/



















































































































































































































































































































































Author: Боровиков В.
Tags: производство соды и поташа щелочи информационные машины машины для обработки данных программирование программное обеспечение обработка данных
ISBN: 5-272-00078-1
Year: 2003




Text
Владимир Боровиков
ДЛЯ ПРОФЕССИОНАЛОВ
STATISTICA
ИСКУССТВО АНАЛИЗА ДАННЫХ НА КОМПЬЮТЕРЕ
2-е ИЗДАНИЕ
Москва - Санкт-Петербург - Нижний Новгород - Воронеж Ростов-на-Дону Екатеринбург - Самара Киев - Харьков - Минск
2003
В. Боровиков
STATISTICA. Искусство анализа данных на компьютере: Для профессионалов
2-е издание
Г чанный редактор Заведующий редакцией Художник Корректор
Верстка
ББК 32.973.233
УДК 661.301
Боровиков В.
Б83 STATISTICA. Искусство анализа данных на компьютере: Для профессионалов 2-е изд. (+CD) — СПб.: Питер. 2003. — 688 с., ил.
ISBN 5-272-00078-1
Во втором, исправленном н дополненном, издании книги, написанной няниным специалистом. научным директором компании StatSoft Russia. изложена концепция и технология современного анализа тайных ua компьютере На основе элементарных hoiixihh описываются ji дубленные методы анализа в системе STATISTICA (StatSoft) с многочисленными примерами из жоиомикн, маркетинга, рекламы, бизнеса, медицины, промышленности и tpyriix областей Второе издание дополнено описанием языка STATISTICA VISUAL BASIC Книга адр_совзна самому широкому Kpyiy читателей, желающих стать профессионалами в компьютерном анализе
К книге прилагается компакт-диск. BKnwiamuiuu учебник StatSoft по анализу данных, учебннк UO .'роыышлепной статистике материалы обучиющих курсов, демо-версии STATISTICA и SNN I iieiipouiibtc cent) и большое количество данных для обученна и проведения самостоятельных неследоваипй u STATISПСА it SNN
© ЗАО Издательский дом «Питер». 2003
ISBN 5-272-00078-1
Лицензия ИД № 05784 от 07 09 01
пм 2 953005 - литература учебная
Краткое содержание
Введение............................................................13
Вступительное эссе: приглашение к анализу данных на компьютере......14
Глава 1. Краткая экскурсия по системе STATISTICA...................44
Глава 2. Элементарные понятия анализа данных......................105
Глава 3. Вероятностные распределения и их свойства................146
Глава 4. Подгонка вероятностных распределений к реальным данным...185
Глава 5. Двумерный визуальный анализ данных.......................210
Глава 6. Трехмерный визуальный анализ данных......................251
Глава 7. Визуальный анализ категоризованных данных................307
Глава 8. Пиктографики.............................................333
Глава 9. Примеры визуального анализа и настройки графиков в STATISTICA.... 341
Глава 10. Описательные статистики.................................409
Глава 11. Построение и анализ таблиц..............................429
Глава 12. Т-критерий сравнения средних в двух группах данных .....487
Глава 13. Непараметрическая статистика.......................... 504
Глава 14. Анализ выживаемости...................... —.....-....533
Глава 15. Анализ соответствий................................... 561
Глава 16. Примеры анализа данных в системе STATISTICA.............577
Глава 17. Нейронные сети..........................................611
Глава 18. Язык 5TATISTICA VISUAL BASIC (SVB)......................641
Приложение 1......................................................667
Приложение 2................................................... 669
Приложение 3................................................ 677
Алфавитный указатель..............................................687
Содержание
аведение......................—..—-..-—
Вступительное эссе: приглашение к анализу данных на компьютере............... 14
Для кого эта книга’...................................................................... 40
Глава 1. Краткая экскурсия ло системе STATISTICA............................................. 44
Вступление ................................................................................44
Командный язык STATISTICA (5CL).............................................................К
Кнопки аптозадач..........................................................................
Взгляд в будущее.......................................................v—.................
гсряые шаги в системе STATISTICA..........................................................85
Графический анализ таблиц сопряженности................................................... 97
Глава 2. Элементарные понятия анализа данных .............................................. 105 ню икос переменная’............................................................................. — *05
гростсйшие описательные статистики..............................................................105
Свойств описательных статистик................................................................ 1°7
шкалы измерений.......................................................................—-........И®
Какие статистики выбирать?--------------------------------------------------------------------- 111
Распределение переменной....................................................................... И?
Зависимости между переменными.............................................,.........—-----------112
Исследование связей между наблюдаемыми переменными в сравнении
с экспериментальными исследованиями............................... г...............ИЗ
Корреляции.............................................................-.............И4
Почему зависимости между переменными являются важными..............—................120
Зависимые и независимые переменные........................... ... • ...........121
Как измерить величину зависимости между оеременчьми.............................. 122
Дее чер1ы зависимости между переменными.............................................123
Что такое статистическая значимость (руровено)?...................., .............. 123
Как определить, является ли результат действительно значимым.......—— К.............124
t .а1ис1ичсская значимость и ко личество выполненных анализов..-....................124
Величина зависимости между переменными в сравнении с тчздежностъю зависимости.......125
Почему более сильные зависимости между переменными являются более значимыми.........125
Почему объем выборки влияет на значимость зависимости...............................125
Почему слабые зависимости могут быть значимо доказаны только на больших выборках....126
Можно ли рассматривать отсутствие связей как значимый результат’............... ,........... 127
Общая конструкция статистических тестов..........................-.....—. .....—....127
Как вычисляется статистическая значимость...........................................127
Содержание
Значимость коэффициента корреляции..........................................................128
Как определить, являются ли два коэффициента корреляции значимо различными..................128
Почему важно нормальное распределение..................................................... 129
Иллюстрация того, как нормальное распределение используется в статистических рассуждениях.......................................................................131
Как проверить нормальность наблюдаемых величин..............................«..............131
Рее ли статистики критериев нормально распределены?...................................... 136
Как узнато последствия нарушений предположений нормальности?................................137
Оценка объема выборки..................................................................... 137
Визуальный подход к анализу мощности ......................................................141
Понижение размерности данных.....................,......................___________________144
Глава 3. Вероятностные распределения и их свойства—.—........................... 146
В чем состоит идея вероятностных рассуждений?----------------------------------------------146
Нормальное распределение...................................,............................... 147
Равномерное распределение..................................................................151
Экспоненциальное распределение................................................................... 152
Распределение Эрланга .................................................................... 153
Распределение Лапласа................S......................................................154
Гамма-распределение........................................................................ 155
Лот нормальное распределение............................................................ 157
Хи-квадрат распределение.................................................................. 15?
Биномиальное распределение..................................................................16С
Распределение арксинуса.................................................................. 16S
Отрицательное биномиальное распределение..................................,.................166
Распределение Пуассона......................................................................167
Геометрическое распределение................................................................170
Гигерсесметрическое распределение......................................................... 171)
Пот иномиальное распределение...............................................................171
Бе :а распределение...................................................... . ................171
Распределение экстремальных значений...................................................... 172
Распределения Релея...........................я........................................... 1??
Распределение Вет-булла.....................................................................173
Распределение Парето........................................................................17/
Гогистическол распределение . ........................178
Хотеллинга Р-распределение.................... ....................... .. ..................179
Распределение Максвелла...............................................—«.................. 180
Распределение Коши....................................................................... 161
Распределение Стьтодента........................... ........ ....... ................... 182
F-распределение... .............. .........................................._.183
Глава 4. Подгонка вероятностных распределений к реальным данным.............................185
Пример 1. Подгонка распределения к данным: посещение непопулярного сайта....................16/
Пример 2 Подгонка распределения к данным: посещение популярного сайта......................193
Пример 3. Скачки вверх и вниз курса акций ... . .....................................19/
11ример 4. Количество покупок в магазине....................................................197
Пример 5. Подгонка распределения Бейбулла к данным об отказах.............................. 200
Глава 5. Двумерный визуальный анализ данных.........................---------------------..............210
I ....................................................................................... 210
Гистограммы и описательные статистики ......................................................212
8
Содержание
Годгсика теоретических распределений к наблюдаемым распределениям...................216
Пересекающиеся катеюрии........................................................... 219
Диаграммы рассеяния.................................................ж.............. 219
Однородность распределений двух переменных (формы зависимостей).....................221
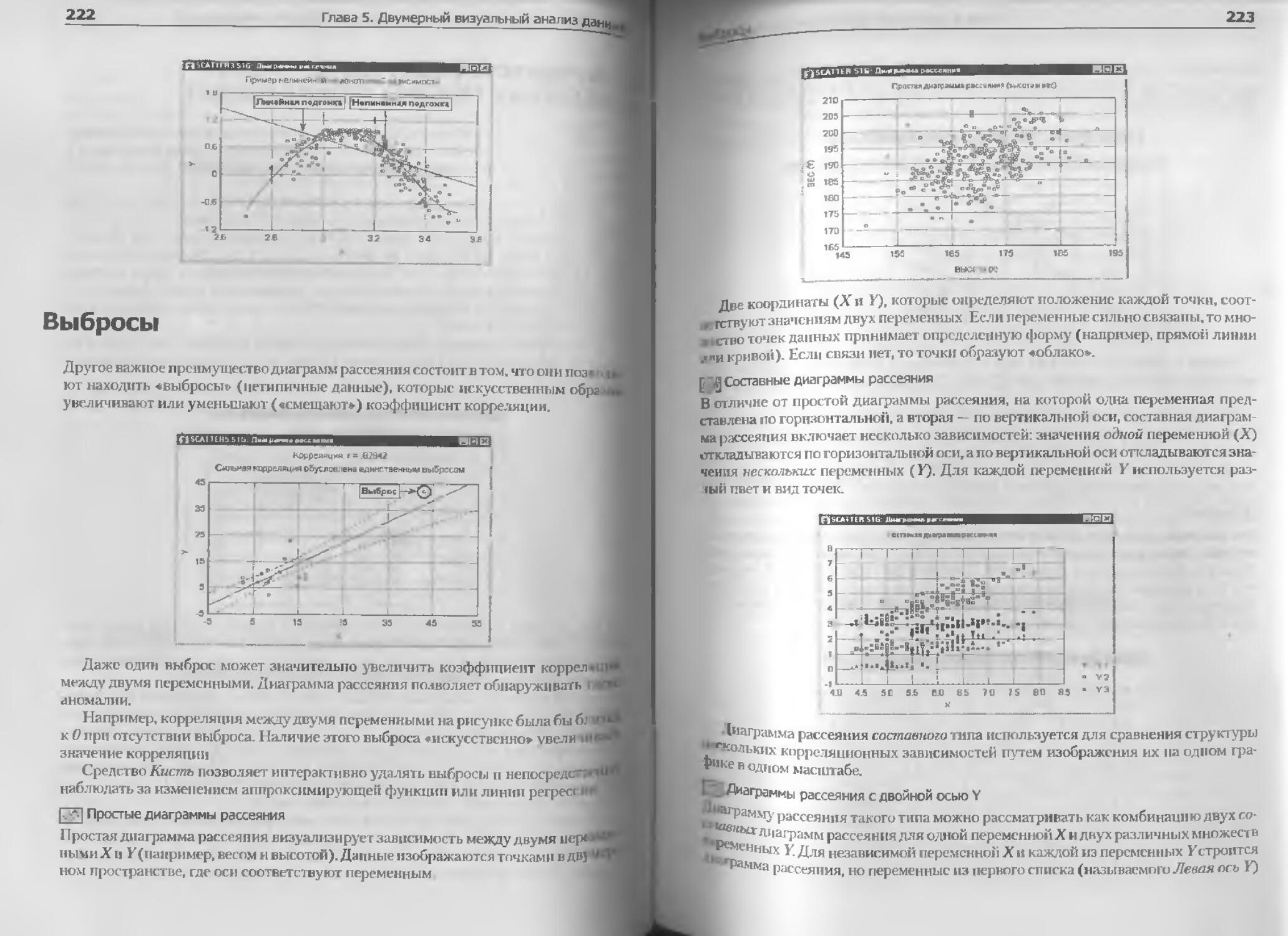
Выбрось......................................................................... 222
Диаграммы рассеяния с гистограммами............................................. 226
Диаграммы рассеяния с диаграммами размаха............................ —...........226
Нормальные вероятностные графики ....................... ........................... 227
Графики вероятность — вероятность..................... - , -W|iflHr“i—1 —.....230
Диаграммы диапазонов........,.......................................................231
Диаграммы размаха..................................................................232
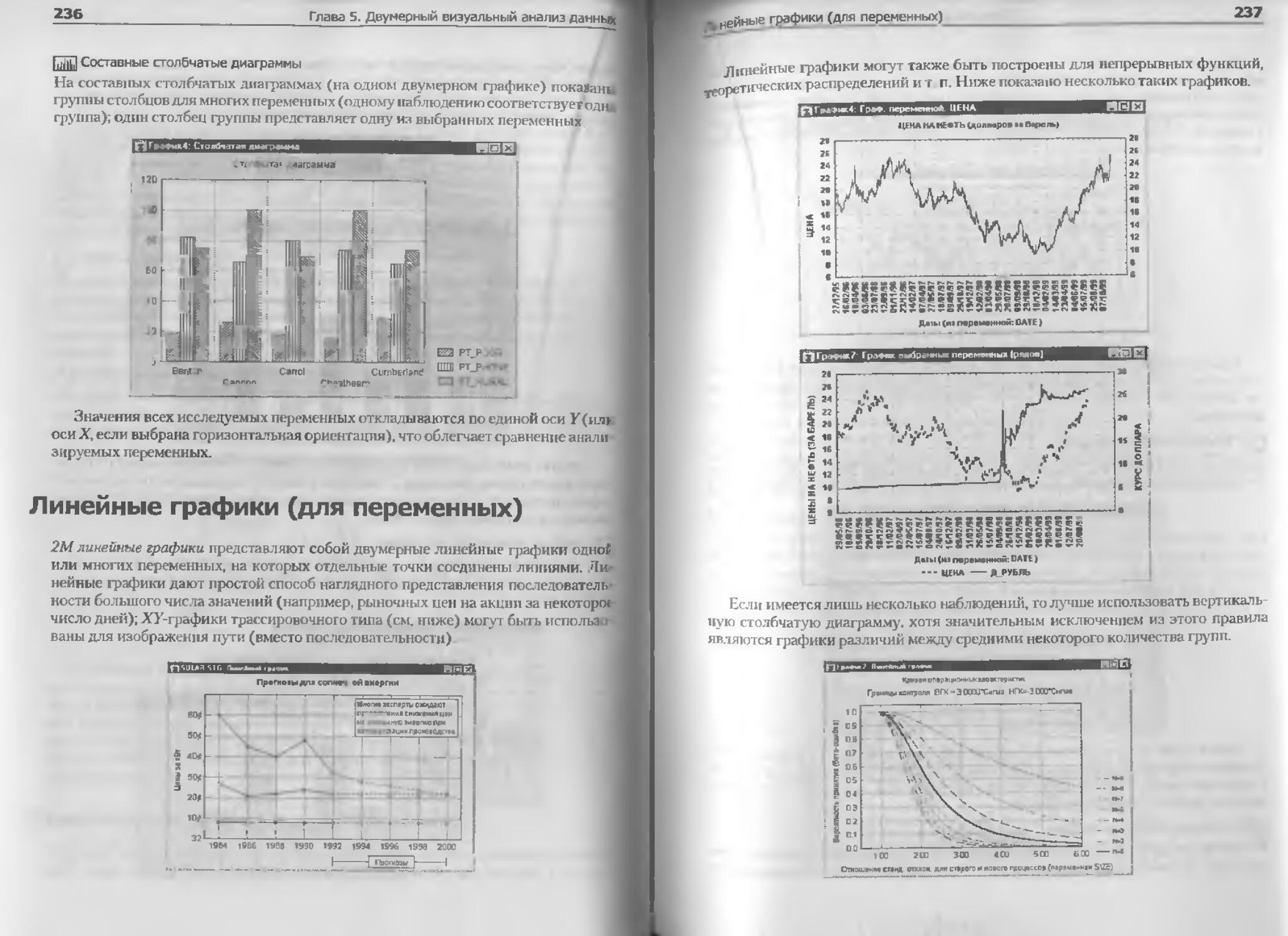
Столбчатые диаграммы...............................................................234
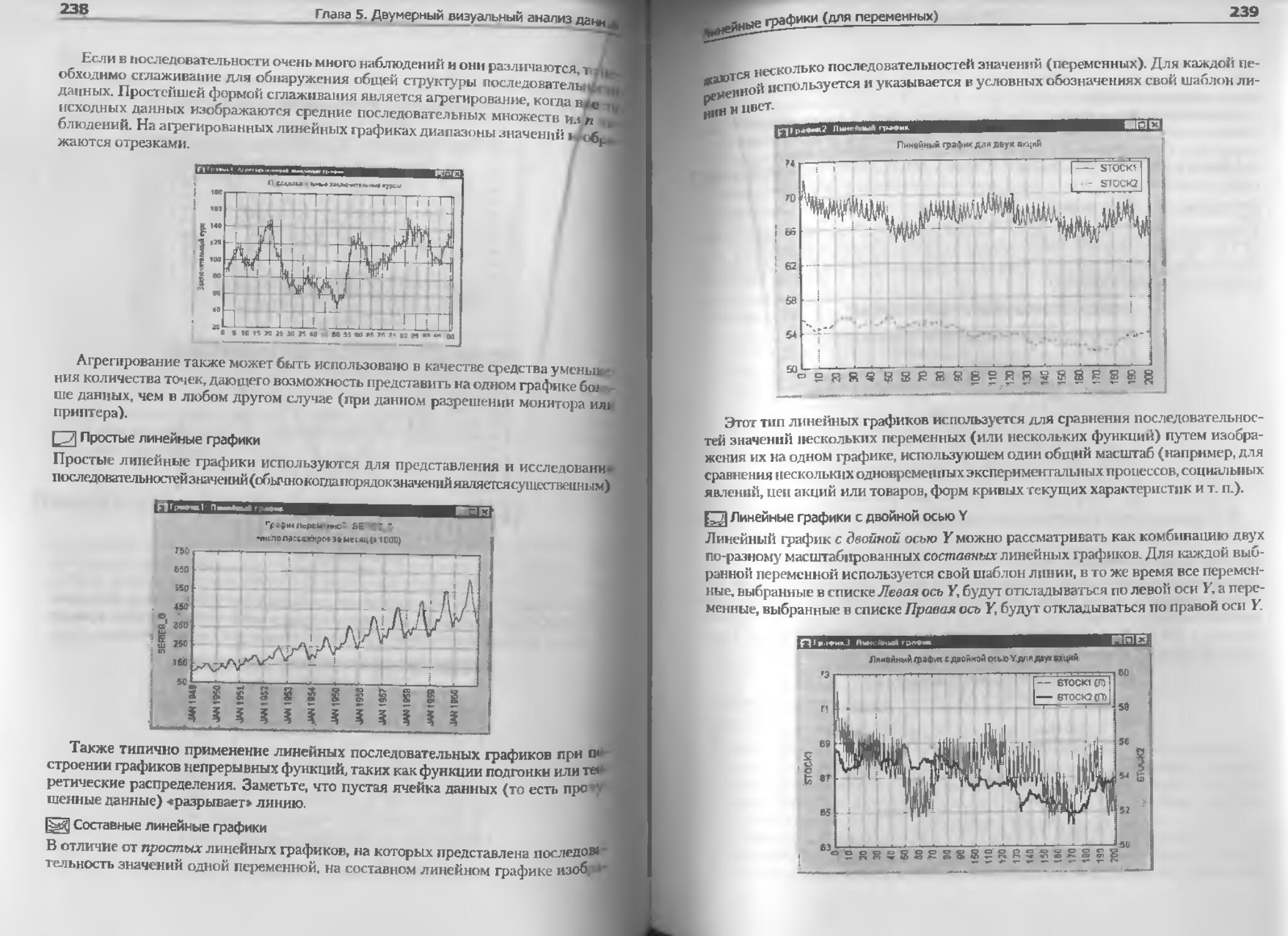
Линейные графики (для переменных)........ ....................... 2 36
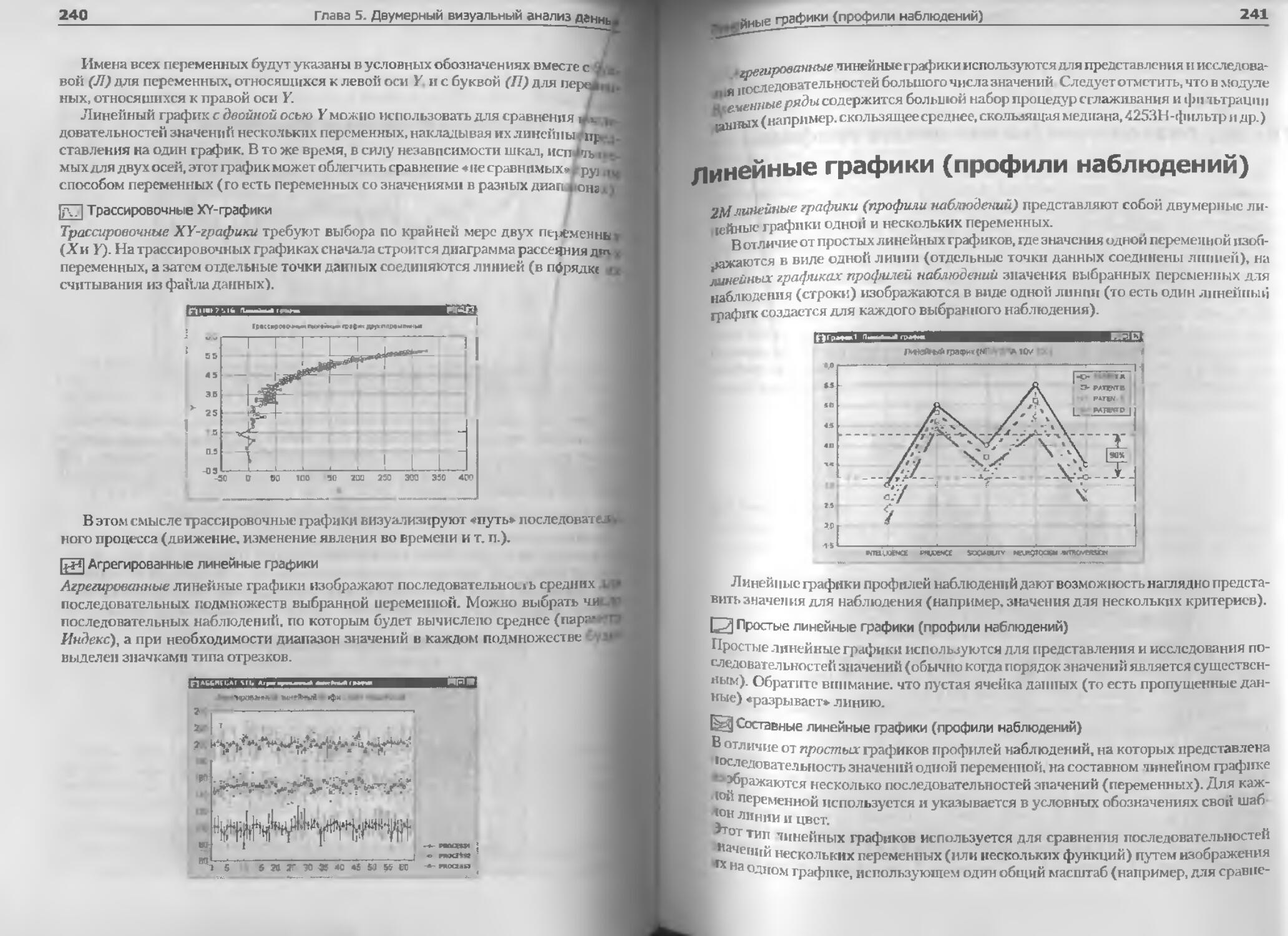
Линейные графики (профили наблюдений)........ ...........................241
Последовательные/чаложенттыеграфики ....... ... ......................242
Круговые диаг ранмы.......................................... .....................247
Диаграммы пропущенных значений и интервалов__________________..____________________248
Графики функций пользователя.............. „............ ......249
пава 6. Трехмерный визуальный анализ данных-------------------------............................251
Гистограммы двух переменных....................—....................................256
ЗМ диаграммы диапазонов............................................................ 26С
ЗМ диаграммы размаха..............................._... .... 264
Трехмерные диа< раммы рассеяния................................................... 269
Графики поверхности.............................................................. 776
Карты линий уровня................................................................ 28С
Трассировочные графики.......................................................... 281
Тернарные графики................................................................. 283
Трехмерные категоризованные графики........................................ ....289
Категоризованные тернарные графики............................................... 293
Графики пользовательских функций....................................... . .... 298
Матричные графики................................................................ 299
лава 7. Визуальный анализ категоризованных данных................................... 307
Что такое категоризованные графики’............................................... 307
Категоризованные графики и матричные графики...................................... 309
Г ис юграммы и описат сльные с атист аки..................................... _ ,...311
Категоризация значений в каждой гистограмме................................... ....312
Категоризация значений в составных графиках..................... . .............312
Категоризованные гистограммы и диаграммы рассеяния................................ 315
Подгонка теоретических распределений к наблюдаемым распределениям...................316
Подгонка распределений к множественным гистограммам.........._................_... 317
Категоризованные диаграммы рассеяния......... ... ....318
Нелинейная зависимость ..........____,... .................................. .... 319
Категоризованные вероятностные графики..............................................320
Катет оризогоннье графики квантиль — квантилг...... ...............321
Ка гег ормзованные г рафики верен г нос ь - вероятность.......................... 322
Категоризованные линейные трафики ... ............... ..........................322
Методы сглаживания...........................................,.............. .... 323
Категоризованные прямоугольные диаграммы........................... .,... . . 323
Содержание
Связанные графики...........................— . ....... .................... 325
Категоризованные круговые диаграммы.......................................... 327
Круговые диаграммы рассеяния................_............................... .. 328
Категоризованные диаграммы пропущенных данных и диаграммы диапазонов . .....329
Категоризованные трехмерные графики................................. ........ 329
Категоризованные тернарные графики.... ............................. _____....331
Глава 8. Пиктографики .......................................................... 333
Анализ пиктографиков.......................................................... 333
Классификация пиктографиков............................................. ........334
Глава 9. Примеры визуального анализа и настройки графиков в STATISTICA.... 341
Пример 1. Настройка двумерных и трехмерных графжоа.............................. 341
Настройка двумерных графиков............. —.......... .................... 341
Насройка трехмерных графиков............................................... ЗЫ
Пример 2. Подгонка функций, увеличение и закрашивание........................... 374
Построение диаграммы рассеянии..............................................374
11рибли.жение полиномами................................................... 375
Интерактивное удаление выбросов (Закрашивание)..............................372
Увеличение .......—>.... -...................................... 379
Рисование пользовательской функции..._ ................................. 381
Добавление зависимости................................._ —-................ 382
Пр»»*® 3. Динамическое закрапывание (Кисть) —...............— ..............—. 384
Файл данных.....................................................—— .—. 384
Пос'роение наличного графика....... ...........................384
Закрашивание в редакторе данных графика................................ 386
Г ример 4. Связывание и внедрение..................... . ,....................387
Расгровье изображения.................................... -.............387
Метафайлы Windows («картинки»)............................................ 387
Собственный графический формат системы STATISTICA......---------—----------388
Копирование и вс’эвка графических объекте..... —...........388
Вставка в виде текста.................._...................................—• 391
Вставка в виде растрового изображения.................................—- 391
Вставка в виде собственного графическою объекта системы STATISTICA. 393
Сепса............................................ .....------------ 394
Функции клиента и сервера в OL=.................. »...................... 395
Создание трехмерной гиоограммь........................................ 395
Внедрение диаграммы рассеяния...................................л...........395
Редактирование внедренного графика........................................ 397
Внедрение или связывание графиков из файлов............................... 392
Автоматическое обновление связанных г рафиков......, .....398
Управление несколькими графическими объектами........................... — 398
Изменение очередности изображения графических объектов.................... 399
Управление графиками системы STATISTICA в других приложениях Windows средствами OLE...................................._..................... 400
Связывание графика системы STATISTICA-------------------------------------— 401
Редактирование связанного графика...........................................402
Пример 5. Добавление заданных пользователем статистических графиков в окно Галерея графиков и в меню Г рафика........................................-............403
Файл данных.............................................................. 404
Определение параметров графика........................................... 404
10
Содержание
Создание нового графика пользователя..........................................405
Выбор заданного пользователем графика.........................................406
Просмотр и редактирование списка графиков пользователя...... .... 407
ава 10. Описательные статистики —...............................................................409
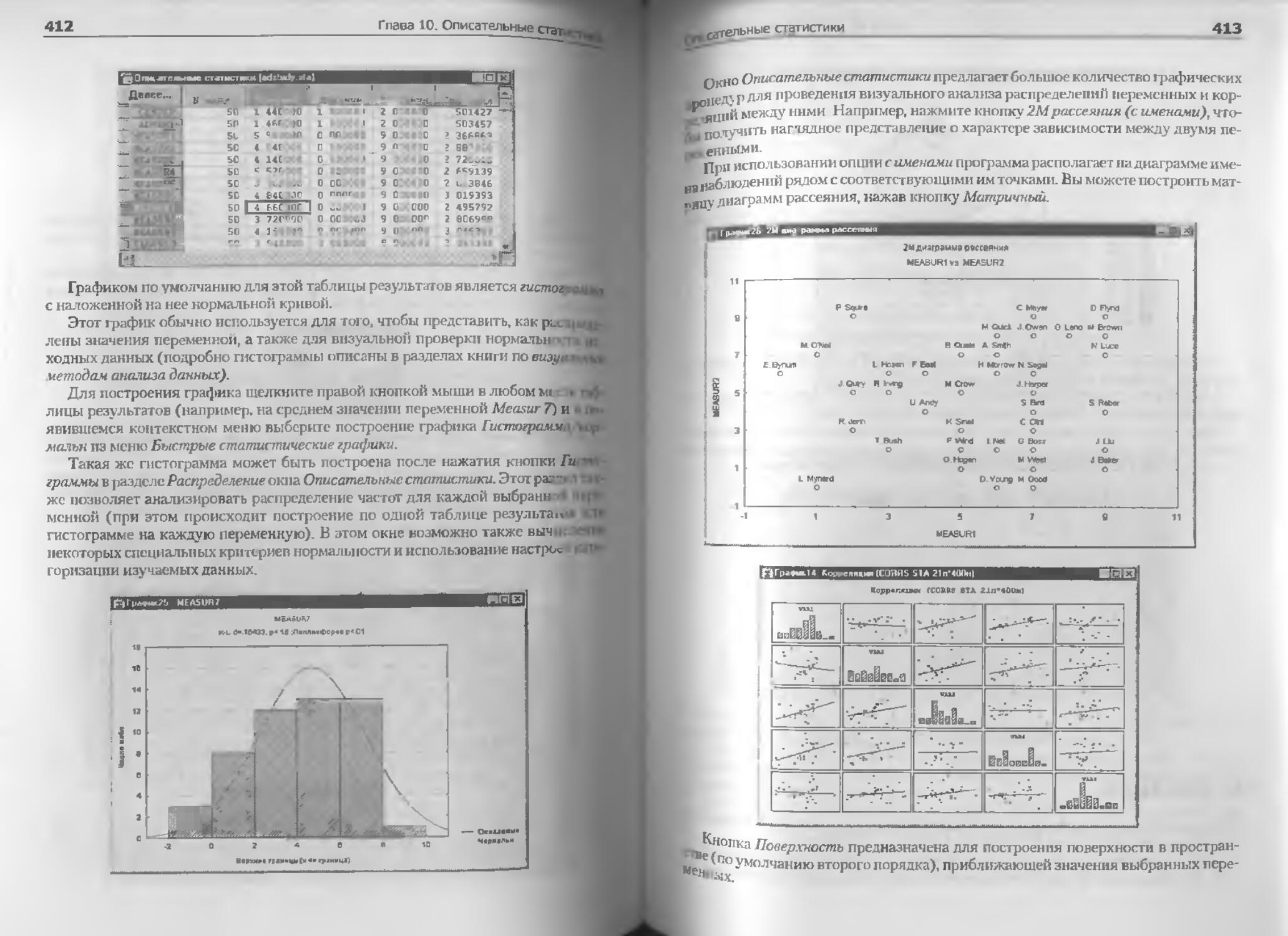
Корреляции..................................................................................414
Вычисление описательных статистик для группированных данных................................ 420
Вчу-ритрупповые корреляции.......................................................—........ 424
ава 11. Построение и анализ таблиц................................................................429
Вводный обзор............................................................................. 429
Таблицы частот............................................................................. 434
Таблицы сопряженности и таблицы флагов и заголовков...................... ..................436
Таблицы флагов и заголовков...........................................................440
Статистики таблиц сопряженности.......................................................442
Статистики, основанные на рантах..................................................... 445
Многомерные отклики и дихотомии.......................................................445
Многомерные отклики...................................................................445
Многомерные дихотомии................................-................................447
Кросс табуляция многомерных откликов и дихотомий.................................... 4-*7
Парная кросстабуияция переменных с многомерными откликами.............................448
С(>едс1Вд построения таблиц системы STATISTICA............................................ 449
Таблицы частот......................................-.................................449
1аблицы сопряженности и таблицы флатств и заголовков................................. 450
Многомерные отклики и дихотомии........................................ «.«..........4Ы
Примеры ...................................................ф.... г ........................................ 452
(’.ример 1. Таблицы частот........................................................... 452
Гример 2. Таблицы флагов и заголовков................................................ 456
Пример 3. 1аблицы сопряженности.......................................................461
Пример 4. Табулирование многомерных откликов и дихотомий..............................463
Пример (анализ продаж)................................................................474
ава 12. Г-критерий сравнения средних в двух группах данных ...................487
Г-критерий для независимых выборок..........................................................489
Формальное определение t-критерия......................................................... 491
Г-критерий для зависимых выборок............................._....,....................... 492
Гример 1................................................................................... 493
Пример 2....................................................................................495
Множественные сравнения.................................................. «...........498
Однофакторный дисперсионный анализ и апостериорные сравнения средних..................500
ава 13. Непараметрическая статистика ...........................................................504
Краткий обзор непараметрических процедур 504
Описание непараметрнческих процедур на примерах.............................................507
Стартовая ганель модуля Непараметрические статистики..................................5С7
Таблицы частот 2 > 2- статистики Хи/v/Фи-квадрат, Макненара, точный критерий Фишера.........5С8
Наблюдаемые частоты е сравнении с ожидаемыми........................................ 511
корреляции (Спирмена R, тау Кендалла, Гамма)... ......... ... ....................512
Матричная диаграмма............................................................... 515
Критерий серий Валтм-,в--Вогьфооица..................................................... 516
U критерий Манна—Уитни............................................».................. 516
Содержание
Двухвьборочный критерий Колмогорова—Смирнова--------------------------------------517
Пример. Критерий серий Вальда—Вольфовица, Манна—Уитни и-критерий, двухвьборочный критерий Колмогорова—Смирнова.......................................517
AKOVA Краскала—Уоллиса и медианный тест............................................522
Критерий знаков................ .............— .................................. $26
Критерий Вм/жоксона........—........................................ —............ 527
ANOVA Фридмана и коэффициент конкордации, или согласия, Кендэлла...................528
Q-критерий Кэхрена................................................................ 529
Описательные статистики............................................................S3U
Медиана------------------------------------------------------------------------ 530
Мода.......................———---------— —.........................................-._... 530
Геометрическое среднее ....—..........— ——...................................... 531
Гармоническое среднее.......................................-......................531
Дисперсии и стандартное отклонение ....................._........................ 531
Размах.................................-................. ——..................... S31
Квартальный размах.—........................ — ........—.................... 531
Асимметрия ..............--—-----------............-----—...................... ,..... 532
Эксцесс.......................................................................... 532
Глава 14. Анализ выживаемости ..^.........................533
Введение в анализ выживаемости........................ .........- ----------—--------— 533
Таблицы времен жизни............_............................................ 534
Сценки Каплана—Мейера............................................................. 538
Сравнение выживаемости в группах........................................................541
Регрессионные модели в анализе выживаемости--------------------------------------------..... 543
Модель Кокса.......................................................................544
Экспоненциальная регрессия__________________________............................. 5*5
Нсрмалиная и логнормальная регрессия................ ..............................547
Сб.юр системы .................................................................... 548
Альтерна1ивные процедуры.........................-—.....—. .......... 549
11ример 1. Таблицы времен жизни..---------------------------------------------—.-.......550
Задание параметров анализа.........................................................55С
Пример 2. Регрессионная модель Кокса________.........____............._..............-.......... 554
Задание параметров анализа.—...______......... -----............ 555
Оценивание параметров_____________, , , ................ ...............---------.......... 556
Результаты------.... ......^ ......................».................... .......... 558
Глава 15. Анализ соответствий...............................................................561
Пример 1 (анализ курильщиков)...........................................................571
Прннер 2 (анализ продаж)........,.......................................... — -574
Глава 16. Примеры анализа данных в системе STATISTICA.......................................577
Построение плана...................................................................589
Задание имени и сохранениеэкслеринентальногоплана —,—— - 591
Анализ .экспериментальных данных.............................. ——— 591
Глава 17. Нейронные сети-611
Пре/постлрсцесгироеаняе....................................................., ---------625
Оценка качества работы сети...................«_»......... . -------------62/
Диалог в модуле Нейронные сети STATIST ICA .»....»......................................62/
Заключительные комментарии........................................... —................ 636
12
Содержание
Глава 1В. Язык STATISTICA VISUAL BASIC (SVB)----------------------------------------------------------641
Структура языка STATISTICA Visual Basic.... ----- ... -------..— 641
Запись макросов...........................— — 642
Макрос анализа........................................................................................ — 642
Запись макроса анализа . 643
Создание графика............. 646
Мао ер макрос...................................................................... •........................648
Клавиатурные макросы.... ....................................................................... 649
Среда npoi раммирования.................................................................................... 649
Основные соггаиения STATISTICA Visual Basic......................................................... 650
Тигы данных, массивы, функции......................................................-.— 652
Операторы управления порядком выполнения команд----------------------------------------------655
Глобальные переменные, передача ар. унесоа по значению и по ссылке 656
Примеры программ с комментариями ..............................— ~........... . — — 658
Пример: формирование коллекции таблиц данных.....................-........—-....-------------658
Создание таблицы данных и запо/атенме ее случай|ыми числами.... ......................-.............654
Вывод индикатора состояния —.................................. —.....................................— 659
Построение гистограммы г подюнкой нормальною распределения.....................——— । — 660
Создание пользовательских диалогов........................................................................ 662
Просмотр объектов и функций............................................................................... 663
Приложение 1............_________....---.....-------------------------------------------------------------- 667
Приложение 2...............................................................................................—.669
Приложение 3.........................................................................................................б??
Словарь терминов пакета SNA (версия 4.С).....................—........................................... 677
Функции активации, реализованные в SNN.....................— .,— -...........................683
Функции ошибок, доступные в SNN-------------685
PSP-функции ................................................................................... 686
Алфавитный указатель--------------------..........---------------------------------------------—------6В7
Введение
В книге, написанной научным директором компании StatSoft Russia, изложен концепция н технология современного анализа данных на компьютере. На основ элементарных понятии описываются углубленные методы анализа в систем STATISTICA (StatSoft), иллюстрированные многочисленными примерами и экономики, маркет инга, рекламы. бизнеса, медицины, промышленности и други областей. Большое внимание уделяется основным понятиям анализа данпьг разведочному анализу данных, группировке, анализу и построению таблиц -важным этапам анализа данных, на которых формируются и проверяются гнпотс зы о структуре данных и связях между ними.
В книге изложены классические п современные методы анализа данных, позы ляющпс получить всестороннее описание данных (например, в задачах массовог обследования и мониторинга), провести классификацию, найти закономерности зависимости между переменными, - иными словами, ответить на важные вопрс сы, которые задает исследователь, впервые столкнувшийся с огромным массиве информации
Подробно описан визуальный анализ как первый этап сложного исследования. -сотни типов графиков в STATISTICA. включая двумерные, трехмерные, катсгорп зоваиные графики и пиктографики подробно рассмотрены с описанием опции з настроек.
Все это делаеткнигу настольной для многочисленных пользователей STATISTICS Предлшасмая книга адресована самому широкому кругу читателей, жслаюшн стать профессионалами в анализе данных па STATISTICA в бизнесе, маркетинге ф| । нэ| icax, управлении, эконом i ikc. промыт ценности, страховании, медпш i не и дру гих приложениях.
Книга дополнена компакт-диском, включающим последнюю версию зпамс питого учебника StatSoft по анализу данных, а также учебник по промышлеп ной статистике, материалы обучающих курсов, демо-версии STATISTICA и SNI (нейронные сети), огромое количество данных для обучения и проведения само стоятетьпых исследований в STATISTICA и SNN.
Во второе издание книги добавлены новые материалы, исправлены ошибки пер вого издания, а также написана новая глава о языке STATISTICA VISUAL BASIC (SVB), появившемся в 6-й версии STATISTICA Кроме того, произведено обнов ление диска с добавлением некоторых программ на SVB. снабженных коммента рпями на русском языке.
вступительное эссе: риглашение к анализу энных на компьютере
Окружающий нас мир насыщен информацией — разнообразные потоки данных окружают нас, захватывая в полссвоего действия, лишая правильного восприятия тсиств|ггелы|ости. Не будет преувеличением сказать, что информация становится чаи ью действительности и нашего сознания.
Без адекватных технологии анализа данных человек оказывается беспомощным в жестокой информационной среде и скорее напоминает броуновскую частицу, испытывающую жестокие удары со стороны п не имеющую возможности рационально принять решение.
Статис гика позволяет компактно описать данные, понять их структуру, провести классификацию, увидеть закономерности в хаосе случайных явлений. Удивите 1ыю, что даже простейшие методы визуального и разведочного анализа данных позволяют существенно прояснить сложную ситуацию, первоначально поражающую нагромождением цифр.
Особенность этой книги заключается в том, что в ней всесторонне, с подробными примерами описано применение разнообразных методов анализа данных.
Вообще, наша идея состояла в том, чтобы вывалить из мешка различные мето ды, написав своего рода популярную энциклопедию всевозможных методов анализа данных, и позволить пользователю, применяя систему STATISTICA, свободно экспериментировать с этими методами, работая как с собственными данными, так и с предлагаемыми нами. Мы дополнили книгу компакт-диском, на котором записаны демо-версии системы ST ATISTIC А,файлы данных, материалы курсов и многое другое. Запустите диск и одновременно читайте книгу — это позволит всесторонне освоить технологии анализа данных.
Мы описываем как классические методы анализа, так и современные, включая нейронные сети, в частности, чрезвычайно интересный анализ соответствий, позволяющий исследовать сложные многомерные таблицы, возникающие в экономике, маркетинге, медицине и других областях. Даже традиционные методы мы стараемся рассмотреть под новым углом зрения, акцентируя внимание на нестандартных приложениях.
Визуальные методы анализа данных чрезвычайно важны, и мы посаящаем им несколько глав. Многие явления, остающиеся за кадром, становятся отчетливыми, если найти подходящее графическое представление
Вступительное эссе: приглашение к анализу данных на компьютере 15
I lanpii.wp. на фафике, прннедеш1<1мнюке. мы видим дна временных ряда: цены па нсф| ь и долларах за баррель и куре доллара по отношению к рублю за несколько лет Рассматривая график. вы видите, какие тенденции имеются в данных. Конец но, это простейший вариант графического представления!
Далее вы можете перейти к построению более сложных моделей, однако первые акоиочсрностя. найденные визуально, сохранятся и в углубленных моделях Нмеп-KI поэтому мы уделяем низу из изашш столь большое внимание.
Множество практических примеров рассмотрено в данной книге. Чтобы сде-шть изложение систематическим, мы начинаем с простейших понятий — которых. : счастью, нс так и много — и учимся говорить па языке анализа данных, рассмат ривая простые и понятные всем примеры, постепенно развивая их до сложных д»аач
М ы не следим тщательно за строгим обоснованием методов, а просто говорим: имею гея такие-то методы и там-то их применение принесло успех Исли вы жслае-попробуйте применить яти методы для анализа собственных данных и, быть лет, по.|уч1ГТС обнадеживающий результат.
Рис. 1. Динамика цены 1-го Барреля нефти (в долларах) и реального курса доллара (покупательной способности доллара, выраженной в рублях)
Но что значит обнадеживающий результат? Если из множества возможных ва-। лантов действий вы с большей вероятностью, чем ваш противник, выбираете правильный вар| 1ант или добиваетесь более ясного noiiимя шя деистыггелыгости, «снимая» случайность, то, очевидно, вы находитесь в лучшей ситуации, чем ранее, когда слагались на волю случая и отдавали себя во власть неопределенности.
Итак, разнообразие методов и обилие примеров — вот основная идея книги, ко-1 эрая по этой причине может быть названа энциклопедией методов анализа и об-астеи их применения. Строгое обоснование методов — не наша цель, так как многие интуитивно понятные методы н родились из решения практических задач и тишь позднее получили строгое математическое обоснование, что никак не уменьшает их прагматической ценности.
Для широкого круга пользователей полезно знать, где и какие методы применялись на практике и когда приве л! к успеху, и мы хотим максимально развить интуитивное представление пользователя об анализе чайных, не предполагая наличия
16
Вступительное эссе: приглашение к анализу данных на компьютере
у него специальной подготовки Таким образом, мы хотим познакомит ь чнтатетя с к1/1ът!)ры1 анализа данных.
В качестне источника данных мы используем, например, Интернет п иллюстрируем применение методов анализа на этих данных Популярность Интернета общеизвестна, но что нового может дать анализ данных в этой области? Вот один из примеров. Вы производите поиск по различным ключевым словам в некоторых поисковых системах и отмечаете количество ссылок; спрашивается, различаются системы поиска или пег? Именно с такого рода примерами мы будем иметь дето.
Ниже приведены графики количества посетителей сайта. Скрашивается, как строго доказать, что реклама имела успех9 Правило 3-сигма позволяет оценить эффекта в । гость рекламной кампан! ш и. следовательно, работу' менеджера по рекламе.
ДНИ
Рис, 2. Оценка эффективности рекламы
График спектральной плотности показывает, что в данных имеется отчетливая периодичность с лагом 7. так как пик спектральной плотности приходится на 7 дней
Спектр, анализ. HOST Число набл.: 72
Веса Хемминга: .0357 J2411.4464 J2411.0357
Рис. 3. График спектральной плотности
Вступительное эссе: приглашение к анализу данных на компьютере
17
График недельной составляющей позволяет увидеть, как изменяется (впршк н-чх) число посещений сайта в зависимости от дня недели. Иссл* и ра.м к*ть па- рузки Интернета в рабочие и выходные дни. можно оценить долю «домашних» подключений к сети.
11одоб| । ого рода закономср! юетн возникают в самых разд и ч 11 ых областях. в тор- овле, бизнесе, промышленности, — важно уметь находить их н использовать н с hoi IX це."ях.
Рис. 4. Зависмость заходоа на сайт от дней недели
Прогнозирование* представьте, что вы имеете данные ежемесячных продаж. Вам нужно спрогнозировать продажи па текущий месяц. Как вам поступить? Вполне разумный подход состоит в гом, чтобы взять в качестве прогноза продажи предыдущего месяца. Далее вы можете развить этот подход, использовать для прогноза продажи нескольких предыдущих месяцев, усреднить их, например, с разными весами Как крайний случай, вы усредняете все продажи. Так из вполне естественных рассуждений возникает метод скользящего среднего.
Если вы хотите учесть сезонный фактор, например прогнозировать продажи в январе текущего года, используя информацию о продажах в январе предыдущего года, то следует использовать сезонное скользящее среднее Если вы хотите учесть псе продажи, но с разными весами, то используется экспоненциальное ci тажлва Пне (exponential smoothing) с очевидными вариациями- сезонное или нессзонное. с трендом (отчетливо выраженной тенденцией) пли без тренда. Обобщение модели скользящего среднего приводит к моделям АРПСС — авторегрессии и проинтегрированного скользящего среднего, или. в английской терминологии, ARIMA (Autoregressive Integrated Moving Average).
Какую из этих моделей выбрать? Ответ: запустите STATISTICA и поэксперн-ме 11 тируйте с различными моделями Разбейте данные на две группы — используйi-те данные второй группы для проверки качества прогноза (для проверки можно оставить, например, пятую часть ряда). STATISTICA позволяет экспериментировать с методами анализа, а это огромное достижение!
В тех ситуациях, когда классические методы нс работают, можно испытать нейронные сети. Мы рассматриваем их как полезный инструмент анализа, пмеюшни своп достоинства и ограничения (см. главе* 17).
18
Вступительное эссе: приглашение к анализу данных на компьютере
Вот типичный пример. Рассмотрим данные о розничных продажах бензина в США (данные доступны на сайте www.economagic.com в разделе Census Bureau; Retail Sales by Kind of Business). В численном виде данные приведены в приложении 1. Прогнозирование тех желанных с помощью нейронных сетей описано в приложении 2.
На графике данные имеют вид:
Рис. 5. Розничные продажи бензина в QUA
С помощью графика можно выделить два временных интервала, на которых поведение ряда существенно различается.
Технологии прогнозирования, описанные в книге Боровиков В. П. Ивченко Г. И. «Прогнозирование в системе STATISTICA в среде Windows», М.: Финансы и статистика, 2000, позволяют построить прогноз продаж бензина с помощью моделей ARIMA — АРПСС (авторегрессии и проинтегрированного скользящего среднего).
Рис. 6. Модуль анализ временных рядов в STATISTICA
Вступительное эссе: приглашение к анализу данных на компьютере______________19
Рис. 7. Построение прогноза продаж с помощью моделей АРПСС
Рис. 8. Прогноз продаж бензина с помощью моделей АРПСС
В качестве альтернативы можно использовать экспоненциальное сглаживание. На следующих рисунках показан прогноз, построенный с помощью экспоненциального сглаживания, который сравнивается с прогнозом на основе модели ARIMA — АРПСС. Мы использовали часть данных для построения модели, а па оставшихся данных сравнивали прогнозы.
20
Вступительное эссе: приглашение к анализу данных на компьютере
« 5 i S3 11 л * % £ Si 8 Hi I t « i ' 1 ii I
Рис. 10. Сравнение прогнозов
Хотя в книге мы обращаем внимание на тонкие моменты исследования, более важная наша задача — показать читателям, на какие результаты вообще можно рас-СЧ1П ывать, применяя данный метод, и как избежать явных ошибок
Итак, нам хотетось бы донести до читателя клише анализа данных: от визуального анализа данных, описания данных с помощью простейших дескриптивных статистик дос южных продвинутых методов, позволяющих понять структуру данных. классифицировать данные и оценить связи между ними.
Рацее, до появления персональных компьютеров, анализ реальных данных был чрезвычайно сложным, требующим больших шпеллектуальиых усилий делом, и пи о каких технологиях нс могло быть и речи. Это было дело небольшого круга посвященных.
Благодаря таким системам, как STATISTICA, открылся путь к новым технологиям анализа данных, максимально сокращающий рутинные процедуры и делающий анализ максимально доступным для широкого круга пользователей.
Наследующих рисунках показан типичный диалог в STATISTICA.
Рис. 11. Рабочее окно STATISTICA с файлом данных о проблемных банках
Вступительное эссе: приглашение к анализу данных на компьютере 21
Рис. 12. Логит-регрессия в STATISTICA — выбор метода оценивания
Рис. 13. Задание начальных приближений и оценки параметров модели
22
Вступительное эссе: приглашение к анализу данных на компьютере
Если раньше каждый шаг исследований: представление данных, перевод их в нужный формат, проверка, группировка, сортировка, сжатие, графическая интерпретация, запуск программы обработки, задание параметров анализа, просмотр результатов, был трудной задачей, то теперь достаточно двух-трех щелчков мыши, чтобы огромные объемы данных чрезвычайно быстро преобразовались, обработались и появились на экране в виде графиков, диаграмм, таблиц, статистик критериев
Наша точка зрения состоит в том, что при современном развитии компьютерных технологий начальные этапы анализа данных, визуальный и описательный анализ, а также пробное применение сложных методов вполне могут проводить специалисты из конкретных областей — те, кому результаты анализа в первую очередь нужны и кто располагает реальными данными, «вжился» в них
Представьте, вы анализируете некоторый рынок, то есть множество товаров, цен, продавцов, покупателей и т. д. Прежде всего, ваша задача состоит в том,чтобы разумно описать рынок, например рынок недвижимости. — ввести данные, провести визуальный анализ, сгруппировать данные и найти некоторые первые устойчивые «акономерности в организации рынка. Уже первые шаги такого анализа показывают. что па цены, в основном, влияет тип квартиры и рапой. Остальные характеристики менее значимы. Так, первый этаж снижает стоимость квартиры примерно на 1 '10, последний — в 2—3 раза меньше. Отсутствие балкона или лоджии также снижает стоимость (примерно на ту же величину, что последний этаж). Наличие или отсутствие телефона практически не влияет на цену, но продать телефонизированную квартиру значительно проше. В общем, разница цен между кирпичными и панельными домами невелика, скажем, процентов 5, — имейте в виду, что данный пример во многом искусственный, — но ближе к центру больше ценятся кирпичные дома и т. д.
Проведение такого рода описательного анализа, построение попятных графиков и ответы на разнообразные простые вопросы типа: «А что у нас по пятницам?» и 1. д. — это первый естественный шаг всякого исследования При этом используются самые простые описательные статистики, графики, группировка данных..
Вступительное эссе: приглашение к анализу данных на компьютере
23
Далее, после разбиения жилья на однородные группы, возникают более слиж-ные аналитические вопросы, например, как влияет па стоимость типового жилья появление элитных квартир9 Или как повлияют большие продали муниципального жилья на пены9 Как зависит спрос от сезонной составляющей9 Как зависят продажи от текущего строительства в городе? Мы рассмотрели рынок недвижимо iTU. но точно такие же методы применяются при исследовании других рынков: финансового, фондовых, товарных, сырьевых..
Здесь нужно перейти от описательного анализа к более сложным статистическим моделям, например регрессионным
Любой рынок но существу своему многомерен, то есть описывается многими параметрами, поэтому необходимо применять многомерные методы, например факторный анализ, чтобы понять, какие факторы в основном влияют на цену квартиры. многомерное шкалирование, деревья классификации п т. д Для апал пза динамики цеп п прогнозирования изменения цен в зависимости от времени применяются методы анализа временных рядов.
Очень многие сложные задачи успешно решаются довольно простыми статпс-1 нческимн методами. Например, известно, что краткосрочная финансовая политика США строится на основе модели линейной регрессии с учетом сезонной ияфор-пип о финансах Однако применение даже простых методов приносит эффект
В бурно развивающейся отрасли средств телекоммуникации важно решать еле у. клипс задачи:
О прогнозировать пиковые нагрузки в сети,
J оценивать недельные колебания нагрузки
> рационально выбирать место строительства новой станции для эффективного развития сети.
В принципе, задача рационального выбора места строительства станции может быть ретена с помощью методов множественной (многомерной) регрессии. Она 1 цолне аналогична разбираемой нам и задачи о строительстве атомной станции.
Оценка колебаний нагрузки сети в зависимости от дней недели решается с помощью метода сезонной декомпозиции. Для npoi позирования нагрузки в сети можно использовать модели авторегрессии и проинтегрированного скользящего среднего.
Регрессионные модели также используются для процентной) выражения прибыли магазина определенного типа в текущем году. В качестве регрессоров всполь-тотся величина спроса, качество товаров, рост доходов и др. (см например, статью Tliurik A. R. (1985). Retail margins d iiring recession and growth. Econ Lett., 17 N- 3, p. 281-284, где даются расчеты по данным реальных наблюдений и финансово-экономический анализ результатов)
Регрессия эффективно применяется для анализа экономической активности в [езл ичных регионах.
Такая модель, например, с успехом применялась для анализа реальных данных б Швеции. Степень вариации пли изменчивости параметров модели для различных муниципалитетов интерпретировалась как пространственная изменчивость, а для эффективного оценивания неизвестных параметров принимались некоторые априорные допущения о величине их изменения, см например, работу Westlund Anders Н. (1986) On econometric analysis of regional structural variability. Adv. Model!. \nd Simul., 5. hfc 3, p. 25-44.
24
Вступительное эссе: приглашение к анализу данных на компьютере
Интересные результаты регрессии д чя прогнозирования доходов телевизионных компаний в зависимости от трех факторов: числа продаваемых телевизоров, общего числа рекламных объявлений и правительственных мер, ограничивающих некоторую рекламу (например, рекламу сигарет), можно также получить с помощью регрессионных моделей и т. л.
Мы употреби чи слово «регрессия», которое в анализе данных имеет почти магическое значение и, возможно, отпугивает своей странностью mhoi их
Но что такое регрессия? В денет вптелыюстп, регрессия — это очень просто, и если отбросить статистический жаргон, включающий такое малопонятное слово, как «регрессия», то вы легко поймете, в чем здесь дело.
Представьте, вы изучает е годовой доход телевизионных компаний. «От чего он может зависеть7» — спрашиваете ны себя и перечисляете следующие факторы, от которых зависит доход: число зрителей, смотрящих ТВ, затраты па рекламу в гад и некоторые дру! не.
Тогда регрессия — это просто уравнение, в котором в левой части стоит интересующая вас переменная, например годовой доход, а в правой число зрителей, умноженное на некоторый коэффициент, плюс затраты на рекламу, умноженные па другой коэффициент, плюс другие параметры. То есть вы имеете уравнение:
ДОХОД = А1 х ЧИСЛО_ЗРИТЕЛЕЙ + А2 х РРКЛАМА+
Итак, у вас есть просто зависимость одной переменной от дру| их. Замечательно, что все параметры (коэффициенты уравнения в правой части) рассчитываются но реальным данным, а не назначаются умозрительно.
«А для чего мне нужна эта зависимость, выраженная в явном виде?» — спросите вы. Предположим, ны расширили сеть кабельного телевидения. то ест ь увеличили число зрителей, тогда вы можете спрогнозировать свой доход. Именно так и поступал R. Sassonc в исследовании, выполненном в 1978 году в США (данные были подучены частично от McCann-Enckson, Гпс., частично от 1 elevision Bureau of Advertising).
Аналогично вы можете спросить себя, каким обра,юм изменятся внутренние цепы на нефть при изменении иен на международном рынке, и попытаться ответа п> на этот вопрос с помощью регрессионного анализа. Типичная задача анализа качества: вы имеете группы поставщиков сырья и показатели качества продукции. Как зависит качество продукции от качества сырья?
Слово «регрессия» мы часто будем заменять словом «зависимость» и надеемся, нас правильно поймут. Вообще, мы будем стараться макепмалыгоуходитьел статистического жаргона и выражаться доступным для ка кдого здравомыслящего человека языком Потому что на этом языке изначальноформулпруютсязалачп апализаданных.
Известны сотни эффективных применении статистических методов в регрес-с ли, в том числе в экономике, маркетинге, финансах, медицине, промышленности и т. д. Результаты выглядят очень простыми, естественными н впечатляющими
Невозможно проведение актуарных расчетов без анализа конкретных данных — клиента интересует реальный риск, а не виртуальный, так как от оценки риска зависит конкретная процентная ставка и реальный платеж.
Важным полем применения статист нческих методов являются современные системы электронной торговли. Успешные действия систем онлай новой торговли требуют от фирм предсказания поведения пндишщуальных покупателей.
Вступительное эссе: приглашение к анализу данных на компьютере
Крупнейшие фирмы, занимаясь электронной коммерцией, несут ежегодно и ромные убытки из-за того, что 5—10% покупателей меняютфпрму или переходят в пассивное сос гояиие (см. Greg М. Allcnbv. Robert Р Leone and Lichung Jen (1999). X dynamic model of purchase timing with application to direct marketing. J. American Statistical Association, v. 94. № 446. p. 365-374). Системы регистрации элсктрон->ii торговли позволяют зафиксировать моменты прихода каждого покупателя в магазин, сумм)' сделки, количество товаров и другие параметры. Здесь уже все го-1>вол’1Я проведения статистического анализа. Важно спланировать его и провести .zinnia системно.
Одна из возможных задач состоит, например, в том, чтобы оценить периоды меж- покупками и изменить страта ию воздействия на покупателя — например, проги более активную рекламную кампанию, если покупатель нс обращается на фирму в течение чрезмерно долгого времени.
Для описания интервалов времени между приходами посетителей в электронный магазин можно использовать, например, гамма-распрсделеппе
На модельных данных, отражающих рсальиуюситуацию. памп подробно разби-згтся пример СУ ПЕРМАРКЕТТ or первичного, описательного анализа данных о «супках в течение дня до у гчублениогоанализа и получения неочевидных выводов
Мы начинаем с корреляционной матрицы продаж:
Рис. 15. Корреляции между покупками различных товаров
Затем рассматриваются графики, исследуется вариабельность покупок в завн пмпсти от дней недели, применяется многомерный анализ. анализируется погре ^чпецьская корзина для различных категории пользователей, различных дней Пеле 111 и т. д.
Рис. 16. Продажа спиртного в зависимости от дней недели
26
Вступительное эссе: приглашение к анализу данных на компьютере
Рис. 17. Продажа колбас в различные дни недели
Рис. 18. Зависимость суммарный покупок от дней недели
Как уже говорилось, много примеров связано с Интернетом. Имея файл с час-1 стами посещений различных страниц сайта, можно изучить структуру посещений разшчных страниц
Рис. 19. Посещение страниц сайта пользователями
Вступительное эссе: приглашение к анализу данных на компьютере
27
В частности, можно получить выводы типа: из 100 человек, посетивших страницу ОФИРМЕ, 70 человек посети ди страницу ПРОДУКТЫ, 50 человек посетили страницу ПОДДЕРЖКА, 20 человек посетили страницу ВАКАНСИИ Все это делается в модуле Основные статистики и таблицы системы STATISTICA. Нетрудно также оценить вероятность того, что пользователь с определенной страницы сайта, например страницы А, перейдет на страницу В. Блуждание пользователя по сайту вполне описывав гея вероятностной моделью. Имея исходные данные, можно оценить параметры этой модели и рассчитать типичный «путы».
В отдельной главе нами всесторонне описываются различные распределен ня вероятностей и их применение на практике. Зная вероятные распределения, можно описать многие реальные явления, например спрогнозировать число покупателей в определенные промежутки времени.
Рис. 20. Приход покупателей в магазин электронной торговли
Рис. 21. Гамма-распределение может быть использовано для моделирования моментов посещения электронного магазина
28
Вступительное эссе: приглашение к анализу данных на компьютере
Общеизвестно применение с i атлетики в медицине и фармаколец j j и. Оценка эффективнее ut лекарств, классификация больных по степени тяжести заболевания, нч юдоваппс кардиограмм, самые разнообразные т< •ты, позволяющие диагностировать пациентов па раннем .этапе заболевания, и многие другие задачи хорошо изндетны. Только математика открывает пуп, к доказательной медицине.
В знаменитом фрэмииiхсмском исследовании, выполненном в США (см. Truer J . Cornfield. J„ and Kendall. W. (1967). Л Multivariate Analysis of the Risk ol Coronary Heart Disease in Framingham, Journal of Chronic Disease 20. p 511—521),» гатистпческпй аиал из применялся для оценивания зависимости рис ка pa jhu гня ишемической болезни сердца от семи факторов.
В тгом исследовании в течение 12 лет были собраны данные о проявлениях и ше-мической болезни у 1929 мужчин и 2540женши1| в возрасте от 30 до 62 тет. В нача-п’ обследования все пациенты были здоровы. Факторами риска служили: возраст, ы |цчеств« холестерина в крови, систолическое давление, вес, количество темен п.юина в крови, количество выкуриваемых вдень сигарет (0—для некурящих, 1 для выкуривающих меньше одной пачки. 2 — одну пачку, 3 — больше одной пдчкн). электрокардпецрамма (0 — нормальная, 1 — ненормальная или неясная).
Проведенный анализ позволил изучить влияние факторов риска на развп-' иг ишемической болезни сердца н стимулировал петый ряд подобных примеров । • 1мых различных медицинских приложениях
Ра<к мотрим классические данные Гринвуда и Юла о влиянии прививки на за-<«. 10В,.-мость холерой (данные относятся к началу XX века, см., например, Спра-I* «ник по прикладной статистике, т. 1,М.: 1989. с. 245)
В приведенной ниже таблице показаны 2663 пациента, части из которых были t деланы прививки против холеры (привитые пациенты), а части пет (непривитые Пациенты)
Не заболевшие Заболевшие Сумма
Привитые 1625 5 1630
Не привитые 1022 11 1033
Сумма 2 647 16 2 663
Ч го можно сказать, глядя на эту таблицу’ Прежде всего, видно, что среди тех, мо сделал прививку, число заболевших меньше, чем среди тех. кто нс сделал приник । (второй столбец таблицы, первая и вторая строка).
Кроме того, число не заболевших средн привитых пациентов больше, чем неза-б . гевших среди кс привитых (первый столбец таблицы). Это делает правдоподобием заключение об эффективности прививки.
11о как перевести эти рассуждения на рациональный язык’ Имеется ли вообще ткойязык?
I Гредставы с. нашелся критик результатов (uoboiu метода лечения, нового ле-ырства), который, заняв крайнюю позицию, резонно ммечает, что и в том и в дру-1ом случае, то есть и среди привитых пациентов, и средн не привитых, были отмечены случаи заболевания, иными словами, полученные результаты носят чисто с лучайный характер, и утверждение об эффективности прививки весьма сомиц-ютьно.
Как рационально ответить на подобную критику?
Вступительное эссе: приглашение к анализу данных на компьютере
Лучше всего воспользоваться вероятностными рассуждениями и подходящим , । атпстическим критерием Для такого рода таблиц, называемых таблицами сопря-кеиноьти, имеются специально разработанные критерии, например критерий хи-квадрат и критерий Фишера, названный по имени знаменитого английского статистика Р. А. Фишера-
Эти критерии измеряют силу связи между признаками (переменными) таблицы, в данном примере между признаком прививка и признаком бояезиь.
Для представленной выше таблицы величина сташстики хи-квадрат раина 6,08, । о значимо па уровне 0,0136 (чтобы получить эти цифры, мы сделали два щелчка мыши в системе STATISTICA).
Следовате шно, с небольшой вероя гпостыо ошибки (меньше 0,0136) вы может е ,-исрждать, что среди привитых пациентов количество заболевших существенно меньше, чем средн непривитых. Поэтому вероятность того, ч го суждение критика неэффективности вакцины справедливо. равна всего 0,0136 (примерно один шанс 11} 70). Ваша же опенка достоверности резу-штатов существенно выше.
Весьма полезным визуальным метолом изучения зависимостей между призна-. ,»чи таблицы являются графики взаимодействий:
Рис. 22. График зависимости БОЛЕЗНЬ—ПРИВИВКА
Здесь показаны две прямые, соответствующие категориям больных: привитые — ie привитые. Если прямые пересекаются, то говорят, что признаки взаимодействуют. влияют дру1 на друга. Если прямые параллельны, то говорят, что взаимодействия или зависимости между признаками нет. Это визуальный подход, точные । -зультаты дают статистические критерии
Первые применения стат котики в медник не, по-видимому, относятся к XVI [I веку, когда в Англии было замечено, что относительная частота смертности мужчин и кеццлш одного возраста, живущих примерно в одинаковых условиях, из года в год колеблется, но колеблется в весьма узких пределах. Самым интересным здесь является замечание: «колеблется в узких пределах», — всем известно, что колебании происходят, — неожиданным фактом являются узкие границы колебания, что позволяет с большой точностью предсказать долю умерших в той и in иной категории населения и служит основой актуарных расчетов
Итак, в случайном явлении — смертности или. наоборот, выживаемости людей — была открыта устойчивая закономерность, относительная частота пли допя для
30
Вступительное эссе: приглашение к анализу данных на компьютере
нолей очного пота и близкого возраста примерно постоянна. А эти удивительное открытие, повлекшее за сивой множество событий, в частности современное страхование.
В современной медицине накопились огромные архивы данных, н их исследование с помощью новых технологий чре шычайно важная задача. STATISTICA позволяет реализовать системный подход к анализу данных.
У кажтого врача имеется собственный архив данных, отражающий многолетний опытен»работы, — огромный массив знании, имеющий большую познавательную ценность
Ценность этой информации может бы гь многократно увеличена, если воспользоваться методами анализа данных. И в этот момент на помощь нрачу приходит ин тема STATISTICA. позволяющая перевести клинический опыт на язык количественных оценок (подробнеео применении статистики в медицине см.: Ст. Глани. Медико-биологическая статистика. М., 1999).
В STATISTICA реализованы множество методов, чрезвычайно полезных врачам для анализа их данных, в частности описательные статистики и таблицы, анализ выживаемости, непараметрическая стат нстнка. дискриминантный анализ и др.
Рис. 23. Анализ выживаемости в системе STATISTICA
Анализ выживаемости позволяет проанализировать неполные или цензурированные данные, например, о выживаемости больных после операции (рис. 24).
Рис. 24. Данные по трансплантации сердца
Одной ил важных характеристик является функция выживаемости (вероятности того, чго пациент проживет! дней после операции. Для оценки функции выживаемости по неполным данным используют так называемую оценку Каплана—Мейера, которая может быть легко получена в STATISTICA (рис. 25).
Вступительное эссе: приглашение к анализу данных на компьютере 31
Рис. 25. Функция выживаемости после операции
Этот график легко «читается»: вы легко видите, например, что доля пациентов, проживших больше 10ОО дней, равна 0.4.
Можно сравнить функции выживаемости в разных больницах, для разных возрастных групп (рис. 26).
Рис. 26. Сравнение выживаемости е разных группах
Рис 27. Модуль Непзранетрические статистики в системе STATISTICA
32
Вступительное эссе: приглашение к анализу данных на компьютере
Опишем еще одну важную область применения статистических меоi юн — современное высокотехнологичное производство.
Традиционную область применения статистичевшн о анализа данных < с i авляет промышленность.
Обычно любая машина или станок, используемые на производст ве, позволяют операторам производить настройки, чтобы воздействовать на качество производимого продукта. Изменяя настройки, инженер стремится добиться максимального эффек та, а также выяснить, какие факторы играют наиболее важную роль в улучшении качества продукции Использование этой информации позволяет достигнуть оптимального качества в условиях данного пронзиодсгна.
Например, на производстве (см. например, книгу: Box, Draper (1990), Empirical inudel-binkling and response surfaces. New York: Wiley, 115) проводился эксперимент по нахождению оптимальных условий для и иотовлеиня красителя ткани. Кпчтшю красителя описывается насыщенностью, яркостью н стойкостью.
Другими словами, в этом эксперименте нам хотелось бы выявить факторы, наиболее заметно (значимо) влияющие на яркость, насыщенность и стойкость производимого красителя. В примере Бокса и Дрейпера рассматривается 6 различных факторов, влияние которых оценивается с помощью так называемого плана 2**°* В данном плаце первоначально рассматривались 6 факторов, принимающих 2 значения, то есть всего имелось 26 “ 32 различных вариантов установок. Результаты эксперимента выявили три наиболее важных фактора: Polysulfide ( Поли сульфид). Time (Время) и Temperature (Температура).
Можно представить ожидаемое воздействие на интересующую нас переменную (например, светостойкость окрас кн) в виде так называемой кубической диаграммы. которая показывает ожидаемую (предсказываемую) среднюю стойкость краски. нанесенном на ткань, на верхних и нижних уровнях каждого нз трех факторов, и определить тс значения факторов, которые обеспечивают максимальное качество продукции (рис. 28).
Рис 28. Кубическая диаграмма показывает значимость факторов, установленных на разных уровнях
Вступительное эссе: приглашение к анализу данных на компьютере
33
Глядя на эту диаграмму, легко можно понять, что наилучшее расположение факторов для максимина цин качества красителя следующее: Poly sulfide установлен на верхнем уровне HIGH. Time — на верхнем уровне LONG, Temperature — на верхнем уровне HIGH Таким образом, оптимум достигается на дальней вершине ку ба (см. рис. 28).
В описанном эксперименте присутствовало 6 факторов, нередки, однако, случаи, когда очень много (до 100) различных факторов являются потенциально важными на производстве, однако заранее вы не знаете, какие факторы важны, а какие нет.
Специальные планы, например план Плакетта—Бермана или планы с матрицей Ддамара, позволяют эффективно «просеять* или, как говорят на статистическом сленге, ироскри пировать большое число факторов, используя минимальное число наблюдений.
Например, вы можете спланировать и проанализировать эксперимент со 127 факторами, используя всего 128 опытов, азатем оценить главный эффект каждого фактора, определив, какие факторы играют доминирующую роль, а какие нет.
Выход продукта многих химических реакций является функцией времени и температуры. Ксожалению, эти переменные влияют на выход нелинейно. Другими товамп. нельзя сказать: «чем больше продолжительность реакции, тем больше выход» и «чем выше температура, тем больше выход». Цель экспериментатора заключается в определении оптимального выхода или экстремальной точки поверхности выхода, образованной двумя переменными: временем и температурой.
При проведении таких экспериментов используют так называемые центральные композиционные планы, позволяющие инженерам-технологам оценить поверхность регрессии (рис. 29 и 30) и найти экстремумы этой поверхности, или точки, отвечающие заданному значению зависимой переменной.
Подоб] ibie планы применялись, например, для исследования ракетного топлива, в состав которого входили три компоненты: связывающее вещество, окислитель и горючее, а характеристикой качества являлась эластичность продукта (см. также планы для смесей в модуле Планирование эксперимента в системе STATISTICA)
Требовалось найти такие пропорции (доли) компонент, чтобы эластичность дожигала заданного значения (см. Kurotori I. S. (1966). Experiment with mixtures of components having lower bounds. Industrial Quality Control, № 2, p. 592-596).
Рис, 29. Поверхность регрессии
34
Вступительное эссе- приглашение к анализу данных на компьютере
Рис. 30. Визуальные методы STATISTICA при планировании экспериментов
Это типичные задач и планирования эксперимента, возникающие на производстве, и система STATISTICA предоставляет эффективные методы их решения.
Ниже показаны методы планирования эксперимента, доступные в системе.
Не менее важны в промышленности задачи контроля качества.
Для всех производственных процессов возникает необходимость установить пре-зелы характеристик изделия, в рамках которых произведенная продукция удовлетворяет своему предназначению. Вообще говоря, существует два «врага» качества продукции:
1. Уклонен ня от значений плановых спецификаций изделия.
2. Слишком высокая изменчивость реальных характеристик модели й относительно значений плановых спецификаций, что говорит о несбалансированности процесса
Вступительное эссе: приглашение к анализу данных на компьютере
35
На Л шее ранних стадиях отладки производственного процесса для оптимизации этих двух показателей качества производства часто используются описанные выше методы планирования эксперимента.
Методы контроля качества предназначены для построения процедур контроля качества продукции в процессе ее производства, то есть текущего контроля качества Детальное описание принципов построения контрольных карт и подробные примеры можно натп и в работах: Buffa (1972) Operation management: Problems and models (3"1 ed), New York: Wiley', Duncan (1974) Quality control and industrial statistics, Homewood, IL: Richard D. Irwin, Granl and Leavenworth (1980) Statistical quality control (5lfc ed.) New York: McGraw-Hill. Juran and Gryna (1988) Quality planning „ »d analysis (2n,,ed.) New York: McGraw-Hill. Montgomery (1985) Statistical quality control New York: Wiley. Montgomery (1991) Design and analysis of experiment (34 cd ) New York: Wiley, Shirland (1993) или Vaughn (1974).
В качестве превосходного вводного курса, построенного на основе подхода «ь.|К — чтобы», можно указать монографию Hart and Hart (1989) Quantitative methods юг quality improvement. Milwaukee, WI. ASQC Quality Press.
Особенно интенсивно методы контроля качества используются в США, Германии, Японии.
Общий подход к текущему контролю качества заключается в следующем.
В процессе производства из произведенной продукции или поступающего । лрья проводится отбор выборок изделий заданного объема. После этого на специально разлинованной бумаге строятся диаграммы средних значений и измен-.шости выборочных значений плановых спецификаций в этих выборках и рае-< магрпвастся степень их близости к плановым значениям. Если диаграммы обнаруживают наличие тренда выборочных значений или выборочные значения иываются вне заданных пределов, то считается, что процесс вышел из-под контроля, и предпринимаются необходимые действия для того, чтобы найти лри-11 «ну разладки.
Гакпе специальные карты называются контрольными картами Шухарта(назван-। де в честь W. A, Shewhart, который! общепризнанно считается первым, ггримеи пищим их на практике в начале 30-х годов XX века).
Один из примеров карты Шухарта показан па рис. 33. Смысл этой карты ясен. В нес цдовательно поступающих партиях нефтепродуктов измерялась примесь вредных веществ. Строятся два линейных графика: для средних и размахов (разит теп между максимальными и минимальными значениями выборки, что характеризует изменчивость характеристик производственного процесса).
Вначале посмотрим на график средних. Если средние выходят за определенные границы, то мы говорим о неудовлетворительном качестве сырья. На графике сред- 'качений партии неудовлетворительного качества имеют специальную М1тк>.
Далее рассматриваем график размахов. Размах — это разность между максимальным и минимальным значением выборки. Прагматическая ценность этой характеристики в том, что она служит мерой изменчивости. По расположению точек иа I рафике размахов принимают решение о случайности или система! цчиости от-*• юнсния в качестве продукции.
Ниже показаны карты контроля качества, доступные в системе
36
Вступительное эссе: приглашение к анализу данных на компьютере
Рис. 32. Контрольные карты системы STATISTICA
На практике могут возникнуть трудности при выборе наилучшей контрольной карты. Чтобы сделать выбор осознанно, нужно учитывать специфику производства, например, если исследуется концентрация определенных веществ в химическом процессе в режиме реального времени, то сложно провести группировку данных п следует применять карты для индивидуальных наблюдений В отличие от этого, в машиностроении при измерении параметров продукции, например диаметров поршневых колец, легко разбить партию данных на подгруппы и применить соответствующие X- и R-карты (рис. 33).
Еше одной типичной проблемой, с которой сталкиваются инженеры по контролю качества на производстве, является следующая: определить, сколько именно изделий из партии (например, полученной от поставщика) необходимо исследовать, чтобы с высокой степенью уверенности утверждать, что изделия всей партии обладают приемлемым качеством.
Допустим, что у вашей автомобильной компании есть поставщик поршневых колец для небольших двигателей, и ваша цель — разработать процедуру выборочного контроля поршневых колец в присылаемых партиях, обеспечивающую требуемое качество.
Процедуры выборочного контроля применяются в том случае, когда нужно решить, удовлетворяет ли определенным спецификациям партия изделий, не изучая при этом все изделия.
Рис. 33. X- и R-карты Шухарта для группированных данных
эссе: приглашение к анализу данных на компьютере
В силу природы проблемы — принимать или не принимать партию изделий — эти методы иногда называют статистическим приемочным контролем. (acceptance sampling).
Очевидное преимущество выборочного контроля над полным, или сплошным, контролем продукции состоит в том, что изучение только выборки (а не всей партии целиком) требует меньше времени и финансовых затрат. В некоторых случаях исследование изделия является разрушающим (например, испытание стали на предельную прочность), и сплошной контроль уничтожил бы всю партию.
Наконец, с точки зрения управления производством отбраковка всей партии или поставки от данного поставщика (на основании выборочного контроля) вмес-браковки лишь определенного процента дефектных изделий (на основании си юшногоконтроля) часто заставляет поставщиков строже придерживаться стандартов качества.
Если взять повторные выборки определенного объема из совокупности, скажем, поршневых колец и вычислить их средние диаметры, то распределение этих средних значений будет приближаться к нормальному распределению с определенным средним значением и стандартным отклонением (или стандартной ошибкой; для выборочных распределений термин «стандартная ошибка* предпочтительнее, чтобы отличать изменчивость средних значений от изменчивости изделий в генерал ь-। юй совокупности).
К счастью, нет необходимости брать повторные выборки из совокупности, что-ы оценить среднее значение и изменчивость (стандартную ошибку) выборочного аспределения. Располагая хорошей оценкой того, какова изменчивость (стандарт-? отклонение, или сигма) в данной совокупности, можно вывести выборочное распределение среднего значение. В принципе этой информации достаточно, чтобы оценить объем выборки, необходимый для обнаружения некоторого изменения । ачества (по сравнению с заданными спецификациями).
Обычно технические условия задают некий диапазон допустимых значений. Например, считается приемлемым, если значения диаметров поршневых колец лежат в пределах 74,0 мм ± 0,02 мм. Таким образом, нижняя граница допуска для данного '•роцесса равна 73,98; верхняя граница допуска — 74,02. Разность между верхней границей допуска (ВГД) я нижней границей допуска (НГД) называется размахом допуска
Простейшим и самым естественным показателем пригодности производственного процесса служит потенциальная пригодность. Она определяется как отношение размаха допуска к размаху процесса; при использовании правила 3 сигма данный показатель можно выразить в виде
Ср = (ВГД - НГД)/(6 X сигма).
Данное отношение выражает долю размаха кривой нормального распределения, «опадающую в границы допуска (при условии, что среднее значение распределения является номинальным, то есть процесс центрирован).
В книге Bhote (1988) World class quality. New York- AMA Membership Publications отмечается, что до повсеместного внедрения методов статистического контроля качества (до 1980 г.) обычное качество производственных процессов в США состав-чя то примерно Ср = 0,67. Иными словами, два хвоста кривой нормального распре
38
Вступительное эссе: приглашение к анализу данных на компьютере
деления, каждый из которых содержал 33/2% общего количества изделий, попадали за границы допуска.
В конце 80-х годов лишь около 30% производств в США находились на этом или еще худшем уровне качества (см. Bbote, 1988, стр. 51). В идеале, конечно, было бы хорошо, если бы этот показатель превышал 1, то есть хотелось бы достигнуть такого уровня пригодности процесса, чтобы никакое (или почти никакое) изделие не выходило аа границы допуска. Любопытно, что в начале 80-х годов японская промыш тонкость приняла в качестве стандарта Ср 1,33! Пригодность процесса, требуемая для изготовления высокотехнологичных изделий, еще выше; компания Minolta установила показатель Ср - 2.0 как минимальный стандарт для себя (Bhote, 1988, с. 53) и как общий стандарт для своих поставщиков
Заметим, что высокая пригодность процесса обычно приводит к более низкой, а ие к более высокой себестоимости, если учесть затраты на рекламацию, связанную с низким качеством производимой продукции.
Как правило, более высокое качество обычно приводит к снижению общей себестоимости. Хотя издержки производства при этом увеличиваются, но убытки, вызванные плохим качеством, например из-за рекламаций потребителей, потери доли рынка и т. п., обычно намного превышают затраты на контроль качества.
На практике два или три хорошо спланированных эксперимента, проведенных в течение нескольких недель, часто позволяют достичь высокого показателя Сг
В качестве одного из интересных примеров применения статистики в промышленности отметим задачу классификации сортов бензина, решаемую с помощью дискриминантного анализа.
Важная роль статистики в управлении экономикой США отмечена в статье: Moynihan D. Р. (1999) Data and dogma in public policy, J. American Statistical Association, v. 94, № 446, p. 359—364: «статистика, — no словам автора, — помогает понять си ты, воздействующие на экономику». Без статистики трудно выделить основные факторы, влияющие на экономику, и предпринимать шага, позволяющие минимизировать неблагоприятные флуктуации рынка.
Разнообразные задачи могут быть решены с помощью статистики на региональном уровне, начиная с задач описательной статистики, например цел на потребительском рынке продуктов питания, зависимости внутрирегиональных цен от цен в соседних регионах, ввоза товаров из других регионов в пределах экономической террцторш 1 pel иона доходов населения» описания рынка труда, уровня жизни, экологической ситуации, здравоохранения и т. д.
Также могут быть решены задачи оценки технического состояния транспортных средств города, расчет налоговых льгот для осуществления инвестиций в транспортную систему, классификация объектов незавершенного строительства, классификация должников, классификация источников выбросов зшрязняющих веществ и множество других, гае до сих пор применяются эмпирические правила
Методы множественной регрессии позволяют исследовать рынок сельскохозяйственной продукции. В качестве примера укажем статью Ношпа Masayoshi, Hayami Yujioro (1986) Structure of agricultural protection in industrial countries, J. Int. Econ., 20. Nsl —2, p. 115—129, в которой исследована система протекции 10 индустриально развитых стран и дан социально-экономический анализ коэффициентов регрессии. Известно, что сельскохозяйственная политика индустриально развитых стран ха-
вступительное эссе: приглашение к анализу данных на компьютере
39
растеризуется сильными протекционистскими (защитными) мерами в отношении собственных производите лей, иными с швами, создаются такие торговые ограничения и система управления ценами, которые позволяют собственным производителям находиться в заведомо выгодном положении. Система протекции включает, в частности, экспортные налоги и завышенные обменные курсы валют. Следствие такой политики — дискриминационное положение сельскохозяйственных производителей развивающихся стран и неравномерное распределение продовольствия в мире. Подобные методы можно, конечно, применить и к изучению российского рынка
Kai. и все математические науки, статистика родилась из практики. Подобно ,, лу как древние египтяне после разливов Нила вынуждены были заново измерять свои участки и для этого разработали начала геометрии, так и современные тю гп, вовлеченные в стремительно меняющиеся потоки данных (Интернет, газеты, ТВ. слухи, сплетни, мнения экспертов и т. д.), вынуждены анализировать их. (ля этого попросту нет ничего иного, кроме статистики и анализа данных.
Классическая математика имеет дело с детерминированными величинами и принципиально не приспособлена для работы со случайными данными. Конечно, мы стремимся интуитивно сузить пределы случайности, максимально уменьшить неопределенность, но сделать это полностью не удастся.
По-видимому, случайность является важным элементом мироздания- выброшенные в открытый хаотически меняющийся мир, мы вынуждены либо приспосабливаться к нему и побеждать, либо погибнуть или влачить жалкое существование, нс понимая ни сущности вещей, ни событий, происходящих в нем
Ни у кого не вызывает сомнения, что при строительстве дома следует исподьзо-wгь начальныезнания геометрии. Попробуйте точно начертить прямоугольник на 'чап ке земли, и вы увидите, что сделать это нс так просто.
Как проверить, что начерченный четырехугольник действительно является ||рям!>угольн11ком? Если вы не знаете, что диагонали прямоугольника равны, то то жнетесь с непростой задачей.
Точно так же при исследовании сложных систем, хаотических явлений и пото- в информации вы применяете статистику, в которой для измерения случайнос-। • й разработаны как простейшие, но очень полезные инструменты, подобные цнр-тю и транспортиру, так и весьма тонкие и совершенные методы.
Интересен следующий пример, приведенный Ж. Бертраном в его курсе «Исчнс-генпе вероятностей*: Некто, прогуливаясь в Неаполе, увидел человека из Базиликаты, который держал пари, что теперь же выбросит 3 шестерки, бросив 3 игральные сти... Удивительный человек из Базиликаты на глазах изумленной публики сделал >тп я затем повторил фокус 2,3,4 и 5 раз подряд. «Черт побери, — воскликнул Hi что, — кости же, конечно, налиты свинцом!» — и был прав, потому что наблюдаемое событие, бросить 3 кости 5 раз подряд и каждый раз получать 3 шестерки, имеет ничтожно малую вероятность, равную ((1/6) х( 1/6 х(1/6)У'5 = 4,71 х 10 " Другими словами, он имел лишь 471 шанс из 10 х 1012 ошибиться в своем .гаклю-‘1СНШ1. Заметим, что склонность использовать случай в свою пользу быласвойствеп-на еще египетским фараонам, в гробнице которых обнаружены игральные кости со смещенными центрами тяжести.
Классическим, и вместе с тем забавным, является пример шевалье де Мере, когда ставший известным в веках благодаря своей любознате imiocth, азартный
40
Вступительное эссе: приглашение к анализу данных на компьютере
игрок спросил себя: стоит ли ему ставить на выпадение двух шестерок одновременно при бросании двух костей 24 раза пли нет? Его собственные вычисления показали, что стоит, так как вероятность данного события при 24 бросках костей больше 1/2. Как же он удивился, когда с течением времени обнаружил, что постоянно оказывается в проигрыше! Оскорбленный игрок во всем обвинил статистику. И только знаменитый Паскаль нашел, в чем состоит ошибка игрока: оказывается, вероятность данного события 0,49 (меньше 0,5’), следовательно, в длинной серии игр, состоящих в 24 подбрасываниях двух костей, выигрыш происходит лишь и 49%, а не в более 50% игр, как ожидал де Мере.
В STATISTICA эта задача, то есть вычисление вероятности выпадения двух шестерок, решается несколькими щелчками мыши.
Интересно, что не стоит делать ставку на выпадение двух шестерок при 24 бросках пары костей, но стоит это делать при 25 бросках, так как вероятность выпадения хотя бы раз пары костей при 25 бросках больше 1 2, следовательно, в длинной серии игр игрок, поставивший на две шестерки, будет в выигрыше чаше, чем в про-игрыше. Если бы правила игры были изменены и проводи чось25 бросков, то в длинной серии игр де Мере оказался бы в выигрыше.
Конечно, теперь этот пример кажется забавным. Современное взаимодействие статистики с практикой много изощреннее, но суть остается той же- применяя статистические методы, вы должны найти устойчивые закономерности в случайных данных и воспользоваться ими с пользой для себя.
Применение даже простых статистических методов позволяет добиться эффектов там, гае непосвященные опускают руки.
Одной из таких задач является пересчет голосов при голосовании. Предположим, что в ходе выборов одни из кандидатов уступил другому несколько десятых процентов голосов. Так как разница очень небольшая, то потерпевший неудачу может усомниться в правильности подсчета и поставить вопрос о пересчете. Если пересчет подтвердит результаты голосования, то, во закону, ему нужно будет оплатить расходы, связанные с пересчетом. В противном случае он окажется победителем. Формально, на языке статистики, эта задача сводится к проверке гипотезы о неравенстве математических ожиданий двух биномиальных величин, см. например, работу, Harns Bernard (1988) Election recounting, Amer. Statis., 42, № 1, p, 66-68
Для кого эта книга?
Книга рассчитана на самый широкий круг читателей, для которых важен анализ данных: статистиков, экономистов, маркетологов, аналитиков, актуариев, бизнесменов, инженеров, лиц, принимающих решения, и многих дру1 их
Иными словами, она полезна тем, кто интуитивно понимает, что из анализа данных можно извлечь реальную пользу. Всех их мы хотим научить искусству анализа данных на компьютере.
Она также чрезвычайно полезна врачам, инженерам, научным работникам, преподавателям и студентам.
Разбираемые нами примеры охватывают самый широкий спекгр приложений.
Предлагаемая киш а является синтезом двух частей: описания разнообразных статистических методов — от элементарных понятий и принципов до возможных
Вступительное эссе: приглашение к анализу данных на компьютере
41
.онкретнык приложении, и описание анализа данных с помощью этих методов в системе STATISTIC А в среде Windows и отражает многолетний опыт автора ватой ufi части
Система STATISTICA включает в себя все известные истоды статистического ;мытпза (Энных и позволяет сделать процесс анализа высокотехнологичным. Ме-।, 5ы. известные ранее по учебникам и научным публикациям, теперь доступны всем
В книге содержится подробное описание основных возможностей системы STATISTIC А. описаны основные диалоговые окна и команды системы. Особое внимание уделено повой технологии компьютерной обработки данных, максимально . вмещенной со стандартами Windows.
STATIST ICA позволяет реализовать системный подход к анализу данных, в час-. <ч и. средсч вамп STATISTICA можно создать своп модули анализа данных <4-и. рис. 34). Дополненные методами визуального программирования, эти сред-гт моткрывают захватывающие перспективы.
Каждая глава книги наряду с примерами содержит большой справочный мате-I. Книга написана в двух срезах — для неподготовленного пользователя, нпер- лакомящегося с методами анализа, и для тех, кто имеет специальную матема-
। iлуЮ подготовку и опыт работы па компьютере.
Начнем мы с изложения элементарных попятим. Вообще эти понятия следует , । j- тш ь на два класса понятия, относящиеся собственно к статистике, и попя-- относящиеся к анализу данных. И здесь есть некоторая тонкость. В статнети--их исследованиях, например в эконометрике (приложении методов статистики в н ономпке). мы исходим из априорной экономической модели и пытаемся оце-Mirrj, параметры. Это так называемый дедуктивный подход, в котором первична ь. а данные используются для оценки неизвестных параметров и проверки «з очных гипотез относительно модели Здесь возникают понятия качества оце-। < >к. 7] >вця значимости и т. д.
Рис. 34. Настройка STATISTICA на конкретный проект
Вступительное эссе: приглашение к анализу данных на компьютере
В анализе данных мы желаем исходить из данных как таковых, имея минимум априорных идей относительно их структуры. Далее мы стремимся понять, как организованы данные, какие переменные или группы переменных связаны (коррелируют) между собой, иными словами, стремимся понять структуру данных, исходя из них самих. Наиболее известная крайняя точка зрения этого подхода выражена в лозунге Бепзекри (Benzecri), одного из создателей анализа соответствий: «Модель должна соответствовать данным, а не наоборот’* Насколько правомерен такой подход, судить философам, но он существует и его нельзя отвергать.
Приверженцы анализа данных зачастую критикуют эконометрику, утверждая, что она имеет дело с абстрактными гипотезами, которые никогда не работают па практике
В действительности, между этими направлениями нет бездонной пропасти — известно, что анализ данных черпает свои идеи из классической статистики и наоборот. Типичный пример — анализ соответствий, чисто индуктивный метод, корни которого «тем не менее» лежат в математической статистике и свойствах знаменитого критерия хи-квадрат, открытого Карлом Пирсоном.
Рис. 35. Рабочие окна STATISTICA
Пример индуктивного подхода можно найти в интересной статье F.-X. Micheloud, бывшей долгое время доступном насайте http://www.micheloud.eom/FXM/cor/e/genera.htm.
Вступительное эссе: приглашение к анализу данных на компьютере
43
где разведочный анализ данных (анализ соответствий) применяется к исследованию уровня образования жителей Лозанны (Швейцария). Автор, не используя прямо статистические рассуждения, работаете выборкой из 169 836 человек. Спрашивается. а почему нс с выборкой, состоящей из 100 человек? Очевидно, что для него интерес представляют перманентные, или устойчивые, выводы Но понять, с какой выборкой нужно иметь дело, можно тишь с помощью теоретико-вероятностных и статистических рассуждений.
В данной книге мы стремились синтезировать классические методы статистики с методами анализа данных и таким образом открыть новые возможности для ис • гдедователей.
Лейтмотивом нашей книги является утверждение, что невозможно умозрительно научиться анализу данных. Если вы хотите овладеть анализом данных, вам следует совместить основные принципы анализа данных с работой в системе STATISTICA.
Ключевым является понятие технологии, совмещение идей (Хоуо^) с действием (теХУ’аш), иными словами, вы нс просто мыслите, но и производите с помощью компьютера действия, которые усиливают и развивают ваши мысли.
Мы трактуем нейронные сети как развитие классических методов анализа, основное отличие состоит в том, что в нейронных сетях используется специальный оазис исходных функций, и собираются сложные многомерные зависимости из элементарных одномерных функций, реализуемых нейронами. Таким образом, вы можете использовать нейронные сети для построения сложных нелинейных зависимостей или нелинейных классификаций, которые недоступны другим методам. Формально нейронные сети woiyr быть изложены чисто математически, без привлечения понятия нейрон, однако биологический язык и нейронная интерпретация создают новую реальность, открывающую массу возможностей для исследователя.
Математическим основанием нейронных сетей является знаменитая теорема Колмогорова, утверждающая, что сложные нелинейные функции могут быть собраны на двухслойных или трехслойных сетях персептронов. В частности, если нужно приблизить непрерывную и-мерную функцию, то достаточно сети с одним • крытым слоем, содержащим 2п + 1 нейрона. Ник го не утверждает, что вам удастся быстро построить нужную сеть, которая хорошо приближает сложную зависимость на имеющихся реальных данных, однако заведомо невозможно сделать это чист . умозрительно. Используя компьютерные технологии, вы можете испытать как классические методы анализа, так и нейронные сети.
В нашем наложении мы опирались на фундаментальные тексты Кендалла Ы. Дж. и Стьюарта А., особенно на их замечательную книгу Статистические выводы и связи. М: Наука, 1973
Д 1я описания функций распределения мы использовали фундаментальное издание: Вероятность и математическая статистика. М.: Большая российская энциклопедия, 1999.
В ряде случаев нам оказались полезными справочники:
Айвазян С. А, Енюков И. С.. Мсшалкпн Л. Д. Прикладная статистика: основы Моде пирования и первичная обработка данных. М,: Финансы и статистика, 1983.
Справочник ио прикладной статистике под редакцией Э. Ллойда и У, Ледерма-на> 1 1,2. №.: Финансы и статистика, 1989.
На этом позвольте закончить наш, возможно, слишком продолжительный экскурс в анализ данных и перейти к систематическому изложению материала.
Краткая экскурсия
по системе STATISTICA
Вступление
STATISTICA — это интегрированная система анализа и управления данными STATISTICA — этоикструментразработки пользовательских приложений в бизнесе, экономике, финансах, промышленности, медици не, страховании и других областях. STATISTICA легка в освоении и использовании.
Все аналитические инструменты, имеющиеся в системе, доступны пользователю и могут быть выбраны с помощью альтернативного пользовательского интерфейса. Пользователь может всесторонне автоматизировать свою работу, начиная с применения простых макросов для автоматизации рутинных действий вплоть до углубленных проектов, включающих, в том числе, интеграцию системы с другими приложениями или Интернетом. Технология автоматизации позволяет даже неопытному пользователю настроить систему на свой проект.
Процедурысистемы STATISTICA имеют высокую скорость и точность вычислений.
Гибкая и мощная технология доступа к данным позволяет эффективно работать какстабдидах5иданныхналокальномдиске,такисудаленнымихранилищамнданных.
Система обладает следующими общепризнанными достоинствами:
О содержит полный набор классических методов анализа данных: от основных методов статистики до продвинутых методов, что позволяет гибко организовать анализ;
о является средством построения приложений в конкретных областях;
о в комплект поставки входят специально подобранные примеры, позволяющие систематически осваивать методы анализа:
О отвечает всем стандартам Windows, что позволяет сделать анализ высокоинтерактивным;
О система может быть интегрирована в Интернет;
О поддерживает web-форматы: HTML, JPEG, PNG;
О легка в освоении, и как показывает опыт, пользователи из всех областей применения быстро осваивают систему;
о данные системы STATISTIC А легко конвертировать в различ ные базы данных и электронные таблицы;
О поддерживает высококачественную графику, позволя ющую эффектно визуализировать данные п проводить графический анализ;
Вступление
О является открытой системой: содержит языки программирования, которые позволяют расширять систему, запускать ее из других Windows-приложений. например, из Excel.
STATISTICA состоит из набора модулей, в каждом из которых собраны тема-м, и связи ые Группы процедур. При переключении модулей можно либо остав-•. । «крытым только одно окно приложения STATISTICA, либо все вызванные . модули, поскольку каждый из них может выполняться в отдельном окне (как , состоятельное приложение Windows).
При исполнении модулей STATISTICA как самостоятельных приложений влю-' й м «пент времени в любом модуле имеется прямой доступ к «общим» ресурсам ( пк ицам данных, языкам BASIC и SCL. графическим процедурам).
При инсталляции системы программа установки [Setup) создает на рабочем столе ; .пну при вожений под названием STATISTICAn помещает туда значки окна Лере-<чючатечь модулей (пиктограмма STATISTICA — первая в группе, см. рис.), моду-< 'новные статистики и таблицы и некоторых других программ [Help, Setup). Пользователю может показаться более удобным запускать модули, щелкая по их зпач! , м на рабочем столе (вместо того чтобы пользоваться окном Переключатель моду чей); поэтому он, вероятно, захочет создать дополнительные пиктограммы для моду чей помимо тех, которые будут автоматически созданы программой установки (Setup). для Того чтобы создать еще один значок в данной группе, следуйте стандартной процедуре Windows (выберите пункт Новый в меню Файл в окне Диспетчер программ (Program Manager) и создайте новый программный элемент).
Настройка системы STATISTICA. В системе предусмотрена возможность на-<трпйкн множества характеристик и интерфейса программы в соответствии с пред-
Глава 1. Краткая экскурсия по системе STATISTICA
почтениямн пользователя. Можно изменить, например, процессзапуска,а именно — отмен»! ь установленный по умолчанию полноэкранный режим, изменять вил стартовой панели, панели инструментов, таблиц с данными и другие параметры.
Настройка общих параметров системы. Настройку обицгх параметров системы можно изменить в любой момент работы с программой. Эти парамет ры определяют:
О обил te аспекты поведения программы (максимизация окна STATIS ПСА при запуске. Рабочие книги, инструмент Переглядеть и отпустить — Drag-and-Drop, автоматические связи между графиками и данными, многозадачный режим н т. Д-):
О режим вывода (например, автоматическая распечатка таблиц пли графиков, формат ы отчетов, буферизация и т. д.):
Э общи if вид окна приложения (значки, панели инструментов и т. д.);
Э вид окон документов (цвета, шрифты).
Каждый из этих параметров можно настроить в соответствующем окне, доступ к которому осуществляется через меню Сервис. На следующих рисунках показаны тва примера таких окон.
Вступление
Все общие мрамстры могут быть настроены i независимо от ч ипа окна документа (например, таблица или график), которое активно в данный момент.
Настройка пользовательского интерфейса. При работе с системой STATISTICA имеется возможность настройки пользовательского интерфейса программы таким образом, >ггобы он стал более «продуманным» сточки зрения потребностей конк-пг гного пользователя.
В зависимости от требований задачи и личных предпочтений (а также эстетических соображений) можно использовать разнообразные «режимы» и условия обиты программы.
48
Глава 1. Краткая экскурсия по системе STATISTICA
Поддержка нескольких различных конфигураций системы STATISTICA. До внесения специальных изменений STATISTICA будет хранить все текущие настройки и параметры по умолчанию.
То обстоятельство, что сведения о конфигурации системы хранятся в той же папке, из которой вызывается программа STATISTICA, позволяет иметь в своем распоряжении различные варианты конфигурации программы для разных проектов или видов работ. Например, можно вызывать программу из разных папок на диске, каждая из которых содержит определенный связный набор документов, и для каждой из этих папок система может быть сконфигурирована со своими настройками вывода, параметрами графиков по умолчанию и т. д. Можно создать несколько значков STATISTICA в разных группах приложений на рабочем столе Windows (каждая из которых соответствует определенному проекту или виду работ) и задать для них различные значения в поле Рабочая директория (Working Directory) (с помощью диалогового окна системы Windows Свойства программного элемента (Program Item Properties)).
Многозадачность. STATISTICA поддерживает режим многозадачности (между своими модулями или другими приложениями).
При обработке очень больших объемов информации или выполнении сложных процедур анализа можно переключиться в другой модуль STATISTICA (или другое приложение Windows), используя возможность вести процесс обработки данных в фоновом режиме.
Работа в одном окне приложения STATISTICA (вместо многооконного режима). Один из вариантов глобальной системной настройки пакета STATISTICA позволяет пользователю задать режим, в котором по умолчанию будет работать про-
Вступление
49
грамма — н одном окне приложения или же как набор приложений (каждое в своем окне). Одним из непосредственных следствий этого выбора будет то, в каким режиме будет работать окно Переключатель модулей: при двойном щелчке на имени модуля в этом окне выбранный модуль будет открываться либо вместо утке открытого, либо для него будет открываться новое окно приложения, причем предыдущее окно останется открытым.
Выбор того или другого режима работы производится в поле Переключение мо-пгяей:режим одного приложения в диалоговом окне Параметры по умолчанию: общие настройки (вызывается из меню Сервис). Если это поде отмечено, STATISTICA Гл'дет работать в режиме одного приложения.
Режим одного приложения. При выбранном режиме одного окна приложения переключение с одного модуля на другой будет происходить без открытия новых окон. Новый модуль всякий раз будет открываться в том же самом окне, заменяя предыдущий. Некоторые пользователи предпочтут именно такой «простой» режим работы, поскольку весь анализ будет происходить в одном окне приложения, а количество активных программ на рабочем столе будет минимальным.
Примерно такого же эффекта можно достичь, нажимая кнопку Закончить и переключиться в диалоговом окне Переключатель модулей: при этом окно приложения текущего модуля закроется, но не будет заменено новым окном; вместо этого система откроет «следующее» окно приложения.
Режим нескольких приложений. Основное преимущество режима нескольких приложений — возможность параллельного выполнения различных процедур ана-1 иза (модули) в разных одновременно открытых окнах приложения. При этом мож
50
Глава 1. Краткая экскурсия по системе STATISTICA
но переключаться между модулями, не закрывая предыдущие. и использовать все преимущества работы с независимыми очередями таблиц результатов и графиков для окон приложений разных модулей. Этот режим имеет очевидные преимущества для большинства задач аиал нза данных п даст возможность использовать различные методы анализа (и сравнивать полученные результаты).
Интерактивный анализ данных в STATISTICA. Система не требует, чтобы пользователь еще до проведения анализа указал всю информацию, которую следует вывести на экран Ведь анализ даже простого плана может породить большое число таблиц результатов и просто необозримое количество графиков, поэтому при проведении реального анализа, до изучения основных результатов, трудно представить, какие графики пли таблицы следует анализировать в первую очередь. Именно поэтому STATISTICA предоставляет пользователю возможность выбрать определенные типы вывода и интерактивно провести последовательные сравнения и моделирующий анализ уже послетою, как данные обработаны и получены основные результаты.
Количество выводимых окоп также может быть настроено, чтобы нс перегружать экран компьютера.
Гибкие вычислительные процедуры STATISTICA и широкий выбор методов графического представления данных любого типа открывают перед пользователем безграничные возможности проведения разведочного анализа и проверки статистических гипотез.
Какие возможности предоставляют рабочие книги Рабочие книги помогают организовывать наборы файлов (например, таблиц результатов, графиков, тек-
Вступление
cTOHiJx/графлческнх отчетов. пользовательских программ п т д.). которые были созданы ичн использовались (например. просматривались) во время анализа набора данных. Рабочие книги хранят список всех файлов, использовавшихся с те-( . щим набором данных.
Обновленный список этих файлов автоматически сохраняется с файлом дан-Еслн поставить пометку в поле Авто около имени файла,то он будет автома-
ки открываться с текущим набором данных
52
Глава 1. Краткая экскурсия по системе STATISTICA
Справочная система и интерактивное (электронное) руководство. Чтобы подучить дополнительную информацию о некоторых функциях системы, нажмите клавишу справки (F1), когда выделена соответствующая команда или пункт меню. STATISTICA содержит Электронное руководство — справочную информацию по всем процедурам и функциям программы, доступную в контекстно-зависимом режиме при нажатии клавиши F1 или кнопки справки в строке заголовка всех диалоговых окон (справочник содержит свыше 10 мегабайт документации в сжатом виде). Благодаря динамической организации Электронного руководства с помощью г нперссылок (и различным возможностям его настройки), как правило, быстрее использовать эту справочную систему, чем искать нужную информацию в напечатанном виде. Справку также можно вызвать двойным щелчком на поле сообщений строки состояния в нижней части окна приложения STATISTICA (в поле сообщений тоже отображаются краткие комментарии о функциях выпадающих меню или кнопках панели инструментов соответственно при выделении пункта меню или нажатии кнопки).
Статистический советник. Статистический советник представляет собой интерактивную справочную систему. После выбора пункта Советник из выпадающего меню [Справка) программа задаст вам несложные вопросы о характере решаемой проблемы и типе исходных данных, а затем предложит список наиболее подходящих процедур (и объяснит, где их найти в системе STATISTICA)
С помощью гиперссылок можно непосредственно перейти из раздела Статистический советник к подробному описанию соответствующих статистических методов и процедур в разделе Вводный обзор.
Мультимедийный учебник CD-версия STATISTICA включает ряд анимационных примеров, иллюстрирующих некоторые из наиболее часто используемых возможностей STATISTICA. Эти примеры шаг за шагом показывают, как провести типичныйстатистический анализ и построить графики. Полный список имеющихся
Вступление
53
в данной версии системы мультимедийных обзоров находится в подменю Л/^льтд-“"Энйныйучебник выпадающего меню (Справка)
Отметим, что длязапуска этих мультимедийных иллюстраций нсобходимазву-. вая карта. Если ваша версия STATISTICA не содержит мультимедийный учсб-ннк (или содержит лишь часть примеров), вы можете загрузить соответствующие г ай ты из Интернета (http://www.statsoft.com) или заказать их в компании StatSoft.
Приложения Все рассмотренные возможности (доступные в любой момент ра- ты с системой) могут служить весомой альтернативой или дополнением к обыч-•му интерактивному пользовательскому интерфейсу, поскольку они позволяют шатизировать рутинный процесс многократного выполнения одних» тех же, » юм числе весьма сложных, задач. Например, макрокоманда (вызываемая щелч->м мыши по кнопке на панели инструментов Кнопки автозадач или одним нажа-1 нем клавиши) может содержать длинный список переменных, часто используемый I рафик, операцию внедрения и т. и.
Автоматические отчеты и автоматическая распечатка таблиц результатов. Не-висимо от того, происходит ли обработка в пакетном режиме пли интерактивно запрашивается пользователем, может быть выбран режим вывода Автоотчет Этот ' • ’Жим позволяет автоматически, без каких-либо действии со стороны пользователя распечатывать ( или направлять в окно отчета или в файл) содержание всех окон вывода, которые получаются в процессе анализа.
Режим автоматического вывода каждой строящейся на экране таблицы резуль-1 <п< ш и цЛ11 графика может оказаться полезным не только для создания полного
54
Глава 1. Краткая экскурсия по системе STATISTICA
отчета о результатах анализа, но и при разведочном анализе данных, когда возникает необходимость вернуться к предыдущему шагу и просмотреть результаты, полученные на ранних этапах обработки данных. Для этого всю выходную информацию (таблицы результатов и графики) можно направить во временное Окно тек-ста/вывида с прокруткой и уже затем в случае необходимости сохранить ее, распечатать или скопировать в файл текстового редактора.
Автоматическая печать графиков. Режим автоматической печати всех возникающих на экране графиков особенно полезен как средство пакетной графической печати.
Как правило, печать графиков занимает довольно много времени. Поэтому имеет смысл воспользоваться этим режимом для распечатки последовательности (•♦каскада») графиков, получающихся при применении определенных методов анализа (например, для зрительного представления конфигураций средних при исследовании связей высших порядков в дисперсионном анализе необходима длинная последовательность графиков, а для многомерных таблиц — каскад трехмерных гистограмм для двух переменных).
Однако гораздо эффективнее направить создаваемую последовательность графиков в Окнотекста/вывода. В STATISTICA предусмотрена возможность пакетной печати всех ранее сохраненных графиков и таблиц результатов; для этого нужно выбрать пункт Печать файлов в выпадающем меню Файл.
Буфер обмена. Наиболее быстрый и во многих случаях наиболее простой способ получения данных из других приложений Windows (например, электронных таблиц) — это использование буфера обмена, который в STATISTICA поддержи-ваетспециальныеформаты данных, создаваемые такими приложениями, как MS Excel или Lotus для Windows. Например, STATISTICA правильно интерпретирует форматированные (например, 10ОО ООО пли $10) п текстовые значения. Буфер обмена и преобразование файлов данных можно также использовать для экспорта данных из системы STATISTICA в другие форматы. При импорте и экспорте данных STATISTICA использует один и тот же набор форматов и типов данных.
Вступление
55
функции импорта файлов. Файлы данных из приложений Windows и другнр операционных систем также можно переводить в формат системы STATISTICA с помощью функций импорта файлов, которые включают доступ ко всем базам данных (через поддержку метода ODBC), а также возможности импорта форматированных текстовых файлов и текстовых файлов свободного формата (ASCII).
Импорт файлов без использования буфера обмена имеет свои преимущества:
) он позволяет пользователю точно указать, как должен проводиться импорт (например, выбирать из файлов диапазоны значений, импортировав ь или не импортировать имена переменных, текстовые значения и имена наблюдений и указывать способ их интерпретации):
> он предоставляет пользователю доступ к типам данных, которые недоступны (или труднодоступны) при операцияхе буфером обмена (например, длинные метки значений или специальные коды пропущенных данных).
Связи DDE. STATISTICA поддерживает соглашения динамического обмена данными (DDE), что позволяет динамически связывать диапазон данных в таблице ис-• тных данных с набором данных других приложений (Windows). Эта процедура ни самом деле гораздо проще, чем опа может показаться, и ее легко освоить, не имея гех|П1чсскихзнаш1йомеханизмеРРЕ’,особе1П1опрп использовании команды Усто-чонито связь (вместо ввода описания связи). Связи DDE (динамического обмена
•иными) можно установить между файлом-источником (сервером), например ровной таблицей MS Excel, и файлом данных системы STATISTICA (фай-ам-кдцентом), так что при внесении изменений в файл-источник данные в cool -вегп вугощей части таблицы исходных данных STATISTICA (фай че-клиенте) буду 1 автоматически обновляться.
56 Глава 1. Краткая экскурсия по системе STATISTICA
Обычно два файла динамически связываются в промышленных установках, koi да к последовательному порту компьютера, на котором находится файл данных системы STATISTICA, подключено измерительное устройство (например, для ежечасного автоматического обновления определенных измерений).
Связи DDE можно установить с помощью команды Установить связь выпадающего меню Правка таблицы исходных данных или введя определение связи в поле Длинное имя (метка, формула, связь)- диалогового окна спецификаций переменной.
Если связь установлена, то можно управлять ею в диалоговом окне Диспетчер связей (вызывается с помощью команды Связи... выпадающего меню Правка).
Форматы Дата и Время. В файлах данных системы (которые организованы как базы данных) формат отображения значений применяется ко всей переменной, а не к отдельным ячейкам (как в Excel). Поэтому значения, которые в Excel были отформатированы как даты, в файле системы STATISTICA будут отображаться как юлианские (целые) значения (например, 34092 вместо Мау 3, 1993), если для соответствующих переменных не установлен формат Дотла или Время
Поддерживает ли STATISTICA интерфейс ODBC? Да, для того чтобы реализовать эту возможность, существует список команд Импорт данных, который вызывается из выпадающего меню Файл любого модуля. Интерфейс ODBC STATISTICA включает возможности для объединения полей из нескольких таблиц н предоставляет доступ к множеству файлов баз данных, включая форматы больших И персональных компьютеров ( например, d BASE д ih Windows. Paradox. Sybase, Oracle, SAS и т. д.).
Вступление
57
Импорт через ODBC можно автоматизировать с помощью функции ODBC/UIao-iHiii пли программ на языке SCL.
Типы объектов. Если задан режим Новый объект, то тип создаваемого объекта хит быть выбран из списка приложений Windows, которые поддерживают сред-'t OLE. После выбора типа и нажатия кнопки ОК будет открыто окно соответ-। 01 цего приложения для создания нового объекта. Если задан режим Объект из . л то тип объекта для вставки также выбирается из списка приложений s, поддерживающих средства OLE- после выбора типа будут показаны все . .рптельно сохраненные файлы этого приложения. В режиме Картинка из на можно вставить объект, несовместимой с методом OLE, но записанный в . ом из графических форматов Windows: в формате метафайла (файл с расшире-.ксм * umf) или растрового изображения (файл с расширением *.Ьтр).
Связывание и внедрение. STATISTICA поддерживает средства OLE(связыва- и внедрения объектов) как в режиме клиента, так it в режиме сервера. Таким м, возможна не только динамическая настройка графиков STATISTICA в их приложениях (режим сервера), но также внедрение и последующее преоб-Р - займе OLE-совместимых объектов других приложений (например, графиков п-it- таблиц) или собственных объектов в графики STATISTICA. Другими словами. помимо присоединения внешних элементов к графикам STATISTICA с помощью вставки можно обращаться непосредственно к объектам, содержащимся в » 1 на диске (например, перетащить их непосредственно из окна Диспетчер Фаи /и, яяи Проводник (Windows Explorer) и поместить на график STATISTICA).
58
Глава 1. Краткая экскурсия по системе STATISTICA
STATISTICA поддерживает как связанные (то есть динамически присоединенные), так и внедренные (то есть статически «встроенные») объекты При этом они могут быть расположены в любом файле, созданном приложениями Windows, включая файлы в собственном графическом формате STATISTICA (с расширением *stg). Более того, STATISTICA одновременно может являться как клиентом, так п сервером в методе OLE, поддерживая при этом уникальную возможность создания вложенных составных документов (до четвертого порядка включительно), то есть документ STATISTICA с внедренным документом может быть, в свою очередь, внедрен в другой документ этой системы.
Заметим, что каждый из этих двух способов присоединения (связывание it внедрение) имеет свои преимущества и недостатки.
Связанные объекты. Графики со связанными объектами медленнее перерисовываются, поскольку при этом мохут быть задействованы связи с внешними файлами. В то же время, эти графики обновляются автоматически (статус связей может быть установлен в диалоговом окне Связи донныхи графика, которое вызывается из графического меню Правка), а это позволяет легко создавать составные документы, которые включают именно «текущее» содержимое других файлов
Вступление
59
Внедренные объекты Графики с внедренными объектами перерисовываются быстрее, чем со связанными объектами, поскольку здесь отсутствуют связи с обновляемыми внешними файлами. Если дважды щелкнуть на внедренном объекте, то будет вызвано приложение-сервер (то есть источник), в котором можно изменить данный объект. При этом обновить внедренный объект можно двумя способами отредактировать его или заменить вручную.
В меню Правка можно настроить все параметры внешних объектов {связанных ичи внедренных), а также их связи с другими компонентами графика. Кроме того, щелкнув на объекте правой кнопкой мыши, можно выбрать нужные команды па-стройки из контекстного меню. Единственным исключением является способ присоединения объекта {связывание или внедрение), который определяется в момент подключения файла (после этого только связанный объект можно преобразовать во внедренный, но не наоборот (см. команду Преобразовать во внедренный уз выпадающего меню Правка)).
Настройка связанных или внедренных объектов OLE. Объекты ОЛЕ-графиков STATISTICA могут быть отредактированы после двойного щелчка мышью на объекте; при этом приложение-источник будет открыто в режиме сервера OLE с готовым к редактированию объектом. Если этот объект является графиком STATISTICA, то в текущем модуле откроется новое графическое окно, что позволит гистсме одновременно выступать как в роли клиента, так и сервера
Когда редактирование завершено, можно применить любое из стандартных со-’ лишений OLE для выхода из режима сервера и обновления графика в системе S ГА riSTICA (используя команды Обновить, Обновить и вернуться к_ и т. д.
60
Глава 1. Краткая экскурсия по системе STATISTICA
я выпадающем меню приложения Файл, эти команды доступны только в случае, если приложение запущено в режиме сервера).
Графические форматы Метафайл и Растровое изображение. Для вставки графического файла в приложения, не поддерживающие методы OLE, используются команды Сохранить метафайл или Сохранить растровое изображение (из выпадающего графического меню Файл). График в формате метафайла Windows будет записан в файл с расширением * кт/ ав формате растрового изображения — с расширением *.Ьтр. Эти форматы, описанные в двух следующих параграфах, не позволяют полностью реализовать все возможности настройки графиков STATISTICA, но в тоже время совместимы со всеми приложениями, поддержива-Ю] цимп графические форматы Windows.
Что такое метафайл Windows? Графический формат Метафайл — это один из стандартов для записи графических файлов (с расширением * ш/ и их представления в буфере обмена Windows. Он содержит картинку в виде описаний и определений всех компонент графика и его атрибутов (например, элементов линий, их цветов и шаблонов, шаблонов заполнения, описания текста и его параметров).
По сравнению со стандартом растрового изображения (см. ниже) формат метафайла дает возможности более гибкой настройки OLE-несовместимых объектов в приложениях Windows.
Например, при открытии метафайла в программе Microsoft Draw можно «разложить» изображение графика, выделить и изменить отдельные линии, шаблоны заполнения или цвета, а также отредактировать текст и изменить его атрибуты.
Однако не все приложения Windows полностью поддерживают все возможности формата метафайла, доступные в системе STATISTICA Некоторые параметры графиков, записанных системой STATISTICA в этом формате, могут измениться при их воспроизведении в других приложениях. Например, может исчезнуть поворот некоторых шрифтов. Поэтому по возможности используйте графический формат STATISTICA и методы OLE для работы с графиками в других приложениях, чтобы иметь доступ ко всем возможностям настройки самой STATISTICA
Вступление 61
Ограничения стандартного формата Метафайл Windows. Сложные графические изображения, создаваемые системой STATISTICA, могут оказаться слишком большими (по числу представленных точек данных) для записи в формате метафан «и, [.нторый по умолчанию используется системой Windows для большинства операций по связыванию и внедрению графических объектов. В таких случаях нужно использовать растровое изображение. За дополнительной информацией обратитесь к 31ектроиному руководству из диалогового окна Дополнительные пара-л<е,,рг' егорое вызывается из вкладки Графика диалоп!Вого окна Пара-метры страницы. 'вывода
Что такое формат растрового изображения? Формат Растровое изображение -это второй стандартный графический формат системы Windows, который используется «ля представления графических файлов (с расширением * Ьтр) и передачи изоб-1 лженпя чер< -.-буфер обмена (как и формат Метафайл). В этом формате несохраня-tun-Я никакие дополнительные данные или параметры, кроме изображения самой ь/ртпнки
?. ст ычие от метафайла растровое изображение представляет собой «пассив-
• эчечнне отображение графического окна. Возможности настройки такого
графика в других приложениях Windows очень ограничены. Обычно они включа-ю । лью операции растяжения, сжатия, вырезания, вставки и рисования поверх гр«фика. Как уже отмечалось выше, для работы с графиками в других приложен 11-ях уд- Знсе использовать запись в графическом формате STATISTICA и методы OLE. чтобы иметь доступ ко всем возможностям настройки самой системы STATISTICA.
Что такое собственный графический формат STATISTICA? Графические фай-э( системы STATISTICA имеют расширение *-s(g. Их основное отличие от метафайлов и растровых изображений состоит в том, что они содержат не только картин -у, но и всю информацию, необходимую для настройки графика и анализа данных Здесь записаны все представленные на графике данные, их связи, уравие-ш 11 агонии, параметры внедренных объектов, связи графиков и рисунков и т. п. Записанные в таком формате графики можно впоследствии открыть в любом из м . -й системы STATISTICA для продолжения настройки и анализа данных. К; того, их можно распечатать в пакетном режиме с помощью команды Печать
1 из выпадающего меню Файл Графические файлы в собственном формате • т»яы STATISTICA можно динамически связать с документами приложений 'Л ’ । г 'low s с помощью методов OLE.
Экспорт через буфер обмена {вставка или специальная вставка методами OLE) Использование буфера обмена — это самый быстрый способ экспорта графика в другое приложение. При копировании в буфер обмена создается три графи-• представления объекта: в собственном формате STATISTICA, в формате ' файла Windows и в формате растрового изображения. Каждое из них может быть и юльзовано в других приложениях,
Графики системы STATISTICA могут присутствовать в других приложениях (pt торах или электронных таблицах) как в качестве связанных, так и внедренных < йъектов. При использовании методов OLE они сохраняют свою связь с систе-- й STATISTICA и, следовательно, могут интерактивно редактироваться в рам-ьз* j, угих приложений.
62
Глава 1. Краткая экскурсия по системе STATISTICA
Доступ ко всем данным графика. Данные, представленные на графиках системы, можно непосредственно просматривав и изменять независимо от их типа во встроенном Редакторе данных графика. Это метут быть исходные данные, части таблицы результатов или ряд рассчитанных значений (например, вероятностный (рафик)
Для каждого графика создается связанное с ним «дочернее» окно Редактора, которое закры вастся вместе со своим графическим окном. Редактор организован в виде групп столбцов, представляющих отдельные зависимости данного графика (см. следующий параграф).
Вступление
Категоризованные графики Для созда| 11 |Я категоризованных графиков данные разбиваются на подфуппы. На одном изображении будет одновременно представлено несколько [рафиков, по одному для каждой из заданных подгрупп. Например, можно построить [рафики отдельно для субъектов .мужского нженского пола, раздел нть пациентов па группы женщин с высоким давлением, женщин с низким давление», мужчин с высоким давлением, разделить товары по качеству, странам-производителям пт. п. Разбиение данных на однородные труппы и исследование связей между этим» группами — чрезвычайно важный прием анализа данных.
Категоризованные графики широко применяются в системе STATISTICA:
> Они доступны в большинстве диалоговых окон с результатами анализа (эти графики автоматически создаются в тех процедурах, i де анализируются группы пли подгруппы данных, например при классификации, проверки t-критериев, в дисперсионном, дискриминантном и непараметрическом анализе).
j Эти типы графиков присутствуют в списке Быстрые статистические графики в контекстных меню всех таблиц исходных данных и таблиц результатов.
> Их можно вызвать из списка Статистические графики (в выпадающем меню Графика), при построении которых предлагается большой выбор раз тпчных методов категоризации данных.
Методы категоризации, предлагаемые в системе STATISTICA, описаны в сле-|1) нищ м пункте.
64
Глава 1. Краткая экскурсия по системе STATISTICA
Каким образом задаются «категории* для категоризованных графиков? Итак, вначале нужно разбить данные на группы. При построении категоризованных графиков из диалоговых окон с результатами анализа подгруппы данных определяются автоматически (поскольку такое разделение является частью исследования цяпных). При построении статистических графиков предлагаются различные способы задания подгрупп по одной или двум группирующим переменным. Кроме того, разбиение на подгруппы может организовать сам пользователь, используя любые комбинации переменных из текущего набора данных.
Существует несколько методов выделения категорий:
о по целым значениям группирующих переменных (Целые числа);
о разделением группирующих переменных на заданное число интервалов (Категории)',
о разделением группирующих переменныхна интервалы с заданными гранггч-пыми значениями (Границы)',
о с помощью задания конкретных значений (кодов) группирующих переменных (Коды)’,
О путем формирования сложных подгрупп (Сложные подгруппы); для этого пользователь может ввести условия выбора наблюдений практически неограниченной сложности и использовать значения любой переменной текущего файла данных, кате показано ниже.
На следующем рисунке показан достаточно сложный график, категоризованный по двум признакам. При этом использован смешанный метод выделения подгрупп. Категоризация по двум признакам означает, что элементы графика располагаются как элементы двухвходовой таблицы, полученной после использования двух различных методов категоризации.
Вступление
65
Две строки на приведенном выше графике предстааляют разделение на под-гр\ ппы по значениям переменной Ноте_2 (на наблюдения, для которых значение тгий переменной меньше либо равно 104,624, и наблюдения, для которых оно Г. .(ыле 104,624). Три столбца графика представляют подгруппы, заданные специальным образом по номерам наблюдений (нулевая переменная) и значениям переменной Ноте_7. Ниже показано диалоговое окно, где задавались параметры этого графика
PuMBiUtHMe
! BS *• QuW"**»
53 Двруюяишг- | Каг-Х: Сл.подгруппы KSr.Y: HCJME_2
«•рем. К WORK 1
Пчюм-Y: WORK.*'
Переменная: Сд.пМГМПЛ» ' ЛершчепншсЯОМО ' Целые числе ' Г" Целые числа
Г Категории- г? g 1« р g t~ Грашмес: нет С Грениаы: и<И
Г Кодае кет I Г* Коды, нш
<• Сложные иадгиппы Сложные подгрцям
ST 3<wot> поагИ|ОПм £ |£Д Иомднггь поременнзю ]
КООРДИНАТЫ
IIjXaEISS^ “ Поачзные
На каждом маленьком графике представлена зависимость между переменными Work_ 1 и Worh_2 (в качестве X и Yсоответственно). Первая категоризация (Кате-tuu поХ— «столбцы* графиков) проводится методом Сложные подгруппы в диа-
k.-i окне, вызываемом кнопкой Задать подгруппы:
66
Глава 1. Краткая экскурсия по системе STATISTICA
Второй класс (Категории по Y или «строки» графиков) определяется группирующей переменной Ноте_2. Диапазон этой переменной разделен на два равных интервала. Для этого в диалоговом окне задания параметров графика в поле Категории введено значение 2 (при этом распределение переменной Ноте_2 разделено на две группы: наблюдения, для которых значения меньше либо равны 104,62, и наблюдения со значениями данной переменной, большими этого числа).
Тернарные графики поверхности и карты линий уровня. При выводе результатов анализа по составлению смесей в модуле Планирование эксперимента можно построить тернарные графики в виде трехмерных поверхностей или карт линий уровня.
Вступление
67
Тернарные графики можно построить из подменю Статистические XYZ-гра-фики. Статистические категоризованные графики и Пользовательские графики выпадающего меню Графика.
Графики в полярных координатах. Некоторые типы графиков можно построить в полярных координатах. К ним относятся графики рассеяния, линейные графики и последовательные вложенные графики из подменю Статистические 2М графики (оно вызывается из выпадающего меню Графика).
R полярных координатах можно построить и категоризованные графики.
Многие графики, построенные в обычной прямоугольной системе координат, полно представить в полярных координатах. Для этого нужно установить со-111 Мтствующпй переключатель в диалоговом окне Общая разметка в положение Молярные.
Глава 1. Краткая экскурсия по системе STATISTICA
Как поместить на трафик системы STATISTICA графический объект из другого приложения? Для вставки любых графических объектов, совместимых с системой Windows, можно использовать все описанные выше операции вставки посредством буфера обмена (включая связывание и внедрение методами OLE) Эти операции можно совершать над растровым» объектами, метафайлами Windows, графиками в формате STATISTICA, а также любыми OLE-совместимыми объектами.
Как поместить текст на график STATISTICA (отчеты, таблицы и т. п.)? С помощью описанных выше операций с буфером обмена на графики STATISTICA можно поместить очень большой текстовый объект (например, отчет длиной несколько страниц). Этот текст редактируется и изменяется в окне Редактор текста графика системы STATISTICA или в соответствующем приложении, которое является сервером в методе OLE.
Все описанные в предыдущем разделе операции вставки и использования буфера обмена применимы к любым совместимым с Windows графическим объектам, а операции связывания и внедрения выполняются для всех объектов, поддерживающих методы OLE.
Галерея графиков STATISTICA. С помощью этой кнопки открывается диалоговое окно Галерея графиков STATISTICA. Эта кнопка присутствуете диалоговом окне каждого типа графиков.
Вступление
69
Отсюда быстро и легко вызываются все статистические и пользовательские графики, пустые графические окна и статистические графики полъэовате тя. Для этого нужно выделить название нужного чипа графика и дважды щелкнуть на нем (или нажать кнопку ОК)
Пользовательские и статистические графики Помимо специализированных графиков, которые вызываются непосредственно из итогового диалогового окна любой программы статистической обработки, существуют еще два основных типа графиков, доступных из меню или панели инструментов любой таблицы: пользовательские графики и статистические (и быстрые статистические) графики.
Главное различие между двумя основными типами графиков заключается в источнике данных для отображения. Более подробно эти различия описаны в следующих разделах.
0[^1ЙЕ)^^ользовог”ельски€ гРаФики Пользовательский график дает возможность отобразить любую заданную пользователем комбинацию значений из таблиц исходных данных или таблиц результатов (а также из любой комбинации их строк и/или столбцов). В меню предлагается пять типов таких графиков: 2М пользовательские графики, ЗМ пользовательские последовательные графики, ЗМ пользовательские диаграммы рассеяния и поверхности, пользовательские матричные графики и пользовательские пиктографики. При выборе одного из них открывается соответствующее диалоговое окно, где для отображения на графике можно задать диапазон данных текущей таблицы. Содержание этого диалогового окна зависит от выбранного типа пользовательского графика. Начальный выбор данных для построения графика, предлагаемый в этом диалоговом окне, определяется положением курсора в текущей таблице В каждом диалоговом окне пользовательского графика при задании параметров предусмотрена возможность выбора определенного вида графика (в рамках основного типа). Вид графика также можно подобрать и после построения (с помощью диалоговых окон Общая разметка или Размещение графика, которые открываются при двойном щелчке мышью на области фона графического окна или при выборе соответствующей строки выпадающего .меню Разметки).
Ц® Й? «Л Стат истические графики. В отличие от пользовательс-
ких графиков, которые представляютсобойсредствонаглядногоотображения числовых данныхлюбых таблиц (исходных данных или результатов, с.м. выше), статистические графики предлагают сотни заранее определенных типов графических представлений,включаюшиханалитическоеобобшеннестатистическихданных. Они вызываютсяиз диалоговогоокна Галерея графиков, которое открывается с помощью одноименной кнопки панели инструментов |gj или из выпадающего меню Графика.
70
Глава 1. Краткая экскурсия по системе STATISTICA
При построении таких графиков используются значения непосредственно из файла данных, которые не зависят от содержания текущей таблицы, выделения блоков и положения курсора. При этом предлагаются либо стандартные методы графического анализа исходных данных (различные графики разброса значений, гистограммы, графики средних значений, например медиан), либо стандартные аналитические методы исследований (графики нормальной плотности распределения. вероятностные графики с исключенным трендом или графики доверительных интервалов линий регрессии). При построении статистических графиков программа учитывает условия выбора и веса наблюдений.
^Быстрые статистические графики. Наиболее широко используемые типы статистических графиков (вызываемых из меню Графика, см предыдущий параграф) представлены в меню Быстрые статистические графики. Эти списки графиков не предоставляют такой широкий спектр возможностей, как меню Статистические графики, но в отличие от последних упрощают и ускоряют процедуру построения графика. Быстрые статистические графики:
О вызываютсяиз контекстныхменюилиспзнели инструментов любой таблицы (обычноонн не требуют обращения к выпадающим меню или диалоговым окнам),
О не требуют от пользователя выбора переменных (этот выбор определяется теку щим положением курсора в таблице) и промежуточной настройки параметров (формат соответствующих графиков определяется по умолчанию).
При выборе пункта Быстрые статистические графики (с помощью кнопки на панели инструментовиз контекстного меню или из выпадающего меню Графика) появляется меню выбора статистического графика для текущей переменной таблицы, то есть той, на которую в настоящий момент указывает курсор.
Если курсор не указывает ни на одну из переменных, то перед построением любо го графика из меню Быстрые статистические графики будет предложено выбрать переменную из списка. При создании таких графиков система STATISTICA учи тывает текущие условия выбора и веса наблюдений.
Блоковые статистические графики. Эти типы (пользовательских) графиков вызываются из пунктов контекстных меню Статистики блока по столбцам и Статистики блока по строкам или из диалогового окна Галерея графиков.
Любой из этих вариантов дает возможность построить итоговый статистический график для выделенного блока, чтобы сравнить значения в строках (Статистики блока по строкам) или в столбцах таблицы (Статистики блока по столбцам). Данный тип графиков похож на те пользовательские графики, на которых отображаются данные текущего блока таблицы.
Другие специализированные графики Помимо стандартного набора быстрых статистических графиков некоторые таблицы позволяют строить и более специализированные статистические графики (например, временные последовательности в модуле Временные ряды, пиктографики регрессионных остатков, а также контурные графики в модуле Кластерный анализ). Как уже упоминалось ранее, специализированные графики, которые связаны нес конкретной таблицей результатов, а с определенным методом анализа данных (например, графики аппроксимирующих функций в модуле Нелинейное оценивание или средних в модуле Дисперсионный анализ), вызываются непосредственно из диалогового окнас результатами анализа (то есть из окна, содержащего выходные параметры используемого метода обработки данных),.
Настройка графика до и после его построения. Любые изменения параметров графика в STATISTICA осуществляются из активного графического окна (после отображения графика на экране). Как правило, сначала имеет смысл построить график, приняв значения параметров но умолчанию, а затем уже вносить различные изменения, Однако в тех редких случаях, когда построение графика занимаетслишком много времени (при создании сложных составных графических изображений или обработке больших наборов данных), можно вмешаться в этот процесс, чтобы
72
Глава 1 Краткая экскурсия по системе STATISTICA
сделать необходимые настройки. Прервать рисование можно одним нажатием клавиши или щелчком мыши в любом месте экрана, а затем продолжить его после ввода необходимых изменений.
Предусмотрено два основных метода настройки графика — добав тение и редактирование пользовательских графических объектов, изменение структурных элементов графика.
Применяются ли к различным типам графиков различные методы настройки?
Нет. Независимо от способа создания графика для его настройки и изменения можно использовать любые возможности, предусмотренные в системе STATISTICA. К любому графику можно добавить новый график, объединить его с другим графиком, поместить в него связанный или внедренный объект. Кроме того, график можно любым образом изменять, рисовать на нем и использовать различные методы подгонки функций. Эти же методы настройки доступны при работе с графиками, которые были предварительно сохранены и вызваны из дискового файла.
Настройка статистического графика до и после его построения. В разделе Как настроить график STATISTICA показано, что большинство возможностей настройки (сотни различных вариантов графического представления) доступны непосредственно после построения графика. Для этого достаточно щелкнуть на конкретном элементе графика или выбрать соответствующий пункт в диалоговых окнах Общая разметка или Размещение графика, которые вызываются из выпадающего меню Разметки.
В то же время, отдельные параметры, которые определяют источник данных, нужно задать до построения графика, например переменные, метод категоризации, значения меток, имена наблюдений, метки осей. В данном примере перед построением графика нужно выбрать переменные и метод категоризации, а также при необходимости задать значения некоторых параметров с помощью кнопки Параметры (которая здесь не исполъзовзна).
Теперь вернемся к нашему примеру. После построения графика при щелчке на любом месте фона графического окна появится диалоговое окно Общая разметка, в котором регулируются параметры общего расположения графика.
В этом окне можно изменить тип графика и задать построение карты линий уровня (используйте для этого поле Тип графика). Кроме того, можно изменить пара-
Вступление
73
метр Число сечений с установленного по умолчанию со значением 15 х 15 на 25 х 25 (этот параметр определяет точность построения карты линий уровня):
После внесения изменений нажмите ОК, и вы увидите новый график-
Снова вернемся к диалоговому окну Общая разметка и выберем для типа кон туриой линии значение Зона. Кроме того, в первые три строки заголовка графика
Глава 1. Краткая экскурсия по системе STATISTICA
поместим управляющие символы @F(1,1], @F| 17| н @F11,3]. чтобы записать там уравнения аппроксимирующей квадратичной функции для первой зависимости (цифра 1 на месте первого параметра в квадратных скобках) для каждого из трех отдельных графиков (цифры 1,2 и 3 в качестве вторых параметров):
Для быстрейшего отображения и всестороннего форматирования уравнений функций лучше использовать аналоговое окно Параметры, которое вызывается из диалогового окна Статистические графики Нажмите ОК, и вы увидите измененный график:
Вступление
75
Теперь можно продолжить знакомство с различными способами настройки графика. Самый простой (и самый быстрый) способ изменения параметрон какого-либо элемента — это двойной щелчок на нем кнопкой мыши. Кроме того, с помощью одного щелчка правой кнопкой мыши на данном объекте можно вызвать соответствующее ему контекстное меню.
Например, при щелчке правой кнопкой мыши на одной из осей графика появится показанное ниже контекстное меню, в котором предлагается выбор вариантов настройки для данной оси:
На показанном ниже графике с помощью кнопки панели инструментов подобраны другие пропорции графического окна, кроме того, изменен статус условных обозначений с фиксированного на перемещаемый, а их текст отредактирован, упорядочен и перемещен на другое место.
Метут ли графики автоматически обновляться при изменении файла да иных? Да, могут. Все графики сохраняют связи с таблицей исходных данных, по которым они построены. При этом, если обновление не происходит вручную и связи не отменены, график автоматически обновляется при изменении исходных данных Для управления связями имеется специальное диалоговое окно Связи данных и графика. Оно вызывается из выпадающего меню Графика.
76
Глава 1. Краткая экскурсия по системе STATISTICA
Здесь можно установить автоматический режим связи, когда график автомата чески обновляется при изменении данных, по которым он построен. Можно также задать режим Вручную или временно заблокировать связь. Кроме того, можно установить режим Связь с текущим файлом данных и построить такой же график или серию графиков для других файлов данных. Способ связи можно i тобалыю изменить с помощью команды выпадающего меню Сервис.
STATISTICA поддерживает и «вложенные» связи с другими приложениями. Например, можно установить связь графика с данными электронной таблицы Excel 5 путем динамического обмена данными (DDE). При нажатии клавиши F9 для пересчета таблицы Excel произойдет автоматическое обновление как данных этой таблицы, так и соответствующего им графика в системе STATISTICA. См. также два следующих пункта.
Графический формат STATISTICA. Графики и рисунки могут быть сохранены в графическом формате STATISTICA в файле с расширением * stg. Для этого используются команды Сохранить и Сохранить как., из выпадающего меню Файл. Именно этот формат рекомендуется д.чя записи графического фай та, если предполагается в дальнейшем снова открывать его в системе STATISTICA или присоединять к другим приложениям методами OLE. В отличие от других графических форматов формат STATISTICA хранит не только саму картинку, но и Редактор данных графика со всеми представленными на графике данными, все аналитические параметры (уравнения подгонки, эллипсы и пр.), а также другие параметры, позволяющие впоследствии продолжить анализ графических данных. Этот формат наиболее удобен при связывании или внедрении графика в другой график STATISTICA. Сохраненные в данном графическом формате файлы можно распечатать в пакетном режиме с помощью команды Печать файлов из выпадающего меню Файл.
Командный язык STATISTICA (SCL)
STATISTICA содержит два встроенных языка программирования: STATISTICA BASIC и SCL (командный язык). Оба языка предназначены для работы в среде
Командный язык STATISTICA (SCL)
11
STATISTICA и содержат встроенные операции для обращения к таблицам исходных данных, таблицам результатов и графическим функциям.
Язык STATISTICA BASIC представляет собой простой и одновременно достаточно мощный язык программирования. С его помощью можно создать широкий спектр приложений, начиная от простых программ преобразования данных и кончая сложными пользовательскими процедурами комплексного анализа и вывода информации.
Этот язык программирования пригоден для решения больших вычислительных задач, поскольку обрабатываемые массивы данных могут иметь до 8 измерений и нет ограничений на размеры массивов. Таким образом, пользователь может использовать всю доступную память и создавать процедуры, включающие операции с боль-щими многомерными матрицами.
Встроенный язык STATISTICA BASIC доступен в любой момент анализа вместе с интегрированной средой, которая позволяет писать, редактировать, проверять, отлаживать (предварительно прогонять) и выполнять программы.
Язык STATISTICA BASIC как обычный язык программирования поддерживает циклические операции и условные переходы, функции и подпрограммы, а также работу с динамическими библиотеками (DLL). В то же время, он «понимает* структуру файлов данных системы STATISTICA и позволяет организовать интерактивную обработку данных в среде самой системы с помощью пользовательских диалоговых окон. С помощью этого языка пользователь может создавать свои собственные сложные программы анализа данных, одновременно используя готовые алгоритмы расчетов и построения графиков, предусмотренные в системе STATISTICA.
Командный язык SCL (STATISTICA Command Language) предназначен для организации пакетной обработки данных и создания собственных приложений на основе процедур, содержащихся в системе STATISTICA. Для того чтобы пользователь мог при этом реализовать собственные алгоритмы расчетов, предусмотрена возможность интеграции языков STATISTICA BASIC и SCL.
Программы, написанные на встроенных языках системы STATISTICA, доступны в любом модуле системы и на любом этапе анализа данных, при этом их можно вызывать и выполнять как с помощью кнопок автозадач, так и непосредственно из окна редактирования. Пользователь также имеет возможность создавать собственные библиотеки функций и подпрограмм и таким образом значительно расширять предлагаемый набор процедур обработки данных и представления результатов.
Ввод и исполнение SCL-программ. STATISTICA может работать в «истинном» пакетном режиме как система, управляемая командами, с помощью встроенного языка управления приложениями SCL (STATISTICA Command Language), доступного в любом модуле системы из выпадающего меню Анализ. Можно ввести последовательность команд для выполнения определенных действий, а затем сколько угодно раз исполнять ее в пакетном режиме.
Возможен и другой способ действий — использование диалогового окна Мастер команд для быстрого выбора и ввода требуемого списка команд.
78
Глава 1, Краткая экскурсия по системе STATISTICA
Для написания и отладки «пакетов* команд используется интегрированная среда языка SCL. Она включает текстовый редактор, совмещенный с окном Мастер команд (см. иллюстрацию выше — кнопка Мастер команд на панели инструментов Командный язык), систему помощи по синтаксису языка с примерами и интегрированные средства проверки правильности программ (доступны из выпадающего меню Сервис).
Пользовательские расширения языка SCL. Программы на языке SCL могут включать не только предопределен ные параметры и команды для выполнения действий по статистической обработке, управлению и графическому выводу данных (см. кнопки Справка-примеры и Справка: синтаксис на панели инструментов), но и пользовательские «команды», определенные с помощью инструмента Назначить клавиши (Send Keys) (в соответствии с правилами, принятыми в MS Visual BASIC).
Написанные таким образом программы могут выполнять, например, операции с буфером обмена (Копировать, Вставить), менять параметры вывода, принятые I по умолчанию в различных процедурах, и выполнять другие функции.
^Сопрограммы могут также включать в себя программы и процедуры, написанные на языке STATISTICA BASIC (языке STATISTICA предназначенном для преобразования данных и графиков и управления ими, который доступен на любого модуля пакета). Например, определенные пользователем графические или вычислительные процедуры наязыке STATISTICA BASICMoiyr выполняться как часть пакета команд SCL
Пользовательский интерактивный интерфейс для SCI-программ Несмотря на то что в командном языке SCL не заложен в непосредственном виде специальный пользовательский интерактивный интерфейс, тем не менее для этих целей можно использовать программы на языке STATISTICA BASIC, вызываемые из SCi-npo- '
Командный язык STATISTICA (SCL)
79
грамм, например для создания диалоговых окон, позволяющих выбирать переменные, файлы данных и т. и. в ходе выполнения программы (см. примеры в Электронном руководстве).
Исполняемый модуль STATISTICA. Командный язык содержит специальный Исполняемый модуль, позволяющий разрабатывать приложения «подключ», которые вызываются двойным щелчком на значке соответствующего «пользовательского приложения» на рабочем столе Windows.
Эта возможность позволяет экономить время пользователя, когда многократно повторяется одна и та же процедура или последовательность процедур анализа, а также дает возможность использовать 5С£-нрограммы пол ьзователямн, которые не знакомы с соглашениям» системы STATISTICA.
Чтобы создать такое приложение «под ключ», сначала нужно написать саму SCL-программу и сохранить ее обычным образом (например, в файле Programiscl). Затем в окне Диспетчер программ системы Windows нужно создать пиктограмму для исполняемого модуля с именем Sra_run.exe (оно находится в папке STATISTICA надиске).
Модуль
80
Глава 1. Краткая экскурсия по системе STATISTICA
Б поле команд нужно задать имя SCL программы, подлежащей исполнению (например, d:\data\program1.set). Теперь при щелчке мышью на этом значке будет начинаться выполнение программы (в данном случае Programi .set). Описанным способом можно создать любое количество пользовательских приложений а с помощью окна Диспетчер программ дать им содержательные имена, соответствующие тем задачам анализа данных, которые эти приложения выполняют.
Кнопки автозадач
Кнопки автозадач — это всплывающая настраиваемая панель инструментов (включить или выключить ее можно клавишами CTRL+M).
Кнопки на этой панели инструментов можно назначить, переопределить с помощью кнопки Настройка... (или нажатия на соответствующую кнопку при удерживаемой клавише CTRL). В диалоговом окне, которое при этом открывается, можно присвоить имена уже имеющимся и новым кнопкам
кнопки автозадач 81
Перейдем к более систематическому изложению.
Часто при выполнении сложной задачи возникает необходимость выполнять одну и ту же последовательность действий, например открывать ранее сохраненные графики, данные или листинги программ. Постоянная потребность выполнять мало относящиеся к основной работе операции может отнимать время или даже раздражать. В системе STATISTICA предусмотрены возможности, которые избавляют пользователя от однообразных операций и способствует созданию комфортных условий работы.
Кнопки автозадач — это настраиваемая панель, которую в случае необходимости вы легко можете убрать с экрана или снова восстановить (восстановить или скрыть эту панель можно с помошью комбинации кнопок CTRL+M).
На панели «Кнопки автозадач» нажмите кнопку Настройка...
Откроется окно настройки кнопок автозадач В центральной части окна расположен столбец кнопок, позволяющий:
о Изменить или задать кнопку. Нажав на эту кнопку, вы можете задать последовательность нажатий кнопок клавиатуры. Для организации такой последовательности достаточно нажать кнопку Запись в правой части диалогового окна. С этого момента система автоматически начнет запоминать и переводить на язык команд ваши действия. Нажав, например, на клавиатуре кнопку Alt, вы попадете в главное меню, по которому сможете передвигаться с помощью стрелок и клавиши Enter. Свободно перемешаться внутри диалоговых окон вам поможет клавиша Tab и т. д. Для окончания записи нажмите CTRL+F3. В нижней части окна Настройка кнопок автозадач будут описаны кнопки перемещений по окнам и соответствующий им синтаксис.
о Удалить кнопку. В любой момент вы можете удалить ставшую ненужной кнопку.
О Задать последовательность функций или операций на Командном языке STATISTICA (SCI).
О Использовать написанные на языке STATISTICA BASIC процедуры вычислительного характера, преобразования данных, операции по управлению данными, графические процедуры, а также процедуры, написзнные на любом другом языке программирования, вызываемые из STATISTICA BASIC.
о Открывать файлы данных и любые вспомогательные файлы системы STATISTICA.
О Создавать и редактировать макрокоманды (последовательности нажатий клавиш), соответствующие часто выполняемым процедурам, заданиям или настройкам. Такие редактируемые команды можно вводить в текстовом виде или, например, как последовательности движений мышью.
В каждом из описанных выше окон предусмотрена возможность создания сочетаний 'горячих клавиш». Вы можете назначить сочетание клавиши CTRL и любой буквы от А до Z или цифры от 0 до 9. После сохранения этой установки вам будет Достаточно нажать определенную комбинацию клавиш, что будет равносильно нажатию на кнопку автозадачи.
82
Глава 1. Краткая экскурсия по системе STATISTICA
Панель инструментов может быть глобальной или локал ьной и содержать большие библиотеки пользовательских заданий и процедур. Локальная панель инструментов связана с конкретным модулем или проектом. Имя открытой в данный момент панели высвечивается в строке заголовка диалогового окна.
Настроенную панель инструментов Кнопки автозадач можно затем сохранить, используя команды диалогового окна Настройка...
Панель инструментов Кнопка автозадач можно использовать как удобный интерфейс для пользовательских расширений стандартных процедур.
Кнопки автозадач
Ее можно ле1 ко настроить так, чтобы она занимала очень мало места на экране.
Размеры панелей инструментов можно менять с помощью мыши:
Панель можно зафиксировать, переместив ее к границе окна приложения системы STATISTICA, как показано на следующем рисунке.
84
Глава 1. Краткая экскурсия по системе STATISTICA
Как уже былоотмечено, кнопки панели инструментов Кнопки автозадач можно настроить или переназначить в диалоговом окне Настройка кнопок автозадач (которое открывается с помощью кнопки Настройка.. на панели инструментов). Кроме того, отдельные кнопки можно отредактировать и/или переназначить непосредственно в соответствующем окне настройки; для этого нужно щелкнуть мышью по этой кнопке при нажатой клавише CTRL.
При этом откроется окно настройки данной конкретной кнопки.
Выбирая последний пункт контекстного меню, которое появляется по щелчку правой кнопкой мыши где-либо на панели инструментов, можно быстро переключаться между различными предварительно сохраненными панелями инструмен тов Кнопки аетоэадач.
Взгляд в будущее
STATISTICA постоянно развивается, открывая новые возможности для пользователей Если говорить кратко, то развитие системы происходит в духе развития современных Windows-технологий. Гибкая настраиваемость для задач конкретного проекта, широкий набор статистических опций, доступных пользователю из других приложений, глобальная интеграция с другими приложениями, например, с помощью VB, C++, Java, оптимизация для Web и мультимедийных приложений — ближайшие перспективы STATISTICA.
Первые шаги в системе STATISTICA
85
В таблицы с данными (мультимедийные электронные таблицы) можно будет встраивать различные объекты: звук, фото и т. д.
Первые шаги в системе STATISTICA
Наше знакомство с системой STATISTICA, конечно, следует начать с ввода данных. Вы увидите, как легко вводятся в STATISTICA самые разнообразные данные. Предполагается, что система STATISTICA установлена на вашем компьютере и вы последовательно повторяете описываемые действия.
В качестве конкретной области выберем медицинский пример.
Как вы уже знаете, исходные данные в системе STATISTICA организованы в виде таблиц. Если у вас имеется опыт работы с электронными таблицами (типа MS Excel), то вы быстро привыкнете к таблицам STATISTICA. Заметим, что табличная структура данных STATISTICA позволяет естественно отобразить большинство реальных данных.
Электронная таблица состоит из строк и столбцов. Столбцы таблицы STATISTICA называются Variables — Переменные, а строки Cases — Наблюдения.
Например, в медицине наблюдения — это пациенты, переменные — пол,возраст. Дата поступления в больницу, дата диагноза, дата операции, перевода в другую больницу, выписки и т. д. Вы можете представить такую таблицу как страницу записной книжки врача, где строки — это, например, имена пациентов, столбцы — характеристики (переменные, описывающие течение болезни).
86
Глава 1. Краткая экскурсия по системе STATISTICA
Для того чтобы создать таблицу с данными, проделайте следующее"
1. Запустите программу STATISTIСА.
2. Откроется меню Статистических модулей (STATISTICA Module Switcher).
3. Выберите из меню модуль Основные статистики и таблицы и щелкните по нему мышью.
4. Теперь вы находитесь в модуле Основные статистики и таблицы, в котором можете выбрать любую статистическую процедуру, входящую в этот модуль. Но поскольку у вас другая цель, просто щелкните мышью по кнопке Выход (Cancel).
Итак, вы находитесь в рабочем окне модуля Основные статистики и таблицы системы STATISTICA. В основном рабочем окне системы подведите курсор мыши к строке меню Файл и щелкните левой кнопкой. В выпадающем меню выберите команду Создать данные. На экране компьютера сразу же появляется окно Создание данных (см. рисунок ниже)
В этом окне можно ввести имя файла, например medicinel sta (файл может быть назван и по-русски, однако по ряду причин целесообразнее использовать английские имена).
Теперь поместите курсор мыши в поле Filename — Имя файла и наберите с клавиатуры нужное имя.
После нажатия клавиши Enter на клавиатуре или кнопки Save программа со здаст пустую таблицу, содержащую 10 строк и 10 столбцов
Первые шаги в системе STATISTICA
87
Вы легко можете увеличить или уменьшить как количество строк, так и количество столбцов этой таблицы. Создайте в таблице столько строк и столбцов, сколько н\'жно. Для этого используйте кнопки Пяре*«ииы* J Навлвдвниг! иа панели инструментов.
Нажмите, например, кнопку Наблюдения. После нажатия кнопки на экране возникнет меню, предлагающее следующий выбор для наблюдений таблицы: Доба-вить, Пере честить, Копировать, Удалить, Ввести имена наблюдений. Выберите, напри мер. пун кт Добавить, дважды щелкнув левой кнопкой мыши. Откроется окно, в котором можно задать число наблюдений, добавляемых в таблицу:
Нажмите ОК, и количество строк (наблюдений) в таблице увеличится на 2, то есть станет равным 12. Аналогичным образом измените число переменных в таблице. В данном случае понадобятся 11 переменных. Нажмите кнопку Переменные на панели инструментов. С помощью курсора мыши в выпадающем меню выберите пункт Добавить. На экране появится окно, где выполните установки, как показано ниже.
Нажмитееще раз кнопку Наблюдения и выберите пункт меню Имена. На экране появится диалоговое окно, в котором можно определить, сколько символов в таблице будет зарезервировано для имен наблюдений. Раздвинуть поле для имен наблюдении можно также с помощью мыши.
Итак, вы сделали первый шаг к достижению цели — создали электронную таблицу, которая имеет 11 столбцов и 12 строк, атакже место для ввода имен наблюдений (см. рисунок).
Теперь необходимо ввести название таблицы (ее заголовок) и имена переменных Н работаете, используя мышь и клавиатуру. Запомните основной принцип: дважды
88
Глава 1. Краткая экскурсия по системе STATISTICA
щелкая мышью по полям заголовков, вы открываете диалоговые окна, позволяющие вводить заголовки, описывать переменные и т. д. Введите заголовок таблицы. Для этого дважды щелкните мышью на верхней строке таблицы, пустой строке, которая находится над переменными. В появившемся окне введите заголовок таблицы
Наберите с клавиатуры заголовок, нажмите ОК. Введенный текст отобразится в заголовке таблицы В поле Информация о файле и примечания можно записать дополнительную информацию, которая будет полезна при работе с файлом.
Аналогично редактируются имена переменных и наблюдений. Например, чтобы ввести имена, необходимо дважды щелкнуть мышью в поле Имя наблюдения и в появившемся окне ввести имена пациентов:
Для того чтобы описать переменную, необходимо дважды щелкнуть мышью по ее имени — например, после щелчка по заголовку переменном (VAR1) откроется окно, в котором можно задать ее имя (или переименовать ее), формат переменной метку, связь ит. д.
Первые шаги в системе STATISTICA
89
Теперьзалолните созданную таблицу данными. Данные вводятся непосредственно с клавиатуры. Возмож! юсти экспорта, например в MS Word, мы обсудим позднее. Если нужно ввести числовые данные, используйте клавиатуру и стрелки перемещения курсора. Поставьте курсор на нужную ячейку таблицы и введите числовые данные. Текстовые значения вводятся иначе. Подведите курсор к ячейке переменной с текстовыми значениями и дважды щелкните мышью. В ячейке появится код 9999 — это код пропущенных значений. Сотрите код, используя кнопку DEL на клавиатуре. Затем введите нужное текстовоезначение В итоге можно получить следующую таблицу:
Таким образом, вы научились создавать таблицы и вводить в них данные. Повторив несколько раз описанные действия с другими данными, вы прочно закрепите полученные навыки.
Поскольку система STATISTICA является обычным Windows-приложением, можно легко и быстро импортировать данные, полученные в системе STATISTICA, в другое Windows-приложение, например в MS Word.
Лучше всего проделать это следующим образом: нажмите одновременно кнопки ALT и F3. На экране вместо курсора мыши появится значок «прицел». Используя мышь, поместите прицел в верхний левый угол таблицы. Затем нажмите левую кнопку мыши, зафиксируйте прицел и. удерживая кнопку мыши, переместите прицел в новое место таблицы. Выделенная часть таблицы будет отмечена прямоугольной рамкой. После того как вы отпустите кнопку мыши, отмеченная часть таблицы будет помещена в буфер обмена. Если теперь открыть нужный документ Word и набрать на клавиатуре комбинацию кнопок CTRL и V, то выбранный сегмент таблицы будет скопирован в документ.
Замечания. Вы работали в модуле Основные статистики и таблицы, подобным же способом можно ввести данные в любом модуле системы STATISTICA. С точки зрения общих возможностей по управлению данными, модули системы одинаковы.
В системе STATISTICA имеется специальный модуль Управление данными (Data management), который содержит расширенные возможности, позволяющие быстро создать электронную таблицу, объединить две таблицы, вырезать часть таблицы, отсортировать наблюдения по какому-либо признаку: например, расположить имена пациентов в алфавитном порядке или упорядочить их по возрасту и т. д. (см. рисунок ниже).
Упражнение. Проведите сортировку данных файла medicine1.sta по возрасту пациентов и по городам. Используйте модуль Управление данными и опцию Сортировка набчюдений
Глава 1. Краткая экскурсия по системе STATISTICA
Еще один пример
Из переключателя модулей системы STATISTICA запустите модуль Основные статистики и таблицы. Для этого выберите в меню модуль Основные статистики и таблицы и щелкните по нему мышью. Модуль будет выбран из списка модулей. Затем подведите курсор мыши к кнопке Переключиться в и нажмите ее. Произойдет запуск системы STATISTICA, и на экране появится рабочее окно модуля Основные статистики и таблицы. Именно в этом модуле мы будем работать.
Первые шаги в системе STATISTICA 91
В модуле Основные статистики и таблицы создайте файл данных, как показано на рисунке.
В файле содержатся результаты опроса 10 женщин (данные являются модельными) относительно их семейного положения и состояния уровня тревожности Первая переменная СЕМ_ПОЛ описывает семейное положение женщин. Эта переменная принимает два значения: П_семья — полная семья, Нсемья — неполная семья. Вторая переменная, ТРЕВОГА, описывает самооценку личностной тревожности женщины. Она принимает два значения; низкая, высокая. Известно, что личностная тревожность характеризуется устойчивой склонностью воспринимать жизненную ситуацию как угрожающую (содержащую в себе тайную угрозу). Вы видите, что первая опрошенная женщина — наблюдение номер 1 (первая строка в таблице) — имеет полную семью и характеризует свое душевное состояние как тревожное. Вторая опрошенная женщина — наблюдение номер 2 (вторая строка таблицы) — имеет неполную семью и оценивает уровень своей тревожности как низкий и т. д.
Назовите этот файл a omen 1.sta.
Заметьте, переменныев этом файле принимают текстовые значения, что типично для социологических опросов.
Примите совет, позволяющий эффективнее организовать ввод текстовых данных. Переменные принимают текстовые значения, и если каждый раз вводить текст в таблицу, то это займет слишком много времени. Для удобства лучше использовать численные значения, а затем перейти в текстовый режим, нажав кнопку на панели инструментов. Удобно закодировать значения переменных. Покажем, как это делается. Начнем с переменной СЕМ_ПОЛ. Дважды щелкните по ее заголовку левой кнопкой мыши, и на экране отобразится окно Диспетчер текстовых значений - СЕМПОЛ.
В этом окне в колонке Текст наберите в первой строке П_семья, а в колонке Число наберите 1. Это приведет к тому, что текстовому значению П_семья будет присвоен код 1. Во второй строке Диспетчера текстовых значений наберите Н_семья, а в колонке Число наберите 2 — текстовому значению Н семья будет присвоен код 2. Далее нажмите кнопку ОК.
92
Глава 1. Краткая экскурсия по системе STATISTICA
Теперь введите значения 1 в те ячейки переменной СЕМ_ПОЛ. и которых должно стоять текстовое значение П__семья.
Введите значения 2 в те ячейки переменной СЕМПОЛ, в которых должно сто -ять текстовое значение Н_семья
Теперь достаточно нажать кнопку на панели инструментов STATISTICA
чтобы получить нужные текстовые значения.
Точно такимжеобраэом введите текстовые значешы в ячейку переменной ТРЕВОГА.
Итак, вы создали файл women 1 sta. Теперь построим, исходя из этого файла исходных данных, таблицу сопряженности. Это очень легко сделать в STATISTICA
Шаг 1. Подведите курсор мыши к пункту Анализ. Щелкните по нему мышью. Б появившемся меню сделайте выбор: Стартовая панель.
Вы увидите различные виды анализа, которые доступны в модуле. Выберите анализ: Таблицы и заголовки и нажмите кнопку ОК.
На экране появится окно Задайте таблицы.
Шаг 2. Сначала в строке Анализ выберите Таблицы сопряженности (возможен вариант Таблицы флагов и заголовков').
Провыв шаги в системе STATISTICA 93
Шаг 3. Далее нажмите кнопку Задать таблицы. В появившемся окне выберите перемен ные, которые будут табул прогоны в таблице Эти переменные задают разбие • ние исходных данных на группы, поэтому часто их называют также группирующими переменными. В данном случае нужно табулироватьзначения переменных СЕМ ПОЛ иТРЕВОГА
Поэтому выберите их, как это показано на рисунке ниже.
Заметьте, что вообще можно выбрать до 6 списков группирующих переменных, что позволяет построить чрезвычайно сложные таблицы, содержащие гораздо большее число переменных, чем в описываемом примере. Именно такие таблицы часто возникают при массовых обследованиях, и их нужно уметь строить.
После выбора переменных нажмите кнопку ОК. Вы вновь вернетесь в диалоговое окно, показанное на рисунке. Обратите внимание, что окно немного изменилось: около надписи Число таблиц появилась цифра 1, потому что вы выбрали переменные и попросили систему построить одну таблицу.
Шаг 4. Нажмите Enter на клавиатуре или кнопку ОК в верхнем правом углу диалогового окна.
Система произведет вычисления и предложит посмотреть результат в окне Результаты кросстабуляции.
Шаг 5. В окне Результаты кросстабуляции нажмите кнопку Просмотреть итоговые таблицы. На экране появится следующая таблица сопряженности-
94
Глава 1, Краткая экскурсия по системе STATISTICA
Вы видите, что в этой таблице табулированы переменные СЕМПОЛ и ТРЕВОГА. На пересечении строк и столбцов стоят абсолютные значения, вычисленные из исходного файла данных womenl sta
Мы табулировали совместно значения двух переменных, СЕМ ПОЛ и ТРЕВОГА, и такое действие часто называется кросстабуляцией (от английского cross — пересекать).
Из построенной таблицы, называемой на сленге таблицей сопряженности, видно, что три женщины имеют полную семью и низкий уровень тревоги, две женщины имеют неполную семью и низкий уровень тревоги и т. д. Если вас интересует раздельная табуляция каждой переменной, посмотрите на крайний правый столбец и нижнюю строку таблицы. Вы увидите, что всего среди опрошенных женщин пять имели полную семью и пять — неполную семью; пять женщин имели высокий уровень тревожности (см. крайний правый столбец), пять — низкий уровень тревожности (см. нижнюю строку).
Часто возникает необходимость вместе с абсолютными значениями привести в таблице проценты. Система STATISTICA позволяет выбрать те проценты, которые требуются: например, только проценты по строке, или проценты по столбцу, или проценты от общего количества, или же и те и другие.
Проценты по столбцу — это проценты, вычисленные относительно суммарного значения частот по столбцу. Проценты построке — это проценты, вычисленные относительно суммарного значения частот по строке. Проценты от общего числа вычисляются относительно суммы частот в таблице Рассмотрим, как это делается.
Шаг 6. Нажмите кнопкуЦалее в верхнем левом углу таблицы (см. рисунок).
Вы вновь вернетесь в окно Результаты кросстабуляции.
Шаг 7. В окне Результаты кросстабуляции обратите внимание на опции в праной части, объединенные в группу Таблицы.
Выберите, например, опцию Проценты от общего числа. Подведите курсор мыши к соответствующему квадрату и щелкните мышью. В окне Результаты кросстабу ляции нажмите кнопку Просмотреть итоговые таблицы. На экране появится еле -дующая таблица:
Здесь рядом с абсолютными значениями появились относительные величины — проценты, вычисленные от общего числа женщин, то есть от 10.
Первые шаги в системе STATISTICA
95
Итак, из таблицы видно (пожалуйста, проверьте!), что:
О 30% женщин имеют полную семью п низкий уровень тревоги (первая клетка таблицы),
О 20% женщин имеют полную семью и высокий уровень тревоги (вторая клетка таблицы),
> 20% женщин имеют неполную семью и низкий уровень тревоги,
О 30% женщин имеют неполную семью и высокий уровень тревоги.
Построенную таблицу можно отредактировать, изменить ее вид. надписи и т. д.
Шаг 8. Редактирование таблицы.
Дважды щелкните, например, по полю Всего % в построенной таблице. В появившемся окне Имя строки таблицы результатов вместо Всего % введите %
Вы получите таблицу вида-
Шаг 9. Построение отдельных таблиц с процентами.
Вернитесь вновь в окно Результаты кросстабуляции и обратите внимание на опцию Отображать выбранные % в отдельных таблицах
Сделайте следующие установки: выберите опцию Проценты от общего числа и опцию Отображать выбранные % в отдельных таблицах. Затем нажмите кнопку Просмотреть итоговые, таблицы.
96
Глава 1. Краткая экскурсия по системе STATISTICA
Вы увидите две таблицы, одна из которых будет содержать только абсолютн_. значения, а другая — проценты, вычисленные от общего количества опрошенных.
Шаг 10. Создание автоотчета.
В системе STATISTICA имеется полезное средство подготовки отчета, которое позволяет представить все полученные результаты в формате RTF; далее отчет можно вывести на принтер, отредактировать и красиво распечатать.
Проделайте следующее: войдите в меню Вид и выберите опцию Окно текста/ вывода. Из построенных таблиц (они находятся в рабочем окне системы) выберите ту, которую нужно сохранить для отчета. Щелкните по ней мышью. Вновь войдите в меню Файл и выберите опцию Печать. Отмеченная таблица результатов будет распечатана.
В этом окне можно, например, отредактировать таблицу и подготовить ее в том формате, какой требуется для исследовательского отчета или статьи.
ИТОГО Б it OON 5 Ы.ООХ 10 100 ООМ
97
Графический анализ таблиц сопряженности
Обратите внимание, что в процессе работы ни разу не использовался какой-либо язык программирования, все действия носят интерактивный характер, и это большое достоинство системы STATISTICA. Работать в ней так же просто, как, например. в текстовом редакторе MS Word. В заключение вам предлагается упражнение, которое закрепит полученные навыки.
Пример. Создайте в STATISTICA файл womeri2jsta. Для градации значений переменных используются более реалистичные шкалы. Шкала семейного положения женщины: одинокая, неполная семья, полная семья. Шкала тревожности женщины: низкая, умеренная, высокая.
анализ таблиц сопряженности
Графический
Таблицы сопряженности позволяют компактно описывать данные. Они удобны и требуют минимум комментариев, поэтому популярны среди врачей, социологов, маркетологов. В системе STATISTICA очень легко строятся даже самые сложные таблицы сопряженности.
Здесь мы рассмотрим, как визуализировать построенные таблицы, то есть познакомимся со средствами STATISTICA, позволяющими графически проанализировать таблицы. Визуально гораздо проще увидеть закономерности, содержащиеся в таблицах. В примерах используются данные небольшого объема, чтобы можно было отчетливо представить основные приемы работы. Представьте, в каком сложном положении вы оказались, если бы имели дело с громадными таблицами, а именно такие таблицы возникают на практике. «Делайте вслед занами!» — по-прежнему остается нашим главным девизом.
Итак, система STATISTICA запущена на компьютере, вы работаете в модуле Основные статистики и таблицы (в английской версии STATISTICA модуль Основные статистики и таблицы называется Basic Statistics and Tables').
Пример (продолжение)
Файл данных womenlsta, с которым вы работаете, открыт в рабочем окне. Напомним, что в этом файле приведены результаты опроса 10 женщин (данные являются Модельными) относительно их семейного положения и уровня тревожности.
98
Глава 1. Краткая экскурсия по системе STATISTICA
Первая переменная СЕМПОЛ семейное положение женщин. Эта переменная принимает два значения: П семья — полная семья, Н_семья — неполная семья.
Вторая переменная ТРЕВОГА — самооценка личностной тревожности женщины. Она принимает два значения: низкая, высокая. Известно, что личностная тревожность характеризуется устойчивой склонностью личности воспринимать жизненную ситуацию как угрожающую. В данном упрощенном примере мы использовали две степени тревожности: низкая и высокая.
Вы видите, что первая опрошенная женщина — наблюдение номер 1 (первая строка в таблице) — имеет полную семы» и характеризует свое состояние как тревожное. Вторая опрошенная женщина — наблюдение номер 2 (вторая строка таблицы) — имеет неполную семью и оценивает уровень тревожности как низкий ит. а.
Шаг 1. Подведите курсор мыши к пункту Анализ. Щелкните по нему мышью. В появившемся меню сделайте выбор: Стартовая панель.
Выберите анализ: Таблицы и заголовки и нажмите кнопку ОК
С помощью опций окна задания таблицы произведите табулировку переменных СЕМ_ПОЛ и ТРЕВОГА
графический анализ таблиц сопряженности
Шаг 2. После того как система построит таблицу, посмотрите внимательно на окно Результаты кросапабуляции.
Обратите внимание на кнопки в правом нижнем углу диалогового окна Результаты кросстабуляции.
ШагЗ. В диалоговом окне Результаты кросстабуляции нажмите кнопку Кате-гори «манные гистограммы:
100
Глава t. Краткая экскурсия по системе STATISTICA
Смысл этих гистограмм следующий; опрошенные женщины разбиты на две группы (категории): женщины из полной семьи и женщины из неполной семьи
Обычная гистограмма для этих переменных выглядит следующим образом;
ных. На обычной гистограмме количество женщин с высокой и низкой тревожностью одинаково. На категоризованной гистограмме количество женщин с высоким уровнем тревожности в неполных семьях выше, чем в полных. Уровень тревожности женщин в полных семьях ниже, чем уровень тревожности в неполных семьях.
Продолжение примера
Рассмотрим файл данных womeri2.sta. Для градации значений переменных мы использовали более реалистичные шкалы: одинокая женщина, неполная семья, полная семья. Шкала тревожности женщины: низкая, умеренная, высокая.
Шаг 1. Подведите курсор мыши к пункту Анализ. Щелкните по нему мышью. В появившемся меню сделайте выбор: Стартовая панель.
Выберите Таблицы и заголовки и нажмите кнопку ОК.
Шаг 2. В строке Анализ выберите Таблицы сопряженности (возможен вариант Таблицы флагов и заголовков).
Графический анализ таблиц сопряженности 101
Далее нажмите кнопку Задать таблицы. В появившемся окне выберите переменные, которые будут табулированы в таблице (подробности см. выше). В данном случае необходимо табулировать значения переменных СЕМ_ПОЛ и ТРЕВОГА
Нажмите кнопку Коды и выберите коды (значения) табулируемых качественных признаков. В этом примере количество значений переменных увеличилось, так как используется более точная шкала измерения.
Если вы хотите, чтобы табулировались все значения переменных, нажмите кнопку Выбрать все в правом нижнем углу.
Заметьте, что вообще можно выбрать любой набор кодов. Коды переменных можно просмотреть, нажав кнопку Ииф.
Например, переменная СЕМ_ПОЛ принимает следующие значения:
Шаг 3. Нажмите Enter на клавиатуре или кнопку ОК в верхнем правом углу Диалогового окна.
STATISTICA произведет выч исления, табулирует данные п предложит результат в окне Результаты кросстабуляции (см. рисунок).
102
Глава 1- Краткая экскурсия по системе STATISTICA
Шаг 4. В окне Результаты кросстабуляции паямплекнопку Просмотреть итоговые таблицы. На экране появится таблица:
Шаг 5. Нажмите кнопку Далее в верхнем углу таблицы, и вы вернетесь в окно результатов. В диалоговом окне Результаты кросстабуляции нажмите кнопку Категоризованные гистограммы.
Смысл гистограмм заключается в следующем: женщины разбиты на 3 группы или категории: женщины из полной семьи, женщины из неполной семьи, одинокие женщины (ср. с предыдущим примером). Для каждом группы построена отдель-
Графический анализ таблиц сопряженности
103
цая гистограмма, и все эти гистограммы собраны вместе на одном графике, что позволяет визуально сравнить группы.
Шаг 6. В диалоговом окне Результаты кросстабуляции нажмите кнопку ЗМ гистограммы.
На экране появится трехмерная гистограмма.
Смысл этой гистограммы следующий: составляются всевозможные комбинации значении двух переменных: семейное положение и уровень тревожности, и подсчитывается, сколько раз встречалась каждая комбинация.
Трехмерная гистограмма очень наглядно воспроизводит таблицу кросстабуляции. Вы положили таблицу на плоскость и в каждую клетку поставили по столбцу, высота которого равна количеству наблюдений в клетке таблицы.
Если вас не устраивает ракурс построенной трехмерной гистограммы, можно его изменить, воспользовавшись средствами системы. STATISTICA предлагает удивительный инструмент работы с. графиками. Например, их можно повернуть.
Нажмите кнопку Вращение, расположенную на панели инструментов.
На экране появится окно, в котором можно провести вращение и подобрать нужную перспективу.
Для вращения графика используйте линейку прокрутки. Немного поэкспериментируйте с ней. Сначала, например, с помощью мыши сдвиньте курсор прокрутки в крайне левое положение. Вы увидите следующую картинку:
104
Глава 1. Краткая экскурсия по системе STATISTICA
Сдвиньте теперь курсор прокрутки правее.
Каждый раз, когда сдвигается курсор, происходит поворот графика. Выберите тот вариант, который вас устраивает. Нажмите кнопку ОК Нужный график появится на экране.
Шаг7. Построение графиков взаимодействий частот В окне Результаты кросс-табуляции нажмите кнопку Графики взаимодействий частот. На экране появится график взаимодействий:
Смысл этого графика простой: он показывает, как взаимодействуют или как связаны между собой частоты наблюдений из разных групп.
Все построенные графики показывают, что женщины из разных семей различаются по уровню тревожности. Является ли это различие значимым, показывают статистические тесты.
2
Элементарные понятия анализа данных
В этой главе предлагается краткое обсуждение элементарных статистических понятий, лежащих в основе процедурв любой области статистического анализа данных. Выбранные нами темы иллюстрируют основные допущения, принимаемые в большинстве статистических методов для описания «численной природы» действительности, а изложение ведется на языке, доступном для широкого круга читателей.
Мы начнем с самых простых, интуитивно ясных понятий и рассмотрим связи между ними, фактически представим описание языка, на котором говорят при проведении анализа данных.
Что такое переменная?
Переменная (английский термин variable) — это то, что можно измерять, контролировать или чем можно манипулировать в исследованиях. Иными словами, переменная — это то, что варьируется, изменяется, а не является постоянным (от английского корня var).
Например, измеряя давление или содержание лейкоцитов в крови, вы получаете различные значения у разных пациентов или значения для одного и того же пациента в разное время суток. Измеряя уровень осадков, получаете различные значения в разные дни недели, а также различные значения в одни и те же дни в разных точках географической карты
Другое примеры переменных из разных областей: анкетные данные, систолическое давление пациентов, количество лейкоцитов в крови, цена акций, товаров, услуг, потребление, инвестиции, доход, государственные закупки товаров и услуг, инструмент государственного регулирования (в экономике); рейтинг программ, доля зрителей, количество посещений сайта (в рекламе); скорость, температура, объем, масса в (физике) и т. д.
Очевидно, что это очень разные по своим свойствам переменные, и поэтому можно сказать, что переменные отличаются характеристиками, в частности, той ролью, которую они играют в исследованиях, типом измерений и т. д.
Простейшие описательные статистики
Так как значения переменных не постоянны, нужно научиться описывать их изменчивость.
106
Глава 2. Элементарные понятия анализа данных
Для этого придуманы описательные или дескриптивные статистики: минимум максимум, среднее, дисперсия, стандартное отклонение, медиана, квартили, мода ит.д.
Идея этих статистик очень проста, вместо того чтобы рассматривать все значения переменной, а их может быть очень много (тысячи и миллионы), вначале стоит просмотреть описательные статистики. Они дают общее представление о значениях, которые принимает переменная.
Минимум и максимум — это минимальное и максимальное значения переменной
Среднее — сумма значений переменной, деленная на п (число значений переменной).
Дисперсия (от английского variance) и стандартное отклонение (от англиггско-го standard deviation) — наиболее часто используемые меры изменчивости переменной. Дисперсия меняется от нуля до бесконечности. Крайнее значение 0 означает отсутствие изменчивости, когда значения переменной постоянны.
Стандартное отклонение вычисляется как корень квадратный из дисперсии. Чем выше дисперсия или стандартное отклонение, тем сильнее разбросаны значения переменной относительно среднего. Часто стандартное отклонение — более удобная характеристика, так как измерена в тех же единицах, что исходная величина
Медиана разбивает выборку на две равные части. Половина значений переменной лежит ниже медианы, половина — выше.
Медиана дает общее представление о том, где сосредоточены значения переменной, иными словами, где находится ее центр. В некоторых случаях, например при описании доходов населения, медиана более удобна, чем среднее.
Квартили представляют собой значения, которые делят две половины выборки (разбитые медианой) еще раз поползм.
Таким образом, медиана и квартили делят диапазон значений переменной на четыре равные части.
Различают верхнюю квартиль, которая больше медианы и делит пополам верхнюю часть выборки (значения переменной больше медианы), и нижнюю квартиль, которая меньше медианы и делит пополам нижнюю часть выборки
Нижнюю квартиль часто обозначают символом 25%, это означает, что 25% значений переменной меньше нижней квартили
Верхнюю квартиль часто обозначают символом 75%, это означает, что 75% значений переменной меньше верхней квартили
Мода представляет собой максимально часто встречающееся значение переменной (иными словами, наиболее «модное» значение переменной), например популярная передача на телевидении, модный цвет платья или марка автомобиля и т д.
С описательными статистиками связаны статистические графики, например приведенный ниже график наглядно показывает, как распределены значения переменной (подробнее см. главу Визуальный анализ данных):
Взгляните на график
На графике приведены описательные статистики для переменной Уровень осадков. Хорошо видно, как распределены значения переменной: от минимального уровня (16 дюймов) до максимального уровня (39 дюймов).
Половина значений переменной лежит ниже 27,5 дюйма, то есть в половине всех наблюдаемых месяцев уровень осадков был меньше 27,5 дюйма Половина
гяпйсгва описательных статистик
107
значений осадков лежит выше 27,5 дюйма, соответствуя тому, что в половине наблюдаемых месяцев уровень осадков был выше 27.5 дюйма.
Свойства описательных статистик
Введем формально определения простейших описательных статистик.
Среднее. Пусть имеется переменная X. тогда оценка среднего, или выборочное среднее, вычисляется как среднее арифметическое наблюдаемых значений. Выборочное среднее обычно обозначается X и читается «X с чертой». Формально имеем:
Выборочное среднее является той точкой, сумма отклонений наблюдений от которой равна 0. Формально это записывается следующим образом:
f(X-Xj=<i
Упражнение: используя определение среднего, убедитесь, что данное свойство действительно имеет место, то есть сумма отклонений наблюдаемых значений от среднего арифметического действительно равна 0
Выборочное среднее — единственная точка, которав обладает данным свойством, и это выделяет ее среди всех других.
Кроме того, выборочное среднее обладает ешеодним замечательным свойством: сумма квадратов расстояний между наблюдаемыми значениями и их средним арифметическим является минимальным. Если вместо среднего арифметического взять любую другую величину, то сумма квадратов расстояний между наблюдаемыми значениями и этой величиной будет только больше, но никак не меньше.
Дисперсия. Выборочная дисперсия переменной X (термин впервые введен Фишером, в 1918 г.) вычисляется по формуле
108
Глава 2. Элементарные понятия анализа данных
в1—^-Х<х-х>’ п — 1 ,=1
Обратите внимание на коэффициент в данной формуле, он ранен и — 1, такая оценка дисперсии является несмещенной (математическое ожидание несмещенной оценки равно в точности значению оцениваемого параметра).
Стандартное отклонение равно корню квадратному из выборочной дисперсии Формально имеем:
в
Медиана выборки (термин был впервые введен Гальтоиом, в 1882 г ) — значение, которое разбивает выборку на две равные части. Половина наблюдений лежит ниже медианы, и половина наблюдений лежит выше медианы.
Наблюдения упорядочивается по возрастанию: Х(1)< ХМ). Получен-
ная последовательность Х<й называется вариационным рядом, а ее элементы — порядковыми статистиками. Если число наблюдений нечетно и = 2т 1, то медиана оценивается как X(ml: med - X^m).
Если число наблюдений четно п 2т, то в качестве оценки медианы берется величина (Х<т) + Х^п)/2.
Медиана обладает следующим замечательным свойством: сумма абсолютных расстояний между точками выборки и медианой минимальна. С вариационным рядом связано много важных статистик, например, спейсннгн, представляющие собой расстояния между соседними порядковыми статистиками.
Квантиль (термин был впервые использован Кендаллом в 1940 г.) выборки представляет собой число хр, ниже которого находится p-я часть (доли) выборки.
Например, квантиль 0,25 для некоторой переменной — это такое значение (хр), ниже которого находится 25% значений переменной.
Аналогично квантиль 0,75 — это такое значение, ниже которого попадают 75% значений выборки.
Формально р-квантиль непрерывного распределения F определяется как ко рень уравнения F(x) -р,0<р<1.
Квартили. Нижняя и верхняя квартили, от слова кварта — четверть (термин впервые использовал Гальтон в 1882 г.), равны соответственно 25-й и 75-й процентилям распределения.
25-я процентиль переменной — это значение, ниже которого располагаются 25% значений переменной
Аналогично, 75-я процентиль равна значению, ниже которого расположено 75% значений переменной
Итак, 3 точки — нижняя квартиль, медиана и верхняя квартиль — делят выборку на 4 равные части.
'/< наблюдений лежит между минимальным значением и нижней квартилью, 'Л — между нижней квартилью и медианой, ’/< — между медианой и верхней квартилью, '/« — между верхней квартилью и максимальным значением выборки.
Квартильный размах. Квартильный размах переменных (термин был впервые использован Талтоном в 1882 г.) равен разности значений 75-й процентили
^йетва описательных статистик _________________________________109
25-й процентили. Таким образом, это интервал, содержащий медиану, в который попадает 50% наблюдений.
Мода- Мода (термин был впервые введен Пирсоном в 1894 г.) — это наиболее <асто встречающееся (наиболее модное) значение переменной.
Мода хорошо описывает, например, типичную реакцию водителей на сигнал светофора о прекращении движения.
Классический пример использования моды — выбор размера выпускаемой партии обуви ПЛИ цвета обоев.
Если распределение имеет несколько мод, то говорят, что оно мультимодально или хяюгомодально (имеет два или более -«пика»).
Мультимодальность распределения дает важную информацию о природе исследуемой переменной.
Например, в социологических опросах, если переменная представляет собой предпочтение или отношение к чему-то, то мультимодальность может означать, что существуют несколько определенно различных мнений.
Мультимодальность также служит индикатором того, что выборка не является однородной и наблюдения, возможно, порождены двумя или более «наложенными» распределениями.
Асимметрия. Асимметрия, или коэффициент асимметрии (термин введен Пирсоном в 1895 г.), является мерой несимметричности распределения. Если этот коэффициент значительно отличается от 0, распределение является асимметричным (несимметричным). Формально имеем:
IJcx-X)1
Эксцесс. Эксцесс, или коэффициент эксцесса (термин впервые введен Пирсоном в 1905 г.) измеряет остроту пика распределения. Оценка эксцесса, или выборочный эксцесс, вычисляется по формуле:
1£(Х,-Х)*
гае х=1£х, п Z7
Асимметрия и эксцесс полезны для проверки нормальности данных. Нормальное распределение симметрично, следовательно, коэффициент асимметрии равен 0. Эксцесс нормального распределения также равен 0, поэтому по отклонениям выборочного эксцесса и асимметрии от 0 можно судить о близости распределения наблюдаемой переменной к нормальному. Известно, что распределение с более °строй вершиной, чем нормальное, атипичных случаях имеет положительный эксцесс, а с более закругленной — отрицательный.
110
Глава 2. Элементарные понятия анализа данных
Шкалы измерений
Переменные различаются тем, -«насколько хорошо» они могут быть измерены, или, друг ими словами, как много измеряемой информации обеспечивает шкала их измерений, поскольку в каждом измерении присутствует некоторая ошибка, определяющая границы «количества информации*, которую можно получить в данном измерении
Другим фактором, определяющим количество информации, содержащейся в переменной, конечно, является тип шкалы, в которой проведено измерение. Вы можете считать, что шкала — это просто линейка: очень грубая, менее грубая, точная.
Обычно используют следующие типы шкал измерений: (а) номинальная, (Ь) порядковая (ординальная), (с) интервальная, (d) относительная (шкалаотношения).
Соответственно имеются четыре типа переменных: (а) номинальная. (Ь) порядковая (ординальная), (с) интервальная и (d) относительная
(а) Номинальные переменные используются только для качественной классификации. Это означает, что данные переменные могут быть измерены только в терминах принадлежности к некоторым существенно различным классам, при этом вы не сможете определить количество или упорядочить эти классы. Типичными примерами номинальных переменных являются фирма-производитель, тип товара, признак (болен — здоров) и т. д. Часто номинальные переменные называются категориальными. Близкими к ним являются категоризованные переменные, то есть переменные, искусственно превращенные в категориальные (см. ниже).
(Ь) Порядковые переменные позволяют ранжировать (упорядочить) объекты, если указано, какие из них в большей или меньшей степени обладают качеством, выраженным данной переменной. Однако они не позволяют определить «на сколько больше» или «на сколько меньше» данного качества содержится в переменной.
Порядковые переменные иногда также называют ординальными Типичный пример — социоэкономический статус семьи. Мы понимаем, что верхний средний уровень выше среднего уровня, однако сказать, что разница между ними равна, допустим, 18%, мы не можем. Само расположение шкал в порядке возрастания их информативности — номинальная, порядковая, интервальная — является хорошим примером порядковой переменной. Например, можно сказать, что измерения в номинальной шкале предоставляют меньше информации, чем в порядковой шкале, а в порядковой — меньше, чем в интервальной. Однако невозможно придать термину «меньше» точный количественный смысл или сравнить между собой эти различия.
Другой пример порядковой переменной — это интенсивность использования определенного цвета в картине художника.
Категориальные и порядковые переменные особенно часто возникают при анкетировании, так как естественно отражают характер мышления человека. Например, измерение интенсивности посещения ресторанов можно проводить в следующей шкале: не посещаю, посещаю редко, посещаю, посещаю часто.
Как легко понять, категориальные и порядковые шкалы часто используются для описания качественных признаков.
(с) Интервальные переменные позволяют не только упорядочивать объекты измерения, но и численно выражать и сравнивать различия между ними.
Такого рода переменные часто возникают в естественных науках, при снятии показателей с физических приборов, в медицине и т. д. Например, температура, измеренная в градусах по Фаренгейту или Цельсию, образует интервальную шкалу. Вы можете не только сказать, что температура 40 градусов выше, чем температура 30 градусов, ни и то, что увеличение температуры с 20 до 40 градусов вдвое больше увеличения температуры от 30 до 40 градусов.
(d) Относительные переменные очень похожи на интервальные переменные. В дополнение ко всем свойствам переменных, измеренных в интервальной шкале, их характерной чертой является наличие определенной точки абсолютного нуля, таким образом, для этих переменных являются обоснованными утверждения типа: .г в два раза больше, чем у. Например, температура по Кельвину образует шкалу отношения, и вы можете нс только утверждать, что температура 200 градусов выше, чем 100 градусов, но и то, что она вдвое выше. Интервальные шкалы (например, шкала Цельсия) не обладают данным свойством шкалы отношения. Однако в большинст ве статистических процедур не делается топкого различия между свойствами интервальных шкал и шкал отношения.
Заметим, что всегда можно перейти от более богатой шкалы к менее богатой. Так, непреры вные переменные можно искусственно превратить в категориальные, то есть категоризовать.
Например, непрерывная переменная «рост человека в сантиметрах» можетбыть превращена в порядковую переменную с градациями: низкий, средний, высокий или очень низкий; низкий, средний, высокий, высокий*; или очень низкий, средне-низкий. низкий, средний, высокий, очень высокий; для размера одежды используют следующую порядковую шкалу. S, М, L, XL, XXL, XXXL, XXXXL и г. д.
Категоризованные данные часто представляют в виде частот наблюдении, попавших в определенные категории или классы. Для описания категориальных переменных полезной оказывается мода.
В реальной жизни, например при проведении массовых опросов, мы имеем все типы переменных, представленных в одном исследовании.
Какие статистики выбирать?
Среднее и медиана оценивают положение центра выборки, вокруг которого группируются значения переменной.
Среднее обладает рядом замечательных свойств. Однако эта оценка чувствительна к выбросам, которые вносят в нее сдвиг. Чтобы избежать сдвига, иногда используют взвешенное среднее (каждому значению переменной приписывают определенный вес в соответствии с его важностью, а затем для взвешенных наблюдений вычисляется обычное среднее).
Медиана является средней точкой вариационного ряда, поэтому она не так чувств и те льна к выбросам.
В официальной статистике США именно медиана используется в качестве оценки Центральной точки доходов населения.
Если распределение несимметрично (сдвинуто влево или вправо), то медиана и межквартильный размах могут дать больше информации о том. в какой области концентрируются наблюдения.
112
Глава 2. Элементарные понятия анализа данных
Если медиана меньше среднего, то распределение сдвинуто вправо. Если медиана больше среднего, то распределение сдвинуто влево.
Обычно имеется следующая схема выбора (при условии, что распределение имеет одну моду). Если данные категоризованы, то используйте моду. Если не все имеющиеся значения переменной представляют интерес, распределение несимметрично и имеются выбросы, используйте медиану. В противном случае работайте со средним.
Распределение переменной
Самый простой вопрос, который естественно задать, анализируя значения переменной, — какова вероятность того, что переменная примет данное значение или значение из данного интервала. Иными словами, мы интересуемся тем, как распределены значения переменной.
Например, оценивается вероятность того, что брошенная монета выпадет гербом, вероятность того, что пациент проживет дольше определенного времени, или вероятность того, что доля дефектных изделий в партии меньше 95%.
Описательные статистики дают общую информацию о распределении переменной. Например, медиана отражает то, что с вероятностью 0,5 значение переменной будет больше данного значения или, наоборот, меньше этого значения
Полный ответ дает функция распределения.
ПустьХ — некотораяпеременная,принимающаязначениянапрямой.Тогдафунк-11ия распределения этой переменной, обозначаемая F(x), есть вероятаостьтого, что Х<х.
Для описания реальных явлений статистиками используются различные распределения: нормальное. Стьюдента, хи-квадрат, Коши, биномиальное, отрицательное биномиальное и др. Распределения вероятностей, возникающие на практике, подробно описываются в отдачьной главе.
Зависимости между переменными
Независимо от типа две или более переменных связаны (зависимы) между собой, если наблюдаемые значения этих переменных распределены с отпасованным образом.
Другими словами, мы говорим, что переменные зависимы, если их значения каким-то образом согласованы друг с другом в имеющихся наблюдениях. Заметьте, мы не определяем, как именно происходит это согласование, возможно, его вовсе нельзя записать в явном виде.
Например, переменные Пол и WCC (число лейкоцитов) могли бы рассматриваться как зависимые, если бы большинство мужчин имело высокий уровень WCC, а большинство женщин — низкий WCC, или наоборот. Итак, если бы у мужчин число лейкоцитов в кровн было бы больше, чем у женщин, то можно сделать вывод: категориальная переменная Пол связана с переменной Число лейкоцитов.
Если вы намеряете температуру человека сверхточными датчиками, то регистрируемые значения зависят от точки, в которой проводится измерение
Рост человека очевидно связан с Весом, потому что обычно высокие индивиды тяжелее низких; IQ (коэффициент интеллекта) связан с Количеством ошибок в тесте, так как люди с высоким значением IQ, как правя до, делают меньше ошибок, и т. Д.
Исследование связей между наблюдаемыми переменными
113
Другими типичными примерами связей являются: зависимость между объемом винчестера и его ценой. Если вы рассмотрите предложения в Интернете, то увидите, чтологарифмическаязависимостьхорошоописываетсвязьцена —объем для винчестеров, зависимость между длиной диагонали монитора и ценой монитора, зависимость между зерном и длиной диагонали экрана. В том же ряду находятся: зависимость между количеством транспортных средств и количеством аварий в городе, зависимость между эластичностью спроса и доходов, числом преступлений против собственности и душевым доходом, зависимость между количеством рассылок но почте и посещений сайта и т. д. Более экзотическим примером является зависимость рождаемости от дня недели.
Исследования зависимости между парой переменных, естественно, распространяется на исследование зависимостей между переменной и списком переменных, между двумя или несколькими множествами переменных и т. д. (цена монитора зависит от фирмы-производителя, от диагонали, зерна, развертки, разрешения и других параметров).
Исследование связей между наблюдаемыми переменными в сравнении
с экспериментальными исследованиями
Большинство эмпирических исследований данных можно отнести к одному из двух типов: либо это сбор данных и оценка связей между ними, либо прямой эксперимент. в котором фиксируются некоторые воздействия на объект исследования и регистрируется отклик.
В первом случае вы не влияете (или, по крайней мере, пытаетесь не влиять) на какие-либо переменные, а только собираете их значения и хотите найти зависимости (корреляции) между некоторыми измеренными переменными, например между кровяным давлением и уровнем холестерина. Типичный пример здесь — космическая съемка больших участков Земли и попытка оценить или спрогнозировать урожайность (см., например, сайт американского госдепартамента с данными о сельхозпродукции http://www.n3ss.usda.gov/census/).
В экспериментальных исследованиях вы непосредственно и целенаправленно варьируете некоторые переменные и измеряете воздействия этих изменений на объект. Например, можете искусственно увеличить кровяное давление, а затем измерить уровень холестерина и проделать это несколько раз на ряде объектов.
В исследованиях зависимости спроса на товар от рекламы вы можете активно менять cboki рекламную политику, но такая возможность отсутствует при исследовании большинства экономических данных в маркетинговых исследованиях, где вы просто собираете данные, а затем находите связи между ними (типичный пример — оценка доходов телевизионных компаний).
Анализ данных в экспериментальном исследовании также приходит к вычислению «корреляций» между переменными, а именно между’ переменными, на которые воздействуют, и темп переменными, на которые влияет воздействие Тем не менее экспериментальные данные потенциально снабжают исследователей более качественной информацией
Глава 2. Элементарные понятия анализа данных
Корреляции
Ключевым понятием, описывающим связи между переменными, является корре ляция (от английского correlation — согласование, связь, взаимосвязь, соотношение взаимозависимость); термин впервые введен Гальтоном (Galton) в 1888 г.
Корреляция между парой переменных (парная корреляция).
Если имеется пара переменных, тогда корреляция между ними — это мера связи (зависимости) именно между этими переменными.
Например, известно, что ежегодные расходы на рекламу в США очень теенц коррелируют с валовым внутренним продуктом, коэффициент корреляции междч этими величинами (с 1956 по 1977 г ) равен 0,9699. Число посещений сайта торге вой компании тесно связано с объемами продаж и т. д.
Также тесно корродировано число хостов и число хитов на сайте (см. графики ниже).
Тесно связаны между собой такие, например, переменные, как температура воз духа и объем продажи пива, среднемесячная температура в данном месте текущего и предыдущего года, расходы на рекламу за предыдущий месяц и объем торговли в текущем месяце и т. д.
зрреляции
115
Корреляция м<-жду парой переменных называется парной корреляцией. Статистики предпочитают говорить о коэффициенте парной корреляции, который изменяется в пределах от —1 до +1.
В зависимости от типа шкалы, в которой измерены переменные, используют различные виды коэффициентов корреляции.
Если исследуется зависимость между двумя переменными, измеренными в интервальной шкале, наиболее подходящим коэффициентом будет коэффициент корреляции Пирсона г (Pearson, 1896), называемый также линейной корреляцией, так как он отражает степень линейных связей между переменными. Эта корреляция наиболее популярна, поэтому часто, когда говорят о корреляции, имеют в виду именно корреляцию Пирсона.
Итак, коэффициент парной корреляции изменяется в пределах от -1 до +1. Крайние значения имеют особенный смысл. Значение-1 означает полную отрицательную зависимость, значение +1 означает полную положительную зависимость, иными словами, между наблюдаемыми переменными имеется точная линейная зависимость с отрицательным или положительным коэффициентом.
Значение 0,00 интерпретируется как отсутствие корреляции.
Корреляция определяет степень, с которой значения двух переменных пропорциональны друг другу. Это можно проследить, анализируя графики (см. ниже).
На графике в левом верхнем углу значения парного коэффициента корреляции равны 0,0, на графике в правом верхнем углу коэффициент корреляции постепенно увеличивается и становится равным 0,3.
На нижних графиках коэффициент корреляции увеличивается и становится равным 0,6 и 0,9. Обратите внимание на то, как меняется наклон прямой линии и как группируются точки вокруг этой прямой.
Заметьте, что чем ближе коэффициент корреляции к крайнему значению 1. тем Теснее группируются данные вокруг прямой Та же картина наблюдалась бы н i»p.i
116
Глава 2. Элементарные понятия анализа данных
отрицательных значениях корреляции, только наклон прямой, вокруг которой группируются значения переменных, был бы отрицательным.
При значении коэффициента корреляции, равном ±1, точки точно легли бы на прямую линию, а это означает, что между данными имеется точная линейная зависимость.
Внимательно посмотрите на эти графики. Корреляция — важное понятие, постарайтесь привыкнуть к нему и научиться визуально определять по расположению данных, насколько тесно они коррелированы.
Говорят, что две переменные положительно коррелированы, если при увеличении значений одной переменной увеличиваются значения другой переменной.
Две переменные отрицательно коррелированны, если при увеличении одной переменной другая переменная уменьшается (см. рисунки выше).
Говорят, что корреляция высокая, если на графике зависимость между переменными можно с большой точностью представить прямой линией (с положительным или отрицательным наклоном).
Если коэффициент корреляции равен 0, то отсутствует отчетливая тенденция в совместном поведении двух переменных, точки располагаются хаотически вокруг прямой линии (см. график в левом верхнем углу).
Важно, что коэффициент корреляции — безразмерная величина и не зависит от масштаба измерения. Например, корреляция между ростом и весом будет одной и той же независимо от того, проводились ли измерения в дюймах и футах или в сантиметрах и килограммах.
Проведенная прямая (см. графики), вокруг которой группируются значения переменных, называется прямой регрессии, или прямой, построенной методом наименьших квадратов. Последний тернии связан с тем, что сумма квадратов расстояний (вычисленная по оси Y) от наблюдаемых точек до прямой действительно является минимальной из всех возможных.
Формально коэффициент корреляции г12 Пирсона между переменными Y|t Y2 вычисляется следующим образом:
^(Y.-Vxot-v,)’
где Y, — среднее переменной Y,, Y2 — среднее переменной Y2.
Если переменные измерены в интервальной шкале, то используются ранговые корреляции, которые будут рассмотрены ниже.
Для анализа зависимостей категориальных переменных обычно используют таблицы сопряженности и соответствующие статистики, например хи-квадрат, V-квадрат, точный критерий Фишера, сгатмстикафи-квадрат (альтернатива корреляции) и Др.
Если требуется измерить связи между списками переменных, используются следующие типы корреляции:
О множественная корреляции: измерение зависимости между одной переменной и несколькими переменными;
117
корреляции
О каноническая корреляция: измерение зависимостей между лиумямножеапва-ми переменных;
О частные корреляции
Если вычисляется корреляция между значениями одной переменной, сдвинутыми на некоторый лаг, то говорят об автокорреляции.
Ранговые корреляции.
Ранговые корреляции основаны на рангах, которые соответствуют номеру наблюдения в вариационном ряде. Если ваши данные ранжированы, то вы можете воспользоваться ранговыми корреляциями
формально ранговый коэффициент корреляции Спирмена между переменными Y,, Ya вычисляется следующим образом:
£(r,-rxs,-s)
Д(К, К>'Х(5 s>'
где R, -ранг наблюдения Yt„ S, — ранг наблюдения¥и.
Сравнив этуг формулу с формулой корреляции Пирсона, приведенной выше, вы быстро поймете, что корреляция Спирмена является прямым аналогом корреляции Пирсона. Заменив в формуле Пирсона наблюдения рангами, вы получите корреляцию Спирмена. Большие значения рангового коэффициента корреляции свидетельствуют против гипотезы о независимости переменных Yla Yz.
Частные корреляции. При исследовании «вЛаммозавнсимостей» переменных часто возникают следующие трудности: если одна величина коррелировапа с другой, то это может быть всего лишь отражением того факта, что обе эти величины коррелированы с некоторой третьей величиной или с совокупностью величин, которые, грубо говоря, остаются за кадром и не введены в исследование Указанная ситуация приводит к рассмотрению г/словныл корреляций между двумя величинами при фиксированных значениях остальных величин. Это так называемые частные корреляции.
Если корреляция между даумя величинами уменьшается, когда мы фиксируем некоторую третью случайную величину, то это означает, что взаимозависимость исходных величин возникает частично под воздействием этой величины; если же частная корреляция равна нулю или очень мала, то мы делаем вывод, что их взаимозависимость целиком обусловлена собственным воздействием и никак не связана с новой величиной.
Наоборот, если частная корреляция больше первоначальной корреляции между двумя величинами, то мы заключаем, что третья величина ослабила исходную связь.
Еще одна тонкость состоит в том, что следует помнить — корреляция не есть пР1р1Инность. Иными словами, установив корреляцию даух величин, мы не имеем Права безапелляционно говорить о наличии причинной связи между ними: некого рая совершенно отличная от рассматриваемых в анализе величина может быть источником этой корреляции. Как при обычной корреляции. так и при частных
118
Глава 2. Элементарные понятия анализа данных
корреляциях предположение о причинности должно всегда иметь также собствен ные ос нования, иными словами, соответствовать природе вещей.
Эти интуитивно ясные представления полезно иметь в виду при интерпретации частных корреляций.
Рассмотрим вначале тройку переменных Y„ Y2, Y3. Формально коэффициент частной корреляции rw 3 между переменными Ylf Yz в предположении, что переменная Y:1 фиксирована, имеет вид:
аналогично коэффициент частной корреляции г|я,2 между переменными Y,. Y. в предположении, что переменная Y, фиксирована, имеет вид:
и коэффициент частной корреляции гЮ| между переменными Y„ Y3 в предположении, что переменная Y, фиксирована, имеет вид:
Заметьте, эти формулы вполне симметричные, точкой отделяются переменные, значения которых фиксированы.
Множественная корреляция. Лучше всего понять множественную корреляцию, а также частные корреляции, с точки зрения регрессии, где они возникают естественно из самого существа задачи и обобщаются на любое число переменных
Рассмотрим вначале три переменные: переменную Y и переменные X,, Х2. Переменную Y будем называть зависимой, переменные X,, Х2 независимыми.
Предположим, что между Y и X,, Х2 имеется линейная зависимость вида:
= Ро + Р.Х., + Р2Х2, + е,. « = 1, ..и (*),
где е, - независимые случайные ошибки с нулевым средним, Р,.Р2>Р2 — неизвестные параметры Хорошо известно, что в широких предположениях оптимальными оценками неизвестных параметров в уравнении (*) являются оценки метода наименьших квадратов (мнк-оцепки). Обозначим мнк-оцецки через 0О, Рр Р2. Эти оценки замечательны тем, что сумма квадратов расстояний между наблюдениями Y, и плоскостью (*) минимальна.
Формально подставив мнк-оценки в (*) получаем значения У,, i - . 1
Теперь коэффициент множественной корреляции между Y и Х„ Х2 можно определить как обычный коэффициент корреляции Пирсона между Y и У .
Заметим, что квадрат коэффициента множественной корреляции называется коэффициентом множественной детерминации и показывает, какая доля вариа ции (изменчивости, вариабельности) переменной Y объясняется с помощью iu-нейпой зависимости Y и Х>. Х2. Формально для коэффициента детерминации имеем:
119
Корреляции
Это определение легко обобщается на любое число переменных.
Частные корреляции с точки зрения линейной регрессии. Продолжим наши рассуждения и покажем, как вычислить частные корреляции исходя из уравнения регрессии. Пусть нужно, например, вычислить частную корреляцию между Y и Х|. Идея проста — очевидно, на эту связь влияет переменная Х2. Следовательно, это влияние нужно устранить, для этого вначале находим линейную регрессию Y на Х2, затем находим регрессию X, на Х2.
Формально имеем:
У; ~ Poi + РиХ,,, t —
- Pio + PlS-^2.' t —
Теперь рассмотрим остатки (}' — У(),(ХН — X,,), i = В соответствии с
общей идеей частная корреляция между Y и Xt есть обычная парная корреляция Пирсона между переменными (У-У),(Х( -Х().
Эти рассуждения легко распространяются на любое число переменных.
Нелинейные зависимости между переменными. Корреляция Пирсона г хорошо подходит для описания линейной зависимости. Отклонения от линейности увеличивают общую сумму квадратов расстояний от регрессионной прямой, даже если она представляет «истинные» и очень тесные зависимости между переменными. Поэтому хорошим тоном после вычисления корреляций является построение диаграмм рассеяния, которые позволяют понять, действительно ли между двумя исследуемыми переменными имеется связь.
Например, показанная ниже высокая корреляция плохо описывается линейной функцией.
120
Глава 2. Элементарные поня! ия анализа данных
Олнако, как видно на графике ниже, полипом пятого порядка достаточно хорошо описывает зависимость.
Ложные корреляции. Нужно иметь в виду, что на свете существуют ложные корреляции, и это нарушает идиллическую картину корреляционного анализа.
Другими словами, если вы нашли переменные с высокими значениями коэффициентов корреляции, то отсюда еше не следует, что между ними действительно существует причинная связь; нужна уверенность, что на исследуемые переменные не влияют другие переменные
Лучше всего понять ложные корреляции на следующем шутливом примере.
Известно, что существует корреляция между ущербом, причиненным пожаром, и числом пожарных, тушивших его. Однако эта корреляция ничего нс говорит о том, насколько уменьшатся потери, если будет вызвано меньшее число пожарных.
Задумавшись над полученным результатом, вы будете искать и найдете причину высокой корреляции: причина состоит в том, что имеется третья переменная (величина пожара), которая влияет как па причиненный ущерб, так и на число вызванных пожарных. Если вы будете «контролировать* эту переменную (например, рассматривать только пожары определенной величины), то исходная корре-чяиия (между ущербом и числом пожарных) либо исчезнет, либо, возможно, даже изменит свой знак.
В реальной жизни проводить такие рассуждения и находить «причинные* Переменные, конечно, гораздо сложнее.
Основная проблема ложной корреляции состоит в том, что вы не знаете, чем она вызвана или, фигурально выражаясь, кто является ее агентом. Тем нс менее если вы знаете, где искать, то можно воспользоваться частными корреляциями. чтобы контролировать (частично исключенное) влияние определенных переменных
Почему зависимости между переменными являются важными
Вообще говоря, цель всякого исследования или научного анализа состоит в на хождении связей (зависимостей) между измеряемыми переменными. Далее почти не проводится различия между терминами «связь* и «зависимость*, и во многих
Здвкимые и независимые переменные 121
ситуациях оли рассматриваются как синонимы, хотя поклонники строгих определений, возможно, усмотрят в этом вольность.
Заметим, что не существует иного способа представления знания, кроме как в терминах зависимостей между количествами или качествами.
Таким образом, развитиезнаний всегда заключается в нахождении новых зависимостей между переменными. Исследование корреляций по существу состоит в измерении таких зависимостей непосредственным образом. Тем нс менее экспериментальное исследование не является в этом смысле чем-то отличным. Например, отмеченное экспериментальное сравнение WCC у мужчин и женщин может быть описано как поиск связи между двумя переменными: Пол и WCC Назначение статистики состоит в том, чтобы помочь оценить зависимости между переменными. Действительно, множество статистических процедур может быть рассмотрено в терминах оценки различных типов взаимосвязей между переменными. Итак, специалиста по статистике прежде всего интересует оценка связи между измерен-
ными переменными.
Зависимые и независимые переменные
В повседневной жизни мы хорошо понимаем, что одни величины зависят от других, например потребление, конечно, зависит от дохода, цена квартиры — от площади, число посетителей магазина зависит от количества рекламных объявлений, предпочтение в выборе платья связано с содержимым кошелька, число посетителей ресторана зависит от времени суток и т. д.
Проведем более строго различие между независимыми и зависимыми переменными. Независимыми переменными называются переменные, которые варьируются исследователем, тогда как зависимые переменные — это переменные, которые измеряются или регистрируются. Очевидно, варьируя интенсивность рекламной рассылки, вы можете наблюдать изменение спроса и потока посетителей в магазин; вэтом примере интенсивность рекламы — независимая переменная, поток посетителей — зависимая. Изменяя рекламную кампанию, вы можете заставить покупателя перейти из пассивного состояния (спячки) в активное и т д. В электронной торговле очень важна оценка момента перехода покупателя из категорий пассивный, активный, суперактивный, чтобы иметь возможность влиять на этот процесс.
На первый взгляд может показаться, что проведение этого различия создает путаницу в терминологии, поскольку, как иногда 1 оворят в шутку студенты, «все переменные зависят от чего-нибудь». Тем не менее, однажды отчетливо проведя это различие, вы поймете его необходимость.
Термины зависимая и независимая переменная применяются вэксперименталь-иом исследовании, где экспериментатор манипулирует некоторыми переменными, и в этом смысле они «независимы» от реакций, свойств, намерений и т. д, нри-сущих объектам исследования. Некоторые другие переменные, как предполагается, Должны «зависеть» от действий экспериментатора или от экспериментальных условии. Иными словами, зависимость проявляется в ответной реакции исследуемого ° ъекта, ее можно назвать откликом объекта на воздействие, поэтому термин отклик (response) также иногда используется как синоним зависимой переменной
122
Глава 2. Элементарные понятия анализа данных
Отчасти в противоречии с данным разграничением понятий находится использование их в исследованиях, где вы не варьируете независимые переменные, а только приписываете объекты к «экспериментальным группам», основываясь па некоторых их априорных свойствах. Например, если в эксперименте мужчины сравниваются с женщинами относительно числа лейкоцитов ( WCC), то Пол можно назвать независимой переменной, a WCC—зависимой переменной; вложения в рекламуяв-ляется независимой (варьируемой) переменной, а число клиентов — зависимой ит. д.
Как измерить величину зависимости между переменными
Статистиками разработано много различных мер, позволяющих оценить или измерить степень зависимости между наблюдаемыми переменными.
Выбор определенной меры в конкретном исследовании зависит от числа включенных в анализ переменных, используемых шкал измерения, природы зависимостей и т. д. Большинство этих мер, тем не менее, подчиняется одному общему принципу: они являются попыткой оценить наблюдаемую зависимость, сравни вая ее с «максимально возможной зависимостью» между рассматриваемыми переменными.
Обычный способ выполнить такие оценки заключается в том, чтобы посмотреть. как варьируются значения переменных, и затем подсчитать, какая часть всей имеющейся вариации может быть объяснена наличием «общей» («совместной») вариации двух (или более) переменных.
Проще говоря, сравнивается то, «что есть общего в этих переменных», с тем, «что потенциально было бы у них общего, если бы переменные были абсолютно зависимы». Рассмотрим простой пример.
Пусть в вашей выборке средний показатель (число лейкоцитов) WCCравен 100 для мужчин и 102 для женщин. Следовательно, вы могли бы сказать, что отклонение каждого индивидуального значения от общего среднего (101) содержит компоненту, связанную с полом субъекта, и средняя величина ее равна 1. Это значение, таким образом, предстааляет некоторую меру зависимости между переменными Пол и WCC. Конечно, это очень бедная мера, так как она не дает никакой информации о том, насколько велика эта компонента, скажем, относительно обшего изменения значений WCC. Рассмотрим две крайние возможности:
(а) Если все значения WCCу мужчин были бы точно равны 100, а у женщин 102, то все отклонения значений от общего среднего в выборке всецело объяснялись бы полом. Поэтому вы могли бы сказать, что пол абсолютно коррелиру • ет с WCC, иными словами. 100% наблюдаемых различий между субъектами в значениях IVCC объясняются полом субъектов.
(б) Если же значения WCC лежат в пределах 0-1000, то та же самая разность (21 между средними значениями WCCу мужчин и женщин, обнаруженная в эксперименте, составляла бы столь малую долго общей вар наш ш, что полученное различие считалось бы пренебрежимо малым. Например, введение в р досмотре» ние еще одногосубъекта могло бы изменить разность или даже изменить се знак Поэтому хорошая мера зависимости должна принимать во внимание полнук* изменчивость индивидуальных значений в выборке и оценивать зависимость по тому, насколько эта изменчивость объясняется изучаемой зависимостью I
Что такое статистическая значимость (р-уровень)?
123
две черты зависимости между переменными
Можно отметить два самых простых свойства зависимости между переменными: (я) величину зависимости и (Ь) надежность зависимости.
(а) Величина. Величину зависимости легче понять и измерить, чем надежность. Например, если любой мужчина в вашей выборке имел значение ДОССвыше, чем любая женщина, то вы можете сказать, что величина зависимости между двумя переменными (Пол и WCC) очень высокая. Другими словами, вы мог ли бы предсказать значения одной переменной по значениям другой.
(б) Надежность («истинность»), Надежность взаимозависимости — менее наглядное понятие, чем величина зависимости, однако чрезвычайно важное. Оно непосредственно связано с репрезентативностью той определенной выборки, на основе которой строятся выводы. Другими словами, надежность говорит, насколько вероятно, что зависимость, подобная найденной, будет вновь обнаружена (подтвердится) на данных другой выборки, извлеченной из той же самой популяции. Следует помнить, что конечной целью почти никогда ire является изучение данной конкретной выборки; выборка представляет интерес лишь постольку, поскольку она дает информацию обо всей популяции. Если ваше исследование удовлетворяет некоторым специальным критериям (об этом будет сказано позже), то надежность найденных зависимостей между переменными выборки можно количественно оценить и представить с помощью стандартной статистической меры (называемой р-уров-нем, или статистическим уровнем значимости, см. следующий раздел).
Что такое статистическая значимость (р-уровень)?
Статистическая значимость результата представляет собой оцененную меру уверенности в его правильности.
Говоря проще, не на статистическом жаргоне, уровень значимости показывает, насколько значим для вас полученный результат. Предположим, вы врач, исследующий пациента. Проводя всесторонние исследования (измеряя дааление, беря анализы крови и т. д.), вы приходите к выводу, что пациент с большой вероятностью болен, следовательно, полученные результаты значимы.
Выражаясь формал ыю, уровен ь значимости, или. как еще говорят, р-уровень, — это показатель, находящийся в убывающей зависимости от надежности результата Более высокий р-уровень соответствует более низкому уровню доверия к найденной в выборке зависимости между переменными. Именно p-уровень представляет собой вероятность ошибки, связанной с распространением наблюдаемого результата на всю популяцию. Например, р-уровень = 0,05 (то есть 1/20) показывает, что имеется 5%-я вероятность того, что найденная в выборке зависимость Между переменными является лишь случайной особенностью данной выборки Иначе говоря, если данная зависимость в популяции отсутствует, а вы многократно проводите подобные эксперименты, то примерно в одном из двадцати повторений
124
Глава 2. Элементарные понятия анализа данщ
эксперимента можно ожидать такой же или более сильной зависимости межд< изучаемыми переменными. Во мниих исследованиях р-уровенъ, равный 0,0!» рассматривается как «приемлемая граница* уровня ошибки.
На уровень значимости можно носмотретьс другой стороны. Предположим,чт-, вы врач и выдвигаете гипотезу: пациент болен. Тогда, если вы назначили уровень 0,05, то в среднем в 5 случаях из 100 будете совершать ошибку (то есть принимать неправильную гипотезу — признавать человека больным, когда на самом деле ол здоров).
Как определить, является ли результат действительно значимым
Не существует никакого способа избежать произвола при принятии решения о том, какой уровень значимости следует действительно считать «значимым*. Однако.
Однако статистическую значимость можно перевести в потери (например, финансовые), используя подходящую функцию потерь. Представьте, что вы мне гократно принимаете решение, то есть проверяете гипотезу о направлении изменения курса акций, выбрав некоторый уровень значимости, тогда уменьшение де пег в вашем кошельке покажет ошибочность вашего выбора
Выбор определенного уровня значимости, выше которого результаты отвергаются как яожные, является достаточно произвольным. На практике окончательное решение обычно зависит от того, был ли резу чьтат предсказан априори (то есть до проведения опыта) или обнаружен апостериорно, в результате многих анализов и сравнений, выполненных с множеством данных, а также по традиции, имеющей ся в данной области исследований.
Обычно, что во многих областях результат/? = 0,05 является приемлемой границей статистической значимости, однако следует помнить, что этот уровень все ещо включает довольно большую вероятность ошибки (5%). Результаты, значимые на уровне р = 0,01, обычно рассматриваются как статистически значимые, а результаты с уровнем р - 0,005 или р = 0,001 как высокозначимые. Но следует понимать, что 1-данной классификации уровней значимости имеется произвол и это является все го лишь неформальным соглашением, принятым на основе практического опыта.
Статистическая значимость и количество выполненных анализов
Понятно, что чем большее число анализов вы провели над некоторыми группами данных, тем большее число резу штатов средн них имеют шанс удовлетворить! выбранному уровню значимости Например, если вычисляются корреляции между 10 переменными (то есть имеется 45 различных коэффициентов корреляций)- | можно ожидать, что примерно 2 коэффициента корреляции (1 па каждые 20) случайно окажутся значимыми на уровне/? = 0,05, даже если переменные совершение* случайны и некоррелированы в популяции. Иными словами, имея серию эксле-1 риментов, вы вещда можете подтасовать результаты, выбирая только те опыты, результаты которых подтверждают вашу гипотезу.
Почему объем выборки влияет на значимость зависимости
125
Некоторые статистические методы, включающие множественные, то есть мпо-гократные. сравнения и, следовательно, имеющие хороший шанс повторить такого рода ошибки, используют специальную корректировку, или поправку, на общее число сравнений. Тем не менее многие статистические методы (особенно простые методы разведочного анализа данных) не предлагают какого-либо способа решения этой проблемы. Поэтому исследователь должен с осторожностью оценивать надежность неожиданных находок. Миш не примеры, обсуждаемые в данном руководстве, предлагают специальные советы по поводу того, как это сделать.
Величина зависимости между переменными в сравнении с надежностью зависимости
Величина и надежность представляют собой две различные характеристики зависимостей между переменными. Тем не менее нельзя сказать, что они совершенно независимы. В общем, можно утверждать, что чем больше величина зависимости (связи) между переменными в выборке обычного объема, тем она надежней.
Почему более сильные зависимости между переменными являются более значимыми
Если предполагать отсутствие зависимости между соответствующими переменными в популяции, то с наибольшей вероятностью следует ожидать, что в исследуемой выборке связь между' этими переменными также будет отсутствовать. Таким образом, чем более сильная зависимость обнаружена в выборке, тем менее вероятно, что этой зависимости нет в популяции, из которой она извлечена. Как можно заметить, величи на зависимости и значимости тесно связаны между собой, и можно попытаться вывести значимость из величины зависимости и наоборот. Однако указанная связь между зависимостью и значимостью имеет место только при фиксированном объеме выборки, поскольку при различных объемах выборки одна и та же зависимость может оказаться как высокоэначимой, так и незначимой вовсе (см. следующий раздел).
Почему объем выборки влияет на значимость зависимости
Общая идея статистических методов состоит в том, чтобы по некоторой части популяции вынести суждения о свойствах популяции в целом. Именно такого рода результаты и представляют основной интерес так как являются объективными
Если количество наблюдений невелико, то есть выборка из популяции мала, то соотаетственно имеет место малое количество возможных комбинаций значений этнх переменных и, таким образом, вероятность случайно обнаружить комбинацию значений, показывающую сильную зависимость, относительно высока. Рассмотрим следующий пример. Если вы исследуете зависимость двух переменных (Пол. муж
126
Глава 2. Элементарные понятия анализа данных
чина/женигнна и WCC: высокий/низкий) и имеете только 4 субъекта в выборке (2 мужчины и 2 женщины), то вероятность того, что чисто случайно вы найдете 100%-ю зависимость между двумя переменными, равна 1/8. А именно вероятность того, что оба мужчины имеют высокий WCC, а обе женщины — низким WCC, иди наоборот, равна 1/8. Теперь рассмотрим вероятность подобного совпадения для 100 субъектов; легко видеть, что эта вероятность равна практически нулю.
Рассмотрим более общий пример. Представим популяцию, в которой среднее значение WCC для мужчин и женщин одно и то же. Если теперь вы начнете повторять эксперимент, состоящий в извлечении пары случайных выборок (одна — мужчины, другая — женщины) и вычислении разности выборочных средних №ССдля каждой пары, то в большинстве экспериментов результат будет близок к 0. Однако время от времени будут встречаться пары выборок, в которых различие между мужчинами и женщинами будет существенно отличаться от 0. Как часто будет это происходить’ Чем меньше объем выборки в каждом эксперименте, тем более вероятно появление таких ложных результатов, которые показывают существование зависимости между полом и WCC в данных, полученных из популяции, где такая зависимость на самом деле отсутствует.
Почему слабые зависимости могут быть значимо доказаны только на больших выборках
Предыдущий пример показывает, что если зависимость между переменными «объективно» (другими словами, в популяции) мала, не существует иного способа проверить такую зависимость, кроме как исследовать выборку достаточно большого объема. Даже если ваша выборка совершенно репрезентативна, эффект не будет статистически значимым, если выборка мала. Аналогично, если зависимость «объективно» (в популяции) очень сильная, то она может быть обнаружена с высокой значимостью даже на очень маленькой выборке. Рассмотрим следующий иллюстративный пример. Если монета слегка несимметрична и при подбрасывании орел выпадает чаще решки (например, 60% против 40%), то 10 подбрасываний монеты было бы недостаточно, чтобы убедить кого бы то ни было, что монета ас имметрична, даже если был бы получен совершенно репрезентативный результат, 6 орлов и 4 решки.
Не следует ли отсюда, что 10 подбрасываний вообще не могут доказать что либо? Нет, не следует, потому что если эффект в принципе очень сильный, 10 под • брасываний может быть вполне достаточно. Представьте, что монета настолько несимметрична, что всякий раз, когда вы ее бросаете, выпадает орел Если вы бро саете такую монету 10 раз и всякий раз выпадает орел, большинство людей сочтут это убедительным доказательством того, что с монетой что-то нс то.
Другими словами, это послужило бы убедительным доказательством того, что в популяции, состоящей из бесконечного числа подбрасываний этой монеты, орет, будет встречаться чаше, чем решка Таким образом, если зависимость сильная, онг может быть обнаружена с высоким уровнем значимости даже на малой выборке.
Как вычисляется статистическая значимость
127
можно ли рассматривать отсутствие связей как значимый результат?
ЧсМ слабее зависимость между переменными, тем большего объема требуется выборка. чтобы значимо ее обнаружить. Например, представьте, как много бросков монеты необходимо сделать, чтобы доказать, что отклонение от равных вероятно-тей составляет только 0,000001%! Таким образом, необходимый минимальный размер выборки возрастает, когда степень эффекта, который нужно доказать, убывает. Когда аффект близок к 0, необходимый объем выборки для его отчетливого доказательства приближается к бесконечности. Другими словами, если зависимость между переменными почти отсутствует, объем выборки, необходимым для ее значимого обнаружения, почти равен объему всей популяции. который предполага ется бесконечным. Статистическаязначимость представляет вероятность того, что подобный результат был бы получен при проверке всей популяции в целом. Таким образом, все, что получено после тестирования всей популяции, было бы по определен ию значимым на наивысшем возможном уровне» и эго относится ко всем результатам типа «нет связи».
Общая конструкция статистических тестов
Так как конечная цель большинства статистических тестов состоит в оценке зависимости между переменными, большинство статистических тестов следует некоторому общему принципу. Говоря техническим языком, эти тесты представляют собой отношение групповой изменчивости к полной изменчивости. Например, такой тест может представлять собой отношение той части изменчивости WCC, которая определяется полом, к паяной изменчивости WCC (вычисленной для объединенной выборки мужчин и женщин). Это отношение обычно называется отношением объясненной вариации к полной вариации.
В с тал 1стике термин объясненная вариация нс обязательно означает, что вы даете ей «теоретическое объяснение». Он используется только для обозначения общей вариации рассматриваемых переменных, то есть для указания на то, что часть вариации одной переменной «объясняется» определенными значениями другой переменной. и наоборот.
Как вычисляется статистическая значимость
Предположим, вы уже вычислили меру зависимости между двумя переменными (как объяснялось выше). Следующий вопрос, стоящий перед вами: насколько значима эта зависимость? Например, является ли 40% объясненной дисперсии между двумя переменными достаточным, чтобы считать зависимость значимой? От-Вет будет таким: в зависимости от обстоятельств. Именно значимость зависит в Основном от объема выборки. Как уже объяснялось, в очень больших выборках Да*е очень слабые зависимости между переменными будут значимыми, в то время как в малых выборках даже очень сильные зависимости не являются надежными
128
Глава 2. Элементарные понятия анализа
(значимыми). Таким образом, для того чтобы определить уровень статистически! значимости, вам нужна функция, которая представляла бы зависимость между величиной» и «значимостью» зависимости между переменными для каждого объема выборки. Данная функция указала бы вам точно, насколько вероятно получить зависимость данной величины (или больше) в выборке данного объема в предположении, что в популяции такой зависимости нет. Другими словами, эта функция давала бы вам уровень значимости (р-уровець) и, следовательно, вероятность ошибочно отклонить предположение об отсутствии данной зависимости в популяции Эта «альтернативная» гипотеза (состоящая в том, что нет зависимости в популяции) обычно называется нулевой гипотезой Было бы идеально, если бы функция, вычисляющая вероятность ошибки, была линейна и имела только различные наклоны для разных объемов выборки. К сожалению, эта функция существенно более сложная и нс всегда одна и та же Тем не менее в большинстве случаев ее форма известна, и это можно использовать для определения уровней значимости при исследовании выборок заданного размера. Большинство этих функций связано с очень важным классом, называемым нормальным.
Значимость коэффициента корреляции
Допустим, вы оценили коэффициент корреляции между двумя переменными. Оч< видно, чем больше по абсолютной величине значение коэффициента, тем больше вероятность, что между переменными имеется связь, то есть с тем меньшей вероятностью ошибки можно отвергнуть гипотезу оботсутствии связи между переменными
Иными словами, чем больше абсолютное значение коэффициента корреляции, тем более обоснованно опровергается гипотеза, что между переменными нет связи. Спрашивается: какие именно значения значимы7
Ответ зависит как от величины коэффициента корреляции, так и от объема выборки, по которой он вычислен.
Например, анализируя данные огодовых урожаях в Восточной Англии за 20 лет, Фишер вычислил коэффициент корреляции между годовым урожаем пшеницы и осенним уровнем дождей. Этот коэффициент, как и ожидалось, оказался отрица тельным (чем выше уровень осенних осадков, тем меньше урожай, то есть переменные отрицательно коррелированны) и равным... 0,629, что значимо на уровне 0,01
Если бы выборочный коэффициент корреляции оказался равен 0,45, то реэуль тат был бы значим на уровне 0,1, но незначим на уровне 0,01, и т. д.
Как определить, являются ли два коэффициента корреляции значимо различными
Имеется критерий, позволяющий оценить значимость различия между двумя ко зффнциентами корреляции. Результат применения критерия зависит не тольки от величины разности этих коэффициентов, но и от объема выборок и величины
<У важно нормальное распределение
129
ге этнх коэффициентов Вообще говоря, в соответствии с общим принципом нежность коэффициента корреляции увеличивается с увеличением его абсо-11 тиого значения; относительно малые различия между большими коэффици-итами могут быть значимыми. Например, разница 0,10 между двумя корреляциями может не быть значимой, если коэффициенты равны 0.15 и 0.25, хотя для той же выборки разность 0.10 может оказаться значимой для коэффициентов 0.80 и 0,90-
В системе STATISTICA имеется специальное средство — статистический калькулятор — в диалоговом окне Другие критерии значимости, доступном из стартовой панели модуля Основные статистики и таблицы. Калькулятор позволяет быстро сравнить коэффициенты корреляции, вычисленные по разным
выборкам.
Почему важно нормальное распределение
Нормальное распределение (термин был впервые введен Гальтоном в 1889 г.), иногда называемое гауссовским, важно по многим причинам. Распределение большого ЧНг1а статистик является нормальным или может быть получено из нормального с Помощью некоторых преобразовании.
130
Глава 2. Элеменгтарные понятия анализа данных
Рассуждая философски, можно сказать, что нормальное распределение представляет собой одну из эмпирически проверенных истин относительно общей природы действительности и его положение может рассматриваться как оди низ фундаментальных законов природы. Точная форма нормального распределения (характерная «колоколообразная кривая*) определяется только двумя параметрами, средним и стандартным отклонением.
Характерное свойство нормального распределения состоит в том, что 68% из всех его наблюдений лежат в диапазоне 1 (стандартное отклонение от среднего), а диапазон 2 стандартных отклонений включает 95% значений. Другими словами, при нормальном распределении стандартизованные наблюдения, меныиие —2 или большие +2, имеют относительную частоту менее 5% (стандартизованное наблюдение означает, что из исходного значения вычтено среднее и результат поделен на стандартное отклонение). Это и есть знаменитое правило 2 сигма или 2-стап-дартных отклонения, вместе с правилом 3-сигма чрезвычайно популярное на практике
Плотность нормального распределения имеет вид:
• _____-
/(х; Ц, v) = ——e оу2л
Множество величин на практике имеют нормальное распределение, например распределение приращений индексов развитых стран, курсы акций и т. д.
Двумерное нормальное распределение. Переменная X = (Xt, ХД имеет двумерное нормальное распределение, если любая линейная комбинация Z = aXi + имеет либо нормальное, либо вырожденное распределение (которое также можно считать нормальным с о2 = 0).
Двумерное нормальное распределение имеет плотность вида:
/(х,.хг.ц„|х2.а;,о’.р)------1 хсхр - 1 х
2na,a2Jl-P । 2(!-Р)
.,р*.~И.)г 2р(х,-р,)(.г, и,) , (Xj-Ra/Jj
Х = (л,, х2У, р = /(арД. в,, о, >0. [р]<1
131
1(аК проверить нормальность наблюдаемых величин
_ корреляция переменных Х(, Х2, Щ. о, — среднее и стандартное отклонения ' еменной Xi, Цг. — среднее и стандартное отклонения переменной Х2
Заметим, что двумерное нормальное распределение легко обобщить на многомерное нормальное распределение.
График двумерного распределения показан ниже:
Иллюстрация того, как нормальное распределение используется в статистических рассуждениях
Напомним пример, обсуждавшийся ранее, когда пары выборок мужчин и женщин выбирались из совокупности, в которой среднее значение WCC для му жчин и жен-шин было в точности одно и то же. Хотя наиболее вероятный результат таких экспериментов (одна пара выборок на эксперимент) состоит в том, что разность между средними WCCдля мужчин иженщи н для каждой пары близка к 0, время от времени появляются пары выборок, в которых эта разность существенно отличается от 0. Как часто это происходит? Если объем выборок достаточно большой, то разности «нормально распределены» и, зная форму нормальной кривой, вы можете точ но рассчитать вероятность случайного получения результатов, представляющих различные уровни отклонения среднего отО, — значения гипотетического для всей популяции. Если вычисленная вероятность настолько мала, что удовлетворяет принятому заранее уровню статистической значимости, то можно сделать лишь один вывод: ваш результат лучше описывает свойства популяции, чем «нулевая гипотеза». Следует помнить, что нулевая гипотеза рассматривается только по техническим соображениям как начальная точка, с которой сопоставляются эмпирические результаты.
Как проверить нормальность наблюдаемых величин
При проверке нормальности выборки часто руководствуются следующим принципом Фишера: «Отклонения от нормального вида, если только они не слишком заметны, можно обнаружить лишь для больших выборок, однако сами по себе эти отклонения вносят малое отличие в статистические критерии и другие вопросы». (см. например. Справочник по прикладной статистике под редакцией Э. Ллойда 11 У. Лпндерма|1а М: Финансы и статистика, 1989, с. 270).
132
Глава 2. Элементарные понятия анализа.
На практике для проверки нормальности обычно применяют визуальные мн. тоды, например гистограммы, нормальные вероятностные графики или численные методы с помощью оценки коэффициентов асимметрии и эксцесса; использ, -ется также критерий хи-квадрат.
Пример (проверка нормальности с помощью оценок коэффициентов асимметрии и эксцесса).
Рассмотрим классические данные Р. Фишера о количестве осадков в одном из районов Англии (см. Fisher R. А. (1970). Statistical methods for research worker.. 15-th edition, Macmillan):
Далее приводится последовательность действий, которую лучше всего повто рить, используя систему STATISTICA.
Шаг 1. Создайте файл STATISTICA и введите в пего данные, представлении* в таблице. В первом столбце приведено количество осадков в дюймах. Во втор"’ | столбце записана частота, с которой данное значение встречалось в илмерени j Например, уровень 16 дюймов наблюдался 1 раз, уровень 17 дюймов — 0 раз, урвг вень 18 дюймов — 0 раз и т д.
Шаг 2. Запустите модуль Основные статистики и таблицы.
Шаг 3. В стартовой панели модуля выберите Основные статистики и нажмите ОК.
g3 । сверить нормальность наблюдаемых величин
fllar 4. В появившемся окне Описательные статистики нажмите кнопку Пе-„-,,ные. и выберите переменную УРОВЕНЬ.
Шаг 5. Далее в правом верхнем углу окна нажмите кнопку В. В появившемся окне Задание веса выберите вес из переменной ЧАСТОТА Нажмите ОК
Шаг 6. Нажмите кнопку Другие статистики и дайте указание системе, что вам нужно вычислит ь а< имметрпю и эксцесс, а также их стандартные ошибки (см рисунок)
134
Глава 2. Элементарные понятия анализа данных
Шаг 7. Нажмите ОК в окне Статистики и далее нажмите ОК в появившемся окне Описательные статистики. Следующая таблица с результатами появится на экране
Из этой таблицы видно, что по абсолютной величине оценки асимметрии и эксцесса имеют тот же порядок, что их ошибки. Следовательно, ни одна из полученных величин не значима. Поэтому можно сказать, что данные согласованы с гипотезой нормальности.
Продолжение примера (использование критерия хи-квадрат для проверки нормальности).
Мы работаем с теми же данными по осадкам, что и в предыдущем примере.
Шаг 1. Запустите модуль Непараметрические статистики.
В стартовой панели модуля выберите опцию Подгонка распределения.
Так как нужно проверить согласие данных с нормальным распределением, в списке Непрерывные распределения выберите Нормальное. Далее нажмите кнопку ОК.
Шаг 2. В появившемся диалоговом окне Подгонка непрерывных распределении нажыт кнопку Переменные и выберите переменную УРОВЕНЬ. Нажмите ОК.
Шаг 3. Далее в правом верхнем углу окна нажмите кнопку В. Выберите веса из переменной ЧАСТОТА.
135
Шаг4. В диалоговом окне Подгонканепрерывныхраспределеггий нажмите кнопку ОК
На экране появится следующая электронная таблица с результатами:
Во второй строке заголовка таблицы показано значение статистики хи-квадрат и уровень значимости р = 0,532.
Снова мы можем сказать, что данные согласованы с гипотезой нормальности. Результат согласуется с тем, который был получен в первой части примера, когда в качестве критерия нормальности использовались коэффициенты асимметрии и эксцесса.
замечание -------------------------------------------------------------------
в первой строке заголовка таблицы указаны значения статистики Колмогорова—Смирнова. Этот уитерий также можно использовать для проверки норма/ьности. Результат также незначим.
136
Глава 2 Элементарные понятия анализа данных
Посмотрим на результаты в графическом виде
Шаг 5, В диалоговом окне Подгонка непрерывных распределений нажмите кнопку График
На экране появится гистограмма значении переменной Осадки. Из графика также видно хорошее согласие данных с нормальным распределением.
Этот классический пример иллюстрирует схему действий в системе STATISTICA при проверке нормальности данных.
Все ли статистики критериев нормально распределены?
Не все, но большинство из них либо имеют нормальное распред - тение (особенна при большом числе наблюдений), либо имеют распределение, связанного нормальным и вычисляемое на основе нормального, такое как Г, F или хи-квадрат Обычнг • эти статистики требуют, чтобы анализируемые переменные сами были нормально распределены в совокупности, то есть удовлетворяли бы «предположению».
Многие наблюдаемые переменные действительно нормально распределены, что является еще одним аргументом в пользу того, что нормальное распределение пред -ставляет«фундаментальныйэакон». Проблема может возшгкпутьприиопыткепри менять тесты, основанные на предположении нормальности, к данным, не являющимся нормальными. В подобных случаях вы можете выбрать одно из двух.
Во-первых, вы можете использовать альтернативные «непарамстрическне» тесты (или так называемые «свободно распределенные тесты»), особенно полезные, если число наблюдений мало.
Как альтернативу но многих случаях вы можете все же использовать тесты, ск нованные на предположении нормальности, если уверены, что объем выборки д статочио велик.
Последняя возможность основана на чрезвычайно важном принципе, позволяющем понять популярность тестов, основанных на нормальности: при возрасту нип объема выборки форма распределения статистики критерия приближается к нормальной, даже если распределение исследуемых переменных не является но| мальным Этот принцип называется центральной преданной теоремой.
МГ|^жао6ъема выборки 137
Как узнать последствия нарушений предположений нормальности?
F Хотя многие утверждения предыдущих параграфов можно доказать математически некоторые из них не имеют теоретического обоснования и могут быть проде- мо'нстрированы только эмпирически. с помощью так называемых экспериментов 1 Монте-Карло- В этих экснериментах большое число выборок генерируется на ком- пыотсре. а результаты, полученные из этих выборок, анализируются с помощью I различных тестов. Этим способом можно эмпирически оценить тип и величину ошибок или смещений, которые вы получаете, когда нарушаются определенные
I теоретические предположения используемых тестов, например, вы можете искус-’ ственно изменить распределение выборки, сделать его отличным от нормального
н проверить результат,
Монте-Карловские исследования интенсивно использовались для того, чтобы пцен ит>., насколько тесты, основанные на предположении нормальности, чувствительны к различным нарушениях! предположений нормальности.
Общин вывод этих исследований состоит в том, что последствия нарушения предположения нормальности менее фатальны, чем первоначально предполагалось. Хотя эти выводы не означают, что предположения нормальности можно игнорировать, они увеличили общую популярность тестов, основанных на нормальном распределении.
Оценка объема выборки
В большинстве ситуаций на практике у нас нет доступа ко всей популяции (генеральной совокупности) в целом (например, популяция слишком большая, процесс измерения слиш ком дорог и т. д_). Таким образом, мы имеем дело с ограниченным объемом данных — выборкой, и поставлены перед необходимость принимать решение относительно всей популяции на основе лишь выборочных данных. Для того чтобы оценить некоторую характеристику популяции, которую назовем параметром, мы строим выборку и вычисляем на ее основе некоторую статистику, которую рассматриваем как оценку искомого параметра.
Представьте, вы врач н вас интересует доля людей с данным заболеванием или вы политик и вас интересует доля людей, поддерживающих вашу позицию. Пусть ваш избирательный! округ — большой город, в котором проживают около 1 500 000 человек, имеющих право голоса. В данном случае интересующий параметр л, доля всех людей, поддерживающих вас. Как понять, насколько велика эта доля? Вы можете поступить следующим образом: выбрать наудачу группу людей и выяс-нить их мнение. Назовем выбранную группу выборкой, а количество элементов в Ней (и данном случае людей) объемом выборки. Число людей (/V) в выборке °Удст относительна небольшим в сравнении со всей популяцией Опросив лю-ле” ” выборке, вы получите нс точное значение интересующего вас параметра л. а оценку ~ обозначим се через р.
138
Глава 2. Элементарные понятия анализа данных
Формально р вычисляется так: p—NI/N, vneN1 — число людей, поддерж! ших вашу кандидатуру, N — объем выборки.
Эквивалентная формула имеет вид:
P = p(N) = is,/lV <•>
= 1, если i-й респондент поддерживает вас, = 0 в противном случае. Воз никает вопрос: какова точность этой оценки? В зависимости от ответа на данный вопрос вы предпримете то или иное действие
Очевидно, что параметр я не будет равен в точности оценки р. Величина откло нения р от я называется ошибкой.
Таким образом, в любой построенной по выборке оценке содержится ошибка точная величина которой неизвестна, в противном случае вы могли бы точно вычис -лить значение параметра, что в принципе невозможно сделать, имея дело с часгьк-популяции, то есть с выборкой.
В общем, можно сказать, чем больше объем выборки N, тем меньше ошибка оцен ки. Если вам нужно точное решение относительно параметра р, вам необходимс-взять N достаточно большим, чтобы ошибка была «разумно малой», например, опросить всех жителей города. Если N слишком мало, то мало шансов получить хорошую оценку.
С другой стороны, если взять объем выборки JV слишком большим, улучшение точности оценки окажется незначительным. Итак, если N «достаточно большое». чтобы обеспечить приемлемый уровень точности, то дальнейшее увеличение объема данных не приводит к неоправданной трате времени и средств.
Таким образом, ключевым вопросом является: какой уровень точности будет иметь оценка для данного объема выборки?, а также связанный с ним: какой ра » мер выборки нужно иметь, чтобы достичь приемлемого уровня точности9
Выборочное распределение представляет собой распределение статистики критерия в повторных выборках.
Рассмотрим выборочную оценку р, построенную по выборке объема N в предположении, что значение л в точности равно 50. Статистическая теория утверждает, что р имеет биномиальное распределение (как сумма независимых случайных величин, принимающих два значения: 1 или О).
Это распределение при достаточно больших N в силу теоремы Муавра—Лапласа, являющейся частным случаем центральной предельной теоремы, приближается к нормальному распределению со средним л и стандартным отклонением, вычисляемым по формуле:
и = it)/N .
Заметим, что часто полезной оказывается оценка: а < 1 /2y]i/ N.
Предположим, что объем выборки N равен 100. Тогда распределение р име(1 следующий вид (напомним, мы считаем, что л = 5)-
объема выборки
139
Из рисунка видно, что значения статистики сосредоточены вокруг точки ,5, но небольшой процент значений больше .6 или меньше .4. Этот разброс значений оценок отражает тот факт, что опрос общественного мнения проводился среди 100 человек и поэтому не является абсолютно точным значением вероятности успеха л.
Если бы р была «совершенной» оценкой тс, разброса значений не было бы, и стандартная ошибка равнялась бы 0. Тогда выборочное распределение имело бы выброс в точке 0.5. Выброс выборочного распределения говорит о том, насколько много «шум» смешивается с «сигналом» от параметра.
Заметим, что стандартная ошибка р стремится к 0 при увеличении объема выборки N(jNстоит в знаменателе). Если 7V становится достаточно большим, то оценка р будет все более точной (см. формулу для вычисления ошибки).
Предположим, вы используете критерий, описанный ранее. Допустим, вы решили, что, если р больше 58, то нулевая гипотеза; «я меньше или равно ,50» неверна. Критическая область этого критерия показана ниже.
Проведя несложные подсчеты (например, используя формулу биномиального Распределения), легко определить, что вероятность отвергнуть нулевую гипотезу
140
Глава 2. Элементарные понятия анализа даж
при л — .50 равна .044. Следовательно, для выбранного решающего правила оцц ка I рода а находится на уровне пе ниже .044.
Теперь важно понять, какова мощность этого критерия.
Предположим, что 55% избирателей поддерживают политика, то есть л = . п нулевая гипотеза не верна. В этом случае правильное решение состоит в то»», чтобы отвергнуть нулевую гипотезу в пользу альтернативы
На рисунке ниже показано выборочное распределение р при условии, что л - _5я Ясно, что политики принимают верные решения, поддерживаемые, большинством только в очень малом проценте случаев. Вероятность того, что р больше .58, равна только 541.
Нечего и говорить, что нет смысла проводить эксперимент, в котором вашаточ -ка зрения верна только в 24.1% опытов! В таком случае говорят, что критерий зна -чимости имеет «недостаточную мощность, чтобы обнаружить 5%-ное отклонение от нулевой гипотезы».
Суть проблемы лежит в ширине этих двух распределений (при различных ги потезах). Если объем выборки становится большим, то стандартная ошибка доли уменьшается и область перекрытия двух распределений соответственно уменыпа ется. Таким образом, при достаточно большой выборке можно найти критерий < высокой мощностью и данным уровнем значимости а
Следующие рассуждения вообще типичны при проверке гипотез. Назовем нс ходную гипотезу «нулевая гипотеза» — Но. Например, доля поддерживающих но । литика выше 0.5 или прививка от рриппа привела к снижению заболевасмос*. Для проверки гипотезы мы организуем сбор данных, извлекаем выборку, ^епця зуя статистическую теорию, видим, что гипотеза Но, вероятно, неверна и должН быть отвергнута.
Отвергая Нп, мы обосновываем то, во что верим Эта ситуация, типичная во МЩ тих областях приложения, отвергая нулевую гипотезу, вы подтверждаете теорЦ
Нулевая гипотеза либо справедлива, либо ошибочна, и статистическая npoi дура недвусмысленно указывает на это Нулевая гипотеза либо отвергается, ли не отвергается
Следовательно, до проведения эксперимента вы постулируете, что имеют мес только 4 возможности, показанные ниже:
1ЛЬИ Ий подход к анализу мощности
Верная гипотеза
Но н,
Решения Но Правильное принятие Ошибка II рода Р
н, Ошибка 1 рода о Правильное отвержение
Как вы видите, применение статистического критерия приводит к ошибкам двух видов.
Конечно, идеальным вариантом было бы уменьшение обеих ошибок (первого и второго рода), однако реальное положение вещей такое, что при фиксированном объеме выборки этого достичь нельзя Поэтому мы фиксируем уровень а и стараемся сделать ошибку второго рода Р как можно меньше
Обычно считается, что ошибка первого рода а должна принимать значение .05 или ниже, тогда как ошибка второго рода р должна быть столь малой, насколько это возможно при фиксированном уровне ошибки первого рода.
«Статистическая мощность», которая по определению равна 1 - ₽ (единица минус ошибка второго рода), соответственно, должна быть максимально высокой. Идеальный вариант, когда мощность равна, по крайней мере, .80. чтобы обнаружить paavMHbie отклонения от нулевой гипотезы.
Поставим вопрос: какой объем выборки N необходим, чтобы достичь разумно высокой мощности в ситуации, когда а фиксировано на разумно низком уровне.
Конечно, можно опытным путем установить нужный объем выборки, например, используя метод Монте-Карло. Однако программное обеспечение позволяет это сделать автоматически с помощью нескольких движений мыши. Модуль STATISTICA Анализ мощности предлагает различные аналитические и графические процедуры, позволяющие представить зависимость между мощностью и размером выборки. При работе с модулем Анализ мощности предполагается, что вы будете применять хорошо известный хи-квадрат-критерий чаще, чем тонный би номиальный критерий.
Например, предположим, что в обсуждаемом нами примере политик хочет достичь мощности 80 при л равном 55. Используя выборку объема 607, он получит на выходе мощность, равную 8009. (Реальный уровень Альфа этого критерия равен 0522.)
Визуальный подход к анализу мощности
Основные этапы проведения анализа мощности и вычисления объема выборки состоят в следующем: определяется нулевая гипотеза и альтернативы, выбирается "фитерий и исследуется мощность и требуемый объем выборки для обнаружения Данным критерием эффекта на разумном уровне.
142
Глава 2. Элементарные понятия анализа данных
В разбираемом примере, мы получили, что необходимая мощность (0.8) дости-| гается при выборке объема 607 (р“.8О). На практике, конечно, было бы нсразумн<|1 проводить только одно вычисление, основываясь на одном гипотетическом зиаче нии. Болес естественно рассмотреть, как зависит мощность от различных р, ииы i ми словами, построить функцию зависимости мощности отр.
В обсуждаемом примере мы хотим понять с низкой вероятностью ошибиться2 будут или нет нашу точку зрения поддерживать более половины избирателей.
Графический анализ чрезвычайно полезен для понимания возможности данного статистического критерия обеспечить нужную мощность.
Например, можно построить график зависимости мощности от объема выбор км в предположен»™, что истинная доля поддерживающих равна .55 (т.е. вас поддерживают более 55% жителей).
На следующем графике показана мощность как функция объема выборки в диапазоне от 20 до 2000 наблюдений (используется «нормальная аппроксимация», биномиального распределения).
Из графика видно, что мощность достигает приемлемого уровня (часто этот уровень фиксируют между .80 и .90) на выборке, состоящей примерно из 600 наблюдений.
Следует помнить, что вычисления сделаны в предположении, что истинное значение доли р равно.55. Возможно, что форма кривой (а значит, и наши оценки!) очень чувствительна к величине р. Логично поставить вопрос: как чувствителен наклон графика к изменению величины р?
Имеется несколько подходов к решению данного вопроса. Один состоит в то»' чтобы построить графики зависимости мощности от размера выборки для равных значений р. Ниже показан график зависимости мощности от размера выборки прир-.б.
Можно заметить, что увеличение мощности при возрастании N происходит гораздо быстрее при р - .6 чем при р - 55. Это различие становится более заметно, если построить два графика одновременно.
143
Для данного уровня мощности график зависимости объема выборки отр показывает чувствительность объема выборки к величине р. На следующем графике показана зависимость объема выборки N, позволяющей достичь мощности .90 для различных значений р, когда при нулевой гипотезе р - .50.
144
Глава 2. Элементарные понятия анализа до
Из графика видно, как быстро уменьшается N для р изменяющихся от .55 до .60 Таким образом, чтобы надежно обнаружить различие .05 (от значения при нуле! ' гипотезе 50), требуется взять объем выборки N больше 800, но, чтобы надел обнаружить различие .10 требуется всего лишь 200 (см. значение N при р - 0 Очевидно, гораздо лучше быть осведомленным заранее о точности критерия, че.» оказаться поставленным перед фактом некорректности исследования и ошибка при принятии решения.
Взаключении сделаем замечание общего характера. Результат применения крж
терпя значимости заключается в утверждении — принять или отвергнуть нуле! .» гипотезу. Такой подход часто не устраивает тех исследователей, кто рассматрш^. ет нулевую гипотезу не как утверждение об отсутствии эффекта или ну левого эф.
фекта, а интересуется тем, насколько велик эффект,
чем в точности он равен нуле.
или нет. Таким образом, приходится ставить одну, две или три звездочки по результатов в таблице, или приводить соответствующие р-уровни
Вероятностные уровни иногда могут ввести в заблуждение относительно «силы»
результата, особенно когда они представлены без дополнительной информации Налример, если в таблице дисперсионного анализа один эффект имел р уровень .019, а другой р уровень .048, то утверждение, что первый эффект сильнее вторе , Ы возможно, будет ошибочным. Для правильной интерпретации полученного резуш^ тэта необходима дополнительная информация. Чтобы понять это, предположим, что некто установил р уровень .001 Это могло быть результатом слабого эффекта и чрезмерно большого объема выборки, либо сильного эффекта в поп уляции • умеренного объема выборки, либо очень сильного эффекта и малого объема вь борки. Аналогично,р уровень .075 можно интерпретировать как комбинацию очен». сильного и малой выборки, либо незначительного эффекта и гигантской выборки
Отсюда ясно, что следует внимательно сравнивать р-уровни и принимать во внимание объем выборки и точность эксперимента.
Понижение размерности данных
Исследователи из различных областей части сталкиваются с данными большой размерности, иными словами, с таблицами данных, в которых много переменных (столбцов). Естественное желание исследователя разумно сократить число перемен ных, вводя новые переменные и объединяя некоторые переменные в одну. Конеч но, хотелось, чтобы эти новые переменные имели определенный смысл и допуаз* ли разумную интерпретацию, а не вводились чисто формально.
Если вы хотите понизить размерность непрерывных данных, то можете вослоль -зоваться методами факторного анализа. Аналогом факторного анализа для кшпе гориалъных переменных является анализ соответствий, в котором роль компонеу» дисперсии играют компоненты статистики хи-квадрат.
В анализе главных компонент определяются попарно ортогоналыгые паправ ления максимальной вариации исходных данных, после чего данные проектиру-1 югся на подпространство меньшей размерности, порожденное найденными компонентами. Далее эти компоненты могут рассматриваться как новые переменные.
Визуальный подход к анализу мощности
145
к которым применяются обычные методы многомерного анализа, например, регрессионный анализ.
Для того чтобы понять основную идею, рассмотрим две зависимые непрерывные переменные. Зависимость между двумя переменными можно обнаружить с помощью двумерной диаграммы рассеяния. Полученная путем подгонки линия регрессии дает графическое представление зависимости. Если определить новую переменную на основе линии регрессии, изображенной на этой диаграмме, то такая переменная будет включить в себя наиболее существенные черты обеих коррелированных переменных. Итак, фактически, вы сократили число переменных и замени™ две зависимые переменные одной переменной.
Если вы имеете три зависимые переменные, то аналогичным образом можете построить трехмерную диаграмму рассеяния и вновь провести линию регрессии, вдоль которой разброс данных максимальный. После того, как вы нашли тиипю регрессии, для которой дисперсия максимальна, вокруг нее остается некоторый разброс данных, поэтому процедуру естественно повторить.
В анализе главных компонент именно так и поступают: после выделения первого фактора определяется следующий фактор, максимизирующий остаточную вариапию и т д.
Таким образом, последовательно выделяются главные компоненты, которые по самому способу построения оказываются некоррелированными или ортогональными. Эта идея естественно распространяется на любое число переменных.
3
Вероятностн ые распределения и их свойства
Случай является одним из наиболее загадочных явлений на свете, он внезапно возникает и так же внезапно исчезает, — столь внезапно, что не позволяет нам проникнуть в свою сущность. Только в XX веке математики научились оперироват». с вероятностью, хотя отдельные задачи о подсчете шансов в азартных играх рас сматривал ись еще в XV- XVI веках. Древние греки, приучившие нас к количествен ному взгляду на мир, пришли бы в ужас, если бы узнали, что мы научились с помощью теории вероятностей вычислять шансы и оценивать, какие события более вероятны, а какие менее вероятны, например в актуарных расчетах или азартных играх.
Знаменитые итальянские математики Кардано, Пачоли и Тарталья, а вслед за ними Паскаль, Ферма, Гюйгенс в XVII веке разрабатывали все более и более изош ренные способы подсчета вероятностей в разнообразных игровых задачах и в популярных лотереях. Их изобретательность была поистине удивительной! Используя ограниченный и, на наш взгляд, примитивный язык, они смогли объяснить глубокие явления. Существенное движение вперед произошло в тот момент, когда прозорливые умы вдруг осознали, что очень схожие вероятностные законы возникают в разных, на первый взгляд, задачах.
В чем состоит идея вероятностных рассуждений?
Первый, самый естественный шаг вероятностных рассуждений заключается в еле дующем: если вы имеете некоторую переменную, принимающую значения случайным образом, то вам хотелось бы знать, с какими вероятностями эта переменнам принимает определенные значения. Совокупность этих вероятностей как раз и задает распределение вероятностей. Например, имея игральную кость, можно a prior | считать, что с равными вероятностями 1/6 она упадет на любую грань. И это про исходит при условии, что кость симметричная Если кость несимметричная» тц можно определить большие вероятности для тех граней, которые выпадают чаше а меньшие вероятности — для тех граней, которые выпадают реже, исходя из опыт ных данных. Если какая-то грань вообще не выпадает, то ей можно присвоить ве-
ное распределение
147
зоятность 0. Это и есть простейший вероятностный закон, с помощью которого иожно описать результата бросания кости. Конечно, это чрезвычайно простой пример- но аналогичные задачи возникают, например, при актуарных расчетах, когда на основе реальных данных рассчитывается реальный риск при выдаче страхового полиса.
В этой главе мы рассмотрим вероятностные законы, наиболее часто возникаю-
щие на практике
Графики этих распределений можно легко построить в STATISTICA.
Нормальное распределение
Нормальное распределение вероятностей особенно часто используется в статистике. Нормальное распределение дает хорошую модель для реальных явлений, в ко торых:
1) имеется сильная тенденция данных группироваться вокруг центра;
2) положительные и отрицательные отклонения от центра равновероятны;
3) частота отклонений быстро падает, когда отклонения от центра становятся большими.
Механизм, лежащий в основе нормального распределения, объясняемый с помощью так называемой центральной предельной теоремы, можно образно описать следующим образом. Представьте, что у вас имеются частицы цветочной пыльцы, которые вы случайным образом бросили в стакан воды. Рассматривая отдельную частицу под микроскопом, вы увидите удивительное явление — частица движется. Конечно, это происходит, потому что перемешаются молекулы воды и передают свое движенце частицам взвешенной пыльцы.
Но как именно происходит движение? Вот более интересный вопрос. Аэто движение очень причудливо!
Имеется бесконечное число независимых воздействий на отдельную частицу пыльцы в виде ударовмолекул воды, которые заставляют частицу двигаться повесьма странной траектории. Под микроскопом это движение напоминает многократно и хаотично изломанную линию. Эти изломы невозможно предсказать, в них нет никакой закономерности, что как рази соответствует хаотическим ударам молекул о частицу. Взвешенная частица, испытав удар молекулы волы в случайный момент времени, меняет направление своего движения, далее некоторое время движется по инерции, затем вновь попадает под удар следующей молекулы и т. д. Возникает удивительный бильярд в стакане воды!
Поскольку движение молекул имеет случайное направление и скорость, то вели-чина и направление изломов траектории также совершенно случайны и непредсказуемы. Это удивительное явление, называемое броуновским движением, открытое в XIX веке, заставляет нас задуматься о многом.
Если ввести подходящую систему и отмечать координаты частицы через некоторые моменты времени, то как раз и получим нормальный закон. Более точно, Решения частицы пыльцы, возникающие из-за ударов молекул, будут подчинять-Ся нормальному закону.
148
Глава 3. Вероятностные распределения и их свойст
Впервые закон движения такой частицы, называемого броуновским, на физ! ческом уровне строгости описал А. Эйнштейн. Затем более простой и интуитив] ясный подход развил Ленжеван.
Математики в XX веке посвятили этой теории лучшие страницы, а первый ш был сделан 300 лет назад, когда был открыт простейший вариант центральной!!! дельной теоремы.
В теории вероятности центральная предельная теорема, первоначально нзв& ная в формулировке Муавра и Лапласа еще в XVII веке как развитие знамении закона больших чисел Я. Бернулли (1654-1705) (см. Я. Бернулли (1713), У. Conjectandi). в настоящее время чрезвычайно развилась и достигла своих выс< в современном принципе инвариантности, в создании которого существенна роль сыграла русская математическая школа. Именно в этом принципе наход! снос строгое математическое объяснение движение броуновской частицы.
Идея состоит в том, что при суммировании большого числа независимых величин (уларов молекул о частицы пыльцы) в определенных разумных условиях пол у чаются именно нормально распределенные величины. И это происходит независ». мо, то есть инвариантно, от распределения исходных величин. Иными словами, если на некоторую переменную воздействует множество факторов, эти воздействия независимы, относительно малы и слагаются друг с другом, то получаемая в итоге величина имеет нормальное распределение.
Например, практически бесконечное количество факторов определяет вес человека (тысячи генов, предрасположенность, болезни и т. д.). Таким образом, можно ожидать нормальное распределение веса в популяции всех людей.
Если вы финансист и занимаетесь игрой на бирже, то, конечно, вам известны случаи, когда курсы акций ведут себя подобно броуновским частицам, испытывая хаотические удары многих факторов
юльное распределение
149
Формально плотность нормального распределения записывается так.
<р(х;а,п2) -=-t=J=--е 20 .
у 2 л -о
ццепи а2 — параметры закона, интерпретируемые и ответственно как среднее значение и дисперсия данной случайной величины (ввиду особой роли нормального распределения мы будем использовать специальную символику для обозначения его функции плотности и функции распределения). Визуально график нормальной плотности — это знаменитая колоколообразная кривая.
Соответствующая функция распределения нормальной случайной величины £(а,о2) обозначается Ф(.т, в.гт2) и задается соотношением’
Ф(х;о,о2)=Р{^(а,а2)<х}=-р^=— fe 2"
-ДТП -ст J
Нормальный закон с параметрами а = 0 и а2 ~ 1 называется стандартным.
Обратная функция стандартного нормального распределения, примененная к ветчине 2,0<г<1. называется пробит-преобразовапием г, или просто пробитом z
Rot пользуйтесь вероятностным калькулятором STATISTICA, чтобы по х вычислить г и наоборот.
Основные характеристики нормального закона’
среднее. мода, медиана-££ = = х„гЛ = а\
Дисперсия: = сг;
асимметрия: Д =0;
эксцесс: Д = 0;
150
Глава 3. Вероятностные распределения и их свойства
Центральные моменты порядка к > з:
О при к — 2тп — 1,
1-3 -(2m—1)о2" при к = 2т,
Изформул видно, что нормальное распредетениеописывается двумя параметрами-а — mean — среднее;
а — stantard deviation — стандартное отклонение, читается: «сигма».
Иногда стандартное отклонение называют среднеквадратическим отклонением, но это уже устаревшая терминология.
Приведем некоторые полезные факты относительно нормального распределения.
Среднее значение определяет меру расположения плотности. Плотность нормального распределения симметрична относительно среднего. Среднее нормаль него распределения совпадает с медианой и модой (см. графики).
Плотность нормального распределения с дисперсией 1 и средним 1
Плотность нормального распределения со средним О и дисперсией 0,01
Плотность нормального распределения со средним 0 и дисперсией 4
верное распределение
151
При увеличении дисперсии плотность нормального распределения расплывается или растекается вдоль оси ОХ, при уменьшении дисперсии она, наоборот, сжимается, концентрируясь вокруг одной точки — точки максимального аначсния, совпадающей со средним значением. В предельном случае нулевой дисперсии случайная величина вырождается и принимает единственное значение, равное сред-
Полезно знать правила 2- и 3-сигма, или 2- и 3-стандартных отклонений, которые связаны с нормал ьным распределением и используются в разнообразных приложениях. Смысл этих правил очень простой
Если от точки среднего или, что то же самое, от точки максимума плотности нормального распределения отложить вправо и влево соответственно даа и три стандартных отклонения (2- и 3-сигма), то площадь под графиком нормальной плотности, подсчитанная по этому промежутку, будет соответственно равна95,45% и 99,73% всей площади под графиком (проверьте на вероятностном калькуляторе STATISTICA!).
Другими словами, это можно выразить следующим образом: 95.45% и 99,73% всех независимых наблюдений из нормальной совокупности, например размеров детали или цены акций, лежит в зоне 2- и 3-стандартных отклонений от среднего значения.
Равномерное распределение
Равномерное распределение полезно при описании переменных, у которых каждое значение равновероятно, иными словами, значения переменной равномерно распределены в некоторой области.
Ниже приведены формулы плотности и функции распределения равномерной случайной величины, принимающей значения на отрезке [а, Ь].
- — приа<х</>; h-o
[О прих<аих>Ь.
0 прих<а~,
х-а
--- npuacxiD;
Ь-а
1 при х>Ь.
Из этих формул легко понять, что вероятность того, что равномерная случай Иая величина примет значения из множества [с, d] с [a, fe], равна (d — c)/(b — а).
Положим a-O,b=-1. Ниже показан график равномерной плотности вероятно Сги. сосредоточенной на отрезке [0,1].
152
Глава 3. Вероятностные распределения и их свойства
Числовые характеристики равномерного закона: а+^
среднее, медиана: -хта1 =
дисперсия: ;
асимметрия. R = 0;
эксцесс: л =-1,2.
Экспоненциальное распределение
Имеют место события, которые на обыденном языке можно назвать редкими. Если Т — время между наступлениями редких событий, происходящих в среднем с ин тенсивностъю Л, то величина Тимеет экспоненциальное распределе! |ие с нарамет • ром Л (чямбдп). Экспоненциальное распределение часто используется д чя оппсаиш интервалов между последовательными случайными событиями, например интер валов между заходами на непопулярный сайт, так как эти посещения являются] редкими событиями.
Это распределение обладает очень интересным свойством отсутствия поел, действия, или, как еще говорят, марковским свойством, в честь знаменитого pyi ского математика Маркова А. А., которое можно объяснить следующим образе Если распределение между моментами наступления некоторых событий являет показательным, то распределение, отсчитанное от любого момента t до слсдуюи го события, также имеет показательное распределение (с тем же самым параметром I.
Иными словами, для потока редких событий время ожидания следующего но-сетитсля всегда распределено показательно независимо от того, сколько временя
вы его уже ждали.
Показательное распределение связано с пуассоновским распределением: в единичном интервале времени количество событий, интервалы между которыми н зависимы и показательно распределены, имеет распределение Пуассона. Если hi
тервалы между посещениями сайта имеют экспоненциальное распределение. количество посещений, например в течение часа, распределено по закону Пуассси
распределение Эрланга
153
Показательное распределение представляет собой частный случай распределения Всйбулла.
Если время не непрерывно, а дискретно, то аналогом показательного распределения является геометрическое распределение.
Плотность экспоненциального распределения описывается формулой:
/е(х) = Д,е ^. **0.
Это распределение имеет только один параметр, который и определяет его характеристики.
График плотности показательного распределения имеет вид:
Основные числовые характеристики экспоненциального распределения:
среднее: Е£= —» Л)
=0;
медиана: хта1 ---In 2;
дисперсия: D£ -
1
асимметрия: Д =2;
эксцесс: Д,=6.
Распределение Эрланга
310 Непрерывное распределение сосредоточено на (0,1) и имеет плотность.
, . («Ю” л-1 -«JU ',М=Г(»)Х ' •
I Где Ц, п ~ параметры, ц > 0, п — целое.
154
Глава 3. Вероятностные распределения и их свойства
Математическое ожидание и дисперсия равны соответственно — и —-.
А л/?
Распределение Эрланга названо в честь А. Эрланга (A Erlang), впервые применившего его в задачах теории массового обслуживания и телефонии
Распределение Эрланга с параметрами р и п является распределением суммы п независимых, одинаково распределенных случайных величин, каждая из которых имеет показательное распределение с параметром пр.
При и = 1 распределение Эрланга совпадает с показательным или экспоненциальным распределением.
Распределение Лапласа
Функция плотности распределения Лапласа, или, как его еще называют, двойного экспоненциального, используется, например, для описания распределения оши бок в моделях регрессии. Взглянув на график этого распределения, вы увидите что оно состоит из двух экспоненциальных распределений, симметричных отио ситсльно оси OY
Если параметр положения равен 0, то функция плотности распределения Лапласа имеет вид.-
/(х)=1л.е-« (-»<,«).
Основные числовые характеристики этого закона распределения в предположении. что параметр положения нулевой, выглядят следующим образом:
среднее: Е£=0;
мода: xmod=0;
медиана- хяг„= 0;
Гамма-распределение
дисперсия: D^ = -^;
асимметрия: Д =0;
эксцесс: /?2 =3.
В общем случае плотность распределения Лапласа имеет вид:
дх>4-«
где
а — среднее распределение;
b — параметр масштаба;
е — число Эйлера (2,71...)-
Гамма-распределение
Плотность экспоненциального распределения имеет моду в точке 0, и это иногда неудобно для практических применений. Во многих примерах заранее известно, что мола рассматриваемой случайной переменной не равна 0, например, интерва-
156
Глава 3. Вероятностные распределения и их свой
лы между приходами покупателей в магазин электронной торговав или заход, на сайт имеют ярко выраженную моду. Для моделирования таких событи й испс зустся гамма-рагпреде lenue.
Плотность гамма-распределения имеет вид:
_ь- ‘ ' Г(а) '
О при х<0
приО<х<со;
где Г — Г-функция Эйлера, д — 0 — параметр «формы» и h > 0 — параметр мэ штаба.
В частном случае имеем распределение Эрланга и экспоненциальное распределение.
Основные характеристики гамма-распределения:
среднее: £/(а,Ь) = ^; b
а—1
мода: xmod = - - (при а>1); b
дисперсия: Dy(a,b) =
асимметрия: Д =
эксцесс. рг-—.
а
Ниже приведены два графика плотности гамма-распределения с параметров масштаба, равным 1, и параметрами формы, равными 3 и 5.
распределение
157
Полезное свойство гамма-распределения: сумма любого числа независимых гамма-распредсленных случайных величин (с одинаковым параметром масштаба Ь) у (а ,А) + /2(«2>А)+--+/Я(аг,й) также подчиняется гамма-распредслению, но спарамстрами at +а2 + - -+ав чЬ.
Логнормальное распределение
Случайная величина А называется логарифмически нормальной, или логнормальной. если ее натуральный логарифм (inft) подчинен нормальному закону’ распределения.
Логнормальное распределение используется, например, при моделировании таких переменных, как доходы, возраст новобрачных или допустимое отклонение от стандарта вредных веществ в продуктах питания.
Итак, если величинахимеег нормальное распределение, то вел нчииау = имеет логнормальное распределение.
Если вы подставите нормальную величину в степень экспоненты, то легко поймете, что логнормальная величина получается в результате многократных умножений независимых величин, так же как нормальная случайная величина есть результат многократного суммирования.
Плотность логнормального распределения имеет вид:
Основные характеристики логарифмически нормального распределения
среднее: Ег]=ае^ ;
«ода: х,гкА = ае^
медиана: =а\
Дисперсия: £7 = (Ет?)2^' -\) = ае° (е"*-!);
158
Глава 3- Вероятностные распределения и их свойст
асимметрия: Д =(е° +2);
эксцесс: Д, =(е" +3е2®’ + бе"' +6)
159
ц^^рат-распредепение
- квадрат-расп ре де лен и е
Сумма квадратов т независимых нормальных величин со средним 0 и дисперсией 1 г иуеет хи-квадрат-распределегше с т степенями свободы. Это распределение наи-F более часто используется при анализе данных
формально плотность хи-квадрат-распределения с т степенями свободы имеет
ВИД:
При отрицательных х плотность обращается в О
Основные числовые характеристики хи-квадрат-распределения:
среднее: ££2(т) = т;
мода: =гп-2-.
дисперсия: £>^2(т) = 2/я;
асимметрия: Д =-=;
эксцесс: Д =____.
т
График плотности приводится на рисунке ниже:
160
Глава 3. Вероятностные распределения и их свойства
Биномиальное распределение
Биномиальное распределение является наиболее важным дискретным распредели ннсм, которое сосредоточено всего лишь в нескольких точках. Этим точкам бит миальное распределение приписывает положительные вероятности. Таким обрг лом, биномиальное распределение отличается от непрерывных распределеии (нормального, хи-квадрат и др.), которые приписывают путевые вероятности от дельно выбранным точкам и называются непрерывными.
Лучше понять биномиальное распределение можно, рассмотрев следующую игр’
Представьте, что вы бросаете монету. Пусть вероятность выпадения герба есть р а верояпюсть выпадения решки есть g = 1 - р (мы рассматриваем самый общи случай, когда монета несимметрична, имеет, например, смешенный центр тяж, -ти — в монете сделана дырка).
Выпадение герба считается успехом, а выпадение решки — неудачей. Тогда чис ло выпавших гербов (или решек) имеет биномиальное распределение
Отметим, что рассмотрение несимметричных монет или неправильных играл! пых костей имеет практический интерес. Как отмстил Дж. Нейман в своей паяв] ной книге «Вводный icypc теории вероятностей п математической статистик] люди давно догадались, что частота выпадений очков на игральной кости завис от свойств самой этой кости л может быть искусственно изменена Археологи I пару жили в гробнице фараона две пары костей: «честные» — с равными вероятг стями выпадения всех граней, и фальшивые — с умышленным смещением цент тяжести, что увеличивало вероятность выпадения шестерок.
Параметрами биномиального распределения являются вероятность ус »е р (д = 1 - р) и число испытаний п.
Биномиальное распределение полезно для описания распределения бином альных событий, таких, например, как количество мужчин и женщин в случ.и выбранных компаниях. Особую важность имеет применение биномиального |М пределе) шя в игровых задачах.
Точная формула для вероятности т успехов в п испытаниях записывается та
/(-»)=[—-—Ъ"
|яг!-(и—m)’J
161
рдмиальное распределение
р — вероятность успеха;
а равно 1-р. р. q>~0, p+q~ К
п — число Испытаний, тп - 0,1 ...тп.
Основные характеристики биноминального распределения:
среднее: Evp(n) = np;
модахти): р(л+1)-1^ <X«+D;
дисперсия: Dvp(n) = np(l-рУ,
г, 1~2Р
асимметрия: р - , —;
ylnpil-p)
1-6р(1—р) эксцесс: я, =---
ирО-р)
График этого распределения при различном числе испытаний п и вероятностях успеха р имеет вид:
162
Глава 3. Вероятностные распределения и их свойства
Опальное распределение 163
Биномиальное распределение связано с нормальным распределением и распре-енисм Пуассона (см ниже); при определенных значениях параметров при боль-Iчисле испытаний оно превращается в эти распределен ня. Это легко продсмои-ировать с помощью STATISTICA.
- Например, рассматривая график биномиального распределения с параметра-мир=0,7,и “ ЮО (см. рисунок), мы использовали STATISTICA BASIC, — вы монете заметить, что график очень похож на плотность нормального распределения (так оно и есть па самом деле!).
График биномиального распределения с параметрами р=0,05. п = 100 очень похож па график пуассоновского распределения.
Как уже было сказано, биномиальное распределение возникло из наблюдений за простейшей азартной игрой — бросание правильной монеты. Во многих ситуациях эта модель служит хорошим первым приближением для более сложных игр и случайных процессов, возникающих при игре на бирже. Замечательно, что существенные черты многих сложных процессов можно понять, исходя из простой биномиальной модели.
Например, рассмотрим следующую ситуацию.
Отметим выпаденпе герба как 1, а выпадение решки — минус 1 и будем суммировать выигрыши и проигрыш» в последовательные моменты времени. На графиках показаны типичные траектории такой игры при 1000 бросков, при 5000 бросков и при 10 000 бросков. Обратите внимание, какие длинные отрезки времени траектория находится выше или ниже нуля, иными словами, время, в течение которого один из игроков находится в выигрыше в абсолютно справедливой игре, очень продолжительно, а переходы от выигрыша к проигрышу относительно редки. и это с трудом укладывается в неподготовленном сознании, для которого выражение «абсолютно справедливая игра» звучит как магическое заклинание. Итак, хотя игра и справедлива по условиям, поведение типичной траектории вовсе не справедливо и не демонстрирует равновесия!
Конечно, эмпирически этот факт известен всем игрокам, с ним связана стратегия. когда игроку не дают уйти с выигрышем, а заставляют И1рать дальше.
Результаты Бросаний правильной ыонеты (1000 Бросков)
100 200 390 400 500 500 700 800 900 1500
164
Глава 3. Вероятностные распределения и их свойства.
Рекультаты бросаний правильном монеты (5000 бросков)
500 1000 1500 2000 2500 3000 3500 4000 4500 5500
О 1000 4000 В000 0000 1 0000 1 2000 14000
1000 3000 5000 7000 8000 11000 13000 15000
Рассмотрим количество бросков, в течение которых один игрок находится в выигрыше (траектория выше 0), а второй — в проигрыше (траектория ниже 0). На первый взгляд кажется, что количество таких бросков примерно одинаково. Однако (см. захватывающую книгу: Феллер В. Введение в теорию вероятностей и ее приложения. М: Мир, 1984, с. 106) при 10 000 бросках идеальной монеты (то есть для : испытаний Бернулли с р - q - 0,5, п-10 000) вероятность того, что одна из сторон будет лидировать на протяжении более 9 930 испытаний, а вторая — менее 70. превосходит 0,1.
Удивительно, что в игре, состоящей из 10 000 бросаний Правильной монеты, вероятность того, что лидерство поменяется не более 8 раз, превышает 0.14, а вероятность более 78 изменений лидерства приблизительно равна 0,12.
Итак, мы имеем парадоксальную ситуацию: в симметричном блуждании Бернулли «волны» на графике между последовательными возвращениями в нуль (см. графики) могут быть поразительно длинными. С этим связано и другое обстоя-течьство, а именно то, что для Г/и (доли времени, когда график находится выше оси абсцисс) наименее вероятными оказываются значения, близкие к 1/2.
арксинуса
165
Математиками был открыт так называемый закон арксинуса, согласно которому при кажД°м 0 < а <1 веРоят*1ОСТЬ неравенства — <а, где Т п — число шагов, в течение которых первый игрок находится в выигрыше, стремится к
1 Г° - *** - =—arcsin - Ja.
распределение арксинуса
Это непрерывное распределение сосредоточено на интервале (0,1) и имеет плотность:
р(х) = —
Функция распределения имеет вид:
F(x) = 2n ‘arcsinVx
Распределение арксинуса связано со случайным блужданием. Это распределение доли времени, в течение которого первый игрок находится в выигрыше при бросании симметричной монеты, то есть монеты, которая с равными вероятностями S падает на герб и решку. По-другому такую игру можно рассматривать как случайное блуждание частицы, которая, стартуя из нуля, с равными вероятностями делает единичные скачки вправо или алево. Так как скачки частицы — выпадения герба или решки — равновероятны, то такое блуждание часто называется симметричным. Если бы вероятности были разными, то мы имели бы несимметричное блуждание.
График плотности распределения арксинуса приведен на следующем рисунке:
166______________________Глава 3, Вероятностные распределения и их свойства
Самое интересное — это качественная интерпретация графика, из которой мож но сделать удивительные выводы о сериях выигрышей и проигрышей в справедливой игре. Взглянув на график, вы можете заметить, что минимум плотности на» ходится в точке 0,5. «Ну и что?!» — спросите вы. Но если вы задумаетесь над этим наблюдением, то вашему удивлению нс будет границ! Оказывается, определенная как справедливая, игра в действительности вовсе не такая справедливая, как може, показаться на первый взгляд.
Траектории симметричного случайного, в которых частица равное время проводит как на положительной, так и на отрицательной полуоси, то есть правее или левее нуля, являются как раз наименее вероятными Переходя на язык игроков можно сказать, что при бросании симметричной монеты игры, в которых игроки находятся равное время в выигрыше и проигрыше, наименее вероятны.
Напротив, игры, в которых один игрок значительно чаще находится в выигрыше, а другой соответственно в проигрыше, являются наиболее вероятными. Уди вительный парадокс!
Чтобы рассчитать вероятность того, что доля времени т, в течение которой первый игрок находится в выигрыше, лежит в пределах от tl до t2, нужно из значения функции распределения F(t2) вычесть значение функции распределения F(t1).
Формально получаем:
P{t1<x<t2} - F(t2) - F(t1)
Опираясь на этотфакт, можно вычислитьс помощью STATISTICA, что при 10 000 шагов частица остается на положительной стороне более чем 9930 моментов времени с вероятностью 0,1, то есть, грубо говоря, подобное положение будет наблюдаться не реже чем в одном случае из десяти (хотя, на первый взгляд, оно кажется абсурд-ным;см.замечательиуюпоясностизаметкуЮ. В. Прохорова «Блуждание Бернулли» в энциклопедии «Вероятность и математическая статистика», с. 42—43, М. Большая российская энциклопедия, 1999).
Отрицательное биномиальное распределение
Это дискретное распределение, приписывающее целым точкам k = 0,1,2, .. вероятности:
pt = Р{ЛГ = Л}= Cjnup'C - р)‘, где 0 < р < 1, г > 0.
Отрицательное биномиальное распределение встречается во многих приложениях
При целом г > 0 отрицательное биномиальное распределение интерпретируется как распределение времени ожидания r-го «успеха» в схеме испытаний Бфнупли с вероятностью «успеха»р, например, количество бросков, которые нужно сделать до второго выпадения герба, в этом случае оно иногда называется распределением ( Паскаля и является дискретным аналогом гамма-распределения.
При г - 1 отрицательное биномиальное распределение совпадает с геометрическим распределением.
Пуассона
167
Если Y — случайная величина, имеющая распределение Пуассона со случайным паметром Л, который, в свою очередь, имеет гамма-распределение с плотностью
Г(/2)
Убудет иметь отрицательно биномиальное распределение с параметрами г = д
а
распределение Пуассона
распределение Пуассона иногда называют распределением редких событий. Примерами переменных, распределенных по закону Пуассона, могут служить: число несчастных случаев, число дефектов в производственном процессе и т д.
Распределение Пуассона определяется формулой:
Основные характеристики пуассоновской случайной величины:
среднее: Ev„ =Л;
дисперсия: Ом0=Я;
асимметрия:
Распределение Пуассона связано с показательным распределением и с распределением Бернулли.
Если число событий имеет распределение Пуассона, то интервалы между событиями имеют экспоненциальное или показательное распределение.
График распределения Пуассона:
168
Глава 3. Вероятностные распределения и их свой;
Сравните график пуассоновского распределения с параметром 5 с график распределения Бернулли при p-q=0,5, п=100.
Вы увидите, что графики очень похожи. В общем случае имеется следующ закономерность (см., например, превосходную книгу: Ширяев А. Н. Вероятное М: Наука, с. 76): если в испытаниях Бернулли п принимает большие зпачещ а вероятность успеха р относительно мала, так что среднее число успехов (прока ведение и нар) и не мало и не велико, то распределение Бернулли с параметрами г р можно заменить распределением Пуассона с параметром Л - п х р.
Распределение Пуассона широко используется на практике, например, в кар тах контроля качества как распределение редких событий.
В качестве другого примера рассмотрим следующую задачу, связанную с теле • фонными линиями и взятую из практики (см.: Феллер В. Введение в теорию веро ятностей и ее приложения. М: Мир, 1984,с.205,атакже Molina Е. С. (1935) Probability in engineering. Electrical engineering, 54, p. 423-427; Bell Telephone System Technical Publications Monograph В-854). Эту задачу легко перевести на современный языц например на язык мобильной связи, что и предлагается сделать заинтересованный' читателям.
Задача формулируется следующим образом. Пусть имеется две гелефонны» станции — А и В.
Телефонная станция А должна обеспечить связь 2000 абонентов со станцией В. Ка чество связи должно быть таким, чтобы только 1 вызов из 100 ждал, когда освободится линия.
Спрашивается: сколько нужно провести телефонных линий, чтобы обеспечить за данное качество связи? Очевидно, что глупо создавать 2000 линий, так как длительное время многие из них будут свободными Из интуитивных соображений ясно, что по-видимому, имеется какое-то оптимальное число линий N. Как рассчитать это количество?
Начнем с реалистической модели, которая описывает интенсивность обрэше ния абонента к сети, при этом заметим, что точность модели, конечно, можно про верить, используя стандартные статистические критерии.
Итак, предположим, что каждый абонент использует линию в среднем 2 минуты в час и подключения абонентов независимы (однако, как справедливо замечает Феллер, последнее имеет место, если не происходит некоторых событий, затрагивающих всех абонентов, например войны или урагана).
Тогда мы имеем 2000 испытаний Бернулли (бросков монеты) или подключений к сети с вероятностью успеха р-2/60-1/30.
Нужно найти такое N, когда вероятность того, что к сети одновременно подключается больше N пользователей, не превосходит 0,01. Эти расчеты легко можно решить в системе STATISTICA.
Решение задачи на STATISTICA.
Шаг 1. Откройте модуль Основные статистики. Создайте файл binomlsta, содержащий 110 наблюдений. Назовите первую переменную БИНОМ, вторую переменную — ПУАССОН
Шаг 2. Дважды щелкнув мышью на заголовке БИНОМ, откройте окно Переменная 1 (см. рисунок). Введите в окно формулу, как показано на рисунке. Нажмите кнопку ОК.
Пуассона
169
Шаг 3. Дважды щелкнув мышью на заголовке ПУАССОН, откройте окно Переменная 2 (см. рис.)
Введите в окно формулу, как показано на рисунке. Обратите внимание, что мы вычисляем параметр Л распределения Пуассона по формуле Л - п Хр. Поэтому Л - 2000 X 1/30. Нажмите кнопку ОК.
STATISTICA рассчитает вероятности и запишет их в созданный файл
170
Глава 3. Вероятностные распределения и их свойс
Шаг 4. Прокрутите построенную таблицу до наблюдений с номером 86. Вы yj дите, что вероят! юсть того, что в течение часа из 2000 пользователей сети одиов| менно работают 86 или более, равна 0,01347, если используется биномиальт распределение.
Вероятность того, что в течение часа из 2000 пользователей сети одновремец работают 86 или более человек, равна 0,01293, если используется пуассонова приближение для биномиального распределения.
Так как нам нужна вероятность не более 0,01, то 87 линий будет достаточны чтобы обеспечить нужное качество связи.
Близкие результаты можно получить, если использовать нормальное приближение для биномиального распределения (проверьте это!).
Заметим, что В. Феллер не имел в своем распоряжении систему STATISTIC?, и использовал таблицы для биномиального и нормального распределения.
С помощью таких же рассуждений можно решить следующую задачу, обсуж даемую В. Феллером. Требуется проверить, больше или меньше линий потребу J ется для надежного обслуживания пользователей при разбиении их на 2 группы| по 1000 человек в каждой.
Оказывается, при разбиении пользователей на группы потребуется дополни тельно 10 линий, чтобы достичь качества того же уровня.
Можно также учесть изменение интенсивности подключения к сети в течение дня ,
Геометрическое распределение
Если проводятся независимые испытания Бернулли и подсчитывается количества испытаний до наступления следующего «успеха*, то это число имеет геометрическое распределение. Таким образом, если вы бросаете монету, то число под брасы ва ний, которое вам нужно сделать до выпадения очередного герба, подчиняется гео метрическому закону.
Геометрическое распределение определяется формулой:
гдер — вероятность успеха, х = 1,2,3 ...
Название распределения связано с геометрической прогрессией.
Итак, геометрическое распределение задает вероятность того, что успех насту -пил на определенном шаге.
Геометрическое распределение представляет собой дискретный аналог показательного распределения. Если время изменяется квантами, то вероятность успехам I каждый момент времени описывается геометрическим законом. Если время непрерывно, то вероятность описывается показательным или экспоненциальным законом
Гипергеометрическое распределение
Это дискретное распределение вероятностей случайной величины X, принцы» щей целочисленные значения т = 0,1,2,.., п с вероятностями:
171
>ie неотрицательные числа и М < N, п < N.
1еское распределение обычно связано с выбором без возвраще-например, вероятность найти ровно тп черных шаров в случай -fa п из генеральной совокупности, содержащей Nшаров, среди и N - М. белых (см., например, энциклопедию -«Вероятность и атистика», М.: Большая российская энциклопедия, с. 144). ожидание гапергсомет^мческого распределения не зависит от N и ическим ожиданием д = пр соответствуй «него бпномиалыюп» рас-
2 N—n
.•ргеометрического распределения ст = npq + — не превос-иномиального распределения npq. При N—> со моменты любого порядка гипергеометрического распределения стремятся к соответствующим значениям моментов биномиального распределения.
Это распределение чрезвычайно часто возникает в задачах, связанных с контролем качества.
Полиномиальное распределение
Полиномиальное, или мультиномиальное, распределение естественно обобщает распределение. Если биномиальное распределение возникает при бросании монеты с двумя исходами (решетка или герб), то полиномиальное распределение возникает, когда бросается игральная кость и имеется больше двух возможных исходов. Формально — это совместное распределение вероятностей случайных вел!гчин
Хр. .»ХЛ, принимающих целые неотрицательные значения п,,... nk, удовлетворяющие условию +... + " п, с вероятностями;
F{^i=n, Хк=пк}=——---------рГ'-.р*1, Pj;>0, V.pj =1. (*>
rifl.-.n к! J
Название «полиномиальное распределение» объясняется тем, что мультиномиальные вероятности возникают при разложении полинома (р, + ... + p^f.
Бета-распределение
Бета-распределение имеет плотность вида:
lQ| J •хд>~,(1-л)о>~
= П«,№)
О А.ы ocnuLib ых значений х.
при 0<х<1;
172
Глава 3. Вероятностные распределения и их свойства
Стандартное бета-распределение сосредоточено на отрезке от 0 до 1. Применяв» линейные преобразования, бета-величину можно преобразовать так, что она будеу принимать значения на любом интервале.
Основные числовые характеристики величины, имеющей бета -раг.ппепрчрнн Д
среднее: £/?(а|1а2) =———, а, +а2
(с.-1)
мода: хraod =---!---- (npuat>\ua2> 1);
а, +а2 —2
дисперсия: DB(a., а,) ---------f—--------;
(а, + а2)2(а, +а2 +1)
_ 2(д, — а,)у1а. +а, +1
асимметрия: В = л.______1 _______1
(а, +в2 +2)^/a,a2
эксцесс- /? - 3(с' +в* +1>№ +аг)2 +о,а2(а, +в2 -6)]
а1а1(а1 + а2 +2)(а1 +а2 +3)
Распределение экстремальных значений
Распределение экстремальных значений (тип I) имеет плотность вида:
/(х) = ^-е 4 -е~* ‘
где
6 — параметр положения;
b — параметр масштаба;
е — число Эйлера (2,71...).
Это распределение иногда также называют распределением крайних значений
Распределение экстремальных значений используется при моделирований экстремальных событий, например уровней наводнений, скоростей вихрей, макси мума индексов рынков ценных бумаг за данный год и т. д.
Это распределение используется в теории надежности, например для описания времени отказа электрических схем, а также в актуарных расчетах.
Распределения Релея
Распределение Релея имеет плотность вида-
/(*) ——« ь -е~* * —<*>с.х<«>, 6 > О,
пррледение Вейбулла
173
у___параметр масштаба.
г** РаспреДе'пение Релея сосредоточено в интервале от 0 до бесконечности. Вместо ченкя О STATISTICA позволяет ввести другое значение порогового параметра,
3 торое будет вычтено из исходных данных перед подгонкой распределения Релея. Следовательно, значение порогового параметра должно быть меньше всех наблюдаемых значений.
Если две переменные у, и у2 являются независимыми друг от друга и нормаль-
НОраепределены содинаковой дисперсией, то переменная х = -^у, +у2 будет иметь распределение Релея.
F Распределение Релея используется, например, в теории стрельбы.
Распределение Вейбулла
Распределение Вейбулла названо в честь шведского исследователя Валодди Вейбулла (Waloddi Weibull), применявшего это распределение для описания времен отказов разного типа в теории надежности.
Формально плотность распределения Вейбулла записывается в виде:
г ЙО.
Иногда плотность распределения Вейбулла записывается также в виде:
О < х, Ь > 0, с > О,
где
& — параметр масштаба;
с ~ Параметр формы;
е " константа Эйлера (2,718...).
174
Глава 3. Вероятностные распределения и их свой
Параметр положения. Обычно распределение Вейбулла сосредоточено на луоси от 0 до бесконечности. Если вместо границы 0 ввести параметр а. что ч« бывает необходимо на практике, то возникает так называемое трехпараметрИ' кое распределение Вейбулла.
Распределение Вейбулла интенсивно используется в теории надежности и стр; ванпи.
Как описывалось выше, экспоненциальное распределение часто ислользуе как модель, оценивающая время наработки до отказа в предположении, что вв ятиость отказа объекта постоянна. Если вероятность отказа меняется с течем времени, применяется распределение Вейбулла.
При с - 1 или, в другой параметризации, при а - 1 распределение Вейбул как легко видеть из формул, переходит в экспоненциальное распределение, а л а = 2 в распределение Релея.
Разработаны специальные методы оценки параметров распределения Бейба ла (см. например, книгу: Lawless (1982) Statistical models and methods for lifeti data, Belmont, CA: Lifetime Learning, где описаны методы оценивания, а так проблемы, возникающие при оценке параметра положения для трехлараметрич< кого распределения Вейбулла).
Часто при проведении анализа надежности необходимо рассматривать всроЯ1 ность отказа в течение малого интервала времени после момента времени t пр условии, что до момента t отказа не произошло.
Такая функция называется функцией риска, или функцией интенсивности ос каэов, и формально определяется следующим образом:
Где
й(Г ) — функция интенсивности отказов или функция риска в момент времени f(t) — плотность распределения времен отказов;
— функция распределения времен отказов (интеграл от плотности по инт валу [0, tj).
В общем виде функция интенсивности отказов записывается так:
где Ао> 0 и а > 0 — некоторые числовые параметры.
При а ” 1 функция риска равна константе, что соответствует нормальной 3 плуатации прибора (см. формулы).
При а < 1 функция риска убывает, что соответствует приработке прибора.
При а > 1 функция риска убывает, что соответствует старению прибора.
Типичные функции риска показаны на графике
Вейбулла
175
TIME
Ниже показаны графики плотности распределения Вейбулла с различными параметрами. Нужно обратить внимание на три области значений параметра а:
1. а< 1,
2. а-1,
3. а>1.
В первой области функция риска убывает (период настройки), во второй области функция риска равна константе, в третьей области функция риска возрастает.
Вы легко поймете сказанное на примере покупки нового автомобиля: вначале идет период адаптации машины, затем длительный период нормальной эксплуатации, далее детали автомобиля изнашиваются и функция риска выхода его из строя резко возрастает.
Важно, что все периоды эксплуатации можно описать одним и тем же семейством распределения. В этом и состоит идея распределения Вейбулла
176
Глава 3. Вероятностные распределения и их свойства
Приведем основные числовые характеристики распределения Вейбулла.
Среднее: ЕЕ, =Ла°
;ние Парето
177
здесь Г(г) — так называемая галсиа-функция Эйлера, Г(г) = | x^'e^dx
Распределение Парето
В различных задачах прикладной статистики довольно часто встречаются так называемые усеченные распределения.
Например, это распределение используется в страховании или в налогообложении, когда интерес представляют доходы, которые превосходят некоторую величину с0.
ВД = Р{£<х} = 1
Основные числовые характеристики распределения Парето:
среднее: Е =---с0 (существует при а> Л;
а-1
мода: =с0;
медиана: х^=2а с0;
Дисперсия: DE =------5------
Ъ (а-1) (а-2)
(существует при а>2);
178
Глава 3- Вероятностные распределения
Логистическое распределение
Логистическое распределение имеет функцию плотности:
где
а — параметр положения;
b — параметр масштаба;
е — число Эйлера (2,71...).
179
Хотеллинга Т2-распределение
Это непрерывное распределение, сосредоточенное на интервале (О, Г), имеет плотность:
где параметры п и k, n> k> 1, называются степенями свободы.
При k = 1 Хотеллинга Т2-распределение сводится к распределению Стьюдента, а при любом k > 1 может рассматриваться как обобщение распределения Стью-Цента па многомерный случай.
Распределение Хотеллинга строится исходя из нормального распределения
Пусть А-мериый случайный вектор У имеет нормальное распределение с нулевым вектором средних и ковариационной матрицей L.
Рассмотрим величину
s'У z.Tz„ И
гДе случайные векторы Z независимы между собой и Уи распределены так же, как У
Тогда случайная величина Тг = УТ5~'У имеет Т2-распределение Хотеллинга с ” степенями свободы (У — вектор-столбец, Т — оператор транспонирования).
Если k = 1, то Т1 =
180
Глава 3. Вероятностные распределения и их свой;
где случайная величина Ь имеет распределение Стыодента с к степенями своб; Н (см. «Вероятность и математическая статистика»-, Энциклопедия, с. 792).
Если Yимеет нормальное распределение с ненулевым средним, то соответствую.-щее распределение называется нецентральным Хотеллинга Т’-распределениИ с п степенями свободы и параметром нецентральное™ v.
Хотеллинга ‘P-распределение используют в математической статистике в тад же ситуации, что и t-распределение Стыодента, но только в многомерном случаи Если результаты наблюдений X,,Хя представляют собой независимые, нормальни распределенные случайные векторы с вектором средних д и невырожденной ковариационной матрицей Е, то статистика
Т2=П(Х-^Т51(Х-,Ц,
П№Х = '^Х, u S = -i^y (X
имеет Хотеллинга P-распределение с п - 1 степенями свободы.
Этот факт положен в основу критерия Хотечлшаа.
В STATISTICA критерий Хотеллинга доступен, например, в модуле Основные I статистики и таблицы (см. приведенное ниже диалоговое окно).
Распределение Максвелла
Распределение Максвелла возникло в физике при описании распределения скорое • тей молекул идеального газа.
Это непрерывное распределение сосредоточено на (0, «>) и имеет плотность1 «
наделение Коши
181
функция распределения имеет вид:
де Ф(-0 — функиия стандартного нормального распределения
1 распределение Максвелла имеет положительный коэффициент асимметрии и единственную моду в точке х = \2а (то есть распределение унимодально).
распределение Максвелла имеет конечные моменты любого порядка; математическое ожидание и дисперсия равны соответственно 2,1—0- и ?сг2.
\п л
I Распределение Максвелла естественным образом связано с нормальным распределением.
Если X,, Х2, Х3 — независимые случайные величины, имеющие нормальное распределение с параметрами 0 и о*, то случайная величина >Х, + А 3 + Х3 имеет распределение Максвелла. Таким образом, распределение Максвелла можно рассматривать как распределение длины случайного вектора, координаты которого в декартовой системе координат в трехмерном пространстве независимы и нормально распределены со средним 0 и дисперсией &
Распределение Коши
У этого удивительного распределения иногда не существует среднего значения, так как плотность его очень медленно стремится к нулю при увеличении х по абсолютной величине Такие распределения называют распределениями с тяжелыми хвостами. Если вам нужно придумать распределение, не имеющее среднего, то сразу называйте распределение Коши.
Распределение Коши унимодально и симметрично относительно моды, которая одновременно является и медианой, и имеет функцию платности вида:
/(*) =
1 с
л с*+(х-в)2
где с > о _ параметр масштаба ид — параметр центра, определяющий одновременно значения моды и медианы.
Интеграл от плотности, то есть функция распределения, задается соотношением;
F(x) = ' + — arcth-—— 2 л с
182
Глава 3. Вероятностные распределения и их
Распределение Стьюдента
Английский статистик В. Госсет, известный под псевдонимом «Стьюдент» и и: чавший свою карьеру со статистического исследования качества английского пив получил в 1908 г. следующий результат. Пусть xvxf, —.хт — независимые, (O.s? I нормально распределенные случайные величины:
<(-»)=- -&
описывается функцией:
Это распределение, известное теперь как распределение Стьюдента (крат обозначается какГ(т)-распределения,гдет—числостепенейсвобода),лежитвосно знаменитого t-критерия, предназначенного для сравни гия средних двух совокупносв
Функция плотности f/х) не зависит от дисперсии & случайных величин 5 кроме того, является унимодальной и симметричной относительно точки х — 0
Основные числовые характеристики распределения Стьюдента.
среднее, мода, медиана: ЕЦт) =хтвЛ = хягЛ = 0;
дисперсия: Dt(m) = — (существует только при т>2);
т-2
асимметрия: д =0;
определение
183
I эксцесс: Д =------- (существует только при т>4).
' из—4
t-распределенме важно в тех случаях, когда рассматриваются оценки среднего н неизвестна дисперсия выборки. В этом случае используют выборочную диспер- СИЮ и (-распределение.
При больших степенях свободы (бол ыпих 30) t-распределенис практически совпадает со стандартным нормальным распределением.
График функции плотности t-раслределсния деформируется при возрастании I числа степеней свободы следующим образом: пик увеличивается, хвосты более круто идут к 0, и кажется, будто график функпии плотности t-распределенпя сжи-I мается с боков.
F-pa определение
Рассмотрим + т2 независимых и (0, s2) нормально распределенных величин
И положим
F(mJ,m2) = т' —
Очевидно, та же самая случайная величина может быть определена н как отношение двух независимых и соответствующим образом нормированных х'-распре-Челенных величин x?(mf) и то есть
Р(т,,т2) = -^'
—/’ОМ
»1j
184
Глава 3. Вероятностные распределения и их свой<
Знаменитый английский статистик Р. Фишер в 1924 г показал, что iujoti вероятности случайной величины F(mf, т*) задается функцией:
гдеГ(^} — значение гамма-функции Эйлера в точке#, а сам закон называется F-pac пределением с числами степеней свободы числителя и знаменателя, равными секи ветственно т1 и т}.
Основные числовые характеристики F-распределения:
среднее: EF[m.,m,) = , (существует при m >2);
m2—2
(m.—2)-m, . ...
мода: . - i—!---—(для т >1);
. 2т1(т, +т, -2)
дисперсия: DF(ml,m1) =-------, , (прит(>7);
m,(m2 — 2) (т2 -4)
„ (2m. +m, -2)J8(m2 -4) . ..
астгмметрия: /?. =-------~ , (при m >6);
(fflj—6) J(m,+т2 — 2)m,
3(т2 — 6)(2 +—Д2) эксцесс: Д =-----------»---з( (прит2>Я).
F-распределение возникает в дискриминантном, регрессионном и днелереш ном анализе, а также в других видах многомерного анализа данных.
Подгонка 4 вероятности ых распределений к реальным данным
Подгонкой (английский термин fitting) называют аналитические процедуры, позволяющие подобрать распределение, которое с достаточной степенью точности описывает наблюдаемые данные. Типы различных распределений описаны выше в главе Вероятностные распределения.
Итак, имея значения переменной X, мы проверяем гипотезу, согласно которой распределение X описывается вероятностным законом F.
Одним из популярных и простых критериев согласия наблюдаемых данных с гипотезой является критерий хи-квадрат Пирсона.
Мы сформулируем этот критерий в общем виде, потому что в дальнейшем он используется в нескольких задачах: как критерий согласия, критерий однородности и критерий проверки независимости признаков в таблицах сопряженности (см. главу 11).
Итак, пусть проводится п независимых испытаний, в результате которых наблюдаются частоты (пь ... л») попарно несовместных исходов (X,,.. X*), составляющих полную группу событий, Л) + ... + ял - п. Например, вы можете представить себе, что бросаете игральную кость (кость имеет шесть граней, следовательно “ 6. исходы 1, 2, 3, 4, 5, 6 — выпадающие очки) или наблюдаете независимые реализации случайной величины, область изменения которой разбита на А>1 не-пересекаюгцихся интервалов. Обозначим вероятность появления i-ro исхода в каждом испытании через р,:
i-l,...A,p, + ..+p*- l,pf>0.
Формально статистика хи-квадрат вычисляется так:
хи-квадрат = У (л, - пр,)2/пр, м
Заметим, что иногда используют также греческое обозначение х1 для статистики хи-квадрат.
Предположим, вам нужно проверить гипотезу Нп: р - р°, где р - (рь ... рк).
Р - (р°ь ...р°к). Альтернативой является гипотеза, согласно которой эти вероят-°Сти неравны, иными словами, Ht: р* р°.
186
Глава 4. Подгонка вероятностных распределений к реальным дан>
Для проверки гипотезы Но против альтернативы Hi мы вычисляем статист, хи-квадрат при значениях р - рп(то есть при гипотезе Но). Затем, выбираем у ров, значимости а, и находим 1 — а квантиль х2 распределения с к - 1 степенью сво< ды. Обозначим данную квантиль через %2 щЬ. Тогда критическая область кр» рия Пирсона уровня а имеет вид;
Таким образом, если мы, наблюдая (nlf .. nt), получаем значение статистики jМ превышающее уровень х2 ыь то отвергаем гипотезу Нп в пользу альтернативы Ё.. в противном случае гипотезу не отвергаем.
Обычно критерий хи-квадрат используют при числе наблюдений п > 50,
И;>5,1 - 1, ... k.
Заметим, что при проверке гипотезы, согласно которой случайная величина ЯЯ имеет распределение F, вероятности р® можно вычислять но формуле: Г(Х 4 F(X, i). где [X;, X,-1), >-й интервал группировки.
Взглянув на формулу, вы легко поймете, что статистика хи-квадрат разумгq сравнивает наблюдаемые и ожидаемые частоты. Статистика принимает значенье, от нуля до бесконечности. Чем меньше значение статистики хи-квадрат, тем бо " < вероятно, что гипотеза верна, чем больше значение статистики хи-квадрат, те « меньше вероятность того, что гипотеза соответствует данным.
Итак, статистика хи-квадрат — это разумная мера согласия (соответствия) дщ. ных с гипотезой. Конечно, вы можете предложить собственную меру, напримж вместо квадрата в приведенной формуле использовать модуль или четвертую < Д пень, однако известно, что критерий Пирсона обладает свойством оптимальности
Замечательно, что выборочное распределение статистики хи-квадрат при г < потезе приближенно является распределением хи-квадрат с числом степеней св. > боды k- 1 (число интервалов группировки минус 1) и не зависят от закон.» Г Точность приближения, грубо говоря, зависит от числа наблюдений (что вполиД естественно).
Если у вас имеется много данных, объем выборки большой, вы можете считать что статистика хи-квадрат имеет в точности распределение хи-квадрат, и расе «и тать вероятность ошибки, связанной с отклонением правильной гипотезы
Тонкости применения:
О ячейки, в которых ожидаемые при гипотезе частоты меньше 5, следует об * единить (так как ухудшается качество аппроксимации распределения критериальной статистики распределением хи-квадрат);
О если проверяется параметрическая гипотеза и параметры распределена оцениваются по данным, то число степеней свободы критерия хи-квад равно k — т — 1, где т — число параметров вероятностной модели, кото, должны быть оценены по тем же данным, что и проверяемая гипотеза Я
В системе STATISTICAece необходимые вычисления и поправки на число. «Ч пеней свободы производятся автоматически.
у 1- Подгонка распределения к данным: посещение непопулярного сайта 187
пример 1. Подгонка распределения ' ранным: посещение непопулярного сайта
£ усмотрим данные о числе посетителей нераскрученного сайта
Из файла видно, что за 57 часов сайт не посетило ни одного человека (первая строка файла), за 203 часа — на сайте находился 1 человек (вторая строка), за 383 часа — 2 человека и т, д.
Спрашивается, какой вероятностный закон описывает эти данные?
Графически данные представляются в виде:
Переменная, описывающее число посетителей (переменная varl), принимает Дискретные значения.
Проведем анализ в модуле Непараметрические статистики и подгонка распределений.
Шаг 1. Откройте модуль Непараметрические статистики и подгонка распределений.
Выберите опцию Подгонка распределения.
В окне Дискретные распределения выберите распределение Пуассона (дважды Щелкните мышью).
Глава 4. Подгонка вероятностных распределений к реальным Данны»
Шаг 2. На экране появится следующее окно:
Нажмите кнопку Переменная и выберите переменную varl для анализа.
Шаг 3. Нажмите кнопку веса В, расположенную в правом верхнем углу диалогового окна Подгонка дискретных распределений.
В появившемся окне Задание веса сделайте установки, как показано на рисунв ниже; веса, в данном случае частоты, взяты из переменной var2. Нажмите ОК. За тем нажмите ОК в диалоговом окне Подгонка дискретных распределений.
имер 1- Подгонка распределения к данным: посещение непопулярного сайта 189
Шаг 4. Программа вычислят оценку параметра распределения Пауссона равную 3,864, а также представит результаты в следующих таблицах.
По уровню значимости р - 0,194 можно сделать вывод о том, что данные не противоречат гипотезе о пуассоновском распределении. Вероятность ошибиться при отклонении гипотезы довольно велика, примерно 0,2. Риск ошибиться достаточно велик!
Для построения гистограммы установите переключатель в положение Гисто-*рамма.
190 Глава 4. Подгонка вероятностных распределений к реальным дани
Нажмите кнопку' График в диалоговом окне Подгонка дискретных распре ний. На экран будет выведена гистограмма с наложенным графиком ожида пуассоновских частот.
Проверим, как согласуются другие распределения с данными. В качестве примера рассмотрим биномиальное распределение.
Шаг 1. Вновь войдите в стартовую панель модуля. Проведем для биномиалм ного распределения тот же анализ и сравним полученные результаты. В окне Распределение выберите биномиальное распределение
Шаг 3. В случае биномиального распределения также необходимо задать во наблюдениям. Нажмите кнопку веса В в правом верхнем углу диалогового ок1
1. Подгонка распределения к данным: посещение непопулярного сайта 191
-вившемся окне Задание веса сделайте установки, как показано на рисунке где веса, «данном случае частоты, взяты из переменной var2 Нажмите ОК
Затем нажмите ОК в диалоговом окне Подгонка дискретных распределений.
Щаг4. Биномиальпоераспрсдслениеимеетодинпараметр — вероятность успехар.
Программа оценит эту вероятость, используя метол максимального правдоподобия.
Оцененное значение 0,35129 появится в верхней полосе таблицы.
с 5' Обратите внимание на значение статистики хи-квадрат, число степеней в°бодЬ| и урОвель значимости в данном примере.
. Мистика хи-квадрат принимает очень большое значение, а именно 383 ^головок таблицы).
192
Глава 4. Подгонка вероятностных распределений к реальным да»
Число степеней свободы равно 8 (количество интервалов группировки один оцененный параметр).
Из заголовка таблицы также следует, что гипотезу о согласии данных с б миальным распределением можно отвергнуть на уровне 0,0000. Иными слов» отвергая гипотезу о биномиальном распределении, мы рискуем ошибиться см тически нулевой вероятностью.
Таким образом, делаем вывод: данные абсолютно не согласуются с биномщ ным распределением.
Тот же результат можно увидеть, конечно, и на графике.
Нажав кнопку График (см. окно Подгонка дискретных распределений), и остра гистограмму и график накопленных (кумулятивных) частот (выберите со<т ствующие опции в правой части окна).
Для того чтобы построить график распределения, установите переключатель в положение Кумулятивное распределение и нажмите кнопку График.
Как видите, наблюдаемые частоты далеки от ожидаемых частот.
Таким образом, биномиальное распределение не подходит для описания > •-ныхо числе посетителей нераскрученного сайта Посещения нераскрученного с» »п» по сути являются редкими событиями, и для их описания следует использоваг» пуассоновское распределение.
2. Подгонка распределения к данным: посещение популярного сайта 193
ппимер 2. Подгонка распределения Жданным: посещение популярного сайта
n leniic нескольких сотен часов регистрировалось число посетителей популяр-” '-о сайта. Результаты приведены в таблице:
Интерпретация этих данных проста: за 12 часов сайт не посетило ни одного человека (первая строка файла), за 108 часов — на сайте находился 1 человек (вторая строка), за 316 часов — 2 человека и т. д.
Графически данные представляются в следующем виде:
Переменная, описывающая число посетителей, принимает дискретные значения.
Спрашивается, какой вероятностный закон описывает эти данные?
Проведем анализ в модуле Непараметрические статистики и подгонка распре-Яелеиий.
Шаг 1. Откройте модуль Непараметрические статистики и подгонка распределений.
BbiGepinc опцию Подгонка распреоетения
194
Глава 4. Подгонка вероятностных распределений к реальным дан
В окне Декретные распределения выберите биномиальное ратреде^ (дважды щелкните мышью).
Шаг 2. На экране появится следующее окно
Нажмите кнопку Переменные и выберите переменную varl для анализа.
Ч. Скачки вверх и вниз курса акций 195
|Цат 3. Нажмите кнопку веса В в правом верхнем углу диалогового окна Под д дискретных распределений.
В появившемся окне Задание веса сделайте установки, как показано на рисунке е- веса, в данном случае частоты, взяты из переменной var? Нажмите ОК За-нажмптс ОК в диалоговом окне Подгонка дискретных распределений.
Шаг 4. Программа вычислит оценку параметра биномиального распределения I представит результаты в следующих таблицах*
1036004
309 0114 546 1903 6335527 5039236 27В 3455 105.4258
26.2047
3.8596 25KS
119230
428.242
974432
1607985
2111 90В
2390254
2495680
2521 684
2525744
2526ППЛ
416136 12.23323 21 Ч”’4 25.UBi<*6 19.94. 7 11 .11.2 417-63 1 03740
15280 Л1013
16 9 И
38 5761 636574
83 6068 94.6260
90 *’997
•W137-
9
юз ”1
4J998 69886 4.8097 "?7
16
-5 !«5 Z4258 -22047 91402
ЙСХ-Л, RF—
Значение статистики хи-квадрат очень небольшое, всего 4,16. Вспомните, что ,,р"»лыдне значения статистики хи-квадрат свидетельствуют в пользу гипотезы.
196
Глава 4. Подгонка вероятностных распределении к реальным данные
Вопрос, что такое большое и что такое небольшое значение статистики, снимается понятием уровня значимости.
По уровню значимости р — 0,7612366 окончательно заключаем, что данные «и, рошо согласуются с гипотезой о биномиальном распределении.
Мы настоятельно рекомендуем вам еще раз прочитать ту часть главы Элеме»* тарные понятия, где обсуждается понятие статистического критерия.
Проиллюстрируем приведенные выше таблицы графиком кумулятивного ра пределения. Для этого установите переключатель в положение Кумулятивное ра пределение и нажмите кнопку График.
Для получения простой гистограммы установите переключатель в положение Гистограмма.
Нажмите кнопку График в диалоговом окне Подгонка дискретных распределений. На экране появится гистограмма наблюдаемых частот с наложенным графиком ожидаемых частот.
В качестве легкого упражнения мы рекомендуем вам попробовать подогнав пуассоновское распределение к чанным о числе посетите чей популярного сайт*.
4. Количество покупок в магазине
197
Пример 3. Скачки вверх и вниз курса акций
. же показан фрагмент файла, содержащего колебания курса акции в течение дня ^Единица показывает, что курс вошел вверх (скачок вверх), 0 — курс акций по-вниз (скачок вниз)
В течение дня таких скачков может быть несколько сотен, выдвигается гипоте-что частота тех и Других скачков одинакова. Как быстро проверить-эту гипотезу ^системе STATISTICA?
Выделите данные и вызовите Быстрые основные статистики... Вы увидите следующую таблицу результатов:
Точечная оценка частоты появления 1 равна 0,39,95% доверительный интервал- (0,292732,0,487268). Следовательно, гипотеза о том, что частота скачков уровня вверх и вниз одинакова, должна быть отвергнута.
Пример 4. Количество покупок в магазине
Ниже показан файл с информацией о числе покупателей разной категории в супермаркете
198
Глава 4. Подгонка вероятностных распределений к реальным данг
Мы разбили покупателей на классы по числу сделанных покупок
К категории 0 относятся покупатели, сделавшие не более 4 покупок, к категцЗ рпи 1 — покупатели, сделавшие5-6 покупок к категории 2 — покупатели, сделки^, шие 7-8 покупок, и т. д.
Найдем вероятностный закон, который описывает эти данные. Вы можете псц готовить файл данных и повторить за нами все действия
Шаг 1. Откройте модуль Непараметрические статистики и подгонка распределений/
Выберите опцию Подг<тка распределения. В окне Дискретные распределения выберите геометрическое распределение (дважды щелкните на его названии мышью).
Шаг 2. На экране появится следующее окно:
Нажмите кнопку Переменные и выберите переменную КЛТЕГОР для анализа
Шаг 3. Нажмите кнопку веса В в правом верхнем углу диалогового окна Подгонка дискретных распределений.
В появившемся окне Задание веса сделайте установки, как показано на рисунке ниже; веса (в данном случае — частоты) взяты из переменной ЧИСЛИ-
5. подгонка распределения Вейбулла к данным об отказах
199
щте ОК. Затем нажмите ОК в диалоговом окне Подгонка дискретных растений.
Шаг 4. Ст итема вычислит оценку параметра геометрического распределения н представиг результаты в следующих таблицах.
Глава 4. Подгонка вероятностных распределений к реальным данным
По уровню значимости р = 0,4959796 можно сделать вывод, что данные сов стимы с гипотезой о геометрическом распределении.
Иными словами, наш риск ошибиться составляет примерно 50%, если мы оу, вергаем гипотезу.
Визуально качество подгонки можно увидеть на графике
Нажмите кнопку График, и следующая гистограмма появится па экране-
Вы можете попробовать другие распределения дня описания этих данных и y6i диться, что они очень плохо подходят к ним
Итак, геометрическое распределение вполне адекватно описывает число пою пателей разных категорий в супермаркете.
Пример 5. Подгонка распределения Вейбулла к данным об отказах
Одним из основных понятий качества продукции является ес надежность. Для оценки надежности и времени жизни разработаны различные статистич* • ские методы
Надежность продукции является важным показателем качества, Покупая ма1 • нитофон, пылесос, кофеварку, вы, конечно, хотите иметь представление об их н* дежности. Особенный интерес представляет количественная оценка надежности, позволяющая оценить ожидаемое время жизни, или, в инженерных терминах, вр( мя безотказной работы купленного прибора
Надежность связана с маркетинговой политикой, зная оценки надежности пре даваемых вами бытовых приборов и объемы продаж, вы можете рассчитать ко.~« чество гарантийных мастерских в городе.
Пример из другой области позволяет по-иному взглянуть на ту же ситуации Предположим, вы летите на маленьком личном самолете с единственным двигате -лем. Тогда для вас жизненно важно знать вероятность отказа двигателя на раз i »«»• ных этапах его эксплуатации (например, после 500 часов, после 1000 часов и т. l 1 Очевидно, имея хорошую оценку надежности двигателя и доверительный интер-
iep 5 Подгонка распределения Вейбулла к данным об отказах
201
можно принять рациональное решение о том, когда следует заменить двпга-,#Л или отправить его на капитальный ремонт. Конечно, вы можете положиться * и'олю случая и летать, сколько угодно, однако цель нашей книги — научить вас еапнонально анализировать случайность
™ Обычно времена жизни описываются распределением Вейбулла (см. предыду-гую гчавч). поэтому одним из основных этапов статистических процедур, связан-‘ х с оценкой надежности, является оценка параметров этого распределения.
Для большинства исследуемых приборов функция интенсивности отказов имеет форму и образной кривой: на ранней стадии жизни изделия риск выхода из строя (отказ) достаточно велик, далее интенсивность отказов уменьшается до определенного предела (оптимальный режим функционирования), затем вновь увеличи
вается из-за износа изделия.
! Например, автомобили в начале эксплуатации часто имеют несколько мелких I дефектов и выходят из строя. После того как автомобиль прошел обкатку, риск поломки существенно уменьшается. Затем интенсивность отказов (выходов из ыроя) возрастает, достигая своего максимального значения, например, после 20 лет иссплуаташш и 250 000 миль пробега, когда практически люйой автомобиль вы-
водит из строя.
Распределение Вейбулла позволяет гибко моделировать возникающие на прак-I |Икс функции интенсивности отказов.
Задавая разные параметры распределения, можно получить практически любые функции риска.
Ранняя фаза кривой аппроксимируется распределением Вейбулла с параметром формы меньше 1, постоянная фаза — распределением Вейбулла с параметром формы 1. а фаза старения или износа моделируется распределением Вейбулла с параметром формы больше 1.
После того как на основе реальных данных оценены параметры распределения Вейбулча, можно вычислить раз яичные характеристики надежности, например, когда откажет заданная доля тестируемых приборов
Функция надежности, обычно обозначаемая R(l), представляет собой вероятность того, что объект проживет больше t временных единиц
Формально функция надежности определяется равенством R(t)=1—F(t), где F — функция распределения времени жизни Иногда функция надежности называется также функцией выживания.
Цензурирование. В большинстве исследований по надежности не все объекты завершаются отказами. Иными словами, к концу исследования известно, что определенное количество приборов нс отказало, по исследование завершено и точные времена жизни этих приборов неизвестны. Такне наблюдения называют-' я неполными. или цензурированными. Заметим, что цензурирование может осуществляться разными способами, так же как имеется много различных планов •естирования приборов.
Например, так называемое цензурирование tnm I применяется в ситуации, ко-,ча заранее фиксируется время наблюдения отказов (допустим, мы берем 100 ламп ° оканчцвасм эксперимент, например, после 120 часов после начала).
। В этом случае время эксперимента фиксировано, и число отказавших (перего-
Рсвших) ламп представляет собой случайную величину.
202
Глава 4. Подгонка вероятностных распределений к реальным дан>
При цензурировании типа II заранее определяется доля отказов, но время iufl блюдения не ограничивается (например, мы проводим эксперимент, пока не выедут из строя 50°« компьютеров при данных критических условиях). Очевидно, чЛ при таком подходе время, в течение которого проводится эксперимент, являет» случайной величиной.
Можно задать также направление цензурирования. При испытании комплот J ров или ламп цензурирование происходит в правом направлении по временной оси {правое цензурирование'), потому что исследователь точно фиксирует начали, эксперимента и знает, что нсотказавшие компьютеры будут еще жить некотор^-время после окончания эксперимента. Другой вариант возникает, когда исследователю неизвестно начало времени жизни объекта, например врачу известен м». мент поступления пациента в госпиталь с данным диагнозом, но неизвестен м». мент, когда данный диагноз был поставлен, и тем более неизвестно, когда болезцк! началась. Такое цензурирование называется левым
Конечно, если тестируются старые компьютеры пли мониторы, то это тоже прц мер левого цензурирования, так как не известен момент начала их эксплуатации 4
Наконец, возможны ситуации, в которых цензурирование происходит в ра.» личные моменты времени {многократное цензурирование) пли только в один ми мент времени {однократное цензурирование).
Возвращаясь к эксперименту с тестированием компьют еров в экстремальные условиях, заметим, что если эксперимент заканчивается в определенный момег времени, то мы имеем однократное цензурирование.
Конечно, имеются нетривиальные ситуации, например, данные, собранные директором фирмы по продаже подержанных копировальных аппаратов. Балансы* руя между необходимостью продаж и выдачей гарантий покупателю, ему следует рационально организовать процесс продаж.
Рассмотрим, как оцениваются параметры распределения Вейбулла в системе STATISTICA при простейшем правом однократном цензурировании. Данные С(Н держатся в файле Dodson25.sta
Сам TIME Cf jjrtjur
а
9 io п
14
15
1*
1
19
20
42 1
I 8 83 3 па 7
111 I яь.|
1,« 1* 9 151 3
IP i VM 1 •«.6 £Vf 0 П5 3
Сег «red Carpi t >е Срг
Cut
Сопере
Crr-
Carplete Carpi ete
Centred Carplete Carpi ete Centred Cen - jd Censored Carplete Cent*- *d Complete Censored
5
6
5 Подгонка распределения Вейбулла к данным об отказах
203
Запустите модуль Анализ процессов и повторите вслед за нами наши действия
Шаг 1. Откройте файл Dod.son25.sta. затем выберите Л нализ Вейбулла... на стартовой панели
204
Глава 4. Подгонка вероятностных г зспределений к реальным данг
Рассмотрим опции окна.
Тип анализа.
Исходные данные — используйте этот диалог. если вы анализируете исходные времена отказов с цензурированием или без него.
Группированные данные — используйте диалог для исследования агрепфо. ванных или табулированных времен отказав, например таблиц жизни
Распределение Вейбулла, вероятностный график — открывается диалогов > окно, в котором вы можете построить вероятностный график распределения Be булла, аналогичный нормальному вероятностному графику (графику на норма»*, ной вероятностной бумаге в старой терминологии).
В данном примере используйте анализ исходных данных.
Времена отказов — эта опция выбирается в том случае, когда данные содержа! действительные времена отказов.
Единственная переменная для времен отказов (жизни), переменные с началом и кондом, переменные с датами опция выбирается в тех случаях, когда данные содержат даты с началом или концом каждого наблюдения. Из файла данных программа вычислит разность между временем конца и временем начала, чтобы получить чистые времена отказов для каждого наблюдения, и затем подгонит к ним распределение Вейбулла.
Если выбран Список переменных с временами, программа ожидает ввода одной
или нескольких переменных с временами отказов и дополнительного ввода индикатора цензурирования (группирующей) переменной, которая позволяет определить, какие времена полные, а какие цензурированы.
Если выбрана опция Одна t отказов, две (начало и конец) или шесть (даты), то вы можете в первом списке переменных. I) выбрать одну переменную с временами отказов. 2) выбрать две переменные с временами начала и конца (наблюдения объекта), 3) выбрать 6 переменных, которые также будут рассматриваться как времена начала и конца (как и в случае 2 выше). Эти 6 переменных рассматриваются как месяц, день, год начала и как месяц, день, год окончания испытания.
Выберите переменные для анализа, цензурирующие переменные (индикаторы цензурирования) и коды. Затем нажмите ОК; по умолчанию программа вычислит оценки максимального правдоподобия параметров для двухпараметического рас. пределения Вейбулла и перейдет в диалоговое окно Результаты анализа Бейбу. ла. Заметим, что если оценки максимального правдоподобия нс существуют, пр г цедура использует О, 1, 1 для оценки параметров положения, формы и масшта(« соответственно.
Близкие процедуры содержатся в модуле Анализ выживаемости-, для нецент рированных или полных данных можно использовать визуальные методы граф)»* ки Квантиль-квантиль и Вероятность-вероятность (см. главу Визуальные меть ды анализа).
Выберите переменную Time, содержащую времена отказов и переменную Сеп индикатор цензурирования.
Эта переменная содержит два значения, показывающие, полностью или нет •* блюдались изделия до момента отказа. Заметим, что такая ситуация (наличие да V типов наблюдений) отличается от той, с которой мы имели дело в модуле иеяи
! 5. Подгонка распределения Вейбулла к данным об отказах
205
В —праческце статистики. Точно с такими же типами наблюдений мы имеем * 1О в модуле анализ выживаемости
Коды для полных и цензурированных наблюдений.
Г Эта опция доступна, если выбран индикатор цензурирования. Определите коды ,1ли текстовые значения для полных (нецензурированных) и неполных (цензури-(юванных ) наблюдений. Чтобы просмотреть все коды соответствующей переменяй. дважды щелкните на поле ввода Первые два различных значения, обнаруженных в индикаторе цензурирования, используются по умолчанию как коды для
(очных и цензурированных данных соответственно.
Выберите Complete для полных времен и Censored для цензурированных времен Нажмите ОК, чтобы начать анализ.
Опция: Прибавить пост, к пулевым t отказов/цензур. значениям.
Распределение Вейбулла ограничено слева, это означает, что все значения выборки должны быть больше параметра положения, по умолчанию равного 0. Если (пиия выбрана, программа перед подгонкой или построением графика заменит нулевые времена отказов константой из поля. Если опция нс выбрана, все наблюдения нулевыми временами отказов исключаются из анализа (рассматриваются как про-аушепные данные).
Шаг 2. По умолчанию программа вычислит оценки максимального правдопо-
добия для двухпараметрического распределения Вейбулла, предполагая, что параметр положения равен 0. В окне Результаты анализа эти оценки можно увидеть в
зоне Значения/оценки текущих параметров.
206
Глава 4. Подгонка вероятностных распределений к реальным данным
Оценки параметров. Окно результатов позволяет интерактивно провести подгонку к данным распределения Вейбу чла с различными параметрами.
После того как вы нажмете кнопку Форма & масштаб, программа считает текущее значение параметра положения и вычислит оценки максимального правдоподобия параметров формы и масштаба.
Если вы нажмете кнопку Форма, масштаб, положение, программа вычислит оценки максимального правдоподобия для трехпараметрического семейства. В любом случае оценки будут отображены в полях значения/оценки текущих параметров.
Шаг 3. Просмотр результатов. Все опции, доступные в окне результатов на текущих значениях параметров, указаны в полях значения/оценки текущих параметров независимо от того, определены эти параметры пользователем или оценены программой (например, методом максимального правдоподобия). Однако стандартные ошибки функции надежности можно вычислить только для оценок максимального правдоподобия.
Оценки максимального правдоподобия двухпараметрического распределения Вейбулла равны 3,034 и 216,9 для параметров формы и масштаба (см рисунок).
Вы можете сравнить эти оценки с оценками, построенными с помощью графиков: выберите опцию Непараметрические в рамке Дов. интервалы (нижний левый угол). Тогда все графики будут построены на основе непараметрических (ранговых) оценок функции распределения F(t), и результирующий график может быть использован для оценки параметров распределения Вейбулла. Нажмите кнопку График распределения и постройте график.
Этот график показывает наблюдаемые времена отказов, линейную подгонку » 95%-й непараметрический доверительный интервал функции надежности (более точно, log-log-преобразование; доверительный интервал показан прерывистой линией).
Оценки параметров форыы и масштаба вычисляются из коэффициента наклона и свободного члена линейной подгонки: параметр формы равен коэффициенту наклона, параметр масштаба оценивается как exp(-intercept/s!ope)
5. Подгонка распределения Вейбулла к данным об отказах
207
Эти оценки параметров очень близки к оценкам максимального працдоподо-бия Так как точки достаточно точно ложатся на прямую, мы можем поверить, чтс распределение Вейбулла с оцененными параметрами вполне адекватно данным.
Нажмите кнопку Функция надежности и доверительные интервалы, и вы уви дите результаты в численном виде.
Критерии согласия. Если вы нажмете кнопку Критерии согласия, то увидит* таблицу со статистиками Холлеидера—Прошана или Майна—Шойера -Фертиг и их уровнями значимости.
Критерий Холлеидера-Прошана. Этот критерий сравнивает 1еорстическут функцию надежности с оценкой Каштана—Мейера. Точные формулы вычислени достаточно сложны. Критерий Холлеидера—Прошана применяется к полным, од некратно цензурированным и многократно цензурированным данным, одна» имеет место недостаток этого критерия в некоторых случаях, например , когда дан пые сильно цензурированы. STATISTICA вычис тяет значение критериальной ста тистики и двухсторонний уровень значимости р.
Критерий Манна—Шойера—Фсртига. Критерий был предложен Манном Шойером, Фертигом в 1973 г.
Нулевая гипотеза состоит в том, что данные имеют распределение Вейбулла оцененными параметрами. Нельсон (см.: Nelson (1982) Appl ied life data analysis. Ne\ York: Wiley) отмечает большую мощность этого критерия. Критические значенн вычислены методом Монте Карло и табулированы для объемов выборки от 3 л* 25; для больших объемов выборок критерий не применяется
208
Глава 4. Подгонка вероятностных распределений к реальным даннью
Шаг 4. Оценки параметра положения. Хотя подгонка двухпараметричесх^Л распределения Вейбулла кажется очень хорошей, предположим, что у вас имемВ ся некоторые доводы в пользу того, что параметр положения больше 0. Иныщц словами, вы уверены, что имеется интервал, в течение которого вероятности от L-зов нет. Оценим этот параметр положения. Нажмите кнопку R-квадрат и параметр положения. Этот график показывает зависимость коэффициента детермин*, ции R-кеадрат от параметра положения
Далее нажмите кнопку Форма, масштаб, положение, чтобы вычислить оценю» максимального правдоподобия для трехпараметрического распределения Вей* и.
Для этих данных лучше применять более простую двухпараметрическую мД дель с параметром положения, равным 0.
Шаг 5. Процентили и доверительные интервалы. Нажмите кнопку Процентили и доверительный интервал, чтобы построить таблицу с процентными точками функции надежности.
5 Подгонка распределения Вейбулла к данным об отказах
209
К жиг процентили с приращением 1%; 1,2,3,4 и т. д.
>лину, вы увидите, например, что оценка медианы равна 192,2, ный интервал имеет границы от 154,9996 до 238,437
ми, можно ожидать, что 50% отказов происходит до момента вре-ютветствующим доверительным интервалом).
5
Двумерный визуальный анализ данных
Двумерный, сокращении — 2М визуальный анализ, — это визуальный анализ д, пых на плоскости. В двумерном визуальном анализе используются разнообрази гистограммы, диаграммы рассеяния, вероятностные графики, линейные графц( диаграммы диапазонов, размахов, круговые диаграммы, столбчатые диаграмм последовательные графики (графики последовательных значений) и т. д„ поз1 лякицие увидеть специфику данных.
Гистограммы
Термин гистограмма ввел Карл Пирсон в 1895 году. Гистограммы позвол» увидеть, как распределены значения переменных по интервалам групинрО! то есть как часто переменные принимают значения из различных интервалов.
Особенно полезен этот график для большого числа наблюдений, например62
211
Т^пограмма наглядно показывает, какие значения или диапазоны значений ис-‘ р переменной являются наиболее частыми, насколько сильно они разли-* гея между собой, как сконцентрировано большинство наблюдений вокругсред-Ьявляется распределение симметричным ил в нет, имеет ли оно одну моду или «олько мод, то сеть является мультимодальным.
На простой люгограммс отображаются частоты значений одной переменной, а на тавной можно отобразить одновременно частоты нескольких переменных.
Например, показанная ниже составная гистограмма позволяет увидеть, как ме-_^гся соотношение между покупками мяса и колбасы в супермаркете. Из нее так-Jce видно, что доля колбас и мяса в дорогих покупках (на сумму более 300 рублей)
пшмальна.
Гистограмм! покупок магакино
Изменяя интервал группировки, можно провести более точную сегментацию рынка.
212
Глава 5. Двумерный визуальный анализ дан
С помощью гистограмм можно проверить наличие у распределения тяже хвостов, что важно для актуарных расчетов.
Г истограммы дают возможность визуально оценить сходство наблюдаемых] пределений с теоретическими или ожидаемыми распределениями
Гистограмма, или распределение частот значений переменной по мнтервю представляет интерес по следующим причинам:
о по форме распределения можно охарактеризовать природу исследуемой I ременной (например, наличие двух мод — наиболее высоких столбцов п тограммы, или, как говорят, бимодальность распределения может санам! что выборка неоднородна и состоит из наблюдений, принадлежащих дт различным генеральным совокупностям):
О многие статистики критериев основаны на определенных предположен! о виде распределения, например, на предположении нормальности: пн граммы помогают визуально проверить выполнение этих предположена!
Часто первый шаг визуального анализа нового множества данных состоит в строении гистограмм для всех переменных. При этом выбираются различи» величине интервалы группировки.
Гистограммы и описательные статистики
Хотя некоторые (числовые) описательные статистики легче воспринимать в» таблиц, общую форму распределения значений переменной лучше исследо» графике.
213
Ьнк дает качественную информацию о распределении, которая не может ^полностью выражена какпм-то одним численным показателем.
‘ Vj пример- обшее асимметричное распределение дохода может показывать, что UIHHCTBO людей имеют доход, находящийся гораздо ближе к минимальному, ESiH к максимальному значению.
Хотя эта информация содержится в коэффициенте асимметрии, ее легче полть И запомнить визуально.
ее:
2 toe
I la гистограммах также мопп быть заметны «провалы*, которые несут важную информацию о социальном расслоении группы покупателей или об аномалиях распределения дохода, вызванных, например, недавней налоговой реформой.
Часто гистограммы применяются в маркетинге для сегментации рынка
Группировка
Все окна Статистические графики системы STATISTICA, позволяющие строить гистограммы, содержат стандартный набор методов задания при построении гистограмм интервалов группировки. Диапазон значений переменной разбивается на i интервалы (если переменная непрерывная) или категории (если переменная категориальная ), для которых подсчитываются частоты, изображаемые в виде отдельных столбцов.
Д14 Глава 5. Двумерный визуальный анализ да,
Например, можно построить гистограмму, на которой каждый столбец Л соответствовать интервалу из 10 единиц шкалы, используемой для представлю переменной. Если минимальное значение равно О. а максимальное — 120, то & создано 12 столбцов. Кроме того, можно сделать так, чтобы весь диапазон зн, ний переменной был разделен на указанное число интервалов равной длины i пример, 10); в последнем случае, если минимальное значение равно О, а ми мальное — 120, каждый интервал будет равен 12 единицам шкалы. Можно выб| и более сложный метод группировки. Например, можно применить неравные । пазоны с заданными пользователем границами, чтобы создать более понятные апазопы или объединить выброс и увеличить читаемость средней части гис граммы. Диапазоны можно также создать, определив критерии включени исключения с помощью логических операторов (например, первый столбец । тограммы может представлять людей, которые за последний год летали на сам( те более 10 раз и не более 50% этих поездок связано с бизнесом и т. д.).
Пример. Продвинутые возможности для визуализации группировки имек в модуле Основные статистики и таблицы (см. диалоговое окно Таблицы наспи
Шаг 1. Запустите модуль Основные статистики и таблицы. Откройте ф данных adstudy sta из папки Examples. Внесите в этот файл следующие измене! в пятой, седьмой и двенадцатой строке введите повое значение SPRITE в п< мепную ADVERT (см. рисунок).
Теперь эта переменная принимает 3 значения: PEPSI, СОКЕ, SPRITE.
Шаг2. В стартовой панели выберите диалог Таблицы частот и нажмите кног
Шаг 3. В диалоговом окне Таблицы частот нажмите кнопку Переменные| берите первые 3 переменные из файла данных.
215
jjj 4 Выберите опцию Заданные группирующие коды и нажмите кнопку ря-р с ней-
Шаг 5. В появившемся диалоговом окне выберите те значения переменных, которые вы хотели бы отобразить на гистограммах. Сделайте это, например, так, как «казано на рисунке
Шаг 6. Сделав выбор, нажмите кнопку ОК в окне Коды для выбранных переменных.
После этого вы вернетесь в диалоговое окно Таблицы частот.
Шаг 7. В диалоговом окне Таблицы частот нажмите кнопку Гистограммы.
Вы увидите появляющиеся одну за одной гистограммы на вашем экране. Обратите внимание, что на графике отбражаются не все значения переменных, а только Те что выбраны вами.
216
Права 5. Двумерный визуальный анализ да
КПЗ
Подгонка теоретических распределений к наблюдаемым распределениям
STATISTICA позволяет сравнивать распределение наблюдаемых данных с р делениями: нормальное, бета-экспоненциальное, экстремальное, гамма- гео» ческое, Лапласа, логистическое, логнормальное, Пуассона. Ренея. Вейбулла.
веских распределений к наблюдаемым распределениям
217
[Д простые гистограммы
Простые гистограммы является обычными столбчатыми графиками распределений частот выбранной переменной.
Д Составные гистограммы
Составные гистограммы представляют распределения частот для нескольких не ременных на одном графике. Значения переменных откладываются по единой оси X, что облегчает визуальное сравнение распределения переменных,
На составных гистограммах переменные представлены примыкающими - Руг к Друг,' столбцами; поэтому для каждой категории строится несколько столбов. Следовательно, подогнанные кривые могут либо точно подходить к соответ-
Ующим им гистограммам, либо быть сравнимыми друг с другом.
® истограммы с двойной осью Y
истограмму с двойной осью У можно рассматривать как комбинацию двух состав-г ? рамм. Можно выбрать два списка переменных Будет построено распре-
218 Глава 5. Двумерный визуальный анализ
деление частот для каждом выбранной переменной, но частоты переменны денных в первый список (Левая ось У), будут откладываться но левой оси время как частоты переменных, введенных во второй список (Правая ось У правой оси Y.
Имена всех переменных из двух списков будутвключены в условные обозн; ния, сопровождаемые буквой Л или П, обозначающей левую или правую ось У ответственно. Этот график полезен для визуального сравнения распределений ременных с разными частотами.
Висячие столбцы
Гистограмма висячих столбцов является изысканным визуальным способом
верки нормальности распределения переменной, который помогает наглядно рсдслить области, где возникают расхождения между наблюдаемыми и норм:
ными частотами
В отличие от обычного способа наложения на гистограмму нормальной вой, гистограмма висячих столбдов предлагает альтернативный способ. I столбцы, представляющие наблюдаемые частоты для последовательны* л, эонов значении, * подвешиваются» к нормальной кривой Если исследуемо! предсление приближенно нормальное, то нижние стороны подвешенных п{ угольников ложатся на одну прямую.
(ны рассеяния
219
Пересекающиеся категории
_еме STATISTICA можно задать логические условия выделения подгрупп, ально могут возникнуть пересекающиеся подмножества (одно и то же па-л-идепне попадает в разные группы).
°" ,-щнако действует следующее правило: каждое наблюдение будет помещено 0 в одну подгруппу, а именно в первую из тех, условиям которой оно удов-° „оряет. Поэтому наборы подгрупп (категорий), создаваемые по таким прави-не будут пересекаться ни при каких условиях. Например, если к подгруппе 1
Кожества опрошенных отнесены мужчины, а к подгруппе 2 — опрошенные старее 30 лет, то полученная подгруппа 2 будет содержать только женщин (старше ЭД лет), так как вес мужчины окажутся в подгруппе 1
, Диаграммы рассеяния
| Двумерные диаграммы рассеяния используются для визуального исследования за-
висимости между двумя переменными X и Y(например, весом и ростом человека, рисламой и объемом продаж и т. д.)
220
Глава 5. Двумерный визуальный анализ дан
Данные изображаются точками в двумерном пространстве. Две координат и 1). которые определяют положение каждой точки, соответствуют значениям переменных. Если переменные сильно связаны, то множество точек данных п ннмает определенную форму (например, ложится на прямую линию или крив задаваемую определенным уравнением), как показано н иже на рисунке. '
Подгонка функций к диаграммам рассеяния помогает увидеть зависимо между переменными.
Если переменные не связаны, то точки образуют «облако рассеяния» (см. ниж
1НОСГЬ распределений двух ne^ejjHyx (фо|?мы зависимостей)
221
лпнороДность распределений двух „епеменных (формы зависимостей)
агРаммы рассеяния обычно используются для визуального исследования зави-ИОС.ТН двух переменных (например, кровяного давления и уровня холестерина), рольку ОНИ предоставляют больше информации, чем простое значение коэффициента корреляции.
рНапример, отсутствие однородности в выборке, для которой была подсчитана овеляция, может исказить значение коэффициента корреляции.
Предположим, вычисления производились для данных из различных экспериментальных групп, но этот факт не был учтен, то есть группировка не проводи-jacb. Можно предположить, что экспериментальные действия в одной из групп увеличили значения обеих коррелированных переменных, и таким образом, данные из каждой группы образуют отдельное «облако» на диаграмме рассеяния (как указано на рисунке ниже).
В этом примере высокая корреляция обусловлена наличием двух групп и не отражает действительный характер связи (точнее, ее отсутствие) между перемен-1ЫМИ-
При наличии определенных предположений о структуре данных и информации, а также о возможном способе разделения на группы попробуйте рассчитать корреляции отдельно для каждого подмножества наблюдений или используйте В Кап№горизованную диаграмму рассеяния.
Другой проблемой, которая может быть исследована на диаграммах рассеяния, является нелинейность. Для исследования нелинейной зависимости между пере-“-иным и не существует «автоматических* или простых в употреблении методов.
Коэфф|щ11ент корреляции Пирсона оценивает только линейные зависимости чменно цо этой причине часто называется линейным; некоторые непараметри-критерии, такие как коэффициент корреляции Спирмена R, могут оцени-’ нелинейную зависимость, по только монотонную.
, сс и 'ювание диаграмм рассеяния позволяет определять формы зависимостей, jpj л Ы пот°м можно было выбрать подходящий тип преобразования данных для * чинеаризации* ил н выбора подходящего нелинейного уравнения подгоню! (на-[ ,МеР- вместо пшенной зависимости использовать полиномиальную).
222
Глава 5. Двумерный визуальный анализ
Выбросы
Другое важное преимущество диаграмм рассеяния состоите том, что они поз ют находить «выбросы» (нетипичные данные), которые искусственным об] увеличивают или уменьшают («смещают») коэффициент корреляции.
Даже один выброс может значительно увеличить коэффициент коррел между двумя переменными. Диаграмма рассеяния позволяет обнаруживать аномалии.
Например, корреляция между двумя переменными на рисунке была бы 61 к 0 при отсутствии выброса. Наличие этого выброса «искусственно» увели значение корреляции
Средство Кисть позволяет интерактивно удалять выбросы и непосред наблюдать за изменением аппроксимирующей функции ил и линии регре<
["?] Простые диаграммы рассеяния
Простая диаграмма рассеяния визуализирует зависимость между двумя и ными X и Y(например, весом и высотой). Данные изображаются точками в, ном пространстве, где оси соответствуют переменным
223
Две координаты (X и )), которые определяют положение каждой точки, соот-вгствуют значениям двух переменных Если переменные сильно связапы, то мно-»»ство точек данных принимает определенную форму (например, прямой линии *пи кривой)- Если связи нет, то точки образуют «облако».
[ g Составные диаграммы рассеяния
В отличие от простой диаграммы рассеяния, на которой одна переменная представлена по горизонтальной, а вторая — по вертикальной оси, составная диаграмма рассеяния включает несколько зависимостей: значения одной переменной (X) откладываются по горизонтальной оси, а по вертикальной оси откладываются значения нескольких переменных (У)- Для каждой переменной Y используется раз-ши цвет и вид точек.
Диаграмма рассеяния составного типа используется для сравнения структуры
Кольких корреляционных зависимостей путем изображения их па одном гра-Рчке в одном масштабе.
Циаграммы рассеяния с двойной осью Y
грамму рассеяния такого типа можно рассматривать как комбинацию двух со-’’“^Диаграмм рассеяния для одной переменной X и двух различных множеств енных К Для независимой переменной X и каждой из переменных Yстроится Рамма рассеяния, но переменные из первого списка (называемого Левая ось F)
224
Глава 5. Двумерный визуальный анализ дд<
откладываются по левой оси Y, тогда как переменные из второго сл иска (назы мого Правая ось Y) откладываются по правой оси Y. На каждой из осей мо выбрать свой масштаб.
Имена всех переменных Y из двух списков будут включены в условные < значения, сопровождаемые буквой (Л) или (П). обозначающей левую или прг ось Y соответственно.
Диаграммы рассеяния с двойной осью Y можно использовать для визуалы сравнения структуры нескольких корреляционных зависимостей путем из» жения их на одном графике. При этом в силу независимости масштабов, испац емых для двух списков переменных, этот график облегчает сравнение перец ных, значения которых принадлежат разным диапазонам.
[-/’I Частоты
Эта диаграмма рассеяния позволяет наглядно изобразить частоты перекрываюи ся точек для двух переменных, чтобы наглядно представить веса различных то1 Если для одного значения переменной X имеется несколько значений пера ной Y, то возникает необходимость использовать подобные диаграммы рассеян Подсчитываются и группируются частоты перекрывающихся точек. Размеры I керов точек на графике соответствуют значениям частот.
- 1 нЛл^одвиие
• L7
» В-10 кЛлюдвчий
с -16 наСдюкиий .
”-5 О 5 10 IS 20 И 30 35 40 ’’ • ’6 «йнипий '
225
чтили
311ках квантилей изображается зависимость между квантилями двух пере-К|Х позволяющая визуально оценить сходство эмпирических распределений I jofl переменной.
Если точки данных ложатся на линию регрессии, то можно сделать вывод, что две переменные имеют одинаковое распределение
^Диаграмма Вороного
Jra особая диаграмма рассеяния одной переменной является в большей степени шалитическим средством, нежели просто методом графического представления данных. Пространство разделяется на области точек, максимально близких к наблюдаемым точкам, иными словами можно сказать, что строятся зоны влияния точек.
226
Глава 5. Двумерный визуальный анализ дан»
Обратите внимание, что на изображенной выше диаграмме оси одннакь масштабированы (минимум - 0, максимум - 10) и пропорции диаграммы таков» что обе оси имеют приблизительно одинаковую длину. Разбиения для мозаично диаграммы Вороного будут рассчитаны в предположении равных длин (и маски-бов) осей;такнм образом, пропорции диаграммы и масштабирование по умолчан» (например, автоматическое) могут привести к искаженной мозаичной диаграмм Вороного.
Способы использования этого метода сильно зависят от областей исследовз ния, однако во многих случаях к этой диаграмме полезно добавлять допел нители ные измерения, используя категоризацию и выбор сложных подгрупп.
Диаграммы рассеяния с гистограммами
Этот тип статистических графиков представляет собой составной график с зави снмостью между двумя переменными и распределениями частот для каждой пере меиной.
График состоит из простой диаграммы рассеяния двух заданных перемени! (X и У) и гистограмм распределений частот для переменных X if Y, изображенHt соответственно вдоль осей X и Y диаграммы рассеяния.
Диаграммы рассеяния с диаграммами размаха
Этот тип статистических графиков представляет собой составной график с завн снмостью между двумя переменными и распределениями значений каждой изгУ • выборок (включая выбросы и экстремальные значения). Такой график особен полезен при проверке по указанному пользователем критерию, являются ли • дельные точки данных выбросами или экстремальными значениями и можно W их удалить из выборки. График состоит из простой диаграммы рассеяния двух I **" занных переменных (X и У) и диаграмм размаха для переменных X и У, иэобр" женных соответственно вдоль осей Хи У диаграммы рассеяния.
т йме вероятностные графики
Нормальные вероятностные графики
Эти графики позволяют визуально исследовать, насколько распределение данных близко к нормальному.
Нормальный вероятностный график
Стандартный нормальный вероятностный график строится следующим образом. Сначала все значения переменной ранжируются. По рангам рассчитываются ^-значения (значения стандартного нормального распределения) в предположе-нми. Значение z для j-ro ранга переменной с N наблюдениями вычисляется по формуле:
z. - F-‘[(3 хj-l)/(3 х N+1)],
ГДе^ это обратная функция стандартного нормального распределения (преобразовывающая нормальную вероятностьр в нормальное значение z).
Значения z откладываются по оси Y, наблюдения — по оси X. Если наблюдае-п ‘'Значения распределены нормально, то все значения на графике должны по-•«1 °РЯМ-™ линию. Если значения не являются нормально распредсленны-> то оудет наблюдаться отклонение от прямой.
228 Глава 5. Двумерный визуальный анализ дань
На этом графике можно визуально обнаружить выбросы.
Если наблюдается очевидное несовпадение и данные располагаются отн сительно линии определенным образом (например, в виде буквы 5), то пер, применением статистических методов, для которых существенное значение име нормальность распределения, необходимо каким-то образом преобразовать пер менные (например, логарифмическое преобразование часто используется для тог чтобы «втянуть» конец распределения).
Полунормальный вероятностный график
Полуформальный вероятностный график строится тем же образом, что и стан дар ный нормальный вероятностный график, с тем отличием, что рассматривается л>п положительная часть нормальной кривой. Следовательно, по оси У будут отм дываться только положительные нормальные значения. В частности, полунормал ное вероятностное значение г. для /то упорядоченного значения (ранга) перем г ной с N наблюдениями вычисляется так:
г = F'[(3e х N+3 х j-l)/(6 х W-Ч)), где F ' — снова обратная функция нормального распределения.
Этот график часто используется для исследования распределения остатков, | нужно игнорировать знак остатка, когда нитерес вызывает распределение 4 лютных остатков независимо от их знака.
1Ьние вероятностные графики
229
альный вероятностный график с исключенным трендом
чьный вероятностный график с исключенным трендом строится тем же об-что и стандартный нормальный вероятностный график, с тем отличием, что ,д созданием графика удаляется линейный тренд.
В частности, на этом графике Каждое значение (X.) стандартизируется вычита-«нем среднего и делением на соответствующее стандартное отклонение (s). Нереальное вероятностное значение с исключенным трендом гу для /-го упорядоченного значения (ранга) переменной с я наблюдениями вычисляется так:
z. “ F ‘[(3 Xj-l)/(3 х Л'+1)] - (х;-среднее)А,
вде F 1 — это обратная функция нормального распределения, as — стандартное отклонение.
Графики квантиль-квантиль
График квантилъ-квампилъ (или кратко — трафик К-К) полезен для нахождения наиболее подходящего распределения из выбранного семейства распределений.
Вначале выбирается семейство распределений, внутри которого производится RU'OHKa
230
Глава 5. Двумерный визуальный анализ данны>
Чтобы оценить подгонку распределения, наблюдаемые значения упорядочивя-4 ются (.х( <... < хя), и по этим значениям (х_) строится обратная эмпирическая фу цк. ция распределения.
Затем к ней подгоняется линия регрессии. Если наблюдаемые значения Понадают на линию регрессии, то можно сделать вывод, что они имеют заданное р-пределение. ь
Уравнение линии подгонки (У-а + Ьх) дает оценки параметров а и b (Где а — параметр сдвига, b — параметр масштаба).
Обычно квантильные графики строятся для наиболее употребляемых распре, делений: экспоненциального, экстремального, нормального распределений, распре-деления Релея, бета-, гамма-,логнормального распределения и распределения Вейбулла |
Графики вероятность-вероятность
График вероятность-вероятность (или трафик В-В) полезен для определения насколько хорошо теоретическое распределение подходит для наблюдаемых да« »-ных. На графике В-В строится зависимость между эм лирической функцией распределения и теоретической функцией распределения для оценки подгонки теоретического распределения к наблюдаемым данным. Если все точки графика попадают на диагональную линию (со сдвигом 0 и наклоном 1), то можно сделать вывод, что теоретическое кумулятивное распределение точно приближает наблюдаемое рас пределение.
Если точки данных не попадают на диагональную линию, то этот график мо.» -но использовать для наглядной проверки того, подходит ли распределение к Ла|' ным (например, если точки располагаются в форме S относительно диагопальш л линии, то может потребоваться преобразование данных для того, чтобы привесI1 их распределение к нужному виду).
Для построения этого графика должна быть полностью задана функция теор тического распределения. Следовательно, параметры распределения должны бы либо определены пользователем, либо вычислены по данным (для получения л ‘ ’ волнительной информации о параметрах см. описание соответствующего расГ!» деления).
<Mbl диапазонов
231
г «ообше говоря, если наблюдаемые точ кн имеют выбранное распре деле ние с со-
L -Ттструюшими параметрами, то они попадут на прямую линию на графике В-В. '| воаМетьтс, что для получения используемых здесь оценок параметров (для наире подходящего распределения из семейства распределений) также можно применять график квантиль-квантиль.
Диаграммы диапазонов
Да диаграммах диапазонов представлены диапазоны значений или столбцы ошибок относящиеся к определенным точкам данных, в форме прямоугольников или отрезков. В отличие от стандартных диаграмм размаха, диапазоны или столбцы ошибок не вычисляются поданным, а определяются исходными значениями вы-
ния временных промежутков, а не изменчивости; их также рекомендуется использовать, если у диапазонов очень длинные метки, потому что на горизонтальных диаграммах диапазонов метки не нужно переносить (как в случае, когда длинные метки расположены вдоль оси X).
Глава 5. Двумерный визуальный анализ да(
‘|>|1ЦППИ
Диаграммы размаха
УА& диаграммах размаха (термин введен Тьюки в 1970 году), или так называв
графиках ящики-усы, диапазоны значений выбранной переменной (или перег^ ных) строятся отдельно для групп наблюдений, определяемых значениями Kai
горизующей или группирующей переменной.
Центр (например, медиана или среднее) и статистики диапазонов или вар; ции (например, квартили, стандартные ошибки или стандартные отклонения) । числяются для каждой группы наблюдений.
Впйшя
На графике может быть представлено более одной зависимой переменной возможности сравнения распределений результатов соответствующих измер по группам.
233
MMrig3hiaxa-
Если изменить разметку осей, то можно увидеть следующую картину.
Из этой диаграммы размахов видно (данные носят модельный характер, do в них отражена реальная ситуация), как распределены покупки колбасы и мяса в супермаркете в течение дия. Диаграмма СУММА показывает, как распределена мма всех покупок, сделанных клиентами.
Очевидно, что вариабельность покупок колбас больше вариабельности покупки мяса. Половина покупателей производят покупку колбас в очень узком диапа-*°не (типичный покупатель).
Диаграммы диапазонов отличаются от диаграмм размаха тем, что для диаграмм диапазонов диапазоны для построения определяются значениями выбранных пе-Г*Менных (например, одна переменная содержит минимальные значения диапа-^Вов> а другая — максимальные значения диапазонов), в то время как для дпа-• еамм размаха диапазоны вычисляются по исходным значениям переменной • ’ЯПример, стандартные отклонения, стандартные ошибки или исходные диапазоны).
Как правило, диаграммы размаха применяются в двух случаях- а) для сравне-”я Диапазонов значений отдельных выборок или категорий наблюдений (напри-Ч3- типичная минимаксная диаграмма для акций или товаров или агрегирование диаграммы последовательностей данных с диапазонами) и б) для сравнения спредедении или вариаций результатов в отдельных группах или выборках
234
Глава 5. Двумерный визуальный анагкз,
(например, диаграммы размаха, представляющие среднее в виде точки внутри моуголышка, стандартные ошибки — в виде прямоугольника, а стандартны клонения от среднего — в виде более узкого прямоугольника или отрезка).
Диаграммы размаха, показывающие вариацию значений, дают возмоэ
визуализировать и быстро оценить силу зависимости между группирующей
висимой переменными. В частности, предполагая, что зависимая переменная рас пределена нормально, и зная, какая часть наблюдений попадает в интервал, । пример, ±1 или ±2 стандартных отклонения от среднего, можно легко оцещ результаты эксперимента и показать, что около 95% наблюдений в зкеперпм тальной группе 1 при надлежит к диапазону, отличному от диапазона значений, к] попадают примерно 95% наблюдений в группе 3.
pi] Простые диаграммы размаха
Простые диаграммы размаха используются для представления и исследования ди апазонов значений переменной при категоризации с помощью другой перемен» Когда выбрано более одной зависимой (то есть У) переменной, будет построе последовательность графиков (по одному для каждой выбранной зависимой nej менной).
[7Д Составные диаграммы размаха
В отличие от простых диаграмм размаха, на которых представлены диапазоны 31 чеинй одной переменной, составная диаграмма размаха изображает (на одном Г] фшее) диапазоны значений нескольких переменных.
Для каждой переменной используется и указывается в условных обозначен! свой маркер точек, шаблон заполнения и цвет. Этот тип диаграмм размаха него I зуется для сравнения диапазонов значений нескольких переменных (или негт < ких функций) путем представления их на одном графике, использующем об, шкалы (например, сравнение нескольких одновременныхэкспериментальных 11 Нессов, социальных явлений, пен акций или товаров, форм кривых текущих рактеристик и т. п.).
Столбчатые диаграммы
2М столбчатые диаграммы представляют собой последовательности зна ний в виде столбцов (одно наблюдение представлено одним столбцом). Если |
<атые диаграммы
235
более одной переменной, то каждая диаграмма может быть изображена от-ЕжьНО или все диаграммы могут быть представлены на одном графике в виде групп *биов (одна группа для каждого наблюдения). Например, для этого множества ^,ых будет построена следующая столбчатая диаграмма.
Следует отметить, что для изображения столбцов ошибок, связанных с отдельными измерениями (например, стандартных ошибок, вычисленных поданным или зафиксированным ранее границам диапазона), следует использовать диаграммы диапазонов или диаграммы размаха.
СИ Простые столбчатые диаграммы
Для выбранной переменной строится простая столбчатая диаграмма (если выбрано более одной переменной, то для каждой переменной из списка строится отдельный график).
236 Глава S. Двумерный визуальный анализ данных
[i^lJ Составные столбчатые диаграммы
На составных столбчатых диаграммах (на одном двумерном графике) показами группы столбцов для многих переменных (одному наблюдению соответствует одн| группа); один столбец группы представляет одну из выбранных переменных
Значения всех исследуемых переменных откладываются по единой оси У (иль оси X, если выбрана горизонтальная ориентация), что облегчает сравнение анали зируемых переменных.
Линейные графики (для переменных)
2М линейные графики представляют собой двумерные линейные графики одно® или многих переменных, на которых отдельные точки соединены линиями. Лш нейные графики дают простой способ наглядного представления последовательности большого числа значений (например, рыночных цен на акции за некотороь-число дней); X} -графики трассировочного типа (см. ниже) могут быть использованы для изображения пути (вместо последовательности)
237
жнейные графики (для переменных)
I Линейные графики могут также быть построены для непрерывных функций, теоретических распределений и т п. Ниже показано несколько таких графиков.
ЦЕНА НАМЕеТЬ <дол»»ров •• Пчрег».)
Д»1Ы (»> парам» иной: ПАТЕ )
-- - ЦЕНА -ДРУБЛЬ
Если имеется лишь несколько наблюдений, го лучше использовать вертикальную столбчатую диаграмму, хотя значительным исключением из этого правила являются графики различий между средними некоторого количества групп.
238
Глава 5. Двумерный визуальный анализ дани
Если в последовательности очень много наблюдений и они различаются, обходимо сглаживание для обнаружения обшей структуры последователь данных. Простейшей формой сглаживания является агрегирование, когда в^и исходных данных изображаются средние последовательных множеств и.» л блюдений. На агрегированных линейных графиках диапазоны значений > , жаются отрезками.
Агрегирование также может быть использовано в качестве средства уменья ния количества точек, дающего возможность представить на одном графике бол ше данных, чем в любом другом случае (при данном разрешении монитора илы принтера).
Е>1 Простые линейные графики
Простые линейные графики используются для представления и исследовани|
Также типично применение линейных последовательных графиков при i строении графиков непрерывных функций, таких как функции подгонки или т ретические распределения. Заметьте, что пустая ячейка данных (то есть про шейные данные) «разрывает» линию.
Составные линейные графики
В отличие от простых линейных графиков, на которых представлена последе тельность значений одной переменной, на составном линейном графике изос
(для переменных)
239
несколько последовательностей значений (переменных). Для каждой пе-*аЮТ)|1Ой используется и указывается и условных обозначениях свой шаблон ли-£,н к нвст
Этот тип линейных графиков используется для сравнения последовательностей значений нескольких переменных (или нескольких функций) путем изображения их на одном графике, использующем один общий масштаб (например, для сравнения нескольких одновременных экспериментальных процессов, социальных явлений, цен акций или товаров, форм кривых текущих характеристик и т. п.).
!1 Линейные графики с двойной осью Y
Линейный график с двойной осью Y можно рассматривать как комбинацию двух по-разному масштабированных составных линейных графиков. Для каждой выбранной переменной используется свой шаблон линии, в то же время все переменные, выбранные в списке Левая ось У, будут откладываться по левой оси Y, а переменные, выбранные в списке Правая ось Y, будут откладываться по правой оси Y.
240
Глава 5. Двумерный визуальным анализ двинь
Имена всех переменных будут указаны в условных обозначе ниях вместе сI
вой (Л) для переменных, относящихся к левой оси Y. и с буквой (П) для пег ных, относящихся к правой оси Y.
Линейный график с двойной осью Y можно использовать для сравнения довательностей значений нескольких переменных, накладывая их линейны^
ставления на один график. В то же время, в силу независимости шкал, ист мыхдля двух осей, этот график может облегчить сравнение «не сравнимых» . способом переменных (го есть переменных со значениями в разных диап
|р~~| Трассировочные XY-графики
Трассировочные XY-графики требуют выбора по крайней мере двух пе}леменни (Хи Y). На трассировочных графиках сначала строится диаграмма рассеяния дт переменных, а затем отдельные точки данных соединяются линией (в порядке считывания из файла данных).
В этом смысле трассировочные графики визуализируют «путь» последоват< ного процесса (движение, изменение явления во времени и т, и.).
|frH| Агрегированные линейные графики
Агрегированные линейные графики изображают последовательность средних последовательных подмножеств выбранной переменной. Можно выбрать последовательных наблюдений, по которым будет вычислено среднее (пар; Индекс), а при необходимости диапазон значений в каждом подмножестве I выделен значками типа отрезков.
5 5 И Г » г « <5 51 К К
,НЬ1е графики (профили наблюдений)
241
.тегированные таги^йные графики используются для представления и исследова-доследовате льностей большого числа значений Следует отмстить, что в модуле ряды содержится большой набор процедур сглаживания и фи чьтраццн “' пых ( например, скользящее среднее, скользящая медиана, 4253 Н -фильтр и др.)
Линейные графики (профили наблюдений)
2М чинейные графики (профили наблюдений) представляют собой двумерные ли-гейныс графики одной и нескольких переменных.
В отличие от простых линейных графиков, где значения одной переменной изображаются в виде одной линии (отдельные точки данных соединены линией), на линейных графиках профилей наблюдений значения выбранных переменных для наблюдения (строки) изображаются в виде одной линии (то есть один линейный график создается для каждого выбранного наблюдения).
Линейные графики профилей наблюдений дают возможность наглядно представить значения для наблюдения (например, значения для нескольких критериев).
Простые линейные графики (профили наблюдений)
Простые линейные графики используются для представления и исследования последовательностей значений (обычно когда порядок значений является существенным). Обратите внимание, что пустая ячейка данных (то есть пропущенные данные) «разрывает» линию.
Составные линейные графики (профили наблюдений)
В отличие от простых графиков профилей наблюдений, на которых представлена •оследователыюсть значений одной переменной, на составном линейном графике **збражаются несколько последовательностей значений (переменных). Для каж- °и переменной используется и указывается в условных обозначениях свой шаб <°н линии и цвет.
от ТИп линейных графиков используется для сравнения последовательностей учений нескольких переменных (или нескольких функций) путем изображения На одном графике, использующем один общий масштаб (например, для сравне
242
Глава 5. Двумерный визуальный анализ данн|
ния нескольких одновременных экспериментальных процессов, социальных а лений, цен акций или товаров, форм кривых текущих характеристик и т. и.), f
Последовательные/ наложенные графики
Все типы графиков из этой группы используются для представления по 1едов тельностей значений. В этом отношении они сходны с линейными графиками. Фа тически если для построения выбрана только одна переменная, то отобшжец] данных будет идентично представлению на линейных графиках. В то же врем наложенные графики позволяют реализовать более разнообразные способы гр,» фического представления (зонные, ступенчатые, столбчатые диаграммы й др. у
Единственное значительное различие между представлениями данных на расI сматриваемом типе графиков и на линейных графиках проявляется, когда длс, построения выбирается более одной переменной. На линейных графиках каждая переменная будет построена независимо от других; так, например, если две пер-। менные имеют одинаковые значения для наблюдения 3, то в этой точке (наблюдение | две линии пересекутся или перекроются. В то же время, наложенные графики «складывают» соответствующие значения последовательных переменных (из выбранного списка). J
Так, на этом графике точка, отвечающая наблюдению 3 для второй перемен ной, будет соответственно выше, чем для первой переменной. Переменные сила дываются в том порядке, в каком они были выбраны.
Благодаря такому положенно ну предстанлепию значений последовательныхm ременных линии (или шаги, области, столбцы и т. л.) последовательных перему ных никогда не будут перекрываться, если они больше 0.
Такая интерпретация влечет ограничение, касающееся пропущенных значеН! в изображаемом множестве данных. А именно — положение каждой точки данш на графике для каждой последовательной переменной (из выбранного спнсИ является суммой ее значений и соответствующих значений (то есть значений I того же наблюдения) всех «предшествующих» переменных в списке. Следовать но, если хотя бы одно из предшествующих значений пропущено, сумму нельзя вы числить, и график в этой точке будет «разорван». Таким образом, во множеств
^взтельные/наложенные графики
243
их выбранных для наложенного представления, не должно быть пропущен-ганных (исключая данные для последней переменной).
"ЭтиТМПЫ графиков используются для представления последовательностей зна-нй выбранных переменных. Однако наложенный вид i-рафиков (применяемый ,,я выборе более одной переменной) специально разработан для представления '^льшой категории множеств данных, в которых последовательные переменные вставляют части («порции») целого. Например, каждое наблюдение можетобо-* мчать ВНП за один фискальный год, а каждая переменная — сумму в долларах, Уц-т-yn мятную из каждой отрасли промышленности и из других источников това-«.эн и услуг. Если такие данные были бы представлены на наложенном столбчатом -кафнке, то получившаяся высота каждого столбца обозначала бы суммарный ВНП, а каждый из аложенных сегментов столбца показывал бы относительный вклад соответствующей отрасли.
Если переменные, представленные на графике, отражают проценты и/или всумме дают одно и то жезначение (например, 100%) для каждого наблюдения, то марная высота графика будет постоянной для всех наблюдений
ЦЦ- Линейный график
На этом тиле графика последовательности значений каждой переменной будут представлены последовательными линиями, расположенными одна над другой.
244
Глава 5. Двумерный визуальный анализ д;
gag Зонный график
На этом типе графика последовательности значений каждой переменной 6 представлены последовательными областями, расположенными одна на дру«
Смешанный линейный график
На этом типе графика последовательности значений, выбранных в первом спис переменных, будут предстаалены последовательными областями, располож ными одна на другой, а последовательности значений, выбранных во втором сп кс переменных, будут представлены последовательными чиниями, располож ными одна над другой (над областью, отвечающей последней переменно!! первого списка).
,ятельные/наложенные графики
245
.Ступенчатый график
ом типе графиков последовательности значений каждой переменной будут * вле) гы последовательными ступенчатыми линиями, расположе! шыми одна
; другой.
246
Глава 5. Двумерный визуальный анализ д.
Смешанный ступенчатый график
На этом типе графика последовательности значений, выбранных в первом спи! переменных, будут представлены последовательными ступенчатыми облаете расположенными одна на другой, а последовательность значений выбранных втором списке переменных будет представлена последовательными ступенчап ми линиями, расположенными одна над другой (над областью, отвечающей поел дней переменной из первого списка).
|^gg| Столбчатая диаграмма
В данном случае последовательности значений каждой выбранной переменной дут представлены последовательными сегментами вертикальных столбцов, расг. I воженных друг на друге.
диаграммы
247
руговые диаграммы
вая диаграмма (термин был впервые использован Хаскеллом в 1922 году) ^Г^г°гся одцим из наиболее часто используемых графиков для представления ° ^опш’й Ь зависимости от выбранного типа графика на круговой диаграмме фОПО
изображаться или исходные значения, или частоты особых категорий зна-еннй (как те> которые можно изобразить на гистограмме).
ф Круговые диаграммы частот
Л отличие от круговой диаграммы значений этот тип круговой дпаграм мы (иногда —зываемог! частотной круговой диаграммой) интерпретирует данные так же, как ^гистограмма. Все значения выбранной переменной группируются по выбранному методу категоризации, а затем относительные частоты изображаются в виде «руговых секторов пропорциональных размеров.
Расположение значений, представленных на графике, зависит от метода категоризации и происходит по той же схеме, что и для гистограмм.
<5 (руговые диаграммы значений
Последовательность значений переменной будет изображена в виде последовательных круговых секторов; размер каждого сектора будет пропорционален соответствующему значению. Значения должны быть больше 0 (нулевое и отрицательные значения не могут быть представлены в виде круговых секторов).
248
Глава 5. Двумерный визуальный анализ да»
Этот простой тип круговой диаграммы (иногда называемый круговой диагп мой данных) интерпретирует данные самым непосредственным образом: одцч блюдснпе соответствует одному сектору. Шаблоны круговых секторов, испо« емые для этого графика по умолчанию, можно регулировать в диалоговом! Шаблоны специальных графиков по умолчанию.
|ПВ,| Многоцветные столбчатые диаграммы
Многоцветная столбчатая диаграмма служит для изображения того же типа j пых. что и описанная выше круговая диаграмма значений, однако последовав пые значения выражены высотами вертикальных столбцов (разных цветов и нов), а не площадями круговых секторов.
Преимущество этих диаграмм перед круговыми диаграммами состоит в тс что они дают возможность более точного сравнения представленных значений I • пример, трудно сравнивать маленькие круговые секторы, если они не являиц соседними).
Этот тип графика может также иметь преимущества перед простыми гш * граммами (где для всех столбцов используется один цвет и шаблон запот ния) в случаях, когда требуется быстрая идентификация определенных стол<'«
Диаграммы пропущенных значений и интервалов
Диаграммы пропущенных значений и интервалов дают возможность исследи шаблон расположения или распределение пропущенных данных и/или зах->и пользователем точек «вне диапазона» текущего множества (или подмноя «С наблюдений.
Этот график применяется в разведочном анализе данных для определен!« шчества пропущенных данных (и 'или данных «вне диапазона») а также дл« ясненпя. является ли их распределение более или менее случайным или в 1» положении можно обнаружить некоторую закономерность.
жций пользователя
249
г В сущности, они представляют собой «карту» файла данных (или его частей) и позволяют исследовать структуру пропущенных данных, очень маленьких значений, больших значений и т. п. Категоризованный формат дает возможность сравнивать такие образцы для определенных подмно’кеств данных.
ШННШ 'ЙЦ|НН 'нЬНН!
"Рафики функций пользователя
отличцеот большинства других типов графиков, для 2Мграфика функции пользо-: не требуется выбирать переменные: вместо этого для построения графика
г’РГ’Грамма запросит ввод формулы. Эта процедура создает графики, основанные
250 Глава 5. Двумерный визуальный анализ да нк
ле на значениях переменных в файле данных, а на заданных пользователем 4 мулах (то есть пользовательских функциях), например:
Следует отметить, что для других типов графиков наряду с разнообразными возможностями настройки параметров также предусмотрена возможность на-. । жения пользовательской функции. Например, аналогичные результаты ностро»-ния функций можно получить при помощи регулирования соответствующих Пч раметров настройки для других типов длумерных графиков.
При наложении функции на график диапазоны осей графика автоматически подгоняются к соответствующим диапазонам значений переменных Для рассм 4 г• риваемого типа графика можно явно указать диапазоны значений в диалоговом окне определения графика, которые не будут зависеть от множества данных. Н< пример, можно установить минимум и максимум для обеих осей (X и У) равными Он 100 соответственно.
Обычно эти графики используются для исследования функциональной Й симости (например, для проверки соответствия теоретических моделей экс?” ментальным данным).
Трехмерный визуальный анализ данных
Трехмерный визуальный анализ позволяет анализировать данные в трехмерном пространстве, например, строить трехмерное изображение последовательностей исходных данных (наблюдений) для одной или нескольких выбранных переменных. Выбранные переменные представляются по оси Y, последовательные наблюдения — по оси X, а значения переменных (для данного наблюдения) откладываются по оси Z, как показано ниже:
Такие трехмерные графики используются для визуализации последовательностей значений нескольких переменных. По своей идее они сходны с составными линейными графиками, с тем лишь отличием, что для ЗМ диаграмм исходных данных ленты, линии, параллелепипеды и другие трехмерные представления значений каждой переменной |1е перекрываются (как на двумерном графике), а «раздвигаются* в трехмерной перспективе.
SHE
I
252
Глава 6, Трехмерный визуальный анализ дак
ЗМ диаграммы исходных данных применяются как для отображения ных. так и для аналитических исследований. Наиболее типичным притоке i ЗМ диаграмм исходных данных является наглядное представление имеюш информации (например, о ценах, о росте населения, о взаимосвязи объ продаж и прибыли). Гакне графики позволяют просто и эффектно лредст< последовательности наблюдений, таких, например, как различные типы в•-< ных рядов.
Основное преимущество трехмерных представлений перед двумерными ставными линейными 1рафпкамн заключается в том. что для некоторых множ* данных при объемном изображении легче распознавать отдельные пос дователыюсти значений. При выборе подходящего угла зрения с помощь» £ пример, интерактивного вращения пинии графика не будут перекрываться । «попадать друг на друга», как часто бывает на составных линейных двумер] графиках.
Трехмерные диаграммы также используются в аналитических целях при следовании входных данных, имеющих матричный фермат.
Для интерактивного просмотра поперечных сечений таких трехмерных of ставлений можно использовать метод динамического расслоения
визуальный анализ данных
253
К Заметьте, что для детального исследования изображения отдельные зависимо-। ni (то есть переменные) на графике можно выборочно выделить цветом. Для это-I» нужно нажать левую кнопку мыши в любом месте выбранной зависимости.
Процесс -«просвечивания» дает возможность временно отобразить (с помощью подсветки) целые серии данных, даже если они почти полностью закрыты другими данными.
Столбчатая диаграмма
Этот последовательный трафик представляет отдельные значения одной или не-ЕКольких серий данных по оси Хв виде серий трехмерных столбцов (параллелени-педов). Все серии отделены друг от друга промежутками вдоль осн Y Высота каждого ci । лбца по оси Z отвечает значению соответствующей точки данных
254
Глава 6 Трехмерный визуальный анализ дань
Блоковая диаграмма
Этот последовательный график представляет отдельные значения одной или » скольких серии данных по оси X в виде серий «трехмерных блоков». Все а-п отделены друг от друга промежутками вдоль оси У. Высота начала каждого бЗ по оси Zотвечает значению соответствующей точки данных.
Ленточная диаграмма
Эта диаграмма представляет отдельные значения одной или нескольких серий д:« пых по оси X в виде серий «лент» в трехмерном пространстве
Все серии отделены друг от друга промежутками вдоль оси Y Высота нам каждой ленты по оси Z отвечает значению соответствующей точки данных.
Линейный график
Этот последовательный график представляет отдельные значения одной или не скольких серий данных по оси X в виде ряда непрерывных линий в трехмерна пространстве.
визуальный анализ данных
255
^ерИн отделены друг от друга промежутками па оси К Высота начала каж-по оси Z отвечает значению соответствующей точки дани ых.
доЙ лини и
Диаграмма всплесков
т ый последовательный график представляет отдельные значения одного или * кольких наборов данных по оси X в виде серий «всплесков» (точек с перпепди--е^Ярамн, опущенными на плоскость основания).
Все серии отделены друг от друга промежутками вдоль осп У. Высота каждого перпендикуляра по оси Z отвечает соответствующему значению серии.
F Декретная карта линий уровня
Этот последовательный график можно рассматривать как двумерную проекцию ЗМ ленточной диаграммы.
На этом графике каждая точка данных представлена в виде прямоугольной асти; значениям (или диапазону значений) точек данных соответствуют разные цвета или шаблоны (цветовые шаблоны описаны справа от графика). Зна-1,3 °Дной серии представлены по оси X, а сами серии откладываются по
256
Глава 6. Трехмерный визуальный анализ дан
График поверхности
На последовательном графике к точкам исходных данных подгоняется cris пая сплайнами поверхность.
Последовательные значения каждой серии откладываются по осн X, а сами щ следовательные серин представлены на оси У
Карта линий уровня
Карта линий уровня представляет собой двумерную проекцию сглаженной сш нами поверхности, подогнанной к исходным данным.
Последовательные значения каждой серии откладываются по оси X, а сами следовательные серии представлены на оси У
Гистограммы двух переменных
Трехмерные, или ЗМ, гистограммы двух переменных используются для виз- а запил табулированных значений двух переменных или для визуализации тзц| сопряженности двух переменных Их можно рассматривать как сочетание дву • Д стых гистограмм (то есть гистограмм одной переменной), соединенных такяы1 разом, чтобы можно было исследовать частоты совместного появления знача! двух переменных.
<мы_двух переменных
257
г Распределение частот на трехмерных гистограммах вызывает интерес по двум причинам:
О по форме распределения можно сделать вывод о природе исс ледуемой переменной (например, если распределение бимодально, то можно предположить, что выборка не является однородной и состоит из наблюдений, принадлежащих двум совокупностям, которые приблизительно нормально распределены);
Э многие статистики основаны на определенных предположениях о распределениях анализируемых переменных; ЗМ гистограммы двух переменных помогают проверить выполнение этих предположений для пары переменных.
ЗМ гистограммы и кросстабуляции
ЗМ гистограммы двух переменных предоставляют ту же информацию, что и таблицы сопряженности. Хотя некоторые (числовые) данные по частотам легче воспринимать в виде таблицы, общая форма и глобальные описательные характеристики распределения двух переменных легче исследовать па графике.
Более того, график дает качественную информацию о распределении, которую нельзя полностью выразить каким-то одним показателем. Например, асимметричное распределение двух переменных — скрытых откликов и времени реакции (в эксперименте измерения времени реакции) — может проистекать из изменений повеления субъектов при усталости
258 Глава 6. Трехмерный визуальный анализ пан
Категоризация значений
Все процедуры построения гистограмм имеют стандартный набор методов ка .mJ рнзации, или разбиения наблюдений на группы. Систематично методы кате^Я зации изложены в отдельной главе.
Согласно этим методам, диапазон значений каждой из двух выбранных л njr. фика переменных разбивается на категории (классы), для которых подсчнтыЯ ются частоты, отображаемые в виде отдельных трехмерных столбцов.
Например, можно построить трехмерную гистофамму, на которой каждый < -mJ бец будетсоответствовать 10 единицам шкалы, используемой для персмениой-^Н минимальное значение равно 0, а максимальное равно 120, добудет построено 12 ря. дов столбцов. В качестве другого примера можно разделить диапазон значен «J переменных на определенное число равных интервалов (например, 10); в пос . нем случае, если минимум равен 0, а максимум равен 120, то каждый интерн2 будет равен 12 единицам шкалы Существует возможность проводить и более слс * ную категоризацию.
Так можно создать неравные интервалы группировки, задавая их границы (на пример, для создания легко интерпретируемой картинки или для связывщяЯ выбросов и улучшения представления средней части гистограммы, в которой с< • ш доточена большая часть наблюдений). Дпапаюны также могут быть созданы с п<> мощью логических выражений (например, первый столбец гистограммы моа^п представлять людей, которые в прошлом году путешествовали самолетом б jm 10 раз, и тех, кто проводит более 20% времени в деловых поездках и т. п.) Различные способы категоризации на одном графике
Для каждой из двух переменных, распределение которых представлено на [рафике. могут быть использованы различные методы категоризации, как показано а следующей ЗМ гистограмме двух переменных значений времепи реакции и у* Ш вий эксперимента.
В частности, на этом графике распределение времен реакции (непрерывной I ременной, категоризованной путем разделения всего диапазона значений на 1 л. I тервалов равной длины) представлено для трех условий эксперимента (дис1ф ной переменной с тремя уровнями, имеющими разные метки: Оснолной - Я- L Нормалъный — NORMAL и Двойной — DOUBLE).
Запомните, все элементы графика можно изменить, щелкнув, например, на4 правой кнопкой мыши и вызвав контекстное меню графиков.
^Кгдммы двух переменных 259
улаживание распределений двух переменных
процедуры сглаживания для ЗМ гистограмм двух переменных позволяют подгонять поверхности к трехмерным изображениям данных частот двух переменных. Гак. например, каждая трехмерная гистограмма может быть превращена в сглаженную поверхность. Это представление нецелесообразно использовать для простых категоризованных данных (таких, как изображенная выше гистограмма).
Однако этот способ может оказаться ценным средством для исследования сложной структуры частот.
260
Глава 6. Трехмерный визуальный анализ дан
Он позволяет обнаруживать закономерности, менее заметные на стандартной п мерной гистограмме, например «волнистую* поверхность ла показанном выще сунке.
ЗМ диаграммы диапазонов
Подобно статистическим 2М диаграммам диапазонов трехмерные диаграммы апазонов отображают диапазоны значений млн столбцы ошибок, соответствуг определенным точкам данных
Диапазоны или столбцы ошибок не вычисляются по данным, а определяю исходными значениями выбранных переменных. Для каждого наблюдения ci ится один диапазон или столбец ошибок. Переменные диапазона можно поним как абсолютные значения или как значения, отвечающие отклонениям от сред точки. На графике можно представить одну или несколько переменных
В основном диаграммы диапазонов используются для изображения: а) диг эонов значений для отдельных элементов анализа (наблюдений, выборок и т или б) вариации значении в отдельных группах или выборках (последнее ни смысл, когда величины вариации получены при независимых измерениях; ия более целесообразно использовать ЗМ диаграммы размаха, которые вычисти вариацию для выборок, представленных на графике). Некоторые из этих при жений кратко описаны в разделе ЗМ диаграммы размаха.
Основное различие между диаграммами диапазонов и диаграммами рэ:м1 <тонт в том, что на диаграммах диапазонов все значения, определяющие дни ны («средние точки*, минимум и максимум), не вычисляются по данным, а я ются исходными значениями переменных.
Когда на графике нужно представить только одну переменную, обычно Н точно воспользоваться 2М диаграммой диапазонов; па этом графике также M.I представить несколько переменных (путем сдвига изображений так. что flH лого наблюдения будет отображено последовательно столько диапазонов, ел переменных используется для анализа). Тем tie менее ЗМ диаграмма диал^ часто является более подходящим способом представления диапазонов пес Мм
зимы диапазонов
261
ценных на одном графике, так как она не «разбивает» строки пиктограмм, ставляющих отдельные классы или переменные.
шит- ««- । " —лаз
F После создания графика можно изменить его расположение и вид отдельных элементов. Для этого нужно открыть диалоговое окно Общая разметка: ЗМграфики (с помощью двойного щелчка мышью на фоне графика или из графического выпадающего меню Разметки) или диалоговое окно Размещение ЗМ графика (с помощью команды контекстного меню, вызываемого правой кнопкой мыши для конкретной зависимости, или из графического выпадающего меню Разметки).
Точечные диапазоны
На статистической ЗМ последовательной диаграмме диапазонов такого типа диапазоны изображены в виде маркеров точек (соединенных линией)
Но ^ЛЯ каждого наблюдения строится один диапазон. Переменные диапазона мож-понимать как абсолютные значения или как значения отвечающие отклонениям вазо ДНе*'Т°ЧКИ В эависимости от текущего значения параметра Тип (значения диа-
262
Глава 6. Трехмерным визуальный анализ
Граничные диапазоны
На статистической ЗМ последовательной диаграмме диапазонов такого типа
пазоны представлены зоны). Средние точки
двумя непрерывными линиями
(верхние
и нижние ди
изображены в виде маркеров точек, соединенных
ЛИЛИ
Переменные диапазона можно понимать как абсолютные значения или как
чения, отвечающие отклонениям от центральной точки, в зависимости от те» го значения параметра Тип (значения диапазона).
Диапазоны ошибок
На статистической
ЗМ последовательной диаграмме диапазонов
такого типас
нпе точки изображены в виде маркеров точек, а диапазоны — в виде столбцов >
бок. Для каждого наблюдения строится один столбец ошибок.
Переменные диапазона можно понимать как абсолютные значения или
чения, отвечающие отклонениям от центральной точки, в зависимости от тек го значения параметра Тип (значения диапазона).
Диапазоны двойных лент
Па статистической ЗМ последовательной диаграмме диапазонов такого типа пазоны представлены двумя лентами (верхние и нижние диапазоны).
доны диапазонов
263
Переменные диапазона можно понимать как абсолютные значения или как значения, отвечающие отклонениям от средней точки в зависимости от текущего значения параметра Тип (значения диапазона). Средние точки на графике не изображаются (они могут быть показаны на одном из первых трех типов диаграмм диапазонов).
(Л, «Летящие ящики»
На статистической ЗМ последовательной диаграмме диапазонов такого типа диапазоны представлены в виде «летящих ящиков». Ящики не закреплены на плоскости. а как бы парят в пространстве. В ряде случаев такие графики чрезвычайно эффектны для зрительного восприятия.
Переменные диапазона можно понимать как абсолютные значения или как I анлчения, отвечающие отклонениям от средней точки, в зависимости от теку-Щего значения параметра Тип (значения диапазона). Средние точки на графике Be изображаются (они могут быть показаны на одном из первых трех типов ЧВаграмм диапазонов).
“-Летящие блоки»
статистической ЗМ последовательной диаграмме диапазонов такого типа диа-I юны представлены «летящими блоками».
264
Глава 6 Трехмерный визуальным анализ да»
Переменные диапазона можно понимать как абсолютные значения пли как чения, отвечающие отклонениям от средней точки, в зависимости от текущего, чения параметра Тип (значениядштазона). Средние точки на графике не изоб ются (они могутбыть показаны на одном из первых трех типов диаграмм диапазо!
ЗМ диаграммы размаха
Подобно статистическим 2М диаграммам размаха на ЗМ диаграммах размаха пазоны значений выбранной переменной строятся отдельно для групп набл1 ний, определяемых значениями категоризующей (группирующей) перемен Центральная тенденция (например, медиана или среднее) и диапазон или вар ционные статистики (например, квартили, стандартные ошибки или стандарт отклонения) вычисляются для каждой группы наблюдений, а стиль изображе! определяется Tunau графика.
ЗМ диаграммы диапазонов отличаются от ЗМ диаграмм размаха тем. чт диаграммах диапазонов диапазоны представлены значениями выбранных перем ных (например, одна переменная содержит минимальные значения диапаг" а другая — максимальные значения диапазонов), а для диаграмм размаха диа ны вычисляются по значениям переменных (например, стандартные отклон стандартные ошибки или минимальные и максимальные значения).
^граммы размаха
265
’ Как прав*1 ’1О’ диаграммы размаха используются в двух случаях: а) для изобра-•П1Я диапазонов значений для отдельных наблюдений пли выборок (например, * . чная минимаксная диаграмма для акций или товаров ил и агрегированные по-^£^вагпелшые графики данных с диапазонами) пли 6) для изображения вариа-значеипй в отдельных группах или выборках (например, диаграммы размаха. " бражающпе медиану или среднее для каждой выборки в виде точки внутри «лс-столбца ошибок, а также стандартные ошибки пли квартильный размах. lL-пстя пленные н виде « (етяших ящиков»; см. рисунок ниже).
‘ _____________________
Диаграммы размаха, показывающие вариацию значений, легко позволяют оценить и «интуитивно представить» силу связи между группирующей переменной и »дной или несколькими зависимыми переменными. В частности, предполагая, что ивисимые переменные нормально распределены, и зная, какая часть наблюдений попадает, например, в интервал ±1 или ±2 стандартных отклонения от среднего, ьожно легко попять результаты эксперимента и сделать вывод, что, например, рс-। гльтаты примерно в 95% наблюдений в экспериментальной группе 1 принадлежат диапазону, отличному от диапазона 311ачений порядка 95% наблюдений в группе 2.
Когда на графике нужно представить только одну переменную, обычно достаточно воспользоваться 2М диаграммой размаха; наэтом графике можно также представить несколько переменных (путем сдвига изображений отдельных «ящиков» *»к. что тля каждого наблюдения будет изображено последовательно столько «ящиков», сколько переменных используется для анализа). Тем не менее для пред-леппя нескольких переменных на одном графике более подходящей является - М диаграмма размаха, так как ока не «разбивает» строки пиктограмм для каждой переменной. Например, это часто делает более ясной схему расположения средних и стандартных отклонений или квартильных размахов в выбран пых категориях.
266
Глава 6. Трехмерный визуальный анализ дань
Граничные диапазоны
На статистической ЗМ диаграмме размаха вычисленные по исходным да» диапазоны (например, квартили) представлены двумя непрерывными лик (верхние и нижние диапазоны).
Средние точки (средние значения или медианы) отображаются маркерами т чек и соединены линиями.
Диапазоны ошибок
На статистической ЗМ диаграмме размаха такого типа средние точки (вычи лепные по данным средние значения или медианы) изображены маркерами точе а вычисленные диапазоны (например, квартили) представлены столбцам ошибок.
Для каждого уровня независимой (группирующей) переменной рисуется о," столбец ошибок.
(Д2‘- Точечные диапазоны
На статистической ЗМ диаграмме размаха такого типа средние точки и выч ленные диапазоны (например, квартили) представлены тройками маркеров то (соединенных линией).
)ММЫ размаха
267
Для каждого уровня независимой (группирующей) переменной строится одна фойка значений.
Диапазоны двойных лент
На статистической ЗМ диаграмме размаха такого типа вычисленные диапазоны (например, квартили) представлены двумя лентами (верхние и нижние диапазоны).
На диаграмме этого типа средние точки не изображаются. Чтобы их показать, необходимо перейти к одному из первых трех типов диаграмм размаха (см. выше).
'Летящие ящики»
На статистической ЗМ диаграмме размаха этого типа вычисленные диапазоны (например, квартили) представлены в виде «летящих ящиков».
268
Глава 6. Трехмерный визуальный анализ дан
На диаграмме средние точки ис изображаются. Чтобы их показать, необ» перейти к одному ил норных трех типов диаграмм размаха.
I# «Летящие блоки»
На статистической ЗМ диаграмме размаха вычисленные диапазоны квартили) представлены в виде «летящих блоков».
(напри
На диаграмме средние точки не изображаются. Чтобы их показать, пеобхо перейти к одному из первых трех типов диаграмм размаха.
иг;,uaiii* I У "Г,-
Если увеличить установленное по умолчанию апаче!I не поля X (0 ), то м отдельными «летящими блоками» появятся разрывы, как показано выше на гра»
Всплески
При выборе этого режима точечные диапазоны ini i столбцы ошибок будут । йены с основанием графика линиями.
яые диаграммы рассеяния
269
зехмерные диаграммы рассеяния
г диаграммы рассеяния (называемые также ATZ диаграммами рассеяния)
’** * гав тяют собой наиболее простой тип трехмерных зависимостей Как правило, Кьиспользуются для визуализации свяаей между непрерывными переменными.
Хотя можно найти различные применения трехмерных диаграмм рассеяния, тем не менее их основное преимущество состоит в наглядном представлении сложных взаимосвязей между несколькими переменными.
Рассмотрим простой пример из области маркетинга. Предположим, за определенный период времени (в различное время суток) проводились исследования цены и предложения товара. Если построить на графике значения трех этих переменных (Price, Supply и Hour), то можно выявить сложные многомерные интерактивные связи, которые практически невозможно обнаружить при численном анализе Данных.
270
Глава 6. Трехмерный визуальный анализ да
Например, можно установить, что взаимосвязь усиливается во второй гк J не дня (становится теснее связь между ценой и предложением товара). Одна, форме трафика также видно, что эта связь не сохраняется при низком уровне npj ложения (то есть при малых значениях переменной Supply). Часто такие слоя7 взаимосвязи легче выявить на графике, чем при использовании численных ш дов. особенно в случае криволинейных зависимостей.
Выделение кластеров и подмножеств на выборке из неоднородной совокупности Существует и другая область разведочного анализа данных, где могут быть пол ны XYZ диаграммы рассеяния. Это те случаи, когда ожидается наличие групг,1 блюдсний, которые могут быть выявлены только при исследовании распред^ пня одновременно по трем переменным. Например, наследующей XYZ диагра« рассеяния показаны «классические» данные по классификации ирисов (Fisher, 19’ файл Insdatsta), которые включают наблюдения различных видов ирисов.
Из графика видно, что, построив зависимость ширины лепестков от их длины й ширины чашелистиков, можно сделать вывод о том, что выборка неоднородна. Г
На приведенном выше графике, где подмножества маркированы, легко вы; лить различные виды ирисов.
Изучение результатов многомерного анализа
Часто XYZ диаграммы рассеяния используются в статистике для наглядного I ставления результатов многомерных методов исследования, таких как факте»
aie диаграммы рассеяния
271
и многомерное шкалирование. Например, построение на трехмерном гра-тблюдсний с метками, являющихся трехмерным решением задачи много-шкалирования, может помочь в определении величин и классификации Е^Хных наблюдений.
Вращение
Общая проблема трехмерных диаграмм рассеяния — перекрывающиеся точки, соторые затрудняют изучение графика В некоторых случаях при очень большом
числе наблюдений график почти невозможно понять, если смотреть на него под одним углом зрения. Поэтому при исследовании таких трехмерных графиков особенно полезно показанное ниже интерактивное вращение изображения на экране.
272
Глава 6. Трехмерный визуальный анализ
Диаграмма рассеяния
Этот простой тип XYZ диаграммы рассеяния отражает взаимосвязь между! или более переменными в трехмерном пространстве, при этом каждой точке ветствует тройка координат X, Y и Z.
Заметьте, если выбрано более одной перемен ной Z, то будет построено песте XYZ диаграмм рассеяния для различных наборов данных (соответствуют! скольким переменным Z), которые будут маркированы разными значками
Пространственный график
С помощью этого графика можно реализовать различные способы представлен ЗМ диаграммы рассеяния. Для этого предусмотрена возможность расположен плоскости Х-Y па выбранном пользователем уровне вертикальной оси Z (котор проходит через середину' плоскости).
?ные диаграммы рассеяния
Z73
я пространственные графики используются для тех же типов данных, что
YZ диаграммы рассеяния, их представление может облегчить исследование рьгх трехмерных наборов данных. Рекомендуется сопоставлять данные от-**''нум осям на графике таким образом, чтобы переменную, структуру связей Л*"19 - необходимо выделить, обозначить как Z. Тогда, перемещая плоскость XY оси Zn интерактивно вращая изображение, можно попробовать найти такой **' вень Z на котором изменяется структура связей между Хи У (или X, У и Z).
Сели ожидаемое изменение структуры слишком сложно для ото исследования «дам «сечении», можно воспользоваться спектральным графиком, который по-В оляет наблюдать несколько сечений. Однако поскольку на спектральных графиках представлен набор двумерных сжатых изображений трехмерных данных, здесь могут быть потеряны некоторые действительные трехмерные характеристики, ко--прыс наблюдаются на пространственных графиках.
. Другое приложение пространственных графиков — наглядное представление плотности и направле! пгостиотклонений от определенного уровня (уровня отклонений).
Спектральная диаграмма
Первоначально этот тип графиков применялся в спектральном анализе для исследования нестационарных временных рядов, например речевых сигналов На горизонтальных осях можно откладывать частоты спектра и последовател ы 1ые временные интервалы, а на оси Z — спектральные плотности для каждого интервала.
На этом типе графиков трехмерное пространство разделено на области, в которых данные «сжаты» в соответствующие спектральные плоскости Обратите внимание, что для построения функциональных зависимостей (таких как в спектральном анализе) необходимо упорядочить данные таким образом, чтобы переменная Усодержала категоризующую информацию (тоесть была группирующей переменной ).
Спектральные диаграммы имеют явные преимущества перед обычными ЗМ диаграммами рассеяния, когда необходимо исследовать, каким образом изменяется взаимосвязь между двумя переменными при различных значениях третьей переменной. Это преимущество ясно видно на приведенных ниже двух изображениях одного и того же набора данных.
Глава б. Трехмерный визуальный анализ
Значения переменных X и Z интерпретируются как координаты X и Z точки, а значения переменной Y разделены на равноотстоящие группы, ч ствующие положениям последовательных спектральных плоскостей.
Число спектральных плоскостей можно задать в поле редактирования Чш плоскостей диалогового окна параметров графика или после построения граф в диалоговом окне ЗМ графики, дополнительные свойства
Спектральные графики имеют два основных применения. Первое из них -; исследование функций или последовательно распределенных величин в трех^ ном пространстве (например, график спектральных плотностей, определенны»; последовательных интервалов времени).
В то же время спектральные диаграммы являются «действительно трех МС| ми», а не последовательными графиками, и на них могут быть представлены переменные, содержащие не равноотстоящие данные (например, периодогрЛ с упорядоченными по времени, но не равными интервалами).
диаграммы рассеяния
Z75
ре применение даиных графиков — «расслоение» (или «сжатие») диаграмм Н1'Я Для выявления скрытых структур при разведочном анализе данных
' Если предполагается согласованная взаимосвязь между тремя переменными и
особенно если ожидается, что связь между двумя переменными (X и Z) различна яа разных уровнях третьей переменной (У). то Для исследования этого явления вполне можно использовать спектральные графики. Упростить анализ поможет выбор числа спектральных плоскостей (см. выше) и интерактивное вращение
Заметим, что практически такой же ряд двумерных изображений можно полупить с помощью категоризованных графиков рассеяния, где X н Z — отображаемые переменные, а У- категоризующая переменная, разбитая на несколько интервалов (число которых равно числу спектральных плоскостей). Если вас интересуют подробности расположения данных на отдельных спектральных плоскостях, то проще использовать категоризованные диаграммы рассеяния (по срав-«ешпо с трехмерными спектральными графиками). Однако с помощью таких категоризованных графиков нельзя получить цельное трехмерное представление исследуемых данных, которое может быть полезно для понимания их структуры.
Спектральные диаграммы можно использовать для исследования однородности, поскольку такое свойство, как однородность, трудно изучать на других типах графиков (например, можно исследовать зависимость дисперсии от значений переменной У или распределения выбросов).
В Диграмма отклонений
На этом типе графиков точки данных (заданные координатами X, Ей Z) представлены в виде «отклонений» от определенного базового уровня на оси Z.
276
Глава 6. Трехмерный визуальный анализ
Диаграммы отклонений похожи на пространственные графики. Однакщ в отличие от последних, «плоскость отклонений» «невидима» и необознач чожеиием плоскости Х-У (эти оси здесь всегда находятся в стандартном н положении) С помощью диаграммы отклонений можно исследовать природ мерных наборов данных, изображая их в виде отклонений от пронзволыц рпзонтального) уровня. Как упоминалось выше, такой метод «сечения* выявить динамические связи между исследуемыми переменными
Графики поверхности
Для построения поверхности используется подгонка по точкам трехмерщ фпка рассеяния Такое представление, как и ЗМ диаграммы рассеяния, m выявить скрытую структуру данных и взаимосвязи между тремя перемен!
Графики поверхности используются в разведочном анализе данных, каки санные в предыдущем разделе трехмерные диаграммы рассеяния Кроме тоге полезны для наглядного представления результатов анализа, таких как по/ пользовательской функции или кластерный анализ.
В промышленной статистике графики поверхности обычно псилльзуюк представления центрального композиционного плана эксперимента. Здесь. риментатором задаются конкретные систематические значения двух (или t переменных для оценки их влияния на некоторые зависимые переменные отдаляющие интерес (например прочность синтетическ Л ткани).
| С помощью таких экспериментов можно обнаружить сложные нелинейные паа-мисвязи между переменными.
Часто такой график бывает полезно вращать для более явного проявления ха-цсгерпстик поверхности (например, конкретных выпуклостей и впадин) или скры-
Г а сторон.
Линейное сглаживание
Трехмерная диаграмма рассеяния аппроксимируется линейной функцией ( напри-xep.Z = a + bX + cY)
278
Глава 6 Трехмерный визуальный анализ
Квадратичное сглаживание
Трехмерная диаграмма рассеяния аппроксимируется полиномом второго itop}
Сглаживание методом наименьших квадратов
Поверхность аппроксимируется методом наименьших квадратов с весами,зав щпми от расстояния (влияние отдельных точек уменьшается с расстоянием де всрхности).
ф Экспоненциально взвешенное сглаживание с отрицательным показателем
Поверхность аппроксимируется в координатах XYZметодом экспоненциальв J1 шейного сглаживания с отрицательным показателем (влияние каждой точки поненциально уменьшается с расстоянием до поверхности).
279
Другая функция
Можно самостоятельно задать математическое выражение для описания поверхности
280
Глава б- Трехмерный визуальный анализ данные
Карты линий уровня
Карты линий уровня создаются путем подгонки трехмерной функции понерхно< ти к трехмерной диаграмме рассеяния. Получившиеся в результате контурнь линии (то есть липни равной «высоты*-) проектируются па плоскость Х-К
Подобно графикам поверхности, карты линий уровня используются для выяв ления взаимосвязей между тремя переменными.
Как и графики, описанные в предыдущих пунктах (трехмерные диаграммы par сеяния и поверхности). карты линий уровня находят свое применение в иссгм • вательском анализе данных
-Грассиррвочнь
te графики
281
Кроме того, они полезны для наглядного представления результатов исследований. таких как подгонка пользовательской функции Они менее эффективны по сравнению с графиками поверхности (описанными ранее) для быстрого памятного представления полной пространственной структуры данных. Однако преимущество состоит в том, что карты дают возможность с большой точностью псе тедовать форму поверхности. Карты линий уровня представляют собой серию неискаженных горизонтальных «сечений» поверхности
графики
Как и па ЗМ диаграммах рассеяния, каждая точка данных па трассировочных гра фиках располагается в трехмерном пространстве в соответствии со значениями переменных X. У и Z (которые интерпретируются как координаты) Затем эти точки последовательно соединяются линией (в соответствии с их расположением в файле данных), чтобы показать «след» (трассу) какого-либо процесса (например, движения, изменения чего-либо со временем и т. п.).
Наилучшим примером трассировочного графика является траектория объекта в трехмерном пространстве
В общем случае с помощью трассировочных графиков можно изучать процессы, при которых переменные изменяются одновременно в трех измерениях при постедовательном наблюдении
282
Глава 6. Трехмерный визуальный анализ да
Отличие нескольких трассировочных графиков состоит только в том ц, них можно отображать одновременно ряд «траекторий» для списка перемени
Примером набора данных, который можно сравнить с траекторией, любой многомерный временной ряд. Предположим, в большом городе кам месяц в течение нескольких лет измерялись температура. уровень загрязне| содержание озона в воздухе. Так как эти переменные по своей природе цикл (например, зимой в северном полушарии холодно), то возникает характерна! тина, которая, в то же время, имеет сложную структуру. С помощью таких rj ков можно также изучать зависимость от времени цеп на товары или макроэ! мических показателей.
Другое приложение таких графиков — это создание точных «трехмерных суиков» (с помощью задания координат в трехмерном пространстве) для та объектов, как границы контроля или выделенные области. Обычно трехмер! объекты, нарисованные с помощью трассировочных графиков, можно врата! изменять в перспективе. Обратите внимание, что такие объекты не могут быть рисованы в интерактивном режиме, поскольку не существует способа конт| третьей размерности («глубины»).
Если какое-либо наблюдение содержит пропущенные данные (например. ” три координаты X, Ун Z, а только две из них), то линия трассировочного rpai будет разорвана Это свойство можно использовать для создания отдельных •' тов (как показано ниже).
4bie графики
283
Тернарные графики
Тернарные /рафики используются для исследования связей между несколькими К Временными. когда сумма значений переменных постоянна для всех наблюдений.
Обычно такие графики применяются при экспериментальном исследовании за- вмсимости отклика от относительного содержания трех компонент смеси (например, трех химических соединений), при этом соотношение компонент изменяется
с целью определения его оптимального значения
На тернарных графиках для построения зависимости четырех (или более) переменных (компонент X, У и Z и откликов V1, V2 и т. д.) используется треуголь-система координат на плоскости (тернарные диаграммы рассеяния или линии вия) иди в пространстве (тернарные трехмерные диаграммы рассеяния или в^рхности). При построении тернарного графика относительная доля каждой Мпонснты (для каждого наблюдения) ограничена их общей постоянной суммой так pilMePi )• При создании графика масштаб долей по умолчанию изменяется Г Аразом, чтобы эта сумма была равна 1 для каждого наблюдения.
редположим, имеется смесь, состоящая из трех компонент: А. В и С. Любая Son С0Мпонен™ая смесь может быть обозначена точкой в треугольной системе Г РДИиат, заданной тремя переменными
284
Глава 6. Трехмерный визуальный анализ
Например, возьмем 6 следующих трехкомпопентных смесей:
Сумма компонент в каждой смеси составляет 1,0, и эти значения могут pai . ш триваться как доли. Если отобразить эти данные на обычной трехмерной диаграмм рассеяния, то окажется, что они образуют треугольник в пространстве. Правилыщ смеси будут соответствовать только точки, находящиеся внутри треугольника Q сумма значений компонент равна 1. Поэтому для отображения соотношений комгт нент достаточно просто построить треугольник на плоскости.
Три компоненты представлены осями, которые проходят из вершины тр«^ гольника до середины противоположного основания (медианами треугольник и положение каждой точки определяется значениями, отложенными по соответ• Н ющим осям. Присмотревшись к графику, вы легко заметите, что в вершинах трг| гольника имеется лишь одна ненулевая компонента смеси, тогда как на сгорав! треугольника — две компоненты не равны нулю, а одна компонента нулевая. 1
графики
285
Кные графики можно проиллюстрировать следующим примером, рассмот-работе Вайнера (Wainer, 1995).
рационального бюро по развитию образования (National .Assessment of ol Progress (NAEP)) для студентов показали наличие трех уровней обра-и: Высшее/Профессионольное (AdVanced/Pmficient), Среднее (Basic) и Не-чуднее (Below Basic). Результаты, полученные в различных регионах, мо-жгёьпь изображены на тернарном графике, где по каждой из трех осей отложена студентов соответствующего уровня образованности.
! На показанном выше графике (Weiner, 1995) видно, что 37% студентов штата Айова (Iowa) имеют Высшее (AdVanced) или Профессиональное (Proficient) обра--1 дование, 44% — Среднее (Basic) и 19% — Неполное среднее (Below Basic). Для сравнения, только 1% студентов Вирджинских островов (Virgin Islands) имеют Высшее Kj lAdVanced) или Профессиональное (Proficient) образование, 12% — Среднее (Basic) UU7% Неполное среднее (Below Basic).
Вайнер также обсуждает другое интересное применение графиков в треугольных координатах. Подобный график был использован для изучения доли голосов, ♦"данных за каждую из трех британских иолитичсских партий на всеобщих выбо-мх в 1987 и 1992 гг. Заинтересованные читатели найдут подробную информацию • работе: Weiner (1995). Visual revelations, Chance, 8, p. 48-54.
£. 2M диаграмма рассеяния
к На этих графиках треугольная система координат используется для пиырисния ВЬвлсиМрсГ1| трех (иди более) переменных (компонент X. У и Z) на плоскости.
286
Глава 6. Трехмерный визуальный анализ
На приведенном трафике изображены точки, соответствующие долям пе ных-компонснт(Х. FhZ).
Ql> ЗМ диаграмма рассеяния
На этом типе тернарных графиков в треугольной системе координат в трех» м пространстве строится зависимость четырех (или более) переменных (кпмв^ц X, Yu Zu откликов V1, V2 и т. д.) — тернарные трехмерные диаграммы рассев или графики поверхности
На этом тернарном графике отклики (V/, V2 и т. д.), соответствующие опв ленным долям цсрсменных-компонент (X, Ей Z), откладываются в виде высот^
Поверхность
Здесь па трехмерном тернарном графике поверхность представляет собой рему тат подгонки к набор}' данных из четырех координат.
Карта линий
В данномтипе тернарных графиков трехмерная поверхность (подогнанная 1 ру данных из четырех координат) проектируется на плоскость в виде л уровня.
~pgie графики
287
зонная карта
том типе тернарных графиков трехмерная поверхность (подогнанная к набо-- данных) проектируется на плоскость и виде карты зон
jg) Трассировочный график
В данном случае можно исследовать связи между четырьмя и более переменными <Х У, Z и VI, V2 и т. д.) с помощью соединения точек на графике в той последовательности, в какой они расположены в файле данных.
Кроме перечисленных выше вариантов, после построения графика в диалого-юм окне Общая разметка можно также выбрать следующие типы графиков
Ш Пространственный график
Этот тип тернарных графиков предлагает особенный метод представления трехчерных диаграмм рассеяния с использованием плоскости X- Y-Z (определенной в феугольной системе координат), которая располагается на заданном полыовате-,ем уровне вертикальной осн У(эта ось проходит через середину плоскости).
288 Глава 6. Трехмерный визуальный анализ да.
Уровень расположения плоскости X- Y-Z можно подобрать таким образ- ид « бы разделить пространство Х-Y-Z на значимые части (например, для различной структуры связей переменных).
(7) Диаграмма отклонений
Эта диаграмма похожа на пространственный график, но на ней не отображав плоскость, от которой отсчитываются отклонения
Подгонка
Приведенные ниже четыре уравнения регрессии можно использовать для по гь кп зависимостей на тернарных графиках. Обратите внимание, что уравнения лучены из стандартных полиномов с учетом ограничения на значения комло; (X. Y, Z). сумма которых для каждого наблюдения равна постоянной величине! пример, 7,0).
Простейшая модель первого порядка:
V=c + ilxX + i2xy+i>3xZ
с о граничением Х+ Y+Z= 1, может быть построена с помощью умножения коэф шгента а на 1—Х+ Y+Z:
V-exX+оХ Y+axZ+blxX + b2x Y+b3xZ
Это выражение можно упростить:
V - (а+М ) х X + (о+М) х Y + («+63) х Z
или записать таким образом:
V=M’xX + i2*x V+WxZ
Ниже j перечислены доступные в STATISTICS функции полшюлшалъной регрег-Q Линейное сглаживание (полином первом сте пени):
V=felxX + ft2x Y+b3xZ
О Квадратичное сглаживание (полином второй степени):
V-M хХ + £>2х y+*3xZ+412xXx Y + M3xXxZ + Ь23х YxZ
Q Полное кубическое сглаживание-
V-bl хХ+й2х F+*3xZ+M2xXx y+M3xXxZ+623 х yxZ+Ш *!
Fx(X-Y) + M3xXxZx(X-Z) + 623x YxZx(Y-Z) + 7-123 хXX Y
категоризованные графики
289
г
» ^„ециальное кубическое сглаживание:
Ч+Ь2х y+h3xZ+fel2xXx F+M3xXxZ+i23x FxZ+M23xXx YxZ
Трехмерные категоризованные графики
Tiin статистических графиков позволяет создавать трехмерные категоризо- «гые таграммы рассеяния (и трассировочные график»), карты линий уровня и Твеохности- При этом используются заданные категории выбранной переменной спи ДРУг,|е ся°с°бы логической группировки наблюдений.
I На графике представлена та же информация, что и на трехмерном графике рас-
сеяния, графике поверхности пли карте тений уровня, за исключением того, что щесь для каждой заданной пользователем группы или категор!i и показан свой график. Основной смысл таких графиков — упростить сравнение групп или категорий, отражающих связи между тремя или более переменными.
В общем случае трехмерные XYZ (рафики отображают динамические связи меж-<У тремя переменными. С помощью различных способов категоризации данных можно иссчедовать связи в определенных группах данных
Например, положительная взаимосвязь между возрастом, состоянием здоровья и удовлетворенностью жизнью наблюдается при опросе жен шии, но не мужчин.
290
Глава 6. Трехмерный визуальный анализ данщ
Поскольку категории создаются с помощью лш ических условий, которые опгу деляют подгруппы, то можно пойти дальше и построить другие графики — ра-,м< лив группу мужчин на одиноких или разведенных п женатых, можно вы Ы лить в отдельную группу одиноких мужчин с высокими доходами и т п.
Из приведенных ниже категоризованных графиков повер хности (и соответсти! юших нм карт линий уровня) можно сделать заключение о том. что задание в- чины допусков на приборе не влияет на исследуемую взаимосвязь меж iy pi . н татами измерений (Dependl, Depend? и Height.) за исключением гчучаев, когд;« м величина <3.
Иногда карты линий уровня легче анализировать, чем графики поверхн(»-л| (что хорошо видно из следующего примера)
ID'
tlKJKI linn
Таким образом, ЗМ категоризованные графики представляют собой m«wh! исследовательский инструмент для изучения сложных взаимосвязей м« жду nq меиными п группами наблюдении.
Категоризованная ЗМ диаграмма рассеяния
На этом типе графиков отображаются связи между тремя переменными (предо т; ляющпми координаты X. У и Z (вертикаль) в трехмерном пространстве), ран
Трехмерные категоризованные графики
291
лечными на категории с помощью группирующей переменной пли путем задания подгрупп.
Категоризованный пространственный график
В данном случае в одном графическом окне строится несколько пространственных графиков (для групп категоризованных данных).
Категоризованная спектральная диаграмма
На этом типе графика трехмерное пространство разделено на области, в которых данные «сжаты» в соответствующие спектральные плоскости.
292
Глава б. Трехмерный визуальный анализ данщ
Категоризованная диаграмма отклонений
На этом типе графиков точки данных (заданные координатами X, Yu Z) предстг лены в виде «отклонений» от определенного базового уровня на оси Z.
|gg Категоризованный график поверхности
С помощью этой функции будет построена поверхность (методом сглаживания или по заданному математическому выражению) для категоризованных данных
Карта линий уровня
Карта линий уровня — это проекция трехмерном поверхности на двумерную пло< кость. На ней линиями обозначены одинаковые «высоты» (равные значения nept • менной Z).
((атегоРизованнь1е теРНарные графики
293
«П i Зонная карта
^7 гаком графике одинаковые «высоты» (значения переменной Z) на поверхности (зоны между контурными линиями одинаковой высоты, см. предыдущий тип графика) показаны областями одинакового цвета и вида.
Категоризованные тернарные графики
Категоризованные тернарные графики используются для исследования взаимосвязей между тремя и более переменными, когда три из них представляют собой компоненты смеси для каждого значения группирующей переменной (то есть между ними существует жесткая связь, заключающаяся в том, что их значения в сумме дают постоянную величину для всех наблюдений).
294
Глава 6. трехмерный визуальный анализ даь
На тернарных графиках для построения зависимости четырех (или более/ и< ременных (компонентов X, У и Z и откликов VI. V2 и т. д.) используется тг угольная система координат на плоскости (тернарные диаграммы рассеяния г. линии уровня) или в пространстве (тернарные трехмерные диаграммы ра« • < ния или поверхности). При построения тернарного графика относительная Ш каждой компоненты (для каждого наблюдения) ограничена их общей пии«ч ной суммой (например, 1). По умолчанию при создании графика масштаб д-м изменяется таким образом, что эта сумма для каждого наблюдения смюви i равной 1. В вершинах треугольника имеется только одно ненулевое опачени компонент смеси.
На категоризованных тернарных графиках для каждого уровня труп пир'»Ml переменной (или заданной польюватедсм подгруппы) строится отдельный г фик. Все эти графики располагаются в одном графическом окне для сравняй групп данных (категорий).
Обычно такие графики используклся в экспериментах гд»1 отклик зависит относительного содержания трех компонент (например, трех различных чш ческих соединений). Причем это соотношение варьируется с целью определи его оптимального значения (например, при исследовании смесей) Эти типы i фиков могут быть также использованы в том случае, когда необходимо сравн группы или категории данных при наличии жестко заданной связи между менными.
/X Категоризованная 2М диаграмма рассеяния
На таких графиках треугольная система координат используется для uocip ния зависимости трех (или более) переменных (компонент X, Y а X) па пл кости.
категоризованные тернарные графики 295
Здесь изображены точки, представляющие собой доли переменных-компонент (X, Уи Z).
Q ЗМ диаграмма рассеяния
Для данного типа тернарных графиков в треугольной системе координат в трехмерном пространстве строится зависимость четырех (или более) переменных (компонент X, Yи Хи откликов V1, V2ht. д.) (тернарные трехмерные диаграммы рассеяния или графики поверхности)
На этом тернарном графике отклики ( VI, V2 и т. д_), соответствующие определенным долям переменных-компонент (X, Y и Z), откладываются в виде высот точек.
(SJ Поверхность
Здесь на трехмерном тернарном графике поверхность представляет собой результат подгонки к набору данных из четырех координат.
296
Глава 6, Трехмерный визуальный анализ данщ
Карта линий
В этом типе тернарных графиков трехмерная поверхность (подогнанная к 4-j ному набору данных) проектируется на плоскость в виде линий уровня
£\ Зонная карта
В данном случае трехмерная поверхность (подогнанная к 4-координатному наб| ру данных) проектируется на плоскость в виде карты зон.
Трассировочный график
С помощью таких графиков можно исследовать связи между четырьмя и бол» переменными (X. У, Zu V1, V2 и т. д.) путем соединения точек в той пос ледовател] ности, в какой они расположены в файле данных.
^егоризованные тернарные графики 297
Q Пространственный график
Этот тип тернарных графиков реализует специальный метод представления трехмерных диаграмм рассеяния с использованием плоскости X-Y-Z (определенной в треугольной системе координат), которая располагается на заданном уровне вертикальной оси V (эта ось проходит через середину плоскости).
Уровень расположения плоскости X- Y-Zможно подобрать таким образом, чтобы разделить пространство X-Y-Z на значимые части (например, для выделения различной структуры связей переменных).
(jZJ Диаграмма отклонений
Эта диаграмма похожа на пространственный график (см. выше), по на ней не отображается плоскость, от которой отсчитываются отклонения.
Подгонка
Приведенные ниже четыре уравнения регрессии можно использовать для подгонки Данных на статистических, категоризованных или полыювате'гьских тернарных графиках. Обратите внимание, что эти уравнения получены из стандартных полиномов с учетом ограничения на значения компонент (X, Y, Z). сумма которых Для каждого наблюдения равна постоянной величине (например, 1,0). Например, простая модель первого порядка:
V=« + fe! хХ + 62х Y+b3xZ
298
Глава 6. трехмерный визуальный анализ данн^»
с ограничением X+Y+Z=l может быть построена с помощью умножения коэфф» цпента а на 1 =Х+ Y+Z:
V=cxX + axy+cxZ+*lxX+*2xy+*3xZ
Это выражение можно упростить:
V= (a+bl) X X + (а+Ь2) X У+ (а+*3) х Z
или записать таким образом:
V=bV хХ + Ь2’ хУ+63'xZ
Ниже показаны доступные функции полиномиальной регрессии:
о Линейное сглаживание (полином первой степени):
V’MxX + 62x Y + bdxZ
о Квадратическое сглаживание (полином второй степени):
V-*1 хХ+*2х У + *3xZ+Ы2хХх У+*13xXxZ+*23х yxZ
о Полное кубическое сглаживание:
V MxX + fc2xy+*3xZ+fcl2xXxy+il3xXxZ + *23xyxZ-»
М2 х Xх Ух (Х-У) + ИЗ х Xх Zx (X-Z) + *23 х Ух Zx (У-Z) + М23 х Хх Ух Z
о Специальное кубическое сглаживание:
V = *l хХ + *2 х У+*3xZ+*12 хХх У+*13 xXxZ+*23х Ух Z-»
M23xXxyxZ
Можно задать пользовательскую функцию. Однако такие функции не подгоняются к данным, а лишь накладываются на график.
Графики пользовательских функций
В отличие от других типов графиков, здесь не нужно выбирать переменные. Вместо этого программа попросит вас ввести формулу для построения графика. В этом режиме можно построить график не по значениям переменных файла данных, а п< заданной пользователем формуле (то есть отобразить пользовательскую функцию) например:
грмчные графики
299
На данном типе трафика можно в явном виде задать диапазон изменения пере-f „Пных. Например, можнозадатьлнгнимальноеимаксимальноезначеиия для обеих хей (Х11 Y) равными соответственно О и 100
Есть два основных варианта применения графиков функций, заданных пользователем.
Наиболее очевидный — исследование конкретной функциональной зависимо-ти (например, проверка соответствия данных конкретной теоретической модели [ исследуемого процесса или явления).
Другое направление — это разведочный анализ данных, когда необходимо изу-I 4JtTb форму функциональной зависимости в различных диапазонах значений ар-
С шдуюшпм шагом такого исследования, конечно, является статистическая проверка качества подгонки функции к конкретным данным.
Матричные графики
Матричные графики используются для графического представления зависимостей между переменными некоторого множества в виде матрицы обычных двумерных графиков. Чаще всего в качестве матричных графиков используются диаграммы । 1ссеяния, их можно рассматривать как метод визуализации корреляционных матриц исследуемых переменных
На приведенном графике для каждой пары переменных построена диаграмма сеяния с изображен noil на ней прямой линейной регрессии
Матрицы диаграмм рассеяния могут бы гь не только квадратными (как на приведенном рисунке), но и прямоугольными, если были выбраны два списка пере-д<-ниых (по аналогии с прямоугольными матрицами корреляции). Если испиль-
300
Глава 6. Трехмерный визуальный анализ даш
зуется квадратная матрица, то на диагонали вместо диаграмм рассеяния бу/ построены гистограммы для соответствующих переменных
Подобные графики предоставляют эффективный способ визуального анал1, зависимостей между исследуемыми переменными Например, с их помощью , набора переменных легко выделить переменные, которые не коррелируют с др, гими переменными.
Матрицы линейных графиков
Рассмотренные выше матрицы диа1ра.мм рассеяния обьтчпо используются для гра фического представления зависимостей между некоторыми случайными псрем> ними. Для изображения многоступенчатых процессов применяются, как правц матрицы линейных графиков.
Например, на построенных матричных графиках изображено несколько . личных зависимостей переменной У (состояние процесса) от одной переменной Д (времен и); таким образом, на одном рисунке может быть построено сразу нссксЗ ко изучаемых процессов (временных рядов).
Типичным применением матричных графиков является одновременное из< ражение на одном графике распределений анализируемых переменных к завис мостей между ними
Матричные
графики
301
Матричная диаграмма (FACTOR STA Юл’ЮОн)
Это бывает полезно при выборе масштаба измерении или проведении разведочного анализа данных (например, обработка анкет, экономической ин^юрмацим, данных о контролируемом процессе н т. л.).
При проведении разведочного анализа данных бывает необходимо изучить влияние отдельных наблюдений, удовлетворяющих некоторому условию, на общим вид зависимости между переменными. Это можно сделать с помощью логических Условий выделения подмножества наблюдений для построения матричного гра Фика.
302
Глава б. Трехмерный визуальный анализ данн|
Матрица рассеяния
На этом матричном графике представлены двумерные диаграммы рассеяния, н; каждой из которых значения переменной из строки используются в качестве ко ординат X. а значения переменных из столбца — в качестве координат Y.
Гистограммы, изображающие распределения каждой переменной, расположу ны на главной диагонали матрицы (в квадратных матрицах) или по краям (в пря моутольных матрицах).
ёл Матрица линий
При выборе этого типа графика создается матрица линейных (то есть иепослч довательных) ХУ-графиков (подобно матричной диаграмме рассеяния), на кот i рых отдельные точки соединены линиями в порядке их появления в фай| ле данных.
Гистограммы, изображающие распределения каждой переменной, располаг^ ются на главной диагонали матрицы (в квадратных матрицах) или по краям (в прямоугольных матрицах).
1Тричные^рафики
303
g£] Матрица столбцов
Ла этом графике матрица состоит из сто чбчатых диаграмм, на которых представ-je“bi проекции отдельных точек данных на ось А' (показывающие распределение . 1кснмалы)ых значений).
Гистограммы, изображающие распределения каждой переменной, расположены на главной диагонали матрицы (в квадратных матрицах) или по краям (в прямоугольных матрицах).
Подгонка функции к данным
[/_ Линейная подгонка
Линейная функция (У • а + ЬХ) подгоняется к точкам каждой двумерной диаграммы рассеяния. Параметры а, Ь оцениваются методом наименьших квадратов. Заметьте, что прямая не проходит через наблюдаемые точки, а располагается мак-с,<* " |ьно близко к ним (выбором а, b минимизируется сумма квадратов расстоянию । точек до прямой) То же относится к другим пиниям (см. ниже)
304
Глава 6. Трехмерный визуальный анализ дань
\(~ Логарифмическая подгонка
К данным подгоняется логарифмическая функция вида:
_y-?x[logBx] +b.
где основание логарифма (и) выбирается пользователем (по умолчанию испо? зуется натуральный логарифм по основанию е. где е = 2,71. .).
Экспоненциальная подгонка
По данным подбирается экспоненциальная функция вида. у = Ьх ехр(^хг)
4чные графики
305
подгонка сплайнами
В данном случае производится сглаживание данных бикубическими сплай-нами
|у\ Полиномиальная подгонка
Здесь методом наименьших квадратов данные аппроксимируются полиномом вида
у - Ьв + А,хх + Ь2хх1+Ь3 хх3-г...+ Ья хх”,
где п есть степень полинома (1<п<6). Степень полинома может быть выбрана.
Кривая подгоняется к координатам данных с помощью процедуры сглаживания Методом взвешенных относительно расстояния наименьших квадратов (влияние отдельных точек уменьшается с увеличением горизонтального расстояния от соответствующих точек на кривой).
306
Глава 6. Трехмерный визуальный анализ де
Кривая подгоняется к координатам X, Уданных с. помошью процедуры экспо циально взвешенного сглаживания с отринат • -льным пс ••.н-д.
Влияние отдельных точек уменьшается с увеличением горизонтальном стояния от соответствующих точек на кривой.
— Визуальный анализ / категоризованных данных
Как всегда, мы начинаем главу с обзора всевозможных графиков, преследуя оче- вндцую цель — дать читателю максимально полное представление о способах визуализации ка тегоризованных данных с тем, чтобы привести к осознанному, а не спонтанному выбору необходимого метода. Дополнительный материал и примеры содержатся также в других главах по визуальному анализу.
Вначале поймем идею категоризованных графиков
Что такое категоризованные графики?
Категоризованные графики, также называемые Casement plots (см. фундаментальный труд по визуализации Chambers, et aL (1983) Graphical methods for data analysis. Belmont, C A: Wadsworth), позволяют визуализировать категоризованные данные, иными словами, данные, разбитые на группы (категории) с помощью одной или нескольких группирующих (категоризующих) переменных (от ангаийского categorized variables — категориальные переменные). В качестве группирующих переменных обычно используют категориальные (см. описание типов переменных в главе Элементарные понятия).
О тмстим, что разбиение данных на группы и проведение анализа внутри групп является чрезвычайно важным приемом анализа, постоянно используемом в практической работе. Например, известный прием сегментации рынка представляет I собой частный случай категоризации.
Итак, с помощью группирующих переменных наблюдения из исходного файла данных разбиваются на несколько однородных групп (например, клиенты супер-। маркета разбиваются по уровню дохода или по признаку: имеет — не имеет маши-[ ЧУХ и Для каждой группы строится свой график, показывающий специфику данных
Так как групп несколько, то создаются серии двумерных и трехмерных графиков (гистограммы, диаграммы рассеяния, линейные графики, графики поверхности и др), поодному для каждой выбраннойгруппы — category случаев (непересекаюшихся подмножества наблюдений). Например, такими грушами могут быть пользователи Ин-^нет из Нью-Йорка, Чикаго, Далласа или Москвы, Санкт-Петербурга н Смоленска
I Такие «составные» графики помещаются последовательно, один за другим, наэкране •^мпьютера, позволяя сравнивать данные в каждой группе (например, в группе горо-д°в иди среди клиентов с разным уровнем дохода). Часто удобно собрать категоризо-
I Ванные графики в один составной график для чего в STATISTICA имеются все пт' *-I ®Д1Имые средства
308__________
Глава 7. Визуальный анализ категоризованных да.
Для выбора групп обычно предоставляется широкий набор опций, напбола личная из которых использует категорил/юиу/ю переменную, то есть перемен производящую разбиения на группы своими собственными значениями, напри переменная Город — City стремязначениями Нью-Йорк — New York, Чикаго — Ch, н Даллас — Dallas.
На следующем графике показаны гистограммы модельной переменной, и ряюгцей уровень стресса жителей в трех городах США
Взглянув на графики, можно сделать вывод, что стресс людей, живущих в Д часе, более равномерно распределен, чем стресс жителей Нью-Йорка паи Чик (данные носят модельный характер).
Очевидно, что вместо одной группирующей переменной можно использош две или больше. Далее показаны графики с двумя группирующими переменны
Такие категоризованные графики можно рассматривать как «кросстаЬ>ляп • или «сопряжение» графиков (сравните с таблицами сопряженности). На них к дая из зависимостей представлена на пересечение одного уровня одной группы ющей переменной (например. Город — City) и одного уровня другой группиру щей переменной (например. Время — Time). Таким образом, имеем 6 график (3 уровня переменной Город умножить на 2 уровня переменной Время).
Добавление второго фактора (второй группирующей переменной) покааыв что схемы сообщении о стрессах в Нью-Йорке и Чикаго на самом деле очень сЖ но различаются, если принять во внимание Время опроса. Иными словами, су
Категоризованные графики и матричные графики
ствсино зависят от того, когда именно проводился опрос, утром или вечером. Заметьте, что в Далласе фактор времени суток вносит незначительные изменения.
рассмотрим также модельные данные о работе в Интернете пользователей из различных городов (фрагмент файла см ниже):
Ниже показан категоризованный график, позволяющий визуально представить интенсивность работы в различных городах в зависимости от времени суток.
саз
Время работы
Категоризованные графики и матричные графики
Внешне матричные графики похожи на категоризованные, однако матричные графики строятся для одних и тех же подмножеств наблюдений, тогда как катсгори-
310
Глава 7 Визуальный анализ категоризованных дань
зованные графики строятся для разных, более того, непересекающихся групп • блюдений.
Наличие непересекающейся группы наблюдений и составляет главную особе Л ность категоризованных графиков. Собственно, идея в том и состоит, чтобы pj^. , бить данные на естественные группы и визуально исследовать зависимости меж ** I группами
В категоризованных графиках нужно указывать, по меньшей мере, одну гру >.] пирующую переменную — grouping variable, которая содержит информацию о rpj адI повой принадлежности каждого наблюдения (например, Чикаго — Chicago. Д. _ лас — Dallas). Эта группирующая переменная не будет непосредственно включен^] в график, не будет отображаться на нем. но будет служить критерием разбиении наблюдений на группы.
Выше мы познакомились с категоризованными гистограммами — гистогра--»* > мами, построенными отдельно для каждой группы наблюдений, определяем. 4. значениями группирующей переменной.
В основном гистограммы используются для Toi <>, чтобы исследовать распр. kJ ление значений переменных. Например, гистограммы показывают, какие к»нкр( | I J но значения или диапазоны значений исследуемой переменной встречаюгся на п. более часто, как отличаются значения в разных интервалах, сосредоточено Или г «Я наибольшее число наблюдений вокруг среднего или медианы, имеет ли м<чт си • метрия распределения и т. л.
Гистограммы также используются для оценки сходства (согласия) наблю т«а1 мого или эмпирического распределения с теоретическим распределением
Существуют две основные причины, по которым гистограммы пред< i .iM интерес.
О С помошью гистограммы можно выяснить существо исследуемой пере» ной (например, как распределены пользователи Интернета по возрасте II профессии, просматриваемым сайтам)
О Множество статистик основано на определенных предположениях о рл| делении анализируемых переменных, например, временные интервалы » ду заходами на сайт могут иметь гамма-распределение, и гистограмма н< гает проверить эти предположения.
1„гп~граммы и описательные статистики 311
Если вы описалитип распределения переменных, то можете построить матема-рщескую модель и провести нужные расчеты.
Часто в качестве первого шага в анализе нового набора данных следует построить гистограммы для всех переменных и всех наблюдений и далее подходящим образом их категоризовать
Гистограммы и описательные статистики
Категоризованные гистограммы — Categorized Histograms предоставляют информацию, схожую с описательными статистиками (например, среднее, медиана, минимальное значение, максимальное значение и т. д.). Несмотря на то что некоторые (числовые) описательные статистики легче читаются в таблице, общий вид и глобальные описательные статистики проше исследовать визуально.
График предоставляет качественную информацию о распределении, которая не может быть полностью представлена одним или двумя параметрами.
Например, общее асимметричное распределение дохода может показывать, что большинство людей имеет доход, который гораздо ближе к минимальному значению диапазона дохода, чем к максимальному. Кроме того, при разбиении по половому или этническому признаку эта характеристика распределения дохода может оказаться более выраженной в определенных подгруппах. Хотя эта информация будетсодержаться в коэффициенте асимметрии (для каждой подгруппы) при представлении в графическом виде на гистограмме, она обычно распознается и запо-I Пинается более легко.
Имея свой сайт, вы анализируете статистику посещений и по гистограмме °предечяетс пик интереса к сайту в течение суток.
Гистограмма может также показать «изгибы», которые представляют важную Ваформацию об определенной социальной стратификации исследуемого поколе-ННя или аномалий в распределении дохода в конкретной группе, вызванной, на-I Ример, налоговой реформой.
312
Глава 7. Визуальный анализ категоризованных дак
Категоризация значений в каждой гистограмме
Вес процедуры гистограмм, доступные в STATISTICA, предоставляют больше набор способов разбиения данных па группы.
Эти методы категоризации разделяют весь диапазон значений переменной (| минимума до максимума, если переменная числовая) на некоторое число гр« Н-1И диапазонов, для которых подсчитываются частоты (просто считается коли ство значений, попавших в данный диапазон). Далее полученные частоты пр ставляются на графике в виде отдельных столбцов или полос.
Например, можно создать гистограмму, на которой каждый столбец будет пр ci ав.-|ять диапазон из 10 единиц шкалы, которая используется для представг «ч переменной; если минимальное значение равно 0. а максимальное — 120, то бу создано 12 столбцов. Кроме того, можно сделать так, чтобы весь диапазон знг ний переменной был разделен на указанное число интервалов раяной длины ( пример, 10); в последнем случае, если минимальное значение равно 0, а Mai хгалыюе — 120, каждый интервал будет равен 12 единицам шкалы.
Имеются опции, которые поддерживают более сложные категоризации, наг мер. позволяют создать неравные диапазоны с ладанными пользователем граш ми для каждого диапазона (чтобы создать более попятные диапазоны шли об-нить выброс и увеличить читаемость средней части гистограммы). Диапаз можно также создать, определив критерии включения и исключения с иомен логических операторов (например, первый столбец гистограммы может пре х пять людей, которые за последний год летали на самолете более 10 раз, причи более 50% этих поездок были связаны с бизнесом).
Категоризация значений в составных графиках
Составные графики можно создать для уровней категоризуюшей перемел (например, переменной пол или переменной стресс, характеризующей различ уровни стресса).
,тегоризаиия значений в составных графиках
313
Значения непрерывных переменных (например, возраст, доход, цена) можно избить па заданное число интервалов или создать группы наблюдений с поморю логических условий.
Последняя возможность особен но аффективна, так как позволяет провести разбиение на группы с помощью «правил», которые используют более одной переменной. с заданием логических соотношений между этими переменными (например, таким способом можно выбрать группу, состоящую из всех людей мужского пола старше 30 лет и играющих в гольф и не любящих попсу).
В качестве еще одного примера рассмотрим данные, характеризующие стресс женщин. Значения первой переменной описывают семейное положение опрошенных женщин, значения второй переменной измеряют уровень тревоги. Известно, что точностная тревожность представляет собой устойчивую склонность личности воспринимать жизненную ситуацию как угрожающую и реагировать на нее соответствующим образом (см., например, Кокс Т. (1981) Стресс). Обычно использую! шкалу тревожности: низкая тревожность, умеренная и высокая. Для простоты ограничимся шкалой «низкая — высокая» тревожность. Файл данных показан ниже
-•^Стресс женщин f у 2
£ЕМ ПОЛ | ТРЕВОГА
П_семья Высокая
Несенья Н_семья Г)_свмья
П_с«мья Н_семья П_семья Н_семья
Низкая Высока^
Низкая
Высокая
Низкая
Низкая
Высокая
Низкая
Высокая
Откройте окно Галерея графиков, в котором выберите статистические катего-РнзоваНиые графики (левое меню) и нктограммы (правое меню). Сделав выбор, | На*Мите кнопку ОК.
314
Глава 7. Визуальный анализ категоризованных дзнн
В появившемся далее окне нажмите кнопку Переменные, чтобы выбрать п< меиные для графика.
Выберем в качестве группирующей переменной семейное положение жешд ны. Значения этой переменной разбивают данные па две группы: женщины, жщ, щие в полной семье, и женщины, живущие в неполной семье, включая одинок женщин. Анализируемой переменной будет переменная тревога, выбранная вт] тьем столбце.
Далее сделайте установки для настройки графика, как показано в окне 2М ка тегорижюанные гистограммы.
Категоризованные гистограммы и диаграммы рассеяния
315
I Возможны два способа размещения гистограмм на графике в зависимости от I .^ора. сделанного в опциях Размещение этого диалогового окна (см. графики 1нл*е>
ТРЕВОГА
ТРЕВОГА
! 13 графиков видно, что уровень тревоги женщин в неполных семьях выше, чем ных. Насколько значимо это различие, можно оценить с помощью специаль-татистичсских критериев, например с помощью критерия хи-квадрэт.
В данном примере это различие небольшое, однако и число наблюдений мало, и бы подобное различие (одно наблюдение) имело место для 100 респонден-• то. очевидно, мы отнесли бы его за счет случайной ошибки и не приняли бы во внимание
В этом и состоит существо дела' если визуально вы видите отчетливый эффект, т« ^го не имеет смысла доказывать статистически; если эффект не столь ясен, то меняют статистические критерии.
Категоризованные гистограммы и Диаграммы рассеяния
Эффектным приложением методов категоризации для непрерывных переменных Может оказаться представление связей между тремя переменными на плоскости.
316
Глава 7. Визуальный анализ категоризованных
Наверняка приведенный нами пример визуализации удивит даже искушснц аналитиков. Ниже показана диаграмма рассеяния для двух переменных Load Load 2.
Теперь предположим, что необходимо добавить третью переменную (Out[. рассмотреть ее распределение на различных уровнях совместного распредел Load 1 и Load 2 Этого можно достичь, например, с помощью следующего грае
На графике значения переменных Load 1 и Load 2 разбиты на 5 уровней, и л каждой комбинации уровней построена гистограмма переменной Output.
Подгонка теоретических распределений к наблюдаемым распределениям
Функции подгонки распределений STATISTICA. встроенные в гистограммы, I зволяют сравнивать распределение наблюдаемых данных с такими распределен ями, как нормальное, бета-, экспоненциальное, экстремальных значений, гамм геометрическое,Лапласа,логистическое,.югнсрмальное,Пуассона, Редея и Вейбул
гонка распределений к множественным гистограммам
317
I Это наиболее часто возникающие на практике распределения, и проверка со-(ласпя с ними данных иногда представляет интерес.
Обратите внимание, что программа STATISTICA также включает специальный модуль подгонки распределения (см. Непараметрическая статистика и подгонка распределений), который предоставляет широкий набор теоретических функций распределения, графиков и с татистик для проверки согласия исходных данных с выбранным распределением.
Подгонка распределений к множественным гистограммам
I Несколько архаичный термин «множественный» в анализе данных часто эквива-1ен ген слову «несколько» или «много», таким образом, множественная гистограмма F означает всего лишь, что несколько гистограмм отображены на одном графике.
При построении нескольких гистограмм на одном графике переменные пред-I ставлены смежными полосами, поэтому для каждой группы (обычно достроенной вдоль горизонтальной оси X) строится несколько полос.
Аппроксимирующие кривые могут либо точно соответствовать гистограммам, либо быть сравнимыми друге другом
Поскольку множественные гистограммы создаются для визуального сравнения Распределений в разных группах, например мужчин н женщин (а не для анализа Кач‘ ства подгонки для отдельных переменных), то STATISTICA использует вто
318
Глава 7. Визуальным анализ категоризованных дан
рое решение: ожидаемая теоретическая кривая будет -«прикреплена» к число! значениям (а не к меткам групп) осиХ. На практике это обычно не влияет на 061 нение графика, то есть очевидное отклонение переменной от ожидаемого pacni деления по-прежнему будет очевидно.
Если нам нужно «прикрепить» функции распределения к меткам групп, то мс но изменить соответствующие формулы, так что подогнанные распределения | дут сдвинуты по оси X, чтобы компенсировать сдвиг столбцов гистограмм. '
Категоризованные диаграммы рассеяния
2 М диаграммы рассеяния используются для визуализации зависимости между д в мя переменными X и У (например, вес и рост, цена и качество). В диаграммах рг сеяния отдельные данные представлены точками в двумерном пространстве. Д| координаты (X и У), определяющие расположение каждой точки, соответствуй определенным значениям двух переменных.
Если две переменные сильно связаны, то точки имеют некоторую система! ческую форму (например, группируются вдоль прямой линии или гладкой к| вой). Если переменные не связаны, то точки образуют круглое «облако» (б подробно см. главу Элементарные понятия).
Категоризованные диаграммы рассеяния предоставляют мощные исследи тельские и аналитические методы исследования соотношений между двумя и лес переменными в различных подгруппах
Нелинейная зависимость
319
Нелинейная зависимость
Нелинейность — это другая сторона зависимости между переменными, которую .„-кно исследовать на диаграммах рассеяния. Для измерения нелинейных зависи-, теп между переменными не существует простых в использовании тестов: стан-рутный коэффициент корреляции Пирсона г позволяет измерять линейною зави-: цмость, а некоторые непараметрмческие корреляции, такие как корреляция Спирмена!?, позволяют измерять так ле монотонные нелинейные связи.
Иге тедование диаграмм рассеяния даст возможность определить форму зависимости, так что в дальнейшем можно выбрать соответствующее преобразование ыппых, чтобы «линеаризовать* зависимость или выбрать соответствующее урав -н< ли 1ля нелинейного оценивания.
Глава 7. Визуальный анализ категоризованных данн
320
Категоризованньк вероятностные графики
С помощью категоризованных вероятностных графиков можно определить, нисколько близко распределение переменной следует нормальному распределен] н различных подгруппах.
Категоризованные нормальные вероятностные графики представляют эффект* иый инструмент для проверки нормальности распределения данных в отдель группах.
Если подгонка в основном неверна и данные образуют какую-либо ясную фо] (например, букву S) вокруг прямой линии, то переменную, возможно, пеобхо каким-то образом преобразовать до того, как опа будет использована в проце предполагающей нормальность (например, логарифмическое преобразованиеч
Категоризованные графики квантиль-квантиль
используется, чтобы «втянуть» конец распределения (см. Neter, Wasserman, and Kutner (1985) Applied linear statistical models: Regression analysis of variance and experimental designs, Homewood IL: Irwin).
Нормальные вероятностные графики без тренда строятся так же, как и стандартные нормальные вероятностные графики, за исключением того, что линейное смешение (тренд) убирается до того, как строится график.
Это часто «разбрасывает» график, что позволяет пользователю легко обнаружить отклонения от нормальности, например, если распределение равномерное, то возникает S-образная кривая.
Категоризованные
квантиль-квантиль
графики
Категоризованные графики квантиль-квантиль (К-К) используются для поиска наилучшего распределения в заданном параметрическом семействе распределений.
Вначале нужно выбрать, какое из теоретических распределений аппроксимирует данные. Так как выбранные семейства вероятностных распределений зави-Сят от параметров, например, среднее и стандартное отклонение для семейства йормал ьных распределений, то задача состоит в том, чтобы оценить неизвестные Параметры по имеющимся наблюдениям.
322
Глава 7, Визуальный анализ категоризованных дан>
Чтобы оценить аппроксимацию или качество подгонки наблюдаемых данны, теоретическим распределением, наблюдаемые значения переменной (х <. < упорядочиваются, строится вариационный ряд, азатем эти значения (х) строять по обратной функции распределения вероятности, обозначенной как F ' (точце, F 1 (i - rank^/n + я^, где зависит от распределения, a rank^ и задают^
пользователем).
На графиках проверка согласия проводится визуально.
Если наблюдаемые значения попадают на линию регрессии, то можно сделан вывод, что наблюдаемые значения согласуются с выбранным распределение^ Уравнение аппроксимирующей линии (Y=a + Ах, приводится в заголовке К-К-гр;. фика) дает оценки параметров (а и Ь, где а — параметр положения, h ~ парами» масштаба) распределения.
Категоризованные графики вероятность-вероятность
Категоризованные графики вераятность-вероятшкть {В-В) используются для ош ределеиия того, насколько хорошо определенное теоретическое распределение aj проксимирует наблюдаемые данные.
На В-5-графике наблюдаемая эмпирическая функция распределения (доля зна чений переменной < х) сравнивается с теоретическим (предполагаемым) распределением. Если все точки графика ложатся на прямую с тангенсом угла наклон! I то можно заключить, что теоретическое распределение хорошо апцроксимир'. •*’ эмпирическое распределение.
Чтобы построить такой график, нужно полностью задать теоретическую фун« цию распределения. Поэтому параметры распределения должны либо бытьза.'*' ны пользователем, либо оценены
Категоризованные линейные графики
На линейных графиках отдельные точки соединены линиями. Линейные граф»! предоставляют простой способ визуального представления последовательной большого числа значений (например, уровня цен на бирже за несколько дней).
^дтегоризованные прямоугольные диаграммы
323
Опция категоризованных линейных графиков — Line Plots используется, если нузкпо посмотреть эти данные, разбитые группирующей переменной на фуппы /например, цены при закрытии по понедельникам, вторникам и т. д.) или другими логическими критериями, включая одну или более переменных (например, цены при закрытии только в те дни, когда индекс на двух других биржах и Dow Jones поднялся по сравнению с остальными расценками при закрытии).
В системе STATISTIC А можно экспериментировать с различными стилями визуализации категоризованных последовательностей значений, изменяя Тип графика — Graph Туре в диалоговом окне Разметка графика — Plot Layout.
Методы сглаживания
Процедуры сглаживания доступны также и для категоризованных линейных графиков, например, как показано на следующем рисунке:
Категоризованные прямоугольные Диаграммы
^а прямоугольных диаграммах — Box Plots (термин впервые использовал извест-«Ый статистик Тьюки (Tukey) в 1970 г. — см.: Tukey J.W. (1972) Some graphic at>d semigraphic displays. In7 Statistical Papers in Honor of George W Snedecor;
324
Глава 7, Визуальный анализ категоризованных дан»
ed. Т. A. Bancroft, Arnes, IA‘ Iowa State University Press, p. 293—316) диапазоны эн чений выбранной переменной (или нескольких переменных) строятся отделы для групп наблюдений, определенных значениями категоризующих переменны:
Положение центра данных (медианы или среднего) и диапазон вокруг него а также, например, квартили, стандартные ошибки или стандартные отклонена вычисляются для каждой группы наблюдений
На приведенном графике видны выбросы (в данном случае точки, отстоящи больше или меньше, чем в 1,5 раза по отношению в межквартильному диапазону1
>!
I г!
И4
Фа
Однако на следующем трафике нет очевидного выброса или экстремальных зна чений.
J Н| hg 1
g lit’ ' 1
ЙЙИиЬйб
IIA. HUKf rUMWr ijJ
Для прямоугольных диаграмм существует два типа приложений: а) отображс! диапазонов значений для отдельных объектов наблюдений (например, обычная , кимаксная диаграмма — MIN-MAXplot для акций или товаров, или составные пои Новотельные графики — sequence dataplots с диапазонами) и б) отображение нзм чивости данных в отдельных группах или примерах (например, диаграммы «я пи и усы» или диаграммы размахов, в которых среднее — это точка внутри «яшп! плюс-минус стандартная ошибка «яшмк», а плюс-минус стандартное отклонен^ среднего — более узкий «ящик», или, как иногда говорят, пара «усов»).
Прямоугольные диаграммы позволяютбыстро вычислить и «интуитивно предс вить» силу связи между группирующей и зависимой переменной.
Предполагая, что зависимая переменная распределена нормально, и зная, кая часть наблюдений попадает, например, в ±1 или ±2 стандартных отклопег от среднего, можно легко вычислить результаты эксперимента и сказать, напр
связанные графики
325
I мср>что около 95% наблюдений в экспериментальной группе 1 принадлежат диа-[ паэону. отличному от 95% наблюдении группы 2.
Кроме того, можно строить так называемые усеченные средние значения (trimmed ' wjefl^s), исключая заданный пользователем процент наблюдений из экстремаль-' ных значений.
Связанные графики
«Ящики и усы», или диаграммы размаха
Этот тип статистических категоризованных графиков по умолчанию помещает «яшмк» вокруг центра (то есть среднего пли медианы), который представляет собой выделенный диапазон (то есть стандартную ошибку, стандартное отклонение, минимакс или константу), и «усы» снаружи «ящика», которые отображают другой выбранный тип диапазона.
Ширину «ящика» и засечек «усов», конечно, можно менять.
RH] «Усы», или диаграммы диапазонов
В этом типе прямоугольных диаграмм диапазон (то есть внутригрупповая стандартная ошибка, стандартное отклонение, минимакс или константа) представлен «т'сами» (отрезком прямой с засечками на обоих концах).
«Ящики», или прямоугольники
В этом типе прямоугольных диаграмм вокруг средней точки (то сеть среднего груп Пы или медианы) помещается «ящик», который представляет выбранный днапа-
ЦЩ Столбцы
В этом виде прямоугольных диаграмм для представления средней точки (средне го группы или медианы) используются вертикальные столбцы.
^тргоризованные круговые диаграммы
327
«ул верхние и нижние засечки
Вэтом виде прямоугольных диаграмм «засечки* на «усах» не симметричны, а сдвинуты влево, представляя традиционный график «пен на акции».
Категоризованные круговые диаграммы
Круговые диаграммы являются одним из наиболее часто используемых форматов графиков, которые используются для представления пропорций или значений переменных.
М арх С агоре йог 1
В - Snapprp Empire
С - Snapprrglaeas О - Esit Соя Ware,
Е Dracotrt Oixlet
F - Mike, Мак
Построенные категоризованные круговые диа1-раммы всегда будут рассматриваться как частотные — frequency круговью диаграммы (в противоположность круговым диаграммам данных). Этоттип круговых диаграмм иногда называют чде-Могтюй круговой диаграммой — frequency pie chart.
Относительные частоты представлены как секторы крута пропорциональных Размеров. Поэтому круговые диаграммы предоставляют альтернативный гисто-фаммам метод визуализации данных.
328
Глава 7, Визуальный анализ категоризованных,
Секторы круга можно пометить числовыми или текстовыми значениями, ме ки могут включать непосредственные или относительные значения частот.
Круговые диаграммы рассеяния
Полезным приложением категоризованных круговых диаграмм является предст, ление относительной частоты распределения переменной в каждой точке совме, ного распределения двух других переменных Следующий график наверняка у, вит вас.
Обратите внимание, круги нарисованы только в тех «местах», в которых & данные. Поэтому приведенный выше график выглядит как диаграмма рассеяГ (переменных L1 и L2) с отдельными кругами в качестве указателей точек.
Кроме информации, содержащейся в простой диаграмме рассеяния, ка»У круг показывает относительное распределение третьей переменной па соответсп ющем месте (например, Низкое — Low, Среднее — Medium, Высокое качество — I Quality).
jtatL ’ эризованные трехмерные графики
329
Представленный график служит прекрасным образцом совмещения диаграмм сеяния и круговых диаграмм. О и также показывает, в каком направлении сле-•7" двигаться в визуальном анализе данных, чтобы получить действительно эффективный результат
Категоризованные диаграммы пропущенных данных и диаграммы диапазонов
(Эти графики позволяют определить шаблон распределения пропущенных данных и заданных пользователем точек, лежаших «вне диапазона», для каждой категории наблюдений.
Подобные графики используются в разведочном анализе для того, чтобы определить протяженность и «выход из диапазона» данных.
В большинстве процедур пропущенные данные удаляются, используя попарное пли построчное удаление пропущенных данных или подстановку среднего значения вместо пропуска.
Категоризованные трехмерные графики
К эгому типу относятся трехмерные диаграммы рассеяния (пространственные графики, спектральные графики, диаграммы отклонения и трассировочные графики), диаграммы линий уровня и графики поверхности для наборов случаев, заданных определенными группами выбранной переменной или «руппами, определенными заданными пользователем условиями выбора случая (наборы можно определитьс помощью логических выражений, использующих любые переменные текущего набора данных).
Информация, представленная на этом графике, в точности та же. что и на нека-Тегоризованной трехмерной диаграмме рассеяния, или диаграмме линий уровня, илн графике поверхности, за исключением того, что для каждой заданной пользователем «руины наблюдений строится один «рафик.
330
Глава 7 Визуальный анализ категоризованных дань
Основное назначение данного графика — облегчить сравнение групп или горим независимо от соотношений между тремя или более переменными.
В основном трехмерные XYZграфики обобщают соотношения между тремя пе ременными. Различные способы, которыми могут быть категоризованы данные позволяют посмотреть состав этих соотношений с помощью какого-либо другоп критерия (например, групповой принадлежности).
Заметьте что эффект более заметен, если переключиться на режим отображения линий уровня.
» Bl II IIIIK9
Категоризованные тернарные графики
Категоризованные тернарные графики можно использовать для исследования соотношений между компонентами смеси, сумма значений которых равна констзн-те, для каждого уровня группирующей переменной.
332
Глава 7. Визуальный анализ категоризованных де
На тернарных графиках для построения четырех (или более) переменных (к-поненты X, Y и Z, отклики VI, V2 и т. д.) в двух (тернарные диаграммы рассеяние или линии уровня) „ли трех измерениях (тернарные графики поверхности) „< пользуются треугольные системы координат.
В категоризованных тернарных графиках для каждого уровня групциру» переменной (или заданного пользователем набора данных) строится один состщЗ ной график, и все составные графики отображаются на одном экране, чтобы мох, но было производить сравнения наборов данных (групп).
Типичным приложением этих графиков является эксперимент с результатами зависящими от относительных пропорций компонентов, входящих, наириме» состав нового лекарства, моющего вещества или духов, которые варьируются с щ лью определения оптимального состава.
Этот тип графиков также можно использовать в случаях, когда соотношении между связанными переменными нужно сравнить внутри труни данных.
g Пиктографики
На статистических пиктографиках наблюдения или отдельные испытания пред-сТавлены в виде символов со многими элементами.
Основная идея использования пиктографиков состоит в представлении отдельных наблюдений в виде некоторых графических объектов, где значения переменных соответствуют определенным свойствам или размерам этих объектов (как правило, одно наблюдение равно единому объекту). Это соответствие таково, что внешний вид объекта изменяется в зависимости от набора значений.
Таким образом, появляется возможность однозначно «идентифицировать» объекты по набору значений. Изучение таких пиктограмм помогает обнаружить специфические наборы простых соотношений и взаимосвязей между переменными.
Анализ пиктографиков
В идеальном случае анализ пиктографиков осуществляется в пять этапов.
1) Определяется порядок анализируемых переменных. Очень часто наилучшим решением является случайная последовательность. Можно также попробовать ввести переменные в порядке их расположения в уравнении множественной регрессии в зависимости от величины их факторных нагрузок на интерпретируемый коэффициент или использоватьаналогичные многомерные методы. Это иногда позволяет упростить и сделать «однородным» общий вид пиктограмм, чтобы облегчить задачу распознавания не слишком
334
Глава 8. Пиктографу
отличающихся друг от друга картинок. В то же время, использование т^ед ' методов может усложнить задачу поиска некоторых взаимозависимости На этом этапе невозможно дать никаких ун нверсальных рекомендацищкрЗ ме совета попробовать самый быстрый метод (случайный выбор порядщ । до того, как применять более сложные методы.
2) Проводится поиск любых возможных закономерностей, таких как схддстЯ I между группами пиктограмм, выбросы или специфические соотношения I между элементами пиктограмм (например, «если на пиктограмме звезды первые два луча длинны, то один или два луча с другой сторон ы ni ж гограм- ! мы обычно коротки»). На этом этапе рекомендуется использовать пикты графики кругового типа.
3) Обнаруженные закономерности описываются в терминах используемых переменных.
4) Для проверки найденной структуры соотношений nepeMeinibie сопоставляются с другими элементами пиктограмм. Например, можно попытаться пе- , реместить связанные элементы пиктограммы ближе друг к другу, чтобы упростить дальнейшее сравнение. В некоторых случаях в конце этого этапа рекомендуется исключить из рассмотрения переменные, не вносящие заме ною вклада в исследуемую структуру.
5) Для проверки и количественной оценки обнаруженной зависимости или хотя бы некоторых ее параметров используется, например, регрессионный анализ, нелинейное оценивание, дискриминантный или кластерный анализ.
Классификация пиктографиков
Большинство пиктографиков можно отнести к одному из двух типов: круговому или посчедователъному.
Круговые пиктограммы
Круговые пиктографики (звезды, лучи, многоугольники) имеют форму велосипед него колеса», где значения переменных изображаются в виде расстояний межд~-центром («втулкой») пиктограммы и ее углами
Такие пиктограммы полезны при поиске взаимозависимостей между переменными, поскольку они хорошо отличаются и идентифицируются по внешнему виду который в свою очередь определяется конфигурацией значений изучаемых переменных.
-гификация пиктографиков
335
Чтобы перевести эти «приблизительные соответствия» на язык конкретной мо-и /в терминах соотношений между переменными) или чтобы проверить конк-ZpTiiwe предположения, полезно переключиться па один из последовательных пик-тографпков, использование которых может оказаться более эффективным в том случае, когда уже известно, что нужно искать.
Последовательные пиктограммы
Ла посчедовательных пиктографиках (столбцы, профили, линейные графики) отдельные пиктограммы представляют собой небольшие последовательные графики (разных типов).
Значения следующих другза другом переменных отображаются на этих графиках расстоянием между основанием пиктограммы п последовательно идущими точками последовательности (например, высоты столбцов на показанном выше рисунке). Такие графики могут быть не столь эффективными на начальном этапе анализа, поскольку пиктограммы могут не слишком отличаться друг от друга. Тем не менее, как было указано выше, они могут пригодиться для проверки определенной гипотезы или для описания модели в терминах соотношений между конкретными переменными
Кругоаые диаграммы
Пиктографики в виде круговых диаграмм занимают промежуточное место между пиктографиками двух упомянутых выше типов; все пиктограммы имеют одинаковую форму (круг) и разделены на последовательно идущие друг за другом части в соответствии со значениями переменных, следующих друг за другом.
336
Глава 8. Пиктогр;
Несмотря на их форму, с точки зрения функционального использования, tJJ пиктографики скорее можно отнести к разряду последовательных.
«Лица Чернова»
Этот тип пиктограмм образует отдельную категорию. Разные наблюдения пш схематично представлены в виде лиц. При этом выбранные переменные с Кгв> ствуют конкретным элементам (чертам) лица.
В силу уникальных свойств таких диаграмм некоторые исследоватегМ р . сматривают их в качестве основного многомерного метода исследований, кого выявить скрытые взаимосвязи между переменными, которые невоаио» было бы отыскать, применяя любой другой метод. Это утверждение, однакй, очег похоже на преувеличение
Заметим, что метод «Лиц Чернова» довольно сложен, а его использование требует проведения большого числа экспериментов по сопоставлению черт лица с iNF ходными данными
Пиктографики применяются, как правило, в двух случаях: 1) когда нужно выявить характерные зависимости или группы наблюдений и 2) когда необходим! исследовать предположительно сложные взаимосвязи между несколькими переменными. В первом случае пиктографики используются для классификации блюдений аналогично кластерному анализу.
Предположим, было проведено анкетирование артистов с целью изучении И личных качеств. Пиктографики помогут определить, существуют ли естественна группы артистов, отличающиеся определенными закономерностями полученмМ баллов за ответы на различные вопросы. Например, может оказаться, что некое» рые артисты — чрезвычайно творческие личности, при этом они недисциплиН^ рованны и независимы, в то время как представители второй группы хорошо обр • зованиы, дисциплинированны и уделяют большое внимание успеху у публики. 1
Второй тип применений — исследование связей между несколькими переь ными — больше напоминает факторный анализ, то есть его можно использоМИ при исследовании вопроса и зависимости переменных. Предположим, изучагдЛ мнение группы людей о различных марках автомобилей. Несколько человек полнили детальные анкеты, оценивая различные свойства различных авто-'" билей. В файле данных записаны средние оценки по каждому из свойств (р*-' сматриваемых как переменные) для каждого из автомобилей (рассматриваеМЙ| как наблюдения).
пиктографиков
337
Й,ии «Лип Чернова» (где каждое лицо представляет мнение ободном й) может оказаться, что улыбающиеся лица обычно имеют большие если цене соответствует «величина» улыбки, а динамическим каче-р ушей, это «открытие» означает, что быстрые машины дороги. Ра->чень простой пример, однако при анализе реальных данных приме-________ иода может сделать более очевидными сложные взаимосвязи между переменными.
«Лица Чернова»
На данном nine диаграмм для каждого наблюдения рисуется отдельное «лицо». Значениям выбранных переменных ставятся в соответствие форма и размеры конкретных черт лица (например, длина носа, угол наклона бровей, ширина лица).
55 Звезды
График с пиктограммами в виде звезд — это пиктографик кругового типа. На таких i-рафиках для каждого наблюдения рисуется отдельная пиктограмма в виде звезды, при этом относительные значения выбранных переменных для каждого наблюдения представляются длинами соответствующих лучей (порядок следования которых зафиксирован: по часовой стрелке начиная от луча, направленного вертикально вверх). Концы лучей соединяются линиями.
a G7 А и
A-.ja ALK1 Вил ВиЮ* Corvette Chrjiler
И Г" Д И "<? В
Dodge Еа^'е Ford ивпя fsuai Mazda
® а и Vs eg А
Мегсеоез МВиО м-.мп сиз Poraat Pwsene
W В! И И
Saio тоу-аэ vW vaMj
338 Глава 8. Пиктогр;
Лучи
Графике пиктограммами в виде лучей — это пиктографии кругового типа. Н для каждого наблюдения рисуется отдельная ппктщ-рамма, напоминающая це, при этом все лучи имеют одинаковую длину и каждый из них предстч/ одну из выбранных переменных (порядок следования которых зафикенрон часовой стрелке, начиная от луча, направленного вертикально вверх). Точ лучах, определяемые относительными значениями соответствующих перем * соединяются ломаной линией.
ПИНМ№ИМ!И.11Х№.11—^^»М^И^^Т35ТГ
3,-
х£г А тЬ т^г
Acura Лиа BMW Buick Corvwn елгу*-
i 'к 'йг ~к "к
i Пооае Ечи Fora Hcrci ljuai wki
। тк тк тгкг 'dr i
Mrrreoes Mcui mumi cuss Рэтк рог,ch?
7*7 A К
Soao Гаучи VW vowo
Многоугольники
График с пиктограммами в виде многоугольников — это пиктографик круто! типа. Здесь для каждого наблюдения рисуется пиктограмма в виде многоугол! ка. Относительные значения выбранных переменных для каждого наблюди представлены расстояниями, отсчитываемыми от центра диаграммы до посл^ вательно идущих вершин многоугольника (по часовой стрелке, начиная с напр ления вертикально вверх).
« > Круговые диаграммы
Графики с пиктограммами в виде круговых диаграмм — это пиктографики кр] вого типа (см предыдущий раздел). Значения переменных для каждого цаблю ния изображаются в виде секторов (по часовой стрелке, начиная с направл вертикально вверх). При этом относительные значения выбранных переме! определяют углы раствора соответствующих секторов.
339
пиктогрзфиков
** Столбцы
График с пиктограммами в виде столбцов — это пиктографик последовательного типа. Для каждого наблюдения рисуется отдельный график; относительные значения выбранных переменных соответствуют высотам последовательных столбцов.
Линии
Графики с пиктограммами в виделангш являются пиктографиками последовательного типа.
Ann Auoi bmw Buck corvene Счуиег
О«П» Eatfe Fad Нию» ыои миоа
340
Глава В. Пиктогрё
Для каждого наблюдения рисуется отдельная ломаная линия; при этом othiLJ тельные значения выбранных переменных для каждого наблюдения соотве ч/гД ют высотам последовательных точек излома J
j* Профили
Графики с пиктограммами в виде профилей — это пиктографики последователе него типа (см. предыдущий раздел). Для каждого наблюдения рисуется отдеЗ ный график Относительные значения выбранных переменных соответствуют вы сотам последовательных пиков сечения, ограниченного снизу базовой линией '
~ Примеры визуального * анализа и настройки графиков в STATISTICA
Пример 1. Настройка двумерных и трехмерных графиков
В данном примере описываются способы настройки графиков в системе STATISTICA с использованием диалоговых окон Общая разметка и Размещение графика.
Настройка двумерных графиков
В примере использован файл Poverty.sta из набора примеров, поставляемых с системой STATISTICA, в котором содержатся сравнительные данные результатов переписи 1960 году по 30 случайно выбранным округам США. В качестве названий элементов введены названия округов. Ниже показана часть файла
Предположим, что необходимо построить график, отражающий информацию ° Количестве семей, живущих ниже уровня бедности (Pt Poor). о количестве жителей, имеющих телефоны (PtPhone). и о количестве сельского населения ^^Rural). Для начала построим несколько линейных графиков.
342
глава 9. Примеры визуального анализа и настройки графиков е STATE
Построение нескольких линейных графиков по умолчанию
В любом из модулей системы STATISTICA откройте файл Poverty.sta. Затем с па мощью кнопки Галерея графиков ЕЗ (или из основного меню Графика) выберцЗ пункт Статистические 2М графики — Линейные графики (для переменных) ।
Появится диалоговое окно 2Млинейные графики
Затем нажмите кнопку Переменные и выберите три переменные для постр<й ниязависимостей Pt_Poor, Pt Phone и PtPural(чтобы выбирать переменные вгц«’ иэвольном порядке, при нажатии на имя переменной удерживайте нажатой ₽ п вишу CTRL).
В поле Тип графика приведен список доступных для построения линейны: графиков. По умолчанию выбирается первая строка списка (простой линейны’ трафик одной переменной). Если в данный момент нажать ОК, то для каждой И переменных будет построен один график, то есть три отдельных графика поем довательно, один за другим после нажатия кнопки Еще в графическом окне I
Пример.
Настройка двухмерных и трехмерных графиков
343
Так как цель данного примера — воспроизвести все три зависимости на одном
графике, ставной.
образом:
в диалоговом окне 2М линейные графики не< бходимо выбрать строку Со-Тогда диалоговое окно 2Млинейные графики будет выглядеть следующим
Для вывода установленного по умолчанию графика нажмите ОК.
344
Глава 9. Примеры визуального анализа и настройки графиков в ST/
Удаление кнопок Еще и Выход
Если продолжить работу с данным конкретным графиком, может возни] обходимость убрать кнопки Еще и Вых. из левого верхнего угла графическ
Для этого нужно нажать на кнопку Вых. (после нажатия кнопки Еще явится диалоговое окно 2М линейные графики).
Изменение размеров (пропорций) графического окна Покачанный выше график имеет размеры, установленные по умолчанию. Д менении размеров графического окна оно по умолчанию сохраняет своп di ции, то есть вертикальные и горизонтальные размеры ме| |яются одновремена режим (установленный по умолчанию) действует до тех пор, пока нажата i |Bj Фиксировать пропорции. Если нажать кнопку Изменить пропорции а называемый коэффициент разрешения может быть изменен — например, чсское окно можно сделать квадратным:
Отметим, что установки по умолчанию для пропорций графического oi гут быть изменены в диалоговом окне Отображение графика (оно вызыв! выпадающего меню Вид).
Прерывание построения графика
Программа автоматически перерисовывает график, чтобы отобразить на менения, внесенные вами. Для сложных графиков с несколькими зависим процесс перерисовывания занимает определенное время.
Рисование графика можно прервать, щелкнув левой клавишей мыши i: на экране. Программа закончит рисование текущего элемента, затем песочн исчезнут и полный контроль над настройкой всех параметров будет во । пользователю. Как правило, в этом случае график оказывается незаконче<1
Завершить процесс перерисовывания можно, слегка изменив размеры веского окна или сделав любые другие изменения, требующие псрери< графика
настройка двухмерных и трехмерных графиков
345
Просмотр данных
Нажмите кнопку Ю на панели инструментов, чтобы вызвать Редактор данных графика Это можно сделать и другими способами, например:
1) выбран команду Редактировать данные из выпадающего меню Разметки или ’) щелкнув правой кнопкой мыши где-либо на фоновой поверхности графика, на каком-либо условном обозначении или на одной из линий, а затем выбрав с троку контекстного меню Редактировать данные графика
Напомним, что на двумерных графиках каждая зависимость (в данном случае *нмя) представлена парой столбцов X и К Каждая пара Х-Y соответствует точке ^/Рафике. В этом редакторе можно изменять данные, удалять точки, добавлять Г₽оки или новые зависимости; все сделанные изменения будут отражены на гра-ке после того, как будет нажата кнопка Перерисовать или кнопка Выйти+пере-^вагпь ,1а панели инструментов. Кроме того, в меню имеется много возможнос-ЛЛя изменения представления чисел в Редакторе данных графика. К примеру.
346
Глава 9. Примеры визуального анализа и настройки графиков в STAi
нажмите кнопку Ширина столбца й, чтобы вызвать диалоговое окно На ширины.
Введите число 3 в поле Десятичные разряды и нажмите ОК.
Теперь все данные в редактируемой таблице имеюттри десятичных знака, но изменить также шрифт и размер шрифта (используйте меню Сервис — 31
Для продолжения работы с графиком щелкните в любом месте графин окна, чтобы вынести его на передний план (сделать активным), или закро» доктор данных графика
Основные соглашения по настройке графиков
Средства настройки графиков доступны из выпадающих меню Правка и Рс ки, а также с клавиатуры (кроме того, они могут быть записаны в ваде ма манд и/или поставлены в соответствие кнопкам на панели инструментов / автозадач). Кроме того, есть способы быстрого изменения элементов граф! требующие выполнения большого количества действий (нажатия кнопок I выбора меню и т. д.). Существуют два основных правила редактирования ков.
О Для выбора конкретного способа настройки объекта (или элемента ! _ ка) щелкните правой кнопкой мыши на этом объекте и выберите тш стройки из контекстного меню.
о Чтобы получить доступ к наиболее общим (установленным по умоД'1 способам настройки объекта (или элемента графика), дважды шелкн| объекту
Например, чтобы изменить тип линии, дважды l__ -жните на соответстш линии; для изменения заголовка дважды щелкните по заголовку; чтобы из»
Настройка двухмерных и трехмерных графиков
347
Как видно из диалогового окна Правка заголовков, всего можно ввести 11 заголовков: 5 верхних и по 2 для каждой из остальных осей. Каждый заголовок может иметь собственный шрифт и размер, а также, как показано в последующих примерах, может включать символы форматирования для записи индексов, степеней, условных обозначений, уравнений аппроксимирующих функций и т. д. Эти символы легко вставляются со встроенной панели инструментов Формат.
Возможен и другой способ: сделав двойной щелчок на фоновой поверхности окна, можно вызвать дивлоговое окно Общая разметка 2М графиков, в котором тоже есть режим редактирования заголовков
Я'ЭДе ввода заголовка нажмите ОК, чтобы перерисовать график. Например, бедующего графического окна были введены две строки заголовков.
348
Глава 9. Примеры визуального анализа и настройки графиков в STA1
Диалоговое окно Размещение 2М графика
Как видно из графика, процентные данные, отражающие долю «бедных» пот] телей, расположены в основном ниже значений для переменных Pt_Ph< Pt_Rural. Для каждой из зависимостей масштаб может быть подобран отделы указан на левой или Правой оси Y. Можно добиться «лучшего представления» п< менной PtPoor, если установить для нее отдельный масштаб вдоль правой У, включив при этом автоматический режим оптимального масштабирования
Основные параметры отдельных зависимостей (в данном случае линейных! фиков) задаются в диалоговом окне Размещение графика, причем для кажди! них открывается отдельное окно. Чтобы вызвать его для переменной Pt_Poor, а кните правой кнопкой мыши где-либо на соответствующей линии (или на усj ном обозначении этой зависимости).
Затем выберите строку контекстного меню Изменить размещение завись ти(ей).
1. Настройка двухмерных и трехмерных графиков
349
Построение графика, масштабированного вдоль правой оси Y
Практически в центре появившегося диалогового окна находится поле, обозначенное как Ось Y. Состояние переключателей этого поля определяет, относительно какой из осей Убудет построен график. Пометьте поле Справа, чтобы график переменной Pi Pnor масштабировался вдоль правой оси Y.
Изменение фиксированных условных обозначений
В левом верхнем углу диалогового окна находится поле Фиксир. усл обозначения. Тест в этом поле определяет обозначение данной зависимости на графике. Далее в этом примере это условное обозначение будет преобразовано в пользовательский текст, который может быть помещен в лобую область графического окна. Пока же заменим имеющееся обозначение более информативным ( например. Процент). а затем во второй строке условного обозначения запишем бедные семьи (П). (П) добавлено, чтобы показать, что этот график относится к правой оси Y. Это добавление будет сделано автоматически, если в момент создания графика установить параметр Сдвойн. осью Y.
350
Глава 9. Примеры визуального анализа и настройки графиков в STA1
Для того чтобы изменить обозначения других зависимостей, для каждой из пихт* же необходимо вызвать диалоговое окно Размещение 2М графика. Например, что" вызвать диалоговое окно Размещение 2М графика для второй переменной (PtJP/юг нажмите на кнопку Следующая » (в правам верхнем углу диалогового окна'. Гепы введите другое Фиксир.усл обозначение и сделайте то же самое для следующей завис мости. Закончив изменения, нажмите ОК и вернитесь к графическому окну
Тинейиьй гоафик . ««лвнегра г- - •л «-втепей дп= % аыСрвнььк офугов
Изменение обозначений осей
Как и было задумано, на графике произошло два изменения. Во-первых, длинные условные обозначения стали более информативными и, во-вторых, график «пр*>-цента бедных семей» стал более растянутым вдоль оси У. Поскольку эта завь i ш мость построена теперь вдоль правой оси Y, то на этой оси должны быть и соотресч ствующие обозначения. Если сделать двойной щелчок на правой оси К то появится диалоговое окно Параметры оси: У правая.
гиимер 1- Настройка двухмерных и трехмерных графиков 351
Для каждой из осей можно вызвать подобное диалоговое окно (чтобы перейти L следующей или предыдущей оси, используйте поле Ось в верхней части этого окна)- - v
Чтобы включить поле Значения па оси для правой оси г, надо нажать переключатель Числовые. Обратите внимание, что значение параметра Мин. которое выбирается автоматически (Разметка оси: Авто), равно 10. Таким образом, координата У пересечения с осью X соответствует не 0, а 10 процентам.
Очень часто необходимо показать, что позиция. интуитивно принимаемая за поль. вовсе не соответствует нулевой отметке па графике. Это можно сделать, вве-„ч «разрыв шкалы» па данной оси. Разрыв шкалы по оси X на графике будет выглядеть следующим образом:
5С0 Б00 700
Чтобы ввести разрыв шкалы для правой оси Y, поставьте галочку в соответствующем поле (в нижнем левом углу диалогового окна), при этом установленное по умолчанию положение места разрыва шкалы оставьте неизменным. Теперь установите режим разметки оси Ручная/0, а значения параметров Макс., Шаг и Мин сделайте равными соответственно 45,5 и 11 (ввод значения 11 для параметра Мин. приведет к тому, что минимальное значение не будет показано, потому что оно находится за местом разрыва). Нажмите ОК, чтобы увидеть изменения на графике.
Теперь введенный на графике разрыв шкалы «предупреждает* наблюдателя о Том. что начальная точка правой оси Y не соответствует нулю процентов.
Масштабирование осей
Выбор масштаба по левой оси У тоже не является от и малы ним. в данном конкретном случае минимум шкалы соответствует значению -10. Так как на i рафике Представлены значения в процентах, т»» нольбыл бы более подходящим зилченпем
352
Глава 9. Примеры визуального анализа и настройки графиков в STATISI’
для минимума. Сделав двойной щелчок на левой оси К вызовем диалоговое Параметры оси- Y левая.
Предусмотрено несколько режимов разметки оси: Авто, Авто/0, Ручная и Ру ная/0. Если выбрана разметка Авто, то программа сама выбирает минимальный в максимальный отчеты на шкале так, чтобы весточки на графике были видны. Е. выбрать режим Ручная, то параметры Макс, Шаг и Мин. буд ут определяться п< * v вателем.
Режим масштабирования с привязкой к нулю (/0)
Режим разметки /0 определяет, где расположена «привязка» относительной шк I лы. Объясним это на коротком примере.
Предположим, вручную установлены следующие параметры шкалы. ми«М мум — 3, шаг — 5 и максимум — 25 Если для этой оси применить ручную ра <* -• ку, то метки и риски будут расположены соответственно в точках 3, 3 1 *Л 3+5+5= 13.18и 23. Как правило, желательно иметь «четкую привязку» мегiк > ты к нулю. Если включить режим Ручная/0, то метки и риски на оси окажут позициях 0+5=5,0+5+5=70, 15,20,25 и т. д. Заметим, что режимы Ручная с п. |»« метром Мин., равным 0, и Ручная/0 (Manual/О) эквивалентны.
Для рассматриваемого в примере графика наиболее подходящий разметь । Л! flO как все зпачения представлены в процентах) будет следующая. Ручная/0 со н нем параметра Мин, равным 0, с параметром Шаг, рав ним 10, и параметром МцЯИ равным 109. Установите эти значения и нажмите ОК, чтобы увидеть изменены^ Фв графике.
1. Настройка двухмерных и трехмерных графиков
353
Перемещение условных обозначений
Введенные нами условные обозначения оставляют на трафике много свободного места. В системе STATISTICA условные обозначения могут быть как фиксированными (закрепленными, как в настоящим момент изданном графике), так и преобразованными в пользовательский текст, который можно перемешать, редактировать, как и другие графические объекты. Щелкните правой кнопкой мыши на условных обозначениях и выберите пункт Переместить условные обозначения из контекстного меню.
Линейный график трех демографических показателей длр 30 выбранных округов
354
Глава 9. Примеры визуального анализа и настройки графиков в STATWj
Теперь условные обозначения преобразованы в пользовательский текст, а мег. | то, где они ранее располагались, занято графиком. Чтобы вернуться в фиксим ванный режим, щелкните правой кнопкой мыши где-либо на фоновой поверхно® ти окна и в контекстном меню выберите Фиксированные условные обозначе>-iu (например, можно поместить в свободном месте над условными обозначения*® какой-нибудь поясняющий текст).
Условные обозначения в заголовках
Для удаления какого-либо пользовательского объекта, такого, например, как те.и 1. выделите его (щелкнув по нему кнопкой мыши) и нажмите клавишу Del (или bi берите команду Вырезать объект из меню, вызываемую правой кнопкой мыши Теперь откройте диалоговое окно Общая разметка 2М графиков. Для этого cjfl лайте двойной щелчок где-либо на фоновой поверхности графика (или выбер« пункт Общая разметка из контекстного меню после щелчка правой кнопкой мьи на фоновой поверхности графического окна).
Удачным местом для условных обозначений была бы нижняя область
четкого окна. Нажм^енастрелкувполе.ЗдгатоехмивыбсритесцюкуНа.хяяяосьХ’ 2
□р 1- Настройка двухмерных и трехмерных графиков
355
управляющие символы
_ диалъное форматирование текста на графиках системы ST ATISTICAocviucctb-' 'тся с помощью последовательности управляющих сим волов, которая всегда на-Енаетсч символом @ Эти управляющие символы позволяют включать индексы. • пени, подчеркивание и т. п в любой заголовок пли пользовательский текст. Для Е лоченпя.в текст условного «означения используется следующая последонатель-^7ть управляющих символов: ^Цномер зависимости]. Например. если написать в пе загс, ловка &L[ 1J,i в самом заголовке на графике будет показано условное • -значение первой из зависимостей. Теперь в поле заголовка Нижняя ось Х2вве-цте с lejVKimyio ел ров у &L[1 Роог(П) @Ц2]-% Phone Rural
Н..я:мите ОК чтобы увидеть изменения на графике
Отмстим, что тот же результат можно получить, не удаляя обычный текст •очного обозначения, а переформатировав его (например, в одну строку текста) поместив в нижнюю часть графика (предварительно увеличив нижний отступ,
356
Глава 9. Примеры визуального анализа и настройки графиков в 5ТДгр
чтобы для дополнительного текста было достаточно места, как это сдел, ледуюших примерах).
Представление графиков различных типов
Попробуем представить данные о проценте «бедных» потребителей не в в., нейного графика, а в виде гистограммы. Тпп всех зависимостей на график»I быть одновременно изменен в диалоговом окне Общая разметка 2М граф^Л меиить тип одной зависимости можно в ее диалоговом окне Размещение fpafa.
Вызовите диалоговое окно Размещение графика для первой завг , (% Poor), щелкнув на ее условном обозначен и и (пли па самой линии) иравод кон мыши и выбрав пункт Изменить размещение зависимости (ей)
Теперь щелкните на значке Столбч. диагр. по X в поле Тип графике а. нажмите ОК, чтобы увидеть изменения на графике
Настройка двухмерных и трехмерных графиков
, видно, ширина столбцов на этом графике оказалась не очень удачной. Так от параметр (ширина столбца) является характеристикой только одной из И1Е«мостей (Зависимость /), то именно для нее нужно опять вызвать диалого-** >кно Размещение графика.
налоговом окне Общая разметка 2Мграфиков величина шага по оси X уста-сна равной 1 (это окно можно вызвать, дважды щелкнув мышью на оси X). ** ловательно, если установить ширину столбцов гистограммы равной 0,8. то они ’ nvr занимать 80% ширины интервалов по оси X, но при этом еще будут разделе-промежутками. Установите параметр Ширина в поле Вид диаграммы рав-о g и нажмите ОК, чтобы увидеть результаты изменений.
Изменение стиля обозначений
Представление гистограммы поданным о проценте «бедных* потребителей все же ,е очень удачно, поскольку она закрывает два других линейных графика. По-ви-jpiMoMy, можно решить эту проблему, сделав гистограмму прозрачной.
Чтобы изменить стиль любой линии, точки или самого графического окна, дваж-шелкнцте на нужном элементе, в данном случае — на любом из столбцов гис--‘‘’граммы
^-начала нажмите на поле Шаблон и в открывшемся списке стилей выберите ycToii» (второй сверху).
358
Глава 9. Примеры визуального анализа и настройки графиков в STA1
Обратите внимание, что теперь стали доступны два режима: Непрозрачны Прозрачный Если включить режим Прозрачный, то «сквозь» гистограмму бу видны даже линии направляющей сетки. В данном случае достаточно включит режим Непрозрачный Теперь нажмите ОК, и график будет изменен
Настройку шаблонов линий, точек, заголовков, обозначений осей и других «а ментов графика можно продолжить (для этого нужно дважды щелкнуть мыш! на соответствуюшем элементе).
Сохранение графика
Для сохранения итогового графика воспользуйтесь кнопкой Сохранить фаил\_
па панели инструментов или выберите пункт Сохранить из основного меню Файл Графические фай ты системы STATISTICAL расширением *slg) используются графический формат, который сохраняет все сделанные настройки. Поэтому ' еле открытия графического файла его настройку можно продолжить с того < Я места, где она была прекращена График может быть записан и в других форма таких как Метафайл пли Растровое изображение*
В формате Растрового изображения график представляется в виде посЛь-J дельности точек, поэтому редактировать его заголовки или условные обозначе будет уже невозможно.
,Ер 1. Настройка двухмерных и трехмерных графиков
359
I формат метафайл Windows сохраняет некоторую «структурную» информацию I графике (текст, обозначения и др ). и его можно редактировать в некоторых дру-pjv приложениях
Печать графика (предварительный просмотр печатной страницы)
[ В любой момент график может быть напечатан с помощью команды Печать графика из меню Файл, при злом появляется диалоговое окно Печать графика.
Можно распечатал > график, м цнуя этот этап, с помощью кнопки Печать на панели инструментов
Чтобы посмотреть, как график будет располагаться на странице и установить нужные ноля, можно включить режим Предварительный присмотр из основного меню Файл. При ашм появится диалоговое окно Предварительный просмотр.Что-6ы твнлеть размеры полей, нажмите на кнопку Поля
360
Глава 9. Примеры визуального анализа и настройки графиков в STA1
Размеры этого окна можно изменять, используя в том числе и полно: режим просмотра.
Просмотр графика в том виде, как он будет напечатан (режим WYSIWYG)
При настройке сложных графиков желательно, чтобы пропорции граф1
окна на экране в точности соответствовали тем, которые сформируются п печати. Такой режим получил название WYSIWYG (What You See Is What You
Из меню Вид выберите пункт Пропорции страницы при печати, чтобы <_1_ пропорции графика соответствующими печатной странице. Например, е и» •
логовом окне Принтер предварительно выбрана Книжная ориентация, то н.
1 Настройка двухмерных и трехмерных графиков
361
(tee введенные ранее параметры графика показаны на экране именно (бузут напечатаны.
ка трехмерных графиков
iepe, как и для двумерных графиков, будет использован файл Ртепула. настройка трехмерного графика рассеяния проводится с помощью дна-эн Общая разметка ЗМ графиков п Размещение графика.
е графика по умолчанию
графиков или меню Графика выберите пункт Статистические XYZ/pa-— диаграммы рассеяния. Появится диалоговое окно ЗМдиаграммы рассея-
Нажмитс на кнопку Переменные и выберите в качестве А" переменную Pt_Poor. сачествс У — Р/. Rural, а в качестве Z — Age (средний возраст в соответствующем руге). Затем нажмите на кнопку Параметры Появится диалоговое окно Ста-тпические /рафики: параметры.Для того чтобы на графике были показаны иа-Ышя округов, jaaaiti e режим Имена наблюдений в поле Метки наблюдений.
L аТеч ||И5Км»тс ОК. чтобы вернуться к диалоговому окну ЗМ диаграммы рассе-
362
Глава 9. Примеры визуального анализа и настройки графиков в STAI
Снова нажмите ОК, чтобы построить трехмерную диаг} «mmv рассеяние жмите Вых. для удаления кнопок Еще и Вых.
Чтобы набежать наложения меток (как это произошло на данном граф» можно использовать режим Фильтры изображения.
Просмотр данных графика
Как и в предыдущих примерах, для начала посмотрим данные графика Для э надо вызвать Редактор данных графика Например, щи чкните правой кнопки* ши на какой-либо из точек и выберше Редактировал ^Оаннъи ?-.>язавъ, ими HMf
или нажмите кнопку Редактор данных грофыкд Ю на панели hhcti -.-ментов ВГ
У и Z) для каждой зависнмо'Т»*
торе данных графика показаны три столбца (X.
лмер 1- Настройка двухмерных и трехмерных графиков
363
В данном случае это одна зависимость. При выборе более чем одной переменой 7. в диалоговом окне ЗМ диаграммы рассеяния в Редакторе данных графика будет несколько зависимостей! из трех колонок.
у Как обычно, на этом этапе данные можно изменять, добавлять новые зависимости. изменять представление данных в редакторе и шрифты.
редактирование меток наблюдений
Предположим, что особый интерес представляют округа Jackson и Shelby. В данный момент на графике трудно что-либо разобрать, поскольку многие названия перекрываются Поэтому нужно удалить все не представляющие интереса метки, чтобы «упорядочить» график.
Для редактирования меток точек.
1) дважды щелкните на одной из них или
2) щелкните на любой из них правой кнопкой мыши, выберите пункт Изме нить размещение зависимости(ей), в появившемся диалоговом окне Размещение графика выберите пункт Метки данных
В любом из этих случаев появится диалоговое окно Метки точек данных
Для обозначения точек на графике помимо Текстовых меток можно использовать и значения координат X, Y или Z или любую их комбинацию. Чтобы вызвать Диалоговое окно Правка текстовых меток, нажмите кнопку Правка
Удалите все метки, Kpouejackson и Shelby
364
Глава 9. Примеры визуального анализа и настройки графиков в STATISTII
Нажмите ОК, снова появится диалоговое окно Метки точек данных. Чтобы уь личпть размер шрифта (например, выбрать A rial полужирный 12), нажмите кно ку Шрифт
Нажмите ОК, чтобы увидеть изменения на графике.
Теперь здесь хорошо видны две конкретные точки.
рпимер 1- Настройка двухмерных и трехмерных графиков
365
редактирование заголовков
Как и в предыдущих примерах, для редактирования заголовка дважды щелкните иа нем мышью. Появится диалоговое окно Правка заголовков.
Изменение масштаба
Как и в предыдущих примерах, по двум горизонтальным осям выбран не очень Удобный масштаб. Поскольку переменная Pt_Rural выражена в процентах, то бо-Пее подходящим здесь был бы интервал от 0 до 100 (а не от 10 до 110). Дважды ^лкпите на этой оси, чтобы вызвать диалоговое окно Параметры оси: Y.
366
Глава 9. Примеры визуального анализа и настройки графиков в STA1
В поле Разметка оси выберите режим Ручная с пар шМин >,Шаг-
и Макс. = 100
Вращение трехмерного графика
Все трехмерные графики в системе STATISTICA могут быть поверю гы в np< rpai стве вокруг любой из трех осей. Также может быть изменена перспектива. Выб рите команду Вращать из меню Вид. Появится диа г с -о Пе, • «лиц вращение. Другим способом это окно можно вызвать, нажав кнопку Вращение л фика Щна панели инструментов.
Пиктограмма (упрощенное изображение графика) позволяет предварите’ наблюдать за изменяющейся ориентацией графика и перспективой
Для вращения графика в горизонтальной плоскости используется гори:
тальная линейка прокрутки, для вращения в вертикальной плоскости — nj 1 линейка прокрутки (вверх-вниз). Левая линейка используется для управл • перспективой Перспектива определяет, насколько «близко* находится трехм
367
,ер 1. Настройка двухмерных и трехмерных графиков
цЫЙ график. Далее на рисунке представлен крайний случай, когда левая линейка прокрУ1 ки установлена в самое верхнее положение. Мы видим график словно через сильную широкоугольную линзу.
На следующем графике перспектива выключена (левая линейка прокрутки находится в самом нижнем положении). График виден как бы через телеобъектив.
Когда нужные пространственная ориентация и перспектива наконец выбраны, закройте диалоговое окно Перспектива и вращение. График будет перерисован. Диалоговое окно Размещение графика
Д ля вызова диалогового окна Размещение графика тел книге правой кнопкой мыши гДе~либо на поверхности графического окна. Из контекстного меню выберите пункт ^пенить размещение графика
368 Глава 9. Примеры визуального анализа и настройки графиков в STATIS1
В диалоговом окне Размещение графика проводится настройка параметров кои -кретной зависимости. Например, с помощью кнопки Точки можно изменить значки на диаграмме рассеяния. (Напомним, что это диалоговое окно вызывается Tai. же, если дважды щелкнуть на любой точке графика.)
Выберите, как показано выше, в качестве значков треугольники и установи!* их размер равным 8 (поле Точки). Затем нажмите ОК, чтобы закрыть окно Шаблс» точки Теперь нажмите кнопку Перпендикуляр.
Здесь можно выбрать стиль для вертикальных линий, которые соединяют tov ки с плоскостью Х-Y. Чтобы увидеть изменения на графике, выберите сплошную линию. Нажмите ОК, а затем еще раз ОК в диалоговом окне Размещение график» Все эти изменения появятся на графике, как показано ниже
1. Настройка двухмерных и трехмерных графиков
369
По обычным правилам, установленным в системе STATISTICA, функции этого диалогового окна относятся ко всему графику в целом. Смысл большинства из
них понятен по названиям.
Подгонка поверхности к диаграмме рассеяния
Выберем, к примеру, в поле Тип графика строку График поверхности для того, чтобы заменить диаграмму рассеяния. Заметьте, что изображение и левом верхнем углу тоже изменилось и соответствует новому типу графика. Нажмите ОК, чтобы перерисовать график.
370
Глава 9. Примеры визуального анализа и настройки графиков в STAT1;
В диалоговом окне ЗМ графики: дополнительные свойства, которое вызыва с помощью двойного щелчка на поверхности графика, выбираются параметры гонки поверхности.
Во-первых, на приведенном выше графике метка Shelby «затенена» вовер ностыо. Штриховку здесь можно изменить или сделать поверхность полноеп прозрачной. Нажмите кнопку Показать скрытое, чтобы сделать поверхность про. зрачной, то есть чтобы сделать видимым все, что находится за ней. В результа поверхность на графике станет «сетчатой». Нажмите ОК, чтобы закрыть это ди лотовое окно. Теперь на маленьком графике в диалоговом окне Общая размет, будут видны результаты изменений
Перемещение условных обозначений
Удалите из графического окна условное обозначение поверхности, которое теле потеряло смысл. Щелкните правой кнопкой мыши на каком-либо условном об значении и выберите в контекстном меню пункт Удалить условные обозначен, линий уровня
|ример ! Настройка двухмерных и трехмерных графиков
371
Число сечений поверхности
«[цело сечений, по которым строится данная поверхность, устанавливается в диа- -рговом окне Общая разметка Чтобы вызвать его, дважды щелкните ио поверх-
। ости графического окна. Измените параметры Число сечений дляХ и Уна 30 и 30. Для более точной подгонки поверхности в поле Подгонка (поверхности и контуры) выберите пункт Сглаживание сплайнами. Теперь график будет выглядеть сл»1-I ^уклцим образом.
Дф-.ГТТГН | |1 I
Демен рафи'.сиКне данные пи 30 выбдл в^у<«.т Диаграмма рассеяний, возраст и лроцеь i i>iw: и сел, <их семей
• 1братнте внимание на то, что показанный выше график повернут так чтобы п<»| рхность была лучше видна
Изменение пропорций осей (пропорции трехмерной ячейки)
По умолчанию трехмерный график располагается в кубической ячейке, то есть длины всех осей для него равны. Иногда желательно изменить эти пропорции. Например, на этом графике хотелось бы «растянуть» точки вдоль плоскости X- Y. Другими словами, хотелось бы удлинить оси Хи Уотносительно оси Z. Это можно с злать с помощью диалогового окна ЗМграфики: дополнительные свойства которое уже использовалось в этом примере
Снова вызовите диалоговое окно Общая разметка и нажмите кнопку Дополнительно... (заметьте, что прежде это окно вызывалось с помощью двойного пи • нка ыьгшыо). Затем введите в поле Пропорции осей X:2nY:2
Нажмите ОК, чтобы закрыть окно ЗМ графики: дополнительные свойства и сно-Ва ОК, чтобы закрыть окно Общая разметка
Обратите внимание на то, что такой же результат можно получить, оставив без И-’Менения значения для Хи У (то есть 1), но изменив значение для Z с 1 до 0.5.
372
Глава 9. Примеры визуального анализа и настройки графиков в STATISTIC
Диаграмма par *ямив есзраст и прпцент беднь к сельские семей
Представление трехмерных аппроксимирующих функций в заголовках
Предположим, хотелось бы найти простую линейную взаимосвязь между дол*|‘ бедных потребителей, долей сельского населения и средним возрастом Мож аппроксимировать данные плоскостью, а полученные линейные оценки парам • ров вынести в заголовок графика.
Дважды щелкните на фоновой поверхности графического окна. Появится Ш •*' тоговое окно Общая разметка. В поле Подгонка (поверхности и контуры) выб-л?»** те пункт Линейное сглаживание, а параметр Число сечений верните к значеню.»в установленным по умолчанию (X: 15 и Y: 15). Нажмите ОК. чтобы верну I м к графическому окну.
Управляющие символы
С помощью управляющих символов может быть настроен практически любой теггт на графике (заголовки, метки, пользовательский текст и др.). К примеру, может включать индексы, показатели степени, подчеркивания и т. д. Для появл*’
Пример 1- Настройка двухмерных и трехмерных графиков 373 для в заголовке графика уравнения аппроксимирующей функции одной из зависимостей используйте следующие управляющие символы ©Е[момерзависимости). дражды щелкните на первом заголовке, в строку Заголовок 1 введите текст Функция: ©F[1. 1и нажмите ОК.
Теперь вернитесь к диалоговому окну Правка заголовков, запись в нем изменилась. {г^28.748+0.049*х+0.086*у@}. Этот текст можно редактировать, менять его шрифт и т. п.
Обратите внимание, что часть текста заголовка внутри фигурных скобок ({}), пграниченная символами автоматически обновляется системой STATISTICA; она изменится, например, если отредактировать данные или уравнение функции. После удаления фигурных скобок и символов @ эта запись будет восприниматься как обычный текст.
Пример 2. Подгонка функций, увеличение и закрашивание
Построение диаграммы рассеяния
В любом модуле (например, Основные статистики и таблицы) откройте фай Povertysta. Из меню Графика выберите Статистические 2Мграфики — Диаграммы рассеяния Задайте в качестве переменной X — Pop_chng (изменение числим ности населения), а в качестве Y — Pt_Poor (процент бедных потребителей).
Пример 2. Подгонка функций, увеличение и закрашивание
375
Приближение полиномами
Ка уже обсуждалось в предыдущих примерах, на двумерном графике рассеяния можно построить аппроксимирующую функцию для каждой зависимости в отдель юстп. Щелкните где-либо на графике правой кнопкой мыши и выберите из контекстного меню пункт Изменить размещение графика
Вместо установленной по умолчанию линейной подгонки выберите в поле Под гонка пункт Полиномиальная Обратите внимание, что с помощью расположенной в > । ом поле кнопки Параметры можно задать степень полинома.
376
Глава 9. Примеры визуального анализа и настройки графиков в STATIS
По умолчанию используется полином 5-й степени Теперь закройте это говос окно (нажмите ОК)
Прежде чем продолжить построение, выберите доверительный интервал этого установите переключатель в поле Доверительный интервал в полол^Я
Выйдите из диалогового окна Размещение графика, включив диалоговое ок > Общая разметка
Здесь видно, что запись уравнения новой функции автоматически обновляв ся. потому что во второй строке заголовка введен специальный управляющийся вол @F[1] (использование специальных управляющих символов для формат ир вания рассматривалось в примере 2). Теперь нажмите ОК, чтобы увидеть резучы на графике
рриМЕр 2.
Подгонка функций, увеличение и закрашивание
377
В итоге в заголовок помещены оценки параметров функции, а на графике показана 95*'о доверительная полоса,
Интерактивное удаление выбросов (Закрашивание)
Нажмите кнопку панели инструментов Кисть g) Форма курсора изменится и будет соответствовать показанной на кнопке. Появится диалоговое окно Закрашивание.
Выберите режим Операция — Выключить (чтобы исключить из рассмотрения ^крашенные точки) и включите режим Автообновление, как показано выше (чтобы действия кисти сразу отображались на графике)
Теперь подведите курсор к точке в правом нижнем углу графика, чтобы она оказалась в центре перекрестья.
378
Глава 9. Примеры визуального анализа и настройки графиков в STATI'
Щелкните левой кнопкой мыши, и соответствующая точка будет удалена с ’'на граммы рассеяния, кроме того, изменятся и параметры функции, ьаппсаиноп а второй строке заг итовка.
Такпм образом, инструмент Кисть позволяет интерактивно удалять выбр» 4 с диафаммы рассеяния и наблюдать соответствующее изменение аппроксимир гожей функции В Редакторе данныхграфика удаленные выбросы выделяются Д} гим цветом.
,мер 2. Подгонка функций, увеличение и закрашивание
379
Чтобы «снять выделение* точки (то есть поместить ее обратно на график), поместите курсор на соответствующую строк}’ в окне Редактор данных графика и на ga панели инструментов нажмите кнопку Показать идентификаторы точек гра-
В появившемся диалоговом окне:
измените статус выбранной точки. Выделение будет снято Нажмите на панели инструментов кнопку | Перерисовать] и ранее удаленная точка вновь появится на графике.
Увеличение
Увеличение — это весьма полезный инструмент для подробного изучения выбранной области графика, в частности, когда необходимо удалить отдельныеточки. Если, например, на диаграмме рассеяния есть области «скученности» точек, то можно увеличить эту область, чтобы идентифицировать отдельные точки. Нажмите кнопку Увеличение при этом курсор на поверхности графика примет форму лупы. Подведите его к центру той области, которую вы хотели бы увеличить, и щелкните левой кнопкой мыши.
Если щелкнуть левой кнопкой мыши еще раз, то данная область снова увеличится.
380
Глава 9. Примеры визуального анализа и настройки графиков в STA1
Каждый щелчок левой кнопкой мыши приводит к увеличению соответс шей области примерно в два раза
Для просмотра графика в режиме увеличения можно использовать линей»
крутки. Нажмите кнопку Подобрать область графика сматривать график, как через увеличительное стекло
и поля
0.
и вы сможете
Чтобы снять увеличение, нажмите кнопку Уменьшение и щелкните на ветствующей области трафика. Заметим, что после нескольких успешных и ций увеличения и уменьшения положение графика в графическом окне мохе меняться
Для восстановления первоначального вида графика используйте команд? становить исходные настройки в меню Вид.
График будет вновь перестроен в соответствии с параметрами, заданш умолчанию.
381
Рисование пользовательской функции
Снова вызовите диалоговое окно Размещение графика и нажмите в нем кнопку яъзоватеяым/я. Откроется диалоговое окно Задание функции пользователя Задайте, например, экспоненциальную функцию: у “25 183*ехр(~0.016*3.)
382
Глава 9. Примеры визуального анализа и настройки графиков в
Нажмите ОК в этом диалоговом окне и в диалоговом окне Размещение, Заданная функция будет нарисована на графике (соответственно будете и заголовок).
Обратите внимание, что в данном случае функция просто накладыв график Чтобы найти пользовательскую аппроксимирующую функцию ной зависимости, необходимо использовать модуль Нелинейное оцениваю
Добавление зависимости
Для каждой зависимости на графике можно найти только одну аппрока щую функцию (или наложить на нее только одну функцию) Поэтому для г гния нескольких функций нужно создать дополнительные зависимости. Д. го выполните следующие действия.
Нажмите кнопку Редактор данных графика [Е*| (или вызовите его други минавшимся вышеспособом). Изменю Правка выбертеттсгДобанитьзавиа
В этом диалоговом окне сохраните все установки по умолчанию (нажми! При этом будет добавлена новая зависимость (в показанном ниже Редактц ных графика добавлены два пустых ц голбца).
383
Подгонка функции, увеличение и закрашивание
перь щелкните правой кнопкой мыши на первом столбце и из контекстного выберите пункт Размещение графика. В этом диалоговом окне для зависимо-снова выберите полиномиальную подгонку. Затем нажмите кнопку Следую-К Появится диалоговое окно Размещение графика для второй (новой) завн-
Здесь выберите пункт Другая функция и снова определите ее следующим образом, у ~ 25-183*ехр(-0.016*х).
। - 25.1ВЭ-еч>Н> О16->]
| Закройте диалоговое окно Задание функции пользоватечя и откройте диалоге
вое окно Общая разметка В этом диалоговом окне Общая разметка: 2М графики выберите в списке Заголовки строку Заголовок3. Пользуясь введенными ранее правилами, запишите в качестве заголовка: Функция 2: &F/2J.
Для построения графика нажмите ОК.
РОР_СНЫО
384 Глава 9. Примеры визуального анализа и настройки графиков в STATIJ
Теперь на графике изображены как пользовательская функция, так и вечный полином.
Пример 3. Динамическое закрашивание (Кисть)
Как правило, режим Динамическое закрашивание используется на матричных т» фиках для пробного анализа данных При этом вместо закрашивания опрепрп^Д него диапазона значений переменной (с целью исследования влияния различи mJ! областей на функцию распределения) можно ввести автоматическое движенге кисти (в форме прямоугольника или лассо) и наблюдать «результат»
Область закрашивания определяется на одном из графиков матрицы и автоми* тически перемещается вдоль него (горизонтально, вертикально или в обоих и,, правлениях). Когда в область закрашивания попадают группы точек этого графика, то выделяются соответствующие точки на всех других графиках матрицы. Т
Файл данных
В этом примере использован файл данных Irisdatsta с классическим отчетом Ф> шера (1936). В нем приведены данные о длине и ширине лепестков и чашелисп -ков трех сортов ирисов (Setosa, Versicol, Virginie). Часть этого файла приведеш ниже.
Построение матричного графика
Откройте файл данных Irisdatsta, выберите из Галереи /.рафиков или меню Графа~1 ка пункт Статистические матричные /рафики Появится диалоговое окно Матричные графики.
С помощью кнопки Переменные выберите все переменные. Нажмите ОК. что бы закрыть диалоговое окно выбора переменных В поле Подгонка выберите строя ку Линейная. Снова нажмите ОК для построения матричного графика и удхипв кнопки Вых. и Еще, нажав кнопку Вых.
мер 3. Динамическое закрашивание (Кисть)
385
Нажмите кнопку панели инструментов Появится диалоговое окно Закрашивание. Затем в качестве типа кисти выберите Прямоугольник и включите режим Движение (см. следующий рисунок).
386
Глава 9. Примеры визуального анализа и настройки графиков в STATIST
Курсор примет форму перекрестья. Теперь иаодпом из графикой матрицы но выбрать прямоугольную область. Для исследования и сравнения связен ме четырьмя характеристиками ирисов (Sepallen, Sepaln'id. Petalien и Petaland) I различных сортов (Setose, Virginie n Versicol) выберите одну группу точек на i вом верхнем графике (представляющем один из сортов).
Когда вы отпустите кнопку мыши, прямоугольник начнет периодическое. жение по этому графику При этом на всех остальных графиках будут выделя' соответствующие точки.
№-и»1 >> VW
1-gnZ I
Скорость и направление движения при динамическом закрашивании задаю в диалоговом окне Движение.
Такая динамическая визуализация позволяет выявить разнообразие связей . каждого сорта ирисов. Например, когда прямоугольная область закрашивания п ходит через первую группу (как показано выше), то выделение соответству! точек позволяет судить о различной величине и направлении связи между метрами Sepakctdи Petalien, Sepalundи Petalwtd.
Закрашивание в редакторе данных графика
В системе STATISTICA применяются два метода закрашивания: с использ ем инструмента Кисть [дЦ в графическом окне или соответствующей кнопки в А
<ер 4. Связывание и внедрение
387
пипоре данных графика Если точки данных выбраны в режиме закрашивания (то <сГЬ маркированы, помечены, выключены или подсвечены), то их координаты прсд-тавлены различными цветами в Редакторе данных графика.
Этот Редактор предоставляет «командную» среду. где можно напрямую присваивать атрибуты точкам, нс выбирая их предварител ьно. а используя кнопки панели I иИСтрУМентов, диалоговое окно Идентификаторы точек на графике, контекстные меню или команды выпадающего меню Правка. Таким образом, операции закрашивания имеюг здесь тот же статус, что и режим Автообновление в процедуре закрашивания При этом текущая операция будет выполняться после каждого вы-I бора атрибута, и точки, заданные с помощью курсора (как отдельные точки, так и выделенные блоки), будут сразу же маркироваться, помечаться, выделяться и т д
Заметим, что точки данных графика могут иметь больше одного атрибута (на пример, они могут быть одновременно маркированы и подсвечены), при этом в Редакторе данных графика они отличаются лишь различными цветами п в соотвст-етвни с этим отображаются на обновленном графике (после нажатия кнопки Перерисовать или Выйти и перерш овать).
э В Редакторе, данных графика можно управлять атрибутами точек (маркированная, помеченная, выключенная или подсвеченная) с помощью специаль-
ных кнопок панели инструментов или команд меню.
> Точки данных (значения), выбранные с помощью закрашивания (тоесть маркированные, помеченные, выключенные пли подсвеченные), отображаются в Редакторе данных графика различными цветами
Пример 4. Связывание и внедрение
В этом примере будет показано, как поместить график системы STATISTICA я Тругос графическое окно или в какое-либо приложение Windows, используя сред-ва OLE. При вырезании (удалении) или копировании графика или другого вы
Зе ченного объекта (такого как пользовательский текст, метки, вставки пли рисун-।) он помешается в буфер обмена (Clipboard).
Для совместимости с другими приложениями Windows помимо объекта в собственном графическом формате системы STATISTICA в буфер копируется мета-файл. а также растровое и текстовое представления
Растровые изображения
К растровом изображении не хранятся никакие -готические (структурные) компонент ы графика. При вставке в другой график оно просто uejjenaci образованное из точек (пикселов) отображение графического окна
Метафайлы Windows («картинки»)
Ь отличие от растрового изображения, этот формат сохраняет некоторые струк-1 Урные компоненты графика. Формат метафайла Wmdows хранит картинку в виде набора описаний или определений всех компонент графика и их параметров
388 Глава 9. Примеры визуального анализа и настройки графиков в ST/!
(например, сегментов линий, шаблонов заполнения, текста н его характе и пр.). Поэтому формат метафайла предоставляет более гибкие возможно настройки и преобразования графика в других приложениях Windows.
Например, открыв график в формате метафайла в программе Microsoft Di его можно «разобрать», выделить и изменить отдезьные линии, заполнение । та, отредактировать текст и изменить его параметры и т п. Заметим, что не и программы обеспечивают возможность полноценного редактирования металл лов, например, программа Microsoft Draw не поддерживает режим вращения тещ i
Собственный графический формат системы STATISTICA
Записанный в этом формате график при вставке его в другое графическое oi сохраняет все свои структурные компоненты и объекты таким образом, что распознаются системой STATISTICA. Поэтому при копировании или обмене грз фическими объектами (или целыми графиками) между окнами этот формат вы бирается по умолчанию, чтобы в дальнейшем можно было продолжить редактнро! вание (включая настройки графиков системы STATISTICA я других при чоженияН куда они помещаются средствами OLE).
Копирование и вставка графических объектов
В этом примере использован файл данных Factor sta. Откройте этот файл в одноу из модулей системы STATISTICA (например, в модуле Основные статистик* J таблицы). Из меню Графика или Галерея графиков выберите пункт Статистик*— кие 2М графики — Диаграммы рассеяния. В диалоговом окне 2М диаграммы pact е-яния в поле Тип графика: выберите строку Составной Затем нажмите на кшяиу Переменные и выберите в качестве переменной X — Work_1, a Work 2 и Work_3 — в качестве переменных У. Нажмите ОК, чтобы закрыть диалоговое окно выбора переменных.
Нажмите ОК, и на экране появится график
4. Связывание и внедрение
389
Щелкните правой кнопкой мыши на одном из условных обозначений и выберите из контекстного меню пункт Переместить условные обозначения
Теперь условные обозначения преобразованы в пользовательский текст. Если дважды щелкнуть на них, то в Редакторе текста графика можно будет увидеть текст условных обозначений и управляющие символы.
В окне редактора уберите из текста символ перевода строки (поместите курсор в конец первой строки и нажмите клавишу Del). Две строчки в записи условных обозначений превратятся в одну. Можно поместить четыре дополнительных пробела между условными обозначениями первой и второй зависимости и заменить сим
390 _____ Глава 9. Примеры визуального анализа и настройки графиков в STATfel
волы табуляции (@Т[6}) пробелами. Поскольку условные обозначения не уме ся в одну строку, то табулятор не сможет гарантировать одинаковый интервал ду символами и текстом.
Текст расположен не в центре рамки, потому что в первоначальной запад условных обозначений присутствовали символы межстрочного интервала Дважды щелкните на условных обозначениях ц удалите символы @5. Нажмите ОК, чтобы вернуться к графическому окну.
Теперь дважды щелкните на условных обозначениях в виде пользовательс! текста, затем нажмите CTRL+C или кнопку |^j, чтобы скопировать пользоват ский текст в буфер обмена, и закройте Редактор текста графика
пример 4. Связывание и внедрение 391
Вставка в виде текста
С помощью Дво**ного щелчка на заголовке графика выловите диалоговое окно Прав-ка3аюловков Для встанкм поместите курсор на пустое поле Заголовок2 и нажмите комбинацию клавиш CTRL+V или кнопку^ на встроенном напели инструментов.
Нажмите ОК, чтобы увидеть итоговый график.
Теперь условные обозначения помеще1гы в заголовок.
Вставка в виде растрового изображения
Чтобы выделить условные обозначения в виде пользовательского текста, снова те ткните мышью, поместив над ними курсор. Затем из меню Правка выберите команду Вырезать (можно осуществить эту операцию и другими способами: с помощью комбинации клавиш CTRL+X. кнопки панели инструментов или команды Вырезать контекстного меню). Согласно пояснениям во введении к данному примеру теперь пользовательский текст помещен в буфер обмена в четырех разных форматах: как обычный текст, как растровое изображение, как метафайл и как собственный графический объект системы STATISTICA.
Из меню Правка выберите режим Специальная вставка.
В диалоговом окне Специальная вставка выберите формат Растровое изображение. Включите режим Поместить по умолчанию
392
Глава 9. Примеры визуального анализа и настройки графиков в STATI!
Теперь вставка имеет вид обычных условных обозначений в виде пользовател!-ского текста, но на самом де те это нс так Программа воспринимает ее как набор точек, то есть растровое изображение.
Щелкните на объекте правой кнопкой мыши и выберите из контекстного меню пункт Свойства объекта (или дважды те ткните на объекте, или выделите объект и нажмите комбинацию клавиш ALT+FNTER).
В появившемся диалоговом окне удалите метку около слов Исходные пропор ции (чтобы можно было менять размеры объекта, не заботясь о сохранении первС
пинер 4- Связывание и внедрение
393
Очевидно, что при растяжении или сжатии растрового изображения каждая точка соответственно перемещается, вызывая искажение текста.
Вставка в виде собственного графического объекта системы STATISTICA
Выберите из меню Правка пункт Специальная вставка, а затем режим Внутреннее описание системы STATISTICA.
Первоначально этот объект выглядит как растровое изображен не. Дважды шелк ните на нем. Вы увидите, что размеры шрифта изменить нельзя. Вместо этого откроется окно Редактор текста графика
Таким образом, система STATISTICA воспринимает это изображение как соб-стаеиный графический объект и, следовательно, позволяет его редактировать любыми доступными средствами. Чтобы изменить размер условных обозначении, необходимо выбрать Шрифт большего размера, например Arial Bold 20 Ниже показан график, получившийся после внесения изменений.
Для выравнивания положения текста и других графических объектов испилы; ся функция Направляющая сетка из выпадающего меню Bud (она вызывается т же с помощью комбинации клавиш CTRL+G)
4. Связывание и внедрение
395
I Имеющаяся на графике сетка позволяет очень точно размещать различные Ьъекты (например, текст). Эта сетка не выводится на печать. Удалить ее можно, нова выбрав пункт Направляющая сетка (то есть удалив метку около названия Evhkuihi или нажав комбинацию клавиш CTRL+G).
Г Тля настройки сетки (ееначалаиинтсрвалов)нажмнтекнопкупанели инструментов rg или выберите из меню Вид команду Прикрепить к сетке. При этом также появится возможность прикреплять к узлам сетки объекты (дляточного размещения).
При перемещении и изменении размеров объектов режим прикрепления к сетке можно легко включать и выключать клавишей TAB.
Функции клиента и сервера в OLE
Т»перъ удалите все графические объекты, помещенные в этом примере, на диаграмму рассеяния. Сам этот график будет вставлен в трехмерную гистограмму'. Этот пример продемонстрирует, как система STATISTICA может являться одновременно клиентом и сервером в методе OLE.
Создание трехмерной гистограммы
Из меню Графики выберите пункт Статистические ЗМ последовательные графики -- Гистограммы двух переменных Выберите в качестве переменных Work_1 и Work 2 Нажмите ОК для построения гистограммы двух переменных
Внедрение диаграммы рассеяния
Щелкните на предыдущем изображении диаграммы рассеяния. Затем из меню Правка выберите команду Копировать (или нажмите комбинацию клавиш
396 Глава 9. Примеры визуального анализа и настройки графиков в БТЛ
CTRL+C). Скова щелкните на гистограмме и теперь из меню Правка bi пункт Специальная вставка.
Как и в случае пользовательского текста, возможен выбор из нсскол! фических (файловых) (форматов. При выборе формата Растровое изобрал менение размеров внедренного графика, как и в случае пользовательско» приводит к искажению изображения (см. ниже).
Выберем вместо этого собственный графический формат системы STATIST!
397
Связывание и внедрение
Поскольку этот формат установлен по умолчанию, то достаточно просто вы-Кть команду Вставить или нажать комбинацию клавиш CTRL+V
едакгирование внедренного графика
ните на внедренном графике правой кнопкой мыши. В появившемся кон-1ОМ меню будут показаны все доступные функции редактирования. Внедрен-рафик рассматривается как связанный объект, то есть с ним можно обра-я как с исходным графиком. Если дважды щелкнуть на нем, то он будет ртным образом открыт по соглашениям Windows о связывании и внедре-объектов OLE. Сделайте нужные изменения и выйдите из режима редактщю-ия с помощью команды Закрыть и вернуться из меню Файл. Все изменения дут отображены на внедренном графике.
Внедрение или связывание графиков из файлов
уожно осуществить процедуру внедрения или связывания графиков из имеющееся графического файла. Например, сохраните диаграмму рассеяния в виде собственного графического файла системы STATISTICA (например, в виде файла karter.stg). Затем щелкните на трехмерной гистограмме и из меню Вставка выберите пункт Объект (или нажмите на панели инструментов кнопку Вставка объекта^).
В диалоговом окне Вставка выберите вкладку Объект из файла, при этом в списке Тип объекта укажите График STATISTICA. Проверьте также, включен ли режим Связь с файлом. В этом режиме связанный график будет автоматически об-вовлен при изменении и сохранении исходного графика. В списке Имя файла лыберите предварительно сохраненный файл Scatterstg. Нажмите ОК, и в левом верхнем углу картинки появится график из этого файла.
"В I лава 9. Примеры визуального анализа и настройки графиков в STAT
Автоматическое обновление связанных графиков
Теперь вернемся к диаграмме рассеяния и удалим весь пользовательский тйэс| заголовки (выделим их щелчком мыши, а затем нажмем Del или используем п манду Вырезать в меню Правка).
На рисунке видно, что связанный график был автоматически обновлен.
Управление несколькими графическими объектами
Если на экране находятся одновременно несколько непрозрачных графиче *ИЖ объектов, то важно, чтобы они были расположены в нужном порядке.
Рассмотрим, например, построенную ранее трехмерную гистограмму с внедренным графиком. Ниже показан этот график после добавления к нему стрелки 11 пользовательского текста.
4. Связывание и внедрение
В данном случае желательно нарисовать стречку и пользовательским текст поверх связанного графика, потому что иначе они не будут видны. В настоящий момент элементы графика изображены в правильной последовательности. Но вследу-юще.м параграфе просто с целью демонстрации мы покажем, каким образом вынести этот график на передний план, то есть нарисовать его в последнюю очередь.
Изменение очередности изображения графических объектов
Кнопки цанелп инструментов Вынести на передний план и Перенести на задний п.зд« предназначены для соответствующего перемещения выбранных (выде-
ленных) графических объектов. Щелкните насвязанном графике, чтобы выделить ею, а затем нажмите кнопку Вынести на передний план.
Теперь внедренный график закрывает стрелку и часть пользовательского текста. Можно снова поместить его на задний план (в исходное состояние), нажав кнопку Перенести на задний план
400
Глава 9. Примеры визуального анализа и настройки графиков в ST/
Управление графиками системы STATISTICA в других приложениях Windows средствами OLE
В этом пример будет показано, как связать график системы STATISTICA г Л гим приложением Windows, используя метод Связывания и внедрения afn -Д (OLE). В дакнем случае i рафик будет связан с документом. пр< -днаэначеи^^Н редактирования в программе Microsoft Word, ('вязанный таким образом мм « ис темы STAT1S 1ICA может редактироваться внутри другого приложенной пользованием инструментов настройки системы STATISTICA (если этс. жение поддерживает средства OLE).
Сначала построим в системе STATISTICA приведенный ниже график ’ Предположим, данный график необходимо включить в документ, редгкт* мый в программе Microsoft Word. Ниже показана та часть «отчета», в когор*, >< жен быть помешен график.
,4. Связывание и внедрение
401
График системы STATISTICA нужно вставить между вторым и третьим абза-и текста (после слов следующим образом:}.
гвЯзывание графика системы STATISTICA
Личала откройте систему STATISTICA и постройте необходимый график (на-wHMtp- такой, как показано выше). Затем скопируйте его с помощью комбинации лявиш CTRL+C или команды Копировать из меню Правка.
Переключитесь на документ Word и поместите курсор в то место, с которым шджен быть связан график (в конец второго абзаца). В программе Microsoft Word ыберите из меню Правка пункт Специальная вставка.
Редактор Microsoft Word распознал в буфере обмена график системы STATISTICA Следовательно, по умолчанию график будет помешен в документ как График STATISTICA Для вставки графика нажмите ОК.
Обратите внимание, что таким же образом можно просто вставить график в документ (нажав CTRL+V), поскольку формат График STATISTICA стоит первым
списке форматов буфера обмена (Clipboard).
402
Глава 9. Примеры визуального анализа и настройки графиков в Si
Редактирование связанного графика
Предположим, вы решили включить в показанный выше график
ние переменной Worii__1 Для редактирования графика дважды щелкнули при этом автоматически запустится система ST ATISTIC А, где будет <mcJ ное графическое окно. Можно убедиться, что при этом здесь в меню cbzS лись новые пункты.
Обратите внимание, что система STATISTICA «знает», что данный гр; дрен в документ Microsoft Word. Таким образом, сделав необходимые н можно закрыть систему STATISTICA и вернуться в Word (Закрыть и ся...), обновить график в программе Word и продолжить редактирован»t STATISTICA (Обновить...') или выйти из системы STATISTICA и верн* грамму Word (если график был изменен, то система STATISTICA спрс < ли обновить его в документе Word).
Предположим, к графику добавлен следующий пользова1ельский те
В меню Файл выберите команду Выити и вернуться в Microsoft Wor в документе Word содержится обновленный график.
5- Добавление заданных пользователем статистических графиков
403
Как видно из рисунка, на графике, внедренном в документ Word, присутствует новый текст.
Пример 5. Добавление заданных пользователем статистических графиков в окно Галерея графиков и в меню Графика
STATISTICA позволяет включать в пункт меню Графика дополнительные типы I графиков, определенные пользователем. Это очень удобно при построении типовых графиков с конкретными параметрами настройки. Кроме того, определенные | фльзоватслем графики, а также типовые настройки могут быть поставлены в со к ВТветствие кнопкам на панели инструментов Кнопки автозадач.
Предположим, что в процессе контроля качества обычно производится 25 серии »• мереннй, в каждой из которых берется по 5 образцов продукции. При этом каж-яып раз по этим данным строится минимаксная диаграмма одного и того же типа, патом случае для экономии времени целесообразно включить этот когперетный тип фэ^ягка со всеми его настройками в список графиков, определяемых пользовате "м- Этот список вызывается из меню Графика (в подпункте Статистические графики
404 Глава 9. Примеры визуального анализа и настройки графиков в ST£
Файл данных
В этом примере используется файл данных Pistons^ta В нем содержатся iЫ ты измерений диаметров поршневых колец, 25 серий измерений по 5 код-^Д дом. Часть этого файла представлена на рисунке.
Определение параметров графика
Откройте файл Pistons.sca и выберите в меню Графика пункт Статистически» графики — Диаграммы размаха. Появится диалоговое окт 2М диаграммы.
Нажмите кнопку Переменные и выберите переменную Samples в качеств* горизующей в поле Группы на диаграмме, а в качестве второй — перемени | Нажмите ОК, чтобы закрыть диалоговое окно выбора переменных.
На этом минимаксном графике должны быть показаны средние значения дартные отклонения и интервал (максимум и минимум) для каждой сер^мд ров. Поэтому в списке Средняя точка выберите строку Среднее, в списке мт* угольник — Ст, откл, а в списке Отрезок — Мин-макс. Затем в поле Гр! ”
5. Добавление заданных пользователем статистических графиков
405
поставьте переключатель в положение Коды, нажмите кнопку Задать и выберите их значения с 1 по 25 И наконец, нажмите кнопку Параметры и ^jobiitc режим Текст или даты на осях. Закройте диалоговое окно Статис-графики: параметры. Теперь диалоговое окно 2М диаграммы размаха Кг и я-пит следующим образом:
Создание нового графика пользователя
Все эти настройки могут быть сохранены в виде пользовательского графика, который представляет собой таблицу графических стилем Нажмите кнопку Параметры и снова откроите диалоговое окно Статистические графики: параметры.
,ж щ.*1**и,Те кнопку Добавить кменю как график пользователя, при этом откроет- Роговое окно Новый график пользователя.
406
Глава 9. Примеры визуального анализа и настройки графиков в STai
В данном примере установите режим Сохранить текущие переменны*»
пением графика (Здесь можно изменить имя файла и каталог, в которое жен быть сохранен.) В поле ввода Название пункта меню введите назван!
ка для его обозначения в списке меню Графика (в подпункте Статис графики пользователя). Назовите этот тип графика, например. Контроль i
Закройте это диалоговое окно (нажмите ОК), и заданная диаграмма б
строена.
Выбор заданного пользователем графика
Закройте модуль системы STATISTICA, в котором вы работали, а затем < его опять. Если открывать модуль с помощью кнопки Переключатель moi стемы STATISTICA, то все его настройки вновь будут установлены по ник». Откройте файл Pistonssta, если он еще не открыт по умолчанию П
жим, что этот файл теперь содержит новые данные, полученные ио тип
(то есть в первой переменной записаны 25 идентификационных кодо!
рой — результаты измерений). Чтобы построить этот предварительно < ный пользователем график, выберите в меню Графика подпункт Стать
графики пользователя.
Как видно, к этому списку добавлен ранее сохраненный гржрмк пэд Контроль качества (в том случае, если вы не добавляли в это меню Д| УК ки, график Контроль качества может оказаться единственным в этом с перв выберите его, при этом появится диалоговое окно 2М диаграммы р>
Ч. Добавление заданных пользователем статистических графиков
407
Просмотр и редактирование списка графиков пользователя
(ля просмотра и редактирования списка доступных графиков пользователя вы -фите в меню Сервис пункт Пользовательские графики.
408_______Глава 9. Примеры визуального анализа и настройки графиков в ST4T
Можно изменить порядок графиков в списке Для этого нужно выбрал (строки) для перемещения и щелкнуть па новом месте расположения. Кт можно добавить новые графики (если они предварительно сохранены каг ки пользователя в фагкле с расширением *.sug), изменить названия или при их заново. Ненужные графики можно удалить.
Удаление графика из списка на данном этапе не означает удаление фа] держащего параметры графика (файла с расширением *sug). Операция J" стирает имя графика из ипнпиалнзациоппого файла системы STATT Statistim. Позже этот график снова может быть занесен в пнициалпзациошш (с помощью кнопки Добавить), и опять появится в меню Графики пользой
Описательные статистики
скриптивные, или описательные, статистики рассматривались в главе Зйеиен-аарные понятия анализа данных. Здесь мы покажем, как вычисляются дескрил-вные статистики, и уделим особое внимание описательным статистикам для груп-анных данных.
Дескриптивные статистики очень важны, так как они позволяют в удобной ком-иой форме описатьисходные данные. Представьте, вы издаете журнал и вам нужно описать читательскую аудиторию. Вы проводите анкетирование читателей и просите их указать: пол, возраст, уровень образования, доход и другие параметры. Затем вы яете описательные статистки и находите, что основную аудиторию составля-мужчины в возрасте от 32 до47 лет, имеющие доход свыше а долларов, образова-высшее, женщины от 27 до 35 лет, имеющие доход свыше b долларов, образование дпее и т. д. Разнообразные графики помогают вам визуально представить резуль-вты, которые являются основой для проведения издательской политики и анализа
Заметим, что различные способы построения таблиц, описанные в главе 11, также чрезвычайно полезны для анализа подобных данных.
Мы будем работать с файлом Adstudy sta, который находится в папке Examples J поставляется вместе с системой STATISTICA. Этот файл выбран специально 1ля того, чтобы вы могли повторить наши действия и далее самостоятельно проводили описательный анализ собственных данных, так как позволяют установить ‘Вязь между, например, возрастной категорией и читаемым материалом.
Adstudy.sta содержит 25 переменных и 50 наблюдений. Эти данные были '«ораны путем социологического опроса в одном рекламном исследовании, где Ч*чины и женщины оценивали качество двух рекламных роликов ^Каждому респонденту случайным образом предлагался на просмотр один из *>ек'1амиых роликов {ADVERT: 1 - Coke*,2 - Pepsi*). Затем респонденты oue-•о Afep11 ^,”влскательность ракламы по 23 различным шкалам (с Меры 1 — Measur 1 о JL каждой из шкал респонденты могли дать ответы по десятибалльной шкале, аА о ь ®ысгавить от 0 до 9 баллов. Пол респондента кодировался: 1 — МУЖЧИ-ЖЕНЩИНА.
Е а*мите кнопку Описательные статистики. Далее нажмите кнопку Перемен-I • выберите переменные для анализа.
410
Глава 10. Описательные
В данном случае выберите все переменные. После нажатия ОК в окне вь переменных диалоговое окно Описательные статистики будет выглядеть а ющим образом:
По умолчанию таблицы результатов окна Описательные статистикЛ жат средние значения, число наблюдений без пропусков N, стандартные ния, а также минимальные н максимальные значения для выбранных и
С помощью кнопки У задаются условия выбора наблюдений.
гельные статистики
411
В окне Условия выбора наблюдений можно задать правила выбора наблюдений ’ лз файла дан ных. Таким образом, будут анализироваться не все наблюдения, а только те, которые удовлетворяют заданным условиям.
Кнопка В позволяет ввести веса, таким образом метут быть введены, например, Группированные данные (см. пункт Как проверить нормальность наблюдаемых величин в главе Элементарные понятия анализа)
Нажмите кнопку Другие статистики, чтобы открыть окно Статистики, в котором можно выбрать различные описательные статистики.
I Вы можете выбрать любой набор статистик из предложенного списка. В нашем примере оставьте выбор статистик, сделанный по умолчанию, и нажмите кнопку I Подробные описательные статистики для построения таблицы результатов.
412
Глава 10. Описательные
Графиком по умолчанию для этой таблицы результатов является гисто, с наложенной на нее нормальной кривой.
Этот трафик обычно используется для того, чтобы представить, как ри лены значения переменной, а также для визуальной проверки нормальна ходных данных (подробно гистограммы описаны в разделах книги по визу методам анализа данных).
Для построения графика щелкните правой кнопкой мыши в любом ml лицы результатов (например, на среднем значении переменной Measur 7) явившемся контекстном меню выберите построение графика Гистограмм
мальм из меню Быстрые статистические графики.
Такая же гистограмма может быть построена после нажатия кнопки граммы в разделе Распределение окна Описательные статистики. Этот рад: же позволяет анализировать распределение частот для каждой выбраны -менном (при этом происходит построение по одной таблице результат гистограмме на каждую переменную). В этом окне возможно также выч i
Ги
некоторых специальных критериев нормальности и использование настро
горизапии изучаемых данных.
пьные статистики
413
0КНо Описательные статистики предлагает большое количество графических цеД} Г Лля проведения визуального анализа распределений переменных и кор--цнй между ними Например, нажмите кнопку 2М рассеяния (с именами), что-получить наглядное представление о характере зависимости между двумя пе-
ЛрН использовании опции с именами программа располагает на диаграмме име-^тэблюяений рядом с соответствующими им точками. Вы можете построить мат-»WIV диаграмм рассеяния, нажав кнопку Матричный.
Поверхность предназначена для построения поверхности в простран- ° УМолчанию второго порядка), приближающей значения выбранных пере-
Глава 10. Описательные
Также возможно построение категоризованных диаграмм размаха, гнел диаграмм рассеяния и вероятностных графиков.
Наконец, есть возможность построить ЗМ гистограммы двух перемет изучения двумерного распределения выбранных переменных.
Этот график обычно используется для описательных пелен, а также при деним разведочного анализа данных; однако иногда он может быть поля проверке нормальности двумерного распределения.
Корреляции
Корреляции измеряют степень зависимости между переменными В Ф-" ных имеем несколько шкал (переменные Measur 1 — Measur23)-
Вначале проверим, не коррелируют ли между собой опенки в р*»э*4*" тах, другими словами, не измеряют ли некоторые шкалы, по сути, одни
1ЯЦИИ
415
I йства объекта. Если окажется, что некоторые шкапы завис имы, мы просто со г> тиМ анкету, выбросив из нее лишние пункты.
Игрначвле вычислим корреляции по всем наблюдениям, далее рассмотрим внут-упповые корреляции, то есть корреляции внутри групп. Вообще, вычисление ^ррдяций наряду с группировкой и построением таблиц — стандартный первый “ аг всякого исследования, связанного с анализом данных.
Е стартовой панели Основные статистики и таблицы выберите процедуру Кор-чяционныс матрицы и щелкните ОК (или можете просто дважды щелкнуть на пооП‘№)С Корреляционные матрицы).
После выбора этой процедуры откроется диалоговое окно Корреляции Пирсона.
можете выбрать переменные как ил одного списка (то есть матрица будет ВДратной), так и из двух списков (прямоугольная матрица).
- Данном примере для простоты выберем все переменные для анализа Однако **Ует помнить, что корреляции Пирсона больше подходят для переменных, из -в количественных шкалах.
Для номинальных переменных, таких как GENDER, ADVERT, применяются Методы исследования зависимости (см. главу Построение и анализ та-хотя формально корреляции вычисляются для всех переменных, мы со->Т()чим свое внимание на корреляциях между Measur 1 — Measur23
416
Глава 10. Описательные
Нажмите ОК. чтобы вернуться в диалоговое окно Корреляции Пирсона
Вы можете указать уровень значимости (альфа — 0,05 по умолчанию) деления значимых коэффициентов корреляции в таблице результатов.
Чтобы изменить уровень альфа, щелкните по кнопке Параметры на инструментов таблицы результатов и откройте диалоговое окно Уровень “ сти Введите в это окно уровень значимости 0,001 и щелкните ОК.
417
егко обнаружить высокие корреляции (например, корреляция между Me-. __ Меазиг 5 и Мерой 9 — Меазиг 9 равна — 0,47).
&-акая высокая отрицательная корреляция показывает, что две шкалы оценок _Г * ичМерять одну и ту же характеристику зрительного восприятия рекламы u т J ^_цпа мера этой характеристики возрастающая, а другая — убывающая). |Х°Лве опции из диалогового окна Корреляции Пирсона позволяют получить таб-
v данных с коэффициентами корреляции, а также более подробными стати-^цсами (например,p-значение, число nap N, ^-коэффициент детерминации, t-зна-«гИИЯИТ. Д-)-
Гкогда вы выберете установку Корр, матрицу (отображать р и N), вместе с ко-(Лицпентамм корреляции будут также выведены p-значения и число пар N на-Едений. по которым они вычислены. Данная опция полезна, если в данных есть Спуски и нужно точно знать объем выборки.
Выбор опции
Подробную таблицу результатов в диалоговом окне Корреляции Пирсона возможен только при выборе 20 или меньше переменных для анализа, так как для каждой корреляции автоматически будет выводиться большое количество информации После выбора этой опции будет построена таблица результатов, содержащая соответствующие описательные статистики, коэффициенты корреляции, р-значе-ния и число пар N. а также наклон и отрезок регрессии для каждой переменной.
41В
Глава 10. Описательные
Эту опцию следует использовать только для отдельных корреляций (J подробного анализа), потому что в этом формате для каждого коэффцqS реляций буд ут заняты 22 ячейки таблицы результатов: таким образом, для цы корреляций 20x20 получится таблица результатов с 8800 ячейками )
Вы видите, что корреляция между Measur 5 п Measur9 действительно] (р=.0006). Это говорит о том, что ошибка, связанная с принятием гипотез нисимости, составляет 6 из 10 000.
После тот как получена оценка корреляций, посмотрим зависимости на ip
Чтобы визуализироватьзначения корреляций между переменными м<ч строить график корреляций. Если щелкнуть по соответствующему коэффц корреляции (-6,47) правой кнопкой мыши, то появится меню:
Теперь перейдите в подменю Быстрые статистические графики и вы Диаг. рассеяния/tloeep.
Будет построен график с параметрами, заданными по умолчанию (ди: рассеяния для выбранного коэффициента корреляции с прямой регресс! ритсльнал полоса 95% и уравнение регрессии в за1 оловке).
419
яции
Мы вернемся к этому примеру п рассмотрим зависимость между Measur 5 и Measur 9 для группированных данных.
I \ сейчас опишем некоторые возможности для настройки построенного графи-
ка зависимости.
I Если вы щелкнете где-нибудь на свободном месте снаружи осей графика, появится меню глобальных опций.
Большинство основных настроек формата графика доступно в диалоговом окис и#1# разметка (см. выше первую опцию контекстного меню).
Развитие сюжета далее довольно естественное. Вначале мы вычисляем от ные статистики и корреляции для всего массива данных, затем для груш I. Оказывается, что зависимости в группах данных существенно отлнчаютс
1Риие описательных статистик для группированных данных
421
гостей в исходном массиве данных. Сравнивая полученные результаты, при-вМ к мысли, что группировка — это действительно то, чем следует заниматься ^рвых этапах дескриптивного анализа данных. Например, врач проводит груп-ювку пациентов по полу, возрасту, заболиваниям; экономист группирует лю-по уровню доходов; инженер по контролю качества группирует причины, вы-—иаюшие смещение качества производимой продукции. Проводя группировку, стараемся выделить группы однородных объектов ( исходные реальные данные, к правило, неоднородны) Вы можете воспользоваться методами кластерного анализа ДЛЯ лучшего понимания структуры данных и разбиения их на однородные группы.
В системе STATISTICA вы можете вычислить разнообразные описательные статистики (например, средние, стандартные отклонения) для данных, разбитых ELгруппы одной или несколькими группирующими переменными (например, переменными Псы — Gender и Реклама — Adv). Мы рассмотрим, как это можно сделать.
I Но если бы мы задали вопрос: как вообще провести группировку исходных данных, то мы не могли бы на него ответить. Ответ лежит в предметной области исследования. Итак, интуитивно вы ощущаете, что бы хотелось найти, далее, ис-
I пользуя систему STATISTICA, сравниваете различные способы группировки (воз-| можно, это займет довольно много времени) и находите нужный вариант.
Внутригрупповые описательные статистики вычисляются с помощью проведу ры Группировка и однофакторная ANOVA, доступной из стартовой панели модуля Основные статистики и таблицы.
После выбора процедуры Группировка и однофакторная ANOVA в стартовой панели нажмите кнопку Переменные, и выберите группирующие переменные GEN-D£R {МУЖЧИНА - MALE и ЖЕНЩИНА - FEMALE) и ADVERT.
Ь данном примере выбор группирующей переменной не представляет никакой К вроблемы
422
Глава 10. Описательные стг
Щелкните по кнопке Коды для группирующих переменных и выберите кодь1 группирующих переменных в диалоговом окне Коды для независимых факт и
Чтобы выбрать все коды переменной, можно либо ввести номера кодов в соы встствующем поле ввода, либо нажать кнопку Все, либо поставить * в соответсфмН ющем поле ввода
Щелкнув по кнопке Выбрать все в этом диалоговом окне, вы выберете все г н для каждой переменной. Нажатие ОК без задания каких-либо значений эквим лентно определению всех значений для всех переменных.
Нажмите ОК здесь и в диалоговом окне Внутригрупповые описательные тистики и корреляции для того, чтобы опсрыть диалоговое окно Внутригруп? описательные статистики и корреляции — Результаты.
^целение описательных статистик для группированных данных
423
Диалог Внутригрупповые описательные статистики и корреляции предоставит различные процедуры и настройки для внутригрупповою анализа данных Г/чнализ данных внутри групп). Цель такого анализа — лучшее понимание различий между группами
Бы можете выбрать нужные статист»ки для того, чтобы отобразить их на акра-ре в Итоговой таблице, средних или Подробных двухтодовых таблицах.
В атом примере выберите все пять возможных статистик (сделайте соответствующие установки в группе опции Статистики).
Затем щелкните по кнопке Подробные двухвходовые таблицы, чтобы увидеть •абищу результатов.
В । фиведенной таблице результатов имеются описательные статистики для выбранных переменных, разбитых на группы (прокрутите таблицу, чтобы увидеть Результаты для остальных переменных).
Изучим эту таблицу В первом столбце показаны средние переменной Measur 1 ля различных групп данных'
О для всех мужчин (MALE) среднееMeasur 1 равно 6.29 (см. первую строку мы округлили приведенное в ней значение);
О для мужчин, выбравших PEPSI, среднее Measur 1 равно 6,54 (см вторую строку)
О Ллямужчин, выбравших СОКЕ среднееMeasur 1 равной,07 (см.третью строку)
О для всех женщин (FEMALE) среднее Measur 1 равно 5,41 (см четвертую строку).
424
Глава 10, Описательные ,
О для женщин, выбравших PEPSI, среднее Measur 1 равно 5,43 (см. пятуюj О для женщин. выбравших СОКЕ, среднее Measur 1 равно 5,38 (см. гihtv«|Я О среднее переменной Measur 1, вычисленное по всем наблюдениям 1^1 (см. шестую строку). ' " ‘'
Заметьте, если общее среднее, без учета группировки, равно 5,9, т,, в группах — уже другое.
Спрашивается, велико или мало отличие среднего в разных группах? зе данных для ответа на вопрос имеется специальным критерий, извес t-критерий Стьюдента, который позволяет прояснить ситуацию. Этот кыМ подробно описан в отдельной главе.
Сейчас можно лишь сказать, что имеется слабое различие переменно1 |Дм в группах MALES и FEMALES.
Как можно заметить, имеется слабое различие между группами PEPSI я Q в пределах одного пола. Группы, получающиеся разделением по полу достаточно однородными. Максимальное отличие в средних имеет mi ду группой MALES — PEPSI (среднее равно 6,54) и группой FEMALES Q (среднее равно 5,38).
Внутригрупповые корреляции
Корреляции измеряют степень зависимости между переменными Еслнда
биты на однородные группы, то есть надежда, что зависимости станут бо. «•-четливыми. Именно за это и идет борьба.
Итак, если у вас имеется массив данных, то часто первое, с чего можно на . г. -это группировка данных. Очевидно, если у вас мало данных, то поле действий (анА сокращается. Рассматриваемая нами группировка достаточно проста и npMtfjj^H ся с помощью лишь двух группирующих переменных. Однако если вы, наг.рммИ изучаете зависимость суммарной покупки в супермаркете от дохода покуг«ММ^В или проводите сегментацию рынка, то вам придется достаточно поработать з nXMR. эффективным образом разбить данные на классы.
Итак, проведем группировку данных, рассмотрим зависимости внутри гр/’' ’ «1 сравним с результатами для негруппиронанных наблюдений.
Если у вас имеется массив данных, то первое, с чего следует начать — пр^лШ группировку данных, разбить их на более или менее однородные труппы.
Нажмите кнопку Внутригрупповые корреляции и откройте диалоговое окМ|зМ| берите группу или все группы, в котором можно выбрать группу (или Все гру*ЯЛ1 для корреляционных матриц.
Clt«ER ЯС-JCRT
_г_1
PEPSI СОКЕ
FEIMIE PEPSI
FEHALE СМЕ
корреляции
425
13 частности, нас интересует внутригрупповая корреляция между переменны-5 к Measur 9.
КРанее мы вычислили ее (г — 0.47) для всех данных и увидели, что она высоко-^1има {р<0,001).
В диалоговом окне Выберите группу или все группы дважды щелкните на стро-F Все группы, чтобы получить следующие 4 корреляционные матрицы:
Как можно заметить, корреляции в отдельных группах заметно отличаются друг ►Wдруга, следовательно, отличаются зависимости в разных группах.
| Следующий пащ шаг состоит в представлении зависимости на графиках
Внутригрупповые корреляции можно представить графически, используя ко-чанду Категоризованные диаграммы рассеяния в диалоговом окне Внутригрупповые тщательные статистики и корреляции — Результаты
I Нажав эту кнопку, вы сможете выбрать переменные для графиков.
426
Глава 10- Описательные стат.
Выберем, например, переменную Measur 5 в первом списке и переменную sur9 во втором списке.
Далее нажмите ОК, чтобы построить график.
Из графика отчетливо виднаспльная зависимость между переменными Mt и Measur 9 для группы СОКЕ — FEMALE. Эта группа состоит из женщин, пр читающих коку.
Для всех остальных групп зависимость не значима
Итак, мы нашли группу, в которой отчетливо проявилась зависимость i переменными Measur 5 и Measur 9.
Таким образом, с уверенностью можно сказать, что именно эта группа oi за зависимость между Measur 5 и Measur 9.
Подобное клише анализа применимо п к другим исследованиям.
Рассмотрим, например, корреляционную матрицу данных о продажах в маркете Фрагмент ее показан ниже'
зигрупповые корреляции
427
В этой матрице показаны корреляции между различными покупками, рассмотрим, например, первую строку Она относится к кондитерским из-
I делчям-
В этой строке пескол ько корреляции значим ы. 11а экране они выделяются красным цветом. Рассмотрим максимальную из корреляции — корреляцию между пе-Кемеипыми Кондитерские издечия и Спиртное (г = 0,56).
Хотя корреляция большая, из диаграммы рассеяния видно, что никакой завм-11имости между продажами спиртного и кондитерских изделий нет.
Продолжая исследование, проведем группировку, разбив данные на дни недели.
Обратим внимание на внутригрупповые зависимости, в данном случае — зависимости для каждого дня недели.
На диаграмме рассеяния зависимости для каждого дня недели имеют уже более привлекательный вид:
428
Глава 10. Описательные
Очень полезны также графики взаимодействий'
Из этого графика отчетливо видно, что пик продаж спиртного в течение нед приходится на пятницу, а средние продажи кондитерских изделий максммал! в четверг и пятницу. Такого рода описательный анализ, совмещенный с груп ровкой, является типичным первым шагом анализа данных
-g -g Построение
I I и анализ таблиц
ВОДНЫЙ обзор
Одним из первых шагов анализа является табуляция данных. Табуляция данных может быть очень изощренной, например, как в показанной выше таблице, где на самом деле объединено несколько таблиш
Мы начнем с самых простых таблиц. Приведенная ниже таблица называется одномерной таблицей частот;
Цвет рубашки__________________
Желтый 5
Черный 3
Цвет морской волны 1
Зеленый 1
Белый 7
Другие 10
Всего 27
В этой таблице табулирована переменная цвета рубашки у 27 встреченных мужчин Таблица называется одномерной, так как в ней табулирована только одна переменная — цвет рубашки Так как таблица показывает, насколько часто встреча
430
Глава 11. Построение и
ется тот или другой цвет, опа называется также таблицей частот. Вы ai деть, насколько удобно табличное представление.
Табулируя, например, доход, можно проанализировать различные ц селения по уровню дохода.
Наблюдаемые данные могут быть измерены в разнообразных шкалах вольных, порядковых, поминальных}, поэтому исследование зависимое^ ними может быть затруднено (например, зависимости могут быть нелин данные — неоднородными и т. д.). Отсюда следует, что вначале разумно i ровать данные, разбив па достаточно однородные группы (классы, кай в данном контексте эти слова рассматриваются как синонимы). иптуитиви дая, что зависимости в отдельных группах будут более отчетливыми. I
Таким образом, возникают категоризованные переменные. Часто капа ванную переменную можно рассматривать как некоторую классификация} । юй числовой переменной. Например, количество посетителей сайта в теч<I можно отнести к определенным временным отрезкам, например к часам Ъ можете построить соответствующую группировку.
Однако имеется много ситуаций. когда категоризованная переменная <J жается в терминах какой-либо исходной числовой переменной, а опр- ц самой природой данных. Например, на книжном рынке можно выделить рии Ki । иг по Windows, Windows-приложениям (Word, Excel и др.), Интерну гн, посвященные языкам программирования, научным программам и т. д. очередь, пользователи могут быть разбиты на классы: начинающие пользе^ продвинутые пользователи, профессионалы и т д.
Пример категоризации данных. Рассмотрим файл данных о продажах.
Е - дйПЕЗЯПХСШйД
1UZD0
ООО-
0.00 ООО
3300
104 50
0.00
пои
63 95
ООП Ь'М ООО
0.00 000
Эти данные измерены в количественной шкале.
Предположим, что нас интересует только факт покупки данного товар» Т< количественная шкала явно избыточна. Перейдем к категориальным nepeMd Покажем, как это сделать в системе STATISTICA. Дважды щелкнем на име! ременной КОЛБАСЫ Это 14-я переменная в файле данных. Определим | переменную формулой: (v!4>0). Это уже категориальная переменная, п] мающая два значения: значение 0, если vl4<0 (то есть покупатель не купил i и значение I, если v!4>0 (покупатель купил товар).
Такие переменные называют также индикаторными, так как они являю®
дикатором определенного события (в данном случае факта покупки).
1Й обзор
431
f Построенная категориальная переменная разбивает покупателей на два класса: покупатели, купившие продукт (значение переменной равно 1), и покупатели, не купившие прплук! (значение переменной равно 0)
[ После того как мы записали формулу, значения переменной г 14 будут пересчитаны. и мы получим следующий столбец-
ело
[ Подобную категоризацию можно выполнить для всего списка товаров. ВI itotc юлучим файл данных, состоящий из значений 0 и 1.
Единица показывает, что данный покупатель (строка) купил данный товар Ктолбец)
Заметим, что подобного рода таблицы, содержащие индикаторные переменные, весьма часто появляются в медицинских исследованиях. В них строка — пациент временные — симптомы болезни. Единица отмечает, что у данного пациента присутствует данный симптом, О — симптом отсутствует.
Такого типа таблицы будут подробно рассмотрены также в главе Анализ соответствий.
Теперь еще раз напомшгм идею категоризации, потому что эта идея является [Ключевой.
Итак, идея состоит в том, чтобы разбить множество разнородных наблюдений™ ВДНоро дл ые группы с помощью определи i пых признаков, отражающих существо за-оачч. и провести дальнейшее исследование в каждой группе отдельно. Такие груп-Цы гораздо проще анализировать, чем исходную корзину с разнородными данными.
Например, множество всех покупателей можно поделить на две группы — ку-
вШих и нс купивших мороженое, или на четыре группы — купивших мороже-г и купивших сыр, купивших мороженое и не купивших сыр, не купивших мо-
-Лое и купивших сыр, не купивших мороженое и не купивших сыр и т а.
432
Глава 11. Построение и анализ
В STATISTICA таблицы строятся в модуле Основные статистики и таблица Конкретный способ построения таблиц зависит от целей исследования.
Врач может табулировать частоты различных симптомов заболевания в заем симости от возрастай пола пациентов, социолог имеет возможность построить сводную таблицу результатов опроса и оценить связи между ответами мужчин и xciy»-шин отдельно. В области образования можно табулировать число учащихся покинувших среднюю школу, в зависимости от возраста, пола и этнического про нахождения. Экономисту может понадобиться свести в таблицу количество банк ротств в зависимости от вида промышленности, региона и начального капитал*, а исследователю спроса классифицировать потребителей в зависимости от доходив Менеджеры, размещающие ракламу в Интернете, могут интересоваться частотой посещения различных сайтов в отдельные дни недели.
Более серьезной задачей является установление цен на продукцию с целью эф фективного способа организации продаж: имеются разные категории пользователей, например, учебные заведения, государственные организации, коммерческие структуры и т. д. Покупательские возможности разных категорий различны, по этому разбиение на группы, когда вы имеете дело не со средним покупателем а с покупателем из определенной группы, выглядит совершенно естественно. I
Далее в одной таблице можно табулировать значения двух переменных, тогш возникают таблицы сопряженности. Пример такой таблицы, которую мог бы по мсстить в свою записную книжку метрдотель ресторана, показан ниже:
Дни недели Количество посетителей ресторана «Табу» в 9 часов вечера
Мужчины Женщины Всего
Понедельник 9 11 20
Вторник 7 8 15
Среда 11 7 18
Четверг 9 16 25
Пятница 15 7 22
Суббота 17 5 22
Воскресенье 17 9 26
Всего 85 63 148
Вы видите, как естественно организована таблица: дни недели сопряжены с ко личеством посетителей ресторана, отсюда и название таблицы — таблица сопр*~ женности: на пересечении строки дня недели и столбца показано количество пм-сетителей (мужчин и женщин) в выбранный день недели. В крайнем правом столб: т» с литером ВСЕГО даются суммы значений по строкам таблицы. В последней стр1' ке показаны суммы значений, подсчитанные по столбцам Это так называемые м»| • гинальные частоты.
Рводный обзор
433
Удобство таблиц. Удобство таблиц очевидно. Метрдотелю достаточно взгля-иуть на таблицу, чтобы представить, сколько было посетителей разного пола в различные дни недели. Вместо того чтобы скользить глазами по длинному списку посетителей, он просто бросает взгляд на таблицу. В нижней строке и правом столбце количество посетителей просуммировано. Возможно, метрдотелю интересно знать, сколько всего посетителей было в субботу, и ему вовсе не нужно суммировать частоты в двух столбцах (мужчины и женщины), а достаточно посмотреть на крайний столбец и строку Суббота.
В таблице табулированы значения двух переменных, поэтому она называется двухвходовой. Если табулируется несколько переменных, то имеют дело с многовходовыми (многомерными) таблицами (от английского терм ина multy-way) с двумя или более факторами. Заметьте, что табулированные переменные на сленге анализа данных называют также факторами.
Другой типичный пример таблицы сопряженности показан ниже:
В этой таблице табулированы переменные пол и программа телевидения. Таблица построена из исходного файла данных, в котором отмечался выбор программ ТВ респондентами разного пола.
Итак, представление данных в виде таблиц компактно, удобно и наглядно. Вместо того чтобы иметь дело с файлом исходных данных, содержащим сотни и тысячи наблюдений, вы имеете одну таблицу.
Для проверки факта зависимости между табулированными переменными (например, Пол и ТВ) и оценки степени зависимости или, как иногда выражаются, тесноты связи, разработаны специальные методы.
Анализ таблиц саязан с определенным сленгом, который стоит запомнить. Переменные, табулированные в таблице, называются также факторами. Значения факторов называются уровнями. Например, переменная пол имеет два уровня — мужчина и женщина, переменная TV также два уровня — 1 м2. Конечно, количеством уровней и числом табулируемых переменных можно управлять. Можно, например, ввести дополнительные переменные — возраст, профессию и т. д.
В анализе таблиц также употребляется несколько архаичный термин вход таблицы (от английского way) для обозначения табулированной переменной. Если табулируются две переменные, то говорят о двухвходовой таблице (таблицы с двумя входами), если табулируется три переменные — о трехвходовой таблице и т. д.
Несмотря на кажущуюся простоту идеи, техника работы с таблицами за много лет развилась и стала чрезвычайно изощренной.
Альтернативные методы. Вначале таблицы строятся и анализируются в модуле Основные статистики и таблицы Однако имеются модули Логлинейный анализ и Апазчзкоответпстивий.вкоторыхтакжеможно исследовать таблицы сопряженности.
Методы Логтгнейного анализа (loglinear analysis) позволяют глубоко исследовать сложные многомерные таблицы, возникающие, например, при проведении массовых обследований.
434
Глава 11. Построение и анализ
Анализ соответствии (correspondence analysis') — это разведочный метода» двухвходовых л многовходовых таблиц, позволяющий визуализировать табл исследовать их структуру. Ясно, что гораздо проще анализировать таблицу вц но. чем исследовать в численном виде. Этот разведочный метод анализа приь^ ся в разнообразных областях: в социологии, эконометрике, маркетинге, ме £ (см. например. 1 homas Werani: Correspondence Analysis as a Means for DexbL City Marketing Strategies, 3rd International Conference on Recent AdvJnr
Retailing and Services Science, pp. 22—25. J uni 1996, Tdfs- Buchen ( Osterreicli )\V
Thomas, werani@market,uni-linz.ac at, http://www.marketuni-linz.ac.at). ,
Продвинутый метод исследования таблиц — анализ соответствий — буди дробно описан в отдельной главе.
В данной главе рассмотрим классические методы анализа, реализованные в
типов таблиц начш
дуле Основные статистики и таблицы Обзор различных с наиболее простой таблицы — таблицы частот.
Таблицы частот
Частоты, или одновходовые таблицы, представляют собой простейший метод ан; за категориальных или искусственно категоризованных непрерывных перемен; Часто их используют как одну из процедур разведочного анализа, чтобы поа рсть, каким образом различные группы данных распределены в выборке Напри изучая зрительский интерес к разным видам спорта (возможно, для целен ре мы), вы могли бы представить ответы респондентов в следующей таблице-
Таблипа отображает число и кумулятивную (суммарную) долю респонды характеризующих свой интерес к просмотру футбольных матчей в следую шкале: 1) Всегда интересуюсь — Always interested, 2) Обычно интересуюсь - Us. interested. 3) Иногоа интересуюсь — Sometimes interested или 4) Никогда не ипт суюсь — Never interested.
Точно так же мы могли бы представить информацию о том, насколько ча респондент использует в своей работе Интернет:
STATISTICA обеспечивает разнообразные возможности, позволяющие он различные категории наблюдений в таблице частот (например, используя «в< яичные между собой значения» переменных)
Злицы частот
435
Любая переменная из множества данных может быть проанализирована и представлена в виде таблицы частот. Исследователь может также ввести определенные коты для таблицы, задать интервалы и даже определить ряд логических условий, позволяющих отнести наблюдение к определенной группе
I фактически каждый исследовательский проект начинается с построения таблиц частот. Например, в социологических опросах таблицы частот могут отображать количество мужчин и женщин, число респондентов из определенной этнической группы и т. д. Ответы, измеренные в определенной шкале (например, в шкале интерес к футболу), можно также свести в таблицу частот
Ниже на графике показана табуляция частоты посещения магазина.
В медицинских исследованиях можно табулировать пациентов с определенными симптомами. В промышленности — частоту выхода из строя элементов, приведших к авариям или отказам всего устройства при испытаниях на прочность (на-прпмер для определения, какие детали телевизора действительно надежны после эксп туатации в аварийном режиме и при большой температуре. а какие нет). Обычно еечн в данных имеются категориальные переменные, то для них всегда вычис-1ЯЮТСЯ таблицы частот для каждой переменной.
436
Глава 11. Построение и анализ
Таблицы сопряженности и таблицы и заголовков
Это более сложные таблицы, так как они содержат частоты нескольких ne/t ных. Процесс построения таблицы частот для одной переменной называется-ляцией, для нескольких переменных — кросстабуляцией. На самом деле буляция — это процесс объединения двух (или нескольких) таблиц частоттл каждая ячейка (клетка) в построенной таблице представляется единственной бинацией значений кросстабулированных переменных.
Таким образом, кросстабуляпия позволяет совместить частоты появлени блюдений на разных уровнях рассматриваемых факторов. Исследуя эти чап можно определить зависимости между кросстабулнрованными переменными.
Идея проверки независимости табулированных переменных очень проста Рассмотрим двухвходовую таблицу сопряженности {v(ij), 1 < t < k. 1 <j < щ), в в торой табулированы значения двух переменных (X, У).
Частоты v(».j)/n являются оценками вероятностей p(ij).
При гипотезе независимости эти вероятности обладают свойством мультилл кативности:
P(’J)“P(Ox₽U).
p(i) -р(1.0 + /5(2,0 + - + p(j)-pWp&J)+ p(k,f)
При наличии зависимости между табулированными переменными это раве ство нарушается.
Критерием проверки гипотезы независимости в таблицах сопряженности Я1 ляется хи-квадрат Пирсона, который сравнивает наблюдаемые частоты в ре j ной таблице с ожидаемыми, рассчитанными при условии независимости таб’ i рованных переменных (см. далее).
Пример. Рассмотрим файл данных с информацией о прививках (см. Вступ тельное эссе).
сопряженности^ггаблицы флагов и заголовков
437
Построим таблицу сопряженностей признаков ПРИВИВКА. БОЛЕЗНЬ
Посмотрим на хи-квадрат:
По результатам применения хи-квадрат критерия можно сделать вывод, что есть серьезные основания для того, чтобы отвергнуть гипотезу о независимости признаков.
Общая схема рассуждений.
о Шаг 1. Проверьте гипотезу о независимости признаков.
j Шаг 2. Если гипотеза о независимости отвергается, используйте специальные меры связи, например, статистику гамма, чтобы оценить степень зависимости между табулированными переменными.
Обычно кросстабулнруются номинальные переменные или переменные с относительно небольшим числом значений.
Если вы хотите кросстабулировать непрерывные переменные (например, доход). то вначале их следует категоризовать, разбив диапазон изменения на небольшое число интервалов (например, низкий, средним, высокий)
Таблицы 2x2. Простейшая форма кросстабуляции — это таблица 2 х 2, в которой значения двух переменных «пересечены* (сопряжены) и каждая переменная принимает только два значения, то есть имеет два уровня (поэтому таблица и называется 2 х 2). Рассмотрим поясняющий пример. Предположим, проводится простое исследование, в котором мужчин и женщин спрашивают, какой напиток они предпочитают (газированную воду марки А или газированную воду марки В); файл данных показан ниже:
ПОЛ ГАЗ. ВОДА
аабгюдение 1 МУЖЧИНА
наблюдение 2 ЖЕНЩИНА В
наблюдение 3 ЖЕНЩИНА в
наблюдение 4 ЖЕНЩИНА А
наблкщение 5 МУЖЧИНА В
Результаты кросстабуляции выглядят следующим образом:
ГАЗ. ВОДА: А ГАЗ. ВОДА: В
П0Л: МУЖЧИНА 20 (40%) 30 (60%) 50 (50%)
п0Л: ЖЕНЩИНА 30 (60%) 20 (40%) 50 (50%)
50 (50%) 50 (50%) 100 (100%)
438
Глава 11 Построение и анализ та|
Каждая ячейка таблицы содержит единственную комбинацию значений кросстабулированных переменных (в строке указана переменная ПОЛ, в столб переменная ГАЗ. ВОДА). Каждая ячейка стоит на пересечении столбца и сп
Числа в каждой ячейке на пересечении определенной строки и определенного < -бца показывают, сколько наблюдений соответствует данным значениям, Посмт те на таблицу. Таблица показывает, что женщины больше мужчин предпочмт газированную воду марки Л, мужчины больше предпочитают марку В. Таким о( зом, пол и предпочтение могут быть зависимыми (позже будет показано, как зависимость измерить).
Маргинальные частоты. Значения, расположенные на краях таблицы, -просто одномерные таблицы частот для всех рассматриваемых переменных.
значения важны, так как позволяют оценить распределение частот в отдельн столбцах и строках. Например. 40% и 60% мужчин и женщин (соответственн выбравших марку А (см. первый столбец таблицы), не могли бы показать каю либосвязи между переменными ПОЛ и ГАЗ- ВОДА — еслибы .маргиналы!
частоты переменной ПОЛ были также 40% и 60%. В этом случае они просто от жали бы разную долю мужчин и женщин, учас твующих в опросе. Таким обргт, различия в распределении частот в строках (или столбцах) отдельных перем» ных и в соответствующих маргинальных частотах дают информацию озависим тн кросстабулированных переменных.
Проценты по столбцам, по строкам и кумулятивные проценты. Приведен)! пример показывает, что для оценки зависимости между кросстабулированны переменными необходимо сравнивать маргинальные доли и индивидуальные гл в столбцах и строках. Такие сравнения легче провести с использованием процент Процедура Итоговые таблицы позволяет выдать кросстабулированные чкр ты в таблице результатов вместе с числом наблюдений, попавших в ячейку, щ центами в столбцах и строках, а также суммарными процентами.
Можно построить итоговую объединенную таблицу, в котором каждая я> содержит эти чис ла.
Таблицы сопряженности и таблицы флагов и заголовков
439
Графическое представление кросстабуляций. Отдельные с троки и столбцы таблицы УД°бн° представить в виде графиков. Полезно также отобразить целую I таблицу на отдельном графике. Имеется несколько способов сделать это с помо-дью процедуры Таблицы сопряженности. Таблицы с двумя входами можно визуально представить ЗМ гистограммой.
Другой способ визуализации таблиц сопряженности — построение категоризованной гистограммы, в которой каждая переменная представлена индивидуаль-ными гистограммам и, разбитыми на каждом уровне другой переменной (см. ниже).
Преимущество ЗМ гистограммы в том, что она позволяет представить на одном графике таблицу полностью. Достоинство категоризованного графика заключается в том, что он дает возможность точно оценить специфические частоты в каждой ячейке.
440 Глава 11. Построение и анализ таб/
Таблицы флагов и заголовков
Таблицы флагов и заголовков, или. кратко, таблицы заголовков, позволяют ]9 Сразить несколько двумерных таблиц сопряженности в сжатом виде как одну та' цу. Этот тип таблиц поясняется на примере файла, отражающего интепЗ спорту.
В данной таблице результатов представлены три двухвходовые таблицы, в I». торых интерес к Футболу — Football сопряжен с интересом к Бейсболу — Baseball' Теннису — Tennis и Боксу — Boxing. Таблица содержит информацию о процент м по столбцам, поэтому суммы по строкам равны 100%. Например, число в чев верхнем углу таблицы результатов (85.71) показывает, что 85,71 процентов вс»-« респондентов ответили, что нм всегда интересно смотреть футбол и всегда инте ресно смотреть бейсбол. Рассмотрите первый столбец приведенной таблицы. Вы видите, например, что имеется 2 респондента, обычно интересующихся футболом и всегда интересующихся бейсболом. Также 2 (других) респондента иногда ин j₽ ресуются футболом и всегда интересуются бейсболом. Нет ни одного респО№И1Н та, которому был бы всегда интересе]) бейсбол и никогда не интересен футслыт Аналогично интерпретируются другие столбцы. Если вы прокрутите таблицу вп] г во, то увидите, что процент тех, кому всегда интересно смотреть футбол и вс* -.И интересно смотреть теннис, равен 38,46; для бокса этот процент составляет 7I. ч (см. таблицы ниже).
Проценты в столбце (Всего по строке), показанные после каждого набора пер менных, всегда связаны с общим числом наблюдений. В диалоговом окне Рез-" таты кросстабуляции имеется множество процедур, позволяющих постро»*1 таблицы заголовков в различных форматах Например, можно одновременное
Таблицы сопряженности и таблицы флагов и заголовков
Многовходовые таблицы с контрольными переменными. Когда кросстабули-руются только две переменные, результирующая таблица называется двухвходовой (двумерной) Конечно, общую идею кросстабулирования можно обобщить на большее число переменных. В примере с «газированной водой» добавим третью переменную с информацией о штате, в котором проводилось исследование (Небраска или Нью-Йорк).
пол ГАЗ. ВОДА ШТАТ
наблюдение 1 МУЖЧИНА А НЕБРАСКА
наблюдение 2 ЖЕНЩИНА В нью-йорк
наблюдение 3 ЖЕНЩИНА в НЕБРАСКА
наблюдение 4 ЖЕНЩИНА А НЕБРАСКА
наблюдение 5 МУЖЧИНА В НЬЮ-ЙОРК
Кросстабуляция этих трех переменных представлена в следующей таблице:
ШТАТ: НЬЮ-ЙОРК ГАЗ. ВОДА ГАЗ. ВОДА ШТАТ: НЕБРАСКА
ГАЗ. ВОДА ГАЗ. ВОДА
А В А В
П: МУЖЧИНА 20 30 50 5 45 50
П: ЖЕНЩИНА 30 20 50 45 5 50
50 50 100 50 50 100
Теоретически любое число переменных может быть кросстабулировано в од-ной многовходовой таблице. Однако на практике возникают сложности с проверкой и «пониманием» таких таблиц, если они содержат более четырех переменных.
442
Глава 11. Построение и анализ т
Статистики таблиц сопряженности
Таблицы сопряженности позволяют исследовать зависимость между кросста рованными переменными. Следующая таблица отчетливо показывает очень ную зависимость между двумя переменными: переменная ВОЗРАСТ(ВЗРОС или РЕБЕНОК) и переменная предпочитав чый сорт ПЕЧЕНЬЕ (сорт А или сс
_________ ПЕЧЕНЬЕ: А ПЕЧЕНЬЕ: В ______
ВОЗРАСТ: ВЗРОСЛЫЙ 50 0 50
ВОЗРАСТ: РЕБЕНОК 0 50 50
50 50 100
Из этой таблицы видно, что все взрослые выбирают печенье А, а все дети ченъеВ. В данном случае пет никаких оснований сомневаться в надежности этого
Невозможно поверить, что данная структура частот носит случайный > тер. Мало кто усомнится, что между предпочтениями детей и взрослых ш, отчетливое различие Однако в реальной обстановке зависимости между пер ными значительно слабее, и поэтому возникает вопрос, как их измерить и сцен надежность (статистическую значимость).
Далее обсуждаются общие меры зависимости между двумя группирующими
ременными.
Итак, вначале проверяется гипотеза: имеется ли зависимость между предо ленными в таблице переменными?
Критерий хи-квадрат Пирсона. Хи-квадрат Пирсона — это наиболее прос критерий проверки значимости зависимостей между группирующими перемен ми. Критерий Пирсона основывается на том. что в двухвходовой таблице ожш мые частоты при гипотезе, что между переменными нет зависимости, можно посредственно вычислить.
Критерий хи-квадрат — это непараметрический критерий, его применение как нс связано с распределением табулированных переменных.
Идея критерия очень проста.
Рассмотрим двумерную таблицу сопряженности {v(f,j)}, i = 1,2 _ г, j - 1, | состоящую из г строк и s столбцов.
Обозначим
п(г) = л(1,1) + ... n(i,s). 1=1.2 .. г
"(j) - п(1.» * - n(rj), 7 “ 1.2... г
и = Xw(rj)
Итак, v(i) — сумма элементов в i-й строке, v(j) — сумма элементов в j м ГI п — общее число наблюдений (сумма всех частот в таблице). v(e), v(j) назы! также маргинальными частотами, так как они располагаются по краям та/il
Рассмотрим какую-нибудь ячейку таблицы. Из частоты, стоящей в ячейк I наблюдаемая частота), вычтите ожидаемую частоту (она вычисляется nepewi Г нием маргинальных частот и делением их па общее число наблюдений). Пол,| ную разность возведите в квадрат и разделите на ожидаемую частоту. Далее делайте то же самое со всеми ячейками и результаты сложите.
Таблицы сопряженности и таблицы флагов и заголовков
443
Это и есть знаменитая статистика хи-квадрат Статистика хи-квадрат замечательна тем. что при достаточно большом числе наблюдений ее распределение можно приблизить распределением хи-квадрат и, значит, вычислить приближенный р-уровепь критерия.
формально статистика хи-квадрат вычисляется по формуле-
Хи-квадрат = E[(n(i,/) - n(ij))**2|/n0,j),
где суммирование производится по всем индексам i,j. = v(i) * v(J)/n — ожи-
даемая частота в ячейке i.j.
Большие значения хи-квадрат свидетельствуют против проверяемой гипотезы о независимости признаков, табулированных в таблице.
Представьте, что опрошено 20 мужчин и 20 женщин относительно выбора газированной воды (марка А или марка В). Если между выбором и полом нет зависимости. то естественно ожидать равного выбора марки А и марки В для каждого пола.
Распределение хи-квадрат при проверке независимости можно аппроксимировать хи-квадрат-распрсдслснием с числом степеней свободы (r-t)*(s-l). Однако качество этой аппроксимации ухудшается, если число наблюдений в ячейках мало (см. ниже).
Критерий хи-квадрат становится высокоэначнмым при отклонении реально наблюдаемых частот в таблице от ожидаемых, иными словами, когда выбор мужчин п женшнп различен. Значение статистики хи-квадрат и ее уровень значимости определяется общим числом наблюдений и количеством ячеек в таблице.
Иногда используют статистику хи-квадрат в форме максимального правдоподобия:
МПхи-квадрат = 2 х En(i,j) ln(n(i,j)/n(ij))
По существу, эти две статистики эквивалентны.
Имеется только единственное существенное ограничение использования критерия хи-квадрат (кроме очевидного предположения о случайном выборе наблюдений) — ожидаемые частоты должны быть не слишком малы (см. пример ниже). Это ограничение возникает потому, что хи-квадрат сравнивает наблюдаемые частоты и вероятности в каждой ячейке, и когда частоты в ячейках малы, например, меньше 5 или даже 10, эти вероятности нельзя оценить с достаточной точностью (см например, Everitt B.S. (1977) The analysis of contingency tables, London: Chapman&Hall).
Замечание. Статистика хи-квадрат Пирсона позволяет строить также критерии col часия и однородности (см. главу 4 Подгонка ее/юетшетных распределений).
Поправка Йетса для таблиц 2x2. Для важного класса таблиц 2 х 2, содержащих ячейки с малыми частотами, аппроксимация распределения статистики хи-квадрат Может быть улучшена понижением абсолютного значения разностей между ожидаемым и наблюдаемыми частотами на величину 0,5 перед возведением в квадрат (по-ираеда Йетса).
Поправка Йетса, делающая оценку более умеренной, применяется в случаях, когда Та°лвца содержит ячейки с малыми частотами. Принято считать, что наименьшая
Глава 11- Построение и анализ
-лИцы сопряженности и таблицы флагов и заголовков
ожидаемая частота, позволяющая применять критерий хи-квадрат без пог должна равняться 5. Из приведенной ниже таблицы видно, как могут отд р-уронии критерия хи-квадрат без поправки и с поправкой Йетса. Исхг-щ лица сопряженности имеет вид:
В таблице сопряжены два признака: покупка мороженого и орехов. Стат, для этой таблицы сопряженности имеют вид:
“==
Используя хи-квадрат без поправки Йетса, мы совершили бы грубую ош '
Точный критерий Фишера. Этот критерий применим только для таблиц 2 * 3 « Критерий основан на следующем рассуждении. Даны маргинальные ча< io.’u в таблице. Предположим, что оба фактора в таблице независимы. Зададимся просом: какова вероятность получения наблюдаемых в таблице частот мехом IW
маргинальных? Эта вероятность вычисляется точно исходя из данных мара-
налышх частот. Таким образом, критерий Фишера вычисляет точную верь.-ность появления наблюдаемых частот при нулевой гипотезе. Вычисляют»-» посторонние и двусторонние вероятности.
Мвкнемара хи-квадрат. Этот критерий применяется, когда частоты в та. МЙ 2x2 представляют зависимые выборки. Например, наблюдения одних и тех м •*»-дивидуумов до и после эксперимента Вы можете подсчитывать число студ» • п* имеющих минимальные успехи по математике в начале и в конце семестр?, г-« числяются два значения хи-квадрата: A/Du В/С. Д/О-хи-квадрат проверя»тИ»»*»’ тезу о том, что частоты в ячейках А и D (верхняя левая, нижняя правая) оди вы. В/С-хи-квадрат проверяет гипотезу о равенстве частот в ячейках Вт С(ве| правая, нижняя левая).
Коэффициент фи. Фи-квадрат представляет собой меру зависимости ЯИ двумя группирующими переменными в твблице 2x2. Его значения изме I «V*1 от 0 (нет зависимости между факторами; хи-квадрат - 0,0) до 1 (абсолютная 2ЯЯ симость между двумя факторами в таблице).
Тетрахорическая корреляция. Эта статистика вычисляется (и при меня только для таблиц сопряженности 2x2. Если таблица 2x2 может рассмаг-ся как результат (искусственного) разбиения двух непрерывных переменним! два класса, то коэффициент тетрахорической корреляции будет оценивал» симость между двумя этими переменными.
цоэффициент сопряженности С. Коэффициент сопряженности представля-I собой основанную на статистике хи-квадрат меру зависимости между двумя ппирующими переменными (предложенную Пирсоном). Преимущество этого 2^ффиниента перед обычным хи-квадрат состоит в том, что он легче пнтерпре-•ипуется. так как диапазон его изменения от 0 до 1 (где 0 означает полную независимость).
Недостаток заключается в том, что верхний предел «ограничен» размером таблицы; С может достигать значения 1. только если число классов не ограничено.
Интерпретация мер сопряженности. Существенный недостаток мер зависимости в трудности их интерпретации в обычных терминах вероятности или «доли вариации»-, как в случае коэффициента корреляции г Пирсона.
Статистики, основанные на рангах
Во многих случаях классы, используемые в кросстабуляции, содержат информацию о ранговом упорядочивании объектов; иными словами, имеются измерения лишь в порядковой шкале. Предположим, вы опросили некоторое множество респондентов для того, чтобы выяснить их отношение к некоторым видам спорта. Затем представили измерения в 4-точечной шкале со следующими градациями: 1) всегда — always, 2) обычно — usually, 3) иногда — sometimes и 4) никогда — never interested. Очевидно, что ответ иногда интересуюсь — sometimes interested показывает меньший интерес, чем обычно интересуюсь — usually interested, обычно интересуюсь — usually interested меньший интерес, чем всегда интересуюсь — always
! interested, ит.Д.
Для таких переменных имеются свои типы корреляции, позволяющие числен-
но выразить зависимости между ними (см. главу Непараметрическая статис-
тика).
1 Многомерные отклики и дихотомии
I Переменные типа многомерных откликов или многомерных дихотомий возника-
ют в ситуациях, когда исследователя интересуют не только «простые» частоты со-14 бытии, но также некоторые (часто неструктурированные) качественные свойства
*эбытий. Тниичным примером является опрос общественного мнения, где вопросы, по крайней мере частично, имеют так называемые «открытые концы» (не под- раэумевая однозначного ответа), и респондент делает выбор из неограниченного I °чень большого) списка ответов. Вопрос состоит в том, как разумным сиосо-Ьом закодировать ответы Природ}' многомерных переменных (факторов) лучше «его рассмотреть на примерах.
Многомерные отклики
I Редставьте что в процессе большого исследования вы попросили пользователей вать три лучших, с их точки зрения, сайта Обычным вопрос может выглядеть I Пс’Й’ ищим образом:
446
Глава 11. Построение и анализ
Напишите ниже три лучших сайта: 1:2:3:
Анкета содержит от 0 до 3 ответов. Очевидно, список может быть очеь, шим. Ваша цель — свести результаты в таблицу, в которой, например, б> л считан процент респондентов, предпочитающих определенный сайт
Следующий шаг после получения анкет — занесение ответов в файл J Предположим, в ответах упоминалось 50 различных сайтов. Вы могли бы но, создать 50 переменных — одну для каждого сайта, рассмотреть респон как наблюдения (строки таблицы), ввести код 1 для респондента и перем если он предпочитает данный сайт (О, если нет); например:
Сайт1 Сайт 2 СайтЗ —
наблюдение 1 0 0
наблюдение 2 1 0
наблюдение 3 0 0 1
Такой метод кодирования откликов, то есть приписывания им конкрет w чеиий, очевидно, «расточителен». Заметим, что каждый респондент дл«г мум три ответа; однако для кодирования используется 50 переменных (| интересуетесь только тремя сайтами, то такой метод кодирования 6j - т ’ -.-hi Чтобы табулировать предпочтения в выборе сайта, следует рассмотреть I менные как одну многолгерную дихотомию; см. ниже.)
Кодирование многомерных откликов. Более разумным является следуюгц ход. Введите 3 переменные и определите схему кодирования д ля 50сайтов. За дите соответствующие коды (а?ьфа-метки) для значений переменных и полуЧ| лицу вида:
Ответ! Ответ 2 Ответ_3
набл.1 сайт 1 сайт 17 сайт 13
набл. 2 сайт 2 сайт 21 сайт 77
набл.3 сайт 19 сайт1 сайт 4
Теперь, чтобы получить число респондентов, предпочитающих опред
сайт, рассмотрите переменные Ответ 1 — Ответ 3 как переменную я •** ным откликом Само название переменной показывает, что опа приникЛН мерные значения. Таблица значений такой переменной имеет вид.
N-500 Категория Процент Процент Число ответов наблюдений
сайт! сайт 2 сайтЗ сайт 4 Всего ответов 44 5,23 8,80 5 1 2,60 81 9,62 16,20 74 8,79 14,80 842 100,00 168,40
сопряженности и таблицы флагов и заголовков 447
f И)псрпретация таблиц частот с многомерными откликами- Итак, общее чис-
реснондентов в опросе п=500. Заметьте, что числа в первой колонке таблицы не Г вставляют в сумме 500, как можно было бы ожидать, а равны 842. Вы поймете, I * пчеМУ это так, если вспомните, что каждый респондент может дать несколько ' в(?1 он, так как у него может быть несколько любимых сайтов. Число, приведен-внизу в первом столбце (на границе таблицы), — это общее число ответов.
Всажтый респондент может дать до трех ответов, поэтому общее число ответов I действительности больше числа респондентов.
I " Вторые и третьи столбцы таблицы содержат проценты относительного числа Иыгштов (второй столбец) и респондентов (третий столбец). Таким образом, вход о go в цервой строке последнего столбца таблицы означает, что 8,8% всех респон-Зентоа назвали <айт1 в числе лучших
1г Как учитывать повторяющиеся ответы в одной и той же анкете? В отличие от Г других популярных программ, строящих таблицы для многомерных откликов, про- цедура Кросстабуляция в модуле Основные статистики и таблицы по умолчанию I игнорирует одинаковые отклики. Например, если респондент ответил: сайт 1, I сайт 1, сайт 1, то система STATISTICA учтет из его ответа сайт 1 только один раз. Следовательно, этот респондент в таблице частот будет учтен только один раз в группе сайт 1, иными словами, в эту группу будет добавлена единица, а не тройка.
Многомерные дихотомии
! Предположим, вас интересуют только сайт А. сайт В и сайт С. Как отмечалось, одним из способов кодирования является следующий:
сайт А сайт В сайте
наблюдение 1 1
I наблюдение 3 1
Здесь каждая переменная используется для одного сайта Код 1 будет введен [ в таблицу всякий раз. когда соответствующий респондент указал ее в своем ответе. I Заметим, что каждая переменная является дихотомией, так как принимает только Два з! !ачепия: и «не 1*> (можно ввести 1 и О, но так обычно не делается, можно
I просто рассматривать 0 как пустую ячейку пли пропуск). Когда табулируются такие значения, вы получите итоговую таблицу, очень похожую на ту, которая была Доказана ранее для переменных с многомерными откликами; из нее вы можете
I ^иелнть число и процент респондентов (и ответов) для каждого сайта. Таким [ “Цраюм, вы компактно представили три переменные сайт А, сайт В, сайт С одной I временной [Любимые сайты)—многомернойдихотояией. Заметьте, для кодирова-" ы тРех сайтов использовано 3 одномерные дихотомии, для кодирования десяти
I рлитков понадобится 10 одномерных ДИХОТОМИЙ И т- л.
4>осстабуляция многомерных откликов
" Дихотомий
I а >ц’д- Ра Кросстабуляция модуля Основные статистики и таблицы позволяет рс'1^гштьцросТь1егрупп11рую11шеПерсме1111ые(наПример,ПОЛ: МУЖЧИНА или
448
Построение и анализ таг
ЖЕНЩИНА), многомерные отклики и многомерные дихотомии. Все эти тип ременных можно использовать в таблицах сопряженности. Например, вы м<Ы * «сопрячь» многомерную дихотомию Сайт (закодированную, как описано 2 с многомерным откликам Телевидение (со многими категориями, напрнме]./Я ГРАММА 1, ПРОГРАММА 2 и Т. д.), а также с простой групп ирующей пеп ПОЛ.
Как и в таблице частот для обычных переменных, в таблице частот для ы<. мерных переменных можно вычислить проценты и маргинальные суммы общему числу респондентов, либо по общему числу ответов (откликов). Н^л*** мер, рассмотрим следующего респондента:
ПОЛ сайт 7 сайтЗ сайтЭ ТБ ТВ —
ЖЕНЩИНА 11 12
Этот респондент ЖЕНЩИНА назвал своими любимыми сайт 7 и сайт 3 и г до-граммы ТВ 1 и ТВ2. В полной таблице сопряженности этот респондент будет приставлен следующими наборами-
ПОЛ Сайт ТВ Общее число ответов
TB1 ТВ2
ЖЕНЩИНА сайт 7 X X 2
сайтЗ X X 2
сайт9
МУЖЧИНА сайт 7
сайтЗ
сайт 9
Данный респондент учитывается в таблице четыре раза. Дополнительна « 6»«-дет считаться дважды в сюлбце ЖЕНЩИНА-сайтп7маргинальных частот, ес -» rui столбец запрошен для представления общего числа откликов Если пользе--» i «Ш запрашивает маргинальные суммы, вычисленные как общее число респондетиЦ этот респондент будет учитываться только один раз.
Парная кросстабуляция переменных с многомерными откликами
Лучше всего показать ее на простом примере. Предположим, проводится of •-««**’ ванне нынешних и бывших домовладений респондента. Вы попросили per "- i ’ ” та описать три последних дома, которыми он владел (включая тот кот-: владеет в данный момент). Естественно, для некоторых из респондентов ний дом является самым первым (если до этого они не приобретали до"* » ную собственность). Для каждого дома респондента запрашивается к • нг»«* Я квартир и число жильцов — членов семьи. Ниже показано, как ответ о,"5 пондента (скажем, наблюдение 112) может быть введен в фай т данных:
№ набл_____Комнаты 123_____Число жильцов 12 3
112
334
235
построения таблиц системы STATISTICA
449
I респондент имел три дома: первый из трех комнат, второй также из трех ком-
т третий из четырех комнат. Количество членов семьи также росло: в первом ' Je жили 2 человека, во втором — 3, в третьем — 5.
Допустим, вы хотите кросстабулировать число комнат с числом жильцов для сех респондентов (например, чтобы понять, как количество комнат связано с **ислом жильцов). Один из способов — создать три различные таблицы с двумя Г родами, одну таблицу для одного дома. Вы можете также рассмотреть два фактора этом исследовании {Число комнат, Число жильцов) как переменные со многими /<клпками. Однако очевидно, что нет никакого смысла в приведенном примере г респондентом 112 учитывать значения 3 и 5 в ячейке Комнаты — Жильцы в аблицс сопряженности (которые вы могли бы учитывать, если бы рассматривали эти фактора как одинар! |ые переменные с многомерными откликами). Другими словами, вы хотите игнорировать комбинацию жильцов в третьем доме с числом демдат в первом. Скорее всего, нужно рассматривать переменные попарно; вы । отели бы рассмотреть число комнат в первом доме вместе с числом жильцов в первом оме, число комнат во втором доме вместе с числом жильцов в нем и т. д. Именно так и происходит, когда программа выполняет парную кросстабуляцию многомерных переменных.
Иногда при создании сложных таблиц сопряженности с переменными типа многомерных откликов и дихотомий возникает следующий вопрос (в ваших вычислениях): какую «выбрать дорогу», или как точно будут учитываться наблюдения в файле данных. Лучший способ проверить, как программа строит соответствующую таблицу, — рассмотреть простой пример и увидеть, каким образом учитывается каждое наблюдение (какой оно вносит вклад)
Средства построения таблиц систег .al STATISTICA
Таблицы частот
' Т11'151 пР°тедура позволяет вычислить таблицы частот (и гистограммы) В этих лицах представляются частоты попадания значений переменной (наблюдений) РазнЫе классы (приводятся численные мчи численно-буквенные значения и их Тки). STATISTICA предлагает различные процедуры для определения катего-
450
Глава 11. Построение и анализ
рнй (классов) в таблицах частот (например, целые интервалы, определешг и т д.). Пользователь может табулировать данные с помощью определен»! вин, заданных н виде логических выражений
Например, в показанном выше окне мы включили в категгтрию 1 только и; дения с номерами строго болыне 10, для которых значения v7 строго мсньш
Таблицы частот для этой группы данных имеет вид:
Таблицы сопряженности и таблицы флагов и заголовков
Это процедуры позволяют кросстабулировать данные (таблицы с числом в1 до 6: многовходовые таблицы более высокого уровня можно строить, испо условия выбора) и строить разнообразные таблицы сопряженности. Здесь i доступно большое количество статистик (например, критерии хи-квадрат,фи\ рат гамма и т. д.)_
Средства построения таблиц системы STATISTICA
451
Многомерные отклики и дихотомии
Мод ед ь Основные статистики и таблицы имеет разнообразные возможности построения итоговых таблиц для переменных с многомерными on ликами, а так ко для многомерных дихотомий. Обычно группирующие переменные или факторы дс яг выборку на непересекающиеся (эксклюзивные) группы, например, группу мужчин и женщин. Очевидно, достаточно только одной группирующей переменной. чтобы закодировать пол субъекта. Однако в некоторых нес. шдованиях категории । ie исключают друг друга (пересекаются).
Например, в маркетинговых исследованиях респонденту можно задать вопрос 0 трсх самых любимых безалкогольных напитках. Предположим, 60 различных напитков присутствует в ответах, которые можно закодировать тремя группирующими переменными (первые три предпочтения). В этом случае категории, очевидно, Не являются взаимоисключающими. Действительно, человек может отметить три Различных напитка как предпочтительные. Следовательно, если наблюдение ‘По субъект, то для трех различных группирующих переменных это наблши-нне является общим (не эксклюзивным). Такие группирующие переменные называют переменными с многомерными откликами {многомерные дихотомии по < ству схожи с ними). Эти переменные легко анализировать в модуле Основные статистики и таблицы.
452
Глава 11. Построение и
Пример 1. Таблицы частот
Пример основан на модельных данных опроса об использовании Интернет водился опрос 100 человек относительно степени использования ими сеть I нет. Каждый респондент получил список из семи разделов с просьбой опш свой интерес: 1) Всегда интересуюсь — Always interested, 2) Обычно интерна Usually interested, 3) Иногда интересуюсь — Sometimes interested и 4) Никоим тересуюсь — Never interested.
Ниже приведен файл Intemetsta
Можно щелкнуть по кнопке Отображение числоаых/текстовых значений |^В панели инструментов таблицы исходных данных, чтобы переключиться в чне • еге ное представление значений переменных в таблице.
Напомним, STATISTICA всегда обрабатывает данные в численном ф однако для удобства пользователя можно ввести текстовые значения и у 1S взаимно однозначное соответствие между текстовыми и числовыми зн**« переменных. Это очень удобно для представления и ввода данных *1 ин|^ ции результатов. Например, вместо того чтобы вводить значение ALWA^ но вводить значение 1. вместо SOMETIMES —Зит д.
453
Таблицы частот
Йз стартовой панели Основные статистики и таблицы выберите процедуру Таб-ицы частот, чтобы открыть диалоговое окно Таблицы частот В этом окне щелк-яцте по кнопке Переменные и выберите первые три переменные. Диалоговое окно частот появится па экране в следующем виде:
Это диалоговое окно предлагает множество настроек, позволяющих изменять вид и группировку в таблицах частот, а также проверять нормальность распределения, в том числе и графическими способами. В этом примере используется принятый по умолчанию метод группировки (в частности. Все различные значения, с текстовыми значениями) и опции отображения (Кумулятивные частоты. Проценты '(относительные частоты), Кумулятивные проценты, 100% минус кумулятивные проценты, Логит-преобразование, Пробит-пр'образо-ание), как показано в диалоговом окне выше.
Как можно видеть, 19% респондентов отметили, что они всегда используют Ин-^Рнет длЯ поиска информации по искусству, 33% — обычно его используют и т. д. \ его ?1 % респондентов попали в категории всегда — always, обычно — usually, ино-~ sometimes и только 21% сказали никогда — never.
Большинство результатов в электронной таблице результатов понятно исходя 3Др.-,в<>| о смысла. Разъясним, что такое логшп и лробдеп значения. Этоспецналъ-е преобразования частот, которые часто используются на практике
454
Глава 11. Построение и ана
«еры
455
Логит — это преобразование вида: 1п(х/(1 -х)). где х относителыщ^Д (процент), наблюдаемая в ячейке.
Пробит переменной л — эго стандартное нормализующее преобразс, меннойл. Пробит относительных частот —это обратное нормальное»! *’* юнаипе, примененное к относительным частотам в ячейках. Итак е пробит-преобразоваиця из частот получаются величины, имеющие" = распределение. Такое преобразование применяется в медицинских исс -^ЗИ ’ типа «доза — эффект». '' 1'’
Имея вероятностный калькулятор STATISTICA, можно легко понять di го преобразования (см. также главу Вероятностные распределения).
Посмотрите на таблицу результатов. Например, в первой строке тэ' n,^u ется частота 19 (относительная частота 0,19). Вычислим ее пробит.
Откройте вероятностный калькулятор. Выберите в списке распред^ __
мильное распределение. Далее отметьте опцию Обратная функция и введите в поле р относительную частоту 0,19. Нажмите кнопку BsamcwJ В поле Z вы увидите ц робпт введенной ч.» тоты, он равен 0,877896
Точно такое же значение приведено в электронной таблице для соотиаиЦ^М щей частоты.
Построение гистограмм. Визуализируем таблицы, построив на их б*ж п«^В граммы. Заметим, что можно без труда построить гистограммы всех вы переменных, если вернуться обратно в диалоговое окно Таблицы частот и11 • • I кнопку Гистограммы Каскад гистограмм, по одной гистограмме для ка . ><•* ИЙг бранной переменной, мгновенно появится на экране.
I j системе STATISTICA можно распечатать (пли сохранить в файле) результа-Ьацалнза либо автоматически (koi да содержимое каждой выводимой на экран !йт11«пь! результатов одновременно направляется на принтер и 'или в Окно тек-Ед/t »изо<2л). либо вручную (когда пользователь сам выбирает, какую таблицу ре-штатов пли часть какой таблицы результатов распечатать). Перед тем как рас-чатать результаты анализа, программа попросит вас уточнить направление ывола (то есть Текст, файл. Принтер, Нет и/или Окно) в окне Параметры стра-уцы/вывода (выберите установку Параметры страницы/вывода в выпадающем -ню Файл, настройку Принтер в выпадающем меню Сервис или дважды щелкни -на поле Вывод строки состояния)
Е
В В этом окне можно также определить дополнительную информации ю для печати вместе с таблицей результатов. Доступны следующие формы выводимого отче-Минимальный, Краткий, Средний или Полный.
I Если в окне Параметры страницы/вывода была выбрана настройка Авт пе-'асть всех табшц результатов (автоотчет), то дополнительная информация (количество которой определяется установленным в этом же окне форматом отче-**) а также все результаты анализа будут автоматически выведены на принтер •'®И в файл (в зависимости от того, выбрана ли установка Окно в левой верхней *СТ1’ этого диалогового окна). Этот режим печати полезен, если вы хотите но- Учигь полную сводку всех результатов, выведенных на экран в процессе апа-• Вза
Графические процедуры. Практически все результаты могут быть отображены на | ^Фнках с помощью графических процедур, доступных в данном окне. Прея .и *с«'о I m 11<1|,|Те по кнопке Диаграмма размаха для всех переменных, в появившемся диал< I 0X1 окне выберите Среднив/ст ош./ст.откч и затем нажмите ОК. чтсбы построить I’Рафи к.
456
Глава 11 Построение и ан
457
Печать графиков в пакетном режиме. Если в диалоговом окне стпраницы/вывода выбрана установка Автоматически печатать все грал^л STATISTICA автоматически направит создаваемые графики иди на печать окно вывода (или сохранит в файле вывода, если выбрана Печать в файл в д 3 говом окне Печать графика).
Пример 2. Таблицы флагов и заголовков
Таблицы флагов и заголовков являются экономным способом представлю*® нескольких двухвходовых (двумерных) таблиц в одной. Работая с данными. интересно узнать, имеют те же самые респонденты, которые проявили на. -ший интерес к бизнесу, также наивысший интерес к новостям в Интернет!.
Описание анализа
Используемый файл данных Intemet.sta описан в предыдущем примере. Из , ., • товой панели Основные статистики и таблицы выберите процедуру Tat » заголовки и откройте диалоговое окно Задайте таблицы
Таблица флагов и заголовков по существу содержит несколько двумерна • лиц, собранных вместе. Лучший способ попять эти таблицы — рассмотреть |1 иый пример. В диалоговом окне Задайте таблицы нажмите кнопку За-чн хицы под заголовком Таблицы флагов и заголовков. Программа запрос И переменных для таблицы
Теперь диалоговое окно Задайте таблшуы будет выглядеть следующим образом:
Нажмите ОК в этом диалоговом окне, чтобы открыть диалоговое окно Результаты кросстабуляции.
В этом диалоговом окне нажмите кнопку Таблица флагов и заголовков, чтобы ог°бразить таблицу результатов.
Вы можете рассматривать построенную таблицу как объединение нескольких Я^входовых таблиц. Например, в четырех начальных строках таблицы показаны **астоты двумерной таблицы ARTS - NEWS. Другой способ состоит в том, что зна-Ченпя в четырех начальных строках и четырех начальных столбцах таблишарас-^*Чтриваются как совместное распределение 100 респондентов в 4*4=16 ячейках, “Тзнных пересечением интереса к футболу с интересом к бейсболу. Теперь рас-г?мм различные способы представления результатов.
458
Глава 11. Построением
Частоты по строке. По умолчанию таблица флагов и заголовков от< частоты в строке. Таким образом, видно, например, что 15 (иа 100) pecnoiu, всегда интересуются ARTS и всегда интересуются NEWS. Посмотрите u.i че тую строку таблицы, вы увидите, что из тех респондентов, которые никогда i тересуется ARTS, 17 (9+3+5) интересуются NEWS: всегда — al«ays (9). об л usually (3) или иногда — sometimes (5).
Проценты. Снова вернемся в диалоговое окно Результаты кросстабуяяци «лотовое окно содержит настройки, позволяющие выразить результаты в пр< гах. Проценты могут быть вычислены относительно общего числа иаблюд _ в строке, относительно общего числа наблюдений в столбце или относительно « щего числа наблюдений.
Вы также можете включить в таблицу ожидаемые и/или остаточные час rd (разность наблюдаемых и ожидаемых частот). Выберите настройку Прошить строке и снова нажмите кнопку Таблица флагов и заго ювков.
После того как выбрана настройка Проценты по строке, станет доступН стройка Отображать выбранные % в отдельных таблицах. Так как в одной т? не может быть слишком много информации, выбор этой настройки помешает центы в отдельную таблицу результатов. Мы рассмотрим общую таблшо
459
Из таблицы результатов следует, что из тех респондентов, которые всегда ин-[„асцются — always interested ARTS (все респонденты в первой строке), 78.95% ^ясе всегда интересуются — always interested NEWS.
Поэтому ARTS и NEWS тесно между собой связан ы (в этих данных).
Так же можно найти темы, не связанп ые между собой
Статистики
Iрассмотрим некоторые из этих статистик, представленные в диалоговом окне Ре-! Ъилыпаты кросстабуляции. Наиболее употребляемая статистика — хи-квадрат.
Мерой зависимости меж iv переменными подобно коэффициенту корреляции 1 г Пирсона является ранговая корреляция R Спирмена (см. главу Непараметричес-кая статистика, где систематически описаны ранговые корреляции). Эта мера предполагает, что значения переменных содержат, по крайней мере, ранжированную информацию. Такое предположение разумно в данном примере так как ответы респондентов упорядочены по степени интереса
Выберите опцию Корреляция Спирмена. Диалоговое окно Результаты кросстабуляции примет следующий вид:
Поспе того как выбраны статистики, нажмите кнопку Подробные двухвходовые таблицы для того, чтобы выбрать таблицы для анализа
На экране появится диалоговое окно Выбор таблиц для просмотра, в котором приводится список всех двумерных таблиц:
Можно воспользоваться параметром Все таблицы. чтобы построить каскад двух Входовых таблиц.
460_______________________________________Глава 11. Построение и анаг
В данном примере выберите таблицу ARTS — NEWS и нажмите OK J, дой выбранной таблицы будут построены две таблицы результатов.
Первая содержит наблюдаемые частоты и все остальные характернее бранные вполе Таблицы диалогового окна Результаты кросстабуляции fi. сти. Проценты от общего числа)
СТАТИСТ
10.34%
Вторая таблица содержит результаты хи-квадрат и корреляции Спирл*^;
МОТдГ}rtf-9 р. OODM
<5 305 dl-9 р-ЛОООО i
«fW’ 1-47248 р-‘СТО01
Значение статистики хи-квадрат для этой таблицы равно 44, что явл высокозначимым. ARTS и NEWS являются зависимыми Степень зависим^! дает R Спирмена, равная 0,43.
В дополнение катим методам вы можете построить графики, нажав кногпе. Гр* фики взаимодействий для частот диалогового окна Результаты кросстабу ими (из диалогового окна Результаты кросстабуляции), чтобы визуально исс.зед ~ частоты в выбранных двумерных таблицах.
461
пример 3. Таблицы сопряженности
ML yj-лубленного анализа результатов опроса (см. предыдущий пример) рассмот-м некоторые таблицы более высокого порядка. В частности, определим процент Епондентов, являющихся «фанатами Интернета».
Иными словами, найдем число тех респондентов, которые всегда интересуют-I __ a]ways interested ресурсами и arts, и news, и science в Интернете.
Задание анализа
$ стартовой панели модуля Основные статистики и таблицы выберите процедуру Таблицы и заголовки. Для определения таблицы нажмите на кнопку Задать таб-гицы в разделе Многовходовые таблицы сопряженности диалогового окна Задай-таблицы. Откроется стандартное окно выбора переменных.
В открывшемся окне выбора переменных выберите группирующие переменные (можно выбрать до шести списков группирующих переменных).
Вы можете выбрать одну и более переменных в каждом из шести списков, чтобы создать таблицы со многими входами. Теперь диалоговое окно Задайте табли-Чы будет выглядеть следующим образом:
462
Глава 11. Построение и анализ •
Нажмите ОК в диалоговом окне Задайте таблицы, после этого откг лотовое окно Результаты кросстабуляции.
Это то же диалоговое окно, что и в примере с таблицами флагов и заголс единственное отличие — неактивна кнопка Таблицы флагов и заголовков.
Выберите еще раз параметры таблицы (например, Проценты по строке. Про центы от общего числа и т. д ) и статистики (например. Хи-квадрат, корреля — и т. д.), нажав либо кнопку Просмотреть итоговые таблицы, либо кнопку Под} ные двухвходовые таблицы.
В любом случае на экране появится промежуточное диалоговое окно, в и ром можно выбрать таблицу из уже выбранных. Если использована команда таблицы, то каскад таблиц результатов будет построен для каждой таблицы. п< занной в ттом диалоговом окне.
Для Примера 3 процедура Подробные двухвходовые таблицы дает i ледуюг таблицу:
Примеры
463
I Как можно заметить, 10 респондентов из 1 (JU сообщили, что они всегда иптере-суготся — always interested arts, news, computer.
Развитие этого примера очевидно. Например, в маркетинговых исследованиях гаким образом можно находить группы клиентов, которые всегда покупают определенный набор продуктов.
«работая руками», перебирая множество вариантов, вы добиваетесь четкого представления данных и открываете нетривиальные связи.
Пример 4. Табулирование многомерных откликов и дихотомий
Поимер показывает, как обращаться с многомерными откликами и дихотомиями, часто возникающими в массовых опросах, а также какие возможности для анализа чтих переменных имеются в моду те Основные статистики и таблицы. При проведении массовых опросов имеется своя кухня, с некоторыми рецептами которой мы сейчас познакомимся. Пример с результатами гипотетического опроса находится в панке Примеры.
На основе рассматриваемых данных покажем, как табулируются следующие типы переменных'
Э простые группирующие переменные;
3 переменные с многомерными откликами;
э многомерные дихотомии.
Термпп многомерный отклик на сленге анализа данных означает многомерный ответ, то есть ответ, содержащий в себе несколько ответов (а не один вариант ответа), например, респонденту, возможно, нравится, несколько типов машин, а I |еодна машина, или несколько фильмов, а не один из числа предложенных, несколько развлека-т с тьпых сайтов, а нс одп нит д. Для того чтобы не заключать отвечающих в жесткие рамки, при проведении опроса может допускаться несколько ответов. Число их зара-нее оговаривается
Дихотомия (от греческого бгхоторЕсо — разделять или рассекать па две части) — это переменная, принимающая два значения. О или 1. а в текстовом виде — нет и ти да. Соответственно многомерная дихотомия представляет собой набор нулей И единиц.
Вначале расскажем, как строятся простые таблицы частот для описанных переменных, затем построим и нссчедуем таблицы сопряженности для них.
Описание файла данных
Представьте, что проводится исследование покупательских предпочтений молодых людей. Задаются следующие вопреки: 1) какую систему быстрого питания вы ‘редпочитаете; 2) какой тип автомобиля вы предпочитаете; 3) какой местный ресторан вы посещали в течение последних двух недель. Дополнительно записывается пол респондента Эти ответы записаны в фай л Fastfood sta, переменные которо-1,1 описаны ниже.
464
Глава 11. Построение и анализ таб
Пол (простая группирующая переменная). Пол респондента записывается!ВТ^М пирующую переменную Пол — Gender (Мужчина — Male, Женщина — Female 1
Лучшая «быстрая* еда (многомерный отклик). Вопросник, ислользлц^И в данном исследовании, предлагает респондентам выбрать любимое «быстрое» до (до трех блюд) из следующего списка:
1) Гамбургер — Hamburger
2) Сэндвич — Sandwiches
3) Цыпленок — Chicken
4) Пицца — Pizza
5) Мексиканские блюда — Mexican fast-food
6) Китайские блюда — Chinese fast-food
7) Еда из морепродуктов — Seafood
8) Другие национальные блюда — other ethnic or regionally popular fast-food
У каждого человекаможет быть несколько любимых блюд. Поэтому выбор ка» дого респондента вводится в файл как переменная с многомерными значениям# Например, первый пункт ответа записывается в столбец Еда_1 - Food_1 (ппйкм предпочтение), второй пункт (если он имеется) — в переменную Еда_2 — Food_j и третий — в переменную Еда_3 — Food_3. Таким образом, в данном опросе мы имеем одну переменную, принимающую три значения.
При анализе переменная Еда_1 — Food_1 может рассматриваться как прос.ии группирующая переменная. Далее можно задать вопрос: какое число респонлгя* тов (или их доля) назвало определенный тип системы быстрого питания свог>-любимым — favorite? Однако интерес может представлять также и то, сколько р-^-пондентов выбрали определенную систему быстрого питания как одну из любимых. Такой вопрос приводит нас к тому, чтобы рассматривать переменныеЕда_1 -• Еда_3 (Food_f — Food_3) как одну переменную с многомерным откликом. Таки, переменные можно называть также многомерными
Любимый автомобиль (переменная с многомерными откликами). В эт-Л опросе вас просят назвать три самых любимых типа автомашины (фактор дежг стоимость машины, не учитывается, просто спрашивается о некотором идеалы! м воображаемом автомобиле). Эти ответы (определенные марки и модели) зап»-дированы следующим образом:
1) Отечественный спортивный автомобиль — Domestic sports саг
2) Отечественный седан (закрытый автомобиль) — Domestic sedan
3) Иностранная спортивная машина — Foreign sports car
4) Иностранный седан — Foreign sedan
Данная переменная рассматривается как переменная с многомерными откМ* ками подобно переменной любимая система быстрого питания — faioritefast-fvaA Это означает, что ответы респондентов были введены как значения переменны* Машина_1 — Машина_3 (Саг 1 — Саг_3).
Например, если респондент называл три любимых блюда Гамбургер — Hambu~& Гамбургер — Hamburger и Гамбургер — Hamburger, тогда значение Гамбург^ ~
465
fjamburger будет учитываться только один раз (в переменную Еда_1 — Food_1), асоответствуюшие ячейки переменных Еда_2 — Food_2 и ЕдаЗ — Food? рассматриваются как пустые
Рестораны (многомерная дихотомия). Посетителей ресторана попроси ли назвать, какие из четырех ресторанов они посещали за последние две недели Полученные данные были введены в фай л так, что для каждого ресторана имелась своя переменная. Всего использовано четыре переменные Хозяин_1 — Хозяин _4 (Виг-ger1 — Burger_4) для следующих ресторанов:
1) Бутерброд Мейстер — Burger Meister
2) Лучшие бутерброды у Билла — Bill's Best Burgers
3) Гамбургер ^Блаженство* — Hamburger Heaven
4) Большой бутерброд — Bigger Burger
Если респондент сообщил, что в течение двух недель обедал в одном или нескольких ресторанах, то в соответствующий столбец (столбцы) ставилась единица, если нет, столбец оставался пустым. Таким образом, переменная представляетсобой многомерную дихотомию (созиачениямиДв или пропуск), которую желательно табулировать, то есть указать число (или долю) респондентов, обедавших в каждом из четырех ресторанов.
Заметьте, что можно было бы рассмотреть эту переменную как переменную с многомерными откликами. Однако для этого нужно создать не менее четырех переменных, например, Еда_1 — Еда_4 (Eat_1 — Eat_4), и затем ввести названия ресторанов, например, Бургер_1 — Burger _1,Бургер_2 — Burger_2..., как значения этих переменных в столбцы таблицы (аналогично переменным любимая машина — favorite саг и любимая система быстрого питания — favorite fast-food, см. выше).
Ниже представлены несколько первых наблюдений файла данных Fastfood^ta.
Для того чтобы показать, каким образом каждый опрашиваемый респондент «веден в файл, посмотрите на первое наблюдение. Первый респондент — женщина, поэтому в переменную Пол — Gender введено значение Женщина — Female. Са-N,°e любимое быстро приготовленное блюдо — Пицца — Pizza (введено в перемен
466
Глава 11. Построение и анализ тг
ную Еда_ 1 — Food_ /), второе по предпочтению блюдо — Еда из морепродукп^^Л Seafood (введено в переменную Еда 2 Food_2), трет ин вид еды не указан, му н переменном Еда_3 — Food_3 стоит пропуск.
Далее этот респондент выбрал следующие три типа автомобилей: 1) ний < сдан do/rustu sedan, 2) домашний спортивный автомобиль - domesticфЗ саг, 3) снова домашний спортивный автомобиль — domestic sports — перелпмцЗ Саг 1, Cm 2, Саг_3, — Carl, Саг_2, Саг_3 соответственно. Наконец, он отв что последние две недели обедал в двух ресторанах Burger_1 (Burger Meist~>|_ Burger_3 (Hamburger Heaven), таким образом Да — Yes было записано в яче ?П| соответствующих переменных, значения двух других переменных Burgerост,щ<^Ж пу< тыми
Всего было опрошено 200 респондентов.
11ачнсм с вычисления таблиц частот для простой группирующей переменной По.» ~ Gender и переменных с многомерными откликами. Так как имеются иропущеш^М значения во всех переменных Burger_1 — Burger 4, таблица для них будет опредрд»» позже.
По умолчанию наблюдения со всеми пропусками в переменных Burger исключаются из анализа, и частоты будут вычисляться лишь для респондентов, i тивших, по крайней мере, один из четырех ресторанов. Другой способ обработсц пропусков состоит в том, чтобы сделать отметку в поле Включить ПД как допйЛ га/телыи/ю категорию для каждого фактора
Выберите Таблицы и заголовки в сгартотюй панели В появившемся окне Задаип^ таблицы выберите Таблицы длямногамерныхоткликов в спискеЛногаз, ври этом открс ется диалоговое окно Таблицы многомерных откликов. В этом окне можно онрсдечиП I три типа группирующих переменных’ простые группирующие переменные (Пол -Gender в нашем примере), переменные с многомерными откликами (Eda l — Food_I (Еда_3 — Food 3)iuni Машина_1 — Car_1 (Машина3 — Саг_3))п многомерные дихотомии (Burgerl 4).
примеры
467
Нажмите кнопку Задать таблицы аля того, чтобы определить переменные вдиалоговом окне:
В окне можно выбрать до шести многомерных факторов (простых группирующих переменных, многомерных откликов или дихотомий) для одной таблицы. В первой колонке выберите только переменную Пол — Ginder. программа автоматически рас-сматривает единственную выбранную переменную как простую группирующую (простая группирующая является частным случаем переменной с многомерными откликами, для нее число откликов равно 1). Во второй колонке выберите переменные Еда 1 — Еда_3 (Food_1 — Food_3), в третьей — Машина_1 — МашинаЗ (Car l — С<н 3). Сначала обратите внимание на простые таблицы частот д ля всех выбранных факторов(таблипачастотдляВк®ст^/ — Вн/£ег_4будет исследована позже). Нажмите ОК, чтобы запершить выбор. Теперь в окне Таблицы многомерных откликов можно видеть выбранные переменные.
Термин фактор используется для общего обозначения всех типов переменных (например, такая переменная, как любимая еда — food preference, в действительно-П и состоит из нескольких переменных). Мы употребляем термин многомерный фактор и для простых переменных, и для переменных с многомерными отклика Мн, и для многомерных дихотомий. Заметим, что по умолчанию фактору прис ван-
468
Глава 11. Построение и анализ
469
вается имя (как длинное, так и короткое) первой переменной в соответстт»- - -а списке.
Определение факторов. Расположенная рядом с каждым фактором " зволяет определить его тип. Первая переменная Пол — Gender — это простая*4 ’ пирующая переменная. Для второго и третьего факторов выберите опцию иерный отклик лз**'
Далее выберите коды для определения различных категорий. Выберите ко>ч» бы идентифицировать пол респондента Мужчина - Male и Женщина — Fста.' • । 4 менная Пал — Gender), а также различные типы «быстрой» еды в переменных/а?^ £Ва__? (Food_1 ~ Food_3) и различные типы автомобилей в Машина 1 — Маш Z' (Саг_1 — Саг_3).
Если вы не зададите коды явно (просто нажмете ОК), программа возьме из первой переменной в каждом факторе. Данный способ обычно позволяет м делить все коды, однако может случиться так что определенный код не « сутствует в первой переменной, а присутствует только во второй или в тр< дЗ В этом случае способ по умолчанию не применим, так как ряд значений окам-zr, неучтенными.
Лучше задать все используемые коды точно. После нажатия одной из ЮНН Коды, расположенной рядом с каждым фактором, можно ввести коды для фа»т - г.
В данном примере не так интересно знать, все ли три выбранные машины 6i r> | i определенного типа (в связи с чем чрезмерно увеличивается число идентичны» откликов). Интереснее определить число респондентов, предпочитающие, •*>- I пример, домашнюю закрытую машину. Заметим, что переменные, состав лякли»» фактор Еда — Food, содержат только взаимно исключающие ответы (непер! • ► кающиеся категории), так как респондентам не разрешалось давать ндентичиШ ответы (например. Гамбургер — Hamburger, Гамбургер — Hamburgers Гамбурвлр -• I Hamburger). Их просили сделать выбор из восьми типов быстрой еды без повтор*! ния. Поэтому для фактора Еда — Food данная опция не имеет значения.
Нажмите ОК в диалоговом окне Таблицы многомерных откликов, чтобы нач 1 vt анализ и открыть окно Результаты таблицы многомерных откликов
К Вначале рассмотрим простой вывод Таблицы частот
к Введите в редактируемое поле Выделить частоты число 100 (что приведет MV, ЧТО все частоты больше 100 будут выделены в таблице результатов). Затем Акмите кнопку Таблицы частот
* Таблипа частот для переменном Пол — Gender интерпретируется обычным об-аязом. И на ней мы останавливаться не будем. Таблицы частот для других двух факторов показаны ниже.
Всего в исследовании было опрошено 200 респондентов (число опрошенных №*200 отображается в верхнем левом углу таблицы).
Столбец Частота показывает число респондентов, назвавших данный способ питания как один из любимых. Напомним, что учитываются только уникальные ответы (см выше) и, таким образом, ответ каждого респондента может быть пос читан только один раз в этом столбце. Отсюда вы можете прийти к заключению, что Пицца — Pizza была самой популярной системой быстрого питания, указанной либо в цервой, либо во второй, либо в третьей позиции 138 респондентами. Гамбургер — Hamburger был вторым по популярности (114). Все типы систем быс Т]юго питания отметили только 40-50 респондентов.
Во втором столбце таблицы результатов вычислены относительные частоты, соответствующие числам первого столбца. Можно сказать, например, что 26,44% (ЮО* 138/522) всех указанных в ответах предпочтений составляет Пицца — Pizza В отличие от этой колонки третья колонка таблицы показывает проценты респондентов, отмстивших соответствующий тип еды как первый, второй или третий.
— Рггга как лучшую систему быстрого питания выбрал и 69% (100*138/200) всех респондентов.
Аналогично рассматривается таблица частот для фактора Машина Саг. Ино-стРанцые спортивные машины отмечены 157 респондентами на одной из трех по-
470
Глава 11. Построение и анализ
зииий (учитываются только различные ответы); отечественные спорт-ш^! шины отмечены 123 респондентами. Вторая колонка показывает 37,31 3 для иностранных спортивных машин; эти числа не так легко проилтерпьв вать, так как подсчитывались только различные ответы (несколько одииЭ о гнетов рассматривались как один). Таким образом, если респондент указал ь те три иностранные спортивные машины, то этот ответ учтен только одинрЗ if в третьей колонке (Процент набл.) более икформати ины; из них, напримелifl что 78,5% всех респондентов назвали иностранные спортивные машины трех самых любимых
Возвратимся в диалоговое окно Таблицы многомерных откликов (нажми и-1 мена в окне Результаты), чтобы задать многомерную дихотомию в обсле^в посетителей ресторанов. Нажмите кнопку Задать таблицы, отмените пр-ц uiiiii выбор и выберите Burger I Burger_4 как пер«“менные первого mho^M
Далее установите опцию Многомерная дихотомия радом с первым фак с
в диалоговом окне Таблицы многомерных откликов. Как и ранее, можете и< »► .т» вать опцию Длинные метки факторов для того, чтобы ввести подходящее има^ж* тора. Например, можно назвать этот фактор Patron: Recently patronizedrestaur.-tnlt -Хозяин: Недавно посещенные рестораны.
471
рам также необходимо задать код, который использовался в факторе много-01“i дихотомии Patron для того, чтобы определить, обедал или нет респондент Г хтветствующем ресторане в течение двух недель перед опросом. Задайте нуж-6 код в поле Счетчик ниже списка факторов. Так как код, равный 1 (числовой кв11Валент значения Да — Yes; см. Управление данными, глава 7), использовался иля того, чтобы определить, какой ресторан посещался респондентом, то можно просто принять код, предложенный по умолчанию.
Напомним, каким образом многомерные дихотомии интерпретируются программой. Переменные, из которых построен фактор, рассматриваются какого уровни затем подсчитывается число уровней со значениями, равными значению, ука-1 данному в счетчике. Все значения, нс равные этому значению, игнорируются. Вы I можете ст роить более «сложные» схемы кодирования (а не просто 1-0, как в атом I примере)- задавая подходящие значения в поле Счетчик.
Например, можно использовать отдельный код (отличный от 1) для обозначения ответа -вдаже никогда не думал там обедать» Вы могли бы ввести код 2 в переменные Burge.r_1 — Bwger_4 для обозначения таких резко отрицательных ответов и отношении определенных ресторанов, задать этот код в поле Счетчик и табулировать ответы. Таким образом, задавая различные значения для кодов многомерной дихотомии, можно идентифицировать взаимоисключающие ответы.
Из диалогового окна Результаты снова выберите процедуру Таблицы частот. Интерпретация чисел, представленных в этой таблице, аналогична таблицам для
многомерных откликов.
Всего 157 респондентов обедали в одном из четырех ресторанов (п-757); 60 респондентов обедали в Burger Meister, 68 — в Bill’s Best Burgers и т. д. Значения во второй колонке {Процент откликов) выражают эти числа в процентах отобще-13 числа респондентов, обедавших хотя бы в одном ресторане (то есть от 157 респондентов).
Предполагается, что четыре (воображаемых) ресторана делят рынок быстрого питания в городе и что 157 респондентов (из 200) вболыпей или меньшем степени представляют мнение общего рынка Поэтому значения во второй колонке табли-ПЫ показывают долю рынка, которым владеет каждый ресторан.
Например, из всех мест (где подаются гамбургеры), которые посещались рес-Поиден гам и в течение двух недель до опроса. Burger Meister посещали 24.19%, Bill's cst Burger ~ Q7,A2% и т. д. Третья колонка (Процент набл.) содержит процент рес-°нде1пов, обедавших последние две недели в соответствующих ресторанах
473
472
Глава 11. Построение и анализ Tafi,
Примеры
Напомним, что проценты вычислены для п - 157, то есть относительно числа поцдентов, обедавших, по крайней мере, в одном из четырех ресторанов. Поэтому ।, но сказать, что38,22% респондентов, обедавших в каком-то одном из четырех peci • нов, где подают гамбургеры, обедали также в Burger Meister, 43.31 % обедали в Bill's j Burger и т д.
Заметим, что можно легко построить линейные графики или гистограммы I тот и процентов с помощью процедур меню Пользовательские графики.
Покажем, как строить таблицы сопряженности для переменных с многомерными откликами и многомерных дихотомий. Нажмите Отмена в диалоговом окне Результаты для того, чтобы вернуться в диалоговое окно Таблицы многомерных от-, кликов. Прежде всего, посмотрим на таблицу сопряженности Пол — Gender •> Машина — Саг. Иными словами, исследуем интерес к различным тинам машин у Мужчин — Males и Женщин — Females. Нажмите кнопку Задать таблицы и в г.р крывшемся диалоговом окне выберите Пол — Gender как единственную пере» гл-ную в первом множестве, а переменные Машина_1 — Машина З (Саг * — Cat f) как переменные во втором множестве
Нажмите ОК и вернитесь в диалоговое окно Таблицы многомерных откликов. Задайте далее коды для фактора Машина — Саг, чтобы идентифицировать четыре различных типа автомобилей. Возможно, вы захотите изменить описание фактора, тогда воспользуйтесь кнопкой Длинные метки факторов.
Для этой таблицы отмените опцию Считать только уникальные отклики. Напомним, что назначение этой опции — исключить одинаковые ответы (одинаковые ответы одного и того же респондента на разные пункты считаются как один ответ). В данном примере, напротив, вы можете захотеть включить такие ответы в таблицу. Получившаяся таблица сопряженности будет показывать общее число различных типов машин, определенных респондентом как первая, либо как вторая, либо как третья, разбитых на классы значениями переменной Пол -Gender. Нажмите ОК и откройте диалоговое окно Результаты таблицы многомерных откликов
Нажмите кнопку Просмотреть итоговые таблицы. В результате будет построена следующая таблица:
По умолчанию Быстрым статистическим графикам для згой таблицы является Ш гистограмма. Нажмите правую кнопку мыши и выберите в меню опцию ЗМ гистограмма.
Рассмотрев приведенную выше таблицу, можно прийти к выводу, что и мужчины, и женщины отмечали спортивные машины чаще, чем седаны. Разницу в общ. и числе машин, отмеченных мужчинами и женщинами, можно объяснить тем. чтм число мужчин и женщин в выборке существенно различается (если вы посмотри» 1 с на таблицу частот переменной Пол — Gender, то увидите, что в выборке ирис’т-ствует только 36 женщин).
Вместо ЗМ гистограммы можно использовать линейный график. Вернитесь в ди* алоговос окно результатов и выберите опцию Графики взаимодействий частот
Здесь разница в предпочтении спортивных машин более отчетлива у м ,<тнНЙ П’м у женщин (линия, соответствующая женщинам, более сглаженная, чем лми*И чужчин).
ример (анализ продаж)
Рассмотрим данные о продажах в магазине. Мы хотим провести разведочный ан«« -
1........................................................... 1
Примеры
475
Категоризируем исходные данные (способ категоризации количественных переменных в системе STATISTICA описан выше), то есть будем работать с данными вила:
В этом файле первая переменная — день недели, каждая оставшаяся переменная принимает два значения*. О, если данный иокупательне купил данный товар, и 1, t.iH данный покупатель купил данный товар. Покупатели записаны в строках, I' шары в столбцах.
Для данного покупателя 1 означает, что он купил соответствующий товар.
Мы хотели построить модель покупателя. Для этого нам нужно знать, как распределены покупки и как они связаны между собой
Работаем в модуле Основные статистики. Введите показанные данные в свой файл или сгенерируйте нечто похожее, чтобы повторить действия.
Несколько тонких вопросов будут отмечены в ходе анализа и указаны альтернативные способы исследования.
Распределение числа покупок. Вначале введем переменную (в наших данных что будет переменная var24), подсчитывающую общее число покупок, сделанных покупателем (она равна сумме всех индикаторов покупок).
Тогда файл выгляди' так-
Вначале посмотрим, как распределено число покупок Откройте процедуры описательной статистики
476
Глава 11. Построение и анализ таб/
Выберите все переменные, в которых записаны покупки различных продуктов и нажмите кнопку Подробные описательные статистики.
На экране появится таблица с описательным и статистиками.
Таблица с описательными статистиками имеет вид:
Примеры
477
В этой таблице для нас прежде всего интересен второй столбец, в котором показано, как часто покупались различные продукты. Но вначале построим гистограмму числа покупокN.
Из гистограммы видно, что наибольшее число покупателей делает от одной до четырех покупок.
Редактор данных графика позволяет просмотреть да| шые графика в численном виде. Нажмите кнопку Редактор данных графика, и вы увидите данные в численном виде.
Итак, общее число покупателей равно 674. Из них 90 сделали одну покупку, 110 сделали 2 покупки, 110 сделали 3 покупки, 102 сделали 4 покупки и т. д.
Глава
и анализ та{
Случай одной покупки. Рассмотрим покупателей, сделавших только одни купку. Для этого введем условие выбора наблюдений.
Группировка по дням недели. Рассмотрим, как распределены покупатели, cj& давшие одну покупку, по дням недели. Выберите переменную День и построй-^ гистограмму.
вереду
Какие продукты наиболее часто относятся к одиночным покупкам?
Найдем, какие продукты наиболее часто являются «одиночными». Выборе*
переменные ил файла, кроме первой. Вычислим средние величины.
Из таблицы следует, что если покупатель сделал только одну покупку, рее всего, это было мясо, хлеб, овощи, кондитерские изделия или колбасы, i
ность сделать одиночную покупку из оставшейся части списка практически в пая.
Заметьте, что средние, приведенные во втором столбце таблицы с результа! представляют собой оценки вероятностей покупки данного товара.
Таким образом, если покупатель пришел в магазин и решил сделать только» покупку, то с вероятностью 0.26 он купит мясо, с вероятностью 0,133 купит х с вероятностью 0,11 купит овошн, с вероятностью 0,11 купит кондитерские и лия. с вероятностью 0,9 купит колбасные изделия.
Примеры
479
Вероятность того, что покупатель сделает только 1 покупку, раина 90/677= 0.13 (см. таблицу с распределением N).
Модель покупателя, делающего одну покупку. С вероятностью 0,13 покупа-течь, пришедший в магазин, делает одну покупку. С вероятностью 0,26 он покупает мясо, с вероятностью 0,133 — хлеб, с вероятностью 0.11 — овощи, с вероятностью 0,11 — кондитерские изделия, с вероятностью 0,9 — колбасные изделия
Случай двух покупок. Рассмотрим покупателей, сделавших две покупки.
Число таких покупателей равно 110.
Для этих покупателей N=2. Изменим условие выбора случаев.
Заметьте, в условии выбора наблюдений можно употреблять имя переменной.
41 с н было сделано в данном случае
Вычислим описательные статистики ври условии, что N=2.
480
Глава 11. Построение и анализ табг
Из этой таблицы видно, что если покупатель сделал две покупки, то наиболе I вероятно, что в эти покупки вошли овощи, хлеб, молоко, кондитерские изделия, колбасы, мясо.
1 {оставим вопрос, какие пары покупок наиболее вероятны.
Ответ на этот вопрос можно получить с помощью простейших действий
Всего переменных 22. Конечно, мы не будем перебирать все 22 х 21 = 462 пары переменных и строить для них таблицы.
С помощью некоторых разумных приемов, например, рассмотрев корреляции
переменных, можно существенно сократить процедуру поиска.
За несколько минут можно найти наиболее вероятные пары покупок (см таб типы ниже).
Примеры
481
Полезными здесь являются гамма-статистики, массив которых сразу для всех переменных можно вычислить с помощью непараметрнческих процедур (не забудьте при вычислении поставить условие N = 2).
Просматривая таблицу и выбирая максимальные коэффициенты, можно определить наиболее вероятные парные покупки.
Так же можно определить несовместимые пары.
Вероятность того, что покупатель сделает две покупки, равна 110/677- 0,16 (см. таблицу с распределением N).
В принципе, те же самые действия можно провести для остальных N, при этом полезно использовать язык STATISTICA BASIC.
Однако очевидно, здесь мы сталкиваемся с довольно сложной переборной задачей, поэтому наметим различные подходы к ее решению.
В частности, используем анализ соответствий и геометрическую интерпретацию частот.
Здесь же рассмотрим, какие дополнительные возможности имеются в модуле-Основные статистики и таблицы.
482
Глава 11. Построение и анализ таблиц
Случай трех и четырех покупок. Воспользуемся процедурами группщ Не забудьте отменить условия выбора случаев, назначенные ранее.
В диалоге Группировка и однофакгпорная ANOVA прежде всего выберите пер< -мепные для анализа. Группирующие переменные — день и N. Вес остальные пер< -мерные определите как зависимые.
Выберем коды для группирующих переменных, как показано ниже Конечно, можно было бы выбрать все коды для N, но мы ограничимся тремя и четырьмя покупками как наиболее типичными.
Теперь окно выглядит следующим образом.
Нажмите ОК и проанализируйте результаты.
Примеры
483
Прежде всего, нажмите кнопку Итоговая таблица средних.
На экране появится таблица средних, вычисленная для каждой группы данных. Всего имеются 14 групп: 7 дней недели, умноженные на 2 (мы задали два кода переменной W- группа покупателей, сделавших три покупки, и группа покупателей сделавших четыре покупки).
Ориентироваться в этой таблице очень просто. Рассмотрим, например лере-менную КОЛБАСЫ.
Вы видите, что в понедельник покупатель, сделавший три покупки, с вероятно стью 0,25 покупает колбасу, а покупатель, сделавший четыре покупки, покупает ее с вероятностью 0,75.
Рассмотрев вероятности по строке, можно видеть, что в понедельник покупа Те-чь, сделавший три покупки (первая строка таблицы), скорее всего, купил хлеб. к°ндитерские изделия или молоко.
Статистики критерия хи-квадрат показаны ниже
Значение гамма-статистики 0,38 говорит о наличии неярко выраженной св »-" между признаками.
После того как гипотеза о независимости отвергается с помощью критерия о квадрат или точного критерия Фишера, необходимо измерить силу связи при • »
Одной из таких мер принято считать гамма-статистику.
О Если модуль меры больше 0.8, то мы имеем сильную связь табулирован' ♦ переменных.
о Если модуль меры связи принимает значения от 0,3 до 0,8, то говорят с •,_ ярко выраженной связи.
О Меньшие значения модуля меры связи свидетельствуют об отсутствии св» ’ • ‘
Как и во всех задачах, связанных с оценкой зависимости, здесь очень поГ-ЛЯД визуализация.
Рассмотрим при трех покупках степень связи между переменными- хлеб н момЛ
Примеры
485
Из приведенной таблицы следует, что при трех покупках из 55 человек, купив-пих хлеб, 21 купили молоко, 34 не купили молоко (вторая строка таблицы).
Из 55 человек, не купивших хлеб, 24 купили молоко, 31 не купили молоко.
С помощью критерия хи-квадрат проверим гипотезу о независимости табулированных переменных.
Критерий хи-квадрат не позволяет отвергнуть гипотезу о независимости.
Как понимать это положение?
Рассмотрим внутренние ячейки таблицы с покупками хлеба и молока при трех юланных покупках.
Из таблицы получим следующпеопенки вероятностей (при условии трехпокупок!).
Вероятность того, что покупатель:
1) не купит ни молока, ни хлеба — 31/110 - 0,28;
2) не купит молоко, но купит хлеб — 24/110 - 0,22:
3) купит хлеб, не купит молоко — 34/110 - 0,31;
4) купит хлеб и молоко -21/110-0.19.
Эти оценки получены из наблюдаемых частот.
Рассмотрим маргинальные частоты, эти частоты располагаются по краям таб-нщы и при гипотезе незваисимости позволяют оценить ожидаемые частоты.
Имеем (см. таблицу):
О покупатель, пришедший в магазин и сделавший три покупки, с вероятностью 65/110 - 0,59 не купит молоко, а с вероятностью 45/110 - 0,41 купит молоко;
О покупатель, пришедший в магазин и сделавший три покупки, с вероятностью 55/110 - 0,5 купит хлеб, с вероятностью 55/110 = 0,5 не купит хлеб.
Перемножая эти вероятности, получаем:
О 0,59 х 0.5 - 0,295 — вероятность того, что покупатель не купит ни молока, ни хлеба;
486
Глава 11 Построение м анализ табг
О 0,59 х 0,5 - 0,295 — вероятность того, что покупатель не купят молоко, но г । пит хлеб;
О 0,5 х 0,41 - 0,205 — вероятность того, что покупатель купит хлеб, но не купи] молоко;
о 0,5 х 0.41 =0,205 — вероятность того, что покупатель купит хлеб и купитмолокн
Можно видеть, что эти вероятности очень близки к вероятностям, вычисленным ранее в 1-4.
Критерии хи-квадрат как раз и измеряет «расстояние» между этими частотами
Итак, если покупатель делает три покупки, то покупка молока и покупка хлеба независимы.
Заметим, что продвинутый анализ покупателей, сделавших даже три покупки, связан с очевидными трудностями В частности, не так просто найти группы тони- г ров, наиболее вероятно объединяющиеся в тройки.
Далее мы применим к данным о продажах разведочные методы анализа соо --ветствнй (см. главу Анализ соответствий)
«g q Г-критерии сравнения I А средних в двух группах данных
Анализ данных начинается с группировки и вычисления описательных статистик в группах, например, вычисления средних и стандартных отклонений.
Если у вас имеется две группы данных, то естественно сравнить средние в этих группах. Такого рода задачи во множестве возникают на практике, например, вы можете захотеть сравнить средний доход двух jpynn людей: имеющих высшее образование и не имеющих высшего образования.
В данной главе мы будем иметь дело с переменными, измеренными в непрерывной шкале, такими переменными являются, например, доход или артериаль пос давление. Переменные, измеренные в бедных шкалах, исследуются с помощью пениальных методов. В частности, категориальные переменные исследуются i помощью таблиц сопряженности (см. главу Анализ и построение таблиц). Переменные, измеренные в порядковых шкалах, исследуются методами непараметрн -ческой статистики (см. главу Нспараметричел кая статистика).
Рассмотрим типичную задачу. Предположим, при производстве бетона вы придумали добавлять в него некоторую новую компоненту и полагаете, что опа увели-ш г прочность бетона. Чтобы проверить свои предположения и доказать их потребителю. вы взяли несколько образцов бетона с добавкой и несколько образцов без лбавки и измерили прочность каждого образца.
Таким образом, получили два столбца (две группы) цифр: прочность образцов добавкой и прочность образцов без добавки Как разумно сравнить эти группы?
Очевидный подход состоит в том, чтобы сравнить описатетьпые статистики, например, средние двух групп. Конечно, можно было бы сравнивать медианы пли другие описательные статистики, но естественно начать со сравнения средних значений. Итак, вы имеете два средних: среднее для первой группы и среднее для второй группы.
Можно формально вычесть одно среднее из другого и по величине разности ».делатъ вывод о наличии эффекта. Однако целесообразно принять во внимание разброс данных относительно средних, то есть вариацию (см. главу Элементарные понятия). Очевидно, разумная процедура должна принимать во внимание вариацию Первое, что приходит в голову. — подходящим образом нормировать разность средних двух выборок (групп данных), поделив ее. например, на стандартное от клоненне (корень квадратным из вариации).
Именно так и рассуждал В. Госсет — английский статистик, известный под псевдонимом Стьюдент, придумавший t-критерий для сравнения средних двух выборок
489
468
Глава 12. Г критерий сравнения средних в двух группах дащ ।
^.критерий для независимых выборок
Допустим, мы проверяем гипотезу о том, что добавка неэффективна (или к», ? рят на сленге анализа данных- чет аффекта обработки), иными словами, сре^Д в двух группах равны. Этому положению соответствует альтернатива, согласно м<гн& рой имеется эффект — прочность бетона увеличивается при добавлении в него н,»щ компоненты
Обратим внимание, альтернатива может быть выражена и по-другому, нап]«д мер, средние не равны или средняя прочность образцов увеличилось (добавка п>^. вела к увеличению прочности бетона).
Заметим далее, что возможны два варианта организации данных: вы мож< че-иметь дело с независимыми группами наблюдений или с зависимыми группа^ наблюдений.
Если вы случайным образом разбили выборку на две части и сравниваете пок« | затели в первой и второй группе, то, скорее всего, вы имеете дело с независимым» группами.
В STATISTICA t-критерий доступен в обоих вариантах организации данные
Естественным развитием сюжета сравнения средних является обобще t-критерия на три и более групп данных, что приводит к дисперсионному ан > in-зу (в английской терминологии ANOVA — сокращение от Analysts of Variation Л Дисперсионный анализ), а также на многомерный отк тик. Если мы имеем в •.." с многомерным откликом, то используем методы MANOVA Итвк, методы дисиф* ci [онного анализа позволяют разумным образом сравнить групповые средние, ei.ro количество групп больше двух. Например, если вы хотите сравнить доход жителей нескольких регионов, то можно использовать дисперсионный анализ. Если вы исследуете два региона, то применяйте t-критерий.
Опишем один случай, не укладывающийся в общую схему. Представьте, вы ЧЖ чаете категориальную переменную, принимающую два значения, 0 и 1. и хопЙИ сравнить различие частот появления единиц в двух группах. Например, вы же.-5*4, сравнить относительное число голосов, поданных за кандидата в двух избирасаЛИ ных округах. Термин ^относительное число» означает число голосов, ноданныл • кандидата, деленное на общее число голосовавших. Статистический критерий ЛИ сравнения частот (далей, пропорций...) реализован в модуле Основные статист»# и таблицы в диалоге Другие критерии значимости
Т-критерий для независимых выборок
Т-критерий является наиболее часто используемым методом, позволяющим выявить различие между средними двух выборок Fine раз напомним, переменные должны быть измерены в достаточно богатой шкале, например количественной.
Конечно, применение t-критерия имеет некоторые ограничения, впрочем, очень
слаоые.
Теоретически /-критерий может применяться, даже если размер выборки очень небольшой (например, 10; некоторые исследователи утверждают, что можно ис-с юдовать н меньшие выборки) и если переменные нормально распределены (внутри групп), а дисперсии наблюдений в группах нс слишком различны. Известно, что / критерий устойчив к отклонениям от нормальности.
Предположение о нормальности можно проверить, исследуя распределение (например, визуальное помощью гистограмм) или применяя критерий нормальности. Следует заметить, что эффективно проверить гипотезу о нормальности можно для достаточно большого объема данных (см. замечание Фишера о проверке нормальности, цитированное нами в главе Элементарные понятия анали-
за данных)
Болес осторожно нужно подходить к различию дисперсий сравниваемых групп. Равенство дисперсий в двух группах, а это одно из предположений /-критерия, можно проверить с помощью F-критерпя (который включен в таблицу вывода ^критерия в STATISTICA). Также можно воспользоваться более устойчивым критерием Девена
При сравнении средних, как и всегда в анализе данных, чрезвычайно полезны визуальные методы. Например, на приведенной ниже категоризованной диаграмме Размаха видно существенное различие средних значений для мужчин и женщин. На диаграмме точками показаны средние значения, а также стандартные отклонения (прямоугольники) и стандартные ошибки (отрезки прямых линий), вычисленные отдельно для мужчин и женщин.
490
Глава 12. Г-критерий сравнения средних в двух
На i-рафике заметно различие дисперсий в группах — высота прямого^ FEMALE больше высоты прямоугольника MALE.
Если условия применимости t-критерия не выполнены, то можно оценш личие между двумя группами данных с помощью подходящей нспараметр^ц альтернативы £ критерию (см. главу Непараметрическая статистика, где п дается вопрос применения альтернативных процедур/
P-уровень значимости £-критерия равен вероятности ошибочно отвергну потезу об отсутствии различия между средними выборок, когда она верна (а когда средние в действительности равны).
Некоторые исследователи предлагают в случае, когда рассматриваются чия только в одном направлении (например, переменная X больше (мсныц<? | вой группе, чем во второй), рассматривать одностороннее {-распределение лить полученный для двухстороннего г-критерия р-уровень пополам. Л предлагают всегда работать со стандартным двухсторонним £-крптсрием.
Чтобы применить {-критерий для независимых выборок, требуется, по 11|1 мере, одна независимая (группирующая) переменная и одна зависимая перем (например, тестовое значение некоторого показателя, которое сравнивает ;М I группах).
Вначале с помощью значений группирующей переменной, например, ц на и женщина, если группирующей переменной является Пол, или Имеет шее образование и Не имеет высшего образования, если группирующем t-»« ной является Образование, данные разбиваются на две группы Далее в к. группе вычисляется среднее значение зависимой переменной, например риальное давление или доход. Эти выборочные средние сравниваются • собой.
Конечно, при применении t-крцтерия, как и при применении любог<> л критерия в анализе данных, нужно сохранять здравый смысл. Применение < терпя мало оправданно, если значения двух переменных несопоставимее мер, если вы сравниваете среднее значение некоторого показателя в вы< НИСНТОВ до и после лечения, но используете различные методы вычи«.
определение f-критерия
491
[-пличественного показателя или другие единицы во втором измерении, то высо-возначимые значения «-критерия могут быть получены искусственно, за счет изменения единиц измерения. Аналогично, не имеет смысла сравнивать доходы, вы--длзенные в рублях, при многократной девальвации или высокой инфляции.
* g следующем разделе даются формулы вычисления статистики критерия Стыо-пента для проверки равенства средних двух выборок. Если вас интересует только практическое применение, вы можете пропустить этот раздел.
формальное определение t-критерия
| формально в случае двух групп (А = 2) статистика «-критерия имеет вид:
V "| ”1
где Я, (л,) и Х2 (н2) — выборочные средние первой и второй выборки. У2 — оценка дисперсии, составленная из оценок дисперсий для каждой группы данных:
У2 = — — [(л, -1)5,2 (и,) + (л? -1)$2 («2)]:
Л, + «2 - 2
*,’(«) =— (и))2, 7 = 1.2-
Л. — • м1
Если гипотеза: «средние в двух группах равны* — верна, то статистика Г(л, +я, -2) имеет распределение Стьюдента с (л, +л2 -2) степенями свободы (см. например, справочное издание Айвазян С. А , Енюков И. С., Мешалкин Л. Д„ Прикладная статистика., М.: Финансы и статистика, 1983. С. 395—397).
Большие по абсолютной величине значения статистики f(nt +п2 -2) свидетельствуют против гипотезы о равенстве средних значений.
С помощью вероятностного калькулятора STATISTICA найдем 100а/2% -ю точ ку распределения Стьюдента с (л, +л2 -2) степенями свободы.
Обозначим найденную точку через t(a/2).
Если | f (л, + л2 - 2)| > t(a/2), то гипотеза отвергается
Заметим, чтобольшиеабсолютнысзпачашя статистики Стьюдента t(n, +п2 -2)мо-ГУт возникнуть как из-за значимого различия средних, гак и из-за значимого различия Дисперсий сравниваемых rpyiui
Статистический критерий равенства или однородности дисперсии двух нор мальных выборок основан на статистике.
492
Глава 12. Г-критерий сравнения средних в двух группах дак
i>.. п:
^,-1.^-1)=-^ *:>
-_>Х<Х2 -^(Лг))2
которая при гипотезе: «дисперсии в двух группах равны» имеет распредели Г(и,-1,л2-1).
Зададимся уровнем значимости а.
С помощью вероятностного калькулятора вычислим 100(1 — а/2)%п 100(сс .1
точки распределения Г(л, -1, л2 -1) -
Если Е' (и, — 1, и2 — 1) < F(«, — 1, п2 — 1) < Г'Дл, —1. и, —1), то гипотеза об
породности дисперсии не отвергается.
-критерий для зависимых выборок
Степень различия между средними в двух группах зависит си внутригруппц вариации (дисперсии) переменных. -ч
В .зависимости от того, насколько различны эти значения для каждой группы ♦грубая разность» между групповыми средними показывает более сильную ил» более слабую степень зависимости между независимой (группирующей) и зависим мой переменными.
Например, если при исследовании среднее значение WCC (число лейкоцитов^ равнялось 102 для мужчин и 104 для женщин.то разность только на велнчину2мсж-ду внутригрупповыми средними будет чрезвычайно важной в том случае, < ли ва«| значения WCC мужчин лежат в интервале от 101 до 103, а все значения WCC женщин — винтервале 103-105. Тогда можно довольно хорошо прсдсп , >.ть WCC(.4l*-| чсние зависимой переменной) исходя из пола субъекта (независимой переменк'ь*] Однако если та же разность 2 получена из сильно разбросанных данных (напри ыа изменяющихся в пределах от 0 до 200), то разностью вполне можно пренебречь. I
Таким образом, попятно, что уменьшение внутригрупповой вариации унсчичМ вает чувствительность критерия.
Г-критерий для зависимых выборок дает преимущество в том случае, кш и • * ный источник внутригрупповой вариации (или ошибки) может быть легко опрг! лен и исключен из анализа. В частности, это относится к экспериментам. в рых две сравниваемые группы наблюдений основываются на одной и той выборке наблюдений (субъектов), которые тестировались дважды (например I циенты до и после лечения).
В таких экспериментах значительная часть внутригрупповой изменчив (вариации) в обеих группах может быть объяснена индивидуальными раэлйА ми субъектов. Заметим, что на самом деле такая ситуация не слишком отчичЯ от той, когда сравниваемые группы совершенно независимы (см. г-крптсрий , независимых выборок), где индивидуальные отличия также вносят вклад в д
зимер 1
493
персию ошибки. Однако в случае независимых выборок вы ничего не сможете родетать с этим, так как не сможете определить (или «удалить*) часть вариации, сВязаиную с индивидуальными различиями субъектов. Если та же самая выборка тестируется дважды, то можно легко исключить эту часть вариации.
Вместо исследования каждой группы отдельно и анализа исходных значений можно рассматривать просто разности между двумя измерениями (например, «до теста» и «после теста») для каждого субъекта. Вычитая первые значения из вторых (для каждого субъекта) и анализируя затем только эти «чистые (парные) разности», вы исключите ту часть вариации, которая является результатом различия в исходных уровнях индивидуумов.
В сравнении с r-критерием для независимых выборок, такой подход дает всегда «лучший» результат, так как критерий становится более чувствительным.
Теоретические предположения г-критерия для независимых выборок также применимы к критерию зависимых выборок. Это означает, что парные разности должны быть нормально распределены. Если это не выполняется, то можно воспользоваться одним из альтернативных непараметрических критериев (см. главу Непараметрическая статистика).
В системе STATISTICA г-критерий для зависимых выборок может быть вычислен для списков переменных и просмотрен далее как матрица. Пропущенные данные при этом обрабатываются либо попарным, либо построчным способом
При этом возможно возникновение «чисто случайно» значимых рсзультатов. Если вы имеете много независимых экспериментов, то «чисто случайно» можете найти один или несколько экспериментов, результаты которых значимы.
Как уже говорилось, сравнение средних в более чем двух группах проводится с помощью дисперсионного анализа (английское сокращение — ANOVA).
Если имеется более двух «зависимых выборок» (например, до лечения, после ..ечения-1 и после лечения-2), то можно использовать дисперсионный анализ с по-етсрными измерениями. Повторные измерения в дисперсионном анализе можно рассматривать как обобщение t-критерия для зависимых выборок позволяющее увеличить чувствительность анализа.
Например, дисперсионный анализ позволяет одновременно контролировать не только базовый уровень зависимой переменной, но и другие факторы и включать в план эксперимента более одной зависимой переменной.
Интересен следующий прием объедипения результатов нескольких t-критериев. Этот прием можно использовать также для объединения результатов других критериев (см.: Справочник по прикладной статистике/Под редакцией Э. Ллойда и У Ледермана, т. 1. М.: Финансы и статистика, 1989. С. 274). Для нас этот пример также интересен тем, что мы можем продемонстрировать новые возможности STА-TISTICA.
Пример 1
Предположим, используя независимые эксперименты, вы получили уровни значимости с(1), я(2)... а(т). Предположим, эти уровни недостаточно убедительны. Если уровни значимости неубедительны, то, возможно, имеет смысл объединить Данные и рассмотреть их как результат одного целого эксперимента
494
Глава^г. 7-кршерий сравнения средних в двух
При нулевой гипотезе уровни значимости, рассматриваемые как слу» личины, имеют равномерное распределение.
Следовательно, величина
L - -2 X (£n(a(l)) + Zn(o(2)) ч ... + Ln(a(m}) имеет хи-квадрат-распредсленне с числом степеней свободы 2т. Например, если в испытаниях на прочность бетона были получены нем но убедительные уровни 0,047,0,054, 0,042, то уровень значимости обьейЗ эксперимента равен 0,005547 и гипотеза о неэффективности добавки явн.. гается.
Для того чтобы понять это. воспользуемся средствами системы STAT” Сначала вычислим величину L, например, задав формулу в алектриниой • Создайте файл и в первой строке введите запись:
Переменная иаг7содержит значение L, вычисленное по формуле.
Затем откройте вероятностный калькулятор системы STATISTICA в в нем распределение хи-квадрат, введите число степеней свободы 6 а в i квадрат введите величину 18,29.
495
ПримерЗ___________________________________
!В результате в полер мы получили 0,005547
Таким образом, получен объединенный уровень значимости трех (-критериев /сравните с результатами, приведенными в Справочнике по прикладной статистике, под редакцией Э. Ллойда и У. Ледермана. Т. 1 М.; Финансы и статистика, IF ig89. С. 275). Это явно высокий уровень значимости, поэтому нулевая гипотеза I отвергается.
Пример 2
I Здесь мы будем работать с файлом inlemet2000sta. Можно также использовать файл aJstudysia из папки Examples.
В файле intemel2000jsta собраны результаты опроса нескольких пользователей относительно их восприятия сайтов ENNUI и POURRITURE.
Такого рода данные несложно получить с помощью Интернета. Вы можете, на-I пример, вывесить на сайт анкету, которая будет заполняться посетителями.
В этом модельном примере пользователи оценивали сайты в разных шкалах I (полнота, технологичность решения, информативность, дизайн и др.) В каждой из
I шкал респонденты давали оценку сайту по десятибалльной шкале, от 0 до 9 баллов.
Интересен вопрос: различается ли восприятие сайтов мужчинами и женщинами?
Мужчины могут в некоторых шкалах давать более высокие или низкие оценки по сравнению с женщинами.
Для решения этой задачи можно использовать /-критерий для независимых вы борок. Группирующая переменная Пол разбивает данные на две ipyniiw. Выборки мужчин и женщин будут сравнены относительно среднего их оценок по каждой шкале. Вернитесь к стартовой панели Основные статистики и таблицы и щелкни те на процедуре t-критерий для независимых выборок, чтобы открыть диалоговое окно Т-критерий для независимых выборок (групп).
496
Глава 12. /"-критерий сравнения средних в двух группах гр
Щелкните по кнопке Переменные, чтобы открыть стандартное диалоговое о«ж для выбора переменных. Здесь вы можете выбрать и независимые (груплти®. шие), и зависимые переменные. “
Для нашего примера выберите переменную Пол как независимую пере» ,
и переменные от 3 до 25 (содержащие ответы) в качестве зависимых переменны®*
Щелкните на кнопке ОК в этом диалоговом окне, чтобы вернуться в диалог _ окно Т-критерий для независимых выборок (групп), где отобразится ваш выбор
,имер 2
497
I Из диалогового окна Т-критерий для независимых выборок (групп) доступно «кже много других процедур.
Щелкните на кнопке ОК для вывода таблицы результатов.
—>Г4»,у> 4 714266 _ ДГТ** jX Б 464266 ;
3 821429
S71429
^_ДЙ
7764Ы
235692
3094S I
28152 |
52707 !
16S47 67196
3?91С
735Б0 26564 07920
196615
779521
600572
869267
067309
5 409091 642667 ! 4 409091 321429 ' 3 909091 5 464286 1 5 590909 3 357143 4 727273 • 714266 " 5 ООС-Ю ; 3 636104 3 590909 3 616364
Самым быстрым способом изучения таблицы является просмотр пятого столбца (содержащего р-уровни) и определение того, какие из p-значений меньше установленного уровня значимости 0,05.
Для большинства зависимых переменных средние по двум группам (МУЖЧИНЫ - MALES и ЖЕНЩИНЫ — FEMALES) очень близки.
Единственная переменная, для которой t-критерийсоответсгвуетустановленно-му уровню значимости 0,05, — это Measur 7, для нее р-уровень равен 0,0087. Как показывают столбцы, содержащие средние значения (см. две первые колонки), для мужчин эта переменная принимает в среднем существенно большие значения — в выбранной шкале измерений для мужчин она равна 5,46, а для женщни — 3,63. При этом нельзя исключить вероятность того, что полученная разница на самом деле отсутствует и получилась лишь в результате случайного совпадения (см. ниже), хотя это выглядит маловероятным.
Графиком по умолчанию для этихтаблиц результатов является диаграмма размаха. Для построения этой диаграммы щелкните правой кнопкой мыши в любом месте строки, соответствующей зависимой переменной (например, на среднем для Measur 7).
В открывшемся контекстном меню выберите построение графика Диаграмма размаха из подменю Быстрые статистические графики. Далее выберите опцию Среанее/ст.ош./ст.откл. окна Диаграмма размаха и нажмите ОК для построения графика.
Разность средних на графике выглядит более значительной и ие может быть объяснена только на основании изменчивости исходных данных.
Однако на графике заметно еще одно неожиданное отличие. Дисперсия для группы женщин намного больше дисперсии для группы мужчин (посмотрите на прямо-тодыпши, которые изображают стандартные отклонения, равные корню квадратно-«У из вариации).
Если дисперсии в двух группах существенно отличаются, то нарушается одно Иэ требований для использования t-критерия, и разность средних должна рассмат-| Риваться особенно внимательно.
Кроме того, дисперсия обычно коррелирована со средним значением, то есть чеМ больше среднее, тем больше дисперсия.
498
Глава 12. 7~-критерий сравнения средних в двух группах
Однако в данном случае наблюдается нечто противоположное. В такой сит 4<пм они гный исследователь предлодожил бы. что распределение переменной ft
возможно, не является нормальным (для мужчин, женщин или для тех и Aj'Vr«i>
Поэтому рассмотрим критерий равенства дисперсий для того, чтобы пре является ли наблюдаемое на графике отличие действительно заслуживаш^М внимания.
Вернемся к таблице результатов и прокрутим ее вправо, увидим резу F-критерня. Значение F-крнтерия действительно соответствует указанном ню значимости 0,05, что означает существенную разность дисперсий пер&имш4 Measur 7 в группах МУЖЧИНЫ - MALES и ЖЕНЩИНЫ ~ FEMALES.
Однако значимость наблюдаемой разности дисперсий близка к граничц..му уровню значимости (ее р-уровень равен 0,029).
Большинство исследователей посчитало бы один этот факт педостати шаМ < признания недействительным «критерия разности средних, дающего выссимЙ) вень значимости для этой разности (р = 0,0087).
Множественные сравнения
При проведении сравнений средних в трех и более группах можно исполком процедуры множественных сравнений Сам термин «множественные ера» означает просто многократные сравнения.
Пример 2
499
Проблема состоит в следующем: мы имеем и > 2 независимых групп данных п хотим разумным образом сравнить их средние. Предположим, мы применили р-критернй н отклонили гипотезу: «средние всех групп равны». Наше естествен-вое желание — найти однородные группы, средние которых равны между собой.
Конечно, мы можем сравнить группы с помощью г -критерия и найти путемлно-
щкратных сравнений однородные группы. Но, оказывается, трудно вычислить ошибку выполненной процедуры или, как говорят, составного критерия, отправляясь от заданного уровня значимости каждого /-критерия.
Тонкость состоит в том, что сравнивая с помощью /-критерия много групп, вы чисто случайно можете обнаружить эффект. Представьте, что в 1000 клиник вы провели испытание нового лекарства, сравнивая в каждой клинике группу больных. принимающих препарат, с группой больных, принимающих плацебо. Конечно, чисто случайно может найтись клиника, где вы найдете эффект. Однако с высокой степенью вероятности это может быть арт-эффект.
Чтобы обезопасить себя от подобного рода случайностей, используются специ-
альные критерии для множественных или многократных сравнений.
В системе STATISTICA процедуры множественного сравнения реализованы в модуле Основные статистики и табшцы в диалоге Апостериорные сравнения средних.
Описание процедур множественного сравнения можно найти, например, в книге-Кендалл М. Дж. иСтьюарт А. Статастнческиевыводыисвязи. М/ Наука, 1973. С 71—79.
Заметим, что самые общие методы сравнения нескольких групп реализованы в модуле Общий дисперсионный анализ.
Однофакторный дисперсионный анализ можно провести в модуле Основные статистики и таблицы.
500
Глава 12. F-критерий сравнения средних в двух группах,
Эднофакторный дисперсионный анализ л апостериорные сравнения средних
Итак, если вы хотите продвинуться в исследовании различий нескольких труп»» то дальнейший анализ следует вести в диалоге Группировка и однофакторный оч-персионный анализ (ANOVA). Мы работаем с данными, которые находятся в фсл ле adstudysta (папка Examples).
Сделайте вслед за нами следующие установки
Вначале стандартным образом выберите группирующие и зависимые перем« ц> ные в файле данных.
Затем выберите коды для группирующих переменных. С помощью этих кцди наблюдения в файле разбиваются на несколько групп, сравнение которых мы ( у дем проводить.
После того как выбраны переменные для анализа и определены коды грУ> -1 *' рующих переменных, нажмите кнопку ОК и запустите вычислительную пр- -»*"*
дуру.
В появившемся окне вы можете всесторонне просмотреть результаты лиза.
501
Посмотрите внимательно на диалоговое окно. Результаты можно отобразить в виде таблиц и графиков. Например, можно проверить значимость различий в средних с помощью процедуры Дисперсионный анализ.
I Цслкните на кнопке Дисперсионный анализ, и вы увидите результаты однофакторного дисперсионного анализа для каждой зависимой переменной
Заметьте, что в таблице дисперсионного анализа мы имеем уже дело с F-критерием.
Как следует из результатов, для переменных Measur 5. Measur 7 и Measur Рщю-Цедура одпофакториого Дисперсионного анализа дала статистически значимые ре-Т’льтаты на уровне р<0,05.
Эти результаты показывают, что различие средних значимо. Итак, с помощью К "Критерия (этот критерий обобщает /-критерий на число групп больше двух) мы отвергаем гипотезу об однородности сравниваемых групп.
Возвратитесь в диалоговое окно результатов и нажмите кнопку Апостериорные сравнения средних для того, чтобы оценить значимость различий между среди и-Ми конкретных групп. Прежде всего нужно выбрать зависимую переменную. В дан-Ио'1 примере выберем переменную Measur 7.
После того как вы нажмете ОК в окне выбора переметой. на экране появится I Залоговое окно Апостериорные сравнения средних.
502
Глава 12. Г-критерий сравнения средних в двух группах
В этом окне можно выбрать несколько апостериорных критериев. Выберем, например. Критерии наименьшей значимой разности (НЗР). Критерий НЗР эквивалентен t-критерию для независимых выборок , по ному на N сравниваемых группах.
г-крлтерий для независимых выборок показывает (проверьте на STATISTIC что имеется значимое различие между ответами МУЖЧИН - MALES и отв •-ЖЕНЩИН — FEMALES для переменной Measur 7.
Используя процедуру Группировка и однофакторная ANOVA. мы видим (см. лицу результатов), что значимое различие средних имеется только для лиц, бравших СОКЕ.
Графическое представление результатов. Различия средних можн< ,।м на графиках, доступных в диалоговом окне Внутригрупповые описательные мистики и корреляции — Результаты.
Например, для того чтобы сравнить распределения выбранных перемен! внутри групп, щелкните по кнопке Категоризованные диаграммы размаха II вм рите опцию Медиана/кварт./размах из диалогового окна Диаграмма размол v
После того как вы нажмете OK. STATISTICA построит каскад диаграмм ра
503
Из графика видно, что между группой FEMALE — СОКЕ и группой MALE -СОКЕ имеется явное различие.
Такого рода анализ с последовательно усложняющейся группировкой и сравнением средних в получающихся группах, особенно часто применяемый в массовых обследованиях, может быть с успехом выполнен в STATISTICA
-g *Э Непараметрическая I статистика
Одним из факторов, ограничивающих применения критериев, основанных на nj положении нормальности, является объем выборки. До тех пор пока выбор» л » статично большая (например, 100 или больше наблюдений), можно считатц. выборочное распределение нормально, даже если вы не уверены, что распре«ц ние переменной в популяции является нормальным Тем не менее, если вы( •< иола, эти критерии следует использовать только при наличии уверенности, переменная действительно имеет нормальное распределение. Однако нет сш . л» проверить это предположение из малой выборке.
Использование критериев, основанных на предположении нормальности, мс того, ограничено шкалой измерений (см. главу Эзеиентарные понятия анализ данных). Такие статистические методы, как t-критерий, регрессия и т. д., преппс вы гают, что исходные данные непрерывны. Однако имеются ситуации, когда данн 4 г. скорее, просто ранжированы (измерены в порядковой шкале), чем измерены точ •>
Типичный пример дают рейтинги сайтов в Интернете- первую позицию занимл-;т сайт с максимальным числом посетителей, вторую позицию занимаете «шт с маю и сальным числом посетителей средн оставшихся сайтов (среди сайтов, из кот .; ’4> удален первый сайт) и т. д. Зная рейтинги, мы можем сказать, что число посе .щг. пей одного сайта больше числа посетителей другого, но насколько больше, сгии уже нельзя. Представьте, вы имеете 5 сайтов: А. В, С, D, Е, которые располагаем*» га 5 первых местах Пусть в текущем месяце мы имели следующую расстаи -«*'• Л, В, С, D, Е, а в предыдущем месяце: D, Е, А, В, С. Спрашивается, про».к«иШ .ущественные изменения в рейтингах сайтов или лет"? В данной ситуации, очг «О-«). мы не можем использовать t-критсрий. чтобы сравнить эта две группы д »*• м * 1 переходим в область специфических вероятностиых вычислений (а любойст» гистический критерий содержит в себе вероятностную калькуляцию!). Мы p t :уждаем примерно следующим образом: насколько велика вероятность того. •»• • ггличие в двух расстановках сайтов вызвано чисто случайными причинами »то отличие слишком велико и пе может быть объяснено за счет чистой с*уЧЦМ юсти. В этих рассуждениях мы используем лишь ранги или перестановки 1дЛ"" । никак не используем конкретный вид распределения чиста посетителей на
Для анализа малых выборок и для данных, измеренных в бедных шкала». пр* пеняют непараметрическис методы
>аткий обзор непараметрических процедур
1“ существу, для каждого параметрического критерия имеется, по крайней к •дна непараметрическая альтернатива
Краткий обзор непараметрических процедур
505
В общем, эти процедуры попадают в одну из следующих категорий*
О критерии различия для независимых выборок;
Э критерии различия для зависимых выборок,
3 оценка степени зависимости между переменными.
Вообще, подход к статистическим критериям в анализе данных должен быть прагматическим и не отягощен лишними теоретическими рассуждениями. Имея в своем распоряжении компьютер с системой STATISTICA, вы легко примените к своим данным несколько критериев. Зная о некоторых подводных камнях методов, вы путем экспериментирования выберете верное решение. Развитие сюжета довольно естественно: если нужно сравнить значения двух переменных, то вы используете t-критерий. Однако следует помнить, что он основан на предположении нормальности и равенстве дисперсий в каждой группе. Освобождение отэтих предположений приводит к непараметрическим тестам, которые особенно полезны для малых выборок.
Далее имеются две ситуации, связанные с исходными данными: зависимые и независимые выборки, в которых применяется t-критерий для зависимых н независимых выборок соответственно.
Развитие t-критерия приводит к дисперсионному анализу, который используется, когда число сравниваемых групп больше двух. Соответствующее развитие непараметрических процедур приводит к непараметрическому дисперсионному анализу, правда, существенно более бедному, чем классический дисперсионный анализ.
Для оценки зависимости, или, выражаясь несколько высокопарно, степени тесноты связи, вычисляют коэффициент корреляции Пирсона. Строго говоря, его применение имеет ограничения, связанные, например, с типом шкалы, в которой измерены данные, и нелинейностью зависимости, поэтому в качестве альтернативы используются также непараметрические, или так называемые ранговые, коэффициенты корреляции, применяемые, например, для ранжированных данных Если данные измерены в номинальной шкале, то их естественно представлять в таблицах сопряженности, в которых используется критерий хи-квадрат Пирсона с различными вариациями и поправками на точность.
Итак, по существу имеется всего несколько типов критериев и процедур, которые нужно знать и уметь использовать в зависимости от специфики данных. Вам нужно определить, какой критерий следует применять в конкретной ситуации.
Непараметрическне методы наиболее приемлемы, когда объем выборок мал. Если данных много (например, п >100), часто не имеет смысла использовать непа-ра.мегрическую статистику.
Если размер выборки очень мал (например, и - 10 или меньше), то уровни значимости для тех непараметрических критериев, которые используют нормальное приближение, можно рассматривать только как грубые оценки
Различия между независимыми группами. Если имеются две выборки (напри-МеР- мужчины и женщины), которые нужно сравнить относительно некоторого среднего значения, например, среднего давления или количества лейкоцитов в кро-ви то можно использовать t-тест для независимых выборок.
Непараметрическими альтернативами этому тесту являются критерий серий палъда—Волъфовица, Манна—Уитни U-тыл и двухвыборочный критерий Колмогорова— Смирнова.
Глава 13. Непараметрическая сгатиг
Различия между зависимыми группами. Если вы хотите сравнить две . leinibie, относящиеся к одной и той же выборке, например, медицинские ели одних и тех же пациентов до и после приема лекарства, то обычно неги тся t-критерий для зависимых выборок.
Альтернативными непараметрическими тестами являются критерий зна/ ритерий Вилкоксона
Если рассматриваемые переменные категориальны, то подходящим явля и-кеадрат Макнемара.
Если рассматривается более двух переменных, относящихся к одной и то ыборке, то обычно используется дисперсионный анализ (ANOVA) с повтори
Альтернативным пепараметрическим методом является Ранговый диспввяувЛ ый анализ Фридмана и Q-критерий Кохрена.
Исследование зависимости между порядковыми переменными.
Для того чтобы оценить зависимость между двумя переменными, обычно е^ исляют коэффициент корреляции Пирсона. Непараметрическимн аналогами i> ффпциецта корреляции Пирсона являются коэффициенты ранговой коррелрцц Ъшрмена R, статистика Кендалла и коэффициент Гамма (более подробно ( апример, книгу Кендалл М. Дж., Ранговые корреляции, 1975).
Коэффициент ранговой корреляции (rank correlation coefficients) оцени««-еличину зависимости между переменными, измеренными в порядковых ш«;>пв о есть между порядковыми переменными.
Прозрачный способ построения парных коэффициентов корреляции из оАЛ ценного коэффициента корреляции предложил Daniels (Daniels Н. Е., 1 А Honietrika, v. 35, р, 416-417), см. также заметку Е. В. Кучинской в Энциклет < ж” Вероятность и математическая статистика», 1999. С. 537-538. Обобщенный *0 ффнциент корреляции определяется формулой:
г- У°-*!
це atj = а(Х', XJ, — b(Yt, К) — некоторые функции пар наблюдений X и Y с-гс* етственно, суммирование ведется по всем парам i, j.
Заметим, что при а. “ X. - X, bv = Y. - У. получаем обычный коэффициент *Яf еляции Пирсона. Если переменные ранжированы, то мы работаем с рангами. У"» ядочим значения X по возрастанию, то есть построим вариационный ряд эти? »г мчим. 11омер величины X в этом ряде называется ее рангам и обозначается Г
Затем упорядочим значения У в порядке возрастания. Номер величине 1, этом ряде называется ее рангом и обозначается
Коэффициент ранговой корреляции Спирмена вычисляется как обобщении ээффицпепт парной корреляции с заменой наблюдений их рангами. Форм;*>м» зя обобщенного коэффициента корреляции нужно положить^.-R — ~ '
Коэффициент Кендалла вычисляется, если в формуле для обобщенного " ф пциента положить а.. = 1 при R.< Rh а 1 при /? > /?. Величины «алогичными соотношениями с заменой рангов Дна ранги ^наблюдений Y ИпН ы ясно видим, что идея всех корреляций возникает из одного и того же источШ‘«
Если имеется более двух переменных, то используют коэффициент конх >,•' шКендалла Например, он применяется для оценки согласованности мнений Н-
,ние непараметрических процедур на примерах
507
В пнсимых экспертов (судей), например баллов, выставленных одному и тому же частнику конкурса.
’ Если имеются две категориальные переменные, то для оценки степени зависи-
остц используют стандартные статистаки и соответствующие критерии для таб-F * сопряженности: xu-квадрат, фи-коэффициент. точный критерий Фишера.
Нелегко дать простой и однозначный совет, касающийся использования этих В оЦед\'р Каждая имеет свои достоинства и свои недостатки.
I Г Например, двухвыборочный критерий Колмогорова—Смирнова чувствителен яе только к различию в положении двух распределений, но также и к форме рас-I пределения. Фактически он чувствителен к любому отклонению от гипотезы однородности, но нс указывает, с каким именно отклонением мы имеем дело.
! Критерий Вилкоксона предполагает, что можно ранжировать различия между сравниваемыми наблюдениями. Если этого сделать нельзя, то используют критерий знаков, который учитывает лишь знаки разностей сравниваемых величин
В общем, если результат исследования является важным и наблюдений немного (например, отвечает на вопрос — оказывает ли людям помощь определенная очень дорогая и болезненная лекарственная терапия?), то всегда целесообразно испытать пепараметрические тесты. Возможно, результаты тестирования I (разными тестами) будут различны В таком случае следует попытаться понять, I почему7 разн ые тесты дали разные результаты.
С другой стороны, непараметрические тесты имеют меньшую мощность, чем их параметрические конкуренты, и если важно обнаружить даже слабые эффекты (например, при выяснении, является ли данная пищевая добавка опасной для здоровья), следует провести многократные испытания и особенно внимательно выбирать статистику критерия.
Описание непараметрических процедур на примерах
Стартовая панель модуля Непараметрические статистики
Стартовая панель модуля имеет вид:
508
Глава 13. Непараметрическая статИ(
таблицы частот 2x2: статистики Хи/У/Фи-квадрат, Макнемара
509
частот 2x2: статистики Xn/V/Фи-Макнемара,точный критерий
Опция открывает диалоговое окно, в котором можно ввести частоты в 2x2 (состоящую из двух строк и двух столбцов) и вычистить различные ei тики, позволяющие оценить зависимость между двумя переменными, пр-^ шими только два значения.
Типичный пример таких таблиц — определение, например, числа мужчин i »•*» шин, предпочитающих рекламу ПЕПСИ или КОКИ, или числа заболевши* и Ш заболевших людей из числа сделавших и не сделавших прививки, и т д.
Итак, одна переменная — ПОЛ, другая переменная — НАПИТОК Перв.л ,и• ременная имеет 2 уровня (принимает 2 значения) — мужчина, женщина. Вп , > < переменная, НАЛИТОК, также имеет 2 уровня, например, ПЕПСИ или КОК*
Задача состоит в том, чтобы оценить зависимость между двумя тсбулщ щ|(Д ними переменными.
Укажем на важное методологическое отличие использования слова связ | висимостъ) в повседневной жизни и в анализе данных (см главу 33 фунд тального текста Кендалла и Стьюарта «Статистические выводы и связи»)- СХичМЛ мы говорим, что два признака А и В связаны между собой, если они часто bci г' v -ются вместе. В анализе данных дается строгое определение: если А ветре* j тг • относительно чаще с В, чем с не-В, то А и В связаны Или, переходя на язык тео -«п» вероятностей, Р(АХВ) должна бытьболыне Р(АХне-В). Оценкой вероятности т*-ляется частота.
В приведенной выше таблице пусть признак А — пол, признак В — напиток ’р • нимающий, например, два значения: пепси — не-пепси. Пусть а, b — частот,« ОфВ вой строке, c,d— частоты во второй строке. Если а/(а+с) = b/(b+d). то i qasaaifl независимы. Формально имеем: 17/(17+27) - 0,39, 19/(19+29) “ 0396. нам нужно понять, существенно или нет различие в частотах Статистически* ИД терии, реализованные в этом диалоге, как раз и позволяют эго сделать. В .>•••«*** случае различие, конечно, несущественно (или. как говорят в анализе да, • незначимо). Следовательно, признаки независимы — пол не связан с вы? ор*44 напитка.
Опция 2x2 может быть использована как альтернатива корреляциям, е: »** ••Ч рассматриваемые переменные являются категориальными.
Дополнительно к стандартному критерию хи-квадрат Пирсона и скоррекЯШ ванному xu-квадрат ( V-квадрат) вычисляются следующие статистики.
69.В70Я
92
20Б52К
23 и бгги_
17 92654 Б2174И
р- 3259 р- 9283 р- 9039
₽-5<ВЗ р-1 OODO
р- 1049 1 р- 3020
Классическая статистика хи-квадрат Пирсона замечательна тем, что ее распределение приближается распределением хи-квадрат, для которого имеются подробные таблицы. Процентные точки распределения хи-квадрат могут быть также эффективно вычислены в системе STATISTICAc помощью вероятностного калькулятора.
Свойство критерия xu-квадрат (точность аппроксимации распределения статистики распределением хи-квадрат) для таблиц 2 х 2 с малыми ожидаемыми частотами может быть улучшено за счет уменьшения абсолютного значения разностей между ожидаемыми и наблюдаемыми частотами на величину 0,5 перед возведением в квадрат.
Это так называемая поправка Йетса на непрерывность для таблиц частот 2x2, которая обычно применяется, когда ячейки содержат только малые частоты и некоторые ожидаемые частоты становятся меньше 5 (или даже меньше 10).
Фи-коэффициент. Статистика фи-квадрат представляет собой меру связи между номинальными или категориальными переменными, значения которых нельзя упорядочить.
Пусть даны маргинальные или суммарные частоты в таблице 2x2. Предположим, что оба фактора в таблице независимы Зададимся вопросом: какова вероятность получить наблюдаемые частоты, исходя из маргинальных? Замечательно, что эта вероятность вычисляется точно, подсчетом всех возможных таблиц, которые можно построить, основываясь на данных маргинальных частотах. Это и делается в критерии Фишера. STATISTICA вычисляет p-уровни одностороннего и двустороннего критерия Фишера.
Если сумма частот небольшая, то лучше использовать точный критерий Фишера вместо критерия хи-квадрат
Известны рекомендации Кокрена для таблиц 2x2: если сумма всех частот в таблице меньше 20, то следует использовать точный критерий Фишера.
Если сумма частот больше 40. то можно применять критерий хи-квадрат с поправкой на непрерывность.
Однако эти рекомендации не универсальны (см., например. Справочник по при кладной статистике /Под. ред. Э. Ллойда и У Ледермана С. 375—376).
Рассмотрим следующий пример.
Пример. Исследуются 30 человек, совершивших преступления. У каждого из преступников есть брат-близнец. Спрашивается, имеется ли связь между род
510
Глава 13- Непараметрическая статис
ственпыми отношениями и преступлением (см. Справочник по прикладнсЦ, тпстике /Под. ред. Э. Ллойда и У. Ледермана С. 376).
Данные приведены в таблице*
Оба брата Только один брат Сумма В
преступники преступник
Однояйцевые близнецы 10 3 13
Разнояйцевые близнецы 2 15 17
Сумма 12 18 18
Проверяемая гипотеза состоит в том. что зависимости между родством и п|* ступностью нет. Альтернативная гипотеза заключается в следующем, чем те imq родственные связи, тем более вероятно совместное участие в преступлении (то • k I между признаками имеется положительная связь). Заметьте — этоод1юсторо> нац альтернатива, так как нас интересует отклонение от гипотезы лить в одну стсф^м (вольно выражаясь, с сохранением знака больше)
Введем данные в систему STATISTICA.
После нажатия на кнопку ОК получим следующую электронную таблиц.'.' с pci зультатами:
Значение статистики хи-квадрат равно 13,03.
Так как в данных имеются ячейки с малыми частотами (2 и 3), то для ул | ния точности критерия хи-квадрат используем поправку Йетса. Пос - иль» интересует односторонняя альтернатива, мы делим уровень р 0,0012 подо получаем 0,0006.
Точное значение одностороннего критерия Фишера равно 0,0005 (см. та! цу). Оба эти результата высокозначимы, следовательно, мы отвергаем исхсо гипотезу об отсутствии зависимости между родством и преступлением в п< альтернативы: «между признаками имеется тесная положительная связь*.
5лиЦЫ частот 2x2: статистики Хи/У/Фи-квадрат, Макнемара
511
Заметьте, что сумма всех частот в таблице меньше 40, но оба критерия, точный I Л)И|Пера и хи-квадрат Йетса, дают почти одинаковые результаты.
Критерий хи-квадрат Макнемара. Этот критерий применяется, когда частоты таблинс 2x2 получены по зависимым выборкам Например, когда наблюдения I Фиксируются до и после воздействия на оЭнли и там же экспериментальном материале. | 4 STATISTICA включает также модуль Логлинейный анализ, позволяющий вы-I полнить полный тоглинейный анализ многовходовых таблиц сопряженности STATISTICA содержит программу па STATISTICA BASIC для вычисления критерия Ментела—Хенцела (файл Manthaenstb в каталоге STBASIC). позволяющего сравнить две группы данных. Обратитесь к комментариям в программе Manthaenxth ^дополнительной информацией.
Наблюдаемые частоты в сравнении с ожидаемыми
Опция позволяет оценить согласие набл юдаемых частот с произвольным набором ожидаемых частот
Процедура предлагает пользователю ввести две переменные: одна содержит ожидаемые, другая — наблюдаемые частоты. Для проверки согласия наблюдаемых и ожидаемых частот вычисляется критерий хи-квадрат.
Следующий пример основан на данных (искусственных) об авариях на шоссе (данные содержатся в файле Accidentsta). Данные записывались с интервалом, равным месяцу, в 1983 и 1985 годах.
Допустим, что в 1984 году были потрачены значительные средства с тем. чтобы '•'лучишть безопасность движения на этом шоссе. Если затраченные средства ни к 4eWv ,11’ привели (нулевая гипотеза), то число несчастных случаев в 1985 году мог-ю бы прогнозироваться на том же уровне, что и в 1983-м (при условии, что общее ЧИс-’10 маш11Н на трассе и интенсивность движения не менялись). Таким образом ^зниые за 1985 год рассматриваются здесь как ожидаемые значения, данные за | 83 год — как наблюдаемые.
512
Глава 13. Непараметрическая статц-
Задание анализа. После запуска модуля Непараметримеские статист распределения откройте файл Acctdent.sta и выберите в стартовой панели о Наблюдаемые в сравнении с ожидаемыми. В появившемся диалоговом окне Я даемые и ожидаемые частоты нажмите кнопку Переменные и выберите У т' переменную с наблюдаемыми частотами и У_/5Й5 — переменную с ожида» частотами.
После нажатия О/Стаблица с результатами появится на экране.
Из таблицы ясно видно, что снижение числа аварий в 1985 году по сравн< с 1983 годом высокозначимо.
Заметим, что в нижней части таблицы результатов показано общее числе, рий за каждый год (Сумма); разности между наблюдаемыми и ожидаемыми з ниями даны в третьем столбце, квадраты разностей, деленные на ожидаемые чения (слагаемые лги-квадрат), — в четвертом столбце.
Обратите внимание на число степеней свободы (сс) распределения хи-ква в этом примере оно равно 11
Корреляции (Спирмена R, тау Кендалла, Гамма)
Опция позволяет вычислить три различные альтернативы коэффициент । ляции Пирсона: корреляцию Спирмена R, статистику may Кендалла и стат Гамма. Посте выбора опции на экране появится диалоговое окно, в которой но выбрать переменные и определенный тип корреляции для вычисл» ния вычислить одну непараметрнческую корреляцию или матрицу пенарам ких корреляций.
ibl частот 2 х 2: статистки Хи/У/Фи-хвадрат, Макнемэра
513
Следующий пример основывается на данных (файл Stri.ving.sta), представленных Siegel and Castellan (1988) Nonparametric statistics for the behavioral sciences (2nd ed.) New York: McGraw-Hill.
Двенадцать студентов ответили на вопрос анкеты, чтобы оценить связь между двумя переменными, авторитарностью и борьбой за социальное положение. Авторитарность (Adorno и др., 1950) — психологическая концепция, состоящая, грубо говоря, в том, что властные люди имеют тенденцию считать, что власть должна быть жесткой и ей следует подчиняться (иными словами, придерживаются принципа: -«закон и порядок*).
Данные показаны ниже.
Цель исследования состояла в том, чтобы выяснить, зависимы, в действительности, эта две переменные или нет.
Задание анализа. После запуска модуля Непараметрические статистики и распределения откройте файл Accidentjta и выберите в стартовой панели опцию Корреляции (Спирмена, may Кендалла, Гамма). В появившемся диалоговом окне нажмите кнопку Переменные и выберите Ам/ЛопГкак первую переменную, Striving — как вторую переменную.
Модуль Непараметрические статистики и распределения вычисляет также корреляционные матрицы. В этом примере выберите просто Спирмена RuПодробный отчет.
514
Глава 13. Непараметрическая ста.
После нажатия ОКтаблица с результатами появится наэкране.
Вы видите, что корреляция между двумя шкалами высокозпачпма, имоя , лать вывод, что индивидуумы, имеющие внутреннюю установку па авторптаг в свою очередь, стремятся к борьб< ia свое положение в обшесп нс (при услож* анкета адекватна данному исследованию), тем самым подтверждается кон» Адорно.
Авторитаризм — внутренняя установка (еетрудно непосредственно изм« В отличие от этого борьба за положение в обществе и продвижение по нер<п кой лестнице наблюдается отчетливо. Итак, между властностью и карьер имеется отчетливая зависимость.
Вы можете визуализировать найденную зависимость двчмя способам» нажав кнопку Матричная диаграмма в диалоговом окне Непараметриче. I реляции (после того как выбрали переменные), либо щелкнув правой кг мыши на таблице результатов и выбрав опцию Диаграммарассеяния/доверк. Быстрые статистичепсие графики.
Параметрическая корреляция (г Пирсона) между шкалами (г = 0.77) пс i в заголовке графика (см. ниже). Интересно, что эта корреляция меньше pat корреляции Спирмена (Спирмена R равно 0,82).
Если бы в этом примере мы располагали большим объемом данных, Н бы сделать вывод, что рассмотрение рангов (а нс самих наблюдений) в • тельности улучшает оценку зависимости между переменными, так как «И" ст» случайную изменчивость и уменьшает воздействия выбросов.
Статистики Кендалла тау иГамма. Для сравнения вернитесь в окно Пенара четкие корреляции и выберите опцию Статистика may Кендала, ятюо.т ОШИ* на. Обе статистики, Клмдаячатаун Гамма, бтаутвычнелены покажутся равньп
,рлицы частот 2x2: статистики Хи/У/Фи-квадрат, Макнемара
515
Как было сказано ранее, эти статистики тесно связаны между собой, по отличаются от статистики Спирмена. Статистику Спирмена R можно представить себе лак вычисленную по рангам корреляцию Пирсона, то есть н терминах доли изменения одной величины. связал ной с изменением другой. Статистики Кендалла may ц1омлш скорее оценивают вероятности, точнее, разность между вероятностью того, что наблюдаемые значения переменных имеют один и тот же порядок, и вероятностью того, что порядок различный.
Матрицы двух списков. Опция вычисляет только корреляции между неременными, заданными в первом списке, и переменными, заданными во втором списке.
Квадратная матрица. Опция вычисляет корреляции для одного списка переменных (квадратная матрица). Заметим, если выбраны два списка переменных, «затем выбрана эта опция, то списки будут «объединены» в один
Матричная диаграмма
Нажмите кнопку, чтобы построить матричную диаграмму рассеяния для выбранных переменных.
вип;
Этот график полезен тем, что он позволяет быстро оценить и сравнить распре-*ленпя выбранных переменных и форму зависимости между ними (например, КоэФфнциент ранговой корреляции R Спирмена может измерять нелинейную мо-потонную зависимость между переменными).
516_____________________________Глава 13. Непараметрическая стати -11
Критерий серий Вальда—Вольфовица
Критерий серий Вальда—Вольфовица представляет собой непараметрищ^^И альтернативу t-критерию для независимых выборок. Данные имеют тот , * что и в t-критерии для независимых выборок. Файл должен содержать гру-пц,-ющую (независимую) переменную, принимающую, по крайней мере, два рщ -,.J ных значения ( кода), чтобы однозначно определить, к какой группе относится дое наблюдение в файле данных.
Программа открывает диалоговое окно выбора группирующей переменно » списка зависимых переменных (переменных, по которым две группы сравню -|<J3 ся между собой), а также кодов для группирующей переменной (опция Кодь I
Критерий серий Вальда—Вольфовица устроен следующим образом. Пред» чы,- ] те, что вы хотите сравнить мужчин и женщин по некоторому признаку. Вы можг> упорядочить данные, например, по возрастанию, и найти те случаи, когда суГ«к®>« ты одного и того же пола примыкают друг к другу в построенном вариацио:- .। ряде (иными словами, образуют серию).
Если нет различия между мужчинами и женщинами, то число и длина <сери-1. относящиеся к одному и тому же полу, будут более или менее случайными. В п тивном случае две группы (мужчины и женщины) отличаются друг от друга, m есть не являются однородными.
Критерий предполагает, что рассматриваемые переменные яаляются непрер; (I ними и намерены, по крайней мере, в порядковой шкале.
Критерий серий Вальда—Вольфовица проверяет гипотезу о том, что две неоа висимые выборки извлечены из двух популяций, которые в чем-то существе» -различаются между собой, иными словами, различаются не только средними, «р также формой распределения. Нулевая гипотеза состоит в том, что обе выбо^жл извлечены из одной и той же популяции, то есть данные однородны.
U-критерий Манна—Уитни
Критерий Манна—Уитни представляет непараметрическую альтернативу г-крн терию для независимых выборок. Опция предполагает, что данные распол™ таким же образом, что и в i-критерни для независимых выборок. В частности, (>»«’ должен содержать группирующую переменную, имеющую, по крайней мере разных кода для однозначной идентификации принадлежности каждого наб - * ния к определенной группе.
Критерий (7 Манна—Уитни предполагает, что рассматриваемые переменны* мерены, по крайней мере, в порядковой шкале (ранжированы). Заметим, ч1 » всех ранговых методах делаются поправки на совпадающие ранги.
Интерпретация теста, по существу, похожа на интерпретацию резул’ т ,»»• t-критерия для независимых выборок за исключением того, что ff-критерив <д| числяется как сумма индикаторов парного сравнения элементов первой вы ’г ки с элементами второй выборки
б?-критерий — наиболее мощная (чувствительная) непараметрическая ал ’ г натнва t-критерию для независимых выборок, фактически, в некоторых он имеет даже большую мощность, чем t-критерий (см. например. Холленде|» 1Я
серий Вальда—Вольфовица
517
R ьф Л- А- (1983). Непараметрические методы статистики, а также заметку М С Никулинав Энциклопедии-«Вероятность и математическая статистика». С. 299).
формально статистика Манна—Уитни вычисляется как:
fAe yz— так называемая статистика Вилкоксона,
(1, если X, <¥,, 4=]
J [0 в противном случае.
Таким образом, статистика U считает общее число тех случаев, в которых элементы второй группы, например мужчины, превосходят элементы первой группы, например женщин.
Двухвыборочный критерий
Колмогорова—Смирнова
Критерий Колмогорова—Смирнова — это непараметрическая альтернатива ^-критерию для независимых выборок. Формально он основан на сравнении эмпирических функций распределения двух выборок. Данные имеют такую же организацию, как в t-критерии для независимых выборок Файл должен содержать кодовую {независимую) переменную, имеющую, по крайней мере, два различных кода для однозначного определения, к какой группе принадлежит каждое наблюдение.
Опция открывает диалоговое окно выбора кодовой переменной и списка зависимых переменных (переменных, по которым две группы сравниваются между собой), а также кодов, используемых в кодовой переменной для идентификации двух групп (опция Коды).
Критерий Колмогорова—Смирнова проверяет гипотезу о том, что выборки извлечены из одной и той же популяции, против альтернативной гипотезы, когда выборки изалечены из разных популяций. Иными словами, проверяется гипотеза однородности двух выборок.
Однако в отличие от параметрического t-критерия для независимых выборок и от U-критерия Манна—Уитни (см. выше), который провернет различие вположе-нии двух выборок, критерий Колмогорова—Смирнова также чувствителен к различию общих форм распределений двух выборок (в частности, различия в рассеянии, асимметрии и т. д.).
Пример. Критерий серий Вальда—Вольфовица, Манна—Уитни U-критерий, двухвыборочный критерий Колмогорова—Смирнова
®сеэти критерии представляют собой альтернативы r-критерпю для независимых выборок. Пример основан на исследовании агрессивности четырехлетних мальчи-и Девочек (Siegel, S. (1956) Nonparametrjc statistics for the behavioral sciences ' ed.) New York: McGraw-Hill). Данные содержатся в файле Aggressn.sta.
518
Глава 13 Непараметрическая
Двенадцать мальчиков и двенадцать девочек наблюдались в течение 15-ц, ной игры; агрессивность каждого ребенка оцепи валясь в баллах (в термина ты и степени проявления агрессивности) и суммировалась в один иидет-сивности. который вычислялся для каждого ребенка.
Задание анализа. После запуска модуля Непараметрические статистики. кройте электронную таблиц}' с данными (файл Aggrevmsta), выберите опцадМ терий серий Вальда—Волъфовица
Далее нажмите ОК.
Нажмите кнопку Переменные и выберите переменную Пол — Gender кв* iЩШ пирующую и переменную Aggressn Kai' зависимую.
Коды для однозначного отнесения каждого наблюдения к определенном] будут автоматически выбраны программой.
Критерий серий Вальда—Вольфоаица
519
Как нндно из таблицы результатов, различие между агрессивностью мальчиков и девочек в этом исследовании высокозначимо.
Выполните то же самое исследование с помощью критерия Манна—Уитни.
520
Глава 13. Непараметрическая crari
Выберите опцию Двухвыборочный критерий Колмогорова—Смирнова
Нажмите кнопку Переменные и выберите переменную Псы — Gender как гр | пирующую и переменную Aggressn — как зависимую.
Коды для однозначного отнесения каждого наблюдения к определенному по jV будут автоматически выбраны программой.
Критерий серий Вальда—Вольфовича
Электронная мультимедийная таблица с результатами имеет вид:
Заметьте, что стандартные отклонения в обеих группах не равны (см. шестой и седьмой столбец в таблице результатов) и мы не можем непосредственно применить t-крнтерий.
График по умолчанию для этих тестов — диаграмма размаха. Вы можете построить его двумя способами: нажав кнопку Диаграмма размаха в окне Критерий знаков или щелкнув на таблице результатов правой кнопкой мыши и выбрав затем onnj по Диаграмма размаха в меню Быстрые статистические графики. Далее программа попросит выбрать переменные. В этом примере выберите обе переменные. Затем выберите тип графика в окне Диаграмма размаха: (см. ниже). Выберите Медиа}1а/кварт./размах и нажмите ОК.
На диаграмме размаха для каждой переменной показаны: медиана, квартильный размах (25%, 75% процентили), размах (минимум, максимум).
Из графика видно, что мальчики более агрессивны, чем девочки.
Для того чтобы увидеть распределение зависимой переменной, разбитой нагруп-чы, нажмите кнопку Категоризованная гистограмма
522
Глава 13. Непараметрическая сте
ANOVA Краснела—Уоллиса и медианный тест
Эти два теста являются непараметрическими альтернативами одпофакторцогп -..it перснонного анализа. Мы применяем t-критерий, чтобы сравнить средние зн, нпя двух переменных. Если переменных больше двух, то применяется дисперсионный анализ. Английское сокращение дисперсионного анализа — ANCXV А (analysis of variation).
Критерий Краскела—Уоллиса основан на рангах (а нс на исходных наблюденм > •1 и предполагает, что рассматршйемая переменная непрерывна и измерена как мивй|| мум в порядковой шкале. Критерий проверяет гипотезу: имеют ли сравниваемы* борки одно и то же распределение или же распределения с одной и той же меди ••••* Таким образом, интерпретация критерия схожа с интерпретацией лараметри— однофакторной ANOVA за исключением того, что этот критерий основан на ран< • о а нс на средних значениях.
Медианный тест — это «грубая* версия критерия Краскела—Уоллиса ST V TISTICA просто подсчитывает число наблюдений каждой выборки, которые надают выше или ниже общей медианы выборок, и вычисляет затем знач.* *• лн-квадрат для таблицы сопряженности 2 х k
критерий серий Вальда—Вольфовицз 523
При нулевой гипотезе (все выборки извлечены из популяций с равными меди-злами) ожидается, что примерно 50% всех наблюдений в каждой выборке попадают выше (или ниже) общей медианы. Медианный тест особенно полезен, когда шкала содержит искусственные границы, и многие наблюдения попадают в ту или Buiyio крайнюю точку (оказываются «вне шкалы»).
Пример основан на данных, представленных н книге Hays (1981) Statistics (3,а cd ) New York: CBS College Publishing, которые содержатся в файле Kruskal.sta. «Откройте файл данных,
фай I содержит результаты исследования маленьких детей, которые случайным образом приписывались к одной из трех экспериментальных групп. Каждому ребенку предлагалась серия парных тестов, например, давались два мяча: красный и зеленый. Далее ребенка просили выбрать зеленый мяч. если он делал правильный выбор, то получал вознаграждение
В цервой группе тестом была форма (группа 1-Форма — 1-Рогт), во второй — цвет (qiynna 2-Цвет — 2-Color), в третьей — размер (3-Размер — З-Sue) предмета. Зависимая переменная, показанная во втором столбце, — это число исньп аннй. которые потребовались каждому ребенку, чтобы получить вознаграждение.
Задание анализа. После запуска моду’л я Непараметрические статистики и рае-преде ]ения и выбора файла Kruskalsta выберите опцию ANOVA Краскела—Уоллиса и медианный тест, чтобы открыть диалоговое окно Дисперсионный анализ Краскела- Уоллиса и медианный тест
Далее нажмите кнопку Переменные и выберите переменную Conditn как независимую п переменную Perfrmnc — как зависимую.
Нажмите кнопку Коды и выберите все коды для независимой переменной (наймите кнопку Все).
524
Глава 13. Непаранетрическая crai
Результаты. В диалоговом окне нажмите ОК для начала анализа Результат» ранговой ANOVA Краскела— Уоллиса будут показаны в первой таблице ррз«,‘.чпм1 тов, результаты медианного теста — во второй.
Вы видите, что критерий Краскела—Уоллиса высокозначим (р= 0,001). Так IV образом, характеристики различных экспериментальных групп значимо отлнч ются друг от друга. Напомним, что процедура Краскела—Уоллиса, по сушесп является дисперсионным анализом, основанным на рангах. Суммы рангов (д каждой группы) показаны в правом столбце таблицы результатов. Наибольш ранговая сумма (самое худшее выполнение теста) относится к Размеру — $ке •; J тот I гараметр, который надо различить, чтобы получить вознаграждение). Наиме» шая ранговая сумма (лучшее выполнение) относится к Форме — Form.
Медианный критерий также значим, однако в меньшей степени (р ” 0,0131)
НЕПАРЛМ СТАТИСТ
E0C0D0
-’ОООВО-
1200000* 120-:« 3600000
БООООО 6 С *00
1DOOOO НОииОТ
ю.оотоо le.ooooc БИМО
525
В таблице результатов показано число детей в каждой группе, число попыток которых меньше (или равно) общей медианы, и число наблюдений, лежащих выше обшей медианы.
И вновь оказывается, что наибольшее число испытуемых с числом попыток (до получения вознаграждения) выше общей медианы относятся к группе Размер — Size.
Больше всего испытуемых с числом попыток ниже медианы относятся к группе Форма — Form.
Таким образом, медианный тест также подтверждает гипотезу, согласно которой форма предмета наиболее легко различается детьми, тогда как размер различается хуже всего
Графическое представление результатов. График по умолчанию для этих тестов - диаграмма размаха Его можно построить двумя способами: нажав кнопку Диаграмма размаха в окне Дисперсионный анализ Краске ча—Уоллиса и медианный тест или щелкнув на таблице реэуаьтатов правой кнопкой мыши и выбрав опцию Диаграмма размаха в меню Быстрые статистические графики. Далее программа попросит выбрать переменные для графика. В этом примере выберите обе переменные. Затем выберите тип статистики для графика в окне Диаграмма размаха- (см. ниже). Выберите опцию Медиапа/квартп./размах и нажмите ОК
На диаграмме размаха для каждой переменной показаны: медиана, квартильный размах (25%, 75% процентили), размах (минимум, максимум)
526
Глава 13. Непараметрическая
Отчетливо видно, что выполнение теста в группе Форма — Form был»! любого другого; медиана числа испытаний при этом условии ниже, чем пр₽ ; другом.
Для того чтобы увидеть распределение зависимой переменной, разбитой на пы, нажмите кнопку Категоризованная гистограмма. Этот график снова пог ждает, что в группе Форма — Form выполнение «лучше» (распределение с скошено влево), чем при других условиях. Самое худшее выполнение, как < явно видно из графиков, относится к группе Размер — Size.
Отсюда также можно заключить, что наиболее легко дети различают Фо/ Form
ритерий знаков
i)TO непараметрическая альтернатива Г-критерию для зависимых выборок
Критерий применяется в ситуациях, когда исследователь проводит два изм<*р~ ия (например, при разных условиях) одних и тех же субъектов и желает уста* ить наличие или отсутствие различия результатов.
Нигерии серий Вальда—Вольфовица
527
(I Для применения этого критерия требуются очень слабые предположения (на-I йтример. однозначная определенность медианы для разности значений). Не нужно I никаких предположений о природе или форме распределения.
Критерий основан па интуитивно ясных соображениях. Подсчитаем количество I положи тельных разностей между значениями переменной (Л) п значениями переменной^).
При нулевой гипотезе (отсутствие э(|мректа обработки) число положительных разностей имеет биномиальное распределение со средним, равным половине объема выборки (положительных разностей будет примерно столько же. сколько отрицательных). Основываясь на биномиальном распределения, можно вычислить критические значения. Для малых объемов выборки п (меньше 20) предпочтительнее использовать значения, табулированные Siegel and Castellan (1988) Nonparametric statistics for the behavioral sciences (2nJ cd.) New York. McGraw-Hill, чтобы оценить статистическую значимость результатов.
Критерий Вилкоксона
Критерий Вилкоксона парных сравнений является пепарамстрической альтернативой / критерию для зависимых выборок.
Пос ле выбора опции па экране появится диалоговое окно, в котором можно выбрать переменные из двух списков. Каждая переменная первого списка сравнивается с каждой переменной второго списка. Это то же самое расположение данных, что и в t-критсрии (зависимые выборки) в модуле Основные статистики и таблицы
Предполагается, что рассматриваемые переменные ранжированы. IV — статистика Ви ткоксоиа равна сумме рангов элементов второй выборки в общем вариаци-°11!юм ряду двух выборок. Итак, наблюдения двух групп объединяются, строится общий вариационный ряд и вычисляется сумма рангов второй группы в построением ряде.
Требования к критерию Вилкоксона более строгие, чем к критерию знаков. Однако если они удовлетворены, то критерий Ви зкиксона имеет большую мощность, чем критерий знаков.
528
Глава 13. Непаранетрическая стан
•ритерий серий Вальда—Вопьфовица
529
ANOVA Фридмана и коэффициент конкордации • или согласия, Кендалла '
ANOVA Фридмана — это непараметрическая альтернатива адмофакторномтАЯ перепоил ому анализу с повторными измерениями. Коэффициент конкордации гласил) Кендалла - аналог R Спирмена (непараметрический ко:-)ффицнен?К( . ’1 реляции между двумя переменными), когда число переменных больше длу|
Теперь нажмите ОК, таблица с результатами появится на экране. Можно отме-И рть. что между каталогами имеются высокозначимые различия. Дополнительно также видно, что эксперты, выставившие оценки, согласованы друг сдругом — кон- Иордания Кендалла равна 0,57 (среднее ранговых корреляций равно 0,53).
В следующем файле приведены рейтинги, выставленные пятью каталогам пг-i. грамм независимыми экспертами. Экспертов просили учесть информативн» -wu издания, привлекательность, качество рекламы.
Анализ преследовал следующие цели:
1. Определить, можно ли на основании оценок экспертов сделать вывод о .ней чимых различиях между каталогами. Этот вопрос может быть решен с ч»е-мощью рангового дисперсионного анализа (ANOVA) Фридмана.
2. Можно ли доверять экспертам? Иными словами, согласованы их оценки и.-,-, нет (зависимы или нет эксперты)? Если нет, то вы, очевидно, не можете д верять их оценкам. Гипотезу о том, что эксперты согласованы в большей ст г -пени, чем можно было бы ожидать из-за чисто случайных совпадений >гт мнений, можно проверить с помощью коэффициента конкордации Кендалл»а
Задание анализа. После запуска модуля Непараметрические статистики и распределения к выбора файла cataloge.sta выберите опцию ANOVA Фридмана и ко кордация Кендалла.
is
График по умолчанию для этих таблиц результатов — диаграмма размаха. Его можно построить двумя способами: нажав кнопку Диаграмма размаха в окне Ранговый дисперсионный анализ Фридмана или щелкнув на таблице результатов правой кнопкой мыши и выбрав опцию Диаграмма размаха в меню Быстрые статистические графики Далее программа попросит выбрать переменные для графика. В этом примере выберите все 20 переменных. Затем выберите тип статистики для графика в окт- Диаграмма размаха: (см. ниже). Выберите опцию Медиана/кварт./размахч нажмите ОК.
Q-критерий Кохрена
Q-критерий Кохрена — это развитие критерия xu-квадрата Макнемара. Критерий Проверяет, значимо или нет различаются между собой несколько сравниваемых переменных, принимающих значения 0—1. После выбора опции Q-критерий Кохре-в стартовой панели программа предложит определить список переменных и коды, идентифицирующие две категории или два уровня факторов.
Реализация критерия в системе STATISTICA предполагает, что переменные закодированы как единицы и нули, и коды, определенные пользователем, соответственно преобразуются в эти значения (только для данного анализа, сам по себе файл не будет изменен)
530
531
Глава 13. Непараметрическая
Описательные статистики
Выбор этой опции позволяет вычислит ь разнообразные описательные ст»4 ки: медиана, процентили, квартили, размах, квартильный размах, а также cpt-гармоническое среднее, геометрическое среднее, стандартное отклонение .им рия. эксцесс, дисперсия, гармоническое среднее, сумма.
Пользователь может также вычислить заданные процентили. Эти опции л, няют опции основных статистик.
Медиана
Медиана разбивает выборку пл две равные части. Пятьдесят процентов наб-imfc* ннй лежит ниже медианы, пятьдесят процентов — выше медианы. Если зн "'|»я медианы существенно отличается от среднего, то распределение < кошено (" подробно см. главу Элементарные понятия}.
Мода
Мода — это максимально часто встречающееся значение в выборке. Частота в"" * чаемости также отображается. Если имеется несколько значений с максимал частотой, то распределение мультимодально. Если каждое значение встреча * •
тррйй серий Вальда—Вольфовица
j0>J1№ одни раз, программа делает запись, моды нет (см. электронную таблицу с. ре-I Т..дьтатами).
Геометрическое среднее
Геометрическое среднее — это произведение всех значений переменной, вознедсн-I ное в степень 1/п (единица, деленная на число наблюдений). Геометрическое среднее полезно, например, если шкала измерений нелинейная.
Пусть наблюдается переменная X. принимающая только положительные зна-I чения. Тоща геометрическое среднее вычисляется как
С(Х) = (ЙХ, >
Гармоническое среднее
Пусть наблюдается переменная X, имеющая отличные от 0 значения Тогда гармоническое среднее вычисляется как
Гармоническое среднее меньше геометрического среднего, которое, в свою очередь, меньше среднего арифметического.
Гармоническое среднее иногда используется для усреднения частот.
Дисперсия и стандартное отклонение
Выборочная дисперсия и стандартное отклонение — наиболее часто используемые меры изменчивости (вариации) данных. Дисперсия вычисляется как сумма квадратов отклонений значений переменной от выборочного среднего, деленная на п-1 (но не ца и). Стандартное отклонение вычисляется как корень квадратный из оценки дисперсии
Размах
Размах переменной является показателем изменчивости, вычисляется как максимум минус минимум.
Квартильный размах
Кварт ильный размах, по определению, равен: верхняя квартиль минус нижняя квар-ти ть (75% процентиль минус 25% процентиль). Так как 75% процентиль (верхняя Киартиль) — это значение, слева от которого находятся 75% наблюдений, a 25zo про-1 вентиль (нижняя квартиль) — это значение, слева от которого находится 25% на-блюдений, то квартильный размах представляет собой интервал вокруг медианы, который содержит 50% наблюдений (значений переменной).
Эксцесс
Эксцесс — это характеристика формы распределения, а именно мера остроты м пика (относительно нормального распределения, эксцесс которого равен О) ’ i правило, распределения с более острым пиком, чем у нормального, имеют I жительный эксцесс; распределения, пик которых менее острый, чем пик норма ного распределения, имеют отрицательный эксцесс. Эксцесс связан с четверто. и j моментом и определяется формулой (см. также главу 2):
л Анализ
I Hr выживаемости
Введение в анализ выживаемости
Методы анализа выживаемости интенсивно применяются в медицине, биологии, страховании и промышленности
Одной из важных характеристик, описывающих течение болезни, является продолжительность жизни пациентов с момента поступления в клинику или после проведения операции.
В принципе, для описания средних времен жизни и сравнения новой методики со старой можно использовать стагшартные статистические методы.
Однако рассматриваемые данные имеют специфику, которую след »«т учитывать. Дело в том, что в медицинской практике мы часто имеем дето с неполными данными.
Это связано с тем, что трудно наблюдать все время жизни пациента после операции. так как пациент мог быть выписан или переведен в другую клинику и связь с ним была утеряна. При этом мы располагаем не полной информацией о времени жизни пациента, а лишь частичной.
Естественное желание исследователя использовать все данные, то есть анализировать как полные времена жизни, так и неполные, и не терять с трудом собранную информацию.
Для этого и предназначены методы анализа выживаемости, которые позволяют изучать неполные, или цензурированные, данные
Наблюдения, которые содержат неполную информацию, называются неполными, или цензурированными (например, «пациент А был жив по крайней мере 4 месяца после того, как был переведен в другую клинику и контакт с ним был потерян»). Это пример цензурированного наблюдения: информация о том, чго пациент был жив 4 месяца, важна и может быть использована для построения оценок.
Наблюдения от момента операции до летального исхода называются полными.
Итак, в анализе выживаемости различают полные (по-английски complete') и неполные, или цензурированные, наблюдения (по-английски censored).
Конечно, можно было использовать только полные времена жизни, но тотла мы имели бы в своем распоряжении очень жало наблюдений и соответственно неточные пленки.
Использование, наряду с полными наблюдениями, неполных, или цензурированиях, наблюдении является главной особенностью методов анализа ныжпвае-Мости.
534
Глава 14. Анализ выжие
Таблицы времен жизни
Прежде всего, постараемся оценить вероятность того, что пациент npoxi < f uie t дней после операции. Это важный показатель, называемый функцией вания.
Наиболее естественный способ описания функции выживаемости состоиИ строении Таблиц времен жизни.
Это один из старейших приемов анализа данных о выживаемости и традищ но используется, например, в страховании, где такие таблицы называются |<л цами дожития.
Организация данных
Исходный файл данных имеет вид:
ли. .
69.
AUGUI
ain
В N'T
H1U.VF Л
БЮЕСЕМ11
Ев Ж
68 IP HJ0EP 1Л
M.iUVEwaEr
Б9 MAY
fi
» тмы
О>'тмвро цЛсфочм •
MARCH I»
IA.
Организация файла следующая.
Пациенты располагаются в строках. В столбцах записаны даты операш даты завершения пребывания в больнице Например, из первой строки вмг что пациенту была сделана операция 6 января 1968 (первые три юитки).
сался 21 января 1968 года (вторая тройка клеток). Далее связь с. ним была ряна. таким образом, это неполное наблюдение (значение переменнс 4 мер 7 — censored).
Восьмая переменная AGE содержит возраст пациентов.
Переменные 9, 10 содержат специальную медицинскую информацию о бснностях операции.
введение
в анализ выживаемости
535
Значение переменной 11 — название госпиталя, где сделана операция. Ниже показана таблица жизни для этого файла данных.
Конечно, подобную таблицу жизни можно рассматривать как ♦расширенную* таблицу частот. Однако обычная таблица частот строится по полным наблюдениям. В таблице жизни учтены как полные, так и неполные наблюдения.
Идея таблиц жизни, или дожития, в терминологии страхования, проста. Нам нужно вычислить простейшие статистики, чтобы описать время выживания пациентов.
Для этого временная ось разбивается на некоторое число интервалов. В приведенной выше таблице это число равно 12 В системе STATISTICA количество интервалов па временной оси пользователь может выбрать по своему усмотрению
Для каждого интервала вычисляется число объектов, которые в начале рассматриваемого ин гервала были «живы» (см соответствующий столбец в электронной таблице — переменная ЧИСЛО В НА ЧАЛЕ), и число объектов, которые «умерли» в данном интервале (переменная ЧИСЛО УМЕРШИХ).
Также вычисляется число цензурированных или изъятых из наблюдения объектов на каждом интервале — переменная ЧИСЛО ИЗЪЯТЫХ (в таблицах жизни употребляют термин изъятые — withdrawn для цензурированных наблюдений, в данном примере это выписанные больные). Вычисляются доли этих объектов.
Для понимания таблиц полезно помнить, что на данном временном интервале наблюдение может быть либо цензурировано (больной выписан или переведен в apviyio клинику), либо наблюдается фатальный исход.
Рассмотрим более формально переменные в электронной таблице жизни.
Число в начале
Это число объектов, которые были «живы» в начале рассматриваемого временного интервала.
Число изъятых
Это чпсло цензурированных па данном интервале объектов (объектов, изъятых из ^’б.'Подения). Эти объекты имеют метку цензурирование (censored).
536
Глава 14. Анализ вы>
Число изучаемых
Это число объектов, которые были «живы» в начале рассматриваемого вг го интервала, минус половина от числа изъятых
Число умерших
Это число объектов, умерших на данном интервале. Умершие или отказ объекты обычно имеют метку complete.
! В .КИВ
Доля умерших
Эта отношение числа объектов, умерших в соответствующем интервале, к объектов, изучаемых на этом интервале.
Прокрутим электронную таблицу вправо и рассмотрим оставшиеся пег ные таблицы.
• ийт г«
005561
.582759
.569514
.537874
500760
457234
349549'
317063
247227 .185420
09271Л
•061826
.ОБ77Й0 .068779 .071668
076883
08в°.’9
090<яй '
-093012 д 095468 "
104196
ObuJO 000284 .000115 Л00192 .000224
872414
866667
977273
944444
931036
91*3043*
764706
909091
777778
750000
500000
0 000000
00242Е 000805 000142 000354 000443 ППП5БЭ ОО"." D01 ЧЯ1 001549 001771 004131
0Г<70 01-Ы07 0004 к 00063.
ДШ1КЙБ .000082 .000196 .01 130 0002 0606
J8OO147 _000438 000303 000575
ДОЛЯ ВЫЖИВШИХ
Эта доля равна единице минус доля умерших.
i".
00
О'«ВЦ ОМЧ»
О
00'11
Кумулятивная доля выживших объектов, или функция выживания
Это — оценка функции выживания, то есть вероятность того, что пациент переживет данный ингервхз. Опа равна произведению долей выживших объбИМН ио всем предыдущим интервалам. Если посмотреть на столбец КУМ.Д(-1<Я ВЫЖИВШ. приведенной выше таблицы, то можно увидеть, например, «”• 0,582759 = 0,672414 х 0,866667, 0,569514 = 0,582759 х 0,977273 и т. д.
Плотность вероятности
Это плотность вероятности смерти на данном интервале, когда из функции вы вания на данном интервале вычитается функция выживания па слггуюЩ'"** тервале и делится на длину и цтервала, показанную во втором столбце табл I Например, (1 - 0,672414)/161,3636 - 0,00203.
На графике оценки плотности видно, что вероятность смерти в первые 16п -после операции максимальна. Далее она резко падает.
Большие вероятности смерти расположены также в интервалах от 161 до от 968 до 1129 и др.
Введение в анализ выживаемости
537
функция риска
Это также одна из важных характеристик, описывающих течение болезни. Функция мгновенного риска является важной прогностической характеристикой описывающей течение болезни. В анализе выживаемости риск имеет точное определение
Формально функция риска равна вероятности того, что пациент умрет в данном интервале, при условии, что в начале интервала был он жив.
График функции риска достаточно наглядно показывает, что в первые дни риск смерти очень велик, затем он падаети спустя некоторое время вновь начинает возрастать. Заметим, что именно функция риска используется для прогностических целей.
Позвольте сделать отступление. Одним из лейтмотивов нашей книги является непредвзятость и критическое отношение к полученным результатам. Такая критичность особенно важна в медицине. Мы доверяем результатам, полученным с помощью компьютера, однако всесторонне их проверяем.
Итак, нас интересует функция риска, однако реально мы получаем лишь оцен-риска. Поэтому важна точность полученных оценок. Из простых соображений ^ВДует, что мы не доверяем оценкам с большой погрешностью. Например, мы не ьУлем доверять оценкам, погрешность которых имеет тот же порядок, что и сами °Ценки Поэтому внимательно просмотрите построенную таблицу и выбросите из Иее плохие оценки (оценки с большой погрешностью). Это чрезвычайно важный Принцип анализа данных!
538
Глава 14. Анализ
Известно, что для получения надежных оценок параметров и ошибся цах жизни требуется как минимум 30 наблюдений
Взгляните иа таблицу. Заметьте, в ней наряду с оценками приведены 9| пые ошибки полученных оценок.
Медиана ожидаемого времени жизни
По определению, медиана равна моменту времени, в котором функция ния становится равной 'А Например, из первой строчки таблицы вы видит*-, пациент с вероятностью ’Л будет жить 809 дней после операции.
Если пациент пережил первый временной интервал (161 день после операции,
с вероятностью 'Лои проживет еще 1036 дней (см. вторую строчку таблицы ) «
В общем случае таблица времен жизни дает хорошее представление о ра л делении отказов или смертей, если наблюдений достаточно много.
Однако для прогноза часто необходимо знать форму функции выживания
этой цели используются различные семейства распределений.
Наиболее важны следующие семейства распределений: экспоненциальное
булла и распределение Гомперца.
Эти распределения имеют неизвестные параметры, которые программ! ниваст. Процедура оценивания параметров основана на методе наймем квадратов. Для проведения оценивания применима модель линейной ре сии, поскольку все перечисленные семейства распределений могут быть «с< к чинейным* (относительно параметров) с помощью подходящих нреобразс Такие преобразования приводят иногда к тому, что дисперсия остатки» Э( от интервалов (то есть дисперсия различна на разных интервалах). Чтобы это, в алгоритмах подгонки дополнительно используются оценки взв< наименьших квадратов двух типов.
Оценки Каплана—Мейера
Напомним, что одна из задач анализа выживаемости состоит в том, чтобы 1I функцию выживав ия S(t), то есть вероятность того, что пациент проживе’ • i t дней после операции. Формально S(t) — Р{х > t}, где х — случайная вели
сц Каплана—Мейера
539
пнсывающая время жизни после операции. Заметьте, что функция выживания дрдяется убывающей функцией, равном 1 при Г=0, и обращающейся в 0 при больших значенияхt
Если все наблюдения являются полными. то оценка S(t) строится легко: мы прото подсчитываем количество пациентов, проживших t дней после операции, и делим *х на общее число пациентов. Наличие неполных наблюдений усложняет ситуацию.
Оказывается, что для цензурированных наблюдений функцию выживания можно оценить непосредственно, не используя таблицу времен жизни Такой метод ^первые предложили Каплан и Мейер в 1958 году.
Представьте, что вы имеете фатгл, в котором записаны в хронологическом порядке отдельные события. Тогда имеет место следующая оценка функции выживания:
Я0 = п|(л-Л/(п-/+Ов ]
В этом выражении S(t) — оценка функции выживания, п — общее число событий (объем выборки),/ — порядковый (хронологически) номер отдельного события, 8(j) равно 1. если J-e событие означает отказ (смерть), и 8(j) равно 0, если j-с событие означает потерю наблюдения (индикатор цензурирования). П означает произведение по всем наблюдениям j, завершившимся к моменту t.
Данная оценка функции выживания состоит из произведения нескольких сомножителей, поэтому она также называется множительной оценкой.
Рассмотрим тот же файл данных, что и для таблиц времен жизни. Оценка Каплана— Мейера функции выживания, построенная по этим данным, показана в следующей таблице:
540
Глава 14. Анализ выживаг
дЯНение выживаемости в группах
541
Из таблицы видно, например, что вероятность того, что пациент проживет I ше 25 дней, равна 0.966, вероятность того, что пациент проживет больше Зэ равна 0,9299 и т. д
В первом столбце таблицы показаны номера наблюдений, для которых е □ ный момент времени произошло некоторое событие, знак + означает, что паЛ цензурирован (быт выписан).
Прокрутите электронную таблицу с результатами вниз по временной
АНАЛИЗ ВЫЖИВ
Л1029О
4021W
442016
Л92902 .343799
«68.000
499.000
661.000
699.000
592.000
824000
680000
730.000
916.000
538.000
В39.000
В76.000
994.000
1024.000
1108 000
Стана ”]
Ошибка , |
Л74004
0774Ы
000768
.086422
007734
Обратите внимание на ошибки оценок. Стандартная ошибка функция выж ния достаточно мала (сравните с ошибками для таблиц времен жизни).
Ниже показан график функции выживания.
Отметим, что для удобства интерпретации на графике полные наблюдения мечены точками, неполные наблюдения отмечены крестиками
Преимущество метода Каплана—Мейера (по сравнению с методом таблица® ни) состоит в том, что оценки не зависят от разбиения времен жизни на интервалы
Таким образом, нам не нужно разбивать временную ось на интервалы. О Каплана—Мейера строятся в STATISTICA одним щелчком мыши.
Сравнение выживаемости в группах
/Интересно сравнить времена жизни пациентов в различных группах, например, 1 группах мужчины и женщины. В STATISTICA имеются специальные процедуры fna сравнения выживаемости в группах.
Если количество групп — две, то используется диалог Сравнение двух выборок
Если количество групп больше двух, то используется диалог Сравнение нескольких выборок.
Для сравнения выживаемости в группах имеется несколько критериев: вариант известного непараметрического критерия Вилкоксона, предложенный для неполных наблюдений Геханом и Пето, а также F-критерий Кокса и логарифмический ранговый критерий.
Большинство этих критериев приводят соответствующие z-значения (нормального приближения), которые могут быть использованы для статистической проверки различий между группами.
Однако критерии дают надежные результаты лишь при достаточно больших объемах выборок. При малых объемах выборок эти критерии не столь надежны. В любом случае всегда полезны визуальные методы.
542
Глава 14. Анализ вы>
Эти графики позволяют увидеть различие между группами.
Кроме этого STATISTICA содержит программу на STATISTICA BASIC Mant.haen.slh), вычисляющую критерий Мептсла-Хеццела для сравнен^ групп данных (см. Lee Е.Т. (1992) Statistical methods for survival data an Этот критерий может быть полезен во многих клинических и эпидсуиол^ клх работах для того, чтобы контролировать эффект смешивающих ных.
Критерий основан па анализе таблиц 2x2 (например, Группировка 1/2 м жиеаемость), стратифицированных или расслоенных с помощью категории переменной (смешанной переменкой; например, Положением). Критерий^ ляет проверить, являются две переменные в таблицах 2x2, например, перемщ Группировка и Выживаемость. зависимыми пли нет.
Нс существует твердо установленных рекомендаций по применению onj ленных критериев.
Известно, что F-крнтерий Кокса обычно мощнее, чем критерий Внлкол» Гехана, если:
О данных мало (объем группы п меньше 50);
О выборки извлекаются из экспоненциального распределения или распре ния Вейбулла-,
О нет цензурированных наблюдений.
В работе Lee, Dcsu, and Gehan (1975) A Monte-Carlo study of the power vfl two-sample tests, Biometrika, 62, p 425-532, критерий Гехана сравнивался c i торымн другими критериями. Показано, например, что критерии Кокса—Me I и логарифмический ранговый критерий являются более мощными, ес.ш вы5| имеют определенное распределение, например, экспоненциальное или Befit < При этих условиях между критерием Кокса—Ментола и логарифмическим pi вым критерием почти нет различия.
В работе Ли (Lee Е. Т. (1980) Statistical methods for survival data analysis. BeJni CA: Lifitime Learning) обсуждается мощность различных критериев более дЯ ио. Если вас затрудняет выбор определенного критерия, рекомендуем обрати к эт им работам.
Если сравниваются две или более группы, важно проверить доли цензур) ванных наблюдений в каждой. В частности, в медицинских исследованиях ст«I цензурирования может зависеть, например, от различий в методике лечения циенты, которым стадо много лучше или стало хуже, с большой вероятное оде ряются из наблюдения. Различие в степени цензурирования может приве к смешению в статистических выводах.
Это очень важный момент. Чтобы подогнать результат, недобросовестный следователь может искусственно исключить из исследования тяжелых Поэтому при проведении сравнения различных методик нужно руководчвол ся здравым смыслом. Ясно, что если в одной группе доля цензурировании • блюдеиий существенно больше, чем в другой, нужно принять естественные MJ предосторожности, но крайней мере, точно указать проблему.
’pgrpeccwoNHwe модели в анализе выживаемости
543
>грессионные модели в анализе
В предыдущих разделах мы кратко обсуждали задачу оценивания функции выжи-Мния на основе реальных данных.
Болес трудной задачей является оценка функции мгновенного риска, которая представляет собой вероятность летального исхода в малый промежуток времени при ус ювни, что в напало исследуемого промежутка пациент бы i жив. Зто важ-1ия характеристика прогноза развития болезни.
Непосредственная оценка функции mi новенного риска может потребовать большого количества наблюдений, поэтому применяются специальные модели, одна ja которых — это модель Кокса пропорциональных рисков, или, на языке теории надежности, пропорциональных интенсивностей.
Большая проблема медицинских и биологических исследований состоит в выяснении того, являются ли некоторые переменные связанными с наблюдаемыми временами жизни. Если зависимость есть, то ее нужно оценить числении.
Существуют две главные причины, по которым в таких исследованиях нельзя непосредственно использовать классическую регрессию. Во-первых, времена жи <ни обычно не являются простыми линейными функциями от соответствующих регрессоров, поэтому анализ методами множественной регреа ни может привести к ошибочным выводам, например, не позволит обнаружить важных рарессоров. Во-вгорых, вновь возникает проблема неполных наблюдений, так как не! • торые наблюдения могут быть незавершенными.
Анализ выживаемости предлагает пять общих регрессионных моделей для неполных данных:
1) модель пропорциональных интенсивностей Кокса (Сох (1972) Regression models and life tables. Journal of the Royal Statistical Sociaty, 34. p. 187-220);
2) модель Кокса с зависящими от времени коварматами;
3) экспоненциальную регрессионную модель (см. книги Prentice (1973) Exponential survivals with censoring and explanatory variables, Biometrika, 60. p. 279-288);
4) нормальную линейную регрессионную модель (см., например, Wolynetz (1979) Maximum likelihood estimation in a linear model from confined and censored normal data, Applied Statist ics. 28, p. 185-206);
5) логнормальную линейную регрессионную модель (являющуюся модифшеа-цией нормальной модели)
Для каждой из этих моделей STATISTICA позволяет вычислить оценки максимального правдоподобия (Maximum likelihood estimations).
544
Глава 14. Анализ выжис
Модель Кокса
Модель пропорциональных интенсивностей, или пропорциональных рисков, К । са — наиболее общая регрессионная модель, в которой предполагается, что ф.-, । ция интенсивности имеет вид: й(Г) - Ло(0 y(z,.ги). Множитель hfl(t) назъпвЯ
базовой функцией интенсивности
Модель может быть параметризована, например, в виде:
Л[С«).(«!. г2> - гЛ ” Ло(О х exp(fe|X 2, +...+ bmXzn)
Заметьте, в правой части стоит произведение двух функций, причем каждая ки них зависит от своего множества переменных.
Функция интенсивности h0(t) может рассматриваться как функция интенсивно . ти при равенстве нулю всех ковариат. Она не зависит от переменных z (называ-ч-д , ковариатами). Второй сомножитель зависит от переменных z, которые, возможно, зависят от t.
Приведем пример такой модели.
Пусть изучается воздействие некоторого препарата на состояние больной | az — категориальная переменная со значениями 1 для больных, принимавших новое лекарство, и О — для больных, не принимавших это лекарство. Тогда функцию риска можно записать в виде;
А(г^) = й0(г) х ехр{6, х z+fe2x [z х log(r)-100]}
Обратите внимание, что функция интенсивности в момент t (левая часть формулы) есть функция: 1) функции интенсивности Лй, 2) ковариаты z и 3) z, умноженной на логарифм времени.
Умножение ковариаты z на логарифм времени позволяет учесть, например, фа! тор времени при приеме нового цекарства
Константа 100 в этом примере использована просто как нормировка, так как среднее логарифма времени жизни для этого множества данных равно 100.
Зная оценки параметров Ь,,Ь2 и функцию интенсивности h0, можно оценить функцию мгновенного риска через время t после операции.
Самое замечательное, что такие модели позволяют учитывать интуицию медицинских исследователей. Построение и оценка адекватности модели в конкргт- I ных исследованиях — отдельная нетривиальная задача.
Другой пример, h(t,s,x)- риск коронарной смерти для пациента возраста с ’ при условии, что в возрасте s его систолическое артериальное давление было > Meshalkin L. D, Kagan А. В. (1972) A contribution to the discussion upon the | »'»-f «Regression models and life tables» by D. R Cox, J. R. Statist. Soc. Ser. B, № 2).
Итак, функция мгновенного риска в модели Кокса представлена в виде п^ *И-ведения двух сомножителей, од|пг из которых характеризует объект, другой - б*’ | зовую функцию мгновенного риска
Предикторы определяются постановкой задачи, например, пол пациента, раст, наличие определенных сопутствующих заболеваний пли прием нов(«п« карства. Выбор предикторов определяется интуицией исследователя. Bps' ***** жет попытаться предсказать на основе определенного набора предикторов стеле*** риска на ближайшие несколько дней Имея прогноз, он может изменить мет •' ку лечения. I
Уцргрессионные модели в анализе выживаемости__________________________545
Займемся некоторой математической кухней. Модель Кокса можно лнпеари-яовать. поделив обе части соотношения на h0(t) и взяв натуральный логарифм от
I обеих частей’
МЛ[(С).(г...)]/Ап(О} = X Z,+.. + Ьк X гя
I Таким образом, мы получили линейную модель.
! Итак, еше раз отметим, в основе модели Кокса лежат два предположения. Во-первых, зависимость между функцией интенсивности и логлинейпой функцией ковариат является мультипликативной. Это предположение называется гипотезой пропорциональности. Реально оно означает, что для двух заданных наблюдений с различными значениями независимых переменных отношение их функций интенсивности не зависит от времени (чтобы ослабить это предположение, используются ковариаты. зависящие от времени-, см. ниже). Второе предположение состоит в логлинейной зависимости функции интенсивности и регрессоров.
] [редположение пропорциональности рисков часто подвергается сомнению. На-I пример, рассмотрим гипотетическое исследование, в котором ковариатой является категориальная переменная, а именно индикатор того, подвергнут пациент хирургической операции или нет. Пусть пациент 1 подвергнут операции, в то время как пациент 2 — нет.
Согласно предположению пропорциональности, отношение функций интенсивностей для обоих пациентов не зависит от времени и означает, что риск для прооперированного пациента постоянно более высокий (или более низкий), чем риск пациента, не подвергнутого операции (при условии, что оба дожили до рассматриваемого момента).
Реалистичней другая модель, когда сразу после операции риск прооперированного пациента выше, но при благоприятном исходе операции с течением времени убывает и становится меньше риска не оперированного пациента. В этом случае используются регрессоры, зависящие от времени.
Можно привести много других примеров, где предположение о пропорциональности неприемлемо. Так, при изучении физического здоровья возраст является одним нз факторов выживаемости после хирургической операции. Ясно, что возраст — более важный предиктор для риска сразу после операции, чем по прошествии некоторого времени после операции (например, вслед за первыми признаками выздоровления).
В случае категориальных ковариат, например, учитывающих. был или нс был пациент подвергнут хирургической операции, рекомендуется обратиться к стратифицированному анализу выживаемости, в котором, исходя из априорных знаний. исследователь разбивает пациентов на однородные по фактору риска группы.
Можно провести подгонку модели пропорциональных интенсивностей отдельно Для каждой группы наблюдений Таким образом, можно явно представить функцию интенсивности для каждой группы. Иногда предположение пропорциональности не выполняется. В таком случае можно явно определить ковариаты как функции времени.
В главе Подгонка вероятностных распределений показано, как с помощью кри-ГеРия хи-квадрат проверяется выполнимость предположений модели Коксавсис-теме STATISTICS
Заметим, что арифметические выражения, которые определяют ковариаты. не Должны содержать ссылок на длительности жизни Однако допускается, чтобы
546
Глава 14. Анализ выжис
некоторые ковариаты были функциями двух или большего числа других
Это, например, удобно в моделях многофакторных экспериментов. Для
фактора можно создать переменную в файле данных, чтобы установить эЛ контрасты. Логика и выбор априорных значений коэффициентов контр; же, что и в дисперсионном анализе. Если специфицируются ковариаты гресспопной модели пропорциональных интенсивностей, то можно также» лить взаимодействия факторов.
Например, предположим, что фактор А имеет 2 уровня. Всем субъектам] сенным к первому уровню этого фактора, мы приписываем -1 как значение ветствующеи переменной (переменной Л) в файле данных. Аналогично субъектам, отнесенным ко второму уровню, приписываем значение +1. н фактор, также с двумя уровнями, будет «кодирован тем же способом (переменно После того как переменные л и В опреде тены как ковариаты, выражение А *В третья ковариата для проверки взаимодействия между этими двумя факторами
Для задания зависящих от времени ковариат можно использовать тотжес^ с иптаксис, который используется в формулах электронной таблицы. I____
В некоторых случаях есть основание нрсдпола|ать, что влияние одной или н< скольких ковариат на функцию интенсивности не является непрерывным по ь| .пени. Например, риск для пациента после операции может зависеть от вр«эд0 прошедшего после операции в течение первых двух дней, и, во вторую очер*9Ш некоторых других факторов. В таком случае можно использовать некоторые яI ческие операции, которые также поддерживаются при вводе формул электроин таблиц.
Например, можно определить зависящую от времени коварнату с помошьн» । .»•
дующего выражения:
Agex(T_<2)
Логическое выражение Т< 2 равно 0 (ложь), если после операции прошло! лнь-Iне 2 дней, и равно 1 (истина), если меньше. Таким образом, здесь явно учтен фект первых двух послеоперационных дней.
Экспоненциальная регрессия
Эта модель записывается в виде*
S(z) - ехр(а + bfX z] + b2X z^+. + bmX zni)
S(z) обозначает время жизни, а — неизвестная константа, Ь. параметры регра Вновь можно использовать критерий согласия хи-квадрат, чтобы оценить,] ватность модели.
Статистика хи-квадрат может быть вычислена как функция логарифма и доподобия для модели со всеми оцененными параметрами (/.,) и логарифма и доподобия модели, в которой все ковариаты обращаются в О (£.„).
Если значение хи-квадрат значимо, отвергаем нулевую гипотезу и принт что независимые переменные значимо влияют на время жизни
Олин из способов проверить адекватность экспоненциальной модели строить остатки времен жизни и сравнить их со значениями стандартных 3 ненциальных порядковых статистик
^ссионные модели в анализе выживаемости
547
Если предположение о том, что данные имеют экспоненциальное распределение, справедливо, то все точки на графике хорошо ложатся на прямую линию.
Нормальная и логнормальная регрессия
В этой модели предполагается, что времена жизни (или их логарифмы) имеют нормальное распределен не. Модель совпадает с обычной моделью множественной регрессии и может быть записана следующим образом:
t-a + btxzt + haxzi-*- +Ьтх.2п.
где г — время жизни.
Если принимается модель логнормальной регрессии, то г заменяется In I
Модель нормальной регрессии особенно полезна, поскольку часто данные можно преобразовать в прибчизителъно нормальные с помощью подходящего преобразования.
Таким образом, в некотором смысле это наиболее общая параметрическая мо-кль (в противоположность модели пропорциональных интенсивностей Кокса, которая является непараметрической).
Для всех регрессионных моделей в системе STATISTICA досtv пен стратифицированный анализ, который открывается в окне Результаты.
548
Глава 14- Анализ
L
Цель стратифицированного анализа — проверить гипотезу о том. чти iwJ же регрессионная кривая подходит дли разных групп данных. Итак, стамддп! образом мы разбиваем данные на несколько однородных групп. 1
Затем строятся регрессионные модели отдельно для каждой группы. СмМ гармфмов правдоподобия для разных моделей представляет собой логариф^ доподобия модели с разными коэффициентами регрессии (и свободными^ ми, если требуется) в разных группах.
Далее ко всем данным обычным образом подгоняется регрессионная м' не учитывая разбиение на группы, и вычисляется общий логарифм правда бия. По разности двух логарифмов правдоподобия проверяется значимому тпчия между группами.
В стратифицированном анализе на основе априорных соображений ио J ватель разбивает объекты на однородные группы риска, которые называются тами, и проводит регрессионный анализ внутри каждой группы (см., напри^ТД книгу Кокрен У. (1976) «Методы выборочного исследования», где нсе<тпгмм|мД обсуждаются методы построения групп). Во многих ситуациях put i--r рупгшЯ ранее известны, технически пх можно получить, введя группирующие менные.
Для модели пропорциональных интенсивностей Кокса система STATIS Г.’(. V предлагает опцию подгонки к стратифицированным данным модели с обгпиммдЖ1 эффициентами для разных групп, но с разными базовыми функциями инте ». .< пости. В результате наблюдения в отдельной группе удовлетворяют предпо.«МЙМ нию пропорциональности, но это предположение необязательно выполняется наблюдений объединенных групп.
STATISTICA позволяет исследовать модель Кокса с ковариатами, зависями»-ми от времени, а также сравнить модель с зависимыми от времени ковариатыМИ • постоянными ковариатами.
Подробное введение в анализ выживаемости можно найти, например, в р» юг<МГ Bain (1978), Barlow and Proseban (1975) — русский перевод: Барлоу Р., Прогнав Ф/ Статистическая теория надежности и испытаний на безотказность. М: Наука, г1М4« Сох and Oakes (1984) — русский перевод: Кокс Д. Р., Дуке Д. Анализ данных ПИВ времени жизни. М : Финансы и статистика. 1988. Elandt-Johnson am! Johnson (1 '*O| Gross and Clark (1975). Lawless (1982), Lee (1980, 1992), Miller (1981), and (1982). Инженерные приложения этой техники обсуждены у Hahn and Sh (1967) — русский перевод: Хаи Г., Шапиро С. Статистические модсти в июючф” ных задачах. М: Мир, 1969.
На этом мы закончим общий обзор методов анализа выживаемости и пере.иМ к их реализации в системе STATISTICA, а также к примерам.
Обзор системы
Модуль Анализ выживаемости системы STATISTICA предназначен для аьлЛН цензурированных или неполных данных о выживаемости и отказах.
Модуль содержит процедуры для описания времен жизни и оценивания Ф,-" ими выживания, интенсивности л плотност вероятности, для подгонки Т1
системы
549
•яческих распределений выживаемости кданиым и для сравнения выживаемости двух И более выборках. Модуль Анализ выживаемости содержит также регрес-«ониые процедуры для подгонки объясняющих моделей к цензурированным шным (модель пропорциональных интенсивностей Кокса, в том числе с зави-ЦЦЦМИ °т времени ковариатами, экспоненциальная регрессия, нормальная и эпюрмальная регрессия).
Все процедуры в модуле Анализ выживаемости автоматически преобразуют дап-дыс в числовой формат. Таким образом, чтобы получить интересующие данные, пользователь может записать даты начала и даты окончания наблюдений, связанные с отказами или цензурированием (потерями объектов).
Таблицы времен жизни могут быть построены по исходным данным. Однако
можно анализировать и готовые таблицы времен жизни.
Для всех регрессионных моделей доступны оценки максимального правдоподо -бия При вычислении этих оценок для моделей пропорциональных интенсивностей и экспоненциальной регрессионной модели используется процедура безусловной максимизации. Для нормальной и логнормальной регрессионных моделей
оценки параметров проводятся с помощью £А/-ал|Т)ритма. Этот алгоритм был впервые предложен в работе Dempster, Laird,and Rubin (1977) Maximum likelihood from incomplete data via the EM algorithm. Journal of the Royal Statistical Sociaty. 39, p. 1 -38, и обсуждается в книге Сох and Oakes (1984) Analysis of survival data, New York: Chapman&Hall.
Общая значимость регрессионной модели может быть оценена с помощью критерия хи-квадрат, вычисляемого на основе логарифмов правдоподобия для подогнанной п нулевой моделей.
Для оценки адекватности подогнанной модели предоставляется большой выбор графических опций. В случае моделей пропорциональных интенсивностей пользователь может построить функции выживания для различных значений независимых переменных. Для экспоненциальной регрессионной модели есть воз-
можность построения графиков зависимости остатков и экспоненциальной порядковой статистики, остатков и предсказанных с помощью регрессионного уравнения времен жизни, остатков и логарифмов наблюдаемых времен жизни. Для нормальной и логнормальной линейной регрессионной модели пользователь может воспроизвести на экране график зависимости наблюдаемых и подогнанных времен жизни, подогнанных времен жизни и остатков подгонки, а также нормальный вероятностный график остатков.
Альтернативные процедуры
Альтернативные процедуры возможны для нецензурированцых данных.
Если данные о продолжительности жизни (безотказной работы) нецензу-рированы, то применимо большинство непараметрических статистик. Для пецензу-РИрованных данных можно также использовать нелинейное оценивание, чтобы Подогнать определенную регрессионную модель (включая пробит, логит и экспоненциальную модели) к данным.
Если продолжительность жизни или безотказной работы описывается бинарной переменной, то могут быть применены логит или пробит регрессионные Модели
550
Глава 14. Ала л из выживар>
Пример 1- Таблицы времен жизни
551
Другой общий метод сравнения выживаемости в различных группах оса стся с помощью таблиц частот. Если времена жизни, или наработки до ыО1 отказа. распределены по нескольким временным интервалам, может быть » '
зована общая логл и ценная модель. "
Пример 1. Таблицы времен жизни
В атом примере мы рассчитаем таблицу времен жизни, оценим функцию вы ния. плотность вероятности и функцию интенсивности для различных вреь, и'** и нтервалов, а также найдем теоретическое распределение, наилучшпм обралмЗ пасующееся с данными. Данные основаны на работе Crowley. J., & Hu М - -г Covariance analysis of heart transplant survival data, Journal ofthc American St-Association, 72, p. 27-36.
Задание параметров анализа
В модуле Анализ выживаемости откройте файл Heart.sta.
Далее выберите Таблицы и распределения времен жизни из стартовой панели Анализ выживаемости и времен отказов
Можно анализировать как исходный файл данных, так п сгруппированные ин -ные. В данном случае мы анализируем исходные данные.
Нажмите кнопку Переменные и выберите шесть переменных в первом спи ЯМ
Первые три переменные — дата начала (например, дата операции). оставпйЯИ три переменные — дата наступления события.
Программа интерпретирует первую и четвертую переменные как месяцы, нт рую и пятую — как дни. а третью и шестую — как год.
Заметим, что можно сразу ввести времена жизни (одна переменная в файле лан-IlWx или латы в другом формате - две переменные).
Далее необходимо определить переменную Censored как индикатор цензурирования во втором списке.
Диалоговое окно Таблицы и распределения времен жизни будет теперь выглядеть
Поскольку были использованы коды по умолчанию для индикатора цензурирования (О -полное, 1 — неполное), STATISTICA автоматически отображает Код для завершенных наблюдений и Код для цепочных или цензурированных наблюдений.
Дополнительно можно определить для таблицы времен жизни число ишперва лов или ширину интервалов.
Процедура подгонки теоретического распределения к данным невозможна при наличии интервалов, не содержащих ни смертей (отказов), ни изъятых наблюдений.
Если вы хотите сделать подгонку, установите флажок Исправить интервалы, не содержащие смертей/отказов.
Если таблица времен жизни используется только в описательных целях и не предполагается подгонка распределения, то корректировку интервалов делать не нужно.
Оставив опции по умолчанию, нажмите ОК После того как все наблюдения обработаны, откроется диалоговое окно Результаты для таблиц и распределении времен жизни.
552
Глава 14. Анализ выж>
Нажмите на кнопку Таблица времен жизни, чтобы отобразить на экране л oj таблицу результатов времен жизни.
На рисунке показана часть полной таблицы жизни.
Можно подгонять к данным основные семейства распределений, исполь_-*я обычный метод наименьших квадратов или две модификации метода взвешен] j наименьших квадратов.
Чтобы выбрать наиболее подходящее семейство распределений, сначала JI смотрим модель с экспоненциальным распределением (выбрав позицию Экс i ненциалъная в поле Модель).
Оценка согласия проводится с помощью критерия хи-квадарт
Нажмите кнопку Оценки параметров, чтобы посмотреть оценки для дан! семейства распределений, а также значение критерия хи-квадрат.
пимер 1- Таблицы времен жизни
553
Если критерий значим, делается заключение, что подогнанное распределение значимо расходится с наблюдаемыми данными. Поэтому мы отвергаем это семейство распределений и говорим, что оно не согласуется с данными.
Из таблицы результатов следует, что ни один метод подгонки не дает экспоненциального распределения удовлетворительного согласия. Тот же результат хорошо виден па 1-рафиках.
Нажмите кнопку График функции выживания На приведенных ниже графиках ни одна из экспонент также нс аппроксимирует наблюдаемую функцию выживания удовлетворительно. Видно, что оцененная функция выживания сильно отклоняется от аппроксимирующих функций выживания.
Можно просмотреть оценки параметров для различных семейств распределений, Вначале выберите соответствующее семейство из поля списка Модель, а затем нажмите кнопку Оценки параметров. Если проанализировать все эти семейства, можно сделать вывод, что только для семейства Вейбулла (см. главу вероятностные распределения) нет значимого отличия от наблюдаемых значений при оценивании параметров по минимуму суммы взвешенных квадратов.
Ниже показаны графики функции выживания из семейства Вейбулла, подо данные тремя разными способами.
554
Глава 14. Анализ выживав.
Для третьего набора параметров (соответствующего Weight 3) имеется летворитсльное согласие с данны ми. Хи-квадрат - критерий для этой ситуации -не дает значимого отклонения (р~О.5б). Следовательно, можно сделать вывод, ч то распределение Вейбулла с этим набором параметров удовлетворительно описывает наблюдаемые времена жизни.
В заключение заметим, что модуль Анализ выживаемости STATISTICA позы ляет анализировать также табулированные данные (для этого нужно выбрать о<-цию Таб ища времен жизни в поле списка Входные данные).
НЕ
Файл с табулированными данными должен содержать 3 переменные со ющей информацией:
1) нижняя граница временных интервалов;
2) число цензурированных или неполных наблюдений;
3) число отказов (число умерших в каждом времегшом интервале)
После выбора Таблиц времен жизни откроется диалоговое окно Таблицы up пределения времен жизни, в котором можно выбрать эти переменные
Пример 2. Регрессионная модель Кокса
Файл данных Heart sta содержит дополнительные переменные: возраст пашг"ИЗ во время трансплантации (переменная Возраст — Age) и медицинские xapav - г*' стики: мера антигенной несовместимости (переменная Антиген — Antigen) и м« тканевой несовместимости (переменная Несовместимость — Mismatch).
рпимер Регрессионная модель Кокса________________________ 555
I Представляет интерес зависимость между переменными Возраст — Age. Анти-
рП — Antigen и Несовместимость — Mismatch п временами жизни. Наиболее об-2 гей регрессионной моделью, не накладывающей ограничения на форму функции иь1эК)1ва,|1,я, является модель пропорциональных интенсивностей Кокса. Рассмотрим как можно оценить коэффициенты регрессии для этих трех независимых пе-еменных для того, чтобы предсказать времена жизни с помощью модели пропорциональных интенсивностей Кокса.
Задание параметров анализа
Нажмите опцию Регрессионные модели на Стартовой панели, чтобы открыть диалоговое окно Регрессионные модели для цензурированных данных.
Чтобы выбрать переменные для анализа, нажмите кнопку Переменные и задайте все времена жизни и цензурирующую переменную, как это было сделано ранее.
Необходимо также выбрать независимые переменные пли регрессоры (Возраст - Age, Антиген — Antigen. Неа/вместимость - Mismatch).
Группирующую переменную в данном примере мы нс отмечаем.
Теперь выберите коды для цензурирующей переменной С помощью этих кодон STATISTICA разобьет данные на 2 группы, полные и неполные По умолчанию STATISTICA использует следующий код: 0 ~ завершенное наблюдение. 1 = цензурированное.
Если вы используете другой код, дважды щелкните по полю ввода Коды завершенного наблюдения и Коды цензурированного наблюдения и выберите коды из списка.
556
Глава 14. Анализ выжив;
Диалоговое окно Регрессионные методы для цензурированных данныхщ на экране:
Оценивание параметров
Выберите в списке Модель позицию Регрессионная модель Кокса. Нажмите ОК откройте диалоговое окно Оценивание регрессионной модели
Это диалоговое окно позволяет задать параметры процедуры оценивания
Процедура оценивания максимизирует логарифм правдоподобия регрсссиЩЦ ной модели с помощью метода Ньютона—Рафсона.
Алгоритм оценивание параметров является итеративным и начинается с не! рых начальных значений параметров (кнопка Начальные значения). Далее прог ма делает несколько итераций, последовательно приближаясь к оценкам цеп»ияТ’ ных параметров. Разность между текущими оценками и оценками, нолученнымй н» предыдущем шаге, называется невязкой. Если невязка удовлетворяет критерии »"• дпмости (см. поле Критерий сходимости), то процесс приближения заверша^^ Максимальное число итераций и критерий сходимости указываются в соответс •
ЮЩИХ ПОЛЯХ.
Значения, предлагаемые программой по умолчанию, обычно приемлемы, г • этому просто нажмите ОК и начните процедуру оценивания.
Регрессионная модель Кокса
557
С помощью этого диалогового окна можно наглядно проследить, как происходит процесс оценивания. В столбцах Параметры показаны оценки параметров на каждом шаге
После того как критерий сходимости будет выполнен, процедура оценивания останавливается.
Обыч ио процедура поиска быстро сходится, если приближения за заданное число итераций неудовлетворительны, программа запросит дополнительно некоторое количество итераций. Вы можете изменить начальные значения, используя, например, оценки параметров, полученные на предыдущем экспериментальном материале.
В данном примере наилучщие оценки параметров найдены, итеративная про-
цедура сходится, поэтому предлагается
в диалоговое
окно
Результаты регрессии
нажать ОК, чтобы перейти
558
Глава 14. Анализ выж*
Результаты
.Это диалоговое окно позволяет просмотреть результаты. Значение статистик терпя хи-квадрат для данной модели высокозцачимо, поэтому можно закл> что. по крайней мере, некоторые независимые переменные значимо действ! но связаны с выживаемостью.
1[ажмите кнопку Оценки параметров, чтобы увидеть оценки параметра стандартные ошибки.
Стандартные ошибки вычисляются как часть процедуры оценивания и по сва^ природе являются асимптотическими. Они вычисляются на основе частных пр водных второго порядка от логарифма функции правдоподобия. Это означает, i и (.-значения тоже должны рассматриваться только как приближенные. Обычно ли -» оценка параметра (регрессионной модели), которая по крайней мере в два раза КД0В восходит свою стандартную ошибку (t>2,0), может рассматриваться как статпетич^ кп значимая (на уровнер<0,05).
Элек тронная таблица с результатами также содержит статистику критерия Вальда для каждого коэффициента (см. книгу Рао С. Р. «Линейные статистические методы и их применения»). Из приведенной таблицы следует, что возраст пациента л тканевая несовместимость — наиболее важные предикторы для функции мгновенного риска.
Итак, значимые переменные в модели — AGE и MISMATCH Рассмотрим гр^ фи кп функции выживания как функции независимых переменных. Пусть все Ш -зависимые переменные равны своим средним значениям, тогда график функции выживания имеет вид (нажмите кнопку График выживаемости для средних)'
Пример 2, Регрессионная модель Кокса 559
I Средние значения независимых переменных и ст андар тные ошибки можно по-
I смотреть в таблице:
Зададим определенные значения предикторов. Мы имеем зпачихтые псремснныс-AGE — возраст п MISMATCH — тканевая несовместимость. Увеличим возраст больного до 55 лет.
График функции выживания изменится и будет иметь вид:
В заключение заметим, что с помощью кнопки Редактор санных графика можно представить функцию выживания в численном виде:
560
Глава 14. Анализ выжив1
46.0П о.ео
47.00 48 00
50.00
077 0.7?
50.00 068
51 00 0 68
5100 I 0 80
54 00 ' 0.56
60 00 0 52
6300 0 46
Таким образом проводится регрессионный анализ в модуле Анализ выжие емости.
*g “ Анализ
I О соответствий
Данная глава продолжает тему главы Построение и анализ таблиц Мы рекомендуем просмотреть ее, а затем приступить к чтению данного текста и упражнениям на STATISTICA.
Анализ соответствий (по-английски correspondence analysis) — это разведочный метод анализа, позволяющий визуально и численно исследовать структуру таблиц сопряженности большой размерности.
В настоящее время анализ соответствий интенсивно применяется в разнообразных областях, в частности в социологии, экономике, маркетинге, медицине, управлении городами (см., например, Thomas Werani, Correspondence Analysis as a Means for Developing City Marketing Strategies, 3rd International Conference on Recent Advances in Retailing and Services Science, p. 22-25. Juni 1996, Telfs-Buchen (Osterreich) Werani, Thomas).
Известны применения метода в археологии, анализе текстов, где важно исследовать структуры данных (см. Greenacre, М. J., 1993, Correspondence Analysis in Practice, London: Academic Press).
В качестве дополнительных примеров приведем:
□ Исследование социальных групп населения в различных регионах со статьями расхода по каждой группе.
о Исследования результатов голосования в ООН по принципиальным вопросам (1 — за, 0 — против, 0,5 — воздержался, например, в 1967 году исследовалось 127 стран по 13 важным вопросам) показывают, что по первому фактору страны отчетливо разделяются на две группы: одна с центром США, другая с центром СССР (двухполюсная модель мира). Другие факторы могут интерпретироваться как изоляционизм, неучастие в голосовании и т. д.
О Исследование импорта автомобилей (марка машины — строка таблицы, страна-производитель — столбец).
3 Исследование таблиц, испольэуемыхв палеонтологии, когда по выборке разрозненных частей скелетов животных делаются попытки их классифицировать (отнести к одному из возможных типов: зебра, лошадь и т. д.).
э Исследование текстов. Известен следующий экзотический пример: журнал New-Yorker попросил лингвистов установить анонимного автора скандальной книги об одной президентской кампании. Экспертам были предложены тексты 15 возможных аяторов и текст анонимного издания. Тексты представлялись строками таблицы. В строке г отмечалась частота данного
562
Глава 15. Анализ сс
слова j. Таким образом получалась таблица сопряженности. М<, анализа соответствии был определен наиболее вероятный авто дальнего текста.
Применение анализа соответствий в медицине связано с исследование» туры сложных таблиц, содержащих индикаторные переменные, показы! наличие или отсутствие у пациента данного симптома Подобного рода г имеют большую размерность, и исследование их структуры представляет не виальную задачу.
Задачи визуализации сложных объектов могут быть также исследован» крайней мере, к ним можно найти подход, с помощью анализа соответствий Из! ражен ие — это многомерная таблица, и задача состоит в том, чтобы найти дд кость, позволяющую максимально точно воспроизвести исходное изображены
Математическое основание метода. Анализ соответствия опирается на стать стику хи-квадрат. Можно сказать, что эго новая интерпретация статистики хи-к рат Пирсона.
Метод во многом похож па факторный анализ, однако в отличие от него, ц исследуются таблицы сопряженности, а критерием качества воспроизведения i гомерной таблицы в пространстве мсныией размерности является значение L тнетики хи-квадрат. Неформально можно говорить об анализе соответствий | о факторном анализе категориальных данных и рассматривать его также как; тод сокращения размерности.
Итак, строки или столбцы исходной таблицы представляются точками пре страиства, между которыми вычисляется расстояние хи-квадрат (аналогии! тому, как вычисляется статистика хи-квадрат для сравнения наблюдаемым ожидаемых частот).
Далее требуется найти пространство небольшой размерности, как прави.1 двумерное, в котором вычисленные расстояния минимально искажаются, и в этом, смысле максимально точно воспроизвести структуру исходной таблицы с сохранением связей между признаками (если вы имеете представление о методах многомерного шкалирования, то почувствуете знакомую мелодию)
Итак, мы исходим из обычной таблицы сопряженности, то есть таблицы, в которой сопряжены несколько признаков (подробнее о таб ищах сопряженности сы главу Построение и анализ таблиц).
Допустим, что имеются данные о пристрастии к курению сотрудников некото рой компании. Подобные данные имеются в файле Smokingsta, входящем в стан} дартный комплект примеров системы STATISTICA.
В этой таблице признак курение сопряжен с признаком должность.
Г диализ соответствий 563
I Это простая двухвходовая таблица сопряженности Вначале рассмотрим I строки.
Можно считать, что 4 первых числа каждой строки таблицы (маргинальные ча-I етоты. то есть последний столбец нс учитывается) являются координатами строки в 4-мерном пространстве, а значит, формально можно вычислить расстояния хи-I квадрэт между этими точками (строками таблицы).
При данных маргинальных частотах можно отобразить эти точки в пространстве размерности 3 (число степеней свободы равно 3).
Очевидно, что чем меньше расстояние, тем больше сходство между группами, и наоборот — чем больше расстояние, тем больше различие.
Теперь п] )едположим, что можно найти пространство меньшей размерности, i ia-прнмер. размерности 2, для представления точек-строк, которое сохраняет всю или. точнее, почт и всю информацию о различиях между строками.
Возможно, такой подход неэффективен для таблиц небольшой размер! iocti i, как приведенная выше, однако полезен для больших таблиц, возникающих, например, в маркетинговых исследованиях.
11апрпмер. если записаны предпочтения 100 респондентов при выборе 15 сортов пива, то в результате применения анализа соответствий можно представить 15 сортов (точек) на плоскости (см. далее анализ продаж). Анализируя расположение точек, вы увидите закономерности при выборе пива, которые буау > полезны при проведении маркетинговой кампании.
В анализе соответствий используется определенный сленг.
Масса. Наблюдения в таблице нормируются: вычисляются относительные частоты для таблицы, сумма всех элементов таблицы становится ранной 1 (каждый элемент делится на общее число наблюдений, в данном примере па 193). Со.»даег-ся аналог двумерном плотности распределения. Полученная стандартизованная таблица показывает, как распределена масса по ячейкам таблицы пли по точкам пространства. На сленге анализа соответствий суммы по строкам и столбцам в матрице относительных частот называются массой строки и столбца соответственно.
Инерция. Инерция определяется как значение xn-квадрат Пирсона тля двухвходовой таблицы, деленный на общее количество наблюдений. В данном приме ре: общая инерция “Хг/193 - 16,442.
Инерция и профили строк и столбцов. Если строки и столбцы таблицы полностью независимы (между ними нет связи — например, курение ие зависит от должности), то элементы таблицы могут быть воспроизведены при помощи сумм по строкам и столбцам или, в терминологии анализа соответствий, при помощи профилей строк и столбцов (с использованием маргинальных частот: см. главу Построение и анализ таблиц с описанием критерия хи-квадрат Пирсона и точный критерий Фишера).
В соответствии с известной формулой вычисления хи-квадрат для днухвлодо-вых таблиц ожидаемые частоты таблицы, в которой столбцы и строки независимы, вычисляются перемножением соответствующих профилей столбцов и строк с делением полученного результата на общую сумму.
Любое отклонение от ожидаемых величин (при гипотезе о полной независимости переменных по строкам и столбцам) будет давать вклад в статистику Х|’-квадрат.
564
Глава 15- Анализ сс
Анализ соответствий можно рассматривать как разложение статистики хи
рат на компоненты с целью определения пространства наименьшей раз»
позволяющего представить отклонения от ожидаемых величин (см. таблицу i Здесь показаны таблицы с ожидаемыми частотами, рассчитанными при тезе независимости признаков, и наблюдаемыми частотами, а также таблица
дов ячеек в хи-квадрат:
Например, из таблицы видно, что число некурящих младших сотрудников примерно на 10 меньше, чем можно было бы ожидать при гипотезе независимости Число некурящих старших собрудников, наоборот, на 9 больше, чем можно быте бы ожидать при гипотезе независимости, и т. д. Однако хотелось бы иметь общ/ л картину.
Цель анализа соответствий состоит в том, чтобы суммировать эти отклонения от ожидаемых частот не в абсолютных, а в относительных единицах.
Вфф 3.49234В 1362354 2 431777 3152565 16.44164
Анализ строк и столбцов. Вместо строк таблицы можно рассматривать таю столбцы и представить их точками в пространстве меньшей размерности, котор максимально точно воспроизводит сходство (и расстояния) между отиосительн ми частотами для столбцов таблицы. Можно одновременно отобразить на "ти графике столбцы и строки, представляющие всю информацию, содержав i »1 в двухвходовой таблице. И этот вариант — самый интересный, так как позво.'
провести содержательный анализ результатов.
Анализ соответствий
565
результаты. Результаты анализа соответствий обычно представляются в виде фафиков. как было показано выше а также в виде таблиц т ппа:
Число измерений Процент инерции Кумуля 1 ивнин процент Хи-квадрат
| 87.75587 87.7559 14.42851
2 11.75865 99.5145 1.93332
3 0.48547 100.0000 0,07982
Посмотрите на эту таблицу. Как вы помните, цель анализа — найти пространство меньшей размерности, восстанавливающее таблицу, при этом критерием качества является нормированный хи-квадрат, или инерция. Можно заметить, что если в рассматриваемом примере использовать одномерное пространство, то есть одну ось, можно объяснить 87,76% инерции таблицы.
Две размерности позволяют объяснить 99.51% инерции.
Координаты строк и столбцов Рассмотрим получившиеся координаты в двумерном пространстве
Можно изобразить это на двумерной диаграмме
566
Глава 15. Анализ соответс
Очевидным преимуществом двумерного пространства является то, что строки отображаемые в виде близких точек, близки друг к другу и по относительным ча. -тотам.
Рассматривая положение точек по первой оси, можно заметить, что Ст. сотрудники и Секретари относительно близки по координатам. Если же обратить внимание на строки таблицы относительных частот (частоты стандартизованы так, что их сумма по каждой строке равна 100%), то сходство данных двух групп по категориям интенсивности курения становится очевидным.
Проценты по строке:
Группа сотрудников Кнтстррт и курящих
(1) ail (3) Средне курятине (4) Сильно курящие Всего по строке
11) Старшие менеджеры 36.36 18.18 27.27 18.18 НЮ,00
(2) В''“«чшнс менеджеры 2’ ->2 16Д7 38.89 2222 11*00
(3) VJ - ЛЛ г*|ики 4-/Д2 19,61 23.53 1X4 11. 00
(4) Mj сотрудники 20.45 ?7 77 37» 14. Цю.ОО
<51 Секретари 40.00 24.00 28.01» 8.00 10(100
Окончательной целью анализа соответствий является интерпретация векторов в полученном пространстве более низкой размерности. Одним из способов, кот -рын может помочь в интерпретации на-.учеппых результатов, является представление на диаграмме столбцов. В следующей таблице показаны координаты столбцов:
Категории куряипк Измерение 1 Измерение 2
Некурящие 4)393308 0.030492
Слабо курящие 0,1 -0.141064
Средне курящие 0.196321 -0.007359
Сильно курящие 0.293776 0.197766
Можно сказать, что первая ось дает градацию интенсивности курения. Сл< нательно, большую степень сходства между Старшими менеджерами и Cei
диализ соответствий
567
тарями можно объяснить наличием в данных группах большого количества Некурящих.
Метрика координатной системы. В ряде случаев термин расстояние использовался для обозначения различий между строками и столбцами матрицы относительных частот, которые, в свою очередь, представлялись в пространстве меньшей размерности в результате использования методов анализа соответствий
В действительности расстояния, представленные в виде координат в пространстве соответствующей размерности, — это не просто евклидовы расстояния, вычисленные по относительным частотам столбцов и строк, а некоторые взвешенные расстояния.
Процедура подбора весов устроена таким образом, чтобы в пространстве более низкой размерности метрикой являлась метрика хи-квадрат, учитывая. что сравниваются точки-строки и выбирается стандартизация профилей строк или стандартизация профилей строк и столбцов или же сравниваются точки-столбцы п выбирается стандартизация профилей столбцов или стандартизация профилей строк и столбцов.
Оценка качества решения. Имеются специальные статистики, помогающие оценить качество полученного решения. Все и ли большинство точек должны быть правильно представлены, то есть расстояния между ними в резутьтате применения процедуры анализа соответствий не должны искажаться. В следующей таблице показаны результаты вычисления статистик по имеющимся координатам строк, основанные только на одномерном решении в предыдущем примере (то есть только одно измерение использовалось для восстановления профилей строк матрицы относительных частот).
Координаты и вклад в инерцию строки:
Группа сотрудников Координаты IIJMup 1 Масса Качество Относит, инерция Инерция Косинус**?
Старшие менеджеры -0.065768 0,056995 0.092232 0.031376 0.003298 0.092232
Младшие менеджеры 0.258958 О.093264 0.526400 0.1’9467 0.0м ?659 0.526400
Старшие сотрудники -0380595 0.264249 0,999033 0.449750 0.512006 0,999033
Младшие . сотрудники 0,232952 0.455959 0.941934 0,308354 0.330974 0.941934
Секретари -0.201089 0.129534 0.865346 0.071053 0.070064 11Д65346
Координаты. Первый столбец таблицы результатов содержит координаты, интерпретация которых, как уже отмечалось, зависит от стандартизаин и Размерность выбирается пользователем (в данном примере мы выбрали одномерное пространство), и координаты отображаются для каждого измерения (то есть отображается По одному столбцу координат на каждую ось).
Масса. Масса содержит суммы всех элементов для каждой строки матрицы относительных частот (то есть для матрицы, где каждый элемент содержит соответствующую массу, как уже упоминалось выше)
Если в качестве метода стандартизации выбрана опция Профили строк или опция Профили строк и столбцов. которая установлена по умолчанию, то коордпна-
568__________________________________________Глава 15. Анализ соотееъч^м
ты строк вычисляются по матрице профилей строк Другими словами, коор, ц. ты вычисляются на основе матрицы условных вероятностей, представл.^мЗ в столб| (е Масса
Качество Столбец Качество содержит информацию о качестве ппе л< та»J соответствующей точки-строки в координатной системе, определяемой выбры^З размерностью. В рассматриваемой таблице было выбрано только одно измем^З поэтому числа в столбце Качество являются качеством представления рр<Д"чгД в одномерном пространстве. Видно, что качество для старших менеджеров низкое, но высокое для старших и младших сотрудников и секретарей.
Отметим еще раз, что в вычислительном и тане целью анализа соответствие ляется представление расстояний между точками в пространстве более низ» а —т, мерности.
Если используется максимальная размерность (равная минимуму числа ст] «к п столбцов минус один), можно воспроизвести все расстояния в точности.
Качество точки определяется как отношение квадрата расстояния от плини* точки до начала координат, в пространстве выбранной размерности, к кв. цмг» расстояния до начала координат, определенному в пространстве максиму»мВ размерности (в качестве метрики в этом случае выбрала метрика хи-квадрат, уже упоминалось ранее) В факторном анализе имеется аналогичное повелю общность.
Качество, вычисляемое системой STATISTICA, не завысит от выбраниогц метода стандартизации и всегда использует стандартизацию. установив! I ну to по чанию (то есть метрикой расстояния является хи-квадрат, и мера качества м<,.- с интерпретироваться как доля хи-квадрат, определяемая соответствующей стр • и в пространстве соответствующей размерности).
Низкое качество означает, что плюющееся число измерений недостаточнн ММ рошо представляет соответствующую строку (столбец).
Относительная инерция. Качество точки (см. выше) представляет отношцщр вклада данной точки в общую инерцию {Хи-квадрат), что может объяснять bi | ’ ранную размерность.
Качество не отвечает па вопрос, насколько в действительности и в каких разорах соответствующая точка вносит вклад в инерцию (величину хи-квадрат). Я
Относительная инерция представляет долю общей инерции, принадлежавши .данной точке, и нс зависит от выбранной пользователем размерности. Отме гпм. что какое-либо частное решение может достаточно хорошо представлять т~'-» • (высокое качество), но та же точка может вносить очень малый вклад в об'»-. •• инерцию (то есть точка-строка, элементами которой являются относительны» «»-стоты, имеет сходство с некоторой строкой, элементы которой представляю- -бой среднее по всем строкам).
Относительная инерция для каждой размерности Данный столбец содермя» относительный вклад соответствующей точки-строки в величину инерции, словленный соответствующей размерностью. В отчете данная величина прив< t "
для каждой точки (строки пли столбца) и для каждого измерения.
Косинус**2 (качество, или квадратичные корреляции с каждой размерное тью). Данным столбец содержит качество для каждой точки, обусловленное С’*1 ветствуютей размерностью. Если просуммировать построчно элементы стс < косинус* *2 для каждой размерности, то в результате получим столбец величин л •
диализ соответствий
569
чество, о которых уже упоминалось выше (так как в рассматриваемом примере была выбрана размерность 1, то столбец Косинус 2 совпадает со столбцом Качество). Эта величина может интерпретироваться как «корреляция» между соответствующей точкой и соответствующей размерностью. Термин Косинус**2 возник по причине того, что данная величина является квадратом косинуса угла, образованного данной точкой и соответствующей осью.
Дополнительные точки. Помощь в интерпретации результатов может оказать включение дополнительных точек-строк или столбцов, которые на первоначальном этапе не участвовали в анализе. Имеется возможность для включения как дополнительных точек-строк, так и дополнительных точек-столбцов. Можно так же отображать дополнительные точки вместе с исходными на одной диаграмме Например, рассмотрим следующие результаты:
Группа сотрудников Измерение 1 Измерение 2
С тарные менеджеры -С ’ --768 0,193737
Младшие менеджеры 0.2' «58 0,243305
Старшие со грудники 0,3- 15 0, и «60
Младшие сотрудники 0.232 < 52 -0, >7744
Секретари 0,201089 0,078911
Национальное среднее -0.258368 -0.117648
Данная табл ада отображает координаты (для двух размерностей), вычисленные дая частотной таблицы, состоящей из классификации степени пристрастия к курению средн сотрудников различных должностей.
Строка Национальное среднее содержит координаты допол! нтельной точки, которая является средним уровнем (в процентах), подсчитанным по различным национальностям курящих. В данном примере это чисто модельные данные.
Если вы построите двумерную диаграмму групп сотрудников и Национального среднего, то сразу убедитесь в том, что данная дополнительная точка и труп па Секретари очень близки друг к другу и расположены по одну сторону горизонтальной оси координат с категорией Некурящие (точкой-столбцом)- Другими словами, выборка, представленная в исходной частотной таблице, содержит больше курящих. чем Национальное среднее.
Хотя такое же заключение можно сделать, взглянув на исходную таблицу' сопряженности, в таблицах больших размеров подобные выводы, конечно, не столь очевидны.
Качество представления дополнитетъных точек. Еще одним интересным результатом, касающимся дополнительных точек, является интерпретация качества, представления при заданной размерности.
Еще раз отметим, что целью анализа соответствий является представление расстояний между координатами строк или столбцов в пространстве более низкой Размерности. Зная, как решается данная задача, необходимо ответить на вопрос, является ли адекватным (в смысле расстояний до точек в исходном пространстве) представление дополнительной точки в пространстве выбранной размерности. Ниже представлены статистики для исходных точек и для дополнительной точки Национальное среднее применительно к задаче в двумерном пространстве.
570
Глава 15- Анализ соответг,
рример 1 (анализ курильщиков)
Косину с”2 Группа сотрудников Качество Измерение ) Измерение 2
Сгаршнс менеджеры 0.892568 0.092232 0.800336
Младшие менеджеры 0,991082 0.52L .30 0.4М' . 1
Старшие сотрудники (1оао§[7 0.999033 0.00им>4
Мт* цииесоц - I лки 0.У9У810 0.941934 0. 7876
Секрстчрн 0.9- -603 0.865346 0.133257
Национальное среднее 0.761324 0.630578 0.130746
Напомним, что качество точек-строк или столбцов определено как отними квадрата расстояния отточки по начала координат в пространстве снижение, мерности к квадрату расстояния от точки до начала координат в исходном 1 странстве (в качестве метрики, как уже отмечалось, выбирается расстояние квадрат).
В определенном смысле качество является величиной, объясняющей долю рата расстояния до центра тяжести исходного облака точек.
Дополнительная точка-строка Национальное среднее имеет качество, раян«|с 0,76. Это означает, что данная точка достаточно хорошо представлена в де . jh»-|юм пространстве Статистика Косинус**2 — это качество представления fl ветствующей точки-строки, обусловленное выбором пространства заданной р*» мерности (если просуммировать построчно элементы столбцов Косинус 2 д «« каждого измерения, то в результате мы придем к величине Качество, получении® Н ранее).
Графический анализ результатов. Это самая важная часть анализа. По существу. вы можете забыть о формальных критериях качества, однако руковоЛши j ваться некоторыми простыми правилами, позволяющими понимать графики.
Итак, на графике представляются точки-строки и точки столбцы. Хор.,и гм I тоном является представление и тех и других точек (мы ведь анализируем свя Щ строк и столбцов таблицы1).
Обычно горизонтальная осьсоотвстствуст максимальной инершш Около стр <к Я показан Процент общей инерции, объясняемый данным собственным знамен»• ч я Часто указывают также соответствующие собственные значения, взятые из та!1 •» - j цы результатов. Пересечение двух осей — это центр тяжести наблюдаемых тс«м*. соответствующий средним профилям. Если точки принадлежат одному II том/ I типу, то есть являются либо строками, либо столбцами, то чем меньше расстш между ними, тем теснее связь. Для того чтобы установить связь между точками разно го типа (между строками и столбцами), следует рассмотреть углы между ними с шиной в центре тяжести.
Общее правило визуальной оценки степени зависимости заключается в < < :»• ющем.
о Рассмотрим 2 произвольные точки разного типа (строки и столбцы тЛ липы).
о Соединим их отрезками прямых с центром тяжести (точка с кшртчЛИИ ми 0.0). gg
О Если образовавшийся угол острый, то строка и столбец положительно радированы.
О Если образовавшийся угол тупой, то корреляция между переменными отрицательная
О Если угол прямой, корреляция отсутствует.
Рассмотрим анализ конкретных данных в системе STATISTICA.
Пример 1 (анализ курильщиков)
Щаг 1. Запустите модуль Анализ соответствий.
В стартовой панели модуля имеются 2 вида анализа: Анализ соответствий и Многомерный анализ соответствий.
Выберите Анализ соответствий. Многомерный анализ соответствий будет рассмотрен в следующем примере.
Шаг 2. Откройте файл данных smokingsta папки Examples.
В файле содержатся данные о распространении курения среди сотрудников фирмы.
Файл уже представляет собой таблицу сопряженности, поэтому табуляция не требуется. Выберите вид анализа — Частоты без группирующей переменной. Шаг 3. Нажмите кнопку Переменные с частотами и выберите переменные для анализа.
В данном примере выберите все переменные.
Глава 15. Анализ соответг
Пример 1 (анализ курильщиков)
Шаг 4 Нажмите ОК и запустите вычислительную процедуру. На экране появи'п’» окно с результатами
Шаг 5. Рассмотрим результаты с помощью опций данного окна.
Обычно сначала рассматриваются графики, для чего имеется группа кнг-График координат.
Графики доступны для строк и столбцов, а также для строк и столбцов
временно.
Размерность максимального простарнства задается в опции Размерность.
Наиболее интересна размерность 2. Заметьте, что на графике, особен» IИ имеется множество данных, метки могут накладываться друг на друга, по.»гв< может быть полезной опция Сократить метки.
Нажмите третью кнопку 2М в диалоговом окне. На экране появится графив
Заметьте, что на графике представлены оба фактора: группа сотрудников — строки и интенсивность курения — столбцы.
Соедините отрезком прямой категорию СТАРШИЕ СОТРУДНИКИ а также категорию НЕТ с центром тяжести
Образовавшийся угол будет острым, что на языке анализа соответствий говорят о наличии положительной корреляции между этими признаками (просмотрите исходную таблицу, чтобы убедиться в этом).
Координаты строк и столбцов можно посмотреть и в численном виде с помощью кнопки Координаты строк и столбцов.
Используя кнопку Собственные значения, можно увидеть разложенце статистики хи-квадрат по собственным значениям.
Опция График только выбранных измерений позволяет просмотреть координаты точек по выбранным осям.
574
Глава 15. Анализ соответс
Группа опций Просмотр таблиц в правой части окна позволяет просмей « исходную и ожидаемую таблицу сопряженности, разности между частотами ц гие параметры, вычисленные при гипотезе независимости табулированных ч знаков (см. главу Построение и анализ таблиц, критерий хи-квадрат).
Таблицы большой размерности лучше всего исследовать постепенно, ввозя, мерс надобности дополнительные переменные. Для этого предусмотрены опцц Добавить точки-строки. Добавить точки-столбцы
Пример 2 (анализ продаж)
В главе Анализ и построение таблиц был рассмотрен пример, связанный с ана w* зом продаж. Применим к данным анализ соответствий
Ранее отмечалось, что вопрос, какие именно покупки произвел покупатель при условии, что куплено 3 товара, является сложным.
Действительно, всего мы имеем 21 продукт. Чтобы просмотреть все таблиш* сопряженности, требуется выполнить 21x20x19 “ 7980 действий. Число действий катастрофически возрастает при увеличении товаров и количества признаков, Применим анализ соответствий. Откроем файл данных с индикаторными пет»*-меннымн. отмечающими купленный продукт.
В стартовой панели модуля выберем Многомерный анализ соответствий
Зададим условие выбора наблюдений.
пример
(анализ продаж)
575
Это условие позволяет выбрать покупателей, сделавших ровно 3 покупки.
Поскольку мы имеем дело с петабу тированными данными, выберем вид анали-
Исхндные данные (требуется табуляция).
Для удобства дальнейшего графического представления выберем небольшое
количество переменных.
Выберем также дополнительные переменные (см. окно
Запустим вычислительную процедуру.
В появившемся окне Результаты книгочерного анализа соответствий просмотрим результаты.
576
Глава 15. Анализ соответс
С помощью кнопки 2М выводится двумерный график переменных
На этом графике дополнительные переменные отмечены красными точи что удобно для визуального анализа.
Заметьте, что каждая переменная имеет признак 1, если товар куплен, и щ знак 0, если товар не куплен. 1
Рассмотрим график. Выберем, например, близкие пары признаков — МЯС> I и ОВОЩИ.1, СЫРЫ-.1 и КОЛБАСЫ:1 — и присоединим к ним переменную ХЛ*»,
2М график столбцов
В итоге получим следующее:
Аналогичные исследования можно провести и для других данных когда otfM' ствуют какие-либо априорные гипотезы о зависимостях в данных
«I £- Примеры анализа I О данных в системе
STATISTICA
В этой главе мы рассмотрим несколько примеров анализа данных с помощью системы STATISTICA. Первый пример относится к области маркетинга (мы показываем возможности модуля Множественная регрессия). три следующие примера — к промышленным приложениям (мы показываем возможности модулей Планирование эксперимента и Карты контроля качества), пятый пример иллюстрирует возможности STATISTICA по наложению результатов анализа на географические карты.
Еще раз отметим, что современная STATISTICA—это средство разработки приложений в конкретных областях (бизнесе, медицине, промышленности и др.). Библиотека STATISTICA содержит более 10 000 тщательно отлаженных и проверенных на практике процедур анализа данных. Развитие системы естественно приводит к созданию средств разработки собственного интерфейса и использования библиотеки STATISTICA для создания оригинальных модулей, включающих, наряду с процедурами STATISTICA, алгоритмы разработчика. Все эти процедуры объединяются общим интерфейсом, средствами управления данными и 1рафикой STATISTICA
Именно в создании средств для разработки приложений мы видим будущее систем анализа данных.
Пример 1
Пример основан на реальных данных, описывающих рынок пива в Г рении (см. статью Kioulofas К. Е. «Ап Application of Multiple Regression Analysis to the Greek Beer Market* в журнале «Journal of Operational Research Society», Vol. 36, № 8, p. 689-696. 1985).
Известно, что этот рынок поделен между 5 фирмами, обозначенными далее А В, С, D и Е. До 1981 года на рынке присутствовали фирмы А, В и С, в 1981 году на рынок пришли фирмы D и Е. Но уже в 1983 году фирма D не выдержала конкуренции, а у фирмы А возникли финансовые проблемы.
Фирна/год 1980 1981 1982
А 27,6 21,3 21,3
В 28,6 22,0 22,0
С «,8 33,8 33,8
D — 14,7 14,7
Е - 8,2 8,2
578
Глава 16. Примеры анализа данных в системе STATIS
В следующей таблице представлены объемы продаж в отрасли и доля кг фирмы.
Фирма/ Год 1980 1981 1982
Знач. % Знач. % Знач. %
В целом 7 646,287 100,0 10458,140 100,0 13 475,974 100,0
А 1 926,300 25,2 1571,417 15,0 1595,742 11,8
В 2 347,987 30,7 3 073,511 29,4 3 660,954 27,3
С 3 372,000 44,1 4 381,000 41,9 5677,000 42,1
D 596,755 5.7 1042,278 2,7
Е 835,457 8,0 1500,000 11,1
1980 г. 1981г.
Можно заметить, что после появления фирм D и Е произошло резкое снижение доли фирмы Л. Две новые фирмы D к F по-разному освоили рынок. Фирма D имела большие производительные способности, чем фирма Е, но заменю отстал» по объемам продаж. Этот пример интересен тем. что показывает соотношение затрат на рекламу и производство.
Будем считать, что основным показателем эффективности рекламы являете? объем продаж фирмы. В этой таблице представлены расходы на рекламу каж • ч фирмы и ее доля в рекламе
Фирма/ Год 1980 1981 1982
Знач. % Знач. % Знач. %
В целом 44,596 100,0 136,273 100,0 187,997 100,0
А 12,667 28,4 6,747 5,0 22,298 П.9
В 13,897 31,2 38,174 28,0 43,079 22,9
С 18,050 40,4 39,581 29,0 65,114 34,6
D — — 21,340 15,7 20,687 11,0
Е - — 30,421 22,3 36,519 19,6
Понятно, что вхождение в отрасль фирм D и Е потребовало больше расходов 1 • рекламу (в процентном отношении к объему продаж). Это отчетливо видно нзел! дующей таблицы:
Примеры анализа данных в системе STATISTICA
579
1981 1982
фирна/ год____1980
1980°г. 1981 г.
Заметим, фирма D в 1982 году резко снизила расходы на рекламу, что, возможно. стало причиной потери рынка.
Предполагается, что для рекламы используются следующие средства массовой информации: телевидение, тачеты, журналы и радио.
Эффективность рекламы в каждом случае различна, и возникает вопрос о ко личествеипых зависимостях между объемом продаж и расходами на рекламу в каждом из средств массовой информации. Обычно доля телевидения составляет 70 -90%. и поэтому в таблице, представляющей распределение расходов на рекламу между средствами массовой информации, вес СМИ, кроме телевидения, объединены в одну группу «другие»
На реальный объем продаж пива влияют также такие факторы, как температура воздуха, число туристов и индекс потребительских цен (инфляция).
В предлагаемой модели теоретическая зависимость основывается на предположении, что объем продаж за период t (далее это месяцы) является функцией объект продаж за прошлый период расходов на рекламу в периоды I и t-1, количества туристов, значений температуры и индекса розничных цен
S, = Ьо + b,S + М + И-. + ЬЛ, + W + ЬьР. •
где
S’, — объем продаж (в лрахмах);5
At — ассигнования на рекламу;
Т, — число туристов в месяц t;
Wt — средняя температура воздуха;
Р, — индекс розничных цен.
580 Глава 16. Примеры анализа данных в системе STATIST^-
—ч
Итак, мы построили модель зависимости, но коэффициенты этой модели г всстиы. Эти коэффициенты оцениваются из исходных данных в модуле ственная регрессия.
Оценка коэффициентов по методу наименьших квадратов выявила статт, чсскую незначимость переменных IV и Р„ и они были исключены из дальне Имгги анализа.
В результате получилось уравнение, содержащее меныпее число переменииы
S, = b0 +b,S,_, +Ь,А, +ЬА,_1 +btT, (*).
Оценим коэффициенты этого уравнения, используя реальные данные
Для анализа использовались данные о месячных продажах за 2 года. Число наблюдений равнялось 24. Результаты регрессии приведены в таблице:
Фирмы SM А, Ar.i Т, R2 н С. о. Р.
Отрасль 0,56 11,81 0,52 0,801 1,56 132,11
А 0,29 7,93 0,22 0,881 1,95 35,82
6 0,49 3,85 11,75 0,25 0,893 1,14 43,28
С 0,45 12,41 0,19 0,703 -0,21 55,09
D 0,59 од 0,73 0,317 0,21 37,75
Е 0,60 2.6 13,9 0,600 -0,68 41,76
Значения коэффициента детерминации R2, близкие к единице, говорят о хор i шем приближении линии регрессии к наблюдаемым данным и о возможности пн-строения качественного прогноза.
Низкое значение коэффициента детерминации R2 для фирмы D объясняется низкой эффективностью рекламной кампании и трудностями на административном уровне. Можно сделать вывод, что модель плохо применима к фирме D.
Статистики Дарбина—Уотсона свидетельствуют об отсутствии автокорреляции остатков при 5%-м уровне значимости, так как все ее значения по модулю меньше 1,96.
Все значения регрессионных коэффициентов значимы при уровне значимо ста 0,5, за исключением коэффициентов при А для фирм В, D и Е
Одним из возможных объяснений этого факта является то, что показал ли этих фирм зависят от рекламной деятельности за прошлый период времени. И' есть от Ar г
Это подтверждается тем, что для этих фирм коэффициенты при At, значимы на уровне 95%. Более того, можно заметить, что показатели всех фирм. кр~-»н фирмы Е, имеют положительную корреляцию с числом туристов. НезцачшцМ ную корреляцию между туризмом и объемами продаж фирмы Е можно об"»*--пить недавним появлением этой фирмы. Объемы продаж всех фирм также на. дятся под влиянием объемов продаж в прошлом периоде, St!, возможно, благо, эффекту «привычки» потребителей к торговым маркам. Значимость этого г - -метра с распределенным лагом также наводит на мысль о некоторых обучаюми» эффектах.
Продажи фирмы А имеют значительную положительную корреляцию с ее рм ходами на рекламу за период t, что отличает ее от других фирм. Окончате вьно в- ’ •
Примеры анализа данных в системе STATISTICA
„мосвязь между рыночными продажами и совокупными расходам! i на рекламу положительна и значима при уровне 5%.
Представленные выше результаты регрессии образуют основу оценки эффективности совокупных расходов на рекламу.
Покажем, как строятся такие модели в системе STATISTICA. Для этих целей обычно используется модуль Множественная регрессия.
В этом модуле собраны методы, позволяющие оценить зависимость одной переменной от нескольких других переменных.
Переменная, для которой строится зависимость, называется зависимой (по-английски dependent variable"). Эта переменная входит в левую часть уравнения, описывающего зависимость (см. уравнение (*)). Переменные, от которых мы хотим построить зависимость, называются независимыми переменными (по-английски independent variables), или предикторами (от ангзийского predict — предсказывать). Эта переменная входит в правую часть уравнения, описывающего зависимость. Сам термин множественная регрессия (по-английски multiple repression) означает, что модель может содержать несколько предикторов, позволяющих предсказывать зависимую переменную.
Итак, общая идея состоит в том, чтобы по значениям предикторов предсказывать значения зависимой переменной, например, по значениям продаж ц расходам на рекламу в текущем и предыдущем месяце предсказывать продажи в следующем месяце.
Конечно, количество предикторов можно увеличить, например, ввести объем продаж у конкурентов или какие-то другие, имеющие смысл и доступные наблюдению переменные. Однако здесь имеется тонкость — предикторы могут оказаться зависимыми между собой
Переменные, которые следует включить в модель, определяет специалист в предметной области. Затем нужно выполнить следующие действия.
Шаг 1. Запустите модуль Множественная регрессия.
Шаг 2. Введите исходные данные в файл системы STATISTICA Назовите его, например, Beersta.
582
Глава 16- Примеры анализа данных в системе STATISTIC
Шаг 3- Определите переменные в модели. Задайте S в качестве зависимой лере менной и Si ..Р — в качестве независимых переменных, или предикторов. Послг этого стартовая панель модуля будет выглядеть так:
примеры анализа данных в системе STATISTICA
583
Шаг 4 Нажмите кнопку ОК. Появится диалоговое окно результатов, в котором отображаются итоги стандартной процедуры.
Измените процедуру на Пошаговую с включением Для этого нажмите на кнопку Отмепа и в появившемся диалоговом окне Опредскние модели выберите в поле Процедура опцию Пошаговая с включением. В этой процедуре система начинает построение модели с одного предиктора, затем, используя F-критернй, в модель включается еще один предиктор и т. д. На каждом шаге вычисляется коэффициент множественной корреляции. Квадрат коэффициента множественной корреляции, коэффициент детерминации, свидетельствует о качестве построенной модели. Нажмите кнопку ОК.
В появившемся окне Пошаговая множественная регрессия снова нажмите ОК
Теперь перед вами диалоговое окно результатов, полученных с помощью пошаговой процедуры с включением. Следует отметить, что в нем указаны стандартизованные коэффициенты регрессии
Заметим, если вы предполагаете, что в модели должно присутствовать небол> шое число предикторов, то естественно использовать пошаговый метод с включением предикторов. Если вы предполагаете, что в модели должно присутствовать большое число предикторов, то естественно использовать метод с исключением
5В4
Глава 16. Примеры анализа данных в системе STATIS1
Шаг 5. Нажмите кнопку Итоговая таблица регрессии. Появится таблица зультатов с подробными статистиками.
В столбце БЕТА показаны стандартизованные коэффициенты регрессии, а в столбце В — нестандартиэованные коэффициенты. Все коэффициенты в таблице значимы, так как p-значения для каждого из них меньше заданной величины 0,05.
Шаг 6. В окне результатов нажмите кнопку Анализ остатков.
Шаг7. В диалоговом окне Анализ остатков нажмите кнопку Статистика/, бина—Уотсона. Эта статистика позволяет исследовать зависимость между ос ками. Формально остатки представляют собой разность: наблюдаемые значе зависимой переменной минус оцененные с помощью модели значения завис» переменной.
примеры анализа данных в системе STATISTICA
585
Зачем проверять зависимость остатков? Идея проста: если остатки существенно коррелированны (зависимы), то модель неадекватна (нарушено важное предположение о независимости ошибок в регрессионной модели).
Рассмотрим более подробно статистику Дарбина—Уотсона. Мы уделяем этой статистике так много внимания, потому что статистика Дарбина -Уотсона является стандартом для проверки ««которыхвидов зависимости остатков и с ней нужно научиться работать.
Статистика Дарбина—Уотсона используется для проверки гипотезы о том, что остатки построенной регрессионной модели некоррелированы (корреляции равны Нулю), против альтернативы: остатки связаны авторегрессионной зависимостью вида
E, = pei1 + 6i (*), где d — независимые случайные величины, имеющие нормальное распределение <_ параметрами (0, s), i - 1... п.
Формально статистика Дарбина—Уотсона вычисляется следующим образом:
*'=Ё(Е.-ен) /Зя
Иными словами, сумма квадратов первых разностей остатков нормируется суммой квадратов остатков. Проведя вычисления, вы легко выразите статистику Дар-61 । на—Уотсона через коэффициент корреляции. d = 2(1 — р).
Критические точки статистики Дарбина—Уотсона табулированы (см., например, ДраГшср Н., Смит Г. Прикладной регрессионный анализ. М.: Финансы и статистика. т 1. с. 211, см. также таблицу, показанную ниже).
гв
1 100 изо 1.160 1.1Н0 1 200 1 220 1.240 1.260 1.270 1.290 1.300
дес 1.330
1.400 1.410
1.420
1 430 1.440
1.450
1.450
1.460
1.470
.950
9В0 1.020 1.050 1.0В0 1.100 1.130 1.150. 1 170 1.190 1.210 1 220 1.240 1.260 1 270 1.2В0
1.530
1.530] 1 540
1.540
1.540
1.540
1.550
1.550 1 550
1 560 1 560
.вго .860 .900
930 970 1.000 1.030 1.050 1.ОВ0 1.100 1.120
woo
I 210
1 730 1.710 1.690 1.600 1.600 1.670 1.660 1.060 1.660 1.660 1.650 1.65D 1.650 1.650 1.650
.690 .740 .700
.его
.860
.sod" .930
960 990
1.010
I 040
1 060
1.000
1 100
1.120
1.970 1.930 t.900 1.670 I.B50
I.B3D 1.010 i.Boq 1.790 1.700
1.770 1.7Б0
.620 .670 .710
750 .790 .030 .060 .900’ .930 .950 .980
1.010 1 030
1.050
1 070
2.210 2.150
2.Ю0 2,060 ,
2.020 ’ 1 990 1
1.960 1
1.940 Jl
1.920 1 900
1.090 ,
1 eao j
1.660 1
1.650 i
1.640
1.630
Примеры анализа данных в системе STATISTICA 587
Итак, вы находите строку с нужным ч ислом наблюдений в дна смежных столбца с нужным числом предикторов. На пересечении строки и столбцов располагаются нижние и верхние критические точки статистики Дарбина—Уотсона.
Если нужно проверить гипотезу: «остатки независимы, то есть р = 0», против обшей альтернативы р * 0, поступают следующим образом. Вычисляют значение статистики Дарбина -Уотсона d. Для данного числа наблюдений и числа предикторов находят критические точки DL_k и DU_k в таблице, составленной для определенного уровня а. В приведенной таблице уровень а = 0.05.
Если d < DL к или 4 — d < DL_k, то гипотеза о независимости остатков отвергается на уровне 2а. Если d > DU_k и 4 — d > DU_k, то гипотеза о независимости остатков не отвергается на уровне 2а
Если нужно проверить гипотезу, «остатки независимы, р = 0», против альтернативы р > 0, то есть остатки лаголситдльноавтокоррелированы, поступают следующим образом. Вычисляют значение статистики Дарбина—Уотсона d. Находят по таблице критические точки DL_k и DU_k, вычисленные для определенного уровня а. Заметьте, в приведенной таблице а - 0,05.
Если d < DL_k,то гипотеза о независимости остатков отвергается на уровне а в пользу альтернативы.
Если d > DU_k, то гипотеза о независимости не отвергается на уровне ос Случай DL_k < d < DU_k яаляется сомнительным (см. рисунок).
В таблице приведены два критических значения статистики Дарбина—Уо1 > • »-иа: DL_k и DU_k — нижнее и верхнее, зависящие как от числа наблюдений, по к.» торым оцениваются параметры, так и от числа предикторов к, которые включена! в модель.
На графике видно, как меняются значения DL_k и DUJk в зависимости от ч». ла наблюдений (к - 1,2,3,4Г 5).
Число наблюдений, для которого рассчитаны критические значения, указ-»*’ в заголовках строк приведенной таблицы.
Если нужно проверить гипотезу-, «остатки независимы, р = 0>. против альтернативы: р < 0. то есть остатки отрицательно автокоррелпрованы, то вместо d следует рассмотреть значение 4 d и повторить рассуждения предыдущего абзаца, которые использовались для проверки гипотезы «остатки независимы, р ~ 0>, против альтернативы р > 0.
После того как мы познакомились со статистикой Дарбина -Уотсона, продолжим работу в модуле Множественная регрессия
Шаг 8. Нажмите кнопку Предсказанные и наблюдаемые.
588
Глава 16. Примеры анализа данных в системе STAT1S
Нажмите кнопку ОК. Появится таблица результатов предсказания.
На рисунке выделена ячейка, содержащая прогнозируемый объем продаж на следующий месяц.
пример 2
Этот пример относится к промышленной статистике (см. Cornell J. А (1990). Н<™’ to Apply Response Surface Methodology, vol. 8 in Basic References in Quality Contr-at Statistical Techniques, edited by S. S. Shapiro and E Mykytka. Milwaukee* АшепсмИ Society for Quality Control).
Любая машина или станок, используемые на производстве, позволяют onef-i-торам производить настройки, чтобы воздействовать на качество производимое* продукта Изменяя настройки, инженер стремится добиться максимального эф фекта, а также выяснить, какие факторы играют наиболее важную роль в улучи) * нии качества продукции.
Примеры анализа данных в системе STATISTICA
589
В системе STATISTICA имеется мощный модуль планирования экспериментов . позволяющий эффективно планировать и анализировать эксперименты.
Задача состояла в том, чтобы исследовать факторы, влияющие на качество производимых пластиковых дисков.
Известно, что наибольшее влияние на качество оказывают следующие два фактора:
1) материал, характеризующийся отношением наполнителя к эпоксидной резине,
2) расположение диска в форме.
В качестве зависимой переменной рассматривалась плотность полученного диска.
Сначала использовался дробный факторный плзн 22 для того, чтобы опреде-1ить адекватность модели первого порядка. В этой модели оба фактора комбинировались друге другом на верхних и нижних значениях (всего имеется 4 комбинации). Но оказалось, что модель оказалась адекватной лишь для некоторой области значений факторов и неадекватной для всей значений факторов. На самом деле зависимость между факторами и откликом была нелинейной. Поэтому было решено использовать центральный композиционный план и применить модель второго порядка.
Построение плана
Центральный композиционный план может состоять из куба и звезды. Куб соответствует полному факторному плану — точки эксперимента располагаются в вершинах куба (фактически это факторный план 2г).
Звезда содержит дополнительное множество точек, расположенных на одинаковых расстояниях от центра куба на отрезках, исходящих из центра и проходящих через каждую сторону куба.
В данном исследовании применялся ротатабельный план, в котором дисперсия отклика является постоянной во всех точках, одинаково удаленных от центра плана.
Пусть фактор А — это характеристика материала, из которого изготовлен диск, более точно, так называемое композиционное отношение (disk composition ratio), фактор В — положение диска в форме (position of disk in mold). Зависимая переменная, пли отклик эксперимента, — плотность диска (Thickness)
590
Глава 16. Примеры анализа данных в системе STATIST цд
Запустите модуль Планирование эксперимента.
На стартовой панели выберите Центральные композиционные планы, по пости отклика п нажмите кнопку ОК
В появившемся диалоговом окне выберите опцию Построение плана, а ,ц. Факторы/блоки/опыты — строку 2/1/10. Нажмите кнопку ОК
Появится диалоговое окно План эксперимента для поверхности откли^, ц жмите на кнопку Имена факторов, значения и заполните таблицу в диалоговом окне Итоги для переменных так, как показано на рисунке
Нажмите кнопку Далее и выберите опции для настройки отображения пл ми •гак, как показано на следующем рисунке Сделайте точно все показанные настройки, чтобы получить нужный результат!
»~1П< СТШЦРТВЛт ПШ1-2-|<1 ryf«.
числа Н1 ,-l.alphaJ
Просмотрите план. Для этого нажмите Просмотр/Правка/Созраиенив.
ЗД»з>|. фиюлри
<п>каартимй cattail ныл
Примеры анализа данных в системе STATISTICA 591
Задание имени и сохранение экспериментального плана
Выберите Сохранить как файл данных..., появится соответствующее диалоговое окно Задайте имя плана disksta и нажмите кнопку ОК.
Вернитесь в диалоговое окно План эксперимента для nt верхностпи отклика.
1 |ажмите кнопку Печать итогов. В зависимости от насгроек вывода в диалоговом окне Параметры страницы/вывода результаты плана будут распечатаны па принтере или выведены в отчет.
В построенной таблице показан порядок сбора экспериментальных данных Данные, полученные в результате эксперимента, занесены в таблицу
Номер Black Ratio Maid Thickness
0,75 0,5 7,3
2 1 0,9 0,5
3 1 0,75 1 7.1
4 1 0,9 1 8
5 1 0,718934 0,75 7,6
6 1 0,931066 0,75 7,4
7 1 0,825 0,396447 7,4
8 1 0,825 1,103553 7,9
9 J 0,825 0,75 8,2
10 1 0,825 0,75 8,3
Анализ экспериментальных данных
Проведем анализ полученных данных.
В диалоговом окне План эксперимента для поверхности отклика нажмите кнопку Отмена. Вы возвратитесь к диалогу Центральные композиционные планы.
Глава 16. Примеры анализа данных в системе STATI'
анализа данных в системе STATISTICA
592
Выберите опцию Анализ результатов. Нажмите кнопку Переменные. Задайте thick в качестве зависимой переменной, ratio и mold в качестве независимых переменных и block в качестве блоковой переменной.
В поле Для перекодирования использовать оставьте принятое по умолчанию положение уровни факторов из файла данных. Теперь нажмите ОК.
На экране появится следующее окно системы STATISTICA:
t-1 Правок о
Прежде всего оцените адекватность модели второго порядка
Для оценки адекватности воспользуйтесь таблицей дисперсионного анализа и графиками. На панели Включить в модель выберите опцию гл. лин./кв. эф ' » 2-взаимодействия, а на панели Член ошибки ДА — Остаточная сумма квадрат^ Нажмите на кнопку Дисперсионный анализ.
Из этой таблицы следует, что статистически значимые эффекты (уровень р<0,05) имеют два квадратичных члена- ratio (Q) и mold (Q).
Для того чтобы определить, насколько модель хорошо описывает экспериментальные данные, будем использовать тест lack-of-fit (потери согласия).
Вернитесь к диалоговому окну результатов анализа, выберите Чистую ошибку для Члена ошибки ДА и снова нажмите кнопку Дисперсионный анализ. Система добавит в таблицу значения потери согласия и чистой ошибки
Вследствие того, что p-значение использованного дополнительного теста больше 0,05, модель второго порядка представляется адекватной для описания отклика
Установите снова Член ошибки ДА в положение Остаточная сумма квадратов.
Теперь рассмотрим вероятностный график.
Для этого нажмите на кнопку Нормальный график.
Из рисунка видно, что квадратичные члены с меткой Q находятся в стороне от линии нормального распределения, что указывает на статистическую значимость их влияния на отклик.
Примеры анализа данных в системе STATISTICA
Итак, квадратичные члены модели лают значимые эффекты. Соответствующие им колонки пересекают вертикальную линию, которая представляет 95%-ю доверительную вероятность.
Определим теперь область значений факторов, в котором плотность пластиковых дисков является максимальной. Для этого лучше всего использовать график поверхности отклика. Нажмите на кнопку Поверхность.
Эта поверхность имеет экстремум, равный примерно 0,9. Для более детального рассмотрения области максимума целесообразно рассмотреть контурный график (цветная квадратная кнопка рядом с кнопкой Поверхность). На графике показаны линии уровня поверхности. Это весьма удобно для исследования поверхности
Посмотрите на цветовые метки, расположенные слева от графика. Эти метки, показывающие интенсивность цветов, позволят легко сориентироваться и понять, что максимальная плотность достигается при изменении параметров в центральном эллипсе, положение главных осей которого легко оценить графически.
Например, максимально прочные диски будут получены при значениях композиционного соотношения, изменяющихся от 0,78 до 0,86, и значениях mold, изменяющихся от 0,6 до 0,9 Более строго — все значения независимых переменных, попадающие в центральный эллипс, приводят к наивысшему качеству п частиковых дисков.
Пример 3
В этом эксперименте изучается ракетное топливо, которое представляет собой комби нацию ою 1слителя, горючего и связывающего вещества Интересующим лас свойством топлива является его эластичность. Цель состоит в том, чтобы найти пропорции, дтя которых эластичность достигает величины 3 000 Задача такова — по результатам эксперимента найти математическую формулу, позволяющую связать эластичность с компонентами топлива.
П ример основан на данных, описанных в книге: Kurotori I. S. (1966). Experiments with Mixtures of Components Having Lower Bounds, Industrial Quality Control, 22, p. 592-596.
Начнем с построения плзна эксперимента.
Запустите модуль Планирование эксперимента.
Примеры анализа данных в системе STATISTICA
5S6_______________ Глава 16. Примеры анализа данных в системе STATIS,
В данном счучае выберите Планы для смесей, потому что компоненты. ньХД женные в долях, в сумме должны равняться 1. Нажмите кнопку ОК.
В появившемся диалоговом окне выберите опцию Построение плана, дале- , жите Симплекс-ирнтроидный план, введите3 в поле Число факторов и выпЛД опцию Дополнить внутренними точками.
Нажмите кнопку ОК. Появится диалоговое окно План эксперимента для смеси.
Нажмите на кнопку Имена факторов, значения и заполните появившуюся таГ» лицу следующим образом.
Нажмите кнопку Далее. Полученный план можно просмотреть, нажав накнопку Пр • ошлгф/Правка/Сохранение, предварительно определив опции, как показано на рист нм ниже
Сохраните план. Для этого выберите из меню Файл — Сохранить как файл данных: появится соответствующее диалоговое окно. Задайте имя плана rocket sta и нажмите кнопку ОК
План построен. Это позволяет организовать сбор данных.
Предположим, что вы организовали эксперимент согласно построенному плану и для разных значений компонент измерили эластичность ракетного топлива.
После того как данные собраны, задача состоит в том. чтобы провести анализ и найти зависимость между эластичностью и компонентами ракетного топлива
Откроите файл данных rocket.sta и добавьте переменную elastic, содержащую данные для 10 откликов, полученных экспериментальным путем.
Глава 16- Примеры анализа данных в системе STATIS7 1гд
Примеры анализа данных в системе STATISTICA
599
Введите данные В диалоговом окне Планирование экспериментов для см -выберите Анализ результатов.
Нажмите кнопку Переменные Задайте elastic в качестве зависимой Пересе ной, binder, oxidizer и fuel — в качестве независимых переменных.
В поле Перекодировать факторы оставьте принятое по умолчанию положение Автоматически определяемые мин./макс. значения. Теперь нажмите ОК. Появится диалоговое окно Анализ эксперимента для смеси
На панели Модель выберите Специальная кубическая.
Нажмите на кнопку Дисперсионный анализ. Появятся две таблицы. В одной и • них приведена сводка проведенного анализа, а в другой — результаты днсперсцВ «иного анализа для специальной кубической модели.
Значимые модели выделены красным цветом.
Из таблицы видно, что статистически значимые эффекты наблюдаются в квад ратической н специальной кубической моделей (p-значения меньше 0,05).
Качество регрессионной модели оценивается с помощью коэффициента детерминации R-квадрат.
Так как у специальной кубической модели среднеквадратичная ошибка меньше, а значения коэффициента детерминации R-квадратов больше, чем у квадратической модели, мы будем использовать специальную кубическую модель.
Нажмите кнопку Оценки псевдокомпонент. Программа отобразит статистики, рассчитанные для специальной кубической модели.
Как следует из полученных результатов, все члены специальной кубической модели имеют значимые эффекты (р < 0,05), кроме одного члена АВ.
Таблица дисперсионного анализа показывает весьма неплохие результаты для подобранной специальной кубической модели (р-значсние гораздо меньше 0,05).
Чтобы проиллюстрировать данные результаты, рассмотрим графики. Нажмите на кнопку Поверхность.
На графике поверхности отклика хорошо виден максимум эластичности топ-чина. Заметьте, что зависимость эластичности от компонент смеси носит нелинейный характер. _
Для точного определения оптимальных доле»! рассмотрим контурный график Он вызывается кнопкой Контур.
600
Глава 16 Примеры анализа данных в системе STATIST!
На [рафике визуально легко определить, при каких значениях FUEL, BINDER OXI DIZER достигается нужная эластичность
Эластичность 3000 лежит вблизи доли связующего вещества 0.2л доли ок <.« лителя 0,45 п доли горючего0.25 Более точ11ые значения пропорций компонен • н следующие* связывающее вещество — 0.26667: окислитель — 0,46667 и горюче? -0.26667
Можно выбрать некоторые пропорции компонент, которые дают значенн» эластичности, близкие к 3000. Например, набор компонент (0 25; 0.5; 0,25) Д-'1*’ эластичность 2927.7. набор (0 25:0.45; 0.3) — эластичность 3 042.9
Примеры анализа данных в системе STATISTICA
601
На значения компонент могут быть наложены дополнительные ограничения, нацрпмср, можно максимизировать эластичность для значений окислителя или -взвывающего вещества, лежащих в определенных пределах.
Для нахождения таких ранений опции STATISTICAоказываются незаменимыми.
Чтобы оценить эластичность по любому набору компонент, воспользуйтесь кнопкой Предсказать зависимую переменную. Задайте значения факторов, например, как показано ниже.
Нажмите кнопку ОК
На экране появится таблица прогнозируемых значений эластичности В нижней части таблицы показывается значение Предсказ. = 2 396,872 предсказанной эластичности для исходных компонент. Также приводятся верхние и нижние границы 95%-го доверительного интерната и границы для прогноза Измените значения компонент топлива, например, BINDER - 0,27, OXIDIZER - 0.43. FUEL = 0,3.
примеры анализа данных в системе STATISTICA
ример 4
тот пример иллюстрирует возможности системы STATISTICA для промыш-?нных приложений, связанных с контролем качества. Мы рассматриваем хи-ичсское производство, но вы легко можете представить и другую облаеп I рименения, например, пищевую промышленность или металлургическую про- । ышлепностъ.
Пример основан па данных, взятых из книги Montgomery D. С., Runger G С L994). Applied Statistics and Probability for Engineers (N. Y- Wiley & Sons).
Предположим, необходимо контролировать концентрацию некоторого веще гва на выходе химического процесса. Вы наблюдаете процесс в реальном времени течение 20 часов и снимаете с датчиков нужную характеристику каждый час читается, что процесс выходит из-под контроля, если концентрация превысит опустимый уровень и выходит за верхнюю контрольную границу.
Рассмотрим данные, представленные в таблице.
1 3 4 5 6 7 89 10
02 95 98 98 102 99 99 98 100 98
11 12 13 14 15 16 17 18 19 20
01 99 101 98 97 97 100 101 97 101
Особенностью процессов, протекающих в реальном времени, является то. что них не является естественным группировать измерения, так как, производя труп -.нровку, вы с запаздыванием реагируете на ухудшение качества. Группируя даВ-1ыс, вы добиваетесь более точных оценок параметров процесса, однако плата з« очность — запаздывание в управлении. Поэтому воспользуемся контрольным* • юртами для индивидуальных наблюдений. Назовем контролируемый параметр oncent.
Шаг 1. Введите исходные данные в файл системы STATISTICA, например- • [меием Chemipro
603
Шаг 2. Запустите модуль Интерактивный контроль качества
ШагЗ. На стартовой панели выберите Отдельные наблюдения и скользящий раздал и нажмите кнопку ОК.
В появившемся диалоговом окне выберите concent в качестве переменной с измерениями.
Шаг 4. Постройте контрольную карту скользящих размахов для последовательности наблюдений.
Ремеры анализа данных в системе STATISTICA
Шаг 5. Известно, что для всех производственных процессов возникает необхс -шмость установить пределы характеристик изделия, в рамках которых произв<-дениая продукция удовлетворяет своему предназначению.
Вообще говоря, существует два «врага» качества продукции:
1) отклонения от значений плановых спецификаций изделия и
2) слишком высокая изменчивость реальных характеристик изделий относительно значений плановых спецификаций, что говорит о несбаламсировав, ности процесса.
Вы видите, что на X карте скользящих средних все точки попадают внутрь ко1 рольных границ.
605
На контрольной карте скользящих размахов (MR-карте) все точкитакже иахо «тля внутри контрольных границ. Размахи служа! оиенкоп изменчивое™ мрак-
Гнозтому можно сказать, что кишентрщ.» вснествапотчвияетснтребо-Т.1ЯМ статистического контроля по уровню средних и изменчивости
Продолжение анализа. Следует иметь к волу, что карты для
„ J >ь»ьч наблюден.. 11 не способны отражать щ .ь,т вмевеии среднего уров-“концентрации. которые, однако. могут играть существе....™ роль в реальном "P7io3T»™H™ анализа данных воспользуемся также контрольными картами «а-копленных су мм.
Шаг 6. Выявление малых изменений средних значении.
Запустите модуль Карты контроля качества.
Шаг 7. На стартовой панели выберите CVSUM карта оля ккаркрыакъа пере иеияыа- и нажмите кнопку ОК.
Заметьте, термин CUSVM происходи, от сокращения ку.нуляпшояьи., копленные, суммы. _ __
Шаг 8. В появившемся диалоговом окне выберите concent в качеств Р
ной с измерениями.
Тип анализируемых данных: исходные данные. Нажмите кнопку ОК. На экране появится CUSUM-xapma.
606
Глава 16. Примеры анализа данных в системе STATIST! •
На карте изображена также так называемая V-маска, имеющая следующим смысл.
Запомните: если в наблюдаемом процессе имеется значимое смещение средне го значения, то точки выходят за пределы V-маски.
В системе STATISTICA V-маска строится автоматически, и вам не нужно думать о ее определении. В нашем случае точки не выходят за пределы маски, поэтов му можно сделать заключение о том. что исследованный химический процесс удов летворяет требованиям контроля качества.
Из приведенного графика следует, что все точки данных попадают внутрь кон трольного интервала.
Шаг 9. Опции STATISTICA позволяют всесторонне исследовать результаты i управлять процессом, находя незначительные сдвиги в значениях (см. опцию Обнаружить сдвиг больше чем..)
Примеры анализа данных в системе STATISTICA
607
Например, нажмите на кнопку Описательные статистики на панели. Вы увидите следующую таблицу с результатами.
Шаг 10. Можно продолжить анализ, например, просмотреть Гистограммы средних. Для этого нажмите кнопку Гистоерамчы средних. Далее задайте желаемые значения контрольных пределов и числа категорий и нажмите кнопку ОК.
Пример 5
На этом примере мы покажем, как наложить результаты анализа на географическую карту. Мы намеренно берем грубую реализацию карты и очень простые данные. чтобы показать принципиальную возможность метода.
Представьте, что имеется файл данных о заболеваниях определенного вида и т равматизме для каждого региона России (данные носят чисто модельный характер, не отражают реальной ситуации и необходимы лишь для иллюстрации возможностей).
608
Глава 16. Примеры анализа данных в системе STATISTICS
Примеры анализа данных в системе STATISTICA
609
I
Координаты границ регионов задаются в отдельном файле данных. ST ATI •
TICA отображает карту России следующим образом.
Следующее меню предлагает выбрать способ отображения карты. Линейное разбиение позволяет задать число интервалов или категорий (цветов), на которые бу ivt разбиты все регионы.
Зададим, например, число интервалов, равное 4
Конечно, эту карту можно улучшать, делать более точными границы регионов» увеличивать и т. л. Мы намеренно берем самую грубую реализацию
На карте цвета задаются случайным образом.
Наложим данные о заболеваемости на эту карту Выберем опцию Шкалирование карты в диалоговом окне выбора слайда Показанные далее диалоговые окна не являются частью какого-либо модуля STATISTICA, они легко создаются с помощью языка STATISTICA BASIC
Далее выберем переменную, с помощью значений которой мы хотим прове М раскраску карты, выберем, например. Заболевание. Идея проста: мы хотим добити-ся того, чтобы регионы с большей интенсивностью заболевания были окрашен** более интенсивным цветом.
Последний шаг — выбор общего цвета (раскраска карты производится путем тональной градации выбранного цвета в зависимости от уровня заболевания):
В результате мы получили карту, раскрашенную в 4 !1вета. Все регионы раэои-ты на группы по значению показателя Заболевание. Самый темный цвет соответствует группе (региону), в котором наблюдаются самые большие значения показателя Заболевание.
610
Глава 16. Примеры анализа данных в системе STATIJ
Изменим число градаций цвета, возьмем 10 и наложим на карту графики STATISTICA, тогда можно получить, например, следующую карту
Теперь регионы разбиты на 10 групп по степени заболеваемости
Конечно, такой анализ может быть гораздо изощреннее: на карте можно ш Сразить корреляции, зависимости между различными параметрами. напркИ между использованием мобильной связ и и Интернета в различных регионах. м«>»I рассмотреть карту отдельного региона и т. д.
< Нейронные
I / сети
Идея нейронных сетей возникла в результате попыток смоделировать поведение живых существ, воспринимающих воздействия внешней среды и обучающихся на собственном опыте. Такого рода идеи па стыке различных областей знания характерны для науки современного времени.
Наша цель состоит в том. чтобы кратко описать идею нейронных сетей п научить читателя экспериментировать с нейронными сетями в системе STATISTICA Более подробная информация о нейронных сетях доступна в текстах Уссермен Ф Нейрокомпьютерная техника, М_: Мир, 1992, Lippman R Р. An introduction to computing with neural nets, IEEE ASSP Magazine. Apr. 1987, p. 4-22. п др.
Ключевым является понятие нейронов — специальных нервных клеток, способных воспринимать, преобразовывать и распространять сигналы.
Начнем со следующей модели нейрона. Хотя эта модель очень простая, она работает. Итак, нейрон имеет несколько каналов ввода информации — дендриты, и один канал вывода информации — аксон. Аксоны нейрона соединяются с депдри-ia.Mii других нейронов с помощью синапсов. При возбуждении нейрон посылает сигнал по своему аксону. Через синапсы сигнал передается другим нейронам, которые, в свою очередь, могут возбуждаться или, наоборот, оказываться в состоянии торможения.
Заметьте, биологические образы естественны при описании процесса обучения, создавая контекст для математических рассуждений.
Нейрон возбуждается, когда суммарный уровень сигналов, пришедших в него, превышает определенный уровень (порог возбуждения или активации). Интенсивность сигнала, получаемого нейроном, зависит от активности синапсов.
Итак, запомним следующее.
О Нейрон получает сигналы через несколько входных каналов. Каждый сигнал проходит через соединение — синапс, имеющее определенную интенсивность, или вес, который соответствует синаптической активности нейрона.
о Текущее состояние нейрона определяется формулой:
«, = + и<«.0) (О.
где x(j),j — 1,2-N — входные сигналы. Коэффициенты w(ij) называются весами синаптических связей, положительное значения которых соответствуют возбуждающим синапсам, отрицательные значения - тормозящим синапсам. Если w(ij) = О, то говорят, что связь между нейроном f и ней роном j отсутствует. Величина u (i,O) называется пороговым значением
612
Глава 17. Нейронные сет.
О Полученный нейроном сигнал преобразуется с помощью функции акппц. цни или переда точной функции f в выходной сигнал
%=/(«.) (2)
Это одна из первых моделей нейрона предложена МакКаллоком и TIhtqm и 1943 году.
Заметим также, что имеется стохастическая модель нейрона, н которой выхо; ной сигнал является случайной величиной, принимающей пару значений, которые соответствуют торможению или возбуждению.
С математической точки зрения в модели нейрона мы имеем нелинейное пре ъ разование вектора х( 1)х(2). x(N) в выходной сигнал у,.
Функция активации или передаточная функция f в формуле (2) — ото некогш< рая нелинейная функция, моделирующая процесс передачи возбуждения.
Простейшие пример такой функции — индикаторная или скачкообразная фу» кция, определяемая равенствами: f(u)=1 если u>=O,f(u)-1, если и<0.
Если выбрать функцию f вида
где h>0, то получится так называемый сигмоидальный нейрон л т.д.
Объединенные между собой нейроны образуют сеть, с математической точи я зрения задающую сложное многомерное преобразование, собранное из прости!-шпх преобразований Замечательно, что с помощью таких простейших преобра** ваний можно приближать очень сложные многомерные функции, следователь»^ оценивать сложные зависимости (заметим, замечательная теорема Колмогорова является математическим основанием нейронных сетей).
STATISTICA позволяет задавать различные передаточные фу hki щи. например линейную, логистическую и др. (эти функции можно выбрать в диалоговом окне Network Editor, доступном из меню File).
Выходы нейронов соединяются с входами других нейронов, таким обра^ л‘ сигнал от одного нейрона передается другим нейронам (нейрон информирует о своем состоянии другие нейроны). Конечно, с математической точки зрения мы име ем преобразование исходных значений X па входе сети в значения Y на вых '4* На биологическом языке входы и выходы соответствуют сенсорным и двигат< Ш ным нервам. Кроме входных и выходных нейронов в сети могут присутствовать еще промежуточные (скрытые) слои нейронов. Простейшие сети имеют структур
нейронные сети
613
прямой передачи сигнала- сигналы проходят от входов через скрытые элементы и в конце концов поступают на выходные элементы (см. рисунки).
Рис. 1. Окно Редактор Сети системы STATISTICA с набором передаточных функций
Рис. 2. Двухслойная сеть, имеющая 12 входов, 1 выход и 6 элементов на промежуточном слое
Рис. 3. Трехслойная сеть, имеющая 12 входов и 1 выход
614
Глава 17. Нейронные i
Итак, каждый нейрон как элемент сети описывается своим набором пара! ров (см. формулы 1,2).
Входной слой служит для ввода значений входных переменных, выход; слой — для вывода результатов. Скрытые выходные нейроны соединены со вс элементами предыдущего слоя. Последовательность слоев и их соединений паз вается архитектурой сети.
При работе сети на входные алементы подаются значения входных переме ных (входной сигнал), затем возбуждаются нейроны первого промежуточного слей далее — второго промежуточного слоя, в итоге преобразованный сигнал поступай на выходной слой.
Преобразование сигнала проводится следующим образом.
Последовательно для каждого нейрона в сети вычисляется значение активации, берется взвешенная сумма выходов элементов предыдущего слоя и вылетается пороговое значение. Затем значения активации преобразуются с помощью передаточной функции, и в результате получается выход нейрона, поступающий на вход нейронов, с которыми он соединен.
Обучение сети
Обычно нейронные сети используют в задачах классификации, прогнозирования и построения нелинейных зависимостей (нелинейная регрессия).
Но для этого сеть нужно обучить. Замечательный факт состоит в том, что нейронную сеть действительно можно обучить!
Теорема Колмогорова—это высший уровень абстракции, рассмотрение нейронов — самый низкий или глубокий. Объединяя эти два уровня, мы пытаемся по существу понять, как организовано мышление, когда состоящий из простейших нейронов человеческий мозг постигает глубочайшие закономерности. Процесс получения знания моделируется с помощью нейронных сетей
Мы знаем, что знания получаются последовательно, иными словами они не даются в законченном виде, а достигаются с помощью обучения, этот принцип использован в нейронных сетях. Итак, мы построили модель нейрона и нейронной сети, теперь нужно предложить модель обучения
Как мы уже отмечали, формально соотношения (1), (2) задают простое преоГг разование величин с различными функциями f. Пусть мы имеем сложное преобразование F исходного набора данных (который поступает на вход сети) в выходной набор (который наблюдается па выходе сети)
Возникает вопрос; как реализовать преобразование F с помощью нейроннс fi сети. На математическом языке мы должны приблизить неизвестную сложну*' функцию простейшими преобразованиями, задаваемыми уравнениями (1), (2 i Теорема Колмогорова утверждает в принципе, что такая сеть существует, но не говорит, как именно ее настроить. Мы используем общий подход связанный с o6v4i -нием, то есть последовательным получением знаний, наказанием за неправ! шьныи ответ и поощрением за правильный ответ.
Вначале мы определяем архитектуру сети, то есть устанавливаем количестве нейронов и связи между ними, выбираем конкретную синаптическую функции | моделирующую процесс передачи возбуждения.
Разобьем данные на две части, обучающие и контрольные, на сленге нейрон пых сетей — обучающую и контрольную выборку.
Нейронные сети 615
Общая идея состоит в следующем* вначале на вход сети подается обучающая вЫборка с известными результатами, величины X и наблюдаются отклики У=F(X).
Меняя веса и значения порога активации для каждого нейрона мы настраиваем сеть, иными словами, находим как можно более точное приближение функции F.
Далее на тестовой выборке экзаменуем простроенную сеть или сети, если их несколько (в общем случае мы получаем ансамбль сетей). Например, в задаче классификации мы можем потребовать, чтобы сеть правильно классифицировала не менее 90% наблюдений. В задаче прогнозирования мы можем стремиться к тому, чтобы точность прогноза на определенное количество шагов вперед была не ниже заданной. Если сеть прошла экзамен. мы можем использовать ее для анализа данных, построить прогноз или провести классификацию
Очевидно, невозможно умозрительно организовать данный процесс в силу его трудоемкости и сложного преобразования данных, только компьютерные техпо-Ю1 пи позволяют эффективно сделать это.
Конечно, в данном процессе имеется определенный произвол связанный, например, с выбором обучающей выборки и риском применения сети на реальных данных, но тот же произвол возникает при применении тюбых математических методов на практике, именно потому, что эти методы имеют дело с сырыми данными (действительностью), а не с возвышенными числами, с которыми они призваны оперировать.
В замечательной модели нейронных мы имеем синтез различных методов, которые могут «ожить* только с помощью компьютерных технологий.
Рассмотрим идею обучения на простой и ясной модели Розенблатта однослойного персептрона. Анализируя алгоритм, вы можете заметить, что он основан на древнем как мир принципе кнута и пряника. Если сеть правильно классифицирует сигнал, она получает пряник, в противном случае кнут.
Модель Розенблатта
(однослойный персептрон — single layer perceptron)
Как видно из названия, в этой модели число слоев равно 1, поэтому исключим второй индекс и рассмотрим только веса »*(«). 1 < i £А(см. формулы (1), (2)).
Конечно, заранее эти веса ле известны, и их нужно найти с помощью разумной процедуры.
На вход сети подается сигнал (х1, х2 .. xN). Пусть входной сигнал может принадлежать либо классу А, либо классу Б. Предположим, для простоты, что мы анализируем двумерным сигнал, иными словами, число N *= 2.
Обучение однослойного персептрона
Шаг 0. Начальные установки: веса ю!( 1). wM. 1) и порог Т задаются случайным образом.
Будем обозначать t шаг обучения. Вначале г - 0.
Шаг 1. Положим Предъявим сети входной сигнал из обучающей выбор-
ки: (л 1(0. л 2(0).
Определим d(t) - 1, если входной сигнал принадлежит классу А, и о(0 “ * Тли входной сигнал принадлежит классу Б.
Шаг 2. Вычислим состояние нейрона в момент времени t (просто суммируем входные сигналы® весами и вычитаем порог 7):s(0=ff’l (О Хл*1(0+«'2(0 х *2(0 ~
616
Глава 17. Нейронные се.,
Шаг 3. Вычислим выходной сигнал нейрона y(t) в момент i (заметьте, испод зустся скачкообразная функция): у(£) = sign(s(0)
Шаг 4. С учетом результата обучения вычислим новые веса нейрона по фо., мулам: и>1(0 = гс>1(£-1) + г X (у(г) - <И(Г)), К’2(г) = »>2(£-1) + г(у(£) - </(£)), г — уцЗ обучения
Шаг 5. Если шаг обучения г меньше объема обучающей выборки L. то перс мЯ дим к шагу 1.
В противном случае обучение заканчивается
Таким образом, получается обученный персептрон, который может решать простые задачи классификации. Если вы захотите доказать, что это действительно обученный персептрон, то вам следует воспользоваться методами теории вероятности пли проверить это утверждение экспериментально, например с помощью статистического моделирования
Многослойный персептрон
Обобщение однослойного персептрона приводит к многослойному персептрон у (см. рис. 2 и 3).
В многослойном персептроне каждый элемент сети строит взвешенную сумм своих входов с поправкой в виде слагаемого, а затем пропускает вычисленное значение через передаточную функцию. Таким образом, по общим правилам получается выходное, значение персептрона.
Нейроны организованы в послойную структуру с прямой передачей сигнала. Веса и пороговые значения являются свободными параметрами модели, которые оцениваются в процессе обучения.
Многослойный персептрон может моделировать функцию практически любой степени сложности.
Имея в своем распоряжении STATISTICA, вы можете всесторонне экспериментировать с моделями, переходя от простых моделей к более сложным
Конечно, с математической точки зрения, нейронная сеть осуществляет преобразование одного сигнала в другой Фокус состоит в том, что это преобразование подчиняется рекурсивным правилам и может быть реализовано технически.
Общий взгляд
Сделаем шаг в сторону и посмотрим па нейронные сети с общих позиций. Как мы говорили (см. главу 2), одной из основных задач анализа данных является оценка зависимости между переменными, например, между переменной X и переменной Y. Наблюдая различные значения переменной X и соответствующие значения переменной У, мы хотим оценить зависимость У= F(X).
В частном случае мы хотим оценить линейную зависимость F(X) = « ’А + К где a, Ь неизвестные константы, или полиномиальную зависимость, когда Епред ставляет собой полином некоторой степени. Можно также разложить функпп» Ь в рад Фурье и, используя комбинации синусов и косинусов или других базисным функций, последовательно приближать функцию F. В различных разделах анализа используются различные методы решения этой задачи.
В нейронных сетях мы собираем функцию F из простейших нейронов, комби пируя их разнообразным образом друг с другом. Получая на вход набор X. с помощью простейших функций мы преобразуем X в Y, ожидая при этом, что собраны» сеть приближает искомую функцию F. Конечно, такая игра может показаться бес
Нейронные сети
617
смысленной, ио знаменитая теорема Колмогорова, о которой часто нс подозревают практики, утверждает, что такие упражнения вполне оправданы. — действуя подобным образом можно в принципе собрать из простейших нейронов сколь угодно сложную функцию F Теорема Ко имогорова утверждает также, что достаточно иметь не более двух скрытых слоев нейронов в сети лля восстановления зависимости.
Заметьте, явный вид собранной функции нам не интересен, для нас важно в принципе знать, что опа близка к искомой.
Как проверить, насколько собранная функция близка той, которую мы пшем7
Одним из естественных подходов к решению лтой задачи является следующий, тайные разбиваются на две части, по одной из которых строится оценка функции, собранной из нейронов, на второй части данных проверяется, насад лысо построенная функция близка искомой (такая процедура называется к]м>.1-прош*ркон. см. также раздел Обучение сети"). Конечно, подобное решение нсматематична (действительно, оно зависит, например, оттого, как именно произведено разделение данных на обучающую и тестовую выборку) и не может удовлетворить любителей строгости, однако оказывается вполне приемлемым во многих прикладных задачах. Заметим, что программа SNN предлагает различные способы проверки качества построенной сети
Теперь можно приступить к экспериментированию с нейронными сетями в системе STATISTICA.
Обратим внимание, что в модуле Нейронные сети системы STAI'lSlICA имеется Советник, подсказывающий выбор архитектуры сети (см описанный ниже пример классификации с помощью нейронных сетей).
I кжажем, как построить многослойный персептрон в системе STATISTICA
Построение многослойного персептрона в системе STATISTICA
Шаг 1. Запустите модуль Нейронные сети.
Шаг 2. Откройте, например, файл sen ’j_g.sla из папки Examples. Используйте меню File-Open. Файл содержит данные о месячных авиаперевозках пассажиров.
Если вы хотите создать свой набор данных в модуле Нейронные сети, поступите следующим образом:
о Войдите в диалоговое окно Создать набор данных Create Data Sei с помощью команды Набор данных — DataSet... из меню Файл—Новый File—Hi i
Рис. 4. Создание файла данных
3 Введите нужные значения для количества входных - Inputs и выгонных Outputs переменных в наборе данных Введите, например. 17 л 7.
и 11ажмите кнопку Со. дать — Create
618
нейронные сети
619
Глава 17. Нейронные се
Заметьте, что имена входных переменных имеют черный цвет, имя ныхо переменных — голубой цвет; входы от выходов отделяются темной вертикал линией.
Рис. 5. Определение числа входных и выходных наблюдений
В данном примере, однако, мы нс будем создавать нового файла, а будем р?Х,,. тать с имеющимся файлом series g.sta.
Шаг 3. После того как файл данных series p.sta открыт, перейдем к создан» сети.
Для этого в менюЯ/е выберите команды: New—Network — Новая Сеть (см. риг <Я
Шаг 1. Вначале создадим структуру сети. В появившемся диалоговом ою|е сделайте установки, как показано на рис. 7.
В поле Туре — Тип выберите тип сети. Многослойный персептрон.
Задайте параметр Временное окно — Steps равным 12. Мы выбрали эту услано»»-ку. так как в ряде имеется сезонная составляющая с лагом 12.
Установите параметр Горизонт — Lookahead равным 1.
Рис 6- Рабочее окно модуля Нейронные сети
Рис. 7. Диалоговое окно построения сети
Данные содержат значения одной переменной. Для нейронной сети эта переменная будет служить одновременно входной и выходной (в разные моменты времени). Для того чтобы определить переменную как входную/выходную. нужно выделить ее щелчком на заголовке таблицы, а затем в появившемся меню выбрать пункт Input/Output.
Обратите внимание на установку в окне No Layers — Число слоев.
Мы выбрали сеть, содержащую 3 слоя. В таблице ниже для слоя 2 наказано: Layer 2 — Слой 2:1
В вашем распоряжении имеются две кнопки Advise — Советовать и Create -Создать.
Нажмите кнопку Advise — Советовать.
Заметьте, что после нажатия кнопки Advise — Советовать значение р поле No Layers — Число слоев изменится и станет равным 6.
Система советует выбрать 6 элементов на промежуточном слое. Вы можете воспользоваться советом или построить персептрон со своей структурой.
Например, вы можете щелкнуть мышью на поле Layer2 и ввести любое значение для числа нейронов на слое 2. Гибкий интерфейс позволяет вам задавать архитектуру сети.
Шаг 5. Нажмите кнопку Create — Создать. На экране появится следующая сеть:
620
Глава 17. Нейронные
Таким образом, можно создать персептрон с нужным количеством слоев и J лом элементов па каждом слое.
В окне Редактор сети STATISTICA можно послойно просмотреть и отре, тировать сеть, выбирать передаточную функцию для каждого слоя, а также по< синаптический потенциал или значение активации нейрона.
Итак, создана архитектуру сети. Мы продолжим рассмотрение этого приме! но вначале дадим необходимые теоретические сведения.
Обучение многослойного персептрона
После того как структура многослойного псрсеп грона определена, его нужно of чнть, то есть найти значения весов и порогов сети, являющиеся свободными (не» вестными) параметрами. Их нужно определить, чтобы сеть решала поставлена задачу. Представьте, вы случайным образом выбрали значения этих параметров, I вряд л и такая сеть будет для вас полезной. Трудно угадать нужные значения пар метров, однако имеется процесс, называемый обучением, который позволяет яс, .педовагпельно находить эти параметры, приближаясь к лучшей сети.
Процесс обучения представляет собой подгонку модели, которая реализуется tv, тью, к обучающим данным, например, с известным ответом. Ошибка для конкретной сети определяется путем прогона всех имеющихся наблюдений и сравнения реально выдаваемых выходных значений сети с целевыми ( правильными) значениями. Грубо говоря, мы обучаем есть, продвигаясь в сторону уменьшения ошибок
В качестве функции ошибки, например, можно взять сред • •квадратичную ошибку, вычисляемую следующим образом: ошибки выходных элементов для всех наблюдений возводятся в квадрат и затем суммируются
В модуле Нейронные сети выдается так называемая среднеквадратичная ошибка: описанная выше величина нормируется па число наблюдений и переменных, после чего из нее извлекается квадратный корень.
Это достаточно разумная мера ошибки, усредненная по всему обучающему множеству и повеем выходным элементам. Конечно,эта мера ошибки се юственна в нелинейной регрессии, но вряд ли она полезна взадачах классификации, где критерием качества может я вляться доля правильно клас сифицированных наблюдении. Заметим,что разнообразные функции ошибок можно выбрать в окне Редактор Сети
Итак, после того как мы задали архитектуру сети, нам нужно найти параметры, минимизирующие ошибку или максимизирующие качество работы сети.
В -инейныхмоделях можно определить параметры, дающие абсолютный минимум ошибки.
С нелинейными моделями дело обстоит гораздо сложнее. Настраивая сеть с нс лью минимизации ошибки, нельзя быть уверенным, что алгоритм обучения Рп'--тиг глобального минимума. иными словами, утверждать, что нельзя добиться л у шего результата
Поверхность ошибок
Для контроля обучения сети полезна поверхность ошибок, к описанию котзрЧ мы сейчас переходим.
Каждому из весов и порогов сети (то есть свободных параметров модели. Ч общее число мы обозначим через N) соответствует одно измерение в многомерно пространстве. (#+1)-мсрное измерение соответствует ошибке сети.
Нейронные сети
621
Для данного набора весов соответствующую ошибку сети можно изобразить точкой в fN+V-мсриом пространстве. В итоге все такие точки образуют некоторую поверхность — поверхность ошибок
Цель обучения нейронной сети состоит в том. чтобы найти самую низкую точку этой поверхности В случае линейной модели с суммой квадратов в качестве функции ошибок поверхность ошибок представляет собой параболоид, и минимум находится легко.
В общем случае поверхность ошибок имеет сложную структуру, в частности, может иметь локальные минимумы (точки,самые низкие в некоторой своей окрестности, но лежащие выше глобального минимума), седловые точки и т. д.
Обучение нейронной сети заключается в исследовании поверхности ошибок. Отталкиваясь от некоторой начальной конфигурации весов и порогов, алгоритм обучения производит поиск глобального минимума.
Как правило, для этого вычисляется градиент в данной точке, а затем эта информация используется для продвижения вниз но склону на поверхности В конце концов, алгоритм приводит к некоторой нижней точке (ниже спуститься нельзя), которая, однако, может оказаться лишь точкой локального минимума. Очевидно, <ледует использовать различные начальные приближения.
STA P1STICA предлагает следующие методы обучения многослойного персептрона:
Рис. 9. Алгоритмы обучения многослойного персептрона
Для обучения многослойных персептронов в пакете Neural Nell. orks реализова-н< > пять различных алгоритмов: алгоритм обратного распространения, быстрые методы второго порядка — методы сопряженпыхградпентов и Левенберга—Маркара, я также методы быстрого распространения и Дельта-дельта с чертой (вариация метода обратного распространения) Все эти методы являются итеративными, то есть последовательно приближаются к минимуму, начиная с некоторого начального зпачегшя
Выбор алгоритма обучения
В большинстве случаев вначале следует испытать метод сопряженных 1радиеп-тов — в этом случае обучение происходит достаточно быстро (иногда на порядок быстрее, чем, например, методом обратного распространения).
Последний метод следует предпочесть в случае, когда в очень сложной задаче требуется быстро найти удовлетворительное решение пли когда данных очень много (порядка десятков тысяч наблюдений).
Метод Левенберга—Маркара для некоторых типов задач может оказаться эффективнее метода сопряженных градиентов, но его можно использовать только
622
Глава 17.
в сетях с одним выходом, квадратичной функцией ошибок и нс очень болыщ(ч числом весов. Фактически область его применения ограничивается небокц^^^^Ь по объему задачами нелинейной регрессии
Итеративное обучение. Итеративный алгоритм обучения последовательной! ходит ряд так называемыхэлох — Epochs, на каждой из которых на вход сети пода- Г стся наблюдение за наблюдением — весь набор обучающих данных, вычисляю!®* ошибки и по ним подправляются веса сети.
Известно, чт о итеративные алгоритмы подвержены нежелательному явленнм переобучения (когда сеть хорошо учится выдавать те же выходные значения, что ц I в обучающем множестве, но оказывается нс способна обобщить закономерности на новые данные). Поэтому качество работы сети следует проверять на кажд «1 эпохе с помощью специального проверочного множества (для этого нужно выбр$ «| опцию Кросс проверка — Cross verification в диалоговом окис обучения).
Контроль обучения
За ходом обучения можно с-ледитьв окне График ошибки обучения — TratningErrot Graph (оно открывается из меню Статистики — Statistics), где на графике отобра • жается среднеквадратичная ошибка на обучающем множестве па данной эпохе.
Если выбрана опция Кросс-проверка — Verification, выводится также сред!*’-квадратичная ошибка па проверочном множестве.
С помощью расположенных под графиком элементов управления можно менять масштаб изображения, а если график целиком не помещается в окне, под ним появляются линейки прокрутки.
Рис. 10. График ошибок обучения
Если требуется сопоставить результаты различных этапов обучения, нажмите кнопку Переустановить — Reinitialize в окне обучения, а затем еще раз нажми М кнопку Обучить — Train (повторное нажатие кнопки Обучить — Train без установки — Reinitialize просто продолжит обучение сети с того места, где оно бызм прервано).
Чтобы облегчить сравнение результатов, имеется возможность перед нажапимг кнопки Обучить — Tram задать для графика Метку — Label: тогда очередная чини* будет рисоваться новым цветом, а информация о пей будет добавлена в легенду в правой части окна По окончании обучения график можно переслать в STATISTIC Л (кнопка IWh
На графике обучения можнолегкозаметить эффект переобучения. Вначалеовш^г ка.1>бучения и проверочная ошибка убывают При возникновении эффекта
Нейронные сети
623
пия ошибкаобучения продолжает убывать, а ошибка проверки растет. Рост проверочной ошибки сигнализирует о начале переобучения. Если наблюдается переобучение, то обучение следует прервать, нажав кнопку Стоп — Slop в окне обучения или нажав клавишу ESCAPE.
Можно также задать автоматическую остановку программы 57 Neural Networks с помощью условий остановки, которые задаются в окне Условия остановки — Stopping бо/ийГю?к(доступкко1оромулро|1сходитчсрезменюО^/чение допааалпечъные — Train-Auxiliary).
....... !"
Ь. . (« 'К --J
Рис 11. Задание, условий остановки обучения
Кроме максимального числа эпох, отводимого на обученно, можно потребовать, чтобы обучение прекращалось при достижении определенного уровня ошибки или koi да ошибка перестает уменьшаться на определенную величину (остановка по невязке).
Борьба с переобучением
Самое лучшее средство борьбы с переобучением — задать нулевой уровень минимального улучшения. Однако поскольку при обучении присутствует шум, обычно не рекомендуется прекращать обучение тишь потому, что на очередной эпохе ошибка ухудшилась. Поэтому в диалоге Stopping Conditions — Условия остановки имест-1 я специальное Окно — Window, в котором задается число эпох, на протяжении которых должно наблюдаться ухудшение, и только после этого обучение будет остановлено. Обычно в этом окне устанавливают значение 5
Сохранение лучшей сети
Вы можете восстановить наилучшую конфигурацию сети из всех, полученных в процессе обучения.с помощью опции Лучшая сеть — Best Network... (меню Обучение дополнительные — Tram-Auxiliary).
Если опция Сохранить лучшую - Retain Best включена, программа Neural Networks автоматически сохраняет наилучшую из сетей, полученную в ходе обучения.
Если включена опция Учитывать все прогоны обучения — Span training runs, то это делается и для прогонов обучения различных сетей.
Таким образом, программа Neural Networks автоматически хранит наилучишй результат всех экспериментов.
624
Глава 17. Нейронные се
ЙИ, А
Рис. 12 Опция: лучшая сеть
Можно также установить Штраф за з и-мент - Unit. Penalty с тем, чтобы при сравнении штрафовать сети с большим числом элементов (наилучшая есть обычно п]>еитавляег < обой компромисс между качеством работы и размером).
Наилучшая сеть
Для того чтобы вызвать i шплучшую сеть, нажмите кнопку Восстановить — Resi. .«г Такая возможность, как правило, очень помогает, однако ясно, что она отрицательно скалывается на эффективное! и (программа Neural Networks должна копировать и сохранять сеть каждый раз, когда достигается улучшение), поэтому в некоторых случаях имеет смысл отключить эту опцию.
IJX-CI . Д ;
Рис. 13. Ошибки обучения
Ошибки сети (во время и по ре штатам обучения) можно наблюдатьтакже в окц» Ошибки наблюдений — Case Errors (доступ — через меню Статистики — Statistic ? Здесь выводится диаграмма ошибок для отдельных наблюдений Установив о нн'М Пересчитывать походу Real-time Update можно следить за изменением ошибок о г эпохи к эп<зы
Обратное распространение
Перед применением алгоритма обратного распространения необходимо задать 30»-чсния ряда управляющих параметров.
Наиболее важными параметрами являются скорость обучения, инерция и го ремешивание наблюдений в процессе обучения
Скорость обучения — Learning rate задает величину шага при изменении вес в случае недостаточной скорости алгоритм медленно сходится, а при слишком большой алгоритм неустойчив. К сожалению, величина наилучшей скорости »авнсн'
Пре/постпроцессиравание
625
от конкретной задачи; для быстрого и грубого обучения подойдут значения от 0.1 до 0,6, для достижения точной сходимости требуются гораздо меньшие значения (например, 0.01 или даже 0,001. если эпох много тысяч).
Рис 14. Опции алгоритма обратное распространение
Иногда поделю уменьшить скорость обучения. В программе Neural Networks можно задать начальное и конечное значения скорости, и по мере обучения производится интерполяция между ними Начальная скорость задается в левом поле, конечная —в правом.
Инерция. — Momentum помогает алгоритму, когда он застреваетвнизинахи локальных минимумах. Этот коэффициент может иметь значения в интервале от нуля до единицы.
Реально «правильное* значение можно найти только опытным путем, и для ♦того в STATISTICA имеются все возможности.
Перемешивание наблюдений
Перемешивать порядок наблюдения обычно рекомендуется, когда для решения задачи используется метод обратного распространения, поскольку этот способ уменьшает вероятность того, что алгоритм застрянет в локальном минимуме, а также уменьшает эффект переобучения. Чтобы воспользоваться такой возможностью, установите опцию Перемешивать наблюдения — Shuffle Cases.
При работе с нейросетями следует помнить о важном моменте - процессировании, или преобразовании, данных.
Пре/постпроцессирование
Передаточная функция для каждого элемента сети обычно выбирается так, чтобы ее входной аргумент мог принимать произвольные значения, а выходные значения лежали бы в строго ограниченном диапазоне. При этом возможен эффект насыщения. когда элемент сети оказывается чувствительным лишь к входным значениям, лежащим в некоторой ограниченной области.
На этом рис. 15 представлена логистическая функция.
Логистическая функция является гладкой, ее производная легко вычисляется, что существенно для алгоритмов минимизации на этапе обучения сети (вэтом также кроется причина того, что ступенчатая функция для этой цели практически не используется). Если применяется логистическая функция для вычисления вы-
626
Глава 17. Нейронные.
Чтобы согласовать вход-выход при р шепни задач методами нейронных сетей, требуются этапы предварительной обработки (Bishop, (1995) Neural Networks with Pattern recognition, Oxford: University Press). Эти преобразования включают, в частности, шкалирование и преобразование категориальных переменных в чне левую форму.
Шкалирование
Числовые значения должны быть приведены в масштаб, подходящий для сети В пакете Нейронные сети ST реализованы алгоритмы минимакса и среднего/стан • даргного отклонения, которые автоматически находят масштабирующие параметры для преобразования числовых значений в нужный диапазон.
В некоторых случаях более подходящим может оказаться нелинейное шкалирование (например, если заранее известно, что переменная имеет экспоненциальное распределение, есть смысл взять ее логарифм). Можно шкалировать перемен ную с помощью средств преобразования данных в STATISTICA, а затем работать с ней в модуле Нейронные сети ST.
Номинальные переменные
Поминальные, или категориальные, переменные преобразовываются в числовую форму (например. Муж = О, Жен = 1). Для кодирования многомерных номинальных переменных используется так называемый метод 1-M3-N, так как при наивном способе кодирования, например Собака = О. Овца = 1, Кошка = 2, может возникнуть ложное упорядочивание значений категориальной переменной: Овца окажется чем-то средним между Собакой и Кошкой.
В методе 1-H3-N одна номинальная переменная представляется несколькими числовыми переменными Количество числовых перемен ных равно числу возможных значений номинальной переменной; при *том всякий раз ровноодна из А’псре-менных принимает ненулевое значение (например. Собака — {1,0,0}, Овца ~ {0.1.0}. Кошка - (0,0, /}). Заметим, что этот метод кодирования требует большого количества чистовых переменных, если номинальная переменная принимает много значений J
диалог в нодуле Нейронные сети STATISTICA
КЭ7
Оценка качества работы сети
После того как сеть обучена, стоит гроверпть, насколько хорошо она работает Для этою доступны несколько показателей.
Среднеквадратичная ошибка, которая выдастся в окне График ошибки обучения — Training Error Graph, представляет лишь грубую меру производительности. Более полезные характеристики выводятся в окнах Статистики классификации — Classification Statistics п Статистики регрессии — Regression Statistics (доступ к обоим происходит через меню Статистики — Statistics).
Окно Статистики классификации — Classification Statistics применяется для номинальных выходных переменных Здесь выдаются сведения о том, сколько наблюдении каждого класса (классы соответствуют номинальным значениям) из файда данных было классифицировано правильно. сколько неправильно и сколько , ie классифицировало, а также приводятся подробности об ошибках классификации. Обучив сеть, нужно просто открыть это окпо и нажать в нем кнопку Запуск —Run. Статистики выдаются раздельно для обучающего, проверочного и тестового множеств (внимание: чтобы увидеть тестовые стати*аГИК», нужно прокрутить таблицу вправо) В верхней час ш таблицы ffpi июдятся суммарные став icthkh (общее числа наб нодений в каждом классе, сколько из них классифицировано правильно, нспра-вптьнои «екяассифицировано),авниж11еп части — кросс-результаты классификации Ггколысо наблюдений из данного столбца было отнесено к данной строке).
Окно Статистики регрессии — Recession Statistics действует в случае числовых выходных переменных. В нем < уммнруется точность регрессионных оценок.
Наиболее важной статистикой является S. D. ratio — отношение стандартного гклонсния ошибки прогноза к стандартному отклонению исходных данных.
Если бы у пас вообще не бы то входных данных, то лучшее, что мы могли бы взять в качестве прогноза для выходной переменной, — это се выборочное среднее, а ошибка такого прогноза была бы равна стандартному отклонению выборки.
Если нейронная сеть работает результативно, мы вправе ожидать, что ее средняя ошибка на имеющихся наблюдениях будет близка к нулю, а стандартное оттенение этой ошибки будет меньше стандартного отклонения выборочных значений (иначе сеть давала бы результат не лучше, чем простое угадывание)
Таким образом, если S. D. ratio значительно меньше единицы, тосстьэффсктивна.
Величина, равная единице минус S. D. ratio, является долей объясненной дисперсии модели.
Перейдем к работе с нейронными сетями в системе STATISTICA
Для того чтобы понять, как решаются задачи прогнозирования с помощью нейросетей, мы будем использовать файл series_g.sta, для задач классификации псполь-। .’см файл irissta.
Диалог в модуле Нейронные сети STATISTICA
Мы продолжаем работатьс файлом Series gsta. Это классический файл данных, обычно исполыуемый для тестирования методов прогнозирования (см., например, книгу Бокс Дж., Дженкинс Г. Д. Анализ временных рядов и прогнозирование. Мг Мир. 1974)
628
Главз 17. Нейронные сет*
Шаг 1. Откройте файл данных Series_g.sta на папки Examples.
Данные содержатзначения одной переменной: месяч 11ые перевозки пассажиров. I мы ужезамепип], длянейронной сети этапеременнаябудсг служить ах<к)1юй/выхо^!л (так как мы прогнозируем будущие значения ряда на основе предыдущих значений),
Рис. 16. Выбор файла
Поэтому задайте тип переменной как входная/выходпая
Рис. 17. Задание типа переменной
Для этого выделите переменную в открытом файле данных (щелчком па заголовке столбца). Затем нажмите правую кнопку мыши и выберите из появившегося контекстного меню пункт Вхадная/выходная — fripul/Output. Имя переменной высветится зеленым цветом.
Шаг 2. С помощью мыши выберите команду Сеть — Network.. из меню Файл -Новый — File—New.
Рис. 1В- Построение сети
диалог в модуле Нейронные сети STATISTICA
629
На экране появится диалоговое окно Создать сеть — Create Nefteoik.
Рис. 19. Задание параметров персептрона
В поле Туре — тип выберите тип сети Многослойный персептрон — Multilayer Perceptron и сделайте следующие установки'
Входы — Inputs - 1, Выходы — Outputs - 1.
Задайте число слоев равным трем. No Layers = 3. Выберите трехслойный персептрон. Задайте параметр Временное окно — Steps равным 12 (данные представляют собой ежемесячные авиаперевозки с присутствующей в них сезонной состав-чяющей), а параметр Горизонт — Lookahead — равным 1. После этого нажмите кнопки Совет — Advise и Создать — Create. На экране появится схема трехслойного персептрона. Этот персептрон имеет 12 входов.
Рис. 20. Трехслойный персептрон
Шаг 3. Обучение сети. Структура сети определена. Теперь ее нужно обучить.
В файле данных выберите 66 обучающих — Training и 66 контрольных — Verification наблюдений. Всего в файле содержится 144 наблюдения. Первые 12 резервируются для построения прогноза на первом шаге
630
Глава 17. Нейронные
Рис. 21. Из файла данных выбрано 66 обучающих и 66 контрольных наблюдений
Далее воспользуйтесь опцией Shuffle - Перелетать.
Заметьте, во временном ряд* при перемешивании нельзя пс.ц Group Sets
Рис. 22. Выбор функции Shuffle—Перемешивание позволяет случайным образом перемешать наблюдения в процедуре обучания
Опция перемешивания позволяет расщ хлпть обучающие и контрольные наблюдения в файле данных Для обучения сети воспользуемся методом сопряженных градиентов.
Рис. 23. Выбор метода сопряженных градиентов для обучения сети
Рис. 24. Окно минимизации методом сопряженных градиентов
диалог в модуле Нейронные сети STATISTICA
631
Обратите внимание на кнопку Переустановить — Reinitialize: она позволяет случайным образом выбрать новые начальные значения свободных параметров сети и провести обучения, исходя из этих установок.
Опция Кросс-проверка — Cross verification позволяет провести обучение с кросс-проверкой (проверять сеть на контрольном множестве на каждой эпохе обучения).
Шаг 4. Проекция временного ряда.
Проекция ряда строится следующим образом:
О сеть обрабатывает начальный набор значений (первые 121 наблюдений) и выдает прогноз;
о первое наблюдение из исходного набора отбрасывается, вместо него ставится прогноз, полученный на первом шаге;
•j по новому набору входных значений строится следующий прогноз и т. д.
Процесс проектирования можно продолжать неограниченно.
Для построения проекции откройте окно Проекция временного ряда — Time Series Pivjection командой Проекция временного ряда — Time Series Pjvjedion... меню Запуск — Run
Рис. 25. Открытие окна Проекция временного ряда
В модуле Нейронные сети можно построить проекцию временного ряда с некоторого наблюдения текущего набора (см. опции окна). Выбирая опции окна, можно получить разнообразные проекции и прогноз ряда с помощью построенной и обученной сети.
Рис 26. Проекция временного ряда на 44 наблюдения
632
Глава 17- Нейронные сеп«
Чтобы оценить качество работы сети, откройте окно Статистики регрессии Regression Statistics и нажмите кнопку Запуск — Run
Рис. 27. Описательные статистики позволяют оценить качество прогноза
Шаг 5. Для того чтобы построить прогноз на 1 шаг с помощью обученной сети, выберите команду меню Run — Single Case...
Рис. 28. Выбор команды Run Single Case
На экране появится диалоговое окно Run Single Case. В поле Case No введите номер наблюдения, для которого нужно построить прогноз, и нажмите кнопку Run.
Рис. 29. Прогноз на один шаг вперед, построенный с помощью обученной сети
В строке Output появится прогноз ряда на один шаг вперед. В строке Target стоит знак ? так как в исходном файле всего 144 наблюдения.
диалог в модуле Нейронные сети STATISTICA
633
Классифи нация
Для решения задачи классификации воспользуемся файлом данных Irissta и Мастером решения задач.
Это классические данные Фишера, для классификации которых применяется дискриминантный анализ, дающий оптимальное линейное решающее правило. Заметим, что альтернативным вариантом исследования являются деревья классификации.
Мы используем эти данные только в иллюстративных целях: на простых и ясных примерах можно познакомиться с возможностями нейронных сетей по классификации данных.
Рис. 30. Мастер решения задач (начало диалога)
Шаг 1. Откройте файл Irissta. Первые 4 переменные — это параметры цветков ириса. Категориальная переменная IRISTYPE обозначает тип ириса. Измеряя параметры цветка, нужноотнести его к одному из трех типов (Setnsa, Versicol, Vwginic).
Мастер решения задач последовательно открывает диалоговые окна, в которых просит сделать несложный выбор.
Шаг 2. Одно окно уже открыто — это Problem Туре — Тип задачи Укажите тип задачи и нажмите кнопку Next.
Рис 31. Выберите стандартный тип
Шаг 3. В следующем окне выберите зависимую переменную.
634
Глава 17. Нейронные сеш
Рис. 32. Выберите переменную iristype как выходную {зависимую) переменную
Выходная переменная — номинальная, она принимает три значения: Setosa Versicol, Virginie. Нажмите кнопку Next.
Шаг 4. В следующем диалоговом окне выберите входные (независимые) пере менные
Нажмите кнопку Next Мастер решения разобьет выборку на обучающую (чер пый цвет значений), контрольную (синий цвет) и тестовую выборку (красный цвет). Также автоматически будет произведено перемешивание наблюдений.
Шаг 5. Наэкране появится окно Duration of Design Process — Длительиостьпоиска
Рис, 34. В окне Длительность поиска можно задать длительность поиска (быстрый, средний, полный, ограниченный по времени)
Заключительные комментарии
635
Шаг 6. Далее на экране появится окно Saving Networks — Сохранение сетей В этом окне можно задать способы сохранения сетей, например, максимальное чис ло сохраняемых сетей, сохранить сети с лучшим качеством решения и т. д.
Рис. 35. В этом окне можно задать способы сохранения сетей
Затем откроется окно, в котором указаны опции представления результатов.
Рис. 36. В этом окне выбираются опции представления результатов
Шаг 7. Нажмите кнопку Finish. STATISTICA произведет вычисления и представит результаты в следующем виде таблицы.
В этой таблице показаны 10 лучших сетей, найденных советником. В столбце Туре — Тип указан тип сетей: RBF— радиальные базисные функции. Linear—линейные . MLP — многослойный иерсептрон. Далее в таблице результатов идут столбцы: ошибка, входы, скрытые. В столбце Perfomance — Качество указаны доли правильно классифицированных цветков каждой сетью.
Рис. 37. В результаты работы советника найдено 10 сетей
636
Глава 17. Нейронныеq
аключительные комментарии
Указанная и таблице на рис. 37 сеть радиальной базисной функции (RBF) цм« промежуточный слой из радиальных элементов, каждый из которых восппаианпл!_
гауссову поверхность отклика. Сети RBF иногда имеют некоторое преимущества перед сетями MLP. Во-первых,они моде тируют любую нелинейную функцию с помощью только одного промежуточного слоя. Во-вторых, параметры линейной коу, бинацни в выходном слое можно оптимизировать с использованием известных ме тодов линейного программирования. В задачах классификации выходной элемепя должен выдавать большой сигнал, если данное наблюдение принадлежит к интересующему нас классу, и слабый — в противоположной ситуации. Имеется н более тонкий способ интерпретацпи уровней выходного сигнала сети — вероят-i ностный. В этом случае сеть выдает несколько большую информацию, чем прост<» «да/нст»: она сообщает, с какой вероятностью наблюдение принадлежит данному классу. В модуле Нейронные сети имеются методы, позволяющие интерпретировать выходной сигнал сети как вероятность, в результате чего сеть, по существу, учите» моделировать плотность вероятности распределения для наблюдений из данного класса.
Линейная модель представляет собой сеть без промежуточных сдоев, которая в выходном слое содержит только линейные элементы (то есть элементы с линейной функцией активации). Линейная модель обычно записывается с помо щыо матрицы N к А и вектора смещения размера N. Веса соответствуют элементам матрицы, а пороги — компонентам вектора смещения. Сеть умножает некто)» входов на матрицу весов, а затем к полученному вектору прибавляет вектор сме тения. Можно создать линейную сеть и обучить се с помощью стандартного алгоритма оптимизации, основанного на псевдообратных матрицах Тот же алго ритм реализован в модуле Множественная регрессия системы STATISTICA Эти самый простой тип сетей. Линейная сеть позволяет сравнить качество построенных сетей. Может оказаться так, что задача успешно решается не только с иомо щью сложных нейронных сетей, но и простыми линейными методами. Заметим, что в модуле Нейронные сети реализованы также другие типы нейронных сетей. например, сети Кохонсна, вероятностные сети, обобщенно-регрессионные лей ровные сети (GRNN), предназначенные для решения задач регрессии, однаю* описание этих сетей выходит за рамки данной главы
Рассмотрим подробнее столбцы таблицы на рис. 37.
Тип — Туре. В этом столбце указан тип нейронной сети. В большинстве сл*.ч* св это многослойные персептроны (MLP), радиальные базисные функции (RBF или линейные сети.
Ошибка — Error. Здесь указана ошибка сети, полученная на контрольном нс множестве, которая вычисляется по всем контрольным наблюдениям. Чем мень ше значение ошибки, тем лучше качество сети
Входы Inputs. В этом столбце указано число входных переменных, исподь зуемых нейронной сетью. Заметим, что лучше использовать сеть с меньшим ч» . лом входных переменных, если это не ухудшает существенно ее качество по срав нению с сетями, использующими большее количество переменных на входе
Заключительные комментарии
637
Скрытые — Hidden. Здесь указано число скрытых элементов сети. Заметьте, линейные сети не имеют скрытых элементов, поэтому для них в этом столбце указан пропуск.
Качество - Performance. В этом столбце показано качество сети, которое определяется по контрольному подмножеству. Для задач классификации качество — это доля правильно классифицированных наблюдений Очевидно, предпочтительнее использовать сети с лучшими показателями качества. Однако заметим, что в задачах классификации меньшее значение ошибки не всегда соответствует лучшему качеству. Иногда сеть может улучшить ошибку на некотором множестве уже правильно классифицированных наблюдений за счет неправильной классификации дополнительного наблюдения. В результате может оказаться, что такой вариант имеет меньшую ошибку и одновременно худшее качество по сравнению с другим вариантом сети.
Лучшая сеть отмечена * (в данном примере это сеть с номером 10, см. рис. 37).
Заметьте, что в набор сетей включены и некоторые сети с плохим качеством (см. например, сеть с номером 2, которая правильно классифицирует лишь 65% наблюдений). На примере таких сетей можно понять, какой результат дают простые модели.
Сети низкого качества легко удалить из набора. Чтобы сделать это, выделите сеть, щелкнув на ней мышью, азатем нажмите правую кнопку мыши и выберите п.з появившегося меню команду Удалить — Delete. Выделенная сеть будет удалена
Можно сделать выделенную нейронную сеть активной с помощью команды всплывающего меню Выбрать — Select
Если набор нейронных сетей заполнен. uporpaMMaSTNemalNetuorks должна определить, какие из имеющихся сетей заменять вновь создаваемыми. Нажм нте кнопку Опции — Options...в диалоговом окне Редактор набора сетей — Network Ser Editor.
Рис. 38. Настройка параметров набора сетей
Глава 17. Нейронные ।
Заключительные комментарии
639
На экране появится диалоговое окно Параметры набора сетей — Network Vw Opiions.
В этом окне задается максимальное количество сетей в наборе. Ео умолчание» максимальный размер составляет 30 нейронных сетей
Если вы хотите, чтобы программа сообщала вам об удалении сети, включил и режим Вначале сообщать пользователю — Inform User First.
Кроме того, взглянув наокно (рис. 38), мы видим, что при попытке добавить се? . в уже полный набор программа по умолчанию будет использовать режим Сохранять разнообразие — KeepDiverse... Вэтомслучасрсшсниеотом.замснптьлиновопсетъю какую-либо из существующих, будет принято с учетом необходимости сохранить в наборераэнообразныесоотношения между качеством и сложностью сетей (принтом всегда сохраняетсялучшаясеть каждого типа, независимо от се сложности).
Установив нужные значения параметров набора сетей, нажмите кнопку 3t -крыть — Close
Если вы не хотите удалять некоторую есть из списка, заблокируйте ее командой Блокировать — Lock из выпадающего меню правой кнопки мышц. Забтокь рованныесети выделяются голубым цветом и никогда нс удаляются, независимо с-т их качества. Чтобы разблокировать сеть, используйте команду Разблокировать — Unlock.
Иногда требуется изменить порядок сетей в списке, например, cipynniijxiBai i их по типам или рассортировать по ветичн не ошибки или качеству Чтобы осуик ствить это, щелкните правой кнопкой мыши на названии столбца п выберите т_» выпадающего меню команду Сортировать по возрастанию - Sort Ascending или Сортировать по убыванию — Sort Descending.
Для исследования важности входных перемен пых обученной сети полезен ана-
лиз чувствительности.
Представьте, вы имеете обученную сеть и вам нужно знать, как изменится качество работы сети, если некоторые входные переменные будут удалены. Чтобы ответить па этот вопрос, выберите команду Чувствительность — Sensitivity.. из выпадающего меню Статистики — Statistics.
В появившемся окне Анализ чувствительности нажмите кнопку Обновить — Update.
Рис 40. Диалоговое окно Анализ чувствительности
Программа построит таблицу, в которой б’ дет покажи ia чувствительность сети по отношению к каждой переменной. Посмотрите на таблицу (рис 40).
В таблице приводятся три показателя: Ранг — Rank, Ошибка — Error н Отношение —Ratio. Показатели чунствтстышсти даются отдельно для обучающего (первые три строки) и контрольного набора наблюдений. Столбцы таблицы — это переменные исходного <]>айла данных.
Вначале рассмотрим строку Error. Для каждой переменной значение Error показывает, каким будет качество сети, если данную переменную исключить из числа входных переменных. Очевидно, более важным для классификации переменным отвечают большие значения ошибок
Отношение — Ratio представляет собой отношение между значением в строке Ошибка — Error и основной ошибкой (Baseline Error). Baseline Eiror вычисляется для сети со всеми входными переменными. Если Отношение — Ratio меньше единицы, то исключение данной переменной улучшает качество работы сети.
В строке Ранг — Rank переменные просто ранжированы в порядке убывания ошибки.
Упражнение. Исследуйте данные об ирисах и найдите параметры цветов, наиболее важные для классификации. Сравните результаты, полученные с помощью нейронных сетей, с результатами классических методов классификации
Заметим, что для экспериментирования с набором входных переменных в SNN имеются Алгоритмы отбора входных переменных — Feature Selection Algorithms, чтобы проверять различные комбинации входных переменных и строить так называемые вероятностные сети, используемые для поиска лучшего набора входных переменных.
640 Глава 17. Нейронные сети
Эти алгоритмы, включающие в себя пошаговое включение, пошаговое исключение входных переменных и так называемый генетический алгоритм отбора входных, переменных, иногда позволяют найти варианты, пропущенные процедурой Intelligen,' Problem Solver.
Упражнение. Постройте с помощью нейронных сетей прогноз продаж бензина (см. данные в приложении 1) и сравните с результатами классических методов прогнозирования.
4 Q Язык STATISTICA
I О VISUAL BASIC (SVB)
В этой главе мы кратко опишем возможности языка STATISTICA VISUAL BASIC (SVB), доступного в новой версии STATISTICA.
Этот язык открывает огромные возможности для пользователей нз самых различных областей, предоставляя намного больше возможностей, чем просто ^вспомогательный язык программирования», который используется для создания пользовательских приложений.
STATISTICA Visual Basic (SVB) использует огромные преимущества объектно-ориентированной структуры системы STATISTICA и позволяет получить доступ практически ко всем функциям пакета Сложные процедуры анализа графический вывод результатов можно записать как макрос или сценарий анализа для дальнейшего многократного использования и редактирования. Макросы представляют собой самостоятельные блоки, которые легко встраиваются в другие приложения
STATISTICA Visual Basic добавляет богатый арсенал ил более чем 10,000 новых статистических и аналитических функций к стандартному синтаксису Microsoft Visual Basic и является, таким образом, одним из самых функционально богатых средств прикладного программирования.
Пользователь может представлять макрос как сценарий действий, который затем может быть многократно «проигран» в STATISTICA. При этом не нужно повторять эти действия, а достаточно нажать одну лишь кнопку, выведенную ла панель управления.
Мы еше раз подчеркнем, что SVB предназначен для самого широкого круга пользователей, а не для узких программистов. Именно с помощью SVB пользователи из различных областей могут создать собственный модуль анализа данных.
Структура языка STATISTICA Visual Basic
STATISTICA Visual Basic состоит из двух основных компонент:
1. общая среда программирования Visual Basic, содержащая визуальные средства создания пользовательского интерфейса, включая собствен |ые диалоговые окна пользователя;
2. библиотекаSTATISTICA, содержащая тысячифункшш,обеспеч1шаюшлх доступ практически ко всем аналитическим и графическим процедурам STATISTICA. Среда программирования Visual Basic удовлетворяет стандартным сог мщениям Microsoft Visual Basic. Небольшие отличия имеются в основном между способами создания диалоговых окон и появились они для того, чтобы предоставить
642
Глава IS. Язык STATISTICA VISUAL BASIC
пользователю большую гибкость в разработке собственного шгтерфейса при написании сложных программ анализа данных.
Библиотека STATISTICA (более 10 000 аналитических и графических процедур) открыта для использования не только в Visual Basic, но и в других языках программирования, например C/C++, Java или Delphi.
Запись макросов
Существуют три основные категории макросов, которые могут быть созданы при работе в STATISTICA 6.0:
о макросы анализа, используемые в одном модуле;
О мастер-макросы (объединение нескольких макросов анализа в один макрос пли сценарий выполнения нескольких видов анализа);
О клавиатурные макросы, полезные, например, для атоматизации ddjlf.
Когда вы создаете макрос анализа (используя команду Options — Create Macro — Параметры — Создать макрос), точная последовательность действий сохраняется в виде программы на STATISTICA Visual Basic. Эта программа может быть в дальнейшем запущена с целью воспроизведения данного анализа.
Рассмотрим макросы и приведем примеры их записи. Мы рекомендуем вслед за нами повторить описанные нами действия, а также самостоятельно поэкспериментировать с системой, чтобы убедиться, как легко записываются макросы в STATISTICA. Надеемся, что макросы или сценарии анализа станут привычным для вас способом работы в STATISTICA.
Мы начнем с самого простого макроса STATISTICA, который относится к одному модулю или анализу STATISTICA. Ключевым является слово событие
Событие — это операция, которая совершается пользователем при работе с системой. например, нажатие кнопки мыши, клавиши клавиатуры, изменение значений переменных, открытие таблицы данных или рабочей книги, — это события. В STATISTICA могут отслеживаться также некоторые события, которые происходят во внешних приложениях Они также могут быть обработаны и перепрограммированы. Данные возможности расширяют возможности STATISTICA по созданию пользовательских программ
Обработка событий - мощное средство, встроенное в STATISTICA, которое позволяет программировать сложные задачи.
Макрос анализа
Обычно анализ данных включает определенную последовательность действий: выбор анализа, открытие файла данных, выбор переменных, задание условий выбора наблюдений, выбор весов, выбор аналитической процедуры, установка параметров, просмотр результатов и т. д.
Заметим, что термин «анализ» в STATISTICA означает определенную задачу, выбранную в меню Statistics или Graphs. Задача может быть как простой, например
Запись макросов
643
построение диаграммы рассеяния из меню Graphs — Графика, так и достаточно сложной, например пошаговая множественная регрессия, включающая разнообразные опции просмотра результатов и трафики.
Запись макроса анализа
Следующий пример показывает создание макроса анализа для простого типа анализа: э Запустите STATISTICA.
j Откройте файл heart.sta. Это знакомый нам файл, содержащий данные об операциях на сердце (см. главу 14).
Э Выберите команду Basic Statistics/Tables — Основные стагпистики/Габлицы из меню Statistics.
У В стартовой панели модуля Basic Statistics and Tables — Основные статистики и таблицы выберите опцию Descriptive Statistics — Описательные статистики и нажмите кнопку ОК.
3 В диалоговом окне Descriptii е Statistics — Описательные статистики щелкните на кнопке Variables — Переменные и выберите для анализа переменную Agt Возраст из открытого файла данных.
Э Далее нажмите кнопку Summary: Descriptive statistics — Подробные описатель ные статистики, чтобы вывести на экран таблицу результатов, содержащую описательные статистики
J Когда таблица результатов появится на экране, диалоговое окно анализа свора-чивается на панели Analysis — Анализ.
□ Нажмите кнопку Descriptive Statistics — Описательные статистики на панели Analysis — Анализ, чтобы развернуть диалоговое окно анализа.
О Затем выберите вкладку Normality — Нормальность и нажмите кнопку Histograms — Гистограммы; для переменной Age — Возраст пациента будет построена следующая гистограмма-
644
Глава 16- Язык STATISTICA VISUAL BASIC (SVB)
Код программы па STATISTICA Visual Basic, который woi ветствует проведенному анализу, можно посмотреть в окне редактора STATISTICA Visual Basic Editor двумя способами.
Ес тп диалоговое окно текущего анализа свернуто, нажмите правую кнопку мыши на свернутом окне анализа на панели Analysis —Анализ и выберите команду Create Macro — Создать макрос.
Если диалоговое окно анализа развернуто, воспольэуйтссыкнопкон |iS?№*»>-. т] и выберите из появившегося меню команду Create Macro — Создать макрос.
Запись макросов
645
После этого запись завершается и появляется диалоговое окно New Macro -Новый макрос
Э В поле Name введите текст и назовите вновь созданный макрос МуМасп Э Нажмите кнопку ОК, чтобы открыть новый макрос в автономном окне
О Чтобы запустить макрос, нажмите клавишу F5 или кнопку у Run Моего -Выполнить макрос па панели Макрос.
о Нажмите клавишу F5 или кнопку и вы увидите, что STATISTICA повторит ваши действия и построит приведенную выше шетограмму возраста пациентов.
Заметьте, что имеется различие между автономными макросами и т.н» «льны-ми макросами.
Автономные макросы перед выполнением должны быть предварительно открыты в системе, в то время как глобальные макросы становятся частью STATISTICA.
646
Глава 18. Язык STATISTICA VISUAL BASIC (SVB)
Для того чтобы создать глобальный макрос, воспользуйтесь командой As Global Macro, доступной из меню File — Файл.
В появившемся на экране окне нажмите кнопку Сохранить.
Впоследствии глобальный макрос будет загружен автоматически при очеред ном запуске системы STATISTICA.
По умолчанию глобальные макросы доступны через диалог Маст Manager — Менеджер макросов (вызываемый командой Macros — Макросы из меню Tools -Macro — Сервис — Макрос).
Глобальные макросы расположены по умолчанию в директории, где расположены файлы запуска ЗГЛ77577СА Если вы выбираете команду Save as Global Маст из меню File — Файл, то STATISTICA предложит сохранить глобальный макрос именно в этой директории.
Создание графика
Приведем еще один пример, когда запись данного макроса полезна
Предположим, вы проводите разведочный анализ данных, используя множественную регрессию. В некоторый момент своего исследования, пользуясь командой Scatterplots — Диаграммы рассеяния в меню Graphs — Графика, вы создаете диаграмму рассеяния, которая, на ваш взгляд, заслуживает внимания
Чтобы сохранить последовательность операций выполненных при построении данной диаграммы, вы выбираете Create Macro — Создать макрос из быстрого меню (которое можно вызвать нажатием правой кнопкой мыши на кнопке анализа) и зы писываете всю последовательность действий, которую сделали при построении данной диаграммы (с помощью команд Graphs — Scatterplots — Графика —Диаграммы рассеяния).
Записанный макрос отражает все необходимые настройки и не содержит информации по проведению многомерного регрессионного анализа или о других графиках, которые вы строили и которые не представляют интерес.
Запись макросов
647
Данный макрос содержит информацию о настройках и условиях выбора для построения только интересующего вас типа графика (Scatierplols — Диаграммы рассеяния'). Записанный макрос может выглядеть следующим образом.
Как видно из рисунка, запись началась в текущем анализе. Создается объект для диаграммы рассеяния.
При запуске макроса будет создан нужный вам график. Таким образом, вы можете записать макрос, чтобы затем включить его в окончательный отчет или повторно запускать для разведочного анализа других данных
648
Глава 1В. Язык STATISTICA VISUAL BASIC (SVB)
1астер-макрос
При записи простого макроса анализа мы работали только в одном модуле STATISTICA, однако при проведении сложных исследований возникает необходимость переключат ься в различные модули системы. Здесь полезен Мастер-макрос.
В отличие от простого макроса, с помощью Мастер-макроса вы можете записать сценарий исследования, который включает несколько видов анализа, например. анализ ставных компонент и множественную регрессию, множес i венную регрессию и анализ временных рядов, различные методы классификации, например деревья классификации и дискриминантный анализ и т д.
Итак, Мастер-макрос представляет собой сценарий исследования, включающий в себя несколько видов анализа и модулей STATISTICA.
В отличие от простого макроса анализа, вы можете в любой момент начать запись Мастер-макроса или приостановить ее*
Таким образом, управляя моментом начала записи и моментом окончания, вы записываете, в единый макрос только те этапы исследования, которые необходимы. поскольку в Мастер-макрос попадут лишь действия, которые совершены меж
ду началом записи и се окончанием.
Данная возможность придает системе большую гибкость и позволяет связы-ва I ь различные виды анализа.
Для создания Мастер-макроса STATISTICA выполните следующие действия. О Выберите команду Ret ording Log of Analyses (Master Macro) — Записать жур нал анализа (Мастер-макрос) из меню Tools — Маст — Сервис — Макрос
Заметим, после старта записи Мастер-макроса на экране появляется панель инструментов Record — Запись.
о Начните проведение анализа.
О Чтобы приостановить запись, нажмите на кнопку остановки записи на панели инструментов Record — Запись.
Среда программирования
649
После нажатия кнопки остановки весь код, записанный с помощью синтаксиса Visual Basic (отражающий все виды анализа, выполненные во время сессии), будет перенесен в окно редактирования Visual Basic.
О Мастер-макрос может быть в дальнейшем отредактирован, сохранен или запущен на исполнение, с целью точного повторения записанной последовательности действий.
Замечание: если вы одновременно выполняете несколько видов анализа, например, Basic Statistics — Основные статистики и Multiple Regression — Множественная регрессия, то эти действия будут записаны одно за другим. В результате когда вы воспроизведете Мастер-макрос, то вначале получите таблицу результатов Basic Statistics — Основные статистики, затем таблицу результатов Multiple Regression — Множественной регрессии Далее могут быть выведены гистограммы, построенные в модуле Basic Statistics — Основные статистики, предсказа! гные значения зависимой переменной, построенные в модуле Multiple Regre^ion — Множественная регрессия и т. д.
Итак, следует запомнить:
основная цель мастер-макроса заключается в том, чтобы сохранять всю последовательность действий при проведении сложного исследования данных, включающего несколько видов анализа.
Когда вы запускаете этот макрос «как есть», будет повторена вся последовательность анализа
Клавиатурные макросы
Если вы выбираете команду Start Recording Keyboard Macro — Записать клавиатурный макрос в меню Сервис — Макрос — Tools — Macro, то STATISTICA записывает последовательность нажатия клавиш, которую вы производите.
По окончании записи в редакторе STATISTICA Visual Basic Editor открывается окно с простой программой, содержащей единственную команду SendKeys с символами, которые перечисляют все нажатия клавиш во время рабочей сессии в STATISTICA.
Заметим, что в данном типе макроса запоминается лишь последовательность нажатия клавиш, а не команды, которые выбираются при этом Несмотря на простоту, данный макрос также оказывается полезным, например, для автоматизации ввода данных.
Среда программирования
Итак, мы показали, как можно записать последовательность действий в STA TISTICA. Вы проводите анализ данных в STATISTICA, программа записывает код сценария, имея код, можно многократно повторять его.
Очевидно, можно непосредственно записать код сценария на языке SVB и заставить программу выполнить его.
Писать такой код довольно легко, язык SVB предназначен для самого широкого круга пользователей.
Вначале вы можете писать программы по образцу или просто скопировать какой-либо пример, чтобы затем модифицировать его.
650
Глава 18. Язык STATISTICA VISUAL BASIC
Далее вы легко научитесь писать полезные для себя небольшие программы Е- ы вам понравится написание простых программ, вы сможете перейти к более c.nnwj ным. Поэкспериментируйте с языком, вы быстро освоите его. Наши примеры таь-же помогут вам в этом.
Наше популярное изложение основано, главным образом, на текстах нрогрг и комментариях к ним. Так же как при изучении иностранных языков вы стара,-тссь совместить чтение текста с правилами грамматики, так и при изучении язы»л программирования изучение программ следует совместить с основными правилу, ми и сог [ашевнями языка. Мы настоятельно рекомендуем вам экспериментировать с STATISTICA, писать собственные программы и модифицировать иэвг% »• ные Лейтмотивом нашей книги является слово «эксперимента, нельзя научиться анализировать данные, нс экспериментируя всесторонне с программой.
Представьте, вы врач, проводящий обследование пациентов. Вы получаете таблицу результатов обследования, в которой по строкам записаны имена пациентов в столбцах признаки (возраст, пол), характеристики обследования, например параметры крови, результаты ультразвукового обе юдованпя и т. а.
Заметьте, таких переменных может быть достаточно много, также может был ь большое количество пациентов, которые прошли обследование, ппчтоыу вам тр- д -по обозреть полученные результаты
Получив таблицу, вы хотели бы визуально представить полу ценные резутьти ты. например, выделить определенным цветом группу пациентов, которые нс укладываются в норму, или выделить группы пациентов, которые близки друг к другу по ряду параметров, и т. д. В выборе способа выделения ваша фан i азия ничг : 11 к ограничивается. Конечно, каждый модуль системы STATISTICA предлагает специальные средства визуализации результатов анализа, однако вам хотелось бы
получить нечто свое
Здесь паступаеттворческий момент связанный с использованием SVB, многие исследователи из самых различных областей, не имеющие представления о топке* стях программирования (и не обязанные их иметь!), могут получить очень эффе» тивные результаты. Среда визуального программирования создана именно дл« решения таких задач, а действия, которые нужно провести, просты и понятны каз» дому.
Конечно, наше описание не яаляется полным, для всей город него знакомств^ следует использовать руководство по стандартному Visual Basic.
В следующем разделе приводятся некоторые грамматические правила языка. Вообще представление о программе как о тексте, написанном с помощью опре М-денных правил, поможет вам продвинуться в изучении SVB.
Основные соглашения STATISTICA Visual Basic
О Основная программа: как минимум, в каждой программе имеется npoi г Р> Main, которая декларирована как Sub Main в начале программы.
О Процедура завершается оператором End Sub. Между Sub Main и End Sub пишется текст программы.
г
Основные соглашения STATISTICA Visual Basic
651
О Комментарии: любая строчка, которая начинается с апострофа, считается комментарием.
О Комментарии не исполняются программой, однако очень удобны для ее понимания.
О Разбиение длинной команды на несколько строк: вы можете разбить одну команду на несколько строк, каждая из которых должна начинаться символом подчеркивания (символом «_»; который, в свою очередь, должен отстоять от предыдущего текста как минимум на один пробел).
О Справочник по ключевым словам SVB: в любой момент вы можете высветить текст и нажать клавишу F1, чтобы вывести на экран общую справку по синтаксису SVB для данной конкретной команды и просмотреть пример се использования.
О Для того чтобы записать код программы на SVB. нужно выполнить следующие действия.
Вначале выберите команду File New — Файл Создать.
Далее в диалоге Create New Document — Создать новый документ выберите Macro (SVB) — Макрос (SVB) и создайте макрос, например с именем Example 1. Далее нажмите ОК
652
Глава 18. Язык STATISTICA VISUAL BASIC ।
В появившемся окне напишите текст программы. Нажмите клавишу F5 »ц)В кнопку и пошлите код на исполнение
Типы данных, массивы, функции
Следующая простая программа вычисляющая корень квадратный из суммы квад ратов. иллюстрирует, как объявляются и используются переменные и массивы в SVB. Она также показывает, как следует объявлять подпрограммы (или функции) и каким образом передавать в них ар17мснты.
Текст программы-
SJb Mair.
I ji х >| "•? |t • As Double
I - SAttikM# ШМИ *4 -StTMig
|1- , «
For i •) *l 1Г
Em4
Просмотрите программу заметьте, что для явного объявления переменных ис пользуется оператор Dim. который имеет следующий синтаксис:
Dim Имя_переменной [As Тип данных]
Например, вы видите, что строка Dim i As Integer объявляет переменную, при ппмающую целые значения, Dim х (1 То 10) As Double объявляет вещественный массив. Dim Sum As Double, ResText As String объявляет вещественную переменную и строковую.
Числа. Типы данных Double, Integer и Long наиболее часто используются в вычислениях.
Переменные, объявленные как Double, могут хранить вещественные числа в интервале от ±1 7Е + 308 (приблизительно 15 знаков точности); переменные.
Основные соглашения STATISTICA Visual Basic
653
объявленные как Integer, содержат целые числа в интервале от —32.768 до 32,767 и, наконец, переменные типа Long содержат целые числа» интервале от -2.147.483.648 до 2,147/83,647.
Просмотрите программу и найдите, где используются эти тины данных.
Строки. Для операций со строками произвольной длины используется, как вы уже видели, тип данных String
Логический тип. Переменная типа Boolean (логическая переменная) принимает два значения: True (/) и False (0)
Приведем некоторые другие типы: Currency (денежная величина) Date (дата/ время). Object (объект). Variant
Тип данных Object служит для хранения объектов. Заметим, язык SVB работает с объектами анализа, например для того, чтобы запустить анализ, относящийся к модулю Basic Statistics — Основные статистики, нужно создать объект анализа с константой в копструкторе scBasicStatistics и (необязательно) имя файла дан ных (путь к файлу, содержащему входную таблицу). Посте создания объекта анализа, например, Basic Statistics — Основные статистики, фактически в к<>де программы вы по шагам задаете параметры, обычно задаваемые в диалотных окнах, при проведении соответствующего анализа в STATISTICA.
Если вы хотите связать объект с переменной, используйте команду Set Variable = Object.
Тип данных Variant устанавливает тип данных в зависимости от содержимого и может меняться в ходе выполнения программы. Переменные, декларированные как Variant, могут: быть пустыми, принимать численные значения, иметь денежный формат, значения дат, содержать строки, быть объектом или кодом ошибки, vicaja-телсм null или массивом. При использовании SVB для включения статистических модулей (функций) в пользовательскую npoipaMMv inn Variant оказывается полезным. например, когда приходится иметь дело со списком переменных Переменная может быть определена как строковая (то есть. Variables= 'Му VarNsunc"). численная (то есть .Variables=2) или массив (,Variables=VarArray).
Заметим, что переменная, явно неописанная, по умолчанию имеет тин Variant.
Этот тип иногда называют также хамелеоном, потому что он принимает значения в зависимости от выполнения программы.
Массивы. Приведенный пример также иллюстрирует применение массивов в Visual Basic Массив — это набор элементов определенного тина, кж» лып из которых имеет свой порядковый номер (индекс). Для объявления массива также ис пользуется оператор Dim с указанием в круглых скобках максимального порядке вого номера либо с указанием верхней и нижней границы.
По умолчанию массивы имеют нулевой элемент; это означает, что массив, объявленный как Dim х(5), на самом деле содержит шесть элементов: первый элтоэент х(0), потом х(1) и шестой элемент—х(5). Вы также можете декларировать массивы с точными границами; объявление Dim х(1 to 5) говорит о том, что массив б\ ici иметь только пять элементов, и к первому элементу можно обратиться как х(1)
Вы также можете поместить в начало программы команду Option Base 1. кот.» рая по умолчанию декларирует все массивы как массивы с первым элементом, имеющим номер 1.
654
Глава 18. ЯЗЫК STATISTICA VISUAL BASIC
Например, Dim x (1 To 10) As Double объявляет массив с номерами 1,2 . li, Для того чтобы определить нижнюю и верхнюю границу массива, используют! ся функции Lbound (Массив, Размерность), Ubound (Массив, Размерность) I
Эти функции помогают определить фактические размеры массива. Посмотрите на приведенную в начале раздела программу, и вы поймете, как используют^ яти функции
Естественным образом задаются многомерные массивы, верхние границы юшй рых разделяются запятыми, например,
D’T Xj (1 10) AS
Этот двумерный массив ху содержит 22 значения (2x11 = 22).
Коллекции и массивы. Во многих случаях работа с коллекциями более удоб) ш чем ]>аб<>та г массивами. В STATISTICA Visual Basic все таблицы результат» м н графики из анализа сохраняются по умолчанию как коллекции. которые допускс»-ют редактирование, сохранение и делают дальнейшую обработ «у данных michi удобной.
Циклы. Для многократного выполнения одного или нескольких операторов применяются циклы. В разбираемой нами программе применяется никл вида;
For - • - ТО «г. |. step ц
Next r«*r»<v
Действие этого оператора легко понять. Рассмотрим только цикл вид*.
For г- Нечапыт •‘зчелие То Косное чначение
Next t -v «•
В приведенной программе вы легко найдете цикл
1 •] ТО JI
«•
Nt ..i
Счетчиком в нашем случае является переменная i, объявленная как Integer (см. программу). В начале цикла значение счетчика принимает начальное значение (в нашем случае 1), выполняются все операторы.
Значение счетчика увеличивается на 1 Если это значение становится равным или превышает Конечное_знанение, цикл завершается.
Если значение счетчика меньше величины Конечноезкачение, цикл повто р«-ется. Значение счетчика вновь увеличивается на 1 и т. Д.
Если число проходов зависит от некоторого условия, то применяется конструкция цикла типа: Do... Loop.
Приведем еше один пример цикла-
г<у Н *1 М»>С*'иг'»-й«п л-.в; »arag<
]
3 , . •<- «-oetapai -ления мте'-тнпьья» ’Срекечныл загакая те<сговые и •. ные значения «егда
Основные соглашения STATISTICA Visual Basic
655
Операторы управления порядком выполнения команд
Хотя эти операторы не встретились нам в программе, кратко их опишем. Наиболее часто используется оператор If... Then.
Однострочный синтаксис этого оператора имеет вид:
If Условие Then Оператор [Else Cnepatop]
Заметьте, в квадратных скобках как всегда мы записываем необязательную часть оператора.
Часто этот оператор записывают в несколько строк (блочный синтаксис), при этом в последней строке следует написать End If, например:
If Ret-0 Then
VartablesSpecTfications-False Else
VariablesSpeci/«cations-Тrue End If
Этот оператор выпог-гет проверку значении Ret
В случае если Ret-0 то присваиваем Vari ablesSped flcations значение 'False, иначе значение True
Приведем еще один пример:
if CjrrentDataSet.MissingDatafvr VarCodeNurrberrjl) Then GoTo NextCase
Else
Set r(jj - CurrentDataSet Cells <v” VarCodeNirber(jl) End If
Приведем еще несколько фрагментов программ, позволяющих почувствовать SVB.
Фрагмент 1:
’Создаем рабочую книгу в которую будут включены таблицы результатов и графики
Set RestiltsWorkbook - Application Workbooks New 'Начинаем анализ для всех возможных комбинаций 'категорий переменных
For 1 - 1 То NirberOfCategCorrbrs
Объявляем модуль Statlstica для использования в
'данном анализе и определяем набор данных, с которым
'будет связан анализ
Din newanalysis As Analysis
Set newanalysis - Analysis iscMultipleRegression. CurrentDataSet/
'Добавляем папки в ребочую книгу и задаем для них имена, папки
'будут содержать результаты для каждой комбинации категорий.
Set Folder-ResultsWorkbook InsertFolder( _
ResultsWorkbook Root scWorkbookLastCbild)
Folder Name-'"
Folder Name- FolderTitle * FolderCaseNametl)
656
Глава 18. Язык STATISTICA VISUAL BASIC (<
Фрагмент 2:
’Хьхвлжл --pent-—irai
Cwhrtlbli. *4 £rrt(^
Cm i If?T<t r- <1 «ring c - Ms* ' AS '/rifig D - i i. As 'J.' ng ьявгяс • "•’ременные типам Lone
Г-Var т*»м6ег() м Lt*j
О— J* Long D—• h :аь*а l: i ' имел -- — иуюти : tng.
j’ - itrtjerAnalys 'SVarLis- •, A^ •к’’™; ъя-.1яем Long
Dm NumberCnterionVars As Long ьявг--- _»c—»луо типа String
tf'-i Adc • »-
"ЪЯВЛЯСп jpcncrryB типа HoriXjA
-lie ШиШИИМ* As
•ъя«п««< 'M*"/ '“па l> <i г Й ЯО«ЧД
пявмм -rw «rttaJitam
?u6 I «. ‘•'A*- A. II*
‘Cc^tfiaWM . « fcrr*Stfaat
Р<м c ^.jrretAitiawt U Sc*«aUMcr
Фрагмент 3:
Эт;^К."1Ен ни, перенем»л для оналг-1
ЙиИ 'Ч 4 ум-МТ ЧЦ - ".*
I • I I < ф— =- «
L гше -и- AIM"
I , Ир - Inrtww>ri<jpnt vari ;
'33.4M M>«
ж»Г>- 1 • Tv'i )ч ч га lArtt1,.
ой*а.« <: - . релу ю • - > •.-
-•«. <rMt-*»: As л»п—а'аа»а t
’адге- •• j. пь™рупщий ? | •» .
T A’ »'»ch
" Т Маятой - Tfl’’ As илам
Глобальные переменные, передача аргументов по значению и по ссылке
Оператор ByRef. В разбирасмои нами программе используется функция Compute-SumOfSqrs.
По умолчанию переменные передаются в процедуры и функции по ссылке Это позволяет процедурам и функциям изменять переданную переменную.
Таким образом, если в процедуре или функции необходимо изменять определенное значение, передавайте его по ссылке (то есть исполыуите режим по умолчи-
Основные соглашения STATISTICA Visual Basic
657
пню или в явном виде в заголовке функции декларируйте аргументы как передаваемые по ссылке с помощью оператора ByRef)- Когда переменная передается в процедуру или функцию ио ссылке, то передается сама переменная (если говорить более точно, то в процедуру передается не сама переменная, а ее адрес, отсюда и название «по ссылке»). Если внутри процедуры ее значение изменяется, эти изменения сохраняются и после завершения процедуры. Таким образом, в то место, откуда была вызвана процедура, возвращается уже измененная переменная.
Место вызова процедуры.
ComouteX х. yl у2
'Описание процедуры.
Sub ComputeXtByRef х As Double. ByVai yl As Double.
ByVai yZ As Double)
' or Sub tanputeXCx As Double. ByVa? yl As Double
By Vai y2 As Double)
x-yl+y2
End Sub
Оператор ByVai. Переменные также могут быть переданы в процедуру или функцию по значению. Эго означает, что в процедуру передается не сама переменная, а вишь ее копия С практической точки зрения это выражается в том, что если внутри процедуры значение копии меняется, это никак не изменяет переменную (ее значение в том блоке, откуда вызвали процедуру, остается без изменения); таким образом, аргументы, передаваемые по значению, используются только как входные переменные.
Приведем пример:
Место вызова функции.
х - Co<TputeX(yl.y2)
Описание функции.
Function Computed By Vai yl As Double ByVai y2 As Double) As Double
CwnputeX-yl+y2
End Function
Глобальные переменные. Вы можете декларировать некоторые переменные вне процедур и функций. В таком случае они имеют характер «глобальных» и доступны во всех подпрограммах и функциях соответствующей SVB-программы.
Задание глобальных переменных.
Jim х as double, yl as double y2 as double
Sub Main
’Место вызова процедуры.
ComputeX
End Sub
658
Глава 1В. Язык STATISTICA VISUAL BASIC («
Списание процедуры. Обратите внимание на то. что при использовании ’глобальных переменных описание их в процедурах или в функциях не требуется.
Sub Compute •
x»yl*yj
Передача массивов. Кроме отдельных значений, процедуры и функции Visual Basic могут быть вызваны с артументэми, которые являются массивами. Массивы всегда передаются но ссылке.
’Описание массива.
Опп ху(3) As noble
’Место вызова процедуры для массива ху.
Computed ху
’Описание процедуры.
Sub Сотри*«X () As I - .-Jf ।
xyti) =«> ;..»»• n
End Sub
Приведем еще несколько примеров программ
Примеры программ с комментариями
-uD Main
Замечание, файл exp sta может находиться и друнм нт ie
В зависимости от места »лоложения вашей уста «>-« й директории
Также вы можете гоздатъ этот код при помощи На<_ гер-лакрос по умолчание по>едоват«к>иость »ч-'».ов буд»> объявти »т кап newanalysTsl newanalysisZ. а таблицы данныл буду’ объявлены как SI. S2 и т д
Set newana'bi s - Analysis (sUbstc.iz t»t'cx "j .STATISTICA'icxanpIes'iData ц jLj • newanaly. <s Dialog Sf.nistiis - stamtayr. • । newanalysis Run
newanaly.i> Dialog Variables - "1-8"
Замечание следумая строка отображает нанпростейший путь визуализации проведенного анализа
newanalyTis Dialog Sumary visible - True
F'“l Sub.
Пример: формирование коллекции таблиц данных
Выберите команду File New — Файл Создать.
В диалоге Create New Document — Создать новый документ выберите диалог Macro (SVB) Program — Макросы и создайте макрос.
Примеры программ с комментариями
659
Затем введите код:
чЬ Main
Замечание файл exp sta помет находиться в другом месте
В зависимости от места расположения вайей установочной директ-т»»
с newanalysis - Analysis < и «asic List
j 'STAIlSIICA\£xample« ..jtaset^exp sta’i
newanalysis Dialog Statistics - эгЬн'-ллгж
newanalysis Run
newanalysis.Dialog Variables - "1-8”
• t s-newanalysis Dialog Sumary
л Visible-False
MsgBox "Number of Spreadsheets. • s Count
IteuKs Count).Visible-True
rod Sub
Создание таблицы данных и заполнение ее случайными числами
Следующая программа создаст новую таблицу результатов и заполняет се случайными значениями. Первый столбец заполняется равномерно распределенными случайными числами. Второй столбец — нормально распределенными случайными числами.
□Lion Base I
jb Main
)im r As Long 4 As Long
rlOOO
Создаем ноеуо таблицу результатов.
Dim s As New Spreadsheet
Задаем размеры таблицы: n - число наблодеиий 2 - число переменных.
s SetSize(n.2)
Заполняем таблицу случайными числами.
s Value(i.l)-Rndi 1)
s Valued Z)-RndNormaUl'
Next i
' Устанавливаем имена переменных.
s VariableNametD-UnifbrnT
s VariableNamefZJ-’NormaT'
s Visible-True
End Sub
Вывод индикатора состояния
Иногда в процессе длительных вычислений желательно отображать индикатор состояния, который показывает процент выполненных операций Индикатор состояния отображается в STATISTICA во время вычислений на больших объемах данных Приведем пример кода, реализующего индикатор состояния в программе, генерирующей нормально распределенные случайные числа-
660_______________________________________Глава 18- Язык STATISTICA VISUAL BASIC (SVB)
Option Base 1
Sub Hain
Dim n As Long.! As Long n-1000
' Создаем новую таблицу результатов.
Dim s As New Spreadsheet
Задаем размеры таблицы: л - число наблюдений. 2 - число переменных « SgtSizetr ,?) Устанавливаем индикатор состояния.
Dim pb As ProgressBar
Set pb - AddProgressBarl"Generating randan nunbers" J ni
For 1-1 To n
' Обновляем индикатор состояния, pb.Currentcounter - i
Заполняем таблицу случайными числами.
s.Valued.l)-Rnd(l)
s Valued 2)-RndNonnai(l)
Next i
Закрываем индикатор состояния.
Set pb - Nothing
' Сохраняем имена оерененних.
s. VanableNameC 1 )-"Uni form"
s VariableName(2)-'Normal"
s Visible-True
End Sub
гистограммы с подгонкой о распределения
Следующий пример иллюстрирует построение гистограмм для выборки, сгенерированной ранее.
Option Base 1
Sub Main
Dim n As Long
n-1000
Dim s As New Spreadsheet
Заполняем таблицу s случайными числами.
CorputeRandomNuTtoers s. n
Строим гистограмму для s.
CreateHistograms s
End Sub
‘ Описание процедуры заполнения таблицы s случайными числами
Sub COTputeRandcmNunbers (s As Spreadsheet n As Long)
Dim i As Long
ReDim x(n.2) As Double
s SetS1ze(n,2)
For i-1 To n
xd.l)-Rnd(l)
xti .2)-RndNorma)(l)
Next i
Примеры программ с комментариями
661
s Data-x
s VariableNareCD-’Unifornr
s V0riableNameC2)“"NonnalR
End Sub
Описание процедуры построения гистограммы.
Sub CreateHistograms (s As Spreadsheet) Задание и описание вида анализа.
Dim newanalysis As Analysis
Set newanalysis - Analysis (scZdHistograms. s) Описание параметра гистограммы.
With newanalysis Dialog
Variables - "1 2 | '
GraphType - scHistgoramRegularPlot
End With
' Активация гистограммы (построение гистограммы}, newanalysis Dialog.Graphs Visible - True
End Sub
Отметим, что в программе вызываются две процедуры: подготовка данных и построение гистограммы.
Гистограмма строится с использованием встроенных процедур STATISTICA.
Раскраска таблицы
Option Base 1
Данный макрос выделяет ячейки рабочей таблицы
‘рифтом Arial Black с наклоном, размером 12 и цветом (255.12.255).
где (x.y.zl- координаты цвета в (красном.зеленом.синем) тонах.
’Предполагается, что таблица содержит в ячейках числа, отличные от 0.
Sub Main
662
Глава 18- Язык STATISTICA VISUAL BASIC (SVB)
Выбираем активную таблицу
Set j = ActiveSpreadsheet
цикл no переменным таблицы
For з-l To s NunterOfVariables
'Цикл по наблюдениям таблицы
For т-l To s NurberOfCases-1
'Условия выбора ячейки которую мы «лик отметить
If •».Valued.j«s Value(i+1 j)>l Then
'Задание названия шрифта в данной ячейке
s Cells(i.j) Font Name - "Anal Black"
'Задание размера шрифта в данной ячейке
s Cells(i.j) Font.Size - 12
Задание наклона шрифта в данной ячейке
s Cel l;(i ,j) Font Italic - True
Задание цвета шрифта в данной ячейке
s.Cellslt J) Font Color - RGB(255.1f Т'-б)
End If
Next 4
Next j
End Sub
оздание пользовательских диалогов
Нажмите левую верхнюю кнопку User Dialog, на экране появится окно User Dialog Editor. Это редактор пользовательских диалоговых окон, который позволяет вам визуально создавать необходимые диалоговые окна.
Например, работая только мышью, вы мгновенно создадите окно.
Последовательность ваших действий очень проста: с помощью мыши вы выбираете кнопку в левой части и перетаскиваете ее в нужное место справа в создаваемом диалоговом окне Итак, из типовых заготовок вы последовательно собираете нужное вам окно.
Просмотр объектов и функций
663
Двойной щелчок левой мышью на кнопке позволяет редактировать свойства кнопки, вносить текст, менять положение и т.д.
Просмотр объектов и функций
Нажав на клавиатуре кнопку F2 или кнопку Object Browser, вы откроете окно, в котором можете просмотреть доступные вам объекты.
664
Глава 18- Язык STATISTICA VISUAL BASIC (SVB)
В левом списке выбираются классы объектов, в правом прокручиваются элементы выбранного класса. В нижней части окна приводится краткое описание выбранного объекта (см. рисунок).
Кнопка fn позволяет просмотреть доступные в SVB функции, например, выбрав, в левом окне тип Distributions - Распределения вы можете просмотреть функции распределения, плотности и обратные функции распределения.
Заметьте, имена обратных функций распределения начинаются с буквы V. имена интегральных функций распределения начинаются с I, плотности распределения записываются непосредственно.
Например, Norma! обозначает плотность нормального распределения, INormal кумулятивную или интегральную функцию распределения (интеграл от плотности), VNorma! обратную кумулятивную функцию распределения. Эти функции подробно описаны в главе 3.
Вы можете, например, использовать обратные функции распределения для того, чтобы преобразовать равномерно распределенную случайную величину в переменную, имеющую данное распределение F.
Более точно, пусть переменная X имеет равномерное распределение на отрезке [О, 1]. Тогда переменная VF(X) имеет распределение F. Например, переменная VNormal(Xft, 1) будет иметь стандартное нормальное распределение со средним О и дисперсией 1. Переменная VPareto(X,2) будет иметь распределение Парето с параметром 2 и т. д.
Этот прием удобен, если вы хотите сгенерировать случайную величину, имеющую заданное распределение, исходя из равномерно распределенной переменной.
В SVB доступно огромное количество функций, например, вы можете выполнить разнообразные действия с матрицами. Выберите в разделе Category пункт Matrix
Прокрутив правый список, вы увидите набор доступных матричных функций, например, декомпозицию Холецкого, вычисление собственных значений, собственных векторов, вычисление обратных матриц, обобщенных псевдообратных, выметания и т. д. Таким образом, вам не нужно программировать эти методы, а следует воспользоваться ими в своей программе.
Просмотр объектов и функций
665
В заключение приведем список библиотек и модулей SVB на английском и русском языках.
Список библиотек и модулей STATISTICA Visual Basic
Модуль Библиотека Константа
ANOVA* STAMANOVA SCMANOVA
Basic Statistics STABascStatsocs scBastoStadstics
Canonical Analysis STACanonkal scCarxxncalAratys s
Cl assfication Trees STAQulckTrees scClassitationTrees
Cluster Analysis STACIuster scClusterAnalysis
Correspondence Analysis STACorrespondence scCorrespondenceAnalysis
Dtscrim nant Analysis STADiscnminant scDiscriminantAnalysls
Crstrtxition Fitting’ STANonparametncs scDistributions
Experimental Design (DOE) STAExperimental scDesignOfExpenments
Factor Analysis STAEactor scFactorAnalysls
General CHAID Models STAGCHAID scGCHAID
General Classification and Regresston Trees STAGTrees scGTrees
General Dtscrmnant Analysis Models STAGDA scGDA
Generalized Additive Models STAGAM SCGAM
Generalized Linear/Nonllnear Models STAGLZ scGLZ
General Linear Models STAGLM SCGLM
General Partial Least Squares Models STAPLS scPLS
General Regression Models STAGRM scGSR
Log-Linear Analysis STALoglinear scLoglnearAraiyss
Multidimensional Scaling STAMuftidjnens oral scMultidimenslora Scaling
Multiple Regression STARegression scMuHpteRegressron
Nonlinear Estimation STANonlinear scNonFnearEstimabon
Nonpara me tries STANonparametncs scNonparametrics
Principal Componentsand Classification Analysis' STAFactcr scAdvancedPCA
Process Analysis Techniques STAProcessAralysfe scProcessAnalysis
Quality Control STAQuality scQuaMyControl
Reliability/Item Analysis STARekability scRellabilltyandltemAnalysis
666
Глава 18. Язык STATISTICA VISUAL BASIC (SVB)
Модуль Библиотека Константа
Survival Analysis STASurvival scSuvrvalAnatysrs
Time Series STATimeSeries scTimeSeries
Variance Components STAVarianceCompcnents scVarianceComponents
Дисперсионный анализ* STAMANOVA SCMANDVA
Основные статистики STABasicStati stfcs scBasicStatistics
Канонический анализ STACanonical ScCanonicalAnalysls
Деревья классификации STAQuickTrees scOassificationTrees
Кластерный анализ STAOuster scCiusterAnalysis
Анализ coo 1 вел. 1 вий STACorrespondence «CorrespondenceAnalysis
Дискриминантный анализ STADiscriminant scDiscnminantAralysis
Подгонка распределений' STANonparametrics sd>stnfcut>ons
Планирование эксперимента STAExperimental scDesignCfExparmerts
Факторный анализ STAFactor scFactorAnalysis
Общие модели хи-квадрат STAGCHAID scGCHAID
Общие модели деревьев классификации/регрессии STAGTVees scGTrees
Общие модели дискриминантного анализа STAGDA SCGDA
Обобщенные аддитивные модели STAGAM ScGAM
Обобщенные линейные/нелинейные модели STAGLZ scGLZ
Общие линейные модели STAGLM scGLM
Общие нодегм частных наименьших квадратов STAPLS scPLS
Общие регрессионные модели STAGRM SCGSR
Логлинейный анализ STALogUnear scLogllnearAnalysis
Многомерное шкалирование STAMuitkSmensional scMultidimensorialScaling
Множественная регрессия STARegression scMuIbpleRegression
Нелинейное оценивание STANonhnear scNonlineerEsUmatjon
Непараметрические методы STANonparametrics scNonparametrics
Анализ главных компонент и классификация’ STAFactor scAdvancedPCA
Анализ процессов STAProcessAnalyss scProcessAnalysis
Контроль качества STAQuality scQualfiyContrcI
Надежность и позиционный анализ STAReliaWity scFteiabdityandlterr Analysis
Анализ выживаемости STASurvival scSurvivalAnaiyse
Временные ряды STATimeSenes scTimeSeries
Компоненты дисперсии STAVarianceCcmponents scVananceCompooerts
• Функция доступа kANOVA Дисперсигапючщ анализу содержатся в библиотеке General Linear Models — Общие линейные модели.
* Функции н процедуры мцдучя Dismbu.ion Fitting — Подгонка распределений являются чяп библиотеки Nonparametncs — Непараметрическая статистика
• Методы Principal Components — Главные кампыенты и Classification Analysts — Классификация собраны в библиотеке Factor Analysis — Факторный анализ
Замечание 1: Список модулей и процедур STATISTICA, доступных в Visual Basic, постоянно расширяется. Советуем регулярно отслеживать информацию на сайте StatSoft, Inc (www.statsoft com)
Замечание 2: Процедуры, реализующие все команды меню Graphs — Графика, полностью содержатся в справочной библиотеке STATISTICA. В диалоге Object Browser — Просмотр объектов вы можете просмотреть соответствующие константы, которые передаются в конструктор объекта — анализа (графика) и инициализируют его.
Приложение 1
Розничные продажи бензина в США (источник: www.economagic.com в разделе Census Bureau: Retail Sales by Kind of Business).
Переменные: T - месяц/год, V - объем продаж.
т V
Янв-1967 1697 Янв-1971 2332 Янв-1975 3546 Янв-1979 5026
Фев-1967 1599 Фев-1971 2164 Фев-1975 3305 Фев-1979 4873
Мар-1967 1765 Мар-1971 2404 Мар-1975 3708 Мар-1979 5460
А пр-1967 1803 Алр-1971 2446 Аир-1975 3756 Аир-1979 5590
Май-1967 1891 Май-1971 2551 Май-1975 4026 Май-1979 6055
Июя-1967 1986 Июл-! 971 2635 Пюи-1975 4065 Июн-1979 6282
И юл-1967 2009 Июл-1971 2766 Июл 1975 441(1 Июл-1979 6366
Авг-1967 1969 Авг-1971 2763 Авт 1975 4448 Авт 1979 6834
Сен-1967 1893 Сен-1971 2607 Сен-1975 4078 Сев-1979 6531
Окт-1967 1900 Окт-1971 2646 Окт-1975 4145 Окт-1979 6822
Ноя-1967 1914 Ноя-1971 2633 Ноя-1975 3966 Ноя-1979 6777
Дек-1967 1936 ДсК-1971 2673 Дек-1975 4150 Дек-1979 6905
Яне-1968 1858 Янв-1972 2529 Янв-1976 3974 Янв-1980 6800
Фев-1968 1799 Фев-1972 2401 Фев-1976 3781 Фев-1980 6818
Мар-1968 1966 Мар-1972 2641 Мар-1976 4113 Мар-1980 7401
Алр-1968 2013 Алр-1972 2612 Аир-1976 4193 Апр-1980 7580
Май-1968 2106 Май-1972 277' Май-1976 4287 Май-1980 7964
Июн-1968 2165 Июн 1972 2817 Июн-1976 4446 Июи-1980 8205
Ию.т-1968 2220 Июл-1972 •>934 Июл 1976 4714 Июл-1980 8456
Авт-1968 2232 Авг-1972 2943 Авг-1976 4602 Авг-1980 8425
Сен-1968 2051 Сен-1972 2782 Сен-1976 4353 Сен-1980 7946
Окт-1968 2105 Окт-1972 2871 Окт-1976 4494 Окт-1980 8215
Ноя-1968 2102 Ноя-1972 2853 Ноя-1976 4438 Ноя-1980 7936
Дек-1968 2133 Дек-1972 2914 Дек-1976 4642 Дек-1980 8347
Янв-1969 2051 Янв 1973 2771 Янв-1977 4339 Я нв-1981 8062
Фев-1969 1896 Фев-1973 2648 Фев-1977 4053 Фсв-1981 7643
Мар-1969 2126 Мар-1973 2970 Мар-1977 4555 Мар-1981 8419
Алр-1969 2151 Апр-1973 3009 Алр-1977 4749 Аир-1981 8'38
Май-1969 2Ц7 Май 1973 3160 Май-1977 4828 Ман-1981 8,64
Июн-1969 2283 Июн 1973 3226 Июи-197" 4862 Июл-1981 9046
Июл-1969 2331 Июл 1973 3314 Июл-1977 5101 Июл-1981 9219
Авг-1969 2323 Ааг-1973 3246 Авг-1977 5011 Авт-1981 8989
Сен-1969 2173 Сен-1973 3046 Сен-1977 4736 Сен-1981 8665
Окт-1969 2242 Окт-1973 3203 Окт-1977 4806 Окт-1981 8762
Нол-1969 2179 Ноя-1973 3221 Ноя-1977 4699 Поя-1981 8341
Дек-1969 2269 Дек 1973 3128 Дек-1977 4899 Дек 1981 8604
Яна-1970 2220 Яив-1974 3005 Япв-1978 45— Янв-1982 8102
Фев-1970 2053 Фсв-1974 2898 Фев-1978 43nr> Фев 1982 7416
Мар-1970 2287 Мар-1974 3325 Мар-1978 4802 Мар-1982 ’850
Апр-1970 2347 Arip-1974, 3427 Апр-1978 4790 Апр-1982 7735
Май-1970 2484 Мий-1974 3674 Май-1978 5059 Маи-1982 т.>9
Ивон-1970 2541 Июн-1974 3815 Июн-1978 5163 Июн-1'KiZ 1 я»5
Июл-1970 2625 Июл-1974 3987 Июл-1978 5196 Июл-1982 8758
Авг-1970 2482 Аяг-1974 4034 Авг-1978 5307 Авт-1982 8508
Сен-1970 2366 Сен 1974 3700 Сеи-1978 5122 Ссп-1982 8110
Окт-1970 2506 Окт-1974 3831 Окт-1978 5202 Окт 1982 8'’97
Нол-1970 2458 Ноя-1974 3675 Ноя 1978 5144 Ноя-1982 8utll
Дек-1970 2534 Дек-1974 Jf *3 Дек-1978 5273 Дек-1982 8249
668
Приложение 1
V V т V
Янв-1983 7717 Янв-1987 7761 Янв-1991 11297 Яна-1995
Фев-1983 7092 Фев-1987 7481 Фев-1991 10064 Фев-1995 11443
Мар- 19X3 7835 Мар-1987 8278 Мар-1991 10883 Мар-1995 12790
Апр-1983 8124 Аир-1987 «639 Апр-1991 11052 Аар-1995 12701
MaR-1983 8704 Май-1987 8916 Май-1991 1I96O Май 1995 13937
Иган-1983 8992 Иган-1987 9144 Июн-1991 11846 Июн-1995 14210
Ию л-1983 9388 Июл-1987 9490 Июл-1991 I2O91 Июл-1995 14013
Авг-1981 9417 Авг-1987 9446 Авт-1991 12406 Авг-1995 14186
Сен-1983 8929 Ссн-1987 8928 Сен-1991 11350 Сен-1995 13213
Окт-1983 8953 Окт-1987 9092 Окт-1991 11678 Окт-1995 13190
Ноя-1983 8704 Ноя-1987 8672 Ноя-199! 11360 Ноя 1995 1’650
Дек 1983 9072 Дек-1987 8902 Дек-1991 11 ЗОЙ Дек-1995 12931
Янв-1984 8497 Яш-1988 8408 Яш-1992 10508 Янв-1996 12456
Фев-1984 8108 Феа-1988 8119 Феа-1992 10071 Фев 1996 12203
Мар 1984 8763 Мар-1988 8830 Мар-1992 10725 Мар-1996 13518
Анр-1984 8812 Апр-1988 8957 Алр-1992 IOK85 Лир-1996 13998
Май-1984 9341 Маи-1988 9415 Май-1992 11836 Май-1996 15258
Июи-1984 9411 Игам-1988 9484 К юн-1992 11874 Иган-1996 14840
Июп-1984 9357 Иган-1988 9689 И юл-1992 12225 И юл-1996 14839
Ahi-1984 9358 Авг-1988 книга Авт-1992 12218 Авг-1996 15034
Сен-1984 8908 Сен-1988 9359 Сен-1992 IIS69 Сен-1996 13885
Окт-1984 9179 Окт-1988 9532 Окт-1992 12002 Окт-1996 14488
Ноя 1984 8954 Ноя-1988 9179 Иоя-1992 11418 Ноя-1996 14007
Дек-1984 8877 Дек-1988 9363 Дея-1992 11619 Дек-1996 14224
Янв 1985 8620 Яш-1989 8840 Яш 1993 10839 Янв-1997 13732
Фев-1985 7796 Фев-1989 8505 Фе в-1993 10498 Фе в-1997 12863
Мар-1985 8793 Мар-1989 9590 Мер-1993 11476 Мар-1997 14240
Аир-1985 9265 Апр-1989 10195 Алр-1993 11684 Апр-1997 14163
Ман-1985 9794 Маи-1989 11058 Май-1993 12346 Май-1997 14912
Иган-1985 9814 Июл-1989 11044 Июн-1993 12291 Иган-1997 14786
Ияол 1985 10189 Июл-1989 II147 Иган 1993 12638 И ЮЛ-1997 15077
Авг-1985 10169 Авт-1989 10967 Авг-1993 12418 Авг-1997 15348
Сен-1985 9522 Сен-1989 10268 Сен-1993 11679 Сен-1997 14547
Окт-1985 9879 Окт-1989 10572 Окт-1993 12237 Окт-1997 14827
Ноя-1985 9528 Ноя-1989 10221 Ноя-1993 11806 Ноя-1997 13685
Дек-1985 9972 Дек-1989 10475 Дек-1993 11785 Дек-1997 13901
Янв-1986 9407 Янв-1990 10120 Янв 1994 10966 Яне-1998 12945
Фев-1986 8368 Фев-1990 9434 Фев-1994 10652 Фев-1998 11982
Мар-1986 8468 Мар 19% 10497 Мар-1994 11800 Мар-1998 13088
Апр-1986 8229 Алр-1990 10537 Алр-1994 11842 Апр-1998 13394
Мои-1986 8846 Май-1990 11210 Май-1994 12491 Май-1998 14366
Ниш-1986 8875 Иган-1990 11442 Июн-1994 12835 Июн-1998 14412
Июл-1986 8812 Июл-1990 11548 Игал-1994 13207 Игал-1998 14820
Авт-1986 8482 АВТ-1990 12739 Аяг-1994 13710 Авг-1998 14393
Сен-1986 8191 Сен-1990 12406 Сен-1994 I28S4 Сен-1998 13505
Окт-1986 8356 Окт-1990 13242 Окт 1994 12983 Окт-1998 13947
Ноя 1986 7919 Ноя-1990 12952 Ноя-1994 12647 Ноя-1998 12943
Дек-1986 8140 Дек-1990 12377 Дек-1994 12880 Дек-1998 13404
Яне-1999 12624 Янв-2000 15272
Фев-1999 11924 Фев-2000 15971
Мвр-1999 >3700 Мар-2000 18313
Л пр-1999 14633 Апр-2000 17259
Мая-1999 15185 Май-2000 18619
Иган-1999 15289 Июн-2000 19649
Ию л-1999 16325 Июл-2000 19561
Авг-1999 16622 Авг-2000 19387
Сен-1999 15938 Сен-2000 18901
Окт-1999 16339 Окт-2000 18856
Ноя-1999 15657 Ноя-2000 17856
Дек-1999 16737 Дек-2000 17647
Янв-2001 16941
Приложение 2
Прогнозирование месячных розничных продаж на бензоколонках США с помощью мастера решения задач STATISTICA Neural Networks (версня 4.0).
Ниже приведены последовательные диалоговые окна, которые возникают в SNN при построении прогноза данных о продажах бензина, приведенных в приложении 1. Данные имеются также надиске.
Рис. 1. Открытие файла данных retail!.
Переменная varl — исходный ряд месячных продаж, переменная var2 — первые разности
Рис. 2 Файл данных и рабочее окно SNN
Рис 3. Вызов мастера решения задач — Intelligent Problem Solver
670
Приложение 2
Рис. 4. Выбор в мастере решения задач режима Advanced
Рис. 5. Выбор в мастере решения задач типа задачи — Problem Туре. Решаемая задача — прогнозирование временного ряда — predict later values from earlier ones
Рис. 6. Задание периода ряда (анализируемый ряд имеет период 12).
Если период неизвестен или ряд непериодичный, то в поле Period ставится 1
Рис. 7. Выбор «выходной» или прогнозируемой переменной
Приложение 2
671
Рис. 8. В этом окне выбираются входные (независимые) переменные. Переменная varl — исходный ряд. Переменная var2_— ряд первых разностей. На первом этапе в качестве единственной независимой переменной выбираем varl
Рис. 9. Задание обучающего, контрольного и тестового множества
Рис. 11 Количество нейронов в скрытом слое (трехслойный персептрон)
вп
Приложение 2
Рис. 12. Способы поиска сети (по полноте и времени)
Рис. 13. Количество сохраняемых сетей
Рис. 15. Окно сообщений. Процесс поиска:
30 секунд работы, найдено 2 конфигурации сети, способных решить задачу
Приложение 2
673
Рис. 16. Окно сообщений спустя 3 минуты
Рис. 17. Список найденных сетей в порядке убывания ошибки — error
Рис. 18. Статистики лучшей сети
Рис. 19 Архитектура сети
674
Приложение 2
Рис. 20. Процедура кваэинькяоновского дообучения (кнопка Q — Run Quasi Newton Training — на панели инструментов)
Рис. 21. График ошибки обучения
Рис. 22. Восстановление наилучшей сета
Рис 23. Построение прогноза на 50 шагов, начиная с наблюдения 200
Рис. 24. Исходный временной ряд месячных продаж бензина
I I I I I I I i i
г» ifeaA rfbiiClitataffM
Линейный графи* (RETAJL1 STA <v’265cj
-- ПРОГНОЗ исходный
Рис. 25. Сравнение исходного ряда и прогноза на 1 шаг
576
Приложение 2
Рис. 26. Прогноз «тестового» множества на 2 года (24 точки)
Комментарий. Для повышения качества прогноза рекомендуется добавить еще одну переменную — иаг2 (см. рис. 8). Тогда прогноз будет строиться исходя из двух рядов: исходного ряда varl и ряда первых разностей var2. Заметьте, для построения прогноза можно использовагьтакже другие дополнительные переменные (предикторы).
Рис. 27. Новый прогноз и реальные данные из тестового множества
Рис. 28. Сравнение прогнозов
Приложение 3
Словарь терминов пакета SNN (версия 4.0)
Add
Add Cases
Add Variables
Advanced Intellegent Problem Solver
Advise
Accept
Action
Activation
Activation Function
Add Cases
All Layers
Append Network
Apply
Area Under Curve
Assigned Cases
Automatic Network Design
Automatic Network Designer
Automatic update on Exit
Auxiliary
Back Propagation
Backwards Stepwise
Baseline Errors
Basic
Basic Intellegent Problem Solver
Best
Best Network Retention
Candidate Network Types
Cases (Train, Verify, Test)
Case Errors
City-Block Error
Class Labeling
Class Labeling of Radial Units
Добавить
Добавить наблюдения
Добавить переменные
Расширенный мастер решения задач Совет
Припять
Действие
Активация
Функция активации Добавить наблюдения Все слои
Присоединить сеть
Применить
Площадь под кривой Связанные наблюдения Автоматическое построение сети Автоматический конструктор сети Автоматически обновлять при выходе Дополнительно
Обратное распространение Пошаговое исключение Исходные ошибки Основной
Основной мастер решения задач
Лучшая
Сохранение лучшей сети
Типы сетей, среди которых производится поиск (сети-кандидаты) Наблюдения (обучающие, контрольные, тестовые) Ошибки наблюдений
Ошибка «городских кварталов» Разметка классов
Присвоение меток классов радиальным элементам
67В
Приложение 3
Classes
Classification
Classification Output Type
Classification Statistics
Classification Confidence Threshold
Classification Statistics Datasheet
Cluster Diagram
Clustering Networks
Commit Network to Network Set
Complexity
Confidence
Confidence limits
Conjugate Gradient Descent
Convert
Create Data Set
Create Network
Cross Verification
Crossover Rate
Current Layer
Data Management
Data Set
Data Set Datasheet
Data Set Editor
Data Set Shuffle
Default
Definition
Delimiter
Delta-Bar-Delta
Details
Detail Shown
Deviation
Dimenionality Reduction
Direct
Discard
Division
Division of Cases
Duration of Design Process
Dynamic Link Library
Edit Case Names
Editing Pre Tost Processing
Enlarge Set
Entropy
Epochs
Epsilon
Error
Классы
Классификация
Форма результата классификации
Статистики классификации
Доверительный порог классификации Таблица статистик классификации Диаграмма кластеров
Сети для кластеризации
Поместить сеть в набор сетей
Сложность
Доверие
Доверительные границы
Спуск по сопряженным градиентам
Преобразование
Создать набор данных
Создать сеть
Кросс-проверка
Скорость скрещивания
Текущий слой
Управление данными
Набор данных
Таблица данных
Редактор данных
Перемешать данные
По умолчанию
Определение
Разделитель
Дельта-дельта с чертой
Подробности
Степень подробности
Отклонение
Понижение размерности
Прямой
Отвергнуть
Деление
Разбиение наблюдений
Длительность поиска
Динамически подключаемая библиотека
Редактировать имена наблюдений
Редактирование параметров пре/пост-процессирования
Увеличить набор
Энтропия
Эпохи
Эпсилон
Ошибка
Приложение 3
679
Error function
Error Mean
Explicit Deviation Assignment
Exponential distribution
Feature Selection
Hidden
Hidden Units
Generalized Regression
Generalized Regression Training
Generation
Genetic Algorithm Input Selection
GRNN
Group Sets
Ignore
Inform User First
Initialization Algorithms
Input Variable
Input Feature Selection
Input/Output Variable
Inputs Datasheet
Intelligent Problem Solver
Intelligent Problem Solver Message
IO Settings
Isotropic
Isotropic Deviation Assignment
Iterations
Jog Weights
Keep Diverse
K-Means
К-Means Center Assignment
К-Nearest Neighbor Deviation
Kohoncn Network
Kohonen Training
Layer
Layers Datasheet
Layers Shown
Learned Vector Quantization Training Learning rate Levenberg—Marquardt
Linear
Linear Network
Lock
Logistic
Lookahead
Loss Coefficient
Loss Matrix
Функция ошибки
Среднее ошибки
Явное задание отклонений
Экспоненциальное распределение
Отбор признаков
Скрытый
Скрытые элементы
Обобщенная регрессия
Обучение обобщенной регрессии
Поколение
Генетический алгоритм отбора
входных данных
Обобщенно-регрессионные сети Сгруппировать множества
Не учитывать
Сначала сообщать пользователю
Алгоритмы инициализации
Входная переменная
Отбор входных признаков Входная/выходная переменная Таблица входных значений
Мастер решения задач
Сообщения мастера решения задач
Параметры ввода/вывода
Изотропный
Изотропный выбор отклонений
Число итераций
Встряхнуть веса
Сохранять разнообразие
К-средних
Выбор центров по К-средним
Отклонение по К-ближайшим соседям
Сеть Кохонена
Обучение Кохонена
Слой
Таблица слоев
Показываемые слои
Квантование обучающего вектора
Скорость обучения Левенберга—
Маркара
Линейный
Линейная сеть
Блокировать
Логистическая
Горизонт
Коэффициент потерь
Матрица потерь
680
Приложение 3
Main Главное
Mask Маска
Max/SD МаксимальноеД стандартное
отклонение)
Mean/SD СреднееДстандартное отклонение)
Median Медиана
Medium Средняя (длительность поиска)
Merge Объединить
Method Метод
MicroScroll Микропрокрутка
Min/Mean Минимум/среднее
Minimax Минимаксное
Minimum Improvement Минимальное улучшение
Min Proportion Минимальная доля
Missing Value Пропущенное значение
Momentum Инерция
Move Cases Переместить наблюдения
Multilayer Perceptron (MLP) Многослойный персептрон
Mutation Rate Скорость мутаций
Name Имя
Name and Nominate Имя и номинальные
Nearest Neighbor Ближайший сосед
Neighborhood Окрестность
Network Advisor Наставник
Network (Append)... Сеть(добавить)
Network Illustration Схема сети
Network Set Набор сетей
Network Set Editor Редактор набора сетей
Network Set Options Параметры набора сетей
Network to Replace Заменяемая сеть
Network Wizard Мастер создания сети
Networks for Classification Сети для задач классификации
Neuro-Genetic Input Нейрогенетический алгоритм
Selection Algorithm отбора входных данных
No Layers Число слоев
Noise Шум
Nominal Variables Номинальные (категориальные)
переменные
Nonlinear Нелинейный
Normal Distribution Нормальное распределение
Normalization Нормировка
One-off Input Datasheet Таблица задания одного входного
вектора
One-of-N Один-из-N
Open Data Set Открыть набор данных
Open Network Открыть сеть
Optimum Threshold Оптимальный порог
Приложение 3
681
Options
Output Type
Output Variable
Outputs Datasheet
Outputs Shown
Partially or unusually defined text values
Penalty
Performance
Plot
PNN
Population
Popup Class Selector
Predict
Prediction
Pre/Post Processing
Pre/Post Processing Datasheet
Pre/Post Processing Editor
Pre/Post Processing Editor's Datasheet
Principal Components
Principal Components Analysis
Prior probabilities
Probabilistic
Probabilistic Training
Problem Type
Producing a Reduced Data Set
Prune
Pseudo-Inverse
PSP-function
Quick Propagation
Radial Basis Function (RBF)
Radial Sampling
Rank
Range
Range selection
Ratio
Real number fields
Real-time update
Receiver Operating
Characteristic (ROC)
Redundancy of variables
Regression
Regression Statistics
Regularization
Reinitialize
Опции
Тип выхода
Выходная переменная
Таблица выходных значений
Показывать при выводе
Частично или нестандартно заданные текстовые значения
Штраф
Качество
График
Вероятностная нейронная сеть
Популяция
Контекстный выбор класса Прогнозировать, предсказывать
Прогноз
Пре/постпроцессирование
Таблица пре/постпроцессирования Редактор пре/постпропессирования
Таблица редактора пре/постпроцессирования Главные компоненты
Анализ главных компонент
Априорные вероятности
Вероятность
Вероятностное обучение
Тип задачи
Формирование уменьшенного набора данных
Удалить
Псевдообратный
Постсинаптическая функция Быстрое распространение Радиальные базисные функции Радиальная выборка
Ранг
Диапазон, размах
Выделение диапазона ячеек Отношение
Поля для вещественных чисел Пересчитывать по ходу Операционная характеристика
Избыточность переменных
Регрессия, зависимость
Статистики регрессии Регуляризация
Переустановить, инициализировать
682
Приложение 3
Reject
Replace
Replace Oldest
Replace Worst
Response Graph
Response Surface
Restore
Retain Best Network
RMS (Root Mean Squared) error
Run
Run All Cases
Run Data Set
Run One-off Case
Run Single Case
Run/Activations
S.D. (Standard Deviation) Ratio
Sample
Subsample
Save as Type
Scale
Select
Sansitivity Ananlysis
Set Case Types
Set Variable Types
Set Weights
Shift
Shuffle
Shuffle Cases
Single Case
Single output networks
Smoothing
Smoothing Constant
Sort Ascending
Sort Descending
Standard (each case is independent)
Statistics
Step
Stopping Conditions
Sum-squared error function
Target Error
Test
Text Import Wizard
Threshold
Thorough
Time Series
Отвергнуть
Заменить
Заменить самую первую
Заменить худшую
График отклика
Поверхность отклика
Восстановить
Восстановить лучшую сеть
Среднеквадратичная ошибка
Запуск
Прогнать все наблюдения
Прогнать набор данных
Прогнать отдельное наблюдение
Прогнать одно наблюдение
Запуск/активации
Отношение стандартных отклонений
Выборка
Подвыборка
Тип сохраняемого файла
Масштаб
Выбрать
Анализ чувствительности
Задать типы наблюдений
Задать типы переменных
Задать веса
Сдвиг, смешение
Перемешать
Перемешать наблюдения
Одно наблюдение
Сети с одним выходом
Сглаживание
Константа сглаживания
Сортировать по возрастанию
Сортировать по убыванию
Стандартная (наблюдения независимы)
Статистики
Шаг
Условия остановки
Функция ошибки как сумма квадратов разностей между выходами сети и целевыми значениями
Целевая ошибка
Тестовое (множество)
Мастер импорта текста
Порог
Полный (режим поиска)
Временной ряд
Приложение 3
683
Time Series Репой
Time Series
(predict later values from earlier ones)
Time Series Projection
Topological Classes
Topological Map
Total
Train
Train RMS (Root Mean
Squared) Error
Training Error
Training Error Graph
Training Graph
Training Set
Train-Multilayer Perceptrons
Two-State Conversion
Type
Type of Network
Unit Length
Unit Names
Unit Penalty
Unit Number
Unknown
Unlock
Update
Value
Variable Definition
Variable type in Data Files
Variant
Verbose
Verification Error
Verification Standard Deviation Ratio
Verification Set
Verify
Weigend Weight Regularization
Weights Distribution
Win Frequencies Datasheet
Период временного ряда
Временной ряд (прогноз следующих значений по предыдущим) Проекция временного ряда Топологические классы Топологическая карта
Всего
Обучить, обучающее множество
Среднеквадрап щная ошибка обучения
Ошибка обучения
График ошибки обучения
График обучения
Обучающее множество
Обучение многослойного персептрона Преобразование в два значения Тип
Тип сети
Единичная длина
Имена элементов
Штраф за элемент
Номер элемента Неизвестно
Разблокировать
Пересчитать, обновить
Значение
Определение переменной
Тип переменных в файлах данных Вариант
Подробно
Контрольная ошибка
Контрольное отношение стандартных отклонений
Контрольное множество Контрольное (множество) Регуляризация весов по Вигенду Распределение весов Таблица частот выигрышей
Функции активации, реализованные в SNN
Все эти функции доступны в окне Network Editor, вызываемом из меню Edit -Network... или с помощью кнопки [>>] на панели инструментов.
684
Приложение 3
Линейная. Уровень активации нейрона передается на выход в неизменном виде. Эта функция используется в сетях различных типов, в том числе линейных, а также в выходных слоях сетей радиальных базисных функций.
Логистическая. Ее график имеет форму S-образной кривой, выходные значения лежат в интервале (0,1). Этот тип функций активации нейронов используется в сетях наиболее часто.
Гиперболическая. Функция гиперболического тангенса (tanh). Ее график также имеет вид S-образной кривой, выходные значения лежат в интервале (-1,+1). Эта функция часто дает лучшие результаты, чем логистическая из-за свойства симметрии.
Экспоненциальная с отрицательным показателем. Экспоненциальная функция с аргументом со знаком минус.
Софтмакс. Экспоненциальные функции с нормировкой. При использовании этой функции сумма всех активаций е слое становится равной 1. Применяется в многослойных персептронах для задач классификации, так что выходные значения сети можно интерпретировать как вероятности, задающие принадлежность к классу.
Квадратный корень. Функция квадратного корня.
Синус. Может быть полезна для распознавания радиально распределенных данных. По умолчанию не используется.
Кусочно-линейная. Кусочно-линейный вариант S-образной функции.
Ступенчатая (кусочно-постоянная). Дает на выходе значения 0. если аргумент отри цательный. и 1, если аргумент неотрицательный Может использоваться при моделировании простых сетей, например персептронов.
Ниже приведены точные формулы функции активации.
Функции активации
Название Формула Значения
Линейная к (-оо.+оо)
Логистическая 1 1+е-л (0,+1)
Г иперболичестая е* — е~х
е +е
Приложение 3
685
Название Формула Значения
Экспоненциальная е~я (0. +°°)
е*
Софтмакс (0,+1)
Квадратный корень л (0, 4-00)
Синус sln(x) С-1,+1]
-] х<-1
Кусочно-линейная ± X И Л IV И [-1.+1]
Ступенчатая (0 х<0 1+1 х2>0 [0,+Ц
Функции ошибок, доступные в SNN
Функции ошибок — Error functions выбираются в том же окне Netu ork Editor, что и функции активации
Квадратичная. Ошибка полагается равной сумме квадратов разностей между целевыми и фактическими выходными значениями каждого выходного элемента
При обучении сетей такая функция ошибок является стандартной, часто применяется для задач регрессии (построения нелинейных зависимостей).
Городских кварталов. Ошибка равна сумме абсолютных значений разностей между целевыми и фактическими выходнымизначениями каждого выходного элемента.
Эта функция менее чувствительна к выбросам, чем среднеквадратичная функция ошибок.
Кросс-энтропия (простая и множественная). Ошибка этого типа вычисляется как сумма произведении целевых значений на логарифмы ошибок по всем выходным элементам. Имеется два варианта функции: для сетей с одним выходом (двумя классами) и для сетей с несколькими выходами.
Эта функция ошибок специально предназначена для задач классификации. Ее применение может улучшить результаты классификации сети, особенно если в выходном слое сети используются логистическая (случай одного выхода) или софтмакс (несколько выходов) функции активации.
Кохонена. Вычисление ошибки по КохонСну предполагает, что второй слой сети состоит из радиальных элементов, представляющих центры кластеров. Ошибка вычисляется как расстояние от входного набора данных до ближайшего из этих центров.
Функция ошибок Кохонена предназначена для использования только в сетях Кохонена.
686
Приложение 3
PSP-функции
Эти функции также доступны в диалоговом окне Network Editor.
В пакете STATISTICA Neural Networks используются два основных типа PSP-функций.
Линейная. Линейные PSP-элементы берут взвешенную сумму своих входов и сдвигают на пороговое значение (Threshold), см. нижнюю часть диалогового окна, приведенного выше.
Такие элементы стремятся осуществить классификацию, разбивая пространство входов на классы с помощью системы гиперплоскостей.
Радиальная. Радиальные PSP-элементы вычисляют квадрат расстояния между двумя точками в N-мерном пространстве (где N—число входов), соответствующими входному вектору и вектору весов данного элемента.
Такие элементы стремятся осуществить классификацию, измеряя расстояния от входных наборов до эталонных точек в пространстве входов (координаты этих эталонных точек хранятся в весах элементов).
Линейные PSP-элсменты используются в многослойных персептронах и линейных сетях, а также в последних слоях сетей на радиальных базисных функциях, вероятностных и регрессионных сетей.
Радиальные элементы используются во втором слое сетей Кохонена, радиальных базисных функций, вероятностных и регрессионных сетей и не используются ни в каких других слоях сетей стандартной архитектуры.
В пакете SNN имеется еще один тип РБР-фуикций, предназначенный только для регрессионных сетей
Деление. Эта функция ожидает, чго один из входных весов равен +1, другой -1, все остальные — нулю. Значение, которое выдает функция, равно частному отделения входа, соответствующего +1, на вход, соответствующий —1.
Алфавитный указатель
Анализ выживаемости
Модель Кокса, 544
Оценка Каплана-Мейера, 538
регрессионные модели, 552
согласие, 552
составная таблица времен жизни, 554
Сравнение выживаемости в ipynnax. 541
Функция риска, 537
Анализ мощности, 141—144
Анализ соответствий, 561
Асимметрия. 109
Анализ таблиц времен жизни. 550
Б
Броуновское движение, 148,149
Вероятностный калькулятор STATISTICA, 454
Внутригрупповая вариация, 492
Гамма распределение. 155
Гистограмма, 210—212
Графики
для табл и ц результатов. 418
Группировка
итоговая таблица средних. 423
пример, 421
Группирующая переменная, 464
д
Дисперсия, 106
Дисперсионный анализ, однофакторкыи, 421.50!
3
Зависимость, 112—113
Зависимые переменные, 496
Значимость 128
К
Корреляции
выделение значимых корреляций. 416
корреляция Пирсона 414
Корреляции (хуюдолжемие) ложные, 120 множественные, 118—119 ранговые, 117 частные. 117,118 частные корреляции с точки зрения линециой регрессии. 119
Контроль качества. 32—38.602—607
Кохопена ошибка, 685
Коа^фшиептсопряжениости, 445 Критерий Столетия (1-крптеркй), 480-481 Критерий Фишера, 507 Критерий хи-квадрат
Макнемара хи-квадрат, 444
Пирсона хи-квадрзт. 442 поправка Йетса 443
Кросстабуляция графическое представление 439 2 на 2 таблицы, 437
КросстаЛчяяция данных, 432.436,442 Крос<~'йутяц11я многомерных откликов м дихотомий, 472
Л
.кинетическая. 684
ЛоглииеЙ! 1ЫЙ анализ
кросста; ляцпя данных, 432
Медиана, 108
Мода, 109
Макнемара хи-квадрат, 444
Маргинальные частоты. 438
Меры сопряженности. 445
Мнйговходовые таблицы с контрольными переменными, 441
Многомерные дихотомии. 445,466
задание многомерм! дихотомии. 470
кроен а> г линия многомерных дихотомий, 447
определение факторов. 468
переменные 465
пример, 463
Многомерные откликл, 447.466
кодирование многомерных переменных, 446
кросстабуляцли многомерных откликов, 447
определение факторов, 468
688
Алфавитный указатель
парная кросстлбу мщня
переменные. 445
пример, 463
таблицы частот. 468
448
I It ^виепмые переменные 496
математическая моден, нейрона, 611 612
ч||ыт1слойныи персептрон. 616
пр • шины обучения, 614
№ чрхность ошибки, 620
примеры
классификация, 633,634
погнеппрование. 627-632
Неи-нметрпческис критерии. Я i "07 1 !оминальные переменные 110,111
Однофакторнып дисперсионный анализ
апостсриг^мые сравнения
срелепх, 501
пример, 421
Оценка объема выборки, 137.141
Переменная
категориальная, 110,111
порядковая. 111
Планированиеэксперимента, 32—34 504—602
Прогнозирование, 17—20
Переменная с многомерными откликами, 464
Поправка Йетса 443
Порог, 686
Построение графиков для таблиц
[хаультатов, 418
Р
Распределение
Арксинуса 165—166
Бега. 171-182
Биномиальное, 160—165
Вейбулла, 173-177
Гамма, 155—157
Геометрическое, 170
Гипергеометрнческое 170-171
Коши. 181
Далласа 154—155
Логнормальное, 157—158
Логистическое. 178
Максвелла, 160—181
Нормальное, 147—151
Отрицательное Биномиальное 166—167
Парето. 177-178
Полиномиальное (мулътимннальное), 171
Пуассона, 167—170
равномерное, 151—152
Редея, 172
Распределение (фодотжены')
Сгыолснта ((-распределение), 182—183
Фишера (F-распределение), 183—184
хи-квадрат. 159—160
Хотеллинга. 179—160
Экспоненциальное, 152-153
Экстремальных значений, 172
Эрланга, 153—154
Разность между средними
((-критерий). 495
Распределения
подгонка. 550
Регрессия. 23,24.577—583
Согласие 552
Среднее. 107
Стан «фтное отклонение. 108
Статистика Дарбина-Уотсопа. 584
Стыодента t -критерий
(-критерий для зависимых
выборок 492
(-критерий для независимых выборок 489
графики. 497
матрицы (-критериев, 493
разности между средними, 495
результаты, 497
Таблицы 2 на 2 437
Таблицы времен жизни,анализ, 554
Таблицы времен жизни
в страховании, 550
Таблицы сопряженности 461
Таблицы флагов н заготовкой 440.456
Таблицы частот. 434 452
Ф
Функция риска 535
Фу кпцпя выживаемости, 30-31
Фи-квадрат, 444
X
хи-квадрат критерий согласия, 192-193,
хи-квадрат критерий независимости признаков
в таблицах сопряженности. 440—442
ч
Частоты преобразования логит, 452 пробит. 452 маргинальные, 438
э
Эксцесс, 109 множественная. 685 простая, 685