентов, сервер же только предо¬
ставляет возможности хранения информации и файлового доступа.
В архитектуре «клиент-сервер» помимо хранения данных на сервере
осуществляется работа серверного программного обеспечения, вы¬
полнение прикладных программ, обработка данных и т. п.
Хост (host — хозяин, принимающий гостей), или узел — любое
устройство, предоставляющее сервисы формата «клиент-сервер»
13
в режиме сервера по каким-либо интерфейсам и уникально опре¬
деленное на этих интерфейсах. В более частном случае под хостом
могут понимать любой компьютер, сервер, подключенный к ло¬
кальной или глобальной сети. Иногда при упоминании конкретного
устройства в сети также используют термин «узел» (очевидно, по
аналогии с прототипом компьютерной сети, ведь реальная сеть, на¬
пример рыболовная, состоит из нитей, соединенных между собой
множеством узлов).
По типу среды передачи данных сети разделяются на проводные
и беспроводные (радиоканалы, спутниковые каналы). Принципы и
технологии передачи информации в тех и других будут разъяснены
далее.
ТОПОЛОГИИ КОМПЬЮТЕРНЫХ СЕТЕЙ
При организации связи между несколькими компьютерами
возникает проблема выбора конфигурации физических связей
или топологии. Под топологией сети понимается конфигурация
графа, вершинам которого соответствуют конечные узлы сети и
коммуникационное оборудование, а ребрам — каналы связи между
ними. Иными словами, топология компьютерных сетей — это кон¬
фигурация физических связей компьютеров и различных сетевых
устройств.
От выбора топологии связей зависят многие характеристики
сети — можно сбалансировать загрузку отдельных каналов, сделать
сеть легко расширяемой, минимизировать затраты за счет умень¬
шения суммарной длины линий связи и т.д.
Множество топологий можно условно разделить на три базовые
группы: «звезда», «кольцо» и «общая шина» (рис. 1.1).
Топология «звезда» подразумевает такую конфигурацию, когда
каждый компьютер сети подключается к концентратору по от¬
дельной линии связи (рис. 1.1, а). Концентратор — это устройство,
способное передавать информацию от одного компьютера сети
другому или сразу всем компьютерам.
Кольцевая конфигурация образует соединение компьютеров в
замкнутое кольцо (рис. 1.1, б). При этом данные передаются от
одного компьютера к другому до тех пор, пока не найдут своего
адресата.
Топология «общая шина» подразумевает подключение всех
компьютеров к одной линии связи, например высокочастотному
14
Рис. 1.1. Топологии сетей:
а — «звезда»; б — «кольцо»; в — «общая шина»
кабелю (рис. 1.1, в). При построении сети по шинной схеме каждый
компьютер присоединяется к общему кабелю, на концах которого
устанавливаются терминаторы. Сигнал проходит по сети через все
компьютеры, отражаясь от конечных терминаторов.
Выше были перечислены базовые топологии. Но наряду с ними
на практике применяются комбинированные (смешанные) тополо¬
гии. К ним относится древовидная структура (рис. 1.2). Комбини¬
рованная топология типа «дерево» применяется в крупных сетях,
где объединяются несколько подсетей, имеющих топологию разных
типов.
Сети со структурой типа «дерево» применяются там, где невоз¬
можно непосредственное применение базовых сетевых структур
в чистом виде. Для подключения большого количества рабочих
станций применяют мосты, сетевые усилители, коммутаторы
и т. п. В настоящее время дерево является самым распространен¬
ным типом топологии связей как в локальных, так и в глобальных
сетях.
1.3.
КАБЕЛЬНЫЕ ЛИНИИ СВЯЗИ
Кабельные линии связи строятся на основе проводников, за¬
ключенных в несколько линий изоляции, и характеризуются следу¬
ющими параметрами: полоса пропускания, степень защищенности
кабеля от помех, затухание и др. Более подробно физические
характеристики каналов передачи информации будут изложены в
следующей главе. А пока рассмотрим виды кабелей, используемые
в компьютерных сетях (рис. 1.3):
■ коаксиальный кабель;
■ кабель типа «витая пара»;
■ оптоволоконный кабель.
Коаксиальный кабель. Коаксиальный кабель представляет собой
медный проводник (жилу), заключенный в диэлектрик и металли¬
ческую оплетку, которая сверху также покрывается изолирующим
материалом (рис. 1.3, а).
Металлическая оплетка экранирует внутренний проводник,
защищает его от помех, вызываемых посторонними электромаг¬
нитными полями. Коаксиальный кабель применяется, как правило,
в сетях с топологией «общая шина».
Существуют «тонкий» и «толстый» коаксиальные кабели. « Тон¬
кий» коаксиальный кабель имеет волновое сопротивление 50 Ом,
1Б
диаметр внутреннего медного провода составляет 0,89 мм и внеш¬
ний диаметр около 5 мм. «Толстый» коаксиальный кабель имеет
такое же волновое сопротивление при диаметре внутреннего про¬
водника 2,17 мм и внешнем диаметре порядка 10 мм.
Кабель типа «витая пара». Кабель типа «витая пара» представ¬
ляет собой одну или несколько пар изолированных проводников,
скрученных между собой (с небольшим числом витков на единицу
длины), покрытых пластиковой оболочкой (рис. 1.3, б).
Кабель на основе витых пар может быт экранированным (Shielded
Twisted Pair — STP) и неэкранированным (Unshielded Twisted Pair —
UTP). Экранированная «витой пары» помещается в металлическую
оплетку, что способствует повышению помехозащищенности и
улучшению защиты от «прослушивания». Для неэкранированной
«витой пары» присуща слабая защищенность от внешних электро¬
магнитных воздействий.
Существует несколько категорий кабеля «витая пара» (табл. 1.1),
различающихся частотой.
Преимущества использования «витой пары» по сравнению с
коаксиальным кабелем:
■ возможность работы в дуплексном режиме, т.е. передавать и
принимать информацию;
■ низкая стоимость кабеля «витой пары»;
■ более высокая надежность сетей при неисправности в кабеле;
м меньше минимально допустимый радиус изгиба кабеля;
■ большая помехоустойчивость.
Оптоволоконный кабель. Структура оптоволоконного кабеля
очень проста и похожа на структуру коаксиального кабеля, только
вместо центрального медного провода здесь используется тонкое
(диаметром порядка 1... 10 мкм) стекловолокно, а вместо внутренней
а
б
в
Рис. 1.3. Виды кабелей:
/ * о '
а — коаксиальный; б — «витая пара»; в — оптоволокно
'fori
Таблица 1.1. Категории кабеля «витая пара»
Категория
Полоса частот,
МГц
Применение
1
<1
Телефонные и старые модемные линии
2
1
Старые терминалы (такие как IBM 3270)
3
16
10BASE-T, 100BASE-T4 Ethernet
4
20
Token Ring, в настоящее время не ис¬
пользуется
5
100
100BASE-TX Ethernet
5е
100
100BASE-TX Ethernet — усовершен¬
ствованная категория 5 (уточненные/
улучшенные спецификации). Скорость
передачи данных до 100 Мбит/с при
использовании 2 пар и до 1000 Мбит/с
при использовании 4 пар. Подавляющее
большинство локальных сетей ориенти¬
рованы на кабель категории 5е
6
250
Fast Ethernet, Gigabit Ethernet (10GBASE-T
Ethernet)
ба
500
Gigabit Ethernet (10GBASE-T Ethernet)
7
600
Gigabit Ethernet (10GBASE-T Ethernet)
7а
до 1200
Gigabit Ethernet (40GbE, lOOGbE)
изоляции — стеклянная или пластиковая оболочка, не позволяющая
свету выходить за пределы стекловолокна (рис. 1.3, в).
В данном случае мы имеем дело с режимом так называемого
полного внутреннего отражения света от границы двух веществ
с разными коэффициентами преломления, так как у стеклянной
оболочки коэффициент преломления значительно ниже, чем у
центрального волокна. Металлическая оплетка кабеля обычно от¬
сутствует, так как экранирование от внешних электромагнитных
помех здесь не требуется, однако иногда ее все-таки применяют для
механической защиты от окружающей среды (такой кабель иногда
называют броневым, он может объединять под одной оболочкой
несколько оптоволоконных кабелей).
В зависимости от характера распространения света определяют
следующие виды оптоволоконного кабеля:
■ одномодовое волокно;
18
■ многомодовое волокно со ступенчатым изменением показателя
преломления;
■ многомодовое волокно с плавным изменением показателя пре¬
ломления.
Мода луча — это угол отражения луча в сердцевине. Одномодовое
волокно подразумевает использование сердечника с очень маленьким
диаметром, соизмеримым с длиной волны света (8... 9 мкм). Поэтому
в таком кабеле возможна только одна мода. Например, одномодово¬
му кабелю 9/125 мкм соответствует кабель с диаметром сердечника
оптоволокна 9 мкм и диаметром стеклянной оболочки 125 мкм.
Одномодовый кабель очень дорогой, поскольку производство
стеклянного волокна столь малого диаметра является сложным
технологическим процессом. Но его характеристики существенно
выше в сравнении с дешевыми мнгомодовыми кабелями, и это дает
возможность использовать его для передачи данных на большие
расстояния.
В многомодовых кабелях применяются широкие сердцевины
(например, кабели 50/125 мкм, 62,5/125 мкм), и они обходятся де¬
шевле, нежели одномодовые кабели. В таком кабеле с большим диа¬
метром свет может распространяться по различным траекториям,
отражаясь под разными углами, таким образом, существует более
одной моды луча. Множество мод приводит к дисперсии импульса
передачи, интерференции лучей, и, как следствие, к ухудшению
характеристик кабеля. Поэтому многомодовые кабели используют¬
ся в основном при передаче данных на небольшие расстояния (до
2000 м) на скорости не более 1 Гбит/с.
КОНТРОЛЬНЫЕ ВОПРОСЫ
1. Что представляет собой вычислительная сеть?
2. Чем различаются локальные и глобальные сети?
3. Назовите основные различия клиент-серверной и файл-
серверной архитектур.
4. Какие основные типы кабелей используются для построения
компьютерных сетей?
5. Приведите основные типы оптоволоконных кабелей.
В. Каковы основные характеристики производительности сети?
7. Что означает масштабируемость сети?
8. Перечислите характеристики надежности сети.
9. Какое устройство называют хостом?
10. В чем разница между полносвязными и неполносвязными
сетями?
19
11. Какие преимущества дает использование технологии с комму¬
тацией пакетов?
12. Что означает интегрируемость сети?
13. Каковы преимущества кабеля «витая пара» в сравнении с
коаксиальным кабелем?
14. Какими факторами определяется пропускная способность ка¬
нала?
15. Каковы ограничения на скорость оптоволоконных линий? Чем
они определяются?
16. Опишите основные характеристики проводных каналов связи.
17. Каковы преимущества и недостатки оптоволоконных систем
связи по сравнению с кабельными?
Глава 2
ТЕХНОЛОГИИ ПЕРЕДАЧИ И ОБМЕНА ДАННЫМИ
В КОМПЬЮТЕРНЫХ СЕТЯХ
2.1.
ФИЗИЧЕСКАЯ ПЕРЕДАЧА ДАННЫХ
Среда передачи данных — это линии или каналы связи, через
которые происходит обмен информацией между компьютерами.
Передача информации осуществляется с помощью сигналов, со¬
ответствующих физической природе канала. Например, передача
данных по коаксиальному кабелю или «витой паре» осуществляется
с помощью электрических сигналов, передача по оптоволоконному
кабелю — с помощью световых, а в беспроводных каналах — с по¬
мощью радиоволн. Поэтому, чтобы передать информацию, ее нужно
преобразовать в тот или иной вид сигнала, т. е. закодировать.
В вычислительной технике для представления данных иполь-
зуется двоичный код. Внутри компьютера единицам и нулям дан¬
ных соответствуют дискретные электрические сигналы. Выбор
той или иной системы кодирования зависит от характеристик
физической среды передачи информации, стоимости сетевого
оборудования, применяемого для кодирования и декодирования
информации. Использование различных методов кодирования
может существенно влиять на достоверность и скорость передачи
информации. В одной и той же физической среде передачи при
различных системах кодирования скорость передачи может зна¬
чительно различаться.
Существуют различные способы кодирования двоичных цифр,
например потенциальный способ, при котором единице соответ¬
ствует один уровень напряжения, а нулю — другой, или импульс¬
ный способ, когда для представления цифр используются импульсы
различной полярности.
Аналогичные подходы применимы для кодирования данных и
при передаче их между двумя компьютерами по линиям связи.
21
Однако эти линии связи отличаются по своим характеристикам
от линий внутри компьютера, в первую очередь гораздо большей
протяженностью, а также тем, что они проходят в пространстве,
зачастую подверженному воздействию сильных электромагнит¬
ных помех. Поэтому для надежного распознавания импульсов на
приемном конце линии связи при передаче данных внутри и вне
компьютера не всегда можно использовать одни и те же скорости
и способы кодирования.
В вычислительных сетях применяют как потенциальное, так и
импульсное кодирование дискретных данных, а также специфиче¬
ский способ представления данных, который никогда не использу¬
ется внутри компьютера, — модуляцию. При модуляции дискретная
информация представляется синусоидальным сигналом той частоты,
которую хорошо передает имеющаяся линия связи. Потенциальное
или импульсное кодирование применяется на каналах высокого
качества, а модуляция на основе синусоидальных сигналов предпо¬
чтительнее в том случае, когда канал вносит сильные искажения в
передаваемые сигналы.
Еще одной проблемой передачи сигналов является проблема
взаимной синхронизации передатчика одного компьютера с при¬
емником другого. Внутри компьютера все модули синхронизиру¬
ются от общего тактового генератора. Проблема синхронизации
при связи компьютеров может решаться разными способами, как
путем обмена специальными тактовыми синхроимпульсами по
отдельной линии, так и путем периодической синхронизации за¬
ранее обусловленными кодами или импульсами характерной фор¬
мы, отличающейся от формы импульсов данных. Для повышения
надежности передачи данных между компьютерами, как правило,
используется стандартный прием — подсчет контрольной суммы
и передача полученного значения по линиям связи после каждого
байта или после некоторого блока байтов.
Существует большое количество характеристик, связанных с
передачей трафика через физические каналы. Ниже перечислены
некоторые из них.
Заявленная (предложенная) нагрузка — поток данных, поступа¬
ющий от пользователя на вход сети. Предложенную нагрузку можно
характеризовать скоростью поступления данных в сеть в битах в
секунду (или килобитах, мегабитах и т.д.).
Скорость передачи данных — фактическая скорость потока
данных, прошедшего через сеть. Эта скорость может быть меньше,
чем скорость заявленной нагрузки, так как данные в сети могут
искажаться или теряться.
22
Емкость канала связи, называемая также пропускной способ¬
ностью, представляет собой максимально возможную скорость
передачи информации по каналу Спецификой этой характеристики
является то, что она отражает не только параметры физической
среды передачи, но и особенности выбранного способа передачи
дискретной информации в этой среде. Например, емкость канала
связи в сети Ethernet на оптическом волокне равна 10 Мбит/с. Эта
скорость является предельно возможной для сочетания технологии
Ethernet и оптического волокна. Однако для того же самого опти¬
ческого волокна можно разработать другую технологию передачи
данных, отличающуюся способом кодирования данных, тактовой
частотой и другими параметрами, которая будет иметь другую
емкость. Так, технология Fast Ethernet обеспечивает передачу дан¬
ных по тому же оптическому волокну с максимальной скоростью
100 Мбит/с, а технология Gigabit Ethernet — 1000 Мбит/с. Пере¬
датчик коммуникационного устройства должен работать со скоро¬
стью, равной пропускной способности канала. Эта скорость иногда
Называется битовой скоростью передатчика.
Полоса пропускания — этот термин может ввести в заблуждение,
потому что он используется в двух разных значениях. Во-первых,
с его помощью можно характеризовать среду передачи. В этом
случае он означает ширину полосы частот, которую линия пере¬
дает без существенных искажений. Из этого определения понятно
происхождение термина. Во-вторых, термин «полоса пропускания»
используется как синоним термина емкость канала связи. В первом
случае полоса пропускания измеряется в герцах (Гц), во втором —
в битах в секунду. Различать значения термина нужно по контексту,
хотя иногда это достаточно трудно. Конечно, лучше было бы приме¬
нять разные термины для различных характеристик, но существуют
традиции, которые изменить трудно. Такое двойное использование
термина «полоса пропускания» уже вошло во многие стандарты.
Еще одна группа характеристик канала связи связана с возмож¬
ностью передачи информации по каналу в одну или обе стороны.
При взаимодействии двух компьютеров обычно требуется пере¬
давать информацию в обоих направлениях. Даже в том случае,
когда пользователю кажется, что он только получает информацию
(например, загружает видеофайл из Интернета) или только ее пере¬
дает (отправляет электронное письмо), обмен информацией идет
в двух направлениях. На самом деле существуют основные потоки
данных, которые интересуют пользователя, и вспомогательный
поток противоположного направления — сообщения о получении
этих данных. Физические каналы связи делятся на несколько типов
23
в зависимости от того, могут они передавать информацию в обоих
направлениях или нет.
Дуплексный канал обеспечивает одновременную передачу ин¬
формации в обоих направлениях. Это могут быть две физические
среды, каждая их которых используется для передачи информации
только в одном направлении. Либо возможен вариант, когда одна
среда служит для одновременной передачи встречных потоков;
в этом случае применяют дополнительные методы выделения каж¬
дого потока из суммарного сигнала.
Полудуплексный канал также обеспечивает передачу информа¬
ции в обоих направлениях, но не одновременно, а по очереди, т. е.
в течение определенного периода времени информация передается
в одном направлении, а в течение следующего периода — в об¬
ратном.
Симплексный канал позволяет передавать информацию только
в одном направлении. Часто дуплексный канал состоит из двух
симплексных каналов.
ЗАДАЧИ СЕТЕВОГО ВЗАИМОДЕЙСТВИЯ
2.2.
В сети производится множество операций, обеспечивающих
передачу данных от одной рабочей станции к другой. Пользователя
не интересует, как именно это происходит, ему необходим доступ
к приложению или компьютерному ресурсу, расположенному на
другом компьютере. В действительности же передаваемые данные
проходят множество этапов обработки.
Прежде всего информация разбивается на блоки — сетевые
пакеты, каждый из которых снабжается управляющей инфор¬
мацией — метками и идентификаторами. Это делается для того,
чтобы потом данные можно было привести к такому виду, какими
они были до разбиения. Каждый из этих пакетов преобразуется в
соответствующие сигналы (кодируется) в соответствии с исполь¬
зуемой средой передачи данных. Пакеты передаются с помощью
электрических или световых сигналов по сети в соответствии с
выбранным методом доступа. На стороне принимающей рабочей
станции данные проходят обработку в обратном порядке: прини¬
маются, декодируются, собираются из блоков, принимая первона¬
чальный вид. Это, конечно, упрощенное описание происходящих
процессов.
Часть из указанных процедур реализуется только программно,
другая часть — аппаратно, а какие-то операции могут выполняться
24
как программами, так и аппаратурой. Но при передаче сообщений
оба участника сетевого обмена должны принять множество согла¬
шений. Они должны определить уровни и форму передаваемых
сигналов, способ определения длины сообщений, определить ме¬
тоды контроля достоверности получаемой информации и многое
другое.
Сеть —- это соединение разного оборудования, поэтому одной
из наиболее острых проблем является проблема совместимости.
Без соблюдения всеми производителями общепринятых правил
разработки оборудования прогресс в конструировании сетей был
бы невозможен. Поэтому все развитие компьютерных технологий
в конечном счете отражено в стандартах. Любая новая технология
только тогда приобретает «законный» статус, когда ее содержание
закрепляется в соответствующем стандарте.
Открытая система — это некая вычислительная среда, состоя¬
щая из аппаратных и программных продуктов и технологий, раз¬
работанных в соответствии с общедоступными и общепринятыми
международными стандартами. Открытыми системами являются
компьютер, вычислительная сеть, операционная система, программ¬
ный пакет, другие аппаратные и программные продукты.
Открытой может быть названа любая система, которая построе¬
на в соответствии с открытыми спецификациями. Под термином
«спецификация» в вычислительной технике понимают формали¬
зованное описание аппаратных или программных компонентов,
способов их функционирования, взаимодействия с другими ком¬
понентами, условий эксплуатации, особых характеристик.
Основой стандартизации в компьютерных сетях является много¬
уровневый подход к разработке средств сетевого взаимодействия.
Именно на основе этого подхода была создана стандартная модель
взаимодействия открытых систем, ставшая своего рода универсаль¬
ным языком сетевых специалистов. Сетевая модель обеспечивает
возможность стандартизации всех выполняемых в сети процедур,
разделения их на уровни и подуровни, взаимодействующие между
собой. Они устанавливают соглашения о том, как передавать и при¬
нимать данные на всех этапах взаимодействия. При этом сетевые
модели позволяют правильно организовать обмен информацией
как абонентам внутри одной сети, так и самым разным сетям на
различных уровнях.
В многоуровневом представлении в процессе обмена сообще¬
ниями участвуют две стороны. Таким образом, необходимо орга¬
низовать согласованную работу двух «иерархий», работающих
на разных компьютерах. Оба участника сетевого обмена должны
25
принять множество соглашений. Например, они должны согласо¬
вать уровни и форму электрических сигналов, способ определения
длины сообщений, договориться о методах контроля достовер¬
ности и т. п. Другими словами, соглашения должны быть приняты
для всех уровней, начиная от самого низкого (уровня передачи
битов) до самого высокого, реализующего сервис для пользова¬
телей сети.
Протоколы — это формализованные правила, определяющие
порядок и формат сообщений, которыми обмениваются сетевые
компоненты, представляющие один уровень, но находящиеся в раз¬
ных узлах сети. Иными словами, протоколы — это набор процедур
и правил, регулирующих порядок обеспечения связи в сети.
Модули, реализующие протоколы соседних уровней и находя¬
щиеся в одном узле, также взаимодействуют друг с другом в соот¬
ветствии с четко определенными правилами с помощью стандарти¬
зированных форматов сообщений. Эти правила принято называть
интерфейсом (рис. 2.1).
Интерфейс определяет последовательность и формат сообще¬
ний, которыми обмениваются сетевые компоненты, лежащие на
соседних уровнях в одном узле. Интерфейс определяет набор услуг,
предоставляемый данным уровнем соседнему уровню.
На первый взгляд, протокол и интерфейс выражают одно и то
же понятие, но на самом деле у них разные задачи: протоколы
определяют правила взаимодействия модулей одного уровня в
разных узлах, а интерфейсы — модулей соседних уровней в одном
узле.
Уровень 1
Уровень 2
Уровень 3
Рис. 2.1. Организация взаимодействия уровней
26
Иерархически организованный набор протоколов, достаточный
для организации взаимодействия узлов в сети, называется стеком
коммуникационных протоколов.
Коммуникационные протоколы могут быть реализованы как
программно, так и аппаратно. Протоколы нижних уровней часто
реализуются комбинацией программных и аппаратных средств,
а протоколы верхних уровней, как правило, только программными
средствами.
Протоколы реализуются не только компьютерами, но и другими
сетевыми устройствами — концентраторами, мостами, коммутато¬
рами, маршрутизаторами и т. д. В зависимости от типа устройства
в нем должны быть встроенные средства, реализующие тот или
иной набор протоколов.
Открытый характер стандартов и спецификаций важен не толь¬
ко для коммуникационных протоколов, но и для разнообразных
устройств и программ, выпускаемых для построения сети.
2.3.
СЕТЕВАЯ МОДЕЛЬ OSI
Международной организацией по стандартизации (ISO) в конце
1970-х гг. был предложен стандарт, который покрывает все аспек¬
ты сетевой связи — это эталонная модель обмена информацией
открытой системы OSI (Open System Interconnection). Модель OSI
разбивает все процессы взаимодействия и передачи данных по сети
на семь уровней: прикладной, представительный, сеансовый, транс¬
портный, сетевой, канальный, физический (табл. 2.1). Для каждого
уровня определяются выполняемые ими функции, даются термины
и определения основных понятий.
В литературе наиболее часто принято начинать описание уровней
модели OSI с 7-го уровня, называемого прикладным, на котором
пользовательские приложения обращаются к сети. Модель OSI
заканчивается 1-м уровнем — физическим, на котором определе¬
ны стандарты, предъявляемые независимыми производителями к
средам передачи данных:
■ тип передающей среды (медный кабель, оптоволокно, радиоэфир
и др.);
н тип модуляции сигнала;
■ сигнальные уровни логических дискретных состояний (нуля и
единицы).
Любой протокол модели OSI должен взаимодействовать либо с
протоколами своего уровня, либо с протоколами на единицу выше
27
Таблица 2.1. Модель OSI
Тип данных
Номер
Уровень (layer)
Функция
Данные
7
Прикладной
(application)
Доступ к сетевым
службам
Поток
6
Уровень пред¬
ставления
(presentation)
Представление и шиф¬
рование данных
Сеансы
5
Сеансовый
(session)
Управление сеансом
связи
Сегменты
4
Транспортный
(transport)
Прямая связь между
конечными пунктами и
надежность
Пакеты / Дей¬
таграммы
3
Сетевой (network)
Определение маршрута
и логическая адресация
Кадры
2
Канальный
(data link)
Физическая адресация
Биты
1
Физический
(physical)
Работа со средой пере¬
дачи, сигналами и дво¬
ичными данными
и/или ниже своего уровня (рис. 2.2). Взаимодействия с протокола¬
ми своего уровня называются горизонтальными, а с уровнями на
единицу выше или ниже — вертикальными.
Каждому уровню условно соответствует свой логически не¬
делимый элемент данных, которым на отдельном уровне можно
оперировать в рамках модели и используемых протоколов. На фи¬
зическом уровне мельчайшая единица — бит, на канальном уровне
информация объединена в кадры, на сетевом — в пакеты и т.д.
Любой фрагмент данных, логически объединенных для передачи
(кадр, пакет, дейтаграмма), считается сообщением.
Модель OSI описывает только системные средства взаимодей¬
ствия, не касаясь приложений конечных пользователей. Прило¬
жения реализуют свои собственные протоколы взаимодействия,
обращаясь к системным средствам. Следует иметь в виду, что
приложение может взять на себя функции некоторых верхних
уровней модели OSI, в таком случае при необходимости межсете¬
вого обмена оно обращается напрямую к системным средствам,
выполняющим функции оставшихся нижних уровней модели OSI.
Например, некоторые системы управления базами данных имеют
28
Рис. 2.2. Модель взаимодействия открытых систем
встроенные средства удаленного доступа к файлам. Приложение
конечного пользователя может использовать системные средства
взаимодействия не только для организации диалога с другим при¬
ложением, выполняющимся на другой машине, но и просто для по¬
лучения услуг того или иного сетевого сервиса, например, доступа
к удаленным файлам, получение почты или печати на разделяемом
принтере.
Когда приложение обращается с запросом к прикладному уров¬
ню, например к файловому сервису, то программное обеспечение
прикладного уровня на основании этого запроса формирует со¬
общение стандартного формата, в которое помещает служебную
информацию (заголовок) и, возможно, передаваемые данные. Поле
данных сообщения может быть пустым или содержать какие-либо
данные, например те, которые необходимо записать в удаленный
файл. Но для того чтобы доставить эту информацию по назначению,
предстоит решить еще много задач.
29
Протокол представительного уровня на основании информации,
полученной из заголовка прикладного уровня, выполняет требуемые
действия и добавляет к сообщению собственную служебную инфор¬
мацию — заголовок представительного уровня, в котором содержатся
указания для протокола представительного уровня машины-адресата.
Полученное в результате сообщение передается вниз сеансовому
уровню, который в свою очередь добавляет свой заголовок и т. д. Не¬
которые протоколы помещают служебную информацию не только в
начале сообщения в виде заголовка, но и в конце, в виде так называе¬
мого «концевика», или, как иногда его называют, «терминатора». На¬
конец, сообщение достигает нижнего физического уровня, который,
собственно, и передает его по линиям связи компьютеру-получателю.
К этому моменту сообщение «обрастает» заголовками всех уровней.
Когда сообщение по сети поступает на другую машину, оно после¬
довательно перемещается вверх с уровня на уровень. Каждый уро¬
вень анализирует, обрабатывает и удаляет заголовок своего уровня,
выполняет соответствующие данному уровню функции и передает
сообщение вышележащему уровню (рис. 2.3).
Физический уровень. Физический уровень — нижний уровень
модели, который определяет метод передачи данных, представленных
в двоичном виде, от одного устройства (компьютера) к другому.
Физический уровень определяет такие виды сред передачи
данных, как оптоволокно, витая пара, коаксиальный кабель, спут¬
никовый канал передачи данных и т. п. К этому уровню относятся
характеристики физических сред передачи данных, такие как по-
Сообщение
л-го уровня
Рис. 2.3. Структура сообщений различных уровней
30
лоса пропускания, помехозащищенность, волновое сопротивление
и др. На этом же уровне определяются характеристики электриче¬
ских сигналов, передающих дискретную информацию — крутизна
фронтов импульсов, уровни напряжения или тока передаваемого
сигнала, тип кодирования, скорость передачи сигналов. Кроме того,
здесь стандартизируются типы разъемов и назначение каждого
контакта.
Кратко можно определить функции физического уровня:
■ передача битов по физическим каналам;
■ формирование электрических сигналов;
■ кодирование информации;
■ синхронизация;
■ модуляция.
Физический уровень реализуется аппаратно. Функции физиче¬
ского уровня реализуются на всех устройствах, подключенных к
сети. На этом уровне работают концентраторы, повторители сигнала
и медиаконвертеры. Со стороны компьютера функции физического
уровня выполняются сетевым адаптером или последовательным
портом. К физическому уровню относятся физические, электриче¬
ские и механические интерфейсы между двумя системами.
Примером протокола физического уровня может служить спе¬
цификация 10Base-T технологии Ethernet, которая определяет в
качестве используемого кабеля неэкранированную витую пару
категории 3 с волновым сопротивлением 100 Ом, разъем RJ-45,
максимальную длину физического сегмента 100 м, манчестерский
код для представления данных в кабеле, а также некоторые другие
характеристики среды и электрических сигналов.
Канальный уровень. Канальный уровень предназначен для
обеспечения взаимодействия сетей по физическому уровню и кон¬
тролем над ошибками, которые могут возникнуть. На физическом
уровне просто пересылаются биты. При этом не учитывается, что
в тех сетях, в которых линии связи разделяются попеременно не¬
сколькими парами взаимодействующих компьютеров, физическая
среда передачи может быть занята.
Одной из задач канального уровня является проверка доступ¬
ности среды передачи. Другой задачей канального уровня является
обнаружение и исправление ошибок. Для этого биты группируются
в наборы, называемые кадрами. Канальный уровень обеспечива¬
ет корректность передачи каждого кадра, помещая специальную
последовательность бит в начало и конец каждого кадра, для его
выделения, а также вычисляет контрольную сумму, обрабатывая
все биты кадра определенным способом, и добавляет контрольную
31
сумму к кадру. Когда кадр приходит по сети, получатель снова вы¬
числяет контрольную сумму полученных данных и сравнивает ре¬
зультат с контрольной суммой из кадра. Если они совпадают, кадр
считается правильным и принимается. Если же контрольные суммы
не совпадают, то фиксируется ошибка. Канальный уровень может
не только обнаруживать ошибки, но и корректировать их за счет
повторной передачи поврежденных кадров.
Необходимо отметить, что функция исправления ошибок для
канального уровня не является обязательной, поэтому в некоторых
протоколах этого уровня она отсутствует, например в Ethernet.
Канальный уровень обычно подразделяют на два подуровня:
1) логической передачи данных (Logical Link Control, LLC);
2) управления доступом к среде (Media Access Control, MAC).
Уровень MAC обеспечивает корректное совместное использова¬
ние общей среды. После получения доступа к среде ею может поль¬
зоваться более высокий уровень LLC, который реализует функции
интерфейса с прилегающим к нему сетевым уровнем. Протоколы
уровней MAC и LLC взаимно независимы. Поэтому каждый про¬
токол уровня MAC может применяться с любым протоколом уровня
LLC, и наоборот.
Функции канального уровня:
■ управление доступом к передающей среде;
■ выделение границ кадра. Среди возможных решений этой за¬
дачи — резервирование некоторой последовательности, обо¬
значающей начало или конец кадра;
■ аппаратная адресация (или адресация канального уровня). Тре¬
буется в том случае, когда кадр могут получить сразу несколько
адресатов. В локальных сетях аппаратные адреса (МАС-адреса)
применяются всегда;
■ обеспечение достоверности принимаемых данных. Во время
передачи кадра есть вероятность, что данные будут искажены.
Важно это обнаружить и не пытаться обработать кадр, содер¬
жащий ошибку. Обычно на канальном уровне используются
алгоритмы контрольных сумм, дающие высокую гарантию об¬
наружения ошибок;
■ адресация протокола верхнего уровня.
Функции уровня LLC обычно реализуются программно соот¬
ветствующим модулем операционной системы, а функции уровня
MAC реализуются программно аппаратно-сетевым адаптером и
его драйвером.
Сетевой уровень. Сетевой уровень модели предназначен для
определения пути передачи данных. Отвечает за трансляцию ло¬
32
гических адресов и имен в физические, определение кратчайших
маршрутов, коммутацию и маршрутизацию, отслеживание непола¬
док и «заторов» в сети. Сетевой уровень должен также обеспечивать
обработку ошибок, мультиплексирование (передачу нескольких
потоков с меньшей пропускной способностью по одному каналу),
управление потоками данных.
Протокол канального уровня локальных сетей обеспечивает до¬
ставку данных между любыми узлами только в сети с соответству¬
ющей типовой топологией. Это очень жесткое ограничение, которое
не позволяет строить сети с развитой структурой, например, сети,
объединяющие несколько сетей предприятия в единую сеть, или
высоконадежные сети, в которых существуют избыточные связи
между узлами.
Для того чтобы, с одной стороны, сохранить простоту процедур
передачи данных для типовых топологий, а с другой — допустить
использование произвольных топологий, используется дополни¬
тельный сетевой уровень. На этом уровне вводится понятие «сеть».
В данном случае под сетью понимается совокупность компьютеров,
соединенных между собой в соответствии с одной из стандартных
типовых топологий и использующих для передачи данных один из
протоколов канального уровня, определенный для этой топологии.
Таким образом, внутри сети доставка данных регулируется ка¬
нальным уровнем, а доставку данных между сетями осуществляет
сетевой уровень. Основная задача сетевого уровня — маршрутиза¬
ция данных, т. е. передача данных между сетями. Проблема выбора
наилучшего пути (маршрутизация) и ее решение являются одной из
главных задач сетевого уровня. Эта проблема осложняется тем, что
самый короткий путь — не всегда самый лучший. Часто критерием
при выборе маршрута является время передачи данных — оно за¬
висит от пропускной способности каналов связи и интенсивности
трафика — показателей, которые могут с течением времени изме¬
няться. Некоторые алгоритмы маршрутизации пытаются приспо¬
собиться к изменению нагрузки, в то время как другие принимают
решения на основе средних показателей за длительное время. Вы¬
бор маршрута может осуществляться и по другим критериям, таким
как надежность передачи.
В общем случае функции сетевого уровня шире, чем функции
передачи сообщений по связям с различной структурой, как, напри¬
мер, объединение нескольких локальных сетей. Сетевой уровень
также решает задачи согласования разных технологий, упрощения
адресации в крупных сетях и создания надежных и гибких барьеров
на пути нежелательного трафика между сетями.
33
Сообщения сетевого уровня называют пакетами. При органи¬
зации доставки пакетов на сетевом уровне используется понятие
«номер сети». Адрес получателя состоит из номера сети и номера
узла в этой сети. Все узлы одной сети должны иметь одну и ту же
старшую часть адреса, поэтому термину «сеть» на сетевом уровне
можно дать и другое, более формальное, определение: сеть — это
совокупность узлов, сетевой адрес которых содержит один и тот
же номер сети.
На сетевом уровне определяются два вида протоколов:
1) сетевые протоколы, реализующие движение пакетов через сеть;
2) протоколы обмена маршрутной информацией (протоколы
маршрутизации). С помощью этих протоколов маршрутизато¬
ры собирают информацию о топологии межсетевых соедине¬
ний. Протоколы сетевого уровня реализуются программными
модулями операционной системы, а также программными и ап¬
паратными средствами маршрутизаторов.
Примерами протоколов сетевого уровня являются протокол меж¬
сетевого взаимодействия IP стека TCP/IP и протокол межсетевого
обмена пакетами IPX стека Novell.
Транспортный уровень. Транспортный уровень является своего
рода связующим звеном между более высокими уровнями, кото¬
рые очень зависят от приложений, и нижними уровнями, более
привязанными к линиям связи. Можно сказать, что транспортный
уровень модели предназначен для обеспечения надежной пере¬
дачи данных от отправителя к получателю. Задачей транспортного
уровня является обеспечение доставки информации с требуемым
качеством между любыми узлами сети, а именно:
■ разбивка сообщения сеансового уровня на пакеты, их нумера¬
ция;
и буферизация принимаемых пакетов;
■ упорядочивание прибывающих пакетов;
ш адресация прикладных процессов;
■ управление потоком.
Как правило, все протоколы, начиная с транспортного уровня
и выше, реализуются программными средствами конечных узлов
сети — компонентами их сетевых операционных систем. В качестве
примера транспортных протоколов можно привести протоколы TCP
и UDP стека TCP/IP и протокол SPX стека Novell.
Протоколы четырех нижних уровней обобщенно называют
сетевым транспортом или транспортной подсистемой, так как они
полностью решают задачу транспортировки сообщений с заданным
уровнем качества в составных сетях с произвольной топологией и
34
различными технологиями. Остальные три верхних уровня решают
задачи предоставления прикладных сервисов на основании име¬
ющейся транспортной подсистемы.
Сеансовый уровень. Сеансовый уровень отвечает за поддержа¬
ние сеанса связи, позволяя приложениям взаимодействовать между
собой длительное время, иными словами, обеспечивает координа¬
цию связи между двумя рабочими станциями сети.
Уровень организует сеанс обмена данными, управляет созданием
и завершением сеанса, синхронизацией задач, определением права
на передачу данных и поддержанием сеанса в периоды неактив¬
ности приложений.
Синхронизация передачи обеспечивается помещением в поток
данных контрольных точек, чтобы в случае отказа можно было
вернуться назад к последней контрольной точке, вместо того чтобы
начинать все с начала. На практике немногие приложения исполь¬
зуют сеансовый уровень, и он редко реализуется.
Уровень представления. Уровень представления обеспечивает то,
что информация, передаваемая прикладным уровнем, будет понятна
прикладному уровню в другой системе. С его помощью преодоле¬
ваются различия, например, между всевозможными кодировками
символов и синтаксиса.
Уровень представления выполняет преобразование форматов
данных в некоторый общий формат представления, а на приеме,
соответственно, выполняет обратное преобразование. На этом
уровне могут выполняться шифрование и дешифрование данных,
благодаря которому секретность обмена данными обеспечивается
сразу для всех прикладных сервисов. Примером протокола, рабо¬
тающего на уровне представления, является протокол Secure Socket
Layer (SSL), который обеспечивает секретный обмен сообщениями
для протоколов прикладного уровня стека TCP/IP.
Прикладной уровень. Прикладной уровень обеспечивает взаи¬
модействие сети и пользователя. Уровень разрешает приложениям
пользователя иметь доступ к сетевым службам, таким как обра¬
ботчик запросов к базам данных, доступ к файлам, пересылке
электронной почты. Также отвечает за передачу служебной ин¬
формации, предоставляет приложениям информацию об ошибках
и формирует запросы к уровню представления. Пример: HTTP,
POP3, SMTP.
Прикладной уровень — это в действительности просто набор
различных протоколов, с помощью которых пользователи сети
получают доступ к разделяемым ресурсам, таким как файлы, прин¬
теры или гипертекстовые веб-страницы, а также организуют свою
35
совместную работу, например, с помощью протокола электронной
почты. Единица данных, которой оперирует прикладной уровень —
сообщение.
Функции всех уровней модели OSI могут быть отнесены к одной
из двух групп: к функциям, зависящим от конкретной технической
реализации сети, либо к функциям, ориентированным на работу с
приложениями.
Три нижних уровня (физический, канальный и сетевой) являют¬
ся зависимыми от сети, т. е. протоколы этих уровней тесно связаны
с технической реализацией сети и используемым коммуникаци¬
онным оборудованием. Например, переход на оборудование FDDI
означает полную смену протоколов физического и канального
уровней во всех узлах сети.
Три верхних уровня (прикладной, представительный и сеансо¬
вый) ориентированы на приложения и мало зависят от технических
особенностей построения сети.
На протоколы этих уровней не влияют никакие изменения в
топологии сети, замена оборудования или переход на другую се¬
тевую технологию. Так, переход от Ethernet к высокоскоростной
технологии lOOVG-AnyLAN не потребует никаких изменений в
программных средствах, реализующих функции прикладного, пред¬
ставительного и сеансового уровней.
Транспортный уровень является промежуточным, он скрывает
все детали функционирования нижних уровней от верхних. Это по¬
зволяет разрабатывать приложения, не зависящие от технических
средств непосредственной транспортировки сообщений.
Модель OSI представляет только одну из многих моделей ком¬
муникаций. Эти модели и связанные с ними стеки протоколов
могут отличаться количеством уровней, их функциями, форматами
сообщений, сервисами, предоставляемыми на верхних уровнях и
прочими параметрами.
ПРОТОКОЛЫ И СТАНДАРТЫ
2.4.1. Общая характеристика протоколов
Взаимодействие компьютеров в сетях происходит в соответствии
с определенными правилами обмена сообщениями и их форматами,
т. е. в соответствии с определенными протоколами. Иерархически
организованная совокупность протоколов различных уровней, до¬
36
статочных для организации взаимодействия узлов в компьютерной
сети, называют стеком протоколов. В отличие от сетевой модели,
представляющей собой концептуальную схему взаимодействия
систем, стек протоколов представляет набор конкретных специфи¬
каций, позволяющих реализовать сетевое взаимодействие.
Существует довольно много стеков протоколов, широко приме¬
няемых в сетях. Примерами популярных стеков протоколов могут
служить стек IPX/SPX фирмы Novell, стек TCP/IP, используемый в
сети Интернет и во многих сетях на основе операционной системы
UNIX, стек OSI международной организации по стандартизации,
стек DECnet корпорации Digital Equipment и др.
Использование в сети того или иного стека коммуникационных
протоколов во многом определяет характеристики сети. В не¬
больших сетях может использоваться один стек. В крупных кор¬
поративных сетях, объединяющих различные сети, параллельно
используются, как правило, несколько стеков.
В коммуникационном оборудовании реализуются протоколы
нижних уровней, которые в большей степени стандартизованы,
чем протоколы верхних уровней, и это является предпосылкой для
успешной совместной работы оборудования различных произво¬
дителей. Перечень протоколов, поддерживаемых тем или иным
коммуникационным устройством, является одной из наиболее
важных характеристик этого устройства.
Компьютеры реализуют коммуникационные протоколы в виде
соответствующих программных элементов сетевой операционной
системы, например, протоколы канального уровня, как правило,
выполнены в виде драйверов сетевых адаптеров, а протоколы
верхних уровней — в виде серверных и клиентских компонент
сетевых сервисов. Умение хорошо работать в среде той или иной
операционной системы является важной характеристикой комму¬
никационного оборудования.
Часто можно прочитать в рекламе сетевого адаптера или кон¬
центратора, что он разрабатывался специально для работы в сети
NetWare или UNIX. Это означает, что разработчики аппаратуры
оптимизировали ее характеристики применительно к тем протоко¬
лам, которые используются в этой сетевой операционной системе,
или к данной версии их реализации, если эти протоколы исполь¬
зуются в различных операционных системах. Из-за особенностей
реализации протоколов в различных операционных системах в ка¬
честве одной из характеристик коммуникационного оборудования
используется его сертифицированность на возможность работы в
среде данной операционной системы.
37
Протоколы, используемые для обмена информацией в локальных
сетях, делятся по своей функциональности на три вида:
1) прикладные;
2) транспортные;
3) сетевые.
Прикладные протоколы выполняют функции трех верхних уров¬
ней модели OSI — прикладного, уровня представления и сеансового.
Они обеспечивают взаимодействие приложений и обмен данными
между ними.
Транспортные протоколы реализуют функции транспортного и
сеансового уровня модели OSI. Они инициализируют и поддержи¬
вают сеансы связи между узлами сети и обеспечивают требуемый
пользователем уровень надежности передачи данных.
Сетевые протоколы выполняют функции трех нижних уровней
модели OSI — сетевого, канального и физического. Эти протоколы
управляют адресацией, маршрутизацией, проверкой ошибок и по¬
вторной передачей кадров, обеспечивая услуги связи, определяют
правила осуществления связи в отдельных средах передачи данных,
например Ethernet или Tolken Ring. Принадлежность протоколов
различным уровням модели OSI представлена в табл. 2.2.
Протоколы ориентированы на работу в различных операци¬
онных системах и с различными аппаратными платформами и в
значительной степени имеют общие черты как для локальных, так
и для глобальных сетей.
Таблица 2.2. Протоколы, используемые для обмена данными
в сетях
Тип протокола
Уровень модели OSI
Протокол
Прикладные
протоколы
7
Прикладной
FTAM, Х.400, Х.500, SMPT,
FPT, SNMP, Telnet, SMB,
NCP, Apple Talk и Apple
Share, AFP, DAP
6
Представления
5
Сеансовый
Транспортные
протоколы
TCP, SPX, NetBIOS, ATP,
NBP
4
Транспортный
Сетевые
протоколы
3
Сетевой
IP, IPX, NetBEUI, DDP
2
Канальный
1
Физический
38
В 1980 г. в институте инженеров по электротехнике и электро¬
нике IEEE (Institute of Electrical and Electronics Engineers) был
организован комитет 802 по стандартизации локальных сетей,
и результате работы которого было принято семейство стандартов
IEEE 802.x, содержащих рекомендации по проектированию нижних
уровней локальных сетей. Позже результаты работы этого комитета
легли в основу комплекса международных стандартов ISO 8802-1...5.
Эти стандарты были созданы на основе очень распространенных
фирменных стандартов сетей Ethernet, ArcNet и Token Ring. Стан¬
дарты семейства IEEE 802. х охватывают только два нижних уровня
семиуровневой модели OSI — физический и канальный. Это связа¬
но с тем, что именно эти уровни в наибольшей степени отражают
специфику локальных сетей.
2.4.2. Стек протоколов OSI
Следует различать стек протоколов OSI и модель OSI. Стек
OSI— это набор вполне конкретных спецификаций — протоколов,
образующих согласованный стек. Это международный, независи¬
мый от производителей стандарт. Взаимодействие между корпора¬
циями, партнерами и поставщиками осложняется из-за проблем с
адресацией, именованием и безопасностью данных. Все эти пробле¬
мы в стеке OSI частично решены. Протоколы OSI требуют больших
затрат вычислительной мощности центрального процессора, что
делает их более подходящими для мощных машин, а не для сетей
персональных компьютеров. По вполне очевидным причинам стек
OSI в отличие от других стандартных стеков полностью соответству¬
ет модели взаимодействия OSI, он включает спецификации для всех
семи уровней модели взаимодействия открытых систем.
На физическом и канальном уровнях стек OSI поддерживает
протоколы Ethernet, Token Ring, FDDI, а также протоколы LLC,
X.25 и ISDN. Сервисы сетевого, транспортного и сеансового уров¬
ней также имеются в стеке OSI, однако они мало распространены.
На сетевом уровне реализованы протоколы как без установления
соединений, так и с установлением соединений. Транспортный про¬
токол стека OSI в соответствии с функциями, определенными для
него в модели OSI, скрывает различия между сетевыми сервисами
с установлением соединения и без установления соединения, так
что пользователи получают нужное качество обслуживания неза¬
висимо от нижележащего сетевого уровня. Чтобы обеспечить это,
транспортный уровень требует, чтобы пользователь задал нужное
39
качество обслуживания. Определены 5 классов транспортного
сервиса — от низшего класса 0 до высшего класса 4, которые от¬
личаются степенью устойчивости к ошибкам и требованиями к
восстановлению данных после ошибок.
Сервисы прикладного уровня включают передачу файлов, эму¬
ляцию терминала, службу каталогов и почту. Из них наиболее
перспективными являются служба каталогов (стандарт Х.500), элект¬
ронная почта (Х.400), протокол виртуального терминала (VT), про¬
токол передачи, доступа и управления файлами (FTAM), протокол
пересылки и управления работами (JTM).
Стек протоколов OSI, направленный на обеспечение однород¬
ности при построении сетей и, следовательно, универсальности
взаимодействия, был воспринят многими как слишком усложнен¬
ный и мало реализуемый. Причина в том, что разработка и внедре¬
ние стека OSI предполагали отказ от существующих протоколов и
переход на новые на всех уровнях стека. Это сильно затруднило
реализацию стека и послужило причиной для отказа от него многих
компаний, сделавших значительные инвестиции в другие сетевые
технологии.
2.4.3. Стек протоколов TCP/IP
Стек протоколов TCP/IP — набор сетевых протоколов пе¬
редачи данных, используемых в сетях, включая сеть Интернет.
Название TCP/IP происходит из двух наиважнейших протоколов
семейства — Transmission Control Protocol (TCP) и Internet Protocol
(IP), которые были разработаны и описаны первыми в данном
стандарте.
Стек TCP/IP, называемый также стеком Internet, является одним
из наиболее популярных и перспективных стеков коммуникаци¬
онных протоколов. Стек был разработан по инициативе Мини¬
стерства обороны США (Department of Defence, DoD) для связи
экспериментальной сети ARPAnet с другими сателлитными сетями
как набор общих протоколов для разнородной вычислительной
среды. Сеть ARPA поддерживала разработчиков и исследователей в
военных областях. В сети ARPA связь между двумя компьютерами
осуществлялась с использованием протокола Internet Protocol (IP),
который и по сей день является одним из основных в стеке TCP/IP
и фигурирует в названии стека.
Большой вклад в развитие стека TCP/IP внес Калифорнийский
университет в Беркли, реализовав протоколы стека в своей вер¬
40
сии ОС UNIX. Широкое распространение ОС UNIX привело и к
широкому распространению протокола IP и других протоколов
стека. На этом же стеке работает всемирная информационная сеть
Интернет.
Несмотря на то что стек TCP/IP имеет многоуровневую струк¬
туру, соответствие уровней стека TCP/IP уровням модели OSI до¬
статочно условно, так как TCP/IP был разработан до появления
модели взаимодействия открытых систем ISO/OSI.
Структура протоколов TCP/IP приведена в табл. 2.3. Протоколы
TCP/IP делятся на 4 уровня.
Самый нижний уровень стека (уровень IV) — уровень межсете¬
вых интерфейсов, соответствует физическому и канальному уровню
модели OSI. Этот уровень в протоколах TCP/IP не регламентирует¬
ся, но поддерживает все популярные стандарты физического и ка¬
нального уровня: Ethernet, Token Ring, FDDI для локальных каналов,
собственные протоколы работы на аналоговых коммутируемых и
выделенных линиях SLIP/PPP для глобальных каналов.
Следующий уровень (уровень III) — это уровень межсетевого
взаимодействия, который занимается передачей дейтаграмм с ис¬
пользованием различных локальных сетей, территориальных сетей,
линий специальной связи и т. п. В качестве основного протокола
сетевого уровня (в терминах модели OSI) в стеке используется
протокол IP. Он предназначен для передачи пакетов в составных
сетях, состоящих из большого количества локальных сетей. Поэтому
протокол IP хорошо работает в сетях со сложной топологией, ра¬
ционально используя наличие в них подсистем и экономно расходуя
.
Таблица 2.3. Стек протоколов TCP/IP
Уровень модели
OSI
Протокол TCP/IP
Уровень
TCP/IP
7
FTP, TFTP. Gopher, Telnet, SMTP,
SNMP...
I
6
5
TCP, UDP
II
4
3
IP, ICMP, RIP, OSPF
III
2
He регламентировано, но поддержи¬
ваются все популярные стандарты
IV
1
41
пропускную способность низкоскоростных линий связи. Протокол IP
является дейтаграммным протоколом.
К уровню межсетевого взаимодействия относятся также все
протоколы, связанные с составлением и модификацией таблиц
маршрутизации:
■ RIP (Routing Internet Protocol) и OSPF (Open Shortest Path First) —
протоколы сбора маршрутной информации;
■ ICMP (Internet Control Message Protocol) — протокол для обмена
информацией об ошибках между маршрутизатором и шлюзом,
системой-источником и системой-приемником, т.е. для органи¬
зации обратной связи.
Уровень II называется основным и обеспечивает функции транс¬
портировки информации по сети. На этом уровне функционируют
протокол управления передачей TCP (Transmission Control Protocol)
и протокол дейтаграмм пользователя UDP (User Datagram Protocol).
TCP обеспечивает логическое соединение между удаленными при¬
кладными процессами и использующий принцип автоматической
повторной передачи пакетов, содержащих ошибки. UDP обеспечи¬
вает передачу прикладных пакетов дейтаграммным методом, т. е. без
установления логического соединения, и поэтому не обеспечивает
проверку на наличие ошибок и подтверждение доставки пакета.
UDP является упрощенным вариантом TCP.
К уровню I (прикладному) относятся такие широко используемые
протоколы, как протокол копирования файлов FTP, протокол эму¬
ляции терминала Telnet, почтовый протокол SMTP, используемый
в электронной почте сети Интернет, гипертекстовые сервисы до¬
ступа к удаленной информации, такие как WWW и многие другие.
Остановимся несколько подробнее на некоторых из них.
SNMP (Simple Network Management Protocol) используется для
организации сетевого управления. Протоколы передачи управля¬
ющей информации определяют процедуру взаимодействия сервера
и клиента. Они определяют форматы сообщений, которыми обме¬
ниваются клиенты и серверы, а также форматы имен и адресов.
Другая задача связана с контролируемыми данными. Стандарты
регламентируют, какие данные должны сохраняться и накапливать¬
ся в шлюзах, имена этих данных и синтаксис этих имен.
FTP (File Transfer Protocol) —- протокол передачи файлов, реа¬
лизующий удаленный доступ к файлу. Для того чтобы обеспечить
надежную передачу, FTP использует в качестве транспорта прото¬
кол с установлением соединений — TCP. Кроме передачи файлов
протокол FTP предоставляет пользователю возможность интерак¬
тивной работы с удаленным компьютером, например, распечатать
42
содержимое ее каталогов. FTP позволяет пользователю указывать
run и формат запоминаемых данных, выполнять аутентификацию
пользователей.
TFTP (Trivial File Transfer Protocol) — простейший протокол пере¬
дачи файлов, в качестве транспорта использующий более простой,
чем TCP, протокол без установления соединения — UDP.
2.4.4. Стек IPX/SPX
Этот стек является оригинальным стеком протоколов фирмы
Novell, который она разработала для своей сетевой операционной
системы NetWare в начале 1980-х гг. Изначально стек ориентиро¬
вался на работу в локальных сетях небольших размеров и имеющих
небольшие вычислительные мощности.
Семейство протоколов фирмы Novell и их соответствие модели
ISO/OSI представлено в табл. 2.4.
На физическом и канальном уровнях в сетях Novell используют¬
ся все популярные протоколы этих уровней (Ethernet, Token Ring,
FDDI и др.).
На сетевом уровне в стеке Novell работает протокол IPX, а так¬
же протоколы обмена маршрутной информацией RIP и NLSP. IPX
является протоколом, который занимается вопросами адресации
и маршрутизации пакетов в сетях Novell. Маршрутные решения
IPX основаны на адресных полях в заголовке его пакета, а также
на информации, поступающей от протоколов обмена маршрутной
информацией. Например, IPX использует информацию, поставляе-
Таблица 2.4. Стек протоколов IPX/SPX
Уровень модели OSI
Протокол IPX/SPX
7
NCP, SAP
6
5
4
SPX
3
IPX, RIP, NLSP
2
Поддерживаются все популярные стандарты
1
43
мую либо протоколом RIP, либо протоколом NLSP (NetWare Link
State Protocol) для передачи пакетов компьютеру назначения или
следующему маршрутизатору. Протокол IPX поддерживает только
дейтаграммный способ обмена сообщениями, за счет чего экономно
потребляет вычислительные ресурсы. Можно сказать, протокол IPX
обеспечивает выполнение трех функций:
1) задание адреса;
2) установление маршрута;
3) рассылку дейтаграмм.
Транспортному уровню модели OSI в стеке Novell соответствует
протокол SPX, который осуществляет передачу сообщений с уста¬
новлением логических соединений.
SPX (Sequenced Packet exchange) — коммуникационный про¬
токол, разработанный для использования в сетях NetWare. SPX
обеспечивает гарантированную доставку и порядок сообщений в
потоке пакетов, для передачи которых использует протокол IPX.
На верхних уровнях (прикладном, представительном и сеансо¬
вом) работают протоколы NCP и SAP.
NCP (NetWare Core Protocol) является протоколом взаимодей¬
ствия сервера NetWare и оболочки рабочей станции. Этот протокол
прикладного уровня реализует архитектуру «клиент-сервер» на
верхних уровнях модели OSI. С помощью функций этого протокола
рабочая станция производит подключение к серверу, отображает
каталоги сервера на локальные буквы дисководов, просматривает
файловую систему сервера, копирует удаленные файлы, изменяет
их атрибуты, а также осуществляет разделение сетевого принтера
между рабочими станциями.
SAP (Service Advertising Protocol) — протокол объявления о
сервисе — концептуально подобен протоколу RIP. Подобно тому
как протокол RIP позволяет маршрутизаторам обмениваться марш¬
рутной информацией, протокол SAP дает возможность сетевым
устройствам обмениваться информацией об имеющихся сетевых
сервисах.
Тот факт, что стек IPX/SPX является собственностью фирмы
Novell и на его реализацию нужно получать у нее лицензию,
долгое время ограничивали распространенность его только сетями
NetWare. Однако к моменту выпуска версии NetWare 4.0, Novell
внесла и продолжает вносить в свои протоколы серьезные измене¬
ния, направленные на приспособление их для работы в корпоратив¬
ных сетях. Сейчас стек IPX/SPX реализован не только в NetWare,
но и в нескольких других популярных сетевых ОС — SCO UNIX,
Sun Solaris, Microsoft Windows NT.
44
2.4.5. Стек NetBIOS/SMB
Фирмы Microsoft и ЮМ совместно работали над сетевыми сред-
' тами для персональных компьютеров, поэтому стек протоколов
I Jol.BIOS/SMB является их совместным проектом. Средства NetBIOS
появились в 1984 г. как сетевое расширение стандартных функций
Пановой системы ввода/вывода (BIOS) IBM PC для сетевой програм¬
мы PC Network фирмы IBM. В дальнейшем NetBIOS был заменен
протоколом NetBEUI. При этом NetBIOS был сохранен для обеспе¬
чения совместимости приложений (табл. 2.5).
NetBIOS работает на трех уровнях модели взаимодействия
открытых систем: сетевом, транспортном и сеансовом. NetBIOS
может обеспечить сервис более высокого уровня, чем протоколы
IPX и SPX, однако не обладает способностью маршрутизации.
И протоколе обмена кадрами NetBIOS не вводится такое понятие,
как сеть. Это ограничивает применение протокола NetBIOS ло¬
кальными сетями, не разделенными на подсети. NetBIOS поддер¬
живает как дейтаграммный обмен, так и обмен с установлением
соединений.
SMB, соответствующий прикладному и представительному уров¬
ням модели OSI, регламентирует взаимодействие рабочей станции
с сервером. В функции SMB входят четыре операции.
1. Управление сессиями. Создание и разрыв логического канала
между рабочей станцией и сетевыми ресурсами файлового сер¬
вера.
2. Файловый доступ. Рабочая станция может обратиться к «файл-
серверу» с запросами на создание и удаление каталогов, создание,
открытие и закрытие файлов, чтение и запись в файлы, переиме-
Таблица 2.5. Стек протоколов NetBIOS/SMB
Уровень модели OSI
Протокол NetBIOS/SMB
7
SMB
6
5
NetBIOS, NetBEUI
4
3
2
Поддерживаются все популярные стандарты
1
45
нование и удаление файлов, поиск файлов, получение и установку
файловых атрибутов, блокирование записей.
3. Сервис печати. Рабочая станция может ставить файлы в оче¬
редь для печати на сервере и получать информацию об очереди
печати.
4. Сервис сообщений. SMB поддерживает простую передачу со¬
общений со следующими функциями:
■ послать простое сообщение;
■ послать широковещательное сообщение;
■ послать начало блока сообщений;
■ послать текст блока сообщений;
■ послать конец блока сообщений;
■ переслать имя пользователя;
и отменить пересылку;
■ получить имя машины.
Из-за большого количества приложений, которые используют
функции API, предоставляемые NetBIOS, во многих сетевых опе¬
рационных системах эти функции реализованы в виде интерфейса
к своим транспортным протоколам.
АДРЕСАЦИЯ УЗЛОВ В СЕТИ
2.5.1. Общее представление
об адресации в сетях
Для передачи данных в локальных и глобальных сетях устройство-
отправитель должно знать адрес устройства-получателя. Поэтому
каждое сетевое устройство имеет уникальный адрес (идентифи¬
катор):
■ физический или аппаратный (МАС-адрес);
■ логический или сетевой (1Р-адрес);
■ символьный.
На самом деле адресация производится не для самих устройств,
а для их сетевых интерфейсов. Напомним, что интерфейс — это
набор средств и правил, позволяющих осуществлять обмен ин¬
формацией. Один узел сети может иметь несколько сетевых ин¬
терфейсов.
Адреса могут использоваться для идентификации:
■ отдельных интерфейсов;
■ их групп (групповые адреса) — данные могут направляться сразу
нескольким узлам;
46
■ сразу всех сетевых интерфейсов сети (широковещательные адре¬
са) — данные должны быть доставлены всем узлам сети.
Адреса могут быть:
■ числовыми и символьными;
■ аппаратными и сетевыми;
■ плоскими и иерархическими.
Примером плоского числового адреса является МАС-адрес (Me¬
dia Access Control), используемый для уникальной идентификации
сетевых интерфейсов в локальных сетях.
При иерархической схеме адресации множество адресов ор¬
ганизовано в виде вложенных друг в друга подгрупп, которые,
последовательно сужая адресуемую область, в итоге определяют
отдельный сетевой интерфейс. Примером иерархически органи¬
зованных адресов служат обычные почтовые адреса, в которых по¬
следовательно уточняется местонахождение адресата: страна, город,
улица, дом, квартира. Типичными представителями иерархических
числовых адресов являются сетевые IP- и IPX-адреса. В них под¬
держивается двухуровневая иерархия, адрес делится на старшую
часть (номер сети) и младшую (номер узла). Такое разделение по¬
зволяет передавать сообщения между сетями только на основании
номера сети, и затем, после доставки сообщения в нужную сеть,
использовать номер узла. Точно так же, как название улицы ис¬
пользуется почтальоном только после того, как письмо доставлено
в нужный город.
Символьные адреса или имена предназначены для запоминания
людьми и поэтому обычно несут смысловую нагрузку. Символьные
адреса можно использовать как в небольших, так и в крупных
сетях. Для работы в больших сетях символьное имя может иметь
иерархическую структуру,
В современных сетях для адресации узлов, как правило, приме¬
няются все три приведенные выше схемы одновременно, так как
сетевой интерфейс компьютера может одновременно иметь не¬
сколько адресов-имен. В зависимости от того, использование какого
вида адресации наиболее удобно, применяется соответствующее
множество адресов. Пользователи адресуют компьютеры символь¬
ными именами, которые автоматически заменяются в сообщени¬
ях, передаваемых по сети, на числовые номера. С помощью этих
числовых номеров сообщения передаются из одной сети в другую,
а после доставки сообщения в сеть назначения вместо числового
номера используется аппаратный адрес компьютера. Сегодня та¬
кая схема характерна даже для небольших автономных сетей, где,
казалось бы, она явно избыточна — это делается для того, чтобы
47
при включении сети в большую сеть не нужно было менять состав
операционной системы.
Для преобразования адресов из одного вида в другой использу¬
ются специальные вспомогательные протоколы разрешения адресов
(address resolution) — ARP. Проблема установления соответствия
между адресами различных типов, которой занимаются протоколы
разрешения адресов, может решаться как централизованными, так;
и распределенными средствами. В случае централизованного под¬
хода в сети выделяется один или несколько компьютеров (серверов
имен), в которых хранится таблица соответствия друг другу имен
различных типов, например символьных имен и числовых номеров.
Все остальные компьютеры обращаются к серверу имен, чтобы по
символьному имени найти числовой номер компьютера, с которым
необходимо обменяться данными.
Конечной целью пересылаемых по сети данных являются не
компьютеры или маршрутизаторы, а выполняемые на этих устрой¬
ствах программы -— процессы. Поэтому в адресе назначения наря¬
ду с информацией, идентифицирующей порт устройства, должен
указываться адрес процесса, которому предназначены посылаемые
данные. После того как эти данные достигнут указанного в адресе
назначения сетевого интерфейса, программное обеспечение ком¬
пьютера должно их направить соответствующему процессу. Понят¬
но, что адрес процесса не обязательно должен задавать его однознач¬
но в пределах всей сети, достаточно обеспечить его уникальность в
пределах компьютера. Примером адресов процессов могут служить
номера портов TCP и UDP, используемые в стеке TCP/IP.
2.5.2. Физическая адресация
Физический адрес — это локальный адрес узла, определяемый
технологией, с помощью которой построена отдельная сеть и в
которую входит данный узел.
Не существует двух одинаковых физических адресов. Эти адреса
назначаются производителями оборудования и являются уникаль¬
ными адресами, так как управляются централизованно. Каждый
сетевой адаптер, маршрутизатор или другое сетевое устройство не¬
зависимо от того, подключено оно к сети или нет, имеет уникальный
физический адрес, называемый МАС-адресом.
МАС-адрес (Media Access Control — управление доступом к
среде) — это уникальный идентификатор, присваиваемый каждой
единице активного оборудования компьютерных сетей.
48
В широковещательных сетях, таких как сети на основе Ethernet,
МАС-адрес позволяет уникально идентифицировать каждый узел
сети и доставлять данные только этому узлу. Таким образом, МАС-
адреса формируют основу сетей на канальном уровне OSI, кото¬
рую используют протоколы более высокого (сетевого) уровня. Для
преобразования МАС-адресов в адреса сетевого уровня и обратно
применяются специальные протоколы (например, ARP и RARP в
сетях IPv4 и NDP в сетях на основе IPv6).
МАС-адрес обычно применяется только аппаратурой, поэтому
его стараются сделать по возможности компактным и записывают
в виде двоичного или шестнадцатеричного значения. МАС-адреса
обычно встраиваются в аппаратуру компанией-изготовителем; их
называют еще аппаратными (hardware) адресами. Использование
таких адресов является жестким решением — при замене аппа¬
ратуры, например сетевого адаптера компьютера, изменяется и
физический адрес компьютера. МАС-адреса фиксируются в обо¬
рудовании сетевых интерфейсов, при этом адрес не повторяется
нигде в мире, поскольку за распределением диапазонов физических
адресов для сетевого оборудования следит институт инженеров
по электротехнике и электронике IEEE (Institute of Electrical and
Electronics Engineers).
МАС-адрес представляет собой двоичное число длиной 48 бит.
Для простоты восприятия и работы с ними МАС-адреса обычно
записываются в виде 12 цифр в шестнадцатиричной системе счис¬
ления, например 6D-BB-AB-C7. При этом первые шесть цифр ука¬
зывают на производителя этого сетевого устройства, а остальные
шесть цифр идентифицируют данное устройство, выпущенное этим
производителем.
На основе МАС-адреса можно управлять доступом к сетевым
ресурсам. Обычный пользователь может столкнуться с МАС-
проблемой в том случае, если, например, провайдер, используя
МАС-фильтрацию, предоставляет доступ к Интернету. Самый
простой пример, это когда вы подключили свой компьютер к Ин¬
тернету, потом решили подключить еще один компьютер через
роутер. Все соединили, а Интернета нет. Дело в том, что провайдер
присвоил вам IP-адрес и заодно прописал у себя МАС-адрес вашей
сетевой карты, и разрешает доступ только оборудованию с этим
МАС-адресом. У роутера свой уникальный МАС-адрес, который
отличается от МАС-адреса вашей сетевой карты, и, соответственно,
он не совпадает с МАС-адресом, который прописан у провайдера.
В результате роутер не может получить Интернет, а соответственно,
и компьютеры, подключенные к роутеру, не получают Интернет.
49
Существуют специально зарезервированные адреса, например,
широковещательный адрес, состоящий из одних двоичных еди¬
ниц — FF-FF-FF-FF-FF-FF.
2.5.3. IP-адрес
Примером логических адресов служат сетевые IP-адреса, кото¬
рые использует при работе протокол 1Р-стека TCP/IP. Ввиду того
что протокол IP относится к сетевому уровню, то и IP-адреса часто
называют сетевыми адресами.
IP-адрес (Internet Protocol Address) — уникальный сетевой адрес
узла в компьютерной сети, построенной по протоколу IP. В сети Ин¬
тернет требуется глобальная уникальность адреса; в случае работы
в локальной сети требуется уникальность адреса в пределах сети.
Локальный IP-agpec назначается устройству для получения до¬
ступа к определенным ресурсам, находящимся в локальной сети.
Внешний IP-agpec — это IP-адрес, уникальность которого опреде¬
ляется не в локальной сети, а глобально во всей сети Интернет.
IP-адреса — это основной тип адресов, на основании которых
сетевой уровень передает сообщения, называемые IP-пакетами.
IP-адрес представляет собой двоичное число. В версии протокола
IPv4 IP-адрес имеет длину 4 байта или 32 бита, ограничивающие
адресное пространство 4 294 967 296 (232) возможными уникальны¬
ми адресами. IPv4 (Internet Protocol version 4) —• четвертая версия
IP-протокола, первая широко используемая версия. В 6-й версии
IP-адрес является 128-битовым. Pv6 (Internet Protocol version 6) —
новая версия протокола IP, призванная решить проблемы, с которы¬
ми столкнулась предыдущая версия (IPv4) при ее использовании в
Интернете, за счет использования длины адреса 128 бит вместо 32.
В настоящее время протокол IPv6 уже используется в нескольких
тысячах сетей по всему миру (более 14 000 сетей на осень 2013 г.),
но пока еще не получил столь широкого распространения в Интер¬
нете, как IPv4.
Удобной формой записи IP-адреса (IPv4) является запись в виде
четырех десятичных чисел (от 0 до 255), разделенных точками (на¬
пример, 192.168.0.1). Это традиционная десятичная форма пред¬
ставления адреса. При этом каждое из четырех десятичных чисел
можно записать в двоичной системе счисления, используя восемь
бит. В этом случае максимальным будет число, состоящее из вось¬
ми двоичных единиц — 11111111, что в пересчете в десятичную
систему счисления будет равно 255. Таким образом, каждое из
50
гырех чисел IP-адреса в десятичном представлении не может
Пить больше 255.
П’-адрес состоит из двух частей: адреса сети и номера узла.
Адрес сети (идентификатор сети) — это один сетевой сегмент
и более крупной объединенной сети (сети сетей), использующей
протокол TCP/IP. IP-адреса всех систем, подключенных к одной
сети, имеют один и тот же идентификатор сети.
I 1омер узла (идентификатор, адрес узла) определяет узел ТСР/
IP (рабочую станцию, сервер, маршрутизатор или другое TCP/IP-
у< тройство) в пределах каждой сети. Идентификатор узла уникаль¬
ным образом обозначает систему в том сегменте сети, к которой
она подключена. Не нужно забывать, что IP-адрес идентифицирует
но отдельный узел в сети, а отдельный сетевой интерфейс. Узел
может входить в несколько сетей, и в этом случае он должен иметь
несколько IP-адресов, по количеству связанных с ним сетей. Так, на¬
пример, маршрутизатор по определению входит сразу в несколько
сетей. Поэтому каждый порт маршрутизатора имеет собственный
II’-адрес. Конечный узел также может входить в несколько 1Р-сетей.
В этом случае компьютер должен иметь несколько IP-адресов, по
числу сетевых связей.
Существует пять классов IP-адресов, различающихся количе¬
ством бит, отведенных под идентификацию номера сети и номера
узла (рис. 2.4).
В крупных сетях масштаба региона или страны используют
IP-адреса класса А, число таких сетей ограничено. Сети класса В
Класс А
Класс В
Класс С
Класс D
Класс Е
Рис. 2.4. Структура IP-адреса
51
имеют средние размеры и обычно применяются большими ком¬
паниями. Адреса класса С используют в малых сетях, имеющих
небольшое количество узлов. Адреса класса D используют для
обращения к группам компьютеров. Адреса класса Е зарезер¬
вированы для будущего использования. По значению первого
байта адреса можно определить, к какому классу сетей относится
1Р-адрес.
В сети класса А адрес начинается с 0 и номер сети занимает
один байт, остальные 3 байта интерпретируются как номер узла в
сети. Сети класса А имеют номера в диапазоне от 1 до 126 (номер О
не используется, а номер 127 зарезервирован для специальных
целей). Количество узлов в сети класса А может достигать 224, т. е.
16 777 216 узлов.
В сети класса В под номер сети и номер узла отводится 16 бит,
т. е. по 2 байта. Таким образом, максимальное количество узлов в
сети класса В составляет 216.
Если адрес начинается с последовательности 110, то это сеть
класса С. Под номер сети отводится 24 бита, а под номер узла —
8 бит. Это самый распространенный класс сетей, количество узлов
в них ограничено 28 узлами.
Адрес класса D начинается с последовательности 1110. Это осо¬
бый групповой адрес — multicast. Пакет с таким адресом должны
получить все узлы, которым присвоен данный адрес.
Если адрес начинается с последовательности НПО, то данный
адрес относится к классу Е. Адреса этого класса зарезервированы
для будущих дополнений в схеме адресации IP.
В табл. 2.6 приведены диапазоны номеров сетей и максимальное
число узлов, соответствующих каждому классу сетей.
Таблица 2.6. Характеристики IP-адресов разного класса
Класс
Первые биты
IP-адреса
Наименьший
номер сети
Наибольший
номер сети
Максимальное
число узлов
в каждой сети
А
0
1.0.0.0
126.0.0.0
2“4
В
10
128.0.0.0
191.255.0.0
216
С
110
192.0.0.0
223.255.255.0
28
D
1110
224.0.0.0
239.255.255.255
Групповые
адреса
Е
11110
240.0.0.0
255.255.255.255
Резерв
52
Существуют специально зарезервированные IP-адреса. К ним
относятся:
■ адрес, состоящий только из двоичных нулей. Обозначает тот
же самый узел сети, который сгенерировал пакет, содержащий
такой 1Р-адрес;
■ адрес, в котором номер сети содержит все нули. Обозначает
данную сеть, т. е. ту же сеть, в которой находится компьютер,
сгенерировавший пакет с этим адресом;
■ адрес, в котором номер узла содержит все нули. Обозначает
узел, принадлежащий той же сети, что и узел, сгенерировавший
пакет;
■ адрес состоит только из двоичных единиц — обозначает, что
пакет с таким адресом предназначен всем узлам той же сети, что
и источник пакета. При этом такой пакет не выйдет за пределы
данной сети, поэтому такая рассылка называется ограниченным
широковещанием;
■ пакет с адресом 127.0.0.1 не передается в сеть, а возвращается
верхним уровням стека протоколов, как только что принятый.
Адреса, начинающиеся с 127, используются для тестирования
программного обеспечения и взаимодействия сетевых процессов
в пределах отдельного узла. Поэтому в сети запрещается при¬
сваивать компьютерам адреса, начинающиеся с 127.
Разбиение IP-адресов на классы приводит к достаточно жесткой
системе адресации, не всегда рациональной. Для того чтобы сделать
систему адресации более гибкой, используются маски IP-адресов.
Маской подсети, или маской сети, в терминологии сетей TCP/IP на¬
зывается битовая маска, определяющая, какая часть IP-адреса узла
сети относится к адресу сети, а какая к адресу самого узла в этой
сети. Для этого одна сеть разбивается на несколько подсетей, раз¬
деляя адресное пространство на непересекающиеся друг с другом
диапазоны. Маска как бы «маскирует» часть IP-адреса. Двоичная
запись маски содержит единицы в тех разрядах, которые должны
в IP-адресе интерпретироваться как номер сети. Там, где значение
бита маски равно единице, адресация узлов запрещена; там, где
значение равно нулю — разрешена. При этом «маскировка» про¬
исходит от старшего бита к младшему. Для стандартных классов
сетей маски имеют следующие значения:
■ класс А — 11111111.00000000.00000000.00000000 (255.0.0.0);
■ класс В — 11111111. 11111111.00000000.00000000(255.255.0.0);
■ класс С — 11111111. 11111111. 11111111.00000000 (255. 255. 255.0).
Механизм масок широко распространен в 1Р-маршрутизации,
при этом маски могут использоваться для самых разных целей.
53
С помощью масок администратор может структурировать свою
сеть, не требуя от поставщиков услуг дополнительных номеров
сетей. Поставщики услуг используют механизм масок для объеди¬
нения адресного пространства нескольких сетей, вводя так назы¬
ваемые «префиксы». Таким образом, уменьшается объем таблиц
маршрутизации, и, следовательно, повышается производительность
маршрутизаторов.
Если сеть является частью Internet, то номера сетей назначают¬
ся централизованно. Если сеть работает изолированно, то номера
сетей назначаются произвольно.
2.5.4. Протокол динамической
настройки узла DHCP
Для возможности обмениваться информацией по сети каждому
сетевому интерфейсу узла необходим свой IP-адрес. Назначение
IP-адресов интерфейсам может производиться как вручную, так и
автоматически.
Ручное назначение адресов обычно производится в процессе
настройки конфигурации работы сетевого интерфейса, при этом
новые назначаемые адреса не должны повторять уже используемые
IP-адреса в сети. Естественно, что даже при небольших размерах
сетей такая настройка представляет утомительную процедуру и
может вызвать некоторые проблемы.
Автоматическое назначение IP-адресов упрощает процесс опре¬
деления адресов для каждого сетевого интерфейса и освобождает
администратора, занимающегося настройкой сетевого взаимо¬
действия, от рутинной работы. Для автоматического назначения
IP-адресов используется вспомогательный протокол динамической
конфигурации узлов DHCP.
DHCP (Dynamic Host Configuration Protocol) — сетевой протокол,
позволяющий компьютерам автоматически получать IP-адрес и
другие параметры, необходимые для работы в сети TCP/IP. Данный
протокол работает по модели «клиент-сервер». Для автоматической
конфигурации компьютер-клиент на этапе конфигурации сетевого
устройства обращается к так называемому серверу DHCP и получа¬
ет от него нужные параметры. Сетевой администратор может задать
диапазон адресов, распределяемых сервером среди компьютеров.
Это позволяет избежать ручной настройки компьютеров сети и
уменьшает количество ошибок. Протокол DHCP используется в
большинстве сетей TCP/IP.
54
DHCP предназначен для автоматической настройки параметров
стека TCP/IP рабочей станции. В момент загрузки операционной
системы рабочая станция посылает широковещательный запрос
параметров своей конфигурации, получив который сервер DHCP
посылает в ответ сведения, содержащие IP-адрес этой рабочей
станции, а также прочую информацию, необходимую при настрой¬
ке' сетевого взаимодействия. При этом предполагается, что клиент
DHCP, т.е. рабочая станция, пославшая широковещательный запрос,
и сервер DHCP находятся в одной локальной сети.
Существуют два способа распределения адресов по интерфейсам
при автоматическом способе — статический, динамический.
При статическом способе сервер DHCP в ответ на запрос ра¬
бочей станции посылает ей произвольный IP-адрес, выбранный
из диапазона наличных адресов. Диапазон адресов задается при
настройке сервера DHCP. Выбранный для рабочей станции адрес
дается ей в пользование на неограниченный срок, при этом при
последующих обращениях к серверу станция будет получать этот
же IP-адрес.
При динамическом распределении адрес выдается компьютеру
не на постоянное пользование, а на определенный срок. Это дает
возможность впоследствии повторно использовать этот IP-адрес
для назначения другому компьютеру. Поскольку при таком распре¬
делении один и тот же адрес может использоваться несколькими
интерфейсами, а также за счет того, что обычно одновременно
работают далеко не все зарегистрированные в сети рабочие стан¬
ции, появляется возможность экономить IP-адреса, выделяя их под
конкретные нужды, а не под простаивающие узлы. Можно постро¬
ить IP-сеть с количеством узлов, превышающем имеющееся число
IP-адресов в распоряжении администратора.
Независимо от используемого метода применение DHCP по¬
зволяет избежать конфигурирования стека TCP/IP на каждом от¬
дельном узле сети и проводить гибкую централизованную политику
администрирования сети.
Для определения локального (физического) адреса по IP-адресу
используется протокол разрешения адреса ARP (Address Resolution
Protocol). Протокол ARP работает различными способами в зависи¬
мости от того, какой протокол на канальном уровне работает в сети.
В локальных сетях для определения нужного адреса ARP использует
рассылку широковещательных запросов. Протокол разрешения
адресов формирует запрос, указывая в нем сетевой адрес, для ко¬
торого нужно определить соответствующий физический адрес узла,
инкапсулирует этот запрос в кадр протокола канального уровня,
55
используемого в данной сети, и производит широковещательную
рассылку полученного кадра.
Узел сети, получивший такой запрос, сравнивает указанный в
запросе сетевой адрес со своим сетевым адресом. В случае если
адреса совпали, узел формирует ответ, содержащий оба адреса узла
(физический и сетевой) и отправляет его отправителю исходного
ARP-запроса, на который передается ответ. Если искомого IP-адреса
нет в локальной сети и локальная сеть не соединена шлюзом, то
разрешить запрос не получится. Такие пакеты будут уничтожаться
с сообщением «превышен лимит времени на разрешение запроса».
При этом модули прикладного уровня не могут отличить физиче¬
ских неполадок в сети от ошибки адресации. Пакеты, содержащие
ARP-запросы и ARP-ответы, имеют одинаковый формат.
Для решения обратной задачи, т. е. определение IP-адреса по из¬
вестному физическому адресу, используется протокол обратного
разрешения адресов RARP (Reverse Address Resolution Protocol).
Необходимость использования протокола обратного разрешения
адресов обычно обусловливается использованием бездисковых
рабочих станций, загрузка операционной системы которых произ¬
водится с единого сервера.
2.5.5. Система доменных имен
Для идентификации компьютеров аппаратное и программное
обеспечение в сетях TCP/IP использует IP-адрес, чтобы программа
правильно поняла, к какому хосту ей обратиться. Например, коман¬
да http://81.19.70.3 откроет начальную страницу интернет-портала
«Рамблер». Но пользователи предпочитают работать с символьными
именами компьютеров, и, например, в адресной строке браузера в
данном случае удобнее ввести rambler, ru. Человеку гораздо проще
запомнить осмысленные имена, чем наборы цифр. В настоящее
время существует слишком много IP-адресов, чтобы можно было
запомнить хотя бы их малую часть. Поэтому кроме числовых схем
адресации также применяется символьное представление адресов.
Следовательно, в сетях TCP/IP должны существовать символьные
имена хостов и механизм для установления соответствия между
символьными именами и IP-адресами.
Раньше символьная адресация обеспечивалась средствами опера¬
ционных систем, хранившими таблицы соответствия физического
адреса узла сети и его символьного адреса. Эти системы изначально
разрабатывались для работы в небольших локальных сетях. Имена
56
узлов имели линейную структуру и не разделялись на части. Для
того чтобы определить физический адрес узла, соответствующий
некоторому символьному имени, проводился опрос всех узлов
локальной сети с помощью механизма широковещательных запро-
еок. Но такой способ установления соответствия хорошо работает
только в небольшой локальной сети, не разделенной на подсети.
И больших сетях, а также в сетях, объединяющих несколько под¬
сетей, более эффективно использование иерархической системы
пдресации и, соответственно, адресов, состоящих из нескольких
«вложенных» друг в друга частей, так как плоские имена не дают
возможности разработать единый алгоритм обеспечения уникаль¬
ности имен.
В стеке TCP/IP применяется доменная система имен, которая
имеет древовидную структуру, допускающую использование в
имени произвольного количества составных частей.
DNS (Domain Name System — система доменных имен) — это
система, позволяющая преобразовывать символьные имена доме¬
нов в IP-адреса и, наоборот, в сетях TCP/IP.
Домен (domain) — определенная зона в системе доменных имен
(DNS) Интернета, выделенная какой-либо стране, организации или
для иных целей.
Доменное имя может состоять из нескольких частей, отделенных
друг от друга точками, например mail.rambler.ru. Каждая из таких
частей тоже называется доменом.
В домене слева записывается имя узла, входящего в домен, име¬
ющий самый низкий уровень в иерархии, а справа — домен, име¬
ющий самый высокий иерархический уровень. Поэтому крайний
справа домен называется доменом верхнего или первого уровня.
Следующий слева домен, отделенный точкой, является дочерним
доменом по отношению к домену первого уровня, т. е. входит в него
как его составная часть. Этот домен называется доменом второго
уровня.
Домены, которые являются дочерними для домена второго уров¬
ня, называются доменами третьего уровня и т.д.
Так, например, в адресе mail.rambler.ru доменом верхнего
(первого) уровня является домен «ги», доменом второго уровня —
«rambler», слово «mail» является 3-м уровнем — именем хоста
(рис. 2.5).
Хост понимается как сервер, дающий возможность разместить
определенную область информации, всевозможные файлы, которые
предназначены как для личного использования, так и открытого
доступа для всех пользователей сети Интернет.
57
Рис. 2.5. Компоненты имени домена
Иерархия доменных имен аналогична иерархии имен файлов,
принятой в файловой системе. Названия доменов первого уровня
назначаются централизованно в соответствии с международным
стандартом. Имена доменов первого уровня могут обозначать стра¬
ны или типы организаций и обычно представляют собой двух- или
трехбуквенные аббревиатуры (табл. 2.7).
Таблица 2.7. Примеры доменов первого уровня
Домен
Назначение
Общие (типы организа¬
ций)
сот
Коммерческие
edu
Образовательные
gov
Правительственные
int
Международные
mil
Военные
info
Информационные
net
Сетевые
org
Некоммерческие
Региональные (страны
и регионы)
ru
Российская Федерация
ua
Украина
us
США
jp
Япония
de
Германия
gb
Великобритания
au
Австралия
za
Южная Африка
58
Доменом второго уровня обычно является псевдоним организа-
ции, которой принадлежит корпоративная сеть или хост-компьютер,
для адресации которых используется этот домен. Домены третьего
и последующих уровней являются частью доменов второго уров¬
ня и на практике обычно представляют некоторые подсети либо
дочерние хосты, которые продаются или бесплатно передаются в
пользование другим организациям или физическим лицам. Очень
часто на таких хостах размещаются домашние страницы пользова¬
телей Интернета. Если один домен входит в другой домен как его
составная часть, то такой домен могут называть поддоменом, или
субдоменом (subdomain).
Разделение имени на части позволяет разделить администра¬
тивную ответственность за назначение уникальных имен между
различными людьми или организациями в пределах своего уровня
иерархии. Это позволяет решить проблему образования уникаль¬
ных имен без взаимного согласования организаций. Очевидно, что
должна существовать одна организация, отвечающая за назначение
имен верхнего уровня иерархии.
DNS является распределенной базой данных. База данных DNS
и меет структуру дерева, называемого доменным пространством
имен (рис. 2.6). Имя домена идентифицирует его положение в этой
базе данных по отношению к родительскому домену, при этом
точки в имени отделяют части, соответствующие узлам домена.
Корневое имя (root's name) имеет нулевую метку и обозначается
одиночной точкой («.»). Каждый узел (node) дерева представляет
раздел общей базы данных или домен (domain). Каждый домен в
дальнейшем может делиться на подразделы — поддомены — по¬
томки своих родительских узлов (parent nodes). Каждый домен
Корень (root)
59
имеет метку (label), которая идентифицирует его местоположение
относительно его родительского домена.
Полное доменное имя представляет собой последовательность
меток от корневого домена, которые разделяются между собой
символом «.», например main.rambler.ru. С помощью сервиса DNS
централизованно осуществляется установление соответствия до¬
менных имен сетевым адресам. Часть пространства доменных имен,
контролируемых DNS-сервером, называется зоной (рис. 2.7).
Принцип работы сервиса DNS основан на использовании ар¬
хитектуры «клиент-сервер», где определены DNS-серверы и DNS-
клиенты. DNS-сервер (сервер имен) — программное обеспечение,
которое хранит информацию о пространстве доменных имен. DNS-
клиенты обращаются к серверам с запросами об отображении до¬
менного имени в IP-адрес. Любой узел может получить сведения об
искомом IP-адресе любого узла сети. Для этого узел последовательно
обращается ко всем DNS-серверам, находящимся выше по иерар¬
хии, пока не дойдет до сервера, расположенного в домене, общем
для данного узла, осуществляющего поиск, и искомого узла. Далее
происходит последовательное обращение к серверам, находящимся
ниже по доменной иерархии, пока домен, содержащий искомый
узел, не будет найден. Поиск начинается с наиболее близких к ис¬
комому DNS-серверов, если информация о них есть в кэше и не
устарела, сервер может не запрашивать DNS-серверы.
Как было отмечено ранее, одной из основных целей разработки
DNS являлось создание распределенной базы данных с децентрали¬
зованным управлением. Это достигается посредством делегирова¬
ния полномочий. Организация, администрирующая домен, может
разбить его на поддомены и передать права на управление этими
Корень (root)
Рис. 2.7. Пример зоны «ru» домена «ru»
60
поддоменами другим организациям. Это означает, что организация,
которой переданы права на управление (делегированы полномочия),
становится ответственной за поддержание и управление всеми
данными этого поддомена. Она может свободно изменять данные,
разбивать свой поддомен на поддомены более низкого уровня и
делегировать их другим организациям. Родительский домен со¬
держит только указатели на источники данных своих поддоменов
(обычно указатели на серверы имен), чтобы он имел возможность
перенаправлять запросы к ресурсам этих поддоменов.
Один IP-адрес может иметь множество имен, что позволяет под¬
держивать на одном компьютере множество веб-сайтов (виртуаль¬
ный хостинг). Обратное тоже справедливо — одному имени может
быть сопоставлено множество IP-адресов, что позволяет создавать
балансировку нагрузки.
Для повышения устойчивости системы используется множество
серверов, содержащих идентичную информацию, а в протоколе
есть средства, позволяющие поддерживать синхронность инфор¬
мации, расположенной на разных серверах.
Можно следующим образом определить характеристики DNS.
1. Распределенность хранения информации. Каждый узел сети в
обязательном порядке должен хранить только те данные, которые
входят в его зону ответственности и (возможно) адреса корневых
DNS-серверов.
2. Иерархическая структура, в которой все узлы объединены в
дерево, и каждый узел может или самостоятельно определять ра¬
боту нижестоящих узлов или делегировать (передавать) их другим
узлам.
3. Безопасность и резервирование. За хранение и обслуживание
своих узлов (зон) отвечают (обычно) несколько серверов, разделен¬
ные как физически, так и логически, что обеспечивает сохранность
данных и продолжение работы даже в случае сбоя одного из узлов.
Все программные решения DNS требуют защиты, потому что
если хакер атакует DNS-сервер, то пользователи будут попадаться
в ловушку, даже не подозревая об этом. С этим подвидом атак свя¬
заны следующие опасности:
■ в результате DNS-атак пользователь рискует не попасть на нуж¬
ную страницу. При вводе адреса сайта атакованный DNS будет
перенаправлять запрос на подставные страницы;
■ в результате перехода пользователя на ложный IP-адрес хакер
может получить доступ к его личной информации. При этом
пользователь даже не будет подозревать, что его информация
рассекречена;
61
■ DDoS-атаки, приводящие к неработоспособности DNS-сервера.
При недоступности DNS-сервера пользователь не сможет по¬
пасть на нужную ему страницу, так как его браузер не сможет
найти IP-адрес, соответствующий введенному адресу сайта.
DDoS-атаки на DNS-сервера могут осуществляться как за счет
невысокой производительности DNS-сервера, так и за счет не¬
достаточной ширины канала связи.
Процедура получения доменного имени называется регистра¬
цией домена. Заключается в создании записей, указывающих на
администратора домена, в базе данных DNS. Порядок регистрации
и требования зависят от выбранной доменной зоны. Регистрация
домена может быть выполнена как организацией-регистратором,
так и частным лицом, если это позволяют правила выбранной до¬
менной зоны.
2.5.6. URL — универсальный
идентификатор ресурсов
URL (Uniform Resource Locator) — это стандартизированный
способ записи адреса ресурса в сети Интернет. URL был изобретен
Тимом Бернерсом-Ли в 1990 г. в Европейском совете по ядерным
исследованиям в Женеве. URL стал фундаментальной инновацией
в Интернете. Изначально URL предназначался для обозначения
мест расположения ресурсов (чаще всего файлов) во Всемирной
паутине.
Сейчас URL применяется для обозначения адресов почти всех
ресурсов Интернета и позиционируется как часть более общей си¬
стемы идентификации ресурсов URI (Uniform Resource Identifier —
последовательность символов, идентифицирующая абстрактный
или физический ресурс). Стандарт URL регулируется организацией
IETF и ее подразделениями.
Изначально URL был разработан как система для максимально
естественного указания на местонахождение ресурсов в сети. Су¬
ществует следующая традиционная форма записи URL:
<схема>://<логин>:<пароль>@<хост>:<nopT>/<URL-
путь>?<параметры>#<якорь>
В этой записи:
схема — схема обращения к ресурсу; в большинстве случаев
имеется в виду сетевой протокол;
логин — имя пользователя, используемое для доступа к ресурсу;
62
пароль — пароль указанного пользователя;
хост — полностью прописанное доменное имя хоста в системе
I >NS или IP-адрес хоста в форме четырех групп десятичных чисел,
разделенных точками; числа — целые в интервале от 0 до 255;
порт — порт хоста для подключения;
URL-путь — уточняющая информация о месте нахождения
ресурса, зависит от протокола;
параметры — строка запроса с передаваемыми на сервер пара¬
метрами. Разделитель параметров — знак &;
якорь — идентификатор «якоря», ссылающегося на некоторую
часть (раздел) открываемого документа. Страница в зависимости от
указанного якоря может в браузере выглядеть по-разному.
Общепринятые схемы (протоколы) URL включают:
ftp — протокол передачи файлов FTP;
http — протокол передачи гипертекста HTTP;
rtmp — Real Time Messaging Protocol проприетарный про¬
токол потоковой передачи данных, в основном используется для
передачи потокового видео- и аудиопотоков с веб-камер через
Интернет;
rtsp — потоковый протокол реального времени;
https — специальная реализация протокола HTTP, использу¬
ющая шифрование (как правило, SSL или TLS);
gopher — протокол Gopher;
mailto — адрес электронной почты;
news — новости Usenet;
nntp — новости Usenet через протокол NNTP;
telnet — ссылка на интерактивную сессию Telnet;
file — имя локального файла;
data — непосредственные данные (Data: URL);
tel — звонок по указанному телефону.
Приведем пример простого адреса URL:
http://academia-moscow.ru/about/elektronnyy_
kontent/index.php#sel
В данном случае путь состоит из доменного адреса машины, на
которой установлен сервер HTTP, и пути от корня дерева сервера
к файлу index, php. Схема HTTP — основная для www — содержит
идентификатор, адрес машины, TCP-порт, путь в директории сер¬
вера, поисковый критерий и метку. Это наиболее распространен¬
ный вид URL, применяемый в документах www. В качестве адреса
машины допустимо использование и IP-адреса.
63
КОНТРОЛЬНЫЕ ВОПРОСЫ
1. Что называют средой передачи данных?
2. Что такое емкость канала связи?
3. Что определяет полоса пропускания?
4. Какая система называется открытой?
5. В чем заключается многоуровневый подход в организации
сетей?
6. Что такое протокол?
7. Каково назначение сетевой модели OSI?
8. На что ориентированы протоколы 1 -3-го уровня в 7-уровне¬
вой модели OSI?
9. На что ориентированы протоколы 5 —7-го уровня в 7-уровне¬
вой модели OSI?
10. Какой уровень обеспечивает связь со средой передачи?
11. Какой уровень прокладывает путь через сеть?
12. Какой уровень обеспечивает обнаружение и исправление оши¬
бок?
13. Какой уровень определяет процедуру представления переда¬
ваемой информации в нужную сетевую форму?
14. Приведите примеры протоколов физического уровня.
15. Какие прикладные протоколы Internet вы знаете?
16. Для чего применяется система доменных имен?
17. Почему стек Internet является наиболее перспективным стеком
коммуникационных протоколов?
18. Каковы особенности стека IPX/SPX?
19. Что представляет собой физический адрес сетевого устрой¬
ства?
20. Что представляет собой IP-адрес?
21. Что представляет собой символьный адрес сетевого устрой¬
ства? Как он формируется?
22. Перечислите по порядку уровни в архитектуре протокола ТСР/
IP.
23. Какую функцию выполняет протокол TCP?
24. Какую функцию выполняет протокол IP?
25. Что входит в систему адресов Internet?
2В. Какую структуру имеет адрес Ethernet?
27. Какую структуру имеет IP-адрес?
28. Что такое зарезервированные IP-адреса?
29. Что такое сервер доменных имен?
Глава 3
БАЗОВЫЕ ТЕХНОЛОГИИ
ЛОКАЛЬНЫХ СЕТЕЙ
За время, прошедшее с появления первых локальных сетей, было
разработано несколько сотен самых разных сетевых технологий,
Однако заметное распространение получили всего несколько сетей,
что связано в первую очередь с поддержкой этих сетей известны¬
ми фирмами и высоким уровнем стандартизации принципов их
организации.
3.1.
СЕТИ TOKEN RING
Сеть Token Ring была предложена фирмой IBM в 1985 г. (пер¬
вый вариант появился в 1980 г.). Назначением Token Ring было
объединение в сеть всех типов компьютеров, выпускаемых IBM.
Token-Ring является в настоящее время международным стандар¬
том IEEE 802.5. Это ставит данную сеть на один уровень по статусу
с Ethernet.
По сравнению с аппаратурой Ethernet аппаратура Token Ring
оказывается заметно дороже, так как использует более сложные
методы управления обменом, поэтому распространена сеть Token-
Ring значительно меньше. Однако ее применение становится
оправданным, когда требуются большие интенсивности обмена
(например, при связи с большими компьютерами) и ограниченное
время доступа.
В качестве метода управления доступом станций к переда¬
ющей среде используется метод маркерного кольца (Token Ring),
который рассчитан на кольцевую топологию сети. Он использует
специальный трехбайтовый фрейм, названный маркером, который
65
Рис. 3.1. Сеть на основе Token Ring: логическая топология «кольцо»,
физическая — «звезда»
перемещается вокруг кольца. Владение маркером предоставляет
право обладателю передавать информацию на носителе. Если узел,
принимающий маркер, не имеет информации для отправки, он про¬
сто переправляет маркер к следующей конечной станции. Каждая
станция может удерживать маркер в течение определенного мак¬
симального времени, имеется возможность назначать различные
приоритеты разным рабочим станциям.
Вообще топология сети Token Ring больше похожа на тополо¬
гию звезды, чем на топологию кольца (рис. 3.1). Вместо того чтобы
соединяясь друг с другом, формировать кольцо, рабочие станции
Token Ring подключаются радиально к концентратору. Но концен¬
траторов может быть несколько, и в этом случае концентраторы
действительно объединяются в кольцо через специальные разъемы.
Если используется один концентратор, то объединяющие разъемы
можно не закольцовывать.
В качестве передающей среды применяется витая пара или
оптоволоконные кабели. Скорость передачи данных — 4 или
16 Мбит/с.
Token Ring является надежной сетью и идеальной для примене¬
ния там, где задержка должна быть предсказуема и важна устойчи¬
вость функционирования сети. Технология получила распростране¬
ние везде, где есть ответственные приложения, для которых важна
не столько скорость, сколько надежная доставка информации. Но
в настоящее время эта сеть вытеснена технологией Ethernet, кото¬
рая по надежности не уступает Token Ring и существенно выше по
производительности.
66
3.2.
ОПТОВОЛОКОННЫЙ ИНТЕРФЕЙС FDDI
Технология Fiber Distributed Data Interface (FDDI) была разрабо-
1.111,1 в 1980 г. комитетом ANSI. Была первой технологией локальных
сетей, использовавшей в качестве среды передачи оптоволоконный
с.н н'ль. Причинами, вызвавшими его разработку, были возраста¬
ющие требования к пропускной способности и надежности сетей.
)то стандарт передачи данных в локальной сети, протянутой на
большие расстояния (до 200 км), основанный на протоколе Token
King. Кроме того, сеть FDDI способна поддерживать несколько
тысяч пользователей.
В качестве среды передачи данных в FDDI чаще используется
волоконно-оптический кабель, однако можно использовать и мед¬
ный.
За основу стандарта FDDI был взят метод маркерного доступа,
предусмотренный международным стандартом IEEE 802.5 Token
King. Небольшие отличия от этого стандарта определяются необ¬
ходимостью обеспечить высокую скорость передачи информации
па большие расстояния.
Топология сети FDDI — это кольцо, причем применяется два раз¬
нонаправленных оптоволоконных кабеля, что позволяет в принципе
использовать полнодуплексную передачу информации с удвоенной
эффективной скоростью 200 Мбит/с (при этом каждый из двух
каналов работает на скорости 100 Мбит/с).
Применяется и звездно-кольцевая топология с концентрато¬
рами, включенными в кольцо. Данные в кольцах циркулируют в
разных направлениях. Одно кольцо считается основным, по нему
передается информация в обычном состоянии; второе — вспомо¬
гательным, по нему данные передаются в случае обрыва на первом
кольце (рис. 3.2). Это позволяет FDDI достичь практически полной
заявленной пропускной способности. В процессе нормального
функционирования первичное кольцо используется для передачи
данных, вторичное кольцо простаивает. Таким образом, кольца об¬
разуют основной и резервный пути передачи данных между узлами
сети. Наличие двух колец — это основной способ повышения от¬
казоустойчивости в сети FDDI, и узлы, которые хотят воспользо¬
ваться этим повышенным потенциалом надежности, должны быть
подключены к обоим кольцам.
Сеть FDDI может полностью восстанавливать свою работоспо¬
собность в случае отказов одного из ее элементов. Если отказов
множество, то сеть распадается на несколько не связанных сетей.
Технология FDDI дополняет механизмы обнаружения отказов тех-
67
нологии Token Ring механизмами еконфигурации пути передачи
данных в сети, основанными на наличии резервных связей, обе¬
спечиваемых вторым кольцом.
Кольца в сетях FDDI рассматриваются как общая разделяемая
среда передачи данных, поэтому для нее определен специальный
метод доступа. Этот метод очень близок к методу доступа сетей
Token Ring и также называется методом маркерного кольца. От¬
личия метода доступа заключаются в том, что время удержания
маркера в сети FDDI не является постоянной величиной, как в
сети Token Ring. Это время зависит от загрузки кольца — при не¬
большой загрузке оно увеличивается, а при больших перегрузках
может уменьшаться до нуля.
В настоящее время большинство сетевых технологий поддер¬
живают оптоволоконные кабели в качестве одного из вариантов
физического уровня, и стандарты FDDI прошли проверку временем
и устоялись, так что оборудование различных производителей по¬
казывает хорошую степень совместимости.
Ethernet — технология пакетной передачи данных, применяе¬
мая в основном в локальных сетях. Дословно с английского языка
«ethernet» можно перевести как «эфирная сеть», т. е. сеть, по кото¬
рой вы связаны с другим компьютером (или сервером) «в прямом
эфире».
Ethernet — это самый распространенный на сегодняшний
день стандарт локальных сетей. В настоящий момент миллионы
локальных сетей используют интернет-протокол Ethernet. Для
подключения к порту LAN в компьютере должна быть установле-
ТЕХНОЛОГИЯ ETHERNET
68
на сетевая карта Ethernet, а само подключение идет по проводу,
представляющему собой витую пару, коаксиальный или оптиче¬
ский кабель.
Эту технологию передачи данных изобрел в 1973 г. Роберт
Меткалф, в то время работник компании Xerox. Это привело к
созданию наиболее известного стандарта Ethernet DIX (DEC, Intel,
Xerox). Собственно, он и является протоколом для большинства
локальных сетей.
Сама технология Ethernet за долгие годы со времени создания
претерпела некоторые изменения, в частности увеличила скорость.
11ервоначальные версии имели скорость передачи или приема всего
3 Мбит/с и пользовались полудуплексным режимом работы (т. е.
либо передавать, либо принимать). Затем пришли более совершен¬
ные технологии, использовавшие полный дуплекс:
■ 10-мегабитный Ethernet — 10BASE5 (толстый Ethernet), 10BASE2
(тонкий Ethernet), StarLAыN 10 и др.;
■ быстрый Ethernet (100 Мбит/с) — 100BASE-T, 100BASE-S и др.;
■ гигабитный Ethernet — 1000BASE-X, 1000BASE-T и др.;
■ 10-гигабитный Ethernet — 10GBASE-CX4, 10GBASE-LR и др.,
■ в итоге 40-гигабитный и 100-гигабитный Ethernet — 40GBASE-
SR4, 100GBASE-SR10 и др.
3.3.1. Первая технология Ethernet
Впервые сеть Ethernet появилась в 1973 г., ее разработчиком
была известная фирма Xerox. Сеть оказалась довольно удачной,
и вследствие этого ее в 1980 г. поддержали такие крупнейшие
фирмы, как DEC (Digital Equipment Corporation) и Intel. В резуль¬
тате сотрудничества этих фирм в 1985 г. сеть Ethernet стала между¬
народным стандартом, ее приняли крупнейшие международные
организации по стандартам: комитет 802 IEEE (Institute of Electrical
and Electronic Engineers) и ECMA (European Computer Manufacturers
Association).
Ethernet вытеснила устаревшие технологии Arcnet и Token ring.
Стандарт получил название IEEE 802.3 — он определяет множе¬
ственный доступ к моноканалу типа «шина» с обнаружением кон¬
фликтов и контролем передачи, т. е. с методом доступа — CSMA/
CD (Carrier Sense Multiple Access with Collision). Так же называют
сетевой протокол, в котором используется схема CSMA/CD. Про¬
токол CSMA/CD работает на канальном уровне в модели OSI. Этот
метод доступа можно описать следующим образом:
69
■ все устройства, подключенные к сети, равноправны, т. е. любая
станция может начать передачу в любой момент времени (если
передающая среда свободна);
■ данные, передаваемые одной станцией, доступны всем станциям
сети. Сообщение, отправляемое одной рабочей станцией, при¬
нимается одновременно всеми остальными, подключенными к
общей шине. Сообщение, предназначенное только для одной
станции (оно включает адрес станции назначения и адрес стан¬
ции отправителя), принимается этой станцией и игнорируется
остальными. Аппаратура автоматически распознает конфликты
(коллизии). После обнаружения конфликта станции задержи¬
вают передачу на некоторое время. Это время небольшое и для
каждой станции свое. После задержки передача возобновляется.
Реально конфликты приводят к уменьшению быстродействия
сети только в том случае, если работает порядка 80—100 стан¬
ций;
■ при увеличении числа пользователей эффективность работы
сети снижается. В этом случае оптимальным является увеличение
числа сегментов в сети с меньшим числом пользователей. Но
существуют ограничения и на максимальное количество сегмен¬
тов в сети, так же как и на максимальное количество рабочих
станций, подключенных к сети.
При проектировании стандарта Ethernet было предусмотрено,
что каждая сетевая карта, так же как и встроенный сетевой ин¬
терфейс, должна иметь уникальный шестибайтный номер (МАС-
адрес), прошитый в ней при изготовлении. Этот номер используется
для идентификации отправителя и получателя кадра.
Популярности Ethernet в мире в немалой степени способствовало
то, что с самого начала все характеристики, параметры, протоколы
сети были открыты для всех, в результате чего огромное число про¬
изводителей во всем мире стали выпускать аппаратуру Ethernet,
полностью совместимую между собой.
Большинство Ethernet-карт и других устройств имеют поддержку
нескольких скоростей передачи данных, используя автоопределение
скорости и дуплексности для достижения наилучшего соединения
между двумя устройствами. Если автоопределение не срабатывает,
скорость подстраивается под партнера, и включается режим по¬
лудуплексной передачи. Например, наличие в устройстве порта
Ethernet 10/100 говорит о том, что через него можно работать по
технологиям 10BASE-T и 100BASE-TX, а порт Ethernet 10/100/1000 —
поддерживает стандарты 10BASE-T, 100BASE-TX и 1000BASE-T. Это
стандарты реализации Ethernet с использованием витой пары.
70
1. 10BASE-T — физический интерфейс Ethernet, позволяющий
компьютерам связываться при помощи кабеля типа «витая пара».
I In знание 10BASE-T происходит от некоторых свойств физической
основы кабеля. Число 10 ссылается на скорость передачи данных в
К) Мбит/с. Слово BASE — сокращение от baseband signaling (ме¬
тод передачи данных без модуляции). Это значит, что только один
I I hornet-сигнал может находиться на линии в конкретный момент
примени. Иными словами, не используется мультиплексирование, как
и широкополосных каналах. Буква «Т» происходит от словосочетания
twisted pair (витая пара), обозначая используемый тип кабеля.
2. 100BASE-TX — развитие стандарта 10BASE-T для использо¬
вания в сетях топологии «звезда». Задействована витая пара кате¬
гории 5, фактически используются только две неэкранированные
пары проводников, поддерживается дуплексная передача данных,
расстояние — до 100 м.
3. 1000BASE-T — стандарт, использующий витую пару категорий
5е, В передаче данных участвуют 4 пары. Скорость передачи дан¬
ных — 500 Мбит/с по одной паре. Расстояние — до 100 м.
Таким образом, в зависимости от скорости передачи данных и
передающей среды существует несколько вариантов технологии
Ethernet.
3.3.2. Fast Ethernet
Новые требования к производительности сетей, предъявляемые
современными приложениями, такими как мультимедиа, распреде¬
ленные вычисления, системы оперативной обработки групповых
операций, вызвали насущную необходимость расширения соот¬
ветствующих стандартов.
С начала 1990-х гг. большое распространение получает версия
Ethernet, использующая в качестве среды передачи витые пары,
позже был определен также стандарт для применения в сети опто¬
волоконного кабеля. В стандарты были внесены соответствующие
добавления. В 1995 г. появился стандарт на более быструю версию
Ethernet, работающую на скорости 100 Мбит/с (так называемый
Fast Ethernet, стандарт IEEE 802.3u), использующую в качестве
среды передачи витую пару или оптоволоконный кабель. Позже
появилась и версия на скорость 1 000 Мбит/с (Gigabit Ethernet,
стандарт IEEE 802.3z), о которой будет рассказано ниже.
Стандарт 802.Зи не является самостоятельным стандартом,
а представляет собой дополнение к существующему стандарту
71
802.3. Это стандарт протокола канального уровня для сетей,
работающих при использовании как медного, так и волоконно-
оптического кабеля со скоростью 100 Мб/с. Изменения коснулись
нескольких элементов конфигурации средств физического уров¬
ня, что позволило увеличить пропускную способность, включая
типы применяемого кабеля, длину сегментов и количество кон¬
центраторов.
Фактически спецификация Fast Ethernet охватывает три типа
схем передачи по различным физическим носителям (табл. 3.1).
1. 100Base-TX — наиболее популярный и в связи с использовани¬
ем проводной связи очень похожий на 10BASE-T. Здесь используется
медная витая пара категории 5 для подключения концентраторов,
коммутаторов и оконечных узлов посредством общего с 10Base-T
разъема RJ45.
2. 100Base-FX — вариант Fast Ethernet с использованием воло¬
конно-оптического кабеля. В данном стандарте используется длин¬
новолновая часть спектра, передаваемая по двум жилам: одна — для
приема, а другая — для передачи. Длина сегмента сети может до¬
стигать 400 м в полудуплексном режиме с гарантией обнаружения
коллизий и 2 км в полнодуплексном при использовании много¬
модового волокна. Работа на больших расстояниях возможна при
использовании одномодового волокна.
Таблица 3.1. Характеристики спецификаций технологии
Fast Ethernet
Характеристика
Спецификация
100Base-TX
100Base-T4
100Base-FX
Тип кабеля
UTP5, STP1
UTP3
Многомодовое
оптоволокно
Метод доступа
CSMA/CD
CSMA/CD
CSMA/CD
Максимальное
число узлов в сети
1 024
1024
1 024
Максимальная
длина сегмента, м
100
100
2 000 при полноду¬
плексной передаче,
412 при полуду¬
плексной
передаче
Топология
Звезда
Звезда
Звезда
Диаметр сети, м
205
205
—
72
3. 100Base-T4 — самая поздняя реализация Fast Ethernet, пол¬
нившаяся позднее спецификаций 100Base-TX и 100Base-FX. Как и
((стальные спецификации Fast Ethernet, она описывается стандартом
IHEE 802.Зи. В этой технологии используется кабель, состоящий из
четырех витых пар третьей категории. При этом из четырех пар
одна всегда направлена к концентратору, одна — от концентра¬
тора, а остальные две переключаются в зависимости от текущего
направления передачи данных. Таким образом, в каждый момент
времени из четырех пар для передачи используется три, а одна
используется для прослушивания несущей частоты с целью об¬
наружения коллизий. В отличие от стандарта 100Base-TX, где для
передачи используется только две витых пары кабеля, в стандарте
IOOBase-T4 используются все четыре пары. Причем при связи рабо¬
чей станции и повторителя посредством прямого кабеля данные от
рабочей станции к повторителю идут по витым парам 1, 3 и 4, а в
обратном направлении — по парам 2, 3 и 4. Пары 1 и 2 используются
для обнаружения коллизий подобно стандарту Ethernet. Другие две
11ары 3 и 4 попеременно в зависимости от команд могут пропускать
сигнал либо в одном, либо в другом направлении.
В качестве физической среды передачи данных уже не исполь¬
зуются коаксиальный кабель, только витая пара и оптоволокно,
которые позволяют поддерживать требуемые скорости соединений,
и при этом являются более удобным и экономичным решением.
3.3.3. Высокоскоростные технологии
Gigabit Ethernet
Сеть Gigabit Ethernet — это естественный, эволюционный путь
развития концепции, заложенной в стандартной сети Ethernet. Со¬
хранение преемственности позволяет довольно просто соединять
сегменты Ethernet, Fast Ethernet и Gigabit Ethernet в единую сеть и,
самое главное, переходить к новым скоростям постепенно, вводя
гигабитные сегменты только на самых напряженных участках сети.
К тому же далеко не везде такая высокая пропускная способность
действительно необходима. Если же говорить о конкурирующих
гигабитных сетях, то их применение может потребовать полной
замены сетевой аппаратуры, что сразу же приведет к огромным
затратам средств.
В сети Gigabit Ethernet сохраняется все тот же хорошо за¬
рекомендовавший себя в предыдущих версиях метод доступа
CSMA/CD, используются те же форматы пакетов (кадров) и те
73
же размеры, т. е. никакого преобразования протоколов в местах
соединения с сегментами Ethernet и Fast Ethernet не потребуется.
Единственное, что нужно — это согласование скоростей обмена.
Поэтому главной областью применения Gigabit Ethernet станет
в первую очередь соединение концентраторов Ethernet и Fast
Ethernet между собой.
С появлением сверхбыстродействующих серверов и распро¬
странением наиболее совершенных персональных компьютеров
преимущества Gigabit Ethernet становятся все более явными. От¬
метим, что 64-разрядная системная магистраль PCI, ставшая уже
фактическим стандартом, вполне достигает требуемой для такой
сети скорости передачи данных.
А началась эта разработка еще летом 1996 г., когда компанией
Gigabit Ethernet Alliance было объявлено о создании группы 802.3z
для разработки протокола, в максимальной степени подобного
Ethernet, но с битовой скоростью 1 000 Мбит/с. Утверждение ряда
стандартов Gigabit Ethernet было закончено летом 1999 г.
Как уже упоминалось выше, Gigabit Ethernet является преем¬
ственной по отношению к предшественникам (10 и 100 Мбит/с), по¬
зволяя простой переход к работе с сетями более высокой скорости.
Все три скорости Ethernet используют один и тот же формат кадра
передачи данных IEEE 802.3, полнодуплексные операции и методы
управления потоком данных. В полудуплексном режиме Gigabit
Ethernet использует тот же самый метод множественного доступа
с опросом несущей и разрешением конфликтов. Поддерживаются
все основные виды кабелей, используемых в Ethernet и Fast Ethernet:
волоконно-оптический, витая пара категории 5, коаксиальный ка¬
бель (табл. 3.2). Тем не менее разработчикам технологии Gigabit
Ethernet для сохранения приведенных выше свойств пришлось
внести изменения не только в физический уровень, как это было
в случае FastEthernet, но и в уровень MAC.
Перед разработчиками стандарта Gigabit Ethernet стояло не¬
сколько трудно разрешимых проблем. Одной из них была задача
обеспечения приемлемого диаметра сети для полудуплексного ре¬
жима работы. В связи с ограничениями, накладываемыми методом
CSMA/CD на длину кабеля, версия Gigabit Ethernet для разделяемой
среды допускала бы длину сегмента всего в 25 м при сохранении
размера кадров и всех параметров метода CSMA/CD неизменными.
Так как существует большое количество применений, требующих
диаметра сети хотя бы 200 м, необходимо было каким-то образом
решить эту задачу за счет минимальных изменений в технологии
Fast Ethernet.
74
Таблица 3.2. Характеристики спецификаций технологии
Gigabit Ethernet
Характеристика
Спецификация
1000Base-LX
1000Base-SX
1000Base-T
Тип кабеля
Многомодовый и
одномодовый ка¬
бель с длинновол¬
новым лазером
(1 300 нм)
Оптоволокно
4-парный
неэкраниро-
ванный UTP5
Максимальная
длина сегмен¬
та, м
Многомодовый:
550 м (62,5 мкм);
550 м (50 мкм)
Одномодовый:
5 км (9 мкм)
220 м
(62,5 мкм);
500 м
(50 мкм)
100
Другой сложнейшей задачей было достижение битовой скорости
1 000 Мбит/с на основных типах кабелей. Даже для оптоволокна
достижение такой скорости представляет некоторые проблемы,
так как технология Fibre Channel, физический уровень которой
был взят за основу для оптоволоконной версии Gigabit Ethernet,
обеспечивает скорость передачи данных всего в 800 Мбит/с. Но
эти проблемы были решены.
Среди первых продуктов для Gigabit Ethernet оказались гига¬
битные модули для коммутаторов и сетевые платы для серверов.
Соединение коммутаторов Fast Ethernet по Gigabit Ethernet позво¬
ляет резко поднять пропускную способность магистрали локальной
сети и поддерживать в результате большее число как коммутируе¬
мых, так и разделяемых сегментов Fast Ethernet. Установка сетевой
платы Gigabit Ethernet на сервер дает возможность расширить
канал с сервером и таким образом увеличить производительность
пользователей мощных рабочих станций.
В качестве физической среды передачи данных для технологии
Gigabit Ethernet стандарт 802.3z определяет одномодовый и много¬
модовый оптоволоконный кабель, а также экранированную витую
пару с волновым сопротивлением 75 Ом. Чуть позже была разрабо¬
тана реализация Gigabit Ethernet для кабеля на основе витой пары
категории 5. Также определены и соответствующие физическим
средам спецификации.
1. 1000Base-LX стандарт, использующий одномодовое или много¬
модовое оптическое волокно во втором окне прозрачности с длиной
волны 1310 нм. Дальность прохождения сигнала зависит только от
75
типа используемых приемопередатчиков и, как правило, составляет
для одномодового оптического волокна до 5 км и для многомодового
оптического волокна до 550 м.
2. 1000Base-SX — стандарт, использующий многомодовое волок¬
но в первом окне прозрачности с длиной волны 850 нм. Дальность
прохождения сигнала составляет до 550 м.
3. 1000Base-T использует для передачи все четыре витые пары
кабеля категории 5. Передача происходит параллельно по каждой
паре со скоростью 250 Мбит/с. Показатели максимального числа
подключаемых узлов, длины сегмента, диаметра сети остаются
стандартными для кабеля на основе витой пары пятой кате¬
гории.
Новым скачком в развитии технологий высокоскоростной пере¬
дачи данных стал стандарт IEEE 802.3ае — 10 Gigabit Ethernet (10 Gb,
Ethernet 10G, 10 Гбит/с), одобренный в июне 2002 г. С его появле¬
нием область использования Ethernet расширилась до масштабов
городских (MAN) и глобальных (WAN) сетей. В стандарте описано
несколько спецификаций, определяющих использование в качестве
среды передачи данных одно- и многомодовые оптоволоконные
кабели, методы кодирования, применяемые длины волн и т.д.
Новый стандарт 10-гигабитного Ethernet включает в себя семь
стандартов физической среды для LAN, MAN и WAN.
1. 10GBASE-CX4 — технология 10-гигабитного Ethernet для ко¬
ротких расстояний (до 15 м), используется медный кабель СХ4 и
коннекторы InfiniBand.
2. 10GBASE-SR — технология 10-гигабитного Ethernet для ко¬
ротких расстояний (до 26 или 82 м в зависимости от типа кабеля),
используется многомодовое волокно. Он также поддерживает рас¬
стояния до 300 м с использованием нового многомодового волокна
(2 000 МГц/км).
3. 10GBASE-LX4 — использует уплотнение по длине волны для
поддержки расстояний от 240 до 300 м по многомодовому волокну.
Также поддерживает расстояния до 10 км при использовании одно¬
модового волокна.
4. 10GBASE-LR и 10GBASE-ER — эти стандарты поддерживают
расстояния до 10 и 40 км соответственно.
5. 10GBASE-SW, 10GBASE-LW и 10GBASE-EW — эти стандарты
используют физический интерфейс, совместимый по скорости и
формату данных с интерфейсом ОС-192 / STM-64 SONET/SDH.
Они подобны стандартам 10GBASE-SR, 10GBASE-LR и 10GBASE-
ER соответственно, так как используют те же самые типы кабелей
и расстояния передачи.
76
6. 10GBASE-T, IEEE 802.3an-2006 — принят в июне 2006 г. по¬
сле 4 лет разработки. Использует витую пару категории 6 (мак¬
симальное расстояние — 55 м) и 6а (максимальное расстояние —
100 м).
7. 10GBASE-KR — технология 10-гигабитного Ethernet для кросс-
млат (backplane/midplane) модульных коммутаторов/маршрутиза-
торов и серверов (Modular/Blade).
Компания Harting заявила о создании первого в мире 10-ги-
габитного соединителя RJ-45, не требующего инструментов для
монтажа — HARTING RJ Industrial 10G.
В 2010 г. международная ассоциация IEEE объявила об офици¬
альном утверждении Ethernet-стандарта IEEE 802.ЗЬа 40 Гбит/с и
100 Гбит/с. Эти стандарты являются следующим этапом развития
группы стандартов Ethernet, имевших до 2010 г. наибольшую ско¬
рость 10 Гбит/с. В новом стандарте IEEE Std 802.3ba-2010 обеспечи¬
вается скорость передачи данных 40 и 100 Гбит/с при совместном
использовании нескольких 10 Гбит/с или 25 Гбит/с линий связи.
Интересно, что данный стандарт является первым, предназначен¬
ным для определения двух различных скоростей (40 и 100 Гбит/с)
передачи информации. Как утверждает IIЕЕ, новый стандарт по¬
может встретить во всеоружии растущий во всем мире спрос на
широкополосные сети и представляет собой основу для следующей
волны технологических инноваций.
По сути, новый стандарт IEEE 802.Зbа является поправкой к
Ethernet-стандарту IIЕЕ 802.3, а одним из преимуществ от подобной
стандартизации станет возможность реализации 10-гигабитного
Ethernet-соединения в дата-центрах, что, вероятно, позволит повы¬
сить их производительность и пропускную способность.
КОНТРОЛЬНЫЕ ВОПРОСЫ
1. Поясните принцип работы концентраторов в технологии Token
Ring.
2. В чем недостаток технологии Arcnet?
3. Как обеспечивается высокая отказоустойчивость в сетях
FDDI?
4. Почему технология Ethernet получила большее распростране¬
ние?
5. Что определяет стандарт IEEE 802.3?
6. Опишите метод доступа CSMA/CD.
7. В чем различие стандартов 10BASE-T, 100BASE-TX,
10OOBASE-T?
77
8. Какие схемы передачи описывает спецификация Fast Ether¬
net?
9. Возможно ли использование в сети Gigabit Ethernet метода
доступа CSMA/CD?
10. В чем различия спецификаций 10OOBase-LX, IOOOBase-SX,
10OOBase-T?
11. Опишите особенности стандарта IEEE 802.ЗЬа?
Глава 4
ТЕХНИЧЕСКИЕ СРЕДСТВА
КОМПЬЮТЕРНЫХ СЕТЕЙ
Компьютерная сеть представляет собой сложный комплекс про¬
граммных и аппаратных средств, с помощью которых осуществляет¬
ся связь компьютеров и других устройств между собой. К техниче¬
ским средствам сетей относят компьютеры, оснащенные сетевыми
адаптерами, каналы связи (кабельные, спутниковые, телефонные,
цифровые, волоконно-оптические, радиоканалы и др.), различного
рода преобразователи сигналов и прочее сетевое оборудование.
4.1.
СЕТЕВЫЕ АДАПТЕРЫ
Сетевой адаптер (сетевой карты, сетевой платы, Ethernet-
адаптер, NIC — Network Interface Controller) — это периферийное
устройство, позволяющее компьютеру взаимодействовать с другими
устройствами сети.
Сетевой адаптер контролирует доступ к среде передачи данных
и обмен данными между сетевыми устройствами. Сетевой адаптер
решает задачи обмена двоичными данными, представленными со¬
ответствующими электромагнитными сигналами, по внешним ли¬
ниям связи. Как и любой контроллер компьютера, сетевой адаптер
работает под управлением драйвера операционной системы, и рас¬
пределение функций между сетевым адаптером и драйвером может
изменяться от реализации к реализации. Набор выполняемых адап¬
тером функций зависит от конкретного сетевого протокола. Ввиду
того что сетевой адаптер и в физическом, и в логическом смысле
находится между устройством и сетевой средой, его функции мож¬
но разделить на функции сопряжения с сетевым устройством и
79
функции обмена с сетью. Если в качестве сетевого устройства вы¬
ступает компьютер, то связь с сетевой средой можно реализовать
двумя способами: через системную магистраль (шину) или через
внешние интерфейсы. Наиболее распространенным является спо¬
соб сопряжения через шину. При этом адаптер буферизует данные,
поступающие с системной магистрали, и вырабатывает внутренние
управляющие сигналы.
Обычно сетевые адаптеры делятся на адаптеры для клиентских
компьютеров и адаптеры для серверов. В адаптерах для клиент¬
ских компьютеров значительная часть работы перекладывается на
драйвер, поэтому адаптер оказывается проще и дешевле. Адаптеры,
предназначенные для серверов, обычно снабжаются собственными
процессорами, которые самостоятельно выполняют большую часть
работы по передаче кадров из оперативной памяти в сеть и в об¬
ратном направлении.
Сетевые адаптеры различаются между собой технологией по¬
строения сети, а также по конструктивной реализации:
я внешние сетевые карты (вставляющиеся в ISA, PCI, PCI-E-слот
или USB-разъем);
я встроенные или интегрированные в материнскую плату.
Плата сетевого адаптера имеет один или несколько внешних
разъемов для подключения к ней кабеля сети.
Внешние сетевые платы устанавливаются в системный блок
компьютера дополнительно (отдельной платой расширения) или
же, как другое внешнее устройство. В PCI-разъемы вставляются
сетевые карты, имеющие PCI-интерфейс (рис. 4.1).
Сам по себе PCI-интерфейс обладает пиковой пропускной спо¬
собностью для 32-разрядного варианта, работающего на частоте
Рис. 4.1. PCI сетевая плата
80
33,33 МГц в 133 Мбайт/с, потребляемое напряжение разъема 3,3
или 5 В.
Бывают адаптеры и другой разновидности -— Wi-Fi для орга¬
низации беспроводных сетей. Интерфейс подключения один PCI,
а принцип работы совсем иной. О них подробнее будет рассказано
в следующей главе.
Сейчас в связи с постепенным «отмиранием» интерфейса PCI
выпускаются сетевые карты формата PCI Express-lx (рис. 4.2).
Стандарт PCMCIA (Personal Computer Memory Card International
Association — международная ассоциация компьютерных карт
памяти) изначально разрабатывался для карт расширения памяти,
на сегодняшний день спецификация расширена и используется
для подключения различных периферийных устройств. Теперь
через этот интерфейс также возможно подключение сетевых карт
(рис. 4.3). Эти устройства актуальны для ноутбуков или других
устройств, в которых нет сетевой карты, но есть разъем PCMCIA
(некоторые модели КПК).
Рис. 4.3. Сетевая карта с интер¬
фейсом PCMCIA
81
Рис. 4.4. Сетевые адаптеры с USB-интерфейсом
USB-сетевые карты имеют схожие функции со своими PCI-
аналогами, но стоят, как правило, дороже. Их главным достоинством
является универсальность: такой адаптер можно подключить к лю¬
бой системе, где есть USB-порт (рис. 4.4). Еще это весьма актуально,
когда в наличии нет свободного PCI-разъема, что в наше время
огромного количества периферийных устройств — не редкость.
Во многие современные материнские платы сетевые карты уже
встроены. Если сетевая карта интегрирована в системную плату,
то вы экономите PCI-разъем. В некоторые материнские платы
встроены гигабитные адаптеры. Учитывая цены на гигабитное обо¬
рудование, это отличное дополнение. В некоторых моделях есть
даже две сетевые карты.
КОНЦЕНТРАТОРЫ
Сетевой концентратор, или хаб (hub — центр) — устройство
для объединения компьютеров в сеть Ethernet с применением ка¬
бельной инфраструктуры типа «витая пара» (рис. 4.5). В настоящее
время концентраторы вытеснены сетевыми коммутаторами.
Сетевые концентраторы также могли иметь разъемы для под¬
ключения к существующим сетям на базе «толстого» или «тонкого»
коаксиального кабеля.
Концентратор работает на первом (физическом) уровне сетевой
модели OSI, ретранслируя входящий сигнал с одного из портов в
сигнал на все остальные (подключенные) порты, реализуя, таким
образом, свойственную Ethernet топологию «общая шина», с раз¬
делением пропускной способности сети между всеми устрой¬
ствами и работой в режиме полудуплекса. Попытка двух и более
устройств начать передачу одновременно (коллизии) обрабатыва-
82
Рис. 4.5. Концентратор
ются аналогично сети Ethernet на других носителях — устройства
самостоятельно прекращают передачу и возобновляют попытку
через случайный промежуток времени, говоря современным
языком, концентратор объединяет устройства в одном домене
коллизий.
Сетевой концентратор также обеспечивает бесперебойную
работу сети при отключении устройства от одного из портов или
повреждении кабеля, в отличие, например, от сети на коаксиальном
кабеле, которая в таком случае прекращает работу целиком.
Единственное преимущество концентратора — низкая стои¬
мость — было актуально лишь в первые годы развития сетей Et¬
hernet. По мере совершенствования и удешевления электронных
микропроцессорных компонентов данное преимущество концен¬
тратора полностью сошло на нет.
Недостатки концентратора являются логическим продолжением
недостатков топологии «общая шина», а именно снижение про¬
пускной способности сети по мере увеличения числа узлов. Кроме
того, поскольку на канальном уровне узлы не изолированы друг
от друга, все они будут работать со скоростью передачи данных
самого худшего узла. Например, если в сети присутствуют узлы со
скоростью 100 Мбит/с и всего один узел со скоростью 10 Мбит/с,
то все узлы будут работать на скорости 10 Мбит/с, даже если узел
10 Мбит/с вообще не проявляет никакой информационной актив¬
ности. Еще одним недостатком является вещание сетевого трафика
во все порты, что снижает уровень сетевой.
Позже появились интеллектуальные устройства, работающие на
втором (канальном) уровне по модели OSI, — коммутаторы. В от¬
личие от концентраторов они способны обеспечивать независимую
и выборочную передачу кадров Ethernet между портами за счет
вскрытия заголовков кадров и пересылки их по нужным портам в
83
соответствии с МАС-адресом получателя. Коммутаторы сначала ис¬
пользовались для разгрузки и оптимизации больших Ethernet-сетей,
а затем полностью вытеснили концентраторы.
РЕПИТЕРЫ
Одной из первых задач, которая стоит перед любой технологией
транспортировки данных, является возможность их передачи на
максимально большое расстояние. Физическая среда накладывает
на этот процесс свое ограничение — с увеличением расстояния
мощность сигнала падает, и прием становится невозможным.
Репитеры, или повторители (repeater), восстанавливают осла¬
бленные сигналы (их амплитуду и форму), приводя их к исходному
виду. Цель такой ретрансляции сигналов состоит исключительно в
увеличении длины сети. Если длина сети превышает максималь¬
ную длину сегмента сети, необходимо разбить сеть на несколько
сегментов, соединив их через репитер.
Репитер повышает надежность сети, так как отказ одного сег¬
мента (например, обрыв кабеля) не сказывается на работе других
сегментов. Однако, разумеется, данные не могут проходить через
поврежденный сегмент. В терминах модели OSI работает на физи¬
ческом уровне.
Репитеры не преобразуют ни уровни сигналов, ни их физи¬
ческую природу. Привычное для аналоговых систем усиление не
годится для высокочастотных цифровых сигналов. Разумеется, при
его использовании какой-то небольшой эффект может быть достиг¬
нут, но с увеличением расстояния искажения быстро нарушится
целостность данных. В таких ситуациях применяют не усиление,
а повторение сигнала. При этом устройство на входе должно при¬
нимать сигнал, далее распознавать его первоначальный вид, и ге¬
нерировать на выходе его точную копию.
Такая схема в теории может передавать данные на сколь угодно
большие расстояния (если не учитывать особенности разделения
физической среды в Ethernet).
Первоначально в Ethernet использовался коаксиальный кабель
с топологией «общая шина», и нужно было соединять между собой
несколько протяженных сегментов. Для этого обычно использова¬
лись повторители (репитеры), имевшие два порта. Несколько позже
появились многопортовые устройства, называемые концентратора¬
ми. Их физическое устройство было таким же, но восстановленный
сигнал транслировался на все активные порты, кроме того, с ко¬
84
торого пришел сигнал. С появлением протокола l0baseT (витой
пары) во избежание терминологической путаницы многопортовые
повторители для витой пары стали обычно называться сетевыми
концентраторами (хабами), а коаксиальные — повторителями, или
репитерами.
4.4. СЕТЕВЫЕ МОСТЫ
Крупные сети, где насчитываются сотни и тысячи узлов, не могут
быть построены на основе одной разделяемой среды даже с учетом
возможностей такой скоростной технологии, как Gigabit Ethernet,
и не только потому, что практически во всех технологиях количе¬
ство узлов в разделяемой среде ограничено. Основные недостатки
начинают проявляться при превышении некоторого порогового
количества узлов. При достижении этого порогового значения
пропускная способность сети начинает стремительно уменьшаться,
а продолжительность задержек перед получением доступа к разде¬
ляемой среде — увеличиваться. Для решения этой проблемы сеть
начали разделять на несколько сред передачи данных, объединен¬
ных мостами. Мост служит для связи между локальными сетями,
передает кадры из одной сети в другую.
Сетевой мост, бридж (bridge) — сетевое устройство второго
уровня модели OSI, предназначенное для объединения сегментов
компьютерной сети в единую сеть.
Мосты по своим функциональным возможностям являются
более усовершенствованными устройствами, чем концентраторы.
Мосты не повторяют шумы сети, ошибки или испорченные кадры.
Для каждой соединяемой сети мост является узлом — абонентом
сети. При этом мост принимает кадр, запоминает его в своей бу¬
ферной памяти, анализирует адрес назначения кадра. Если кадр
принадлежит сети, из которой он получен, мост не должен на этот
кадр реагировать. Если кадр нужно переслать в другую сеть, он туда
и отправляется. Доступ к среде осуществляется в соответствии с
теми правилами, что и для обычного узла.
СЕТЕВЫЕ КОММУТАТОРЫ
Сетевой коммутатор (switch — переключатель) — устрой¬
ство, предназначенное для соединения нескольких узлов компью¬
терной сети в пределах одного или нескольких сегментов сети.
85
Коммутатор работает на канальном (втором) уровне модели OSI.
Коммутаторы были разработаны с использованием мостовых
технологий и часто рассматриваются как многопортовые мосты
(рис. 4.6).
В отличие от концентратора, который распространяет трафик от
одного подключенного устройства ко всем остальным, коммутатор
передает данные только непосредственно получателю. Исключение
составляют широковещательный трафик всем узлам сети и трафик
для устройств, для которых неизвестен исходящий порт коммута¬
тора. Это повышает производительность и безопасность сети, из¬
бавляя остальные сегменты сети от необходимости обрабатывать
данные, которые им не предназначались.
Поскольку наиболее популярным среди стандартов локальных
вычислительных сетей сегодня является Ethernet, далее будут рас¬
смотрены только коммутаторы для этой технологии. Схема под-
Рис. 4.7. Схема подключения к коммутатору
86
ключения двух различных локальных сетей к коммутатору Ethernet
представлена на рис. 4.7.
Коммутатор хранит в памяти таблицу коммутации, хранящуюся
и ассоциативной памяти, в которой указывается соответствие МАС-
адреса узла порту коммутатора. При включении коммутатора эта
I'аблица пуста, и он работает в режиме обучения. В этом режиме
поступающие на какой-либо порт данные передаются на все осталь¬
ные порты коммутатора. При этом коммутатор анализирует фреймы
(кадры) и, определив МАС-адрес хоста-отправителя, заносит его в
таблицу на некоторое время. Впоследствии, если на один из портов
коммутатора поступит кадр, предназначенный для хоста, МАС-адрес
I оторого уже есть в таблице, то этот кадр будет передан только че¬
рез порт, указанный в таблице. Если МАС-адрес хоста-получателя
не ассоциирован с каким-либо портом коммутатора, то кадр будет
отправлен на все порты, за исключением того порта, с которого
он был получен. Со временем коммутатор строит таблицу для всех
активных МАС-адресов, в результате трафик локализуется.
Коммутаторы подразделяются на управляемые и неуправляемые
(наиболее простые). Многие управляемые коммутаторы позволяют
настраивать дополнительные функции.
МАРШРУТИЗАТОРЫ И СЕТЕВЫЕ ШЛЮЗЫ
Концентраторы (хабы), организующие рабочую группу, мосты,
соединяющие два сегмента сети и локализующие трафик в преде¬
лах каждого из них, а также коммутаторы, позволяющие соединять
несколько сегментов локальной вычислительной сети — это все
устройства, предназначенные для работы в сетях IEEE 802.3 или
Ethernet.
Однако существует особый тип оборудования, называемый
маршрутизаторами, или роутерами (routers), который приме¬
няется в сетях со сложной конфигурацией для связи ее участков
с различными сетевыми протоколами, в том числе и для доступа
к глобальным (WAN) сетям, а также для более эффективного раз¬
деления трафика и использования альтернативных путей между
узлами сети. Основная цель применения роутеров — объединение
разнородных сетей и обслуживание альтернативных путей.
Различные типы маршрутизаторов отличаются количеством и
типами своих портов, что собственно и определяет места их исполь¬
зования. Маршрутизаторы, например, могут быть использованы в
локальной сети Ethernet для эффективного управления трафиком
87
при наличии большого числа сегментов сети, для соединения сети
типа Ethernet с сетями другого типа, например Token Ring, FDDI,
а также для обеспечения выходов локальных сетей на глобальную
сеть.
Маршрутизаторы не просто осуществляют связь разных типов
сетей и обеспечивают доступ к глобальной сети, но и могут управ¬
лять трафиком на основе протокола сетевого уровня (третьего в
модели OSI), т. е. на более высоком уровне по сравнению с ком¬
мутаторами. Необходимость в таком управлении возникает при
усложнении топологии сети и росте числа ее узлов,
Поскольку маршрутизатор работает на основе протокола, он
может принимать решение о наилучшем маршруте доставки дан¬
ных, руководствуясь такими факторами, как стоимость, скорость
доставки и т. д. Кроме того, маршрутизаторы позволяют эффективно
управлять трафиком широковещательной рассылки, обеспечивая
передачу данных только в нужные порты.
Таблица маршрутизации содержит информацию, на основе кото¬
рой маршрутизатор принимает решение о дальнейшей пересылке
пакетов. Таблица состоит из некоторого числа записей — марш¬
рутов, в каждой из которых содержится адрес сети получателя,
адрес следующего узла, которому следует передавать пакеты и др.
Зачастую для построения таблиц маршрутизации используют тео¬
рию графов.
Новые современные маршрутизаторы также выполняют защит¬
ную функцию — защищают локальную сеть от внешних угроз. Они
являются регуляторами доступами пользователей сети к интернет-
ресурсам, раздают IP-адреса, занимаются шифровкой трафика и
многое другое.
Иногда вместо понятия «маршрутизатор» используется понятие
«сетевой шлюз». На самом деле маршрутизаторы являются лишь
одним из примеров аппаратных сетевых шлюзов.
Сетевой шлюз (gateway) — аппаратный маршрутизатор или
программное обеспечение для сопряжения компьютерных сетей,
использующих разные протоколы, например, локальной и глобаль¬
ной.
Обычный маршрутизатор сам по себе принимает, проводит и
отправляет пакеты только среди сетей, использующих одинако¬
вые протоколы. Но если обеспечивается конвертация протоколов
одного типа физической среды в протоколы другой физической
среды (сети), то речь уже идет о сетевом шлюзе. Например, при
соединении локального компьютера с сетью Интернет обычно ис¬
пользуется сетевой шлюз.
88
Сетевые шлюзы работают на всех известных операционных
системах. Сетевые шлюзы могут быть аппаратным решением,
программным обеспечением или тем и другим вместе, но обычно
г1'о программное обеспечение, установленное на роутер или ком¬
пьютер. Сетевой шлюз должен понимать все протоколы, исполь¬
зуемые роутером. Обычно сетевые шлюзы работают медленнее,
чем сетевые мосты, коммутаторы и обычные маршрутизаторы.
Сетевой шлюз — это точка сети, которая служит выходом в другую
сеть. В сети Интернет узлом или конечной точкой может быть или
сетевой шлюз, или хост.
Интернет-пользователи и компьютеры, которые доставляют веб¬
страницы пользователям, — это хосты, а узлы между различными
сетями — это сетевые шлюзы. Например, сервер, контролирующий
график между локальной сетью компании и сетью Интернет, — это
сетевой шлюз.
В крупных сетях сервер, работающий как сетевой шлюз, обычно
интегрирован с прокси-сервером и межсетевым экраном. Эти по¬
нятия будут рассмотрены в последующих главах.
КОНТРОЛЬНЫЕ ВОПРОСЫ
1. Что представляет собой серверный сетевой адаптер?
2. Какие интерфейсы используются в сетевых адаптерах?
3. Что такое сетевой концентратор?
4. Для чего служат трансиверы и репитеры?
5. Для чего предназначены сетевые порты?
6. Что называют сетевым коммутатором?
7. Для чего предназначены маршрутизаторы?
8. Чем отличаются сетевые шлюзы от маршрутизаторов?
Глава 5
БЕСПРОВОДНЫЕ ТЕХНОЛОГИИ
Беспроводная локальная сеть требует несколько иного набора
компонентов оборудования, чем традиционная проводная сеть.
Очевидно, что наибольшим отличием является отсутствие проводов
между сетевым сервером, компьютерами беспроводных клиентов
и другими устройствами, формирующими сеть.
В этой главе определяются компоненты, формирующие беспро¬
водную сеть, представлены описания различных свойств и функций
точек доступа, сетевых адаптеров, антенн.
БЕСПРОВОДНЫЕ ЛИНИИ СВЯЗИ
Помимо кабельных каналов в компьютерных сетях часто исполь¬
зуют также беспроводные линии связи. Иногда возникают ситуа¬
ции, когда прокладка кабельной системы затруднена или экономи¬
чески нецелесообразна. В таких случаях для организации сети без
прокладки дополнительных линий связи используют беспроводные
локальные сети (Wireless LAN — WLAN), позволяющие объединить
в единую информационную систему разрозненные локальные сети
и компьютеры для обеспечения доступа всех пользователей этих
сетей к единым информационным ресурсам.
В качестве носителя информации в таких сетях выступают
радиоволны. В каналах связи используются передатчики и при¬
емники соответствующих радиоволн. В основу технологии легла
методика передачи данных по радиоканалу на частоте 2,4 ГГц с
использованием кодирования сигнала рабочими частотами и специ¬
альными приложениями.
90
( 'труктура беспроводной сети задается базовой WLAN-станцией,
называемой точкой доступа (или иногда шлюзом), подключенным к
• Рычной Ethernet-сети. Поскольку точка доступа может работать и
Кпк WLAN-клиент, сеть из нескольких точек доступа может функ¬
ционировать как беспроводная (рис. 5.1).
Можно утверждать, что беспроводные линии связи позволяют
создавать вычислительные сети, полностью соответствующие стан¬
дартам для обычных проводных сетей, без использования кабельной
проводки. Эта технология дает пользователю возможность ощущать
себя как в привычной Ethernet-сети.
Беспроводные линии связи различаются частотным диапазоном
и дальностью передачи. Ясно, что максимально возможное рас¬
стояние от точки доступа до клиента зависит от среды распростра¬
нения радиоволн в пределах WLAN, где используется система. Как
известно, железобетонные перекрытия, как и множество помех,
излучаемых различным оборудованием, существенно снижают
максимальную дальность связи. Кроме того, при распространении
радиоволн имеет место явление интерференции, что также снижа¬
ет радиус действия WLAN-систем. В зависимости от излучаемой
мощности и чувствительности приемника на открытой местности
максимальное расстояние между точкой доступа и клиентом может
составлять до 300 м, а в офисных зданиях — до 50 м. В заводских
корпусах оно обычно менее 50 м.
Специальные антенны, как на WLAN-станции, так и на кли¬
ентском оборудовании, могут позволить значительно увеличить
максимальную дальность. При использовании узконаправленных
антенн с высоким коэффициентом усиления возможна работа
на расстояниях до 20 км. Для организации беспроводной сети в
Рис. 5.1. Объединение компьютеров с помощью беспроводной технологии
91
замкнутом пространстве применяются передатчики с всенаправ¬
ленными антеннами.
Беспроводные сети называют по-разному. Например, часто
встречается сокращение от Wireless Local Area Network, т. e. WLAN,
или по-русски — беспроводная локальная сеть. Самым популярным
названием сетей без проводов стало Wi-Fi. Интересно, что термин
«Wi-Fi» изначально был придуман как игра слов для привлечения
внимания потребителя «намеком» на Hi-Fi (High Fidelity — высо¬
кая точность).
Несмотря на то что поначалу в некоторых пресс-релизах WECA
и фигурировало словосочетание Wireless Fidelity, на данный момент
от такой формулировки отказались, и аббревиатура Wi-Fi никак не
расшифровывается, а является сокращенным названием зареги¬
стрированной торговой марки Wi-Fi Aliance.
Технология беспроводной передачи данных обладает определен¬
ными достоинствами:
■ возможность разворачивания сети без использования кабеля,
что уменьшает стоимость организации и/или дальнейшего рас¬
ширения сети. Это особенно важно в местах, где отсутствует
возможность прокладки кабеля;
■ предоставление доступа к сети мобильным устройствам;
■ широкое распространение на рынке Wi-Fi-устройств, а также
их гарантированная совместимость благодаря обязательной
сертификации оборудования Wi-Fi Alliance;
■ мобильность клиентов и возможность пользования Интернетом
в любой обстановке;
■ возможность подключения к сети в зоне действия Wi-Fi не¬
скольких пользователей с различных устройств — телефонов,
компьютеров, ноутбуков и т. п.;
■ низкий уровень излучения Wi-Fi-устройствами в момент пере¬
дачи данных (в 10 раз меньше, чем у мобильного телефона).
Среди недостатков технологии следует отметить то, что реальная
скорость передачи в сети Wi-Fi зависит от наличия физических пре¬
пятствий между устройствами, наличия помех от других электрон¬
ных устройств, взаимного расположения устройств и количества
одновременных пользователей.
СТАНДАРТЫ БЕСПРОВОДНОЙ СВЯЗИ
5.2.
Беспроводные сети базируются на технологии локальных вычис¬
лительных сетей со связью по радиоканалу, описанной в стандарте
92
IEEE 802.11. В стандарте определены диапазоны частот для связи и
cкорости передачи данных.
Список используемых в настоящее время стандартов приведен
и табл. 5.1.
11олоса частот и подчастот для устройств стандарта 802.11 вы¬
деляется и регламентируется в каждой конкретной стране уполно¬
моченным на то правительственным органом. Также местным за¬
конодательством регламентируются правила эксплуатации самих
устройств, их мощность, разбиение частотного диапазона, мощ¬
ности передатчика и другие характерные особенности.
В нашей стране таким органом является Министерство связи
и массовых коммуникаций Российской Федерации. В последнем
нормативном документе этого министерства прописано, что в РФ
разрешена эксплуатация всех вариантов стандартов 802.11 (а, Ь,
g, n) на всех базовых частотах. Как и все стандарты этого семей¬
ства, Wi-Fi 802.11 работает на нижних двух уровнях модели ISO/
OSI — физическом и канальном. Поэтому сетевые приложения и
сетевые протоколы, которые работают в сети Ethernet (стандарт
802.3), такие, например, как TCP/IP, могут аналогичным образом
использоваться и в Wi-Fi-сетях 802.11. Иными словами, если есть
некий Ethernet-маршрутизатор с несколькими входами, то для сети
безразлично, будет ли к нему подключено проводное устройство
стандарта 802.3 или беспроводное Wi-Fi-устройство стандарта
802.11: все периферийные устройства будут видеть друг друга и
правильно взаимодействовать.
Для защиты Wi-Fi-устройств от несанкционированного доступа
используются механизмы шифрования Wired Equivalent Privacy
(WEP). WEP-шифрование может быть статическим или динамиче¬
ским. При статическом WEP-шифровании ключ не меняется. При
Таблица 5.1. Стандарты беспроводной связи
Наименование
стандарта
Скорость передачи,
Мбит/с
Частота, ГГц
802.11
1, 2
2,4
802.11а
54
5
802.11b
5,5 и 11,0
2,4
802.1 lg
54
2,4
802.1 In
600
2,4 —2,5, 5
93
динамическом способе шифрования периодически происходит
смена ключа шифрования. В 2004 г. была опубликована поправка
к стандарту 802.11 с новыми алгоритмами безопасности WPA и
WPA2. Технология WEP была признана устаревшей. Новые методы
обеспечения безопасности WPA и WPA2 (Wi-Fi Protected Access)
совместимы между множеством беспроводных устройств как на
аппаратном, так и на программном уровнях.
Wi-Fi-адаптер выполняет ту же функцию, что и сетевая карта
в проводной сети. Он служит для подключения компьютера поль¬
зователя к беспроводной сети, т. е. представляет собой интерфейс
между компьютером и сетью. В беспроводной сети адаптер со¬
держит радиопередатчик, отправляющий данные с компьютера в
сеть, и приемник, который детектирует входящие радиосигналы с
данными из сети и передает их на компьютер.
Wi-Fi PCI-адаптеры обеспечивают беспроводное подключе¬
ние к сети стационарных компьютеров с PCI-интерфейсами.
Wi-Fi PCI-адаптер считается одним из самых распространенных
ОБОРУДОВАНИЕ ДЛЯ ОРГАНИЗАЦИИ
БЕСПРОВОДНЫХ СЕТЕЙ
5.3.1. Wi-Fi-адаптеры
Рис. 5.2. Сетевые адаптеры Wi-Fi с интерфейсом PCI
94
Рис. 5.3. Wi-Fi Card-Bus-адаптер с
интерфейсом PCMCIA
Рис. 5.4. Внешние Wi-Fi USB-
адаптеры
типов сетевых контроллеров для персональных компьютеров
(рис. 5.2).
PCI-адаптер оснащается одной, двумя или тремя внешними
всенаправленными антеннами с расширенным радиусом действия
и высоким коэффициентом усиления, что особенно важно в по¬
мещениях сложной конфигурации. Поддерживаемые Wi-Fi PCI-
адаптерами стандарты 802.11 (a,b,g,n) обеспечивают устойчивый
прием сигнала и скорость передачи данных до 300 Мбит/с. Защиту
сетевых данных обеспечивает шифрование WEP, WPA и WPA2.
Wi-Fi Card-Bus-адаптеры с интерфейсом PCMCIA обеспечивают
беспроводное высокоскоростное подключение к сети ноутбука или
карманного персонального компьютера со слотом расширения PC
Card (рис. 5.3). Имеют встроенную антенну, компактны и просты
в настройке, обеспечивают гибкое и удобное подключение к Wi-
Fi-сетям.
Внешние адаптеры —Wi-Fi USB-адаптеры для беспроводных
локальных сетей позволяют быстро подключить к беспровод¬
ной сети любой настольный или мобильный компьютер с USB-
интерфейсом и не требуют для работы внешнего источника пи¬
тания (рис. 5.4).
95
5.3.2. Беспроводные точки доступа
Беспроводная точка доступа (Wireless Access Point, WAP) —
это беспроводная базовая станция (комплекс приемопередающей
аппаратуры), с помощью которой обеспечивается беспроводной
доступ к уже существующей сети (беспроводной или проводной)
или создается новая беспроводная сеть. Часто их называют Wi-Fi-
точки доступа.
Через точку доступа осуществляется взаимодействие и обмен
информацией между беспроводными адаптерами, а также связь с
проводным сегментом сети. Таким образом, точка доступа играет
роль коммутатора. Точка доступа Wi-Fi имеет один или несколько
сетевых интерфейсов, при помощи которых эта точка может быть
подключена к обычной проводной сети. Через этот же интерфейс
может осуществляться и настройка точки.
Точка доступа может использоваться как для подключения груп¬
пы компьютеров (каждый с беспроводным сетевым адаптером)
в самостоятельные сети (режим Ad-hoc), так и для выполнения
функции моста между беспроводными и кабельными участками
сети (режим Infrastructure).
Точка доступа передает свой идентификатор сети SSID (Service
Set Identifier) с помощью специальных сигнальных пакетов. Зная
SSID-сети, клиент может выяснить, возможно ли подключение к
данной точке доступа.
При попадании в зону действия двух точек доступа с идентич¬
ными SSID приемник может выбирать между ними на основании
данных об уровне сигнала. Стандарт Wi-Fi дает клиенту полную
свободу при выборе критериев для соединения. Однако стандарт
не описывает всех аспектов построения беспроводных локальных
сетей Wi-Fi, поэтому каждый производитель оборудования решает
эту задачу по-своему, применяя те подходы, которые он считает
наилучшими с той или иной точки зрения.
Точки доступа могут быть выполнены как для наружного ис¬
пользования и защищены от воздействий внешней среды, так и для
использования внутри помещений.
5.3.3. Антенны
Антенны используются для увеличения дальности работы бес¬
проводной сети и одновременно улучшают передачу и прием
сигналов. Wi-Fi-антенны не требуют программного обеспечения
96
Рис. 5.5. Антенны направленные [а] и всенаправленные (б)
для конфигурирования или инсталляции, могут иметь различные
коэффициенты усиления.
Радиус распространения Wi-Fi-связи зависит от антенн и
окружающей обстановки. Капитальные стены могут значительно
уменьшить мощность сигнала. Серьезным препятствием может
стать мелкая металлическая сетка. На практике расстояние Wi-Fi-
связи варьируется от нескольких десятков до нескольких сотен ме¬
тров, а при использовании специальных антенн даже нескольких
километров. Для построения небольшой сети внутри помещения
достаточно стандартных антенн, поставляемых в комплекте с
Wi-Fi-адаптерами и точками доступа, но иногда возникает не¬
обходимость в использовании отдельно приобретаемых внешних
антенн. Основная характеристика антенн — это коэффициент
усиления антенны. Очевидно, что чем коэффициент усиления
больше, тем лучше.
Существует два типа антенн — направленные и всенаправлен¬
ные (рис. 5.5, а, б соответственно). Всенаправленными антеннами
оснащены встроенные Wi-Fi-сетевые адаптеры, точки доступа,
маршрутизаторы.
5.3.4. Wi-Fi-маршрутизаторы
Wi-Fi-маршрутизаторы позволяют быстро и легко настроить
общий доступ в Интернет для проводной или беспроводной сети.
97
Рис. 5.6. Wi-Fi-роутер
Wi-Fi-роутеры (беспроводные маршрутизаторы), как и проводные
роутеры, предназначены для маршрутизации трафика в компью¬
терной сети. Wi-Fi-роутер имеет одну или две антенны для работы
с сетью Wi-Fi и кабельные порты LAN для подключения пользо¬
вателей внутри сети и WAN подключения внешнего канала связи
(рис. 5.6).
Таким образом, Wi-Fi-роутер объединяет проводные сети и
сети Wi-Fi и осуществляет маршрутизацию между ними. Все Wi¬
Fi-роутеры управляются через веб-интерфейс.
Защиту данных, передаваемых по Wi-Fi, обеспечивают прото¬
колы WPA/WPA2-RADIUS, WPA /WPA2-PSK и WEP. Фильтр МАС-
адресов предотвращает неавторизованный доступ к сети.
5.3.5. Wi-Fi ADSL-модемы
xDSL (Digital Subscriber Line, цифровая абонентская линия) —
семейство технологий, позволяющих значительно повысить про¬
пускную способность абонентской линии телефонной сети общего
пользования путем использования эффективных линейных кодов
и адаптивных методов коррекции искажений линии на основе со¬
временных достижений микроэлектроники и методов цифровой
обработки сигнала.
Технологии xDSL появились в середине 90-х годов XX в. как
альтернатива цифровому абонентскому окончанию ISDN.
В аббревиатуре xDSL символ «х» используется для обозначения
первого символа в названии конкретной технологии.
98
Texнологий xDSL позволяют передавать данные со скоростями,
значительно превышающими те скорости, которые доступны даже
лучшим аналоговым и цифровым модемам.
Эти технологии поддерживают передачу голоса, высокоскорост¬
ную передачу данных и видеосигналов, создавая при этом значительные преимущества как для абонентов, так и для провайдеров.
Многие технологии xDSL позволяют совмещать высокоскоростную
передачу данных и передачу голоса по одной и той же медной паре.
Существующие типы технологий xDSL различаются в основном по
используемой форме модуляции и скорости передачи данных.
ADSL (Asymmetric Digital Subscriber Line, асимметричная цифро-
II,hi абонентская линия) — модемная технология, в которой доступ¬
ная полоса пропускания канала распределена между исходящим и
входящим трафиком асимметрично. Так как у большинства пользователей объем входящего трафика значительно превышает объем
исходящего, то скорость исходящего трафика значительно ниже.
' )то ограничение стало неудобным с распространением пиринговых
сотой и видеосвязи.
Wi-Fi ADSL-модемы являются многофункциональными устрой¬
ствами, предназначенными для доступа в Интернет через теле¬
фонную линию и организующими беспроводной доступ в рамках
локальной сети с возможностью выхода в Интернет (рис. 5.7).
ADSL-модемы разделяют на четыре отдельные группы:
I) внутренние PCI-модемы;
Рис. 5.7. Wi-Fi ADSL-модем
99
2) внешние модемы с интерфейсом USB;
3) внешние модемы с интерфейсом Ethernet;
4) внешние маршрутизаторы (роутеры) с интерфейсом Ethernet.
Большинство ADSL-роутеров поддерживают РРРоЕ про¬
токол.
РРРоЕ (Point-to-point protocol over Ethernet) — сетевой протокол
канального уровня передачи кадров РРР (Point-to-Point Protocol,
двухточечный протокол канального уровня OSI) через Ethernet.
РРРоЕ предоставляет дополнительные возможности, такие как
аутентификация, сжатие данных, шифрование. ADSL-роутеры
способны при необходимости самостоятельно авторизоваться у
провайдера без установки РРРоЕ-клиента на пользовательский
компьютер. Поэтому ADSL-роутер способен легко заменить от¬
дельный сервер, полностью обеспечивая функционирование и
доступ в Интернет небольшой локальной сети. Роутеры подклю¬
чаются через интерфейс Ethernet, а настройка подобных ADSL-
модемов осуществляется через веб-интерфейс с помощью любого
браузера.
Также используются ADSL-роутеры со встроенными свитчами,
точками доступа Wi-Fi, принт-серверами и другими возможно¬
стями. Пожалуй, в настоящее время они представляют собой
наиболее продвинутый вид пользовательского ADSL-модема.
С помощью такого оборудования можно организовать неболь¬
шую домашнюю сеть, подключить услуги связи без использова¬
ния каких-либо дополнительных устройств, что не только весьма
удобно, но и обходятся дешевле покупки сразу нескольких типов
оборудования.
Wi-Fi-репитеры представляют собой устройства, предназна¬
ченные для расширения зоны покрытия беспроводной сети, и
позволяющие использовать уже установленное оборудование для
увеличения расстояния между точками доступа и беспроводными
сетевыми адаптерами.
КОНТРОЛЬНЫЕ ВОПРОСЫ
1. Какие компоненты формируют беспроводную сеть?
2. Какими достоинствами обладает технология беспроводной
передачи данных?
3. Какие скорости передачи соответствуют стандартам 802.11,
802.11а, 802.11b, 802.11 g, 802.11n?
4. В чем принципиальное различие стандартов 802.11 и
802.3?
100
5. Для чего нужны Wi-Fi-адаптеры?
6. Чем различаются Wi-Fi PCI-адаптеры и Wi-Fi внешние адаптеры?
7. Что называют беспроводной точкой доступа? Каковы ее функции?
8. Какие возможности предоставляет Wi-Fi-маршрутизатор?
9. Какие возможности предоставляет технология xDSL?
Глава 6
СЕТЕВОЕ ПРОГРАММНОЕ
ОБЕСПЕЧЕНИЕ. СЛУЖБЫ И СЕРВИСЫ
МНОГОУРОВНЕВЫЕ АРХИТЕКТУРЫ
«КЛИЕНТ-СЕРВЕР»
Компьютеры и программы, входящие в состав информационной
системы, как правило, не являются равноправными. Некоторые из
них владеют ресурсами (файловая система, процессор, принтер,
база данных и т. д.), другие имеют возможность обращаться к этим
ресурсам. Компьютер или программу, управляющую каким-либо
ресурсом, называют сервером этого ресурса («файл-сервер», сер¬
вер базы данных, вычислительный сервер и т.д.). Клиент и сервер
какого-либо ресурса могут находиться как в рамках одной вычис¬
лительной системы, так и на различных компьютерах, связанных
сетью.
кКлиент-сервер» (client-server) — вычислительная или сетевая
архитектура, в которой задания или сетевая нагрузка распределены
между поставщиками услуг, называемыми серверами, и заказчика¬
ми услуг, называемыми клиентами.
Любое конечное устройство может выступать в роли клиента
или сервера. Сервер предоставляет некоторые сервисы или ресур¬
сы клиенту. Клиент — это объект, запрашивающий информацию
по сети. Как правило, это персональный компьютер или рабочая
станция, запрашивающая информацию у сервера.
Важно понимать, что отличие между клиентом и сервером и в
том, какое программное обеспечение установлено на них и как
оно настроено. Например, если взять домашний компьютер и по¬
ставить на него приложение веб-сервер Apache, то можно сказать,
что компьютер выступает в роли сервера. Если взять большой
сервер IBM, поставить на него MS Windows и пользоваться веб¬
браузером, то можно сказать, что это оборудование используется
как клиентская машина. Таким образом, разница между клиентом
102
ii (I'|жором находится на уровне приложений модели OSI; с точки
(рения нижестоящих уровней этой модели, разницы между ними
нет.
11а одном хосте может быть запущено несколько серверов.
И небольших организациях часто практикуется один физический
сервер, на котором работают одновременно, например, веб-сервер,
почтовый сервер, файловый сервер и др. К каждому из этих серве¬
ров могут подключаться свои клиенты.
Преимущества использования архитектуры «клиент-сервер»
очевидны:
■ отсутствие дублирования кода программы-сервера программами-
клиентами;
■ так как все вычисления выполняются на сервере, то требования
к компьютерам, на которых установлен клиент, снижаются;
■ все данные хранятся на сервере, который, как правило, защищен
гораздо лучше большинства клиентов. На сервере проще обеспе¬
чить контроль полномочий, чтобы разрешать доступ к данным
только клиентам с соответствующими правами доступа.
Среди недостатков можно отметить то, что неработоспособность
сервера может сделать неработоспособной всю вычислительную
сеть. Неработоспособным сервером следует считать сервер, произ¬
водительности которого не хватает на обслуживание всех клиентов,
а также сервер, находящийся на ремонте, профилактике и т. п.
Кроме того, поддержка работы данной системы требует отдельного
специалиста — системного администратора.
Существуют так называемые многоуровневые архитектуры
«клиент-сервер» — разновидность архитектуры «клиент-сервер»,
в которой функция обработки данных вынесена на один или не¬
сколько отдельных серверов. Это позволяет разделить функции
хранения, обработки и представления данных для более эффектив¬
ного использования возможностей серверов и клиентов. Частным
случаем является трехуровневая архитектура, в которой клиент
обращается с запросом к серверу баз данных через сервер при¬
ложений.
Трехуровневая, или трехзвенная, архитектура — архитектурная
модель программного комплекса, предполагающая наличие в нем
трех компонентов: клиентского приложения (обычно называемого
«тонким клиентом»), сервера приложений, к которому подключено
клиентское приложение, и сервера базы данных, с которым рабо¬
тает сервер приложений.
Более подробно механизмы трехуровневой клиент-серверной ар¬
хитектуры будут изложены во втором разделе данного учебника.
103
6.2.
СЕТЕВЫЕ СЛУЖБЫ И СЕТЕВЫЕ СЕРВИСЫ
С функциональной точки зрения вычислительная сеть рас¬
сматривается как совокупность сетевых служб, предоставляющих
пользователю определенный набор услуг, например, доступ к ап¬
паратным или программным средствам, либо к информационным
ресурсам другого узла сети.
Служба — это сетевой компонент, реализующий некоторый
набор услуг.
Сетевой сервис — это интерфейс между потребителем услуг
(например, пользователем) и поставщиком услуг (службой).
К сетевыми услугам относятся:
■ хранение данных;
■ поиск информации;
■ почтовые услуги (электронная почта);
■ передача данных между узлами в сети;
■ организация сеансов взаимодействия между прикладными про¬
цессами.
Потребителями сетевых услуг являются пользователи, програм¬
мы, операционные системы, функциональные блоки, вычислитель¬
ные процессы и т. д. Поставщиком сетевых услуг является сетевая
служба, реализующая услуги или набор услуг. Так, поставщиками
услуг являются средства обеспечения общего доступа и использо¬
вания локальных и удаленных ресурсов и услуг.
Кроме доступа к аппаратным, программным средствам и данным
сетевые службы решают и другие, более специфические задачи,
например задачи, связанные с распределенной обработкой данных.
К таким задачам относятся обеспечение синхронизации нескольких
копий данных, размещение на разных узлах (служба репликации),
или организация выполнения одной задачи параллельно на несколь¬
ких машинах сети (служба вызова удаленных процедур).
Серверная часть сетевой службы производит обработку и вы¬
полнение запросов, полученных от клиентской части службы и каса¬
ющихся использования или получения доступа к сетевым ресурсам,
с которыми данная сетевая служба связана. Как правило, сетевая
операционная система предоставляет услуги основных сетевых
служб, обеспечивающих стандартные функции вычислительной сети.
Дополнительные услуги могут предоставляться сетевыми службами,
реализуемыми системными сетевыми приложениями или утилитами,
работающими под управлением операционной системы.
Сетевая служба, предоставляющая пользователю доступ к ре¬
сурсам и возможностям электронной почты, называется почтовой.
104
Файловая служба обеспечивает взаимодействие клиента с удален¬
ными файловыми системами. Сетевая служба печати позволяет
производить печать с использованием принтера. Серверная часть
может предоставлять сетевые услуги клиентской части по инициа¬
тиве этой клиентской части.
Одним из главных показателей качества сетевой службы яв¬
ляется ее удобство, и в первую очередь удобство работ с ней для
пользователя. Именно поэтому сетевые службы обеспечиваются
специальным интерфейсом, в большинстве случаев интуитивно
понятным пользователю.
Для использования сервисов, предоставляемых сетевой службой,
на машине пользователя должна быть установлена клиентская часть
данной службы. Для одной службы может существовать множество
клиентов, различающихся по набору функций и удобству интерфей¬
са. Главное, чтобы клиент обращался к серверу (серверной части
службы) с запросами в соответствии с правилами, понятными сер¬
веру. В связи с этим при разработке сетевых служб исключительно
важной задачей является выбор протокола (правил) сетевых взаи¬
модействий клиентской и серверной части, распределение функций
между ними, согласование протоколов различных вычислительных
сетей. Проблема согласования протоколов особенно важна в свя¬
зи с тем, что узлы вычислительной сети во многих случаях имеют
разные аппаратные платформы и соответственно разные сетевые
программные средства, которые вымогают множество протоколов
сетевого взаимодействия.
По степени интеграции сетевой службы в операционную систе¬
му различают следующие виды программной реализации сетевой
службы:
■ высокая степень интеграции, когда сетевая служба является
частью операционной системы;
■ средняя степень интеграции, когда сетевая служба представляет
собой надстройку над операционной системой;
■ низкая степень интеграции, когда сетевая служба является само¬
стоятельным программным продуктом.
Набор предоставляемых пользователю сетевых услуг зависит от
имеющихся аппаратных и программных средств сети. В последнее
время, особенно с развитием Интернета, число сетевых служб зна¬
чительно возросло. Пользователи имеют дело именно с сетевыми
службами, при этом работа базовых сетевых программных и аппа¬
ратных средств для пользователя становится все менее заметной.
Серверное программное обеспечение — программный компо¬
нент вычислительной системы, выполняющий сервисные функции
105
по запросу клиента, предоставляя ему доступ к определенным ре¬
сурсам или услугам.
Формат запросов клиента и ответов сервера определяется про¬
токолом. Спецификации открытых протоколов описываются откры¬
тыми стандартами, например, протоколы Интернета определяются
в документах RFC.
В зависимости от выполняемых задач одни серверы, при отсут¬
ствии запросов на обслуживание, могут простаивать в ожидании.
Другие могут выполнять какую-то работу, например работу по
сбору информации. У таких серверов работа с клиентами может
быть второстепенной задачей.
Важно понимать, что сервер, предоставляющий какой-либо
сервис, например прокси-сервер, всегда является программой или
программным модулем, выполняющейся на каком-то аппаратном
обеспечении. Без этой программы аппаратное обеспечение не мо¬
жет ничего предоставлять.
6.3.
СЕТЕВАЯ ОПЕРАЦИОННАЯ СИСТЕМА
Операционную систему компьютера (ОС) можно представить
как комплекс управляющих и обрабатывающих программ, который
обеспечивает эффективное управление ресурсами компьютера
(памятью, процессором, внешними устройствами, файлами и др.),
а также предоставляет пользователю удобный интерфейс для ра¬
боты с аппаратурой компьютера и разработки приложений. Это
определение применимо к большинству современных операцион¬
ных систем общего назначения.
Сетевая операционная система — операционная система со
встроенными возможностями для работы в компьютерных сетях.
Сетевая операционная система обеспечивает доступ к ресурсам
удаленных компьютеров и устройств сети и предоставляет ресур¬
сы своей ЭВМ удаленным пользователям. Операционная система
компьютерной сети во многом аналогична операционной системе
локального компьютера.
При организации сетевой работы операционная система играет
роль интерфейса, скрывающего от пользователя все детали функ¬
ционирования низкоуровневых программно-аппаратных средств
сети. Например, вместо числовых адресов компьютеров сети, таких
как МАС-адрес и IP-адрес, операционная система компьютерной
сети позволяет оперировать удобными для запоминания символь¬
ными именами. В результате в представлении пользователя сеть с ее
106
множеством сложных реальных деталей превращается в достаточно
понятный набор разделяемых ресурсов.
На разных ЭВМ сети могут работать одинаковые или различ-
ные операционные системы. Например, на всех компьютерах
сети может работать одна и та же ОС UNIX. Более реалистичным
вариантом является сеть, в которой работают разные операцион¬
ные системы, например часть компьютеров работает под управ¬
лением ОС UNIX, другая часть — под управлением ОС NetWare,
а остальные — под управлением ОС семейства Windows. Все эти
операционные системы функционируют независимо друг от друга
в том смысле, что каждая из них принимает независимые решения
о создании и завершении своих собственных процессов и управ¬
лении локальными ресурсами. Но в любом случае операционные
системы компьютеров, работающих в сети, должны включать
взаимно согласованный набор коммуникационных протоколов для
организации взаимодействия процессов, выполняющихся на разных
компьютерах сети, и разделения ресурсов этих компьютеров между
пользователями сети.
Если операционная система локального компьютера позволя¬
ет ему работать в сети, т. е. предоставлять свои ресурсы в общее
пользование и/или потреблять ресурсы других компьютеров сети,
то такая операционная система этого компьютера также является
сетевой ОС.
На рис. 6.1. показаны основные функциональные компоненты
сетевой операционной системы.
Средства управления локальными ресурсами реализуют функ¬
ции распределения оперативной памяти между процессами, пла¬
нирования и диспетчеризации процессов, мультипроцессорное
управление и другие функции управления ресурсами локальных
операционных систем.
Сетевые средства в свою очередь можно разделить на три ком¬
понента:
1) средства предоставления локальных ресурсов и услуг в общее
пользование — серверная часть операционной системы;
2) средства запроса доступа к удаленным ресурсам и услугам —
клиентская часть операционной системы;
3) транспортные средства операционной системы, которые со¬
вместно с коммуникационной системой обеспечивают переда¬
чу сообщений между компьютерами сети.
Клиентская часть операционной системы не может получить не¬
посредственный доступ к ресурсам другой ЭВМ. Она может только
«попросить» об этом серверную часть ОС, работающую на том
107
Рис. 6.1. Основные функциональные компоненты сетевой операционной
системы
компьютере, которому принадлежат эти ресурсы. Эти «просьбы»
выражаются в виде сообщений, передаваемых по сети. Сообщения
могут содержать не только команды на выполнение некоторых дей¬
ствий, но и собственно данные, например содержимое некоторого
файла.
Управляют передачей сообщений между клиентской и сервер¬
ными частями по коммуникационной системе сети транспортные
средства ОС. Эти средства выполняют такие функции, как фор¬
мирование сообщений, разбиение сообщения на части (пакеты,
кадры), преобразование имен компьютеров в числовые адреса,
организацию надежной доставки сообщений, определение марш¬
рута в сложной сети и т. д. Правила взаимодействия компьютеров
при передаче сообщений по сети фиксируются в коммуникаци¬
онных протоколах, таких как Ethernet, Token Ring, IP, IPX и пр.
Чтобы две ЭВМ смогли обмениваться сообщениями по сети,
транспортные средства их операционных систем должны поддер¬
живать некоторый общий набор коммуникационных протоколов.
Программные модули операционной системы, реализующие эти
коммуникационные протоколы, переносят сообщения клиентских
и серверных частей операционной системы по сети, не вникая в
их содержание.
Клиентские части сетевых ОС выполняют также преобразова¬
ние форматов запросов к ресурсам. Они принимают запросы от
прикладных программ на доступ к сетевым ресурсам в локальной
108
форме, т. е. в форме, принятой в локальной части операционной
системы. В сеть же запрос передается клиентской частью в дру¬
гом форме, соответствующей требованиям серверной части ОС,
работающей на компьютере, где расположен требуемый ресурс.
Клиентская часть также осуществляет прием ответов от серверной
части и преобразование их в локальный формат, так что для при¬
кладной программы выполнение локальных и удаленных запросов
не различимо.
Сетевая операционная система предоставляет пользователю не¬
который набор сетевых услуг при помощи сетевых служб. Таким
образом, сетевая служба представляет собой сетевой компонент,
предоставляющий пользователям сети некоторый набор услуг.
' >ти услуги иногда называют также сетевым сервисом (service).
11еобходимо отметить, что этот термин в технической литературе
переводится и как «сервис», и как «услуга», и как «служба». Хотя
указанные термины иногда используются как синонимы, следует
иметь в виду, что в некоторых случаях различие в значениях этих
терминов носит принципиальный характер. Правильнее под «служ¬
бой» мы будем понимать сетевой компонент, который реализует
некоторый набор услуг, а под «сервисом» — описание того набора
услуг, который предоставляется данной службой. Таким образом,
сервис — это интерфейс между потребителем услуг и поставщиком
услуг (службой).
Каждая служба связана с определенным типом сетевых ресур¬
сов и/или определенным способом доступа к этим ресурсам. На¬
пример, служба печати обеспечивает доступ пользователей сети к
разделяемым принтерам сети и предоставляет сервис печати, а по¬
чтовая служба предоставляет доступ к информационному ресурсу
сети — электронным письмам. Среди сетевых служб можно выде¬
лить такие, которые ориентированы не на простого пользователя,
а на администратора. Такие службы используются для организации
работы сети.
От того, насколько богатый набор услуг предлагает операционная
система конечным пользователям, приложениям и администраторам
сети, зависит ее позиция в общем ряду сетевых ОС.
Первые сетевые операционные системы представляли собой
совокупность уже существующей локальной ОС и надстроенной
над ней сетевой оболочки. При этом в локальную ОС встраивал¬
ся минимум сетевых функций, необходимых для работы сетевой
оболочки, которая выполняла основные сетевые функции. Однако
в дальнейшем разработчики сетевых ОС посчитали более эффек¬
тивным подход, при котором сетевая ОС с самого начала работы
109
над ней задумывается и проектируется специально для работы
в сети. Сетевые функции у этих операционных систем глубоко
встраиваются в основные модули системы, что обеспечивает ее
логическую стройность, простоту эксплуатации и модификации,
а также высокую производительность. Важно, что при таком под¬
ходе отсутствует избыточность. Если все сетевые службы хорошо
интегрированы, т.е. рассматриваются как неотъемлемые части ОС,
то все внутренние механизмы такой операционной системы могут
быть оптимизированы для выполнения сетевых функций.
В сетях с выделенными серверами используются специальные
варианты сетевых операционных систем, которые оптимизированы
для работы в роли серверов и называются серверными ОС. Поль¬
зовательские компьютеры в этих сетях работают под управлением
клиентских операционных систем.
Специализация операционной системы для работы в качестве
сервера является естественным способом повышения эффективно¬
сти серверных операций. А необходимость такого повышения часто
ощущается весьма остро, особенно в крупной сети. При существо¬
вании в сети сотен или даже тысяч пользователей интенсивность
запросов к совместно используемым ресурсам может быть очень
большой, и сервер должен справляться с этим потоком запросов
без больших задержек.
Очевидным решением этой проблемы является использование
в качестве сервера компьютера с мощной аппаратной платфор¬
мой и операционной системой, оптимизированной для сервер¬
ных функций. Чем меньше функций выполняет ОС, тем более
эффективно можно их реализовать, поэтому для оптимизации
серверных операций разработчики ОС вынуждены ущемлять
некоторые другие ее функции, причем иногда вплоть до полного
их отбрасывания.
Однако слишком узкая специализация некоторых серверных
ОС является одновременно и их слабой стороной. Так, отсутствие
в некоторых ОС универсального интерфейса программирования и
средств защиты приложений не позволяет использовать ее в каче¬
стве среды для выполнения прикладных программ, что приводит к
необходимости включения в сеть других серверных операционных
систем. Поэтому разработчики многих серверных операцион¬
ных систем отказываются от функциональной ограниченности и
включают в состав серверных ОС все компоненты, позволяющие
использовать их в качестве универсального сервера и даже в ка¬
честве клиентской ОС. Такие серверные операционные системы
снабжаются развитым универсальным графическим пользователь¬
110
ским интерфейсом. Можно следующим образом сформулировать
отличительные особенности класса серверных ОС:
■ поддержка мощных аппаратных платформ, в том числе мульти¬
процессорных;
■ поддержка большого числа одновременно выполняемых про¬
цессов и сетевых соединений;
■ поддержка сетевого оборудования;
■ поддержка сетевых протоколов, протоколов маршрутизации;
■ поддержка фильтрации сетевого трафика;
■ включение в состав операционной системы компонентов цен¬
трализованного администрирования сети (например, справочной
службы или службы аутентификации и авторизации пользова¬
телей сети);
■ более широкий набор сетевых служб.
Клиентские операционные системы в сетях с выделенными
серверами обычно освобождены от серверных функций, что зна¬
чительно упрощает их организацию. Разработчики клиентских
ОС уделяют основное внимание пользовательскому интерфейсу и
клиентским частям сетевых служб. Наиболее простые клиентские
ОС поддерживают только базовые сетевые службы — обычно фай¬
ловую службу и службу печати. В то же время существуют так назы¬
ваемые универсальные клиенты, которые поддерживают широкий
набор клиентских частей, позволяющих им работать практически
со всеми серверами сети.
Многие компании, разрабатывающие сетевые операционные си¬
стемы, выпускают два варианта одной и той же операционной систе¬
мы. Один вариант предназначен для работы в качестве серверной ОС,
а другой — в качестве клиентской. Эти варианты чаще всего основа¬
ны на одном и том же базовом коде, но отличаются набором служб и
утилит, а также параметрами конфигурации, некоторые из которых
устанавливаются по умолчанию и не поддаются изменению.
ОБЛАЧНЫЕ СЕРВИСЫ
И ИХ ВОЗМОЖНОСТИ
Облачные вычисления (cloud computing) — модель обеспечения
повсеместного и удобного сетевого доступа по требованию к об¬
щим вычислительным ресурсам (сетям передачи данных, серверам,
устройствам хранения данных, приложениям и сервисам), которые
могут быть оперативно предоставлены и освобождены с минималь¬
ными эксплуатационными затратами.
111
Наименование «облачные» компьютерные системы изначально
получили из-за упрощенного обозначения компьютеров, находя¬
щихся в составе одной сети в виде облака с изображенными внутри
него данными. В этом случае каждый компьютер не рассматривает¬
ся в качестве самостоятельной единицы, а является частью целого.
Под целым же подразумевается та область системы, которая не¬
посредственно задействована при работе с пользователем. Таким
образом, все сетевые ресурсы, доступные нам через серверы, по
сути, можно назвать «облаком».
Наибольшую популярность облачные системы получили благо¬
даря развитию сервисов, позволяющих осуществлять хранение фай¬
лов не в памяти компьютера, а в специальном интернет-хранилище.
Подобные функциональные возможности обеспечили пользова¬
телям невиданную ранее свободу выбора, так как все хранимые
в облаке файлы доступны владельцу в любое время и с любого
устройства, подключенного к Интернету. Также облачные сервисы
можно использовать в качестве резервных хранилищ личных дан¬
ных. В случае выхода из строя жесткого диска компьютера всегда
можно вернуть всю необходимую информацию, предварительно
сохраненную в облаках.
Не менее эффективно облачные хранилища можно использовать
и для синхронизации данных между различными компьютерными
устройствами. Например, можно внести изменения в файл на рабо¬
чем компьютере и быть уверенным, что все сделанные исправления
будут внесены во все его копии, хранящиеся на других устройствах,
которые синхронизированы с облачным сервисом.
К наиболее популярным облачным файловым хранилищам от¬
носятся: Google Диск, Яндекс. Диск, Microsoft SkyDrive, Dropbox,
iCloud и др. Практически все они после регистрации предоставляют
пользователям некоторое количество бесплатного места для хране¬
ния файлов (как правило, от 5 до 10 Гб). Если же этого покажется
мало, то за дополнительную плату можно организовать хранилище
емкостью от 20 Гб до нескольких десятков терабайт.
Одним из представителей облачных программ является офисный
пакет Microsoft Office 365. Включая в себя все самые популярные
офисные приложения, такие как Word, Excel, PowerPoint и др., он
обеспечивает доступ к вашим документам отовсюду, где есть до¬
ступ к Интернету, и позволяет работать над ними с самых разных
устройств, даже на которых не установлен пакет Office. Помимо
этого пользователи получают возможность совместно работать над
документами, обмениваться мгновенными сообщениями и не бес¬
покоиться о защищенности собственных данных.
112
Все доступные современному пользователю «облачные» системы
можно поделить на четыре категории:
1) модель SaaS (Software-as-a-Service) — программное обеспече¬
ние как услуга или программное обеспечение по требова¬
нию;
2) модель PaaS (Platform-as-a-Service) ■— платформа как услуга;
3) модель DaaS (Desktop-as-a-Service) — рабочий стол как услуга;
4) модель IaaS (IaaS or Infrastructure-as-a-Service) — инфраструкту¬
ра как услуга.
SaaS — бизнес-модель продажи и использования програм¬
много обеспечения, при которой поставщик разрабатывает
веб-приложение и самостоятельно управляет им, предоставляя
заказчику доступ к программному обеспечению через Интернет.
Основное преимущество модели SaaS для потребителя услуги со¬
стоит в отсутствии затрат, связанных с установкой, обновлением и
поддержкой работоспособности оборудования и работающего на
нем программного обеспечения.
В модели SaaS приложение приспособлено для удаленного
использования и одним приложением пользуется несколько кли¬
ентов.
PaaS — модель предоставления облачных вычислений, при кото¬
рой пользователь получает доступ к использованию информационно¬
технологических платформ: операционных систем, систем управ¬
ления базами данных, связующему программному обеспечению,
средствам разработки и тестирования, размещенным у облачного
провайдера. В этой модели вся информационно-технологическая
инфраструктура, включая вычислительные сети, серверы, систе¬
мы хранения, целиком управляется провайдером, провайдером
же определяется набор доступных для потребителей видов плат¬
форм и набор управляемых параметров платформ, а потребителю
предоставляется возможность использовать платформы, создавать
их виртуальные экземпляры, устанавливать, разрабатывать, тести¬
ровать, эксплуатировать на них прикладное программное обеспе¬
чение, при этом динамически изменяя количество потребляемых
вычислительных ресурсов.
Модель DaaS является логическим продолжением SaaS. Услуга
DaaS дает клиентам полностью готовое к работе стандартизиро¬
ванное виртуальное рабочее место, которое каждый пользователь
имеет возможность дополнительно настраивать под свои задачи.
Таким образом, пользователь получает доступ не к отдельной про¬
грамме, а к необходимому для полноценной работы программно¬
му комплексу. Физически доступ к рабочему месту пользователь
113
может получить через локальную сеть или Интернет. Устройство
доступа используется в качестве тонкого клиента и требования к
нему минимальны.
На сегодняшний день технология DaaS считается перспективным
облачным направлением и позволяет разворачивать полноценное
рабочее место, готовое круглосуточно к работе со всем необхо¬
димым программным обеспечением. При этом все приложения
хранятся в специальном дата-центре, что позволяет эффективно
использовать этот инструмент даже на маломощных компьютерах,
ноутбуках, планшетах и даже смартфонах.
Модель обслуживания IaaS позволяет пользователям самостоя¬
тельно управлять облачными ресурсами, предоставляя в аренду
как аппаратные средства (серверы, клиентские системы, сетевое
оборудование и т.д.), так и операционные системы и необходи¬
мое прикладное программное обеспечение. В большинстве своем
данная технология используется корпоративными клиентами для
создания собственного сервиса облачных вычислений. Потреби¬
тель может контролировать операционные системы, виртуальные
системы хранения данных и установленные приложения, а также
ограниченный контроль набора доступных сервисов. Контроль
и управление основной физической и виртуальной инфраструк¬
турой облака, в том числе сети, серверов, типов используемых
операционных систем, систем хранения осуществляется облачным
провайдером.
Использование облачных сервисов имеет свои положительные
и отрицательные стороны. Преимуществами можно назвать:
■ возможность входа в систему и доступа к личным данным с лю¬
бого устройства, подключенного к Интернету;
■ возможность организации резервного хранения данных;
■ синхронизация данных на всех пользовательских устрой¬
ствах;
■ невысокие требования к исходному программному и техническо¬
му обеспечению устройств для работы в облачных сервисах;
■ возможность использования сложных программных комплексов
на маломощном оборудовании.
К недостаткам можно отнести:
■ невозможность контролировать доступ к хранящимся данным;
■ потребность устанавливать с сервисом интернет-соединение
каждый раз при необходимости получения доступа к файлам
или приложениям;
■ необходимость пользоваться услугами и предложениями опреде¬
ленного разработчика, которому принадлежит сервис.
114
СЛУЖБЫ СЕТЕВОЙ БЕЗОПАСНОСТИ
Б.5.
Технологии Интернета изменяют отношение к обеспечению
сетевой безопасности. Существует широкий спектр технологий
(>Оеспечения информационной безопасности, которые управляют
доступом к информационным ресурсам, контролируют целостность
и подлинность информации и сетевых соединений, проходящих
как через Интернет, так и через внутренние сети организации и
ее партнеров. Из наиболее часто упоминаемых внешних средств
iii щиты информации, соответствующих постоянно возрастающим
требованиям, следует отметить следующие две системы: брандмауэ¬
ры и прокси-серверы.
6.5.1. Прокси-сервер
Прокси-сервер (proxy — представитель, уполномоченный) —
служба или комплекс программ в компьютерных сетях, позволя¬
ющая клиентам выполнять косвенные запросы к другим сетевым
службам.
Клиент подключается к прокси-серверу и запрашивает какой-
либо ресурс (например, e-mail), расположенный на другом сервере,
после чего прокси-сервер либо подключается к указанному серверу
и получает ресурс у него, либо возвращает ресурс из собственного
кэша. Прокси-сервер позволяет защищать компьютер клиента от не¬
которых сетевых атак и помогает сохранять анонимность клиента.
Цели применения прокси-серверов можно сформулировать при¬
веденными ниже способами.
1. Кэширование данных — если часто происходят обращения к
одним и тем же внешним ресурсам, то можно сохранять их копию
на прокси-сервере и выдавать по запросу, снижая тем самым на¬
грузку на канал выхода во внешнюю сеть и увеличивая скорость
получения клиентом информации.
2. Сжатие данных — прокси-сервер загружает информацию из
Интернета и передает ее конечному пользователю в сжатом виде.
Такие прокси-серверы позволяют экономить внешний сетевой
трафик.
3. Защита локальной сети от внешнего доступа: например,
можно настроить прокси-сервер так, что локальные компьютеры
будут обращаться к внешним ресурсам только через него, а внеш¬
ние компьютеры не смогут обращаться к локальным вообще (они
«видят» только прокси-сервер).
115
4. Ограничение доступа из локальной сети к внешней (можно
запретить доступ к определенным веб-сайтам, ограничить использо¬
вание Интернета каким-то локальным пользователям, устанавливать
ограничения на трафик, фильтровать опасный контент).
5. Анонимность доступа к различным ресурсам. Прокси-сервер
может скрывать сведения об источнике запроса или пользователе.
Существуют также искажающие прокси-серверы, которые пере¬
дают целевому серверу ложную информацию об истинном поль¬
зователе.
6. Обход ограничений доступа. Прокси-серверы популярны среди
пользователей стран, где доступ к некоторым ресурсам ограничен
законодательно.
Прокси-сервер, к которому может получить доступ любой поль¬
зователь Интернета, называется открытым.
Функционирование прокси-сервера кратко можно описать сле¬
дующим образом. Все сетевые соединения конкретной программы
или операционной системы по некоторому протоколу совершаются
не на IP-адрес сервера, а на IP-адрес прокси-сервера. Клиентский
компьютер открывает сетевое соединение с прокси-сервером (на
нужном порту) и совершает обычный запрос, как если бы он об¬
ращался непосредственно к ресурсу. Распознав данные запроса,
проверив его корректность и разрешения для клиентского ком¬
пьютера, прокси-сервер, не разрывая соединения, сам открывает
новое сетевое соединение непосредственно с ресурсом и делает
тот же самый запрос. Получив данные (или сообщение об ошиб¬
ке), прокси-сервер передает их клиентскому компьютеру. Прокси-
сервер является полнофункциональным сервером и клиентом для
каждого поддерживаемого протокола и имеет возможность при¬
менения заданных администратором политик доступа на каждом
этапе работы протокола.
В настоящее время, несмотря на возрастание роли других се¬
тевых протоколов, переход к тарификации услуг сети Интернет
по скорости доступа, а также появлением дешевых аппаратных
маршрутизаторов с функцией NAT, прокси-серверы продолжают
широко использоваться на предприятиях.
6.5.2. Брандмауэр
Брандмауэр представляет собой программный или аппаратный
комплекс, который проверяет данные, входящие через Интернет
или сеть, и в зависимости от параметров брандмауэра блокирует
или разрешает их передачу на компьютер.
116
брандмауэр поможет предотвратить проникновение хакеров или
вредоносного программного обеспечения в компьютер через сеть
иди Интернет, а также помогает предотвратить отправку вредонос¬
ных программ на другие компьютеры.
брандмауэр позволяет разделить сеть на две или более частей
п реализовать набор правил, определяющих условия прохождения
пакетов из одной части в другую.
Как правило, эта граница проводится между локальной сетью
предприятия и Интернетом, хотя ее можно провести и внутри ло¬
кальной сети предприятия. Брандмауэр, таким образом, пропускает
через себя весь трафик.
Для каждого проходящего пакета брандмауэр принимает ре¬
шение пропускать его или отбросить. Для того чтобы брандмауэр
мог принимать эти решения, ему необходимо определить набор
правил.
Все брандмауэры можно разделить на три типа:
1) пакетные фильтры;
2) сервера прикладного уровня;
() сервера уровня соединения.
Все типы могут одновременно встретиться в одном бранд¬
мауэре.
Брандмауэры с пакетными фильтрами принимают решение
о том, пропускать пакет или отбросить, просматривая IP-адреса,
флаги или номера TCP портов в заголовке этого пакета. IP-адрес и
помер порта — это информация сетевого и транспортного уровней
соответственно, но пакетные фильтры используют и информацию
прикладного уровня, так как все стандартные сервисы в TCP/IP
ассоциируются с определенным номером порта.
Брандмауэры с серверами прикладного уровня используют сер¬
вера конкретных сервисов (FPT, электронная почта, www и т.д.),
запускаемые на брандмауэре и пропускающие через себя весь
график, относящийся к данному сервису.
Таким образом, между клиентом и сервером образуются два
соединения: от клиента до брандмауэра и от брандмауэра до места
назначения.
Полный набор поддерживаемых серверов различается для каж¬
дого конкретного брандмауэра. Использование серверов приклад¬
ного уровня позволяет скрыть от внешних пользователей структуру
локальной сети, а также дает возможность аутентификации (под¬
тверждения идентичности) на пользовательском уровне. Серверы
протоколов прикладного уровня позволяют обеспечить наиболее
высокий уровень защиты — взаимодействие с внешним миром реа-
117
лизуется через небольшое число прикладных программ, полностью
контролирующих весь входящий и выходящий трафик.
Сервер уровня соединения представляет собой транслятор ТСР-
соединения. Пользователь образует соединение с определенным
портом на брандмауэре, после чего последний производит соеди¬
нение с местом назначения по другую сторону от брандмауэра. Во
время сеанса этот транслятор копирует байты в обоих направлени¬
ях, действуя как провод. Как правило, пункт назначения задается
заранее, в то время как источников может быть много. Используя
различные порты, можно создавать различные конфигурации.
Такой тип сервера позволяет создавать транслятор для любого
определенного пользователем сервиса, базирующегося на TCP,
осуществлять контроль доступа к этому сервису, сбор статистики
по его использованию.
Ряд брандмауэров позволяет также организовывать виртуальные
корпоративные сети, т. е. объединить несколько локальных сетей,
включенных в Интернет в одну виртуальную сеть. Виртуальные
сети позволяют организовать прозрачное для пользователей
соединение локальных сетей, сохраняя секретность и целостность
передаваемой информации с помощью шифрования. При этом
при передаче по Интернету шифруются не только данные поль¬
зователя, но и сетевая информация — сетевые адреса, номера
портов и т. д.
Брандмауэр может использоваться в качестве внешнего роуте¬
ра, используя поддерживаемые типы устройств для подключения
к внешней сети.
КОНТРОЛЬНЫЕ ВОПРОСЫ
1. Дайте определение понятиям «клиент» и «сервер».
2. Каковы преимущества использования архитектуры «клиент-
сервер»?
3. В чем особенность трехуровневой архитектуры «клиент-сер¬
вер»?
4. Что называют сетевой службой и сетевым сервисом?
5. Что можно отнести к сетевым услугам?
6. От чего зависит набор предоставляемых пользователю сетевых
услуг?
7. Какое программное обеспечение называется серверным?
8. Что такое сетевая операционная система?
9. Перечислите основные функциональные компоненты сетевой
операционной системы.
118
10. Каковы различия между операционной системой и серверной
операционной системой?
11. Каковы отличительные особенности серверных ОС?
12. Как классифицируются сетевые приложения?
13. Сформулируйте определение облачных сервисов.
14. Перечислите основные категории облачных систем.
15. Дайте определения моделям SaaS, PaaS, DaaS, laaS.
16. Каковы преимущества и недостатки использования облачных
сервисов? Какие недостатки?
17. Для чего используется прокси-сервер?
18. Что такое брандмауэр?
ТЕХНОЛОГИЯ РАЗРАБОТКИ
И ЗАЩИТЫ БАЗ ДАННЫХ
РАЗДЕЛ
Глава
Глава
Глава
Глава
Глава
7. Основные положения теории баз
данных, хранилищ данных, баз знаний
8. Модели данных
9. Реляционная модель данных
10. Принципы построения концептуальной,
логической и физической модели
данных
11. Архитектура данных
12. Основы SQL
13. Обеспечение целостности данных
14. Современные системы управления
базами данных
Глава 7
ОСНОВНЫЕ ПОЛОЖЕНИЯ ТЕОРИИ
БАЗ ДАННЫХ, ХРАНИЛИЩ ДАННЫХ,
БАЗ ЗНАНИЙ
7.1.
БАЗЫ ДАННЫХ И ИНФОРМАЦИОННЫЕ
СИСТЕМЫ. ОСНОВНЫЕ ОПРЕДЕЛЕНИЯ
В современном мире информация становится фактором, опреде¬
ляющим эффективность любой сферы деятельности. Возрастают
информационные потоки, повышаются требования к скорости
обработки данных, и теперь уже большинство операций не может
быть выполнено вручную, они требуют применения наиболее
передовых и перспективных компьютерных технологий. Большую
роль в настоящее время играют системы хранения и обработки
информации.
Информация — это сведения об объектах, явления, процессах,
событиях окружающего мира, уменьшающие неопределенность
знаний о них.
Информация должна быть полной, достоверной, своевременной,
непротиворечивой, адекватной. Своевременная выдача достоверной
информации для принятия решений — основная цель информаци¬
онных систем.
Информационная система — это совокупность технических и
программных средств, обеспечивающих сбор, хранение, обработку,
поиск, выдачу информации в задачах любой области.
Информационные системы обеспечивают долгосрочное хране¬
ние и качественный анализ информации, помогают решать про¬
блемы и создавать новые информационные продукты.
Предметная область — часть реального мира, данные о кото¬
рой хранятся и используются в информационной системе.
Предметная область подлежит изучению с целью организации
управления и, в конечном итоге, автоматизации. Предметная об¬
ласть характеризуется совокупностью объектов, процессов, исполь¬
зующих эти объекты, а также множеством пользователей, которые
121
имеют единый взгляд на предметную область. Анализ предметной
области предшествует созданию любой информационной систе¬
мы. Предметная область конкретной информационной системы
рассматривается как некоторая совокупность реальных объектов,
представляющих интерес для пользователей. Каждый из этих объ¬
ектов обладает определенным набором свойств и признаков.
Информационный объект — это описание некоторой сущности
предметной области — объекта, процесса, явления или события,
существующих или происходящих в реальном мире. Информацион¬
ный объект является совокупностью логически связанной информа¬
ции, т. е. между информационными объектами могут существовать
разного рода связи.
В информационных системах циркулируют большие объемы
информации, имеющей достаточно сложную структуру. В наиболее
общем виде информационную систему можно условно представить
в виде схемы, состоящей из следующих блоков (рис. 7.1):
■ блок ввода информации (сбор информации о состоянии объектов
внешней среды);
■ база данных (хранилище данных);
■ блок обработки информации (поиск, фильтрация, сортировка,
агрегирование, анализ, вывод информации);
■ блок обратной связи (передача информации, переработанной
потребителем для коррекции входной информации).
База данных является основой информационной системы, ее
центральным звеном.
Данные — это информация, зафиксированная в некоторой фор¬
ме, пригодной для последующей обработки, передачи и хранения,
Обратная
связь
Рис. 7.1. Общее представление информационной системы
122
например, находящаяся в памяти ЭВМ или подготовленная для
инода в ЭВМ.
Паза данных (БД) — именованная совокупность взаимосвязан-
ных данных, отображающая состояние объектов и их отношений
и некоторой предметной области, используемых несколькими
пользователями.
Структурой данных называют совокупность правил и ограни¬
чений, которые отражают связи, существующие между отдельными
частями (элементами) данных.
Обработка данных — это совокупность задач, осуществляющих
преобразование массивов данных. Обработка данных включает в
себя ввод данных в ЭВМ, отбор данных по каким-либо критериям,
преобразование структуры данных, перемещение данных во внеш¬
ней памяти ЭВМ, вывод данных, являющихся результатом вычис¬
лений или других преобразований (в табличном или в каком-либо
ином удобном для пользователя виде).
Система обработки данных (СОД) — это набор аппаратных
и программных средств, осуществляющих выполнение задач по
управлению данными.
Управление данными — весь круг операций с данными, которые
необходимы для успешного функционирования системы обработки
данных.
Метаданные — это описание собственной структуры базы
данных. Их еще называют «данные о данных». Это системные та¬
блицы, в которых содержится информация обо всех объектах БД.
Метаданные обеспечивают независимость данных от программ их
обработки. Если описание данных хранится вместе с данными, то
можно запрашивать и модифицировать данные без написания до¬
полнительных программ обработки структуры данных.
Конечно, требования к качеству и надежности структур хранимых
и обрабатываемых данных очень высоки. Структура базы данных
должна быть таковой, чтобы данные в ней были полными, непроти¬
воречивыми, целостными. Кроме того, базы данных должны быть
спроектированы таким образом, чтобы можно было осуществить
корректный ввод данных и обеспечить возможность своевременного
получения достоверной информации. Поэтому проектирование струк¬
туры базы данных, а также выбор методов доступа к ней является
чрезвычайно важной задачей. Ошибочная или неверная организация
данных в информационной системе делают невозможным соблюдение
этих условий, а саму систему — непригодной для использования.
С понятием базы данных неразрывно связано понятие системы
управления базами данных.
123
Система управления базами данных (СУБД) — это совокуп¬
ность языковых и программных средств, предназначенных для
управления созданием и использованием баз данных.
Системы управления базами данных являются инструменталь¬
ными средствами для извлечения данных, их обработки, изменения
структуры данных и их анализа. СУБД предоставляет удобный,
быстрый и, что очень важно, контролируемый доступ к данным,
обеспечивает возможность ввода и модификации информации в ба¬
зах данных, а также выдачи ее пользователю, обладает средствами
для обеспечения целостности данных и поддержания баз данных
в рабочем состоянии. СУБД обычно сочетает в себе автоматизиро¬
ванные средства структуризации и манипулирования данными со
средствами обеспечения секретности, восстановления и сохран¬
ности информации в многопользовательском окружении.
Система управления базами данных предназначена в основном
для профессиональных разработчиков. Обычный пользователь
осуществляет управление БД и работу с ее данными с помощью
специальных прикладных программ, называемых приложениями.
Приложения могут создаваться в среде или вне среды СУБД с помо¬
щью системы программирования, использующей средства доступа
к базам данных.
В общем случае с одной базой данных могут работать множество
различных приложений. Например, если база данных моделирует
некоторое предприятие, то для работы с ней может быть создано
несколько приложений: обслуживающее подсистему учета кадров,
работу подсистемы расчета заработной платы сотрудников или
подсистему складского учета и т.д. При рассмотрении приложе¬
ний, работающих с одной базой данных, предполагается, что они
могут работать параллельно и независимо друг от друга. Именно
СУБД должна обеспечить работу нескольких приложений с единой
базой данных таким образом, чтобы каждое из них выполнялось
корректно, но учитывало все изменения в базе данных, вносимые
другими приложениями (рис. 7.2).
Однопользовательская система — это система, в которой в
одно и то же время к базе данных может получить доступ не более
одного пользователя.
Многопользовательская система — это система, в которой в
одно и то же время к базе данных может получить доступ несколько
пользователей.
Основная задача большинства многопользовательских систем —
позволить каждому отдельному пользователю работать с системой
как с однопользовательской. Различия однопользовательской и
124
многопользовательской систем заклю-
ч(потея в их внутренней структуре, ко¬
нечному пользователю они практически
но видны.
Современной формой организации
хранения и доступа к информации яв¬
ляется банк данных. Существуют разные
определения банка данных. Сформули¬
руем наиболее полное из них.
Банк данных (БнД) — это система
специальным образом организованных
данных (баз данных), программных, язы¬
ковых, организационно-методических
средств, предназначенных для обеспечения централизованного на¬
копления и коллективного многоцелевого использования данных.
Банк данных является сложной системой, включающей в себя
все обеспечивающие подсистемы, необходимые для автоматизиро¬
ванной обработки данных. В этом определении обозначены и основ¬
ные отличительные особенности банков данных. Прежде всего это
то, что базы данных создаются обычно не для решения какой-либо
одной задачи для одного пользователя, а для многоцелевого ис¬
пользования. Другой отличительной особенностью банков данных
является наличие специальных языковых и программных средств,
облегчающих для пользователей выполнение всех операций, свя¬
занных с организацией хранения данных, их корректировки и до¬
ступа к ним. Таким образом, банк данных — это совокупность базы
данных с соответствующей системой управления базами данных.
База данных — централизованное хранилище в ЭВМ опреде¬
ленным образом организованной информации. СУБД — специ¬
альный комплекс программ, осуществляющий функции создания
базы данных, поддержание ее в рабочем состоянии, выдача из нее
информации, необходимой для обрабатывающих программ и т.д.
Словарь данных (СД) представляет собой подсистему банка
данных, предназначенную для централизованного хранения ин¬
формации о структурах данных, взаимосвязях файлов базы данных
друг с другом, типах данных и форматах их представления, раз¬
граничения доступа к данным и т. п. Словарь данных является тем
средством, которое позволяет при проектировании, эксплуатации
и развитии базы данных поддерживать и контролировать инфор¬
мацию о данных.
В некоторых БД предполагается не централизованное хранение
данных, а распределенное в компьютерной сети.
125
Распределенная база данных (РБД) — это база данных, вклю¬
чающая фрагменты из нескольких баз данных, которые располага¬
ются на различных узлах сети компьютеров и, возможно, управля¬
ются различными СУБД.
Распределенная база данных выглядит с точки зрения пользова¬
телей и прикладных программ как обычная локальная база данных.
Распределенная база данных повышает возможности совместного
использования удаленных данных, надежность, доступность и про¬
изводительность системы, позволяет полупить экономию средств и
улучшить масштабируемость системы.
Современные информационные системы используют не только
базы данных, но и базы знаний.
Знания — это выявленные закономерности предметной обла¬
сти (принципы, связи, законы), позволяющие решать задачи этой
области.
База знаний — совокупность знаний предметной области.
Системы, использующие знания, называются интеллектуаль¬
ными.
После того как был раскрыт смысл основных понятий теории баз
данных, можно перейти к вопросам их разработки и реализации.
Но к приведенным выше формулировкам и определениям рекомен¬
дуется еще периодически возвращаться (после изучения следующих
разделов курса) для их более четкого усвоения.
В заключение еще определим основные категории пользовате¬
лей и разработчиков баз данных и их роль в функционировании
банка данных.
Конечные пользователи — это основная категория пользовате¬
лей, в интересах которых и создается база данных. Это могут быть
случайные пользователи, обращающиеся к БД время от времени
за получением некоторой информации (например, клиенты фир¬
мы, просматривающие каталог продукции или услуг), могут быть
регулярные пользователи (например, сотрудники, работающие со
специально разработанными для них программами при выполнении
своих должностных обязанностей). От конечных пользователей не
должно требоваться каких-либо специальных знаний в области вы¬
числительной техники и программирования.
Разработчики и администраторы приложений — это группа
пользователей, которая функционирует во время проектирования,
создания и реорганизации БД. Администраторы приложений коор¬
динируют работу разработчиков при разработке конкретного при¬
ложения или группы приложений, объединенных в функциональ¬
ную подсистему. Разработчики конкретных приложений работают
126
| той частью информации из базы данных, которая требуется для
конкретного приложения.
Не всегда могут быть выделены все типы пользователей. При раз¬
работке информационных систем с использованием персональных
СУВД администратор банка данных, администратор приложений и
разработчик часто существовали в одном лице. Однако при построе¬
нии современных сложных корпоративных баз данных, которые
используются для автоматизации всех или большей части бизнес-
процессов в крупной фирме или корпорации, могут существовать
и группы администраторов приложений, и отделы разработчиков.
Наиболее сложные обязанности возложены на группу админи¬
стратора БД.
Администраторы баз данных — группа пользователей, кото¬
рая на начальной стадии разработки БД отвечает за ее оптимальную
организацию и одновременную работу конечных пользователей.
На стадии развития и реорганизации эта группа пользователей
отвечает за возможность корректной реорганизации БД без изме¬
нения или прекращения его текущей эксплуатации.
В составе группы администратора БД должны быть:
■ системные аналитики;
■ проектировщики структур данных и внешнего по отношению к
банку данных информационного обеспечения;
■ проектировщики технологических процессов обработки дан¬
ных;
■ системные и прикладные программисты;
■ операторы и специалисты по техническому обслуживанию.
СИСТЕМЫ УПРАВЛЕНИЯ БАЗАМИ
ДАННЫХ. ОСНОВНЫЕ ФУНКЦИИ СУБД
Файл с точки зрения прикладной программы — это именованная
область внешней памяти, в которую можно записывать и из которой
можно считывать данные.
Правила именования файлов, способ доступа к данным, храня¬
щимся в файле, и структура этих данных зависят от конкретной
системы управления файлами и от типа файла. Система управления
файлами берет на себя функции распределения внешней памяти,
отображения имен файлов в соответствующие адреса во внешней
памяти, обеспечения доступа к данным. Однако этого оказывается
недостаточно для построения даже простых информационных си¬
стем. Системы управления файлами не обеспечивают возможности
127
поддержания логически согласованного набора файлов, обеспече¬
ния языка манипулирования данными, восстановления информации
после разного рода сбоев, параллельной работы нескольких поль¬
зователей. Прикладная программа должна опираться на некоторую
систему управления данными, обладающую этими свойствами.
Такой системой и является система управления базами данных.
Системы обработки данных включают в себя собственно данные,
систему управления базами данных и прикладное программное
обеспечение, которое обращается к данным через систему управ¬
ления БД.
Можно выделить следующие функции систем управления ба¬
зами данных:
■ управление данными во внешней памяти;
■ управление данными в оперативной памяти;
■ управление транзакциями;
■ журнализация, резервное копирование и восстановление;
■ поддержка языков БД.
Управление данными во внешней памяти (на дисках). СУБД
должна предоставлять пользователям возможность:
■ сохранять, извлекать и обновлять данные в базе данных;
■ контролировать доступ к данным;
■ обеспечивать параллельную работу нескольких пользователей;
ш поддерживать целостность данных.
Возможность сохранять, извлекать и обновлять данные в базе
данных — самая фундаментальная функция СУБД. Причем способ
реализации этой функции должен быть скрыт от конечного пользо¬
вателя (использует ли СУБД файловую систему, как организованы
файлы и т.п.).
Контроль доступа к данным — это возможность обеспечить
только санкционированный доступ к базе данных, используя защиту
паролем, поддержку уровней доступа к базе данных и отдельным ее
элементам и т. д. Каждый пользователь должен иметь возможность
работы только с теми данными из БД, которые доступны для него
в соответствии с его пользовательскими правами. Таким образом,
обеспечивается безопасность в системах управления данными.
Управление параллельностью заключается в том, что СУБД име¬
ют механизм, который гарантирует корректное обновление данных
многими пользователями при одновременном доступе. Коллизии
при совместной работе могут привести к нарушению логической
целостности данных, поэтому система должна предусматривать
меры, не допускающие обновление данных пользователем, пока
эти данные используются кем-то еще. В описанных случаях ис¬
128
пользуются так называемые «блокировки». Существуют разные
типы блокировок — табличные, страничные, строчные и другие,
которые отличаются друг от друга количеством заблокированных
записей.
Поддержка целостности данных осуществляется инструмен¬
тальными средствами контроля для того, чтобы данные и их изме¬
нения соответствовали заданным правилам. Целостность БД есть
свойство базы данных, означающее, что в ней содержится полная,
непротиворечивая и адекватно отражающая предметную область
информация. Поддержание целостности БД включает проверку
целостности и ее восстановление в случае обнаружения противо¬
речий в базе данных.
Целостное состояние БД описывается с помощью ограничений
целостности в виде условий, которым должны удовлетворять хра¬
нимые в базе данные. Примером таких условий может служить
ограничение диапазонов возможных значений атрибутов объектов,
сведения о которых хранятся в БД, или отсутствие повторяющихся
записей в таблицах реляционных БД.
Управление данными в оперативной памяти. Размер базы
данных, с которой работает СУБД, достаточно велик — обычно
существенно больше доступного объема оперативной памяти. По¬
нятно, что если при обращении к любому элементу данных будет
производиться обмен с внешней памятью, то вся система будет
работать со скоростью устройства внешней памяти. Практически
единственным способом реального увеличения этой скорости яв¬
ляется буферизация данных в оперативной памяти.
Буферы представляют собой области оперативной памяти, пред¬
назначенные для ускорения обмена между внешней и оперативной
памятью. В буферах временно хранятся фрагменты БД, данные из
которых предполагается использовать при обращении к СУБД или
планируется записать в базу после обработки.
В развитых СУБД поддерживается собственный набор буферов
оперативной памяти с собственными правилами замены буферов.
Возможно, что в будущем объем оперативной памяти компьютеров
будет настолько велик, что позволит не беспокоиться о буфери¬
зации.
Управление транзакциями. Транзакция — это совокупность дей¬
ствий над базой данных, рассматриваемых СУБД как единое целое,
т.е. последовательность операций с данными, когда выполняются
все операции либо ни одна из них (принцип «все или ничего»).
Если транзакция выполняется успешно, то СУБД фиксирует из¬
менения БД, произведенные этой транзакцией, во внешней памяти,
129
либо все изменения в рамках транзакции отменяются и ни одно из
них никак не отражается на состоянии БД.
Понятие транзакции необходимо для поддержания логической
целостности БД. Примером транзакции является операция перевода
денег с одного счета на другой в банковской системе. Нужно либо
совершить все действия (увеличить счет одного клиента и умень¬
шить счет другого), либо не выполнить ни одно из этих действий.
Нельзя уменьшить сумму денег на одном счете, но не увеличить
сумму денег на другом.
Предположим, что после выполнения первого из действий
(уменьшения суммы денег на счете) произошел сбой. Например,
могла прерваться связь клиентского компьютера с базой данных
или на клиентском компьютере мог произойти системный сбой, что
привело к перезагрузке операционной системы. Что в этом случае
стало с базой данных? Команда на уменьшение денег на счете пер¬
вого клиента была выполнена, а вторая команда — на увеличение
денег на другом счете — нет, что привело бы к противоречивому,
неактуальному состоянию базы данных. Сначала снимают деньги
с одного счета, затем добавляют их к другому счету. Если хотя бы
одно из действий не выполнится успешно, результат операции ока¬
жется неверным и будет нарушен баланс между счетами. Поэтому
в этом случае система должна вернуться в предыдущее состояние
до начала цепочки операций.
Контроль транзакций важен в однопользовательских и много¬
пользовательских СУБД, где транзакции могут быть запущены
параллельно.
При параллельном выполнении нескольких транзакций воз¬
можно возникновение конфликтов, разрешение которых является
также функцией СУБД. При обнаружении таких случаев обычно
производится «откат» транзакции, т. е. отмена изменений, произ¬
веденных одной или несколькими транзакциями. Более подробно
механизм транзакций и управление транзакциями будет рассмотрен
при изучении вопросов обеспечения целостности данных.
Журнализация, резервное копирование и восстановление.
При работе ЭВМ возможны сбои (например, из-за отключения
электропитания) и повреждение машинных носителей данных.
При этом могут быть нарушены данные, что приводит к невоз¬
можности дальнейшей работы. Одним из основных требований к
СУБД является надежность хранения данных во внешней памяти,
в том числе защита физической и логической целостности. Под
надежностью хранения понимается то, что СУБД должна иметь
возможность восстановить последнее согласованное состояние БД
130
после любого аппаратного или программного сбоя (логических или
физических отказов).
Защита физической целостности включает в себя журнализацию
изменений, резервное копирование и восстановление базы данных
после сбоев.
Журнализация изменений в простейшем случае заключается в
последовательной записи во внешнюю память всех изменений,
выполняемых в базе данных. Записывается следующая информа¬
ция: порядковый номер, тип и время изменения; идентификатор
транзакции; объект, подвергшийся изменению (номер хранимого
файла и номер блока данных в нем, номер строки внутри блока);
предыдущее и новое состояние объекта.
Журнал изменений базы данных — это и есть формируемая
таким образом информация. Журнал содержит отметки начала и
)завершения транзакции и отметки принятия контрольной точки. Он
является особой частью базы данных, недоступной пользователям
СУБД. Ведение журнала поддерживается с особой тщательностью,
в которую поступают записи обо всех изменениях основной части
базы данных. Иногда создаются и поддерживаются две копии жур¬
нала, располагаемые на разных физических дисках.
Резервное копирование базы данных — процесс создания копии
данных на носителе, предназначенном для восстановления данных
в оригинальном или новом месте их расположения в случае их по¬
вреждения или разрушения.
Восстановление базы данных — это функция СУБД, которая
в случае логических и физических сбоев приводит базу данных
в актуальное состояние. Как уже отмечалось выше, сбой может
произойти в результате выхода из строя системы или запомина¬
ющего устройства, возможны ошибки аппаратного и программного
обеспечения, которые могут привести к остановке работы СУБД.
Во всех подобных случаях СУБД должна предоставить механизм
восстановления базы данных и возврата к ее непротиворечивому
состоянию.
В случае физического отказа, если повреждены как журнал
изменений, так и сама база данных, то восстановление возможно
только на момент выполнения резервной копии.
Поддержка языков БД. Для работы с базами данных исполь¬
зуются специальные языки, в целом называемые языками баз
данных. В современных СУБД обычно поддерживается единый
интегрированный язык, содержащий все необходимые средства для
работы с БД, начиная от ее создания, и обеспечивающий базовый
пользовательский интерфейс с базами данных. Стандартным язы-
131
ком наиболее распространенных в настоящее время реляционных
СУБД является язык SQL (Structured Query Language).
Кроме основных функций СУБД еще предоставляет некоторый
набор различных вспомогательных служб. Вспомогательные утили¬
ты обычно предназначены для эффективного администрирования
базы данных, что включает в себя:
■ экспорт/импорт данных;
■ мониторинг базы данных — отслеживание характеристик функ¬
ционирования и использования базы данных;
■ статистический анализ, позволяющий оценить производитель¬
ность или степень использования базы данных;
■ реорганизация индексов;
■ сборка «мусора» (неиспользуемых записей) и перераспределение
памяти для физического устранения удаленных записей с запо¬
минающих устройств, объединение освобожденного простран¬
ства и перераспределение памяти в случае необходимости.
Организация типичной системы управления базой данных и
состав ее компонентов соответствует рассмотренному нами набору
функций.
В современной системе управления базами данных можно
выделить ядро СУБД, процессор языка базы данных, подсистему
поддержки времени выполнения, а также сервисные программы
(внешние утилиты), обеспечивающие дополнительные возможности
по обслуживанию БД. В некоторых системах эти части выделяются
явно, в других — нет, но логически такое разделение можно про¬
вести во всех системах управления базами данных.
Ядро СУБД отвечает за управление данными во внешней па¬
мяти, управление буферами оперативной памяти, управление
транзакциями и журнализацию. Иными словами, ядро СУБД — это
набор программных модулей, необходимый и достаточный для
создания и поддержания БД — универсальная часть, решающая
стандартные задачи по информационному обслуживанию поль¬
зователей.
Сервисные программы предоставляют пользователям ряд до¬
полнительных возможностей и услуг, зависящих от описываемой
предметной области и потребностей конкретного пользователя.
Процессор языка БД компилирует операторы языка баз данных
в некоторую выполняемую программу, представляемую в машин¬
ных кодах.
Наконец в отдельные утилиты БД обычно выделяют такие про¬
цедуры, как например, загрузка и выгрузка БД, сбор статистики,
глобальная проверка целостности БД и т.д. Утилиты программи¬-
132
руются с использованием интерфейса ядра СУБД, а иногда даже с
пpoникновением внутрь ядра.
АРХИТЕКТУРА БАЗЫ ДАННЫХ.
ФИЗИЧЕСКАЯ И ЛОГИЧЕСКАЯ
НЕЗАВИСИМОСТЬ
Идеи многоуровневой архитектуры СУБД впервые были сфор¬
мулированы в отчете комитета по стандартизации Американского
национального института стандартов (ANSI), опубликованном в
1975 г. В нем была предложена обобщенная трехуровневая модель
архитектуры СУБД, включающая внешний, концептуальный и фи¬
зический (внутренний) уровни (рис. 7.3). Основная цель введения
подобной архитектуры заключается в отделении пользовательского
представления базы данных от ее физического представления. На
различных уровнях архитектуры СУБД поддерживается разный
уровень абстракции данных.
Архитектура СУБД должна обеспечивать в первую очередь раз¬
граничение пользовательского и системного уровней.
Уровень внешних моделей — самый верхний уровень, где каж¬
дая модель имеет свое представление данных. Отдельные группы
пользователей работают только с теми данными, к которым имеется
доступ в рамках данного приложения, т. е. каждое приложение ви¬
дит и обрабатывает только те данные, которые необходимы именно
этому приложению.
Рис. 7.3. Трехуровневая модель системы управления базой данных
133
Например, если база данных моделирует некоторое предприятие,
то для работы с ней может быть создано несколько приложений.
Приложение, обслуживающее подсистему учета кадров, исполь¬
зует личные данные сотрудников — год рождения, паспортные
данные, адрес и т.д. Приложение, в котором ведется учет товаров
на складе, сотрудники рассматриваются как лица, принимающие
и отпускающие товар и их личные сведения здесь не нужны, но
нужна информация о товарах и поставщиках. При этом вся эта
информация хранится в одной базе данных.
Разные приложения могут быть созданы с использованием раз¬
личных языков программирования. Прикладные программисты
чаще применяют либо языки высокого уровня, либо специальные
языки СУБД.
При рассмотрении приложений, работающих с одной базой
данных, предполагается, что они могут работать параллельно и не¬
зависимо друг от друга. Именно СУБД должна обеспечить работу
нескольких приложений с единой базой данных таким образом,
чтобы каждое из них выполнялось корректно, но учитывало все
изменения в базе данных, вносимые другими приложениями.
Описание представления данных для группы пользователей
называется внешней схемой. В системе БД могут одновременно
поддерживаться несколько внешних схем для различных групп
пользователей или задач.
Концептуальный уровень архитектуры является основным
и служит для представления базы данных в общем виде для всех
ее приложений и независимого от них. Концептуальный уровень
является промежуточным уровнем в трехуровневой архитектуре
и обеспечивает представление всей информации базы данных
в абстрактной форме. Это формализованная информационно¬
логическая модель предметной области, т.е. это полное представ¬
ление требований к данным предметной области, не зависящее от
способов их представления и хранения. Описание базы данных на
этом уровне называется концептуальной схемой. Концептуальная
схема включает объекты и их атрибуты, связи между объектами,
ограничения, накладываемые на данные, семантическую инфор¬
мацию о данных, обеспечение безопасности и поддержки целост¬
ности данных.
Концептуальная схема — это единое логическое описание всех
элементов данных и отношений между ними, логическая структура
всей базы данных. Как любая модель, концептуальная схема отра¬
жает только существенные с точки зрения обработки особенности
объектов реального мира.
134
Физический (внутренний) уровень архитектуры поддержи¬
вает представление базы данных в среде хранения. Описание базы
данных на физическом уровне называется внутренней схемой, или
схемой хранения.
Физический уровень — собственно данные, расположенные в
файлах или в страничных структурах, расположенных на внеш¬
них носителях информации. Это физическая реализация базы
данных. На этом уровне необходимо достичь оптимальной произ¬
водительности и обеспечить экономное использование дискового
пространства.
На физическом уровне осуществляется взаимодействие СУБД
с методами доступа операционной системы с целью размещения
данных на запоминающих устройствах, создания индексов, извле¬
чения данных и т. д.
На физическом уровне хранится информация о распределении
дискового пространства для хранения данных и индексов, описание
подробностей сохранения записей (с указанием реальных размеров
сохраняемых элементов данных), сведения о размещении записей,
сведения о сжатии данных и выбранных методов их шифрования.
Физический уровень контролируется операционной системой,
но под руководством СУБД. В настоящее время физический уровень
практически полностью обеспечивается СУБД. Основной акцент
при проектировании БД переносится на создание модели концеп¬
туального уровня.
В архитектурной модели ANSI предполагается наличие в СУБД
механизмов, обеспечивающих межуровневое отображение данных.
Функциональные возможности этих механизмов обеспечивают
абстракцию данных и определяют степень независимости данных
на всех уровнях.
В соответствии междууровневыми отображениями принято вы¬
делять логическую и физическую независимость данных.
Логическая независимость означает защищенность внешних
схем от изменений, вносимых в концептуальную схему. Кроме
того, логическая независимость предполагает возможность изме¬
нения одного приложения без корректировки других приложений,
работающих с этой же базой данных, и реорганизации механизма
доступа к физическим данным.
Физическая независимость означает защищенность концептуаль¬
ной схемы от изменений, вносимых в схему хранения. Физическая
независимость предполагает также возможность переноса храни¬
мой информации с одних носителей на другие при сохранении ра¬
ботоспособности всех приложений, работающих с базой данных.
135
КОНТРОЛЬНЫЕ ВОПРОСЫ
1. Дайте определение следующим понятиям: «информация»,
«информационная система», «информационный объект» и
«информационная технология».
2. Что называется базой данных и каково ее место в информа¬
ционной системе?
3. В чем отличие между данными и метаданными?
4. Каково назначение систем управления базами данных?
5. Каким образом прикладные программы взаимодействуют с
базой данных?
6. Чем банк данных отличается от базы данных?
7. Какие компоненты входят в состав банка данных?
8. Для чего используется словарь данных?
9. Перечислите основные категории пользователей и разработ¬
чиков баз данных. Какова их роль в функционировании банка
данных?
10. Каковы функции систем управления базами данных?
11. Для чего нужна журнализация в базах данных?
12. Что такое транзакция?
13. Какие вспомогательные службы предлагает СУБД?
14. Что означает целостность базы данных?
15. Что представляет трехуровневая архитектура СУБД?
16. В чем особенность уровень внешних моделей?
17. В чем особенность концептуального уровня?
18. В чем особенность физического уровня?
19. Что называется схемой базы данных?
20. Что означает физическая и логическая независимость дан¬
ных?
Глава 8
МОДЕЛИ ДАННЫХ
8.1.
ПОНЯТИЕ МОДЕЛИ ДАННЫХ
В классической теории баз данных модель данных есть формаль¬
ная теория представления и обработки данных в системе управле¬
ния базами данных.
Длительное время термин «модель данных» использовался без
формального определения. Одним из первых специалистов, который
достаточно точно определил это понятие, был Э. Кодд. Хотя понятие
модели данных было введено Коддом, наиболее распространенная
трактовка модели данных принадлежит Кристоферу Дейту. Согласно
его определению модель данных включает три аспекта:
1) аспект структуры — методы описания типов и логических
структур данных в базе данных;
2) аспект манипуляции — методы манипулирования данными;
3) аспект целостности — методы описания и поддержки целост¬
ности базы данных.
Аспект структуры определяет, что логически представляет со¬
бой база данных.
Аспект манипуляции содержит спецификацию одного или не¬
скольких языков, предназначенных для написания запросов к БД. Эти
языки могут быть абстрактными, не обладающими точно прорабо¬
танным синтаксисом. Основное назначение манипуляционной части
модели данных — обеспечить эталонный язык БД, уровень вырази¬
тельности которого должен поддерживаться в реализациях СУБД,
соответствующих данной модели. Аспект манипуляции определяет
способы перехода между состояниями базы данных —- способы мо¬
дификации данных и способы извлечения данных из базы данных.
Аспект целостности определяет средства описаний корректных
состояний базы данных. В целостной части модели данных описы-
137
ваются механизмы ограничений целостности, которые обязательно
должны поддерживаться во всех реализациях СУБД, соответству¬
ющих данной модели.
В теории баз данных модель данных является ядром любой базы
данных. Модель данных описывает информационные объекты пред¬
метной области, взаимосвязи между ними и позволяет:
■ определить границу между логическим и физическим аспектами
управления базой данных (независимость данных);
■ обеспечить конечным пользователям и программистам возмож¬
ность и средства общего понимания смысла данных (коммуни¬
кабельность);
■ определить языковые понятия высокого уровня, обеспечива¬
ющие возможность выполнения однотипных операций над боль¬
шими совокупностями записей (в общем случае разнотипных
данных) как единую операцию (обработка множеств).
В модели данных описывается некоторый набор понятий и
признаков, которыми должны обладать все конкретные СУБД и
управляемые ими базы данных, если они основываются на этой
модели. Наличие модели данных позволяет сравнивать конкретные
реализации, используя один общий язык.
К числу классических относятся следующие модели данных:
■ иерархическая;
■ сетевая;
■ реляционная.
Кроме того, в последние годы стали более активно внедряться
на практике следующие модели данных:
■ многомерная;
■ объектно-ориентированная.
Разрабатываются также всевозможные системы, основанные
на других моделях данных, расширяющих известные модели. В их
числе можно назвать объектно-реляционные, дедуктивно-объектно-
ориентированные, семантические, концептуальные и ориентиро¬
ванные модели. Некоторые из этих моделей служат для интеграции
баз данных, баз знаний и языков программирования. В некоторых
СУБД поддерживается одновременно несколько моделей данных.
ТЕОРЕТИКО-ГРАФОВЫЕ МОДЕЛИ ДАННЫХ
Иерархическая модель данных использует представление пред¬
метной области БД в форме иерархического дерева, узлы которого
связаны по вертикали отношением «предок — потомок».
138
Дерево — это связный неориентированный граф, который
не содержит циклов. При работе с деревом выделяют какую-то
конкретную вершину, определяют ее как корень дерева и
рассматривают особо — в эту вершину не заходит ни одно ребро.
В этом случае дерево становится ориентированным, ориентация
определяется от корня.
Конечные вершины, т. е. вершины, из которых не выходит ни
одной дуги, называются листьями дерева. Количество вершин
па Пути от корня к листьям в разных ветвях дерева может быть
различным. В иерархических моделях данных используется
ориентация древовидной структуры от корня к листьям. Графическая
диаграмма схемы базы данных называется деревом определения.
Иерархическая структура предполагает неравноправие между
данными — одни жестко подчинены другим. Создание иерархиче¬
ской модели обосновывается тем, что в реальном мире очень многие
связи соответствуют иерархии, когда один объект выступает как
родительский, а с ним может быть связано множество подчинен¬
ных объектов.
Каждая вершина дерева соответствует сущности предметной
области. Эта сущность характеризуется произвольным количеством
атрибутов. Пример иерархической базы данных показан на
рис. 8.1.
Передвижение по дереву всегда начинается с корневой вершины,
от которой можно прейти на конкретный экземпляр записи любой
вершины следующего уровня. Эта вершина становится текущей
вершиной, а экземпляр — текущим экземпляром (записью).
От этой записи можно перейти к другой записи данной вершины,
к экземпляру записи родительской вершины или экземпляру записи
подчиненной вершины.
В соответствии с определением типа «дерево» можно заключить,
что между предками и потомками автоматически поддерживается
контроль целостности связей.
Основное правило контроля целостности формулируется сле¬
дующим образом: потомок не может существовать без родителя,
а у некоторых родителей может не быть потомков. Механизмы
поддержания целостности связей между записями различных де¬
ревьев отсутствуют.
К достоинствам иерархической модели данных относятся эффек¬
тивное использование памяти ЭВМ и неплохие показатели време¬
ни выполнения основных операций над данными. Иерархическая
модель данных удобна для работы с иерархически упорядоченной
информацией.
139
Рис. 8.1. Представление связей в иерархической модели
Основными недостатком иерархической модели данных являются
дублирование данных, ее громоздкость для обработки информации
с достаточно сложными логическими связями, а также сложность
понимания для обычного пользователя.
Расширением иерархического подхода к организации данных яв¬
ляется сетевой подход. В сетевой модели данных любой объект может
быть одновременно и главным, и подчиненным, и может участвовать
в образовании любого числа взаимосвязей с другими объектами.
Сетевая БД состоит из набора записей и набора связей между этими
записями, а если говорить более точно — из набора экземпляров
каждого типа из заданного в схеме БД набора типов записи и набора
экземпляров каждого типа из заданного набора типов связи.
Сетевая модель данных позволяет отображать разнообразные
взаимосвязи элементов данных в виде произвольного графа, обоб¬
щая тем самым иерархическую модель данных.
Сетевые базы данных обладают рядом преимуществ.
140
■ Гибкость. Множественные отношения предок/потомок позво¬
ляют сетевой базе данных хранить данные, структура которых
была сложнее простой иерархии.
■ Стандартизация.
■ быстродействие. Вопреки своей большой сложности, сетевые
базы данных достигали быстродействия, сравнимого с быстро¬
действием иерархических баз данных.
Недостатком сетевой модели данных является высокая слож¬
ность и жесткость схемы БД, построенной на ее основе, а также
( ложность для понимания и выполнения обработки информации в
БД обычным пользователем. Кроме того, в сетевой модели данных
ослаблен контроль целостности связей вследствие допустимости
установления произвольных связей между записями.
| РЕЛЯЦИОННАЯ МОДЕЛЬ
Реляционная модель относится к теоретико-множественным
моделям данных и на сегодняшний день является самой попу¬
лярной как среди пользователей, так и среди профессиональных
разработчиков. Реляционная модель появилась вследствие стремле¬
ния сделать базу данных как можно более гибкой. Данная модель
предоставила простой и эффективный механизм поддержания
связей данных. Реляционные системы управления базами данных
представляют собой одну из наиболее удачных технологий обра¬
ботки данных. Большая часть данных в мире бизнеса хранится в
реляционной форме.
Реляционная модель единственная из всех обеспечивает едино¬
образие представления данных. В реляционной модели данных
информационные объекты представляются в виде таблиц. Каждая
таблица базы данных представляется в виде совокупности строк
и столбцов. Строки (записи) соответствуют экземпляру объекта,
конкретному событию или явлению. Столбцы (поля) соответствуют
атрибутам, т. е. признакам, характеристикам или параметрам объ¬
екта, события или какого-либо явления (рис. 8.2).
Таблица может не содержать ни одной строки, т. е. может быть
пустой. Все строки одной таблицы имеют одинаковую структуру. Таб¬
лица в реляционной базе данных может содержать не менее одного
столбца. Каждый столбец имеет конкретный тип данных. В базах
данных используется некоторое количество типов данных, похожих
на те, которые применяются в обычных языках программирования.
Поля таблицы должны содержать неделимую информацию.
141
Рис. 8.2. Схема таблицы базы данных
В каждой таблице базы данных необходимо наличие хотя бы
одного уникального ключа.
Уникальный ключ — это поле или набор полей, однозначно иден¬
тифицирующий каждый экземпляр объекта (запись). Уникальных
ключей в таблице может быть несколько. Один из уникальных клю¬
чей определяют как первичный ключ. Так же как и для уникальных
ключей, в таблице не допускается наличие двух и более записей
с одинаковыми значениями первичного ключа. Он должен быть
минимально достаточным, а значит, не содержать полей, удаление
которых не отразится на его уникальности.
С помощью одной таблицы удобно описывать простейший вид
связей между данными, а именно деление одного объекта (явления,
сущности, системы и прочее), информация о котором хранится в
таблице, на множество подобъектов, каждому из которых соот¬
ветствует строка или запись таблицы. При этом каждый из пред¬
ставителей объектов имеет одинаковую структуру или свойства,
описываемые соответствующими значениями полей записей. На¬
пример, таблица может содержать сведения о группе студентов кол¬
леджа, о каждом из которых известны следующие характеристики:
фамилия, имя и отчество, пол, возраст и образование. Поскольку
в рамках одной таблицы невозможно описать более сложные ло¬
гические структуры данных из предметной области, применяют
связывание таблиц.
Физическое размещение данных в реляционных базах на внеш¬
них носителях легко осуществляется с помощью обычных файлов.
Достоинство реляционной модели данных заключается в про¬
стоте, понятности и удобстве физической реализации на ЭВМ.
Именно простота и понятность для пользователя стали основными
причинами их широкого использования. Проблемы же эффектив¬
ности обработки данных этого типа оказались технически вполне
разрешимыми. Основным недостатком реляционной модели явля¬
ется сложность описания иерархических и сетевых связей.
142
Последние версии реляционных СУБД имеют некоторые свой¬
ства объектно-ориентированных систем. Такие СУБД часто назы¬
вают объектно-реляционными. Примером такой системы можно
считать продукты Oracle 8.x.
8.4.
ПОСТРЕЛЯЦИОННАЯ МОДЕЛЬ ДАННЫХ
Классическая реляционная модель предполагает неделимость
данных, хранящихся в записях таблиц, и не допускает избыточности
данных. Постреляционная модель представляет собой расширенную
реляционную модель, где нет ограничения неделимости данных.
Эта модель допускает составные (многозначные) поля, т. е. значе¬
ние поля может состоять из подзначений. Набор значений много¬
значных полей считается самостоятельной таблицей, встроенной
в основную таблицу.
Достоинством постреляционной модели является возможность
представления совокупности связанных реляционных таблиц одной
постреляционной таблицей. Это обеспечивает высокую нагляд¬
ность представления информации и повышение эффективности
ее обработки.
Недостатком постреляционной модели является сложность ре¬
шения проблемы обеспечения целостности и непротиворечивости
хранимых данных. Эта проблема решается включением в СУБД
соответствующих механизмов.
8.5.
МНОГОМЕРНАЯ МОДЕЛЬ ДАННЫХ
В развитии концепций информационных систем можно вы¬
делить следующие два направления: системы оперативной обра¬
ботки и системы аналитической обработки (системы поддержки
принятия решений). Реляционные СУБД предназначаются для
информационных систем оперативной обработки информации и
в этой области являются наиболее эффективными. Однако в си¬
стемах аналитической обработки они показали себя недостаточно
гибкими. Здесь более эффективными являются многомерные
системы управления данными. Многомерные системы позволяют
оперативно обрабатывать информацию для проведения анализа и
принятия решения. По сравнению с реляционной моделью много¬
мерная организация данных обладает более высокой наглядностью
и информативностью.
143
В многомерных СУБД данные организованы в виде упорядо¬
ченных многомерных массивов — гиперкубов. Они обеспечивают
более быструю реакцию на запросы данных за счет того, что об¬
ращения поступают к относительно небольшим блокам данных,
необходимых для конкретной группы пользователей.
Технология многомерных баз данных — достаточно новая тех¬
нология. Несмотря на то что многомерный подход к представлению
данных в базе появился практически одновременно с реляционным,
реально работающих многомерных СУБД сначала было очень мало.
Только с середины 1990-х гг. интерес к ним стал приобретать мас¬
совый характер.
Многомерность модели данных означает не визуальное пред¬
ставление, а логическую организацию структуры информации при
описании и в операциях манипулирования данными. Для иллюстра¬
ции вышеизложенного на рис. 8.3 приведены реляционное (а) и
многомерное (б) представления одних и тех же данных (в таблицах
хранятся сведения об объемах продаж мебели).
Рассмотрим основные понятия многомерных моделей данных —
измерение, мера и срез.
Измерение — это множество однотипных данных, образующих
одну из граней гиперкуба. Другими словами, измерения являются
осями многомерной системы координат. Примерами наиболее часто
используемых временных измерений являются «Дни», «Месяцы»,
«Кварталы» и «Годы». В качестве географических измерений ши¬
роко употребляются «Города», «Районы», «Регионы» и «Страны».
В многомерной модели данных измерения играют роль индексов,
служащих для идентификации конкретных значений в ячейках
гиперкуба.
Мера (ячейка, показатель) — это поле, значение которого одно¬
значно определяется фиксированным набором измерений. Тип поля
Модель
Месяц
Объем
Шкаф
Июнь
12
Шкаф
Июль
24
Шкаф
Август
5
Диван
Июнь
2
Диван
Июль
18
Стол
Июль
19
а
Модель
Июнь
Июль
Август
Шкаф
12
24
5
Диван
2
18
Стол
19
Рис. 8.3. Реляционное и многомерное представление данных
144
Февраль
Январь
Склад 1
Склад 2
Склад 3
Склад 4
Мебель
1 000
200
100
200
Аксессуары
500
50
25
50
Ткань
500
50
25
50
Рис. 8.4. Пример гиперкуба
чаще всего определен как числовой. Это могут быть объемы продаж
н количественном или денежном выражении, товарные остатки на
складе, издержки и т. п.
В качестве мер в трехмерном кубе, изображенном на рис. 8.4,
использованы суммы продаж, а в качестве измерений — время,
товар и склад. Измерения представлены на определенных уровнях
группировки: товары группируются по видам, а данные о времени
совершения операций — по месяцам.
Куб совсем не обязательно должен быть трехмерным. Он мо¬
жет быть и двух-, и многомерным — в зависимости от решаемой
задачи.
Однако куб сам по себе для анализа не пригоден. Даже трех¬
мерный куб сложно отобразить на экране компьютера так, чтобы
были видны значения интересующих мер. Для визуализации дан¬
ных, хранящихся в кубе, применяются, как правило, привычные
двумерные табличные представления, имеющие сложные иерар¬
хические заголовки строк и столбцов. Эта операция называется
«разрезанием» куба. Термин этот опять же образный.
Аналитик как бы берет и «разрезает» измерения куба по инте¬
ресующим его направлениям. Пользователь получает естественную,
интуитивно понятную модель данных. Это дает возможность полу¬
чать сводные или детальные сведения о бизнес-процессе и осущест¬
влять прочие манипуляции, которые придут в голову пользователю
в процессе анализа. Этим способом аналитик получает двумерный
срез куба и с ним работает. Примерно так же лесорубы считают
годовые кольца на спиле. Соответственно, «неразрезанными», как
правило, остаются только два измерения — по числу измерений
таблицы
Срез представляет собой подмножество гиперкуба, полученное
в результате фиксации одного или нескольких измерений. Фор¬
мирование «срезов» выполняется для ограничения используемых
пользователем значений, так как все значения гиперкуба практи-
145
Склад 1
Склад 2
Склад 3
Склад 4
Январь
2 000
300
150
300
Февраль
3 000
1000
200
1 000
Рис. 8.5. Двумерный срез куба для одной меры
чески никогда одновременно не используются. На рис. 8.5 изобра¬
жен двумерный срез куба для одной меры — «Количество» и двух
«неразрезанных» измерений — «Склад» и «Время». На риС. 8.6
представлено лишь одно «неразрезанное» измерение — «Склад», но
здесь отображаются значения двух мер — «Количество», «Сумма».
Двумерное представление куба возможно и тогда, когда «неразре¬
занными» остаются и более двух измерений. При этом на осях среза
(строках и столбцах) будут размещены два или более измерений
«разрезаемого» куба (рис. 8.7).
Недостатком многомерной модели данных является ее гро¬
моздкость для простейших задач обычной оперативной обработки
информации.
Основные преимущества многомерных СУБД следующие:
■ общая простота системы, что позволяет осуществлять быстрое
встраивание технологий многомерных СУБД в приложения.
Системы на основе многомерных баз данных требуют меньше
специальных навыков по разработке и администрированию;
и относительно низкая общая стоимость владения, а также бы¬
стрый возврат инвестиций;
■ в случае использования многомерных СУБД поиск и выборка
данных осуществляются значительно быстрее, чем при много¬
мерном концептуальном взгляде на реляционную базу данных,
так как многомерная база данных обеспечивает оптимизирован¬
ный доступ к запрашиваемым ячейкам;
■ многомерные СУБД легко справляются с задачами включения в
информационную модель разнообразных встроенных функций,
тогда как объективно существующие ограничения языка SQL
делают выполнение этих задач на основе реляционных СУБД
достаточно сложным, а иногда и невозможным.
Склад 1
Склад 2
Склад 3
Склад 4
Количество
200
100
50
300
Сутчма
3 000
1000
200
1 000
Рис. 8.6. Двумерный срез куба для нескольких мер
14В
Январь
Февраль
Склад 1
Склад 2
Склад 3
Склад 4
Склад 1
Склад 2
Склад 3
Склад 4
количество
200
100
50
300
200
100
50
300
Сумма
3 000
1000
200
1 000
3 000
1000
200
1000
Рис. 8.7. Двумерный срез куба с несколькими измерениями на одной оси
При хранении данных в многомерных структурах возникает
потенциальная проблема «разбухания» за счет хранения пустых
значений. Ведь если в многомерном массиве зарезервировано ме¬
сто под все возможные комбинации меток измерений, а реально
заполнена лишь малая часть (например, ряд товаров продается
только в небольшом числе регионов), то большая часть куба будет
пустовать, хотя место будет занято. Современные системы умеют
справляться с этой проблемой.
Примерами систем, поддерживающими многомерные модели
данных, являются Essbase (Arbor Software), Media Multi-matrix
(Speedware), Oracle Express Server (Oracle), Cache (Inter Systems). Не¬
которые программные продукты, например Media/MR (Speedware),
позволяют одновременно работать с многомерными и реляцион¬
ными БД. В СУБД Cache, в которой внутренней моделью данных
является многомерная модель, реализованы три способа доступа
к данным: прямой (на уровне узлов многомерных массивов), объ¬
ектный и реляционный.
8.6.
ОБЪЕКТНО-ОРИЕНТИРОВАННАЯ МОДЕЛЬ
Объектно-ориентированные системы управления базами данных
являются результатом совмещения возможностей и особенностей
баз данных и возможностей объектно-ориентированных языков
программирования. Объектно-ориентированные СУБД позволя¬
ют работать с объектами баз данных так же, как с объектами в
объектно-ориентированных языках программирования. Они расши¬
ряют языки программирования, прозрачно вводя долговременные
данные, управление параллельной работой с данными, восстанов¬
ление данных, ассоциированные запросы и другие возможности.
Появление объектно-ориентированных СУБД было вызвано по¬
требностями программистов на объектно-ориентированных языках
в средствах для хранения объектов, не помещавшихся в оператив¬
ной памяти компьютера. Также была важна задача сохранения
147
состояния объектов между повторными запусками прикладной
программы. Поэтому большинство объектно-ориентированных
систем управления базами данных представляют собой библиотеку,
процедуры управления данными которой включаются в прикладную
программу.
В объектно-ориентированной модели при представлении дан¬
ных имеется возможность идентифицировать отдельные записи
базы. Между записями базы данных и функциями их обработки
устанавливаются взаимосвязи с помощью механизмов, подобных
соответствующим средствам в объектно-ориентированных языках
программирования.
Структура объектно-ориентированной БД графически представ¬
лена в виде дерева, узлами которого являются объекты. Свойства
объектов описываются некоторым стандартным типом (например,
строковым — string) или типом, конструируемым пользователем
(определяется как class).
Пример логической структуры объектно-ориентированной базы
данных «Колледж» представлен на рис. 8.8.
Рис. 8.8. Логическая структура объектно-ориентированной базы данных
«Колледж»
148
Логическая структура объектно-ориентированной базы данных
внешне похожа на структуру иерархической базы данных. Основ¬
ное отличие между ними состоит в методах манипулирования дан¬
ными. Для выполнения действий над данными в рассматриваемой
модели базы данных применяются логические операции, усиленные
(>бъектно-ориентированными механизмами.
Основным достоинством объектно-ориентированной модели
данных в сравнении с реляционной является возможность отобра¬
жения информации о сложных взаимосвязях объектов. Объектно-
ориентированная модель данных позволяет идентифицировать от¬
дельную запись базы данных и определять функции их обработки.
Недостатками объектно-ориентированной модели являются вы¬
сокая понятийная сложность и неудобство обработки.
Реакцией производителей реляционных СУБД на возраста¬
ющую популярность объектных технологий стало появление
объектно-реляционных баз данных, так называемых универ¬
сальных серверов. Объектно-реляционная СУБД — реляционная
СУБД, поддерживающая некоторые технологии, реализующие
объектно-ориентированный подход: объекты, классы и наследо¬
вание реализованы в структуре баз данных и языке запросов.
Объектно-реляционными СУБД являются, например, широко из¬
вестные Oracle Database, Informix, DB2.
Основными преимуществами объектно-реляционной модели
являются возможность повторного и совместного использования
компонентов.
Очевидным недостатком подхода с использованием объектно-
реляционной СУБД являются сложность и связанные с ней повы¬
шенные расходы. Простота и ясность, присущие реляционной мо¬
дели, теряются при использовании подобных типов расширения.
КОНТРОЛЬНЫЕ ВОПРОСЫ
1. Что такое модель данных?
2. Для чего строится модель данных?
3. Какие аспекты включает в себя модель данных?
4. Перечислите классические и современные модели представ¬
ления данных.
5. Укажите достоинства и недостатки иерархической модели дан¬
ных.
В. Как организуется физическое размещение данных в БД иерар¬
хического типа?
7. Охарактеризуйте сетевую модель данных.
149
8. Охарактеризуйте реляционную модель данных.
9. В чем особенность постреляционной модели данных?
10. Где находят применение многомерные модели данных?
11. Укажите достоинства и недостатки многомерной модели.
12. Охарактеризуйте многомерную модель данных.
13. Назовите и объясните смысл операций, выполняемых над дан¬
ными в случае многомерной модели.
14. Приведите примеры многомерных таблиц.
15. Укажите достоинства и недостатки объектно-ориентированной
модели представления данных.
16. Раскройте смысл понятий, используемых в многомерных СУБД:
«измерение», «ячейка», «срез».
Глава 9
РЕЛЯЦИОННАЯ МОДЕЛЬ ДАННЫХ
ОСОБЕННОСТИ РЕЛЯЦИОННОЙ МОДЕЛИ
ДАННЫХ
9.1.1. Основные понятия и компоненты
Теоретической основой реляционной модели данных стала
теория отношений. Множество отношений замкнуто относительно
некоторых специальных операций, т. е. образует вместе с этими
операциями абстрактную алгебру. Это важнейшее свойство отно¬
шений было использовано в реляционной модели для разработки
языка манипулирования данными, связанного с исходной алгеброй.
Американский математик Э. Ф. Кодд в 1970 г. впервые сформулиро¬
вал основные понятия и ограничения реляционной модели. Пред¬
ложения Кодда были настолько эффективны для систем баз данных,
что за эту модель он был удостоен престижной премии Тьюринга в
области теоретических основ вычислительной техники.
Основными понятиями реляционных баз данных являются:
■ отношение;
■ тип данных;
■ домен;
■ атрибут;
■ кортеж;
■ первичный ключ.
Для начала покажем смысл этих понятий на примере отноше¬
ния «Студенты», содержащего информацию о студентах колледжа
(рис. 9.1).
Отношение является фундаментальным понятием реляционной
модели данных. По этой причине модель и называется реляционной
(от лат. relatio — «отношение», «связь»).
Отношения на физическом уровне представляют собой двумер¬
ные таблицы в виде строк и столбцов, в ячейках которых хранятся
данные. Каждая таблица содержит информацию об объектах одного
9.1.
151
Атрибуты
Отношение
«Студенты»
Код
ФИО
Группа
Специальность
Пол
1
Иванов Ф.И.
35
Туризм
М
2
Дремина Е.Е.
35
Туризм
Ж
3
Латыпова Ж. А.
44
Реклама
Ж
4
Лесовая В.Н.
44
Реклама
Ж
5
Попенко Б.С.
35
Туризм
М
6
Потапов В.С.
35
Туризм
М
7
Федорова Д.С.
35
Туризм
Ж
8
Таран О.С.
44
Реклама
м
9
Дудко О.В.
35
Туризм
ж
I Кортежи
' Первичный ключ
Рис. 9.1. Соотношение основных понятий реляционного подхода
типа, а совокупность всех таблиц образует единую базу данных.
Строка таблицы называется записью, столбец таблицы — полем.
Каждое поле должно иметь уникальное в пределах таблицы имя.
Особенности организации таблиц зависят от конкретной СУБД,
используемой для создания и ведения базы данных.
Данные ■— это совокупная информация, хранимая в базе дан¬
ных в виде одного из нескольких различных типов. С помощью
типов данных устанавливаются основные правила для данных,
содержащихся в конкретном столбце таблицы, в том числе размер
выделяемой для них памяти.
Понятие «тип данных» в реляционной модели полностью аде¬
кватно понятию «тип данных» в программировании. Значения
данных, хранимые в реляционной базе данных, являются типизиро¬
ванными, т. е. известен тип каждого хранимого значения. В каждом
столбце записывается свой определенный тип данных. Обычно в
современных реляционных базах данных допускается хранение
символьных, числовых данных, специализированных числовых
данных (например, «денежный»), а также специальных данных
(дата, время, временной интервал). Кроме того, в реляционных си¬
стемах поддерживается возможность определения пользователями
собственных типов данных.
Понятие «домен» более специфично для баз данных, хотя и
имеются аналогии с подтипами в некоторых языках программиро-
нания. Некоторые авторы отождествляют понятия «домен» и «тип
данных». Более того, в некоторых реляционных СУБД понятие
«домен» даже не используется.
В общем виде домен определяется путем задания некоторого
базового типа данных, к которому относятся элементы домена,
и описания их ограничений. С каждым доменом связывается имя,
уникальное среди имен всех доменов соответствующей базы дан¬
ных. Домен можно определить как допустимое ограниченное под¬
множество значений данного типа. Например, домен ФИО в нашем
примере определен на базовом типе символьных строк, но в число
его значений могут входить только символы русского алфавита, и не
могут входить цифры и т. д. Домен ПОЛ также является символьным,
но имеет ограничение по длине (только 1 символ) и по множеству
допустимых значений (только символы «м» или «ж»).
Следует отметить также семантическую составляющую понятия
«домен»: данные считаются сравнимыми только в том случае, когда
они относятся к одному домену. Например, бессмысленно сравни¬
вать домены ФИО и СПЕЦИАЛЬНОСТЬ. Несмотря на то что они от¬
носятся к символьному типу, их значения не сравнимы.
Атрибут — это свойство (характеристика) объекта предметной
области, информация о котором хранится в базе данных. Атрибут
характеризуется именем и значением, которое должно принад¬
лежать некоторому домену. Каждый экземпляр объекта в каждый
момент времени однозначно характеризуется набором конкретных
значений атрибутов (см. рис. 9.1).
Схема отношения (заголовок отношения) — это именованное
множество пар {имя атрибута, имя домена}. Степень или
«арность» схемы отношения — мощность этого множества, т. е.
количество атрибутов. Схему отношений можно представить как
строку заголовков столбцов таблицы (см. рис. 9.1).
Кортеж, соответствующий данной схеме отношения, •— это
множество пар {имя атрибута, значение}, которое содержит
одно вхождение каждого имени атрибута, принадлежащего схеме
отношения. «Значение» является допустимым значением домена
данного атрибута. Таким образом, кортеж можно представить как
строку таблицы (см. рис. 9.1). Тогда отношение можно предста¬
вить как множество кортежей, соответствующих одной схеме от¬
ношения. Телом отношения называется произвольное множество
кортежей.
Первичный ключ (ключ отношения) — это минимальный на¬
бор атрибутов, значения которых однозначно определяют кортеж
отношения. Для каждого отношения полный набор его атрибутов
153
уникален. Однако при формальном определении первичного ключа
требуется «минимальность», т. е. в набор атрибутов первичного клю¬
ча не должны входить такие атрибуты, которые можно отбросить
без ущерба для основного свойства — однозначное определение
кортежа. Это можно увидеть на примере отношения «Студенты»
(см. рис. 9.1), где каждый кортеж уникален, но можно из всего на¬
бора атрибутов выбрать один — «Код», который однозначно иден¬
тифицирует каждого студента (каждый кортеж или запись).
Определение ключа для таблицы означает возможность автома¬
тической сортировки записей, а также контроль отсутствия повто¬
рений значений в ключевых полях записей и повышение скорости
выполнения операций поиска в таблице. Ключевой атрибут может
иметь определенный смысл. Однако очень часто ключевое поле не
несет никакой смысловой нагрузки и является просто идентифика¬
тором объекта в таблице. Часто для определения первичных ключей
в таблицах используют поля с автоматической генерацией значений
(«счетчики», autoincrement field). При этом вся ответственность по
поддержанию уникальности ключевого поля снимается с пользова¬
теля и перекладывается на процессор баз данных. Поле счетчика
представляет собой четырехбайтовое целое число и автоматически
увеличивается на единицу при добавлении пользователем новой
записи в таблицу.
Итак, в основе реляционной модели данных лежит понятие от¬
ношения, которое задается списком своих элементов и перечисле¬
нием их значений. Отношение может быть представлено таблицей.
Заголовки столбцов таблицы носят название атрибутов. Список их
имен носит название схемы отношения. Каждый атрибут опреде¬
ляет тип представляемых им данных, который вместе с областью
его значений называется доменом. Вся таблица целиком называется
отношением, а каждая строка таблицы носит название кортежа
отношения. Конечно, терминология реляционной модели данных
несколько непривычна, и чаще используются термины обычных
таблиц (говорят про «столбцы таблицы», имея в виду «атрибуты
отношения»), И когда мы перейдем к рассмотрению практических
вопросов организации реляционных баз данных и средств управле¬
ния, то будем использовать эту привычную для нас терминологию.
Подобной терминологии придерживаются в большинстве коммер¬
ческих реляционных СУБД.
Введем ряд математических определений, связанных с понятием
отношения.
N-арным отношением R, или отношением R степени п, называют
подмножество декартова произведения множеств Dv D2,..., Dn (п> 1),
154
не обязательно различных. Исходные множества Du D2,..., Dn назы¬
вают в модели доменами. Декартово (прямое) произведение — это
множество, элементами которого являются всевозможные упоря¬
доченные пары элементов исходных двух множеств.
Пусть А1(D1,), A2(D2), ... An(Dn) — имена атрибутов. Тогда схемой г
отношения R называется конечное множество имен атрибутов r={A,(D,)( A2(D2), ... An(Dn)}.
Отношением со схемой г на конечных множествах Du D2t..., Dn на¬
зывается подмножество R декартового произведения Dx-D2-,...,- Dn.
Элементы отношения (du d2,—, dn), как уже упоминалось выше,
называются кортежами. Кортеж (d„ d2, ..., dn) имеет л компонен¬
тов. Для обозначения кортежа применяется и сокращенная форма
записи dt, d2, ..., dn. Использование понятия декартового произве¬
дения для определения отношения в реляционной модели данных
делает модель конструктивной. С математической точки зрения
это означает, что все остальные понятия модели определяются в
рамках строго математического построения на базе декартового
произведения.
9.1.2. Свойства отношений
Остановимся теперь на некоторых важных свойствах отноше¬
ний, которые следуют из приведенных ранее определений.
Отсутствие кортежей-дубликатов следует из определения
отношения как множества кортежей. Из этого свойства вытекает
наличие у каждого отношения первичного ключа.
Множество математически по своему определению не может
иметь совпадающих элементов, и, следовательно, кортежи в от¬
ношении можно различить лишь по значению их компонент. Это
тоже очень важное для модели обстоятельство — в реляционной
модели полностью исключается дублирование данных об объектах
предметной области.
Отсутствие упорядоченности атрибутов. Для ссылки на значе¬
ние атрибута в кортеже отношения всегда используется имя атрибу¬
та. Атрибуты отношений не упорядочены, так как по определению
заголовок отношения есть множество пар {имя атрибута, имя
домена}. СУБД сама принимает решение о том, в каком физиче¬
ском порядке следует хранить значения атрибутов кортежей (хотя
обычно один и тот же физический порядок поддерживается для
всех кортежей каждого отношения). Кроме того, это свойство об¬
легчает выполнение операции модификации схем существующих
155
отношений не только путем добавления новых атрибутов, но и
путем удаления существующих.
Атомарность значений атрибутов означает, что атрибут не
может быть множеством, т. е., например, значение атрибута «Ива¬
нов И. И., ул. Ленина, 8» неверно ввиду того, что включает в себя
множество характеристик (ФИО, улица, дом). Это свойство следует
из определения домена как потенциального множества значений
простого типа данных.
Отсутствие упорядоченности кортежей — физически кортежи
хранятся в порядке их ввода. Это свойство является следствием
определения тела отношения как множества кортежей. Отсутствие
требования к поддержанию порядка на множестве кортежей от¬
ношения придает СУБД дополнительную гибкость при хранении
баз данных во внешней памяти и при выполнении запросов к базе
данных.
Конкретные примеры применения свойств отношений будут
рассмотрены в следующих разделах при изучении вопросов про¬
ектирования и нормализации реляционных баз данных.
ОСНОВЫ РЕЛЯЦИОННОЙ АЛГЕБРЫ
Реляционная алгебра (реляционная алгебра Кодда) — это зам¬
кнутая система операций над отношениями в реляционной модели
данных. Операции реляционной алгебры также называют реляци¬
онными операциями.
Основная идея реляционной алгебры состоит в том, что если
отношения являются множествами, то средства манипулирования
отношениями могут базироваться на традиционных теоретико¬
множественных операциях, дополненных некоторыми специаль¬
ными операциями, специфичными для баз данных. Реляционная
алгебра представляет собой набор таких операций над отношения¬
ми, что результат каждой из операций также является отношением.
Это свойство алгебры называется замкнутостью.
Операции реляционной алгебры Кодда можно разделить на две
группы: базовые теоретико-множественные и специальные реля¬
ционные. Первая группа операций включает в себя классические
операции теории множеств. Вторая группа представляет собой раз¬
витие обычных теоретико-множественных операций в направлении
к реальным задачам манипулирования данными.
В состав теоретико-множественных операций входят опе¬
рации:
9.2.
156
157
■ объединения отношений;
■ пересечения отношений;
■ вычитание отношений;
■ прямого произведения отношений.
Специальные реляционные операции включают:
■ ограничение отношения;
■ проекцию отношения;
■ деление отношений;
■ соединение отношений.
Кроме того, в состав алгебры включается операция присваива¬
ния, позволяющая сохранить в базе данных результаты вычисления
алгебраических выражений, и операция переименования атрибу¬
тов, дающая возможность корректно сформировать заголовок (схе¬
му) результирующего отношения. Операции реляционной алгебры
могут выполняться над одним отношением (например, проекция)
или над двумя отношениями (например, объединение). В первом
случае операция называется унарной, а во втором — бинарной.
При выполнении бинарной операции участвующие в операциях
отношения должны быть совместимы по структуре.
Некоторые отношения формально не являются совместимыми
из-за различия в названиях атрибутов, но становятся таковыми по¬
сле применения операции переименования атрибутов.
JV-арную реляционную операцию / можно представить функци¬
ей, возвращающей отношение и имеющей п отношений в качестве
аргументов:
Поскольку реляционная алгебра является замкнутой, в качестве
операндов в реляционные операции можно подставлять другие вы¬
ражения реляционной алгебры (подходящие по типу):
Совместимость структур отношений означает совместимость
имен атрибутов и типов соответствующих доменов. Частным слу¬
чаем совместимости является идентичность (совпадение).
Объединением двух совместимых отношений Rt и R2 (R\ UNION
R2) одинаковой размерности является отношение R, содержащее
все элементы исходных отношений с исключением повторений,
т. е. полученное отношение включает все кортежи, которые входят
хотя бы в одно из отношений-операндов.
Например, пусть отношением R1 будет множество студентов из
группы 35, а отношение R2 — множество студентов-юношей. Тогда
Отношение Rl
ФИО
Группа
Пол
Иванов Ф.И.
35
М
Кириллова Е.Е.
35
Ж
Потапов В.С.
35
м
Дудко О.В.
35
ж
Отношение R2
ФИО
Группа
Пол
Иванов Ф.И.
35
М
Потапов В.С.
35
м
Таран О.С.
44
м
Ильин Г.С.
44
м
Отношение R (R1 UNION R2)
ФИО
Группа
Пол
Иванов Ф.И.
35
М
Кириллова Е.Е.
35
Ж
Потапов В.С.
35
м
Дудко О.В.
35
Ж
Таран О.С.
44
м
Ильин Г.С.
44
м
Рис. 9.2. Объединение отношений
отношение R обозначает множество, включающее в себя студентов
группы 35, или студентов-юношей, либо тех и других (рис. 9.2).
Пересечение двух совместимых отношений R1 и R2 (R, INTERSECT
R2) одинаковой размерности порождает отношение R, включающее
в себя кортежи, которые входят в оба исходные отношения. Для
отношений и R2 из предыдущего примера (см. рис. 9.2) резуль¬
тирующее отношение R будет означать всех студентов из группы
35 мужского пола (рис. 9.3).
Вычитание совместимых отношений R1 и R2 (7?, MINUS R2) оди¬
наковой размерности есть отношение, состоящее из множества
кортежей, принадлежащих R1, но не входящих в отношение R2. Для
тех же отношений Rx и R2 из предыдущего примера (см. рис. 9.2)
отношение R будет представлять собой множество студентов группы
35 женского пола (рис. 9.4).
Произведение отношения R1 степени а{ и отношения R2 степени
а2 (R1 TIMES R2), которые не имеют одинаковых имен атрибутов —
158
Отношение R
Отношение R2
Группа
Куратор
Курс
35
Кирсанова Л.Н.
3
44
Никитина Л.П.
4
ФИО
Группа
Пол
Иванов Ф.И.
35
М
Таран О.С.
44
М
Отношение R (R1 TIMES R2)
ФИО
Группа
Пол
Группа 1
Куратор
Курс
Иванов Ф.И.
35
М
44
Никитина Л.П.
4
Таран О.С.
44
м
35
Кирсанова Л.Н.
3
Иванов Ф.И.
35
м
35
Кирсанова Л.Н.
3
Таран О.С.
44
м
44
Никитина Л.П.
4
Рис. 9.5. Пример произведения отношений
это такое отношение R степени (ах + а2), заголовок которого пред¬
ставляет сцепление заголовков отношений .R, и R2, а тело имеет
всевозможные соединения кортежей отношений R{ и R2, такие,
что первые оц элементов кортежей принадлежат множеству Rh
а последние а2 элементов — множеству R2. При необходимости
получить произведение двух отношений, имеющих одинаковые
имена одного или нескольких атрибутов, применяется операция
переименования. Пример произведения отношений представлен
па рис. 9.5.
Основной смысл включения операции произведения в состав
реляционной алгебры Кодда состоит в том, что на ее основе опреде¬
ляется действительно полезная операция соединения.
Первой специальной операцией реляционной алгебры является
горизонтальный выбор, или операция фильтрации, или операция
ограничения отношений.
Операция ограничения (выборка) WHERE требует наличия двух
операндов: ограничиваемого отношения и простого условия ограни¬
чения. Операция ограничения (выборка) отношения R по формуле
f (R WHERE f) представляет собой новое отношение с таким же за¬
головком и телом, состоящим из таких кортежей отношения R, кото¬
рые удовлетворяют истинности логического выражения, заданного
формулой /. Для записи формулы используются имена атрибутов
(или номера столбцов), константы, логические операции (AND — И,
OR — ИЛИ, NOT — НЕ), операции сравнения (« = », « Ф »,
« > », « > », « < », « < ») и скобки. На рис. 9.6. пред¬
ставлен пример выполнения операции ограничения отношения
R — выборка студентов группы 44 (WHERE Группа = 44).
159
Результатом проекции отношения А на множество атрибутов {а1;
а2, аЛ} (PROJECT А {а1( а2, .... ап}) является отношение с заголов¬
ком, определяемым множеством атрибутов {щ, а2, ..., ап}, и с телом,
состоящим из кортежей вида <a1:vu a2:v2r an:vn>, таких, что в
отношении А имеется кортеж, атрибут ах которого имеет значение
vb атрибут а2 имеет значение v2, .... атрибут ап имеет значение vn.
Тем самым при выполнении операции проекции выделяется «вер¬
тикальная» выборка отношения с удалением кортежей-дубликатов.
Иначе говоря, проекция отношения А на атрибуты {а1( а2,ап}, где
множество {а1( а2, ..., ап} является подмножеством полного списка
атрибутов заголовка отношения А, представляет собой отношение
с заголовком {аи а2, ап} и телом, содержащим кортежи отноше¬
ния А, за исключением повторяющихся кортежей.
Операция проекции допускает следующие дополнительные ва¬
рианты записи:
■ отсутствие списка атрибутов подразумевает указание всех атри¬
бутов (операция тождественной проекции);
и результатом пустой проекции является пустое множество;
■ операция проекции может применяться к произвольному от¬
ношению, в том числе и к результату выборки.
Например, для отношения R из предыдущего примера (см.
рис. 9.6) результатом проекции PROJECT СТУДЕНТЫ {Группа}
будет отношение, состоящее из двух кортежей (рис. 9.7).
Операция проекции чаще всего употребляется как промежуточ¬
ный шаг в операциях горизонтального выбора, или фильтрации.
Кроме того, она используется самостоятельно на заключительном
этапе получения ответа на запрос.
160
Операция деления отношений до¬
статочно сложная, и требует пошаго¬
вого рассмотрения. Пусть заданы два
отношения: А и В с заголовком {а1г а2,
ап, b1( b2, bт} и {b1г b2 bт} со¬
ответственно. Атрибуты Ы (i = 1, 2, ....
m) определены на одном и том же до¬
мене и имеют одинаковые имена, т. е.
общие для двух отношений. Назовем
множество атрибутов {а/} составным
атрибутом а, а множество атрибутов {bj} — составным атрибутом
Ь. Тогда делением отношений А на В (A DIVIDE BY В) называют
отношение с заголовком а и телом, содержащим множество всех
кортежей {а}, таких, что существует кортеж {а, Ь}, который при¬
надлежит отношению А для всех кортежей {Ь}, принадлежащих
отношению В. Другими словами, результат содержит такие значе¬
ния из А, для которых соответствующие значения b из отношения
А включают все значения b из отношения В. Операция деления
удобна тогда, когда требуется сравнить некоторое множество ха¬
рактеристик отдельных атрибутов.
Приведем пример выполнения операции деления. В базе данных
имеются отношение R1 {ФИО, Дисциплина, Оценка} и унарное
отношение В2{Дисциплина} (рис. 9.8). Тогда результат деления
161
(R1 DIVIDE BY R2) даст данные обо всех студентах, получивших
оценки по всем дисциплинам из отношения R2 (результат операции
приведен также на рис. 9.8).
Соединение Cf (Ru R2) отношений R, и R2 по условию, заданно¬
му формулой /, представляет собой отношение R, которое можно
получить путем декартова произведения отношений R{ и R2 с
последующим применением к результату операции выборки по
формуле /.
Эта операция предназначается для тех случаев, когда нужно
соединить вместе два отношения на основе некоторых условий или
формулы. Правила записи формулы f те же, что и для операции
выборки.
Другими словами, соединением отношения R{ по атрибуту а с от¬
ношением R2 по атрибуту b (отношения не имеют общих имен атри¬
бутов) является результатом выполнения операции вида (.R1TIMES
R2) WHERE a Q b, где Q — логическое выражение над атрибутами,
определенными на одном (нескольких — для составного атрибута)
домене. Соединение Cf (Rv R2), где формула / имеет произвольный
вид (в отличие от частных случаев), называют также Q-соединением.
Для иллюстрации операций соединения мы немного изменим за¬
головки и тела отношений, которые использовались ранее в приме¬
рах. Предположим, что в базе данных имеются отношение R1{ФИО,
Группа, Пол} и отношение ^{Группа, Куратор, Курс} (рис. 9.9).
Необходимо найти соединение отношений и Д2 по атрибутам
Группа (обозначим их как Rx. Группа и R2. Группа соответственно
для каждого отношения).
В результате производится отношение R, кортежи которого
производятся путем объединения кортежей первого и второго от¬
ношений и удовлетворяют условию (Rx. Группа = R2. Группа),
т. е. списки студентов и кураторы их групп. Можно наложить еще
условие — выбрать только студентов 3-го курса: (R {Кг TIMES
Rz) WHERE (Ri. Группа = R2. Группа) AND (Kypc=3)).
Важными с практической точки зрения частными случаями
соединения являются эквисоединение и естественное соедине¬
ние.
Операция эквисоединения характеризуется тем, что формула
задает равенство операндов. Иногда эквисоединение двух отно¬
шений выполняется по таким столбцам, атрибуты которых в обоих
отношениях имеют соответственно одинаковые имена и домены.
В этом случае говорят об эквисоединении по общему атрибуту. При¬
веденный выше пример демонстрирует частный случай операции
эквисоединения по одному столбцу.
162
Отношение К[ Отношение R2
Группа
Куратор
Курс
35
Кирсанова Л.Н.
3
44
Никитина Л.П.
4
38
Петрова Е.М.
3
24
Долинская Н.А.
2
ФИО
Группа
Пол
Иванов Ф.И.
35
М
Кириллова Е.Е.
35
Ж
Потапов В.С.
35
м
Дудко О.В.
38
ж
Таран О.С.
44
м
Ильин Г.С.
44
м
Федорова Д.С.
35
ж
Медведева Ж.А.
44
ж
Пушкина А. А.
44
ж
Отношение R (Rt TIMES R2) WHERE Rt Группа = R2 Группа
ФИО
Группа
Пол
Куратор
Курс
Иванов Ф.И.
35
М
Кирсанова Л.Н.
3
Потапов В.С.
35
м
Кирсанова Л.Н.
3
Дудко О.В.
38
ж
Петрова Е.М.
3
Таран О.С.
44
м
Никитина Л.П.
4
Ильин Г.С.
44
м
Никитина Л.П.
4
Рис. 9.9. Операция соединения
Операция естественного соединения (операция JOIN) при¬
меняется к двум отношениям, имеющим общий атрибут (простой
или составной). Этот атрибут в отношениях имеет одно и то же
имя (совокупность имен) и определен на одном и том же домене
(доменах).
Результатом операции естественного соединения является от¬
ношение R, которое представляет собой проекцию эквисоединения
отношений Ri и R2 по общему атрибуту на объединенную совокуп¬
ность атрибутов обоих отношений.
Теперь можно кратко сформулировать определения операций
реляционной алгебры Кодда.
1. При выполнении операции объединения (UNION) двух от¬
ношений с одинаковыми заголовками производится отношение,
включающее все кортежи, которые входят хотя бы в одно из отно¬
шений-операндов.
2. Операция пересечения (INTERSECT) двух отношений с оди¬
наковыми заголовками производит отношение, включающее все
кортежи, которые входят в оба отношения-операнда.
3. Отношение, являющееся разностью (MINUS) двух отношений
с одинаковыми заголовками, включает все кортежи, входящие в
163
отношение-первый операнд, такие, что ни один из них не входит
в отношение, которое является вторым операндом.
4. При выполнении произведения (TIMES) двух отногценийг
пересечение заголовков которых пусто, производится отношение,
кортежи которого производятся путем объединения кортежей
первого и второго операндов.
5. Результатом ограничения (WHERE) отношения по некоторому
условию является отношение, включающее кортежи отношения -
операнда, удовлетворяющее этому условию.
6. При выполнении проекции (PROJECT) отношения на заданное
подмножество множества его атрибутов производится отягощение,
кортежи которого являются соответствующими подмножествами
кортежей отношения-операнда.
7. При соединении (JOIN) двух отношений по некоторому усло¬
вию образуется результирующее отношение, кортежи которого
производятся путем объединения кортежей первого и второго от¬
ношений и удовлетворяют этому условию.
8. При операции реляционного деления (DIVIDE BY) результи¬
рующее отношение состоит из кортежей, включающих значения
первого атрибута кортежей первого операнда таких, что Множе¬
ство значений второго атрибута (при фиксированном значении
первого атрибута) включает множество значений второго опе¬
ранда.
Алгебра Кодда избыточна; более того, введение операции де¬
картова произведения в качестве базовой операции алгебры может
ввести в заблуждение неопытных читателей. Тем не менее с этой
несколько устаревшей и небезупречной теории начинают обсуж¬
дение базовых манипуляционных механизмов реляционной Модели
данных практически во всех учебных пособиях по реляционным
базам данных. Потому что семантика языка SQL (структурирован¬
ного языка запросов) во многом базируется именно на этой алгебре,
и нам будет проще изучать SQL, предварительно познакомившись
с алгеброй Кодда.
9,3.
ИНДЕКСИРОВАНИЕ
Данные сохраняются в таблице в том порядке, в котором 0ни
вводятся пользователем. Это так называемый физический порядок
следования записей. Однако часто требуется представить данные
в другом, отличном от физического, порядке, отсортировав их по
каким-либо полям. Сортировка заключается в упорядочивании за-
164
кисой по определенному полю в порядке возрастания или убывания
содержащихся в нем значений. Например, может потребоваться
просмотреть данные о студентах, упорядоченные по номерам групп
м/или по алфавиту (рис. 9.10).
Кроме того, часто бывает необходимо найти в большом объеме
информации запись, удовлетворяющую определенному критерию,
гример найти студента по дате его рождения. Простой перебор
минеей при поиске в большой таблице может потребовать доста¬
точно много времени и поэтому будет неэффективным. Эффек¬
тивным средством решения этих задач является использование
индексов.
Индексы можно представить как специальные структуры в ба¬
зах данных, которые позволяют ускорить поиск и сортировку по
определенному полю или набору полей в таблице. Индексы также
используются для обеспечения уникальности данных, т. е. для по¬
строения первичных или уникальных ключей.
Физически индекс представляет собой таблицу, используемую
для определения адреса записи. При наличии индексов во многих
случаях поиск данных может выполняться гораздо быстрее, чем при
отсутствии индекса, потому что значения в индексе упорядочены,
а сам индекс относительно мал. Индекс создается пользователем
или системой для конкретной таблицы.
Повышение скорости выполнения различных операций в индек¬
сированных таблицах главным образом происходит за счет того, что
основная часть работы производится с небольшими индексными
файлами, а не с самими таблицами. Наибольший эффект повыше-
Группа
ФИО
35
Иванов Ф.И.
35
Кириллова Е.Е.
35
Потапов В.С.
35
Дудко О.В.
48
Таран О.С.
44
Ильин Г.С.
35
Федорова Д.С.
44
Медведева Ж.А.
44
Пушкина А.А.
Группа
ФИО
35
Дудко О.В.
35
Иванов Ф.И.
35
Кириллова Е.Е.
35
Потапов В.С.
35
Федорова Д.С.
44
Ильин Г.С.
44
Медведева Ж.А.
44
Пушкина А. А.
48
Таран О.С.
а б
Рис. 9.10. Физический порядок следования записей (а); записи в таблице
упорядочены по полю «Группа»(б)
165
ния производительности работы с индексированными таблицами
достигается для значительных по объему таблиц. Индекс содержит
ключевые значения для каждой записи в таблице данных. Клю¬
чевые значения определяются на основе одного или нескольких
полей таблицы. Кроме того, индекс содержит уникальные ссылки
на соответствующие записи в таблице и, таким образом, позволя¬
ет искать строки, удовлетворяющие критерию поиска. Ускорение
работы с использованием индексов достигается еще и за счет того,
что индекс имеет структуру, оптимизированную под поиск (напри¬
мер, сбалансированного дерева).
Индексы можно сравнить с оглавлением в книге. При поиске
нужного фрагмента текста мы ищем, в какой главе или в каком
параграфе он находится, и затем открываем книгу на нужной
странице, указанной в оглавлении и уже там осуществляем поиск
текста. Индекс выполняет роль указателя таблицы, просмотр кото¬
рого предшествует обращению к записям таблицы. По указанному
значению индекса система находит нужный блок информации в
массиве данных, который и выдает пользователю. Таким образом,
индекс позволяет ускорить процесс поиска данных в таблице,
а иногда и ускорить упорядочение данных, полученных по запро¬
су пользователя. Теперь первичный ключ мы можем определить
как индекс, позволяющий идентифицировать каждую запись в
таблице.
Способы организации физического доступа к информации в
таблицах зависят в основном от следующих факторов:
■ вида содержимого в поле ключа записей индексного файла;
■ типа используемых ссылок (указателей) на запись основной
таблицы;
■ метода поиска нужных записей.
При разработке приложений, работающих с базами данных, наи¬
более широко используются простые индексы. Простые индексы
используют значения одного поля таблицы. Примером простого
индекса в таблице «Студенты» может служить поле «Идентифика¬
тор» (индивидуальный номер) (рис. 9.11).
Хотя в большинстве случаев для представления данных в
определенном порядке достаточно использовать простой индекс,
построенный по одному полю, часто возникают ситуации, где не
обойтись без использования составных индексов. Составной ин¬
декс строится на основе значений двух или более полей таблицы.
Хорошей иллюстрацией использования составных индексов может
служить таблица «Сотрудники» (рис. 9.12). Понятно, что использо¬
вание в качестве простого индекса по фамилии человека в данном
166
Идентификатор
ФИО
Группа
Пол
101
Иванов Ф.И.
35
М
102
Кириллова Е.Е.
35
Ж
103
Потапов В.С.
35
м
104
Дудко О.В.
35
ж
105
Таран О.С.
44
м
106
Ильин Г.С.
44
м
107
Федорова Д.С.
35
ж
108
Медведева Ж.А.
44
ж
109
Пушкина А.А.
44
ж
Рис. 9.11. Пример простого индекса по столбцу «Идентификатор»
случае неэффективно. В данном случае возможно использование
составного индекса, основанного на следующих полях таблицы:
«Подразделение», «Табельный номер».
Таблицы в базе данных могут и не иметь индексов. В этом случае
для большой таблицы время поиска определенной записи может
быть весьма значительным и использование индекса становится
необходимым. С другой стороны, не следует увлекаться созданием
слишком большого количества индексов. Увеличение числа индек¬
сов замедляет операции добавления, обновления, удаления строк
таблицы, поскольку при этом приходится обновлять сами индексы.
Для оптимальной производительности запросов индексы обычно
создаются на тех столбцах таблицы, которые часто используются
в запросах. Кроме того, индексы занимают дополнительный объем
Номер
подраз¬
деления
Табельный
номер
ФИО
Должность
Оклад
001
1
Иванов Федор Иванович
Директор
50000
001
2
Потапов Валерий Самуилович
Зам.директора
40 000
001
3
Таран Олег Сергеевич
Гл. инженер
40000
002
1
Ильин Иван Васильевич
Гл. бухгалтер
45000
002
2
Берковская Ольга Николаевна
Бухгалтер
20000
002
3
Дремина Елена Евгеньевна
Бухгалтер
20 000
003
1
Попенко Борис Сергеевич
Гл. механик
35 000
003
2
Федорова Дарья Сергеевна
Инженер
30 000
Рис. 9.19. Пример составного индекса по столбцам «Подразделение»
и «Табельный номер»
167
памяти, поэтому перед созданием индекса следует убедиться, что
планируемый выигрыш в производительности запросов превысит
дополнительную затрату ресурсов компьютера на сопровождение
индекса.
4 СВЯЗЫВАНИЕ ТАБЛИЦ. ПОНЯТИЕ
ССЫЛОЧНОЙ ЦЕЛОСТНОСТИ
Связи между объектами реального мира могут находить свое
отражение в структуре данных БД. Обычно реляционная база
данных состоит из набора взаимосвязанных таблиц. Организация
связи между двумя или несколькими таблицами называется свя¬
зыванием таблиц.
Связи между таблицами можно устанавливать при создании
таблицы и при выполнении приложения, используя средства, предо¬
ставляемые СУБД. Связывать можно две или более таблиц. Это мо¬
гут быть как равноправные связи, так и отношения подчиненности,
такие, что для каждой записи главной таблицы (называемой еще
родительской) возможно наличие одной или нескольких записей в
подчиненной таблице (называемой еще дочерней). В реляционной
БД кроме связанных таблиц могут быть и отдельные таблицы, не
соединенные ни с одной другой таблицей.
Для связывания таблиц используют поля связи — «совпада¬
ющие» поля. Поля связи обязательно должны быть индексирован¬
ными и быть одинакового типа. В подчиненной таблице для связи
с главной таблицей задается индекс, который называется внешним
ключом. Состав полей этого индекса должен полностью или частич¬
но совпадать с составом полей индекса главной таблицы.
Выделяют три разновидности связи между таблицами базы
данных:
1) «один ко многим»;
2) «один к одному»;
3) «многие ко многим».
Отношение «один ко многим» имеет место, когда одной записи
родительской таблицы может соответствовать несколько записей
дочерней. Связь «один ко многим» иногда называют связью «мно¬
гие к одному». И в том, и в другом случае сущность связи между
таблицами остается неизменной. Связь «один ко многим» является
самой распространенной для реляционных баз данных. Она позво¬
ляет моделировать и иерархические структуры данных. Для иллю-
168
ID
NAME_GROUP
К_ШК
1
38-пкс
Федоров С.В.
2
18-пкс
Иванов Ф.И.
3
44-э
Попенко Б.С.
4
36-тг
Филин О.К.
I 'ис. 9.13. Таблица «Группы»
cтрации связи «один ко многим» будем использовать две таблицы.
И одной хранится список групп учебного заведения (рис. 9.13),
и другой — список студентов (рис. 9.14).
Таблица «Группы» имеет следующую структуру:
■ ID ■— идентификатор записи, ключевое поле целочисленного
типа;
■ NAME GROUP — наименование группы, поле символьного типа;
■ k_RUK — классный руководитель, поле символьного типа.
Таблица «Студенты» содержит следующие поля:
■ ID — идентификатор записи, ключевое поле целочисленного
типа;
■ NAME_STUD — ФИО студента, поле символьного типа;
■ ID_GROUP — идентификатор группы, индексное поле целочис¬
ленного типа.
В данной ситуации главной является таблица «Группы», а под¬
чиненной — таблица «Студенты». При этом таблицы связаны
полями «ID» и «ID_GROUP» из таблиц «Группы» и «Студенты»
соответственно, т. е. по идентификатору группы можно определить
принадлежность студента той или иной группе.
ID
NAME_STUD
ID_GROUP
1
Иванов Петр Иванович
1
2
Петров Иван Сергеевич
1
3
Таран Ольга Сергеевна
2
4
Дудко Олеся Владимировна
3
4
Дремина Елена Евгеньевна
1
5
Федорова Дарья Сергеевна
2
6
Лесовая Вера Николаевна
2
7
Семенова Елена Геннадьевна
3
8
Никитина Любовь Петровна
4
9
Курганский Владимир Иванович
4
Рис. 9.14. Таблица «Студенты»
169
После связывания обеих таблиц при выборе записи с какой-либо
группой из таблицы «Группы» в таблице «Студенты» будут доступны
только записи со студентами, обучающимися в этой группе. Напри¬
мер, если в первой таблице указатель будет установлен на записи
группы «18-пкс» (ID=2 ), то в таблице студенты будут доступны
только три записи, в которых ID_GR0UP=2 (рис. 9.15).
Предположим, что из таблицы «Группы» будет удалена запись
(случайно или преднамеренно), тогда в подчиненной таблице «Сту¬
денты» для соответствующих записей будет нарушена связь, по
идентификатору группы уже невозможно будет определить при¬
надлежность этих студентов какой-либо группе, т. е. произойдет
потеря информации, что недопустимо. Следовательно, нужно либо
запретить удаление записи в главной (родительской) таблице, если у
нее есть связанные записи в подчиненной таблице, либо удалять со¬
ответствующие записи в подчиненной таблице вместе с записью из
главной таблицы. Точно так же нельзя вводить данные в подчиненной
таблице без привязки их к какой-либо записи в главной таблице, т. е.
оставлять поле связи пустым или вводить значения, которых нет в
главной таблице. При изменении значения в ключевом поле главной
таблицы или в поле связи подчиненной таблицы связь также будет
нарушена, что приведет к потере или искажению информации.
Отношение «один к одному» имеет место, когда одной записи
в родительской таблице соответствует одна запись в дочерней та¬
блице. Это отношение встречается намного реже, чем отношение
«один ко многим». Его используют, если не хотят, чтобы таблица
БД «разрасталась» от второстепенной информации. Например,
в какой-нибудь таблице хранится архив сведений о сотрудниках,
ID
NAME_GROUP
K_RUK
ID
NAME_STUD
lD_GROUP
1
38-пкс
Федоров С.В.
1
Иванов Петр Иванович
1
2
18-пкс
Иванов Ф.И.
2
Петров Иван Сергеевич
1
3
44-э
Попенко Б.С.
3
Таран Ольга Сергеевна
2
4
36-тг
Филин О.К.
4
Дудко Олеся Владимировна
3
4
Дремина Елена Евгеньевна
1
5
Федорова Дарья Сергеевна
2
б
Лесовая Вера Николаевна
2
7
Семенова Елена Геннадьевна
3
8
Никитина Любовь Петровна
4
9
Курганский Владимир Иванович
4
Рис. 9.15. Пример соответствия записей таблиц «Группы» и «Студенты»
Cодоржащий более сотни полей (характеристик) и несколько co¬
in и тысяч записей. Из этого архива постоянно используются
только «ФИО», «дата рождения» и «домашний адрес». Было бы
Нерационально, с точки зрения использования оперативной памяти, каждый раз считывая эти данные открывать всю таблицу и
загружать в память огромный массив данных. Поэтому ее можно
раз бить на две — в одной хранить часто запрашиваемые сведения,
| и другой — редко используемую информацию. Тогда связать эти
таблицы можно связью «один к одному». Еще бывают случаи, когда
чисть сведений нужно «засекретить», и тогда данные, которые не
у )джны быть доступны всем пользователям, можно также вынести
и от дельную таблицу и «обезопасить» ее, поставив пароль.
Отношение «многие ко многим» применяется в следующих слу¬
чаях:
■ Одной записи в родительской таблице соответствует более одной
записи в дочерней;
■ одной записи в дочерней таблице соответствует более одной
записи в родительской.
На практике отношение «многие ко многим» используется
достаточно редко. Причинами являются сложность организации
связи между таблицами и взаимодействия между их записями.
Кроме того, для отношения «многие ко многим» понятия главной
и подчиненной таблицы не имеют смысла. Всякую связь «многие
ко многим» в реляционной базе данных необходимо заменить на
связь «один ко многим» (одну или более) с помощью введения до¬
полнительных таблиц.
Ссылочная целостность в реляционной базе данных — это
согласованность между связанными таблицами. Ссылочная целост¬
ность обычно поддерживается путем комбинирования первичного
ключа и внешнего ключа. Для соблюдения ссылочной целостности
требуется, чтобы любое поле в таблице, объявленное внешним
ключом, могло содержать только значения из поля первичного клю¬
ча родительской таблицы. Ссылочная целостность предотвращает
ввод несогласованных данных пользователями или приложениями.
В большинстве реляционных СУБД имеются различные правила
ссылочной целостности, которые можно применить при создании
связи между двумя таблицами.
Работа со связанными таблицами имеет следующие особен¬
ности:
■ при изменении (редактировании) поля связи может нарушиться
связь между записями двух таблиц. Поэтому при редактировании
поля связи записи главной таблицы нужно соответственно из-
171
менять и поле связи и значения поля связи всех подчиненных
таблиц (каскадное изменение);
■ при удалении записи главной таблицы нужно удалять и соот¬
ветствующие ей записи в подчиненной таблице (каскадное
удаление);
■ при добавлении записи в подчиненную таблицу значение ее
поля связи должно быть установлено равным значению поля
связи главной таблицы.
Ограничения по каскадному удалению, каскадному изменению,
установке нового значения могут быть наложены на таблицы при
их создании или реструктуризации. Эти ограничения наряду с опи¬
санием полей и индексов и другими элементами входят в структуру
таблицы и действуют для всех приложений, работающих с этой базой
данных. Подобные ограничения можно также реализовывать и про¬
граммным способом: устанавливать и удалять связи между таблицами,
контролировать или запрещать редактирование полей связи и т. д.
ПРИНЦИПЫ ПОДДЕРЖКИ ЦЕЛОСТНОСТИ
В РЕЛЯЦИОННОЙ БАЗЕ ДАННЫХ
9.5.
Целостность данных является одним из основополагающих по¬
нятий в технологии баз данных. Эта характеристика подразумевает
наличие средств, позволяющих удостовериться, что информация в
базе данных всегда остается корректной и полной. Должны быть
установлены правила целостности, и они должны храниться вместе
с базой данных и соблюдаться на глобальном уровне. Целостность
данных должна обеспечиваться независимо от того, каким образом
данные заносятся в память (в интерактивном режиме, посредством
импорта или с помощью специальной программы).
В реляционной модели объекты реального мира представлены
в виде совокупности взаимосвязанных отношений. Целостность
можно определить как соответствие информационной модели
предметной области объектам реального мира и их взаимосвязям в
каждый момент времени. Любое изменение в предметной области,
значимое для построенной модели, должно отражаться в базе дан¬
ных, и при этом должна сохраняться однозначная интерпретация
информационной модели в терминах предметной области.
Ограничения целостности обеспечивают непротиворечивость дан¬
ных при переводе системы баз данных из одного состояния в другое и
позволяют адекватно отражать предметную область данными, храни¬
мыми в БД. Ограничения целостности делятся на явные и неявные.
172
Неявные ограничения определяются самой структурой данных.
Например, тот факт, что записи типа «Студент» являются обязатель¬
ными членами какого-либо экземпляра набора данных «Группа»,
служит, по существу, ограничением целостности, означающим,
что каждый студент непременно должен числиться в какой-либо
группе.
Явные ограничения задаются в схеме базы данных с помощью
средств языка описания данных (DDL, Data Definition Language).
И качестве явных ограничений чаще всего выступают условия, на¬
кладываемые на значения данных.
Например, оклад сотрудника не может быть отрицательным,
а дата приема сотрудника на работу обязательно будет меньше, чем
дата его перевода на другую работу. За выполнением этих ограни¬
чений следит СУБД в процессе своего функционирования.
Различают также статические и динамические ограничения
целостности. Статические ограничения присущи всем состояниям
предметной области, а динамические определяют возможность
перехода предметной области из одного состояния в другое. При¬
мерами статических ограничений целостности могут служить тре¬
бования уникальности номера паспорта или ограничения на дату
рождения, которая не может быть больше текущей даты. В качестве
примера динамического ограничения целостности можно привести
ограничение банковской системы, в соответствии с которым нельзя
удалить сведения о клиенте, пока у него не закрыт счет.
К средствам обеспечения целостности данных на уровне СУБД
относятся:
■ встроенные средства для назначения первичного ключа, в том
числе средства для работы с типом полей с автоматическим
приращением, когда СУБД самостоятельно присваивает новое
уникальное значение;
■ средства поддержания ссылочной целостности, которые обе¬
спечивают запись информации о связях таблиц и автоматиче¬
ски пресекают любую операцию, приводящую к нарушению
ссылочной целостности.
Поддержка целостности в реляционной модели данных имеет
следующие аспекты.
Во-первых, это поддержка структурной целостности, которая за¬
ключается в том, что реляционная СУБД должна допускать работу
только с однородными структурами данных типа «реляционное
отношение». При этом понятие «реляционное отношение» должно
удовлетворять всем ограничениям, накладываемым на него в клас¬
сической теории реляционной БД.
173
Реляционная СУБД работает только со структурой данных типа
реляционное отношение. Необходимо поддерживать правила, со¬
ответствующие реляционной таблице:
■ в таблице нет одинаковых кортежей;
■ столбцы соответствуют атрибутам отношения;
■ всегда есть первичный ключ;
■ каждый атрибут имеет уникальное имя;
■ порядок строк в таблице произвольный;
■ два отношения, отличающиеся только порядком следования
столбцов, считаются одинаковыми.
Во-вторых, это поддержка языковой целостности, которая со¬
стоит в том, что реляционная СУБД должна обеспечивать языки
описания и манипулирования данными не ниже стандарта SQL. Не
должны быть доступны иные низкоуровневые средства манипули¬
рования данными, не соответствующие стандарту.
В-третьих, это поддержка ссылочной целостности, которая
означает обеспечение одного из заданных принципов взаимосвязи
между экземплярами атрибутов взаимосвязанных таблиц:
■ строки подчиненной таблицы уничтожаются при удалении стро¬
ки основной таблицы, связанной с ними;
■ строки основной таблицы модифицируются при удалении стро¬
ки основной таблицы, связанной с ними, при этом на месте
ключа родительской таблицы ставится неопределенное Null
значение.
Ссылочная целостность обеспечивает поддержку непротиво¬
речивого состояния БД в процессе модификации данных при вы¬
полнении операций добавления или удаления.
Структурная, языковая и ссылочная целостность определяют
правила работы СУБД с реляционными структурами данных. Тре¬
бования поддержки этих трех видов целостности говорят о том,
что каждая СУБД должна обеспечивать выполнение этих правил,
а разработчики должны это учитывать при построении баз данных
с использованием реляционной модели и разработке приложения
для реляционных баз данных.
ДОСТОИНСТВА И НЕДОСТАТКИ
РЕЛЯЦИОННОЙ МОДЕЛИ ДАННЫХ
9.6.
Реляционный подход к организации баз данных был заложен в
конце 1960-х гг. Эдгаром Коддом и далеко не сразу получил широкое
распространение и популярность. В то время как основные теоре-
174
тчоские результаты в этой области были получены еще в начале
1070-х гг., и тогда же появились первые прототипы реляционных
| 'УВД, долгое время считалось невозможным добиться эффективной
реализации таких систем. Однако преимущества реляционного под¬
хода и развитие методов и алгоритмов организации и управления
реляционными базами данных привели к тому, что реляционные
системы заняли на мировом рынке СУБД доминирующее положе¬
ние. Уже в середине 1980-х гг. реляционные системы практически
вытеснили с мирового рынка ранние СУБД. И в настоящее время
реляционные СУБД остаются наиболее эффективными.
Этому способствовали существенные достоинства реляционной
модели данных.
1. Прежде всего это простое табличное представление, на основе
которого можно моделировать наиболее распространенные предмет-
иые области. Реляционная модель предоставляет средства описания
данных на основе только их естественной структуры. Нет необхо¬
димости введения каких-либо дополнительных структур, чтобы по¬
лучить машинное представление данных. Соответственно, эта модель
обеспечивает основу языка данных высокого уровня, который под¬
держивает максимальную независимость программ, с одной сторо¬
ны, и машинного представления и организации данных — с другой.
Эти абстракции могут быть точно и формально определены.
2. Другим достоинством реляционной модели данных является
наличие простого и в то же время мощного математического аппа¬
рата, базирующегося на теории множеств и математической логики
и обеспечивающего теоретический базис реляционного подхода
к организации баз данных. Кроме того, реляционный подход обе¬
спечивает возможность манипулирования данными без необходи¬
мости знания конкретной физической организации баз данных во
внешней памяти.
Наряду с общепризнанными достоинствами реляционная модель
обладает и рядом недостатков.
1. Присущая реляционным системам некоторая ограниченность,
что является прямым следствием их простоты. Это особо ощущается
при использовании реляционных СУБД в нетрадиционных областях
применения (например, в системах автоматизированного проекти¬
рования) , в которых требуются очень сложные структуры данных.
2. Невозможность адекватного отражения семантики предметной
области. И это тоже является платой за простоту их структуры.
Современные исследования в области постреляционных систем
главным образом посвящены именно устранению этих недостат¬
ков.
175
КОНТРОЛЬНЫЕ ВОПРОСЫ
1. Дайте определение основным понятиям реляционной модели
данных: «отношение», «тип данных», «домен», «атрибут», «кор¬
теж», «схема отношения», «первичный ключ».
2. Дайте математическое определение понятиям: «отношение»,
«тип данных», «домен», «атрибут», «кортеж», «схема отноше¬
ния», «первичный ключ».
3. Опишите основные свойства отношений.
4. Что называется реляционной алгеброй.
5. Опишите базовые теоретико-множественные операции реля¬
ционной алгебры.
6. Опишите специальные реляционные операции.
7. Что называется унарной, а что бинарной операцией?
8. Приведите примеры объединения, пересечения, вычитания от¬
ношений.
9. Почему произведение отношений используется редко?
10. Что общего между операцией произведения и соединения?
11. В чем особенность операций эквисоединения и естественного
соединения?
12. Что называется индексом в базе данных?
13. За счет чего происходит увеличение скорости работы с данны¬
ми в индексированной таблице?
14. Объясните механизм связывания таблиц в базах данных.
15. Что означает понятие «целостность данных»?
1 В. Опишите особенности работы со связанными таблицами.
17. Охарактеризуйте типы связи «один к одному», «один ко мно¬
гим», «многие ко многим».
18. В каких случаях используется связь «один к одному»?
19. Почему нужно избавляться от связи «многие ко многим»?
20. Перечислите достоинства и недостатки реляционной модели
данных.
Глава 10
ПРИНЦИПЫ ПОСТРОЕНИЯ
КОНЦЕПТУАЛЬНОЙ, ЛОГИЧЕСКОЙ
И ФИЗИЧЕСКОЙ МОДЕЛИ ДАННЫХ
10.1.
ЗАДАЧИ ПРОЕКТИРОВАНИЯ БАЗ ДАННЫХ
Процесс проектирования баз данных длительный, он требует
обсуждений с заказчиком, со специалистами в предметной обла¬
сти. При разработке серьезных корпоративных информационных
систем проект базы данных является тем фундаментом, на котором
строится вся система в целом.
Проектирование баз данных состоит в построении комплекса
взаимосвязанных моделей данных. Причем процесс построения
модели данных неотделим от процессов обработки и манипулиро¬
вания данными.
Проектирование базы данных состоит из двух основных фаз: ло¬
гического и физического моделирования. Во время фазы логического
моделирования разработчик собирает требования к разрабатывае¬
мой БД, составляет описание предметной области и разрабатывает
модель, не зависящую от конкретной СУБД. Во время фазы физиче¬
ского моделирования разработчик создает модель, оптимизирован¬
ную для СУБД и конкретных приложений пользователей.
При создании базы данных для информационной системы
наиболее важными являются задачи, связанные с разработкой
правильной логической структуры данных, обеспечивающей вы¬
полнение всего требуемого набора функций информационной си¬
стемы. Плохо продуманная база данных оказывается, как правило,
неэффективной и даже бесполезной.
Разработка базы данных является достаточно сложной задачей.
Зачастую к ней предъявляется много противоречивых требований.
Создание правильной логической структуры предусматривает ком¬
плексный анализ всех факторов, влияющих на формирование и
обработку данных.
177
Хорошо спроектированная база данных:
■ удовлетворяет всем требованиям пользователей к содержимому
базы данных. Перед проектированием базы необходимо про¬
вести исследование требований пользователей к функциониро¬
ванию базы данных;
■ гарантирует непротиворечивость и целостность данных;
■ обеспечивает естественное, легкое для восприятия структуриро¬
вание информации. Качественное построение базы позволяет
делать запросы к базе более «прозрачными» и легкими для
понимания; следовательно, снижается вероятность внесения
некорректных данных и улучшается качество сопровождения
базы;
■ удовлетворяет требованиям пользователей к производительно¬
сти базы данных. При больших объемах информации вопросы
сохранения производительности начинают играть главную роль,
сразу «высвечивая» все недочеты этапа проектирования.
Задача проектировщика состоит в учете всех этих факторов с
целью разработки наиболее оптимальной базы данных. Основные
задачи проектирования баз данных можно сформулировать сле¬
дующим образом:
■ обеспечение хранения в БД всей необходимой информации;
■ обеспечение возможности получения данных по всем необхо¬
димым запросам;
■ сокращение избыточности и дублирования данных;
■ обеспечение целостности базы данных.
В том, как решаются эти задачи, мы и будем разбираться. Но
прежде нужно вспомнить определение некоторых терминов.
Предметная область — часть реального мира, данные о которой
мы хотим отразить в базе данных. Например, в качестве предметной
области можно выбрать студенческую библиотеку, бухгалтерию
предприятия, отдел кадров, банк, магазин и т.д.
Предметная область содержит как существенные понятия и
данные, так и малозначащие или вообще не значащие. Так, если
в качестве предметной области выбрать учет товаров на складе,
то понятие «накладная» является существенным. В то же время
количество детей сотрудника, принимающего накладные для учета
товаров, является несущественной информацией. Но для расчета
заработной платы данные о наличии детей являются необходимы¬
ми. Таким образом, любая предметная область имеет свои границы
рассмотрения и при проектировании БД необходимо выделить
информационные объекты внутри границ предметной области и аб¬
страгироваться от информации вне границ предметной области.
178
Модель предметной области — это формализованные знания
о предметной области, выраженные при помощи каких-либо
средств. В качестве таких средств могут выступать текстовые описания предметной области (должностные инструкции, описание
документооборота, примеры первичных документов, выходных
отчетов и т.п.). Гораздо более информативными и полезными при
разработке баз данных являются описания предметной области,
вы полненные при помощи специализированных графических
нотаций. От того, насколько правильно смоделирована предметная
область, зависит успех дальнейшей разработки информационной
системы.
Процесс проектирования БД представляет собой последователь¬
ность переходов от неформального словесного описания инфор¬
мационной структуры предметной области к формализованному
описанию объектов предметной области в терминах некоторой
модели.
В общем случае можно выделить следующие этапы проектиро¬
вания.
1. Системный анализ и словесное описание информационных
объектов предметной области.
2. Проектирование концептуальной (инфологической) модели
предметной области — частично формализованное описание объ¬
ектов предметной области в терминах некоторой семантической
модели.
3. Даталогическое или логическое проектирование БД, т. е. опи¬
сание БД в терминах принятой логической модели данных.
4. Физическое проектирование БД, т. е. выбор эффективного
размещения БД на внешних носителях для обеспечения наиболее
эффективной работы приложения.
На каждом из этих этапов разрабатывается та или иная модель
данных. Если мы учтем, что между вторым и третьим этапами не¬
обходимо принять решение, с использованием какой стандартной
СУБД будет реализовываться наш проект, то условно процесс про¬
ектирования БД можно представить последовательностью выпол¬
нения соответствующих этапов (рис. 10.1).
Концептуальное (инфологическое) проектирование — построе¬
ние семантической модели предметной области, т. е. информаци¬
онной модели наиболее высокого уровня абстракции. Такая модель
создается без ориентации на какую-либо конкретную СУБД и мо¬
дель данных. Термины «семантическая модель», «концептуальная
модель» и «инфологическая модель» являются синонимами. Кроме
того, в этом контексте равноправно могут использоваться слова
179
Рис. 10.1. Этапы проектирования базы данных
«модель базы данных» и «модель предметной области» (например,
«концептуальная модель базы данных» и «концептуальная модель
предметной области»), поскольку такая модель является как об¬
разом реальности, так и образом проектируемой базы данных для
этой реальности.
Конкретный вид и содержание концептуальной модели базы
данных определяются выбранным для этого формальным аппара¬
том. Обычно используются графические нотации, подобные ER-
диаграммам.
Чаще всего концептуальная модель базы данных включает в
себя:
■ описание информационных объектов, или понятий предметной
области и связей между ними;
н описание ограничений целостности, т. е. требований к допусти¬
мым значениям данных и к связям между ними.
Логическое (даталогическое) проектирование — создание схе¬
мы базы данных на основе конкретной модели данных, напри¬
мер реляционной. Для реляционной модели данных логическая
модель — набор схем отношений, обычно с указанием первичных
ключей, а также «связей» между отношениями, представляющих
собой внешние ключи. Преобразование концептуальной модели в
логическую модель, как правило, осуществляется по формальным
правилам. Этот этап может быть в значительной степени автома¬
тизирован.
На этапе логического проектирования учитывается специфика
конкретной модели данных, но может не учитываться специфика
конкретной СУБД.
Физическое проектирование — создание схемы базы данных
для конкретной системы управления базами данных. Специфика
конкретной СУБД может включать в себя ограничения на имено-
180
вание объектов базы данных, ограничения на поддерживаемые
прототипы данных и т. п. Кроме того, специфика конкретной СУБД при
физическом проектировании включает выбор решений, связанных
I физической средой хранения данных (выбор методов управления
дисковой памятью, разделение БД по файлам и устройствам, мето¬
дов доступа к данным), создание индексов и т.д.
В области проектирования и разработки баз данных используются различные средства моделирования предметной области и БД,
причем даже в рамках одной конкретной системы необходим целый
1'омплекс моделей разного назначения. Далее рассмотрим каждый
ив этих этапов более подробно.
АНАЛИЗ ПРЕДМЕТНОЙ ОБЛАСТИ
Анализ предметной области предшествует созданию любой ин¬
формационной системы и является частью ее разработки. На этом
этапе определяются потребности пользователей в информации,
которые в свою очередь предопределяют структуру и содержание
базы данных для будущей системы. Предметная область — неко¬
торая совокупность реальных объектов. Каждый из этих объектов
обладает определенным набором свойств (атрибутов). Между объ¬
ектами предметной области могут существовать связи, имеющие
различный содержательный смысл. Создавая базу данных для ин¬
формационной системы, пользователь стремится упорядочить ин¬
формацию по различным признакам. Это делается для того, чтобы
но необходимости извлекать нужную совокупность данных — по¬
лучать выборку с желаемым сочетанием признаков. Осуществить
это возможно только тогда, когда данные структурированы, т. е.
отвечают соглашениям о способах представления данных.
Модель предметной области имитирует структуру и/или функ¬
ционирование исследуемой предметной области и должна быть
адекватной этой области. Особую роль модели предметной области
играют на стадии формирования требований к будущей информационной системе при ее создании. Предварительное моделирование
предметной области позволяет сократить время и сроки проведения
проектировочных работ и получить более эффективный и каче¬
ственный проект. Без проведения моделирования предметной об¬
ласти велика вероятность допущения большого количества ошибок
в решении стратегических вопросов, приводящих к экономическим
потерям и высоким затратам на последующее перепроектирование
системы.
10.2.
181
Исследование предметной области необходимо проводить в
целом для разрабатываемой системы, частью которой является и
база данных. При этом модель данных может быть создана только
в случае, если выявлены все объекты системы, логика их взаимо¬
действия, потоки передаваемой информации. База данных является
хранилищем передаваемых данных, которые используются систе¬
мой при работе. Можно сказать, что база данных — это фундамент
системы, следовательно, к ее созданию нужно подходить очень
серьезно. Очень много ошибок при создании базы данных про¬
исходит по причине недостаточной продуманности ее структуры
и некачественного выполнения этапа проектирования, который и
начинается с исследования предметной области.
Очень важно на этапе проектирования достичь взаимопонима¬
ния как между разработчиками системы, так и между экспертами
предметной области, заказчиками, так как каждый имеет свое ви¬
дение проекта. При этом работа сводится к поэтапному выделению
объектов, значимых функций системы, информационных потоков
и системы их взаимосвязей. Точки зрения участников разработки
по определенным проблемам могут совпадать, при этом формы их
представления могут быть различными, что ведет к осложнению
совместной работы над одним проектом. Важным инструментом в
данном случае является использование единого языка представле¬
ния проектных решений — языка моделирования. Нужно опреде¬
лить систему обозначений, правил описания процессов, объектов,
явлений и их взаимосвязи, позволяющую всем участникам проекта
понимать друг друга («говорить на одном языке»).
Язык моделирования — это набор графических нотаций, ко¬
торые используются для описания моделей в процессе проектиро¬
вания.
Нотация представляет собой совокупность графических объ¬
ектов, используемых в модели, и является синтаксисом языка
моделирования. Язык моделирования, с одной стороны, должен
делать решения проектировщиков понятными пользователю,
с другой — предоставлять проектировщикам средства достаточно
формализованного и однозначного определения проектных реше¬
ний, подлежащих реализации в виде программных комплексов,
образующих целостную систему.
Комплексность подхода и использование единой нотации очень
важно, не только на этапе моделирования предметной области, но
и на последующих этапах разработки программной системы.
Изучение предметной области складывается из непосредствен¬
ного наблюдения протекающих в ней процессов, изучения доку-
182
! м игов, циркулирующих в системе, а также интервьюирования
участников этих процессов.
11ри разработке модели предметной области определяют неко-
|о|)ые границы, в пределах которых можно развивать логическую
модель данных, т. е. моделировать объекты, не выходящие за преде-
лы рассматриваемой предметной области. При этом все второсте¬
пенные детали опускаются, чтобы чрезмерно не усложнять процесс
и исследования полученной модели.
Результатом проведения исследования предметной области
должен стать перечень системных требований, спецификаций,
информационных потоков и их описание. Очень часто для этого
применяются стандартные способы описания предметной области
| использованием моделей DFD (диаграмма потоков данных), UML
(унифицированный язык моделирования).
10.3.
КОНЦЕПТУАЛЬНОЕ МОДЕЛИРОВАНИЕ
Концептуальная модель — это определенное множество поня¬
тий и связей между ними, являющихся смысловой структурой рас¬
сматриваемой предметной области. Концептуальная модель являет¬
ся начальным прототипом будущей базы данных, но строится без
привязки к конкретной СУБД. Процесс разработки концептуальной
модели предметной области является творческим и довольно трудно
поддается формализации. Для построения концептуальной модели
необходимо хорошее знание предметной области, ее семантики,
понимание логических взаимосвязей ее информации.
Разработка концептуальной модели предметной области базиру¬
ется на анализе информационных потребностей пользователей про¬
ектируемой системы. Можно сказать, что концептуальная модель
состоит из перечня взаимосвязанных понятий, используемых для
описания предметной области, вместе со свойствами и характери¬
стиками, классификацией этих понятий, по типам, ситуациям, при¬
знакам в данной области и законов протекания процессов в ней.
К модели предметной области предъявляются следующие тре¬
бования:
■ формализация, обеспечивающая однозначное описание струк¬
туры предметной области;
■ понятность для заказчиков и разработчиков на основе примене¬
ния графических средств отображения модели;
■ реализуемость, подразумевающая наличие средств физической
реализации модели предметной области в ИС;
183
■ легкость модификации (в модель по разным причинам часто
приходится вводить новые объекты или модифицировать су¬
ществующие; модель должна обеспечивать возможность ввода
новых данных без изменения ранее определенных);
■ обеспечение возможности оценки эффективности реализации
модели предметной области на основе определенных методов и
вычисляемых показателей.
Главный критерий адекватности модели предметной области
заключается в функциональной полноте разрабатываемой базы
данных.
Концептуальная модель должна включать такое формализован¬
ное описание предметной области, которое легко будет «читаться»
не только специалистами по базам данных. И это описание долж¬
но быть настолько емким, чтобы можно было оценить глубину и
корректность проработки проекта БД, и конечно, как говорилось
ранее, оно не должно быть привязано к конкретной СУБД. Выбор
СУБД — это отдельная задача, для корректного ее решения необ¬
ходимо иметь проект без ориентации на какую-либо конкретную
СУБД.
В 1970—1980-е гг. в литературе концептуальное проектирование
баз данных обозначалось терминами «инфологическое проекти¬
рование» и «инфологическая модель». На рис. 10.2 дается схема
построения концептуальной модели от исходной информации до
результата.
Рис. 10.2. Схема построения концептуальной модели
184
11аще всего концептуальная модель базы данных включает в
| сг5я;
■ описание информационных объектов, или понятий предметной
области и связей между ними;
■ описание ограничений целостности, т. е. требований к допусти¬
мым значениям данных и связям между ними.
Концептуальное проектирование прежде всего связано с по¬
пыткой представления семантики предметной области в модели
(Ki ii.i данных. Специалисты в области технологий баз данных всегда
интересовались проблемой представления семантики в моделях.
И 1970-е гг. были разработаны несколько различных моделей дан¬
ных, названных семантическими моделями. У всех моделей были
спои положительные и отрицательные стороны.
В 1976 г. Питером Ченом была предложена так называемая
модель «сущность — связь» (entity — relationship). Она включает
сущности и взаимосвязи, отражающие основные бизнес-правила
предметной области. В настоящее время для модели «сущность —
связь» общепринятым стало сокращенное название — ER-модель.
II дальнейшем многими авторами были разработаны свои варианты
подобных моделей. Но все варианты моделей «сущность—-связь»
исходят из одной идеи — графическое изображение нагляднее
текстового описания. В настоящее время ER-модель стала факти¬
чески стандартом для семантической структуризации предметной
области — стандартом при концептуальном моделировании баз
данных.
Семантическую основу ER-модели составляют следующие пред¬
положения:
■ часть реального мира, т. е. совокупность взаимосвязанных объек¬
тов, сведения о которых должны быть помещены в базу данных,
может быть представлена как совокупность сущностей;
■ сущности можно классифицировать по типам сущностей: каж¬
дый экземпляр сущности (представляющий некоторый объект)
может быть отнесен к определенному классу — типу сущностей,
каждый экземпляр которого обладает общими для них и отли¬
чающими их от сущностей других классов свойствами.
Здесь следует еще раз подчеркнуть информационную природу
понятия «сущность» и его соотношение с материальными или вооб¬
ражаемыми объектами предметной области. Любой объект предмет¬
ной области обладает свойствами, часть из которых выделяется как
значимые с точки зрения прикладной задачи. При этом, например,
в процессе анализа и систематизации предметной области обычно
выделяются классы.
185
Класс — это совокупность объектов, обладающих одинаковым
набором свойств, задаваемых в виде наборов атрибутов.
Набор свойств для всех объектов данного класса будет одина¬
ковым, но конкретные значения этих характеристик и особенно
сочетание этих значений будут отличаться от объекта к объекту,
что, собственно, и отличает один экземпляр объекта от другого.
На уровне представления предметной области, т.е. ее концеп¬
туальной модели, объекту, рассматриваемому как понятие (объект
в сознании человека), соответствует понятие «сущность»; объекту
как части материального мира (и существующему независимо от
сознания человека) соответствует понятие «экземпляр сущности»;
классу объектов соответствует понятие «тип сущности».
В дальнейшем, поскольку в концептуальной модели рассматри¬
ваются не отдельные экземпляры объектов, а классы, мы не будем
различать соответствующие понятия этих двух уровней, т. е. будем
предполагать тождественность понятий объект и сущность, свой¬
ство объекта и свойство сущности.
В качестве стандартной графической нотации, с помощью
которой можно визуализировать ER-модель, была предложена
диаграмма «сущность — связь» (ER-диаграмма). ER-диаграмма изо¬
бражается с помощью трех конструктивных элементов: сущность,
атрибут и связь.
Сущность — это класс однотипных объектов, информация о
которых имеет существенное значение для рассматриваемой пред¬
метной области. Каждая сущность должна иметь имя, выраженное
существительным в единственном числе. Имя сущности должно
быть уникальным в пределах модели.
Сущность, с помощью которой моделируется класс однотипных
объектов, определяется как «предмет, который может быть четко
идентифицирован». Так же как каждый объект уникально харак¬
теризуется набором значений свойств, сущность должна опреде¬
ляться таким набором атрибутов, который позволял бы различать
отдельные экземпляры сущностей.
Сущность представляет собой множество экземпляров реальных
или абстрактных объектов (людей, событий, состояний, предметов
и т. п.).
Экземпляр сущности — это конкретный представитель данной
сущности. Каждый экземпляр сущности должен быть отличим
от любого другого экземпляра той же сущности (это требование
аналогично требованию отсутствия кортежей-дубликатов в ре¬
ляционных таблицах). Сущность представляет собой множество
экземпляров реальных или абстрактных объектов (людей, событий,
186
состояний, предметов и т. п.). Например, представителем сущности
"Сотрудник» может быть «Сотрудник Иванов И.И.». Экземпляры
сущностей должны быть различимы, т.е. сущности должны иметь
Никоторые свойства, уникальные для каждого экземпляра этой сущности. Например, для однозначной идентификации каждого
и экземпляра сущности «Сотрудник» вводится атрибут «Табельный
номер», который вследствие своей природы будет всегда иметь
, штильное значение в рамках предприятия. То есть уникальным
идентификатором сущности может являться атрибут, комбинация
атрибутов, комбинация связей или комбинация связей и атрибутов,
однозначно отличающая любой экземпляр сущности от других эк-
|земпляров сущности того же типа.
Как уже отмечалось выше, существует несколько систем нотаций
условных обозначений, языков) для описания объектно-связного
представления предметной области. Нотация Баркера является
наиболее распространенной. Будем придерживаться этой нотации.
Для построения диаграммы «сущность—связь» нам придется вспом¬
нить некоторые определения из теории реляционных баз данных.
11а диаграмме в нотации Баркера сущность изображается пря¬
моугольником, иногда с закругленными углами (рис. 10.3).
Каждая сущность обладает одним или несколькими атрибу¬
тами.
Атрибут сущности — это именованная характеристика, явля¬
ющаяся некоторым свойством сущности. Наименование атрибута
должно быть выражено существительным в единственном числе
(возможно, с характеризующими прилагательными). Примерами
атрибутов сущности «Сотрудник» могут быть такие атрибуты,
как «Табельный номер», «Фамилия», «Имя», «Отчество», «Долж¬
ность», «Зарплата» и т. п. Атрибут предназначен для квалификации,
идентификации, классификации, количественной характеристики
или выражения состояния сущности (рис. 10.3, б). Атрибут, таким
а б в
Рис. 10.3. Обозначения сущности в нотации Баркера:
а — без атрибутов; б — с указанием атрибутов; в — с уточнением атрибутов и их
типов; # — ключевой, * — обязательный, о — необязательный
187
образом, представляет собой некоторый тип характеристик или
свойств, ассоциированных с множеством реальных или абстракт¬
ных объектов. Природа свойства, как и характер связи свойства с
сущностью (объектом), может быть различной. Рассмотрим основ¬
ные виды свойств (атрибутов).
Экземпляр атрибута — определенная характеристика конкрет¬
ного экземпляра сущности, значение атрибута (например, «цвет» —
это атрибут, а «зеленый» — экземпляр атрибута).
Атрибут может быть множественным или единичным — т. е.
атрибут, задающий свойство, может одновременно иметь несколько
значений или, соответственно, только одно. Например, сотрудник
может иметь несколько специальностей, но единственное значение
ИНН.
Атрибут может быть простым (не подлежащим дальнейшему
делению с точки зрения прикладных задач) или составным — если
его значение составляется из значений простых свойств. Например,
свойство «Год рождения» является простым, а свойство «Адрес» -—
составным, так как включает значения простых свойств: «Город»,
«Улица», «Дом».
Как определить необходимую степень детализации атрибута?
Например, если в задачах требуется печатать в документах адрес
клиента, но не требуется дополнительного анализа полного адреса,
т. е. города, улицы, дома, квартиры, то мы можем принять весь адрес
за простое свойство, и он будет храниться полностью, а пользова¬
тель сможет получить его только как полную строку символов из БД.
Если же в наших задачах существует анализ частей, составляющих
адрес, например города, где расположен клиент, то нам необходимо
выделить город как отдельный элемент данных, только в этом случае
пользователь может получить к нему доступ и выполнить, например,
запрос на поиск всех клиентов, которые проживают в конкретном
городе, например в Санкт-Петербурге.
Однако если пользователю понадобится и полный адрес клиента,
то остальную информацию по адресу также необходимо хранить в
отдельном поле, которое может быть названо, например, «Сокра¬
щенный адрес». В этом случае для каждого клиента в БД хранится
как «Город», так и «Сокращенный адрес».
В некоторых случаях полезно различать базовые и производные
свойства. Например, «Поставщик» может иметь свойство «Общее
количество поставляемых деталей», которое вычисляется сумми¬
рованием количества деталей, поставляемых им по проекту. Если
наличие некоторого свойства для всех экземпляров сущности не
является обязательным, то такое свойство называется условным.
188
11,(пример, не все сотрудники обладают свойством «ученая сте¬
пень».
Значения атрибутов могут быть постоянными (статическими)
иди динамическими, т. е. меняться со временем. Например, свойство
и| 1НН» является статическим, а «Адрес» — динамическим. Свой-
| тио может быть неопределенным, если оно является динамическим,
по ого текущее значение еще не задано.
Первичный ключ сущности — это неизбыточный набор атри-
оутов, значения которых в совокупности являются уникальными
для каждого экземпляра сущности. Неизбыточность заключается
о том, что удаление любого атрибута из состава ключа приведет к
нарушению его уникальности.
Первичный ключ предназначен для уникальной идентификации
каждого экземпляра сущности, т. е. представляет собой совокуп¬
ность признаков, позволяющих идентифицировать объект. Клю¬
чевые атрибуты помещают в начало списка и помечают символом
«#» (рис. 10.3, в).
Может случиться, что в данной предметной области свойства
объекта не представляют для нас интереса. В связи с этим в ER-
модели возможно наличие объектов, не имеющих свойств и пред¬
ставленных только своими идентификаторами.
Атрибуты делятся на ключевые и описательные. Ключевые атри¬
буты — атрибуты, входящие в состав первичного ключа. Прочие
атрибуты называются описательными.
Описательные атрибуты могут быть обязательными или необя¬
зательными. Обязательные атрибуты для каждой сущности всегда
имеют конкретное значение, необязательные — могут быть не
определены. Обязательные и необязательные описательные атри¬
буты помечают символами «*» и «о» соответственно.
Связь — это отношение одной сущности к другой или к самой
себе. Каждая связь может иметь одну из двух модальностей свя¬
зи. Обязательная связь — если любой экземпляр одной сущности
связан хотя бы с одним (т. е. не менее чем с одним) экземпляром
другой сущности, обозначается сплошной линией (рис. 10.4, а).
Необязательная связь означает, что экземпляр одной сущности
может быть связан с одним или несколькими экземплярами дру¬
гой сущности, а может быть и не связан ни с одним экземпляром,
обозначается пунктирной линией (рис. 10.4, б). Связь может иметь
разную модальность с разных концов (рис. 10.4, в).
Каждая сущность может обладать любым количеством связей
разного типа («один к одному», «один ко многим», «многие ко мно¬
гим») с другими сущностями модели (рис. 10.5).
189
в
Рис. 10.4. Модальность связи:
а — обязательная; 6 — необязательная; в — смешанная (пунктир показывается до
середины линии)
Используя данную терминологию, можно определить типы связи
следующим образом. Связь типа «один к одному» означает, что один
экземпляр первой сущности связан только с одним экземпляром
второй сущности. Такая связь, скорее всего, свидетельствует о том,
что была неверно разделена одна сущность на две (хотя иногда к
такому типу связи прибегают в случае, если есть необходимость
«засекретить» часть данных).
Связь типа «один ко многим» означает, что каждый экземпляр
первой сущности связан с несколькими экземплярами второй
сущности. Связь типа «многие ко многим» означает, что каждый
экземпляр первой сущности может быть связан с несколькими эк¬
земплярами второй сущности, и наоборот. Такой тип связи является
временным типом связи, допустимым на ранних этапах разработки
модели. В дальнейшем такую связь необходимо заменить двумя
связями типа «один ко многим» путем выделения промежуточной
сущности.
Независимая сущность представляет независимые данные, кото¬
рые всегда присутствуют в системе. Они могут быть как связаны с
другими сущностями, так и нет.
а б в
Рис. 10.5. Обозначение разных типов связи в нотации Баркера:
а — «один к одному»; б — «один ко многим»; в — «многие ко многим»
190
Сущность 1
—
Сущность 2
,
Ассоциированная сущность
V /
Рис. 10.6. Обозначение ассоциированной сущности в нотации Баркера
Зависимая сущность представляет данные, зависящие от других
сущностей системы, поэтому она всегда должна быть связана с
другими сущностями.
Ассоциированная сущность представляет данные, которые ас¬
социируются с отношениями между двумя и более сущностями.
Обычно данный вид сущностей появляется в модели для разреше¬
ния отношения «многие ко многим» (рис. 10.6).
Если экземпляр сущности полностью идентифицируется своими
ключевыми атрибутами, то говорят о полной идентификации сущно¬
сти. В противном случае идентификация сущности осуществляется
с использованием атрибутов связанной сущности, что указывается
черточкой на линии связи (рис. 10.7).
Некоторые ограничения целостности задаются на ER-диаграмме,
другие описываются на естественном языке.
В качестве примера рассмотрим базу данных, отражающую про¬
цесс поставки и продажи некоторого товара постоянным клиентам.
База данных проектируется для автоматизированной информаци¬
онной системы «Склад оптовой торговли».
Исходя из анализа предметной области, можно выделить следу¬
ющие сущности — «Товар», «Поставщик» и «Покупатель».
Сразу возникает очевидная связь между сущностями — «по¬
купатели могут приобретать много товаров», «товары могут при¬
обретаться многими покупателями». Аналогичная связь между
«товарами» и «поставщиками». Подобные связи относятся к типу
«многие ко многим» (рис. 10.8).
Однако реляционная модель данных требует заменить отно¬
шение «многие ко многим» на несколько отношений «один ко
многим». Для разрешения этого отношения добавим еще один тип
сущностей, отображающий процесс продажи/покупки товаров —
Идентифицирующая сущность
Идентифицируемая сущность
Рис. 10.7. Обозначение идентификации посредством другой сущности
в нотации Баркера
191
введем ассоциированные сущности «Приходная накладная» и «Рас¬
ходная накладная» (рис. 10.9).
Установим связи между объектами. Один покупатель может
неоднократно покупать товары, поэтому между объектами «Поку¬
патель» и «Расходная накладная» имеется связь «один ко многим».
Каждое наименование товара может неоднократно участвовать в
сделках, в результате между объектами «Товар» и «Расходная на¬
кладная» имеется связь «один ко многим». Аналогично строятся
связи между сущностями «Приходная накладная» и «Товар».
Проанализируем атрибуты сущностей. Каждый поставщик и
покупатель является юридическим лицом и имеет наименование,
адрес, банковские реквизиты. Каждый товар имеет наименование,
цену, характеризуется единицей измерения. Каждая накладная име¬
ет уникальный номер, дату выписки, список товаров с количествами
и ценами, а также общую сумму накладной. Покупатели покупают
товары, получая при этом расходные накладные, в которые внесены
данные о количестве и цене приобретенного товара. Каждый по¬
купатель может получить несколько накладных. Каждая накладная
должна выписываться на одного покупателя. Каждая накладная
должна содержать не менее одного товара (не может быть «пустой»
накладной). Каждый товар в свою очередь может быть продан не¬
скольким покупателям по нескольким накладным. Аналогичную
цепь рассуждений можно выстроить для определения связей между
сущностями «Товар» и «Поставщик». Покупатель может быть одно-
Рис. 10.9. Промежуточный вариант ER-диаграммы
192
временно и поставщиком, поэтому эти два объекта объединены в
одну сущность «Контрагент».
Важной задачей в создании базы данных является определение
атрибутов, которые однозначно определяют каждый экземпляр сущ¬
ности, т.е. выявление первичных ключей. Для таблицы «Товар» на¬
звание товара не может служить первичным ключом, так как товары
разных типов могут иметь одинаковые названия, поэтому введем
первичный ключ «Код», под которым можно понимать, например,
артикул товара. Точно так же «Наименование» не может служить
первичным ключом в таблице «Контрагенты». Введем первичный
ключ «Код» для поставщиков и покупателей, под которым можно
понимать номер паспорта, идентификационный номер налогопла¬
тельщика или любой другой атрибут, однозначно определяющий
каждого контрагента. Для таблиц «Расходная накладная» / «Приход¬
ная накладная» первичным ключом является поле «Номер», так как
помер однозначно определяет каждую накладную. В качестве пер¬
вичного ключа можно было бы выбрать не одно поле, а некоторую
совокупность полей, но для иллюстрации процесса моделирования
ограничимся простыми первичными ключами.
Теперь можно все это внести в диаграмму. Таким образом, по¬
сле уточнения диаграмма будет выглядеть, как представлено на
рис. 10.10.
Данная диаграмма должна быть проверена с точки зрения воз¬
можности получения всех выходных данных, показанных на диа¬
грамме потоков данных разрабатываемой системы.
Понятия «объект» и «свойство» являются относительными. Что
в каждой из моделей предметной области следует считать само-
193
стоятельным объектом, а что — свойством другого объекта, будет
зависеть от аспекта рассмотрения данной предметной области.
Например, пусть строится информационная система учета книг.
Для книг указывается наименование издательства. Больше никакой
информации об издательствах не хранится; никакой специальной
обработки по этому признаку не производится. В этом случае не
стоит выделять отдельный объект «Издательство», а следует счи¬
тать его свойством соответствующего объекта — «Книги». Если
же в предметной области отражается дополнительная информация
об издательствах, например их адрес, телефон, то «Издательство»
следует рассматривать как самостоятельный объект.
В общем случае можно дать следующие рекомендации по поводу
того, что следует выделять в качестве самостоятельного объекта в
ER-модели.
В качестве самостоятельного объекта в ER-модели следует изо¬
бражать сущности:
■ для которых фиксируются какие-либо их свойства;
■ которые участвуют более чем в одной связи.
При возникновении сомнений лучше принять решение о созда¬
нии самостоятельного объекта, так как это в дальнейшем потребует
меньших переделок модели.
Следует помнить, что количественные характеристики всегда
являются свойствами какого-либо объекта, и никогда — самостоя¬
тельными объектами. Например, год рождения не может рассма¬
триваться как самостоятельный объект.
В ER-модели должно быть отображено все, о чем идет речь в
данной предметной области (во входных документах, выходных до¬
кументах и т. п.). После построения полной ER-модели необходимо
определить состав хранимых показателей. Переход от ER-модели к
логической модели должен производиться только для сохраняемых
показателей.
Рассмотрим еще один пример построения ER-диаграммы.
Предположим, что нужно построить модель данных для автома¬
тизированной информационной системы «Абитуриент». Целью
ее разработки является организация приема абитуриентов, под¬
готовка информации для проведения вступительных испытаний
и формирования необходимой отчетности по итогам приема. Ис¬
ходные данные в систему поступают из заявлений абитуриентов,
документов об образовании, справок и т.д.
В модели данных разрабатываемой автоматизированной инфор¬
мационной системы непременно должна быть сущность «Абиту¬
риент».
194
Проанализируем атрибуты этой сущности: пол, дата рождения,
место рождения, национальность, ИНН, страховой номер, домаш¬
ний адрес (область/республика, город, улица, дом), паспортные
данные, данные страхового полиса, законченное образовательное
195
учреждение, документы, дающие право на льготы, дополнительные
сведения (инвалид, сирота, участник военных действий ит.д.), све¬
дения о родителях (ФИО, место работы), средний балл аттестата
и т. д. Из них атрибуты «Школа», «Национальность», «Форма обуче¬
ния», «Специальность», «Улица», «Город», «Область» являются наи¬
менованиями отдельных сущностей. При этом значение атрибута
«Населенный пункт» полностью определяется значением сущности
«Улица», а значение атрибута «Область» определяется значением
сущности «Населенный пункт».
На рис. 10.11 показаны основные отношения между указанными
сущностями.
На следующем шаге определяем атрибуты каждой сущности и
уточняем их типы (атрибуты, используемые для дополнительной
идентификации сущности другой сущностью, не указываются, так
как они описываются в соответствующей сущности). Теперь можно
внести все это в диаграмму (рис. 10.12).
При изображении предметной области надо стремиться отобра¬
зить информацию как можно более детально, так как это в даль¬
нейшем даст возможность принять более обоснованные решения
при проектировании структуры базы данных. Так, например, если
«Адрес», «ФИО» являются составными характеристиками, то же¬
лательно это отразить в ER-модели.
Построение концептуальной модели может выполняться как
«вручную», так и с использованием автоматизированных средств
проектирования — CASE-средств.
10.4.
ЛОГИЧЕСКОЕ ПРОЕКТИРОВАНИЕ
И ФИЗИЧЕСКАЯ МОДЕЛЬ БАЗЫ ДАННЫХ
При проектировании логической структуры БД осуществляется
преобразование исходной концептуальной модели в модель данных,
поддерживаемую конкретной СУБД, и проверка адекватности по¬
лученной логической модели отображаемой предметной области.
Для любой предметной области существует множество вари¬
антов проектных решений ее отображения в логической модели.
Методика проектирования должна обеспечивать выбор наиболее
подходящего проектного решения.
Этап создания логической модели называется логическим про¬
ектированием. При переходе от концептуальной (инфологической)
модели к логической (даталогической) следует иметь в виду, что
концептуальная модель должна включать в себя всю информацию
196
и предметной области, необходимую для проектирования базы
данных. Преобразование концептуальной модели в логическую
осуществляется по формальным правилам. Логическая модель базы
данных строится в терминах информационных единиц, допустимых
и гой конкретной СУБД, в среде которой мы проектируем базу
данных.
Описание логической структуры базы данных на языке СУБД
пн п.1вается схемой данных.
Спроектировать логическую структуру базы данных означает
определить все информационные единицы и связи между ними,
in дать их имена; если для информационных единиц возможно ис¬
пользование разных типов, то определить их тип. Следует также
I, |дать некоторые количественные характеристики, например длину
ПОЛЯ.
Любая система управления данными оперирует с допустимыми
для нее логическими единицами данных. Кроме того, многие СУБД
накладывают количественные и иные ограничения на структуру
опзы данных. Поэтому прежде чем приступить к построению логи¬
ческой модели, необходимо детально изучить особенности СУБД,
возможности и целесообразности ее использования, ознакомиться
с существующими методиками проектирования, а также проанали¬
зировать имеющиеся средства автоматизации проектирования.
Хотя логическое проектирование является проектированием
логической структуры базы данных, на него оказывают влияние
возможности физической организации данных, предоставляемые
конкретной СУБД. Поэтому знание особенностей физической
организации данных является полезным при проектировании ло¬
гической структуры.
В базе данных отражается определенная предметная область.
Поэтому процесс проектирования БД предусматривает предвари¬
тельную классификацию объектов предметной области, система¬
тизированное представление информации об объектах и связях
между ними. На проектные решения оказывают влияние особен¬
ности требуемой обработки данных. Поэтому соответствующая
информация должна быть определенным образом представлена и
проанализирована на начальных этапах проектирования БД.
В концептуальной модели должна быть отображена вся инфор¬
мация, циркулирующая в информационной системе. Но это не озна¬
чает, что вся она должна храниться в базе данных и все сущности,
зафиксированные в концептуальной модели должны в явном виде
отражаться в логической модели. Прежде чем строить логическую
модель, необходимо решить, какая информация будет храниться
197
в базе данных. Например, в концептуальной модели должны быть
отражены вычисляемые показатели, но совсем не обязательно,
что они должны храниться в базе данных. В связи с этим одним
из первых шагов проектирования является определение состава
БД, т. е. перечня тех показателей, которые целесообразно хранить
в базе данных.
Кроме того, не все виды связей, существующие в предметной
области, могут быть непосредственно отображены в конкретной
логической модели. Так, многие СУБД не поддерживают непосред¬
ственно отношение «многие ко многим» между элементами. В этом
случае в логическую модель вводится дополнительный вспомога¬
тельный элемент, отображающий эту связь (таким образом, отно¬
шение «многие ко многим» как бы разбивается на два отношения
«один ко многим» между этим вновь введенным элементом и ис¬
ходными элементами). Пример этого был приведен ранее.
Опишем типовую пошаговую процедуру преобразования диа¬
граммы «сущность — связь» в реляционную схему базы данных.
1. Каждая сущность превращается в таблицу. Имя сущности
становится именем таблицы. Экземплярам типа сущности соот¬
ветствуют строки соответствующей таблицы.
2. Каждый атрибут становится столбцом таблицы с тем же име¬
нем; может выбираться более точный формат представления дан¬
ных. Столбцы, соответствующие необязательным атрибутам, могут
содержать неопределенные значения; столбцы, соответствующие
обязательным атрибутам, — не могут.
3. Компоненты уникального идентификатора сущности пре¬
вращаются в первичный ключ таблицы. Если имеется несколько
возможных уникальных идентификаторов, для первичного ключа
выбирается наиболее характерный. Если в состав уникального иден¬
тификатора входят связи, к числу столбцов первичного ключа добав¬
ляется копия уникального идентификатора сущности, находящейся
на другом конце связи. Для именования этих столбцов используют¬
ся имена концов связей и/или имена парных сущностей.
4. Связи «один к одному» становятся внешними ключами.
Необязательные связи соответствуют столбцам внешнего ключа,
допускающим наличие неопределенных значений; обязательные
связи — столбцам, не допускающим неопределенных значений.
Если между двумя сущностями А и В имеется связь «один к одному»,
то соответствующий внешний ключ по желанию проектировщика
может быть объявлен как в таблице А, так и в таблице В.
5. Для поддержки связи «многие ко многим» между типами
сущности А и В создается дополнительная таблица С с двумя обя-
198
штильными столбцами, один из которых содержит уникальные
индикаторы экземпляров сущности А, а другой — уникальные
идентификаторы экземпляров сущности В.
(>. Индексы создаются для первичного ключа (уникальный ин¬
декс), внешних ключей и тех атрибутов, на которых предполагается
и основном базировать запросы. Как отмечалось выше, вопросы
определения индексов и других вспомогательных структур данных
относятся к этапу физического, а не логического проектирования
ушных. Конечно, на практике эти этапы часто перекрываются
но времени. Заметим, кстати, что в SQL-ориентированных СУБД
индексы для всех возможных и внешних ключей, как правило,
создаются системой автоматически.
Для привязки логической модели к среде хранения используется
модель данных физического уровня, для краткости часто называе¬
мая физической моделью. Эта модель определяет способы физиче-
| кой организации данных в среде хранения. Модель физического
уровня строится с учетом возможностей, предоставляемых СУБД.
| )писание физической структуры базы данных называется схемой
хранения. Соответствующий этап проектирования БД называется
11ш:шческим проектированием. СУБД обладают разными воз¬
можностями по физической организации данных. В связи с этим
различаются для конкретных систем сложность и трудоемкость
физического проектирования и набор выполняемых шагов.
Физическая модель данных описывает данные средствами кон-
I ротной СУБД. На этапе физического проектирования учитывается
специфика конкретной модели данных и специфика конкретной
СУВД. Отношения, разработанные на стадии формирования ло¬
гической модели данных, преобразуются в таблицы, атрибуты
становятся столбцами таблиц, для ключевых атрибутов создаются
уникальные индексы, домены преображаются в типы данных,
принятые в используемой СУБД. Ограничения, имеющиеся в ло¬
гической модели данных, реализуются различными средствами
СУБД, например, при помощи индексов, ограничений целостности,
триггеров, хранимых процедур. При этом решения, принятые на
уровне логического моделирования, определяют некоторые гра¬
ницы, в пределах которых можно развивать физическую модель
данных. Точно так же в пределах этих границ можно принимать
различные решения. Например, отношения, содержащиеся в ло¬
гической модели данных, должны быть преобразованы в таблицы,
по для каждой таблицы можно дополнительно объявить различные
индексы, повышающие скорость обращения к данным. Многое тут
зависит от конкретной СУБД.
199
Физическое проектирование БД предполагает также выбор эф¬
фективного размещения БД на внешних носителях для обеспечения
наиболее эффективной работы приложения.
На этапе физического моделирования производится оценка
требований к вычислительным ресурсам, необходимым для функ¬
ционирования системы, выбор типа и конфигурации ЭВМ, типа и
версии операционной системы. Выбор зависит от таких показате¬
лей, как:
■ примерный объем данных в БД;
■ динамика роста объема данных;
■ характер запросов к данным (извлечение и обновление отдель¬
ных записей, обработка групп записей, обработка отдельных
отношений или соединение отношений);
и интенсивность запросов к данным по типам запросов;
и требования к времени отклика системы по типам запросов.
Выбор СУБД и инструментальных программных средств явля¬
ется одним из важнейших моментов в разработке проекта базы
данных, так как он принципиальным образом влияет на весь про¬
цесс проектирования БД и реализации информационной системы.
Теоретически при осуществлении этого выбора нужно принимать
во внимание десятки факторов. Но на практике разработчики руко¬
водствуются лишь собственной интуицией и несколькими наиболее
важными критериями, к которым, в частности, относятся:
■ тип модели данных, которую поддерживает данная СУБД, аде¬
кватность модели данных структуре рассматриваемой ПО;
■ характеристики производительности СУБД;
■ запас функциональных возможностей для дальнейшего развития
информационной системы;
в степень оснащенности СУБД инструментарием для персонала
администрирования данными;
и удобство и надежность СУБД в эксплуатации;
■ стоимость СУБД и дополнительного программного обеспече¬
ния.
Подводя итог изложенного, основные этапы и задачи процесса
проектирования базы данных можно представить в виде таблицы
(табл. 10.1). Каждый из этапов характеризуется определенной по¬
следовательностью работ, определенным уровнем представления
данных.
Проектирование является важнейшей стадией при создании
базы, так как именно на этом этапе принимаются очень важные
стратегические решения, влияющие на весь процесс создания эф¬
фективной информационной системы.
200
. Этапы проектирования БД
10.5.
ПРОЕКТИРОВАНИЕ БАЗЫ ДАННЫХ
НА ОСНОВЕ ПРИНЦИПОВ НОРМАЛИЗАЦИИ
С теорией нормализации связана классическая технология про¬
ектирования реляционных баз данных. Нормализация представляет
собой процесс реорганизации данных путем ликвидации избыточ¬
ности данных и иных противоречий с целью приведения таблиц к
виду, позволяющему осуществлять непротиворечивое и корректное
редактирование данных.
Иными словами, нормализация предназначена для приведения
структуры базы данных к виду, обеспечивающему минимальную
логическую избыточность, и не имеет целью уменьшение или
увеличение производительности работы или же уменьшение или
увеличение физического объема базы данных. Цель нормализации
сводится к получению оптимальной структуры базы данных.
Общее назначение процесса нормализации заключается в сле¬
дующем:
■ исключение некоторых типов избыточности;
■ устранение некоторых аномалий обновления;
■ разработка проекта базы данных, который является достаточно
«качественным» представлением реального мира, интуитивно
понятен и может служить хорошей основой для последующего
расширения;
■ упрощение процедуры применения необходимых ограничений
целостности.
Метод нормализации основан на теории реляционных моделей
данных. Исходной точкой является представление предметной
области в виде одного или нескольких отношений, и на каждом
шаге проектирования производится некоторый набор таблиц, об¬
ладающих «улучшенными» свойствами. Процесс проектирования
представляет собой процесс нормализации схем отношений. Иными
словами, осуществляется декомпозиция отношения, находящегося
в предыдущей нормальной форме, в два или более отношения, удо¬
влетворяющих требованиям следующей нормальной формы.
Декомпозиция (разбиение) таблицы — это процесс деления
таблицы на несколько таблиц с целью устранения избыточности
данных.
Под избыточностью данных понимают дублирование данных, со¬
держащихся в базах данных. При этом различают простое (не избы¬
точное) дублирование и избыточное дублирование. Не избыточное
дублирование является естественным и допустимым. Избыточность
202
данных проявляется в том, что в нескольких записях таблицы базы
данных повторяется одна и та же информация, удаление которой в
одном месте не приведет к ее полной потере в базе данных.
В теории реляционных баз данных обычно выделяется следу¬
ющая последовательность нормальных форм:
■ первая нормальная форма (1нф, 1 Normal Form, INF);
■ вторая нормальная форма (2нф, 2NF);
■ третья нормальная форма (Знф, 3NF);
■ нормальная форма Бойса-Кодда (BCNF);
■ четвертая нормальная форма (4нф, 4NF);
■ пятая нормальная форма, или нормальная форма проекции-
соединения (5нф, 5NF, или PJ/NF).
Каждой нормальной форме соответствует некоторый опреде¬
ленный набор ограничений, и отношение находится в некоторой
нормальной форме, если удовлетворяет свойственному ей набору
ограничений. Обычно на практике применение находят только
первые три нормальные формы, которые и будут рассмотрены
далее.
Процесс проектирования базы данных с использованием метода
нормальных форм является пошаговым. Проектирование начина¬
ется с определения всех объектов, информация о которых должна
содержаться в базе данных, определения атрибутов этих объектов.
Атрибуты всех объектов сводятся в одну таблицу, которая является
исходной. Эта таблица приводится к первой нормальной форме в
соответствии с ее требованиями. Затем эта таблица декомпозирует¬
ся на две или несколько таблиц, те в свою очередь тоже могут быть
преобразованы в другие таблицы. Так последовательно создается
совокупность взаимосвязанных таблиц, отвечающих требованиям
нормальных форм. На практике обычно используют первые три
нормальные формы.
Для примера разработаем базу данных для хранения сведений
о студентах: ФИО, год рождения, группа, классный руководитель,
шифр и наименование специальности. Приведенная таблица имеет
довольно простую структуру, на практике таблица содержала бы
гораздо больше данных. Но для демонстрации процедуры нормали¬
зации этих данных вполне достаточно. Тип и размер полей в данном
случае большой роли не играют, поэтому ограничимся только их
названиями. Созданную таблицу будем рассматривать как одно¬
табличную базу данных.
Для того чтобы таблица соответствовала требованиям формы
1нф, должно выполняться следующее условие — поля таблицы
должны содержать неделимую (атомарную) информацию.
203
ФИО
Год рож¬
дения
Специальность
Шифр
Группа
Классный
руководитель
Иванов Ф.И.
1998
Информационные системы
230401
35и
Попенко Б.С.
Кириллова Е.Е.
1998
Информационные системы
230401
35и
Попенко Б.С.
Потапов В.С.
1998
Информационные системы
230401
35и
Попенко Б.С.
Дудко О.В.
1997
Информационные системы
230401
35и
Попенко Б.С.
Таран О.С.
1998
Обработка металлов давлением
150412
48о
Демина Е.Е.
Ильин Г.С.
1998
Компьютерные сети
230111
44к
Павлова Н.И.
Федорова Д.С.
1998
Информационные системы
230401
35и
Попенко Б.С.
Медведева Ж.А.
1997
Компьютерные сети
230111
44к
Павлова Н.И.
Пушкина А. А.
1998
Компьютерные сети
230111
44к
Павлова Н.И.
Рис. 10.13. Таблица, соответствующая форме 1нф
Приведем исходную таблицу к форме 1нф. Тогда в таблице «Сту¬
денты» будет 6 столбцов: ФИО, год рождения, шифр, специальность,
группа, классный руководитель (рис. 10.13).
К форме 2нф предъявляются следующие требования:
■ таблица должна удовлетворять требованиям формы 1нф;
■ любое неключевое поле должно однозначно идентифицировать¬
ся ключевыми полями.
Другими словами, таблица находится в форме 2нф в том и только
в том случае, если эта таблица соответствует форме 1нф и каждый
неключевой атрибут полностью зависит от первичного ключа. На¬
помним, что неключевым называется любой атрибут отношения,
не входящий в состав первичного ключа.
Записи таблицы, приведенной к форме 1нф, не являются уни¬
кальными. Таблица на рис. 10.13 соответствует форме 1нф, но ввиду
отсутствия первичного ключа не соответствует форме 2нф.
С достаточно большой вероятностью в одной учебной группе
могут оказаться однофамильцы, и тогда таблица будет содержать
дублированные данные. Чтобы обеспечить уникальность записей
введем в таблицу ключевое поле — номер студенческого билета.
При этом значение ключа будет однозначно идентифицировать
каждую запись в таблице (рис. 10.14)
Записи этой таблицы имеют значительное избыточное дубли¬
рование данных, так как классный руководитель указывается для
каждой группы, а наименование специальности — для каждого
шифра специальности. Избавиться от дублирования можно, разбив
таблицу. При этом таблицы будут соответствовать форме Знф.
Требования формы Знф следующие:
204
Ном.
ФИО
Г од рож¬
дения
Специальность
Шифр
Группа
Классный
руководитель
101
Иванов Ф.И.
1998
Информационные системы
230401
35и
Попенко Б.С.
102
Кириллова Е.Е.
1998
Информационные системы
230401
35и
Попенко Б.С.
103
Потапов В.С.
1998
Информационные системы
230401
35и
Попенко Б.С.
104
Дудко О.В.
1997
Информационные системы
230401
35и
Попенко Б.С.
105
Таран О.С.
1998
Обработка металлов давлением
150412
48о
Демина Е.Е.
106
Ильин Г.С.
1998
Компьютерные сети
230111
44к
Павлова Н.И.
107
Федорова Д.С.
1998
Информационные системы
230401
35и
Попенко Б.С.
108
Медведева Ж. А.
1997
Компьютерные сети
230111
44к
Павлова Н.И.
109
Пушкина А.А.
1998
Компьютерные сети
230111
44к
Павлова Н.И.
Рис. 10.14. Таблица, соответствующая форме 2нф
■ таблица должна удовлетворять требованиям формы 2нф;
■ неключевые поля не зависят друг от друга.
На рис. 10.14 таблица не соответствует форме Знф, потому что
значение поля «Классный руководитель» зависит от номера, а наи¬
менование специальности зависит от шифра, и наоборот. Для того
чтобы привести таблицу в соответствие форме Знф, следует разбить
ее на несколько таблиц. Информацию о специальностях и группах
11ужно вынести в отдельные таблицы, в каждой из которых опреде¬
лить свой первичный ключ.
После приведения к форме Знф база данных будет иметь струк¬
туру, показанную на рис. 10.15.
В таблице «Студенты» теперь вместо полной информации о
специальности и группы хранится только код специальности и код
группы соответственно (рис. 10.16).
Следование требованиям нормальных форм не всегда является
обязательным. С ростом числа таблиц усложняется структура базы
Рис. 10.15. База данных после привидения к форме Знф
205
Ном.
ФИО
Год рож¬
дения
Код
спец.
Код
группы
101
Иванов Ф.И.
1998
10
13
102
Кириллова Е.Е.
1998
10
13
103
Потапов В.С.
1998
10
13
104
Дудко О.В.
1997
10
13
105
Таран О.С.
1998
30
15
106
Ильин Г.С.
1998
20
14
107
Федорова Д.С.
1998
10
13
108
Медведева Ж.А.
1997
20
14
109
Пушкина А.А.
1998
20
14
Код
Специальность
Шифр
10
Информационные системы
230401
20
Обработка металлов давлением
150412
30
Компьютерные сети
230111
Код
группы
Группа
Классный
руководитель
13
35и
Попенко Б.С.
15
48о
Демина Е.Е.
14
44к
Павлова Н.И.
Рис. 10.16. Таблицы в форме Знф
данных и увеличивается время обработки данных. В ряде случаев
для упрощения структуры можно позволить частичное дублиро¬
вание данных, при этом не допуская нарушения их целостности и
соблюдая непротиворечивость.
Несмотря на то что идеи нормализации весьма полезны для про¬
ектирования баз данных, они отнюдь не являются универсальным
или исчерпывающим средством повышения качества проекта БД.
Это связано с тем, что существует слишком большое разнообразие
возможных ошибок и недостатков в структуре БД, которые норма¬
лизацией не устраняются. Несмотря на эти рассуждения, теория
нормализации является очень ценным достижением реляционной
теории и практики, поскольку она дает научно строгие и обосно¬
ванные критерии качества проекта БД и формальные методы для
усовершенствования этого качества.
Существует мнение, что нормализация — это просто «здравый
смысл», и любой компетентный профессионал и сам «естественным
образом» спроектирует полностью нормализованную базу данных
без необходимости применять теорию нормализации. Однако
нормализация в точности и является теми принципами здравого
смысла, которыми руководствуется в своем сознании профессио¬
нальный проектировщик, т. е. принципы нормализации — это и
есть формализованный здравый смысл.
206
СОВРЕМЕННЫЕ ИНСТРУМЕНТАЛЬНЫЕ
СРЕДСТВА РАЗРАБОТКИ СХЕМЫ
БАЗЫ ДАННЫХ
10.6.1. Основные определения
Базы данных, как и другие информационные системы, проходят
Iразные этапы своего жизненного цикла, начиная от замысла систе-
мы, предпроектного обследования, включая этапы проектирования,
эксплуатации, а далее — модернизации системы.
Создание крупных проектов практически невозможно без ис¬
пользования средств автоматизации проектирования.
Для автоматизации проектирования и разработки информаци¬
онных систем в 1970— 1980-е гг. широко применялась структурная
методология — использовались графические средства описания
различных моделей информационных систем с помощью схем и
диаграмм. При ручной разработке информационных систем такие
графические модели разрабатывать и использовать очень трудо¬
емко.
Эти обстоятельства послужили одной из причин появления
программно-технологических средств, получивших название
CASE-средств и реализующих CASE-технологию создания и сопро¬
вождения информационных систем. Кроме структурной методо¬
логии в ряде современных CASE-средств используется объектно-
ориентированная методология проектирования.
Термин CASE (Computer Aided Software Engineering) дословно
переводится как разработка программного обеспечения с помо¬
щью компьютера. В настоящее время этот термин получил более
широкий смысл, означающий автоматизацию разработки инфор¬
мационных систем.
Современные CASE-средства охватывают обширную область
поддержки многочисленных технологий проектирования информа¬
ционных систем от простых средств анализа и документирования
до полномасштабных средств автоматизации. Их использование
позволяет не только ускорить работы и повысить качество их вы¬
полнения, но и дает инструменты для организации коллективного
труда группы проектировщиков.
CASE-средства представляют собой программные средства,
поддерживающие процессы создания и/или сопровождения ин¬
формационных систем, такие как: анализ и формулировка требо¬
ваний, проектирование баз данных и приложений, генерация кода,
207
тестирование, обеспечение качества, управление конфигурацией
и проектом.
CASE-систему можно определить как набор CASE-средств,
имеющих определенное функциональное предназначение и вы¬
полненных в рамках единого программного продукта.
CASE-технология представляет собой совокупность методологий
анализа, проектирования, разработки и сопровождения сложных
систем и поддерживается комплексом взаимоувязанных средств
автоматизации. CASE-технология — это инструментарий для
системных аналитиков, разработчиков и программистов, заме¬
няющий бумагу и карандаш компьютером, автоматизируя процесс
проектирования и разработки программного и информационного
обеспечения. При использовании методологий структурного ана¬
лиза появился ряд ограничений (сложность понимания, большая
трудоемкость и стоимость использования, неудобство внесения
изменений в проектные спецификации и т.д.). С самого начала
CASE-технологии и развивались с целью преодоления этих огра¬
ничений путем автоматизации процессов анализа и интеграции
поддерживающих средств.
Средства автоматизации проектирования различаются совокуп¬
ностью используемых языковых средств и алгоритмами преобразо¬
вания концептуальной модели в модели базы данных. Это в свою
очередь сказывается на методике построения модели в их среде.
Большинство современных CASE-средств содержат инструмен¬
тальные средства для описания данных в формализме ER-модели.
ER-модель положена в основу значительного количества коммерче¬
ских CASE-продуктов, поддерживающих полный цикл разработки
баз данных или отдельные его стадии. При этом многие из них не
только поддерживают стадию концептуального проектирования
предметной области разрабатываемой системы, но и позволяют
осуществить на основе построенной их средствами модели стадию
логического проектирования базы данных для выбранной СУБД,
например, схемы базы данных для какого-либо сервера или кон¬
кретной СУБД. Моделирование предметной области в этом случае
базируется на использовании графических диаграмм, включающих
сравнительно небольшое число компонентов, и самое важное —
технологию построения таких диаграмм.
Появлению CASE-технологии и CASE-средств предшествовали
исследования в области методологии программирования. Про¬
граммирование обрело черты системного подхода с разработкой
и внедрением языков высокого уровня, методов структурного и
модульного программирования, языков проектирования и средств
208
их поддержки, формальных и неформальных языков описаний си¬
стемных требований и спецификаций и т.д. Кроме того, появлению
CASE-технологии способствовали и такие факторы, как:
■ подготовка аналитиков и программистов — специалистов об¬
ласти модульного и структурного программирования;
■ широкое внедрение и постоянный рост производительности
компьютеров, позволившие использовать эффективные гра¬
фические средства и автоматизировать большинство этапов
проектирования;
■ внедрение сетевой технологии, предоставившей возможность
объединения усилий отдельных исполнителей в единый процесс
проектирования путем использования разделяемой базы данных,
содержащей необходимую информацию о проекте.
Использование инструментальных средств при проектировании
баз данных затрагивает разные этапы жизненного цикла инфор¬
мационных систем. Оно в определенной мере предопределяет
процесс обследования и дает инструмент для отображения его
результатов.
CASE-индустрия объединяет сотни фирм и компаний различной
ориентации. Практически все серьезные зарубежные программ¬
ные проекты осуществляются с использованием CASE-средств,
а общее число распространяемых пакетов превышает 500 наи¬
менований.
Основная цель CASE-систем и средств состоит в том, чтобы от¬
делить проектирование программного обеспечения от его кодиро¬
вания и последующих этапов разработки (тестирование, докумен¬
тирование и пр.), а также автоматизировать весь процесс создания
программных систем, или инжиниринг (от англ, engineering — «раз¬
работка»).
Разработка программ начинается с некоторого предварительного
варианта системы. В качестве такого варианта может выступать
специально разработанный для этого прототип либо устаревшая
и не удовлетворяющая новым требованиям система. В последнем
случае для восстановления знаний о программной системе с целью
последующего их использования применяют повторную разработ¬
ку — реинжиниринг.
Повторная разработка сводится к построению исходной модели
программной системы путем исследования ее программных кодов.
Имея модель, можно ее усовершенствовать, а затем вновь перейти
к разработке. Так часто и поступают при проектировании. Одним
из наиболее известных принципов такого типа является принцип
«возвратного проектирования» — Round Trip Engineering (RTE).
209
Наибольшее распространение в настоящее время получили
системы, которые позволяют с помощью графических языков ото¬
бразить предметную область (построить концептуальную модель)
и затем осуществить автоматический переход от концептуальной
модели к модели данных в среде выбранной целевой СУБД. Ис¬
пользование CASE-систем такого типа объединяет не только про¬
ектировщиков информационных систем, но и заказчиков системы,
и поэтому отдельные механизмы, а именно нотации, используемые
на этапе концептуального моделирования системы, должны грамот¬
но восприниматься всеми разработчиками.
Различают прямое проектирование (forward-engineering) — про¬
цесс получения структуры базы данных для выбранной целевой
СУБД на основе построенной ER-модели, и обратное проектирова¬
ние (reverse-engineering — реверс-инжиниринг) — когда ER-модель
получается на основе существующей базы данных. CASE-средства
обычно поддерживают оба эти процесса.
Различные схемы, построенные с использованием языков
графического моделирования, могут использоваться в разных
режимах: режим эскиза, режим проектирования и режим языка
программирования. Это же относится и к использованию систем
моделирования данных. Более того, CASE-средства обычно предо¬
ставляют возможности представления моделей разных уровней,
что позволяет выбрать подходящий механизм моделирования для
каждого из режимов/стадий проектирования.
Обычно к CASE-средствам относят любое программное сред¬
ство, автоматизирующее ту или иную совокупность процессов
жизненного цикла программного обеспечения. Ниже приводятся
основные характерные особенности, которыми должны обладать
CASE-средства.
Первая особенность — мощные графические средства для
описания и документирования информационных систем, обеспе¬
чивающие удобный интерфейс с разработчиком и развивающие
его творческие возможности. CASE-технологии обеспечивают всех
участников проекта, включая заказчиков, единым строгим, нагляд¬
ным и интуитивно понятным графическим языком, позволяющим
получать обозримые компоненты с простой и ясной структурой.
При этом программы представляются простыми схемами (кото¬
рые проще в использовании, чем многостраничные описания),
позволяющими заказчику участвовать в процессе разработки,
а разработчикам — общаться с экспертами предметной области,
разделять деятельность системных аналитиков, проектировщиков
и программистов, облегчая им защиту проекта перед руководством,
210
также обеспечивая легкость сопровождения и внесения измене¬
нии в систему.
Следующей особенностью является возможность использования
специальным образом организованного хранилища проектных ме¬
таданных (репозитория). Основа CASE-технологии — использова¬
ние базы данных проекта для хранения всей информации о проекте,
которая может разделяться между разработчиками в соответствии с
их правами доступа. Содержимое репозитория включает не только
информационные объекты различных типов, но и отношения между
их компонентами, а также правила использования или обработки
них компонентов. Репозиторий может хранить структурные диа¬
граммы, определения экранов и меню, проекты отчетов, описания
данных, логику обработки, модели данных, исходные коды, элемен¬
ты данных и т. п.
Еще одной отличительной чертой является интеграция отдельных
компонент CASE-средств, обеспечивающая управляемость процес¬
сом разработки информационных систем. На основе репозитория
осуществляется интеграция CASE-средств и разделение системной
информации между разработчиками. При этом возможности ре¬
позитория обеспечивают несколько уровней интеграции: общий
пользовательский интерфейс по всем средствам, передачу данных
между средствами, интеграцию этапов разработки через единую
систему представления фаз жизненного цикла, передачу данных
и средств между различными платформами.
Поддержка коллективной разработки и управления проек¬
том также является важной особенностью CASE-средств. CASE-
технология поддерживает групповую работу над проектом, обе¬
спечивая возможность работы в сети, экспорт и импорт любых
фрагментов проекта для их развития и/или модификации, а также
планирование, контроль, руководство и взаимодействие, т. е. функ¬
ции, необходимые в процессе разработки и сопровождения про¬
ектов. Эти функции также реализуются на основе репозитория.
В частности, через репозиторий может осуществляться контроль
• безопасности (ограничения и привилегии доступа), контроль версий
п изменений и др.
Вся документация по проекту генерируется автоматически на
базе репозитория. Несомненное достоинство CASE-технологии
заключается в том, что документация всегда отражает текущее со-
(тояние дел, поскольку любые изменения в проекте автоматически
отражаются в репозитории.
CASE-технология обеспечивает автоматическую верификацию
и контроль проекта на полноту и состоятельность на ранних этапах
211
разработки, что влияет на успех разработки в целом. Все CASE-
системы имеют развитые средства документирования процесса
разработки БД, автоматические генераторы отчетов позволяют
подготовить отчет о текущем состоянии проекта БД с подробным
описанием объектов БД и их отношений как в графическом виде,
так и в виде готовых стандартных печатных отчетов, что суще¬
ственно облегчает ведение проекта. Пока еще не существует еди¬
ной общепринятой системы обозначений для ER-модели, и разные
CASE-системы используют разные графические нотации, но разо¬
бравшись в одной, можно легко понять и другие нотации.
10.6.2. Классификация CASE-технологий
Все современные CASE-средства могут быть классифицированы
в основном по типам и категориям. Классификация по типам отра¬
жает функциональную ориентацию CASE-средств. Классификация
по категориям определяет степень интегрированности по выпол¬
няемым функциям.
Использование CASE-средств позволяет улучшить качество соз¬
даваемых проектов, а при создании крупных корпоративных систем
является практически неизбежным. Однако использование CASE-
средств не освобождает проектировщика от понимания не только
общей сущности, но и деталей логического проектирования.
При классификации CASE-средств используют следующие при¬
знаки:
■ ориентацию на этапы жизненного цикла;
■ функциональную полноту;
■ тип используемой модели;
■ степень независимости от СУБД;
■ допустимые платформы.
Рассмотрим классификацию CASE-средств по наиболее часто
используемым признакам.
По ориентации на этапы жизненного цикла выделяют следу¬
ющие основные типы CASE-средств:
■ средства анализа, предназначенные для построения и анализа
моделей предметной области;
■ средства анализа и проектирования, обеспечивающие создание
проектных спецификаций;
■ средства проектирования баз данных, обеспечивающие моде¬
лирование данных и разработку схем баз данных для основных
СУБД;
212
■ средства разработки приложений.
11о функциональной полноте CASE-системы и средства можно
условно разделить на следующие типы:
■ системы, предназначенные для решения частных задач на одном
или нескольких этапах жизненного цикла;
■ интегрированные системы, поддерживающие весь жизненный
I щкл информационных систем и связанные с общим репозито¬
рием.
По типу используемых моделей CASE-системы условно можно
I разделить на три основные разновидности: структурные, объектно-
ориентированные и комбинированные.
Исторически первые структурные CASE-системы основаны на
методах структурного и модульного программирования, структур¬
ного анализа и синтеза.
Объектно-ориентированные методы и CASE-системы получили
массовое использование с начала 1990-х гг. Они позволяют сокра¬
тить сроки разработки, а также повысить надежность и эффектив¬
ность функционирования информационных систем.
Комбинированные инструментальные средства поддерживают
(^повременно структурные и объектно-ориентированные методы.
По степени независимости от СУБД CASE-системы можно раз¬
делить на следующие группы:
■ независимые системы поставляются в виде автономных систем,
не входящих в состав конкретной СУБД;
■ встроенные в СУБД системы обычно поддерживают главным
образом формат баз данных СУБД, в состав которой они входят
(возможна поддержка и других форматов баз данных).
На сегодняшний день Российский рынок программного обеспе¬
чения располагает многими развитыми CASE-средствами. Кроме
того, на рынке постоянно появляются как новые для отечественных
пользователей системы, так и новые их версии и модификации.
Далее будет произведен их краткий обзор.
КОНТРОЛЬНЫЕ ВОПРОСЫ
1. Перечислите основные этапы проектирования баз данных.
2. Для чего строится модель предметной области?
3. Что называется концептуальной моделью?
4. Какие требования предъявляют к модели предметной обла¬
сти?
5. Какие базовые понятия используются на этапе концептуально¬
го проектирования?
213
6. Какие задачи решаются на этапе концептуального проектиро¬
вания?
7. Что включает в себя концептуальная модель базы данных?
8. Перечислите шаги концептуального проектирования.
9. Что составляет семантическую основу ER-модели?
10. Что называется сущностью и экземпляром сущности?
11. Что называется атрибутом сущности и экземпляром атри¬
бута?
12. Что называется связью между сущностями?
13. Какая сущность является ассоциированной?
14. Как определить необходимую степень детализации атрибута?
15. Что означает модальность связи и как она обозначается в ER-
диаграмме?
16. Что означает полная идентификация сущности?
17. Что называется логической моделью данных?
18. Какие базовые понятия используются на этапе логического
проектирования?
19. Какие задачи решаются на этапе логического проектирова¬
ния?
20. Перечислите шаги логического проектирования.
21. На каком этапе производится оценка требований к вычисли¬
тельным ресурсам, необходимым для функционирования БД?
22. Опишите типовую пошаговую процедуру преобразования диа¬
граммы «сущность—связь» в реляционную схему базы дан¬
ных.
23. Для чего используется модель данных физического уровня?
24. Какие базовые понятия используются на этапе физического
проектирования?
25. Перечислите шаги физического проектирования.
2В. Какие задачи решаются на этапе физического проектирова¬
ния?
27. Назовите цели нормализации.
28. Чем опасно избыточное дублирование информации?
29. Назовите основные свойства нормальных форм.
30. Какие ограничения таблиц относят к формам 1 нф, 2нф и Знф?
31. Приведите примеры таблиц, соответствующих и не соответ¬
ствующих требованиям нормальных форм.
32. Дайте определение CASE-средствам и CASE-технологии.
33. Перечислите требования к перспективной CASE-системе.
34. Назовите признаки классификации CASE-средств.
Глава 11
АРХИТЕКТУРА ДАННЫХ
11.1.
АРХИТЕКТУРА «ФАЙЛ-СЕРВЕР»
В архитектуре «файл-сервер» базы данных хранятся на сервере,
клиент обращается к серверу с файловыми командами, а механизм
управления всеми информационными ресурсами находится на
компьютере клиента (рис. 11.1).
Файл-серверные базы данных могут быть доступны многим
клиентам через сеть. Сама база данных хранится на сетевом «файл-
сервере» в единственном экземпляре. Для каждого клиента во время
работы создается локальная копия данных, с которой он манипу¬
лирует. При этом возникают проблемы, связанные с возможным
одновременным доступом нескольких пользователей к одной и той
же таблице или записи. Эти проблемы решаются разработчиками
приложений баз данных (каждый раз при обращении к данным
проверяется их доступность).
Архитектура «файл-сервер» обладает значительными недостатка¬
ми. Одним из них является непроизводительная загрузка сети. При
каждом запросе клиента данные в его локальной копии полностью
обновляются из базы данных на сервере. Даже если запрос отно¬
сится всего к одной записи, обновляются все записи базы данных.
Если записей в базе данных много, то даже при небольшом числе
клиентов сеть будет загружена очень основательно, что серьезно
скажется на скорости выполнения запросов. В результате цирку¬
ляции в сети больших объемов избыточной информации резко
возрастает нагрузка на сеть, что приводит к соответствующему
снижению ее быстродействия и производительности информаци¬
онной системы в целом. Значительный сетевой трафик особенно
сказывается при организации удаленного доступа к базам данных
на «файл-сервере» через низкоскоростные каналы связи.
215
Другой недостаток связан с тем, что забота о целостности данных
при такой организации работы возлагается на программы клиентов.
Одним из традиционных средств, на основе которых создаются
файл-серверные системы, являются локальные СУБД. Такие систе¬
мы, как правило, не отвечают требованиям обеспечения целостности
данных, в частности, они не поддерживают обработки транзакций
(завершенных операций с документами). Поэтому при их исполь¬
зовании задача обеспечения целостности данных возлагается на
клиентские приложения, что приводит к их усложнению. Если они
недостаточно тщательно продуманы, в базу данных легко занести
ошибки, которые могут отразиться на всех пользователях.
Кроме того, в файл-серверной архитектуре изменения, сделан¬
ные в базе данных одним пользователем, не видны другим пользо¬
вателям. Пока один пользователь редактирует какую-либо запись,
она заблокирована для других клиентов. Возникает необходимость
синхронизации работы отдельных пользователей, связанная с бло¬
кировкой записей.
И еще один недостаток — управление базой данных осущест¬
вляется с разных компьютеров, поэтому в значительной степени
затруднена организация контроля доступа, соблюдения конфи¬
денциальности, что также усложняет поддержку целостности базы
данных.
Тем не менее файл-серверная архитектура привлекает своей про¬
стотой и доступностью. Поэтому файл-серверные информационные
системы до сих пор представляют интерес для малых рабочих групп
и, более того, нередко используются в качестве информационных
систем в масштабах предприятия.
Часто файл-серверные СУБД называют «настольными». Настоль¬
ные СУБД используются для сравнительно небольших задач (неболь¬
216
шой объем обрабатываемых данных, малое количество пользователей).
С учетом этого указанные СУБД имеют относительно упрощенную
архитектуру, в частности, функционируют в режиме «файл-сервер»,
поддерживают не все возможные функции СУБД (например, не
ведется журнал транзакций, отсутствует возможность автоматиче¬
ского восстановления базы данных после сбоев и т.п.). Тем не менее
такие системы имеют достаточно обширную область применения.
Прежде всего это государственные (муниципальные) учреждения,
сфера образования, сфера обслуживания, малый и средний бизнес.
Специфика возникающих там задач заключается в том, что объемы
данных не являются катастрофически большими, частота обновлений
не бывает слишком высокой, организация территориально обычно
расположена в одном небольшом здании, количество пользователей
колеблется от одного до 10 человек. В подобных условиях использо¬
вание настольных СУБД для управления информационными система¬
ми является вполне оправданным, и они с успехом применяются.
Одними из первых СУБД были так называемые dBase-совме¬
стимые программные системы, разработанные разными фирмами.
Первой широко распространенной системой такого рода была
система dBase III — PLUS (фирма Achton-Tate). Развитый язык
программирования, удобный интерфейс, доступный для массо¬
вого пользователя, способствовали широкому распространению
системы. В то же время работа системы в режиме интерпретации
обусловливала низкую производительность на стадии выполнения.
Это привело к появлению новых систем-компиляторов, близких к
системе dBase III — PLUS: Clipper (фирма Nantucket Inc.), FoxPro
(фирма Fox Software), FoxBase+ (фирма Fox Software), Visual FoxPro
(фирма Microsoft). Ранее достаточно широко использовалась СУБД
PARADOX (фирма Borland International).
В последние годы очень широкое распространение получила си¬
стема управления базами данных Microsoft Access, которая входит
в целый ряд версий пакета Microsoft Office (фирма Microsoft).
Для крупных организаций ситуация принципиально меняется.
Там использование файл-серверных технологий является непри¬
емлемым по описанным выше причинам. Поэтому используются
более дорогостоящие серверные СУБД.
АРХИТЕКТУРА «КЛИЕНТ-СЕРВЕР»
Архитектура «клиент-сервер» предназначена для разрешения
проблем файл-серверных приложений путем разделения компо-
217
нентов приложения и размещения их там, где они будут функ¬
ционировать наиболее эффективно. Особенностью архитектуры
«клиент-сервер» является наличие выделенных серверов баз дан¬
ных, принимающих запросы на языке структурированных запросов
(Structured Query Language, SQL) и выполняющих поиск, сортиров¬
ку и агрегирование информации.
В общем случае предполагается, что клиент и сервер функциони¬
руют на разных компьютерах. Серверное и клиентское программ¬
ное обеспечение имеют разное назначение.
Сервер — программа, реализующая функции СУБД: опреде¬
ление данных, запись, чтение, удаление данных, поддержку
схем внешнего — концептуального — внутреннего уровней,
диспетчеризацию и оптимизацию выполнения запросов, защиту
данных.
Клиент — программа, написанная поставщиком СУБД или
пользователем, внешняя или «встроенная» по отношению к СУБД.
Программа-клиент организована в виде приложения, обращающе¬
гося для выполнения операций с данными к компонентам СУБД
через интерфейс внешнего уровня.
Разделение процесса выполнения запроса на «клиентскую» и
«серверную» часть позволяет:
■ различным прикладным (клиентским) программам одновременно
использовать общую базу данных;
■ централизовать функции управления, такие как защита инфор¬
мации, обеспечение целостности данных, управление совмест¬
ным использованием ресурсов;
■ обеспечивать параллельную обработку запроса;
■ высвобождать ресурсы компьютеров-клиентов;
■ повышать эффективность управления данными за счет исполь¬
зования специализированных компьютеров — серверов баз
данных.
База данных на платформе «клиент-сервер» используется для
систем с большим количеством пользователей (как правило, более
десяти). В контексте базы данных клиент управляет пользова¬
тельским интерфейсом и логикой приложения, действуя как ра¬
бочая станция, на которой выполняются приложения баз данных.
Программа-клиент принимает от пользователя запрос, проверяет
синтаксис и генерирует запрос к базе данных на языке SQL или
другом языке базы данных, соответствующем логике приложения.
Затем передает сообщение серверу, ожидает поступления ответа и
форматирует полученные данные для представления их пользовате¬
лю. Мощный сервер, ориентированный на операции с запросами,
218
принимает и обрабатывает запросы к базе данных, после чего от¬
правляет полученные результаты обратно клиенту. Такая обработка
включает проверку полномочий клиента, обеспечение требований
целостности, а также выполнение запроса и обновление данных.
Помимо этого поддерживается управление параллельностью и
восстановлением.
В системах «клиент-сервер» необходимо спроектировать при¬
ложение так, чтобы оно максимально использовало возможности
сервера и минимально нагружало сеть, передавая через нее только
минимум информации.
Описанная архитектура является двухуровневой и называется
«толстым клиентом» (рис. 11.2), поскольку функционально нагру¬
жает «клиента».
В настоящее время архитектура «клиент-сервер» получила
признание и широкое распространение как способ организации
приложений для рабочих групп и информационных систем корпо¬
ративного уровня. Подобная организация повышает эффективность
работы приложений за счет использования возможностей сервера
базы данных, снижения нагрузки на сеть и обеспечения контроля
целостности данных. Повышение безопасности информации свя¬
занно с тем, что обработка запросов всех клиентов выполняется
единой программой, расположенной на сервере. Сервер уста¬
навливает общие для всех пользователей правила использования
БД, управляет режимами доступа клиентов к данным, запрещая
в частности, одновременное изменение одной записи разными
пользователями.
Также уменьшается сложность клиентских приложений за счет
отсутствия у них кода, связанного с контролем БД и разграниче¬
нием доступа к ней.
Клиент Клиент Клиент Клиент
Рис. 11.2. Двухуровневая архитектура «клиент-сервер»
219
Исходя из этого, можно описать разграничение функций между
сервером и клиентом следующим образом. Функции приложения-
клиента:
■ формирование и передача запросов серверу;
■ интерпретация результатов запросов, полученных от сервера;
■ представление результатов пользователю в некоторой форме
(интерфейс пользователя).
Функции серверной части:
■ прием запросов от приложений-клиентов;
■ интерпретация запросов;
■ оптимизация и выполнение запросов к БД;
■ отправка результатов приложению-клиенту;
■ обеспечение системы безопасности и разграничение доступа;
■ управление целостностью БД;
■ реализация стабильности многопользовательского режима ра¬
боты.
В архитектуре «клиент-сервер» работают так называемые «про¬
мышленные» СУБД. Промышленными они называются из-за того,
что именно СУБД этого класса могут обеспечить работу инфор¬
мационных систем масштаба среднего и крупного предприятия,
организации, банка. К разряду промышленных СУБД принадле¬
жат MS SQL Server, Oracle, Informix, Sybase, DB2, InterBase и ряд
других.
Как правило, SQL-сервер обслуживается отдельным сотрудни¬
ком или группой сотрудников (администраторы SQL-сервера). Они
управляют физическими характеристиками баз данных, производят
оптимизацию, настройку и переопределение различных компо¬
нентов БД, создают новые БД, изменяют существующие, а также
выдают привилегии (разрешения на доступ определенного уровня
к конкретным БД, SQL-серверу) различным пользователям.
Кратко основные достоинства архитектуры «клиент-сервер» по
сравнению с архитектурой «файл-сервер» можно сформулировать
следующим образом:
■ обеспечивается более широкий доступ к существующим базам
данных;
■ повышается общая производительность системы: поскольку
клиенты и сервер находятся на разных компьютерах, их процес¬
соры способны выполнять приложения параллельно. Настройка
производительности компьютера с сервером упрощается, если
на нем выполняется только работа с базой данных;
■ снижается стоимость аппаратного обеспечения — достаточно
мощный компьютер с большим устройством хранения нужен
220
только серверу — для хранения и управления базой данных, нет
необходимости в мощных рабочих станциях;
■ снижается нагрузка на сеть. Приложения выполняют часть опе¬
раций на клиентских компьютерах и посылают через сеть только
запросы к базам данных, что позволяет значительно сократить
объем пересылаемых по сети данных;
■ повышается уровень непротиворечивости данных. Сервер может
самостоятельно управлять проверкой целостности данных, по¬
скольку лишь на нем определяются и проверяются все ограни¬
чения. При этом каждому приложению не придется выполнять
собственную проверку.
К числу недостатков можно отнести более высокие финансовые
затраты на аппаратное и программное обеспечение, необходимость
администрирования сервера, а также то, что большое количество
клиентских компьютеров, расположенных в разных местах, вы¬
зывает определенные трудности со своевременным обновлением
клиентских приложений на всех компьютерах-клиентах. Тем не
менее архитектура «клиент-сервер» хорошо зарекомендовала себя
на практике, в настоящий момент существует и функционирует
большое количество БД, построенных в соответствии с данной
архитектурой.
Двухуровневые схемы архитектуры «клиент-сервер» могут
привести к некоторым проблемам в сложных информационных
приложениях с множеством пользователей и запутанной логикой.
Решением этих проблем может стать применение многоуровневой
архитектуры.
11.3.
ТРЕХУРОВНЕВАЯ АРХИТЕКТУРА
«КЛИЕНТ-СЕРВЕР»
Дальнейшее расширение двухуровневой архитектуры «клиент-
сервер» предполагает разделение функциональной части клиента
на две части — «тонкий клиент» и сервер приложений (рис. 11.3).
«Тонкий» клиент — это компьютер или программа-клиент
в сетях с клиент-серверной или терминальной архитектурой,
который переносит все или большую часть задач по обработке
информации на сервер. Примером «тонкого» клиента может
служить компьютер с браузером, использующийся для работы с
веб-приложениями. «Тонкий» клиент на рабочей станции управ¬
ляет только пользовательским интерфейсом, тогда как средний
уровень обработки данных управляет всей остальной логикой
221
приложения. Третьим уровнем в данной архитектуре является
сервер базы данных.
На нижнем уровне на компьютерах пользователей расположены
приложения клиентов, выделенные для выполнения функций и
логики представлений, обеспечивающие программный интерфейс
для вызова приложения на среднем уровне.
На среднем уровне расположен сервер приложений, на котором
выполняется прикладная логика, и с которого логика обработки
данных выполняет операции с базой данных, т. е. этот уровень
обеспечивает обмен данными между пользователями и распреде¬
ленными базами данных. Сервер приложений размещается в узле
сети доступно всем клиентам.
На третьем, верхнем, уровне расположен удаленный специали¬
зированный сервер базы данных, принимающий информацию от
сервера приложений. Сервер баз данных выделен для услуг обра¬
ботки данных и файловых операций.
Кратко можно описать работу СУБД с трехзвенной архитектурой
«клиент-сервер» следующим образом:
■ база данных в виде набора файлов находится на жестком диске
специально выделенного компьютера (сервера сети);
■ СУБД располагается также на сервере сети;
■ на специально выделенном сервере приложений располагается
программное обеспечение (бизнес-логика);
■ на каждом из множества клиентских компьютеров установлено
клиентское приложение пользователя («тонкий» клиент), реали¬
зующее интерфейс пользователя. Используя предоставляемый
приложением пользовательский интерфейс, он инициирует
обращение к программному обеспечению, расположенному на
сервере приложений;
222
■ сервер приложений анализирует требования пользователя и
формирует запросы к БД. Для общения используется специаль¬
ный язык запросов SQL, т. е. по сети от сервера приложений к
серверу БД передается лишь текст запроса;
■ СУБД инкапсулирует внутри себя все сведения о физической
структуре БД, расположенной на сервере;
■ СУБД инициирует обращения к данным, находящимся на серве¬
ре, в результате которых результат выполнения запроса копиру¬
ется на сервер приложений;
■ сервер приложений возвращает результат в клиентское прило¬
жение (пользователю);
■ приложение, используя пользовательский интерфейс, отобра¬
жает результат выполнения запросов.
Достоинства трехуровневой архитектуры следующие:
■ разгрузка сервера баз данных от выполнения части операций,
перенесенных на сервер приложений;
■ уменьшение размера клиентских приложений за счет разгрузки
их от лишнего кода;
■ единое поведение всех клиентов;
■ упрощение настройки клиентов — при изменении общего кода
сервера приложений автоматически изменяется поведение при¬
ложений клиентов.
Трехуровневая архитектура устраняет недостатки двухуровневой
модели «клиент-сервер». Она позволяет еще больше сбалансировать
нагрузку на сеть. С ростом систем ««клиент-сервер»» необходимость
трехуровневой организации становится все более очевидной.
|Щ КЛАСТЕР СЕРВЕРОВ
Для того чтобы организовать бесперебойную, устойчивую к
отказам, конкурентную работу для значительного количества
пользователей с объемными базами данных, используют кластеры
серверов.
Кластер — совокупность нескольких вычислительных систем,
работающих совместно для выполнения общих приложений,
и представляющихся пользователю единой системой.
Клиент взаимодействует с кластером так, как будто кластер
является единым сервером, даже если он физически представляет
собой объединение нескольких серверов. Группа серверов обладает
большей надежностью и большей производительностью, чем один
сервер.
223
В состав кластера входит два и более узла (серверов), каждый
из которых конфигурируется таким образом, чтобы приложение
могло работать на любом из них. При этом само приложение вир-
туализируется, т. е. становится независимым от какого-либо узла.
Обязательным условием является наличие общей для всех узлов
системы хранения. Основное приложение и все необходимые для
его работы ресурсы, такие как файловые ресурсы или сетевое под¬
ключение, объединяются в общую кластерную группу. В случае не¬
доступности одного из ресурсов кластерной группы управляющее
приложение инициирует перевод работы основного приложения и
всей кластерной группы на другой узел. Чаще всего серверы груп¬
пируются посредством локальной сети.
Кластеры позволяют уменьшить время расчетов по сравнению
с одиночным компьютером, разбивая задание на параллельно
выполняющиеся ветки, которые обмениваются данными по
связывающей сети. В настоящее время становятся популярны
системы распределенных вычислений. Их не принято считать
кластерами, но их принципы в значительной степени сходны с
кластерной технологией. Их также называют grid-системами.
В этих системах узлы подключаются и отключаются в процессе
работы, поэтому задача должна быть разбита на ряд независимых
друг от друга процессов, так как невозможно гарантировать ра¬
боту узла в заданный момент времени. Такая система в отличие
от кластеров не похожа на единый компьютер, а служит упро¬
щенным средством распределения вычислений. Нестабильность
конфигурации в таком случае компенсируется большим числом
узлов.
Часто кластер серверов организуют программно. В таких случаях
кластер серверов определяется как логическое понятие, которое
обозначает совокупность процессов, обслуживающих одни и те
же данные. В данном случае кластер серверов можно определить
как группу серверов, объединенных логически, способных обраба¬
тывать идентичные запросы и используемые как единый ресурс.
Объединение серверов в один ресурс происходит на уровне про¬
граммных протоколов.
В большинстве случаев кластеры серверов функционируют на
раздельных компьютерах. Это позволяет повышать производитель¬
ность за счет распределения нагрузки на аппаратные ресурсы и
обеспечивает отказоустойчивость на аппаратном уровне. Однако
принцип организации кластера серверов на уровне программного
протокола дает возможность функционировать и на одном ком¬
пьютере.
224
11.5.
ОБЪЕКТЫ СЕРВЕРА БАЗ ДАННЫХ
Объекты базы данных содержат всю информацию о ее струк¬
туре и данных. Объекты базы данных так же упоминаются, как
метаданные («данные о данных»). База данных состоит из различ¬
ных объектов, таких как таблицы, домены, хранимые процедуры,
триггеры и т. д. Ниже даются определения объектов серверных
баз данных. Некоторые из этих объектов будут рассмотрены под¬
робно.
Таблица (table) — это основной объект любой реляционной
базы данных. В таблицах хранятся все данные и метаданные базы
данных. Таблица — это плоская двумерная структура, содержащая
произвольное количество строк.
Домен (domain) — объект базы данных, описывающий некоторые
характеристики столбца. На домен можно ссылаться при описании
столбцов создаваемой таблицы или при изменении характеристик
столбцов существующей в базе данных таблицы.
Индекс (index) — объект базы данных, предназначенный для
ускорения выборки данных из таблицы, для упорядочения резуль¬
татов выборки данных из таблицы, для создания связей между
таблицами (первичные, уникальные и внешние ключи). Каждый
индекс создается для одной конкретной таблицы. Индекс представ¬
ляет собой множество упорядоченных строк, каждая из которых
содержит значение полей, входящих в состав индекса, и указатель
па строку таблицы, содержащую соответствующие значения этих
полей. Существуют средства для активации/деактивации индексов,
улучшения их характеристик. Для первичных, уникальных и внеш¬
них ключей индексы создаются автоматически.
Генератор (generator) — объект реляционной базы данных,
предназначенный для получения уникального числового значения,
используемого, как правило, для формирования значения первич¬
ного ключа или иногда уникального ключа.
Хранимая процедура (stored procedure) — программа, напи¬
санная на процедурном расширении языка SQL (который также
называется языком хранимых процедур и триггеров), и хранящаяся
в области метаданных базы данных, позволяющая выполнять раз¬
личные действия с данными в базе данных. К хранимым проце¬
дурам могут обращаться хранимые процедуры этой базы данных,
пользовательские (клиентские) программы. Хранимая процедура
выполняется на стороне сервера, что во многих случаях может резко
сократить сетевой трафик и заметно увеличить скорость решения
задач предметной области.
225
Триггер (trigger) — как и хранимая процедура, является про¬
граммой, написанной на процедурном расширении языка SQL, хра¬
нящейся в области метаданных и выполняемой на сервере. Однако
обращение напрямую к триггеру невозможно. Он автоматически
вызывается при наступлении одной из фаз события, связанного с
изменением данных в таблицах, или события, связанного с под¬
ключением к базе данных и с работой с транзакциями. События
таблицы — добавление данных, изменение строки таблицы, удале¬
ние строки. Фазами являются «до» (before) выполнения действия и
«после» (after) выполнения действия.
Пользовательские исключения (exception) — это объект реля¬
ционной базы данных, который позволяет создавать, а затем выда¬
вать сообщения пользователю при появлении некоторой ситуации
в процессе работы программ с базой данных. Это могут быть как
ошибочные ситуации, возникающие при каких-либо нарушениях
в базе данных, так и любые другие особые случаи обработки дан¬
ных в базе данных. Эти исключения могут использоваться только
в хранимых процедурах и триггерах.
События базы данных (event) — объекты, дающие возможность
из хранимых процедур и триггеров передавать некоторые сообще¬
ния всем клиентским приложениям, работающим с конкретной
базой данных. Это средство позволяет во многих случаях осущест¬
влять синхронизацию отображения данных либо выполнять более
сложные действия по взаимодействию клиентских приложений при
их совместной одновременной работе с базой данных
Представление (view, другие названия — обзор, просмотр) —
это результат выборки данных из одной или более таблиц базы
данных на основании конкретных часто довольно сложных кри¬
териев. Основой представления является оператор SELECT любой
сложности. Представление является как бы виртуальной таблицей,
которая на самом деле не хранится в базе данных. Представление —
удобное средство для получения данных в случае достаточно слож¬
ной выборки данных, когда от пользователя нужно скрывать слож¬
ные условия такой выборки. Кроме того, представления являются
полезным средством скрыть от пользователя некоторые столбцы
таблиц, значения которых не предназначены для просмотра этим
пользователем.
Функции, определенные пользователем (User Defined
Functions, UDF) — функции, написанные на любом языке про¬
граммирования и хранящиеся вне базы данных, но описанные в
этой базе. Могут использоваться для расширения возможностей
языка SQL и соответствующих языков программирования. Часто
226
КОНТРОЛЬНЫЕ ВОПРОСЫ
1. Как организована работа с базой данных в архитектуре «файл-
сервер»?
2. Каким образом обеспечивается надежность работы с данными
в файл-серверной архитектуре?
3. Что можно отнести к недостаткам файл-серверной архитек¬
туры?
4. Как организована работа с базой данных в архитектуре
«клиент-сервер»?
5. Какие достоинства имеет архитектура «клиент-сервер» в срав¬
нении с файл-серверной архитектурой? Какие недостатки?
В. Что называют кластером серверов?
7. Может ли кластер серверов быть организован на одном ком¬
пьютере?
8. Какие преимущества дает использование кластера серве¬
ров?
9. Какие объекты базы данных называют просмотрами (пред¬
ставлениями)?
10. Что называется хранимой процедурой?
11. Чем триггер отличается от хранимой процедуры?
12. Для чего используется генератор?
13. Какие объекты базы данных называют пользовательскими ис¬
ключениями?
14. Как используются в работе с БД объекты, называемые собы¬
тиями?
15. Для чего нужны функции, определенные пользователем?
позволяют описывать довольно сложные действия с данными из
опви данных (или с данными, передаваемыми в виде входных
мпраметров).
Глава 12
ОСНОВЫ SQL
12.1.
ВВЕДЕНИЕ В ЯЗЫК SQL
В начале 1970-х гг. прошлого столетия в одной из исследова¬
тельских лабораторий компании IBM была разработана экспе¬
риментальная реляционная система управления базами данных,
для которой затем был создан специальный язык SQL (Structured
Query Language — язык структурированных запросов). Стандарт на
язык SQL был выпущен Американским национальным институтом
стандартов (ANSI) в 1986 г., а в 1987 г. Международная организация
стандартов (ISO) приняла его в качестве международного.
В настоящее время язык SQL является первым и пока единствен¬
ным стандартным языком работы с базами данных. Язык SQL под¬
держивается многими СУБД различных типов, разработанных для
самых разнообразных вычислительных платформ. Практически все
крупнейшие разработчики СУБД в настоящее время создают свои
продукты, нацеленные на использование языка SQL.
SQL является прежде всего информационно-логическим языком,
предназначенным для описания, изменения и извлечения данных,
хранимых в реляционных базах данных. Это непроцедурный язык;
более того, его нельзя назвать языком программирования. Язык
SQL ориентирован на операции с данными, представленными в
виде логически взаимосвязанных таблиц, что позволило создать
компактный язык с небольшим набором предложений. Важней¬
шей особенностью структуры языка SQL является ориентация на
конечный результат обработки данных, а не на процедуру этой об¬
работки. Язык SQL сам определяет, где находятся данные, индексы
и даже какие наиболее эффективные последовательности операций
следует использовать для получения результата, а потому указывать
эти детали в запросе к базе данных не требуется. Кроме того, язык
228
SQL может использоваться как для выполнения запросов к данным,
так и для построения прикладных программ.
Для расширения функциональных возможностей многие раз¬
работчики, придерживающиеся принятых стандартов, добавляют
к стандартному языку SQL различные расширения.
Реализацией языка SOL называется программный продукт SQL
соответствующего производителя.
Все конкретные реализации языка несколько отличаются друг
от друга. В интересах самих же производителей гарантировать,
чтобы их реализация соответствовала современным стандартам
ANSI в части переносимости и удобства работы пользователей. Тем
не менее каждая реализация SQL содержит усовершенствования,
отвечающие требованиям того или иного сервера баз данных. Эти
усовершенствования или расширения языка SQL представляют
собой дополнительные команды и опции, являющиеся добавле¬
ниями к стандартному пакету и доступные в данной конкретной
реализации.
Язык SQL включает только команды определения и манипули¬
рования данными и не содержит каких-либо команд управления
ходом вычислений. Подобные задачи должны решаться либо с
помощью языков программирования, либо интерактивно — дей¬
ствиями самих пользователей. Язык SQL может использоваться
двумя способами:
1) интерактивная работа, заключающаяся во вводе пользователем
отдельных SQL-операторов;
2) внедрение SQL-операторов в программы на процедурных язы¬
ках.
Язык SQL относительно прост в изучении. Поскольку это не
процедурный язык, в нем необходимо указывать, какая инфор¬
мация должна быть получена, а не как ее можно получить. Иначе
говоря, SQL не требует указания методов доступа к данным. Язык
SQL может использоваться широким кругом специалистов, вклю¬
чая администраторов баз данных, прикладных программистов и
множество других конечных пользователей, не имеющих навыков
программирования.
По типу производимых действий различают следующие опе¬
рации:
■ идентификация данных и нахождение их позиции в БД;
■ выборка (чтение) данных из БД;
■ включение (запись) данных в БД;
■ удаление данных из БД;
■ модификация (изменение) данных БД.
229
Основные категории команд языка SQL предназначены для
выполнения различных функций, включая построение объектов
базы данных и манипулирование ими, начальную загрузку данных
в таблицы, обновление и удаление существующей информации,
выполнение запросов к базе данных, управление доступом к ней и
ее общее администрирование.
Основные категории команд языка SQL:
■ DDL — язык определения данных;
■ DML — язык манипулирования данными;
■ DQL — язык запросов;
■ DCL — язык управления данными;
в команды администрирования данных;
□ команды управления транзакциями.
Язык определения данных DDL (Data Definition Language) по¬
зволяет создавать и изменять структуру объектов базы данных,
например, создавать и удалять таблицы. Основными командами
языка DDL являются следующие:
■ CREATE TABLE — создание таблицы;
я ALTER TABLE — изменение таблицы;
■ DROP TABLE — удаление таблицы;
■ CREATE INDEX — создание индекса;
н ALTER INDEX — изменение индекса;
■ DROP INDEX — удаление индекса.
Язык манипулирования данными DML (Data Manipulation
Language) используется для манипулирования информацией внутри
объектов реляционной базы данных посредством трех основных
команд:
■ INSERT — вставка записей;
и UPDATE — обновление записей;
s DELETE — удаление записей.
Любая модель данных определяет множество действий, которые
допустимо производить над некоторой реализацией БД для ее пере¬
вода из одного состояния в другое.
Язык запросов DQL (Data Query Language) наиболее известен
пользователям реляционной базы данных, несмотря на то что он
включает всего одну команду SELECT, которая возвращает строки
из базы данных и позволяет делать выборку одной или нескольких
строк или столбцов из одной или нескольких таблиц. Любая опе¬
рация над данными включает в себя селекцию данных (select), т.е.
выделение из всей совокупности именно тех данных, над которыми
должна быть выполнена требуемая операция, и действие над вы¬
бранными данными, которое определяет характер операции. Усло-
230
пне селекции — это некоторый критерий отбора данных, в котором
могут быть использованы логическая позиция элемента данных, его
значение и связи между данными.
Язык управления данными DCL (Data Control Language) включа¬
ет команды управления данными, которые позволяют управлять
доступом к информации, находящейся внутри базы данных. Как
правило, они используются для создания объектов, связанных с до¬
ступом к данным, а также служат для контроля над распределением
привилегий между пользователями. Команды управления данными
следующие:
■ GRANT — установить права доступа;
■ REVOKE — аннулировать права доступа.
Синтаксис этих команд зависит от СУБД. Для того чтобы
упростить процесс управления доступом, многие СУБД предо¬
ставляют возможность объединять пользователей в группы или
определять роли — совокупность привилегий, предоставляемых
пользователю.
Такой подход позволяет предоставить конкретному пользователю
определенную роль или соотнести его определенной группе поль¬
зователей, обладающей набором прав в соответствии с задачами,
которые на нее возложены.
С помощью команд администрирования данных пользователь
осуществляет контроль над выполнением действий с базой данных,
анализирует операции базы данных, анализирует производитель¬
ность системы и т. п. Следует отметить, что администрирование
данных и администрирование базы данных не одно и то же. Ад¬
министрирование базы данных представляет собой общее управ¬
ление базой данных и подразумевает использование команд всех
уровней.
Команды управления транзакциями включают в себя следующие
команды:
■ COMMIT — подтверждение транзакции;
■ ROLLBACK — откат транзакции;
■ SAVEPOINT — установка точки прерывания (неполный откат);
ш SET TRANSACTION — начало транзакции.
Для успешного изучения языка SQL необходимо привести
краткое описание структуры SQL-операторов и нотации, которые
используются для определения формата различных конструкций
языка. Оператор SQL состоит из зарезервированных слов, а также
из слов, определяемых пользователем. Зарезервированные слова
являются постоянной частью языка SQL и имеют фиксированное
значение. Слова, определяемые пользователем, задаются им самим
231
(в соответствии с синтаксическими правилами) и представляют со¬
бой идентификаторы или имена различных объектов базы данных.
Слова в операторе размещаются также в соответствии с установ¬
ленными синтаксическими правилами.
Идентификаторы языка SQL предназначены для обозначения
объектов в базе данных и являются именами таблиц, представлений,
столбцов и других объектов базы данных. Стандарт SQL задает на¬
бор символов, который используется по умолчанию. Он включает
строчные и прописные буквы латинского алфавита (A— Z, a — z),
цифры (0 — 9) и символ подчеркивания (_). На формат идентифи¬
катора накладываются следующие ограничения:
■ идентификатор может иметь длину до 128 символов;
■ идентификатор должен начинаться с буквы;
■ идентификатор не может содержать пробелы.
Большинство компонентов языка не чувствительны к регистру.
Язык, в терминах которого дается описание языка SQL, называ¬
ется метаязыком. Синтаксические определения обычно задают с по¬
мощью специальной металингвистической символики, называемой
Бэкуса-Наура формулами (БНФ). Для записи зарезервированных
слов используются прописные буквы. Строчные буквы употребля¬
ются для записи слов, определяемых пользователем. Применяемые
в нотации БНФ символы и их обозначения показаны в табл. 12.1.
Ранее мы уже определили данные как совокупную информацию,
хранимую в БД в виде одного из нескольких различных типов.
С помощью типов данных устанавливаются основные правила для
данных, содержащихся в конкретном столбце таблицы, в том числе
размер выделяемой для них памяти.
В языке SQL имеется шесть скалярных типов данных, опреде¬
ленных стандартом (табл. 12.2).
Таблица 12.1. Металингвистическая символика БНФ
: : =
Равно по определению
I
Необходимость выбора одного из нескольких приведен¬
ных значений
<...>
Описанная с помощью метаязыка структура языка
{-}
Обязательный выбор некоторой конструкции из списка
[-]
Необязательный выбор некоторой конструкции из списка
[, ...п]
Необязательная возможность повторения конструкции от
нуля до нескольких раз
232
Таблица 12.2. Скалярные типы данных
Тип данных
Объявление
Символьный
CHAR|VARCHAR
Битовый
BIT|BIT VARYING
Точные числа
NUMERIC|DECIMAL|INTEGER|SMALLINT
Округленные числа
FLOAT|REAL|DOUBLE PRECISION
Дата/время
DATE|TIME|TIMESTAMP
Интервал
INTERVAL
Символьные данные состоят из последовательности символов,
входящих в определенный создателями СУБД набор символов.
Поскольку наборы символов являются специфическими для раз¬
личных диалектов языка SQL, перечень символов, которые могут
входить в состав значений данных символьного типа, также зависит
от конкретной реализации.
При определении столбца с символьным типом данных пара¬
метр «длина» применяется для указания максимального количе¬
ства символов, которые могут быть помещены в данный столбец.
Символьная строка может быть определена как имеющая фикси¬
рованную (CHAR) или переменную (VARCHAR) длину. Если строка
определена с фиксированной длиной значений, то при вводе в нее
меньшего количества символов значение дополняется до указанной
длины пробелами, добавляемыми справа. Если строка определена с
переменной длиной значений, то при вводе в нее меньшего коли¬
чества символов в базе данных будут сохранены только введенные
символы, что позволит достичь определенной экономии внешней
памяти.
Битовый тип данных используется для определения битовых
строк, т. е. последовательности двоичных цифр (битов), каждая из
которых может иметь значение либо 0, либо 1.
Тип точных числовых данных применяется для определения
чисел, которые имеют точное представление, т. е. числа состоят из
цифр, необязательной десятичной точки и необязательного символа
знака. Данные точного числового типа определяются точностью и
длиной дробной части. Точность задает общее количество значащих
десятичных цифр числа, в которое входит длина как целой части,
так и дробной, но без учета самой десятичной точки. Масштаб ука¬
зывает количество дробных десятичных разрядов числа.
233
Типы NUMERIC и DECIMAL предназначены для хранения чисел
в десятичном формате. По умолчанию длина дробной части равна
нулю, а принимаемая по умолчанию точность зависит от реализации.
Тип INTEGER (INT) используется для хранения больших положи¬
тельных или отрицательных целых чисел. Тип SMALL INT — для хра¬
нения небольших положительных или отрицательных целых чисел;
в этом случае расход внешней памяти существенно сокращается.
Тип округленных чисел применяется для описания данных,
которые нельзя точно представить в компьютере, в частности дей¬
ствительных чисел. Округленные числа или числа с плавающей
точкой представляются в научной нотации, при которой число за¬
писывается с помощью мантиссы, умноженной на определенную
степень десяти (порядок).
Тип данных «дата/время» используется для определения момен¬
тов времени с некоторой установленной точностью. Стандарт SQL
поддерживает следующий формат.
Тип данных DATE используется для хранения календарных дат,
включающих поля YEAR (год), MONTH (месяц) и DAY (день). Тип
данных TIME — для хранения отметок времени, включающих поля
HOUR (часы), MINUTE (минуты) и SECOND (секунды). Тип данных
TIMESTAMP — для совместного хранения даты и времени.
Данные типа INTERVAL используются для представления пе¬
риодов времени.
РАБОТА С ТАБЛИЦАМИ. ОГРАНИЧЕНИЯ
ЦЕЛОСТНОСТИ
12.2.1. Работа с доменами
Домен — объект реляционной базы данных, позволяющий опи¬
сывать характеристики столбцов таблиц.
При создании или изменении любой таблицы при описании
столбцов можно ссылаться на существующий домен для копирова¬
ния всех его характеристик в столбец таблицы. Иногда в нескольких
таблицах баз данных присутствуют столбцы, обладающие одними и
теми же характеристиками. В таком случае можно предварительно
описать тип такого столбца и его поведение с помощью домена,
а затем поставить в соответствие каждому из одинаковых столбцов
имя домена. При копировании в столбец отдельные характеристики,
описанные в домене, могут быть изменены и дополнены. Домены
234
также можно использовать при описании локальных переменных
и параметров в хранимых процедурах и триггерах.
Основной характеристикой домена является тип данных. Типы
данных задаются при создании или изменении доменов, при созда¬
нии или изменении характеристик столбцов таблиц, при описании
внутренних переменных в хранимых процедурах и триггерах. Типы
данных можно объединить в группы, или категории — числовые
данные, строковые, данные даты и времени, а также единственный
в группе двоичный тип данных BLOB.
Домен определяется оператором CREATE DOMAIN, имеющим
следующий формат:
CREATE DOMAIN <имя домена> [AS] <тип данных>
[DEFAULT <значение по умолчанию»]
[NOT NULL] [CHECK (<условие ограничения:») ]
[COLLATE <порядок сортировки>]
Предложение DEFAULT определяет выражение, которое по
умолчанию заносится в колонку, ассоциированную с доменом, при
создании записи таблицы. Это значение будет присутствовать в со¬
ответствующем столбце записи до тех пор, пока пользователь не из¬
менит его каким-либо образом. Значения по умолчанию могут быть
выражены как литерал-значение (числовое, строковое или дата).
Предложение CHECK определяет требования к значениям каж¬
дого столбца, ассоциированного с доменом. Столбцу не могут быть
присвоены значения, не удовлетворяющие ограничениям, наложен¬
ным в предложении CHECK. Формат ограничения, накладываемого
на значения полей, ассоциированных с доменом:
<условие ограничения домена>: := {
VALUE <оператор> <значение>
|VALUE [NOT] BETWEEN <значение 1> AND <значение 2>
IVALUE [NOT] LIKE <значение> [ESCAPE <значение>]
|VALUE [NOT] IN (<значение1> [, <значение2>...]
IVALUE IS [NOT] NULL
IVALUE [NOT] CONTAINING <значение>
IVALUE [NOT] STARTING [WITH] <значение>
Ограничения домена>
Ограничения домена> OR Ограничения домена>
Ограничения домена> AND Ограничения домена>
}
где
<оператор> = { = I < I > I <= I >= I !< I ! > I <> I != };
235
VALUE <оператор> <значение> — значение домена находит¬
ся с параметром <значение> во взаимоотношениях, определяемых
параметром <оператор>. Другими словами , VALUE означает все
правильные значения, которые могут быть присвоены столбцу,
ассоциированному с доменом;
BETWEEN <значение1> AND <значение2> — значение
домена должно находиться в промежутке между <значение1> и
<значение2>, включая их;
LIKE <значение1> [ESCAPE <значение2>] — задает
шаблон подобия, при этом символ «%» указывает любое значение
любой длины, а символ «_» — любой одиночный символ. ESCAPE
используется, если в операторе LIKE символы «%» и «_» присут¬
ствуют в шаблоне как обычные символы. В этом случае выбирается
некоторый символ <значение 2>, после которого служебные
символы теряют свой специальный статус и входят в поисковую
строку как обычные параметры. Например, CHECK (VALUE LIKE
«% ! %» ESCAPE « !») — любое количество символов « ! » окан¬
чивается «%»;
IN (<значение 1> [, <значение 2>...] —значение домена
должно совпадать с одним из приведенных в списке параметров;
IS [NOT] NULL — столбцы обязательно должны содержать
какое-либо значение, отличное от пустого;
CONTAINING <значение> — значение домена обязательно
должно содержать вхождение параметра <значение>, неважно в
каком месте;
STARTING [WITH] <значение> — значение домена должно
начинаться параметром «значение».
Может быть задана комбинация условий, которым должно со¬
ответствовать значение домена. В этом случае отдельные условия
соединяются оператором AND или OR.
Например, создадим домен ОТДЕЛЫ символьного типа с усло¬
вием, что данные, записываемые в этот домен, будут начинаться
с комбинации символов «отд» и содержать внутри себя строку
«018»;
CREATE DOMAIN ОТДЕЛЫ AS VARCHAR(IO)
CHECK (VALUE STARTING WITH «отд» AND VALUE CONTAINING
«018»)
Для изменения определения домена используется оператор:
ALTER DOMAIN <имя>
{ [SET DEFAULT {литерал |NULL |USER }]
236
||DROP DEFAULT]
| | ADD [CONSTRAINT] CHECK ^ограничения домена>)]
I|DROP CONSTRAINT]}
Оператор позволяет изменить параметры домена, определенного
ранее оператором CREATE DOMAIN. Однако нельзя изменить тип
данных и определение NOT NULL, если в столбцах уже есть зна¬
чения, не соответствующие устанавливаемому типу данных, либо
являющимися пустыми. Все сделанные изменения будут учтены для
всех столбцов, определенных с использованием данного домена.
В этом операторе:
■ [SET DEFAULT] —устанавливает значения по умолчанию по¬
добно тому, как это делается в операторе CREATE DOMAIN;
■ [DROP DEFAULT] — отмена текущих значений по умолчанию,
назначенных по умолчанию;
■ [ADD [CONSTRAINT] CHECK (Сограничения домена>)] —
добавление условий, которым должны соответствовать значения
столбца, ассоциированного с доменом. При этом возможно
определение условий, рассмотренных выше для предложения
CHECK оператора CREATE DOMAIN;
■ [DROP CONSTRAINT] —удаление условий, определенных для
домена в предложении CHECK оператора CREATE DOMAIN или
предыдущих операторов ALTER DOMAIN.
Примеры использования доменов будут рассмотрены после того,
как изучим операторы создания таблиц.
12.2.2. Управление таблицами
После создания общей структуры базы данных можно присту¬
пить к созданию таблиц, которые представляют собой отношения,
входящие в состав проекта базы данных. Напомним, что таблица —
основной объект для хранения информации в реляционной базе
данных. Она состоит из содержащих данные строк и столбцов,
занимает в базе данных физическое пространство и может быть
постоянной или временной. Поле, также называемое в реляцион¬
ной базе данных столбцом, является частью таблицы, за которой
закреплен определенный тип данных. Каждая таблица базы данных
должна содержать хотя бы один столбец. Строка данных — это
запись в таблице базы данных, она включает поля, содержащие
данные из одной записи таблицы.
Перед созданием таблиц базы данных необходимо продумать
определение всех столбцов таблицы и характеристик каждого столб-
237
ца, индексов, ограничений целостности по отношению к другим
таблицам. Предварительно должны быть определены домены, если
они используются в таблицах. База данных, в которую добавляется
создаваемая таблица, должна быть открыта, т. е. с ней должно быть
установлено активное соединение.
Создание таблицы БД осуществляется оператором CREATE
TABLE. Базовый синтаксис оператора создания таблицы имеет
следующий вид:
CREATE TABLE <имя таблицы>
({сопределение столбца>|<определение ограничения
таблицы;»}
[,..., {Сопределение столбца> | сопределение ограничения
таблицы>}]}
После задания имени таблицы через запятую в круглых скобках
должны быть перечислены все предложения, определяющие отдель¬
ные элементы таблицы — столбцы или ограничения целостности:
■ <имя таблицы> — идентификатор создаваемой таблицы;
■ Сопределение столбца> — задание имени, типа данных
и параметра отдельного столбца таблицы. Названия столбцов
должны соответствовать правилам для идентификаторов и быть
уникальными в пределах таблицы;
■ сопределение ограничения таблицы> — задание некото¬
рого ограничения целостности на уровне таблицы.
С помощью предложения сопределение столбца> задаются
свойства столбца:
сопределение столбца> : : =
Симя столбца> Стип данных>
[Сограничение столбца>] [,..., Сограничение столбца>]
Рассмотрим назначение и использование параметров:
■ Симя столбца> — идентификатор, задающий имя столбца
таблицы;
и стип данных> — тип данных столбца;
и Сограничение столбца> — с помощью этого предложения
указываются ограничения, которые будут определены для столб¬
ца. Синтаксис предложения следующий:
сограничение столбца>;;=
[CONSTRAINTChmh ссылочной целостности;»]
{ [DEFAULT Свыражение>]
|[NULL|NOT NULL]
238
I[PRIMARY KEY|UNIQUE]
|[FOREIGN KEY REFERENCES <имя главной таблицы>
[ (<имя столбца> [,...,п] ) ]
[ON DELETE {NO ACTION|CASCADE|SET DEFAULT|SET NULL}]
[ON UPDATE {NO ACTION|CASCADE|SET DEFAULT|SET NULL}]
]
|[(СНЕСКСусловие столбца>)]
}
Рассмотрим назначение параметров.
CONSTRAINT — необязательное ключевое слово, после которого
указывается название ограничения на значения столбца (<имя
ссылочной целостности;»). Имена должны быть уникальны в
пределах базы данных. Имя ссылочной целостности не является
обязательным. Оно присутствует в системных сообщениях от¬
носительно нарушения целостности и может использоваться при
изменении структуры таблиц. В случае если это имя отсутствует,
будет установлено системное имя. Для удаления непоименованной
целостности придется использовать ее системное имя.
DEFAULT — задает значение по умолчанию для столбца. Это
значение будет использовано при вставке строки, если для столбца
не указано никакое значение.
NULL | NOT NULL — ключевые слова, разрешающие или запре¬
щающие хранение в столбце значений NULL. Ключевое слово NULL
используется для указания того, что в данном столбце могут содер¬
жаться значения NULL. Значение NULL отличается от пробела или
нуля — к нему прибегают, когда необходимо указать, что данные
недоступны, опущены или недопустимы. Если указано ключевое
слово NOT NULL, то будут отклонены любые попытки поместить
значение NULL в данный столбец. Если указан параметр NULL,
помещение значений NULL в столбец разрешено. По умолчанию
стандарт SQL предполагает наличие ключевого слова NULL.
PRIMARY KEY — определение первичного ключа. Если по столб¬
цу строится первичный ключ, столбцу может быть приписан атри¬
бут PRIMARY KEY. Если в первичный ключ входит единственный
столбец, спецификатор ставится при определении столбца. Если
в состав первичного ключа должны входить несколько столбцов,
спецификатор ставится после определения всех столбцов. В любом
случае поля, по которым строится первичный ключ, не могут быть
пустыми, поэтому указывается спецификатор NOT NULL.
UNIQUE — атрибут, означающий, что в столбце не может быть
два одинаковых значения. Уникальный ключ строится по столбцу
239
(столбцам), когда столбец не входит в состав первичного ключа,
но тем не менее его значение должно всегда быть уникальным.
Столбец, объявленный с этим атрибутом, как и первичный ключ,
может применяться для обеспечения ссылочной целостности между
родительской и дочерней таблицей. Для соединения с родительской
таблицей в дочерней таблице строится внешний ключ. В таблице
может быть создано несколько ограничений целостности UNIQUE.
FOREIGN KEY — внешний ключ, создается для обеспечения
ссылочной целостности в подчиненной таблице.
Формат определения внешнего ключа:
FOREIGN KEY (<список столбцов подчиненной таблицы>)
REFERENCES <имя главной таблицы>
[<список столбцов главной таблицы>]
[ON DELETE {NO ACTION|CASCADE|SET DEFAULT|SET NULL}]
[ON UPDATE {NO ACTION|CASCADE|SET DEFAULT|SET NULL}]
В списке столбцов подчиненной таблицы содержатся те поля,
которые входят в состав внешнего ключа. В списке столбцов глав¬
ной таблицы содержатся те поля, которые являются ключевыми для
связи таблиц (список можно опускать, если связь с родительской
таблицей осуществляется по первичному ключу).
Необязательные параметры ON DELETE, ON UPDATE указывают,
что должен делать сервер при удалении и изменении первичного
ключа родительской таблицы соответственно:
■ NO ACTION — при наличии подчиненных записей в дочерней
таблице удаление или изменение соответствующих записей
головной таблицы запрещено;
■ CASCADE — при удалении записи в головной таблице проис¬
ходит удаление всех подчиненных записей в дочерней таблице;
при изменении записей изменяются значения ключевого поля
во всех подчиненных ей записей дочерней таблицы;
■ SET DEFAULT — при удалении или изменении записей в голов¬
ной таблице ключевому полю во всех записях дочерней таблицы
присваивается значение по умолчанию, указанное при опреде¬
лении поля; если это значение отсутствует в первичном ключе,
возбуждается исключение; причем используется значение по
умолчанию, имевшее место на момент определения ссылочной
целостности, если впоследствии это значение будет изменено,
ссылочная целостность при SET DEFAULT все равно будет ис¬
пользовать прежнее значение;
■ SET NULL — в ключевое поле подчиненных записей дочерней
таблицы заносится пустое значение NULL.
240
Ограничения, накладываемые на столбцы таблицы, определя¬
ются с помощью предложения CHECK (<условие столбца>),
общий формат которого приводится ниже:
<условие столбца>: := {
VALUE <оператор> <значение>
|VALUE [NOT] BETWEEN <значение 1> AND <значение 2>
|VALUE [NOT] LIKE <значение> [ESCAPE <значение>]
| VALUE [NOT] IN (<значение1> [, <значение2>...]
I VALUE IS [NOT] NULL
|VALUE [NOT] CONTAINING<значение>
|VALUE [NOT] STARTING [WITH] <значение>
}
В данном условии ограничения на значение столбца описывают¬
ся в том же формате, что и при определении домена:
<оператор> = { = I < I > I <= I >= I !< I !> ] <> I != };
VALUE <оператор> <значение> — значение домена находит¬
ся с параметром <значение> во взаимоотношениях, определяемых
параметром <оператор>;
BETWEEN <значение1> AND <значение2> — значение
домена должно находиться в промежутке между <значение1> и
<значение2> включительно;
LIKE <значение1> [ESCAPE <значение2>] — задает
шаблон подобия, при этом символ «%» указывает любое значение
любой длины, а символ «_» — любой одиночный символ. ESCAPE
используется, если в операторе LIKE символы «%» и «_» присут¬
ствуют в шаблоне как обычные символы. В этом случае выбирается
некоторый символ <значение 2>, после которого служебные
символы теряют свой специальный статус и входят в поисковую
строку как обычные параметры. Например, CHECK (VALUE LIKE
«%!%» ESCAPE « ! »)—любое количество символов «!» оканчи¬
вается «%»;
IN (<значение 1> [, <значение 2>...] —значение домена
должно совпадать с одним из приведенных в списке параметров;
IS [NOT] NULL — столбцы обязательно должны содержать
какое-либо значение, отличное от пустого;
CONTAINING <значение> — значение домена обязательно
должно содержать вхождение параметра <значение>, неважно в
каком месте;
STARTING [WITH] <значение> — значение домена должно
начинаться параметром «значение».
241
Может быть задана комбинация условий, которым должно со¬
ответствовать значение домена. В этом случае отдельные условия
соединяются оператором AND или OR.
Описание существующих в базе данных таблиц (характеристик
столбцов, их порядка, наличие различных ключей или ограничения
CHECK) можно изменять после создания таблиц.
Проиллюстрируем вышесказанное примерами.
Определим таблицу ОТДЕЛЫ с полями Номер и Наименова¬
ние:
CREATE TABLE ОТДЕЛЫ
(Номер INTEGER NOT NULL,
Наименование VARCHAR(20) )
Определим таблицу ОТДЕЛЫ с полями Номер, Наименование и
первичным ключом по полю Номер:
CREATE TABLE ОТДЕЛЫ
(Номер INTEGER NOT NULL PRIMARY KEY,
Наименование VARCHAR(20))
Та же таблица, но с первичным ключом уже по двум полям
(определение ограничений на уровне таблицы):
CREATE TABLE ОТДЕЛЫ
(Номер INTEGER NOT NULL,
Наименование VARCHAR(20) NOT NULL,
PRIMARY KEY (Номер, Наименование)
Теперь приведем пример использования в таблице домена.
Создадим домен Домен_Номер, имеющий целочисленный тип с
ограничением — больше или равно 100:
CREATE DOMAIN Домен_Номер AS INTEGER CHECK (VA-
LUE>=100);
В определении таблицы СОТРУДНИКИ поле Номер ассоциировано
с доменом Домен_Номер:
CREATE TABLE СОТРУДНИКИ
(Номер Домен_Номер NOT NULL,
ФИО VARCHAR (20 ),
PRIMARY KEY (Номер) )
Создадим две таблицы. Главная таблица ТОВАРЫ с полями Товар
и цена, а также с первичным ключом по полю Товар:
CREATE TABLE ТОВАРЫ
242
(Товар VARCHAR (20) NOT NULL,
Цена INTEGER NOT NULL,
PRIMARY KEY (Товар) )
Подчиненная таблица ПРОДАЖИ имеет первичный ключ по полю
Номер и внешний по полю Товар для обеспечения ссылочной
целостности с таблицей ТОВАРЫ. Поскольку не указывается поле
связи в главной таблице, то для связи используется первичный
ключ таблицы ТОВАРЫ:
CREATE TABLE ПРОДАЖИ
(Номер INTEGER NOT NULL PRIMARY KEY,
Дата DATE,
Товар VARCHAR (20) NOT NULL,
FOREIGN KEY (Товар) REFERENCES ТОВАРЫ)
Определение общих полей главной и подчиненной таблиц долж¬
но в точности совпадать. Если будут различия в порядке сортировки
символов, то столбцы связи не будут фактически идентичными, что
приведет к нарушению ссылочной целостности.
Еще один пример построения связи между таблицами ТОВАРЫ
и ПРОДАЖИ.
В подчиненной таблице указываются действия сервера при
изменении значения в составе первичного ключа и при удалении
записи в главной таблице:
CREATE TABLE ПРОДАЖИ
(Номер INTEGER NOT NULL PRIMARY KEY,
Дата DATE,
Товар VARCHAR (20) NOT NULL,
CONSTRAINT FK1 FOREIGN KEY (Товар) REFERENCES ТОВАРЫ
ON UPDATE NO ACTION
ON DELETE NO ACTION)
Теперь для таблицы ТОВАРЫ будет установлена блокировка уда¬
ления или изменения значения в столбце Товар, если в таблице
ПРОДАЖИ имеются записи о продаже этого товара. При этом ссы¬
лочной целостности в данном примере было присвоено имя FK1.
Изменение структуры таблиц, уже заполненных данными, яв¬
ляется одним из наиболее опасных действий, которое часто при¬
водит к исключениям базы данных или к потере существующих в
таблице данных.
Для изменения структуры существующих таблиц используется
оператор ALTER TABLE, упрощенный синтаксис которой пред¬
ставлен ниже: ■
243
ALTER TABLE <имя таблицы>
{ [ADD <имя столбца> <тип данных> [
NULL | NOT NULL ] ]
I[DROP [COLUMN] <имя столбца>]}
В одном операторе можно выполнить произвольное количество
изменений в таблице.
Различные операции по изменению существующей таблицы
отделяются друг от друга запятыми. Оператор ALTER TABLE по¬
зволяет:
■ добавить определение нового столбца;
■ удалить столбец из таблицы;
и удалить атрибуты целостности таблицы или отдельного столбца;
■ добавить новые атрибуты целостности.
Изменение характеристик столбца, а также удаление столбца
может закончиться неудачей, если:
■ столбец приобретает атрибуты PRIMARY KEY или UNIQUE, но
старые значения в столбце нарушают требования уникальности
данных;
■ удаленный столбец входил как часть в первичный или внешний
ключ, что привело к нарушению ссылочной целостности между
таблицами;
■ столбцу были приписаны ограничения целостности на уровне
таблицы;
в столбец используется в иных компонентах базы данных в про¬
смотрах, триггерах, выражениях для вычисляемых столбцов.
Таким образом, в случае необходимости изменения атрибутов
столбца или в случае удаления столбца сначала необходимо тща¬
тельно проанализировать, какие последствия для таблицы и базы
данных в целом может повлечь такое изменение или удаление.
Добавление нового столбца:
ALTER TABLE <имя таблицы> ADD <определения столбца>
Добавление нового ограничения целостности:
ALTER TABLE <имя таблицы> ADD [CONSTRAINT <имя огра-
ничения>] <определения целостности>
Удаление столбца:
ALTER TABLE <имя таблицы> DROP <имя столбца>
Удаление ограничения целостности:
ALTER TABLE <имя таблицы> DROP <имя ограничения>
244
Удаление таблицы производится оператором:
DROP TABLE <имя таблицы>
Например, добавление столбца в таблицу можно осуществить
следующей командой:
ALTER TABLE KLIENT
ADD ADRES VARCHAR(50)
Добавление ограничения целостности (первичного ключа) в
таблицу можно выполнить командой:
ALTER TABLE KLIENT
ADD CONSTRAINT PK_ KLIENT
PRIMARY KEY (ID)
Пример удаления таблицы:
DROP TABLE KLIENT
Удаление может быть блокировано для главных таблиц, для ко¬
торых в подчиненных таблицах (на данный момент не удаленных)
имеются ссылки по внешнему ключу этих таблиц. Действительно,
удаление главной таблицы разрушило бы ссылочную целостность.
Поэтому следует либо удалить ограничения ссылочной целостности
во всех подчиненных таблицах, либо, по необходимости, сначала
удалить сами подчиненные таблицы, а затем уже удалять главную
таблицу.
12.3.
ВЫБОРКА ДАННЫХ. ОПЕРАТОР SELECT
Оператор SELECT относится к подразделу языка запросов DQL
DML. Это один из самых сложных и самых мощных операторов
SQL. Этот оператор имеет довольно сложную и развитую струк¬
туру. Его необходимо знать любому специалисту, так или иначе
связанному с базами данных. Поэтому в этом учебном пособии ему
уделяется достаточно много внимания.
На рис. 12.1 приведена модель базы данных, которая в дальней¬
шем изложении будет использоваться в качестве примера.
Таблица Товары связана с таблицей Продажи то полю Товар
связью «один ко многим». Аналогично таблица Клиенты связана
с таблицей Продажи по полю Клиент связью «один ко многим».
Для того чтобы более наглядно проиллюстрировать результаты
выполнения запросов, в качестве примера будем использовать за¬
полненные таблицы (рис. 12.2).
245
Поле
Тип поля
Описание
Товар
Строка
Наименование товара
ЕИ
Строка
Единица измерения
Цена
Число
Цена
а
Поле
Тип поля
Описание
Клиент
Строка
Клиент
ИНН
Строка
ИНН клиента
Город
Строка
Город
Телефон
Строка
Телефон
б
Поле
Тип, поля
Описание
Номер
Число
Номер документа
Дата
Дата
Дата документа
Товар
Строка
Наименование товара
Количество
Число
Количество товара
Клиент
Строка
Клиент
в
Рис. 12.1. Структура таблиц, используемых для примеров:
а — таблица ТОВАРЫ; б — таблица КЛИЕНТЫ; в — таблица ПРОДАЖИ
SELECT (англ., «выбрать») — оператор языка SQL, возвраща¬
ющий набор данных (выборку) из базы данных, удовлетворяющий
заданному условию. Он позволяет производить выборки данных
из одной или нескольких таблиц базы данных и преобразовывать X
нужному виду полученные результаты. Этот оператор способен вы¬
полнять действия, эквивалентные операторам реляционной алгебры-
При его помощи можно реализовать сложные и громоздкие условия
отбора данных из различных таблиц. Если выборка осуществляется
из нескольких таблиц, то говорят об операции слияния.
При формировании запроса SELECT пользователь описыва¬
ет желаемый набор данных (набор столбцов, критерии отбора
записей, группировка значений, порядок вывода записей и т. п.)-
Сначала извлекаются все записи из таблицы, а затем для каждой
записи набора проверяется ее соответствие заданному критерию. Если осуществляется слияние из нескольких таблиц, то сначала
составляется произведение таблиц, а уже затем из полученного на¬
бора отбираются требуемые записи. В самом общем виде оператор
SELECT имеет следующий синтаксис:
246
SELECT [ALL|DISTINCT ] {*| [имя_столбца [AS новое_
имя]] } [, . . . n]
FROM имя_таблицы [ [AS] псевдоним] [, . . . n]
[WHERE <условия>]
[GROUP BY имя_столбца [, . . . n] ]
[HAVING <критерии выбора групп>]
[ORDER BY имя_столбца [, . . . n] ]
Оператор SELECT определяет поля (столбцы), которые будут
входить в результат выполнения запроса. В списке они разделяются
запятыми и приводятся в такой очередности, в какой должны быть
представлены в результате запроса. Если используется имя поля,
Рис. 12.2. Исходное состояние таблиц:
а — таблица ТОВАРЫ; б — таблица КЛИЕНТЫ; в — таблица ПРОДАЖИ
247
содержащее пробелы или разделители, его следует заключить в
квадратные скобки. Символом * можно выбрать все поля, а вместо
имени поля применить выражение из нескольких имен. Если обра¬
батывается несколько таблиц, то при наличии одноименных полей
в разных таблицах в списке полей используется полная специфи¬
кация поля, т. е. Имя Таблицы. Имя Поля.
Обработка элементов оператора SELECT выполняется в следу¬
ющей последовательности:
■ FROM — список таблиц базы данных, из которых будет проис¬
ходить выборка данных;
■ WHERE — выполняется фильтрация строк объекта в соответствии
с заданными условиями;
■ GROUP BY — образуются группы строк, имеющих одно и то же
значение в указанном столбце;
■ HAVING — фильтруются группы строк объекта в соответствии
с указанным условием;
■ SELECT — устанавливается, какие столбцы должны присутство¬
вать в выходных данных;
■ ORDER BY — определяется упорядоченность результатов выпол¬
нения операторов.
Порядок предложений и фраз в операторе SELECT не может
быть изменен. Только два предложения SELECT и FROM являются
обязательными, все остальные могут быть опущены. SELECT —- за¬
крытая операция: результат запроса к таблице представляет собой
другую таблицу. Существует множество вариантов записи данного
оператора, что иллюстрируется приведенными ниже примерами.
Например, создать набор данных, состоящий из всех столбцов
и всех записей таблицы Клиенты, можно с помощью такого опе¬
ратора:
SELECT * FROM Клиенты
Такой же набор данных можно получить, если вместо звездочки
перечислить все столбцы таблицы:
SELECT Клиент,ИНН,Город,Телефон
FROM Клиенты
Результат выполнения запроса может содержать дублирующиеся
значения, поскольку оператор SELECT не исключает повторяющих¬
ся значений при выполнении выборки данных. Предикат DISTINCT
следует применять в тех случаях, когда требуется отбросить блоки
данных, содержащие дублирующие записи в выбранных полях.
Значения для каждого из приведенных в инструкции SELECT полей
248
должны быть уникальными, чтобы содержащая их запись смогла
войти в выходной набор. Причиной ограничения в применении
DISTINCT является то обстоятельство, что его использование может
резко замедлить выполнение запросов.
Откорректируем предыдущий запрос следующим образом:
SELECT DISTINCT КЛИЕНТЫ.Город
FROM КЛИЕНТЫ
В результате получим список городов — местонахождение кли¬
ентов.
Оператор WHERE используется для включения в набор данных
лишь нужных записей. В этом случае оператор SELECT имеет сле¬
дующий формат:
SELECT {* | <значение1> [, <значение2> . . .] }
FROM <таблица1> [, < таблица2> . . . ]
WHERE <условие>
За ключевым словом WHERE следует перечень условий поиска.
В набор данных, возвращаемый оператором SELECT, будут вклю¬
чаться только те записи, которые удовлетворяют условию поиска,
указанному после WHERE. Далее будут рассмотрены весьма слож¬
ные условия выбора данных из различных таблиц, а пока разберем
простейшие.
Основные типы условий поиска (или предикатов) приведены
ниже.
1. Сравнение: сравниваются результаты вычисления одного вы¬
ражения с результатами вычисления другого, либо значения разных
столбцов.
2. Диапазон: проверяется, попадает ли значение столбца либо
результат вычисления выражения в заданный диапазон значений.
3. Принадлежность множеству: проверяется, принадлежит ли
значение столбца либо результат вычислений выражения заданному
множеству значений.
4. Соответствие шаблону: проверяется, отвечает ли некоторое
строковое значение заданному шаблону.
5. Значение NULL: проверяется, содержит ли данный столбец
определитель NULL (неизвестное значение).
Например, список клиентов из Санкт-Петербурга из таблицы
КЛИЕНТЫ можно получить с помощью запроса:
SELECT *
FROM КЛИЕНТЫ
WHERE КЛИЕНТЫ. Город = «Санкт-Петербург»
249
В языке SQL можно использовать следующие операторы срав¬
нения:
=
равно
<
меньше
>
больше
<=
меньше или равно
>=
больше или равно
о
не равно
Например, показать все операции продажи товаров, где количе¬
ство проданного товара больше 10:
SELECT *
FROM ПРОДАЖИ
WHERE Количество>10
Более сложные предикаты могут быть построены с помощью
логических операторов AND, OR или NOT, а также скобок, используе¬
мых для определения порядка вычисления выражения. Вычисление
выражения в условиях выполняется по следующим правилам:
■ выражение вычисляется слева направо;
■ первыми вычисляются подвыражения в скобках;
■ операторы NOT выполняются до выполнения операторов AND
и OR;
■ операторы AND выполняются до выполнения операторов OR.
Для устранения любой возможной неоднозначности рекомен¬
дуется использовать скобки. Приведем примеры использования
более сложных условий поиска. В результате следующего запроса
выводится список товаров, цена которых больше или равна 50 и
меньше или равна 100:
SELECT Товар, Цена
FROM ТОВАРЫ
WHERE Цена>=50 AND Цена<=100
Этот же запрос можно выполнить с помощью оператора
BETWEEN. Ключевое слово BETWEEN используется для поиска
значения внутри некоторого интервала, определяемого своими
минимальным и максимальным значениями. При этом указанные
значения включаются в условие поиска:
250
SELECT Товар, Цена
FROM ТОВАРЫ
WHERE Цена BETWEEN 50 And 100
Полученная выборка будет аналогична выборке из предыдущего
примера.
При использовании отрицания NOT BETWEEN будут получены
значения вне границ заданного диапазона.
Оператор IN используется для сравнения некоторого значения со
списком заданных значений, при этом проверяется, соответствует ли
результат вычисления выражения одному из значений в предостав¬
ленном списке. При помощи оператора IN может быть получен тот
же результат, что и в случае применения оператора OR, однако опера¬
тор IN выполняется быстрее. NOT IN используется для отбора любых
значений, кроме тех, которые указаны в представленном списке.
Например, для того чтобы вывести список клиентов, не про¬
живающих ни в Москве, ни в Санкт-Петербурге, необходимо вы¬
полнить запрос:
SELECT Клиент, Город
FROM КЛИЕНТЫ
WHERE Город NOT IN («Москва»,»Санкт-Петербург»)
С помощью оператора LIKE можно выполнять сравнение выра¬
жения с заданным шаблоном, в котором допускается использование
символов-заменителей:
■ символ «%» — вместо этого символа может быть подставлено
любое количество произвольных символов;
■ символ « » заменяет один символ строки.
Например, в результате выполнения следующего запроса будет
выведен список клиентов, у которых в номере телефона вторая
цифра — 4:
SELECT *
FROM КЛИЕНТЫ
WHERE КЛИЕНТЫ. Телефон LIKE '_4%'
В результате будет найден клиент «Федорова Д. С.» с телефоном
4449602.
Для того чтобы выбрать клиентов, у которых в фамилии или
названии встречается слог «ва», нужно составить запрос с исполь¬
зованием двух символов «%»:
SELECT *
FROM КЛИЕНТЫ
WHERE КЛИЕНТЫ.Клиент LIKE '%ва%',
251
Такая форма поиска применяется в тех случаях, когда пользова¬
тель не знает или не помнит всех данных о нужном объекте.
Оператор IS NULL используется для сравнения текущего
значения со значением NULL — специальным значением, указы¬
вающим на отсутствие любого значения (важно подчеркнуть, что
NULL — это не знак пробела или нуль). Выражение IS NOT NULL
используется для проверки присутствия значения в каком-либо
поле.
Например, необходимо найти клиентов, у которых не указан
телефон (поле Телефон не содержит никакого значения):
SELECT Клиент
FROM КЛИЕНТЫ
WHERE Телефон IS NULL
Выборка клиентов, у которых есть телефон (поле Телефон со¬
держит какое-либо значение):
SELECT Клиент
FROM КЛИЕНТЫ
WHERE Телефон IS NOT NULL
В общем случае строки в результирующем наборе данных SQL-
запроса никак не упорядочены. Однако их можно отсортировать в
определенном порядке. Для этого в оператор SELECT помещается
ключевое слово ORDER BY, которая сортирует данные выходного
набора в заданной последовательности. Сортировка может выпол¬
няться по нескольким полям, в этом случае они перечисляются за
ключевым словом ORDER BY через запятую.
Способ сортировки (по возрастанию или по убыванию) задает¬
ся ключевым словом, указываемым в рамках параметра ORDER BY
следом за названием поля, по которому выполняется сортировка.
По умолчанию реализуется сортировка по возрастанию. Явно она
задается ключевым словом ASC.
Для выполнения сортировки в обратной последовательности
необходимо после имени поля, по которому она выполняется,
указать ключевое слово DESC. Фраза ORDER BY позволяет упо¬
рядочить выбранные записи в порядке возрастания или убывания
значений любого столбца или комбинации столбцов, независимо
от того, присутствуют эти столбцы в результирующем наборе или
нет. Фраза ORDER BY всегда должна быть последним элементом в
операторе SELECT. Например, необходимо вывести список товаров
в алфавитном порядке:
252
SELECT *
FROM ТОВАРЫ
ORDER BY ТОВАРЫ.Товар
В предложении ORDER BY может быть указано и больше одного
элемента. Тогда критерием для сортировки служит результат «склеи¬
вания» всех перечисляемых полей. Например, таблицу продажи
можно упорядочить по полям Товар и Дата:
SELECT *
FROM ПРОДАЖИ
ORDER BY ПРОДАЖИ.Товар, ПРОДАЖИ.Дата
В следующем запросе сортировка осуществляется сначала по
имени покупателя, затем по названию товара и, наконец, по дате:
SELECT Клиент, Товар, Дата, Количество
FROM Продажи
ORDER BY Клиент, Товар, Дата
Соединение — это процесс, когда две или более таблицы объеди¬
няются в одну. Способность объединять информацию из нескольких
таблиц или запросов в виде одного логического набора данных
обусловливает широкие возможности SQL, которые и будут рас¬
смотрены далее.
Ранее мы уже определили оператор WHERE как средство для
наложения ограничений на результат запроса. Но если в каче¬
стве условия ограничения установить связь между таблицами по
определенным столбцам, то это и будет соединением двух таблиц.
В условиях объединения могут участвовать поля, относящиеся к
одному и тому же типу данных и содержащие один и тот же вид
данных, но они не обязательно должны иметь одинаковые имена.
Блоки данных из двух таблиц объединяются, как только в указанных
полях будут найдены совпадающие значения.
Чтобы выбрать все записи о продажи товаров из таблицы ПРО¬
ДАЖИ и для каждого товара указать его цену из таблицы ТОВАРЫ,
можно выполнить такой запрос:
SELECT ПРОДАЖИ.*, ТОВАРЫ.ЦЕНА
FROM ПРОДАЖИ, ТОВАРЫ
WHERE ПРОДАЖИ.ТОВАР = ТОВАРЫ.ТОВАР
При выполнении этого оператора для каждой записи из таблицы
ПРОДАЖИ ищется запись в таблице ТОВАРЫ, у которой значение в
поле Товар совпадает со значением в поле Товар текущей записи
таблицы ПРОДАЖИ (рис. 12.3).
253
Рис. 12.3. Результат внутреннего соединения таблиц
При этом безразлично, в каком порядке перечислять таблицы в
условии поиска, т. е. безразлично, какая из таблиц будет упомянута
слева, а какая справа. Такой способ соединения таблиц называется
внутренним соединением.
Приведем еще один пример внутреннего соединения таблиц.
Выберем все записи о расходе товара из таблицы ПРОДАЖИ и для
каждого клиента укажем его Город из таблицы КЛИЕНТЫ:
SELECT ПРОДАЖИ.*, КЛИЕНТЫ.Город
FROM ПРОДАЖИ, КЛИЕНТЫ
WHERE КЛИЕНТЫ. Клиент = ПРОДАЖИ. Клиент
Как можно видеть из примера (рис. 12.4), в результирующий на¬
бор данных не включены записи из таблицы КЛИЕНТЫ, для которых
нет записей в таблице ПРОДАЖИ.
При внутреннем соединении двух таблиц последовательность
формирования результирующего набора данных можно предста¬
вить следующим образом. Из столбцов, которые указаны после
слова SELECT, составляется промежуточный набор данных путем
связывания каждой записи из первой таблицы с каждой записью из
второй таблицы. Из получившегося набора данных отбрасываются
Рис. 12.4. Соединение таблиц ПРОДАЖИ и КЛИЕНТЫ
254
нее записи, не удовлетворяющие условию поиска в предложении
WHERE.
В рассмотренных выше примерах связывания таблиц в перечнях
возвращаемых столбцов после слова SELECT и в условии поиска
мосле WHERE перед именем столбца через точку пишется название
таблицы, например:
WHERE КЛИЕНТЫ. Клиент = ПРОДАЖИ. Клиент
Перед именем столбца необходимо указывать имя таблицы в тех
случаях, когда в разных таблицах есть одноименные столбцы (как в
данном примере). Использование имен таблиц для идентификации
столбцов неудобно, так как делает его громоздким и трудночи¬
таемым. Намного лучше присвоить каждой таблице какое-нибудь
краткое имя — псевдоним. Псевдоним отделяется от фактического
имени таблицы пробелом в списке таблиц-источников после клю¬
чевого слова FROM. Например, запрос
SELECT ПРОДАЖИ.*, КЛИЕНТЫ.Город
FROM ПРОДАЖИ, КЛИЕНТЫ
WHERE КЛИЕНТЫ. Клиент = ПРОДАЖИ. Клиент
после введения в него псевдонимов таблиц выглядит намного ком¬
пактнее:
SELECT П.*, К. Город
FROM ПРОДАЖИ П, КЛИЕНТЫ К
WHERE К.Клиент = П.Клиент
Для расчета значений вычисляемых столбцов результирующего
набора данных используются арифметические выражения. При
этом после оператора SELECT в списке столбцов вместо имени вы¬
числяемого столбца указывается выражение. Например, следующий
запрос возвращает все записи о продаже товаров из таблицы ПРО¬
ДАЖИ и для каждого факта реализации товара рассчитывает общую
стоимость отпущенного товара:
SELECT П.*, Т.Цена, П.Количество * Т.Цена
FROM ПРОДАЖИ П, ТОВАРЫ Т
WHERE П.Товар =Т.Товар
Результат выполнения данного запроса можно увидеть на
рис. 12.5.
Для создания вычисляемого поля применяются арифметические
операции сложения, вычитания, умножения и деления, а также
встроенные функции языка SQL. Можно указать имя любого
255
Рис. 12.5. Создание вычисляемого поля
столбца таблицы, но использовать имя столбца только той таблицы
или запроса, которые указаны в списке предложения FROM. При
построении сложных выражений используются скобки. Можно
явным образом задавать имена столбцов результирующей таблицы,
для чего применяется фраза AS. В следующем запросе выводится
список товаров с указанием года и месяца продажи:
SELECT Т.Товар, Year(П.Дата) AS Год, Month(П.Дата)
AS Месяц
FROM ТОВАРЫ Т, ПРОДАЖИ П
WHERE Т. Товар=П.Товар
В запросе использованы встроенные функции Year и Month для
выделения года и месяца из даты.
Агрегатные (итоговые) функции предназначены для вычисления
итоговых значений операций над всеми записями набора данных.
К агрегатным относятся следующие функции:
я COUNT (<выражение>) -—определяет количество записей в
выходном наборе SQL-запроса (число вхождений значения вы¬
ражения во все записи результирующего набора данных);
в SUM (<выражение>) —суммирует значения выражения;
в AVG (<выражение>) —эта функция позволяет рассчитать сред¬
нее значение множества значений, хранящихся в определенном
поле отобранных запросом записей. Оно является арифметиче¬
ским средним значением, т. е. суммой значений, деленной на их
количество;
в МАХ (<выражение>) — определяет максимальное значение;
в MIN (<выражение>) —определяет минимальное значение.
Все эти функции оперируют со значениями в единственном
столбце таблицы (столбцами нескольких таблиц) или с арифмети¬
ческим выражением и возвращают единственное значение. При
вычислении результатов любых функций сначала исключаются
все пустые значения, после чего требуемая операция применяется
256
только к оставшимся конкретным значениям столбца. Вариант
COUNT (*) — особый случай использования функции COUNT, его
назначение состоит в подсчете всех строк в результирующей
таблице, независимо от того, содержатся там пустые, дублиру¬
ющиеся или любые другие значения. В результате выполнения
следующего запроса будет подсчитано количество строк в таблице
ПРОДАЖИ:
SELECT Count (*) AS Количество Продаж
FROM ПРОДАЖИ
Если из группы одинаковых записей нужно учитывать только
одну, то перед выражением в скобках включают ключевое слово
DISTINCT:
COUNT(DISTINCT Клиент)
DISTINCT не имеет смысла для функций MIN и МАХ, однако его
использование может повлиять на результаты выполнения функций
SUM и AVG, поэтому необходимо заранее обдумать, должно ли оно
присутствовать в каждом конкретном случае. Кроме того, ключевое
слово DISTINCT может быть указано в любом запросе не более
одного раза.
Например, в следующем запросе вычисляется количество по¬
купателей, приобретавших товары на складе:
SELECT COUNT(DISTINCT ПРОДАЖИ.КЛИЕНТ) AS Кол Клиен¬
тов
FROM ПРОДАЖИ
В другом примере вычисляется общая стоимость отпущенных
товаров за один день:
SELECT SUM(П.Количество*! . Цена) AS ОбщСтоимость
FROM ПРОДАЖИ П,ТОВАРЫ Т
WHERE (П.Товар=Т.Товар) AND (П.Дата='02.04.2013')
Функции COUNT, MIN, МАХ применимы как к числовым, так и не¬
числовым полям. Функции SUM и AVG могут использоваться только
в случае числовых полей.
Иногда в запросах требуется формировать промежуточные ито¬
ги, т. е. получить результат выполнения функции не для всего набора
данных, а для определенных групп записей (например, подсчитать
итог для каждого клиента, для каждого товара, за определенную
дату). Для этой цели в операторе SELECT используется предложение
GROUP BY. Запрос, в котором присутствует GROUP BY, называется
257
группирующим запросом, поскольку в нем группируются данные,
полученные в результате выполнения операции SELECT. Для каж¬
дой отдельной группы создается единственная итоговая строка.
После оператора SELECT перечисляются те столбцы, которые не
меняют значения в группе, т. е. участвуют в группировке. Напри¬
мер, группируя запрос по товарам в таблице ПРОДАЖИ, нельзя в
предложении SELECT указать еще и дату, так как каждому товару
могут соответствовать разные даты продажи и, следовательно, по¬
добный запрос будет неверен:
SELECT П.Товар, П.Дата, SUM (П . Количество)
FROM ПРОДАЖИ П
GROUP BY П.Товар
Для того чтобы получить общее количество проданного товара
(рис. 12.6), следует использовать запрос:
SELECT П.Товар, SUM(П.Количество)
FROM ПРОДАЖИ П
GROUP BY П.Товар
А чтобы получить количество проданного товара за каждую
дату, нужно откорректировать предыдущий запрос следующим
образом:
SELECT П.Товар, П.Дата, SUM (П . Количество)
FROM ПРОДАЖИ П
GROUP BY П.Товар, П.Дата
Другими словами, все имена полей, приведенные в списке пред¬
ложения SELECT, должны присутствовать и во фразе GROUP BY, за
исключением случаев, когда имя столбца используется в агрегатной
функции. В то же время в предложении GROUP BY могут быть име¬
на столбцов, отсутствующие в списке предложения SELECT.
Еще один пример использования группировки в запросах — под¬
счет количества покупок, осуществленных каждым клиентом:
Рис. 12.6. Результат выполнения группирующего запроса
258
BLILCT Клиент, COUNT (* )
ROM ПРОДАЖИ
GROUP BY Клиент
Исли совместно с GROUP BY
in пользуется предложение WHERE,
m оно обрабатывается первым,
.1 группированию подвергаются
только те строки, которые удо¬
влетворяют условию поиска.
11апример, для того чтобы оп¬
ределить, на какую сумму был
продан товар каждого наименования, можно составить запрос
(рис. 12.7):
SELECT П. Товар, SUM (П. Количество^ . Цена)
FROM ПРОДАЖИ П, ТОВАРЫ Т
WHERE Т . Товар = П . Товар
GROUP BY П..Товар
Чтобы определить количество покупателей на каждую дату, нужно выполнить такой запрос:
SELECT Дата, COUNT(DISTINCT Клиент)
FROM ПРОДАЖИ
GROUP BY Дата
Если в результирующем наборе данных нужно наложить огра¬
ничения на значения итоговых строк, то после предложения GROUP
BY используют предложение HAVING. Это дополнительная воз¬
можность «отфильтровать» выходной набор. Важно отметить, что
итоговые функции могут использоваться только в списке предло¬
жения SELECT и в составе предложения HAVING, в то время как в
предложении WHERE такие функции указывать нельзя. Например,
следующий запрос позволяет вывести список товаров, проданных
на сумму более 3 000 р.:
SELECT П. Товар, SUM(n. Количество^. Цена)
FROM ПРОДАЖИ П, ТОВАРЫ Т
WHERE Т.Товар = П.Товар
GROUP BY П.Товар
HAVING SUM(n. Количество*^ Цена) >3000
Показать даты продажи товаров, в которых суммарное коли¬
чество отпускаемого товара было не менее 10 единиц, причем в
каждую дату было совершено более одной операции продажи:
259
SELECT Дата, COUNT(*)
FROM ПРОДАЖИ
WHERE Количество>=10
GROUP BY Дата
HAVING COUNT (*)>1
Иногда в запросах при использовании операций сравнения зна¬
чение, с которым надо сравнивать результат запроса, заранее не
определено и представляет собой не одно, а несколько значений,
либо должно быть получено путем выполнения другого оператора
SELECT. В таких случаях используются подзапросы (вложенные
запросы).
Подзапрос (вложенный запрос) — это инструмент создания вре¬
менной таблицы, содержимое которой извлекается и обрабатывает¬
ся внешним оператором. Текст подзапроса должен быть заключен в
скобки. Оператор SELECT с подзапросом имеет следующий вид:
SELECT . . .
FROM . . .
WHERE Сравниваемое значение> <оператор> (SELECT . . .)
Существует два типа подзапросов.
1. Скалярный подзапрос возвращает единственное значение.
В принципе, он может использоваться везде, где требуется указать
единственное значение.
2. Табличный подзапрос возвращает множество значений, т. е.
значения одного или нескольких столбцов таблицы, размещенные
в более чем одной строке. Он возможен везде, где допускается на¬
личие таблицы.
Подзапросы бывают:
■ некоррелированные — не содержат ссылки на запрос верхнего
уровня, вычисляются один раз для запроса верхнего уровня;
■ коррелированные — содержат условия, зависящие от значений
полей в основном запросе; вычисляются для каждой строки за¬
проса верхнего уровня.
Вложенный запрос имеет тот же синтаксис, что и основной или
внешний, следовательно, вложенный запрос также может содер¬
жать подзапрос. Один оператор SELECT как бы внедряется в тело
другого оператора SELECT.
Внешний оператор SELECT использует результат выполнения
внутреннего оператора для определения содержания окончатель¬
ного результата всей операции.
Внутренние запросы могут быть помещены непосредственно
после оператора сравнения ( =, <, >,<=, >=, <>) в предло-
260
'И41 ия WHERE и HAVING внешнего оператора SELECT. Кроме того,
и и утренние операторы SELECT могут применяться в операторах
INSERT, UPDATE и DELETE (вставка, обновление и удаление запи¬
сей).
К подзапросам применяются следующие правила и ограниче¬
ния:
■ нельзя использовать ORDER BY, хотя эта фраза может присут¬
ствовать во внешнем запросе;
■ список в предложении SELECT состоит из имен отдельных
столбцов или составленных из них выражений, за исключе¬
нием случая, когда в подзапросе присутствует ключевое слово
EXISTS;
■ по умолчанию имена столбцов в подзапросе относятся к та¬
блице, имя которой указано в предложении FROM. Однако до¬
пускается ссылка и на столбцы таблицы, указанной во фразе
FROM внешнего запроса, для чего применяются специфици¬
рованные имена столбцов (т. е. с указанием таблицы) либо их
псевдонимы;
■ если подзапрос является одним из двух операндов, участвующих
в операции сравнения, то запрос должен указываться в правой
части этой операции.
Следующий запрос возвращает даты, когда было продано мак¬
симальное количество товара:
SELECT Количество, Дата
FROM ПРОДАЖИ
WHERE Количество = (SELECT МАХ (Количество) FROM
ПРОДАЖИ)
Очевидно, что вложенный оператор SELECT должен возвра¬
щать единичное значение, а не список. Во вложенном подзапросе
определяется максимальное количество товара. Во внешнем под¬
запросе — дата, для которой количество товара оказалось равным
максимальному. Необходимо отметить, что нельзя прямо исполь¬
зовать предложение
WHERE Количество = Мах(Количество) ,
поскольку применять обобщающие функции в предложениях WHERE
запрещено.
Усложним предыдущий пример. Определим даты, когда со
склада было отгружено максимальное количество товара, и для
каждого клиента, который этот товар приобрел, укажем город
(рис. 12.8):
261
Рис. 12.8. Результат выполнения вложенного запроса
SELECT П.Количество, П.Дата, К. Клиент, К.Город
FROM ПРОДАЖИ П, КЛИЕНТЫ К
WHERE (П. Клиент = К. Клиент)
AND
П.Количество —{SELECT МАХ(Количество) FROM ПРОДАЖИ)
По сравнению с предыдущим примером в запрос включено вну¬
треннее соединение таблиц ПРОДАЖИ и КЛИЕНТЫ.
Еще один пример вложенного запроса — нужно определить даты
покупок, в которых количество товара превышает общее среднее
значение и указать размер отклонения (рис. 12.9):
SELECT Дата, Количество,
Количество- (SELECT AVG (Количество) FROM ПРОДАЖИ)
AS Отклонение
FROM ПРОДАЖИ
WHERE Количество
(SELECT AVG (Количество) FROM ПРОДАЖИ)
В приведенном примере результат подзапроса, представляющий
собой среднее значение количества товара по всем фактам прода¬
жи вообще, используется во внешнем операторе SELECT как для
вычисления отклонения количества от среднего уровня, так и для
отбора сведений о датах.
Часто значение, подлежащее сравнению в предложениях WHERE
или HAVING, представляет собой не одно, а несколько значений —
вложенные подзапросы генерируют промежуточную временную
таблицу.
Применяемые к подзапросу операции основаны на тех опе¬
рациях, которые в свою очередь применяются к множеству,
а именно:
Рис. 12.9. Результат выполнения вложения
запроса в вычисляемом столбце
262
[NOT] IN;
{ALL | SOME | ANY};
[NOT] EXISTS;
Оператор IN используется для сравнения некоторого значения
со списком значений, при этом проверяется, входит ли значение в
предоставленный список или сравниваемое значение не является
элементом представленного списка.
В следующем примере выводится список продаж клиентов,
которые однажды приобрели максимальную партию какого-либо
товара:
SELECT П. *
FROM ПРОДАЖИ П
WHERE П . Клиент IN
(SELECT П1. Клиент FROM ПРОДАЖИ П1
WHERE П1. Количество =
(SELECT МАХ (П2 . Количество) FROM ПРОДАЖИ П2) )
Разъясним логику выполнения этого запроса. Сначала опреде¬
ляется максимальное значение в столбце Количество:
SELECT МАХ (П2 . Количество) FROM ПРОДАЖИ П2
Далее в следующем запросе определяются клиенты, осуществив¬
шие эту покупку:
SELECT П1. Клиент
FROM ПРОДАЖИ П1
WHERE П1. Количество =
(SELECT МАХ (П2 . Количество) FROM ПРОДАЖИ П2)
А затем основной запрос выбирает все записи с найденными
клиентами из таблицы ПРОДАЖИ с помощью оператора IN, т.е.
в результирующий набор данных попадают только те записи из
таблицы ПРОДАЖИ, в которых значение поля КЛИЕНТ принадлежит
множеству, полученному во вложенных запросах (рис. 12.10).
Рис. 12.10. Список покупок клиентов, приобретавших максимальное
количество товара
263
С помощью NOT IN можно получить выборку строк, в которых
сравниваемое значение не входит в множество, полученное во
вложенных запросах.
Ключевые слова ANY и ALL могут использоваться с подзапро¬
сами, возвращающими один столбец чисел.
Отношение сравниваемого значения и значений, возвращаемых
подзапросом, устанавливается операторами ALL и SOME (ANY):
■ ALL указывает, что условие будет истинно только тогда, когда
сравниваемое значение находится в нужном отношении со
всеми значениями, возвращаемыми подзапросом, иначе гово¬
ря, выполняется для всех значений в результирующем столбце
подзапроса;
■ SOME (или ANY) — условие поиска истинно, когда сравниваемое
значение находится в нужном отношении хотя бы с одним значе¬
нием, возвращаемым подзапросом, т.е. выполняется хотя бы для
одного из значений в результирующем столбце подзапроса.
Если в результате выполнения подзапроса получено пустое зна¬
чение, то для ключевого слова ALL условие сравнения будет счи¬
таться выполненным, а для ключевого слова ANY — невыполненным.
Ключевое слово SOME является синонимом слова ANY.
Проиллюстрируем вышесказанное примерами. Определим все
факты продажи товаров, в которых количество единиц продавае¬
мого товара превышает среднее значение:
SELECT * FROM ПРОДАЖИ П1
WHERE П1. Количество ALL
(SELECT AVG (П2 . Количество)
FROM ПРОДАЖИ П2
GROUP BY П2 . Клиент)
И еще один пример использования предложения HAVING и
ключевого слова ALL. Нужно вывести сведения о клиенте, который
приобрел наибольшее количество товаров:
SELECT К. *
FROM КЛИЕНТЫ К
WHERE К.Клиент =
(SELECT П.Клиент
FROM ПРОДАЖИ П
GROUP BY П. Клиент
HAVING SUM(П.Количество) >= ALL
(SELECT SUM (П1. Количество) FROM ПРОДАЖИ П1
GROUP BY П1. Клиент) )
264
Перечислим все факты продажи товаров, в которых количество
единиц продаваемого товара превышает среднее значение продажи
хотя бы одного товара:
SELECT * FROM ПРОДАЖИ П1
WHERE П1. Количество SOME
(SELECT AVG (П2 . Количество)
FROM ПРОДАЖИ П2
GROUP BY П2 . Клиент)
Ключевые слова EXISTS и NOT EXISTS предназначены для ис¬
пользования только совместно с подзапросами. Результат их обра¬
ботки представляет собой логическое значение TRUE или FALSE.
Для ключевого слова EXISTS результат равен TRUE в том и
только в том случае, если в возвращаемой подзапросом результи¬
рующей таблице присутствует хотя бы одна строка. Если результи¬
рующая таблица подзапроса пуста, результатом обработки операции
EXISTS будет значение FALSE. Для ключевого слова NOT EXISTS
используются правила обработки, обратные по отношению к клю¬
чевому слову EXISTS. Поскольку по ключевым словам EXISTS и
NOT EXISTS проверяется лишь наличие строк в результирующей
таблице подзапроса, то эта таблица может содержать произвольное
количество столбцов. Используя ключевое слово EXISTS, можно
составить список всех клиентов, которые хотя бы один раз приоб¬
ретали товар:
SELECT *
FROM КЛИЕНТЫ К
WHERE EXISTS
(SELECT П. *
FROM ПРОДАЖИ П
WHERE К. Клиент = П. Клиент)
Для того чтобы получить список клиентов, которые не сделали
ни одной покупки в этот же запрос, нужно вставить слово NOT:
SELECT *
FROM КЛИЕНТЫ К
WHERE NOT EXISTS
(SELECT П.*
FROM ПРОДАЖИ П
WHERE К. Клиент = П. Клиент)
Если в условии поиска нужно указать, что из таблицы требу¬
ется выбрать лишь те записи, для которых подзапрос возвращает
265
только одно значение, указывается предложение SINGULAR.
Изменим немного предыдущий запрос и получим совсем другой
результат:
SELECT *
FROM КЛИЕНТЫ К
WHERE SINGULAR
(SELECT П. ПРОДАЖИ FROM ПРОДАЖИ П WHERE К. Клиент =
П.Клиент)
Результатом выполнения запроса является список всех клиен¬
тов, приобретавших только один вид товара и только один раз, т.е.
в таблице ПРОДАЖИ для такого клиента присутствует только одна
запись.
Выше были рассмотрены внутренние соединения таблиц базы
данных. Внутреннее соединение используется, когда нужно вклю¬
чить все строки из обеих таблиц, удовлетворяющие условию объ¬
единения. В этом случае строится декартово произведение строк
первой и второй таблиц, а из полученного набора данных отбира¬
ются записи, удовлетворяющие условиям объединения.
Существует также и другой вид соединения таблиц — внешнее
соединение. Оно определяется в предложении FROM согласно такой
спецификации:
SELECT . . .
FROM <таблица1><вид соединения> JOIN <таблица2>
ON <условие соединения>
Внешнее соединение отличается от внутреннего соединения
тем, что в нем одна из таблиц является ведущей. В результирующий
набор данных включаются записи ведущей таблицы соединения,
которые могут объединяться с пустым множеством записей другой
таблицы. Какая из таблиц будет ведущей, определяет вид соедине¬
ния.
Левое внешнее соединение(йЕРТ)— это соединение, в котором
ведущей является первая таблица, в предложении FROM располо¬
женная слева от вида соединения. Соответственно, строки ведущей
(первой) таблицы, не имеющие совпадающих значений в общих
столбцах второй таблицы, также включаются в результирующий
набор данных.
Правое внешнее соединение (RIGHT) — это соединение, когда
ведущей является вторая таблица, в предложении FROM располо¬
женная справа от вида соединения. В результирующем отношении
содержатся все строки правой таблицы.
266
I
Полное внешнее соединение (FULL) — когда ведущими табли¬
цами являются все таблицы. В результирующий набор данных
включаются все записи обеих таблиц. Если для записи первой
таблицы имеются записи второй таблицы, удовлетворяющие усло¬
вию соединения, в результирующий набор данных будут включены
все комбинации соединения таких записей обеих таблиц. Иначе
в результирующий набор данных будет включена запись первой
таблицы, соединенная с пустой записью.
С другой стороны, если для записи второй таблицы имеются
записи первой таблицы, удовлетворяющие условию соединения,
в результирующий запрос будут включены все комбинации соеди¬
нения таких записей обеих таблиц. Иначе в результирующий на¬
бор данных будет включена запись второй таблицы, соединенная
с пустой записью.
Проиллюстрируем это на примере. Выполнение оператора реа¬
лизующего внешнее левое соединение таблиц КЛИЕНТЫ и ПРОДА¬
ЖИ приведет к созданию такого результирующего набора данных
(рис. 12.11):
SELECT ПРОДАЖИ.*, КЛИЕНТЫ.*
FROM КЛИЕНТЫ LEFT JOIN ПРОДАЖИ
ON ПРОДАЖИ.Клиент = КЛИЕНТЫ.Клиент
Как видно из результата, некоторые строки таблицы КЛИЕНТЫ
не имеют парных записей в таблице ПРОДАЖИ, удовлетворяющих
условию соединения. Поэтому эти данные таблицы КЛИЕНТЫ по¬
казаны в соединении с пустыми записями.
Рис. 12.11. Результат внешнего левого соединения таблиц КЛИЕНТЫ и
ПРОДАЖИ
267
Аналогичным образом осуществляется правое внешнее соеди¬
нение:
SELECT ПРОДАЖИ.*, КЛИЕНТЫ.*
FROM КЛИЕНТЫ RIGHT JOIN ПРОДАЖИ
ON ПРОДАЖИ.Клиент = КЛИЕНТЫ. Клиент,
и полное внешнее соединение:
SELECT ПРОДАЖИ.*, КЛИЕНТЫ.*
FROM КЛИЕНТЫ FULL JOIN ПРОДАЖИ
ON ПРОДАЖИ.Клиент = КЛИЕНТЫ.Клиент
Иногда нужно объединить два или более результирующих на¬
бора данных, возвращаемых после выполнения операторов SE¬
LECT. Такое объединение производится при помощи оператора
UNION. Объединяемые наборы данных должны иметь одинаковую
структуру, т.е. одинаковый состав полей (тип, размер). Если в ре¬
зультирующих наборах данных имеются одинаковые записи, то в
объединенный набор они будут записаны одной строкой:
<оператор SELECT>
UNION
Соператор SELECT>
С помощью оператора SELECT можно реализовать весьма слож¬
ные условия выбора данных из различных таблиц.
12.4.
ИЗМЕНЕНИЕ ДАННЫХ. ОПЕРАТОРЫ INSERT,
UPDATE, DELETE
Для заполнения базы данных пользовательскими данными, изме¬
нения и удаления существующих данных используются операторы
SQL подраздела DML. Операторы задают, что должно быть сделано
с данными базы данных, не указывая, как именно это должно быть
сделано. Для добавления новых строк в таблицы или в представле¬
ния базы данных используется оператор INSERT. Для изменения
данных в таблицах базы данных применяется оператор UPDATE. Для
удаления строк таблиц используется оператор DELETE.
Все действия по изменению данных выполняются в контексте
(под управлением) какой-либо транзакции. Это может быть пред¬
варительно запущенная в клиенте оператором SET TRANSACTION
транзакция с необходимыми характеристиками или транзакция по
умолчанию, запускаемая системой автоматически при выполнении
любых операций с данными и метаданными базы данных.
268
INSERT INTO ТОВАРЫ
VALUES («Сахар», «кг.», 100)
269
Язык SQL ориентирован на выполнение операций над группами
записей, хотя в некоторых случаях операция может проводиться и
над отдельной записью. Поэтому операторы добавления, изменения
и удаления записей в общем случае вызывают соответствующие
операции над группами записей.
Добавление новых строк в обычную таблицу или таблицу, лежа¬
щую в основе представления, осуществляется с помощью оператора
INSERT. Его синтаксис представлен следующим образом:
INSERT INTO <объект>
[ (столбец1 [, столбец2 ...])]
{VALUES (<значение>[,< значение 2>...] ) | <оператор SE-
LECT>}
<объект> — это таблица базы данных. Список столбцов указы¬
вает столбцы, которым будут присвоены значения в добавляемых
записях. Список столбцов может быть опущен. В этом случае под¬
разумеваются все столбцы объекта, причем в том порядке, в кото¬
ром они определены в данном объекте.
Поставить в соответствие столбцам списки значений можно
двумя способами: явное указание значения после слова VALUES и
формирование списка значений при помощи оператора SELECT.
Явное указание списка значений применяется для добавления
одной записи и имеет формат:
INSERT INTO <объект>
[ (столбец1 [, столбец2 ...] ) ]
VALUES (<значение>[,< значение 2>...] )
Значения присваиваются столбцам по порядку следования тех
и других в операторе: первому по порядку столбцу присваивается
первое значение, второму столбцу второе значение и т.д. Напри¬
мер, в таблицу ТОВАРЫ новую запись можно добавить следующим
оператором:
INSERT INTO ТОВАРЫ
(Товар, ЕИ, Цена)
VALUES («Сахар», «кг.», 100)
Поскольку столбцы таблицы ТОВАРЫ указаны в полном составе
и именно в том порядке, в котором они перечислены при создании
таблицы ТОВАРЫ, оператор можно упростить:
Второй формой оператора INSERT является следующий фор¬
мат:
INSERT INTO <объект>
[ (столбец1 [, столбец2 ...] ) ]
<оператор SELECT>
При этом значениями, которые присваиваются столбцам, яв¬
ляются значения, возвращаемые оператором SELECT. Поскольку
оператор SELECT в общем случае возвращает множество записей,
то и оператор INSERT в данной форме приведет к добавлению в
объект аналогичного количества новых записей.
Предположим, в какой либо базе данных определена таблица
ПРОДАЖИ_ГЛ, по составу и порядку следования полей аналогичная
таблице ПРОДАЖИ:
CREATE TABLE ПРОДАЖИ
(Номер INTEGER NOT NULL,
Клиент VARCHAR(20) NOT NULL COLLATE PXW_CYRL,
Товар VARCHAR (20) NOT NULL COLLATE PXW_CYRL,
Количество INTEGER NOT NULL,
Дата DATE NOT NULL,
PRIMARY KEY (Номер)
Предположим, что данные из этой таблицы необходимо еже¬
дневно добавлять в какую-либо территориально удаленную базу
данных, например ПРОДАЖИ_ГЛ. Тогда ежедневная выгрузка запи¬
сей из таблицы ПРОДАЖИ в таблицу ПРОДАЖИ_ГЛ будет реализована
оператором:
INSERT INTO ПРОДАЖИ_ГЛ
SELECT *
FROM ПРОДАЖИ
WHERE Дата = <дата>,
где<дата> — значение текущей даты.
Для изменения данных в столбцах существующих строк в обыч¬
ной таблице или в таблице, являющейся базовой для изменяемого
представления, используется оператор UPDATE. Оператор за одно
обращение позволяет изменить данные во всех строках или только
в части строк в таблице или в представлении. Его синтаксис пред¬
ставлен следующим форматом:
UPDATE <объект>
SET столбец1=<значение1> [, столбец2=<значение2>...]
[WHERE <условие>]
270
При изменении каждому из перечисленных столбцов присваи¬
вается соответствующее значение. Изменения выполняются для
всех записей, удовлетворяющих условию, которое задается так же,
как в операторе SELECT. Предложение SET задает список выпол¬
няемых изменений: указывается имя изменяемого столбца и после
знака равенства новое значение столбца. Значением, как и в случае
оператора INSERT, может быть сколь угодно сложное выражение.
11ерез запятую в следующих предложениях SET можно перечислять
значения других столбцов таблицы. Предложение WHERE в опера¬
торе определяет множество строк, к которым будет применяться
операция изменения существующих данных. Если это предложение
не указано, то будут изменены все строки таблицы:
UPDATE ПРОДАЖИ
SET Цена=Цена*2
WHERE Товар =«Мука»
В результате выполнения оператора в таблице ТОВАРЫ значение
в поле Цена будет увеличено вдвое во всех записях, в которых зна¬
чение поля Товар равно «Мука».
Оператор DELETE предназначен для удаления группы записей из
объекта. В частном случае может быть удалена только одна запись.
Формат оператора DELETE:
DELETE FROM <объект>
[WHERE <условие>]
Удаляются все записи, удовлетворяющие условию поиска.
Если убрать предложение WHERE, то в объекте будут удалены все
записи.
Ниже приводится пример, в котором из таблицы ПРОДАЖИ будут
удалены все записи о фактах продажи сахара:
DELETE ПРОДАЖИ
WHERE Товар = «Сахар»
12.5.
ХРАНИМЫЕ ПРОЦЕДУРЫ И ТРИГГЕРЫ
12.5.1. Язык хранимых процедур
и триггеров
Хранимые процедуры и триггеры являются программами, кото¬
рые хранятся в области метаданных базы данных. Они выполняются
на стороне сервера, что во многих случаях позволяет сэкономить
271
ресурсы системы и уменьшить сетевой трафик. К хранимым про¬
цедурам возможно обращение из хранимых процедур, триггеров
и клиентских приложений. К триггерам напрямую обращение
невозможно — они вызываются автоматически при наступлении
конкретного события для таблицы (изменения данных) или собы¬
тия базы данных. Для каждого события таблицы существует две
фазы — до наступления соответствующего события (BEFORE) и
после наступления этого события (AFTER).
Для описания алгоритмов обработки данных в хранимых про¬
цедурах и триггерах используется расширение языка SQL. Это
расширение называется процедурным SQL (PSQL) или языком
хранимых процедур и триггеров. Язык содержит обычные опера¬
торы присваивания, операторы ветвления и операторы циклов.
В триггерах могут применяться специфические контекстные
переменные.
Язык хранимых процедур и триггеров содержит все основные
конструкции классических языков программирования. Кроме
того, в нем присутствуют несколько модифицированные опера¬
торы добавления, изменения, удаления и выборки существующих
данных из таблиц базы данных (INSERT, UPDATE, DELETE и
SELECT). В языке хранимых процедур нельзя выполнять какие-
либо изменения метаданных.
В хранимых процедурах и триггерах можно использовать сред¬
ства оповещения клиентов о некоторых событиях (events), возмож¬
ности выдавать пользовательские исключения (exceptions). Недо¬
пустимо выполнять операции соединения с базой данных, нельзя
манипулировать транзакциями, включая старт транзакции, создание
точек сохранения, возврата на точки сохранения, подтверждения
или отмены транзакций. Хранимая процедура и триггер выполня¬
ются в контексте той транзакции, при которой была явно вызвана
хранимая процедура или выполнялась операция манипулирования
данными в базе данных, в результате чего был автоматически за¬
пущен триггер. Если триггер вызывается при соединении с базой
данных и отсоединении от нее, то для него запускается транзакция
по умолчанию.
В синтаксисе создания хранимых процедур и триггеров можно
выделить заголовок и тело. Заголовок содержит имя програм¬
много объекта, описание локальных переменных. Для триггеров
в заголовке указывается событие базы данных и фаза, при кото¬
рой автоматически вызывается триггер. В заголовке хранимой
процедуры можно указать входные и выходные параметры. Тело
хранимой процедуры или триггера представляет собой блок
272
операторов, содержащий описание выполняемых программой
действий. Блок операторов заключается в операторные скобки
BEGIN и END. В самих программах возможно присутствие про¬
извольного количества блоков, как последовательных, так и вло¬
женных друг в друга.
Все действия по выборке, обработке и изменению данных в хра¬
нимых процедурах и триггерах выполняются в блоке операторов,
который заключается в операторные скобки BEGIN и END.
При написании триггеров и хранимых процедур в текстах скрип¬
тов, создающих требуемые программные объекты базы данных, во
избежание двусмысленности относительно использования символа
завершения операторов (по нормам SQL, точка с запятой) приме¬
няется оператор SET TERM, который, строго говоря, не является
оператором SQL. При помощи этого псевдооператора перед нача¬
лом создания триггера или хранимой процедуры задается символ,
являющийся завершающим в конце текста триггера или хранимой
процедуры. После описания текста соответствующего программного
объекта при помощи того же оператора SET TERM значение тер¬
минатора возвращается к обычному варианту — точка с запятой.
Например, при создании некоторого триггера следует выполнить
следующие операторы:
SET TERM л ;
/* Формирование значения первичного ключа таблицы
ТОВАРЫ */
CREATE TRIGGER TBI_STAFF FOR ТОВАРЫ BEFORE INSERT
. . . [Текст триггера}
END Л
Операторы в блоке выполняются последовательно. В расши¬
рениях SQL существуют операторы ветвления (IF-THEN-ELSE),
операторы цикла (WHILE-DO, FOR-SELECT-DO, FOR EXECUTE
STATEMENT), операторы обращения к данным в базе данных (опе¬
раторы выборки данных, добавления, изменения, удаления).
В любом месте текста, где допустим пробел, могут быть поме¬
щены комментарии, которые располагаются между символами /*
и * /. Один такой комментарий может занимать любое количество
строк. Существует и другая форма комментариев: подряд идущие
два символа минус (—). Текст комментария в этом случае продол¬
жается лишь до конца текущей строки.
Для описания одной локальной переменной используется опера¬
тор DECLARE VARIABLE. Его упрощенный синтаксис может быть
представлен следующим образом:
273
DECLARE [VARIABLE] <имя локальной переменной>
{ <тип данных>
I <имя домена>
| TYPE OF <имя домена>
}
В одном операторе можно объявить только одну локальную
переменную. В триггере и хранимой процедуре можно объявлять
произвольное количество локальных переменных, используя для
каждой переменной отдельный оператор DECLARE VARIABLE.
Имя локальной переменной должно быть уникальным среди
имен локальных переменных, входных и выходных параметров
хранимой процедуры в пределах данного программного объекта.
Типом данных может быть любой тип данных, используемый в
SQL. Вместо типа данных можно указать имя ранее созданного
домена.
12.5.2. Работа с триггерами
Триггер является программой, которая хранится в области мета¬
данных базы данных и выполняется на стороне сервера. Напрямую
обращение к триггеру невозможно. Он вызывается автоматически
при наступлении одного или нескольких событий, относящихся к
одной конкретной таблице (к представлению), или при наступле¬
нии одного из событий базы данных. Триггер, вызываемый при
наступлении события таблицы, связан с одной таблицей или пред¬
ставлением, одним или более событиями для этой таблицы или
представления (добавление, изменение или удаление данных) и
ровно с одной фазой такого события (до наступления события или
после этого). Триггер выполняется в контексте той транзакции,
в контексте которой выполнялась программа, вызвавшая соот¬
ветствующее событие. Исключением являются триггеры, реагиру¬
ющие на события базы данных. Для некоторых из них запускается
транзакция по умолчанию.
Существует шесть вариантов соотношения «событие — фаза»
для таблицы (представления):
1) до добавления новой строки (BEFORE INSERT);
2) после добавления новой строки (AFTER INSERT);
3) до изменения строки (BEFORE UPDATE);
4) после изменения строки (AFTER UPDATE);
5) до удаления строки (BEFORE DELETE);
6) после удаления строки (AFTER DELETE).
274
Триггер, связанный с событиями базы данных, может вызывать¬
ся при следующих событиях:
1) при соединении с базой данных (CONNECT), перед выполнени¬
ем триггера автоматически запускается транзакция по умол¬
чанию;
2) при отсоединении от базы данных (DISCONNECT), перед выпол¬
нением триггера запускается транзакция по умолчанию;
3) при старте транзакции (TRANSACTION START), триггер выпол¬
няется в контексте этой транзакции;
4) при подтверждении транзакции (TRANSACTION COMMIT), триг¬
гер выполняется в контексте этой транзакции;
5) при отмене транзакции (TRANSACTION ROLLBACK), триггер вы¬
полняется в контексте транзакции.
Существует возможность создавать триггеры, вызываемые ав¬
томатически для одной таблицы (представления), для одной фазы
и одного события, а также для одной фазы и нескольких событий.
Если для одной таблицы (представления), одного события и
одной фазы существует несколько триггеров, то можно задать по¬
рядок их выполнения, указав позицию триггера в этой цепочке.
Для создания триггера используется оператор CREATE TRIGGER,
синтаксис которого представлен ниже:
CREATE TRIGGER <имя триггера>
[ACTIVE | INACTIVE)
{ ON <событие базы данных>
| FOR {<имя таблицы> | <имя представления^
{BEFORE | AFTER)
<событие таблицы (представления)>
[OR <событие таблицы (представления)>] . . .
| {BEFORE | AFTER}
<событие таблицы (представления)>
[OR <событие таблицы (представления)>] . . .
ON {<имя таблицы> | <имя представления^
}
[POSITION <целое>]
AS <тело триггера>;
<событие таблицы (представления)> : : =
{INSERT | UPDATE | DELETE}
<событие базы данных> : : =
{ CONNECT
| DISCONNECT
| TRANSACTION START
275
I TRANSACTION COMMIT
| TRANSACTION ROLLBACK
}
Триггер может быть активным (ACTIVE) или неактивным (IN¬
ACTIVE) . Если триггер активен (значение по умолчанию), то он
автоматически вызывается при наступлении соответствующего со¬
бытия (событий) таблицы или базы данных. Если триггер неактивен,
то вызов триггера не происходит.
Структура тела триггера:
[<объявление локальных переменных;»]
BEGIN
<оператор>
[<оператор> ... ]
END
После описания локальных переменных в теле триггера следу¬
ет блок операторов, заключенных в операторные скобки BEGIN и
END.
Для триггеров существуют специфические контекстные пере¬
менные OLD и NEW. Более правильное название этих ключевых
слов — префиксы имен столбцов. В триггерах можно обращаться
к значению любого столбца таблицы (представления) до его изме¬
нения в клиентской программе (для этого перед именем столбца
помещается ключевое слово OLD и точка) и после изменения (перед
именем столбца помещается NEW и точка).
Контекстная переменная OLD (префикс имени столбца) для всех
видов триггеров является переменной только для чтения. Она не¬
доступна в триггерах, вызываемых при добавлении данных, неза¬
висимо от фазы события.
Контекстная переменная NEW в триггерах для фазы события
после (AFTER) также является переменной только для чтения. Она
недоступна в триггерах для события удаления данных.
Значение OLD. ИмяСтолбца — позволяет обратиться к состоянию
столбца, имевшему место до внесения возможных изменений.
Значение NEW. ИмяСтолбца — позволяет обратиться к состоя¬
нию столбца после внесения возможных изменений.
Например:
CREATE TRIGGER BU_TOVARY FOR TOVARY
ACTIVE
BEFORE UPDATE
AS
276
BEGIN
IF (OLD. TOVARONEW. TOVAR) THEN
UPDATE PRODAJA
SET TOVAR=NEW. TOVAR
WHERE TOVAR=OLD.TOVAR;
END
В этом примере триггер вносит соответствующие изменения
в таблицу PRODAJA, если в записи таблицы TOVARY изменилось
значение столбца TOVAR.
Нельзя создавать один триггер для нескольких событий таблицы
(представления) или нескольких событий базы данных.
Для изменения заголовка и/или тела существующего триггера
используется оператор ALTER TRIGGER.
В операторе изменения триггера можно изменить его состоя¬
ние активности (ACTIVE / INACTIVE), событие (события) таблицы
(представления) и фазу события, позицию триггера и выполняемые
триггером действия.
Для удаления существующего триггера используется опера¬
тор
DROP TRIGGER <имя триггера>
Триггеры являются полезным инструментом при выполнении
различных действий в случае изменения данных базы данных.
Основным назначением триггеров является автоматическое вы¬
полнение функций по формированию значений искусственного
первичного ключа, выдачи информационных сообщений базы дан¬
ных, связанных с изменениями данных, специфические способы
поддержания декларативной целостности данных и выполнение
определенных действий при добавлении (изменении) некоторых
данных базы данных. Триггеры также могут быть использованы
при наступлении событий, связанных с базой данных в целом, —
соединение с базой данных, отсоединение от базы данных, запуск,
подтверждение или отмена транзакций.
12.5.3. Работа с хранимыми процедурами
Хранимая процедура, так же как и триггер, является програм¬
мой, хранящейся в области метаданных базы данных и выпол¬
няющейся на стороне сервера. В отличие от триггера к хранимой
процедуре могут обращаться хранимые процедуры, триггеры и
клиентские программы. Допустима рекурсия — хранимая про-
277
цедура может обращаться сама к себе. Хранимые процедуры вы¬
полняются в контексте той же транзакции, что и вызывающие их
программы.
Существует два вида хранимых процедур — выполняемые храни¬
мые процедуры (executed stored procedures) и хранимые процедуры
выбора (selected stored procedures).
Выполняемые хранимые процедуры осуществляют обработку
данных, находящихся в базе данных или не связанных с базой
данных. Эти процедуры могут получать входные параметры и воз¬
вращать выходные параметры. Обращение к выполняемым храни¬
мым процедурам осуществляется при выполнении оператора SQL
EXECUTE PROCEDURE.
Хранимые процедуры выбора, как правило, осуществляют вы¬
борку данных из базы данных, возвращая произвольное количество
полученных строк. Процедуры выбора также могут получать вход¬
ные параметры. Значение каждой очередной прочитанной строки
возвращается вызвавшей программе в выходных параметрах. Для
временной приостановки выполнения такой процедуры и передачи
выбранных данных вызвавшей программе в хранимой процедуре
используется оператор SUSPEND. Обращение к хранимой процедуре
выбора осуществляется при помощи оператора SELECT.
Синтаксически создание выполняемой хранимой процедуры от
хранимой процедуры выбора никак не отличается. Для создания
хранимой процедуры используется оператор CREATE PROCEDURE,
синтаксис которого представлен ниже:
CREATE PROCEDURE <имя_хранимой_процедуры>
[ (<список входных параметров:») ]
[RETURNS (<список выходных параметров:») ]
AS
[<список объявления переменных:»]
BEGIN <блок операторов:» END
Хранимой процедуре от вызвавшей программы могут переда¬
ваться входные параметры. Параметры передаются по значению,
т. е. любые изменения значений входных параметров никак не
влияют на значения этих параметров в вызвавшей программе.
Входным параметрам может присваиваться значение по умолчанию.
Параметры, для которых заданы значения по умолчанию, должны
располагаться в самом конце списка. Если входной параметр осно¬
ван на домене, которому также задано значение по умолчанию в
предложении DEFAULT, то новое значение по умолчанию перекры¬
вает указанное при описании домена.
278
Хранимая процедура может возвращать вызвавшей программе
произвольное количество выходных параметров. Если при описании
параметра, локальной переменной процедуры указано имя домена,
•го для него копируются все характеристики этого домена. В теле
хранимой процедуры может быть описано произвольное количество
локальных переменных.
Список входных параметров хранимой процедуры записыва¬
ется после имени хранимой процедуры и заключается в круглые
скобки:
Ссписок входных параметров> : := (Сописание параметра>
[, сописание параметра:»] . . .)
Выходные параметры описываются в предложении RETURNS:
RETURNS (Ссписок выходных параметров:»)
Описание выходного параметра соответствует описанию вход¬
ного параметра.
Локальные переменные триггеров и процедур, входные и вы¬
ходные параметры, используемые только в хранимых процедурах,
являются внутренними переменными. Имена внутренних пере¬
менных могут совпадать с именами столбцов используемых таблиц
базы данных. Это не вызовет проблемы двусмысленности имен.
При использовании внутренних переменных в операторах SELECT,
INSERT, UPDATE или DELETE именам внутренних переменных
всегда должно предшествовать двоеточие, чтобы не спутать их с
именами столбцов таблицы. Во всех остальных случаях в любых
других операторах имена внутренних переменных записываются
обычным образом без двоеточия.
Синтаксис операции присваивания значения внутренней пере¬
менной имеет следующий вид:
<имя переменной:» = <выражение>;
Выражением может быть любое правильное выражение SQL.
Оператор EXIT позволяет из любой точки триггера или храни¬
мой процедуры перейти на конечный оператор END, т. е. завершить
выполнение программы:
EXIT [<метка>]
Оператор SUSPEND временно приостанавливает выполнение
хранимой процедуры выбора (процедуры, которая чаще всего со¬
держит оператор SELECT, выбирающий множество строк таблицы,
обращение к такой процедуре также выполняется при помощи
279
оператора SELECT) и передает вызвавшей программе значения
выходных параметров.
Триггеры и хранимые процедуры могут вызывать хранимые про¬
цедуры при использовании оператора EXECUTE PROCEDURE:
EXECUTE PROCEDURE <имя процедуры>
[ (<параметр> [, <параметр>] . . .) ]
[RETURNING_VALUES (<параметр>[,<параметр>]...)
| <параметр>[,<параметр >...]]
Оператор FOR SELECT DO имеет следующий формат:
FOR
<оператор SELECT>
DO
<оператор>
Алгоритм работы оператора FOR SELECT DO заключается в
следующем. Выполняется оператор SELECT, и для каждой строки
полученного результирующего набора данных выполняется опе¬
ратор, следующий за словом DO. Этим оператором часто бывает
SUSPEND, который приводит к возврату выходных параметров в
вызывающее приложение.
Для изменения существующей хранимой процедуры использу¬
ется оператор ALTER PROCEDURE. Для удаления существующей
хранимой процедуры используется оператор DROP PROCEDURE.
Приведем примеры создания хранимых процедур.
Следующая процедура выдает все факты продажи конкретно¬
го товара, определяемого содержимым входного параметра То-
вар_вход.
CREATE PROCEDURE PRODAJA_TOVARA
(Товар_вход VARCHAR (20) )
RETURNS (Дата_вых DATE, Клиент_вых VARCHAR (20) ,
Количество_вых INTEGER) AS
BEGIN
FOR SELECT Дата, Клиент, Количество
FROM Продажи
WHERE Товар =:Товар_вход
INTO :Дата_вых, :Клиент_вых, :Количество_вых
DO
SUSPEND;
END
Сначала выполняется оператор SELECT, который возвращает
дату продажи, наименование покупателя и количество расхода
280
товара для каждой записи, у которой поле Товар содержит зна¬
чение, идентичное значению во входном параметре Товар_вход.
Указанные значения записываются в выходные параметры (соот¬
ветственно Дата_вых, Клиент_вых, Количество_вых). После
выдачи каждой записи результирующего набора данных выполня¬
ется оператор SUSPEND. Он возвращает значения выходных пара¬
метров вызвавшему приложению и приостанавливает выполнение
процедуры до запроса следующей порции выходных параметров от
вызывающего приложения. Такая процедура является процедурой
выбора, поскольку она может возвращать множественные значения
входных параметров в вызывающее приложение.
Другая процедура Клиенты__список возвращает имена всех
клиентов, которые сделали покупки товара Товар__вход в коли¬
честве, превосходящем средний размер покупки по этому товару.
В случае если наименование клиента — пустое значение, вместо
имени клиента выводится «Данные отсутствуют».
CREATE PROCEDURE Клиенты_список (Товар_вход VAR¬
CHAR (20) )
RETURNS (Клиент_вых VARCHAR (20) ) AS
DECLARE VARIABLE Сред_количество INTEGER;
BEGIN
SELECT AVG (Количество)
FROM Продажи
WHERE Товар =:Товар_вход
INTO : Сред__количество;
FOR
SELECT Клиенты
FROM Продажи
WHERE Количество >: Сред_количество
INTO :Клиент__вых
DO
BEGIN
IF (: Клиент_вых IS NULL) THEN
Клиент_вых=«Данные отсутствуют»;
SUSPEND;
END
END
Преимуществами хранимых процедур является то, что они, во-
первых, выполняются на стороне сервера, что во многих случаях
может резко сократить сетевой трафик; во-вторых, один раз напи¬
санная и отлаженная хранимая процедура может использоваться
281
многими программами — хранимыми процедурами, триггерами,
клиентскими программами.
Хранимая процедура выбора используется, как правило, для
выборки достаточно большого количества данных из базы данных.
Алгоритм выборки данных в таких случаях достаточно сложный.
Подобного вида процедуры обычно используются в том случае,
когда декларативных средств оператора SELECT недостаточно для
выполнения всех действий по выборке релевантных данных из
таблиц или представлений. Такая процедура также может получать
входные параметры и возвращать выходные параметры.
Хранимые процедуры улучшают целостность приложений и БД,
гарантируют актуальность коллективных операций и вычислений.
Улучшается сопровождение таких процедур, а также безопасность
(нет прямого доступа к данным).
Однако следует помнить, что перегрузка хранимых процедур
прикладной логикой может перегрузить сервер, что приведет к
потере производительности. Эта проблема особенно актуальна
при разработке крупных информационных систем, когда к серверу
может одновременно обращаться большое количество клиентов.
Поэтому в большинстве случаев следует принимать компромиссные
решения: часть логики приложения размещать на стороне сервера,
часть — на стороне клиента (системы с разделенной логикой).
РАБОТА С ИНДЕКСАМИ
Индекс — это объект базы данных, содержащий значения ука¬
занных столбцов конкретной таблицы и ссылки на строки этой
таблицы, содержащие данные значения.
Индекс создается пользователем или системой для конкретной
таблицы, что позволяет во многих случаях ускорить процесс поиска
данных в этой таблице, а иногда и ускорить упорядочение данных,
полученных по запросу пользователя на основании предложения
ORDER BY в операторе SELECT. Каждая строка индекса содержит
значение столбцов, входящих в состав индекса и указатель на стро¬
ку в таблице, которая имеет те же самые значения столбцов.
При наличии индексов во многих случаях поиск данных может
выполняться гораздо быстрее, чем при отсутствии индекса, потому
что значения в индексе упорядочены, а сам индекс относительно
мал. Не следует создавать индексов для столбцов, которые имеют
небольшое количество вариантов значений, например для столбцов,
имеющих два значения, в частности для столбцов, моделирующих
282
логический тип данных, где столбец может иметь только значения
TRUE и FALSE, или в случае задания пола человека — мужской
или женский. Такие индексы только занимают место во внешней
памяти и не дают никакого выигрыша в производительности при
выполнении операций выборки и упорядочения данных.
Для ограничений первичного ключа, уникального ключа и внеш¬
него ключа система автоматически строит индексы.
Важное правило: нельзя создавать индекс по структуре и по упо¬
рядоченности соответствующий индексу, который автоматически
создается системой для первичного, уникального или внешнего
ключа, при попытке выборки данных это может привести к ава¬
рийному завершению работы сервера базы данных.
Индекс может быть создан как уникальный (ключевое слово
UNIQUE). В этом случае в таблице не допускается присутствие двух
различных строк, имеющих одинаковое значение столбцов, входя¬
щих в состав уникального индекса.
Индекс может быть упорядочен по возрастанию значений столб¬
цов, входящих в его состав (ASCENDING — значение по умолчанию)
или по убыванию этих значений (DESCENDING). В любой момент
времени работы с базой данных индекс может быть сделан актив¬
ным (ACTIVE), т.е. все изменения столбцов таблицы, входящих
в состав этого индекса, тут же отражаются в самом индексе, или
неактивным (INACTIVE), когда никакие изменения в строках со¬
ответствующей таблицы базы данных не затрагивают содержание
индекса.
Для создания индекса для существующей таблицы базы данных
используется оператор:
CREATE [UNIQUE] [ASC[ENDING] | DESC[ENDING]]
INDEX <имя индекса> ON <таблица>
(<столбец> [, <столбец>] .-•)
Имя индекса должно быть уникальным среди имен всех ин¬
дексов базы данных, а также среди имен ограничений на уровне
столбцов таблицы и ограничений на уровне таблиц. Когда при за¬
дании ограничений первичного, уникального или внешнего ключа
вы указываете и имя ограничения в предложении CONSTRAINT,
система строит индекс с тем же самым именем.
Ключевое слово UNIQUE задает создание уникального индекса,
оно указывает, что в индексе не может быть двух строк с одина¬
ковыми значениями всех столбцов индекса. Столбцы, входящие в
состав уникального индекса, не могут также иметь пустого значения
NULL.
283
Ключевое слово ASCENDING (сокращенный вариант ASC) означа¬
ет, что записи индекса упорядочиваются по возрастанию значений
столбцов, входящих в состав индекса. Этот вариант принимается
по умолчанию.
Ключевое слово DESCENDING (сокращение DESC) указывает,
что записи индекса упорядочиваются по уменьшению значений
столбцов индекса.
В состав индекса не могут входить столбцы, имеющие тип
данных BLOB, а также столбцы любого типа данных, являющиеся
массивами.
Например. Если для таблицы ПРОДАЖИ требуются и возраста¬
ющий и убывающий индексы по столбцу, хранящему наименование
товаров Товары, то нужно создать два индекса, выполнив следу¬
ющие операторы:
CREATE ASCENDING INDEX I_ASC ON ПРОДАЖИ (Товары)
CREATE DESCENDING INDEX I_DESC ON ПРОДАЖИ (Товары)
При первоначальном создании индекс становится по умолчанию
активным — все вновь добавленные строки в таблицу или выпол¬
ненные изменения в индексированных столбцах базовой таблицы
тут же отражаются на состоянии индекса.
В некоторых случаях бывает полезным на некоторое время «от¬
ключить» индекс, сделать его неактивным. Это может сэкономить
время при выполнении так называемых пакетных операций с та¬
блицей, когда в таблицу, для которой создан индекс, из какого-либо
файла записывается достаточно большое количество строк или в
таблице изменяется или из таблицы удаляется большое количество
строк. Перед началом такой операции индекс переводится в не¬
активное (INACTIVE) состояние, а после завершения операции —
снова в активное (ACTIVE). При этом при активизации индекса
осуществляется полное пересоздание индекса. Все вновь введенные,
измененные или удаленные строки будут учтены в новом состоянии
индекса.
Изменение состояния индекса осуществляется при помощи
оператора:
ALTER INDEX <имя индекса> (ACTIVE | INACTIVE)
Ключевое слово ACTIVE задает перевод неактивного индекса в
активное состояние. Ключевое слово INACTIVE указывает, что ин¬
декс переводится в неактивное состояние. После перевода индекса
из неактивного в активное состояние система заново полностью
создает весь индекс.
284
Этот оператор не может быть использован для изменения струк¬
туры индекса или его упорядоченности. Если есть необходимость
внести изменения в структуру индекса или изменить порядок, то
следует удалить существующий индекс (см. следующий раздел),
а затем создать индекс с тем же именем и с требуемыми характе¬
ристиками.
Для удаления индекса, созданного пользователем, используется
оператор
DROP INDEX <имя индекса>
Нельзя таким образом удалить индекс, созданный автоматически
системой для первичного, уникального или внешнего ключа. Можно
только удалить индекс, который был создан пользователем.
12.7.
ГЕНЕРАТОРЫ
Генератор (generator) — это самый простой объект базы дан¬
ных. Генератором называется хранимый на сервере БД механизм,
возвращающий уникальные значения, никогда не совпадающие со
значениями, выданными тем же самым генератором в прошлом.
Он позволяет хранить целые числа в очень широком диапазоне
значений. Под него отводится 8 байтов памяти. Это подходящее
средство для формирования значений искусственных первичных
ключей. Для каждого искусственного первичного ключа любой
таблицы базы данных пользователем создается свой собственный
генератор, с которым выполняются все действия по формированию
значений этого первичного ключа.
В принципе, генераторы могут использоваться и для получения
последовательностей неповторяющихся целых чисел для любых
других целей.
Для создания генератора используется следующий оператор:
CREATE GENERATOR <имя генератора>
Имя генератора должно быть уникальным среди имен всех ге¬
нераторов базы данных.
В момент создания генератора ему присваивается значение 0.
Последующие обращения к функции GEN_ID, в параметрах кото¬
рой используется имя этого генератора, изменяют это значение
на указанную величину. Обычно приращением является единица,
но можно использовать и любые другие целые числа, отличные
от нуля (нуль по правилам синтаксиса тоже можно использовать,
285
однако это не позволит получить уникальную последовательность
чисел).
Установка значения генератора осуществляется оператором:
SET GENERATOR <имя генератора> ТО <стартовое значе-
ние>
Для получения уникального значения используется функция
GEN_ID (ИмяГенератора, шаг)
Не рекомендуется переустанавливать стартовое значение гене¬
ратора или менять шаг при разных обращениях к функции GEN_ID.
В этих случаях генератор может выдать не уникальное значение и
как следствие будет возбуждено исключение при попытке запоми¬
нания новой записи в таблице базы данных.
Генератор можно удалить, используя оператор SQL
DROP GENERATOR <имя генератора>
Д\алять генератор следует только после того, как будут удалены
из базы данных все триггеры и хранимые процедуры, ссылающиеся
на этот генератор.
Следующий пример иллюстрирует использование генератора
при добавлении новой строки. Пусть в базе данных определен ге¬
нератор для столбца Номер в таблице ПРОДАЖИ:
CREATE GENERATOR Ген_номер;
SET GENERATOR Ген_номер ТО 0;
Обращение к генератору непосредственно из оператора INSERT
можно записать следующим образом:
INSERT INTO PRODAJA
(Номер, Дата, Количество, Товар, Клиент)
VALUES (
GEN_ID (Ген_номер, 1),
'01.05.2013',
100, «Сахар»,
«ООО Ромашка»)
С помощью триггера может быть реализовано присваивание
ключевому столбцу уникального значения, вызываемого перед за¬
писью новой строки в базе данных:
CREATE TRIGGER BI_PRODAJA FOR ПРОДАЖА
ACTIVE
BEFORE INSERT
286
AS
BEGIN
NEW. Номер = GEN_ID (Ген_номер, 1)
END
Для генерирования уникальных значений можно использовать
хранимую процедуру:
CREATE PROCEDURE GEN_PROC
RETURNS (N INTEGER)
AS
BEGIN
N= GEN_ID (Ген_номер, 1)
SUSPEND
END
Важной особенностью генераторов является то, что работа
с ними выполняется вне контекста какой-либо транзакции. Это
означает, что при одновременном обращении к одному и тому же
генератору разных конкурирующих транзакций никогда не воз¬
никнет конфликта блокировки, и каждый параллельный процесс
получит уникальное новое числовое значение. Значение зависит
от времени обращения к генератору.
12.8.
ПРЕИМУЩЕСТВА ЯЗЫКА SQL
Язык SQL в настоящее время получил очень широкое распростра¬
нение и фактически превратился в стандартный язык реляционных
баз данных. Все крупнейшие разработчики систем управления база¬
ми данных в настоящее время создают свои продукты с использова¬
нием языка SQL. В него делаются огромные инвестиции со стороны
и разработчиков, и пользователей. Он стал частью архитектуры
приложений, является стратегическим выбором многих крупных и
влиятельных организаций. Таким образом, SQL можно представить
как мощнейший инструмент, который обеспечивает пользователям,
программам и вычислительным системам доступ к информации.
Язык SQL предоставляет пользователю возможности:
я создавать различные объекты базы данных, в том числе таблицы
с полным описанием их структуры;
■ выполнять основные операции манипулирования данными: до¬
бавление, модификацию и удаление данных из таблиц;
и выполнять различные запросы, в том числе и очень сложные и
громоздкие, осуществляющие преобразование данных.
287
Следует отметить, что язык SQL решает все указанные выше
задачи при минимальных усилиях со стороны пользователя, а струк¬
тура и синтаксис его команд достаточно просты и доступны для
изучения.
Основные достоинства языка SQL:
■ стандартность — использование языка SQL в программах
стандартизировано международными организациями;
0 независимость от конкретных СУБД — все распространен¬
ные СУБД используют SQL, так как реляционную базу данных
можно перенести с одной СУБД на другую с минимальными
доработками;
■ возможность переноса с одной вычислительной системы на
другую;
■ реляционная основа языка — SQL является языком реляционных
баз данных, поэтому он стал популярным тогда, когда получила
широкое распространение реляционная модель представления
данных. Табличная структура реляционной БД хорошо понятна,
а потому язык SQL прост для изучения;
■ возможность создания интерактивных запросов — в интерак¬
тивном режиме можно получить результат запроса за очень
короткое время без написания сложной программы;
■ язык SQL легко использовать в приложениях, которым необхо¬
димо обращаться к базам данных. Одни и те же операторы SQL
употребляются как для интерактивного, так и программного до¬
ступа, поэтому части программ, содержащие обращение к БД,
можно вначале проверить в интерактивном режиме, а затем
встраивать в программу;
■ обеспечение различного представления данных — с помощью
SQL можно представить такую структуру данных, что тот или
иной пользователь будет видеть различные их представления.
Кроме того, данные из разных частей БД могут быть ском¬
бинированы и представлены в виде одной простой таблицы,
а значит, представления пригодны для усиления защиты БД
и ее настройки под конкретные требования отдельных поль¬
зователей;
■ возможность динамического изменения и расширения структуры
базы данных — язык SQL позволяет манипулировать структурой
базы данных, тем самым обеспечивая гибкость. Создавать и
удалять объекты базы данных, изменять их структуру можно во
время выполнения приложения. Это очень важно с точки зрения
приспособленности базы данных к изменяющимся требованиям
предметной области;
288
■ возможность работы в архитектуре «клиент-сервер» — SQL
является одним из лучших средств для реализации взаимо¬
действия клиента и сервера, более того, служит связующим
звеном между взаимодействующей с пользователем клиент¬
ской системой и серверной системой, управляющей БД, по¬
зволяя каждой из них сосредоточиться на выполнении своих
функций.
Создание языка SQL способствовало не только выработке
необходимых теоретических основ, но и подготовке успешно
реализованных технических решений. Начали появляться спе¬
циализированные реализации языка, предназначенные для новых
рынков — систем управления обработкой транзакций (OnLine
Transaction Processing, OLTP) и систем оперативной аналитической
обработки или системы поддержки принятия решений (OnLine
Analytical Processing, OLAP).
КОНТРОЛЬНЫЕ ВОПРОСЫ
1. Какие требования предъявляются к языку работы с базами
данных?
2. Что называется реализацией языка SQL?
3. Почему язык SQL стал популярен среди разработчиков?
4. Какие категории имеются в SQL?
5. Какие команды относятся к каждой категории языка?
6. Какие типы данных используются в SQL?
7. Каким образом используются домены при создании таблиц?
8. Какие ограничения могут быть описаны в домене?
9. Как задается первичный ключ при создании таблицы в языке
SQL?
10. Что называется ограничением ссылочной целостности и как
оно создается в языке SQL?
11. Как создается связь при определении таблиц в языке SQL?
12. Опишите формат оператора SELECT.
13. Какие функции можно использовать в операторе SELECT?
14. Как сгруппировать результат запроса?
15. Как наложить ограничение на результат запроса?
16. Как отсортировать результат запроса?
17. Что называется внутренним соединением таблиц?
18. В каких случаях в запросах используется предложение
HAVING?
19. Что называется подзапросом?
20. Какой подзапрос называется скалярным, а какой — таблич¬
ным?
289
21. Для чего в подзапросах используются предложения SINGULAR,
EXISTS, ALL, SOME?
22. Что называется внешним соединением таблиц и чем внешнее
соединение отличается от внутреннего?
23. Что называется генератором?
24. Для чего используются триггеры?
25. При каких событиях происходит вызов триггера?
26. Каковы преимущества использования хранимых процедур и
триггеров?
27. В чем основное отличие триггера от хранимой процедуры?
28. В каких случаях следует создавать индексы?
29. Как осуществляется добавление новых строк в таблицу с по¬
мощью SQL?
30. Как осуществляется удаление строк в таблице с помощью
SQL?
31. Как осуществляется изменение данных в таблице с помощью
SQL?
32. Каковы преимущества использования языка SQL?
Глава 13
ОБЕСПЕЧЕНИЕ ЦЕЛОСТНОСТИ
ДАННЫХ
13.1.
МЕХАНИЗМ ТРАНЗАКЦИЙ
Применение СУБД для работы с серверными базами данных
выявило особую важность проблемы целостности БД. Под целост¬
ностью БД понимают соответствие имеющейся в базе данных ин¬
формации ее внутренней логике, структуре и всем явно заданным
правилам, т.е. верная структура и непротиворечивость ее содер¬
жимого. Нарушение целостности может быть вызвано, например,
программными ошибками или техническими сбоями, так как в этом
случае система не в состоянии обеспечить нормальную обработку
или выдачу правильных данных. Для обеспечения целостности в
случае ограничений на базу данных, а не какие-либо отдельные
операции, служит механизм транзакций.
Транзакция — это неделимая, с точки зрения воздействия на
данные, последовательность операций манипулирования данными.
Для пользователя транзакция выполняется по принципу «все или
ничего». Либо транзакция выполняется целиком и переводит базу
данных из одного целостного (непротиворечивого) состояния в дру¬
гое целостное состояние и подтверждает изменения (commit) либо,
если по каким-либо причинам одно из действий транзакции невы¬
полнимо, или произошло какое-либо нарушение работы системы,
база данных возвращается в исходное состояние, которое было до
начала транзакции, т. е. происходит откат (rollback) транзакции.
Работает этот механизм следующим образом. Когда стартует
каждая из транзакций, они по порядку получают свой внутренний
уникальный номер. Также транзакция обладает копией внутренней
структуры, называемой Transaction Inventory Page (TIP), по кото¬
рой она получает информацию о состоянии других транзакций
на момент ее старта. Когда транзакция воздействует на строку
291
в таблице (изменяя, добавляя или удаляя и т.д.), создается новая
версия строки и помечается уникальным номером породившей е< ■
транзакции. Теперь, когда другая транзакция выполняет запрос на
выборку записей, который возвращает эту строку данных, сервер
выдаст наиболее новую версию.
Понятие транзакции имеет непосредственную связь с поняти¬
ем целостности БД. Часто в транзакцию объединяются операции
над несколькими таблицами, когда производятся действия по
внесению в разные таблицы взаимосвязанных изменений. Пред¬
положим, осуществляется перенос записей из одной таблицы в
другую.
Если запись сначала удаляется из первой таблицы, затем зано¬
сится во вторую таблицу, то при возникновении сбоя, например,
из-за перерыва в энергопитании компьютера, возможна ситуация,
когда запись уже удалена, но во вторую таблицу не попала. Если
запись сначала заносится во вторую таблицу, а затем удаляется из
первой таблицы, то при сбое возможна ситуация, когда запись будет
находиться в двух таблицах.
В обоих случаях имеет место нарушение целостности и не¬
противоречивости БД. Для предотвращения подобной ситуации
операции удаления записи из одной таблицы и занесения ее в дру¬
гую таблицу объединяются в одну транзакцию. Выполнение этой
транзакции гарантирует, что при любом ее результате целостность
БД нарушена не будет.
Существуют средства использования вложенных транзакций,
когда создаются определенные контрольные точки, и откат транз¬
акции можно выполнить не на самое начало транзакции, а на
определенную контрольную точку.
Транзакции могут быть длинными и короткими. При работе
с базой данных клиентские программы могут использовать как
длинную, так и короткую транзакцию. Длинная транзакция явля¬
ется активной в течение довольно большого промежутка времени.
В ее контексте может выполняться большое количество операций
с базой данных. Короткая транзакция от момента ее старта и до
момента ее подтверждения или отката является активной доли
секунды. Как правило, в контексте такой транзакции выполняется
весьма ограниченное количество изменений в базе данных.
Длинные транзакции обычно используются в случае чтения дан¬
ных БД. Короткие транзакции являются наиболее подходящими в
случае внесения изменений в таблицы базы данных.
Требования к транзакционной системе управления базой данных
описываются следующим образом:
292
■ атомарность (Atomicity) гарантирует, что никакая транзакция не
будет зафиксирована в системе частично. Будут либо выполнены
все ее операции, либо не выполнено ни одной;
■ согласованность (Consistency) — транзакция, подтвердившая
свое успешное завершение, сохраняет согласованность базы
данных;
■ изолированность (Isolation) — во время выполнения транзакции
параллельные транзакции не должны оказывать влияние на ее
результат. Это свойство будет рассмотрено ниже;
■ надежность (Durability) — изменения, сделанные успешно за¬
вершенной транзакцией, должны остаться сохраненными после
возвращения системы в работу. Другими словами, если поль¬
зователь получил подтверждение от системы, что транзакция
выполнена, он может быть уверен, что сделанные им изменения
не будут отменены из-за какого-либо сбоя.
Совокупность этих требований обозначается акронимом ACID.
ТРАНЗАКЦИИ И БЛОКИРОВКИ.
УПРАВЛЕНИЕ ПАРАЛЛЕЛЬНЫМИ
ПРОЦЕССАМИ
Когда множество пользователей работает с базой данных, воз¬
никает необходимость введения ограничений на непосредственный
доступ к данным для того, чтобы предотвратить одновременное
обновление одной и той же записи. В этом случае прибегают к ис¬
пользованию блокировок.
Блокировка — это временное ограничение на выполнение не¬
которых операций обработки данных. Блокировка может быть нало¬
жена на отдельную запись таблицы, на таблицу и даже на всю базу
данных. Управляет блокировками на сервере объект, называемый
менеджером блокировок, который контролирует их применение и
разрешение конфликтов.
Транзакции накладывают блокировки на данные, чтобы обе¬
спечить выполнение требований ACID. Без использования бло¬
кировок несколько транзакций могли бы изменять одни и те же
данные.
Различают два вида блокировки:
1) блокировка записи — транзакция блокирует строки в таблицах
таким образом, что запрос другой транзакции к этим строкам
будет отменен;
293
2) блокировка чтения — транзакция блокирует строки так, что за¬
прос со стороны другой транзакции на блокировку записи этих
строк будет отвергнут, а на блокировку чтения — принят.
Решение проблемы параллельной обработки БД заключается в
том, что строки таблиц блокируются, а последующие транзакции,
модифицирующие эти строки, отвергаются и переводятся в режим
ожидания.
Если в системе управления базами данных не реализованы
механизмы блокирования, то при одновременном чтении и изме¬
нении одних и тех же данных несколькими пользователями могут
возникнуть проблемы одновременного доступа:
■ проблема последнего изменения возникает, когда несколько
пользователей изменяют одну и ту же строку, основываясь на
ее начальном значении; тогда часть данных будет потеряна, так
как каждая последующая транзакция перезапишет изменения,
сделанные предыдущей. Выход из этой ситуации заключается в
последовательном внесении изменений;
■ проблема «грязного» чтения возможна в том случае, если поль¬
зователь выполняет сложные операции обработки данных,
требующие множественного изменения данных перед тем, как
они обретут логически верное состояние. Если во время измене¬
ния данных другой пользователь будет считывать их, то может
оказаться, что он получит логически неверную информацию.
Для исключения подобных проблем необходимо производить
считывание данных после окончания всех изменений;
■ проблема неповторяемого чтения является следствием неодно¬
кратного считывания транзакцией одних и тех же данных. Во
время выполнения первой транзакции другая может внести
в данные изменения, поэтому при повторном чтении первая
транзакция получит уже иной набор данных, что приводит к на¬
рушению их целостности или логической несогласованности;
■ проблема чтения фантомов появляется после того, как одна
транзакция выбирает данные из таблицы, а другая вставляет или
удаляет строки до завершения первой. Выбранные из таблицы
значения будут некорректны.
Для того чтобы избежать подобных проблем, требуется вырабо¬
тать некоторую процедуру согласованного выполнения параллель¬
ных транзакций. Эта процедура должна удовлетворять следующим
правилам:
■ в ходе выполнения транзакции пользователь видит только со¬
гласованные данные. Пользователь не должен видеть несогла¬
сованных промежуточных данных;
294
■ когда в БД две транзакции выполняются параллельно, то СУБД
гарантированно поддерживает принцип независимого выпол¬
нения транзакций, который гласит, что результаты выполнения
транзакций будут такими же, как если бы вначале выполнялась
транзакция 1, а потом транзакция 2, или, наоборот, сначала
транзакция 2, а потом транзакция 1.
Корректное поддержание транзакций является основой обе¬
спечения целостности баз данных, а также составляет базис изо¬
лированности пользователей в многопользовательских системах.
При соблюдении обязательного требования поддержки целостности
базы данных возможно наличие нескольких уровней изолирован¬
ности транзакций.
Уровень изолированности транзакций — значение, определя¬
ющее уровень, при котором в транзакции допускаются несогласо¬
ванные данные, т. е. степень изолированности одной транзакции
от другой. Более высокий уровень изолированности повышает
точность данных, но при этом может снижаться количество парал¬
лельно выполняемых транзакций. С другой стороны, более низкий
уровень изолированности позволяет выполнять больше параллель¬
ных транзакций, но снижает точность данных.
При соблюдении обязательного требования поддержания це¬
лостности базы данных возможны следующие уровни изолирован¬
ности транзакций.
Самый высокий уровень изолированности соответствует про¬
токолу сериализации транзакций. Это уровень, называемый
SERIALIZABLE (упорядочиваемость), обеспечивает полную изоля¬
цию транзакций и полную корректную обработку параллельных
транзакций.
Следующий уровень изолированности называется уровнем
подтвержденного чтения — REPEATABLE READ. На этом уровне
транзакция не имеет доступа к промежуточным или окончательным
результатам других транзакций, поэтому такие проблемы, как про¬
павшие обновления, промежуточные или несогласованные данные,
возникнуть не могут. Однако во время выполнения своей транзак¬
ции вы можете увидеть строку, добавленную в базу данных другой
транзакцией. Поэтому один и тот же запрос, выполненный в течение
одной транзакции, может дать разные результаты, т. е. проблема
строк-призраков остается. Однако если такая проблема критична,
лучше ее разрешать алгоритмически, изменяя алгоритм обработки,
исключая повторное выполнение запроса в одной транзакции.
Другой уровень изолированности связан с завершенным чте¬
нием, он называется READ COMMITED (чтение фиксированных
295
данных). На этом уровне изолированности транзакция не имеет
доступа к промежуточным результатам других транзакций, поэтому
проблемы пропавших обновлений и промежуточных данных воз¬
никнуть не могут. Однако окончательные данные, полученные в
ходе выполнения других транзакций, могут быть доступны нашей
транзакции. В этом случае отсутствует черновое, «грязное» чтение
(т. е. чтение одним пользователем данных, которые не были зафик¬
сированы в БД командой COMMIT).
Тем не менее в процессе работы одной транзакции другая
может быть успешно завершена и сделанные ею изменения за¬
фиксированы. В итоге первая транзакция будет работать с другим
набором данных. Это проблема неповторяемого чтения. При этом
уровне изолированности транзакция не может обновлять строку,
уже обновленную другой транзакцией. При попытке выполнить
подобное обновление транзакция будет отменена автоматиче¬
ски, во избежание возникновения проблемы пропавшего обнов¬
ления.
И наконец, самый низкий уровень изолированности называется
уровнем неподтвержденного, или «грязного», чтения. Он обозна¬
чается как READ UNCOMMITED. При этом уровне изолированно¬
сти текущая транзакция видит промежуточные и несогласованные
данные, и также ей доступны строки-призраки. Если несколько
транзакций одновременно пытались изменять одну и ту же строку,
то в окончательном варианте строка будет иметь значение, опреде¬
ленное последней успешно выполненной транзакцией. Однако даже
при этом уровне изолированности СУБД предотвращает пропавшие
обновления.
Чтобы обеспечить изолированность транзакций, в СУБД должны
использоваться какие-либо методы регулирования их совместного
выполнения.
Пусть в системе одновременно выполняется некоторое множе¬
ство транзакций. Способ выполнения набора транзакций, в кото¬
ром операции разных транзакций чередуются или выполняются
параллельно, называется сериальным, если результат совместного
выполнения транзакций эквивалентен результату некоторого по¬
следовательного выполнения этих же транзакций.
Сериализация транзакций — это механизм их выполнения по
некоторому сериальному плану. Обеспечение такого механизма
является основной функцией компонента СУБД, ответственного
за управление транзакциями. Система, в которой поддерживается
сериализация транзакций, обеспечивает реальную изолированность
пользователей.
296
13.3.
ЖУРНАЛИЗАЦИЯ ИЗМЕНЕНИЙ
И ВОССТАНОВЛЕНИЕ ДАННЫХ
Журнализация изменений является одной из функций СУБД,
которая сохраняет информацию, необходимую для восстановления
базы данных в предыдущее согласованное состояние в случае логи¬
ческих или физических отказов. Журнализация изменений, т. е. со¬
хранение во внешней памяти информации обо всех модификациях
БД, тесно связана с управлениями транзакциями.
В простейшем случае журнализация изменений заключается
в последовательной записи во внешнюю память всех изменений,
выполняемых в базе данных. Журнал изменений содержит детали
всех операций модификации данных в базе данных, в частности,
старое и новое значение модифицированного объекта, системный
номер транзакции, модифицировавшей объект. Формируемая
таким образом информация и есть журнал изменений базы дан¬
ных. Журнал содержит отметки начала и завершения транзакции
и отметки принятия контрольной точки. Система периодически
устанавливает контрольные точки. Во время выполнения этого про¬
цесса все незаписанные данные переносятся на внешнюю память,
а в журнал пишется отметка принятия контрольной точки. После
этого содержимое журнала, записанное до контрольной точки,
может быть удалено.
В случае физического отказа, если ни журнал, ни сама база дан¬
ных не повреждены, выполняется процесс прогонки (rollforward).
Журнал сканируется в прямом направлении, начиная от предыду¬
щей контрольной точки. Все записи извлекаются из журнала вплоть
до конца журнала. Извлеченная из журнала информация вносится в
блоки данных внешней памяти, у которых отметка номера измене¬
ний меньше, чем записанная в журнале. Если в процессе прогонки
снова возникает сбой, то сканирование журнала вновь начнется
сначала, но фактически восстановление продолжится с той точки,
откуда оно прервалось. Рассмотрим случаи необходимости восста¬
новления базы данных:
■ индивидуальный откат транзакции может быть инициирован
либо самой транзакцией (командой ROLLBACK), либо системой
СУБД, может инициировать откат транзакции в случае возник¬
новения какой-либо ошибки в работе транзакции (например,
деление на нуль);
■ «мягкий» сбой системы (аварийный отказ программного обе¬
спечения) характеризуется утратой оперативной памяти систе-
297
мы. При этом поражаются все выполняющиеся в момент сбоя
транзакции, теряется содержимое всех буферов базы данных.
Данные, хранящиеся на диске, остаются неповрежденными.
«Мягкий» сбой может произойти, например, в результате неу¬
странимого сбоя процессора;
■ «жесткий» сбой систем (аварийный отказ аппаратуры) характе¬
ризуется повреждением внешних носителей памяти. Жесткий
сбой может произойти, например, в результате поломки дис¬
ковых накопителей или в результате аварийного отключения
электрического питания.
Во всех трех случаях основой восстановления является избыточ¬
ность данных, обеспечиваемая журналом транзакций.
СПОСОБЫ КОНТРОЛЯ ДОСТУПА
К ДАННЫМ И УПРАВЛЕНИЯ
ПРИВИЛЕГИЯМИ
Базы данных, как и данные, хранимые в файлах базы данных,
должны быть защищены. Система управления пользователями —
обязательное условие безопасности данных, хранящихся в любой
базе данных. В языке SQL не существует единственной стандартной
команды, предназначенной для создания пользователей БД, — каж¬
дая реализация имеет свои команды, иногда схожие. Но независимо
от конкретной реализации все основные принципы одинаковы.
После проектирования логической структуры базы данных, свя¬
зей между таблицами, ограничений целостности и других объектов
необходимо определить круг пользователей, которые будут иметь
доступ к базе данных.
Как правило, в СУБД организована двухуровневая настройка
ограничения доступа к данным. На первом уровне необходимо
создать так называемую учетную запись для подключения к само¬
му серверу, что еще не дает возможности доступа к базам данных.
На втором уровне для каждой базы данных сервера на основании
учетной записи необходимо создать запись пользователя для под¬
ключения к базе данных. Учетную запись пользователя можно до¬
бавить, изменить или удалить.
Таким образом, сервер обеспечивает двухуровневую защиту
данных:
1) аутентификация на уровне сервера;
2) идентификация на уровне базы данных.
298
После завершения аутентификации и получения идентифика¬
тора учетной записи пользователь считается зарегистрированным
и ему предоставляется доступ к серверу. Учетная запись пользова¬
теля сама по себе не дает ему никаких прав на работу с объектами
базы данных. Права доступа устанавливаются командой GRANT.
Пользователь, выдающий права командой GRANT, может присвоить
другому пользователю только те права, которыми он владеет сам,
или более слабый набор прав. Для работы с таблицей или с пред¬
ставлением пользователь должен обладать правами на выполнение
команд SELECT, INSERT, UPDATE, DELETE или REFERENCES. Для
того чтобы задать привилегии на все эти команды сразу, можно
использовать привилегию ALL. Для вызова хранимой процедуры в
приложении пользователь или объект должны обладать правом на
выполнение команды EXECUTE.
Перед тем как присвоить пользователю новые права, необходимо
забрать у него старые. Это позволяет сделать команда REVOKE.
Привилегии, которые были предоставлены указанному поль¬
зователю другими пользователями, не могут быть затронуты опе¬
ратором REVOKE. Следовательно, если другой пользователь также
предоставил данному пользователю удаляемую привилегию, то
право доступа к соответствующей таблице у указанного пользова¬
теля сохранится
Как правило, в работе с учетными записями используют более
крупные объекты — роли.
Роль представляет собой объект базы данных, обладающий не¬
которыми правами и содержащий в себе учетные записи пользова¬
телей. Работать с ролью гораздо удобнее, чем с отдельными пользо¬
вателями. Намного проще переопределить права одной роли, чем
каждой учетной записи в отдельности. Роль позволяет объединить
в одну группу пользователей, выполняющих одинаковые функции.
Для создания роли используется оператор:
CREATE ROLE <имя_роли>
Одна учетная запись может состоять сразу в нескольких ролях.
Но во время одной сессии клиент может работать только под одной
ролью. Это может быть удобно только в тех случаях, когда один
пользователь должен иметь разные права доступа в зависимости
от ситуации. Пользователь, работающий под правами какой либо
роли, наследует собственные права.
Каждая СУБД должна поддерживать механизм, гарантирующий,
что доступ к базе данных смогут получить только те пользователи,
которые имеют соответствующее разрешение. Язык SQL включает
299
операторы GRANT и REVOKE, предназначенные для организации
защиты таблиц в базе данных. Механизм защиты построен на ис¬
пользовании идентификаторов пользователей, предоставляемых им
прав владения и привилегий.
13.5.
РЕЗЕРВНОЕ КОПИРОВАНИЕ ДАННЫХ
Резервное копирование (backup сору) — процесс создания копии
данных на носителе, предназначенном для восстановления данных
в оригинальном или новом месте их расположения в случае их по¬
вреждения или разрушения.
Причин повреждения баз данных множество, среди них:
■ дефекты и неисправности серверного компьютера, особенно
дисков, дисковых контроллеров, оперативной памяти компью¬
тера и кэш-памяти RAID-контроллеров;
■ некорректное соединение с многопользовательской базой дан¬
ных одного или более клиентов (пользователей);
■ файловое копирование или другой файловый доступ к базе дан¬
ных при запущенном сервере;
■ отсутствие свободного дискового пространства во время работы
с базой данных.
Резервное копирование может защитить данные от потери и
является практически самым надежным способом защиты данных
от потери в результате программных и аппаратных сбоев, повреж¬
дений и пр.
Резервное копирование не является обычным файловым копи¬
рованием. Резервное копирование базы данных — это считывание
информации из базы данных, выполняемое специальной утилитой
в режиме клиентского доступа.
Резервное копирование имеет некоторые особенности:
■ копирование базы данных может осуществляться одновременно
с работой обычных клиентских программ;
■ копия базы данных содержит данные, которые находились в
БД на момент начала подключения утилиты, осуществляющей
резервное копирование. Все изменения, проводимые выполня¬
ющимися параллельно процессу резервного копирования кли¬
ентскими программами, в резервную копию не попадают;
■ во время резервного копирования происходит считывание каж¬
дой записи из всех таблиц в базе данных. Версии записей или их
фрагменты, которые не являются актуальными, уничтожаются.
Оставшиеся записи оптимизируются;
300
■ в процессе резервного копирования происходит перестройка
индекса, что улучшает производительность операций, которые
используют эти индексы.
Резервное копирование сохраняет базу данных на резервном
носителе информации. Здесь важно заметить, что недостаточно
одного лишь резервного копирования, нужно иногда проверять
восстанавливаемость базы данных из резервной копии, потому что
бывают случаи, что база данных при нормальном резервном копи¬
ровании в силу определенных причин не восстанавливается.
Для обеспечения максимальной надежности хранения данных
следует регулярно проводить резервное копирование на внешние
носители.
КОНТРОЛЬНЫЕ ВОПРОСЫ
1. Что такое транзакция?
2. Перечислите проблемы совместной работы нескольких транз¬
акций.
3. Что называется целостностью базы данных?
4. В чем заключается проблема «грязного» чтения?
5. Каким правилам должна удовлетворять процедура согласован¬
ного выполнения параллельных транзакций?
6. Что называется уровнем изоляции транзакции?
7. Охарактеризуйте каждый из уровней изолированности транзак¬
ций.
8. Какая информация записывается в журнал транзакций.
9. Приведите пример, демонстрирующий необходимость исполь¬
зования транзакций.
10. Разъясните механизм транзакций.
11. Что происходит в случае логического отказа?
12. Что происходит в случае физического отказа?
13. Каковы цели использования транзакций?
14. В каких случаях требуется восстановление базы данных?
Глава 14
СОВРЕМЕННЫЕ СИСТЕМЫ
УПРАВЛЕНИЯ БАЗАМИ ДАННЫХ
14.1.
ТРЕБОВАНИЯ К СОВРЕМЕННЫМ СУБД
В настоящее время к системам управления базами данных предъ¬
являются очень высокие требования.
Одним из наиболее важных требований, с точки зрения поль¬
зователей и администраторов СУБД, является высокая произво¬
дительность, т. е. способность быстро обрабатывать запросы
пользователей и выполнять транзакции. В этом вопросе большую
роль играют средства оптимизации выполнения запросов и при¬
менения индексов.
Помимо производительности одной из наиболее востребован¬
ных функций современных СУБД является встроенная поддержка
безопасности, т. е. способность обеспечить пользователю доступ
к чтению и редактированию данных в соответствии с заранее за¬
данными правилами, определяемыми в рамках решаемой задачи,
а также надежная защита таблиц, хранящих эти правила. Способы
реализации этого требования могут быть различными •— от шиф¬
рования данных до аудита и анализа его результатов.
Масштабируемость — способность сохранять свою функцио¬
нальность и производительность при возрастающей нагрузке и со¬
ответствующем ей обновлении аппаратного обеспечения, таком как
расширение объема оперативной памяти, увеличение количества
процессоров и аппаратных серверов. Масштабируемость и произ¬
водительность СУБД взаимосвязаны, так как без масштабируемости
рост производительности ограничен. И если СУБД не будет обеспе¬
чивать растущие потребности пользователей даже при добавлении
дополнительных ресурсов, это станет серьезной проблемой. Подоб¬
ные ограничения (максимальный объем данных, число записей в
таблице, количество пользователей) присущи в большей или мень¬
302
шей степени всем СУБД, и если они встречаются, то наблюдаются
снижение производительности, возникновение ошибок, отказы
в предоставлении доступа или в выполнении запросов. Именно
поэтому важна способность преодоления подобных ограничений за
счет поддержки подключения новых ресурсов, например создания
кластеров из нескольких компьютеров
Корректная обработка транзакций — в настоящее время раз¬
работчики и администраторы наиболее высоко оценивают средства
корректной обработки транзакций СУБД компаний Oracle и IBM,
а также Microsoft SQL Server.
Для разработки структур баз данных и проектирования запросов
принято использовать специализированные инструменты — сред¬
ства моделирования данных. Такие инструменты могут выпускаться
как производителями СУБД, так и независимыми поставщиками.
Поддержка СУБД производителями подобных инструментов, как
и наличие их в ассортименте программного обеспечения произ¬
водителя СУБД, считается важным требованием к современным
системам управления базами данных.
Многие современные СУБД содержат средства администри¬
рования в комплекте поставки. Помимо этого нередко доступны и
средства администрирования СУБД независимых производителей.
Чем более популярна СУБД и чем более гибкой является политика
работы с партнерами ее производителя, тем, как правило, больше
средств администрирования этой СУБД доступно на рынке. С этой
точки зрения лидерами являются Oracle и Microsoft.
В последнее время стало важным для пользователей современ¬
ных СУБД требование поддержки XML, поскольку XML является
стандартом для генерации документов и обмена данными между
самыми разнообразными приложениями.
Поддержка различных платформ важна для разработчиков
приложений, работающих в разнородной среде, и наиболее суще¬
ственна для крупных компаний, имеющих, как правило, весьма
разнообразную ИТ-инфраструктуру.
14.2.
ОБЗОР СОВРЕМЕННЫХ СУБД
Informix Dynamic Server. Первая версия реляционной СУБД
Informix (INFORMation on unIX) была выпущена в 1981 г. Совре¬
менные версии этой СУБД (современное название которой —
Informix Dynamic Server) характеризуются высокой скоростью
обработки транзакций, большой надежностью и простотой адми-
303
нистрирования. Наиболее часто Informix Dynamic Server исполь¬
зуется на крупных предприятиях, в основном в крупных сетях
розничной торговли и телекоммуникационных компаниях — на
основе этой СУБД создано несколько очень популярных биллин¬
говых систем.
Сейчас Informix Dynamic Server принадлежит IBM. Последняя
версия этой СУБД обладает высокими производительностью, мас¬
штабируемостью, доступностью, развитыми средствами поддержки
репликаций, а также поддержкой кластеров, баланса загрузки,
средствами обработки конкурирующих транзакций, средствами
контроля доступа к данным на основе меток безопасности (вплоть
до значений отдельных ячеек), средствами поддержки XML и
создания SOA-решений. Сервер баз данных поставляется вместе
с инструментом IBM Data Studio, включающим средства создания
форм Informix 4GL, средства поддержки Blade-серверов, объектно-
ориентированные средства создания клиентских приложений.
Дальнейшие планы развития Informix Dynamic Server включают
совершенствование средств поддержки репликаций, повышения
производительности, автоматизации различных задач, связанных с
администрированием базы данных, инструментов для упрощения
конфигурирования.
IBM DB2. Первая версия DB2 была создана компанией IBM в
1983 г. для мэйнфреймов MVS и стала первой СУБД, поддержи¬
вающей язык SQL, который был разработан автором реляционной
модели данных Э. Ф.Коддом. Современная версия DB2 является
объектно-реляционной СУБД и поддерживает операционные систе¬
мы Linux, UNIX и Windows на различных аппаратных платформах,
а также разные операционные системы IBM. Она поддерживает
средства сжатия данных, предсказания возможных проблем и под¬
держки XML.
Несмотря на то что и Informix Dynamic Server и DB2 предна¬
значены для крупных предприятий и принадлежат одной и той же
компании IBM, они отлично сосуществуют за счет того, что созданы
для решения разных задач.
Если Informix Dynamic Server предназначен в первую очередь для
создания решений, требующих высокопроизводительной обработки
транзакций, то основные задачи, которые решаются с помощью
DB2, — это создание и эксплуатация хранилищ данных и обработка
сложных запросов.
Средства обеспечения безопасности DB2 высоко оцениваются
ее пользователями наряду с производительностью и масштабируе¬
мостью.
304
Microsoft SQL Server. СУБД Microsoft SQL Server была создана
в результате совместного проекта компаний Microsoft и Sybase в
1990 г. Через несколько лет эти компании на основе совместно соз¬
данного кода начали разрабатывать собственные СУБД, и версия 7.0
этого продукта была создана уже без участия Sybase. Версии этой
СУБД существуют только для операционных систем производства
Microsoft.
Основными особенностями последних версий SQL Server явля¬
ются средства OLAP и аналитической обработки данных, средства
хранения геопространственных данных, а также удобные в при¬
менении средства администрирования, организации репликаций
и поддержки кластеров.
Основные потребители Microsoft SQL Server — это средние и
крупные предприятия, хотя редакции этой СУБД для небольших
компаний также успешно используются.
MySQL. Первая версия СУБД MySQL была выпущена в 1995 г.
разработчиками, считающими коммерческие СУБД слишком до¬
рогостоящими. Будучи СУБД с открытым кодом, MySQL стала не¬
вероятно популярной — число загрузок ее дистрибутива составляет
до 50 тыс. в день.
Сервер MySQL можно применять свободно. Исключение со¬
ставляет случай, когда эта СУБД является частью коммерческого
продукта — тогда MySQL следует лицензировать. Платной также
является техническая поддержка продукта.
MySQL используется в большом количестве интернет-решений,
в качестве встроенной СУБД, приложениях для телекомуникацион-
ных компаний, а также в некоторых других бизнес-приложениях.
Особенностями этой СУБД являются надежность, высокая про¬
изводительность и простота применения. Ее архитектура позволяет
отказаться от функций, не требующихся для решения конкретной
задачи, и тем самым повысить производительность приложения —
статистика опросов показывает, что 80 % пользователей этой СУБД
применяют только 30 % ее возможностей.
В настоящее время СУБД MySQL принадлежит компании Sun
Microsystems, которая предоставляет для нее дополнительные услу¬
ги, позволяющие использовать эту СУБД на серверах производства
Sun и совместно с программными решениями Sun.
Oracle Database. Самая первая версия СУБД Oracle была соз¬
дана в 1979 г. и стала единственной на тот момент коммерческой
СУБД, позволившей разработчикам бизнес-приложений прекратить
создание собственных решений для хранения данных и перейти к
универсальным решениям, функционирующим на разных платфор-
305
мах. К середине 1980-х гг. корпорация Oracle стала лидером рынка
и сохраняет лидирующие позиции до сих пор.
Последние версии этой СУБД отличаются высокой надежностью,
доступностью, безопасностью и производительностью, удобны¬
ми средствами администрирования. Эта СУБД в первую очередь
предназначена для крупных предприятий, а также компаний, для
которых критичны обработка транзакций и построение хранилищ
данных, в том числе для предприятий среднего и малого бизнеса.
Отметим также активную поддержку компанией Oracle разработ¬
чиков, использующих технологии NET и Java, а также наличие
инструмента Application Express для создания веб-приложений на
основе СУБД Oracle.
PostgreSQL. СУБД PostgreSQL, как и СУБД компании Oracle,
можно отнести к ветеранам — первые версии продукта, ставшего
впоследствии тем, что ныне известно как PostgreSQL, появились
еще в 1980-х гг. С 1996 г. PostgreSQL является СУБД с открытым
кодом.
Основное назначение PostgreSQL — выполнение задач для
крупных предприятий, требующих высокой степени безопасности
и надежности. Эта СУБД используется в государственных органах
многих стран, а также в тех отраслях и областях, где требуется об¬
работка больших объемов данных и надежное выполнение транзак¬
ций (таких как генетические исследования, геоинформационные
технологии, приложения для финансового сектора).
СУБД Postgre SQL состоит из ядра и необязательных к приме¬
нению модулей, созданных сообществом разработчиков и предо¬
ставляющих самую разнообразную функциональность. Впрочем,
применение большого числа модулей одновременно может сделать
данную СУБД сложной в конфигурации, а кроме того, среди таких
модулей до сих пор нет средств анализа данных. Однако доступ¬
ны встраиваемые модули для процедурных языков, что позволяет
создавать серверный код и добавлять к СУБД дополнительную
функциональность.
Среди СУБД с открытым кодом PostgreSQL является наиболее
масштабируемой (она поддерживает до 32 процессоров, тогда как
масштабируемость MySQL ограничивается 12). На данный момент
в планах дальнейшего развития этой СУБД — повышение произ¬
водительности, усовершенствование средств поддержки кластеров
и восстановление после сбоев.
Sybase Adaptive Server Enterprise. СУБД компании Sybase перво¬
начально была результатом совместного проекта компаний Microsoft
и Sybase, начатого в 1980-х гг. В последующем эти компании начали
306
отдельные проекты по дальнейшему развитию этого совместного
продукта, а в середине 1990-х гг. Sybase SQL Server был переиме¬
нован в Adaptive Server Enterprise.
Особенностями Adaptive Server Enterprise являются надежность,
оптимальная стоимость и высокая производительность. В послед -
11 ие годы особое внимание при развитии этого продукта уделялось
средствам обеспечения безопасности и повышению производи¬
тельности. Именно безопасность, производительность и масштаби¬
руемость наиболее высоко оцениваются сегодня пользователями и
администраторами этой СУБД.
Firebird (FirebirdSQL). Компактная, кроссплатформенная, сво¬
бодная система управления базами данных, работающая на Linux,
Microsoft Windows и разнообразных Unix-платформах.
В качестве преимуществ Firebird можно отметить многовер-
сионную архитектуру (параллельная обработка оперативных и
аналитических запросов: читающие пользователи не блокируют
пишущих), компактность (дистрибутив 5 Мб), высокую эффектив¬
ность и мощную языковую поддержку для хранимых процедур и
триггеров. Firebird используется в различных промышленных систе¬
мах (складские и хозяйственные, финансовый и государственный
сектора) с 2001 г. Это коммерчески независимый проект разработ¬
чиков мультиплатформенных систем управления базами данных,
основанный на исходном коде, выпущенном корпорацией Borland
25 июля 2000 г. в виде свободной версии Interbase 6.0.
Среди недостатков: отсутствие кэша результатов запросов, пол¬
нотекстовых индексов, значительное падение производительности
при росте внутренней фрагментации базы.
КОНТРОЛЬНЫЕ ВОПРОСЫ
Т. Назовите особенности каждого этапа развития СУБД.
2. Какую роль в развитии технологии баз данных сыграло появ¬
ление персональных компьютеров?
3. Чем характеризуется современный этап развития технологий
работы с данными?
4. Какие перспективные направления развития БД?
5. Какие основные требования предъявляются современным
СУБД?
6. Дайте характеристику наиболее популярным современным
СУБД?
Список литературы
Раздел I. Инфокоммуникационные системы и сети
1. ВисандулБ.Д. Основы компьютерных сетей : учеб, пособие / [Б. Д.Висан-
дул и др.] ; под ред. Л. Г. Гагариной — М. : ИД «ФОРУМ» : ИНФРА. — М.,
2007.
2. Кондратенко С. В. Основы локальных сетей. Курс лекций : учеб, по¬
собие для вузов / С. В. Кондратенко, Ю. В. Новиков. — М. : ИНТУИТ. РУ,
2005.
3. Максимов Н.В. Компьютерные сети : учеб, пособие для студ. учреж¬
дений сред. проф. образования / Н.В.Максимов, И.И.Попов. — М. : ФО¬
РУМ, 2008.
4. Нанс Бэрри. Компьютерные сети : пер. с англ. / Бэрри Нанс. — М. :
БИНОМ, 1996.
5. Норенков И. П. Телекоммуникационные технологии и сети / И. П. Но-
ренков, В. А. Трудоношин. — М. : Изд-во МГТУ им. Н.Э. Баумана, 1998.
6. Новиков Ю.В. Аппаратура локальных сетей : функции, выбор, разра¬
ботка / Ю. В. Новиков, Д. Г. Карпенко ; под общ. ред. Ю. В. Новикова. — М. :
ЭКОМ, 1998.
7. Олифер В. Компьютерные сети. Принципы, технологии, протоколы /
В. Олифер, Н. Олифер. — СПб. : Питер, 2006.
8. Олифер В. Основы компьютерных сетей / В. Олифер, Н. Олифер. —
СПб. : Питер, 2009.
9. Палмер М. Проектирование и внедрение компьютерных сетей. Учеб¬
ный курс / М. Палмер, Р. Б. Синклер. — 2-е изд.— СПб. : БХВ — Санкт-
Петербург, 2003.
10. Спортак М. Компьютерные сети. Кн. 1. Всеобъемлющее руководство
по устройству, работе и проектированию. Энциклопедия пользователя /
М. Спортак, Ф. Паппас, Э. Резинг. — М. : ДиаСофт, 1998.
11. Храмцов П.Б. Администрирование сети и сервисов Internet /
П.Б.Храмцов. — Центр Информационных Технологий, 1997.
12. Фролов А. В. Локальные сети персональных компьютеров. Исполь¬
зование протоколов IPX, SPX, NETBIOS / А. В. Фролов, Г. В. Фролов. —
2-е изд. — М. : Диалог, 1995.
13. Шатт Стэн. Мир компьютерных сетей : пер. с англ. / Стэн Шатт —
Киев : BHV-Киев, 1996.
14. Douglas Е. Comer, Internetworking with TCP/IP, Vol. 1, 2: Principles,
Protocols, and Architecture (Third Edition) / E. Douglas. — Prentice-Hall,
1995.
308
Раздел II. Технология разработки и защиты
баз данных
1. Вирт Н. Алгоритмы и структуры данных : пер. с англ. / Н.Вирт. —
ML : Мир, 1989.
2. Грофф Дж. SQL: полное руководство : пер. с англ. / Дж. Грофф,
П.Вайнберг. — 2-е изд. — К. : BHV, 2001.
3. Дейт К.Дж. Введение в системы баз данных : пер. с англ. / К. Дж. Дейт. —
7-е изд. — М. : Вильяме, 2001.
4. Диго С. М. Проектирование и использование баз данных : учебник /
С.М.Диго — М. : Финансы и статистика, 1995.
5. Дунаев С. Б. Доступ к базам данных и техника работы в сети. Прак¬
тические приемы современного программирования / С. Б. Дунаев. — М. :
ДИАЛОГ-МИФИ, 1999.
6. Каменнова М. Управление электронными документами: технологии и
решения / М. Каменнова // Открытые системы. — 1995. — № 4.
7. Карпова Т. С. Базы данных: модели, разработка, реализация / Т. С. Кар¬
пов. — СПб. : Питер, 2001.
8. Ким Вон. Технология объектно-ориентированных баз данных / Вон
Ким // Открытые системы. — 1994. — № 4.
9. Когаловский М. Р. Абстракции и модели в системах баз данных /
М. Р. Когаловский // Открытые системы. — 1998. — № 4 — 5.
10. Кузнецов С.Д. Основы современных баз данных / С. Д. Кузнецов //
URL: www.citfo-rum.ru, 2002.
11. Малкольм Г. Программирование для Microsoft SQL Server 2000 с ис¬
пользованием XML : пер. с англ. / Г. Малкольм. — М. : Издательско-торго¬
вый дом «Русская редакция», 2002.
12. Фаронов В. В. Delphi 4. Руководство разработчика баз данных /
В. В. Фаронов, П. В. Шумаков. — М. : Нолидж, 1999.
13. Фокс Дж. Программное обеспечение и его разработка / Дж. Фокс. —
М. : Мир, 1985.
14. Цикритзис Д. Модели данных / Д.Цикритзис, Ф.Лоховски. — М. :
Финансы и статистика, 1985.
15. Шпеник М. Руководство администратора баз данных Microsoft SQL
Server 2000 : пер. с англ. / М. Шпеник, О. Следж. — М. : Вильяме, 2001.
Оглавление
Предисловие
4
РАЗДЕЛ I
ИНФОКОММУНИКАЦИОННЫЕ СИСТЕМЫ И СЕТИ
Глава 1. Основные понятия, элементы и структуры компьютерных
сетей 9
1.1. Основные понятия и определения. Классификация
компьютерных сетей 9
1.2. Топологии компьютерных сетей 14
1.3. Кабельные линии связи 16
Глава 2. Технологии передачи и обмена данными в компьютерных
сетях 21
2.1. Физическая передача данных 21
2.2. Задачи сетевого взаимодействия 24
2.3. Сетевая модель OSI 27
2.4. Протоколы и стандарты 36
2.4.1. Общая характеристика протоколов 36
2.4.2. Стек протоколов OSI 39
2.4.3. Стек протоколов TCP/IP 40
2.4.4. Стек IPX/SPX 43
2.4.5. Стек NetBIOS/SMB 45
2.5. Адресация узлов в сети 46
2.5.1. Общее представление об адресации в сетях 46
2.5.2. Физическая адресация 48
2.5.3. IP-адрес 50
2.5.4. Протокол динамической настройки узла DHCP 54
2.5.5. Система доменных имен 56
2.5.6. URL — универсальный идентификатор ресурсов 62
Глава 3. Базовые технологии локальных сетей .* 65
3.1. Сети Token Ring 65
3.2. Оптоволоконный интерфейс FDDI 67
3.3. Технология Ethernet 68
3.3.1. Первая технология Ethernet 69
310
3.3.2. Fast Ethernet 71
3.3.3. Высокоскоростные технологии Gigabit Ethernet 73
I лава 4. Технические средства компьютерных сетей 79
4.1. Сетевые адаптеры 79
4.2. Концентраторы 82
4.3. Репитеры 84
4.4. Сетевые мосты 85
4.5. Сетевые коммутаторы 85
4.6. Маршрутизаторы и сетевые шлюзы 87
Глава 5. Беспроводные технологии 90
5.1. Беспроводные линии связи 90
5.2. Стандарты беспроводной связи 92
5.3. Оборудование для организации беспроводных сетей 94
5.3.1. Wi-Fi-адаптеры 94
5.3.2. Беспроводные точки доступа 96
5.3.3. Антенны 96
5.3.4. Wi-Fi-маршрутизаторы 97
5.3.5. Wi-Fi ADSL-модемы 98
Глава 6. Сетевое программное обеспечение. Службы и сервисы 102
6.1. Многоуровневые архитектуры «клиент-сервер» 102
6.2. Сетевые службы и сетевые сервисы 104
6.3. Сетевая операционная система 106
6.4. Облачные сервисы и их возможности 111
6.5. Службы сетевой безопасности 115
6.5.1. Прокси-сервер 115
6.5.2. Брандмауэр 116
РАЗДЕЛ II
ТЕХНОЛОГИЯ РАЗРАБОТКИ И ЗАЩИТЫ БАЗ ДАННЫХ
Глава 7. Основные положения теории баз данных, хранилищ данных,
баз знаний 121
7.1. Базы данных и информационные системы. Основные
определения 121
7.2. Системы управления базами данных. Основные функции
СУБД 127
7.3. Архитектура базы данных. Физическая и логическая
независимость 133
Глава 8. Модели данных 137
8.1. Понятие модели данных 137
8.2. Теоретико-графовые модели данных 138
311
8.3. Реляционная модель 141
8.4. Постреляционная модель данных 143
8.5. Многомерная модель данных 143
8.6. Объектно-ориентированная модель 147
Глава 9. Реляционная модель данных 151
9.1. Особенности реляционной модели данных 151
9.1.1. Основные понятия и компоненты 151
9.1.2. Свойства отношений 155
9.2. Основы реляционной алгебры 156
9.3. Индексирование 164
9.4. Связывание таблиц. Понятие ссылочной целостности 168
9.5. Принципы поддержки целостности в реляционной
базе данных 172
9.6. Достоинства и недостатки реляционной модели данных 174
Глава 10. Принципы построения концептуальной, логической
и физической модели данных 177
10.1. Задачи проектирования баз данных 177
10.2. Анализ предметной области 181
10.3. Концептуальное моделирование 183
10.4. Логическое проектирование и физическая модель
базы данных 196
10.5. Проектирование базы данных на основе принципов
нормализации 202
10.6. Современные инструментальные средства разработки
схемы базы данных 207
10.6.1. Основные определения 207
10.6.2. Классификация CASE-технологий 212
Глава 11. Архитектура данных 215
11.1. Архитектура «файл-сервер» 215
11.2. Архитектура «клиент-сервер» 217
11.3. Трехуровневая архитектура «клиент-сервер» 221
11.4. Кластер серверов 223
11.5. Объекты сервера баз данных 225
Глава 12. Основы SQL 228
12.1. Введение в язык SQL 228
12.2. Работа с таблицами. Ограничения целостности 234
12.2.1. Работа с доменами 234
12.2.2. Управление таблицами 237
12.3. Выборка данных. Оператор SELECT 245
12.4. Изменение данных. Операторы INSERT, UPDATE, DELETE ... 268
12.5. Хранимые процедуры и триггеры 271
12.5.1. Язык хранимых процедур и триггеров 271
312
12.5.2. Работа с триггерами 274
12.5.3. Работа с хранимыми процедурами 277
12.6. Работа с индексами 282
12.7. Генераторы 285
12.8. Преимущества языка SQL 287
Глава 13. Обеспечение целостности данных 291
13.1. Механизм транзакций 291
13.2. Транзакции и блокировки. Управление параллельными
процессами 293
13.3. Журнализация изменений и восстановление данных 297
13.4. Способы контроля доступа к данным и управления
привилегиями 298
13.5. Резервное копирование данных 300
Глава 14. Современные системы управления базами данных 302
14.1. Требования к современным СУБД 302
14.2. Обзор современных СУБД 303
Список литературы 308
Учебное издание
Федорова Галина Николаевна
Разработка и администрирование баз данных
Учебник
Редактор О. Ю. Румянцева
Компьютерная верстка: Е. Ю. Назарова
Корректор Л. В. Гаврилина
Изд. № 101116888. Подписано в печать 05.06.2015. Формат 60x90/16.
Гарнитура «Балтика». Бумага офс. № 1. Печать офсетная. Уел. печ. л. 20,0.
Тираж 1 500 экз. Заказ № 8951
ООО «Издательский центр «Академия», www.academia-moscow.ru
129085, Москва, пр-т Мира, 101В, стр. 1.
Тел./факс: (495) 648-0507, 616-00-29.
Санитарно-эпидемиологическое заключение № РОСС RU. АЕ51. Н 16679 от 25.05.2015.
Отпечатано с электронных носителей издательства.
ОАО «Тверской полиграфический комбинат», 170024, г. Тверь, пр-т Ленина, 5.
Телефон: (4822) 44-52-03, 44-50-34. Телефон/факс: (4822) 44-42-15
Home раде — www.tverpk.ru. Электронная почта (E-mail) — sales@tverpk.ru
ACADEIVTA
]
Предлагаем
вашему вниманию
следующие книги:
А. В. РУДАКОВ
ТЕХНОЛОГИЯ РАЗРАБОТКИ ПРОГРАММНЫХ
ПРОДУКТОВ
Объем 208 с.
В учебнике рассмотрены история возникновения, современное со¬
стояние, принципы организации, основные положения и перспективы
развития технологии разработки программных продуктов.
Учебник может быть использован при освоении профессионального
модуля ПМ.ОЗ «Участие в интеграции программных модулей» (МДК.03.01)
по специальности «Программирование в компьютерных системах».
Для студентов учреждений среднего профессионального образования.
В учебном пособии в систематизированном виде приведены необ¬
ходимые теоретические сведения, практические задания и примеры их
выполнения; представлены задания на построение моделей программ¬
ных продуктов с использованием как структурного, так и объектно-ори¬
ентированного подхода (с применением стандартного языка модели¬
рования UML и современных CASE-средств), задания на разработку
тестов, справочной системы, а также на создание инсталляционных па¬
кетов программных продуктов.
Учебное пособие может быть использовано при изучении професси¬
онального модуля ПМ.ОЗ «Участие в интеграции программных моду¬
лей» (МДК.03.01) в соответствии с требованиями ФГОС СПО для спе¬
циальности «Программирование в компьютерных системах» и является
частью учебно-методического комплекта.
Для студентов учреждений среднего профессионального образования.
А. В. РУДАКОВ, Г. Н. ФЕДОРОВА
ТЕХНОЛОГИЯ РАЗРАБОТКИ ПРОГРАММНЫХ
ПРОДУКТОВ: ПРАКТИКУМ
Объем 192 с.
www. academia-moscow. ru
Г. Н. ФЕДОРОВА
ИНФОРМАЦИОННЫЕ СИСТЕМЫ
Объем 208 с.
В учебнике подробно рассмотрены основные направления развития
информационных систем, их информационные ресурсы и технологии.
Раскрыты положения и методологические принципы современных ин¬
формационных систем управления. Проанализированы принципы по¬
строения интегрированных корпоративных информационных систем.
Определены понятия жизненного цикла информационной системы и
сопровождающих его процессов. Рассмотрены методы оценки эффек¬
тивности автоматизированных информационных систем.
Учебник может быть использован при освоении общепрофессиональ¬
ной дисциплины ОП.05 «Устройство и функционирование информаци¬
онной системы», а также при освоении профессионального модуля
ПМ.02 «Участие в разработке информационных систем» (МДК.02.01)
по специальности «Информационные системы (по отраслям)» укрупнен¬
ной группы специальностей «Информатика и вычислительная техника».
Для студентов учреждений среднего профессионального образова¬
ния.
Е. И. ГРЕБЕНЮК, Н. А. ГРЕБЕНЮК
ТЕХНИЧЕСКИЕ СРЕДСТВА ИНФОРМАТИЗАЦИИ
Объем 352 с.
В учебнике рассмотрены физические основы, аппаратные средства,
конструктивные особенности, технические характеристики и особенно¬
сти эксплуатации современных технических средств информатизации:
компьютеров, устройств подготовки ввода и отображения информации,
систем обработки и воспроизведения аудио- и видеоинформации, те¬
лекоммуникационных средств, устройств для работы с информацией на
твердых носителях. Уделено внимание организации рабочих мест при
эксплуатации технических средств информатизации. Приведена инфор¬
мация о технологии производства процессоров, основных характерис¬
тиках многоядерных процессоров, современных и перспективных но¬
сителях информации, цифровых звуковых системах, технологии 3D-3By-
ка, веб-камерах, трехмерных принтерах и сканерах, электронных план¬
шетах, сенсорных устройствах ввода информации, технологии беспро¬
водной связи Bluetooth и Wi-Fi, смартфонах и коммуникаторах.
www. academia-moscow. ru
Е. В. МИХЕЕВА
ИНФОРМАЦИОННЫЕ ТЕХНОЛОГИИ
В ПРОФЕССИОНАЛЬНОЙ ДЕЯТЕЛЬНОСТИ
Объем 384 с.
В учебном пособии излагаются основы базовых понятий по совре¬
менным информационным технологиям, а также возможности практи¬
ческого применения в профессиональной деятельности программ об¬
работки графической информации (CorelDraw); программ сканирова¬
ния и распознавания информации (FineReader); программ автоматичес¬
кого перевода текстов (Promt, Lingvo); бухгалтерских информационных
систем на примере программы «1 С: Предприятие»; компьютерных спра¬
вочно-правовых систем на примере «Консультант Плюс»; программ
работы в сети Интернет.
Учебное пособие может быть использовано для изучения общепро¬
фессиональных дисциплин технических специальностей в соответствии
с ФГОС СПО.
Для студентов учреждений среднего профессионального образования.
Е. В. МИХЕЕВА
ПРАКТИКУМ ПО ИНФОРМАЦИОННЫМ
ТЕХНОЛОГИЯМ В ПРОФЕССИОНАЛЬНОЙ
ДЕЯТЕЛЬНОСТИ
Объем 256 с.
Учебное пособие предназначено для приобретения практических
навыков работы с наиболее часто используемыми в профессиональной
деятельности прикладными программами. Содержит задания по основ¬
ным разделам учебного пособия «Информационные технологии в про¬
фессиональной деятельности». Задания снабжены подробными указа¬
ниями для исполнения и уточняющими видами экранов соответствую¬
щей программы для наглядности. Для закрепления и проверки получен¬
ных навыков практикум содержит дополнительные задания. Максималь¬
ный эффект дает параллельное использование учебного пособия и прак¬
тикума.
Учебное пособие может быть использовано для изучения общепро¬
фессиональных дисциплин технических специальностей в соответствии
с ФГОС СПО.
Для студентов учреждений среднего профессионального образования.
www. academia-moscow. ru
И.Г.СЕМАКИН, А. П. ШЕСТАКОВ
ОСНОВЫ АЛГОРИТМИЗАЦИИ
И ПРОГРАММИРОВАНИЯ
Объем 304 с.
В учебнике рассмотрены основные принципы алгоритмизации и про¬
граммирования на базе языка Паскаль (версия Турбо Паскаль 7.0). Даны
основные понятия объектно-ориентированного программирования и его
реализация на языке Турбо Паскаль. Описана интегрированная среда
программирования Delphi и визуальная технология создания графичес¬
кого интерфейса программ. Показана разработка программных моду¬
лей в этой среде.
Учебник может быть использован при изучении общепрофессиональ¬
ной дисциплины ОП «Основы алгоритмизации и программирования» в
соответствии с требованиями ФГОС СПО для специальностей «Компь¬
ютерные системы и комплексы» и «Информационные системы (по от¬
раслям)» укрупненной группы специальностей «Информатика и вычис¬
лительная техника».
Для студентов учреждений среднего профессионального образования.
И.Г.СЕМАКИН, А.П.ШЕСТАКОВ
ОСНОВЫ АЛГОРИТМИЗАЦИИ
И ПРОГРАММИРОВАНИЯ. ПРАКТИКУМ
Объем 144 с.
Учебное пособие является второй частью УМК совместно с учебни¬
ком «Основы алгоритмизации и программирования». Практикум вклю¬
чает в себя все основные типы задач, ориентированных на освоение
структурной методики программирования, а также основы объектно-
ориентированного и визуального программирования. Практикум может
использоваться как для обучения программированию на базе языка
Паскаль, так и для других языков процедурного программирования.
Учебное пособие может быть использовано при изучении общепро¬
фессиональной дисциплины ОП «Основы алгоритмизации и програм¬
мирования» в соответствии с требованиями ФГОС СПО для специаль¬
ностей «Компьютерные системы и комплексы» и «Информационные си¬
стемы (по отраслям)» укрупненной группы специальностей «Информа¬
тика и вычислительная техника».
Для студентов учреждений среднего профессионального образования.
www. academia-moscow. ru
Э. В. ФУФАЕВ, Д. Э. ФУФАЕВ
БАЗЫ ДАННЫХ
Объем 320 с.
В учебном пособии изложены теоретические основы проектирова¬
ния баз данных и методология их практического применения в процес¬
сах принятия решений при управлении производством и бизнесом.
Для студентов учреждений среднего профессионального образования.
Э. В. ФУФАЕВ, Д. Э. ФУФАЕВ
РАЗРАБОТКА И ЭКСПЛУАТАЦИЯ УДАЛЕННЫХ БАЗ
ДАННЫХ
Объем 256 с.
В учебнике даны теоретические основы и практические рекоменда¬
ции по разработке и эксплуатации удаленных баз данных при соеди¬
нении информационных систем для различных задач управления. Рас¬
смотрены современные технологии доступа к удаленным базам данных.
Для студентов учреждений среднего профессионального образова¬
ния. Может быть полезен для специалистов, работающих в области уп¬
равления производством и бизнесом.
Г. И. ХОХЛОВ
ОСНОВЫ ТЕОРИИ ИНФОРМАЦИИ
Объем 320 с.
В учебнике приведено современное определение информации. Рас¬
смотрены основные информационные процессы, формы и виды суще¬
ствования информации, виды ее преобразований. Изложены основные
положения двух теорий информации — вероятностной и комбинатор¬
ной. В каждой из этих теорий исследуются меры количества информа¬
ции, источники, каналы и их основные характеристики. С позиций тео¬
рии информации рассмотрены дискретизация и квантование информа¬
ции, даны основы теории и практики кодирования, теории сжатия и ар¬
хивирования информации.
Для студентов учреждений среднего профессионального образования.
www. academia-moscow. ru
асаБсм'д
Издательский центр
«Академия»
Учебная литература
для профессионального
образования
Наши книги можно приобрести (оптом и в розницу)
Москва: 129085, Москва, пр-т Мира, д. 101в, стр. 1
Филиалы:
(м. Алексеевская)
Тел.: (495) 648-0507, факс: (495) 616-0029
E-mail: sale@academia-moscow.ni
Северо-Западный
194044, Санкт-Петербург, ул. Чугунная,
д. 14, оф. 319
Тел./факс: (812) 244-9253
E-mail: spboffice@acadizdat.ru
Приволжский
603101, Нижний Новгород, пр. Молодежный,
д. 31, корп. 3
ТелУфакс: (831) 259-7431, 259-7432, 259-7433
E-mail: pf-academia@bk.ru
Уральский
620142, Екатеринбург, ул. Чапаева, д. 1а, оф. 12а
Тел.: (343) 257-1006
Факс: (343) 257-3473
E-mail: academia-ural@mail.ru
Сибирский
630007, Новосибирск, ул. Кривощёковская, д. 15, корп. 3
ТелУфакс: (383) 362-2145, 362-2146
E-mail: academia_sibir@mail.ru
Дальневосточный
680038, Хабаровск, ул. Серышева, д. 22, оф. 519, 520, 523
ТелУфакс: (4212) 56-8810
E-mail: filialdv-academia@yandex.ru
Южный
344082, Ростов-на-Дону, ул. Пушкинская, д. 10/65
Тел.: (863) 203-5512
Факс: (863) 269-5365
E-mail: academia-UG@mail.ru
Представительства:
в Республике Татарстан
420034, Казань, ул. Горсоветская, д.17/1, офис 36
ТелУфакс: (843) 562-1045
E-mail: academia-kazan@mail.ru
в Республике Казахстан
Алматы, пр-т Абая, д. 26А, оф. 209
Тел.:(727)250-0316, моб.тел.:(701) 014-3775
E-mail: academia_kazakhstan@mail.ru
в Республике Дагестан
Тел.: 8-928-982-9248
www.academia-moscow.ru