






















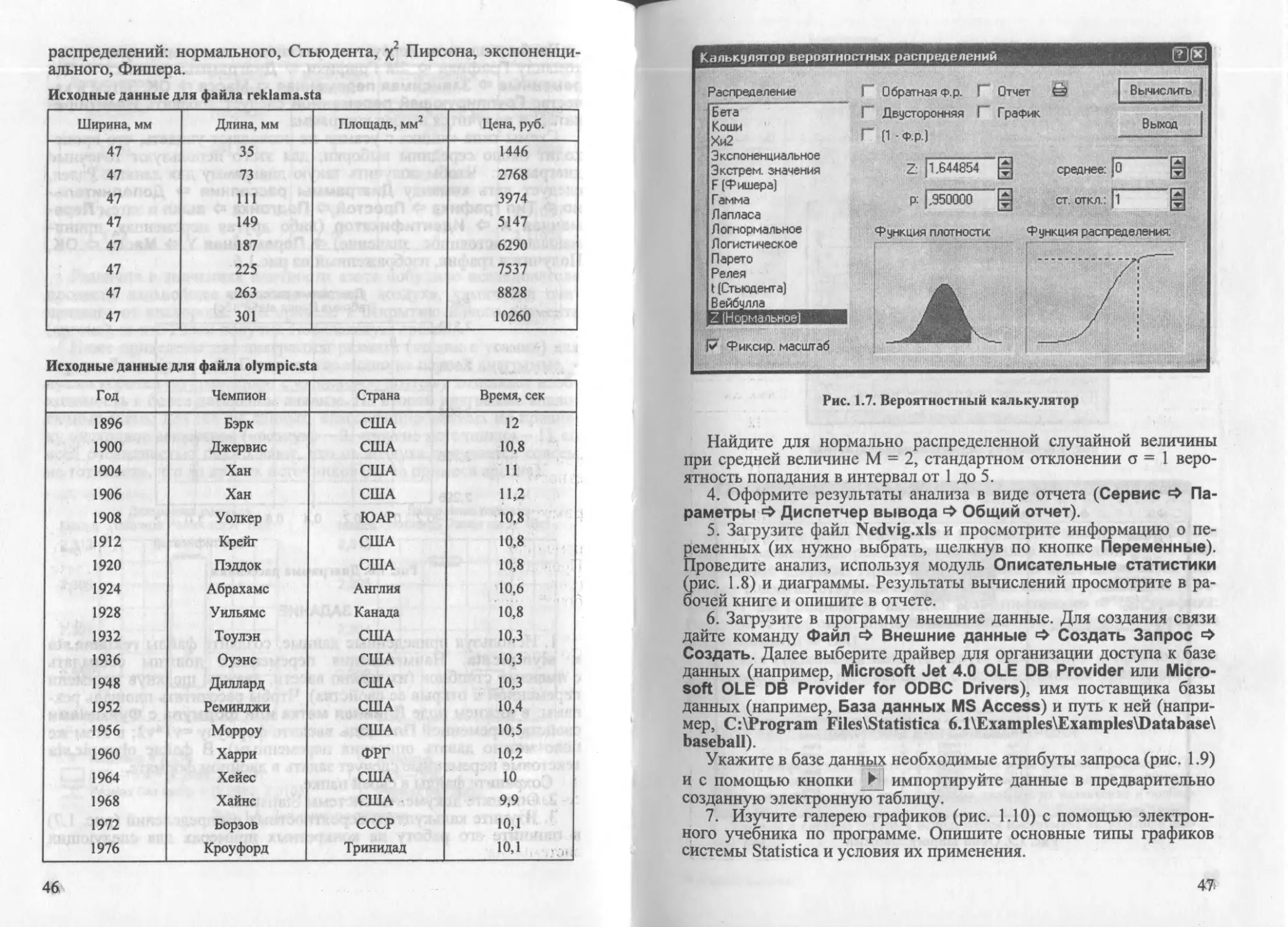

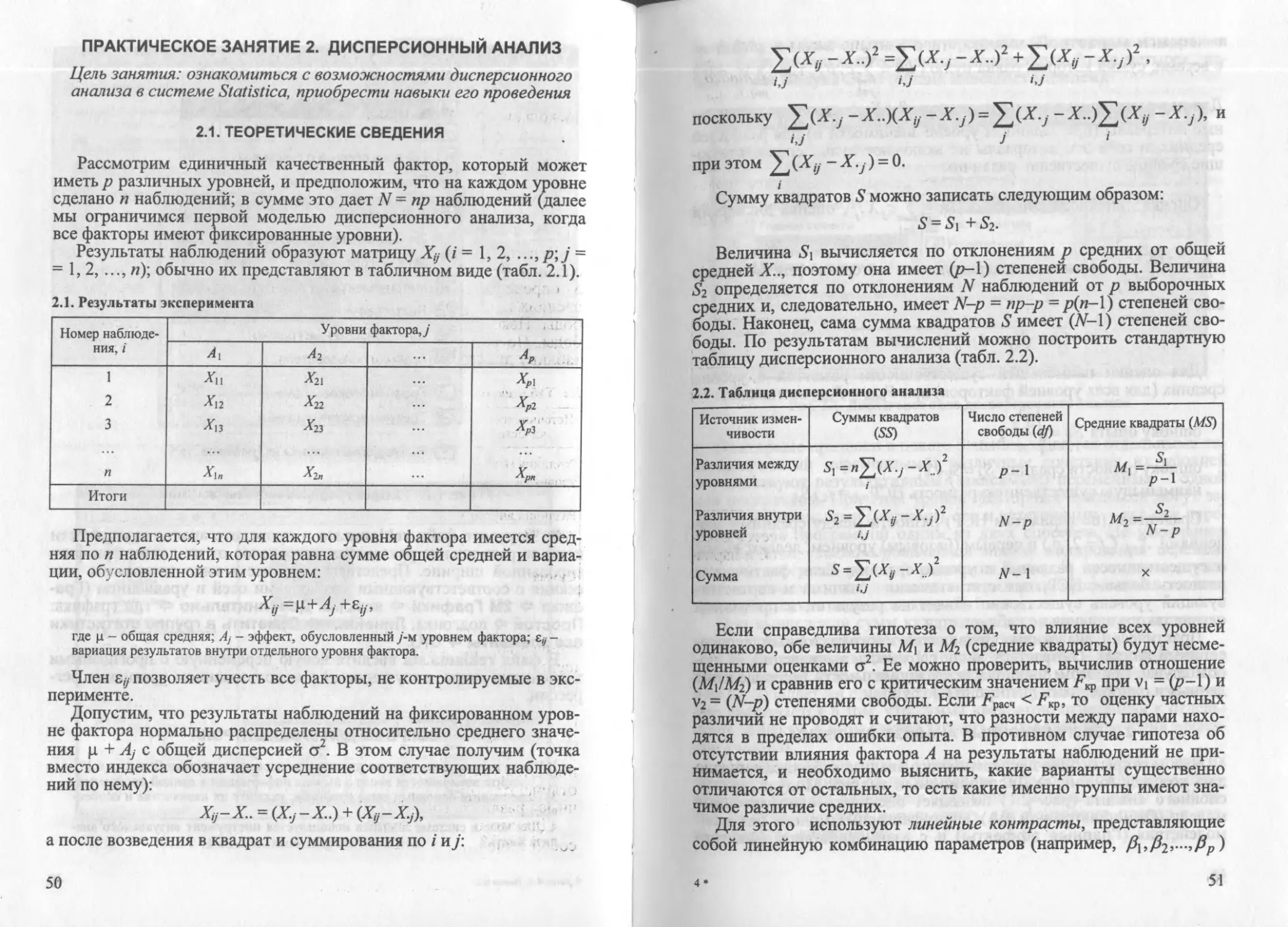



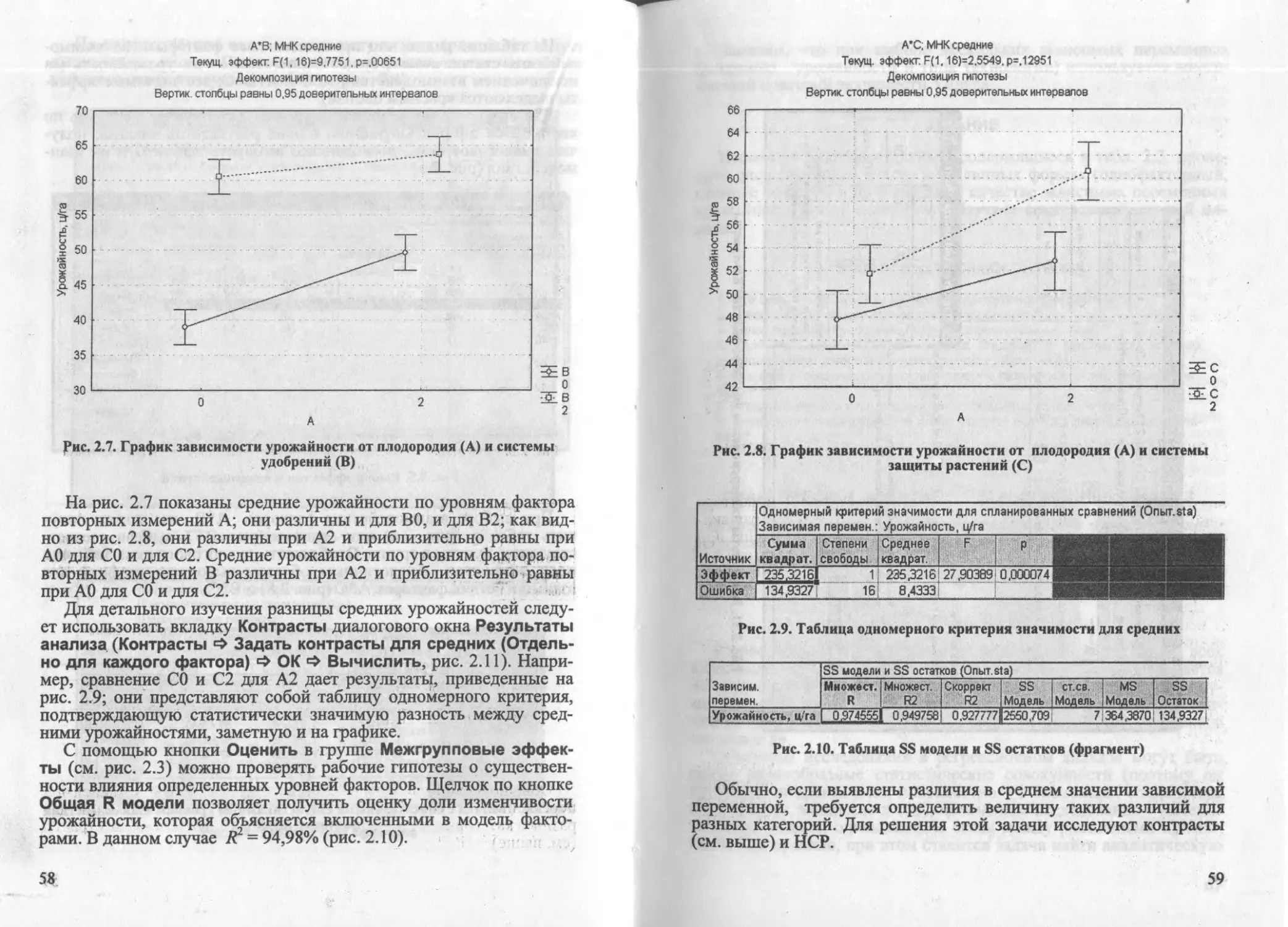





























































































Author: Паклин Н.Б. Кацко И.А.
Tags: автоматика системы автоматического управления и регулирования интеллектуальная техника технология управления оборудование систем управления техническая кибернетика учебники и учебные пособия по кибернетике информатика
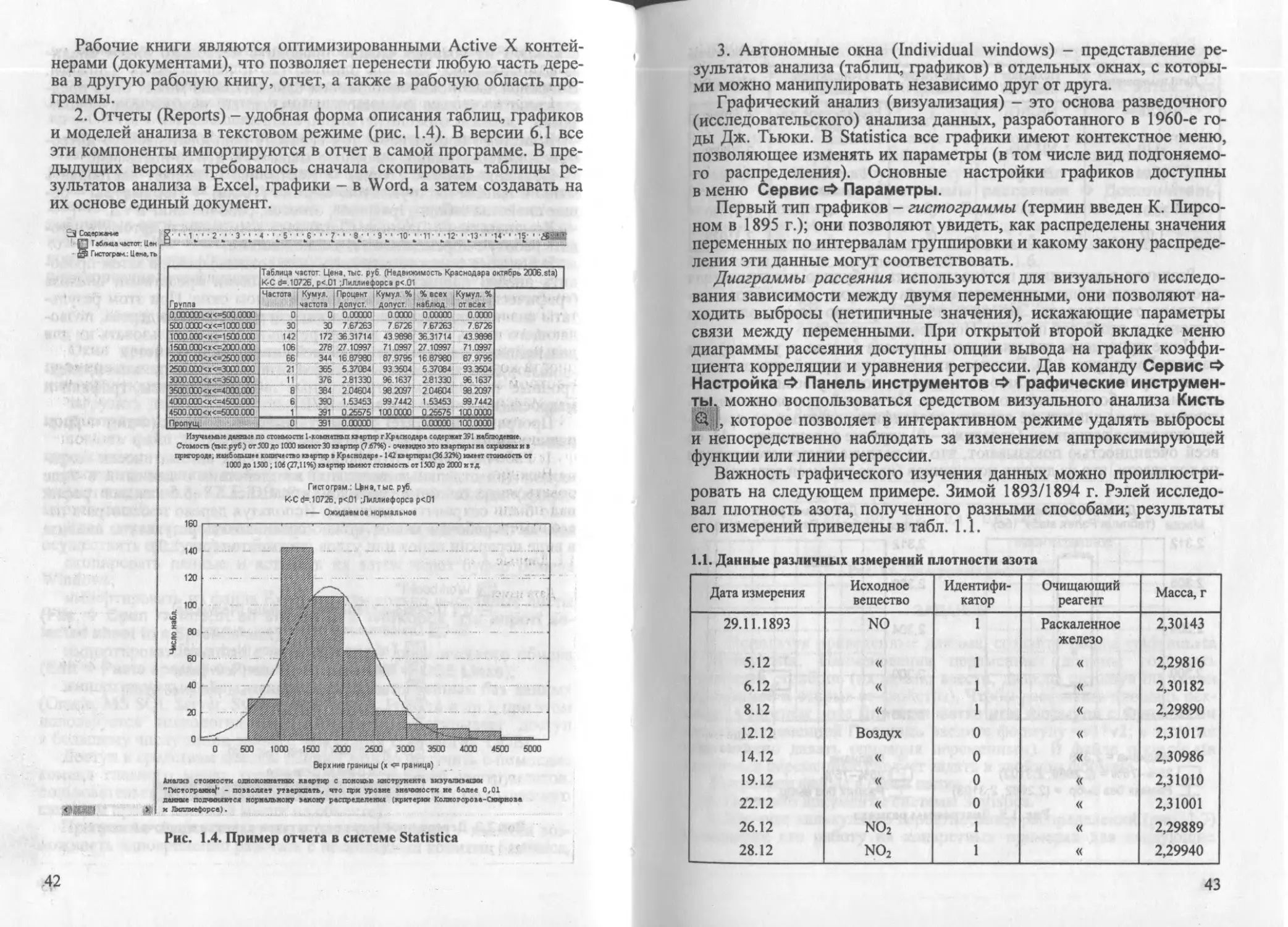
ISBN: 978-5-9532-0624-2
Year: 2009
УЧЕБНИКИ И УЧЕБНЫЕ ПОСОБИЯ ДЛЯ СТУДЕНТОВ
ВЫСШИХ УЧЕБНЫХ ЗАВЕДЕНИЙ
И.А. КАЦКО, Н.Б. ПАКЛИН
ПРАКТИКУМ
ПО АНАЛИЗУ ДАННЫХ
НА КОМПЬЮТЕРЕ
Под редакцией профессора Г. В. Гореловой
Допущено Учебно-методическим объединени-
ем по образованию в области прикладной ин-
форматики в качестве учебно-практического
пособия для студентов высших учебных заве-
дений, обучающихся по специальности «При-
кладная информатика (по областям)» и другим
специальностям
МОСКВА «КолосС» 2009
УДК 681.51(075.8)
ББК32.81я73
К12
Редактор В.И. Письменный
Рецензенты: доктор техн, наук, профессор Н.Н. Лябах (РГУ); доктор
экон, наук, профессор НИ. Ниворожкина (РГЭУ)
Кацко И.А., Паклин Н.Б. Практикум по анализу данных на
К12 компьютере / Под ред. Г.В. Гореловой. - М.: КолосС, 2009. -
278 с.: ил. - (Учебники и учеб, пособия для студентов высш,
учеб, заведений).
ISBN 978-5-9532-O624-2
Изложены теоретические и практические основы анализа данных на ком-
пьютере с использованием современных программных средств. В первой части
книги приведены материалы для практических занятий по всем стандартным
направлениям многомерного статистического анализа в рамках специализиро-
ванного пакета Statistics (дисперсионный анализ, корреляционно-регрессион-
ный анализ, временные ряды и др.). Вторая часть посвящена технологии интел-
лектуального анализа данных (на примере аналитической платформы Deductor).
Для студентов вузов по специальности «Прикладная информатика (по об-
ластям)» и другим специальностям.
УДК 681.51(075.8)
ББК 32.81я73
Оригинал-макет книги является собственностью издательства
«КолосС», и его воспроизведение в любом виде, включая электронный,
без согласия издателя запрещено.
ISBN 978-5-9532-0624-2
© Издательство «КолосС», 2009
ПРЕДИСЛОВИЕ
В настоящее время информационные системы на предпри-
ятиях выполняют в основном функции сбора, обработки, хране-
ния, передачи и представления информации. Недостаточно
внимания уделяется возможностям ее обработки - проведению
анализа, построению прогнозов и сценариев развития.
На приведенной далее схеме система управления предпри-
ятием представлена в виде традиционной иерархической струк-
туры (см., например, Э.А. Трахтенгерц. Компьютерная под-
держка принятия решений. - М.: СИНТЕГ, 1998). Производст-
венное предприятие (на схеме - прямоугольник) состоит из трех
блоков: подготовки и обслуживания производства, собственно
производства, сбыта готовой продукции. Система управления
изображена в виде треугольника, а каналы, по которым прохо-
дят информационные потоки, - в виде стрелок. В основании
треугольника расположены системы сбора, обработки, хране-
ния, передачи и представления информации, образующие ин-
формационную модель предприятия, на его вершине - руково-
дители, принимающие решения в соответствии с установлен-
ными целями (получение прибыли и др.). Среднее звено (систе-
мы поддержки принятия решений, СППР) в основном состоит
из специалистов, которые на основании данных информацион-
ных систем проводят многовариантные расчеты для получения
прогнозов и сценариев развития, оптимизации параметров про-
изводства, решения других задач.
Считается, что описанная трехуровневая схема управления
является универсальной и позволяет исследовать деятельность
системы любой сложности - от индивидуума до правительства
страны.
Вместе с тем функционирование организационных систем,
их взаимодействие с окружающей средой чаще всего невоз-
можно представить в виде традиционных формальных количе-
ственных взаимосвязей. В значительной степени их приходится
описывать на качественном уровне, а последствия принятия тех
или иных решений часто оказываются неоднозначными или во-
все неопределенными. Наличие таких условий позволяет отне-
сти проблемы управления организациями к слабоструктуриро-
ранным.
3
Управляющие
воздействия
Информация
обратной связи
Материальные и
энергетические
потоки
Информационные
потоки
Укрупненная схема предприятия: производство,
организация и управление
Структурированными (или хорошо структурированными,
well-structured) называют проблемы, в которых существенные
зависимости ясно выражены и могут быть адекватно представ-
лены в числах или символах. Это проблемы «количественно
выраженные»; для их решения чаще всего используют методо-
логию исследования операции.
Слабоструктурированные проблемы характеризуются нали-
чием как качественных, так и количественных элементов, при-
чем первые имеют тенденцию доминировать. К этому классу
4
относится большинство сложных задач в области техники, по-
литики, экономики.
Неструктурированные проблемы могут быть выражены
главным образом в качественных признаках, не поддающихся
количественному описанию и численным оценкам. Их исследо-
вание возможно только эвристическими методами, ибо здесь
отсутствуют условия для применения логически упорядоченных
процедур поиска решений.
Практика управления сложными системами и ситуациями
потребовала создания систем поддержки принятия управленче-
ских решений для всех перечисленных видов проблем.
Принятие решений - наиболее сложный и ответственный
этап деятельности человека в различных организационных
структурах. Компьютерное моделирование этого процесса ста-
новится сегодня одним из главных направлений автоматизации
управления. С этой целью разрабатывают автоматизированные
управленческие организационные системы. Опыт свидетельст-
вует о том, что системы поддержки повышают производитель-
ность лиц, принимающих решения, - прежде всего потому, что
они получают возможность рассмотреть возможные альтерна-
тивы и получить оценки их последствий на базе компьютерно-
го моделирования.
При наличии больших объемов информации для решения
проблем первых двух типов используют компьютерные средст-
ва, основанные на методах исследования операций, прикладной
статистики, а также интеллектуального анализа данных.
В настоящем издании рассматриваются методы прикладной
статистики, хранилищ данных (Data Warehouse), многомерного
анализа данных (OLAP), добычи данных (Data Mining), обнару-
жения знаний в базах данных (Knowledge Discovery in Databas-
es). Все они предполагают обработку табличных данных боль-
шого объема для решения задач анализа и прогнозирования и
относятся к наиболее востребованным в современной практике
управления.
При расширении классов решаемых задач также используют
методы:
генетических алгоритмов (в комбинаторных и оптимизаци-
онных задачах);
нечеткой логики (для задач управления в сложных систе-
мах);
когнитивных карт (в задачах первичного анализа сложных
организационных систем) и др.
Важное достоинство практикума - описание в едином стиле
основных методов анализа табличных данных большого объе-
ма, иллюстрированное их применением в различных областях
деятельности. Заметим, что анализ данных на компьютере - это
5
не только наука, но и искусство. Чтобы овладеть им, необходи-
мо постоянно работать с данными: формулировать и проверять
гипотезы об их природе и структуре, варьировать применяемые
модели и т.д. Другими словами, нужно научиться проводить
разведочный анализ данных, которому, в сущности, и посвяще-
на эта книга. Есть все основания считать, что она будет полезна
в учебном процессе и послужит делу подготовки нового поко-
ления экономистов, способных осознанно применять на практи-
ке методы компьютерного анализа массовых данных.
Г. В. Горелова, доктор техниче-
ских наук, профессор кафедры
ГиМУ ЮФУ (г. Таганрог), ака-
демик МАНВШ
ВВЕДЕНИЕ
Изучение систем в окружающем мире - это сложная задача, ко-
торая решается либо экспертно, либо статистически (в идеале оба
подхода должны комбинироваться).
Допустим, что в результате ежегодных наблюдений за некото-
рым объектом (например, сельскохозяйственными предприятиями
Краснодарского края) был получен ряд показателей Xj (для /-го
предприятия - xtj). Тогда исходные статистические данные можно
представить в виде так называемых панелей, или матриц, строки
которых соответствуют объектам, а столбцы - наблюдениям:
'*11 *12 . - х\к '
*21 *22 • х2к
*/л2 •• хтк )
Если Т\п ~ {t\, ti, tn) - вектор-строка, обозначающая п лет на-
блюдений, то исходные данные с помощью произведения Кронеке-
ра можно представить в виде блочной матрицы Т ® X размерности
к*тп\ Т®X = faX, t2X, ...,tnX).
Графически произведение Кронекера в данном случае можно
представить как трехмерный куб (см. рисунок). В настоящее время
существует несколько подходов к изучению подобных структур.
1. Рассмотрение срезов куба в пространстве и во времени. Исхо-
дя из этого, практически все методы многомерного статистического
анализа (прикладной статистики) ориентируются на решение трех
типов задач:
выявление сходства между объектами - строками матрицы
(одномерная классификация объектов - простая или комбиниро-
ванная группировка; многомерная классификация - кластерный и
дискриминантный анализ);
анализ взаимодействия между признаками - столбцами матри-
цы (дисперсионный анализ, корреляционно-регрессионный анализ,
ковариационный анализ, факторный и компонентный анализ, путе-
вой анализ и т.д.);
выявление закономерностей (трендов, сезонностей, циклов) из-
менения признаков предприятия во времени (анализ одномерных и
многомерных временных рядов).
7
Представление данных в виде куба OLAP
2. Применение оператора векторизации, который преобразует
матрицу в вектор. Это позволяет получить матрицу размерности
пт х &, и ее затем можно представить в виде модели ковариацион-
ного анализа.
3. Рассмотрение моделей панельных данных, предполагающих
изучение зависимостей и в пространстве, и во времени.
4. Представление данных в виде многомерной модели OLAP-
куба с возможностями свертки (обобщение одного или нескольких
измерений и агрегирование соответствующих показателей); раз-
вертки (получение подробной информации об одном или несколь-
ких измерениях); расщепления и разрезания (развертка на один
уровень вниз по одному или нескольким измерениям для ограни-
ченного количества элементов); построения кросс-таблиц и кросс-
диаграмм. Последняя операция для небольших объемов данных
доступна в Excel (Данные <=> Сводная таблица).
5. Представление данных в виде пространственной базы данных
с привязкой к некоторой базовой системе координат (например,
земной поверхности) и использование в географических информа-
ционных системах (ГИС) для решения задач визуализации (нанесе-
ние информации на карту в виде различных векторных слоев с ин-
формацией о земельных участках, экологическом районировании,
почвах, социальных, экономических показателях и т.д.), тематиче-
ского поиска, анализа местоположения, топографического анализа,
анализа потоков (связности, кратчайших путей), пространственного
анализа (поиск шаблонов, центров, автокорреляций), измерений
(расстояний, периметров, очертаний, направлений).
8
Первые три подхода рассматриваются в рамках прикладной ста-
тистики и эконометрики. Остальные два относятся к информацион-
ным технологиям многомерных баз данных и прикладной стати-
стики.
Выявление сходства между объектами, анализ взаимодейст-
вий между признаками в пространстве и во времени, поиск законо-
мерностей позволяют получить описание исследуемых объектов
в виде формул, удобных для решения задач управления и прогно-
зирования.
Опыт применения эконометрических моделей (подходы 1-3) по-
казывает, что зачастую они неадекватно описывают реальную со-
циально-экономическую ситуацию, то есть мало подходят для до-
стижения целей моделирования (получения моделей, объясняющих
имеющиеся данные и пригодных для предсказания и управления).
Это серьезная проблема, для понимания которой следует рассмот-
реть философские концепции, лежащие в основе методов анализа
данных, такие как учение о причинности, детерминизм, «мягкие»
вычисления и др.
Учение о причинности предполагает, что все социально-эконо-
мические явления - это следствия вполне определенных причин.
Причинность, в свою очередь, означает наличие связи, посредством
которой причина порождает следствие. Один из основных принци-
пов планирования экспериментов основывается на методе разли-
чий, который позволяет установить такую связь. Например, если
при постоянстве условий проведения полевого опыта отличие меж-
ду делянками состоит только в дозе внесения удобрений либо
в способе обработки почвы, то наблюдаемые различия в урожайно-
сти обусловлены исключительно указанными причинами.
На протяжении столетий в науке господствующим философским
учением был детерминизм. Согласно такому подходу, в мире суще-
ствуют некоторые универсальные функциональные зависимости,
предопределяющие (детерминирующие) все наблюдаемые процес-
сы и явления. Его значимость была подвергнута сомнению после
того, как в 1927 г. В. Гейзенберг доказал, что в микромире причин-
но-следственные связи не действуют, и сформулировал известный
«принцип неопределенности».
В этом контексте следует отметить, что пока не оценены по до-
стоинству понятия «жесткой» и «мягкой» модели, введенные ака-
демиком В.И. Арнольдом в 1997 г. и соответствующие представле-
ниям о знаниях в интеллектуальных системах [20]. Этот известный
математик показал, что «мягкие» модели (модели, поддающиеся
изменениям) могут учитывать так называемые НЕ-факторы, отра-
жающие неопределенность и неоднозначность путей развития [6].
Детерминированными являются лишь «жесткие» модели - в них
все предопределено заранее априорными условиями и предположе-
ниями.
9
По-видимому, основная причина разочарования практиков
в экономико-математических моделях - «жесткость» применяемых
технологий программирования и математической статистики (эко-
нометрии). В их основе должен лежать принцип учета НЕ-факторов
при использовании показателей и управляющих воздействий. Разу-
меется, нет необходимости полностью отвергать «жесткие» модели;
их следует рассматривать как возможное «идеальное» состояние
системы в близко прогнозируемом будущем.
По мнению Лотфи Заде, одного из классиков теории искусст-
венного интеллекта, создателя теории нечетких множеств и автора
термина «Soft Computing» («мягкие вычисления», 1994 г.), для по-
строения «мягких» моделей следует использовать методы «вычис-
лительного интеллекта» (эволюционного моделирования, нейрон-
ных сетей и др.).
Несмотря на неутихающие споры о том, существуют ли законо-
мерности объективно, или они носят сугубо локальный характер и
с их помощью можно прогнозировать состояние системы (объекта)
лишь в соответствующей (локальной) области, одной из основных
целей современной науки остается поиск связей между перемен-
ными, принадлежащими одинаковым или разным типам шкал, и
установление соответствующих закономерностей в рамках границ,
обусловленных факторами неопределенности.
Многие специалисты (И.И. Елисеева, В.О. Рукавишников и др.)
справедливо отмечают, что методы изучения связей внутренне про-
тиворечивы. Использование прямых методов приводит к идеализа-
ции связей и введению жестких детерминированных зависимостей
(регрессионный анализ). С другой стороны, косвенные методы ос-
нованы на измерении сопряженности вариации переменных, и по-
лучаемые при этом результаты не подлежат прямой содержатель-
ной интерпретации. Так, показатели тесноты связи, определяемые
при корреляционном анализе, содержат неявную предпосылку о
наличии такой связи, что часто вызывает критику (так называемая
проблема ложной корреляции).
Несмотря на все эти сомнения, в экономической науке преобла-
дает негласно принятый детерминистский подход, предполагаю-
щий наличие причинно-следственных связей; эти связи обусловли-
вают динамическое и статическое состояние системы и дают воз-
можность эффективно управлять производством (организацией).
Знание взаимодействующих факторов и количественных мер их
влияния создает основу для практического воздействия (управле-
ния), прогнозирования и т.д.
Общая цель методов анализа данных - свертка имеющейся ин-
формации для решения прикладных задач: объяснения особенно-
стей функционирования изучаемой системы, экономического ана-
лиза, управления, прогнозирования. При этом практические задачи
в переводе на научный язык интерпретируются как проблемы раз-
10
ведочного анализа данных, сводящиеся к первичной обработке и
визуализации, исследованию и построению зависимостей, класси-
фикации и снижению размерности данных. В последние десятиле-
тия в связи с развитием информационных технологий к ним доба-
вились задачи поиска ассоциаций, последовательностей, паттернов
в данных и т.д. Очевидно, с развитием применяемых технологий
будут появляться новые задачи и новые методики их решения.
В настоящее время в моделях, базирующихся на статистической
информации, используют следующие основные подходы:
1) вероятностный, с предположением о нормальности распреде-
ления изучаемых величин (модели математической статистики);
2) геометрический, согласно которому данные не имеют вероят-
ностной природы и образуют в многомерном пространстве струк-
туры с определенными свойствами;
3) содержательный, предполагающий достижение определенных
целей моделирования.
Первые два подхода реализуются в прикладной статистике, тре-
тий - при интеллектуальном анализе данных. И первый и второй
подходы предполагают, что имеется некоторая модель реальных
событий (обычно линейная), и наша цель - найти для нее опти-
мальные параметры. Напротив, методы интеллектуального анализа
(с помощью нейронных сетей, эволюционного программирования и
других методов машинного обучения) итеративно подбирают мо-
дель, в определенном смысле наилучшим образом описывающую
исходные данные.
Следует отметить, что анализ данных - это процесс движения от
простых методов ко все более сложным. И если простая (детерми-
нированная или вероятностная) модель позволяет успешно решать
задачи управления (анализа, прогнозирования), нет смысла искать
более сложные. Здесь вполне применим тезис средневекового анг-
лийского философа Оккама «не плодить сущности сверх потребно-
сти». В соответствии с подобной идеологией в настоящее время
рабочая группа BaseGroup Labs рассматривает возможности по-
строения системы анализа, двигаясь от простейших методов к бо-
лее сложным, - пока не будут достигнуты поставленные цели.
Здесь важно учитывать еще один фактор - стоимость разрабо-
ток. М. Киселев и Е. Соломатин в свое время указывали, что в Рос-
сии «...основным сдерживающим фактором развития сферы анали-
тических услуг являлся низкий спрос. Неплатежеспособные потре-
бители были слабо заинтересованы в получении эффективных ре-
шений - экономическая конъюнктура позволяла получать прибыль
другими способами. Сейчас, казалось бы, изменился инвестицион-
ный климат, появился спрос на аналитический консалтинг, более
того, производителям и продавцам программного обеспечения есть
что предложить - рынок вроде бы созрел и снизу, и сверху. Про-
блема, однако, не в том, чтобы предложить нужный инструмент, -
11
оказалось, что потенциальные пользователи не могут его взять»
(Л/ Киселев, Е. Соломатин. Средства добычи знаний в бизнесе и
финансах. - Открытые системы, 1997. - № 4). Ведь средства интел-
лектуального анализа данных - не просто рыночный продукт; это
специфическая идеология бизнеса. И сейчас, 10 лет спустя, ситуа-
ция практически не изменилась; разрыв между разработчиками со-
временных средств анализа данных и их пользователями остается
очень большим.
В силу указанных причин настоящее пособие состоит из двух
частей, посвященных методам прикладной статистики (часть I) и
интеллектуального анализа (часть II), в совокупности образующим
современную методологию анализа данных. Его можно использо-
вать для системного, последовательного изучения всех основных
методов анализа структурированных данных - от прикладной ста-
тистики до хранилищ данных и Data Mining. Исходные данные для
изучения приведенных в практикуме примеров и выполнения инди-
видуальных заданий размещены на веб-сайте BaseGroup Labs
(http://www.basegroup.ru/download). Там же можно загрузить сво-
бодно распространяемую версию аналитической платформы Deduc-
tor Academic.
Авторы выражают благодарность доктору экон, наук, профессо-
ру СПбГПУ В.Н. Волковой и доктору техн, наук, профессору, про-
ректору СПбГПУ В.Н. Козлову за ежегодную организацию научной
конференции «Системный анализ в проектировании и управлении»,
благодаря которой состоялась встреча авторов книги и был осуще-
ствлен этот совместный проект.
ЧАСТЬ I. СТАТИСТИЧЕСКИЙ АНАЛИЗ ДАННЫХ
МЕТОДЫ СТАТИСТИЧЕСКОГО АНАЛИЗА
Наблюдение за реальными объектами и процессами позволяет
зафиксировать множество признаков, которые можно анализиро-
вать эмпирически. Обычно предполагается, что большая совокуп-
ность признаков достаточно хорошо описывает изучаемый объект.
На практике эта идея приводит к построению таблиц многомерных
данных, которые и являются предметом изучения прикладной ста-
тистики. Современные методы многомерного статистического ана-
лиза (MCA) являются естественным обобщением таких традицион-
ных средств, как проверка статистических гипотез, дисперсионный
и корреляционно-регрессионный анализ (как правило, предпола-
гающих вероятностную природу данных) на многомерный случай.
Методы MCA (рис. 1.1) обычно разделяют на две группы - веро-
ятностного анализа данных (проверка многомерных гипотез, оце-
нивание многомерных данных) и логико-алгебро-геометрические.
Последние по классам решаемых задач можно подразделить сле-
дующим образом:
методы поиска и исследования зависимостей (дисперсионный
анализ, ковариационный анализ, корреляционно-регрессионный
анализ, канонические корреляции и др.);
методы классификации (дискриминантный анализ - так назы-
ваемая классификация с учителем, кластерный анализ - классифи-
кация без учителя);
методы снижения размерности и сжатия данных (главные ком-
поненты, факторный анализ, многомерное шкалирование и др.).
Многие методы пересекаются; например, объединение регрес-
сионного и факторного анализа в одну схему приводит к созданию
структурных моделей.
Весь круг перечисленных выше (и некоторых других) методов
обработки данных в современной литературе иногда называют при-
кладной статистикой или анализом данных.
1. ОБЩАЯ ХАРАКТЕРИСТИКА
Социально-экономические, технические, технологические, при-
родные процессы и явления зависят от большого числа факторов,
что порождает трудности при выявлении структуры и взаимосвязей
изучаемых параметров. Поэтому, чтобы принимать верные решения
13
при управлении или прогнозировании на основе анализа неполной
информации (в условиях неопределенности), необходимо исполь-
зовать методы многомерного статистического анализа для построе-
ния моделей, адекватных изучаемым процессам. Эти методы бази-
руются на представлении исходной информации в многомерном
признаковом пространстве и позволяют выявить латентные (неяв-
ные), но объективно существующие закономерности в структуре и
тенденциях развития изучаемых явлений.
- все гауссовские одномерные
методы имеют аналоги;
- нет аналога одномерной
непараметрической статистике;
- нет аппарата в случае
негауссовского распределения
Цель - изучение вероятностной
природы данных и первичная
обработка
канонических корреляций,
путевой анализ);
- методы сжатия информации и
снижения размерности (метод
главных компонент, факторный
анализ, многомерное
шкалирование);
- методы классификации
(кластерный анализ,
дискриминантный анализ)
Цель - изучение геометрической
природы данных
Рис. 1.1. Методы многомерного статистического анализа
14
Теорию MCA следует рассматривать как логическое развитие
теории вероятностей и математической статистики. Принципиаль-
ное ее отличие состоит в том, что изучаемые объекты и экономиче-
ские явления рассматриваются с учетом не одного-двух, а множе-
ства признаков одновременно (обычно обрабатываются многомер-
ные совокупности размерностью от 2 до 33). Возникновение мно-
гомерного статистического анализа как науки можно датировать
1901-1904 гг., когда появились статьи К. Пирсона и Ч. Спирмена,
посвященные теории факторного анализа.
Но прежде чем говорить о зависимости или независимости при-
знаков, их нужно измерить по какой-либо шкале. Различают коли-
чественные (конечные и бесконечные, дискретные и непрерывные)
и качественные шкалы, которые не совпадают по составу допусти-
мых операций (табл. 1.1).
1.1. Классификация шкал
Шкалы Допустимые опера- ции Комментарии
Качественные:
номинальная (шкала наиме- нований или категорий) X- Y, X * У (срав- нения) Названия или имена могут заменяться числами (например, «пол» = 1 для мужчин, «пол» = 0 для женщин)
порядковая (ординальная) X=Y,X<Y, Х> Y (сравнения и порядка) Числа позволяют упорядочивать сово- купность (например, всех анкетируе- мых по коэффициенту IQ)
Количественные:
интервальная Y-X В этой шкале измеряется календарное время, температура в градусах Цельсия или Фаренгейта и т.д.
отношений X=Y,X> Y,X<Y, X+Y,X-Y В этой шкале измеряются рост, вес, время
Методы MCA базируются на геометрическом представлении
данных. Наблюдаемые объекты располагаются в абстрактном про-
странстве, размерность которого соответствует числу признаков
(элементарных или латентных), характеризующих эти объекты,
причем:
1) в общем случае рассматривается «-мерное евклидово про-
странство;
2) при п > 3 все задачи решаются только логически и алгебраи-
чески;
3) если признаки разнородны, их нормируют;
4) при анализе «-мерных наблюдений используют математиче-
ский и экономико-статистический анализ.
15
Важно, чтобы в результате анализа не было получено противо-
речивых результатов.
Нередко при обработке и представлении данных приходится
сталкиваться с так называемым «проклятием размерности» - когда
желательно работать не со всеми п признаками, а с гораздо мень-
шим их количеством т (т « п). Такая проблема возникает, в част-
ности, при необходимости:
наглядного представления (визуализации) данных;
упрощения статистической модели для ее содержательной ин-
терпретации;
сжатия информации в базе данных без явных потерь ее практи-
ческой ценности.
Существует три основных предпосылки, создающих возмож-
ность перехода к меньшей размерности:
дублирование информации;
неинформативность признаков (их малая вариабельность при
переходе от одного объекта к другому);
возможность агрегирования признаков (простого или взвешен-
ного их суммирования).
2. МЕТОДЫ СТАТИСТИЧЕСКОГО ОЦЕНИВАНИЯ И СРАВНЕНИЯ
Рассматриваемые методы основаны на многомерном нормаль-
ном распределении A-мерной случайной величины Х= (хь х2, ..., xfi
со следующей функцией плотности вероятности:
где /л =
- Л-мерный вектор математических ожиданий; X 1 - мат-
рица, обратная ковариационной матрице Z размерности (АХЛ); |Е| - опре-
делитель матрицы Е, которая считается симметрической и положительно
определенной.
Для одномерного случая (£=1) получаем обычные формулы для
одномерной случайной величины:
v 2
X — сгц — а ,
(х-/*)2
16
При к = 2:
*1 ” 4
<*2 ~^2)
а\2^
°22>
, где
°12 -<Т21;
хехр<
/(*) =
1
-т—г
(х|-/'|)2
2(1-р2).
-1
_2р(*1~~^)(*2^2)(*2 -А2)2
^12
<7?
2
.2
С/ 12
где p = ——----коэффициент корреляции, ст
CTjCTj
Выборку из ^-мерной генеральной совокупности объемом п еди-
ниц можно представить в виде матрицы данных
22
*11
*21
*12
*22
x\k
x2k
_*Л1
*и2
Тогда А/” =*Г =-У*/т’
п1А
хпк _
п
Г - оценка m-го момента переменной
5 =
R =
5п
521
sk\
г2\
Л1
512
s22
sk2
П .
r12
r22
г*2
— Кацко И.А.. Паклин Н.Ь.
•••
• •• s2k
- оценка ковариационной матрицы Z
••• skk_
\Хц
... rXk
••• r2k
•••
- оценка корреляционной матрицы,
17
slj
trq Гц =-----оценка парного коэффициента корреляции.
sllsJJ
Для вектора р можно построить ^-мерные доверительные эл-
липсоиды.
Если ковариационная матрица S известна, то вектор /7 с неко-
торой доверительной вероятностью р = 1 - а накрывается довери-
тельной областью, задаваемой неравенством
Если матрица S неизвестна, то вектор р с некоторой довери-
тельной вероятностью р = 1 - а накрывается доверительной по-
верхностью, задаваемой уравнением
п(п-к)
В этой формуле k n_k = ~~—— Fa к п_к - статистика Т2 Хотел-
’ ’ п-к ’ ’
линга, Fa к п_к - критическая точка распределения Фишера - Сне-
декора, соответствующая уровню значимости а со степенями сво-
боды к и п-к.
Проверка гипотез о параметрах многомерной нормально распре-
деленной генеральной совокупности основывается на критериях,
использующих статистики %2 Пирсона и Т2 Хотеллинга. Как прави-
ло, в пакетах статистических программ статистическое оценивание
и сравнение выполняются автоматически.
3. ДИСПЕРСИОННЫЙ АНАЛИЗ
Дисперсионный анализ как метод исследования впервые был
использован Р. Фишером в его работах 1918-1935 гг. для выявле-
ния условий, при которых испытываемый сорт сельскохозяйствен-
ной культуры дает максимальный урожай (первым фактором был
тип почвы, вторым - способ обработки). Дальнейшее развитие он
получил в работах Йетса. Данный метод позволяет ответить на во-
прос, имеется ли статистически существенное влияние тех или
иных факторов на изменчивость фактора, значения которого могут
быть получены в результате опыта; при этом предполагается слу-
чайность их вариации.
В дисперсионном анализе один или несколько факторов изме-
няются заданным образом, и изучению подлежит влияние этих из-
18
менений на результаты наблюдений. Такой подход все шире ис-
пользуется в экономических, социологических, биологических и
других исследованиях, особенно после появления программных
средств, снявших проблему громоздкости статистических вычисле-
ний. Если изучаемые факторы имеют качественный характер (на-
пример, при оценке влияния на экономическую эффективность но-
вой системы управления производством), дисперсионный анализ
приобретает особую ценность, так как становится единственным
статистическим средством, позволяющим дать такую оценку.
Сейчас теорию дисперсионного анализа можно считать вполне
завершенной, но способы организации эксперимента и вычисли-
тельные схемы продолжают совершенствоваться.
Постановка задачи осуществляется следующим образом. В ряде
испытаний имеется несколько факторов, вызывающих изменчи-
вость средних значений наблюдаемых случайных величин - ре-
зультативных признаков. Эти факторы могут принадлежать к од-
ному или нескольким источникам изменчивости (например, распо-
ложение торговых заведений в центре и на окраине города, измене-
ния в законодательстве, разные климатические условия, разные
уровни образования и т.п.). Очевидно, что даже при самом тща-
тельном исследовании не удастся выявить все источники изменчи-
вости, а иногда в этом нет необходимости или смысла. Но эксперт
при наличии должного опыта и в зависимости от цели исследова-
ния всегда может выдвинуть гипотезу о влиянии тех или иных фак-
торов на результативный признак.
Дисперсионный анализ позволяет установить, оказывает ли тот
или иной из рассматриваемых факторов существенное влияние на
изменчивость признака, а также определить количественно «удель-
ный вес» каждого из источников изменчивости в их общей сово-
купности. При этом можно получить ответ лишь о наличии сущест-
венного влияния; в противном случае вопрос остается открытым и
требует дополнительных исследований (чаще всего - увеличения
числа опытов).
В дисперсионном анализе используют следующие термины:
фактор (X) - признак, который, по мнению аналитика, оказыва-
ет влияние на результат (результативный признак) Y;
уровень фактора или способ обработки (иногда его можно пони-
мать буквально, например, способ обработки почвы) - значения,
которые может принимать фактор (Xj,j = 1, 2,..., J).
отклик - значение измеряемого признака (величина результа-
та Yt).
Техника дисперсионного анализа меняется в зависимости от
числа изучаемых независимых факторов. Если факторы, вызываю-
щие изменчивость среднего значения признака, принадлежат к од-
ному источнику, мы имеем простую группировку или однофактор-
ный дисперсионный анализ; далее, соответственно, двойную груп-
> *
19
пировку и двухфакторный анализ, в общем случае - ш-факторный
анализ.
Факторы в многофакторном анализе принято обозначать латин-
скими буквами: А, В, Си т.д.
Задача дисперсионного анализа — исследование влияния тех или
иных факторов (или уровней факторов) на изменчивость средних
значений наблюдаемых случайных величин.
Сущность дисперсионного анализа состоит в том, чтобы выде-
лить и оценить отдельные факторы, вызывающие изменчивость ре-
зультативного признака. С этой целью производят разложение об-
щей дисперсии сг2 наблюдаемой частичной совокупности (общей
дисперсии признака), вызванной всеми источниками изменчивости,
на составляющие дисперсии, порожденные независимыми факто-
рами. Каждая из этих составляющих дает оценку дисперсии сг2а,
2
ав,..., вызванной конкретным источником изменчивости, в общей
совокупности. Для проверки значимости этих оценок дисперсии их
сравнивают с общей дисперсией в общей совокупности по крите-
рию Фишера.
Например, в двухфакторном анализе мы получим разложение
вида:
2 2 2 2 2
°C ~ °А + &В + аАВ + аЕ ’
где ст2 - общая дисперсия изучаемого признака С; ст2, сгв, су2ав ,
сг2 - части общей дисперсии, вызванные соответственно влиянием
фактора А, фактора В, взаимодействием факторов А и В, неучтен-
ными случайными причинами.
В дисперсионном анализе в качестве нулевой гипотезы Но при-
нимается утверждение, что ни один из рассматриваемых факторов
не оказывает влияния на изменчивость признака. Значимость каж-
дой из оценок дисперсии проверяется по величине ее отношения
к оценке случайной дисперсии путем сравнения с соответствую-
щим критическим значением ^-распределения Фишера - Снедекора
при уровне значимости а. Гипотеза Но относительно того или иного
источника вариации отвергается, если FpaC4 > FKp (например, для
фактора В: SbIS? > FKp).
При проведении анализа необходимо различать эксперименты,
в которых:
все факторы имеют систематические (фиксированные) уровни;
все факторы имеют случайные уровни;
есть факторы, имеющие как случайные, так и фиксированные
уровни.
Эти типы экспериментов соответствуют трем типам моделей,
рассматриваемым в дисперсионном анализе.
20
4. КОРРЕЛЯЦИОННО-РЕГРЕССИОННЫЙ АНАЛИЗ
Наблюдения за объектом в некоторый момент времени могут
быть представлены матрицей Хтк. Обычно считается, что часть пе-
ременных являются независимыми (входными, объясняющими или
факторными, Xj), а часть - зависимыми (выходными или результа-
тивными, У).
Цель корреляционного анализа в узком смысле слова - дать
оценку степени тесноты связи (степени линейной зависимости) ме-
жду переменными, двумя или несколькими, а в широком смысле -
помимо оценки тесноты получить также уравнение зависимости
(регрессионный анализ). Корреляционный анализ позволяет ото-
брать факторы, влияющие на результативную переменную, на ос-
новании корреляционной матрицы
П1 г\2 - г\к
R_ г2\ г22 ••• г2к
_гк\ гк2 - гкк_
sli
где г/. = —---оценка паоного коэффициента корреляции.
Регрессионный анализ - один из самых распространенных мето-
дов обработки результатов наблюдений; он служит основой для
целого ряда других методов математической статистики, таких как
планирование эксперимента, дисперсионный анализ, многомерный
статистический анализ.
Цель исследования в данном случае - установить по результа-
там статистических наблюдений (пассивных или активных) адек-
ватную аналитическую зависимость (уравнение регрессии) между
показателями и факторами, которые характеризуют изучаемые сис-
темы. Это соответствует одной из наиболее общих задач статисти-
ки - оценке степени и формы связи между величинами.
Стандартный подход предполагает, что имеет место линейная
зависимость вида
р
yj=bo+Yjbjxy+£i ’ (<= (1.1)
7=1
где у, - п случайных величин (наблюдаемые выходные переменные), пред-
ставляемые как линейные комбинации Ху с р неизвестными постоянными
bb b2, ...,ЬР плюс ошибки £Ь е2, ..., £„; Ху - известные значения наблюдений
(постоянные коэффициенты).
21
Чтобы определить неизвестные параметры линейной модели,
используют метод наименьших квадратов (МНК), позволяющий
находить параметры из условия минимизации суммы квадратов
ошибок: £с2 —* m*n (рис. 1.2). Его применение предполагает вы-
полнение классических условий Гаусса - Маркова:
входные переменные измерены без ошибок и не коррелирован-
ны (гу <0,6); в противном случае смещенные оценки ^-коэффици-
ентов можно получить с помощью гребневой регрессии, либо нуж-
но отбросить один из факторов;
дисперсия ошибок должна быть постоянной (в противном слу-
чае используется взвешенный МНК);
ошибки подчиняются нормальному закону (многочисленные ис-
следования показали, что это условие можно ослабить).
Вектор
ошибки е
Проекция
вектора
зависимой
переменной
Рис. 1.2. Интерпретация метода наименьших квадратов для случая двух
независимых переменных
Отбор переменных в уравнение регрессии должен осуществ-
ляться по смыслу и может подкрепляться корреляционным анали-
зом, а также методом пошаговой регрессии, основанным на исполь-
зовании F-критерия Фишера для оценки статистической значимо-
сти каждой переменной. Входные переменные Xj можно разделить
на ненаблюдаемые (латентные) и наблюдаемые (явные). Среди
последних выделяют контролируемые и управляемые переменные,
позволяющие проводить соответственно активные (планируемые) и
пассивные эксперименты.
5. КОВАРИАЦИОННЫЙ АНАЛИЗ
Основную идею ковариационного анализа целесообразно рас-
смотреть на конкретном примере, относящемся к сельскому хозяй-
22
ству. В настоящее время идет поиск наиболее рациональных мето-
дов обработки результатов многолетних полевых опытов; обычно
при этом используют различные модели дисперсионного анализа.
В ходе опыта часто регистрируют целый ряд сопутствующих не-
контролируемых переменных, меняющихся при его повторении, -
например, погодные условия на разных стадиях развития растений,
выражаемые переменными Xs (ковариаты).
Пусть ковариаты наблюдаются на фоне двухфакторного иерар-
хического опыта: фактор В (доза внесения удобрений) «сгруппиро-
ван» внутри главного фактора А (предшественники). При этом ве-
личины Xs, которые часто называют «сопутствующими» перемен-
ными, на самом деле могут иметь большее значение для объясне-
ния различий в средней урожайности, чем указанные основные
факторы.
Для совместного учета перечисленных количественных и каче-
ственных факторов Р. Фишер еще в 1932 г. предложил использо-
вать модель ковариационного анализа, которая в нашем случае бу-
дет иметь следующий вид:
р ___
Уук ~ 1bs (xijsk ~ s ) + &ijk »
5=1
где ц - многолетняя средняя; Г,- - член формулы, отражающий влияние
главного фактора A (i = 1,..., 5); - член формулы, отражающий влияние
фактора В для определенного значения (г) главного фактора А (у = 1, 2, 3);
^^s(xijsk ~ Уs^~ уравнение регрессии, связывающее у и хь ..., хр (его
5=1
коэффициенты bs отражают влияние сопутствующих переменных на вели-
чины уД
Уравнение регрессии призвано снизить значение остаточной
дисперсии для получения более надежных результатов дисперси-
онного анализа.
Следует отметить, что ковариационный анализ сводится к дис-
персионному или к регрессионному; в последнем случае для этого
необходимо ввести в уравнение регрессии фиктивные переменные,
характеризующие качественные факторные признаки. Применение
ковариационного анализа (в классическом случае) предполагает
нормальное распределение опытных данных и равенство коэффи-
циентов регрессии по группам.
Приведенная формула имеет общий характер и в зависимости от
типа значений {Ху} может описывать три различные схемы:
если Ху = {0; 1}, возникает модель дисперсионного анализа;
если переменные Ху пробегают непрерывное множество значе-
ний (например, время I, температура Т и т.п.), мы имеем дело с мо-
делью регрессионного анализа;
23
если некоторые их этих переменных дискретны, а другие непре-
рывны, речь идет о модели ковариационного анализа.
В настоящее время существует обобщенное представление дан-
ной формулы в виде общей линейной модели, которая позволяет
рассматривать несколько результативных переменных и получать
удовлетворительные решения в случаях, когда классический под-
ход не срабатывает.
6. КОМПОНЕНТНЫЙ АНАЛИЗ
С точки зрения системного подхода любой сложный объект
(фирма, банк, предприятие) может быть охарактеризован только
при помощи сложного набора признаков (параметров, показателей).
Обычно по этому набору строят корреляционную матрицу, элемен-
ты которой характеризуют степень линейной зависимости между
признаками. Но в том случае, когда таких признаков много, интер-
претировать выявленные связи (или хотя бы отделить существен-
ные от несущественных) оказывается очень непросто. Возникает
потребность в сжатии информации, то есть в описании объектов
меньшим числом обобщенных показателей. Их функцию могут вы-
полнять главные компоненты - укрупненные показатели, отра-
жающие объективно существующие закономерности, не поддаю-
щиеся непосредственному наблюдению.
Конечная цель регрессионного анализа - построить уравнение
регрессии, допускающее содержательную интерпретацию. В методе
главных компонент (МГК) корреляционная матрица - это ступень
для дальнейшего анализа данных. Негативная сторона такого под-
хода - сложность математического аппарата, но эту проблему мож-
но обойти при использовании современных программ статистиче-
ского анализа.
В расчетах необходимо найти все и компонент, однако большая
доля изменчивости признаков объясняется гораздо меньшим их
числом (ти). По признакам всегда можно описать компоненты, а по
компонентам - признаки. МГК одинаково хорошо приближает и
дисперсии и ковариации.
При использовании МГК обычно ставятся следующие задачи:
поиск скрытых закономерностей;
описание изучаемого процесса в пространстве меньшей размер-
ности;
выявление и изучение стохастической связи признаков с глав-
ными компонентами;
использование полученных главных компонент для прогнозиро-
вания на основе построенного по ним уравнения регрессии.
МГК имеет важное преимущество перед обычным регрессион-
ным анализом: мультиколлинеарность факторов не влияет на ре-
зультаты моделирования.
24
7. ФАКТОРНЫЙ АНАЛИЗ
При исследовании сложных систем (например, в биологии, пси-
хологии, социологии и т.д.) часто нельзя непосредственно измерить
величины, определяющие свойства этих объектов (факторы); ино-
гда нам неизвестны даже их число и содержательный смысл. Для
измерения могут быть доступны другие величины, тем или иным
способом зависящие от факторов. При этом, когда влияние неиз-
вестного фактора проявляется в нескольких измеряемых признаках,
эти признаки могут обнаруживать тесную связь между собой (на-
пример, коррелированность), поэтому общее число факторов может
быть гораздо меньше, чем число измеряемых переменных, которое
обычно выбирается исследователем достаточно произвольно. Для
обнаружения латентных переменных, влияющих на измеряемые,
и предназначены методы факторного анализа. Его часто иллюстри-
руют методом главных компонент, который основан на аналогич-
ной идее; но в факторном анализе используются и другие методы
(рис. 1.3). В частности, в МГК дисперсия признаков полностью объ-
ясняется латентными факторами, тогда как в факторном анализе
допускается возможность того, что часть этой дисперсии не распо-
знается.
Рис. 1.3. Классификация методов факторного анализа
Возникновение факторного анализа обычно связывают с поя-
вившейся в 1901 г. статьей К. Пирсона «Переход по линиям и плос-
костям к визуализированным системам точек в пространстве»,
25
в которой впервые была высказана идея построения главных осей -
основы метода главных компонент. Первоначально факторный ана-
лиз предполагалось использовать в психологии для построении ма-
тематических моделей способностей и поведения человека. Глав-
ную роль здесь сыграл Ч. Спирмен, опубликовавший в 1904 г. ста-
тью «Общие сведения об объективных решениях и измерениях» и
посвятивший около 40 лет развитию методов факторного анализа.
Затем это направление развивали Л. Гуттман, Г. Хотеллинг, Л. Тэр-
стоун, Г. Харман и др.
Основная задача факторного анализа - сжатие информации и ви-
зуализация данных; данный метод может эффективно использо-
ваться в корреляционно-регрессионном, кластерном и путевом ана-
лизе.
8. МЕТОДЫ АВТОМАТИЧЕСКОЙ КЛАССИФИКАЦИИ
Кластерный анализ представляет собой совокупность методов,
позволяющих классифицировать многомерные наблюдения, каждое
из которых описывается набором исходных переменных х\, х„.
Цель кластерного анализа - образование групп сходных объектов,
которые принято называть кластерами (класс, таксон, сгущение).
В отличие от обычных статистических группировок, это приводит
к разбиению совокупности по всем признакам одновременно, что
позволяет выявлять внутренние связи между ее единицами и давать
их более надежную классификацию. Кроме того, кластерный ана-
лиз может использоваться и с целью сжатия информации.
Основные задачи кластерного анализа:
классификация объектов с учетом признаков, отражающих их
природу (известно, что еще Аристотель классифицировал предметы
исходя из их сходства и различия);
проверка предположений, высказываемых о структуре данных;
построение новых классификаций.
При этом используют следующие методы:
агломеративные (объединяющие отдельные объекты в группы);
итеративные (метод ^-средних);
дивизимные (разделяющие группы на отдельные объекты).
Дискриминантный анализ решает задачу различения (дискрими-
нации) объектов наблюдения по определенным признакам; при
этом новые кластеры не образуются, а формулируется правило, по
которому новые единицы совокупности относятся к одному из уже
существующих классов. Такой подход позволяет интерпретировать
различия между существующими классами (например, с помощью
дискриминантной функции), а также относить объекты к тому или
иному классу с помощью различных средств (функций классифи-
кации, метода эталона, метода ближнего соседа, метода дальнего
соседа и др.).
26
Одна из основных проблем в методах классификации - выбор
адекватной меры расстояния. Например, если имеются две точки
А (хь л) и в (*2, Уг), то, согласно мере Евклида, расстояние между
ними определяется по формуле
Ре(АВ) = +(У2-У02
Вместе с тем, если А и В - это граничные точки одной из диаго-
налей прямоугольника, представляющего собой городской квартал,
то для водителя автомобиля расстояние между ними будет выра-
жаться формулой
рг(^В) = |х2-х1| + |у2-у1|.
Очевидно, что подобных мер может быть сколько угодно; глав-
ное - чтобы они не противоречили содержательному смыслу ре-
шаемой задачи.
9. КАНОНИЧЕСКИЕ КОРРЕЛЯЦИИ
Метод канонических корреляций (МКК) относится к статисти-
ческим методам анализа связей между массовыми общественными
явлениями. В экономико-статистических исследованиях часто воз-
никает необходимость выявить на основании эмпирических данных
зависимость результативных показателей производственно-
хозяйственной деятельности Y от факторов X, их определяющих.
Если Y зависит от одной переменной X, то степень связи харак-
теризуется парным коэффициентом корреляции у^.
Если Y зависит от нескольких переменных X/, степень связи ха-
рактеризуется матрицей парных коэффициентов корреляции
г г у
УУ Х\У ХкУ
У У г
р_ 'yxt 'XiXi ••• rxkXi
У У .У
\_УХк ХхХк гхкхк]
Если несколько выходных переменных Yg зависят от нескольких
переменных Xj, то вводится понятие канонической корреляции yuv -
корреляции между новыми компонентами (каноническими пере-
менными) U и V, где
C/ = <7jXi + а2Х2 +... + акХк‘, V = b\Y\ +b2Y2 +... + bmYm;
_cov(C7,r)
Г11У ~
27
Пусть, например, эффективность работы сельскохозяйственных
предприятий оценивается такими результативными показателями,
как У] — производительность труда, Y2 — фондоотдача основных
фондов, У3 — прибыль, У4 - рентабельность, а в роли факторов вы-
ступают Х\ — численность работающих, Х2 — стоимость основных
фондов, Х3 - оборачиваемость оборотных средств, Х4 — удельный
вес потерь от брака, Х5 - трудоемкость единицы продукции. В этом
случае МКК дает возможность одновременно анализировать не-
сколько входных и несколько выходных переменных, и при этом не
требуется (!) отсутствие их коррелированности.
Главная цель МКК - поиск максимальных корреляций между
группами факторных и результирующих признаков, то есть оты-
скание пары канонических переменных U и V с максимальным зна-
чением Гцу.
В отличие от rxv Пирсона, знак гцу не свидетельствует о направ-
лении связи между переменными и может выбираться в зависимо-
сти от экономического смысла изучаемых показателей.
Математический аппарат метода основан на использовании мат-
рицы ковариаций для нахождения максимума ruv с помощью мето-
да множителей Лагранжа и вычисления собственных значений век-
тора. Таким образом, МКК, наряду с общими линейными моделями
(GLM), позволяет дать оценку взаимосвязи нескольких факторных
переменных не с одной, а сразу с несколькими результативными.
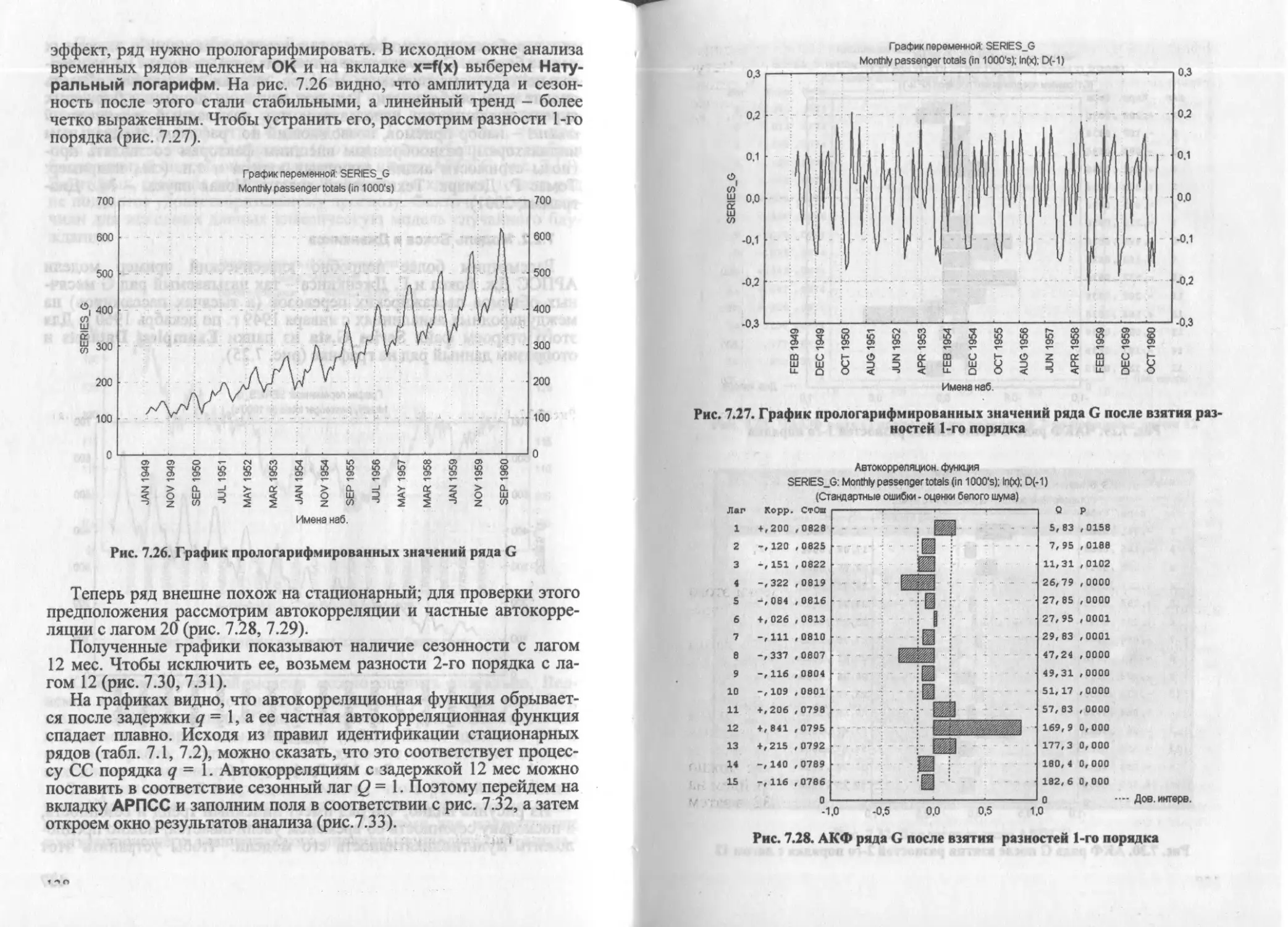
10. ВРЕМЕННЫЕ РЯДЫ
Наблюдения, проводимые за одним или несколькими факторами
в течение некоторого времени, приводят к формированию времен-
ных рядов (одномерных и многомерных соответственно). Опреде-
лим дискретный временной ряд как последовательность измерений
значений переменной (процесса) за определенный период через
одинаковые промежутки времени:
Zi, Z2,..., Z6 ..., Zn.
Последовательные наблюдения обычно зависимы, что с детер-
министской точки зрения можно представить так:
Zt=f(t) + zh
где t = 1, 2, ..., n,f- гладкая (непрерывная и дифференцируемая)
функция, характеризующая долгосрочное изменение переменной во
времени (тренд); 8, - случайный ряд возмущений, наложенный на
тренд.
Анализ временных рядов может преследовать различные цели,
в том числе:
описание поведения ряда;
построение модели, объясняющей наблюдаемые изменения;
28
прогнозирование показателей ряда исходя из предположения,
что основная тенденция сохранится в будущем.
Для достижения поставленных целей используют модели, осно-
ванные на детерминистском, стохастическом, спектральном и дру-
гих подходах. В общем случае в модель включают следующие ком-
поненты:
тренд или долгосрочные колебания;
регулярное движение относительно тренда;
сезонную компоненту;
случайный остаток.
Временной ряд может быть представлен как сумма или как про-
изведение перечисленных компонент; соответствующая модель на-
зывается аддитивной или мультипликативной.
11. ЭЛЕМЕНТЫ ПРИКЛАДНОЙ СТАТИСТИКИ
Прикладная статистика отличается от математической тем, что
использует предположения не только о вероятностной, но и о гео-
метрической природе данных (забегая вперед, отметим, что методы
интеллектуального анализа точно так же предполагают существо-
вание содержательной, или когнитивной, природы данных).
Важным моментом при выборе математического инструмента-
рия исследования является разведочный анализ данных (РАД).
Обычно его используют, когда таблица многомерных данных уже
имеется, а априорная информация о механизме их генерации и при-
чинных связях неполна или вообще отсутствует. Основная цель
РАД - построить в указанных условиях статистическую модель
данных (описать их структуру), которую затем необходимо вери-
фицировать (проверить).
Создателем данного метода считается Дж. Тьюки (1962 г.). РАД
может оказать большую помощь при описании структуры данных
в компактном и понятном исследователю виде, сохраняя при этом
всю существенную информацию. Если в результате визуализации
этой структуры встает вопрос о детальном исследовании с помо-
щью тех или иных средств MCA, он может использоваться в каче-
стве инструмента подтверждающего анализа.
В процессе разведочного анализа применяются различные пре-
образования данных и способы их наглядного представления, по-
зволяющие выявить внутренние вероятностные и геометрические
закономерности, сформировать рабочие гипотезы и провести их
верификацию. В отличие от традиционных приемов проверки гипо-
тез, связанных с оценкой априорных предположений (таких как
«имеется отрицательная корреляция между возрастом человека и
его склонностью к риску»), РАД применяется для нахождения свя-
зей между переменными в ситуациях, когда какие-либо представ-
ления о природе этих связей отсутствуют или недостаточны.
29
Как правило, при разведочном анализе учитывается и сравнива-
ется большое число переменных, а для поиска закономерностей мо-
гут использоваться самые разные методы. В 1960-1970 гг. преобла-
дал «ручной» подход, с использованием математических таблиц,
логарифмической линейки, карандаша, кальки и миллиметровой
бумаги для построения графиков. В связи с компьютеризацией об-
щества уже с 1980-х годов все шире стали применяться методы ви-
зуализации (2D и 3D графики, пиктограммы, диаграммы и др.). Вы-
числительные средства РАД включают как основные статистиче-
ские методы, так и более сложные, специально разработанные для
отыскания закономерностей в многомерных данных. К ним отно-
сятся, в частности, анализ распределений переменных (например,
чтобы выявить переменные с несимметричным или негауссовым
распределением, в том числе и бимодальные), просмотр корреляци-
онных матриц с целью поиска коэффициентов, превосходящих по
величине определенные пороговые значения, анализ многовходо-
вых таблиц частот и др. РАД образует основу современной методи-
ки оперативной аналитической обработки многомерных баз данных
(online analytical processing, OLAP; см. [8, 17, 20, 28]).
В разведочном анализе используются следующие методы.
1. Визуализация данных и манипуляция с данными на основе
графического изображения (диаграммы, гистограммы, «ящик
с усами», «лица Чернова», «лассо», вращение, закрашивание, 3D и
4D графики, категоризированные графики).
Заметим, что термин «категоризированные графики» впервые
был использован в программе Statistica компании StatSoft в 1990 г.
(Becker, Cleveland и Clark из Bell Labs называют их графиками на
решетке). Они представляют собой наборы двумерных, трехмер-
ных, тернарных или «-мерных графиков (включая гистограммы,
диаграммы рассеяния, линейные графики, поверхности, тернарные
диаграммы рассеяния и др.), по одному графику для каждой вы-
бранной категории наблюдений (например, для опрашиваемых из
Москвы, Краснодара и т.д.). Эти входящие графики располагаются
последовательно в одном графическом окне, позволяя сравнивать
структуру данных для каждой из указанных подгрупп. Для выбора
этих подгрупп можно использовать множество методов, самый
простой из которых - введение категориальной переменной.
2. Использование активных и иллюстративных переменных
(обучающей и экзаменующей последовательности).
3. Преобразования данных, облегчающие выявление их структу-
ры, линеаризация связей, анализ остатков и другие методы MCA.
Одная из задач РАД - выявление выбросов или артефактов (не-
типичных, редких значений признаков); они могут соответствовать
действительности или возникать в результате ошибок наблюдения,
но в любом случае существенно искажают основные закономерно-
сти (рис. 1.4).
30
Центральная точка - среднее
арифметическое наблюдений
ВГ - верхняя граница (среднее
плюс стандартное отклонение)
НГ - нижняя граница (среднее
минус стандартное отклонение)
Центральная точка - медиана
ряда наблюдений
ВГ - верхняя граница (75%-ный
квартиль)
НГ - нижняя граница (25%-ный
квартиль)
ш = (ВГ - НГ) - ширина
к>0 - произвольный коэффициент
(по умолчанию, согласно Дж. Тьюки, к = 1,5)
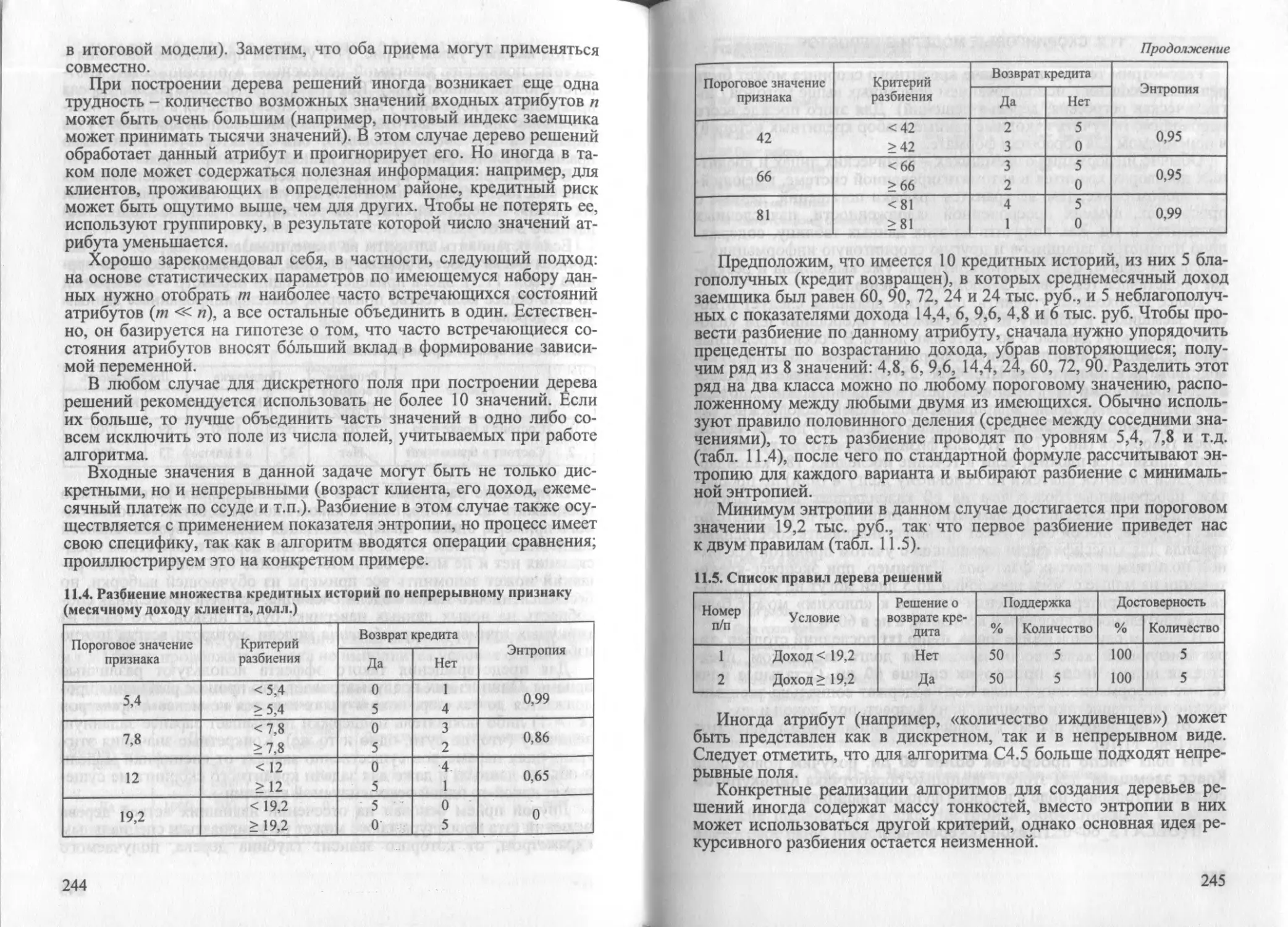
Рис. 1.4. Диаграммы размаха с изображением выбросов (Дж. Тьюки, 1970)
Для верификации результатов РАД рекомендуется использовать
аппарат иллюстративных переменных и объектов.
Более подробно с современными методами прикладной стати-
стики можно ознакомиться по литературным источникам [3-5,
14-16, 19, 23, 25], а также по электронным учебникам фирмы Stat-
Soft, которые в основном соответствуют описанию статистических
модулей пакета Statistica (Электронный учебник по промышленной
31
статистике. - М.: StatSoft, 2001; см. также http: //www. statsoft.
ru/home/portal/textbook_ind/default.htm).
12. СОВРЕМЕННЫЕ ПАКЕТЫ ПРИКЛАДНЫХ ПРОГРАММ
МНОГОМЕРНОГО СТАТИСТИЧЕСКОГО АНАЛИЗА
С появлением персональных компьютеров методы анализа дан-
ных стали использоваться гораздо шире, чем прежде. Примерно
с середины 1980-х годов соответствующие программы стали при-
обретать коммерческие организации, правительственные и меди-
цинские учреждения. На Западе они превратились в общеупотреби-
тельный инструмент плановых, аналитических, маркетинговых от-
делов крупных и средних компаний. Даже представители мелких
фирм прибегают к методам анализа данных - либо самостоятельно,
либо обращаясь к консультантам-посредникам. Типичные сферы
его применения - прогнозирование валютных курсов, цен, спроса
на продукцию, контроль качества продукции, анализ эффективно-
сти нововведений, построение классификаций и т.п.
Компьютер освобождает пользователя от рутинной работы -
расчетов, построения графиков и таблиц; ему остается только твор-
ческая работа: постановка задачи, выбор метода, оценка качества
модели, интерпретация результатов.
В России первой книгой, посвященной анализу данных на ком-
пьютере, была монография А. Афифи и С. Эйзена «Статистический
анализ: подход с использованием ЭВМ» [7]. Сейчас это уже клас-
сика жанра (см. также [11-15, 21, 22, 36, 37, 40, 41, 52-55]).
Многие инструменты MCA имеются в СУБД и табличных про-
цессорах (например, в Excel), но для систематического использова-
ния гораздо лучше подходят специализированные статистические
пакеты (СПП). Некоторые из них (BMDP, SAS, SPSS) первоначаль-
но разрабатывались для больших ЭВМ, другие появились уже
в эпоху персональных компьютеров (SYSTAT, Statistica и др.). Да-
лее мы дадим краткий обзор наиболее популярных программ, осно-
ванный на аналитической статье С.А. Айвазяна и В.С. Степанова
«Программное обеспечение по статистическому анализу данных:
методология сравнительного анализа и выборочный обзор рынка»
(http://isl.cemi.rssi.ru/ruswin/publication/ep97001t.htm).
Всего в настоящее время известно около тысячи СПП; их стои-
мость в основном колеблется в пределах от 20 тыс. до 40 тыс. руб.
Принято различать три типа таких программ:
профессиональные, которые могут работать с очень большими
базами данных и включают узкоспециализированные методы (SAS,
BMDP); их стоимость может быть очень большой;
универсальные - близкие по возможностям к профессиональным
и гораздо более доступные по цене, такие как SPSS, Statistica,
SYSTAT, S-PLUS;
32
специализированные на использовании конкретных методов
(одного-двух) или предназначенные для конкретных целей (анализ
временных рядов, классификация, контроль качества промышлен-
ной продукции и др.).
Заметим, что информация о любых компьютерных средствах
быстро устаревает. На этом рынке постоянно происходят процессы
вытеснения и консолидации - выигрывают те фирмы, которые мо-
гут предложить наилучший продукт быстрее других и по более
низкой цене. Для оценки их рейтинга можно использовать схему,
приведенную на рис. 1.5.
Рис. 1.5. Схема оценки рейтинга программных продуктов
В России наибольшее распространение получили пакеты SAS,
SPSS и Statistica. Имеются как русские, так и англоязычные их вер-
сии (последние примерно на 10% дешевле). Распространяющие их
компании ведут ценовую политику, направленную на завоевание
российского рынка; учебным и государственным учреждениям
предоставляются скидки. Основные характеристики этих и некото-
рых других программ приведены в табл. 1.2.
Главная проблема, с которой сталкиваются производители ста-
тистических пакетов в России, - недостаточное знание потенциаль-
ными пользователями возможностей их продуктов. В СССР стати-
стическая информация была практически закрыта, а возможности
использования публикуемых материалов крайне ограничены. Есте-
ственно, что и соответствующее программное обеспечение приме-
нялось крайне редко.
3 КацкоИ.Л.. Паклин H.I
33
1.2. Обзор статистических пакетов, представленных на российском рынке
спп Год выпуска первой версии, допол- нительная информация Пользователи
SAS Base (http://www.sas. com/russia/) 1976 г. Может работать в 12 операцион- ных системах (DOS,Windows и др.) Около 3 млн в 120 странах мира. В России: Центро- банк, биржи, торговые фирмы, атомные станции, медицинские и геофизиче- ские центры
SPSS (http://www.spss. ru/) 1965-1967 гг. Создатели - Н. Най и Д. Вент, студенты-политологи. В 1994 г. фирма приобрела SYSTAT, в 1996 г.-BMDP Статистики-профессионалы
SYSTAT 1980-е годы. Изначально спроектирован под IBM PC, в 1991г. признан лучшим универсальным пакетом. В 1994 г. поглощен SPSS Около 150 учебных заведе- ний во всем мире, более 200 тыс. пользователей
STATGRA- PHICS 1980-е годы. В начале 1990-х годов делил 2-3-е места с SAS, в 1995 г. вышел на 1 -е место Статистики-профессиона- лы, учебные заведения
Statistica (http://www. statsoft.ru) 1991 г. В 2000 г. по обзору журнала «Futures Magazine Review» Statis- tica (версия 5.5) получила наи- высший рейтинг, опередив SPSS (версии 10) Статистики-профессиона- лы, учебные заведения, банки, отделы маркетинга и производства в корпора- циях, медицинские учреж- дения
Продолжение по горизонтали
СПП Плюсы Минусы
SAS Base (http://www. sas.com/ russia/) 1. Мощное статистическое ядро 2. Поддержка 5 архитектур кли- ент-сервер (OLE, DDE и др.) 3. Включает более 20 программ- ных продуктов, объединенных средствами доставки IDS (Infor- mation Delivery System), что по- зволяет выполнять любые опера- ции в любой операционной сис- теме, в том числе решаемые в Word, Excel и других офисных приложениях 1. Громоздкость 2. Трудность в освоении 3. Высокие требования к квали- фикации пользователя 4. Высокие требования к аппа- ратному обеспечению 5. Высокая цена 6. Сложная документация (объем более 5000 с.)
34
Продолжение
СПП Плюсы Минусы
SPSS (http://www. spss.ru/) 1. По мощности соизмерим с SAS 2. Имеется документация на рус- ском языке 3. Большой набор инструментов по работе с нечисловыми данны- ми Высокая цена (если приобретает- ся несколько модулей, действует система скидок)
SYSTAT 1. Подробная документация (4 тома) 2. Наличие удобных графических средств, высокая точность вы- числений 3. Наличие модулей дисперсион- ного анализа, планирования экс- периментов 4. Наличие редко применяемых средств статистического анализа 1. Часть команд доступна только из командной строки 2. Отсутствует хороший редактор отчетов 3. Число переменных ограничено (в версии 5.04 - 256). Начиная с 6-й версии, это ограничение сня- то, но цена пакета резко возросла
STATGRA- PHICS 1. Связь со всеми приложениями Windows 2. Включает более 250 статисти- ческих процедур 3. Наличие модуля Statadvisor 4. Умеренная цена (749 долл, за базовую систему). За модули контроля качества, анализа вре- менных рядов, многомерного анализа необходимо платить от- дельно 1. Низкая точность вычислений (4—5 знаков) 2. Уступает по мощности SYSTAT и SPSS 3. Сложен в освоении
Statistica (http://www. statsoft.ru) 1. Имеются русскоязычные вер- сии 5.5 и 6.1. 2. Поддержка OLE, DDE 3. Имеется русифицированная справка и документация для вер- сии 5.5-3000 с., для версии 6.1 - 1343 с. 4. Имеется русифицированный электронный учебник объемом 10 Мб (описано около 30 моду- лей, соответствующих версии 5.5) 5. Наличие модуля Statadvisor 1. Справки иногда слишком де- тальны, иногда недостаточно полны 2. Вывод результатов в версии 6.1 осуществляется в виде рабо- чих книг и отчетов, с иерархиче- ским оглавлением, но в вер- сии 5.5 этого нет 3. Высокая цена (для учебных учреждений предоставляется скидка)
Но и в наши дни многие руководители и специалисты по-преж-
нему считают, что статистические исследования - это бессмыслен-
ная трата денег. В последние 10-15 лет большинство крупных
предприятий и научных учреждений, особенно в аграрном секторе,
35
боролись за выживание и не могли себе позволить развивать систе-
мы контроля качества, аналитические отделы, заниматься поста-
новкой опытов и обработкой получаемых данных. Сейчас, однако,
ситуация в стране изменилась, в связи с чем необходим качествен-
ный скачок в сознании предпринимателей и администраторов,
а также систематическое обучение студентов методам статистиче-
ского анализа данных. В этом плане можно высоко оценить работу
компании StatSoft Russia, равернувшей активные действия на рос-
сийском рынке, разработавшей русскоязычную версию пакета Sta-
tistica (1999 г.) и электронный учебник для нее, активно и профес-
сионально рекламирующей эту программу [11, 12, 25, 31].
ПРАКТИЧЕСКОЕ ЗАНЯТИЕ 1. ЗНАКОМСТВО С СИСТЕМОЙ
STATISTICA 6.1. КРАТКИЙ ОБЗОР ПАКЕТА И ВОЗМОЖНОСТЕЙ
ВИЗУАЛИЗАЦИИ
Цель занятия: ознакомиться с особенностями интерфейса, воз-
можностями настройки программы; получить навыки ввода дан-
ных и вывода результатов анализа; ознакомиться с возможно-
стями графического представления данных, получить навыки их
визуализации и редактирования графиков
1.1. ОБЩИЕ СВЕДЕНИЯ
Пакет Statistica 5.5 (русскоязычная версия) появился на россий-
ском рынке в 1999 г. и с тех пор является одним из лидеров в об-
ласти визуализации и статистического анализа данных (рис. 1.1).
Он имеет полностью русскоязычный интерфейс, контекстную
справочную систему, около 3000 с. документации с примерами.
Программа обеспечивает импорт из популярных электронных таб-
лиц, публикацию результатов в Интернете, создание макрокоманд,
включает мастера запросов к ODBC-базам данных и встроенный
язык программирования (Statistica BASIC). В следующей версии
(Statistica 6.1), появившейся в 2004 г., обеспечивается вывод ре-
зультатов в виде рабочих книг и отчетов, которые содержат в левой
части иерархическое оглавление. Все результаты, относящиеся
к конкретному виду анализа, помещаются в отдельную папку, мо-
жет одновременно осуществляться структуризация информации
в рабочей книге и создаваться отчет (который удобно описывать и
редактировать).
В версии 6.1 появился также интегрированный в систему язык
Statistica Visual Basic, поддерживающий все возможности Statistica
BASIC и SQL и обеспечивающий профессиональную среду для на-
писания пользовательских приложений.
В новой версии улучшены процедуры импорта данных из фай-
лов различных форматов и баз данных, расширены графические
36
возможности пакета, сняты ограничения на размер текста в назва-
ниях, усовершенствован интерфейс (диалоговые окна разделены на
вкладки).
Statistica 6.1 не состоит, как прежде, из нескольких модулей, ка-
ждый из которых является отдельным Windows-приложением, что
создавало определенные неудобства. Все виды анализа теперь
доступны из команды меню Statistics => Анализы; их подроб-
ное описание можно найти в электронном учебнике или в справоч-
ной системе. Для большинства методов снято ограничение на раз-
мер файла исходных данных (5000x20000), существовавшее в вер-
сии 5.5.
Рис. 1.1. Пакет Statistica
Компания StatSoft предлагает русскоязычные версии Statisti-
ca 5.5 и 6.1 различной комплектации. Для версии 6.1 базовая ком-
понента Statistica Base for Windows может дополняться модулями
Углубленные методы анализа, Многомерный разведочный ана-
лиз, Промышленная статистика и Шесть сигма, Анализ мощно-
сти, Нейронные сети. Все они могут рассматриваться и как от-
дельные приложения. Statistica - система для визуализации и стати-
стического анализа данных, управления базами данных и разработ-
ки пользовательских приложений. Пакет содержит широкий набор
современных средств анализа данных, в том числе:
классические статистические методы (корреляционно-регрес-
сионный, дисперсионный, кластерный, дискриминантный, фактор-
ный, компонентный анализ и др.);
37
специальные методы, традиционно относимые к методам добы-
чи данных (Data Mining - нейронные сети, деревья решений и др.),
а также специализированные процедуры добычи данных в базах
данных и текстовой добычи в Web и из файлов.
Базовые модули Statistica (основные статистики и таблицы, мно-
жественная регрессия, дисперсионный анализ, непараметрическая
статистика, подгонка распределений) используются для первичного
анализа данных. Всего программа предлагает более 10 тыс. вычис-
лительных процедур, сгруппированных по основным направлениям
анализа в более чем 60 модулей (многие виды анализа доступны из
разных модулей). Их список можно получить, дав команду Sta-
tistics => Анализ. Так, блок модулей Углубленные методы анали-
за включает различные современные обобщения регрессионного и
дисперсионного анализа, логит- и пробит-регрессию, анализ выжи-
ваемости, логлинейный анализ, анализ временных рядов и прогно-
зирование, моделирование структурными уравнениями (рис. 1.2).
Каждый модуль имеет две вкладки: Быстрый (Quick) и Допол-
нительно (Advanced), позволяющие проводить первоначальный и
более подробный анализ. Щелкнув по кнопке Переменные (Va-
riables), можно отобрать переменные для анализа. Например, в мо-
дуле Множественная регрессия (Statistics Multiple Regression)
можно указать Зависимые (Dependent) и Независимые (Indepen-
dent) переменные. При необходимости следует выбрать специаль-
ные методы обработки и варианты вывода результатов.
Корпоративные системы Statistica (системы добычи данных, по-
лучения зависимостей, прогнозов и классификаций, включая со-
временные средства бурения и расслоения, ассоциативные правила
и многое другое) обычно используются для работы с большими
базами данных.
Statistica Enterprise Wide Data Mining System (SDM) представляет
собой универсальное средство взаимодействия с различными база-
ми данных и создания готовых отчетов, реализующее графически-
ориентированный подход. SDM включает более 300 основных про-
цедур, специально оптимизированных под решение задач Data
Mining, средства логической связи между ними, управляет потока-
ми данных, позволяет конструировать собственные аналитические
методы.
Statistica Enterprise Wide Data Analysis System (SEDAS) - это
многопользовательская система для решения аналитических задач
в области финансов, маркетинга, а также для интеграции базовой
системы с внешними источниками данных (системами мониторин-
га, сбора данных в режиме реального времени, измерительными
приборами и т.д.).
Statistica Enterprise Wide SPC System (SEWSS) включает локаль-
ные и глобальные корпоративные приложения по контролю качест-
ва (в том числе Шесть сигма).
38
Рис. 1.2. Виды анализа данных в системе Statistica 6.1
Новейшая англоязычная версия Statistica 7 (см. http://www. stat-
soft.ru/_rainbow/documents/NewFeatures_6(7).pdf) содержит допол-
нительные возможности по управлению данными и их графическо-
му отображению, экспорту и импорту данных, выводу результатов;
кроме того, в системе появились опции группового анализа.
Продукты StatSoft можно классифицировать по типу (однополь-
зовательские, корпоративные, на основе интернет-технологий) и по
области применения: добыча данных (добытчик данных, текстовый
добытчик, добытчик качества, нейронные сети, OLAP), хранилища
данных (Data Warehouse), анализ данных (углубленные методы,
нейронные сети, анализ мощности, SEDAS, OLAP), управление до-
кументами (Data Warehouse, Document Management System, OLAP),
контроль качества (карты контроля качества, анализ процессов,
планирование экспериментов, добытчик качества, SEWSS).
1.2. ИНТЕРФЕЙС И ВОЗМОЖНОСТИ ПРОГРАММЫ
Окно программы оформлено в соответствии со стандартами,
принятыми в среде Windows. Сразу после ее запуска можно выпол-
нить следующие операции:
загрузить данные, представленные в виде файла формата .sta и
просмотреть их в табличном виде (Файл Открыть);
создать файл данных и задать двойной формат для текстовых
переменных;
загрузить внешние данные из базы данных, из одного из допус-
тимых поставщиков OLE DB или из электронной таблицы (напри-
мер, из Excel).
Ввод данных, подготовленных в другом приложении, можно
осуществить следующим образом:
скопировать данные и вставить их затем через буфер обмена
Windows;
импортировать из файла Excel все или только выбранные листы
(File => Open Ф Import all sheets to a Workbook или Import se-
lected sheet to a Spreadsheet);
импортировать данные с возможностью динамического обмена
(Edit => Paste special => Paste Link, либо Edit => DDE Links);
импортировать файлы наиболее распространенных баз данных
(Oracle, MS SQL Server, Sybase, MS Access, Fox Pro и др.); при этом
используется технология OLE DB, которая открывает доступ
к большему числу типов данных, чем старая технология ODBC.
Доступ к средствам анализа данных можно получить с помощью
команд главного меню, горячих клавиш, панелей инструментов,
пользовательских панелей, контекстного меню (вызываемого
щелчком правой кнопкой мыши на объекте).
Программа поддерживает многозадачный режим - имеется воз-
можность одновременно работать с несколькими копиями Statistica,
40
в каждой из которых можно проводить несколько видов анали-
за одновременно, как над одними, так и над разными данными.
В нижней части окна приложения одновременно может быть пред-
ставлено несколько функциональных частей, называемых «анали-
зами».
В системе предлагается три варианта пользовательского интер-
фейса: интерактивный, на основе языка SVB и Web-интерфейс.
Подменю Сервис (Tools) => Настройка позволяет настраивать
меню и панели инструментов, Сервис (Tools) Параметры - об-
щие свойства таблиц, графиков, отчетов, рабочих книг и т.д.
Команды меню Данные (Data) дает возможность автоматизиро-
вать работу с переменными и наблюдениями.
В Statistica 6 можно загрузить (или создать) файл, а затем прово-
дить анализ данных, пользуясь различными средствами анализа
(графическими и аналитическими) в одном окне. При этом резуль-
таты анализа представляются в виде иерархического дерева, позво-
ляющего иметь доступ к любым результатам и использовать их для
дальнейшего анализа (как в рабочей книге, так и в отчете).
К документам системы Statistica относятся рабочие книги, элек-
тронные таблицы (мультимедийные таблицы), отчеты, графики и
макросы (программы на языке SVB).
Программа позволяет управлять выводом данных (Файл => Дис-
петчер вывода) по трем основным каналам.
1. Рабочие книги (Workbooks), в которых автоматически сохра-
няются (на отдельных вкладках) все действия с данными в виде
электронных таблиц и графиков (в Statistica 5.1-5.5 каждый график
надо было сохранять отдельно). Используя дерево просмотра в ле-
вой части рабочей книги, можно организовать результаты анализа
в виде иерархии папок или узлов документов (рис. 1.3).
в| WorkbookV
В-Основные статистики/таблицы (Nedvig.sta)
Ё Описательные статистики - диалог
||Ц Таблица частот: Район (Nedvig.sta)
Ц] Таблица частот: Общая (Nedvig.sta)
[ Щ Таблица частот: Цена, тыс. руб. (Nedvig.sta)
@ Гистограм.: Район
Гистограм.: Общая
@ Гистограм.: Цена,тыс. руб.
Диаграмма размаха__________________
Описательные статистики (Nedvig.sta)
Рис. 1.3. Дерево просмотра результатов анализа в рабочей книге
41
Рабочие книги являются оптимизированными Active X контей-
нерами (документами), что позволяет перенести любую часть дере-
ва в другую рабочую книгу, отчет, а также в рабочую область про-
граммы.
2. Отчеты (Reports) - удобная форма описания таблиц, графиков
и моделей анализа в текстовом режиме (рис. 1.4). В версии 6.1 все
эти компоненты импортируются в отчет в самой программе. В пре-
дыдущих версиях требовалось сначала скопировать таблицы ре-
зультатов анализа в Excel, графики - в Word, а затем создавать на
их основе единый документ.
£3 Свержение g , . , . . . 2 . • 3 • ' • 4 • • • 5 • ' • 6 • ' • 7 • ' • 8 • ' • 9 • W 'IV '12' 1 -13- ' '14-
П Таблица частот Цен -й------_±-------‘------Ь------Я-------~±------------i------S-------i------±------—------i-------1----Z-----
0 Гистограм.: Цена.ть
Таблица частот. Цена, тыс. руб. (Недвижимость Краснодара октябрь 2006.sta)
Группа______________
0 000000_<х<=500 0000
5oboboo<x<=ibooodo
1000.000<х<=1500.000
isma»<xo=2ooo обо
2000 000<х<-25СС 000
2500.000<х'<=3000 000
3000.00б<х~<=3600.000
зёоо.ооо<х<=40оаооо
4000.000<х<=450000б
4500.000<х<=5000.000
Пропущ,
К-С d=.1O726, р<.01 тЛиллиефорса рк.ОТ__________________
Частота | Кумул. i Процент [Кумул. %| % всех (Кумул. %
'частота ; допуск ' допуст. наблюд i от всех
0
30'
142'
106
0 0 00000
30 7 67263
172 36 31714
278 27.10997
344 16 87980
365 5.37084
О 0000 0.00000 0.0000
7 6726 7 67263 7.6726
43 9898 36.31714 43 9898
71.0997 27.10997 71.0997
87.9795 16 87980 87.9795
93.3504 5.37084 93.3504
376 2.81330 96.1637 2.81330 96.1637
384 2.04604 98.2097 2.04604 ' 98.2097
390 1.53453 99.7442 1.53453 99.7442
391 0 25575 100.0000 ' 0 25575 100.0000
391 0 00000 0.00000 100 0000
Изучаемые данные по стоимости 1-комнатных квартир г Краснодара содержат 391 наблюдение.
Стомостъ (тыс руб.) от500 до 1000 имеют 30 квартир (7-67%) - очевидно это квартиры ка окраинах и в
пригороде; наибольшее количество квартир в Краснодаре -142 квартиры (3632%) имеет стоимость от
1000 до 1500 ; 106 (27,11%) квартир имеют стоимость от 1500 до 2000 кт.д.
Верхние границы (х <= граница)
Анализ стоимости однокомнатнюс квартир с помощью инструмента визуализации
"DfCTorpaKMaf' - позволяет утверждать, что при уровне значимости не более 0,01
данные подчиняются нормальному закону распределения (критерии Колмогорова-Смирнова
и Лиллиефорса).
Рис. 1.4. Пример отчета в системе Statistica
.42
3. Автономные окна (Individual windows) - представление ре-
зультатов анализа (таблиц, графиков) в отдельных окнах, с которы-
ми можно манипулировать независимо друг от друга.
Графический анализ (визуализация) - это основа разведочного
(исследовательского) анализа данных, разработанного в 1960-е го-
ды Дж. Тьюки. В Statistica все графики имеют контекстное меню,
позволяющее изменять их параметры (в том числе вид подгоняемо-
го распределения). Основные настройки графиков доступны
в меню Сервис => Параметры.
Первый тип графиков - гистограммы (термин введен К. Пирсо-
ном в 1895 г.); они позволяют увидеть, как распределены значения
переменных по интервалам группировки и какому закону распреде-
ления эти данные могут соответствовать.
Диаграммы рассеяния используются для визуального исследо-
вания зависимости между двумя переменными, они позволяют на-
ходить выбросы (нетипичные значения), искажающие параметры
связи между переменными. При открытой второй вкладке меню
диаграммы рассеяния доступны опции вывода на график коэффи-
циента корреляции и уравнения регрессии. Дав команду Сервис <=>
Настройка => Панель инструментов => Графические инструмен-
ты. можно воспользоваться средством визуального анализа Кисть
Ф I, которое позволяет в интерактивном режиме удалять выбросы
и непосредственно наблюдать за изменением аппроксимирующей
функции или линии регрессии.
Важность графического изучения данных можно проиллюстри-
ровать на следующем примере. Зимой 1893/1894 г. Рэлей исследо-
вал плотность азота, полученного разными способами; результаты
его измерений приведены в табл. 1.1.
1.1. Данные различных измерений плотности азота
Дата измерения Исходное вещество Идентифи- катор Очищающий реагент Масса, г
29.11.1893 NO 1 Раскаленное железо 2,30143
5.12 « 1 « 2,29816
6.12 « 1 « 2,30182
8.12 « 1 « 2,29890
12.12 Воздух 0 « 2,31017
14.12 « 0 « 2,30986
19.12 « 0 « 2,31010
22.12 « 0 « 2,31001
26.12 no2 1 « 2,29889
28.12 no2 1 « 2,29940
43
Продолжение
Дата измерения Исходное вещество Идентифи- катор Очищающий реагент Масса, г
9.01.1894 NH4NO2 1 Раскаленное же- лезо 2,29849
13.01 NH4NO3 1 « 2,29889
27.01 Воздух 0 Гидроокись железа 2,31024
30.01 « 0 « 2,31030
1.02 « 0 « 2,31028
Различия в значениях плотности азота побудило исследователя
провести дальнейшее изучение состава воздуха, химически очи-
щенного от кислорода. Это привело к открытию нового элемента
(аргона), за что Рэлей получил Нобелевскую премию.
Ниже приведены две диаграммы размаха («ящик с усами») для
данных Рэлея (рис. 1.5). Главное, что видно на первой диаграмме, -
«усы» коротки по сравнению с «ящиком», поэтому возникает необ-
ходимость в более детальном анализе. На второй диаграмме анало-
гичные схемы для тех же данных, классифицированных по призна-
ку «исходное вещество» («воздух» - 0, «другие источники» - 1), со
всей очевидностью показывают, что из воздуха получается совсем
не тот «азот», что из других источников (из-за примеси аргона).
Диаграмма размаха
Масса (таблица Рэлея sta5v* 15с)
о Медиана = 2,318
I I 25%-75% = (2,2989, 2,3102)
~Т~ Размах без выбр. = (2,2982, 2,3103)
фикатор
о Медиана
□ 25%-75%
ZE Размах без выбр.
Рис. 1.5. Диаграммы размаха
44
Чтобы получить первую из указанных диаграмм, нужно дать
команду Графика => 2М Графики Ф Диаграммы размаха => Пе-
ременные => Зависимая переменная => Масса Ф ОК. Затем в ка-
честве Группирующей переменной следует добавить Идентифи-
катор, и получится вторая диаграмма.
Схемы типа «ящика с усами» не позволяют увидеть, что проис-
ходит около середины выборки; для этого используют точечные
диаграммы. Чтобы получить такую диаграмму для данных Рэлея,
следует дать команду Диаграммы рассеяния <=> Дополнитель-
но *=> Тип графика => Простой => Подгонка => выкл и затем Пере-
менная X Идентификатор (либо другая переменная, прини-
мающая постоянное значение) => Переменная Y => Масса Ф ОК.
Получится график, изображенный на рис. 1.6.
Рис. 1.6. Диаграмма рассеяния
ЗАДАНИЕ
1. Используя приведенные данные, создайте файлы reklama.sta
и oiympic.sta. Наименования переменных должны совпадать
с именами столбцов (их можно ввести, дважды щелкнув по имени
переменной и открыв ее свойства). Чтобы рассчитать площадь рек-
ламы, в нижнем поле Длинная метка или формула с Функциями
свойств переменной Площадь введите формулу =vl*v2; в этом же
поле можно давать описания переменным). В файле oiympic.sta
текстовые переменные следует задать в двойном формате.
Сохраните файлы в своей папке.
2. Опишите документы системы Statistica.
3. Изучите калькулятор вероятностных распределений (рис. 1.7)
и опишите его работу на конкретных примерах для следующих
45
распределений: нормального, Стьюдента, %2 Пирсона, экспоненци-
ального, Фишера.
Исходные данные для файла reklama.sta
Ширина, мм Длина, мм Площадь, мм2 Цена, руб.
47 35 1446
47 73 2768
47 111 3974
47 149 5147
47 187 6290
47 225 7537
47 263 8828
47 301 10260
Исходные данные для файла olympic.sta
Год Чемпион Страна Время, сек
1896 Бэрк США 12
1900 Джервис США 10,8
1904 Хан США 11
1906 Хан США 11,2
1908 Уолкер ЮАР 10,8
1912 Крейг США 10,8
1920 Пэддок США 10,8
1924 Абрахамс Англия 10,6
1928 Уильямс Канада 10,8
1932 Тоулэн США 10,3
1936 Оуэнс США 10,3
1948 Диллард США 10,3
1952 Реминджи США 10,4
1956 Морроу США 10,5
1960 Харри ФРГ 10,2
1964 Хейес США 10
1968 Хайнс США 9,9
1972 Борзов СССР 10,1
1976 Кроуфорд Тринидад 10,1
46
Рис. 1.7. Вероятностный калькулятор
Найдите для нормально распределенной случайной величины
при средней величине М - 2, стандартном отклонении о = 1 веро-
ятность попадания в интервал от 1 до 5.
4. Оформите результаты анализа в виде отчета (Сервис Ф Па-
раметры => Диспетчер вывода => Общий отчет).
5. Загрузите файл Nedvig.xls и просмотрите информацию о пе-
ременных (их нужно выбрать, щелкнув по кнопке Переменные).
Проведите анализ, используя модуль Описательные статистики
(рис. 1.8) и диаграммы. Результаты вычислений просмотрите в ра-
бочей книге и опишите в отчете.
6. Загрузите в программу внешние данные. Для создания связи
дайте команду Файл Внешние данные Ф Создать Запрос
Создать. Далее выберите драйвер для организации доступа к базе
данных (например, Microsoft Jet 4.0 OLE DB Provider или Micro-
soft OLE DB Provider for ODBC Drivers), имя поставщика базы
данных (например, База данных MS Access) и путь к ней (напри-
мер, C:\Program Files\Statistica 6.1\Examples\Examples\Database\
baseball).
Укажите в базе данных необходимые атрибуты запроса (рис. 1.9)
и с помощью кнопки импортируйте данные в предварительно
созданную электронную таблицу.
7. Изучите галерею графиков (рис. 1.10) с помощью электрон-
ного учебника по программе. Опишите основные типы графиков
системы Statistica и условия их применения.
47>
------------------------------------------------—
Олисагояьмме статжпгуки. Hudviu.tta _____
Переменные: | нет
Быстрый | Дополнительно | Нормальность j Диаграммы | Катет, графики Опции |
НтЁгт! Подробные описательные статистики
яи®
Удаление ПД
Г' Построчное
'(* Попарное
Щ Таблицы частот | кЯМ Гистограммы |
ЙИ| Диаграмма размаха для всех переменных |
Рис. 1.8. Модуль Описательные статистики
Рис. 1.9. Окно запроса Statistica
Графика
Продолжить... Ctrl+R
Гистограммы...
Диаграммы рассеяния...
[й*1 Г рафики средних с ошибками...
1^ Графики поверхностей...
И 2М Г рафики ►
ЗМ Последовательные графики ►
ЗМ XYZ графики ►
Матричные графики...
Пиктографики...
® д Категоризованные графики ►
Г рафики пользователя ►
Щ Г рафики блоковых данных ►
1^ Г рафики исходных данных ►
Размещение нескольких графиков ►
Рис. 1.10. Галерея графиков системы Statistica
8. Загрузите файл reklama.sta и проведите анализ зависимости
цены за размещение рекламных материалов от их длины при фик-
сированной ширине. Представьте данные в виде диаграммы рас-
сеяния с соответствующими заголовками осей и уравнением (Гра-
фика <=> 2М Графики вкладка: Дополнительно Ф тип графика:
Простой *=> подгонка: Линейная Отметить в группе статистики
все элементы => ОК).
В файл reklama.sta введите новую переменную с прогнозными
значениями цены, полученными с использованием уравнения рег-
рессии.
ВОПРОСЫ ДЛЯ САМОКОНТРОЛЯ
1. Какие направления анализа данных реализованы в системе Statistica 6.1?
2. Опишите возможности ввода и вывода информации в данной программе.
3. Перечислите основные типы графиков, укажите их назначение и особен-
ности.
4. Для чего в системе Statistica используется инструмент визуального ана-
лиза Кисть?
4 Капко И.Л., Паклнн Н.Б.
49
ПРАКТИЧЕСКОЕ ЗАНЯТИЕ 2. ДИСПЕРСИОННЫЙ АНАЛИЗ
Цель занятия: ознакомиться с возможностями дисперсионного
анализа в системе Statistica, приобрести навыки его проведения
2.1. ТЕОРЕТИЧЕСКИЕ СВЕДЕНИЯ
Рассмотрим единичный качественный фактор, который может
иметь р различных уровней, и предположим, что на каждом уровне
сделано п наблюдений; в сумме это дает N = пр наблюдений (далее
мы ограничимся первой моделью дисперсионного анализа, когда
все факторы имеют фиксированные уровни).
Результаты наблюдений образуют матрицу Ху(i = 1,2, ..., p;j =
= 1,2, ..., и); обычно их представляют в табличном виде (табл. 2.1).
2.1. Результаты эксперимента
Номер наблюде- ния, i Уровни фактора,/
Ai Аг Ар
1 Хп Х21 ... Хру
2 Х12 Х22 Хр2
3 Х\з Хгз Хрз
п х1п Хг„ Хрп
Итоги
Предполагается, что для каждого уровня фактора имеется сред-
няя по п наблюдений, которая равна сумме общей средней и вариа-
ции, обусловленной этим уровнем:
— Ц "Ь ,
где ц - общая средняя; - эффект, обусловленный /-м уровнем фактора; Су -
вариация результатов внутри отдельного уровня фактора.
Член &у позволяет учесть все факторы, не контролируемые в экс-
перименте.
Допустим, что результаты наблюдений на фиксированном уров-
не фактора нормально распределены относительно среднего значе-
ния ц + Aj с общей дисперсией о2. В этом случае получим (точка
вместо индекса обозначает усреднение соответствующих наблюде-
ний по нему):
Ху-Х.^(Х,-Х.) +(Ху-Ху),
а после возведения в квадрат и суммирования по i и у:
50
^(Ху-Х..)2 ^(X.j-X.-f + '^tXy-X.j)2 ,
i,J ‘J ij
поскольку ^(Х7-Х..ХХу-Х7) = ^(Х7-Х..)^(Х/у-^7), и
i,J J I
при этом (Xy - X.j) = 0.
i1
Сумму квадратов S можно записать следующим образом:
S = $i + S2.
Величина 5] вычисляется по отклонениям р средних от общей
средней X.., поэтому она имеет (р-1) степеней свободы. Величина
S2 определяется по отклонениям N наблюдений от р выборочных
средних и, следовательно, имеет N-p = пр-р = р(«-1) степеней сво-
боды. Наконец, сама сумма квадратов £ имеет (Л7—1) степеней сво-
боды. По результатам вычислений можно построить стандартную
таблицу дисперсионного анализа (табл. 2.2).
2.2. Таблица дисперсионного анализа
Источник измен- чивости Суммы квадратов (S3) Число степеней свободы (df) Средние квадраты (MS)
Различия между уровнями S^^X.j-XJ)2 i P- 1 p-l
Различия внутри уровней S2^xt-x-^2 IJ N-p 2 N-p
Сумма S^(Xy-X,)2 IJ N- 1 X
Если справедлива гипотеза о том, что влияние всех уровней
одинаково, обе величины М\ и М2 (средние квадраты) будут несме-
щенными оценками ст2. Ее можно проверить, вычислив отношение
(Л/1/Л/2) и сравнив его с критическим значением при Vi = (р-1) и
v2 = (N-p) степенями свободы. Если Fpac4 < FKp, то оценку частных
различий не проводят и считают, что разности между парами нахо-
дятся в пределах ошибки опыта. В противном случае гипотеза об
отсутствии влияния фактора А на результаты наблюдений не при-
нимается, и необходимо выяснить, какие варианты существенно
отличаются от остальных, то есть какие именно группы имеют зна-
чимое различие средних.
Для этого используют линейные контрасты, представляющие
собой линейную комбинацию параметров (например, рър^.,Рр)
51
р р
с весами, сумма которых равна нулю (Lk = , где = О ).
/=1 j=i
Для пар взаимно независимых оценок /?•(%.•) строят доверитель-
ные интервалы (при заданном уровне значимости а) для разностей
средних, и если эти интервалы не включают нуль, соответствую-
щие средние существенно различны.
__ р
Оценка линейного контраста Lk = ^CjX.j , оценка дисперсии
У=1
2 Р с2
sTk • Границы доверительного интервала для Lk имеют
7=1 nJ
ВИД
Для оценки наименьшей существенности различий в уровне
средних (для всех уровней факторов) при F^C4 > Fn6n вычисляют:
ошибку опыта =J—- ;
V п
ошибку разности средних Sd ;
наименьшую существенную разность НСРал = ta,kSd-
Сравнивая (по вариантам НСР) разности между средними зна-
чениями X.j (у = 2, /?) и первым (базовым) уровнем, делают вывод
о существенности различий в уровне средних. Если фактическая
разность больше НСР, она статистически значима и соответст-
вующий уровень существенно влияет на результат, в противном
случае такого влияния не наблюдается.
Практически аналогично проводится многофакторный диспер-
сионный анализ - возрастает лишь сложность вычислений. В лю-
бом случае при этом предполагается нормальность распределения
данных и однородность дисперсий по группам.
2.2. ДИСПЕРСИОННЫЙ АНАЛИЗ В STATISTICA
Чтобы открыть окно дисперсионного анализа в Statistica, нужно
дать команду Анализ => Дисперсионный анализ. Модуль диспер-
сионного анализа (рис. 2.1) позволяет оценивать однофакторные
модели (Однофакторный ДА), многофакторные модели без взаи-
модействия (Главные эффекты) и с взаимодействием (Фактор-
52
ный ДА), а также опыты с повторениями (Повторные измерения
ДА). Если число категориальных переменных более четырех, ис-
пользуется модуль GLM (общих линейных моделей).
Рис. 2.1. Диалоговое окно дисперсионного анализа
Факторные признаки в пакете Statistica задаются отдельными ка-
тегориальными переменными; различные сочетания их уровней
соответствуют результативным (зависимым) переменным - одной
или нескольким. При этом уровни факторных признаков могут за-
даваться как числами (метками), так и категориями - все они пере-
кодируются программой одним из двух способов. По умолчанию
используется сигма-ограниченная модель кодирования перемен-
ных, когда сумма уровней равняется нулю. В противном случае
рассматривается так называемая сверхпараметризованная модель,
последовательно задающая коды 0, 1 и т.д.
При вычислении сумм квадратов в программе может использо-
ваться один из шести способов их образования.
Сумма квадратов типа I (последовательная) дает разделение
предсказанной суммы квадратов для полной модели. Этим свойст-
вом не обладает ни один из других типов суммы. Важное ограниче-
ние заключается в том, что сумма квадратов, отнесенная к отдель-
ному эффекту, в этом случае зависит от порядка включения эффек-
тов в модель.
Сумма квадратов типа II (частная) контролирует влияние других
эффектов. В отличие от предыдущего типа, она инвариантна отно-
сительно порядка включения эффектов в модель. Суммы I и II ти-
пов не рекомендуется использовать для факторных планов с раз-
ным числом наблюдений.
53
Сумма квадратов типа III (ортогональная) вычисляется для эф-
фекта, контролируемого для любых эффектов с такой же или
меньшей степенью, и ортогонального любым эффектам взаимодей-
ствия старшего порядка, которые его содержат. Этот тип суммы не
подходит для планов с пустыми ячейками.
Для проверки сбалансированных гипотез для эффектов малого
порядка в планах с пропущенными ячейками была разработана
сумма квадратов типа IV (оцениваемая); большинство исследовате-
лей не рекомендуют ее использовать.
2.3. Влияние плодородия почвы, системы удобрений и системы защиты рас-
тений на урожайность пшеницы
Номер на- блюдения А В С Урожайность, ц/га Тип технологии
1 0 0 0 37,93 экстенсивная
2 0 0 0 42,23 экологически чистая
3 0 0 0 35,63 экстенсивная
4 0 0 2 39,60 экстенсивная
5 0 0 2 41,25 экологически чистая
6 0 0 2 37,31 экстенсивная
7 0 2 0 52,40 экологически чистая
8 0 2 0 57,00 экологически чистая
9 0 2 0 61,28 почвозащитная
10 0 2 2 62,69 »
11 0 2 2 63,27 »
12 0 2 2 66,34 »
13 2 0 0 44,60 экологически чистая
14 2 0 0 50,43 »
15 2 0 0 45,73 »
16 2 0 2 55,02 »
17 2 0 2 53,13 »
18 2 0 2 49,05 »
19 2 2 0 58,89 »
20 2 2 0 60,40 почвозащитная
21 2 2 0 56,82 экологически чистая
22 2 2 2 66,25 почвозащитная
23 2 2 2 71,41 »
24 2 2 2 68,74 в
54
В планах с пропущенными ячейками, а также в дробных фак-
торных планах применяется сумма квадратов типа V (полный ранг).
Суммы квадратов типа VI используют сигма-ограниченное ко-
дирование эффектов категориальных предикторов, что позволяет
получать уникальные оценки эффектов (даже эффектов малого по-
рядка) для планов с неоднородными коэффициентами наклона,
гнездовых планов, смешанных моделей и др. Именно этот тип сум-
мы обычно задается по умолчанию.
Рассмотрим несложный пример трехфакторного дисперсионного
анализа для опыта по схеме 2x2^2 в трех повторениях (табл. 2.3,
файл onbiTl.sta).
В опыте изучается влияние на урожайность пшеницы следую-
щих факторов:
А - плодородие почвы (0 - исходное плодородие, 2 - 400 т/га
навоза + Рдоо);
В - система удобрений (0 - без применения удобрений, 2 - сред-
няя норма удобрений);
С - система защиты растений от сорняков, вредителей и болез-
ней (0 - без применения средств защиты растений, 2 - весной в фа-
зе кущения применяется гербицид акрил-М).
Выбрав в рассмотренном ранее диалоговом окне (рис. 2.1) фак-
торный ДА, получим новое окно (рис. 2.2), в котором предлагается
выбрать зависимые и независимые переменные. В данном случае
зависимой переменной будет урожайность, независимыми - факто-
ры А, В, С.
Рис. 2.2. Диалоговое окно факторного дисперсионного анализа
55
На вкладке Итоги окна анализа результатов (рис. 2.3) следует
щелкнуть по кнопке Проверить все эффекты, после чего будет
выведена соответствующая таблица (рис. 2.4).
Рис. 2.3. Окно анализа результатов, вкладка Итоги
Эффект Одномерный критерий значимости для Урожайность, ц/га (Onwr.sta) Сигма-ограниченная параметризация Декомпозиция гипотезы
SS Степени свободы MS F Р
Св. член 67989,62 1 67989,62 8062,050 0,000000
А 290,79 1 290,79 34,481 0,000024
В 1900.68 1 1900,68 225,379 0,000000
С 208.39 1 208,39 24,710 0,000139
А*В 82,44 1 82,44 9,775 0,006508
А*С 21,55 1 21,55 2,555 0,129512
В*С 45.65 1 45,65 5,413 0.033446
А’В’С 1,22 1 1,22 0,144 0,709257
Ошибка 134,93 16 8,43
Рис. 2.4. Таблица всех эффектов
56
Из таблицы видно, что практически все факторы и их взаимо-
действия статистически существенно влияют на урожайность (за
исключением взаимодействий А*С и А*В*С; все значимые эффек-
ты выделяются красным цветом).
Для визуализации различий в урожайности нужно щелкнуть по
кнопке Все эффекты/графики в окне результатов анализа; полу-
чим диалоговое окно, позволяющее выбирать эффекты и их взаи-
модействия (рис. 2.5).
Рис. 2.5. Выбор эффектов и взаимодействий
При выборе взаимодействия факторов А*В мы можем полу-
чить таблицу (рис. 2.6) или график (рис. 2.7), выбрав соответ-
ствующие пункты в группе Отображать диалогового окна Таблица
всех эффектов. Аналогичным образом выводятся графики для
взаимодействия факторов А*С (рис. 2.8) и В*С.
N ячейки А*В; МНК средние (Onwr.sta) Текущ. эффект F(1,16)=9,7751, р= ,00651 Декомпозиция гипотезы
А В Урожайность, ц/га Среднее Урожайность, ц/га Стд.ош. Урожайность, ц/га -95,00% Урожайность, ц/га +95,00% N
1 0 0 38,99167 1,185558 36,47840 41,50494 6
2 0 2 60,49667 1,185558 57,98340 63,00994 6
3 2 0 49,66000 1,185558 47,14673 52,17327 6
4 2 2 63,75167 1,185558 61.23840 66,26494 6
Рис. 2.6. Таблица с описательными статистиками по уровням взаимодействия
факторов А и В
57
А’В; МНК средние
Текущ. эффект. F(1,16)-9,7751, р=,00651
Декомпозиция гипотезы
Рис. 2.7. График зависимости урожайности от плодородия (А) и системы
удобрений (В)
На рис. 2.7 показаны средние урожайности по уровням фактора
повторных измерений А; они различны и для ВО, и для В2; как вид-
но из рис. 2.8, они различны при А2 и приблизительно равны при
АО для СО и для С2. Средние урожайности по уровням фактора по-
вторных измерений В различны при А2 и приблизительно равны
при АО для СО и для С2.
Для детального изучения разницы средних урожайностей следу-
ет использовать вкладку Контрасты диалогового окна Результаты
анализа (Контрасты Задать контрасты для средних (Отдель-
но для каждого фактора) ЭОКЗ Вычислить, рис. 2.11). Напри-
мер, сравнение СО и С2 для А2 дает результаты, приведенные на
рис. 2.9; они представляют собой таблицу одномерного критерия,
подтверждающую статистически значимую разность между сред-
ними урожайностями, заметную и на графике.
С помощью кнопки Оценить в группе Межгрупповые эффек-
ты (см. рис. 2.3) можно проверять рабочие гипотезы о существен-
ности влияния определенных уровней факторов. Щелчок по кнопке
Общая R модели позволяет получить оценку доли изменчивости
урожайности, которая объясняется включенными в модель факто-
рами. В данном случае R2 = 94,98% (рис. 2.10).
58
А*С; МНК средние
Текущ. эффект. F(1.16)=2,5549, р=,12951
Декомпозиция гипотезы
Рис. 2.8. График зависимости урожайности от плодородия (А) и системы
защиты растений (С)
Одномерный критерий значимости для спланированных сравнений (Опыт, st а)
Зависимая перемен.: Урожайность, ц/га
Источник
Эффект
Ошибка
Сумма Степени
квадрат, свободы [квадрат.
235,3216
134,9327 i
Среднее
1
16
235,3216
8,4333
F
27,90389 0,000074
Рис. 2.9. Таблица одномерного критерия значимости для средних
Зависим, перемен. SS модели и SS остатков (Onursta)
Множест. R Множест. [Скоррект R2 1 R2 SS Модель ст.св. Модель MS Модель SS Остаток
Урожайность, ц/га 0,974555 0,949758 ! 0,927777 2550,709 7 364,3870 134,9327
Рис. 2.10. Таблица SS модели и SS остатков (фрагмент)
Обычно, если выявлены различия в среднем значении зависимой
переменной, требуется определить величину таких различий для
разных категорий. Для решения этой задачи исследуют контрасты
(см. выше) и НСР.
59
Рис. 2.11. Результаты дисперсионного анализа: вкладка Контрасты
Заметим, что при выборе нескольких зависимых переменных
(например, урожайности и типа технологии) используется много-
мерный критерий значимости Уилкса.
ЗАДАНИЕ
Используя исходные данные, содержащиеся в табл. 2.3, прове-
дите дисперсионный анализ в различных формах (однофакторный,
главные эффекты и др.), выбрав в качестве зависимых переменных
урожайность и тип технологии. Изучите контрасты по данной мо-
дели.
ВОПРОСЫ ДЛЯ САМОКОНТРОЛЯ
1. Что является предметом изучения в дисперсионном анализе?
2. В чем состоит сущность модели дисперсионного анализа?
3. Какая гипотеза проверяется при дисперсионном анализе?
4. Если гипотеза о равенстве средних отвергается, как оценить, в каких
именно группах имеется значимое различие средних?
5. Как оценить наименьшую существенную разность в уровне средних при
/7 > /7 9
грасч 1 табл*
6. Опишите методы кодирования категориальных переменных.
7. Какие типы сумм квадратов могут использоваться в дисперсионном ана-
лизе?
ПРАКТИЧЕСКОЕ ЗАНЯТИЕ 3. РЕГРЕССИОННЫЙ АНАЛИЗ
Цель занятия: ознакомиться с возможностями корреляционно-
регрессионного анализа, получить навыки анализа данных с исполь-
зованием модуля множественной регрессии; провести анализ ре-
альных данных о стоимости жилья
3.1. ТЕОРЕТИЧЕСКИЕ СВЕДЕНИЯ
Регрессионный анализ занимает особое положение среди всех
известных методов математической статистики. Это объясняется
не только его широкой распространенностью, но и тем, что он слу-
жит основой целого ряда других методов - планирования экспери-
мента, дисперсионного анализа, многомерного статистического
анализа и др.
Объектом исследования в регрессионном анализе могут быть
самые разнообразные статистические совокупности (поэтому он
применяется практически повсеместно - в экономике, социологии,
политологии, медицине и т.д.), предметом исследования - матема-
тические модели, описывающие связи между различными призна-
ками. Как правило, при этом ставится задача найти аналитическую
61
зависимость (уравнение регрессии), наиболее точно выражающую
эти связи.
Для иллюстрации основной идеи регрессионного анализа можно
использовать кибернетический подход, изображающий изучаемую
систему в виде черного ящика (рис. 3.1).
Рис. 3.1. Регрессионная модель
Здесь X - (X', Z) - факторы модели (вектор входных перемен-
ных); X' - управляемые независимые переменные; Z - контроли-
руемые, но не управляемые факторы; Y- отклик системы («показа-
тель качества управления», «выход» и т.п.), f(y) - закон распреде-
ления, mY - математическое ожидание случайной величины г, W -
помехи.
Чаще всего предполагается, что зависимость между признаками
носит линейный характер (этот раздел регрессионного анализа раз-
работан наиболее хорошо). В матричной форме получим Y = ХВ +
+ в, где Y - вектор наблюдений; X - матрица значений независи-
мых переменных; р, В - соответственно векторы коэффициентов и
их оценок; е - вектор ошибок:
я' ’1хп*12...х1у...хи ГА’ V
У2 A £2
Y = У, ; х = lx,! Xj2 ;B = A » 8 £i
Л. 1 xnl xn2 • xnj" • xnk Pa. .£n_
Для определения искомых коэффициентов регрессии В решают
систему нормальных уравнений, которая в матричной форме запи-
сывается так: „ , „
В = (ХТХ)-‘ХТ¥.
62
Условие разрешимости этой системы - ненулевой детерминант
матрицы (ХТХ).
Нулевую гипотезу (Но: bj = 0) о равенстве нулю коэффициентов
к
уравнения регрессии у = /3$ +^Ьуху- оценивают с помощью /-кри-
У=1
терия Стьюдента для двусторонней области при заданном уровне
значимости а и числе степеней свободы v = п-к-\:
t _ I у ।
*расч — —- .
Здесь Су - элемент главной диагонали матрицы (ХТХ)-1, =
= и - общее число наблюдений, к - число факторов,
2 Еи-Л)2 „
S£ = —-----------дисперсия остатков. Если гипотеза принимает-
п-к-1
ся для всех J, на этом регрессионный анализ заканчивается. В про-
тивном случае незначимые факторы можно отбросить, однако при
коррелированности факторов такое механическое исключение час-
то приводит к исключению слишком большого их числа.
Для значимых факторов рассматривают интервальные оценки
коэффициентов регрессии и самого уравнения регрессии. Так, до-
верительный интервал для ру составит:
bj ~ ^кр С jj ~ Рj ~^j + ^кр •
Адекватность полученной модели обычно оценивают с помо-
щью дисперсионного анализа (табл. 3.1) или критерия значимости
множественного коэффициента корреляции.
Если Т^расч > Ркр при заданном уровне значимости a (%) и указан-
ных числах степеней свободы, гипотеза Но: bj = 0 (у = 1,Аг) отверга-
ется с риском ошибиться не более чем в а случаев из 100 и уравне-
ние регрессии считается статистически значимым.
Доля суммы квадратов, объясняемая регрессией, называется
множественным коэффициентом детерминации'.
R
2 объясненная вариация
общая вариация
£(л-у)2
,0<Я<1.
Квадратный корень из этой величины называется множествен-
ным коэффициентом корреляции.
63 ,
3.1. Таблица дисперсионного анализа (основное разложение)
Вариация Число сте- пеней сво- боды (df) Суммы квад- ратов (55) Средние квадраты (Л/5) Fрасч Ftp
Обусловлен- ная регресси- ей (SSj) к Е(Я-У)2 1=1 1/П ^1 Л-/5 о - —- Л к Fa(k,n-k-\)
Относитель- но регрессии (остаток, 552) п-к-\ £и-й)2 i=i 2 _ 552 н-А-1 X X
Общая, скор- ректирован- ная на сред- нее значение Y(SS) п-\ EU-J7)2 1=1 X X X
Значимость R2 оценивают по F-критерию: FKp = Fa(k, п-к-\\
R2(n-k-\)
Fnac„ =-----z----. Если Лрасч > Гкр, нулевая гипотеза п(): R = О
Р (1-Л2)£
отвергается и связь между факторами X и результатом Y считается
статистически значимой.
Для одномерной модели (результат у зависит от единственного
фактора х) R = г, где г - парный коэффициент корреляции.
С учетом потери числа степеней свободы вариации рассматри-
вают также исправленный коэффициент детерминации:
-2 (1-Л2)(и-1)
К — 1-------------.
(п-к-1)
Частный коэффициент корреляции характеризует связь меж-
ду двумя переменными (х/ и xv) при фиксированном влиянии треть-
ей (х/). Он может использоваться для выявления ложной корреля-
ции, когда наблюдаемая зависимость между х/ и xv объясняется их
взаимодействием с xt.
Для выбора наилучшего уравнения регрессии (наиболее точно
описывающего исследуемый процесс) можно использовать коэф-
фициент множественной детерминации R2 или дисперсионный ана-
лиз. Усложняя уравнение (например, повышая в полиномиальном
случае степень многочлена), можно наращивать значение R2, пока <
это увеличение не станет пренебрежимо малым. При этом, однако,
рекомендуется сначала изучить все возможные варианты линейной
зависимости.
64
Вывод о корректности модели по условию R2 «1 не всегда ве-
рен. В конце концов, результата R2 »1 можно добиться простым
увеличением числа факторов. Ясно, что при к = N получим R2 = 1,
но модель от этого не станет адекватной, поскольку ее содержа-
тельная интерпретация будет невозможной.
В экономических исследованиях иногда используют фиктивные
переменные, принимающие только два значения. Например, при
анализе стоимости жилья можно ввести переменную, принимаю-
щую значение 1, если дом кирпичный, и значение 0 в противном
случае.
В регрессионном анализе рассматривают различные модели -
линейные, нелинейные, а также модели бинарных откликов. К ли-
нейным относятся модели:
1) парные линейные: у = Ьо+ Ь\х;
2) парные криволинейные (например, у = а + bx + ex', у = а +
+ Z>sinx);
к
3) множественные линейные: y = bQ + ^bjXj (в Statistica: Ана-
У=1
лиз => Множественная регрессия);
4) множественные нелинейные, например, у = а0 + aixt + а2х2 +
+ азх2 + ЩХ22 + <75X1X2 (в Statistica: Анализ Ф Углубленные методы
анализа Множественная нелинейная регрессия);
к
5) ортогональные полиномиальные: у = Ь0 +^Ь}<ру(х), где (pj-
7=1
некоторые функции (например, это могут быть ортогональные по-
линомы Чебышева).
Существуют также модели, нелинейные относительно парамет-
ров, например, у = а + Ьесх (в Statistica: Анализ «Ф Углубленные
методы анализа => Нелинейное оценивание).
В моделях бинарных откликов выходная переменная принимает
значения на отрезке [0; 1]; примером может служить логит-
регрессия у = exp (/>о + ^bjXj) / (l+exp(Z>0 + Sz>yx7)) или пробит-
регрессия, где результат линейно связан с независимыми перемен-
ными и подчиняется нормальному закону распределения. Модели
множественной пробит/логит-регрессии являются расширением
аналогичных стандартных моделей на случай, когда зависимая пе-
ременная имеет более двух значений (например, не только «Да,
Нет», а «Да, Нет, Не знаю»); при этом она подчиняется не биноми-
альному, а мультиномиальному закону распределения.
В Statistica указанные виды регрессии также вводятся командой
Анализ Ф Углубленные методы анализа => Нелинейное оцени-
вание.
5 Капко И.А.. Пак.иш Н.Б.
65
Практически все перечисленные типы моделей можно построить
с помощью той или иной модификации метода наименьших квад-
ратов (МНК). Их адекватность можно проверить с помощью дис-
персионного анализа (по схемам, аналогичным рассмотренным
выше) или по коэффициенту множественной детерминации R2. При
этом, однако, неявно предполагается выполнение классических ус-
ловий Гаусса - Маркова, которые далеко не всегда соблюдаются.
Обычно, когда вид зависимости априори неизвестен, ошибки не
подчиняются нормальному закону распределения (законы больших
чисел для конечных выборок не действуют). Случайные ошибки
имеются не только на выходе, но и на входе и т.д.
В настоящее время существуют методы, использующие функции
ошибок (функции потерь): Хубера, Пуанкаре, Винзора, Андрюса,
Мешалкина, Рамсея, Гуды, джеккнайф-оценки и др.; они позволяют
получать эффективные параметры регрессии и в том случае, когда
ошибки не подчиняются нормальному закону распределения. Если
ошибки имеются как на выходе, так и на входе, вводится понятие
ортогональной регрессии (параметры уравнения находят, миними-
зируя сумму квадратов расстояний до поверхности регрессии). Ес-
ли входные переменные коррелированы (случай мультиколлинеар-
ности), используют ридж-оценки, метод главных компонент, метод
автоматического отсева переменных и т.д.
В случае множественной регрессии выбор наилучшего уравне-
ния связи осуществляется с помощью пошагового приближения
(последовательного включения и отбрасывания входных перемен-
ных), факторного анализа, анализа главных компонент.
Если часть наблюдений, используемых в регрессионном анали-
зе, имеет сильно отличающиеся дисперсии, используют «взвешен-
ный» МНК.
В последние десятилетия для решения задач регрессионного
анализа все чаще привлекают методы из других разделов матема-
тики - топологии, теории групп, функционального анализа. Обоб-
щение регрессионных моделей на бесконечномерные (гильбертовы)
пространства привело к созданию так называемых коллокационных
моделей, что дало возможность решать очень сложные задачи про-
гнозирования (например, в финансовой сфере). Существует также
метод общих линейных моделей (GLM), позволяющий оперировать
как с непрерывными входными переменными, так и с категориаль-
ными, исследовать несколько результативных переменных в одной
модели и получать единственное решение для плохо обусловлен-
ной матрицы плана X т X.
Важным моментом при построении искомой зависимости явля-
ется отбор факторов Xj, существенно влияющих на результативную
переменную у. Известно достаточно много путей отбора, условно
их можно разделить на два класса: формальные и содержательные
(семантические).
66
Формальные методы основаны на переборе различных уравне-
ний (например, путем пошаговой регрессии с последовательным
включением или исключением независимых переменных) до мо-
мента достижения некоторого критерия, например F Фишера, ха-
рактеризующего (при заданном уровне значимости а) вклад пере-
менной в объясняемую уравнением регрессии вариацию результа-
тивной переменной.
Содержательные методы предполагают достижение конкретных
целей моделирования. При этом, как уже отмечалось ранее, разли-
чают:
физические модели, описывающие функциональные особенно-
сти изучаемых процессов; это достаточно редкий случай, так как
принципиально невозможно учесть все причинно-следственные
связи и их взаимодействия;
модели, предназначенные для управления процессом; при этом
предполагается, что для любого у, можно найти такие значения Ху
(управляющие воздействия), которые позволяют получить желае-
мый результату,-;
модели, используемые для прогнозирования, которые по задан-
ным Xij позволяют предсказать величину у,.
Набор данных, полученных в процессе наблюдения за сложным
объектом, можно представить в виде множества точек некоторого
фазового пространства. Физические модели, модели управления и
предсказания представляют собой проекции изучаемого объекта на
различные плоскости, поэтому обычно эти модели не совпадают.
Очевидно, что для практических целей важнее всего модели,
описывающие содержательные стороны изучаемого процесса. Со-
вмещение формальных и содержательных критериев - это типичная
многокритериальная задача, которая, как правило, не имеет одно-
значных решений.
Альтернативой описанным выше приемам поиска «наилучшей
регрессии» являются всевозможные методы машинного обучения,
реализуемые с помощью нейронных сетей, методов эволюционного
программирования и метода группового учета аргумента (см. прак-
тическое занятие 6).
3.2. РЕГРЕССИОННЫЙ АНАЛИЗ В STATISTICA
Для решения задач регрессионного анализа в системе Statistica
следует дать команду Анализ Ф Множественная регрессия. От-
кроется окно, представленное на рис. 3.2, после чего, щелкнув по
кнопке Переменные, можно выбрать зависимые и независимые
переменные для анализа. Файл исходных данных может представ-
лять собой как таблицу, так и корреляционную матрицу. Вкладка
Дополнительно позволяет перейти к пошаговой или гребневой
регрессии, получать описательные статистики и матрицы корреля-
5 ♦
67
ций, провести вычисления с повышенной точностью, а также осу-
ществить пакетную обработку и печать.
Рис. 3.2. Диалоговое окно множественной регрессии в Statistica 6.1
В качестве примера рассмотрим построение и анализ модели
стоимости жилья в г. Краснодаре в октябре 2006 г.; для этого загру-
зим файл Nedvig.xls (рис. 3.3).
В данном примере рассматриваются следующие переменные:
VI - порядковый номер; V2 - микрорайон; V3 - число комнат
в квартире; V4 - тип дома; V5 - индикаторная (фиктивная) пере-
менная, принимающая значение 1, если дом кирпичный, в против-
ном случае - 0; V6 - общая площадь, м , V7 - жилая площадь, м2;
V8 - площадь кухни, м2; V9 - цена жилья, тыс. руб.
Для изучения переменной V9 дадим следующую команду
(рис. 3.4): Графика => 2М Графики => Гистограммы <=> вкладка
Дополнительно => тип графика: Простой распределение: Нор-
мальное “=> переменная: 9 "=> ОК. Результат представлен на гисто-
грамме (рис. 3.5); цены на квартиры при значимости не более 0,01
подчиняются нормальному закону распределения со средним зна-
чением 2075,02 и средним квадратическим отклонением 1369,95;
максимальное значение переменной V9 составляет 41706,898, ми-
нимальное - 270. Очевидно, что максимальное значение цены не
удовлетворяет правилу трех сигм и скорее всего является аномаль-
68
ным или ошибочным. Наше предположение подтверждает диа-
грамма рассеяния, представленная на рис. 3.6.
1 Nt п п 2 Район 3 Число комнат 4 Тип дома 5 Индикаторная переменная 6 Общая площадь 7 Жилая площадь 8 Площадь кухни 9 Цена, тыс. руб.
1 1 ЮМР 1 блочный 0 40 20 10 1596ДО
2 2 ЮМР 2 блочный 0 60 32 10 1876ДО
' 3 3 ЮМР 2 блочный 0 77 40 16 3500,00
4 4 ЮМР 3 блочный 0 66 42 9 2074 ДО
5 5 ЮМР 3 блочный 0 70 44 10 2156 ДО
6 6 СМР 3 кирпичный 77 46 10 2828 ДО
7 7 СМР 3 блочный 0 70 34 12 2436ДО
Л 8 ГМР 3 кирпичный 1 75 42 15 2489 ДО
9 9 ГМР 3 блочный 0 75 42 15 2489 ДО
10 10 СМР 3 кирпичный 1 72 42 9 2156,00
11 11 ЮМР 3 кирпичный 1 64 42 8 1970,36
12 12 ЮМР 3 блочный 0 67 42 12 2592,80
Рис. 3.3. Данные по стоимости жилья в г. Краснодаре за октябрь 2006 г.
Рис. 3.4. Диалоговое окно построения гистограммы
69
Цена, тыс. руб. Число набл
Гистограмма (Nedvig sta 9v* 1573с)
41059.4465
Рис. 3.5. Гистограмма стоимости квартир
№ п/П
Рис. 3.6. Диаграмма рассеяния стоимости квартир
Используя инструмент Кисть, удалим аномальное значение
(свыше 40 000 тыс. руб.), в результате получим обновленную диа-
грамму рассеяния (рис. 3.7). На ней видно, что выбросы остались,
но они уже значительно меньше отличаются от основной массы
совокупности.
12000
Диаграмма рассеяния (Nedvig sta 9v*1573c)
10000
8000
6000
4000
2000
-2000
-200
200 400 600 800 1000 1200 1400 1б| g Сохранить пар^ры
№ п/п
С Добавить метки
Выключить
Выбор кисти —.
с Точка г Плоек. X
Блок Г Плоек. Y
С Лассо Г .
г
....................
Р Подвижная кисть
Р' Сохранение выбора
кистей
Г" Автоанимация
Анимировать \
UD
£
Рис. 3.7. Диаграмма рассеяния стоимости квартир после удаления выброса
С помощью диаграмм средних или диаграмм размаха можно
увидеть (рис. 3.8), что квартиры размером от 1 до 5 комнат имеют и
выбросы, и крайние точки, что указывает на неоднородность дан-
ных (Графики Ф 2М графики *=> Диаграммы размаха).
Далее мы будем рассматривать только данные по однокомнат-
ным квартирам; для этого с помощью^ кнопки Выбрать случаи
cftsEs У в модуле анализа или кнопок Й? на панели инструментов
Таблица данных откроем условия выбора переменных (рис. 3.10) и
зададим условие, при котором будут отбираться только одноком-
натные квартиры: V3 = 1 (как видно на рис. 3.8, аномальное значе-
ние относится к двухкомнатным квартирам).
Проанализируем парные корреляции факторов V6-V9; для этого
дадим команду Анализ Основные статистики и таблицы Ф
Парные и частные корреляции => Матрица парных корреляций.
Результат, представленный на рис. 3.9, показывает, что практиче-
ски все переменные значимо коррелируют между собой; но, как
известно, корреляцию менее 0,6 на практике можно игнорировать.
71
Поэтому в нашем случае мы оставим в качестве независимых пере-
менных общую площадь и площадь кухни. Коэффициент корреля-
ции между жилой и общей площадью очень высок (0,93), поэтому
из этих переменных нужно выбрать одну. Лучше взять общую
площадь, так как она коррелирует с ценой больше, чем другие пе-
ременные (0,83).
Рис. 3.8. Диаграммы размаха стоимости квартир
Переменная Корреляции (Nedvig.sta) Отмеченные корреляции значимы на уровне р <,05000 N=389 (Построчное удаление ПД)
Общая площадь Жилая площадь Площадь кухни Цена, тыс. руб.
Общая площадь 1,00 0,93 0,52 0,83
Жилая площадь 0,93 1,00 0,29 0,80
Площадь кухни 0,52 0,29 1.00 0,45
Цена, тыс. руб. 0,83 0,80 0,45 1.00
Рис. 3.9. Матрица парных корреляций
72
Рис. 3.10. Диалоговое окно условий выбора наблюдений
Открыв модуль множественной регрессии (Анализ => Множест-
венная регрессия => вкладка Дополнительно) и выбрав Описа-
тельные статистики, матрицы корреляций => ОК (рис. 3.11), бу-
дем последовательно рассматривать результаты регрессионного
анализа.
1. На вкладке Дополнительно выберем кнопку Средние и стд.
отклонения (рис. 3.12). Получим, что средняя площадь одноком-
натной квартиры составляет 59,284 м2 при стандартном отклонении
о = 24,1616; средняя площадь кухни - 10,234 м2 при о = 3,9375;
средняя цена однокомнатной квартиры - 1777,295 тыс. руб. при о =
= 687,3189 (рис. 3.13).
2. Стандартное отклонение общей площади и цены довольно
большие - это объясняется большим разбросом значений общей
площади однокомнатных квартир. Поэтому вернемся на шаг назад
(кнопка Отмена на рис. 3.11) и добавим в условия отбора (рис. 3.8),
например, «and v6<=70» (отбор квартир с площадью не более
70 м2). Далее, используя кнопки Средние и стд. Отклонения и
Диаграмма размаха, получим более правдоподобный результат
(рис. 3.14).
3. После просмотра описательных статистик щелкнем ОК и пе-
рейдем в диалоговое окно результатов анализа (рис. 3.15).
4. Щелкнув по кнопке Итоговая таблица регрессии, получим
таблицу, изображенную на рис. 3.16. Отметим, что площадь кухни
73
слабо коррелирует с ценой, поэтому статистически значимым явля-
ется только общая площадь жилья.
Рис. 3.11. Диалоговое окно модуля Множественная регрессия
Рис. 3.12. Диалоговое окно просмотра описательных статистик
74
Переменная Средние и станд. отклонения (Nedvig.sta)
Средние Ст.Откл. N
Общая площадь 59.284Г 24.1616; 389
Площадь кухни 10.234; 3,9375: 389
Цена, тыс. руб. 1777,295 687,3189 389
Рис. 3.13. Описательные статистики для однокомнатных квартир
Рис. 3.14. Описательные статистики и диаграммы размаха для однокомнат-
ных квартир с площадью менее 70 м2
Уравнение регрессии имеет вид:
Цена = 413,4210 + 24,2698*V6 - 8,4703*V8.
Таким образом, увеличение на 1 м2 общей площади однокомнат-
ной квартиры в Краснодаре (не более 70 м2) повышает ее стоимость
в среднем на 24,27 тыс. руб., а увеличение площади кухни на 1 м2 -
уменьшает ее на 8,47 тыс. руб. (бета-коэффициенты указывают, на
сколько стандартных отклонений изменится цена при увеличении
площади на одно стандартное отклонение).
5. Щелчок по кнопке Дисперсионный анализ в окне результа-
тов позволяет получить соответствующую таблицу, которая пока-
зывает, что уравнение статистически значимо (рис. 3.17).
Чтобы провести анализ остатков, дадим команду ОК Ф вкладка
Вероятностные графики Ф Нормальный график остатков. По-
лученный график (рис. 3.18) показывает, что распределение остат-
ков отклоняется от нормального закона (в идеале все точки долж-
ны находиться на одной линии).
75
Рис. 3.15. Диалоговое окно Результаты множественной регрессии
№284 Итоги регрессии для зависимой переменной: Цена, тыс. руб. (Nedvig.sta) R= ,71864566 R2= ,51645158 Скорректир. R2= ,51300996 F(2,281)=150,06 p<0,0000 Станд. ошибка оценки: 295,39
БЕТА Стд. Ош. БЕТА В Стд. Ош. В ‘(281) р-уров.
Св.член 413,4210 77,91366 5 ДВ14 0,000000
Общая площадь 0,732725 0,043080 24,2698 1,42693 17,00842 0,000000
Площадь кухни -0,061140 0,043080 -8,4703 5,96835 -1,41921 0,156947
Рис. 3.16. Итоги регрессионного анализа
Эффект Дисперсионный анализ; ЗП: Цена, тыс. руб. (Nedvig.sta)
Сумма квадрат сс Средн, квадрат F р-уров.
Регресс. 26187224 2 13093612 150,0603 0,000000
Остатки 24518834 281 87256
Итого 50706058
Рис. 3.17. Таблица дисперсионного анализа для уравнения регрессии
7
Нормальный вероятностный график остатков
Для построчного анализа выбросов перейдем на вкладку Вы-
бросы и выполним команду Стандартные остатки (>2*сигма) =>
Построчный график выбросов; получим график, который пока-
зывает, какие значения остатков превышают две сигмы (рис. 3.19).
Станд. остатки (Nedvig.sta)
Выбросы
Станд. остатки Набл. -5. -4. -3. ±2. 3. 4. 5. На блюд. Значение Предск. Значение Остатки Станд. предск. Станд. Остатки Стд.Ош. предск.
431 . . * . 594.000 1299,511 -705911 -0,678450 0,251111 -2,38840 -2,31005 22,12998
437 . . . 899.910 1582,278 -682368 2032012
630 . . •. 599,400 1269,053 -669,653 -0,778577 -2,26701 31.67023
755 ...*.. 796,500 1388,120 -591,620 -0,387160 -2,00284 21,90101
898 • 3375,000 1590,748 1784252 0278956 6,04031 18,46468
964 . . .» . 853,200 1720,568 -867,368 0,705720 -2,93634 2167073
965 . . . » . 899,100 1703 627 -804,527 0,650030 -2,72360 2229240
1051 ...*... 1149,930 1749,885 599,955 0,802095 -2,03105 47,91794
1111 • 3780 ДЮ 1889,316 1890 684 1,260456 6,40062 30,48077
1127 * 3250,800 1947,467 1303,333 1,451620 4,41224 33,39287
1177 . . . . • 2565,000 1942,902 622,098 1,436615; 2,10602 65,38434!
1183 ....... 1404,000 2036.076 -632,076 1.742910 -2.13979 36,101471
Нкнимух . . . • . 594,000 1269,053 -867,368 0,778577 -2,93634 18,464681
Максин. ..... 3780,000 2036,076 1В90.684 1,7429101 6,40062 6538434]
Среднее . . . .» . 1680,570 1676,629 3,941 0,561277 : 0fl1334 ~0,677875 -2,08542 3036555 ZD.JUOOi? ;
Медиана . . . « . 1024 920 1712,098 -616915
Рис. 3.19. Построчный график выбросов
77
6. Исключим выбросы, выходящие за пределы двух сигм от
средней величины; это наблюдения с номерами 431, 437, 630, 755,
898, 964, 965, 1051, 1111, 1127, 1177, 1183. Для этого в диалоговом
окне условий выбора наблюдений (см. рис. 3.10) в поле Номера на-
блюдений секции Исключить наблюдения из Анализа/Графиков
перечислим указанные номера (разделяя их пробелом). После этого
проведем регрессионный анализ по той же схеме, что и ранее. Из
итоговой таблицы (рис. 3.20) видно, что после исключения выбро-
сов увеличился коэффициент корреляции (R = 0,8126) и детермина-
ции (R2 = 0,6603). Площадь кухни по-прежнему отрицательно влия-
ет на стоимость жилья: с ее увеличением на 1 м2 стоимость кварти-
ры снижается в среднем на 9,76 тыс. руб.
N=272 Итоги регрессии для зависимой переменной: Цена, тыс. руб. (Nedvig.sta) R= ,81256522 R2= .66026224 Скорректир. R2= ,65773631 F(2,269)=261,39 p<0,0000 Станд. ошибка оценки: 208,45
БЕТА Стд.Ош. БЕТА В Стд.Ош. В t(269) р-уров.
Св.член 478,4440 56,67195 8,44234 0,000000
Общая площадь 0,829057 0,036689 23,1586 1,02485 22,59697 0,000000
Площадь кухни -0,082053 0,036689 -9,7646 4,36608 -223646 0,026142
Рис. 3.20. Итоги регрессии после исключения выбросов
Данные дисперсионного анализа показывают, что выявленная
зависимость значима при уровне а < 0,01 (рис. 3.21).
Эффект Дисперсионный анализ; ЗП: Цена, тыс. руб. (Nedvig.sta)
Сумма квадрат сс Средн, квадрат F р-уров.
Регресс. 22715224 2 11357612 261,3936 0,00
Остатки 11688113Т 269 43450
Итого 34403337!
Рис. 3.21. Таблица дисперсионного анализа
Если в качестве независимых переменных взять жилую площадь
и площадь кухни (без учета выбросов), будет получено следующее
уравнение регрессии (рис. 3.22):
Цена = 398,1817 + 29,3242* V7 + 33,5215* V8.
В этой модели, несмотря на меньшее значение множественного
коэффициента корреляции (R = 0,7069), значимыми являются оба
фактора, причем площадь кухни влияет на стоимость квартиры по-
ложительно.
78
N=284 Итоги регрессии для зависимой переменной: Цена, тыс. руб. (Nedvig.sta) R= ,70693761 R2= ,49976078 Скоррекгир. R2= .49620036 F(2,281)=140,37 p<0,0000 Станд. ошибка оценки: 300,45
БЕТА Стд.Ош. БЕТА В Стд.Ош. В t(281) р-уров.
Св.член 398,1817 80,55112 4,94322 0,000001
Жилая площадь 0,701591 0,042677 29,3242 1.78376 16,43953 0,000000
Площадь кухни 0,241961 0,042677 33,5215 5,91251 5,66959 0,000000
Рис. 3.22. Итоги регрессии с другими независимыми переменными (жилая
площадь, площадь кухни)
Недостаток первой модели заключается в том, что площадь кух-
ни входит в общую площадь квартиры, а это не вполне корректно
для пары независимых переменных; поэтому более приемлемой бу-
дет вторая модель, несмотря на несколько меньший коэффициент
множественной корреляции.
Если ввести в условия отбора данных равенство «V5 = 1», полу-
чим модель для анализа стоимости однокомнатных квартир в кир-
пичных домах. Аналогичным образом можно получить уравнение
связи для квартир, расположенных не в кирпичных домах (V5 = 0).
Нетрудно заметить, что как коэффициенты регрессии, так и показа-
тели связи в этих моделях заметно различаются (рис. 3.23, 3.24).
N=99 Итоги регрессии для зависимой переменной: Цена, тыс. руб. (Nedvig.sta) R= .63116315 R2= .39836693 Скоррекгир. R2= .38583290 F(2,96)=31,783 p<,00000 Станд. ошибка оценки: 319,31
БЕТА Стд.Ош. БЕТА В Стд.Ош. В t(96) р-уров.
Св.член I 512.6002 135.2431 3,790212 0,000263
Жилая площадь 0,612441 0,080732 23,8615 3,1454 7,586111 0,000000
Площадь кухни 0,314278 0,080732 34,3728 8,8297 3,892857 0,000183
Рис. 3.23. Итоги регрессии для однокомнатных квартир в кирпичных домах
Итоги регрессии для зависимой переменной: Цена, тыс. руб. (Nedvig.sta)
R= ,74919444 R2= .56129232 Скоррекгир. R2= .55647136
F(2,182)=116,43 p<0,0000 Станд. ошибка оценки: 287,37_______________________
N=185 БЕТА Стд.Ош. БЕТА В I Стд.Ош. В t(182) р-уров.
Св.член 337.5967 101,6748 3,32036 0,001086
Жилая площадь 0,741557 0,049278 32,36481 2,1507 15,04850 0,000000
Площадь кухни 0,187704 0,049278 31,83021 8,3564 3,80910 0,000191
Рис. 3.24. Итоги регрессии для однокомнатных квартир не в кирпичных
домах
В заключение выскажем ряд соображений, касающихся массива
исходных данных только что рассмотренного примера (цены на
79
квартиры в г. Краснодаре в октябре 2006 г.). Очевидно, что цены
индивидуальных продаж даже абсолютно одинаковых квартир мо-
гут отличаться от их «нормальной» рыночной стоимости (из-за
личных мотивов, осведомленности, условий сделки и т.д.)- В прак-
тикуме предлагается рассматривать их как случайную величину,
зависящую от числа комнат, района, типа дома, жилой площади,
общей площади и площади кухни. На практических занятиях 3, 5
и 6 для изучения этой совокупности предлагается использовать ме-
тоды многомерного статистического анализа (визуализация дан-
ных, построение регрессионных моделей для совокупности в целом
и для классов, на которые ее можно разбить).
Разумеется, число и состав переменных могут быть изменены,
данные должны регулярно обновляться и быть массовыми. Следует
также учитывать разницу между ценами продавца, покупателя, реа-
лизации, предложения, спроса, сделки и др. Мы рассматривали це-
ны предложения (эта информация наиболее доступна), хотя, конеч-
но, наибольший интерес представляет средняя цена сделки, наибо-
лее точно отражающая ситуацию на рынке недвижимости.
Следует отметить, что общая методология оценки средней стои-
мости квартир на основании имеющейся статистической информа-
ции давно известна и применяется на практике как у нас в стране,
так и за рубежом. Кроме того, можно получить законченное анали-
тическое решение для оценки стоимости недвижимости с использо-
ванием любой из известных программ (Statistica, PolyAnalyst, De-
ductor) при условии постоянного пополнения базы данных о рынке
недвижимости.
ЗАДАНИЕ
1. Загрузить файл с данными о стоимости жилья в Краснодаре
Nedvig.xls (или файл с аналогичными данными по городу, в кото-
ром находится ваш вуз). Провести регрессионный анализ по одно-
му из указанных в табл. 3.2 вариантов. Провести сравнительный
корреляционно-регрессионный анализ данных о стоимости квартир
в целом по городу и по указанному микрорайону, а также по этому
микрорайону с учетом ограничений по общей площади и числу
комнат.
3.2. Варианты заданий
Номер вари- анта Микрорайон Ограничения
По общей площади, м2 По числу ком- нат, не более
1 СМР, ФМР Менее 50 1
2 КМР, ЗИП От 50 до 70 1
80
Продолжение
Номер вари- анта Микрорайон Ограничения
По общей площади, м2 По числу ком- нат, не более
3 ГМР, ЗИП Более 70 1
4 ФМР, Центр Менее 50 2
5 СМР, 40-летия Победы От 50 до 70 2
6 Центр, ФМР Более 70 2
7 Центр, ЧМР Менее 50 3
8 ФМР, Центр От 50 до 70 3
9 Центр, ЧМР Более 70 3
10 ФМР, ЮМР Более 70 4,5
2. Дать оценку адекватности полученных моделей с использова-
нием критериев F Фишера и средней ошибки аппроксимации.
ВОПРОСЫ ДЛЯ САМОКОНТРОЛЯ
1. В чем состоит смысл постановки задачи регрессионного анализа?
2. Какими методами решают задачи регрессионного анализа?
3. Перечислите основные типы регрессионных зависимостей.
4. Как оценить полученную регрессионную модель?
5. Назовите основные условия, при которых возможно применение метода
наименьших квадратов.
ПРАКТИЧЕСКОЕ ЗАНЯТИЕ 4. КОВАРИАЦИОННЫЙ АНАЛИЗ
Цель занятия: ознакомиться с возможностями модуля общих ли-
нейных моделей, приобрести навыки ковариационного анализа
4.1. ТЕОРЕТИЧЕСКИЕ СВЕДЕНИЯ
В настоящее время в аграрной науке продолжается поиск опти-
мальных методов обработки результатов многолетних полевых
опытов. Следует отметить, что проблема оценки влияния на уро-
жайность различных факторов, несмотря на почти столетнюю ис-
торию, до сих пор остается дискуссионной. На практике при ее
решении обычно используют различные модели дисперсионного
анализа.
При проведении полевого опыта, как правило, регистрируют ряд
сопутствующих неконтролируемых переменных, меняющихся при
его повторении (погодные условия на разных стадиях развития рас-
6 Кацкл II.Л.. Пакллн Н Б.
81
тений, элементы структуры урожая и др.). Так, в многолетнем мно-
гофакторном эксперименте в ст. Ленинградской Краснодарского
края фиксировались следующие факторы:
содержание влаги в слое почвы глубиной 0-30 см: Х\ - в период
посева, Х2 - в период возобновления весенней вегетации, Х3 - в пе-
риод выхода в трубку, Х4 - в период колошения, Х5 - в период пол-
ной спелости;
содержание влаги в слое почвы 0-100 см: Х6~ в период посева,
Xq - в период возобновления весенней вегетации, Х% - в период вы-
хода в трубку, Х§ — в период колошения, Х\0- в период полной спе-
лости;
количество осадков: Хц - за весь сельскохозяйственный год
(с августа прошлого по июль текущего года), Xi2 - за период осен-
ней вегетации (с сентября по ноябрь прошлого года), Х^ - за пери-
од весенне-летней вегетации (с апреля по июнь текущего года),
Х)4~ за период от колошения до созревания (май-июнь текущего
года).
Перечисленные климатические факторы, выражаемые перемен-
ными-ковариатами Х5, наблюдались на фоне двухфакторного ие-
рархического опыта. Фактор В (дозы внесения удобрений) был
сгруппирован внутри главного фактора А (предшественники). При
этом фактор А наблюдался на пяти уровнях (эспарцет, озимая пше-
ница, подсолнечник, кукуруза, озимая пшеница), а фактор В - на
трех (без удобрений, средняя доза NPK, органоминеральная систе-
ма). Опыт проводился с 1979 по 1998 г., и его результаты были
оформлены в одну таблицу, в которой годовые данные использова-
лись в качестве повторений (по 20 повторений для каждого сочета-
ния предшественника и дозы внесения удобрений).
Как уже отмечалось, величины Xs, которые часто называют «со-
путствующими» переменными, на самом деле могут иметь большее
значение для объяснения различий в средней урожайности, чем
предшественник или доза внесения удобрений.
Для совместного учета перечисленных количественных и каче-
ственных факторов Р. Фишер еще в 1932 г. предложил использо-
вать модель ковариационного анализа (см. вводную главу раздела I,
п. 5). В конечном счете он сводится к дисперсионному или к рег-
рессионному анализу; в последнем случае для этого необходимо
ввести в уравнение регрессии фиктивные переменные, характери-
зующие качественные факторные признаки.
4.2. КОВАРИАЦИОННЫЙ АНАЛИЗ В STATISTICA
Чтобы получить доступ к модулю GLM (General Linear Models,
общие линейные модели), нужно дать команду Анализ *=> Углуб-
ленные методы анализа <=> Общие линейные модели, после чего
откроется диалоговое окно, представленное на рис. 4.1. Описание
82
всех средств этого модуля можно найти в справочной системе; пока
лишь отметим, что он включает практически все модели дисперси-
онного, регрессионного и ковариационного анализа, в которых рас-
сматривается не одна, а сразу несколько зависимых переменных.
Это позволяет (с помощью метода обобщенных обратных матриц)
получать единственное решение при плохой обусловленности мат-
рицы плана, а также использовать, наряду с обычными суммами
квадратов, многомерные критерии адекватности.
Общие линейные модели (GLM): Севорокавказский Филиал КНИИСХ ИВ®
Быстрый
Виа анализа:
Задание анализа:
В ок
Отмена
[Н* Однофакторный ДА
(Ш. I”равные эффекты
Факторный ДА
№1 Г нездовой план
Большие сбаланс. планы
Повторные измерения
Ь#" Простая регрессия
Множественная регрессия
Факторная регрессия
|\Д Полиномиальная регрессия
Регрессия поверхности отклика
Регрессия поверхности смеси
Диалог
Ejig Ковариационный анализ
|^g] Неоднородные кооф. наклона
Однородные коэф, наклона
Общие линейные модели
Мастер анализа
Редактор кода
Используйте kb вариационный
анализ для анализа эффекте»
категориальных независимых
переменных (факторов). а
также для управления
эффектами одного или
нескольких предикторов
(ковариат).
Для любого вида анализа
можно выбрать несколько
зависимых переменных. При
этом будут доступны как
одномерные.так и
многомерные результаты.
jjSl Опции ▼
[г22? Данные
I Взвешенные
момйпы
г- Степ, сьоб. = -
. & 34. ГК
См. также модуль Планирование экспериментов и Компоненты дисперсии.
Рис. 4.1. Диалоговое окно GLM
В качестве примера рассмотрим построение и анализ ковариа-
ционной модели урожайности по данным описанного ранее (в под-
разделе 2.2) полевого опыта (файл Северокавказский филиал
КНИИСХ.хЬ). В окне модуля GLM дадим команду Ковариацион-
ный анализ => Диалог и выберем в открывшемся диалоговом окне
(рис. 4.2) подлежащие анализу зависимые переменные, а также ка-
тегориальные и непрерывные предикторы (ковариаты).
6»
83
После щелчка по кнопке ОК откроется диалоговое окно вывода
результатов, аналогичное окну результатов дисперсионного анали-
за (см. рис. 2.3). Нажав на кнопку Все эффекты, получим соответ-
ствующую таблицу (рис. 4.3), из которой видно, что практически
все факторы и их взаимодействия статистически существенно
влияют на урожайность (за исключением фактора JV, - содержание
влаги в слое почвы глубиной 0-30 см в период посева). В таблице,
выводимой на экран, все значимые эффекты выделяются красным
цветом.
Рис. 4.2. Окно выбора переменных в модуле GLM
Эффект Одномерный критерий значимости для Y0 (Северокавказский филиал KHMHCKSTA) Сигма-ограниченная параметризация Декомпозиция гипотезы
SS Степени Свободы MS F Р
Св. член 4876.74 1 4876,743 48,35132 0,000000
хг 287.911 1 287,909 2,85452 0,092219
-Х2- 498,21 1 498,214 4,93963 0,027038
хз- 229393 1 2293,928 22,74355 0,000003
"Х4" 7477,57 1 7477,571 74,13769 0,000000
•Х5- 3987,13 1 3987,133 39,53113 0,000000
ПРЕД_К 4650,04 3 1550,014 15,36788 0,000000
ДОЗА.УД 17238,39. э 8619,196 85,45653 0,000000
ПРЕД К*Д03А УД 2511ДЗ 6 418,505 4,14934 0,000516
Ошиб. 28543,55 283 100,861
Рис. 4.3. Таблица всех эффектов
84
Для визуализации различий урожайности выберем кнопку Все
эффекты/графики; откроется диалоговое окно (рис. 4.4), позво-
ляющее выбирать эффекты и их взаимодействия. Выберем эффект
взаимодействия факторов Предшественник*Доза удобрений, от-
метим в группе Отображать переключатель График и щелкнем
ОК; на экран будут выведены графики, представленные на рис. 4.5.
Нетрудно заметить, что урожайность по эспарцету во всех случаях
(при любых дозах удобрений) выше, чем по другим предшествен-
никам. Для средней дозы удобрений по уровню влияния на уро-
жайность за эспарцетом следуют подсолнечник, кукуруза и озимая
пшеница; то же соотношение наблюдается и при органоминераль-
ной системе удобрений.
Рис. 4.4. Окно таблицы всех эффектов
Выбрав в группе Отображать переключатель Таблицу, получим
описательные статистики по взаимодействию рассматриваемых
факторов (рис. 4.6). В ней указаны средние урожайности и их дове-
рительные интервалы при уровне значимости не менее 0,05, опре-
деленные с учетом эффекта взаимодействия.
С помощью кнопки Оценить в группе Межгрупповые эффек-
ты окна Результаты анализа можно задавать уровни оцениваемых
параметров и проверять тем самым рабочие гипотезы о существен-
ности влияния определенных уровней факторов. Щелкнув по кноп-
ке Общая R модели, можно узнать долю вариации урожайности,
объясняемой построенной моделью; в данном случае R2 = 0,627
(рис. 4.7).
85
N ячейки ПРЕД_К7ДОЗА_УД МНК средние (Северокавказский филиал КНИИСХ.ЗТА) Текущий эффект: F(6. 283)=4,14931 р= ,00052 (вычислено для ковариат в их средних)
ПРЕД_К ДОЗА_УД Y0 Среднее Y0 Ст. Ош. Y0 -95,00% Y0 495,00% N
1 эспарцет неудобре 47,15611 2,258107 42,71130 51,60093 20
2 эспарцет средняя 52,71111 2,258107 48,26630 57,15593: 20
3 эспарцет органоми 53,37611 2,258107 48,93130 57,82093 20
4 озимая п неудобре 29,34334 1,590495 26,21264 32,47405 40
5 озимая п средняя 44,22334 1,590495 41,09264 47,35405 40
6 озимая п органоми 47,11084 1,590495 43,98014 50,24155 40
7 подсолне неудобре 27,36094 2,251826 22,92849 31,79339 20
8 подсолне подсолне средняя 50,20094 2,251826 45,76849 54,63339 20
9 органоми 52,35094 2,251826 47,91849 56,78339 20
10 кукуруза неудобре 28,40126 2,249278 23,97382 32,82870 20
11 кукуруза средняя 47,94126 2,249278 43,51382 52,36870 20
12 кукуруза органоми 50,40126 2,249278 45,97382 54,82870| 20
Рис. 4.6. Описательные статистики по уровням взаимодействия факторов
Предшественник и Доза удобрений
Зависим. Перемен. SS модели и SS остатков (Северокавказский филиал KHHHCX.STA)
Множеств R Множеств (Скоррект R2 I R2 SS Модель сс I MS Модель (Модель SS Остаток сс Остаток MS Остаток F Р
W 0.791616 0,626973 0.6С6833 47975,19 16 2998,450 28543,55 1 283 1 СЮ ,8606 29,72665 0,00
Рис. 4.7. Оценка качества модели
Открыв вкладку Отчет в окне результатов анализа (рис. 4.8),
можно получить уравнение для прогнозируемой урожайности в ви-
де сигма-ограниченной модели, в которой категориальным пере-
менным ставятся в соответствие значения, сумма которых равна
нулю. В данном случае на экран будет выведен следующий текст:
Предок, уравнение для: Y0: "урожайность, ц/га (без удоб-
рений) "
Y0 = 27.0953646 + .052946164*"Х1" +.133697715*"Х2"
- .26522900*"ХЗ" + .408402893*"Х4" + .213219871*"Х5"
+ 6.86632419* "ПРЕД К"("эспарцет")
- 3.9889446*"ПРЕД_К7Г("озимая п")
- .91051586*"ПРЕД_К"("подсолне")
- 11.149375*"Д03А_УД"("неудобре")
+ 4.55437500*"ДОЗА_УД"("средняя")
+ 7.22437500*"ПРЕД_К"*"Д03А_УД"(1)
- 2.9243750*"ПРЕД К"*"ДОЗА_УД"(2)
+ .266875000*"ПРЕД К"*"Д03А_УД"(3)
- .55687500*"ПРЕД_К"*"ДОЗА_УД"(4)
- 4.7939583*"ПРЕД К"*"ДОЗА УД"(5)
+ 2.34229167*"ПРЕД К"*"Д03А УД"(6)
87
Рис. 4.8. Вкладка Отчет окна результатов анализа
После того как подтверждены различия в среднем значении за-
висимой переменной, обычно требуется установить величину раз-
личий для заданных категорий. Для решения этой задачи проводят
исследование контрастов (см. практическое занятие 2).
Заметим, что ковариационный анализ, строго говоря, предпола-
гает нормальное распределение опытных данных, однородность
дисперсий и равенство коэффициентов регрессии по группам. Для
построения адекватной модели в классическом смысле слова необ-
ходимо проверить гипотезу о нормальном распределении, приме-
нить многомерные критерии проверки однородности дисперсий и
ковариаций Бокса, а также критерий параллельности. Вместе с тем
выполнение указанных условий не является критичным, и на прак-
тике допускаются значительные отклонения от них.
ЗАДАНИЕ
Используя файл исходных данных Северокавказский филиал
КНИИСХ.хЬ (или аналогичный файл данных, полученных вами из
88
других источников), проведите ковариационный анализ. В качестве
зависимой переменной выберите урожайность, в качестве катего-
риальных предикторов - предшественник и дозу внесения удобре-
ний. В качестве непрерывных предикторов (ковариат) используйте
наиболее подходящий, с вашей точки зрения, набор переменных Xs
(5= 1,19).
Сравните результаты анализа с ковариатами и без них.
ВОПРОСЫ ДЛЯ САМОКОНТРОЛЯ
1. Что является объектом изучения в ковариационном анализе?
2. Укажите моменты сходства и различия между ковариационным анали-
зом, с одной стороны, дисперсионным и регрессионным анализом - с дру-
гой.
3. Как строится модель ковариационного анализа?
4. Назовите классические условия применимости ковариационного анализа.
ПРАКТИЧЕСКОЕ ЗАНЯТИЕ 5. КЛАСТЕРНЫЙ
И ДИСКРИМИНАНТНЫЙ АНАЛИЗ
Цель занятия: ознакомиться с возможностями выделения в имею-
щихся данных однородных групп и их изучения с помощью средств
кластерного и дискриминантного анализа
5.1. ТЕОРЕТИЧЕСКИЕ СВЕДЕНИЯ
Кластерный анализ используется для выделения в имеющихся
данных однородных групп объектов или иных единиц, называемых
кластерами. Известно четыре класса прикладных задач, решаемых
указанным способом:
разработка классификации объектов;
изучение различных вариантов группировки объектов;
получение гипотез на основе анализа данных (разведочный ана-
лиз);
проверка гипотез о существовании выделенных групп объектов.
Нередко все эти задачи приходится решать параллельно.
Методы кластерного анализа в основном носят эвристический
характер, причем разные подходы порождают различные кластеры.
Близость объектов друг к другу характеризуется мерой сходства,
в качестве которой может использоваться коэффициент корреля-
ции, мера расстояния, коэффициент ассоциативности, вероятност-
ная мера сходства.
Пусть X- {Х\,..., XN} - некоторое подмножество (набор точек)
^-мерного вещественного пространства Rk, X, = (хц, xi2,..-, х.к), 271 -
матрица, обратная ковариационной. Тогда основные меры близости
89
между произвольными векторами Xh Xj из X можно выразить
обычными математическими формулами (табл. 5.1).
5.1. Основные меры близости между точками пространства данных, исполь-
зуемые в кластерном анализе
Мера близости Математическая формула
Расстояние Махаланобиса Квадрат евклидова расстоя- ния Евклидово расстояние Манхэттенское расстояние [City-block (Manhatten) dis- tances] Расстояние Чебышева Степенное расстояние Мин- ковского Процент несогласия 1-г Пирсона p^.X^^-Xj^fX^Xj) 5=1 1 к р£(х,,Ху)= | 5=1 | Pc (^ ’ Xj ) ~ -1 |^Z5 ~ %js | I 5~1 Poo (*,, Xj) = 1 - xjs 1 I 5 = 1 рРй(Х,,Хj) = (количество xis * Xj^/k, 5 = 1,..., к Pp(XhXj) = \-r
Наибольшее распространение получили метрические меры
сходства, основанные на классических метриках р2Е, рЕ, pc, р™, Рм-
Расстояние Махаланобиса связано (через ковариационную матри-
цу) с корреляциями отдельных компонент векторов наблюдений.
Оно не является метрикой, так как для него не выполняются аксио-
мы метрики (симметрия, неравенство треугольника, различимость
нетождественных и неразличимость идентичных объектов). Про-
цент несогласия используется, когда данные являются категориаль-
ными. Меру 1-г Пирсона применяют, если нужно сократить раз-
мерность вектора данных X за счет выявления групп сильно связан-
ных компонент.
Нетрудно заметить, что формула для расстояния Махаланобиса
р0 имеет наиболее общий характер; она учитывает ситуацию, ко-
гда компоненты вектора наблюдений X зависимы. Следующие ме-
ры можно считать ее частными случаями:
90
евклидово расстояние рЕ подходит, когда компоненты вектора
наблюдений независимы, однородны и подчиняются нормальному
закону распределения с постоянной дисперсией (иногда при этом
признаки нормируют);
квадрат евклидова расстояния р2Е используется, если нужно
придать большие веса более отдаленным друг от друга объектам;
манхэттенское расстояние рс приводит в кластерном анализе
практически к тем же результатам, что и евклидово, но влияние
больших разностей (выбросов) уменьшается.
Расстояние Чебышева рх используется, если необходимо разли-
чать объекты, отличающиеся хотя бы по одной координате.
Степенное расстояние Минковского рм подходит в том случае,
когда нужно изменить в большую или меньшую сторону вес раз-
мерности, по которой объекты сильно отличаются. Параметр р
влияет на постепенное взвешивание по координатам, q - на про-
грессивное взвешивание больших расстояний между объектами.
При p = q = 2 мера Минковского совпадает с евклидовой.
Основная идея кластерного анализа состоит в разбиении про-
странства наблюдений на ряд подмножеств (кластеров) таким обра-
зом, чтобы все точки внутри каждого кластера были близки друг
к другу (исходя из выбранной меры близости), а точки различных
кластеров удалены на некоторое расстояние. Для этого необходимо
определить меру расстояния уже не между отдельными точками,
а между подмножествами. Например, если имеется два кластера 5,
и Sm с п, и пт элементами соответственно, которые объединяются
в один кластер S„ то расстояние между произвольным кластером St
и кластером должно быть выражено через расстояние между точ-
ками кластера S, и кластеров Sh Sm. В табл. 5.2 указаны различные
способы определения такого расстояния; в приведенных формулах
Ру - расстояние между произвольными точками i и у, соответ-
ствующее выбранной мере близости (рЕ, рЕ, рс, р™, Рм и др.).
Меры близости, перечисленные выше, используются в иерархи-
ческих агломеративных процедурах, позволяющих из отдельных
точек по указанным правилам получать кластеры, которые обычно
изображают в виде древовидного графа (дендрограммы). Первона-
чально предполагается, что каждая точка образует отдельный кла-
стер. Процесс объединения происходит поэтапно - на основании
матрицы расстояний или сходства последовательно объединяются
наиболее близкие объекты, пока все данные не будут сведены
в один кластер (в иерархических дивизимных процедурах, наоборот,
из одного кластера путем разложения получают ряд дочерних).
При использовании метода «ближайшего соседа» за расстояние
между классами принимается наименьшее расстояние между всеми
элементами, принадлежащими этим классам; метода «дальнего со-
91
седа» - наибольшее расстояние между ними. Все правила объеди-
нения, кроме метода Варда, работают с метриками.
5.2. Процедуры классификации
Правило объединения Формула
Метод одиночной связи («бли- жайшего соседа») Метод полной связи («дальнего соседа») Невзвешенное попарное среднее Взвешенное попарное среднее Невзвешенный центроидный метод Взвешенный центроидный метод Метод Варда (Уорда) Pmin(^.5,) = min(p/„pmf) Pmax(5r,S/) = max(p/f,pm/) PUPGMA^r^t)- 2 _ ГС С ч - + nmPmt PwPGMAV^r^t)- П/+Пт pix^x^+pjx^x,) PUPGMCyPr^t)- 2 Q 4_ ntp(X l,X t) + nmp(X m,X t) PwPGMC^r^t)- nl + nm Vr^^Xij~^jr)2 M j=\
Метод Варда объединяет объекты, которые дают наименьшее
приращение величине Vr, тем самым минимизируя дисперсию
внутри кластеров. Он ориентирован на создание кластеров пример-
но равных размеров, имеющих гиперсферическую форму. Этот ме-
тод чаще, чем другие, позволяет получать результаты, поддающие-
ся содержательной интерпретации.
Общее правило кластерного анализа состоит в том, чтобы для
конкретной совокупности данных подобрать меру близости и пра-
вило объединения, позволяющие получить их группировку (клас-
сификацию), имеющую реальный смысл. Часто рассматривается
возможность классификации данных не только по объектам (на-
блюдениям), но и по признакам (переменным).
Кроме иерархического кластерного анализа (joining clustering,
tree clustering), который часто является лишь первым этапом при
оценке возможного числа кластеров, используют метод ^-средних
(£-means clustering) и двухвходовую процедуру (two-way joining).
Метод ^-средних позволяет итеративно подобрать заданное число
центров, для которых расстояния внутри кластеров минимальны,
а между кластерами - максимальны.
92
Двухвходовая процедура объединения используется, если иссле-
дователь предполагает, что на образование кластеров одинаково
влияют как наблюдения (строки), так и факторы (столбцы таблицы
данных).
Оценку адекватности разбиения всей массы наблюдений на кла-
стеры можно получить с помощью дисперсионного анализа.
Дискриминантный анализ, в отличие от кластерного, исходит
из предпосылки, что классификация объектов уже известна; по этой
причине первый нередко называют классификацией с учителем,
а второй - классификацией без учителя.
Линейный дискриминантный анализ (разработанный Фишером)
обычно основан на предположении, что данные подчиняются мно-
гомерному нормальному закону. При этом рассматриваются две
задачи:
1) установить правило, согласно которому объект относится
к одному из известных классов; обычно (если выполняется условие
линейной разделимости данных) для этого используют линейную
функцию от признаков S, = с, + + w/2x2 + - + WimX„ (функцию
классификации);
2) по найденным правилам классифицировать новые объекты
(объект относится к z-му классу, если значение функции классифи-
кации St для него наибольшее).
Значимость разделения объектов на классы можно оценить
с помощью дисперсионного анализа, а также используя специаль-
ную функцию - /.-статистику Уилкса (чем ее значение меньше,
тем разделение на классы точнее).
5.2. КЛАСТЕРНЫЙ И ДИСКРИМИНАНТНЫЙ АНАЛИЗ В STATISTICA
Кластерный анализ в программе Statistica начинается с выбора
метода кластеризации (рис. 5.1); чтобы открыть соответствующее
окно, нужно дать команду Анализ => Многомерный разведочный
анализ Ф Кластерный анализ (Дискриминантный анализ). Что-
бы лучше ориентироваться в средствах и приемах анализа, пользо-
вателю рекомендуется изучить несложные примеры (классифика-
ция автомобилей различных марок, различение цветов ириса), со-
держащиеся в справочной системе Statistica 6.1.
Для иллюстрации возможностей кластерного анализа использу-
ем данные по недвижимости г. Краснодара, рассмотренные на
практическом занятии 3. Осуществим их иерархическую классифи-
кацию, используя правило объединения Варда и евклидову меру
близости, ограничившись следующими признаками: общей площа-
дью квартиры, ее жилой площадью, площадью кухни и стоимо-
стью. Дадим команду Анализ "=> Многомерный разведочный
анализ Ф Кластерный анализ => Иерархическая классификация
и в открывшемся окне заполним поля в соответствии с рис. 5.2. По-
93
еле щелчка по кнопке ОК выберем пункт Вертикальная диаграм-
ма; появится дендрограмма, изображенная на рис. 5.3.
Рис. 5.1. Диалоговое окно Методы кластеризации
.-*5 Кластерный анализ: иерархическая классификация: Nedvig.sta НЯ®
Быстрый Дополнительно S ОК |
Переменные: Файл данных: Объекты- Общая-Цена,тыс. руб. Отмена
Исходные данные )Д1 Опции ▼
Наблюдения (строки) ▼] Я1КТ и j n । casts a J <E> a [ -Удаление ПД— Построчное f* Замена средним
Правило объединения: |Метод Варда Мера близости: | Евклидово расстояние > I2 0 1 0 Г Пакетная обработка и печать
Рис. 5.2. Параметры иерархической классификации
Судя по диаграмме, можно предположить, что в данном случае
имеются три кластера (которые соответствуют расстоянию объеди-
нения 20 000); найдем их, используя метод Л-средних. Для этого
вернемся в предыдущее окно и выберем указанный метод: Отмена
Кластеризация методом К средних (рис. 5.4).
94
Дендрограмма для 389 набл
Метод Варда
С_586 С_889 С_585 С_307 С_1245 С_1167 С 1136 С_286
С_779 С_295 С_124 С_1503 С_1340 С_1046 С_1182
Рис. 5.3. Вертикальная дендрограмма иерархической классификации одно-
комнатных квартир
Рис. 5.4. Окно кластеризации методом ^-средних
Расстояние между первым и вторым кластером составит
724,719; между первым и третьим - 1117,047; между вторым и
третьим - 392,4 (рис. 5.5). Средние характеристики для кластеров
приведены на рис. 5.6. Дисперсионный анализ показывает, что вы-
бранные переменные (общая площадь, площадь кухни, полезная
площадь и цена) статистически существенно влияют на результаты
классификации (рис. 5.7).
Кластер Номер Евклидовы расст. между кластерами (Nedvig.sta) Расстояния под диагональю Квадраты расстояний над диагональю
Но. 1 Но. 2 Но. 3
Но. 1 0,000] 525217,1 1247794
Но. 2 724,719 0.0 153957
Но.З 1117,047 392,4 0
Рис. 5.5. Матрица расстояний и квадратов расстояний между кластерами
перемен. Средн.класт. (Nedvig.sta)
Кластер Но. 1 Кластер Но. 2 Кластер Но. 3
Общая 104,5171 71,766 43,426
Жилая 63,700* 43,899 22,871
Кухня 14,067 10,726 9,311
Цена, тыс. руб. 3529,633 2080,705 1296,753
Рис. 5.6. Средние для кластеров
перемен. Дисперсионный анализ (Nedvig.sta)
Между SS сс Внутри SS сс F значим. Р
Общая 137020 2 89488 386 295,513 0,000000
Жилая 66934' 2 37693 386 342,721 0,000000
Кухня 653 2 5362 386 23,516 0,000000
Цена, тыс. руб. 153775100 2 29518880 386 1005,411 0,000000
Рис. 5.7. Дисперсионный анализ результатов классификации
График средних для кластеров (рис. 5.8) показывает, что най-
денная классификация достаточно хорошо отражает различия меж-
ду данными. Еще более наглядный результат можно получить, ис-
пользуя нормализацию; для этого нужно скопировать переменные
V6-V9 в соседний диапазон и выполнить команду Данные «Ф
Стандартизировать (рис. 5.9).
96
4000
График средних для каждого кластера
Кластер 1
Кластер 2
Кластер 3
Переменные
Рис. 5.9. График со стандартизированными значениями переменных
1 КлшоИ.Л.. Пакшн Н.Б.
Описательные статистики для найденных кластеров представле-
ны на рис. 5.10-5.12.
перемен. Описат. статистики для кластера 1 (Nedvig.sta) Кластер содержит 30 набл.
Среднее Стандарт отклон. Дисперс.
Общая площадь 104,5171 28,6767 822,4
Жилая площадь 63,700' 17,3062 299,5
Площадь кухни 14,067 5,8542 34,3
Цена, тыс. руб, 3529,633 463,8381 215145,8
Рис. 5.10. Описательные статистики для 1-го кластера
перемен. Описат.статистики для кластера 2 (Nedvig.sta) Кластер содержит 153 набл.
Среднее Стандарт отклон. Дисперс.
Общая площадь 71.766. 15,9526 254,49
Жилая площадь 43,899' 10,4691 109,60
Площадь кухни 10,726 4,1311 17,07
Цена, тыс. руб. 2080,705 272,5651 74291,76
Рис. 5.11. Описательные статистики для 2-го кластера
перемен. Описат.статистики для кластера 3 (Nedvig.sta) Кластер содержит 206 набл.
Среднее Стандарт отклон. Дисперс.
Общая площадь 43,426. 11,4674 131,50
Жилая площадь 22,871' 7,7611 60,23
Площадь кухни 9,311 2,9420 8,66
Цена, тыс. руб. 1296,753 241,8153 58474,63
Рис. 5.12. Описательные статистики для 3-го кластера
Чтобы сохранить найденную классификацию, следует в окне
результатов анализа (рис. 5.13) щелкнуть по соответствующей
кнопке, а затем выбрать переменные для сохранения. Кроме тех,
которые использовались при кластеризации, отметим также пере-
менные, характеризующие район и тип дома (рис. 5.14).
98
Рис. 5.13. Сохранение найденной классификации
Выберите перем, для сохранения с класт, идент... 0®
|i N- n/n 11-Жил<
' И12-Плои
}3-Число комнат ________________13-Цена
2-Район
14-Тип дома
|5-Индикагорная переменная
iG-Общая площадь
7-Жилая площадь
'8-Площадь кухни
‘9-Цена., тыс, руб.__________
10-0бщая площадь
Выбрать все
Выберите переменные, или нажм. Отмена:
J р-;- - —-И
ОК
Отмена
Больше
Инфо
Рис. 5.14. Выбор сохраняемых переменных
Рис. 5.15. Таблица сохраненных кластеров
Используя полученную таблицу (рис. 5.15), можно определить
функции классификации, позволяющие отнести любой новый объ-
ект (квартиру) к одному из классов по наибольшему значению
соответствующей функции. Для этого закроем окно кластерного
анализа, дадим команду Анализ => Многомерный разведочный
анализ Ф Дискриминантный анализ и выберем группирующую и
независимые переменные (рис. 5.16). В окне модуля дискрими-
нантного анализа (рис. 5.17) щелкнем по кнопке Функции класси-
фикации, а затем - Матрица классификации.
Рис. 5.16. Выбор группирующей переменной и независимых переменных
Полученные результаты представлены на рис. 5.18, 5.19. Матри-
ца классификации показывает, что более 95% квартир были клас-
сифицированы правильно.
Графическое изображение классов подтверждает эффективность
проведенной классификации (рис. 5.20). Первый канонический ко-
рень дискриминирует первый класс и совокупность второго и
третьего классов. По вертикальной оси точки первого класса сдви-
нуты вниз (вкладка Дополнительно => Канонический анализ =>
Диаграмма рассеяния для канонических значений).
Матрица факторной структуры полученного решения (таблица
коэффициентов корреляции между переменными и каноническими
корнями) позволяет оценить вклад отдельных факторов в класси-
фикацию. Первый корень наиболее сильно связан с ценой, второй -
с жилой площадью (рис. 5.21). Это означет, что структура исход-
ных данных в основном обусловлена названными факторами
(вкладка Дополнительно Ф Канонический анализ Дополни-
тельно => Факторная структура).
101
Результаты анализа дискримина>пных Функций. Таблица кластеров sta
ев®
Число переменных в модели:6
Лямбда Уилкса: ,1276367 приближ.F (12,762) = 114,2403 р < 0,0000
Быстрый | Дополнительно Классификация |
Функции классификации
Клвссифжация выбранных
наблюдений
[ffl
И'ЛЗ Выбрать
Матрица классификации
I Априорные вероятности классификации —i
, <* Пропорциональные размерам групп
J С Одинаковые для всех групп
I С Заданные пользователем
Отмена
Опции |
классификация наблюдений
fffl Квадраты расстояний Махаланобиса j
Апостериорные вероятности
Сохранить результаты
; Сохранить для каждого наблюдения:
J (* Результаты классификации
Расстояния
С Апостериорные вероятности
М акс. число наблюдений в г------------гст
одной таблице результатов: Р 00000 g
Рис. 5.17. Диалоговое окно модуля дискриминантного анализа
Переменная Функции классификации; г руппировка: КЛАСТЕР (Таблица кластеров.sta)
G 1:1 р-,07712 G 2:2 р= ,39332 G 3:3 р= .52956
Район :Б70 3.475 3,433
Индикаторная переменная 0,608 -0,260 0,322
Общая площадь •0,574 -0,522 -0,474
Жилая площадь 0,875 0,810 0530
Площадь кухни -0,055 0,276 0,413
Цена, тыс. руб. 0558 0,037 0.027
Конст-та -309,607 -229392 -205,958
Рис. 5.18. Функции классификации
Группа Матрица классификации (Таблица кластеров.sta) Строки: наблюдаемые классы Столбцы: предсказанные классы
Процент правиль. G_1:1 р=,07712 G 2:2 р= ,39332 G 3:3 р= ,52956
G_1:1 96,66666 29 1 0
G 2:2 95,42484 0 146 7
G 3:3 95,63107 0 9 197
Всего 95,62982] 29 156 “204]
Рис. 5.19. Матрица классификации
6
Кор.1 от Корня 2
Переменная Матрица факторной структуры (Таблица кластеров, sta) Корр, переменных и функции дискрим. (объединенные внутригруп. корреляции)
Кор. 1 Кор. 2
Район -0,018805] -0,346319
Индикаторная переменная 0,069916. -0,190149
Общая площадь -0,500842 0,496489
Жилая площадь -0,533196 0,781726
Площадь кухни -0,141762 -0,113818
-0,932696 -0,167251
Рис. 5.21. Корреляционная матрица переменных и канонических корней
После того как классы выявлены, поиск аналитической зависи-
мости между ценой однокомнатной квартиры и определяющими ее
факторами целесообразно производить в каждом классе отдельно.
Для любой новой квартиры с помощью функций классификации
можно установить ее принадлежность к одному из трех классов,
а затем, на основе регрессионной зависимости, дать оценку ее
средней ожидаемой стоимости.
103
ЗАДАНИЕ
1. Используя один из вариантов задания по регрессионному ана-
лизу (см. табл. 3.2), провести классификацию ^/-комнатных квартир
(без учета районов) и построить для каждого из выделенных клас-
сов уравнения, описывающие зависимость цены квартиры от вхо-
дящих переменных.
2. На основе корректных обучающих выборок, полученных
на предыдущем занятии, и классификационных функций провести
классификацию квартир одного из районов, представленных в ва-
шем варианте, и дать оценку их возможной средней стоимости.
ВОПРОСЫ ДЛЯ САМОКОНТРОЛЯ
1. Для решения каких задач предназначены методы кластерного и дискри-
минантного анализа?
2. В чем заключается отличие методов классификации с учителем и без
учителя?
3. Перечислите наиболее известные меры сходства и различия элементов
(объектов)и классов.
4. Опишите процедуры классификации, чаще всего применяемые в кла-
стерном анализе.
ПРАКТИЧЕСКОЕ ЗАНЯТИЕ 6. ФАКТОРНЫЙ АНАЛИЗ
Цель занятия: ознакомиться с возможностями анализа данных
с помощью метода главных компонент и факторного анализа
6.1. ТЕОРЕТИЧЕСКИЕ СВЕДЕНИЯ
Задача факторного анализа состоит в том, чтобы выразить пара-
метр данных Xj как комбинацию скрытых гипотетических факторов.
Наиболее распространены два варианта такого описания: выделе-
ние максимальной дисперсии и наилучшая аппроксимация выбо-
рочных корреляций. Они соответствуют двум главным подходам к
решению указанной задачи - методу главных компонент и фак-
торному анализу.
Модель компонентного анализа имеет вид
к
Xj~^ajpFp^
р=\
где каждый из наблюдаемых параметров (/ = 1,..., к) зависит от к
не коррелиреющих между собой компонент (факторов) F\, ..., Fk,
причем каждая следующая компонента дает максимальный вклад
104
в суммарную дисперсию параметров, так что вся дисперсия описы-
вается полностью (иногда часть незначимых компонент отбрасыва-
ется).
Модель факторного анализа выглядит иначе:
XJ = ^^aJp^p + №j ’
p=i
где каждый из параметров (/’ = 1, ..., к) зависит от 5 общих факто-
ров (F\, ... , Fs) и одного характерного (ф. Общие факторы учиты-
вают корреляции между параметрами, а характерный фактор - ос-
тавшуюся дисперсию (в том числе связанную с различными по-
грешностями). Коэффициенты при факторах Fp, Ц называют на-
грузками.
Основная проблема, которую при этом приходится решать, -
сложность интерпретации полученного уравнения; обычно для это-
го систему факторов приходится подвергать вращению в много-
мерном пространстве. Существуют методы вращения, позволя-
ющие получить понятную (содержательно интерпретируемую)
матрицу нагрузок, то есть перейти к факторам, которые отмечены
для некоторых переменных высокими нагрузками, а для других -
низкими. Наиболее известные среди них - варимакс, квартимакс,
эквимакс, облимакс, квартимин, облимин и др. [38].
Заметим, что в рамках факторного анализа существует множест-
во конкурирующих подходов. Различия между ними часто поверх-
ностны и обусловлены расхождениями в небольшом числе исход-
ных предпосылок. На практике в большинстве случаев они приво-
дят к примерно одинаковым решениям.
Чаще всего факторный анализ используется при обработке мас-
совых данных в психологии и социологии. Кроме того, его методы
нередко применяют для решения таких задач, как сокращение чис-
ла переменных (сжатие информации), определение структуры свя-
зей между ними (классификация переменных), подтверждение
предположений, касающихся факторной структуры различных вы-
борок.
6.2. ФАКТОРНЫЙ АНАЛИЗ В STATISTICA
Окно модуля факторного анализа (рис. 6.1) открывается коман-
дой Анализ => Многомерный разведочный анализ <=> Факторный
анализ. Здесь можно выбрать один из двух допустимых типов ис-
ходных данных: Исходные данные или Корреляционная матри-
ца. Переключатель Удаление ПД задает один из способов обработ-
ки пропущенных значений (построчное или попарное исключение,
подстановка среднего значения вместо пропущенных).
105
Рис. 6.1. Диалоговое окно модуля Факторный анализ
Для иллюстрации метода откроем файл Factor.sta (один из
стандартных примеров системы Statistica 6.1), в котором собраны
результаты опросов 100 взрослых людей о степени их удовлетво-
ренности жизнью. Щелкнув в окне выбора переменных (рис. 6.2) по
Рис. 6.2. Окно выбора переменных
106
кнопкам Выбрать все и Больше, получим расширенное описание
10 используемых в данном примере переменных (три из них харак-
теризуют удовлетворенность работой, три - домашней жизнью, по
две - свободным временем и общую удовлетворенность).
После щелчка по кнопке ОК откроется окно выбора метода фак-
торного анализа (рис. 6.3). Первый шаг - это вычисление корреля-
ционной матрицы (если она не была задана сразу). Вкладка Описа-
тельные позволяет получить средние и стандартные отклонения,
корреляции, построить диаграммы рассеяния, провести регресси-
онный анализ.
Рис. 6.3. Диалоговое окно выбора метода факторного анализа
Укажем в качестве метода выделения Главные компоненты и
щелкнем ОК; когда появится окно результатов факторного анализа,
откроем вкладку Вращение факторов (рис. 6.4). На этой вкладке
можно выбрать различные способы поворота осей; нам нужно най-
ти вариант, имеющий содержательную интерпретацию.
Выберем сначала первую строку без вращения и щелкнем по
кнопке 2М график нагрузок; получим график, представленный на
рис. 6.5.
В данном случае не совсем ясно, какой смысл можно придать
двум выделенным факторам и как в этих терминах описывать удов-
107
летворенность жизнью индивидуума. Рассмотрим поэтому другой
вариант: вращение факторов методом Варимакс нормализован-
ных. Проанализируем полученный график (рис. 6.6) и корреляци-
онную матрицу (рис. 6.7).
Рис. 6.4. Методы вращения факторов в системе Statistica 6.1
Первый фактор в данном случае можно истолковать как удовле-
творение, получаемое опрошенными на работе, поскольку соответ-
ствующие переменные (Work_l - Work_3) достигают максимума
по этой оси и малы по другой. Второй фактор также имеет очевид-
ную интерпретацию: он отражает удовлетворенность домашней
жизнью. Таким образом, благодаря факторному анализу нам уда-
лось свести 10 исходных переменных к двум факторам, достаточно
точно описывающим результаты психологического теста.
ЗАДАНИЕ
1. Создайте, используя справочную систему Statistica 6.1, корре-
ляционную матрицу Перепись.вшх (рис. 6.8). Проведите фактор-
ный анализ на основании этой матрицы, полученной путем анкети-
рования 1 тыс. респондентов.
108
Фактор нагрузки, фактор 1 и фактор 2
Вращение: без вращ.
Выделение: Главные компоненты
Фактор 1
Фа,аоР2 Фактор 2
НОМЕ-2.
HOMEhPIqE-3
О *“ °
Рис. 6.5. График факторных нагрузок без вращения
Фактор.нагрузки, фактор 1 и фактор 2
Вращение: Варимакс нормал.
Выделение: Главные компоненты
1.0
0.8
0.6
0,4
0.2
0.0
-0.2
0.0 0,1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0,9 1.0
Фактор 1
Рис. 6.6. График факторных нагрузок после вращения методом Варимакс
W(W_2
WORK 1
О “....
Перемен. Фактор.нагрузки (Варимакс нормал.) (Factor, sta) Выделение: Главные компоненты (Отмечены нагрузки >,700000)
Фактор 1 Фактор 2
WORK 1 0,830827 -0,005746
WORK 2 0,901325 0,073641
WORK 3 0,869058 0,096808
HOBBY 1 0,730235 0,594896
HOBBY 2 0,723177 0,496371
HOME 1 0,083802 0,831157
HOME 2 0,151040 0,899830
HOME 3 0,154555 0,846798
MISCEL 1 0,759727 0,573045
MISCEL 2 0,740557 0,514289
Общ.дис. 4,493483 3,425568
Доля общ 0,449348] 0,342557
Рис. 6.7. Корреляционная матрица переменных и канонических корней
Рис. 6.8. Корреляционная матрица Переписьлтх
2. Используя один из вариантов задания по регрессионному ана-
лизу (см. табл. 3.2, без учета района), проведите факторный анализ
исходных данных о стоимости жилья.
ВОПРОСЫ ДЛЯ САМОКОНТРОЛЯ
1. Для решения каких задач предназначены методы главных компонент и
факторного анализа?
2. Чем отличаются эти методы?
3. В чем состоит основная проблема при практическом использовании ука-
занных методов?
НО
ПРАКТИЧЕСКОЕ ЗАНЯТИЕ 7. АНАЛИЗ ВРЕМЕННЫХ РЯДОВ
Цель занятия: ознакомиться с методами анализа временных рядов,
получить навыки анализа данных с использованием модуля «Вре-
менные ряды и прогнозирование»
7.1. ТЕОРЕТИЧЕСКИЕ СВЕДЕНИЯ
7.1.1. Методы анализа временных рядов
Задачи анализа и обработки временных рядов возникают очень
часто во многих областях науки и техники: микро- и макроэконо-
мике, социологии, сельском хозяйстве, радиоэлектронике, геофизи-
ке, при проектировании и испытании различных технических
средств и т.д. Особенно интенсивно анализ временных рядов ис-
пользуется на финансовых рынках (валютном, фондовом и др.).
Как уже указывалось ранее, дискретный временной ряд - это по-
следовательность значений переменной (процесса), измеренных за
определенный период через одинаковые промежутки времени:
Z], Z2,..., Z6 ..., Zn.
С детерминистской точки зрения этот ряд можно представить
следующим образом:
^=/(0 + е6
где t = 1, 2, ... , n,f- гладкая (непрерывная и дифференцируемая) функция,
характеризующая долгосрочное изменение переменной во времени (тренд);
в,-случайный ряд возмущений, наложенный на тренд.
Анализ структуры временного ряда, содержащего сезонные или
циклические колебания, начинается с предположения о том, что
Zz=T + C + L( + £t(аддитивнаямодель), или
Z,= Т С Ц-Et (мультипликативная модель),
где Т - тренд, С - сезонность, Ц - цикличность.
Цикличность отличается от сезонности большей протяженно-
стью колебаний и может не выделяться в отдельную составляющую
ряда. Если амплитуда колебаний увеличивается или уменьшается,
рассматривается мультипликативная модель, в противном случае
(когда колебания практически неизменны) - аддитивная.
Последовательные наблюдения обычно зависимы. При наличии
во временном ряду тенденции и циклических колебаний значения
каждого последующего уровня ряда зависят от предыдущих; такая
корреляционная зависимость называется автокорреляцией. Количе-
ственно ее можно измерить с помощью линейного коэффициента
корреляции между уровнями исходного временного ряда и уровня-
111
ми этого же ряда, сдвинутыми на один или несколько шагов во
времени.
Так как коэффициент автокорреляции характеризует линейную
связь, по нему можно судить о наличии линейной или близкой
к линейной тенденции; чем ближе этот коэффициент к единице, тем
сильнее она выражена. Для некоторых временных рядов, имеющих
явную нелинейную тенденцию, коэффициент автокорреляции
уровней исходного ряда может приближаться к нулю.
Последовательность коэффициентов автокорреляции первого,
второго порядка и т.д. называют автокорреляционной функцией.
Если самым большим оказался коэффициент первого порядка, ис-
следуемый ряд содержит только тенденцию. Если, напротив, наи-
более высоким оказался коэффициент автокорреляции порядка т, то
ряд содержит циклические или сезонные колебания с периодично-
стью в т моментов времени. Если же ни один коэффициент не явля-
ется значимым, ряд либо вообще не содержит тенденции и цикли-
ческих колебаний, либо имеет сильную нелинейную тенденцию.
Число периодов, по которым рассчитывается коэффициент авто-
корреляции, называют лагом.
Построение функции, моделирующей тенденцию (тренд) вре-
менного ряда, называют аналитическим выравниванием. Эта тен-
денция может принимать разные формы, и для ее выражения ис-
пользуют функции, подобранные путем визуализации временного
ряда. Такой подход, несмотря на заслуженную критику, использу-
ется и в настоящее время.
Второй подход (стохастический) предложил Эдни Юл в 1927 г.
Он использовал для его иллюстрации пример, объясняющий, что
будущее состояние системы зависит как от детерминированной со-
ставляющей, так и от воздействия разного рода случайностей. Эта
идея привела к созданию теории стохастических процессов, важ-
нейшим разделом которой является теория стохастических времен-
ных рядов.
Третий подход к анализу временных рядов - спектральный ана-
лиз в частотной области, который обычно используется, если дан-
ные имеют явную периодичность. Частотой (v) называют число
циклов (периодов колебаний ряда) в единицу времени; тогда пери-
од Т = 1/v. Цель спектрального анализа - выявление циклов раз-
личной длины в изучаемых рядах и представление их в виде суммы
различных синусоидальных функций.
В частности, может использоваться разложение в ряд Фурье,
причем обычно рассматривается не более пяти гармоник (к< 5):
к
zt = ао + X (aJ cos у7 + bJsin '
J=1
112
Параметры aj и bj определяют с помощью МНК; расчеты показы-
вают, что
। п 2 п 2 л
^о=-У2/» aj ^~yztcosjt, bj=-Yzts\njt.
В спектральном анализе для выявления (подтверждения) сезон-
ности или цикличности используется периодограмма, которую
можно рассчитать как
где Pj - значение периодограммы на частоте vy-, п - длина ряда.
Величину Pj можно интерпретировать как дисперсию (вариа-
цию) данных на j-й частоте. Периодограмму изображают в зависи-
мости от частот, периодов, логарифмов периодов. Если ряд не име-
ет циклов и все его значения взаимно независимы (так называемый
«белый шум» - случайный процесс, который является реализацией
нормально распределенных случайных величин с постоянной дис-
персией и нулевым математическим ожиданием), значения перио-
дограммы будут иметь экспоненциальное распределение. Перед
началом анализа рекомендуется привести ряд к стационарному ви-
ду, то есть вычесть тренд и среднее значение.
Оценка периодичности по периодограмме не всегда однозначна.
Например, месячная периодичность может приводить к появлению
пиков, которые соответствуют двух-, трех-, четырехмесячным и
другим кратным периодам. Это так называемые эхо-эффекты, со-
ответствующие повторениям спектра на низких частотах.
Отделить тренд и сезонность в общем случае невозможно, так
как они взаимно проникают друг в друга. После их выделения оста-
ется колеблющийся ряд. Удаление тренда (сглаживание временного
ряда) можно осуществить с помощью скользящей средней (СС);
в отличие от простой средней для всей выборки, она содержит све-
дения о тенденции изменения данных.
Для этого к первым (2w + 1) точкам исходного ряда подбирают
полином
Qp(t} = aptp + ap-\t^ + ap-^tp2 +...+ a\t + a0,
определющий значения тренда в (m + 1)-й точке, и минимизируют
сумму
т
YSZt ~aptP ~ ар-1‘Р~' ~ap-2tP~2 Я/-Я0)2-
t=-m
8 Хацко И Л . Паклпн Н.Б.
113
Затем подбирают полином того же порядка для второго, третье-
го, ..., (2т + 2)-го наблюдения. Эта процедура продолжается вдоль
всего ряда вплоть до последней группы из (2т + 1) точек. В дейст-
вительности, однако, нет необходимости подбирать полином каж-
дый раз. Например, для полинома третьей степени (р = 3) и пяти
точек значение тренда в какой-либо точке равно средневзвешенно-
му значению пяти точек с данной точкой в качестве центральной и
весами -^-[-3, 12, 17, 12, -3]. При р = 1 получаем простую сколь-
зящую среднюю:
а0 ~—(z-2+z-l+z0+zl+z2)-
Помимо только что рассмотренного, существуют и другие спо-
собы определения СС: использование простых СС, формулы Спен-
сера и т.д. В рамках нашего примера (р = 3, т = 2) следует отметить
проблему двух крайних точек - они не оцениваются.
Сглаживание может производиться также скользящей медианой,
которая более устойчива и является альтернативной оценкой цен-
тра распределения.
Рассмотренные выше СС (иногда их называют линейными
фильтрами) являются симметричными, то есть их коэффициенты
(веса) симметричны относительно среднего.
В статистике для прогнозирования могут применяться и асим-
метричные фильтры. Так, в пакете Statistica иногда заменяют не
средний, а последний уровень ряда в промежутке сглаживания.
Скользящая средняя используется для расчета значений в прогно-
зируемом периоде на основе значения переменной для указанного
числа предшествующих периодов по формуле
1 N
7V Л=0
где N - число предшествующих периодов, входящих в СС; Zh -
фактическое значение в момент времени Л; Fh - прогнозируемое
значение в тот же момент времени.
Асимметричные СС иногда могут учитывать степень «устарева-
ния» данных; в этом случае каждое новое наблюдение будет иметь
больший вес, чем предыдущие, например:
Fl+l=(l-a)(AtU+aAl+a2At_l+... )=(1-а)^а'Л/_/+1 ,0<а<1.
/=0
Рассмотренный подход к определению асимметричных СС но-
сит название экспоненциального сглаживания или экспоненциадь-
114
ных средних (ЭС). Они предназначены для предсказания значения
Fl+l на основе прогноза для предыдущего периода Ft, скорректиро-
ванного с учетом погрешностей в этом прогнозе (А, - F():
Ft+i = Ft + а(Л - Ft) -aAr + (l-a)F„
где Ff+i - прогноз в момент времени (t +1), F, - прогноз в момент времени t,
At - преобразованное значение ряда в тот же момент времени.
Изменяя a (0<а<1), можно регулировать влияние текущих или
предшествующих наблюдений.
Перечисленные выше фильтры могут комбинироваться - напри-
мер, в 4253/7 фильтре. Он включает несколько последовательных
преобразований:
1) вычисляется 4-точечная скользящая медиана, центрированная
скользящей медианой 2;
2) вычисляется 5-точечная скользящая медиана;
3) вычисляется 3-точечная скользящая медиана;
4) рассчитывается 3-точечная взвешенная скользящая средняя
с весами 0,25; 0,5; 0,25 (Hanning weights)',
5) вычисляются остатки путем вычитания преобразованного ря-
да из исходного;
6) шаги 1-4 повторяются для остатков;
7) преобразованные остатки добавляются к преобразованному
ряду.
На практике этот метод фильтрации дает сглаженный ряд, со-
храняющий основные характеристики исходного (детали изложены
в справочной системе Statistica 6.1).
Сглаживая временной ряд, мы устраняем случайные колебания и
получаем ряд, который проще прогнозировать. Кроме того, выде-
ленный тренд позволяет планировать управляющие воздействия
(например, в экономике это может быть план закупок товаров, про-
ведение рекламных акций и т.д.). Временной интервал, для которо-
го производится сглаживание, называют окном. Выбор ширины
скользящего окна не является однозначным: если она слишком ма-
ла, сглаживания (усреднения шума) не происходит, а если она
слишком велика, усредняется не только шум, но и регулярная со-
ставляющая.
Лучше всего рассматривать несколько вариантов скользящего
окна и отбирать нужный исходя из содержательной интерпретации
модели (для объяснения поведения ряда или получения наилучшего
прогноза).
Помимо уже перечисленных, существует еще целый ряд методов
сглаживания и экстраполяции временных рядов. Так, модель Холь-
та - Уинтерса содержит три параметра си, а2, а3 и позволяет учесть
сезонность. Модель Харрисона является модификацией предыду-
щей и выражает сезонность через гармоники; эти методы были раз-
работаны для анализа экономических процессов. Широкую извест-
8 *
115
ность получили также модель Бокса - Дженкинса, фильтры Калма-
на и Бюсси.
Применение скользящих средних сопряжено с рядом проблем -
может искажаться циклическое движение, случайные колебания
после сглаживания теряют часть динамики и могут быть приняты
за долгосрочную тенденцию. Кроме того, производный ряд стано-
вится более гладким, чем исходный, и в нем могут обнаруживаться
систематические колебания, выражающиеся в появлении ненуле-
вых корреляций (эффект Слуцкого - Юла).
В 60-е годы XX в. Шискин разработал для Бюро переписи США
программу, известную как Census Mark II; она предназначалась для
разделения сезонных и остаточных колебаний. Известно несколько
вариантов этой программы. В системе Statistica имеются соответст-
вующие модули для выделения сезонностей - Census I (классиче-
ская сезонная декомпозиция) и Census II (производится месячная
и квартальная корректировка), описание которых можно найти
в справочной системе.
Практически все рассмотренные методы содержат предположе-
ния относительно вида генератора (модели) изучаемого временного
ряда. Критерием ее адекватности может служить только реальное
достижение целей анализа (описание поведения ряда, объяснение
наблюдаемых изменений, прогнозирование).
7.1.2. Стационарные временные ряды
Временной ряд, не имеющий тренда (либо с исключенным трен-
дом), называется стационарным", его можно определить также как
ряд, свойства которого не зависят от начала отсчета времени (меха-
низм, генерирующий ряд, не меняется со временем, хотя и носит
вероятностный характер). Поэтому перечисленные ниже параметры
являются для него постоянными:
A/(zz) = М, M(zt - Л/)2 = а2 = Z)(z,); M[(zt - M)(zl+k - M)] = ck - k-я
автоковариация,
ck
p* =P-k - 2 ~ соответствующая автокорреляция.
о
Иногда совокупность значений р* представляется на графике и
называется коррелограммой или автокорреляционной функцией
(АКФ). Если рк вычисляется после исключения влияния наблюде-
ний с лагом меньше к, получается соответствующая частная ав-
токорреляционная функция (ЧАКФ).
Если процесс не удовлетворяет условию стационарности, то его
преобразуют (выделяя тренды, логарифмируя значения ряда). Один
из способов удаления тренда заключается в переходе к разностям
ряда; это используется, например, в рассматриваемой ниже модели
116
Бокса и Дженкинса авторегрессии проинтегрированного скользя-
щего среднего (АРПСС, [10, 30]). При этом следует помнить, что
если случайные компоненты ряда были взаимно независимы, то
после взятия разностей новые случайные компоненты будут корре-
лировать между собой.
Для стационарного процесса рассматривают три основных типа
моделей (соответствующие определенным типам стационарных
стохастических процессов).
1. Модели авторегрессии (АР) порядка р, в которой текущее зна-
чение z, выражается через линейную комбинацию р предыдущих
значений процесса плюс случайный импульс £,:
zt = + a2z,_2 +• •.+ at-^t-p + •
Важными частными случаями являются:
а) при р = 1 - модель процесса Маркова (процесс с отсутствием
последействия, когда каждое следующее значение зависит только
от предыдущего):
zt = a\zt-\ + е,.
б) при р-2- модель процесса Юла:
Zt = a\zt-\ + ад,_2 + •
2. Модели скользящей средней (СС):
— — Z>2£/-2 ~• • •“* bt-qZt-q.
Термин «скользящая средняя» не означает, что сумма весов при
е, равна 1. Предполагается, что последовательные значения ряда
сильно зависимы и генерируются последовательностью независи-
мых импульсов £,, которые являются реализацией случайных вели-
чин, подчиняющихся нормальному закону распределения с нуле-
вым средним и дисперсией а2е (в технике последовательность £,,
£/_i, £z_2, ... называется белым шумом).
3. Модели авторегрессии - скользящей средней (АРПСС):
Zf ~ Gl]Zt-\ + (22^/-2 Of-pZt-p b\£t-\ ~ 62&t~2 —• • •“ "Ь £/.
Обычно на практике используют модели ср, q < 2.
Для описания нестационарных процессов пользуются экспонен-
циально взвешенными средними (см. выше). В более общем случае
рассматривают упомянутые выше модели Бокса и Дженкинса,
в которых тренд исключается переходом к разностям ряда
(VZ, = Zt - Zr_j) и допускается коррелированность остатков.
Без учета сезонных эффектов модель имеет вид
V^Z, -a.xVdZt_x -...-apVdZ(_p = ct + 0|E,_i +... + p?£,_9.
117
Рассмотрим оператор сдвига назад В, определяемый как BZt =
= Z/_b тогда V = 1 - В и предыдущую формулу можно переписать
в следующем виде:
aWd-^/Z^pWe,,
где а(5) и р(В) - полиномы от В порядка pnq.
Таким образом, необходимо определить три параметра: р, q, d\
считается, что на практике их значения не превышают 2. Для этого
с помощью графиков изучаемого ряда, соответствующих функций
АКФ и ЧАКФ визуально оценивают его стационарность или не-
стационарность. Если ряд признан нестационарным, вычисляют его
разности до момента, пока он не станет стационарным; это позво-
ляет дать оценку параметра d. Необходимая для достижения ста-
ционарности разность <7(0, 1, 2) предполагает затухание АКФ, соот-
ветствующей порядку этой разности.
Параметры puq определяют, используя функции АКФ и ЧАКФ
[10, 15]. Приближенные критерии оценки этих параметров в модели
АРПСС (р, q) приведены в табл. 7.1, 7.2.
7.1. Примерные критерии подбора моделей АРПСС (р, q) для р + q < 2 на ос-
нове графиков АКФ
Характеристики моделируемого процесса
ai>0 Д]<0
Экспоненциально затухает
Л]>0 ai>0 Д]<0 й]<0
а2>0 а2<0 а2<0 а2>0
Затухает синусоидально или экспоненциально
118
Продолжение
119
7.2. Примерные критерии подбора моделей АРПСС (р, q) для р + q < 2 на ос-
нове графиков ЧАКФ
Параметры
модели
Характеристики моделируемого процесса
Р = 1,<7 = 0
Выброс на лаге 1 (нет корреляций для других задержек)
Выбросы на сдвигах 1 и 2 (нет корреляций для других задержек)
Экспоненциально затухает монотонно или осциллируя (меняя знак)
Для процесса авторегрессии порядка р АКФ спадает плавно,
а ЧАКФ обрывается после задержки (лага) р. Для процесса сколь-
зящей средней порядка q АКФ обрывается после задержки q,
а ЧАКФ спадает плавно. Для смешанного процесса АРПСС (р, q)
АКФ после (q - р) задержек выглядит как сумма экспонент и зату-
хающих синусоид, а ЧАКФ приобретает такой же вид после (р - q)
задержек. Поведение АКФ процесса авторегрессии похоже на по-
ведение ЧАКФ процесса скользящей средней.
120
Продолжение табл. 7.2
bi>0 bi>0 bi<Q bi<0
b2>0 b2<'Q Ь2<0 62>0
Синусоидальная волна или экспоненциально затухает
(Xaj<l 0<а,<1 ^<^<0 -1<а,<0 - 1<а,<0 a^b^l
Q<bx<ax -1<6(<0 1<6]<0 ax<bx<Q 0<6]<1 0<bj<l
Экспоненциально затухает монотонно или осциллируя (меняя знак)
На практике обычно не достигается полное сходство между вы-
борочной и теоретической АКФ. Например, для реальных процес-
сов АКФ может иметь всплески и тренды, в связи с чем необходи-
мо ориентироваться на ее главные характеристики.
Следует отметить, что модель АРПСС (р, d, q) может быть
обобщена и представлена в виде мультипликативной сезонной мо-
дели АРПСС (р, d, q) х (pS) ds, qs)s. В этой модели к параметрам р, d,
q добавлены сезонный параметр авторегрессии ps, сезонная раз-
ность ds и сезонный параметр скользящего среднего qs (s > 1). На-
пример, модель АРПСС (0, 1, 1) х (0, 1, l)i2 содержит один пара-
метр скользящего среднего и один сезонный параметр скользящего
среднего, полученные после взятия разности с лагом 1, а затем се-
зонной разности с лагом 5 =12.
Сезонность может идентифицироваться с помощью АКФ и
ЧАКФ, а также с помощью графика спектральной плотности изу-
чаемого ряда. Адекватность полученных моделей оценивается
121
с помощью остатков АКФ. Если график АКФ не содержит перио-
дических колебаний, систематического смещения и сильных корре-
ляций (более 0,5-0,6), модель считается адекватной.
Если в силу внешних причин поведение ряда резко изменяется,
целесообразно проводить анализ моделей АРПСС с интервенцией.
Для оценки запаздывающей зависимости между временными ряда-
ми используют анализ распределенных лагов, позволяющий стро-
ить для таких зависимостей уравнения регрессии.
Следует отметить, что описанные выше (и многие другие) моде-
ли используют априорные предположения о процессе, генерирую-
щем изучаемый временной ряд. Реальные данные (особенно малого
объема, порядка нескольких десятков наблюдений) часто им не со-
ответствуют. Поэтому были созданы разнообразные методы анали-
за и прогнозирования, позволяющие обходиться без этих классиче-
ских схем. В них используются теории хаоса, оптимизационные
модели, нейронные сети, модели искусственного интеллекта и др.
Критерий выбора, как уже отмечалось, в таких случаях лишь один -
достижение практически значимого результата.
7.2. АНАЛИЗ ВРЕМЕННЫХ РЯДОВ В STATISTICA
Чтобы открыть окно анализа временных рядов (рис. 7.1), необ-
ходимо дать команду Анализ => Углубленные методы анализа =>
Временные ряды и прогнозирование.
Рис. 7.1. Диалоговое окно анализа временных рядов
100
Рассмотрим операции, доступные в этом окне. Щелчок по кноп-
ке Переменные открывает доступ к переменным открытого в дан-
ный момент файла. В верхней части окна, в информационном поле,
указываются имена анализируемых и преобразованных перемен-
ных. В поле Число копий на переменную (ряд) можно проставить
числа от 3 до 99; если, например, выбрано три копии, то при чет-
вертом преобразовании первое преобразование будет удалено. Если
сделать двойной щелчок в поле преобразованной переменной на
колонке Блок, она будет заблокирована (появится отметка L).
В анализе временных рядов, как и в других блоках системы Sta-
tistica, предполагается, что используемые данные не имеют пропус-
ков; поэтому программа предлагает различные способы их запол-
нения. На вкладке Обработка пропусков можно выбрать следую-
щие способы замены пропущенных внутри ряда данных: общим
средним, рассчитанным по всему ряду, интерполяцией по ближай-
шим (не пропущенным) точкам, средним уровнем ближайших зна-
чений, медианой ближайших значений, результатом линейной рег-
рессии (рис. 7.2).
&
Методы Обработка пропусков j
р Замена пропущенных данных:----------------—
общим средним
интерполяцией по ближайшим точкам
средним N ближайших значений; N: В g
медианой N ближайших значений;
значениями линейной регрессии
Рис. 7.2. Вкладка Обработка пропусков
Практически все методы анализа временных рядов предполага-
ют наличие в ряде регулярной составляющей (тренд, цикличные
колебания) и шума. Для фильтрации шума программа предлагает
различные методы преобразований и сглаживания. Чтобы получить
к ним доступ, нужно в исходном окне щелкнуть по кнопке ОК
(Преобразования, авто- и кросскорреляции, графики) и выбрать
одну из вкладок (рис. 7.3-7.6).
Вкладка Графики позволяет построить графики одной или не-
скольких переменных (как исходных, так и преобразованных),
в том числе с разными масштабами (рис. 7.7). С помощью вкладки
Описательные можно вывести описательные статистики ряда, по-
строить гистограммы, графики на нормальной вероятностной бума-
123
ге разных типов. Вкладка Сдвиг позволяет осуществлять сдвиг ря-
да с заданным лагом вперед или назад.
Преобразования Й—-----------------— -------- ————————i——----------------------;----------------
Прибавить константу (х«х+С) С-|6 § Г' Вычесть среднее (х«х-М) ,, И
Г4 Степень (х»х”С) . g Стандартиз. (x»{x-M)/SD) Н-jo, g SD-ji, . pj
С Обратная степень (x*x”1ZC) С=|2.00 Q & Оценить среднее [Mju.c/am. лткл. JSC'Jиздамнь -
Г Натуральный логарифм (x=ln(x)) С Вычесть тренд (x-x-(a+b«t)) о- р> g Ь*|Г------g
С Экспонента(х»ехр(х)) С' Двтокорр.(х=х-(а+Ь*х(лаг))) a='|(L g g
|7 Оценить a'b из данных •р g
Рис. 7.3. Вкладка X = f(x)
Сглаживание временного ряда --------------------------------—-----—-----i----
(* N-точ. скольз. средним N=|2 [Ц Г По пред. Г" Взвеш. Задать веса
Г* N-точ. скольз. медианой U- р g] Г” ’« пред.
С Простое экспоненциальное сглаж. л-.г, | g]
Г 4253Н Фильтр
• ’ IJ • j> ’> т « f rt , j > « F
Рис. 7.4. Вкладка Сглаживание
Преобразование-------------------т—-----------—:—
Разность (х=х-х(лаг)) лаг= П §
Г* Сумма (х=х+х(лаг)) лаг= га
Пер. с начальными набпгзде»!И:йм.-! j 2AKPbiТИЕ
Рис. 7.5. Вкладка Разность, Сумма
Окно сглаживв!
Г Датмэля
С Тыоки
Хемминга
Г* Действит. и мнимая часть
Г4 Обратное преобр. Фурье
|ДЁр Mh»t« (mpj: J
Рис. 7.6. Вкладка Фурье
Преобразования временного ряда
Косинус-сглаживание
% сглаживания:
Выб*рит« преобраэо1эни« для
1ЫД4Л4НН0М переменной (ряда);
доступны также методы
дшомпотндии спектрального (Фурье)
анализа.
Парзена
Бартлетта
124
ffl ПВОСМОТР выдел. переменной [ Г рафик
ffl Просмотр нескольких перем. I^l График
|у>.] Г рафик двух списков перем, в разных масшг.
р* Г рафик после каждого преобразования
Отображать только подмножество набл.
Г* Задать масштаб по оси X (мин. значение, шаг)
р g (Uar- [100 g
г-Пометить точки
С Именами наблюдений
Г* Номерами наблюдений
(• Датами из переменной
Переменная: | Дата
С Целыми числами
Рис. 7.7. Вкладка Графики
Сезонности и циклы можно определять, используя автокорреля-
ции и частные автокорреляции (устраняющие влияние автокорре-
ляций меньшего порядка, рис. 7.8). Кроме того, в системе Statistica
используются специальные методы поиска циклов - Census 1 и
Census 2.
Для анализа нестационарных процессов часто используется мо-
дель АРПСС.
Автокорреляции и кросскорреляции.....
□ав . I выделяем. ГпклИ
НЯ Автокорреляции [ р.уроеень. 1-иьи й
17 Стандартные ошибки белого ш^иа
ПЯ Частные автокорреляцщ|
Ей Кросскорреляции
Диаграммы рассеяния с лагом
[^1 2М рассеяния
Г рафик выделенной переменной с лагом:
Г Пометить точки в диаграммах рассеяния
Число лагов: fl 5 [$]
Рис. 7.8. Вкладка Автокорреляции
7.2.1. Преобразование переменных
Для иллюстрации возможностей программы по преобразованию
переменных рассмотрим ряд котировок валютных пар доллар/иена
(USDJPY) за период с 1.01. 2002 г. по 17.11. 2006 г. (файл Коти-
PObkh.xIs). По мнению многих аналитиков, цена закрытия позволя-
ет лучше оценить основные тенденции, поэтому из всего набора
данных выберем для анализа именно эту переменную. В исходном
окне (см. рис. 7.1) щелкнем ОК, затем выделим переменную За-
крытие и на вкладке Графики в переключателе Пометить точки
укажем Датами из переменной. На полученном графике (рис. 7.9)
четко видны наличие тренда и нестационарность ряда.
125
График переменной: ЗАКРЫТИЕ
Рис. 7.9. График переменной Закрытие
Откроем теперь вкладку Сглаживание и выберем сглаживание
7-точечной скользящей средней (N = 7). Снова построим график по
той же схеме, что и ранее, и получим сглаженный временной ряд
(рис. 7.10), который имеет меньше «зубцов» и лучше демонстриру-
ет понижающую тенденцию. Эта тенденция смещает оценки авто-
корреляционной функции, поэтому тренд следует удалить. Для это-
го на вкладке x=f(x) пометим переключатель Вычесть тренд и вы-
ведем новый график (рис. 7.11).
Выделим преобразованный ряд и щелкнем по кнопке Автокор-
реляции; выяснится, что для всех значений лага от 1 до 15 наблю-
дается сильная автокорреляция (рис. 7.12). Для уточнения исполь-
зуем кнопку Частная автокорреляция; это позволяет искать авто-
корреляции для всех уровней лага без учета влияния автокорреля-
ций с меньшими лагами. График ЧАКФ (рис. 7.13) показывает, что
автокорреляции с лагом выше 1 действительно обусловлены трен-
дом. Таким образом, на каждое последующее значение ряда реаль-
но влияет только предыдущее значение.
Вернемся на вкладку x=f(x) и удалим автокорреляцию, пометив
соответствующий переключатель. Рассмотрим разность первого
порядка для переменной Закрытие (вкладка Разность, Сумма =>
ОК); получим график, указывающий на возможную стационарность
процесса (рис. 7.14).
126
Г рафик переменной: ЗАКРЬГГИЕ
7 тч перед ск средн.
Рис. 7.10. График переменной Закрытие, преобразованной с помощью
7-дневной скользящей средней
График переменной: ЗАКРЫТИЕ
Рис. 7.11. График переменной Закрытие после удаления линейного тренда
Автокорреляцией, функция
ЗАКРЫТИЕ: х-121,4+0099’t
(Стандартные ошибки - оценки белого шума)
] Q р
1 + ,993 , 0280 ШЛШШ. | 1259, 0, 000
2 +,986 ,0280 2502, 0, 000
3 + ,979 ,0280 шшш 3729, 0, 000
4 +,973 ,0280 4939, 0, 000
5 +,966 ,0279 - : шяш 6134, 0, 000
б +,958 ,0279 : - - ; шяшш 7311, 0, 000
7 +,951 ,0279 ... шшш. 8471, 0, 000
8 +,943 ,0279 :- - - ; ШШШ 9614, 0,000
9 +,937 ,0279 шяш. 107Е2 0, 000
10 +,930 ,0279 шшш 119Е2 0, 000
11 +,923 ,0279 129Е2 0, 000
12 + , 917 , 0279 шиш 140Е2 0, 000
13 +,910 ,0279 151Б2 0, 000
14 +,903 ,0278 162Е2 0, 000
15 +,897 ,0278 ' • ШШВ 172Е2 0, 000
0 0 - Дов интерв
-1.0 -0.5 0.0 0.5 1
Рис. 7.12. График АКФ после удаления линейного тренда
Частная автокорреляцион. функция
ЗАКРЫТИЕ: х-121,4+,0099’t
(Ст. ошибки предполагают порядок АР к-1)
—- Дов. интерв.
Рис. 7.13. График ЧАКФ после удаления линейного тренда
Рис. 7.14. График переменной Закрытие после взятия разности 1-го порядка
Рассмотрим теперь АКФ и ЧАКФ переменной Закрытие после
взятия разности 1-го порядка (рис. 7.15). Автокорреляция практи-
чески отсутствует, что не соответствует модели АРПСС. Однако
если взять разности второго порядка (рис. 7.16), обнаружатся зна-
чимые автокорреляции (рис. 7.17, 7.18); это объясняется наличием
тренда 2-го порядка, хорошо заметного на рис. 7.11.
Исходя из приведенных критериев идентификации (табл. 7.1,
7.2), процесс, получившийся после взятия разности 2-го порядка,
следует отнести к процессу СС 1-го порядка. Это можно объяснить
наличием нелинейной составляющей 2-го порядка, которая заметна
уже на графике исходного ряда (см. рис. 7.9).
Таким образом, динамику котировок валютных пар доллар/иена
по переменной Закрытие можно идентифицировать как процесс
АРПСС(О, 2, 1).
Найдем параметры модели. Выйдем из окна преобразований,
щелкнув Cancel, и дадим команду Методы АРПСС и автокорре-
ляционные функции. Далее заполним поля в открывшемся окне
в соответствии с рис. 7.19 и щелкнем ОК.
В диалоговом окне Результаты АРПСС (рис. 7.20) выберем
кнопку Оценки параметров и получим таблицу, изображенную на
рис. 7.21.
9 Каике И.А.. Паклим Н.Б.
129
Лаг
1
2
3
4
S
6
7
8
9
10
11
12
13
14
15
Лаг
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
Автокорреляцией, функция
ЗАКРЫТИЕ: D(-1)
(Стандартные ошибки - оценки белого шума)
Частная автокорреляцией, функция
ЗАКРЫТИЕ: О(-1)
(Ст. ошибки предполагают порядок АР к-1)
Рис. 7.15. Графики АКФ и ЧАКФ для переменной Закрытие после взятия раз-
ности 1-го порядка
Г рафик переменной: ЗАКРЫТИЕ
D(-1);D(-1)
Даты (из переменной: Дата
Рис. 7.16. График переменной Закрытие после взятия разности 2-го порядка
Автокорреляцион. функция
ЗАКРЫТИЕ: D(-1); D(-1)
(Стандартные ошибки - оценки белого шума)
р
о, ООО
0,000
О, ООО
0,000
0,000
О, ООО
О, ООО
0,000
О, ООО
0,000
0,000
0,000
0,000
0,000
0,000
Дов.интерв.
Рис. 7.17. График АКФ после взятия разности 2-го порядка
Частная автокорреляцией функция
ЗАКРЫТИЕ: О{-1); О(-1)
(Ст. ошибки предполагают порядок АР к-1)
лаг Корр, стош
1 491 ,0200
2 -,370 ,0280
3 -,234 ,0280
4 -,224 ,0280
5 -,175 ,0280
б -,128 ,0280
7 -,060 ,0280
8 -,131 ,0280
9 -,083 ,0280
10 -,079 ,0280
11 -,085 ,0280
12 -,094 ,0280
13 -,062 ,0280
14 -,058 ,0280
15 -,065 ,0280
0
-1.0 -0.5 0.0 0.5 1.0
Рис. 7.18. График ЧАКФ после взятия разности 2-го порядка
Рис. 7.19. Диалоговое окно АРПСС
Рис. 7.20. Окно результатов АРПСС
Параметр Исход. ЗАКРЫТИЕ (Котировки USDJPY.sta) Преобразования: 2*D(1) Модель(0,2,1) MS Остаток^ ,42879
Парам. Асимпт. [Асимпт. Ст.ошиб. I t( 1271) Р Нижняя 95% дов. Верхняя 95% дов.
Ж1> 0,977495. 0,0056451173.1658 0,00 0,966420 0,988569
Рис. 7.21. Оценка параметра Ьг
Параметр модели СС(1) Ь\ - 0,977495 с доверительным интерва-
лом (0,966420; 0,988569) при уровне значимости 0,05 (доверитель-
ной вероятностью 0,95). Этот параметр достоверен при уровне зна-
чимости не более 0,01. Затем в окне результатов АРПСС выберем
вкладку Распределение остатков и далее Гистограмма и Нор-
мальный. Мы получим гистограмму остатков и график нормаль-
ной вероятности для них (рис. 7.22), которые не противоречат ги-
потезе об их нормальном распределении.
Следующий шаг - проверка коррелированности остатков. В окне
результатов АРПСС откроем вкладку Автокорреляции и выберем
последовательно Автокорреляции и Частные автокорреляции.
График (рис. 7.23) показывает, что остатки не коррелируют.
133
Лаг
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
Лаг
1
2
3
4
5
6
1
8
9
10
11
12
13
14
15
Автокорреляцион. функция
ЗАКРЫТИЕ. АРПСС (0,2,1) остатки ;
(Стандартные ошибки - оценки белого шума)
Частная автокорреляцион. функция
ЗАКРЫТИЕ: АРПСС (0,2,1) остатки ;
(Ст. ошибки предполагают порядок АР к-1)
Рис. 7.23. АКФ и ЧАКФ остатков
В поле Число наблюдений введем «24» и щелкнем по кнопкам
Прогноз, График ряда и прогнозов; программа выведет прогноз
на заданное число дней (рис. 7.24). Модель хорошо описывает изу-
чаемый процесс, однако к полученному прогнозу следует относить-
ся очень осторожно. Есть несколько причин для такого скептициз-
ма. Во-первых, параметр СС почти равен 1; это означает, что про-
цесс близок к нестационарному (в этом можно убедиться, выбрав
более точный способ оценки параметров в окне АРПСС, рис. 7.19).
Во-вторых, границы доверительной области расходятся, то есть ряд
не поддается удовлетворительному прогнозу. Фактически мы полу-
чили для исходных данных классическую модель случайного блу-
ждания.
Прогнозы: Модель:(0,2,1) Сезонный лаг. 12
Исход: ЗАКРЫТИЕ
Рис. 7.24. График прогноза для ряда Закрытие
Качество полученной модели можно оценить визуально. Вер-
немся в исходное окно анализа временных рядов (см. рис. 7.1),
щелкнем ОК и на вкладке Графики отметим переменные Закрытие
и Закрытие: +прогнозы, Модель: (0,2,1). Снова щелкнем ОК и
получим график, подтверждающий хорошее соответствие модели
исходному временному ряду.
Завершая данный подраздел, отметим, что в российской эконо-
мике в настоящее время трудно найти примеры достаточно длин-
ных и однородных временных рядов. Поэтому для иллюстрации
соответствующего аналитического аппарата приходится обращать-
136
ся к зарубежным материалам или к котировкам акций и валютных
пар на биржах. Следует также учитывать, что, несмотря на универ-
сальность рассматриваемых методов, каждая предметная область
вносит свои особенности. Так, при изучении динамики биржевых
курсов традиционно используется так называемый технический
анализ - набор приемов, позволяющий по графикам, специальным
индикаторам, разнообразным внешним факторам составлять про-
гнозы стоимости акций, валютных курсов и т.п. (см., например:
Томас Р. Демарк. Технический анализ. Новая наука. - М.: Диа-
грамма, 2001).
7.2.2. Модель Бокса и Дженкинса
Рассмотрим более подробно классический пример модели
АРПСС Дж. Бокса и Г. Дженкинса - так называемый ряд G месяч-
ных объемов пассажирских перевозок (в тысячах пассажиров) на
международных авиалиниях с января 1949 г. по декабрь 1960 г. Для
этого откроем файл Series_G.sta из папки Examples/ Datasets и
отобразим данный ряд на графике (рис. 7.25).
Г рафик переменной: SERES_G
Monthly passenger totals (in 1000's)
700 --------------------•--------------»----т---------•----•----•----•--------т----700
Имена наб.
Рис. 7.25. График ряда G
Из рисунка видно, что ряд имеет линейный тренд и сезонность,
а поскольку сезонность со временем увеличивается, можно предпо-
ложить мультипликативность его модели. Чтобы устранить этот
137
эффект, ряд нужно прологарифмировать. В исходном окне анализа
временных рядов щелкнем ОК и на вкладке x=f(x) выберем Нату-
ральный логарифм. На рис. 7.26 видно, что амплитуда и сезон-
ность после этого стали стабильными, а линейный тренд - более
четко выраженным. Чтобы устранить его, рассмотрим разности 1 -го
порядка (рис. 7.27).
Г рафик переменной: SERIES_G
Имена наб.
Рис. 7.26. График прологарифмированных значений ряда G
Теперь ряд внешне похож на стационарный; для проверки этого
предположения рассмотрим автокорреляции и частные автокорре-
ляции с лагом 20 (рис. 7.28, 7.29).
Полученные графики показывают наличие сезонности с лагом
12 мес. Чтобы исключить ее, возьмем разности 2-го порядка с ла-
гом 12 (рис. 7.30, 7.31).
На графиках видно, что автокорреляционная функция обрывает-
ся после задержки q = 1, а ее частная автокорреляционная функция
спадает плавно. Исходя из правил идентификации стационарных
рядов (табл. 7.1, 7.2), можно сказать, что это соответствует процес-
су СС порядка q = 1. Автокорреляциям с задержкой 12 мес можно
поставить в соответствие сезонный лаг Q - 1. Поэтому перейдем на
вкладку АРПСС и заполним поля в соответствии с рис. 7.32, а затем
откроем окно результатов анализа (рис.7.33).
График переменной: SERIES_G
Monthly passenger totals (in 1000's); ln(x); D(-1)
Имена наб.
Рис. 7.27. График прологарифмированных значений ряда G после взятия раз
ностей 1-го порядка
Автокорреляцион. функция
SERIES_G: Monthly passenger totals (in 1000's); ln(x); D(-1)
(Стандартные ошибки - оценки белого шума)
Лаг Корр. СтОш Q Р
1 +,200 ,0828 • " dul 5, 83 ,0158
2 -, 120 , 0825 - i - - -;И -1 - - - 7, 95 ,0188
3 151 ,0822 Д : 11,31 ,0102
4 -,322 ,0819 ...... ; - 26,79 ,0000
5 -,084 ,0816 1 " i 1 : 27, 85 ,0000
6 4,026 ,0813 : : 27, 95 ,0001
7 -,111 ,0810 - |14- •• — 29, 83 , 0001
8 -,337 ,0607 ....... 4 " ;•• • - 47,24 ,0000
9 -,116 ,0804 1- 49,31 ,0000
10 -, 109 , 0801 i — 51,17 ,0000
11 +,206 ,0798 ;- gggj 57, 83 ,0000
12 ♦,841 ,0795 169, 9 0,000
13 +,215 ,0792 • - - - - - - |Ц|| - 177,3 0,000
14 -,140 ,0789 Д : • 180, 4 0, 000
15 -,116 ,0786 - - ! 182, 6 0, 000
о ---------------------------------•-----------о — Дов. интерв.
-1.0 -0.5 0.0 0.5 1.0
Рис. 7.28. АКФ ряда G после взятия разностей 1-го порядка
Частная автокорреляцион. функция
SERIES_G: Monthly passenger totals (in 1000's); ln(x); D(-1)
(Ст. ошибки предполагают порядок AP k-1)
Лаг Корр. СфОш
1 +,200 ,0836
2 -, 167 , 0836
3 -,096 ,0836
4 -,311 ,0836
5 +,008 ,0836
6 -,075 ,0836
7 -,210 ,0836
8 -,495 ,0836
9 -, 192 , 0836
10 -,532 ,0836
11 -,302 ,0836
12 +,586 ,0836
13 +,026 ,0836
14 -,181,0836
15 +,120 ,0836
0
-1.0 -0,5 0.0 0.5 1.0
Дов. интерв.
Рис. 7.29. ЧАКФ ряда G после взятия разностей 1-го порядка
Автокорреляцион. функция
SERIES_G: Monthly passenger totals (in 1000's); ln(x); D(-1);D(-12)
(Стандартные ошибки - оценки белого шума)
Лап Корр. Ст Ош Q P
1 -,341 , 0864 • • - - “ * • 15,60 ,0001
2 + , 105 ,0860 ! i: 17,09 , 0002
3 -,202 , 0857 - |Ц|' : - - • 22, 65 , 0000
4 + ,021 ,0854 1 1 J 22,71 ,0001
5 + , 056 ,0850 i |i • 23, 14 ,0003
6 + , 031 , 0847 4 1 i 23,27 ,0007
7 -, 056 0844 i В I ’ 23,70 ,0013
8 -,001 0840 - | - ; - 23,71 ,0026
9 + , 176 0837 - - - | ЦЦ • 28,15 , 0009
10 -,07б 0833 \ 28,99 ,0013
11 + ,064 0830 ! 1 i 29,59 ,0018
12 -,387 0826 - | ; • - 51, 47 , 0000
13 + , 152 ,0823 - ; - 54, 87 , 0000
14 -,058 0819 i 1 ; 55,36 ,0000
15 + ,150 0816 58,72 , 0000
о -----------•-----------*---------•—;---------- о —• Дов. интерв.
-1.0 -0.5 0.0 0.5 1,0
Рис. 7.30. АКФ ряда G после взятия разностей 2-го порядка с лагом 12
Частная автокорреляцион. функция
SERIES_G: Monthly passenger totals (in 1000's); ln(x); D(-1); D(-12)
Рис. 7.31. ЧАКФ ряда G после взятия разностей 2-го порядка с лагом 12
Рис. 7.32. Диалоговое окно АРПСС
Рис. 7.33. Окно результатов АРПСС
Щелкнув по кнопке Оценки параметров, получим таблицу,
представленную на рис. 7.34. При уровне значимости 0,05 (с дове-
рительной вероятностью 0,95) оценки параметров мультипликатив-
ной модели АРПСС (0,1,1)х(0,1,1 )(2 составят:
bi = 0,377162 с доверительным интервалом (0,200445; 0,553880);
0у(1) = 0,572379 с доверительным интервалом (0,431529;
0,713229) и т.д.
Параметр Hcxoa.:SERIES_G: Monthly passenger totals (in 1000's) (Series_G.sta) Преобразования: ln(x),D(1),D(12) Модель(0,1.1 )(0,1,1) Сезонный лаг 12 MS Остаток= ,00141
Парам. Асимпт. Ст.ошиб. Асимпт. t( 129) Р Нижняя 95% дов. Верхняя 95% дов.
0,377162 0,089318 4,222697 0,000045 0,200445 0,553880
0,572379 0,071189 8,040233 0,000000 0.431529 0,7132291
Рис. 7.34. Оценки параметров мультипликативной модели АРПСС
(0,l,l)X(0,l,l)i2
142
В явном виде полученную модель можно записать в виде раз-
ностного уравнения
zt — zz_] — zt-\2 + zt-\3 = £/ — 0,377162 E/-i —0,572379 £z_j2 +
+ 0,377162 0,572379 £/_i3,
или (для прогноза на к шагов вперед):
Zt+k = zl+k-\ + zl+k-n - Zt+k-13 + £/+* - 0,377162 £/+a_] - 0,572379 £^12 +
+ 0,215879608 е^з-
Обычно для получения прогнозов неизвестные значения zt заме-
няются прогнозными, а неизвестные £z - нулями; известные £z - это
уже вычисленные на шаг вперед ошибки:
£z = zt -iM(l).
Перейдем на вкладку Распределение остатков и выберем по-
следовательно Гистограмма, Нормальный и Автокорреляции,
Частные автокорреляции (рис. 7.35, 7.36). Из полученных графи-
ков видно, что остатки имеют нормальное распределение и не кор-
релируют. Таким образом, все исходные предположения выполня-
ются, и приведенная выше модель может считаться адекватной.
В окне результатов АРПСС заполним поля следующим образом:
Число наблюдений - 36, Начать с - 133, Уровень доверия - 0,9
и отметим флажок Добавить прогнозы к исходному ряду при
выходе. Щелкнув по кнопке График ряда и прогнозы, получим
прогноз для ряда G и соответствующие доверительные интервалы
(рис. 7.37).
Применим к исходному ряду G процедуры экспоненциального
сглаживания. Для этого в исходном окне анализа временных рядов
щелкнем по кнопке Экспоненциальное сглаживание и прогноз,
после чего заполним поля, в открывшемся окне, исходя из предпо-
ложения, что ряд имеет мультипликативную сезонную компоненту
с лагом 12 и мы желаем получить прогноз на 24 дня (рис. 7.38).
Для поиска параметров данной процедуры воспользуемся вклад-
кой Автоматический поиск; в результате получим сглаженный ряд
и прогноз на 24 дня (рис. 7.39). Найденное значение а для модели
составит 0,717.
Чтобы получить график сглаженного ряда G, прогноза на 24 дня
и исходного ряда, откроем вкладку Прогноз, во второй строке вы-
берем График, отметим нужные ряды и щелкнем ОК (рис. 7.40).
Нетрудно заметить, что модель экспоненциального сглаживания
дает хороший результат - как по воспроизведению исходного ряда,
так и по качеству прогнозирования. Ее недостатком считается от-
сутствие вероятностной интерпретации, а следовательно, и невоз-
можность построения доверительных интервалов для прогноза.
143
3 н «Штюц v h 0]
Гистограмма, перем.: SERES.G норм, вероятн. график SERES G
Верхние границы (х<=граница) Зиач
Рис. 7.35. Гистограмма и график распределения остатков
Автокорреляцией, функция Частная автокорреляцией, фрикция SERES.G: АРПСС(0.1.1X0.1.Достатки ; SERES.G: АРПСС(0.1.1Х0.1.1)остатки ;
q р лаг ворр. читмя ,01 ,9366 1 4,007 .0874 ,09 ,9537 2 4,026 ,0874 2,12 ,5484 3 -, 122 ,0874 3,58 ,4661 « -,103 ,0874 4#43 в 4893 4,088 ,0874 5,22 ,5153 6 4,068 ,0674 5,59 ,5882 7 -,086 ,0674 5,68 ,6633 0 -,022 ,0874 7,52 ,5828 9 4,163 ,0874 7,84 ,6443 10 “♦058 ,0874 7,92 ,7201 11 *,027 ,0874 8,01,7644 & 4,020,0874 8,03 ,8418 13 4,049 ,0874 8,22 ,8775 14 -,005 ,0874 8,64 ,8859 15 4,047 ,0874
1 *,007 ,0864 2 4,026 ,0860 3 -,122 ,0857 4 -,103 ,0854 5 4,078 ,0850 6 4,076 ,0847 7 -,051 ,0844 8 -,025 ,0640 9 4, 114 ,0837 10 -,047 ,0833 11 4,024 ,0830 12 -,024 ,0826 13 4,011 ,0823 14 4,036 ,0819 15 4,064 ,0616 0 -1 I . .. 1 1 i н и й 1 а 1 Г 0 8 1 i . . _ _ - _ |.
а 1 I ... 1 • а S в 1
и
.0 -0.5 0.0 0.5 1.0* " ' °-5 °’0 0,5 1,0
Рис. 7.36. АКФ и ЧАКФ для остатков
Прогнозы: Моделы(0.1.1X0.1,1) Сезонный лаг. 12
Исход.: SERIES_G: Monthly passenger totals (in 1000’s)
Рис. 7.37. График прогноза для ряда G
Рис. 7.38. Диалоговое окно экспоненциального сглаживания
Набл. Эксп. сглажив.: Мульт, сезон. (12) S0=110,8 ТО—2,648 (Series_G.sta) Лин.тренд,мульт.сезон.; Альфа= ,717 Дельт=0,00 Гамма=0,00 SERIES G: Monthly passenger totals (in 1000's)
SERIES_G Сглажен. _ряд Остатки Сезонные составл. |
1 112,0000 103,43011 8,5699 91,1856
2 118,0000 108,3489 9,6511 88.2217
3 132,0000 134,3813 -2,3813 100,8068
4 129,0000 130,6282 -1.6282 97.2951
5 121,0000 133,1656 -12,1656 98,1268
6 135,0000 144,1407 -9.1407 111,3347
7 148,0000 155,4299 -7,4299 123,1350
8 148,0000 151,2839 -3.2839 121,4657
9 136,0000 132,5109 3.4891 105,7905
10 119,0000 120,0690 -1.0690 92,16911
11 104,0000 106.0500 -2,0500 80,2883
12 118,0000 119,8533 -1,8533 90.1807
157 471,6331
158 458,6386
159 526,7340
160 510,9609
Рис. 7.39. Таблица итогов экспоненциального сглаживания и прогноз
на 24 дня
Рис. 7.40. График ряда G, сглаженного ряда и прогноза на 24 дня
ю ♦
Метод экспоненциального сглаживания считается относительно
простым; модель АРПСС предоставляет гораздо больше возможно-
стей. Она позволяет описывать как стационарные процессы, так и
достаточно широкий класс нестационарных - например, процессы
со стационарными приращениями порядка d (обычно d = 0, 1,2),
причем разность порядка d является стационарным процессом
с определенными свойствами [10]. Вместе с тем при изучении про-
цессов, происходящих в природе и обществе, вероятностные моде-
ли далеко не всегда применимы (хотя их и необходимо рассматри-
вать в качестве одной из альтернатив).
7.2.3. Сезонная декомпозиция и спектральный анализ
Для иллюстрации возможностей этих методов рассмотрим вре-
менной ряд месячных продаж вина в Австралии за период с января
1980 г. по июнь 1994 г. Исходные данные загрузим из файла Вре-
менные ряды.хк и в качестве анализируемой переменной выберем
общий объем продаж (Total). Соответствующий график представ-
лен на рис. 7.41; на нем видна четко выраженная сезонность и слабо
заметная тенденция сначала к росту (примерно до июля 1987 г.),
а затем к снижению (до января 1990 г.). Эти тенденции можно за-
метить в основном по амплитудам, так как среднегодовые уровни
продаж практически неизменны.
Г рафик переменной: TOTAL
Jan80 Sep81 Мау83 Jan85 Sep86 May88 Jan90 Sep91 May93
Nov80 Jul82 Mar84 Nov85 Jul87 Mar89 Nov90 Jul92 Mar94
Даты (из переменной: Month and year
Рис. 7.41. График общих ежемесячных продаж вина в Австралии
148
Рассмотрение АКФ и ЧАКФ указывает на наличие сезонности
с лагом 12 мес. После удаления сезонности путем взятия соответ-
ствующей разности значимых автокорреляций не наблюдается,
а следовательно, модель АРПСС для данного ряда не подходит.
Открыв вкладку Дополнительно модуля экспоненциального
сглаживания, выберем сезонную компоненту с лагом 12 и адди-
тивную модель без тренда. С использованием процедуры автомати-
ческого поиска, как и в предыдущем примере, найдем значение па-
раметра а = 0,163. Затем построим график ряда Total и соответ-
ствующий сглаженный ряд.
Как видно на рис. 7.42, данная модель дает в целом неплохой ре-
зультат. Вместе с тем из графика видно, что остатки колеблются от
нескольких сотен до нескольких тысяч, поэтому для прогнозирова-
ния эту модель использовать невозможно (хотя общую тенденцию
ряда она описывает).
Рис. 7.42. График общих ежемесячных продаж вина и ряд, полученный после
процедуры экспоненциального сглаживания
Выделим все предполагаемые составляющие ряда с использова-
нием модуля сезонной декомпозиции; для этого заполним диалого-
вое окно в соответствии с рис. 7.43. В поле Сезонный лаг введем
число 12 и в группе Сезонная модель отметим переключатель
Аддитивная.
149
ЙЬ Классическая сезонная декомпозиция (метод Censut 1| продажи вина sta
ПИ®
Рис. 7.43. Диалоговое окно модуля Сезонная декомпозиция
На первом шаге вычисляется скользящая средняя с шириной ок-
на, равной сезонному периоду (при четном лаге для того, чтобы
первое и последнее наблюдение в окне имели неравные веса, необ-
ходимо отметить флажок Центр, скользящее среднее). В группе
опций Добавить в рабочую область для аддитивной модели
можно выбрать следующие компоненты (предварительно заполнив
поле Число копий на ряд): Скользящие средние (с шириной ок-
на, равной сезонному периоду); Отношения/Разности (для адди-
тивной модели - разности: из наблюдаемого ряда вычитаются зна-
чения скользящих средних); Сезон. Составляющие (среднее всех
значений соответствующих сезону); Сезонную корректировку ря-
да (разность между значениями исходного ряда и сезонной состав-
ляющей); Сглаженный тренд-цикл (выявление более длительных
циклов, чем сезонность, за счет сглаживания); Нерегулярную ком-
поненту (погрешность - разность между рядом с сезонной коррек-
тировкой и рядом с тренд-циклической компонентой).
Щелкнув ОК, получим таблицу со всеми выделенными компо-
нентами. Перейдем в окне модуля сезонной декомпозиции на
вкладку Прогноз и щелкнем по кнопке График; получим как от-
дельные графики компонент, так и все графики вместе (рис. 7.44).
Порядок представления компонент на графике соответствует при-
веденному выше их описанию; их можно изучать независимо и ис-
пользовать для построения прогноза.
150
50000
40000
30000
20000
10000
0
-10000
-20000
ООООООСОСОООСООЭООООООООСОООООО)
Г рафик выбранных переменных (рядов)
50000
40000
30000
20000
юооо —T0TAL
—- TOTAL; прбр
0
- TOTAL; np.2
-10000 — T0TAL: пр 3
-• TOTAL; пр.4
-20000 — TOTAL; пр 5
— TOTAL; пр.6
Даты (из переменной: Month and year
Рис. 7.44. Ряд Total и все выделенные компоненты его аддитивной модели
Заметим, что для выявления сезонности и периодичности боль-
ше всего подходит спектральный анализ. Чтобы применить этот
метод, в исходном окне анализа временных рядов щелкнем по
кнопке Фурье (спектральный) анализ и затем дадим команду Од-
номерный анализ Фурье => Просмотр и графики => График <=>
Период Периодограмма. На экран будет выведена периодо-
грамма изучаемого ряда (рис. 7.45). Используя кнопку Увеличить
выделим прямоугольник с тремя максимальными значениями и
получим график, представленный на рис. 7.46. Из него следует, что
исходный ряд имеет 4-месячную сезонность, менее выраженную
6-месячную и еще менее выраженную 12-месячную. Таким обра-
зом, визуальный и содержательный анализ, предполагающий годо-
вую сезонность, оказался ошибочным - на самом деле имеются бо-
лее сильные сезонности с периодичностью 4 и 6 мес.
Вместе с тем, если сгладить ряд с помощью 4-месячной сколь-
зящей средней (устраняющей 4-месячную сезонность), периодо-
грамма будет принимать наибольшее значение уже для периода
в 12 мес (студентам рекомендуется сделать это самостоятельно -
см. рис. 7.47). Таким образом, можно считать, что действительная
периодичность ряда Total - 4 мес, а 12 мес (точнее, 12,1429,
см. рис. 7.48) - это цикличность в данных. Графическое изображе-
ние (рис. 7.49) подтверждает эту закономерность.
151
Рис. 7.46. Периодограмма для ряда Total в увеличенном виде
Спектр, анализ: TOTAL : Total —Total Wine sales
Число набл.: 174
Рис. 7.47. Периодограмма для ряда Total после сглаживания 4-месячной скользящей
средней в стандартном и увеличенном виде
Спектр, анализ: TOTAL: Total --- Total Wine sales; 4 тч.ск (продажи BHHa.sta)
Число набл.: 170 _____
Частота Период Косинус коэфф. Синус коэфф. Периодограмма Плотн. Хемминг веса
0 0,000000 0,00 0,000 0 143092878 0,035714
1 2 0,005882 0,011765 170,0000 85,0000 -1730,07 144,62 663,530 -609,810 291839059 149385687 0,241071
33386645 89582942 0,446429
3 0,017647 56,6667 -339,08 -303,692 17612089 27124946 0,241071
4 0,023529 42,5000 -111,34 -115,824 2194070 8400437 0,035714
5 0,029412 34,0000 -200,21 -215,060 7338479 6097446
Б 0,035294 28,3333 -265,00 -12,932 5983372 6983619
7 0,041176 24,2857 139,16 -231,152 6187690 11315059
8 0,047059 21,2500 -483,81 -294,203 27253474 15865588
9 0,052941 18,8889 -302,56 9,209 7788347 11053804
10 0,058824 17,0000 -186,97 56,872 3246424 4594723
11 0,064706 15,4545 -25,93 19,711 90174 2961710
12 0,070588 14,1667 -287,54 -84,769 7638446 22517534
13 0,076471 13,0769 -73,50 30,734 539479 129552488
14 0,082353 12,14291 -2427,34 560,406 527513808 238021358
15 0,088235 11,3333 305,17 72,121 8358302 131911145 1Л1, „-Л.-1-1ЛТ.
Рис. 7.48. Результаты спектрального анализа после 4-месячного сглаживания
График выбранных переменных (рядов)
50000
40000
30000
20000
10000
0
-10000
-20000
50000
40000
30000
20000
10000
О
-10000
-20000
О 20 40 60 80 100 120 140 160 180
— TOTAL •— TOTAL: прбр. -*- TOTAL; пр.2
Рис. 7.49. Графики переменной Total, 4-месячной сезонности и 12-месячной
цикличности
ЗАДАНИЕ
Рассмотрите примеры временных рядов по объему продаж (файл
временные ряды.хк), выбрав один из вариантов, приведенных
в табл. 7.3. Загрузите исходные данные, проанализируйте их на на-
личие тренда и сезонности. Постройте несколько моделей для про-
гнозирования временного ряда и протестируйте их на предвари-
тельно проставленных точках.
7.3. Варианты заданий по анализу временных рядов
Вариант Номера рядов Вариант Номера рядов Вариант Номера рядов
1 1 3 11 17 16 21 20 27
2 2 5 12 4 18 22 24 28
3 6 7 13 20 19 23 25 29
4 9 8 14 24 20 24 6 30
5 13 10 15 25 21 25 9 31
6 17 11 16 13 22 26 17 32
7 4 12 17 2 23 27 1 17
8 20 14 18 6 24 28 13 21
9 24 15 19 9 25 29 4 15
10 25 16 20 1 26 30 2 16
ВОПРОСЫ ДЛЯ САМОКОНТРОЛЯ
1. Для решения каких задач используют методы анализа временных рядов?
2. Опишите основные подходы к построению моделей временных рядов.
3. Дайте определение понятий «тренд», «сезонность», «цикличность».
4. Назовите основные способы выделения трендов и сезонностей.
5. Что такое автокорреляция?
6. В чем состоит отличие между стационарными и нестационарными вре-
менными рядами?
7. Какие модели используются при описании этих типов временных рядов?
ЧАСТЬ II. ИНТЕЛЛЕКТУАЛЬНЫЙ АНАЛИЗ ДАННЫХ
МЕТОДЫ ИНТЕЛЛЕКТУАЛЬНОГО АНАЛИЗА
1. НОВЫЕ ПОДХОДЫ К АНАЛИЗУ ДАННЫХ
Data Mining (добыча данных), или интеллектуальный анализ
данных (НАД), - новое направление в науке и бизнесе, возникшее
на рубеже 90-х годов XX в. [8, 17, 20, 28]. Оно опирается на эле-
менты прикладной статистики, теории баз данных, концепции ис-
кусственного интеллекта, машинного обучения и др. Его быстрому
развитию способствовало появление персональных компьютеров,
совершенствование технологий записи и хранения данных. Практи-
чески все предприятия сегодня имеют базы данных, содержащие
очень большие объемы информации, и разобраться в них без ис-
пользования новейших средств анализа бывает очень непросто.
Методы Data Mining в основном базируются на теории разве-
дочного анализа данных (РАД), а также концепциях искусственно-
го интеллекта (нейронные сети, деревья решений, эволюционное
программирование, когнитивное моделирование, нечеткая логика).
По мере расширения комплекса решаемых задач стали использо-
ваться также теория хаоса, нелинейная динамика, фрактальные и
вейвлет-преобразования.
Вместе с тем процедура добычи данных существенно отличается
от классического разведочного анализа - она в большей степени
ориентирована на практическое приложение полученных результа-
тов, а не на выяснение природы явления. Иными словами, при до-
быче данных нас не очень интересует конкретный вид зависимо-
стей между переменными, поиск формы связи между ними и т.п.
Основное внимание уделяется поиску решений, на основе которых
можно было бы строить достоверные прогнозы. Это соответствует
доктрине «когнитивной революции» (начавшейся еще в 50-60-е
годы XX в.), согласно которой критерием качества любой теории
является возможность ее практической реализации.
Г. Пятецкий-Шапиро, один из создателей Data Mining, дал ново-
му подходу следующее определение: «Data Mining - это процесс
обнаружения в сырых данных ранее неизвестных, нетривиальных,
практически полезных и доступных интерпретации знаний, необхо-
димых для принятия решений в различных сферах человеческой
деятельности». Как любое определение, оно освещает предмет
156
лишь с одной стороны; поэтому имеет смысл рассмотреть другие
формулировки.
По мнению авторитетных лиц и организаций, Data Mining пред-
ставляет собой:
процесс аналитического исследования больших массивов ин-
формации (обычно экономического характера) с целью выявления
закономерностей и систематических взаимосвязей между перемен-
ными, которые затем можно применить к новым совокупностям
данных. Этот процесс включает три основных этапа: исследование,
построение модели или структуры и ее проверку (StatSoft);
процесс выделения из данных неявной и неструктурированной
информации и представления ее в виде, пригодном для реализации;
процесс анализа, выделения и представления детализированных
данных неявной конструктивной информации для решения про-
блем бизнеса (NCR);
процесс выделения, исследования и моделирования больших
объемов данных для обнаружения неизвестных до этого структур
с целью достижения преимуществ в бизнесе (SAS Institute);
процесс, имеющий целью обнаружить новые значимые корреля-
ции, образцы и тенденции в результате просеивания большого объ-
ема хранимых данных с использованием методик распознавания
образцов, а также статистических и математических методов
(Gartner Group);
процесс автоматического выделения действительной, эффектив-
ной, ранее неизвестной и абсолютно понятной информации из
больших баз данных и использование ее для принятия ключевых
бизнес-решений.
На бытовом уровне это звучит примерно так: «Вы терзаете дан-
ные, пока они не признаются».
Сразу же отметим, что процесс обнаружения знаний не может
быть полностью автоматизирован. Он всегда требует участия поль-
зователя, который должен знать, что именно он ищет, основываясь
на собственных гипотезах и обработке экспертной информации.
И довольно часто вместо подтверждения уже имеющейся гипотезы
процесс поиска приводит к появлению новых. Поэтому его нередко
обозначают термином «discovery-driven data mining» (DDDM) - до-
быча данных, направляемая процессом их изучения. Термины «Data
Mining», «knowledge discovery» - частный случай DDDM. Нередко
наряду с Data Mining (добыча, «раскопки» данных) встречаются
словосочетания KDD (knowledge discovery in databases, обнаруже-
ние знаний в базах данных) и «интеллектуальный анализ данных»,
которые можно считать синонимами Data Mining.
Возникновение всех указанных терминов связано с новым эта-
пом в развитии средств и методов обработки данных. В конечном
счете цель Data Mining состоит в выявлении скрытых правил и за-
кономерностей (паттернов, patterns) в наборах данных.
157
В настоящее время разработаны масштабируемые (допускающие
расширение) инструменты для решения этих сложных проблем,
требующие для своей реализации немалых вычислительных
средств. Инструменты Data Mining методически просеивают дан-
ные, запись за записью, переменную за переменной. Для этого,
в частности, используются алгоритмы машинного обучения (ma-
chine-learning) и поиска закономерностей, такие как нейронные сети
(neural networks), деревья решений (decision trees) и алгоритмы кла-
стеризации (clustering algorithms). При этом обнаруживается ранее
скрытая информация, которую невозможно выявить обычными
средствами из-за огромного объема исходных данных.
Сфера применения Data Mining весьма широка; соответствую-
щие средства могут применяться везде, где для поиска решений
требуется привлекать большие массивы данных. Ниже перечислены
только самые известные бизнес-приложения Data Mining:
в розничной торговле - анализ покупательской корзины, иссле-
дование временных шаблонов, маркетинг, создание прогнозирую-
щих моделей;
в банковском деле - выявление мошенничеств с кредитными
картами, сегментация клиентов, прогнозирование изменений кли-
ентуры;
в сфере телекоммуникаций - анализ характеристик вызовов, вы-
явление лояльности клиентов;
в страховом деле - выявление мошенничеств, анализ рисков.
Выделяют пять стандартных типов закономерностей, которые
позволяют обнаруживать методы Data Mining: ассоциация, после-
довательность, классификация, кластеризация, прогнозирование.
Ассоциация имеет место в том случае, если несколько событий
связаны друг с другом. Например, исследование, проведенное в су-
пермаркете, может показать, что 65% купивших кукурузные чипсы
берут также и кока-колу, а при наличии скидки за такой комплект
кока-колу приобретают уже в 85% случаев. Располагая сведениями
о подобной ассоциации, менеджеры легко могут оценить, насколь-
ко действенна предоставляемая скидка.
Если существует цепочка связанных во времени событий, то го-
ворят о последовательности. Примером могут служить такие дан-
ные: после покупки дома в 45% случаев в течение месяца приобре-
тается новая кухонная плита, а в течение двух недель 60% новосе-
лов обзаводятся холодильником.
С помощью классификации выявляют признаки, характеризую-
щие группу, к которой принадлежит тот или иной объект. Это дела-
ется посредством анализа уже классифицированных объектов и
формулировки некоторого набора правил. В отличие от классиче-
ского дискриминантного анализа, где предполагается, что классы
линейно разделимы, здесь для разделения объектов могут приме-
няться в принципе любые функции.
158
Кластеризация отличается от классификации тем, что сами
группы заранее не заданы. С помощью средств Data Mining можно
выделять самые разнообразные группы (кластеры) однородных
данных.
Основой для всевозможных систем прогнозирования служит ин-
формация, хранящаяся в базах данных в виде временных рядов. Ес-
ли удается построить математическую модель и найти шаблоны,
адекватно отражающие эту динамику, повышается вероятность ус-
пешного предсказания событий, ожидаемых в будущем.
2. КЛАССЫ СИСТЕМ ИНТЕЛЛЕКТУАЛЬНОГО АНАЛИЗА
Прежде чем приступить к детальному рассмотрению различных
программных продуктов Data Mining, имеет смысл предварительно
дать их общий обзор. При этом, однако, следует помнить, что лю-
бая классификация этих средств условна, так как многие програм-
мы предлагают пользователю сразу несколько альтернативных ме-
тодов для решения однотипных задач.
1. Предметно-ориентированные аналитические системы очень
разнообразны. Наиболее широкий подкласс таких систем - так на-
зываемый технический анализ, получивший большую популяр-
ность среди аналитиков, работающих на финансовых рынках. Он
включает нескольких десятков методов прогнозирования цен и вы-
бора оптимальной структуры портфеля, основанных на различных
эмпирических моделях динамики рынка. Эти методы могут быть
как очень простыми (вычитание трендового значения и т.п.), так и
достаточно сложными с математической точки зрения (например,
основанные на теории фракталов). Поскольку чаще всего теория
«зашита» в эти системы изначально, а не строится исходя из анали-
за истории рынка, требования статистической значимости выводи-
мых моделей и возможности их интерпретации в данном случае не
имеют смысла.
Наиболее известные системы анализа фондового рынка (Trading
System) - Metastock и Trade Station. Для оценки рисков, прибыль-
ности бизнес-планов и инвестиционных проектов подходит система
«Бизнес-прогноз». Сейчас на рынке имеется множество программ
этого типа, и, как правило, они довольно дешевы (типичная цена -
от 10 до 30 тыс. руб.).
2. Последние версии почти всех известных статистических па-
кетов включают некоторые элементы Data Mining (см. детальный
обзор этих средств на web-странице http://isl.cemi.rssi.ru/ruswin/in-
dex.htm). Тем не менее основное внимание в них все же уделяется
традиционным статистическим методам - корреляционному, рег-
рессионному, факторному анализу и т.д. К недостаткам систем это-
го класса обычно относят высокие требования к специальной под-
готовке пользователя, а также относительно высокую цену (поряд-
159
ка 100 тыс. руб. и более), что делает их почти недоступными для
малого и среднего бизнеса.
Но есть еще один недостаток принципиального характера, огра-
ничивающий применение статистических пакетов в Data Mining.
Большинство методов, входящих в эти программы, опираются на
традиционную статистическую парадигму, в которой главными фи-
гурантами служат усредненные характеристики выборки. А эти ха-
рактеристики при исследовании сложных жизненных феноменов
часто оказываются фиктивными величинами.
3. Нейронные сети - большой класс аналитических систем, ар-
хитектура которых пытается имитировать строение нервной ткани
живых организмов. Так, в многослойном персептроне с обратным
распространением ошибки эмулируется работа нейронов в составе
иерархической сети, где каждый нейрон более высокого уровня со-
единен своими входами с выходами нейронов нижележащего слоя.
На нейроны самого низкого слоя подаются значения входных па-
раметров, на основе которых нужно принимать какие-то решения,
прогнозировать развитие ситуации и т.д.
Вводимые значения рассматриваются как сигналы, которые пе-
редаются в вышележащий слой, ослабляясь или усиливаясь в зави-
симости от числовых значений (весов), приписываемых межней-
ронным связям. В результате всех этих преобразований на выходе
нейрона самого верхнего слоя вырабатывается значение, рассмат-
риваемое как ответ (реакция всей нейронной сети) на введенные
значения входных параметров.
Для того чтобы сеть можно было применять в дальнейшем, ее
нужно «натренировать» на полученных ранее данных, для которых
известны и значения входных параметров, и правильные ответы.
Суть такой тренировки состоит в подборе весов межнейронных
связей, обеспечивающих наибольшую близость ответов сети к пра-
вильным ответам. Здесь и лежит главный недостаток данного мето-
да - для качественной тренировки требуется большой объем обу-
чающей выборки.
Другой существенный недостаток состоит в том, что даже на-
тренированная нейронная сеть представляет собой «черный ящик».
Знания, зафиксированные как веса нескольких сотен межнейрон-
ных связей, совершенно не поддаются анализу и не имеют содер-
жательной интерпретации.
Наиболее известные системы данного класса - BrainMaker
(CSS), NeuroShell (Ward Systems Group), OWL (HyperLogic). Их
стоимость довольно высока - от 40 тыс. до 200 тыс. руб.
4. Системы рассуждений на основе аналогичных случаев (case
based reasoning, CBR) основаны на чрезвычайно простой идее. Что-
бы сделать прогноз на будущее или выбрать правильное решение,
они находят в прошлом ситуации, похожие на текущую, и выбира-
ют ответ, который ранее оказался эффективным. Поэтому данный
160
метод называют также методом «ближайшего соседа» (nearest
neighbour).
Системы CBR показывают очень хорошие результаты в самых
разнообразных задачах. Главный их минус - то, что они вообще не
создают каких-либо моделей или правил, обобщающих предыду-
щий опыт, а при выборе решения опираются на весь массив до-
ступных исторических данных; поэтому нет никакой возможности
выявить, на основе каких именно факторов строится ответ в каж-
дом конкретном случае. Другой минус состоит в произволе, кото-
рый неизбежно допускается при выборе меры «близости», а от этой
меры в решающей степени зависит подбор прецедентов, которые
нужно хранить в памяти машины для получения удовлетворитель-
ной классификации или прогноза.
Примеры систем, широко использующих CBR, - KATE tools
(Acknoson, Франция) и Pattern Recognition Workbench (Unica,
США).
5. Деревья решений (decision trees) - один из наиболее популяр-
ных методов Data Mining. Речь идет о создании иерархической
структуры классифицирующих правил типа «если... то», имеющей
вид дерева (похожей на определитель видов в ботанике или зооло-
гии). Чтобы решить, к какому классу отнести некоторый объект или
ситуацию, требуется ответить на вопросы, стоящие в узлах этого
дерева, начиная с его корня. Вопросы имеют вид: «Верно ли, что
значение параметра а больше х?». Если ответ положительный, осу-
ществляется переход к правому узлу следующего уровня, если от-
рицательный - к левому, после чего ставится следующий вопрос,
связанный с очередным узлом классификации.
Популярность описываемого подхода связана с его большой на-
глядностью; но он имеет и существенные недостатки. Дело в том,
что отдельным узлам на каждом новом построенном уровне дерева
соответствует все меньшее и меньшее число записей данных - де-
рево дробит данные на большое количество частных случаев. Чем
более детальна классификация, тем меньше примеров подпадает
под каждый из таких случаев и тем менее уверенным становится
вывод, осуществляемый на их основе. Если построенное дерево
слишком «кустистое» и состоит из большого числа мелких ветвей,
оно не будет давать статистически обоснованные ответы.
Как показывает практика, в большинстве систем, использующих
данную методику, эта проблема не находит удовлетворительного
решения. Кроме того, легко доказать, что деревья решений могут
дать полезный результат только в случае независимости признаков,
лежащих в основе классификации; в противном случае создается
лишь иллюзия логического вывода.
Тем не менее данный подход реализован во многих системах -
See5/C5.0 (RuleQuest, Австралия), Clementine (Integral Solutions, Ве-
ликобритания), SIPINA (University of Lyon, Франция), IDIS (Infor-
I I Капко И.А.. Паклин Н.Б.
161
mation Discovery, США) и др.; их стоимость колеблется от 30 тыс.
до 300 тыс. руб.
6. Основную идею эволюционного программирования можно
проиллюстрировать на примере системы PolyAnalyst (стоимость от
12 тыс. до 300 тыс. руб.). В данной системе гипотезы о форме зави-
симости целевой переменной от всех остальных формулируются в
виде программ на некотором внутреннем языке программирования.
Процесс их построения организован в форме эволюции программ
(такой подход несколько напоминает генетические алгоритмы). Ко-
гда система находит программу, достаточно точно выражающую
искомую зависимость, она начинает вносить в нее небольшие мо-
дификации («мутации») и отбирает среди дочерних программ наи-
более эффективные. Таким образом, «выращивается» сразу не-
сколько генетических линий программ, которые конкурируют меж-
ду собой в точности выражения искомой зависимости.
Другое направление эволюционного программирования связано
с поиском зависимости целевых переменных от остальных в форме
функций какого-то определенного вида. Так, в методе группового
учета аргументов (МГУА, один из самых удачных алгоритмов дан-
ного типа) для описания указанных зависимостей используют по-
линомы. В настоящее время одна из продающихся в России версий
МГУА реализована в системе NeuroShell компании Ward Systems
Group.
7. Генетические алгоритмы первоначально вовсе не были ори-
ентированы на Data Mining; основная область их применения - ре-
шение разнообразных комбинаторных задач и задач оптимизации.
Тем не менее сейчас они уже вошли в стандартный инструментарий
интеллектуального анализа данных и поэтому должны быть упомя-
нуты в этом обзоре.
Предположим, что нужно найти решение задачи, оптимальное
с точки зрения некоторого критерия, причем каждое решение мо-
жет быть полностью описано некоторым набором чисел или вели-
чин нечисловой природы. Типичный пример - поиск совокупности
фиксированного числа параметров рынка, наиболее полно опреде-
ляющих его динамику; в данном случае решением считается набор
имен этих параметров. По аналогии с генетикой эти имена можно
рассматривать как совокупность хромосом, определяющих свойст-
ва особи, каковой и считается решение поставленной задачи.
Значения параметров, определяющих это решение, в таком слу-
чае можно сопоставить с биологическими генами, а поиск опти-
мального решения - с эволюцией популяции особей, представлен-
ных соответствующими наборами хромосом. В процессе эволюции
взаимодействуют три механизма: отбор сильнейших, скрещивание
(производство новых особей при помощи смешивания хромосом-
ных наборов) и мутации (случайные изменения генов у некоторых
особей). По мере смены поколений характеристики решений улуч-
162
шаются, пока не будет получен результат, улучшить который не
представляется возможным.
Генетические алгоритмы имеют ряд недостатков. Критерий от-
бора хромосом и сама процедура являются эвристическими и уже
по этой причине не гарантируют нахождения «лучшего» решения.
Как нередко наблюдалось и в реальной эволюции, процесс может
«заклинить» на какой-либо непродуктивной ветви, из которой нет
выхода. И, наоборот, бывают случаи, когда два неперспективных
родителя, исключенные из эволюции генетическим алгоритмом,
в принципе могли бы иметь перспективное «потомство». Эти сбои
особенно учащаются при решении задач большой размерности со
сложными внутренними связями.
Примером систем, использующих данные методы, могут слу-
жить GeneHunter фирмы Ward Systems Group (стоимость от 600 до
1000 долл.) и Evolver (750 долл.).
8. Алгоритмы ограниченного перебора были предложены в сере-
дине 1960-х годов М. Бонгардом как средство поиска логических
закономерностей в данных; с тех пор они продемонстрировали
свою эффективность при решении множества разнообразных задач.
Эти алгоритмы вычисляют частоты комбинаций простых логи-
ческих событий в подгруппах данных. В качестве примеров таких
событий можно указать математические отношения X = а, X < а,
Х> а, а<Х< b и др., гдеX- какой-либо параметр, а и b - констан-
ты. Длина комбинаций простых логических событий ограничена
(у М. Бонгарда - не более трех). На основании анализа вычислен-
ных частот делается заключение о полезности той или иной комби-
нации для установления ассоциаций в данных, для их классифика-
ции, прогнозирования и т.д.
Наиболее удачной из систем, использующих такой подход,
можно считать WizWhy компании WizSoft. Хотя ее автор Абрахам
Мейдан не раскрывает специфику алгоритма, положенного в ее ос-
нову, по результатам тщательного тестирования системы был сде-
лан вывод о важной роли в ней метода ограниченного перебора
(изучались результаты, зависимость времени их получения от числа
анализируемых параметров и другие детали ее работы).
Автор WizWhy утверждает, что его система обнаруживает все
логические правила IF... THEN в данных. На самом деле это, ко-
нечно, не так. Во-первых, максимальная длина комбинации в пра-
виле IF... THEN в системе WizWhy равна шести, а во-вторых, с са-
мого начала работы алгоритма производится эвристический поиск
простых логических событий, на которых потом строится весь
дальнейший анализ. Зная эти особенности WizWhy, можно постро-
ить простейшую тестовую задачу, которую программа вообще не
может решить. Другой негативный момент - решение получается за
приемлемое время только для данных сравнительно небольшой
размерности (не более 20).
н ‘ 163
Несмотря на эти недостатки, на сегодняшний день WizWhy ос-
тается одним из лидеров на рынке продуктов Data Mining.
9. Методы нечеткой логики применяются для решения задач,
исходные данные которых являются «зашумленными» и нечеткими
(см. подробнее в книге: Круглов В.В., Дли М.И. Интеллектуальные
информационные системы: компьютерная поддержка систем не-
четкой логики и нечеткого вывода. - М.: Физматлит, 2002). Они
основаны на теории, изложенной еще в 1965 г. в работе «Нечеткие
множества» американского математика Лотфи Заде, и позволяют
описывать объекты на языке, близком к естественному (в частно-
сти, с помощью лингвистических переменных).
Впоследствии эта теория была существенно усовершенствована
и дополнена. Благодаря усилиям Бартоломея Коско (Bart Kosko)
была исследована взаимосвязь нечеткой логики и теории нейрон-
ных сетей и доказана основополагающая FAT-теорема (Fuzzy
Approximation Theorem, 1993 г.), согласно которой любая матема-
тическая система может быть аппроксимирована системой, осно-
ванной на нечеткой логике. В работах Марии Земанковой (Maria
Zemankova-Leech) были заложены основы теории нечетких СУБД,
способных оперировать неточными данными, обрабатывать нечет-
ко заданные запросы, а также использовать качественные парамет-
ры наряду с количественными. Была разработана нечеткая алгебра,
позволяющая использовать при вычислениях как точные, так и
приблизительные значения переменных. И, наконец, в 1980-х годах
увидели свет изобретенные Коско нечеткие когнитивные модели
(Fuzzy Cognitive Maps, FCM), на которых базируется большинство
современных систем динамического моделирования в финансах,
политике и бизнесе.
Среди программ, использующих методы нечеткой логики, наи-
большую известность получили Fuzzy Logic Toolbox, входящая
в систему Matlab, CubiCalc, FuzzyCalc, JFL.
При использовании нечетких систем нужно учитывать следую-
щие обстоятельства:
формулировка исходных правил для построения функции при-
надлежности осуществляется человеком и может оказаться непол-
ной или противоречивой;
вид и параметры функции принадлежности также задаются че-
ловеком и могут не соответствовать действительности.
Для устранения (хотя бы частичного) этих недостатков предла-
гаются различные средства. Чтобы сделать нечеткие системы адап-
тивными, умеющими «подстраиваться» в процессе работы, были
разработаны так называемые нечеткие (гибридные) нейронные се-
ти. Такая сеть формально идентична многослойной сети с обуче-
нием, но скрытые слои нейронов соответствуют в ней этапам функ-
ционирования нечеткой системы. Каждый из указанных слоев ха-
рактеризуется собственным набором параметров (функциями при-
164
надлежности, нечеткими решающими правилами, активационными
функциями, весами связей, функциями приведения к четкости). Эта
идея реализована в программах Fuzzy Logic Toolbox и Genetic
Training Option.
Другой возможный подход основан на наблюдении, что ограни-
ченный набор нечетких ситуаций может описывать практически
бесконечное число состояний объекта управления. В результате
нечеткого ситуационного вывода идентифицируемая ситуация
сравнивается со всеми типовыми ситуациями, и из последних вы-
бирается наиболее близкая; на ее основе формулируются необхо-
димые управляющие воздействия (см. также Мелихов А.Н., Бер-
штейн Л.С., Коровин С.Я. Ситуационные советующие системы
с нечеткой логикой. - М.: Наука, 1990). Некоторые программы (на-
пример, Fuzzy TECH) позволяют проектировать и отлаживать сис-
темы нечеткого вывода.
Наибольшую известность, однако, получили уже упомянутые
выше FCM - нечеткие когнитивные карты (модели). Термин «ког-
нитивная карта» (cognitive map) Толмен ввел еще в 1948 г.; он обо-
значал математическую модель сложного объекта или проблемы,
позволяющую выявить структуру связей между их элементами,
оценить последствия различных воздействий на них или изменения
характера связей. С формальной точки зрения когнитивная карта -
это ориентированный граф, набор вершин которого и взаимосвязей
между ними представляют сложные объекты и проблемы их функ-
ционирования.
В классическом варианте анализ когнитивных карт был основан
на алгебро-геометрическом подходе и позволял характеризовать
связность, сложность и устойчивость систем, осуществлять выбор
наилучших сценариев их развития. В настоящее время этот подход
существенно расширен благодаря использованию методов теории
информации и нечеткой логики [9].
Модель предметной области (будь то предвыборная ситуация,
структура финансово-промышленной группы или план управления
войсковыми соединениями) в FCM представляется в виде знакового
ориентированного графа с обратными связями. В вершинах графа
располагаются различные события либо ключевые элементы ситуа-
ции, дуги отображают причинно-следственные связи между ними.
Существенно, что параметры событий и степени их взаимного
влияния могут выражаться как точными количественными пара-
метрами, так и нечеткими качественными соотношениями. Это
важно как в бизнесе, так и при моделировании политических си-
туаций, когда точные числовые характеристики недоступны и ис-
следователю приходится оперировать такими зыбкими понятиями,
как «популярность», «социальная напряженность» и т.п.
Сегодня элементы FCM можно найти в десятках промышленных
изделий - от систем управления электропоездами и боевыми верто-
165
летами до пылесосов и стиральных машин. Рекламные кампании
многих фирм (особенно японских) преподносят успехи в использо-
вании нечеткой логики как особое конкурентное преимущество. Без
применения FCM сейчас уже невозможно представить политиче-
ские ситуационные центры развитых стран, в которых принимают-
ся ключевые решения и моделируются всевозможные кризисные
ситуации.
Типичным примером может служить комплексное моделирова-
ние системы здравоохранения и социального обеспечения Велико-
британии (National Health Service, NHS), впервые позволившее точ-
но оценить и оптимизировать расходы на социальные нужды. На-
бор моделей, использованных для решения этой задачи, можно
найти в библиотеке примеров популярного пакета iThink.
Что общего у всех перечисленных систем анализа данных?
Во-первых, все они ориентированы на извлечение информации
из табличных данных (числовых или текстовых) и превращение ее
в знания, необходимые для принятия решений.
Во-вторых, практически все применяемые в них аналитические
средства основаны на теориях 1960-х годов, которые традиционно
относят к разным областям: прикладной статистике, кибернетике,
теории машинного интеллекта, информатике и др.
В-третьих, в отличие от классических моделей статистики и
эконометрики, вид изучаемых связей теперь не задается априори,
а подбирается итеративно с целью наилучшего описания данных.
В-четвертых, в качестве критериев адекватности новых моде-
лей обычно используются формальные вероятностные методы (не-
смотря на частые утверждения их авторов об абсолютной незави-
симости новых подходов от теории вероятностей и математической
статистики).
В-пятых, основной целью использования всех перечисленных
выше систем является получение информации для объективного
анализа (содержательно-целевой подход). Если в основе формаль-
ных методов лежит достижение некоторого критерия (например,
F Фишера), то новые методы предполагают прежде всего достиже-
ние содержательных целей моделирования.
Таким образом, все (или почти все) перечисленные выше классы
систем позволяют решать одни и те же задачи, но делают это с по-
мощью разных средств.
Своеобразным стандартом де-факто в коммерческих системах
Data Mining можно считать наличие языков визуального моделиро-
вания. Аналитик, строящий различные модели на основе имеющих-
ся массивов данных, использует специальные диаграммы; это по-
хоже на проектирование в языках структурного моделирования
(SADT, IDEF0 и т.п.). Все действия (от получения данных до выво-
да конечных результатов) разбиваются на ряд элементарных опера-
ций, таких как импорт, фильтрация, сортировка, замена значений,
166
проведение расчетов, построение моделей (дерева решений, логи-
стической регрессии и др.), слияние источников, экспорт, визуали-
зация.
Готовое аналитическое решение представляет собой граф (дере-
во), где входом и выходом каждого узла является один или не-
сколько наборов данных. Это позволяет наглядно отобразить по-
следовательность действий, необходимых для решения конкретной
задачи и получения результата, такая последовательность и есть
формализованное знание пользователя (аналитика). При появлении
новых данных легко повторить на них ту же последовательность
действий, получив прогноз или ответ системы. Пример такого гра-
фа, построенного средствами платформы SPSS Clementine, приве-
ден на рис. II. 1.
3. ОСНОВНЫЕ ПРОДУКТЫ DATA MINING
Рынок систем Data Mining сейчас быстро развивается, на нем ак-
тивно работают практически все крупнейшие производители про-
граммного обеспечения (см., например, http://www.kdnuggets.com).
В частности, Microsoft непосредственно руководит большим секто-
ром данного рынка, издает специальный журнал, проводит конфе-
ренции, разрабатывает собственные продукты.
Существуют профессиональные программы, реализующие сис-
темный подход к анализу данных и включающие методы Data
Mining. Наиболее известные из них - SAS Enterprise Miner, SPSS
Clementine, STATISTICA Data Miner, PolyAnalyst, Deductor. Интер-
фейс этих продуктов соответствует идеологии Windows, преобла-
дает графически ориентированный подход. Результаты анализа
представляются в виде дерева, в узлах которого располагаются
папки с графиками, таблицами, моделями). Практически во всех
системах доступны методы визуализации и разведочного анализа в
базах данных, а также методы построения моделей, предназначен-
ных для формулировки научных или практических выводов.
Из продукции российских разработчиков наибольшую извест-
ность получили два продукта класса Data Mining - PolyAnalyst
(http://www.megaputer.ru) и Deductor (http://www.basegroup.ru). Обе
системы подходят для организации рабочего места аналитика,
имеющего дело с данными большого объема.
Первая из названных программ появилась в 1994 г., а в 2008 г.
была анонсирована 6-я версия PolyAnalyst. Компания-разработчик
системы, кроме того, предлагает программный продукт WebAnalyst
для анализа данных в веб-среде, а также модули текстового анализа
Text OLAP и Taxonomies, сортирующие тексты на классы, опреде-
ляемые пользователем. Отличительная особенность Poly Analyst -
использование собственных алгоритмов анализа, основанных на
принципах эволюционного моделирования.
167
Рис. ПЛ. Концепция визуального моделирования в Data Mining
У
Система Deductor компании BaseGroup Labs первоначально
(с 2001 г.) представляла собой совокупность самообучающихся ал-
горитмов для решения основных задач KDD (обнаружение знаний
в базах данных с возможностями предобработки информации), за-
тем была дополнена системой тиражирования знаний, а в настоя-
щее время превратилась в аналитическую платформу, позволяю-
щую поставить анализ данных на конвейер (рис. II.2).
Если большинство систем Data Mining уделяют основное внима-
ние аналитическому аппарату (например, PolyAnalyst - эволюцион-
ному программированию) и проблеме очистки данных, то Deductor
предоставляет также инструменты для построения физического и
виртуального хранилища данных, создания сценариев их обработки
и экспорта.
В развитие концепции KDD Пятецкого-Шапиро предлагается
идея «тиражирования знаний», когда отчеты, модели и правила,
полученные экспертом, могут использоваться любым сотрудником
организации без необходимости самостоятельно осваивать методы
получения аналогичных результатов (рис. П.З).
169
[Knowledge Discovery in Databases
Выборка
Очистка
Трансформация
Data Mining
Интерпретация
Источники данных
Исходные данные
Очищенные данные
Трансформированные данные
Шаблоны
Знания
Рис. П.З. Этапы открытия знаний в базах данных
Кроме PolyAnalyst и Deductor на российском рынке представле-
ны продукты Data Mining ряда всемирно известных компаний
(табл. II. 1). Впрочем, некоторые из них, такие как IBM, Insightful
Corp, и другие, даже не продвигают свои решения в области интел-
лектуального анализа данных, что можно объяснить относительно
низким спросом на них со стороны российского потребителя.
II. 1. Обзор коммерческих продуктов Data Mining в России
Продукт Компания- разработ- чик Наличие визуаль- ного мо- делиро- вания Особенности Цена, тыс. руб.
Statistica Data Miner StatSoft Да (гра- фы) Большое количество алгоритмов, инте- грация с пакетом Statistica От 600, сервер - от 2500
Enterprise Miner SAS Insti- tute Да (гра- фы) Масштабируемое, мультиплатформен- ное приложение. Ориентировано на работу с огромными массивами дан- ных. Встроенный язык программиро- вания. Интеграция с собственным хра- нилищем данных, с веб-средой. Боль- шой объем методических и учебных материалов. Имеется множество от- раслевых решений (для банков, торго- вых компаний и др.) От 3000
170
Продолжение
Продукт Компания- разработ- чик Наличие визуаль- ного мо- делиро- вания Особенности Цена, тыс. руб.
KXEN KXEN Inc. Нет дан- ных Акцент на статистические алгоритмы. Присутствуют алгоритмы машин опорных векторов (SVM). Поддержка хранилища и витрин данных От 1500
Poly Ana- lyst Megaputer Inc. Да (гра- фы) Оригинальные алгоритмы, основанные на концепции эволюционного про- граммирования. Начиная с версии 6 - среда визуального моделирования н. св.
MS SQL Server 2008 Microsoft Corp. Нет Ориентирован на разработчика. Удоб- ное и многофункциональное хранили- ще данных. Поддержка OLE DB Data Mining. Стандартные и оригинальные алгоритмы Data Mining, разработанные в исследовательском центре Microsoft Research. Имеется модуль Text Mining От 60
Oracle Data Mining Oracle Corp. Нет Ориентирован на разработчика. По- ставляется как расширение к СУБД Oracle Database. Оригинальные мас- штабируемые алгоритмы Data Mining От 600
SPSS Clemen- tine SPSS Inc. Да (гра- фы) Большое количество алгоритмов, мо- дульность. По функциональным воз- можностям близок к SAS Enterprise Miner От 350
Deductor BaseGroup Labs Да (дере- вья) Ориентирован на бизнес-аналитика. Собственное хранилище данных на трех платформах (Firebird, MS SQL, Oracle), обширная документации на русском языке, интеграция с 1 С, удоб- ный интерфейс, отличная визуализа- ция. Возможности предобработки дан- ных (сглаживание, удаление аномалий, пропусков). Начиная с версии 5.0, включает серверные компоненты 35 (про- фессио- нальная версия), 350 (сер- вер), акаде- миче- ская версия - бес- платно
В заключение отметим, что Data Mining - не панацея и не всемо-
гущая технология. Как и любой другой инструмент, она имеет свои
ограничения и сферу применимости. Незнание этих ограничений
171
приводит к тому, что разработчик и клиент зря теряют время и
деньги на бесполезные эксперименты.
Потенциальному пользователю важно учитывать следующие
моменты.
1. Data Mining работает только с табличными данными. Если ис-
ходную информацию невозможно структурировать, соответствую-
щие программы будут бесполезны.
2. Data Mining - эффективное средство поиска скрытых законо-
мерностей, позволяющее узнать, какие комбинации из 50-100 при-
знаков объекта влияют на его поведение. Если таких признаков
мало, особой пользы от Data Mining нет, так как зависимости между
2-3 переменными несложно выявить, используя OLAP. Если их не
более 3-5, скорее всего, Data Mining не откроет ничего нового.
В частности, если массив данных состоит из названий объектов и
их реквизитов, нет никакой необходимости вкладывать деньги
в средства интеллектуального анализа.
ии
ПРАКТИЧЕСКОЕ ЗАНЯТИЕ 8. АНАЛИТИЧЕСКАЯ ПЛАТФОРМА
DEDUCTOR 5.0: ХРАНИЛИЩЕ ДАННЫХ
Цель занятия: ознакомиться с архитектурой, основными частями
и пользовательским интерфейсом Deductor, получить навыки соз-
дания сценариев обработки и визуализации данных, создания и на-
полнения хранилища данных
8.1. ПЛАТФОРМА DEDUCTOR
Deductor - это аналитическая платформа класса KDD (Know-
ledge Discovery in Databases) и Data Mining, предназначенная для
создания законченных прикладных решений в области анализа
данных. Имеющиеся в ней средства позволяют на базе единой ар-
хитектуры реализовать все этапы построения аналитической систе-
мы - от создания хранилища данных до автоматического подбора
моделей и визуализации полученных результатов (в виде кубов
OLAP, таблиц, диаграмм, гистограмм, карт, графов и т.д.). Данная
платформа состоит из трех компонент: многомерного хранилища
данных Deductor Warehouse; аналитического приложения Deductor
Studio; средства тиражирования знаний Deductor Viewer (рис. 8.1).
Warehouse
Хранилище данных
Рис. 8.1. Компоненты платформы Deductor
Deductor Viewer
Визуализация построенных
в Deductor Studio отчетов
Deductor Warehouse - многомерное хранилище данных (ХД), ак-
кумулирующее из разных источников всю необходимую информа-
цию для анализа какой-либо предметной области. Использование
единого хранилища позволяет обеспечить непротиворечивость
данных, их централизованное хранение и необходимую поддержку
процесса их анализа. Платформа оптимизирована для решения
именно аналитических задач, что положительно сказывается на
скорости доступа к данным.
Deductor Studio - это программа, предназначенная для анализа
информации, полученной из различных источников. Она реализует
173
функции импорта, обработки, визуализации и экспорта данных.
В нее включен полный набор механизмов, позволяющий выбрать
информацию из произвольного источника, провести весь цикл ее
обработки (очистку, трансформацию данных, построение моделей),
отобразить полученные результаты наиболее удобным образом
(OLAP, диаграммы, деревья) и экспортировать их во внешнее при-
ложение. Программа может функционировать и без хранилища
данных, но оптимальным решением будет ее совместное использо-
вание с Deductor Warehouse.
Deductor Viewer представляет собой облегченную версию De-
ductor Studio, предназначенную для отображения построенных
в данной программе отчетов. Она не содержит средств создания
сценариев, но обладает полноценными возможностями по их вы-
полнению и визуализации результатов. Viewer позволяет тиражи-
ровать знания для конечных пользователей, которых не интересуют
способы и механизм их получения.
Для образовательных целей компанией-разработчиком выпуще-
на академическая версия Deductor Academic; в ней разрешен им-
порт данных только из собственного хранилища и текстовых фай-
лов. Программу можно загрузить с сайта www.basegroup.ru; все
практические занятия рекомендуется проводить на ее основе.
Вся работа в Deductor сводится к использованию нескольких
мастеров - подключений, импорта, обработки, визуализации и экс-
порта. Платформа не имеет собственных средств ввода-вывода ин-
формации, но мастера импорта и экспорта обеспечивают взаимо-
действие с произвольными источниками и приемниками данных,
для которых существуют стандартные механизмы доступа (ODBC,
ADO и т.п.).
Обработка и визуализация в Deductor (рис. 8.2) допускают лю-
бые манипуляции над набором данных - от самых простых, таких
как сортировка, до весьма сложных (например, построение модели
нейронной сети). Обработчик можно представить в виде «черного
ящика», на вход которого подается исходный набор данных, а на
выходе формируется преобразованный набор. Реализованные в De-
ductor обработчики позволяют осуществлять как анализ данных,
так и различные операции с ними (очистка, слияние, объединение,
фильтрация).
Сценарий представляет собой иерархическую последователь-
ность (дерево) операций по обработке и визуализации наборов дан-
ных (рис. 8.3). Он состоит из ряда узлов и реализует встроенный
язык визуального моделирования. Сценарий всегда начинается
с импорта набора данных из произвольного источника, за которым
следует произвольное число обработчиков любой степени глубины
и вложенности. Каждой операции обработки соответствует отдель-
ный узел дерева (объект сценария); набор данных служит механиз-
мом, соединяющим все эти объекты.
174
Рис. 8.2. Схема обработки и визуализации данных
PI S Сценарии
3 Q Характеристики торговых магазинов
Fl Т’ Фильтр ([Название города] ='Москва')
Ё) Замена значений: Канал дистрибьюции
Самоорганизующаяся карта - сегментирование
Й Дерево решений - объяснение сегментации
Экспорт правил (HTML)
Й М Калькулятор: Добавление поля ONE;
В {1 Группировка (Номер кластера; Кол-во. ONE)
Й я! Сортировка: Номер кластера
В Й Калькулятор: Усредненный объем продаж
Экспорт данных (MS Word)
Рис. 8.3. Пример сценария в Deductor
С точки зрения аналитика, сценарии - самый естественный спо-
соб представления этапов разработки моделей. Они позволяют бы-
стро создавать модели, обладающие большой гибкостью и расши-
ряемостью, а также сравнивать несколько моделей.
Непосредственно для работы со сценариями предназначены
мастера импорта, обработки, визуализации и экспорта. Первый из
них позволяет получать данные из внешних источников (сначала
в нем открывается список всех предусмотренных в системе типов
источников данных). Число шагов мастера импорта, а также набор
настраиваемых параметров зависят от типа источника.
Мастер обработки настраивает параметры выбранного узла-
обработчика, мастер визуализации позволяет в пошаговом режиме
выбрать наиболее удобный способ представления данных. В зави-
симости от узла, из которого исходит ветвь сценария, список дос-
тупных для него видов отображений будет различным. Например,
после построения деревьев решений их можно отобразить с помо-
щью визуализаторов «Деревья решений» и «Правила», недоступ-
ных для других обработчиков.
175
Рис. 8.4. Главное окно Deductor Studio 5.0
Мастер экспорта позволяет в пошаговом режиме выполнить экс-
порт данных в файлы и базы данных наиболее распространенных
форматов (в том числе в Deductor Warehouse).
Для настройки подключений к внешним источникам и приемни-
кам данных используется мастер подключений.
Главное окно Deductor Studio представлено на рис. 8.4; в его ле-
вой части расположено oRho с вкладками «Сценарии» (предназна-
чено для визуального моделирования потоков данных и узлов),
«Отчеты» и «Подключения» (содержит список доступных подклю-
чений); в правой части окна отображаются визуализаторы.
8.2. ХРАНИЛИЩЕ ДАННЫХ
Deductor Warehouse - это специально организованная база дан-
ных, ориентированная на решение задач анализа данных и под-
держки принятия решений, обеспечивающая максимально быстрый
и удобный доступ к информации.
В деловых организациях часто хранятся большие объемы ин-
формации, но она плохо структурирована, не согласована, разроз-
ненна, не всегда достоверна, так что практически невозможно по-
лучить необходимые сведения в едином формате. Для устранения
этого противоречия, когда при фактическом наличии и даже избыт-
ке данных невозможно провести их анализ, и создается хранилище
данных. Deductor Warehouse позволяет по заранее установленному
регламенту (например, 1 раз в сутки) выгружать данные из одной
или нескольких учетных систем (1 С-бухгалтерия, специальные ре-
гистры оперативного учета и др.). Тем самым обеспечивается соор
и консолидация информации, необходимой для анализа.
Хранилище данных (рис. 8.5) включает, помимо потоков ин-
формации (таблиц данных), поступающей из различных источни-
ков, специальный семантический слой, содержащий так называе-
мые метаданные (данные о данных). Благодаря этому слою тради-
ционное табличное представление, характерное для реляционных
БД, можно привести к многомерному, наиболее удобному для ана-
литических процедур.
Запрос к хранилищу данных осуществляется непосредственно
через семантический слой, который через скрытую от пользователя
внутреннюю систему команд подбирает запрашиваемую информа-
цию из всего многообразия хранимых данных. Работу этого слоя
можно сравнить с действиями библиотекаря, который по просьбе
читателя достает с разрозненных полок нужные книги, раскрывая
их на нужных страницах.
Благодаря семантическому слою и многомерному представле-
нию информации работа с данными из хранилища Deductor Ware-
house осуществляется в терминах предметной области (в бизнес-
терминах). Это очень удобно для пользователя, поскольку от него
12 Кацко И.Л.. Пакзпи Н.Б. 177
не требуется знания структуры хранения данных и специального
языка запросов; он работает с привычными ему терминами бизнес-
среды (отгрузка, товар, клиент и т.д.).
Для хранения данных в программе используются структуры ти-
па «снежинка» (рис. 8.6); в их центре расположены таблицы фак-
тов, из которых исходят «лучи» измерений, причем каждое измере-
ние может ссылаться на любое другое.
Измерение
Процесс
Рис. 8.6. Структура хранилища данных
178
Информация о том, какие данные являются фактами, а какие -
измерениями, задается на этапе проектирования структуры храни-
лища и фиксируется в семантическом слое. Такая архитектура
больше всего подходит для задач анализа данных. Каждая «сне-
жинка» называется процессом и описывает определенное действие,
такое как продажа товара, его отгрузка, поступление денежных
средств и т.п.
В Deductor Warehouse может одновременно храниться множест-
во процессов, имеющих общие измерения (например, измерение
«Товар» фигурирует в процессах «Поступления» и «Отгрузка»).
В упрощенном варианте организации хранилища все данные в про-
цессе обязательно должны быть определены как измерение, атри-
бут либо факт (рис. 8.7).
Рис. 8.7. Проектирование структуры хранилища данных
Измерение - это последовательность значений одного из анали-
зируемых параметров. Так, для параметра «время» это последова-
тельность календарных дней, для параметра «регион» - список го-
родов. Каждое значение измерения может быть представлено коор-
динатой в многомерном пространстве процесса (например, в про-
странстве товар, клиент, дата).
Атрибут является свойством измерения (точки в пространстве
данных). Он как бы скрыт внутри другого измерения и помогает
пользователю полнее описать исследуемое измерение. Скажем, для
измерения товар атрибутами могут выступать цвет, вес и габариты
товара.
Факт представляет собой конкретное значение, соответствую-
щее тому или иному измерению; это данные, отражающие сущ-
ность события. Чаще всего фактами являются численные значения
(например, количество отгруженного товара, его стоимость, пре-
доставленная скидка).
12 •
179
Некоторые бизнес-понятия (в хранилище данных им соответ-
ствуют определенные измерения) могут образовывать иерархии,
например, товар может включать продукты питания и лекарст-
венные препараты, которые, в свою очередь, подразделяются на
группы продуктов и лекарств и т.д. В этом случае первое измерение
содержит ссылку на второе, второе - на третье и т.д. Иногда для
повышения скорости доступа к данным отказываются от иерархии
измерений; в этом случае схема «снежинка» превращается в более
простую схему «звезда».
Сведения о принадлежности данных к определенному типу (из-
мерение, ссылка на измерение, атрибут или факт) содержатся в се-
мантическом слое хранилища. При этом таблицы измерений содер-
жат только справочную информацию (коды, наименования и т.п.),
а при необходимости - ссылки на другие измерения, тогда как таб-
лицы процессов содержат только факты и коды измерений (без их
атрибутов).
Измерение Атрибут
Рис. 8.8. Таблицы данных по продажам
180
В качестве иллюстрации рассмотрим данные по продажам раз-
личных товаров; на рис. 8.8 представлены фрагменты соответ-
ствующих таблиц. В таблице процесса хранится информация о зна-
чениях измерений (как правило, это коды измерений) и значениях
фактов. Например, в ее первой строке содержится информация,
что 05.06.2006 г. клиент № 3 приобрел товар № 386 в количестве
100 шт. на сумму 25 500 руб., причем наценка составила 3825 руб.
Кем является клиент № 3 и какой товар закодирован под № 386,
в таблице процесса не указано. Информация с описанием (атрибу-
тами) клиентов и товаров находится в таблицах измерений, которые
можно сравнить со словарями, хранящими справочную информа-
цию по измерениям. Поэтому прежде чем загружать таблицу про-
цесса, необходимо загрузить все измерения. Напротив, дата явля-
ется измерением без атрибутов, и поэтому она присутствует только
в таблице процесса.
Взаимоотношение процесса, измерений, атрибутов и фактов це-
лесообразно рассмотреть более подробно. Например, для анализа
работы сети аптек могут привлекаться данные из четырех таблиц:
Товары, Группы, Отделы и Продажи (табл. 8.1-8.4). Выясним, ка-
кие данные являются измерениями, какие - атрибутами, какие -
фактами, и что представляет собой процесс.
8.1. Товарные группы
Код группы Наименование группы
33 Иммуномодуляторы
48 Общетонизирующие средства и адаптогены
50 Местные анестетики
108 Микро- и макроэлементы
198 Витамины и витаминоподобные средства
223 Желчегонные средства и препараты желчи
247 Антисептики и дезинфицирующие средства
320 Биологически активные пищевые добавки
8.2. Товары (фрагмент)
Код товара Наименование товара Код группы
774 Альмагель 1
810 Иммунорм 33
824 Ревит 198
898 Настойка пустырника 48
181
8.3. Отделы
Код отдела Наименование отдела
1 Аптека № 1
2 Аптека № 2
3 Аптека № 3
8.4. Продажи (фрагмент)
Дата Код отдела Код товара Час покупки Количество Сумма
01.01.2008 1 31052 13 1 56,5
01.01.2008 1 36259 16 1 72,48
01.01.2008 1 40315 15 1 15,84
01.01.2008 1 40315 15 3 47,52
01.01.2008 3 810 14 1 163,50
Рис. 8.9. Измерения, атрибуты и факты внутри процесса продаж
В табл. 8.1 код группы является измерением, а наименование
группы - его атрибутом. В табл. 8.2 код товара является измерени-
ем, наименование товара - его атрибутом, а код группы - ссылкой
на одноименное измерение. В табл. 8.3 код отдела является измере-
нием, а наименование отдела - его атрибутом.
В табл. 8.4 дата является измерением, коды отдела, товара и
группы, как уже было сказано выше, измерениями, час покупки -
измерением, количество и сумма - фактами. Таким образом, эта
таблица является описанием процесса продаж в трех аптеках.
Заметим, что час покупки не может быть фактом, так как комби-
нация оставшихся трех измерений (дата, отдел, код товара) уни-
кально не определяет точку в многомерном пространстве: в один и
тот же день может быть продано несколько одинаковых товаров
в одном и том же отделе.
Взаимоотношение измерений, атрибутов и фактов внутри про-
цесса продаж показано на рис. 8.9. В силу того что визуально мож-
но представить только трехмерное пространство, на рисунке отра-
жено взаимодействие только трех измерений (дата, отдел, код това-
ра). На самом деле в данном примере измерений гораздо больше,
и каждое из них может быть представлено новой осью.
8.3. СОЗДАНИЕ НОВОГО ХРАНИЛИЩА
Deductor позволяет создавать хранилища данных на основе трех
СУБД: InterBase/FireBird, Microsoft SQL Server и Oracle (начиная
с 9-й версии). Их выбор зависит от многих факторов: стоимости,
производительности, сложности администрирования и др. В рас-
сматриваемом ниже примере используется FireBird, но и с другими
СУБД Deductor работает аналогичным образом (для работы с SQL
Server и Oracle нужна версия Deductor Enterprise). FireBird имеет то
преимущество, что на ее основе хранилище данных можно созда-
вать и локально, используя библиотеку fbclient.dll.
Для создания нового хранилища данных или подключения к су-
ществующему в Deductor Studio необходимо перейти на вкладку
Подключения и запустить мастера подключений (рис. 8.10).
На экране появится первое окно мастера (рис. 8.11); в нем нужно
выбрать тип источника (приемника), к которому предполагается
подключиться (в данном случае следует указать Deductor Ware-
house).
На следующем шаге из единственно доступного в списке типа
базы данных выберем FireBird и перейдем к третьему окну мастера.
В нем зададим параметры базы данных, в которой будет создана
физическая и логическая структура хранилища данных (рис. 8.12):
База данных - D:\farma.gdb (или любой другой путь на диске);
Логин - sysdba, Пароль - masterkey.
Кроме того, следует установить флажок Сохранять пароль.
183
Сценарии X В Отчеты X @ Подключения X
[Подключение
Ctrl+Enter
Показать
ЙГ Настроить
& Тестирование соединения'J”'
< Активный '
Мастер подключений...
Конструктор... F5
... .......
X. Удалить узел... Ctrl+Del
Переименозать : F2 '
Описание
Сохранить настройки подключений
Рис. 8.10. Создание (подключение) хранилища данных
Мастер подключений
Мастер подключений
Название | Описание
S Хранилища данных Ж
3 Deductor Warehouse Deductor Warehouse (кросс-плат...
S Бизнес-приложения
1G» 10-Предприятие v7.7
|l£| 1 C-Пред приятие v8.0
S Базы данных
Oracle
MS SQL
& Sybase
(д) Firebird
ЯД Interbase
MySQL
l^ODBC
MS SQL (OLE DB)
Й DBase (ADO)
База данных • 10-Предприятие v...
База данных - 10-Предприятие v...
База данных - Oracle
База данных MS SQL
База данных - Sybase
База данных - Firebird
База данных Interbase
База данных - MySQL —
База данных ODBC
База данных - MS SQL (OLE DB)
Таблицы в Формате DBase (ADO)
Далее >
Отмена
Рис. 8.11. Окно выбора типа подключения
Рис. 8.12. Установка параметров базы данных
В следующем окне (рис. 8.13) выберем последнюю версию для
работы с ХД Deductor Warehouse 5 (предыдущие версии необходи-
мы для совместимости с предыдущими хранилищами).
Рис. 8.13. Выбор версии хранилища данных
185
На следующем шаге при нажатии на кнопку l3| Создать файл
базы данных с необходимой структурой метаданных по указан-
ному ранее пути будет создан файл farma.gdb (и появится сообще-
ние о его успешном создании). Это и есть пустое хранилище дан-
ных, готовое к работе. После этого осталось выбрать визуализатор
для подключения (в данном случае - Сведения и Метаданные) и
указать имя, метку и описание для нового хранилища (рис. 8.14).
Имя хранилища должно быть написано латинскими буквами.
Рис. 8.14. Настройка семантики узла подключения
После нажатия на кнопку Готово на дереве узлов подключений
появится метка хранилища (рис. 8.15).
Подключения X
gL
чса
В (§) Подключения
Q СИ Хранилища данных
QJ Фармация
Рис. 8.15. Хранилище данных «Фармация»
186
Для проверки доступа к новому хранилищу данных воспользу-
емся кнопкой . Если через некоторое время появится сообщение
«Тестирование соединения прошло успешно», хранилище готово
к работе. После этого нужно сохранить настройки подключений,
выбрав одноименный пункт в контекстном меню.
Если соединение по какой-либо причине установить не удалось,
будет выдано соответствующее сообщение. В этом случае нужно
проверить параметры подключения хранилища данных и при необ-
ходимости внести в них изменения, используя кнопку Й* Настро-
ить подключение).
8.4. ПРОЕКТИРОВАНИЕ СТРУКТУРЫ ХРАНИЛИЩА
После создания хранилища необходимо спроектировать его
структуру, так как в пустом хранилище нет ни одного объекта
(процесса, измерения, факта). Для этого предназначен редактор ме-
таданных, который вызывается кнопкой на вкладке Подключе-
ния. Откроется окно конструктора хранилища; отметив узел Изме-
рения, при помощью кнопки Добавить включим в метаданные из-
мерение кода группы со следующими параметрами:
идентификатор - GRJD;
имя - Группа.Код;
тип данных - Целый.
Имя - это семантическое название объекта хранилища данных,
которое будет отображаться для пользователя, работающего с ХД.
Аналогичные действия следует осуществить для всех остальных
измерений, используя параметры, приведенные в табл. 8.5.
8.5. Параметры измерений
Измерение Идентификатор Имя Тип данных
Код группы GRJD Группа.Код Целый
Код товара TVJD Товар.Код Целый
Код отдела PARTJD Отдел. Код Целый
Дата S.DATE Дата Дата/время
Час покупки S_HOUR Час Целый
Таким образом, структура метаданных нашего хранилища будет
содержать 5 измерений (рис. 8.16). К каждому измерению, кроме
двух последних, теперь добавим по текстовому атрибуту - соответ-
ственно Группа.Наименование, Товар.Наименование, Отдел.На-
именование. Каждое измерение может ссылаться на другое изме-
рение, реализуя тем самым иерархию измерений. В данном случае
измерение Товар.Код ссылается на измерение Группа.Код. Эту
187
ссылку и установим путем простого добавления, отображаемого
значком ^4 (рис. 8.17).
Объект Имя
® |W] Процессы
Э Измерения
Й-Х4 Группа. Код 12 GR_ID
1 ЁгАП Атрибуты
Измерения
EB"t4 Товар.Код
&• Л4 Отдел. Код
®44 Час
12 TVJD
12 PARTJD
0 S.DATE
12 S HOUR
Рис. 8.16. Структура метаданных
Рис. 8.17. Проектирование структуры ХД
Когда все измерения созданы, можно переходить к формирова-
нию процесса. Назовем его «Продажи» и добавим в него ссылки на
четыре имеющихся измерения (Дата, Отдел.Код, Товар.Код, Час),
используя кнопку + . Кроме них в рассматриваемом процессе
присутствуют два факта: Количество и Сумма, причем первый -
188
целочисленный, а второй - вещественный (рис. 8.18). На этом про-
ектирование структуры хранилища и соответствующих метаданных
закончено, и можно закрыть окно редактора.
Рис. 8.18. Создание метаданных процесса
8.5. ЗАГРУЗКА ИНФОРМАЦИИ
При загрузке данных в хранилище сначала загружаются измере-
ния со своими атрибутами, и только после этого - данные в про-
цесс. В рассматриваемом примере информация содержится в четы-
рех текстовых файлах, которые нужно импортировать в Deductor:
groups.txt - товарные группы;
produces.txt - товары;
stores.txt - отделы;
sales.txt - продажи товаров по дням.
Рассмотрим порядок импорта только для первого файла, по-
скольку для остальных файлов он идентичен. Сначала перейдем
в Deductor Studio на вкладку Сценарии и запустим мастер импорта.
В его первом окне (рис. 8.19) следует выбрать источник информа-
ции; в данном случае это будет Text (Direct), то есть текстовый
файл с разделителями.
На следующем шаге следует указать имя файла для импорта
(groups.txt), причем в данном случае лучше использовать относи-
тельный путь (рис. 8.20). Это означает, что он должен находиться
в той же папке, что и файл со сценарием Deductor.
189
Рис. 8.19. Первое окно мастера импорта
Рис. 8.20. Выбор текстового файла для импорта
В третьем окне можно указать параметры импорта, специфич-
ные для текстовых файлов; оставим установки, принятые по умол-
чанию (рис. 8.21).
Рис. 8.21. Параметры импорта
Заметим, что если в установленной на компьютере операцион-
ной системе в качестве разделителя целой и дробной частей числа
используется запятая, а в качестве разделителя компонентов даты -
не точка, а какой-то иной символ, необходимо внести соответст-
вующие изменения в параметры импорта; в противном случае тек-
стовые файлы будут прочитаны некорректно.
В последующих окнах мастера можно принять настройки, уста-
новленные по умолчанию, просто щелкая по кнопке Далее.
После того как те же действия будут выполнены для трех ос-
тальных файлов, получим сценарий, состоящий из четырех ветвей.
По умолчанию будет предложен визуализатор Таблица, отобра-
жаемый в правом подокне (рис. 8.22).
Теперь, после импорта, можно приступать к загрузке данных
в хранилище. Первыми следуют таблицы измерений, последней -
таблица процесса sales.txt. Менять порядок веток сценария можно
при помощи клавиатурных комбинаций CTRL+T и CTRL+J,.
191
Сценарии
[3] Файл Правка Вид Сервис Окно ?
Сценарии
Группа.Код
Г руппа. Наименование
И ммуномодуляторы
Текстовый Файл (groups.txtj
33: Иммуномодуляторы
48 Общетонизирующие средства и адаптогены
50
j 6 *1 £ |.р£ fe X
»• 3) Текстовый Файл (produces.txt)
3'1 Т екстовый Файл (stores, txt)
Текстовый файл (sales.txt)
Местные анестетики
108 Микро- и макроэлементы
198
223
247
320
Витамины и витаминоподобные средства
Желчегонные средства и препараты желчи
Антисептики и дезинфицирующие средства
Биологически активные пищевые добавки
□ &
J
Рис. 8.22. Сценарий в Deductor
Покажем последовательность загрузки данных в измерение на
примере измерения Группа.Код. Для этого, пометив первый узел,
вызовем мастер экспорта, и из списка типа приемников выберем
Deductor Warehouse (рис. 8.23).
Рис. 8.23. Экспорт в хранилище данных
192
В следующем окне из списка доступных хранилищ укажем соз-
данное ранее пустое хранилище FAR.MA. Далее требуется указать,
в какое именно измерение будет загружаться информация; выберем
Группа.Код (рис. 8.24).
Рис. 8.24. Выбор объекта для экспорта
Рис. 8.25. Настройка соответствий полей
13 Кзяко П.Л., Пакши Н.Б.
193
После этого нужно установить соответствие элементов объекта
хранилища с полями источника данных (таблицы groups.txt). Если
имена полей в текстовом файле и метки в семантическом слое хра-
нилища совпадают, делать ничего не нужно (рис. 8.25). На сле-
дующем шаге мастера, после щелчка по кнопке Пуск, данные будут
загружены в измерение Группа.Код. При этом старые данные, если
они имеются, будут заменены новыми.
Проделав аналогичные операции для двух других измерений -
Отдел.Код и Товар.Код, получим сценарий загрузки (рис. 8.26).
□•£] Сценарии
Текстовый Файл (groups.txt)
3 Загрузка данных в Хранилище данных - FAR МА: GRJD
В Текстовый Файл (produces.txt)
; • (5 Загрузка данных в Хранилище данных - FARMA: TV_ID
Текстовый файл (stores.txt)
(3 Загрузка данных в Хранилище данных • FARMA: PART JD
Текстовый Файл (sales.txt)
Рис. 8.26. Фрагмент сценария загрузки данных в хранилище
Загрузка измерений на этом заканчивается; осталось еще два из-
мерения (без атрибутов): Дата и Час, включенные в таблицу про-
цесса. Но эти измерения не участвуют в иерархии, поэтому их зна-
чения можно загрузить на этапе экспорта в процесс (для этого при
загрузке должен быть установлен флаг Автоматически добавлять
значения измерений).
Теперь, когда все измерения загружены (определены все коор-
динаты данных в многомерном пространстве), можно загружать
данные в процесс Продажи. При этом в мастере экспорта появятся
два новых окна, отсутствовавших при загрузке измерений. В одном
из них следует указать измерения, по которым необходимо удалять
данные из хранилища (рис. 8.27). Это требуется для контроля не-
противоречивости информации: мы указываем выполняемое дейст-
вие в ситуации, когда в хранилище загружается информация, кото-
рая совпадает по значениям из нескольких измерений.
Вариантов может быть два: удалить «старые» данные и загру-
зить новые либо запретить удаление и оставить то, что уже было
загружено ранее. В нашем случае, когда измерение Дата установ-
лено на удаление, при повторной загрузке в процесс Продажи из
него будут удалены и загружены заново данные за те даты, которые
совпадают в источнике и в хранилище. Например, если в храниди-
194
ще есть данные о том, что на 01.03.2004 определенному клиенту
было продано 1000 единиц конкретного товара, и загружаются дан-
ные, что их было продано 1200, будет сохранена именно последняя
информация. Правила, в каких случаях удалять старые данные, а в
каких оставлять их, диктуются бизнес-процессами деятельности
компаний.
Рис. 8.27. Параметры для контроля непротиворечивости информации
в хранилище данных
В последнем окне мастера лучше оставить настройки, принятые
по умолчанию (рис. 8.28). Файл сценария следует сохранить (на-
пример, под именем load.ded) в той же папке, где находятся тек-
стовые файлы таблиц.
В результате всех описанных действий хранилище данных будет
создано и заполнено конкретными сведениями, а также создан сце-
нарий загрузки в него информации из внешних источников. Очень
важно, что такого рода сценарий привязан не к самим данным,
а лишь к их структуре, то есть в нем смоделирована последователь-
ность действий, которые нужно выполнить для загрузки данных
в хранилище: указаны имена файлов-источников, соответствие по-
лей и т.д.
Таким образом, сценарий может использоваться неоднократно
для пополнения хранилища; для этого достаточно выгрузить новую
информацию о продажах и измерениях в текстовые файлы. Как
правило, эти процедуры проводятся по регламенту в нерабочее
время (например, ночью) с использованием пакетного режима; со-
ответствующие настройки являются прерогативой системного ад-
министратора.
13 *
195
Рис. 8.28. Вспомогательные параметры загрузки данных в процесс
8.6. ИЗВЛЕЧЕНИЕ ИНФОРМАЦИИ
Для извлечения данных из хранилища используется мастер им-
порта; в качестве иллюстрации рассмотрим последовательность
действий по импорту данных из процесса Продажи за последние
3 мес.
1. С помощью мастера импорта выберем тип источника данных
Deductor Warehouse, на следующем шаге - ХД Фармация, затем -
процесс Продажи.
2. Определим, какие измерения и атрибуты из выбранного на
предыдущем шаге процесса следует импортировать (рис. 8.29). За-
метим, что внутри измерения Товар.Код появилась возможность
доступа к измерению Группа.Код.
3. Укажем импортируемые факты и способы их агрегирования
(в большинстве случаев при этом потребуется суммирование дан-
ных - см. рис. 8.30).
4. Определим срезы для выбранных измерений. Это особенно
важно при большом количестве значений измерения, так как позво-
ляет загружать с сервера, на котором размещается хранилище,
только интересующие пользователя значения и тем самым эконо-
196
мить время загрузки. На рис. 8.31 указан интересующий нас срез
3 месяца от текущей даты.
В завершение операции импорта данных следует указать способ
их отображения.
Рис. 8.29. Выбор импортируемых измерений и атрибутов
Рис. 8.30. Выбор импортируемых фактов
197
Рис. 8.31. Выбор среза из хранилища данных
ЗАДАНИЕ
1. Повторите самостоятельно все действия, описанные выше:
создайте пустое хранилище данных Фармация, спроектируйте его
структуру и загрузите в него информацию из следующих текстовых
файлов: groups.txt, produces.txt, stores.txt, sales.txt. Результатом
работы должен стать сценарий загрузки load.ded.
2. Убедитесь, что в хранилище загружена вся информация о
продажах.
3. Импортируйте информацию о продажах из ХД Фармация,
включая атрибуты товара. Установите следующие срезы: а) кроме
последнего периода в 1 мес от имеющихся данных; б) по какой-
либо одной товарной группе.
ВОПРОСЫ ДЛЯ САМОКОНТРОЛЯ
1. Для каких целей используют хранилища данных?
2. Из каких частей состоит такое хранилище?
3. Что представляет собой семантический слой и для чего он нужен?
4. Опишите структуру данных «снежинка».
5. Приведите примеры объектов хранилища данных.
198
ПРАКТИЧЕСКОЕ ЗАНЯТИЕ 9. МНОГОМЕРНЫЕ ОТЧЕТЫ И OLAP
Цель занятия: освоить навыки извлечения информации из храни-
лища данных, построения многомерных отчетов и их анализа
9.1. МНОГОМЕРНЫЙ АНАЛИЗ ДАННЫХ
OLAP (OnLine Analytical Processing, оперативная аналитическая
обработка данных) является на сегодня одним из самых популяр-
ных методов анализа. Его основное назначение - поддержка анали-
тической деятельности, а также произвольных (не регламентиро-
ванных) запросов лиц, принимающих решения. В частности, на ос-
нове OLAP строятся многочисленные системы поддержки приня-
тия решений и подготовки отчетов.
Эта технология позволяет осуществлять многомерный анализ
данных. Она может применяться не только для построения отчет-
ности, но и для первичной проверки гипотез об изучаемой пред-
метной области. Такие гипотезы неизбежно возникают в процессе
анализа; для выработки качественных решений они должны быть
проверены на основе имеющейся информации.
Обычно речь идет о зависимости между анализируемыми пара-
метрами (зависимость объема продаж от региона, времени, катего-
рии товара или, скажем, зависимость количества выздоравливаю-
щих пациентов от применяемых средств лечения, возраста и т.п.).
Число таких параметров может варьировать в широких пределах,
и традиционные средства анализа данных, представленных в виде
таблиц реляционной СУБД, оказываются недостаточно эффектив-
ными. Чаще всего нужная для анализа информация хранится в раз-
розненных таблицах, и нужно затратить немало сил и времени, что-
бы свести ее воедино, не говоря уже об изучении связей между па-
раметрами процесса.
В OLAP-системах предварительно подготовленная информация
преобразуется в форму многомерного куба; такими данными гораз-
до легче манипулировать, используя необходимые для анализа сре-
зы (рис. 9.1).
Для иллюстрации концепции OLAP-куба вернемся к рассмот-
ренному в предыдущем разделе примеру по продажам лекарств
в компании, имеющей три аптеки. Предположим, нас интересуют
объемы продаж за последние два месяца по товарным группам и по
каждой аптеке за каждый месяц.
Очевидно, что ответ на любой из этих вопросов будет оформлен
в виде двумерной таблицы; в первом случае строками и столбцами
таблицы будут соответственно названия товарных групп и месяцы,
во втором - номера аптек и месяцы. Вместе, с тем осуществлять
анализ данных, представленных в таком виде, крайне неудобно -
постоянно будет возникать необходимость в «соединении» данных,
хранящихся в разных таблицах.
199
Гораздо удобнее использовать три равноправных измерения (ап-
тека, товарная группа, месяц), то есть размещать данные не в дву-
мерных таблицах, а по клеткам куба (рис. 9.2). Такая модель позво-
лит получать нужную для аналитика информацию, производя соот-
ветствующие сечения (срезы) OLAP-куба; эти срезы выводятся на
экран в виде кросс-таблицы и/или кросс-диаграммы.
Кросс-таблица отличается от обычной плоской таблицы наличи-
ем нескольких уровней вложенности (например, она допускает раз-
биение строк на подстроки, а столбцов - на подстолбцы). Кросс-
диаграмма представляет собой диаграмму заданного типа (гисто-
грамму, линейную диаграмму и т.д.), построенную на основе кросс-
таблицы. В отличие от обычной диаграммы, она однозначно соот-
ветствует текущему состоянию кросс-таблицы и изменяется соот-
ветственно любому изменению в этой таблице.
Кросс-таблица
Плоские таблицы /V-мерный куб Отображения среза
Рис. 9.1. Технология OLAP
В рассматриваемом примере получим срез куба из хранилища
Фармация по продажам за последние два месяца в трех аптеках по
всем товарным группам; соответствующий многомерный отчет
приведен на рис. 9.3.
В анализе может использоваться любое число измерений, каж-
дое из которых (например, час покупки) будет представлено новой
осью. Конечно, для OLAP-куба с размерностью более трех геомет-
рическая интерпретация не имеет смысла (тем более что речь идет
не о реальном, а об информационном пространстве). В конце кон-
200
цов, само понятие «многомерный куб» - всего лишь служебный
термин, используемый для описания метода.
Рис. 9.2. Трехмерная модель представления данных
Следует отметить, что задача расчета и визуализации куба
с большим числом измерений, во-первых, может потребовать
слишком больших вычислительных ресурсов, а во-вторых, ее со-
держательная интерпретация весьма затруднительна.
Как правило, человек не способен анализировать больше 5-7
измерений одновременно. Поэтому сложные задачи, требующие
анализа данных большой размерности, следует по возможности
сводить к нескольким более простым.
9.2. OLAP В DEDUCTOR
Технология OLAP представлена в Deductor в виде визуализатора
«Куб» с двумя типами отчетов внутри него (кросс-таблица, кросс-
диаграмма). Для иллюстрации рассмотрим многомерный отчет по
ХД Фармация, отражающий динамику сумм продаж по месяцам
года в разрезе групп и аптек. В хранилище данных измерение Ме-
сяц отсутствует (имеется лишь измерение Дата); чтобы решить эту
проблему, следует применить к узлу импорта из хранилища обра-
ботчик Дата и время. В параметрах обработчика зададим для поля
Дата тип разбиения Год и Месяц (рис. 9.4).
201
Рис. 9.3. OLAP-отчет по продажам за последние два месяца
.S'-
Рис. 9.4. Обработчик Дата и время
После применения данного обработчика в выходном наборе бу-
дет создано два новых столбца с метками Дата (Год) и Дата (Ме-
сяц), а сценарий будет состоять из двух узлов (рис. 9.5).
еЬ-0 Импорт изХД • FAR МА: Продажи
• ПИ Преобразование даты (Дата: Год + Месяц)
Рис. 9.5. Фрагмент сценария
Далее запускаем мастер визуализации (щелкнув по кнопке 1*П на
панели инструментов или выбрав соответствующий пункт во
всплывающем меню), после чего укажем способ отображения дан-
ных в виде куба (рис. 9.6).
Затем следует произвести настройку назначений полей куба, то
есть указать измерения и факты (рис. 9.7). В данном случае измере-
ния - это Дата (Месяц), Дата (Год), Отдел.Наименование и Груп-
па.Наименование, а факты - Количество и Сумма (с агрегацией
203
Сумма). Информационное поле Дата не будет отображаться при
построении кросс-таблицы и кросс-диаграммы, но будет доступно
в детализации.
Название_______________| Описание
В Г” Т абличные данные
Г“1 Таблица
Г Статистика
Диаграмма
Г Гистограмма
В р OLAP анализ
Отображает данные в виде таблицы
Отображает статистические данные выборки
Отображает данные в виде диаграммы
Отображает данные в виде гистограммы
Zt Куб i Многомерное отображение (кросс-таблица и кросс-диаграмма]
В Г Прочее
Г" Сведения
Сведения о параметрах
Рис. 9.6. Выбор способа отображения данных
Рис. 9.7. Настройка назначений полей куба
204
На следующем шаге задаем размещение измерений по стро-
кам/столбцам (рис. 9.8). В последнем окне мастера определяем, ка-
кие факты следует отображать в кросс-таблице на пересечении из-
мерений. В программе предусмотрено несколько способов объеди-
нения (агрегирования) фактов в кросс-таблице: Сумма, Среднее
(вычисляется сумма или среднее значение объединяемых фактов),
Минимум, Максимум (среди всех объединяемых в таблице фактов
отображается только минимальный или максимальный), Количест-
во (в кросс-таблице будет показано количество объединенных фак-
тов) и др. (рис. 9.9).
Рис. 9.8. Настройка размещения полей куба
Полученная в результате кросс-таблица показана на рис. 9.10.
Фильтрация данных в ней может производиться по значениям фак-
тов или по значениям измерений путем непосредственного выбора
этих значений из списка или их отбора по условию. Эта операция
осуществляется отдельно по каждому измерению.
В данной кросс-таблице представлены следующие измерения:
Отдел.Наименование - Аптека 1, Аптека 2 и Аптека 3;
Дата (Месяц) - месяцы работы отделов (01 Январь, 02 Фев-
раль и т.д.);
Группа.Наименование - названия групп лекарственных препа-
ратов, присутствующих в продаже (Антисептики и др.).
При этом измерения Дата (Месяц) и Отдел.Наименование яв-
ляются рабочими, а Группа.Наименование - скрытым.
Фактами в данном случае будут стоимость (сумма) и количество
проданных медикаментов.
205
Рис. 9.9. Настройка отображения фактов
Чтобы осуществить фильтрацию, необходимо во всплывающем
меню или на панели инструментов нажать кнопку Т , после чего
появится окно селектора (рис. 9.11). Оно возникает при фильтрации
данных по значениям фактов; в его левой части отображаются все
измерения кросс-таблицы и поле Факты.
Справа размещаются следующие элементы:
выпадающий список Измерение, задающий измерение, значе-
ния которого будут отфильтрованы;
окно Факты и варианты агрегации, в котором указывают факт,
по значениям которого будет производиться фильтрация, а также
функцию агрегации, в соответствии с которой следует выполнить
отбор записей (будут выбраны только те записи, агрегированные
значения которых удовлетворяют выбранному условию);
выпадающий список Условие, позволяющий указать условие
отбора записей по значениям выбранного факта.
В поле Условие можно выбрать различные способы фильтра-
ции, в том числе:
Первые N - значения фильтруемого измерения сортируются
в порядке убывания факта и выбираются первые N значений (задав
такое условие, можно, в частности, определить лидеров продаж -
206
первые 10 наиболее продаваемых товаров, первые 5 наиболее удач-
ных дней и т.п.);
1 р^нпа Наименование | Отдел Наименование | i
|Аптека 1 Аптека 2 Аптека 3 Итого:
|| Дата (Месяц) X Сумма X Коли X Сумма X Коли X Сумма X Коли X Сумма X Коли
01 Январь 33 284.0 573 33 284.0 573
02 Февраль 33 809.2 623 33809.2 623
03 Март 32 241.2 534 32 241.2 534
04 Апрель 33 488.0 527 19 370.6 353 ._. 52 858.6 880
05 Маи 22 377.6 449 10 759.3 224 33 1 36.9 673
06 Июнь 21 364.1 425 8160.5 186 29 524.5 611
07 Июль 13 536.4 373 8158.1 164 21 694.5 537
08 Август 14 324.6 312 10 764.9 227 25 089.5 539
09 Сентябрь 23 436 4 453 15 008.2 278 38 444.6 731
10 Октябрь 31 328.3 536 21 777.8 361 35 965.4 566 89 071.6: 1463
11 Ноябрь 33 413.9 i 588 16 416.8 281 46 399.3 603 96 229.9 1472
12 Декабрь 32 596.5 591, 21 365.7 350 43121.3 655 97 083.5! 1596
Итого: 325 200.1 5984 131 781.9 2424 125 486.0 1824 582 468.0 1Р232||
Рис. 9.10. Кросс-таблица
Рис. 9.11. Окно селектора
207
Отдел Наименование w Дата (Месяц) ••
| Группа. Наименование у S Сумма S Коли
Антисептики и дезинфицирующие средства 171 903.8 4186
Биологически активные пищевые добавки 3 740.9 24
Витамины и витаминоподобные средства 200 440.5 2290
Желчегонные средства и препараты желчи 3 454.7 134
Иммуномодуляторы 160 210.4 2024
Местные анестетики 14 353.0 621
Микро-и макроэлементы 10 614.9 573
Общетонизирующие средства и адаптогены 17 749.6 380
Итого: 582 468.0 10232
Рис. 9.12. Кросс-таблица перед фильтрацией данных
Измерение |ab Группа.Наименование y'fi
Факты и варианты'3^"^
S- 9.0 Сумма I Сумма
L... (• £ Сумма
ЁЬ 9-0 Количество | Сумма
L•• 0 £ Сумма
!
Рис. 9.13. Параметры фильтрации
Последние N - фильтрация осуществляется аналогичным обра-
зом, но отбираются последние А значений (например, 10 наименее
популярных товаров);
Доля от общего - значения фильтруемого измерения сортиру-
ются в порядке убывания факта и выбирается столько первых зна-
чений измерения, чтобы в сумме получить заданную долю от об-
щей суммы (например, отобрать клиентов, приносящих 80% при-
были, или товары, дающие 50% объема продаж);
Диапазон, Больше, Меньше - отбираются записи, для которых
значение соответствующего факта лежит в заданном диапазоне,
больше или меньше указанного значения.
Вернемся к полученной ранее кросс-таблице и предположим,
что нужно определить товарные группы, приносящие 80% выручки.
Исходная таблица по измерению Группа.Наименование содержит
8 товарных групп (рис. 9.12). Применив к ней селектор с парамет-
рами, указанными на рис. 9.13, найдем товарные группы, прино-
сящие основной доход.
Аналогичную выборку можно получить по любому факту и спо-
собу агрегации. Выше использовалась агрегация Сумма; если
фильтровать данные по параметру Количество, получим товары,
пользующиеся наибольшим спросом.
9.3. РАЗРАБОТКА СИСТЕМЫ АНАЛИТИЧЕСКОЙ ОТЧЕТНОСТИ
В процессе работы специалисту-аналитику приходится выпол-
нять множество операций над имеющимися данными, детали кото-
рых не представляют интереса для конечных пользователей (на-
пример, для руководства фирмы). В частности, им нет необходимо-
сти вникать в последовательность расчетов, знать особенности
математического аппарата и методов, применяемых при анализе
данных. Для представления полученных результатов в соответ-
ствующей форме в Deductor используется специальное средство
визуализации и консолидации данных - аналитическая отчетность.
Используя это средство, можно получить быстрый доступ к резуль-
татам анализа; при этом пользователь не видит сценарий анализа,
ему доступен только конечный продукт работы аналитика.
Отчеты строятся в виде древовидного иерархического списка,
узлами которого могут быть отдельный отчет или папка, содержа-
щая несколько отчетов. Каждый узел дерева отчетности связан
с определенным узлом в дереве сценария, и для каждого отчета на-
страивается свой способ отображения (таблица, кросс-таблица, гис-
тограмма, кросс-диаграмма и т.д.). Это удобно, так как несколько
отчетов могут быть связаны с одним узлом дерева сценария.
Для построения аналитической отчетности необходимо в меню
Вид выбрать пункт Отчеты или нажать соответствующую кнопку
на панели инструментов, после чего в рабочей части экрана появит-
I 4 Кацко И.А.. Пак шн Н.Б.
209
ся панель Отчеты. Чтобы создать новый отчет, следует нажать на
кнопку Добавить узел на панели инструментов или выбрать соот-
ветствующую команду из всплывающего меню. Откроется окно
Выбор узла, в котором нужно выделить узел дерева сценария, где
содержится нужная выборка данных, и щелкнуть по кнопке Вы-
брать.
Я Отчеты ? ▼ Я X
W 01 (S ШI X
В-Я Отчеты
В Динамика продаж
Продажи по отделам
h jtT| Продажи по товарным группам
; - j]T| Загруженность отделов в течение дня
©О АВС анализ
=-Ш) АВС анализ клиентов
- - АВ С анализ товаров
ф 1°П Анализ клиентов
В Г~1 Прогноз продаж на следующий месяц
• •(§) Прогноз продаж по товарным группам
h (и) Прогноз по товарным группам с учетом остатков на складе
• (W| Прогноз продаж по товарам
; Прогноз продаж по товарам с учетом остатков на складе
Рис. 9.14. Дерево отчетов
Для создания новой папки для хранения отчетов необходи-
мо нажать на кнопку Добавить папку на панели инструментов
или выбрать соответствующую команду в контекстном меню. Что-
бы поместить новый отчет в уже имеющуюся папку, ее нужно
выделить перед созданием отчета (точнее, перед командой Доба-
вить узел).
Пример готового дерева отчетов приведен на рис. 9.14.
ЗАДАНИЕ
Разработайте систему аналитической отчетности для созданного
на предыдущем практическом занятии хранилища данных Фарма-
ция. Для этого напишите в Deductor Studio сценарий обработки
данных, сохраните его под именем olap.ded и выберите любые 5-7
210
пунктов из списка, приведенного ниже. Кроме кросс-таблицы, са-
мостоятельно изучите кросс-диаграмму.
1. Постройте кросс-таблицу и кросс-диаграмму по трем измере-
ниям (отдел, месяц года, товарная группа), в ячейках которой ото-
бражается стоимость (сумма) и объем (количество единиц) продан-
ной продукции за все периоды, данные по которым имеются в ХД.
Определите, какая торговая точка и какая товарная группа дает
наибольшую сумму продаж.
Постройте кросс-диаграмму сумм продаж, включающую общую
сумму продаж, продажи по торговым точкам, продажи по товарным
группам.
2. То же за последние 3 месяца, данные по которым имеются
в хранилище.
3. То же за последние 3 недели по имеющимся данным.
4. Найдите сумму максимальной и средней стоимости покупки
за последний месяц по имеющимся данным.
5. Сформируйте многомерный отчет и график загруженности
торговых точек по времени суток и торговым точкам. Определите,
на какие часы приходятся пики продаж.
6. То же за последние 3 месяца по имеющимся данным.
7. Сформируйте многомерный отчет и график загруженности
торговых точек по дням недели.
8. То же за последний месяц по имеющимся данным.
9. Сформируйте многомерный отчет и график загруженности
торговых точек по дням месяца.
10. То же за последние 3 месяца по имеющимся данным.
11. Определите 20 товаров, дающих самый большой суммарный
объем продаж за все периоды.
12. То же, но за последние 3 недели по имеющимся данным.
13. Определите 10 товаров, дающих самый большой объем про-
даж по воскресеньям.
14. Определите товары, дающие 50% объема продаж.
15. То же, но за последние 3 месяца по имеющимся данным.
16. То же, но за последнюю неделю по имеющимся данным.
17. Определите 10 товаров, дающих самый большой объем про-
даж с 18 до 21 ч.
18. Определите товары, дающие летом 50% объема продаж.
ВОПРОСЫ ДЛЯ САМОКОНТРОЛЯ
1. Что представляет собой OLAP-анализ, в чем состоит его назначение?
2. Опишите технологию OLAP-анализа.
3. Какие преимущества дает использование кросс-таблиц и кросс-диа-
грамм?
4. Как осуществляется фильтрация данных в кросс-таблицах?
5. Для чего нужна аналитическая отчетность и как она реализована в сис-
_ теме Deductor?
14 *
211
ПРАКТИЧЕСКОЕ ЗАНЯТИЕ 10. ИСКУССТВЕННЫЕ НЕЙРОННЫЕ
СЕТИ. МНОГОСЛОЙНЫЙ ПЕРСЕПТРОН
Цель занятия: изучить принципы функционирования искусствен-
ных нейронных сетей, освоить методы их построения на примере
аппроксимации нелинейной многомерной функции
10.1. ТЕОРЕТИЧЕСКИЕ СВЕДЕНИЯ
10.1.1. Искусственные нейронные сети
Концепция искусственных нейронных сетей (ИНС), или просто
нейронных сетей (нейросетей, НС), восходит к разработкам 1940-х
годов, когда МакКаллок и Пите впервые попытались создать мо-
дель работы нейрона (нервной клетки). Хотя эти исследования но-
сили медицинский характер, вскоре стало ясно, что данная модель
может использоваться для решения самого широкого круга техни-
ческих проблем.
В последующие десятилетия развитие вычислительных возмож-
ностей ЭВМ позволило приступить к практической реализации
нейросетевых моделей. В 1982 г. Хопфилд предложил метод под-
стройки связей между нейронами, основанный на алгоритме обрат-
ного распространения ошибки.
К концу 1980-х гг. теория НС была в целом сформирована,
а стремительный прогресс компьютерной техники сделал вполне
реальной обработку больших массивов данных с помощью нейрон-
ных сетей за приемлемое время. Сегодня они широко применяются
в качестве универсального средства моделирования сложных сис-
тем и процессов, а нейросетевые алгоритмы все чаще встраиваются
в коммерческие программные продукты. К числу популярных биз-
нес-задач, которые успешно решают НС, относятся распознавание
речи и текста, обнаружение мошенничеств с кредитными картами,
кредитный скоринг и др.
В продуктах Data Mining для решения задач классификации и
регрессии используют так называемые нейронные сети прямого
распространения (их также называют многослойным персептро-
ном). Такая сеть (рис. 10.1) состоит из совокупности узлов (нейро-
нов), соединенных между собой связями. Каждый узел является
своеобразным обрабатывающим модулем. Все связи имеют опреде-
ленный вес (числовой параметр), а ориентация соединяющих линий
соответствует пути прохождения сигнала.
Существует три типа узлов: входной, скрытый и выходной.
Входные узлы формируют первый слой сети. В большинстве НС
каждому из них соответствует один входной атрибут (возраст, пол,
доход и т.д.). Перед обработкой исходное значение входного при-
знака должно быть отмасштабировано (чаще всего в диапазоне от
-1 до 1).
212
Рис. 10.1. Примеры нейронных сетей
Скрытые узлы расположены в промежуточных слоях; они полу-
чают входные сигналы от узлов предыдущего слоя, производят
с ними определенные вычисления и результат обработки передают
на вход узлов следующего слоя. Каждый нейрон скрытого слоя со-
единен со всеми нейронами предыдущего. Наличие скрытого слоя
крайне важно, поскольку это позволяет моделировать нелинейные
зависимости между входами и выходами сети.
Выходные узлы соответствуют зависимым (предсказываемым)
переменным модели; на выходе сети формируется вещественное
число в диапазоне от 0 до 1. В принципе НС может иметь несколь-
ко выходных узлов, однако почти всегда ее можно представить как
совокупность сетей с одним выходом.
В режиме прогнозирования НС работает довольно просто: по-
ступающие сигналы подаются на входы и «прогоняются» через
сеть, в результате чего на выходе генерируется рассчитанное зна-
чение; затем оно подвергается денормализации в исходное значе-
ние (для непрерывных) или в исходное состояние (для дискретных
атрибутов).
Существуют нейронные сети, в которых сигнал проходит не
только в прямом, но и в обратном направлении, так что в структуре
их связей присутствуют замкнутые циклы, но на практике они при-
меняются редко.
После того как архитектура нейронной сети сформирована (за-
дано число слоев и нейронов в каждом слое), запускается процесс
обучения сети; суть его состоит в нахождении оптимальных значе-
ний весовых коэффициентов. Это сложный вычислительный про-
цесс, который может длиться довольно долго. На его начальном
этапе в качестве весов используют случайные числа. Затем на каж-
дой итерации все примеры из обучающей выборки «прогоняют»
через сеть с текущими весовыми коэффициентами, определяют вы-
ходные значения и величину ошибок. На основе информации об
ошибках по специальному правилу (которое зависит от выбранного
213
алгоритма обучения) веса НС корректируют, добиваясь все более
точной ее работы.
Здесь необходимо более подробно рассмотреть понятие актива-
ционной функции, получившей свое название от биологического
термина «активация» (возбуждение нервной клетки). Каждый ней-
рон в НС, как указывалось ранее, представляет собой элементарный
блок, который суммирует входные сигналы и генерирует на их ос-
нове выходной (аналогичный уровню возбуждения в биологии). На
рис. 10.2 эти две функции (суммирование входов и расчет выхода)
показаны наглядно.
Рис. 10.2. Нейрон как элементарный процессор
Суммирование чаще всего осуществляется путем расчета сред-
ней взвешенной (линейной комбинации входных сигналов и их ве-
сов), а для определения выходного значения как раз и используется
активационная функция. Как известно, в биологическом нейроне
небольшие изменения во входном сигнале иногда вызывают очень
сильные изменения в выходном, и наоборот. Аналогичные свойства
имеет и его компьютерный аналог, что позволяет нейронной сети
моделировать нелинейные зависимости.
Существует несколько несложных аналитических функций,
удовлетворяющих данному требованию. Чаще всего в НС исполь-
зуют две из них: сигмоиду /= 1/(1 + еа) и гиперболический тангенс
/= th(a) = (еа - е~°У(еа + е~а}, где а - параметр крутизны функции,/-
выходное значение (рис. 10.3). Выходное значение сигмоиды изме-
няется от 0 до 1, гипертангенса - от -1 до 1.
Важнейший вопрос, возникающий при построении нейросетевой
модели, - определение архитектуры НС, в частности количества
скрытых слоев и нейронов в них. При его решении рекомендуется
руководствоваться следующими правилами.
1. Количество скрытых слоев в большинстве случаев не должно
быть больше двух.
214
Сигмоида
Рис. 10.3. Функции активации
2. Если две обученные нейросети имеют одинаковый порядок
ошибок обучения и обобщения, предпочтение следует отдать более
простой (содержащей меньше скрытых слоев и нейронов).
3. Количество примеров обучающей выборки должно быть
в 1,5-2 раза больше числа связей (весов). В противном случае ко-
личество подбираемых параметров будет равно либо меньше числа
прецедентов, что статистически незначимо, и нейронная сеть про-
сто «запомнит» все примеры.
Количество нейронов в скрытых слоях (при ограничениях, при-
нятых в п. 3) можно приблизительно рассчитать по формуле cyjnm ,
где п - число входных нейронов, тп - число выходов сети, с - кон-
станта (по умолчанию с = 4).
Другой существенный вопрос - определение момента, когда
обучение сети следует прекратить. Проблема состоит в том, что
слишком долгое обучение может привести к адаптации параметров
НС (весов) к любым нерегулярностям в обучающих данных (так
называемое «переобучение сети»). Этот эффект часто наблюдается,
если весов слишком много. Для его предупреждения в обучающем
множестве выделяют область контрольных данных (тестовое мно-
жество), которые в процессе обучения используют для оперативной
проверки фактически достигнутых результатов.
Истинная цель обучения сети состоит в таком подборе ее архи-
тектуры и параметров, которые обеспечат минимальную погреш-
215
ность распознавания тестового множества данных, не участвовав-
ших в обучении.
Ошибка предсказания (как правило, среднеквадратическая), по-
лученная на обучающем множестве, называется погрешностью
обучения, ошибка на тестовом наборе - погрешностью обобщения.
Многочисленные эксперименты показали, что погрешность обуче-
ния при увеличении количества итераций монотонно уменьшается,
тогда как погрешность обобщения снижается только до определен-
ного момента, после чего снова начинает расти.
10.1.2. Алгоритм обратного распространения ошибки
Рассмотрим более детально один из классических алгоритмов
обучения нейронной сети - алгоритм обратного распространения
ошибки (back propagation). Именно его используют для обучения
многослойного персептрона, который, как уже отмечалось, состоит
из входного и выходного, а также из нескольких внутренних (скры-
тых) слоев.
Входной слой имеет размерность входного вектора модели х =
= [Х|, ..., х„]. Обычно его размерность увеличивают на единицу, до-
бавляя xq = 1; это делается для включения величины смещения
функции активации в множество весовых коэффициентов. Каждый
нейрон первого скрытого слоя (к = 1) осуществляет суммирование
входящих сигналов:
7=0
Выходной сигнал нейрона преобразуется с помощью функции
активации
z,*=G(u*),I = DVt;*=iX>
где Nk - число нейронов в A-слое, Кс - число слоев.
В качестве функции активации используется сигмоида
G(z) =------------.
1 + ехр(-/? 5)
Производная от этой функции выражается через значение самой
функции:
^ = /?G(j)(1-G(z)).
as
216
Выходные преобразованные сигналы суммируются на после-
дующем слое вплоть до последнего (выходного):
Nk-i ____ ______
uf = Xwij1 2 *j'l> =G(u’‘),i = \,Nt,k = \,Kc, (10.1)
7=0
так что
Z°=x,j = A (10.2)
Построенная таким образом нейронная сеть содержит весовые
коэффициенты Wy,i = \,Nk,j = 0,Nk_{,к = \,Кс, требующие опре-
деления в процессе обучения.
Для обучения используется система данных, представляющая
собой набор наблюдаемых точек (xj,fj), j = l,p, где x,f- входной
вектор и вектор функции соответственно. Система данных из р то-
чек делится на две выборки: обучающую (ху, fj\ j = 1,Л и прове-
рочную (xJ,fj\ j = h + \,p. Весовые коэффициенты нужно подоб-
рать таким образом, чтобы они обеспечили минимальное отклоне-
ние рассчитываемых в сети значений у от имеющихся f, то есть да-
вали бы минимум целевой функции:
1 т
= min- (10-3)
2 /=1
Здесь И7 - вектор коэффициентов yv^, i = l,Nk , j = » к =
= \,Kc,q - номер предъявляемой для обучения пары из выборки
{x4 * *,f\q^Vh.
Для решения задачи (10.3) применим метод наискорейшего
спуска. Для этого сначала задаем нулевое приближение w случай-
ным образом на промежутке (0,1) и в точке вычисляем градиент
функции g° = VF(ff^).
На шаге t путем одномерного поиска в направлении g‘ находим
минимум F(PF), определяемый величиной X* = arg min [F(PFl -
- X#')]. В результате находится точка И7'"1 = W' - X*#' (в упрощен-
ном варианте алгоритма величина X* задается пользователем из
диапазона от 0 до 1).
Процесс заканчивается, когда абсолютная величина g' станет
меньше заданного малого числа. Для его реализации на каждой
итерации необходимо вычислять составляющие градиента функции
217
dF -------- ------- ------
F(fF), то есть величины —/ = \,Nk,j = 0,Л^_ь к = \,КС ; их опре-
м
деляют по алгоритму обратного распространения ошибки.
По правилу дифференцирования сложной функции производную
dF
—- можно представить в следующем виде:
м
dF _ 8F dz[ ди[
dw‘ ~ dz* dukt dwk '
Далее получим:
—t = z,- , согласно (10.1);
м
M==$ - g(u-‘ })=
du- du-
(Ю.4)
dF _ dF &)+| _ fe' 8F dz-+l 8u*+I
“ Zj о £+1 ^k ~ 2^
dz
dzj+l ozk ^dzf du*+‘ dzk
SF dG(uf) t+1
dukp W‘J
nc sk 8F dG(uk)
Обозначим 5j = —--------. Тогда формулу (10.5) можно запи-
dz- du*
сать следующим образом:
(Ю.5)
(10.6)
sk ^(м^)
Sl [Jr w’ рг
а выражение для составляющих градиента целевой функции примет
вид
екк-\
= ZJ
(Ю.7)
Целевая функция при этом вычисляется согласно выражению
01 я
f NKc-\
G
(Ю.8)
1 т
2 Z=1
Алгоритм обучения многослойного персептрона реализован
следующим_образом. Из обучающей выборки системы данных
(х7, fj\ j = 1, h случайным образом выбирается пара (хч, f4). При
исходных значениях весовых коэффициентов FF0 производится рас-
чет выходных сигналов сети по формулам (10.1), (10.2), а затем из
соотношения (10.8) находят:
dF
du™
Далее по формулам (10.6), (10.7) для к = Kc - 1 и до к = 1 вычис-
dF • Гу-
ляют все составляющие градиента целевой функции —г, i = \,Nk,
_________ щ
j = 0,Nk-\, к-\,Кс.Затем по алгоритму наискорейшего спуска на-
ходят следующее приближение W‘, и итерации повторяются до
достижения приемлемого значения ошибки Sfc. Итак, алгоритм
работает до тех пор, пока ошибка не станет меньше заданной вели-
чины J. Суммарную ошибку сети оценивают по выражению (10.8).
В процессе обучения нейронную сеть проверяют на тестовой
выборке; по его завершении НС можно использовать для решения
задач прогнозирования и обобщения.
10.2. ПРИМЕР ФУНКЦИОНИРОВАНИЯ НЕЙРОСЕТИ В ПРЯМОМ
НАПРАВЛЕНИИ
Рассмотрим теперь конкретный пример распространения сигна-
ла от входов к выходу в прямом направлении для многослойного
персептрона со структурой 3-3-2 (рис. 10.4). Для простоты изложе-
ния откажемся от обычно используемого порога активационной
функции (смещения).
Предположим, что на вход нейронной сети поступает вектор
х = [0,4; 0,6; 0,8]; веса связей приведены в табл. 10.1.
На каждый нейрон первого (скрытого) слоя поступает один и тот
же входной вектор. На выходах сумматоров этого слоя будут полу-
чены следующие значения:
50) = x1w$ + x2m$ + x3w$ = 0,4-0,25 + 0,6-1,2 + 0,8-0,45 = 0,1 +
+ 0,72 + 0,36= 1,18;
219
4° = *1W12+X2W22+X3W32 = Ml,2 + 0,60,75 + 0,81,9 = 0,48 +
+ 0,45 + 1,52 = 2,45;
5Р = х|И,^ + х24'з) + х3м’^ = 0,4(—1,5) + 0,6(~0,7) + 0,80,9 =
= -0,6 - 0,42 + 0,72 = -0,30.
Рис. 10.4. Пример нейронной сети
10.1. Веса связей
Связи первого слоя Веса Связи второго слоя Веса
0,25 0,17
1,2 1,25
w13 -1,5 -0,25
0,5 2,25
0,75 0,65
-0,7 0,76
W31 0,45
1,9
0,9
220
Рассчитаем выходы нейронов первого слоя при условии, что ис-
пользуется логистическая активационная функция с параметром
крутизны, равным 1:
^)=/(4‘))=(1 + еи8)7>=0Л6;
^|)=/(41))=(1 + е-2’45)'1=0,92;
И1) = /Й1,)=(1^°41=0.42.
Итак, вектор входов для нейронов второго слоя имеет вид Xi =
= [0,86; 0,92; 0,42]. Рассчитаем сумматоры этого слоя:
5(2)=j(1)w(2) -ь^М^ + ^Ч^ = 0,86-0,17 + 0,92 (-0,25) +
+ 0,42 0,65 = 0,15- 0,23 + 0,27 = 0,19;
5(2) = yp)w(2) +^(1)^(2)+ J;(i)w(2) = 0,864,25 + 0,92-2,25 +
+ 0,42-0,76 = 1,08 + 2,07 + 0,32 = 3,47.
Таким образом, на выходах нейронной сети будут получены
следующие значения:
yp) = /(,p))=(1 + e-»'”f =0,54;
лР = /(42))=(1 + «-М7)’1=0>97.
10.3. ПРИМЕР РАБОТЫ МНОГОСЛОЙНОГО ПЕРСЕПТРОНА
Рассмотрим решение задачи регрессии с помощью многослой-
ного персептрона на примере прогнозирования результата умноже-
ния двух чисел. Для этого потребуется файл multi.txt, который со-
держится в директории демонстрационного примера программы
Deductor.
В файле содержится таблица со следующими полями: Аргу-
мент!, Аргумент? - множители, Произведение - их произведение.
Импортировав данные из файла, можно посмотреть результат ум-
ножения, используя визуализатор Таблица (рис. 10.5).
Предположим, что нужно построить нейросетевую модель, на
вход которой подаются два множителя, а на выходе получается их
произведение. Для этого, находясь на узле импорта, следует вы-
звать мастер обработки и в его первом окне выбрать обработчик
Нейросеть, после чего перейти к следующему шагу. Во втором ок-
не нужно установить назначение полей: Аргумент! и Аргумент?
представить как входные, а поле Произведение - как выходное
(рис. 10.6).
221
Рис. 10.6. Задание входов и выходов
На следующем шаге предлагается настроить разбиение исходно-
го множества данных на обучающее и тестовое; оставим опции,
принятые по умолчанию (рис. 10.7). В третьем окне мастера нужно
указать параметры архитектуры многослойного персептрона и ак7
222
тивационной функции; для данной задачи вполне достаточно одно-
го скрытого слоя с двумя нейронами (рис. 10.8).
Вслед за этим выбирают алгоритм обучения многослойного пер-
септрона и указывают его параметры (рис. 10.9). Отметим рассмот-
ренный выше алгоритм обратного распространения Back Propa-
gation, а коэффициенты, отвечающие за скорость и момент обуче-
ния, оставим без изменений.
Способ разделения исходного множества данных
Множество
.ЯОбучакпцее
0 Т естовое
ИТОГО:
---------------------------- Порядок сортировки
В процентах В строках-------
95.00 I 61 По возрастанию
______ 5.00 j 3 По возрастанию
'_____100.00 64
Рис. 10.7. Разбиение выборки на обучающую и тестовую
Рис. 10.8. Структура нейронной сети
Далее нужно настроить условия остановки обучения. Примем,
что пример следует считать распознанным, если ошибка станет ме-
нее 0,005, и укажем в поле Эпоха 10 000. В следующем окне мастер
223
предложит запустить процесс обучения, в ходе которого можно на-
блюдать как величину ошибки, так и процент распознанных приме-
ров (рис. 10.10). Параметр Темп обновления показывает, через
какое количество эпох обучения начинает выводиться данная ин-
формация.
“Алгоритм —-------------:-------------------
(* iBack_^Propagationi
Обучение в режиме "онлайн". Коррекция
весов производится после предъявления
каждого примера обучающего множества.
Г R esibent Propagation (R PR 0 P]
Обучение в режиме "оффлайн".
Коррекция весов производится после
предъявления всех примеров обучающего
множества. Учитывается только знак
градиента по каждому весу.
Параметры
Скорость обучения J0.1
Задает градиентную составляющую в
суммарной величине коррекции веса
Момент [ОЗ
Задает инерционную составляющую,
учитывающую величину последнего
изменения веса в суммарной величине
коррекции веса.
Рис. 10.9. Параметры алгоритмов обучения
~ Обучающее множество ——
017 Макс, ошибка ! 1.81 Е-02
0|7 Средн, ошибка [ 1.12Е-03
Распознано (%) j 96.72
- Т естовое множество---------~
0 Г iMaKC- ошибка^ 8.05Е-03
0 р Средн, ошибка 3.97Е-03
Распознано [%] ' 66.67
Эпоха
| юооо]
Время обучения
| 0:00:03~|
5 000 5 500 6 000 6 500 7 000 7 500 8 000 8 500 9 000 9 500
Темп обновления
Г“ Рестарт
Г Пуск
Гj Пауза
Г" ргоп
Рис. 10.10. Обучение нейронной сети
После того как процесс обучения сети завершится, выберем сле-
дующие визуализаторы: Граф нейросети; Диаграмма рассеяния;
Что-если (рис. 10.11). Первый из них позволяет представить ней-
224
ронную сеть графически, со всеми нейронами и синоптическими
связями. При этом можно увидеть не только структуру НС, но и
значения весов для всех связей. В зависимости от веса их цвет ме-
няется, а соответствующее числовое значение можно определить на
цветовой шкале, расположенной в нижней части окна (рис. 10.12).
| Название | Описание
Н d Data Mining 1 П
|7 Граф нейросети Отображает нейронную сеть в виде графа
[7 Что-если Анализ построенной модели по принципу что-если I
Г” Обучающий набор Обучающее и тестовое множества
|7 Диаграмма рассеяния Отображает диаграмму отклонения прогнозируем...
£1[“ Табличные данные
Г" Таблица Отображает данные в виде таблицы
П Статистика Отображает статистические данные выборки
Г” Диаграмма Отображает данные в виде диаграммы
П Гистограмма Отображает данные в виде гистограммы
S Г" OLAP анализ
Г Куб Многомерное отображение [кросс-таблица и крое...
Bf” Общие Л
Второй визуализатор (диаграмма рассеяния) позволяет оценить
качество полученной модели; он показывает отклонение прогнози-
руемых данных от эталонных (рис. 10.13). Черные кружки на диа-
15 К;щко И.A.. Н Б.
225
грамме соответствуют примерам из обучающей выборки, причем
их абсцисса равна эталонному значению, а их ордината - выходно-
му значению, рассчитанному обученной моделью. Прямая диаго-
нальная линия представляет собой линию точных значений; чем
ближе к ней кружок, тем меньше ошибка модели.
Рис. 10.13. Диаграмма рассеяния
Рис. 10.14. Визуализатор Что-если
Третий визуализатор (Что-если) дает возможность провести
эксперимент, введя любые значения множителей Аргумент! и Ар-
гумент2 и рассчитав результат по модели. Так, в обучающей вы-
борке не было примера, в котором первый аргумент равен 5, а вто-
рой - 7. Если ввести эти данные в визуализатор, получим 35,37, что
весьма близко к истине (рис. 10.14).
226
10.4. АППРОКСИМАЦИЯ МНОГОМЕРНЫХ ФУНКЦИЙ
При решении самых разнообразных задач (инженерных, эконо-
мических, научных) нередко возникает потребность подобрать не-
прерывную функцию, наиболее точно выражающую фактически
наблюдаемые взаимосвязи между параметрами.
Предположим, в частности, что имеется набор пар данных типа
вход-выход {(*], У1), (х2,у2), • (хп, уп)}, которые генерируются не-
известной функцией, искаженной шумом. Задача аппроксимации
состоит в нахождении неизвестной функции у = F(x), которая
в точках х\, Х2, ...,хп принимает значения, как можно более близкие
Kyi, У2, Уп- На практике вид искомой функции чаще всего опре-
деляют с помощью точечного графика, позволяющего наглядно
проследить характер зависимости между х и у. Так, на рис 10.15
видно, что на графике слева взаимосвязь переменных близка к ли-
нейной; поэтому фактические значения лучше всего аппроксими-
руются прямой линией. Отклонения от этой линии можно интер-
претировать как случайные колебания. Напротив, на графике спра-
ва реальная взаимосвязь величин х и у явно имеет нелинейный ха-
рактер: какую бы прямую линию мы ни провели, отклонения точек
от нее будут слишком большими, чтобы считаться случайными.
В данном случае необходимо использовать параболу второго или
третьего порядка, и тогда можно получить достаточно хорошее
приближение.
Рис. 10.15. Подбор аппроксимирующей функции
Помимо уже указанных функций, при решении данной задачи
используют также гиперболу, логарифм и экспоненту. Когда вид
приближающей функции установлен, остается лишь определить
оптимальные значения ее параметров (например, с помощью мето-
да наименьших квадратов).
227
Ситуация заметно осложняется, когда необходимо проанализи-
ровать зависимость выходной переменной у не от одной, а от не-
скольких входных переменных сразу. В этом случае аппроксимация
осуществляется с помощью многомерной функции у = F(x), где
х = [хц х2, х„,] - вектор с т компонентами. Естественно, графи-
ческий метод, позволяющий использовать для решения задачи гео-
метрическую интуицию, здесь не подходит. Модели на основе ис-
кусственных нейронных сетей снимают эту проблемы, поскольку:
доказано, что нейронные сети - универсальные аппроксимато-
ры, и позволяют имитировать любую непрерывную функцию с за-
данной точностью;
исследователь избавлен от необходимости самостоятельно вы-
двигать гипотезы о виде приближающей функции;
существуют быстрые алгоритмы обучения соответствующих
нейронных сетей.
В силу указанных причин нейронные сети стали широко исполь-
зоваться при решении сложных задач, требующих построения ап-
проксимирующих зависимостей.
ЗАДАНИЕ
Выберите один из предложенных ниже вариантов многомерной
нелинейной функции и постройте нейронную сеть, позволяющую
аппроксимировать ее значение (во всех вариантах предполагается
1 < х, <3, i= 1,..., 5).
. г х1+х2
1. f=-l—-+Х4Х5.
х3
2. / = Х| -20sin(x2) + 5x3
х4
ех>
3. / = —у==-+ sin(х4х5) .
7*3
4. j = Xj - х2 - х3 + х4х5.
Т + Х5.
6. f = 5xj +cos(x2 + 7*з") +sin(x4 + —) .
7. f = 3cos(x1x2) + 2sinx3 + lnx4 + 10x|.
q f _ /Y2 . 2 . 2 . 2 . 2
о. J —д1 X| т Х2 т Х3 тХ4 т Х$ .
228
2 I
9. f = x{ + 2cos(x2)+ x3 +y/x4 + sinx5 .
Задание необходимо выполнять в следующем порядке.
1. Подготовить обучающую выборку средствами приложения
Microsoft Excel и оформить ее в виде файла *.csv (текстовый файл
с разделителями).
Чтобы создать набор случайных чисел, нужно использовать
функцию Excel СЛЧИС(). Затем случайные числа следует перевести
в нужный диапазон, используя формулы из подраздела 10.1.2, и
рассчитать значение заданной функции в соседнем столбце.
2. Провести обучение нескольких нейронных сетей (как мини-
мум, двух) с помощью Deductor по алгоритму обратного распро-
странения.
3. Проверить качество каждой обученной сети с помощью диа-
граммы рассеяния, отражающей близость обученной модели к ис-
ходной. Выбрать наилучшую модель и оценить точность аппрокси-
мации.
ВОПРОСЫ ДЛЯ САМОКОНТРОЛЯ
1. Какие задачи можно решать при помощи многослойного персептрона?
2. Как формируется обучающая выборка для решения задачи аппроксима-
ции функции?
3. Как нормируются обучающие данные?
4. Сформулируйте эмпирические правила подбора количества скрытых
слоев, количества нейронов, объема обучающей выборки, коэффициента
обучения.
5. Укажите недостатки алгоритма обратного распространения ошибки.
ПРАКТИЧЕСКОЕ ЗАНЯТИЕ 11. ЛОГИСТИЧЕСКАЯ РЕГРЕССИЯ
И ДЕРЕВЬЯ РЕШЕНИЙ В ЗАДАЧЕ КРЕДИТНОГО СКОРИНГА
Цель занятия: изучить основы методов логистической регрессии и
деревьев решений и освоить технику их практического применения
в Deductor на примере задачи кредитного скоринга
11.1. ТЕОРЕТИЧЕСКИЕ СВЕДЕНИЯ
11.1.1. Кредитный скоринг
Кредитным скорингом называется быстрая, точная и устойчивая
процедура оценки кредитного риска, основанная на математиче-
ской модели его связи с параметрами, характеризующими заемщи-
ка. Как бы ни была сложна такая модель, ее работа в конечном сче-
те сводится к разделению заемщиков на два класса - тех, кому кре-
дит выдать можно, и тех, кому он «противопоказан».
229
В последние годы российский рынок потребительского кредито-
вания развивался очень быстро, и его потенциал по-прежнему
очень велик. Все больше банков запускают программы потреби-
тельского, ипотечного, автомобильного кредитования, выпуска
кредитных карт. Появились крупные банки, специализирующиеся
исключительно на кредитовании населения («Русский стандарт»,
«Росбанк» и др.). В этой ситуации серьезной проблемой становится
отсутствие эффективной методики оценки заемщиков, чему имеет-
ся несколько объективных причин.
Во-первых, в РФ отсутствует единая база о предоставленных
займах, в которой скапливалась бы вся информация о добросовест-
ных и недобросовестных заемщиках. Процесс формирования кре-
дитных бюро в России только начался, и закончится он, судя по
всему, нескоро. Ему препятствуют слабое развитие банковского
сектора в целом, нежелание многих банков раскрывать информа-
цию о клиентах. Во-вторых, даже внутри самих банков часто отсут-
ствуют реальные кредитные истории по потребительским займам.
Кроме того, большинство западных скоринговых методик просто
не подходят для России. В такой ситуации первостепенными фак-
торами становятся социально-экономические характеристики кли-
ента: образование, возраст, должность, уровень доходов и т.п.
Таким образом, комплексная оценка кредитоспособности заем-
щика, с учетом ограниченности временных ресурсов на ее проведе-
ние, становится трудновыполнимой задачей. В результате банки
просто назначают единую процентную ставку, в которую заклады-
вают достаточно высокие риски невозврата. Для добросовестного
заемщика это оборачивается большими издержками; годовые эф-
фективные процентные ставки по экспресс-кредитам нередко дос-
тигают уровня 40-60%.
В условиях острой конкурентной борьбы на рынке потребитель-
ского кредита выигрывает тот, кто может за минимальное время
адекватно оценить риск выдачи займа и предложить самую низкую
процентную ставку. При решении этой задачи без скоринга не
обойтись, поскольку он остается единственным надежным сред-
ством управления рисками при розничном кредитовании.
История скоринга тесно связана с именем американского финан-
систа Дюрана, который впервые разработал балльную модель оцен-
ки заемщика по совокупности его имущественных и социальных
параметров (возраст, пол, профессия и т.д.). Если сумма баллов
превышала определенный порог, заемщик считался кредитоспособ-
ным. И хотя в настоящее время применяют куда более сложные
модели, иногда под скорингом по-прежнему понимают балльную
(рейтинговую) методику оценки заемщика.
Для расчета баллов скоринговой карты сейчас используют два
основных метода - логистическую регрессию и деревья решений,
которые следует рассмотреть более подробно.
230
11.1.2. Логистическая регрессия
Основная цель данного метода, как и множественного регресси-
онного анализа вообще, состоит в выявлении связи между несколь-
кими независимыми переменными (называемыми также регрессо-
рами или предикторами) и зависимой переменной. Бинарная логи-
стическая регрессия применяется в тех случаях, когда зависимая
переменная может принимать только два значения. Иными слова-
ми, с ее помощью можно оценить вероятность того, что одна из
двух альтернатив наступит для конкретного испытуемого (заболе-
вание/выздоровление, возврат кредита/дефолт и т.п.).
Как известно, все регрессионные модели могут быть записаны
в виде формулы
у = F{xx,x2,...,xn).
Например, при множественной линейной регрессии предполага-
ется, что зависимая переменная является линейной функцией неза-
висимых переменных, то есть
у = а + bx*i + Ь2х2 +... + Ьпхп.
Можно ли использовать эту модель для оценки вероятности ис-
хода события? В принципе да; если параметры х, характеризуют
заемщика, то, определив стандартные коэффициенты регрессии bi
и рассчитав величину у, мы можем интерпретировать ее как веро-
ятность возврата долга. Однако здесь возникает проблема: алго-
ритм множественной регрессии «не знает», что переменная отклика
бинарна по своей природе. В результате для некоторых клиентов
модель будет предсказывать значения вероятности больше 1 и
меньше 0, что не имеет смысла.
Зависимая переменная (у)
Рис. 11.1. Логистическая кривая
231
Чтобы устранить это препятствие, необходимо преобразовать
переменную у таким образом, чтобы ее значение никогда не выхо-
дило за границы интервала [0, 1]; с этой целью используют так на-
зываемое логит-преобразование:
\ + е~у ’
где Р - вероятность того, что произойдет интересующее нас событие, у -
независимая переменная в уравнении регрессии.
График этого преобразования приведен на рис. 11.1. Если при-
менить его к обеим частям приведенного выше уравнения связи,
получим стандартную модель линейной регрессии.
Существует несколько способов нахождения коэффициентов ло-
гистической регрессии. На практике часто используют метод мак-
симального правдоподобия, применяемый в статистике для получе-
ния оценок параметров генеральной совокупности по данным вы-
борки. Он основан на функции правдоподобия (likehood function),
выражающей плотность вероятности совместного появления ре-
зультатов выборки Xi, Y2, ..., Yk:
L(Yx,Y2,...Yk,6) = p{Yx,O)...-p(Yk-0Y
Согласно методу максимального правдоподобия в качестве
оценки неизвестного параметра в принимается такое значение
0 = 0(Yx,...,Yk), которое максимизирует функцию L.
Нахождение оценки 0 = 0(УЬ...,}^.) упрощается, если максими-
зировать не саму функцию L, а ее натуральный логарифм InZ, по-
скольку максимум обеих функций достигается при одном и том же
значении в:
Z*(Y,0) = lnZ,(Y,0)->max.
В случае бинарной независимой переменной, которую мы имеем
в логистической регрессии, выкладки можно продолжить следую-
щим образом. Обозначим через Р,- вероятность появления единицы:
Pi = РгоЬ(У = 1). Она будет зависеть от X,W, где X, - строка мат-
рицы регрессоров, W - вектор коэффициентов регрессии:
^=F(X(W), F(z)=—.
1 + е “
Логарифмическая функция правдоподобия имеет вид
L* = In Р,(W) + X Hl - Р, (W)) =
/е/1 /б/о
232
= In P, (W) + (1 - Y,) ln(l - P,\( W))],
Z=1
где /0. /1 - множества наблюдений, для которых У( = 0 и У,- = 1 соответст-
венно.
Для градиента g и гессиана Н функции правдоподобия можно
вывести следующие формулы:
g = X« -ОД, н = -^Р,(1 - Р,)Х'X, < 0.
/ i
Гессиан всюду отрицателен, поэтому логарифмическая функция
правдоподобия всюду вогнута. Для поиска максимума можно ис-
пользовать метод Ньютона, который в данном случае будет всегда
сходиться:
w,+1 = w,= W, - AW,.
Рис. 11.2. Представление логистической регрессии в виде нейронной сети
Логистическую регрессию можно представить также в виде од-
нослойной нейронной сети (рис. 11.2). Известно, что такая сеть мо-
жет успешно решать лишь задачи линейной сепарации, поэтому
моделировать нелинейные зависимости с помощью логистической
регрессии невозможно. Однако, как вскоре будет показано, для
оценки качества классификации логистической регрессии сущест-
вует эффективный инструмент в виде ROC-анализа, что в извест-
ной мере снимает указанную проблему.
11.1.3. ROC-анализ
Предположим, у нас имеется бинарная модель, предсказываю-
щая, что заемщик с параметрами х, вернет долг с вероятностью Р.
Как воспользоваться ею практически? Очевидно, нужно выдвинуть
233
некий критерий в виде порогового уровня вероятности: например,
при Р > 0,8 кредит предоставляется, а в противном случае (при Р <
< 0,8) в кредите будет отказано. Значение Р = 0,8 будет выполнять
роль так называемой точки отсечения (cut-off value), в соответст-
вии с которым все множество потенциальных заемщиков делится
на два класса: «хороших» и «плохих» клиентов банка.
Данный пример представляет собой частный случай гораздо бо-
лее общей проблемы бинарной классификации, когда в соответст-
вии с тем или иным критерием изучаемое множество разбивается
на два класса: с положительными исходами и с отрицательными
исходами (в рассматриваемой задаче положительный исход означа-
ет возврат долга). При этом предполагается, что имеется некоторый
параметр, при изменении которого это разбиение будет меняться.
Например, если вместо критерия Р = 0,8 мы примем Р = 0,6, многие
клиенты, которые раньше считались «плохими», перейдут в класс
«хороших». Поскольку в моделях логистической регрессии искомая
величина может изменяться в диапазоне от 0 до 1, то и точка отсе-
чения должна находиться в этом интервале.
Для оценки качества данной модели необходимо более детально
рассмотреть ошибки, которые могут возникнуть при ее использова-
нии. Очевидно, при любой бинарной классификации их может быть
только две: принять положительный случай за отрицательный (на-
пример, добросовестного заемщика за банкрота) или, наоборот, от-
рицательный - за положительный; их принято называть ошибками
первого и второго рода.
Введем следующие обозначения:
TP (True Positives) - количество верно классифицированных мо-
делью положительных примеров (так называемые истинно положи-
тельные случаи);
TN (True Negatives) - количество верно классифицированных от-
рицательных примеров (истинно отрицательные случаи);
FN (False Negatives) - количество положительных примеров,
классифицированных моделью как отрицательные (ошибок первого
рода);
FP (False Positives) - количество отрицательных примеров,
классифицированных как положительные (ошибок второго рода).
При оценке модели важную роль играют следующие соотноше-
ния, выраженные в процентах:
доля истинно положительных примеров, распознанных моделью
(True Positives Rate):
TP
TPR =--------100%;
TP + FN
доля ложно положительных примеров (False Positives Rate), то
есть отношение истинно отрицательных примеров, классифициро-
?3z1
ванных данной моделью как положительные, к общему числу таких
примеров:
FP
FPR =---------100%.
TN + FP
Очевидно, что чем мягче критерий отбора «хороших» клиентов,
тем больше кредитоспособных заемщиков будут признаны таковы-
ми и тем ближе величина TPR к 100%. Но одновременно будет воз-
растать и доля ошибок второго рода, доля неверно квалифициро-
ванных «плохих» клиентов, отражаемая показателем FPR. Таким
образом, варьируя критерий отбора, мы можем уменьшать долю
ошибок либо первого, либо второго рода, но не обе эти доли одно-
временно.
Величина Se = TPR называется также чувствительностью моде-
ли (Sensitivity), а величина Sp = 100 - FPR, характеризующая долю
верно распознанных отрицательных случаев, - ее специфичностью
(Specificity). Эти два показателя определяют объективную ценность
любого бинарного классификатора. Когда один из них стремится
к нулю, другой принимает значения, близкие к 100, и наоборот (по-
скольку, как мы только что заметили, величины TPR и FPR всегда
изменяются в одном направлении).
Сами термины «чувствительность» и «специфичность», не очень
понятные в контексте задачи кредитного скоринга, происходят из
теории систем обработки сигналов; под чувствительностью здесь
понимается способность воспринимающего устройства (Receiver)
распознать полезный сигнал, под специфичностью - отсечь беспо-
лезный сигнал (шум). Если провести аналогию с рассматриваемой
нами задачей, «полезным сигналом» для банка будет запрос на кре-
дит со стороны добросовестного заемщика, а «шумом» - со сторо-
ны банкрота.
Модель с высокой чувствительностью часто дает истинный ре-
зультат при наличии положительного исхода (обнаруживает поло-
жительные примеры). Наоборот, модель с высокой специфично-
стью чаще дает истинный результат при наличии отрицательного
исхода (обнаруживает отрицательные примеры). Для наглядного
отображения указанных характеристик используется так называе-
мая ROC-кривая (Receiver Operator Characteristic), которая строится
следующим образом.
1. Для каждого значения порога отсечения, изменяемого с шагом
dx (например, 0,01) от 0 до 1, рассчитывают значения чувствитель-
ности Se и специфичности Sp (в качестве альтернативы можно про-
сто взять каждое последующее значение примера в выборке).
2. Строят график зависимости TPR от FPR, то есть по оси орди-
нат откладывают значение чувствительности Se, а по оси абсцисс -
величину FPR =100- Sp.
235
Полученный график обычно дополняют диагональной линией
TPR = FPR (рис. 11.3).
Рис. 11.3. Кривая ROC
Для идеального классификатора график ROC-кривой проходит
через верхний левый угол, где доля истинно положительных случа-
ев составляет 100% (идеальная чувствительность), а доля ложно
положительных примеров равна нулю. Поэтому чем ближе кривая
к верхнему левому углу, тем выше предсказательная способность
модели. И, наоборот, чем меньше изгиб кривой и чем ближе она
расположена к диагонали квадрата, тем менее эффективна модель.
Диагональная линия соответствует «бесполезному» классификато-
ру, то есть полной неразличимости двух классов.
Это правило позволяет оценить сравнительную эффективность
моделей по виду их ROC-кривых (рис. 11.4); в данном случае оче-
видно, что модель, соответствующая кривой А, лучше.
Иногда ROC-кривые располагаются достаточно плотно или пе-
ресекаются, и их визуальное сравнение затруднено. В этом случае
для оценки эффективности модели можно использовать площадь
под кривой (AUC, Area Under Curve). Поскольку ROC-кривая все-
гда расположена выше диагонали, треугольник под диагональю
площадью 0,5 всегда входит в состав измеряемой области, а меня-
ется лишь ее часть, закрашенная на рис. 11.5 серым цветом. Таким
образом, показатель AUC может изменяться от 0,5 («бесполезный»
классификатор) до 1,0 (идеальная модель). Его обычно рассчиты-
вают по экспериментально полученным точкам методом трапеций
(или каким-то иным численным методом расчета площадей).
236
А В
100 - специфичность (FPR)
Рис. 11.4. Сравнение ROC-кривых
Рис. 11.5. Площадь под ROC-кривой
При прочих равных условиях чем больше площадь под ROC-
кривой, тем лучше модель. Вместе с тем следует учитывать два об-
стоятельства:
237
1) показатель AUC больше подходит для сравнения моделей,
чем для оценки эффективности каждой из них самой по себе;
2) он не содержит никакой информации о чувствительности и
специфичности модели.
Идеальная модель обладает 100%-ными чувствительностью и
специфичностью. Но добиться этого невозможно, поскольку, как
уже отмечалось, при изменении порога отсечения эти характери-
стики меняются в противоположных направлениях (рис. 11.6). По-
этому возникает задача поиска оптимального порога отсечения
(optimal cut-off value); ее решение зависит от требований, которые
выдвигаются пользователем модели.
Рис. 11.6. Графики чувствительности и специфичности модели
В качестве критерия оптимальности могут, в частности, высту-
пать следующие условия:
1) максимальная чувствительность при заданном уровне специ-
фичности (например, при специфичности не ниже 80%);
2) максимальная специфичность при заданном уровне чувстви-
тельности (например, при чувствительности не ниже 80%);
3) максимальная сумма чувствительности и специфичности мо-
дели Se + Sp —> max);
4) достижение баланса между чувствительностью и специфич-
ностью (Se ~ Sp\
Если принимается последний вариант, оптимальный порог отсе-
чения соответствует точке пересечения двух кривых (см. пунктир-
ную линию на рис. 11.6).
238
Для решения данной задачи применяют и более сложные мето-
ды; например, ошибкам первого и второго рода назначают различ-
ные веса, интерпретируемые как «цена ошибки». Но тогда возника-
ет задача объективного назначения этих весов, которая может ока-
заться не менее сложной.
11.1.4. Деревья решений
Деревья решений (decision trees), вероятно, являются на сего-
дняшний день самой популярной технологией Data Mining. Она
имеет ряд бесспорных преимуществ: быстрота построения модели,
легкость интерпретации и др. Как показывает опыт, деревья реше-
ний дают хорошие результаты в задачах кредитного скоринга.
В основе данной технологии лежит идея последовательного раз-
биения множества объектов на подмножества таким образом, чтобы
значения зависимой переменной в каждом из них были как можно
более однородными. На каждом шаге разбиение производится толь-
ко по одной независимой переменной, а именно по такой, которая
делает его наилучшим. По завершении всего процесса получается
дерево последовательных разбиений, по существу - дерево реше-
ний, то есть набор правил выбора в иерархической структуре.
Каждый путь от вершины до листа дерева (конечного узла) об-
разует правило. В режиме предсказания новый объект «прогоняет-
ся» сквозь дерево правил и «оседает» в каком-либо листе; образно
это можно сравнить с падением шарика в пинболе.
а если
СовокупныйДоход < 7950 ТОГДА ВозврагКредига = Нет
S СовокупныйДоход >= 7950
ф СовокупныйДоход < 18350
•: ф СовокупныйЕжПлатеж < 7362.5
; ф Количество детей на иждивении <2.5
! ; S СовокупныйДоход < 10850
| | j | & СовокупныйЕжПлатеж < 3664.4
; ; i :•••• СовокупныйЕжПлатеж < 2946.9 ТОГДА ВозврагКредига = Да
; ; ; I ЭСовокупныйЕжП латеж >= 2946.9
| - СовокупныйДоход < 9750 ТОГДА ВозврагКредига = Нет
- СовокупныйДоход >= 9750 ТОГДА ВозврагКредига = Да
: СовокупныйЕжПлатеж >= 3664.4 ТОГДА ВозврагКредига = Нет
Рис. 11.7. Пример фрагмента дерева решений
Существуют несколько методов построения деревьев решений.
Например, можно использовать различные формулы для определе-
ния варианта разбиения. Допускается как бинарная форма дерева
239
(в этом случае каждый узел имеет двух потомков), так и небинар-
ная. Максимальная длина ветви (глубина дерева) может быть огра-
ничена предварительно заданным числом, но можно и построить
дерево с полной глубиной, а затем отсечь часть его узлов.
Для построения дерева решений чаще всего используется алго-
ритм ID3 и его усовершенствованный вариант С4.5. Последний
может работать с числовыми, категориальными, пропущенными и
зашумленными данными. На рис. 11.7 приведен фрагмент дерева
решений, предназначенного для классификации заемщиков.
Рассмотрим конкретный пример. Предположим, что у нас име-
ются данные по 3000 заемщиков с известными кредитными исхо-
дами, и для простоты изложения ограничимся тремя переменными,
приведенными в табл. 11.1: пол, семейное положение (состоит
в браке или нет), количество лет проживания в регионе. Зависимой
бинарной переменной является возврат кредита («да» - в случае
успеха, «нет» - в случае дефолта).
11.1. Разбиение множества кредитных историй по признакам, характеризую-
щим клиента
Возврат кредита Пол Состояние в браке Длительность проживания в регионе
Мужской Женский Да Нет До 1 года 1-3 года Свыше 3 лет
Да 1100 900 1700 300 400 700 900
Нет 500 500 200 800 600 200 200
Каждая колонка в таблице представляет собой пару «атрибут-
значение» для одного из входных атрибутов (переменных, факто-
ров кредитоспособности), каждая строка - возможное состояние
зависимой переменной, каждая ячейка - комбинацию значений
входной и зависимой переменных.
Цифры в ячейках характеризуют частоту конкретных комбина-
ций; например, в данном случае из 2000 человек, вернувших ссуду,
1700 состояли в браке, 300 - не состояли в нем и т.д. На основе таб-
лицы для наглядности обычно строят графики (гистограммы) час-
тот (рис. 11.8).
На первом этапе построения дерева решений нужно выбрать ат-
рибут, после разбиения по которому полученные подмножества
будут состоять из однотипных заемщиков (способных или, напро-
тив, не способных вернуть кредит). Естественно, в полной мере
этого добиться невозможно, и нужно искать самое удачное разбие-
ние. Из приведенных гистограмм видно, что наилучшим будет ат-
рибут «состояние в браке»; два графика, соответствующие его раз-
личным значениям, отличаются между собой гораздо больше, чем
альтернативные графики по другим атрибутам.
240
Пол Состояние Проживание в
в браке регионе, лет
чины щины
□ Дефолт □ Возврат кредита
Рис. 11.8. Гистограмма частот
Разумеется, машинный алгоритм не может опираться на интуи-
тивные оценки; необходим формальный критерий оценки качества
разбиения на классы. В данном случае вполне подходит показатель
энтропии, широко используемый в теории информации. В общем
случае энтропия представляет собой меру неопределенности, свя-
занную с конкретным событием; чем выше энтропия, тем больше
эта неопределенность. Для рассматриваемой задачи нам нужно
найти математическую формулу для оценки «чистоты» набора кре-
дитных историй, полученных после разбиения на классы по како-
му-либо атрибуту. Эта формула должна удовлетворять следующим
условиям:
если все случаи возврата кредита попадают в один класс, а не-
возврата - в какой-либо другой (идеальная классификация, полно-
стью устраняющая неопределенность), энтропия равна нулю;
если кредитные истории обоих типов равномерно представлены
во всех классах (наихудшая классификация, оставляющая полную
неопределенность), энтропия имеет максимальное значение.
Указанным требованиям удовлетворяет следующая формула:
Н{р\,р2, ...,Рп) = -p\\ogip\ -pi^gipi -... -А1оЙ2Рл,
где Н- энтропия; р^, i = 1, ..., п - вероятности появления каждого из
п возможных состояний зависимой переменной, р\ + ...+/?„= 1.
В рассматриваемой задаче зависимая переменная имеет лишь
два состояния (возврат кредита или дефолт), так что п = 2. Исполь-
зуя приведенную формулу, рассчитаем энтропию для разбиений по
каждому из трех атрибутов:
7/(1700; 200) + 7/(300; 800) = 0,485 + 0,845 = 1,330 (состояние
в браке);
16 КапкоП.Л.. ll.iKiiiH Н.Б
241
//(1100; 500) + //(500; 900) = 0,896 + 0,940 = 1,836 (пол);
//(400; 600) + //(700; 200) + //(900; 200) = 0,97 + 0,764 + 0,684 =
= 2,418 (длительность проживания в регионе).
Таким образом, разбиение по атрибуту «состояние в браке» об-
ладает наименьшей энтропией, то есть ведет к наибольшему устра-
нению неопределенности; точная формула подтверждает выбор,
сделанный нами ранее исходя из анализа гистограмм. Следователь-
но, данный атрибут и должен находиться в корне дерева решений
(рис. 11.9). Далее процесс разбиения будет продолжен для каждого
узла в отдельности на основе соответствующей таблицы частот и
выбранного критерия (минимальной энтропии). Так, в табл. 11.2
приведены значения частот для подмножества элементов «состоит
в браке = да».
Все
заемщики
Рис. 11.9. Первый этап построения дерева решений
Указанная процедура (создание узлов второго, третьего порядка
и т.д.) будет продолжаться, пока не выполнится условие останова.
11.2. Разбиение подмножества кредитных историй, соответствующих условию
«состоит в браке = да» по признакам, характеризующим клиента
Возврат кре- дита Пол Состояние в браке Длительность проживания в регионе
Муж- ской Жен- ский Да Нет До 1 года 1-3 года Свыше 3 лет
Да 1000 700 1700 0 250 650 800
Нет 150 50 200 0 100 50 50
242
Под каждым узлом на рис. 11.9 указаны процентные значения -
частоты появления зависимой переменной в подмножестве, соот-
ветствующем данному узлу. Как только процесс построения дерева
прекращается, конечный узел «ветви» превращается в «лист». Мак-
симальное значение частоты зависимой переменной для такого узла
называется его достоверностью’, она характеризует количество
правильно классифицированных данным узлом примеров.
В рассматриваемом примере достоверность составляет 89% для
узла «состоит в браке = да» и 73% для узла «состоит в браке = нет».
Их можно интерпретировать как рейтинговый балл заемщика, по-
павшего в этот узел.
Если остановить алгоритм на этапе, показанном на рис. 11.9, по-
лучится очень простое дерево решений, содержащее всего два пра-
вила (табл. 11.3). Здесь приведен еще один параметр - поддержка,
то есть общее количество примеров, классифицированных данным
узлом дерева.
11.3. Список правил дерева решений
Номер п/п Условие Решение о возврате кредита Поддержка Достоверность
% Количество % Количество
1 Состоит в браке = да Да 63 1900 89 1700
2 Состоит в браке = нет Нет 37 1100 73 800
В принципе разбиение узлов и создание новых ветвей можно
продолжать до тех пор, пока в каком-либо узле остается более од-
ного примера, однако такая детализация нецелесообразна. Прямой
связи между числом узлов, ветвистостью дерева и качеством пред-
сказания нет и не может быть. Построенное «до конца» дерево ре-
шений может запомнить все примеры из обучающей выборки, но
бессмысленность такой модели очевидна: ее предсказательная спо-
собность на новых данных наверняка будет низкой. Это один из
типичных примеров переобучения модели, которого всегда нужно
избегать.
Для предотвращения такого эффекта используют различные
приемы. Один из них предусматривает, что процесс разбиения про-
должается до тех пор, пока в узлах имеется не менее к примеров
(к >1) либо показатель поддержки превышает заранее заданную
величину (что, по сути, одно и то же). Конкретные значения этих
граничных параметров существенно зависят от специфики модели
и объема данных, и даже для задачи кредитного скоринга не суще-
ствует какой-то одной рекомендуемой величины.
Другой прием основан на отсечении излишних ветвей дерева
решений (эта процедура также может регулироваться специальным
параметром, от которого зависит глубина дерева, получаемого
243
в итоговой модели). Заметим, что оба приема могут применяться
совместно.
При построении дерева решений иногда возникает еще одна
трудность - количество возможных значений входных атрибутов п
может быть очень большим (например, почтовый индекс заемщика
может принимать тысячи значений). В этом случае дерево решений
обработает данный атрибут и проигнорирует его. Но иногда в та-
ком поле может содержаться полезная информация: например, для
клиентов, проживающих в определенном районе, кредитный риск
может быть ощутимо выше, чем для других. Чтобы не потерять ее,
используют группировку, в результате которой число значений ат-
рибута уменьшается.
Хорошо зарекомендовал себя, в частности, следующий подход:
на основе статистических параметров по имеющемуся набору дан-
ных нужно отобрать т наиболее часто встречающихся состояний
атрибутов (т « п), а все остальные объединить в один. Естествен-
но, он базируется на гипотезе о том, что часто встречающиеся со-
стояния атрибутов вносят больший вклад в формирование зависи-
мой переменной.
В любом случае для дискретного поля при построении дерева
решений рекомендуется использовать не более 10 значений. Если
их больше, то лучше объединить часть значений в одно либо со-
всем исключить это поле из числа полей, учитываемых при работе
алгоритма.
Входные значения в данной задаче могут быть не только дис-
кретными, но и непрерывными (возраст клиента, его доход, ежеме-
сячный платеж по ссуде и т.п.). Разбиение в этом случае также осу-
ществляется с применением показателя энтропии, но процесс имеет
свою специфику, так как в алгоритм вводятся операции сравнения;
проиллюстрируем это на конкретном примере.
11.4. Разбиение множества кредитных историй по непрерывному признаку
(месячному доходу клиента, долл.)
Пороговое значение признака Критерий разбиения Возврат кредита Энтропия
Да Нет
5,4 <5,4 >5,4 0 5 1 4 0,99
7,8 <7,8 >7,8 0 5 3 2 0,86
12 < 12 > 12 0 5 4 1 0,65
19,2 < 19,2 > 19,2 5 0 0 5 0
244
Продолжение
Пороговое значение признака Критерий разбиения Возврат кредита Энтропия
Да Нет
42 <42 >42 2 3 5 0 0,95
66 <66 >66 3 2 5 0 0,95
81 <81 >81 4 1 5 0 0,99
Предположим, что имеется 10 кредитных историй, из них 5 бла-
гополучных (кредит возвращен), в которых среднемесячный доход
заемщика был равен 60, 90, 72, 24 и 24 тыс. руб., и 5 неблагополуч-
ных с показателями дохода 14,4, 6, 9,6, 4,8 и 6 тыс. руб. Чтобы про-
вести разбиение по данному атрибуту, сначала нужно упорядочить
прецеденты по возрастанию дохода, убрав повторяющиеся; полу-
чим ряд из 8 значений: 4,8, 6, 9,6, 14,4, 24, 60, 72, 90. Разделить этот
ряд на два класса можно по любому пороговому значению, распо-
ложенному между любыми двумя из имеющихся. Обычно исполь-
зуют правило половинного деления (среднее между соседними зна-
чениями), то есть разбиение проводят по уровням 5,4, 7,8 и т.д.
(табл. 11.4), после чего по стандартной формуле рассчитывают эн-
тропию для каждого варианта и выбирают разбиение с минималь-
ной энтропией.
Минимум энтропии в данном случае достигается при пороговом
значении 19,2 тыс. руб., так что первое разбиение приведет нас
к двум правилам (табл. 11.5).
11.5. Список правил дерева решений
Номер п/п Условие Решение о возврате кре- дита Поддержка Достоверность
% Количество % Количество
1 Доход < 19,2 Нет 50 5 100 5
2 Доход > 19,2 Да 50 5 100 5
Иногда атрибут (например, «количество иждивенцев») может
быть представлен как в дискретном, так и в непрерывном виде.
Следует отметить, что для алгоритма С4.5 больше подходят непре-
рывные поля.
Конкретные реализации алгоритмов для создания деревьев ре-
шений иногда содержат массу тонкостей, вместо энтропии в них
может использоваться другой критерий, однако основная идея ре-
курсивного разбиения остается неизменной.
245
11.2. СКОРИНГОВЫЕ МОДЕЛИ В DEDUCTOR
Рассмотрим теперь, как задача кредитного скоринга может быть
решена в Deductor с использованием описанных выше методов (ло-
гистическая регрессия, деревья решений). Для этого прежде всего
необходимо получить исходные данные (набор кредитных историй)
в приемлемом для обработки формате.
Обычно информация о заемщиках - физических лицах и кредит-
ных договорах хранится в автоматизированной системе, имеющей-
ся в любом банке; там же хранятся графики погашений, данные о
просрочках, суммах просроченной задолженности, начисленных
процентах и т.д. Как получить из этих данных таблицу, содержа-
щую параметры заемщиков и другую скоринговую информацию, -
отдельная задача; будем считать, что она уже выполнена и резуль-
тат представлен текстовым файлом loans_demo.txt.
Далее необходимо уточнить, по каким правилам следует отно-
сить заемщиков к одному из двух классов («хороший» или «пло-
хой»), используя данные о возврате ими долга. В России кредитные
организации при определении категории заемщика обязаны руко-
водствоваться Положением ЦБ РФ № 254-П «О порядке формиро-
вания кредитными организациями резервов на возможные потери
по ссудам, по ссудной и приравненной к ней задолженности»
(в ред. Указания ЦБ РФ от 20 марта 2006 г. № 1671-У). В частности,
в нем говорится (пп. 3.7.3), что для физических лиц обслуживание
долга признается плохим, если в течение последних 180 календар-
ных дней имеются платежи по основному долгу и (или) по процен-
там, просроченные более чем на 60 календарных дней. Вместе
с тем данное положение регламентирует лишь величину обязатель-
ных резервов; любой банк имеет право устанавливать собственные
правила для классификации заемщиков с учетом принятой кредит-
ной политики и других факторов. Например, при экспресс-креди-
товании на малые суммы просрочки до 5 дней могут не учитывать-
ся вовсе, за критерий отнесения клиента к «плохим» может быть
взята длительность просрочки в 90 дней, а не в 60, и т.д.
В данном случае в файле loans_demo.txt последний столбец, ха-
рактеризующий качество обслуживания долга заемщиком, пред-
ставлен полем Число просрочек свыше 60 дн. Остальные поля
(кроме информационного поля Код) содержат социально-экономи-
ческие характеристики заемщиков: их возраст, пол, доход и др.
Создадим новый проект в Deductor и импортируем в него этот
файл (рис. 11.10).
Из поля Число просрочек более 60 дн. получим новое поле
Класс заемщика; для этого с помощью обработчика Калькулятор
создадим строковое поле и в строке функции напишем:
1Р(ОЕЬАУ8_60>0;"Плохой";"Хороший").
246
Имя столбца C0L1
12 Код
12 Возраст ab Пол
Метка столбца Код
ab Состоит в браке 12 Иждивенцы Т ип данных 12 Целый ▼ |
9.0 Доход 9.0 Опыт работы 9.0 Срок проживания 9.0 Недвижимость 9.0 Месячный платеж 12 Число просрочек более 60 дн. Вид данных — Непрерывный |
Назначение О Информационное j
Рис. 11.10. Импорт файла в проект
Теперь все готово для построения скоринговой модели. Добавим
в ветвь сценария обработчик Логистическая регрессия и на пер-
вом шаге мастера зададим входные и выходные значения столбцов
(рис. 11.11). Поле Код будет информационным, Число просрочек
более 60 дн. - неиспользуемым, Класс заемщика - выходным,
остальные поля - входными.
У
HJl Возраст
С^Пол
Состоит в браке
^Иждивенцы
Доход
Опыт работы
Срок проживания
Недвижимость
^Месячный платеж
X Число просрочек более 60 дн.
Класс заемщика
Настройка нормализации...
Рис. 11.11. Настройка параметров столбцов
После щелчка по кнопке Настройка нормализации появится
диалоговое окно, представленное на рис. 11.12.
247
Рис. 11.12. Настройка нормализации
Для логистической регрессии необходимо настроить:
способы кодирования дискретных входных полей (битовая мас-
ка или уникальные значения);
значения положительного и отрицательного событий для выход-
ного поля.
В рассматриваемом случае имеется два входных дискретных по-
ля - Пол и Состоит в браке; для них рекомендуется указать способ
кодирования Уникальные значения. Порядок списка таких значе-
ний влияет на кодирование значений полей. Так, для поля Пол пер-
вое уникальное значение («женский») будет закодировано нулем,
второе («мужской») - единицей. Это значит, что при расчете кре-
дитного рейтинга по уравнению логистической регрессии женщи-
нам всегда будет начисляться 0 баллов, а мужчинам - какой-либо
отличный от нуля балл. Аналогичным образом для поля Состоит
в браке зададим кодирование по уникальным значениям в сле-
дующем порядке: «нет» (значение 0), «да» (значение 1).
Для выходного поля Класс заемщика порядок сортировки уни-
кальных значений (их всегда два) определяет тип события: первое -
отрицательное, второе - положительное (рис. 11.13). В данном слу-
чае чем выше рейтинг, тем выше кредитоспособность, поэтому зна-
чение «хороший» будет положительным исходом события, а «пло-
хой» - отрицательным.
248
Параметры нормализации | Гистограмма |
и
т
*
- Параметры линейного преобразования----------
Параметры линейного преобразования не доступны
Рис. 11.13. Задание типов событий
В следующих окнах мастера будет предложено настроить обу-
чающие и тестовые множества (рис. 11.14), а также изменить пара-
метры алгоритма логистической регрессии (рис. 11.15). По умолча-
нию предлагается порог классификации, равный 0,5; оставим это
значение, как и все остальные, без изменений.
Рис. 11.14. Настройка разбиения набора данных
После щелчка по кнопке Пуск в последнем окне будет построена
модель и нужно будет выбрать визуализаторы узла (рис. 11.16).
Отметим флажками следующие: ROC-анализ, Коэффициенты ре-
грессии, Что-если, Таблица сопряженности, Таблица.
249
Р Максимальное число итераций |б00I
Алгоритм расчета коэффициентов завершится, когда очередное значение
логарифмической Функции правдоподобия -2xLog likehood прекратит
изменяться в пределах заданной точности.
Т очность Функции оценки
Оценочной Функцией является значение логарифма Функции правдоподобия
(2xLog(Likehood)J.
Порог отсечения
Задача бинарной классификации будет решена на основе заданного порога
отсечения для поля со значением рейтинга
Считать пример распознанным, если ошибка меньше
|035
Рис. 11.15. Настройки алгоритма логистической регрессии
Название | Описание
• - — — — ” - - 1 * 3 * S - -f* Эр Data Mining !j
ROC-анализ j Отображает R 0 С-кривую/граФики баланса
р Коэффициентыре... Отображение коэффициентов регрессии
р Что-если Анализ построенной модели по принципу что-если
Г~ Обучающий набор Обучающее и тестовое множества
р Таблица сопряже... Результаты построения модели в виде таблицы сопряженности
3 J7 Т абличные данные
р Таблица
Р Статистика
Р Диаграмма
Р Гистограмма
S Р OLAP анализ
Г Куб .
1|
Отображает данные в виде таблицы
Отображает статистические данные выборки
Отображает данные в виде диаграммы
Отображает данные в виде гистограммы
в
Многомерное отображение (кросс-таблица и кросс-диаграмма]
Рис. 11.16. Выбор визуализаторов узла
Визуализатор Таблица показывает, что после применения обра-
ботчика Логистическая регрессия в массиве данных появились
две новые колонки: Класс заемщика_О11Т и Класс заемщика Рей-
тинг (рис. 11.17). Рейтинг представляет собой значение независи-
мой переменной у, рассчитанное по уравнению логистической рег-
рессии, а первое поле - принадлежность случая к тому или иному
классу в зависимости от установленного порога классификации
(в данном случае он равен 0,5).
Визуализатор Коэффициенты регрессии (рис. 11.18) дает ин-
формацию о влиянии факторов (входных параметров модели) на
результат. Например, каждый дополнительный иждивенец умень-
шает кредитный рейтинг заемщика на 1,91 (до логит-преобразо-
вания), а каждый дополнительный год стажа работы увеличивает
его на 0,0038.
Класс заемщика Класс заемщика_01Л Класс заемщика Рейтинг
Плохой Плохой 0,2926
Хороший Хороший 0,9305
Плохой Плохой 0,0107
Хороший Хороший 0,5031
Хороший Плохой 0,0114
Плохой Плохой 0,0127
Плохой Плохой 0,0511
Хороший Хороший 0,6941
Хороший Хороший 1,0000
Хороший Хороший 1,0000
Хороший Хороший 0,5003
Хороший Хороший 1,0000
Рис. 11.17. Визуализатор Таблица
Рис. 11.18. Коэффициенты регрессии
Визуализатор ROC-анализ выводит график ROC-кривой, на ко-
тором по умолчанию отмечается (белым квадратным маркером)
251
текущий порог отсечения, значения чувствительности и специфич-
ности, показатель AUC и типы событий (рис. 11.19). В данном слу-
чае площадь под кривой AUC = 0,959 на обучающем множестве и
AUC = 0,936 на тестовом, что говорит об очень хорошей предсказа-
тельной способности построенной модели.
Рис. 11.19. График ROC-кривой скоринговой модели
Оптимальный порог отсечения для данной модели не равен
предварительно установленной величине 0,5; чтобы определить
его, нужно в выпадающем меню кнопки Q » выбрать пункт Мак-
симум. Оказывается, что максимум суммарной чувствительности и
специфичности достигается в точке 0,41, для которой Se = 92%,
Sp = 88%. Это означает, что 92% благонадежных заемщиков будут
выявлены классификатором, а 100 - 88 = 12% недобросовестных
заемщиков получат одобрение при запросе кредита (кредитный
риск). Для установки нового порога отсечения, равного 0,41, необ-
ходимо перенастроить узел-обработчик логистической регрессии,
нажав кнопку Й*.
Нетрудно видеть, что скоринговая модель с высокой специфич-
ностью соответствует консервативной кредитной политике (чаще
происходит отказ в выдаче кредита), а с высокой чувствительно-
стью - политике рискованных кредитов. В первом случае миними-
зируется кредитный риск, вызванный неплатежами, во втором -
коммерческий риск, связанный с упущенной выгодой. Это хорошо
252
иллюстрирует визуализатор Таблица сопряженности (рис. 11.20).
Он позволяет сравнить категориальные значения выходного поля
исходной выборки (обучающей или тестовой) с рассчитанными по
модели с выбранным порогом отсечения (в данном случае - 0,41).
Рабочая выборка
Классифицировано
Фактически | Плохой Хороший Итого i
Плохой 404 н 459 |
Хороший 37 1 440
Итого 441 458 899
Тестовая выборка
Классифицировано
Фактически | Плохой Хороший Итого |
Плохой 40 8 48
Хороший 8 44 52
Итого 48 52 100
Рис. 11.20. Таблицы сопряженности
На обучающем множестве (рабочая выборка) модель реже отка-
зывала в выдаче «хорошим» заемщикам (37 ошибочных случаев) и
чаще выдавала кредит «плохим» клиентам; точность классифика-
ции составила 89%. На тестовом множестве наблюдается примерно
та же картина (точность классификации (40 + 44): 100 = 84%). Если
такое решение не соответствует кредитной политике банка, можно
поднять порог отсечения и добиться того, чтобы модель чаще вы-
давала отрицательное решение.
Визуализатор Что-если позволяет определить, как будет вести
себя построенная модель при подаче на ее вход тех или иных дан-
ных. Другими словами, проводится эксперимент, в котором, изме-
няя значения входных полей обучающей или рабочей выборки для
модели логистической регрессии, можно увидеть, как изменяются
выходные значения модели.
Возможность такого анализа особенно ценна, поскольку позво-
ляет исследовать правильность работы системы, ее устойчивость и
достоверность полученных результатов. Устойчивость в данном
случае означает, что достоверность полученных результатов не бу-
дет резко снижаться при попадании на вход системы нетипичных
значений (выбросов, пропусков данных и т.п.). Кроме того, это дает
возможность определить, какую предварительную обработку дан-
ных нужно провести перед построением модели.
253
Окно визуализатора включает два представления - табличное и
графическое, которые формируются одновременно (рис. 11.21).
В верхней части таблицы отображаются входные поля, в нижней -
выходные и расчетные. Изменяя значения входных полей, пользо-
ватель дает команду на выполнение расчета и может отслеживать
значения, получаемые на выходе логистической регрессии. Расчет-
ные поля (например, Рейтинг), в отличие от выходных, отсутству-
ют в исходном наборе данных и создаются только в процессе их
обработки.
28
женский
Да
0
9000
9
Поле j Значение
Входные
I И; 9.0 Возраст
> 1 ab Пол
ab Состоит в браке
? 9.0 Иждивенцы
= 9.0 Дож»
i 9.0 Опыт работы
9.0 Срок проживания 1
\ ?; • 9.0 Недвижимость 0
9.0 Месячный платеж
= *
G W> Выходные
ab Класс
9-W> Расчетные
У
9.0 Класс Рейтинг
Рис. 11.21. Визуализатор Что-если
В графическом представлении визуализатора по горизонтальной
оси отображается весь диапазон значений текущего поля выборки,
а по вертикальной - значения соответствующих выходов модели.
Это позволяет видеть, при каком уровне входных переменных из-
254
меняется ожидаемый результат. Например, если во всем диапазоне
входных значений выходное значение для данного поля нс изменя-
лось, диаграмма будет представлять собой горизонтальную прямую
линию. На рис. 11.21 видно, что кредитный рейтинг клиента ли-
нейно растет при увеличении срока его проживания в регионе (ос-
тальные входные переменные при этом зафиксированы на постоян-
ном уровне).
Помимо моделей логистической регрессии, Deductor позволяет
использовать для решения задачи кредитного скоринга деревья ре-
шений. Для этого нужно добавить в ветвь сценария одноименный
обработчик (рис. 11.22).
! Б Ш Сценарии
Й Q Текстовый Файл (loans_demo.txt)
В Н Калькулятор: Класс
=И- Логистическая регрессия (9; 0,41)
L- Дерево решений (Целевой столбец: Класс заемщика)
Рис. 11.22. Сценарий в Deductor
Рис. 11.23. Настройка алгоритма дерева решений
255
® Ч 6 |<fcf
В l—***! ЕСЛИ {По результату)
[) Доход < 8100 ТОГДА Класс • Плохой
gfr-lagw] Доход < 21050
: tjh-Г—Иждивенцы < 2,5
У.зел ?5г
17
Класс | № ... Л
i Плохой ) 3 5,66 EZ.... 1
Хоро... 50 94.30 Ьмг' -у-1
Пееде... 53 5.90 Г~ ' J
!»»-Ч Иждивенцы < 0,5 ТОГДА Класс = Хорой
;....|ию»|«1 Месячный платеж < 2332 ТОГДА Кл
; '[—я| Месячный платеж >• 2332 ТОГ ДА К
[—1 Месячный платеж >» 3639 ТОГДА Класс =
£&-!—»! Иждивенцы <1,5
{ Месячный платеж < 2742 ТОГДА Класс
!-|иий| Месячный платеж >« 2742 ТОГДА Клас
Доход >=16650 ТОГДА Класс = Хороший
Иждивенцы >= 2.5 ТОГДА Класс = Плохой
Г*^а5й| Доход > 21050 ТОГДА Класс = Хороший
ЕСЛИ
Доход >= 8100 И
Доход < 21050 И
Иждивенцы < 2,5 И
Доход >= 16650
ТОГДА
Класс = Хороший
Рис. 11.24. Визуализатор Дерево решений
Первые два окна мастера обработки аналогичны описанным ра-
нее для обработчика Логистическая регрессия. На третьем шаге
откроется окно выбора параметров алгоритма С4.5 (рис. 11.23).
Здесь нет необходимости менять настройки, принятые по умолча-
нию, за исключением минимального количества примеров в узле,
при котором будет создаваться новый. Примем этот параметр рав-
ным 1% от объема всей выборки; меньшее значение может привес-
ти к появлению недостоверных правил, большее - к почти полному
отсутствию таковых («бедное» дерево решений). На следующем
шаге дерево решений будет построено; выберем нужные нам ви-
зуализаторы Дерево решений, Правила, Значимость атрибутов,
Что-если, Таблица сопряженности и Таблица.
В результате работы алгоритма С4.5 было выявлено 19 правил,
точность классификации на обучающей выборке составила 91%, на
тестовой - 89%. Построенная ранее модель логистической регрес-
сии с порогом отсечения 0,41 обеспечивала примерно такую же
точность. Это означает, что между входами и выходами наблюда-
ются преимущественно линейные зависимости, и модель дерева
решений, способная выявлять нелинейные связи, в данном случае
не имеет никаких преимуществ.
256
г
Визуализатор Дерево решений позволяет увидеть полученный
набор правил в схематическом виде, а также выводит показатели
достоверности и поддержки для каждого узла (рис. 11.24). Эти же
правила в виде импликаций «если - то» можно просмотреть с по-
мощью визуализатора Правила.
Целевой атрибут: Класс
№ Атрибут Значимость, % / |
!. 5 Доход I I 69.416 j
Месячный платеж ЙВ I 14,604
4 Иждивенцы » I 13,669 |
8 Недвижимость И I 1,298
1 Возраст 11 1 1,012
3 Состоит в браке 1 1 0,000
2 Пол 1 1 0,000
6 Опыт работы 1 1 0,000
7 Срок проживания 1 0.000 1
Рис. 11.25. Значимость атрибутов в дереве решений
Визуализатор Значимость атрибутов представляет собой таб-
лицу, состоящую из трех столбцов. В них указываются соответст-
венно номер поля, название переменной и ее значимость в процен-
тах (рис. 12.25). Чем больший вклад вносит входной атрибут при
классификации выходного поля, тем выше уровень значимости;
фактически он характеризует степень нелинейной зависимости ме-
жду фактором, включенным в модель, и независимой переменной.
ЗАДАНИЕ
Используя предложенный преподавателем набор кредитных ис-
торий, хранящихся в текстовом файле potreb.txt, решите самостоя-
тельно в системе Deductor следующие задачи.
1. Постройте скоринговую модель на основе логистической рег-
рессии.
2. Определите оптимальный порог отсечения и порог, при кото-
ром чувствительность модели Se = 90%.
3. Постройте несколько моделей деревьев решений при различ-
ных настройках алгоритма, а также отдельные деревья решений для
заемщиков, состоящих и не состоящих в браке. Выберите модель,
которая чаще отказывает в выдаче кредита.
4. Сравните качество полученных моделей и сформулируйте ре-
комендации по их выбору при различной кредитной политике.
17 КацкоИ.А.. Паклим Н.Б. ,
257
ВОПРОСЫ ДЛЯ САМОКОНТРОЛЯ
1. Что представляет собой скоринг?
2. Почему скоринг имеет важное значение в розничном кредитовании?
3. Какие алгоритмы используются при построении скоринговых моделей?
4. Как строится ROC-кривая?
5. Как рассчитывают показатели чувствительности и специфичности моде-
ли и в чем состоит их смысл?
6. Как можно определить оптимальный порог отсечения?
7. Какие преимущества имеет алгоритм С4.5?
8. Какие достоинства и недостатки имеют модели логистической регрессии
и деревьев решений применительно к задаче кредитного скоринга?
ПРАКТИЧЕСКОЕ ЗАНЯТИЕ 12. АССОЦИАТИВНЫЕ ПРАВИЛА
Цель занятия: изучить технику применения ассоциативных правил
на примере задачи стимулирования розничных продаж
12.1. ТЕОРЕТИЧЕСКИЕ СВЕДЕНИЯ
12.1.1. Основные понятия
Аффинитивный анализ {affinity analysis} - один из самых рас-
пространенных методов изучения массовых данных. Его название
происходит от английского слова affinity (близость, сходство), а его
цель - обнаружить ассоциации между событиями, то есть найти
правила для количественного описания взаимной связи между дву-
мя или более событиями, которые происходят совместно. Такие
правила принято называть ассоциативными {association rules}.
С помощью данного метода решаются многие практические за-
дачи, в том числе:
выявление товаров, которые часто покупаются вместе (в одном
наборе);
определение доли клиентов, положительно относящихся к ново-
введениям в сфере обслуживания;
создание профиля посетителя веб-ресурса;
определение доли случаев, в которых новое лекарство вызывает
нежелательные побочные эффект и т.д.
Базовым понятием в теории ассоциативных правил является
транзакция - некоторое множество событий, происходящих совме-
стно. Типичным примером может служить приобретение клиентом
некоторого набора товаров в супермаркете. Как правило, такой на-
бор формируется не случайно; покупка одного товара влияет на
вероятность приобретения других (увеличивает или уменьшает ее).
Эту связь и устанавливают ассоциативные правила; так, может
быть обнаружено, что покупатель, купивший молоко, с вероятно-
стью 75% купит также и хлеб.
258
Анализ рыночной корзины (market basket analysis) — стандартная
область применения аффинитивного анализа. Современные кассо-
вые аппараты в супермаркетах позволяют собирать обширную ин-
формацию о покупках, которая затем может сохраняться в базе
данных и использоваться для поиска ассоциативных правил.
В табл. 12.1 приведен простейший пример, содержащий данные
о 10 транзакциях, касающихся 13 видов продуктов. Хотя на практи-
ке чаще приходится иметь дело с тысячами и даже миллионами
транзакций, в которые вовлечены десятки и сотни различных про-
дуктов, этого будет достаточно для иллюстрации основных особен-
ностей рассматриваемого метода.
12.1. Пример набора транзакций
Номер транзакции Состав рыночной корзины
1 2 3 4 Сливы, салат, помидоры Сельдерей, конфеты Конфеты Яблоки, морковь, помидоры, картофель, конфеты
5 6 7 8 9 10 Яблоки, апельсины, салат, конфеты, помидоры Персики, апельсины, сельдерей, помидоры Фасоль, салат, помидоры Апельсины, салат, морковь, помидоры, конфеты Яблоки, бананы, сливы, морковь, помидоры, лук, конфеты Яблоки, картофель
Сопоставление приведенных данных показывает, что все четыре
транзакции, в которых фигурирует салат, включают также и поми-
доры, и что четыре из семи транзакций, содержащих помидоры,
также содержат и салат. Таким образом, салат и помидоры в боль-
шинстве случаев покупаются вместе. Ассоциативные правила и
предназначены для описания таких совпадений.
Любое ассоциативное правило состоит из двух наборов предме-
тов, один из которых называется условием (antecedent), другой -
следствием (consequent), а также логической связи между ними
(оператора «если - то»). Записывают его в виде X —> Y, что означает
«из X следует У», или «если X, то У»; примером может служить
только что выявленная закономерность {помидоры} -> {салат}.
Условие и следствие часто называют соответственно левосто-
ронним (LHS - left-hand side) и правосторонним (RHS - right-hand
side) компонентом ассоциативного правила.
Связь между условием и следствием характеризуется двумя по-
казателями - поддержкой и достоверностью, обозначаемых соот-
259
ветственно S (support) и C (confidence). Если через Р обозначить
число транзакций, удовлетворяющих определенному условию, на-
званные показатели для правила А—>В можно рассчитать следую-
щим образом:
S(A—>В) = Р(АПВ) = (Количество транзакций, содержащих А и В):
(Общее количество транзакций)
С(А-+В) = Р(Л|2?) = Р(АГ\В)/Р(А) = (Количество транзакций, содержа-
щих А и В) : (Количество транзакций, содержащих А)
Показатель поддержки характеризует частоту, с которой интере-
сующий нас набор АВ встречается в общей совокупности данных,
а показатель достоверности - частоту, с которой в этой совокупно-
сти соблюдается правило А-+В («если А, то В»). Если поддержка и
достоверность велики, это позволяет с достаточной степенью уве-
ренности утверждать, что любая будущая транзакция, которая
включает условие, будет также содержать и следствие.
Рассчитаем показатели поддержки и достоверности для ассоциа-
ции {салат} -> {помидоры} из табл. 12.1. Поскольку количество
транзакций, содержащих оба элемента, равно 4, а их общее число -
10, поддержка данной ассоциации составит:
S ({салат} -> {помидоры}) = 4:10 = 0,4.
Количество транзакций, содержащее только условие {салат},
равно 4; следовательно, достоверность данной ассоциации
С ({салат} {помидоры}) = 4:4 = 1.
Таким образом, все наборы покупок, содержащие салат, содер-
жат также и помидоры, из чего следует, что данная ассоциация мо-
жет рассматриваться как правило. Интуитивно это вполне объяс-
нимо, поскольку оба продукта часто используются вместе для при-
готовления различных блюд.
Теперь рассмотрим другую ассоциацию: {конфеты} -> {поми-
доры}. Эти продукты слабо совместимы в гастрономическом плане
(тот, кто хочет сделать домашний салат, вряд ли станет покупать
конфеты, а покупатель, желающий приобрести что-нибудь сладкое
к чаю, скорее всего, не станет заодно покупать и помидоры). Под-
держка данной ассоциации 5 = 4:10 = 0,4, а достоверность С = 4:7 =
= 0,57. Сравнительно низкая достоверность дает повод усомниться
в том, что она является правилом.
При анализе предпочтение может отдаваться правилам, имею-
щим высокую поддержку или высокую достоверность, но чаще
принимают во внимание лишь те ассоциации, по которым оба пока-
зателя достаточно велики. Правила, для которых значения под-
держки или достоверности превышают некоторый порог, заданный
пользователем, называются сильными (strong rules). Например, ана-
260
литика может интересовать, какие товары в супермаркете, поку-
паемые вместе, образуют ассоциации с минимальной поддержкой
20% и минимальной достоверностью 70%. С другой стороны, при
анализе мошенничеств уровень поддержки может быть уменьшен
до 1%, поскольку к этой категории относится лишь очень неболь-
шая часть транзакций.
12.1.2. Значимость ассоциативных правил
Высокие уровни поддержки и достоверности сами по себе еще
не свидетельствуют о значимости обнаруженной ассоциации. На-
пример, если товар А встречался в 70 транзакциях из 100, а товар
В - в 80, и в 50 случаях из 100 они оказываются в одном наборе, то
ассоциация А—>В не может считаться правилом, хотя в данном слу-
чае 8 = 0,5, а С = 0,5:0,7 = 0,71. Просто эти товары очень популяр-
ны и только поэтому часто встречаются в одной транзакции.
Если решения о покупке двух товаров независимы, естественно,
говорить о каком-то правиле, их связывающем, не приходится. Из
математической статистики известно, что если условие и следствие
не зависят друг от друга, поддержка правила в целом будет при-
мерно равна произведению поддержки только условия и поддержки
только следствия. В данном случае 8(A) = 0,7, S(B) = 0,8, а их про-
изведение S(A)S(B) - 0,56, то есть примерно совпадает с 8(А-*В) =
= 0,5. Таким образом, предположение о независимости решений о
покупке товаров А и В достаточно обоснованно.
Фиктивные «правила», игнорирующие указанное обстоятельст-
во, встречаются довольно часто. Например, если статистика дорож-
но-транспортных происшествий по Москве показывает, что из 100
аварий в 70 участвуют иномарки, то, на первый взгляд, это выгля-
дит как правило: «если {авария}, то {иномарка}». Однако если
учесть, что московский парк легковых автомобилей на две трети
состоит из иномарок, такое правило нельзя назвать значимым.
Таким образом, кроме поддержки и достоверности при поиске
ассоциативных правил необходимо использовать показатели, отра-
жающие степень независимости причины и следствия; самый про-
стой из них - так называемый лифт
S(B) Р(А)Р(В)
Лифт - это отношение частоты появления следствия в транзак-
циях, которые также содержат и условие, к частоте появления след-
ствия в целом. Поэтому, если L > 1, более вероятно появление
следствия в транзакциях, содержащих условие, чем во всех осталь-
ных. Можно сказать, что лифт является обобщенной мерой связи
двух предметных наборов: при L > 1 связь положительная, при L =
= 1 она отсутствует, а при L < 1 - отрицательная.
261
Например, для ассоциации {помидоры}{салат} из табл. 12.1
получим
L(A-^B) = 0,4:[0,70,4] = 1,425.
Точно так же для ассоциации {помидоры}{конфеты}
ЦА-+В) = 0,4:[0,70,6] = 0,95 » 1.
Таким образом, в первом случае между элементами ассоциации
обнаруживается положительная связь, а во втором случае какая-
либо связь отсутствует.
12.1.3. Поиск ассоциативных правил
Простейший алгоритм поиска состоит в том, что для всех ассо-
циаций, которые могут быть построены на основе базы данных, оп-
ределяется поддержка и достоверность, а затем отбираются те из
них, для которых эти показатели превышают заданное пороговое
значение. Однако в большинстве случаев такое элементарное ре-
шение неприемлемо, поскольку число ассоциаций, которое при
этом придется анализировать, слишком велико. Так, если выборка
содержит всего 100 предметов, количество образуемых ими ассо-
циаций будет порядка 1031, а в реальных ситуациях (например, при
анализе покупок в супермаркете) номенклатура учитываемых про-
дуктов может достигать нескольких тысяч и более. Очевидно, что
никаких вычислительных мощностей на такой расчет не хватит.
Поэтому на практике при поиске ассоциативных правил исполь-
зуют различные приемы, которые позволяют снизить пространство
поиска до размеров, обеспечивающих приемлемые затраты машин-
ного времени. Сейчас одним из наиболее распространенных явля-
ется алгоритм a priori (Agrawal и Srikant, 1994), основанный на по-
нятии популярного набора (frequent itemset, часто встречающийся
предметный набор). Этот термин обозначает предметный набор,
частота появления которого в общей совокупности транзакций пре-
вышает некоторый заранее заданный уровень.
Таким образом, алгоритм a priori включает два этапа:
1) поиск популярных наборов;
2) формулировка ассоциативных правил, удовлетворяющих за-
данным ограничениям по уровням поддержки и достоверности.
12.2. ПРИМЕР: СТИМУЛИРОВАНИЕ ПРОДАЖ В ИНТЕРНЕТ-МАГАЗИНЕ
12.2.1. Построение набора правил
В Deductor для решения задач рассматриваемого типа применя-
ется обработчик Ассоциативные правила, в котором реализован
алгоритм a priori. На входе он запрашивает два поля: идентифика-
тор транзакции и элемент транзакции. В качестве идентификатора
262
может использоваться, например, номер чека или код клиента; в
этом случае элементом будет наименование заказанного товара или
услуги.
По завершении работы алгоритма формируется набор данных
следующей структуры (табл. 12.2).
12.2. Поля результирующего набора данных
Номер Имя Метка Тип Описание
1 N № Целый Номер ассоциативного прави- ла
2 ANTECEDENT Условие Строковый Условие ассоциативного пра- вила (заключено в двойные кавычки)
3 CONSEQUENT Следствие Строковый Следствие ассоциативного правила (заключено в двой- ные кавычки)
4 SUPPORTCOUNT Поддержка, количество случаев Целый Число транзакций, удовле- творяющих данному правилу
5 SUPPORT Поддерж- ка, % Веществен- ный Поддержка ассоциативного правила в процентах
6 CONFIDENCE Достовер- ность, % Веществен- ный Достоверность ассоциативно- го правила в процентах
Вся прочая информация, полученная в результате решения, дос-
тупна через специализированные визуализаторы Правила, Попу-
лярные наборы, Дерево правил, Что-если.
Рассмотрим конкретный пример из области розничной торговли.
Компания Adventure Work Cycle Russia является дистрибьютором
спортивных (серия Sport), горных (серия Mountain) и дорожных
(серия Road) велосипедов и комплектующих к ним компании Ad-
venture Work Cycle на территории России и стран СНГ. Офисы
компании работают в шести городах России, а также на Украине и
в Казахстане. В большинстве регионов компания работает через
своих партнеров, центральный офис находится в Москве. У фирмы
есть склад и собственная сборочная база.
Отдел маркетинга заинтересован в увеличении продаж через ин-
тернет-магазин, размещенный на web-сайте компании. Для этого
важно знать, какие товары покупатели могут выбрать в дальнейшем
в зависимости от того, что уже имеется в их корзинах. Такой про-
гноз позволит также оптимизировать структуру сайта - товары,
часто покупаемые вместе, будут расположены по соседству на од-
ной web-странице.
Для решения поставленной задачи отдел маркетинга предоста-
вил данные о 5 тыс. чеков от предыдущих покупателей; соответст-
263
вующая информация содержится в сценарии cycles.ded. Откроем
Deductor Studio, загрузим в программу этот сценарий и создадим
новый проект.
Импортируем данные из текстового файла cycle_store.txt; в этом
наборе имеются два строковых поля (столбца): ID (код чека) и ITEM
(наименование товара). Рассмотрим решение задачи в Deductor по
шагам. К узлу импорта добавим обработчик Ассоциативные пра-
вила, причем поле ID сделаем идентификатором транзакции,
a ITEM - ее элементом (рис. 12.1).
Рис. 12.1. Настройка назначений столбцов
Далее следует выбрать параметры построения правил, то есть,
по сути, параметры работы алгоритма a priori (рис. 12.2). В данном
окне можно указать пороговые уровни (максимальный и мини-
мальный) поддержки и достоверности искомых правил, а также
максимальную численность популярных наборов, которые про-
грамма будет рассматривать (параметр Максимальная мощность
искомых часто встречающихся множеств). Например, если
в этом поле установить значение «4», генерация популярных набо-
ров будет остановлена после получения множества 4-предметных
наборов. Такое ограничение позволяет избежать появления длин-
264
ных ассоциативных правил, которые с трудом поддаются содержа-
тельной интерпретации.
Рис. 12.2. Настройка параметров алгоритма
Оставим настройки, принятые по умолчанию, и щелкнем по
кнопке Далее. Будет запущен алгоритм поиска ассоциативных пра-
вил, и по завершении его работы появится окно, содержащее сле-
дующую информацию (рис. 12.3):
Кол-во множеств - число популярных наборов, удовлетворяю-
щих заданным условиям минимальной поддержки и достоверности;
Кол-во правил - число сгенерированных программой ассоциа-
тивных правил.
В следующем окне следует выбрать способы представления ре-
зультатов анализа; отметим все специализированные визуализато-
ры, а также визуализатор Таблица (рис. 12.4).
Все визуализаторы (кроме Что-если) позволяют более детально
рассмотреть те или иные аспекты полученного решения; рассмот-
рим их подробнее.
На вкладке Популярные наборы, как и следует из ее названия,
отображается множество найденных популярных предметных на-
боров в виде списка. Кнопка zl ’ позволяет выбрать несколько
1S Кацко И.А.. Паклин И.Б.
265
вариантов сортировки списка, а кнопка вызывает окно настрой-
ки фильтрации множеств. Например, задав в фильтре минимальное
значение поддержки 6% и отсортировав их по убыванию этого па-
раметра, получим следующие 16 популярных наборов (рис. 12.5).
Отмена
Рис. 12.3. Результаты поиска
Название j Описание
Я Р Data Mining
: Отображение текста ассоциативных правил
р| Популярные наборы Отображение текста часто встречающихся множеств
р Дерево правил
р Что-если
S Р Т абличные данные
р Таблица
Г“ Статистика
Г Диаграмма
Г" Гистограмма
ВГ OLAPанализ
Дерево правил сгруппированных либо по условию, либо по еле...
Анализ правил по принципу "что-если"
Отображает данные в виде таблицы
Отображает статистические данные выборки
Отображает данные в виде диаграммы
Отображает данные в виде гистограммы
Рис. 12.4. Выбор средств визуализации
266
Фильтр: Поддержка >= 6,00%
Итого множеств: 16
Ns Множество ft Поддержка
% Кол-во
27 Фляга 19,17 392
1 Велокамера Mountain 14,28 292
23 Пластыри для велокамеры 14,08 288
5 Велосипед Mountain-200 10,81 221
2 Велокамера Road 10,17 208
17 Держатель фляги Mountain 9,78 200
28 Шапочка велосипедная 9,73 199
4 Велокрыло Mountain 9,54 195
70 Держатель фляги Mountain И Фляга 8.17 167
16 Втулка Logo Jersey 7,53 154
18 Держатель фляги Road 7,43 152
26 Тенниска фирменная 7.14 146
3 Велокамера Touring 7,04 144
29 Шина HL Mountain 6,50 133
72 Держатель фляги Road И Фляга 6,41 131
11 Велосипед Road-750 6,31 129
Рис. 12.5. Популярные наборы
На вкладке Дерево правил предлагается удобное средство ото-
бражения полученных ассоциативных правил; они выводятся в ви-
де дерева, которое может строиться двумя способами: либо по ус-
ловию, либо по следствию. В первом случае на верхнем уровне
располагаются узлы с условиями, на нижнем - узлы с соответст-
вующими следствиями. Во втором случае порядок ассоциаций бу-
дет противоположным: из следствий «вырастают» ветви условий
(рис. 12.6).
Если выделить мышью любую из ветвей, в правой части окна
будет выведен список правил, построенных по этому узлу, и для
каждого из них указан уровень поддержки и достоверности. Если
дерево построено «по условию», оно приводится в верхней части
списка, состоящего из обнаруженных следствий. Такие правила от-
вечают на вопрос: какие товары и с какой вероятностью будут куп-
лены при заданном условии.
Если же дерево построено «по следствию», можно получить от-
вет на другой вопрос: какие товары должны быть куплены предва-
рительно, чтобы ожидать этого следствия (то есть покупки товара
или товарного набора, который мы хотим продать).
18 *
267
В-ф Ассоциативные правила (по следствию) I
Й si" Велокамера Mountain (14,28%; 292)
Й S^ Велокамера Road (10,17%; 208)
I- +> Шина HL Road (2,59%; 53)
j | +> Шина ML Road (2,59%; 53)
'=- +ia Шина Road (2,44%; 50)
И +i" Шина Тcuring (4,55%; 93)
Й si" Велокамера Тcuring (7,04%; 144)
Й Si" Держатель фляги Mountain (9,78%; 2С
= Велосипед Mountain-500 (0,98%; 21
| Mfr Фляга (8,17%; 167J
| ' s> Фляга И Шапочка велосипедная |
Й +> Фляга (19,17%; 392)
£р Держатель Фляги Mountain (8,17^
;••• S^3 Держатель фляги Road (6,41%; 1G|
Правило N-15; Следствие: Фляга
S> Условие
Поддержка !
। ““ । Достоверность, %
Велокрыло... 29
Велокрыло... 29
Держатель... 167
1,42 76,30 У........ |
1,42 14,90 Я ~~|
8J 7? 83,50 IB |
Белокрыло Mountain Й Держателг
Ь +J3 Велосипед Mountain-200 И Держа;
+> Велосипед Road-750 И Держаггел?
Рис. 12.6. Дерево ассоциативных правил
12.2.2. Интерпретация полученных правил
Сами по себе ассоциативные правила, полученные в результате
работы некоторого алгоритма, еще непригодны к использованию.
Их нужно правильно интерпретировать, то есть понять, какие из
них представляют практический интерес, отражают реальные зако-
номерности, а какие носят случайный характер или вообще являют-
ся артефактом. Этот этап требует тщательной аналитической рабо-
ты и глубокого понимания предметной области, в которой решается
задача поиска ассоциаций.
Весь массив ассоциативных правил можно разделить на три
группы:
полезные правила, содержащие новую информацию, которая
может быть содержательно интерпретирована, имеющие ясную ло-
гику. Такие правила могут использоваться на практике для приня-
тия эффективных решений;
тривиальные правила, отражающие действительность, легко
объяснимые, но не дающие никакой новой информации (например,
при изучении рыночных корзин самую высокую поддержку и дос-
товерность покажут товары - лидеры продаж, что ясно и без всяко-
го анализа). Практическая ценность таких правил близка к нулю;
непонятные правила, содержащие информацию, которую нельзя
внятным образом объяснить. Они могут отражать как случайности
выборки, так и глубоко скрытые взаимосвязи. Напрямую их ис-
пользовать невозможно, поскольку принимаемые на их основе ре-
шения, подобно «интуиции» биржевого игрока, не имеют четкого
268
обоснования и могут привести к непредсказуемым последствиям.
В этих случаях по возможности следует провести дополнительный
анализ выявленных закономерностей.
Изменяя верхний и нижний пределы поддержки и достоверности
(см. рис. 12.2), можно избавиться от тривиальных и статистически
недостоверных закономерностей и увеличить долю полезных пра-
вил, генерируемых программой. Оптимальные значения этих пара-
метров очень сильно зависят от особенностей предметной области,
поэтому какие-либо конкретные указания здесь невозможны. Тем
не менее существуют рекомендации общего порядка, которые мо-
гут оказаться полезными.
1. При большом значении параметра Максимальная поддержка
программа будет формировать множество тривиальных правил, не
содержащих никакой новой информации и не представляющих
практического интереса. Поэтому не рекомендуется устанавливать
его на уровне более 20%.
2. Хотя большинство практически ценных правил обнаружива-
ется при невысоком значении порога поддержки, слишком низкий
его уровень приводит к генерации статистически недостоверных
зависимостей. Поэтому правила, которые кажутся интересными, но
имеют низкую поддержку, нужно анализировать дополнительно,
с учетом показателя лифта.
3. Как уже отмечалось, следует ограничивать параметр Мощ-
ность часто встречающихся множеств. Правила, в условие кото-
рых включено более 2-3 предметов, обычно очень трудно интер-
претировать.
4. Уменьшение порога достоверности приводит к необоснован-
ному увеличению количества правил, поэтому значение этого па-
раметра не должно быть слишком низким. Кроме того, правило
с достоверностью порядка 10%, даже если оно отражает реальные
взаимосвязи, чаще всего не будет иметь никакого практического
значения.
5. Правила с очень большой достоверностью (85-90% и более)
также не имеют ценности в контексте решаемой задачи. Товары,
входящие в следствие такого правила, покупатель, скорее всего,
купит сам, без каких-либо усилий со стороны маркетинговых
служб.
Вернемся к рассматриваемой задаче по стимулированию продаж
в интернет-магазине (файл данных cycle_store.txt. содержит сведе-
ния о продажах товаров для велосипедного спорта). При настрой-
ках алгоритма, принятых по умолчанию, будет получено 18 правил
(рис. 12.7); рассмотрим их содержательную интерпретацию.
Например, третье правило {Велокамера Mountain —> Шина HL
Mountain} имеет уровень поддержки S = 4,7%, достоверности С =
= 72,2% и лифт L = 5,1. Напомним, в чем состоит смысл этих пока-
зателей.
269
p
id'
00
о
CD CO o\° CD cn' ID «\« CD CD ID CM
CO ♦\* CD CM CD4 Csl' o\° cm'
CD 4-' CD in' CO id' CD ЧГ >
=c
c S’’" Ю
о E о Ct о Ct i?
E r r ? E <0 r (Z <u
Э 3 3 3
Ъ
О tY
ЯЗ
S"
<4
g <D CD
2
X
я
4
о
S
(T - тривиальное, ? - непонятное правило)
1. Если покупатель решил приобрести что-либо в данном мага-
зине, с вероятностью 4,7% это будет набор Шина HL Mountain +
Велокамера Mountain.
2. Если клиент положил в корзину товар велокамера Mountain,
то с вероятностью 72,2% он купит и Шину HL Mountain,
3. Клиент, купивший Велокамеру Mountain, в 5,1 раза чаще вы-
берет Шину HL Mountain, чем какой-либо другой товар.
Аналогичным образом следует интерпретировать и другие пра-
вила, приведенные на рис. 12.7. Содержательный анализ показыва-
ет, что все они, кроме двух, тривиальны:
шины, велокамеры и велосипеды часто встречаются в условиях
и следствиях правил, это лидеры продаж магазина (см. табл. 12.5),
поэтому и правила с ними имеют высокую достоверность (до 85%);
правила, входящие в группы {Велокамера —* Шина} и {Шина —>
Велокамера}, тривиальны сами по себе: понятно, что эти запчасти
обычно меняют одновременно;
правила типа {Фляга —* Держатель фляги} тоже тривиальны,
так как никому не нужна велосипедная фляга без возможности за-
крепить ее на раме;
наконец, правила типа {Велосипед —> Фляга} хотя и тривиальны,
но, возможно, имеют ценность; никогда не будет лишним при по-
купке велосипеда предложить флягу и держатель к ней.
Теперь рассмотрим правило {Пластыри для велокамеры + Шина
HL Mountain —> Велокамера Mountain}. Его условие непонятно: по-
чему пластыри покупаются именно с шинами Mountain, ведь есть и
другие шины? Возможно, это происходит из-за того, что велокаме-
ры Mountain продаются чаще других камер (что, в свою очередь,
объясняется популярностью велосипедов Mountain}. Анализ попу-
лярных наборов подтверждает такую гипотезу.
| Следствие (Условие ▼ Z Лифт | Е Поддер: £ Д остове)
“Пластыри для велокамеры" "Средство для чистки велосипеда" : 1,8 1,2% 25,8%
"Велосипедные перчатки" 1.4 1.SX 26.9 %
"Фляга" "Питьевой рюкзак" 2.0 1,1 % 39,0 %
"Шапочка велосипедная" 1,4 2,6% 27,1 %|
"Шапочка велосипедная" "Тенниска фирменная" 2,9 2,0% 28,1 %
Рис. 12.8. Правила, полученные при измененных настройках алгоритма
Обратим внимание на следующее обстоятельство: все правила,
приведенные на рис. 12.7, имеют уровень достоверности более
40%, и даже при достоверности 42-43% получаются тривиальные
правила. Вероятно, имеет смысл сделать следующее:
запустить заново алгоритм a priori с интервалом допустимой
достоверности от 25% до 40%;
271
не рассматривать правила, в следствиях и условиях которых со-
держатся велосипеды, шины и велокамеры (очевидные лидеры
продаж).
После повторного «прогона» алгоритма получим пять новых
правил (рис. 12.8). Очевидно, их можно считать полезными: они
нетривиальны, но вполне объяснимы и имеют достаточно высокий
уровень достоверности.
ЗАДАНИЕ
Небольшая сеть из трех магазинов, продающих мелкие штучные
товары, желает провести исследование связанных покупок. По
мнению специалистов компании, знание того, какие товары поку-
паются совместно, поможет правильно расположить их на витри-
нах. С этой целью были собраны все чеки за последние три месяца
(около 20 тыс.). В них присутствуют 17 товаров (анальгетик, дезо-
дорант, журнал, зубная паста, карандаши и др.). Таблица данных
содержится в файле transactions.txt и включает два столбца: Тран-
закция и Товар.
Опираясь на имеющиеся данные, выполните следующие дейст-
вия.
1. Решите задачу поиска ассоциаций в Deductor.
2. Выделите непонятные, на ваш взгляд, ассоциативные правила,
а также правила, представляющие интерес. Сколько правил попало
в эти категории?
3. Найдите правило, имеющее максимальный лифт.
4. Заказчика данного исследования интересует, какие товары по-
купают с поздравительной открыткой. Сколько таких товаров ока-
залось в выбранном перечне? Какая из ассоциаций представляет
в этом плане наибольший интерес (имеет максимальный лифт)?
ВОПРОСЫ ДЛЯ САМОКОНТРОЛЯ
1. В чем состоит цель аффинитивного анализа и какие практические задачи
решаются с его помощью?
2. Дайте определение понятия «транзакция».
3. Из каких элементов состоит ассоциативное правило?
4. Как рассчитывается поддержка и достоверность ассоциативного правила
и какое значение имеют эти показатели в процессе их поиска?
5. В чем состоит смысл показателя «лифт»?
6. Какие параметры необходимо указать при настройке алгоритма a priori!
7. На какие группы подразделяются ассоциативные правила при их содер-
жательной интерпретации?
8. Перечислите рекомендации, которых следует придерживаться при ана-
лизе ассоциаций в программе Deductor и объясните их смысл.
ЛИТЕРАТУРА
Книги
1. Адлер Ю.П. Предисловие к русскому изданию книги: Ф. Мос-
теллер, Дж. Тьюки. Анализ данных и регрессия: Вып.2 /Пер. с англ.
Б.Л. Розовского; Под ред. и с предисл. Ю.П.Адлера. - М.: Финансы и
статистика, 1982.-239 с.
2. Айвазян С.А. Основы эконометрики. - М.: ЮНИТИ - ДАНА,
2001.-432 с.
3. Айвазян С.А., Бухштабер В.М., Енюков И. С. и др. Прикладная
статистика. Классификация и снижение размерности. - М.: Финансы и
статистика, 1989. -607 с.
4. Айвазян С. А., Енюков И. С., Мешалкин Л.Д. Прикладная стати-
стика. Основы моделирования и первичная обработка данных. - М.:
Финансы и статистика, 1985. - 472 с.
5. Айвазян С.А., Мхитарян В.С. Теория вероятностей и прикладная
статистика. - М.: ЮНИТИ-ДАНА, 2001. - 656 с.
6. Арнольд В.И. «Жесткие» и «мягкие» математические модели. -
М.: МЦНМО, 2000.-32 с.
7. Афифи А., Эйзен С. Статистический анализ: подход с использо-
ванием ЭВМ /Пер. с англ. - М.: Мир, 1982. - 488 с.
8. Баргесян А.А., Куприянов М.С., Степаненко В.В., Холод И.И.
Технологии анализа данных: Data Mining, Visual Mining, Text Mining,
OLAP. - 2-е изд., перераб. и доп. - СПб.: БХВ-Петербург, 2007. -
384 с.
9. Борисов В.В., Бычков И.А. и др. Компьютерная поддержка слож-
ных организационно-технических систем. - М.: Горячая линия - Теле-
ком, 2002. - 154 с.
10. Боровиков В.П. Программа Statistica для студентов и инжене-
ров. - 2-е изд. - М.: КомпьютерПресс, 2001. - 301 с.
11. Боровиков В.П. STATISTICA. Искусство анализа данных на
компьютере для профессионалов. - 2-е изд. - СПб.: Питер, 2003. -
688 с.
12. Боровиков В.П., Ивченко Г.И. Прогнозирование в системе Statis-
tica в среде Windows. Основы теории и интенсивная практика на ком-
пьютере: Учеб, пособие. - 2-е изд., перераб. и доп. - М.: Финансы и
статистика, 2006. - 368 с.
13. Волкова В.Н., Денисов А.А. Основы теории систем и системного
анализа. - СПб.: СПбГТУ, 1997. - 510 с.
14. Горелова Г.В., Кацко И.А. Теория вероятностей и математиче-
ская статистика в примерах и задачах с применением Excel: Учеб, по-
собие. - 4-е изд., испр. и доп. - Ростов-на-Дону: Феникс, 2006. - 476 с.
273
15. Дрейпер И., Смит Г. Прикладной регрессионный анализ: В 2-х
кн. /Пер. с англ. - 2-е изд., перераб. и доп. - Кн. 1: М.: Финансы и ста-
тистика, 1986. - 366 с.; Кн. 2: М.: Финансы и статистика, 1987. - 351 с.
16. Дубров А.М., Мхитарян В. С., Трошин Л.И. Многомерные стати-
стические методы: Учебник. - М.: Финансы и статистика, 1998. -
352 с.
17. Дюк В., Самойленко А.В. Data Mining: учебный курс. - СПб.,
2001.-368 с.
18. Кендэл М. Временные ряды /Пер. с англ. Ю.П. Лукашина. - М.:
Финансы и статистика, 1981. - 199 с.
19. Орлов А.И. Прикладная статистика. - М.: Экзамен, 2006. -
611 с.
20. Прикладная информатика: Справочник. /Под ред. В.Н. Волко-
вой и В.Н. Юрьева. - М.: Финансы и статистика; ИНФРА-М, 2008. -
768 с.
21. Руководство по кредитному скорингу /Под ред. Э. Мейз. -
Минск: Гревцов Паблишер, 2008. - 464 с.
22. Тьюки Дж. Анализ результатов наблюдений. Разведочный ана-
лиз. -М.: Мир, 1981. - 693 с.
23. Тюрин Ю.Н., Макаров А.А. Анализ данных на компьютере/
Под ред. В.Э. Фигурнова. - 3-е изд., перераб. и доп. - М.: ИНФРА-М,
2003. - 544 с.
24. Хайкин С. Нейронные сети: полный курс. - М.: Вильямс,
2006.- 1104 с.
25. Халафян А.А. Статистический анализ данных. Statistica 6.0:
Учеб, пособие. - 2-е изд., испр. и доп. - Краснодар: КубГУ, 2005. -
307 с.
26. Харман Г. Современный факторный анализ. - М.: Статистика,
1972.-486 с.
27. Хьюстон А. Дисперсионный анализ /Пер. с англ. А.Г. Кругли-
кова. -М.: Статистика, 1971. - 88 с.
28. Data Mining. Теория и практика /Под ред. И.Н. Брянцева. - М.:
Издательская группа БДЦ-пресс, 2006. - 208 с.
Сетевые ресурсы
29. http://www.sas.com - сайт компании SAS.
30. http://www.spss.ru -русскоязычный сайт SPSS.
31. http://www.statsoft.ru - русскоязычный сайт Statistica.
32. http://www.megaputer.ru - сайт создателей системы Poly Analyst.
33. http://www.basegroup.ru - сайт создателей Deductor.
34. http://www-personal.buseco.monash.edu.au/~hyndman/TSDL -
электронная библиотека временных рядов.
ОГЛАВЛЕНИЕ
Предисловие.............................................................3
Введение................................................................7
Часть I. Статистический анализ данных..................................13
Методы статистического анализа.........................................13
1. Общая характеристика............................................13
2. Методы статистического оценивания и сравнения...................16
3. Дисперсионный анализ............................................18
4. Корреляционно-регрессионный анализ..............................21
5. Ковариационный анализ...........................................22
6. Компонентный анализ.............................................24
7. Факторный анализ................................................25
8. Методы автоматической классификации.............................26
9. Канонические корреляции.........................................27
10. Временные ряды.................................................28
11. Элементы прикладной статистики.................................29
12. Современные пакеты прикладных программ многомерного
статистического анализа.............................................32
Практическое занятие 1. Знакомство с системой Statistica 6.1.
Краткий обзор пакета и возможностей визуализации.......................36
1.1. Общие сведения.................................................36
1.2. Интерфейс и возможности программы..............................40
Задание.............................................................45
Вопросы для самоконтроля............................................49
Практическое занятие 2. Дисперсионный анализ...........................50
2.1. Теоретические сведения.........................................50
2.2. Дисперсионный анализ в Statistica..............................52
Задание.............................................................61
Вопросы для самоконтроля............................................61
Практическое занятие 3. Регрессионный анализ...........................61
3.1. Теоретические сведения.........................................61
3.2. Регрессионный анализ в Statistica..............................67
Задание.............................................................80
Вопросы для самоконтроля............................................81
Практическое занятие 4. Ковариационный анализ..........................81
4.1. Теоретические сведения.........................................81
4.2. Ковариационный анализ в Statistica.............................82
Задание.............................................................88
Вопросы для самоконтроля............................................89
275
Практическое занятие 5. Кластерный и дискриминантный анализ.............89
5.1. Теоретические сведения..........................................89
5.2. Кластерный и дискриминантный анализ в Statistica................93
Задание.............................................................104
Вопросы для самоконтроля............................................104
Практическое занятие 6. Факторный анализ...............................104
6.1. Теоретические сведения.........................................104
6.2. Факторный анализ в Statistica..................................105
Задание.............................................................108
Вопросы для самоконтроля............................................110
Практическое занятие 7. Анализ временных рядов.........................111
7.1. Теоретические сведения.........................................111
7.1.1. Методы анализа временных рядов...........................111
7.1.2. Стационарные временные ряды..............................116
7.2. Анализ временных рядов в Statistica............................122
7.2.1. Преобразование переменных................................125
7.2.2. Модель Бокса и Дженкинса.................................137
7.2.3. Сезонная декомпозиция и спектральный анализ..............148
Задание.............................................................155
Вопросы для самоконтроля............................................155
Часть II. Интеллектуальный анализ данных...............................156
Методы интеллектуального анализа.......................................156
1. Новые подходы к анализу данных..................................156
2. Классы систем интеллектуального анализа.........................159
3. Основные продукты Data Mining...................................167
Практическое занятие 8. Аналитическая платформа Deductor 5.0:
хранилище данных.......................................................173
8.1. Платформа Deductor.............................................173
8.2. Хранилище данных...............................................177
8.3. Создание нового хранилища......................................183
8.4. Проектирование структуры хранилища.............................187
8.5. Загрузка информации.......................................... 189
8.6. Извлечение информации..........................................196
Задание.............................................................198
Вопросы для самоконтроля............................................198
Практическое занятие 9. Многомерные отчеты и OLAP.................... 199
9.1. Многомерный анализ данных......................................199
9.2. OLAP в Deductor................................................201
9.3. Разработка системы аналитической отчетности....................209
Задание........................................................... 210
Вопросы для самоконтроля.......................................... 211
Практическое занятие 10. Искусственные нейронные сети.
Многослойный персептрон.............................................. 212
10.1. Теоретические сведения........................................212
276
10.1.1. Искусственные нейронные сети.............................212
10.1.2. Алгоритм обратного распространения ошибки................216
10.2. Пример функционирования нейросети в прямом направлении.........219
10.3. Пример работы многослойного персептрона........................221
10.4. Аппроксимация многомерных функций..............................227
Задание..............................................................228
Вопросы для самоконтроля.............................................229
Практическое занятие 11. Логистическая регрессия и деревья
решений в задаче кредитного скоринга....................................229
11.1. Теоретические сведения.........................................229
11.1.1. Кредитный скоринг........................................229
11.1.2. Логистическая регрессия..................................231
11.1.3. ROC-анализ...............................................233
11.1.4. Деревья решений..........................................239
11.2. Скоринговые модели в Deductor..................................246
Задание..............................................................257
Вопросы для самоконтроля.............................................258
Практическое занятие 12. Ассоциативные правила..........................258
12.1. Теоретические сведения.........................................258
12.1.1. Основные понятия.........................................258
12.1.2. Значимость ассоциативных правил..........................261
12.1.3. Поиск ассоциативных правил...............................262
12.2. Пример: стимулирование продаж в интернет-магазине..............262
12.2.1. Построение набора правил.................................262
12.2.2. Интерпретация полученных правил..........................268
Задание..............................................................272
Вопросы для самоконтроля.............................................272
Литература...........................................................273
ОБ АВТОРАХ
Кацко Игорь Александрович - кандидат технических наук,
профессор кафедры статистики и прикладной математики Кубан-
ского государственного аграрного университета (г. Краснодар). Ав-
тор четырех книг и свыше 50 публикаций. Преподает курсы «Тео-
рия вероятностей и математическая статистика» и «Эконометрика»
на факультете прикладной информатики и экономических факуль-
тетах КубГАУ. Область научных интересов - прикладная статисти-
ка, интеллектуальный анализ данных, когнитивное моделирование.
Паклин Николай Борисович - кандидат технических наук,
доцент кафедры информационных технологий Рязанского филиа-
ла Московского государственного университета экономики, стати-
стики и информатики (МЭСИ), сотрудник компании BaseGroup
Labs. Имеет свыше 20 научных публикаций. Область научных ин-
тересов - интеллектуальная обработка информации, машинное обу-
чение, нечеткая логика, эволюционные вычисления, хранилища
данных.
Уважаемые читатели!
В издательстве «КолосС» вышло в свет учебное пособие
Практикум по информатике
А.П. Курносов, А.В. Улезько, С.А. Кулев и др.; под ред. А.П. Кур-
носова, А.В. Улезько
Изложены практические основы работы пользователя с техниче-
скими и программными средствами современных персональных
компьютеров. Подробно описаны приемы решения основных задач
в наиболее часто используемых программах (Word, Excel, Internet
Explorer, Outlook Express, антивирусах, справочных правовых сис-
темах и др.). По всем темам предлагается набор сквозных практи-
ческих заданий, выполнение которых позволяет получить навыки,
достаточные для самостоятельной работы на компьютере.
Ддя студентов вузов по специальности «Экономика и управле-
ние на предприятии АПК».
Учебное издание
Кацко Игорь Александрович,
Паклив Николай Борисович
ПРАКТИКУМ ПО АНАЛИЗУ ДАННЫХ НА КОМПЬЮТЕРЕ
Учебное пособие для вузов
Компьютерная верстка В. И. Письменного
Корректоры В. Ф. Березницкая, М. Д. Писарева
Сдано в набор 18.09.08. Подписано в печать 24.12.08. Формат 60 х 88/16.
Бумага офсетная. Гарнитура Таймс. Печать офсетная.
Усл.печ.л. 17,15. Изд. № 063. Тираж 3000 экз. (1-й завод: 1—1000 экз.).
Заказ №544.
ООО «Издательство «КолосС», ,
101000, Москва, ул. Мясницкая, д. 17.
Почтовый адрес: 129090, Москва, Астраханский пер., д. 8.
Тел/факс (495) 680-14-63, e-mail: sales@koloss.ru,
наш сайт: www.koloss.ru
Отпечатано с готовых диапозитивов
в ОАО «Марийский полиграфическо-издательский комбинат»,
424002, г. Йошкар-Ола, ул. Комсомольская, 112