








































































































































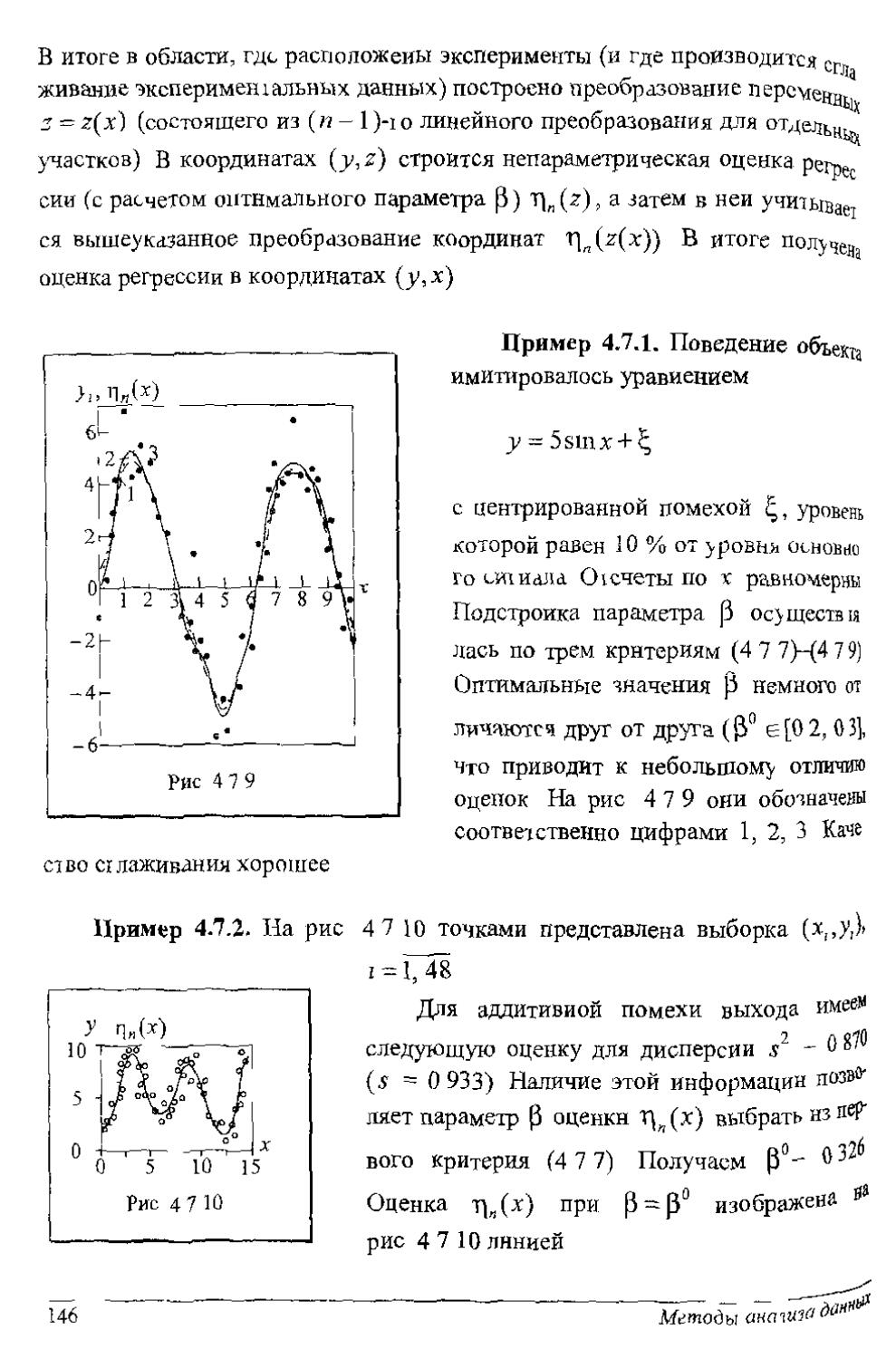
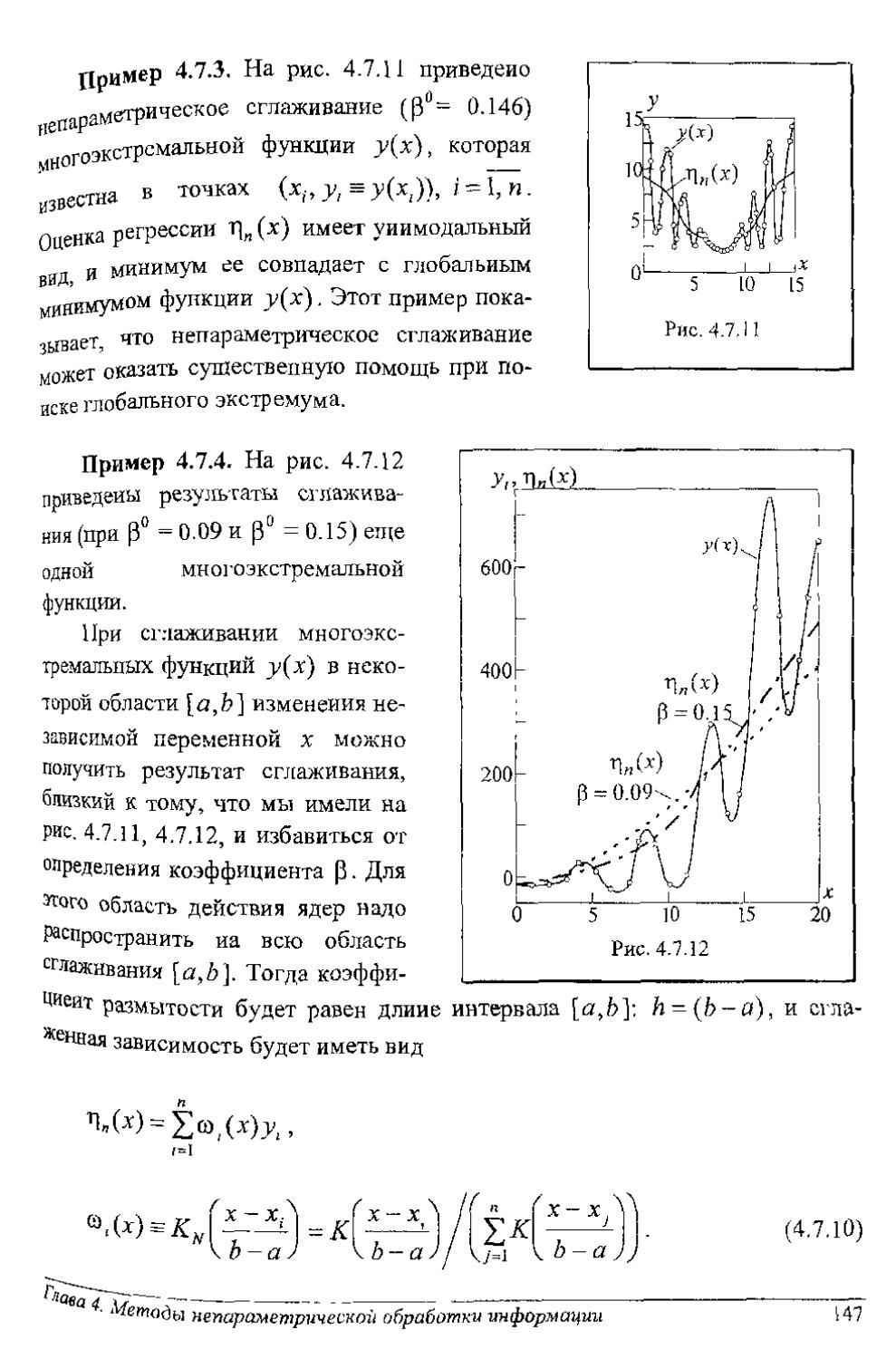







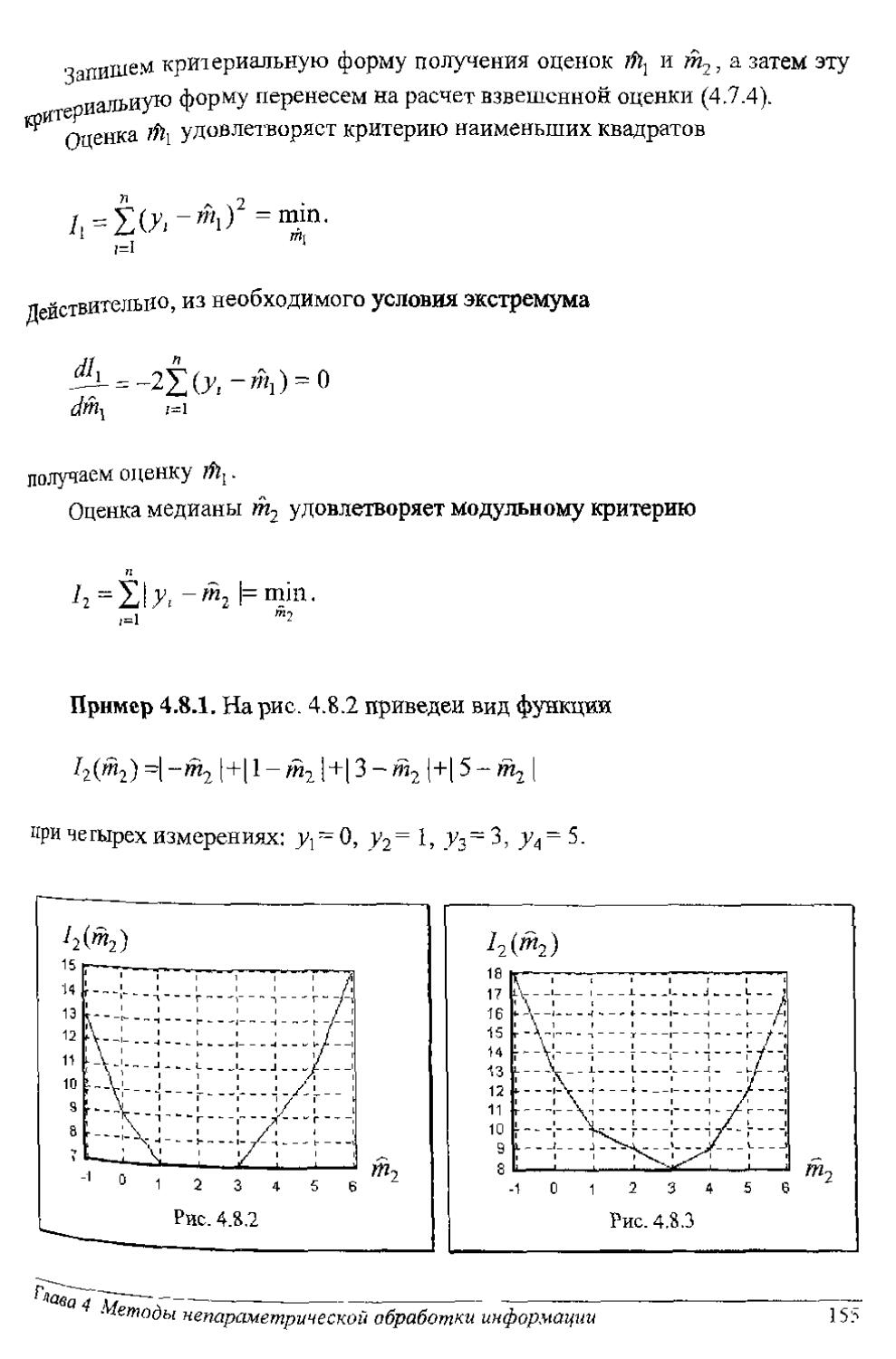


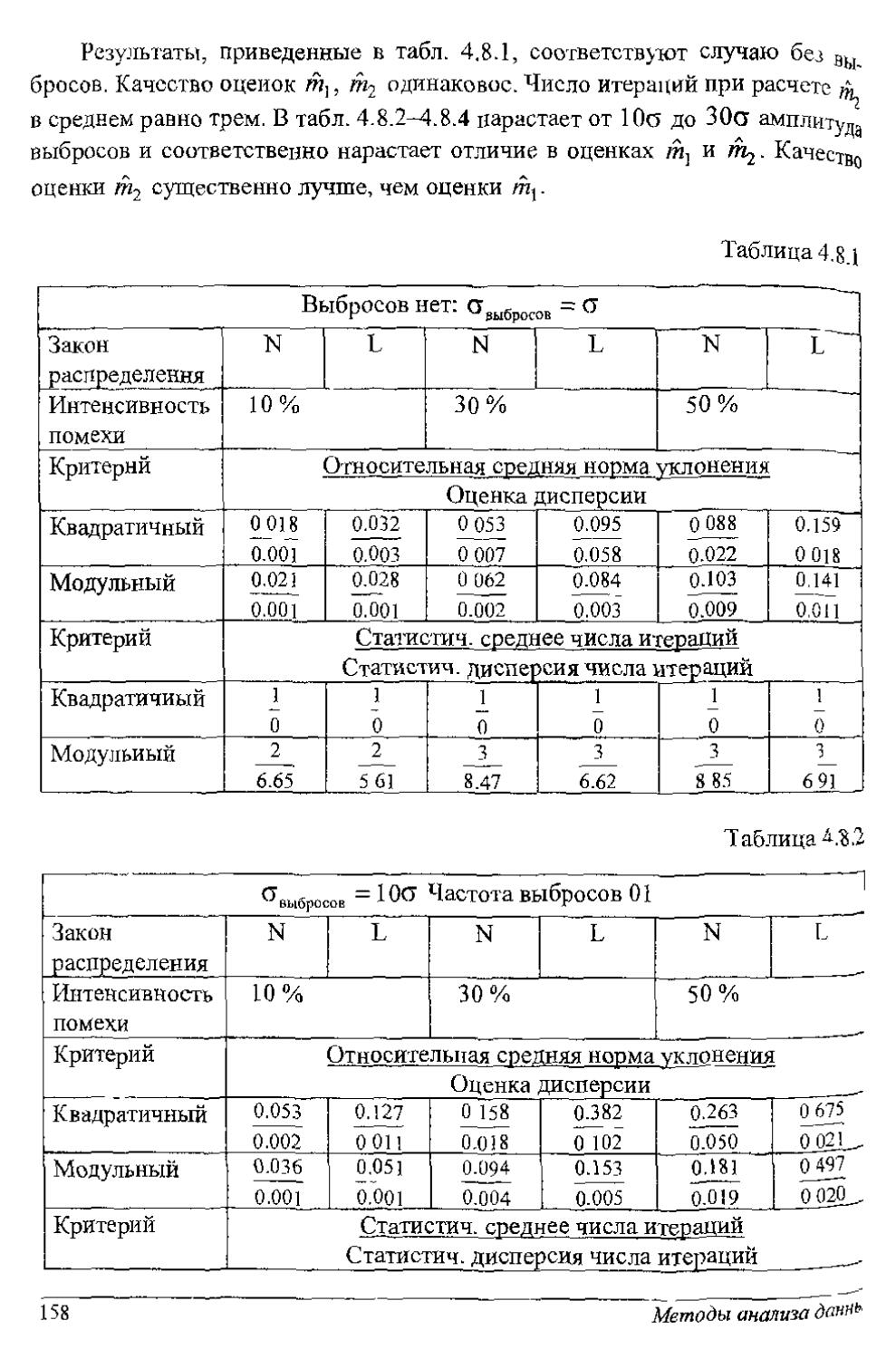











































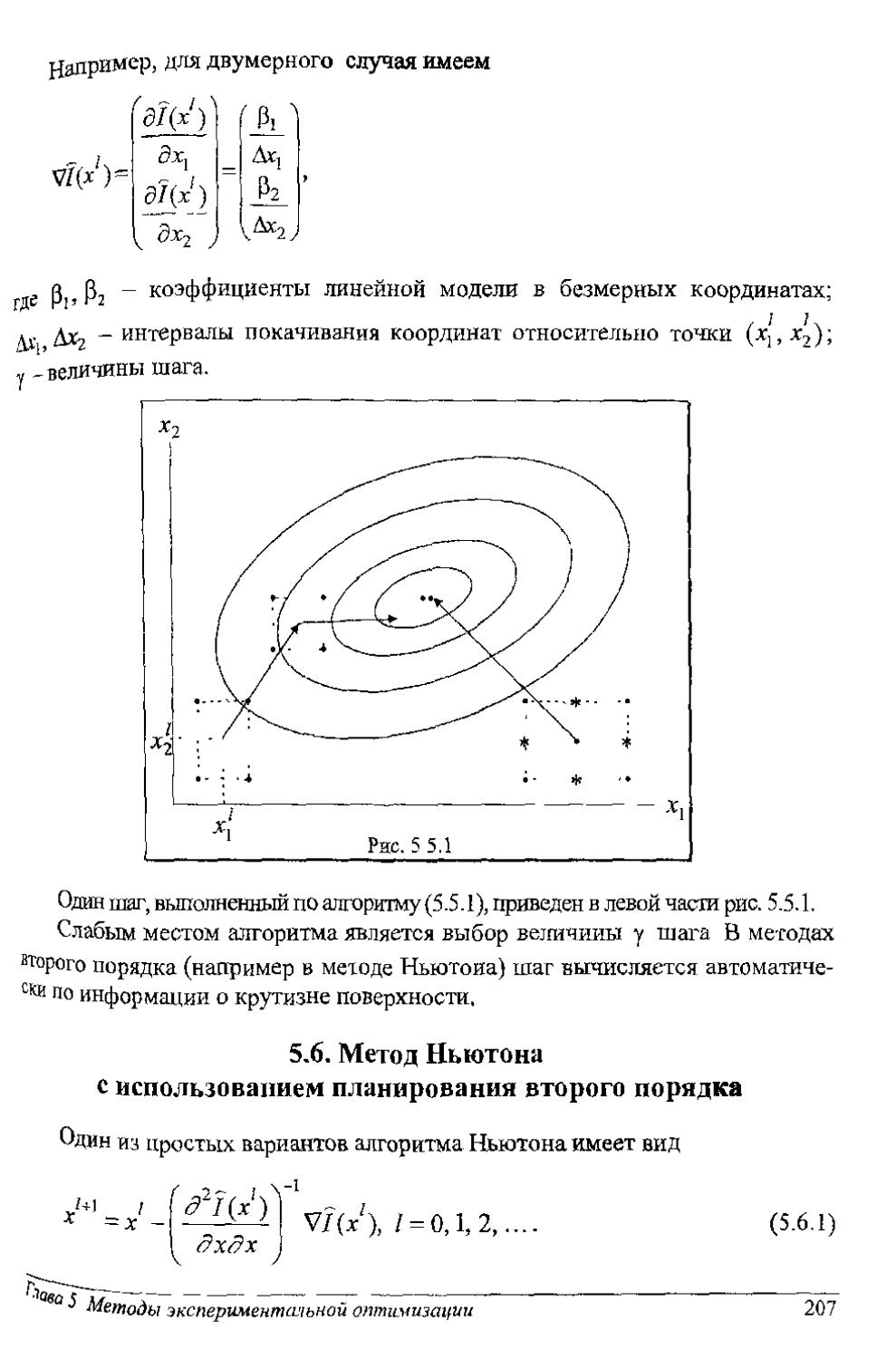




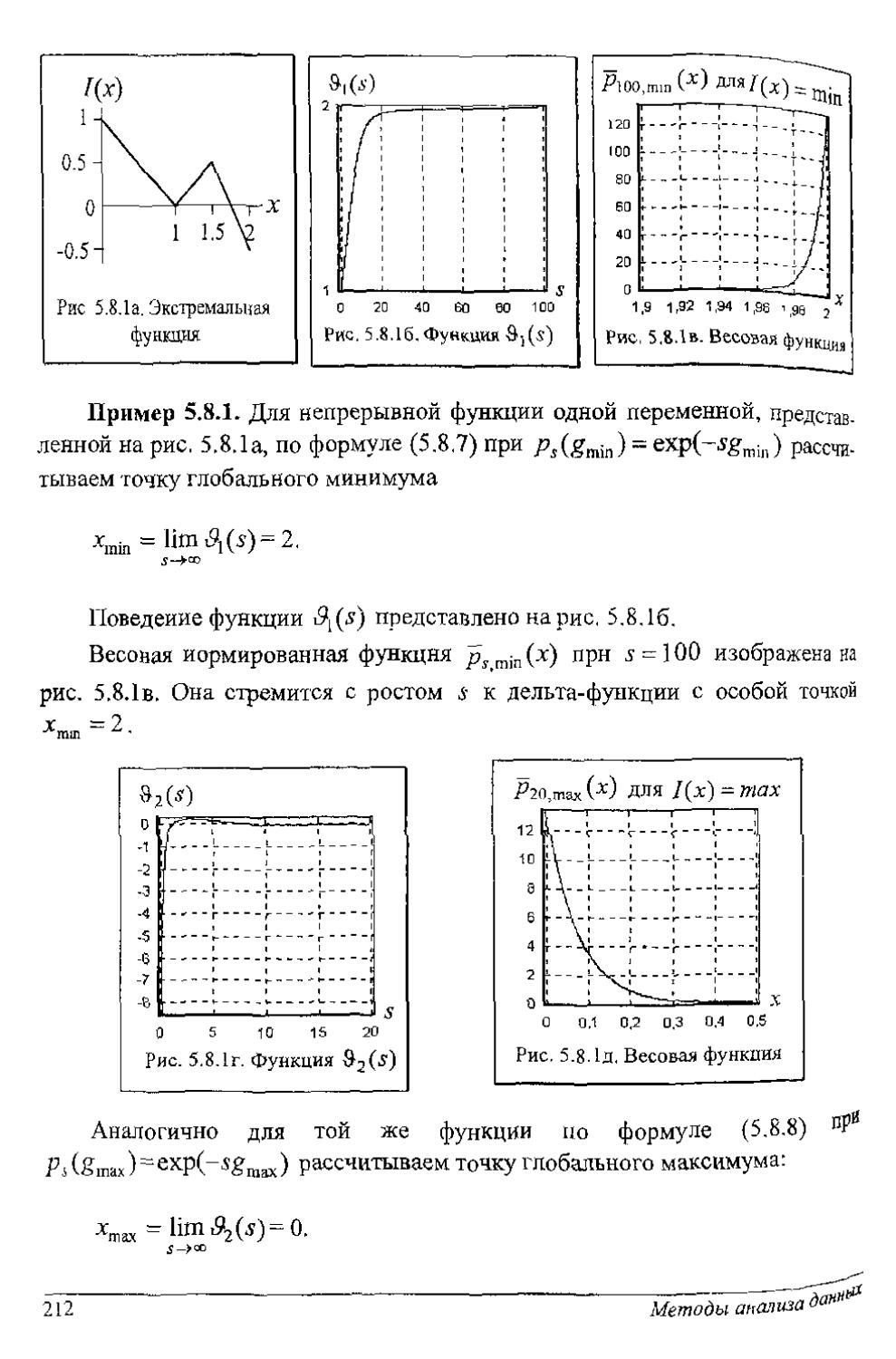





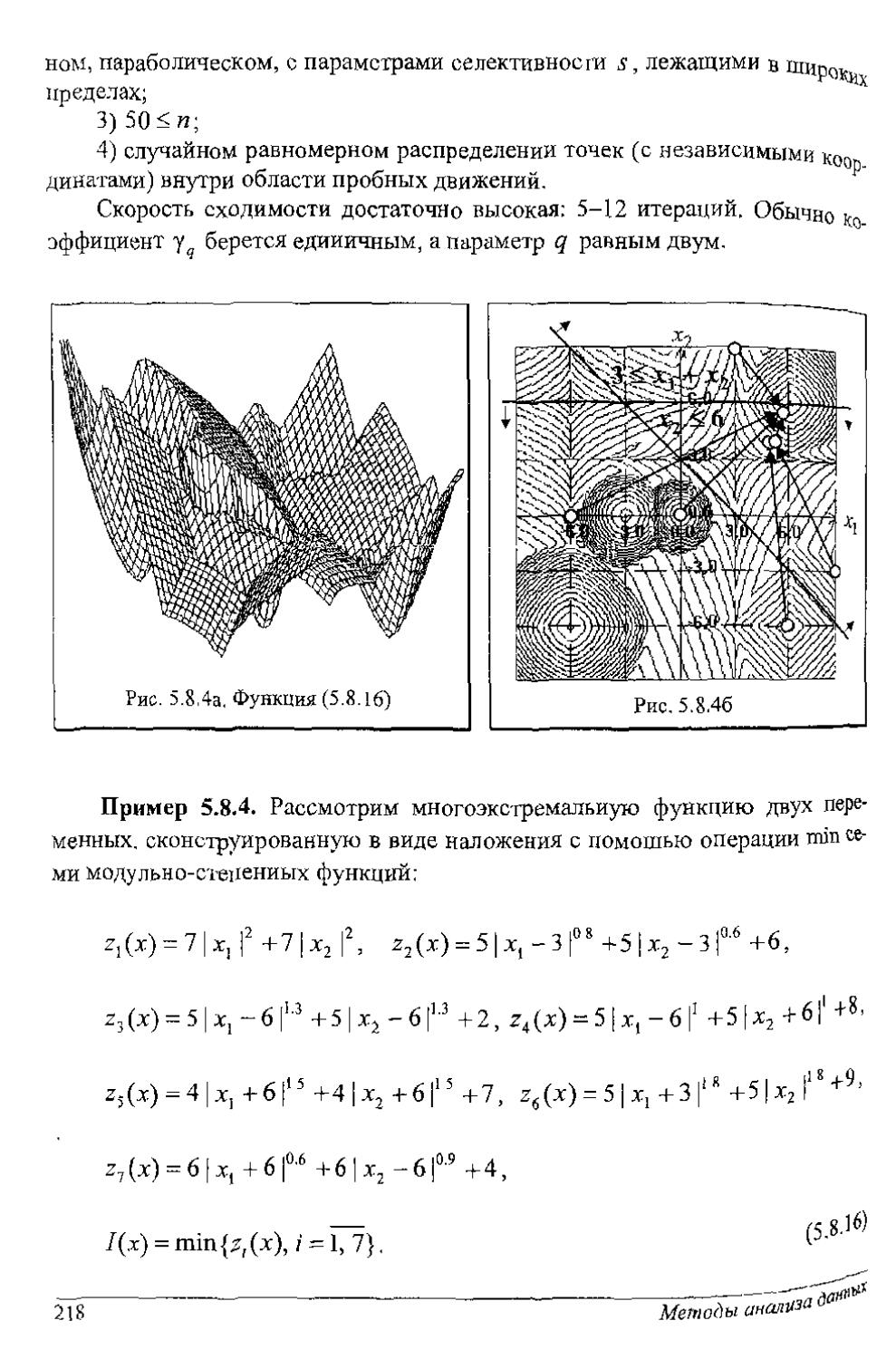
























































































Author: Рубан А.И.
Tags: автоматика системы автоматического управления и регулирования интеллектуальная техника технология управления оборудование систем управления техническая кибернетика математика данные анализ данных
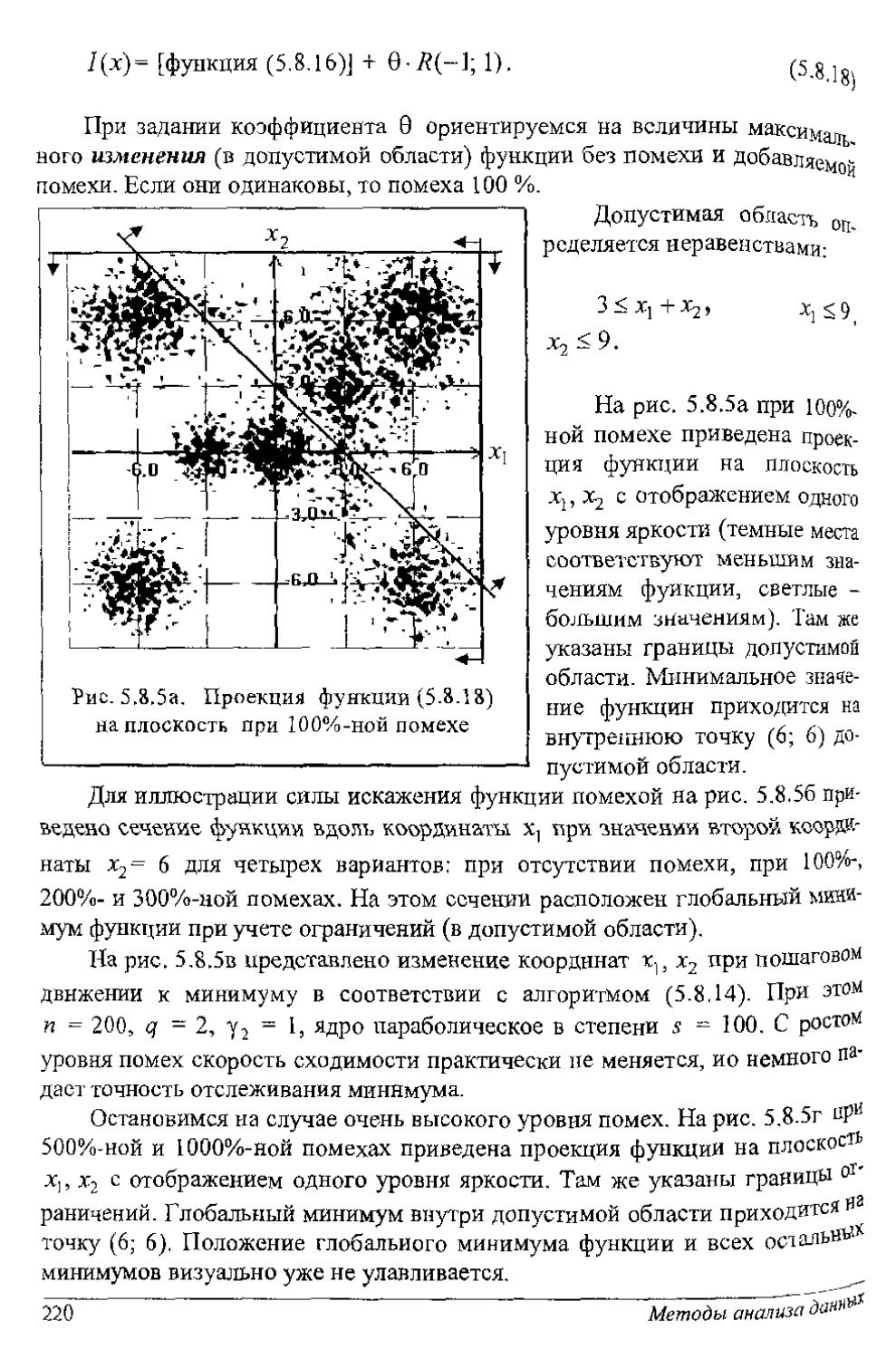
ISBN: 5-7636-0638-8
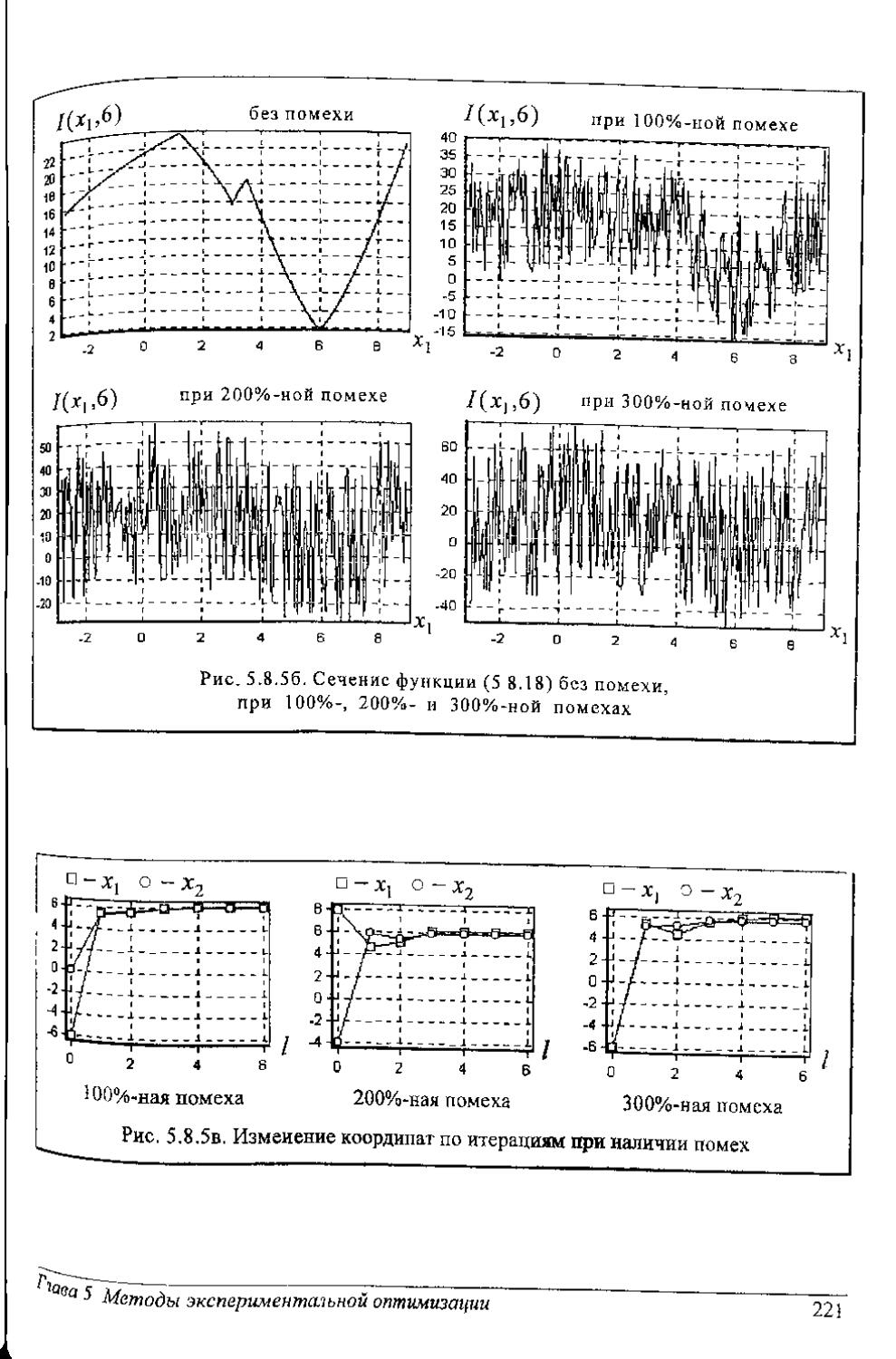
Year: 2004




Министерство образования и науки Российской Федерации Красноярский государственный технический университет
А. И. Рубан
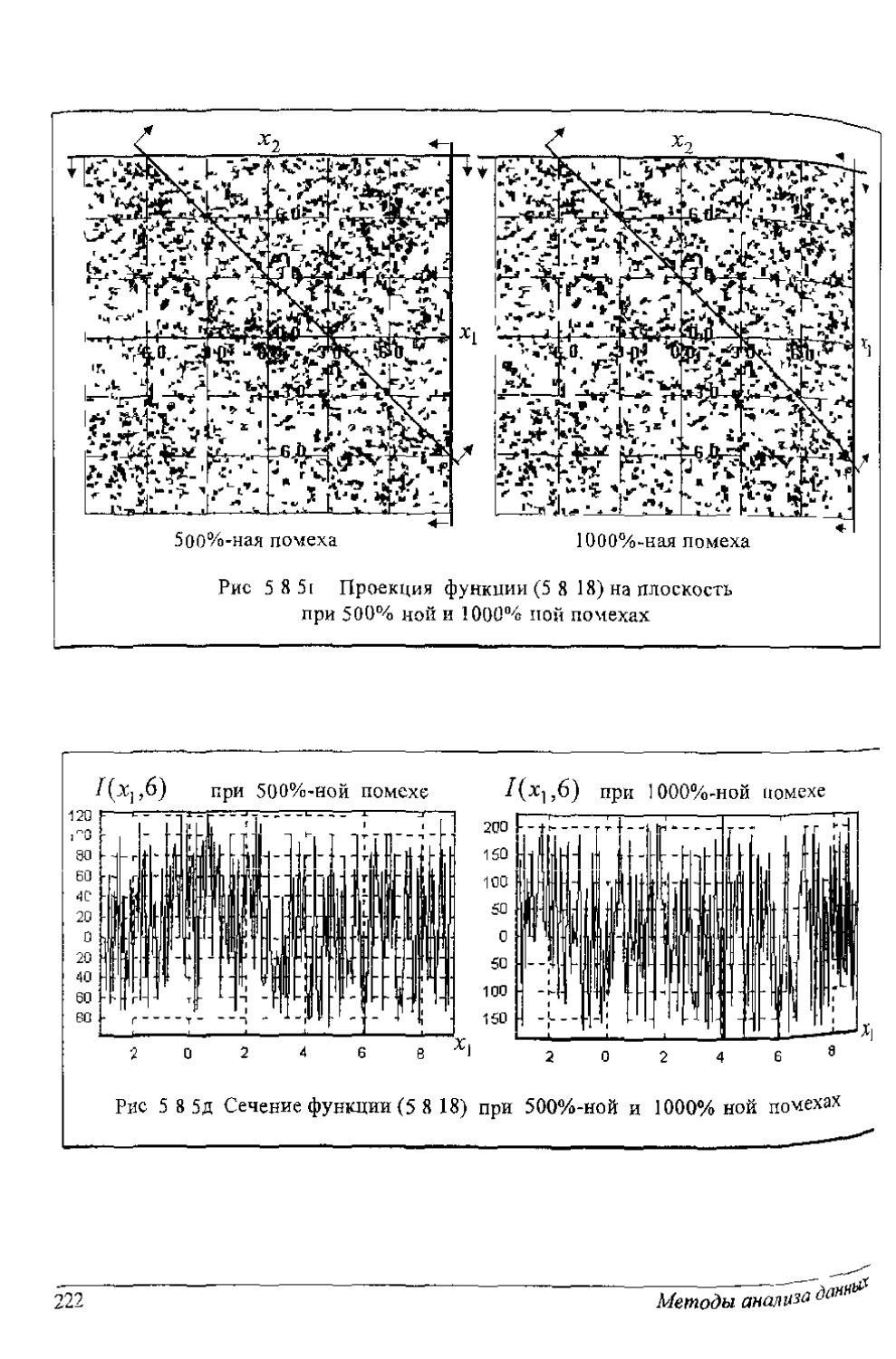
МЕТОДЫ АНАЛИЗА ДАННЫХ
Рекомендовано Сибирским региональным учебно-методическим центром высше’1 с профессионального образования для межвузовского использования по направлениям 550200, 552800, 553000, 651900, 654600, 654700
Красноярск 2004
УДК 681.51:519(07)
Р 82
Рецензенты:
кафедра автоматизированных систем управления Томского государственного университета систем управления и радист лектроники,
Г. А. Доррер, доктор технических наук, профессор, заведующий кафедрой системотехники Сибирского государственного технологического университета
Р82 Рубан, А. И.
Методы анализа данных: Учеб, пособие. 2-е изд., неправд, и доп. /
А. И. Рубан. Красноярск: ИПЦ КГТУ, 2004. 319 с.
ISBN 5-7636-0638-8
Представлены основные идеи, методы и алгоритмы статистической проверки гипотез, классификации в распознавании образов, планирования эксперимента, непараметрической обработки информации, экспериментальной оптимизации, идентификации статических и динамических моделей объектов, адаптивного управления с идентификацией Приведены методы обработки информации для стохастических объектов, включающие как классические результаты, так и современные научные достижения, в том числе опубликованные в последние 15-20 лет в статьях, трудах конференций, монографиях
Предназначено для студентов направлений подготовки бакалавров и дипломированных специалистов 550200, 552800, 553000, 651900, 654600, 654700, а также для аспирантов, преподавателей и научных сотрудников, специализирующихся по технической кибернетике, информатике, автоматизированным и автоматчикамс^стрмам управления.
' библиотека”
Красноярского государственного технического университета
УДК 681.51:519(07)
ISBN 5-7636-0638-8
© КГТУ, 2004
© А. И. Рубан, 2004
Редактор Л. И. Злобина
Гигиенический сертификат № 24,49 04 953 П. 0003 38,05.01 от 25.05,2001
Подп. в печать 08 07.2004. Формат 60x84/16 Бумага тип № 1 Офсетная печать.
Уел пи л. 18,6. Уч.-изд. и. 16,0. Тираж 300 экз Заказ С 171
Отпечатано в ИПЦ КГТУ
660074, Красноярск, ул Киренского, 28
ПРЕДИСЛОВИЕ
В основу учебного пособия легли лекции одноименного курса, читаемого автором с 1988 г. студентам и аспирантам технических вузов Томска и Красноярска (в объеме 51 ч лекции и 51 ч практики).
Предполагается, что читатели знакомы с курсом "Теория вероятностей и математическая статистика". Материал книги рассчитан на его дальнейшее использование в таких дисциплинах, как "Компьютерный статистический анализ данных", "Обучающие системы обработки информации и управления" и Др., а также при решении широкого спектра задач обработки информации и управления для стохастических объектов.
Учебное пособие охватывает широкий круг проблем, решаемых инженером-исследователем прн современной обработке информации. Такого единого издания в библиотеках вузов нет. Включение в курс соответствующих разделов определялось их перспективностью при решении практических проблем, завершенностью теории и, конечно, участием автора в научных исследованиях по отдельным вопросам многих разделов. Проведение практических занятий позволило сформировать примеры и упражнения, способствующие закреплению теоретического материала. Все, что удалось автору сделать по этому курсу к настоящему времени, нашло отражение в предлагаемом пособии. Оно может быть использовано студентами, аспирантами, научными сотрудниками и преподавателями любых технических вузов.
Библиографический список приведён с разделением по главам, и в нём помещены только основные и доступные источники.
Текст первого издания (Методы анализа данных: Учеб, пособие: В 2 ч. Красноярск; КГТУ, 1994. Ч. 1. 220 с. Ч. 2. 125 с.) дополнен новыми разделами, пояснениями, рисунками, примерами. Устранены опечатки и неточности.
В книге принята двухнндексная нумерация параграфов: номер главы и номер параграфа в главе. Формулы имеют соответственно трехиндексную нумерацию: номер главы, номер параграфа и номер формулы. Аналогичная схема нумерации относится к рисункам н таблицам.
Автор благодарен рецензентам профессорам Г. А. Дорреру, А. М. Корикову, которые первыми высказали свое благожелательное критическое отношение к содержанию рукописи пособия. Замечания и пожелания читатели могут направлять по адресу: 660074, Красноярск-74, а/я 16773.
Предисловие
3
Главы и их основные положения
Глава 1. Статистическая проверка гипотез. Приводится общая схема проверки гипотез и на её основе решаются задачи проверки гипотез: о математическом ожидании, дисперсиях, равенстве математических ожиданий, выявлении аномальных измерений, об однородности ряда дисперсий, согласованности выбранного закона распределения и гистограммы,
Глава 2. Классификация в распознавании образов. Строится общая схема системы распознавания и обсуждается идея классификации. Даются: байесовская теория принятия решений, прямые методы восстановления решающих функций, схема персептрона.
Глава 3. Планирование эксперимента. Рассматриваются: планирование эксперимента при построении линейной статической модели объекта, метод крутого восхождения по поверхности отклика, полный факторный эксперимент первого порядка, дробные реплики, насыщенные планы, устранение кусочно-постоянного дрейфа за счет разбиения матрицы планирования на блоки, алгоритмы обработки результатов эксперимента, ортогональные н ротатабельные планы второго порядка, метод случайного баланса.
Глава 4. Методы иепараметрической обработки информации. Излагается общая идея оценивания статистических характеристик стохастических объектов, представленных в виде функционалов от плотностей распределения вероятностей. Строятся оценки для функции и плотности распределения (простейшие, полиграммы, к ближайших соседей, Розенблатта - Парзена) и приводятся нх свойства. На основе оценок Розенблатта - Парзена получены состоятельные оценки: моментов случайных величин, энтропии, условной энтропии, условной плотности распределения, регрессии, средней условной энтропии, среднего количества информации, дисперсионных характеристик. Синтезируются робастные оценки регрессии. На основе использования непа-раметрическнх оценок инверсных регрессий строятся алгоритмы: адаптивного управления при априорной неопределенности, оптимального управления, управления экстремальными объектами, минимизации функций, классификации в распознавании образов.
Глава 5. Методы экспериментальной оптимизации. Рассматриваются: методы одномерного поиска минимума унимодальных функций, метод одномерного глобального поиска, последовательный симплексный метод, метод деформируемого многогранника, градиентный алгоритм с использованием ортогонального планирования первого порядка, алгоритм Ньютона с использованием планирования второго порядка, методы случайного поиска, новый метод (усреднения координат) глобальной оптимизации недифференцируемых стохастических функций.
Глава 6. Идентификация статических моделей. Дается общая постановка задачи подстройки параметров нелинейных моделей. Анализируются
4
Методы анализа данных
различные варианты критерия наименьших квадратов. Рассматриваются алгоритмы метода наименьших квадратов при линейной параметризации модели и исследуются свойства полученных параметров. На основе метода последовательной линеаризации строятся алгоритмы расчета параметров нелинейных моделей с использованием квадратичных критериев и спектра критериев, обеспечивающих получение оценок робастных по отношению к выбросам помех Рассматривается система алгоритмов адаптивной обработки информации на основе критериев наименьших квадратов, робастных критериев, при частичном забывании старых экспериментальных данных, при линейных и нелинейных моделях, стационарных и нестационарных параметрах моделей. Структура рекуррентных алгоритмов для всех вышеуказанных штучаев сохраняет свой вид, в них меняются лишь отдельные элементы. В заключение этого раздела построен и исследован простейший адаптивный алгоритм перестройки параметров линейных н нелинейных моделей Проведены обобщения алгоритма на более сложные векторно-матричные модели. Изложена идея многоэтапного метода селекции при построении моделей сложных объектов.
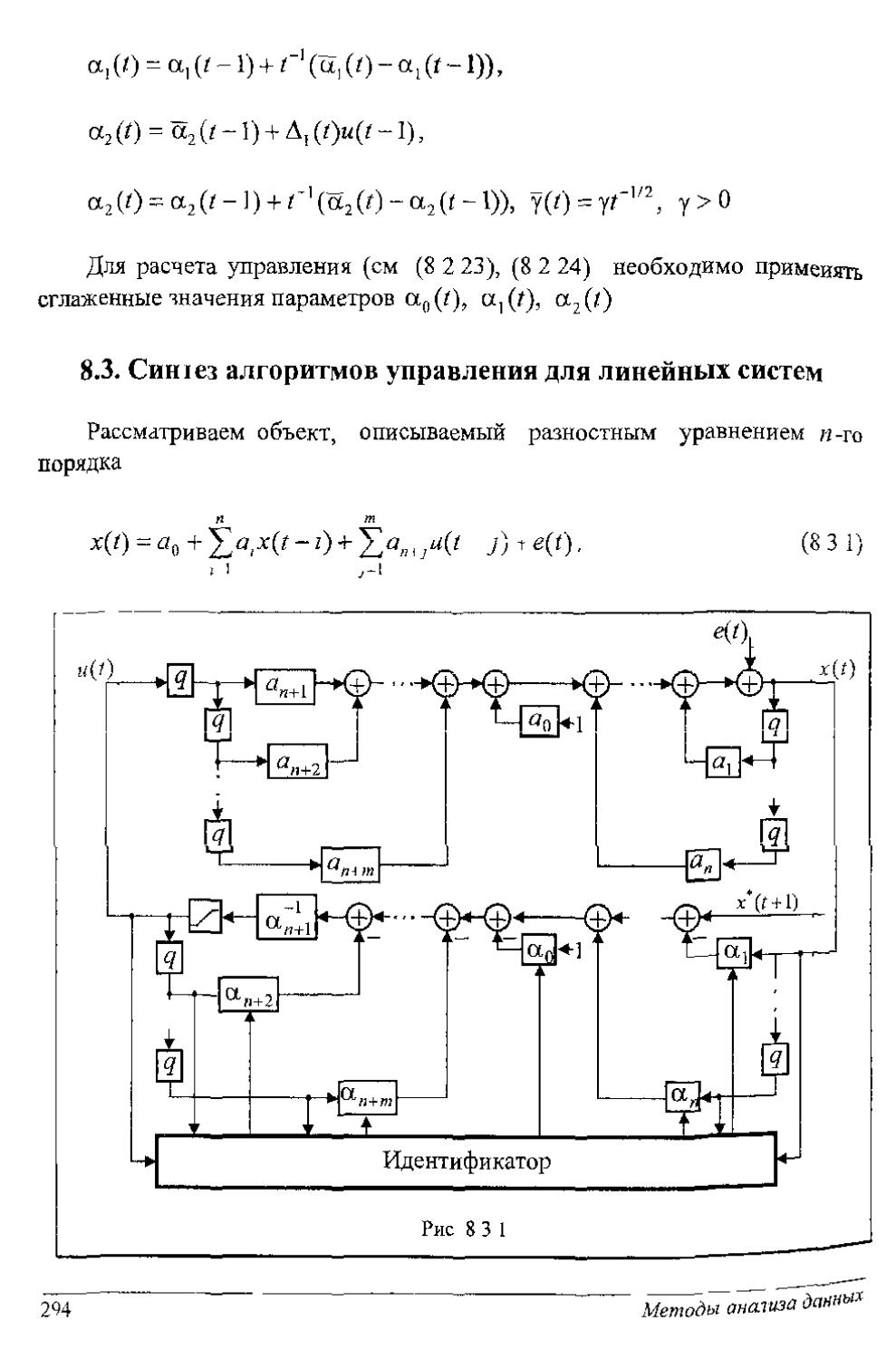
Глава 7. Иден!нфнкация динамических моделей объектов. Рассматриваются вопросы синтеза оптимальной структуры дискретных динамических моделей стохастических объектов. Строятся алгоритмы подстройки параметров моделей с использованием как функций чувствительности, так и итеративных моделей. Рассматриваются простейший адаптивный алгоритм и модифицированный алгоритм наименьших квадратов. Построенные алю-ритмы применяются в следующем разделе при ьинтозе устройств адат и иного управления стохастическими объектами.
Глава 8. Адаптивное управление с идентификацией. Дается постановка задачи адаптивного управления динамическими стохастическими объектами и анализируются основные подходы к синтезу алгоритмов управления. За основу рассмотрения выбран подход, основанный на построении (идентификации) моделей прогноза выхода систем. На простых примерах проводится синтез алгоритмов управления, строятся структурные схемы устройств управления, вычисляется ошибка работы систем. Метод синтеза обобщается на основные классы динамических систем- линейные, нелинейные, с чистыми запаздываниями и без них.
Лредисювие
5
Глава 1. СТАТИСТИЧЕСКАЯ ПРОВЕРКА ГИПОТЕЗ
Данная глава имеет самостоятельное значение в математической статистике. Алгоритмы различения гипотез широко используются в технике, физике, химии, биологии. Разработанные подходы к проверке гипотез позволяют в дальнейшем (см. гл. 2) построить эффективные алгоритмы классификации в распознавании образов.
1.1. Общая схема проверки гипотез
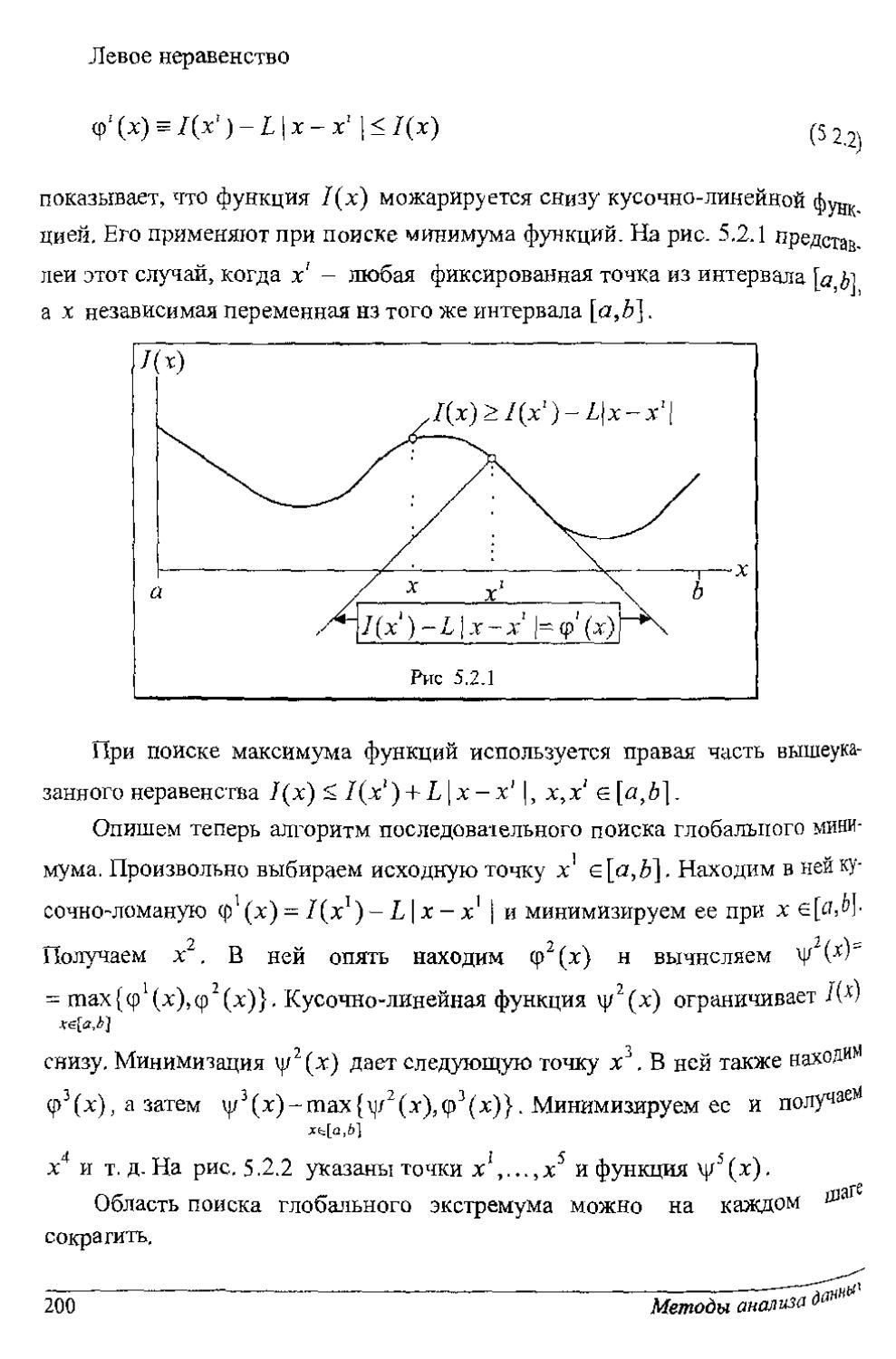
Случай 1. Имеем случайную величину А при условии, что верна гипотеза Яр Х\Нх и гипотеза Я2 Х|Я2. Необходимо по измерению х случайной
величины X принять решение о том, что вернаЯ] или верна Я2.
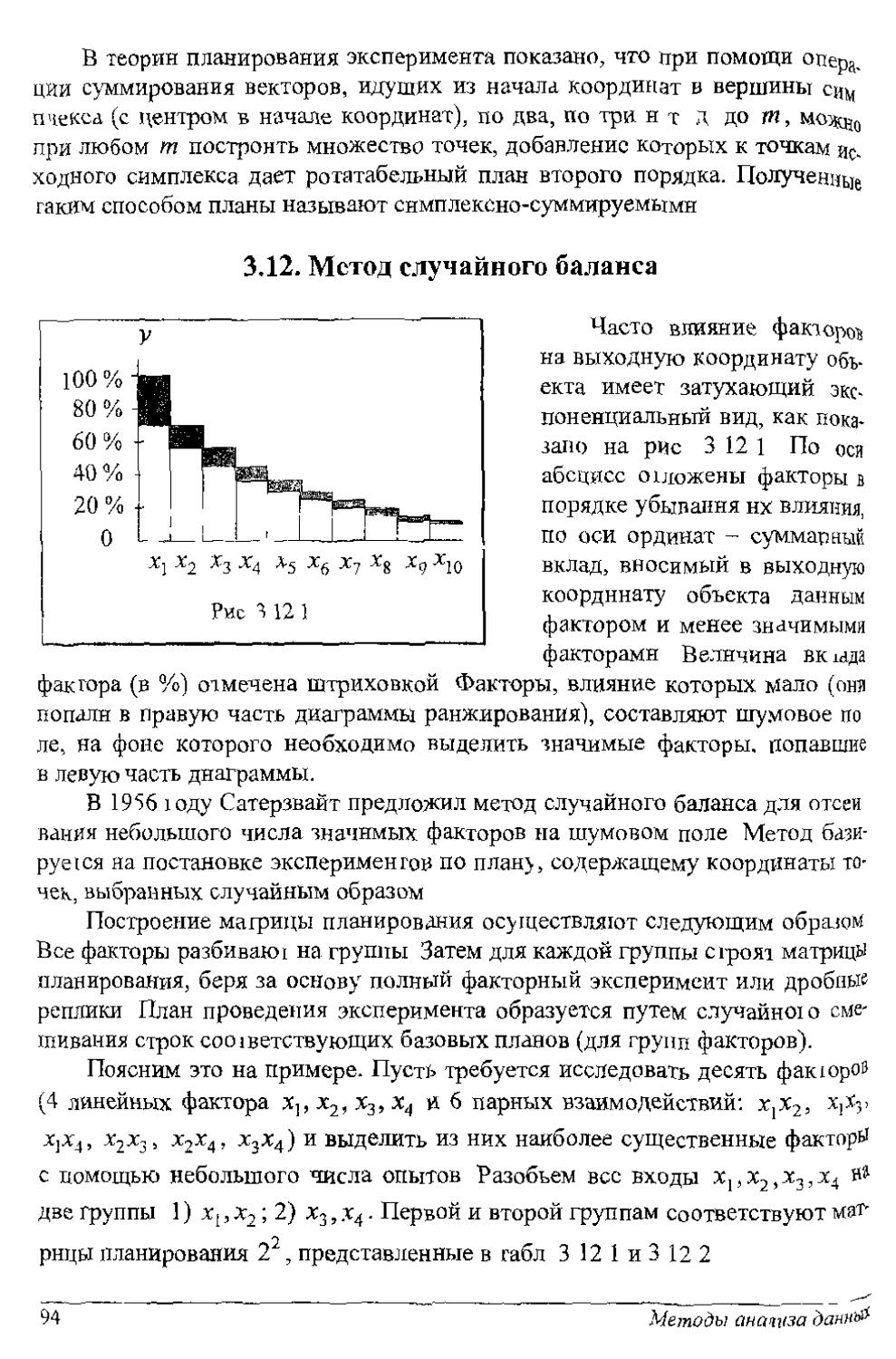
Считаем. Что известны условные плотности распределения вероятности /(х|Я1) и /(х|Я2). Они изображены на рнс. 1.1.1.
Решающее правило различения гипотез имеет вид: если с < х, то верна гипотеза Я2; если х < с, то верна гипотеза , где с - порог. На рисунке приведены
также условные вероятности ошибочных решений:
а= J/(x|^)Jx, 0= ]7(х|Я2уЯ}
6ч
а - вероятность принять Я2, в то время как верна Я,; [5 - вероятность принять Я}, в то время как верна Я2.
Алгоритмы расчета порога будут рассмотрены при решении конкретных задач.
Случай 2. В отличие от предыдущего случая решение об истинности гипотез выносится не по одному измерению, а по целой серии: хп ..хв.
Произведем сжатие этой информации: г = Я/ь хл). Здесь ?() - известная функция.
Считаем, что условные плотности распределения и f (г|Я2)
известны. Дальнейшая схема проверки гипотез та же, что и в первом случае (рис. 1,1.2).
6
Методы анализа данных
Частные варианты. Часто исследователя интересуют не две гипотезы, а одна; Их-Н- Прн этом известна только плотность распределения /(z}#). Для построения правила распознавания (как мы убедились только что) необходимо иметь две конкурирующие гипотезы. Следовательно, вводим вторую гипотезу. Здесь возможны 2 варианта:
1) Нг=Нь т. е. в конкурирующую
гипотезу вводятся все остальные возможности (варианты), которые могут в принципе встретиться, кроме II. Если принимается Н, то это означает, что Н отвергается;
2) Н2 "= часть Н , т, с. в гипотезу Н вводится дополнительное ограничение (например, для И : = т2 имеем: Н.т{ т2; часть Н: тх > т2).
Остановимся подробнее на этих случаях.
1. Осуществляется проверка гипотез Н н Н при известной плотности /(?]Н), где z - известное преобразование от выборки х13 ..., Теперь в области изменения z приходится вводить два порога: сх н с2 . Правило проверки гипотез Н и Н выглядит следующим образом (рис. 1.1.3):
если q < z < с2, то принимается гипотеза Н;
если z < q либо q < z, то гипотеза Н отвергается.
На рис. 1.13 введены обозначения: сг
р - j/(z| H)dz - вероятность пра-<ч
вильного решения, т. е. это вероятность того, что принимается гипотеза Н в то время, когда она верна;
« = Л i n^dz + С । ~
вероятность ошибочного решения, т. е. это вероятность отвергнуть гипотезу Н
в то время, когда она верна. Вероятность а называется уровнем значимости. Уровень значимости задается исследователем априори.
Обычно вероятность ошибки а равномерно распределяется (по сх/2) на областях z < q н z > с2, т. е. | H)dz = а/2 и f(z | H)dz = а/2.
Гпава 1 Статистическая проверка гипотез
7
Если распределение f(z\H) симметрично (рис. 1.1.4) относительно нуля, > то пороги с} = -с, с2 = с симметричны относительно нуля.
2. Осуществляется проверка гипотез: Н и часть Н.
Дополнительная информация о конкурирующей гипотезе Н может приводить к тому, что при проверке гипотез требуется вводить только один порог с (рис. 1.1.5).
Примером может служить случай, когда плотность распределения вероятности f (z| часть Н2) находится справа от
Схема расчета порога обычно имеет следующий вид.
Исследователем задается вероят
ность ошибки а. а затем из уравнения (см. рис. 1.1.5)
f/(21 H')dz = а
вычисляется порог с, т. е. с - с(а)
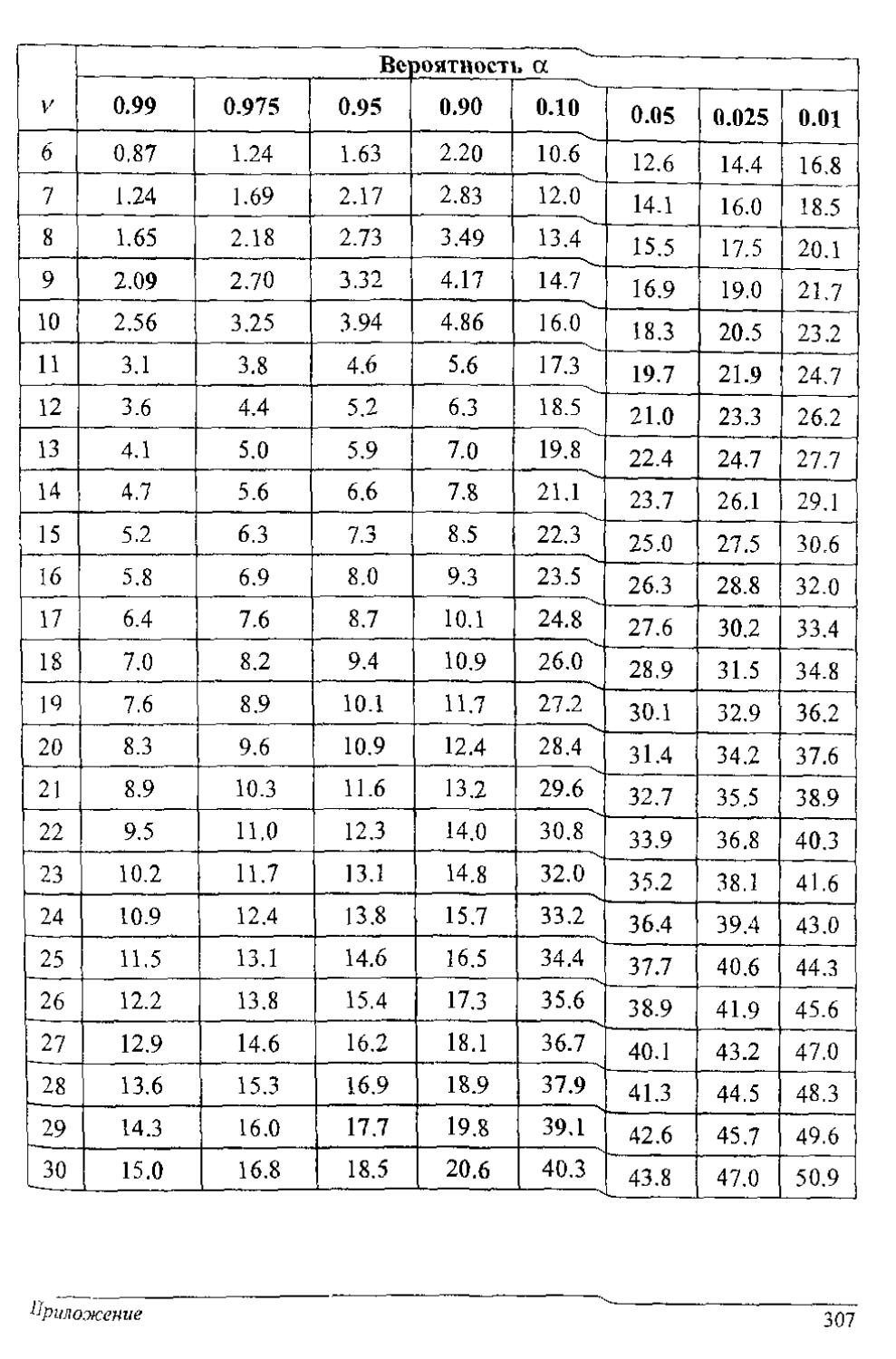
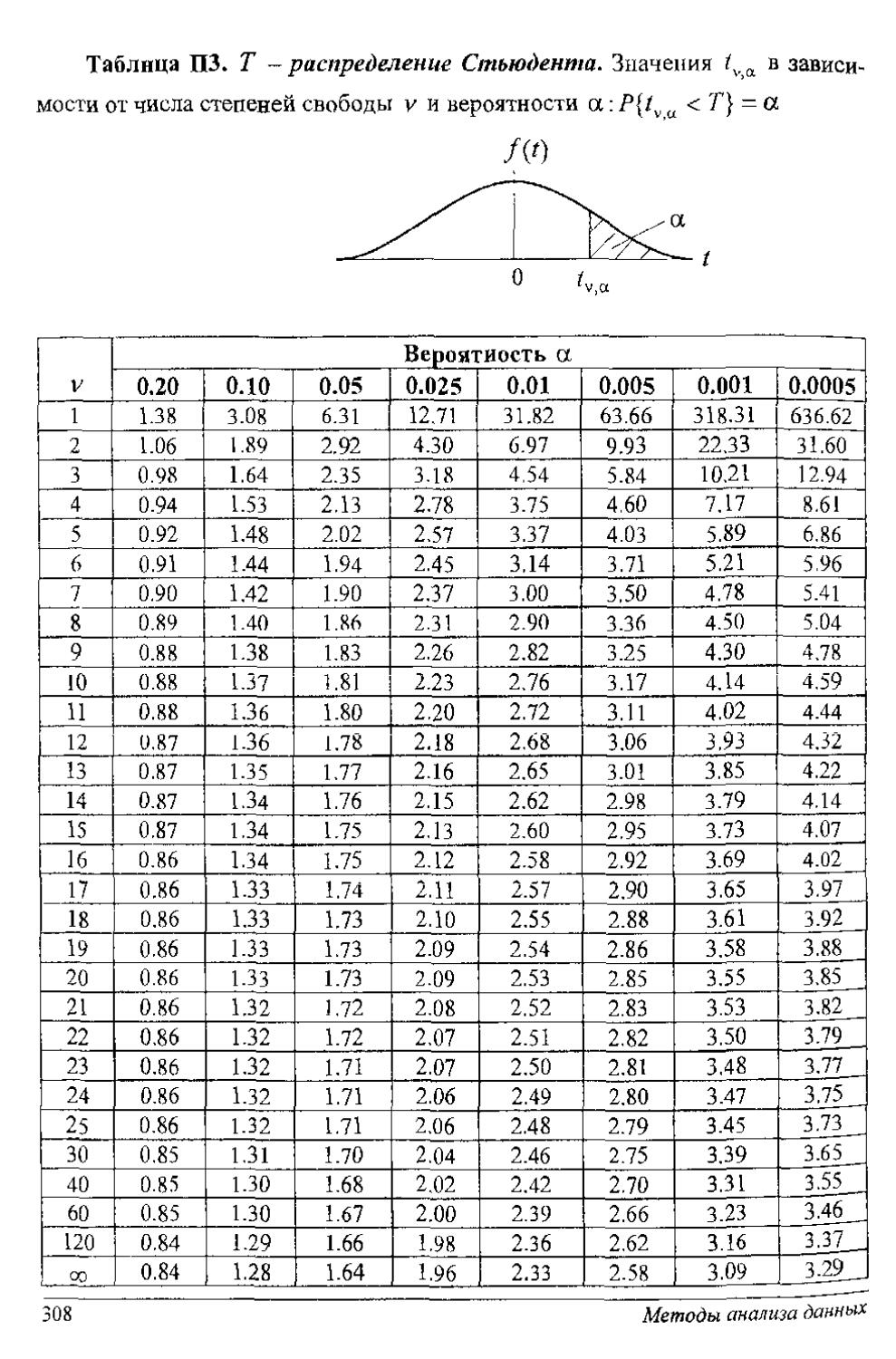
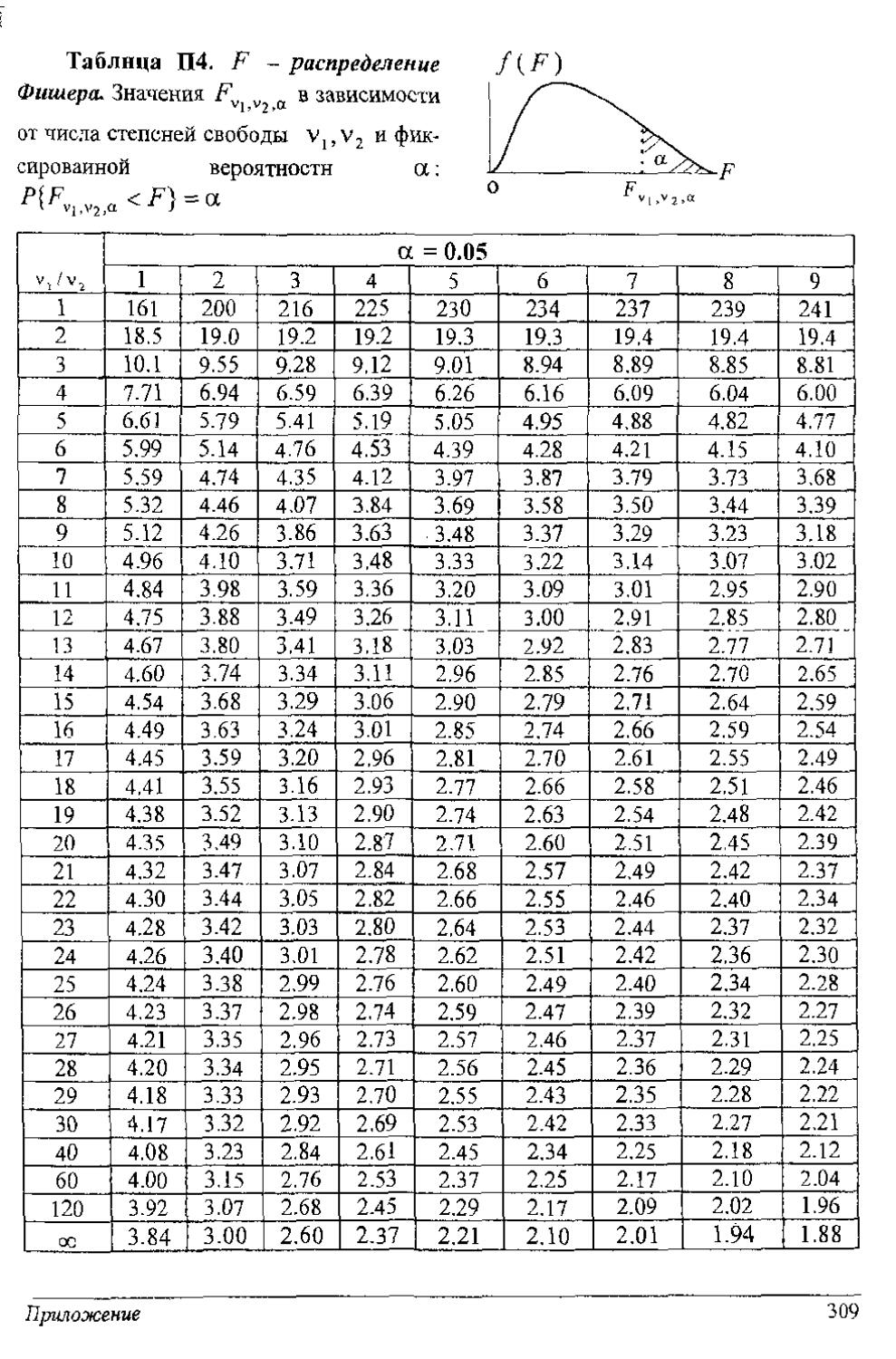
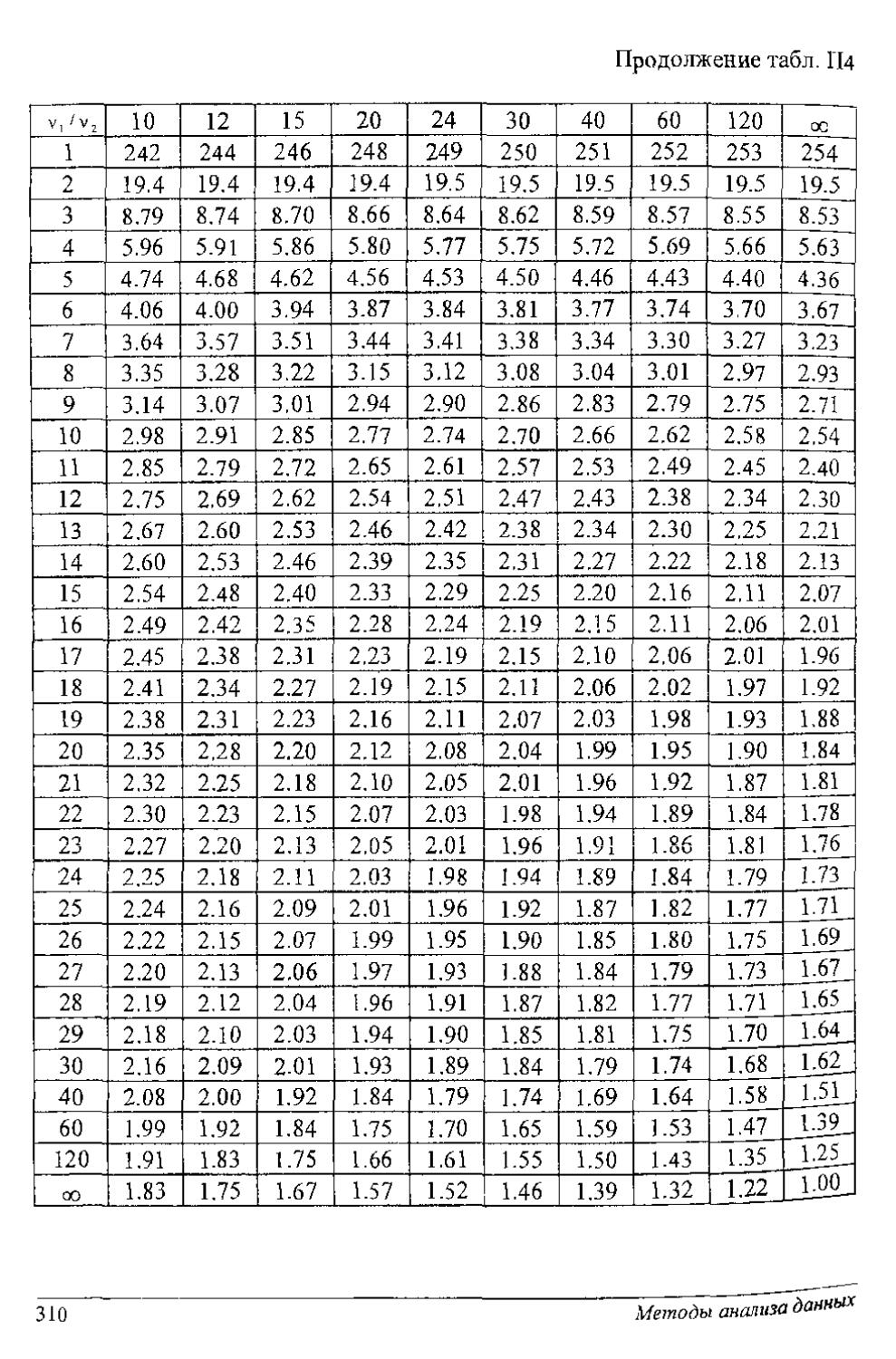
Для известных плотностей /(т'Н) (нормальное распределение, распределение Стьюдента, хн-квадрат, Фшнера н др.) получено решение этого уравнения, и пороги сведены в табл. П1-П5 приложения.
1.2. Проверка гипотезы о математическом ожидании
Задача 1, Считаем, что случайная величина X распределена по нор-мальноМУ закону Л'т(щ,су ) с неизвестным математическим ожиданием т и известной дисперсией сГ - Необходимо по независимой выборке jq, ..., х принять решение о том, что т = т0, где mQ - известная величина. Таким образом, здесь основной гипотезой Н является гипотеза о том, что т = т0, а конкурирующей является: а) либо гипотеза Нг = Н\т Ф т^, б) либо гипотеза Н2 =частьН;т > В первом случае имеем двупороговую процедуру распознавания, во втором - однопороговую.
8
Методы анализа данных
Вводим статистику
m~mQ сг/л/п
1 "
где . Статистика z (когда верна гипотеза Н) имеет нормальный
П^}
закон распределения с нулевым математическим ожиданием и единичной дисперсией:
/(z|H) = ^L-exp -Z-V 2П 2
Закон симметричен относительно нуля.
а) Н2 = U'.m *- т0. Левый с, = -с и правый с2 = с пороги (в алгоритме проверки гипотез) зависят только от одной константы с. Этот случай отражен на рис. 1.2.1. Гипотеза Н верна, если величина |2|< с.
Порог с находим из условия
Решение этого уравнения приведено в табл. Ш приложения: с = с(а/ 2).
Если закон распределения для случайной величины X неизвестен, то в соответствии с центральной предельной теоремой статистика z имеет нормальный предельный закон распределения ЛДО; 1). При больших значениях и (более 30) все предыдущие результаты имеют место с высокой точностью.
Пример 1.2,1. Для нормально распределенной случайной величины с известным средним квадратическим отклонением су = 40 получена независимая выборка объема и - 64 и по ней найдена оценка математического ожидания т = 136.5. Необходимо при уровне значимости а =0.01 проверить гипотезу Н: т = 130 при конкурирующей гипотезе Я: т 130.
Вычисляем статистику:
Г^ава I Статистическая проверка гипотез
9
находится из условия (см. рис
m-mQ 136.5 130
су/л/л 40/8
Из табл. Ш приложения находим порог- с - c(ct/2) = с(0.005) —2.58.
Так как - 2.58 < 1.3 < 2.58, то верна гипотеза Н
б) Н2 -- часть И: т >т$. Порог с
1.2.2)
Р{с < z} - а,
т. е (см табл. П1 приложения) с = с(а).
Пример 1-2.2. В условиях предыдущего примера прн Н2 = часть Н т> Шц н том же уровне значимости получаем, Что с =с(а)=с(0.01)-2 33 Так как 1.3 < 2.33, то верна гипотеза Н
Задача 2. Рассмотрим случай, когда случайная величина X распределе-2
на по нормальному закону .V(m, ст ) с неизвестным математическим ожида-2
нием т и неизвестной дисперсией о . Необходимо по независимой выборке хь. .,хи случайной величины X. принять решение о том, что верна либо гипотеза Н, т. е. о том, что т - тп, либо гипотеза Н о том, что т
Вводим статистику:
где/и — — 2^х(; су = J•
Если верна гипотеза //, то величина z имеет симметричное распределение Сгьюдента 7^(0; 1) с «'1 степенями свободы. Этот закон симметричен относительно математического ожидания. Принимается гипотеза Н, если |z|< с Порот с находим из условия
Р{е < z] = а/2.
10
Методы анализа данных
Порог с удовлетворяет такому же уравнению, как и в задаче 1, только для закона распределения Стыодента.
Если конкурирующей является гипотеза Н2 =частьН'.т>тй, то в однопороговой процедуре различения гипотез порог находится их условия Р{с < z} = а.
В табл. ИЗ приложения результат (порог с) решения уравнения Р{с <z}-a. Исходные данные в таблице: уровень значимости а (либо а/2 при двупороговой процедуре) и число степеней свободы v = п - 1.
При больших п (не менее 30) закон Стьюденза близок к нормальному распределению и результаты решения задачи 1 и 2 оказываются близки (в том числе и при неизвестном законе распределения случайной величины X).
Пример 1.2.3. Сравнить результаты действия двух снотворных лекарств А и В при испытаниях их на 10 больных. Добавочные часы сна под действием этих лекарств приведены во втором и третьем столбцах табл. 1.2.1.
В четвертом столбце приведены разности между добавочными часами сиа для лекарства В и А . Это и есть исходная выборка ..., хп, на базе которой проверяется гипотеза Н\ т=(). Конкурирующей является ги-потеза Н2 = Н'. т 0 Если гипотеза Н бу-дет принята, то это будет означать, что дей-ствие обоих лекарств одинаково. Считаем, что выборка хр ..., хп независима и привад лежит нормально распределенной случайной величине. Вычисляем статистику (Стыодента) z - (in ~ то)/(д!4п) — 4.06 Таблица 1.2.1
i А В 1 i
1 +0.7 +1.9 +1.2
2 -1.6 +0.8 12.4
3 -0.2 +1.1 +1.3
4 -1.2 W.1 +1.3
5 -0.1 -0.1 0.0
6 +3.4 +4.4 +1.0
7 +3.7 +5.5 1-1.8
8 +0.8 +1.6 +0.8
9 0.0 +4.6 +4.6
10 +2.0 +3,4 + 1.4
и из табл. 113 приложения находим порог (процедура двупороговая; а - 0.01):
С ~ *9;0 005 - 3.25 .
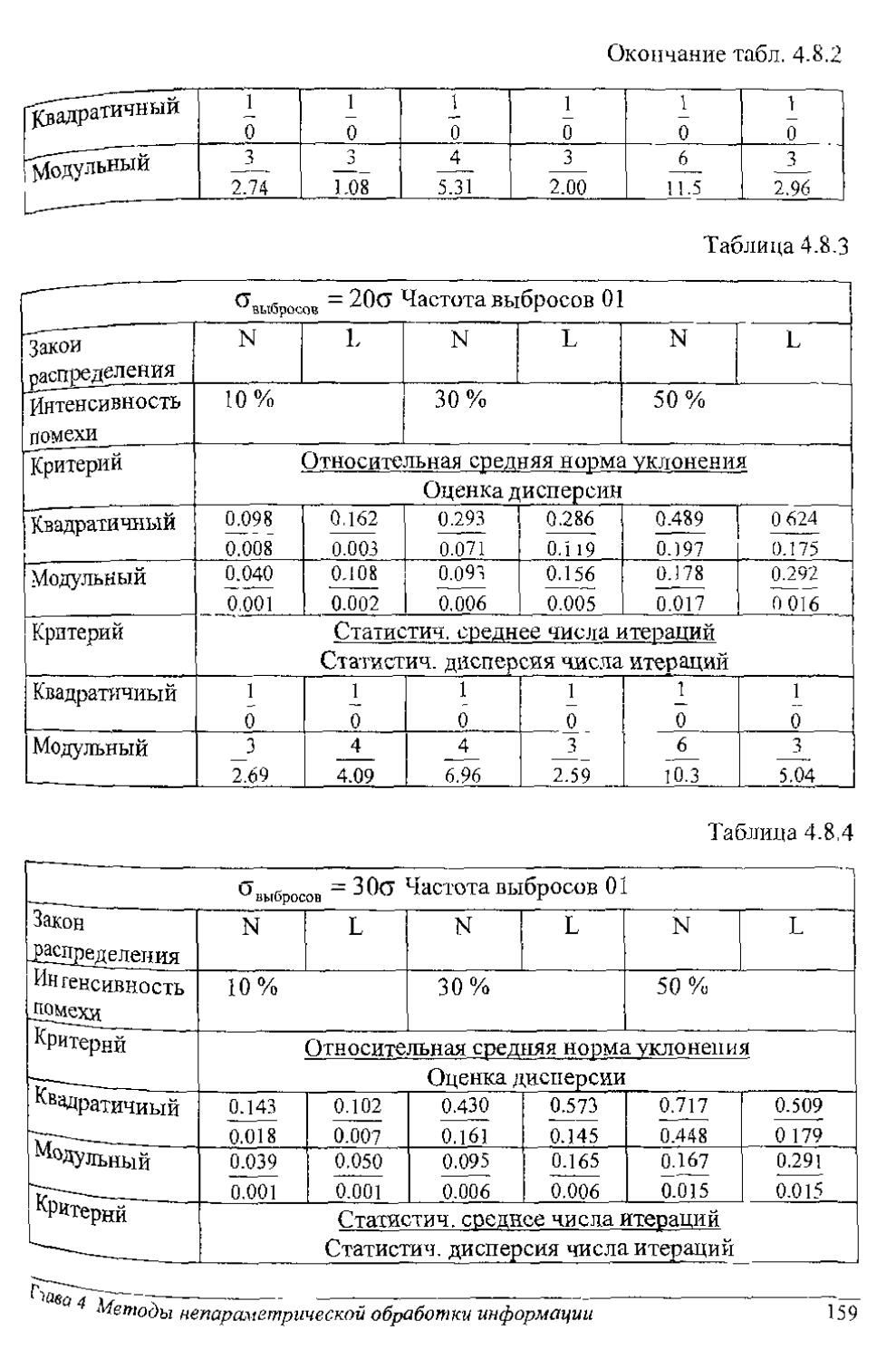
Так как 3.25 < 4.06, то гипотеза 7? отвергается, т. е. действие лекарств различное: второе действует сильнее первого.
Гчава 1 Статистическая проверка гипотез
1]
1.3. Проверка гипотезы о дисперсиях
Задача 3. Полагаем, что случайная величина X распределена по нормальному закону 7V(m,cr2) с неизвестным математическим ожиданием т 2 и неизвестной дисперсией <у
Необходимо по независимой выборке jq,,,,, хп проверить истинность нли ложность гипотезы Н о равенстве дисперсии а фиксированной вели-чине' <у где сг0 - величина известная. Конкурирующая гипотеза Н о том, ЧТО <У Ф СГ0 ,
Вводим статистику (хи-квадрат):
2 (и - 1)д2 и = Х - ------~
<*0
2 1" 2
где & =-EU”™)
« U1
Вели справедлива гипотеза Н, то величина /г2 с (и - 1) степенями свободы имеет распределение хи-квадрат f„ ](%2 [ZZ) (рис 13,1), Пользуясь таблицами (табл. П2 приложения) функции распределения, находим пороговые 2 2
значения %2 и , соответствующие условиям
Р{Ъ <Х2) = “ +/> = ! —
Принятие гипотез соответствует правилу, 2 2 2
если Х2 < % < X] , то принимается гипотеза Н ; 2 2 2
если х < Хг либо Xi < X > т0 гипотеза 77 отвергается, Одиопороговый критерий рассмотрите самостоятельно.
Методы анализа данных
Пример 1,3,1. По независимой выборке объема /7 = 21 нормально распределенной случайной величины найдена оценка дисперсии ё2 =16.2. Необходимо при уровне значимости а =0.01 проверить гипотезу Н : <j2=15 при конкурирующей гипотезе (часть Я): 15 < п'. Находим значение статистики "хи-квадрат":
7
Z -т - 2
CF0 15
2
и величину порога (из табл. П2 приложения) X2o;o.oi - ^7.6. Процедура различения гипотез однопороговая. Так как 21.6 < 37.6, то принимается гипотеза Я.
Задача 4. Теперь рассмотрим случай, когда имеем две случайные величины X и У, распределенные по нормальным законам и
Я(т2,су2) соответственно, с неизвестными математическими ожиданиями 2 2
т} и m2 дисперсиями а, и о2.
Необходимо по независимым выборкам Xj,..., и у},уп2 принять гипотезу Я : ст2 = или конкурирующую гипотезу Я2 = часть Я: сг2 <ст2. Для того чтобы в таком однопороговом варианте проверялась основная гипотеза, вводится статистика
-2
= 2т = к-^2 - ’
в которой в числитель ставится наибольшая из оценок. Здесь .2 1 ._2 1 ~ .2
Если справедлива гипотеза Я, то величина F имеет распределение Фишера (Я -распределение) с [(vL - п} -1), v2 =(и2 -1)1 степенями свободы. Этот закон не симметричен, так же как закон /2 .
В таком случае, если z<c, то принимается гипотеза Я (рис. 13.2). Порог с выбирается из табл. П4 приложения. Исходными данными таблицы являются: уровень значимости а, число степеней свободы числителя v, = п} -1 и число степеней свободы знаменателя v2
Гнава 1. Статистическая проверка гипотез
13
Пример 1.3,2, По двум независимым выборкам объемами п} = 11, - 14
нормально распределенных случайных величин найдены оценки дисперсий: ^2 2
в[ =0.76; 6'2-0.38. Необходимо при уровне значимости а = 0.05 проверить 2 2
гипотезу Н : сг1 = <т2 при конкурирую-— 2 2
шей гипотезе (часть Н ): сг2 < О'1.
Вычисляем статистику
F-^2
0.38
и из табл. П4 распределения Фишера находим порог Flo l3 005 - 2.67. Правило принятия гипотез однопороювое. Так как 2 < 2.67, то принимается гипотеза о равенстве дисперсий.
1.4. Проверка гипотезы о равенстве математических ожиданий
Задача 5. Случайные величины X и Y распределены по нормальным ? ?
законам N(muG]) и Л'(т2,о,2) с неизвестными математическими ожида-2 2
ниями т}, тг и известными дисперсиями cfj э ег2- Имеются две гипотезы’ одна Н о том, что ~ т,, и конкурирующая гипотеза (772 = Н ) о том, что Эти гипотезы проверяются по независимым выборкам хь ..., х ;
ур ..., у по статистике
т, - т-,
Z = , - 2 ’
+СГ2/«2
где т2 =— £у( .
«1 1=1 «2-1
При истинности Н случайная величина z распределена по нормальному закону 7V(0; 1). Порог с находится из табл. Ш (см. задачу 1): с = с(а/ 2)
Условия принятия гипотез Н, Н таковы:
если - с < z < с, го принимаем 77;
если z < -с или с < z, то отвергаем Н.
14
Методы анализа данных
Пример 1.4.1. Для двух нормально распределенных случайных величин получены независимые выборки объемами = 40, = 50, а по ним вычислены оценки магматических ожиданий = 130, = 140. Считая диспер-
2 2
сии известными <5j = 80, сг2 = 100, при уровне значимости а^0.01 проверим гипотезу о равенстве математических ожиданий (И : т{ = т2) при конкурирующей гипотезе Н т2.
Вычисляя статистику
z = (т} - т2)/(^/п{ +с1/п2')^2 --5
и находя из табл. Ш порог
с = с(а/2) ~ с(0.005)=2.58,
получаем, что значение статистики, равное величине -5, находится слева от порога - с = -2.58, т. с. гипотеза Н отвергается.
Задача 6. Имеем величины X и Г, распределенные по нормальным за-2 Т 2
конам N(ml,CFj ) и Х(т2,а2) соответственно. Рассмотрим ситуацию, когда тх и т-2 неизвестны, а дисперсии одинаковы (erL = сг2 = О') и неизвестны. Проверяем шпотезу Н о равенстве математических ожиданий = т2 по независимым выборкам Xj,.,., х„; yt,..., .
Введем статистику
т, -- гХ
z = —!—L-—, + 1/я2
где
n 1 И 7 J1
е = +Е(у;-™2) )
«! + «2 - 2 |=[
Если гипотеза Н верна, что z имеет распределение Стьюдента. Пороги находим, как в задаче 2 (см. параграф 1.2).
Пример 1.4.2. Имеются данные, полученные из наблюдения веса некоторого (фиксированного) объема азота при / = 15 °C и Р = 160 мм рт. ст,
Гчава 1. Статистическая проверка гипотез 15
Вначале взвешиваем азот, приготовленный из азотистых соединений (результаты заносим в колонку I табл. 1.4 1), затем - азот, приготовленный из воздуха (результаты заносим в колонку 11 табл. 1.4.1). По этим экспериментальным данным вычисляем оценки математических ожиданий ^=2.29947 г, т2~1.31016 г и их разность: т2 - тх = 0.01069 г, т. е. азот воздуха на 1/200 тяжелее азота, изготовленного из азотистых соединений. Для выяснения значимости этой разницы используем статистику Стыодента
Вычисляем значение статистики:
Таблица 1.4.1
i 1 I 2.30143 11 231017 0.01069Г 8-10 Т 0.0009z|_S +10 J и из таблиц получаем порог (для двупороговой решающей процедуры при а = 0.001) *16,0.0005 “ 4'02. Так как 4.02 < 24, то гипотеза о равенстве математических ожиданий не проходи 1, I. е. отличие веса является не случайным. Действительно, вскоре было показано, что на-блюдавшаяся в опытах разность весов определя-
2 3 2.29890 2 29816 2.30986 2.31010
4 2.30182 2.31010
5 2.29869 2 31024
6 2 29940 2.31010
7 8 9 2.29849 2.29889 2.31028 2.31035 2.31035
10 — 2.31024
ется присутствием в азоте, полученном из воздуха, небольшого количества газа, более тяжелого, чем азот. 1 ак был открыт
аргон.
Пример 1.4.3. По двум независимым выборкам объемами ч.‘ Г2, и2 ~ 18 нормально распределенных случайных величин найдены оценки математических ожиданий тх =31.2, /й2=29.2 и дисперсий с^-0.84, С2 -- 0.40. Необходимо при уровне значимости а = 0.05 проверить гипотезу Н: т{ - m2 при конкурирующей гипотезе Н:
Задачу решаем в два этапа. На первом по одностороннему критерию Фишера проверяем гипотезу о равенстве дисперсий:
С = 0.84/0.40 = 2.1, F1U7;005 =2.7, 2.К2.7.
Гипотеза о равенстве дисперсий принимается. Теперь уже можно использовать статистику Стыодента
16
Методы анализа данных
тх — т2
-.2 -2
Выразим оценку дисперсии с через оценки Qj, ст2
е = (X + п2 - 2) (£(х; - тА) + £(уу - т2) ) = г=1 7=1
— 1 9 Э
= («i + M2-2) ((«, -1)0, +(«2-1Ю-
Таким образом,
? = 3.7, ?2Я ,о 025 = 2.05.
Так как 2.05 < 3,7, то гипотеза Н отвечается.
1.5. Выявление аномальных измерений
Задача 7. Положим, что случайная величина X распределена по нор-
2 2
мальиому закону N(m, <У ), где т - неизвестно, а дисперсия <5 - известная величина. .Имеется выборка хрхл и х - новое измерение случайной величины X. Необходимо по независимой выборке хр ...,хи, х проверить истинность гипотезы 77: принадлежит ли измерение х случайной величине Х,т. е. х g X, или л - аномальное измерение.
Строим статистику:
х - т z~ ——.
СУ
Пороги находим, как в параграфе 1.2 для задачи 1. Решающее правило двулороговое.
Теперь рассмотрим ситуацию, когда дисперсия су2 неизвестна. Стати-
X —171
стика имеет вид z = ——. При истинности гипотезы Н случайная величина СУ
z распределяется по закону Стьюдента. Пороги находим, как в параграфе 1 2 Для задачи 2. Решающее правило двупороговое.
Глава 1 Статистическая проверка гипотез 17
1.6. Гипотеза об однородности ряда дисперсий
Задача 8. Имеем несколько случайных величин Х2,.., распре-2 2
деленных по нормальному закону №(тг, од ),..., СА) Все параметры /п,,(Т2, i-l,k неизвестны. Для каждой случайной величины производятся независимые измерения одинакового объема п и проверяется гипотеза о ра-2 2 2
вепстве дисперсий: сг1 - сг2 = ~®к- Строим статистику по методу Кочре-иа (W. G. Cochran), так как для всех случайных величии имеем одинаковое число повторных опытов п.
Статистика имеет вид
2 ^тах ^тах S j ’
где = max{oj,стА}
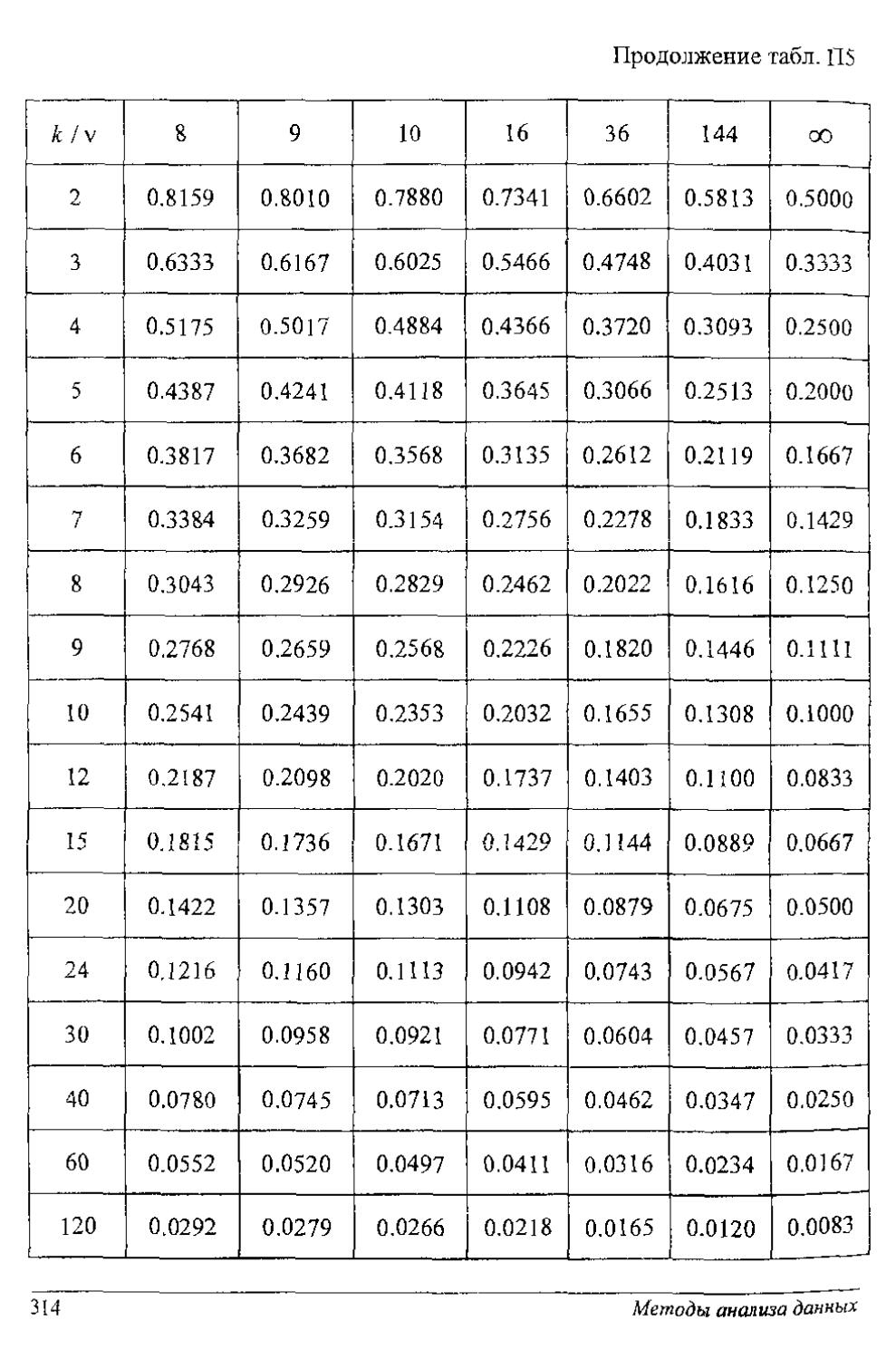
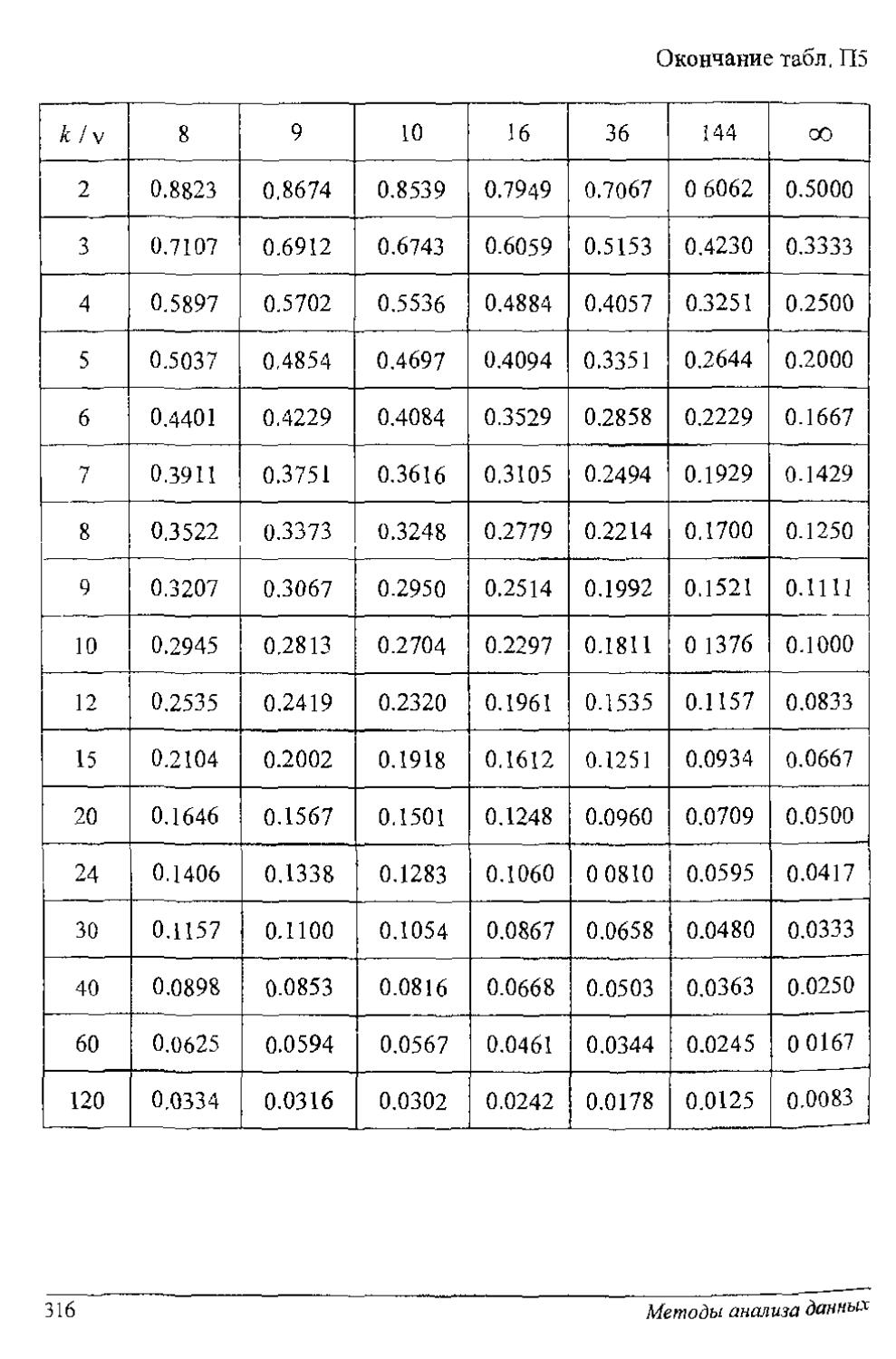
Статистика Кочреиа - это отношение максимальной из оценок дисперсий к сумме всех оценок дисперсий. Гипотеза об однородности рада дисперсий принимается, если экспериментальное значение статистики Кочрена G'max не превышает порогового значения, выбираемого из табл. П5 приложения.
Пример 1.6.1. Из текущей продукции горизоитально-ковочной машины за семь смен ее работы отобрано семь проб, по одной пробе в смену численностью в 17 штамповок. По данным каждой из проб подсчитаны оценки дисперсий (мм2): 0.067; 0.136; 0.168; 0.068; 0.066; 0.102; 0.137. Требуется прове-рить гипотезу об однородности ряда дисперсий (Н: = сг2 = ... = сгА), т. е.
гипотезу об отсутствии разладки машины.
Вычисляем значение статистики Кочрена
^тах
0,168_____
0,067 + ,,.+ 0.137
0.2258
и из таблиц (при v=n-1 = 17 -1 = 16, к~1, сс = 0.05) находим пороговое значение G7j6i005 = 0.2756. Так как значение статистики меньше порога, то принимается гипотеза однородности ряда дисперсий. За 7 смен разладки ковочной машины не произошло.
18
Методы анализа данных
1.7. Проверка гипотезы о распределениях
Задача 9. Считаем для конкретности, что рассматривается непрерывная случайная величина X . По независимой выборке хь х2,..., хп строим гистограмму. Для этого весь интервал возможных значений случайной величины X разбиваем па подынтервалы (xj,xj+i), / = 1Д длиной rj каждый. Число выборочных значений, попадающих в у'-й интервал, обозначим через л? к
причем X nj ~ п и все 5 < . Относительная частота попадания выборки в
каждый у-й интервал равна величине ~п !п. Это оценка вероятности попадания случайной величины X в этот интервал Р(х; < X < х и).
Обозначим через f(x ( 0t,..., 0Z) предполагаемый закон распределения (плотность распределения вероятности), заданный с точностью до параметров 0. Вместо параметров 0 ставим оценки 0, полученные по исходной выборке. Тогда вероятность попадания случайной величины X в у -й интервал
(1-7-1)
XJ
Гистограмма представляет собой кусочно-постоянную оценку плотности вероятности, построенную на интервалах (xj,xJ+i), т. е. состоит из примыкающих друг к другу прямоугольников площадью pj каждый и высотой АЛт
Необходимо проверить гипотезу Н о том, согласуется ли выбранный закон распределения fix 101?..., 0j) с гистограммой (с экспериментальными данными). Проверка этой гипотезы базируется на статистике, построенной на уклонениях ff и р \
. пул
J=1 Pj Г-1 nPj ;.лпр}
При больших п эта статистика имеет распределение хи-квадрат с {k -1 -1) степенями свободы. Здесь к - число интервалов, I - число параметров, входящих в плотность распределения /(х 10],..., 0Z).
Глава I. Статистическая проверка гипотез
19
Задаем уровень значимости а и Из табл, ПЗ приложения находим порог а одностороннего критерия. Если теперь оказывается, что а < "к , то гипотеза 77 отвергается, т. е. выбранный закон распределения f{x10],..не согласуется с экспериментальными данными. Если же то гипотеза 77 принимается и в качестве оценки истинной неизвестной плотности /(%) можно использовать закон распределения /т, Л)
Пример 1.7.1. Произведено измерение 200 деталей. Отклонение этих измерений от номинального размера дает исходную выборку х15...,х„. В табл. 1.7.1 приведены границы выбранных интервалов (х7,х7+1), частоты п и вероятности pt (см. (1.7.1), рассчитанные при нормальном законе распределения Л'Хт.Д"). Здесь т-4.3 мкм, о = 9.71 мкм - оценки, рассчитанные по выборке.
Таблица 1.7.1
Интервал j микрон Pj
1 -20, -15 7 0.0239
2 -15,-10 11 0.0469
3 -10, -5 15 0.0977
4 -5, 0 24 0.1615
5 0, 5 49 0.1979
6 5, 10 41 0.1945
7 10, 15 26 0.1419
8 15, 20 17 0.0831
9 20, 30 10 0.0526
k-9 п -200 ==i j
Вычисляем статистику (1.72) % -6.31 и пороговую величину 2
Хб.оо5=12.6 при числе степеней свободы v - к-1 =9-2-1 = 6и
2 2
уровне значимости а - 0.05. Так как % < о 05 * то принимается гипотеза
2
нормальный закон распределения ЛГ(/п,ст ) отклонений размера деталей оз номинального значения не противоречит наблюдениям.
20
Методы анализа данных
В компактном виде основная исходная информация, гипотезы, статистики и решающие правила для всех рассмотренных в параграфах 1.2-1.7 задач представлены в табл. 1.7.2.
Таблица 1.7,2
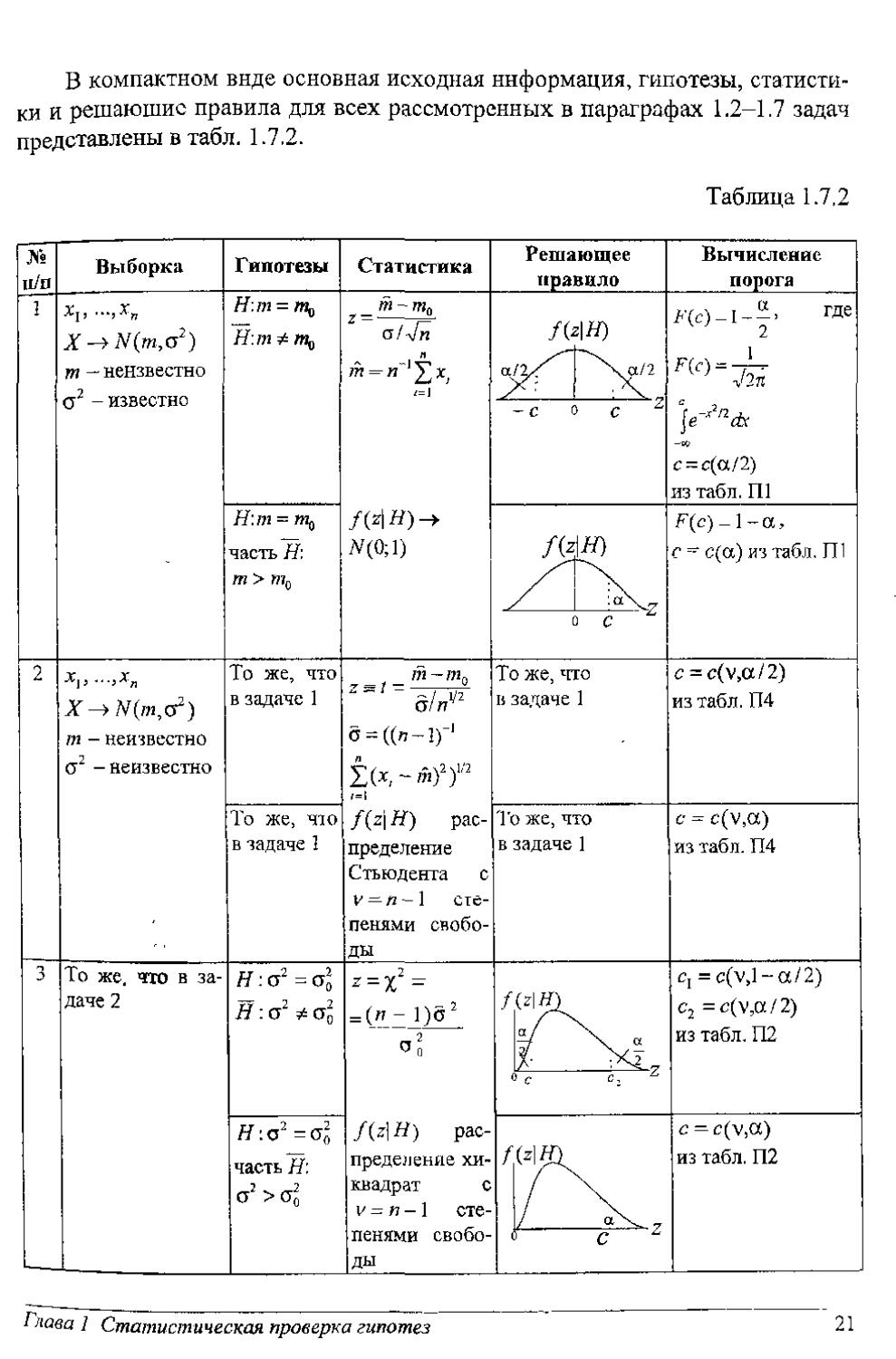
№ н/п Выборка Гипотезы Статистика Решающее правило Вычисление порога
1 Xj, ...,хп т — неизвестно а2 - известно Н.т = т9 Н.т^Шц II в 1 Г(с)-1-Я где т(г)=да 4271 ]е~^2^ с = с(а/2) из табл. П1
- С о с
Н:т = т^ часть Н: т > т0 яда z F(c) -1 - а, с ~ с(а) из табл, П1
0 С
2 т - неизвестно О2 - неизвестно То же, что в задаче 1 т - тп т ™ , 2. ’ а/Я2 а = ((«-])-' f(z\ Н) распределение Стьюдента с V —я-1 степенями свободы То же, что в задаче 1 с = c(v,ct/2) из табл. П4
То же, h i о в задаче 1 То же, что в задаче 1 с = с(у,а) из табл. П4
3 То же, что в задаче 2 /7: ст2 = Од Н : ст2 * Од = (Л7 - о f{z\H) распределение хи-квадрат с v = и -1 степенями свободы / WH) «/ / \ а с, = c(v,l-a/2) с2 =c(v,a/2) из табл. П2
с С,
/7: С2 -Оо часть Н: (J > / z ?да. с — c(v,a) из табл. П2
с
^-чава 1 Статистическая проверка гипотез
21
Продолжение табл. 1.7.2
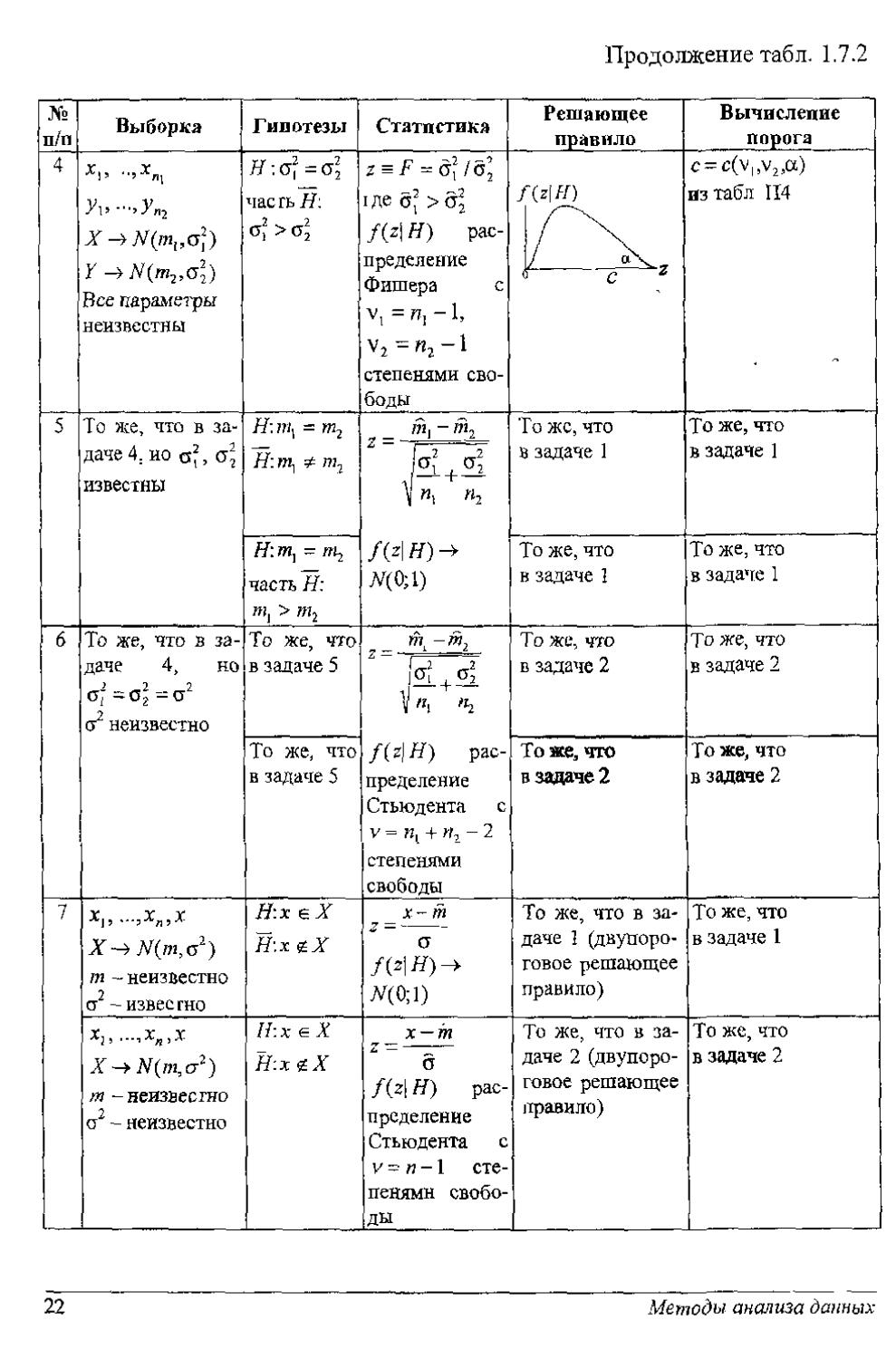
№ п/п Выборка Гипотезы Статистика Решающее правило Вычисление порога
4 Ур-,УЛ2 X -^Я(т,,ст2) У N(m2,sl) Все параметры неизвестны Я: ст2 = ст2 часть Н: ст2 >ст2 z F = о2 /б2 1де б2 >б| f(z\H) распределение Фишера с vi =^-1, v2 = кг-1 степенями свободы 7 “(zf/7) / с 2 c = c(v,,v2,a) из табл 114
5 То же, что в задаче 4: ио о*, ст2 известны г. I £ £ II Н Г ST 1 1^ | 2 2 | СУ, СТ; J— + — \ «1 «2 /W)^ Я(0;1) То же, что в задаче 1 То же, что в задаче 1
f/:m, = нд часть Я: wij > тг То же, что в задаче 1 То же, что в задаче 1
6 То же, что в задаче 4, но > - — 2 — „2 ~ — ст ст2 неизвестно То же, что в задаче 5 Й -W. Z = — \^L + ^2. «1 fh f(z\H) распределение Стьюдента с v = wt + и, - 2 степенями свободы То же, что в задаче 2 То же, что в задаче 2
То же, что в задаче 5 Тоже, что в задаче 2 То же, что в задаче 2
7 JCj, ...,ХЛ, X X -4 М/ЩСГ2) т ~ неизвестно 2 ст -известно Я:х еХ Н’.х £Х _х~т М0;1) То же, что в задаче 1 (двупороговое решающее правило) То же, что в задаче 1
х!5 ...,хл!х X -> N(m, сг2) /ч -неизвестно о2 - неизвестно Ii:x е X Н.хеХ __ х — т б f(z\ Я) распределение Стьюдента с v = и -1 степенями свободы То же, что в задаче 2 (двупороговое решающее правило) То же, что в задаче 2
22
Методы анализа данных
Окончание табл. 1.7.2
№ п/п Выборка Гипотезы Статистика Решающее правило Вычисление порога
8 хи, Х^|, ..., Х{ ^N(mxsfy Хк^М(тк,(5гк) Все парамегры неизвестны gO Q fa * Q g II t С-4 a w il 3 U a nj *“ _ - Г-g " К H e 2 « s j- ta s d *-rJ Q II II g v Д 9 к я " e ц от - —- * з к z = G - -Ндаа-спаи i xs; /(л| Н) рас- пределение Кочрена с v-h-I^ степенями свободы / а х Z—"2 с = c(k,v,a) из табл П5
9 По независимой выборке Х],Х2, . строится гистограмма. (а\,хЛ1) - подынтервалы, я -число выборочных значений, попадающих в J -й подынтервал , и, > 5, г -длина j -го подынтервала; =и,М - оценка вероятности р = " J /(Х|ё)£&’ /Ие„...Д) -предполагаемая плотность, заданная с точностью до параметров; § - оценки параме!-ров, полученные по исходной выборке Н. согласуется закон распределения /<Лj 0) с г истограм-мой; Н2: не согласуется II II 1М 1^' I Мд 1 Тз 1 !l То же, что для однопорогово го решающего правила задачи 3 с = c(v,a) из табл. П2
Гпава 1 Статистическая проверка гипотез
23
Упражнения Ш
Примеры заимствованы из задачника [1.1J и учебного пособия [1.3].
1.2.1. Для нормально распределенной случайной величины с известным средним квадратичным отклонением а = 5.2 получена независимая выборка объема и = 100 и по ней найдена оценка математического ожидания т = 27.56. Необходимо при уровне значимости а = 0.05 проверить гипотезу Н:т - 26 при конкурирующей гипотезе Н'.т 26 .
1.2.2. Для нормально распределенной случайной величины с известной дисперсией а2 =1600 получена независимая выборка объема и - 64 и по ней найдена оценка математического ожидания т = 136.5. Требуется при уровне значимости а = 0.01 проверить гипотезу Н: т = 130 при конкурирующей гипотезе Н : т 130.
1.2.3. Решить предыдущую задачу при конкурирующей гипотезе "часть Н"- т>130.
1.2.4. Установлено, что средний вес (математическое ожидание) таблетки лекарства сильного действия должен быть равен mQ =0.50 мг. Выборочная проверка 121 таблетки полученной партии лекарства показала, что средний вес таблетки этой партии т - 0.53 мг. Требуется при уровне значимости а = 0.01 проверить гипотезу Н : т - - 0.50 при конкурирующей гипоте-
зе "часть Н"\ 0.50 < т. Многократными предварительными опытами по взвешиванию таблеток, поставляемых фармацевтическим заводом, было установлено, что вес таблеток распределен нормально со средним квадратным отклонением а = 0.11 мг.
1.2.5. По выборке объема п = 16 для нормально распределенной случайной величины найдены оценки для математического ожидания т = 118.2 и для среднего квадратичного отклонения о = 3.6. Требуется при уровне значимости 0.05 проверить гипотезу Н'.т =120 при конкурирующей гипотезе Н:т 120.
1.2.6. Решить Предыдущую задачу, приняв в качестве конкурирующей гипотезы "часть Н"\ т < 120.
24
Методы анализа данных
1,2.7. Проектный контролирующий размер изделий, изготовляемых станком-автоматом, w0 = 35 мм. Измерения 20 случайно отобранных изделий дали следующие результаты;
контролируемый размер х: 34.8 34.9 35.0 35.1 35.3;
частота (число изделий) nf 2 3 4 6 5.
Требуется при уровне значимости 0,05 ( и при условии нормальности распределения размера изделий) проверить гипотезу Н:т - т0 =35 при конкурирующей гипотезе Н; т 35.
1.2.8. Норма времени на выполнение операции на конвейере равна 8 с. Произведено 11 замеров интервалов времени, затраченных на эту операцию; 9.9 с; 12.5 с; 10.3 с; 9.2 с; 6.0 с; 10.9 с; 10.3 с; 11.8 с; 11.6 с; 9.8 с; 14.0 с. Выяснить, равны ли реальные затраты времени нормативным или превосходят норму при уровне значимости 0.001.
1.3.1. По выборке нормально распределенной случайной величины объема п - 21 найдена оценка дисперсии ё2 = 16.2. Требуется при уровне значимости 0.01 проверить гипотезу Н <У =15 при конкурирующей гипотезе "часть Н": 15 < а2.
1.3,2. По выборке нормально распределенной случайной величины объема п = 17 найдена оценка дисперсии а2 = 0.24. Требуется при уровне значимости 0.05 проверить гипотезу Н : 02 =0.18, приняв в качестве конкурирующей гипотезы "'часть Н0.18 < а2 .
1.3.3. Для нормально распределенной случайной величины получена выборка объема п = 31:
выборочные значения 10.1 10.3 10.6 11.2 11.5 11.8 12.0;
частоты nt 1 37 106 3 1.
Требуется при уровне значимости 0.05 проверить гипотезу Н: а2 - 0.18 при конкурирующей гипотезе "часть Н 0.18 < а2.
1.3.4. Точность работы станка-автомата проверяется по дисперсии контролируемого размера изделий, которая не должна превышать (Тд =0.1. Взята проба из 25 случайно отобранных изделий, причем получены следующие результаты измерений:
Глава I Статистическая проверка гипотез
25
размеры изделий пробы xt 3.0 3.5 3.8 4.4 4.5;
частота nf 2 6 9 7 1.
Требуется при уровне значимости 0.05 проверить, обеспечивает ли станок требуемую точность.
1.3 5 В результате длительного хронометража времени сборки узла различными сборщиками усыновлено, что дисперсия этого времени Со = 2 мин2 . Результаты 20 наблюдений за работой новичка таковы.
время сборки одного
узла в минутах х 56 58 60 62 64;
частота п1 14 10 3 2.
Можно ли при уровне значимости 0.05 считать, что новичок работает ритмично (в том смысле, что дисперсия затрачиваемого им времени существенно ие отличается от дисперсии времени остальных сборщиков)7
1,3.6. Партия изделий принимается, если дисперсия контролируемого размера значимо не превышает 0.2. Оценка дисперсии, найденная по выборке объема п= 121, оказалась равной величине (У2 =0.3. Можно ли принять парпзю при уровне значимости 0.01 и при уровне значимости 0.05?
1 3.7. На выходе усилителя переменного тока проведено 12 измерений значения напряжения, обусловленного внутренними шумами усилителя С учетом того, что математическое ожидание измеряемого напряжения равно
Л
нулю (ffl = 0), получена оценка дисперсии о2 = д-1^\2 -120 мкВ2. Теорети-
1=1
ческии расчет предсказывает значение (Уд =80 мкВ2. Выяснить, свидетельствуют ли данные эксперимента о превышении расчетной величины дисперсии при уровне значимости 0.05.
1.3.8. По двум независимым выборкам объемами — 11, - 16 нор-
мально распределенных случайных величин найдены оценки дисперсий (У2 =34.02, (У2 =12.15. Требуется при уровне значимости 0.05 проверить W- Y О 2 Ьм*
1ипотезу п : <yt = (У2 о равенств дисперсии при конкурирующей гипотезе "часть Н”: (У2 < (У2
1.3.9. По двум независимым выборкам объемами = 12, =10 двух
нормально распределенных случайных величин найдены оценки дисперсий б2=0.84, &2=2.52. При уровне значимости 0 025 проверить гипотезу
26 Методы анализа данных
Н \С2} =(522 0 равенстве дисперсий при конкурирующей гипотезе Н‘. (5\ < О2.
1.3.10. По двум независимым выборкам объемами — 9, п2 ~ 6 двух нормально распределенных случайных величин найдены оценки дисперсий Oi = 14.4, о2 = 20.5. При уровне значимости 0.05 проверить гипотезу Я : б2 = ОI ПРИ конкурирующей гипотезе Я: о^ < о2.
1.3.11. Двумя методами проведены измерения одной и той же физической величины. Получены следующие результаты: а) 9.6; 10 0; 9.8; 10 2; 10.6; б) 10.4; 9.7; 10.0; 10.3. Можно ли считать, что оба метода обеспечивают одинаковую точность измерений, если принять уровень значимости 0.05? Предполагается, что измерения распределены по нормальному закону и выборки независимы.
1.3.12. Для сравнения точности двух сганков-автоматов взяты пробы объемами =10, п2 =8. Результаты измерения контролируемого параметра изделий следующие: а) 1.08; 1.10; 1.12; 1.14; 1.15; 1,25; 1.36; 1.38; 1.40; 1.42; б) 1.11; 1.12; 1.18; 1.22; 1.33; 1.35; 1.36; 1.38. Можно ли считать, что станки производил изделия с одинаковой точностью (Н : о^ = б2) при уровне значимости 0.05.
1.3.13. Оценивается качество работы двух стабилизаторов температуры: с усовершенствованием и без него, - эффективность стабилизаторов температуры измерения даваемой ими дисперсией температур. Для оценивания дисперсии первого стабилизатора проведено 4 опыта, второго — шесть. Оценки дисперсий оказались равными величинам: о^ = 0.016; =0.07 Необ-
ходимо выяснить по результатам эксперимента, можно ли при уровне значимости 0.05 считать усовершенствование эффективным.
1.4.1. По двум независимым выборкам (нормально распределенных случайных величин) объемами щ - 30, п2 = 40 найдены оценки математических ожиданий /ftj = 10,/^2 = 11. Дисперсии известны; Оу - 15, 02=20. Требуется при уровне значимости 0.05 проверить гипотезу Н: = т2 при конкурирующей гипотезе Н: тп,\ *
1.4.2. По выборке объема = 30 найден средний вес изделий fft\ = 130 г, изготовленных на первом станке; по выборке объема /^ = 40 найден сред
Глава 1 Ст Аскетическая проверка гипотез 21
ний вес rh2 ~ 125 г изделий, изготовленных на втором станке. Истинные дисперсии для веса изделий, изготовленных на станках, равны величинам
— 60 г1 2, СТ2 =80 г2. Требуется при уровне значимости 0.05 проверить гипотезу Н : т}- т2 ПРИ конкурирующей гипотезе Н ; т} ф т2 . Предполагается, что вес изделий подчиняется нормальному закону распределения и выборки независимы.
1.4.3. По выборке объема = 50 найден средний размер г%[ =20,1 мм диаметра валиков, из1 отовленных автоматом № 1; по выборке объема = 50 найден средний размер т2 =19.8 мм диаметра валиков, изготовленных автоматом № 2. Дисперсии диаметра валиков известны и равны величинам су2 = 1.750 мм2, в} = 1.375 мм2. Требуется при уровне значимости 0.05 проверить гипотезу Н : тх = т2 при конкурирующей гипотезе II: Т т2. Предполагается, что случайные величины X (диаметр валиков, изготавливаемых на первом автомате) и Y (диаметр валиков, изготавливаемых на втором автомате) распределены нормально и выборки независимы.
1 4.4. По двум независимым выборкам (объемами ~ 10, = 8) нор-
мально распределенных случайных величин X и Y найдены оценки математических ожиданий (ти, =142.3, =145.3) и дисперсий (д2=2.7,
(У2 = 3.2). При уровне значимости 0.01 проверить гипотезу Н: - т2 при
конкурирующей гипотезе Н : ту^т2.
1 4 5 Из двух партий изделии, изготовленных на двух одинаково настроенных станках, извлечены выборки, объемы которых = 10, п2 = 12.
Получены следующие результаты:
контролируемый размер изделий первого станка частота (число изделий) контролируемый размер изделий второго стайка
частота
х, 3.4 3.5 3.7 3.9;
2 3 4 1,
3 2 3.4 3.6;
2 2 8.
Требуется при уровне значимоеги 0.02 проверить гипотезу Н\т{ = т2 при конкурирующей гипотезе Н:ту т2. Предполагается нормальный закон распределения изделий, изготавливаемых на обоих станках.
28
Методы анализа данных
1 4.6. На уровне значимости 0 05 требуется проверить гипотезу - /«2 0 равенстЕе математических ожиданий двух нормально распределенных случайных величин А’ и К при конкурирующей гипотезе "часть Я": п1 > m2 по независимым выборкам:
значения 12.3 12.5 12 8 13.0 13.5
частота «г 1 2 4 2 1;
значения У> 12.2 12 3 13.0;
частота nJ 6 8 2
1.6.1. По четырем независимым выборкам одинакового объема и - 17 (для нормально распределенных случайных величин) найдены оценки дисперсий: 0.21; 0.25; 0.34; 0.40. Требуется при уровне значимости 0.05 проверить гипотезу об однородности дисперсий. Если гипотеза проходит, то необходимо оценить истинную дисперсию системы случайных величин.
1.6.2 На шести приборах произведено по семь измерений, которые дали следующие оценки дисперсий измерения: 3,82; 1.70; 1.30; 0.92; 0.78, 0 81. Проверить 1 ипотезу об однородности ряда дисперсий при уровне значимости 0.05.
1 6.3. По шести независимым выборкам одинакового объема и = 37 (для нормально распределенных случайных величин) найдены опенки дисперсий: 2.34; 2.66; 2.95; 3.65; 3.86, 4.54. '1ребуется проверить гипотезу об однородности ряда дисперсий при уровне значимости: а) 0.01; б) 0.05
1.6 4 Доказать, что значение статистики Кочрена не изменится, если все оценки дисперсий умножить на одно и ю же постоянное число.
1.6.5. По пяти независимым выборкам одинакового объема п = 37 (для нормально распределенных случайных величин) найдены оценки дисперсий-0.00021; O.OOO35; 0.00038; 0.00062; 0.00084. Требуется при уровне значимости 0.05 проверить гипотезу об однородности дисперсий.
Глава I Статистическая проверка гипотез
29
Глава 2. КЛАССИФИКАЦИЯ
В РАСПОЗНАВАНИИ ОБРАЗОВ
2.1. Схема системы распознавания
Процесс распознавания включает в себя ряд этапов, одним из которых является процесс классификации. По мере расширения областей применения для систем распознавания образов расширяются области использования и алгоритмов классификации. Они встраиваются в системы диагностики, построения моделей, адаптивного и оптимального управления и др. Однако основные идеи и алгоритмы классификации лучше и полнее изложены в монографиях по математической статистике и распознаванию образов.
Система распознавания образов состоит из нескольких подсистем- датчики исходной информации об объекте, формирователь информативных признаков, классификатор (рис. 2.1.1). Датчики воспринимаю! исходную информацию об объекте и преобразуют ее к виду, удобному для последующей обработки на цифровой вычислительной технике. Датчики устанавливаются на объектах технической и медицинской диагностики; они снимают отражённые колебания от различных слоев земли при сейсмической разведке, аналогичная исходная информация содержится в отчетах экспедиций, анкетах социологических опросов.
Формирование информативных признаков и классификация - родственные по духу задачи, и провести грань между ними бывает трудно. Чем лучше справляется со своими задачами формирователь информативных признаков, тем более упрощается работа классификатора, и наоборот, ''всесильный" классификатор не нуждается в формирователе информативных признаков. На практике существует золотая середина, когда умеренная сложность обоих устройств дает прекрасные результаты классификации.
Поясним теперь сущность задачи классификации. Она заключается в разбиении пространства признаков иа иецересекающиеся обпасти по одной для каждого класса. Допустим, имеются два информативных признака
30
Методы анализа данных
(х13х2) И два класса. На рис. 2.1.2 приведена обучающая выборка (кружки, когда истинным является первый класс, и точки, когда истинным является второй класс). Решающее правило: если решающая функция T](xt, х2) больше нуля (пОч, х2) > 0), то принимается решение об ис
тинности первого класса; если решающая функция меньше нуля х2) < 0), то принимается решение об истинности второго класса; и граница, разделяющая область на две подобласти: С?) и G2.
Обучающая выборка служит для построения решающей функции Г[(Х1, х2). Качество разделения области на две подобласти оценивается по проверяющей (экзаменующей) выборке.
При обучении параметры решающей функции т,(х]5 х2) (или разделяющей поверхности y|(Xj,x3) - 0) подбираются таким образом, чтобы ошибка классификации была наименьшей. На этом этапе опять можно применять параметрический и непараметрический подходы. При параметрическом подходе уравнение решающей функции задается априори с точностью до неизвестных параметров. Непараметрический подход обеспечивает построение решающей функции без привлечения информации об ее структуре.
Универсальный вид решающей функции строится по обучающей выборке, а некоторые параметры этой функции (и при непараметрическом подходе тоже присутствуют параметры, которые надо подстраивать) вычисляются по экзаменующей выборке из условий наилучшей классификации. Оба эти этапа можно реализовать на одной обучающей выборке методом "скользящего экзамена". По всем точкам выборки, за исключением одной, строится решающая функция, а в этой точке (которая не участвовала в построении решающей функции) осуществляется проверка качества классификации. Затем берется другая точка и в ней вновь происходит проверка качества распознавания, осуществленного с учетом всех точек, кроме данной. Таким способом происходит проверка качества классификации во всех точках обучающей выборки. Полученный суммарный показатель качества классификации минимизируется по параметрам решающей функции.
Twea 2. Классификация в распознавании образов
31
2.2, Байесовская теория принятия решений при дискретных признаках
1. Одномерный вариант
Рассматриваем т классов (полную группу несовместных случайных событий) и один дискретный информативный признак X,
Полностью известны:
условные вероятностные характеристики (при условии истинности того или иного класса) для информативного признака;
априорные вероятности классов /’(у), j ~ 1,ти.
Указанные исходные данные записываем в виде табд. 2,2.1.
решение (строим алгоритм работы решающего устройства) об истинности одного из т возможных классов - рис. 2.2.1.
Решающее устройство ► 1 Решающее устройство выносит решение об истинности одного из т классов ► т Рис 2 2 1
По формуле Байеса вычисляем апостериорные вероятности для всех рассматриваемых классов:
П । Р( j) т ___
РО\Х = х,)=,1Л1 X j = Vm. (2.2.1)
рх, /=1
32
Методы анализа данных
Выносим решение об истинности тош класса (с номером v), для коюро-го апостериорная вероятность максимальная.
(2 2 2)
Построенное решающее правило называется байесовским, и оио обеспечивает минимальное значение вероятности вынесения ошибочного решения и одновременно максимальное значение вероятности вынесения правильного решения. Сумма этих вероятностей равна единице.
Пример 2.2.1. Имеются два класса. Заданы два ряда распределения вероятностей (при истинном первом и втором классах) и априорные вероятности классов (табл. 2.2.2).
Таблица 2.2.2
-1 0 1 Р(2)
0.05 0.8 0.15 0.5
Px.v 0.1 0.2 0.7 0.5
Считаем, чго измерение признака дало следующий резулыат: = U. Вычисляем апостериорные вероятности классов:
Р0|А1) + А^(2) °’8 0.5 + 0.2 0.5 0.5
р<21 х = о)=-—=—°+5— = £! = о,2. + 0.8-0.5 + 0.2’0.5 0.5
Наибольшей среди них является Р(1 [ X = 0) = 0.8. Решающее устройство принимает решение об истинности первого класса.
Предполагаем, чю измерение дискретного признака дало значение
X =1. Теперь
= ____________= __=^=0.17б.
АцР(1) + А|2Р(2) 0.15-0.5 + 0.7-0.5 0.425
Тмеа 2 Классификация в распознавании образов 33
Р1рР(2) =___0.7-0-5 = 0-35 = 0 824
Дц/ЧЦ + йр-Ра) 0.15-0.5 + 0.7 0.5 0.425
Решающее устройство принимает решение об истинности второго класса.
Если в результате измерения информативный признак принял значение X ~ — 1 (вероятность этого события достаточно мала и равна 0.1), то обе апостериорные вероятности одинаковы:
Р(1| X = -1) = М5-О.5 ^ 0.025 =
+ 0-05 0.5+ 0.1.0.5 0.075
Р-}]2Р(1) 0.1 0.5 0.05
Т?„1!1Р(1) + Р-1\1Р(2) 0.05-0.5 + 0.1-0.5 0.075
и решающее устройство выносит решение об истинности второго класса.
Решающее правило (2.2.2) можно скорректировать. Сравниваемые апостериорные вероятности имеют одинаковый и всегда не нулевой знаменатель, поэтому при вынесении решения достаточно сравнивать только числители. Решение выносится об истинности того класса (с номером v), для которого максимальны числители апостериорных вероятностей (взвешенные условные вероятности р \ P(j) ):
7\iv P(v) - max P(J)7~J^m\.
(2.2.3)
При исходных данных предыдущего примера взвешенные условные вероятности приведены в табл. 2,2.3. Выносимые решения (при Л - г. ) об ис-
тинности первого или второго класса остаются, естественно, без изменения.
Если признак принял значение Х--1, то принимается решение об истинности второго класса. Вероятность ошибки при этом равна величине 0.025, а вероятность правильного решения равна 0.05.
Таблица 2.2.3
-1 0 1
0 025 С°‘4> 0 075
Л^(2)( ^0?05) 0.1 ^.35^
Если признак принял значение X = 0, то принимается решение об истинности первого класса и вероятность ошибки равна 0.1, вероятность правильного решения равна 0.4,
34
Методы анализа данных
Если признак принял значение У = 1, то принимается решение об истинности второго класса, вероятность ошибки равна 0.075, вероятность правильного решения равна 0.35.
Рассчитаем теперь суммарную вероятность ошибки классификации: Р(ош.) 0.025 + 0.1 I 0.075 = 0.2, и суммарную вероятность правильного решения: Р(прав. реш.) 0.05 + 0.4 + 0.35 = 0.8. Сумма этих вероятностей равна единице.
Убедитесь, что изменение решающего правила (по сравнению с байесовским) даже при одном возможном значении информативного признака приводит к увеличению вероятности вынесения ошибочного решения и одновременно к уменьшению вероятности вынесения правильного решения.
1, Многомерный вариант
Имеется несколько дискретных информативных признаков X. Для простоты считаем, что имеются два информативных признака X, У.
X принимает возможные значения х15х2, У - значения у^у2, Полной вероятностной характеристикой системы дискретных информативных признаков Х,У является таблица значений вероятностей
= р^, ] = 1,п2.
Считаем, что такие таблицы вероятностей известны при условии истинности всех классов:
Й(Х = х,)(Г = Ъ)|/)еЛ1.Г)|„ (2.2.4)
z-l3 л,5 J ц2? / = у т_
Известны также априорные вероятности классов P(Z), Z = 1, т.
Приведенная информация является полной для осуществления классификации. Задача классификации состоит в создании решающего правила, которое позволяет по результатам измерения признаков (X - xt, У - уу) выносить решение об истинности одного из т классов (рис. 2.2.2).
По формуле Байеса (см. для одномерного случая формулу (2.2.1) вычисляем апостериорные вероятности для всех рассматриваемых классов:
Л у \к —
Р(4|[(Х = х,.)(У = Щ]>.Р(*|х,,Ш=^^-----------, к = 1,т. (2.2.5)
1-1
Глава 2 Классификация в распознавании образов
35
Х = х, г Решающее устройство —► 1 D Решающее ус1роиство выносит (в соответствии с некоторым правы юм) решение об истиииости одного из т классов ► т
Рис 2 2 2
Выносим решение об истинности того класса (v-ro класса), для которого апостериорная вероятность максимальная’
P(v [~ игах {f*(k | х;, j ), к = \,т\.
(2 2 6)
В этом решающем правиле (2.2.6) можно сравнивать не апостериорные вероятности, а только их числители, ибо знаменатель у них положительный и одинаковый Решение выносится об истинности того класса (с номером v), для которого максимальны числители апостериорных вероятностей (взве шенные условные вероятности рх у Р(к) ).
A, y7|v^(v) - max{pX)^Р(к), к = 1,т].
(2 2 7)
Пример 2.2.2. Имеются два класса Заданы два распределения вероятностей дискретных признаков (табл. 2.2 4). В верхней части каждой клетки таблицы стоит соответствующая вероятность рх v ц при истинном первом классе, а нижней части - рх у |2 при истинном втором классе Рядом с таблицей указаны априорные вероятности классов.
Таблица 2.2.4
м 1 0 1
2 0.1 0.2 0.2 0.1 01 0.3
3 0.35 0.2 0.05 0.1 0.2 j 0.1
истинный первый класс--.
}Р(1) = 0.4
истиниыи второй класса / }
истинный первый класс/х.
Р = 0.6
-истинный второй классг
36
Методы анализа данных
Вычисляем взвешенные вероятности 7\i3j,j]-P(l); pXj ,?у|2Л2). Они приведены в табл. 2.2.5 также в верхней и нижней части каждой клетки.
Таблица 2.2.5
м -1 0 1
Г- 0.04 CjD.08^ ~0?04j
2 ^5
3 "о.оГ
0.12 Ej).06j
Выносится решение об истинности первого класса
Выносится решение об истинности второго класса
По этой информация выносится решение об истинности того или иного класса. Например, если информативные признаки приняли значения; X - 3, Y -1, то выносится решение об истинности первого класса, ибо первая взвешенная вероятность 0.08 больше второй 0.06 (для этого варианта вероятность ошибки равна 0.06, а вероятность правильного решения равна 0.08). Если же информативные признаки приняли значения X ~ 2, У = -1, то решающее устройство принимает решение об ишннности второго класса (для этого варианта вероятность ошибки равна 0.04, а вероятность правильного решения равна 0.12).
Суммарная вероятность ошибки классификации равна величине Р(ош.) - 0.04 + 0.06 + 0.04 + 0.12 + 0.02 + 0.06 = 0.34.
Суммарная вероятность вынесения правильного решения равна величине ?(прав. реш.) = 0.12 + 0.08 + 0.18 +0.14 + 0.06 + 0.08 = 0.66.
Сумма этих вероятностей равна единице.
Очевидно, что отклонение от байесовского решающего правила (даже при одном возможном сочетании информативных признаков) приводит к увеличению вероятности вынесения ошибочного решения и одновременно к уменьшению вероятности вынесения правильного решения.
2.3. Байесовская теория принятия решений при непрерывных признаках
Считаем, что имеются два класса и один или несколько признаков X Сами признаки (за счет, например, ошибок их измерения) и их связь с классами являются статистическими. Такое предположение соответствует нашей Действительности, в которой случайность играет не последнюю роль. Об этом читатель может узнать в популярных и увлекательных книгах профессора Л. А. Растригина: "Этот случайный, случайный, случайный мир", "По воле случая'1.
Глава 2, Классификация в распознавании образов 37
Обозначим через /(х| /), / = 1, 2, условные плотности распределения вероятности для признаков (если истинным является i -й класс), а через P(i), i = 1,2, - априорные вероятности для классов. Найдем по формуле Байеса апостериорные вероятности классов при условии измерения признаков х:
P(i|x) = —i = 1,2.
f(x)
При распознавании выносим решение о том классе, для которого апостериорная вероятносхь больше (рис. 2.3.1):
если Р(1|х) > Р(2| Л') , то принимается решение о 1-м классе, если Р(2|х) > Р(1| х) , то принимается решение о 2-м классе.
Отсюда с учетом формулы Байеса (после сокращения на /(х) > 0; в области принятия решения f (х) Ф 0) получаем решающее правило;
если f (х|1)?(1) > f (х]2)Р(2), то принимается 1 -й класс;
если /(х|2)?(2)>/(х|1)Р(1), то принимается 2-й класс.
Обобщение правила максимума апостериорной вероятности на случай т классов выглядит следующим образам: принимается решение об у-м классе, если
Р(/ (х) - тах{Р(г | х), f =
Как и для двух классов, преобразуем это правило к эквивалентному виду. Принимается решение об j -м классе, если
f(x [ j)P( j) = max {f(x | /)?(/), i = 1,..., m}
(2.3.1)
Это правило классификации (распознавания) иллюстрируют рис. 2.3.2, 2 3.3.
38
Методы анализа данных
Рис. 2.3.2 соответствует двум классам и одному информативному признаку. На рис. 2.3.3 для случая трех классов показано, что области решений могут состоять из нескольких подобластей.
Пример 23.1. При наличии двух классов условные плотности вероятности приведены ниже и представлены на рис. 2.3.4 и 2.3.5.
1 - I -4 |х|<1.
О, 1 < | х
/ИОН
—--------------х
0 1 2
Рис. 2.3 5
Априорные вероятности классов равны величинам: ?(1) = 0.25, Р(2) = 0.75.
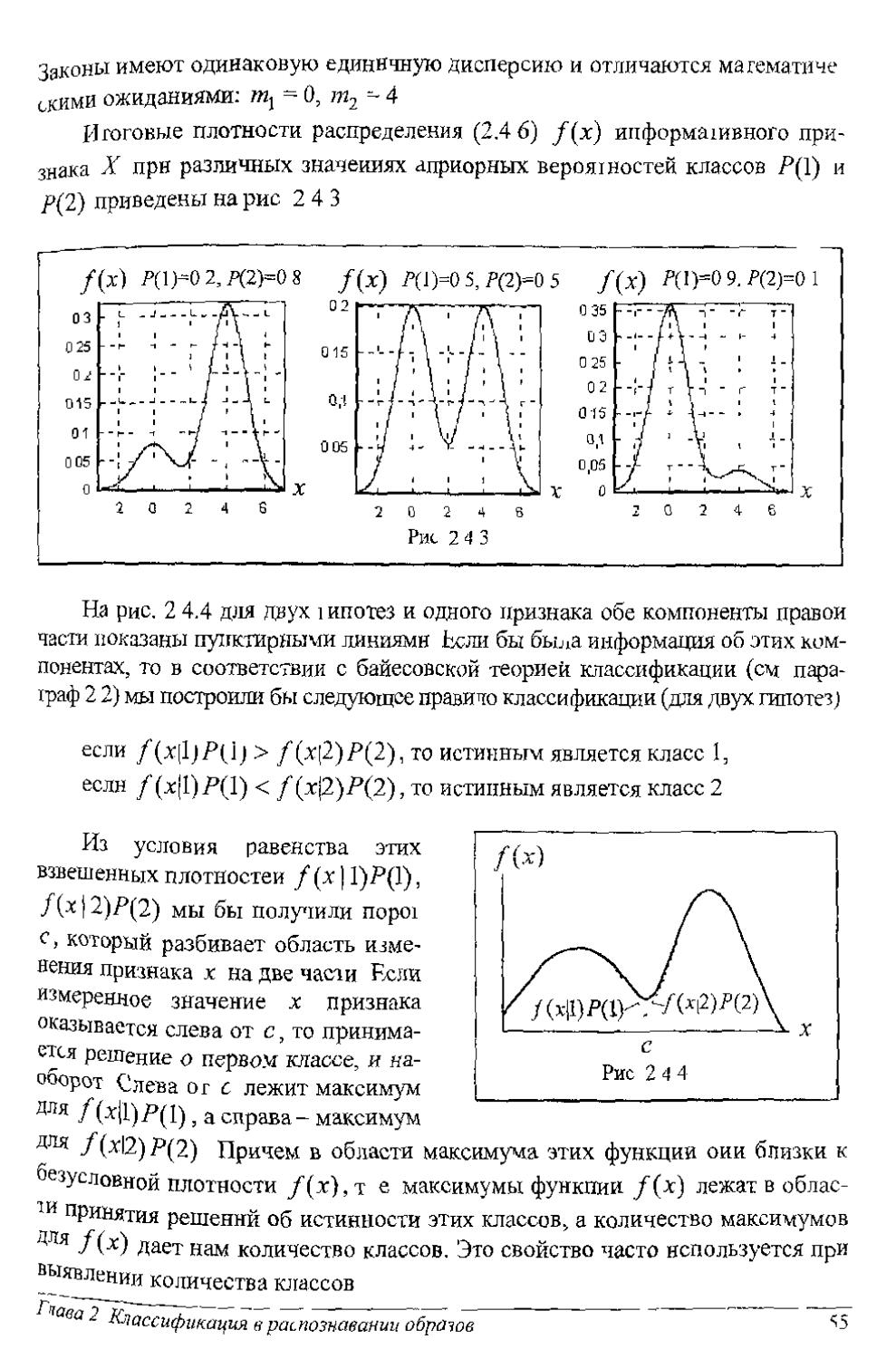
На рис. 2.3.6 приведены взвешенные условные плотности вероятности: f(x 11)Р(1), /(х|2)/*(2). Безусловная плотность распределения информативного признака /(х) = /(х [ 1)Р(1)+ /(х|2)Р(2) будет ненулевой на интервале (-1; 2) . Вне этого интервала информативный признак не сущесгву-ет, и, следовательно, измерения признака приходятся только на этот интервал. -—. г——п
Порог с = 0.25. При -1 < л- < 0.25 прини- I [/(* 12)73(2)i
мается решение об истинности первого \
класса, а при 0.25 < х < 2 - об истинности \
второго класса. ___
Рассчитаем теперь вероятность ошиб- _] qC 1 2
ки классификации. Рассмотрим случаи рис 9
Двух классов. За счет перекрытия взвешен- ---------------—--------------
2. Классификация в распознавании образов 39
;/(х|1)Р(1)1[/(х|2)Р(Д
-1 0 е 1 2
Рис. 2.3.6
ных плотностей распределения /(х|1)Р(1) и f (х|2)Р(2) возникают две ошибки Одна связана с тем, что принимается класс 2 (когда х е G2), но истинным является класс 1 Величина вероятности этой ошибки равна площади под кривой /(х[1)Р(1) при х eG2
Лш1- J/(x | 1)Р(1)б?Х
Вероятность второй ошибки вычисляется аналогично:
J/O|2)P(2)dx
Ч
Она представляет собой вероятность принятия класса 1, в то время как истинным является класс 2
Сумма этих вероятностей дает вероятность ошибки классификации (рис 2 3 7)
Ли - Р(х g G., 1) + Р(х е G,, 2) =
= Р(х eG2|l)P(l) + Р(х eG1|2)/’(2) = (2 3.2)
= j/(x|l)dxP(l)+j/(xl2)AP(2), С?2
которая равна вероятности вынесения неправильного решения при классификации
Оказывается, что вышеприведенное правило классификации (2 3 1) обеспечивает минимум вероятности ошибки классификации и эта минималь
но Методы анализа данных.
ная ошибка равна величине, записанной в формуле (2.3.2). Для доказательства этого утверждения границу областей с сдвинем вправо (либо влево) на положительную величину (вариацию границы) Ас. На рис. 2.3,8 видно, что вероятность ошибочного решения увеличится на положительную величину др (Ас ) Сдвиг границы с влево дает такой же результат.
То же самое правило классификации удовлетворяет и критерию максимума вероятности правильного решения:
Рправ = Р(АГбСгр1) + Р(АГЕС2,2) =
= Р(АГеЦ[1)Р(1) + Р(%Е(?2[2)Р(2)= (23.3)
= J/(x)l)ticP(l)+ j/(x|2)dx-P(2)-max.
G, G? . . ; •
Для того чтобы убедиться в этом, обратимся к рис. 2.3.9. Оба слагаемые предыдущей формулы обозначены Л1?аэ.ь Афавш помечены различной штриховкой и представляют собой площади лод кривыми взвешенных плотностей вероятности /(xjl) Р(1) и f(x\2)P(2). Сдвиг границы областей (Sy, С?2 из точки с в точку с + Ас дает уменьшение вероятности правильного решения (см. рис. 2.3.10) на величину APnp3R.(^c). Утверждение тоже доказано.
Свойство (2.3.3) является очевидным, если учесть, что сумма вероятностей ошибочного и правильного решений равна единице:
Л™ + PnpaB. - Р(х е (?2,1) + Р(х е G},2)+P(X е G151) + Р(Х ^G2.T) =
= P(Q 1) + P(Q 2) = Р(О. | I)P(l) + P(Q 12)P(2) - P(l) + P(2) - 1.
Здесь Q - достоверное случайное событие.
Гэовд 2. Классификация в распознавании образов
41
В общем случае, когда в рассмотрении участвуют т классов, решающее правило (2 3.1) удовлетворяет критерию максимума вероятности правильного решения:
Гправ = S I 0^(0 ~ тах
Итак, что же мы имеем в итоге? Правило классификации (2,3.1) может быть получено из трех критериев: 1) из условия максимума апостериорной вероятности классов; 2) из условия минимума вероятности неправильной классификации, 3) из условия максимума вероятности вынесения правильного решения.
Недостатком этих критериев является то, что в них не присутствует информация о предпочтениях одних классов перед другими. Система ценностей для различных объектов в обществе непрерывно меняется и ее надо учитывать при классификации.
Рассмотрим пример распознавания летящих объектов двух классов (птиц и самолетов) по результатам радиолокационного зондирования атмосферы. Первый класс составляют птицы, второй - самолеты. Понятно, что важнее не пропустить самолеты, чем птиц. Вероятность ошибки второго рода Лт 2 (вероятность принять при классификации самолеты за птиц) надо уменьшать, по вероятность ошибки первого рода i при этом всегда будет возрастать, От прежнего значения (рис. 2.3.11) границу надо смещать влево. Этот эффект достигается за счет введения в минимизируемую величину вероятности ошибки классификации Рош коэффициента у > 1 перед вторым слагаемым (перед ошибкой второго рода) правой части формулы (2.3.2). Получаемая величина взвешенной вероятности ошибки классификации имеез вид (для случая двух классов)
R - J/(x 11)<*сР(1) +у Щх12)ЛР(2) G2 Gl
и называется средним риском. Это еще не полный вариант записи среднего риска. Из условия минимума его получаем, что в прежнем правиле классификации величину /(х|2)/7(2) надо умножить иа у .
На рис. 2,3.11 представлен характер изменения правила классификации Граница между областями G) и G2 по сравнению с прежним случаем (при у -1) смещается влево. При этом вероятность ошибки второго рода Рош2 уменьшается (этого мы и хотели), а вероятность ошибки первого рода ] увеличивается. Это неизбежная плата за введенное предпочтение.
42
Методы анализа данных
На базе этого же примера распознавания объектов двух классов поясним особенности построения полной величины среднего риска. Правило классификации (2.3.1) одновременно удовлетворяет критериям (минимуму вероятности неправильной классификации (2.3.2) и максимуму вероятности правильного внесения решения (2.33);
РоШ = min, ?прав = max.
Второй критерий запишем в эквивалентном виде через операцию "минимум", для чего необходимо у оптимизируемой величины изменить знак на противоположный. Тогда получаем, что
Рош - min, -Рпран = min.
Объединяем оба критерия в один:
ОШ
Тиран min.
(23.4)
Заметим, что мы сделали такие преобразования критериев, чтобы правило классификации (23.1) продолжало удовлетворять последнему критерию. В левой части (23.4) стоит так называемый "средний риск", только в упрощенном виде с единичными весами для ею элементов. Вероятности неправильных решений (ошибки первого и второго рода) стоят с положительными весами (+1), а вероятности правильных решений входят с отрицательными весами (- 1), т. е. правильные решения приносят не потери, а прибыль. Если теперь мы единичные веса заменим произвольными, то получим обшую форму записи среднего риска, и решающее правило будет находиться из критерия его минимума:
R = J/(x|1)P(1)A + K12 11)P(1)<* +
Gl G2
+ j/(r12)P(2)dx+V22 J/(x(2)P(2)dx = min. (23.5)
Gy G2
Етйвд 2 Классификация в распознавании образов
43
Весовая матрица
^2
^22
включает в себя потери, связанные с ошибками первого (Г12) и второго (У?1) рода и с правильными решениями Еп, У22. Так как правильные решения дают прибыль (а не потерн), то веса У22 отрицательны. В критерии (2.3.4) веса принимали значения: Г12 - Г21 -1, ^ц-И22^-1.
Из минимума среднего риска получено следующее правило классификации:
если (И12 - ThW [ 1)^(1) > (Е21 - МЛ* I 2)^(2), то принимается первый класс;___________________________
если (Г12 - /11)/(х!1)/’(1) < (F2I - М/МЖЮ , то принимается второй класс.
(2.3.6)
Элементы матрицы V должны удовлетворять неравенствам: ^12 “ ^11 > ^21 “ ^22 > О-
При наличии т классов из критерия минимума среднего риска
ГЛ W
я = £ 2Х J/w7)^0)^ =
G,
получаем правило классификации:
принимается решение об у-м классе, если выполняется (m — 1) неравенств:
__________________________________
Итак, структуры байесовских распознавателей мы построили. Если в них условные плотности распределения вероятностей /(х|у) и априорные вероятности классов P(j') неизвестны, то их можно заменить оценками (параметрическими или пепараметрическнми), построенными по обучающей выборке.
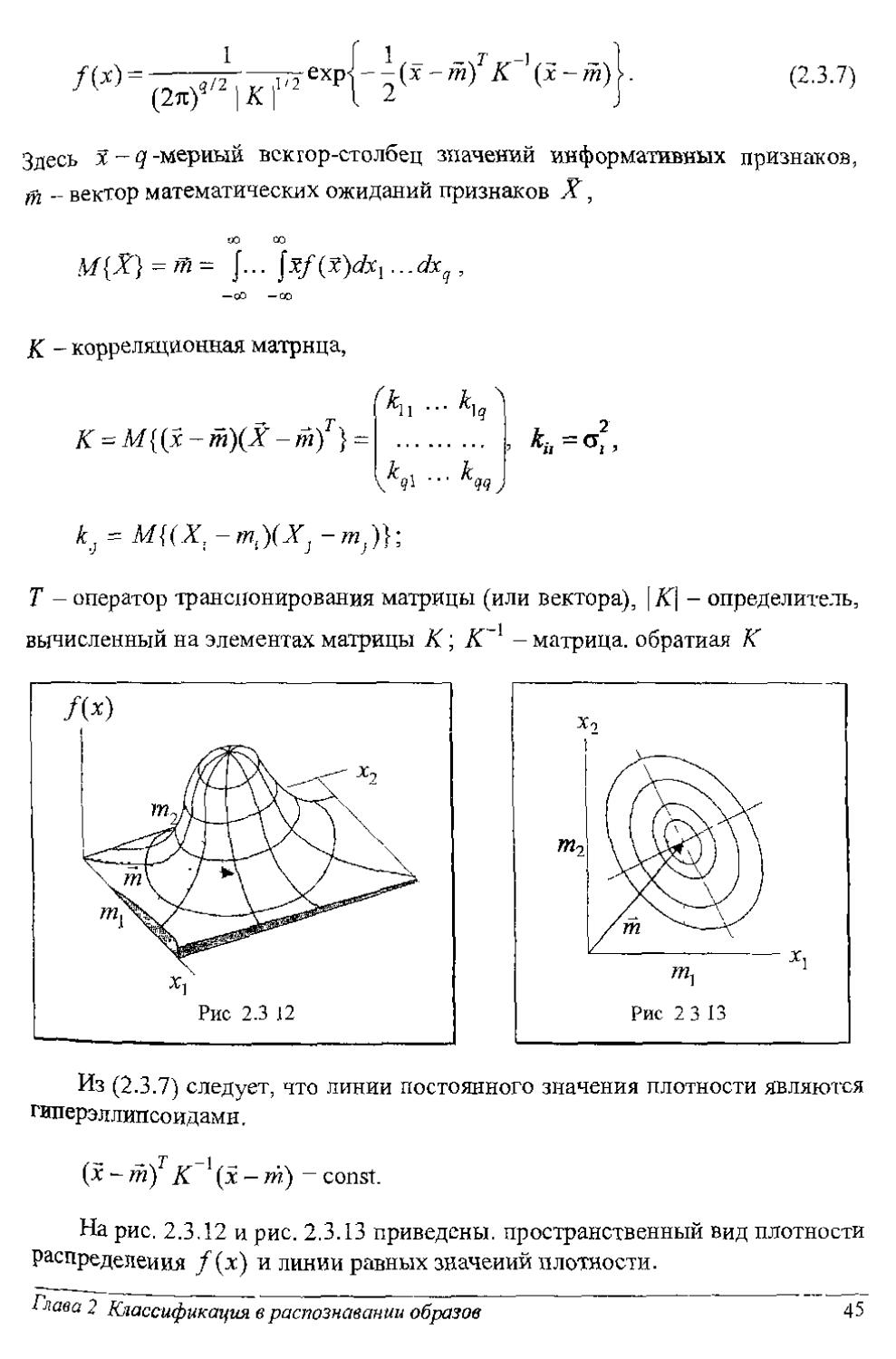
В качестве примеров рассмотрим разделяющие функции (поверхности) при нормальном законе распределения информативных признаков [2.2]:
44 Методы анализа данных
I f 1 _ _ 7' -] _ 1
f(x) =---775--^exp)--(x-m) К
71 (2л/ Г 1 2 J
(2.3.7)
Здесь Я -мерный вскгор-столбец значений информативных признаков, т - вектор математических ожиданий признаков X,
М{Х}^т- J... ...dx^ ,
К - корреляционная матрица,
К = М{(х~т)(Х -т/} ~
% ...
^q\ ^qq у
*й=<*
2
Т - оператор транспонирования матрицы (или вектора), | АГ| - определитель, вычисленный на элементах матрицы К; К~1 - матрица, обратная К
Из (2.3.7) следует, что линии постоянного значения плотности являются гиперэллипсоидами.
— 7" — 1
(* - т) К (5с - тй) - const.
На рис. 2.3.12 и рис. 2.3.13 приведены, пространственный вид плотности распределения /(х) и линии равных значений плотности.
Глава 2 Классификация в распознавании образов 45
Пример 2.3.2. При одном информативном признаке разделяющая поверхность вырождается в одну или несколько точек. Они разделяют область изменения признака (одномерную ось) на подобласти, соответствующие выбранным классам.
Считаем, что имеются два класса. Разделяющие точки с находятся из условия
/(х|1)Д1) = /(*|2)Л2),
(2.3 8)
где
< f </ V} I I Y — I
/Ж—ехр -- --, 1 = 1,2. . (23.9)
-V 2л ст, 2^ ст, J
2 2 2
Вариант 1. Дисперсии одинаковы; ст1 - ст2 = ст , математические ожидания различны: т}
Подставляем (2.3.9) в (2.3.8) и получаем линейное (в силу равенства дисперсий) уравнение относительно порога. Из него находим
2
га,+дт, ст . Д(1) с - + - - In --^2..
2 т2 Р(2)
(2.3.10)
После выделения областей G,, G2 (если т- < ): G} - (х: х < е),
G2 - (х: с < х) - классификатор работает по следующему алгоритму. Если измеренное значение х признака X принадлежит Gt (либо, если х < с), то принимается класс 1, если же х принадлежит G2 (т. е. если с <х), то принимается класс 2.
Рассчитаем вероятность ошибки классификации:
Лш - P(l) J/(X | P)dx + Р(2) J/(x|2)</x =
= Ж 1 - И -
\ у ) J уст
46
Методы анализа данных
I -m, =m И ~2~
CT
+--------
m2 - mx
Л2)
+ P(2) I-/7!
m2 -n?1
i m
^2“^ Л2)
Здесь
1 Z 2
/7(z) = -_ jexp(-r /2)dt
V2n
- табличная функция распределения нормально распределенной случайной величины с нулевым математическим ожиданием и единичной дисперсией. При равновероятных гипотезах Р(1) - Р(2) - 1 / 2 и при тг=ту + 2<з, ?п2 =277, + 4ст, т2 = ТП\ + бст получаем соответственно:
1)Л>Ш = 1-F(l)-i -0.84=0.16;
2)Р0Ш = 1-^(2)=!-0.98 =0.02;
3)Р0Ш = 1 - 0.999 = 0.001.
Вариант 2. Дисперсии различны. Подставляем плотности распределения (2.3.9) для информативного признака в уравнение границы (2.3.8) между областями G15 G2
_Д)_ 42л CTj
Л2)
'Ч 2тт ст 2
и получаем относительно х квадратичное уравнение:
ехр< - -
, 1Гст/(2) .
21 сг2 И ст2Р(1)’
х2 - 2xm^ + 2 ln С) = 0. (2Л11)
с? с2 ст1^(2)
2 X + 2ту 2т ? л х + -о
СТ2 2 2 У СТ1 СТ2 )
2 ^ассификация в распознавании образов
47
Это уравнение имеет один (например, прн оу = = су) или
два (например, при тх = пь ~ т) корня. Второй случай представлен на рис. 2.3.14. Область G2 состоит из двух подобластей, когда х < Су или с2 <х.
Пример 2.3.3. Имеются два информативных признака, распределенных по нормальному закону (для каждого нз классов):
*=Н, й(7>НлД ад=Н(/) Дс/)1 ух2у 1Л1С/) J
J = 1, 2;
у-1,2. (2.3.12)
Корреляционная матрица всегда симметрична относительно диагонали, ибо ку2 - к21 Отличие в распределениях обусловлено различием математических ожиданий т(1), ш(2) и корреляционных матриц А?(1), К(2).
Разделяющая линия т](х1,х2) = 0, которая делит плоскость (х,,х2) на две области 6), G2, определяется равенством
/(х1,х2[1)Н1) = /(х1Л2|2)Л2)-
(2.3.13)
Разделяющая линия описывается уравнением второго порядка. В простейших случаях она вырождается в прямую линию Один из таких случаев рассмотрен ниже.
Вариант 3. Корреляционные матрицы Л(1), К(2) одинаковы и признаки некоррелированиы:
f 2
ВД = 7Ц2) =
2
^1)
48
Методы анализа данных
Тогда
2 2 j у Д/2 v' 1
I K\ = C2, IК ] = O] a2, A
И условные плотности распределения (2.3.12) приобретают вид
/(ХрЛо |у)
1
27пд1ст2
7 = 1,2.
Подставляем их в формулу (2 3 13) и получаем уравнение разделяющей функции:
( %! -^(1)Y х2 -re2(l)Y
I С1 / Л а2 )
q х 2
+21П-®,
I a, J ( «2 ) р0)
«i(l)-wi(2) m2(l)-w2(2) _
-------2----*1 + 2 X2 ~~
ПА CT2
2 7 7 9
(2) ml (l)-m2 (2) P(2)
j — -t———=--------h in '—
2<з{ 2cr| P(l)
Разделяющая функция является прямой линией.
При сг1 = сг2 - ст и Р(1) Р(2) на рис 2.3.15 представлены линии равных значений для условных плотностей и разделяющая линия. Классификатор в этом случае работает по минимуму расстояния от J до wij и . С возрастанием Р(2) (по отношению к ^(1)) разделяющая линия смещается к m(l).
Гтава 2 Классификация в распознавании образов
При увеличении числа классов, но при сохранении условия равенства дисперсий (Tj = сг2 _. . = ст и априорных вероятностен
= Р(2) - ... = -Ff#), классификатор буде1 также работать по минимум} расстояния (рис 2 7.2)
Вариант 4. Корреляционные матрицы одинаковы: £(1) = А)(2) = К, и признаки коррелированны. Разделяющая линия
‘(x-m(l)) + lnP(l) =
= -|(Ж - й>(2))Г K~' (S - m(2)) + lnP(2)
вновь переходит в прямую линию
wr(x-fo) = O,
где
w = А?ч(й(1) - т(2У);
m(l) + т(2) (w(l) - тм(2)) ln(.P(l) / P(2J)
2 (m(l) - m(2})T K~[ (ш(1) - ш(2)) ’
Так как направление w - 2<-1(»1(1) - m(2)) нс совпадает с направлением (т(1) - от(2)), то разделяющая линия (гиперплоскость при 9 = 3,4,...) не ортогональна отрезку, соединяющему /й(1) и >й(2). В го же время в слу-чае равных априорных вероятное гей (T'(l) = Р(2) - 0.5) она пересекает этот
отрезок в точке
х0 = (m(l) + т(2)) / 2,
находящейся посередине между средними значениями >й(1) и >й(2) (рис. 2.3 16) При неравных априорных вероятностях разделяющая линия смещается, удаляясь от центра (математического ожидания) более вероятного класса
50
Методы анализа данные
Вариант 5 Корреляционные матрицы различны. Разделяющая поверхность соответствует уравнению
Это уравнение второго порядка.
Разделяющая поверхность может име!Ь любую из общих поверхностей второго порядка: i иперплоскостей, гиперсфер, гиперэллипсоидов, гиперпараболоидов. Виды этих поверхностей (линий) для двумерного случая изображены на рис 2.3.17. В самом простом случае признаки некоррелированы Для каждого фиксированного класса. Разделяющие поверхности (и сами Плотности /(x|z)) различаются исключительно из-за различия между дисперсиями. На рис 2.3.17, а дисперсии для /(х|2) меньше, чем для /(х|1) Внутри класса для каждого признака дисперсии одинаковы. Разделяющая линия представляет собой окружность, внутри которой лежит . При уве-личении внутри каждого класса дисперсии по х2 (рис 2 3.17, б) разделяющая линия вытягивается в эллипс. Рис. 2.3.17, е иллюстрирует случай, когда обе плотности имеют одинаковые дисперсии для признака хр но для х2 диспер
2 Классификация в распознавать образов 51
сия больше для /(х|1) по сравнению с /(х|2). Гранила между классами представляет собой параболу, С росюм дисперсии С72(1) второго признака в первой плотности /(х|1) граница (рис. 2.3.17, г) превращается в гиперболу В особом случае симметрии разделяющей линии (2.3.14) гиперболическая граница вырождается в пару прямых - рис. 2.3,17, б,
2.4. Идея классификации
Каждый объект классификации имеет свои информативные признаки X . Для них либо известны полностью, либо известны частично, либо совсем неизвестны плотности распределения вероятностей f (x|j), Здесь i - номер истинного класса. В зависимости от исходной информации возможны следующие случаи классификации.
Случай 1. Известны полностью условные плотности распределения вероя I кости для признаков /(х| I),-", Для одномер-
ного случая (один признак) указанные плотности распределения приведены иа рис. 2.4,1, Здесь рассматриваются два класса. Так как априорные вероятности Д(1), •• •, Р(т) неизвестны, то ориентируемся на наихудший случай (соответствую-
щий максимальной энтропии): Р(1) = • • • - Р(т) - = 1 / т ,
Байесовское решающее правило при двух классах имеет вид:
если 0.5/(х 11) > 0.5/(х| 2), то принимается класс 1; если 0.5/(х 11) < 0.5/(х 12), то принимается класс 2.
Оно совпадает с решающим правилом, рассмотренном в главе 1 (см. рис 2.4.1):
если f (х|1) > f (х|2), то принимается класс 1; если /(х|1) </(х|2), то принимается класс 2.
Пороговое условие
/(Х|1)-/(Х₽)
52 Методы анализа данных
в этом правиле классификации позволяет получить для признака граничное значение с, которое разбивает область изменения признака на две подобласти (л. и G2 Тогда решающее правило можно записать в виде:
если X £ Cq, то принимается класс 1,
если х е G2, то принимается класс 2.
Вышеприведенное правило классификации обеспечивает минимальное значение вероятности р + а и вероятности ошибки 0.5(3 + а).
При наличии двух признаков х — (хр х2) решающая функция
х2) = f (ХрА^ jl) — У(Х| ,х2 j2)
позволяет записать следующее решающее правило (рис. 2.4.2):
если ц(хр х2) > 0, то принимается класс 1, если ц(х1, х2) < 0, то принимается класс 2 .
Оно означает, что после измерения признаков принимавши решение о том классе, для которого плотность распределения f (хр х2 | i) больше.
Случай 2. Условные плотности распределения вероятностей для признаков х известны не полностью, а с точностью до параметров 0: /(х, 0 11), /(х, 02 | 2). Неизвестные параметры 01, 02 доопределяются с помощью одного из методов математической статистики, например с помощью метода максимального правдоподобия, на основе обучающей выборки:
2 Классификация в распознавании образов 53
х',.^,...,.** ,когда истинным является класс 1,
_ 7 —2 -"2 _
xf, х2,..., хп?, когда истинным является класс 2,
(2 4.1)
Дальнейшая классификация проводится, как и в случае 1.
По обучающей выборке доопределяются и априорные вероятности:
Случай 3. Условные плотности распределения вероятности неизвестны, но известна обучающая выборка. Здесь возможны два варианта.
Вариант 1. Восстанавливается решающая функция Т[(х) Этот вопрос рассмотрим в параграфе 2.5.
Вариант 2 По обучающей выборке восстанавливаются условные плотности f (х j г), 1 -1,т. Методы решения этой задачи рассмотрим в главе 4,
Случай 4. Число классов неизвестно и нет обучающей выборки. Вернее, нет учителя, который мог бы измерения признаков разбить на группы, соответствующие своим классам Это самая сложная и распространенная на практике ситуация Приходится строить самообучающиеся системы классификации Вопросы самообучения будут рассмотрены в отдельных спецкурсах Мы остановимся лишь иа одном подходе к выделению количества классов.
По измерениям признаков восстанавливается безусловная плотность распределения /(X). Здесь можно использовать методы главы 4, которые позволяют не привлекать информацию о структуре плотности f (X).
Плотность распределения f (S') удовлетворяет соотношению
/Щ=Г/Й7)Л7).
7 = 1
(2.4.2)
Пример 2.4.1. Считаем, что имеются два класса (т = 2), одни информативный признак и условные плотности /(х}у), j ~ 1, 2, - это нормальные законы распределения:
, 1 Эл4)2
/(-г11) = —2 , /(х(2) = -т==е 2 , — ос <х<со. У2тг У2тг
54
Методы анализа данных
Законы имеют одинаковую единичную дисперсию и отличаются магематине скими ожиданиями: = 0, т2 ~~ 4
Итоговые плотности распределения (2.4 6) f(x) ип форма 1 явного признака X при различных значениях априорных вероягностей классов Р(1) и р(2) приведены на рис 2 4 3
1
/(х) Р(1 У=0 2, Р(2)=0 8 f(x) ?(1)=0 5,Р(2>0 5 Дх) Р(1)=0 9. Р(2)-0 1
20246 20246 20246
Рис 2 4 3
На рис. 2 4.4 для двух i ипотез и одного признака обе компоненты правой части показаны пунктирными линиями Если бы была информация об этих компонентах, то в соответствии с байесовской теорией классификации (см параграф 2 2) мы построили бы следующее правило классификации (для двух гипотез)
если /(х[1)Р(1) > /(х|2)Р(2), то истинным является класс 1, если f (x(l)P(l) < / (х|2)Р(2), то истинным является класс 2
Из условия равенства этих взвешенных плотностей f(x | ,
f 12)Р(2) мы бы получили порог который разбивает область изменения признака х на две части Если измеренное значение х признака оказывается слева от с, то принимается решение о первом классе, и на-ооорот Слева о г с лежит максимум Для /(х|1)р(1) 5 а справа- максимум
ДПя /(х12) Р(2) Причем в области максимума этих функции оии близки к безусловной плотности f (х), т е максимумы функпии f (х) лежат в облас-111 принятия решений об истинности этих классов, а количество максимумов для f (х) дает нам количество классов. Это свойство часто используется при
выявлении количества классов
2 Классификация в распознавании образов
Далее строится процедура последовательного (итерационного) расчета порога (в многомерном случае - разделяющей поверхности) с. Например, задается нулевое приближение порога , Оно разбивает исходную выборку (по которой оценивалась безусловная плотность /(х) на две части. Выборка становится обучающей. По ней (как было рассмотрено выше) оцениваются условные взвешенные плотности /(х)1)Р(1) и /(^2)Р(2); а следовательно, решающая функция и новое приближение порога с1 (разделяющей поверхности) и т. д
Возможны и другие пути самообучения.
2.5. Прямые методы восстановления решающей функции
Имеется обучающая выборка (2.4.1).
х[, х2,..., х} , когда истинным является класс 1;
—2 -^2
%] , х2 ,..., , когда истинным является класс 2;
(2-5.1)
общего объема + п2 ~п.
Вводится фиктивная переменная у. указывающая на принадлежность к тому или иному классу каждого выборочного значения обучающей выборки. Например, для двух классов
J 1, если истинным является класс 1, [-1, если истинным является класс 2.
(2.5.2)
На оси х рис. 2.5.1 показаны точки (черными и белыми кругами) обучающей выборки (для двух классов). Затем на этом же рисунке отмечены новые точки (помечены квадратами), соответствующие точкам обучающей выборки, в координатах х, у. По этим точкам проводится линия т](х) (с использованием критерия иаилучшего сглаживания), которая представляет собой
56
Методы анализа данных
ещающую функцию На этапе построения решающей функции -q(x) приме
нимы идеи параметрического и непараметрического подходов
При параметрическом подходе задается уравнение решающей функции с точностью до параметров Д:
м
Т|(^Л)=Х^Ф7 (*Ь
/=1
(2.5.3)
где {(ру()} _ известные базисные функции, и из некоторого критерия, например из критерия наименьших квадратов
Л (д) = Ё (л - > "))2 = mm - (2 5-4)
1=1 5
вычисляются параметры 3 решающей функции.
Основной проблемой при данном подходе является выбор базисных (опорных) функций {ф;()}. Для каждой группы объектов классификации и выбранных классов существуют свои наборы базисных функций. Но для задач классификации в целом ясно одно: базисные функции должны иметь такой же вид, как и т](х) (см. рис 2.5.1). Мы гем самым неизбежно приходим к преобразованиям, выполняемым в нейронах Этот вопрос будет рассмотрен в параграфе 2.6
Кроме критерия наименьших квадратов (2.53) используются другие критерии, например знаковый критерий-
Л(«) = |Ё0 “ sgnb;n(\ Л)]) = пнп (2.5.5)
2 r=i
Здесь sgn[-] - знаковая функция. Она равна 1 при положительном значении аргумента (при этом осуществляется правильная классификация с помощью решающей функции тД ): знаки у у и Т] совпадают) и равна -1 при отрицательном значении аргумента (при эюм происходит неправильная классификация на основе решающей функции тД ). При правильной классификации на всех точках обучающей выборки (2.5.1) показатель Д равен нулю. Чем на большем числе точек осуществляется неправильная классификация, тем большее значение принимает Z2 . Экстремальная функция в зависимости от параметров S является кусочно-постоянной Из-за этого при поиске ее минимума неприменимы алгоритмы дифференцируемой оптимизации. С це-Глава 2 Классификация в распознавании образов 57
лью устранения этого недостатка вводятся более гладкие показатели качества классификации, например,
п Г| ? I z < О
<2-5-6)
При непараметрическом подходе (см. параграф 4.13) решающая функция строится без привлечения информации о ее структуре.
2.6. Персептроны
В истории возникновения различных направлений теории и практики распознавания схема персептрона [2.3] занимает особое место. Персептрон был предложен американским ученым Ф. Розенблаттом в 1957 году Сразу после своего появления он занял одно из важнейших мест в распознавании. Этому способствовал целый ряд Причин: исключительная простота схемы персептрона; возможность обучения распознаванию конкретных объектов, допускающая легкую техническую реализацию, относительная успешность решения частных модельных задач (это вызвало далеко идущие оптимистические прогнозы) и даже то, что необычное и интригующее название ’'персептрон" сразу перекочевало на страницы научно-популярной литературы. По-видимому, в распознавании вряд ли можно найти другое направление, относительно которого было бы столько разноречивых высказываний - от абсолютного неприятия (например, сторонниками теории автоматов) до столь же безоговорочной поддержки. Однако очарование простоты и названия персептрона не могло сгладить узости его возможностей и компенсировать отсутствие серьезной теории.
С течением времени ряды поклонников персептрона стали редеть (этому способствовало резкое сокращение финансирования персептронного направления в США), нбо попытки его использования в прикладных задачах оказывались чаще всего безуспешными. Было строго доказано, что первоначальная схема персептрона не обладает нужной способностью к экстраполяции, т. е к распознаванию обьектов, не участвовавших в процессе обучения. Попытки усовершенствования персептрона, предпринятые в разное время отдельными сторонниками этой схемы, также не привели к ощутимым положительным результатам. Назрела необходимость создания полноценной теории параллельных вычислительных устройств, подобных персептрону, теории, учитывающей специфику конкретных задач и позволяющей прогнозировать разрешимость тех или иных задач. Первой попыткой создания такой теории можно считать монографию М. Минского и С. Пейперта [2.3].
58 Методы анализа данных
Преобразователи, предикаты, нейроны
Усилители
устройство SgnT]
Блок обучения
Рис 2 6 1
Схема параллельного вычислительного устройства персептронного типа приведена на рис. 2.6.1. Здесь использованы обозначения предыдущего параграфа. Блок обучения может реализовывать алгоритм решения одной из экстремальных задач, рассмотренных в параграфе 2.5.
2.7. Простые алгоритмы классификации в стохастическом случае
Основные алгоритмы заимствованы из систем классификации с известными, достаточно простыми плотностями /(%Ю с заменой в них таких параметров, как математические ожидания и дисперсии их оценками, вычисленными по обучающей выборке (2.5,1). Алгоритмы применяются для различных задач классификации, когда отсутствует информация о структурах плотностей. Структура алгоритмов, как правило, самая простая (это и привлекает внимание как инженеров-исследователей, так и инженеров-практиков), а за счет обучения их можно настроить на решение достаточно сложных реальных задач классификации (см , например, гл. 12 в (2.3])
Считаем, что имеются один информативный признак X н два класса. Если условные плотности f (х)1), f (х|2) имеют нормальные законы распределения с одинаковыми дисперсиями и априорные вероятности одинаковы, т° байесовское решающее правило
^если /(х|1) > /(х|2), То истинным является класс 1;
если f (х|1) < /(х|2), то истинным является класс 2;
эквивалентно следующему правилу (при < т2\.
если х <с, то истинным является класс 1, если е < х, то истинным является класс 2.
Здесь с = (тх + т2) / 2.
При неизвестных математических ожиданиях т15 т2 их заменяют оценками т}, th2t полученными по обучающей выборке (2.5.1).
Полученное решающее правило является правилом минимального расстояния от измеренного значения признака х до тг и до т2: если расстояние |х-nij hmin{|х-т} |, !х-тй2|}. то принимается решение об истинности класса j (где / может принимать значения 1,2). Правило минимального рас-сгиянмя от х до "центров тяжести" (оценок математических ожиданий) классов распространяется иа случай двух и более признаков и многих классов На рнс. 2.7.1 и рис. 2.7.2 точками показаны ‘'центры гяжести11 классов и разделяющие линии для случая двух признаков. При нескольких классах (рис. 2 6.2) разделяющие линии состоят из взаимно примыкающих огрезков прямых линий
Упражнения Ш
Имеются два класса. Заданы два ряда распределения вероятностей (при истинном первом и втором классах) и априорные вероятности классов:
2.2.3
X, Х1 х2 х3 P(f)
Рх,\\ 0.1 0.2 0.7 0.7
Рх,\1 0.5 0.3 0.2 0.3
2.2.4
X] х2 х3 И/)
0.1 0.3 0.6 05
Рх, 12 0.6 0.2 0.2 0 5
Вычислите два ряда распределения апостериорных вероятностей Р(1[х2), />(2|х,)3 7 = 1, п (либо Л1(2^(2), Z = 1, и), и укажите,
об истинности какого из классов выносится решение, если признак принял то или иное значение. Определите вероятное^ ошибочного и правильного решений.
Имеются три класса. Заданы три ряда распределения вероятностей (при истинности первого, второго и третьего классов) и априорные вероятности классов:
2.2.5 2.2 6
Х[ Х2 P(J)
^,11 0.1 0.9 0.1
Л,|2 0.8 0.2 0.6
Рх.13 0.3 0.7 0.3
X] х2 х3 х^ КП
г М 0.01 0.09 0.7 0.2 0.3
Рх,\2 0.07 0.6 03 0.03 0.3
Рх, Т 0.8 0.1 0.07 0.03 04
2.2.7
х} х2 х3 Л»
7\[1 0.1 0.2 0.7 0.5
Л,’2 0.5 0.3 0.2 0.3
/*,|3 0.1 0.6 0.3 02
2.2.8
X, X] х2 х3 пл
0.1 0 3 0.6 0.2
?\|2 0.2 0.6 0.2 0.1
^,|3 0.7 0.2 0.1 0 7
Вычислите три ряда распределения апостериорных вероятностей
Р(2| Х]), Р(3]х,), i = l, и (либо prjlP(l), PXipP(2), рХ(|3Р(3),
2 Классификация в распознавании образов 61
i = 1, и), и укажите, об истинности какого из классов выносится решение, если признак принял то или иное значение.
Определите вероятности ошибочного и правильною решений.
+77. 0 2 4
1 0.05-' 0.25 4Й0 0.05 о.нГ 0.35
3 1 0.35 0.20 Q.05 0.1 0.2f1 0.05 .
Имеются два класса Заданы две таблицы распределения вероятностей дис-крешых признаков X, Y.
В верхней части каждой клетки таблицы стоит соответствующая вероятность рх ц при истинном первом классе,
а нижией части - у^_ |2 при истинном втором классе.
Составьте таблицы взвешенных вероятностей рх у цР(1), рх у рР(2) и покажите, при каких наборах информативных признаков выносится решения об истинности первого класса, а при каких - об истинности второго класса Наборы априорных вероятностей классов приведены ниже.
2 2.9. Р(1)’0.2; Р(2) = 0,8. 2.2 10 Р(1)^0.4; Р(2) = 0.6.
2 2 11 7>(1)^0.5; Р(2) = 0 5.2.2.12. Р(1) = 0.7; Р(2) = 03.
Вычислите суммарную вероятность ошибки классификации и суммарную вероятность вынесения правильного решения.
'Ъ
2 3 1. На основе критерия минимума вероятности ошибки классификации необходимо получить разделяющие пороги, выписать решающее правило и найти вероятность ошибки классификации. Информативный признак (при истинности первого и второю класса) распределен по равномерному закону:
I о, хё[агД], / = 1,2.
Варианты.
а) интервалы Ja-pPjL Га2>р21 не перекрываются,
б) интервалы [a^Px], [ct2,P2] перекрываются, а взвешенные условные плотности f(x 11)Р(1), /(х 12)Р(2) равны;
в) интервалы [, Р] J|a2, Р2 ] перекрываются, а взвешенные условные плотности f(x11)Р(1), /(х|2)Р(2) неравны;
62
Методы анализа данных
г) интервал включает в себя интервал [сх2,р>2].
решение сопровождайте графическими пояснениями.
2 3 2 При наличии одного информативного непрерывного признака X и двух классов условные плотности вероятности f(x 11), /(х|2) имеютрав-номерное распределение;
/ОФ) = | о,
ФЧ 1], х^Ь-1; 1];
ЛД2)= °05
х е [0; 2], х£[0; 2].
Выделите области возможных значений информативного признака X, при попадании в который принимается решение об истинности соответствующего класса. Априорные вероятности классов /*(1), Р(2) принимают значения:
а) ^(2) =0.6; б) Р(1)- 0.5, Р(2) =0.5;
в) Р(1)=0.6, Р(2)= 0.4; г) />(!)= 1, Р(2) = 0.
2.3.3. На основе критерия минимума вероятности ошибки классификации необходимо вычислить разделяющие пороги, выписать решающее правило и найти вероятность ошибки классификации. Условные плотности вероятности для информативного признака имеют вид1
/(х|1) - равномерный закон распределения в интервале [0; 1],
f (х|2) - равномерный закон распределения в интервале [0.75; 2.25].
Варианты:
а)/>(!)-0.1, Р(2) = 0.9;б) Р(1) = 0.4, /*(2)-0.6,
в) Р(1) =р(2) = 0.5; г) Р(1) - 0.8, Р(2) = 0.2.
2.3.4. На основе байесовской теории принятия решений вычислите разделяющие пороги, выпишите решающее правило и найдите вероятность ошибки классификации. Условные плотности вероятности для информативного признака имеют вид:
1-(хЦх)<1, |ехр{-х}, х> 0,
f (х2) - 4
0, |х|> 1; J V 1 7 |0, х < 0.
Варианты:
a) /’(I) = Р(1) , б) Р(1)*Р(2).
Решение сопровождайте графиками.
71 " ———- ._ , __. ______- ... - . • —““—н . — _
лава 2 Классификация в распознавании образов 63
/«!) =
2.3 5. Необходимо построить байесовское решающее правило и найти вероятности ошибок классификации. Условные плотности вероятности для информативного признака имеют вид (нормальный закон распределения)
, (X"Wf)2 :
1 2 Г
I 2стГ J
f(x I 0 = -дГ—е*Р-У2л ст,
z = l, 2.
Варианты:
а) т} т2, erf = erf, Р(У) = Л2 * *);
б) т2 ги2, cf = erf, Р(1) Р(2);
в) т} т2, erf т5 cf, Р(1) Р(2);
г) тх - т2, ’ Hl) J°(2);
д) т} = 1, т2 ~ 3; CTj = 1, сг2 = 2= ^0) = ^(2) i
е) - 3, т2 - 9; сц = 3, сг2 = 4; Р(1) -1/3, Р(2) - 2/3;
е) тх - 1, т2 = 1; = 1, ст2 = 2; Л(1) - Р(2) ;
ж) т} - 0, т2 -1; Gj = 1, 02 = 3; ^*(1) - 0.25, р(2) - 0.75.
Решение сопровождайте графическими пояснениями
2.3.6. На основе байесовской теории принятия решений вычислите разделяющие пороги, выпишите решающее правило и найдите вероятность ошибки классификации. Условные плотности вероятности для информативного признака имеют вид (распределение Лапласа)
,z , 1 f 1х ~ т J
/О10 = —-ехр/ -'-----—1
2YI < Yr
7 = 1,2.
Варианты.
а) ??75 ^т2, Yi =у2, Р(1) = Р(2);
б) Wj т2> Y] Y?, ^(1) “ ^(2);
в) т{ ф т2, у} Ф у2> ^С1) ф ^(2);
г) т) ^т2, у; т^2> Ж ^^(2);
д) - 0, т2 = 2, Y] ' 1, у2 - 2, Р(1) - Р(2).
2 3.7. На основе критерия минимума вероятности ошибки классифика-
ции необходимо вычислить разделяющие пороги, выписать решающее пра-
вило и найти вероятность ошибки классификации. Условные плотности ве-
роятности для информативного признака имеют вид
64
Методы анализа данных
/(х|1) = 0.5ехр{-|х|}, /(х|2) = РЧх 2|’
J v [0, х £[1; 3]
Варианты:
а) Р(1) - ^(2); б) />(3) = «-2, Л2) - 0.8;
в)р(1) = 0.9, Р(2) = 0.1;г) Р(1) = 0.7, Р(2) = 0.3.
2.3.8. На основе критерия минимума вероятности ошибки классификации необходимо вычислить разделяющие пороги, выписать решающее правило и найти вероятность ошибки классификации. Условные плотности вероятности для информативного признака имеют вид
/(хЦ) = У! 4 /(х| 2) = 0.5ехр{-j х-21).
Варианты:
а) Р(1) = 1/3, Р(2) = 2/3;
б) />(1) = Р(2); в) Р(1) - 2 / 3, Р(2) - 1 / 3.
2.3.9. На основе байесовской теории принятия решений необходимо вычислить разделяющие пороги, выписать решающее правило и найти вероятность ошибки классификации. Условные плотности вероятности для информативного признака имеют вид
/(х 11) = 0.5ехр{-1 х |}, /(х|2) = /2Ь
1^0, х < 0.
Варианты:
а)/*(1) = 0.2, Р(2) = 0.8;б) Р(1) = Р(2);в) Р(1) = 0.8, Р(2) = 0.2.
2.3.10. На основе байесовской теории принятия решений вычислите разделяющие пороги, выпишите решающее правило и найдите вероятность ошибки классификации. Условные плотности вероятности для информативного признака имеют вид
{2
хехр{-х /2}, х>0,
0, х < 0.
Варианты:
а) р(1)=1/45 р(2) = 3/4;б) Р(1) - Р(2); в) Р(1) = 3 / 4, ^(2) = 1/4.
Йлава 2 Классификагр/я в распознавать образов 65
2.3,11. На основе байесовской теории принятия решений вычислите разделяющие пороги, выпишите решающее правило и найдите вероятность ошибки классификаций. Условные плотности вероятности для информативного признака имеют вид
/Щ1) = 0.5ехрНЩ. /Щ2) = К’
Варианты:
а) Р(1) = 1/3, Р(2) = 2/3; б) Р(1) = Р(2); в) Р(1) - 2 / 3, Р(2) - 1 / 3 .
2 3.12. На основе байесовской теории принятия решений вычислите разделяющие пороги, выпишите решающее правило и найдите вероятность ошибки классификаций. Условные плотности вероятности для информативного признака имеют вид:
f(x |1) -= 0.5ехр{-) х|}; f(x [2) =
J е , х О, [О, х < 0;
х е[-2;-1], хй[-2-1].
Варианты:
а) Р(1) - Р(2) = Р(3) = 1/3;
б) Р(1) - 1 /4, Р(2)-1/2, Р(3) - 1/4 ;
в) Р(1) = 1/6, Р(2) = 1/2, Р(3)~1/3;
г) Р(1)- 1/2, Р(2) = 3/8, Р(3)-1/8.
2 3.13. На основе байесовской теории принятия решений необходимо вычислить разделяющие пороги, записать решающее правило и найти вероятность ошибки классификации. Условные плотности вероятности для информативного признака имеют вид
/(x|l) = -rLexp
У 2
/(x|2) = 0.5expHxj}.
Варианты.
a) P(P^P(2y,fy Р(1>1/4, Р(2)-3/4;в) Р(1) = 3/4, Р(2) = 1/4.
66
Методы анализа данных
2.3.14. На основе критерия минимума вероятности ошибки классифика ции необходимо вычислить разделяющие пороги, выписать решающее правило и найти вероятность ошибки классификации. Условные плотности ве-оятности для информативного признака имеют вид:
2
О,
Варианты:
а) Р(1) = 3/4, Р(2) = 1 / 4; б) Р(1) = 3/5, Р(2') =-2/5;
в) />(1) = Р(2) - 1/2; г) Р(1) = 1/4, Р(2) = 3/4.
2.3.15. На основе байесовской теории принятия решений вычислите разделяющие пороги, выпишите решающее правило и найдите вероятность ошибки классификации. Условные плотности вероятности для информативного признака имеют вид (экспоненциальное распределение)
[\e’M к
f (х | /) =
х > О,
х < 0; 7 = 1, 2.
Варианты;
a) Aq л2, 2*(1) = (°(2); б) А] Л2? ^(0 75 ^(2);
в) Xj =Х2, Р(1)*Р(2).
2.3.16. На основе байесовской теории принятия решений необходимо вычислить разделяющие пороги, выписать решающее правило и иайти вероятность ошибки классификации. Условные плотности вероятности для информативного признака имеют распределение Релея:
[0, х<0;
f - 1, 2.
Варианты:
a) CTj * Р(1) = Р(2); б) gJ * g|, Р(1) * Р(2);
в) G] />aw(2).
^ава 2, Классификация в распознавании образов
67
2.3.17 Имеются два информативных признака, распределенных по нормальному закону.
j =1, 2, х=Р I m(j) =
U2J
K(j) =
^(/) MjP Л1О) ^(7);
WjG)^ w2(j)J’
А2ОРЫА 7 = 1’2-
Необходимо найти разделяющую функцию и выписать решающее правило, основываясь иа байесовском подходе
Варианты:
, гг м f0
а) признаки некоррелированные: л. (у) = q ,
Р е>;0')у
/й(1) * ^(2), ТОД ф К{2\ Р(1) у Р(2),
б)признаки некоррелированные: К(1) = К(2), G]=o, -о.
2.3 18. Имеется m информативных признаков, распределенных по нормальному закону (см. упражнение 2.3.17). Необходимо найти разделяющую поверхность и построить решающее правило в соответствии с байесовской теорией принятия решений Корреляционные матрицы одинаковые (К(1) = К(2) = К), а признаки коррелированные.
Варианты: а) Р(1) Ф Р(2} ; б) £*(1) = /*(2).
2.3.19. Для случая двух информативных признаков иа основе критерия минимума вероятности ошибки классификации необходимо построить разделяющие функции, выписать решающее правило и найти вероятности ошибок классификации. Условные плотности вероятности для информативных признаков имеют равномерные законы распределения; признаки некоррелированные, априорные вероятности для всех классов одинаковые
Варианты:
а) два класса; области ненулевых значений плотностей (т. е. области существования признаков) не пересекаются;
68 Методы анализа данных
б) два класса; области ненулевых значений плотностей частично пересекаются;
в) три класса; области ненулевых значений плотностей не пересекаются;
г) три класса; области ненулевых значений плотностей частично пересекаются.
Процесс поиска решения желательно сопровождать графиками в пространстве двух информативных признаков.
2.3.20. Рассмотреть исходную постановку задачи классификации и получить байесово решающее правило для случая, когда из двух информативных признаков одни дискретный, второй - непрерывный.
„ г г- 1 I
При наличии двух классов известна обучающая выборка: х,,...,х ; if,х^ общего объема щ + п2 - и. По ней необходимо доопределить априорные вероятности и параметры в соответствующих (указанных ниже) законах распределения информативного признака, а также записать байесовские решающие правила.
За основу рассмотрения необходимо взять следующие законы распределения для информативного признака:
2.4.1. Равномерное распределение (см. упражнение 2.3.1), неизвестные параметры а,, Рг, / =1, 2.
2.4.2. Нормальное распределение (см. упражнение 2.3.5), неизвестные параметры , of, i = 1,2.
2.4.3. Распределение Лапласа (см. упражнение 2.3.6), неизвестные параметры ур i -1} 2.
2.4.4. Экспоненциальное распределение (см. упражнение 2.3.15), неизвестные параметры А.г, i - 1, 2.
2.4.5. Распределение Релея (см. упражнение 2.3.16), неизвестные параметры с(5 i=l,2.
^оссификация в распознавании образов 69
Глава 3. ПЛАНИРОВАНИЕ ЭКСПЕРИМЕНТА
3.1. Что такое планирование эксперимента
У = Ф(мн >
Целью планирования эксперимента является создание таких планов покачивания входных переменных, которые обеспечивают более быстрое и точное построение модели объекта (рис. 3.1.1).
Выход объекта у состоит из неизвестного сигнала (функции ср() от входов) и центрированной помехи = 0).
(3.11)
Функцию (р() часто называют функцией (или поверхностью) отклика, а входные переменные и - факторами.
Если мы имеем дело с малоизученным объектом, то вид функции ср() неизвестен и удобным представлением ее является степенной ряд Тейлора в некоторой базовой точке w° - ).
т л 1 ’п т л л
+ -«f)(Uj-w°) + ... + /7 (3.12)
г=1 г=1 ./=1
Здесь
о о. 3(р(м0) . -— а2(р(й°) . . -—
ас=ф(«1Ч , 1<т‘, а = , *,.7 = 1, т; ....
ди[ oUjdUj
Модель объекта строим также в виде отрезка степенного ряда:
т
Т = «0 +!>,(«, - 4°) + ИХ; («, "«,°)(«; -«;) +
'=1 i£ j
+ ... + £...£а, /и,-М“)...(И;-М“).
(3.1.3)
70
Методы анализа данных
Это уравнение называется уравнением регрессии. В нем (в охличие от ряда исключены зависимые переменные, такие, например, как
(lL> " щ)(и1 ~~ ’ и^° “ ^2^(и1 " м1°) = (н1 “ W1°)(M2 ~ м?) ’ а коэффициент
ТЬГ1/2 й Др- включены в параметры а. Уравнение регрессии отражает сред-н10ю связь выхода объекта со входами. Параметры модели вычисляются обычно но методу наименьших квадратов на основе экспериментов (а^У!; ...;
й ,У„)> полученных в результате реализации одного из планов, иапример ортогональных.
С помощью планирования эксперимента решаются не только задачи построения модели объекта. Примером служит задача о взвешивании тел.
Взвешивание трех тел (Л,/?, С)
можно провести по традиционной схеме, приведенной в табл. 3.1.1. В ней "+" означает, что тело положено иа весы, " указывает на отсутствие тела на весах.
Вначале проводится "холостое" взвешивание и тем самым определяется "нулевая" точка весов. Затем по очереди взвешивается каждое из тел. Вес каждого тепа оценивается по результатам двух
Таблица 3.1.1
п А В с .у,
1 - - - У1
2 4- - - У1
3 - + - Уз
4 - - + У4
опытов:
вес А = у2 - У]. вес В - у3 - , вес С = у4 - .
Если измерения независимые и равноточные, то дисперсия результатов взвешивания тел запишется в виде
а2(вес А) = о2 (у2 - у,) - 2о2 (у) ~ и2 (вес В) - о2 (вес С),
где а (у) - дисперсия ошибки взвешивания.
Проведем теперь взвешивание по иной схеме, представленной в табл 3.1.2. Вес каждого тела определяется по формулам: аблица 3.12
вес А = У]- - -v2 + >’з ^ Зй
2
вес В = + Уа ~ Уз ~ У4
2
Biaea 3 Планирование эксперимента
п А В С Уг
1 + + + У\
2 - + - У2
3 + - Уз
4 - - + У4
71
вес г^У1-У2' Уз+У4
2
В числителе стоят элементы последнего столбца со знаками, указанными в соответствующих столбцах А, В, С. Мы видим, что при вычислении, скажем, веса объекта А он входит в числитель два раза, и поэтому в знаменателе стоит число 2. Вес объекта А, вычисленный по приведенной выше формуле, оказывается неискаженным весами объектов 5 и С, так как вес каждою из них входит в формулу для веса объекта А дважды и с разными знаками.
Найдем дисперсию, связанную с ошибкой взвешивания при новой схеме постановки эксперимента:
2. лх “ Л + У1 + 3’Л 2. .
о (вес А) = а =----о (у).
\ 2 J 4
Аналогичным способом находим:
о2(вес В) - су2 (у); о2(вес С) = а2(у).
Видно, что при новой схеме взвешивания дисперсия веса объектов получается вдвое меньше, чем при традиционном методе взвешивания, хотя в обоих случаях выполнялось по четыре опыта.
Увеличение точности эксперимента в два раза происходит по той причине, что в первом случае эксперимент был поставлен так, что каждый вес мы получали лишь по результатам двух опытов При новой схеме эксперимента каждый вес вычисляется уже по результатам всех четырех опытов, отсюда и удвоение точности.
При изучении планирования эксперимента рекомендуется использовать учебное пособие [3.1] и монографию [3.2].
3.2. Построение линейной статической модели объекта
Считаем, что входами объекта являются и{) и2, а выходом - у (см. рис. 3.1.1). Уравнение линейной статической модели объекта имеет вид (3.1.3):
л Q
У = ссо + ЕауЦ “«/)•
7=1
(3-2.1)
72
Методы анализа данных
Необходимо на основе эксперимента (на основе нескольких измерений входов и выхода объекта: [wk, и2„.. , и)пг> yt], i = 1, w, вычислить коэффициенты а0,аР -А модели.
Экспериментальные точки для эходных координат зададим в вершинах гиперпрямоугольника. Точки такого плана для т = 2 показаны в верхней части рис. 3.2.1. Эти точки равномерно распределены относительно из-- в / о „(Л
вестной базовой точки и - [и^ ,и2).
Интервалы покачивания Дм],Лм2 относительно базовой точки задаются экспериментатором, и они определяют область изучения объекта. Для этой области и строится линейная модель (3.2 1).
С целью унификации процедур построения планов, исследования их свойств, расчета параметров и исследования качества модели осуществля-
ется переход от размерных входных переменных ulfит к безразмерным хт
Ди
J=\m-
(3 2 2)
Точки плана в вершинах прямоугольника (верхняя часть рис. 3.2.1) в новых координатах оказываются в вершинах квадрата с единичными Координатами (нижняя часть рис. 3.2.1) Центр Плана переходит в начало координат. Полученный План представлен в табл. 3.2.1. В этом плане кроме безразмерных входных переменных х1; г2 Введены столбец фиктивной переменной х0 и
Таблица 3 2.1
п х0 *1 х2 У
1 + т- + Т]
2 + - + У1
3 4- + -- Уз
4 + — - Ул
столбец измерений выхода объекта в каждой точ-
ке плана. Фиктивный столбец состоит из +1 и служит для симметрии расчета Всех коэффициентов модели. Для упрощения записи плана единица опускается и указывается только знак единичной координаты.
р — —____________
ава 3 Планирование эксперимента
73
В новых безразмерных координатах х1,хт линейная модель (3 2Д) также сохраняет линейный вид:
т
Wo + Wj. Р-23)
/=J
только с другими параметрами {f3y }. Подставляем w; - w°, j = 1, m из (3.2.2) в уравнение модели (3.2.1) и получаем линейное уравнение (3.2.3) в координатах х, j =
У = «0 + = Ро + . (3.2 4)
2=1 7=1
Здесь
[30=а0, =ayAwj5 у = 1, т, (3.2.5)
Из этого уравнения получаем алгоритм расчета коэффициентов {а^} по коэффициентам {(3 }:
Коэффициенты a модели (3.2.1) оценивают составляющие
5<p(w°) . -— „
градиента ——- a j = 1, т, от сигнальной части выхода объекта но duj
входным координатам (см. полиномиальное уравнение объекта (3.1 2). Коэффициент сс0 = (30 (см. (3.1,2), (3.1.3) оценивает сигнальную часть <р(й°) выхода объекта в центре плана й°.
Заметим, что в новых координатах (у,Х) полиномиальное уравнение объекта (3 1.2) сохраняет свой вид:
т
у = Ч/(х) + й = 60 + '£ЛХ! +-.- + h.
f=l I <J
(3.2.7)
74
Методы анализа данных
Тогда соответствующая этому уравнению модель объекта в виде отрезка степенного ряда записывается в форме
y = Po+SfV> + 2ЕвДД + ...+£•••£₽, Д.-.-Д. (3.2.8)
i=l ;< j </
Параметры 30, [3;, / = 1,и, модели (3.2.3) рассчитаем по критерию наименьших квадратов
/ = д2 Е(у,-Ро - £P7s)2 = miu’ О-2-9)
>~i j=i
предполагая, что измерения выхода уь ..., уп некоррелированные и равно-2
точные с дисперсией о . Из критерия (3.2.9) получаем систему линейных алгебраических уравнений:
ъ~у2 Е(аду)Р, = (Ч>У)> £ = ОД ..., m. (3.2.10)
Здесь х}, j = 0,1,..., m - столбцы матрицы планирования, включая фиктивный столбец х0, состоящий из "плюс единиц", у - столбец измерений выхода объекта; (xk>x ) и (xify) - скалярные произведения столбцов матрицы планирования:
= Ow)=i>h.T;- (3 2 11)
i=i <=1
При двух входах объекта (ш-2') система линейных алгебраических Уравнений (3.2.10) имеет вид:
%ЪдВ +ОоД)Р1 + (ад2)р21 = Д2(*о>т),
° у !(х1, *о)₽о + <Л> xi)Pi + (Л,*2)Р2]= (ад) > (3.2.12)
[(х2 Д )Ро + (х2 Д )Pj + (х2, х2 )р2 ] = ст“2 (х2, у).
^гава 3 Копирование эксперимента 7^
Если реализован план, представленный в табл. 3.2.1, то векторы-столбцы х0, х15 х2 взаимно ортогональны в соответствии со скалярным произведением (3.2.9), т. е. (x^Xj) ~ (х0,х2) = (х, ,х2) ~ 0. Система уравнений (3.2 12) распадается на независимые уравнения, из которых вычисляются параметры модели:
Здесь учтено, чго скалярные произведения векторов х0, хр х2 самого на себя одинаковы и равны количеству измерений
План (см табл. 3.2.1), у которого столбцы взаимно ортогональны, называется ортогональным планом Такой план впервые был использован при построении модели Боксом и Уилсоном в 1951 г. План называют еще ортогональным планом первого порядка, гак как он предназначен для построения линейной модели, т. е. модели первого порядка. Общая схема построения ортогональных планов первого порядка (полного факторного эксперимента и дробных реплик от него) будет рассмотрена в параграфах 3.4, 3.5.
Корреляционная матрица для параметров, удовлетворяющих критерию наименьших квадратов (3.2.9), равна матрице, обратной матрице системы уравнений (3.2,12).
(хо>хо)
0
о
0
(XpXj)
0
о
(х2,х2) j
76
Методы анализа данных
'ъ\1п о О
О Су/Я О
О о с? /и
< у J
(3.2.14)
Параметры некоррелированны и дисперсия их одинакова:
2
а. = ; = 0.1,2. (3.2.15)
к
Те же закономерности сохраняются при увеличении количества т входов.
Вычислим дисперсию выхода построенной линейной модели (3.2.3):
2 2 Л 2 2 2,. Л 2. 2~ 2 2 Л 2
= М1+ + р ЬР 2>;'
7=1 7=1 7=1
Дисперсия выхода линейной модели одинакова на равном расстоянии от центра плана. Заметим, что план, обладающий указанным свойством, называется ротатабельным, т. е. ортогональный план первого порядка рота-табельный.
3.3. Крутое восхождение по поверхности отклика
В планировании эксперимента поверхностью отклика называют уравнение связи выхода объекта с его входами (ср(-) в (3.1.1) либо \|/(-) в (3.2.7).
В 1951 году Бокс и Уилсон предложили использовать последовательный Шаговый'1 метод движения к экстремуму выхода объекта. Вначале ставится небольшая серия опытов (ортогональный план 1 порядка) для локального описания небольшого участка поверхности отклика полиномом первой степени. Коэффициенты а, линейной модели являются оценками состав ляю-
Шйх градиента: а,=—7=1, т. Далее движение осуществляется по dUj
Поверхности отклика в направлении оценки градиента:
ш -о , -
11 ~ и +ka.
^ава з Планирование эксперимента
77
Здесь к- величина шага. Эт0 движение сопровождается одновременным изменением всех факторов (рИС 3.3 I). ЕСЛИ ОДНО! о шага окажется недостаточно, то в новой точке ставится иовад небольшая серия опытов и находится новое направление на экстремум для движения по поверхности отклика. Шаговый процесс движения по поверхности отклика продолжается до тех пор, пока исследователь не попадет в "почти стационарную область" (окре-
стность экстремума), где линейное приближение оказывается уже недостаточным для описания поверхности отклика. Здесь ставится большая серия опытов и поверхность отклика описывается полиномом второго, а иногда и
третьего порядка.
3.4. Полный факторный эксперимент
Полным факторным экспериментом называется эксперимент, в котором реализуются все возможные сочетания уровней факторов Если число факторов равно /и, а число уровней каждого фактора равно р, то имеем полный факторный эксперимент типа р™ Прн построении линейной модели объекта используется полный факторный эксперимент типа 2т
При планировании эксперимента безразмерные координаты (факторы) принимают значения ± 1. Для простоты записи единицы опускаются и остается только их знак. Условия эксперимента записываются в таблицы, в которых строки соответствуют различным опытам, а столбцы - значениям факторов. Такие таблицы называются матрицами планирования эксперимента. Для удобства математических выкладок в матрицу планирования часто вводят столбец фиктивной переменной , которая во всех опытах принимает значение Н.
1 2
Матрицы планирования для полною факторного эксперимента 2,2, 23, 2 4 (ортогонального плана первого порядка) приведены в табл. 3.4,1.
78
Методы анализа данных
Таблица 3 41
С использованием ортогонального плана первого порядка можно определять не только коэффициенты линейной части модели но и коэффици енты перед факторами взаимодействия xtXj (за исключением |3П, стоящих перед х2), т е можно построить н неполную квадратичную модель Например, при т - 2 можно рассчитать и коэффициент Р12 модели
У - Ро + pjXi + Р2х2 + P12V2
Для этого в матрицу планирования 2 2 вводим (для расчеiа Р, 2) голбец Х1х2 (табл 3 4 2)
Новый столбец ортогонален костальиым Тогда
Ро = Уа + У2 + Уз + У 4
° 4
О —-— — ___
7йба 3 Локирование эксперимента
Таблица 3 4 2
п х0 xs *2 У,
1 4 + + 1 У1
2 + - + - Уз
3 + + - - Уз
4 + - - + >4
79
У1 ~ У2 + З;3 ~ У4
3.5. Дробные реплики
При большом числе входов объекта полный факторный эксперимент 2т
содержит большое число экспериментов. Можно этот план разбивать на блоки (дробные реплики) с сохранением ортогональности плана. При этом по меньшему числу точек определяются (также независимо друг от друга) все
коэффициенты линейной модели.
Чтобы получить дробную реплику, необходимо за основу взять полный факторный эксперимент (например 2J) и в качестве новой переменной (например х4) взять один из столбцов, соответствующий фактору взаимодействия (например х4 = х^ х3). Для данного примера дробная реплика обозначается как 24-1, т. е. (см табл. 3.5.1) это полуреплика от полного факторного экспери-
Таблица 3,5.1
п *1 х2 х3 Х^ = XjX2
1 4- + + +
2 — + + -
3 + — 4- —
4 — 4- +
5 + +
6 — 4- +
7 + — - 4-
8 — -- —
мента 24 с генерирующим соотношением х4 -Xj,x2x3. Вместо генерирую-
щего соотношения иногда удобней писать определяющий контраст 1 - Хр^ХзХд.
Определяющий контраст (нли определяющие контрасты, когда их несколько) позволяет установить разрешающую способность дробной реплики. Разрешающая способность будет максимальной, если лннейпые эффекты будут смешаны с эффектами взаимодействия наибольшего возможного
порядка.
80
Методы анализа данных
Возьмем полуреплику 23 1 с определяющим контрастом 1 = х,х2х3. Тогда X] - Х\Х2Х3 ~ Х2Х3’ х2 ~ *1Х3’ Х3 ~ Х1Х2 и коэффициенты модели буду г оценивать следующие коэффициенты объекта:
Ро “> ^0 + 1 + ^22 + ^33 + ^123 + ‘ ’
р1 +ь2. +
р2 й2 + 613 + “ ‘ >
Р3 + 612 + ‘ ‘.
Процедура выбора реплик большей дробности аналогична рассмотренной выше. С ростом числа факторов увеличивается дробность реплик и усложняется система определяющих контрастов.
Пример 3.5,1. Необходимо: 1) построить дробную реплику 26"3 с гене рируюшими соотношениями: , х5 ~ хрх3, xg - XjX2x3; 2) оценить ее
разрешающую способность; 3) выписать синтезируемую модель; 4) вычислить дисперсию выхода модели.
Таблица 3.5 2
п х2 Хд — Х5 = Х6 — XjX2X3
I + + + н + +
2 + + - — —
3 4 — + — + -
4 — — + + +
5 + + — + —
6 + — — + +
7 + — — — +
Ll_ - — - + + -
! Берем за основу полный факторный эксперимент 23 и формируем 3 дополнительных столбца в соответствии с генерирующими соотношениями. 4 = xj^2, *5 ~ ХуХл, хй = х^х,. Дробная реплика приведена в габл. 3.5.2
2 Записываем определяющие контрасты (другая форма записи генерирующих соотношений): 1 - XjX2x4, 1 - Х]Х3х5, 1 - XjX2x3x6. Перемножая эти
^asa 3 Планирование эксперимента 81
сравнения по два, получаем 3 определяющих контраста (1 = х2х,х4х-5 I = х3х4х6, 1 а перемножая уравнения по три, получаем еще 1 оп-
ределяющий контраст (I - х^х^). В итоге исходные и полученные определяющие контрасты образуют обобщенный определяющий контраст, который записывается в виде: 1 = х^^— х1хзх5= ^р^г^зА'б~ Л'2хэх4х5= хзх4хб~ — X^^X^ — XjX^XjX^ .
На основе обобщенного определяющего контраста получаем линейные связи между переменными:
X] =х2х4= x3x5=x2x3x6~%jx2x3xilx5=x1x-x4x6=x1x2x5x6^x4x5x6,
Х2 Х1Х2Х3Х5^Х]Х3Хб = Х3Х4Х5^Х2Х3Х4Х6 = Х5Хб=Х1Х2Х4Х5Х6,
х3 - х1х2х3х4- Х1Х5~Х1Х2Х6=Х2Х4Х5=Х4Х6=Х2Х3Х5Хб=Х1Х3Х4Х5Х(
'4
1Л2
• । л л л -А- '*2 ’’’* з Л4 "^б 2 □ Л5 ""^З *^6"**2 ^4 ^5 *^6 5 *^6 *
х5
6-
X^X^X^Xg ^^З^Д^З^б ^3'^4 ^2/^5 XjX^X^
Эти связи позволяют оценить разрешающую способность дробной реплики:
0t} —> Ьо + 6] 1 + 622 + ^-14 + ^55 + ^66 + ^124 + ’ “,
Pl -> Z?1 + 624 + £>35 + ^236 + ‘ =
₽2 “> 62 +^14 + 656 + 6136 +“‘ =
Р3 ->Ь3 +£]5 + 646 + Ь126 +
Р>| -> /’д + Й]2 + £36 + 6235 -1-,
+ ^13 +^26 + ^234 +'*?
₽6 ^6 +^34 + &25 + &123 + ‘“ ‘
82
Методы анализа данных
3. В линейную модель
у = Ро + Pl*! + ₽2Х2 + РзХ3 + + Ps*5 + РбЧ
входят 7 параметров, а 8 экспериментов плана позволяют оценить 8 параметров модели. Следовательно, в модель можно включить еще компоненту. Выясним какую? В нее должна входить переменная, линейно не зависящая от остальных переменных, модели, т. е. в модель нс могут входить переменные, совпадающие с х0 = 1, Xj, х2, х3, х4, х5, х6. Эта связь была выявлена в вышеприведенных равенствах. В модель можно включить либо х,х6, либо х2х, и т. п. Модель приобретает, например, вид
У = Ро + Р1*1 + 02*2 + Рз Х3 + 04*4 + Р5*5 + ₽6*6 + Р16*1*6 •
4. При равной точности измерений выхода объекта в точках плана и некоррелированности измерений параметры модели рассчитываются независимо (в соответствии с методом наименьших квадратов), они некоррелированные н их дисперсии одинаковые: Ср = сг^ /п, Тогда
2 2Г1 2 2 2 2 2 2 22,
СГу = СГр [1 + Xj + х2 + х3 + х4 + Xs + х6 + xt Хй |.
3.6. Насыщенные планы. Симплекс
Иногда исследователь ставит цель получения линейного уравнения модели по планам, содержащим минимум точек (количество точек равно числу коэффициентов). Такие плапы называют насыщенными.
Ортогональный план проводится в вершинах правильного симплекса.
Правильным симплексом называется выпуклая правильная фигура в многомерном пространстве, число вершин которой превышает размерность этого пространства на единицу.
Например, в одномерном пространстве правильным симплексом будет ОтРезок - рис, 3.6.1; в двумерном пространстве правильным симплексом будет равносторонний треугольник - рис. 3.6.2; в трехмерном пространстве -Тетраэдр _ риС1 3.6.З и 1. д. Примеры матриц планирования для указанных слУЧаев приведены ниже:
asa 3 Планирование эксперимента 83
Xj x2
X1 X2 X3
Эти планы центральные и ортогональные
Приведём для разнообразия один нз общих способов построения планов
X] %2 Х3 ' хт
' а, а2 а3 “ д>7,
“ а1 ^2 ‘
О -2а2 а3 ат •
О 0 -~За3 ат
,00 0 •“ ~тат}
(3.6.2)
3.7. Насыщенные планы. Планы Плаккета - Бермана 1
Насыщенными планами (н - т +1) являются симплексные планы Ими удобно пользоваться при единичных значениях координат во всех точках плана. Такие симплексные планы существуют при т- I, 3, 7, 15, 31, 63, 127, ., и они являются соответствующими дробными репликами.
Плаккет и Берман в 1946 г предложили способ построения насыщенных планов (с единичными координатами) при т - 11, 19, 23, 27, 31, 35, 39, 43, 47,51,55,59, 63,67,71,....
Задаются базовые строки. Пять из них в качестве примера приведен*1 в табл. 3.7.1
84 Методы анализа дан^
т п
_12
20_
24
32
35 36
Таблица 3.7.i
' Строка
+ + — + + н + —
+ + - —+++—+—+— F + —
+ + Ч ++ — + — + + — — + + —- + .—р . _ —,
-+-+-+++-++ +++++--++-+--+
—+—+++ + + + + + — + + + — — + + - + — + +- + —
Каждая следующая строка матрицы планирования образуется из исход-цой циклическим сдвигом вправо. Получается матрица размером т х т. Последняя + 1 )-я строка матрицы планирования состоит из минус единиц
Прн некоторых значениях т (например, при т = 27) за основу берется система блоков (например, А, В, С) Циклическим сдвигом вправо образует
ся квадратная матрица размером тхт, например,
(А В С\ С А В
[в С Aj
Последняя
строка матрицы планирования также состоит из минус единиц
3.8. Разбиение матрицы планирования на блоки
При проведении эксперимента выход объекта дрейфует Если этот Дрейф кус очно-постоянный, то его можно нейтрализовать, изменяя порядок проведения эксперимента во времени. Для этою разбивают матрицу планирования на блоки и последовательно реализуют (во времени) эту матрицу, вначале один блок, затем другой и т. д.
В качестве примера рассмотрим ортогональный план 2J (табл. 3.8.1). Считаем, что выход объекта имеет аддитивный дрейф на величину Д, (когда проводятся эксперименты с номерами I, 2, 3, 4) и на величину Д2 (когда проводятся эксперименты № 5, 6, 7, 8). Этот дрейф приводит к смещению на 8еличИНу (4д1 -4Д2)/8 параметра р3:
R _ -Цист +............. 3^8ист 4At 4Д3
ГЗ — ----------------------1---------------
8 8
6а 3 Планирование эксперимента
85
Таблица 3 81
п *1 Х2 Адр " Х1Х2Х3 уг Номер блока
1 + Ч У У j/j — У] ист Т I
2 - У У - У 2 = Уз ист + Д1 2
3 + - У - Уз — Уз ист + Д1 2
4 - - + У Уд — У4 ист 3" Д1 I
5 + + - Уз — У? ист Д2 2
6 - У - У Уб = Убист + Д2 1
7 + - У У? ~ У7исг + Д2 I
8 - - - - Уй ~ Уйист Д2 2
Для устранения этого недостатка изменим порядок проведения эксперимента, разбив план на 2 блока Введем дрейфовую переменную хдр ~ и по ней получим 2 блока (табл 3 8 2) Каждый блок представляет собой дробную реплику Реализуем этот план
Таблица 3 8 2
п *1 Х2 Х3 Хдр У,
1 У У У у И := Лист + Д1
2 — - + ч Р2 = УЗист + Д1 Блок 1
3 - У - у Уз ~ Уз жя + Д1
4 У - - у У 4 “ Уч ист + Д1
5 - + + Рй ~ Р5ист + Д 2
6 У - ~~ Уб “ Тб ист + д2 Блок 2
7 У У - - У2 “ Уз ист + Д2
8 — - Л ~ Лист 4 Д2
Нетрудно убедиться, что теперь дрейф не смещает параметров линейной модели
86
Методы анализа данИ&1
3.9. Обработка результатов эксперимента
1 Проверка однородности дисперсий. Если при реализации ортогонального плана остается неизвестным, на самом лн деле дисперсии выходов , бок измерения) одинаковы в каждой точке плана, то необходимо в каж-ой точке плана осуществить несколько дополнительных измерений выхода, найти оценку дисперсии (в каждой точке) и проверить гипотезу о равенстве дисперсий (см. гл. I).
Проверка однородности дисперсий производится с помощью различных статистик. Простейшей из них является статистика Фишера, представляющая собой отношение наибольшей из оценок к наименьшей. Полученная статистика сравнивается с пороговой величиной /у а. Если окажется, что
F <FV V2 а, принимается гипотеза о равенстве дисперсий.
2 ч 2
Второй критерий базируется на статистике Кочрена (лтах =6тах/]Га ’
(см. задачу 8 в гл. 1).
Рассмотренные статистики базируются на нормальном законе распреде ления помехи h (см. гл. 1) выходной координаты объекта. Если имеются существенные отклонения от нормального распределения, то проверка однородности дисперсий может привести к ошибочным результатам.
2 . Проверка адекватности модели. Вычисляем остаточную сумму квадратов /(П1Л (см. (3.2.9), делим ее на число степеней свободы Vj - п-т — 1 и получаем остаточную дисперсию (дисперсию адекватности)
I « 2
а«=-------ЕП-л)
н - т — 1 ,=]
(3-9-1)
Здесь у; - выход объекта в 1 -й точке эксперимента, у) - выход модели в той Же точке. При хорошем описании с помощью модели у сигнальной части Ф() выхода объекта остаточная дисперсия оценивает дисперсию выхода объекта.
На основе дополнительного эксперимента объема п0 в одной из точек цлана (например в центре плана) строим оценку для дисперсии оу выхо-объекта. Число степеней свободы для оценки д? равно величине
V2 «о -1-
Fitted j г/ -------------------—-----—.............———----------------
эксперимента 87
Теперь по статистике Фишера F - <3^1 <3у проверяем гипотезу о равен стве дисперсий, которая совпадает с гипотезой об адекватности модели. Ес^ статистика F не превосходит порогового значения Fv а, то принимаете, гипотеза об адекватности модели- В противоположном случае эта гипотеза отвергается. Тогда надо заново строить модель, например, усложняя ее За счет введения дополнительных факторов, либо отказываться от линейной модели и переходить к квадратичной модели.
Адекватность линейной модели можно проверить другим способом. При рассмотрении разрешающей способности ортогональных планов первого по-рядка мы убедились, что коэффициент 0О модели оценивает в совокупности коэффициент' - ц/(0) и все коэффициенты Ьи, стоящие перед xf полило, метального уравнения сигнальной части объекта (см. параграф 3.5):
т
Po^MSV
В то же время для коэффициента Ьо может быть получена оценка р° ус-редиеннем результатов опыта в центре плана. Разность (30 - 0° является оценкой для суммы коэффициентов £ . Если эта сумма равна нулю
(Н: Ъц = 0), то линейная модель хорошо описывает объект, если нет
* 0)’ то гипотеза адекватности отвергается. Для проверки гипотезы
Р -0°
Н составляем статистику Стьюдеита t = ——Д в знаменателе которой д j4n у
стоит оценка для Ор = о-у/л/й. Гипотеза адекватности принимается, если 1t1< tv а. Здесь v- число степеней свободы оценки с^,.
3 . Проверка значимости коэффициентов заключается в проверке гипотезы (Н:Ь^=0) для каждого у = Если статистика Стьюдепт3
Р, t----лежит внутри интервала (-fva, /va), то принимается гипотеза
о том, что коэффициент модели Ру незначимо отличается от нуля. В это?'1 случае данный член модели можно опустить, но после этого упрощения модели ее надо проверить на адекватность.
88 Методы анализа даю^
4 Интерпретация модели. Производится качественное сопосшвленне ведения полученной модели с реальными процессами объекта. При этом П цвлекается информация от экспертов (например технологов), детально лзучившйх объект. Знак коэффициентов j -1, да, линейной модели показывает характер влияния входа объекта на выход. Знак "+" свидетельствует 0 том что с увеличением входа (фактора) растет величина выхода объекта й наоборот. Величина коэффициентов р; - количественная мера этого ВЛИЯНИЯ.
Если характер связи между входами и выходом объекта на основе построенной модели не соответствует реальным связям (на базе информации от экспертов) в объекте, то такую модель надо поставить под сомнение либо полностью отказаться от нее.
3.10. Ортогональное планирование второго порядка
Построение планов второго порядка - задача в математическом отношении значительно более сложная, чем в случае построения планов первого порядка. Модель второго порядка при т = 3 имеет вид
У = Ро + ppXj + р2х2 + р3х3 + + р23х2х3 + pj^x^
, п 2 „ I о 3
+Pj]X] +Р22Х2 + РзЗХ3 ‘
Для вычисления коэффициентов модели второго порядка необходимо варьировать переменные не менее чем на трех уровнях. Это вызывает необходимость постановки большого числа опытов. Полный факторный эксперимент содержит Зт точек(см. вторую строку табл. 3.10.1).
Таблица 3.10.1
• т 1 2 3 4 5 6 7
—Зт 3 9 27 81 243 729 2187
^Композиционный план и0 = 1 5 9 15 25 43 77 143
В 1951 году Бокс и Уилсон предложили составлять композиционные планы (см. табл. 3.10.1) Число точек плана равно величине
+2да+«0.
——— , __________________
3 Планирование эксперимента
89
Здесь /1] - число точек полною факторного эксперимента 2т или дробп^ реплики 2т~р; 2т - число парных точек, расположенных на осях коордицат 77q - число опытов в центре плана Расположение точек в факторном цр0. странстве для композиционного плана Бокса - Уилсона в случае двух и грех входов показано на рис 3 10-1.
Точки на осях коордццат называют звездными точками Их количество равно удвоен-ному числу факторов. Расстояние от центра плана до звезд ной точки одинаково. Его об0. значакп буквой а и называют звездным плечом
Описанные выше композиционные планы являются
центральными планами, ибо все ючки плана симметрично расположены относительно центра.
Композиционные планы имеют следующие положительные свойства
1 . Они могут быть получены в результате достройки планов первого порядка, поэтому их иногда называют последовательными планами. Это свойство позволяет при получении неадекватной модели первого порядка перейти к построению модели второго порядка, добавив опыты только в звездных точках и в ценгре плана.
2 Дополнительные точки на осях координат и в центре птаю (см. табл. 3.10.2) нс нарушают ортогональности для столбцов, соответствующих факторам и эффектам взаимодействия х,х;. Этот факт открывает возможность независимого получения соответствующих коэффициентов модели
Ортогональность плана нарушается для столбцов х0 и xj, ибо
1=1 J=1
Элементы вышеуказанных столбцов положительны. Чтобы получить полностью ортот овальный план, необходимо произвести некоторое преобразование квадратичных переменных и выбрать величину а звездного плеча.
90 Методы анализа даю№*
Таблица 3.10.2
п х0 Xi х2 Х1%2 2 Xi н lo to %; *2
1 4- + 4- + 4- + 0 0
2 + - + - 4- + 0 0
3 4- + — — + + 0 0
4 + — — + 4- 4- 0 0
5 4- а 0 0 2 а 0 А V
6 4- -а 0 0 2 а 0 А V
7 1 0 а 0 0 2 а V А
8 + 0 -а 0 0 2 а V А
9 0 0 0 0 0 V V
Все элементы каждого столбца х] изменим на постоянную величину (среднее арифметическое):
1 п ---
Г 2 1 V 2 2 2
xi = xi -~2Л=Х1
'1 огда новые столбцы х| ортогональны к х0:
п п ---- п ---
= S Vh = “*?) = Т;ХЪ ~ Пх1 = 0.
г=1 ?=1 г=1
Они также ортогональны к столбцам х,, х2 s xtx2.
Для выполнения условий ортогональности столбцов х/ и xj
f 4^,-0 i=i
выберем соответствующую величину звездного плеча а Эта задача разрешима. В табл. 3.10.3 приведены значения а, вычисленные для различного ЧИсла независимых переменных при nQ ~ 1.
^баЗ Планирование
эксперимента
Таблица 3 10 3
т 2 3 4 5
Ядро планирования 22 23 24 25’1
Величина а 1.000 1.215 1.414 1 547
С учетом новых переменных х'} получаем следующее уравнение модели (дляслучал т-2)
J'’ = Ро + Р1*1 + р2*2 + ₽12Х1Х2 + Р11 (Х1 + *1 ) + ₽2г(х2 + *2 ) ~
= Ро + Р1 РЗ + Рз2*2 + Р1*1 + ₽2Х2 + Р12*1*2 + Р1 1*1 + Рз2*2 =
= Рй "1 Р1*1 + Р;*2 + P12*l*2 + Р11*1 + Рт2*2
Параметры р Рр Рг= Р12’ Рн> р22 в силу ортогональности плана вычисляются независимо, так же как и при использовании ортогонального плана перво! о порядка В заключение остается пересчитать коэффициент
который оценивает сигнальную часть выхода объекта в центре плана
В итоге построена модель второго порядка-
У = Ро + Р1*1 + р2*2 + Р12*1*2 + Р1 Л + $22*2 = <*0 + «1 («1
+ al2(w1-w1)(w2-w2) + cx11(w1-w1) +a22<w2-w2) , Ot0=po, a^Pj/A^.
^2 ~ p2 Au2 , CC12 — Pi2 /(Ам} Au2 ) . (Xj2 “ P11 /(AW] ) , Ct2? — P22 /(Au^)
3.11. Рога1абелыюе планирование
Рассмотрим вопрос о статистических свойствах уравнения модели в целом Мерой статистической неопределенности модели является дисперсия 2
выхода модели . Если эта дисперсия одинакова на равном удалении от центра плана, то такой план называется ротатабельным. ______________________________________ _________________________ - —
92 Методы анализа далнъ^
Ортогональный план первого порядка является ротатабельным. Убедимся в этом. Дисперсия выхода модели
У = Ро +
2-1
равна величине
2 Л 2 2 2 А Д 2. 2 Z1 2.
= +2>рЛ = " М1 + Р
7 т-7 I
(3.11.1)
2 2 / 2 v 2
Здесь сГр - & у / п, р = р, - квадрат расстояния (в эвклидовом простран-стве) от точки X до начала координат. Другими словами, точность предсказания выхода объекта оказалась одинаковой на равных расстояниях от центра и не зависит от направления.
При выводе результата (3.11.1) использован ранее установленный факт (см параграф 3.2), что на основе ортогонального плана первого порядка получаются некоррелированные параметры |3 .
Композиционный план второго порядка можно сделать ротатабельным планом (но при этом нарушается условие ортогональности плана), изменив величину гнездного плеча (X. Если ядром плана служит полный факторный эксперимент (1. е. =2т), то а = 2 , а если ядром служат дробные ре-
плики (^ = 2m'/’))'io а = 2<ст”р)/4.
Существует способ построения ротата-бельиых планов второго порядка из симплексных планов.
Рассмотрим для примера случай двух входов объекта (т = 2). Точки негодного симплексного плана находятся в вершинах равностороннего треугольника (рнс. 3.11.1). Соединим точки в вершинах равностороннего треугольника с началом координат (находящемся в центре греугольника) и по-1уЧи1« три вектора, концы которых дают еще трн точки плана. Складывая Вектора по три, получаем центральную точку. Первоначальные точки и но-точки дают ротатабсльный план в горого порядка.
CiQea ? гг — — -------------——
‘минирование эксперимента
В теории планирования эксперимента показано, что при помощи опера, ции суммирования векторов, идущих из начала координат в вершины сим пчекса (с центром в начале координат), по два, по три. нт Д до т, мозкд0 при любом т построить множество точек, добавление которых к точкам исходного симплекса дает ротятабельный план второго порядка. Полученные таким способом планы называют снмплексно-суммируемымн
3.12. Метод случайного баланса
Часто влияние фактора на выходную координату объекта имеет затухающий экспоненциальный вид, как показано на рис 3 12 1 По оси абсцисс отложены факторы в порядке убывания нх влияния, по оси ординат - суммарный вклад, вносимый в выходную координату объекта данным фактором и менее значимыми факторами Величина вкнда
фактора (в %) отмечена штриховкой Факторы, влияние которых мало (они попали в правую часть диаграммы ранжирования), составляют шумовое по ле, на фоне которого необходимо выделить значимые факторы, попавшие в левую часть диаграммы.
В 1956 ходу Сатерзвайт предложил метод случайного баланса для отсей вания небольшого числа значимых факторов на шумовом поле Метод базируется на постановке экспериментов по плану, содержащему координаты точек, выбранных случайным образом
Построение матрицы планирования осуществляют следующим обратом Все факторы разбивают на группы Затем для каждой группы строят матрицы планирования, беря за основу полный факторный эксперимент или дробньк реплики План проведения эксперимента образуется путем случайною смешивания строк соответствующих базовых планов (для групп факторов).
Поясним это на примере. Пусть требуется исследовать десять факторов (4 линейных фактора хр х2, х3> х4 и 6 парных взаимодействий: XjX2, хй’ XjX4, х2х3, х2х4 ’ хзх4) и выделить из них наиболее существенные фактора с помощью небольшого числа опытов Разобьем все входы х1,х2,х3,х4 и11 две группы 1) xt, х2; 2) х3, х4. Первой и второй группам соответствуют матрицы планирования 22, представленные в габл 3 12 1 и 3 12 2
94 Методы анализа данн&
Затем из этих матриц строится бшая матрица планирования. Каж-° строка этой матрицы состоит из ДлуЧайно выбранных строк обеих базовых матриц- При этом, очевидно, возможна ситуация, когда некоторые строки базовых матриц будут встречаться несколько раз, в то время как
другие - ни разу. Полученный план реализуется на объекте, и результаты анализируются с помощью диаграмм рассеяния. Поясним это на примере.
Допустим, что исследуется влияние трех воющего эксперимента представлены в табл, строятся диаграммы рассеяния (рис. 3.12.2).
факторов. Результаты отсей-3.12.3. По этим результатам
Таблица 3.12.3
п Ч х2 г 1-4 У У
1 + + 24 27
2 — + — 27 27
3 + — — 26 29
4 — — + 29 29
Каждая из диаграмм содержит точки, соответствующие результатам эксперимента. Эти точки разбиты на две группы. Одна из них соответствует тем опытам, когда исследуемый фактор находился на нижнем уровне, вторая -тем опытам, когда фактор находился на верхнем уровне. Для каждой из групп находятся оценки медианы и вычисляется их разность (из оценки медианы правой группы вычитается оценка медианы левой).
Оценка медианы - это среднее по номеру значение упорядоченной выборки. Если число точек нечетное, например 2£ + 1, то оценкой медианы является (А:+1)-я точка упорядоченной выборки. Если число точек чешое, например 2к, то оценка медианы лежит между i-й и (к + 1)-й точками. Обычно берется середина интервала между k -й и (fc +1) -й точками.
Разность между оценками медиан количественно оценивает линейное влияние фактора на выход объекта, и эта разность равна удвоенному значению коэффициента (с учетом знака) в линейном уравнении модели. Чем вы-модуль разности оценок медиан, тем выше степень влияния фактора, оолее значимый фактор исключают из рассмотрения, вводя корректировку в Результаты измерений. После исключения наиболее значимого фактора
______ __ ________________~___________________________
ва 3. Планирование эксперимента 95
или нескольких факторов снова строится диаграмма рассеяния и вся проце. дура повторяется заново.
Поясним сказанное на примере, для которого исходные данные и д^ грамма рассеяния представлены в табл. 3.12.3 и на рнс. 3.12.2. Наиболее су. щественным фактором является . Разность между оценками медиан равщ величине
а □ о 24-27 + 26-29
Aj - 20, = -3; pj ------------
--1.5.
Исключим этот фактор из дальнейшего рассмотрения, введя корректировку в результаты измерения выхода. Для корректировки следует "стабити-зировать" Xj, например^ на нижнем уровне Для этого в тех строках табл. 3.12.3, где X] имеет уровень "+", значения у уменьшаются на величину А ] (с учетом знака). Скорректированные данные приведены в дополнительном столбце табп. 3.12.3. Цо результатам этих экспериментов вновь строятся диаграммы рассеяния для оставшихся факторов, н описанная процедура полностью повторяется
Если окажется, что вклады двух факторов одинаковы, то более существенным нз них считается тот, в диаграмме рассеяния которого больше выделяющихся точек в верхней и нижней частях диаграммы. Например, на рис. 3.12.3 изображена диаграмма с шестью выделяющимися точками. Нэ уровне Xj имеются 4 точки, для которых значение выхода больше, чем самое большое значение выхода на уровне х, . Аналогично, на уровне xf имеются 2 точки, для которых выход меньше, чем самый низкий выход на уровне .хф.
Процесс выделения существенных факторов прекращается, когда на очередной диаграмме рассеяния расстояния между медианами оказываются одного порядка и они незначительны по величине. Оставшиеся эффекты относят к "шумовому полю".
96
Методы анализа даннь&
Упражнения Ш
3.11. Постройте ортогональный план взвешивания 7 тел и 15 тел; опре-чеЛИТе веса тел по результатам взвешивания; вычислите дисперсии получае-моГО веса тел (считая равноточными результаты взвешивания во всех точках пЛана); сравните результаты вышеуказанного взвешивания с результатами обычного поочередного взвешивания тел.
Указание. Матрицы планирования проще всего построить как дробные 7-4 Q15-1I реплики 2,2
3 2.1. Постройте ортогональный полный факторный план 2т при т - 2, 3,4, 5, 6.
3.2,2. Вычислите коэффициенты линейной модели на основе результатов, приведенных в табл. З.У.1.
3.2.3. Вычислите параметры линейной модели, обрабатывая результаты полного факторного эксперимента (табл. З.У.2). На основе этих же результатов определите коэффициенты 012, Р13 > Ргз, Рпз; стоящие в модели перед факторами взаимодействия.
Таблица З.У.1
п %1 х2 У
1 + + 5
2 — + 3
3 + — -1
4 - — -3
3 2.4. Вычислите коэффициенты линейной модели по экспериментальным данным, приведенным в табл. З.У.З. Найдите определяющий контраст этой дробной реплики.
Таблица З.У.2
"----------------
а клнирование эксперимента
Таблица З.У.З
п х2 *3 *4 У
1 + + 26
2 •— + -1 — 20
3 + — + — 5
4 — — + 14
5 + + — — 10
6 — + — + 25
7 + — — 15
8 — — — - 9
97
3 2.5 Вычислите коэффициенты |3(|, РР Р2, р3,Р12, Руз> ₽23’ Pus модели (с учетом факторов взаимодействия) на основе резуль татов планирования, приведенных в табл. 3 У.4.
3.5.1 Определите разрешающую способность дробных реплик 24”1 с определяющими контрастами: а) 1 ~ х1х2х3х4 ; б) -1-х1х2х3х4; в) 1 = ;
г) - 1 = х1х2х4; д) 1 ~ х2х3х4
Таблица З.У 4
п *1 х2 |, *3 Г"
1 + + + J3?
2 — К + 10.4
3 -+ + 7.4
4 — + 4.6
+ + — 4.6
6 '— + — 3.4
7 4- - — 2.£
8 — - I 6_
3 5.2. Постройте дробные реплики 23-‘ с определяющими контрастами I - х3х2х3, -l-XjX^; оцените их разрешающие способности; вычислите коэффициенты линейной модели и найдите дисперсии этих коэффициентов.
3.5.3. Постройте дробную рсплнку 24"1 с определяющим контрастом 1 ~ х1х2х3х4, запишите полную модель, которую можно построить на основе этого плана; выпишите формулы расчета параметров модели; вычислите дисперсию выхода модели.
3.5.4. Выполните задание предыдущего примера для дробных реплик 23-1 с определяющими контрастами 1 - Х1Х2Х4; I х,х3х4; 1 - х2х3х4.
3.5.5. Постройте дробную реплику 2s 2 с генерирующими си01ноше-ниями х4 = XjX2x3, х5 = XjX3; оцените ее разрешающую способность; выпишите синтезируемую модель и вычислите дисперсию выхода модели.
3.5.6. Можно ли в модель включить следующие существенные переменные’ х0, X], х2, х3, х4, XjX2, х2хэ, х2х4, если при планировании эксперимента используется дробная реплика 24'1 с определяющим контрастом 1 = х^х3Х47
3.5.7. Можно ли в модель включить следующие существенные переменные: х0,х1,х2,х3,х4, XjX2, х2х3, х2х4, если прн планировании эксперимента используется дробная реплика 24”1 с определяющим контрастом H.V2x3x4?
98 Методы анализа данн^
3 5 8. Можно ли в модель объекта включить существенные переменные
У %2,х3,х4, х5х2, х2х3, х3х4, если используется дробная реплика 2‘ с определяющим коИТРастом 1 х^х3х^?
3.5.9- Можно ли на основе использования дробной репликн 25"2 с обобщеНнь1М определяющим контрастом 1 - x^x.x^ = XjXjXj = х2х4х5 построить модель, включающую в себя следующие существенные переменные'
а) Хо ’ х] ’ х2 ’ Х3 > Л4 ’ Х5 > Х1Х2 ’
б) -Vq , X], Х2 5 Х3 , Х4 , > Х4 , Х<; ;
в) Х0,Х1,Х2,Х3,Х4,Х5,Х1Х2 , Х]*з, Х1Х4,Х1Х5‘,
Г) х0,Х1,Х2_,ХзЛ4’?С55х1^2> Х2Х4,Х4Х5,Х1Х2Х3 ?
3.5.10- Имеется дробная реплика 25”2 с определяющими контрастами 1 = х[х2х4, 1 = Х]Х2х3х5. Найдите обобщенный определяющий контраст; оцените, какие существенные факторы могут быть включены в модель; определите разрешающую способность дробной реплики.
3.5.11. Определите, какие дробные реплики 24"1 могут быть построены; оцените их разрешающие способности; покажите, какие модели могут быть построены с помощью этих планов.
3 5.12. Выявите все дробные реплики 25^2; оцените разрешающие способности их и выпишите модели, которые могут быть построены с помощью этих планов.
3.5.13. Найдите все возможные дробные реплики 26 J и для трех из них: а) Х4 =Х]Х2, Х5 = Х]Х3, Х6 = Х2Х3; б) Х4 = XjX2s *5 = -Г1Х3’ Х6 = XjX2X3;
*4 = Х]Х3, х5 = х2х3, х6 =х1.х2х3, выпишите структуры оцениваемых моделей.
3'8.1. Для нейтрализации кусочно-постоянного дрейфа необходимо Пвд1ный факторный эксперимент 24 разбить на 2 блока, а затем каждый из тоже на 2 блока. Необходимо убедиться, что при полученном упоря-Д°Ченном во времени планировании дрейф не приводит к смещению пара-МетРов модели.
^лвва 3 ~ ”— --------————-————————————'—
эксперимента 99
3.8.2. Считаем, что через каждые четыре измерения аддитивный ку^ но-постоянный дрейф выхода меняет свое значение. Разбивая полный торный эксперимент 23 на блоки, составьте план, который не приведёт смещению параметров линейной модели за счет' наличия дрейфа.
3.9 1. На основе матрицы планирования 2,-f на объекте поставлен экС-пернмент с одинаковым числом повторных опытов (табл. З.У 5). Проверь^ гипотезу о равной точно-Таблица З.У.5 сти измерений. Если эта
гипотеза принимается, то вычислите оценку диспер. сии для выходной координаты. Далее постройте линейную модель объеь та, оцените значимость всех параметров, незна-
И Xj *2 х3 ?(1) (2) У У4’
’1 + + + 92.3 91.8 92.0 92.4
2 — + — 87.2 88.7 87.5 88.0
3 + — — 84.0 84.9 84.2 84.1
4 - - 4- 87.3 86.1 86.5 87.0
чимые параметры исключите нз модели н проверьте для полученной модели гипотезу адекватности. При решении вышеуказанных. задач уровень значимости а = 0,05.
Таблица З.У.6
к Xj -*2 х3 х4 У
1 + 4- 4- 26
2 — + 4- — 20
3 ч- — 4- — 5
4 — — "Г 4- 14
5 4 4- — — 10
6 — 4- — -I- 25
7 — — 4 15
8 — — — - _ 9
Таблица З.У .7
И X, -ъ Р4 О) У
1 4- 0.5 1.5 1.0
2 — 2.0 2.0 2.1
3 + — 3.0 2.9 3.1
4 — — 4.5 5.5 5.0
3.9.2. На объекте реализован план, представленный в табл. З.У.6 Постройте линейную модель, проверьте значимость коэффициентов, а затем убедитесь в адекватности модели, если б2 =3.06, а = 0.05.
3.9.3. На объекте реализован полный факторный эксперимент 22с повторными опытами (табл. З.У.7)-
Проверьте гипотезу о равноточпо-сти измерений Если эта гипотеза оказывается принятой, то вычислите оцеН' ку дисперсии для выходной координ^' ты объекта. Затем постройте линеййУ*0 модель и проверьте ее на адекватность Уровень значимости примите равн^ 0.05.
100
Методы анализа
3.9 4. В таблице З.У.8 представлены результаты экс-перимента. Оценка Дисперсии ^(у) для выходной координату объекта равна величине 6 5 и имеет 8 степеней свободы. При уровне значимости 0.05 проверьте гипотезы о значимости коэффициентов линейной модели, незначимые коэффициенты исключите из модели и
проверьте гипотезу адекватности модели.
Таблица З.У.8
Найдите также генерирующие соотношения для вышеуказанной -гроб-ной реплики.
3.10 1. Составьте ортогональный композиционный план второго порядка ври т~2 и приведите расчетные формулы для всех параметров модели, дисперсии параметров и дисперсии выхода модели.
3.12.1. Выделите главные факторы с использованием диаграмм рассеяния. Результаты планирования приведены в табл. З.У.9.
3.12.2. По результатам планирования, приведенным в табл. З.УЛО, на основе диаграмм рассеяния выделите главные факторы.
Таблица З.У.9
Таблица 3 У. 10
п У . *2 А'з *4 у
I т + + 3.0
2 + - + М.2
3 - - + — 2.4~
4 — Г - 5.9
5 4* + — — 2.3
6 + - '—• — 2.9
7 - — —— + 5.4
8 - + + 3.8
^ава --------—— ------------—
Жирование эксперимента
101
Таблица 3.13.11
п A'i Х2 У У У
1 + + + + 6.0
2 +- + — - 2.4
3 — - — + 4.8
4 — + — 11.8
5 + — — — 1.6
6 + — + + 5.8
7 — 1- + — 10.8
8 —• + - 4- 7.6
3-12.3. Выделить главные фак!0. ры методом диаграмм рассеяния п результатам планирования эксперт мента, приведенным в табл. 3 У. 1 ].
3.12.4. Методом диаграмм рас. сеяния выделите главные факт:ори используя результаты планирования, приведенные в табл. З.У-12.
3.12.5. Выделите главные факторы с использованием диаграмм рассеяния. Результаты планирования эксперимента приведены в табл. З.У.13.
Таблица З.У.12 Таблица ЗУ. 13
п *1 У .... У *4 У У
1 + 4- + 4- 4" 30
2 + — -к - — 12
3 — — + — + 24
4 — -к + + — 59
5 + + — — — 23
6 1- 1 — — “Г Т" 29
7 — — - + — 54
8 — + - - 4- 38
п У У *3 Х4 У
1 + + — — 10
2 — — — — 9
3 + — — -I- 15
4 — 4 - + 25
5 + + + +- 2б_
6 — — + + 14
7 + — +- — 5
8 — + 4- — До]
Таблица 3 У.] 4 Таблица ЗУ.15
п У *3 Х4 *5 У ~50~ п У У У *4 % У
1 — — — — — 1 4- 4- 4- 4- 4- i£
2 + + — — — 57 2 4- — — 4- +-
3 — — + + — _48_ 46 3 — — 4- — + 31
4 + — + — + 4 — 4- — — 4- Л
5 + + — 4- 65 5 — — 4- + — 3JL
6 + — — + 4- 45 6 — 4- — 4- 11
7 — + — + 55 7 4- 4- 4- - —
8 + + 4- + 53 8 4- — - - — JOJ
3.12.6. По результатам планирования, приведенным в табл. ЗУ, 14, меУ' дом диаграмм рассеяния выделите главные факторы.
102 Методы анализа дан1<ь!'
3 12 7 Методом диаграмм рассеяния выделите главные факторы, ис-ьзуя приведенные в табл. З.У. 15 результаты планирования эксперимента.
3 12 8. Выделите главные факторы объекта на основе метода диаграмм ’сеяния, используя приведенные в табл. З.У. 16 результаты планирования эксперимента.
3 12.9. На основе метода диаграмм рассеяния выделите главные фзкто-используя результаты планирования эксперимента, приведенные в табл. З.У. 17.
Таблица З.У. 16
п *1 х2 У
"Т" + + + 18
2 — -г + 16
3 + — + 12
4 — — + 10
5 + + — 8
6 — Н- — 6
7 + — — 2
8 — — - 0
Таблица З.У. 17
п Xj xi хз У
1 + + + + 19
2 — — + — 17
3 + + — — 29
4 — — — + 27
5 + — — + 16
6 — + — — 32
7 + - -к — 0
8 - + "Г + 20
3.12.10. Методом диаграмм рассеяния выделите главные факторы, используя результаты планирования эксперимента, приведенные в табл. З.У. 18.
'Таблица З.У.18
п х2 хз х4 Х5 х6 У
1 + + + + + + + 12.4
2 — + + + — 6.5
3 + — + + — — 11.5
4 — — 4- + — — + 4.0
5 + + — + — — — 11.8
6 — + — + — + 5.0
7 + — — — — + + 9.9
8 — — — + + + — 2.2
Жирование эксперимента
ЮЗ
Глава 4. МЕТОДЫ НЕПАРАМЕТРИЧЕСКОЙ ОБРАБОТКИ ИНФОРМАЦИИ
Методы статистической обрабогки информации можно условно разде, лить на две группы- параметрические и иепараметрические Параметрически методы используют параметрические семейства зависимостей (разделяют^ поверхности в распознавании образов, плотности распределения вероятности, модели объекта) и существенно используют свойства объектов Непараметрн. веские методы не ориентированы на указанные параметрические семейства, имеют более универсальную структуру и более широкую область применен^ Они работают при большей неопределенности по априорной информации Пл а гой за это служит более сложная обработка исходной выборки и, как пра вило, непараметрические методы с этой выборкой никогда не расстаются В лучшем случае исходная избыточная выборка заменяется укороченной выборкой, которая впитала основную информацию нз исходной выборки
Еще 20-25 лет назад специалисты по статистической обработке информации отмечали три прорыва в непараметрической статистике Первый из них связан с результатами А Н Колмогорова (1933 г ) и Н. В. Смирнова (1939 г ) о предельном поведении уклонений эмпирической функции распре деления от теоретической (так появились известные статистики Колмогорова и Смирнова) Второй - основан на открытии Ф Уилкоксоиом (1945 г ) ранге вых критериев Третий - базируется на использовании Дж Ходжесом и Э Леманом ранговых критериев для оценивания неизвестных параметров (1963 г) Каждый из этих результатов дал толчок Лавинообразному количеству исследований, имеющих и хорошие выходы в практику
В настоящее время можно отметить и четвертый прорыв, заключающий ся в использовании оценок Розенблатта - Парзена (предложены М Розенб паттом в 1956 г и обобщены Э Парзеиом в 1962 г) для решения широкого спектра задач идентификации, фильтрации, адаптивного управления, оптимизации, распознавания образов.
4.1. Оценивание функционалов
В основе получения всех рассматриваемых результатов по обработке экспериментальных данных лежит одна простая и перспективная идея [4 3] Она заключается в представлении оцениваемых характеристик случайных величин в виде функционалов от плотностей распределения вероятностен ив последующей подстановке в функционалы вместо плотностей их непарамез рических оценок При этом единообразен не только подход к построений оценок соответствующих характеристик, но и к исследованию их статистических свойств
104
Методы анализа данН^
Необходимо по выборке хп случайной величины -V найти оценку ф„ функционала
ф = Jcp(x, f(x), ...)f(x)dx.
Здесь Ф0 ~ известная функция от плотности распределения вероятности f(x) и некоторых простых ее преобразований.
рассмотрим некоторые примеры функционалов Многие из них имеют линейный (относительно /(х) вид:
00
т = Jxf (x}dx - M{Aj- - математическое'ожидание,
-□О
а2 = J(х -т')2 f (x)dx = М{(JV-т)г} ~ дисперсия.
Некоторые зависят от f (х) нелинейно, например приведенная энтропия: со
Схема построения оценки Ф,. следующая. Вначале строится оценка для плотности вероятности /д(х), а затем оиа подставляется в функционал.
Основным свойством оценки Фл(хр является ее состоятельность. Оценка Ф/; функционала Ф называется состоятельной оценкой, если при оо она стремится по вероятности к Ф (обозначают Ф„- р >Ф), т- е. если
UmР{|Ф -Ф|> Ф-0.
Здесь - вероятность события А.
Требование состоятельности определяет практическую пригодность оце-Н°К’ ибо в противоположном случае (при несостоятельности оценок) увели-**еНйе обьема исходной выборки не будет приближать оценку к ’’истинной'1
________________ ____________________ _______ _________ . _
1ае« 4 Методы непараметрической обработки информации 105
величине. По этой причине свойство состоятельности должно проверяться й первую очередь
Оценка Ф„ параметра ф называется несмещенной, если
М{Фп} = Ф
Она является асимптотически несмещенной, если
..>Ф
1 п} п~>ай
4.2. Простейшие оценки функции и плотности распределения вероитиости
По упорядоченной независимой выборке х2, - хи случайной величины X построим оценку Fn(x) ДЛЯ функции распределения
F(x) = Р{Х < х}
Считаем, что для некоторого фиксированного х в выборке хь х2, . х„ значения хь х2,хт оказались меньше х, а остальные xt больше х Тогда в качестве оценки для вероятности Р{Х < х} берем частоту появления события {X < х}
m - число исходов, благоприятствующих событию {-У < х) _ п — общее число опытов
1 я
(4.2.1)
где 1(д) - единичная функция; l(z) = < ’
В соо1ветствии с законом больших чисел (теорема Бернулли) оце^ Fn(x) для каждого фиксированного х сходится по вероятности к F(x), т е оценка является состоятельной. Оценка F„(x) также является несмеи^1' ной. График ступенчатой оценки Fn(x) представлен на рис 4.2.1.
106
Методы анализа да^1Ъ
Так как плотность распределения /(х) связана с функцией распределения Е(х) через линейный оператор дифференцирования
/(*) =
dF(x) dx
то из оценки (4.2.1) вытекает следующая оценка для плотности распределения:
r . dFn(х) J A d ,. . 1А „ ' - , Л
А(*) = “ х,) =-Х6(х - х.). (4.2.2)
dx n^idx nt=l
Здесь 6(х-хг) - делъта-фуикция Дирака. Она имеет "игольчатый" ("гребенчатый11) вид: уходит до со в точке х/? а при остальных значениях аргумента х равна нулю и обладает свойствами:
т,+Д
j 5(х - х; )dx = 1,
jФ(х)6(х~xt)dx~ <р(х.).
(4.2.3)
(4.2.4)
Первое свойство (4.2.3) показывает, что, несмотря на экзотическое пове-е дельта-фуикции, площадь под ней единичная.
в -Торое селектирующее свойство (4.2.4) дельта-функции позволяет легко олнять интегрирование. Интеграл оказывается равным подынтегрально-вспВЫраже«ию, стоящему перед дельта-функцией, в особой точке (в точке Леска дельта-функции).
Методы непараметрической обработки информации 107
График "гребенчатой" функции fn(x) представ^ на рис. 4.2.2. Оценка плотно-сти распределения (4.2.2) Яв, ляется несмещенной. но нес#, стоятельнои. В явном виде её использовать нельзя. £t0 удобно пользоваться при вы-
числении оценок моментов (математического ожидания, дисперсии и др.) дш случайной величины или для аналитической функции случайной величины. Получаемые оценки являются состоятельными и часто несмещенными.
Пример 4.2.1. Необходимо по выборке i = 1, п, найти оценку математического ожидания от функции ф(Х) случайной величины:
M{(p(A')} =; J(p(x)/(x)cZr.
(4.2.5)
Оценку строим по схеме, описанной в параграфе 4.1. Берем интегральное выражение (4.2.5) и вместо плотности f (х) ставим ее оценку /„(х) Получаем (с использованием свойства (4.2.4) для 5-функции:
Л7{ф(.¥)}= j ф(х)-^^5(х-л:()с& =
= - £ J Ф(х)8(х - xt )dx - - X фЦ) Им
(4.2.6)
Отсюда при ф(Х) = X получаем оценку
М{Х} =
И М
для математического значения случайной величины X : Л/(Х} = jxf (х)сХ
— □О
Это хорошая оценка (при самых простых условиях оиа состоятельна^ несмещенная и асимптотически нормально распределённая оценка). Г',,а чаще всего используется на практике.
108 Методы анализа даннН*
В многомерном случае (когда рассматривается несколько случайных вели-х = (Xt, >%р) простейшие оценки функции и плотности распределения эероятностн; базирующиеся на независимой последовательности векторов (измерений) , -, , гДе х, ~ (xh имеют следующий вид [4.3]:
п (=1 j-i
f. Ц) = А 01 > • > ь) = - f Л 5(х, - у,) (4.2.7)
«1=1Л1
Например, для двумерной случайной величины (X, У)
= ЛДу) = -Хб(х-^)5(^-^)
п !=1 п (=[
Пример 4.2.2. Вычислим моменты
М{ф(Х)} = j ф(х - m) f (x)dx
для центрированной случайной величины X ~ X - т, причем математическое ожидание т- М{Х} неизвестно. Получаем
М{ф(Х)} = J Ф^х-
7 f Min ) i »
- J ф х - j х-£5(х - x^dx —£5(x-x,)dx =
\_ -оо И J К (-[
j <р(х - m) 6(х - Xt) dx ~ ~Хф(х, -ту, т^-^х^. (4 2.8)
Л г=]_« и J=i
Пример 4.2.3. Оценим дисперсию
£* Д} = j(x - m~)2f(x)dx.
___ -GQ
jT ’- ___ ____________________________________ _______ ___________
ае<3 Методы непараметрической обработки информации 109
Если математическое ожидание т известно, то в соответствии с форму, лой (4.2.6) оценка дисперсии имеет вид
W} = -Z(x,-'«)2.
Оценка состоятельная и несмещенная.
Если математическое ожидание т случайной величины X неизвестно то в соответствии с (4.2.8) имеем
Аш = -Е(л-^)2, ж=-2Х-
П t-l п (=1
Оценка состоятельная, но смещённая. Математическое ожидание ее
(п - 1 А _ .
I — — £) с ростом п стремится к D (оценка асимптотически несмещенная).
Умножив оценку на коэффициент (п / (п -1)), получим несмещенную оценку
Йг{-Т} = — ,Ё(^-А)2
П -1 ,=1
Она также является состоятельной оценкой.
Пример 4.2.4. Оценим коэффициент корреляции для двух случайных величии X и У по независимой выборке х;, yt, i — l^n .
кхУ= J JO “ mJO ~my}f О,y)dxdy.
— CO ”00
Подставляем в эту формулу "гребенчатую" оценку двумерной плотности (4.2.7)
у) = -£б(х - )5(у - у,)
и получаем
кху = J J(x “ тх\У “ ту) -Ё50 “ *JS0 ~ -
-О= 1 = 1
110 Методы анализе да^1
J (x-mx)6(x-xjfifr Hv-w^SCP-z)^
Ml-l-oO
-j-Е (^-^rXh-^) лн
Предлагается самостоятельно рассчитать оценку для кху при неизвестных тх, ту
Кратные измерения При кратных измерениях значение х, появляется к\ раз, *2~k2 Р33’ --'>хт~кт Р33» причем к} + к2 + +кт~п, оценка функции распределения также кусочно постоянная функция, которая имее! скачки величины kJ п в каждой точке х.
m Jy
,=1 И
Оценка плотности сохраняет соо гветственно "гребенчатый" вид
m л
А(х) = Г—8(х-хг)
/-1 п
Используя /„(х), легко получить оценки для многих моментов, имеющих интегральный линей -НИЙ ВИД ОТ плотности
J (*) Например, оценка для момента (4.2.5) вычисляется по формуле
*{<P(x)} = ft(p(x,)
1 — 1 «
с ^енка для плотности распределения вероятности (4 2.2) является не-еЩенной оценкой Действительно,
= 1 J . J j;<5(x- х,)П/(ху)Лу =
__ -00 !=1 У“1
^>поды нелараметрической обработки информации
111
= “ Z J f(\ )6(x - X )dxi = i £ /(x) = /(x). и ,Ы -0= n 1=1
В то же время оценка /л(х) не сходится к /(х). Она не обладает свой-ством равномерной сходимости (т. е. является несостоятельной оценкой) но сходится к /(х) в кусочно-интегральном смысле [4.7].
4.3. Поляграммы. Оценка "К ближайших соседей”
Повысим (по сравнению с (4.2.2) степень гладкости оценки /я(х). Дня этого надо повысить соответственно степень гладкости для оценки функции распре-деления FM(x). Если FM(x) будет состоять из отрезков прямых (рис. 4.3.1), То /я(х) ~ dFn(x) / dx будет состоять из прямоугольников (рис. 4.3.2). Кусочно-постоянная оценка /„(*) называется полиграммой первого порядка.
Она строится на выборочных интервалах, ограниченных выборочными значениями упорядоченной выборки х15 х2, ..., х)Г Площадь каждого прямоугольника равна 1 / (и -1) Высота каждого i -го прямом! ольиика, опирающегося иа выборочный интервал (xJ5x+1), равна величине
1
(и- 1)(х1+1 -х,) "
Аналитически записать полиграмму 1 -го порядка несложно, если ввестй прямоугольную селектирующую функцию
л е[0; 1), ^[0; О-
112
Методы анализа
Тогда
(4 3 В
Полиграмма первого порядка представляет собой совокупность примыкающих ДРУГ к ДРУГУ прямоугольников, построенных на интервалах, ограниченных точками измерений Каждый прямоугольник Имеет одинаковую площадь, равную величине 1 / (и - 1). Это значение есть оценка вероятности попадания случайной величины X в выборочный интервал. Появление оценки вероятности в виде 1 / (и -1) обусловлено известным непараметрическим фактом статистической эквивалентности выборочных блоков [4.7]. Простейшим выборочным блоком является интервал [х;,х;+]], ограниченный соседними упорядоченными отсчетами х;,х1+1. Вероятность попадания случайной величины X в этот выборочный интервал сходится по вероятности к величине !/(«-])
Р{х, < Х<х,41} —-L , = 1,2,.
и-мп И —к
Ку сочно-линейная оценка функции распределения F„(x) (см. рис, 4.3 1) является состоятельной оценкой, а оценка плотности распределения /„(х) (4.3 I) вновь за счет дифференцирования оказалась испорченной. Она несостоятельная. В явном виде ее применять нельзя В то же время её можно использовать, так же как и простейшую оценку (4.2 2), при построении состоятельных оценок линейных функционалов.
Пример 4.3.1. Вычислим оценку магматического ожидания Подставляем оценку плотности вероятности fn (х) в интегральную формулу' для математического ожидания н получаем
м-1
1 я-11
= Е J[x, + я(х,+1 -х,)]- 1 dz -i=10
1
У х/+1-х 1 nvlx( + >
;=1 2 n-\ 2
(4.3.2)
~ 1В
У Методы пенарам етрической обработки информации
Найденная оценка немного по ввду отличается от среднего арнфмезиц^
-1 ”
ского т = п £ х,, но она также несмещенная-.
. 1 VWQ + Л/{х J
= —г —Н;—= гп
м^1,=] 2
и состоятельная.
Самостоятельно убедитесь, что при некоррелированной выборке дисперсия оценки равна величине
1—-1—
2(и-1)
Здесь D - дисперсия случайной величины X. Сравните её с дисперсией обычной оценки’ среднего арифметического.
Пример 4.3.2. Найдем оценку дисперсии При известном математическом ожидании получаем
А = f(*-w)2
1 1
--I——-А
«”1 *=1 (Ли
= ~f[x, + (xl+i-x,)z- mfdz^
1 rt”1 - fY - Y И
= -~D(*.-«) +^-^L + (x, -m)(x,tl -x,)] = n - 1 „! 3
= -±Д‘[О, -OT)O,+1 - m) + fetir <].
(4 3.3)
Если m неизвестно, то вместо него следует использовать оценку (4 3 2).
Двумерная случайная величина. По выборке xt,y;, z - J,л/ двумерно^ случайной величины X, Y построим опенку - полиграмму первого поряди Используем метод аналогий. В одномерном случае мы фактически в 1'Г0' стейшей оценке плотности распределения
114 Методы анализа
1 "
Jn ttl-l
дельта-функции 5(x - x.) заменили дельта-образными функциями
построенными на интервалах между соседними отсчетами, и сократили одно йз слагаемых, распределив его вес между остальными.
В двумерном случае в гребенчатую оценку плотности распределения
Ш) = -£&(х - х,Жр-Х)
И 1=1
под знак суммы входят произведения дельта-функций. Заменим их на дельтаобразные функции и также сократим одно слагаемое (изменив веса слагаемых с 1 / и на 1 / (ц - 1). Получаем оценку
1 и ] j у —- х
«-] (=1(Х, -х,) к*, -х,
1 Г
тт __г ~ к У, -У,)
<4.3.4)
где х{ - ближайшее сверху к х, измерение по координате г, у( - аналогично, ближайшее сверху к р, измерение ио второй координате у.
Пример 4.3.3. Рассчитаем оценку для коэффициента корреляции на базе иолиграммы (4.3.4).
Л-1 i=l
Я]) -Ой -X;/
1 00 / \
ХЛ—7 JCv-w )/ор-ЛТ иу = w-x)-. -у,)
(4 3.5)
непараметрической обработки информации
115
Эта оценка немного отличается от ранее полученной в параграфе 4 2 (пример 4.2,4) оценки. Предельные свойства оценок одинаковы.
Из полученной оценки для коэффициента корреляции вытекает еще одна оценка для дисперсии. Для этого предположим совпадение случайных величин X и К. Гогда х( = уг, тх - ту и в упорядоченной выборке xt, i = величина х} равна х;+1. В итоге имеем
А =
ч 2
I + X ]
2 х)
(4.3 6)
Некоторые особенности полиграммы первого порядка (4.3.1). В отличие от "игольчатой" оценки (4.2 2) в полиграмме вместо дельта-функции 6(х - л;) стоят дельта-образные прямоугольные функции
5„(х-Ы = ——J
х(+1 -X, -xj
Площадь под ними (так же как и под дельта-функциями) равна единице С ростом п расстояние между отсчетами (х1+1 - ) сокращается И стремится к нулю при п -> оо. При этом дельта-образная функция стремится к дельта-функцин; б„ )---------->5(x-xf).
Основной недостаток этой дельта-образной функции состоит в том, что она не обладает сглаживающим свойством, ибо построена на интервале между двумя соседними измерениями. Если в выборке xf, ? = !,«, окажутся близко расположенные измерения х;+1 и х;, то на интервале |хг+1,хД будет сильный всплеск дельта-образной функции. Полиграмма из-за этого явля?1Ся оценкой, содержащей резкие всплески и с их ростом п все больше.
На рис. 4.3.3, 4 3.4 представлены полиграммы при различных объемах fl соответственно для случайных величин, имеющих равномерный и нормаль' ный законы распределения (т = 0.5; <3 = 0.166).
Полученная оценка плотности вероятности (полиграмма первого порядка) не наделена сглаживающим свойством и с ростом п она приближается к "игольчатой" ("гребенчатой") оценке. Статистическое моделирование подтвер' ждает это свойство. Полиграмма I-го порядка является асимптотически несмещенной, но не состоятельной оценкой плотности распределения вероятности
Для улучшения сглаживающих свойств оценки плотности построен^ поднграммы более высоких порядков. На рис. 4.3.5 в качестве нллюстраци11 приведены полнграммы первого (л), второго (б) и третьего (в) порядков. Пй' диграмма &-го порядка для каждого фиксированного k является такЖе
116
Методы анализа дамнь^
мптотически несмещенной несостоятельной оценкой Для состоятетьно-полнграммы необходимо с ростом объема выборки п увеличивать поря-
аси СТИ
док
полиграммы
7ав° Методы непараметрической обработки информации
117
Если выполняются условия к.. —> ос и кп! п —> 0 при и -> <» (т. е растет не быстрее объема п выборки), то полиграмма кГ: -го порядка является асимптотически несмещенной и состоятельной оценкой в каждой точке х непрерывности плотности распределения вероятности f (х). Зависимость кп от п может иметь вид kn=cnq, где с - положительная константа, 0<с<оо,а 0 < # < 1.
Метод "К ближайших соседей”
Считаем, что для одномерной случайной величины X имеется и независимых наблюдений Зафиксируем некоторое целое положитель-
ное число кп: 1 < кп <п.
Для каждой выбранной точки х существует интервал длительное^10 2р(£п,/7,х), который охватывает кп ближайших к х точек выборки xv (рис. 4.3.6). Одна точка попадает на границу интервала, а кп_х точка вн/П* интервала Оценкой плотности распределения вероятности /и(х) слу^ частота (кп - 1) / п попадания в интервал 2р, приведенная к единичной в^ чине интервала:
118 Методы анализа даи^
n2p(fcM ,п, х)
Если выполняются ус-к лови* к„ -» ®, -* -> 0 при
Г1 ос (т. е с ростом объема выборки количество точек, попадающих в интервал 2р, растет не быстрее, чем растет объем выборки), то оценка является асимптотически
несмещенной и состоятельной в каждой точке непрерывности плотности вероятности /(х).
Для т-мерной случайной величины X независимая выборка х}, ...,хп состоят из п точек щ-мерного пространства. В выбранной метрике вводится расстояние Л(х,у) между двумя точками х и у т -мерного пространства. Для выбранной точки х ближайшие (по расстоянию R) к ней кп точек попадают в тар радиуса Rk: Q(x) = {уЛ(х,у) < 2?^), причем одна точка лежит на границе этого шара (рис. 4.3.7). Объем шара равен величине Р(М,х) = \dy П(х)
Тогда оценкой /Дх) плотности распределения вероятности служит частота
~ 1) X попадания и шар, приведенная к еданнЧному объему шара’
= —АЩ .
ПУ(кп,П,х)
условия сходимости оценки /„(х) к J с Р°стом объема выборки к те же, Й в Номерном случае
От Сл°аиям сходимости удовлетворяет следующий вид зависимости
"с п?> 0 < с, 0 < д <1.
ef>iodbj непараметрической обработки информации
119
Способ построения оценки "К ближайших соседей" близок и к способу построения полиграммы К порядка. Возьмем для конкретности одномерщ^ случай (X ~ одномерная случайная величина). Если полиграмма строится ца выборочных интервалах (интервалах, ограниченных выборочными значе. ниями), то оценка " К ближайших соседей" основывается на выборочные подынтервалах (они ограничены выборочным значением только с одной сто. роны) Частота попадания в интервал длительностью 2р (или в выборочный полуинтервал), равная (kn - 1) / п, является также предельной (при и од вероятностью попадания случайной величины X в этот выборочный полу, интервал Именно такой непараметрнческин факт положен и в основу ц0. строения полиграммы К порядка.
4.4. Оценка Розенблатта - Парзена
Плотность распределения вероятности связана с функцией распределения через оператор дифференцирования
f (х) = dF(x) / dx.
Это уравнение берем за основу при построении опенки fn(x) плотности распределения вероятносш Заменяем в предыдущем уравнении производную конечной разностью
F(x + h)~ F(x ~
J 2h
а функции распределения F(x + h), F(x ~h) - их простейшими кусочно-постоянными оценками (4.2.1)
^(х + Л)--^1(х + /?-х(),
FAx~h) = -]Н(х-/?-х;), «Н
построенными (см. параграф 4.2) на основе выборки для одномер'
ной случайной величины X Оценка плотности тогда приобретает вид
-£1(х+Л-х£)-^]Г1(х-/2-х )
2й
120 Методыанали# да^
1 " 1 Цх F - JC,) - 1(jc - h - xj
n^\h 2
11(.х + h - )
На рис. 4.4-1 показано^ что под знак суммы
этой
опенки входит селектирующее прямо-
угольное ядро
1(х + й-хД-1(х-й-хг) = У х-хД
_____ I /г J’
где
ГОД |г|<1, м=к 1Ф1.
(4-4.1)
----г—1 —-------- х( - п х; х( + п х
1(х-й-х,)
х; - h хг хг + h х
1(х+А-х^) - )
1—к 1—н— -------
хг —h Xj х; +/? х
Ядро I(z) симметричное, и площадь под кривой 1(2) равна единице. Эта функция ничем не отличается от плотности распределения вероятности случайной величины z, равномерно распределенной в интервале [-1; 1]. В итоге оценка для плотности распределения вероятности имеет вид
x;—h х х{ + h ,l/2^).
"ч о’ Г”
Рис. 4А 1
1 «1 (X — п^\п \ И
Впервые оценка предложена в 1956 году Розенблаттом (Rosenblatt М. Remarks on some nonparametric estimates of a density functions //' AMS. 1956. 27. Pp. 832-837). Дальнейшие обобщения данного вида оценок осуществлены Парзеном [Parsen Е. On estimation of a probability density function and mode // A-MS. 1962, 33. Pp. 1065-1076]. В настоящее время специалистами принято ИМен°зать данный класс оценок оценками Розенблатга - Парзена.
Оценка Розенблатта - Парзена по структуре совпадает с простейшей то-Чечн°й оценкой
^(х) = ^-£5(х-х ),
льКо в He£ ЛС711Га_фуИКцИЯ 5(х-х() заменена дельта-образной прямо-J Ольн°й функцией
иепараметрической обработки информации
121
- -X. V 1 [ X -h ) h I h
Дельта-образная прямоугольная функция имеет ширину 2й, высоту 1 / (2й), она расположена симметрично около точки хг. Площадь под дельта образной функцией единичная.
На рис 4.4.2 4 4.5 приведен простейший иллюстративный пример ф0^ мирования оценки Розенблатта - Парзена при различной ширине h прямоугольных ядер. На каждом рисунке даны итоговая оценка /„(х) и все ее слагаемые. С ростом h сглаживающие свойства оценки нарастают. По h для каждого конечного обьема выборки существует некоторый оптимум, ибо при малых h оценка представляет собой набор непересекающихся (или слабо не. ресекающихся) дельта-образных функций и оценка теряет свой смысл, а при большом h оценка становится сильно заглаженной и не отражает индивидуальных особенностей плотности распределения вероятности.
CieneHb гладкости оценки плотности зависит от степени гладкости ядра Заменим в оценке /и(х) прямоугольное ядро Z(z) иа произвольное K(z) и почучим
Х~ХЛ hh I h J
(4 4 2)
Здесь h - коэффициент размытости ядра Примеры треугольного, параболического и кубического ядер приведены ниже
1ф|,
(4 4 3)
К(2)= 0-75(1-Л И21,
[о, 1 <| z |,
—___
° 4 Методы не параметрической обработки информации
(4 4 4)
(4 4.5)
Вид этих ядер изображен на рис 4 4 6 Все они нормированы на 1 счет последнего свойства оценка Розенблатта - Парзена удовлетворяет условию нормировки для плотности вероятности’
=° 1 » 00 1 ( у „ v 'S Iй1 / \ 1 п
!К(^=1^1 = 1.
» л 1 h ) 1-1 »<-1
Оценка (4.4 2) при любых неотрицательных ко-локолообразных симметричных усечённых нормированных на 1 ядрах является состоятельной, если для коэффициента размытости h(ri) выполняются два условия.
1) /?(и) -> 0, 2) nh(n) —> ос (4 4 6)
h(n) стремится к нулю, но нс быстрее, чем п стре мится к бесконечности Это условие эквивалентно условию, накладываемому на параметр кп в оценке "к ближайших соседей" Зависимость коэффициента размытости А(и) от объема выборки п имеет вид
(4 47)
где 0 < q < 1, 0 < с <эд .
Величина h(n) (в отличие от дискретного параметра кп в оценке " к ближайших соседей") является непрерывной.
Для каждого фиксированного значения х* при расчетах оценки ffSx) участвует только несколько близлежащих к х* точек хг выборки, которЫ6
попали в область действия ядра Х4 —--- , когда оио принимает не н}Ле0°е
( h
значение, т е при |х — xt\<h, но точки х{, которые ближе к х*, иМеи': большие веса - рис. 4 4 7 при треугольном виде ядра
Методы анализ
Использование в оценке Розенб-о-гта - Парзена латта «сеченных ядер Х(г) приводит к существенному сокращению объема вычислений (по сравнению с применением неусеченных ядер).
При выполнении для коэффициента размытости й(н) двух условий (4.4 6) кроме свойства состоятельно
сти оценка Розенблатта - Парзена будет асимптотически несмещенной и асимптотически нормально распределенной.
В мно1 омерном случае, когда рассматривается т случайных величин У1; , Хт и для иее получена независимая выборка (х]15 , xw/), i -1, п,
оценка плотности равна сумме с весом 1 / п дельта-образных многомерных функций, которые можно выбрать в виде произведения одномерных дельтаобразных функций:
”*h)" A(xw
и ,=]
п \ I hx
А1 X. *1
Хт Xmi hx
(4.4.8)
Если при любых неотрицательных колоколообразных симметричных печённых нормированных на 1 ядрах
1)\(ц)—>0, ...,/?х (и)---------------------------------->0;
1 V 7 м->00 ’
(«)...-А (и)---------->0,
1 хт 7 п—
(4.4.9)
То °Ценка f „х *
Jnxx, у) обладает свойствами:
г .
1 tf ---——_____________ ~------ --------------
°оы непараметрической обработки информации
125
1) она состоятельная',
2) асимптотически несмещенная' М fh{x,.. , у)- „ , у),
3) асимптотически нормально распределенная
Коэффициенты размытости, удовлетворяющие условиям (4.4 9), имедц вид
hx (н) =сх п 4 , Q <cXj < ft <q <1/ т, j =i, т. (4 410)
При использовании квадратичного критерия наилучшего соответствия между оценкой и истинной плотностью
Д?Л())=[ rn,n (4.4.11)
' -со 0«j<Vm
*0
получаем,что
q ~ 1 / (т + 4),
(4 4 12)
ядра К() - усеченные параболические
Заметим также, что чувствительность функции качества I к виду ядер К() слабая Функция качества мало отличается по величине для треугольного, кубического и других ядер, близких по форме к усеченному параболическому ядру Усечеиность ядер позволяет при реализации алгоритмов на ЭВМ существенно (в десятки, сотни и тысячи раз) сократить объем вычислений Это обусловлено тем, что каждое ядро охватывает только несколько ючек (-10-20 точек при п = 100 - 1000) всей выборки и вычисления проводятся только для этих точек, а не для всей выборки
Численный пример. Приведем результаты статистического моделирования на ЭВМ Взята случайная величина, имеющая нормальный закон распределения
1 (*-0 5)2
/(х)=7Д1е 2 '
Выборка генерировалась с помощью датчика псевдослучайных чисел о указанным законом распределения Оценка Розенблатта - Парзеиа имеет па раболическое ядро (4 4 4) и коэффициент размытости /?(и) = сп~1/5 ОцеИи' ванне проводилось при различных коэффициентах с > 0 и различных объе' мах выборки Хорошее сглаживание наблюдается при 0 4<с^0^
126 Методы анализа
с 4.4.8 для с-0.4 представлены истинная плотность и ее оценка при личных и Качество оценок хорошее при и > 100.
Р33 Вводим функцию соответствия (адекватности) оценки и истинной плот-тй распределения вероятности
«1=1
Графики изменения этой функции от и при фиксированных с и от с Прй фиксированных и приведены на рис. 4.4.9, 4.4.10. Из графиков вид
но, что основные изменения функции качества (4.4.13) происходят при и < 500 (для различных с). С ростом п чувствительность J к с резко падает . Это означает, что при больших п любые с (из рассматриваемого интервала [0,1; 0.5]) обеспечивают оценки одинакового качества.
Адаптивная перестройка оценок. Основной недостаток оценок Розенблатта - Парзена заключается в том, что при расчете оценки /д(х) в каждой фиксированной т°чке х (из области Q) ^обходимо "перелопачи-Вать выборку, попадающую в область действия Щеренного ядра. Пос летательно смещая х в ласти Q 5 приходится Огократно обращаться
(4.4.13)
ЛА) А л)
2 <7 2 ’ д
у 'Ч / \
1 // \'\ // 4 \ ' /| . !, V- 1 7 \
С 0,4 0,8 1 0 0,4 0,8 1 '
и - 1; h = 0.4 /7 = 1000; /г = 0.1
ЛА) ЛА)
2 АХ б 2 Г рек е
/ У
I 7 \ 1 _ / \ / \
\ 1 ' 1 у / \ у 1. 1 v
( 0,4 0,8 1 0 0,4 0,8 1
и = 50; h = 0.18 и = = 2000; /2 = 0.087
ЛА) ЛА)
2 ’ /\ 6 2 ж
1 J \ 1 L 7 \
" 1 1 1 1 Ча. у у
) 0,4 0,8 1 ) 0,4 0,8 1
и = 100; /2 = 0.15 и = 3000; /? = 0.08
2 \Г\ ‘ 1 / \ 2 /А» 3
1 1 \
с. ।—j ; -^5=- — х
0 0,4 0,8 1 ) 0,4 0,8 1
п = 500; /г = 0.11 и = 5000; /г = 0.07
Рис. 4.4.8
непараметрической обработки информации
127
к выборке. Закой способ обработки информации не является экономичны^ Существенной экономии вычислений можно добиться, если обрабатывав информацию последовательно по мере ее поступления и если отказаться от накопления выборки.
Вдобавок к этому желательно было бы и распараллелить расчеты в це. лях повышения быстродействия системы обработки информации. Распарад. леливание осуществляется за счет фиксации точек х (из области И), в которых необходимо иметь значения оценок плотностей. Например, в одномер. ном случае для решения практических задач достаточно иметь оценку цдот. ности в 20 -50 дискретных точках х.
/(«)
0.09г-
0.07^
* !...*1— п
1000 2000 4 000 4000 5000
Рис 44 9
0.03
0 01
о
В каждой фиксированной точке х е П оценку Розеиблагга - Нарзена вычисляем по формуле (4.4.2) (.либо (4.4.8) в многомерном случае), но коэф^ фициент размытости h делаем зависящим от текущего объема выборки i.
Iй 1 х-х = --
Теперь этой оценке можно придать рекуррентный вид:
/»->Р)+1д-;4ч7т')3
п h(ri) \ й(и) )
п
-А-1О) , /0(х) = 0
(4.4 14)
(4.4 15)
128
Методы анализа
1еДО0ателЬНО меняя в эт°м выражении п (п - 1, 2, 3, ...), мы коррекги-оценку /и(х) 110 меРе поступления новых выборочных значений хл. гЬй)йПиеит размытости здесь меняется по ранее установленному правилу ^0 Выборку хранить в памяти теперь не надо. Вычислительные устрой-а реализованные, например, на микропроцессорах и выполняющие one-с ’и указанные в (4.4.13), могут вести обработку информации в реальном масштабе времени.
В многомерном случае формула (4.4.15) приобретает вид
(4.4 16)
Ш = 4=-—, j = 15ш , И = 1,2,3, /й(х) = 0.
т 4-4
Метод "К ближайших соседей" (см. параграф 4.3) близок по основной идее к меюду построения оценок Розенблатта - Парзена. В первом из них учитывается количество ближайших к х точек, во втором - также усеченным ядром выбирается несколько близлежащих к х точек, только теперь формой ядра учитывается и вес этих точек. Если ядро прямоугольное, то веса точек одинаковые и обе оценки совпадают. Отличие оценок в форме вычислений. В первой оценке преобладают логические операции, во второй - арифметические.
4.5. Оценки моментов случайных величии и энтропии
Рассчитаем на основе оценки Розенблатта - Парзена оценки для математического ожидания случайной величины т, дисперсии D, математического Здания функции случайной величины А/[^>(х)}, коэффициента корреляции для ВеЛИЧин к , приведённой энтропии.
Пример 4.5.1. Оценка для математического ожидания имеет вид
(хк
-ос «г=1/? h ) \ h )
непараметрической обработки информации
129
= -£ [(.г +hz)K(z')dz = \K(z)dz + h (zK(z)dz] =
«1=1 l «r=l -i -1
Iя Iй
= -Ё1л+/г-01=
«/=1 HJ=1
Это известная оценка. Она является состоятельной, несмещенной, асимптотически нормально распределенной N(m,o2 /л) с математическим ожиданием М{тп } = т и дисперсией ст2 - ст2 / и. Здесь т и ст2 соответственно математическое ожидание и дисперсия случайной величины X.
Пример 4.5.2. Получим теперь оценку дисперсии t) при известном математическом ожидании т и прямоугольном виде ядра в оценке Розенблакга-Парзена
00 1 Л 1 ( V _ у У 1 И 1 1
$ = Uc= -X f(x, -m + hzf — dz =
nt^}h \ h J 2
1 и -j n J,2 I n
= !>,- И-J = -S (*, - X Л = -> I (x, - my . (4.5 2)
П 3 W/=1 3 h->0 n,=1
Она смещена па величину А'/з по сравнению с известной оценкой
—У (х; ~ т) , полученной иа основе использования простейшей оценки И.=1
1 " плотности распределения / (х) = — У 5(х - х ).
И 2=1
Если в оценке плотности вероятности ядро треугольного типа, то
Л = -1-2Ж-'’02+—]; (4'53)
п 1=1 6
если ядро параболического типа, то
130 Методы анализа даи^
£=1-Пи-т)2+^Л’
рименении кубического ядра
апрцп
1 ” -> 2/?
£> = i DU,-м>--."Г
(4.5.4)
(4 5.5)
Пример 4.5.3. Вычислим теперь оценку математического ожидания аналитической функции случайной величины <р(Х) при прямоугольном ядре в оценке плотности.
М{ф(Х) = J (р(х, + Az)-Uz = i£ J[<р(л-,) +^^hz + и ,=I , 2 /7 j=! dx
2 dx2 J2 нм dx 3!
A(x,)A4
+ j 4
(4.5.6)
Задание г провести расчеты оценки вышеуказанной величины с использованием ядер треугольного, параболического и кубического типов.
Пример 4.5.4. Оценка для коэффициента корреляции имеет вид
У,= J Ju - mJO - У—H-Jff =
3 n^hx \ hx Jhy [ hy J
Im30 1 / Л co 1 f .. |
К -Up =
hx < hx J hy hy )
1 n
(xi ~mx)(yf-my). (4.5 7)
При неизвестных моментах mximy в (4.5.7) будут стоять их оценки.
а Методы непараметрической обработки информации 131
В оценках (4 5 2)-(4 5 6) появилось смещение, обусловленное конечно^ коэффициентов размытости h Для ликвидации этого смещения и упрощу расчетов в оценке плотности вероятности по интегрируемым переменным цел сообразно брать не дельта-образную функцию, а дельта-функцию НапрИМе рассмотрим трехмерную случайную величину (X,E,Z) и считаем извести^
что оценка плот ности при дальнейших расчетах входит линейно в интегралы^ преобразование по у, тогда целесообразно оценку брать в виде
п 1=1 \ “х ) 4 V /ц )
Пример 4.5.5. Вычислим оценку для величины
у(х,т)= f<p(y)/(x, y,z)dy
После подстановки в правую часть приведенной выше оценки плотности вероятности интеграл (в силу наличия в нем дельта-функции) легко вычвечя ется и мы получаем оценку
ЧЬ(*Ю =
“ ФО.)/
J п.
41
и
Энтропия Это важная статистическая характеристика, которая исдоль зуется прн количественной оценке информационного содержания ситнала Энтропия является мерой неопред елейно ели ситуации
Впервые количественная мера неопределенности введена была в 1928 го ду американским инженером по связи Р Хартли
Я(Л) - logm
Здесь событие А имеет т возможных исходов Эта мера неопреде1еН ности не учитывает вероятности различных исходов
К Шеннону удалось развить понятие меры неопределенности с уче^ информации о вероятное 1ях . ,рт возможных т исходов
Я!
Н(А) = -Хр< *°gP, / 1
Если исходы равновероятны (pt - р = 1 / тп, т = 1, т), то неопреде11е ность по Шеннону переходит в неопределенность по Хартли
132 Методы ансыиза
Дз1Я дискретной случайной величины Хет возможными состояниями с вероятностями принятия этих состояний равными pf, 1 = энтропия учитывается по вышеприведенной формуле.
Р Для непрерывной случайной величины X используеюя понятие приведенной энтропии
00
Н(Х) = ~ J/(*)log/(*)^.
— ФО
(4 5 8)
Пример 4.5.6. Рассчитаем оценку дпя приведенной энтропии Н(Х)
В выражение для приведенной энтропии (4.5 8) подставляем простейшую 1 п
оценку /л(т) = ^5(х-т() вместо лииейно входящей в функционал плот-п ,=1
нести fix')- а вместо f [х) под знаком логарифма используем сосгоятсль-
1 Д 1 ( х~х
ную оценку Розенблатта - Парзена /и(х) - — и получаем со-
R ,-1/Ц h J
стоятельную оценку для энтропии:
HJX) = - j [log/n(х)]-X5(х -xt)dx = --2>ёЛ(х,)= Я ;-1 Я
1 ”
—Dog
И.-1
h~cn
-1/5
(4 5 9)
Рис 4 5 1
На
'ad Рйс 4 5 1 представлены результаты статистического расчета оценки
Пия ИИ Равн°мерио распределенной случайной величины (исгиниая энтро ^На нУлю) при различных значениях параметра размытости с
ЛеКн ~ ^Ис 4.5 2 представлены тс же оценки, но для нормально распреде-чеСтп слУчайион величины (истинное значение энтропии равно -0 27). Ка-
оценок хорошее
4 — —— -_______ —- —_______________— _ -
е^одъ1 непараметрической обработки информации
133
Многомерный случай. Энтропия системы случайных величин фОр мально записывается в виде уравнения (4.5.8) с заменой скаляра % на вектор.
H(X1,...iyj„)--j...f/(x1,...,xm)log/(x1,...,xffJ)dx1...c/xm=
= -M{log/(Xl,...1Xm)}.
При построении оценки энтропии заменяем оператор М {•} операторов статистического усреднения 1 / ц^(-) , а плотность распределения - оценкой Розенблатта - Парзена, т е
1 н т ]
1 П 1 п w 1 |
•..*„) = —Liog -1ПИ
и,.| я Л/ 1
*h ~ Xjj ht .
(4.5.10)
W 7 = 1/~1 Л/
где v(xI(,..., xjt,..., xmJ, i — 1, n, - выборка системы случайных величин.
4.6. Оценка условной плотности вероятности
Рассмагриваем объект, имеющий случайный вход (либо несколько входов) Хн выход К. Связь между случайными величинами X и Y характеризуют условные характеристики, например, условная плотность распределе ния вероятности f (yj х), условное математическое ожидание (регрессия) Л/{У]х}, условная энтропия //(Kjx) Наиболее полной характеристикой является условная плотность распределения вероятности f (у\х). Зная ее, можно вычислить любые другие условные характеристики объекта.
Условная плотность распределения вероятности f (у|х) выражается через безусловные плотности нз формулы умножения плотностей:
= /(х). (4 61)
Необходимо по выборке х,,у,, i = 1,и, входа X и выхода Y объекта найти оценку условной плотности вероятности (4.6.1). Подставляем оценки Розенблатта - Парзена в (4.6.1) и получаем искомую оценку условной плотности распределения вероятности:
fn (У к)
1 £ £ J 1 J У~У, n^ihx I hx Jhy hy
1 Д 1 (х - хЛ
—-
к ьх j
134
Методы анализа
Кол око л о образная функция
(4.6.2)
(4.6.3)
по форме повторяет ядро &() и отличается от него на нормирующий множитель 1 / XК\ Щ Засчетэтого iKN\ =1
Ux J ,=i ( hx J
Так как колоколообразиые ядра неотрицательны, то и весовые функ-
1 | цой комбинацией дельта-образных функций ~~7ы h„ I
. Это свойство мо-
ции К(') неотрицательны. Следовательно, оценка /„(у|х) является выпук-
У~У,
жетнам помочь при анализе этой оценки и других порождаемых ею оценок
Структура коэффициентов размытости в оценках совместных
плотностей была нами рассмотрена в параграфе 4.4, и она имеет вид
К = cxn~q, hy = супч, > О, су >Q, q- 1/(ш + 4) = 1/6
Здесь т - число переменных в плотности распределения; их у нас две; Jr и у
Для объекта с несколькими входами ...,х)Я) = х и одним выходом
У оценка плотности вероятности (4.6.1), построенная по выборке
,У,, т = 1,и, на базе оценок Розенблатта - Парзена, принимает вид
= А,...,5уЛ™Ь
*=1 \ "хт ) hy \ J
т %т hY
W Y —
П^Г7 /=1
N
К
п т
1 1ГИ
-с и \ 7-1, т,
К
4 Методы непараметрической обработки информации
135
hy = cyn q, ^ = l/(w + 5), щ > 0, j - 1, w, cy >0 (464j
Если оценка /Др|х) входит в функционал линейно и используется расчете соответствующих условных характеристик (например условных м0 ментов) путем интегрирования по переменной у, то вместо дельта-образцу функции по у целесообразно брать дельта-функцию:
А (Л 1 *) = Х^л ( ~~ h) 1=1 \ \ J
(4 6 5)
При этом интегрирование существенно упрощается и не появляется смещение, пропорциональное коэффициенту размытости h .
Адаптивный расчет оценок. Если выборочные значения (xt,yz) по ступают последовательно во времени и в каждый момент времени необходи мо иметь оценку fn()’\x), то алгоритмам следует придать рекуррентный вид, позволяющий корректировать оценку по меРе поступления инфор-
мации Эту операцию мы уже выполняли в конце параграфа 4 4 для оценок безусловных плотностей Аддитивный вид числителя и знаменателя оценки (4 6 2) легко позволяет придать ей рекуррентную форму (меняя при этом зависимость h от п на зависимость h от текущего объема i выборки).
п 1 Г г - у А
п IM*)}
(4 6 6)
Необходимость в запоминании выборки и в постоянном обращении к ней отпадает, если по формуле (4 6 б) ведется расчет в фиксированной точк6 (х,у) После прихода нового выборочного значения (гя,рл), на основе нет0 вычисляются только корректирующие слагаемые в числителе и знамена геле оценки fn (у| х) Поэтому, если требуется знание оценки Д (р|х) в ряде сированных точек (х,у) области возможных значений, то расчеты в каЖД011 точке можно выполнять параллельно по экономичным в вычислительном иошенни рекуррентным формулам (4 6 6)
136 Методы анализа
4.7. Оценка регрессии
регрессией называют первый начальный условный момент
СО
M{Y I *} = lyfCr I = rKx)
—co
(4.7.1)
^ro некоторая усредненная количественная зависимость между выходом и входом объекта. Регрессия (4-7.1) удовлетворяет квадратичному критерию
7(х)^Л/{(К-у*)2 |x} = miti. (4.7.2)
у
Действительно, приравниваем нулю производную от функции I по искомой величине у (т. е. используем необходимое условие минимума)
^^=-2Л/-{(Г-У)|х} = 0
и отсюда находим у - Л/{У]х).
Подставляем в правую часть уравнения (4.7.1) оценку (4.6.5) условной плотности распределения вероятности и получаем непараметрическую оценку регрессии
Л ( У"-------Yl f У ______________________________ V А
= л„(х) = Ш —-Ч М.У ~ y,)dy = Ь
;=1 к Н J J=1 у h J
jz ( X ~~ X A (x - X( X " X A
=xuxr /SP ~~r sm.«-к n J \ h J] j,\ \ h )
(4.7.3)
О^ика представляет собой выпуклую комбинацию измерений уг выхода °оъекта. Веса KN(-) в этой выпуклой комбинации определяются входом °°ъекта. Чем ближе измерение хг к значению х, для которого мы рассчиты-ваем оценку чп(х), тем вес нормированного ядра KN(J) больше.
^сечённость весовой функции (в силу усечённости ядра К(-) 0зволяет при построении оценки ч»(-т) в каждой фиксированной ючке х Цтывать только несколько близлежащих значении х и не "перелопачивать" йс.7л с-всю выборку.
а 4 Методы непараметрцческои обработки информации 137
Выбор оптимальной формы ядра и коэффициента размытости осуществляется так же, как и для оценок плотностей (см. параграф 4.4), писывается квадратичный критерий оптимальности
I(K,h)= jA'HbbOO-T'lOOf }^ = min
Л
и из него отыскивается решение [4.4, 4.5]:
(7
0.75(l-z), |zl<l, ад = от->,> 0<с
0, l<|z|,
Функция качества I(K,h) от формы усеченных ''колоколообразных" ядер ХД) зависит слабо [4 5]. Основное влияние оказывает положительная константа с, но зависимость I от с при возрастании п ослабевает. Форма ядра усеченная параболическая. Константа с, определяющая коэффициент размытости, вычисляется но выборке путём минимизации эмпирических искателей (характеризующих нанлучшее сглаживание экспериментальных данных)
Если в (4.7.1) вместо У стоит известная функция от Y, например <р(Х), то по аналогии с вышерассмотренным получаем следующую иепараметриче-скую оценку условного момента:
М{<р(У) | х} =
Для объекта с т входами х - (xt,..., хт) и одним выходом оценка регрессии имеет следующий вид [4.5]:
(л) = Е ®, (х )у, > , (*) = 1, 0 < и, (х),
1=Л 2 = 1
7=1 V
(х;
С „-Ц-+4)
U!<1,
f3 Г1 _ 2Э
ВД =4 ° Z I °’
138 ~
Методы анализа й*11
Оценка регрессии (4 7.4) удовлетворяет квадратичному критерию
со со
Цд,К(У)= J- - ..dxm = mm
-00 -oo .
M)
него получено, что ^ = l/(m + 4) в коэффициенте размытости = сх п q, а ядра j<(-) - усеченные параболические.
В оценке (4.7.4) неизвестными являются положительные постоянные параметры cXj, ] - 1, m.
Анализ оценок при т = 1. Считаем, что объем выборки п фиксирован. Перейдем от размерного параметра сх = с (его размерность, обратная размерности х) к безразмерному 0:
0 = счДи1/55
(4 7.5)
где А = xi+1 - х, (i = 1,и - 1) при равномерных отсчетах по входной переменной х и А - max{(x;+l - хД i = 1,и- 1} при неравномерных отсчетах Найдем интервал изменения коэффициента 0.
f х — х 3
При 0 = 0 ядро К\ р——Л_ - = - не зависит от х, а весовые ко-
\ А ) 4
эффициенты
также ие зависят ог х и все одинаковы. Оценка Регрессии равна среднему арифметическому вы-°°Р°чных значений выхода объекта для любых •* (рис 4.7.1):
непараметрической обработки информации
Возьмем теперь другое крайнее состояние 0: 0=1. Оценка регрессии т]л(х) проход через экспериментальные точки и состоит а кусков линий, соединяющих точки выбору рис. 4.7.2. Убедимся в этом.
Выбираем, например, х = х. (либ0 х равное любому другому выборочному значению). Поведение весовой функции
X - х
A
н соседних с ней весовых функций о)2(х), cd4(x) представлено на рис. 4.7 2 В каждой точке х - х; только один весовой коэффициент <йг (х?) оказался не нулевым и равным единице. Следовательно,
Оценка регрессии проходит через экспериментальные точки.
При х; < х А х^ оценка колеблется около прямой линии, соединяющей точки (x/syj и (х;+1, у;+1). Для х; < х < (х( + у) онаидетвыше А'
прямой, а при (г. + —-) < х < x/+J - ниже прямой, а в точке х = х, + А / 2 лежит на прямой.
Оптимальный параметр 0 лежит в интервале [0; 1]. Поведение оценки регрессии при этом представлено на рнс. 4.7.3. Поиску оптимального значения р мы несколько позже уделим особое внимание.
Интересно знать, как ведет себя оценка регрессии Т]п(х) при 0>^ Во-первых, она всегда проходит через экспериментальные точки т|„ (xs) = /г Эго свойство очевидно, ибо оно начинает проявляться при 0 = 1 из-за тог°! что весовая функция в точке х (см. рис. 4.7.2) не охватывает соседних тоЧеК х !, х,+1. Прн 0 > 1 ширина весовой функции сокращается.
140 Методы анализа
Поведение Ля(х) ®ПРИ Д-'1Я х* х,, i представлено на рИС д у 4^1 7 6 С ростом Р появляются плоские участки (рис 4 7 4), затем онИ расширяются и при р ~ 2 (рис 4 7 5) оценка !)„(*) становится кусочно-постоянной
При увеличении р > 2 появляются зоны (рис 4 7 6), где оценка Пя(х) ме определена С ростом Р эти зоны расширяются и при р °° оценка рп(х) ие определена везде, за исключением точек л,, I = 1, п, а в них она равна у , I = 1,и
Свойства оценок становятся более понятными, если представить себе поведение весовых функций СО, (х) оценки регрессии Л.;(х) -рис 4 7 7 На нижнем графике этого рисунка изображены области, где весовые функции Не определены
Еще одно свойство оцен-Ки Ел(х) вытекает из свойств ВЬ1пукдых комбинаций
ГС ____
'--1. n)<r[z?(x) = XC0I(x)Z тах{к> Z = E«}
р~~ ——. _______ ____ _______________________
а * Методы непараметрическои обработки информации
141
Оно справедливо для любых коэффициентов 0.
В многомерном случае поведение оценки регрессии по каждой вход координате соответствует полностью рассмотренному одномерному варйа” гу, Переход от размерных параметров с^, j = 1, т оценки (4.7.4) к §е3р^ мерным р , j - 1, т, осуществляется по формуле, аналогичной (4.7.5)'
₽,, = j = l,m, (476,
где Д =|ху/+|-х7г|(1 = 1,и-1) при равномерных измерениях й
- max(|x -(+1 -xj;|, i - 1,« - I) при неравномерных измерениях. Каждый параметр р (/ = 1, т) лежит в пределах от 0 до 1. Если I -й параметр (3,-0 то для всех i = 1,и, АДО) = 3/4 и исчезает зависимость в оценке Г|л(х) m I -й входной координаты xz, При всех Р; - I (у = 1, т) и равномерных измерениях оценка (4.7.4) проходи! через экспериментальные точки Г|я (х,) ~ у[(
Критерии подстройки параметра Р при т — 1. Будем базироваться на квадратичном критерии оптимальности. Это связало в первую очередь с тем, что ре1рессия удовлетворяет квадратичному критерию (4,7.2), и минимальное значение принимает не только функция 7(х), но и усредненное значение
I = Мх {/(.¥)} = мх rX{(Y - М\У))2}.
Найдем оценку для нее, заменив регрессию М{У) х) ее оценкой Т|П(Д а оператор Л/{-} - оператором статистического усреднения по выборке ‘кт и
4 = -X(b-%(\))2-п,=|
Дальше можно было бы минимизировать 1п по коэффициентам с (л0^0 р, см. (4.7.5), (4.7.6) модели (4-7.4) т)л(х). Этот шаг нам ничего не дает, предыдущий анализ оценки регрессии т|л(х) показал, что при |3 > 1
проходит через экспериментальные точки, т. е. т]л (х;) — . Функция кач^ 142 Методы мализада^
этом принимает нулевое значение: 1п - 0 при |3 > 1. Оптимальный ко-02 0 < & s 1 этим путем найти не удается. Надо либо модифнциро-
эффШ< г
ь функцию качества 1п , либо на базе нее строить другой показатель каче-0аГ£> глаэкивания. Ниже мы рассмотрим три варианта минимизируемых подателей качества.
1 Представим се^е’ что ВЫХ°Д объекта Y сосюит из сигнала Л/{У|х) и цоМехВ '
y = M{Y |х} + £-
Применяя к обеим частям оператор М{]х), получаем
M{Y\x} = Л/{К|х} + М{ф},
т е. | х} = 0 .
В каждой фиксированной точке х помеха q имеет нулевое матемашче-ское ожидание (т, е. она центрирована).
Считаем, что дисперсия помехи £ не зависит от х и известна ее оценка s1 Аналогичную оценку для дисперсии помехи дает показатель качества 1„, зависящий от параметра (или параметров для многомерного случая) (3. Выбираем р из условия минимального квадратичного уклонения s2 и 1п :
VC’24)2=n™> 0<р<1.
(4 7.7)
2 . Второй критерий основан на использовании "скользящего экзамена1':
г •' ------------------------ -------------------------- '•
-ПП(Л))2 =min, Hn(x() =
Я 3=1 t I
(4.7.8)
Здесь вся выборка х у (i - 1,л) своеобразно разбивается на две части. °ДНа используется для построения модели Т)„(х), вторая - для ее проверки (по кРитерию (4.7.8). Первое слагаемое в 12» (ПРИ z’ ~ 1) равно квадрату не-ЯЗКи МеЖду выходом объекта у} и выходом модели T]n (xi) в первой экзаме-К^Щей точке Эта экзаменующая точка не участвует в построении
непараметрической обработки информации
143
(в обучении) модели f]H(xj). Затем берется вторая экзаменующая (х2 ,у2) ив ней вычисляется квадриг невязки между выходами объекта у2 t модели т[п(х2), где модель т[„(х2) построена по оставшейся части (кр01Че точки (х2,_у2) выборки, и т. д Функция качества имеет по р хорошо Qbtpa женный минимум У этого критерия есть свои особенности
При равномерных измерениях по х (с интервалом Л между отсчетами) специфика расчета функции r[n (х;) приводит к сокращению интервала изме. рения р: 0<р<0.5. В оценке т)п(х() (в точке xf) выборочное значение (х2 ,_у;) не используется, а ближайшими учитываемыми точками выборки яв ляются (Vi’Z-i), (Л+i’-b+i) При Э1 ом шиРииа h ядра К() пе должна быть меньше расстояния между х;-1 и х(+1, которое равно 2Л Увеличение же в 2 раза критического значения ширины ядра приводит соответственно к сокращению в цва раза верхней границы для параметра р. При 0.5 оценка т% (х;) остается постоянной:
т е не зависящей от Р Следовательно, функция качества 12п перестает зависеть ос Р, Если оптимальное значение (по другому критерию) параметра [J находится в интервале [0 5, 1 0], то минимизацией функции качеств^ 72fJ мы его не найдем (см. кривую 1 на рис. 4.7 8), Второй вариант (кривая 2 рис. 4 7 8) соответствует более лучшей ситуации, когда р° лежит внутри допустимого интервала 0 < р S 0.5.
Заметим также, что при р > 1 оценка Т]„ (х,) уже не определена.
3 Третий показатель качества основан иа прямом разбиении выборки на две части
х,,^,/еМИ[,
По одной нз них (объема щ) строится оценка регрессии, по второй (объ^-3 п2) - показатель качества
ЛЯ2=— Z (у, =min, ПП1(*)= Z&Xx)y,>
«2 >^Л2 Р
144
Методы анализа da^lbt
X - X;
A ’
(4.7 9)
В одномерном случае разбиение на множества Мп^, МП2 сделать срав-
йтельно легко. Надо упорядочить выборку х;,у7, i = по х, т. с. сделать выборке все х{ < х[+1. Затем выборочные точки с нечетными номерами ог-ести к перв°й группе, с четными номерами - ко второй группе. Заметим, что после настройки параметра [3 оценка Т]П(Л) (при дальнейшем использова
ний) строится по всей выборке. Правда, существуют приемы сокращения выборки за счет исключения неинформативных измерений. Из исходной выборки формируется укороченная выборка [4.2].
Для поиска параметра [3 в одномерном случае хорошо подходят: метод
деления отрезка пополам и метод золотого сечения (см. гл. 5). Они просты в реализации, достаточно быстросходящисся, не требуют дифференцирования функции качества и хорошо описаны во всех учебниках по методам оптими
зации,
Если оценка Т[„(х) применяется многократно с изменением объема и выборки, то необходимо при фиксированном п рассчитав (3, затем пересчитать постоянный для этого объекта параметр с (см. (4.7.5) и найти оценку Т[в(х) по формуле (4.7,4) для других значений п.
На всесилие критериев (4.7.8), (4.7.9) надеяться не надо. Они хорошо "работают" при хороших помехах например, при некоррелированной во времени помехе. Наличие корреляции резко ухудшает картину сглаживания, Коэффициенты j3, вычисляемые из критериев (4.7.8), 4,7.9), становятся завышенными, и оценка регрессии вместо отсеивания помехи начинает следить за ее трендами, нейтрализуя только малую часть помехи.
При неравномерных измерениях по х возможен переход к новой переменной z с равномерными отсчетами, Каждый интервал [х ;х(+1] для переменной х линейно отображается в интервал [ZpZJ+l] для новой переменной 2 с Равномерными на ней отсчетами:
z - z{ + Az-----------при Xj < х < xj+l
ие'параметрической обработки информации
145
В итоге в области, где расположены эксперименты (и где производится Crj] живание экспериментальных данных) построено преобразование перемер з ~ я(х) (состоящего из (п - 1 )-ю линейного преобразования для отдедЬн^ участков) В координатах (у, г) строится непараметрическая оценка регрес сии (с расчетом оптимального параметра (3) а затем в ней учитывает
ся вышеуказанное преобразование координат Г|я(д(х)) В итоге пол^еца оценка регрессии в координатах (у,х)
ст во сглаживания хорошее
Пример 4.7.1. Поведение объект имитировалось уравнением
у - 5smx + ^
с центрированной помехой уровень которой равен 10 % от уровня освоено го сигнала Отсчеты по х равномерны Подстройка параметра [3 осуществи Лась по трем критериям (4 7 7)-(4 7 9) Оптимальные значения J3 немного от личаются друг от друга (3° е[0 2, 03], что приводит к небольшому отличим оценок На рис 4 7 9 они обозначены соответственно цифрами 1, 2, 3 Каче
Пример 4.7.2. На рис
4 7 10 точками представлена выборка (хру,)’ I-Ц48
Для аддитивной помехи выхода имеел следующую оценку для дисперсии s2 - 0 ($ ~ 0 933) Наличие этой информации позв^ ляет параметр (3 оценки Т^я(х) выбрать из пер" вого критерия (4 7 7) Получаем
Оценка т^Дх) при (3-0° изображен^ !)3 рис 4 7 10 линией
146
Методы anoint
ПриМеР 4.7.3. На рис. 4.7.11 приведено „епараметрическое сглаживание (0°= 0.146) ^□экстремальной функции Xх), которая 0НО1 и ____
известна в точках (х<> Т, = Ж)), ' = Оценка регрессии т]„ (х) имеет унимодальный
и минимум ее совпадает с глобальным ВИД?
минимумом функции Xх) Этот пример пока
зывает ЧТО непараметрическое сглаживание может оказать существенную помощь при поиске глобального экстремума.
Пример 4.7.4. На рис. 4.7.12 приведены результаты сглаживания (при Р° = 0.09 и [3° =0.15) еще одной многоэкстремальной функции.
При сглаживании многоэкс-тремальпых функций Xх) в некоторой области [й,Ь] изменения независимой переменной х можно получить результат сглаживания, близкий к тому, что мы имели на рис, 4.7.11, 4.7.12, и избавиться от определения коэффициента р. Для ЭТ0ГС| область действия ядер надо Распространить иа всю область сглаживания Тогда коэффи
циент размытости будет равен длине интервала h-{b — д), и сгла-Женная зависимость будет иметь вид
^w=i;©/(x)z.
f=i
® (х)^„ — -X.UX.XJL \b-aJ xb-a
(4.7.10)
b - а
неоараметртеской обработки информации
147
Эта форма сглаживания (только при использовании обратной зависну^ сти входа х от выхода у) позволит нам в 1 лаве 5 построить эффективные а1 горитмы поиска минимума сложных (в том числе и многоэкстремальньы функций
В векторном случае, когда каждая компонента х{ вектора х имеет сВо^ интервал изменения
bp I - 1, m,
в формуле стлаживания (4 7 10) весовые функции имеют вид
(!)
Рекуррентный расчет оценки регрессии, Для каждого фиксированного х на основе использования рекуррентной схемы (4.6.6) расчета оценки условной плотности вероятности /и(_у|х) получаем алгоритм адаптивного сглаживания:
n„W =-VA,
д,
И 1 I X/ - Х,„ I B„,+n——к -—-h,
(4.7.Н)
= 7 = I/(m + 4), n = l,2,..M = =
На рис, 4 7.13 представлены результаты адаптивной перестройки оценки Ди(х) по формуле (4.7.11). Это тот же пример, которому соответствует рис 4 7.9, За исходное приближение была взята кривая 1 рис. 4 7,9, Но вй' численному {3° (из критерия (4,7.7) пересчитан коэффициент с (не завис)1' Ший от и), Далее при появлении новых измерений коррекция оценки в фиксированных точках х проводилась по формуле (4 7.11). ДополНителЬЙ° появившиеся точки выборки и оценка Д„(х) представлены на рис 4 7.13-
148 Методы анализа
рекуррентный расчет оценки рег-й (4.7.11) распараллеливает вы-^слеНИЯ и избавляет от необходимости хранить выборку.
Пример 4.7.5. Проведем сравнение непараметрического метода построения Этической модели объекта с соответствующими параметрическими методами Необходимо восстанавливать по экспериментальным данным
х y i=l^n, полученным с опытной установки (см. второй и третий столбпы табл. 4.7.1), статическую характеристику магистрального нефтепровода - зависимость падения давления у на ли
нейном участке (между насосными станциями) магистрального нефтепровода от расхода х нефти, Эта модель достаточно хорошо изученной структура ее имеет вид
у; = ,/ = 1, п .
Параметры у!з у3 подстраивались по критерию наименьших квадратов в логарифмических уклонениях:
1 п
Il = -У (Inу. -Iny. -y2lnx,)2 = 'min ,
«Z1 ' ‘ ' H1.Y2
и к обычных невязках:
-у^2)2 = mm.
«^1 У|.?2
После расчета параметров у1?72 по первому критерию выход модели /SI,«, представлен в 4-м столбце табл, 4.7.1, по второму критерию в 5-м столбце.
ге же экспериментальные данные были обработаны без учета структуры рй^еЛИ' Оценка регрессии Пл(х) , параметр 0 которой был найден по крнте-С1д находится в 6-м столбце табл. 4.7.1. Для сравнения качества
в последней строке табл. 4.7.1 помещена оценка 5 средпеквад-
а 4 Методы непараметрической обработки информации 149
ратического значения помехи s ~ ~ум)2 , где VlM= у лад
V и s=i и
у1М = Лп (хг) Непараметрическое сглаживание лучше, чем параметрическОе сглаживание с использованием первого критерия (7t - min), и незначитель^ уступает сглаживанию по второму критерию.
Таблица 4.7.1
i х. У> л л ТШ)
1 0.182 1,880 1.712 1.695 2.420
2 0.213 2.420 2.331 2.109 2.180
3 0.232 2.470 2.771 2.489 2.957
4 0.262 3.490 3.405 3,151 3.554
5 0.303 4.630 4.441 4.176 4.613
6 0.347 5.740 5.734 5.431 5.434
7 0.359 6.240 6.083 5.801 6,497
8 0.393 7.250 7.176 6.913 7.558
9 0.437 8.860 8.743 8.492 9,281
10 0.501 11.300 11.249 11.070 11.374
11 0.556 13.900 13.591 13,540 12.722
12 0.559 14.150 13.845 13,680 14.898
13 0.598 15.900 15.565 15.600 16.129
14 0.641 18.100 17.641 17.840 17.622
15 0.678 19.350 19.608 19.890 19.242
16 0.687 20.400 20.036 20.410 20.047
17 0.692 20.750 20.339 20.690 20.798
18 0.698 21.200 20.623 21.040 21.230
34 0.711 21,700 21,395 21.810 22,219
20 0.730 23.200 22.403 22,950 25.060
21 0.815 28.400 27.417 28.420 27.305
22 0.856 31.400 30,032 32,250 31.312
23 0.898 34.250 32.763 34.290 33.888
24 0.924 36.400 34.919 36.240 36.427
25 0.933 36.600 35.143 36.930 38.151
26 0.976 39.900 38,186 40.300 39.456
27 1.002 42.300 40.104 42.400 41.949
28 1.056 44.000 44.655 46.940 44.712
29 1.062 47.100 44.602 47.460 48.260
30 1.120 52.500 49,159 52.610 51.840
31 1.163 56.600 53.376 56.600 54,784
32 1.170 57.100 53.231 57,260 57,596
_33 1.179 58.600 53 890 58.120 59.411
150
Методы анализа даннъ1*
Окончание табл. 4.7.1
/ х! К Л
34 1.209 61.700 56.404 61.020 61.798
35 1.247 65.000 50.727 64.790 63.900
36 1.258 66.100 61.825 65 900 67.138
37 1.288 69.300 63.403 68.980 67.924
38 1.297 69.750 64.174 69.920 69.937
39 1.297 70.600 64.127 69.920 70.173
40 1.303 70.600 64.702 70.550 70.596
5 - - 2.793 0.557 0.748
Инверсная модель. Для объекта с одним входом X и одним выходом у основной инверсной характеристикой является регрессия
|х/(х]у)бй.
(4.7.12)
Ее необходимо оценить по изменениям xf ,у:, i = 1, п.
Подставляем в (4.7.12) вместо условной плотности /(х|у) ее непараметрическую оценку (с дельта-функцией по х, ибо по этой переменной производится интегрирование):
/ч I у) = ££1Дч
\ ) UM \ )! j--' I \ )
и получаем оценку инверсной регрессии:
-=1 К
Если в (4.7.12) вместо входа X стоит известная функция от X, т. е.
^ф(^0 I р} = J фО) f ОI у)&,
0 °Ценка этого условного момента имеет вид
ф^Ь у '
в Методы непараметрической обработки информации
151
Модифицированная одномерная оценка регрессии. В оценке регрессу
Л (х ~ X \ / п I У"Х )
е/ех --у )=] V П ) / jH \ П )
числитель и знаменатель умножаем па 1 / nh. Это как раз тот множитель В1 который в свое время (см параграф 4.6) производилось сокращение (в оцеВ1ч условной плотности вероятности). Получаем
, , п (-i h \ h
п Й h h
В знаменателе теперь стоит оценка плотности распределения /(%) входа X Если эта плотность известна, то вместо оценка надо использовать эц плотность Например, если измерения входа находятся на равных расстояниях Л друг от друга в интервале [а,Ь], т. е
Xj = а + А, х2 - а + 2Д,..., хп = а + пА = Ь,
то f (х) имеет равномерный закон распределения в интервале |п,6]:
1
/(%) = < b-а ’
а <х <Ь,
О, х £[а,Ь].
В этом случае
b-а " 1
W= —Х?* и h
Эта более упрощенная формула расчета оценки регрессии имеет °б°^ щение. Если интервалы между отсчетами не равномерные, выбора х;, у,, i = 1, п, упорядочена по х, то оценка ретрессии имеет вид
h
(4 7131
152
Методы анализа
и хявляется регрессия . Оценим ее по эталонной выбор-
i = 1,н.
р ипогдв называют оценкой Пристли в память об ее авторе.
фильтрация. Статический фильтр - это безынерционный преобразова-входпою сигнала х в желаемый у выходной сигнал. По критерию мима среднеквадратического отклонения наилучшим уравнением связи
-» f г S —
межДУ У
ке ’
Выборка означает, что если на вход фильтра поступает сигнал х(, го идеальный выходной сигнал равен у;*.
Непараметрическая оценка регрессии М{у |х}
Л I У" __________ "У
k у'
представляет собой алгоритм работы оптимального статического фильтра По тестовым сигналам настраивается непараметрический фильтр, а затем при некотором входном сигнале х{ фильтр рассчитывает оценку ) для уГ . Входные сигналы xt должны лежать в той же области, в которой находятся тестовые входы xI3 i = 1,и, ибо только для этой области построено уравнение фильтра.
4.8. Робастные оценки регрессии
В реальной ситуации исходные экспериментальные данные х,, у,, могут содержать аномальные измерения, называемые выбросами Д^е наличие малого процента выбросов приводит к сильному искажению °Цеиок. Поставим задачу построения оценки регрессии, которая была бы бо-•Jee устойчивая (малочувствительная, робастная (в переводе с английского крепкая") к выбросам по отношению к ранее построенной оценке (4 7 4)
' к h J
'^Г° ВзвеШениая
оценка и веса зависят от х .
ненараметрической обработки информации
Как строить робастные оценки при одинаковых весах
1
й
известно. Этот подход описан ниже. Одинаковые веса в оценке (4.7 4j п 1 ”
дают ей вид zfy - — £ уг.
И, = 1
Это статистическое среднее выборочных значений [у;, z - 1, ??], и оценивает математическое ожидание случайной величины Y. Оценка сильно реагирует на выбросы. В этом легко убедиться, поставив следую^ простой мысленный эксперимент. Допустим, в упорядоченной выбора i = 1,л) содержится одно, сильно отличающееся от других, измерение
т е. yt « уп, i - 1,и - 1. Это измерение будет давать основной вклад (осо
бенно при малом числе измерений и) в оценку fit] Оценка с возрастанием у„ будет ''тянуться" за этим измерением. Основным слагаемым в оценке zfy будет уп1 я.
Кроме математического ожидания случайной величины Y есть другая характеристика среднего положения Y - медиана. Медиана - это среднее по вероятности значение: P(Y < т2)~ Р(т2 < У) - 0.5. Даже для несимметричных (скошенных влево или вправо) законов распределения математически ожидание и медиана мало отличаются друг от друга.
Состоятельная оценка медианы имеет вид т2 - med{yt, z — 1,и]. Она представляет собой среднее по номеру значение в упорядоченной выборке
Например, med {у,, у2, у3, у4, у5} = у3, med , у2. у3, у4} = Если
имеется нечетное число измерений п — 2к +1 (где к - целое положительное число), то т2 - ук u. При четном п - 2 к числе измерений оценкой медианы открытого интервала например
Величина аномального измерения не меняет номеров остальных членов по следовательностн (при том же условии у, « уп, i = l,z? -1) и тем самым не МейЯ’ ет оценки т2 (рнс. 4.8.1). Оценка мсДИ^ th} более робастна к выбросам измерь1
является любое число из = +л+1)/2.
т2 = Уз
_ !
У1 ЭЭЭзЭЭ Уз
Рис 4.8.1
по сравнению по средним арифметическим
154 Методы анализ dafllltl'
ЗаПИшем критериальную форму получения оценок zfy и т2, а затем эту иальиую форму перенесем на расчет взвешенной оценки (47.4).
к^Оценка удовлетворяет критерию наименьших квадратов
Л п
/1=Е(ь-'”1) 1=1
- min.
Действительно, из необходимого условия экстремума
= О,-й1) = 0
dmx i=i
получаем оценку .
Оценка медианы т2 удовлетворяет модульному критерию
Л=Х!л “'"г 1= min.
1 тэ
1=1
Пример 4.8.1. На рис. 4.8.2 приведен вид функции
/2(т2) =| -тг |+| 1 - тг }+| 3 - т2 |+| 5 - т2 [
при четырех измерениях: = 0, у2= 1, У3= 3, у^5.
На рис 4.8 3 представлена функция
Z2(m2) "I I 41 ~ ^2 1+1 3~ т2 [+| 4- m21+| 5 - т21
при пяти измерениях. ^ = 0, у2~ 1, Уз~3, У1 = 4, у5= 5.
Построим итерационный алгоритм вычисления оценки медианы. Предку рительное упорядочение выборки в этом алгоритме проводить не надо Задаем нулевое приближение т2 искомой оценки т2. т2 можно задать, например, 1 ”
в виде статистического среднего т2 -~^уг, т. е. равной оценке .
Следующую оценку т2 вычисляем из минимума квадратичной алпрок, симации функции /2 в точке т2:
1=J |у, - т2I
Записываем условие минимума по п?2
,1т Ц 1
1У/ -«21
= 0
и получаем взвешенную оценку
_1
т2
п
-1L
~о.-1/Д. „о,-:
™2 \ ^Ь\У2-т2\
На следующей итерации т2 заменяем новой величиной ш2 и получаем следующее приближение т2 оценки медианы (рекуррентную формулу):
_/+i Л . _i .-m2 = X IZ - "h I
У2-т2\ 1 /=0,1,2,... .
(4.8-0
Итерационная коррекция оценок прекращается, когда невязка на сосеД' них итерациях становится меньше заданного малого числа е :
\т[+х -т\
156 ’ " ~
Методы анализа
лученное '1Начение ^2+1 является искомой оценкой т2 (оценкой медианы)
Пример 4.8.2. Рассмотрим в качеств иллюстрации работоспособности 1Ц]еприведенного алгоритма резулыаты статистического моделирования. Выборка уг генерировалась в виде некоторой известной константы
я и аДДйтивН0Г0 Центрированного шума с известными характеристиками:
Константа с регулирует интенсивность шума (в процентах) по отноше-ю к сигналу а . Помеха имеет либо нормальный закон распределения (обозначаемый буквой N);
/Й-л/2каеХР< г!2’’
либо закон распределения Лапласа (L):
=
На эту помеху накладывались выбросы. Частота их появления равна 0 1 (по сравнению с основной помехой), т. е. в среднем из десяти измерений девять содержат обычную помеху со среднеквадратичным отклонением (5, а одно измерение содержит выброс. Средиеквадратическое отклонение для выбросов равно поочередно (в различных сериях эксперимента) Юа, 20с, 30(5. По выборке yf, i ~1,п, производили расчет оценок тх и т2 Оценку медианы т2 вычисляли но итерационному алгоритму, описанному выше. Такое моделирование проводили многократно в одних и тех же уело-вВДх, и по полученным результатам вычисляли статистическое среднее и оценку дисперсии. Все эти данные приведены в табл. 4.8.1-^1.8.4.
Относительная средняя норма уклонения оценок тх и т2 от истинного значения а рассчитывается по формуле
I 1 № Г1 /
Ь№Л)-02 =J—£((»Л-а)2 А / =
।л ;=1 У W /=1 /
Здесь А - число реализаций при статистическом моделировании, тх -йя Пр
реализация оценки тх (удовлетворяющей квадратичному критерию);
2j J-я реализация оценки т2 (удовлетворяющей модульному критерию).
Методы иелардуиетрыческой обработки информации 157
Результаты, приведенные в табл. 4.8.1, соответствуют случаю без atib бросов. Качество оценок т}, т2 одинаковое. Число итераций при расчете в среднем равно трем. В табл. 4.8.2-4.8.4 нарастает от 10(5 до ЗОо амплитуд выбросов и соответственно нарастает отличие в оценках т} и . Качество оценки т2 существенно лучше, чем оценки /щ.
Таблица 4.8.1
Выбросов нет: авыбросов = (5
Закон распределения N L N L N
Интенсивность помехи 10% 30% 50%
Критерий Относительная средняя норма уклонения
Оценка дисперсии
Квадратичный 0 018 0.001 0.032 0.003 0 053 0 007 0.095 0.058 Q088 0.022 0.159 0018
Модульный 0.021 0.001 0.028 0.001 0 062 0.002 0.084 о.ооз’ о.юз 0.009 0J41 0.0Г1
Критерий Статистич. среднее числа итераций Статистич. дисперсия числа итераций
Квадратичный J 0 1 0 1 0 1 0 J 0 i 0
Модульный 2 6.65 2 5 61 3 8.47 3 ?62 3 885 3_ 691
Таблица
выбросов = 10(5 Частота выбросов 01
Закон распределения N L N L N L
Интенсивность помехи 10% 30% 50%
Критерий Относительная средняя норма уклонения Оценка дисперсии
Квадратичный 0.053 0.002 0.127 ООП 0 158 0.018 0.382 0 102 0.263 0.050 0^675 0 02J_
Модульный 0.036 сГооТ 0,051 0.001 0.094 0.004 0.153 0.005 0,181 0.019 0 497 0020_
Критерий Статистич. среднее числа итераций Статистич. дисперсия числа итерации
158
Методы анализа дан№
Окончание табл. 4.8.2
ХваДР^ичНЫЙ
Модульный
2 0 1 0 2 0 2 0 1 0 X 0
3 4 3 6 3
1 *. 1 1.1» — 1 III - - -
2.74 1.08 5.31 2.00 11.5 2.9б_
Таблица 4.8.3
^выбросов = 20° Частота выбросов 01
Закон распределения N L N L N L
Интенсивность помехи 10% 30% 50%
Критерий Относительная средняя норма уклонения
Оценка дисперсии
Квадратичный 0Ю98 0.008 0,162 0.003 0.293 0.071 0.286 O.j 19 0.489 0.197 0 624 0.175
Модульный 0.040 0,001 0.108 0.002 0.093 0.006 0.156 0.005 0.178 0.017 0.292 0016
Критерий Статистич. среднее числа итераций Статистич. дисперсия числа итераций
Квадратичный 1 0 0 1 6 2 0 2 0 1 0
Модульный _3 2.69 4 4.09 4 6.96 3 2.59 6 10.3 3 5.04
Таблица 4.8,4
и выбросов 3 0(7 Частота выбросов 01
Закон -Определения N L N L N L
Интенсивность .помехи 10% 30% 50 %
критерий Относительная средняя норма уклонения
-^7_~ - Оценка дисперсии
квадратичный 0.143 0.018 0.102 0.007 0.430 | 0.573 0.161 0.145 0.717 0.448 0.509 0 179
Модульный . 0.039 0.001 i 0.050 I 0.001 0.095 0.165 0.006 0.006 0.167 0.015 0.291 0.015
кРИтернй Статистич. среднее числа итераций Статистич. дисперсия числа итераций
° 4 Методы непараметрической обработки информации ~— 159
Квадратичный 2 0 2 0 2 0
Модульный 2 1 99 3 0.90 4 651
По вышеприведенной схеме построим робастную непараметрическу^ оценку Л2л(х) Для регрессии. Обычная оценка Т|Дх) удовлетворяет^ каждого фиксированного х) квадратичному критерию с весами Х(>):
h (х) = 1 (Z ~ ПХ2 И ) - min.
k h ) nr
Действительно, из условия экстремума
^! = -4(х-л„)аХ -А Но г! V ь
получаем
э.И=X М ~г-\ Х^ у, =XKv —н-. k « Ji j=i к h JJ i-i к « )
Робастную оценку регрессии Д2и(х) отыскиваем (также при каждом фиксированном значении входа х объекта) из минимума модульного взвешенного показателя:
Л (*) = 1! z - т12л 1к(= min •
(-1 \ п J У\2п
Итерационная формула расчета оценки Д2м(х) имеет вид (4.8.1) с коррекцией иа весовые коэффициенты К(-):
э“« = Х
i к - nl(x) Г1
________ у А 7
" i \ ((х-х,)А
XIЛ ~У(ЧГ чХг2
\ " )
А I ( X — X
~7^ И” / =
;=1 \ Л )
160
(4 8 2)
Методы анализа до11^
Итерационная коррекция оценки заканчивается, как только выполняется условие
Тогда Л2₽1(х) дает минимум функции качества /2(х); т е q2w(x) = rl2 (х)
Оценка (4 8 2) также осталась взвешенной, ио несколько изменилась вели-а весовых коэффициентов Наличие выброса (по у,) в какой-либо точке х, приводит к уменьшению (за счет сомножителя j у; - (х() | 1) весового коэф-
фцциента ®2 () и тем самым ослабляется влияние выброса на оценку ц2л (х)
Пример 4.8.3. Решим задачу, аналогичную той, которая иллюстрируется рис 4 7 9, но теперь помеха £ содержит выбросы Час юта выбросов 0 1
Выборка x(,yj; г = 1>и, представлена на рис 4 8 1 точками Почти все сбросы уходят за поле рисунка. Значения их ординат у, указаны на краях Рисунка На рис 4 8 1 показаны истинная зависимость у - 5 sin х между вы-к°Дом и входом и две оценки регрессии т|я(х) > параметр Р которых найден По критериям 1 и 3 Сравнение с рис 4 7.9, i де нет выбросов, показывает, что ^злая доля больших по амплитуде выбросов сильно искажает оценку т|„ (х)
Расчет оценки т|п(х) регрессии по модульному критерию (4 8 2) сильно °С11абляет (так же как для оценки медианы) влияние аномальных измере-йий'рис 4 82
'ьг непараметрическои обработки информации
161
Модульный критерий не является единственным для получения робасг ных оценок Более общий критерий имеет вид
Zt V h J л
Некоторые виды функций F(v) приведены в табл 4 8 5 Составим ите. рационный алгоритм вычисления оценки регрессии т]и (х).
J/ X V/ х2 -Л)
Ц*) = - Л) -/ Ч2 = тш
i-1 (z - л) V h ) 11
Теперь нетрудно составить квадратичную аппроксимацию функций чества по т| в точке r|Z и из минимума ее
162 Методы анализа d^Mil
(Z-Л)2 I h J в
Z+l / \
ауЧйСЛИТЬ Т|„ (х)
n'+X) = IX (*)?,, ;=1
Xх)
-лХ))кГ
(у, ~пХ))2 I J
~Y,(*)) XХ-* Y
£(у,-пХ))2 I * J
I = 0,1, 2,
Это рекуррентная формула расчета робастной оценки регрессии в каждой фиксированной точке х
4.9. Оценки условной энтропии и количества информации
На основе независимой выборки (xf,j/;), 1 = 1,п, случайной двумерной непрерывной величины (X.Y) вычислим оценку условной энтропии
Н(У |л) =- J[log/O I х)]/(у I x)dy.
-со
(4-9-1)
Вместо линейно входящей плотности подставляем оценку условной Ш(°тности (4.6 5) [в ней вместо дельта-образной функции по у взята дельта-Функция], под знак логарифма - обычную оценку (4.6.2), и получаем, что
ЗДх)— ] [logAWx)] укя
h.
3(y-z)
hog/Ду, |х) =
(=1 ( /?, I
=~lx|V4Iog
- I к ) ь-’
- I x'xf I 1 N 7~~ ,
( «V М,
hy J.
--------'———----———-—~~——----------------- —— Методы пепараметрическоИ обработки информации
(4.9.2)
163
Найдём теперь оценку приведенной средней условной энтропии
оо
Я(У|Х) = /Я(Г|х)/(х)сЯ=
= - J /[log/(У I *)]/(? I x)f(x)dxdy =
-CO
СП CCj
= - f f[log/(^|x)]/(x,^)tZr(/ys-A/{log/(X|X)} (4.9.3)
— TO — <JQ
по той же независимой выборке (xr yj,
CO CO
Я„(Г|АЛ)=- J fUogAOl
—a? co
--Dog/Jz Z)^--Xlog
«/=1 «; = 1
(4 9 4)
Теперь остаётся получить оценку среднего количества информации, содержащейся в случайной величине X о случайной величине У (4.6 1).
/(У | X) = Я(У) Я(У | X) = Н(Х) + Я(У) - Н(Х, К).
(4 9 5)
hcnujib tyeM вначале первую часть этого равенства.
In(Y\X^Hn{Y}-Hn{Y\X^
— -f>gA(z)+-l>g АСУ I
нг-\ Я;=1
=lflogA^)==lflog.
«>=1 Л(х) «^1
)h.
h,
--Elog
/=1
( х, - х,
----- 1 J
_ N AN
1=1 \ «Y J
h,
У,~У1 К,
(4 9 6)
1 п 1 к
164
Методы анализа
а затеМ вторую часть:
4(У (.X) - Ял(%) + Я„(П - Н„(Х, У) =
-fiog/д^)- -f;iog/„(x)+-EiogA(^5^)=
w;=l П/-1 Я ;Ы
1 ”
= iZlog
ACw.) _ XA)A(z)
i n
= -Iiog
n (=1
”t\hx I hx
Iй n [ X — X 1
= -£log «E^N ^7-^ AN «;=1 L J-l I h>: J
(4-9 7)
Итоговые результаты, естественно, совпадают.
Приведённые (в этом и предыдущих параграфах) примеры демонстрируют применимость оценок Розенблатта - Парзена при решении некоторых задач математической статистики. Другие важные для практики статистические задачи (идентификации, управления, оптимизации, классификации) будут рассмотрены в последующих параграфах.
4.10. Оценки дисперсионных характеристик
Для объекта с т входами Хг,... , Хт и одним выходом У на основе независимой выборки (_х1(, ...,х^(,у;), i = 1,и, оценим дисперсионные характеристики (см. параграф 3,13 [4.6]),
Остановимся теперь на дисперсионных характеристиках и для про-CT0TbI начнем рассмотрение с одномерного объекта,
Средний квадратичный разброс выхода объекта У" относительно функ-регрессии характеризуется условной дисперсией
Й{Щ}= лД(у-.why')2!*}
(4,10.1)
“ 165
'СО
непарешетричес^ой обработки информации
Формуле для условной дисперсии Д(х) можно придать другую фор^,
Д (*)= ](/ -2>м{г|х}+[м{У|х}р)/(_у|х)й?у=:
= ]y2f(ylx)<fy ~2M{r[x}ajyf(y^x)cfy +ри{/|х}р f/(>|x)dy =
-OO -Of —oo
- У2/(У I - 2[W{Г|х}р + ИГ^
=м{г2|х}-[м{г|х}р. (4.10.2)
После усреднения условной дисперсии Е\(х) по X получается средняя условная дисперсия-
Мх{/){Щг}}= ]ф|х}/(х)<&= /Д(х)/(х)А-
-00 —00
00 оо
= f {(у-Л/{У1хД/(>’|х)/(х)г&<7у=
= J (4.103)
-00 -оо
Аналогично вводится понятие дисперсии условного математического ожидания (т. е. средней дисперсии регрессии)
£>м{рх} = Мх )(лф X}- м(г))2 [= }(м(Г I х) - туУ f(x)dx=
—Л
® С 03 V
= {I f#(^ I *}dy - I = A <4'10
Существует теорема о разложении дисперсии выхода па сумму диспеР сий Dj, D2:
П{Г} = Д + Р2. (4.1°5}
Вывод этого равенства приведен в [4.6]. Смысл составляющих в р^еН стве (4.10.5) заключается в следующем.
166 Методы анализа
Дисперсия условного математического ожидания В2 характеризует ту Cfb флуктуаций выхода объекта У, которая вызвана влиянием входной пененной X Средняя условная дисперсия Dx определяется совокупностью оСтальных переменных объекта, кроме входной переменной I, т. е, Dy зктеризует степень неопределенности описания объекта. Если объект полностью описан регрессионной зависимостью М[К|т|(х), то Д- 0 и одновременно ПРИ эг0М D2 =D{ У} Если объект никак не описан регрессией П(*)> т0 Д=^ П и одновременно Д= 0.
Обратные утверждения имеют место не всегда. Эют факт обусловлен тем что дисперсии нс являются универсальными характеристиками объекта. Однако для грубой ориентации ими можно пользоваться, в том числе при обратных утверждениях.
На основе дисперсии условного математическою ожидания £)2 строится дисперсионное отношение
, £>2
£>{Г} £>{/}’
(4.10,6)
которое лежит в интервале [0; 1].
Величина Т|^ достигает предельных значений в следующих случаях. 1]^ = 0, если выход объекта Y не зависит от входа X. Обратное утверждение верно не всегда.
Т]^ = 1, если Y и X связаны жесткой зависимостью в виде функции Е = (р(%). Тогда М{У|х} - ф(х). В этом случае другие воздействия (кроме Х) ие влияют на Y и Dy — 0 (т. е. D2 - 7){У] ).
Нормированный коэффициент корреляции между выходом Y и входом X
М{(Х )(Y -т }
= — -------~= г, (4 10.7)
ГДе тх>ту - математические ожидания; ст,, ст* - средние квадратические ог-и°Нения соответственно для X и Y, связан с дисперсионным отношением Неравенством
(4.10 8)
___~____________________~ _________________________________
Че° 4 Методы непараметрической обработки информации 167
В левой части стоит квадрат нормированною коэффициента Koppejlj[ ции. Равенство достигается, если регрессия Т|(х) линейна но х.
В многомерном случае (у объекта т входов X н один выход У) в вышеприведенные соотношения сохраняются, В них лишь скалярную С]^ чайную величину X надо заменить на векторную X, а в неравенстве (4До gj вместо квадрата коэффициента корреляции гД будет стоять квадрат множе. ствеиного коэффициента корреляции Он вычисляется по известны^ стандартным формулам и является нормированной (на 1) характеристикой степени линейной связи между выходом и входами:
Например,
(4.10,9)
Вводятся также понятия степени нелинейности кривой регрессии лО)
X2 2 „2
5>|! =ТЫ"Д
(4.Ю.10)
и относительной степени нелинейности
2 2 1 2 ‘
V ^1*
(4 10.11)
Обе величины лежат в пределах [0; 1].
Для условной дисперсии Д(х) (4.10.2)
находим вначале оценку второго условного момента МуУ2|х
168
М&тоЪы аш^иза ^Н>1
л?{г2|*}= J/
— 30
-=о 2 = 1 к И
f/50 - у, Мг=
i-i S % J-K
~—- т’-л)^ hxm )
а затем (с использованием ранее полученной оценки регрессии (4,7.3) получаем итоговую оценку условной дисперсии:
’-1 V "х,
(4 10 12)
Далее, так как средняя условная дисперсия Л нолучаеюя уиреднени-
00
ем по X условной дисперсии Д(х): Д = ]Д (f )/(Я)<йс, то применение
вместо /(х) простейшей оценки приводит к нижеследующей оценке сред
ней условной дисперсии:
Х~±ь,(х,)=
П,=\
1"Гп Г Y g^h
1А
(4.10.13)
Аналогично находим оценки для дисперсии условного математиче-
Ског° ожидания (средней дисперсии регрессии) (4.10.4)
СО
й2=
(4.10.14)
“ 169
бг УУК(А
rl 1=] и 7=1
4 Методы непараметрической обработки информации
00
и для дисперсии выхода объекта D{ У} = - ту)2 f {y)dy \
—00
Так же как и для истинных дисперсий D{ У}, Д, D2 [см. (4 10 5)] Су ществует теорема о разложении оценки дисперсии выхода
£{У} = д+Д.
Действительно,
Д + Ьг
{1 к О л
п t=l Л (=1
N <-Л /=1 I Ти "л„
9 л
--Е
Я 1=1
—2
ytmy + ту =
л
5Х
1 И О И -1П
=~ЁУ/ --ЁуА+^у=-Ё(У/-'”у) =Dy-
Лы «м И/-1
Здесь использовано свойство симметрии ядер
Л xi
170
Методы анализа даи^
йУс
довйе нормировки
их
Цз(4.10 15) следует оценка для дне иерс ионного отношении (4.10.6):
оценка для относительной степени нелинейности (4.10.11):
-2 -2
(4.10.16)
где оценка квадрата множественного коэффициента корреляции вычисляется с использованием критерия наименьших квадратов при линейной модели:
(4.10.17)
Рассмотрим результаты статистического моделирования. Два объекта описываются параболическими зависимостями:
О = х(2 + -а<х;<а,
г = 1,и,
WieM в первом случае задействованы обе ветви параболы, во втором -ь одна ветвь. Первый объект характеризуется существенно нелинейной , симостью выхода от входа, второй - тоже нелинейной зависимостью, но у4овлетв0рИтельно„ аппроксимируемой линейной моделью. £, - нормально е^ПреДеленная аддитивная помеха с нулевым математическим ожиданием и 0 Дисперсией. Константа с определяет интенсивность помехи, и
Расчитывается по заданной величине р отношения "сигнала к шуму"
° Методы непараметрической обработки информации 171
р=/ш]2/с
V n ,.1 /
Сигналом является незашумленный выход х2 объекта Если р = Ю т это означает, что сигнал по амплитуде в среднем превышает шум в 10 раз е шум десятипроцентный (по отношению к сигналу) Если р = 1, то сигн^^ шум соизмеримы, т е шум стопроцентный, и т д
ине 410 1
Из имитационных уравнений объекта получена исходная выборка Она обработана по вышеприведан ным алгоритмам и полутень! оценки регрессии Al{y|x}, множественного коэффициента корреляции ?2; й дисперсионных характеристик
На рис 4 10 1 в качестве ичлю страцни приведена реализация оцен ки регрессии при р - 10
172 Методы анализа
ггдя существенно нелинейного объекта 1 на рис. 4,10.2, 4.10.3 даны нки дисперсионных характеристик в зависимости от отношения "сигнал -° "л Оценка степени нелинейности объекта у*. близка к 1. В то же вре-щуМ Р 71
величина оценки квадрата множественного коэффициента корреляции л = характеризующего степень линейной связи выхода со входом, близка к нулю. При р < 10 помеха начинает играть существенную роль. Уровень стохастичности объекта с уменьшением р (увеличением уровня помехи п0 отношению к сигналу) существенно повышается. Индикатором этого факта служит повышение оценки Д (средней условной дисперсии). Величина же оценки дисперсии Д (средней дисперсии регрессии) при этом не меняв!-ся Этот факт говорит о сохранении хорошего качества непараметрического оценивания регрессии М {
Для второго слабо нелинейного объекта 2 характер поведения оценок дисперсий Ь{ У), Ь2, не изменился, а их величина сместилась мало. Поэтому можно ориентироваться на тот же рис. 4Л 0.2. Поведение же остальных характеристик (см. рис. 4.10.4) принципиально изменилось. Оценка степени ^-2
нелинейности объекта у сравнительно мала, что говорит о том, что и с помощью линейной модели можно "удовлетворительно" описать нелинейный объект. Но это описание хуже (ибо г^х меньше т)^), чем с помощью непараметрической оценки регрессии. Чем ближе к 1, тем непараметрическая модель лучше описывает объект.
Пример иллюстрирует факт, что мы располагаем хорошим статистическим аппаратом для оценивания качества пепараметрической модели нелинейного объекта.
Адаптивное управление при априорной неопределенности
Адаптацией природа наделила все живое, Она представляет собой приспособление к различным изменениям. Эти изменения происходят как внут-Ри живого организма, так и во внешней среде.
Свойством адаптации человек наделил и созданные им устройства, равление в этих устройствах осуществляется таким образом, чтобы как или ° бЬ1стРее и лучше нейтрализовать влияние непредвиденных изменений приспособиться к пим. Приспособление может идти за счет изменения 'Olac ^Ь1 УстР°йств управления и их параметров. Еще совсем недавно эти
СЬг Систем управления называли соответственно самоорганизующимися
а 4 Методы пепараметрической обработки информации
173
и самонастраивающимися системами. В настоящее время их стали назыв адаптивными системами, которые применяются для управления объект?111 различной природы (и в первую очередь технологическими процессах, в условиях неопределенности.
Причины неопределенности могут быть разными. Например, модели ут[раЕ ляемых объектов либо известны не полностью (например, с точностью до Hetl' военных параметров), либо вовсе неизвестны. В процессе адаптации прямо косвенно эти характеристики доопределяются. Причем слежение осуществляв ‘ и за дрейфующими характеристиками. Практически каждая система управлещ^, (объект и устройство управления) подвержена также влиянию внешних н внуг реиних возмущений, точные законы изменения которых неизвестны.
При создании адаптивных систем управления идут двумя путями. В первое классе систем в процессе адаптации подстраивается модель объекта, а затем по модели также непрерывно по времени вычисляются управляющие воздействия Во втором классе систем на основе критериев оптимальности синтезируется структура устройств управления, а затем в процессе адаптации подстраиваются параметры этих устройств. Жесткого различия между этими классами адашив-них систем нет. Всть области, где принципиального различия в их свойствах нет
и дело, как говорится, вкуса, какой системе отдать предпочтение.
В данном и следующем параграфах мы рассмотрим непараметрическив
подход к синтезу алгоритмов адаптивного управления статическими режимами работы объектов. Модели объектов полностью неизвестны. В процессе адаптации восстанавливается не прямая, а обратная непараметрическая модель, дающая искомое управляющее воздейетвие. Такой же прием применяется и в параметрических моделях, но в основном при использовании линейных моделей объектов.
Рассматриваем объект, который находится в ряде статических состояний. Необходимо найти такое его состояние, которое соответствует наи лучшему режиму его работы. Структура системы управления представлена на рис. 4.11.1, Объект имеет два входа: один управляемый w, втоРоИ наблюдаемый. Необходимо найти алгоритм Р3' боты управляющего устройства, чтобы обеспе411’ валось движение системы по заданной трае^11 рии дВ, z = 1, 2,..., т. е. чтобы выход системы )s
в каждый текущий дискретный момент времени как можно меньше чался бы от . К моменту времени ts управляющее устройство располагаеТ измерениями выхода объекта у, контролируемого входа объекта Ц, -г1‘°
ляющими воздействиями и и желаемым выходом системы ;
174 Методы анализа да
h ?s-\ ts
1 1 * У> ... Hl •и2-У2 У1 Л-1 и, л
(4.11.1)
В момент времени ts с измерительного устройства поступила свежая ирфОрмация известно также значение 7* желаемой траектории системы и необходимо вычислить и подать па объект управляющее воздействие us. Заметим, что только после окончания переходных процессов в объекте, вы-30анных воздействиями pE,ws, происходит измерение выхода объекта ys. После этого осуществляется переход к следующему такту управления,
Поиск управляющего воздействия us можно вести двумя путями. Первый (традиционный подход) основан на построении прямой модели объекта и последующем вычислении us из условия иаилучтпего приближения выхода модели к желаемому выходу замкнутой системы. Кратко опишем jjoj подход, основываясь на иепарамстрической оценке регрессии Гем. параграф. 4.7).
Все переменные объекта являются случайными величинами.
Уравнением объекта (наилучшим по минимуму среднеквадратичного отклонения) является регрессия М{у | м,ц}. Оценив ее по выборке (4.9.1), мы подучаем прямую модель объекта:
М{у | м,ц} = К(и,ц) = р = ^KN
Г=1
н-н, h
Используем се для прогноза выхода объекта в момент времени ts. Для эт°го подставляем вместо U его новое измеренное значение :
сравниваем прогнозируемый выход желаемому выходу :
, Л’,.
I hu \ J
4 —~~-------------—--------—— -----—-------
етоды непараметринеской обработки информации
175
Из этого нелинейного уравнения вычисляем и и получаем иско^ управляющее воздействие us объекта в момент времени ts. ' °е
Если на управление и накладывается ограничение и е U , то для дОй us надо использовать критерий наилучшего приближения к наприм / \ 2 Р’
(л-ь) =га1«-
v&J
Результатом минимизации локальной (только для момента времени /) функции качества является искомое управление us.
Расчет управления является непростой обратной задачей, тем более она решается на каждом такте ts. Эта задача усложняется, если управлений несколько. Чтобы избавиться от решения этой обратной задачи, воспользуемся обратным уравнением объекта. Это дает второй путь решения проблемы.
Выборка (4.11.1) позволяет нам оценить не только прямую, но и обратную регрессию: М{и | у, ц}, т. е.
М{и = Г"‘О,ц) = и = 2Х J — |«/ м I. hy J
Поставляя в правую часть вместо li его новое измерение , а вместо у его желаемое значение у*, получаем искомое управляющее воздействие:
гт
(4.11.2)
KN
Особенностью нспарамстрических моделей (в том числе и (4.11-2) ется то, что область их действия не выходит за область экспериментов (С(Л параграф 4.7). Всегда в силу выпуклой комбинации точек и, в (4.11.2)
гат{м,, z = 1,5 - 1} < и* < тах{м2, i = 1, s -1}.
......... _
Методы анализа №*
Если область наблюдений мала, а для достижения желаемого значения
* требуется управление us вывести из этой области, то надо к управляю-^еМУвоздействию (4.11.2) добавлять изучающую компоненту [4.1] :
us — И5 +
(4.11.3)
На начальном этапе управления, когда фактически идет процесс обуче-Щ1Я роль изучающей добавки велика. Обычно формирую! Ау. в виде некоторой функции от невязки е = . Со временем эта невязка уменьша-
ется и влияние изучающей добавки также падает. Аналогом изучающей добавки является задание первых значений управления на границе области ее возможных значений. Остальные us рассчитывают по формуле (4.11.2) и находят внутри области возможных изменений управления.
Изучающая добавка Ду к управлению должна удовлетворять условиям
у—> СО 3—>00
Выполнение их обеспечивает асимптотическую сходимость:
М{у,}~->у'. V—>00
Если внешнее возмущение L1 объекта отсутствует либо оно остается постоянным в процессе управления, то непараметрическое управление статическим режимом работы объекта зависит (см. (4.11.2) только от измеряемых калений выхода объекта у, желаемого выхода у н предшествующих зпа-ченвй управления:
i=] । П,,
(4*11.4)
4 44=к[ Кг й ) 44 44
Ц. ^ри нескольких управляющих воздействиях расчет каждого управления °Водится по формулам (4.11.2), (4.11.4):
^е^оды непараметрической обработки информации
177
h
j-i f * A
* y r b -y. L
<=1 { hy J
k*=l, ...,m.
Пример 4.11.1. При статистическом моделировании поведение объект подчинялось простейшим уравнениям’
К = Л +cL> Л =1~У-> « = 1, 2,....
Помеха £, равномерно распределена в интервале [-1; 1]. Константа с за. дает уровень помехи. Он был взят равным 5 %
На рис. 4 11 2, а, 4.11.3, а справа показана статическая характерце11*^ объекта, слева - желаемая траектория у* (тонкая линия) и истинный вЬ^0' объекш у (более жирная линия). На первых двух шагах управление приН11 мало два крайних значения (0 и 2). Это позволило охватить всю область ₽°3
178 Методы анализа У11"*
ядро ТГ(-) - параболическое. Приведенный на рис 4.11.2, п,
ясных изменений входа и и на дальнейших шагах не использовать изу-ча101дую добавку Расчеты управления велись по формуле (4.11.4), где
V"
4 Ц 3, первый участок траекторий по и наглядно демонстрирует хо-
oJljee качество адаптивного управления. Со временем объем информации врастает, инверсная характеристика объекта оценивает все лучше. Это при-в0ДИТ к улучшению управления.
Заметим, что в параметрических методах адаптивного управления по
мере поступления информации уточняются оценки параметров прямых или йНВерсных моделей. В непараметрических методах оценивается вся характеристика объекта. Платой за отсутствие информации о структуре модели является усложнение алгоритмов обработки информации и нарастание объема хранимой выборки. Последний недостаток легко устраняется за счет вывода из системы слабоинформативных выборочных значений.
Инвертирование характеристики объекта = -1 + уЛ не меняет свойств
адаптивной системы управления - рис. 4.11.2, б, 4.11.3, б, но вновь надо процесс начать с изучающего покачивания входа объекта на первых тактах
управления.
Изменение вида характеристик обьекта (лишь бы они были однозначные) и включение в объект дополнительного измеряемого входного воздействия ц нс меняет основных свойств адаптивной системы управления (см. [4.1]).
4.12. Управление экстремальным объектом
Вновь рассматриваем систему адаптивного управления, представленную нарис. 4.11.1. Но теперь характеристика объекта у - 7?(w,/z) экстремальная, L е, имеет по w либо минимум, либо максимум. Цель управления заключается в выходе на экстремальное значение величины у и в удержании объекта в этом^положении. Дрейф экстремума происходит за счет внешнего воздействия ц. Так же как и в параграфе 4.11 считаем, что с помехами измеряются вЫход объекта у и внешнее воздействие и, распределение помех неизвестно а Неизвестна модель объекта.
Если характеристика объекта дрейфует, но экстремальная величина вы-ХоДа у Не меияется (под действием ц), то для поиска управлений полностью пРименимы формулы параграфа 4.11, но с соответствующим выбором значений т/ п
Л Они выбираются так же, как cs в предыдущей задаче на поиск ми-НмУМа а. в итоге имеем (если у > 0):
- -_
а 4 Методы не параметрической обработки информации 179
-,^^Мч+Д«й * = 1,2,,., (4.i2h
I Ks his J 11
7.’ = Xs min{yJ,z = l,*'-l},O<x,<l,XJ-->l, J->co
либо
}\ = inf у - для минимума;
Z = Xs maX{Z >l = 1>J ” U,Xs - - >1.
либо
уь > sup у - для максимума.
Если же внешнее воздействие и меняет не только положение экстреш ма выхода у объекта, но и величину у, то в формуле (4.12.1) прн расчете оценки экстремального значения выхода надо в расчет брать только те у для которых аргумент ((ц^ -Ц,)/Л2г) ядра К() по pi не превосходит 1, т с когда значение ядра не равно нулю:
Л. -ц
}\ = Xs min {Z J 1 К\ ~--L > 0} - для минимума;
< A2s J
ys =Xs max(z Д : ~~ > 0} “ Д™ максимума.
I h2s J
Пример 4.12.1. Поведение объекта и измерительных устройств ДЛЯ вЫ' хода объекта и для возмущающего воздействия описывается простейший уравнениями:
у, =z ~ч)2>
ISO
Методы ан да аза
- 0-3, / — 1, 2,,,.,
p =ц;+с2^, ц, =1.5 + 0.2sin(A/;).
Уровень помех измерения равен 5 % п0 01иошению к сигналам. На рис. 4.12.1 показаны: экстремальная характеристика объекта и ее предельное положение при дрейфе (4.12.1, б), поведение возмущающего воздействия и изменение значений выхода объекта у при адаптивном управлении (4.12.1, а) в соответствии с алгоритмом (4.12.1). Экстремум отыскивается достаточно быстро, а затем осуществляется слежение за ei о дрейфом.
4.13. Минимизация функции
Вышерассмотренный непараметрический алгоритм управления экстремальным объектом полностью применим для минимизации (максимизации) функций: I(x) = min.
X
Функция качества 7(х) может быть не задана аналитически, она может быть разрывной и даже многоэкстремальной. Требуется лишь одно, чтобы при каждом заданном значении х' можно было вычислить значение функции качества Г. Возможность поиска минимума разрывных и многоэкстремальных функций на основе алгоритмов непараметрического сглаживания обусловлена именно свойством сглаживания. Сглаживаются и разрывы, и локальные экстремумы (см., например, рис. 4.7.11 в параграфе 4.7).
Независимая переменная х векторная. Она состоит из т компонент: х = (х.. J=l, т). Перед совершением 5-й итерации при поиске минимума MbI Располагаем выборкой
(х ,/') = (х;,х',..., х'„, I!), i = 1,5-1.
Следующую 5-ю коррекцию параметров х совершаем по алгоритму 12-1), в котором убираем зависимость от ц:
,,Qea 4 Метод
ы непараметрической обработки информации
181
j = 1,..., m, 1 = 2,3,...,
где Г1 = пйп{Г, i =1, s-lj-e,, e5>0, — >0, либо I * ~ inf J.
Если нижняя грань I функции качества I известна и в процессе поиск9 минимума она не меняется, то алгоритму (4,13,1) легко придать рекуррещ ный внд:
X* - + &х}, j ~ 1,,,,, т,
Л .Л-i 1 L-S-l /. .
AJ^AJ +TK\—Г~~ xj > t4-13-2)
J J h \ h J \ S 2
1 ( I* — Is~^
zr - bs~[ +—zd —-— L s = 2, з, J 1 К I hs f
A’=B‘,0.
Текущие значения на каждой итерации сразу обрабатываются и больше к ним не возвращаются. Тем самым мы избавляемся от необходимости хра-нения всей выборки.
Достоинство алгоритмов (4,13.1), (4,13,2) также в том, что вес компоненты вектора -7 рассчитываются независимо, и тем самым распараллеливается процесс вычислений.
4.14. Непараметрическое сглаживание в классификации
Возвращаемся к решению задач классификации, рассмотренных в главе 2.
Для простоты рассматриваем случай двух классов 1, 2 и проблему в^' с гановления решающей функции (см, параграф 2.4) Т](х) по обучающей выборке хр...,хя, которая состоит из двух подвыборок;
xJf I el , кохда истинным является класс 1, (4.14.0
х., i е J, когда истинным является класс 2.
1 &2 А-Ышоды анализа
Объемы этих подвыборок пх и «2, причем пх + п2 = и, Принадлежность уборочных значений тому или иному классу можно характеризовать новой ременной:
[ 1, если i е 1п ,
1 / (4.14.2)
-1, если i е 1 .
I ’ л2
В пространстве переменных (x,j) на базе указанных экспериментальных точек строится решающая функция в виде непараметрическон оценки регрессии:
= jz- (4.14.3)
Решающее правило на базе нее, как известно (см. гл. 2), имеет вид.
если т|и(х)>0, т0 принимается решение об истинности класса 1; (4.13.4) если Т|^(х) < 0, то принимается решение об истинности класса 2.
Параметр с коэффициента размытости h(n) ~ сп 1/5 находим по экзаменующей выборке Xj,i - 1,п' (которая также состоит из двух подвыборок, принадлежность которым характеризуется переменной у', введенной по правилу (4.14.2) на базе экстремального критерия, например:
7(с) = -1% О' ))2 = min. (4.14 5)
j=i
В многомерном случае (когда имеется несколько информативных признаков) схема решения не меняется. В этом случае колоколообразная нормированная весовая функция в (4.14.3) зависит от всех информативных призна-Ков (см. параграф 4 7), а по критерию (4.14.5) ведется настройка нескольких ^раметров. Настройку параметров с коэффициентов размытости h можно ^водить, используя ту же обучающую выборку (4.14.1). При этом все точ-141 выборки попеременно участвуют в обучении и в экзамене, Это так назы-Ваемый метод скользящего экзамена.
В точке Xj непараметрическая решающая функция (4.14.3) строится с УЧетом всех точек,вернее, только тех точек, которые охватывает колоколооб-Рзздая нормированная функция KN(-) обучающей выборки за исключением Порочной точки Xj-:
___ ___________________________________________ _____ __
а 4 Методы непарамегпрической обработки информации 183
Точка (х7 ,у}), не участвовавшая в построении решающей функции, цс пользуется в критерии настройки с. Например,
A(c) = E(t7~4j(^))2 =mjn- . (4.14.7)
После расчета h(n) при классификации (4.14,4) применяется прежде вид (4.14 3) решающей функции,
Непараметрнческая реализации байесовского подхода
При байесовском подходе к принягию решений решающая функция имеет вид (см. параграф 2.3)
П(х) = /(х|1)Р(1)-/(х|2)Р(2). (4.14.8)
По обучающей выборке находим непараметрические оценки условных плотностей /(х)1) и априорных вероятностей Р(1) :
/(х|/) = — У И. = сп-у\Р(Г)=\ /-1,2.
h у h ) и
Подставляем их в уравнение (4.14.8) и получаем непараметрическую оценку решающей функции:
- z \ 1 V 1 1 V 1 Ах rt2
л„(*)= - L ,'У —/ —— Z тх —г1- =
«1 ,s/ h \ h ) п «2 ,е/П2 h \ h ) п
(41491 п I=i h у h j
Гак как решающая функция сравнивается с нулем, то знаки неравенств не меняются, если ту, (х) умножить на nh > 0 и разделить °а £*=1К((х - х;)/7-1) > 0. Тогда fjn(x) переходит в туДх) (см.(4.14 3) с с° хранением решающего правила (4.14.4). w
Известно, что байесовское решающее правило обеспечивает мини ; вероятности ошибки классификации (см. параграф 2.3):
184 Методы аназизв д0"
р(оШ.) = J f (Д1) p(l)<^ + f f (x|2) P(2)dx ~ mm. G2 Gj
^дый интехрал в Р(ош ) можно записать с учетом всей области у = GiLJ^ изменения х Для этого в подынтегральное выражение нсобхо-ввести сомножителем селектирующую функцию, которая равна 1, если х принадлежит соответствующей подобласти G , и равна нулю при противоположном исходе, а именно
j/(x 11)Р(1)с6с = |1(-Т]„ (х))/(х 11)Р(1)<Д,
с: х
J/(x 12)Р(2)Л = fl(n„ (x))/(x 12)P(2) A.
Gj X
Здесь l(z) - единичная функция.
1(2) =
j 1, z > О, [О, z < 0;
Т1П(Д) -оценка [4,14,3) (или (4,14,9)] решающей функции.
Правило классификации на базе Т]„(х) имеет, как известно, вид (4,14,4) Тогда
?(ош.)= Jl(-p„(x))/(x 11)Р(1)4Йс + (1(л/хП/2(х ] 2}P(2)dx -
X X
= М{1(^(Х))|1}Р(1)+ A/{1(^WW(2), (4.14.10)
Для расчета оценки Рп,(ош.) для Р(ош.) необходима дополнительная контрольная (экзаменующая) выборка
значения х;', i g Pf/,, соответ ствуют 1 классу,
значения х', i е 1'п,, соответствуют 2 классу,
мощности множеств Г,, I'. равны соответственно и[, п'2 и п\ + п’2 = п'.
Ес
Ли же црц вычислении оценки Р„(опг.) использовать ту же обучаю-В1)1борКу, на KOTOpOg п0СТрОена непараметрическая оценка решающей
4 __________..........................................—
т°оьг непараметрической обработки информации 18^
функции Г|„ (х), то найдется бесчисленное множество значений вект0 которые дают нулевое значение (абсолютный минимум) оценки евр. ° риска. Классификация будет безошибочной, но только на обучающей Это иллюзорная безошибочная классификация. Проверка решающею правИ1!^е друз их экзаменационных выборках может дать очень большую ошибку кл' фикации. Обойтись одной обучающей выборкой можно лишь в одном сду^' разделив выборку па две части (см, (4,14,6), (4,14.7), На базе одной из нихвьрщ ’ ляется разделяющая поверхность (х), на другой - оценка вероятности
ки Рл(ош.). Причем деление можно осуществить довольно изощренным способом, когда все точки обучающей выборки участвуют в расчетах функции д и вероятности Рп(ош,), но при этом Рп(ош.) имеет по параметрам с хороший экстремальный вид, В каждой точке х( обучающей выборки решающая функция строится без учета этой точки х( и далее это значение т[,(х = х) участвует в формировании соответствующего i -го слагаемого (в точке х = х ) оценки вероятности ошибки Ря(ош.). Перебирая все точки xit строя в них не
сколько искаженные решающие функции т\ (х!) и рассчитывая соответствующие компоненты в оценке вероятности ошибки, получаем в итоге оценку Рп (ош.). Она имеет минимум во с,
Находим по проверочной (экзаменующей) выборке (, i г 7', J ) оценку вероятности ошибки, заменяя в уравнении (4,14.10) оператор математического ожидания случайной величины М{-} оператором статистического 1 х--
среднсго — д(') п0 проверочной выборке случайной величины: п!
Л(ош.) = Ц,(1)ф У1(-пл(х;))+РД2)ф Е1(тю;», = «j/«', Р„ (2) = п'21п’.
Преобразуем это выражение:
Л'(ош-) = “ ^ООМ4-14,111
п L'e74 ,е/Ф J п ,=1
= j
1 1>г'е /ГП'
I И2
18б“ ~ ——
Методы анализ0
дри минимизации оценки вероятности ошибки (4.14.11) по параметрам эффнциентов размытости h надо учесть, что зависимость Рг (ош.) от с С ывиая- Для оптнмизации необходимо использовать квазиградиептпые Р3^ итМы, в которых вместо градиентов от Рп, по с используются их оцен-/„вазиградиенты). Можно применить метод июбальной оптимизации, в главе 5.
Испытания непараметрического алгоритма классификации на различных истовых примерах и при решении реальных задач показали его универсальность и хорошее качество работы.
Упражнения
4.2 1 На основе простейшей оценки для плотности распределения вероятности вычислите оценку математического ожидания случайной величины Рассчитайте для нее математическое ожидание и дисперсию.
4,2.2. На основе использования простейшей оценки для плотности распределения вероятности вычислите оценку математического ожидания от аналитической функции центрированной случайной величины.
А/{ф(Аг)}= jip(x - m) f(x)dx.
-со
4.2.3. Используя оценку, вычисленную в предыдущем примере, найдите оценку дисперсии случайной величины.
4.2.4. Используя краткую выборку случайной величины и построенную на основе нее простейшую оценку плотности распределения вероятности, вычислите оценки для математического ожидания случайной величины, ее Дисперсии и для математического ожидания функции случайной величины
4 2 5. Используя выборку системы нескольких случайных величин, по-стройте простейшую оценку совместной плотности распределения вероятно-0111 и на основе нее найдите оценки элементов корреляционной матрицы.
4 3.1. На основе полиграммы первого порядка найдите оценку матема-еского ожидания случайной величины. Покажите, что эта оценка является СМеЩенион и состоятельной.
^^4-3.2. Для оценки математического ожидания случайной величины, ио-иной по полиграмме 1-го порядка, вычислите дисперсию и сравните ее с
С11еРсией обычной оценки.
4 3'3. Оценку дисперсии (4.3.3)
Д' V ~— —-—---------------------——— ------------- — —~
методы непараметрической обработки информации 187
Д = £ [(х, - т)(х,+1 - т) + 1
»-lf=i 3
исследуйте на смещенность {т известно).
4.3.4. Исследуйте на смещенность следующую оценку дисперсии (4.3 (j).
А + x-+i Y ,
------> —-------—-т (т известно). и-1,=А 2 J
4 4Л. В одномерном случае запишите оценку Розенблатта - Парзена.
4,4.2. Запишите оценку Розенблатта - Парзена для двумерной случайной величины.
4.4.3. Постройте модифицированную оценку Розенблатта - Парзена и придайте ей рекуррентный вид.
Ъ
4.5.1. Придайте рекуррентный вид оценке математического ожидания
1Л
т = ~2_1х1 -см. формулу (4.5.1).
«/=1
4.5.2, Придайте рекуррентный вид оценкам, рассмотренным в упражнениях 4.2.2, 4.2.3, 4.2.4, 4.3.1.
4 5.3. Рассчитайте оценку математического ожидания случайной величины на основе оценки Розенблатта - Парзена при треугольном виде ядра
4.5.4. Рассчиташе оценку математического ожидания случайной величина на основе оценки Розенблатта - Парзена при параболическом виде ядра.
4,5.5. Рассчитайте оценку математического ожидания аналитическом функции случайной величины на основе использования оценки Розеиблапа-Парзена при треугольном виде ядра. Используя полученный результат, получите оценку дисперсии и исследуйте ее на смещенность.
4,5.6. Выполните задание предыдущего примера при использовании параболического вида ядра.
4.5.7. На основе оценки Розенблатта — Парзена постройте оценку фициента корреляции.
4.5.8. На основе оценки Розенблатта - Парзена постройте оценку энтр0" пии двумерной случайной величины.
4.6.1. Запишите оценку условной плотности распределения вероятно^ используя оценки Розенблатта - Парзена для совместных плотностей
пости (у объекта 2 входа и один выход).
188
Методы анализа М*
д.6.2. Придайте рекуррентный вид оценке условной плотности распределения вероятности.
4,7,1. Для объекта с одним входом и одним выходом постройте непара-метрические оценки прямой и обратной регрессий.
4,7.2. Для объекта с двумя входами и одним выходом постройте непара-метрическую оценку прямой и инверсных регрессии.
4.7.3. Для объекта с двумя входами и двумя выходами постройте непа-раметрические оценки прямых и инверсных регрессий.
4.7.4. Для объекта с одним входом и одним выходом постройте адаптивные непараметрическйе оценки прямой и инверсной регрессий.
4.8.1. Запишите алгоритм расчета робастной непараметрической оценки регрессии для объекта с двумя входами и одним выходом.
4.9.1. На основе оценки Розенблатта - Парзена получите оценки средней условной энтропии и среднего количества информации (объект с двумя входами и одним выходом).
'Ь
4.11,1. Запишите алгоритм адаптивного управления (используя непараметрические оценки инверсных регрессий) объектом с двумя управляющими входами н одним выходом.
4.11.2, Синтезируйте алгоритм адаптивного управления (на основе использования нспараметрической оценки инверсной регрессии) для объекта с одним входом и двумя выходами.
4.11.3, Синтезируйте алгоритм адаптивного управления (на основе использования непараметрнчсских оценок инверсных регрессий) объектом с Двумя управляющими входами и двумя выходами.
'Ь
4.12.1. Синтезируйте алгоритм адаптивного управления экстремальным объектом с двумя управляющими входами и двумя выходами.
'Ь
4.13,1 Синтезируйте непараметрический алгоритм минимизации функ-Ии двух переменных.
Г
ва 4, Методы непараметрической обработки информации 189
Глава 5. МЕТОДЫ ЭКСПЕРИМЕНТАЛЬНОЙ ОПТИМИЗАЦИИ
Задача (параметрической) оптимизации в экстремальной постанове сводится к минимизации функции многих переменных, /(х) = min .
хеХ
Функция I от искомых величин х часто зависит сложным образов Можно представить две ситуации, встречающиеся на практике.
1. Имеется объект, с которым нельзя активно экспериментировать и поведение которого описывается большим числом дифференциальных, интегральных и другие уравнений, в том числе частных производных. Варьирование параметров реального объекта заменяют варьированием аналогичных параметров модели. Функция качества I, которая входит в вышеприведен-ный критерий оптимальности, рассчитывается по результатам решения сложных уравнений модели. Примерами таких объектов являются' взрывоопасные химические реакторы, ядерные реакторы, генераторы электрического тока с использованием явления сверхпроводимости.
Использование для оптимизации обычных методов дифференциальной оптимизации (когда вычисляются первая и вторая производные от функции качества) затруднено из-за чрезвычайной сложности аналитического вычисления производных. При этом приходится вести оптимизацию только по вычислениям функции качества в конечном и малом количестве точек х
2. Для многих объектов при фиксированных значениях параметров х измеряется только значение функции качества I. Моделей для этих объектов еще нс существует. Из-за отсутствия модели отсутствует аналитическая связь между /их. Оптимизацию приходится вести только по измерениям функции качества в фиксированных точках х. Примерами таких объектов служат технологические процессы, например: завод по производству кирпича, комбинат по обработке древесины, завод по производству железобетонных изделий, завод по производству обуви, фабрики пошива одежды н др.
5.1. Методы одномерного поиска минимума унимодальных функций
Рассмотрим вначале самый простой случай, когда оптимизация осу®6 ствлястся только по одной переменной и функция I является одноэкстре мальной, т. е. унимодальной функцией. Однопараметрическая оптимизация часто является составной частью методов оптимизации в пространстве гих переменных. Например, после того как найдено направление п°йС g (в пространстве многих переменных), оптимизация вдоль этого направле представляет собой оптимизацию относительно одной переменной.
190 Методы там30
Имеется функция одной переменной. Необходимо найти ее минимум х изменяющемся в интервале [a,b]: Z(x) = min.
Непрерывная функция /(х) с минимумом явля-тся унимодальной на интервале [а,Ь], если сущест-такая точка х° е[«,£], что на отрезке [а,х°]
®У о }
фикция /(х) убывает, а на отрезке |х ,Ь] возрастает Озис 5.1.1)- Строго выпуклая функция является примером унимодальной функции. Примеры: Z(x) = x2Sl, L-у 2,И Д = ---j 1 -ехр {-х2А}, к -1, 2,
exp {-|x| }, к = 1, 2,....
Основное свойство унимодальной функции, используемое в методах поиска ее минимума, состоит в том, что вычисление двух любых значений /(х1), /(х2) из интервала [<7,bj (причем i1 ^х2) позволяет уменьшить интервал локализации точки минимума х°. Можно убедиться фис. 5.1.2), что если Цх1) < /(х2), где х1<х^,то
/(х‘) > /(х2), где х1 < х2, то х° е[х1,й].
Метод деления отрезка пополам
Метод позволяет исключать иа каждой итерации в точности половину интервала. Иногда этот метод называют трехточечным поиском на равных интервалах, поскольку его реализация основана на выборе трех пробных т°чек, равномерно распределенных в интервале поиска.
Шаг 1, Положить хт~(а+Ь)/2 и L-b-а, Вычислить значение V).
Шаг 2, Положить х1 - а + L/ 4 и х2 ~b - LI Точки х1 ,хт,х2 де-Лят отрезок [а,Ь] на четыре равные части. Вычислить значения /(х1) и V).
ШагЗ. Сравнить /(xL) и 7(хт). Если /(х1) < Z(x"1), исключить интер-1т т
- >положив 5 = х (рис. 5.1.3, а). Средней точкой нового интер-Поиска становится точка х1. Следовательно, необходимо положить *1Цагу * ПереЙТИ К шагУ 5. Если /(х1) £/(хт) (рис. 5.1,3, в), перейти
------- — — - -— —— ——--------------------—_— ------------------— — ЗДоды экспериментальной оптимизации______________________191
Шаг 4. Сравнить Z(x2) и /(хт). Если Z(xm) > Z(x2), исключить интервал [«,х'и), положив а - хт (рис. 5 I 3, б). Так как средней точкой нового интервала становится точка х2, положить хт - х2 Перейти к шагу 5. Если /(х"1) < }(х2), то исключить интервалы (сцх1), (х2, Ь] (рис. 5.1.3, ^положить b = х2 и а = х1. Заметим, что хт продолжает оставаться средней точкой нового интервала. Перейти к шагу 5.
Шаг 5. Вычислить L~b- а . Если величина \L\ мала, закончить поиск В противном случае вернуться к шагу 2
Особенности метода-
1 . На каждой итерации алгоритма исключается в точности половина интервала поиска,
2 Средняя точка последовательно получаемых интервалов всегда совпадает с одной из пробных точек х1, х2 или хт, найденных на предыдущей итерации Следовательно, на каждой итерации требуется не более двух вычислений значения функции
3 Если проведено п вычислений значения функции, то длина полученного интервала составляет (1 / 2)”/2 величины исходного Интервала
4 В литературе показано, что из всех методов поиска на равных интервалах (двухточечный, трехточечный, четырехточечный и т, д,) трехточечны0 поиск, или метод деления ишервала пополам, отличается наибольшей эффективностью.
Метод золотого сечения
Золотым сечением отрезка называют деление его па две неравные частй так, что отношение длины всего отрезка к длине большей части равно от№ шеиию длины большей части к длине меньшей часги отрезка, Нарис 5. точки х1 и х2 осуществляют золотое сечение отрезка \а,Ь\ Оказываем 1 2 '
что точка х осуществляет золотое сечение отрезка [я?х ]? а точка
192 Методы анализа
ка ГлЛЛ- Этот факт позволяет на каждой итерации (за исключением ой) добавлять только по одной экспериментальной точке (с учетом зо-^оГо сечения). Итерационная процедура сокращения отрезка [iZ3Z>] выгля-дйт следующим образом.
g точках х , х
J5
; = д + --у^-(й"а)-й + 0.381966...(й~й),
2 = tr+2^1(b-a) = а + 0.612033,. ,(Ь-а)
* 2
золотого сечения вычисляется мая функция Дх1), Дх2).
Если
Ь\
Если
л г
минимизируе-
2 -2
же
то
цринимается
Дх1) > Д?), то
содержит х0,
его длина Внутри значением
ней целевой функции
Отрезок
равна ~o'i=[(V5 -1)/2](6~й).
[А|Д1 содержится точка х2 со
д пиДДх1), 2(хД }. Точка х2 производит золотое сечение отрезка
а1 = х , - Ъ,
в
На п-т шаге после вычисления Дх1), Дх2), ДхЯт1) найден отрезок
[ЙИ!ЬП], включающий х°. Точка хл+1 такая, что
/(хч+1) = пппДх'), i - 1,н + 1, п > 1; Д -ап ~ [(75-1) / 2]Д2> -а).
Следующей является точка xrt+2 ~ал+Ьл -х,1+1, которая производит 10л°тое сечение отрезка Пусть для определенности
< х"!'2 < хиИ < Ъп, Случай х”+1 < х”'12 рассматривается аналогично.
Ьсли Дхл+2) <ДхпИ) , то полагаем сги+1 =йи,Ьи+] -х”+1,хи?2 =х"+2.
Дх"+2)>/(хл+1), то Ди+5-хп+2,Д+1-Д,х^2 =х”+\ Новый ^ез°к [алИД+1] длиной Д+1 ~ди+1 ^[(75-1)/2]п+1(й-а) содержит производит золотое сечение отрезка и
——---------------- ------------—-—— -------— ---—-------
^Sfnodbi экспериментальной оптимизации 193
7(х"+2) = min(Z(xf), i = l,n + 2} = min{Z(x”+2), I(x^})}
По заданной величине 8 точности поиска х° из раведСТв [(Т5-1)/2]"(7>-а) = 8 вычисляется необходимое число шагов п
Для существенного уменьшения погрешности вычисления 1Т)Че х" (н > 2) необходимо вместо использования формулы х1+2 = ап + Ьп - ущ произвести непосредственное золотое сечение отрезка и в качестве
х"+2 взять ту из точек д„ + (Ьп - д„)(3 - V5) / 2, а„ + (bn - ап )(7$ -1), Ко. торая наиболее удалена от х"+1.
Сравнение методов
Проведем сравнение относительных эффективностей рассмотренных методов исключения интервалов. Обозначим длину исходного интервала через Ц, а длину интервала, получаемого в результате п вычислений значений функции, - через Ln. В качестве показателя эффективности того и:ш иного метода исключения интервалов введем в рассмотрение характеристику относительного уменьшения исходного интервала 91(и) — L„ / L}. Эта величина равна (0,5/’/2 для метода деления отрезка пополам и равна (0,618),J 1 для метода золотого сечения, В табл. 5.1.1 представлены значения F(n), соответствующие выбранным п для двух методов поиска
Таблица 5.1.1
Величина относительного уменьшения интервала 91(и)
Метод поиска
Деления отрезка пополам
Золотого сечеиня
Количество вычислений значений функции
п - 2 5 10 Г15 20
0.5 0.177 0.031 0,006 0.00
0.618 0.146 0,013 0.001 J о.оо
Из таблицы следует, что поиск с помошью метода золотого сечения» одной стороны, обеспечивает наибольшее относительное уменьшение исх иого интервала при одном и том же количестве вычислений значений ф) ции. С другой стороны, можно сравнить количество вычислений зНаЧ^оГ0 функции, требуемых для достижения заданной величины относитель
уменьшения интервала или заданной степени точности.
Если величина 91 (и) = 91 задана, то значение п вычисляется по лам: для метода деления отрезка пополам п - 21п(91) / 1п(0,5), Д-пЯ
фор*-' мето'13
золотого сечения и = 1 + [ln(9l) / ln(0,618)].
___________________— —
194
Р табл. 5.1.2 приведены данные о количестве вычислений функции,
бходимых для определения координаты точки минимума с заданной
це°
тоЧЦОСТЬЮ.
Таблица 5.1.2
Требуемые количества вычислений значений функции
^ТОДПОИска Заданная точность
91 = 0.1 0.05 0.01 0.001
'фГления отрезка пополам 7 9 14 20
Полотого сечения 6 8 11 16
Метод золотого сечения оказывается более эффективным, поскольку он требует меньшего числа измерений функции для достижения одной и той же заданной функции.
При фиксированном количестве п измерений функции 7(х) наибольшую точность расчета оптимального значения х° обеспечивает метод с использованием чисел Фибоначчи [5.4, параграф 4.2].
Метод с использованием квадратичной аппроксимации
При реализации метода оценивания функции 1(х) с использованием квадратичной аппроксимации предполагается, что на ограниченном интервале можно аппроксимировать функцию 7(х) квадратичным полиномом, а затем использовать аппроксимирующую функцию для оценивания координаты точки истинного минимума функции /(х) .
Если задана последовательность точек х\х2,х3 из интервала [«,£] и известны значения функции /' = Дх1), /2 = Z(x4), /J = Z(xJ), то можно определить три коэффициента д0,д(,а2 из условия, что значения квадра-тичной функции
9(х) = а0 + ат(х - х1) + <72(х - х])(х - х2)
ПаДут со значениями Дх) в трех указанных точках.
Условия I1 = /(х1) = ^(х1) = а0 находим коэффициент ~ Z1. Да-еиэ Условия
/2 5 Ях2) = д(х2) = /1+а1(х2-х1)
——________________________________________________________
еМобы экспериментальной оптимизации 195
получаем = (I2 - 71) / (x2 - x1). Наконец, при x = x3 имеем уравнение
/3=/(х)-9(х ) = /“+[(/2-/!)/(х2-х')] (x3-x) +
+д2(х3 -x’)(x3 -x2),
из которого находим коэффициент:
1 р3-/1 /2--Н„ 1 р3-/’
Й2 " (х3 х2)' г - х1 х2 -x'J ” (х3 -Xl)lx3 -х1
Находим теперь точку х, обеспечивающую минимум квадратичной аппроксимации.
---- а1 + а2(х- х2) + а2(х- х1) = 0, 2а2х = «2(х] +ХЪ “Др dx
х = (х1 + хЛ) / 2 - (tfj / 2а2 ).
Можно ожидать, что величина х является приемлемой оценкой координаты точки истинного оптимума х°,
На следующей итерации рассматриваются также три точки: х и две из трех ранее рассматриваемых точек, в которых функция 7(х) принимает меньшие значения.
Если х выходи 1 за границу допустимого интервала, то в качестве ре* шення следует брать граничное значение.
Пример 5.1.1. Минимизируется функция 7(х) - х2 + 16 / х на интерва’ ле 1 < х < 5 В точках х1 = 1, х2 - 3, х3 = 5 вычисляем значения функдйИ Z1 ~ 17; I2 -14.33; Z3 -28.2, Затем определяем параметры аплроК симирующей функции.
14.33- 17 , 1 <28.2-17 э лб7
а ~ _——.— = -1,335, сц =-------- ——-------к 1,335 = 2.00/ -
3-1 " 5~31. 5-1 )
Подстановка этих значений в формулу для х позволяет получить
__———
Методы
196
±3 jLl3!!'] = 2.323,/(x) -12,284.
2 U-2.067J 7
Точный минимум 1° - 12 достигается в точке х° = 2.
Совершаем еще одну итерацию, оставляя точки, в которых функция наименьшая:
р=17, х2=х = 2,323, 12.284: х3 = 3, Л! =14.33.
По аналогии с вышерассмотренным получаем
12.284 -17 1 [14.33-17 0 ^ПА
а =——----—- = -3,565; а, =-------- --------+ 3.565 -3.294;
1 2.323-1 3-2.3231 3-1 )
_ 1 + 2.323 Г-3.565Л
Y_-------______ =2.202, /(л) — 12,115,
2 ^2-3.294; v 7
На третьей итерации аппроксимирующую параболу проводим через точки: ? = 2.202, /'= 12.115, х2 = 2.323, 12 = 12.284, х3 = 3, 73 = 14.33 и получаем
^=1.413, а2 =2.013, х = 1.911, 7(х) = 12.024.
Квадратичная аппроксимация лежит в основе метода, разработанного Пауэллом [Powell М. J. D. Ап efficient method for finding the minimum of a function of several variables without calculating derivatives // Computer J. 1964
155-162]. Приведем схему алгоритма. Допустим х1 - начальная точ-и’а Ах - выбранная величина шага.
Шаг 1. Вычислить х2 = х1 + Ах.
Шаг 2. Вычислить Iх = /(х1) н I2 = Дх2),
Шаг 3, Если Iх > I2, положить х3 = х1 + 2Лх, Если Iх < I2, положить Г -- 1
-Ах.
Шаг 4, Вычислить /3=/(х3) н найти Imra = minf/1,/2,/3} и xmm ^соответствующую 7ПШ)).
5, По точкам х\х2,х3 построить квадратичную аппроксимацию делить х.
^аг Проверить одновременное выполнение двух условий окончания
СКа а) является ли разность Zmm - Дх) достаточно малой; б) является ли
—- -—_-------------- _ _--------------------_____-------
е1поды экспериментальной оптимизации 197
разность xmin - х достаточно малой. Если оба условия выполняются, зак0(| нить поиск, В противном случае перейти к шагу 7.
Шаг 7. Выбрать наилучшую из точек (хгаш, х) и две точки по обе СТо роиы от пес. Если при этом оказывается только одна точка (слева или сцрада от наилучшей), то вторая добавляется с учетом заранее установленной длщщ шага Лх. Точки обозначить в естественном порядке и перейти к шагу 4,
Пример 5.1.2. Минимизируем функцию 7(х) - 2х2 + 16 / х методом Пауэлла. Выбираем начальную точку х1 = 1 и длину шага Лх - 1. Ддя проверки окончания поиска используем условия: а) ((разность значений I)// (<0.003, б) ((разность значений х )/х [<0.03.
Итерация 1.
Шаг 1. х2 - х1 + Ах = 2.
Шаг2. /(х1) = 18, 7(х2) =16.
ШагЗ, 7(х1)>/(х2), следовательно , полагаем х3 = 1 +2 = 3.
Шаг 4. Z(xJ)= 23.33, Zmjn = 16, хтш=х2=2.
ШагЗ.^^
1 2-1
1 23,33-18 . 5.33 _
——{—------------л.} =----+ 2 = 4,665.
3-2 3-1 2
—^—^—- = 1.5 + -—^— = 1.714, /(х) = 15.210.
2(4.665) 4.665 7
Проверка условий окончания поиска:
_ 1 + 2 х =----
2
Шаг 6.
0.0519 > 0.003. Следовательно, продолжаем поиск.
Шаг 7, Наилучшей точкой является х. Окружают ее х3 = 1 и х'=2 Переобозначаем их в естественном порядке: х3 = 1, х2= 1,714, х3= 2, 11ере' ходим к итерации 2, которая начинается с шага 4.
Итерация 2, 2
Шаг 4. хт= 1, Z(x’) = 18, х2= 1.714, Z(x2) = 15.21=Zmin, -W х3 = 2, I(x3) = 16.
, 15.21-18
Шаг 5. а, =------— - -3.908,
1 1.714-1
1 (16-18 ПЛОЧ1 1.908
а, = ------———— - (3.908) 1 = ——6.671,
2-1.714 [ 2-1 J 0.286
2 714 - 3 908
у ---------' -°- = 1.357 + 0.293 = 1.65, Z(x) = 15.142.
2 2(6.671) 7
198
_____ ——-—
Методы анализа
Ц1аг 6, Проверка условий окончания поиска:
1Л21—15J42 _ q qq45 > q QQ3 условие не выполняется, } 15.142
Шаг 7. Наилучшей является точка х = 1,65, а окружают ее точки х1= 1
0 х2-1.714.
Итерация 3.
Шаг 4. х1= 1, Дх1) — 18, х2 = 1.65, Дх2)= 15.142 =Zmin, xmin= х2, /=1.714, Дх3) = 15.21.
15.142-18
Шаг 5, а =-------—— = “4,397,
1 1.65-1
а2 =----1—_ Jllllzl? _ (-4.397)1 = 7.647,
2 1.714-1.65 [ 1.714-1 J
_ 2.65 -4.397 . rf~ _1Э,
х = —-----------= 1.6123, Дх) = 15.123,
2 2(7.647)
Шаг 6, Проверка условий окончания поиска: а)
15.142-15.123
15.123
-0,0013 <0.003, б)
1.65-1.6125
1.6125
- 0,023 < 0.03 . Условия выполняются.
Поиск закончен.
5.2. Одномерный глобальный поиск
Наиболее эффективные и теоретически обоснованные алгоритмы глобальной аппроксимации трудны для реализации. Поэтому чаще реализуют б°лее простые алгоритмы, отвечающие частным критериям рациональности. Один из них (предложенный независимо двумя авторами - Пиявским и щУбертом) на примере одномерной оптимизации приведен ниже.
Считаем, что минимизируемая функция Дх), а < х < bt - липшицева Фикция с известной константой L:
1/^2)“/(х1)|<Дх2 -х,|.
(5.2.1)
Отсюда получаем два неравенства:
1х - х' | < Дх) - Дх')<£ | х-х' х,х' е [а,Ь].
Методы экспериментальной оптимизации
199
Левое неравенство
(р1 (х) = I(x’) - L | х - х1 | < /(х)
Р 2.2)
показывает, что функция /(х) можарируется снизу кусочно-линейной фущ. дней, Его применяют при поиске минимума функций. На рис. 5,2.1 представ леи этот случай, когда х - любая фиксированная точка из интервала [а а х независимая переменная из того же интервала [а,й].
При поиске максимума функций используется правая часть вышеуказанного неравенства /(х) < Z(x') + L | х - х' х,х' е [я,6].
Опишем теперь алгоритм последовательного поиска глобального минимума. Произвольно выбираем исходную точку х1 с [а, й], Находим в ней кусочно-ломаную (р1 (х) = Цх1) - L | х - х1 | и минимизируем ее при х Получаем х2, В ней опять находим (р2(х) н вычисляем х/С*)' = тах((р1(х),(р2(х)}. Кусочно-линейная функция \р2(х) ограничивает Лх)
снизу. Минимизация у2 (х) дает следующую точку х3, В ней также находим ф3(х),азатем у3 (х) - max {\/2(х)3р3(х)}. Минимизируем ее и полу416*1 л
х4 и т. д. На рис, 5.2.2 указаны точки х\...,х5 и функция \р5(х). Область поиска глобального экстремума можно на каждом ^аГ сократить,
200 Методы анализа
На рис. 5.2.2 после совершения 5 шагов приведена величина - min i - 1,5}. Неравенство \|/5(х) > Г выделяет область Z)4 . Для этого множества гарантировано выполнение неравенства I(х) > 1+, значит, множество может быть исключено из рассмотрения. Подмножество [а, \ D+, в котором надо вести поиск минимума, помечено нарис. 5.2.2 жирной линией. Если длина наибольшего подынтервала в подмножестве [a, b] \ D+ меньше e/i, то поиск можно прекратить, так как дальнейшая оптимизация не может улучшить достигнутое значение больше чем на с.
При увеличении числа итераций метод ломаных сходится.
5.3. Последовательный симплексный метод
Метод предложен в 1962 г. Спендли, Хекстом, Химсвортом [Spendly ’Hext G.R., Himsworth F.R. Sequential application of simplex designs in optimization and evolutionary operation // Texnometrics. 1962. V. 4. Pp. 441-461.J. РЧ поиске экстремума используются значения минимизируемой функции Iх) в вершинах симплекса (в пространстве вектора х).
Правильный симплекс - это регулярный многогранник в Rm с (т +1) Рщйнами. В двумерном пространстве правильный (регулярный) симплекс 0 вставляет собой равносторонний треугольник, в трехмерном - тетраэдр, ^ловимся на одном из способов построения правильного симплекса.
^Начале построим симплекс, одна из вершин которого находится в на-^^оорДИнаг Координаты вершин определяются матрицей
а $ Методы экспериментальной оптимизации
201
у 0 ... О О л
£1 g g g
g g\ g g
g g g g
g g gi g
<g g ... g gj
g! =—+ l -l + m);
(V/И + 1 - 1) ,
<53 1)
в каждой строке которой расположены координаты соответствующей верши-ны Ребро симплекса равно г.
Для т ~ 1, г = 1 симплексом является отрезок с координатами 0, 1
Для т = 2, г ~ 1 симплексом является правильный треугольник с координатами вершин (0; 0), (0,96; 0.26), (0.26; 0.96)
Симплекс можно из начала координат переместить в любую выбран-
1 , 1 1 1 ч
ную точку х -iXj, х2, хдД пространства:
Гй д Л2 . .. Хт < I L + X
g xf ... — -> У~ 4- х1
g х2 .. т 1 1 х2 J*? =5 + т 1 у + X №1 + 1 . 1 чу + х ;
(5.3.2)
После вычисления (или измерения) в вершинах симплекса целевой функции находим ее максимальное значение. Допустим, Z(x) максимальна в вершине 1 (см. рис. 5.3.1). Вершину 1 отражаем через центр противоположной I рани и получаем симплекс с вершинами 2, 3, 4. В вершине 4 вычисляем 7(х). Дальнейшие шаги повторяются. Формализуем их.
Шаг 1. Задается исходная вершина симплекса х1 = Р33’
мер г симплекса и строится симплекс (5.3.2).
Шаг 2. В вершинах симплекса вычисляется минимизируемая фуя^”8 Z(x‘), i = \,т + 1.
Шаг 3. Осуществляется проверка выполнения условий окончания 110 иска оптимума:
202 Методы анализа
(5.3.3)
Поиск завершается, когда или размеры симплекса (первое условие в (5 3.3), или разности между значениями функции в вершинах (второе условие в (5.3.3) становятся достаточно малы. Можно требовать и одновременно выполнения двух условий в (5.3.3).
При выполнении условия (5.3.3) процесс поиска заканчивается. Решением задачи (с выбранной точностью) является: х1,1(х1) — точка с минимальным значением функции /(х).
Если неравенство (5.3.3) не выполняется, то осуществляется перемеще-НИе к оптимуму за счет перехода одного симплекса к другому.
Шаг 4. Находится наихудшая вершина симплекса. Эта вершина с максимальным значением У(х).
Вычисляется центр тяжести хт+2 противоположной грани:
.*л+2
1 w+1
(5.3.4)
203
1ы экспериментальной оптимизации
Шаг 5. Осуществляется отражение вершины хр относительно х
хи+3 - хт+2 + (хт+2 - хр) - 2хт*2 -х\ (5 3
и в точке хт+3 вычисляется функция /(хт+3).
Шаг 6. Если точка хт+3 оказывается хуже всех остальных точек новог симплекса, то осуществляется возврат к прежнему симплексу с после дующим его сжатием относительно лучшей из вершин х1:
1(х!) - min{7(xf), i -l,m + l), симплекса:
х' = ух' + (1 - у)х' ,1 = 1,/и +1,0 < у < 1.
Здесь у - коэффициент сжатия симплекса. Осуществляется переход к шагу 2.
Если же точка хт+3 не является "худшей" в новом симплексе, то продолжается дальнейшее движение (переход к шагу 4).
5.4. Метод деформируемого многогранника (Нелдера - Мида)
В целях ускорения сходимости, повышения точности при подходе к экстремуму и устранения трудностей на искривленных оврагах симплексный метод был модифицирован Нелдером и Мидом [Nelder J. A., Mead R. A simplex method Гог function minimization /7 Compurer J. 1965. V. 7. Pp. 308-3131 Правильный симплекс в процессе поиска меняет свою форму и становится неправильным, а добавление к нему дополнительных точек трансформирует его в деформируемый многогранник. Деформируемый многогранник (даже деформируемый симплекс) по сравнению с правильным симплексом адаптируется к топографии целевой функции, вытягиваясь вдоль длинных наклонных плоскостей, меняя направление в изогнутых впадинах и сжимаясь в ок-рссшости минимума.
Опишем алгоритм поиска для деформируемого симплекса. Обозн3' чим через х1 (к) = (х[ (А), .. ,х^ (A))(z - 1,т + 1) z-io точку на к -м этапе поиска. Многогранник (неправильный симплекс) состоит из т + 1 вершин^ Вершины х^(А;)и х1(к) соответствуют наибольшему [/(хР(^)
- max(Z(x'(£), z — l,w + l}] и наименьшему [/(x^i) = mln(Z(^ (^'
204 Методы анализа данН&
значению целевой функции Обозначим через хп>+2(к) центр ^еСти трани, противоположной худшей вершины хр(к)
1 т+1
х”+2ц)=-:>>'(*)•
1*р
Процедура отыскания вер-щинЫ о меньшим значением /(х) сое гоит из следующих операций.
1. Отражение вершины xp(£) через центр тяжести про-тивоположнои грани, х (я) = = т”Щ4)+а(х'”+2(4)-х'’Д)), где а > 0 - коэффициент отражения (рис 5 4.1, а), например, а = 1
2. Растяжение. Если оказывается (см операцию 1), что /(х"1+3(#)) < Дх1 (к)), то вектор (xm+j(k) - хт12(&)) растягивается: тм+4(&) = хт+2(£)+Р(хт-г3(#)^х"'+2(А:)), где р>1 - коэффициент растяжения (рис 5 4.1, б) Если /(xw+4(^)) < 1(х\кУ), то хр(к) заменяется на
(к) и процедура продолжается снова с операции 1 при к = к +1 Если же 1(хп,+А(ку) > 1(х1(кУ)> то хр(к) заменяется на хт+3(к) и также осуществляется переход к операции 1 при к = к +1.
3. Сжатие. Если Z(x'"+J (кУ) > 1(х1 (£)) для всех i р, го вектор (х₽(&) - хт+2(кУ) сжимается. х'м+3 (к) = хт+\к') + у(хр(к) - хт н2(&)), где 0<У<1 - коэффициент сжагия. Затем хр(к) заменяется на хг},+5(к') й осуществляется возврат к операции 1 для продолжения поиска На (к + 1)_м шаге.
4. Редукция. Если /(хп,+3(А)) > 1(хр(к)), то все векторы (х(Г)-х'(£)), / = ф т +1, уменьшаются в 5 раз (например, в 2 раза) в соот-
л&ва j Методы эксперш^ентальноИ оптимизации
205
ветствии с формулой х1 (А) - х1 (к) + 5-1(х'(&) - / -1,т + 1, й
ществляется возврат к операции 1 для продолжения поиска на (к + шаге.
Критерий окончания поиска может иметь вид
! »1+i л1'2
----Z(/(xWW(r"W Se, m +1 ,.i J
где б - заданное малое число.
Используя указанные 4 операции и критерий окончания, петрудНо построить схему поиска методом деформируемого многогранника.
Рассмотрение тестовых примеров разных типов выявило наиболее пред, почтительные диапазоны задания параметров: а = 1; 2.8 < |3 <3.0,
0.4 у < 0.6 ; 5=2. Влияние изменения у на эффективность поиска наиболее значительное, При 0< у <0.4 существует вероятность того, что из-за сжатия многогранника будет иметь место преждевременное окончание процесса. Прн 0.6 < у может потребоваться избыточное число шагов я больше времени для достижения окончательного результата.
5.5. Градиентный метод с использованием планировании первого порядка
Простейший градиентный алгоритм поиска минимума функции имеет вид
?+I =?-y'W(?), Z-0,1,2,..., у'>0. (5 51)
Оценка составляющих градиента вычисляется за счет обработки экспериментальных данных (значений минимизируемой функции в точках плана), полученных с использованием ортогонального планирования пеР' вого порядка. В результате планирования и обработки его результатов «а' ходим параметры J},, р2, ко горые являются оценками градиента0
безразмерных координатах. При переходе к размерным координатамс0 ставляющие градиенты принимают вид:
ст = —— Ах 171
206
Методы анализ
Например, ДО131 ДвУмеРного случая имеем
VZ(x )=
Эх, 5Z(x) < Зх2 ,
'JL Afj А < ^*2
где 0р 02 “ коэффициенты линейной модели в безмерных координатах; ду Дх2 - интервалы покачивания координат относительно точки (хр х2); v - величины шага.
Рис. 5 5.1
Один шаг, выполненный по алгоритму (5.5.1), приведен в левой части рис. 5.5.1.
Слабым местом алгоритма является выбор величины у шага В методах дорого порядка (например в методе Ньютона) шаг вычисляется автоматиче-СКй по информации о крутизне поверхности.
5.6. Метод Ньютона
с использованием планирования второго порядка
Один из простых вариантов алгоритма Ньютона имеет вид
х*' = / _[? 4х )] v/(Д / = 0,1, 2.....
дхдх J
вй Методы экспериментальной оптимизации
(5.6.1)
~207
Для расчета оценок градиента и матрицы вторых производных осущес ортогональное композиционное планирование второго порядка. Посде^1^ богкн измеренных (вычисленных) в гонках плана значений минимнздруе функции получаем параметры безразмерной модели (при т - 2): r
Р12 = Рз! ’ '
По этим коэффициентам вычисляем элементы матриц:
v7(?) =
4V Axj JL
ЭЧ(х')
дхдх
' 2Р„ AxjAXj
Р12 _
AxtAx2
2^22
Лх2Дх2 }
В правой части рис. 5 5.1 приведен один шаг, выполненный в соответ ствии с алгоритмом Ньютона. Если функция 1(х) хорошо аппроксимируется уравнением второго порядка, то алгоритм Ньютона за один шаг обеспечивает выход в окрестность минимума.
5,7. Методы случайного поиска
Наиболее простой способ использования случайности при поиске минимума функции заключается в следующем. Внутри области, где отыскивается экстремум, последовательно по случайному механизму распределяются точки х и в них измеряется функция качества. Точки, обеспечивающие наименьшее значение функции качества, запоминаются. Процесс поиска заканчивается, когда число безрезультатных проб превысит порог.
Проба считается безрезультатной, если значение функции качества больше, чем наименьшее значение функции, встретившееся во всех преДН' дущих пробах.
Недостатком данного способа поиска экстремума является чрезвычайно большое число испытаний.
Второй, более эффективный по отношению к предыдущим, способ за ключается в случайном выборе направления поиска и детерминирований поиске (одномерном поиске) вдоль данного направления.
Рассмотрим еще один способ Будем считать, что 7(х) имеет нескор минимумов н среди них необходимо отыскать наименьший, т. е. глобаЛЬН^ минимум При поиске глобального минимума эффективным является с°ч т_ ние локальных детерминированных методов поиска со случайным проС ром области X. Простейшая схема поиска выглядит следующим образом^ _-----————---------------_---------.—-----------------_ — --
208 Методы анатза
g3 области X случайно выбираются точки х. Они шгужат нулевым ближением для спуска в локальный экстремум. На этом этапе может быть ^длизовая любой из алгоритмов поиска локального минимума. После каж-Р 0 локального спуска полученное значение функции качества /(х*) срав-йрается с предыдущим. Если получено меньшее значение I, то запоминается нОВое х* и 1(х ). В противном случае проба считается безрезультатной. После многих испытаний основные минимумы будут выявлены, а в памяти будут храниться х и 1(х ), соответствующие глобальному минимуму. По-яск заканчивается, когда число безрезультатных проб превысит заданный
порог.
Случайный механизм распределения точек в некоторой области применяется для оценивания первых и вторых производных от функции качества с последующим использованием оценок в известных регулярных методах поиска.
5.8. Глобальная оптимизация методом усреднения координат
Метод усреднения координат. Приведём формулы последовательного расчета координат положения глобального экстремума (минимума или максимума) ограниченной однозначной функции 7(х) многих переменных ^(^•зХд) в ограниченном пространстве Считаем, что гло-
бальный экстремум (минимум или максимум) функции /(х) единственен. Глобальный экстремум может находиться внутри области X, на границе её, а также на границах подобластей, из которых она состоит.
Рассматриваем любую непрерывную ограниченную в X функпию ф(х"). Вводим последовательность {ps(y), 5 = 1,2,...} непрерывных, положительных в У] функций таких, что для любых у < z (где у, zc/i1) последовательность 5 = 1, 2,... [ с ростом д монотонно нарастает:
1Ф1 л?(е) п , . .
Д} = сс’ У <2 Примерами функции ps\y) являются:
exp(-sy) f
—- -- = lim exp(5(z - у)) - то, у < z;
exp(-5z) Я—
DlZ1: Нт ~ lim У“со, у < z, 1 < 5;
J—2 s—>оо
3) [Xs при положительных у : lim ~ lim ~ = °о ; у < z.
5->л> 2 S ^уJ
а Д Методы экспериментальной оптимизации
209
При выполнении указанных выше условий справедлив результат:
ФО™ ) = lim jФ(*)Р. п™ (*)^, (*) = Т”7прт
х
Для точки глобального максимума: х^ при х е X - справедливо условие
-arg sup/ух) arg inf(-/(X))
Ф(*тах ) = lim [Ф(Х)£7 max (X)dx, Ps тЭх (*) =
s^x \pS-Ktydt
x
(5-8 1)
(5.8 2)
аналогичное (5 8.1) с заменой в нем Z(x) на (-Z(x)). Этот факт обусловлен эквивалентностью задач максимизации функции 7(х) и минимизации функ-ции(-/(х)).
В качестве непрерывной функции ф(х) в (5.8.1), (5.8.2) берем v-ю координату вектора х (т. е. ф(х) - xv) и тогда получаем формулы покоординатного расчета точки глобального минимума:
mm = Um J-vА.тщ <*)dx, V = 1, Ж , pm (x) = ; (5.8 3)
^x J/W)M
X
и соответственно глобального максимума функции 7(х):
ps max(x) = ‘
п^х JPsbW)^
X
Формулы (5.8.3), (5.8.4) имеют следующий векторный вид:
Xmm = lim Jxp m(х)<&, p (x) = ; (5 * 8 5)
’-**x JPjUDXi
X
x^ = lim fx p (x)dx, p (x) = (5 S
s^x \ps(~I(ty}dt
x
210 Методы анализ0 ^atl
СчИтаеМ, что известны точная верхняя /тах = supl(x) и точная нижняя
= infZ(*) границы рассматриваемой функции Z(x). Для удобства рас-хеХ
qeTa и повышения точности вычислений в (5,8,5), (5,8,6) используем безразмерные неотрицательные переменные gmin(-), gmax(-), лежащие в интервале
= Нт Ы,тт(^= 7\min(x)= (5 8
5-><и X Агах Ат
r&^max^. gmaxW=-),1!“~'W (5-8-8) Апах Ат
Кроме ранее приведенных ядер ps(g) (экспоненциального: exp(-sg), степенного: s~8, гиперболического: g~s) могут использоваться, например: линейное, параболическое, кубическое и т, д. в степени 5 : ps(g) - (1 - gr)s, г = 2, 3,.,., Эти виды ядер, а также два из ранее приведенных (экспоненциальное exp(-.sg) и гиперболическое g~s) конструируются по единому образцу.
За основу берется убывающая в интервале [0; 1] функция p(g), а затем она возводится в степень s: ps(g) = (p(g)Y Для таких p(g) всегда при y<z. Следовательно, ядра p5(g) удовлетворяют основному условию теоремы: lim (р(у)У/(р(^)У = lim (р(у)/р(?))л - 00;
Перечисленный набор ядер ps(g) пока достаточен для решения задач Эобальпой оптимизации, С ростом s растет "селективность" (способность к ^аллзации положения глобального экстремума) нормированных ядер \nun(jr), PJ>max(x).
--J^gTHM, что ядра (параболическое, кубическое и т, д.) в степени s
- gr)s, г = 2, 3, ..,) в отличие от ранее рассмотренных в окрестно-^Ти ~ -—J
точки g - о являются выпуклыми вниз. Это свойство оказалось полез-
Г'*РИ оптимизации многоэкстремальных функций, искажённых помехами.
~ ..._____
Методы экспериментальной оптимизации 211
1,3 । rax i i i gg 2
Рис, 5,8.1В. Весовая функция
Пример 5.8.1. Для непрерывной функции одной переменной, представленной на рис. 5,8,1а, по формуле (5,8,7) при Л(&тп) ~ eXP(~J£min) рассчитываем точку глобального минимума
xmin = lim ^(5) = 2.
5-*-^
Поведение функции ^(j) представлено на рис, 5,8,16,
Весовая нормированная функция ps mjn (х) при 5 = 100 изображена на рис. 5,8.1в. Она стремится с ростом 5 к дельта-функции с особой точкой
Аналогично для той же функции по формуле (5,8,8) ПРЙ P.s(gimx)=eKp(-5gmax) рассчитываем точку глобального максимума:
хтах = итад=о.
5->=о
212
Методы анализа
Поведение функции представлено на рис 5 8 1г
Весовая нормированная функция pjmax(x) лри 5 = 20 изображена на г g 1д Она стремится с ростом s к дельта-функции с особой точкой
max
Рис 5 8 2 Эксремальная функция
Пример 5.8.2. На рис 5 8 2 приведена функция, гЧОбальному минимальному значению которой соот-ветствует не одна точка, а интервал значений переменной X [4,5] Максимальному значению тоже соответствует интервал [0,1] Расчет по формулам (5 8 7), (5 8 8) дае1 хт1П = 4 5, *^=0 5 Эти точки соответствуют минимуму и максимуму функции 1(х) Это произошло в силу замкнутости множеств
возможных значений х, соответсзвующнх минимуму и максимуму функции /(х), и полученные значения хП1Ш, хтах попадают в эти множества
Пример 5.8.3. Функция, приведенная на рис 5 8 3, имеет в двух точках (1,3) одинаковое минимальное значение и также в двух точках (0, 2) одинаковое максимальное значение По формуле (5 8 7) получаем, что хт1п —5/3 Оно не соохветствует ни минимуму, ни максимуму Если интервал возможных значений [0, 3] разбить на подынтервалы [0, 2], [2, 3], в каждом из которых имеется один гло-
/(X)
Рис 5 8 3
бальный минимум, ю по формулам (5 8 7) получаем истинные результаты xmm “ 1“ 3 При поиске максимума ситуация аналогична вышеприведенной
Поведение нормированных весовых функций pjmin(x) (или pjmax(x))
в окрестности особой точки xm,n (или xffiax) определяется поведением в этой окрестности самой исследуемой па экстремум функции 1(х), Весовые функции имеют односторонний скошенный вид, если точка xmm находится на границе области X - см рис 5 8 1в, 5 8 1д Они являются разрывными, если Кх) разрывная в особой точке хтш (или хП1ах) Прн непрерывности /(х) ве-с°вие функции p5inm(x), pj max(x) тоже непрерывны, а при симметрично-
Ях) они симметричны
Метод усреднения координат допускает обобщение и развитие на реше-е оолее сложных многоэкстремальных проблем 1) минимаксной злобаль-011 оптимизации, 2) многокритериальной глобальной оптимизации, 3) опти-аЦии функций при наличии ограничений равенств и ограничений ^Равенств
е° Методы экспериментальной оптимизации
213
Простота теоретического результата (5,8,1) является его основные таинством, Он позволяет конструировать сравнительно простые и эффек^С' ные алгоритмы поиска глобального экстремума.
Построим алгоритмы численного поиска экстремума. Приведение выше теоретический результат дает строгое обоснование сходимости вычцс* ляемой последовательности параметров в точку глобального экстремума прд увеличении s - коэффициента селективности весовых функций Д А,шах(х)- Ои позволяет построить целый спектр практически реализуемых алгоритмов, обеспечивающих поиск глобального экстремума с вероятностью близкой к единице.
С ростом я (где 0 < s) нормированные неотрицательные ядра ps mm(x) A,max(x) становятся все более узкими. Они приближаются к дельта-функции с особой точкой, соответствующей либо глобальному минимуму, либо глобальному максимуму функции 7(х). Но с ростом з становится все труднее вычислять соответствующий интеграл — см., например, формулы (5,8,7), (5,8,8). Надо иметь подынтегральную функцию во все большем количестве точек в окрестности указанной особой точки, ио эта точка неизвестна. Мн должны ее найти. Локализация mi/J(x), Лпык(х) наводит на мысль о построении итерационных процедур с сокращением иа каждой итерации области усреднения. Область усреднения надо последовательно уменьшать по мере локализации ядер ps^m(x), pSjmm(x).
Приведем возможный вариант алгоритмов поиска глобального минимума;
= A,„mW=fafeminWH.
Х‘ = tf n X, IT = [x( - Ax,', x( + Axf ] X X [x^ - Ax;, x‘n + Ax', ],
yx1 )
(5.8.9)
Z = 0,1, 2, ...;[0</?, ge{l, 2,-},0<з].
Здесь I - номер итерации; у q, s - подбираемые фиксированные параМеТ ры, II' - прямоугольная область в окрестности точки х1,
214 Методы анализа да^^
Вопросы исследования свойств этих алгоритмов при различных Наборах а^етров, в том числе доказательство сходимости в глобальный экстре-
ЙуМ жЯУг своего решения,
При изменении х внутри прямоугольной области П/ с центром в точке 1 ка]Кдое значение х удобно представить в следующем виде;
х^х'+Дх'-w,, wve[-l;l], v = l,m.
(5.8.10)
Покажем, что в алгоритмах (5.8.9) при 0 < у9 < 1 всегда Дх^+1 < Лх' , у-ри, а, следовательно, прямоугольная область Пг (и соответственно Х!) от итерации к итерации будет сжиматься.
Действительно, для каждого v = н ^ = 1, 2,... имеем, что
(5 8.11)
Здесь учитывается, что:
1) | uv |9< 1, так как uv находится в интервале [-1; 1];
2) J А,щш (х) = 1 в силу нормировки X>mm О)
X1
Примеры показывают, что в алгоритме (5,8.9) скорость сжатия прямоугольной области П7 можно сделать достаточно высокой. Но в го же время °Ка должна быть такой, чтобы не пропустить глобальный экстремум. Это Достигается за счет выбора вида ядер ps(g), на которых строятся нормиро-&аннь1е ядра п1ш(х), ps тях(х), и параметра (их "селективности").
Принимаем во внимание уравнение (5.8.10) линейной связи х с и и за-Писываем класс алгоритмов поиска глобального минимума (5,8,9) в эквивалентном виде:
х/+] 1 * 1 г -I /
= х„ + Дх„- Кр,>1ПШ(х)Жс, х’ _____________________ -• ____________________________
8<а 5 Методы экспериментальной оптимизации 215
As,min (X) Ps (Amin (x)) JPs (Amin (0) >
X1 =n/Cl%,n/ =[xj - Дх(,х{ + Дх1/]х-..х[л4 -Дх'^х^ +Дх^],
Hv I^As,mm(X)^
\V$
, v = l,m,
(5.8,12)
f = 0,1, 2, ..,; [0<yg, ge{l, 2, ...}, 0<s].
Приведенная форма алгоритмов более удобна при использовании.
При практической реализации алгоритмов (5,8.12) на каждой итерации необходимо выполнять численное интегрирование. Это достигается за счет размещения в области X пробных точек (их количество «) х(г\ i = 1, п, вычисления в них минимизируемой функции = I(x^), i - 1, п, и соответствующей замены суммированием операции интегрирования.
При получении пробных точек х(‘\ z = 1, и, последовательно генерируются точки в прямоугольной области П7 (см. (5,8.10) с центром в точке х1
х[р = x'v + Дх^ • иу е[-1;1], v = l,m, i - 1, 2,(5.8.13)
и из них оставляется п точек, попадающих в допустимую область X. Пробные лежат в области X1 =nz
Исходная точка х° и размеры Ах ° прямоугольной области П° выбираются так, чтобы П° охватывала допустимую область X или ту её часть, где расположен искомый глобальный экстремум.
В результате указанного перехода от интегрирования к соответствующему суммированию алгоритмы (5,8.12) приобретают следующий вид:
х/+1 = X й =УЛ(г) (5.8J4)
Xv Xv + Wv,min As,min 5 '
f=l
_ As (Amin) *(0 _ Anin
r^min n so min A 7 j
SAfemin)
216 Методы анализо
Ax'*'=/,'Arv^SIUv) I’/CuJ
v -1, m,
/ = 0, 1, 2, [0 < у?, # e {1, 2,...), 0<.s].
Здесь /max =max{/(J),» =1, n}, fmin =mm{F(,), i = 1, и); в переменных wj*\ ДО для упрощения записи опущен номер итерации I. Весовые коэффици-/я?1П1П
езты (ядра) нормированы на системе п пробных точек; = 1.
При поиске максимума функции 7(х) в (5.8,14) необходимо заменить
6) иа '
£mm ИЭ *niax
/+1 I л / — — V"1 (0—(О Л г О |Г\
+ Д*,. ’ м,'max ’ Mv,max — Z-2A Ps,max. > (5,8.15)
гЫ
—0) __ Pi(^max) rtW — ^max ~~
n 5 o max у у ’
J-l
z n \ l/q
M*' = Y, Д< Ш “v’ r?,('L . V = 1, m.
V-l /
/^o, 1, 2, . [0< Y(?, (?g{1,2,,„), 0<sJ,
Очевидно, что и при i = 1, n лежат в интервале [0; 1].
Останов алгоритма можно проводить как обычно либо по величине сжа-ТИя области пробных движений, max {j Дх' v = 1, т} < е}, либо по величине Наиболыиего уклонения минимизируемой функции на множестве пробных тонек- 1 т < р пмх 1 пип - ь2‘
Тестирование большого числа многоэкстремальных функций показало, Чт° ^горитм (5 8 14), (5,8.15) имеет устойчивые достаточно высокие резуль-131111 (по скорости сходимости и точности) при;
1) 0.8<7? <1.2; l<q-
2) степенных сипах ядер, экспоненциальном, гиперболическом, линей-_ ___________________-
ва Методы экспериментальной онтмлш <aifwu 217
ном, параболическом, с параметрами селективноеги j, лежащими в nmpQXii, пределах; Х
3) 50 < и;
4) случайном равномерном распределении точек (с независимыми коо динатами) внутри области пробных движений.
Скорость сходимости достаточно высокая; 5-12 итераций. Обычно эффициент берется единичным, а параметр q равным двум.
Пример 5.8.4. Рассмотрим многоэкстремальиую функцию двух переменных, сконструированную в виде наложения с помощью операции min семи модульно-степенных функций;
z/x) - 7 I х] ]2 + 7 I х2 Р, z2(x) = 5 | х, - 3 |08 +5 | х2 - 3 ]°'6 +6,
23(х) - 5 | х} ~6 |'3+5 | х2 - 6 |1J+2, z4(x) = 5 | х, - 6 |] +5 |х2 + 61’ +8,
z5(x) = 4 | Xj+ 61*5+4 | х3+ 6 р5+7, 26(х) - 5 | х} + 3 j1 я+51 х2 I
z7(x) = 6|x, +6|0'6 +6 | х2 -6|09 +4,
___ /г О ]6)
I(x) = min{zf(x), / = 1, 7}, '
.—-------______---------—_____-----„-------—___-----————
218 Методы ан^заи
дна (см. рис, 5.8.4а) имеет абсолютный июбальный минимум в начале ко0рдинат (7(0; 0) = 0), и относительно него функция не является симмет-«чной.чт0 характерно для обычных тестовых функций.
Р На рис. 5,8.46 на фоне линий равных уровней минимизируемой функции g 16) указаны границы допустимой области;
3 < х, + х2,
х2<6.
(5.8,17)
Допустимая область лежит выше линии 3 = х3 + х2 и ниже линии х2 = 6 (и включает границы), В этой области глобальный минимум приходится на точку (б; 6) (в ней /(6;6) = 2), которая находится на границе области. Этот минимум определяет компонента z3(x) формулы (5.8.16),
На рис. 5,8.4б приведено 5 траекторий движения в глобальный условный минимум (функции (5,8.16) в допустимой области (5,8,17) при использовании параболического ядра с з= 100 и при п= 100. д = 2, у2= 1, Па первом или втором шаге происходит выход в окрестность глобального минимума, а на последующих шагах - его более точное отслеживание.
На рис. 5.8.4в представлено изменение координат х1; х2 от шага к шагу
Движении к глобальному минимуму на основе алгоритма (5,8,14), При ЭТом ядро параболическое в степени j = 100, п - 100, q = 2, у2= 1.
Продемонстрируем теперь работоспособность алгоритма (5,8.14) при Наличии аддитивных помех в оптимизируемой функции.
Пример 5.8.5. Берем многоэкстремальную функцию (5.8,16) из преды-чего примера и накладываем на неё аддитивную случайную равномерно пРеДеленную помеху 7?(-0; 0) = 0 7?(-1; 1), принадлежащую интервалу
____ _
° 5 Методы экспериментальной оптимизации
219
1(х)= [функция (5,8,16)] + 0 7?(~ 1; 1).
(5-8.18)
Рис. 5.8.5а, Проекция функции (5-8.18) на плоскость при 100%-ной помехе
При задании коэффициента 0 ориентируемся на величины максииадь ново изменения (в допустимой области) функции без помехи и добавляемо^ помехи. Если они одинаковы, то помеха 100 %.
Допустимая область определяется неравенствами;
3 < Xj + х2, -X] 2 9
х2 < 9.
На рис. 5.8.5а при 100%-ной помехе приведена проекция функции на плоскость jq, х2 с отображением одного уровня яркости (темные места соответствуют меньшим значениям функции, светлые -большим значениям). Там же указаны границы допустимой области. Минимальное значение функции приходится на внутреннюю точку (6; 6) допустимой области.
Для иллюстрации силы искажения функции помехой на рис, 5,8.56 приведено сечение функции вдоль координаты х1 прм значении второй коерди-наты х2 = 6 для четырех вариантов: при отсутствии помехи, при 100%-, 200%- и 300%-ной помехах. На этом сечении расположен глобальный минимум функции при учете ограничений (в допустимой области),
Па рис. 5,8.5в представлено изменение координат х2 при пошаговом движении к минимуму в соответствии с алгоритмом (5.8.14). При этом п = 200, q = 2, у2 = 1, ядро параболическое в степени 5 = 100, С ростом уровня помех скорость сходимости практически не меняется, ио немного падает точность отслеживания минимума.
Остановимся на случае очень высокого уровня помех. На рис, 5,8.5г пр11 500%-ной и 1000%-ной помехах приведена проекция функции на плоскость X), х2 с отображением одного уровня яркости. Там же указаны границы о1 раничений. Глобальный минимум внутри допустимой области приходится на точку (6; 6). Положение глобального минимума функции и всех остальН^ минимумов визуально уже не улавливается, 220 Методы анализа дан^
lQf?a 5 Методы экспериментальной оптимизации
221
500%-ная помеха 1000%-ная помеха
Рис 5 8 51 Проекция функции (5 8 18) на плоскость при 500% ной и 1000% пой помехах
Рис 5 8 5д Сечение функции (5 8 18) при 500%-ной и 1000% ной помехах
222
Методы анализа
На рис. 5.8.5д представлено сечение функции вдоль координаты х} при рачении второй координаты х2 = 6 и при 500%-ной и 1000%-ной помехах. По-доясение глобального минимума функции также визуально не улавливается. Однако алгоритм его выявляет достаточно надежно и с хорошей точностью.
500%-ная помеха
1000%-ная помеха
1000%-вая помеха
Рис. 5.8.5с. Изменение координат по итерациям при очень высоком уровне помех
Алгоритмы (5.8.14), (5.8.15) принадлежат к классу алгоритмов с разнесенными пробными и рабочими движениями. Но возможны варианты с их совмещением. Можно также по ходу движения к экстремуму организовать процедуру экономии количества вычислений функции за счет использования ранее полученных значений функции иа предыдущих итерациях.
Предложенный метод построения алгоритмов поиска глобального экстремума [5.4] допускает обобщение и развитие с целью синтеза алгоритмов решения более сложных многоэкстремальных проблем: 1) поиска главных экстремумов, 2) вычисления координат седловой точки при минимаксной глобальной оптимизации, 3) решения задач многокритериальной глобальной оптимизации, 4) оптимизации функций при наличии ограничений равенств и ограничений неравенств.
Упражнения Ш
5.1.1. Необходимо найти минимум функции
Ф0 = X2 +16/х
Г[РЙ 1 < х < 5 на основе:
а) метода деления отрезка пополам,
б) метода золотого сечения,
s) метода с использованием квадратичной ^проксимации.
Qeci Методы экспериментальной оптимизации
/(х) = х2 +16/х
1 1,5 2 2,5 3 3,5 4 4,5 5
223
5.1,2. Необходимо найти минимум функции
1 1.5 2 2,5 3 3,5 4 4,5 5
Дх) = х + 1/х
1 1.21,41,61,8 2 2,22,42,62,8 3
Дх) ~ 2х2 + 16/ х
при 1 < х < 5 на основе методов: а) деления отрезка пополам, б) золотого сечеиия,
в) с использованием квадратичной ап-проксимации.
5,1.3. Необходимо найти минимум функции
Дх) = х+ 1/х
при 1 < х < 3 на основе методов: а) деления отрезка пополам, б) золотого сечения.
в) с использованием квадратичной аппроксимации.
5.1.4, Необходимо найти минимум функции
7(х) - х + 4/х
при 1 < х < 4 на основе методов: а) деления отрезка пополам, б) золотого сечеиия, в) с использованием квадратичной
аппроксимации.
5.1.5, Необходимо найти минимум функции
7(х) = (х-2)2
при 1 < х < 4 иа основе методов: а) деления отрезка пополам, б) золотого сечения, „ т1,
в) с использованием квадратичной
проксимации.
224
Методы анализа
5.1.6. Необходимо иайти минимум функции
7(х) =|*-2|
при 1 х - на ОСИ0ве методов: а) деления отрезка пополам, б) золотого сечеиия, в) с использованием квадратичной аппроксимации.
Необходимо войти в окрестность минимума функции двух переменных 5.3.1. /(хих2) - 6|Xj + х21 + Iх; ~ x2l> 0<6<1
53.2. 2(х.,х2) = (j х, -11 +1) (| х2 - 21 +1)
5.3.3. Цхьх2) - л-2 + xf | ц |< 2
Пространственный вид функции
Линии равных уровней при р -1
5 3 4. 7(хрх2) -j х, I + I x2 I +рхгг2, | p |< 1
на основе.
а) симплексного метода,
б) простейшего градиентного аргумента с использованием планироваяИЙ первого порядка для оценивания составляющих градиента.
226
Методы
анализа
Глава 6. ИДЕНТИФИКАЦИЯ СТАТИЧЕСКИХ МОДЕЛЕЙ ОБЪЕКТОВ
Идентификация - это процесс построения моделей объектов различной
природы. Теория идентификации имеет в своем арсенале достаточно эффектные методы и алгоритмы, на базе которых разработаны и широко исполь-
Зуются программные комплексы.
Процесс идентификации складывается из двух взаимосвязанных этапов идентификации структуры моделей и идентификации параметров в моделях выбранной структуры. При построении структуры модели (или набора конкурирующих либо взаимодополняющих структур) используется априорная информация об объекте. Для каждого класса объектов формируются банки структур с сопутствующей информацией.
Обычно перед каждым использованием моделей для решения конкрет
ных задач (прогнозирования, фильтрации, управления) по свежим экспериментальным данным корректируются параметры моделей На этом вопросе мы остановимся в данной и следующих главах.
Особым режимом идентификации параметров моделей является адаптивный режим При этом непрерывно по мере поступления измерений входов и выходов объекта перестраиваются параметры. Для этого режима идентификации алгоритмам придают особый, более удобный вид.
Модели делятся на статические и динамические. Первые из них описывают обьекты в стационарных режимах нх работы. Динамические модели описывают переходные процессы в объектах, например, возникающие при переходе с одного стационарного режима работы объекта па другой.
Особые подходы сформированы к построению структуры и подстройке параметров моделей стохастических объектов. При этом влиянием помех в объекте уже нельзя пренебречь и приходится брать за основу не только лри-вЦчные детерминированные модели, но и строить стохастические модели. Стохастическая часть в них, как правило, строится на невязках выходов объекта и модели.
6.1. Постановка задачи подстройки параметров нелинейных моделей
То
Имеется объект, ло измерениям ы(,Т]15 i ~ 1, п входа и выхода которо-йеобходимо рассчитан. параметры а модели (рис. 6,1.1).
Sa б Идентификация статических моделей объектов
227
г Объект Нл = т] (*/,#) + £ Н Модель |-> р = т](гт, а) Рис 6 1 1
Считаем, что выход объекта со стоит из полезного сигнала центрированной помехи Е, (т е Л/(£) = 0). Сигнальная часть выхода представляет собой известную фуНк цию от входа с неизвестными параметрами а . В структуру функции т](м, а) вкладывается вся априорная информация об объекте. Все, что не удается описать в объекте, относят к помехе.
Модель объекта берем в виде функции r](w,a). Это естественно, ибо при построении модели мы должны учесть всю априорную информацию о ранее изученных закономерностях для объекта. Основная задача теперь сводится к расчету параметров а модели. Алгоритмы расчета будем строить используя критерий наименьших квадратов и близкие к нему критерии, например наименьших модулей невязок. В зависимости от свойств помехи критерий наименьших квадратов приобретает различные формы - от простейшей до самой обшей.
6.2. Критерий наименьших квадратов
Считаем, что в каждый момент времени t, (момент измерения входа и выхода объекта) помехи Е,,, i = 1,и , являются центрированными случайными величинами с дисперсиями ст2, г = Если дисперсии различны, то измерения называются неравноточными. Считаем также, что t = 1,н, некоррелированны, т. е. М{^}} = кц - 0 при г ^ / . Тогда критерий наименьших квадратов имеет вид
"1
(Ч-Ч)2 =min, т](
^1 о, а
(6.2.D
При равноточных измерениях весовые коэффициенты 1 / of, харакгери зующие информативность измерений, одинаковы 1/ о2. Тот да имеем
СТ “Д «
228
Методы анализа дан*
весовой коэффициент 1 / сТ теперь на результаты расчетов параметров мо-
дели
не влияет, поэтому его часто опускают.
Если все помехи i = 1,п , коррелированны, г, е.
(6,2.3)
т0 критерий наименьших квадратов базируется на элементах Су матрицы, обратной корреляционной:
Л Л
/(«) = £ S (ч ~ Ч Ч (И* - П,) = min. ,=1 ;=1 "
(6.2,4)
Это общая форма критерия. Она включает в себя (при соответствующих упрощениях) все предыдущие формы.
Запишем критерий (6.2.4) в матричном виде. В водим обозначения:
Ч
Я* = ... , Я(а) =
Теперь критерий (6.2.4) принимает вид
(6.2.5)
Ца) = (Я*К^(Н* -#(cO) = min, (6.2 6)
а
Критерий наименьших квадратов совпадает с известным критерием максимума функции правдоподобия, если помеха см. (6,2,5) имеет иор-Чальный закон распределения. Тогда критерий максимума функции правдоподобия L для невязок — Н — Н (а)
^ = (2тс)-"/г |ХГГШ ехр(-|у^-'О =
ехр -1(Я’-Н(а))тК ’(Н*-77(a)) =тах
^валентен критериям
б ^денншфикация статических моделей объектов
^(Ч^Р
л(чг,«Ь
Uinj J
а
229
In/. = max,--(Я* -/7(a))7 К ’(Я* -77(a)) - max ct 2 «
и критерию наименьших квадратов (6.2.6).
6.3. Метод наименьших квадратов при линейной параметризации модели
Модель объекта задана в виде линейной комбинации известных (базИ ных) функций ср, (и),ср,и (и):
П(а, а) = (м)а; = Ф? (и)а = аГф(м)
7=1
Вектор-столбец значений выхода модели (в моменты времени I = и) имеет вид
(6.3.1)
Параметры а находим по критерию наименьших квадратов (6.2.6):
7(a) = (Я*-Фа) 1 К 1 (Я’-Фа) = min. а
(6.3 2)
Необходимое условие минимума V/ = О (где V7 - градиент от 7(d) по а) приводит к системе линейных алгебраических уравнений
ФгЯ“'фа - Ф7 К~ХН\
(6.3.3)
которая имеет единственное решение, если матрица ФГЯ-1Ф невырожден3' Эта матрица вырождается, если: 1) либо базисные функции лииейио зависимы, 2) либо число изменений п меньше числа т искомых параметров (п < т\ 3) либо измерения не информативны. Запишем теперь решение сие* темы (6.3.3):
230
а - (ФГЯ ’фу'Ф7^ 1Я* = Я0Я*.
(6.3.4)
Методы анализа данных
Для частного случая, когда помеха £ н скоррелирована и измерения точные: К <~>~Е (где Е - единичная матрица), К'[ =<з~2Е - система ра\нений (6.3.3) приобретает вид vpa₽n
о^2ФгФа = <5~2с$Н . (6.3.5)
Этому уравнению можно придать другой вид, основанный на использовании ПОНЯТИЯ скалярного произведения функций:
(Ф/,ф*) = сг”2Ёф/(ч)ф/иЛ (Ф/,п*) = ^”2Еф/(^)л*’ (6-3.6)
Очевидно, что
^i(wi) ... Ф/и^УфА) Фт(м1Р Г(<РгФ1) -'-(фжР
О2ф7ф = g“2 ... ... =
<Ф« (и,) ... <pw(w„ )(ип) ... ф„ (Ч,) , Дфт,Ф]) ... (фт,фт);
С-2Ф7Я' =(У’2
чфЛм]) ••• ФЖ)Дт]*и ЦФшХ);
Теперь система уравнений (6.3.5) запишется в форме
/(ф,,фЛ..(ф,,ф,Г!) Ya, Г(Ф1,П*)
(6.3 7)
1(фйрФ1)---(фга)ф,„)Да„Д Цф,„,пД
Если измерения выхода объекта некоррелированы, но неравноточны, то система (6.3.7) сохраняет свой вид. Меняется лишь понятие скалярного произведения (в него вводятся веса G, '. i = 1, и):
п -_п
(ф/=ф^ = Еф/М<Д2ф>(ч)- (Ф/,л*) = Хф/(м;)сГ211*- (6-3-8)
Г = 1 1=1
При коррелированных измерениях система (6.3.3) также эквивалентна (6-3.7) со следующим скалярным произведением (см. обозначение (6.2.3) Дементов матрицы, обратной к К)1.
Eiaea б Идеитификоцггя статических моделей объектов 231
п п п л
(ф^<р*) = ХХф/(«Хф*<ЧЬ (ф/.л*) = S2>/(«()vb (б.з
!=1 J=1 ,=1 J=1
Если базисные функции ортогональны на заданной системе экспери ментальных точек (и конечно, с учетом используемого скалярного произведения функций (6.3.6), (6.3.8), (6.3.9), т. е. если
[О, 1Фк,
«ФмФД 1 = к,
(6.3.10)
то система уравнений (6.3.7) распадается на т независимых уравнений:
(ф/,ф/)°-/ =(фм<),/ = 1,ш.
(6.3.11)
Именно к такому случаю мы приходили, когда использовали ортогональные планы 1-го и 2-го порядка при активном экспериментировании над объектом (гл. 3).
Исследуем свойства оценок наименьших квадратов (6.3.4). Найдем математическое ожидание оценки
.Я{а}-(ФгЯ’1Ф)’1ФЯ’1Л/{Я‘}-(ФгЯчФ)^1ФгЯ^Фя = а. (6.3.12)
Оценка а несмещенная. Здесь использовано представление выхода объекта (см. параграф 6.1) в виде суммы сигнала и центрированной помехи:
Я* = Я(а) + £ = Фа + £, М(^) = 0.
Корреляционная матрица для вектора параметров а равна значению
Яа - М{(а - д)(а - а)г} -
=Л1((Ф7Я-1Ф)’1Ф?Я”1^Я_1Ф(ФГЯ"1Ф)“1) =
- (Ф^Я^Ф)-1 Ф7'Я-1ЯЯ ‘Ф^Я^Ф)-1 = (ФГЯ’1Ф)^1. (б.з-13)
Эта матрица вычисляется при решении (6.3.4) системы уравнен^ (6.3.3). Диагональными элементами корреляционной матрицы Ка явля*°тС дисперсии составляющих вектора параметров а модели.
232 ~ " Методы анализа да^
Найдем дисперсию выхода модели T|(w,a) ~ <pr(w)a в каждой фиксированной точке и:
= а) - Мт](м, а))2} =
= М{фг(м)(а~а)(а-я)гф(м)} - фг (z/)A7acp(w). (6.3.14)
Оказывается, что оценка наименьших квадратов (6.3.4) имеет наименьшую дисперсию по сравнению с любой другой линейной (а = А(Я‘) несмещенной (М{а] ~ а) оценкой, т. е. ст2, j = 1, т. Этот результат устанавливает известная теорема Гаусса - Маркова.
Построим доверительный интервал для параметров а полезного сигнала Г|(г/, о) выхода объекта. Считаем, что измерения выхода некоррелированные, равноточные н нормально распределенные. Доверительные интервалы для всех компонент вектора а имеют вид
(a, -caai,ai ),/ = !,?«, (6.3.15)
где с - порог, вычисляемый (см. гл. 1) из таблиц нормального закона распределения (если СУ2 известна) или закона Стьюдента (если используется оценка о2 дисперсии помехи с v степенями свободы). Аналогично строится доверительный интервал для полезного сигнала Т|(м,й);
(п(и,сх) -+ (6.3.16)
Для проверки гипотезы адекватности (при некоррелированных равноточных измерениях выхода) строится статистика
Г-(и-т)^(Я*-Фа)Г(Я+ -Фа)/б2, , (6.3.17)
Когорад ПрИ выполнении гипотезы адекватности модели имеет распределение Фнщера. Затем из таблиц (см. задачу 4 гл. 1) выбираем порог Яп (гДе v _ ЧИсл0 степеней свободы оценки дисперсии 52, (3 - уровень значи-м°сти) и, если выполняется неравенство F < Fn т v р, то принимаем гипотезу адекватности построенной модели.
_________ ___________________________________________
1£/йс) Идентификация статических моделей объектов 233
Пример 6,3.1. Для объекта с одним входом и одним выходом по крц рию наименьших квадратов (6.2.2) (для случая некоррелированных равн точных измерений) необходимо вычислить параметры линейной модели
Я т|(м,а) «j + а2(н - w),w - п~] .
/=1
(6-3 18)
Базисными функциями являются: cpj — 1, ф2 = и — и . Скалярное Пронзведе
ние имеет внд (6.3.6), а система линейных алгебраических уравнений
(6 3.7)
(п О А
1 '
ст2 0 ^(м: - и)2
\ /=1 )
(6-3.19)
распадается на 2 независимых уравнения, из которых вычисляются параметры модели [см. (6.3.11)]:
н / п
а2 = - w)n* / - Ю2
/=1 /
(6.3.20)
Корреляционная матрица (6.3.13) для параметров а диагональная и диагональные элементы (дисперсии параметров) равны величинам:
1,=ЫА, < -«у.
(63 21)
а1 =
i=l
На основе (6.3.14) нетрудно рассчитать дисперсию выхода модели:
<у2 о Ал 1 з
(м~«)) 2 I - ="«, +°ч(«-«)2' (6Л22)
О с?
Полученные дисперсии служат основой построения доверительных ИН тервалов (6.3.15), (6.3.1). Доверительный интервал (6.3.16) для Г|(м’й) кЭК функция от и имеет параболические границы (6.3 22) с минимальным значе нием в точке и = й.
Полученные дисперсии служат основой построения доверительных тервалов (6.3.15), (6.3.16). Доверительный интервал (6.3.16) для функция от и имеет "ослабленные параболические" границы с минЯмаЛ ным уклонением от p(w,a) в точке и = й - рис. 6.3.1.
_____________________'_______________________ —------------
234 Методы
Пример 6.3.2. Для объекта с друмя входами (щ, и2) н од-н>{ выходом П на основе сВериментальных данных и1;,и2/Л*> i = с учетом некоррелированности н неРав' поточности измерений составим систему линейных уравнений (6.3.7) метода наименьших квадратов Для параметров а а2, оц линейной модели
т|( и, а) = «! + + а2м2.
Базисными функциями являются; ф. (и) = 1. ф2(w) = w,, ф_ (у) = и2.
Система уравнений (6.3.7) приобретает вид
J " ы 1=1 я 1ХЧ J=f
л п л
1X4 ы V1 -2 ,2 «1, V (у~2и, и-, 1 и 1=1
л п п
<1-1 i=i 1=1
f al a2 zzz .. V аГ 1 - сч - 0 ft (6.3.24)
ka3> /=1 fl
) <i=i 7
Пример 6.3.3. Рассматриваем объект с двумя вхо-Дами wb и2 и одним выходом т|* и считаем, что эксперимент спланирован гак, что выход измерен = = 1,ти) для всех пар (м1;,н2/),
у = 1,т, значений входов — см. рис. 6.3.2. Из-Мерения выхода равноточные. Критерий наименьших аратов имеет вид
и2
^2»?^ * ' " *
tz22j . «...
и211 . .....
•—г—~1-----г 1Д
ZZU и\1‘ и1п
Рис 632
““J С ~ ч "*
° XX(<-n(«n,«27))2 = min-7=1
lQe06UA~~----- ~ -— ------——— —-—~— —
Литификация статических моделей объектов
235
Рассматриваем линейную модель
t](w(,w2) = т] + a^Wj -м1) + а2(м2 -м2),
| п т j п ] in
где ц* =—Х5Х, «2 =-ZM2/ Так как выполняется
пт J=1 J=i п /=i т j-!
равенство
j? т п т
ZEK -"i)(w2j -Й2) = Х(М1, -й2) = 0,
iH J=1 1=1 7=1
то система линейных алгебраических уравнений для ара2 распадается на независимые уравнения
л ц т
о -Й,)2a, =o”32>l
t—i <=1 7=1
m m n
ct"2«2(w2j - w2)2 a2 =a’22(UU - "2)E(Hv - n*),
7-1 J=1 i=J
из которых вычисляются параметры модели. Определите, коррелировали ли параметры и вычислите их дисперсии.
6.4. Метод последовательной линеаризации при подстройке параметров
на основе критерия наименьших квадратов
Этот метод (метод минимизации функционала) включает в себя иа каждой итерации две стадии [6.8] На первой из них строим квадратичную ап проксимацию (относительно траектории) минимизируемою функционала Реализацию этой стадии мы рассмотрим в следующем параграфе, когда 6j дут минимизироваться неквадратичиые функционалы. На второй стадии^ квадратичную аппроксимацию функционала (либо в сам функционал, е он является квадратичным, например 7(a) в критерии наименьших кваДР iob) подставляем линейную аппроксимацию выхода модели по искомым
236 Методы анвли30^
деграм (либо по их приращениям). После этих двух этапов на каждой из итераций в явном виде вычисляем Приращения параметров. Затем по иим наХодим параметры на следующей итерации из условия монотонной сходимости минимизируемого функционала. Эти итерации повторяются последо-зателъно, и получаемая последовательность параметров сходится к искомому
решению.
Построим итерационную процедуру расчета параметров а модели в соответствии с критерием наименьших квадратов (6.2.6). Так как функционал квадратичный, то первая стадия метода не реализуется и на каждой итерации используется только линейная аппроксимация выхода модели по параметрам:
Н(а) *И(а') +
(6.4.1)
Здесь Act/4'1 =а — а/ - искомое приращение параметров, Z - номер итерации, с(/ - вектор параметров на / -й итерации. После подстановки линейной аппроксимации (6.4.1) в функционал (6.2.6) получаем относительно Да/И обычный (при линейной параметризации) критерий наименьших квадратов:
7(Да'+1) = (//'- Н(а‘)- dH(a!)^Мутк~1(Н‘-Н(а!)-da
-^^Aa/+1) - min. (6.4.2)
da да/+1
Необходимое условие минимума приводит к системе линейных алгебраических уравнений
dH da
Aoc(+1
' лгу Y
— \ -Я(а'))
da J
(6АЗ)
или
= -V/(oc/),
Рвение которой записывается в виде
Aa/+1 =(^/)-1(-V/(a/)).
J-Г"""’—--- _ _____________________________ _____
^аб Идентификация статических моделей объектов
(6.4.4)
237
После этого находим параметры модели иа (Z + 1) -й итерации
а'" / = 0,1,2, ... (6<5)
Положительный коэффициент у} > 0 выбираем из условия /(а141) </(</)) монотонной сходимости по функции качества. Примеров выбора последовательности для у служит последовательность: 1, 1/2, 1/4 Последовательно в качестве у берутся элементы этою убывающего ряда наступления вышеуказанного неравенства для функции качества.
Пример 6.4.1. По выборке , ту, i = 1, п прн условии равноточности измерений необходимо рассчитать параметр а модели r|(w,a) = и'1 Критерий наименьших квадратов имеет вид (6.2.2)
I ~ ст 2У (ц, - w“)2 = min
Находим аппроксимацию функции качества, подставляя в /(а) линейное приближение модели в точке аУ, и приходим к простейшей экстремальной задаче
J(Aaf+1) -о”2 У |г< -[w^ 1пм,]Даг+1Г - min,
I=1 '
Из необходимого условия минимума {di /г/АоУ1 = 0) получаем линейное уравнение для приращения искомого параметра.
£[wa In н ]2лУ+1 = InwJCq* -uf). i=i i=i
Следующее приближение для искомого параметра находим по формуй (6.4.5).
6.5. Робастные оценки параметров
Параметры модели (которые являются оценками параметров объекта), полученные па основе критерия наименьших квадратов, сильно реагируй на выбросы помех [6.9]. Аномальные отклонения в измерениях очень ред^ 238 Методы анализа данн^
0 амплитуда их велика. Рассмотрим простейший пример. Считаем что мо-деЛь объекта равна одному параметру: П(М,а) = а. Из критерия наименьших ^адратоя (6.2.2) получаем, что а есть среднее арифметическое измеренных учений выхода. т](н,а) ~ (1/и)£т^ --а. Считаем, что измерения выхода
<=1
упорядочены и одно измерение, например т|*, содержит очень большую помеху. Тогда основной вклад в выход модели вносит слагаемое ц’/л и выброс существенно искажает модель.
Если в качестве критерия взять не квадратичный (6.1.2) а модульный критерий [6 9] ’
Л(а) = £|П* - а 1= min ,
(6.5.1)
то параметром сх является оценка медианы* среднее по номеру значение з упорядоченной выборке Аномальное измерение т|* теперь не
меняет параметра сх. Следовательно, критерий (6.5.1) обеспечивает получение более робастных (более крепких по отношению к выбросам измерений) параметров модели.
Кроме критерия (6.5.1) существуют другие, близкие к нему критерии [6.9]:
П
1(a) = £p~lw(e<)= main’ = ч - п(ч ,«),
(6.5.2)
где р/ - известные весовые коэффициенты. Примерами функций ф(е) являются:
\д(е) =| е I (рис. 6.5.1 а); \ц(е) =jе[С 0 <ц < 2 (рис. 6.5.1 б):
[е2, !е|<А, .
\д(е) = ] (рис. 6.5.1 в)
(J е I A, И>Д
Для расчета параметров а применим метод последо-ВательноЙ линеаризации. Вна-находим квадратичную ^Прокснмацню функционала I [см. (6.5.2)] относительно Д^ктории (ег, i - 1,и), на коброй он построен:
jT _____________- ------------------—--------
Дава б Идентификация статических моделей объектов
239
м 1=1
(6-5.3)
Здесь / - номер итерации; е, - ц* - Г|(м ,(/) - невязка, к, - коэффициент которые для приведенных на рис. 6.5 I случаев равны величинам.
в)^ =
<Р,, к'М, l^i> А.
(6-5.4)
Теперь подставим в правую часть уравнения (6.5.3) (в квадрагичный функционал) линейную аппроксимацию выхода модели
'q(wi, а) T](w , а1) + (vp(w;, a1 ))Т Act/+1
(6.5 5)
и решаем обычную задачу наименьших квадратов
7(Ааж) = -ц(у,a')-(vr^a'))7 Аа/+1{ = шш (6.5.6)
!-1 Дк '
относительно приращения параметров Act/+1:
Ла/+!
лА(^‘Жа')К
t=i
(6 57)
Следующее приближение параметров вычисляем по формуле (6 2.5).
сЛ1 - а' + /Ааж, 7 = 0,1,2,....
(6 5.8)
В отличие от обычного критерия наименьших квадратов при исполь30 вании неквадратичных критериев в алгоритме метода последовательной^11 неаризации меняются лишь весовые коэффициенты. Для измерений с вЫ°Р° сами автоматически понижаются весовые коэффициенты. За счет этого вышается робастность оценок.
0
Методы анализа
6.6. Адаптивные алгоритмы метода наименьших квадратов
Если непрерывно по мере поступления измерений вести перестройку параметров модели, то эффективней на каждом шаге объединить алгоритм метода последовательной линеаризации (естественно, при нелинейной параметризации модели объекта) и обычный рекуррентный алгоритм наименьших квадратов. Вначале рассмотрим классический алгоритм наименьших квадратов при линейной параметризации модели:
г|(«,а) = <рг(«)а.
(6.6.1)
Обозначим через ал-1 вектор параметров, вычисленный по критерию наименьших квадратов
(/< )а,_1 )2 = min
Z7 “л-1
(6.6.2)
на основе некоррелированной неравноточной выборки у(,т|(, / - 1,и -1. При появлении дополнительного измерения оценка наименьших
квадратов будет ct„. Чтобы иа каждом таком шаге ие решать систему линейных уравнений (6 3.3), были получены рекуррентные уравнения (см пример 6.6.1 в конце параграфа):
,<PQO
^+<pr(wJ^an_l<l>(Kn)’
^4 = (E - Y„<pr (Mn , n = w0 +1, na + 2,.... (6 6.3)
Начальными значениями служат оценка наименьших квадратов а„о и ее
вариационная матрица К
"° А
i-L i=l
(6.6.4)
ПРЙ ^сходном объеме измерений п0.
—— ___________. ________________________
йе° Идентификация статических моделей объектов
241
При равноточных некоррелированных измерениях меняются весов^ коэффициент в критерии наименьших квадратов
Л
о'2 х(П* - фт (ч)«J2 = min (6 6 51
(-1 аН
и в рекуррентном уравнении (6.6.3):
К„ ф(и„)
a.-a^+y/^-cp^wJa^), уп = 2 т~~Г о +<р (а„)Кап
-(£-у„фГ(и.)Жа„ «-«0 + 1,ий+2,.... (666)
Напоминаем, что Кщ - корреляционная матрица для вектора параметров а„.
Если в критерии наименьших квадратов (6.6.2) взять произвольные весовые коэффициент у?~1,т. е.
ХлЧч-фЧи.Ю2 =min, (6 6 7)
то в рекуррентном уравнении (6 6.3) сГ следует заменить иа рп и матрицу Ка обозначить другим символом, ибо она не является корреляционной матрицей для параметров (за исключением случая, когда р! = ).
Г„-1Ф(Ц„)
-ап_1+Уй(п»-ф/(«й)а„-1)3 Уп = Г/ Лг- ,
(6 6 8)
Г„ =(£-Г,/РГ(«й))Г„-р « = + «о + 2,....
Начальное значение апо рассчитывается из системы линейных алгеб-(п° "° । * Й
раических уравнений XА~1ф(м,)фГ(м1) =Хл Ф(ч)Ч’ получено
V“1 / 1=1
из критерия (6 6.7) при и = н0. Г„о - это матрица, обратная матрице этой
(п° V'
системы: = Ха ‘фО, V<А) •
242
Методы ан^и^
С ростом объема измерений п оценки наименьших квадратов (6.6.3),
0 6 6), (6.6.8) стремятся к постоянным величинам а - параметрам сигналь-$ части выхода объекта. Текущие измерения с ростом п оказываю! все унылее влияние иа оценки ctM , т. е. обратная связь к измерениям ослабевает
л при и—> 00 полностью исчезает Это происходит потому, что построенные алгоритмы ориентированы на отслеживание постоянных параметров объек-та Если параметры дрейфуют, то с помощью вышеприведенных алгоритмов
удается отследить эти параметры.
Чтобы отслеживать с помощью модели дрейфующую характеристику объекта, необходимо в критерий оптимальности ввести дополнительные веса, Они должны быть больше для последних измерений и должны убывать для более старых измерений. Примером таких весовых коэффициен
тов служит убывающая последовательность д," i ~ п, п-1, п-2,...,
0< X, < I. Вводим ее в критерий (6.6.7):
=min,
1=1
(6.6.9)
и получаем рекуррентный алгоритм с забыванием информации:
ап=ай_]+уч(п^-фГ(мОал-])5 У»
Г„-1ФЮ
Гл =(Е-у„(рг(ил))Гл Д \ п = пй + 1, и0 + 2,.... (66.10)
Практические исследования алгоритма показали, что параметр Л целесообразно выбирать из интервала 0.9 < X. < 0.995.
При нелинейной параметризации модели ч = Т|(н,а) и использовании критерия (6.6.9)
-nk,«J)2 =min
i=I
(6.6.11)
применяем на каждой итерации линейную аппроксимацию модели
П(а,ал>т](и,«„_[) +V^n(w,«„_!)(«„ "“„л)- (6.6.12)
^есь ~ вектор-столбец градиента по параметрам. В итоге приходим Калгоритму (6.6.10) с заменой в нем вектора столбца базисных функций ср
На Вектор-столбец градиента VaT| и срг(и)а - на 4(Xct):
_________ ____________________ _________________________________
аеч 6 Идентификация статических моделей объектов 243
+Yn(n*.
Г, « = «о+1, п0+2,.... (6.6.13)
При линейной параметризации вектор градиента Var| равен вектору базисных функций (р и (6.6.13) переходит в (6.6.10).
В работе Б. Т. Поляка [6.3] получен простой алгоритм адаптивной коррекции параметров;
= «п-1 +YnP;1Va'q(M,J,a„_i)('nL~'n(wn5a„_i))>
аи = »„_!+и-!(а,и = 1,2,..., уп = уп~1/2, у > 0. (6.6.14)
Алгоритм состоит из двух частей. В первой части осуществляется перестройка параметров по простейшему градиентному алгоритму. Во второй части алгоритма производится усреднение полученных в первой части оценок:
1 « J л—1 1 и — 1 1 ”-1 1
а» +-а,? =---------+ а„ =ап_: +п~1(а,1 -а„_,)
П 1=| П ,=1 п п п-1 ,=1 и
Получаемая последовательность параметров а....., а.. ... имеет те же предельные свойства (в том числе и по скорости сходимости), что и для опенок обычного метода наименьших квадратов.
В заключение параграфа рассмотрим подстройку нестационарных стохастических параметров объекта. Считаем, что их изменение подчиняется известному уравнению
а, =/(«,.[) + v,, j = 1,2, ...,п
(6.6.1Я
где /() - известная функция, Vf - центрированная некоррелированная времени помеха с корреляционной матрицей для момента времени i, Р33 величине
(6.б.16>
Методы тай^^“‘
244
Тогда при адаптивной перестройке параметров в алгоритме (6.6.13) ^значительно меняются первое и третье уравнения:
а„ ХХ-О + Г/П, 'ПкА-i))’
_____Ги_1УаП(мй,аиЧ)
У” Р Л + У а П(«„ > )r,w)y аШ,, а„-1) ’
Гл Ч£-уХп(^,а„ч))Г„-Л ’ п = и0 + 1,и04-2,.... (6.6.17)
Бопее простой алгоритм (6.6.14) для этого нестационарного случая приобретает вид
йя = /(ап-г) + ?ЙР„’У аП(«й, )01й - П(«й, ай-!)),
1 + «“’(«„-а„_Д « = у>0. (6.6.18)
Пример 6.6.1. Получим рекуррентную формулу расчета оценок наименьших квадратов:
IX2 СП* -чЛчЮ2 =min. (6.6.19)
Параметры удовлетворяют системам линейных уравнений:
XX = EXXOl* (гДе X ~ £<2ф(мг)фТ(м1)Х (6.6.20)
1=1 >=i
XLan-] =Х<2ф(м.)П* (гДе = Еа72ф<и/>Г(к/))- (6.6.21)
<=1 1=1
Вычитаем из (6.6.20) уравнение (6.6.21) н, учитывая, что
.,+ а;2ф(И„)фг(хя). (6.6.22)
Хчаем
=(СХСТ"2^и"^ГХ)Хл+а;2ф(мл)т1^ (6.6.23)
6 Йденгп^фикация статических моделей объектов 245
Отсюда после умножения слева на Ка следует. формула рекуррентного не ресчета параметров1.
+ £ая<^2ф(«„)(п» -<Pr(«Jaw-i)- (6.6.24)
Найдём теперь рекуррентное уравнение для ковариационной матрицы параметров.
Умножив (6.6.22) слева на матрицу , а справа на , получим
Ка =Ка +Каа;\(и„^т(ип')Ка
1 ttn ЛТК п z т к п/ <Х;Г_ 1
Из этого равенства следует, что
Х.,_,ф(«,) = ^а,ф(В»)а + С;2фГ(«»Жа,.,ф(“»))-
(6.6 25)
Тогда
,ф(Мл)
Ср(М ) =------ -------------------
ИЛИ
= ^ал;2ф(м„)=
К„ ф(и„) т \ И <
(СТп +фГ(«пИал_1Ф(Мг1))
(6.6.26)
Этот вектор-столбец коэффициентов усиления стоит перед невязкой (выхода объекта и выхода модели) в рекуррентной формуле (6 6.24) пересчета параметров. В правую часть (6.6.26) входил матрица Ка } , вычисленная на предыдущей итерации.
Рекуррентная формула для Ка^ следует из (6.6.25) с учетом (6.6.26):
(6.6 2?)
Объединяем (6.6.24), (6.6 27) в единую рекуррентную процедуру (6-^ расчета параметров модели и ковариационной матрицы:
* г К„ <р(м„)
= а„_, + 7„Оъ -Ф («„Kj)> У, = ’
сгп+ф (ип)Ка^(ип)
246
Методы апализо дян
, п = и0 + 1,п0 +2,
(6.6.28)
Пример 6.6.2. Считаем, что измерения выхода некоррелированные рае-цоточные^ а выход модели не зависит от входа и имеет вид т|(м, а) = а -
В соответствии с критерием наименьших квадратов (6.6.5)
п
,= 1 “п
получаем, что
П 1 « гг2
-1 -2V * 2 * 2 / -2 С>
а пап=<з 2,4 , <*п = “2,4 > <4Й =(а «) =—, ,=\ п ,_i п
где а„ - это оценка математического ожидания выхода объекта. Простейшая рекуррентная формула её расчёта имеет вид
а, = —afl_,+-з1;=а._]+-(п;-ал_,), л-1,2,..., ао-О. (6.6.29) п п п
В то же время из (6.6.6) получаем:
= а. !+¥,.(П»-а»->). 7„ = —•
ст +К°^
к«. =(1-Г,)Ка,.,, « = 2,3......................... (6.6.30)
Начальные значения: ( — Г||, Ка = а2( = а2.
Убедитесь в эквивалентности этих формул расчёта (х„. В отличие от (6.6.29) в формуле (6.6.30) иа каждом шаге рассчитываем и дисперсию пара-"етрао^; Ка . ‘ u л u /1
Пример 6.6.3. Исходные условия те же, что и в предыдущем примере, ыяучим формулы рекуррентного пересчета параметра ct при забывании ^Формации. Берём взвешенный критерий наименьших квадратов
2Е^ *(4 “ ап ; )2 ~ ПИП, 0 < А, < 1.
>=1 ’ “ЛА
__ ____ ____________________________ _____
°в° Идентификация статических моделей объектов
(6.6.31)
247
Вес последнего (и-го) измерения самый большой (равен 1). Для пред^ дущего измерения он равен А,, для следующего - А2 и т. д.
Из необходимого условия экстремума следует оценка ОД х:
'"п*
|а„Л = a’2£x."”ri;, а„Л=-“---------= (6.6.32)
;=i ) м ^АЛ'
Дисперсия этой линейной (относительно некоррелированных измерений (т[),..Т|л ) оценки имеет вид
\i=l /
Заметим, что теперь дисперсия оценки не равна обратной величине от коэффициента, стоящего перед ал , в линейном уравнении (6.6.32).
Первый способ рекуррентного пересчета оценки afi х заключается в рекуррентной коррекции ее числителя и знаменателя (с последующим их делением для каждого и):
Л = + <, в„ = ?A-i +1, п = 1,2,..., л = о, bq - о.
Второй способ состоит в рекуррентной перестройке всей оценки а. „у Записываем уравнения для аиД и ап_1Х:
=i>-n;, . <б-б'зз)
1=1 1=1 1=1 1=1
Обозначаем через Bn
= У А,'! 1. Для него уже было выписано рекурре1ГГ11°е г=1
соотношение
+ ц-1.2?.., 5о=О.
248
Методы анализа даН
умножаем второе уравнение в (6.10.33) на Z, вычитаем из первого и учитываем связь между Вп и
В„ алЛ = а„-1л + < = (Вп -1) а„„и + П;.
Отсюда получаем основную рекуррентную формулу пересчета оценки ап к:
а„Л - а«-1Л + (Л* -cVix)-
В итоге мы имеем:
айЛ == алдл +Л1(*П Л
и = 1, 2,-, аох=О, В0 = О. (6.6.34)
Третий способ близок к предыдущему, но в нем рекуррентно пере-
страивается [см. (6.6.10)] коэффициент Г„, определяющий обратную связь:
, Г _
а„Л =а„_1з> +у„Сп„ -ая u)> Y, =
1>(1-Гя)Гп-Л-1, и = 2,3,.... (6.6.35)
( э п V*
Так как Гй — 5 т0 из 6.32) следует, что
п
а„л = Ги СГ^Г-1 л; Тогда дисперсия линейной относительно некоррели-f=i
данных равноточных измерений (ц т|* ) равна величине
оК.Л = г>-у^-''.
(6.6.36)
Пример 6,6.4. Считаем, что измерения выхода некоррелированные НеРавнотоЧные, а выход модели также не зависит от входа и равен констан-Те: П(и,а) = а.
_______ _ _ _ ______________________, _____
lQea 6 Идентификация статических моделей объектов 249
Из критерия наименьших квадратов (6.6.2)
=min
получаем уравнение для искомого параметра аи:
i>.-4=ix2<
!=i l—l
Отсюда
<ч=1х2п:/£<
>=1 / 7 = 1
(6 6.37)
(6.6.38)
Дисперсия этой линейной относительно некоррелированных равноточных измерений (т;*,..., р*) оценки равна величине
Ж„} = Ёа,Чг/(£а;2] =l/t<
) / /=1
(6.6.39)
Рекуррентный пересчет оценок тл можно осуществлять также двумя способами.
Первый способ. В (6.6.38) рекуррентно корректируется числитель и знаменатель:
а = А = w=l,2,-, А-0, Во = 0. (6.6.40)
Второй способ. Рекуррентно пересчитывается вся оценка ал по форму' ле (6.6.3):
А?
а. «и-1 + Ь(ПП ~ у(1 = 2—,
n = 2,3,...,a1=TI;,D{«x1} = aJejCai; (6.6.4D
250 ~~ ~ Методы'анализа
Пример 6.6.5. При исходных условиях предыдущего примера получим формулы рекуррентного пересчета оценки а„д с забыванием информации. Опенка осп ? удовлетворяет взвешенному критерию наименьших квадратов (6.6-9)-
Усг;2Хп_‘(т|* -а„Л)2 - min, 0<Х<1, (6.6.42)
;=1 ’ Л
т е. линейному алгебраическому уравнению
, (6.6.43)
l-l 1-1
из которого следует искомый параметр
ап,> = . (6.6.44)
,=i / j-t
Дисперсия этой линейной оценки равна величине
Р{а.д} = taA2,"-° /[ 1 . (6.6.45)
<=] / )
Оценка ая х рекуррентно пересчитывается по формуле (6.6.10):
/ * \ Г .
+ УпС1„ “ a.-u)- Уп = 2, г
сцЛ + Г^
Г.=(1-Г„)Г„_,Г‘. Л = «0 + 1,«0 + 2,...; (6.6.46)
ai =Л1, Г, -су,;
пРИчём В{а„ А} = 2Я2(и и> естественно, совпадает с (6.6,45).
f=l л
Если л — I (нет забывания информации), то В{осп ]} - Ги Z<2=r,. J-l ~ --- -_____________________________________-____________________““ —
Ова 6 Идентификация статических модеъей объектов
251
6.7. Адаптивные алгоритмы подстройки робастных оценок параметров
Обобщим результаты по адаптивной перестройке параметров лидейнь (6.6.10) и нелинейных (6.6.13) моделей на базе критерия наименьших каа ратов (6.6.9) на критерии (6.5.2), обеспечивающие получение робастных (к выбросам помех измерений) параметров моделей. При этом на кажд0£ итерации минимизируются квадратичные аппроксимации функционалов Как следует из параграфа 6.5, в соответствующих алгоритмах метода наименьших квадратов меняются лишь весовые коэффициенты для моментов измерений Эти же весовые коэффициенты переходят и в алгоритмы адаптивной перестройки параметров:
а(! (Л* -пОЛ-Х
V + v , ^-1 )Г„__1 VaT](nM, а„ч) ’
и = «о+1,*о+2,.... (6.7.1)
Для критериев (6.5.2) и функций ц/, представленных на рис. 6,5.1, коэффициенты имеют вид (6.5.4):
а) К, = Р„ К 1.6) к„ =р„ |е„ 'Ъ) к, =-| ’ , . \"|1 (67-2)
!лТ„|л‘, Л<К!
Здесь ew - невязка между выходами объекта и модели,
= л* -
А - порог, равный среднему квадратическому значению ст помехи, умноженному на коэффициент 1 < у < 1.8, который зависит от процентного содержания выбросов в помехе.
Существуют другие алгоритмы робастной идентификации [6.4, 6.6]:
= <Vi +УЛГ(П*
252
Методы анализа данных
________________________________
Yn АЛ + VanK, )Г„_! VaT)( а = <Vi) ’
Гл =(£-?Хл(А>°^-1))гп Л’1» « = w0 + l, «0+2,.... (6.7.4)
Для функций \p(z), представленных на рис. 6.5.1, их производная у нмеет вид:
. „ , . [z, I z ]< А,
a)ip'(z) = sgnz, б)\р 0)=И sgnz, в)у (2) = ] (6.7.5)
[Asgnz, \z |> А.
Здесь sgnz - знаковая функция.
Алгоритм (6.6,14) Б. Т. Поляка [6.5] применительно к расчету робастных оценок параметров приобретает вид
= a„-i +/Лйт1(ип)сёп_1А/(^-т, «„_,)),
=аг;_( +и-1(а„« = 2,уп = угГ}!2,у> 0. (6.7.6)
При оценивании нестационарных параметров, удовлетворяющих уравнению (6.6.15), в первом уравнении формул (6.7.6) необходимо ос., j заменить на /(осп_|)(см. (6.6.18), когда использовался квадратичный критерий оптимальности).
В последние годы построен еще один алгоритм [6.1], близкий к алгоритму (6.7.4):
а, = “ Л(Ч,«„-J),
5. = (аЛ +
К =Г,-1ЧхП(ЫЛ5а,;-Л’
Гя Л’\ " = А +2,... . (6.7.7)
В отличие от (6.7.4) в первом уравнении аргумент функции у(-) умножается на множитель 5„,
----------------—-------- -----------------------------———--- —. - лйва б Идентификация статических моделей объектов----------------253
6.8. Простейший адаптивный алгоритм подстройки параметров
Стремление получить простые алгоритмы перестройки параметров объ ектов никогда не оставляло как исследователей, так и инженеров-практиков Примером этому служат сравнительно недавно разработанные алгоритмы (6.6.14), (6.6.18), (6.7.6), и это, несмотря на то, что освоен широкий арсенал алгоритмов метода наименьших квадратов.
В данном параграфе мы рассмотрим алгоритм, который относится к самым первым применяемым в адаптации алгоритмам [6,7]. В силу его предельной простоты и часто неплохих свойств его применяют и в настоящее время либо в первозданном виде, либо с небольшими модификациями. Последовательно остановимся на подстройке параметров линейных и нелинейных моделей.
Линейная параметризация модели: Г|(м,сх) - фГ(ы)о.. На каждой итерации, например п и п - 1, параметры модели находим из условия равенства выходов модели и объекта:
(6 81)
Каждому уравнению в пространстве параметров соответствует своя линия (рис. 6.8.1) либо гиперплоскость, т. е. каждому уравнению соответствует бесчисленное множество решений (за исключением скалярного случая). Чтобы получить единственное решение, надо наложить дополнительное условие.
Первое уравнение в (6.8.1) запишем через приращение параметров па соседних итерациях:
Лп kX-i +92 -апЧ) = q/(un)aH_1 + фГ(мп)Аа„. (6 8.2)
Теперь из уравнения (6.8.2) будем отыскивать Аосп, наложив на него ог-
l!Aa„ = min.
(6.8.3)
Ойо соответствует минимуму энергет#46 ских затрат на изменение параметр06. На рис. 6.8.1 показано, что точка ап выбираетсЯ В Ре' из условия минимума расстояния от осл л зультате решения задачи (6.8.2), (6.8.3) ПО^У43 алгоритм расчета а,,:
254
Методы анализ^
«« " a»-i +~7гт;т фЮ -ф (ч)ф(м«)
= ал-1 +0% и = 1, 2,....
(6.8.4)
Здесь знак "+'1 - псевдообращения (обобщенного обращения) матрицы |б2]. Последовательное движение на рис. 6.8.1 к точке пересечения прямых (6 8-1) показано пунктирными линиями. Если помеха измерения £ отсутствует,то тД = <рг (ип)а и точкой пересечения прямых являются истинные параметры а объекта.
Рис. 6 8.1 иллюстрирует сходимость простейшего адаптивного алгоритма (6 8.4) подстройки параметров. Сходимость доказывается и алгебраически. Из рис. 6.8.1 также видно, как можно многократно последовательно использовать два измерения входа и выхода объекта.
Если есть помеха, т. е. if - q/(wn)o(. + то из (6.8.4) получаем, что
—= ~ ф(ив)-
ф (Ч)ф(Ч)
(6.8.5)
Дополнительная помеха в оценках параметров асимптотически не убывает и для ее нейтрализации необходимо применять дополнительно сглаживание получаемых оценок at,a2,как это делалось, например, в алгоритме (6.6.14):
=а„ч +я-1(а„ ~ап Д и = 1,2,.,.. (6.8.6)
Усреднение можно провести с учетом экспоненциального забывания иаформации:
ч + &;'к -а.-,),
(=1 i-1
(6.8.7)
Д = 1 + ХД- 0, к = 1,2,...,
< 1, например, 0.9 < X < 0.995 - или методом скользящего среднего:
«-.---Л1 £аг = a„_t + к l(ctw-а,.,), п = к + \, Л + 2,..., (6.8.8)
; - ______ _______________________________________________________________________
б Идентификация статических моделей объектов 255
к - количество усредняемых значений. Алгоритмы (6.8.7), (6.8.8) применяют при подстройке дрейфующих параметров объекта.
Чувствительность к помехам можно уменьшить, вводя в алгоритм (6.8,4) д0. полнительиый положительный параметр [6.7]. Его вводят двумя способами:
осл = ос
-f- у — ...........—— --------------------——
(6.8.9)
7>0, . = 1,2, у+ ср (Ч,ЖМ«)
(6.8 10)
Второй способ часто оказывается более предпочтительным, ибо параметр у осуществляет регуляризацию алгоритма, когда ср Г ср приближается к нулю.
Пример 6-8.1. Для линейной модели Г|(м,а) - + ос2г/ простейший
адаптивный алгоритм перестройки параметров а.13а2 имеет вид
Яп а1,Л-1 а2,Л-1И,
ot, =а
1 + ^
Пл -°Ч„ 1 !Мп
«2Л =<*2л-1 +----------И = 1,2,....
Пример 6.8.2. Для линейной относительно параметров и нелинейной относительно входа модели т](м,а) = ос, +ос2м+ а3м”! получаем следующий алгоритм подстройки параметров:
-0Чл-1мл (X3,n-iw
«1>л = «1>в-| +-----~-------------------
l + M„+wn
а2,л ” а2,л-1
Лп-а^-а^ч^-а^а;1 i+«B +<2
и
- а
1 + ип2 +и~2
Ми -I Ip
-----и , K= 1, A
256
Методы ан^а
Нелинейная модель. На каждом шаге линеаризуем модель и приращения параметров отыскиваем из равенства (эквнваленгного (6.8.2) для линейного случая) выхода модели и линеаризованной модели
т] * = ПК, , <4-1 )Аал
с учетом критерия (6.8.3). В итоге получаем алгоритм перестройки параметров нелинейной модели
ос = ос
" = 1,2,.... (6.8.11)
Пример 6.8,3. Дпя нелинейной модели п(м>а) = 04sin(a2«) алгоритм (6.8.10) приобретает вид
Л* sinfa^aj
at„ - ос] - -2~----------------—SHXa^uJ,
(sm(a7n„lMJ) +(af^1M„cos(a2„_1w„))
_______П*,-tx^^sinCoc^^J_______ (sm(ou,!4wj)2 cos(a2„_!«„))2
xaln-!M«C0S(a2?!-A1), w = 1,2, ... .
Векюриая линейная модель. Простейший адаптивный алгоритм 8 4) не меняет своей формы при подстройке параметров матрицы А век-торной модели т| = А(р(м). Здесь г} и <р(н) - векторы-столбцы различных размерностей. Векторная модель состоит из нескольких скалярных моделей, а каждой из которых используются одни и те же базисные функции. Выпивая для каждой строки матрицы А уравнение (6.8.4) и объединяя их в ^трицу, получаем простейший адаптивный алгоритм подстройки парадов в виде
А А
4 ЛЛ-]
+ лАа^<рЮфг(Ия)=
<Р О„)ф(«„)
(6 8.12)
~~~257
Чч +ОЪ ' Ап^(р(м„))ф+(«и), п = 1, 2,....
^ентификация статических, моделей объектов
Дальнейшее обобщение алгоритма связано с использованием при чете ал не одного равенства в (6.8.1) г|л = фГ (ип )осл, а нескольких (напри. мер, р равенств):
1Ъ=ФГ(ХК> к = п,п-\, р + \, Р>\. (6.8.13)
Перепишем систему равенств (6.8,13), выделяя приращения параметров ActJ; = и.п-и.„_р
Ф„Да„ = ЯЙ* -Ф„ап_,
7
ф («J
I
(6.8.14)
У (Х-,+1);
Для получения единственного решения системы (6.8.13) учитываем ограничение (6.8.3) 1| Дал ||2= min и находим приращение параметров:
л^ФЖ’-Фд-,),
где + - символ псевдо обращения матрицы [6.2]. Затем вычисляем параметры
ал =ал_] +Дос„.
(6.8.15)
(6.8,16)
Увеличение памяти (р> 1) по входам и выходам объекта приводит к резкому увеличению скорости сходимости алгоритма и к уменьшению влияния помех на оценки а/; параметров а объекта.
При подстройке матрицы параметров А векторной модели Т[(м, А)= - Аср(п) алгоритм с памятью принимает вид
А„ = An_j +(У -АЛ_]ФЛ)ФЛ, п = 1,2,....
(6.8. И)
6.9. Многоэтапный метод селекции при построении моделей сложных объектов
Инициатор развития указанного направления в кибернетике А- Г- №аХ иенко назвал развитый им метод [6.3] методом группового учёта аргуме (МГУА). Коллектив, руководимый А. Г. Ивахненко (в институте кибер»
258 Методы анализа №
0 Украины), создал теорию метода, решил широкий спектр задач и обеспе-чйЛ исследователей комплексами программ. Метод внешне похож иа много-пядйьгй "персептронный” метод восстановления решающей функции в классификации (гл. 2). Но это только внешне. Основная идея в МГУ А базируется [ja иде£ селекции, которая лежит в основе процесса самоорганизации в кибернетике. Многовековое успешное использование селекции при получении растений и животных с желаемыми свойствами перенесено в алгоритмы оп-^малыюй переработки информации и управления в сложных системах. Эти уравнения кибернетики интенсивно развиваются и тоже обеспечивают же
лаемые результаты.
При селекций, растений высевается некоторое количество семян. В результате перекрёстного опыления растений образуются наследственные признаки. Селекционеры отбирают некоторую часть растений с наиболее сильными интересующими свойствами (это критерий отбора). Семена этих растений снова высевают и процедура повторяется. Через несколько поколений селекция прекращается. При этом часто желаемый результат достигается. Если чрезмерно продолжать селекцию, то наступает вырождение. Существует оптимальное число поколений (оно невелико и равно обычно 4-6) и опти-
мальное число семян, отбираемых в каждом из них.
Продемонстрируем идею МГУА применительно к идентификации статических моделей.
В отличие от постановки задачи, приведённой в параграфе 6.1, структура сигнальной части выхода объекта неизвестна н характер взаимодействия "сигнала" и ''помехи11 неизвестен - см, рис. 6.9.1. Такой же Уровень неопределённости был при построении в главе 4 модели объекта на осно-
Объект]—> Модель)-» т| = ?
Рис 6.9,1
йе Применения непараметрических оценок плотностей вероятности. Теперь в соответствии с МГУА мы будем поэтапно наращивать сложность итоговых параметрических моделей до тех пор, пока этот процесс не приведёт к ухудшению качества итоговой модели. На каждом этапе строится множено простых параметрических моделей, но в совокупности с моделями Предыдущих этапов итоговые модели объекта непрерывно усложняются. ^Ри наращивании сложности итоговых моделей достаточно быстро (За 4--6 этапов) наступает насыщение. Показатель качества моделей, начиная с ^которого этапа, ухудшается. Этот момент надо выявить; естественно, Прекратить процесс построения множества моделей и из полученных "хоро-111 моделей оставить и аи лучшую. Она является "оптимальной по сложности"
моделью.
^°ва б Идентификация статических моделей объектов
259
Считаем, что объект имеет т входов ult и2,..., ит и один выхОд * Число входов достаточно велико: порядка 10-15. Модель строится на ос3 выборки и,, Л,, i' — 1, п, которую лучше разбить на две части: обучав л------------.— ----- -------------—. j П£,юЩук
и экзаменующую 7£Л,КЗ[- По обучающей выбору будем строить модели, а по экзаменующей выборке - оценивать качество д0
строенных моделей.
^об
Для первого ряда селекции строим ~ моделей у - f(uk, fy) ПРИ различных парных сочетаниях входов - см. рис. 6.9.2. В качестве базовой функции f(, -) может выступать квадратичный степенной полином, например.
34 = / («о «/) = %] + + а9,зи/ + .
Параметры каждой модели вычисляем на основе обучающей выборки, например из квадратичного критерия:
S (ч - У у У = 2 (ч - f(uk> - ии ))2 = min.
^поё ач
260 Методы анализа
Далее по экзаменующей выборке проверяем качество
1,=^- -Уч, 1> 9 = 1.
"экз
всех построенных моделей и из них оставляем N наилучших;
Эти модели для удобства мы заново перенумеровали.
Показатель качества первого этапа селекции оцениваем в виде среднего значения час i ных показателей качества лучших моделей;
Г = — У Z z
Выходы лучших моделей служат входами для следующего ряда селекции Далее всё повторяется по аналогии с вышеописанным
Обычно для сильно стохастических объектов на первых рядах селекции показатель качества убывает. Процесс прекращается прн начале его роста - рис, 6.9,3, Из полученной группы лучших моделей последнего этапа (на рисунке пятого этапа) оставляется лучшая моделей. Она и представляет
собой построенную модель объекта.
Дня получения выхода итоговой модели (при каждой реализации входов объекта и ) необходимо проводить несколько пересчётов по более простым
моделям всех предшествующих рядов селекции.
Для объектов со сравнительно малым количесгвом входов необходимо Искусственно увеличивать их количество (до 10-15) за счёт выбранных преобразований входов. Например, для объекта с одним входом и можно сформировать дополнительные входы за счёт степенных преобразований реаль-
2 Ю тг
иого входа; wT - и, м2 = и , .~ и , Лучше использовать и другие преобразования, которые ранее применялись при построении параметрических Моделей рассматриваемого объекта.
Глава б Идентификация статических моделей объектов 261
На базе основной идеи МГУА в литературе появилось множество моди фнкаций, многие из которых опробованы на реальных объектах и подтер дили правильность данного пути решения сложных задач кибернетики.
Упражнения Щ
6.3.1. Для модели т)(и,а) - а найти параметр а из критерия наимевь-тих квадратов при:
а) некоррелированных равноточных измерениях,
б) некоррелированных неравноточных измерениях,
в) коррелированных измерениях.
6.3 2 Для объекта с двумя входами /д, и одним выходом т)’ эксперимент спланирован так, что выход измерен (д’, i = l,n, для всех
пар i ~ J - значений входов, а измерения выхода некор-
релированные равноточные (см. пример 6.3 3) Записать критерий наименьших квадратов и уравнения расчёта параметров линейной модели:
г|(н,,м?) = ап -ьаДм, -м,) + а2(н2 - м2), й2=-£м2
я ™ J=1
6.3.3. Вычислить параметры линейной модели Т|(м,а) = а0 + на основе критерия наименьших квадратов при:
а) некоррелированных равноточных измерениях,
б) некоррелированных неравноточных измерениях,
в) коррелированных измерениях.
6.3 4. Составить уравнения расчета параметров на основе критерия наименьших квадратов при некоррелированных неравноточных измерениях следующих моделей:
a) r|(w,a) = a0 + a,w + ct2 —, б) Г|(м,а) = an + sincijM + а2 cos^’ u
в) T|(w,a) = a0 + а,м + а2м2, г) т)(м,а) = a0 + + а2м2
1 -и
д) п(и,а) = а0 + а, -у, е) п(«,а)- а0 + а^-ь а2<? “. и
262~ ’ -- — - -
6.4.1. Построить алгоритм расчета параметров по критерию наименьших ^адратов для следующих нелинейных относительно параметров моделей:
1) г|(м, ct) - а^^3, 2) т|(м,a) = a, sin(a2w),
3) т|(м,а) = сц sin(®M + a2), 4) r](w,a) = a1sin(a1n + a2),
5) п(н,а) = —~6) ц(м,а) = a.1eot3“, a2 + аэн
при:
а) некоррелированных равноточных измерениях,
б) некоррелированных неравноточных измерениях.
6.5.1. Записать алгоритмы вычисления робастных оценок параметров моделей:
а) т](м, a) = a, б) Г|(м,а) = a0 в) ц(м,а) - otji/, + а2м2,
г) i)(u,a) - ctji/*3, д) г|(н,а) = c^sinfctjM+ ct2), е) r|(w,ct) - а,еа?\
6.6.1. Записать адаптивный алгоритм идентификации параметров моделей;
а) т|(м,а) - ан2, б) т|(м,а) = а0 + а}и, в) ц(и, а) = иа,
г) р(м, а) = ар***2, д) T|(w,a) = - , е) р(м,а) - а]е“?и.
1 + а2м
За основу взять критерий наименьших квадратов с забыванием инфор-МаЧии при некоррелированных перавноточных измерениях.
6.7.1. Построить алгоритмы адаптивного расчета робастных оценок па-Р^етров моделей
а)ц(и.ct)-a. б) ц(м,а) = а0 + а3м; в) ц(«5а) = а,и{ +a2w2,
г) т|(м,а) = ма, д) Г|(м, а) = а^113, е) Г|(м,а) - a]Sin(a2w), ц(п, а) - а, 5т(а,м + а,2), з) r|(w,ct) - а^2".
а 6 Идентификация статических моделей объектов 263
6.8.1. Записать простейший адаптивный алгоритм идеитификап моделей:
а) а, б) а0 + щи + щи2, в) а0 + щи +
б) а0 + щи + а2п2,
1 .
г) а, + а2 д) а0 + а, sin^w, + a2sinco2M2, е) а]м1 + а2п2) и
ж) а0 + а]«1 + а2м2 + а3н3, з) a, sin(a2w + а3),
и) cqexp — a^L 2а,
\ exo clau \ 4“ Ct-j И
к) а}и 2 +а3е 4 5 л)----------------J—s м)--------1---1----
а2 + а3а а3 + a+u + а5м3 ’
264
Методы анализа дан^
Глава 7. ИДЕНТИФИКАЦИЯ ДИНАМИЧЕСКИХ МОДЕЛЕЙ ОБЪЕКТОВ
В динамическом режиме поведение объектов описывается различными динамическими уравнениями [7.2, 7.6]: обыкновенными дифференциальными, интегральными, интегродифференциалънымиуравнениями; уравнениями с запаздываниями; уравнениями в частных производных и их дискретными аналогами [7.4] С целью упрощения изложения материала мы будем рассматривать наиболее простые дискретные модели. Последние выбраны именно потому, что получаемые алгоритмы идентификации и управления 0-д 8) напрямую реализуемы на цифровой вычислительной технике (минн-, микро-ЭВМ. микропроцессоры).
Дискретные модели привязаны к номерам дискретных моментов времени и поэтому основным аргументом для входных м(/) и выходных х(/),_у(/) переменных является номер дискреты / — О, 1, 2,... . Например, линейное й нелинейное разностные уравнения имеют вид:
х(/) = Лх(?-1) + Bu(t -1), t -1, 2,..., х(0) = х0;
х(7) -1), u{t -!),(£ -1), a), l = 1, 2,..., х(0) - х0.
7.1* Дискретные динамические модели стохастических объектов
Считаем, что объект описывается дискретным уравнением
x(z) -ax(t -1) + bu\t -1) 4- е(£) + ce(t -1), t - 1, 2,... . (7.1 1)
Здесь х,и - измеряемые скалярные выход и вход объекта; e(t) - некоррелированная во времени центрированная помеха (белый шум); e(t) + се(1-1) = ~^(/) - коррелированная (окрашенная) помеха; а, Ь, с — неизвестные параметры.
Обозначим через у(0 выход модели в момент времени t.
Исследования показали [7.2, 7.5], что оптимальная (в смысле минимума среднего квадратического значения невязки s(/) = x(f)~ y(t);
= min) модель имеет вид
ЯО = «х(/ - 1) + bu{t -1) + с(х(/ - 1) - y(t - ])). (7 1 2)
р”"----------~------------------— ——.--------------------------—— —
1ава 7 Идентификация динамических моделей объектов 265
Ппи этом невязка в(/) между выходами объекта и модели обладает теад же свойствами, что и помеха е(/), т. е. ф) - некоррелированная во вреМени центрированная случайная величина, дисперсия которой равна дисперсии помехи е(Г). Следовательно, объект (7.1.1) е помощью модели (7.1.2) улает. ся описать только с точностью до помехи е(0.
Структуру уравнения модели (7.1.2) можно легко получить из уравнения объекта (7,1. 1), сделав замену е(?) на х(/)-у(О, е(/- 1) на x(t - Г) ~ у(( - 1) и переобозначив параметры объекта а,Ь,с на параметры 5, Ь, с модели. 'Эту
' схему построения модели линейно-
го объекта мы будем применять и для нелинейных объектов. Заметим, окрашенная помеха ^(/) = е(/) -г се(г - Г) приложена к выходу объекта (7.1.1) (рис. 7.]. 1); ? _ оператор запаздывания сигнала на такт). Если даже некоррелированная помеха е{1) приложена ко входу объекта (рис. 7.1.2)
x(t) ~ ыА'(/ -1) + b(u(t - 1) + e(t -1)),
(7.1.3)
то оптимальная модель имеет вид
(7.1.4)
у(0 - ay{t - \) + hu(t-1), z = l, 2,....
Эта модель всегда с обрат-ной связью по у, в то время как модель (7.1.2) будет либо с обратной связью по выходной координате у, когда помеха £(0 окрашена (с^О), либо без обратной связи по у, когда помеха 4(0 является белым шумом (т. е. 4(/) = е(0).
Более общее ло сравнению с (7.1,1) линейное уравнение объекта имеет
вид
x(z)- ^а,х(?-г)+Ё^м(/"^) + Хс^(/“^) + Ф). ,=i у=1 *=1
266 Методы анализа да»1461
Оптимальная линейная модель получается из (7.1.5) заменой е(р) на (х(р)-У(.РУ) и параметров й=(йр..., ай, сд)т объекта
лапараметры а = (5,,..., ап, сд)т модели:
ЯО = - 0 + XbjU(t - j) + £ск (х(7 “ Л) - y{t - к}}. (7.1.6)
j=i j=i k-i
Если помеха £(/) не окрашена, г. е.
ВД = Хсье(* ~ к) + <0 = е(0,
*=1
то последняя группа слагаемых в (7.1.5) отсутствует и модель становится без обратной связи по у:
л m
яо=Е5Х'~о+Йи('-7)- р.17)
.л /-1
Если на основе модели удалось отследить истинные параметры объекта (1. е. а i = 1,и; b.-Ъ^ j - l,w, ck = ck, к = !,<?), то из (7.1.6) или (7.1.5) получаем, что
х(г)-у(7)-<7), (7.1.8)
т. е. после построения оптимальной модели рассогласование между выходами объекта и модели равно помехе е(7) . Точнее модель построить нельзя.
Аналогичные результаты имеют место, если в (7.1.5) основные переменные х,и,е являются векторами, а параметры - матрицами параметров.
Линейные разносгные уравнения объекта могут по сравнению с (7.1.5) Одержать интегральные суммы, чистые запаздывания по времени и т. п. Схема построения оптимальной модели не меняется. Рассмотрим пример. Объект описывается уравнением
х(/) - ax(f-l) + йм(7-1) + Cje(Z -1) + с2е(Г-т) + е(Г),
7-1,2,..., т > 1, (7.1.9)
- ___________________________— -——,— ----------— ___—.---
^&а7 Идентификация динамических люделей объектов 267
с чистым запаздыванием г в линейном фильтре для окрашенной Помехи
ВД = -1) + c2e(t - т) + e(t).
Делаем в (7 1.9) замену переменных (7.1.8) и параметров (объекта на ца раметры модели) и получаем динамическое уравнение модели
у(0 ~ ~ 1) + Ьи(1 - 1) + C]X(Z -1) - у(/ -1) +
+ с2(х(/-т)-Я^^))- (7.1.10)
Это разностное уравнение с чистым запаздыванием по координате у Оно переходит в обыкновенное уравнение без обратной связи по у (с входами модели х, и и выходом jp):
у(/) - ax(t - 1) + bu{t - I),
если помеха является (при с - с2 = 0) белым шумом е(?).
Для нелинейного объекта с линейным фильтром для аддитивной окрашенной помехи £,(?)
х(/) - /(х(/ - V),u(t - 1),л) + ce(t -1) + e(t) (7.1.П)
после замены е(р) на [х(р) а параметров объекта а, с на парамет-
ры модели а, с получаем модель объекта в следующем виде:
у(0 = f(x(t-1), и(/ П, а) + c(x[t -1)-у>(/-1)). (7.1.12)
Если фильтр для помехи отсутствует, т. е. ^(7) = е(/), то в модели (7 1.12) исчезает обратная связь по координате у и модель приобретает 5°' лее простой вид:
y(0 = /W~l)> w(z-l), а). (71>13)
Если в объекте имеется нелинейный фильтр для помехи £(/)♦т- е-
Х0 = Л(^-1), «(*-1), й) + /3(с,е(?-1))+ <?(/),
268~ ' ~ ’ Ме^Ганализа дан»^
0 моДелЬ объекта имеет следующую структуру:
M('-X «) + Л(^ (7.1.15)
Модель построена по той же схеме, что и для линейных объектов. (Эпохальность ее не доказана. Остается лишь на базе выбранной структуры ^дели оптимально распорядиться ее параметрами. В следующих параграфах данной главы мы будем рассматривать лучшие из существующих алгоритмы перестройки параметров моделей.
Второй подход к построению моделей несколько отличается от предыдущего. Он является преобладающим в современной теории и практике адаптивной идентификации [7.2, 7.5] и рассчитан иа непрерывную во времени перестройку параметров. В каждый момент времени t в моделях (7 1 2), (7.1.5), (7.1.10), (7.1.12), (7.1.15) обратная связь по координате у своеобразно разрывается (без потери общности модели). Это приводит к тому, что отпадает необходимость рассчитывать функции чувствительности к параметрам. Вычисление функций чувствительности заменяется дополнительны -ми расчетами выходов модели при ранее найденных параметрах модели Сравнительный анализ эффективности этих двух подходов к идентификации ждс) еще своего решения.
Рассмотрим вначале объект (7.1.1) и оптимальную структуру модели (7 1 2). Введем обозначения:
z(t | a(t -1)) - выход модели в момент времени t при значениях параметров а(/ — 1), вычисленных в момент времени t - 1;
z(t | a(Z)) - выход модели в момент времени t при значениях параметров a(Z). полученных в момент времени t на основе всей поступившей к этому моменту информации: x(Z); x(t -1). u(t - 1); ... .
Тогда
z(t | a(z -])) == a(l -l)x(f -1) + b(t - \)u(t-1) +
+ c(z - l)e(z -1) - (pr (Z)a(Z -1),
e(/-l) = x(Z-l)-z(/-l|a(/-l)), (7.1.16)
z(t | a(z)) = a(t)x(J -1) + b(f)u(t -1) + c(f)e(t -1) = (pr (Z)a(Z).
Здесь a(Z) = (a(t), b(t), c(t))r - вектор параметров модели; 40 = (х(/ -1), u(t -1), e(t - 1))т - вектор измеренных координат, е(Г) -°Ченка значения помехи е(г).
______________ . . _________- ___-- —__-__________-_________— —_-—— г1аад 7 Идентификация динамических моделей объектов____________269
Модель линейна относительно искомых параметров сх(О- Для Их расчета в параграфе 7.3 будут использованы алгоритмы, описанные накщ в главе 6 при подстройке параметров статических моделей.
Для структуры модели с чистым запаздыванием (7.1.10) итеративная модель типа (7.1.16) приобретает вид:
z(z| a(f-l)) = a(t- l)x(f -1) + 6(f-!)?/(/-1) +
+ сД?- 1)е(/ -1) + с2(/ - 1)ё(/ -т) = (р7(/)а(?-1),
e(t - 1) = x(t- 1) -z(t -11 cc(f -1)),
ё(/ - t) = x(Z - t) - z(t - т | а(Г -1))
z(/1 ct(/)) =a(t)x(t~ 1) + b(t)u(t-1) + (7.1.17)
+ cl (?)<?(/ - 1) + c2 (f)e(f - t) - (pr (t)a(t),
фг (/) = (x(f -1), u(j -1), eft - 1), eft - t)) ,
ct(/) = (5(f), b(t), c}(t), c2«.
На базе нелинейной модели (7.1.15) получаем следующую итеративную модель:
z(z | aft -1)) = f} (x(f -1), uft -1), aft -1)) + f2 fcft -1), eft -1)),
eft-1) - x(t -1) -zft -1| aft -1)) (7.1.18)
4' I a(0) = Z OG - D, -1)> 5(0)+/2 (£(0> £(' - 0) •
7.2. Подстройка параметров с использованием функций чувствительности
Остановимся для примера на модели (7.1.2) объекта (7.1.1)
у(/1 а(/)) = й(/)х(/ -1) + b(t)u(t- 1) + с(/)[х(?-1) -y(t-11 а(0)]
Построим алгоритм расчета параметров а(/) (5(f), b(t), ^(0) ли в момент времени t на основе следующей информации: x(f); х(^
270 ” ~ ~
x(j-2), ... .Такая ситуация присуща адаптивным систе-
маМ управления с идентификацией (см. гл. 8). В этих системах в момент t т0дько после построения модели рассчитывается и подается на вход объекта управляющее воздействие u(t). Это воздействие будет участвовать в расчете параметров модели в следующий момент времени.
Линеаризуем модель (7.2.1) относительно параметров а(?-1), вычисленных в предыдущий момент времени;
y(t | а(Г)) « y(t | а(Г -1)) + соа (Г)Да(г) + ОЙ(/)Д6(/) + ©е(/)Дс(/) -
- y(t [ a(t - 1)) + п/ (г)Да(г).
(7.2.2)
Здесь y(t | сх(/ — 1)) - выход модели в момент времени t при значениях параметров, полученных в предыдущий момент времени t — 1,
y(t | а(/ -1)) = 5(t - l)x(t -1) + b(t - - 1) +
+ c(t - l)[x(/ ~ 1) - y(t -11 a(r -1))];
(7.2.3)
to(0 - вектор-столбец функций чувствительности выхода модели к параметрам модели <й(г) = (ffls(f), GJg(f), й}^(0)Г
Функции чувствительности (Pa(f) ~ dy(f)/da,... удовлетворяют уравнениям чувствительности:
(Г) = ~c(i - l)(od (г -1) + x(i -1), (0) = 0,
а6-(г) = -c(f - I)cosG “ 1) + «0 - О, ®И°)= 0 ’
(7.2.4)
со, (г) = —c(t - 1)(0с- (Г -1) + (х(/ -1) - y(t -1| ос( Г -1))), (0) = 0,
М, 2,... .
Каждое уравнение чувствительности получается дифференцированием Уравнения модели по соответствующему параметру. В правой части урав-Нения модели (7.2.1) в явном виде присутствует интересующий параметр ^Фферснцированне по нему дает возмущающее воздействие в уравнениях ^ствительности (7.2.4), а выход модели у (г - 1) также (но неявно) зависит
°1' соответствующего параметра (дифференцирование этого слагаемого дает мОравой части (7.2.4) компоненту - со).
л°й° 7 Идентификация динамических моделей объектов 271
Для расчета параметров а (7) модели в момент t используем рекуррент ные алгоритмы, рассмотренные в параграфах 6.6-6.8, с соответствующей заменой в них: индекса п на момент времени t, выхода статической модели на выход y(t | а(/ - 1)) динамической модели, вектора градиента Vr[() на вектор функций чувствительности ш(/). В результате алгоритм (6.6 13) метода наименьших квадратов с экспоненциальным забыванием информации приобретает вид:
а(Г) = а(/ -1) 4- у(0О(0 “ У(/ I а(Г -1))
7(7) =- Г(/ -1)0(7) /(p(t)E + сог (Г)Г (г - !)©(/)), (7 2 5)
Г(г) = (Е -у(7)сог (7))Г(7 — 1)Х-1, t = tQ + 1, t0+2,.. .
А.нало1ично записываем простой алгоритм (6.6.14) Б. Т. Поляка:
а(г) = а(Г -1) + у(г)^-1 (r)o(/)(x(r) - y(t | а(г -1)),
а(7) - а(7 -1) 4-г 1 (а(7) - а(/-1)), / = 1, 2,..., (7.2.6)
у(/) = уГ1/2, у>0;
простейший адаптивный алгоритм (6.8.11).
< = 1,2,...; (7.2-7)
' сог(г)о(<)
алгоритм (6.6.17) оценивания нестационарных параметров
a(0 = /(a(r-1) + v(r)
объекта:
а(Г) - /(а(Г -1) 4- у(Г)[х(Г) - у (f I а(г -1))],
у(0 = Г(г - 1)0(г)/[р(г А + й/ (Г)Г(/ -1)0(0], <7-2'8)
Г(Г) = [£-у(Г)0г(Г)]Г(Г- 1)Г’ + Г(г), 7-1,2, ... ;
171 ~~ ~ —- Методы
алгоритм (6.7.1)
a(f) - a(t -1) + 7(/)е(г), е(Г) = x(t) - y(t | a(t -1)),
y(/) = Г(/ - 1)со(г)/[Й7(/)Х + 0г(г)Г(г - 1)®(г)],
ПО = [£ - у(/)ог (Г)]Г(Г - 1)Г‘, Г = ?0 +1, '0 + Л .... (7.2.9)
= MOI е(О I, б) k(f) = p(f)\ е(г) |2"\
ГрШ-ЛЖД,
U(O| е(г) ( ! A, | s(O |> А;
алгоритм (6.7.4):
а(Г) = а(/-Г) + у(г)ц/'(Е(г)), е(О = ЯО ->’(da(*-l)).
у(0 - Г(/ - 1)(о(г)/[р(г)Х + ®г (г)Г(Г - 1)<о(Г)], (7.2.10)
ПО = [Е -у(/) + со7(е)]Г(/-1)Х t = t0 + 1, /0 + 2, ...
и алгоритм (6.7.6):
а(0 - a(f-1) + у(О^(Оч/'(Е(О)’е(/‘) ~ х(0_у0 1^0 -1)),
а(0 = ос(/ -1) + Г1 (а(/) - а(Г-1)), t = 1, 2,..., (7.2.11)
у(О-у/’1П, у>0,
Расчета робастных параметров модели.
Для других типов моделей (7.1.6), (7.1.7), (7.1.10), (7-1.12), (7.1.15) ^Горитмы расчета параметров (7.2.5)-(7.2.11) не меняются. Необходимо по выбранной модели рассчитывать свой выход модели y(t | л(7 -1)) свон функции чувствительности <о(0 На последнем вопросе мы остано-й1!^ся подробнее.
Наиболее простой среди вышеуказанных является модель без обратной (7.1.7)
Лйв° Идентификация динамических моделей объектов 273
>'(/) = 0 + (7.2.12)
1-1 ;=1 7
Функции чувствительности равны соответственно х,м (отпадает необ ходимость решать уравнения чувствительности):
МГ)=х<Г”гЬ * = ^(Г)-м(Г-у), 7 = 1,м. (7.2.13)
Для модели (7,1.6)
Уф = 2Х х(г " 0 + ЕМГ - 7) + JX (х(Г - *) - y(t ~ *)) (7.2.14)
i=l 7=1 *=1
функции чувствительности удовлетворяют уравнениям
°s, W = -ЕХЙО[ (z - k) +x(.f ~ 0, ' = L ” ;
k=i
я
(0=(.f -k) - у)’ j = tm; (7-2-15)
; Ul J
% (7) = ~E^°c7 (/ ~ *) +0(7 - 0 - у(* - 0)> 1 = !> я ui
В работе [7 3] показано, что для получения каждого набора функций чувствительности |о)й ], j, } надо решить не систему уравнений, а лишь одно уравнение (фазовыми координатами этого уравнения являются функции чувствительности);
<t=i
-2(0--X^s2(7-Zr)+w(7-l),
jt=i
<*>-bj(0 = +1 -7)> 7 = i=m;
274
(7.2-1^
7/ёт^ъГан^^^
*3(0=(f -k) ~ i) ~ x* - U),
юг/(0-2з(? + 1“0> l^^q-
В уравнениях (7.2.16) в качестве параметров (cj берутся параметры последней итерации {ct(7-1)}.
Модель (7.1,10) с чистым запаздыванием
y{t) = ax(t -1) + bu(t - 1) + Cj (х(Г -1) ~ y(t - 1)) +
+ c2(x(r- т)-у(Г-т)) (72.17)
порождает следующие уравнения чувствительности с чистым запаздыванием;
(t) = -с]аг(/ -1) - c2®a(t - т) + х(Г -1),
Ч(/) - -с,(ь£ (/ -1) - с2оу (t - т) + i/(r - 1), (7.2.18)
®q (0 = (Г -1) - с2сое (Г - т) + (х(г -1) - y(t -1)) , ®е2 (0 = ~^®с2 D - S2&c2 Т) + (X(f ~ Т) - y(t ~ Т)) .
Для получения функций чувствительности к параметрам с15 с2 достаточно решить одно уравнение [7.3];
z(r) = -c,z(Z - 1) - c2z(t - -t) + (x(f -1) - y(t -1)),
«г,(/) = г(0, aS2(Z) = z(r + l-T). (7.2.19)
Все нелинейные ранее рассмотренные модели (7.1.12), (7.1.13), (7.1.15) ^ишем в виде уравнения
Х')=лх'~а р-2-20)
ot ~ вектор-столбец искомых параметров. Уравнения чувствительности аМеК)тВИд
aW-w(f~l)Vy/ + Va/. (7.2.21)
--- ___________________- -. ________________________-_- — -- — — Идентификация динамических моделей объектов____________275
7,3, Метод, основанный на использовании итеративных моделей
Как и в предыдущем параграфе, начнем рассмотрение с простой оптимальной модели (7.1.2) объекта (7 1,1)
у(1) = ах(Г-1) + Ьм(г-1)ч c(x(t -1)- y(f-l)). (7.3.1)
Используем структуру оптимальной модели (7 3.1) для построения итеративной модели. Обозначим через z(?|a(Z-1)) выход модели в момент времени / при значениях параметров, вычисленных в момент времени г-1-
z(t | a(t-1)) = a(r-l)x(r-1) + b(j~ l)w(r-1) + с(Г- l)e(r -1),
ё(( -1) - х(Г - 1) - z(t -1 (а(Г-1)). (7.3.2)
Выход модели в момент времени t при значениях параметров, вычисленных в момент времени t, записывается в виде
л(/|а(/)) = J(r)x(r- 1) + l) + c(t)e(t-1) - фг(f)a(t')- (73.3)
В (7,3.2), (7.3.3) e(t~ 1) - это оценка помехи e(t ~ 1) объекта (7 1 1). Она вычисляется по значениям параметров модели, полученным в момент времени t - 1. За счет этого в модели (7.3.3) e(t - 1) выступает как самостоятельное воздействие н не зависит от искомых параметров. Так разрывается обратная связь (по у в модели (7,3.1)
В модели (7.3.3) (t) = (x(t - 1), u(t - 1), е(Г-1)\ а(0~
=(«(?), b(f), c(tyf. Параметры ее находим по рекуррентным алгоритмам параграфов 6.6-6.8 либо параграфа 7.2, сделав замену в последних ®(0 на ф(/), т(? I a(.f ~ 0) на 1 а(Г ~ 1)) Например, алгоритм (7.2.5) принимает вид
a(t) = a(t -1) + Y(r)[x(r) - z(t j a(r -1)],
/ 7 П 3’4)
T(0 = T(z - l)<p(/)/[p(0X + <p r(/)I'(Z - l)<p(/)l,
HO=[£ - то)<рг (0)Г(/ - 1)Х-‘, I = i, г....
Г(0)=ЛЛ p>\.
276 Методы
По аналогии с (7 3.3) строим рекуррентные линейные модели, соответствующие оптимальным линейным моделям (7 1.6), (7.1.7), (7.1.10) :
л(/1 а(Г)) (t)x(t - ?) + (t)u(t - J) + ;=]
+ Х^е(Г-к) = /(Г)а(/), (7 3.5)
jt-i
e(t - k) = x(t - k) - z(t - к j а(Г - £)),
z(t | a(Z)) = - z) + £^м(Г - j) = срг(/)а(Г); (7.3.6)
<=i ,=i
z(f I a(0) = a(t)x(t -1) + b( f)tt(t - 1) + c, (t)e(t - 1) +
+ с2(г)ё(/-1) = <pr(z)a(r), (7.3.7)
e(t - 1) - x(t -1) - z(t -11 a(r - ])), e(t - t) = .x(r - t) - z(t - т | a(t - t)) .
Нелинейные модели (7 1.12), (7.1.13), (7.1.15) представим в обобщенном виде
у(/) = /(х(/-1), М(Г~1), х(Г-1)-у(Г-1), а). (7.3.8)
С учетом этого рекурсивная модель приобретает вид
л(/1 а(Г)) = f(x(t -1), u(t - 1), е(/ - 1), а(Г)),
е(г -1) = x(t - 1) - z(t - 1 j а(/ - 1)) (7.3.9)
Линеаризуя ее по а в точке ос(£ -1), получаем возможность воспользоваться алгоритмами параграфа 7.2 с заменой в них y(t j a(t -1)) иа 2(( |ct(r-1)) - f(x(t~ 1), w(r-l), t?(r-l),«(/-!)) и вектора функций чув-^ителъиостн щ(/) иа вектор градиента от z(t | a(t -1)) по а: ^й/(х(/-1), u(t ~ 1), e(t- 1), a(f- 1)). Например, алгоритм (7.2.6) записы-^ется в виде
а» = а(г -1) + (r)Vaz(/1 а(Г - 1))е(/),
E(0=x(/)~z(r|a(r-l)),
(7.3.Ю)
a(f) = а(г _ +1-1 (а(г) - -1)), / = 1, 2,...,
v('W-|,2,y>o
Идентификация динамических моделей объектов
277
7.4. Применение простейшего адаптивного алгоритма
Рассчитаем параметры линейных и нелинейных динамических моделей (параграфы 7.1-7,3) иа основе простейшего адаптивного алгоритма (параграф 6 8).
Если в основе подстройки параметров лежит использование функций чувствительности (см. параграф 7,2), то простейший адаптивный алгоритм записывается в виде (см. (6.8.4), (6.8.11), (7.2.7)
ат-а(/-1) + (Х-^^ 7 = 1,2,.... (7.4,1)
со (t)a(t) 1
Здесь y(t | а(/ - 1)) - выход модели в момент времени t при значениях параметров а(7 - 1), вычисленных в момент времени t - 1.
Пример 7.4.1. Рассматриваем модель (7.1.7), (7.2.12) без обратной связи
п ш
хо=ZaX' - о+- j)
1=1 7=1
(7.4.2)
Функциями чувствительности выхода модели к ее параметрам являются измеренные значения выхода и входа объекта (см. (7.2.13):
= i = (7) = //(/-у), J = (7А.З)
В каждый текущий момент времени t на основе измерений х(7); х(7 -1),u(t - l);x(7 - 2),u(t - 2) параметры корректируем по простейшему адаптивному алгоритму (7.4.1):
a,(f) = a,(Г- 1) + ЙД-ЛЛИДД)» i = l,n-
IX-W+ZX- (г)
!=[ J = l 7
bj(0 = g,(t-l) + (*(<) --1 —«(<-7); 7 = 1,?»; (7'4-4)
2X (0+ZX-, (0 i=l ;=l 7
y(r | a(t -1) = £4 (Г - W - /) + E(t ~1W ” 7) t=i j=i
278 ~мё^одыанал^а dafltlblX
Пример 7.4.2. Для нелинейной модели без обратной связи
У(0 = /(*('-!), w(r-l),a13aj
(7.4.5)
получаем следующие выход модели y(t {а(г -1)) и функции чувствительности-y(r |a(r-l) = /(х(?-1), u(t- 1),а1 (/- 1),а2(Г-1)),
df(x(t -1), н(/ -1), а, (г -1), а2 (/ -1)) ша! V/
Эа1
(7.4 6)
m (t\ = ~ *)’ ai (г ~ *)’ аг (г ~ D)
ша2 V/
Эа2
а также алгоритм (7.4,1) перестройки параметров:
г,- м_п- (f n I
а1(0 °М/ 1) + 2 . . 2 , х ^cqV/’
%(*) + <%(')
«2(0 - а2^~ i) +--Г77 1 / X ~Maz (О-
<(«)+<%(')
(7.4.7)
Пример 7.4.3. Если в модели (7.4.5) появляется обратная связь по выходу, т. е.
>’(*) =/(X*-1),х(Г-1), wO-lXa,,^), (7.4 8)
то меняется расчет выхода модели н функций чувствительности (см. (7.2 21):
у(( Iа(/ -1) = f(y(t -11 a(i - 1)),х(/ -1),
w(r-l),di(/-l),a2 (/-!)) = /(•),
У (г ~ 11 а(Г -1) = f(y(r - 21 a(r - 2)),x(t - 2),
w(r-2),a](t-l),a3(r-l))>
(7.4.9)
Ша (()=йа
аЛ } 7 ду За,
%(0 = Юя (Г-1)^^.
2 v 7 “2 v 7 ду Эаг
а Формула перестройки параметров сохраняет свой вид (7.4.7).
7 Идентификация динамических моделей объектов
279
При применении итеративных моделей (см. параграфы 7.1, 7.3)
z(r |а(0) = /(х(Г-1), w(r-l), e(t- 1), ct.(f))>
-1) = х(?) - z(t - 11 a(t -1)) (7.4.10)
простейший адаптивный алгоритм (6,8.11) перестройки параметров принимает вид
у\ / x(f}-z(i I a(t -1)) _ ... , „
а(Г>а(Г-1)+ t = 1,2,...; (7,4.11)
z(t (a(l -1)) = f(x(t - 1), w(r-l), ee(r-l), a(t -1)) = /(-).
Здесь z(t j a(t -1)) - выход модели в момент времени i при значениях параметров а(/ -1), вычисленных в момент времени t -1.
Пример 7.4.4. Для итеративной модели (7.1.16)
z{l [ сс(Г)) = a(t)x(t 1) f b(t)u(t 1) + -1) - q/ ,
e(t -1) = x(r -1) - z(t -11 a(r -1)) (7.4.12)
градиент Va/(-) равен (p(f) = (x(Z -1), u(t -1), e(t - 1))T. Получаем по алгоритму (7.4.11) нижеследующую покомпонентную перестройку параметров модели во времени;
a(0 = a(t-1) + Д(г)х(/ -1), b(f) - b(t —1) + 1), (7.4.13)
с(О = с(Г-1) +Д(Ое(7-1), Д(Г) =
x(Q - z(71 a(7 -1)) x2(r-1) + u2(t-1) +ё2(/-1) ’
z(t j cc(r -1)) = a(t - 1)х(/ -1) + b(t - l)w(r - 1) + c(t - 1)ё(/ -1) =
= <рг(/)а(/-1) 28lT
Методы анализа дани#*
Пример 7.4.5. Для итеративной динамической модели с чистым запаздыванием (7 1.17)
z(t [ a(z)) - a(l)x(t - 1) + b(i)u(t- 1) + Cj(f)e(t -1) + c2e(t - т) =
=(/ (Z)a(Z), г/ (0 - (x(Z -1), u(t - 1), е(( -1), е(Г - т)), (7.4.14)
a(Z) = (5(Z), £(Z), ^(Z), c2(z))r,
е(1 -1) = x(l -1) - г(/ -1 j a(z -1)), e(Z - t) = x(Z -1) - z(Z - x j a(f -1)) получаем следующий простейший адаптивный алгоритм перестройки параметров
d(t) = a(t - 1) + A(z)x(Z -1), b(f) - b(t-1) + A(z)w(Z-1),
C] (Z) - c} (Z -1) + A(z)e(z -1), c2 (Z) = c2(t -1) + A(Z)e(Z - x), (7.4 15)
A(z) ~ ------, z(z | o(Z -1)) = pr (f)a(/ -1),
x2(Z-l) + z?(Z-l) + e2(Z-l) + e2(Z-x)
e(t - t) = x(z - x) - z(z - t I a(Z -1)). z(t - x | a(z -1)) = cpr (z - x)a(Z -1).
7.5. Применение модифицированного алгоритма наименьших квадратов
Алгоритм метода наименьших квадратов (см. параграф 6.6) хорошо зарекомендовал себя при оценке параметров моделей объектов, не замкнутых контуром управления (так называемых разомкнутых систем). Идентификация объектов в замкнутом контуре управления требует модификации алгоритмов наименьших квадратов [7.1]. При этом устраняется вырождение Процесса идентификации.
За основу возьмем линейную относительно параметров рекурсивную Модель (см. параграфы 7.1, 7.3)
ДЦа(г)) = <р7(0а(/) (7.5 1)
11 предложенный в [7.1] модифицированный алгоритм наименьших квадратов:
-- —- ' ——------“— —— ------------------- —-
7. Идентификация динамических моделей объектов 281
сср) = ар-1) + ур)Ер),
ер) = х(Г)- z(t | ар -1)) - хр) - ср7 (t)a(t -1),
Y(/) - Р(/)гр - IMO W) + <крг р)гр - 1)фР)),
(7.5.2)
_ к(0, если v(r) = О,
г (г) = )
[/'О -1), если v(r) - 1,
гр) = гр-1) + (/р)(рр), г0 = 1,
Л М) Г с г,. 1Л фГ (0Г2(/- 1)ф(О
О, если —-— S Гр-1)-------------------------
r(z -1Д Л? -1) + Ф (ого - 1)фО)
V(O - <
или (срг (Г)Г(Г - 1)срр)/г(1 -!)) +1 > к, 1 в противоположном случае, где к >,1
(Гр-1), если v(f) = §>ky
ПО = ( гр) < _Гр-1)фр)</р)Гр-1) ~)
[гр- 1Д гр -1) + ср7 (огр- 1)фО)/
если vp) = l,
Г(0)>0МГ(0)<^5рМ(0) = 1,
рОМ
ншп(1; гр)/(сргр)Гр-1)фр))), если гр) - О, [1, если гр) = 1.
Алгоритм занимает промежуточное положение между алгоритмом наименьших квадратов и простейшим адаптивным алгоритмом. При к = 00 все' гда vp) - 1 и имеем алгоритм наименьших квадратов. При Г(0) -к = и? (где т - число параметров в векторе а) получаем v(0' ’ Гр) - тЕ, р(0 = ш”1 и приходим к простейшему адаптивному алгоритму.
При подстройке нелинейных параметров рекурсивной модели в алГ° ритме (7.5.2) надо вектор-столбец базисных функций фр) заменить вектор столбцом градиента по параметрам от выхода модели z(t | а(г - 1)) 282 ’ ~ ~~~Методы анализа дан^{Х
Если при подстройке параметров используются функции чувствительности (см. параграф 7.2), то в алгоритме (7.5.2) вектор cp(z) необходимо заменить вектором функций чувствительности co(Z) .
Алгоритм (7.5 2) допускает обобщение на случай экспоненциального забывания информации и использования неквадратичных критериев оптимальности По схемам, рассмотренным в параграфах 6.6, 6.7, в алгоритм вводятся параметры Л и
Упражнения Ш
Для объектов, описываемых уравнениями:
1. x(z) ~ bu(t -1) + e(z),
2. x(Z) = bu(t - 1) + ce(t -1) + e(Z),
3. x(Z) = bu(t - 1) + cte(Z - 1) + c2e(t - 2) + e(z),
4 x(Z) = bu(l - 2) -t-e(Z),
5. x(Z) = 6w(Z-3) + ce(Z-l) + e(Z)J
6 x(Z) = ax(Z -1) + bu(t - 2) + ce(Z -1) + e(z),
7. x(z) = ax(t ~ 1) + bu(t -1 - rt) + cte(z -1) + c2e(t -1 - r2) + e(t),
8 x(Z) = ax(t -1)/ w(Z -1) + e(t),
9 x(Z) - ax(t- 1)/m(Z - l) + ce(z -l) + e(Z),
10. x(Z) - ax(t - l)w(Z - 3) + £(z), иеобходимо построить оптимальную структуру модели и вычислить пара-Метры модели с использованием рекурсивной модели на основе:
а) рекуррентного алгоритма наименьших квадратов;
в) простейшего адаптивного алгоритма;
д) алгоритма Поляка.
_----_ —---------------.--- - —------------------------- ---
7 Идентификация динамических моделей объектов 283
Глава 8. АДАПТИВНОЕ УПРАВЛЕНИЕ С ИДЕНТИФИКАЦИЕЙ
В адаптивных системах обработки информации и управления [8.1-8.10] происходит приспособление к изменяющимся условиям и неизвестным характеристикам объекта. Адаптивные устройства управления в системах управления строятся на основе двух принципов [8.2]. В соответствии с первым из них на основе некоторых критериев (например, теории устойчивости, теории инвариантности, критериев рациональности) выбирается структура устройства управления с точностью до настраиваемых параметров. Блок адаптации на основе свежей информации о входах и выходах объекта перестраивает параметры в темпе с управлением объектом (рис. 8.0.1).
Объект управления
Объект управления
[
Регулятор
» фиксированной
' I структуры
структуры
Блок перестройки параметров регулятора
Устройство управления
Сиш езируемый регулятор
Блок перестройки 4— параметров модели ♦—
Устройство управления
и
Z
Z
Рис. 8.0.1
Рис. 8.0,2
В основе второго подхода лежит использование модели объекта. Задается (или синтезируется, см. параграф 7.1) структура модели с точностью до параметров. На базе нее из критериев оптимальности синтезируется управление, которое, естественно, зависит от параметров модели. Параметры модели перестраиваются блоком идентификации непрерывно по мере поступления новой информации об объекте (рис. 8.0.2). В данной главе мы будем рассматривать именно этот подход [8.3, 8.5, 8.7]. При его реализации используем ранее рассмотренные алгоритмы адаптивной перестройки параметров статических (параграфы 6.6-6.8) и динамических (гл. 7) моделей.
Реализация адаптивных систем с идентификатором (АСИ) [8.5] позволяет осуществить достаточно эффективное управление малоизученными объектами, для которых пе были известны ни структура, пи параметры их моде’ 284 Методы анализа данных
дей. Например, реализация АСИ на одном прокатном стане Первоуральского новотрубного завода [8.7] обеспечила экономический эффект в 700 тыс. руб. з год (в ценах 1973 г.) только за счет экономии металла. Для данного объекта использованы простейшие линейные статические модели, простейшие адаптивные алгоритмы идентификации (см. параграф 6.8) и простейшие алгоритмы управления. Исследование АСИ для этого объекта показало, что исключение из контура управления блока идентификации делает систему полностью неработоспособной. В процессе реализации АСИ выяснилось также, что одни и те же алгоритмы работы АСИ можно применять для широкого спектра объектов различной природы. Это обстоятельство позволяет решать задачу автоматизированного проектирования математического обеспечения АСИ.
8.1. Постановка задачи адаптивного управления
Рассматриваем адаптивную систему с идентификацией (АСИ), представленную па рис. 8.0.2. Синтезируем алгоритм расчета управления (алгоритм работы устройства управления) u(t) в каждый текущий момент времени t. Исходными экспериментальными данными о входе и выходе объекта являются: x(z); x(t -1), u(t — 1); x(Z - 2), u{t - 2);.... Они включают в себя последнее измерение выхода объекта х(/) и предыдущие синхронные измерения входа и выхода (онн хранятся в памяти вычислительного устройства), Необходимо рассчитать управляющее воздействие w(Z), обеспечивающее Достижение следующей цели: наименьшего уклонения выхода системы х от заданной траектории х в каждый текущий момент времени.
Считаем, что поведение объекта в динамическом режиме описывается разностным уравнением
x(z)-/(x(Z -1), м(/-1), a) + ^(Z), / = 1,2,... . (8.1.1)
Здесь f (•) - известная функция, а - неизвестные параметры, £(Z) - окрашенный либо белый шум. Так как в данной главе мы сосредотачиваем свое внимание на синтезе управлений (построении алгоритма работы регулятора, см. рис. 8.0.2), то для простоты считаем помеху ^(Z) белым шумом e(t). Если шум окрашенный (см. гл. 7), то он представляется как функция от e(Z), e(t - 1),... и параметры этой зависимости также доопределяются в процессе идентификации. Алгоритмы работы идентификатора нами рассмотрены в Параграфах 6.6-6.8 и в главе 7.
Eiasa 8. Адаптивное управление с идентификацией 285
Обозначим через у(к\а(1У) выход модели в момент времени к при значении вектора параметров а(7), вычисленных в момент времени Z. Если шум [£(Z) = e(Z)] белый, то
у(к I а(/)) = f(x(k -1), и(к -1), а(/)).
(8.1.2)
Эта модель используется как для целей идентификации параметров a(Z) (при этом к принимает значение t,t - 1,...), так и расчета управления м(г) (при этом к полагаем равным I + 1). При к = t + 1 из (8.1.2) получаем прогноз выхода объекта для следующего момента времени:
y(z +11 а(0) = /(x(z), «(?), а(0).
(8.1.3)
Параметры a(Z) поступают из идентификатора, где они рассчитываются по одному из адаптивных алгоритмов (см. гл. 7). Неизвестным в правой части уравнения (8.1,3) остается управление w(Z). Его вычисляем из условия наилучшего приближения выхода модели y(Z +11 oc(Z)) к желаемой траск горни х (Z +1) в момент времени Z +1:
(y(z +1 [a(z))~x*(z + l))2 -min при w(z) ct7(z).
(8.1.4)
Здесь U(f) - множество допустимых значений управления. Примером служит интервал [щ, м2], ограниченный известными значениями.
8.2. Примеры синтеза устройств управления для простейших линейных систем
Пример 8.2.1. Считаем, что объект описывается уравнением
x(Z) - х(( -1) + u(t~ 1) + /7(Z-1), Z = 1, 2,...
(8.2.1)
Здесь h - неизвестное внешнее воздействие на объект. СтрукгуРнаЯ схема объекта приведена в верхней части рис. 8.2.1. Через q обозначеН оператор запаздывания сигнала на один такт.
2S6
Методы анляиза данных
Необходимо найти алгоритм расчета управляющего воздействия u(t) в каждый текущий момент времени t на основе информации о структуре модели н на основе измерений
х(Г); x(Z-1), -1);... входа и выхода объекта, чтобы достигалась цель управления: движение системы по заданной траектории х .
Формируем модель объекта
у(к | a(r))=х(к -1)+и(к -1)+а(Г). (8.2.3)
Параметр a(Z) оценивает неизвестное внешнее возмущение h(t) объекта.
Вычислим a(t), приравняв выход
Рис. 8.2.1
модели y(Z | а(/)) и выход объекта x(f) в момент времени t:
x(t) - x(t -1) + u(t -1) + ct(Z).
(8.2 4)
Это уравнение лежит в основе простейшего адаптивного алгоритма
(см. параграфы 6.8, 7.4). Из (8.2.4) получаем параметр
a(z) = x(Z)-x(Z-l)- u{t —1).
(8.2.5)
Структурная схема для блока идентификации представлена в нижней части устройства управления на рис. 8.2.1.
Для расчета управления w(t) находим по уравнению модели (8.2.3) прогноз выхода объекта на момент времени t + 1
y(r +11 a(z)) = x(z) + w(z) + a(z)
(8.2.6)
и из локального квадратичного критерия оптимальности
7Д) = О(/ + )|а(0)-Г(/ + 1))2= , min (8.2.7)
рассчитываем оптимальное управление:
(^(Z), если v(Z) < М] (Z), v(Z), если Wj (Z) < v(Z) < w2 (Z), M2(Z), еспи u2(Z)<v(Z).
(8.2.8)
Глава 8 Адаптивное управление с идентификацией
287
Преобразователь (8.2.8) представляет собой обыкновенный ограннчи-тель по амплитуде для сигнала v(Z). Значение v(z) обеспечивает абсолютный минимум функции Ци) (без учета ограничения на и):
^ = 2(X< + l)|a(Z))-x,(f + l)) = 0, аи
y(t +11 a(Z)) = х* (Z + l),x(Z) + v(0 + а(0 ~ х* (t + 1),
(8.2.9)
v(f) ~ х* (t +1) ~x(z) - a(Z).
Рис. 8.2.2 демонстрирует факт, что оптимальное решите экстремальной задачи (8.2,7) имеет вид (8.2.8). На рис. 8 2.2 показаны три возможных положения квадратичной функции качества /(м). Если абсолютное значение минимума лежит слева от г/]3 то функция качества 1(и) достигает в допустимой области [м.,м2] мини-мум в точке . Остальные ситуации рассматрн-
ваются аналогично данной.
Блок-схема полученного алгоритма управления (8.2.8), (8.2.9) приведена в верхней части устройства управления на рис. 8.2.1. Блок адаптивного управления состоит из двух частей: регулятора (8.2.8), (8.2.9) и идентификатора (8.2.5). Причем в момент времени t после получения нового измерения выхода объекта x(Z) вначале срабатывает идентификатор (он вычисляет 0.(1), а затем регулятор с учетом нового значения неизвестного параметра a(Z).
Вычислим теперь ошибку работы системы для следующего момента времени Z + 1 (ибо она зависит от найденного управления м(/) :
e0(Z +1) - x(Z +1)- x*(z +1).
(8.2.Ю)
Подставляем сюда x(Z + 1) из уравнения движения объекта
х(Г +1) = х(/) + w(Z) + h(t),
а х (Z +1) - из уравнения (8.2.9) для управления v-(Z) (без учета ограничений)
2sT~ ~ ~М^оды анализа данных
x* (z +1) = x(z) + v(z) + a(z),
н получаем,что
Eo (f +1) = [A(Z) - a(Z)] + [w(Z) - v(Z)] = e} (t +1) + e2 (/ +1). (8.2.11)
Ошибка работы системы состоит из двух частей: из ошибки с/Г +1) идентификации внешнего возмущения h и ошибки £2(Z +1), обусловленной ограниченностью управления. Если ресурса по управлению хватает (т. е. ?/(Z) = v(Z), то s2(z +1) = 0. Ошибку идентификации точно рассчитать нельзя в силу неизвестности h, но ее можно оценить, если есть некоторая информация об h.
В уравнение для a(Z)
Ot(Z) = x(Z) - x(Z -1) - w(Z -1)
подставляем x(£) из уравнения движения объекта
x(z) - x(Z - 1) -t- m(z - 1) + h(t - 1) и получаем, что
= (8.2.12)
Параметр модели a(Z) точно отслеживает возмущение h(j - 1), действующее на объект в предыдущий момент времени, ибо информация об h(i -1) содержится в измеренном значении x(Z) выхода объекта.
Ошибка идентификации (с учетом (8.2.12) равна величине приращения возмущения в соседние моменты времени:
Ej(t +1) - A(z) - a(Z) - /?(z) -h(t-1). (8.2.13)
Здесь h(t) - неизвестное значение возмущения.
Если в течение некоторого интервала времени возмущение остается постоянным:
h(z) - с, t - Z|, Z, + 1,..., tz,
то в момент времени Zj +1 идентификатор вычисляет эту константу и ошибка идентификации равна нулю для моментов t-tl +1,..., Z2. При Z = Z2 +1 меняет свое значение возмущение и ошибка идентификации равна величине
EiersaS Адаптивное управление с идентификацией 289
С[ (Z2 + 2) — h[t2 +1)— с
Если известно, что возмущение /?(/) лежит в заданном интервале, т. е !/?(Z)|</i1, то для ошибки идентификации получаем следующий интервал ее изменения:
I е, (г +1) | = | Л(<) - а(г) | < | Л(г) | + | h(t -1) | < 2Л, .
Если известен интервал изменения для приращения возмущения A/i(Z) = /1(7) - h(t - 1), т. е. |A/z(Z)|< Д], то ошибка идентификации находится внутри того же интервала:
!£,(/ +1)| = |/i(Z)-a(Z)[ = |/i(z) -Л(г-1) | < А).
Если /i(Z) дрейфует во времени по линейному закону
h(t)=ta, (8.2.14)
тс в модель объекта вводим параметр а(г), оценивающий в момент времени t неизвестный коэффициент а :
у(к | a(Z)) - х(к -1) + и(к -1) + (к - l)a(z). (8.2.15)
Как и в предыдущем случае, из условия равенства x(f) н у(/ | a(z))
x(Z) - x(Z —1) + u(t -l) + (Z-l)a(Z) (8.2.16)
находим a(Z):
a(Z) - (Z-l)-I(x(Z)-x(Z-l) — u(t - 1)), (8.2.17)
а затем из критерия оптимальности (8.2.7) получаем оптимальное управ ление (8.2.8), где
v(f) - х (t +1) - х(7) -Zct(Z). (8.2.18)
Ошибка работы системы равна величине
e0(Z + 1) = x(Z + l) -x*(Z +1) = t(a - a(Z)) +
ZR 2 19) + [«(0 - ^(0] = E, (Z + 1) + E2(z + 1) .
290 Метод# анализа дан
а
а(г + 1)] л
а(/-1)-| <
Рис 8.2.3
Вычисляем ошибку идентификации е/? + 1). Берем уравнение для расчета a(f) (см, (8,2,17), подставляем в него x(f) из уравнения движения объекта и подучаем, что
a(z) = (t~ I)”1 (х(1 -1) + и(/ -1) + (z - 1)а - x(t -1) - u(t -1)) - а,
1. е. идентификатор точно оценивает постоянный параметр а. Ошибка идентификации равна нулю. Когда идеальное управление v(z) лежит внутри допустимой (для управления) области, то и ошибка управления равиа нулю. Система осуществляет точное движение по предписанной траектории в каждый текущий момент времени t.
Составьте теперь самостоятельно структурную схему системы управления.
Линейный дрейф (8.2,14) возмущения /?(?) можно отследить по-иному. Параметры a(f), a(z-l) вычисляем как обычно по формуле (8.2,5), но в модель y(t +11 a(t)) прогноза выхода объекта (8,2,6) вместо a(f) подставляем линейный прогноз а(/ + 1), вычисленный по последним двум значениям параметра a(f-l), cc(f) (рис. 8.2.3)'
a(t +1) - 2ос(Г) - a(r -1).
Для получения этого равенства берем уравнение линии ai+tfy't и из двух условий, что линия проходит через a(t -1) и через a(t)
О] + а2 (/ -1) = a(t -1),
а} +а2 находим параметры линии
а2
Q] = a(f -1) - а2 (1 -1) - a(r -1) - [a(/) - а(Г -1)] •(?-!).
Затем вычисляем прогнозируемое по этой линии значение на момент (г+1);
а(Г +1) - О] + а2 (t +1) = 2ос(Г) - a(r -1), “ — — ----------— ——-------------— —-—-———™-— --------—- —
Яава8 Адаптивное управление с идентификацией 291
В оптимальном управлении (8.2.8), (8.2.9) вместо a(z) ставим а(/ + При этом а(/ +1) равно величине
+1) = 1) - -2).
Ошибка идентификации Ej(f +1) в ошибке работы системы (8,2,11) равна величине
£,(/ + 1) = /?(z)- a(t +1) = h(t) - 2h(t -1) + h(t - 2).
Это конечная разность второго порядка (ускорение) для возмущения h. Если h(t) меняется линейно во времени (8,2.14)
Z?(0 = ta,
хде а - неизвестный параметр, то ошибка идентификации равна нулю; Е{(г + 1) = 0.
Пример 8.2.2. Объект описывается уравнением
х(О = +a,x(J~ 1) +<32w(f -1) + e(j), (8.2.20)
где e(Z) - белый шум; а0, а}, а2 - неизвестные параметры. Необходимо построить алгоритм расчета управляющих воздействий w(f) (для каждого текущего момента времени t), чтобы система (объект плюс устройство управления) двигалась По назначенной траектории х . Исходными измерениями в момент времени t являются: x(Z); x(t -1), u(t -1); .... Заменяя е(?) иа x(z)-y(z), параметры объекта - на параметры модели, получаем модель объекта;
у(к | a(z)) - a0 (/) + a, (t)x(k -1) + a2{t)u{k -1). (8.2,21)
При решении задачи идентификации индекс к может принимать значе ния t, t -1,а при расчете управления к -значение t + 1,
Параметры модели могут быть найдены с помощью одного нз адаптив ных алгоритмов (параграфы 6.6-6,8, гл. 7), Приведем простейший адаптив ный алгоритм: _
292 ~ ~~ - ~ Методы анализа дани#*
аМ = “»(< -,)+'1)+AW’
а/О = а, (/ -1) + Д(г)х(/ -1), (8,2.22)
а2 (Г) = а2 (Г -1) + Д(г)ы(г - 1).
Затем по модели находим прогноз выхода объекта для следующего момента времени:
у(1 +11 ос(О) = «о (О + «1(0X0 + (8,2,23)
и из квадратичного критерия
(^(/+11 а(0) - х* (Г +1))2 = min
lq < и (/ К ы2
находим управляющее воздействие (8,2,8), где
v(t)- ol;l(()(x+ |r + l)-a0(z)-a1(z)x(r)), (8.2.24)
Ошибка работы системы
е0 (t +1) - x(t +1) - х* (/ +1) - [х(Г +1) - y(t +11 a(t))] +
+ O(' +11 «(0) - x'(t +1)] = [a0 ~ a0(/)) + - a/z)Xt) 4-
+ (a2 - a2 (r))w(f)] + a2 (t)[w(O - v(?)J + e(t +1)
состоит из ошибки идентификации, ошибки, вызванной ограниченностью управления, и помехи.
При подстройке параметров можно использовать простой алгоритм (7,2.6) Б, Т. Поляка:
«о (0 = «о (' ~ 0 + У(0(х(0 - У(? 1 «(' “ U) “о - О + Ai (0 =
«о (С = а0 (' ~ 1) +1~' (a0 (0 “ a(' ~ 1)).
a, (t) = а, (Г -1) + Ai - О, (8.2.25)
Aasa g Ддантиеное управление с идентификацией
293
a!(Z)^a1(z-l) + z"1(u,(z)-aI(r-l))J
a3(Z) = a2(z-l)+ £,(/>(/-]),
а2(?) = а2(?-]) + ?’'(а2(?)-а2(г-1)), у(/) = уГ,/3, у>0
Для расчета управления (см (8 2 23), (8 2 24) необходимо применять сглаженные значения параметров a0(Z), a/Z), a2(z)
8.3. Сивиез алгоритмов управления для линейных систем
Рассматриваем объект, описываемый разностным уравнением и-го порядка
ХО = до + ЕчХ? - 0+IX < X' J)" ХО <8 3Ь
( 1 ?-1
Рис 8 3 1
294
Методы анолизо данны
Парамегры модели
X* I а(0) = «о(О + !>; OW " О + (t)<k ~ j) (8 3.2)
i=i j=j
рассчитываем по одному из адаптивных алгоритмов (см, гл. 6, 7), Оптимальное управление находим из критерия
(Я7 + 1 |а(0)-х*(Г+1))2 = min (8-3.3)
и получаем его в виде (8.2,8), т. е. идеальное управление
40 - (' + 0 ~ ао(О - £сс((Г)х(' +1 - 0 -
<=1
~Xa„+7(0w(^ + l- 7)) (834)
7'2
пропускается через ограничитель по амплитуде (8,2,8),
Структурная схема системы управления представлена на рис. 8.3,1.
Ошибка работы системы, равная величине
е0(Г + 1) ~ х(' + 1)-х*(Г + 1) = [x(r + l)~7(f+ 1 j ot(f))] +
+ IX' +11 a(0) - 4 (' + 01 = [«о + +1 “ 0 +
;=i
+ +1 - 7) + e(t +1) -а0(Г) - £аг (')x(i +1 — j) —
7-1
- ix+; (')«(' +1 - 7)] + [«0 (') + 2>, (')*(' +1 - 0 +
7 = 1 1 = 1
+ E a.+7 W«(' +1 - 7) + aM+1 (z)w(') - a0 (z) - Ё a, (t)x(t +1 - i) -
;=2 j-I
- 7 (')«(' +1 - 7) - a,tH (t)v(r)] = [[a0 - a0(0] +
J=2
+ “ a, (z)]x(r + 1-0 +XK+J “ a„+; (t)]«(r + 1 - 7)] +
7 = 1
+(Чи№(0-Х')]+4' + 0,
складывается из ошибки идентификации, ошибки управления (обусловленной ограниченностью ресурса для управляющего воздействия) и помехи.
Г 1ава 8 Адаптивное управление с идентификацией
295
8.4. Алгоритмы адаптивного управления для нелинейных систем
Объект описывается нелинейным разностным уравнением
x(j) ~ f (x(t -1), w(Z-l), a, Г-1) + е(Г), / = 1,2,.,,. (84.1)
Структурная схема объекта представлена на рис. 8.4,1,
Построим алгоритм распета управляющего воздействия w(z) в каждый текущий момент времени t на основе измерений, поступивших в устройство управления к этому моменту времени: x(z); x(t - 1), u(t - 1); .,. ,
Модель объекта (см. параграф 7.1) имеет вид
Х^1а(0)=(8.4.2)
Ее используют для целей идентификации параметров ос(Г) (при к - Г, t - 1,,,,) и расчета управляющего
воздействия (при к = 1 + 1).
Параметры модели вычисляем по одному из рекуррентных алгоритмов, описанных в гл. 6, 7, с использованием идеи линеаризации модели. Для примера приведем алгоритм Б. Т, Поляка
a(r) = a(z -1) + y(r)Vay(? | - 1))е(г) ,
£(Г) - х(Г) - у(! | a(z -1)),
(8АЗ)
а(0 = а(/-1) + r‘(oc(O--1)), t = = у>0.
С учетом скорректированных (по повой информации) параметров ос(0 прогнозируем (с помощью модели выход объекта y(t + ] | a(f)) и из квадратичного критерия находим управляющее воздействие. Ойо получается на выходе ограничителя по амплитуде, на вход которого подается идеальное управление
40 = /"' W), * (t +1), a(r), 0 (8Л4)
296~~ Методы анализа данных
Оно является решением уравнения
Х'+1|а(0) =
/(x(r),v(r),a(fU)= x‘(Z+l).
(8.4,5)
Структурная схема системы управления представлена на рис, 8.4.1,
Пример 8.4.1. Считаем, что нелинейный по каналу вход-выход объект описывается разностным уравнением
x(t) = ax(t - l)w(7 -1) + е(Г), t -1, 2,,,..
Здесь a - неизвестный коэффициент, e(Z) - ограниченный по амплитуде шум | е(7)| < ё.
Строим модель объекта
у(к 1 а(Г)) = ot(?)x(fc - Vyu(k -1),
Из условия максимальной близости выходов модели y(t ] a(f)) и объекта в момент t находим параметр модели:
x(t') - a(f)x(f - l)w(7 -1), а(0 =
Управляющее воздействие u(f) вычисляем из квадратичного критерия:
(X* +1 j a(f)) - х*(г +1))2 = min, где Wj < u(t) < w2, и получаем, что
Wj, если w(f) = s v(r), если \и2, если
v(z)= V- 7
x(0
«I и(0 £ w2, «2 v(0’
Г‘ава 8 Адаптивное управление с идентификацией
297
Алгоритм системы управления построен. Структурная схема системы представлена на рис. 8 4.2. Оценим теперь качество работы замкнутой системы Ошибка работы системы равна величине
e0(z + 1) = x(t +1) -х*Ц +1) = [х(7 +1) - y(z + l | a(r))] +
4- [y(t +11 a(r)) - x* (/ -h 1)] - [ax(t)u(t) + e(t +1) - oc(Z)x(/)w(?)] -p
+ f a(7)x(r)«(7) - a(f)x(r)v(7)] = [a - a(z)W>(0 +
+ fu(f) - + e(t +1) - E] (t +1) + e2 (t +1) + e(t +1)
Она состоит из ошибки идентификации е, (7 +1), ошибки е2 (t +1), вызванной ограниченностью управления, и помехи e(t +1). Ошибка идентификации
е1(г + 1)= ---------------------
|_x(r-I)«(r-l) х(/-1>Ц-1)
? z. п *(')««)= x(t-Y)u{i -1)
x(f)w(f) x(f - l)w(f -1)
e(z) = -a(z)w(z)e(r).
Если помеха e(t) равна нулю, то ошибка идентификации тоже нулевая.
Если помеха ограничена | e(t) | < ё, то О1раничена и ошибка идентификации
ЫХ + 1Ж |а(Г)и(Г)| ё.
8.5. Управление динамическими системами с чистыми запаздываниями
Рассматриваем объект, описываемый разностным уравнением
х(7) = /(x(z- l),w(/ -1 - т),а) + е(Г), t = 1, 2,....
(8 5.1)
Здесь а - вектор неизвестных параметров, e(t) - белый шум, т - чистое запаздывание на т тактов по каналу ''вход-выход". Цель управления остается прежней' обеспечить движение системы по иазначениой траектории
Строим модель объекта
ЯЛ|а(Ц) = u(k -1 - т), a(f)).
(8.5.2)
298
Методы анализа данчь1Х
При идентификации параметров a(Z) индекс времени k в модели может принимать значения t, t — 1, ,,. При этом применимы все алгоритмы, рассмотренные в гл, 6, 7,
Для расчета управляющего воздействия осуществляем по модели (8,5,2) прогнозирование выхода объекта на момент времени Z + 1 + т (при этом выход модели будет зависеть от искомого управления «(f).
У(* +11 а(0) = fW),- т), «(0) 5
у(г + 2 | а(7)) = f (y(t + 11 a(0)X' +1 - X,a(0),
(8.5.3)
y(t + t: ! «(0) f(y(t + т -11 a(f)),u(t -1), a(z)),
X' +1 + T I a(0) f(y(t + * ! a(0),X0, a(0) -
В правую часть уравнения модели, начиная с момента t + 2, входят вместо неизвестных выходов объекта х(/+1), х(/+2),,.. соответствующие им выходы модели y(t + 11 a(f)), y(t + 21 ос(г)),.... Уравнения (8.5,3) решаем последовательно.
Выход модели в момент (f +1 + т) зависит от искомого управления u(f), Его находим из критерия наименьших квадратов:
Z(w) = (y(t + 1+ т | a(f))-x*(f + 1 + т))2 - min . (8.5.4)
Решение получается в форме (8.2,8) (если u(t) имеет один минимум внутри допустимой области):
1w15 если v(r) <п.р
v(f), если u]<v(t)<u2, (8.5.5)
и2, если и2 < v(f),
гДе идеальное управление v(?) вычисляем из решения уравнения
y(t + 1 + т | a(f)) - x’(f +1 + т), (8.5.6)
f(y(t + т | a(f)), XX a(0) = x* (Г +1 + т).
Формальное решение уравнения (8,5.6) записываем в виде
v(f) = f~'(y(l + т j a(f)),x*(r + 1 + (8,5,7)
^ава 8 Адаптивное управление с идентификацией 299
Пример 8.5.1. Для объекта, описываемого уравнением
x(r) = a0+a1x(r-l) + O2M(z~3) + e(t)J / = 1, 2, .,,, т = 2, строим модель
У<к I «(О) = ос0 (0 + ос, (г) х(к -1) + а2 Ц)и(к - 3).
Идентификацию параметров проводим по простейшему адаптивному алгоритму
! r(r) - ос0 (Г -1) -а// - 1)х(г-1) ? g2(r- ])и(/ - 3)
= а0(/~1) + А(/),
аД/)-«](/-1) + А(/)х(/-1) ,
а2 (?) = а2 (г -1) + A(z)w(r - з), t = I, 2,....
Рассчитываем управление. Находим прогнозируемое значение выхода объекта иа момент времени t + 3, последовательно решая уравнения
y(t +11 а(/)) = а0 (?) + а, (/>(/) + а2 (/>(/ - 2),
р(/ + 2|а(/))^ а0(/)+ а, (z)y(z + l (а(/)) + а2 (/)«(/-!),
y(t+ 3 । а(^) - а0(Г) + а,(t)y(t + 21 а(/)) + a2(t)u(t).
Из условия равенства выхода модели р(7 + 31 ос(/)) и желаемой траектории х (t + 3) получаем идеальное управление
v(z) - ос21(/)(*' О' + 3) - а0(/) - а, (t)y(t + 21 а(/))),
затем ограничиваем его по амплитуде (см, (8,5.5) и получаем оптимальное управление z/(f).
Пример 8.5.2. Управление температурным режимом жидких сред [8.3].
Задачи управления нагревом и охлаждением жидких, твердых и газообразных сред являются одними из наиболее распространенных в технике и в быту. Для их решения в реальном масштабе времени с помощью цифр0’ вых вычислительных машин можно использовать описанные выше алгорИГ’
^00 Методы анализа данных
мы. В подтверждение этого рассмотрим задачу поддержания температурного режима жидкой среды, например электролита гальванической ванны.
Считаем, что измерение температуры жидкости x(f) производи гея в фиксированной точке ваины, а управление ведется за счет изменения расхода a(f) пара в трубопроводе, греющем ванну Управление «(?) лежи г в пределах [0;ы2ф Охлаждение жидкости в ванне происходит за счет отвода тепла окружающей средой и дополнительного теплоотвода более холодной жидкостью, проходящей, например, по змеевику, помещенному в ванну Считаем, что расход и температура холодной жидкости и температура греющего пара постоянны.
Процесс теплообмена в гальванической ванне можно описать линейным дифференциальным уравнением в частных производных второго порядка. При постоянной температуре греющего носителя динамика температуры в любой точке внутри раствора ванны описывается уже обыкновенным линейным дифференциальным уравнением второго порядка с чистым запаздыванием во входном сигнале. Если входной сигнал (расход пара) меняется только в дискретные моменты времени, а в интервалах между дискретами остается постоянным (это случай соответствует управлению объектом от цифрового регулятора), то от дифференциального уравнения второго порядка существует однозначный переход к эквивалентному разностному уравнению
х(/) = д0 + агх({ -1) 4- a2x(t - 2) + a3u(t -1-т) +
+ 2-т) + e(r), Г = 1,2,....
Параметры at, (г = 0, 1, ..4) неизвестны. Константа обусловлена в основном влиянием внешнего теплоносителя окружающей среды.
В дискретные моменты реального времени /' = ГЙ, где S - интервал дискретизации, производятся: измерение температуры х(г), ввод этой информации в цифровое управляющее устройство, расчет управляющего воздействия u(t) и подача его на исполнительный орган. Необходимо синтезировать закон управления, обеспечивающий изменение температуры жидкости в ванне по заданному закону х (/ +1 + т)(? S1). При х ft +1 + т) = х = = const цель управления заключается в стабилизации температуры на Уровне х*.
кла 8 Адаптивное управление с идентификацией
301
ЮОр I
50 । —:----------------------
о I---------------1:---.
О 20 40 60 80 100 t
Рис 8 5 1
На каждом такте выработки оптимального управления строится модель прогноза температуры (решается задача идентификации) и по ней рассчитывается оптимальное управление В качестве алгоритма идентификации использован простейший адаптивный алгоритм (с небольшой модификацией).
На рис. 8 5 1 на примере гальванической ванны одного из заводов при однопроцентном уровне помех приведены входная и выходная переменные замкнутой системы управления, а также кусочно-постоянный заданный температурный режим х*(/) В начальный момент температура ванны равна 20 °C. На первых двадцати тактах происходит основная настройка параметров модели, хотя и далее алгоритм коррекции параметров продолжает непрерывно работать Если в объекте произойдут какие-либо изменения, го идентификатор отследит их После осповпой коррекции параметров алгоритм управления обеспечивает перевод системы на новый уровень стабилизации за минимальное время и без перерегулирования.
Упражнения Ш
Синтезируйте алгоритмы адаптивного управления для следующих объектов.
1) х(г) - bu(t - 1) + h(t), b - известный коэффициент, h(t} - неизвестное возмущающее воздействие,
2) х(Г) = bu(t - 1) + h(t), b - неизвестный коэффициент,
3) х(О - bu(t - 1) + Л(г) + ce(t -1) + e(f), e(f) - случайное воздействие типа белого шума,
4) x(r) = ax(f -1) + bu(t -1) + е(/),
5) х(О - bu(J -1) + ще(/ - 1) + c2e(t -2) + е(г);
6) x(t) = bu(t - г) + /?(/), г > 1,
7) x(t) = bu(t - г) + ce(t - г) 4- e(f), т > 1,
8) х(Г) = x(r - l)w(z -1) + ce(t - 1) + e(t).
302 Методы анализа данных
БИБЛИОГРАФИЧЕСКИЙ СПИСОК
К главе 1
1.1. Гмурман, В. Е. Руководство к решению задач по теории вероятностей и математической статистике: Учеб, пособие для студентов вузов / В. Е. Гмурман. Изд. 5-е. стер. М.: Высш. шк„ 1999. 400 с.
1.2. Гмурман, В. Е. Теория вероятностей и математическая статистика; Учеб, пособие для студентов вузов / В. Е. Гмурман. М.: Высш. шк., 1977. 479 с.
1.3. Красовский, Г. И. Планирование эксперимента: Учеб, пособие / Г. И. Красовский. Г. Ф. Филаретов. Минск: Изд-во БГУ, 1982. 302 с.
К главе 2
2.1. Горелик, А. Л. Методы распознавания: Учеб, пособие для вузов / А. Л. Горелик. В. А. Скрипкин. М.: Высш, шк., 1977. 222 с.
2.2. Дуда, Р. Распознавание образов и анализ сцен / Р. Дуда. П. Харт.М.: Мир, 1976. 511 с,
2.3. Минский, М. Персептроны / М Минский, С Пейперт. М.: Мир, 1971. 261 с.
К главе 3
3,1. Красовский, Г. И. Планирование эксперимента: Учеб, пособие / Г. И. Красовский, Г. Ф. Филаретов. Минск: Изд-во БГУ, 1982. 302 с.
3.2. Хартман, К Планирование эксперимента в исследовании технологических процессов / К. Хартман и др. М.; Мир, 1977. 552 с.
К главе 4
4.1. Живоглядов, В. П. Непараметрическне алгоритмы адаптации / В, И, Живоглядов, А. В. Медведев. Фрунзе: Илим, 1974. 134 с.
4.2. Медведев, А. В. Непараметрические системы адаптации / А. В. Медведев. Новосибирск: Наука, 1983. 174 с.
4.3. Непараметрическое сглаживание функционалов по стационарным выборкам / Ю. Г. Дмитриев, Г. М. Кошкин, В. А. Симахин и др. Под ред. Ф. П. Тарасенко. Томск: Изд-во Томск, ун-та, 1974. 91 с.
4.4. Рубан, А. И. Идентификация и чувствительность сложных систем / А. И. Рубан. Томск: Изд-во Томск, ун-та, 1982. 302 с.
4.5. Рубан, А. И. Идентификация стохастических объектов на основе непараметрического подхода / А. И. Рубан // Автоматика и телемеханика. 1979. №11. С. 106-117.
4.6. Рубан, А. И. Теория вероятностей и математическая статистика / Л. И. Рубан. Красноярск: ИПЦ КГТУ, 2002. 320 с.
библиографический список
303
Тарасенко Ф. П. Hen арамезрнческая статистика / Ф. П. Тарасенко, Томск: Изд-во Томск, ун-та, 1976. 292 с.
К главе 5
5.1. Банди, Б. Методы оптимизации. Вводный курс / Б. Банди. М.: Радио и связь, 1988. 128 с.
5.2. Первозванский, А. А. Поиск / А. А. Первозванский. М.: Наука, 1970. 264 с.
5.3. Реклейтис, Г. Оптимизация в технике: В 2-х кн. / Г. Реклейтис, А. Рейвиндран, К. Рэгсдел. М.: Мир, 1986. 669 с.
5.4. Рубан, А. И. Методы оптимизации; Учеб, пособие / А. И. Рубан. Красноярск: НИИ ИЛУ, 2001. 528 с.
К главе 6
6.1. Cipra, Т. Ro bast Smoothing and Forecasting Procedures / T Cipra, A. Rubio, J. L. Canal // Czechoslovak Journal for Operations Reseach. 1992, Vol. 1. №1. Pp. 41-56.
6.2. Гантмахер, Ф P. Теория матриц / Ф. P. Гантмахер. M.: Наука, 1967. 575 с.
6.3. Ивахненко, А. Г. Принятие решений на основе самоорганизации / А. Г. Ивахненко, Ю. П. Зайченко, В. Д. Димитров. М.: Сов, радио, 1976. 280 с.
6.4. Поляк, Б. Т Robust identification / Б. Т Поляк, Я. 3. Цыпкин // Automatica. 1980. Vol. 16, Nol. Рр. 53-65.
6.5. Поляк, Б. Т. Новый метод типа стохастической аппроксимации / Б. Т. Поляк // Автоматика и телемеханика. 1990. № 7. С. 98-107.
6.6. Поляк, Б. Т Робастные псевдоградиентные алгоритмы адаптации / Б Т Поляк, Я 3. Цыпкин // Автоматика и телемеханика. 1980. № 10. С. 91-97.
6.7. Райбман, Н. С. Построение моделей процессов производства / Н. С. Райбман, В. М. Чадеев. М.: Энергия, 1965. 376 с.
6.8. Рубан, А. И. Идентификация и чувствительность сложных систем / А. И. Рубан. Томск: Изд-во Томск, ун-та, 1982. 302 с.
6.9. Хъюбер, П Дж. Робастность в статистике / П. Дж. Хъюбер. М.: Мир, 1984. 303 с.
/С главе 7
7.1. Кульчицкий, О. Ю. Адаптивное управление линейными динамическими объектами с помощью модифицированного метода наименьших квадратов / О. Ю. Кульчицкий // Автоматика и телемеханика. 1987. № 1-С. 89-105.
7.2, Лъюнг, Л. Идентификация систем. Теория для пользователя / Л. Лъюнг. М.: Наука, 1991.432 с.
304 МетодЙйпйЦизадаЙ№
7.3. Рубан, А И. Чувствительность дискретных линейных моделей / А. И. Рубан // Автоматика и телемеханика. 1991. № 9. С. 159-168.
7.4. Стрейц, В Метод пространства состояний в теории дискретных линейных систем управления / В. Стрейц. М.: Наука, 1985. 296 с.
7.5. Цыпкин, Я. 3. Основы информационной теории идентификации / Я. 3. Цыпкин. М.; Наука, 1984. 320 с.
7.6. Эйкхофф, П. Основы идентификации систем управления / И Эйкхофф. М.: Мир, 1975. 683 с.
К главе 8
8.1. Адаптивные системы автоматического управления: Учеб, пособие / В. Н. Антонов, А. М. Пришвин, В. А. Терехов, А Э. Янчевский / Под ред. В Б Яковлева. Л.: Изд-во Ленинградского ун-та, 1984. 204 с.
8.2. Александров, А. Г. Оптимальные и адаптивные системы: Учеб, пособие / А. Г Александров. М.: Высш, шк., 1989. 263 с.
8.3. Изер:лаи. Р. Цифровые системы управления / Р. Изерман. М.: Мир, 1984. 541 с.
8.4. Козлов, В. II. Вычислительные методы синтеза систем автоматического управления / В. Н. Козлов, В. Е Куприянов, В. С. Заборовский. Л.: Изд-во Ленинград, ун-та, 1989. 224 с.
3.5. Рубан, А И. Адаптивное управление с идентификацией / А. И. Рубан. Томск: Изд-во Томск, ун-та, 1983. 135 с.
8.6. Справочник по теории автоматического управления / Под ред. А А Красовского. М.: Наука, 1987. 712 с.
8.7. И. АСИ-адапгивная система с идентификацией / В. А. Трапезников, 11 С Райбман, В. М. Чадеев и др. М.: Институт проблем управления, 1980. 67 с.
8.8. Уидроу, Б. Адаптивная обработка сигналов / Б. Уидроу. С. Стирнз. М.: Радио и связь, 1989. 440 с.
8.9 Фрадков, А. Я. Адаптивное управление в сложных системах; беспо-исковые методы / А. П. Фрадков. М..: Наука, 1990. 296 с.
8.10. Цыкунов, А. М. Квадратичный критерий абсолютной устойчивости в теории адаптивных систем / А. М. Цыкунов. Фрунзе: Илим, 1990. 156 с.
Библиографический список
305
ПРИЛОЖЕНИЕ
Таблица П1. Пороговое значение ха нормально распределенной случайной величины №(0; 1) в зависимости от доверительной вероятности а: Р{ха < А'} - а
Лх)
О ха
а 0.20 0.10 0.05 0.025 0.01 0.005 0.001 0.0005
ха 0.84 1.28 1.64 1.96 2.33 2.58 3.09 3.29
Таблица П2. Распределение %2. Величина порога х$а в зависимости от числа степеней свободы v и вероятности a: Р{% [ а < /2} - а
/а2)
V Вероятность а 0.01
0.99 0.975 0.95 0.90 0.10 0.05 0.025
1 0.00016 0.00098 0.0039 0.016 2.7 3.8 5.0 6.6
2 0.020 0.051 0.103 0.211 4.6 6.0 7.4_
3 0.115 0.216 0.352 0.584 6.3 7.8 9.3
4 0.30 0.48 0.71 1.06 7.8 9.5 11Л_ 21^-
5 0,55 0.83 1.14 1.61 9.2 11.1 12.8 J52J
306 Методы анализа дан
Вероятность а
V 0.99 0.975 0.95 0.90 0.10 0.05 0.025 0.01
6 0,87 1.24 1.63 2.20 10.6 12,6 14,4 16.8
7 1,24 1,69 2.17 2,83 12,0 14.1 16,0 18.5
8 1,65 2.18 2.73 3,49 13,4 15,5 17.5 20,1
9 2,09 2,70 3.32 4.17 14.7^ 16,9 19.0 21.7
10 2.56 3,25 3.94 4,86 16,0 18,3 20.5 23,2
11 3,1 3.8 4,6 5.6 17,3 19,7 21.9 24.7
12 3.6 4.4 5,2 6,3 18.5 21,0 23.3 26.2
13 4,1 5,0 5,9 7.0 19,8 22.4 24,7 27.7
14 4.7 5.6 6,6 7,8 21,1 23,7 26.1 29.1
15 5.2 6.3 7.3 8.5 22,3 25.0 27.5 30.6
16 5,8 6,9 8.0 9,3 23.5 26.3 28.8 32.0
17 6.4 7.6 8,7 10,1 24.8 27,6 30,2 33,4
18 7,0 8,2 9,4 10,9 26,0 28,9 31.5 34.8
19 7.6 8,9 10.1 11,7 27.2 30.1 32,9 36,2
20 8.3 9,6 10,9 12.4 28,4 31,4 34,2 37.6
21 8,9 10.3 11.6 13,2 29.6 " 32,7 35.5 38.9
22 9,5 11,0 12,3 14,0 30,8 33,9 36.8 40,3
_23 10.2 11,7 13,1 14.8 32.О' 35,2 38.1 41.6
24 10.9 12,4 13,8 15,7 33,2 36,4 39,4 43,0
J>5 11.5 13,1 14.6 16,5 34.4 37.7 40,6 44,3
26 12.2 13,8 15.4 17,3 35,6 " 38.9 41,9 45.6
27 12,9 14,6 16,2 18.1 36.7 ' 40,1 43.2 47.0
J8 13,6 15,3 16,9 18.9 37.9 41,3 44.5 48.3
29 14.3 16,0 17,7 19,8 39.1 42,6 45,7 49.6
J0 15.0 16,8 18,5 20.6 40,3 43,8 47,0 50,9
приложение
307
Таблица ПЗ. Т - распределение Стьюденша. Значения I в зависимости от числа степеней свободы v и вероятности а: P{tv ы < Т} - а
fm
V Вероятность а
0.20 0.10 0.05 0.025 0.01 0.005 0.001 0.0005
1 1.38 3.08 6.31 12.71 31.82 63.66 318.31 636.62
2 1.06 1.89 2.92 4.30 6.97 9.93 22.33 31.60
3 0.98 1.64 2.35 3.18 4.54 5.84 10.21 12.94
4 0.94 1.53 2.13 2.78 3.75 4.60 7.17 8.6!
5 0.92 1.48 2.02 2.57 3.37 4.03 5.89 6.86
6 0.91 1.44 1.94 2.45 3,14 3.71 5.21 5.96
7 0.90 1.42 1.90 2.37 3.00 3,50 4.78 5.41
8 0.89 1.40 1.86 2.31 2.90 3.36 4.50 5.04
9 0.88 1.38 1.83 2.26 2.82 3.25 4.30 4.78
10 0.88 1.37 1.81 2.23 2.76 3.17 4.14 4.59
11 0.88 1.36 1.80 2.20 2.72 3.11 4.02 4.44
12 0.87 1.36 1.78 2.18 2.68 3.06 3,93 4.32
13 0.87 1.35 1.77 2.16 2.65 3.01 3.85 4.22
14 0.87 1.34 1.76 2.15 2.62 2.98 3.79 4.14
15 0.87 1.34 1.75 2.13 2.60 2.95 3.73 4.07
16 0.86 1.34 1.75 2.12 2.58 2.92 3.69 4.02
17 0.86 1.33 1.74 2.11 2.57 2.90 3.65 3.97
18 0.86 1.33 1.73 2.10 2.55 2.88 3.61 3.92
19 0.86 1.33 1.73 2.09 2.54 2.86 3.58 3.88
20 0.86 1.33 1.73 2.09 2.53 2.85 3.55 3.85
21 0.86 1.32 1.72 2.08 2.52 2.83 3.53 3.82
22 0.86 1.32 1.72 2.07 2.51 2.82 3.50 П 3.79
23 0.86 1.32 1.71 2.07 2.50 2.81 3,48 3.77
24 0.86 1.32 1.71 2.06 2.49 2.80 3.47 3,75 _
25 0.86 1.32 1.71 2.06 2.48 2.79 3.45 3.73_
30 0.85 1.31 1.70 2.04 2.46 2.75 3.39 3.65_
40 0.85 1.30 1.68 2,02 2.42 2.70 3.31 3.55_
60 0.85 1.30 1.67 2.00 2.39 2.66 3.23 3.46_
120 0.84 1.29 1.66 1.98 2.36 2.62 3.16 3.37___
СО 0.84 1.28 1.64 1.96 2.33 2.58 3.09
308
Методы анализа данных
Таблица П4. F - распределение Фишера. Значения Fv >о в зависимости от числа степеней свободы Vj, v2 и фиксированной вероятности а; p^w<f">=a
f(F)
V1 / Vz а = 0.05
1 2 3 п 4 5 6 7 8 9
1 161 200 216 225 230 234 237 239 241
2 18.5 19.0 19.2 19.2 19.3 19.3 19,4 19.4 19.4
3 10.1 9.55 9.28 9,12 9.01 8.94 8.89 8.85 8.81
4 7.71 6.94 6.59 6.39 6.26 6.16 6.09 6.04 6.00
5 6.61 5.79 5.41 5.19 5.05 4.95 4.88 4.82 4.77
6 5.99 5.14 4.76 4.53 4.39 4.28 4.21 4.15 4.10
7 5.59 4.74 4.35 4.12 3.97 3.87 3.79 3.73 3.68
8 5.32 4.46 4.07 3.84 3.69 3.58 3.50 3.44 3.39
9 5.12 4.26 3.86 3.63 3.48 3.37 3.29 3.23 3.18
10 4.96 4.10 3.71 3,48 3.33 3.22 3.14 3.07 3.02
И 4.84 3.98 3.59 3.36 3.20 3.09 3.01 2.95 2.90
12 4.75 3.88 3.49 3.26 3.11 3.00 2,91 2.85 2.80
13 4.67 3.80 3,41 3,18 3,03 2.92 2.83 2.77 2.71
14 4.60 3.74 3.34 3.11 2,96 2.85 2.76 2.70 2.65
15 4.54 3.68 3.29 3.06 2.90 2.79 2,71 2.64 2.59
16 4.49 3.63 3.24 3.01 2.85 2.74 2.66 2.59 2.54
17 4.45 3.59 3.20 2,96 2.81 2.70 2.61 2.55 2.49
18 4,41 3.55 3.16 2.93 2.77 2.66 2.58 2,51 2.46
19 4.38 3.52 3.13 2.90 2.74 2.63 2.54 2.48 2.42
20 4.35 3.49 3.10 2.87 2.71 2.60 2.51 2.45 2.39
21 4.32 3.47 3.07 2.84 2.68 2.57 2.49 2.42 2.37
22 4.30 3.44 3.05 2.82 2.66 2.55 2.46 2.40 2.34
23 4.28 3.42 3.03 2.80 2,64 2.53 2.44 2.37 2.32
24 4.26 3.40 3.01 2.78 2.62 2.51 2.42 2,36 2.30
25 4.24 3.38 2.99 2.76 2.60 2.49 2.40 2.34 2.28
26 4.23 3.37 2.98 2,74 2.59 2.47 2.39 2.32 2.27
27 4.21 3.35 2.96 2.73 2.57 2.46 2.37 2,31 2.25
28 4.20 3.34 2.95 2.71 2.56 2.45 2.36 2.29 2.24
29 4.18 3.33 2.93 2.7(П 2.55 2.43 2.35 2.28 2.22
30 4.17 3.32 2.92 2,69 2.53 2.42 2.33 2.27 2.21
40 4.08 3.23 2.84 2.61 2.45 2.34 2.25 2.18 2.12
60 4.00 3.15 2.76 2.53 2.37 2.25 2.17 1 2.10 2.04
120 3.92 3.07 2.68 2.45 2.29 2.17 2.09 2.02 1.96
ос 3.84 3.00 2.60 2.37 2.21 2.10 2.01 1.94 1.88
Приложение
309
Продолжение табл. Г14
V, zv2 10 12 15 20 24 30 40 60 120 ОС
1 242 244 246 248 249 250 251 252 253 254
2 19.4 19.4 19.4 19.4 19.5 19.5 19.5 19.5 19.5 19.5
3 8.79 8.74 8.70 8.66 8.64 8.62 8.59 8.57 8.55 ^8.53
4 5.96 5.91 5.86 5.80 5.77 5.75 5.72 5.69 5.66 5.63
5 4.74 4.68 4.62 4.56 4.53 4.50 4.46 4.43 4.40 4.36
6 4.06 4.00 3.94 3.87 3.84 3.81 3.77 3.74 3.70 3.67
7 3.64 3.57 3.51 3.44 3.41 3.38 3.34 3.30 3.27 3.23
8 3.35 3.28 3.22 3.15 3.12 3.08 3.04 3.01 2.97 2.93
9 3.14 3.07 3,01 2.94 2.90 2.86 2.83 2.79 2.75 2.71
10 2.98 2.91 2.85 2.77 2.74 2.70 2.66 2.62 2.58 2.54
11 2.85 2.79 2.72 2.65 2.61 2.57 2.53 2.49 2.45 2.40
12 2.75 2.69 2.62 2.54 2,51 2.47 2.43 2.38 2.34 2.30
13 2.67 2.60 2.53 2.46 2.42 2.38 2.34 2.30 2,25 2.21
14 2.60 2.53 2.46 2.39 2.35 2.31 2.27 2.22 2.18 2.13
15 2.54 2.48 2.40 2.33 2.29 2.25 2.20 2.16 2,11 2.07
16 2.49 2.42 2.35 2.28 2.24 2.19 2.15 2.11 2.06 2.01
17 2.45 2.38 2.31 2,23 2.19 2.15 2.10 2,06 2.01 1.96
18 2.41 2.34 2.27 2.19 2.15 2.11 2.06 2.02 1.97 1.92
19 2.38 2.31 2.23 2.16 2.11 2.07 2.03 1.98 1.93 1.88
20 2.35 2,28 2.20 2.12 2.08 2.04 1.99 1.95 1.90 1.84
21 2,32 2.25 2.18 2.10 2.05 2.01 1.96 1.92 1.87 1.81
22 2.30 2.23 2.15 2.07 2.03 1.98 1.94 1.89 1.84 1.78
23 2.27 2.20 2.13 2,05 2.01 1.96 1.91 1.86 1.81 1.76
24 2.25 2.18 2.11 2.03 1.98 1.94 1.89 1.84 1.79 1.73
25 2.24 2.16 2.09 2.01 1.96 1.92 1.87 1.82 1.77 1-71 ..
26 2.22 2.15 2.07 1.99 1.95 1.90 1.85 1.80 1.754 1.69
27 2.20 2.13 2.06 1.97 1.93 1.88 1.84 1.79 1.73 1.67_
28 2.19 2.12 2.04 1.96 1.91 1.87 1.82 1.77 1.71 1.65_
29 2.18 2.10 2.03 1.94 1.90 1.85 1.81 1.75 1.70 1.64_
30 2.16 2.09 2.01 1.93 1.89 1.84 1.79 1.74 1.68 1.62_
40 2.08 2.00 1.92 1.84 1.79 1.74 1.69 1.64 1.58 Ь51_
60 1.99 1.92 1.84 1.75 1.70 1.65 1.59 1.53 1.47 1.39
120 1.91 1.83 1.75 1.66 1.61 1.55 1.50 1.43 1.35 _ 1,25_
ОО 1.83 1.75 1.67 1.57 1.52 1.46 1.39 1.32 1.22
310
Методы анализа данных
Продолжение табл. П4
V1 V2 а = 0.025
1 2 1 3 4 5 6 7 8 Г 9
1 648 800 864 900 922 937 948 957 963
2 38.5 39.0 39.2 39.2 39.3 39.3 39.4 39.4 39.4
3 17.4 16.0 15.4 15.1 14.9 14.7 14.6 14.5 14.5
_4_ 12.2 10.6 9.98 9.60 9.36 ^9.20 9.07 8.98 8.90
5 10.0 8.43 7.76 7.39 7.15 6.98 6.85 6.76 6.68
6 8.81 7.26 6.60 6.23 5.99 5.82 5.70 5.60 5.52
7 8.07 6.54 5.89 5.52 5.29 5.12 4.99 4,90 4.82
8 Г 7.57 6.06 5.42 5.05 4.82 4.65 4.53 4.43 4.36
9 7.21 5.71 5.08 4.72 4.48 4.32 4.20 4.10 4.03
10 6.94 5.46 4.83 4.47 4.24 4.07 3.95 3.85 3.78
11 5.72 5.26 4.63 4.28 4.04 3.88 3.76 3.66 3.59
12 6.55 5.10 4.47 4.12 3.89 3.73 3.61 3.51 3.44
13 6.41 4.97 4.35 4.00 3.77 3.60 3.48 3.39 3.31
14 6.30 4.86 4.24 3.89 3.66 3.50 3.38 3.29 3.21
15 6.20 4.77 4.15 3.80 3.58 3.41 3.29 3.20 3.12
16 6.12 4.69 4.08 3.73 3.50 3.34 3.22 3.12 3.05
17 6.04 4.62 4.01 3.66 3.44 3.28 3.16 3.06 2.98
18 5.98 4.56 3.95 3.61 3.38 3.22 3.10 3.01 2.93
19 5.92 4.51 3.90 3.56 3.33 3.17 3.05 2.96 2.88
20 5.87 4.46 3.86 3.51 3.29 3.13 3.01 2.91 2.84
21 5.83 4.42 3.82 Г 3.48 ^3.25 3.09 2.97 2.87 2,80
22 5.79 4.38 3.78 3.44 3.22 3.05 2.93 2.84 2.76
23 5.75 4.35 3.75 3.41 3.18 3.02 2.90 2.81 2.73
24 5.72 4.32 3.72 3.38 3.15 2.99 2.87 2.78 2.70
25 Г 5.69 4.29 3.69 3.35 3.13 2.97 2.85 2.75 2.68
26 5,66 4.27 3.67 3.33 3.10 2.94 2.82 ^2.73 2.65
27 5.63 4.24 3.65 3.31 3.08 2.92 2.80 2.71 2.63
28 5.61 4.22 3.63 3.29 3.06 2.90 2.78 2.69 2.61
29 5.59 4.20 3.61 3.27 3.04 2.88 2.76 2.67 2.59
30 5.57 4.18 3.59 3.25 3.03 2.87 2.75 2.65 2.57
! 40 5.42 4.05 3.46 3.13 2.90 2.74 2.62 2.53 2.45
60 5.29 3.93 3.34 3.01 2,79 2.63 2.51 2.41 2.33
120 5.15 3.80 3.23 2.89 2.67 2.52 2.39 2.30 2.22
. 00 5.02 3.69 3.12 2.79 2.57 2.41 2.29 2.19 2.11
Приложение 311
Окончание табл. 114
10 12 15 20 24 30 40 60 120 00
1 969 977 985 993 997 1001 1006 1010 1014 1018
2 39.4 39.4 39.4 39.4 39.5 39.5 39.5 39.5 39.5 39.5
3 14.4 14.3 14.3 14.2 14.1 14.1 14.0 14.0 13.9 13.9
4 8.84 8.75 8.66 8.56 8,51 8.46 8.41 8.36 8.31 8.26
5 6.62 6.52 6.43 6.33 6,28 6.23 6.18 6.12 6.07 6.02
6 5.46 5.37 5.27 5.17 5.12 5.07 5.01 4.96 4.90 4.85
7 4.76 4.67 4.57 4.47 4.42 4.36 4.31 4.25 4.20 4.14
8 4.30 4.20 4.10 4.00 3.95 3.89 3.84 3.78 3.73 3.67
9 3.96 3.87 3.77 3.67 3.61 3.56 3.51 3.45 3.39 3.33
10 3.72 3,62 3.52 3.42 3.37 3.31 3.26 3.20 3.14 3,08
11 3.53 3.43 3.33 3.23 3.17 3.12 3.06 3.00 2.94 2.88
12 3.37 3.28 3.18 3.07 3.02 2.96 2.91 2.85 2.79 2.72
13 3.25 3.15 3.05 2.95 2.89 2 84 2,78 2.72 2,66 2.60
14 3.15 3.05 2.95 2.84 2.79 2.73 2.67 2,61 2.55 2.49
15 3.06 2.96 2.86 2.76 2.70 2.64 2.59 2.52 2.46 2.40
16 2 99 2.89 2.79 2.68 2.62 2.57 2.51 2,45 2.38 2.32
17 2.92 2.82 2.72 2.62 2.56 2.50 2.44 2,38 2.32 2.25
18 2.87 2.77 2.67 2.56 2.50 2.44 2.38 2.32 2.26 2.19
19 2.82 2.72 2.62 2,51 2.45 2.39 2.33 2.27 2.20 2.13
20 2.77 2.68 2.57 2.46 2.41 2.35 2.29 2.22 2.16 2.09
21 2.73 2.64 2.53 2.42 2.37 2.31 2.25 2.18 2.11 2.04
22 2.70 2.60 2.50 2.39 2.33 2.27 2.21 2.14 2.08 2.00
23 2.67 2.57 2.47 2.36 2.30 2,24 2.18 2.11 2.04 1.97
24 2.64 2.54 2.44 2.33 2.27 2.21 2.15 2.08 2.01 1.94
25 2.61 2.51 2.41 2.30 2.24 2.18 2,12 2.05 1.98 1,91
26 2.59 2.49 2.39 2.28 2.22 2.16 2.09 2.03 1.95 1.88
27 2.57 2.47 2.36 2.25 2.19 2.13 2.07 2.00 1.93 1,85
28 2.55 2.45 2.34 2.23 2.17 2.11 2.05 1.98 1.91 1.83__
29 2.53 2.43 2.32 2.21 2.15 2,09 2.03 1.96 1.89 1.81__
30 2.51 2.41 2.31 2.20 2.14 2.07 2.01 1.94 1.87 1.79_
40 2.39 2.29 2.18 2.07 2.01 1.94 1.88 1.80 1.72 1.64__
60 2.27 2.17 2.06 1.94 1.88 1.82 1.74 1.67 1.58 1.48_
120 2.16 2.05 1.94 1.82 1.76 1.69 1.61 1,53 1.4з1 1,31
00 2.05 1.94 1.83 1.71 1.64 1.57 1.48 1.39 1.27 _L00j
312
Методы анализа данных
Таблица П5. G - распределение Кочрена. Значения G,_ va в зависимости от числа степеней свободы v, числа выборок к н фиксированной вероятности а: P{Gt v а < G} = а
f(G)
а = 0.05
k / v 1 2 3 4 5 6 7
2 0,9985 0.9750 0.9392 0.9057 0.8772 0.8534 0.8332
3 0.9669 0.8709 0,7977 0.7457 0,7071 0.6771 0.6530
4 0.9065 0.7679 0.6841 0.6287 0.5895 0.5598 0.5365
5 0.8412 0.6838 0.5981 0.5440 0.5063 0.4783 0.4564
6 0.7808 0.6161 0.5321 0.4803 0.4447 0.4184 0.3980
7 0.7271 0.5612 0.4800 0.4307 0.3974 0.3726 0.3535
8 0.6798 0.5157 0.4377 0.3910 0.3595 0.3362 0.3185
9 0.6385 0.4775 0.4027 0.3584 0.3286 0.3067 0.2901
10 0.6020 0.4450 0.3733 0.3311 0.3029 0.2823 0.2666
12 0.5410 0.3924 0.3264 0.2880 0.2624 0.2439 0.2299
15 0.4709 0.3346 0.2758 0.2419 0.2195 0.2034 0.1911
20 0.3894 0.2705 0.2205 0.1921 0.1735 0.1602 0 1501
24 0.3434 0.2354 0.1907 0.1656 0.1493 0.1374 0.1286
30 0.2929 0.1980 0.1593 0.1377 0.1237 0.1137 0.1061
40 0.2370 0.1576 0.1259 0.1082 0.0968 0.0887 0.0827
60 0.1737 0.1131 0.0895 0.0766 0.0682 0.0623 0.0583
120 0.0998 0.0632 ! 0.0495 0.0419 0.0371 0.0337 0.0312
Приложение
313
Продолжение табл. 115
k /У 8 9 10 16 36 144 СО
2 0.8159 0.8010 0.7880 0.7341 0.6602 0.5813 0.5000
3 0.6333 0.6167 0.6025 0.5466 0.4748 0.4031 0.3333
4 0.5175 0.5017 0.4884 0.4366 0.3720 0.3093 0.2500
5 0.4387 0.4241 0.4118 0.3645 0.3066 0.2513 0.2000
6 0.3817 0.3682 0.3568 0.3135 0.2612 0.2119 0.1667
7 0.3384 0.3259 0.3154 0.2756 0.2278 0.1833 0.1429
8 0.3043 0.2926 0.2829 0.2462 0.2022 0.1616 0.1250
9 0.2768 0.2659 0.2568 0.2226 0.1820 0.1446 0.1111
10 0.2541 0.2439 0.2353 0.2032 0.1655 0.1308 0.1000
12 0.2187 0.2098 0.2020 0.1737 0.1403 0.1100 0.0833
15 0.1815 0.1736 0.1671 0.1429 0.1144 0.0889 0.0667
20 0.1422 0.1357 0.1303 0.1108 0.0879 0.0675 0.0500
24 0,1216 0.1160 0.1113 0.0942 0.0743 0.0567 0.0417
30 0.1002 0.0958 0.0921 0.0771 0.0604 0.0457 0.0333
40 0.0780 0.0745 0.0713 0.0595 0.0462 0.0347 0.0250
60 0.0552 0.0520 0.0497 0.0411 0.0316 0.0234 0.0167
120 0.0292 0.0279 0.0266 0.0218 0.0165 0.0120 0.0083
314
Методы анализа данных
Продолжение табл. П5
а = 0.01
к / v 1 2 3 4 5 6 7
2 0.9999 0.9950 0.9794 0.9586 0.9373 0.9172 0.8988
3 0.9933 0.9423 0.8831 0.8355 0.7933 0.7606 0.7335
4 0.9676 0.8643 0.7814 0.7212 0.6761 0.6410 0.6129
5 0.9279 0.7885 0.6957 0.6329 0.5875 0.5531 0.5259
6 0.8828 0.7218 0.6258 0.5635 0.5195 0.4866 0.4608
7 0.8376 0.6644 0.5685 0.5080 0.4659 0.4347 0.4105
8 0.7945 0.6162 0.5209 0.4627 0.4226 0.3932 0.3704
9 0.7544 0.5727 0.4810 0.4251 0.3870 0.3592 0.3378
10 0.7175 0.5358 0.4469 0.3934 0.3572 0.3308 0.3106
12 0.6528 0.4751 0.3919 0.3428 0.3099 0.2861 0.2680
15 0.5747 0.4069 0.3317 0.2882 0.2593 0.2386 0.2228
20 0.4799 0.3297 0.2654 0.2288 0.2048 0.1877 0.1748
24 0.4247 0.2871 0.2295 0.1970 0.1759 0.1608 0.1495
30 0.3632 0.2412 0.1913 0.1635 0.1454 0.1327 0.1232
40 0.2940 0.1915 0.1508 0.1281 0.1135 0.1033 0.0957
60 0.2151 0.1371 0.1069 0.0902 0.0796 0.0722 0.0668
120 0.1252 0.0759 0.0585 0.0489 0.0429 0.0387 0.0357
Приложение
315
Окончание табл, П5
k / V 8 9 10 16 36 144 СО
2 0.8823 0,8674 0.8539 0.7949 0.7067 0 6062 0.5000
3 0.7107 0.6912 0.6743 0.6059 0.5153 0.4230 0.3333
4 0.5897 0.5702 0.5536 0.4884 0.4057 0.3251 0.2500
5 0.5037 0,4854 0.4697 0.4094 0.3351 0.2644 0.2000
6 0.4401 0.4229 0.4084 0.3529 0.2858 0.2229 0.1667
7 0.3911 0.3751 0.3616 0.3105 0.2494 0.1929 0.1429
8 0.3522 0.3373 0.3248 0.2779 0.2214 0,1700 0.1250
9 0.3207 0.3067 0.2950 0.2514 0.1992 0.1521 0.1111
10 0.2945 0,2813 0.2704 0.2297 0.1811 0 1376 0.1000
12 0.2535 0.2419 0.2320 0.1961 0.1535 0.1157 0.0833
15 0.2104 0.2002 0.1918 0.1612 0.1251 0.0934 0.0667
20 0.1646 0.1567 0.1501 0.1248 0.0960 0.0709 0.0500
24 0.1406 0.1338 0.1283 0.1060 0 0810 0.0595 0.0417
30 0.1157 0.1100 0.1054 0.0867 0.0658 0.0480 0.0333
40 0.0898 0.0853 0.0816 0.0668 0.0503 0.0363 0.0250
60 0.0625 0.0594 0.0567 0.0461 0.0344 0.0245 0 0167
120 0,0334 0.0316 0.0302 0.0242 0.0178 0.0125 0.0083
316
Методы анализа данных
ОГЛАВЛЕНИЕ
Предисловие................................................... 3
Глава 1. Статистическая проверка гипотез...................... 6
1.1. Общая схема проверки гипотез ....................... 6
1.2. Проверка гипотезы о математическом ожидании .......... g
1.3. Проверка гипотезы о дисперсиях....................... 12
1.4. Проверка гипотезы о равенстве математических ожиданий. 14
1.5. Выявление аномальных измерений....................... 17
1.6. Гипотеза об однородности ряда дисперсий ............. 18
1.7. Проверка гипотезы о распределениях .................. 19
Упражнения................................................ 24
Глава 2. Классификация в распознавании образов............... 30
2.1. Схема системы распознавания......................... 30
2.2. Байесовская теория принятия решений при дискретных признаках................................................ 32
2.3. Байесовская теория принятия решений при непрерывных признаках................................................ 37
2.4. Идея классификации ............................ 52
2.5. Прямые методы восстановления решающей функции ...... 56
2.6. Персептроны...................................... 58
2.7. Простые алгоритмы классификации в стохастическом случае ..... 59
Упражнения............................................... 60
Глава 3. Планирование эксперимента........................... 70
3.1. Что такое планирование эксперимента.................. 70
3.2. Построение линейной статической модели объекта ...... 72
3.3. Крутое восхождение по поверхности отклика............ 77
3.4. Полный факторный эксперимент ...................... 78
3.5. Дробные реплики ..................................... 80
3.6. Насыщенные планы. Симплекс .......................... 83
3.7. Насыщенные планы. Планы Плаккета - Бермана ........ 84
3.8. Разбиение матрицы планирования на блоки.............. 85
3.9. Обработка результатов эксперимента.................. 87
3.10. Ортогональное планирование второго порядка ......... 89
3.11. Ротатабельиое планирование ......................... 92
3.12. Метод случайного баланса............................ 94
Упражнения............................................... 97
Оглавление
317
Глава 4. Методы непара.метрнческой обработки информации....................................*................ 104
4.1. Оценивание функционалов .............................. 104
4.2. Простейшие оценки функции и плотности распределения вероятности ............................................. 106
4.3. Полиграммы. Оценка "К ближайших соседей"............. 112
4.4. Оценка Розенблатта - Парзена ........................ 120
4.5. Оценки моментов случайных величин и энтропии .......... 129
4.6. Оценка условной плотности вероятности ................. 134
4.7. Оценка регрессии ...................................... 137
4.8. Робастная оценка регрессии............................. 153
4.9. Оценки условной энтропии и количества информации....... 163
4.10, Оценки дисперсионных характеристик.................... 165
4,11. Адаптивное управление при априорной неопределенности . 173
4.12. Управление экстремальным объектом..................... 179
4.13. Минимизация функции .................................. 181
4.14. Не параметрическое сглаживание в классификации........ 182
Упражнения................................................ 187
Глава 5. Методы экспериментальной оптимизации ................. 190
5.1. Методы одномерного поиска минимума унимодальных функций ................................................ 190
5.2. Одномерный глобальный поиск .......................... 199
5.3. Последовательный симплексный метод .................. 201
5.4. Метод деформируемого многогранника (Нелдера-Мида).... 204
5.5. Градиентный метод с использованием планирования первого порядка................................................. 206
5.6. Метод Ньютона с использованием планирования второго порядка................................................ 207
5.7. Методы случайного поиска.............................. 208
5.8. Глобальная оптимизация методом усреднения координат.. 209
Упражнения................................................. 223
Глава 6. Идентификация статических моделей объектов.......... 227
6.1. Постановка задачи подстройки параметров нелинейных моделей 227
6.2. Критерий наименьших квадратов ......................... 228
6.3. Метод наименьших квадратов при линейной параметризации модели.................................................. 230
6.4. Метод последовательной линеаризации при подстройке параметров на основе критерия наименьших квадратов ...... 236
318 Методы анализа данных
6.5, Робастные оценки параметров....................... 238
6.6. Адаптивные алгоритмы метода наименьших квадратов . 241
6.7. Адаптивные алгоритмы подстройки робастных оценок параметров ......................................... 252
6.8. Простейший адаптивный алгоритм подстройки параметров... 254
6.9. Многоэтапный метод селекции при построении моделей сложных объектов ................................... 25g
Упражнения........................................... 262
Глава 7. Идентификация динамических моделей объектов .. 265
7.1. Дискретные динамические модели стохастических объектов. 265
7.2. Подстройка параметров с использованием функции чувствительности ..................................... 270
7.3. Метод, основанный па использовании итеративных моделей. 276
7.4. Применение простейшего адаптивного алгоритма...... 278
7.5. Применение модифицированного алгоритма наименьших квадратов ..................................... 281
Упражнения............................................ 283
Глава 8. Адаптивное управление с идентификацией................ 284
8.1. Постановка задачи адаптивного управления ......... 285
8.2. Примеры синтеза устройств управления для простейших линейных систем ...................................... 286
8.3. Синтез алгоритмов управления для линейных систем . 294
8.4. Алгоритмы адаптивного управления для нелинейных систем. 296
8.5. Управление динамическими системами с чистыми запаздываниями........................................ 298
Упражнения....................................... 302
Библиографический список ................................. 303
Приложение .....................................*......... 306
Оглавление
319
Сведения об авторе
Рубан Анатолий Иванович, 1943 года рождения. Окончил в 1965 г. Томский государственный университет, в 1968 г. - там же аспирантуру. Кандидат физико-математических наук (1969), доцент (1973), доктор технических наук (1981), профессор (1983), академик Международной академии наук высшей школы (1994) и Академии информатизации образования (1996), заслуженный деятель науки РФ (1998), почетный работник высшего профессионального образования РФ (2002), заведует организованной им кафедрой «Информатика» (1992) Красноярского государственного технического университета. Автор более 250 научных работ (из них 3 монографии) и 6 учебных пособий. Основные направления научных исследований; идентификация, адаптивное управление, теория чувствительности, оптимизация.
1004514 НТБКГТУ www. lib. krgtu.ru