/












































































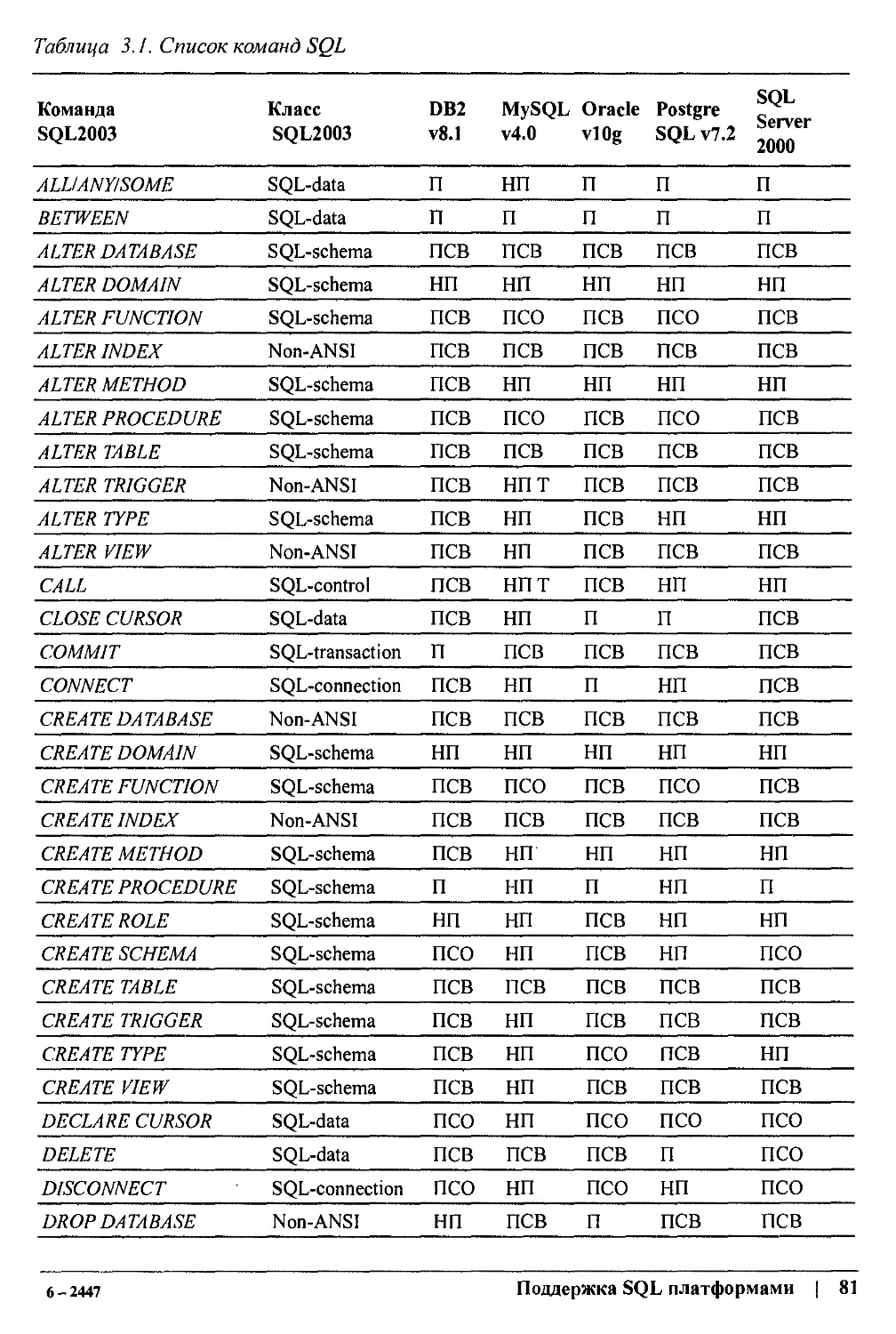
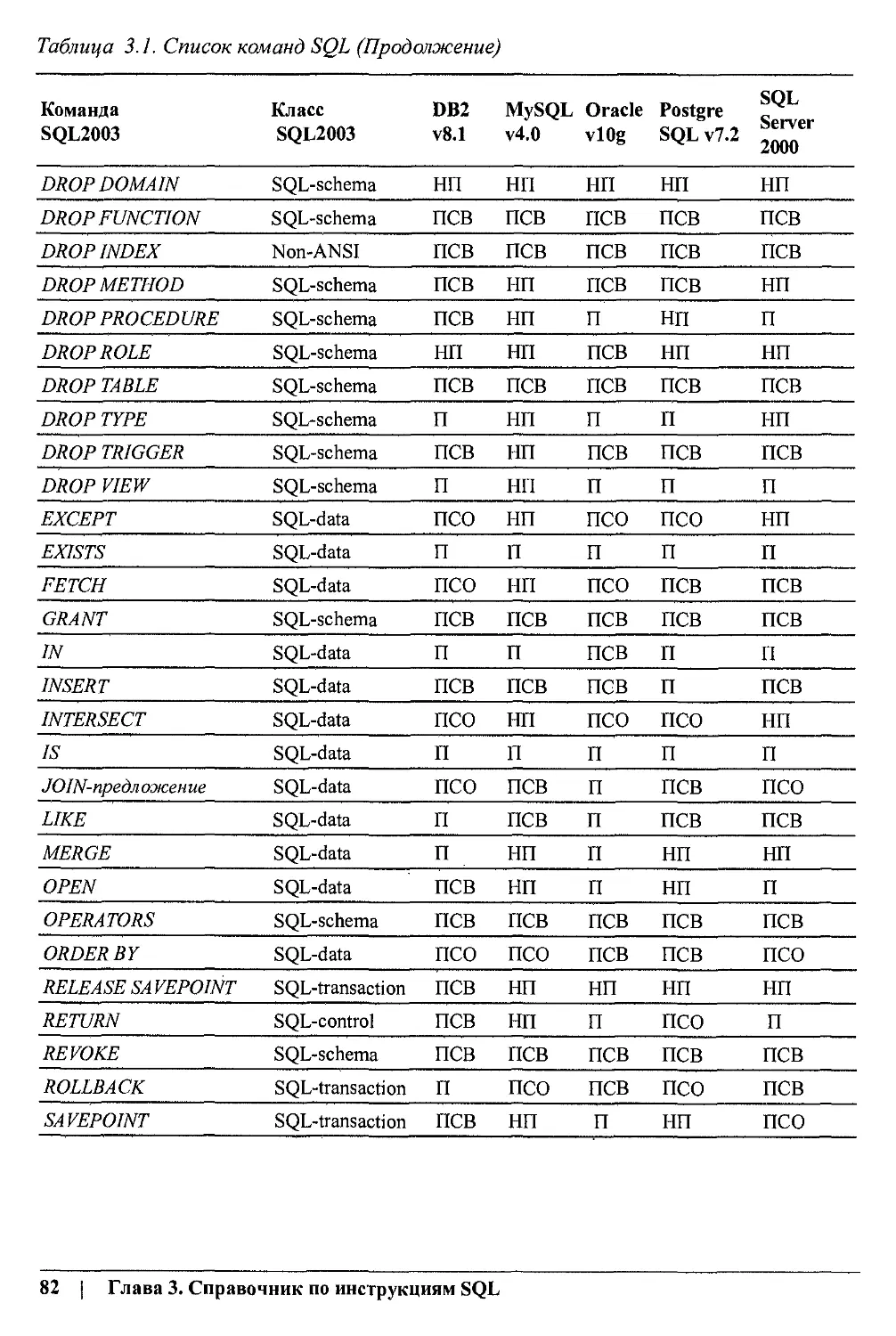



















































































































































































































































































































































































































































































































































































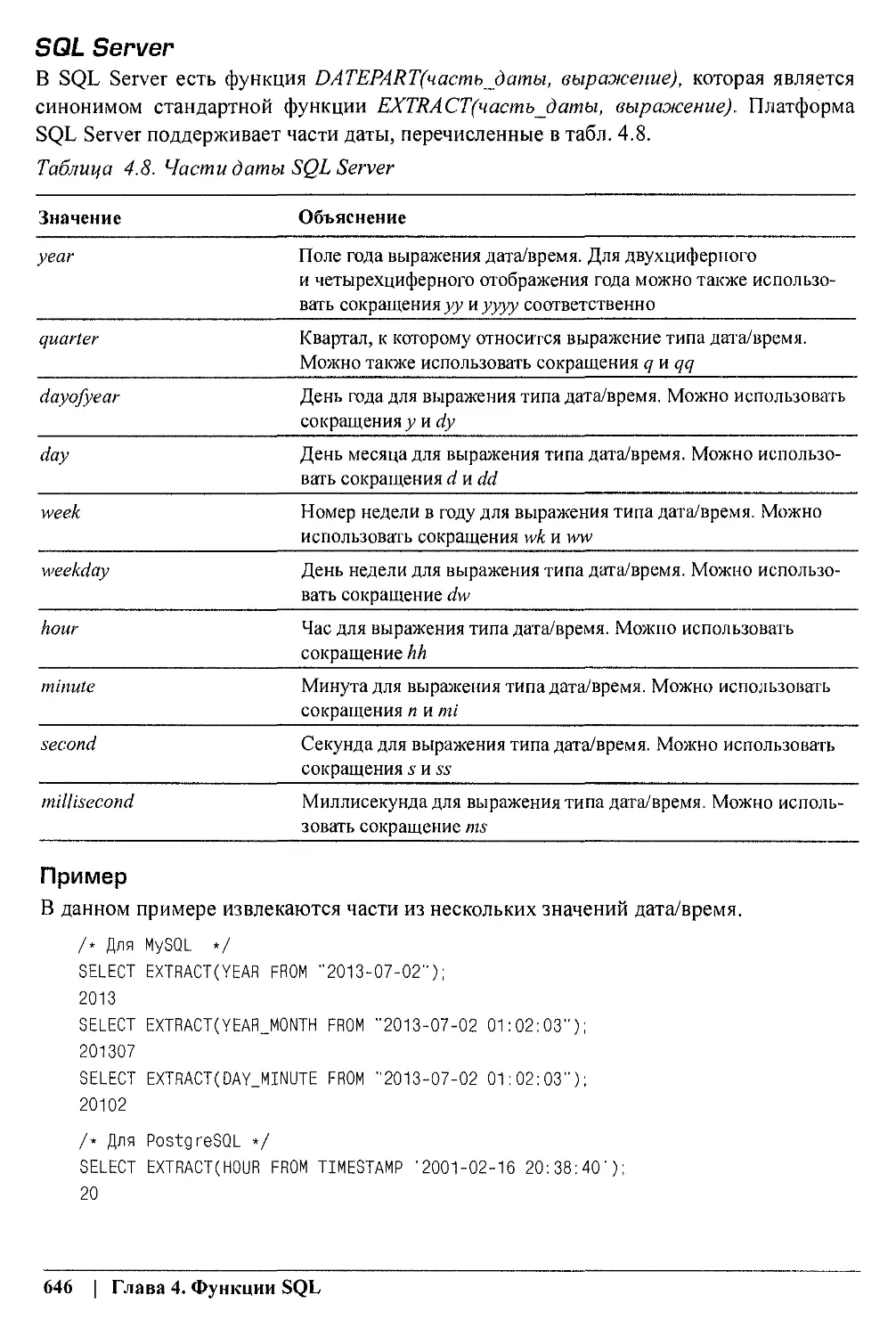













































































































































































Author: Клайн К.
Tags: компьютерные технологии программирование программное обеспечение базы данных
ISBN: 5-9579-0114-8
Year: 2006




Text
СПРАВОЧНИК
КУДИЦ-ОБРАЗ
O’REILLY®
Кевин Клайн
при участии Дэниела Клайна
и Бренда Ханта
IN A NUTSHELL
A Desktop Quik Referen ce
Second Edition
Kevin E. Kline
with Daniel Kline and Brand Hunt
O’REILLY®
Beijing • Cambridge • Farnham • Kdln Paris • Sebastopol • Taipei • Tokyo
Кевин Клайн
при участии Дэниела Клайна
и Бренда Ханта
SQL
СПРАВОЧНИК
2-е издание
Включает SQL Server, DB2,
MySQL, Oracle и PostgreSQL
КУДИЦ-ОБРАЗ
Москва • 2006
ББК 32.973-018.2
УДК 681.3
К 47
Клайн К.
при участии Клайна Д. и Ханта Бр.
SQL. Справочник. 2-е издание / Пер. с англ. - М.: КУДИЦ-ОБРАЗ, 2006 - 832 с.
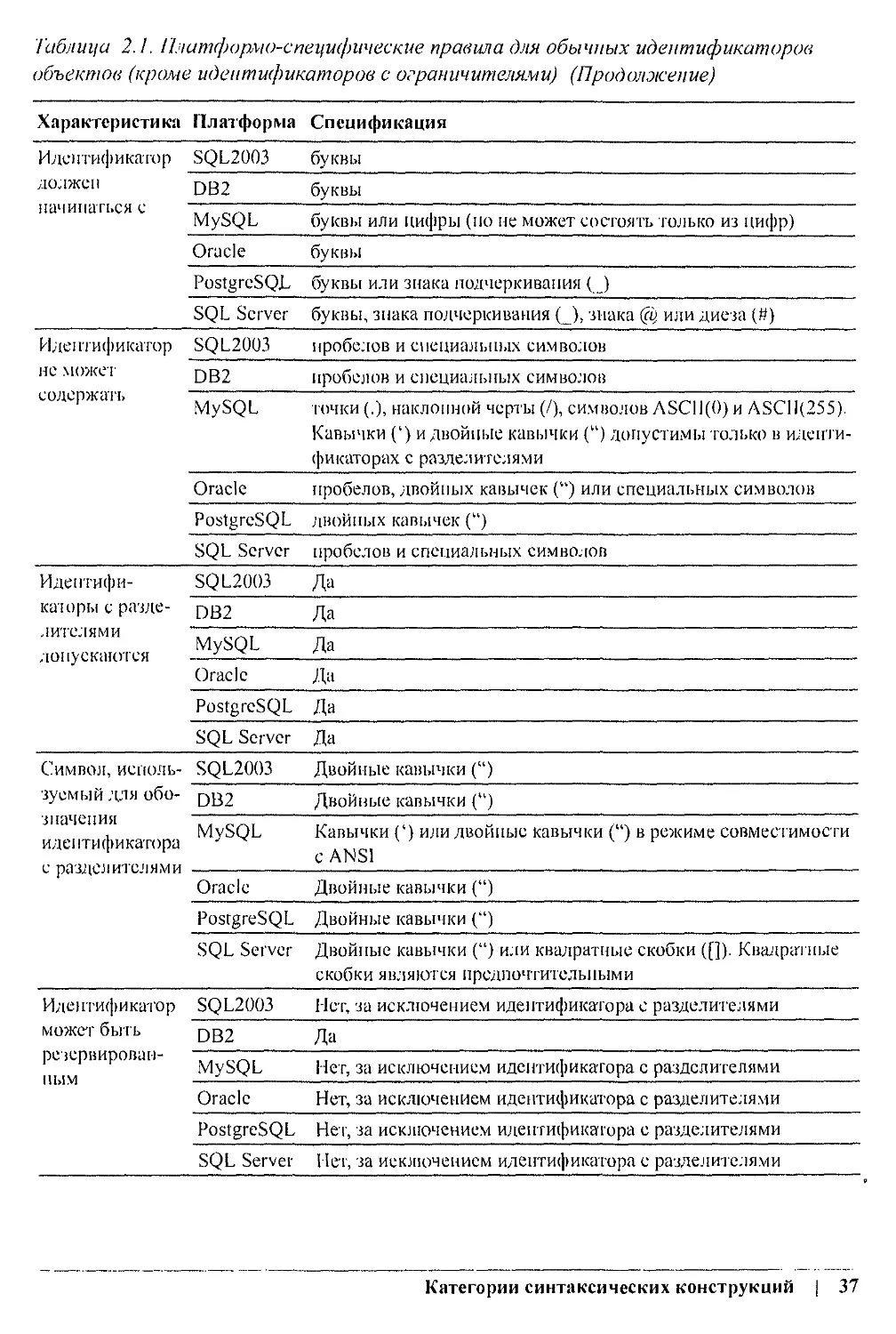
Данная книга является справочником по SQL стандарта ANSI SQL2003 и реализациям
этого стандарта на наиболее распространенных платформах: Microsoft SQL Server, DB2
Universal Database версии 8.0 от компании IBM для Linux, Unix и Windows, Sybase Adaptive
Server версии 12.5, Oracle Database 10g и двух продуктов с открытым исходным кодом -
MySQL версии 4 и PostgreSQL версии 7.
Книга является настольным практическим справочником для администраторов
и разработчиков баз данных, а также разработчиков прикладного программного
обеспечения.
Кевин Клайн
при участии Дэниела Клайна и Бренда Ханта
SQL. Справочник. 2-е издание
Перевод с англ. С. М. Лунин Редактор Л. Б. Сиховец Корректор В. Г Клименко Макет О. В. Горкина
ООО «ИД КУДИЦ-ОБРАЗ»
119049, Москва, Ленинский пр-т., д. 4', стр. 1А
Тел.: 333-82-11, ok@kudits.ru Подписано в печать 22.11.2005 Формат 70x100/16. Печать офсетная. Бумага офсетная Усл. печ. л. 67,1. Тираж 2000. Заказ 2447 Отпечатано с готовых диапозитивов в ОАО «Щербинская типография» 117623, Москва, ул. Типографская, д. 10
ISBN 5-9579-0114-8 (рус.) ISBN 0-596-00481-8 © Перевод, макет и обложка «ИД КУДИЦ-ОБРАЗ», 2006 © 2004 O'Reilly Media, Inc.
© ООО «ID Kudits-Obraz» 2006. Authorized translation of the English edition Copyright © 2001,
2004 O'Reilly Media, Inc. This translation is published and sold by permission of O'Reilly Media, Inc.,
the owner of all rights to publish and sell the same.
Авторизованный перевод англоязычного издания публикуется с разрешения правообладателя
O'Reilly Media, Inc. Copyright © 2001,2004.
Русское издание опубликовано издательством КУДИЦ-ОБРАЗ, © 2006. Все права защищены.
Никакая часть этой книги не может воспроизводиться или распространяться в любой форме или
любыми средствами, электронными или механическими, включая фотографирование,
магнитную запись или информационно-поисковые системы хранения информации без
разрешения O'Reilly Media, Inc.
Предисловие
С момента своего появления в 70-х годах язык структурированных запросов (Structured
Query Language, SQL) развивался на волне информационного бума, и в результате он
сейчас является наиболее широко распространенным языком манипулирования базами
данных в бизнесе и промышленности. Многие компании, связанные с программным обес-
печением, а также разработчики программ, в том числе те, которые участвуют в движении
за открытый исходный код, на конкурентной основе разрабатывали свои собственные диа-
лекты SQL, отвечающие их профессиональным запросам. Все это время организации
по стандартизации продолжали работу по расширению списка функциональных возмож-
ностей общего назначения.
В книге «SQL: справочник» описываются самые последние версии SQL-команд,
соответствующие стандарту ANSI SQL2003, а также приводятся реализации этих
команд для каждой платформы. В этой книге вы найдете краткое описание модели
Системы управления реляционной базой данных (СУРБД), четкое объяснение основ-
ных концепций СУРБД, а также подробные сведения по синтаксису и командам SQL.
Наиболее важным, особенно если вы являетесь программистом или разработчиком,
является то, что в книге «SQL: справочник» приводится ясное описание наиболее по-
пулярных сейчас на рынке коммерческих пакетов (Microsoft SQL Server, DB2 Universal
Database от компании IBM, Sybase Adaptive Server и Oracle), а также двух наиболее
известных продуктов с открытым исходным кодом - MySQL и PostgreSQL (http://
www.opensource.org). Внимание, которое уделяется в данной книге SQL-платформам
с открытым исходным кодом, является признанием возрастающей роли движения за
открытый исходный код в компьютерном сообществе.
В этой книге охватываются следующие платформы.
• IBM DB2 UDB, версия 8.0 для Linux, Unix и Windows.
• MySQL, версия 4.
• Oracle Database 10g.
• PostgreSQL, версия 7.0.
• Microsoft SQL Server 2000.
• Sybase Adaptive Server, версия 12.5.
Зачем нужна эта книга?
Основным источником информации по реляционным базам данных является доку-
ментация и файлы справки, создаваемые их производителями, Хотя документация
каждого производителя является обязательным источником, к которому обращается
большинство программистов и администраторов баз данных, она имеет несколько
ограничений.
• Она охватывает только один продукт конкретного производителя. Не рассматри-
ваются вопросы преобразования, переноса данных и интеграции.
• Методы программирования обычно описываются во множестве небольших, не
связанных друг с другом документов или справочных файлов.
• В ней описываются отдельные команды, часто с излишними подробностями,
а простые и ясные способы использования команд, применяемых программистами
и администраторами в повседневной практике, освещены плохо.
Иными словами, документация, которую включает в базу данных производитель,
представляет собой исчерпывающее объяснение всех аспектов данной платформы.
В конце концов, справочные тексты направлены на сообщение основных фактов по
данному продукту. Они дадут вам информацию о синтаксисе команд (и всех его мало-
понятных вариантах) и в общих словах расскажут о том, как его применять. Однако,
если вы переходите с одной базы данных на другую и вам нужно сделать это очень
быстро, вы вряд ли будете использовать эти непонятные варианты команд, а будете
применять обычные возможности, с которыми вы встречаетесь в реальной жизни.
Эта книга начинается там, где заканчивается документация производителей, она
содержит опыт профессиональных администраторов и разработчиков баз данных, ко-
торые используют эти варианты SQL изо дня в день для обеспечения работы сложных
приложений масштаба предприятия. Вы сможете воспользоваться их опытом, пред-
ставленным в компактном и удобном формате. Независимо от того, являетесь ли вы
новичком в SQL или используете SQL с самых первых его дней, всегда есть сведения,
которые можно узнать, и методы, которыми можно овладеть. А когда вы переходите от
одной реализации языка к другой, важно изучить эти реализации, чтобы не пострадать
от недостаточной информированности или неаккуратности.
Кому нужно прочитать эту книгу?
Книга «SQL: справочник» будет полезна нескольким группам пользователей. Она
нужна программистам, которым требуется краткое и удобное справочное руководство
по SQL. Она будет полезна разработчикам, которые хотят переходить с одного диалек-
та SQL на другой. И наконец, она будет полезна администраторам баз данных,
которым приходится запускать несметное число выражений SQL, чтобы обеспечивать
работу баз данных своего предприятия, а также создавать такие объекты, как таблицы,
индексы и представления, и управлять ими.
6 | Предисловие
Эта книга представляет собой справочное пособие, а не учебник. Она не включает
в себя разъяснения. Например, мы не будем объяснять концепцию простейшего цикла.
Опытные разработчики уже имеют представление о таких вещах. Вам нужна суть.
Поэтому мы будем подробно объяснять, например, работу с курсором стандарта
ANSI, то, как он функционирует на различных описываемых нами платформах, специ-
альные возможности курсоров на каждой платформе, различные, связанные с курсорами
подводные камни, и то, как их обходить.
Мы не предназначаем книгу «SQL: справочник» для использования в качестве
учебника или руководства по проектированию баз данных, но обязательно включаем
краткое описание этих тем и надеемся, что вы найдете такой способ изложения полез-
ным. В главах 1 и 2 приводится краткое введение в SQL с описанием его происхожде-
ния, общей структуры и основ работы языка. Если вы являетесь новичком в SQL, эти
главы помогут вам войти в курс дела.
Структура книги
Книга «SQL: справочник» разделена на пять глав и два приложения.
Глава 1. История и реализации SQL
Обсуждается реляционная модель баз данных, описаны текущие и более ранние
стандарты SQL. Знакомство с реализациями SQL, которые описываются в данной
книге.
Глава 2. Основные концепции
Описываются фундаментальные концепции, необходимые для понимания реляци-
онных баз данных и команд SQL.
Глава 3. Справочник по командам и выражениям SQL
Представляет собой отсортированный в алфавитном порядке справочник по ин-
струкциям SQL. Для каждой команды приводится вариант, соответствующий по-
следнему стандарту ANSI, SQL2003, а также реализация команды в DB2, MySQL,
Oracle, PostgreSQL и SQL Server.
Глава 4. Функции SQL
Отсортированный по алфавиту перечень функций SQL2003 с описанием реализации
всех функций SQL2003 производителями. Кроме этого, глава 4 включает описание
всех платформо-специфичных функций, уникальных для каждой реализации.
Глава 5. Программирование баз данных
Приводится общий обзор программирования баз данных с использованием раз-
личных методов установления соединения. Среди прочих методов обсуждаются
ADO.NET и JDBC.
Приложение A. Sybase Adaptive Server
Sybase Adaptive Server и Microsoft SQL Server имеют общее происхождение.
Поэтому большая часть команд SQL Server, описанных в главе 3, и большинство
функций, описанных в главе 4, будут работать и с продуктом Sybase. Однако
«большинство» - это еще не все, и в данном приложении мы показываем, чем
Sybase отличается от SQL Server.
Предисловие | 7
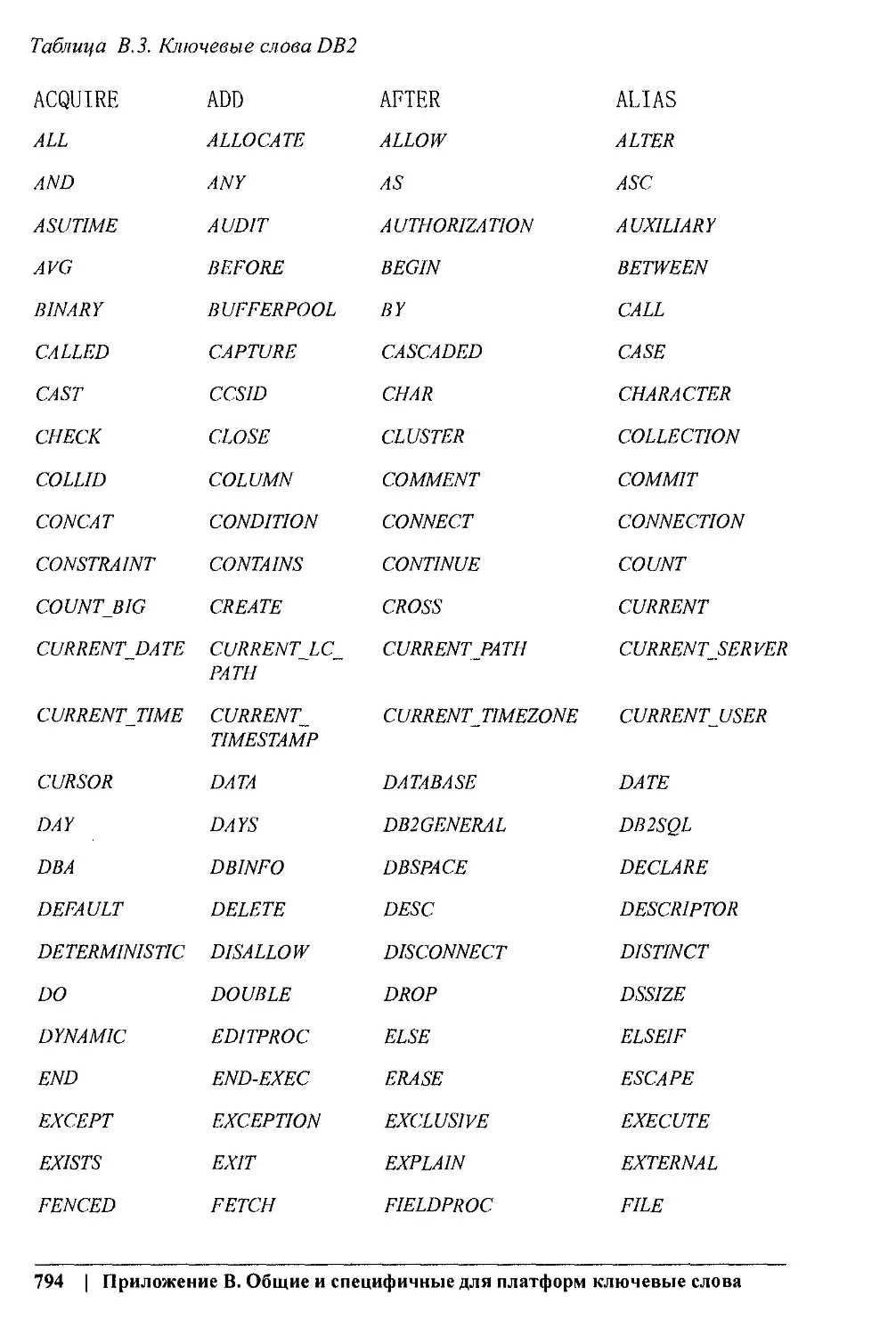
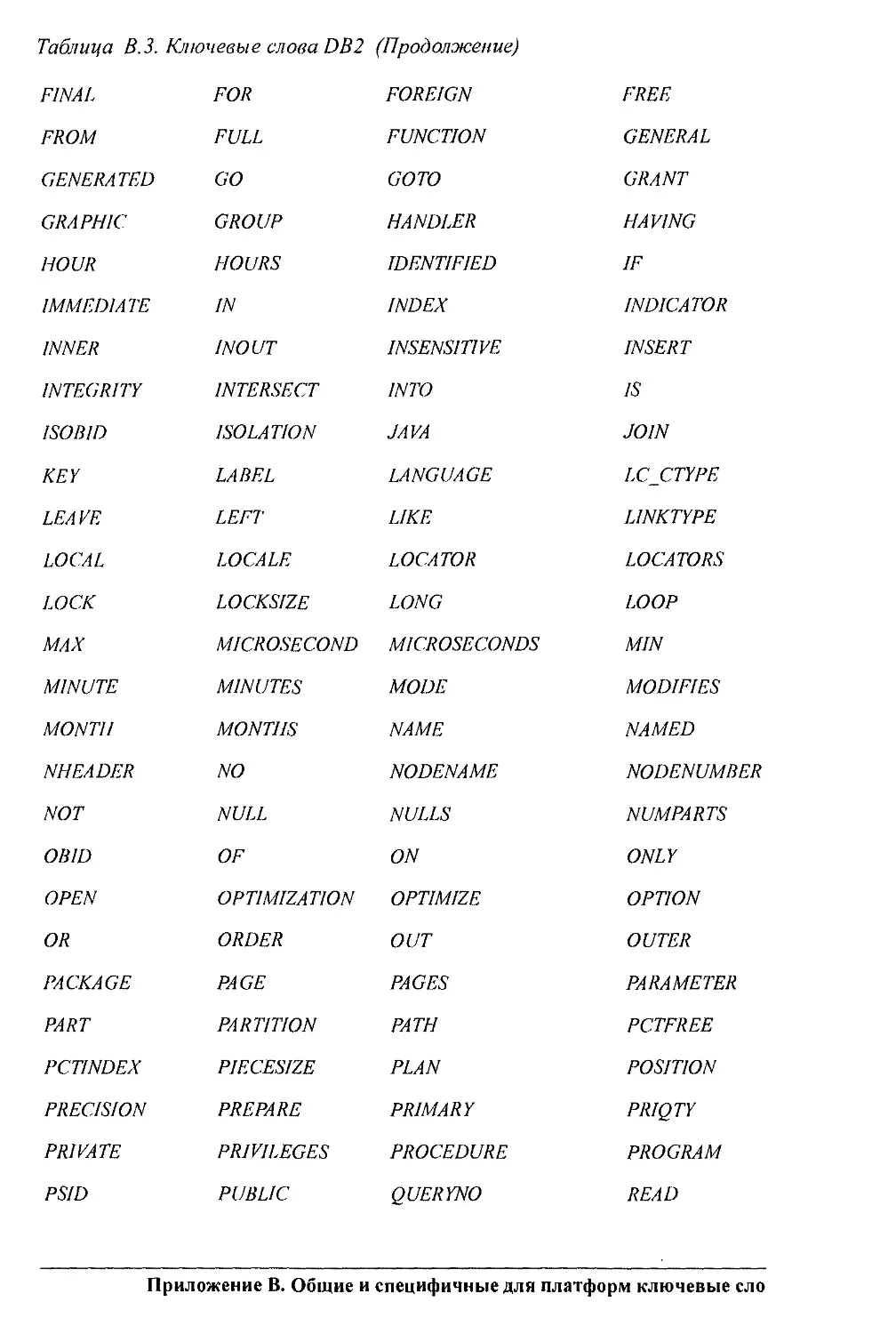
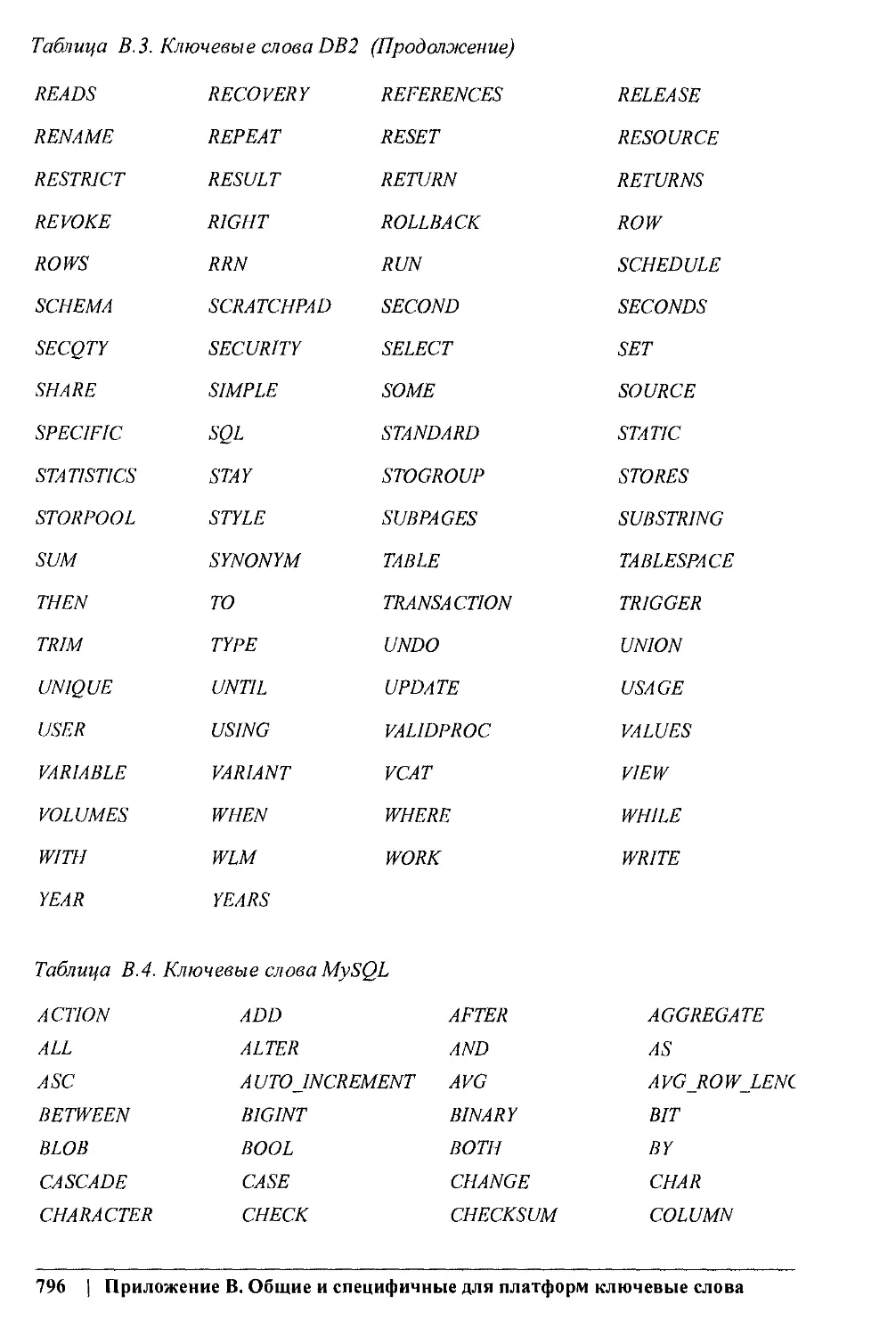
Приложение В. Общие и платформо-специфичные ключевые слова
Приводится таблица ключевых слов, заявленных в стандарте SQL2003 и в раз-
личных платформах. Эту таблицу можно использовать для того, чтобы не приме-
нять эти слова в качестве имен объектов и переменных.
Соглашения, используемые в этой книге
моноширинный шрифт
Используется для обозначения синтаксиса, фрагментов кода и примеров.
моноширинный курсив
Используется для обозначения в коде переменных, которые нужно заменять значе-
ниями.
моноширинный жирный
Используется в коде, чтобы выделить определенный фрагмент.
Курсив
Используется для выделения новых терминов, расстановки акцентов, выделения
команд или указанных пользователем файлов и директорий, а также для выделе-
ния в тексте имен переменных.
Жирный
Используется для обозначения имен объектов баз данных, таких, как таблицы,
колонки и сохраняемые процедуры.
ЗАГЛАВНЫЙ КУРСИВНЫЙ
Показывает ключевые слова SQL, появляющиеся в тексте.
'V1
м*’ л «
. Ду
Этим значком обозначается совет, предложение или общее примечание.
Этим значком обозначается предостережение.
Как пользоваться этой книгой?
Книга «SQL: справочник» - это в первую очередь справочник по командам. Следователь-
но, вы, вероятно, будете искать в ней различные команды и функции SQL. Однако описа-
ние каждой команды для пяти платформ и с документацией стандарта ANSI может стать
очень большим.
8 | Предисловие
Чтобы сделать описание команд менее обширным, мы сравниваем реализацию
языка для каждой платформы со стандартом SQL2003. Если платформа поддерживает
оператор, описанный в разделе, посвященном SQL2003, мы не повторяем описание
этого оператора.
При описании команд SQL2003 предлагаются также общие, переносимые на
другие платформы примеры. Поскольку стандарт SQL2003 берется за основу в боль-
шинстве платформ, не приводятся примеры тех элементов стандарта SQL2003,
которые не поддерживаются ни одной из описываемых в этой книге платформ. Кроме
того, для каждой платформы приводятся дополнительные примеры, которые
подчеркивают уникальные для этой платформы расширения и усовершенствования.
Мы понимаем, что при данном подходе может возникнуть необходимость перехо-
дить от описаний команды в разделе, посвященном реализации языка для платформ,
к соответствующему ее описанию в стандарте SQL2003. Однако мы полагаем, что это
все же лучше, чем вводить в книгу сотни страниц избыточной информации.
Как с нами связаться
Мы проверили информацию, приводимую в этой книге, как можно более тщательно, по
вы можете обнаружить, что какие-то свойства изменились (или можете даже обнару-
жить наши ошибки!). Нам бы хотелось, чтобы вы связались с нами, особенно если вы
располагаете информацией, которая могла бы помочь улучшить эту книгу. Пожалуйста,
сообщайте нам обо всех ошибках, которые вы найдете, а также выдвигайте предложения
для будущих изданий. Пишите по адресу:
O’Reilly Media, Inc.
1005 Gravenstein Highway North
Sebastopol, CA 95472
(800) 998-9938 (США и Канада)
(707) 829-0515 (международные контакты)
(707) 829-0104 (факс)
У нас есть web-сайт, посвященный этой книге, на котором приведены все при-
меры, списки опечаток и планы по будущим изданиям. Эту страницу вы можете найти
по адресу:
http://www. oreilly. com/cutalog/sqlnut2/
Пожалуйста, помогите нам и укажите опечатки и синтаксические ошибки, с которыми
вы встретитесь. (Представьте, как трудно править книгу, охватывающую стандарт ANSI
и пять разных продуктов.) Также вы можете задать технические вопросы или написать
свой комментарий, послав электронное письмо на адрес:
bookquestions@oreilly.com
За дополнительной информацией о книгах, конференциях, программном обес-
печении, центрах ресурсов и O’Reilly Network обращайтесь на web-сайт O’Reilly:
http://www. oreilly. com
Предисловие | 9
Safari Enabled
Если на обратной стороне своей любимой технической книги вы видите значок Safari®
Enabled, это означает, что данная книга доступна в режиме онлайн в системе O’Reilly
Network Safari Bookshelf.
Система Safari предлагает решение, которое даже лучше электронных книг. Это
виртуальная библиотека, которая позволяет проводить поиск среди тысяч лучших тех-
нических книг, копировать фрагменты кода, скачивать главы и быстро находить
ответы тогда, когда вам требуются наиболее точные и современные сведения.
Бесплатно опробовать эту систему можно по адресу http://scrfari.oreilly.com.
Ресурсы
На следующих web-сайтах вы можете получить дополнительную информацию по раз-
личным платформам, описанным в этой книге.
DB2
Поддержка баз данных DB2 от компании IBM осуществляется на сайте http://
www.software.ibm.com/data/db2/. У DB2 есть активное и энергичное сообщество
пользователей, общающихся на сайте http://www.idug.org.
MySQL
Корпоративным сайтом MySQL является http://wvitw.mysql.com. Еще один хоро-
ший сайт - http://theoryx5.uwinnipeg.ca/mysql. Отличным ресурсом для разра-
ботчиков с массой полезных советов является сайт Devshed.com. Информацию по
SQL можно найти на странице http://www.devshed.com/Server_Side/MySQL/.
PostgreSQL
Домашняя страница этой базы данных с открытым кодом находится по адресу
http://www.postgresql.org. Помимо большого количества полезной информации для
скачивания на этом сайте также осуществляется поддержка списков рассылки для
пользователей PostgreSQL. Еще один сайт, на который стоит заглянуть, это http://
www.pgsql.com. Этот сайт осуществляет поддержку коммерческих клиентов.
Oracle
Домашняя страница Oracle в виртуальном мире располагается по адресу http://
www.oracle.com. Отличным ресурсом для активных пользователей Oracle является
страница http://www.oracle.com/technology. Всю документацию Oracle вы также
можете найти на сайте http://tahiti.oracle.com.
SQL Server
Официальный сайт Microsoft SQL Server находится по адресу http://www.mi-
crosoft.com/sql/. Еще один хороший ресурс можно найти на домашней странице
организации Professional Association for SQL Server (PASS) по адресу http://
ww. sqlpass.org.
10 | Предисловие
Изменения, появившиеся во втором издании
Хотя комитет по стандартизации ANSI выпустил текущую версию SQL в 2003 году
(SQL2003), эта книга динамически развивается в нескольких различных направлениях
в соответствии с требованиями наших читателей. Фактически, если вы сравните
первое и второе издание книги «SQL», вы увидите, что второе издание представляет
собой по сути совершенно новую книгу. Ниже мы более подробно перечислим изме-
нения, появившиеся во втором издании.
Новый формат
Мы разработали совершенно новый формат, который уменьшает избыточность
информации и увеличивает широту охвата стандарта SQL2003 и всех реализаций
языка. Вместо разъяснительной формы первого издания мы приняли формат опи-
сания ключевых слов, где все ключевые слова и операторы разделяются на не-
большие фрагменты.
Новые платформы
Мы добавили полное описание платформы IBM DB2 UDB под Unix, Linux
и Windows. Кроме того, мы добавили приложение, в котором описывается реали-
зация команд SQL на платформе Sybase там, где она отличается от реализации
в Microsoft SQL Server.
Программирование баз данных
Мы добавили главу, в которой объясняется, как программист может реализовать
взаимодействие своей программы-клиента с серверной платформой, описанной
в этой книге.
Более полное описание
Мы добавили много примеров и дополнительных команд SQL, не вошедших
в первое издание. Кроме того, мы приводим гораздо более полное описание функ-
ций SQL и, в частности, специфических функций разных производителей, которые
не входят в стандарт SQL2003.
Больше примеров
Примеров не бывает слишком много. Мы добавили примеры самых основных
способов применения команд, входящих в стандарт SQL2003, и даже еще больше
примеров, которые показывают уникальные расширения возможностей языка,
предлагаемые в каждой из платформ.
Благодарности
Мы бы хотели поблагодарить нескольких очень хороших людей из O’Reilly Media.
Во-первых, мы должны выразить огромную благодарность Джонатану Геннику
(Jonathan Gennick), редактору второго издания. Джонатан не давал нам отклониться
от задачи даже тогда, когда все силы мира стремились пустить проект под откос.
Именно вниманию Джонатана к деталям, его отличным административным навы-
кам и его таланту редактора мы обязаны тем, что книга сегодня лежит перед вами.
Спасибо! И конечно, спасибо Тиму О’Рейли (Tim O’Reilly), который имел самое
прямое отношение к рождению этой книги.
Предисловие | 11
Мы также должны выразить благодарность нашим техническим рецензентам:
Питеру Галатзяну (Peter Gulutzan) (SQL Standard), Томасу Локхату (Thomas Lockhart)
(PostgreSQL), Алану Болье (Alan Beaulieu) (Oracle), Байя Павлиашвили (Baya Pavliachvili)
(Microsoft SQL Server), Бобби Филдингу (Bobby Fielding) (DB2), Дугу Дулу (Doug
Doole) (DB2), Рику Свогерману (Rick Swagerman) (DB2), Джошу Стеллану (Josh Stellan)
(DB2), Брайану Лелонду (Brian Lalonde) (Программирование баз данных), Джону
Хейду (John Haydu), Фани Арега (Phani Arega) (Oracle) и Полу Дюбуа (Paul DuBois)
(MySQL). Мы выражаем вам самую сердечную признательность! Ваш вклад значи-
тельно увеличил точность, понятность и ценность этой книги. Без вас разделы, посвя-
щенные расширениям языка, не имели бы прочного основания. Кроме того, мы хотим
снять шляпу перед Питером Галатзяном (Peter Gulutzan) и Труди Пельцером (Trudy
Pelzer) и их книгой «SQL-99 Complete, Really!», которая помогала нам понять стан-
дарты ANSI SQL2003.
Благодарности Бренда Ханта
Моей жене Мишель, без чьей постоянной поддержки и любви я не смог бы работать
над этим проектом. Я ценю каждый момент, который мы провели вместе, и то, что ты
прощала мне, что я не давал тебе спать постоянным щелканьем клавиш компьютера.
Моим родителям Рексу и Джеки, двум самым большим причинам всех моих пра-
вильных поступков, особенно там, где необходимо делать все новые и новые попытки
(например, при написании книги).
Огромная благодарность моим соратникам Кевину, Дэниелу и Джонатану за то,
что дали мне возможность работать над этим проектом и проявили так много терпе-
ния в обучении свежеиспеченного автора компании O’Reilly. Ваш профессионализм,
этика и способность сделать веселой самую утомительную работу так восхитили
меня, что я планирую украсть у вас все это и использовать как свое собственное!
Огромное спасибо моим друзьям и коллегам из Rogue Wave Software, ProWorks,
NewCode Technology, System Research and Development, предоставившим мне макси-
мум возможностей для совершенствования навыков работы с SQL, базами данных,
бизнесом, разработкой программного обеспечения, написанием книг, а также свою
дружбу: Газу Уотерсу (Gas Waters), Грегу Корперу (Greg Koerper), Марку Менли (Mark
Manly), Венди Мин (Wendi Minne), Эрину Фоули (Erin Foley), Элейн Кулл (Elaine
Cull), Рендолу Робинсону (Randall Robinson), Дейву Ритеру (Dave Ritter), Эдину
Зулику (Edin Zulic), Дэвиду Но (David Noor), Джиму Шо (Jim Shur), Крису Мосбра-
керу (Chris Mosbrucker), Дэну Робину (Dan Robin), Майку Фо (Mike Faux), Джейсону
Протеро (Jason Protero), Тиму Романовски (Tim Romanowski), Энди Мосбракеру (Andy
Mosbrucker), Джефу Джонасу (Jeff Jonas), Джефу Батчеру (Jeff Butcher), Чарли Барбу
(Charlie Barbour), Стиву Данхему (Steve Dunham), Брайану Мейси (Brian Масу) и Зееву
Мелеру (Ze’ev Mehler).
12 | Предисловие
Благодарности Дэниела Клайна
Мне бы хотелось поблагодарить моего брата Кевина за постоянную готовность рабо-
тать со мной, моих коллег из University of Alaska, Anchorage, за высказанные предло-
жения, а также читателей и пользователей первого издания книги «SQL» за неоценимые
сведения и конструктивную критику. Я также хотел бы поблагодарить переводчиков
первого издания книги на японский язык - Риоко Акаике (Ryoko Akaike), японского
редактора O'Reilly, Ишии Татсуо (Ishii Tatsuo), менеджера по открытому коду из Software
Research Associates, Inc. и автора книги «PostgreSQL Perfect Guide», а также Тору Мия-
хара (Toru Miyahara) из CEO of BigiNet Со., Ltd за тщательное рецензирование
и ценные замечания.
Благодарности Кевина Клайна
Эту большую толстую книгу, которую вы держите в руках, помогали создавать многие
люди. Мы хотим здесь выразить нашу признательность тем, кто способствовал появ-
лению этой книги на свет.
Прежде всего нужно похлопать по плечам Дэна и Бренда, чьим тяжелым трудом
создавалось то, что вы сейчас читаете. Бренду приходилось работать над книгой
ночами до и после его свадьбы. Спасибо Вам, Мишель, что одолжили нам Бренда,
когда он был нужен Вам более всего.
Жму руку и обнимаю Джонатана Генника (Jonathan Gennick), нашего редактора
в O’Reilly Media. Вам пришлось пройти через тяжелый многомесячный труд, чтобы
книга появилась на свет. Я думаю, что тому, кто взвалит на себя столько же терпения,
профессионализма и юмора, сколько Вы, будут выделены особые блага.
Мы также должны выразить глубокую благодарность и признательность нашим
техническим рецензентам, которые обнаружили множество дефектов, упущений и оче-
видных ошибок и уберегли нас от многих огорчений.
• ANSI SQL - Питеру Галатзяну (Peter Gulutzan), автору книг «SQL-99 Complete,
Really!» и «SQL Performance Tuning».
•
DB2 - Дугу Доулу (Doug Doole), Бобби Филдингу (Bobby Fielding) и Ричарду
Свагерману (Richard Swagerman) из IBM и Джошу Стеффану (Josh Steffan) из
Quest Software.
• MySQL - Полу Дюбуа (Paul DuBois), автору MySQL.
• Oracle - Фани Apera (Phani Arega) из Quest Software и рецензентов из Oracle.
• PostgreSQL - Томасу Локхату (Thomas Lockhapt), автору исходной документации
по открытому коду PostgreSQL.
• SQL Server - Байя Павлиашвили (Вауа Pavliachvili) из Healthstream, Inc.
• Программирование баз данных - Брайану Лелонду (Brian LaLonde).
Очень большое спасибо всем моим коллегам из Quest Software за поддержку
и одобрение. Рони Лернер (Rony Lerner), Деб Йенсон (Deb Jenson), Эйял Аронов (Eyal
Предисловие | 13
Aronoff), Джон Ньюсом (John Newsome) и Винни Смит (Winny Smith) - спасибо за то,
что поверили в меня и сделали эти последние три года Quest Software такими яркими.
Спасибо всем ребятам из команды SQL Server, которые сделали наши продукты
лучшими на рынке: Джону Терону (John Theron), Патрику О’Кифу (Patrick O’Keeffe),
Джону Ортеге (John Ortega), Марку Саймону (Mark Simon), Хасану Фихими (Hasan
Fahimi), Ли Гриссому (Lee Grissom), Джо Мотли (Joe Motley), Эдриану Тюдору (Adrian
Tudor), Исраелю Калашу (Israel Kalush), Эмиту Кубовски (Amit Kubovsky) и Россу
Дерингу (Ross Doering). Я не могу желать лучшей команды и лучших друзей.
Спасибо команде SQL Server в Microsoft за то, что держали меня в курсе событий:
Эану Гардену (Euan Garden), Ричарду Веймару (Richard Waymire), Джо Йонгу (Joe
Yong), Дону Петерсону (Don Peterson), Марку Сузе (Mark Sousa), Стивену Дайбингу
(Steven Dybing), Фернандо Каро (Fernando Саго), Тому Риццо (Tom Rizzo) и Биллу
Бейкеру (Bill Baker). Ваш продукт потрясающий!
И наконец, для моей семьи. Трудно работать долгие часы и месяцы напролет над
повседневной работой и написанием книги, не принося определенных жертв. И все же
нам иногда удавалось хорошо проводить вместе время. Кэти Йо, пока я писал эту
книгу, ты научилась говорить. И я до сих пор поражаюсь, когда слышу твое «Я любью
тебя, папоська». Анна Линн, твоя неиссякаемая энергия спасала меня много раз, когда
у меня было плохое настроение. И в следующий раз, когда меня нужно будет спасать,
я хочу услышать, что «супердевочка спешит на помощь». А вот секрет: «Я держу на
своем столе стаканчик фисташек просто потому, что ты их любишь». Эмили, спасибо,
что разрешаешь красить тебе ногти. Не все дочки подпускают отцов так близко.
Дилан, ты побил меня в такое количество игр на PS2, что я даже не знаю, почему тебе
все еще хочется играть со мной. Но когда-нибудь я тебя все-таки сделаю! Келли, ты
мое тонизирующее средство, мое лекарство и мой врач. Одно прикосновение или
взгляд на твою улыбку, - и мои ночи превращаются в дни, а разочарование - в надежду.
Спасибо вам за любовь, поддержку и за то, что смотрите за мной, пока я работаю.
14 | Предисловие
История
и реализации SQL
В начале 70-х годов плодотворный труд исследователя из IBM доктора Кодда (Е. F. Codd)
привел к созданию продукта, связанного с реляционной моделью данных под названием
SEQUEL (Structured English Query Language, структурированный английский язык для за-
просов), который впоследствии превратился в SQL (Structured Query Language, струк-
турированный язык запросов).
Компании IBM, а также другим производителям реляционных баз данных был
нужен стандартизованный метод доступа к реляционной базе и манипулирования
хранящимися в ней данными. Хотя компания IBM первая разработала теорию реляцион-
ных баз данных, первой па рынок с этой технологией вышла компания Oracle. Через
какое-то время SQL завоевал на рынке достаточную популярность и привлек внимание
Американского национального института по стандартизации (American National Standards
Institute, ANSI), который в 1986, 1989, 1992, 1999 и 2003 годах выпустил стандарты
языка SQL. Начиная с 1986 года несколько конкурирующих между собой языков позво-
ляли программистам и разработчикам обращаться к реляционным данным и манипу-
лировать ими. Однако очень немногие из них были настолько же просты в изучении
и повсеместно приняты, как SQL. Программистам и администраторам теперь можно
изучить один язык, который с небольшими изменениями можно применять к разно-
образным платформам баз данных, приложениям и прочим продуктам.
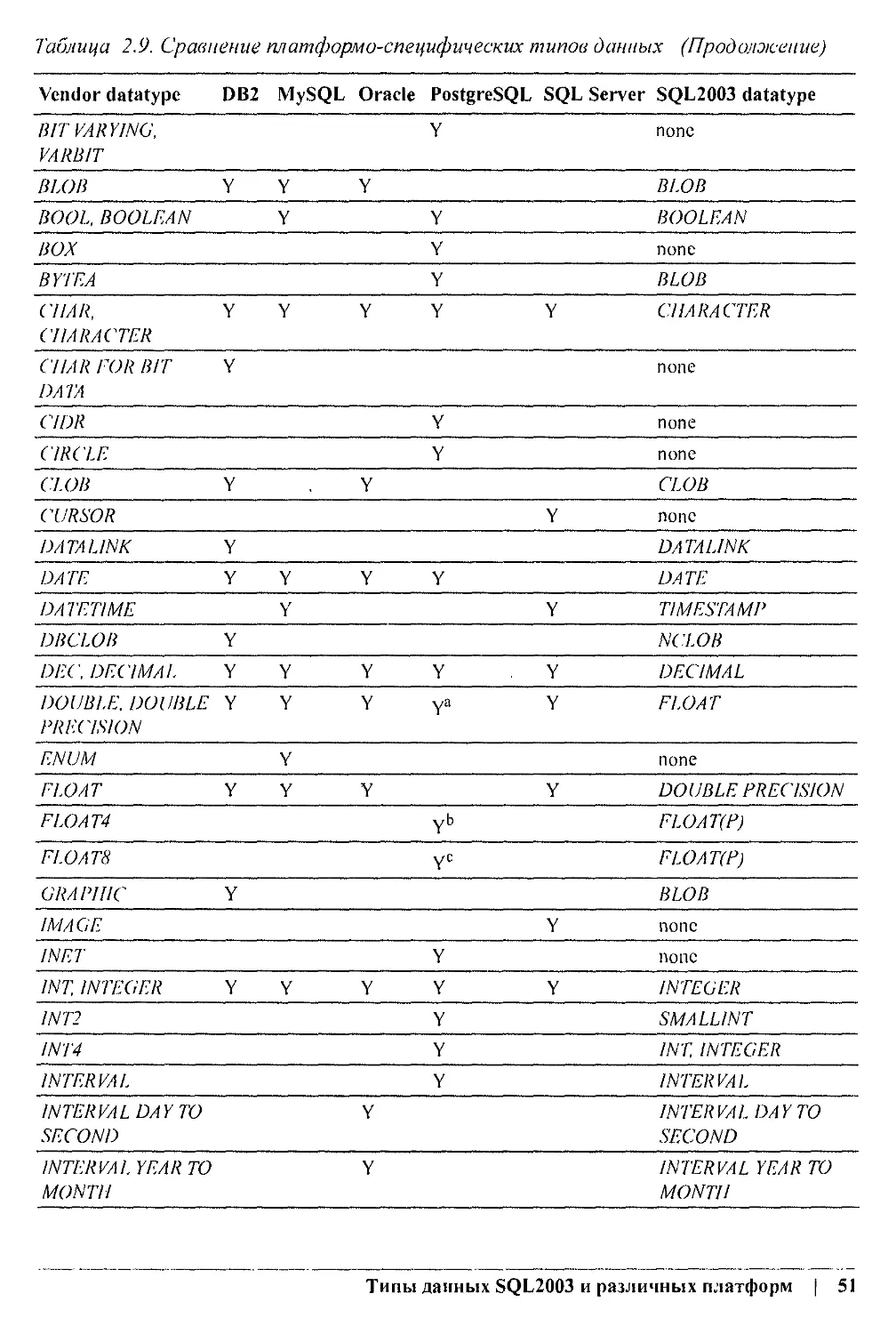
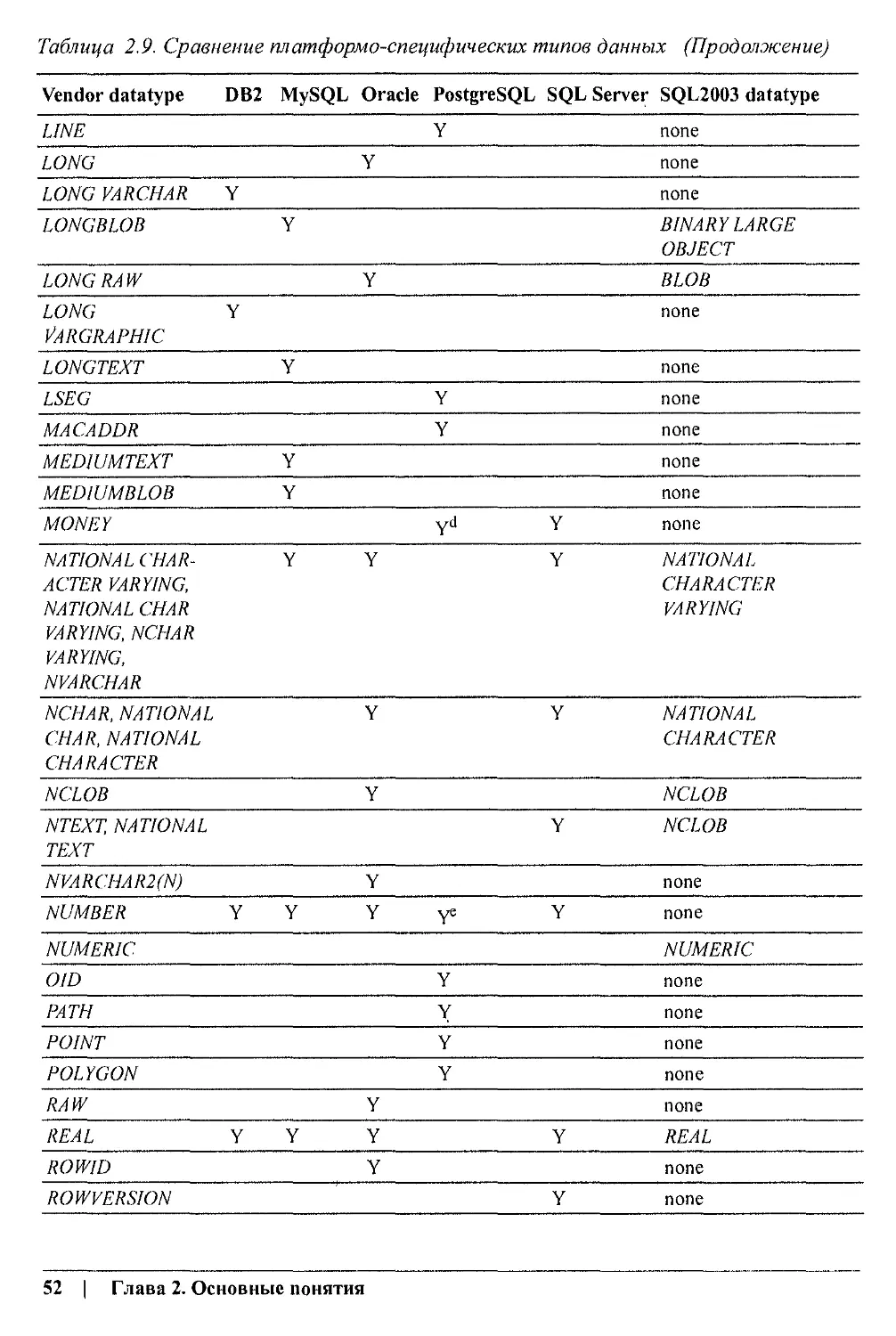
В книге «SQL: справочник» описываются пять распространенных реализаций
SQL2003.
• IBM DB2 Universal Database, версия 8 для Linux, Unix и Windows.
• MySQL, версия 4.
• Oracle Database 10g.
• PostgreSQL, версия 7.
• Microsoft SQL Server 2000.
Мы также рассмотрим Sybase Adaptive Server Enterprise (ASE), но менее подробно,
в приложении В.
Реляционная модель и ANSI SQL
Системы управления реляционными базами данных (Relational Database Management
Systems), такие, как те, которые мы рассматриваем в этой книге, - это основа ин-
формационных систем по всему миру, и особенно в веб-приложениях и распределен-
ных вычислительных системах типа клиент-сервер. Они позволяют множеству поль-
зователей быстро и одновременно обращаться к данным, создавать их, редактировать
и манипулировать ими, не мешая другим пользователям и не оказывая влияния на их
действия. Они также позволяют разработчикам создавать удобные приложения для
доступа к ресурсам, а также предоставляют администраторам необходимые средства
для обслуживания, обеспечения безопасности и оптимизации данных в организации.
Реляционная СУБД - это система, пользователи которой видят данные в форме
набора таблиц, связанных друг с другом посредством общих значений. Данные хра-
нятся в таблицах, которые состоят из строк и столбцов. Таблицы, содержащие неза-
висимые данные, можно связать (или соотнести) друг с другом, если в каждой из них
есть столбец уникальных идентификационных данных (называемых ключами),
которые представляют те данные, которые являются общими для таблиц. Е. F. Codd
первым описал теорию реляционных баз данных в своей основополагающей работе
«Relational Model of Data for Large Shared Data Banks», опубликованной в журнале
Communications of the ACM (Association for Computing Machinery) в июне 1970 года.
Согласно новой реляционной модели Кодда данные были структурированными (в таб-
лицы, состоящие из строк и столбцов), ими можно было манипулировать с помощью
таких операций, как выборка (selection), проекция (projection) и соединение (join),
и они оставались непротиворечивыми как результат правил целостности, таких, как
целостность ключей и ссылочных данных. Кодд также обозначил правила проектиро-
вания баз данных. Процесс применения этих правил сейчас называется нормализацией.
Правила Кодда для систем реляционных баз данных
Кодд применил к управлению данными строгие математические теории, и в первую
очередь теорию множеств. Он составил список критериев, которым должна удовле-
творять реляционная база данных. В своей основе концепция реляционной базы данных
концентрируется на хранении данных в таблицах. Сейчас эта концепция настолько
обычна, что кажется тривиальной. Однако еще не так давно разработка системы, удовле-
творяющей критериям реляционной модели, считалась работой с ограниченной обла-
стью применения, рассчитанной, скорее, на долгосрочную перспективу. Ниже приведе-
ны сформулированные Коддом двенадцать принципов реляционных баз данных,
1. Информация логически представлена в виде таблиц.
2. Логический доступ к данным должен осуществляться по таблице, первичному
ключу и столбцу.
3. Пустые значения нужно всегда рассматривать как «отсутствие информации», а не
как пустые строки, пробелы или нули.
16 | Глава 1. История и реализации SQL
4. Метаданные (данные о базе данных) должны храниться в базе данных, как и все
прочие данные.
5. Для определения данных, представлений, ограничений по целостности, авториза-
ции, транзакций и манипуляций должен использоваться один язык.
6. В представлениях должны отображаться обновления, вносимые в таблицы базы,
и наоборот.
7. Каждое из приведенных действий должно осуществляться при помощи одной
отдельной операции: извлечение данных, вставка данных, обновление данных
и удаление данных.
8. Пакетные операции и операции конечных пользователей логически отделены от
физических методов хранения и доступа.
9. Пакетные операции и операции конечных пользователей могут изменять схему
базы данных без необходимости повторного создания базы и приложений,
построенных на ее основе.
10. Ограничения, обеспечивающие целостность данных, должны храниться в мета-
данных, а не в прикладной программе.
11. Язык манипулирования данными реляционной системы не должен учитывать, где
и как распределены данные физически, и не должен требовать внесения измене-
ний в зависимости от того, являются данные централизованными или распреде-
ленными.
12. Любой процесс обработки строк в системе должен подчиняться правилам
обеспечения целостности данных и ограничениям, которым подчиняются
процессы обработки наборов данных.
Эти принципы продолжают оставаться «лакмусовой бумажкой» для проверки
«реляционных» характеристик платформ. База данных, не удовлетворяющая всем
этим критериям, не является полностью реляционной. Хотя эти правила и не приме-
няются к разработке приложений, они тем не менее определяют, можно ли считать
истинно «реляционным» само функциональное ядро базы данных. В настоящее время
большинство коммерческих реляционных СУБД проходят тест Кодда. Среди всех
платформ, обсуждаемых в книге «SQL: справочник», только MySQL не поддерживает
все эти требования.
Понимание принципов Кодда помогает программистам и разработчикам правиль-
но проектировать и разрабатывать реляционные базы данных. В следующих разделах
подробно рассказывается, как выполняются некоторые из этих требований в SQL при
использовании реляционных баз данных.
Структура данных (правила 1,2 и 8)
В первом и втором правилах Кодда говорится, что «информация логически представ-
лена в виде таблиц» и что «логический доступ к данным должен осуществляться по
таблице, первичному ключу и столбцу». Поэтому процесс создания таблицы в SQL не
требует, чтобы прикладная программа указывала базе данных, как ей нужно взаимо-
2 - 2447
Реляционная модель и AI\SI SQL | 17
действовать с низкоуровневыми физическими структурами данных. Более того, SQL
логически изолирует процесс доступа к данным и физическое обслуживание этих
данных в соответствии с правилом 8: «пакетные операции и операции конечных поль-
зователей логически отделены от физических методов хранения и доступа».
В реляционной модели данные логически представляют собой двухмерную таб-
лицу, которая описывает одну сущность (например, деловые расходы). Теоретики на-
зывают таблицы сущностями, а столбцы - атрибутами. Таблицы состоят из строк,
или записей (теоретики называют их кортежами), и столбцов (называемых атрибута-
ми, поскольку каждый столбец таблицы описывает определенный атрибут (признак)
сущности). Точка пересечения записи и столбца дает одиночное значение. Столбец
или столбцы, значения которых однозначно идентифицируют каждую запись, играют
роль первичного ключа. Сейчас такое представление кажется элементарным, но когда
оно было впервые предложено, оно было весьма передовым.
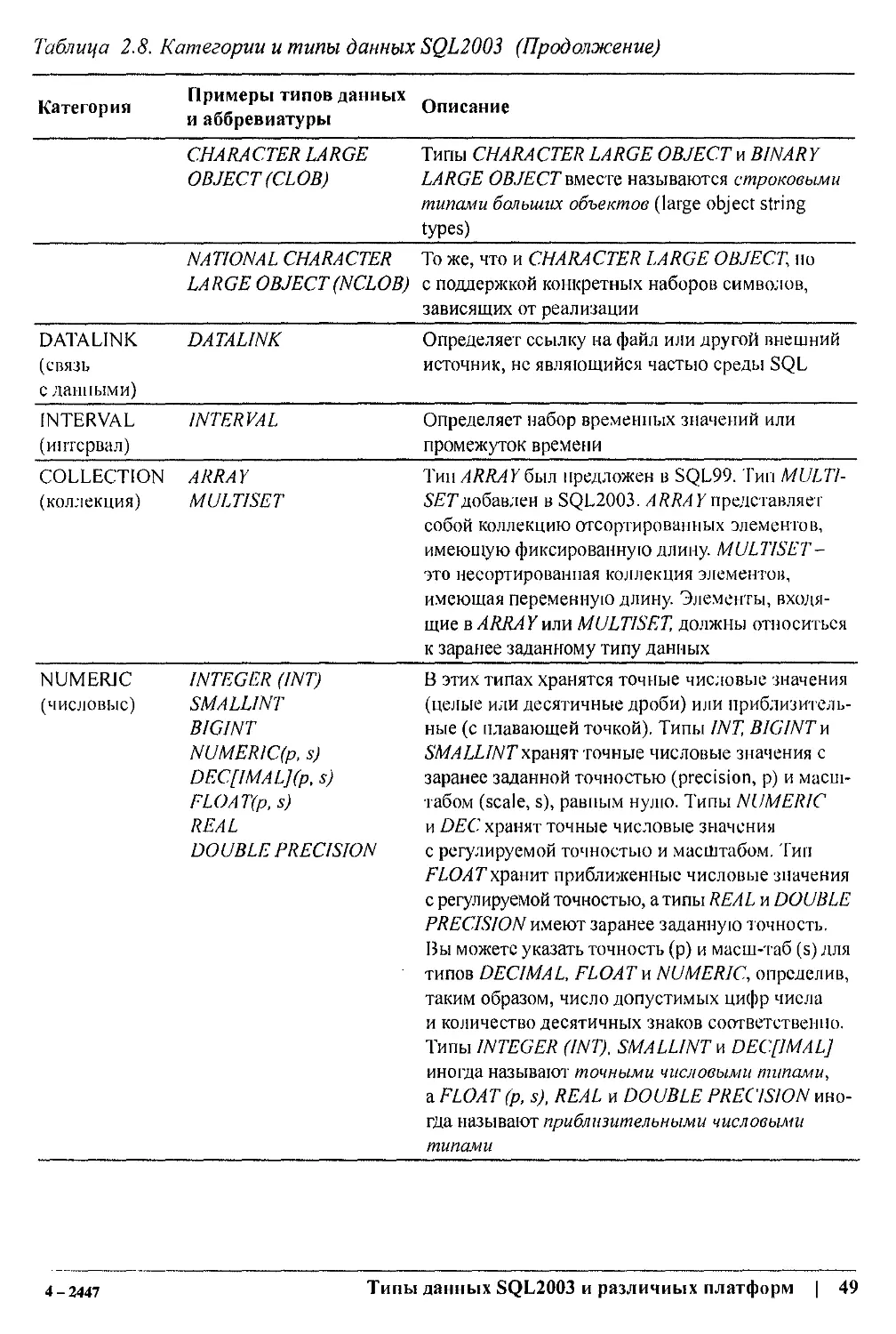
В SQL2003 описывается вся структура данных, выходящая за пределы простых
таблиц, хотя таблицы остаются основой структуры данных. При реляционном проек-
тировании работа с данными ведется потаблично, а не по записям. Такая ориентация
на таблицы - основа программирования баз данных с использованием наборов дан-
ных. В результате почти все команды SQL гораздо эффективнее оперируют с данными
нескольких таблиц, чем отдельными записями. Иными словами, эффективное про-
граммирование на SQL требует, чтобы вы мыслили наборами данных, а не отдельны-
ми записями.
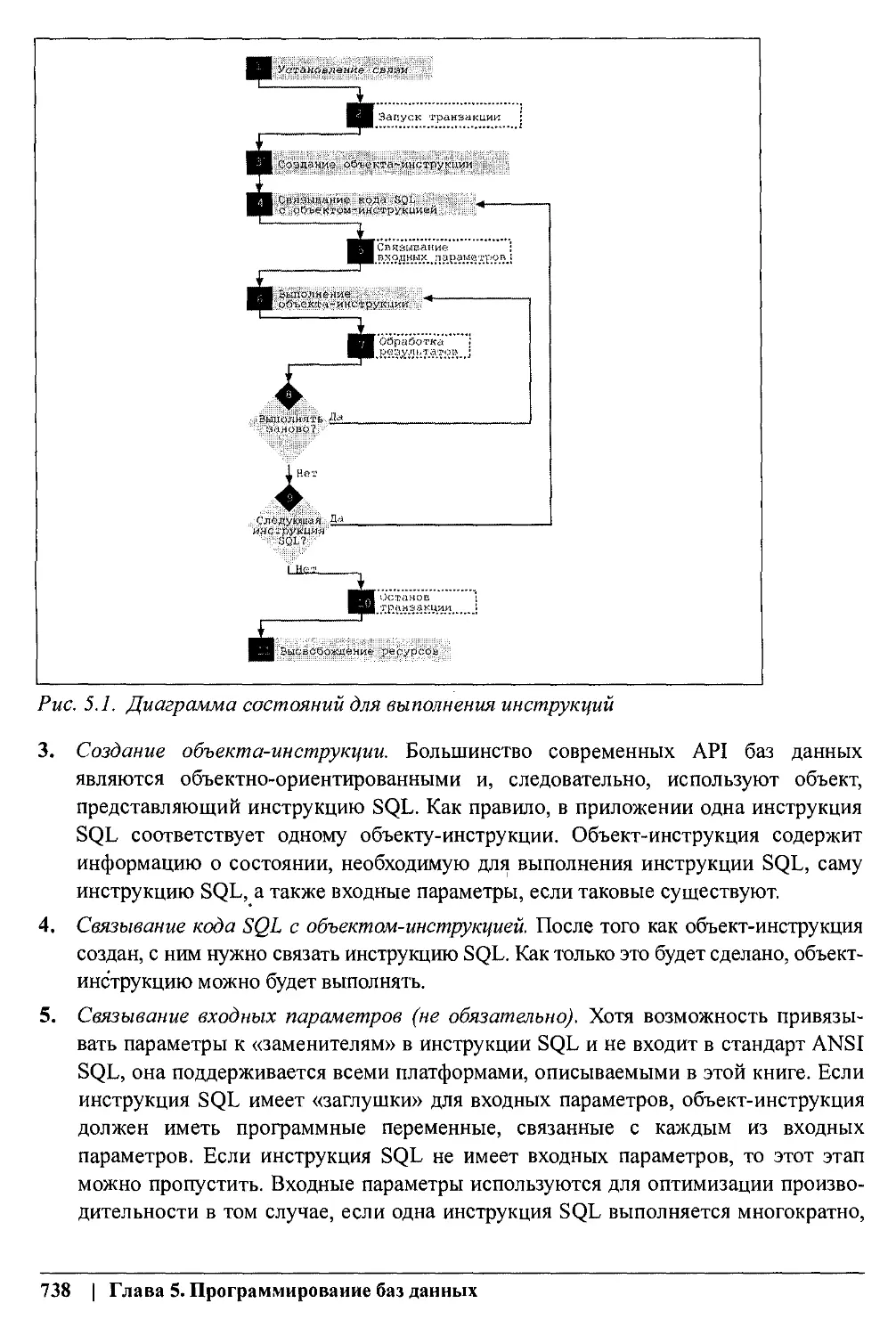
На рис. 1.1 приводится терминология SQL2003, применяемая для описания
иерархических структур данных, используемых в реляционной базе данных: кла-
стеры содержат набор каталогов, каталоги содержат набор схем, схемы содержат
набор объектов, таких, как таблицы и представления. Таблицы состоят из набора
столбцов и записей.
Например, в таблице Business_Expense1 столбец под названием Expense_Date
может показывать дату, когда были произведены данные расходы. Каждая запись в таб-
лице описывает конкретную сущность, в данном случае - все, что повлекло за собой де-
ловые расходы (когда это случилось, какова стоимость, кто произвел трату, с какой
целью и т. п.). Предполагается, что каждый признак расходов, иными словами, каждый
столбец является неделимым, т. е. допускает одно и только одно значение в каждом ряду.
Если таблица создается таким образом, что на пересечении столбца и записи может со-
держаться несколько значений, это нарушает одно из главных требований, предъявляе-
мых SQL к структуре базы. (Конечно, некоторые платформы баз данных, описываемые
в этой книге, позволяют размещать в столбце больше одного значения при помощи
типов данных VARRAY или TABLE.)
Для значений в столбце существуют определенные правила. Самое главное состоит
в том, что значения столбца должны относиться к одному домену, который больше из-
вестен под названием тип данных. Например, в поле Expense_Date нельзя поместить
1 Business Expense - деловые расходы. - Примеч. пер.
18 | Глава 1. История и реализации SQL
I
I
I
I
I
Кластеры
Содержи l ОлШН
или несколько
Кластер - vro набор каталогов. имеющий уникальное имя и
доступный в сеансе SQL. On приблизительно сткн веге гнус г
экземпляру приложения - реляционной базы. Согласно
стандарту ANSI кластеры определяют кто получает доступ к
данным и какие виды допусков могут существовав» ;.щя
иоя1»зова1с.‘юй
I
। Каталог- -.по набор схем, имеющий уникальное имя. Ь.слп вы
а* лс in | яв_!ЯеГесь ||ол|,-з{)|};ггелсм Oracle или Microsoft SQLServer, вы
/должны быт ь более знакомы с этим элементом
Содержи! один
или несколько
Схема -эго имеющим уникальное имя набор объектов или
, данных, принадлежащих данному пользователю. Каждый
„ , * Kaiajorдолжен содержа!(.схему INFORMATION SCHEMA.
е.хсьн.1 в к()Н)рая содержит мечаланные обо всех объектах, хранящихся
в каталоге. Схема примерно иоогнетегиусг бак-данных
Содержи! О/Bin
или несколько
Обьскг - >то имеющий уникальное имя набор данных пли
функциональное!!, SQL. Обьскты схем включают в себя
I таблицы, представления, модули и подиро! рамки»), г. с.
J процедуры или фуикшш
Если обьсКI ирсдстав.1яс'1 COOoit таблицу иля
ирсдс।автсннс, он можс! содсржа!ь один if щ
несколько
Cio.'juch •• это имеющий уникальное- имя набор значений,
который определяет специфический атрибут 1аблипы-сун1нос1 о
I
I
I
I
i
i
I
I
Содержи г один
или iiccko.ji.ko
I
I
I
I
i
i
I
I
Доменные т ипы
или типы.
определяемые ?-
пользователем f
Правила и
утверждения
ASSERTIONS
Определяют набор допустимых значений для
данного столбца
Представляют собой допо. щптсльиыи иранита. определяющие
допустимые значения для данного столбца. I йшример, ipni t ер
лредстивляет собой правило SQL
I
I
I
I
I
I
I
Puc. 1.1. Иерархия наборов данных SQL2003
значение ELMER. Значение ELMER представляет собой строку, а не дату, а в поле
ExpenseJDate могут содержаться только даты. Следовательно, данный столбец опреде-
ляется как столбец, содержащий тип данных DATE. Кроме этого, SQL2003 позволяет
осуществлять дополнительный контроль над значениями столбца при помощи ограниче-
ний (constraints) и утверждений (assertions). (Ограничения подробно обсуждаются позже
в главе 2.) С помощью ограничений SQL можно ограничить данные по столбцу
Expcnse_Date только теми расходами, которые были выполнены не более года назад.
Кроме этого, доступ к данным для всех пользователей и компьютерных процессов
контролируется на уровне схем по Авторизационному ID (AuthorizationlD) или по
пользователю (user). Каждому пользователю можно предоставлять или запрещать
доступ к конкретным наборам данных.
Реляционная модель и ANSI SQL | 19
Более того, в базах данных на основе SQL также применяются наборы символов
(character sets) и сопоставлений (collations). Наборы символов - это «символы» или
«алфавиты», используемые в «языке» данных. Например, американский английский
набор символов не содержит буквы п, характерной для испанского набора символов.
Сопоставления представляют собой множество правил сортировки, применяемых
к набору символов. Сопоставление определяет, как данная операция манипуляции
данными будет их сортировать. Например, американский английский набор символов
можно сортировать по алфавиту с учетом регистра и по алфавиту без учета регистра.
5* *
_____
В стандарте ANSI не говорится, как нужно проводить сортировку. Плат-
формы должны сами предоставлять общие методы сортировки для кон-
' кретного языка.
При написании кода SQL для конкретной платформы базы данных важно знать,
какое сопоставление вы используете, поскольку это напрямую влияет на выполнение
запросов, и в частности на предложения WHERE и ORDER BY инструкции SELECT.
Например, запрос, в котором данные сортируются с помощью двоичного сопоставле-
ния, возвратит данные в совершенно ином порядке, чем запрос, который сортирует
данные, например, с использованием сопоставления, определенного для американско-
го английского алфавита.
Пустые данные (правило 3)
Большинство баз данных позволяют хранить значения типа NULL для любых под-
держиваемых типов данных. Неопытные программисты и разработчики, работающие
на SQL, часто думают, что NULL - это ноль или пробел. На самом деле это ни то ни
другое. В SQL2003 значение NULL буквально означает, что значение неизвестно или
является неопределенным. (А нужно его считать неизвестным или неопределенным -
это предмет ученых дискуссий.) Такая дифференциация позволяет разработчику базы
данных различать те сущности, в которых сознательно введены нулевые значения (на-
пример), и те, в которых данные не записаны в систему или явно введены в форме
NULL. Чтобы показать это семантическое различие, рассмотрим систему, осуществ-
ляющую фиксирование платежей. Если для цены продукта указано значение NULL,
это не означает, что продукт бесплатный. NULL показывает, что величина стоимости
неизвестна или, возможно, еще не определена.
Платформы баз данных весьма различаются в том, как они обрабаты-
вают значения NULL. Это приводит к существенным проблемам при пере-
носе данных, включающих значения NULL, между платформами. Напри-
мер, пустая строка (т. е. строка, равная NULL) в базах Oracle вставляет-
ся как значение NULL. Все прочие базы данных, рассматриваемые в этой
книге, за исключением Sybase, вставляют пустую строку в столбцы значе-
ний VARCHAR или CHAR.
20 | Глава 1. История и реализации SQL
Одним из побочных эффектов неопределенного характера значений NULL являет-
ся то, что их нельзя использовать в вычислениях или сравнениях. Вот несколько крат-
ких, но очень важных правил стандарта ANSI о поведении значений NULL, которые
необходимо запомнить при использовании таких значений в инструкциях SQL.
• Значения типа NULL нельзя вставлять в столбцы, определенные как NOT NULL.
• Значения NULL не равны друг другу. Распространенная ошибка - сравнивать два
столбца, содержащие значения NULL, и ожидать, что они совпадут. (Правильный
метод идентификации значений NULL в предложениях WHERE или в булевых
выражениях - это использование таких выражений, как «value IS NULL» и «value
IS NOT NULL».)
• Столбец, содержащий значение NULL, игнорируется при вычислении агрегатных
значений, таких, как AVG, SUM или MAX. COUNT.
• Если столбцы, содержащие значения NULL, перечислены в предложении GROUP
BY запроса, выходные данные запроса будут содержать для значений NULL всего
одну строку. По сути стандарт ANSI рассматривает все найденные значения NULL
как одну группу.
• В предложениях DISTINCT или ORDER BY, как и в предложении GROUP BY,
значения NULL не отличаются друг от друга. Для предложения ORDER BY произ-
водитель платформы сам выбирает, нужно ли по умолчанию ставить значения
NULL в начало или в конец полученного набора данных.
Метаданные (правила 4 и 10)
Четвертое правило Кодда для реляционных баз данных гласит, что данные о базе
данных должны храниться, как и все прочие данные, в стандартных таблицах. Мета-
данные - это те данные, которые описывают саму базу. Например, каждый раз, когда
вы создаете в базе данных новую таблицу или представление, создается и сохраняется
запись, описывающая эту таблицу. Данный метод реализован в большинстве ком-
мерческих баз данных на основе SQL и баз с открытым исходным кодом. Например,
в SQL Server используются так называемые «системные таблицы», в которых отсле-
живается вся информация о базах данных, а также таблицах и объектах в любой базе.
В этой СУБД также есть «системные базы данных», в которых отслеживается информация
о сервере, на котором инсталлирована и сконфигурирована база.
Язык (правила 5 и 11)
Правила Кодда не требуют, чтобы в реляционной базе данных использовался язык
SQL. Правила, и в частности правила 5 и 11, только указывают, как должен работать
язык с реляционной базой данных. Когда-то SQL конкурировал с другими языками
(например, с RDO от Digital или Fox/PRO), которые могли соответствовать реляцион-
ным законам, однако SQL победил в силу трех причин. Во-первых, SQL относительно
прост, интуитивно понятен, похож на английский язык и реализует большинство ас-
пектов манипулирования данными. Во-вторых, SQL - достаточно высокоуровневый
язык. Программист или администратор базы данных не должен тратить время на про-
верку того, в каких регистрах памяти хранятся данные и кешируются ли они на диск.
Реляционная модель и ANSI SQL | 21
Система управления базой данных (СУБД) выполняет эти задачи автоматически.
И наконец, поскольку SQL не принадлежит ни одному производителю, его внедрили
на множестве платформ.
Представления(прввило 6)
Представление (view) - это виртуальная таблица, которая не существует как физиче-
ское хранилище данных, а создается «на ходу» из инструкции SELECT при выполне-
ния соответствующего запроса. Представления позволяют создать различные пред-
ставлении одних и тех же исходных данных для различных групп пользователей, не
изменяя самого способа хранения данных.
4* ч
-----
Некоторые производители применяют объекты баз данных, называемые
л материализованными представлениями. Материализованные представле-
' ния не подчиняются правилам ANSI, которым подчиняются стандартные
представления.
Операции с наборами данных (правила 7 и 12)
Другие языки манипулирования базами данных, например, такие, как древний Xbase,
выполняют операции с данными совершенно не так, как это делает SQL. Эти языки
требуют, чтобы вы указали программе, как конкретно нужно обрабатывать данные,
а именно последовательно, по одной записи. Поскольку такая программа перебирает
в цикле список записей, выполняя логические операции над всеми записями по очере-
ди, такой тип программирования часто называют обработкой строк или процедурным
программированием.
Программы SQL оперируют логическими наборами данных (sets). Теория наборов
данных (теория множеств) применяется в большинстве инструкций SQL, таких как
SELECT, INSERT, UPDATE или DELETE. В результате данные отбираются из набора
данных, называемого таблицей. В отличие от обработки строк программист, исполь-
зующий набор данных, просто указывает, что ему нужно, а не то, как нужно обраба-
тывать каждый фрагмент данных. Иногда обработка наборов данных называется дек-
ларативной обработкой, поскольку программист просто объявляет, какие данные ему
нужны, например: «Выдать сведения обо всех служащих в южном регионе, которые
получают более 70 000 $ в год». Ему не нужно составлять процедуру для извлечения
и обработки данных.
ч
--1
Теория множеств была детищем математика Георга Кантора, он создал
4ее в конце 19-го столетия. В то время теория множеств (а также его
теория бесконечного) была предметом споров. Сегодня теория множеств
является настолько обычной частью жизни, что ее изучают в общеобразо-
вательной школе.
Примеры использования теории множеств применительно к реляционным базам
данных подробно обсуждаются в следующем разделе.
22 | Глава 1. История и реализации SQL
Правила Кодда в действии: Простые примеры
с использованием инструкции SELECT
До этого момента в данной главе мы рассказывали об отдельных аспектах реляционных
баз данных, как они определяются Коддом и реализуются в ANSI SQL. В этом разделе
мы дадим высокоуровневое описание самой важной инструкции SQL - SELECT, а также
некоторых ее наиболее ярких моментов, а именно реляционных операций, называемых
проекциями (projections), выборками (selections) и соединениями (joins).
Проекция
Извлечение указанных столбцов данных.
выборка
Извлечение указанных строк данных.
Соединение
Извлечение столбцов и строк из двух и более таблиц в один набор данных.
Хотя на первый взгляд может показаться, что инструкция SELECT работает только
с реляционной операцией выборки, на самом деле SELECT реализует все эти опера-
ции. (См. раздел «Инструкция SELECT» главы 3.)
Следующая инструкция реализует операцию «проекция», отбирая имя и фамилию
автора, а также штат, в котором он проживает, из таблицы authors.
SEi.EC". au.tnaroe. au.lnaate. stare
FROM authors
Результатом любой такой инструкции SELECT будет являться другая таблица данных.
au_fname au_lname state
Johnson White CA
Marjorie Green CA
Cheryl Carlson CA
Michael O' Leary CA
Meander Smith KS
Morniogstai Greene TN
Heginalo Blotcher-Halls OR
Innec del Castillo MT
Получившиеся данные иногда называют результирующим набором (result set),
рабочей таблицей (work table) или производной таблицей (derived table), в отличие
от базовой таблицы (base table) базы данных, которая является целью инструкции
SELECT.
Нужно отметить, что реляционная операция «проекция» (а не «выборка») выпол-
нена с помощью предложения SELECT (т. е., ключевого слова SELECT, за которым
шел список извлекаемых значений) инструкции SELECT. Выборка, т. е. операция из-
влечения строк данных, определяется с помощью предложения WHERE инструкции
SELECT. Предложение WHERE отфильтровывает ненужные строки данных, возвращая
только запрошенные. Используя предыдущий пример, отберем только тех авторов,
которые живут не в Калифорнии (СА).
Реляционная модель и ANSI SQL | 23
SELECT au_fname, au_lname, stats
FROM authors
WHERE state <> ' CA'
В предыдущем запросе были выведены все авторы. Результатом данного запроса
будет гораздо меньший набор записей.
au_fname au_lname state
Meander Smith KS
Morningstar Greene TN
Reginald Blotchet-Halls OR
Innes del Castillo MI
Комбинируя возможности проекции и выборки в одном запросе, с помощью SQL вы
можете извлекать только те столбцы и строки, которые вам нужны в данный момент.
Соединения - это следующая и последняя реляционная операция, о которой мы
будем говорить в этом разделе. Соединение связывает одну таблицу с другой и получает
набор, состоящий из связанных друг с другом данных из обеих таблиц.
Разные производители позволяют соединять разное число таблиц в одной
операции. Например, Oracle не ограничивает количество соединяемых таб-
лиц, a Microsoft SQL Server позволяет соединять в одной операции не более
256 таблиц.
Стандартный метод ANSI для выполнения соединений - использование в инструк-
ции SELECT предложения JOIN. В более старом методе, называемом тета-соединением
(theta-join), анализ соединения производится в предложении WHERE. В приведенном
ниже примере показаны оба подхода. В каждой инструкции извлекается информация
о служащих из базовой таблицы employee, а также сведения о работах из базовой таб-
лицы jobs. В первой инструкции SELECT используется более новое предложение
JOIN стандарта ANSI, а во второй инструкции - тета-соединение.
--стиль ANSI
SELECT a.au_fname, a.au_lname, t.title_id
FROM authors AS a
JOIN titleauthor AS t ON a.au_id=t.au_id
WHERE a. stateO'CA’
--стиль тета
SELECT a.au_fname, a.au_lname, t.title_id
FROM authors AS a,
titleauthor AS t
WHERE a.au_id = t.au_id
AND a.state <> 'CA’
За дополнительной информацией о соединениях обращайтесь к разделу «Предло-
жение JOIN» главы 3.
24 | Глава 1. История и реализации SQL
История стандарта SQL
Поскольку диалекты SQL начали быстро размножаться, в 1986 году ANSI опублико-
вал первый стандарт SQL, чтобы обеспечить большую согласованность работ произ-
водителей, а в 1989 году - второй, широко распространившийся стандарт. Между-
народная организация по стандартизации (International Standards Organization, ISO)
также одобрила стандарт SQL. В 1992 году ANSI выпустил обновление стандарта, из-
вестное как SQL92, или SQL2, а в 1999 году - новое обновление, SQL99, или SQL3.
Сейчас стандарт усовершенствован, и мы обычно применяем промышленный стан-
дарт SQL2003. Каждый раз при пересмотре стандарта ANSI добавляет новые свойства
и включает в язык новые команды и возможности. Например, в стандарте SQL99 была
добавлена группа возможностей, связанная с расширениями, касающимися объектно-
ориентированных типов данных.
Что нового в SQL2003?
В SQL99 было две основные части: Foundation:99 и Вindings:99. В раздел Foundation
SQL2003 вошли все стандарты из частей Foundation (Основы) и Bindings (Связывания)
SQL99, а также появился новый раздел под названием Schemata (Схемы).
Базовые (Core) требования в SQL2003 по сравнению с SQL99 не изменились. Так
что платформы, соответствующие базовым требованиям SQL99, автоматически будут
соответствовать базовым требованиям SQL2003. Хотя в базовые требования в SQL2003
не вводилось никаких дополнений (за исключением нескольких новых зарезервирован-
ных ключевых слов), подверглись обновлению или изменению несколько отдельных
инструкций и то, как они работают. Поскольку эти обновления отражены в описаниях
синтаксиса инструкций в главе 3, мы не будем тратить на них время здесь.
Несколько элементов базовых требований SQL99 в SQL2003 были удалены,
включая:
• типы данных BIT и BIT VARYING’,
• предложение UNION JOIN ;
• инструкцию UPDATE...SETROW.
Кроме этого, были добавлены, удалены или переименованы несколько свойств,
большая часть которых довольно невразумительна. В настоящий момент многие из
этих новых свойств стандарта SQL2003 представляют чисто академический интерес,
поскольку ни одна из платформ еще не поддерживает эти возможности. 'Гем не менее
есть несколько новых свойств, имеющих нс только преходящий интерес.
Базовые функции OLAP
Добавлена поправка в Оперативную аналитическую обработку данных (Online
Analytical Processing, OLAP), включающая несколько оконных функций для под-
держки широко используемых вычислительных операций, таких, как скользящее
среднее и нарастающий итог. Оконные функции представляют собой агрегаты,
вычисляемые по определенному окну (фрагменту) данных: ROW NUMBER,
RANK, DENSE_RANK, PERCENT RANK и CUME D1ST. Функции OLAP полностью
История стандарта SQL | 25
описываются в разделе Т611 стандарта. Некоторые платформы уже начали поддержи-
вать функции OLAP. За подробностями обращайтесь к главе 4.
Отбор (Sampling)
К предложению FROM добавлено предложение TABLESAMPLE. Эта возможность
полезна для выполнения статистических запросов к большим базам данных,
таким, как хранилища. <
Улучшенные функции для числовых операций
Добавлено большое число функций для числовых операций. В данном случае
стандарт просто уловил тенденцию в индустрии, поскольку новые функции уже
поддерживаются одной или несколькими платформами. За деталями обращайтесь
к главе 4.
Еще одно важное изменение состоит в том, что SQL99 строится на основе уровней
соответствия SQL 92.
Уровни соответствия
Впервые уровни соответствия стандарту были предложены в SQL92. Были определены
три категории: Entry, Intermediate и Full (начальный, средний и полный). Чтобы произво-
дитель мог утверждать, что его продукт соответствует стандарту ANSI SQL, соответствие
должно быть не ниже уровня Entry. Национальный институт стандартов и технологий
США (NIST) позже предложил еще один уровень - Transitional (Промежуточный), распо-
ложенный между уровнями Entry и Intermediate. Так что уровни соответствия по NIST
были следующие: Entry, Transitional, Intermediate и Full, а по ANSI - только Entry, Interme-
diate и Full. Каждый более высокий уровень являлся расширением предыдущего уровня.
Это означает, что каждый более высокий уровень соответствия стандарту включал в себя
все свойства более низкого уровня.
Позже, в SQL99 основные уровни соответствия были изменены. Исчезли уровни
с названиями Entry, Intermediate и Full. Чтобы производитель мог заявлять и писать,
что его продукт соответствует стандарту SQL99, ему нужно было реализовать функ-
циональность самого нижнего уровня соответствия - Core SQL99. Уровень Core
SQL99 включил в себя функциональность уровня Entry старого стандарта SQL92,
некоторую функциональность из других уровней SQL92, а также некоторую совершенно
новую функциональность. Производитель может также реализовывать дополнительные
пакеты функциональности, описываемые в стандарте SQL991.
Пакеты дополнительной функциональности стандарта
SQLSOO3
Стандарт SQL2003 представляет собой идеал. Продукты очень немногих производи-
телей в настоящее время соответствуют требованиям Core SQL2003 или выходят за
эти пределы. Стандарт Core очень напоминает ограничение скорости на автомагистра-
1 Core SQL2003 включает в себя все свойства уровня Entry SQL92, многие свойства уровней
Transitional и Intermediate SQL92, отдельные свойства уровня Full SQL92 и SQL99, а также
новые свойства SQL2003. -Примеч. пер.
26 | Глава 1. История и реализации SQL
лях между штатами: одни водители едут быстрее, другие - медленнее, но очень
немногие едут точно с указанной скоростью. Точно так же могут сильно различаться
реализации разных производителей.
Девять пакетов дополнительной функциональности, представляющих собой
набор команд, не являются обязательными для реализации на платформе. Какая-то
функциональность может присутствовать в нескольких пакетах, а какая-то может
вообще отсутствовать. Эти пакеты и заключенная в них функциональность описы-
ваются в приводимом ниже перечне.
Эти определения были написаны членами двух комитетов - одного от ANSI,
а другого -- от ISO. Оба эти комитета были составлены из представителей практически
всех производителей реляционных СУБД. В таком сотрудничестве, иногда с учетом
определенных политических факторов, производители договорились о том, какая
часть предлагаемой функциональности будет включена в новый стандарт,
Во многих случаях новая функциональность включалась в стандарт ANSI из уже
существующих продуктов или из новых исследований и разработок научного сообщества.
Следовательно, внедрение стандартов ANSI разными производителями может подчас
быть весьма неоднородным. Относительно новым дополнением стандарта SQL2003
является SQL/XML. Другие части стандарта SQL2003 сохранились от SQL99, хотя их
названия могли измениться, а структура могла быть несколько перестроена.
Чисть / - SQUFramework
Включает общие определения и концепции, используемые в стандарте. Определяет
структуру стандарта и взаимоотношения его частей. Описывает требования по соот-
ветствию стандарту, составленные комитетом по стандартам.
Часть 2 - SQL/Foundation
Включает в себя основу - Core, являющуюся модификацией SQL99 Core. Эта
часть стандарта является самой большой и наиболее важной.
Часть 3 ~ SQL/CL1 (Call-Level Interface) (интерфейсуровня вызовов)
Определяет интерфейс уровня вызовов для динамически запускаемых инструкций
SQL из внешних прикладных программ. SQL/CL1 также включает более 60 специ-
фикаций подпрограмм для помощи в разработке по-настоящему переносимого,
коробочного программного обеспечения.
Часть 4 - SQL/PSM (Persistent Stored Modules) (постоянные хранимые модули)
Описывает стандарты конструкций процедурных языков, напоминающих те,
которые встречаются среди платформо-специфичных диалектов SQL типа PL/SQL
и Transact-SQL.
Часть 9 - SQL/MED (Management of External Data) (управление внешними данными)
Определяет управление данными, расположенными вне платформы базы данных,
с помощью каналов передачи данных (datalink) и оболочечного интерфейса.
Часть 10 - SQL/OBJ (Object Language Binding) (связывание с объектными языками)
Описывает, каким образом инструкции SQL встраиваются в программы на Java.
Эти возможности очень близки к JDBC, но имеют перед JDBC ряд преимуществ.
Они также весьма отличаются от традиционного связывания с базовым языком,
допустимого в ранних версиях стандарта.
История стандарта SQL | 27
Часть 11 SQL/Shemata
Определяется более 85 представлений (на три больше, чем в SQL99), которые
используются для описания метаданных каждой базы данных. Представления
хранятся в специальной схеме, называемой INFORMATIONSCHEMA. Проведено
обновление нескольких представлений из стандарта SQL99.
Часть 12 - SQL/JRT (Java Routines and Types) (прог/еОуры и типы Java)
Несколько процедур и типов SQL определяются с помощью языка программиро-
вания Java. Теперь поддерживаются такие конструкции Java, как статические
методы и классы Java.
Часть 14 - SQL/XML
Добавлен новый тип, называемый XML, четыре новые инструкции (XMLPARSE,
XMLSERIALIZE, XMLROOT и XMLCONCAT), несколько новых функций (описан-
ных в главе 4) и новый предикат IS DOCUMENT. Включены также правила ото-
бражения элементов SQL (таких, как идентификаторы, схемы и объекты) в соот-
ветствующие элементы XML.
Заметьте, что части 5, 6, 7 и 8 отсутствуют по плану.
Нужно знать, что платформа реляционной СУБД может быть заявлена как совмес-
тимая с SQL2003, если она будет удовлетворять стандартам Core SQL99. Чтобы уви-
деть полное описание свойств, соответствующих стандартам ANSI, обращайтесь
к соответствующей информации производителя. Зная, какие свойства входят в девять
пакетов свойств, вы получите правильное представление о возможностях конкретной
реляционной СУБД и о том, как перенос кода SQL на другие платформы отразится на
функциональности.
Стандарты ANSI, которые охватывают извлечение данных, манипулирование и управ-
ление данными с помощью таких команд, как SELECT, JOIN, ALTER TABLE и DROP,
формализуют то, как себя ведет язык SQL и его синтаксические конструкции на раз-
личных платформах. Эти стандарты становятся еще более важными по мере того, как
растет популярность платформ с открытым исходным кодом, таких, как MySQL и Postgre
SQL, создаваемых виртуальными командами, а не большими корпорациями.
В книге «SQL: справочник» объясняются реализации SQL в пяти популярных
СУРБД. Данные продукты не соответствуют всем стандартам SQL2003. Фактически
все производители платформ реляционных СУБД постоянно «играют в догонялки»
с организациями по стандартизации. Много раз, как только производители близко
подходили к стандартам, организации по стандартизации обновляли, уточняли или
еще каким-то образом изменяли эталоны. И наоборот, производители часто реализуют
новые свойства, которые еще не являются частью стандартов.
Классы инструкций SQLSOO3
При сравнении классов инструкций SQL2003 еще больше отдаляется от SQL92.
Однако вам все равно придется слышать упоминаемые ниже термины, так что нужно
их знать. В SQL92 инструкции SQL делятся на три большие категории.
28 | Глава 1. История и реализации SQL
Язык манипулирования данными (Data manipulation Language, DML)
Содержит специальные команды для манипулирования данными, например
SELECT, INSERT, UPDATE и DELETE.
Язык определения данных (Data Definition Language, DDL)
Содержит команды, которые обеспечивают доступ к объектам базы и манипу-
лирование ими. В частности, CREATE и DROP.
Язык управления данными (Data Control Language, DCL)
Содержит команды, связанные с разрешением/ограничением доступа к данным,
GRANT и REVOKE.
В SQL2003 существует семь основных категорий, которые теперь называются клас-
сами и которые образуют классификационную схему типов команд, имеющихся в SQL.
Эти «классы» инструкций несколько отличаются от категорий инструкций SQL92,
поскольку в них делается попытка более точно и логически обоснованно распределить
инструкции по классам. Более того, поскольку язык SQL непрерывно развивается, для
новых свойств и команд, фиксируемых в стандарте, могут потребоваться новые классы
инструкций. Поэтому в SQL2OO3 появились новые наборы классов инструкций, которые
исходно были добавлены к стандарту SQL99 и сделали его более понятным и логичным.
Кроме того, новые классы инструкций позволили правильно классифицировать неко-
торые не попадающие ни в одну из старых категорий инструкции.
В табл. 1.1 приведены классы инструкций SQL2003 и перечислены некоторые
команды, относящиеся к этим классам. Каждая из этих команд будет подробно рас-
смотрена позже. Сейчас же главное - это запомнить названия классов инструкций.
Таблица 1.1. Классы инструкций SQL
Класс Описание Примеры команд
SQL-инструкции для установ- ления связи Устанавливают и разрывают кли- ентское соединение CONNECT. DISCONNECT
SQL-инструкции для управле- ния Управляют выполнением набора команд SQL CALL. RETURN
SQL-инструкции для работы с данными Могут оказывать на данные устойчивое и длительное влияние SELECT. INSERT, UPDATE, DELETE
SQL-инструкпии для диагно- стики Выдают диагностическую информацию, выдают исключения и ошибки GET DIAGNOSTICS
SQL-инструкции для работы со схемами Мо1ут оказывать устойчивое и дли- тельное влияние на схему базы дан- ных и на объекты в ней ALTER, CREATE. DROP
SQL-инструкции для работы с сеансами Контролируют выполняемые по умолчанию действия и другие параметры сеанса Инструкции 1ина SET, например SET CONSTRAINT
SQL-инструкции для работы е транзакциями Определяют начало и конец транзакции COMMIT ROLLRACK
История стандарта SQL | 29
Тем, кто регулярно работает с SQL, должны быть знакомы и старые (SQL92)
и новые (SQL2003) классы инструкций, поскольку для обозначения того, что относится
к SQL, применяются обе терминологии.
Диалекты SQL
Постоянное развитие стандарта SQL способствовало появлению среди разных произ-
водителей и платформ многочисленных диалектов SQL. Эти диалекты развивались
главным образом потому, что сообществу пользователей конкретной базы данных тре-
бовались какие-то возможности, до того как комитет ANSI разрабатывал стандарт.
Однако иногда новую функциональность вводит научно-исследовательское сообщест-
во по причине давления со стороны конкурирующих технологий. Например, многие
производители баз данных к существующим возможностям программирования своих
продуктов добавляют Java (как это делается в DB2, Oracle и Sybase) или VBScript
(как это делает Microsoft). В будущем программисты и разработчики будут использо-
вать эти языки программирования в SQL-программах наряду с самим SQL.
Многие из этих диалектов включают средства условной обработки (например, под
контролем оператора IF... THEN), управляющие операторы (например, циклы WHILE),
переменные и обработку ошибок. Поскольку ANSI пока не разработал стандарты для
такой важной функциональности, а пользователи уже требуют ее, разработчики реля-
ционных СУБД были вправе создавать свои собственные команды и синтаксис. Фак-
тически многие из наиболее старых разработчиков сохранили с 80-х годов свои вари-
анты самых элементарных команд (например, SELECT) поскольку их реализация
предшествовала появлению стандарта. Сейчас ANSI производит уточнение стан-
дартов, чтобы сгладить эти несоответствия.
В некоторых диалектах для обеспечения более полной функциональности языка
программирования введены процедурные команды. Например, процедурные реализа-
ции содержат команды для обработки ошибок, операторы, контролирующие направ-
ление выполнения программы, условные команды, средства работы с переменными
и массивами, а также многие другие дополнения. Хотя все эти процедурные реализа-
ции являются технической дивергенцией языка, здесь они называются диалектами.
Пакет SQL/PSM (Persistent Stored Module) предлагает широкий спектр функциональ-
ности, связанной с хранимыми программными процедурами, и включает в себя
многие расширения, содержащиеся в таких диалектах.
Вот некоторые популярные диалекты SQL.
PL/SQL
Используется в Oracle. PL/SQL - это сокращение от Procedural Language/SQL.
Он во многом похож на язык Ada.
Transact-SQL
Используется в Microsoft SQL Server и Sybase Adaptive Server. По мере того как
Microsoft и Sybase все больше отходят от общей платформы, которую они исполь-
зовали в начале 90-х годов, их реализации Transact-SQL также подвергаются
дивергенции.
30 | Глава 1. История и реализации SQL
JpgSQL
Название диалекта и расширений SQL, реализованных в PostgreSQL. Является сокра-
щением от Procedural Language/postgreSQL.
)LPL
Самый новый диалект от DB2 (SQLProcedural Language). Основан на стандартных
операторах управления SQL. Большинство других диалектов предшествовало
стандарту, и это означает, что вы найдете в них массу отличий от стандарта SQL.
Однако SQLPL появился после стандарта, и он гораздо более совместим с ним.
Если вы планируете серьезно работать с одной системой, вам следует изучить все
1трости выбранной платформы и диалекта SQL.
Диалекты SQL | 31
2
Основные понятия
SQL предлагает простой, интуитивно понятный способ взаимодействия с базой дан-
ных. Хотя в стандарте SQL2003 определение понятия «база данных» не дается, в нем
определяются все функции и понятия, которые необходимы пользователю для того,
чтобы создавать базы данных, извлекать из них информацию, производить обновле-
ние и удаление данных. Важно понимать типы синтаксических конструкций, опреде-
ляемых стандартом SQL2003, а также синтаксис, специфичный для разных платформ.
Платформы баз данных, описываемые
в этой книге
В книге «SQL: справочник» описывается стандарт SQL2003 и реализации языка для
пяти ведущих систем управления реляционными базами данных (СУРБД).
DB2
Популярная СУРБД от IBM, работающая на различных аппаратных платформах,
от персональных компьютеров до больших мейнфреймов. Эта система работает
под управлением многих операционных систем, в том числе под все более распро-
страняющейся системой Linux. Система DB2 очень популярна в корпоративной
среде, особенно там, где осуществляются значительные вложения в программное
обеспечение, оборудование или услуги от компании IBM. В этой книге описыва-
ется версия 8.1 DB2 Universal Database для Linux, Unix и Windows.
MySQL
MySQL - это популярная СУРБД с открытым исходным кодом, известная своей
высокой производительностью. Она работает под многими операционными систе-
мами, в том числе под многими вариантами Linux. Для достижения большей про-
изводительности в этой системе реализован меньший набор функций, чем в других
СУРБД. В данной книге рассматривается версия MySQL 4.0.
Oracle
Система Oracle является ведущей СУРБД в коммерческом секторе. Она работает
во многих операционных системах и аппаратных платформах. Масштабируемость
и надежность архитектуры этой системы способствовали тому, что ее выбирают
для работы многие пользователи. В книге «SQL: справочник» рассматривается
версия Oracle Database 10g.
PostgreSQL
Среди баз данных с открытым исходным кодом PostgreSQL имеет наиболее бога-
тый набор функций. Если система MySQL известна своей высокой производи-
тельностью, PostgreSQL наиболее известна отличной поддержкой стандарта ANSI
и хорошими средствами для обработки транзакций, а также поддержкой множест-
ва типов данных и объектов базы данных. Помимо широкого набора функций
PostgreSQL работает со многими операционными системами и аппаратными плат-
формами. В этой книге рассматривается версия PostgreSQL 7.2.
SQL Server
Microsoft SQL Server - популярная СУРБД, которая работает только на Windows-
платформе. Характерными особенностями являются простота использования,
огромный набор функций, низкая цена и высокая производительность. В этой
книге рассматривается Microsoft SQL Server 2000.
Помимо упомянутых пяти баз данных в приложении А отдельно рассматривается
система Sybase Adaptive Server Enterprise (ASE), версия 12.5. Поскольку Sybase и SQL
Server имеют общее происхождение, в приложении рассказывается о различиях
между широко распространенным синтаксисом SQL Server и специфическими осо-
бенностями и расширениями, присутствующими в Sybase ASE.
Категории синтаксических конструкций
Чтобы начать использовать SQL, вы должны понять, как пишутся инструкции. Син-
таксические конструкции SQL делятся на четыре основные категории. В приведенном
ниже перечне мы коротко познакомим вас со всеми категориями, а более подробные
объяснения будут даны в последующих разделах.
Идентификаторы
Представляют собой пользовательские или системные имена объектов баз дан-
ных, таких, как база данных, таблица, ограничение в таблице, столбцы таблицы,
представления и т. п.
Константы
Представляют собой созданные пользователем или системой строки или значе-
ния, не являющиеся идентификаторами или ключевыми словами. Константы
могут представлять собой строки, например «hello», числа, например «1234»,
даты, например «1 января 2002», или булевы значения, например TRUE.
Операторы
Символы, показывающие, какое действие выполняется над одним или несколькими
выражениями, чаще всего в инструкциях DELETE, INSERT, SELECT или UPDATE.
Операторы также часто применяются для создания объектов базы данных.
Зарезервированные и ключевые слова
Имеют специальный смысл для обработчика кода SQL. Например, SELECT GRANT,
DELETE или CREATE. Зарезервированные слова (Reserved words), обычно команды
3 - 2447
Категории синтаксических конструкций | 33
и инструкции SQL, нельзя использовать в качестве идентификаторов на данной
платформе. Ключевые слова (keywords) - это слова, которые могут стать заре-
зервированными в будущем. Вы можете обойти ограничение на использование заре-
зервированных слов и ключевых слов в качестве идентификаторов, используя иден-
тификаторы, ограниченные кавычками (которые будут описаны чуть ниже). Так по-
ступать не рекомендуется! Везде в книге (за исключением этого абзаца) мы будем
обозначать термином «ключевые слова» оба данных понятия.
Идентификаторы
Помните, что СУРБД созданы на основе теории множеств. В терминологии ANSI
кластеры содержат множество каталогов, каталоги содержат множество схем, схемы
содержат множество объектов и т. д. В большинстве платформ применяются дополни-
тельные термины: экземпляры (instances) содержат одну или несколько баз данных, базы
данных содержат одну или несколько схем, схемы содержат одну или несколько таблиц,
представлений, хранимых процедур и привилегий, связанных с каждым объектом.
На каждом уровне структуры элементам необходимы уникальные имена (т. е., иденти-
фикаторы), чтобы к ним могли обращаться программы и системные процессы. Это
означает, что каждый объект (будь то база данных, таблица, представление, столбец,
индекс, ключ, триггер, хранимая процедура или ограничение) в СУРБД должен
получить свой идентификатор. Если вы запускаете команду, которая создает объект базы
данных, вы должны указать идентификатор (т. е. имя) этого нового объекта.
Есть два важных набора правил, которые опытный программист держит в уме при
выборе имени объекта.
Соглашения об именах
Сюда входят практические руководства или соглашения об именах, применение
которых в конечном счете улучшает структуру базы и отслеживание данных. Они
являются не столько требованиями SQL, сколько накопленным опытом практи-
кующих программистов.
Правила создания идентификаторов
Они определены в стандарте SQL и реализованы в платформах. Эти правила
включают, например, такие параметры, как максимальная длина имени. Эти согла-
шения описываются ниже в этой главе применительно к каждому производителю.
Соглашения об именах
Соглашения об именах определяют стандартную основу для выбора идентификатора
объекта. В этом разделе мы приводим список соглашений (правил выбора идентифи-
катора), которые основываются на многолетнем опыте. В стандарте SQL ничего не го-
ворится об этих соглашениях, за исключением того, что идентификатор должен быть
уникальным, что его длина не должна превышать определенных значений и что все
символы в идентификаторе должны быть допустимыми.
Выбирайте имя так, чтобы оно было осмысленным, наглядным и соответствовало
назначению объекта
Не называйте таблицу ХРОЗ, назовите лучше Expenses_2005, чтобы было ясно,
что в ней содержатся расходы за 2005 год. Помните, что и другим людям скорее
34 | Глава 2. Основные понятия
всего придется использовать таблицу и базу данных, и возможно, еще в течение
долгого времени после того, как вы уйдете. Имена должны быть понятны с перво-
го взгляда. У каждого производителя есть свои ограничения на длину имени объ-
ектов, но, как правило, имена могут быть достаточно длинными, чтобы любой мог
понять их смысл.
Используйте в именах один и тот же регистр по всей базе
Используйте для всех имен объектов базы либо верхний, либо нижний регистр.
Некоторые серверы баз учитывают регистр, и использование смешения регистров
может позже вызвать проблемы.
Будьте последовательны в использовании сокращений
Как только сокращение выбрано, его нужно последовательно использовать
по всей базе данных. Например, если вы используете ЕМР как сокращение слова
EMPLOYEE, то используйте ЕМР по всей базе данных. Не используйте в одних
местах ЕМР, а в других - EMPLOYEE.
Для удобства восприятия используйте полные, наглядные и осмысленные имена с симво-
лами подчеркивания
Имя столбца VPPERCASEWITHLNDERSCORES не такое понятное, как
UPPERCASEW1THUNDERSCORES.
Не помещайте название компании и продуктов в имена объектов баз данных
Компании приобретают друг друга, и продукты меняют названия. Такие элементы
преходящи, и их не нужно включать в имена объектов базы.
lie используйте слишком очевидные префиксы и суффиксы
Например, не используйте в качестве префикса имени базы данных сочетание
«ЭВ», а в качестве префикса всех представлений - «V_». Простые запросы к сис-
темным таблицам базы могут дать администратору или программисту базы сведе-
ния о том, к какому типу относится объект, который представляет идентификатор.
Не заполняйте все пространство, отведенное для имени объекта
Если платформа позволяет использовать имя таблицы из 32 символов, попробуйте
оставить хотя бы несколько пустых мест в конце. Некоторые платформы при ма-
нипуляции временными копиями таблиц иногда добавляют к именам таблиц пре-
фиксы и суффиксы.
Не используйте идентификаторы с разделителями
Иногда имена объектов заключают в двойные кавычки. (Стандарт ANSI называет
такие имена идентификаторами с разделителями (delimited identifiers). Такое за-
ключение идентификатора в кавычки позволяет создавать имена, которые могут
оказаться сложными в использовании и которые впоследствии могут вызывать
проблемы. Такие идентификаторы чувствительны к регистру. Например, вы
можете включать в них пробелы, специальные символы, символы в разных реги-
страх и даже управляющие символы. Однако, поскольку некоторые инструмен ты,
выпускаемые сторонними производителями (и даже производителем самой базы),
могут не обрабатывать специальные символы в именах, широко использовать по-
добные идентификаторы не следует. Некоторые платформы разрешают использо-
вать другие символы-ограничители, помимо двойных кавычек. Например, в SQL
Категории синтаксических конструкций | 35
Server для обозначения идентификаторов с ограничителями применяются
квадратные скобки [].
Если вы будете следовать соглашениям об именах, вы получите несколько пре-
имуществ. Во-первых, ваш код SQL и объекты базы данных станут по сути самодоку-
ментированными, поскольку выбранные имена будут осмысленны и понятны другим
пользователям. Во-вторых, ваш код SQL и объекты базы данных станет проще обслу-
живать, особенно для тех, кто придет после вас, ведь имена ваших объектов будут по-
следовательны. И наконец, правильный выбор имен улучшает функциональность
базы данных. Если базу данных когда-либо придется преобразовывать или переносить
в другую СУРБД, последовательность и понятность имен сэкономит и время и силы.
Потратьте с самого начала несколько минут на продумывание имен объектов SQL,
и вы избавитесь от многих проблем.
Правила создания идентификаторов
Правила создания идентификаторов - это правила идентификации объектов в базе
данных, реализуемые платформой. Эти правила применимы к обычным идентифика-
торам и не применяются к идентификаторам с ограничителями. Правила, определяе-
мые стандартом SQL2003, как правило, несколько отличаются от правил, реализуемых
производителями конкретных баз данных. В табл. 2.1 приведены правила SQL2003
и правила пяти рассмотренных в этой книге СУРБД.
Таблица 2.1. Платформо-специфические правила для обычных идентификаторов
объектов (кроме идентификаторов с ограничителями)
Характеристика Платформа Спецификация
Размер SQL2003 128 символов
идентификатора DB2 128 символов, зависит от объекта
MySQL 64 символа
Oracle 30 байт (число символов зависит от набора символов). Имена баз данных не более 8 байт
PostgreSQL 31 символ (значение свойства NAMEDATALEN минус единица)
SQL Server 128 символов (имена временных таблиц - нс более 116 символов)
Идентификатор SQL2003 любые цифры, буквы и знак подчеркивания
может содержать DB2 любые цифры, буквы в верхнем регистре, цифры и знак подчеркивания
MySQL любые цифры, буквы и символы
Oracle любые цифры, буквы, знак подчеркивания (_), знак диеза (#) и доллара($)
PostgreSQL любые цифры, буквы и знак подчеркивания (_)
SQL Server любые цифры, буквы, знак @, знак подчеркивания (_), знак диеза (#) и доллара ($)
36 | Глава 2. Основные понятия
Таблица 2.1. Платформо-специфические правила для обычных идентификаторов
объектов (кроме идентификаторов с ограничителями) (Продолжение)
Характеристика Платформа Спецификация
Идентификатор SQL2003 буквы
должен DB2 буквы
начинаться с MySQL буквы или цифры (но не может состоять только из цифр)
Oracle буквы
PostgreSQL буквы или знака подчеркивания (_)
SQL Server буквы, знака подчеркивания (_), знака фц или диеза (#)
Идентификатор SQL2003 пробелов и специальных символов
нс может DB2 пробелов и специальных символов
содержать MySQL точки (.), наклонной черты (/), символов ASCI 1(0) и ASCI 1(255). Кавычки (') и двойные кавычки (“) допустимы только в иденти- фикаторах с разделителями
Oracle пробелов, двойных кавычек (“) или специальных символов
PostgreSQL двойных кавычек (“)
SQL Server пробелов и специальных символов
Идеи гиф и- SQL2003 Да
каюры с разде- DB2 Да
лителями допускаются MySQL Да
Oracle Да
PostgreSQL Да
SQL Server Да
Символ, иепо.чь- SQL2003 Двойные кавычки (“)
зуемый для обо- DB2 Двойные кавычки (“)
значения идентификатора с разделителями MySQL Кавычки (‘) или двойные кавычки (“) в режиме совместимости с ANSI
Oracle Двойные кавычки (“)
PostgreSQL Двойные кавычки (“)
SQL Server Двойные кавычки (“) или квадратные скобки ([]). Квадратные скобки являются предпочтительными
Идентификатор SQL2003 Нет, за исключением идентификатора с разделителями
может бы ть DB2 Да
резервирован- ным MySQL Нет, за исключением идентификатора с разделителями
Oracle Нет, за исключением идентификатора с разделителями
PostgreSQL Нет, за исключением идентификатора е разделителями
SQL Server Нет, за исключением идентификатора с разделителями
Категории синтаксических конструкций | 37
Таблица 2.1. Платформо-специфические правила для обычных идентификаторов
объектов (кроме идентификаторов с ограничителями) (Продолжение)
Характеристика Платформа Спецификация
Адресация SQL2003 Катал ог. схема, объект
в схемах DB2 Схема.объект
MySQL База_данных. объект
Oracle Схема.объект
PostgreSQL База_данных.схема. объект
SQL Server Сервер. база_данных. схема, объект
Идентификатор SQL2003 Да
должен быть DB2 Да
уникальным MySQL Да
Oracle Да
PostgreSQL Да
SQL Server Да
Другие правила SQL2003 Нет
DB2 Нет
MySQL Не должны содержаться только цифры
Oracle Ссылки на базы данных не должны быть больше 128 байт и не должны являться идентификаторами с разделителями
PostgreSQL Нет
SQL Server Нет
Идентификаторы должны быть уникальны в пределах своей области действия.
Таким образом, в иерархии объектов имена баз данных не должны повторяться в преде-
лах данного экземпляра сервера базы, а имена таблиц, представлений, функций, триг-
геров и хранимых процедур - уникальны в пределах данной схемы. С другой стороны,
таблица и хранимая процедура могут иметь одно имя, поскольку они являются объекта-
ми разных типов. Имена столбцов, ключей и индексов должны быть уникальны в преде-
лах одной таблицы или представления и т. д. За более подробной информацией обра-
щайтесь к документации платформы. В некоторых платформах уникальность идентифи-
каторов является обязательным условием, а в других - нет. Например, платформа DB2
требует, чтобы все идентификаторы индексов были уникальны по всей базе данных,
a SQL Server требует, чтобы идентификаторы индексов были уникальными только в пре-
делах таблицы, к которой они относятся.
Помните, что для обхода некоторых этих правил можно использовать идентифика-
торы с ограничителями (т. е. имена объектов, заключенные в специальные символы-огра-
ничители, обычно в двойные кавычки). В частности, идентификаторы с разделителями
можно применять для того, чтобы давать имена с зарезервированными словами, или для
того, чтобы использовать в имени обычно не употребляемые там символы. Например,
38 | Глава 2. Основные понятия
чаше всего вы не можете использовать в имени таблицы знак процента (%). Однако, если
это необходимо, вы можете его использовать, если будете всегда заключать это имя табли-
цы в двойные кавычки. Чтобы назвать таблицу expense%%ratios, нужно заключить это
имя в кавычки - “expense%%ratios”. Также помните, что в SQL2OO3 такие имена иногда
называются идентификаторами с разделителями (deli-mited identifiers).
Если вы используете в качестве имени объекта идентификатор с разделитечя-
ми, мы рекомендуем всегда ссылаться на него, применяя эти ограничители.
Константы
В SQL константами считаются любые числовые значения, строки символов, значения,
связанные с представлением времени (дата и время), и булевы значения, которые нс
являются идентификаторами или ключевыми словами. Базы данных на основе SQL
разрешают использовать в коде SQL различные константы. Допустимы большинство
числовых, символьных и булевых типов данных, а также даты. Например, к числовым
типам данных SQL Server можно (среди прочих) отнести типы INTEGER, REAL
и MONEY. Таким образом, числовые константы могут выглядеть так.
30
-1'7
-883 3888
-6. 66
$70000
2Е5
7Е-3
Как показывает приведенный пример, в SQL Server допустимы числа со знаком
и без знака, в обычной и экспоненциальной записи. А поскольку в SQL Server есть
денежный тип данных, в константы можно включать даже знак доллара. В численных
констан тах SQL Server не разрешается использовать другие символы (за исключением
01 23456789 + -S.Ее), поэтому не включайте в них запятые (или точки, приме-
няемые в Европе)1. Большинство баз данных интерпретируют запятую в числовой
константе как ограничитель элементов. Так, константа 3,000 будет интерпретировать-
ся как 3 и отдельно 000.
Булевы значения, строковые константы и даты выглядят примерно так.:
TRUE
'Hello world!'
'0С~-28-1966 22:14:30:00'
Строковые константы должны всегда заключаться в одинарные кавычки (*’),
которые являются стандартным ограничителем всех строковых констант. Символы
в строковых константах не ограничиваются алфавитными символами. По сути, любой
Имеются в виду знаки, которые в американской и европейской нотации отделяют друг от
друга разряды числа. - Примеч. пер.
Категории синтаксических конструкций | 39
символ из набора символов можно представить в виде строковой константы. Все при-
веденные ниже выражения являются строковыми константами.
'1998'
'70,000 + 14000’
'Жил-был один человек из Нантакета’
'Oct 28, 1966'
Все приведенные примеры фактически являются совместимыми с типом данных
CHARACTER. Не путайте строковую константу ‘1998’ с числовой константой 1998.
Когда только строковые константы связаны с типом данных CHARACTER, не стоит
использовать их в арифметических вычислениях, не преобразовав их явным образом
в числовой тип. Некоторые базы данных выполняют автоматическое преобразование
строковых констант, содержащих числа, при выполнении сравнения их с любыми
значениями, относящимися к типам DATE или NUMBER.
При необходимости вы можете отобразить в строковой константе символ оди-
нарной кавычки. Для этого его необходимо написать два раза; т. е., каждый раз, когда
вам нужно написать внутри строки одинарную кавычку, вы должны написать две.
Проиллюстрируем эту идею примером из SQL Server.
SELECT 'So he said ''who’’s Le Petomaine?'1'
Получится следующий результат.
So he said 'Who’s Le Petomaine?'
Операторы
Оператор - это символ, обозначающий действие, выполняемое над одним или
несколькими выражениями. Операторы наиболее часто используются в инструкциях
DELETE, INSERT, SELECT или UPDATE, а также часто применяются при создании
объектов базы данных, таких, как хранимые процедуры, функции, триггеры и пред-
ставления.
Операторы, как правило, делятся на следующие категории.
Арифметические операторы
Поддерживаются всеми базами данных.
Операторы присваивания
Поддерживаются всеми базами данных.
Побитовые операторы
Поддерживаются Microsoft SQL Server.
Операторы сравнения
Поддерживаются всеми базами данных.
Логические операторы
Поддерживаются в DB2, Oracle, SQL Server и PostgreSQL.
Унарные операторы
Поддерживаются в DB2, Oracle и SQL Server.
40 | Глава 2. Основные понятия
Арифметические операторы
Арифметические операторы выполняют математические действия над двумя значе-
ниями любого типа, относящегося к числовой категории. Перечень арифметических
операторов приведен в табл. 2.2.
Таблица 2.2. Арифметические операторы
Арифметический оператор Действие
+ Сложение
Вычитание
* Умножение
/ Деление
% Остаток отделения (только SQL Server). Возвращает оста-
ток от операции деления в виде целого числа (integer)
л 1
I '' I В DB2, Oracle и SQL Server операторы + и-могут применяться для выпол-
। 'л?1' пения арифметических операций над датами.
Операторы присваивания
За исключением Oracle, где для этой цели применяется оператор оператор присваи-
вания (-) присваивает' значение переменной или псевдониму (alias) заголовка столбца.
В SQL Server в качестве оператора для присваивания псевдонимов таблицам или заго-
ловкам столбцов может служить ключевое слово AS.
Побитовые операторы
В Microsoft SQL Server существуют побитовые операторы, являющиеся удобным
средством манипулирования битами в двух выражениях целого типа (см. табл. 2.3).
Для побитовых операторов доступны следующие типы данных: binary, bit, int, smalliiii,
tinyint и varbinary.
Таблица 2.3. Побитовые операторы
Побитовый оператор Действие
& Поразрядное И (два операнда)
I Поразрядное ИЛИ (два операнда)
Л Поразрядное исключающее ИЛИ (дна операнда)
Категории синтаксических конструкций | 41
Операторы сравнения
Операторы сравнения проверяют равенство или неравенство двух выражений. Резуль-
татом операции сравнения является булево значение: TRUE, FALSE или UNKNOWN.
Также заметьте, что по стандарту ANSI сравнение выражений, когда одно или оба
значения равны NULL, дает результат NULL. Например, выражение 23 + NULL дает
NULL, как и выражение Feb 23, 2003 + NULL. В табл. 2.4 приведены операторы срав-
нения.
Таблица 2.4. Операторы сравнения
Оператор сравнения Действие
= Равно
> Больше
< Меньше
>= Больше или равно
<= Меньше или равно
о Не равно
Не равно (не соответствует стандарту ANSI)
!< Не меньше (не соответствует стандарту ANSI)
!> Не больше (не соответствует стандарту ANSI)
Булевы операторы сравнения наиболее часто используются в предложениях
WHERE для отбора строк, соответствующих условиям поиска. В следующем примере
из SQL Server используются операторы сравнения «больше или равно».
SELECT *
FROM Products
WHERE Product ID >= ©MyProduct
Логические операторы
Логические операторы обычно применяются в предложении WHERE для проверки
истинности какого-либо условия. Логические операторы возвращают булево значение
TRUE или FALSE. Логические операторы также обсуждаются в разделе «Инструкция
SELECT» главы 3. Не все базы данных поддерживают все операторы. Список логических
операторов приведен в табл. 2.5.
42 | Глава 2. Основные понятия
Таблица 2.5. Логические операторы
Логический оператор Действие
ALL THUE, если весь набор сравнений дает результат TRUE
AND TRUE, если оба булевых выражения дают результат TRUE
ANY TRUE, если хотя бы одно сравнение из набора дает результат TRUE
BETWEEN TRUE, если операнд находится внутри диапазона
EXISTS TRUE, если подзапрос возвращает хотя бы одну строку
IN TRUE, если операнд равен одному выражению из списка или одной или нескольким строкам, возвращаемым подзапросом
LIKE TRUE, если операнд совпадает с шаблоном
NOT Обращает значение любого другого булевого оператора
OR TRUE, если любое булево выражение равно TRUE
SOME TRUE, если несколько сравнений из набора дают результат TRUE
Унарные операторы
Унарные операторы выполняют операцию над одним выражением любого тина, отно-
сящимся к числовой категории. Унарные операторы можно применять к целым типам,
хотя операторы положительности и отрицательности можно применять к любому число-
вому типу данных (см. табл. 2.6).
Таблица 2.6. Унарные операторы
Унарный оператор Действие
+ Числовое значение становится положительным
Числовое значение становится отрицательным
Поразрядное НЕ, возвращает двоичное дополнение числа (нет в Oracle и DB2)
Приоритет операторов
Иногда выражения, включающие операторы, могут быть довольно сложными. Когда
в выражении присутствуют несколько операторов, последовательность их выполне-
ния определяет приоритет операторов. Порядок выполнения может существенно по-
влиять на результат вычисления.
Ниже перечислены уровни приоритета операторов. Оператор с более высоким
приоритетом выполняется до оператора с более низким приоритетом. В списке опера-
торы перечислены в порядке от самого высокого к самому низкому приоритету.
Категории синтаксических конструкций | 43
’ () (выражения, стоящие в скобках)
• +, -, ~ (унарные операторы)
• *, /, % (математические операторы)
• +, - (арифметические операторы)
• =, >, <, >=, <=, <>, !=, !>, !< (операторы сравнения)
• л (побитовое исключающее ИЛИ), & (побитовое И), | (побитовое ИЛИ)
• NOT
• AND
• ALL, ANY, BETWEEN, IN, LIKE, OR, SOME
• = (присваивание значение переменной)
Если операторы имеют одинаковый приоритет, вычисления производятся слева
направо. Для того чтобы изменить применяемый по умолчанию порядок выполнения
операторов, в выражении используются скобки. Выражения, заключенные в скобки,
вычисляются первыми, а уже после них - все, что находится за скобками.
Например, следующие выражения в запросе Oracle возвращают очень разные
результаты.
SELECT 2*4+5 FROM dual
- - Вычисляется сумма 8 + 5 с результатом 13.
SELECT 2*(4+5) FROM dual
- - Вычисляется произведение 2*9 с результатом 18
Если применяются вложенные скобки, то первыми выполняются выражения
в наиболее глубоко вложенных скобках.
В следующем примере используются вложенные скобки, где на самом глубоком
уровне находится выражение 5 - 3. Результатом этого выражения будет число 2. Затем
в операторе сложения к этому результату прибавляется число 4, что дает в итоге значение 6.
И наконец, данный результат умножается на 2, что дает окончательный результат 12.
SELECT 2 * (4 + (5 - 3)) FROM dual
- - Вычисляется 2 * (4 + 2), т.е. 2*6,
- - итоговым результатом будет 12
RETURN
Системные ограничители и операторы
Строковые ограничители обозначают границы строки, состоящей из буквенно-цифро-
вых символов. Системные ограничители - это такие символы из набора символов,
которые имеют для сервера базы данных особое значение. Ограничители - это символы,
которые применяются для определения иерархического порядка процессов и элемен-
тов списка. Операторы - это ограничители, используемые для определения значений
при операциях сравнения, в том числе символы, обычно используемые для арифме-
тических и математических операций. В табл. 2.7 перечислены системные ограничи-
тели и операторы, допустимые в SQL.
44 | Глава 2. Основные понятия
Таблица 2.7. Ограничители и операторы SQL
Символ Область применения Пример
4- Оператор сложения. В SQL Server также используе тся н качестве оператора конка- тенации На всех платформах: SELECT MAX(emp_id) + 1 FROM employes
Оператор вычитания. Также индикатор диапазона в ограничениях CHECK Как оператор вычитания: SELECT MAX(emp_id) ~ 1 FROM employee Как оператор диапазона в ограничениях CHECK: АО ER TABlE autnors ADD CONSTRAINT authors_z.i o_num CHECK (zip LIKE '%[0-9T%')
$ Оператор умножения SELECT salary « 0.05 AS 'bonus' FROM employee;
/ Оператор деления SELECT salary / 12 AS 'monthly FROM employee:
Оператор равенства SELECT - FROM employee WHERE iname = ‘cudd'
Оператор неравенства (Нестандартным эквивален- том, используемым на некоторых платформах, является !=) На всех платформах: SELECT * FROM employee WHERE Iname <> ‘ Fudd’
Меньше Меньше или равно SELECT Iname, eirp_ia, (salary < 0.05) AS bonMs FROM employee WHERE (salary « 0.05) <= 10000 AND exempt .status < 3
Больше Больше или равно SELECT Iname, emp_td. (salary * 0.025) AS bonus FROM employee WHERE (salary « 0.025) > 10000 AND exempt_status >= A
% Индикатор группы симво- лов (см. раздел «Оператор LIKE» в главе 3) SELECT FROM employee WHERE Ira.me LIKE 1 Fud%'
Категории синтаксических конструкций | 4:
Таблица 2.7. Ограничители и операторы SQL (Продолжение)
Символ Область применения Пример
( ) Выражения, вызовы функ- ций, порядок операций и ограничитель подзапроса Выражение: SELECT (salary/12) AS monthly FROM employee WHERE exempt_status >= 4 Вызов функции: SELECT SUM(travel_expenses) FROM "expense%%ratios" Порядок операций: SELECT (salary/12) AS monthly, ((salary/12) / 2) AS biweekly FROM employee WHERE exempt_status >= 4 Подзапрос: SELECT * FROM stores WHERE stolid IN (SELECT stor_id FROM sales WHERE ord_date > '0l-Jan-2004’
Разделитель элементов списка SELECT Iname, fname, ssn, hire_date FROM employee WHERE Iname = ' Fudd'
Разделитель в описателе идентификатора SELECT * FROM scott.employee WHERE Iname = ' Fudd'
Индикатор строки символов SELECT * FROM employee WHERE Iname LIKE 1Fud%’ OR fname = 1 ELMER1
Индикатор идентификаторов с разделителями SELECT expensejate, SUM(travel^expense) FROM "expense%%ratios" WHERE expense_date BETWEEN '01-Jan-2004' AND ’01-Apr-2004’
Ограничитель комментария, занимающего одну строку (две черты, после них - пробел) -- Обнаруживает всех служащих с -- фамилиями типа Fudd, Fudge и Fudston SELECT * FROM employee WHERE Iname LIKE ‘Fud%'
46 | Глава 2. Основные понятия
Таблица 2.7. Ограничители и операторы SQL (Продолжение)
Символ Область применения Пример
/* Обозначает начало мио- /> Обнаруживает всех служащих с
гострочного комментария фамилиями типа Fudd, Fudge / Fudstc." / SE-ECT •
*/ Обозначает конец мио- FROM employee
гострочного комментария WHERE Iname LIKE 1Fud%'
Ключевые и зарезервированные слова
Наряду с символами, которые имеют особый смысл и функции в SQL, существуют
и некоторые слова и фразы, имеющие особую значимость. Ключевые слова SQL - это
слова, которые настолько тесно связаны с функционированием реляционной базы дан-
ных, что их нельзя использовать ни для каких других целей. Как правило, такие слова
используются в инструкциях SQL. (Заметьте, что на большинстве платформ т можно
использовать в качестве идентификаторов, хотя этого делать не следует.) Например,
слово «SELECT» является зарезервированным словом, и его не следует использовать
в качестве имени таблицы.
Нужно стараться избегать давать столбцам и таблицам имена с ключе-
выми словами любых крупных платформ, поскольку базы данных часто
переносятся с одной платформы на другую.
С другой стороны, зарезервированные слова в настоящий момент не имеют специ-
ального назначения, но они могут приобрести его в будущем. Чтобы подчеркнуть тот
факт, что ключевые слова не следует использовать в качестве идентификаторов, но
тем не менее такая возможность существует, в стандарте SQL они называются
«незарезервированными ключевыми словами». Зарезервированные и ключевые слова
SQL не всегда представляют собой слова, используемые в инструкциях SQL, они
также могут быть связаны с технологией использования базы данных. Например,
слово CASCADE применяется для описания таких манипуляций с данными, в которых
действие (например, удаление или обновление) распространяется «вниз», т. е. «каска-
дом» на все нижележащие таблицы. Зарезервированные и ключевые слова часто пуб-
ликуются, чтобы программисты не использовали их в качестве идентификаторов
и чтобы в дальнейшем, в следующих версиях, не возникали проблемы.
В SQL2003 определяется свой список зарезервированных и ключевых слов.
Кроме этого, платформы баз данных также имеют свои собственные списки ключевых
и зарезервированных слов, поскольку в каждой из них есть свои расширения набора
команд SQL. Ключевые слова для стандарта SQL, а также для различных реализаций
языка приведены в приложении В.
Категории синтаксических конструкций | 47
Типы данных SQL2003 и различных
платформ
Таблица может содержать один или несколько столбцов. Для каждого столбца должен
быть определен тип данных, дающий общую классификацию данных, которые будут
храниться в данном столбце. В реальных приложениях типы данных предоставляют
определенный контроль над созданием таблицы и тем, как в ней хранятся данные,
а также обеспечивают эффективность этого процесса. Использование специфических
типов данных позволяет создавать более действенные и понятные запросы, а также
помогает контролировать целостность данных.
Хитрость в том, что типы данных SQL2003 не всегда точно совпадают с соответ-
ствующей их реализацией на платформах. Хотя платформы определяют «типы дан-
ных» как соответствующие типам SQL2003, они не всегда являются истинными
типами SQL2003. Например, реализация типа BIT в MySQL по сути идентична значе-
нию типа CHAR(l). Тем не менее все типы данных в платформах близки к стандарт-
ным достаточно, чтобы их можно было легко понять и работать с ними.
Официальные типы данных SQL2003 (в отличие от платформо-специфических)
делятся на несколько основных категорий, приведенных в табл. 2.8. (Заметьте, что стан-
дарт SQL2003 содержит несколько редко используемых типов данных (ARRAY, MULTISET,
REF и ROW), которые показаны только в табл. 2.8 и нигде более в этой книге.)
Таблица 2.8. Категории и типы данных SQL2003
Категория Примеры типов данных и аббревиатуры Описание
BINARY (двоичные) BINARY LARGE OBJECT (BLOB) В этом типе данных хранятся двоичные строковые значения в шестнадцатеричном формате. Двоичные строки хранятся без всяких ссылок на наборы символов и без ограничений длины
BOOLEAN (булевы) BOOLEAN В этом типе данных хранятся сведения об истин- ности - TRUE (истина) или FALSE (ложь)
CHARACTER строковые типы (символьные) CHAR CHARACTER VARYING (VARCHAR) В этом типе данных могут храниться любые ком- бинации символов из допустимого набора. Вариабельные (varying) типы позволяют хранить строки переменной длины, тогда как остальные - только строки фиксированной длины. Кроме того, вариабельные типы данных автоматически удаляют замыкающие пробелы, а другие типы все пробелы оставляют
NATIONAL CHARACTER (NCHAR) NATIONAL CHARACTER VARYING (NCHAR VARYING) Типы данных, связанные с национальными симво- лами, разработаны для поддержки конкретных наборов символов, зависящих от реализации
48 | Глава 2. Основные понятия
Таблица 2.8. Категории и типы данных SQL2003 (Продолжение)
Категория Примеры типов данных и аббревиатуры Описание
CHARACTER LARGE OBJECT (CLOB) Типы CHARACTER LARGE OBJECT и BINARY LARGE OBJECT вместе называются строковыми типами больших объектов (large object string types)
NATIONAL CHARACTER LA RGE OBJECT (NCLOB) To же, что и CHARACTER LARGE OBJECT по с поддержкой конкретных наборов символов, зависящих от реализации
DATA LINK (связь с данными) DATALINK Определяет ссылку на файл или другой внешний источник, не являющийся частью среды SQL
INTERVAL (интервал) INTERVAL Определяет набор временных значений или промежуток времени
COLLECTION (коллекция) ARRAY MULTISET Тин ARRAY был предложен в SQL99. Тип MULTI- SET добавлен в SQL2003. ARRAY представляет собой коллекцию отсортированных элементов, имеющую фиксированную длину. MULTISET - это несортированная коллекция элементов, имеющая переменную длину. Элементы, входя- щие в ARRAY или MULTISET, должны относиться к заранее заданному типу данных
NUMERIC INTEGER (INT) В этих типах хранятся точные числовые значения
(числовые) SMALLINT BIGINT NUMERIC(p, s) DEC[IMAL](p, s) FLOATfp, s) REAL DOUBLE PRECISION (целые или десятичные дроби) или приблизитель- ные (с плавающей точкой). Типы INT, BIGINT и SMALLINT хранят точные числовые значения с заранее заданной точностью (precision, р) и масш- табом (scale, s), равным нулю. Типы NUMERIC и DEC хранят точные числовые значения с регулируемой точностью и масЩтабом. Тин СТОЛ Г хранит приближенные числовые значения с регулируемой точностью, а типы REAL и DOUBLE PRECISION имеют заранее заданную точность. Вы можете указать точность (р) и масш-таб (s) для типов DECIMAL, FLOAT и NUMERIC, определив, таким образом, число допустимых цифр числа и количество десятичных знаков соответственно. Типы INTEGER (INT), SMALLINT и DECIMAL] иногда называют точными числовыми типами, a FLOAT (р, s), REAL и DOUBLE PRECISION ино- гда называют приблизительными числовыми типами
4 - 2447
Типы данных SQL2003 и различных платформ | 49
Таблица 2.8. Категории и типы данных SQL2003 (Продолжение)
Категория Примеры типов данных и аббревиатуры Описание
TEMPORAL (время) DATE TIME TIME WITH TIMEZONE TIMESTAMP TIMESTAMP WITH TIME- ZONE В этих типах хранятся данные, связанные с време- нем. Типы DATE (Дата) и TIME (Время) понятны без объяснений. Типы с дополнением WITH TIMEZONE (с часовым поясом) включают в себя сдвиг, соответ- ствующий часовому поясу. Типы TIMESTAMP (отметка времени) хранят значение, показывающее точный момент времени. Эти типы данных также называют типами datetime (дата-время)
XML XML Этот тип хранит данные формата XML. Его можно использовать везде, где допустимо приме- нение типов данных SQL, т. е. в столбцах таб- лицы, полях строк и т. п. Операции с данными типа XML предполагают древовидную внутреннюю структуру данных. Эта внутренняя структура базируется на Рекомендации информационного множества XML (XML Infor- mation Set Recommendation (Infoset) с примене- нием нового элемента информации - документа, названного XML root information item
Не каждая платформа базы данных поддерживает все типы ANSI SQL. В табл. 2.9
сравниваются типы данных на пяти платформах. Таблица отсортирована по названию
типа данных. Изучая таблицу, будьте внимательны и следите за сносками, поскольку
бывает так, что некоторые платформы поддерживают тип данных с указанным назва-
нием, но реализуют его несколько по-другому или совершенно не так, как это описано
в стандарте ANSI или у других производителей.
Хотя платформы могут поддерживать типы данных с похожими назва-
***lt£**pS) ниями, их реализации могут различаться. Пожалуйста, обращайтесь
l------ к приводимой в этой главе подробной информации о специфических требо-
ваниях для типов данных для каждой платформы.
Таблица 2.9. Сравнение платформо-специфических типов данных
Vendor datatype DB2 MySQL Oracle PostgreSQL SQL Server SQL2003 datatype
BFILE Y none
BIGINT Y Y Y BIGINT
BINARY Y BLOB
BINARY_FLOAT Y FLOAT
BINARY-DOUBLE Y DOUBLE PRECISION
BIT Y Y Y none
50 | Глава 2. Основные понятия
Таблица 2.9. Сравнение платформо-специфических типов данных (Продолжение)
Vendor datatype DB2 MySQL Oracle PostgreSQL SQL Server SQL2003 datatype
BIT VARYING, VARBIT Y none
BLOB Y Y Y BLOB
BOOL, BOOLEAN Y Y BOOLEAN
BOX Y none
BYTEA Y BLOB
CHAR, CHARACTER Y Y Y Y Y CHARACTER
CHAR FOR BIT DATA Y none
CIDR Y none
CIRCLE Y none
CI.OB Y Y CLOB
CURSOR Y none
DATA LINK Y DATA LIN К
DATE Y Y Y Y DATE
DATETIME Y Y TIMESTAMP
DBCLOB Y NCLOB
DEC, DECIMAL Y Y Y Y Y DECIMAL
DOUBLE. DOUBLE PRECISION Y Y Y Ya Y FLOAT
ENUM Y none
FLOAT Y Y Y Y DOUBLE PRECISION
FLOAT4 Yb FLOAT(P)
FLOATS Yc FLOAT(P)
GRAPHIC Y BLOB
IMAGE Y none
/NET Y none
/NT, INTEGER Y Y Y Y Y INTEGER
INT2 Y SMALLINT
INT4 Y /NT, INTEGER
INTERVAL Y INTERVAL
INTERVAL DAY TO SECOND Y INTERVAL DAY TO SECOND
INTERVAL YEAR TO MONTH Y INTERVAL YEAR TO MONTH
Типы данных SQL2003 и различных платформ | 51
Таблица 2.9. Сравнение платформо-специфических типов данных (Продолжение)
Vendor datatype DB2 MySQL Oracle PostgreSQL SQL Server SQL2003 datatype
LINE Y none
LONG Y none
LONG VARCHAR Y none
LONGBLOB Y BINARY LARGE OBJECT
LONG RAW Y BLOB
LONG Vargraphic Y none
LONGTEXT Y none
LSEG Y none
MACADDR Y none
MEDIUMTEXT Y none
MEDIUMBLOB Y none
MONEY Yd Y none
NATIONAL CHAR- ACTER VARYING, NATIONAL CHAR VARYING, NCHAR VARYING, NVARCHAR Y Y Y NATIONAL CHARACTER VARYING
NCHAR, NATIONAL CHAR, NATIONAL CHARACTER Y Y NATIONAL CHARACTER
NCLOB Y NCLOB
NTEXT, NATIONAL TEXT Y NCLOB
NVARCHAR2(N) Y none
NUMBER Y Y Y Ye Y none
NUMERIC NUMERIC
O1D Y none
PATH Y none
POINT Y none
POLYGON Y none
RAW Y none
REAL Y Y Y Y REAL
ROWID Y none
ROWVERSION Y none
52 | Глава 2. Основные понятия
Таблиг/а 2.9. Сравнение платформо-специфических типов данных (Продолжение)
Vendor datatype DB2 MySQL Oracle PostgreSQL SQL Server SQL2003 datatype
SERIAL. SERIAL4 Y none
SERIAL8, BIGSERIAL Y none
SET Y none
SMALLDATETIME Y none
SMALLINT Y Y Y Y SMALLINT
SMALLMONEY Y none
SQL VARIANT Y none
TABLE Y none
TEXT Y Y Y none
TIME Y Y TIME
TIMESPAN Y INTERVAL
TIMESTAMP Y Y Y Y TIMESTAMP
TIMETZ Y TIME WITH TIME ZONE
TINYINT Y none
UNIQUEIDENTIFIER Y none
UROWID Y none
PA RB INA RY Y BLOB
PARCIIAR, CHAR VARYING, CHARACTER VARYING Y Y Y1 Y Y CHARACTER VARYING(N)
VARCIIAR2 Y CHARACTER VARYING
VARCHAR FOR BIT DATA Y BIT VARYING
VARGRAPIIIC Y NCHAR VARYING
XMLTYPE Y XML
а Синоним для FLOA T.
ь Синоним для REAL..
v Синоним для DOUBLE PRECISION.
J Синоним для DECIMALS,2).
с Синоним для DECIMAL.
f Синоним для VARCHAR2.
В следующих разделах приведены платформо-специфичные типы данных, соответ-
ствующая категория типов данных SQL (если есть) и необходимые сведения. Описания
касаются типов данных, не соответствующих SQL2003.
Типы данных SQL2003 и различных платформ | 53
Типы данных DB2
Как показано ниже, DB2 поддерживает множество разных типов данных, в том числе
большинство типов SQL2003.
BIGINT (тип данных SQL2003: BIGINT)
Хранит целые числа со знаком или без знака в диапазоне от - 9 223 372 036 854
775 808 до 9 223 372 036 854 775 807. Для хранения требуется 8 байт.
BLOB (тип данных SQL2003: BLOB)
Хранит двоичные данные переменной длины до 2 147 483 647 байт.
CHAR(n), CHARACTER^) (тип данных SQL2003: CHARACTER(n))
Хранит символьные данные фиксированной длины до 254 байт. Для хранения тре-
буется (п) байт.
CHAR(n) FOR BIT DATA (тип данных SQL2003: отсутствует)
Хранит фиксированное количество значений. Для хранения требуется (п) байт.
CLOB (тип данных SQL2003: CLOB)
Хранит символьные данные переменной длины до 2 147 483 647 байт.
DATALlNK(n) (тип данных SQL2003: DATAL1NK)
Хранит ссылку на файл, являющийся внешним по отношению к базе данных. Для
хранения требуется п + 54 байта.
DATE (тип данных SQL2003: DATE)
Хранится календарная дата без учета времени суток. Для хранения требуется 4 байта.
DBCLOB(n) (тип данных SQL2003: NCLOB)
Хранит символьные данные с двухбайтным кодом символа, фиксированной
длины, до 1 073 741 823 символов.
DEC(p, s), DECIMAL(p, s) (тип данных SQL2003: DECIMAL, DECIMAL (р, s))
Может иметь точность (precision, р) от 1 до 31 и масштаб (s) от 0 до 31. Для хранения
требуется число байт, равное целой части выражения (р/2) + 1 (где р - точность).
DOUBLE, DOUBLE PRECISION (тип данных SQL2003: DOUBLE PRECISION)
Хранит числа с плавающей точкой в диапазоне от -1.79769Е + 308 до 1.79769Е + 308.
Для хранения требуется 8 байт.
FLOAT (тип данных SQL2003: FLOAT)
Синоним DOUBLE PRECISION.
FLOAT(p) (тип данных SQL2003: REAL, DOUBLE PRECISION)
p изменяется в диапазоне от 1 до 53. Если р<=24, то FLOAT(p) является синони-
мом REAL. Если 24 <р <= 53, то FLOAT(p) - синоним DOUBLE PRECISION.
GRAPHICS) (тип данных SQL2003: NATIONAL CHARACTER)
Этот тип данных применяется не для рисунков. Он хранит символьные строки
фиксированной длины (DBCS) длиной до 127 символов. При использовании двух-
байтовых символов для хранения требуется п*2 байт, при использовании однобай-
товых символов требуется п байт.
INT, INTEGER (тип данных SQL2003: INTEGER)
Хранит целые числа со знаком и без знака в диапазоне от -2 147 483 648 до 2 147
483 647. Для хранения требуется 4 байта.
54 | Глава 2. Основные понятия
LONG VARCHAR (тип данных SQL2003: VARCHAR)
Хранит символьные данные переменной длины до 32 700 байт. Для хранения тре-
буется 24 байта.
LONG VARCHAR FOR BIT DATA (тип данных SQL2003: BIT VARYING)
Хранит символьные данные переменной длины до 32 700 байт. Для хранения тре-
буется 24 байта.
LONG VARGRAPHIC (тип данных SQL2003: отсутствует)
Хранит символьные строки фиксированной длины из двухбайтных символов
(DBCS) длиной до 16 350 символов. Для хранения требуется 24 байта.
NUM(p, s), NUMERlC(p, s) (тип данных SQL2003: NUMERIC, NUMERIC(p, s))
Синоним DECIMAL. Для хранения требуется число байт, равное целой части
выражения (р/2) + 1 (где р - точность).
REAL (тип данных SQL2003: REAL)
Хранит числа с плавающей точкой в диапазоне от-3.402Е 38 до 3.402Е + 38. Для
хранения требуется 4 байта.
SMALLINT (тип данных SQL2003: SMALLINT)
Хранит целые числа со знаком или без знака в диапазоне от-32 768 до 32 767. Для
хранения требуется 2 байта.
TIME (тип данных SQL2003: TIME)
Хранит время суток. Для хранения требуется 3 байта.
TIMESTAMP (тип данных SQL2003: TIMESTAMP)
Хранит дату и время. Для хранения требуется 10 байт.
VARCHAR(n), CHAR VARYING(n), CHARACTER VARYlNG(n) (типы данных SQL2003:
CHARACTER VARYING, CHARACTER VARYING(n))
Хранит символьные данные переменной длины до 32 672 байт. Для хранения тре-
буется п + 4 байта.
VARCHAR(n) FOR BIT DATA (тип данных SQL2003: отсутствует)
Хранит переменное число значений. Для хранения требуется п + 4 байта.
VARGRAPHlC(n) (тип данных SQL2003: NCHAR VARYING)
Хранит символьные строки из двухбайтных символов фиксированной длины до
16 338 символов. Для хранения необходимо (w*2) + 4 байта.
Типы данных MySQL
Числовые типы данных MySQL имеют следующие дополнительные атрибуты.
UNSIGNED
Предполагается, что данное числовое значение будет неотрицательным (т. е. поло-
жительным или равным нулю). То место в памяти, которое обеспечивает возмож-
ность хранить положительные или отрицательные значения в фиксированных
типах данных, таких, как DECIMAL и NUMERIC, используется для хранения
части числа, и это несколько увеличивает диапазон по сравнению с DECIMAL
и NUMERIC. (Дополнительного атрибута SIGNED в данном случае нет.)
Типы данных SQL2003 и различных платформ | 55
ZEROFILL
Этот атрибут, используемый для отображения форматирования, заставляет MySQL
дополнять числовые значения до полного размера нулями, а не пробелами. При ис-
пользовании атрибута ZEROFILL автоматически включается атрибут UNSIGNED.
В MySQL также принудительно вводится ограничение на отображаемый размер
столбцов, составляющее 255 символов. Столбцы с данными, превышающими по
длине 255 символов, хранятся должным образом, но отображаются из них только
255 символов. Числовые типы с плавающей точкой могут иметь после десятичной
точки не более 30 цифр.
В приводимом ниже перечне видно, что MySQL поддерживает большую часть
типов SQL2003, а также в нем есть несколько дополнительных типов для хранения
списков значений, а также больших двоичных объектов (BLOB). К расширениям
стандарта ANSI относятся типы TEXT, ENUM, SET и MEDIUMINT. К специальным
атрибутам, выходящим за рамки стандарта ANSI, также относятся AUTOJNCREMENT,
BINARY, NULL, UNSIGNED и ZEROFILL.
BIGINT[(n)] [UNSIGNED] [ZEROFILL] (тип данных SQL2003: BIGINT)
Хранит числа co знаком и без знака. Диапазон для чисел со знаком составляет от
-9 223 372 036 854 775 808 до 9 223 372 036 854 775 807. Диапазон для чисел без
знака составляет от 0 до 18 146 744 073 709 551 615. При использовании типа
BIGINT вычисления могут быть неточными из-за округлений.
BIT, BOOL (тип данных SQL2003: отсутствует)
Синоним TINYINT.
BLOB (тип данных SQL2003: BLOB)
Хранит до 65 535 байт данных. Поддержка индексирования столбцов BLOB есть
только в версиях MySQL 3.23.2 и выше (этой возможности нет больше ни в одной
из рассматриваемых в книге платформ). В MySQL тип BLOB функционально эк-
вивалентен типу MySQL VARCHAR BINARY (который обсуждается ниже) с задан-
ным по умолчанию верхним ограничением на размер. При сравнении данных типа
BLOB нужно всегда учитывать регистр. Отличие этого типа от используемого
в MySQL типа VARCHAR BINARY состоит в том, что нельзя устанавливать значе-
ния по умолчанию (DEFAULT), а также в том, что в BLOB не удаляются заключи-
тельные пробелы. К столбцам BLOB не следует применять операции GROUP BY
и ORDER BY. Они также хранятся отдельно от таблицы, в то время как все прочие
типы данных MySQL сохраняются в структуре самого файла таблицы.
CHAR(n) [BINARY], CHARACTER^) [BINARY] (тип данных SQL2003: CHARACTER(n))
Содержит символьную строку фиксированной длины от 1 до 255 символов. При со-
хранении значений тип CHAR дополняется пробелами, а при извлечении пробелы
обрезаются, как в типе ANSI SQL2003 VARCHAR. Атрибут BINARY позволяет произ-
водить поиск двоичных данных, а не только словарный поиск без учета регистра.
DATE (тип данных SQL2003: DATE)
Хранит дату в диапазоне от 1000-01-01 до 9999-12-31 (ограниченную кавычками).
По умолчанию MySQL отображает эти значения в формате ГГГГ-ММ-ДД, хотя
пользователь может указать и какой-нибудь другой формат отображения.
56 | Глава 2. Основные понятия
DATETIME (тип данных SQL2003: TIMESTAMP)
Хранит значение даты и времени в диапазоне от 1000-01-01 00:00:00 до 9999-12-
31 23:59:59.
DECIMAL [р, (s)] [ZEROFILL] (тип данных SQL2003: DECIMAL(PRECISION, SCALE))
Хранит точные числовые значения в виде строк, используя один символ для
каждой цифры. Если точность не указана, она принимается равной 10, а масштаб
(если не указан) - равным нулю.
DOUBLE [(р, s)] [ZEROFILL], DOUBLE PRECISION [(р, s)] [ZEROFILL] (тип данных
SQL2003: DOUBLE PRECISION)
Хранит числовые значения двойной точности, а во всем прочем идентичен
типу FLOAT двойной точности, за исключением того, что допустимы диапазо-
ны от -1.7976931348623157Е + 308 до -2.2250738585072014Е - 308, 0, и от
2.2250738585072014Е - 308 до 1.7976931348623157Е + 308.
ENUM ("зпач1 ”. "зпач2”,...п) (тип данных SQL2003: отсутствует)
Тип данных, значением которого могут быть: одно из списка указанных значений
(написанных в виде строк, но хранимых в виде целых чисел), NULL или пустая
строка (“”), служащая признаком ошибочного значения. Разрешается использо-
вать до 65 535 разных значений.
FLOAT](p)J [ZEROFILL], floatfp, s) [ZEROFILL] (тип данных SQL2003: FLOAT(P))
Хранит числа с плавающей точкой от -3.402823466Е+38 до -1.175494351Е-38 и от
1.175494351Е - 38 до 3.402823466Е -1- 38. Тип FLOAT без указания точности или
с точностью <L- 24 является типом с одинарной точностью, иначе - с двойной. При
указании точности без масштаба можно использовать значения от 0 до 53. При указа-
нии и точности и масштаба точность может быть до 255, а масштаб - до 253. Все
вычисления для типа FLOAT в MySQL выполняются с двойной точностью. Поскольку
FLOAT - это тип для приближенных значений, возможны ошибки, связанные с округ-
лением.
INTfEGER] [UNSIGNED] [ZEROFILL] [AUTO INCREMENT]
(тип данных SQL2003: INT, INTEGER)
Хранит целые числа со знаком и без знака в диапазоне от -2 147 483 648 до 2 147
483 647 для таблиц с индексно-последовательным методом доступа (ISAM). Для
чисел без знака допустимый диапазон в таблицах ISAM - от 0 до 4 294 967 295.
В других типах таблиц диапазон значений несколько отличается. Атрибут
AUTO INCREMENT доступен для всех вариантов типа INT. Этот атрибут создает
для каждой вновь добавляемой строки уникальный идентификатор строки.
(За дополнительной информацией об атрибуте AUTO INCREMENT обращайтесь
к разделу «Инструкция CREATE/ALTER TABLE» главы 3.)
LONGBLOB (тип данных SQL2003: BINARY LARGE OBJECT)
Хранит данные BLOB длиной до 4 294 967 295 символов. Заметьте, что для неко-
торых протоколов связи клиент/сервер такой объем данных может оказаться
слишком большим.
Типы данных SQL2003 и различных платформ | 57
LONGTEXT (тип данных SQL2003: CLOB)
Хранит данные типа TEXT длиной до 4 294 967 295 символов. Заметьте, что для
некоторых протоколов связи клиент/сервер такой объем данных может оказаться
слишком большим.
MEDIUMBLOB (тип данных SQL2003: отсутствует)
Хранит данные типа BLOB длиной до 16 777 215 символов.
MEDIUMTEXT (тип данных SQL2003: отсутствует)
Хранит данные типа TEXT длиной до 16 777 215 символов.
MEDIUMINT[(n)] [UNSIGNED] [ZEROFILL] (тип данных SQL2003: отсутствует)
Хранит целые числа со знаком и без знака в диапазоне от 8 388 608 до -8 388 608.
Диапазон для чисел без знака - от 0 до 16 777 215.
NCHAR(n) [BINARY], [NATIONAL] CHAR(n) [BINARY]
(тип данных SQL2003: NCHAR(n))
Синонимы для CHAR. Типы NCHAR обеспечивают поддержку набора UNICODE,
начиная с MySQL 4.1.
NUMERlC(p, s) (тип данных SQL2003: DECIMAL)
Синоним типа DECIMAL.
NVARCHAR(n) [BINARY], [NATIONAL] VARCHAR(n) [BINARY], NATIONAL CHAR
VARYlNG(n) [BINARY] (тип данных SQL2003: NCHAR VARYING)
Синонимы типа VARYING [BINARY], Хранит символьные строки переменной
длины до 255 символов. Если не используется ключевое слово BINARY, значения
хранятся и сравниваются без учета регистра.
REAL (тип данных SQL2003: REAL)
Синоним типа DOUBLE PRECISION.
8ЕТ(“знач1", “знач2", ...п) (тип данных SQL2003: отсутствует)
Символьный тип данных, значения которого должны быть равны нулю или несколь-
ким значениям из указанного списка. Список может содержать до 64 элементов.
SMALLINT[(n)] [UNSIGNED] [ZEROFILL] (тип данных SQL2003: SMALLINT)
Хранит целые числа со знаком или без знака. Диапазон для чисел со знаком - от
-32 768 до 32 767. Диапазон для чисел без знака - от 0 до 65 535.
TEXT (тип данных SQL2003: отсутствует)
Хранит до 65 535 символов данных. Данные типа TEXT хранятся отдельно от таб-
лиц, в то время как остальные типы хранятся в структуре файла соответствующей
таблицы. Тип TEXT функционально эквивалентен типу VARCHAR без указания
верхней границы (за исключением максимального размера столбца). Сравнение вы-
полняется без учета регистра. Тип TEXT отличается от стандартного типа VARCHAR
тем, что нельзя указывать значения по умолчанию (DEFAULT), а также тем, что
в TEXT не удаляются заключительные пробелы. К столбцам TEXT не следует приме-
нять операции GROUP BY и ORDER BY. Кроме того, поддержка индексирования
столбцов TEXT появилась только в MySQL 3.23.2 и выше.
58 | Глава 2. Основные понятия
Типы данных Oracle
Как показано ниже, Oracle поддерживает множество типов данных, в том числе боль-
шинство стандартных типов SQL2003.
В FILE (тип данных SQL2003: DATA LINK)
Содержит указатель на объект типа BLOB, хранимый вне пределов базы данных,
но находящийся на локальном сервере и имеющий размер до 4 Гб. База данных
осуществляет потоковый доступ по чтению (но не по записи) к этому внешнему
объекту. Если вы удалите строку, содержащую значение типа BFILE, будет удален
только указатель. Исходная структура файлов не затрагивается.
BINARYFLOAT (тип данных SQL2003: FLOAT)
Хранит 32-битное число с плавающей точкой.
BINARY DOUBLE (тип данных SQL2003: FLOAT)
Хранит 64-битное число с плавающей точкой.
BLOB (тип данных SQL2003: BLOB)
Хранит большой двоичный объект (binary large object, BLOB) размером от 8 до 128
терабайт в зависимости от размера блока в базе данных. В Oracle большие дво-
ичные объекты (BLOB, CLOB, NCLOB) имеют следующие ограничения.
• Их нельзя выбирать с удаленной машины.
• Их нельзя сохранять в кластерах.
♦ Их нельзя объединять в тине varray.
• Они не могут быть компонентом предложений ORDER BY и GROUP BY в запросе.
• Их нельзя использовать в агрегатных функциях запроса.
• На них нельзя ссылаться в запросах при помощи инструкций DISTINCT
nUNIQUE или в соединениях.
• На них нельзя ссылаться в предложениях ANALYZE...COMPUTE и ANALYZE...
ESTIMATE.
• Они не могут быть частью первичного ключа или ключа индекса.
• Их нельзя использовать в предложении UPDATE OF триггера UPDATE.
CHAR(n)[BYTE | CHAR], CHARACTER(n)[BYTE | CHAR] (тип данных SQL2003:
CHARACTER(n))
Хранит массив символьных данных фиксированной длины до 2000 байт. При ука-
зании атрибута BYTE длина массива измеряется в байтах. При указании атрибута
CHAR длина измеряется в символах.
CLOB (тип данных SQL2003: CLOB)
Хранит большой символьный объект (large character object, CLOB) размером от 8 до
128 терабайт в зависимости от размера блока в базе данных. См. список ограничений
использования типа CLOB в пункте «.BLOB».
DATE (тип данных SQL2003: DATE)
Хранит дату и время в диапазоне от 00:00:00 01-01-4712 до н. э. до 23:59:59 31-12-9999.
DECIMALfp, s) (тип данных SQL2003: DEClMAL(p, s))
Синоним типа NUMBER, принимающий в качестве аргументов точность и масштаб.
Типы данных SQL2003 и различных платформ | 59
DOUBLE PRECISION (тип данных SQL2003: DOUBLE PRECISION)
Хранит значения с плавающей точкой двойной точности. То же, что FLOAT(I26).
FLOAT(n) (тип данных SQL2003: FLOAT(n))
Хранит числовые данные с плавающей точкой с двоичной точностью до 126.
INTEGER(n) (тип данных SQL2003: INTEGER)
Хранит целые числа со знаком и без знака с точностью до 38. Тип INTEGER счита-
ется синонимом NUMBER.
INTERVAL DAY (п) ТО SECOND (х) (тип данных SQL2003: INTERVAL)
Хранит промежуток времени, измеряемый в днях, часах, минутах и секундах, п -
число цифр в поле «день» (допустимые значения 0-9, по умолчанию - 2), а х-
число цифр для долей секунды в поле секунд (допустимые значения 0-9,
по умолчанию - 6).
INTERVAL YEAR (п) ТО MONTH (х) (тип данных SQL2003: INTERVAL)
Хранит промежуток времени, измеряемый в годах и месяцах, где п - число цифр
в поле года. Значение п может быть от 0 до 9, по умолчанию - 2.
LONG (тип данных SQL2003: отсутствует)
Хранит массив символьных данных переменной длины до 2 Гб. Тем не менее
нужно заметить, что Oracle в долгосрочной перспективе не планирует поддержи-
вать тип LONG. Вместо этого типа старайтесь везде, где возможно, использовать
другие типы, например CLOB.
LONG RAW (тип данных SQL2003: отсутствует)
Хранит сырые двоичные данные переменной длины до 2 Гб. Типы LONG RAW
и RAW обычно используются для хранения графики, звуковых данных, документов
и других больших структур. Использование типа BLOB является более предпочти-
тельным, чем применение LONG RAW, поскольку BLOB имеет меньше ограниче-
ний. Тип LONG RA Wтакже выходит из употребления.
NATIONAL CHARACTER VARYING(n), NATIONAL CHAR VARYING(n), NCHAR VARYING(n)
(тип данных SQL2003: NCHAR VARYING(n))
To же, что и NVARCHAR2.
NCHAR(n), NATIONAL CHARACTER(n), NATIONAL CHAR(n) (тип данных SQL2003:
NATIONAL CHARACTER)
Хранит данные в формате символов UNICODE длиной от 1 до 2000 байт.
По умолчанию - 1 байт.
NCLOB (тип данных SQL2003: NCLOB)
Представляет собой CLOB с поддержкой многобайтовых символов и UNICODE
размером от 8 до 128 терабайт в зависимости от размера блока базы данных.
См. список ограничений использования типа NCLOB в пункте «BLOB».
NUMBER(p, s), NUMERIC(p, s) (тип данных SQL2003: NUMERIC(p,s))
Хранит числа с точностью в пределах от 1 до 38 и масштабом от-84 до 127.
NVARCHAR2(n) (тип данных SQL2003: отсутствует)
Представляет собой рекомендуемый Oracle тип для хранения символьных данных
переменной длины. Может занимать от 1 до 4000 байт.
60 | Глава 2. Основные понятия
RAW(n) (тип данных SQL2003: отсутствует)
Хранит массив сырых данных переменной длины до 2000 байт. Значение п указы-
вает размер типа данных. В Oracle 10g тип RAW исключен. См. LONG RAW.
REAL (тип данных SQL2003: REAL)
Хранит значения с плавающей точкой с одинарной точностью. То же, что FLOAT(63).
ROWID (тип данных SQL2003: отсутствует)
Представляет собой уникальный идентификатор типа base-64 для каждой строки
таблицы. Часто используется с псевдостолбцом ROWID.
SMALLINT (тип данных SQL2003: SMALLINT)
То же, что INTEGER.
TlMESTAMP(n){[WITH TIME ZONE] | [WITH LOCAL TIME ZONE]} (тип данных
SQL2003: TIM ESTAMP [WITH TIMEZONE])
Значение полной даты и времени, где п - количество цифр для долей секунды
в поле секунд (допустимые значения 0 - 9, по умолчанию - 6). При указании атри-
бута WITH TIME ZONE сохраняется переданный в качестве параметра часовой
пояс (по умолчанию - часовой пояс текущего сеанса) и значение времени выдает-
ся с учетом этого часового пояса. При указании атрибута WITH LOCAL TIME
ZONE данные хранятся с учетом часового пояса текущего сеанса и возвращаются
также с учетом часового пояса текущего сеанса.
UROWID [(п)] (тип данных SQL2003: отсутствует)
Хранит значение типа base-64, показывающее логический адрес строки в таблице.
По умолчанию размер составляет 4000 байт. Вы можете при желании указать
размер в пределах до 4000 байт.
VARCHAR(n), CHARACTER VARYING(n), CHAR VARYING(n) (тип данных SQL2003:
CHARACTER VARYlNG(n))
Хранит символьные данные размером от 1 до 4000 байт.
Oracle не рекомендует использовать тип VARCHAR. В течение многих лет
***|^*j^i Oracle поощряет использование типа VARCHAR2.
VARCHAR2(n [BYTE | CHAR]) (тип данных SQL2003: CHARACTER VARYING(n))
Хранит символьные данные переменной длины до 4000 байт (определяется пара-
метром и). Атрибут BYTE показывает, что размер измеряется в байтах. Если вы ис-
пользуете атрибут CHAR, база Oracle должна провести внутреннее преобразова-
ние в определенное количество байт, которое должно соответствовать ограниче-
нию в 4000 байт.
XMLTYPE (тип данных SQL2003; XML)
Хранит в базе Oracle данные формата XML. Доступ к данным XML осуществляет-
ся с помощью выражений XPath, а также нескольких встроенных XPath-функций,
функций SQL и пакетов PL/SQL. Тип XMLTYPE определяется системой, поэтому
его можно использовать в качестве аргумента функций, а также типа данных для
столбца в таблице или представлении. При использовании этого типа в таблице
данные можно сохранить в форме CLOB или связанного объекта.
Типы данных SQL2003 и различных платформ | 61
Типы данных PostgreSQL
База данных PostgreSQL поддерживает большинство типов данных SQL2003 плюс
огромный набор типов для хранения пространственных и геометрических данных.
PostgreSQL может похвастаться богатым набором операторов и функций, специально
предназначенных для геометрических типов данных. Сюда входят такие средства, как
поворот, поиск пересечений и масштабирование. В PostgreSQL также есть поддержка
дополнительных версий существующих типов данных, которые характерны тем, что
занимают меньше места на диске, чем соответствующие исходные версии. Например,
в PostgreSQL предлагается несколько вариантов типа INTEGER для хранения больших
и небольших чисел, соответственно занимающих больше или меньше места.
BIGSERIAL
См. SERIALS.
BIT (тип данных SQL2003: BIT)
Битовая строка фиксированной длины.
BIT VARYlNG(n) varbit(n) (тип данных SQL2003: BIT VARYING)
Обозначает битовую строку переменной длины в п бит.
BOOL, BOOLEAN (тип данных SQL2003: BOOLEAN)
Хранит логическое булево значение (true/false/unknown). Рекомендуемыми значе-
ниями являются ключевые слова TRUE и FALSE, хотя PostgreSQL допускает при-
менение нескольких литеральных значений для «true»: TRUE, t, true, у, yes и 1. Допус-
тимыми значениями для «false» являются: FALSE, f, false, n, no и 0.
BOX ((xl, у I), (x2, y2)) (тип данных SQL2003: отсутствует)
Хранит значения, определяющие прямоугольную область на плоскости. Значения
занимают 32 байта и представлены в виде ((xl, yl), (х2, у2)), что соответствует
противоположным углам прямоугольника (правый верхний и левый нижний соот-
ветственно). Внешние скобки являются необязательными.
BYTEA (тип данных SQL2003: BINARY LARGE OBJECT)
Сырые, двоичные данные, используемые, например, для хранения графики, звука
и документов. Для хранения этого типа требуется 4 байта плюс реальный размер
битовой строки.
CHAR(n), СНАRA CTER(n) (тип данных SQL2003: CHARACTER(n))
Содержит символьную строку фиксированной длины, дополняемую пробелами до
длины п. Попытка вставить значение, превышающее по длине п, приводит
к ошибке (если только лишние символы не представляют собой пробелы, которые
в таком случае обрезаются так, чтобы длина составила п символов).
CIDR(x.x.x.x/y) (тип данных SQL2003: отсутствует)
Описывает адрес сети или хоста в формате версии 4 протокола IP. Адрес занимает
12 байт. Допустимыми значениями являются любые допускаемые протоколом
IPv4 сетевые адреса. В типе CIDR данные представлены в форме х.х.х.х/у, где
х.х.х.х - IP-адрес, а у - количество бит сетевой маски. В CIDR не допускается
использование ненулевых битов справа от нулевого бита сетевой маски.
62 | Глава 2. Основные понятия
CIRCLE x, у, г (тип данных SQL2003: отсутствует)
Описывает окружность на плоскости. Значения занимают 24 байта и представлены
в форме х, у, г. Значения х и у представляют собой координаты центра окружности,
а г - длину ее радиуса. Значения х, у и г при желании можно ограничи ть скобками
или фигурными скобками.
DATE (тип данных SQL2003: DATE)
Хранит календарную дату (год, день и месяц) без времени суток. Занимает
4 байта. Даты должны быть в диапазоне от 4713 до н. э. до 32767 п. э. Предел
разрешения для типа DATE, естественно, один день.
DATETIME (тип данных SQL2003: TIMESTAMP)
Хранит календарную дату с указанием времени суток.
DECIMAL ['(р, s)], NUMERIC [(р, s)J (тип данных SQL2003: DECIMAL (PRECISION
SCALE), NUMERIC (s, p))
Храпит точные числовые значения с точностью (р), равной 9, и масштабом (s),
равным нулю, без верхнего предела.
FLOAT4, REAL (тип данных SQL2003: FLOAT(p))
Хранит значения с плавающей точкой с точностью, равной 8 или менее, и 6 знака-
ми после занятой.
FLOATS, DOUBLE PRECISION (тип данных SQL2003: FLOAT(p), 7<= р < 16)
Хранит значения с плавающей точкой с точностью, равной 16 или менее, и 15 зна-
ками после запятой.
INET (х.х.х.х/у)
Хранит адрес сети или хоста в формате версии 4 протокола 11’. Адрес занимает 12
байт. Допустимыми значениями являются любые допускаемые протоколом IPv4
сетевые адреса. х.х.х.х - IP-адрес, у - количество бит сетевой маски. По умолча-
нию сетевая маска равна 32. В отличие от CIDR, в INET допускается использова-
ние ненулевых битов справа от сетевой маски.
SMALLINT (тип данных SQL2003: SMALLINT)
Хранит двухбайтные целые числа со знаком и без знака в диапазоне от -32 768 до
32 767. Синоним - INT2.
INTEGER (тип данных SQL2003: INTEGER)
Хранит 4-байтные целые числа со знаком или без знака в диапазоне от -2 147 483 648
до 2 147 483 647. Синоним - INT4.
1NT8 (тип данных SQL2003: отсутствует)
Хранит 8-байтные целые числа со знаком или без знака в диапазоне от
-9 223 372 036 854 775 808 до 9 223 372 036 854 775 807.
INTERVAL(p) (тип данных SQL2003: отсутствует)
Хранит общеупотребимые значения интервалов времени в диапазоне от -178 000 000
до 178 000 000 лет. Занимает 12 байт. Самым низким разрешением типа INTERVAL яв-
ляется микросекунда. Этот тип хранения даты отличается от стандарта ANSI, который
требует указывать спецификатор интервала, например INTERVAL YEAR ТО MONTH.
Типы данных SQL2003 и различных платформ | 63
LINE ((xl, yl), (x2, y2)) (тип данных SQL2003: отсутствует)
Хранит информацию о прямой линии на плоскости, без конечных точек. Значения
занимают 32 байта и представлены в виде ((xl, yl), (х2, у2)), что обозначает
начальную и конечную точку линии. Скобки в синтаксисе типа LINE являются не-
обязательными.
LSEG ((xl, yl), (х2, у2)) (тип данных SQL2003: отсутствует)
Хранит отрезок прямой линии (line segment, LSEG) на плоскости, с конечными
точками. Значения занимают 32 байта и представлены в виде ((xl, yl), (х2, у2)).
Скобки в синтаксисе типа LSEG являются необязательными. Для интересующих-
ся: «отрезок» - это то, что большинство людей обычно называют линией. Напри-
мер, линии на игровом поле в действительности являются отрезками.
В настоящей геометрической терминологии линия распространяется
в бесконечность и не имеет концов, а отрезок имеет конечные точки.
В PostgreSQL существуют типы для хранения и того и другого, но функ-
ционально они эквивалентны.
MACADDR (тип данных SQL2003: отсутствует)
Может хранить значение МАС-адреса сетевой карты компьютера. Занимает 6 байт.
Тип MACADDR допускает несколько форм адреса, соответствующих промышленным
стандартам, например:
08002В:010203
08002В-010203
0800.2В01.0203
08-00-2В-01-02-03
08:00:213:01:02:03
MONEY, DECIMAL(9,2) (тип данных SQL2003: отсутствует)
Хранит денежные значения в формате США в диапазоне от -21474836.48 до
21474836.47.
NUMERlC[(p, s)], DECIMAL[(p, s)] (тип данных SQL2003: отсутствует)
Хранит точные числовые данные с точностью (р) и масштабом (s).
O1D (тип данных SQL2003: отсутствует)
Хранит уникальные идентификаторы объектов.
PATH ((xl, yl), ... п), Path ((xl, yl), ... n) (тип данных SQL2003: отсутствует)
Описывает открытый или закрытый геометрический контур на плоскости. Значе-
ния представлены в виде ((xl, yl), ... п) и занимают 4 + 32и байт. Каждая пара
значений (х, у) соответствует точке контура. Контуры бывают либо открытыми,
когда первая и последняя точка не совпадают, или закрытыми, когда первая и послед-
няя точка совпадают. Для обозначения закрытых контуров выражение заключают
в круглые скобки, а для обозначения открытых - в квадратные.
POINT (х, у) (тип данных SQL2003: отсутствует)
Хранит значение, описывающее геометрическую точку на плоскости. Занимает
16 байт. Значения представлены в виде (х, у). Точка является основой других двух-
64 | Глава 2. Основные понятия
мерных пространственных типов данных, поддерживаемых в PostgreSQL. Скобки
в синтаксисе этого типа являются необязательными.
POLYGONE ((xl,у!), ... п) (тип данных SQL2003: отсутствует)
Хранит значение, описывающее закрытый геометрический контур на плоскости.
Занимает 4 + 32и байт. Значения представлены в виде ((xl, yl), ... п). По сути тип
POLYGONE эквивалентен типу, используемому для хранения закрытого контура.
SERIAL, SER1AL4 (тип данных SQL2003: отсутствует)
Хранит автоматически инкрементируемое, уникальное целое значение ID, приме-
няемое для индексирования и перекрестных ссылок. Этот тип хранит до 4 байт
данных (диапазон чисел от 1 до 2 147 483 647). Таблицы, определенные с этим
типом данных, нельзя удалять напрямую. Сначала нужно подать команду DROP
SEQUENCE, а только после этого подавать команду DROP TABLE.
SER1AL8, BIGSERIAL (тип данных SQL2003: отсутствует)
Хранит автоматически инкрементируемое, уникальное целое значение ID, приме-
няемое для индексирования и перекрестных ссылок. Этот тип хранит до 8 байт
данных (диапазон чисел от 1 до 9 223 372 036 854 775 807). Таблицы, определенные
с этим типом данных, нельзя удалять напрямую. Сначала нужно подать команду
DROP SEQUENCE, а только после этого подавать команду DROP TABLE.
TEXT (тип данных SQL2003: CLOB)
Хранит большой массив символьных строк переменной длины до 1 гигабайта.
PostgreSQL автоматически сжимает строки типа TEXT, поэтому место, занимае-
мое на диске, может быть меньше, чем размер строк.
TIME [(р)] [WITHOUT TIMEZONE | WITH TIME ZONE] (тип данных SQL2003: TIME)
Хранит время суток либо без учета часового пояса (используется 8 байт), либо
с учетом часового пояса, в котором находится сервер базы данных (используется
12 байт). Допустимый диапазон значений: 00:00:00.00 - 23:59:59.99. Наименьшее
значение - 1 микросекунда. Заметьте, что в большинстве систем UNIX информа-
ция о часовом поясе доступна только для дат с 1902 по 2038 год.
TIMESPAN (тип данных SQL2003: отсутствует)
Хранит значение, представляющее собой конкретный промежуток времени. Наи-
более похожим на тип TIMESPAN в стандарте ANSI является тип INTERVAL.
TIMESTAMP [(р)] [WITHOUT TIMEZONE | WITH TIMEZONE] (тип данных SQL2003:
TIMESTAMP [WITH TIMEZONE ! WITHOUT TIMEZONE])
Хранил дату и время с учетом и без учета часового пояса сервера базы данных.
Допустимый диапазон значений - от 4713 до н. э. до 1 465 001 н. э. Одно значение
типа TIMESTAMP занимает 8 байт. Самое наименьшее значение - 1 микросекунда.
Заметьте, что в большинстве систем UNIX информация о часовом поясе доступна
только для дат с 1902 по 2038 год.
T1METZ (тип данных SQL2003: TIME WITH TIMEZONE)
Хранит значение времени суток с учетом часового пояса.
VARCHAR(n), CHARACTER VARYlNG(n) (тип данных SQL2003: CHARACTER VARYlNG(n))
Хранит символьные строки переменной длины длиной до п. Заключительные про-
белы не сохраняются.
5 - 2447
Типы данных SQL2003 и различных платформ | 65
Типы данных SQL Server
Приводимый ниже список показывает, что Microsoft SQL Server поддерживает боль-
шинство типов данных SQL2003. Также SQL Server поддерживает дополнительные
типы данных, используемые для однозначной идентификации строк данных в таблице
и на многих серверах, например UNIQUEIDENTIFIER, что соответствует аппаратной
философии «роста в ширину», исповедуемой Microsoft (т. е. внедрение базы на мно-
жестве серверов на платформах Intel), вместо «роста в высоту» (т. е. внедрение на
одном огромном мощном UNIX-сервере или Windows Data Center Server).
Интересное отступление, касающееся дат на SQL Server: SQL Server под-
держивает даты начиная с 1753 года. Вы не можете хранить более
ранние даты ни в одном типе данных базы SQL Server. Почему? Причина
в том, что англоговорящий мир начал использовать григорианский кален-
дарь в 1753 году (до сентября 1753 года использовался юлианский кален-
дарь), а преобразование дат юлианского календаря в григорианский могло
оказаться весьма сложным.
BIGINT (тип данных SQL2003: BIGINT)
Хранит целые числа со знаком и без знака в диапазоне от-9 223 372 036 854 775
808 до 9 223 372 036 854 775 807. Занимает 8 байт. См. тип INT, где указаны прави-
ла свойства IDENTITY, также применимые к типу BIGINT
BlNARY[(n)](mun данных SQL2003: BLOB)
Хранит двоичное значение фиксированной длины от 1 до 8000 байт. Значение
типа BINARY занимает п + 4 байта.
BIT (тип данных SQL2003: BOOLEAN)
Хранит значения 1, 0 или NULL, которое обозначает «unknown». В одном байте
может храниться до 8 значений из столбцов типа BIT таблицы. В еще одном байте
можно разместить дополнительные 8 значений типа BIT. Столбцы типа BIT нельзя
индексировать.
CHAR[(n)], CHARACTER^)] (тип данных SQL2003: CHARACTER(n))
Хранит символьные данные фиксированной длины от 1 до 8000 символов. Все
неиспользованное место по умолчанию заполняется пробелами. (Автоматическое
заполнение пробелами можно отключить.) Тип занимает п байт.
CURSOR (тип данных SQL2003: отсутствует)
Специальный тип данных, используемый для описания курсора в форме перемен-
ной или параметра хранимой процедуры OUTPUT. Тип нельзя использовать в ин-
струкции CREATE TABLE. Тип CURSOR может принимать значение NULL.
DATETIME (тип данных SQL2003: TIMESTAMP)
Хранит значение даты и времени в диапазоне с 01-01-1753 00:00:00 до 31-12-9999
23:59:59. Для хранения требуется 8 байт.
66 | Глава 2. Основные понятия
DECIMAL (p, s), DEC (p, s), NUMERIC (p, s) (тип данных SQL2003: DECIMAL (p, s),
NUMERIC (p. s))
Хранит десятичные дроби длиной до 38 цифр. Значения pus определяют, соответ-
ственно, точность и масштаб. Масштаб по умолчанию равен 0. Занимаемое значе-
нием место определяется используемой точностью.
При точности 1-9 используется 5 байт.
При точности 10-19 используется 9 байт.
При точности 20-28 используется 13 байт.
При точности 29-39 используется 17 байт.
См. чип INT, где указаны правила свойства IDENTITY, также применимые к типу
DECIMAL.
DOUBLE PRECISION (тип данных SQL2003: отсутствует)
Синоним FLOAT(53).
FLOAT [(n)J (тип данных SQL2003: FLOAT, FLOAT (п))
Хранит значения с плавающей точкой в диапазоне от-1.79Е + 308 до 1.79Е + 308.
Точность, определяемая параметром п, может изменяться в пределах от 1 до 53.
Для хранения 7 цифр (и - от 1 до 24) требуется 4 байта. Значения, превышающие
7 цифр, занимают 8 байт.
IMAGE (тип данных SQL2003: BLOB)
Хранит двоичное значение переменной длины до 2 147 483 647 байт. Этот тип
данных часто используется для хранения графики, звука и файлов, таких, как до-
кументы MS Word и электронные таблицы MS Excel. Значениями типа IMAGE
нельзя свободно манипулировать. Столбцы типа IMAGE и TEXT имеют множество
ограничений на способы использования. См. описание типа TEXT, где приведен
список команд и функций, которые применимы и к типу IMAGE.
INT [IDENTITY [(seed, increment)] (тип данных SQL2003: INTEGER)
Хранит целые числа со знаком или без знака в диапазоне от -2 147 483 648 до
2 147 483 647. Занимает 4 байта. Все целочисленные типы данных, а также типы,
хранящие десятичные дроби, поддерживают свойство IDENTITY, identity - это
автоматически инкрементируемый идентификатор строки. Обращайтесь к разделу
«Инструкция CREATE/ALTER TABLE» главы 3.
MONEY (тип данных SQL2003: отсутствует)
Хранит денежные значения в диапазоне от -922337203685477.5808 до
922337203685477.5807. Значение занимает 8 байт.
NCHAR(n), NATIONAL CHAR(n), NATIONAL CHARACTER(n) (тип данных SQL2003:
NA TIONA L CHA RA CTER(n))
Хранит данные формата UNICODE фиксированной длины до 4000 символов. Для
хранения требуется п*2 байт.
NTEXT, NATIONAL TEXT (тип данных SQL2003: NCLOB)
Хранит фрагменты текста в формате UNICODE длиной до 1 073 741 823 символа.
См. описание типа TEXT, где приведен список команд и функций, которые приме-
нимы и к типу NTEXT.
Типы данных SQL2003 и различных платформ | 67
NUMERIC(p, s) (тип данных SQL2003: DECIMAL (p, s))
Синоним типа DECIMAL. См. описание типа INT, где приведены правила, относя-
щиеся к свойству IDENTITY.
NVARCHAR(n), NATIONAL CHAR VARYING(n), NATIONAL CHARACTER VARYING(n)
(тип данных SQL2003: NATIONAL CHARACTER VARYING(n))
Хранит UNICODE-данные переменной длины до 4000 символов. Занимаемое
место вычисляется как удвоенное значение длины всех символов, вставленных
в поле (число символов * 2). В SQL Server системный параметр SET
ANSI PADDING^ для полей NCHAR и NVARCHAR всегда установлен (ON).
REAL, FLOAT(24)(mun данных SQL2003: REAL)
Хранит значения с плавающей точкой в диапазоне -3.40Е+38 до 3.40Е+38. Зани-
мает 4 байта. Тип REAL функционально эквивалентен типу FLOAT(24).
ROWVERSION (тип данных SQL2003: отсутствует)
Уникальное число, хранимое в базе данных, которое обновляется всякий раз,
когда обновляется строка. В более ранних версиях называется TIMESTAMP.
SMALLDATETIME (тип данных SQL2003: отсутствует)
Хранит дату и время в диапазоне от ‘01-01-1900 00:00’ до ’06-06-2079 23:59’
с точностью до минуты. (Минуты округляются до меньшего значения, если значе-
ние секунд 29.998 и менее, в противном случае они округляются до большего
значения.) Значение занимает 4 байта.
SMALLINT (тип данных SQL2003: SMALLINT)
Хранит целые числа со знаком или без знака в диапазоне от -32 768 до 32 767.
Занимает 2 байта. См. описание типа 1NT, где приведены правила, относящиеся
к свойству IDENTITY, которые также применимы и к этому типу.
SMALLMONEY (тип данных SQL2003: отсутствует)
Хранит денежные значения в диапазоне от 214748.3648 до -214748.3647. Значе-
ния занимают 4 байта.
SQL VARIANT (тип данных SQL2003: отсутствует)
Хранит значения, относящиеся к другим поддерживаемым SQL Server типам дан-
ных, за исключением типов TEXT, NTEXT, ROWVERSION и других значений типа
SQL_VARIANT. Может хранить до 8016 байт данных, поддерживаются значения
NULL и DEFAULT. Тип SQL_VARIANTиспользуется в столбцах, параметрах, пере-
менных и возвращаемых функциями и хранимыми процедур, ми значениях.
TABLE (тип данных SQL2003: отсутствует)
Специальный тип, хранящий получившийся в результате работы последнего про-
цесса набор данных. Используется исключительно для процедурной обработки
и не может применяться в инструкциях CREATE TABLE. Этот тип данных умень-
шает необходимость создания временных таблиц во многих приложениях. Может
уменьшить необходимость перекомпиляций процедур, ускоряя, таким образом,
выполнение хранимых процедур и пользовательских функций.
1 Дополнение пробелами по стандарту ANSI. - Примеч. пер.
68 | Глава 2. Основные понятия
TEXT (тип данных SQL2003: CLOB)
Хранит очень большие фрагменты текста длиной до 2 147 483 647 символов.
Значениями типа TEXT и IMAGE часто гораздо труднее манипулировать, чем, ска-
жем, значениями типа VARCHAR. Например, нельзя создавать индекс по столбцу
типа TEXT или IMAGE. Значениями типа TEXT можно манипулировать при
помощи функций DATALENGTH, PATINDEX, SUBSTRING. TEXTPTR и ТЕХ-
TVALID,tmK7Ke коками READTEXT, SET TEXTSIZE, UPDATETEXT и WRITETEXT.
TIMESTAMP (тип данных SQL2003: TIMESTAMP)
Хранит автоматически генерируемое двоичное число, обеспечивающее уникаль-
ность в текущей базе данных и, следовательно, отличающееся от типа данных
TIMESTAMP стандарта ANSI. Тип TIMESTAMP занимает 8 байт. В настоящее
время вместо TIMESTAMP для однозначной идентификации строк лучше приме-
нять значения типа ROWVERSION.
TINY1NT
Хранит целые числа без знака в диапазоне от 0 до 255 и занимает 1 байт. См. опи-
сание типа INT, где приведены правила, относящиеся к свойству IDENTITY,
которые также применимы и к этому типу.
UNIQUEIDENT1FIER (тип данных SQL2003: отсутствует)
Представляет собой значение, уникальное для всех баз данных и всех серверов.
Представлено в виде хххххххх-хххх-хххх-хххх-хххххххххххх, в котором каждый «х»
представляет собой шестнадцатеричное число в диапазоне 0-9 или а - f. Единст-
венными операциями, которые можно производить над значениями этого типа,
являются сравнение и проверка на NULL. В столбцах этого типа можно использо-
вать ограничения и свойства, за исключением свойства IDENTITY.
VARBINARY[(n)] (тип данных SQL2003: BLOB)
Представляет собой двоичное значение переменной длины, до 8000 байт. Зани-
маемое место соответствует размеру вставленных данных плюс 4 байта.
VARCHAR[(n)], CHAR VARYING [(п)], CHARACTER VARYING [(n)] (тип данных
SQL2003: CHARACTER VARYING (n))
Хранит символьные данные фиксированной длины размером от 1 до 8000 симво-
лов. Занимаемое место равно реальному размеру введенного значения в байтах,
а не значению п.
Ограничения
Ограничения позволяют автоматически обеспечивать целостность данных и фильтро-
вать данные, помещаемые в базу. По сути ограничения - это правила, которые опреде-
ляют, какие данные являются допустимыми при выполнении операций INSERT,
UPDATE и DELETE. Если при транзакции, связанной с модификацией данных, нару-
шается ограничение, транзакция отменяется.
В стандарте ANSI существует четыре типа ограничений: CHECK, PRIMARY KEY,
UNIQUE и FOREIGN KEY. (На разных платформах СУРБД может быть больше допус-
тимых видов ограничений. За описанием этих исключений обращайтесь к подразде-
Ограничения | 69
лам, посвященным соответствующим платформам, в разделе «Инструкция CREATE/
ALTER TABLE» главы 3.)
Область применимости
Ограничения могут применяться на уровне столбцов и на уровне таблиц.
Ограничения уровня столбцов
Объявляются при создании столбца и применимы только к нему.
Ограничения уровня таблиц
Объявляются независимо от определений столбцов (по традиции в конце инструк-
ции CREATE TABLE) и могут применяться к одному или нескольким столбцам
таблицы. Ограничение уровня таблицы необходимо в том случае, если вам нужно
создать ограничение, применимое более чем к одному столбцу.
Синтаксис
Ограничения определяются при создании таблицы или при внесении в нее изменений.
Общий синтаксис ограничений приведен ниже.
CONSTRAINT [имя-ограничения] тип_ограничения [ (столбец[,...]]
[предикат] [откладывание_ограничения] [время_откладывания]
Синтаксические элементы следующие.
CONSTRAINT [имяограничения]
Начинает определение ограничения и при желании присваивает ограничению
имя. Если вы опустите параметр имя_ограничения, система создаст имя автома-
тически. На некоторых платформах, например DB2, вы также можете опустить
и ключевое слово CONSTRAINT. Имена, генерируемые системой, часто являются
малопонятными. Хорошей практикой является давать ограничениям осмыслен-
ные, читаемые имена.
тип_ограничения
Объявляет ограничение одного из следующих типов: CHECK, PRIMARY KEY,
UNIQUE или FOREIGN KEY, Дополнительная информация о каждом из этих
типов будет дана ниже в этом разделе.
столбец [,...]
Связывает с ограничением один или несколько столбцов. Столбцы перечисляются
через запятую. Список столбцов должен заключаться в скобки. Для ограничений
уровня столбцов список столбцов следует опустить. Столбцы указываются не во
всех ограничениях. Например, в ограничениях типа CHECK, как правило, ссылки
на столбцы не используются.
предикат
Определяет предикат для ограничений типа CHECK.
откладываемое-Ограничение
Определяет для ограничения тип DEFERRABLE (допускающий откладывание)
или NOT DEFERRABLE (не допускающий откладывание). Если ограничение
допускает откладывание, вы можете указать, чтобы проверка нарушения правил
70 | Глава 2. Основные понятия
производилась в конце транзакции. Если ограничение не допускает откладывания,
выполнение правил проверяется после выполнения каждой инструкции SQL.
время_откладывания
Для ограничений, допускающих откладывание, определяется, является ли оно
изначально откладываемое {INITIALLY DEFERRED) или изначально безотлагатель-
ным {INITIALLYIMMEDIATE). Если ограничение определено как изначально откла-
дываемым, то время проверки ограничения сдвигается до конца транзакции, даже
если она состоит из множества инструкций SQL. Если ограничение определяется
как изначально безотлагательное, то проверка ограничения производится в конце
каждой инструкции SQL. В этом случае ограничение может быть как допускающим
откладывание {DEFERRABLE), так и не допускающим его {NOT DEFERRABLE).
По умолчанию ограничения являются изначально безотлагательными.
Отметьте, что в платформах разных производителей этот синтаксис может иметь
некоторые вариации. За более подробной информацией обращайтесь к подразделам,
посвященным разным платформам в разделе «Инструкция CREATE/ALTER TABLE»
главы 3.
Ограничения типа PRIMARY KEY
Ограничения типа PRIMARY KEY (первичный ключ) объявляются для одного или не-
скольких столбцов, значения которых однозначно идентифицируют каждую запись
таблицы. Данное ограничение считается особым случаем ограничения UNIQUE. Вот
некоторые правила, касающиеся первичных ключей.
• В таблице в данный момент времени может существовать только'один первичный
ключ.
• Столбцы первичных ключей не могут содержать типы данных BLOB, CLOB,
NCLOB и ARRAY.
• Первичные ключи можно определять на уровне столбца (одностолбцовый ключ)
или на уровне таблицы, если первичный ключ состоит из нескольких столбцов.
• Значения в столбце)ах) первичного ключа должны быть уникальны и не равны NULL.
• В многостолбцовом первичном ключе, который называется составным ключом
(concatenated key), комбинация значений во всех столбцах ключа должна быть
уникальна и не равна NULL.
• Для установления прямой взаимосвязи таблиц (или, возможно, хотя и редко, для
установления связи в пределах одной таблицы) можно объявлять внешние ключи,
ссылающиеся на первичный ключ таблицы.
Следующий код, соответствующий стандарту ANSI, включает варианты создания
ограничения типа PRIMARY KEY уровня столбца и уровня таблицы в таблице distri-
butors. В первом примере приводится ограничение PRIMARY KEY уровня столбца,
а во втором примере - уровня таблицы.
Ограничения | 71
-- Создание ограничений уровня столбца
CREATE TABLE distributors
(dist.id CHAR(4) NOT NULL PRIMARY KEY,
dist_name VARCHAR(4O),
dist_address1 VARCHAR(40),
dist_address2 VARCHAR(40),
city VARCHAR(20),
state CHAR(2)
zip CHAR(5)
phone CHAR(12) ,
sales_rep INT );
-- Создание ограничений уровня таблицы
CREATE TABLE distributors
(dist_id CHAR(4) NOT NULL,
dist_name VARCHAR(4O),
dist~address1 VARCHAR(4O),
dist_address2 VARCHAR(40),
city VARCHAR(20),
state CHAR(2)
zip CHAR(5)
phone CHAR(12)
sales_rep INT
CONSTRAINT pk_dist_ld PRIMARY KEY (dist_id));
В примере, в котором показан первичный ключ уровня таблицы, мы легко могли
бы создать сцепленный ключ, перечислив несколько столбцов, отделенных друг от
друга запятыми.
Ограничения типа FOREIGN KEY
Ограничения типа FOREIGN KEY (внешний ключ) объявляются для одного или не-
скольких столбцов таблицы, ссылающихся на столбец с ограничением UNIQUE или
PRIMARY KEY другой таблицы. (Внешний ключ может ссылаться на значение с при-
знаком уникальности или на первичный ключ в той же таблице, где он находится сам,
но такие ключи встречаются редко.) После этого внешние ключи могут предотвратить
ввод в таблицу данных, для которых нет соответствующих значений в связанной таб-
лице. Внешние ключи являются главными способами определения взаимосвязи
таблиц в реляционной базе данных. Вот некоторые правила, касающиеся внешних
ключей.
• В одной таблице могут одновременно существовать несколько внешних ключей.
• Внешний ключ можно объявить для определения ссылки на первичный ключ или
на значение с признаком уникальности для установления прямой связи между
двумя таблицами.
72 | Глава 2. Основные понятия
Полный синтаксис SQL2003 для внешних ключей более сложен, чем общий син-
таксис ограничений, показанный ранее, и он также зависит от того, объявляете вы его
на уровне таблицы или на уровне столбца.
-- Внешний ключ уровня таблицы
[CONSTRAINT [имя_ограничения]]
FOREIGN KEY (лоыльный_столбер [,...])
REFERENCES связанная_таблица [ (связанный~столбец [....]) ]
[MATCH {FULL I PARTIAL | SIMPLE}]
[ON UPDATE {NO ACTION i CASCADE | RESTRICT | SET NULL | SET DEFAULT}]
[ON DELETE {NO ACTION | CASCADE | RESTRICT } SET NULL | SET DEFAULT}]
[огклаАызание._ограничения] [ время-Откладывачия ]
-- Внешний ключ уровня столбца
[CONSTRAINT [имя_ограничения]]
REFERENCES связанная^таблица [ (связанный_столбец [,...]) ]
[MATCH {FULL I PARTIAL | SIMPLE}]
[ON UPDATE {NO ACTION | CASCADE | RESTRICT ! SET NULL | SET DEFAULT}]
[ON DELETE {NO ACTION | CASCADE | RESTRICT | SET NULL | SET DEFAULT}]
I откладывание..ограничения] [время_откладывания]
Ключевые слова, общие с объявлением стандартного ограничения, описаны выше
в разделе «Синтаксис». Ключевые слова, специфические для внешних ключей, описа-
ны в следующем перечне.
FOREIGN KEY (локальный^ столбег) [,...])
В создаваемой или изменяемой таблице объявляется один или несколько столб-
цов, к которым применяется ограничение типа FOREIGN KEY. Эта конструкция
используется только при объявлениях уровня таблицы и опускается при объявле-
ниях уровня столбца. Мы рекомендуем делать так, чтобы порядковое место и тип
данных каждого столбца в списке локальный-Столбец сравнительно совпадали
с порядковым положением и типом данных столбцов списка связанныйстолбец.
REFERENCES связан11ая_таблица[(связанный_столбец [,...])]
Называется таблица и, где нужно, столбец (столбцы), хранящий допустимый для
внешнего ключа список значений. Связаниыйстолбец должен уже быть опреде-
лен в предложениях NOT DEFERRABLE PRIMARY KEY или NOT DEFERRABLE
UNIQUE KEY. Типы таблиц должны совпадать. Например, если одна таблица
является временной локальной таблицей, то они обе должны быть временными
и локальными.
MATCH [FULL I PARTIAL | SIMPLE}
Определяет необходимую степень совпадения связывающего (локального) столб-
ца и связанного (внешнего) столбца при наличии в столбцах значений NULL..
FULL
Совпадение является приемлемым, если: 1) ни один из связывающих столбцов
не равен NULL и все значения совпадают со всеми значениями связанного
Ограничения | 73
столбца или 2) все значения связывающих столбцов равны NULL. Как прави-
ло, следует использовать параметр MATCH FULL или же обеспечить для всех
задействованных столбцов ограничения NOT NULL.
PARTIAL
Совпадение является приемлемым, если по меньшей мере один из связы-
вающих столбцов равен NULL, а остальные совпадают с соответствующими
значениями связанного столбца.
SIMPLE
Совпадение является приемлемым, когда любое значение в связывающем
столбце равно NULL или совпадает с соответствующим значением связанного
столбца. Этот вид совпадения принимается по умолчанию.
ON UPDATE
Указывает, что в том случае, если операция обновления UPDATE захватывает один
или несколько связанных_столбцов первичного или уникального ключа в связан-
ной таблице, следует выполнить соответствующее действие, чтобы ссылочная цело-
стность данных внешних ключей не была нарушена. Предложение ON UPDATE
можно объявить отдельно или же вместе с предложением ON DELETE. Если предло-
жение опущено, по умолчанию принимается ON UPDATE NO ACTION.
ON DELETE
Указывает, что в том случае, если операция удаления DELETE захватывает один
или несколько связанных_столбцов первичного или уникального ключа в связан-
ной таблице, следует выполнить соответствующее действие, чтобы ссылочная це-
лостность данных внешних ключей не была нарушена. Предложение ON DELETE
можно объявить отдельно или же вместе с предложением ON UPDATE. Если пред-
ложение опущено, по умолчанию принимается ON DELETE NO ACTION.
NO ACTION | CASCADE | RESTRICT | SET NULL | SET DEFAULT
Определяет действия, которые выполняет база данных для обеспечения ссы-
лочной целостности внешнего ключа, когда изменяется или удаляется значение
связанного первичного или уникального ключа.
NO ACTION
Указывает, что в том случае, если изменяется или удаляется значение
первичного или уникального ключа, связанного с внешним ключом, база
данных не выполняет никаких действий.
CASCADE
Указывает, что в том случае, если изменяется или удаляется значение
первичного или уникального ключа, база данных выполняет то же самое дей-
ствие (т. е. удаление или обновление) над внешним ключом.
RESTRICT
Указывает, что база данных не позволит изменить значение первичного или
уникального ключа, связанного с внешним ключом.
SET NULL
Указывает, что в случае изменения или удаления первичного или уникального
ключа база данных установит значение внешнего ключа в NULL.
74 | Глава 2. Основные понятия
SETDEFAULT
Указывает, что в случае изменения или удаления первичного или уникального
ключа база данных устанавливает для внешнего ключа значение по умолча-
нию (используя заданные вами для столбцов значения по умолчанию).
Как и в примере кода с первичными ключами, этот общий синтаксис можно ис-
пользовать и для внешних ключей уровня столбцов, и для внешних ключей уровня
таблицы. Заметьте, что ограничения уровня столбцов и уровня таблицы работают со-
вершенно одинаково. Они просто определяются на разных уровнях команды CREATE
TABLE. В следующем примере мы создадим одностолбцовый внешний ключ в столбце
salesrep, который будет ссылаться на столбец empid таблицы employee. Мы создадим
этот внешний ключ двумя способами, сначала на уровне столбца, а потом на уровне
таблицы.
-- Создание ограничения уровня столбца
CREATE TABLE distributors
(dist_id
dist_name
dist_addressi
dist_address2
city
state
zip
phone
sales_rep
CHAR(4) PRIMARY KEY,
VARCHAR(40),
VARCHAR(4C),
VARCHAR(40),
VARCHAR(20),
CHAR(2)
CHAR(5)
CHAR(12)
INT NOT
NULL REFERENCES employee(empid));
-- Создание ограничения уровня таблице1.
CREATE TABLE distributors
(dist„id CHAR(4) NOT NULL,
dist.name VARCHAR(40),
dist.address1. VARCHAR(40)
dist. address2 VARCHAR(40),
city VARCHAR(20),
state CHAR(2)
zip CHAR(5)
phone CHAR(12)
sales_rep INT
CONSTRAINT pk_dist_id PRIMARY KEY (dist_id),
CONSTRAINT fk_empid FOREIGN KEY (sales.rep)
REFERENCES employee(empid));
Ограничения | 75
Ограничения типа UNIQUE
Ограничения UNIQUE, которые иногда называют потенциальными ключами, объяв-
ляют, что значения в одном столбце или комбинация значений в нескольких столбцах
должны быть уникальны. Правила, связанные с ограничениями типа UNIQUE, сле-
дующие.
• Столбцы в уникальном ключе не могут содержать типов данных BLOB, CLOB,
NCLOB или ARRAY.
• Столбец или столбцы в уникальном ключе не могут быть идентичны столбцу или
столбцам других уникальных ключей или любым столбцам первичного ключа
таблицы.
• Если уникальный ключ допускает значения NULL, разрешается одиночное значе-
ние NULL.
• SQL2003 позволяет заменять список столбцов, показанный в общей схеме синтак-
сиса ограничений, ключевым словом (VALUE). UNIQUE (VALUE) обозначает, что
все столбцы таблицы являются частью уникального ключа. Ключевое слово
VALUE также отменяет все прочие уникальные и первичные ключи таблицы.
В следующем примере мы ограничиваем количество распространителей (distributors),
с которыми мы работаем, одним распространителем на почтовую зону (на ZIP-код). Мы
также допускаем наличие одного (и только одного) «общего» распространителя с ZIP-
кодом NULL. Эту схему можно реализовать при помощи ограничения UNIQUE либо на
уровне столбца, либо на уровне таблицы.
Создание ограничения уровня столбца
CREATE TABLE distributors
(dist_id CHAR(4) PRIMARY KEY,
dist_name VARCHAR(40),
dist_addressl VARCHAR(40),
dist_address2 VARCHAR(40),
city VARCHAR(20),
state CHAR(2)
zip CHAR(5) UNIQUE ,
phone CHAR(12)
sales_rep INT NOT NULL
REFERENCES employee(empid));
-- Создание ограничения уровня таблицы
CREATE TABLE distributors
(dist^id CHAR(4) NOT NULL,
dist_name VARCHAR(40),
dist_address1 VARCHAR(40),
dist_address2 VARCHAR(40),
city VARCHAR(20),
state CHAR(2)
76 | Глава 2. Основные понятия
zip CHAR(5)
phone CHARU2) ,
salec_rep INT
CONSTRAINT pk..dist_id PRIMARY KEY (dist_id),
CONSTRAINT fk._onip_.id FOREIGN KEY (за1ео_-ер)
REFERENCES eniployee(ompid),
CONSTRAINT unq_zip UNIQUE (zip) );
Ограничения типа CHECK
Ограничения типа CHECK (проверочные ограничения) позволяют выполнять опера-
ции сравнения, чтобы определить, соответствуют ли значения определенным задан-
ным условиям. Синтаксис ограничений типа CHECK очень похож на общий синтак-
сис ограничений.
CONSTRAINT [имя ограничения] CHECK (условия_поиска)
[ откладывание..ограниченияj [еремя_откладывания]
С другими элементами этого ограничения мы познакомимся в этом разделе.
условияпоиска
Параметр определяет с помощью одного или нескольких выражений и предиката
одно или несколько условий поиска, которые накладывают ограничения на значе-
ния, вставляемые в столбец или таблицу. Для столбца можно указать несколько
условий поиска с помощью операторов AND и OR. (Вспомните предложение
WHERE.)
Считается, что значение удовлетворяет ограничению типа CHECK, если результа-
том проверки условий поиска является значение TRUE или UNKNOWN. Ограничения
типа CHECK используют только булевы операторы (например, =, >=> <= или <>), хотя
они могут включать любые предикаты SQL2003, например IN или LIKE. Ограничения
типа CHECK можно соединять друг с другом (при проверке одного столбца) с помо-
щью операторов AND и OR. Вог еще несколько правил, касающихся ограничений типа
CHECK.
• Столбец или таблица могут включать одно или несколько ограничений типа
CHECK.
• Условия поиска не могут содержать агрегатные функции, исключением является
их использование в подзапросе.
• В условиях поиска нельзя использовать недетерминированные функции и подза-
просы.
• Ограничение типа CHECK может ссылаться только на идентичные объекты.
Поэтому, если ограничение объявлено в глобальной временной таблице, оно не
может ссылаться на постоянную таблицу.
• В условиях поиска нельзя ссылаться на следующие функции ANSI:
CURRENTUSER, SESSION USER, SYSTEM USER, USER, CURRENTPATH,
CURRENTDATE, CURRENTTIME, CURRENTJ1MESTAMP, LOCALTIME
и LOCALTIMESTAMP.
Ограничения | 77
В следующем примере в столбцы dist_id и zip добавляется проверочное ограниче-
ние. (В этом примере используется общий код, работающий на SQL Server.) ZIP-код
должен соответствовать типичным диапазонам почтовых ZIP-кодов, а значения столб-
ца dist_id могут содержать или четыре буквенных символа, или два буквенных и два
числовых символа.
-- Создание ограничений CHECK уровня столбца
CREATE TABLE distributors
(dist.id CHAR(4)
CONSTRAINT pk_dist_id PRIMARY KEY
CONSTRAINT ck_dist_id CHECK
(dist_id LIKE '[A-Z][A-Z][A-Z][A-Z]' OR
dist_id LIKE '[A-Z][A-Z][0-9][0-9]'),
dist_name VARCHAR(40),
dist_addressl VARCHAR(40),
dist_address2 VARCHAR(40),
city VARCHAR(20),
state CHAR(2)
CONSTRAINT def_st DEFAULT ("CA"),
zip CHAR(5)
CONSTRAINT unq_dist.zip UNIQUE
CONSTRAINT ck_dist_zip CHECK
(zip LIKE '[0-9][0-9][0-9][0-9][0-9]’),
phone CHAR(12),
sales_rep INT
NOT NULL DEFAULT USER REFERENCES employee(emp_id))
78 | Глава 2. Основные понятия
3
Справочник
по инструкциям SQL
Эта глава самая главная в книге «SQL: справочник». Она представляет собой расположен-
ный в алфавитном порядке перечень инструкций SQL с подробными объяснениями и при-
мерами. Каждая инструкция или функция определяется в табл. 3.1 как «поддерживаемая»,
«поддерживаемая с вариантами», «поддерживаемая с ограничениями» и «не поддерживае-
мая» каждым из пяти диалектов SQL, описываемых в этой книге: DB2, MySQL, Oracle,
PostgreSQL, SQL Server. После краткого описания стандарта SQL2003 коротко, ио основа-
тельно, обсуждаются все реализации с приведением примеров. Если какая-то платформа
не поддерживает данную команду, этот факт фиксируется в таблице, предваряющей описа-
ние команды, после чего описание команды для этой платформы не приводится. Также,
хотя книга «SQL: справочник» и не является полным обзором стандарта SQL2003, каждая
команда сравнивается со стандартом SQL2003.
Как работать с этой главой
При изучении команды в этой главе:
1. Прочитайте раздел «Поддержка SQL платформами».
2. Изучите таблицу поддержки команд платформами.
3. Прочитайте раздел, посвященный синтаксису SQL2003, и описание, даже если
вам нужна реализация команды на конкретной платформе.
4. И наконец, прочитайте информацию, относящуюся к реализации команды на
конкретной платформе.
В этой главе обсуждаются все свойства, общие для разных реализаций команды,
а затем они сравниваются с соответствующей темой SQL2003. Таким образом, подраз-
дел, посвященный реализации команды на конкретной платформе, может не давать
описания всех аспектов этой команды, поскольку некоторые детали попадают в раз-
дел, относящийся к SQL2003. Пожалуйста, обратите внимание, что если ключевое
слово есть в синтаксисе, но отсутствует его описание, это означает, что мы решили не
повторять описания, приведенного в разделе, относящемся к стандарту ANSI.
Если вы перейдете прямо к реализациям команд на платформе и не увидите
обсуждение интересующего вас ключевого слова или предложения, это оз-
начает, что оно приведено в разделе SQL2003, в подразделе, посвященном
этой команде (это замечание применимо ко всем описанным платформам).
Поддержка SQL платформами
В табл. 3.1 приведены инструкции SQL, поддерживающие их платформы и уровни
поддержки инструкции данной платформой. Ниже приводятся советы по чтению табл. 3.1,
а также расшифровка обозначений. В последующих разделах подробно описываются
команды, входящие в таблицу.
1. Первый столбец содержит отсортированный по алфавиту список команд SQL.
2. Для каждой команды во втором столбце указан класс, к которому она принадлежит.
3. В следующих столбцах перечислены уровни поддержки команд платформами.
Поддерживается (П)
Платформа поддерживает для данной конкретной команды стандарт SQL2003.
Поддерживается с вариантами (ПСВ)
Платформа поддерживает для данной конкретной команды стандарт SQL2003,
используя специфичный для производителя код или синтаксис.
Поддерживается с ограничениями (ПСО)
Платформа поддерживает некоторые, но не все функции, определяемые стан-
дартом SQL2003 для данной команды.
Не поддерживается (ПП)
Платформа не поддерживает данную команду в соответствии со стандартом
SQL2003.
Помните, что даже если какая-то команда SQL2003 указана как «не поддерживае-
мая», платформа обычно предлагает альтернативный код или синтаксис, которые мо-
делируют функциональность данной команды или функции. Поэтому обязательно чи-
тайте обсуждение и примеры, приведенные для каждой команды, ниже в этой главе.
Более того, несколько команд из табл. 3.1, которые отсутствуют в стандарте SQL2003,
помечены словами «Не-ANSI» в столбце, озаглавленном «Класс SQL2003».
И наоборот, несколько команд ANSI, приведенных в таблице (например, CREATE
DOMAIN и ALTER DOMAIN) в настоящее время не поддерживаются ни одной из плат-
форм, упомянутых в этом тексте. Поскольку в этой книге основное внимание уделяет-
ся реализации языка SQL, неподдерживаемые команды ANSI приведены в табл. 3.1,
но они не документируются больше нигде в этой книге.
80 | Глава 3. Справочник по инструкциям SQL
Таблица 3.1. Список команд SQL
Команда SQL2003 Класс SQL2003 DB2 v8.1 MySQI v4.0 j Oracle vlOg Postgre SQL V7.2 SQL Server 2000
ALLIANYISOME SQL-data П НП П П П
BETWEEN SQL-data П П П П П
ALTER DATABASE SQL-schema ПСВ ПСВ ПСВ ПСВ ПСВ
ALTER DOMAIN SQL-schema НП НП НП НП НП
ALTER FUNCTION SQL-schema ПСВ ПСО ПСВ ПСО ПСВ
ALTER INDEX Non-ANSI ПСВ ПСВ ПСВ ПСВ ПСВ
ALTER METHOD SQL-schema ПСВ НП НП НП НП
ALTER PROCEDURE SQL-schema ПСВ ПСО ПСВ ПСО ПСВ
ALTER TABLE SQL-schema ПСВ ПСВ ПСВ ПСВ ПСВ
ALTER TRIGGER Non-ANSI ПСВ НПТ ПСВ ПСВ ПСВ
ALTER TYPE SQL-schema ПСВ НП ПСВ НП НП
ALTER VIEW Non-ANSI ПСВ НП ПСВ ПСВ ПСВ
CALL SQL-control ПСВ НПТ ПСВ НП НП
CLOSE CURSOR SQL-data ПСВ НП П П ПСВ
COMMIT SQL-transaction П ПСВ ПСВ ПСВ ПСВ
CONNECT SQL-connection ПСВ НП П НП ПСВ
CREATE DATABASE Non-ANSI ПСВ ПСВ ПСВ ПСВ ПСВ
CREATE DOMAIN SQL-schema НП НП НП НП НП
CREATE FUNCTION SQL-schema ПСВ ПСО ПСВ ПСО ПСВ
CREATE INDEX Non-ANSI ПСВ ПСВ ПСВ ПСВ ПСВ
CREATE METHOD SQL-schema ПСВ НП НП НП НП
CREATE PROCEDURE SQL-schema П НП П НП П
CREATE ROLE SQL-schema НП НП ПСВ НП НП
CREATE SCHEMA SQL-schema ПСО НП ПСВ НП ПСО
CREATE TABLE SQL-schema ПСВ ПСВ ПСВ ПСВ ПСВ
CREATE TRIGGER SQL-schema ПСВ НП ПСВ ПСВ ПСВ
CREATE TYPE SQL-schema ПСВ НП ПСО ПСВ НП
CREATE VIEW SQL-schema ПСВ НП ПСВ ПСВ ПСВ
DECLARE CURSOR SQL-data ПСО НП ПСО ПСО ПСО
DELETE SQL-data ПСВ ПСВ ПСВ П ПСО
DISCONNECT SQL-connection ПСО НП ПСО НП ПСО
DROP DATABASE Non-ANSI НП ПСВ П ПСВ ПСВ
6-2447
Поддержка SQL платформами | 81
Таблица 3.1. Список команд SQL (Продолжение)
Команда SQL2003 Класс SQL2003 DB2 v8.1 MySQI v4.0 a Oracle viog Postgre SQL v7.2 SQL Server 2000
DROP DOMAIN SQL-schema НП НП НП НП НП
DROP FUNCTION SQL-schema ПСВ ПСВ ПСВ ПСВ ПСВ
DROP INDEX Non-ANSI ПСВ ПСВ ПСВ ПСВ ПСВ
DROP METHOD SQL-schema ПСВ НП ПСВ ПСВ НП
DROP PROCEDURE SQL-schema ПСВ НП П НП П
DROP ROLE SQL-schema НП НП ПСВ НП НП
DROP TABLE SQL-schema ПСВ ПСВ ПСВ ПСВ ПСВ
DROP TYPE SQL-schema П НП П П НП
DROP TRIGGER SQL-schema ПСВ НП ПСВ ПСВ ПСВ
DROP VIEW SQL-schema П НП П П П
EXCEPT SQL-data ПСО НП ПСО ПСО НП
EXISTS SQL-data П П П П П
FETCH SQL-data ПСО НП ПСО ПСВ ПСВ
GRANT SQL-schema ПСВ ПСВ ПСВ ПСВ ПСВ
IN SQL-data П П ПСВ П П
INSERT SQL-data ПСВ ПСВ ПСВ П ПСВ
INTERSECT SQL-data ПСО НП ПСО ПСО НП
IS SQL-data П П П П П
JOIN-предл ожение SQL-data ПСО ПСВ П ПСВ ПСО
LIKE SQL-data П ПСВ П ПСВ ПСВ
MERGE SQL-data П НП П НП НП
OPEN SQL-data ПСВ НП П НП П
OPERATORS SQL-schema ПСВ ПСВ ПСВ ПСВ ПСВ
ORDER BY SQL-data ПСО ПСО ПСВ ПСВ ПСО
RELEASE SA VEPOINT SQL-transaction ПСВ НП НП НП НП
RETURN SQL-control ПСВ НП П ПСО П
REVOKE SQL-schema ПСВ ПСВ ПСВ ПСВ ПСВ
ROLLBACK SQL-transaction П ПСО ПСВ ПСО ПСВ
SAVEPOINT SQL-transaction ПСВ НП П НП ПСО
82 | Глава 3. Справочник по инструкциям SQL
Таблица 3.1. Список команд SQL (Продолжение)
Команда SQL2003 Класс SQL2003 DB2 v8.1 MySQL v4.0 Oracle vlOg Postgre SQL v7.2 SQL Server 2000
SELECT SQL-data ПСВ (под- держи- ваются соеди- нения ANSI) ПСВ (частич- но под- держи- ваются соеди- нения ANSI) ПСВ (под- держи- ваются соеди- нения ANSI) ПСВ (частично под- держива- ются соедине- ния ANSI) ПСВ (под- держива- ются со- единения ANSI)
SET SQL-session П [1 ни П п
SET CATALOG SQL-scssion НП 1ГГ1 НП НП НП
SET COLLATION SQL-session НП НП НП НП НП
SET CONNECTION SQL-connection ПСО НП НП НП ПСО
SET CONSTRAINT SQL-connection НП НП ПСВ ПСВ пп
SET DESCRIPTOR SQL-session НП НН пп НП III I
Справочник по командам SQL
Операторы ALL/ANY/SOME
Оператор ALL выполняет булеву проверку подзапроса на предмет того, во всех ли
строках существуют значения. Оператор ANY и его синоним SOME выполняют булеву
проверку подзапроса на предмет того, существует ли хоть одно значение в анали-
зируемых строках.
Платформа Команда
DB2 Поддерживается
MySQL Не поддерживается
Oracle Поддерживается
PostgreSQL I (оддерживастся
SQL Server I (оддсрживается
Синтаксис SQL2003
SELECT ...
WHERE выражение сравнение {ALL | ANY | SOME} {подзапрос)
Справочник по командам SQL | 83
Ключевые слова
WHERE выражение
Скалярное выражение (например, столбец) в случае ALL сравнивается со всеми
значениями в подзапросе, а в случае ANY или SOME - с каждым выражением
в подзапросе до тех пор, пока не будет найдено совпадение. В случае оператора
ALL, чтобы возвращаемым значением было TRUE, все строки должны совпадать
с выражением. В случае оператора ANY или SOME с выражением должна совпасть
одна или несколько строк.
сравнение
Сравнивает выражение и подзапрос. Сравнение должно представлять собой стан-
дартный оператор сравнения, такой, как =, <>, !=, >, >=, < или <=.
Общие правила
Оператор ALL возвращает булево значение TRUE в одном из двух случаев: либо под-
запрос возвращает пустой набор данных (т. е. не возвращает записей), либо все записи
в наборе выдерживают сравнение. Оператор ALL возвращает значение FALSE, если
сравнение выдерживают не все записи в наборе. Операторы ANY и SOME возвращают
булево значение TRUE, если хотя бы одна запись подзапроса выдерживает сравнение,
и FALSE, если ни одна из записей не выдерживает сравнение (или когда подзапрос
возвращает пустой набор данных). Если хотя бы одно возвращаемое подзапросом
значение равно NULL, то результатом проверки будет NULL, а не TRUE.
Не включайте в подзапрос специальные предложения, такие, как ORDER
BY, GROUP BY, CUBE, ROLLUP, WITH и m. n. За дополнительной информа-
цией обращайтесь к запросу «Подынструкция SUBQUERY».
Например, мы хотим увидеть всех авторов, не имеющих напечатанных произведений.
SELECT au_id
FROM authors
WHERE au_id <> ALL(SELECT au_id FROM titleauthor)
Операторы ANY/SOME вы можете использовать для создания различного рода
фильтров. Например, в следующем запросе из таблицы employees извлекаются записи
обо всех служащих, работающих в Анкоридже и внесенных в таблицу
employeesarchive.
SELECT *
FROM employees
WHERE job_lvl = ANY(SELECT job_lvl FROM employee_archive WHERE city = 'Anchorage')
Приведенный выше запрос покажет информацию о служащих, которые имеют уро-
вень joblvl такой же, как любой служащий, работающий в Анкоридже, штат Аляска.
84 | Глава 3. Справочник по инструкциям SQL
Советы и хитрости программирования
Операторы ALL и ANY/SOME довольно сложно использовать. Большинство разра-
ботчиков считают, что гораздо легче использовать сходные функции IN н EXISTS.
Оператор EXISTS семантически эквивалентен оператору ANY/SOME.
Различия в реализациях на разных платформах
Все платформы поддерживают операторы ALL и ANY/SOME в том виде, как это описа-
но выше, за исключением MySQL, в котором до версии 4.0 не было поддержки подза-
просов. На платформах MySQL версий более ранних, чем 4.0, попробуйте вместо
операторов ANY/SOME использовать операторы IN и EXISTS.
В Oracle поддерживается небольшая вариация, отличительной особенностью которой
является то, что вы можете задать вместо подзапроса список значений. Например,
можно найти всех служащих, у которых job_lvl равен 9 или 14.
SELECT * FROM employee
WHERE job_lvl = ALL (9. 14)
В DB2 и SQL Server поддерживаются дополнительные операции сравнения: не
более (!>) и не менее (!<).
См. также
ALL/ANY/SOME
BETWEEN
EXISTS
SELECT
WHERE
Оператор BETWEEN
Оператор BETWEEN выполняет булеву проверку значения на соответствие диапазону
значений. Оператор возвращает TRUE, если значение входит в диапазон, и FALSE, если
значение не входит в диапазон. Если любое значение диапазона равно NULL (неизвестно),
то результат будет NULL.
Платформа Команда
DB2 Поддерживается
MySQL Поддерживается
Oracle Поддерживается
PostgreSQL Поддерживается
SQL Server Поддерживается
Справочник по командам SQL | 85
Синтаксис SQL2003
SELECT ...
WHERE выражение [NOT] BETWEEN нижняя_граница AND верхняя_граница
Ключевые слова
WHERE выражение
Проверяет скалярное выражение (например, столбец) на соответствие диапазону
значений, лежащих между верхней_границей и нижней_границей.
[NOT] BETWEEN нижняя_граница AND верхияяграница
Сравнивает выражение с нижней ^границей и верхней_границей. Сравнение
включает крайние значения, т. е. это все равно что «где выражение [не] больше
или равно нижней_границе и меньше или равно верхией границе».
Общие правила
Оператор BETWEEN используется для проверки выражения на соответствие диапазо-
ну значений. Оператор BETWEEN может использоваться с любым типом данных, за
исключением BLOB, CLOB, NCLOB, REF и ARRAY.
Например, нам нужно увидеть номера произведений (title_id), для которых
объемы продаж с начала года (ytd_sales) лежат в диапазоне от 10000 до 20000.
SELECT title_id
FROM titles
WHERE ytd._sales BETWEEN 10000 AND 20000
Оператор BETWEEN включает границы диапазона. В данном случае в результат
будут включены значения 10000 и 20000. Если вам нужно провести поиск, не включая
границы диапазона, вы должны использовать символы «больше» (>) и меньше (<).
SELECT title_id
FROM titles
WHERE ytd_sales > 10000
AND ytd_sales < 20000
Оператор NOT позволяет проводить поиск за пределами диапазона, указанного
в операторе BETWEEN. Так, вы можете найти номера всех произведений (titleid),
которые публиковались не в 2003 году.
SELECT title.id
FROM titles
WHERE pub.date NOT BETWEEN '01-JAN-2003' AND ' 31-DEC-2003'
Советы и хитрости программирования
Некоторые программисты очень привередливо относятся к тому, как в предложениях
WHERE используется ключевое слово AND. Чтобы незнакомый с кодом человек не по-
думал, что оператор AND, используемый в операторе BETWEEN, является логическим
оператором, вы можете заключить все предложение BETWEEN в скобки.
86 | Глава 3. Справочник по инструкциям SQL
SELECT title.id
FROM titles
WHERE (ytd_sales BETWEEN' 1OOOO AND 20000)
AND pubdate >= '1991-06-12 00:00:00.000'
Различия в реализациях на разных платформах
Все платформы поддерживают оператор BETWEEN в том виде, как это описано выше.
См. также
ALL/ANY/SOME
EXISTS
SELECT
WHERE
Инструкция CALL
Инструкция CALL вызывает хранимую процедуру.
Платформа Команда
DB2 Поддерживается с вариантами
MySQL Не поддерживается
Oracle Поддерживается с вариантами
PostgreSQL Не поддерживается
SQL Server Не поддерживается
Синтаксис SQL2003
CALL имя_процедуры ([параметр [,...]])
Ключевые слова
CALL имя_иро1/едуры
Указывает имя хранимой процедуры, которую вы хотите вызвать. Это должна
быть заранее созданная процедура, доступная в контексте текущего пользователя
(в экземпляре, базе данных, схеме и т. п.).
(параметр [,...])
Определяет значения входных параметров, необходимых для хранимой процеду-
ры. Нужно, чтобы каждый указанный параметр процедуры находился на своем
порядковом месте. Следовательно, параметр, указанный пятым, передает значе-
ние пятому аргументу хранимой процедуры. Параметры должны быть заключены
в скобки и отделяться друг от друга запятыми. Отметьте, что скобки необходимы
даже в том случае, если параметры отсутствуют [т. е. даже если нет параметров,
Справочник по командам SQL | 87
вы все равно должны писать CALL ( )]. Строки нужно заключать в одинарные
кавычки. Если хранимая процедура имеет только выходные (OUT) параметры,
помещайте соответствующие переменные или маркеры параметров в скобки.
Общие правила
Инструкция CALL облегчает вызов хранимой процедуры. Просто укажите имя храни-
мой процедуры и все используемые ею параметры, заключив их в скобки.
В этом примере кода для Oracle создается простая хранимая процедура, а затем
выполняется ее вызов.
CREATE PROCEDURE update_employee_salary
(emp_id NUMBER, updated_salary NUMBER)
IS
BEGIN
UPDATE employee SET salary = updated_salary
WHERE employee_id=emp_id
END;
CALL update_employee_salary(1517, 95000);
Советы и хитрости программирования
Возвращаемое значение хранимой процедуры, как правило, определяется с помощью
команды GET DIAGNOSTIC. Эта команда не очень распространена среди платформ
баз данных, поэтому подробную информацию ищите в документации платформы.
Многие платформы также поддерживают альтернативную команду EXECUTE,
имеющую те же возможности. В некоторых случаях EXECUTE может оказаться пред-
почтительнее, чем CALL, поскольку ее можно использовать для запуска любого зара-
нее подготовленного кода SQL, в том числе методов, функций и пакетов кода SQL.
DBS
Платформа DB2 поддерживает оператор CALL с дополнительными возможностями
DESCRIPTOR.
CALL имя_процедуры {[параметр | USING DESCRIPTOR имя_дискриптора{
Где:
USING DESCRIPTOR имя Дескриптор a
Определяет структуру SQL Descriptor Area (SQLDA), которая содержит описания
хост-переменных1. SQLDA представляет собой коллекцию переменных, которые
необходимы для выполнения инструкции SQL DESCRIBE. Переменные SQLDA -
это опции, которые могут использоваться в инструкциях PREPARE, OPEN,
FETCH, EXECUTE и CALL. Значения в SQLDA должны быть определены до
Хост-переменная (базовая переменная) - переменная, используемая в операциях в базе
данных. Может содержать значение из столбца таблицы. - Примеч. пер.
88 | Глава 3. Справочник по инструкциям SQL
запуска команды CALL. В DB2 эта функциональность исчезает. Мы рекомендуем
использовать вместо нее стандартный синтаксис CALL proc (param, param).
Платформа DB2 позволяет везде, где это нужно, заменять хост-переменные
именем процедуры или параметрами. При использовании предложения USING DESCRIPTOR
переменные должны быть строковыми, длиной не более 254 символов.
В DB2 возвращаемое хранимой процедурой значение помещается в поле SQLERRD
в SQLCA (SQL Communication Area). Вы также можете использовать инструкцию
GET DIAGNOSTIC для получения значения RETURNJSTATUS (-1 указывает на ошибку)
или числа строк.
MySQL
Не поддерживается.
Oracle
Платформа Oracle позволяет использовать инструкцию CALL для вызова самостоятельных
хранимых процедур, функций и методов, а также хранимых процедур и функций,
содержащихся внутри типа или пакета. Вот синтаксис Oracle.
CALL [схема. )[{имя_типа | имя_пакета[.] имя_процедуры@с1ЬИпк
[(.параметр [,...])]
[INTO имя~переменной [[INDICATOR] : имя_индикатораТ\
Где:
CALL [schema.][{имя_типа | имя_пакета}.] нмя_ироцедуры@с1ЬНпк
Вызов именованного объекта. Вы можете указать имя объекта полностью, в том
числе схему, тип и т. п., или позволить Oracle предположить, что объект находится
в текущей схеме и текущем экземпляре базы данных. Если процедура или функ-
ция находится в другой базе данных, просто укажите эту базу с помощью имени
связи с базой данных (параметр @dblink в синтаксисе). Параметр @dblink должен
ссылаться на ранее созданное соединение с базой данных.
INTO :имя_переменной
Указывается имя ранее объявленной переменной, которая будет хранить возвра-
щаемое вызванной функцией значение. Параметр INTO используется и является
необходимым только в том случае, если вызывается функция.
INDICATOR :имя_инднкатора
Хранит предложение для хост-переменной - например, равно ли возвращаемое
значение NULL для функций, откомпилированных в процедуре Рго*С/С+-1 .
В параметры, применяемые в Oracle, нельзя включать псевдостолбцы или функ-
ции VALUE и REF. Вы должны использовать хост-переменные для любых параметров,
соответствующие аргументу OUT или IN OUT вызванной хранимой процедуры.
PostgreSQL
Не поддерживается.
Справочник по командам SQL | 89
SQL Server
He поддерживается. Вместо этой команды используется не входящая в стандарт ANSI
инструкция EXECUTE.
См. также
CREАТЕ/ALTER PROCEDURE
Инструкция CLOSE CURSOR
Инструкция CLOSE CURSOR закрывает курсор, созданный на серверной стороне
соединения с помощью инструкции DECLARE CURSOR.
Платформа Команда
DB2 Поддерживается с вариантами
MySQL Не поддерживается
Oracle Поддерживается
PostgreSQL Поддерживается
SQL Server Поддерживается с вариантами
Синтаксис SQL2003
CLOSE имя~курсора
Ключевые слова
имя_курсора
Имя курсора, ранее созданного с помощью инструкции DECLARE CURSOR.
Общие правила
Инструкция CLOSE закрывает курсор и удаляет связанный с ним результирующий
набор данных. Во всех платформах снимаются блокировки, связанные с курсором,
хотя это и не указано в стандарте ANSI. Пример:
CLOSE author_names_cursor;
Советы и хитрости программирования
Вы также можете закрыть курсор неявно, используя инструкцию COMMIT или, для
курсоров, которые были определены с предложением WITH HOLD, с помощью инструк-
ции ROLLBACK.
DBS
В DB2 для инструкции CLOSE поддерживается дополнительное необязательное пред-
ложение WITH.
90 | Глава 3. Справочник по инструкциям SQL
CLOSE имя_курсора [WITH RELEASE]
Где:
WITH RELEASE
Производится попытка снять все блокировки чтения, связанные с курсором.
Заметьте, что DB2 не всегда может снять все блокировки, поскольку некоторые
блокировки могуч использоваться другими операциями.
Предложение WITH RELEASE игнорируется для курсоров уровня изоляции 3 CS
или UR, если курсор определяется в методе, если курсор определяется в функции или
если курсор определяется в хранимой процедуре, которая вызывается функцией или
методом. Предложение WITH RELEASE может привести к таким аномалиям, как фан-
томное чтение или невоспроизводимое чтение, при работе на уровнях изоляции RS
и RR. За подробными объяснениями уровней изоляции, в том числе фантомных чтений
и невоспроизводимых чтений, обращайтесь к пункту SET TRANSACTION ISOLATION
LEVEL.
PostgreSQL
Платформа PostgreSQL поддерживает стандартный синтаксис ANSI. В PostgreSQL
команда CLOSE неявно выполняется для каждого открытого курсора при заверше-
нии транзакции с помощью инструкций COMMIT или ROLLBACK.
SQL Server
В Microsoft SQL Server поддерживается стандартный синтаксис ANSI, а также допол-
нительное ключевое слово GLOBAL.
close [.global] имя курсора
Где:
GLOBAL
Идентифицирует ранее определенный курсор как глобальный.
Согласно стандарту ANSI при закрытии курсора удаляется результирующий набор
данных. Блокировка является физическим свойством каждой платформы и входит
в ANSI SQL. Тем не менее все описываемые здесь платформы снимаю! блокировки,
созданные курсором. Еще одной деталью физической реализации является то, что
SQL Server не переводит память, занимаемую курсором, в общий пул памяти. Для
завершения этого перевода вы должны подать команду DEALLOCATE имя курсора.
В данном примере для Microsoft SQL Server производится открьпие курсора и выборка
набора данных обо всех служащих, чья фамилия начинается на «К».
DECLARE epployes.-Cursor CURSOR FOR
SEi.FCT i.nurne. friame
f.ROM pubs opo. employee
rtHEFE. J.-rime LIKE 'K%'
OPEN o,7iOiCyee_CL'rsor
Справочник по командам SQL | VI
FETCH NEXT FROM employee_cursor
WHILE @@FETCH_STATUS = О
BEGIN
FETCH NEXT FROM employee_cursor
END
CLOSE employee_cursor
DEALLOCATE employee_cursor
GO
См. также
DECLARE CURSOR
FETCH
OPEN
Инструкция COMMIT
Инструкция COMMIT явным образом закрывает открытую транзакцию и делает изме-
нения в базе данных постоянными. Открываться транзакции могут неявно, например
при выполнении инструкций INSERT, UPDATE или DELETE, или явно, с помощью
инструкции START. В любом случае открытая транзакция закрывается явно командой
COMMIT.
Платформа Команда
DB2 Поддерживается
MySQL Поддерживается с вариантами
Oracle Поддерживается с вариантами
PostgreSQL Поддерживается с вариантами
SQL Server Поддерживается с вариантами
Синтаксис SQL2003
COMMIT [WORK] [AND [NO] CHAIN]
92 | Глава 3. Справочник по инструкциям SQL
Ключевые слова
COMMIT [WORK]
Заканчивает текущую открытую транзакцию и записывает данные, которыми
манипулировала транзакция, в базу данных. Необязательное ключевое слово WORK
является пустым, не оказывает никакого влияния.
AND [NO] CHAIN
Параметр AND CHAIN указывает, что СУРБД должна работать со следующей
транзакцией так, как если бы она была частью текущей транзакции. В результате
эти две транзакции, будучи отдельными частями работы, совместно используют
общую среду транзакции (например, уровень изоляции). Если использовать не-
обязательное ключевое слово NO, СУРБД получит явное указание использовать
действия, принятые в стандарте ANSI по умолчанию. Слово COMMIT без других
ключевых слов функционально эквивалентно инструкции COMMIT WORK AND
NO CHAIN.
Общие правила
В простых случаях вы будете осуществлять транзакции (т. е. выполнять код SQL,
который манипулирует данными и объектами базы или изменяет их) без явного их
объявления. Однако лучше всего управлять транзакциями, если явно включить их
в инструкцию COMMIT. Поскольку записи и даже целые таблицы могут оказаться
заблокированы на время выполнения транзакции, чрезвычайно важно, чтобы транзак-
ции выполнялись как можно быстрее. Следовательно, ручной запуск команды
COMMIT с транзакцией может помочь справиться с проблемами, связанными с одно-
временным использованием базы и блокировкой.
Советы и хитрости программирования
Самая важная хитрость состоит в том, чтобы понять, что некоторые базы данных вы-
полняют автоматические неявные транзакции, а другие базы требуют явного их указа-
ния. Если вы сделаете необоснованное допущение, что платформа использует один
метод выполнения транзакций, а не другой, вы можете за это поплатиться. Следова-
тельно, при переходе с одной платформы на другую вы должны использовать стан-
дартный, заранее установленный метод обращения с транзакциями. Мы рекомендуем
всегда использовать явные транзакции с инструкцией START TRAN в начале (если
платформа ее поддерживает) и COMMIT или ROLLBACK в конце.
Помимо завершения одной или нескольких операций по манипулированию дан-
ными инструкция COMMIT оказывает интересное влияние на другие аспекты транзак-
ции, Во-первых, она закрывает все связанные с ней открытые курсоры. Во-вторых, все
временные таблицы, для которых указано предложение ON COMMIT DELETE ROWS
(дополнительное предложение в инструкции CREATE TABLE), очищаются. В-третьих,
проверяются все отложенные ограничения (deferred constraints). Если хоть одно из них
не выполняется, транзакция отменяется. И наконец, снимаются все блокировки, соз-
данные при транзакции. Пожалуйста, обратите внимание, что в SQL2003 определяет-
ся, что транзакции открываются неявно при выполнении следующих инструкций:
Справочник по командам SQL | 93
ALTER
CLOSE
COMMIT AND CHAIN
CREATE
DELETE
DROP
FETCH
FREE LOCATOR
GRANT
HOLD LOCATOR
INSERT
OPEN
RETURN
REVOKE
ROLLBACK AND CHAIN
SELECT
START TRANSACTION
UPDATE
Если вы не открыли явным образом транзакцию при запуске одной из указанных
выше команд, то в соответствии со стандартом платформа СУРБД откроет транзакцию
сама.
DBS
В DB2 поддерживается стандарт, за исключением Предложения AND [NO] CHAIN.
MySQL
В MySQL команда COMMIT и транзакции поддерживаются только в таблицах InnoDB.
Предложение AND [NO] CHAIN не поддерживается.
Oracle
В Oracle поддерживается стандарт, за исключение^ предложения AND [NO] CHAIN.
Кроме этого, в Oracle есть пара расширений стандартной инструкции.
COMMIT [WORK] [{COMMENT 'текст' | FORCE ' текст' < [, int]}];
Где:
COMMENT 'текст ’
Связывает с текущей транзакцией комментарий. ‘Текст ’ - это литеральная строка
длиной до 255 символов. Текстовая строка, на случай отмены транзакции, хранится
в представлении-словаре данных Oracle DBA2PCPENDING с ID транзакции.
94 | Глава 3. Справочник по инструкциям SQL
FORCE 'текст' [ ini J
Позволяет вручную выполнить сомнительную распределенную транзакцию.
'Текст' - эго литеральная строка, определяющая локальный или глобальный ID
транзакции. Определить ID транзакции можно, послав запрос к представлению-
словарю данных Oracle DBA_2PC_PENDING. Необязательный параметр int
представляет собой целое число, которое явным образом присваивает транзак-
ции системный номер изменения (system change number, SCN). Если параметр
int не указывается, транзакция выполняется с текущим SCN.
При подаче команды COMMIT с предложением FORCE будет совершена только та
транзакция, которая явно указана в предложении FORCE. Это не окажет влияния на
текущую транзакцию, если она не будет явно определена. Предложение FORCE нс
используется в инструкциях PL/SQL.
В следующем примере выполняется транзакция, с которой связывается коммен-
тарий.
COMMIT WOHK COMMENT 'сомнительная транзакция, звоните (949) 555-’’234' ;
PostgreSQL
В PostgreSQL реализован следующий синтаксис.
COMMIT [WOOK I TRANSACTION],
В PostgreSQL ключевые слова WORK и TRANSACTION являются необязательны-
ми. При подаче команды COMMIT все открытые транзакции записываются на диск
и результаты этих транзакций становятся видимыми для других пользователей.
Например:
INSERT INTO sales VAluIS('7896'. ' 8R3435: . Oct 28 1997'. 25.
Net 60', 'BU7832');
COMMIT WORK
SQL Server
SQL Server поддерживает предложение ANO [NO] CHAIN. SQL Server поддерживает
ключевое слово TRANSACTION как эквивалент слова WORK. Синтаксис следующий.
COMMIT {[TRAN[SACT10N] [имя_транзакции] । [WORK]}
Платформа Microsoft SQL Server позволяет создавать специфические именован-
ные транзакции с помощью инструкции START TRAN. Синтаксическая конструкция
COMMIT TRANSACTION позволяет явно указать имя транзакции при ее закрытии или
для сохранения имени транзакции в переменной. Любопытно, что SQL Server все
равно выполняет только самую последнюю открытую транзакцию, не учитывая вве-
денное имя транзакции.
Когда вы используете команду COMMIT WORK, SQL Server завершает все открытые
транзакции и записывает все изменения в базу данных. При использовании команды
COMMIT WORK вы можете не указывать имя транзакции.
Справочник по командам SQL | 95
См. также
ROLLBACK
START TRANSACTION
CONNECT
Инструкция CONNECT устанавливает соединение с СУРБД и конкретной базой
данных в этой СУРБД.
Платформа Команда
DB2 Поддерживается с вариантами
MySQL Не поддерживается
Oracle Поддерживается
PostgreSQL Не поддерживается
SQL Server Поддерживается с вариантами
Синтаксис SQL2003
CONNECT ТО {DEFAULT | }[имя_сервера} [AS имя_соединения] [USER имя_пользователя]}
Ключевые слова
DEFAULT
Инициируется сеанс связи с сервером по умолчанию, для которого по умолчанию
прописаны авторизация пользователя и текущая база данных. В стандарте указа-
но, что команда CONNECT ТО DEFAULT неявно подразумевается, если вы начи-
наете сеанс SQL, не подав предварительно команду CONNECT.
имя_сервера
Устанавливается соединение с сервером, имеющим имя. Параметр имяуервера может
представлять собой строковый литерал, заключенный в одинарные кавычки, или
хост-переменную.
AS имя_соединения
Устанавливается соединение с именем имя-Соединения, которое отображается
в одинарных кавычках. Необязательный параметр имя_соединения может пред-
ставлять собой строковый литерал, заключенный в одинарные кавычки, или хост-
переменную. Этот параметр является необязательным только для первого соеди-
нения с сервером. Все последующие сеансы должны включать предложение AS.
Это нужно для того, чтобы различать пользовательские соединения в тех случаях,
когда много пользователей, а возможно и один пользователь, имеют много откры-
тых сеансов работы с одним сервером (имясервера).
96 | Глава 3. Справочник по инструкциям SQL
USER имяпользователя
Соединение с указанным сервером устанавливается с использованием указанного
имени пользователя.
Общие правила
Используйте инструкцию CONNECT для того, чтобы установить интерактивный сеанс
связи на SQL с СУРБД. Промежуток времени между подачей команд CONNECT
и DISCONNECT обычно называется сеансом (session). Как правило, вся работа с СУРБД
производится в ходе явным образом открытого сеанса.
Если вы не указываете имя сервера, имя соединения или имя пользователя, то
платформа СУРБД использует значения по умолчанию. Эти значения различны для
разных платформ.
Чтобы соединиться с сервером «Houston» под определенным пользовательским 1D,
вы должны подать такую команду:
CONNECT ТО Houston USER pubs_admin
Если СУРБД требует, чтобы соединения имели имена, вы можете использовать
следующий альтернативный синтаксис.
CONNECT ТО Houston USER pubs_admin AS
puba_adm rust rat ive_session;
Если вам нужно простое быстрое соединение, вы можете использовать настройки
по умолчанию.
CONNECT ТО DEFAULT
Советы и хитрости программирования
Если инструкция CONNECT запускается без явного отключения предыдущего сеанса,
предыдущий сеанс переходит в состояние бездействия, а активным становится теку-
щее соединение. Затем вы можете переключаться между соединениями при помощи
инструкции SET CONNECTION.
* «
r-rW8?-
1 ' • I В инструменте Oracle SQL *Plus команда CONNECT используется несколько
1 ,Л<'' Ж иначе ~~ <)ля сое^инения пользователя с конкретной схемой.
DBS
Платформа DB2 поддерживает несколько расширений стандарта ANSI.
CONNECT {[ТО] {[имя_сервера] [IN SHARE MODE |
IN EXCLUSIVE MODE [ON SINGLE DBPARTITIONNUM] | [RESET] }
[USER нмя_пользователя] {[USING пароль] | [NEW пароль CONFIRM пароль]}
Где:
CONNECT
Если используется без других ключевых слов - эквивалентно CONNECT ТО
DEFAULT.
7 - 2447
Справочник по командам SQL | 97
ТО имя_сервера
Определяется сервер, с которым устанавливается соединение. Параметр
имя_сервера может представлять собой строковый литерал или переменную сим-
вольного типа, включающую 8 или менее символов (UDB) или 16 и менее симво-
лов (OS/390 или z/OS).
IN SHARE MODE
Устанавливается соединение конкурентного типа, позволяющее другим пользова-
телям соединяться с базой данных. Не позволяет другим пользователям под-
ключаться в эксклюзивном режиме.
IN EXCL USIVE MODE
Устанавливается эксклюзивное соединение с сервером приложения. Все прочие
пользователи не могут соединиться с базой, если только они не используют тоже
имя-Пользователя и пароль. Дополнительное предложение ON SINGLE DBPART1-
T1ONNUM используется только в секционированной (partitioned) базе данных. Это
предложение показывает, что подключение к координационной секции базы
данных произведено в эксклюзивном режиме, а все остальные секции подключены
в общем (SHARE) режиме.
RESET
Выполняется инструкция COMMIT, после чего сеанс отключается от сервера.
USER имя_пользователя
Соединение устанавливается с использованием имени пользовательской учетной
записи. Параметр имя-Пользователя может представлять собой строковый ли-
терал или переменную символьного типа длиной 8 символов и менее.
USING пароль
Указывается пароль пользовательской учетной записи имя_полъзователя. Может
представлять собой строковый литерал или переменную символьного типа
длиной 18 символов и менее.
NEW пароль CONFIRM пароль
Указывается новый пароль для пользовательской учетной записи под именем
имя-Пользователя. Может представлять собой строковый литерал или перемен-
ную символьного типа длиной 18 символов и менее.
Например, вам может понадобиться сменить пароль пользовательской учетной
записи sam на mephrun, используя хост-переменную VARCHAR(8) с именем appjserver
для хранения имени сервера приложений.
CONNECT ТО ;app_server USER sam NEW 'mephrun’ CONFIRM ’mephrun’;
MySQL
He поддерживается.
Oracle
Команда CONNECT позволяет устанавливать соединение с базой данных под опреде-
ленным именем пользователя. Кроме того, можно установить соединение со специ-
альными привилегиями AS SYSOPER или AS SYSDBA. Синтаксис Oracle следующий.
98 | Глава 3. Справочник по инструкциям SQL
CONN[ECT] [[имя_пользователя/пароль] [AS {SYSOPER | SYSDBA}]
Где:
CONN [ЕСТ] имя_пользователя/пароль
Устанавливается соединение с экземпляром базы данных.
AS {SYSOPER | SYSDBA}
Соединение устанавливается с присвоением одной из двух возможных системных
ролей.
Если уже ус тановлено другое соединение, команда CONNECT выполняет команду
COMMIT для всех открытых транзакций, закрывает текущий сеанс и открывает
новый.
Также Oracle позволяет использовать инструкции CONNECT в инструментах
SQL*Plus и iSQL*Plus.
PostgreSQL
11латформа PostgreSQL не имеет явной поддержки инструкции CONNECT. Однако она
поддерживает инструкцию SP1CONNECT в Server Programming Interface и инструк-
цию PGCONNECT в пакете PG/TCL.
SQL Server
Платформа SQL Server поддерживает основные элементы инструкции CONNECT
в языке Embedded SQL (который встраивается в программы Ст+ и Visual Basic). Син-
таксис следующий.
CONNECT го [имя..сервера ]имя._базь данных [AS имя_соединения}
USER {пользовательское.,имя[. пароль] | Sintegrated}
Где:
CONNECT ТО имя_cepeepa.имя .базы данных
Определяется имя сервера и базы данных, с которыми нужно установить соедине-
ние. Вы можете опустить имя_сервера, если хотите использовать локальный
сервер.
AS имя соединения
Соединению присваивается имя, представляющее собой буквенно-числовую
строку длиной до 30 символов. Разрешаются и другие символы, за исключением
дефиса (-), но первым символом имени должна быть буква. Слова CURRENT
и ALL являются зарезервированными, и их нельзя использовать в качестве имени
соединения. Указывать имя соединения нужно только в том случае, если соедине-
ний несколько.
USER {пользовательское_имя[. пароль | integrated]}
Сеанс открывается под указанным именем и паролем или же с применением
внутренней системы безопасности Windows. При указании имени пароль является
необязательным параметром.
Например, мы можем соединиться с сервером new_york с пользовательским
именем Windows pubs_admin.
CONNECT ТО пеи_уогк. pubs 'USER pubs_admin
Справочник по командам SQL | 99
Та же команда с использованием стандартной системы безопасности SQL Server:
EXEC SQL CONNECT TO new_york.pubs USER pubs_admin
Та же команда с использованием встроенной системы безопасности Windows:
EXEC SQL CONNECT TO new_york, pubs USER {integrated
Для переключения на другое соединение нужно использовать инструкцию SET
CONNECTION.
См. также
SET CONNECTION
Инструкция CREATE/ALTER DATABASE
В стандарте ANSI в действительности нет инструкции CREATE DATABASE. Однако,
поскольку работать с SQL-базами данных без этой команды почти невозможно, мы
внесли эту инструкцию в книгу. Почти все платформы баз данных поддерживают
какой-нибудь вариант этой инструкции.
Платформа Команда
DB2 Поддерживается с вариантами
MySQL Поддерживается с вариантами
Oracle Поддерживается с вариантами
PostgreSQL Поддерживается с вариантами
SQL Server Поддерживается с вариантами
Общие правила
Эта команда создает новую пустую базу данных с указанным именем. Большинство
платформ СУРБД требуют, чтобы для создания новой базы пользователь имел приви-
легии администратора. Как только новая база данных создана, вы можете заполнять ее
объектами (такими, как таблицы, представления, триггеры и т. п.), а таблицы заполнять
данными. Команда CREATE DATABASE может также создавать в файловой системе,
в зависимости от платформы, соответствующие файлы, содержащие данные и мета-
данные базы.
Советы и хитрости программирования
Поскольку команда CREATE DATABASE не входит в число стандартных инструкций
ANSI, между платформами существуют довольно большие различия в ее синтаксисе.
DBS
Инструкция DB2 CREATE DATABASE инициализирует новую базу с различными,
определяемыми пользователем характеристиками, например опциями автоматическо-
100 | Глава 3. Справочник по инструкциям SQL
го конфигурирования и сопоставления (collation). Кроме того, инструкция создает три
исходных табличных пространства, системные таблицы и журналы восстановления,
необходимые для базы данных DB2.
CREATE {DATABASE | DB} имя_базы_данных
[AT DBPARITIONNUM] [ON путь_и__диск] [ALIAS псевдоним_базы_данных]
[USING CODESET набор_кодов TERRITORY регион']
[COLLATE USING {COMPATIВILTIY | IDENTITY | NLSCHAR | SYSTEM} ]
[NUMSEGS int] [DFT_EXTENT_SZ int]
[CATALOG TABLESPACE определение_табличного_пространства]
[USER TABlESPACE определение_табличного_пространства]
[TEMPORARY TABLESPACE определение_табличного~пространства] [WITH " комментарии'"]
[AUIOCCNFIGURE [USING параметр значение [,..] ]
[APPlY {DB ONLY | DB AND DBM | NONE} ]
Где:
CREATE {DATABASE | DB} имя_базы-данных
Создается база данных с именем ил1Я_базы_данных. Имя должно быть уникаль-
ным среди других имен баз данных в локальной и системной директории баз дан-
ных.
А Т DBPA R T1T1ONNUM
База данных создается в той секции, в которой была выполнена команда. Эта команда
используется только для повторного создания удаленной базы данных. Ее нельзя
использовать для создания совершенно новой базы. При подаче команды CREATE
DATABASE AT DBPARTIT1ONNUM база данных должна быть немедленно восста-
новлена на узле.
ON путь _u _диск
Указывается диск и путь к создаваемой базе данных в Windows- или Unix-системе,
длиной до 205 символов. Если это предложение опущено, база создается в месте,
определяемом диском, и путем по умолчанию, указанными в параметре dftdbpath
конфигурационного файла менеджера баз данных.
ALIAS псевдоним_базы_даиных
В системной директории баз данных объявляется псевдоним базы данных.
USING CODESET набор_кодов TERRITORY регион
Объявляется набор кодов и регион, используемый в базе данных. После объявления
менять эти значения нельзя.
COLLATE USING {COMPATIBILITY | IDENTITY | NLSCHAR j SYSTEM}
Определяет тин сопоставления (collation) для базы данных. После этого схему
сопоставления изменить будет нельзя. Варианты таковы:
COMPATIBILITY
Используется схема сопоставления DB2 v2 для обратной совместимости.
IDENTITY
Используется схема сопоставления по идентичности, когда строки сравни-
ваются побайтно.
Справочник ио командам SQL | 101
NLSCHAR
Используется схема сопоставления, уникальная для набора кодов и региона
базы данных. В настоящее время эта опция поддерживается только для Тайской
кодовой страницы (СР874).
SYSTEM
Используется схема сопоставления для текущего региона.
NUMSEGS int
В виде целого числа (int) указывается число директорий сегментов, которые соз-
даются для хранения файлов DAT, IDX, LF, LB и LBA для любых табличных про-
странств по умолчанию, относящихся к типу SMS (System Managed Space). Этот
параметр не влияет на табличные пространства DMS, табличные пространства
SMS с явно указанными параметрами создания и табличные пространства SMS,
созданные после того, как была создана база данных.
DFT EXTENT SZ int
В виде целого числа (int) указывается значение по умолчанию предельного раз-
мера табличных пространств базы данных.
CATALOG TABLESPACE определение_табличного_пространства
Определяется табличное пространство, в котором хранятся таблицы каталога.
Подробности синтаксиса параметра определение_табличного__пространства при-
ведены ниже. Если это предложение опущено, таблицы каталога будут создавать-
ся в табличном пространстве SMS с именем SYSCATSPACE, а его параметры
будут определяться значениями предложений NUMSEGS и DFT_EXTENT_SZ.
USER TABLESPACE определение_табличного_пространства
Определяется табличное пространство, которое представляет собой исходное таб-
личное пространство пользователя. Подробности синтаксиса параметра определе-
ние_табличного_пространства приведены ниже. Если это предложение опуще-
но, пользовательское табличное пространство будет создаваться в табличном про-
странстве SMS с именем USERSPACE1, а его параметры будут определяться
значениями предложений NUMSEGS и DFT_EXTENT_SZ.
TEMPORARY TABLESPACE определение_табличного_пространства
Определяется табличное пространство, которое представляет собой исходное вре-
менное табличное пространство системы. Подробности синтаксиса параметра
определение_табличного_пространства приведены ниже. Если это предложение
опущено, временное табличное пространство системы будет создаваться в таб-
личном пространстве SMS с именем TEMPSPACE1, а его параметры будут опре-
деляться значениями предложений NUMSEGS и DFT_EXTENT_SZ.
WITH “комментарии ’’
Создается описание базы данных в директории баз данных длиной до 30 символов.
AUTOCON FIGURE [USING параметр значение [...]]
Определяются пользовательские настройки важных системных параметров,
таких, как размер буферного пула. При использовании команды без предложения
USING платформа DB2 вычисляет оптимальные параметры и использует их. Ниже
приводится список параметров и их возможные значения.
102 | Глава 3. Справочник по инструкциям SQL
mem_ percent
Определяет процентную долю памяти, отведенную базе данных. По умолча-
нию установлено значение 25, допустимыми являются значения в диапазоне
1-100. Если на сервере работают другие приложения, не устанавливайте здесь
значение 100.
workload_tyре
Определяет тип рабочей нагрузки базы данных. Варианты: ‘simple’, ‘mixed’,
‘complex’1. По умолчанию установлено значение ‘mixed’. При указании
значения ‘simple’ параметры ввода/вывода настраиваются под эффективное
выполнение транзакций, а при указании параметра ‘complex’ система
настраивается на запросы, требующие большой нагрузки на процессор.
Значение ‘mixed’ соответствует настройкам, которые эффективны, хотя и не
оптимальны, для обоих видов нагрузки.
num_stmts
Определяет количество инструкций в единице работы. По умолчанию уста-
новлено значение 25, допустимые значения -1-1 000 000.
tpm
Определяет ожидаемое количество транзакций в минуту. По умолчанию - 60,
допустимые значения -1-50 000.
admin ^priority
Параметр определяет, как нужно настраивать базу данных - повышать произ-
водительность {значение = ‘performance’), улучшать время восстановления
{значение<= ‘recovery’) или придерживаться середины {значение = ‘both’). По-
следнее значение установлено по умолчанию.
numjocalapps
Определяет количество подключенных локальных приложений. По умолча-
нию - 100, возможные значения - 0-5000.
п um_rem ote_apps
Определяет количество соединений с удаленными приложениями. По умолча-
нию - 100, возможные значения - 0-5000.
isolation
Определяет уровни изоляции транзакций для приложений, подключающихся
к базе данных. По умолчанию - RR. Допустимые значения - RR, RS, CS и UR.
За более подробной информацией об уровнях изоляции DB2 обращайтесь
к пункту SET TRANSACTION ISOLATION LEVEL.
bp_resizable
Определяет, можно ли изменять размер буферных пулов. По умолчанию -
‘yes’, можно также указать значение ‘по’.
Имеются в виду простые (simple), сложные (complex) и смешанные (mixed) запросы.
Примеч. пер.
Справочник по командам SQL | 103
APPLY {DB ONLY | DB AND DBM | NONE}
Определяет область действия параметров автоматического конфигурирования,
установленных с помощью предложения AUTOCONFIGURATION.
DB ONLY
Параметры применяются только к конфигурации базы данных и буферных
пулов.
DB AND DBM
Параметры применяются к конфигурации менеджера баз данных, к конфи-
гурации базы данных и к конфигурации буферных пулов.
NONE
Рекомендуемые параметры выводятся, но не применяются.
Параметр определение_табличного_пространства, используемый в DB2, имеет
свой собственный синтаксис.
MANAGED BY
{SYSTEM USING (‘контейнер' [,...]) |
DATABASE USING ({FILE | DEVICE} 'контейнер' int [,...])}
[EXTENTSIZE int] [PREFETCHSIZE int] [OVERHEAD int] [TRANSFERRATE int]
Где:
MANAGED BY
Определяет, будет табличное пространство управляться системой (System Managed
Space, SMS) или базой данных (Database Managed Space, DMS).
SYSTEM USING (‘контейнер ’ [,...])
Определяет для SMS один или несколько контейнеров длиной до 240 байт.
Контейнер может представлять собой абсолютное или относительное имя
директории.
DATABASE USING ({FILE | DEVICE} ‘контейнер' int[,...])
Определяет один или несколько контейнеров для DMS, длиной до 254 байт.
Контейнер может представлять собой абсолютное или относительное имя
директории. Также указывается тип контейнера (FILE - имя файла, DEVICE -
существующее устройство), его размер (int), к которому добавляется суффикс
К (килобайты), М (мегабайты) или G (гигабайты). Если в данный момент ука-
занный файл не существует, DB2 создаст его. Чтобы можно было использо-
вать устройство, оно должно уже существовать в системе.
EXTENTSIZE int
Определяет количество страниц (int), которое записывается в контейнер до того,
как система перейдет к следующему контейнеру. (Размер страниц определяется
параметром PAGESIZE.) В качестве альтернативы значение EXTENTSIZE int можно
указать в байтах, если добавить к числовому значению суффикс К (килобайты),
М (мегабайты) или G (гигабайты).
PREFETCHSIZE int
Определяет количество страниц (int), которое читается из табличного пространст-
ва в ходе предварительной выборки данных. (Размер страниц определяется пара-
104 | Глава 3. Справочник по инструкциям SQL
метром PAGESIZE.) В качестве альтернативы значение PREFETCHSIZE int можно
указать в байтах, если добавить к числовому значению суффикс К (килобайты),
М (мегабайты) или G (гигабайты).
OVERHEAD int
Определяет нагрузку на контроллер ввода/вывода, время поиска на диске и ла-
тентное время в миллисекундах, int, которое используется в оценке стоимости
операции ввода/вывода при оптимизации запросов. Значение (int) должно быть
усредненным для всех контейнеров, относящихся к табличному пространству.
TRANSFERRATE int
Определяет время считывания одной страницы в память, в миллисекундах, int.
Используется для определения стоимости операции ввода/вывода при оптимизации
запросов. Значение (int) должно быть усредненным для всех контейнеров, относя-
щихся к табличному пространству.
Заметьте, что табличные пространства DB2 можно также создавать с помощью
специфичной команды DB2 CREATE TABLESPACE.
На тех серверах DB2, которые поддерживают протокол LDAP (Lightweight Directory
Access Protocol), новая база данных автоматически регистрируется в директории LDAP.
-♦шЧ’ "I
i" DB2 не поддерживает инструкцию ALTER DATABASE.
i
---Д)Л'
В следующем примере создается база данных с именем sales и с указанными
параметрами NUMSEGS, DFT EXTENT S?,, с включенной и применяемой опцией
A UTOCONF1GURA TION.
CREATE DATABASE :;a.ies
NUMSEGS /00 OFE_EXTEM_SZ 1000
WITH “Временная база гю продажам"
AUTOCONF1GUBF ADPLY OB ONLY;
Предложение WITH добавляет в директорию баз данных описание базы данных sales.
MySQL
В MySQL команда CREATE DATABASE по сути создает новую директорию, содержащую
объекты базы данных.
CREATE DATABASE (ГЕ NOT EXISTS] имя_базы_данных
Где;
CREATE DATABASE имя базы данных
Создается база данных и директория с именем имя базы_данных. Директория
базы данных находится в директории данных MySQL. Таблицы MySQL поме-
щаются в виде файлов в директорию базы данных.
IF NOT EXISTS
Позволяет избежать ошибок, если база данных уже существует.
Справочник по командам SQL | 105
Например, мы можем создать на сервере MySQL базу данных с именем
sales_archive. Если база данных уже существует, нам нужно отменить команду, чтобы
не произошла ошибка.
CREATE DATABASE IF NOT EXISTS sales_archive
Любые таблицы, которые мы будем создавать в базе sales_archive, будут появ-
ляться в виде файлов в директории sales_archive.
MySQL не поддерживает инструкцию ALTER DATABASE.
Oracle
Платформа Oracle позволяет не только дать базе данных имя и указать путь для хране-
ния файлов, но и предоставляет очень серьезные возможности контроля файловых
структур базы данных. В Oracle CREATE DATABASE и ALTER DATABASE очень
мощные команды. Некоторые наиболее изощренные конструкции лучше всего могут
использовать только опытные администраторы. Эти команды могут быть очень боль-
шие и сложные. (Одна команда ALTER DATABASE занимает в документации Oracle
более 50 страниц!)
Новички должны помнить, что при запуске команды CREATE DATABASE
стираются все данные в соответствующих файлах, если они существуют. Точно так же
теряются данные во всех таблицах.
Ниже приведен синтаксис для создания базы данных в Oracle.
CREATE DATABASE [имя_базы_данных]
{[USER SYS IDENTIFIED BY пароль | USER SYSTEM IDENTIFIED BY пароль]}
[CONTROLFILE REUSE]
{[LOGFILE определение [,...] ] [MAXLOGFILES int] [[MAXLOGMEMBERS] int]
[[MAXLOGHISTORY] int] [{ARCHIVELOG | NOARCHIVELOG}] [FORCE LOGGING]}
[MAXDATAFILES int]
[MAXINSTANCES int]
[CHARACTER SET набор_символов]
[NATIONAL CHARACTER SET набор_символов]
[EXTENT MANAGEMENT {DICTIONARY | LOCAL}]
[DATAFILE определение [,...] ]
[SYSAUX DATAFILE определение [,...]]
[DEFAULT TABLESPACE имя_табличного_пространства
[DATAFILE определение_файла]
EXTENT MANAGEMENT {DICTIONARY |
LOCAL {AUTOALLOCATE | UNIFORM [SIZE int [К | M] } } ]
[ [{ BIGFILE | SMALLFILE}] DEFAULT [TEMPORARY] TABLESPACE
имя__табличного_пространства
[TEMPFILE определение_файла]
EXTENT MANAGEMENT {DICTIONARY |
106 | Глава 3. Справочник по инструкциям SQL
LOCAL {AUTOALLOCATE | UNIFORM [SIZE int [К | M] } } ]
[ [{ BIGFILE | SMALLFILE}] UNDO TABLESPACE tablespace_name
[DATAFILE определение_временного_файла_данных} ]
[SET TIME_ZONE = ' { {+ | -} hh:mi | часовой_пояс}']
[SET DEFAULT {BIGFILE | SMALLFILE} TABLESPACE]
А вот синтаксис для изменения существующей базы данных.
ALTER DATABASE [имя_базы_данных']
[ARCHIVELOG | NOARCHIVELOG] |
{MOUNT [{STANDBY | CLONE} DATABASE] |
OPEN [READ WRITE | READ ONLY
[RESETLOGS | NORESETLOGS] | [UPGRADE | DOWNGRADE] } |
{ACTIVATE [PHYSICAL | LOGICAL] STANDBY DATABASE
[SKIP [STANDBY LOGFILE] ] |
SET STANDBY [DATABASE] TO MAXIMIZE {PROTECTION | AVAILABILITY i
PERFORMANCE} |
REGISTER [OR REPLACE] [PHYSICAL i lOGICAL] LOGFILE ['file']
[FOR имя_сеанса_1одтпег] |
{COMMIT I PREPARE} TO SWITCHOVER TO
{{[PHYSICAL | LOGICAL] PRIMARY I STANDBY} [WITH[OUT]
SESSION SHUTDOWN] [WAIT | NOWAIT]} |
CANCEL} |
START LOGICAL STANDBY APPLY [IMMEDIATE] [NODELAY]
[{INITIA! int | NEW PRIMARY имя_связи | {FINISH |
SKIP FAILED TRANSACTION] } ] |
{STOP I ABORT} LOGICAL STANDBY APPlY |
[[NO]PARALLEL int] } |
{RENAME GLOBAL_NAME TO база_данных[,домен[.домен ...]] |
CHARACTER SET набор_символов |
NATIONAL CHARACTER SET набор_символов |
DEFAULT TABLESPACE имя_табличной__области |
DEFAULT TEMPORARY TABLESPACE {GROUP int | имя_табличной~области} |
{DISABLE BLOCK CHANGE TRACKING | ENABLE BLOCK CHANGE TRACKING [USING
FILE 'файл' [REUSE] } |
FLASHBACK {ON j OFF} |
SET nME_Z0NE = '{ {+ | -} hh:mi | часовой_пояс}' |
SET DEFAULT {BIGFILE | SMALLFILE} TABLESPACE } |
{ENABLE i DISABLE} { [PUBLIC] THREAD int | INSTANCE 'имя^экземпляра ' } ।
{GUARD {ALL I STANDBY | NONE} } |
{CREATE DATAFILE 'файл' [,.. ] [AS {NEW | определение_файла [...]}][
{DATAFILE 'файл' | TEMPFILE 'файл'} [,...]
{ONLINE I OFFLINE [FOR DROP | RESIZE int [К | M] |
END BACKUP | AUTOEXTEND {OFF | ON [NEXT int [К | M] [MAXSIZE
[UNLIMITED | int [K | M] } |
{TEMPFILE 'файл' [ TEMPFILE 'файл'} [,...]
{ONLINE । OFFLINE | DROP [INCLUDING DATAFILES] |
Справочник по командам SQI
RESIZE int [К | M] | AUTOEXTEND {OFF | ON [NEXT int [К | M]
[MAXSIZE [UNLIMITED | int [К | M] } |
RENAME FILE 'файл' [,,..] TO 'новое_имя_файла ' [,...] } |
{[[NO] FORCE LOGGING] | [ [NO]ARCHIVELOG [MANUAL] ] |
[ADD | DROP] SUPPLEMENTAL LOG DATA [(ALL | PRIMARY KEY | UNIQUE |
FOREIGN KEY) [,...] ] COLUMNS |
[ADD | DROP] [STANDBY] LOGFILE
{{[THREAD int | INSTANCE 'имя_экземпляра ’]} {[GROUP int |
имя_журнального_файла [,..,]} [SIZE [К | M]] | [REUSE] |
[MEMBER] 'файл' [REUSE] [,..,] TO имя_журнального_файла [,,..]} |
ADD LOGFILE. MEMBER 'file' [RESUSE] [,...] TO {[GROUP int |
имя_журнального_файла [,..,]} |
DROP [STANDBY] LOGFILE {MEMBER 'файл' | {[GROUP int [имя_журнального_файла
[,...]} }
CLEAR [UNARCHIVED] LOGFILE{[GROUP int \ имя~журнального_файла [,. .]}[....]
[UNRECOVERABLE DATAFILE] } |
{CREATE [LOGICAL | PHYSICAL] STANDBY CONTROLFILE AS 'файл' [REUSE] |
BACKUP CONTROLFILE TO
{'файл' [REUSE] | TRACE [AS ’файл' [REUSE] ] {RESETLOGS |
NORESETLOGS]} } |
{RECOVER
{[AUTOMATIC [FROM 'местоположение'] ] |
{[STANDBY] DATABASE
{[UNTIL {CANCEL | TIME дата | CHANGE int}] |
USING BACKUP CONTROLFILE } |
{{[STANDBY] {TABLESPACE имя~табличного_пространства [,...] | DATAFILE
’файл' [,...] } [UNTIL [CONSISTENT WITH] CONTROLFILE]} |
TABLESPACE имя_табличного_пространства [,...] |DATAFILE 'file' [,...]} |
LOGFILE имя файла [,...] } [{TEST | ALLOW int CORRUPTION | [NO]PARALLEL
mt}]} |
CONTINUE [DEFAULT] |
CANCEL [IMMEDIATE][NOWAIT] }
{MANAGED STANDBY DATABASE
{[[NO]TIMEOUT int] [{[NO]DELAY int | DEFAULT DELAY}] [NEXT int]
[[NO]EXPIRE int] [{[NO]PARALLEL int}] [USING CURRENT LOGFILE]
[UNTIL CHANGE int]
[THROUGH
{ALL ARCHIVELOG | {ALL | LAST | NEXT} SWITCHOVER |
[[THREAD int] SEQUENCE int ] } |
[CANCEL [IMMEDIATE] [{WAIT | NOWAIT}] ] |
[DISCONNECT [FROM SESSION] [{[NO]PARALLEL int}]
FINISH [SKIP [STANDBY LOGFILE]] [{WAIT | NOWAIT}] ] |
{BEGIN | END} BACKUP} }
108 | Глава 3. Справочник по инструкциям SQL
Синтаксические элементы в Oracle таковы:
{CREATE | ALTER} DATABASE
Создается или изменяется база данных с именем имя_базы_данных. Имя базы
данных должно занимать до 8 байт и не может содержать европейских и азиатских
символов. Вы можете опустить имя базы, и тогда Oracle создаст его автоматиче-
ски, однако помните, что Oracle может создать нумерованные имена.
USER SYS IDENTIFIED BY пароль
USER SYSTEM IDENTIFIED BY пароль
Указывается пароль для пользователей .STS' и SYSTEM. Вы можете не указывать
эти предложения вообще, указать оба или указать только одно из них.
CONTROLFILE REUSE
Существующий управляющий файл будет использован повторно. Вы можете указать
существующие файлы в параметре CONTROL FILES файла IN1TORA. Oracle переза-
пишет всю информацию, которую могут содержать эти файлы. Это предложение
обычно используется при повторном создании базы данных. Следовательно, вам, на-
верное, не нужно использовать это предложение с конструкциями MAXLOGFILES,
MAXLOGMEMBER, MAXLOGHISTORY, MAXDATAFILES или MAXINSTANCES.
LOGFILE определение
Определяет для базы данных один или несколько журнальных файлов. Вы можете
указать с помощью параметра file несколько файлов, которые все будут иметь оди-
наковые размеры и характеристики, или же указать несколько файлов, каждый из
которых будет иметь свой размер и характеристики. Полный синтаксис определе-
ния журнального файла довольно велик, но он обеспечивает высокую степень
контроля.
.-OGF1LE {('файл [....]) [SIZE int [К | М]
[GROUP int) г.REUSE] 1 [,...]
Где:
LOGFILE {(‘файл ’ [,...])
Определяется один или несколько файлов, которые будут играть роль
журнальных файлов. Параметр файл - это имя файла и путь к нему. Все
файлы, определяемые в инструкции CREATE DATABASE, связываются с пото-
ком журнала за номером 1. При указании нескольких журнальных файлов
каждое имя файла нужно заключать в одинарные кавычки и отделять от
других имен запятыми. Весь список нужно заключить в скобки.
SIZE int [К I М]
Указывается размер журнального файла в байтах в виде целого числа (int). Вы
также можете определить размер журнального файла в единицах больших,
чем байты. Для этого нужно добавить суффикс К (для килобайт) или М (для
мегабайт).
GROUP int
Определяется целое (int) значение ID для журнальной группы. Значения могут
быть от 1 до значения, указанного в предложении MAXLOGFILES. База данных
Справочник по командам SQL | 109
Oracle должна иметь как минимум две журнальные группы. Если ID группы не
будет указан, платформа создаст группу файлов журнала, по 100 Мб каждый.
REUSE
Использование имеющегося журнального файла.
MAXLOGFILES int
Устанавливается максимальное число (int) журнальных файлов, которые может
использовать создаваемая база данных. Минимальное и максимальное количест-
во, а также количество, установленное по умолчанию, зависит от операционной
системы.
MAXLOGMEMBERS int
Устанавливается максимальное число элементов (т. е. копий) в журнальной груп-
пе. Минимальное значение равно 1, а максимальное и установленное по умолча-
нию значения зависят от операционной системы.
MAXLOGHISTORY int
Устанавливается максимальное число архивированных журнальных файлов, дос-
тупных в Real Application Cluster. Минимальное значение равно 0, а максимальное
и установленное по умолчанию значения зависят от операционной системы.
ARCHIVELOG | NOARCHIVELOG
Определяет способ функционирования журнала. При использовании в инструкции
ALTER DATABASE позволяет изменить текущее значение. При указании параметра
ARCHIVELOG данные, сохраненные в журнале, записываются в архивный файл, что
обеспечивает возможность восстановления носителя. Параметр NOARCHIVELOG
позволяет использовать журнал без архивирования его содержимого. Хотя возмож-
ность восстановления существует в обоих вариантах, параметр NOARCHIVELOG
(установлен по умолчанию) не обеспечивает восстановления носителя.
FORCE LOGGING
Все экземпляры базы данных переводятся в режим FORCE LOGGING (принуди-
тельное протоколирование), при котором в журнал записываются все изменения,
вносимые в базу данных, за исключением изменений во временных табличных
пространствах и сегментах.
MAXDATAFILES int
Устанавливается исходное количество (int) файлов данных, которые может
использовать создаваемая база данных. Отметьте, что параметр DB_FILES файла
INITORA также ограничивает количество доступных файлов для экземпляра базы.
MAXINSTANCES int
Устанавливается максимальное количество (int) экземпляров, которые могут уста-
новить и открыть создаваемую базу данных. Минимальное значение равно 1,
а максимальное и установленное по умолчанию зависят от операционной системы.
CHARACTER SETнабор_символов
Параметр управляет набором языковых символов, используемых для хранения
данных, набор символов не может иметь значения AL16UTF16. Значение пара-
метра зависит от операционной системы.
110 | Глава 3. Справочник по инструкциям SQL
NATIONAL CHARACTER SET набор _символов
Управляет набором национальных языковых символов, используемых для хране-
ния данных в столбцах типа NCHAR, NCLOB и NTARCHAR2. Значением пара-
метра набор_символов должно быть AL16UTF16 (по умолчанию) или UTF8.
EXTENT MANAGEMENT {DICTIONARY | LOCAL}
Создается локально управляемое табличное пространство SYSTEM, в противном
случае управление табличным пространством SYSTEM будет осуществляться с по-
мощью словаря данных. Это предложение требует наличия заданного по умолчанию
временного табличного пространства (default temporary tablespace). Если вы опусти-
те предложение DATAFILE, вы также можете опустить и временное табличное про-
странство по умолчанию, поскольку Oracle создаст их автоматически.
DATAFILE определение
Определяются один или несколько файлов данных для базы. (Все эти файлы
данных становятся частью табличного пространства SYSTEM.) Чтобы создать не-
сколько файлов одного размера и характеристик, вы можете повторять имена фай-
лов. Также вы можете написать несколько раз все предложение DATAFILE,
и каждое из них будет определять один или несколько файлов одинакового раз-
мера и с одинаковыми характеристиками. Полный синтаксис определения файла
данных довольно велик, но он обеспечивает высокую степень контроля.
OATAFILE {('фа/иП' [,...]) [GROUP int] [SIZE int [К | М] [REUSE]
[AUTOEXTEND [OFF | ON] [NEXT int [K j M]
[MAXSIZE [UNLIMITED | int [К | M] ]} [....]
Где:
DATAFILE (‘файл! ’ [,...])
Определяются один или несколько файлов, которые будут играть роль файлов
данных. Параметр файл! - это имя файла и путь к нему. В случае нескольких
файлов каждое имя файла заключается в одинарные кавычки и отделяется от
других имен запятыми. Весь список следует заключить в скобки.
GROUP int
Определяется целое (int) значение ID для группы файлов данных. Значения
могут быть от 1 до значения, указанного в предложении MAXDATAF1LES. База
данных Oracle должна иметь как минимум две группы файлов данных. Если
вы опустите это предложение, платформа создаст файлы данных автоматиче-
ски, по 100 Мб каждый.
SIZE int [К I М]
Указывается размер файла данных в байтах в виде целого числа (int). Вы также
можете определить размер файла данных в единицах больших, чем бай ты. Для
этого нужно добавить суффикс К (для килобайт) или М (для мегабайт).
REUSE
Использование имеющегося файла данных.
AUTOEXTEND
Включается (ON) автоматическое расширение новых или существующих
файлов данных или временных файлов (но не журнальных файлов). Предло-
Справочник по командам SQL | 111
жение NEXT определяет величину следующего инкремента выделяемого
файлу свободного места в байтах, килобайтах (К) или мегабайтах (М) в том
случае, если возникает необходимость в расширении.
MAXSIZE [UNLIMITED | int [К | М]]
Определяется максимальный объем дискового пространства для автоматиче-
ского расширения файла. При указании предложения UNLIMITED файл может
увеличиваться без верхнего предела (за исключением общего объема диска).
В качестве альтернативы вы можете указать предел максимального размера
файла в виде целого числа (int) в байтах, килобайтах (К) или мегабайтах (М).
SYSAUXDATAFILE определение
Определяется один или несколько файлов данных для табличного пространства
SYSAUX. По умолчанию Oracle осуществляет создание и управление табличными
пространствами SYSTEM и SYSAUX автоматически. Вы должны использовать
данное предложение в том случае, если вы определили файл данных для таб-
личного пространства SYSTEM. Если вы опустили предложение SYSA UX при ис-
пользовании файлов, управляемых Oracle, платформа создаст табличное про-
странство интерактивным, постоянным и локально управляемым с одним файлом
данных размером 100 Мб, при использовании автоматического управления про-
странством в сегментах и ведения журнала.
BIGFILE | SMALLFILE
Определяется заданный по умолчанию тип создаваемого далее табличного про-
странства. Параметр BIGFILE показывает, что табличное пространство будет со-
держать один файл данных или временный файл длиной до 8 экзабайт (8 миллионов
терабайт). Параметр SMALLFILE показывает, что табличное пространство будет
представлять собой традиционное табличное пространство Oracle. Если параметр
опускается, значение по умолчанию - SMALLFILE.
DEFAULT TABLESPACE имя_табличного^пространства
Определяется заданное по умолчанию постоянное табличное пространство базы
данных для всех пользователей, не являющихся пользователями SYSTEM. Если
данное предложение опущено, то заданным по умолчанию постоянным табличным
пространством для всех пользователей, не являющихся пользователями SYSTEM,
будет табличное пространство SYSTEM. Предложение EXTENT MANAGEMENT
имеет тот же синтаксис, что и предложение DEFAULT TEMPORARY TABLESPACE,
описанное ниже.
DEFAULT TEMPORARY TABLESPACE имя_табличного_пространства [TEMPFILE
определение_файла]
Определяется имя и местоположение заданного по умолчанию временного таб-
личного пространства базы данных. Пользователи, которые явно не приписаны
к определенному временному табличному пространству, работают с этим про-
странством. Если вы не создаете заданного по умолчанию временного табличного
пространства, Oracle будет использовать табличное пространство SYSTEM.
Будучи использованным в инструкции ALTER DATABASE, это предложение позво-
ляет изменить заданное по умолчанию временное табличное пространство.
112 | Глава 3. Справочник по инструкциям SQL
TEMPFILE определение_файна
Определение временного файла является необязательным, если установлен
параметр DB~CREATE_FILE_DESTфайла INIT.ORA. В противном случае вам
нужно будет определить временный файл самостоятельно. Синтаксис опреде-
ления временного файла идентичен приведенному ранее в этом разделе син-
таксису определения файла данных {DATAFILE).
EXTENT MANAGEMENT {DICTIONARY \ LOCAL {AUTOALLOCATE |
UNIFORM [SIZE int [К | M]]}}
Определяется способ управления табличным пространством SYSTEM. Если
данное предложение опущено, табличное пространство SYSTEM управляется сло-
варем данных. Если создается табличное пространство с локальным управлением,
его нельзя будет преобразовать в пространство, управляемое при помощи словаря
данных, и в базе данных нельзя будет создавать новые табличные пространства,
управляемые словарем данных.
DICTIONARY
Определяется, что табличное пространство будет управляться словарем дан-
ных. Этот параметр задан по умолчанию. При использовании данного предло-
жения предложения AUTOALLOCATE и UNIFORM не применяются.
LOCAL
Определяется, что табличное пространство будет управляться локально. Это
предложение является необязательным, поскольку все временные табличные
пространства по умолчанию имеют локально управляемые экстенты. Для ис-
пользования этого предложения необходимо наличие заданного по умолча-
нию временного табличного пространства (default temporary tablespace). Если
вы не создадите такого табличного пространства, Oracle сделает это автома-
тически. В этом случае оно будет называться TEMP, будет иметь размер 10 Мб
и включенное автоматическое расширение.
AUTOALLOCATE
Определяется, что новые экстенты будут выделяться по мере необходимости
табличным пространством с локальным управлением.
UNIFORM [SIZE int [К | М]]
Определяется, что все экстенты табличного пространства будут иметь одина-
ковый размер, указанный в виде целого числа (int) байт, килобайт (ключевое
слово К) или мегабайт (ключевое слово М).
UNDO TABLESPACE имя„табличного^пространства
[DA ТА FILE опреда1вние_временного_файла_данных]
Определяется имя и местоположение данных для отката с созданием табличного
пространства с именем имя табличиого _пространства, но только в том случае,
если параметр UNDO_MANAGEMENT файла INIT.ORA установлен в AUTO. Если
вы не используете данное предложение, Oracle управляет выделением места для
обработки отката с помощью сегментов отката (rollback segment). (Вы также можете
установить в параметре файла INIT.ORA значение UNDO_TABLESPACE. В этом
8 - 2447
Справочник по командам SQL | 113
случае значение этого параметра и имя_табличного_простраиства в данном пред-
ложении должны быть идентичны.)
Где:
DATAFILE определение_временного_файла_данных
Создается файл данных, в соответствии с определением и связывается с таб-
личным пространством, которое используется для данных отката. Обращайтесь
к вышерасположенному разделу, посвященному файлу данных (DATAFILE), где
приведен полный синтаксис данного предложения. Данное предложение является
необходимым, если вы не указали значение параметра DB_CREATE_FlLEJDEST
^vm&INIT.ORA.
SET TIME_ZONE='{{+ | -}чч:мм | региональный_часовой_пояс] ’
Определяется часовой пояс для базы данных - либо путем указания разницы
с Гринвичским временем (теперь оно называется Координированное всеобщее
время), либо путем указания часового пояса региона. (Чтобы получить список
часовых поясов по регионам, пошлите запрос к столбцу tzname представления
v$timezone_names.) Если вы опустите это предложение, Oracle будет по умолча-
нию использовать часовой пояс операционной системы.
SET DEFAULT TABLESPACE
Все табличные пространства, созданные в текущей инструкции CREATE DATABASE
или ALTER DATABASE, определяются как BIGFILE или как SMALLFILE. При созда-
нии баз данных это предложение также применимо к табличным пространствам
SYSTEM и SYSAUX.
MOUNT [[STANDBY | CLONE] DATABASE]
База данных монтируется (связывается с экземпляром) для пользовательского дос-
тупа. При указании ключевого слова STANDBY монтируется физическая резервная
база данных, которая может получать архивированный журнал из исходного эк-
земпляра. При указании ключевого слова CLONE создается клон базы данных.
Это предложение нельзя использовать с конструкцией OPEN.
OPEN [READ WRITE | READ ONLY]
[RESETLOGS | NORESETLOGS] [UPGRADE | DOWNGRADE]
База данных открывается без учета монтирования. (Сначала смонтируйте базу
данных.) При указании параметра READ WRITE база данных открывается
в режиме «для чтения и записи»; пользователи могут создавать журналы. Пара-
метр READ ONLY позволяет читать, но запрещает изменять журналы. При указа-
нии параметра RESETLOGS сбрасывается вся информация, которая не применя-
лась при восстановлении, а порядковый номер журнала устанавливается в 1.
Параметр NORESETLOGS оставляет журналы в текущем состоянии. Дополни-
тельные предложения UPGRADE и DOWNGRADE указывают, что платформа
должна динамически изменить системные параметры, как это необходимо для
обновления версии базы или для возврата к предыдущей версии соответственно.
Значения по умолчанию - OPEN READ WRITE NORESETLOGS.
114 | Глава 3. Справочник по инструкциям SQL
ACTIVATE [PHYSICAL i LOGICAL] STANDBY DATABASE [SKIP [STANDB Y LOGFILE]]
Резервная база данных превращается в основную. При желании вы можете ука-
зать, является ли резервная база данных физической или логической. Предложе-
ние SKIP используется для немедленного преобразования резервной базы и отказа
от всех не хранимых инструкцией RECOVER MANAGED STANDBY DATABASE
FINISH данных. Конструкция STANDBY LOGFILE никакого влияния не оказывает.
SET STANDBY [DATABASE] TO MAXIMIZE
I PROTECTION I AVAILABILITY | PERFORMANCE)
Определяется уровень защиты данных в главной базе данных. Старые термины
PROTECTED и UNPROTECTED эквивалентны терминам MAXIMIZE PROTECTION
и MAXIMIZE PERFORMANCE соответственно, где:
PROTECTION
Обеспечивает наивысший уровень защиты данных, но увеличивает нагрузку
на базу и отрицательно влияет па доступность. При такой настройке транзак-
ция выполняется только после того, как все данные, необходимые для восста-
новления, будут физически записаны хотя бы в одну физическую резервную
базу данных, использующую транспортный режим синхронизации журналь-
ных файлов (SYNC log transport mode).
AVAILABILITY
Обеспечивает второй после PROTECTION уровень защищенности данных, но
наивысший уровень доступности. При такой настройке транзакции выпол-
няются только после того, как все данные, необходимые для восстановления,
будут физически записаны хотя бы в одну физическую или логическую резерв-
ную базу данных, использующую транспортный режим синхронизации
журнальных файлов (SYNC log transport mode).
PERFORMANCE
Обеспечивает наивысшую производительность, но отрицательно влияет на
защищенность и доступность данных. При такой настройке транзакции выпол-
няются до того, как все данные, необходимые для восстановления, будут
физически записаны в резервную базу данных.
REGISTER [OR REPLACE] [PHYSICAL j LOGICAL] LOGFILE [‘файл ]
При подаче этой команды на резервном сервере выполняется ручная регистрация
журнальных файлов, полученных с аварийного основного сервера. Журнальный
файл можно при желании объявить физическим (PHYSICAL} или логическим
(LOGICAL). Предложение OR REPLACE позволяет провести обновление записей
существующего архивного журнала.
FOR uMK_ceauca_Iogminer
Журнальный файл регистрируется в одном сеансе утилиты LogMiner в среде
Oracle Streams.
{COMMIT \ PREPARE) ТО SWITCHOVER ТО
{[PHYSICAL | LOGICAL] PRIMARY \ STANDBY]
Выполняется корректное переключение текущей основной базы данных в состояние
резервной, а резервная база становится основной. (В среде RAC нужно выключить
Справочник по командам SQL | 115
все экземпляры, кроме текущего.) Для корректного переключения вы должны
подать команду дважды - один раз с использованием синтаксиса PREPARE ТО
SWITCHOVER, с целью подготовки баз данных к обмену файлами журналов перед
переключением. Для понижения статуса текущей основной базы данных и пере-
ключения на резервную базу выполните команду COMMIT ТО SWITCHOVER.
При указании предложения PHYSICAL основная база данных становится физиче-
ской резервной базой. При указании предложения LOGICAL основная база перехо-
дит в режим логической резервной базы. Однако после этого вы должны еще подать
команду ALTER DATABASE START LOGICAL STANDBY APPLY.
WITH [OUT] SESSION SHUTDOWN] [WAIT | NOWAIT]
При указании предложения WITH SESSION SHUTDOWN закрываются все
открытые сеансы приложений, отменяются все незавершенные транзакции при
переключении физических баз данных (но не логических). Параметр WITHOUT
SESSION SHUTDOWN (установлен по умолчанию) приводит к тому, что
инструкция COMMIT ТО SWITCHOVER не будет выполняться, если в наличии
окажутся открытые сеансы приложений. Предложение WAIT возвращает управ-
ление в консоль после завершения команды SWITCHOVER, а предложение
NOWAIT возвращает управление, не дожидаясь завершения команды.
START LOGICAL STANDBY APPLY [IMMEDIATE] [NODELAY]
[{INITIAL int | NEW PRIMARY имя связи] | [FINISH | SKIP] FAILED TRANSACTIONS}]
Запускает процесс применения журналов к логической резервной базе данных.
Предложение IMMEDIATE говорит, что утилита LogMiner должна читать данные
в журнальных файлах резервной базы. Параметр NODELAY указывает, что плат-
форма должна игнорировать задержки в ходе применения (например, недоступ-
ность или отсутствие основной базы). Параметр INITIAL используется, если вы
впервые применяете журнал к резервной базе данных. Параметр NEW PRIMARY
требуется после завершения переключения или после того, как резервная база
обработала все журнальные файлы и другая резервная база стала основной. Пред-
ложение SKIP FAILED TRANSACTIONS используется, чтобы пропустить послед-
нюю транзакцию и перезапустить применение журналов. Параметр FINISH
используется для применения данных из журнальных файлов в том случае, если
основная база отключена.
[STOP | ABORT] LOGICAL STANDBY APPLY
Останавливает процесс применения журнальных файлов к логическому резервно-
му серверу. При указании параметра STOP выполняется корректная остановка,
а параметр ABORT вызывает немедленную остановку.
[NO]PARALLEL [int]
Параметр [NO]PARALLEL определяет, будут ли применяться параллельные процессы
при восстановлении носителя. По умолчанию установлено значение NOPARALLEL,
и этот параметр обеспечивает последовательное чтение журналов с носителя. При
указании параметра PARALLEL без целочисленного значения int уровень параллелизма
выбирает платформа Oracle. Значение int определяет уровень параллелизма.
116 | Глава 3. Справочник по инструкциям SQL
RENAME GLOBAL NAME TO база_данных[.домен[.домен...]]
Изменяется глобальное имя базы данных, база Ванных - новое имя длиной до 8 сим-
волов. Дополнительные параметры домен определяют положение базы данных
в сети. Эта команда не распространяет изменение имени базы данных на зависимые
объекты, такие, как синонимы, хранимые процедуры и т. п.
{DISABLE I ENABLE} BLOCK CHANGE TRACKING [USING FILE 'файл'] [REUSE]
Указывается, что платформа должна соответственно остановить или запустить
процесс отслеживания физического местоположения всех обновлений базы дан-
ных, сохраняя информацию в специальном файле, называемом файлом слежения
за изменениями блоков (block change tracking file). Платформа Oracle автоматиче-
ски создаст этот файл, как это определено в параметре DB CREATE FILE DEST,
если только вы не будете использовать предложение USING FILE ‘файл’, где
’файл'- это имя файла и путь к нему. Параметр REUSE указывает, что платформа
будет переписывать существующий файл слежения за изменениями блоков с гем
же самым именем 'файл ’. Использовать предложения USING и REUSE можно
только с предложением ENABLE BLOCK.
FLASHBACK {ON j OFF}
Переводит базу данных в ретроспективный режим (FLASHBACK) и обратно, соот-
ветственно. Находясь в ретроспективном режиме, база данных Oracle автоматиче-
ски создает и обслуживает ретроспективные журналы базы данных в области
ретроспективного восстановления. При указании параметра OFF ретроспектив-
ные журналы базы удаляются и становятся недоступны.
SET TIME ZONE
Определяется часовой пояс сервера. За дополнительной информацией обращай-
тесь к инструкции SET TIME ZONE.
ENABLE [PUBLIC] THREAD int I DISABLE THREAD int | INSTANCE 'имя экземпляра’
В среде Real Application Cluster (RAC) вы можете включать (ENABLE) или
отключать (DISABLE) поток журнала, указав его номер (int). Кроме этого, вы можете
указывать 'имя экземпляра’, чтобы включать или отключать поток, связанный со
специфическим экземпляром базы данных в среде Oracle Real Application Cluster.
имя экземпляра может быть длиной до 80 символов. Ключевое слово PUBLIC
делает поток доступным для любого экземпляра. Если предложение опушено,
поток становится доступным только при явном к нему обращении. Чтобы можно
было включить поток, с ним должно быть связано не менее двух журнальных
групп. Чтобы можно было отключить поток, база данных должна быть открыта,
по не смонтирована с экземпляром, который использует поток.
GUARD {ALL i STANDBY | NONE}
Этот параметр защищает данные в базе от изменений. Значение ALL не дает
делать изменения никаким пользователям, за исключением SYS. Значение STANDBY
не дает пользователям, кроме SK5, вносить изменения в логическую резервную
базу данных. Значение NONE соответствует обычной системе безопасности базы
данных.
Справочник по командам SQL | 117
CREATE DATAFILE ‘файл’[...] [AS {NEW\ определение_файла}]
Создается новый пустой файл данных, который заменяет существующий. Пара-
метр ‘файл' определяет файл (по имени или по номеру), который был потерян или
поврежден при отсутствии резервной копии. При указании параметра AS NEW
в файловой системе, заданной по умолчанию, создается новый файл, имя которо-
му дает платформа Oracle. Параметр AS определение файла позволяет указать имя
файла и параметры его размера так, как это было описано ранее в этом списке,
в теме определение _файла.
DATAFILE ‘файл’\ TEMPFILE ‘файл’ [...] {ONLINE | OFFLINE [FOR DROP]} |
RESIZE int [К | M] | AUTOEXTEND {OFF | ON[NEXTint[K | M]} [MAXSIZE[UNLIMITED |
int [K | M]]} {END BACKUP [INCLUDING DATAFILES]}
Изменяются атрибуты, например размер, одного или нескольких существующих
файлов данных или временных файлов. Вы можете изменить один или несколько
указанных через запятую файлов, определяемых параметром ‘файл ’ по имени или
по номеру файла. Не перепутайте определения файлов данных и временных фай-
лов. В предложении должны быть либо одни, либо другие.
ONLINE
Файл становится оперативным.
OFFLINE [FOR DROP]
Файл становится автономным с возможностью восстановления носителя.
Предложение FOR DROP нужно, чтобы сделать файл автономным в режиме
NOARCHIVELOG, но файл в действительности не удаляется. Параметр игнориру-
ется в режиме ARCHIVELOG.
RESIZE int [К | М]
Устанавливается новый размер существующего файла данных или временного
файла.
END BACKUP
Описывается ниже, в пункте, посвященном предложению END BACKUP.
Используется только с предложением DATAFILE.
DROP INCLUDING DATAFILES
Удаляется не только временный файл, но также все файлы данных, связанные
с временным файлом в файловой системе. Также Oracle добавляет для каждо-
го удаленного файла запись в журнал предупреждений. Используется только
с предложением TEMPFILE.
A UTOEXTEND {OFF | ON [NEXT int [К | М]} [MAXSIZE [UNLIMITED | int [К | М]]
Параметр описан ранее в этом списке, в пункте, посвященном конструкции
DATAFILE.
RENAME FILE ‘файл’ [,...] ТО ‘новоеимяфайла’ [„..]
Файл данных, временный файл или элемент журнальной группы переименовыва-
ется. Старое имя ‘файл’ меняется на новое ‘новое_имя_файла’. Вы можете пере-
именовать сразу несколько файлов, указав сразу несколько старых и новых имен.
Эта команда не переименовывает файлы на уровне операционной системы.
Вместо этого она указывает новые имена, которые платформа будет использовать
118 | Глава 3. Справочник по инструкциям SQL
для открытия этих файлов. Переименовывать файлы па уровне операционной сис-
темы вы должны самостоятельно.
/ЛО/ FORCE LOGGING
Переводит базу данных в режим принудительного ведения журнала или выводит
ее (NO FORCE LOGGING) из этого режима. В первом случае платформа Oracle за-
писывает в журнал все изменения, вносимые в базу данных, за исключением из-
менений во временных табличных пространствах и сегментах. Значение пара-
метра FORCE LOGGING уровня базы данных замещает собой все объявления
па уровне табличных пространств, касающиеся режима принудительного ведения
журнала.
/NO] ARCHIVELOG [MANUAL]
Указывается, что создавать журнальные файлы должна платформа, но пользова-
тель будет явно определять архивирование журнальных файлов. Используется
только в инструкции ALTER DATABASE и только для обратной совместимости
с более старыми системами резервного копирования па магнитных лентах. Если
это предложение опущено, платформа по умолчанию определяет местоположение
журнальных файлов в соответствии с инициализационным параметром
LOG ARCHIVE DEST n.
[ADD 'DROP] SUPPLEMENTAL LOG DATA
KALL । PRIMARY KEY ; UNIQUE 1 FOREIGN KEY) [,...] COLUMNS]
Параметр ADD при выполнении обновления помещает дополнительные данные
столона в поток журнала. Он также позволяет осуществлять минимальную допол-
нительную журнализацию (minimal supplemental logging), которая обеспечивает
для LogMiner поддержку сцепленных строк (chained rows) и специальных форм
хранения, таких, как кластеризованные таблицы. Дополнительная журнализация
ио умолчанию отключена. Вы можете добавлять предложения PRIMARY KEY
COLUMNS. UNIQUE KEY COLUMNS, FOREIGN KEY COLUMNS или ALL (чтобы
включи ть все три предыдущие предложения), если вам нужно обеспечить полную
ссылочную целостность с помощью внешних ключей другой базы данных, напри-
мер логической резервной базы. В любом случае платформа Oracle помещает
в журнал либо столбцы первичных ключей, либо столбцы уникальных ключей
(или. если нет ни того пи другого, комбинацию столбцов, однозначно опреде-
ляющую строку), либо столбцы внешних ключей, либо все три вида. Предложе-
ние DROP заставляет платформу отключить дополнительную журнализацию.
[ADD \DROP] / STANDBY] LOGFILE [THREAD int]
[GROUP int] [MEMBER] 'файл ' [,...]
Предложение ADD добавляет в экземпляр одну или несколько основных или
резервных журнальных групп. Параметр THREAD связывает добавленные файлы
с указанным номером потока (int) в Real Application Cluster. Если этот параметр
опущен, по умолчанию принимается поток, связанный с текущим экземпляром.
Предложение GROUP связывает журнальные группы с указанной группой потока.
Параметр MEMBER добавляет указанный 'файл' (или группу файлов, отделенных
друг от друга запятыми) к существующей журнальной группе. Предложение
Справочник по командам SQL | 119
DROP LOGFILE MEMBER удаляет один или несколько файлов-элементов
журнальной группы после подачи команды AL TER SYSTEM SWITCH LOGFILE.
CLEAR [UNARCHIVED] LOGFILE GROUP
int имя_журналъного_файла [,...] [UNRECOVERABLE DATAFILE]
Переинициализируется один или несколько оперативных (online) журналов. Укажите
журналы через запятую. При указании параметра UNARCHIVED пропускается
архивирование журналов. Предложение UNRECOVERABLE DATAFILE нужно,
если какой-нибудь файл данных является автономным (offline), а база данных
находится в режиме ARCHIVELOG.
CREATE {LOGICAL | PHYSICAL}STANDBYCONTROLFILE AS 'файл' [REUSE]}
Создается управляющий файл, который сопровождает физическую или логиче-
скую резервную базу данных. Предложение REUSE нужно, если файл уже сущест-
вует.
BACKUP CONTROLFILE ТО {'файл ’ [REUSE] | TRACE [AS 'файл ’ [REUSE]} [RESET-
LOGS | NORESETLOGS]
Создается резервная копия текущего управляющего файла открытой или монтирован-
ной базы данных. Параметр ТО 'файл ’ определяет полный путь и имя управляющего
файла. При указании параметра ТО TRACE в трассировочный файл записываются ин-
струкции SQL, которые могут заново создать управляющий файл. При указании пред-
ложения ТО TRACE AS 'файл’ все инструкции SQL записываются в стандартный
файл, а не в трассировочный. Предложение REUSE нужно, если файл уже существует.
Параметр RESETLOGS инициализирует трассировочный файл инструкцией ALTER
DATABASE OPEN RESETLOGS и используется только в том случае, если оперативные
журналы недоступны. Предложение NORESETLOGS инициализирует трассиро-
вочный файл инструкцией ALTER DATABASE OPEN NORESETLOGS и используется
только в том случае, если оперативные журналы доступны.
RECOVER
Параметр управляет восстановлением носителя базы данных, резервной базы данных,
табличного пространства или файла. В Oracle команда ALTER TABLE является одним
из основных способов восстановления поврежденной или отключенной базы данных,
файла или табличного пространства. Используйте предложение RECOVER, если база
данных монтирована (в эксклюзивном режиме), соответствующие файлы и табличные
пространства не используются (offline) и база данных находится в открытом или
закрытом состоянии. Всю базу данных можно восстанавливать, только если она
закрыта, однако конкретные файлы или табличные пространства можно восстанавли-
вать и в открытой базе данных.
AUTOMATIC [FROM ‘.местоположение’]
Указывается, чтобы платформа автоматически генерировала имя следующего
архивированного журнального файла, необходимого для продолжения операции
восстановления. Если платформа не сможет найти следующий файл, она преду-
предит вас. Предложение FROM ‘местоположение’ укажет, где нужно искать
архивированную журнальную группу. К автоматически восстанавливаемой базе
можно применять следующие предложения.
120 | Глава 3. Справочник по инструкциям SQL
STANDBY
Определяется, что восстанавливаемая база данных или табличное пространство
является резервным.
DATABASE (UNTIL (CANCEL | TIME дата | CHANGE int} |
USING BACKUP CONTROLFILE}
Указывается, что платформа должна восстановить всю базу. Ключевое слово
UNTIL показывает, что Oracle будет продолжать восстановление до тех пор,
пока не будет выполнена команда ALTER DATABASE...RECOVER CANCEL
(CANCEL), или до тех пор, пока не будет достигнуто указанное время (TIME)
в формате ГГГГ-ММ-ДД:ЧЧ24:ММ:СС, или до тех пор, пока не будет достигнут
определенный номер системного изменения (CHANGE) (номер - int). Предло-
жение USING BACKUP CONTROLFILE позволяет использовать резервную
копию управляющего файла, а не его текущий вариант.
[STANDBY] TABLESPACE имя табличиого^пространства [,...] |
DATAFILE 'файл'
Восстанавливаются одно или несколько указанных табличных пространств
или файлов данных соответственно. Вы можете указать несколько табличных
пространств или файлов данных, разделив их запятыми. Также вы можете
восстановить файл данных, указав его номер, а не имя. Табличное пространст-
во может находиться в обычном или резервном режиме. Резервное табличное
пространство или файл данных реконструируется с помощью архивирован-
ных журнальных файлов, скопированных из основной базы данных и управ-
ляющего файла.
UNTIL [CONSISTENT WITH] CONTROLFILE
Указывается, что платформа Oracle должна провести восстановление старого
резервного табличного пространства или файла данных, используя текущий
резервный управляющий файл. Слова CONSISTENT WITH не оказывают ника-
кого влияния.
LOGFILE имя_файла [,...]
Продолжается восстановление носителя, путем применения одного или несколь-
ких перечисленных через запятую журнальных файлов.
TEST i ALLOW int CORRUPTION | [NO] PARALLEL int
При указании предложения TEST выполняется пробное восстановление,
которое позволяет заранее увидеть все проблемы. Конструкция ALLOW int
CORRUPTION показывает, какое количество (int) поврежденных блоков явля-
ется допустимым. Превышение этого числа вызывает отмену восстановления.
Для настоящего восстановления значение int должно быть равно 1, по
в случае тестирования (TEST) можно указать любое значение. Параллелизм
описывался в данном перечне выше.
CONTINUE [DEFA ULT]
Параметр определяет, будет ли восстановление нескольких экземпляров про-
должаться после нарушения. Конструкция CONTINUE DEFAULT аналогична
Справочник по командам SQL | 121
конструкции RECOVER A UTOMATIC, за исключением того, что не нужно вводить
имя файла.
CANCEL [IMMEDIATE] [[NO]WAIT]
Co следующего архивированного журнала отменяется операция автоматиче-
ского восстановления, если она была запущена с помощью предложения
USING CANCEL. При указании ключевого слова IMMEDIATE автоматическое
восстановление отменяется после завершения текущей операции ввода-
вывода или окончания архивированного журнала (в зависимости от того, что
произойдет первым). При указании предложения NOWAIT восстановление
отменяется сразу, независимо от того, какая работа выполняется, а предложе-
ние WAIT позволяет текущему заданию завершиться в обычном режиме.
MANAGED STANDBY DATABASE
Для активного компонента резервной базы данных указывается режим автома-
тического восстановления физической резервной базы. Эта команда используется
только для восстановления носителя, а не для создания новой базы данных.
Применяются следующие параметры.
[NO] TIMEOUT int
В параметре TIMEOUT указывается в минутах (int) время, которое фоновая
операция автоматического восстановления ожидает доступа к следующему
журналу. По истечении этого срока операция отменяется. При указании пред-
ложения NOTIMEOUT (установлено по умолчанию) платформа Oracle будет
ждать следующего журнала неопределенно долго, до момента отключения
экземпляра или до момента подачи команды RECOVER CANCEL.
CANCEL [IMMEDIATE] [[NO]WAIT]
Предложение описано выше.
[NO]DELA Y int | DEFA ULTDELA Y int
Определяет, сколько времени в минутах (int) платформа Oracle должна ожидать,
перед тем как применить архивированный журнал, выбранный для проведения
восстановления. Параметр DEFAULTJOELAYуказывает, что платформа должна
использовать задержку, указанную в параметре LOG_ARCHIVE_DEST_n файла
INIT.ORA. Параметр NODELAY говорит, что платформа должна применить
журнал немедленно.
NEXT int
Определяется, что платформа Oracle должна применить int следующих архи-
вированных журналов как можно быстрее после их архивирования. Предло-
жение несовместимо с предложением FINISH.
[NOJEXPIRE
Указывается время в минутах (int), по истечении которого платформа должна
автоматически завершить восстановление (считая от момента его начала).
Предложение [NO]EXPIRE отключает ранее установленное значение EXPIRE.
Предложение несовместимо с предложением FINISH.
122 | Глава 3. Справочник по инструкциям SQL
USING CURRENT LOGFILE
Вызывается процесс обработки в реальном времени, который позволяет про-
водить восстановление по оперативным резервным журналам по мере их запол-
нения, без необходимости архивировать их в резервной базе данных.
UNTIL CHANGE int
Автоматическое восстановление производится до достижения указанного
в параметре int номера системного изменения (ио не включая сам этот номер).
THROUGH {ALL ARCHIVELOG | {ALL | LAST | NEXT} SWITCHOVER | [TREAD int]
SEQUENCE int}
Определяет, когда платформа должна завершить автоматическое восстанов-
ление с резервного сервера. Параметр THROUGH ALL ARCHIVELOG (ука-
зан по умолчанию) продолжает процесс автоматического восстановления
до тех пор, пока не будут восстановлены все архивные журналы. Параметр
THROUGH...SWITCHOVER контролирует завершение автоматического вос-
становления в том случае, если платформа переключается на вторичный ре-
зервный сервер. Параметр ALL указывает, что автоматическое восстановление
продолжает функционировать без учета переключений. Параметр LAST показы-
вает, что восстановление прекращается при достижении самого последнего
маркера конца журнала (end-of-redo indicator). Параметр NEXT завершает авто-
матическое восстановление после получения следующего индикатора конца
журнала. Параметр THROUGH...SEQUENCE определяет, что автоматическое
восстановление должно завершиться при достижении указанного номера потока
{THREAD) журнала или его порядкового (SEQUENCE) номера.
DISCONNECT [FROM SESSION] [[NO]PARALLEL]
Процесс автоматического восстановления будет происходить в фоновом режиме,
а текущий процесс может заниматься другими задачами. Слова FROM SESSION
не оказывают никакого влияния. Предложение DISCONNECT несовместимо
с предложением TIMEOUT.
FINISH [SKIP [STANDBY LOGFILE]] [{WAIT \ NOWAIT}]]
Восстанавливаются текущие физические оперативные резервные журнальные
файлы для подготовки резервной базы к выполнению роли основной, при
наличии подозрения на выход основной базы из строя. Предложение FINISH
без использования других ключевых слов называется также окончательным
восстановлением (terminal recovery). Дополнительное предложение SKIP
[STANDBY LOGFILE] позволяет подготовить резервную базу к роли основ-
ной, если оперативные резервные журналы недоступны. Предложение FINISH
SKIP, при использовании без других ключевых слов, также называется непол-
ным окончательным восстановлением (terminal incomplete recovery). Пара-
метр WAIT показывает, что платформа должна вернуть управление после за-
вершения процесса восстановления, а параметр NOWAIT - что платформа
должна вернуть управление немедленно. Предложение несовместимо с пред-
ложениями TIMEOUT, DELAY, EXPIRE и NEXT.
Справочник по командам SQL | 123
{BEGIN | END} BACKUP
Определяется режим оперативного резервного копирования (online backup mode).
При указании предложения BEGIN в режим оперативного резервного копирования
переводятся все файлы данных. База данных должна быть смонтирована и откры-
та и находиться в режиме архивирования журналов с включенной опцией восста-
новления носителя (media recovery). (Заметьте, что, пока база находится в режиме
оперативного резервного копирования, экземпляр нельзя отключить, а отдельные
табличные пространства нельзя переводить в автономный (offline) режим, делать
доступными только для чтения или создавать с них резервные копии.) Параметр
END выводит все файлы данных, находящиеся в режиме оперативного резервного
копирования, из этого режима. База данных должна быть смонтирована, но не обя-
зательно открыта.
После такого долгого обсуждения специфического синтаксиса важно определить
некоторые основные понятия Oracle.
Oracle позволяет использовать основные (primary) и резервные (standby) базы дан-
ных. Основная база данных смонтирована и открыта для доступа пользователей.
Основная база данных отправляет свои журналы изменений (redo logs) в резервную
базу данных, где они восстанавливаются, и это делает резервную базу данных в высокой
степени соответствующей основной базе.
Уникальной вещью в среде Oracle является файл INIT.ORA, который определяет
имя базы данных и множество других опций, используемых при создании и запуске
базы. Нужно всегда определять исходные параметры, такие, как имена всех управ-
ляющих файлов, в файле INIT.ORA, иначе база данных не сможет запуститься. Начи-
ная с версии Oracle 9.1, вы можете использовать двоичные файлы параметров вместо
файлов INIT.ORA.
При перечислении группы журнальных файлов они обычно заключаются в скобки.
Скобки не требуются, если создается группа всего из одного элемента, но такое проис-
ходит редко. Вот пример использования списка журнальных файлов, заключенных
в скобки.
CREATE DATABASE publications
LOGFILE ('/s01/oradata/loga01','/s01/oradata/loga02') SIZE 5M
DATAFILE;
В приведенном выше примере создается база данных с именем publications
с явно определенным предложением LOGFILE и автоматически создаваемым файлом
данных. Следующий пример команды CREATE DATABASE для Oracle гораздо более
сложный.
CREATE DATABASE sales_reporting
CONTROLFILE REUSE
LOGFILE
GROUP 1 ('diskE:log01. log ', 'diskF:log01.log') SIZE 15M,
GROUP 2 ('diskE:log02.log', 'diskF:log02.log') SIZE 15M
MAXLOGFILES 5
124 | Глава 3. Справочник по инструкциям SQL
MAXLOGHISTORY 100
MAXDATAFIlES 10
MAXINSTANCES 2
ARCHIVELOG
CHARACTER SET AL32UTF8
NATIONAL CHARACTER SET AL16UTF16
DATAFILE
'diskE:saies_rpt1.dbf' AUTOEXTEND ON,
'diskF:sales_rpt2,dbf' AUTOEXTEND ON NEXT 25M MAXSIZE UNLIMITED
DEFAULT TEMPORARY TABLESPACE tempjrblspc
UNDO ’’ABlESPACE undo_tblspc
SET timf_ZONE = '-08:00';
В этом примере определяются файлы журнала и файлы данных, а также все необ-
ходимые наборы символов. Мы также определили несколько характеристик базы дан-
ных, в частности использование режимов ARCHIFELOG и CONTROLFILE REUSE,
часовой пояс, максимальное число экземпляров, файлов данных и т. д. В примере
также предполагается, что параметр DBCREATEFILEDEST файла INIT.ORA был
уже установлен. Таким образом, нам не нужно определять файлы для предложений
DEFAULT TEMPORARY TABLESPACE и UNDO TABLESPACE.
Если такую команду подаст пользователь с привилегиями SYSDBA, база данных
будет создана и станет доступной для пользователей либо в эксклюзивном, либо
в параллельном режиме (в соответствии со значением инициализационного параметра
CLUSTER DATABASE). Все данные, имеющиеся в заданных файлах данных, будут
стерты. Обычно для базы данных нужно создавать табличные пространства и сегмен ты
отката (обращайтесь к документации производителя по платформо-специфическим
командам CREATE TABLESPACE и CREATE ROLLBACK SEGMENT).
Компания Oracle увеличила безопасность пользовательских учетных записей,
имеющихся по умолчанию в базе данных. Многие учетные записи по умолчанию
при первоначальной установке сейчас заблокированы и более не используются.
Только записи STS, SYSTEM, SCOTT, DBSNMP, OUTLN, AURORASJJSSUTILITYS,
AURORAWRB3UNAUTHENTICATED$ и OSE$HTTP$ADM1N остались такими же,
какими они были в более ранних версиях. Вы должны вручную разблокировать
и присвоить новые пароли всем заблокированным учетным записям, а также при
первоначальной инсталляции присвоить пароль записям STS и SYSTEM.
В следующем примере мы добавляем к текущей базе данных несколько журнальных
файлов, а затем добавляем файл данных.
ALTER DATABASE ADD LOGFILE GROUP 3
('diskf: log3.sales_arch_log','diskg:Log3.sales_arch_log')
SIZE 50M;
ALTER DATABASE sales_archive
CREATE DATAFILE 'diskF;sales_rpt4,dbf'
AUTOEXTEND ON NEXT 25M MAXSIZE UNLIMITED;
Справочник по командам SQL | 125
Мы можем задать новое табличное пространство по умолчанию, как это показано
в следующем примере.
ALTER DATABASE DEFAULT TEMPORARY TABLESPACE sales_tbl_spc_2;
После этого мы выполним простое полное восстановление базы данных.
ALTER DATABASE sales_archive RECOVER AUTOMATIC DATABASE;
В следующем примере мы выполним частичное восстановление, которое потребует
несколько больших усилий.
ALTER DATABASE RECOVER STANDBY DATAFILE ’diskF;sales_rpt4. dbf ’
UNTIL CONTROLFILE;
Теперь мы выполним простое восстановление резервной базы данных в режиме
автоматического восстановления резервной базы.
ALTER DATABASE RECOVER sales_archive MANAGED STANDBY DATABASE;
В следующем примере мы выполним постепенное переключение от основной базы
данных к логической резервной базе и сделаем логическую резервную базу основной.
--Переводим текущую основную базу в состояние логической резервной
ALTER DATABASE COMMIT ТО SWITCHOVER ТО LOGICAL STANDBY;
--Применяем изменения к новой логической резервной базе
ALTER DATABASE START LOGICAL STANDBY APPLY;
--Переводим текущую резервную базу в состояние основной.
ALTER DATABASE COMMIT ТО SWITCHOVER ТО PRIMARY
PostgreSQL
Реализация команды CREATE DATABASE в PostgreSQL создает базу данных и опреде-
ляет местоположение файлов данных.
CREATE DATABASE имя_базы_данных
[ WITH {[LOCATION = путь_к~бд' ] [TEMPLATE = имя_шаблона']
[ENCODING = кодировка]} ]
Где:
WITH LOCATION = 'путькбо ’
Определяет путь к месту, где будет находиться база данных. Вы можете опустить это
предложение и принять местоположение по умолчанию или же указать предложе-
ние WITH LOCATION = DEFAULT. Путь нужно подготовить заранее с помощью
команды initlocation (которая является командой Unix, а не SQL). Как правило,
в PostgreSQL используются имена переменных среды (имя переменной среды - это
путь без наклонных черт). Если вы хотите указать абсолютное значение имени
и пути, например /usr/local/pgsql/dataOl, то вы должны установить для сервера пара-
метр ALLOW ABSOLUTE DBPATH и скомпилировать сервер с этим параметром.
TEMPLATE = имяшиблона
Присваивается имя шаблону, который используется для создания новой базы
данных. Вы можете опустить это предложение и принять шаблон по умолчанию,
126 | Глава 3. Справочник по инструкциям SQL
описывающий местоположение файлов базы данных, или же использовать пред-
ложение TEMPLATE = DEFAULT. Это значение представляет собой копию стан-
дартной системной базы данных templatel. Вы можете также получить «чистую»
базу данных (которая содержит только самые необходимые объекты), указав пред-
ложение TEMPLATE = template/).
ENCODING - кодировка
Указывается многобайтный метод кодировки, который будет использоваться
в новой базе данных либо в виде строкового литерала (например, ‘SQL ANSI’),
либо в виде целочисленного номера кодировки, либо в виде значения DEFAULT,
т. е. кодировка по умолчанию.
Например, создадим базу данных с именем salesrevenue в директории /home/
teddy/privatedb.
CREATE DATABASE sales.revenue WITH LOCATION =
'/nome/reaay/private.db';
Будьте аккуратны при использовании абсолютных имен файлов и путей, посколь-
ку они влияют па безопасность и целостность данных.
В PostgreSQL рекомендуется, чтобы базы данных, используемые в качестве шаб-
лонов, были доступны только для чтения. Не следует использовать шаблонные базы
данных в качестве «базы для копирования».
PostgreSQL не поддерживает команду ALTER DATABASE.
SQL Server
Платформа SQL Server обеспечивает очень серьезные возможности контроля файловых
структур операционной системы, в которых содержится база данных и ее объекты.
Синтаксис инструкции CREATE DATABASE в Microsoft SQL Server выглядит так:
CREATE DATABASE имя_базы_данных
[ ON определение_.файла 1
[. г-TlEGROJP имя файловой_группы определение_файла [>•?) ]
[ uDG ON определение_файла [,...] ]
( СО'. LATE имя-сопсставления]
L FOR LOAD I FOR ATTACH ]
А вот синтаксис команды ALTER DATABASE.
ALTEP. DATABASE имя.базы.данных
{ADD FILE определение.„файла [,...] [TO PILEGROUP имя.файловой.группы]
। ADD LOG FIlE определение_.файла I.....]
I REMOVE FILE имя_файла
j ADD FILFGROuP имя_файловой_группы
\ REMOVE FIlEGROOP имя_файловой группы
i MODIFY FIlE определение-файла
Справочник по командам SQL | 127
I MODIFY NAME = новое_имя_базы_данных
| MODIFY FILEGROUP имя_файловой-Группы
{свойство__файловой_группы | NAME = новое_имя_файловой_групгш }
I SEI {опция-состояния | опциЯ-Курсора | автО-Опция | зр!_опция | опция-восстановления}
[, . .] [ WITH опция_завершения]
I COLLATE имя_сопоставления }
Ниже приводятся описания параметров.
[CREATE | ALTER] DATABASE имя_базы_данных
Создается новая база данных или вносятся изменения в уже существующую базу
с именем имя_базы-данных. Имя не может быть длиннее 128 символов. Если
логическое имя не указывается, то длину имени нужно ограничить 123 символа-
ми, поскольку SQL Server создаст логическое имя путем добавления суффикса
к имени базы данных.
{ON | ADD} определение файла [,...]
Определяется дисковый файл (файлы), в котором будут храниться компоненты
базы данных (для команды CREATE DATABASE), или же дисковый файл (файлы)
добавляется к базе (ALTER DATABASE). Параметр ON требуется только для коман-
ды CREATE DATABASE, если вы хотите создать одно или несколько определений
файла. Синтаксис определения_файла следующий.
{[PRIMARY] ( [NEW][NAME = имЯ-файла)
[, FILENAME = 'имЯ-файла-В-Операционной-Системе']
[, SIZE = int [КВ | MD | GB | ТВ] ] [, MAXSIZE = { int |
UNLIMITED } ] [, FILEGROWTH = int] ) } [,...]
Где:
PRIMARY
Определяемый файл становится основным (primary). В базе данных такой
файл должен быть только один. Если вы не определите основной файл, SQL
Server по умолчанию придаст статус основного файлу, созданному автома-
тически (в отсутствие определенных пользователем файлов), или первому
из определенных пользователем файлов. Основной файл или группа файлов
(которые также называются файловыми группами (filegroups) содержит в себе
логическое начало базы данных, все системные таблицы базы данных и все
прочие объекты, не входящие в пользовательские файловые группы.
[NE W]NA ME=UMfi_(]>awia
Указывается логическое имя файла, определяемого в параметре определе-
ние файла инструкции CREATE DATABASE. В инструкции ALTER DATABASE
параметр NEWNAME определяет новое логическое имя файла. В любом
случае логическое имя должно быть уникальным для этой базы данных. Это
предложение является необязательным при использовании параметра FOR
ATTACH.
FILENAME = ‘имя_файла_в_операционной_системе'
Определяется имя и путь к файлу, указанному в параметре определение_файла,
в операционной системе. Файл должен находиться в несжатой директории
128 | Глава 3. Справочник по инструкциям SQL
файловой системы. Для неформатированных (raw) разделов диска указывается
только буква диска.
SIZE = int [КВ\ MB\GB\ ТВ]
Указывается размер файла, определяемого в параметре определение_файла.
Это предложение является необязательным, но по умолчанию указывается
размер, равный размеру основного файла базы model, который обычно очень
невелик. Файлы журнала и вторичные файлы данных по умолчанию получают
размер 1 Мб. По умолчанию единицей измерения для параметра int являются
мегабайты. Однако вы можете явным образом определить размер файла, ис-
пользуя суффиксы для килобайтов (КВ), мегабайтов (МВ), гигабайтов (GB)
или терабайтов (ТВ). Размер не может быть менее 512 Кб или быть меньше,
чем размер основного файла базы model.
MAXSIZE = {int | UNLIMITED)
Определяется максимальный размер, до которого может вырасти файл.
Допускается использование суффиксов, приведенных в пункте, посвященном
предложению SIZE. Параметр UNLIMITED (установлен по умолчанию) позволяет
файлу увеличиваться до исчерпания свободного места на диске. Не рекомен-
дуется для файлов в неформатированных (raw) разделах.
FILEGROWTH = int
Определяется прирост размера файла за одно его увеличение. Допускается ис-
пользование суффиксов, приведенных в пункте, посвященном предложению
SIZE. Вы также можете использовать суффикс %, показывающий прирост
файла в виде процентной доли дискового пространства, занятого на текущий
момент. Если опустить предложение FILEGROWTH, файл будет расти 10-про-
центными, но не меньшими 64 Кб инкрементами. Не требуется для файлов
в неформатированных разделах.
[ADD] LOG {ON | FILE) определение_файла
В случае команды CREATE DATABASE описывается дисковый файл или файлы,
которые хранят журнал базы данных, или (в случае команды ALTER DATABASE)
дисковые файлы для журнала добавляются в базу. Вы можете создать одно или не-
сколько определений-файлов для журналов транзакций, отделив их друг от друга
запятыми. За полным синтаксисом определения_файла обращайтесь выше, к раз-
делу, посвященному ключевому слову ON.
REMOVE FILE имя_файла
Файл удаляется из базы данных, удаляется также и физический файл. Перед по-
дачей такой команды нужно очистить файл от всего содержимого.
[ADD] FILEGROUP имя_файловой_группы определение_файла [,...]
С помощью этого предложения определяются любые пользовательские файловые
группы, используемые в базе данных. Все базы данных имеют, как минимум, одну
основную файловую группу (хотя многие базы данных используют основную группу,
имеющуюся в SQL Server по умолчанию). Добавление файловых групп и перемещение
файлов в эти группы помогает лучше контролировать дисковый ввод/вывод. (Мы реко-
мендуем не добавлять файловые группы без тщательного анализа и тестирования.)
9 - 2447
Справочник по командам SQL | 129
MODIFY FILE определение_файла
Изменяется определение файла. Это предложение очень похоже на предложение
{ADD | ON} FILE. Например: MODIFY FILE (NAME = имя_файла, NEWNAME =
новое_имя_файла, SIZE = ...).
MODIFY NAME = новое_имя_базы_данных
Имя базы данных изменяется на новое_имя_базы_данных.
MODIFY FILEGROUP имя_файловой_группы {свойство_файловой_группы | NAME =
н овое_имя_ф айл овой_группы}
Это предложение, которое используется в инструкции ALTER DATABASE, имеет две
формы. Первая форма позволяет изменять имя файловой группы, например MODIFY
FILEGROUP имЯ-файловой_группы NAME = новое_гшя_файповой_группы. Вторая
форма позволяет указать свойство файловой группы, которое может принимать
одно из следующих значений.
READONLY
Делает файловую группу доступной только для чтения и не позволяет обнов-
лять никакие объекты, входящие в эту группу. Свойство READONLY могут ус-
танавливать только пользователи, имеющие эксклюзивный доступ к базе дан-
ных. Его нельзя применять к основной (primary) файловой группе.
READWRITE
Отменяет свойство READONLY и позволяет обновлять объекты в файловой
группе. Свойство READWRITE могут устанавливать только пользователи,
имеющие эксклюзивный доступ к базе данных.
DEFAULT
Делает файловую группу группой по умолчанию в базе данных. Все новые
таблицы и индексы связываются с файловой группой по умолчанию, если
иное не указано явным образом. В базе данных может быть только одна фай-
ловая группа по умолчанию. (В команде CREATE DATABASE, если иное не
указано, файловой группой по умолчанию становится основная файловая
группа.)
SET{опция_состояния | опция_курсора | авто_опция | sqlопция | опция_восстановления}
[,-]
Управляет разнообразными действиями в базе данных. Они обсуждаются с приве-
дением соответствующих правил и описаний ниже в этой главе.
WITH опция_завергиения
При использовании после предложения SET предложение WITH определяет функ-
ционирование отката незавершенной транзакции, когда база данных находится
в процессе изменения. Если параметр опущен, транзакции должны быть заверше-
ны или отменены сами по себе с соответствующими изменениями состояния базы
данных. Существует два значения опции_завершения.
ROLLBACK AFTER int [SECONDS} | ROLLBACK IMMEDIATE
Происходит откат изменения через int секунд или немедленно. Ключевое
слово SECONDS никак не влияет на функционирование предложения
ROLLBACK AFTER.
130 | Глава 3. Справочник по инструкциям SQL
NO WAIT
Изменение состояния или опции базы данных отменяется без ожидания
завершения или отката текущей транзакции, если это изменение нельзя
выполнить немедленно.
COLLATE имясопоставления
Определяется или изменяется текущий режим сопоставления (collation), исполь-
зуемый в базе данных. Параметр имя_сопоставления может представлять собой
имя сопоставления, взятое из SQL Server или из Windows. По умолчанию все
новые базы данных получают имя сопоставления из экземпляра SQL Server.
(Чтобы увидеть доступные имена сопоставлений, вы можете выполнить такой
запрос: SELECT * FROM ::fn_helpcollations().) Чтобы изменить сопоставление
в базе данных, вы должны быть единственным пользователем базы, в базе данных
не должно быть объектов, связанных со схемой, зависящей от текущего сопостав-
ления, и изменение сопоставления не должно приводить к дублированию имен
объектов в базе данных.
FOR LOAD | FOR ATTACH
База данных переводится в специальный режим запуска. Параметр FOR LOAD
поддерживается только для обратной совместимости с версиями до 7.0. Он пере-
водит базу в состояние загрузки и режим «dbo use only». При указании предложе-
ния FOR ATTACH база данных создается из набора уже существующих в опера-
ционной системе файлов. Почти всегда это ранее созданные файлы базы данных.
Из-за этого новая база данных должна использовать ту же кодовую страницу
и порядок сортировки, как и предыдущая. Вам понадобится только определе-
ние файла для первого основного файла и тех файлов, путь к которым отличается
от того, который использовался при последнем прикреплении базы. Вообще
говоря, вам лучше использовать системную записанную процедуру sp_attach_db,
если нужно указать более 16 определений файлов.
Команду CREATE DATABASE следует подавать из системной базы данных master.
Фактически вы можете подать команду CREATE_DATABASE имя_базы_данных без
всяких дополнительных предложений и создать очень небольшую базу данных по
умолчанию.
Для создания хранилищ в базах данных SQL Server используются файлы (files),
которые раньше назывались устройствами (devices). Файлы сгруппированы в одну или
несколько файловых групп (filegroups), и к каждой базе прикреплена как минимум
одна, основная (PRIMARY) файловая группа. Файл представляет собой заранее опре-
деляемый блок свободного места, создаваемый в структуре диска. Базу данных можно
хранить в одном или нескольких файлах и файловых группах. SQL Server позволяет
также размещать журнал транзакций отдельно от базы данных при использовании
предложения LOG ON. Эти функции позволяют осуществлять сложно организованное
планирование файловой системы для оптимального контроля дисковых операций
ввода/вывода. Например, мы можем создать базу данных с именем sales_report, содержа-
щую данные и файл журнала транзакций.
Справочник по командам SQL | 131
USE master
GO
CREATE DATABASE sales_report
ON
( NAME = sales_rpt_data, FILENAME =
'c:\mssql\data\salerptdata.mdf',
SIZE = 100, MAXSIZE = 500, FILEGROWTH = 25 )
LOG ON
( NAME = 'sales_rpt_log',
FILENAME = 'c:\mssql\log\salesrptlog.ldf',
SIZE = 25MB, MAXSIZE = 50MB,
FILEGROWTH = 5MB )
GO
Как только база данных создана, все объекты базы данных model копируются
в новую базу данных. После этого все пустое место в файле или файлах, определен-
ных в базе данных, инициализируется (т. е. очищается), и это означает, что создание
новой, очень большой базы может занять определенное время, особенно на медлен-
ном диске.
База данных всегда имеет, как минимум, основной файл данных и файл журнала
транзакций, но может иметь также вторичные файлы для данных и журнала. По умолча-
нию в SQL Server используются следующие расширения имен файлов: .mdf- для основ-
ных файлов данных, .ndf- для вторичных файлов и ,ldf~ для файлов журнала транзакций.
В следующем примере создается база данных с именем sales_archive и с несколькими
очень большими файлами, сгруппированными в две файловые группы.
USE master
GO
CREATE DATABASE sales_archive
ON
PRIMARY (NAME = sales_arch1, FILENAME = 'c:\mssql\data\archdata1.mdf',
SIZE = 100GB, MAXSIZE = 200GB, FILEGROWTH = 20GB),
(NAME = sales_arch2,
FILENAME = 'c:\mssql\data\archdata2.ndf',
SIZE = 100GB, MAXSIZE = 200GB, FILEGROWTH = 20GB),
(NAME = sales_arch3,
FILENAME = 'c:\mssql\data\archdat3.ndf',
SIZE = 100GB, MAXSIZE = 200GB, FILEGROWTH = 20GB)
FILEGROUP sale_rpt_grp1
(NAME = sale_rpt_grp1_1_data,
FILENAME = ' c:\mssql\data\SG1FI1dt.ndf',
SIZE = 100GB, MAXSIZE = 200GB, FILEGROWTH = 20GB),
(NAME = sale_rpt_grp1_1_data,
FILENAME = ' c:\mssql\data\SG1FI2dt.ndf',
SIZE = 100GB, MAXSIZE = 200GB, FILEGROWTH = 20GB),
FILEGROUP sale_rpt_grp2
132 | Глава 3. Справочник по инструкциям SQL
(NAME = sale..rpt_grp2_1_data, FILENAME = ' c:\mssql\data\SRG2ldt.ndf'.
SIZE = 100GB, MAXSIZE = 200GB, FILEGROWTH = 20GB),
(NAME = sale_rpt_.grp2_2_data, FILENAME = ’ c:\mssql\data\SRG22dt.ndf,
SIZE = 100GB, MAXSIZE = 200GB, FILEGROWTH = 20GB),
LOG ON
(NAME - sales_archlog1,
FILENAME = 'd:\mssql\log\archlog1.Idf',
SIZE = 100GB, MAXSIZE == UNLIMITED, FILEGROWTH = 25%),
(NAME = sales_archlog2,
FILENAME - 'd:\ mssql\log\archlog2.Idf',
SIZE = 100GB, MAXSIZE = UNLIMITED. FILEGROWTH = 25%)
GO
Предложение FOR ATTACH обычно используется в ситуациях, когда, например,
продавец путешествует, имея базу данных, записанную на компакт-диске. Это предло-
жение говорит платформе SQL Server, что база данных присоединяется из сущест-
вующей файловой структуры операционной системы, например DVD-ROM, CD-ROM
или переносной жесткий диск. При использовании предложения FOR ATTACH новая
база данных наследует все объекты и данные родительской базы, а не базы model.
В следующих примерах показано, как изменить имя базы данных, файла или фай-
ловой группы.
--Переименовать базу данных
ALTER DATABASE sales_archive MODIFY NAME = sales_history
GO
--Переименовать Файл
ALTER DATABASE sales_archive MODIFY FILE NAME = sales_arch1,
NEWNAME = sales_hist1
GO
--Переименовать файловую группу
ALTER DATABASE sales_archive MODIFY FILEGROUP sale_rpt_grp1
NAME - sales_hist_grpl
GO
Бывают ситуации, когда нужно добавить к базе свободного места, особенно если
вы не включили автоматическое расширение.
USE master
GO
ALTER DATABASE sales.report ADD FILE
( NAME = sales_rpt_added01, FILENAME = 'c:\mssql\data\salerptadded01.mdf'.
SIZE = 50MB, MAXSIZE = 250MB, FILEGROWTH = 25MB )
GO
При внесении изменений в базу данных вы можете указывать для нее много функ- .
циональных опций. Опции состояния (state options), которые показаны в приведенной
Справочник по командам SQL | 133
ранее синтаксической схеме как опция_состояния, контролируют пользовательский
доступ к базе данных. Вот список существующих опций состояния.
SINGLEJJSER | RESTRICTED-USER | MULTIUSER
Указывается количество и тип пользователей, имеющих доступ к базе данных.
Параметр SINGLE USER позволяет обращаться к базе данных за один раз только
одному пользователю. Режим RESTRICTEDMODE разрешает доступ только тем,
кто имеет системные роли db_owner, dbcreator или sysadmin. Режим MULTI_USER
(установлен по умолчанию) разрешает конкурентный доступ к базе всем пользо-
вателям, имеющим допуск.
OFFLINE | ONLINE
Переводит базу данных в режим недоступности (offline) или доступности (online).
READ-ONLY \ READ-WRITE
Переводит базу данных в режим READ-ONLY (только для чтения), в котором за-
прещены любые модификации, или в режим READ WRITE, когда модификация
данных разрешена. Базы данных, находящиеся в режиме READ ONLY, могут
очень быстро работать в условиях большого числа запросов, поскольку в них
почти не требуется блокировки.
Опции курсора в базе данных контролируют заданные по умолчанию действия
для курсоров. В синтаксисе команды ALTER DATABASE, приведенном выше, вы
можете заменить параметр опция_курсора любым из следующих предложений.
CURSOR_CLOSE_ON COMMIT {ON | OFF}
При установке значения ON все открытые курсоры закрываются при совершении
или откате транзакции. При установке значения OFF открытые курсоры остаются
открытыми по совершению транзакции, но закрываются при откате транзакции,
если только курсор не объявлен как INSENSITIVE или STATIC. (Более подробную
информацию см. в разделе «Команда DECLARE CURSOR» ниже в этой главе.)
CURSOR-DEFAULT {LOCAL | GLOBAL}
Задается локальная или глобальная область действия по умолчанию для курсоров
базы данных. (Более подробную информацию см. в разделе «Команда DECLARE
CURSOR» ниже в этой главе.)
В предложении SET параметр авто_опция контролирует автоматическую обработку
файлов базы данных. Вместо параметра авто_опция можно подставлять следующие
конструкции.
A UTO CLOSE {ON | OFF}
При установке значения ON при отключении последнего пользователя база
данных корректно выключается, освобождая все ресурсы. При установке значе-
ния OFF база данных остается открытой и после отключения последнего пользо-
вателя. Значение по умолчанию - OFF.
A UTO-CREA TE-STA TISTICS {ON | OFF}
Если установлено значение ON статистические данные собираются автоматиче-
ски, когда SQL Server замечает, что при оптимизации запросов они оказались
134 | Глава 3. Справочник по инструкциям SQL
потерянными. Если установлено значение OFF, статистика при оптимизации не
собирается. Значение по умолчанию - ON.
A UTO_SHRINK {ON | OFF}
При установке значения ON файлы базы данных могут автоматически сжиматься.
База данных периодически ищет возможность сжать файлы, хотя время этой
операции не всегда можно предсказать. Если указано значение OFF, файлы сжи-
маются только в том случае, если сжатие запускается вручную, явным образом.
Значение по умолчанию - OFF.
A UTO_UPDA TESTA T/STICS {ON | OFF}
При установке значения ON, устаревшие статистические данные в ходе оптимиза-
ции запросов пересматриваются. Если указано значение OFF, статистические
данные переоцениваются только в том случае, если их сбор запускается вручную,
явным образом, с помощью команды SQL Server UPDATE STATISTICS.
Параметр зд1_опция управляет совместимостью базы данных со стандартом ANSI.
Вы можете использовать специальную команду SQL Server SET_ANSI_DEFAULTS ON,
чтобы включить сразу все функциональности ANSI SQL92, вместо того чтобы ис-
пользовать отдельные инструкции, приводимые ниже. В предложении SET вы можете
заменять параметр sql__omjux любым из следующих значений.
ANSI_NULL_DEFAULT {ON | OFF}
При установке значения ON команда CREATE TABLE приведет к присвоению
значения NULL по умолчанию столбцам, для которых не задан параметр nullability
(возможность принимать значения NULL). Если указано значение OFF,
по умолчанию столбцам присваиваются значения NOT NULL. Значением по
умолчанию является OFF.
ANSINULLS {ON | OFF}
При установке значения ON результатом сравнения с участием значения NULL
будет UNKNOWN. Если установлено значение OFF, сравнение дает NULL, если
оба значения (не-UNICODE) равны NULL. Значение по умолчанию - OFF.
ANSI PADDING {ON j OFF}
При установке значения ON для операций вставки и сравнения столбцов VAR-
CHAR и VARBINARYстроки дополняются до одинаковой длины. Если установлено
значение OFF, дополнение строк не производится. Значение по умолчанию - ON.
(Мы не рекомендуем изменять это значение!)
ANSIJVARNINGS {ON | OFF}
При установке значения О/V база данных выводит предупреждение, если возникают
такие проблемы, как «деление на ноль» или «null в агрегатах». Если установлено
значение OFF, эти предупреждения не выводятся. Значение по умолчанию - OFF.
ARITHABORT {ON \ OFF}
Если установлено значение ON, ошибки деления на ноль и переполнения приво-
дят к завершению выполнения запроса или пакета команд Transact-SQL и откату
всех открытых транзакций. Если указано значение OFF, предупреждение выво-
дится, но обработка продолжается. Значение по умолчанию - ON. (Мы не реко-
мендуем изменять это значение!)
Справочник по командам SQL | 135
CONCATNULLYIELDSNULL {ON\ OFF}
Если установлено значение ON, то при конкатенации строки и значения NULL
возвращается NULL. Если указано значение OFF, NULL при конкатенации со
строкой считается пустой строкой. Значение по умолчанию - OFF.
NUMERIC ROUNDABORT {ON | OFF}
Если установлено значение ON, потеря точности в числовом выражении вызывает
ошибку. Если указано значение OFF, потеря точности приводит к округлению
результата числового выражения. Значение по умолчанию - OFF.
QUOTEDJDENTIFIER {ON | OFF}
Если установлено значение ON, двойными кавычками выделяется идентификатор
объекта, содержащий специальные символы или являющийся ключевым словом
(например, таблица с именем SELECT). Если указано значение OFF, идентифика-
торы не могут содержать специальных символов и зарезервированных слов, а все
двойные кавычки обозначают литеральные строковые значения. Значение по
умолчанию - OFF.
RECURSIVE TRIGGERS {ON | OFF}
Если установлено значение ON, триггеры могут запускаться рекурсивно, т. е., дей-
ствия, выполненные одним триггером, могут запустить другой триггер и т. д. Если
указано значение OFF, триггеры не могут запускаться другими триггерами. Значе-
ние по умолчанию - OFF.
Опции восстановления управляют схемой восстановления, применяемой в базе
данных. Вы можете вставлять в синтаксис команды ALTER DATABASE вместо пара-
метра опция_восстановления следующие конструкции.
RECOVERY {FULL | BULK LOGGED | SIMPLE}
Если указано значение FULL, резервные копии и протоколы транзакций базы
данных обеспечивают полное восстановление даже для операций с большими
массивами данных, таких, как SELECT...INTO, CREATE INDEX и т. п. Значение
FULL установлено по умолчанию в SQL Server 2000 Standard Edition и Enterprise
Edition. Опция FULL обеспечивает полное восстановление даже после катастро-
фической аварии носителя, но при этом потребляется больше места. Если уста-
новлено значение BULK_LOGGED, протоколирование операций с большими мас-
сивами минимизировано. При этом экономится дисковое пространство и умень-
шается нагрузка на каналы ввода-вывода, однако риск потери данных здесь выше,
чем в случае FULL. При использовании значения SIMPLE базу данных можно вос-
становить только к состоянию на момент последнего полного или дифференци-
ального резервного копирования. Параметр SIMPLE установлен по умолчанию
для систем SQL Server 2000 Desktop Edition и Personal Edition.
TORN^PAGE^DETECTION {ON\ OFF}
Если установлено значение ON, SQL Server может обнаруживать незавершенные
дисковые операции на дисковом уровне путем проверки каждого 512-байтного
сектора 8-килобайтной страницы базы данных. (Незавершенные страницы
обычно обнаруживаются при восстановлении.) Значение по умолчанию - ON.
136 | Глава 3. Справочник по инструкциям SQL
Например, нам нужно изменить некоторые функциональные параметры базы
данных sales_report без изменения лежащей в ее основе файловой структуры.
ALTER DATABASE sales_report SET ONLINE, READ-ONLY,
AUTO_CREATE_STATISTICS ON
GO
Эта инструкция переводит базу данных в доступный режим и делает ее доступной
только для чтения. Также параметр AUTO CREATE5'7>1Ж77С5'устанавливается в ON.
См. также
CREATE SCHEMA
DROP STATEMENT
Инструкции CREATE/ALTER FUNCTION/PROCEDURE
Инструкции CREATE FUNCTION и CREATE PROCEDURE очень похожи по синтакси-
су и сходны в программировании (как и соответствующие инструкции ALTER).
Инструкция CREATE PROCEDURE создает записанную процедуру, которая прини-
мает входящие аргументы и выполняет обработку различных объектов базы данных
с учетом определенных условий. Согласно стандарту ANSI записанная процедура не
возвращает набора данных (хотя она может возвращать значение в параметре OUTPUT).
Например, вы можете использовать записанную процедуру для выполнения всех вычис-
лений, завершающих учетный цикл.
Инструкция CREATE FUNCTION создает пользовательскую функцию (user-
defined function, UDF), которая принимает входящие аргументы и возвращает одно
выходное значение точно так же, как это делают системные функции, такие, как
CAST() или UPPER0- После создания этих функций к ним можно обращаться в запросах
и в операциях по манипулированию данными, таких, как INSERT, UPDATE
и предложение WHERE команды DELETE. За описаниями встроенных функций SQL
и их реализаций разными производителями обращайтесь к главе 4.
Платформа Команда
DB2 Поддерживается с вариантами
MySQL Поддерживается с вариантами
Oracle Поддерживается с вариантами
PostgreSQL Поддерживается с вариантами
SQL Server Поддерживается с вариантами
Справочник по командам SQL | 137
Синтаксис SQL2003
Для создания записанной процедуры или функции используется следующий синтаксис.
CREATE {PROCEDURE | FUNCTION} имя_объекта
( [{[IN | OUT | INOUT] [имя_параметра] тип_данных [AS LOCATOR] [RESULT]}
[....] ] )
[ RETURNS тип_данных [AS LOCATOR]
[CAST FROM тип_данных [AS LOCATOR] ]
[LANGUAGE {ADA | C | FORTRAN | MUMPS | PASCAL | PLI | SQL}]
[PARAMETER STYLE {SQL | GENERAL}]
[SPECIFIC специальное_имя)
[DETERMINISTIC | NOT DETERMINISTIC]
[NO SQL | CONTAINS SQL | READS SQL DATA | MODIFIES SQL DATA]
[RETURN NULL ON NULL INPUT | CALL ON NULL INPUT]
[DYNAMIC RESULT SETS int]
[STATIC DISPATCH]
блок_кода
Для изменения ранее созданной пользовательской функции или записанной про-
цедуры используйте следующий синтаксис.
ALTER {PROCEDURE | FUNCTION} имя_объекта
[( {имя_параметра тип_данных } [,...])]
[NAME новое__имя__объекта]
[LANGUAGE {ADA | С | FORTRAN | MUMPS | PASCAL | PLI | SQL}]
[PARAMETER STYLE {SQL | GENERAL}]
[NO SQL | CONTAINS SQL | READS SQL DATA | MODIFIES SQL DATA]
[RETURN NULL ON NULL INPUT | CALL ON NULL INPUT]
[DYNAMIC RESULT SETS int]
[CASCADE | RESTRICT]
Ключевые слова
CREATE {PROCEDURE | FUNCTION} [ASLOCATOR] [RESULT] имя_объекта
Создается новая записанная процедура или пользовательская функция с именем
имя_объекта. Пользовательская функция возвращает значение, тогда как записан-
ная процедура, согласно ANSI SQL, - не возвращает.
([IN | OUT | INOUT] [имя_параметра] тип Данных [,...])
Объявляются один или несколько параметров, передаваемых в хранимую процедуру.
Параметры разделяются запятыми, и список заключается в скобки. Параметры,
передаваемые в процедуру, могут быть входными (IN), выходными (OUT) или од-
новременно входными и выходными (INOUT).
Синтаксис объявления параметров следующий.
[{IN | OUT | INOUT}] имя_параметра1 тип_данных,
[{IN | OUT | INOUT}] имя_параметра2 тип_данных, [...]
138 | Глава 3. Справочник по инструкциям SQL
При указании необязательного параметра имя_параметра убедитесь, что это имя
является уникальным в пределах записанной процедуры. Необязательное предло-
жение AS LOCATOR используется при объявлении внешней подпрограммы,
имеющей параметр RETURNS, который представляет собой данные типа BLOB,
CLOB, NCLOB, ARRAY или определенный пользователем тип. Если вам требуется
изменить тип данных параметра RETURNS «на ходу», используйте предложение
CAST (см. функцию CAST в разделе «Функции CASE и CAST» главы 4). Напри-
мер, RETURNS TARCHAR(I2) CAST FROM DATE. При использовании в инструк-
ции ALTER это предложение добавляет параметры к уже существующей записан-
ной процедуре. За подробным описанием типов данных обращайтесь к главе 2.
RETURNS тип_данных [AS LOCA TOR] [CASTFROM тип_данных [AS LOCA TOR]]
Объявляется тип данных для результата, возвращаемого функцией. (Это предло-
жение используется только в инструкции CREATE FUNCTION и не используется
в записанных процедурах.) Основное назначение пользовательских функций -
возвращать значение.
LANGUAGE [ADA | С | FORTRAN | MUMPS | PASCAL I PLI | SQL]
Объявляется язык, на котором написана функция. Большинство платформ не под-
держивает все эти языки и часто поддерживает не упомянутые здесь, например Java.
Если параметр не указан, по умолчанию установлен SQL. При использовании в ин-
струкции ALTER этот параметр заменяет существующее значение LANGUAGE объяв-
ленным значением.
PARAMETER STYLE {SQL | GENERAL]
Определяет, только для внешних подпрограмм, будут ли явным образом в виде опций
передаваться неявные и автоматические параметры (SQL) или не будут {GENERAL).
(Различие между стилями SQL и GENERAL состоит в том, что при указании значения
SQL автоматически передаются SQL-параметры, такие, как индикаторы, а при исполь-
зовании стиля GENERAL параметры автоматически не передаются.) По умолчанию
установлено PARAMETER STYLE SQL. При использовании в инструкции ALTER
этот параметр заменяет существующее значение PARAMETER STYLE объявленным
значением.
SPECIFIC специальное_имя
Однозначно идентифицирует функцию, которая обычно используется с пользова-
тельскими типами данных.
DETERMINISTIC | NOT DETERMINISTIC
Определяет вид значений, возвращаемых функцией (это предложение используется
только в инструкциях CREATE FUNCTION и ALTER FUNCTION). Функции, объявлен-
ные как DETERMINISTIC, всегда возвращаю! одинаковые значения при одном и том
же наборе входных параметров. Функции, объявленные как NOT DETERMINISTIC,
могут возвращать разные результаты при одном наборе входных параметров.
Например, функция CURRENT_TIME относится к типу NOT DETERMINISTIC,
поскольку она возвращает постоянно возрастающее значение, соответствующее
текущему времени.
Справочник по командам SQL | 139
NO SQL | CONTAIN SQL | READS SQL DATA | MODIFIES SQL DATA
Определяет наряду с параметром LANGUAGE тип инструкций SQL, содержащих-
ся в пользовательской функции. При использовании в инструкции ALTER этот
параметр заменяет существующее значение объявленным значением.
NO SQL
Показывает, что в функции не содержится никаких инструкций SQL. Исполь-
зуется с параметром LANGUAGE, отличным от SQL, например LANGUAGE
ADA...CONTAINSNO SQL.
CONTAINS SQL
Показывает, что в функции содержатся инструкции SQL, не связанные с чте-
нием или модификацией данных. Этот значение установлено по умолчанию.
READS SQL DATA
Показывает, что функция содержит инструкции SELECT или FETCH.
MODIFIES SQL DATA
Показывает, что функция содержит инструкции INSERT, UPDATE или DELETE.
RETURN NULL ON NULL INPUT | CALL ON NULL INPUT
Эти опции используются с базовым языком, который не имеет поддержки значений
NULL. Параметр RETURN NULL ON NULL INPUT приводит к тому, что функция
немедленно возвращает значение NULL, если ей передается параметр NULL. Параметр
CALL ON NULL INPUT заставляет функцию обрабатывать значения NULL в соот-
ветствии со стандартными правилами, например возвращать значение UNKNOWN
при сравнении двух значений NULL. (Это предложение используется в инструкциях
CREATE PROCEDURE и ALTER PROCEDURE, CREATE FUNCTION и ALTER
FUNCTION.) При использовании в инструкции ALTER этот параметр заменяет
существующее значение стиля обработки значений NULL объявленным значением.
DYNAMIC RESULT SET int
Определяется, что записанные процедуры могут открыть указанное количество
курсоров {int) и что эти курсоры будут видимы и после возврата из процедуры. Если
это предложение опущено, значением по умолчанию является DYNAMIC RESULT
SET 0. (Это предложение не используется в инструкциях CREATE FUNCTION!)
При использовании в инструкции ALTER этот параметр заменяет существующее
значение DYNAMIC RESULT SET объявленным значением.
STATIC DISPATCH
Возвращаются статические значения определенного пользователем типа данных
или типа ARRAY. Требуется для функций не-SQL, содержащих параметры, исполь-
зующие пользовательские типы или тип ARRAY. Предложение не используется
в инструкциях CREATE PROCEDURE. Это предложение должно быть последним
в объявлении процедуры или функции и перед блокомусода.
блок_кода
Объявляются процедурные инструкции, которые выполняют всю обработку в поль-
зовательской функции или записанной процедуре. Это наиболее важная и обычно
самая большая часть функции или процедуры. Мы предполагаем, что вас интересует
пользовательская функция с параметром LANGUAGE SQL, поэтому отметьте, что
140 | Глава 3. Справочник по инструкциям SQL
блок_кода не может содержать инструкций SQL-Schema, инструкций SQL-Transaction
и инструкций SQL-Connection. Если предполагать, что вас интересуют пользова-
тельские функции и записанные процедуры, основанные на SQL (в конце концов,
эта книга посвящена SQL), то вы можете объявить внешний кодовый блок. Синтаксис
объявления внешнего блока кода следующий.
EXTERNAL [NAME имя_внешней_подпрограммы]
[PARAMERER STYLE {SOL | GENERAL}] [TRANSFORM GROUP имя_группы)
Где:
EXTERNAL [NAME имя_внешпей_подпрограммы]
Определяется внешняя подпрограмма, которой присваивается имя. Если пара-
метр опущен, используется неуточненное (unqualified) имя подпрограммы.
PARAMERER STYLE {SQL | GENERAL}
То же, что и в случае CREATE PROCEDURE.
TRANSFORM GROUP имя_группы
Обеспечивает преобразование значений, относящихся к пользовательским
типам, в хост-переменные и обратно. Если предложение опущено, по умолча-
нию используется TRANSFORM GROUP DEFAULT.
NAME повое имя_объекта
Объявляется новое имя для ранее объявленной пользовательской функции или
записанной процедуры. Это предложение используется только в инструкциях
ALTER FUNCTION и ALTER PROCEDURE.
CASCADE | RESTRICT
Показывает, будут ли изменения распространяться на все зависимые пользова-
тельские функции и записанные процедуры (CASCADE) или же они не будут рас-
пространяться на зависимые объекты (RESTRICT). Мы настоятельно рекомендуем
не применять команд ALTER к пользовательским функциям и записанным про-
цедурам, у которых имеются зависимые объекты. Данное предложение использу-
ется только в инструкциях ALTER FUNCTION и ALTER PROCEDURE.
Общие правила
Для пользовательской функции вы объявляете входные аргументы и один выходной
аргумент, который функция возвращает. После этого вы можете вызывать пользова-
тельскую функцию точно так же, как любую другую функцию, например, в инструк-
циях SELECT, INSERT и в предложениях WHERE команд DELETE.
Когда о пользовательских функг!иях и записанных процедурах говорят одно-
временно, их называют подпрограммами (routines).
Для записанной процедуры объявляются входные аргументы, которые поступают
в процедуру, и выходные аргументы, которые являются результатом ее работы. Запи-
санная процедура вызывается при помощи инструкции CALL.
Справочник по командам SQL | 141
Содержание блока_кода должно соответствовать правилам того процедурного
языка, который поддерживается данной платформой. Некоторые платформы не имеют
своего внутреннего процедурного языка, и вам нужно использовать внешние блоки
(конструкции EXTERNAL блок_кода).
Например, вы можете создать для Microsoft SQL Server пользовательскую функцию,
которая возвращает имя и фамилию человека в виде одной строки.
CREATE FUNCTION formatted_name (@fname VARCHAR(3O),
@lname VARCHAR(3O) )
RETURNS VARCHAR(60)
AS
BEGIN
DECLARE @full_name VARCHAR(60)
SET @full_name = @fname + ' ' + @lname
RETURN @full_name
END
После этого вы можете использовать эту функцию как любую другую.
SELECT formatted_name(au_fname, au_lname) AS name, au_id AS id
FROM authors
Инструкция SELECT в данном примере возвратит набор данных, состоящий из
двух столбцов, паше и id.
Инструкция стандарта ANSI под названием CREATE METHOD на данный
момент поддерживается только в DB2. По сути метод - это специали-
зированная пользовательская функция, имеющая тот же самый синтаксис.
Записанные процедуры функционируют сходным образом. В следующем неболь-
шом примере записанная процедура для Microsoft SQL Server генерирует уникальное
значение, состоящее из 22 цифр (на основе элементов системной даты и времени),
и возвращает его вызвавшему процессу.
--Записанная процедура Microsoft SQL Server
CREATE PROCEDURE get_next_nbr
@next_nbr CHAR(22) OUTPUT
AS
BEGIN
DECLARE @random_nbr INT
SELECT @random_nbr = RAND( ) * 1000000
SELECT @next_nbr =
RIGHT('000000' + CAST(R0UND(RAND(@random_nbr)*1000000, 0))AS
CHAR(6), 6) +
RIGHT('0000' + CAST(DATEPART (yy, GETDATE( ) ) AS CHAR(4)), 2) +
RIGHTCOOO' + CAST(DATEPART (dy, GETDATE( ) ) AS CHAR(3)), 3) +
142 | Глава 3. Справочник no инструкциям SQL
RIGHT('OO' + CAST(DATEPART (hh, GETDATE( ) ) AS CHAR(2)), 2) +
RIGHT('OO’ + CAST(DATEPART (mi, GETDATE( ) ) AS CHAR(2)), 2) +
RIGHTCOO' t CAST(DATEPART (ss, GETDATE( ) ) AS CHAR(2)), 2) +
RIGHT('OOO' + CAST(DATEPART (ms, GETDATE( ) ) AS CHAR(3)). 3)
END
GO
В следующем и последнем примере на ANSI SQL2003 мы изменим имя сущест-
вующей записанной процедуры.
ALTER PROCEDURE gct_next_nbr
NAME 'get_next_ID'
RESTRICT:
Советы и хитрости программирования
Главное преимущество записанной процедуры или функции состоит в том, что она яв-
ляется предварительно скомпилированной. Это означает, что соответствующие планы
запросов, будучи один раз созданными, хранятся в базе данных. Предварительно
скомпилированные процедуры часто (хотя и не всегда) могут кешироваться в память
базы, что дает дополнительный прирост производительности. Записанная процедура
или пользовательская функция за одно соединение с сервером может выполнить
много инструкций, что уменьшает сетевой трафик.
Реализации пользовательских функций и записанных процедур на разных плат-
формах существенно различаются. Некоторые платформы не имеют своего внутрен-
него языка для блокакода. Вы можете использовать только внешние блоки кода.
Обязательно прочитайте об имеющихся вариантах и возможностях разных платформ.
Если вы выполните инструкцию ALTER PROCEDURE или ALTER FUNCTION,
то некоторые объекты могут оказаться нефункциональными после изменения объекта,
от которого они зависят. Будьте осторожны и проверьте все зависимости при измене-
нии пользовательских функций и записанных процедур, от которых могут зависеть
другие функции и процедуры.
DB2
Реализация этих команд на платформе DB2 очень близка к стандарту ANSI. Хотя
схемы синтаксиса довольно длинны, большая их часть идентична стандарту ANSI.
Поэтому раздел, посвященный описанию ключевых слов, который идет следом
за схемой синтаксиса, будет относительно коротким, поскольку многие предложения
уже объяснялись в разделе, посвященном стандарту ANSI.
Платформа DB2 поддерживает несколько типов функций. Каждый тип имеет соб-
ственный набор допустимых синтаксических конструкций, хотя большая их часть
является общей для разных типов. В DB2 можно использовать внешние скалярные
функции, внешние табличные функции, внешние табличные функции OLE-DB,
стереотипные (шаблонные) функции и SQL-функции. DB2 поддерживает два типа
записанных процедур - внешние процедуры и SQL-процедуры.
Справочник по командам SQL | 143
Приводимый ниже синтаксис является общим для создания записанных процедур
и пользовательских функций любого типа. Мы объединили его, чтобы показать
полный перечень определений предложений. Обращайтесь к последующим разделам,
где более подробно объясняются специфические конструкции, допустимые для каж-
дого типа пользовательских функций и записанных процедур. Если вы хотите увидеть
синтаксические конструкции, являющиеся допустимыми, например для SQL-процедур,
переходите сразу к соответствующему разделу. Полный список имеющихся синтак-
сических конструкций для пользовательских функций и записанных процедур сле-
дующий.
CREATE {PROCEDURE | FUNCTION} имя_объекта
[( {[IN | OUT| INOUT] [имя_параметра] тип_данных } [,...])]
RETURNS {тип^данных | {ROW | TABLE} список^столбцов} [AS LOCATOR]
[CAST FROM тип__данных [AS LOCATOR] ]
[LANGUAGE {C | JAVA | COBOL | OLE | SQL]
[PARAMETER STYLE {SQL | DB2GENERAL | GENERAL | GENERAL WITH NULLS | JAVA}]
[SPECIFIC специальное_имя]
[EXTERNAL NAME имя_внешней_процедуры]
[DETERMINISTIC | NOT DETERMINISTIC]
[ [NO] EXTERNAL ACTION]
[NO SQL | CONTAINS SQL | READS SQL DATA | MODIFIES SQL DATA]'
[CALLED ON NULL INPUT | RETURNS NULL ON NULL INPUT]
[DYNAMIC RESULT SETS int]
[STATIC DISPATCH]
[SOURCE имя_объекта | AS TEMPLATE ]
[INHERIT SPECIAL REGISTERS]
[[NOT] FENCED] [[NOT] THREADSAFE]
[PROGRAM TYPE {SUB | MAIN}]
[ [NO] SCRATCHPAD int] [ [NO] FINAL CALL]
[{ALLOW | DISALLOW} PARALLEL]
[ [NO] DBINFO]
[TRANSFORM GROUP имя группы]
[CARDINALITY int]
[PREDICATES (определение^предиката')]
блок_кода
Кроме этого, для изменения уже существующих пользовательских функций
и записанных процедур используйте следующий синтаксис.
ALTER {PROCEDURE | FUNCTION} имя_объекта
[EXTERNAL NAME имя_внешней_процедуры]
[ [NOT] FENCED] [ [NOT] THREADSAFE]
Ниже приводится описание параметров DB2.
144 | Глава 3. Справочник по инструкциям SQL
RETURNS {тип_данных | [ROW\ TABLE} список_столбцов}
Позволяет возвращать одно значение типа тип_данных, строку значений (ROW) или
таблицу значений (TABLE). В параметре список_столбцов используется следующий
синтаксис имя_столбца! тип_данных1, имя_столбца2 тип_данных2
LANGUAGE {С | Java | COBOL | OLE | SQL}
То же, что и в стандарте ANSI, хотя DB2 поддерживает набор языков, отличный от
стандарта. Если вы объявляете параметр LANGUAGE, некоторые другие опции
становятся доступными или недоступными.
PARAMETER STYLE {SQL | DB2GENERAL | GENERAL | GENERAL WITH NULLS \JAVA}
Предложение сходно со стандартом ANSI SQL, но выбор вариантов шире. Пред-
ложение PARAMETER STYLE используется только с внешними записанными про-
цедурами или пользовательскими функциями. Стили определяют способы пере-
дачи параметров.
SQL
Указывается, что если параметры передаются с помощью инструкции CALL,
то наряду с ними передаются индикатор со значением NULL для каждого
параметра, а также уточненное (qualified) и специфическое имя записанной
процедуры или функции. Кроме того, обратно в DB2 передаются параметр
SQLSTATE и диагностическая строка SQL.
DB2GENERAL
Доступно только с предложением LANGUAGE JAVA. Показывает, что передача
параметров происходит с соблюдением соглашений, принятых для Java.
GENERAL
Передача параметров из инструкции CALL в записанную процедуру произво-
дится без использования структуры SQLDA. Значения NULL не передаются.
Доступно только с предложением LANGUAGE С или LANGUAGE COBOL.
GENERAL WITH NULLS
To же, что и GENERAL, но также передаются индикаторы со значением NULL.
JAVA
Передача параметров производится с использованием спецификаций Java
и SQLJ Routines. Например, параметры типа INOUT и OUT передаются в виде
одноэлементного массива. Доступно только с предложением LANGUAGE
JAVA. Параметр является взаимоисключающим с предложениями DBINFO
и PROGRAM TYPE.
EXTERNAL NAME [имя_внешней_подпрограммы]
Регистрируется новая функция или процедура, использующая связываемую
(linked) или работающую через интерфейс (interfaced) программу. Если параметр
имя_внешней_подпрограммы опущен, предполагается, что имя внешней програм-
мы находится в параметре имя_объекта. Метод связывания зависит от параметра
LANGUAGE.
NO SQL | CONTA INS SQL | R EA DS SQL DA TA | MODIFIES SQL DA TA
To же, что в стандарте ANSI, хотя некоторые опции становятся недоступны при
некоторых значениях параметра LANGUAGE.
10 - 2447
Справочник по командам SQL | 145
INHERIT SPECIAL REGISTERS
Объявляется, что обновляемые специальные регистры получают исходное значе-
ние от вызвавшего процесса. Вызвавшим процессом может быть пользовательская
функция, записанная процедура, триггер, представление или пользователь, запус-
тивший команду CALL.
[[NOT] FENCED] [{THREADSAFE | NOT THREADSAFE}]
Указывается, будет (или не будет) внешняя записанная процедура или пользова-
тельская функция «безопасной» для запуска в пространстве процессов и адресов
операционной среды DB2. Параметр используется только для внешних записан-
ных процедур. Процедуры с предложением NOT FENCED (незащищенные) рабо-
тают, как правило, быстрее, но база данных становится открытой для потенциаль-
ных угроз.
[[NOT] THREADSAFE]
Параметр определяет, является ли метод безопасным для запуска в одном процессе
с другими подпрограммами (THREADSAFE) или небезопасным (NOT THREADSAFE).
Если процедура объявлена как THREADSAFE, она считается безопасной для запуска
в одном процессе с другими пользовательскими функциями и записанными проце-
дурами. Процедуры, объявленные как NOT THREADSAFE, могут использоваться
только с процедурами FENCED.
PROGRAM TYPE {SUB | MAIN}
Параметр показывает, должна ли внешняя записанная процедура ожидать пара-
метры в стиле подпрограммы (SUB) или основной программы (MAIN). При указа-
нии значения SUB (по умолчанию) параметры должны передаваться в виде
отдельных аргументов. При указании значения MAIN параметры передаются в виде
счетчика аргументов и вектора (массива) аргументов. Параметр MAIN также тре-
бует, чтобы внешняя записанная процедура называлась «main», и чтобы она была
скомпонована в виде библиотеки коллективного доступа, а не в виде самостоя-
тельного исполняемого файла. Конструкция PROGRAM TYPE MAIN допустима
только с параметрами LANGUAGE С или LANGUAGE COBOL, PARAMETER
STYLE GENERAL, PARAMETER STYLE GENERAL WITH NULLS, SQL или DB2SQL.
[NO] SCRATCHPAD int
Обеспечивает создание временного буфера для внешней функции или процедуры.
Параметр SCRATCHPAD позволяет пользовательской функции сохранять свое со-
стояние между вызовами. По умолчанию установлено значение NO SCRATCH-
PAD. Если указан параметр int, он показывает размер временного буфера в байтах
(по умолчанию - 100 байт). Для ссылки на внешнюю процедуру инициализирует-
ся один временный буфер.
[NO] FINAL CALL
Предложение FINAL CALL приводит к двум дополнительным вызовам подпро-
граммы. Первый вызов происходит перед первой загрузкой данных, и подпро-
грамма может произвести любую необходимую единовременную инициализацию.
Второй вызов происходит последним, и он позволяет подпрограмме произвести
необходимую очистку. Табличные функции всегда имеют параметр FINAL CALL.
146 | Глава 3. Справочник по инструкциям SQL
Данное предложение несовместимо с предложением PARAMETER STYLE JAVA.
Предложение NO FINAL CALL предотвращает выполнение предложения FINAL
CALL.
(ALLOW | DISALLOW} PARALLEL
Предложение ALLOW PARALLEL позволяет при проведении оптимизации на сервере
типа SMP или МРР разделять выполнение подпрограммы на параллельные процессы,
выполняющиеся на нескольких процессорах компьютера (такие подпрограммы также
называются параллелизованными). Иначе (DISALLOW PARALLEL) платформа DB2
производит последовательную обработку подпрограммы на одном процессоре, не
принимая во внимание количество имеющихся в наличии процессоров. По умолча-
нию установлено значение ALLOW PARALLEL, если только подпрограмма не
содержит следующих предложений: NOT DETERMINISTIC, EXTERNAL ACTION,
SCRATCHPAD или FINAL CALL.
[NO] DBINFO
Показывает, принимает ли внешняя записанная процедура при вызове дополни-
тельный аргумент (DBINFO) или не принимает (NO DBINFO по умолчанию).
Аргумент DBINFO включает в себя имя базы данных, ID приложения, авториза-
ционный ID приложения, кодовую страницу, версию базы данных и платформу.
Параметр DBINFO является взаимоисключающим с параметрами LANGUAGE
OLD, PARAMETER STYLE JAVA и DB2GENERAL.
TRANSFORM GROUP имягруппы
Если подпрограмма использует пользовательский структурированный тип данных
для параметра или возвращаемого значения, то объявляется группа для преобразо-
ваний с именем имя _группы.
CARDINALITY int
PREDICA TES (определение_предиката)
Используется в предложении CREATE FUNCTION для создания пользовательского
предиката. Этот параметр применяется при создании пользовательских функций
для работы с расширенными типами индексов DB2. Расширенные типы индексов
(index extension) весьма сложны, и средний пользователь DB2 их не использует.
Следовательно, за дополнительной информацией об этом предложении вам нужно
обращаться к документации DB2, посвященной этой теме. Для использования
параметра PREDICATES необходимы предложения DETERMINISTIC и NO EXTERNAL
ACTION.
Платформа DB2 допускает использование нескольких типов пользовательских
функций: внешние скалярные, OLE-DB, стереотипные/шаблонные, SQL, а также два
вида записанных процедур: внешние и SQL. В каждом из этих типов допускается
одновременно использовать только некоторые из предложений, приведенных выше.
Внешние скалярные пользовательские функции DBS
Этот вариант инструкции CREATE FUNCTION используется для регистрации пользо-
вательской внешней скалярной функции на сервере приложений. (Помните, что ска-
Справочник по командам SQL | 147
лярные функции возвращают одно значение при каждом своем вызове, и они будут
корректными, если допустимыми будут инструкции SQL.) Внешние скалярные поль-
зовательские функции позволяют использовать следующие предложения.
CREATE FUNCTION имя_объекта (имя_параметра тип_данных
[,...]) [AS LOCATOR]
RETURNS тип_данных [AS LOCATOR] [CAST FROM тип_данных
[AS LOCATOR] ]
[LANGUAGE {C | JAVA | OLE} ] [PARAMETER STYLE
{SQL | DB2GENERAL | JAVA}]
[SPECIFIC специальнов-имя]
[EXTERNAL NAME имя_внешней_процедуры]
[DETERMINISTIC | NOT DETERMINISTIC] [STATIC DISPATCH]
[ [NO] EXTERNAL ACTION]
[NO SQL | CONTAINS SQL | READS SQL DATA]
[CALLED ON NULL INPUT | RETURNS NULL ON NULL INPUT]
[INHERIT SPECIAL REGISTERS]
[ [NOT] FENCED [{THREADSAFE | NOT THREADSAFE}] ]
[ [NO] SCRATCHPAD int] [ [NO] FINAL CALL]
[{ALLOW | DISALLOW} PARALLEL]
[ [NO] DBINFO] [TRANSFORM GROUP имя__группы]
[PREDICATES (определение_предиката') ]
блок_кода
Приведенный ниже код является примером внешней скалярной пользовательской
функции под названием report_reader.center, которая определяет центр круга. В инструк-
ции явно объявляются все предложения, дажете, которые имеют значения по умолчанию,
равные объявленным.
CREATE FUNCTION report_reader.center (FLOAT, FLOAT, FLOAT)
RETURNS DECIMALS, 4) CAST FROM FLOAT
SPECIFIC center04
EXTERNAL NAME 'center!focalpt'
LANGUAGE C PARAMETER STYLE SQL DETERMINISTIC FENCED NOT NULL CALL
NO SQL NO EXTERNAL ACTION SCRATCHPAD NO FINAL CALL
DISALLOW PARALLEL
Заметьте, что пользовательская функция report_reader.center использует временный
буфер и может накапливать в нем результаты, а также влиять на них.
Внешние табличные пользовательские функции DBS
Этот вариант инструкции CREATE FUNCTION используется для регистрации пользо-
вательской внешней табличной функции сервером приложений. (Табличную функцию
можно использовать в предложении FROM инструкции SELECT. При этом для инструк-
ции SELECT возвращается таблица, по одной строке за раз). Во внешних табличных
пользовательских функциях можно использовать следующие предложения.
148 | Глава 3. Справочник по инструкциям SQL
CREATE FUNCTION имя_объекта (имя_параметра тип_данных }
[AS LOCATOR]
RETURNS TABLE тип_данных [AS LOCATOR] [,...] ]
[LANGUAGE {C | JAVA | OLE} ] [PARAMETER STYLE
{SQL | DB2GENERAL}]
[SPECIFIC специальное_имя] [EXTERNAL NAME имя_внешней_процедуры]
[DETERMINISTIC | NOT DETERMINISTIC] [ [NO] EXTERNAL ACTION]
[NO SQL | CONTAINS SQL | READS SQL DATA]
[CALLED ON NULL INPUT | RETURNS NULL ON NULL INPUT]
[INHERIT SPECIAL REGISTERS] [ [NOT] FEDERATED]
[ [NOT] FENCED [{THREADSAFE | NOT THREADSAFE}] ]
[ [NO] SCRATCHPAD int] [ [NO] FINAL CALL]
[DISALLOW PARALLEL]
[ [NO] DBINFO] [TRANSFORM GROUP имя_группы]
[CARDINALITY int]
блок_кода
Ниже приводится пример внешней табличной пользовательской функции, которая
извлекает из письма Microsoft Exchange часть текста и информацию из заголовка.
CREATE FUNCTION MAIL( )
RETURNS TABLE (time_rcvd DATE, subjet VARCHAR(15),
Ingth INTEGER, txt VARCHAR(3O))
EXTERNAL NAME 'mail.header!list'
LANGUAGE OLE
PARAMETER STYLE SQL
NOT DETERMINISTIC FENCED CALLED ON NULL INPUT
SCRATCHPAD FINAL CALL
NO SQL
EXTERNAL ACTION DISALLOW PARALLEL
Отметьте, что внешняя функция mail.headerllist должна уже существовать.
Внешние табличные пользовательские функции OLE-DB в DBS
Этот вариант инструкции CREATE FUNCTION регистрирует пользовательскую внеш-
нюю табличную функцию OLE-DB для доступа к данным поставщика OLE-DB. Таб-
личную функцию можно использовать в предложении FROM инструкции SELECT.
Эти функции полезны для подключения к источникам реляционных данных, не отно-
сящихся к DB2. Во внешних табличных пользовательских функциях OLE-DB можно
использовать следующие предложения.
CREATE FUNCTION имя_объекта (имя_параметра тиП-Данных) [,...])
RETURNS TABLE тип_данных [....] ] [SPECIFIC специальное_имя]
[LANGUAGE OLEDB] [EXTERNAL NAME имя_внешней_процедуры]
[DETERMINISTIC | NOT DETERMINISTIC] [ [NO] EXTERNAL ACTION]
[STATIC DISPATCH] [CALLED ON NULL INPUT |
Справочник по командам SQL | 149
RETURNS NULL ON NULL INPUT]
[CARDINALITY int]
блок_кода
В следующем примере регистрируется табличная функция OLE-DB, которая
извлекает информацию о заказе, order, из базы данных Microsoft Access с именем
Northwind.
CREATE FUNCTION orders ( )
RETURNS TABLE (orderid INTEGER, customerid CHAR(5), employeeid INTEGER,
orderdate TIMESTAMP, requireddate TIMESTAMP, shippeddate TIMESTAMP,
shipvia INTEGER, freight DEC(19,4))
LANGUAGE OLEDB
EXTERNAL NAME ''orders!Provider=Microsoft. Jet. OLEDB. 3.51;
Data Source=c:\sqllib\samples\oledb\nwind. mdb';
Отметьте, что строка соединения определяется во внешнем имени функции.
Шаблонные пользовательские функции DB2
Этот вариант инструкции CREATE FUNCTION регистрирует пользовательскую функ-
цию, основанную на другой существующей скалярной или столбцовой функции. С по-
мощью этой инструкции также можно зарегистрировать шаблон функции сервером при-
ложений, который играет роль объединенного сервера (federated server). (Шаблон функ-
ции - это частично реализованная функция, в которой нет исполняемого кода, но есть
связь с функцией-источником данных. Как только связь устанавливается, пользователь
может указывать шаблон функции в запросах к объединенному серверу. Объединенный
сервер будет вызывать функцию-источник данных и возвращать значения, соответст-
вующие тем, которые указаны в части RETURNS определения шаблона.) В шаблонных
пользовательских функциях можно использовать следующие предложения.
CREATE FUNCTION имя_объекта (,имя_параметра тип_данных [,...])
RETURNS тип_данных [,...] ]
[SOURCE {имя_объекта [входной_аргумент [, .. .] ] |
[SPECIFIC специальное_имя~\ ]
[AS TEMPLATE [DETERMINISTIC | NOT DETERMINISTIC]
[ [NO] EXTERNAL ACTION] ]
блок_кода
Например, следующая шаблонная пользовательская функция основывается на
скалярной функции report_reader,center, созданной ранее в этом разделе. Следующая
функция, называющаяся fn_center, принимает только целочисленные аргументы.
CREATE FUNCTION fn_center (INTEGER, INTEGER)
RETURNS FLOAT
SOURCE report_reader.center (INTEGER, FLOAT);
ISO | Глава 3. Справочник no инструкциям SQL
В следующем примере с использованием объединенного сервера (federated server)
мы можем вызывать пользовательскую функцию Oracle под названием statistics из
схемы scott, которая возвращает статистику по таблице в форме значения с пла-
вающей точкой двойной точности.
CREATE FUNCTION scott.statistics (DOUBLE, DOUBLE)
RETURNS DOUBLE AS TEMPLATE
DETERMINISTIC NO EXTERNAL ACTION;
Пользовательские SQL-функции в DBS
Этот вариант инструкции CREATE FUNCTION определяет скалярную, табличную или
строковую SQL-функцию. Данный вариант является наиболее распространенной
формой пользовательских функций DB2. Помните, что скалярная функция при вызове
возвращает одно значение. Табличную функцию можно использовать в предложении
FROM инструкции SELECT, она возвращает таблицу. Строковая функция возвращает
строку. Ее можно использовать в качестве функции для преобразования.
В пользовательской SQL-функции можно использовать следующие предложения.
CREATE FUNCTION имя_объекта [(имя_параметра тип_данных [,,..])]
RETURNS { тип_данных | {ROW | TABLE} список_столбцов}
[SPECIFIC специальное_имя]
[LANGUAGE SQL] [DETERMINISTIC | NOT DETERMINISTIC]
[ [NO] EXTERNAL ACTION]
[CONTAINS SQL | READS SQL DATA] [STATIC DISPATCH]
[CALLED ON NULL INPUT] [PREDICATES {определение_предиката) ]
блок_кода
Вот пример пользовательской SQL-функции, которая возвращает объединенное
имя, составленное из значений разных полей.
CREATE FUNCTION prod.cust_name
(in_custno INTEGER )
RETURNS VARCHAR(31)
LANGUAGE SQL
READS SQL DATA
NO EXTERNAL ACTION
DETERMINISTIC
RETURN
SELECT (c.firstnme CONCAT ' '
CONCAT c. midinit CONCAT '
CONCAT c.lastname)
AS name
FROM prod.customer c
WHERE c.custno = 10;
Справочник по командам SQL | 151
Внешняя хранимая процедура DB2
Этот вариант инструкции CREATE PROCEDURE определяет внешнюю процедуру
в сервере приложений DB2. Обычно внешние процедуры пишутся на языках, отличных
от SQL, например на С или Java. Для внешней процедуры можно использовать сле-
дующие предложения.
CREATE PROCEDURE имя_объекта
[( [IN | OUT | INOUT] имя_параметра тип_данных [,...] ) ]
[SPECIFIC специальное_имя] [DYNAMIC RESULT SETS int]
[NO SQL | CONTAINS SQL | READS SQL DATA | MODIFIES SQL DATA]
[DETERMINISTIC | NOT DETERMINISTIC] [CALLED ON NULL INPUT]
LANGUAGE {C | JAVA | COBOL | OLE}
EXTERNAL NAME имя_внешней_процедуры
[INHERIT SPECIAL REGISTERS]
PARAMETER STYLE {SQL | DB2GENERAL | DB2SQL | GENERAL |
GENERAL WITH NULLS | JAVA}
[ [NOT] FENCED [{THREADSAFE | NOT THREADSAFE}] ]
[PROGRAM TYPE {SUB | MAIN}]
[ [NO] DBINFO]
блок_кода
Ниже приводится пример внешней процедуры. В этом примере мы создаем в DB2
определение процедуры для программы на С, которая, если ей передать ID автора,
выводит количество проданных книг, общий объем продаж в долларах, а также заго-
ловки книг, написанных этим автором.
CREATE PROCEDURE author_sales
(IN au.id INTEGER, OUT books.sold INTEGER,
OUT total_sales DOUBLE, OUT title VARCHAR(50) )
EXTERNAL NAME 'authorsisales'
DYNAMIC RESULT SETS 1 NOT FENCED
LANGUAGE C PARAMETER STYLE GENERAL
Хранимые SQL-процедуры в DB2
Данный вариант инструкции CREATE PROCEDURE определяет SQL-процедуру в сервере
приложений DB2. Для SQL-процедуры можно использовать следующие предложения.
CREATE PROCEDURE имя_объекта [( [IN |
OUT| INOUT] имя_параметра тип_данных [,...] ) ]
[SPECIFIC специальнов-имя] [DYNAMIC RESULT SETS int]
[CONTAINS SQL | READS SQL DATA | MODIFIES SQL DATA]
[DETERMINISTIC | NOT DETERMINISTIC] [CALLED ON NULL .INPUT]
[INHERIT SPECIAL REGISTERS] [LANGUAGE SQL]
блок_кода
Следующая записанная SQL-процедура возвращает запись о клиенте, применяя
функцию SOUNDEX к именам и штатам.
152 | Глава 3. Справочник по инструкциям SQL
CREATE PROCEDURE prod.custlookup
(IN in_lastname VARCHAR(15),
IN in_st CHARACTERS) )
DYNAMIC RESULT SETS 1
LANGUAGE SQL
NOT DETERMINISTIC
CALLED ON NULL INPUT
MODIFIES SQL DATA
INHERIT SPECIAL REGISTERS
PI: BEGIN
DECLARE cursor'! CURSOR WITH RETURN FOR
SELECT *
FROM prod.customer c
WHERE SOUNDEX (c.lastname) = SOUNDEX (in_lastname)
AND c.st = UPPER (in_st);
OPEN cursorl;
END P1;
В DB2 недавно были реализованы новые процедурные расширения SQL. Теперь вы
можете определить блок_кода для пользовательской функции или записанной процедуры
DB2 с помощью условных конструкций типа IF...THEN и циклов WHILE (как показано
в примерах выше).
Параметр RETURNS TABLE при описании возвращаемого значения допустим для
любого параметра LANGUAGE. Здесь разрешаются только следующие предложения:
STATIC DISPATCH, DETERMINISTIC, EXTERNAL ACTION, RETURNS NULL... |
CALLED NULL... ON INPUT и CARDINALITY.
При использовании параметра LANGUAGE SQL допустимы только следующие пара-
метры стиля: READ SQL DATA и CONTAIN SQL. Эти предложения отменяют предложе-
ния CAST и RETURNS NULL ON NULL INPUT. С этими предложениями можно (хотя
не обязательно) использовать следующие предложения: RETURNS {ROW | TABLE},
FEDERATED, PREDICATES и INHERIT SPECIAL REGISTRES.
Инструкции ALTER FUNCTION и ALTER PROCEDURE в DB2 просто изменяют
характеристики существующей пользовательской функции или записанной проце-
дуры. В следующих двух примерах для функции и процедуры соответственно указы-
вается предложение NOT FENCED.
ALTER FUNCTION mail( ) NOT FENCED:
ALTER PROCEDURE employee_pay NOT FENCED:
MySQL
MySQL не поддерживает инструкцию ALTER FUNCTION, а также инструкции
CREATE PROCEDURE и ALTER PROCEDURE.
Пользовательские функции, которые создаются в базе данных MySQL, по сути
являются вызовами внешних функций.
Справочник по командам SQL | 153
CREATE [AGGREGATE] FUNCTION имя_функции
RETURNS {STRING | REAL | INTEGER}
SONAME имя_библиотеки_коллективного_пользования',
Где:
CREAТЕ [AGGREGATE] FUNCTION имя_функции
Создается внешняя функция с именем имя_функции. Имя не может быть длиннее
64 символов. Модуль будет сохранен в директории mysql2/udf с расширением .udf.
Если указано предложение AGGREGATE, то пользовательская функция должна
возвращать агрегатное значение, такое, как SUM() или AVG().
RETURNS (STRING | REAL | INTEGER}
Возвращаемое значение представляет собой тип STRING (символьные данные),
REAL (значения с плавающей точкой) или INTEGER (целые числа).
SONAME имя_библиотечной_ирогроммы_коллективного^пользования
Указывается имя программы на C/C++, которая выполняет обработку. Данная про-
грамма коллективного использования может быть откомпилирована и встроена
в MySQL или же может функционировать как независимая связываемая программа.
Созданную пользовательскую функцию MySQL можно вызывать как любую
другую функцию, такую, как ABSQ или SOUNDEXQ.
Реализация инструкции CREATE FUNCTION в MySQL зависит от работы проце-
дурного кода C/C++ в операционной системе, поддерживающей динамическую загруз-
ку. Название программы C/C++ указывается в параметре библиотечной_программы_кол-
лективного_пользования. Функция может быть скомпилирована прямо с сервером
MySQL, тогда она будет доступна постоянно, или же может быть динамически вызывае-
мой программой. Например, на t/МЛ-сервере может находиться блок кода, используемый
в следующей инструкции, создающей пользовательскую функцию.
CREATE FUNCTION find-radius RETURNS INT SONAME “radius.so"
Oracle
Платформа Oracle поддерживает инструкции ALTER FUNCTION и CREATE FUNCTION,
ALTER PROCEDURE и CREATE PROCEDURE. (Возможно, вы захотите узнать о пакетах
Oracle, которые также можно применять для создания пользовательских функций и запи-
санных процедур. Обращайтесь к документации Oracle.) Синтаксис инструкции CREATE
PROCEDURE в Oracle следующий.
CREATE [OR REPLACE] {FUNCTION | PROCEDURE} [схема. ]имя_объекта
[(параметр! [IN | OUT | IN OUT] [NOCOPY] тип_данных'] [,...] ) ] ]
RETURN тип_данных
[DETERMINISTIC] [AUTHID {CURRENT-USER | DEFINER}]
[PARALLEL_ENABLE [( PARTITION имя_раздела BY {ANY | {HASH | RANGE}
(столбец [,...] ) [{ORDER | CLUSTER} BY (столбец [,...] ) ] ]
{ [PIPELINED | AGGREGATE] USING [схема. }тип_реализации'\ |
[PIPELINED] {IS | AS} }
{блок_кода | LANGUAGE {JAVA NAME имя_внешней_протраммы |
154 | Глава 3. Справочник по инструкциям SQL
C [NAME имя_внешней_программы)
LIBRARY имя_библиотеки [AGENT IN (аргумент [,...]) [WITH CONTEXT]
[PARAMETERS ( параметр [,...]) ] };
Инструкции ALTER FUNCTION и ALTER PROCEDURE, показанные ниже,
используются для перекомпиляции неверно составленных пользовательских функций
и записанных процедур.
ALTER {FUNCTION | PROCEDURE} [схема.]имя_объекта
COMPILE [DEBUG] [параметры_компиляции = value [...] ] [REUSE SETTINGS]
Ниже приводится описание параметров.
CREATE [OR REPLACE] FUNCTION [схема.]имя_объекта
Создается новая пользовательская функция или записанная процедура. Исполь-
зуйте предложение OR REPLACE, чтобы заменить существующую процедуру или
функцию без предварительного ее удаления и последующего переназначения всех
связанных с ней допусков. Некоторые предложения используются только с поль-
зовательскими функциями, в том числе предложения RETURN, DETERMINISTIC
и все варианты предложения USING.
[IN | OUT | IN OUT]
Определяет, является ли параметр для функции входным, выходным или и тем
и другим одновременно.
NOCOPY
Этот параметр увеличивает производительность, если аргумент типа OUT или IN
OUT очень велик (например, относится к типу VARRAY или RECORD).
AUTHID {CURRENT USER | DEFINER]
Принудительно определяет запуск подпрограммы с допусками текущего пользо-
вателя (AUTHID CURRENT_USER) или владельца функции (AUTHID DEFINER).
PARALLEL_ENABLE
Разрешается запуск подпрограммы в параллельной обработке запроса на SMP-
сервере или сервере с параллельными процессами. Это предложение применяется
только к пользовательским функциям. (Не используйте переменные состояния
сеанса и переменные пакетов, поскольку нельзя ожидать, что они будут совместно
использоваться серверами с параллельной обработкой.) Обработку запросов с пред-
ложением PARALLEL_ENABLE можно регулировать при помощи следующих допол-
нительных предложений.
PARTITION имя -раздела BY {ANY\ {HASH | RANGE] (столбец [,...])
Определяется распределение входных данных по функциям с аргументами
типа REF CURSOR. Этот параметр полезен при использовании табличных
функций. Значение ANY разрешает случайное распределение. Вы можете
ограничить процесс распределения определенным диапазоном (RANGE) или
хеш-секцией (HASH), указанной в списке столбцов.
{ORDER | CLUSTER] BY (столбец [...])
Проводится сортировка или кластеризация данных в параллельной обработке
в соответствии со списком перечисленных через запятую столбцов. Предложение
Справочник по командам SQL | 155
ORDER. BY используется на сервере параллельного выполнения для локальной
сортировки строк по списку столбцов. При использовании предложения
CLUSTER BY сервер параллельного выполнения использует только ключевые
значения, указанные в списке столбцов.
{PIPELINED | AGGREGATE} [USING [схема.]типреализации]
При указании предложения PIPELINED результат выполнения табличной функ-
ции выводится итерациями, а не последовательно, как обычно выводятся данные
типа VARRAY или вложенные таблицы. Это предложение применяется только
к пользовательским функциям. Предложение PIPELINED USING типреализации
применяется для внешних пользовательских функций, использующих такие
языки, как C++ и Java. Предложение AGGREGATE USING типреализации опре-
деляет пользовательскую функцию как агрегатную (т. е. такую, которая проводит
вычисления по многим строкам, но выводит только одно значение).
IS\AS
Ключевые слова IS и AS в Oracle идентичны. Любое из них начинает блокрода.
блокрода
Платформа Oracle позволяет использовать для пользовательских функций и запи-
санных процедур блоки кода PL/SQL. В качестве альтернативы (для записанных
процедур на Java и С) вы можете использовать предложение LANGUAGE.
LANGUAGE [JAVA NAME имярнешнейррограммы | С [имярнешнейррограммы]
LIBRARY имя-библиотеки [AGENT IN (аргумент) [WITH CONTEXT] [PARAMETERS
(параметры)]}
Определяется реализация внешней программы на Java или С. Параметры и семан-
тика объявлений специфичны для Java и С, а не для SQL.
ALTER [FUNCTION | PROCEDURE} [схема.]имярбъекта
Перекомпилируется неработающая самостоятельная подпрограмма. Чтобы изме-
нить объявления, аргументы и определения в существующей подпрограмме,
используйте конструкцию CREATE... OR REPLACE.
COMPILE [DEBUG] [REUSE SETTINGS]
Подпрограмма перекомпилируется. Заметьте, что компиляция необходима. (Увидеть
ошибки компиляции можно с помощью команды SQL*Plus SHOW ERRORS.) Подпро-
грамма помечается как рабочая, если не происходит ошибок компиляции. В предложе-
ние COMPILE можно включать следующие дополнительные предложения.
DEBUG
Генерируется и записывается код, который используется отладчиком PL/SQL.
параметрромпилятора - значение [...]
Указывается параметр компилятора PL/SQL. Допустимы следующие пара-
метры: PLSQLJJPTIMIZE_LEVEL, PLSQLCODETYPE, PLSQL DEBUG,
PLSQLJVARNINGS и NLS_LENGTH_SEMANTICS. За подробностями обра-
щайтесь к документации по компилятору PL/SQL.
156 | Глава 3. Справочник по инструкциям SQL
REUSE SETTINGS
Сохраняет существующие командные переключатели настроек компилятора и ис-
пользует их при перекомпиляции. В обычных условиях Oracle удаляет настройки
компилятора и получает их заново.
В Oracle пользовательские функции и записанные процедуры очень сходны по
структуре и составу. Главное отличие состоит в том, что записанная процедура
не может возвращать значение вызвавшему ее процессу, а функция возвращает
вызвавшему процессу одно значение.
Например, можно передать следующей функции название подрядного проекта
и получить величину прибыли этого проекта.
CREATE OR REPLACE FUNCTION project_revenue (project IN varctiar2)
RETURN NUMBER
AS
proj_rev NUMBER(10,2);
BEGIN
SELECT SUM(DECODE(action,'COMPLETED'.amount,0)) -
SUM(DECODE(action, 'STARTED',amount, 0)) +
SUM(DECODE(action,'PAYMENT',amount,0))
INTO proj_rev
FROM construction_actions
WHERE project_name = project;
RETURN (proj_rev);
END;
В данном примере пользовательская функция принимает в качестве аргумента
название проекта. Затем она осуществляет подсчет прибыли проекта (project revenue),
вычитая первоначальные затраты из платежа по завершении и добавляя к результату
дополнительные платежи. Строка RETURN (PROJ_REV) возвращает итоговый результат
в вызвавший процесс.
В Oracle пользовательские функции нельзя использовать в следующих ситуациях.
• В ограничениях типа CHECK или DEFAULT инструкций CREATE TABLE или
ALTER TABLE.
• В инструкциях SELECT INSERT, UPDATE или DELETE пользовательские функ-
ции прямо или косвенно (т. е. будучи вызванными из другой подпрограммы) не
могут:
иметь параметр типа OUT или IN OUT (в непрямых вызовах параметры OUT
или IN OUT использовать можно);
завершать транзакцию командами COMMIT, ROLLBACK, SAVEPOINT или
использовать инструкции CREATE, ALTER и DROP, которые неявно используют
команды COMMIT или ROLLBACK',
использовать инструкции управления сеансом (SET ROLE) или управления
системой (специфическая для Oracle инструкция ALTER SYSTEM);
Справочник по командам SQL | 157
- производить запись в базу данных (если являются компонентом инструкции
SELECT или параллелизованных инструкций INSERT, UPDATE или DELETE)-,
производить запись в таблицу, измененную инструкцией, которая вызвала
пользовательскую функцию.
Обратите внимание, что, когда вы перекомпилируете подпрограмму с помощью
инструкции ALTER, она помечается как работающая, если не возникает ошибок ком-
пиляции. (Если ошибки встречаются, она помечается как неработающая.) Вероятно,
еще более важным является то, что объекты, которые зависят от перекомпилирован-
ной подпрограммы, также помечаются как неработающие независимо от того, возни-
кала ли ошибка компиляции. Вы можете либо перекомпилировать зависимые объекты
самостоятельно, либо позволить платформе потратить некоторое время и перекомпи-
лировать их во время работы.
В качестве примера следующая инструкция перекомпилирует функцию
project_revenue и сохранит информацию, полученную компилятором, для отладчика
PL/SQL.
ALTER FUNCTION project_revenue COMPILE DEBUG;
PostgreSQL
Платформа PostgreSQL поддерживает инструкцию CREATE FUNCTION, но не поддержи-
вает инструкции CREATE PROCEDURE, ALTER FUNCTION и ALTER PROCEDURE.
Поскольку PostgreSQL не имеет собственного внутреннего процедурного языка, пользова-
тельские функции обычно представляют внешние функции, хотя они могут быть и про-
стыми SQL-запросами. Синтаксис, используемый для создания функций, следующий.
CREATE [OR REPLACE] FUNCTION имя_функции
( [ параметр [,...] ] )
RETURNS тип_данных
AS {блок_кода | объектный_файл, связующий_идентификатор}
LANGUAGE {С | SQL | PLPGSQL | PLTCL | PLTCLU | PLPERL |
internal}
[WITH {[ISCACHABLE] [,] [ISSTRICT]} ]
Где:
CREATE [OR REPLACE] имя_функции
Создается новая функция с указанным именем или заменяется уже существующая
функция. Предложение OR REPLACE не позволяет изменять имя, входные пара-
метры или выходные результаты существующей функции. Чтобы изменить эти
параметры, вы должны удалить функцию и создать ее заново.
RETURNS тип данных
Указывается тип данных, возвращаемых функцией.
AS (блок_кода | объектный_файл, связующий-идентификатор)
Определяется состав пользовательской функции. блок_кода может представлять
собой строку, определяющую функцию (и зависящую от параметра LANGUAGE!),
т. е. внутреннее имя функции, имя объектного файла и путь к нему, запрос SQL
158 | Глава 3. Справочник по инструкциям SQL
или текст на процедурном языке. Это определение также может представлять
собой объектный файл и связующий идентификатор (link symbol) (для языка С).
LANGUAGE {С | SQL | PLPGSQL | PLTCL | PLTCLU | internal}
Определяется вызов внешней программы или внутренней SQL-подпрограммы.
Поскольку для всех языковых вариантов, за исключением SQL, программы ском-
пилированы на других языках, они в данной книге не рассматриваются. Однако
для написания пользовательских SQL-функций нужно использовать предложение
LANGUAGE SQL.
Добавить новый язык, не установленный в PostgreSQL по умолчанию,
можно с помощью инструкции CREATE LANGUAGE.
[WITH {[ISCАСНABLE] [,] [ISSTRICT]}]
Параметр оптимизирует производительность PostgreSQL, показывая, что функция
всегда возвращает одно и то же значение при одинаковом наборе параметров.
Предложение WITH ISCACHABLE сходно с параметром ANSI DETERMINISTIC, за
тем исключением, что оно позволяет оптимизатору заранее оценить вызов функ-
ции. Предложение WITH ISSTRICTсходно с параметром ANSI RETURNS NULL ON
NULL INPUT. Если параметр опущен, функционирование, принятое по умолча-
нию, похоже на предложение CALLED ON NULL INPUT. Заметьте, что вы можете
включать в одно объявление функции оба ключевых слова.
Платформа PostgreSQL также позволяет выполнять перегрузку, при которой одно
имя могут носить несколько функций, если они имеют разный набор входных пара-
метров.
ЙГ *
' — “|
Когда вы удаляете существующую функцию, все зависимые от нее объекты
м-У становятся нерабочими, и их необходимо перекомпилировать.
Вот пример простой SQL-функции в PostgreSQL.
CREATE FUNCTION r!iax_project_nbr
RETURNS int4
AS "SELECT MAX(title.ID) FROM, titles AS RESULT"
LANGUAGE 'sql';
В этом примере мы создаем пользовательскую функцию, которая возвращает мак-
симальное значение titlelD из таблицы titles.
В PostgreSQL инструкция CREATE FUNCTION используется как замена инструк-
ции CREATE PROCEDURE, а также определяет действия для инструкции CREATE
TRIGGER.
SQL Server
Платформа SQL Server поддерживает инструкции CREATE и ALTER для обоих типов под-
программ. По умолчанию записанные процедуры SQL Server могут возвращать наборы
Справочник по командам SQL | 159
данных и пользовательские функции SQL Server также могут возвращать наборы данных,
состоящие из одной или нескольких строк, используя в аргументе RETURNS тип данных
TABLE вопреки стандарту ANSI. Однако это делает подпрограммы SQL Server более гиб-
кими и мощными. Для создания пользовательской функции или записанной процедуры
используется следующий синтаксис.
CREATE {FUNCTION | PROCEDURE} [имя_владельца. '\имя_объекта[; int]
( [ {^параметр тип_даниых [VARYING] [=значение_по_умолчанию] [OUTPUT]} [,...]] )
RETURNS {тип_данных | TABLE]
[WITH {ENCRYPTION | SCHEMABINDING | RECOMPILE |
RECOMPILE, ENCRIPTION}]
[FOR REPLICATION]
[AS]
блок_кода
Чтобы изменить существующую пользовательскую функцию или записанную
процедуру, используйте следующий синтаксис.
ALTER {FUNCTION | PROCEDURE} [имя_владельца. "]имя_объекта[; int]
( [{^параметр тип_данных [VARYING] [=значение_по_умолчанию] [OUTPUT]} [,...] ] )
RETURNS { тип_данных | TABLE]
[WITH {ENCRYPTION | SCHEMABINDING | RECOMPILE |
RECOMPILE, ENCRIPTION}]
[FOR REPLICATION]
[AS]
блок_кода
Ниже приводится описание параметров.
CREATE {FUNCTION | PROCEDURE} [нмя_владелъца.]имя_объекта[;т1]
В текущей базе данных создается новая пользовательская функция или записан-
ная процедура. Для записанных процедур SQL Server вы можете дополнительно
указывать номер версии в формате гшя_процедуры;1, где 1 - целое число, показы-
вающее номер версии. Эта возможность позволяет иметь несколько версий одной
записанной процедуры.
{@параметр тип данных [VARYING] [=значение_по_умолчанию] [OUTPUT]} [,...]
Определяется один или несколько входных аргументов для пользовательской
функции или записанной процедуры. Параметры в SQL Server всегда объявляются
с первым символом @.
Где:
VARYING
Используется в записанных процедурах с параметром типа CURSOR. Показы-
вает, что возвращаемый набор данных создается процедурой динамически.
= значение_по_умолчанию
Параметру присваивается значение по умолчанию. Значение по умолчанию
используется в случае, если записанная процедура или функция вызывается
без указания значения параметра.
160 | Глава 3. Справочник по инструкциям SQL
OUTPUT
Параметр используется в записанных процедурах. Он эквивалентен предложе-
нию OUT инструкции CREATE FUNCTION в стандарте ANSI. Значение, хра-
нимое в возвращаемом параметре, возвращается в вызвавшую процедуру
через возвращаемые переменные команды EXEC[UTE]. Выходные параметры
могут относиться к любому типу данных, за исключением типов TEXT
к IMAGE.
RETURNS {тип_данных | TABLE}
Параметр позволяет пользовательским функциям возвращать одно значение типа
тип данных или возвращать множество значений в типе TABLE. Тип данных
TABLE считается встроенным (inline), если не имеет списка столбцов и создается
одной инструкцией SELECT. Если предложение RETURNS возвращает множество
значений в значении типа TABLE и если значение типа TABLE имеет заданные
столбцы и типы данных, то функция называется многокамандной функцией с таб-
личными значениями (multi-statement, multi-valued).
WITH
Позволяет указывать дополнительные характеристики пользовательской функции
или записанной процедуры SQL Server.
ENCRYPTION
Указывается, что платформа SQL Server должна шифровать столбцы системной
таблицы, в которых хранится текст функции для предотвращения несанкциониро-
ванного просмотра кода функции. Используется как в пользовательских функци-
ях, так и в записанных процедурах.
SCHEMABUILDING
Указывается, что функция связана с конкретным объектом базы данных, например
таблицей или представлением. Такой объект базы нельзя изменить или удалить,
пока существует функция (или пока указан параметр SCHEMABUILDING).
Используется только в пользовательских функциях.
RECOMPILE
Указывает, что платформа SQL Server не должна хранить план кеширования
записанной процедуры, а должна перестраивать его при каждом вызове проце-
дуры. Этот параметр полезен, если в процедуре используются нетипичные или
временные значения, однако он может существенно снизить производитель-
ность. Используется только в записанных процедурах. Заметьте, что предложе-
ния ENCRYPTION и RECOMPILE можно вызывать одновременно.
FOR REPLICATION
Запрещается выполнение записанной процедуры на сервере-подписчике. Предло-
жение используется главным образом для создания фильтрующих записанных
процедур, которые выполняются только во встроенной системе репликации SQL
Server. Несовместимо с предложением RECOMPILE.
Как и в случае таблиц (см. команду CREATE TABLE), локальные или глобальные
временные записанные процедуры можно объявлять с префиксом # или ## (соответст-
11 - 2447
Справочник по командам SQL | 161
венно) перед именем процедуры. Временные процедуры существуют только на протя-
жении сеанса работы создавшего ее пользователя или процесса. Когда сеанс заверша-
ется, временная процедура автоматически удаляется.
Записанная процедура или функция SQL Server может иметь до 1024 параметров,
указанных с префиксом @. Параметры определяются с помощью типов данных SQL
Server. (Параметры типа CURSOR должны иметь предложения VARYING и OUTPUT.)
Пользователь или вызвавший функцию процесс должны указать значения всех вход-
ных параметров. Однако для каждого входного параметра можно указать значение по
умолчанию, и тогда процедура сможет выполняться и без указанных пользователем
или процессом параметров. Значение по умолчанию должно представлять собой кон-
станту или значение NULL, и оно также может содержать символы-заменители,
которые описываются ниже в этой главе в разделе «Оператор LIKE».
Платформа SQL Server требует, чтобы для данной пользовательской функции был
указан один или несколько параметров. Параметрами могут быть все поддерживаемые
SQL Server типы данных, за исключением TIMESTAMP, TEXT, NTEXT или IMAGE.
Если нужно встроенное табличное значение, можно использовать параметр TABLE без
указания списка столбцов.
Инструкции ALTER FUNCTION и ALTER PROCEDURE полностью под-
держивают синтаксис, имеющийся в соответствующих инструкциях
CREATE. Инструкции ALTER можно использовать для изменения любых
характеристик существующей подпрограммы без изменения допусков
и влияния на зависимые объекты.
В пользовательских функциях блок_кода представляет собой либо одну инструк-
цию SELECT (для встроенной функции) в формате RETURN (SELECT...), или набор
инструкций Transact-SQL после предложения AS (для многокомандных функций). Вот
еще несколько правил, касающихся пользовательских функций SQL Server.
• При использовании предложения AS блок_кода нужно заключить в ограничители
BEGIN... END.
• Пользовательские функции не могут вносить в данные постоянные изменения или
вызывать другие долгосрочные побочные эффекты. Следствием этого ограничения
является ряд других. Например, инструкции INSERT, UPDATE и DELETE могут
изменять только переменные типа TABLE, локальные по отношению к функции.
• Если пользовательская функция SQL Server возвращает скалярное значение, она
должна содержать предложение RETURN тип_данных, где тип_данных иден-
тичен типу, обозначенному в предложении RETURNS.
• Последней инструкцией блока кода должна быть безусловная команда RETURN,
возвращающая единичное значение или значение типа TABLE.
162 | Глава 3. Справочник по инструкциям SQL
• 6jKJKj<oda не может содержать глобальных переменных, которые возвращают по-
стоянно меняющееся значение, наприме @@CONNECTIONS или GETDATE.
Однако он может содержать глобальные переменные, возвращающие одно неиз-
меняющееся значение, например @@SERVERN4ME.
Ниже приводится пример скалярной функции, возвращающей одиночное значе-
ние. После создания скалярной пользовательской функции ее можно использовать
точно так же, как существующие системные функции. Например:
CREATE FUNCTION metric_volume -- Input dimensions in centimeters.
(©length decimal(4,1),
©width decimal(4,1),
©height decimal(4,1) )
RETURNS decimal(12,3) -- Cubic Centimeters.
AS BEGIN
RETURN ( ©length » ©width * ©height )
ENO
GO
SELECT project_name,
metric_volume(const ruction.height,
construction-length,
const ruction-Width)
FROM housing_construction
WHERE ,metric_volume(construction_height,
construction_length,
construction_width) >= 300000
GO
Встроенная пользовательская функция с табличными значениями возвращает
значение с помощью одной инструкции SELECT с предложением AS RETURN. Например,
можно ввести ID магазина (store ID) и найти все соответствующие заголовки произве-
дений (titles).
CREATE FUNCTION stores_titles (@stor_id varchar(30))
RETURNS TABLE
AS
RETURN (SELECT title, qty
FROM sales AS s
uOIN titles AS t ON t.title_id = s.title_id
WHERE s.stor_id = ©storeid )
Теперь немного изменим пользовательскую функцию, изменив длину для типа
данных входного аргумента и добавив еще одно предложение к конструкции WHERE
(показано жирным шрифтом).
ALTER FUNCTION stores_titles (@stor_id VARCHAR(4))
RETURNS TABLE
Справочник по командам SQL | 163
AS
RETURN (SELECT title, qty
FROM sales AS s
JOIN titles AS t ON t.title_id - s.title_id
WHERE s,stor_id = ©storeid
AND s.city = 'New York')
Пользовательские функции, которые возвращают значения типа TABLE, часто
используются для получения наборов данных или применяются в предложении FROM
инструкции SELECT так же, как обычные таблицы. Эти многокомандные функции
с табличными значениями могут включать в себя очень сложный код, поскольку
блоккода состоит из множества инструкций TransactSQL, которые заполняют данными
возвращаемую переменную-таблицу.
Вот пример вызова много командной функции с табличными значениями в пред-
ложении FROM. Заметьте, что таблице присваивается псевдоним точно так же, как
обычной таблице.
SELECT со. order__id, со. order_price
FROM construction_orders AS co,
fn_construction_projects('Cancelled') AS fcp
WHERE co.construction_id = fcp.construction_id
ORDER BY co.order_id
GO
В записанных процедурах параметр блок_кода содержит одну или несколько
команд Transact-SQL, занимающих до 128 Мб и ограниченных конструкциями
BEGIN и END. Ниже приводятся некоторые правила, касающиеся записанных процедур
Microsoft SQL Server.
• В блоке_кода разрешено использовать большинство существующих инструкций Trans-
act-SQL, однако запрещены конструкции SHOWPLAN TEXTvi SETSHOWPLAN ALL.
• Некоторые другие команды в записанных процедурах имеют ограниченное при-
менение. Эти команды следующие: ALTER TABLE, CREATE INDEX, CREATE
TABLE все инструкции DBCC, DROP TABLE, DROP INDEX, TRUNCATE TABLE
и UPDATE STATISTICS.
• В SQL Server допустимо отсроченное разрешение имен. Это означает, что запи-
санная процедура компилируется без ошибок, даже если она ссылается на еще не
созданный объект. SQL Server создает план выполнения, и ошибка возникает,
только когда вызов объекта действительно происходит (например, в записанной
процедуре), а объект еще не существует.
• Записанные процедуры SQL Server можно легко вкладывать друг в друга. Когда
записанная процедура вызывает другую записанную процедуру, системная пере-
менная @@NESTLEVEL увеличивается на единицу. По завершении вызванной
процедуры она уменьшается на единицу. Чтобы определить текущий уровень
вложенности, используйте в записанной процедуре или в специальном запросе
команду SELECT @@NESTLEVEL.
164 | Глава 3. Справочник по инструкциям SQL
В следующем примере записанная процедура SQL Server генерирует уникальное
значение из 22 цифр (на основе элементов системной даты и времени) и возвращает
его вызвавшему процессу.
-- Записанная процедура Microsoft SQL Server
CREATE PROCEDURE get_next_nbr
@next_nbr CHAR(22) OUTPUT
AS
BEGIN
DECLARE @random_nbr INT
SELECT @random_nbr = RAND( ) * 1000000
SELECT @next_nbr =
RIGHT('000000' + CAST(ROUND(RAND(@random_nbr)*lOOOOOOl0))
AS CHAR(6). 6) t
RIGHT)'0000' + CAST(DATEPART (yy, GETDATE) ) )
AS CHAR(4)), 2) +
RIGHT)'000' + CAST(DATEPART (dy, GETDATE) ) )
AS CHAR(3)), 3) +
RIGHT)'00' + CAST)DATEPART (hh. GETDATE) ) )
AS CHAR(2)), 2) +
RIGHT)'00' + CAST(DATEPART (mi, GETDATE( ) )
AS CHAR(2)). 2) +
RIGHTCOO' + CAST(DATEPART (ss, GETDATE( ) )
AS CHAR(2)), 2) +
RIGHT)'000' r CAST)DATEPART (ms, GETDATE) ) )
AS CHAR(3)), 3)
END
GO
См. также
CALL
RETURN
Инструкция CREATE/ALTER INDEX
Индексы - это специальные объекты, которые надстраиваются над таблицами и ускоряют
многие операции по манипулированию данными, например выполнение инструкций
SELECT, UPDATE и DELETE. Избирательность действия данного предложения
WHERE и имеющиеся планы обработки запросов, из которых оптимизатор запросов
к базе данных может делать свой выбор, обычно основываются на качестве индексов,
которые были построены для данной таблицы и помещены в базу данных.
Команда CREATE INDEX не входит в стандарт ANSI SQL, и, следовательно, ее
реализации у разных производителей значительно различаются.
Справочник по командам SQL | 165
Платформа Команда
DB2 Поддерживается с вариантами
MySQL Поддерживается с вариантами
Oracle Поддерживается с вариантами
PostgreSQL Поддерживается с вариантами
SQL Server Поддерживается с вариантами
Общий синтаксис для всех производителей
CREATE [UNIQUE] INDEX имя_индекса ON имя_таблицы
(имя_столбца
Ключевые слова
CREATE [UNIQUE] INDEXимя_индекса
Создается новый индекс с именем имяинОекса в контексте текущей базы данных
и схемы. Поскольку индексы связаны с конкретными таблицами (или иногда
с представлениями), имя_индекса должно быть уникальным только в пределах
таблицы, от которой индекс зависит. Ключевое слово UNIQUE определяет индекс
как ограничение типа UNIQUE в данной таблице. Оно запрещает повторяющиеся
значения в проиндексированном столбце или столбцах таблицы. (Обращайтесь
к разделу «Ограничения» главы 2.)
ON имя_таблицы
Объявляет, с какой таблицей связывается индекс. Индекс зависит от таблицы.
Если таблица удаляется, то же происходит и с индексом.
(имя_столбца [,])
Определяется один или несколько столбцов таблицы, которые будут индексиро-
ваться. Указатели, полученные из проиндексированного столбца или столбцов,
позволяют оптимизатору запросов базы значительно увеличить скорость манипу-
ляций с данными, например инструкций SELECT или DELETE. Все крупные про-
изводители поддерживают составные индексы (composite index), иначе называемые
сцепленными индексами (concatenated index). Эти индексы используются в тех
случаях, когда лучше всего проводить поиск по двум столбцам как по единому
целому, например по фамилии и имени.
Общие правила
Индексы создаются по таблицам для ускорения операций манипулирования данными,
которые проводятся с таблицами, например предложений WHERE и JOIN. Индексы
способны ускорить и другие операции, например:
• определение значений MINQ или МАХ() по индексированному столбцу;
• сортировку и группировку столбцов таблицы;
• поиск типа IS NULL или IS NOT NULL;
166 | Глава 3. Справочник по инструкциям SQL
• более быстрое извлечение данных, когда нужны только проиндексированные данные.
Инструкция SELECT, которая извлекает данные из индекса, а не напрямую из самой
таблицы, называется покрывающим запросом (covering query). Индекс, который от-
вечает на подобный запрос, называется покрывающим индексам (covering index).
После создания таблицы вы можете создавать индексы по столбцам таблицы.
Хорошей практикой является создание индексов по столбцам, которые часто указы-
ваются в предложениях WHERE к JOIN запросов к таблице. Например, следующая ин-
струкция создает индекс по столбцу таблицы sales, который часто используется
в предложениях WHERE запросов к этой таблице.
CREATE INDEX ndx_ord_date ON sales (ord_date);
В другом случае нам нужно создать уникальный индекс по столбцам pub_name
и country таблицы publishers.
CREATE UNIQUE INDEX unq_pub_id ON publishers (pub_name, country)
Поскольку индекс является уникальным, любая новая запись, вводимая в таблицу
publishers, должна иметь уникальное сочетание имени издателя (pubjiame) и страны
(country).
ЯГ
; ''' । Платформы некоторых производителей позволяют создавать индексы по
| *~*У представлениям точно так же, как по таблицам.
Советы и хитрости программирования
Сцепленные индексы особенно полезны, когда запрос обращается к столбцам индекса,
начиная слева. Если вы опустите находящиеся слева столбцы в запросе к сцепленному
ключу, запрос может вообще не выполниться. Например, предположим, что у нас есть
сцепленный индекс по столбцам (фамилия, имя). Если мы делаем запрос только
к имени, сцепленный индекс, начинающийся с фамилии и включающий в себя имя,
может быть не слишком полезен. Некоторые производители платформ усовершенст-
вовали свои системы обработки запросов, и такая ситуация вызывает гораздо меньше
проблем.
ЯГ
I ' | При создании индекса место, занимаемое таблицей, может увеличиться
j <лУ 4^., в 1.2- 1.5 раза. Убедитесь, что у вас достаточно дискового пространства.
? Большая часть этого пространства после создания индекса высвобожда-
ется.
Вам следует знать, что бывают ситуации, когда слишком большое число индексов
может на самом деле ухудшить производительность системы. Вообще говоря, индексы
значительно ускоряют операции поиска, особенно операции SELECT, в таблице или
представлении. Однако каждый созданный индекс увеличивает нагрузку на систему при
выполнении операций UPDATE, DELETE или INSERT, поскольку база данных должна
Справочник по командам SQL | 167
провести обновление всех зависимых индексов, внеся туда изменившееся значение из
таблицы. На практике для одной таблицы можно создать самое большее 6-12 индексов.
Кроме того, индексы занимают в базе данных дополнительное место. Чем больше
столбцов в индексе, тем больше места ему требуется. Обычно это не представляет
проблемы, но иногда такие ситуации застают врасплох новичков, создающих новую
базу данных.
В большинстве баз данных с помощью индексов создаются статистические вы-
борки, которые обычно называют просто статистикой. С их помощью система обра-
ботки запросов может определить, какой индекс или какая комбинация индексов будет
наиболее полезной для обработки запроса (и будет ли вообще). При первом создании
индексов они всегда будут новыми и полезными, однако с течением времени, когда
записи удаляются, обновляются и вставляются в таблицу, индексы устаревают и их
польза уменьшается. Следовательно, индексы, как вчерашний хлеб, не обязательно
будут полезны, если они старые. Вам следует обязательно обновлять и перестраивать
индексы, а также регулярно проводить обслуживание баз данных, чтобы статистика
индексов была актуальной.
DB2
Платформа DB2 поддерживает инструкцию CREATE INDEX, но не поддерживает ин-
струкцию ALTER INDEX. В DB2 есть инструкция COMMENTS ON INDEX, позво-
ляющая пользователям обновлять комментарии к индексам без его удаления и по-
вторного создания. Кроме того, в DB2 есть инструкция RENAME INDEX, позво-
ляющая переименовать индекс без его удаления и повторного создания. Инструкция
CREATE INDEX имеет дополнительные предложения, которые позволяют произво-
дить разбиение по проиндексированным столбцам, а также другие предложения, ко-
торые влияют на то, как данные физически располагаются на диске.
CREATE [UNIQUE] INDEX тя_индекса
ON имя_таблицы ({имя_столбца [ASC | DESC]} [, . . . ])
[SPECIFICATION ONLY]
[INCLUDE (имя_столбца [ASC | DESC] [,...] )]
[[CLUSTER | EXTEND USING расширение_индекса [(константа [,...]) ] } ]
[PCTFREE int] [MINPCTUSED int]
[[DIS]ALLOW REVERSE SCANS]
[COLLECT [SAMPLED [DETAILED] ] STATISTICS]
Где:
ASC | DESC
Определяет, будут ли значения индекса располагаться в восходящем (ASC) или
нисходящем (DESC) порядке. Если предложение опущено, по умолчанию прини-
мается ASC.
SPECIFIC A TION ONL Y
Предложение используется для того, чтобы показать, что значение, указанное в пара-
метре имя_таблицы, представляет собой псевдоним, т. е. имя таблицы в базе данных
объединения (federated database). База данных объединения в DB2 объединяет данные
168 | Глава 3. Справочник по инструкциям SQL
из гетерогенных источников данных, например таблиц Oracle и SQL Server, и дает им
в базе DB2 локальный псевдоним (nickname). Чтобы уведомить оптимизатор DB2 об
индексах, созданных на основе таких таблиц Oracle и SQL Server, создайте индекс по
псевдониму и объявите его как SPECIFICATION ONLY. После этого платформа DB2
будет знать, что индекс существует и что его может использовать оптимизатор, но сам
индекс создавать нс нужно.
INCLUDE (имя_сто’1бца [,])
К уникальному индексу для повышения избирательности добавляются дополнитель-
ные столбцы, однако такие столбцы не считаются уникальными. Основное назначение
предложения INCLUDE- создание покрывающих индексов (covering indexes). В столб-
цах, добавляемых в предложение INCLUDE, не учитываются максимальные допусти-
мые размеры столбцов в DB2. Предложение INCLUDE является взаимоисключающим
с предложением EXTEND USING и SPECIFICATION ONLY, и его нельзя использовать
при индексировании временных таблиц.
CLUSTER
Объявляется, что индекс является кластеризованным. Кластеризованный индекс
определенным образом контролирует физическое расположение строк таблицы
с целью повышения скорости операций ввода/вывода в запросе. Фактор кластери-
зации сохраняется и динамически регулируется, по мере того как данные встав-
ляются в таблицу. В таблице может быть только один кластеризованный индекс.
Предложение CLUSTER является взаимоисключающим с предложениями EXTEND
USING и SPECIFICATION ONLY, его нельзя использовать во временных таблицах
и таблицах в режиме дозаписи (append mode).
EXTEND USING расширение_индекса [(константа [,...])]
Называется имя расширения индекса, которое будет управлять индексом. Индекс
должен быть определен для одного столбца особого (distinct) или структурирован-
ного (structured) типа. Для параметров, которые необходимы для типа, объявляется
одна или несколько констант. Предложение EXTEND нельзя использовать во времен-
ной таблице. Расширения индексов очень сложны и встречаются достаточно
редко. За подробностями обращайтесь к документации производителя.
PCTFREE int
Указывается процентная доля (int) дискового пространства, которое нужно оста-
вить свободным для каждой страницы индекса при создании этого индекса (целое
число от 0 до 99). Если параметр опущен, значение по умолчанию равно 10. Этот
параметр нельзя использовать для псевдонимов (nickname) и временных таблиц.
M1NPCTUSED int
Указывается процентная доля (int) дискового пространства на одну страницу индекса,
при превышении которого платформа DB2 будет рассматривать вопрос о слиянии
страниц индекса (целое число от 0 до 99). В DB2 рекомендуется значение 50 и ниже,
чтобы база не тратила ресурсы ввода-вывода на слияние страниц индекса. Эго предло-
жение обычно эффективно, только если фоновые процессы имеют возможность
иногда заблокировать таблицу. Если это невозможно из-за интенсивного использова-
Справочник по командам SQL | 169
ния, попробуйте использовать команду REORG INDEXES. Этот параметр нельзя ис-
пользовать для псевдонимов (nickname) и временных таблиц.
[DIS]ALLO W RE VERSE SCANS
Объявляется, что индекс поддерживает (ALLOW) или не поддерживает (DISALLOW)
сканирование в порядке, противоположном тому, в котором индекс создавался.
Значение по умолчанию - DISALLOW. Предложение нельзя использовать для
псевдонимов (nickname).
COLLECT [SAMPLED [DETAILED]] STATISTICS
При создании индекса собирается статистика индекса. Если предложения SAMPLED
и DETAILED не используются, собирается базовая статистика индекса. При указании
предложения DETAILED для индекса собирается дополнительная статистическая
информация, а именно PAGE FETCH PAIRS и CLUSTERFACTOR. Предложение
SAMPLED показывает, что платформа может использовать выборку для сбора
дополнительной статистической информации по предложению DETAILED.
Платформа DB2 не будет создавать новый индекс, если уже существует иден-
тичный индекс. DB2 считает индексы идентичными, если один индекс содержит те же
столбцы, что и другой, расположенные в том же порядке.
Платформа DB2 позволяет использовать таблицу в оперативном режиме (online)
в ходе создания нового индекса. В ходе процесса создания индекса доступ для чтения
существует всегда, однако доступ для записи временно блокируется в конце процесса
построения индекса. Чтобы временно заблокировать таблицу и запретить доступ для
чтения, используйте команду LOCK TABLE. Чтобы обновить статистику индекса
в случае большого изменения данных или после того, как индекс был создан без ука-
зания предложения COLLECT STATISTICS, следует использовать команду RUNSTATS
платформы DB2. Следующие два примера создания индекса функционально эквива-
лентны.
-- сбор базовой статистики при создании индекса
CREATE INDEX ndx_ord_date ON sales(ord_date) COLLECT STATISTICS;
-- сбор статистики индекса после создания индекса
LOCK TABLE sales IN EXCLUSIVE MODE;
CREATE INDEX ndx_ord_date ON sales(ord_date);
RUNSTATS ON TABLE sales AND INDEX ndx_ord_date
Теперь мы соберем подробную статистику по таблице publishers, используя
выборку.
CREATE UNIQUE INDEX unq_pub_id ON punlishers(pub_name, country)
COLLECT SAMPLED DETAILED STATISTICS;
В следующем примере показано, как создается расширенный индекс по столбцу
структурированного типа. Пользовательскому типу данных coordinatejposition тре-
буется строковое значение для поддержки столбца satellite_images.
170 | Глава 3. Справочник по инструкциям SQL
CREATE INDEX satellite_images ON gis_sites(coordinates)
EXTEND USING (coordinate_positions (x '00010010010000100020'));
Платформа DB2 также поддерживает инструкцию CREATE INDEX
EXTENSION. Она используется для определенного пользователем индексирования
объектных (typed) таблиц. За подробностями обращайтесь к документации
производителя.
MySQL
Платформа MySQL поддерживает вариант инструкции CREATE INDEX, но не под-
держивает инструкцию ALTER INDEX. Индексы MySQL всегда хранятся в иерархиче-
ских структурах (B-tree) в файловой системе. Строки в индексе сжимаются одновре-
менно по префиксам и по конечным пробелам. Синтаксис инструкции CREATE INDEX
в MySQL следующий.
CREATE [UNIQUE | FULLTEXT] INDEX имя_индекса
ON имя_габлицы (имя_столбца(,длина') [,...])
Где:
FULLTEXT
Создается индекс для полнотекстового поиска в столбце. Полнотекстовые индек-
сы поддерживаются только для таблиц типа MylSAM и типов данных CHAR,
TARCHAR и TEXT. Предложение (длина) не поддерживается.
Платформа MySQL поддерживает синтаксис инструкции CREATE INDEX основ-
ного промышленного стандарта. Интересно, что MySQL также позволяет создавать
индекс по первым символам из столбцов типа CHAR или VARCHAR (количество сим-
волов определяется параметром длина). В MySQL для столбцов типа BLOB или TEXT
параметр длина указывать необходимо. Указание длины может быть полезно, если
достаточной является избирательность, скажем, по первым десяти символам, и когда
экономия места на диске очень важна. Например:
CREATE UNIQUE INDEX unq_pub_id ON publishers(pub_name(25), country(10))
В этом примере индексируются только первые 25 символов столбца pub_name
и первые 10 символов столбца country.
Если говорить об общих правилах, то MySQL позволяет использовать, как мини-
мум, 16 ключей на таблицу с общей максимальной длиной не менее 256 байт. Однако
эти цифры могут изменяться в зависимости от системы хранения данных.
Oracle
Платформа Oracle позволяет с помощью инструкции CREATE INDEX создавать индек-
сы по таблицам, секционированным таблицам, кластерам и индекс-таблицам (index-
organized tables), а также скалярным атрибутам объектов объектных таблиц (typed
table) и столбцам вложенных таблиц. Платформа Oracle также позволяет использовать
несколько типов индексов, в том числе обычные иерархические (B-tree) индексы, ин-
Справочник по командам SQL | 171
дексы на основе битовых карт (BITMAP) (используются для столбцов, в которых
каждое значение повторяется 100 и более раз), секционированные индексы, индексы,
связанные с функцией (основанные на выражении, а не на значении в столбце),
и предметные индексы (domain index).
Имена индексов Oracle должны быть уникальны в пределах схемы, а не
только в пределах таблицы, с которой они связаны.
Платформа Oracle также поддерживает инструкцию ALTER INDEX. Она используется
для изменения или перестройки существующего индекса без его удаления и повторного
создания.
Синтаксис инструкции CREATE INDEX в Oracle следующий.
CREATE [UNIQUE | BITMAP] INDEX имя_индекса
[ON
{имя__таблицы ( {столбец | выражение} [ASC | DESC] [,...]) [{INDEXTYPE IS
индекса [PARALLEL [int] | NOPARALLEL] [PARAMETERS {'значения') }] |
CLUSTER имя_кластера |
FROM имя_таблицы WHERE условие [LOCAL секционирование) }
[ {LOCAL секционирование | GLOBAL секционирование } ]
[параметры_физических_атрибутов] [{LOGGING | NOLOGGING}] [ONLINE]
[COMPUTE STATISTICS] [{TABLESPACE имя_табличного_пространства | DEFAULT}]
[{COMPRESS int | NOCOMPRESS}] [{NOSORT | SORT}] [REVERSE]
[{PARALLEL [int] | NOPARALLEL}]
Синтаксис инструкции ALTER INDEX следующий.
ALTER INDEX имя_индекса
{ {ENABLE | DISABLE} | UNUSABLE | RENAME TO новое_имя_индекса | COALESCE |
[NO]MONITORING USAGE | UPDATE BLOCK REFERENCES |
PARAMETERS ( ' параметры_00СГ) | параметры_изменения_секционирования_индекса |
параметры_перестройки |
[DEALLOCATE UNUSED [KEEP int [К | M | G | T] ]
[ALLOCATE EXTENT ( [SIZE int [К | M | G | T] ] [DATAFILE ' имя_файла"]
[INSTANCE int] ) ]
[SHRINK SPACE [COMPACT] [CASCADE] ]
[{PARALLEL [int] | NOPARALLEL}]
[{LOGGING | NOLOGGING}]
[ параметрьсфизическиХ-атрибутов) }
Где предложения, не входящие в стандарт ANSI, таковы:
BITMAP
Вместо индексирования каждой строки для каждого значения индекса создается
битовая карта. Битовые карты лучше всего использовать для таблиц с неболь-
шим числом конкурентных запросов, например таблиц с высокой интенсивно-
стью чтения. Индексы на основе битовых карт несовместимы с индексами с гло-
172 | Глава 3. Справочник по инструкциям SQL
бальным секционированием, предложением INDEXTYPE и индекс-таблицами
(index-organized table) без связи с таблицей соответствия (mapped table).
ASC | DESC
Определяет расположение значений индекса в восходящем (ASC) или нисходящем
(DESC) порядке. Если предложение опущено, по умолчанию принимается ASC.
Однако помните, что Oracle считает индексы с предложением DESC индексами,
основанными на функции, так что между индексами с предложением ASC и индек-
сами с предложением DESC есть некоторые функциональные различия. Предложе-
ния ASC и DESC нельзя использовать совместно с предложением INDEXTYPE.
Предложение DESC игнорируется при использовании индексов на основе битовых
карт (BITMAP).
INDEXTYPE IS тип_иидекса [PARAMETERS ('значения')]
Создается индекс определенного пользователем типа тип_индекса. Предметные
индексы (domain index) требуют, чтобы пользовательский тип уже существовал
(обращайтесь к разделу «Инструкция CREATE/ALTER TYPE»). Если для пользова-
тельского типа требуются аргументы, их можно передать с помощью предложения
PARAMETERS. При желании можно параллелизировать создание типизированного
индекса с помощью предложения PARALLEL, которое подробно рассматривается
ниже.
CLUSTER имя к.частера
Объявляется кластерный индекс с указанием существующего имени_кластера.
В Oracle кластерный индекс физически совмещает две таблицы, которые часто
опрашиваются по одинаковым столбцам, обычно столбцам первичного и внешне-
го ключей. (Кластеры создаются специфической для Oracle командой CREATE
CLUSTER.) Таблицы и столбцы в кластерном индексе не нужно объявлять,
поскольку таблицы и индексированные столбцы уже объявлялись в ранее выпол-
ненной команде CREATE CLUSTER.
GLOBAL секционирование
Полный синтаксис следующий.
GLOBAL. PARTITION BY
{RANCE (сгмсок-Столбцов) ( PARTITION ]_имя_раздела~\ VALUE LESS THAN
(список_значений) [physical_attributes_clause] [TABLESPACE
имя__табличной_области) [LOGGING | NOLOGGING] [[,...]), |
HASH (,список__столбцов') ( PARTITION (имя_раздела)
{[TABLESPACE имя_таб/1ичной_области] [[OVERFLOW] TABLESPACE
имя_табличной_области) [VARRAY имя_уаггау STORE AS {LOB
имя_сегмента_1оЬ] [LOB (ямя_1оЬ) STORE AS [имя_сегмента„1оЬ]
[TABLESPACE имя__табличной_области) } } |
[STORE IN (имя_табличной_области [....])] [OVERFLOW STORE IN
(имя_табличной_области [,...] ), } [....] }
В предложении GLOBAL PARTITION объявляется, что глобальный индекс секцио-
нируется вручную методом линейного или хеш-секционирования на секции с име-
нами имя_секции. (По умолчанию индекс секционируется точно так же, как таблица,
Справочник по командам SQL | 173
с которой он связан, если она секционирована.) Вы можете указать до 32 столбцов,
однако ни один из них не может относиться к типу ROWID. Вы можете включить
в список через запятую одину или несколько секций с соответствующими атрибута-
ми. Атрибуты следующие.
RANGE
Создается глобальный индекс с линейным секционированием на основе диапа-
зона значений в столбцах таблицы, которые перечислены в списке_столбцов.
VALUE LESS THAN (список_значений)
Устанавливается верхняя граница текущей секции глобального индекса.
Значения в списке_значений соответствуют столбцам в списке_столбцов.
В обоих этих списках значения перечисляются через запятую. Оба списка за-
висят от префиксов. Это означает, что в таблице со столбцами (а, Ь, с)
вы можете определить секционирование по столбцам (а, Ь) или (а, Ь, с), но не
(Ь, с). Последним значением в списке всегда должно быть ключевое слово
MAXVALUE.
HASH
Создается глобальный индекс с хеш-секционированием, в котором строки
индекса связываются с секциями на основе хеш-функции для значений столбцов
из списка_столбцов. Вы можете прямо указать табличное пространство для
хранения специальных объектов базы данных, таких, как VARRAY, типы LOB,
а также на случай переполнения (OVERFLOW) указанных (или заданных по
умолчанию) табличных пространств.
LOCAL секционирование
Поддерживается локальное секционирование индексов в форме линейного секцио-
нирования (range partitioning), хеш-секционирования (hash partitioning), списочного
секционирования (list partitioning) и комбинированного секционирования (composite
partitioning). Вы можете не определять ни одной секции или определить их несколько
(в списке через запятую) и указать для них атрибуты. Если предложение опущено,
платформа Oracle генерирует одну или несколько секций в соответствии с количест-
вом секций таблицы. Секционирование индекса выполняется одним из трех способов.
Индексы с линейным и списочным секционированием
Применяются к обычным таблицам или таблицам с одинаковыми секциями.
Для индексов с линейным и списочным секционированием (которые являются
синонимами) используется следующий синтаксис.
LOCAL [ (PARTITION [имя_раздела]
{ [параметры_физических_атрибутов] [TABLESPACE имя_табличной_области]
[LOGGING | NOLOGGING] |
[COMPRESS | NOCOMPRESS] } [,...] ) ]
Все параметры аналогичны синтаксису предложения GLOBAL PARTITION
(выше), за исключением того, что по области действия этот индекс является
локальным.
174 | Глава 3. Справочник по инструкциям SQL
Индексы схеш-секционироваиием
Применяются к таблицам с хеш-секционированием. В случае индексов с хеш-
секшюнированием вы можете выбирать между синтаксисом, приведенным
выше, и следующим вариантом синтаксиса:
; ОСЛ_ !SiO['E IN /лбличноё (;блм;ти )
(РАП'.‘."ICN [ нм>1_рз.)дела ;; A5i ESPACT svtyi зОлнчной сбмс-rnj J !
который позволяет сохранить секцию индекса в указанном табличном про-
странстве. Если вы укажете больше имен табличных пространств, чем суще-
ствует секций индекса, платформа Oracle будет при секционировании данных
перебирать эти табличные пространства в цикле.
Индексы с комбинированным секционированием
Индексы с комбинированным секционированием можно применять к таблицам
с комбинированным секционированием. При этом используется следующий
синтаксис.
LC'-CA! ] 3’031 IN ил;я_’< зёллчноё рбллс' a : ]
:;AU7 I 1 - G.'I .ръ/д/эд
i ртсс.тс'ь j: ti: 'атсе ’ ' ЗЛЗ! EO!;AC! лмл облм'
I I GAGING ! NCiOGGJNO] ।
LCOMPPi-Sb i КСС0У|’!,30 j !
| {ОЕЭНЕ IN ',лчл_ глблччнсй__обг,лс7и . j ) ;
(3U3UAIJ r; ;cx /Д!Н_ подриздепа г ’ A3L FSГ;ЛСГ.
ЛМЛ гебллчцсй ^ебЛлСГ-']' 1
Вы можете применять предложение LOCAL STORE, указываемое после опре-
деления индекса с хеш-секционированием, или предложение LOCAL, указы-
ваемое после определения индекса с линейным или списочным секционирова-
нием. (Если вы используете предложение LOCAL, замените ключевое слово
SUBPARTITION па PARTITION.)
нл/ческие атрибуты
Указываются значения одного или нескольких следующих параметров: PCTEREE
ins (обсуждение приводится), IN/TRANS int и STORAGE (обсуждается в разделе
«Инструкция CREATE/ALTER TABLE»). Если предложение опушено, значениями
по умолчанию являются PCTEREE 10 и 1NITRANS 2. Значение по умолчанию для
параметра MAXTRANS зависит от размера блока в системе, который определяют
следующие параметры.
PCTEREE int
11араметр определяет процентную долю свободного места, оставляемого в каждом
блоке индекса при его создании. Эго ускоряет ввод новых элементов и обновление
таблицы. Однако параметр PCTEREE применяется только при создании индекса.
С течением времени он не сохраняется. Следовательно, объем свободною места
со временем может уменьшаться, ио мере того, как записи индекса вставляю гея,
обновляются и удаляются. Этот параметр не применяется в нндекс-таблицах.
Справочник по командам SQL | 175
INITRANS int
Указывается первоначальное количество одновременных транзакций для каж-
дого блока базы данных. Значение может лежать в диапазоне от 1 до 255. Если
предложение физические_атрибуты опущено, по умолчанию принимаются
PCTFREE 10 и JNITRANS 2.
LOGGING | NOLOGGING
Указывается, что платформа Oracle должна записывать (LOGGING) или не записы-
вать (NOLOGGING) информацию о создании индекса в файл журнала. Это предло-
жение также определяет заданные по умолчанию действия для загрузки больших
массивов данных при помощи Oracle SQL*Loader. Для секционированных индексов
это предложение определяет значения по умолчанию для всех секций, сегменты,
связанные с секциями, а также значения по умолчанию, применяемые во всех секци-
ях и подсекциях, добавляемых позже при помощи инструкции ALTER TABLE...ADD
PARTITION. (Если вы используете предложение NOLOGGING, мы рекомендуем сде-
лать полное резервное копирование после загрузки индекса в том случае, если после
сбоя возникла необходимость его перестройки.)
ONLINE
Предложение разрешает манипулирование данными в таблице в период создания
индекса. Даже в том случае, если предложение ONLINE указано, в конце операции
создания индекса существует небольшой промежуток времени, когда таблица бло-
кируется. Все сделанные в основной таблице в это время изменения будут отраже-
ны в создаваемом индексе. Предложение ONLINE несовместимо с предложениями
BITMAP, CLUSTER и PARALLEL. Его также нельзя использовать в индексах по
столбцу UROWID или индекс-таблицах с более чем 32 столбцами первичных
ключей.
COMPUTE [STATISTICS]
Производится сбор статистики в период создания индекса, когда это можно сделать
с относительно малыми затратами ресурсов. В противном случае вам нужно будет
собирать статистику после создания индекса.
TABLESPACE имя_табличной_области | DEFAULT
Назначает индексу определенное табличное пространство. Если предложение
опущено, индекс помещается в табличное пространство по умолчанию. Исполь-
зуйте ключевое слово DEFAULT, чтобы явным образом поместить индекс в таб-
личное пространство по умолчанию. (Когда локальные секционированные индек-
сы помещаются в табличное пространство по умолчанию, секция (или подсекция)
индекса помещается в то же табличное пространство, что и соответствующая
секция (или подсекция) основной таблицы.)
COMPRESS [int] | NOCOMPRESS
Разрешается или запрещается сжатие ключей. При сжатии устраняются повторе-
ния значений ключей, что дает существенную экономию места за счет скорости.
Целочисленное значение int определяет количество сжимаемых префиксных
ключей. Это значение может лежать в диапазоне от 1 до числа столбцов в индексе
(для неуникальных индексов) или от 1 до п-1 столбцов (для уникальных индексов).
176 | Глава 3. Справочник по инструкциям SQL
Значение по умолчанию - NOCOMPRESS, но если вы укажете предложение COM-
PRESS без числа int, по умолчанию принимается COMPRESS п (для нсуникальных
индексов) или COMPRESS п-1 (для уникальных индексов), где п - число столбцов
в индексе. Предложение COMPESS нельзя использовать для секционированных
индексов и индексов на основе битовых карт (BITMAP).
NOSORT 1 REVERSE
При указании предложения NOSORT производится быстрое создание индекса по
столбцу, который уже был отсортирован в восходящем порядке. Если значения
столбца не располагаются строго в восходящем порядке, операция отменяется
и предоставляется возможность повторить ее без параметра NOSORT. При указа-
нии предложения REVERSE блоки индекса на устройстве хранения располагаются
в обратном порядке (за исключением rowid). Предложение REVERSE и предложе-
ние NOSORT являются взаимоисключающими, и предложение REVERSE нельзя
использовать в индексе па основе битовых карт или в индекс-таблицах. Предложе-
ние NOSORT наиболее полезно при создании индекса сразу после загрузки табли-
цы заранее отсортированными данными.
PARALLEL [int] , NOPARALLEL
Для ускорения работы разрешается параллельное создание индекса с использова-
нием нескольких процессов сервера, каждый из которых работает со своей отдель-
ной частью индекса. Необязательное значение int определяет точное число парал-
лельных процессов, используемых в операции. Если это число опушено, плат-
форма Oracle сама вычисляет количество используемых процессов. Предложение
NOPARALLEL (указано по умолчанию) приводит к последовательному созданию
индекса.
{ENABLE । DISABLE}
Включается или отключается существующий индекс, основанный на функции.
В инс трукции ALTER INDEX с предложениями ENABLE или DISABLE нельзя ука-
зывать другие предложения.
UNUSABLE
Индекс (или его раздел или подраздел) маркируется как непригодный. При указа-
нии предложения UNUSABLE индекс (или его раздел или подраздел) можно
только перестроить или удалить и создать заново, прежде чем его можно будет ис-
пользовать.
RENAME ТО новое_имя индекса
Переименование индекса имя_индекса в ноаое_имя_индекса.
COALESCE
Объединяет содержимое блоков индекса, используемых в и i щеке-таблице, чтобы
блоки можно было использовать повторно. Предложение COALESCE сходно с пред-
ложением SHRINK, хотя COALESCE сжимает сегменты не так сильно, как это делает
SHRINK, и не высвобождает неиспользуемое дисковое пространство.
[NO]MONITORING USAGE
Объявляется, что платформа Oracle должна очистить имеющуюся информацию об
использовании индекса и выполнять мониторинг индекса, размещая информацию
12-2447 Справочник по командам SQL | 177
в динамическом представлении производительности V$OBJECT_USAGE, пока не
будет выполнена команда ALTER INDEX...NOMONITOR USAGE.
UPDA ТЕ BLOCK REFERENCES
Производится обновление всех устаревших оценок (guess) адресов блоков данных,
которые хранятся в индексных строках обычных и предметных индексов индекс-
таблицы. Оценка блоков данных содержит корректные адреса соответствующих бло-
ков, определяемых первичными ключами, в базе данных. Это предложение в инструк-
ции ALTER INDEX не может использоваться с другими предложениями.
PARAMETERS (‘параметры ODCI’)
Указывается строка параметров, которая без интерпретации передается в подпро-
грамму ODCI для индексного типа (INDEXTYPE) в предметном (domain) индексе.
Строка параметров может быть длиной до 1000 символов. За более подробной ин-
формацией о строке параметров ODCI обращайтесь к документации производителя.
параметры_изменения_секционирования_индекса
Обращайтесь к подразделу «Разделение таблиц на секции и подсекции в Oracle»
раздела «Инструкция CREATE/ALTER TABLE».
параметры_перестройки
Происходит перестройка индекса или конкретного раздела (или подраздела)
индекса. После успешной перестройки непригодный (UNUSABLE) индекс помеча-
ется как пригодный (USABLE). Синтаксис параметров_перестройки следующий.
REBUILD {[NO]REVERSE | [SUB]PARTITION имя_раздела]
[{PARALLEL [int] | NOPARALLEL}] [TABLESPACE имя_табличной_области]
[PARAMETERS ( ’ODCI_params')] [ONLINE] [COMPUTE STATISTICS]
[COMPRESS int | NOCOMPRESS] [[NO]LOGGING]
[параметры_физических атрибутов]
Где:
[NO] REVERSE
При перестройке индекса байты блока индекса записываются в обратном
порядке, а строки удаляются (REVERSE) или же байты блоков индекса записы-
ваются в обычном порядке (NOREVERSE).
DEALLOCATE UNUSED [KEEP int [K\M\G\T]
Высвобождается неиспользованное место в конце индекса (или в конце каждой
секции линейно- или хеш-секционированного индекса.) Место освобождается для
других сегментов табличного пространства. Дополнительное ключевое слово
KEEP определяет, сколько (int) байт свыше максимального заполнения индекса
нужно оставить после высвобождения места. К значению int можно добавлять
суффикс для килобайтов (К), мегабайтов (М), гигабайтов (G) или терабайтов (Т).
Если предложение KEEP опущено, освобождается все неиспользуемое место.
ALLOC А ТЕ EXTENT ([SIZE int [K\M\G\T]] [DATAFILE ‘wmjpaima'] [INSTANCE int])
Явным образом для индекса выделяется новый экстент с указанными параметра-
ми. Любые параметры можно использовать одновременно и подбирать нужные
значения. Параметр SIZE показывает объем следующего экстента. Размер экстента
178 | Глава 3. Справочник по инструкциям SQL
может выражаться в байтах (без суффикса), килобайтах (К), мегабайтах (М), гига-
байтах (G) и терабайтах ('!’). При указании параметра DATAFILE для экстента ин-
декса выделяется совершенно новый файл данных. Параметр INSTANCE, который
используется только в Oracle Real Application Cluster, делает новый экстент дос-
тупным для группы списков свободных блоков (freelist group), связанной с указан-
ным экземпляром.
SHRINK SPACE [COMPACT] [CASCADE]
Сжимает сегменты индекса, однако сжимать можно только сегменты в табличных
пространствах с автоматическим управлением сегментами. При сжатии сегмента
происходит смешение строк таблицы, так что убедитесь, что в инструкции ALTER
'TABLE...SHRINK используется также предложение ENABLE ROW MANAGEMENT.
Платформа Oracle сжимает сегмент, высвобождает дисковое пространство и на-
страивает максимальный уровень заполнения индекса в том случае, если не \ каза-
ны ключевые слова COMPACT и/или CASCADE. При указании ключевого слова
COMPACT происходит только дефрагментация свободного места и сжатие индек-
са. но не выполняется настройка максимального уровня заполнения индекса и не
происходит немедленного высвобождения свободного места. При указании
ключевою слова CASCADE выполняется та же операция сжатия (с некоторыми
ограничениями и исключениями) для всех зависимых от индекса объектов.
Инструкция ALTER INDEX ... SHRINK SPACE COMPACT функционально эквива-
лентна инструкции ALTER INDEX ...COALESCE.
По умолчанию индексы Oracle являются неуникальными. Также важно знать, ч то
в Oracle обычные иерархические (B-trce) индексы не включают в себя записей,
которые имеют значение ключа NULL.
Платформа Oracle не поддерживает индексирование столбцов со следующими
।инами данных: LONG, LONG RAW, REF (с атрибутом SCOPE) и пользовательские
типы данных. Вы можете создавать индексы для функций и выражении, но не допус-
каются значения NULL или агрегатные функции. Если вы создаете индекс но функ-
ции, эта функция, если у нее нет параметров, должна иметь в качестве параметров
пустой набор данных, например junction пате(). Если функция является пользова-
тельской, она должна иметь предложение DETERMINISTIC.
Платформа Oracle поддерживает специальную индексную структуру, называемую
inideKc-mtio’iinieh (index-organized table, ЮТ). Индекс-таблицы объединяют табличные
данные и индексы но первичному ключу в одной физической структуре, вместо отдель-
ных структур для таблицы и индекса Индекс-таблицы создаются при помощи инструк-
ции CREATE TABLE...ORGANIZATIONINDEX. За более подробной информацией по соз-
данию индекс-таблиц обращайтесь к разделу «Инструкция CREATE/ALTER TABLE».
Платформа Oracle автоматически создает любые дополнительные индексы для
нндекс-таблиц в форме вторичных индексов. Вторичные индексы не поддерживают
11 редл ожс пне RE VERSE.
11лат форма Oracle позволяет создавать секционированные индексы и таблицы с помо-
щью предложения PARTITION. Следовательно, индексы Oracle также поддерживают сек-
Справочник по командам SQL | 179
ционированные таблицы. При указании предложения LOCAL платформа создает отдель-
ные индексы для каждой секции таблицы. При указании предложения GLOBAL плат-
форма создает общий индекс для всех разделов.
Отметьте, что в схеме синтаксиса при каждой ссылке на имя объекта вы при жела-
нии можете указать схему. Это применимо к индексам, таблицам и т. п., но не приме-
нимо к табличным пространствам. Если вы хотите создать индекс в схеме, отличной
от текущей, вы должны иметь явно указанную привилегию.
Например, с помощью инструкции, приведенной ниже, вы можете создать в Oracle
индекс, который является сжатым, создается параллельно и со сбором статистики, но без
записи создания в журнал.
CREATE UNIQUE INDEX unq_pub_id ON publishers (pub_name, country)
COMPRESS 1 PARALLEL NOLOGGING COMPUTE STATISTICS;
Как и в других инструкциях, связанных с созданием объектов, вы можете контро-
лировать занимаемое объектами место и инкременты их роста. В следующем примере
в Oracle создается индекс в указанном табличном пространстве с определенными
параметрами хранения данных.
CREATE UNIQUE INDEX unq_pub_id ON publishers(pub_name, country)
STORAGE (INITIAL 10M NEXT 5M PCTINCREASE 0)
TABLESPACE publishers;
Например, если вы создаете секционированную таблицу housing_construction на
сервере Oracle, вы также должны создать секционированный индекс, имеющий свои
собственные разделы.
CREATE UNIQUE CLUSTERED INDEX project_id_ind
ON housing_construction(project_id)
GLOBAL PARTITION BY RANGE (project_id)
(PARTITION parti VALUES LESS THAN ('H')
TABLESPACE construction_part1_ndx_ts,
PARTITION part2 VALUES LESS THAN ('P')
TABLESPACE construction_part2_ndx_ts,
PARTITION part3 VALUES LESS THAN (MAXVALUE)
TABLESPACE construction_part3_ndx_ts);
Если же таблица housing_construction использует составное секционирование,
нужно будет учесть и это.
CREATE UNIQUE CLUSTERED INDEX project_id_ind
ON housing_construction(project_id)
STORAGE (INITIAL 10M MAXEXTENTS UNLIMITED)
LOCAL (PARTITION parti TABLESPACE construction_part1_ndx_ts,
PARTITION part2 TABLESPACE construction_part2_ndx_ts
(SUBPARTITION subpartIO, SUBPARTITION subpartSO,
SUBPARTITION subpartSO, SUBPARTITION subpart40,
SUBPARTITION subpartSO, SUBPARTITION subpartSO),
PARTITION part3 TABLESPACE construction_part3_ndx_ts);
180 | Глава 3. Справочник по инструкциям SQL
В следующем примере нам нужно перестроить созданный ранее индекс
project_id_ind с использованием параллельных процессов сканирования старого индекса
и построения нового индекса в обратном порядке.
ALTER INDEX project_id_.ind
REBUILD REVERSE PARALLEL
Точно так же мы можем разделить секцию индекса project_id_ind и получить
новую секцию.
ALTER INDEX ргоject_id_ind
SPLIT PARTITION part3 AT (’S’)
INTO (PARTITION part3_a TABLESPACE constr_p3_a LOGGING,
PARTITION part3_b TABLESPACE constr_p3_t>);
PostgreSQL
Платформа PostgreSQL позволяет создавать индексы, отсортированные в восходящем
или нисходящем порядке, а также индексы с признаком уникальности (UNIQUE).
В реализацию также входит настройка производительности с помощью предложения
USING. Синтаксис инструкции CREATE INDEX в PostgreSQL следующий.
CREATE [UNIQUE] INDEX мя_индекса ON имя_таблицы
[USING {BTREE I RTREE | HASH} ]
{имя_функции | (имя_столбца [,...] ) }
[WHERE условие]
Где:
USING [BTREE j RTREE | HASH | GIST]
Указывается один из трех методов динамического доступа, что позволяет оптими-
зировать производительность. Особенно важно то, что индексы полностью дина-
мичны и не требуют периодического обновления статистики. Значения параметра
USING следующие.
BTREE
Для оптимизации индекса используются высокопараллельные структуры в виде
В-деревьев Лемана-Яо (Lehman-Yao high-concurrency B-trees). Этот метод прини-
мается по умолчанию, если не указан никакой другой. Индексы в виде В-деревьев
но умолчанию могут вызываться в операциях сравнения с помощью операторов =,
<, <=, >, >=. В-деревья поддерживают многостолбцовые индексы.
RTREE
Для оптимизации индекса используются структуры в виде R-деревьев алгоритма
квадратичного разделения Гутмана (Guttman’s quadratic-split algorithm R-tree).
Индексы в виде R-деревьев могут вызываться в операциях сравнения с помо-
щью операторов «, &<, &>, », @, ~= и &&. Индексы в виде R-деревьев
должны быть одностолбцовыми.
Справочник по командам SQL | 181
HASH
Для оптимизации индекса используется линейный алгоритм хеширования
Литвина (Litwin’s linear hashing algorithm). Хеш-индексы можно вызывать
в операциях сравнения с помощью оператора =. Хеш-индексы должны быть
одностолбцовыми.
GIST
Для оптимизации индекса используются обобщенные поисковые деревья
(Generalized Index Search Trees, GIST). Индексы GIST могут быть многостолб-
цовыми.
имя_функции
В качестве основы для значений индекса используется указанная функция, а не
столбец базовой таблицы. Индекс на основе функции и обычный индекс на основе
столбцов являются взаимоисключающими.
WHERE условие
Определяется конструкция WHERE для условного поиска, которая затем использует-
ся для создания частичного индекса (partial index). Частичный индекс содержит
записи не для всех строк таблицы, а для выбранного набора строк. При использова-
нии этого параметра вы можете получать интересные эффекты. Например, вы
можете совмещать предложения UNIQUE и WHERE и обеспечивать уникальность
не для всей таблицы, а только для ее части. Предложение WHERE должно:
• ссылаться на столбцы базовой таблицы (хотя столбцы не обязательно должны
быть столбцами самого индекса);
• не использовать агрегатные функции;
• не использовать подзапросы.
В PostgreSQL со столбцом может быть связан операторный класс (operator class),
основанный на типе данных столбца. В операторном классе указываются операторы
для использования в конкретном индексе. Хотя пользователи могут создать для
любого данного столбца любой операторный класс, класс, принимаемый по умолча-
нию, вполне подходит для столбца данного типа.
В следующем примере мы создадим индекс, используя индексный тип GIST.
Также мы задействуем свойство уникальности только для издателей, находящихся за
пределами США.
CREATE UNIQUE INDEX unq_pub_id ON publishers(pub_name, country)
USING GIST
WHERE country <> 'USA';
SQL Server
Синтаксис инструкции CREATE INDEX в SQL Server следующий.
CREATE [UNIQUE] [[NON]CLUSTERED] INDEX имя_индекса
ON {имя_таблицы | имя_представления} (столбец [ASC | DESC] [,...])
[WITH [PAD_INDEX]
182 | Глава 3. Справочник no инструкциям SQL
[[,] FILLFACTOR = int]
[[,] IGNORE_DUP_KEY]
[[,] DROP_EXISTING]
[[.] STATISTICS_NORECOMPUTE] ]
[[,] SORT_IN_TEMPDB] ]
[ON файловая_группа)
Где:
[NON] CLUSTERED
Параметр контролирует физическое расположение данных таблицы с помощью
кластеризованного (CLUSTERED) или некластеризованного (NONCLUSTERED)
индекса. Столбцы кластеризованного индекса определяют порядок, в котором фи-
зически записываются на диск строки таблицы. Таким образом, если вы создаете
отсортированный по возрастанию кластеризованный индекс по столбцу А табли-
цы Foo, записи будут размещаться на диске в алфавитном порядке по возраста-
нию. При указании предложения NONCLUSTERED (по умолчанию), если прочие
значения опущены, создается вторичный индекс, который содержит только указа-
тели и не влияет на то, как строки таблицы записываются на диск.
Л5С | DESC
Параметр определяет, будут ли значения индекса располагаться по возрастанию
(ASC) или по убыванию (DESC). Если предложение опущено, по умолчанию при-
нимается ASC.
WITH
Позволяет указать описание одного или нескольких дополнительных атрибутов
индекса.
PADJNDEX
Указывается, сколько пустого места следует оставлять на каждой 8-килобайтной стра-
нице индекса в соответствии со значением, указанным в параметре FILLFACTOR.
FILLFACTOR = int
Объявляется процентное значение (int, от 1 до 100), которое для SQL Server опре-
деляет, какую часть 8-килобайтной страницы индекса нужно заполнять в момент
создания индекса. Параметр полезен для уменьшения конкуренции за ресурсы
ввода-вывода и уменьшения дробления страниц при заполнении страницы данны-
ми. Если кластеризованный индекс создается с явно определенным значением
FILLFACTOR, это может увеличить размер индекса, но в определенных обстоя-
тельствах также может ускорить обработку.
IGNORE DUP_KEY
Параметр определяет, какие действия выполняются, если в уникальный индекс
в ходе операции вставки или обновления помещается дублирующая запись. Если
для столбца данный параметр указан, из операции исключается только дуб-
лирующая строка. Если значение не установлено, тогда все записи, участвующие
в операции (даже недублирующиеся), отбрасываются как дубликаты.
DROP_EXIST1NG
Удаляются все существующие индексы таблицы, а указанный индекс перестраивается.
Справочник по командам SQL | 183
STA TISTICS NORECOMPUTE
Параметр запрещает SQL Server производить пересчет статистики. Это может
ускорить операцию CREATE INDEX, но также может сделать индекс менее эффек-
тивным.
SORTJNJEMPDB
Все промежуточные результаты, полученные при создании индекса, сохраняются
в системной базе данных TEMPDB. Это увеличивает дисковое пространство, не-
обходимое для создания индекса, но может ускорить обработку, если база
TEMPDB находится на другом диске, чем таблица и индекс.
ON фашовая_группа
Индекс создается в существующей файловой группе. Этот параметр позволяет
размещать индексы на указанном жестком диске или устройстве RAID. Команда
CREATE CLUSTERED INDEX...ONFILEGROUP позволяет эффективно перенести
таблицу в новую файловую группу, поскольку уровень «листьев» кластеризован-
ного индекса будет идентичен реальным страницам данных таблицы.
Платформа SQL Server позволяет создавать уникальные кластеризованные индексы
по представлениям, эффективно материализуя представления. Это может значительно
ускорить операции по извлечению данных из представления. Как только в представле-
нии будет создан уникальный кластеризованный индекс, появляется возможность
добавлять в представление и некластеризованные индексы. Отметьте, что представле-
ние должно быть создано с параметром SCHEMABUILDING. Индексированные пред-
ставления разрешены только в SQL Server 2000 Enterprise Edition, если вы не добавили
к представлению указание NOEXPAND. Индексированные представления поддерживают
извлечение данных, но не поддерживают их модификацию. (Информацию о специфиче-
ских ограничениях индексированных представлений см. в подразделе SQL Server разде-
ла «Инструкция CREATE/ALTER VIEW».)
В SQL Server разрешается использовать до 249 некластеризованных индексов (уни-
кальных и неуникальных) на таблицу, а также один индекс первичного ключа. Столбцы
индекса не могут относиться к типам данных NTEXT, TEXT или IMAGE. Сцепленные
ключи могут содержать до 16 столбцов и/или 900 байт по всем столбцам фиксированной
длины.
Платформа SQL Server автоматически делает создание индекса параллельным,
в соответствии с конфигурационной опцией max degree of parallelism.
Часто бывает необходимо создавать индексы, охватывающие несколько столбцов,
например сцепленные ключи. Вот пример:
CREATE UNIQUE INDEX project2_ind
ON housing_construction(project_name, project-date)
WITH PAD-INDEX, FILLFACTOR = 80
ON FILEGROUP housing_fg
GO
Добавление предложения PAD INDEX и установка параметра FILLFACTOR в 80 пока-
зывает, что платформа должна заполнить страницы индекса и страницы данных на 80%,
184 | Глава 3. Справочник по инструкциям SQL
а не на 100%. В данном примере платформа должна также создать индекс в файловой
группе housing fg, а не в файловой группе, заданной по умолчанию.
См. также
CREATE/ALTER TABLE
DROP
Инструкция CREATE/ALTER METHOD
Инструкция CREATE/ALTER METHOD позволяет создать новый метод базы данных
или изменить уже существующий метод. Можно достаточно просто (хотя и не точно)
представлять метод как пользовательскую функцию, связанную с пользовательским
типом. Например, метод с именем Office, относящийся к типу Address, может прини-
мать входной параметр EARCHAR и возвращать результат типа Address.
Неявно определяемый метод создается каждый раз, когда создается структуриро-
ванный тип (за подробностями обращайтесь к разделу «Инструкция CREATE/ALTER
TYPE»). Пользовательские методы создаются с помощью комбинации инструкции
CREATE TYPE и CREATE METHOD.
Платформа Команда
DB2 Поддерживается с вариантами
MySQL Не поддерживается
Oracle Не поддерживается
PostgreSQL Не поддерживается
SQL Server Не поддерживается
Синтаксис SQLS003
{CREATE | ALTER} [INSTANT | STATIC] METHOD имя_метода
( [ [{IN | OUT | INOUT}] параметр тип_данных [AS LOCATOR] [RESULT] [,. . J )
RETURNS тип_данных
FOR имя_пользовательского_типа
[SPECIFIC специальное_имя)
тело_кода
Ключевые слова
{CREATE | ALTER } [INSTANT | STATIC] METHOD имя_метода
Создается новый метод или изменяется уже существующий и при желании можно
также указать предложения INSTANT или STATIC.
([IN | OUT | INOUT] параметр тип_данных [,...])
Объявляются один или несколько параметров, передаваемых методу, в виде
заключенного в скобки списка, где параметры перечисляются через запятую.
Параметры, используемые методом, могут быть входными (IN), выходными (OUT)
Справочник по командам SQL | 185
или входными и выходными одновременно (INOUT). Синтаксис объявления пара-
метра следующий.
[{IN | OUT | INOUT} имя_параметра1 тип^данных,
{IN | OUT | INOUT} имя_параметра2 тип_данных, [...]
Убедитесь, что имя параметра уникально в пределах метода. При использовании
в инструкции ALTER данное предложение добавляет параметры в уже сущест-
вующий метод. За подробным описанием типов данных обращайтесь к главе 2.
AS LOCATOR
Необязательное предложение AS LOCATOR используется при объявлении внеш-
ней подпрограммы, имеющей параметр RETURNS, который представляет собой
данные типа BLOB, CLOB, NCLOB, ARRAY или определенный пользователем тип.
Иными словами, возвращается локатор (т. е. указатель) на тип LOB, а не все это
значение.
RESULT
Обозначает пользовательский тип. Для стандартных типов данных не требуется.
RETURNS
Объявляется тип данных для результатов, которые возвращает метод. Основное
назначение пользовательского метода - возврат значения. Если вам нужно
«на ходу» изменить тип данных параметра RETURNS, используйте предложение
CAST (обращайтесь к описанию функции CAST в главе 4). Например, RETURNS
VARCHAR(12) CAST FROM DATE.
FOR имя_пользователъского_типа
Метод связывается с заранее определенным пользовательским типом, созданным
с помощью инструкции CREATE TYPE.
SPECIFIC специфическое_имя
Однозначно идентифицирует функцию, которая обычно употребляется с пользо-
вательскими типами.
Общие правила
Пользовательские методы по сути являются иным подходом к выводу данных,
по сравнению с пользовательскими функциями. Например, рассмотрим следующие
два фрагмента кода.
CREATE FUNCTION my_fcn (order_udt)
RETURNS INT;
CREATE METHOD my_mthd ( )
RETURNS INT
FOR order_udt;
Хотя фрагменты кода для функции и метода различаются, они делают одно и то же.
Во всем прочем правила использования и вызова методов те же, что и для функций.
186 | Глава 3. Справочник по инструкциям SQL
Советы и хитрости программирования
Главная трудность методов состоит в том, что они представляют собой объектно-ори-
ентированный подход к тем же задачам, которые решают пользовательские функции.
Поскольку ту же работу они выполняют, используя другой подход, вам может быть
сложно решить, какой подход использовать.
DBS
Платформа DB2 поддерживает и инструкцию CREATE METHOD, и инструкцию
ALTER METHOD.
CREATE [SPECIFIC] METHOD имя_метода
( [ [{IN | OUT | INOUT}] [ларам] тип_даиных [AS LOCATOR] [RESULT] [:...] )
[RETURNS тип_данных [{AS LOCATOR | CAST FROM тип_данных [AS LOCATOR] } ]
FOR имя_пользовательского_типа
EXTERNAL [NAME 'имя'] [TRANSFORM GROUP имя_группы]
тело_кода
Синтаксис инструкции ALTER METHOD несколько проще.
ALTER METHOD имя_метода
FOR имя_пользовательского_типа
EXTERNAL NAME 'имя'
Где:
[SPECIFIC] METHOD имя_метода
Определяется создаваемый или изменяемый метод. При указании дополнительного
ключевого слова SPECIFIC метод идентифицируется с помощью имени, присво-
енного ему (явно или неявно) в инструкции CREATE TYPE. Метод должен сущест-
вовать в указанной или текущей схеме.
CAST FROM тип данных
В вызвавшую инструкцию возвращается тип данных, отличный от того, который
возвращает сам метод.
EXTERNAL [NAME ‘внешнее_имя ’] [TRANSFORM GROUP имя_группы]
Предложение определяет, что инструкция регистрирует внешний метод, а не создает
внутренний (SQL) метод. Пользовательский тип, созданный с помощью инструкции
CREATE TYPE, должен иметь значение параметра LANGUAGE отличное от SQL.
NAME ‘имя’
Определяется имя внешнего кода, который реализует метод. Длина имени
не должна превышать 254 символов. Имя должно соответствовать языку
(LANGUAGE), связанному с пользовательским типом. С помощью этого
предложения также можно определить имя внутреннего (SQL) метода для
пользовательских типов с предложением LANGUAGE SQL.
TRANSFORM GROUP имя_гругты
Определяется группа для преобразований пользовательского структурирован-
ного типа при вызове метода. Если предложение опущено, по умолчанию
используется группа DB2_FUNCTION.
Справочник по командам SQL | 187
Спецификацию метода определяет параметр LANGUAGE инструкции CREATE TYPE,
связанной с методом. Если указано LANGUAGE SQL, спецификация метода - SQL. Для
всех прочих значений параметра LANGUAGE спецификация метода - внешняя.
В следующем примере метод, называющийся officezip, проверяет правильность
почтового zip-кода, используя пользовательский тип address_type.
CREATE METHOD office (address address„type)
RETURNS INTEGER
FOR address_type
RETURN
(CASE
WHEN (self-.zip = address.zip) THEN 1 -- valid
ELSE 0 -- invalid
END);
В следующем примере в методе distance с помощью внешней подпрограммы
и группы для преобразований производится обработка расстояния между двумя адре-
сами типа address_type.
CREATE METHOD distance (address_type)
FOR address_type
EXTERNAL NAME 'addrlib!distance'
TRANSFORM GROUP method_group;
Позже мы можем изменить данный метод, чтобы он использовал другую внеш-
нюю процедуру.
ALTER METHOD distance ( )
FOR TYPE address_type
EXTERNAL NAME 'newaddrlib!distance_2';
MySQL
He поддерживается.
Oracle
He поддерживается.
PostgreSQL
He поддерживается.
SQL Server
He поддерживается.
См. также
CREATE/ALTER TYPE
188 | Глава 3. Справочник по инструкциям SQL
Инструкция CREATE ROLE
Инструкция CREATE ROLE позволяет создать именованный набор привилегий,
который можно присваивать пользователям базы данных. Если роль назначается поль-
зователю, этот пользователь получает все привилегии и допуски, содержащиеся
в данной роли. Роли повсеместно используются как один из самых лучших способов
обеспечения безопасности и управления привилегиями в базе данных.
Платформа Команда
DB2 He поддерживается
MySQL Нс поддерживается
Oracle Поддерживается с вариантами
PostgreSQL Не поддерживается
SQL Server Не поддерживается
Синтаксис SQL2003
CREATE ROLE имя_роли [WITH ADMIN {CURRENT-USER | CURRENT.ROLE}]
Ключевые слова
CREA ТЕ ROLE имя_роли
Создается новая роль, которая отличается от других ролей и от пользователей
СУРБД. Роли можно назначить любой допуск, который можно назначить пользо-
вателю. Важное отличие состоит в том, что роль можно присваивать одному или
нескольким пользователям, предоставляя им, таким образом, все допуски, которые
имеет данная роль.
WITH ADMIN {CURRENT_USER | CURRENT_ROLE}
Роль немедленно присваивается текущему активному пользователю или активной
в данный момент роли, вместе с привилегией передавать роль другим пользовате-
лям. Если параметр не указан, по умолчанию принимается WITH ADMIN
CURRENTUSER.
Общие правила
Использование ролей в системе безопасности баз данных может значительно упро-
стить администрирование и работу с пользователями. Ниже приводятся общие этапы
использования ролей в системе безопасности базы данных.
1. Изучение потребности в ролях и подбор названий ролей (например, администра-
тор, менеджер, ввод_данных, создатель_отчетов и т. п.).
Справочник по командам SQL | 189
2. Присвоение допусков каждой роли с помощью инструкций GRANT (т. е. так, как
для обычных пользователей базы данных). Например, роль «менеджер» может
иметь допуск на чтение и запись всех пользовательских таблиц базы данных,
а роль «создам ел ь_отчетов» может иметь допуски для выполнения отчетных
запросов «только чтение» по определенным отчетным таблицам базы данных.
3. Для назначения пользователям системы ролей в соответствии с работой, которую
они будут выполнять, используйте инструкцию GRANT.
Допуски можно отключить с помощью команды REVOKE.
Советы и хитрости программирования
Главная проблема работы с ролями состоит в том, что администратор базы данных
иногда определяет избыточные допуски - отдельно для роли и отдельно для пользова-
теля. Если вам когда-нибудь понадобится в подобной ситуации запретить доступ поль-
зователя к ресурсу, вам скорее всего придется отключать допуски командой REVOKE
дважды. Сначала нужно отключить пользователя от роли, а затем отключить привилегии,
указанные на уровне пользователя.
DBS
Не поддерживается.
Вместо этой инструкции в DB2 используются системные группы операционной
системы. Следовательно, вы можете получить в DB2 сходные возможности, но для
этого вам необходимо следующее.
1. Создать группу в операционной системе.
2. Назначить или отменить допуски для данной группы.
3. Добавлять пользователей в группу на уровне операционной системы.
Платформа DB2 позволяет связывать группы операционной системы со специаль-
ными административными ролями на уровне экземпляра, используя конфигурацион-
ные параметры sysadmgroup, sysctrlgroup и sysmaintgroup.
MySQL
Не поддерживается.
Oracle
Хотя в стандарте ANSI в настоящее время нет инструкции ALTER ROLE, в Oracle есть
поддержка этой инструкции. Платформа Oracle поддерживает концепцию ролей, но ее
реализация в Oracle очень отличается от стандарта ANSI SQL.
{CREATE | ALTER} ROLE role_name
[NOT IDENTIFIED |
IDENTIFIED {BY password | EXTERNALLY | GLOBALLY |
USING package_name}]
190 | Глава 3. Справочник по инструкциям SQL
Где:
CREATE | ALTER ROLE имя_роли
Определяется имя создаваемой роли или уже существующей роли при ее измене-
нии.
NOT IDENTIFIED
Объявляется, что для прохождения авторизации в базе данных роли не требуется
пароль. Этот параметр установлен по умолчанию.
IDENTIFIED
Объявляется, что пользователь, которому назначена роль, должен пройти аутенти-
фикацию, используя метод, определенный до создания роли при помощи команды
SET ROLE, где:
В Y пароль
Создается локальная роль с аутентификацией по строковому значению пароля.
В пароле допустимы только однобайтовые символы, даже в случае использова-
ния многобайтового набора символов.
EXTERNALLY
Создается внешняя роль, аутентификацию которой производит операционная
система или сторонний поставщик соответствующих услуг. В любом случае
службе внешней аутентификации, скорее всего, потребуется пароль.
GLOBALLY
Создается глобальная роль, аутентификацию которой производит корпоратив-
ная служба каталогов (enterprise directory service), например каталог LDAP.
USING имя_пакета
Создается роль приложения (application role), которую можно применять
только посредством приложения, использующего пакет PL/SQL с именем
имя_пакета. Если схема не указана, платформа предполагает, что пакет нахо-
дится в вашей схеме.
В Oracle сначала создается роль, а потом ей предоставляются привилегии и допуски
с помощью команды GRANT, как обычному пользователю. Если пользователи хотят
получить допуски, предоставляемые ролью, которая защищена паролем, им нужно
использовать команду SET ROLE. Если роль защищена паролем, то пользователь,
который хочет получить доступ, должен указать этот пароль в команде SET ROLE.
В Oracle предлагается несколько готовых ролей. Во всех версиях Oracle доступны
роли CONNECT, DBA и RESOURCE. Более новыми ролями, используемыми в опера-
циях экспорта и импорта, являются EXP FULL DATABASE и !MP_FULL_DATABASE.
В описании инструкции GRANT приводится более детальное обсуждение всех гото-
вых ролей, имеющихся в Oracle.
В следующем примере для определения новой роли в Oracle используется
инструкция CREATE, с помощью команды GRANT ей назначаются привилегии, с помо-
щью инструкции ALTER ROLE назначается пароль, и роль присваивается двум пользо-
вателям.
Справочник по командам SQL I 191
CREATE ROLE boss;
GRANT ALL ON employee TO boss;
GRANT CREATE SESSION, CREATE DATABASE LINK TO boss;
ALTER ROLE boss IDENTIFIED BY le_grande_fromage;
GRANT boss TO emily, jake;
PostgreSQL
Хотя платформа PostgreSQL не поддерживает команду CREATE ROLE, в ней предла-
гаются почти идентичные возможности в специфической инструкции, называющейся
CREATE GROUP. Для изменения существующих групп в PostgreSQL также есть
инструкция ALTER GROUP. В PostgreSQL группа и роль идентичны.
{CREATE | ALTER} GROUP имя
[ [WITH] {SYSID int | USER имя_пользователя [,...] }]
[ {DROP | ADD} имя_пользователя [,...] }
Где:
{CREATE | ALTER) GROUP имя
Создается новая группа (т. е. роль) или изменяется существующая. Параметр имя
определяет имя создаваемой или изменяемой группы.
WITH {SYSID int | USER имя_полъзователя [,...]}
Явным образом присваивает новой группе ID группы (предложение SYSID) или
назначает группу существующим пользователям, перечисленным в указанном
списке. Если предложение опущено, PostgreSQL создаст группу с ID равным
самому большому ID плюс единица (начиная с 1). Предложение WITH используется
только в инструкции CREATE GROUP.
{DROP | ADD) имя подьзователя
Удаляет пользователей из группы или добавляет их в нее. Используется только
в инструкции ALTER GROUP.
Чтобы удалить ненужную группу, используйте предложение DROP GROUP.
SQL Server
Microsoft SQL Server не поддерживает команду CREATE ROLE, но имеет аналогичную
возможность, реализуемую системной записанной процедурой sp_add_role.
См. также
GRANT
REVOKE
192 | Глава 3. Справочник по инструкциям SQL
Инструкция CREATE SCHEMA
Данная инструкция создает схему, т. е. именованный набор взаимосвязанных объектов.
Схема - это набор таблиц, представлений и допусков, присвоенных пользователям
и ролям. Согласно стандарту ANSI сами допуски для конкретных объектов не являются
объектами схемы и не принадлежат к конкретным схемам. Однако роли - наборы при-
вилегий - принадлежат к схемам.
Платформа Команда
DB2 Поддерживается с ограничениями
MySQL Не поддерживается
Oracle Поддерживается с вариантами
PostgreSQL Не поддерживается
SQL Server Поддерживается с ограничениями
Синтаксис SQL2003
CREATE SCHEMA [и«я_схе«ы] [AUTHORIZATION имя_владельца]
[DEFAULT CHARACTER SET имя_набора_символов}
[PATH имя_схемы [,...] ]
[ ANSI CREATE инструкции [...] ]
[ ANSI GRANT инструкции [. . . ] ]
Ключевые слова
CREATE SCHEMA [имя_схемы]
Создается схема с именем имя_схемы. Если имя опущено, база данных создает
имя сама, используя имя пользователя - владельца схемы.
AUTHORIZATION имя_еладелъца
В параметре имя_владельца указывается имя пользователя - владельца схемы.
Если предложение опущено, владельцем схемы будет текущий пользователь.
Стандарт ANSI позволяет опустить либо имя_схемы, либо всю конструкцию
AUTHORIZATION, либо использовать их вместе.
' DEFAULT CHARACTER SET имя_набора_символов
Объявляется набор символов по умолчанию (имя_набора_символов) для всех объ-
ектов схемы.
PATH имя_схемы [,...]
При желании можно указать имя файла и путь к нему для любой неуточненной
(unqualified) подпрограммы (т. е. записанной процедуры, пользовательской функ-
ции и пользовательского метода) в схеме.
ANSI CREATE инструкции [...]
Содержит одну или несколько инструкций CREATE. Запятые между инструкциями
не ставятся.
13 - 2447
Справочник по командам SQL | 193
ANSI GRANT[...]
Содержит одну или несколько инструкций GRANT для объектов, которые были
определены ранее. Обычно объекты создаются выше, в этой же инструкции
CREATE SCHEMA, но это может быть и любой объект, созданный заранее. Запятые
между инструкциями GRANT не ставятся.
Общие правила
Инструкция CREATE SCHEMA - это контейнер, который может содержать много
других инструкций CREATE и GRANT. Наиболее распространенный взгляд на схему
таков: схема - это все объекты, принадлежащие определенному пользователю. Напри-
мер, пользователю jake в его схеме может принадлежать несколько таблиц и представ-
лений, в том числе таблица publishers. Между тем пользователь dylan может владеть
несколькими другими таблицами и представлениями, входящими в его схему, и он
также может владеть собственной отдельной копией таблицы publishers.
Стандарт ANSI требует, чтобы в инструкции CREATE SCHEMA были допустимы
все виды инструкций CREATE. На практике в большинстве реализаций инструкции
CREATE SCHEMA допустимо использование только трех видов вложенных инструк-
ций: CREATE TABLE, CREATE VIEW и GRANT. Порядок расположения команд не
имеет значения, и это означает, что вы можете назначать привилегии таблицам и пред-
ставлениям, для которых инструкции CREATE стоят в инструкции CREATE SCHEMA
ниже инструкций GRANT.
Советы и хитрости программирования
Хотя это и не является обязательным, но все же хорошей практикой является располагать
объекты и назначения привилегий в инструкции CREATE SCHEMA в естественном
для них порядке. Иными словами, инструкции CREATE VIEW должны идти за соот-
ветствующими инструкциями CREATE TABLE, а инструкции GRANT должны распола-
гаться в конце.
Если в вашей системе используются схемы, мы рекомендуем всегда ссылаться на
объекты по имени схемы и имени объекта (например, jake.publishers). Если вы не
введете указатель схемы, платформа, скорее всего, предположит, что это текущая
схема для данного пользовательского соединения.
Некоторые платформы не имеют явной поддержки команды CREATE SCHEMA.
Однако они все же неявно создают схемы, когда пользователь создает объекты базы
данных. Например, платформа Oracle создает схему при создании пользователя.
Команда CREATE SCHEMA - это просто метод для создания за один этап всех таблиц,
представлений и других объектов базы данных вместе с допусками к ним.
DB2
Платформа DB2 поддерживает основные элементы инструкции CREATE SCHEMA.
Она не поддерживает предложения PATH и DEFAULT CHARACTER SET.
194 | Глава 3. Справочник по инструкциям SQL
CREATE SCHEMA [имя_схемы] [AUTHORIZATION имя__владельца]
[ ANSI CREATE инструкции [... ] ]
[ ANSI GRANT инструкции [... ] ]
Во всем прочем синтаксис и применение инструкции аналогичны стандарту
ANSI.
Платформа DB2 неявно создает схему, если в инструкции GRANT или CREATE
есть ссылка на новую схему.
Платформа DB2 не поддерживает инструкцию ALTER SCHEMA.
MySQL
Не поддерживается.
Oracle
В Oracle инструкция CREATE SCHEMA на самом деле схему не создает. Это делает
только инструкция CREATE USER. Инструкция CREATE SCHEMA позволяет пользо-
вателю выполнить несколько инструкций CREATE и GRANT в ранее созданной схеме,
используя только одну инструкцию SQL.
CREATE SCHEMA AUTHORIZATION имя_схемы
L ANSI CREATE инструкции [. .. ] ]
[ ANSI GRANT инструкции [... ] ]
Отметьте, что платформа Oracle разрешает использовать в инструкции CREATE
SCHEMA только стандартные инструкции CREATE TABLE, CREATE VIEW и GRANT.
Нельзя использовать любые расширения этих команд, имеющиеся в Oracle, если эти
команды включены в инструкцию CREATE SCHEMA.
В следующем примере для Oracle в инструкции CREATE SCHEMA назначение
допусков идет перед созданием объектов.
CREATE SCHEMA AUTHORIZATION emily
GRANT SELECT, INSERT ON view_1 TO sarati
GRANT ALL ON table_1 TO sarah
CREATE VIEW viewj AS
SELECT coliunn_1, column_2
FROM table_1
ORDER BY column_2
CREATE TABLE table_1(column_1 INT, coluhin_2 CHAR(2O)):
Как видно в приведенном выше примере, порядок команд в инструкции CREATE
SCHEMA не важен. Платформа выполняет инструкцию CREATE SCHEMA только
в том случае, если все входящие в нее инструкции CREATE u GRANT были выполнены
успешно.
Справочник по командам SQL | 195
PostgreSQL
He поддерживается.
SQL Server
Платформа SQL Server поддерживает основные элементы инструкции CREATE SCHEMA,
за исключением предложений PATH и DEFAULT CHARACTER SET
CREATE SCHEMA AUTHORIZATION имя_владельца
[ ANSI CREATE инструкции [...] ]
[ ANSI GRANT инструкции [... ] ]
Если не выполняется хотя бы одна из инструкций, входящих в инструкцию
CREATE SCHEMA, то не выполняется и вся эта инструкция. Платформа SQL Server не
требует, чтобы инструкции CREATE или GRANT располагались в каком-то порядке, за
исключением того, что вложенные представления должны располагаться в логической
последовательности. Таким образом, если представление view_100 ссылается на пред-
ставление view_10, то представление viewlO должно располагаться в инструкции
CREATE SCHEMA перед view_100.
Например:
CREATE SCHEMA AUTHORIZATION katie
GRANT SELECT ON view_lO TO public
CREATE VIEW view_10(col1) AS SELECT coll FROM Too
CREATE TABLE foo(col1 INT)
CREATE TABLE foo
(coll INT PRIMARY KEY,
col2 INT REFERENCES foo2(col1))
CREATE TABLE foo2
(coll INT PRIMARY KEY,
col2 INT REFERENCES foo(coll))
См. также
CREATE/ALTER TABLE
CREATE/ALTER VIEW
GRANT
Инструкция CREATE/ALTER TABLE
Манипулирование таблицами - один из самых распространенных видов деятельно-
сти, который администраторы баз данных и программисты осуществляют при работе
с объектами баз. В этом разделе подробно описывается, как нужно создавать и изме-
нять таблицы.
Стандарт ANSI является чем-то вроде наименьшего общего знаменателя для всех про-
изводителей, хотя не каждая возможность стандартной версии инструкций CREATE
TABLE и ALTER TABLE реализуется каждым производителем. Тем не менее стандарт ANSI
представляет собой базовую форму, которую можно использовать на всех платформах.
196 | Глава 3. Справочник по инструкциям SQL
В свою очередь, платформы предлагают разнообразные расширения и дополнения к ин-
струкциям CREATE TABLE и ALTER TABLE стандарта ANSI.
Как правило, нужно как следует продумать проект таблицы и способ ее
создания. Этот процесс называется проектированием базы данных. Про-
цесс анализа взаимоотношений таблицы с ее собственными данными
и другими таблицами в базе данных называется нормализацией. Мы реко-
мендуем программистам и администраторам баз данных изучить прин-
ципы проектирования и нормализации перед тем, как использовать
команды CREATE DATABASE.
Платформа Команда
DB2 Поддерживается с вариантами
MySQL Поддерживается с вариантами
Oracle Поддерживается с вариантами
PostgreSQL Поддерживается с вариантами
SQL Server Поддерживается с вариантами
Синтаксис SQL2003
При выполнении инструкции CREATE TABLE стандарта SQL2003 в базе данных соз-
дается постоянная или временная таблица. Синтаксис следующий.
CREATE [{LOCAL TEMPORARY) GLOBAL TEMPORARY}] TABLE имя_таблицы
(,имя_столбца тип_данных атрибуты [,...] ) |
[имя^столбца WITH OPTIONS опции'] |
[LIKE имя_таблицы] |
[REF IS имя_столбца
{SYSTEM GENERATED | USER GENERATED | DERIVED} ]
[CONSTRAINT тип_ограничения [имя_ограничения] [,...] ]
[OF имя_типа [UNDER супер_таблица] [определение_таблицы] ]
[ON COMMIT {PRESERVE ROWS | DELETE ROWS}
Инструкция ALTER TABLE стандарта SQL2003 позволяет вносить в сущест-
вующую таблицу много полезных изменений без удаления индексов, триггеров и до-
пусков, связанных с этой таблицей. Ниже приводится синтаксис инструкции ALTER
TABLE.
ALTER TABLE имя_таблицы
[ADD [COLUMN] имя_таблицы тип_данных атрибуты]
| [ALTER [COLUMN] имя_столбца SET DEFAULT значение_по_умолчанию]
| [ALTER [COLUMN] имя_столбца DROP DEFAULT]
I [ALTER [COLUMN] имя_столбца ADD SCOPE имя^таблицы
I [ALTER [COLUMN] имя_столбца DROP SCOPE {RESTRICT | CASCADE}]
Справочник по командам SQL | 197
I [DROP [COLUMN] имя_столбца {RESTRICT | CASCADE}]
| [ADD табличное_ограничение]
I [DROP CONSTRAINT имя_табличного_ограничения {RESTRICT | CASCADE}]
Ключевые слова
[LOCAL | GLOBAL] TEMPORARY
Объявляется постоянная или временная (TEMPORARY) таблица с локальной
(LOCAL) или глобальной (GLOBAL) областью действия. Локальные временные
таблицы доступны только из создавшего их сеанса, и они автоматически уда-
ляются, когда завершается создавший их сеанс. Глобальные временные таблицы
доступны из всех активных сеансов, но они автоматически удаляются, когда
завершается создавший их сеанс. Не уточняйте имена временных таблиц
именем схемы.
(имя столбца тип_данных атрибуты
Определяется список, в котором через запятую перечислены один или несколько
столбцов, их типы данных и дополнительные атрибуты, например допустимость
значений NULL (nullability). Каждое объявление таблицы должно включать, как
минимум, один столбец, для которого можно указать:
имя_столбца
Указывается имя столбца. Оно должно представлять собой идентификатор,
допустимый с точки зрения правил конкретной СУРБД. Имя должно быть
осмысленным!
тип_данных
Связывает со столбцом с именем имя_столбца определенный тип данных.
Для тех типов данных, которые позволяют указывать их длину, существует до-
полнительный параметр длина, например VARCHAR(255). Тип данных должен
быть допустимым в СУРБД. За полным описанием допустимых типов данных
и их вариантов у конкретных производителей обращайтесь к главе 2.
атрибуты
Связывает со столбцом указанные атрибуты-ограничения. Для одного столбца
с именем имя_столбца можно указывать несколько атрибутов. Запятые не тре-
буются. К типичным атрибутам ANSI относятся следующие.
NOT NULL
В столбце запрещаются значения NULL (или разрешаются, если предло-
жение NOT NULL опущено). Любые инструкции INSERT и UPDATE,
которые попытаются поместить значение NULL, в столбец с атрибутом
NOT NULL не будут выполнены, и произойдет откат.
DEFA ULT выражение
Столбец будет использовать значение выражения, если инструкция
INSERT или UPDATE не вводит никакого значения. Выражение должно
быть допустимым для типа данных столбца; например, в столбце типа
INTEGER нельзя использовать никакие буквенные символы. Выражение
может представлять собой строку или числовой литерал, но вы также
198 | Глава 3. Справочник по инструкциям SQL
можете указать пользовательскую или системную функцию. Стандарт
SQL2003 позволяет использовать в предложении DEFAULT следующие
системные функции: NULL, USER, CURRENT_USER, SESSIONJJSER,
SYSTEM_USER, CURRENT_PATH, CURRENTDATE, CURRENTJ1ME,
LOCALTIME, CURRENTJIMESTAMP, LOCALTIMESTAMP, ARRAY или
ARRAY[].
COLLATE имя_сопоставления
Определяется используемое сопоставление (collation), т. е. порядок сортиров-
ки в соответствующем столбце. Имя сопоставления зависит от платформы.
Если имя сопоставления не определяется, по умолчанию принимается сопос-
тавление по набору символов, используемому в столбце.
REFERENCES ARE [NOT] CHECKED [ON DELETE {RESTRICT \ SET NULL}]
Параметр определяет, будут ли проверяться ссылки в столбце REF, опре-
деленном с опцией области действия (scope). Дополнительное предложе-
ние ON DELETE определяет, будут ли значения в записях, на которые ссы-
лалась удаленная запись, устанавливаться в NULL или же на выполнение
операции будет наложено ограничение.
CONSTRAINTимя_ограничения [тип_ограничения [ограничение]]
Параметр назначает столбцу ограничение и при желании имя ограниче-
ния. Типы ограничений обсуждаются в главе 2. Поскольку ограничение
связывается с конкретным столбцом, в объявлении ограничения предпола-
гается, что этот столбец в данном ограничении будет единственным.
После того как таблица будет создана, ограничение будет считаться огра-
ничением уровня таблицы.
имя_столбца [WITH OPTIONS опции]
Столбец определяется со специальными опциями, такими, как опция области дей-
ствия (scope), опция значения по умолчанию (default), ограничением уровня
столбца или предложением COLLATE. Во многих реализациях предложение WITH
OPTIONS ограничивается созданием объектных (typed) таблиц.
LIKE имя_таблицы
Новая таблица создается с теми же определениями столбцов, что и в сущест-
вующей таблице имя_таблицы.
REF IS имя_стопбца {SYSTEM GENERATED | USER GENERATED | DERIVED]
Определяется столбец объектных идентификаторов (object identifier, OID) в объектных
(typed) таблицах. Объектный идентификатор является необходимым для таблицы,
являющейся корневой в иерархии таблиц. В соответствии с этим параметром столбец
REF может генерироваться системой автоматически (SYSTEM GENERATED), вручную
указываться пользователем при вводе строки (USER GENERATED) или создаваться на
основе другого столбца REF (DERIVED). Параметр требует включать в столбец
имя столбца атрибут REFERENCES.
CONSTRAINTтип_ограничения [имя_ограничения] [„..]
Таблице присваивается одно или несколько ограничений. Этот параметр заметно
отличается от ограничений уровня столбца, поскольку предполагается, что огра-
Справочник по командам SQL | 199
ничения уровня столбца применяются только к столбцу, с которым они связаны.
В случае ограничений уровня таблицы существует возможность связать с огра-
ничением несколько столбцов. Например, в таблице продаж вам может понадо-
биться объявить уникальное ограничение на сцепленный ключ storejd, orderid
и order_date. Сделать это можно только при помощи ограничения уровня табли-
цы. За подробным обсуждением ограничений обращайтесь к главе 2.
OF имя_типа [UNDER супертабпица] [определение_таблицы]
Объявляется, что таблица основывается на готовом пользовательском типе
(см. «Инструкция CREATE/ALTER TYPE»). В этой ситуации таблица может
иметь только один столбец для каждого атрибута структурированного типа плюс
дополнительный столбец, определенный в предложении REF IS. Тип данных REF
подробно описывается в разделе «Инструкция CREATE/ALTER TYPE». Это пред-
ложение несовместимо с предложением LIKE имя_табпицы.
Где:
UNDER супертаблица [определение_таблицы]
Объявляется непосредственная супертаблица для текущей таблицы в той же
схеме (если существует). При желании вы можете указать для супертаблицы
полное определение_таблицы, заполнив его столбцами, ограничениями и т. п.
ON COMMIT {PRESERVE ROWS | DELETE ROWS}
Предложение ON COMMIT PRESERVE ROWS сохраняет строки данных времен-
ной таблицы при выполнении инструкции COMMIT. Предложение ON COMMIT
DELETE ROWS удаляет все строки данных во временной таблице при выполнении
инструкции COMMIT.
ADD [COLUMN] имя_столбца тип_данных атрибуты
В таблицу добавляется столбец с соответствующим типом данных и атрибутами.
ALTER [COLUMN] имя_столбца SET DEFAULT значение_по_умолчанию
В столбец добавляется значение по умолчанию (если оно не существует) или изме-
няется существущее значение.
ALTER [COLUMN] имя_столбца DROP DEFAULT
Значение по умолчанию полностью удаляется из указанного столбца.
ALTER [COLUMN] имя_столбца ADD SCOPE имя_таблицы
В указанный столбец добавляется область действия (scope). Область действия пред-
ставляет собой ссылку на пользовательский тип данных (см. раздел «Инструкция
CREATE/ALTER TYPE»).
ALTER [COLUMN] имя_столбца DROP SCOPE [RESTRICT | CASCADE]
Область действия удаляется из указанного столбца. Предложения RESTRICT
и CASCADE объясняются в конце данного списка.
DROP COLUMN имя_столбца [RESTRICT | CASCADE]
Указанный столбец удаляется из таблицы. Предложения RESTRICT и CASCADE
объясняются в конце данного списка.
ADD табпичное_ограничение
В таблицу добавляется ограничение с указанным именем и характеристиками.
200 | Глава 3. Справочник по инструкциям SQL
DROP CONSTRAINTимя_ограничения [RESTRICT | CASCADE]
Существующее ограничение удаляется из таблицы.
RESTRICT
При указании этого предложения СУРБД отменяет команду, если находит в базе
данных объекты, зависящие от данного объекта.
CASCADE
При указании этого предложения СУРБД удаляет все прочие объекты, зависящие
от данного объекта.
Общие правила
Типичная инструкция CREATE TABLE очень проста. Как правило, в ней указываются
имя таблицы и имена всех столбцов, которые в ней содержатся. Многие определения
таблиц также содержат ограничение по NULL (nullability), как в приведенном примере
кода для SQL Server.
INT
DATE
VARCHAR(50)
NCHAR(20) ,
DECIMAL(4,1),
DECIMALS, 1).
DECIMAL(4,1),
INT )
NOT
NOT
NOT
NULL,
NULL,
NULL,
CHAR(100)
VARCHAR(40)
VARCHAR(40)
VARCHAR(40)
DATETIME
DATETIME
fk_categories FOREIGN KEY (category)
PRIMARY KEY,
UNIQUE,
NOT NULL.
NOT NULL,
CREATE TABLE housing_construction
(project_number
project_date
project_name
construction_color
construction_height
construction_length
const ruction_widtti
construction_volume
В следующем примере в таблицу добавляется внешний ключ.
-- создание ограничения уровня столбца
CREATE TABLE favorite_books
(isbn
book_name
category
subcategory
pub_date
purchase_date
CONSTRAINT
REFERENCES category(cat_name));
Внешний ключ по столбцу категорий (categories) связывает этот столбец со столб-
цом cat_name в таблице category. Этот синтаксис поддерживают все производители,
упомянутые в этой книге.
Примеры ио созданию таблиц с использованием всех типов ограничений
приведены в главе 2.
Справочник по командам SQL | 201
Точно так же внешний ключ можно добавлять постфактум, в виде многостолбцо-
вого ключа, включающего столбцы category и subcategory.
ALTER TABLE favorite_books ADD CONSTRAINT fk_categories
FOREIGN KEY (category, subcategory)
REFERENCES category(cat_name, subcat_name));
Теперь с помощью инструкции ALTER TABLE можно удалить ограничение целиком.
ALTER TABLE favorite_books DROP CONSTRAINT fk_categories RESTRICT;
Ниже приводятся более подробные примеры с использованием базы данных pubs,
которая поставляется с Microsoft SQL Server и Sybase Adaptive Server.
-- Для базы данных Microsoft SQL Server
CREATE TABLE jobs
(job_id SMALLINT IDENTITY(1,1) PRIMARY KEY CLUSTERED,
job_desc VARCHAR(50) NOT NULL DEFAULT 'New Position',
min^lvl TINYINT NOT NULL CHECK (min_lvl >= 10),
max_lvl TINYINT NOT NULL CHECK (max_lvl <= 250))
-- Для базы данных MySQL
CREATE TABLE employee
(emp_id INT AUTO_INCREMENT CONSTRAINT PK_emp_id PRIMARY KEY,
fname VARCHAR(20) NOT NULL,
minit CHAR(1) NULL,
Iname VARCHAR(30) NOT NULL,
job_id SMALLINT NOT NULL DEFAULT 1
REFERENCES jobs(job_id),
job.lvl TINYINT DEFAULT 10,
pub_id CHAR(4) NOT NULL DEFAULT ('9952')
REFERENCES publishers(pub_id),
hire_date DATETIME NOT NULL DEFAULT (CURRENT,DATE( ));
CREATE TABLE publishers
(pub_id char(4) NOT NULL
CONSTRAINT UPKCL_pubind PRIMARY KEY CLUSTERED
CHECK (pub.id IN ('1389', '0736', '0877', '1622', '1756')
OR pub_id LIKE '99[0-9][0-9]'),
pub_name varchar(40) NULL,
city varchar(20) NULL,
state char(2) NULL,
country varchar(30) NULL DEFAULT('USA'))
Если вы будете использовать расширения, создаваемые разными производителя-
ми, команду CREATE TABLE нельзя будет переносить между платформами. Ниже при-
водится пример инструкции CREATE TABLE для Oracle, в которой используется мно-
жество опций хранения.
202 | Глава 3. Справочник по инструкциям SQL
CREATE TABLE classical_music_cds
(music_id INT,
composition VARCHAR2(50),
composer VARCHAR2(5O),
performer VARCHAR2(50),
performance_date DATE DEFAULT SYSDATE,
duration INT,
cd.name VARCHAR2(100),
CONSTRAINT pk_class_cds PRIMARY KEY (music_id)
USING INDEX TABLESPACE index_ts
STORAGE (INITIAL 100K NEXT 2OK),
CONSTRAINT uq_class_cds UNIQUE
(composition, performer, performance_date)
USING INDEX TABLESPACE index_ts
STORAGE (INITIAL 100K NEXT 2OK))
TABLESPACE tabledata_ts;
При использовании инструкций CREATE или ALTER мы рекомендуем, чтобы эта
инструкция была единственной в транзакции. Например, не пытайтесь создать табли-
цу и выбрать из нее данные в одном пакетном задании. Вместо этого нужно: (1) соз-
дать таблицу, (2) проверить операцию, (3) COMMIT и (4) выполнять все последующие
операции с таблицей.
Table_name - это имя новой или существующей таблицы. Имена новых таблиц
должны начинаться с буквы и не должны содержать никаких специальных символов,
кроме знака подчеркивания (_). Длина имени и его точный состав каждый производи-
тель определяет по-своему.
При создании или изменении таблиц, список определений столбцов всегда заключа-
ется в скобки и определения столбцов отделяются друг от друга запятыми.
Советы и хитрости программирования
Пользователь, подающий команду CREATE TABLE, должен иметь соответствующие
права доступа. Точно так же таблица, которую хочет изменить или удалить пользователь,
должна принадлежать к его схеме или он должен иметь соответствующие права для
изменения или удаления таблицы. Поскольку в стандарте ANSI не указываются необхо-
димые привилегии, у разных производителей можно ожидать наличие вариаций.
Вы можете включать инструкции CREATE TABLE или ALTER TABLE в транзакцию
с помощью инструкций COMMIT и ROLLBACK, завершая, таким образом, транзакции
явным образом.
Вы можете хорошо контролировать способ физической записи таблиц на диск
с помощью расширений стандарта ANSI. В DB2 и SQL Server для управления запи-
сью на диск используется метод, называемый кластеризованными индексами. В Oracle
используется функционально сходный метод, называющийся «индекс-таблица» (index-
organized table).
Справочник по командам SQL | 203
Некоторые базы данных блокируют таблицы, которые изменяются при помощи
инструкций ALTER TABLE. Поэтому эту команду нужно выполнять только примени-
тельно к таблицам, которые не используются в рабочей базе данных.
В некоторых базах данных при использовании инструкции CREATE TABLE...LIKE
блокируются и таблица-цель, и таблица-источник.
DB2
В DB2 поддерживается богатый и продуманный набор расширений инструкции
CREATE TABLE.
CREATE TABLE имя_таблицы
{(имя_столбца тип_данных атрибуты ) |
OF имя^типа [{UNDER супертаблица INHERIT SELECT PRIVILEGES |
HIERARCHY имя_иерархии}] [определение_таблицы'] |
AS подзапрос {опции_производной_таблицы |
DEFINITION ONLY [опции_копирования] } |
[LIKE имя_таблицы] [опции_копирования] |
[ [ (вспомогательный_столбец [,., , ] ) ]
FOR имя_таблицы PROPAGATE IMMEDIATE] }
[ORGANIZE BY [DIMENSTIONS] (имя_столбца [,...])]
[DATA CAPTURE {NONE | CHANGES} ]
[IN имя_табличной_области [INDEX IN имя_табличной__области]
[LONG IN имя_табличной_области]]
[VALUE COMPRESSION]
[WITH RESTRICT ON DROP]
[NOT LOGGED INITIALLY]
[{REPLICATED | PARTITIONING KEY (имя^столбца [,.,.] )
[USING HASHING] } ]
[OPTIONS (REMOTE_SERVER 'имя_сервера '
[, REMOTE_SCHEMA 'имя_схемы']
[, REMOTE-TABNAME 'имя_таблицы’] ]
Также богатая расширениями инструкция ALTER TABLE в DB2 позволяет вносить
много полезных изменений в существующие таблицы без удаления существующих
индексов, триггеров и допусков, связанных с ними.
ALTER TABLE имя_таблицы
{[ADD { {[COLUMN] имя_столбца тип_данных атрибуты } |
табличное_ограничение | ключ_секционирования | RESTRICT_ON_DROP } |
{[ALTER { {CHECK | FOREIGN KEY} имя_ограничения определение_ограничения] |
[COLUMN] имя_столбца определение_столбца } |
{[DROP тип_ограничения имя_ограничения] | ключ_секционирования |
RESTRICT_ON_DROP } |
[DATA CAPTURE {NONE | CHANGES [INCLUDE LONGVAR COLUMNS]} |
[ACTIVATE NOT LOGGED INITIALLY [WITH EMPTY TABLE] ] |
[PCTFREE int] |
204 | Глава 3. Справочник по инструкциям SQL
[LOCKSIZE {ROW | TABLE} ] |
[APPEND {ON | OFF} ] |
[ [NOT] VOLATILE [CARDINATITY] ] |
[ [DEACTIVATE VALUE COMPRESSION] } [...] |
SET MATERIALIZED QUERY AS {DEFINITION ONLY | подзапрос]
Параметры для этих команд следующие.
(имя_столбца тип_данных атрибуты [...,])
Определение столбца согласно стандарту ANSI. Однако в DB2 поддерживается
несколько дополнительных атрибутов, специфичных для специальных типов
данных DB2. Поддерживаются все стандартные атрибуты ANSI, например NOT
NULL. За подробностями обращайтесь к главе 2, разделу о типах данных.
UNDER супертаблица INHERIT SELECT PRIVELEGES | HIERARCHY имя_иерархии
Сходно с предложением OF стандарта ANSI в команде CREATE TABLE с двумя до-
полнительными предложениями - INHERIT и HIERARCHY. При указании предложе-
ния INHERIT пользователь или группа, имеющие доступ для чтения в супертаблице,
также должны иметь доступ для чтения в новой таблице. Предложение HIERARCHY
связывает подтаблицу с иерархией таблиц. имя_иерархии - это имя корневой таблицы
иерархии. Если предложение опущено, DB2 генерирует имя_иерархиисамостоятельно.
определение таблицы
Определяются элементы объектной таблицы, в том числе дополнительные опции
столбцов и столбец OID корневой таблицы, а также ограничения таблиц.
A S подзапрос
Материализация таблицы из результатов запроса. Можно включать стандартный
список определений столбцов, но столбцы по количеству и типу данных должны
совпадать со столбцами, которые возвращает подзапрос.
опции производно й_т аблицы
Полный синтаксис опций производной таблицы (derived table) следующий.'
DATA INITIALLY DEFERRED REFRESH {DEFERRED | IMMEDIATE}
[ {ENABLE | DISABLE} QUERY OPTIMIZATION]
[MAINTAINED BY {SYSTEM | USER} ]
Ключевые слова имеют следующие значения.
DATA INITIALLY DEFERRED
Вставка данных в таблицу откладывается до выполнения команды DB2 REFRESH
TABLE.
REFRESH {DEFERRED | IMMEDIATE}
Таблица может обновляться только при подаче команды DB2 REFRESH
TABLE (опция DEFERRED) или сразу после операции по манипуляции данными
(IMMEDIATE).
{ENABLE | DISABLE} QUERY OPTIMIZATION
Включается или отключается таблица, создаваемая для оптимизации запроса,
если система DB2 решает использовать оптимизацию. Конечно, таблица будет
всегда доступна для прямых запросов.
Справочник по командам SQL | 205
MAINTAINED BY {SYSTEM | USER}
Объявляется, что данные производной таблицы поддерживаются автома-
тически системой (SYSTEM по умолчанию) или вручную пользователем
(USER) при помощи команды DB2 REFRESH TABLE. Если вы выберете вари-
ант MAINTAINED BY USER, в таблице также должна быть включена опция
REFRESH DEFERRED.
DEFINITION ONLY [опции_копирования]
Таблица создается без заполнения ее результатами запроса.
опции_копирования
Позволяют изменять предложения DEFINITION ONLY и LIKE. К опциям копиро-
вания относятся следующие.
{INCLUDING | EXCLUDING} [COLUMN] DEFAULTS
Включаются или исключаются значения по умолчанию в столбцах копируе-
мой таблицы соответственно. Опция INCLUDING установлена по умолчанию
для основных таблиц или временных таблиц, в остальных случаях по умолча-
нию устанавливается опция EXCLUDING.
{INCLUDING | EXCLUDING} [IDENTITY] [COLUMN ATTRIBUTES]
Включаются или исключаются атрибуты столбцов копируемой таблицы соот-
ветственно. Дополнительно можно копировать атрибуты IDENTITY столбца.
LIKE имя_таблицы [опции_копирования]
Копируется полный набор определений столбцов из существующей таблицы
имя таблииы, хотя можно также использовать представление или псевдоним
(nickname). Для изменения заданного по умолчанию поведения предложения LIKE
вы можете использовать опциикопирования, показанные выше в списке.
[(вспомогателъный_столбец [...,])] FOR имя_таблицы [PROPAGATE IMMEDIATE]
Определяется промежуточная (вспомогательная) таблица между основной табли-
цей(амии), в которой определяется производная таблица, и самой производной
таблицей. (Естественно, использовать это предложение следует только с предло-
жением AS подзапрос.)
Компоненты данного предложения таковы.
вспомогательный_столбец
Определяется один или несколько вспомогательных столбцов. Однако
список вспомогательных столбцов будет всегда содержать на два столбца
больше, чем имеет производная таблица. Эти столбцы - GLOBALTRANSID
и GLOBALTRANSTIME. При использовании предложения PROPAGATE до-
бавляется еще один столбец - OPERATIONTYPE, который используется для
поддержания соответствий в реплицированной таблице материализованного
запроса. Если предложение опущено, система DB2 создает необходимые
для операции вспомогательные столбцы.
FOR имя_таблицы
Указывается таблица, определяющая вспомогательную таблицу. В качестве пара-
метра гшя_таблицы должно быть указано имя существующей в базе данных про-
изводной таблицы с указанным предложением REFRESH DEFERRED.
206 | Глава 3. Справочник по инструкциям SQL
PRO PA GA ТЕ IMMEDIATE
Это предложение указывает, что изменения, вносимые в соответствующие
таблицы, немедленно распространяются на вспомогательную таблицу.
ORGANIZE BY [DIMENSIONS] (имя_столбца [...,])
Определяет для столбца или группы столбцов кластер или измерение в зависимости
от того, используется ли ключевое слово DIMENSIONS. Таким образом, с помощью
предложения ORGANIZE BY создается кластеризованный индекс, а с помощью
предложения ORGANIZE BY DIMENSIONS создается кластеризованный индекс
по нескольким столбцам (т. е. измерениям).
DATA CAPTURE {NONE | CHANGES}
В журнал записывается дополнительная информация для поддержки репликации баз
данных. Предложение NONE объявляет, что никакая дополнительная информация
записываться не будет, а при указании предложения CHANGES в журнал записывается
информация об изменениях. Предложение DATA CAPTURE CHANGES является необ-
ходимым для реплицированных таблиц. Это предложение несовместимо с созданием
подтаблиц.
IN имя табличного пространства [INDEX IN имя_табличпого_прострапства]
[LONG IN имя_табличного_прострапства]
Объявляется конкретное, уже существующее табличное пространство, в которое
будет помещаться таблица. Это предложение несовместимо с созданием подтаб-
лиц и табличными пространствами, управляемыми системой (System Managed).
Компоненты этого предложения следующие.
INDEX IN имя_табличного_пространства
Объявляется конкретное, уже существующее табличное пространство, в которое
будут помещаться индексы таблицы. Если предложение опущено, по умолчанию
этим табличным пространством будет пространство, в которое помещены
данные.
LONG IN имя ^табличного ^пространства
Объявляется конкретное, уже существующее табличное пространство, в которое
будут помещаться данные длинных типов для таблицы (LONG TARCHAR,
LONG VARGRAPHIC, LOB и т. п.). Если предложение опущено, по умолчанию
этим табличным пространством будет пространство, в которое помещены данные.
VALUE COMPRESSION
Используется высокая степень сжатия при хранении значений NULL и значений
нулевой длины.
WITH RESTRICT ON DROP
Запрещает удалять таблицу и соответствующее табличное пространство.
NOT LOGGED INITIALLY
Это предложение показывает, что любые изменения, вносимые в табличные дан-
ные, которые производятся в одном пакетном задании с созданием таблицы,
в журнал не записываются. С другой стороны, записываются все изменения ката-
логов и параметров хранения. Этот параметр может вызвать в некоторых обстоя-
тельствах полный откат операции, выполненной в пакетном задании.
Справочник по командам SQL | 207
REPLICATED
Это предложение указывает, что данные таблицы реплицируются в каждый раздел
группы разделов базы данных при выполнении копирования данных во все разде-
лы. Это предложение несовместимо с предложением PARTITIONING KEY, но явля-
ется необходимым для производных таблиц.
PARTITIONING KEY (имя_столбца [...,]) [USING HASHING]
Определяется ключ секционирования таблицы. Ключом является указанный стол-
бец. Столбец не может относиться к длинным и специальным типам данных - LONG
VARCHAR, LONG VARGRAPHIC, BLOB, CLOB, DBCLOB, DATALINK- или к струк-
турированным или индивидуальным типам, созданным на их основе. Это предложе-
ние несовместимо с созданием подтаблиц. Если предложение опущено и таблица
определяется в группе разделов базы данных, система DB2 попытается найти метод
секционирования таблицы. В противном случае таблица будет помещена в группу,
состоящую из одного раздела. При указании предложения USING HASHING для рас-
пределения данных по разделам будет использоваться хеширующий алгоритм.
OPTIONS (REMOTE SERVER ‘имя сервера’[, REMOTEJSCHEMA ‘имя_схемы]
[ REMOTE JABNAME ‘имя_таблицы ]
Определяется удаленная операция, например создание, изменение или удаление
таблицы в интегрированной системе. Эта операция называется прозрачный DDL
(transparent DDL). Интегрированные системы очень сложны и не входят в стан-
дарт ANSI. За дополнительной информацией обращайтесь к документации произ-
водителя.
ADD табличное_ограничение
В существующую таблицу добавляется табличное ограничение.
ALTER {CHECK | FOREIGN KEY} имя_ограничения определение_ограничения
Изменяет атрибуты существующего ограничения типа CHECK или FOREIGN KEY
с именем имя_ограничения, присваивая ему новое определение_ограничения.
Также вы можете использовать дополнительные параметры ограничений.
[NOT] ENFORCED
Переводит ограничение в состояние ENFORCED или NOT ENFORCED. При
указании опции ENFORCED ограничение автоматически поддерживается
базой данных. Если указывается опция NOT ENFORCED, то при модификации
данных ограничения не проверяются.
{ENABLE | DISABLE} QUERY OPTIMIZATION
Включает или отключает оптимизацию запросов в ограничении.
ALTER [COLUMN] имя_столбца определение_столбца
Изменяет существующий в таблице столбец с именем имя_столбца. Вы можете
изменять ряд характеристик столбца, не входящих в число стандартных пара-
метров, в том числе SCOPE, COMPRESS и атрибуты IDENTITY (идентификатор).
За информацией об атрибутах, связанных с типами, и других изменяемых атрибу-
тах обращайтесь к материалу, приводимому ниже. В каждом отдельном столбце
можно изменять ряд дополнительных характеристик.
208 | Глава 3. Справочник по инструкциям SQL
SET DATATYPE VARCHAR (int)
Делает длину именованного столбца типа VARCHAR равной int. Значение int
не должно превышать общей длины строки или общей длины первичного
ключа более чем на разрешенное максимальное значение.
SET EXPRESSION AS (генерируемое_выражение)
Изменяет исходное генерируемое выражение, которое напоминает автома-
тически инкрементируемые столбцы идентификаторов (IDENTITY), в указан-
ном столбце на новое генерируемое-выражение. Отличие генерируемых
выражений от столбцов-идентификаторов в том, что идентификаторы автома-
тически обрабатываются системой DB2, а генерируемые выражения позво-
ляют вам полностью контролировать значение, возвращаемое выражением.
Генерируемые выражения могут быть очень сложными, и они описаны в доку-
ментации производителя. Для этого предложения требуется, чтобы таблица
при помощи инструкции DB2 SET INTEGRITY была переведена в «состояние
отложенной проверки», когда ограничения в таблице не проверяются. После
этого все значения необходимо проверить.
SET INLINE LENGTH int
Изменяется встроенная длина указанного столбца структурированного типа.
Значения хранятся вместе со всеми остальными данными в строке.
DROP тип-Ограничения имя_ограничения
Из таблицы удаляется ограничение с именем имя_ограничения. Парамер тип_огра-
ничения может представлять собой любой допустимый тип: первичный ключ, внеш-
ний ключ, проверочные ограничения (CHECK), а также PARTITIONING KEY. Вы так
же можете заменить параметр тип_ограничения на RESTRICT ON DROP, чтобы уда-
лить параметр RESTRICT ON DROP.
DATA CAPTURE {NONE | CHANGES [INCLUDE LONGVAR COLUMNS]}
В журнал записывается дополнительная информация для поддержки репликации.
Применяется с любой необьектной таблицей. Опции предложения DATA CAPTURE
следующие.
NONE
Указывает, что дополнительная информация не записывается.
CHANGES
В таблицу записывается дополнительная информация для поддержки реплика-
ции. Это предложение является необходимым для поддержки репликации.
Предложение несовместимо с таблицами, в которых данные хранятся в разде-
лах, не входящих в каталог. При указании предложения INCLUDE LONGVAR
COLUMNS в репликацию данных включаются столбцы типов LONG VARCHAR
и LONG VARGRAPHIC.
ACTIVATE NOT LOGGED INITIALLY [WITH EMPTY TABLE]
Отключается запись в журнал любых транзакций, приведенных в том же пакет-
ном задании, что и инструкции ALTER TABLE. Не записываются такие инструк-
ции, как INSERT, DELETE, UPDATE, CREATE INDEX, DROP INDEX, или другие
инструкции, такие, как ALTER TABLE. Ведение журнала возвращается к обычному
14 - 2447
Справочник по командам SQL | 209
по окончании текущего пакетного задания SQL. Дополнительное предложение
WITH EMPTY TABLE указывает, что система DB2 должна очищать таблицу дан-
ных. Данные не могут быть восстановлены иначе как с помощью утилиты DB2
RECOVERY.
PCTFREE int
Указывается процентная доля свободного пространства (int), которую DB2 должна
оставлять на каждой странице при загрузке или реорганизации таблицы.
LOCKSIZE {ROW | TABLE}
Указывается, что при чтении или записи данных в таблицу следует выполнять
блокировку на уровне строки (ROW) или таблицы (TABLE). По умолчанию прини-
мается значение ROW. Предложение поддерживается только в корневой таблице
иерархии объектных таблиц.
APPEND {ON | OFF}
Новые данные добавляются в конец таблицы (ON) или записываются в свободные
места на страницах данных этой таблицы (OFF). При указании значения ON сис-
тема DB2 не будет хранить информацию о свободном месте. Предложение
APPEND не применяется в таблицах с кластеризованным индексом.
[NOT] VOLATILE [CARDINALITY]
Указывается, может ли кардинальность таблицы сильно изменяться с течением вре-
мени. Если установлена опция VOLATILE, система DB2 по сути игнорирует стати-
стику в пользу сканирования индекса, поскольку изменяются большие объемы
данных в таблице. Предложение VOLATILE поддерживается только в обычных таб-
лицах и в корневой таблице иерархии объектных таблиц. При указании предложе-
ния NOT VOLATILE система DB2 считает, что большой объем данных по сути явля-
ется статическим, поэтому можно использовать статистику и пути оптимизации.
Добавление дополнительного ключевого слова CARDINALITY показывает, что боль-
шой объем данных в таблице может изменяться, но сама таблица является статической.
[DE]ACTIVATE VALUE COMPRESSION
Включает или отключает в таблицах сжатие данных типа NULL и данных,
имеющих нулевую длину, для таких типов данных, как BLOB, CLOB, DBLOB,
LONG VARCHAR или LONG VARGRAPHIC.
SET MATERIALIZED QUERY {AS DEFINITION ONLY | подзапрос}
Изменяет свойства таблицы материализованного запроса. При указании предложе-
ния DEFINITION ONLY система DB2 считает таблицу обычной таблицей, а не таб-
лицей материализованного запроса. При использовании предложения DEFINITION
ONLY таблицу материализованного представления нельзя реплицировать. Предло-
жение подзапрос - это любой допустимый подзапрос, используемый для создания
таблицы материализованного запроса. При использовании предложения подзапрос
таблица не может быть объектной таблицей, содержать ограничения, уникальные
индексы или триггеры и не может быть определена как таблица материализованного
запроса или не может упоминаться в таблице материализованного запроса.
210 | Глава 3. Справочник по инструкциям SQL
В DB2 есть несколько специальных атрибутов, которые можно применять к столбцам
помимо стандартных ограничений, предоставляемых стандартом ANSI SQL. Эти до-
полнительные атрибуты специфичны для определенных типов данных.
[NOT] LOGGED
Указывается, будут ли изменения, вносимые в столбец, записываться в файл
журнала (LOGGED) или не будут (NOT LOGGED). По умолчанию принято значе-
ние LOGGED. Однако некоторые значения типов LOB, которые имеют размер
более 10 Мб, заносить в журнал не следует, а те, размер которых превышает 1 Гб,
вообще не могут заноситься в журнал.
[NOT] COMPACT
Максимально сжимает значения типа LOB, обычно путем высвобождения допол-
нительного пространства в последней группе, использованной значением LOB,
или позволяя остаться неиспользованным свободному месту в последней группе.
Предложение COMPACT требует дополнительных ресурсов процессора и нагру-
жает каналы ввода-вывода. По умолчанию принимается значение NOT COMPACT.
Допустим, например, что у вас есть таблица emp_images, в которой хранятся фото-
графии ваших служащих для нужд службы безопасности.
CREATE TABlЕ emp_images
(emp_id INT NOT NULL,
emp_photo_image LONGVARGRAPHIC NOT LOGGED COMPACT)
В DB2 поддерживаются следующие атрибуты, относящиеся к соединениям для пере-
дачи данных.
LINKTYPE URL
Определяет URL в качестве типа ссылки.
NO LINK CONTROL
При указании этой опции не будет производиться проверка существования файла.
FILE LINK CONTROL [опции]
При указании этой опции будет производиться проверка существования файла.
Тип проверки могут определять дополнительные опции.
INTEGRITY [ALL]
Устанавливается уровень проверки значения DATALINK и реального файла.
Дополнительное ключевое слово ALL отключает контроль операционной сис-
темы за удалением или переименованием файла.
READ PERMISSION {FS | DB]
Устанавливается доступ для чтения файла либо на уровне файловой системы
(FS), либо на уровне базы данных (DB).
WRITE PERMISSION {FS | BLOCKED | ADMIN]
Устанавливает доступ к файлу по записи на уровне файловой системы (FS), запре-
щает запись (BLOCKED) или доступ определяет Data Links Manager (ADMIN).
Предложение WRITE PERMISSION ADMIN основывается на передаче
маркера. Вы должны также указать предложение [М9Г] REQUIRING TOKEN
FOR UPDATE, которое определяет, является маркер записи (write token) необхо-
димым для завершения операции обновления файла.
Справочник по командам SQL | 211
RECOVERY {YES | NO}
Указывает, что система DB2 должна поддерживать (YES) функцию восстановле-
ния файлов, на которые ссылаются значения в столбцах, в состоянии, сложив-
шемся к определенным моментам времени. Или не поддерживать ее (NO). Для
предложения RECOVERY YES также необходимо предложение INTEGRITY ALL
и либо предложение WRITE PERMISSION BLOCKED, либо WRITE PERMISSION
ADMIN.
ON UNLINK {RESTORE | DELETE}
Указывается, что система DB2 при изменении или удалении значения DATALINK
либо возвращает файл в состояние с исходными допусками (RESTORE), либо
файл при разрыве соединения удаляется (DELETE). Для предложения ON
UNLINK RESTORE также необходимо предложение INTEGRITY ALL и либо
предложение WRITE PERMISSION BLOCKED, либо WRITE PERMISSION ADMIN.
Для предложения ON UNLINK DELETE необходимо предложение READ
PERMISSION DB и либо предложение WRITE PERMISSION BLOCKED, либо
WRITE PERMISSION ADMIN.
MODE DB2OPTIONS
Возвращает заданную по умолчанию группу опций файлового соединения:
INTEGRITY ALL, READ PERMISSIONS, WRITE PERMISSION FS и RECOVERY NO.
В DB2 поддерживаются следующие связанные с типами атрибуты.
SCOPE имя_типа
Объявляется область действия столбца ссылочного типа. Параметр u.wijnuna -
это имя существующей объектной таблицы или представления. Это предложение
является необходимым для столбцов, используемых в левой части оператора
разыменовывания ссылки или в качестве аргумента функции DEREF.
INLINE LENGTH int
Объявляется максимальный размер в байтах (int) для столбца структурированного
типа. Если структурированный тип слишком длинный, DB2 будет автоматически
сохранять структурированные типы в отдельной таблице, примерно так, как хра-
нятся значения типов LOB.
В DB2 поддерживается только один атрибут, связанный с хранением.
COMPRESS SYSTEM DEFA ULT
Указывает, что системное значение по умолчанию в любых столбцах будет сжи-
маться. Не следует использовать это предложение в столбцах типов DATE, TIME
и TIMESTAMP. Вы сможете выиграть немного места за счет производительности.
Для установки значений по умолчанию вы можете использовать следующие атрибуты.
[WITH] DEFAULT {CURRENTSCHEMA | USER | NULL | константа}
Объявляется значение для столбца по умолчанию; т. е., если в инструкциях INSERT,
UPDATE или LOAD не указывается значение для столбца, то DB2 будет использо-
вать указанное вами значение. WITH - необязательное слово. Если данное предло-
жение опущено, то по умолчанию всегда используется NULL. Опции для предложе-
ния DEFA UL Т следующие.
212 | Глава 3. Справочник по инструкциям SQL
CURRENT SCHEMA
Вставляется системное значение CURRENT SCHEMA. Столбец должен отно-
ситься к символьному типу и иметь достаточную длину для хранения значе-
ния CURRENT SCHEMA.
USER
Вставляется системное значение USER. Столбец должен относиться к сим-
вольному типу и иметь достаточную длину для хранения значения USER.
NULL
Вставляется значение NULL. Это значение используется, если предложение
опущено.
константа
Любая строковая константа, дата или число длиной 254 символа и менее.
GENERA TED {ALWA YS\BY DEFA ULT}
Система DB2 будет генерировать значение для столбца, в частности для столбцов
идентификаторов (IDENTITY), либо каждый раз, когда запись вставляется в табли-
цу (ALWAYS), либо когда значение для столбца не указано (BYDEFAULT).
AS выражение
Значение по умолчанию присваивается па основе вычисления выражения. Выра-
жение может представлять собой вид пользовательской функции, подзапрос или
записанную процедуру. Обращайтесь к описанию «ALTER COLUMN...генерируе-
мые выражения» выше в этой главе.
AS IDENTITY [START WITH int | INCREMENT BY int]
Предложение указывает, что столбец с числовым типом данных является автома-
тически инкрементируемым идентификатором (IDENTITY). Идентификаторы
могут формироваться по возрастанию или по убыванию. Система DB2 позволяет
использовать в таблице только один столбец идентификаторов. Все столбцы иден-
тификаторов неявно имеют ограничение NOT NULL. Ниже приводятся дополни-
тельные параметры идентификаторов.
START WITH int
Указывается начальное (стартовое значение) в столбце идентификатора (int).
По умолчанию принимаются значения MINVALUE для идентификаторов по
возрастанию и MAXVALUE для идентификаторов по убыванию.
INCREMENT BY int
Определяет, на какую величину будет увеличиваться (если значение положи-
тельно) или уменьшаться (если отрицательно) величина идентификатора при
каждом инкременте. Значение по умолчанию 1. Отрицательное значение
в предложении INCREMENT BY показывает, что идентификаторы формируют-
ся в порядке убывания.
[NO] {MINVALUE | MAXVALUE} [int]
Указывается значение (int), при котором значение идентификатора либо цик-
лически возвращается к начальному значению, либо более не генерируется.
Оба предложения могут быть атрибутами идентификатора. При указании пред-
ложения NO MINVALUE (принято по умолчанию) DB2 начинает генерировать
Справочник по командам SQL | 213
возрастающие значения со START WITH или с 1, если это предложение опущено.
Предложение M1NVALUE int указывает системе DB2 самое меньшее допусти-
мое значение для нисходящих идентификаторов. При указании предложения
NO MAXVALUE (принято по умолчанию) система DB2 останавливает генера-
цию восходящих идентификаторов или зацикливает ее на максимальном
значении, разрешенном для данного типа данных. Для нисходящих идентифи-
каторов значение по умолчанию - START WITH или, если предложение опуще-
но, -1. В предложении MINVALUE int указывается наибольшее допустимое
значение для восходящих идентификаторов.
[NO] CYCLE
Указывает, что база данных должна возвращаться к началу цикла при генера-
ции значений идентификаторов (CYCLE), когда в восходящих идентифика-
торах превышено максимальное значение (или декрементировано минималь-
ное значение в нисходящих идентификаторах). Или же (NO CYCLE) должна
прекратить генерацию идентификаторов по достижению минимального или
максимального значения. Предложение NO CYCLE установлено по умолча-
нию. При указании предложения CYCLE система DB2 будет генерировать
дублирующиеся значения.
[NO] CACHE [int]
При указании этого предложения DB2 кеширует некоторые заранее выделен-
ные значения в память (CACHE) или не кеширует (NO CACHE). При желании
вы можете указать количество кешируемых с помощью предложения CACHE
int идентификаторов.
[NO] ORDER
Указывает, что значения идентификаторов должны генерироваться в том
порядке, в котором они запрашиваются (ORDER). Если предложение опуще-
но, по умолчанию используется NO ORDER.
Например, наша компания приобрела другую компанию с полным составом
сотрудников. Мы хотим присвоить новым сотрудникам (employees) новый идентифи-
катор emp_id, учитывая при этом максимальное значение в столбце emp_id.
CREATE TABLE temp_emp
(new_emp_id INT NOT NULL GENERATED ALWAYS AS IDENTITY
(START WITH 500, INCREMENT BY 1, NO CYCLE, CACHE),
dept VARCHAR (50) NOT NULL,
mgr_id INT,
location CHAR(30))
В DB2 поддерживается создание временных таблиц, но не при помощи
инструкции CREATE TABLE. Вместо этого используется инструкция
DECLARE GLOBAL TEMPORARY TABLE, описанная в документации DB2.
214 | Глава 3. Справочник по инструкциям SQL
Однако будьте особенно осторожны при внесении изменений в таблицу. Как пра-
вило, вам следует ожидать, что любые процедурные объекты, которые зависят от
данной таблицы, например процедуры и функции, станут нерабочими.
-- Создание ограничений уровня столбца
CREATE TABLE
(isbn
book_name
category
subcategory
oub_date
purchase_date
CONSTRAINT
REFERENCES category(cat.narne));
В следующем примере мы изменяем образец таблицы favorite_books, чтобы не
протоколировались для репликации изменения, вносимые в нее с помощью SQL.
ALTER TABLE favorite_books
PCTFREE 20
DATA CAPTURE NONE
favorite_books
CHAR(100)
VARCHAR(40)
VARCHAR(40)
VARCHAR(40)
DATETIME
DATETIME
fk_categories FOREIGN KEY (category)
PRIMARY KEY,
UNIQUE,
NULL,
NULL,
NOT NULL,
NOT NULL,
И наконец, мы решили, что, хотя записи таблицы изменяются крайне часто, сама
структура таблицы должна оставаться статической.
ALTER TABLE favorite_books NO VOLATILE CARDINALITY
MySQL
Ниже приводится вариант инструкции CREATE TABLE в синтаксисе MySQL для соз-
дания постоянной или локальной временной таблицы в базе данных, в которой была
подана команда.
CREATE [TEMPORARY] TABLE [IF NOT EXISTS] имя_таблицы
{(имя_столбца тип_данных атрибуты
тип_ограничения имя_ограничения [,...] )
[тип_ограничения [имя_ограничения] [,...] ]
[MATCH FULL | MATCH PARTIAL]
[ON {DELETE | UPDATE) {RESTRICT | CASCADE | SET NULL |
NO ACTION | SET DEFAULT}]
LIKE имя_другой_таблицы }
{[TYPE = {ISAM | MylSAM | HEAP | BDB | InnoDB | MERGE |
MRG.MylSAM) |
AUTO_INCREMENT = int |
AVG_ROW_LENGTH = int |
CHECKSUM = {0 | 1} |
COMMENT = "строка" |
DELAY_KEY_WRITE = {0 | 1} |
MAX_ROWS = int |
Справочник по командам SQL | 215
MIN_ROWS = int |
PACK_KEYS = {0 [ 1} |
PASSWORD = " строка" |
ROW_FORMAT= { default | dynamic | static | compressed } |
RAID_TYPE = {1 | STRIPED | RAIDO} |
RAID-CHUNKS = int |
RAID_CHUNKSIZE = int |
INSERT-METHOD = {NO | FIRST | LAST} |
DATA DIRECTORY = " путь_к_директории"
INDEX DIRECTORY = "путь_к_директории"} }
[[IGNORE | REPLACE] инструкция_ее1ес1}
Ниже приводится синтаксис MySQL для инструкции ALTER TABLE, который
позволяет вносить в таблицу изменения и даже переименовывать ее.
ALTER [IGNORE] TABLE имя_таблицы
{[ADD [COLUMN] (имя_столбца тип_данных атрибуты}
[FIRST | AFTER имя_столбца}]
I [ADD [UNIQUE | FULLTEXT] INDEX [имя_индекса}
| (имя_столбца_индекса [,...]) ]
I [ADD PRIMARY KEY (имя_столбца_индекса [,...]) ]
| [ALTER [COLUMN] имя_столбца {SET DEFAULT литерал |
| DROP DEFAULT}]
I [CHANGE | MODIFY] [COLUMN] старое_имя_столбца новое_имя_столбца}
[FIRST | AFTER column_name]
I [MODIFY] имя_столбца тип_данных атрибуты
I [DROP [COLUMN] имя_столбца}
| [DROP PRIMARY KEY]
I [DROP INDEX имя_индекса}
| [{ENABLE | DISABLE} KEYS]
| [RENAME [TO] новое_имя_таблицы}
| [опции_таблицы} } [,...]
Ключевые слова и параметры следующие.
TEMPORARY
Создается таблица, которая существует только в период существования соединения,
в котором она была создана. Как только соединение закрывается, временная таблица
автоматически удаляется.
IF NOT EXISTS
Предотвращает ошибки, если таблица уже существует. Указание схемы не требу-
ется.
тип_ограничения
Позволяет присваивать стандартные ограничения SQL ANSI (см. главу 2) на уровне
таблицы и столбца. Система MySQL полностью поддерживает эти ограничения:
PRIMARY KEY, UNIQUE и DEFAULT (должно представлять собой константу).
В MySQL синтаксически поддерживаются ограничения CHECK, FOREIGN KEY
216 | Глава 3. Справочник по инструкциям SQL
и REFERENCES, но они не функциональны нигде, за исключением таблиц InnoDB.
В MySQL также есть три специальных ограничения.
FULL TEXT [INDEX]
Создается полнотекстовый поисковый список для ускорения поиска больших
блоков текста. Заметим, что полнотекстовые индексы поддерживаются только
в таблицах MylSAM и их можно создавать только по столбцам CHAR, TARCHAR
или TEXT.
AUTO INCREMENT
Столбец числовых данных настраивается так, чтобы его значение автоматиче-
ски увеличивалось на 1 (начиная со значения 1). В MySQL можно использо-
вать только один столбец с предложением A UTOJNCREMENT в таблице.
[UNIQUE] INDEX
Если столбцу присваивается атрибут INDEX, то можно также указать название
индекса. (В MySQL для INDEX есть синоним KEY.) Если имя первичному
ключу не присвоено, то MySQL присваивает имя, состоящее из имени столбца
плюс числовой суффикс (_2, _3, ...), делая его таким образом уникальным.
Все табличные типы, за исключением типа ISAM, поддерживают индексы по
столбцам со значениями NULL, а также типами BLOB и TEXT. Заметьте, что
использование ключевого слова UNIQUE без слова INDEX в MySQL является
допустимым.
YPE
Описывает физический способ храпения данных. Таблицы можно преобразовывать из
одного типа в другой с помощью инструкции ALTER STATEMENT. Возможность вос-
становления таблиц при помощи инструкций COMMIT и ROLLBACK существует
только в таблицах типа InnoDB и BDB. Во всех прочих типах таблиц сбой базы
данных будет сопровождаться потерей данных, но они работают гораздо быстрее и за-
нимают меньше места. По умолчанию принимается тип MylSAM. Ниже приводится
список типов таблиц MySQL.
BDB
Создается таблица с безопасными транзакциями и блокировкой страниц. Таб-
лицы такого типа основываются на системе обработки транзакций BerkleyDB
(http://www.sleepycat.com). Тип BDB сохраняет файлы журнала, отслеживает
контрольные точки (checkpoints) и инструкции ROLLBACK и COMMIT.
В таблицах BDB должен быть объявлен первичный ключ. Некоторые опера-
ции над таблицами BDB выполняются медленнее, чем аналогичные операции
над таблицами MylSAM.
HEAP
Создается хранящаяся в памяти таблица, использующая хеш-индексы. Посколь-
ку такие таблицы хранятся в памяти, транзакции с ними небезопасны. При сбое
сервера все содержащиеся в них данные будут потеряны. Таблицы HEAP можно
считать альтернативой временным таблицам. Если вы используете таблицы
типа HEAP, всегда указывайте опцию MAX_ROWS, чтобы не использовать всю
доступную память. Также таблицы HEAP не поддерживают столбцы BLOB,
Справочник по командам SQL | 217
TEXT, ограничения AUTO-INCREMENT, предложения ORDERBY или записи
в формате с переменной длиной.
InnoDB
Создается таблица с безопасными транзакциями с блокировкой на уровне строк.
Также обеспечивается возможность независимого управления табличными облас-
тями, поддерживаются контрольные точки, чтение без блокировки и быстрое
чтение из больших файлов данных для повышения параллельности и произво-
дительности. Необходим параметр запуска innodb_data_flle_path. В таблицах
InnoDB поддерживаются все ограничения стандарта ANSI, в том числе CHECK
и FOREIGN KEY. (InnoDB - это полная отдельная система обработки транзак-
ций, доступная по адресу http://www.innodb.com. InnoDB используют хорошо
известные web-сайты разработчиков, такие, как Slashdot.org.) InnoDB требует
специальной установки в том числе, возможно, перекомпилирования ядра
MySQL, указания параметров файла init и создания табличных пространств.
Хотя InnoDB по умолчанию включен в дистрибутивы MySQL 4.0 и выше, вам
следует связаться с администратором базы и убедиться, что вы можете исполь-
зовать таблицы InnoDB.
ISAM
Создаются таблицы более старого стиля ISAM. Формат ISAM выходит из
употребления и, возможно, не будет поддерживаться в версиях после SQL 5.0.
MERGE | MRG-MylSAM
Собирает несколько таблиц MylSAM с одинаковой структурой, чтобы их можно
было использовать как одну таблицу. Табличный тип MERGE позволяет использо-
вать некоторые возможности секционированных таблиц. Ключевые слова MERGE
и MRG_MyISAMявляются синонимами. Инструкции SELECT, DELETE и UPDATE
работают с коллекцией таблиц так, как если бы это была одна таблица. Таблицу
типа MERGE можно считать коллекцией таблиц, но не таблицей, содержащей
данные. При удалении таблицы она удаляется только из колекции. Сама таблица
и содержащиеся в ней данные не удаляются из базы. Таблица MERGE определяет-
ся при помощи инструкции иНЮН=(таблица!, таблица2, ...).
MylSAM
Данные хранятся в файлах .MYD, а индексы - в файлах .MYI. Таблицы MylSAM
основываются на ISAM с некоторыми расширениями. MylSAM - это структура
хранения двоичных данных, которая имеет большую переносимость, чем ISAM.
Формат MylSAM поддерживает столбцы AUTO-INCREMENT, сжатые таблицы
(при помощи утилиты myisampack) и таблицы большого размера. В таблицах
MylSAM столбцы BLOB и TEXT могут иметь индексы, и с таблицей могут быть
связаны до 32 индексов.
AUTO-INCREMENT = int
Определяет значение автоматического инкремента (inf) в таблице (только для
MylSAM).
218 | Глава 3. Справочник по инструкциям SQL
AVGROWLENGTH = int
Устанавливается приблизительная средняя длина строки для таблиц с записями
переменной длины. В MySQL произведение avgrowlength *max_rows использу-
ется для определения возможных размеров таблицы.
CHECKSUM = {0\1}
Если установлено значение 1, сохраняется контрольная сумма для всех строк таб-
лицы (только MylSAM). Обработка становится более медленной, но меньше веро-
ятность повреждения.
COMMENT = “строка”
Позволяет вводить комментарий длиной до 60 символов.
DELAY KEY WRITE = {0\ I}
Если указано значение 1, то ключи таблицы обновляются только при закрытии
таблицы (только MylSAM).
MAXROWS = int
Устанавливается максимальное количество строк, хранящихся в таблице. По умолча-
нию максимумом является 4 Гб дискового пространства.
M1NROWS - int
Устанавливается минимальное количество строк, хранимых в таблице.
PACKKEYS = {0 \ 1}
Если установлено значение 1, индексы таблицы сжимаются, что ускоряет чтение,
но замедляет обновление (только для MylSAM и ISAM). По умолчанию сжимают-
ся только строковые значения. Если параметр устанавливается в 1, сжимаются
и строковые, и числовые значения.
PASSWORD = “строка"
С помощью пароля “строка” шифруется файл .FRM, но не сама таблица.
ROW FORMAT = {default | dynamic | static | compressed}
Этот параметр определяет, как будут храниться строки в таблице MylSAM. При
указании опции DYNAMIC строки могут быть переменного размера (т. е. исполь-
зовать тип VARCHAR), в противном случае ожидается фиксированный размер
строк (т. е. CHAR, INT и т. п.).
RA1D_TYPE = {I | STRIPED | RA1D0}
Позволяет таблицам выходить за пределы размера для файла данных MylSAM
(но не файла индекса) в 2 Гб /4 Гб в операционных системах, которые не под-
держивают очень большие файлы. Предложение RAID TYPE задумано как ре-
шение вопроса для серверов, сталкивающихся с упомянутым ограничением раз-
мера файла, поэтому не следует использовать это предложение в операционных
системах, поддерживающих файлы большего размера. Ключевые слова 1,
STRIPED и RAIDZERO представляют собой синонимы, но наиболее часто
встречается STRIPED. Для данного предложения необходимым является ини-
циализационный параметр -with-raid. В настоящее время MySQL автоматически
обрабатывает предложения RAID_CHUNKS и RAID CHUNKSIZE.
Справочник по командам SQL | 219
RAID-CHUNKS = int
Параметр подменяет заданные по умолчанию поддиректории, используемые в пара-
метре RAID-TYPE. В MySQL для всех таблиц MylSAM в директории базы данных
обычно создаются поддиректории с именами 00, 01, 02. Каждая поддиректория
содержит файл имя_таблицы.МТО.
RAID_CHUNKSIZE = int
Устанавливается размер фрагмента данных, отличающийся от заданного по умолча-
нию размера в 1024 байта. По мере того как размер файла таблицы MylSAM растет,
система MySQL циклически выделяет дополнительное место в int байт.
INSERT_METHOD = {NO | FIRST\ LAST}
Необходимый параметр для таблиц MERGE. Если в таблице MERGE этот пара-
метр не указан или установлен в NO, то нельзя производить операции вставки.
При указании параметра FIRST все записи вставляются в первую таблицу коллек-
ции, а при указании параметра LAST- в последнюю таблицу.
DATA DIRECTORY = “путь к директории"
Изменяет заданный по умолчанию путь к директории, которую MySQL использует
для хранения таблиц MylSAM.
INDEX DIRECTORY = “путь к директории”
Изменяет заданный по умолчанию путь к директории, которую MySQL использует
для хранения индексов MylSAM.
[IGNORE | REPLACE] SELECT-инструкция
Создается таблица со столбцами, определяемыми элементами инструкции
SELECT. Новая таблица заполняется результатами инструкции SELECT, если
инструкция возвращает набор данных.
ALTER [IGNORE]
Измененная таблица будет включать все дублирующиеся записи, если не исполь-
зуется ключевое слово IGNORE. В противном случае инструкция завершается
ошибкой; если встречается дублирующаяся строка, таблица имеет уникальный
индекс или первичный ключ и при этом не используется ключевое слово IGNORE.
(ADD | COLUMN] [FIRST] AFTER имя_столбца]
Добавляет или переносит столбец, индекс или ключ в таблицу. При добавлении
или переносе столбца новый столбец становится последним столбцом таблицы,
если только его специально не помещают после указанного столбца (AFTER).
ALTER COLUMN
Это предложение позволяет определять или переустанавливать задаваемое по
умолчанию значение в столбце. Если значение по умолчанию будет! переустанов-
лено, MySQL будет по умолчанию присваивать столбцу новое значение.
CHANGE
Переименование столбца или изменение типа данных.
MODIFY
Изменение типа данных столбца или атрибутов, таких, как NOT NULL. Сущест-
вующие в столбце данные автоматически преобразуются к новому типу.
220 | Глава 3. Справочник по инструкциям SQL
DROP
Удаляется столбец, ключ или индекс. Удаленный столбец также удаляется из всех
индексов, в которых он упоминался.
При удалении первичного ключа, если первичный ключ отсутствует, MySQL уда-
ляет первый уникальный ключ.
{ENABLE | DISABLE} KEYS
Включает или отключает сразу все неуникальные ключи в таблице MylSAM. Это
может быть полезным для загрузки больших объемов, если вы хотите временно
отключить ограничения до тех пор, пока загрузка не завершится. Это также уве-
личивает производительность путем записи в базу данных индексных блоков
в конце операции.
RENAME [ТО] новое_имя_гпаблицы
Переименование таблицы.
Например:
CREATE TABLE test_example
(column_a INT NOT NULL AUTO_INCREMENT,
PRIMARY KEY(column_a),
INDEX(column_b))
TYPE=HEAP
IGNORE
SELECT column_b,column_c FROM samples;
Здесь создается таблица типа HEAP с тремя столбцами: column_a, column_b
и column_c. Позже мы можем изменить тип таблицы на MylSAM.
ALTER TABLE example TYPE = MylSAM;
При создании таблицы MylSAM создаются три файла операционной системы -
файл определения таблицы с расширением .FRM, файл данных с расширением .MYD
и файл индекса с расширением .MYL Для всех прочих таблиц используется файл
данных с расширением .FRM.
Ниже приводится пример создания двух основных таблиц MylSAM, а затем из
них создается таблица MERGE.
CREATE TABLE messagel
(message_id INT AUTO_INCREMENT PRIMARY KEY,
message_text CHAR(20));
CREATE TABLE message2
(message_id INT AUTO_INCREMENT PRIMARY KEY,
message_text CHAR(20));
CREATE TABLE alljnessages
(message_id INT AUTO_INCREMENT PRIMARY KEY,
message_text CHAR(20))
TYPE=MERGE UNI0N=(message1, message2) INSERT_METHOD=LAST;
В следующем примере переименовываются таблица и столбец.
Справочник по командам SQL | 221
ALTER TABLE employee RENAME AS emp;
ALTER TABLE employee CHANGE employee_ssn emp_ssn INTEGER;
Поскольку MySQL позволяет создавать индексы по части столбца (например, по
первым девяти символам столбца), вы можете создавать короткие индексы по очень
большим столбцам.
MySQL позволяет переопределять тип данных существующего столбца. Чтобы из-
бежать потери данных, значения, содержащиеся в столбце, должны быть совместимы
с новым типом данных. Например, столбец с датами можно преобразовать к символь-
ному типу,; но символьный тип не преобразовывается в числовой. Вот пример.
ALTER '(ABLE mytable MODIFY mycolumn LONGTEXT
MySQL позволяет более гибко использовать инструкцию ALTER TABLE, давая
пользователям возможность подавать несколько перечисленных через запятую пред-
ложений ADD, ALTER, DROP и CHANGE в одной инструкции ALTER TABLE. Однако
помните, Что предложения CHANGE имя столбца и DROP INDEX являются расшире-
ниями MySQL и не входят в стандарт SQL2003. MySQL поддерживает предложение
MODIFY имя столбца, имитирующее соответствующую возможность Oracle.
Oracle
В синтаксисе Oracle инструкция CREATE TABLE создает реляционную таблицу либо
путем объявления структуры, либо путем ссылки на существующую таблицу. После
создания таблицы вы можете ее изменить с помощью инструкции ALTER TABLE. Сис-
тема Oracle также позволяет создать реляционную таблицу, применяя пользователь-
ские типы для определения столбцов. Вы также можете создать объектную таблицу,
в которой явно определено хранение специфических пользовательских типов, в част-
ности таких, как TARRAY или NESTED TABLE, а также таблиц XMLType.
Поддерживается стандартный ANSI-стиль инструкции CREATE TABLE, но в Oracle
добавлено (иного сложных расширений. Например, Oracle позволяет осуществлять кон-
троль над; параметрами хранения и производительности таблицы. И в инструкции
CREATE TABLE, и в инструкции ALTER TABLE вы увидите высокую степень вложенно-
сти и повторного использования предложений. Чтобы такие конструкции было проще
читать, мы разбили инструкцию CREATE TABLE системы Oracle на три отдельных вари-
анта (реляционная таблица, объектная таблица и XML-таблица). Это упростит вам
изучение синтаксиса.
Синтаксис инструкции CREATE TABLE для стандартной реляционной таблицы, не
имеющей Объектных свойств и XML-возможностей, следующий.
CREATE [GLOBAL] [TEMPORARY] TABLE имя_таблицы
[ ( {столбец | атрибут} [SORT] [DEFAULT выражение] [{ограничение_для_столбца |
встроенное_ссылочное_ограничение} ] |
{параметры_табличного_ограничения | ссылочное_табличное_ограничение} |
{GROUP журнальная_группа {столбец [NO LOG] [,...]) [ALWAYS] | DATA
{ограничения [,...]) COLUMNS} ) ]
[ON COMMIT {DELETE | PRESERVE} ROWS]
222 | Глава 3. Справочник по инструкциям SQL
[параметрьгтабличного_о граничения]
{ [параметры_физических_атрибутов] [TABLESPACE имя_табличной_области]
[параметры_хранения] [[NOJLOGGING] |
[CLUSTER (столбец [,,..] )] |
{[ORGANIZATION
{HEAP [параметры_физических_атрибутов][TABLESPACE
имя_табличной_области][ параметры_хранения]
[COMPRESS | NOCOMPRESS] [[NOJLOGGING] ;
INDEX [параметры_физических_атрибутов][TABLESPACE
имя_табличной_области][ параметры_хранения]
[PCTTHRESHOLD mt] [COMPRESS [int] | NOCOMPRESS]
[MAPPING TABLE | NOMAPPING][...] [[NOJLOGGING]
[[INCLUDING столбец] OVERFLOW
[параметры-.физических_атрибутов][TABLESPACE имя_табличной_области]
[параметры_хранения] [[NOJLOGGING] } ] |
EXTERNAL ( [TYPE driver_type] ) DEFAULT DIRECTORY имя_директории
[ACCESS PARAMETERS (USING CLOB подзапрос I ( непрозрачный_формат ) } ]
LOCATION ( [имя_директории:]'местоположение' [,...] )
[REJECT LIMIT {int I UNLIMITED] ] } }
[{ENABLE | DISABLE] ROW MOVEMENT]
[[NOJCACHEj [[NO]MONITORING] [[NO]ROWDEPENDENCIES]
[PARALLEL int | NOPARALLEl] [NOSORT] [[NO]LOGGING]]
[COMPRESS [int] | NOCOMPRESS]
[{ENABLE | DISABLE] [[NO]VALIDATE]
{UNIQUE (столбец [....] | PRIMARY KEY | CONSTRAINT имя_ограничения] ]
[USING INDEX {имя_индекса | инструкция_С1?ЕАТЕ_1ЖХ } ] [EXCEPTIONS INTO]
[CASCADE] [{KEEP | DROP] INDEX] ] I
[параметры_секционирования]
[AS-подзапрос]
Синтаксис реляционной таблицы содержи^ множество дополнительных предло-
жений. Однако определение таблицы должно содержать, как минимум, или названия
столбцов и определение типов данных, или предложение AS-подзапрос.
Синтаксис Oracle для объектной таблицы следующий.
CREATE [GLOBAL] [TEMPORARY] TABLE имя_таблицы
AS объектныйугип [[NOT] SUBSTITUTABLE AT ALL LEVELS]
[ ( { столбец | атрибут } [DEFAULT выражение] [{ограничение__для_столбца |
встроенное_ссылочное_ограничение} ] |
{ параметры_табличного_ограничения | ссылочное_табличное_ограничение] |
{GROUP журнальная_группа (столбец [NO LOG] [,...]) [ALWAYS] I DATA
(ограничения [:... ]) COLUMNS] ) ]
[ON COMMIT (DELETE | PRESERVE] ROWS]
[OBJECT IDENTIFIER IS {SYSTEM GENERATED | PRIMARY KEY}]
[OIDINDEX {_имя_ индекса] ([параметры_физических_атрибутов] [параметры_хранения]]]
Справочник по командам SQL | 223
[параметры_физических_атрибутов] [TABLESPACE имя_табличной-области]
[ параметры-хранения]
Синтаксис Oracle для таблицы XML приводится ниже.
Create [global] [temporary] table имя_таблицы
OF XMLTYPE
[ ({ столбец | атрибут } [DEFAULT выражение] [{ограничение_для_столбца |
встроенное_ссылочное_ограничение} ] |
{ параметры_табличного_ограничения | ссылочное_табличное_ограничение} |
{GROUP журнальная_группа (столбец [NO LOG] [,...]) [ALWAYS] | DATA
(ограничения [,...]) COLUMNS} ) ]
[XMLTYPE {OBJECT RELATIONAL [параметры_хранениЯ-хт1] |
CLOB [имя_сегмента_1оЬ] [,параметры_1оЬ]}] [xml_schema_spec]
[ON COMMIT {DELETE | PRESERVE} ROWS]
[OBJECT IDENTIFIER IS {SYSTEM GENERATED | PRIMARY KEY}]
[OIDINDEX [имя_индекса] ([параметры_физических_атрибутов] [параметры_хранения])]
[параметры_физических_атрибутов] [TABLESPACE имя_табличной_области]
[параметры_хранения ]
Синтаксис команды ALTER TABLE в Oracle позволяет изменять свойства таблицы
или столбца, параметры хранения, свойства типов LOB и VARARRAY, параметры
секционирования и ограничений для обеспечения целостности, связанные с таблицей
и/или ее столбцами. Эта инструкция выполняет и другие функции, такие, как переме-
щение существующей таблицы в другую табличную область, высвобождение диско-
вого пространства, сжатие сегмента таблицы и настройка «максимального уровня
заполнения» (hign water mark).
В стандарте ANSI SQL ключевое слово ALTER используется для изменения суще-
ствующих элементов таблицы, однако в Oracle для той же цели применяется ключевое
слово MODIFY. Поскольку по сути это одно и то же, считайте функционально эквива-
лентными конструкции, которые одинаковы во всем прочем (например, инструкции
ANSI ALTER TABLE...ALTER COLUMN и инструкции Oracle ALTER TABLE...MODIFY
COLUMN).
Синтаксис инструкции ALTER TABLE в Oracle следующий.
ALTER TABLE имЯ-таблицы
-- изменяем параметры таблицы
[параметры-физических_атрибутов] [параметры_хранения]
[[NO]LOGGING] [[NO]CACHE] [[NO]MONITORING] [[NO]COMPRESS]
[SHRINK SPACE [COMPACT] [CASCADE] ]
[UPGRADE [[NOT] INCLUDING DATA] имЯ-Столбца тип_данных атрибуты]
[[NO]MINIMIZE RECORDS_PER_BLOCK]
[PARALLEL int | NOPARALLEL]
[{ENABLE | DISABLE} ROW MOVEMENT]
[{ADD | DROP} SUPPLEMENTAL LOG
{GROUP журнальная-группа [(имя-Столбца [NO LOG] [,...] ) [ALWAYS] ] I
DATA ( {ALL | PRIMARY KEY | UNIQUE | FOREIGN KEY} [,...] ) COLUMNS} ]
224 | Глава 3. Справочник по инструкциям SOL
[ALLOCATE EXTENT
[( SIZE int[K|M|G|T] ] [DATATILE 'имя_файла'] [INSTANCE int} ] )]
[DEALLOCATE UNUSED [KEEP int[K|M|G|T] ] ]
[ORGANIZATION INDEX ...
[COALESCE] [MAPPING TABLE | NOMAPPING] [{PCTTHRESHOLD int]
[COMPRESS int | NOCOMPRESS]
[ { ADD OVERFLOW [TABLESPACE имя_табличной_области] [[NO]LOGGING]
[параметры_физических_атрибутов]] ] |
OVERFLOW { [ALLOCATE EXTENT (SIZE int [К | M]] [DATAFILE
'имя_файла'] [INSTANCE int] ) |
[DEALLOCATE UNUSED [KEEP int [К | M]] } ] ]
[RENAME TO новое_имя_таблицы]
- - изменяем параметры столбца
[ADD (имя_столбца тип_данных атрибуты [,...] ) ]
[DROP { {UNUSED COLUMNS | COLUMNS CONTINUE} [CHECKPOINT int] |
{COLUMN имя_столбца | (имя_столбца [,...] ) } [CHECKPOINT int]
[{CASCADE CONSTRAINTS | INVALIDATE}] } ]
[SET UNUSED {COLUMN имя_столбца | (имя_столбца [,...] ) }
[{CASCADE CONSTRAINTS | INVALIDATE}]
[MODIFY { (имя_столбца тип_данных атрибуты [,...] ) |
COLUMN имя_столбца [NOT] SUBSTITUTABLE AT ALL LEVELS [FORCE] } ]
[RENAME COLUMN старое_имя_столбца TO новое_имя_столбца]
[MODIFY {NESTED TABLE | VARRAY} элемент_коллекции [RETURN AS {LOCATOR |
VALUE}]]
- - изменяем параметры ограничения
[ADD CONSTRAINT имя_ограничения параметры_табличного__ограничения]
[MODIFY CONSTRAINT имя_ограничения параметры_состояния_ограничения]
[RENAME CONSTRAINT старое_имя_ограничения TO новое_имя_ограничения]
[DROP { { PRIMARY KEY | UNIQUE (column [,...]) } [CASCADE]
[{KEEP | DROP} INDEX] |
CONSTRAINT имя_ограничения [CASCADE] } ]
- - изменяем параметры секционирования таблицы
[изменения параметров секционирования']
- - изменяем параметры внешней таблицы
DEFAULT DIRECTORY имя_директории
[ACCESS PARAMETERS {USING CLOB подзапрос | ( непрозрачный_формат ) }
LOCATION ( [имя_директории:]'местоположение' [,...] )
[ADD (имя_столбца.. .)][DROP имя_столбца. . .][MODIFY (имя_столбца. . .)]
[PARALLEL int | NOPARALLEL]
[REJECT LIMIT {int | UNLIMITED} ]
[PROJECT COLUMN {ALL | REFERENCED} ]} }
- - параметры перемещения таблицы
[MOVE [ONLINE] [параметры_физических_атрибутов]
[TABLESPACE tablespace_name] [[NO]LOGGING] [PCTTHRESHOLD int]
[COMPRESS int | NOCOMPRESS] [MAPPING TABLE | NOMAPPING]
2447
Справочник по командам SQL
[[INCLUDING столбец} OVERFLOW
[параметры_физических_атрибутов] [TABLESPACE имя_табличной_области]
[[NOJLOGGING]] ]
[LOB ...] [VARRAY ...] [PARALLEL int | NOPARALLEL] ]
-- включение/отключение атрибутов и ограничений
[{ {ENABLE | DISABLE} [[NOJVALIDATE]] {UNIQUE {столбец [,..,] ) |
PRIMARY KEY | CONSTRAINT имЯ-Ограничения} ]
[USING INDEX {имя_индекса | инструкция_СВЕАТЕ_ЖЕХ |
[TABLESPACE имя_табличной-области] [параметры_физических_атрибутов]
[параметры_хранения]
[NOSORT] [[NOJLOGGING]] [ONLINE] [COMPUTE STATISTICS]
[COMPRESS | NOCOMPRESS] [REVERSE]
[{LOCAL | GLOBAL} параметры_секционирования)
[EXCEPTIONS INTO имЯ-Таблицы] [CASCADE] [{KEEP | DROP} INDEX] ] |
[{ENABLE | DISABLE}] [{TABLE LOCK | ALL TRIGGERS}] } ]
Ниже приводятся описания параметров.
ограничения _столбца
Определяется ограничение столбца с использованием синтаксиса, описание которого
приводится ниже.
GROUP журналъная_группа
(столбец [NO LOG]) [,...] [ALWAYS] | DATA (ограничения [,...]) COLUMNS
Для таблицы определяется журнальная группа (вместо одного журнального файла).
ON COMMIT {DELETE | PRESERVE] ROWS
Указывается, нужно ли в объявленной временной таблице держать данные актив-
ными в течение всего сеанса (PRESERVE) или только в период транзакции, в ходе
которой была создана временная таблица (DELETE).
параметры_табличного_ограничения
Определяется ограничение таблицы с использованием синтаксиса, описание
которого приводится ниже.
параметры_физических_атрибутов
Определяются физические атрибуты таблицы с использованием синтаксиса,
описанного в главе 2.
TABLESPA СЕ имя_табличного_пространства
Указывается имя табличного пространства, в котором будет храниться создаваемая
таблица.
параметры-Хранения
Указываются физические параметры хранения таблицы с использованием синтак-
сиса} описание которого приводится ниже.
[NO]LOGGING
Указывается, что при создании объекта будут создаваться записи журнала измене-
ний (redo log) (LOGGING) или же записи создаваться не будут (NOLOGGING).
По умолчанию принимается предложение LOGGING. В случае сбоя в базе данных
при указании предложения NOLOGGING операцию нельзя восстановить, приме-
226 | Глава 3. Справочник по инструкциям SQL
няя файлы журнала, и объект нужно будет создавать заново. Предложение
NOLOGG1NG может ускорить создание объектов базы данных. Предложение
LOGGING заменяет более старое предложение RECOVERABLE, которое вышло
из употребления.
CLUSTER (столбец [,...])
Объявляется, что таблица является частью кластеризованного индекса. Список
столбцов должен в точности соответствовать столбцам ранее объявленного кла-
стеризованного индекса. Поскольку предложение CLUSTER использует место, вы-
деленное для кластеризованного индекса, оно совместимо с параметрами пара-
метры_физических_атрибутов, параметры_хранения и TABLESPACE. Таблицы,
содержащие данные типов LOB, несовместимы с предложением CLUSTER.
ORGANIZATION HEAP
Указывается, как данные таблицы должны записываться на диск. Предложение
HEAP, которое используется в таблице Oracle по умолчанию, указывает, что не суще-
ствует определенного порядка хранения строк данных таблицы (т. е. физического
порядка записи строк на диск). Для предложения ORGANIZATION HEAP существует
несколько дополнительных предложений, описанных в данном списке, которые
управляют хранением, журналированием и сжатием таблицы.
ORGANIZATION INDEX
Указывается, как данные таблицы должны записываться надиск. Предложение INDEX
указывает, что записи таблицы физически записываются на диск в порядке соргиров-
ки, определяемом первичным ключом таблицы. В Oracle это называется индекс-таб-
лицей (index organized table). Наличие первичного ключа является обязательным.
Заметьте, что параметры параметры _физических_атрибутов, TABLESPACE и пара-
метрыхрапения, которые подробно описаны в других местах данного раздела,
а также ключевое слово [NO]LOGGING можно связывать с сегментом, включающим
предложение INDEX, при его создании. Кроме того, с предложением ORGANIZATION
INDEX можно связывать следующие дополнительные предложения.
PCTTHRESHOLD int
Объявляется процентная доля (int) места, которое в каждом индексном блоке
сохраняется для данных. Данные, которые при записи по одной строке не
помешаются в это место, будут записываться в сегмент переполнения (overflow
segment).
INCLUDING столбец
Указывается точка для разделения строки между индексным сегментом и сег-
ментом переполнения. Все столбцы, которые идут после указанного столбца,
будут записываться в сегмент переполнения. Столбец не может представлять
собой столбец первичного ключа.
MAPPING TABLE | NOMAPPING
В базе данных будут созданы соответствия между локальными и физическими
ROWID. Такие соответствия необходимы для создания индекса на основе
битовой карты по индекс-таблице. Если таблица секционируется, эти связи
Справочник по командам SQL | 227
также секционируются. При указании предложения NOMAPING база данных
не будет создавать карту ROWID.
[INCLUDING столбец] OVERFLOW
Указывается, что запись, которая выходит за предел, указанный в параметре
PCTTHRESHOLD, будет помещаться в сегмент, описанный в этом предложении.
Параметры параметры_физических_атрибутов, TABLESPACE и параметры_
хранения, которые подробно описаны в других местах данного раздела, а также
ключевое слово [NO]LOGGING можно связывать с конкретным сегментом
OVERFLOW при его создании. Дополнительное предложение INCLUDING
столбец определяет столбец, по которому делиться строка индекс-таблицы на
индексную часть и сегмент переполнения. Столбцы первичных ключей всегда
хранятся в индексе. Однако все столбцы непервичных ключей, которые идут
после указанного столбца, сохраняются в сегменте переполнения.
ORGANIZA TION EXTERNAL
Указывается, как данные таблицы должны записываться на диск. Предложение
EXTERNAL указывает, что данные таблицы хранятся за пределами базы данных и,
как правило, доступны только для чтения. Метаданные хранятся в базе данных, но
сами данные - за пределами базы. Внешние таблицы имеют несколько ограниче-
ний. Они не могут быть временными не могут содержать ограничения. Они могут
содержать только столбец, тип данных и атрибуты, описывающие столбец. Недо-
пустимы типы LOB и LONG. При использовании предложения EXTERNAL не до-
пускается использовать никакие другие предложения типа ORGANIZATION.
С предложением ORGANIZATION EXTERNAL можно использовать следующие
дополнительные предложения.
TYPE тип_драйвера
Определяет драйвер доступа API для внешней таблицы. По умолчанию при-
нимается ORACLELOADER.
DEFAULT DIRECTORY имя__директории
Указывается директория по умолчанию в файловой системе, в которой нахо-
дится внешняя таблица.
ACCESS PARAMETERS [USING CLOB подзапрос | (непрозрачный_формат)}
Присваивает и передает параметры в драйвер доступа. Система Oracle эти пара-
метры не интерпретирует. При указании предложения USING CLOB подзапрос
система Oracle берет параметры и их значения из подзапроса, который возвра-
щает одну строку с единственным столбцом типа CLOB. Подзапрос не может
содержать предложений ORDER BY, UNION, INTERSECT или MINUS!EXCEPT.
Предложение непрозрачный_формат позволяет указать параметры и их значе-
ния так, как это описывается в руководстве «Oracle9i Database Utilities», раздел
ORACLE LOADER.
LOCATION (имя_директории: 'местоположение' [,-])
Определяется один или несколько внешних источников данных, обычно в виде
файлов. Oracle не интерпретируют эту информацию.
228 | Глава 3. Справочник по инструкциям SQL
REJECT LIMIT (int \ UNLIMITED}
Определяет количество допустимых ошибок конверсии, int, при запросе
к внешнему источнику данных, после которого Oracle отменяет запрос и воз-
вращает ошибку. Предложение UNLIMITED показывает, что система должна
продолжать запрос независимо от того, сколько ошибок было обнаружено.
По умолчанию 0.
{ENABLE | DISABLE} ROW MOVEMENT
Предложение указывает, что строку при необходимости можно перемещать в другой
раздел или подраздел из-за обновления ключа {ENABLE) или ее перемещать нельзя
{DISABLE). При указании предложения DISABLE система Oracle будет возвращать
ошибку, если обновление ключа будет требовать перемещения.
[NO] CACHE
Буферизация таблицы для ускорения чтения. Предложение NOCACHE отключает
эту функцию. Индекс-таблицы имеют предложение CACHE.
[NO]MONITORING
Указывается, что для данной таблицы нужно производить сбор статистики измене-
ний {MONITORING). При указании предложения NOMONITOR1NG сбор статистики
не производится. Предложение NOMONITORING принимается по умолчанию.
[NO]ROWDEPENDENCIES
Указывается, будет ли в таблице использоваться проверка зависимостей на уровне
строк. При этом используется номер системного изменения (system change num-
ber, SCN) больший или равный времени последней транзакции, затронувшей
данную строку. При использовании SCN к каждой записи добавляется дополни-
тельно 6 байт. Проверка зависимостей на уровне строк наиболее полезна в среде
с репликацией и параллельным распространением данных. По умолчанию прини-
мается предложение NOROWDEPENDENCIES.
PARALLEL int | NOPARALLEL
Позволяет создавать таблицу параллельно несколькими процессорами, для ус-
корения операции. Также включается параллелизм запросов и других операций по
манипулированию данными в таблице после ее создания. Дополнительно можно
указать целое значение {int), показывающее число параллельно работающих пото-
ков при создании таблицы, а также тех, которые будут использоваться для обслу-
живания таблицы в будущем. (Система Oracle вычисляет оптимальное количество
параллельных потоков для данной операции, поэтому предложение PARALLEL не
является обязательным.) При заданном по умолчанию предложении NOPARALLEL
таблица создается последовательно и в дальнейшем запрещается параллельная
обработка запросов и операций по манипуляции данными.
COMPRESS [int] | NOCOMPRESS
Определяет, должна ли таблица сжиматься. В индекс-таблице сжимается только
ключ, в таблице типа HEAP сжимается вся таблица. Это предложение значительно
уменьшает место, занимаемое таблицей. По умолчанию принимается предложе-
ние NOCOMPRESS. В индекс-таблицах вы можете указывать количество сжимае-
мых префиксных столбцов {int). По умолчанию значение int равно количеству
Справочник по командам SQL | 229
ключей в первичном ключе минус единица. Вам не нужно указывать значение int
в других предложениях, таких, как ORGANIZATION. Если значение int опущено,
система Oracle применяет сжатие ко всей таблице.
{ENABLE | DISABLE} [[NO]VALIDATE] {UNIQUE (столбец [...] | PRIMARY KEY |
CONSTRAINT имя_ограничения)}
Указывается, нужно ли применять указанный ключ или ограничение ко всем данным
таблицы. При указании предложения ENABLE ключ или ограничение применяется
ко всем новым данным таблицы, а при указании предложения DISABLE ключ или
ограничение в новой таблице не используются. Существуют следующие опции.
[NO] VALIDATE
Производится (VALIDATE) или не производится [NOVALIDATE] проверка
того, что все существующие в таблице данные соответствуют ключу или огра-
ничению [VALIDATE]. Если совместно с предложением NOVALIDATE исполь-
зуется предложение ENABLE, Oracle не проверяет существующие в таблице
данные на соответствие ключу или ограничению, но обеспечивает соответст-
вие ограничению новых данных, добавляемых в таблицу.
{UNIQUE (столбец [,...] | PRIMARY KEY \ CONSTRAINT имя ^ограничения)}
Указывается включаемое или отключаемое ограничение UNIQUE, первичный
ключ или ограничение.
USING INDEX имя_индекса | выражение_СРЕАТЕ_ШОЕХ
Объявляется имя (имя_индекса) существующего индекса (и его параметры),
который будет использоваться для быстрого доступа по ключу или для реализации
ограничения, или же создается новый индекс (.выражение_СРЕАТЕ_!ЫОЕХ).
Если предложение опущено, система Oracle создает новый индекс.
EXCEPTIONS INTO
Указывается имя таблицы, в которую Oracle помещает информацию о строках,
нарушающих ограничение. Для явного создания такой таблицы перед исполь-
зованием этого ключевого слова выполните скрипт utlexptl.sql.
CASCADE
Распространяет операцию включения/отключения на все ограничения, связанные
с целостностью, которые зависят от ограничения, указанного в предложении.
Используется только с предложением DISABLE.
{KEEP | DROP} INDEX
Позволяет сохранить (KEEP) или удалить (DROP) индекс, связанный с уни-
кальным или первичным ключом. Удалить ключ можно только после его
отключения.
параметры-Секционирования
Определяет разбиение таблицы на разделы и подразделы. Синтаксис секциониро-
вания может быть весьма сложным. Обращайтесь к материалу, приведенному
ниже в этом разделе под заголовком «Разбиение таблиц Oracle на разделы
и подразделы», где описывается полный синтаксис и приводятся примеры.
230 | Глава 3. Справочник по инструкциям SQL
AS подзапрос
Определяется подзапрос, который вставляет строки в таблицу при ее создании.
Имена и типы столбцов, используемые в подзапросе, заменяют имена столбцов
и их параметры, определенные для таблицы.
AS объектный_тип
Объявляется, что таблица основывается на существующем объектном типе.
[NOT] SUBSTITUTABLE AT ALL LEVELS
Определяет, можно ли вставлять в объектную таблицу объекты-строки, соответ-
ствующие подтипам. Если предложение опущено, по умолчанию принимается
SUBSTITUTABLE AT ALL LEVELS.
встроеиное_ссылочное_ограничение и табличное_ссылочное_ограничение
Объявляется ссылочное ограничение, используемое в таблице объектного типа
или таблице XMLType. Эти предложения подробно описаны ниже в этом разделе
под заголовком «Таблицы объектного типа и XMLType в Oracle».
OBJECT IDENTIFIER IS {SYSTEM GENERATED | PRIMARY KEY}
Определяет, будет ли идентификатор объекта (object ID, OID) генерироваться систе-
мой (SYSTEM GENERATED) или основываться на первичном ключе (PRIMARYKEY).
Если предложение опущено, по умолчанию принимается SYSTEM GENERATED.
OIDINDEX [имя_индекса]
Объявляется индекс и, возможно, имя индекса, если OID генерируется системой.
При желании вы можете применять к OIDINDEX параметры_физических_атри-
бутов и параметры_хранения. Если OID основывается на первичном ключе, это
предложение является необязательным.
OF XMLTYPE
Объявляется, что таблица основывается на типе данных XMLTYPE.
XMLTYPE {OBJECT RELATIONAL [параметры _хранения_хт1] | CLOB [имя_сегмен-
majob] [параметры Job]}
Определяет хранение типа XMLTYPE. При указании предложения OBJECT
RELATIONAL данные хранятся в объектно-реляционных столбцах. Для этого
предложения необходим параметр xml_schema_spec и схема, предварительно
зарегистрированная с помощью пакета DBMS_XMLSCHEMA. Параметр CLOB
указывает, что данные типа XMLTYPE будут храниться в столбце LOB. При
желании вы можете указать имя сегмента LOB и/или параметры хранения LOB.
xml_schema_spec
Позволяет указать URL зарегистрированной схемы XML и имя элемента XML.
Имя элемента является необходимым параметром, a URL - необязательным.
ADD...
В существующую таблицу добавляется новый столбец, ограничение, сегмент
переполнения или дополнительная журнальная группа.
MODIFY...
В существующей таблице изменяется столбец, ограничение, сегмент переполнения
или дополнительная журнальная группа.
Справочник по командам SQL | 231
DROP...
Из существующей таблицы удаляется столбец, ограничение, сегмент переполне-
ния или дополнительная журнальная группа. Вы можете явным образом удалить
из таблицы столбцы, помеченные как неиспользуемые, с помощью предложения
DROP UNUSED COLUMN, однако система Oracle также будет удалять неисполь-
зуемые столбцы при уделении любого другого столбца. При указании ключевого
слова INVALIDATE любой объект, зависящий от удаленного объекта, становится
нерабочим и неиспользуемым до перекомпиляции или следующего использования.
Предложение COLUMNS CONTINUE используется в том случае, если инструкция
DROP COLUMN закончилась ошибкой и вы хотите продолжить ее выполнение
с текущего места.
RENAME...
Переименование существующей таблицы или столбца или ограничения в сущест-
вующей таблице.
SET UNUSED...
Объявляется, что столбец или столбцы являются неиспользуемыми. Столбец или
столбцы становятся недоступными для инструкций SELECT, хотя они по-прежне-
му учитываются при определении максимально допустимого числа столбцов
в таблице (1000). Предложение SET UNUSED - это самый быстрый способ сде-
лать столбец таблицы неиспользуемым, хотя и не самый лучший. Используйте
предложение SET UNUSED в качестве обходного пути, если вы не можете приме-
нить для удаления столбца инструкцию ALTER TABLE...DROP.
COALESCE
При указании этого предложения сливается содержимое индексных блоков, при-
меняемых при обслуживании индекс-таблицы, и индексные блоки можно исполь-
зовать повторно. Предложение COALESCE похоже на предложение SHRINK,
но COALESCE сжимает сегменты менее плотно, чем SHRINK, и не высвобождает
неиспользуемое место.
ALLOCATE EXTENT
Явно выделяется новый экстент для таблицы с применением указанных пара-
метров. Вы можете смешивать и указывать любые параметры. Размеры экстентов
могут измеряться в байтах (без суффикса), килобайтах (К), мегабайтах (М), гига-
байтах (G) или терабайтах (Т).
DEALLOCATE UNUSED [KEEP int[K \M\G\T]]
Высвобождается неиспользуемое место в конце таблицы, сегмента LOB, раздела
или подраздела. Высвобожденное место после этого могут использовать другие
объекты базы данных. С помощью ключевого слова KEEP указывается, сколько
места нужно оставить при выполнении высвобождения.
SHRINK SPACE [COMPACT] [CASCADE]
Уменьшает размер таблицы, индекс-таблицы, индекса, раздела, подраздела, материа-
лизованного представления или материализованного журнального представления.
Уменьшать можно только те сегменты табличных областей, в которых используется
автоматическое управление сегментом. При уменьшении размеров сегмента происхо-
232 | Глава 3. Справочник по инструкциям SQL
дит перемещение строк таблицы, поэтому в инструкции ALTER TABLE...SHRINK
должно использоваться предложение ENABLE ROW MOVEMENT. Система Oracle
сжимает сегмент, высвобождает место и настраивает уровень заполнения (high water
mark), если только не применяются ключевые слова COMPACTи/или CASCADE. При
использовании ключевого слова COMPACT происходит только дефрагментация про-
странства сегмента, и строка таблицы сжимается для последующего высвобождения
места, но уровень заполнения не настраивается, и место немедленно не высвобожда-
ется. При указании ключевого слова CASCADE выполняется та же самая операция по
уменьшению (с некоторыми ограничениями и исключениями) для всех зависимых
объектов в таблице, включая вторичные индексы и индекс-таблицы. Используется
только в инструкции ALTER TABLE.
UPGRADE [NOT] INCLUDING DATA
Метаданные объектных таблиц и реляционных таблиц с объектными столбцами
преобразуются к последней версии формата каждого упоминаемого типа. При
указании предложения INCLUDING DATA данные преобразуются к последней
версии формата типа или (NOTINCLUDING DATA) остаются неизменными.
MOVE...
Производится перемещение табличной области, индекс-таблицы, раздела или
подраздела в новое место в файловой системе.
[NO]MIN1MIZE RECORDS PER BLOCK
Система Oracle ограничивает или оставляет неизменным количество допустимых
записей в блоке. Ключевое слово MINIMIZE показывает, что система Oracle
должна вычислить максимальное число записей в блоке и установить предел,
соответствующий этому числу (лучше всего это делать, когда в таблицу уже внесен
достаточно репрезентативный объем данных).
PROJECT COLUMN {REFERENCE | ALL}
Предложение определяет, как драйвер внешнего источника данных будет про-
верять строки внешней таблицы при последующих запросах. При указании
ключевого слова REFERENCE обрабатываются только те столбцы, которые входят
в отобранный список элементов. При указании предложения ALL обрабатываются
значения во всех столбцах, даже тех, которые не входят в список отобранных эле-
ментов, и допустимыми признаются строки, содержащие полные и допустимые
элементы столбцов. При указании предложения ALL при возникновении ошибки
строка отбрасывается, даже если ошибка возникает в столбцах, которые не ото-
браны. При предложении ALL возвращаются согласующиеся результаты, тогда как
при предложении REFERENCE количество возвращаемых строк различается в за-
висимости от числа упоминаемых в ссылке столбцов.
{ENABLE | DISABLE} {TABLE LOCK | ALL TRIGGERS}
Включается или отключается блокировка уровня таблицы или все триггеры соот-
ветственно. Предложение ENABLE TABLE LOCK является необходимым, если вы
хотите внести изменения в структуру существующей таблицы, но оно не является
обязательным при изменении или чтении данных таблицы.
Справочник по командам SQL | 233
Глобальная временная таблица доступна для всех пользовательских сеансов,
но данные, хранимые в глобальной временной таблице, доступны только из сеанса,
в котором они были туда занесены. Предложение ON COMMIT, которое можно
использовать только при создании временных таблиц, указывает, что система Oracle
должна либо удалять данные из таблицы после каждой транзакции, проведенной
с этой таблицей (DELETE ROWS), либо удалять данные по завершении сеанса
(PRESERVE ROWS). Например:
CREATE GLOBAL TEMPORARY TABLE shipping_schedule
(ship_date DATE,
receipt_date DATE,
received_by VARCHAR2(30),
amt NUMBER)
ON COMMIT PRESERVE ROWS;
Приведенная выше инструкция CREATE TABLE создает глобальную временную
таблицу shipping_schedule, в которой сохраняются данные многих транзакций.
Параметры_физических_атрибутов в Oracle
Параметр параметры физических ^атрибутов (показан в приводимом ниже фрагмен-
те кода) определяет характеристики хранения всей локальной таблицы или, если таб-
лица секционирована, конкретного раздела (объяснения будут приведены ниже).
Чтобы объявить физические атрибуты новой таблицы или изменить атрибуты сущест-
вующей, просто объявите новые значения.
-- параметры_физических_атрибутов
[{PCTFREE int | PCTUSED int | INITRANS int |
MAXTRANS int | параметрьсхранения}]
Где:
PCTFREE int
Определяет процентную долю свободного места, зарезервированного для каждого
блока данных таблицы. Например, значение 10 резервирует 10% места для встав-
ки новых строк.
PCTUSED int
Определяет минимальную процентную долю занятого места в блоке, чтобы в него
можно было вставлять новые строки. Например, значение 90 означает, что в блок
данных можно вставлять новые строки только тогда, когда объем занятого места
падает ниже 90%. Сумма значений PCTFREE и PCTUSED не должна превышать
100%.
INITRANS int
Редко используется. Выделяется от 1 до 255 исходных транзакций на блок данных.
MAXTRANS int
Определяет максимальное число параллельных транзакций на блок данных.
234 | Глава 3. Справочник по инструкциям SQL
Параметры_хранения в Oracle и типы LOB
Параметр параметры хранения определяет несколько параметров, управляющих
физическим хранением данных.
-- параметры хранения
STORAGE ( [ {INITIAL int [К | М]
| NEXT int [К | М]
| MINEXTENTS int
| MAXEXTENTS { int | UNLIMITED}
| PCTINCREASE int
| FREELISTS int
| FREELIST GROUPS int.
I BUFFER._POOL {KEEP | RECYCLE | DEFAULT} ] )
При указании атрибутов предложения хранения заключайте их в скобки и отде-
ляйте друг от друга пробелами, например: (INITIAL 32М NEXT8M). Имеются сле-
дующие атрибуты.
INITIAL int [К | М]
Определяет размер исходного экстента таблицы в байтах, килобайтах (К) или ме-
габайтах (М). В Oracle 10g используется конструкция [К | М | G | Т], что соответст-
вует размеру в байтах, килобайтах (К), мегабайтах (М), гигабайтах (G) и терабай-
тах (Т).
NEXT int [К \М]
Определяет, сколько дополнительного места выделяется, когда заполняется исход-
ный экстент.
MINEXTENTS int
Указывает, какое минимальное количество экстентов должна создавать система
Oracle. По умолчанию создается только один, но при инициализации объекта
можно создавать и больше.
MAXEXTENTS int
Показывает максимально допустимое количество экстентов. Для этого предложе-
ния можно указать значение UNLIMITED. (Заметьте, что значение UNLIMITED
следует использовать осторожно, поскольку таблица может разрастаться до тех
пор, пока не займет все место на диске.)
PCTINCREASE int
Управляет скоростью разрастания объекта. Исходный экстент выделяется, как указано
в соответствующем параметре. Размер второго экстента определяется параметром
NEXT. Третий экстент вычисляется так: NEXT + (NEXT*PCTINCREASE). Если пара-
метр PCTINCREASE установлен в 0, то всегда используется NEXT. В противном
случае каждый дополнительный экстент будет на значение PCTINCREASE больше
предыдущего.
FREELISTS int
Устанавливается количество свободных блоков (freelist) для каждой группы.
По умолчанию 1.
Справочник по командам SQL | 235
FREELIST GROUPS int
Определяется количество групп свободных блоков (freelist group). По умолчанию 1.
BUFFER POOL {KEEP | RECYCLE | DEFAULT}
Указывается задаваемый по умолчанию пул или кеш буферов для любой некла-
стеризованной таблицы, в которой хранятся все блоки объекта. В индекс-таблицах
могут существовать отдельные пулы буферов для сегментов индекса и сегментов
переполнения. Секционированные таблицы наследуют пул буферов из определе-
ния таблицы, если им только специально не присвоен отдельный пул буферов.
KEEP
Блоки объекта помещаются в пул буферов KEEP, т. е. прямо в память. Это уве-
личивает производительность, поскольку уменьшается количество операций
ввода-вывода в таблице. Предложение KEEP имеет приоритет перед предло-
жением NOCACHE.
RECYCLE
Блоки объекта помещаются в пул буферов RECYCLE.
DEFAULT
Блоки объекта помещаются в пул буферов DEFAULT. Если предложение опу-
щено, по умолчанию используется пул буферов DEFAULT.
Например, таблица books_sales определена в табличном пространстве sales сле-
дующим образом: изначально занимает 8 Мб, прирост - не менее чем по 8 Мб, когда
первый экстент будет полон. Таблица имеет не менее одного и не более 8 экстентов,
что ограничивает ее максимальный размер 64 мегабайтами.
CREATE TABLE book_sales
(qty NUMBER,
period_end_date DATE,
period_nbr NUMBER)
TABLESPACE sales
STORAGE (INITIAL 8M NEXT 8M MINEXTENTS 1 MAXEXTENTS 8);
Пример таблицы large_objects с типами LOB, предназначенной специально для
хранения текста и изображений, может выглядеть следующим образом.
CREATE TABLE large_objects
(pretty_picture BLOB,
lnteresting_text CLOB)
STORAGE (INITIAL 256M NEXT 256M)
LOB (pretty_picture, interesting_text)
STORE AS (TABLESPACE large_object_segment
STORAGE (INITIAL 512M NEXT 512M)
NOCACHE LOGGING);
Точный синтаксис определения столбцов LOB, CLOB и NCLOB определяют пара-
метры lob. Типы LOB в таблице Oracle могут находиться на многих разных уровнях.
Например, отдельные определения типов LOB могут находиться в таблице в опреде-
236 | Глава 3. Справочник по инструкциям SQL
лении раздела, в определении подраздела и в таблице более высокого уровня. Синтак-
сис параметра следующий.
{TABLESPACE имя_табличной-области] [{ENABLE | DISABLE} STORAGE IN ROW]
[предложение-хранения] [CHUNK int] [PCTVERSION int] [RETENTION] [FREEPOOLS int]
[{CACHE | {NOCACHE | CACHE READS} [{LOGGING | NOLOGGING}] }] }
Все параметры_1оЬ идентичны параметрам инструкции CREATE TABLE, которые
определялись ранее на уровне объекта LOB, но следующие четыре параметра уни-
кальны для типов LOB.
{ENABLE | DISABLE} STORA GE IN ROW
Предложение определяет, будет ли значение LOB храниться во встроенном виде,
вместе с другими столбцами строки и указателем (locator), когда его размер примерно
4000 байт и меньше, или же оно будет храниться за пределами строки (DISABLE).
После установки этого параметра изменить его будет нельзя.
CHUNK int
Выделяется int байт для манипуляции с объектом LOB. Значение int должно быть
кратным размеру блока базы данных, в противном случае система Oracle округля-
ет это значение. Значение int. также должно быть меньше или равно значению
NEXT из предложения параметры-Хранения, в противном случае возникает
ошибка. Если предложение опущено, по умолчанию будет использоваться один
блок. После установки изменять этот параметр нельзя.
PCTVERSION int
Определяется процентная доля (int) от общего места, выделенного под хранение
данных LOB, отводимая для сохранения старых версий LOB. Если предложение
опущено, по умолчанию принимается 10%.
RETENTION
Используется вместо предложения PCTVERSION в базах данных, находящихся
в автоматического отката. При указании предложения RETENTION система Oracle
будет сохранять старые версии LOB.
В следующем примере показана наша таблица large_objects с дополнительными пара-
метрами, контролирующими внутреннее хранение и сохранение старых данных LOB.
CREATE TABLE large_objects
(pretty_picture BLOB,
interesting_text CLOB)
STORAGE (INITIAL 256M NEXT 256M)
LOB (pretty_picture, interesting_text)
STORE AS (TABLESPACE large_object_segment
STORAGE (INITIAL 512M NEXT 512M)
NOCACHE LOGGING
ENABLE STORAGE IN ROW
RETENTION);
Справочник по командам SQL | 237
В приведенном примере были добавлены параметры STORAGE IN ROW
и RETENTION. Однако, поскольку мы не указали параметр CHUNK, его значение
устанавливается в соответствии с заданным в Oracle значением по умолчанию для LOB.
Вложенные таблицы в Oracle
Система Oracle позволяет объявлять предложение NESTED TABLE, и в этом случае
таблица, по сути, будет храниться в столбце другой таблицы. Предложение STORE AS
позволяет указать имя для доступа к вложенной таблице, но вложенную таблицу из-
начально нужно создавать как пользовательский тип данных. Эта возможность полез-
на для неплотных массивов данных, но мы не рекомендуем использовать ее для повсе-
дневных задач. Пример:
CREATE- TYPE prop_nested_tbl AS TABLE OF props_nt;
CREATE TABLE proposal_types
(proposal_category VARCHAR2(50),
proposals PROPS_NT)
NESTED TABLE props_nt STORE AS props_nt_table;
В этом примере создается таблица с именем proposal_types, а также вложенная
таблица props_nt, которая записывается как props_nt_table.
Сжатые таблицы в Oracle
Система Oracle 10g (а также Oracle 9i Release 2) позволяет сжимать как ключи, так
и целые таблицы. (Oracle 9i позволяет сжимать только ключи.) Хотя при сжатии
несколько возрастает вычислительная нагрузка, при этом значительно уменьшается
объем места, занимаемого таблицей. Это особенно полезно для баз данных, выходя-
щих за пределы установленных размеров. Сжатие ключей обрабатывается в предло-
жении ORGANIZE INDEX, а сжатие таблицы - в предложении ORGANIZE HEAP.
Таблицы Oracle, разбитые на разделы и подразделы
Oracle позволяет разбивать (секционировать) таблицы на разделы и подразделы. Вы
также можете разделять на собственные разделы и данные типа LOB. Секционирован-
ная таблица может разбиваться на отдельные части, которые могут располагаться
в разных дисковых подсистемах для увеличения производительности ввода-вывода.
При этом используются четыре стратегии: диапазон, хеш, список и комбинация трех
предыдущих. Синтаксис секционирования довольно сложен.
{ PARTITION BY RANGE (столбец (PARTITION [имя_раздела]
VALUES LESS THAN ({MAXVALUE | значение}
[описание_секционирования_таблицы'] ) |
PARTITION BY HASH (столбец [,..,])
{(PARTITION [имя_раздела} [параметры_хранения_раздела'] [,,.,] |
PARTITIONS кол-во_хеш_разделов [STORE IN (табличное_пространство [,.,.])]
[OVERFLOW STORE IN (табличное_пространство [,...])]} I
PARTITION BY LIST (столбец [,..,]) (PARTITION [имя_раздела]
238 | Глава 3. Справочник по инструкциям SQL
VALUES ({MAXVALUE | значение}
[описание_секционирования_таблицы] |
PARTITION BY RANGE (столбец [,,..])
{подразделы_по_списку | подразделы_по_хеи1у}
(PARTITION [имя_раздела] VALUES LESS THAN
({MAXVALUE | значение} [,...])
[описание_секционирования_таблицы} ) }
В следующем примере кода показана таблица orders, секционированная по диапазону.
CREATE TABLE orders
(order_number NUMBER,
order_date DATE.
cust_nbr NUMBER,
price NUMBER,
qty NUMBER,
cust_shp_id NUMBER)
PARTITION BY RANGE(order_date)
(PARTITION pre_yr_2000 VALUES LESS THAN
T0_DATE('01-JAN-2000', 'DD-MON-YYYY'),
PARTITION pre_.yr_2004 VALUES LESS THAN
T0_DATE('01-JAN-2004', 'DD-MON-YYYY'
PARTITION post_yr_2004 VALUES LESS THAN
MAXVALUE) ) ;
В этом примере в таблице orders создаются три раздела: один для заказов до 2000 года
(рге_уг_2000), один для заказов до 2004 года (рге_уг_2004) и еще один для заказов после
2004 года (post_yr_2004). Все разделы основываются на датах, находящихся в столбце
orderdate.
В следующем примере создается таблица orders, основанная на хешировании по
значению cuxiomershippingid.
CREATE TABLE orders
(order_n'jmber NUMBER,
order_date DATE,-
cust_nbr NUMBER,
price NUMBER,
qty NUMBER,
cust_shp_id NUMBER)
PARTITION BY HASH (cust_stip_id)
(PARTITION sdp_id1 TABLESPACE tblspcOI,
PARTITION snp_id2 TABLESPACE tblspc02,
PARTITION shp_id3 TABLESPACE tblspc03)
ENABLE ROW MOVEMENT;
Крупное различие между способами распределения записей между разделами
в примере с хеш-секционированием и линейным (по диапазону) состоит в том, что
при линейном секционировании код явно определяет, в какой раздел попадает запись,
Справочник по командам SQL | 239
а при хеш-секционировании местоположение записи определяет Oracle (с помощью
хеш-алгоритма). Заметьте, что в таблице мы также включили возможность перемеще-
ния строк (ROWMOVEMENT).
Примеры списочного и комбинированного секционирования приведены в сле-
дующем разделе, вместе с информацией о подразделах. Помимо разбиения таблицы
на разделы (для упрощения резервного копирования, восстановления или для повы-
шения производительности) вы также можете проводить дальнейшее разбиение на
подразделы. Синтаксис предложения подразделы _по_списку следующий.
SUBPARTITION BY LIST (столбец)
[SUBPARTITION TEMPLATE
{ (SUBPARTITION имя_подраздела
[VALUES {DEFAULT | {значение | NULL} [,...] }
[параметры_хранения_разделов'] ) |
количество_хеш-подразделов } ]
Например, мы снова создадим таблицу orders, и на этот раз будем использовать ком-
бинированное секционирование линейное-хеш, когда разбивка на разделы производится
по значениям диапазона, а разбивка на подразделы - по хеш-значениям. Списочное раз-
биение на разделы и подразделы производится по небольшому списку конкретных значе-
ний. Поскольку вы должны перечислить все значения, по которым секционируется табли-
ца, значение для разбиения лучше всего брать из небольшого списка. В следующем при-
мере мы добавляем столбец (shpregionid), в котором допустимыми являются четыре
значения регионов.
CREATE TABLE orders
(order_number
order_date
cust_nbr
price
qty
cust_shp_id
shp_region
NUMBER,
DATE,
NUMBER,
NUMBER,
NUMBER,
NUMBER,
VARCHAR2(2O) )
PARTITION BY RANGE(order_date)
SUBPARTITION BY LIST(shp_region)
SUBPARTITION TEMPLATE(
(SUBPARTITION shp_region_north
VALUES ('north',’northeast’,'northwest'),
SUBPARTITION shp_region_south
VALUES ('south','southeast','southwest'),
SUBPARTITION shp_region_central
VALUES ('midwest'),
SUBPARTITION shp_region_other
VALUES ('alaska','hawaii','Canada')
(PARTITION pre_yr_2000 VALUES LESS THAN
TO_DATE('01-JAN-2000', 'DD-MON-YYYY'),
240 | Глава 3. Справочник по инструкциям SQL
PARTITION pre_yr_2004 VALUES LESS THAN
T0_DATE('01 -JAN-2004’, ’DD-MON-YYYY'
PARTITION post.yr_2004 VALUES LESS THAN
MAXVALUE) )
ENABLE ROW MOVEMENT;
В этом примере кода строки таблицы не только посылаются в один из трех разде-
лов в зависимости от даты заказа (order_date), но также посылаются в один из че-
тырех подразделов в зависимости от региона, в который направляется заказ (значение
в столбце shpjregion). При помощи предложения SUBPARTITION TEMPLATE один
и тот же набор подразделов может использоваться во всех разделах, Вы можете
вручную изменить это, указав подразделы для каждого раздела.
Вы можете провести разбиение на подразделы при помощи хеширующего алгоритма.
Ниже приводится синтаксис предложения подразделы _по_хешу.
SUBPARTITION BY HASH (столбец [,..,])
{SUBPARTITIONS количество [STORE IN {имя_табличной_области [,...]) ] I
SUBPARTITION TEMPLATE
{ (SUBPARTITION имя_подраздела [VALUES {DEFAULT | {значение | NULL}
[,,..] } [параметры_хранения__раздела'] ) |
количество_хеш-подразделов }
Предложение описание_секционирования_таблицы, входящее в синтаксис секцио-
нирования (в предыдущем разделе «Таблицы Oracle, разбитые на разделы и подразделы»),
само по себе является весьма гибким и позволяет производить точную обработку
данных LOB и VARRAY.
[параметры_.атрибутов_сегмента] [[NO] COMPRESS [int]] [OVERFLOW параметры.атрибу-
тов.сегмента]
[параметры_подраздела_в_разделе]
[{ LOB { {элемент_1оЬ [,,,.] ) STORE AS параметры_1оЬ |
{элемент_1оЬ') STORE AS {имя_сегмента_1оЬ (параметры_журнала) |
имя_сегмента_журнала | <,параметры_журнала) } } |
VARRAY элемент-Varray {[{[ELEMENT] IS OF [TYPE] (ONLY имя_типа) |
[NOT] SUBSTITUTABLE AT ALL LEVELS}] STORE AS LOB {имя_сегмента_журнала |
[имя_сегмента_журнала1 (параметры_журнала') } I
[{[ELEMENT] IS OF [TYPE] (ONLY имя.тала) |
[NOT] SUBSTITUTABLE AT ALL LEVELS}]
Синтаксис парометров_подраздела_в_разделе следующий.
{SUBPARTITIONS количество_хеш_подразделов [STORE IN (имя табличной_области
[,...])) I
SUBPARTITION имя_подраздела [VALUES {DEFAULT | {значение | NULL} [,...] ]
[параметры_хранение_раздела~\ }
16 - 2447
Справочник по командам SQL | 241
Предложение параметры _хранения_раздела (см. выше «Таблицы Oracle, разби-
тые на разделы и подразделы»), как и предложение уровня таблицы параметры хра-
нения, о котором рассказывалось ранее, определяет, каким образом хранятся элементы
раздела (или подраздела). Синтаксис следующий.
[{TABLESPACE имя_табличной_области'] | [OVERFLOW TABLESPACE
имя_табличной_области] |
VARRAY элемент_уаггау STORE AS LOB имя_журнального_сегмента |
LOB (элемент-Роб) STORE AS { (TABLESPACE имя_табличной_области') |
имя_журнального_сегмента [(TABLESPACE имя_табличной_области') ] }]
В следующем, последнем примере, посвященном секционированию, мы снова созда-
дим таблицу orders, используя комбинированное линейное-хеш секционирование, на этот
раз применительно к данным LOB (конкретно - к столбцу NCLOB), а также элементы, свя-
занные с хранением.
CREATE TABLE orders
(order_number NUMBER,
order_date DATE,
cust_nbr NUMBER,
price NUMBER,
qty NUMBER,
cust_shp_id NUMBER,
shp._region VARCHAR2(20),
order_desc NCLOB )
PARTITION'BY RANGE(order_date)
SUBPARTITION BY HASH(cust_shp_id)
(PARTITION pre^yr_2000 VALUES LESS THAN
TO_DATE('01-JAN-2000', 'DD-MON-YYYY') TABLESPACE tblspcOI
LOB (order_desc) STORE AS (TABLESPACE tblspc_a01
STORAGE (INITIAL 10M NEXT 20M) )
SUBPARTITIONS subpartn_a,
PARTITION pre_yr_2004 VALUES LESS THAN
TO_DATE('01-JAN-2004', 'DD-MON-YYYY') TABLESPACE tblspcO2
LOB (order_desc) STORE AS (TABLESPACE tblspc_a02
STORAGE (INITIAL 25M NEXT 50M) )
SUBPARTITIONS subpartn_b TABLESPACE tblspc_x07,
PARTITION post_yr_2004 VALUES LESS THAN
MAXVALUE (SUBPARTITION subpartnj,
SUBPARTITION subpartn_2,
SUBPARTITION subpartn_3
SUBPARTITION subpartn_4) )
ENABLE ROW MOVEMENT;
В этом, несколько более сложном примере мы определяем таблицу orders с добавле-
нием АООВ-таблицы с именем order_desc. Для разделов рге__уг_2000 и рге_уг_2004 мы
указали, что все данные, не относящиеся к типу LOB, направляются в табличное простран-
242 | Глава 3. Справочник по инструкциям SQL
ство tblspcOl и tb!spc02 соответственно, с отдельными уникальными параметрами хране-
ния. Отметьте, что подраздел subpartn_b в разделе рге_уг_2004 также сохраняется в соб-
ственном табличном пространстве, tb!spc_x07. И наконец, последний раздел
(post_yr_2004) и его подразделы сохраняются в заданном по умолчанию табличном про-
странстве таблицы orders, поскольку значение по умолчанию не заменяется предложения-
ми TABLESPACE уровня раздела или подраздела.
Изменение таблиц, разбитых на разделы и подразделы
После того как таблица создана, можно изменять любые разделы и подразделы,
явно созданные при помощи инструкции CREATE TABLE. Многие предложения,
приводимые ниже, являются повторениями предложений, описанных в предыду-
щем разделе, посвященном созданию секционированных таблиц; например, предло-
жение SUBPARTITION TEMPLATE или предложение MAPPING TABLE. Следова-
тельно, мы не будем повторно описывать эти предложения. Изменение разделов
и подразделов таблицы Oracle управляется следующим синтаксисом.
ALTER TABLE имя_таблицы
[MODIFY DEFAULT ATTRIBUTES [FOR PARTITION имя_раздела~\
[параметры__физических__атрибутов] [параметры_хранения] [PCTTHRESHOLD int]
[(ADD OVERFLOW ... | OVERFLOW ...}] [[NO]COMPRESS]
[{LOB {имя_1оЬ} | VARRAY имя_уаггау} [{параметры_1оЬ')'\ ]
[COMPRESS int | NOCOMPRESS]
[SET SUBPARTITION TEMPLATE {количество_хеш-разделов |
(SUBPARTITION имя_подраздела [слисок_подразделов][параметры_хранения'\)}]
[MODIFY PARTITION имя_раздела
{ [описание_секционирования_таблицы'\ |
[[REBUILD] UNUSABLE LOCAL INDEXES] |
[ADD [специфихация^подраздела] ] |
[COALESCE SUBPARTITION [[NO]PARALLEL] [парам_обновления_индекса] ] |
[{ADD | DROP} VALUES (.значение_раздела [,...] ) ] I
[MAPPING TABLE {ALLOCATE EXTENT ... | DEALLOCATE UNUSUED . ..} ]
[MODIFY SUBPARTITION имя_подраздела {атрибутъ^хеш-подраэдела I
атрибуты_списочного_подраздела} ]
[MOVE {PARTITION | SUBPARTITION} имя_раздела
[MAPPING TABLE] [описание^секционирования^аблицы] [[NO]PARALLEL]
[парам^бновления^ндекса] ]
[ADD PARTITION [имя_раздела'\ [описаниеуаекционирования_таблицы']
[[ NO]PARALLEL] [парам_обновления_индекса'\ ]
[COALESCE PARTITION [[NO]PARALLEL] [парам_обновления_индекса'\ ]
[DROP {PARTITION | SUBPARTITION} имя_раздела [[ND]PARALLEL]
[парам-обновления-индекса] ]
[RENAME {PARTITION | SUBPARTITION} старое_имя_раздела TO старое_имя_раздела~\
[TRUNCATE {PARTITION | SUBPARTITION} имя_раздела
[{DROP | REUSE} STORAGE] [[NOJPARALLEL] [парам_обновления_индекса~[ ]
[SPLIT {PARTITION | SUBPARTITION} имя_раздела {AT | VALUES}
Справочник по командам SQL | 243
{значение [,...])
[INTO (PARTITION [имя__раздела1) (описание_секционирования__таблицьг\ ,
(PARTITION [имя_раздела2'\ [описание_секционирования_таблицы] } ]
[[NO]PARALLEL] [парам^бновления^индекса] ]
[MERGE {PARTITION | SUBPARTITION} имя_раздела1, имя_раздела2
[INTO PARTITION [имя_раздела'\ [атрибуты^раздела] ] [[NO]PARAL.LEL]
[парам_обновления_индекса] ]
[EXCHANGE {PARTITION | SUBPARTITION} имя_раздела WITH TABLE имя^таблицы
[{INCLUDING | EXCLUDING} INDEXES] [{WITH | WITHOUT} VALIDATION]
[.[NO]PARALLEL] [параМ-ОбновлениЯ-ИНдекса] [EXCEPTIONS INTO имя_таблицы] ]
Где:
MODIFY DEFA ULT ATTRIBUTES [FOR PARTITION имя_раздела]
Изменяется широкий диапазон атрибутов текущего раздела или раздела, указан-
ного в параметре имя_раздела. За описанием атрибутов разделов обращайтесь
к части «Таблицы Oracle, разбитые на разделы и подразделы» выше в этой главе.
SET SUBPARTITION TEMPLATE {количество_хеш_подразделов |
(SUBPARTITION имя_подраздела [список_подразделов] [параметры ^хранения])}
Определяется новый шаблон подразделов таблицы.
MODIFY РА R TITION имя_раздела
Изменяет широкий диапазон физических атрибутов и параметров хранения, в том
числе параметры хранения столбцов LOB и VARRAY в существующем разделе или
подразделе с именем имя_раздела. К предложению MODIFY PARTITION имя_раздела
можно добавлять дополнительный синтаксис.
{ [описание_секционирования_таблицы] | [[REBUILD] UNUSABLE LOCAL INDEXES] I
[ADD [спецификация-подраздела] ] |
[COALESCE SUBPARTITION [[NO]PARALLEL] [парам_обновления_индекса]
{ [{UPDATE | INVALIDATE} GLOBAL INDEXES] |
UPDATE INDEXES [ (имя_индекса (
{раэдел_индекса | подраздел_индекса} ))[,...]]}] I
[{ADD | DROP} VALUES (значение_раздела [,...] ) ] |
[MAPPING TABLE {ALLOCATE EXTENT ... | DEALLOCATE UNUSUED ...}
Где:
описание секционирования__m абл ицы
Описано выше, в разделе «Таблицы Oracle, разбитые на разделы и подразделы».
Это предложение можно применять в любой секционированной таблице.
[REBUILD] UNUSABLE LOCAL INDEXES
Раздел локального индекса помечается как непригодный к использованию
(UNUSABLE). При добавлении ключевого слова REBUILD система Oracle
перестраивает непригодные локальные разделы индекса в ходе операции, произ-
водимой инструкцией MODIFY PARTITION. Это предложение не может исполь-
зоваться ни с каким другим предложением инструкции MODIFY PARTITION,
а также не может использоваться в таблице с подразделами. Это предложение
может использоваться в любой разбитой на разделы таблице.
244 | Глава 3. Справочник по инструкциям SQL
ADD [спецификация_подраздела]
К существующему линейному секционированию добавляется хеш- или списочное
разбиение на подразделы, как это описывалось выше, в разделе «Таблицы Oracle,
разбитые на разделы и подразделы». Это предложение можно использовать только
для определения линейного-хеш или линейно-списочного комбинированного сек-
ционирования. Система Oracle заполняет новый подраздел строками из других
подразделов, используя либо хеш-функцию, либо список указанных значений.
Для оптимального распределения нагрузки мы рекомендуем, чтобы общее число
подразделов было равно степени двойки. Вы можете добавлять линейно-спи-
сочные подразделы только в том случае, если у таблицы еще нет подраздела по
умолчанию (DEFAULT). При добавлении линейно-списочных разделов необходимо
предложение, определяющее значение списка (value), но оно не может дублиро-
вать значения, находящиеся в любом другом подразделе текущего раздела. Един-
ственный атрибут, который можно использовать с этим предложением (как для ли-
нейного-хеш, так и для линейно-списочного секционирования), является предло-
жение TABLESPACE.
СОА LESCE SUBPARTITION [[NO] PARALLEL] [параметры_обновления_индекса]
Объединяются подразделы таблицы, разбитой при помощи комбинированного,
линейного-хеш секционирования. При указании этого предложения система
Oracle переносит содержимое последнего хеш-подраздела в один или несколько
оставшихся подразделов, а затем удаляет последний хеш-подраздел. Система
Oracle также удаляет подразделы локального индекса, соответствующие
подразделу, участвующему в слиянии. Предложение параметры_обиовле-
ния_индекса описывается ниже в этом списке. Глобальные индексы могут
быть обновлены или признаны недействительными с помощью синтаксиса
{UPDATE | INVALIDATE} GLOBAL INDEXES. Кроме того, можно обновить
локальные индексы, разделы индексов или подразделы индексов с помощью
синтаксиса UPDATE INDEXES [(имя_индекса {раздел_индекса | подраз-
дел_индекса})].
{ADD | DROP] VALUES (значение_раздела [,...])
Добавляется новое значение (или значения) или удаляются существующие
в существующей таблице со списочным секционированием соответственно.
Локальные и глобальные индексы данное предложение не затрагивает. Нельзя
добавлять или удалять значения в списочном разбиении DEFA ULT.
MAPPING TABLE {ALLOCATE EXTENT. . | DEALLOCATE UNUSED...}
Определяется таблица соответствий для секционированной индекс-таблицы.
Предложения ALLOCATE EXTENT и DEALLOCATE UNUSED описаны ранее
в синтаксисе инструкции CREATE TABLE. Это предложение можно использо-
вать в любом типе секционированных индекс-таблиц.
Справочник по командам SQL | 245
MODIFY SUBPARTITION имя_подраздела
{атрибуты_хеш_подраздела | атрибуты-Списочного_подраздела}
Указанный хеш- или списочный подраздел изменяется в соответствии с атрибута-
ми подраздела, которые описаны ранее в части «Таблицы Oracle, разбитые на раз-
делы и подразделы».
[MOVE {PARTITION | SUBPARTITION} имяраздела [MAPPING TABLE]
[описание_секционирования_таблицы] [[NO]PARALLEL] [параметры_обновления_индекса]]
Перемещение указанного раздела (или подраздела) с именем имя_раздела
в другой раздел (или подраздел), описанный в предложении описание секцио-
нирования^таблицы, о котором рассказывалось ранее в части «Таблицы Oracle,
разбитые на разделы и подразделы». Перемещение раздела создает нагрузку на
каналы ввода-вывода, поэтому эту операцию можно сделать параллельной, указав
предложение PARALLEL. Если предложение опущено, по умолчанию принимается
NOPARALLEL. Кроме того, при желании вы можете обновить или признать недей-
ствительными локальные и глобальные индексы таблицы с помощью предложе-
ния парал1етры_об11Овления_индекса, которое описывается ниже в этом списке.
ADD PARTITION [имя_раздела] [описание_секционирования_таблицы] [[NO]PARALLEL]
Новый раздел или подраздел добавляется к разделу таблицы с именем имя_раздела.
Предложение ADD PARTITION поддерживает все аспекты создания нового раздела
или подраздела при помощи предложения описание_секционирования_таблицы, ко-
торое описывается выше, в части «Таблицы Oracle, разбитые на разделы и подразде-
лы». Добавление раздела может создавать нагрузку на каналы ввода-вывода, поэтому
при желании вы можете сделать операцию параллельной с помощью предложения
PARALLEL. Если предложение опущено, по умолчанию принимается NOPARALLEL.
Кроме того, при желании вы можете обновить или признать недействительными
локальные и глобальные индексы таблицы с помощью предложения пара-
метры_обновления_индекса, которое описывается ниже в этом списке.
параметры _обн овл ен ия_индекса
Управляет состоянием, присваиваемым индексам при изменении разделов и/или
подразделов таблицы. По умолчанию Oracle считает недействующим весь ин-
дексы) таблицы, а не только ту его часть, которая относится к измененному разде-
лу или-подразделу. Вы можете обновить или признать недействительными индек-
сы таблицы ИЛИ обновить один или несколько конкретных индексов соответст-
венно, используя следующий синтаксис.
{ UPDATE | INVALIDATE} GLOBAL INDEXES] |
UPDATE INDEXES [ (.имя_индекса (,{раздел_индекса\подраздел_индекса} ) ) }
COALESCE PARTITION [[NO]PARALLEL] [параметры-Обновления _индекса]
Берет содержимое последнего раздела в наборе хеш-разделов и при помощи хеш-
функции перераспределяет его между другими разделами(ом) набора. После этого
последний раздел удаляется. Очевидно, что это предложение предназначено
только для хеш-секционирования. Можно использовать предложение пара-
метры-Обновления_индекса, показанное выше, чтобы обновить или признать
246 | Глава 3. Справочник по инструкциям SQL
недействительными локальные и/или глобальные индексы таблицы, в которой
производится слияние.
DROP {PARTITION | SUBPARTITION} [имя^раздела] [[NO]PARALLEL]
[описание_секционирования_таблицы]
Из таблицы удаляется существующий линейный или хеш-раздел или подраздел
с именем имя^раздела. Данные, содержащиеся в разделе, также удаляются. Если вы
хотите сохранить данные, используйте предложение MERGE PARTITION. Если
вы хотите убрать хеш-раздел или подраздел, используйте предложение COALESCE
PARTITION. Таблицы, содержащие только один раздел, не затрагиваются инструкцией
ALTER TABLE...DROP PARTITION. Вместо нее нужно использовать инструкцию
DROP TABLE.
RENAME {PARTITION | SUBPARTITION] старое_имя_раздела ТО новое_имя_раздела
Переименование существующего раздела или подраздела старое_имя_раздела
в раздела.
TRUNCATE {PARTITION | SUBPARTITION] имя ^раздела [{DROP | REUSE} STORAGE]
[[NO]PA RA LLEL] [парам_обновления_индекса]
Из раздела или подраздела с именем имя_раздела удаляются все строки. Если вы
урезаете комбинированный раздел, то удаляются также все строки подраздела(ов).
В индекс-таблицах также урезаются разделы таблицы соответствий и разделы для
переполнения. Данные LOB и индексные сегменты, если в таблице есть столбцы
LOB, также урезаются. Отключите все существующие ограничения ссылочной це-
лостности данных или сначала удалите строки из таблицы, а потом урезайте раз-
делы или подразделы. Дополнительные предложения DROP STORAGE и REUSE
STORAGE определяют, будет ли место, высвободившееся при усечении, доступно
для других объектов табличного пространства или останется выделенным для раз-
дела или подраздела соответственно.
SPLIT {PARTITION | SUBPARTITION] имя_раздела {AT | VALUES] (значение [,...])
[INTO (PARTITION [имя_раздела1] [описание_секционирования_таблицы], (PARTITION
[имя_раздела2] [описание_секционирования_ таблицы])] [[NO]PARALLEL]
[парам_обновления_индекса]
Из текущего раздела или подраздела с именем имя_раздела создается два новых раз-
дела (или подраздела) с именами имя_раздела! и имя_раздела2. Эти новые разделы
могут иметь свои собственные параметры, определяемые в предложении описа-
ние_секционирования_таблицы. Если это предложение опущено, новые разделы
на следуют все физические параметры существующих. При разделении раздела
DEFA ULT все значения, заданные для разделения, попадают в раздел имя_раздела1,
а все значения по умолчанию - в имя_раздела2. Для индекс-таблицы система Oracle
разбивает таблицу соответствий так же, как саму таблицу. Oracle также разделяет
сегменты LOB и сегменты переполнения (overflow), но вы также можете указать
собственные параметры хранения LOB и OVERFLOW, которые описывались ранее
в разделе «Таблицы Oracle, разбитые на разделы и подразделы». Дополнительный
синтаксис для этого предложения приводится ниже.
Справочник по командам SQL | 247
{AT\ VALUES} (значение [,...])
Линейные разделы расщепляются (с помощью предложения АТ), а списочные -
(с помощью предложения VALUES) в соответствии с указанным значением или
значениями. В предложении АТ (значение) указывается верхняя граница диапа-
зона (не включая само число) для первого из двух новых разделов. Новое значе-
ние должно быть меньше, чем пограничное значение для текущего раздела, но
больше, чем пограничное значение для следующего раздела (если таковой суще-
ствует). Предложение VALUES (значение!, значение2 [,...] ) определяет значе-
ния, попадающие в первый из двух новых списочных разделов. Первый из
новых списочных разделов начинается со значения!, а второй создается из остав-
шихся в текущем (имя_раздела) разделе значений. Значения должны быть те,
которые уже существуют в текущем разделе, но нельзя указать все значения,
имеющиеся в текущем разделе.
INTO
Определяются два новых раздела, получающиеся в результате расщепления.
Как минимум, необходимо указать в скобках два ключевых слова PARTITION.
Любые характеристики, которые не определены явно для новых разделов, на-
следуются из текущего раздела с именем имя.раздела, в том числе разбиение
на подразделы. Нужно отметить несколько ограничений. При разбиении на
подразделы таблицы с комбинированным линейным-хеш секционированием
в подразделах можно использовать только значение TABLESPACE. Не разре-
шается разбивать на подразделы таблицу с линейно-списочным комбиниро-
ванным секционированием. Любые индексы для таблиц, организованных
по принципу кучи (heap-organized table), становятся недействительными
после расщепления таблицы. Для обновления состояния необходимо исполь-
зовать предложение параметры.обновления.индекса.
MERGE {PARTITION | SUBPARTITION} имя .раздела!, имя_раздела2 [INTO PARTITION
[имя.раздела] [атрибуты.раздела] ] [[NO]PARALLEL] [параметры.обновления.индекса]
Осуществляется слияние содержимого двух и более разделов или подразделов
в один новый раздел. Два исходных раздела после этого удаляются. Линейные раз-
делы, участвующие в слиянии, должны быть смежными и при слиянии соеди-
няются по верхней границе. Если в слиянии участвуют списочные разделы, они не
обязательно должны быть смежными, и результатом будет один новый раздел,
содержащий объединенные наборы значений из двух разделов. Если один из спи-
сочных разделов был разделом по умолчанию (DEFAULT), то разделом по умолча-
нию будет новый раздел. Слияние комбинированных линейно-списрчных разде-
лов допускается, но при этом не может быть нового шаблона подразделов. Систе-
ма Oracle создает шаблон подразделов из существующего(их) или, если такового
нет, создает новый подраздел по умолчанию (DEFAULT). Физические атрибуты,
не указанные явно, наследуются из параметров уровня таблицы. По умолчанию
система Oracle делает все разделы локального индекса и глобальных индексов не-
пригодными (UNUSABLE), если только такое поведение не изменяется при
помощи предложения параметры_обновления_инд,екса. (Исключением из этого
248 | Глава 3. Справочник по инструкциям SQL
правила являются индекс-таблицы, которые, будучи основаны на индексе,
остаются рабочими после операции слияния.) Операцию слияния не разрешается
проводить в таблицах с хеш-секционированием. Вместо этого предложения для
них нужно использовать предложение COALESCE PARTITION.
EXCHANGE {PARTITION | SUBPARTITION} имя_раздела WITH TABLE имяупаблицы
[{INCLUDING | EXCLUDING} INDEXES] [{WITH | WITHOUT} VALIDATION]
[[NO]PARALLEL] [параметры^обиоаления^ицдекса] [EXCEPTIONSINTO имятаблицы]
Обмен сегментами данных и индекса между несекционированной и секциониро-
ванной таблицами или секционированной таблицей одного типа и секционирован-
ной таблицей другого типа. Структура таблиц, в которых производится обмен,
должна быть идентична. Это касается и первичного ключа. Обмен касается всех
атрибутов сегментов (таких, как табличные пространства, журналирование и ста-
тистика) текущей секционированной таблицы (имя_раздела) и таблицы, с которой
производится обмен (имя таблицы). Таблицы, содержащие столбцы LOB, также
выполняют обмен данными LOB и сегментами индекса. Дополнительный синтак-
сис, который в этом списке нигде ранее не упоминался:
WITH TABLE имя таблицы
Определяется таблица, которая будет обмениваться данными с текущим раз-
делом или подразделом.
{INCLUDING | EXCLUDING} INDEXES
При указании предложения INCLUDING INDEXES производится обмен
между разделами или подразделами локального индекса и индексом таблицы
(несекционированной) или локальным индексом (при хеш-секционировании).
При указании предложения EXCLUDING INDEXES все разделы и подразделы
индекса, а также обычный или секционированный индекс второй таблицы по-
лучают статус непригодных (UNUSABLE).
{WITH\ WITHOUT} VALIDATION
При использовании предложения WITH VALIDATION, если любая строка теку-
щей таблицы не соотносится с разделом или подразделом второй таблицы,
генерируется ошибка. Чтобы отменить проверку соответствия строк, исполь-
зуйте предложение WITHOUT VALIDATION.
EXCEPTIONS INTO имя упаблицы
ROWID всех строк, нарушающих ограничение UNIQUE (при указании предложе-
ния DISABLE VALIDATE), помещаются в секционированную таблицу. Если
предложение опущено, Oracle использует таблицу, находящуюся в текущей схеме
и называющуюся EXCEPTIONS. Таблица EXCEPTIONS создается с помощью
скриптов utlexcpt.sql и utlexcptl.sql, поставляемых с системой Oracle. Если вам
нужны эти скрипты, обращайтесь к документации Oracle.
Существует несколько моментов, касающихся изменения секционированной табли-
цы, которые вам следует запомнить. Во-первых, изменение раздела таблицы, которая
служит источником для одного или нескольких материализованных представлений, тре-
бует обновления этих материализованных представлений. Во-вторых, соединительные
Справочник по командам SQL | 249
индексы на основе битовых карт (bitmap join indexes) для измененной секционированной
таблицы будут помечены как непригодные к использованию (UNUSABLE). В-третьих,
если разделы (или подразделы) распространялись на несколько табличных пространств,
использующих разный размер блока, то налагаются некоторые ограничения. Если вам
нужно внести изменения такого рода в секционированную таблицу, обращайтесь к доку-
ментации Oracle.
В нескольких следующих примерах мы используем таблицу orders, секциониро-
ванную так, как показано ниже.
СВЕАТЕ TABLE orders
(order_number NUMBER,
order_date DATE,
cust_nbr NUMBER,
price NUMBER,
qty NUMBER,
cust_shp_id NUMBER)
PARTITION BY RANGE(order_date)
(PARTITION pre_yr_2000 VALUES LESS THAN
TO_DATE('01-JAN-2000', 'DD-MON-YYYY'),
PARTITION pre_yr_2004 VALUES LESS THAN
TO_DATE('01-JAN-2004', 'DD-MON-YYYY'
PARTITION post_yr_2004 VALUES LESS THAN
MAXVALUE) ) ;
В следующем примере будут помечены как непригодные к использованию все
разделы локального индекса таблицы orders, относящиеся к разделу post_yr_2004.
ALTER TABLE orders MODIFY PARTITION post_yr_2004
UNUSABLE LOCAL INDEXES;
Однако теперь мы решили разбить раздел post_yr_2004 таблицы orders на два
новых раздела: рге_уг_2008 и post_yr_2008. Теперь значения меньшие, чем MAXVALUE,
будут сохраняться в разделе post_yr_2008, а значения меньшие, чем 01-J/1W-2008,
будут сохраняться в разделе рге_уг_2008.
ALTER TABLE orders SPLIT PARITION post_yr_2004
AT (T0_DATE('01-JAN-2008','DD-MON-YYYY'))
INTO (PARTITION pre_yr_2008, PARTITION post_yr_2008);
Если предположить, что таблица orders содержит столбец LOB или VARRAY, мы
должны уточнить вносимые изменения, включив информацию, касающуюся обработки
этих столбцов, а также обновить глобальные индексы по завершении операции.
ALTER TABLE orders SPLIT PARITION post_yr_2004
AT (T0_DATE('01-JAN-2008','DD-MON-YYYY'))
INTO
(PARTITION pre_yr_2008
LOB (order_desc) STORE AS (TABLESPACE order_tblspc_a1),
PARTITION post_yr_2008)
250 | Глава 3. Справочник по инструкциям SQL
i.OB (O'de'-.cesc) STO4L AS (TABitSPACt oroer iblspc.ai) )
j^DA’L Gl03AL INDEXES:
Теперь, предполагая, что таблица orders растет в сторону увеличения чисел,
давайте выполним слияние разделов с того конца, где расположены .меныпис числа.
Л|Д ЕР. тдв: Е огсагу.
MERGE PAHIJTLCNS ;ие..уг_2С00. pre.„yi ^2004
INTO PAR’iiJCN yrc_2004 _a.nd._ear] ier;
Еше через несколько лет нам может понадобиться вообще удалить наиболее
старые разделы или если не удалять их, то хотя бы дать им более подходящее имя.
AcTLR IA3LC orders DROP PARTITION угз_2004_ап<! ,earlier;
A: Irii TA3lr orders RENAME PA^TI’ION yrr._2004.and earlier 10 pre_yr 2004
И наконец, давайте отрежем раздел таблицы, удалим из него все данные и высво-
бодим неиспользуемое место для других объектов в табличном пространщве.
AJER TABLE- c'derr
’RJNOATE PARTITCN. pre yr .2004
U:’OP STORAGE:
Как показывают приведенные примеры, все параметры, связанные с разбиением
на разделы и подразделы, которые были указаны при помощи инструкции CREATE
TABLE, впоследствии в Oracle можно изменять, увеличивать или уменьшать при
помощи инструкции ALTER TABLE.
Организованные таблицы; кучи, индекс-таблицы и внешние таблицы
Система Oracle 10g предоставляет мощные способы управления физическим храпением
таблиц.
Наиболее полезной стороной предложения ORGANIZATION HEAP является то,
что теперь в Oracle вы можете сжимать всю таблицу. Это особенно полезно с точки
зрения уменьшения затрат дискового пространства базами данных, содержащими
миоготерабайтиые таблицы. В приведенном ниже примере создается сжатая и журна-
лируемая таблица-куча orders, а также указываются ограничения PRIMARY KEY
и детали хранения.
C4GATE “ABLE orders
(orde’-.r^mbe'' NUMBER.
огрсА-СШ-е DATE.
cust_nbr NUMBER,
pr 1СЙ NUMBER.
qty NUMBER,
cupt_plip NUMBER.
phc.-eg-.on VAIiC;IAR2( 20)
order. depc NCLOB,
CONSTRAINT erd_nbr_p3 PRIMARY KEY (order.rubber) )
ORGANIZATION HEAP
Справочник ио командам SQL | 251
COMPRESS LOGGING
PCTTHRESHOLD 2
STORAGE
(INITIAL 4M NEXT 2M PCTINCREASE О MINEXTENTS 1 MAXEXTENTS '1)
OVERFLOW STORAGE
(INITIAL 4M NEXT 2M PCTINCREASE О MINEXTENTS 1 MAXEXTENTS 1)
ENABLE ROW MOVEMENT;
Чтобы определить ту же самую таблицу в виде индекс-таблицы, основанной на
столбце order_date, следует использовать такой синтаксис.
CREATE TABLE orders
(order_number NUMBER,
order_date DATE,
cust_nbr NUMBER,
price NUMBER,
qty NUMBER,
cust_shp_id NUMBER,
shp_region VARCHAR2(20),
order_desc NCLOB,
CONSTRAINT ord_nbr_pk PRIMARY KEY (order_number) )
ORGANIZATION HEAP
INCLUDING order_date
PCTTHRESHOLD 2
STORAGE
(INITIAL 4M NEXT 2M PCTINCREASE 0 MINEXTENTS 1 MAXEXTENTS 1)
OVERFLOW STORAGE
(INITIAL 4M NEXT 2M PCTINCREASE 0 MINEXTENTS 1 MAXEXTENTS 1)
ENABLE ROW MOVEMENT;
И наконец, мы создадим внешнюю таблицу cust_shipping_external, которая
хранит информацию о поставках. Код, выделенный жирным шрифтом, - это пара-
метры непрозрачного формата {opaque jormatjspec).
CREATE TABLE cust_shipping_external
(external_cust_nbr NUMBER(6),
cust_shp_id NUMBER,
shipping_company -VARCHAR2(25) )
ORGANIZATION EXTERNAL
(TYPE oracle_loader
DEFAULT DIRECTORY dataloader
ACCESS PARAMETERS
(RECORDS DELIMITED BY newline
BADFILE 'upload_shipping.bad'
DISCARDFILE 'upload_shipping.dis'
LOGFILE 'upload_shipping.log'
SKIP 20
252 | Глава 3. Справочник по инструкциям SQL
FIELDS TERMINATED BY OPTIONALLY ENCLOSED BY '
(client_id INTEGER EXTERNAL(G).
shp_id CHAR(20),
shipper CHAR(25) ) )
LOCATION ('upload_shipping.ctl') )
REJECT LIMIT UNLIMITED;
Изучив этот пример, мы увидим, что тип внешней таблицы - ORACLE LOADER,
а директория по умолчанию - DATALOADER. Этот пример иллюстрирует тот факт, что
метаданные таблицы определяются в Oracle, а затем описывается, каким образом мета-
данные связаны с источником данных за пределами самого сервера базы данных Oracle.
Таблицы Oracle типа XMLType и объектных типов
Когда создается таблица XMLType, система Oracle автоматически сохраняет данные
в столбце CLOB, если только вы не создаете таблицу, основанную на XML-схеме
(за более детальным изложением поддержки XML в Oracle обращайтесь к руково-
дству Oracle XMLDB Developer’s Guide). В приведенном примере кода сначала созда-
ется таблица XMLType с именем distributors и неявным сохранением данных CLOB.
После этого идет второй пример кода, таблица suppliers, с более сложным определе-
нием XML-схемы.
CREATE TABLE distributors OF XMLTYPE;
CREATE TABLE suppliers OF XMLTYPE
XMlSCHEMA "http://www. lookatallthisstuf f. co.n/suppliers. xsd"
ELEMENT "vendors";
Основным преимуществом таблицы, основанной на схеме XML, является то, что
вы можете создавать по ним иерархические индексы (В-Tree index). В следующем
примере мы создаем индекс для таблицы suppliercity.
CREATE INDEX supplier_city_index
ON suppliers
(S."XMLDATA"."ADDRESS"."CITY");
Сходным образом можно создавать таблицы, используя смесь стандартных столб-
цов и XMLTYPE. В следующем примере в столбце XMLTYPE данные могут храниться
в виде CLOB или же в указанном вами объектно-реляционном столбце. Например, мы
снова создадим таблицу distributors (в этот раз - с некоторыми дополнительными
параметрами хранения) и таблицу suppliers со столбцами стандартного типа и типа
XMLTYPE.
CREATE TABLE distributors
(distributbr_id NUMBER,
distributbr_spec XMLTYPE)
XMLTYPE distributor_spec
STORE AS CLOB
(TABLESPACE tblspc„dist
Справочник по командам SQL | 253
STORAGE (INITIAL 1OM NEXT 5M)
CHUNK 4000
NOCACHE
LOGGING);
CREATE TABLE suppliers
(supplier_id NUMBER,
supplier_spec XMLTYPE)
XMLTYPE supplier_spec STORE AS OBJECT RELATIONAL
XMLSCHEMA "http://www.lookatallthisstuff.com/suppliers. xsd"
ELEMENT "Vendors"
OBJECT IDENTIFIER IS SYSTEM GENERATED
OIDINDEX vendor_ndx TABLESPACE tblspc_xml_vendors',
При создании XML-таблиц и объектных таблиц вы можете использовать предло-
жения встроенное_ссы:ючное_ограничение и табличное_ссылочное_ограничение.
Синтаксис встроенного_ссылочного_ограничения следующий.
{SCOPE IS таблица_область_действия |
WITH ROWID |
[CONSTRAINT имя_отраничения] REFERENCES объект [ (.имястолбца) ]
[ON DELETE {CASCADE | SET NULL} ]
[состояние_ограничения] }
Единственное различие между встроенным ссылочным ограничением и таб-
личным ссылочным ограничением состоит в том, что встроенное ограничение работает
на уровне столбца, а табличное ограничение - на уровне таблицы. (По сути это то же
самое поведение и правило, как и в стандартных реляционных ограничениях PRIMARY
KEY и FOREIGN KEY). Синтаксис табличного_ссылочного_ограничения следующий.
{SCOPE FOR (связанный-столбец | связанный-атрибут) IS таблица_область_действия |
REF (связанный_столбец | связанный_атрибут) WITH ROWID |
[CONSTRAINT имя_ограничения] FOREIGN KEY (связанный_столбец | связанный_атрибут)
REFERENCES объект [ (имя_столбца) ]
[ON DELETE {CASCADE | SET NULL} ]
[состояние_ограничения] }
Предложение состояние_ограничения содержит несколько опций, которые ранее
были определены в инструкции CREATE TABLE. Однако эти предложения применимы
только к условию ссылки области действия.
[NOT] DEFERRABLE
INITIALLY {IMMEDIATE | DEFERRED}
{ENABLE | DISABLE}
{VALIDATE | NOVALIDATE}
{RELY | NORELY}
EXCEPTIONS INTO имя_таблицы
USING INDEX {имя_индекса | (инструкция_СЙЕАТЕ_1М0ЕХ ) | атрибуты-индекса}
254 | Глава 3. Справочник по инструкциям SQL
Таблицы объектного типа хорошо использовать для создания таблиц, содержащих
пользовательские типы. Например, в следующем фрагменте кода создается тип
building_type.
CREATE TYPE OR REPLACE building_type AS OBJECT
(building_name VARCHAR2(100),
building_address VARCHAR2(200) );
Теперь вы можете создать таблицу offices_object_table, которая содержит этот
объект и определяет некоторые из его параметров, например информацию OID. Кроме
того, мы создадим еще две таблицы, которые ссылаются на объектный тип во встроен-
ном или табличном ссылочном ограничении соответственно.
CREATE TABLE offices_object_table
OF building-type (building_name PRIMARY KEY)
OBJECT IDENTIFIER IS PRIMARY KEY;
CREATE TABLE leased_offices
(office_nbr NUMBER,
rent DEC(9,3),
office_ref REF building_type
SCOPE IS officeS-Object-table);
CREATE TABLE owned_offices
(office_nbr NUMBER,
payment DEC(9,3),
office-ref REF building_type
CONSTRAINT offc_in_bld REFERENCES offices_object_table);
В этих примерах предложение SCOPE IS определяет встрое11ное_ссылочное_огра-
ничение, а предложение CONSTRAINT определяет табличное_ссылочное_ограничение.
Инструкция ALTER TABLE в Oracle
Используя команду Oracle ALTER TABLE, вы можете добавлять, удалять и изменять
все аспекты всех элементов таблицы. Например, в схеме синтаксиса показано, что
метод добавления или изменения столбца включает и атрибуты столбца, но мы
должны ясно сказать, что в эти атрибуты входят все расширения, специфичные
для Oracle т. е. там, где стандарт ANSI позволяет изменять только такие атрибуты, как
DEFAULT и NOT NULL, и ограничения уровня столбца, Oracle разрешает изменять
любые имеющиеся специальные характеристики, такие, как LOB, VARRAY, NESTED
TABLE, индекс-таблицы, CLUSTER и PARTITION.
Например, в следующем фрагменте кода к таблице Oracle добавляется новый
столбец, а также к этой таблице добавляется новое ограничение UNIQUE.
ALTER TABLE titles
ADD subtitle VARCHAR2(32) NULL
CONSTRAINT unq_subtitle UNIQUE;
Справочник по командам SQL | 255
Если в таблицу добавляется ограничение - внешний ключ (FOREIGN KEY), СУБД
проверяет на соответствие этому ограничению все данные таблицы. Если возникает
ошибка, операция ALTER TABLE отменяется.
«У ч
Любые запросы с инструкцией SELECT * возвращают новые столбцы,
балке если это не планировалось. Скомпилированные объекты, такие, как
записанные процедуры, могут возвращать любые новые столбцы, если
в них используется атрибут %ROfVTYPE. В противном случае скомпилиро-
ванный объект не возвращает новых столбцов.
В Oracle разрешается использовать несколько действий, таких, как ADD и MODIFY,
применительно к нескольким столбцам. Действия должны заключаться в скобки. Напри-
мер, следующая команда добавляет в таблицу несколько столбцов в одной инструкции.
ALTER TABLE titles
ADD (subtitles VARCHAR2(32) NULL,
year^of_copyright INT,
date_of_origin DATE);
PostgreSQL
PostgreSQL поддерживает стандарт ANSI для инструкций CREATE TABLE и ALTER
TABLE с несколькими расширениями, которые позволяют быстро создать новую таб-
лицу по определениям уже существующей. Ниже приводится синтаксис инструкции
CREATE TABLE.
CREATE [LOCAL][[TEMPORARY TABLE имя_таблицы
(имя_столбца тип_данных атрибуты
| CONSTRAINT имя_ограничения [{NULL | NOT NULL}]
{[UNIQUE] | [PRIMARY KEY (имя_столбца [,.,.])] | [CHECK (выражение') ]
| REFERENCES связанная_таблица(связанный_столбец [,.,.])
[MATCH {FULL | PARTIAL | default}]
[ON {UPDATE | DELETE}
{CASCADE | NO ACTION | RESTRICT | SET NULL | SET DEFAULT значение}]
[[NOT] DEFERRABLE] [INITIALLY {DEFERRED | IMMEDIATE}] }.[,.,,]
| [табличное-ограничение]}, . . . ]
[WITHfOUT] OIDE]
[INHERITS (таблица-для__наследования [,,,,])]
[ON COMMIT {DELETE | PRESERVE} ROWS]
[AS инструкциЯ-SELECT]
Синтаксис инструкции ALTER TABLE в PostgreSQL следующий.
ALTER TABLE [ONLY] имя_таблицы [»]
[ADD [COLUMN] имя_столбца тип_данных атрибуты [...] ]
| [ALTER [COLUMN] имя_столбца
{SET DEFAULT значение | DROP DEFAULT | SET STATISTICS int}]
256 | Глава 3. Справочник по инструкциям SQL
I [RENAME [COLUMN] имя_столбца TO новое_имя_столбца']
I [RENAME TO новое_имя_таблицы~\
I [ADD табличное_ограничение~\
| [DROP CONSTRAINT имя_ограничения RESTRICT ]
| [OWNER TO новый_владелец]
Описание параметров приводится ниже.
REFERENCES...MATCH...ON {UPDATE | DELETE}...
Значение, вставленное в столбец, сравнивается со значениями в столбце другой
таблицы. Это предложение также может применяться в составе объявления внеш-
него ключа. Для ключевого слова MATCH есть опции FULL, PARTIAL и опция по
умолчанию, если MATCH используется без другого ключевого слова. При полном
совпадении ЦААТСН FULL) все столбцы многостолбцового внешнего ключа либо
должны быть равны NULL, либо должны содержать допустимые значения. При
использовании опции по умолчанию разрешается смешивать NULL и допустимые
значения. MATCH PARTIAL - допустимая синтаксическая конструкция, но она не
поддерживается. Предложение REFERENCES также позволяет определить не-
сколько видов поведения для сохранения ссылочной целостности при удалении
(ON DELETE) и/или при обновлении (ON UPDATE). Делается это следующим
образом.
NO ACTION
При нарушении внешнего ключа генерируется ошибка (предложение по
умолчанию).
RESTRICT
Синоним для NO ACTION.
CASCADE
В столбец, в котором находится ссылка, записывается значение из столбца, на
который он ссылается.
SET NULL
Значение столбца со ссылкой устанавливается в NULL.
SET DEFAULT значение
В столбец со ссылкой записывается указанное значение или NULL, если
значение не указано.
NOT DEFERRABLE [INITIALLY {DEFERRED | IMMEDIATE}]
Опция DEFERRABLE предложения REFERENCES заставляет PostgreSQL отло-
жить проверку всех ограничений до конца транзакции. По умолчанию для предло-
жения REFERENCES принимается значение NOT DEFERRABLE. Сходным с пред-
ложением DEFERRABLE является предложение INITIALLY. При указании предло-
жения INITIALLY DEFERRABLE проверка ограничений откладывается на конец
транзакции. При указании предложения INITIALLY IMMEDIATE проверка огра-
ничений производится после выполнения каждой инструкции (это предложение
задано по умолчанию).
17 - 2447
1
Справочник по командам SQL | 257
FOREIGN KEY
Может объявляться только как ограничение уровня таблицы, но не как ограниче-
ние уровня столбца. В предложении FOREIGN KEY поддерживаются все опции
предложения REFERENCES. Синтаксис следующий.
[FOREIGN KEY (,имя_столбца [,...]) REFERENCES...]
WITH[OUT] OIDS
Это предложение указывает, что строки новой таблицы должны иметь автома-
тически присваиваемые идентификаторы объектов (object ID, OID). Идентифика-
торы присваиваются на основе 32-битного счетчика. Как только счетчик достиг-
нет максимального для себя значения, номера OID начинают повторяться и уни-
кальность более не гарантируется. Мы рекомендуем добавлять уникальный
индекс к любым созданным столбцам OID, чтобы избежать в очень больших таб-
лицах ошибок, связанных с дублированием OID. Таблица, наследующая свою
структуру, получает параметр OID из родительской таблицы.
INHERITS таблица_для_наследования
Указывается таблица или таблицы, из которых создаваемая таблица наследует все
свои столбцы. Создаваемая таблица также наследует функции, прикрепленные
к таблицам, расположенным выше в иерархии. Если наследуемые столбцы по-
вторяются несколько раз, инструкция завершается ошибкой.
ON COMMIT {DELETE | PRESERVE} ROWS
Используется только с временными таблицами. Это предложение управляет пове-
дением временной таблицы после того, как данные были переданы в основную
таблицу. При указании предложения ON COMMIT DELETE ROWS после каждой
отправки все строки из временной таблицы удаляются. Это поведение принимает-
ся по умолчанию, если предложение ON COMMIT опущено. При указании предло-
жения ON COMMIT PRESERVE ROWS после транзакции строки сохраняются во
временной таблице.
AS инструкция elect
Это предложение позволяет создать и заполнить таблицу данными при помощи
допустимой инструкции SELECT. Имена столбцов и типы данных указывать не
следует, потому что они наследуются из запроса. Инструкция CREATE TABLE...AS
функционально сходна с инструкцией SELECT...INTO, но имеет более понятный
формат.
ONLY
Предложение определяет, что инструкция ALTER TABLE затрагивает только ука-
занную таблицу и не влияет на родительские таблицы и таблицы-потомки
в иерархии.
OWNER ТО новый_владелец
Изменяет владельца таблицы на пользователя, указанного в параметре имя_владелъца.
Таблица PostgreSQL не может содержать более 1600 столбцов. Однако вам следует
ограничить количество столбцов значительно меньшим числом, чем 1600, из сообра-
жений производительности. Например:
258 | Глава 3. Справочник по инструкциям SQL
CREATE TABLE distributors
(name VARCHAR(40) DEFAULT 'Thomas Nash Distributors',
dist_id INTEGER DEFAULT NEXTVAL('dist_serial'
modtime TIMESTAMP DEFAULT CURRENT_TIMESTAMP);
Уникальной для PostgreSQL является возможность создавать ограничения
уровня столбца по нескольким столбцам. Поскольку PostgreSQL также
поддерживает стандартные ограничения уровня таблицы, рекомендуется
придерживаться стандартного подхода ANSI.
Реализация инструкции ALTER TABLE в PostgreSQL позволяет добавлять допол-
нительные столбцы с помощью ключевого слова ADD. С помощью инструкции
ALTER COLUMN...SET DEFAULT можно установить новые значения по умолчанию
для существующих столбцов, а с помощью инструкции ALTER COLUMN...DROP
DEFAULT- полностью удалить значения по умолчанию из столбцов. Кроме того, хотя
с помощью инструкции ALTER можно добавлять новые значения по умолчанию, по
влиять эти новые значения будут только на столбцы, которые будут вставляться после
этого. Предложение RENAME позволяет присваивать новые имена существующим
столбцам и таблицам.
SQL Server
Платформа SQL Server предоставляет массу опций, связанных с созданием или изме-
нением таблицы, ее столбцов и ограничений уровня таблицы. Синтаксис инструкции
CREATE TABLE следующий.
CREATE TABLE имя_таблицы
({имя_столбца тип_данных [ [DEFAULT значение_по_умолчанию2
| {IDENTITY [(стартовое_значение, инкремент) [NOT FOR REPLICATION]]]
[ROWGIDCOl][NULL | NOT NULL]
| [{PRIMARY KEY | UNIQUE}
[CLUSTERED | NONCLUSTERED]
[WITH FILLFACTOR = int] [ON (файловая_группа | DEFAULT}] ]
| [[FOREIGN KEY]
REFERENCES связанная_таблица[(.связаннь/й_столбец[, ,,.])]
[ON {DELETE | UPDATE} {CASCADE | NO ACTION}]
[NOT FOR REPLICATION]
| [CHECK [NOT FOR REPLICATION] (выражение)
| [COLLATE имя_сопоставления]
| имя_столбца AS вычисляемое_выражение_для_столбца }
'....]
| [табличнсе_ограничение] [,...] )
[ON { файловая__группа | DEFAULT} ]
[TEXTIMAGE_ON {файловая_группа | DEFAULT} ]
Справочник по командам SQL | 259
Версия инструкции ALTER TABLE в SQL Server выглядит следующим образом.
ALTER TABLE имя_таблицы
[ALTER COLUMN имя_столбца тип_данных атрибуты {ADD | DROP} ROWGUIDCOL]
| [ADD [COLUMN] имя_столбца тип_данных атрибуты~\[, , ,
I [WITH CHECK | WITH NOCHECK] ADD табличное_ограничение)[, . . , ]
| [DROP { [ CONSTRAINT ] имя_ограничения | COLUMN имя_столбца }] [,...]
| [{ CHECK | NOCHECK } CONSTRAINT { ALL | имя_ограничения [,...] }]
| [{ ENABLE | DISABLE } TRIGGER { ALL | имя_триггера [,...] }]
Параметры следующие.
IDENTITY (стартовое^значение, инкремент)
Создается столбец целочисленного типа и заполняется равномерно возрастающи-
ми числами. Начинается отсчет со стартового_значения, которое увеличивается
на значение инкремента. Если какой-либо параметр опущен, по умолчанию при-
нимается 1.
NOT FOR REPLICATION
Предложение показывает, что значения идентификаторов (IDENTITY) и внешних
ключей (FOREIGN KEY) не реплицируются на запрашивающие серверы. Это по-
лезно в ситуациях, когда для разных серверов требуется одна структура таблицы,
но неодинаковые данные.
ROWGUIDCOL
Это предложение определяет столбец как уникальный глобальный идентифика-
тор, который гарантирует, что на любом количестве серверов два значения нико-
гда не повторятся. В таблице можно определить только один такой столбец.
Однако уникальные значения сами по себе не генерируются. Их нужно вставлять
с помощью функции NEWID.
DEFAULT
Применимо к любому столбцу, за исключением типа данных TIMESTAMP или
свойства IDENTITY. Значение может представлять собой константу, например
строку или число, или системную функцию, например GETDATE0, или NULL.
PRIMARY KEY
В таблице определяется ограничение типа «первичный ключ». Объявление
первичного ключа отличается от стандарта ANSI и позволяет присваивать индексу
первичного ключа атрибуты «кластеризованный» или «некластеризованный»,
а также стартовый фактор заполнения (fillfactor). (За дополнительной информацией
обращайтесь к разделу «Инструкция CREATE/ALTER INDEX».) К атрибутам
первичного ключа относятся следующие.
CLUSTERED
Объявляется, что столбец или столбцы первичного ключа определяют физиче-
ский порядок сортировки записей в таблице. Это предложение принимается
по умолчанию, если ключевые слова CLUSTERED или NONCLUSTERED опу-
щены.
260 | Глава 3. Справочник по инструкциям SQL
NONCLUSTERED
Объявляется, что индекс первичного ключа хранит указатели на все записи
таблицы.
WITH FILLFACTOR = int
Указывается процентная доля свободного места (int), которая должна оста-
ваться незаполненной на каждой странице данных при создании таблицы.
Система SQL Server не производит регулярного обслуживания фактора запол-
нения. Вы должны регулярно обновлять индекс.
ON {фашювая_группа | DEFAULT}
Это предложение определяет, что первичный ключ располагается в уже суще-
ствующей, указанной файловой группе или отнесен к файловой группе, задан-
ной по умолчанию (DEFAULT).
FOREIGN KEY
Значения, вставляемые в столбец, проверяются по столбцу другой таблицы для
обеспечения ссылочной целостности. Внешние ключи подробно описываются
в главе 2. Внешний ключ может ссылаться только на столбцы, определенные как
первичный ключ (PRIMARY KEY) или уникальное значение (UNIQUE). Можно
указать действие, которое будет выполняться в связанной_таблш/е, если запись
удаляется или обновляется. Это делается с помощью следующих предложений.
ON {DELETE | UPDATE}
Определяет, какое действие производится в локальной таблице, когда в таблице,
на которую она ссылается, происходит удаление и/или обновление.
CASCADE
Предложение определяет, что операция обновления или удаления в связанной
таблице также происходит со всеми записями, зависящими от значения внеш-
него ключа.
NO ACTION
Предложение определяет, что в связанной таблице не производится никаких
действий при операциях удаления или обновления в текущей таблице.
NOT FOR REPLICATION
Это предложение указывает, что свойство IDENTITY не должно принудитель-
но реализовываться, если данные реплицируются из другой базы данных. Это
приводит к тому, что данным, публикуемым на другом сервере, не будут при-
своены новые значения идентификаторов.
CHECK
Производится проверка того, что значение, вставляемое в указанный столбец таб-
лицы, является допустимым с точки зрения проверочного выражения. Например,
ниже приведен пример таблицы с двумя ограничениями CHECK уровня столбца.
CREATE TABLE people
(people_id CHAR(4)
CONSTRAINT pk_dist_id PRIMARY KEY CLUSTERED
CONSTRAINT ck_dist_id CHECK (dist.id LIKE '
[A-Z][A-Z][A-Z][A-Z]'),
Справочник по командам SQL | 261
people_name VARCHAR(40) NULL,
people_addr1 VARCHAR(40) NULL,
people_addr2 VARCHAR(40) NULL,
city VARCHAR(20) NULL,
state CHAR(2) NULL
CONSTRAINT def_st DEFAULT ("CA")
CONSTRAINT chk_st REFERENCES states(state_ID)
zip CHAR(5) NULL
CONSTRAINT ck_dist_zip
CHECK(zip LIKE ’[0-9][0-9][0-9][0-9][0-9]'),
phone CHAR(12) NULL,
sales_rep empid NOT NULL DEFAULT USER)
GO
Проверочное ограничение на значение peopleid проверяет то, что идентификатор
содержит только буквы, а ограничение на значение zip удостоверяется в том, что
значение содержит только цифры. Ограничение REFERENCE на значение state про-
изводит поиск в таблице states. Ограничение REFERENCE по сути аналогично огра-
ничению CHECK, за исключением того, что оно генерирует список допустимых
значений по значениям в другом столбце. Этот пример также иллюстрирует, каким
образом ограничениям присваиваются имена с помощью синтаксиса CONSTRAINT
имяограничеиия.
COLLATE
Позволяет программистам изменять используемый порядок сортировки и набор
символов в отдельных столбцах.
TEXTIMAGEJON {файловая_группа | DEFAULT}
Управляет размещением столбцов text, ntext и image, позволяя помещать данные
LOB в выбранную файловую группу. Если предложение опущено, эти столбцы
сохраняются в файловой группе по умолчанию, там же, где все прочие таблицы
и объекты базы данных.
WITH [NO]CHECK
Определяет, будут ли данные в таблице проверяться с использованием добавляемых
позже ключей и ограничений. Если ограничения добавляются с опцией WITH
NOCHECK, то оптимизатор запросов игнорирует их до тех пор, пока они не будут
включены с помощью команды ALTER TABLE имя_табпицы CHECK CONSTRAINT
ALL. Если ограничения добавляются с опцией WITH CHECK, то проверка всех дан-
ных, уже имеющихся в таблице, производится немедленно.
[NO]CHECK CONSTRAINT
Существующее ограничение включается (CHECK CONSTRAINT) или выключается
(NO CHECK CONSTRAINT).
{ENABLE | DISABLE} TRIGGER {ALL | имя_триггера [,...]}
Предложение включает или соответственно отключает указанный триггер или
триггеры. Все триггеры в таблице можно включить или выключить, заменив
ключевое слово ALL на имя таблицы: ALTER TABLE employee DISABLE TRIGGER
262 | Глава 3. Справочник по инструкциям SQL
ALL. Вы также можете включить или отключить один триггер с именем
имя_триггера или несколько триггеров, перечислив их имена через запятую.
SQL Server позволяет присвоить имя любому ограничению уровня столбца при
помощи конструкции CONSTRAINT имя_ограничения... (далее идет текст ограниче-
ния). В одном столбце можно использовать несколько ограничений, если только они
не являются взаимоисключающими (например, PRIMARY KEY и NULL).
SQL Server также позволяет создавать локальные временные таблицы, но при
этом не используется синтаксис ANSI. Для локальной временной таблицы, которая со-
храняется в базе данных tempdb, требуется префикс в виде одного знака диеза (#)
перед именем таблицы. Локальную временную таблицу может использовать пользова-
тель или процесс, создавший ее, и она удаляется, когда пользователь завершает соеди-
нение или когда процесс завершает работу. Глобальная временная таблица, которую
могут использовать все пользователи и процессы, подключенные к базе данных,
можно создать, используя в качестве префикса перед именем таблицы двойной знак
диеза (##). Глобальная таблица удаляется, когда завершается работа создавшего его
процесса или разрывается соединение с создавшим ее пользователем.
Система SQL Server также позволяет создавать таблицы со столбцами, которые
содержат вычисляемое значение. Такой столбец не содержит реальных данных. Это
виртуальный столбец, содержащий выражение, использующее другие столбцы, входя-
щие в таблицу. Например, вычисляемый столбец может содержать такое выражение,
как стоимость_заказа AS (цена * количество). Вычисляемые столбцы также могут
содержать константы, функции, переменные, невычисляемые столбцы, которые связа-
ны друг с другом при помощи операторов.
Любые ограничения уровня столбца, которые приведены выше, могут также быть
объявлены на уровне таблицы. Иными словами, ограничения PRIMARY KEY, CHECK
и прочие можно объявлять после объявления всех столбцов в инструкции CREATE
TABLE. Это очень полезная возможность для тех ограничений, которые касаются не-
скольких столбцов. Например, ограничение UNIQUE уровня столбца может приме-
няться только к этому столбцу. Однако, если ограничение объявлено на уровне табли-
цы, это позволяет распространять его действие на несколько столбцов. Ниже приво-
дится пример ограничений уровня столбца и уровня таблицы.
-- Создание ограничений уровня
CREATE TABLE favorite_books
(isbn
book.tiame
category
subcategory
pub„date
purchase_date
GO
CHAR(1OO)
VARCHAR(40)
VARCHAR(40)
VARCHAR(40)
DATETIME
DATETIME
столбца
PRIMARY KEY NONCLUSTERED,
UNIQUE,
NULL,
NULL,
NOT NULL,
NOT NULL)
-- Создание ограничений уровня таблицы
CREATE TABLE favorite_books
Справочник по командам SQL | 263
(isbn CHAR(1OO) NOT NULL,
book_name VARCHAR(40) NOT NULL,
category VARCHAR(40) NULL,
subcategory VARCHAR(40) NULL,
pub_date DATETIME NOT NULL, '
purchase_date DATETIME NOT NULL,
CONSTRAINT pk_book_id PRIMARY KEY NONCLUSTERED (isbn)
WITH FILLFACT0R=70,
CONSTRAINT unq_book UNIQUE CLUSTERED (book_name,pub_date))
GO
Эти две команды дают приблизительно одинаковый результат, за исключением
того, что ограничение уровня таблицы UNIQUE охватывает два столбца, а ограниче-
ние UNIQUE уровня столбца охватывает только один столбец.
В следующем примере к таблице добавляется новое ограничение CHECK, но не
производится проверка того, что существующие в таблице значения удовлетворяют
этому ограничению.
ALTER TABLE favorite_book WITH NOCHECK
ADD CONSTRAINT extra_check CHECK (ISBN >1)
GO
В следующем примере мы добавляем столбец с присвоенным значением по
умолчанию {DEFAULT), который добавляется в каждую существующую в таблице
строку.
ALTER TABLE favorite_book ADD reprint_nbr INT NULL
CONSTRAINT add_reprint_nbr DEFAULT 1 WITH VALUES
GO
-- Теперь отключаем ограничение
ALTER TABLE favorite_book NOCHECK CONSTRAINT add_reprint_nbr
GO
См. также
CREATE SCHEMA
DROP
Инструкция CREATE/ALTER TRIGGER
Триггер - это особый тип записанной процедуры, которая автоматически срабатывает
(отсюда и термин «триггер»), когда в таблице выполняется конкретная инструкция,
связанная с модификацией данных. Триггер прямо связан с таблицей и считается зави-
симым объектом. Например, вам может понадобиться, чтобы все значения
part_numbers в таблице sales обновлялись при изменении значения part_number
в таблице products, обеспечивая таким образом синхронизацию.
264 | Глава 3. Справочник по инструкциям SQL
Инструкция ALTER TRIGGER не поддерживается стандартом ANSI.
Платформа Команда
DB2 Поддерживается с вариантами
MySQL Не поддерживается
Oracle 11оддерживается с вариантами
PostgreSQL Поддерживается с вариантами
SQL Server Поддерживается с вариантами
Синтаксис SQL2003
CREATE TRIGGER имя_триггера
{BEFORE j AFTER} {DELETE | INSERT | UPDATE [OF столбец [....]}
ON имя_таблицы
[REFERENCING {OLD {[ROW] | TABLE} [AS] старое_имя | NEW {ROW | TABLE} [AS]
новое_имя}} [FOR EACH { ROW | STATEMENT }]
[WHEN (условие)}
[BEGIN ATOMIC]
блок кода
[END]
Ключевые слова
CREATE TRIGGER имя_триггера
Создается триггер с именем имя триггера и связывается с конкретной таблицей.
BEFORE|AFTER
Указывается, что логика триггера запускается до (BEFORE) или после (AFTER)
операции по манипуляции данными, которая запустила триггер. Триггеры с пред-
ложением BEFORE выполняются до выполнения операций вставки, обновления
или удаления, и это позволяет даже вообще обходить операции по манипуляции.
Триггеры с предложением AFTER запускаются после завершения операции по
манипуляции, и они полезны для операций, совершаемых постфактум (например,
при пересчете промежуточных сумм).
DELETE | INSERT | UPDATE [OF столбец [...]
Определяется операция по манипуляции данными, которая запускает триггер:
инструкции DELETE, INSERT или UPDATE. При желании вы можете выбрать,
какие столбцы будут запускать триггер обновлений с помощью предложения
UPDATE OF столбец Если обновление будет касаться столбцов, не входя-
щих в список, триггер запускаться не будет.
ON имя_таблицы
Указывается существующая таблица, от которой зависит триггер.
Справочник по командам SQL | 265
REFERENCING {OLD
{[ROW] | TABLE} [AS] старое_имя | NEW {ROW \ TABLE} [AS] новое_имя}
Позволяет присваивать псевдонимы старым и новым строкам (ROW) или табли-
цам (TABLE), с которыми работает триггер. Хотя синтаксис показывает эти опции
как исключающие, вы можете присвоить до четырех ссылок-псевдонимов: один -
для старой строки, один - для старой таблицы, один - для новой строки и один -
для новой таблицы. Псевдоним с предложением OLD относится к данным,
которые содержались в таблице или строке до операции по манипуляции, запус-
тившей триггер, а псевдоним с предложением NEW - к данным, которые будут со-
держаться в таблице после операции, запустившей триггер. Заметьте, что согласно
синтаксису слово ROW является необязательным, а слово TABLE - обязательным
(т. е. OLD ROW AS аналогично OLD AS, но для предложения TABLE единственным
допустимым вариантом будет OLD TABLE AS). Триггеры для операции вставки
(INSERT) не употребляются вместе с OLD, а триггеры удаления (DELETE)
не употребляются с NEW. Ключевое слово ADD не несет полезной информации
и может быть опущено. Если в предложении REFERENCING указаны предложе-
ния OLD ROW или NEW ROW, то обязательным является предложение FOR EACH
ROW.
FOR EACH {ROW | STATEMENT}
Это предложение указывает, что триггер будет применяться к каждой измененной
строке таблицы (ROW) или к каждой инструкции SQL, выполняемой в таблице
(STATEMENT). Например, в одной инструкции UPDATE производится обновление
зарплат 100 служащих. Если вы укажете предложение FOR EACH ROW, то триггер
запустится 100 раз. Если вы укажете предложение FOR EACH STATEMENT, триг-
гер запустится только один раз.
WHEN (условия)
Позволяет определить дополнительные критерии для триггера. Например, у вас
может быть триггер DELETE EMPLOYEE, который будет запускаться при каждом
удалении служащего из таблицы. Если условия, содержащиеся в конструкции
WHEN, возвращают значение ИСТИНА, триггер будет запускаться, в противном
случае он срабатывать не будет.
BEGIN ATOMIC | бдоккода | END
В стандарте ANSI определяется, что блок кода должен содержать только одну
инструкцию SQL или, если их несколько, они должны заключаться между опера-
торами BEGIN и END.
Общие правила
По умолчанию триггеры запускаются один раз на уровне инструкции. То есть одна ин-
струкция INSERT может вставить в таблицу 500 строк, но триггер вставки в этой таб-
лице выполнится только один раз. Некоторые производители позволяют запускать
триггер для каждой операции по модификации данных. В этом случае инструкция,
вставляющая 500 строк в таблицу, запустит триггер уровня строки 500 раз, по одному
разу для каждой строки.
266 | Глава 3. Справочник по инструкциям SQL
Помимо привязки к конкретной инструкции по модификации данной таблицы
(INSERT, UPDATE или DELETE) триггеры имеют конкретное время запуска.
В общем случае триггеры могут запускаться до (BEFORE) обработки инструкции по
модификации, после (AFTER) ее обработки или (если это поддерживается разра-
ботчиком) вместо обработки инструкции (INSTEAD OF). Триггеры, которые запус-
каются до или вместо инструкции по модификации, не видят изменений, производи-
мых инструкцией, тогда как те триггеры, которые запускаются после модификации,
могут видеть эти изменения и воздействовать на них.
Триггеры используют две псевдотаблицы. Эти псевдотаблицы являются таковы-
ми в том смысле, что они не объявляются при помощи инструкций CREATE TABLE,
но логически существуют в базе данных. Эти псевдотаблицы на разных платформах
имеют разные имена, но мы будем здесь называть их Before и After. Их структура
в точности повторяет структуру таблицы, с которой связан триггер. Таблица Before
содержит моментальный снимок всех строк таблицы до запуска триггера, а таблица
After - снимок всех записей после события, запустившего триггер. С помощью опера-
торов сравнения вы можете сравнивать данные до и после запуска триггера, опреде-
ляя, что точно нужно сделать.
Ниже приводится триггер BEFORE платформы Oracle, который использует для
сравнения значений псевдотаблицы OLD и NEW. (Для сравнения: SQL Server таким
же образом использует псевдотаблицы DELETED и INSERTED, a DB2 ТРЕБУЕТ,
чтобы вы в предложении REFERENCING присвоили имена псевдотаблицам.) Этот
триггер создает запись аудита перед изменением записи о зарплате служащего.
CREATE TRIGGER if_errp_changes
BEFORE DELETE OR UPDATE ON employee
FOR EACH ROW
WHEN (new.emp_salary <> old.emp_salary)
BEGIN
INSERT INTO employee_audit
VALUES ('old', :old.emp_id, :old.emp_salary, :old.emp._ssn);
END;
Вы также можете пользоваться возможностями, которые дает каждая платформа,
чтобы сделать триггеры более функциональными и упростить программирование.
Например, в Oracle есть специальное предложение IF..THEN, которое используется
только в триггерах. Это предложение имеет следующие формы: IF DELETING THEN,
IF INSERTING THEN или IF UPDATING THEN. В следующем примере в системе
Oracle создается триггер удаления и обновления, в котором используется предложение
IF DELETING THEN.
CREATE TRIGGER if_emp_changes
BEFORE DELETE OR UPDATE ON employee
FOR EACH ROW
BEGIN
IF DELETING THEN
INSERT INTO employee_audit
Справочник по командам SQL | 267
VALUES ('DELETED', :old.emp_id, :old.emp_salary, :old.emp_ssn);
ELSE
INSERT INTO employee_audit
VALUES ('UPDATED', :old.emp_id, :new.emp_salary, :old.emp_ssn);
END IF;
END;
В примере для SQL Server в базу данных добавлена новая таблица contractor.
Все записи в таблице employee, которые показывают, что служащий работает по кон-
тракту, перенесены в таблицу contractor. Теперь все новые служащие, вносимые
в таблицу employee, попадают вместо этого в таблицу contractor при помощи триггера
INSTEAD OF INSERT.
CREATE TRIGGER if_emp_is_contractor -
INSTEAD OF INSERT ON employee
BEGIN
INSERT INTO contractor
SELECT * FROM inserted WHERE status = 'CON'
INSERT INTO employee
SELECT * FROM inserted WHERE status = 'FTE'
END
GO
Добавление триггеров в таблицу, которая уже содержит данные, не приводит к запуску
триггеров. Триггер запускается только при выполнении инструкции по модификации
данных, указанной в определении триггера, после создания триггера.
Как правило, триггер игнорирует структурные изменения таблицы, например добав-
ление столбца или изменение типа данных существующего столбца, производимые
после создания триггера, если только изменение таблицы не влияет напрямую на дейст-
вия триггера. Например, при добавлении к таблице нового столбца существующие триг-
геры проигнорируют это добавление, за исключением триггеров UPDATE. С другой
стороны, если удалить из таблицы столбец, используемый триггером, триггер будет
генерировать ошибку при каждом своем выполнении.
Советы и хитрости программирования
Одной из ключевых программных проблем, связанных с триггерами, является бесконт-
рольное использование вложенных и рекурсивных триггеров. Вложенный триггер - это
триггер, который запускает операцию по манипуляции данными, которая заставляет запус-
каться другие триггеры. Предположим, например, что у нас есть три таблицы: Tl, Т2 и ТЗ.
В таблице Т1 есть триггер BEFORE INSERT, который вставляет запись в таблицу Т2.
В таблице Т2 есть триггер, который вставляет запись в таблицу ТЗ. Хотя все это не обяза-
тельно плохо заканчивается, если логика хорошо и полностью продумана, но при этом
привносится две проблемы. Во-первых, вставка в таблицу Т1 требует гораздо большего
числа операций ввода-вывода, чем простая операция INSERT в таблице Т1. Во-вторых,
вы можете столкнуться с трудностями, если на самом деле таблица ТЗ выполняет вставку
268 | Глава 3. Справочник по инструкциям SQL
в таблицу Т1. В таком случае вы увидите циклический процесс выполнения триггеров,
который может занять все свободное место на диске и даже вывести сервер из строя.
Рекурсивные триггеры - это такие триггеры, которые запускают сами себя, напри-
мер, триггер INSERT, который выполняет вставку в свою собственную таблицу. Если
процедурная логика в блоке кода не будет правильной, вы столкнетесь с циклическим
запуском триггера. Однако для использования рекурсивных триггеров на различных
платформах требуется установить специальный конфигурационный флаг.
DBS
В DB2 поддерживается расширенный набор опций инструкции CREATE TRIGGER
по сравнению со стандартным ANSI SQL. Система DB2 не поддерживает инструкцию
ALTER TRIGGER. Синтаксис инструкции CREATE TRIGGER следующий.
CREATE TRIGGER имя_триггера
{NO CASCADE BEFORE | AFTER | INSTEAD OF}
{[DELETE] | [INSERT] | [UPDATE [OF (столбец [,...]) .]}
ON имя_таблицы
[REFERENCING
{OLD[_TABLE] [AS] старое_имя | NEW[_TABLE]
[AS] новое_имя} DEFAULTS NULL]
[FOR EACH { ROW | STATEMENT }]
MODE DB2SQL
[WHEN {условия)}
блок_кода
Где:
NO CASCADE BEFORE
Объявляется, что триггер выполняет действия до того, как в таблице выполняется
операция по модификации данных. Это предложение также указывает, что дейст-
вия триггера не будут приводить к запуску других триггеров.
ON имя_таблицы
Указывается существующая таблица или представление, с которым связывается
триггер. Триггеры можно создавать в обычных таблицах, но нельзя создавать во
временных таблицах, таблицах-псевдонимах (nicknames), таблицах каталогов
и таблицах материализованных представлений. В представлениях разрешается
создавать только триггеры INSTEAD OF. Представление должно быть нетипизо-
ванным и не должно использовать предложение WITH CHECK OPTION. Операция
по модификации данных, применяемая к представлению, должна быть переведена
в основную таблицу, чтобы определить, будет она запускать триггер или не будет.
OLD[_TABLE] [AS] имя_для_старых | NEW[_TABLE] [AS] имя_для_новых
Указывается псевдоним для псевдотаблиц before и after стандарта ANSI с помощью
предложений OLD TABLE и NEWfTABLE соответственно. Если опустить ключевое
слово fTABLE, система DB2 будет считать, что операция триггера производится на
уровне столбца, и позволит перед запуском инструкций SQL обратиться к данным
строки (единичным данным). Указание ключевого слова _TABLE позволяет указать
Справочник по командам SQL [ 269
перед запуском инструкций SQL набор (множество) строк данных. Предложения
OLD и OLD TABLE могут использоваться только в триггерах удаления {DELETE)
и обновления (UPDATE). И наоборот, предложения NEW и NEW_TABLE могут ис-
пользоваться только в триггерах вставки (INSERT) и обновления (UPDATE). Предло-
жения OLD и NEW можно указать только по одному разу. Предложения OLD TABLE
и NEW_TABLE можно указать только по одному разу, их нельзя указывать в триг-
герах с предложением NO CASCADE BEFORE.
DEFAULTS
Значения по умолчанию вставляются гуда, где они создаются.
FOR EACH {ROW | STATEMENT}
Предложение указывает, будет ли триггер применяться на уровне строки или на
уровне инструкции. Предложение FOR EACH STATEMENT можно применять
только в триггерах AFTER.
MODE DB2SQL
Объявляется, что режим триггера - DB2 SQL (в настоящее время - единственный
поддерживаемый режим).
WHEN (условия)
Соответствует стандарту ANSI, за одним исключением: в DB2 это предложение
нельзя использовать с триггерами INSTEAD OF.
Система DB2 не препятствует созданию нового триггера с тем же определением,
что и более старый. Таким образом, в одной таблице может существовать два (и более)
триггера AFTER DELETE. В таких ситуациях DB2 всегда запускает триггеры в том
порядке, в каком они были созданы.
Будьте осторожны при создании триггера BEFORE DELETE в таблице с ограниче-
нием, ссылающимся само на себя, и правилом удаления CASCADE. Такой триггер
может дать неожиданные результаты!
DB2 позволяет использовать инструкцию COMMENT ON объектный_тип,
чтобы предоставить дополнительный комментарий для любого объекта,
поддерживаемого DB2. Например, можно подать команду COMMENT ON
TRIGGER имя триггера и ввести комментарий для любого триггера в базе
данных. Также это можно делать в таблицах, представлениях и т. п.
DB2 не производит удаления триггеров, связанных с таблицей или представлени-
ем, при удалении самой таблицы или представления. Следовательно, перед инструк-
цией DROP TABLE вы должны сначала подать команду DROP TRIGGER, чтобы не
оставлять «зависших» триггеров. Кроме того, триггеры не восстанавливаются, если
таблица удаляется, а затем создается заново. Триггеры также нужно создавать заново.
Триггеры с предложениями BEFORE и AFTER можно создавать в объектных таблицах
на любом уровне их иерархии. Триггеры могут активироваться в строках подтаблиц. Если
инструкция SQL активирует несколько триггеров, триггеры выполняются в порядке их
создания, даже если они связаны с разными таблицами в иерархии объектных таблиц.
Л ч
270 | Глава 3. Справочник по инструкциям SQL
MySQL
He поддерживается.
Oracle
Oracle поддерживает стандартную инструкцию CREATE TRIGGER с некоторыми
добавлениями и вариациями.
CREATE [OR REPLACE] TRIGGER имя_триггора
{BEFORE | AFTER | INSTEAD OF}
{ {[событие_объекга'] [событие_базы_данных'] [...] ON {DATABASE | схема. SCHEMA} } :
{[DELETE] [OR] [INSERT] [OR] [UPDATE [OF column [,...] ]] [...]}
ON {имя_таблицы | [NESTED TABLE имя_столбца OF] имя_предсгавления}
[REFERENCING {[OLD [AS] имя_для_старых] [NEW [AS] имя. для_новых]
[PARENT [AS] имя_родителя']}
[FOR EACH ROW] }
[WHEN {условия)}
блок_ кода
Синтаксис инструкции ALTER TRIGGER, которая позволяет переименовывать,
включать или отключать триггер без его удаления и повторного создания, показан
ниже.
ALTER TRIGGER имя_триггера
{ {ENABLE | DISABLE} | RENAME TO новое_имя ।
COMPILE [директивы_компилятора~] [DEBUG] [REUSE SETTINGS]}
Где:
OR REPLACE
Заново создается существующий триггер с именем имя_триггера, которому при-
сваиваются новые определения.
событие ^объекта
В качестве дополнения к стандартным событиям, связанным с модификацией дан-
ных, Oracle позволяет запускать триггеры в зависимости от событий объектов.
Операции с такими событиями могут использоваться с ключевыми словами
BEFORE и AFTER. Событие объекта запускает триггер при возникновении данно-
го события, при этом используются следующие ключевые слова.
A LTER
Триггер запускается при выполнении инструкции ALTER (за исключением
ALTER DATABASE).
ANALYZE
Запускается, когда Oracle проверяет структуру объекта базы данных или
собирает или удаляет статистику по индексу.
ASSOCIA ТЕ STA TISTICS
Запускается, когда Oracle связывает с объектом базы данных статистический
тип.
Справочник по командам SQL | 271
AUDIT
Запускается, когда Oracle отслеживает инструкцию SQL или операцию, при-
меняемую к объекту схемы.
COMMENT
Запускается, если в словарь данных (data dictionary) добавляется комментарий
к объекту базы данных.
DDL
Запускается всякий раз, когда система Oracle встречает любое событие _объекта,
входящее в этот список.
DISASSOCIATE STATISTICS
Запускается, когда система Oracle отсоединяет от объекта базы данных стати-
стический тип.
DROP
Запускается, когда инструкция DROP удаляет объект базы данных из словаря
данных.
GRANT
Запускается, когда пользователь присваивает привилегии или роли другому
пользователю или роли.
NO AUDIT
Запускается, когда инструкция NOAUDIT заставляет систему Oracle прекра-
тить слежение за инструкциями SQL и операциями, применяемыми к объек-
там схемы.
RENAME
Запускается, когда инструкция RENAME изменяет имя объекта базы данных.
REVOKE
Запускается, когда пользователь отменяет назначение привилегий или ролей
другому пользователю или роли.
TRUNCATE
Запускается, если в таблице или кластере выполняется инструкция TRUNCATE,
событие _базы_данных
Помимо стандартных событий, связанных с модификацией данных, Oracle позво-
ляет запускать триггеры на основе событий базы данных. Такие события можно
использовать с ключевыми словами BEFORE и AFTER. Список доступных ключе-
вых слов для предложения событие_базы_данных приводится ниже.
LOGON
Триггер запускается, когда клиентское приложение соединяется с базой данных,,
Применяется только с триггерами AFTER.
LOGOFF
Триггер запускается, когда клиентское приложение отключается от базы данных.
Применяется только с триггерами BEFORE.
SERVERERROR
Запускается, если регистрируется ошибка сервера. Используется только с триг-
герами AFTER.
272 | Глава 3. Справочник по инструкциям SQL
SHUTDOWN
Запускается, когда экземпляр базы данных завершает работу. Используется
только с триггерами BEFORE и предложением ON DATABASE.
STARTUP
Запускается, когда экземпляр базы данных открывается. Используется только
с триггерами AFTER и предложением ON DATABASE.
SUSPEND
Запускается в том случае, если сбой сервера приводит к прерыванию транзакции.
Используется только с триггерами AFTER.
ON {DATABASE | схема.ЕСНЕМА}
Объявляется, что триггер запускается, если любой пользователь базы данных вызвал
событие, запускающее триггер, при наличии предложения ON DATABASE. Затем
триггер запускают события, возникающие в любом месте базы данных. При указа-
нии предложения ON схема.SCHEMA триггер запускается, если пользователь,
вызвавший запускающее событие, входил в систему под схемой с именем схема.
Затем триггер запускают события, возникающие в любом месте текущей схемы.
ON [NESTED TABLE имя_столбца OF] имя_представления
Указывается, что триггер запускается только в том случае, если операция по манипу-
лированию данными применяется к столбцу (столбцам) представления с именем
имя-Представления. Предложение ON NESTED TABLE совместимо только триггерами
INSTEAD OF.
REFERENCING PARENT [AS] имя родителя
Указывается псевдоним для текущей строки родительской таблицы (надтаблицы).
Иначе аналогично стандарту ANSI.
ENABLE
При использовании в инструкции ALTER TABLE включает ранее деактивирован-
ный триггер. В качестве альтернативы вы можете использовать инструкцию
ALTER TABLE имяупаблицы ENABLE ALL TRIGGERS.
DISABLE
При использовании в инструкции ALTER TABLE отключает работающий триггер.
В качестве альтернативы вы можете использовать инструкцию ALTER TABLE
имя таблицы DISABLE ALL TRIGGERS.
RENAME TO новое_имя
Триггер переименовывается в новое_имя, хотя при использовании инструкции
ALTER TABLE его состояние остается неизменным.
COMPILE [DEBUG] [REUSE SETTINGS]
Триггер компилируется независимо от того, является он допустимым или нет,
а также компилируются все объекты, от которых он зависит. Если любой из объек-
тов неработоспособен, триггер будет неработоспособным. Если все объекты рабо-
тоспособны, в том числе блок_кода триггера, то триггер становится работоспособ-
ным. У предложения COMPILE есть несколько дополнительных предложений.
18 - 2447
Справочник по командам SQL | 273
DEBUG
Компилятор PL/SQL будет генерировать и записывать дополнительную информа-
цию, которую сможет использовать отладчик PL/SQL,
REUSESETTINGS
Система Oracle сохранит все настройки компилятора, что поможет сэконо-
мить вам много времени при компиляции.
директивы_компилятора
Указывается специальное значение, используемое компилятором PL/SQL в форма-
те директива = ‘значение’. Существуют следующие директивы: PLSQL_
OPTIMIZE_LEVEL, PLSQL_CODE_TYPE, PLSQL_DEBUG, PLSQL WARNINGS
и NLS LENGTH SEMANTICS. Для каждой из них в инструкции можно указать
значение один раз. Директива действует только в рамках компилируемого модуля.
При ссылке на значения в псевдотаблицах OLD и NEW значения нужно указывать
с префиксом в виде двоеточия (:), за исключением предложения WHEN, где двоеточие
не используется. В приведенном примере мы вызовем в блоке кода процедуру и исполь-
зуем значения -.OLD и :NEW в качестве аргументов.
CREATE TRIGGER scott.sales_check
BEFORE INSERT OR UPDATE OF ord_id, qty ON scott.sales
FOR EACH ROW
WHEN (new.qty > 10)
CALL check_inventory(;new.ord_id, :new.qty, :old.qty);
В одной команде можно объединить несколько триггеров, если они относятся
к одному уровню (строка или инструкция) и принадлежат к одной таблице. Если триг-
геры объединяются в одну инструкцию, то для разделения логики на отдельные сег-
менты можно использовать в блоке кода PL/SQL предложения IF INSERTING THEN,
IF UPDATING THEN и IF DELETING THEN. Также в этой структуре можно использо-
вать предложение ELSE.
Ниже приводится пример триггера, запускаемого по событию базы данных.
CREATE TRIGGER track_errors
AFTER SERVERERROR ON DATABASE
BEGIN
IF (IS_SERVERERROR (04030))
THEN INSERT INTO errors ('Memory error');
ELSE (IS_SERVERERROR (01403))
THEN INSERT INTO errors ('Data not found');
END IF;
END;
В другом примере мы можем создать триггер, действующий в пределах схемы.
CREATE OR REPLACE TRIGGER create_trigger
AFTER CREATE ON scott.SCHEMA
BEGIN
RAISE_APPLICATION_ERROR (num => -20000, msg =>
'Scott created an object');
END;
274 | Глава 3. Справочник по инструкциям SQL
PostgreSQL
В реализацию инструкции CREATE TRIGGER платформы PostgreSQL включена часть
возможностей, входящих в стандарт ANSI. В PostgreSQL триггер может запускаться
до (BEFORE) попытки выполнить операцию по модификации данных и до того, как
выполнятся все ограничения, или же после (AFTER) операции по модификации
(и после проверки всех ограничений). В последнем случае все операции, выполнен-
ные в ходе транзакции, будут видимы для триггера. И наконец, триггер может запус-
каться вместо (INSTEAD OF) операции по модификации данных, полностью заменяя
инструкции INSERT, UPDATE или DELETE какими-нибудь другими действиями. Синтак-
сис инструкции CREATE TRIGGER следующий.
CREATE TRIGGER имя_триггера
{ BEFORE | AFTER }
{ {[DELETE] [CR | ,] [INSERT] [OR I ,] [UPDATE]} [OR ...] }
ON имя_таблицы
FOR EACH { ROW | STATEMENT }
EXECUTE PROCEDURE имя_функции (параметры)
Параметры описываются ниже.
OR
Объявляется дополнительное действие для триггера. Ключевое слово OR анало-
гично запятой.
FOR EACH ROW
Явно объявляется, что триггер функционирует на уровне строки. Это предложе-
ние указано по умолчанию. Хотя система PostgreSQL не отвергает ключевое слово
STATEMENT, она не использует триггеры уровня инструкции.
EXECUTE PROCEDURE имя_функции (параметры)
Выполняет ранее объявленную функцию (созданную с помощью инструкции
CREATE FUNCTION), а не блок процедурного кода. (В PostgreSQL нет собствен-
ного процедурного языка.)
Ниже приводится пример триггера BEFORE для PostgreSQL, который на уровне
строк проверяет наличие в таблице distributors указанного кода дистрибьютора,
перед тем как вставить или обновить строку в таблице sales.
CREATE TRIGGER if_dist_exists
BEFORE INSERT OR UPDATE ON sales
FOR EACH ROW
EXECUTE PROCEDURE check_primary_key
('dist_id', 'distributors', 'dist_id');
Триггеры BEFORE и AFTER поддерживаются стандартом ANSI. Триггеры IN-
STEAD OF в PostgreSQL полностью отменяют операцию по модификации данных
и заменяют ее указанным вами кодом.
Справочник по командам SQL | 275
SQL Server
Платформа SQL Server поддерживает ядро стандарта ANSI с добавлением триггеров
типа INSTEAD OF и проверки изменения столбцов. Эта платформа не поддерживает
предложения REFERENCING и WHEN. Синтаксис приводится ниже.
{CREATE | ALTER} TRIGGER имя_триггера ON имя_таблицы
[WITH ENCRYPTION]
{FOR | AFTER | INSTEAD OF} {[DELETE] [,] [INSERT] [,] [UPDATE]}
[WITH APPEND]
[NOT FOR REPLICATION]
AS
[IF UPDATE(столбец) [{AND | OR} иРОАТЕ(столбец)][. . . ] ]
блок_кода
Где:
{CREATE | ALTER} TRIGGER имя_триггера
Создается новый триггер с именем имя_триггера или изменяется существующий
триггер имя_триггера путем добавления или изменения свойств триггера или
блока кода. При изменении существующего триггера права доступа и зависимости
существующего триггера сохраняются.
ON имяупаб.тицы
Объявляется таблица или представление, от которых зависит триггер. В представ-
лениях могут быть определены триггеры INSTEAD OF, если только эти представ-
ления можно обновлять и они не содержат предложения WITH CHECK.
WITH ENCRYPTION
Текст инструкции CREATE TRIGGER шифруется так, как это определено в табли-
це syscomments. Этот параметр полезно использовать для защиты интеллектуаль-
ной собственности. Предложение WITH ENCRYPTION не дает использовать триг-
гер в схеме репликации SQL Server.
FOR | AFTER | INSTEAD OF
Указывает, когда должен запускаться триггер. (Ключевые слова FOR и Af'TER
являются синонимами.) Предложение AFTER показывает, что триггер запуска-
ется только после запуска успешного выполнения операции по модификации
данных (и других каскадно запускаемых действий и проверок ограничений).
Триггер INSTEAD OF сходен с триггером BEFORE стандарта ANSI в том, что
код триггера может полностью заменить операцию по модификации данных.
При этом триггер запускается вместо операции по модификации, которая запус-
тила триггер. Триггеры типа INSTEAD OF DELETE нельзя использовать, если
удаление вызывает каскадные действия. Доступ к столбцам TEXT, NTEXT или
IMAGE имеют только триггеры INSTEAD OF.
WITH APPEND
В таблицу или представление добавляется дополнительный триггер сущест-
вующего типа. Поддержка этого предложения введена для обратной сов^естимо-
276 | Глава 3. Справочник по инструкциям SQL
ста с более ранними версиями продукта, и это предложение можно использовать
только с триггерами FOR.
NOT FOR REPLICA TION
Предотвращается запуск триггера при выполнении операции по модификации
данных, инициированной встроенной системой репликации SQL Server.
IF UPDATE (столбец) [{AND | OR} иРОАТЕ(столбец)][...]
Позволяет выбрать конкретный столбец, запускающий триггер. Триггеры, специ-
фичные для столбца, запускаются только при операциях UPDATE и INSERT, но не
при операциях DELETE. Если операция UPDATE или INSERT применяется
к столбцу, не входящему в список, триггер не запускается.
Платформа SQL Server позволяет использовать несколько триггеров для одной
операции по манипуляции в таблице или представлении. Таким образом, можно ис-
пользовать сразу три триггера UPDATE в одной таблице. В таблице можно исполь-
зовать несколько триггеров AFTER. Порядок их выполнения является неопределен-
ным, однако первый и последний триггер можно указать явным образом, при
помощи хранимой системной процедуры sp_settriggerorder. В любой таблице допус-
кается использовать только один триггер INSTEAD OF на инструкцию INSERT,
UPDATE или DELETE.
В SQL Server в одной инструкции по созданию триггера можно определить
любую комбинацию триггеров, разделив их запятыми. (При этом один и тот же код за-
пускается для каждой инструкции в определении комбинации.)
Платформа SQL Server неявно использует для триггеров форму FOR EACH
STATEMENT стандарта ANSI.
При запуске триггера SQL Server записывает значения в две важные псевдотабли-
цы: deleted и inserted. Они соответственно эквивалентны псевдотаблицам before
и after, описанным ранее в разделе «Общие правила», относящемся к стандарту ANSI.
Эти таблицы по структуре идентичны таблице, в которой создан триггер, за исключе-
нием того, что они содержат старые данные, до выполнения операции по модифика-
ции (deleted), и новые значения, имеющиеся в таблице после этой операции (inserted).
При указании предложения AS IF UPDATE (столбец) производится проверка
на выполнение операции INSERT или UPDATE в данном столбце или столбцах; это
предложение аналогично конструкции (7РО/17’Е(столбец) в стандарте ANSI. Можно
указать несколько столбцов, добавив отдельные предложения (УРОЛЩстолбец).
Если за предложением AS IF UPDATE (столбец) поставить блок кода Transact-SQL
BEGIN...END, можно выполнить в триггере несколько операций Transact-SQL. Это
предложение функционально эквивалентно операции IF...THEN...ELSE.
Помимо вмешательства в выполнение операций по модификации данных, пока-
занного в примере на ANSI SQL, платформа SQL Server позволяет выполнять другие
виды операций при операции по модификации данных. В следующем примере мы ре-
шили, что таблица sales_archive_2002 более не используется, и тот, кто попытается
вставить в нее данные, получит уведомление о данном ограничении.
Справочник по командам SQL | 277
CREATE TRIGGER archive_trigger
ON sales_archive_2002
FOR INSERT, UPDATE
AS RAISERROR (50009, 16, 10, 'No changes allowed to this table')
GO
Платформа SQL Server не разрешает использовать следующие инструкции в блоке
кода Transact-SQL триггера: ALTER, CREATE, DROP, DENY, GRANT, REVOKE, LOAD,
RESTORE, RECONFIGURE и TRUNCATE. Кроме того, не разрешаются инструкции
DISK и команда UPDA ТЕ STA TISTICS.
Платформа SQL Server позволяет запускать рекурсивные триггеры, используя
параметр recursive triggers хранимой системной процедуры sp_dboption. Рекурсивные
триггеры в результате своего выполнения запускают самих себя. Например, если триг-
герINSERT в таблице Т1 выполняет операцию INSERT в таблице Т1, он может выпол-
нить рекурсивную операцию. Поскольку рекурсивные триггеры могут быть опасны-
ми, они по умолчанию отключены.
Также SQL Server позволяет использовать вложенные триггеры, до 32 уровней
вложенности. Если любой из вложенных триггеров выполняет операцию ROLLBACK,
то последующие триггеры не запускаются. Пример вложенных триггеров: Триггер
в таблице Т1 запускает операцию над таблицей Т2, в которой также есть триггер,
который запускает операцию над таблицей ТЗ. Запуск триггеров отменяется, если
формируется бесконечный цикл. Вложенные триггеры можно разрешить при помощи
параметра nested triggers хранимой процедуры sp_configure. Если вложенные триг-
геры отключены, то рекурсивные триггеры также отключены, независимо от соответ-
ствующего параметра хранимой процедуры sp_dboption.
В следующем примере мы хотим переадресовать пользовательские действия над
таблицей people, особенно транзакции, связанные с обновлением, таким образом,
чтобы изменения строк таблицы people записывались вместо этого в таблицу
peoplejreroute. (Более сложная форма таблицы people показана в пункте «SQL Server»
раздела «Инструкция CREATE/ALTER TABLE».) Наш триггер обновлений будет реги-
стрировать все изменения столбцов 2, 3 и 4 таблицы people и записывать их в таблицу
peoplejreroute. Также триггер будет записывать, какой пользователь выполнял тран-
закцию-обновление и в какое время.
CREATE TABLE people
(peoplejd CHAR(4),
people_name VARCHAR(40),
people_addr VARCHAR(40),
city VARCHAR(20),
state CHAR(2),
zip CHAR(5),
phone CHAR(12),
sales_rep empid NOT NULL)
GO
278 | Глава 3. Справочник по инструкциям SQL
CREATE TABLE people_reroute
(reroute_log_id
reroute_log_type
reroute_people_id
re route_people_name
reroute_people_addr
reroute_city
reroute_state
reroute_zip
reroute_phone
reroute_sales_rep
reroute_user sysname
UNIQUEIDENTIFIER DEFAULT NEWID(
CHAR (3) NOT NULL,
CHAR(4),
VARCHAR(40),
VARCHAR(40),
VARCHAR(20),
CHAR(2),
CHAR(5),
CHAR(12),
empidNOT NULL,
DEFAULT SUSER_SNAME( ),
reroute_changed datetime DEFAULT GETDATE( ) )
GO
CREATE TRIGGER update_person_data
ON people
FOR update AS
IF (COLUMNS_UPDATED(people_name)
OR COLUMNS_UPDATEE(people_addr)
OR COLUMNSJJPDATED(city) )
BEGIN
-- Аудит старых записей.
INSERT INTO people_reroute (reroute_log_type, reroute_people_id,
reroute_people_name, reroute_people_addr, reroute_city)
SELECT 'old', d.people_id, d.people_name, d.people_addr, d.city
FROM deleted AS d
-- Аудит новой записи.
INSERT INTO people_reroute (reroute_log_type, reroute_people_id,
reroute_people_name, reroute_people_addr, reroute_city)
SELECT 'new', n.people_id, n.people_name, n.people_addr, n.city
FROM inserted AS n
END
GO . ' '
Отметьте, что инструкции CREATE в SQL Server позволяют использовать отло-
женное разрешение имен (deferred name resolution). Это означает, что команда обраба-
тывается даже в том случае, если она ссылается на еще не существующий объект базы
данных.
Справочник по командам SQL | 279
См. также
CREATE/ALTER FUNCTION/PROCEDURE
DELETE
DROP
INSERT
UPDATE
Инструкция CREATE/ALTER TYPE
Инструкция CREATE TYPE позволяет создавать пользовательские типы (user-defined
type, UDT), т. e., пользовательские типы данных, или - в терминах объектно-ориен-
тированного программирования - «классы». Пользовательские типы расширяют воз-
можности SQL в сфере объектно-ориентированного программирования, разрешая ис-
пользовать наследование и другую объектно-ориентированную функциональность.
Вы также можете создавать с помощью инструкции CREATE TABLE так называемые
объектные таблицы (typed table), используя предварительно созданный с помощью
инструкции CREATE TYPE тип. Объектные таблицы основываются на пользователь-
ских типах и эквивалентны «экземплярам классов» (instantiated classes) объектно-ори-
ентированного программирования.
Платформа Команда
DB2 Поддерживается с вариантами
MySQL Не поддерживается
Oracle Поддерживается с ограничениями
PostgreSQL Поддерживается с вариантами
SQL Server Не поддерживается
Синтаксис SQLS003
CREATE TYPE имя_типа
[UNDER имя_супертипа]
[AS [имя_нового_пользовательского_типа] тип_данных [атрибут] [,...]
{[REFERENCES ARE [NOT] CHECKED
[ON DELETE
{NO ACTION | CASCADE | RESTRICT | SET NULL | SET DEFAULT} ] ] |
[DEFAULT значение] |
[COLLATE имя__сопоставления] } ]
[ [NOT] INSTANTIABLE]
[ [NOT] FINAL]
[REF IS SYTEM GENERATED |
REF USING тип_данных
[CAST {(SOURCE AS REF) | (REF AS SOURCE) WITH идентификатор} ] |
REF имя_нового_пользовательского_типа [,...] } ]
[CAST {(SOURCE AS DISTINCT) | (DISTINCT AS SOURCE)} WITH идентификатор]
[определение_метода- [,...] ]
280 | Глава 3. Справочник по инструкциям SQL
Следующий синтаксис изменяет существующий пользовательский тип данных.
ALTER TYPE тип_данных {ADD ATTRIBUTE определение_типа |
DROP ATTRIBUTE имя_тта}
Ключевые слова
{CREATE | ALTER} ТУРЕ имя_типа
Создается новый тип или изменяется существующий тип имя_типа.
UNDER имя_супертипа
Создается подтип, который зависит от одного существующего указанного
супертипа. (Пользовательский тип может быть супертипом, если он определяется
как NOT FINAL.)
AS [имя_нового_пользоеательского_типа] тип_данных [атрибут] [,...]
Определяются атрибуты типа, как если бы это были объявления столбцов без огра-
ничений в инструкции CREATE TABLE. Вы должны определить UDT-атрибут либо
для существующего типа данных, например I'ARCHAR(IO), либо для другого, ранее
созданного пользовательского типа, либо даже для пользовательского домена. При
создании пользовательского типа на основе уже существующего типа данных
(например, CREATE TYPE my_type AS INT) создается простой тип (distinct type),
а пользовательский тип, созданный с определением атрибутов, является струк-
турным типам (structured type). Ниже перечислены допустимые атрибуты струк-
турных типов.
ON DELETE NO ACTION
Если происходит нарушение внешнего ключа, генерируется ошибка
(по умолчанию).
ON DELETE RESTRICT
Синоним NO ACT1ON.
ON DELETE CASCADE
В столбце co ссылкой устанавливается значение, равное значению из столбца,
на который он ссылается.
ON DELETE SET NULL
В столбец со ссылкой записывается значение NULL.
ON DELETE SET DEFA ULT значение
Определяется значение по умолчанию для пользовательского типа, если поль-
зователь не указал никакого значения. Подчиняется тем же правилам, что
и предложение DEFAULT, описанное в разделе «Инструкция CREATE/ALTER
TABLE».
COLLATE имя_сопоставления
Пользовательскому типу присваивается сопоставление, т. е. порядок сортиров-
ки. Если предложение опущено, применяется сопоставление из базы данных,
в которой был создан пользовательский тип. Подчиняется тем же правилам, что
и предложение COLLATION, описанное в разделе «Инструкция CREATE/
ALTER TABLE».
Справочник по командам SQL | 281
[NOT] INSTANTIABLE
Указывается, что пользовательский тип может быть реализован. Предложение IN-
STANTIABLE является обязательным для объектных таблиц, но не для стандарт-
ных пользовательских типов.
[NOT] FINAL
Является обязательным для всех пользовательских типов. Предложение FINAL оз-
начает, что пользовательский тип не может иметь подтипов. Предложение NOT
FINAL означает, что пользовательский тип может иметь подтипы.
REF
Указывается созданное системой или пользователем описание ссылки, т. е. своего
рода уникального идентификатора, который играет роль указателя, на который
может ссылаться другой тип. Ссылаясь на существующие типы с помощью описа-
ния ссылки, новые типы могут наследовать свойства уже имеющихся. Существует
три способа указать для СУБД, каким образом столбец ссылок объектной таблицы
будет получать значения (т. е. описание ссылки). Эти способы таковы:
имя_нового_пользовательского_типа [,...]
Объявляется, что описание ссылки предоставляет другой существующий
пользовательский тип с именем имя_нового_полъзовательского_типа.
IS SYSTEM GENERA TED
Объявляется, что описание ссылки будет генерироваться системой. (Это
можно считать автоматически инкрементируемым столбцом.) Если предложе-
ние REF опущено, этот вариант используется по умолчанию.
USING тип_данных [CAST {(SOURCE AS REF) | (REF AS SOURCE) WITH иденти-
фикатор] ]
Объявляется, что описание ссылки предоставляет пользователь. Это осуществ-
ляется при помощи существующего типа данных и при желании с использова-
нием приведения типа значения. Вы можете использовать конструкцию CAST
(SOURCE AS REF) WITH идентификатор, чтобы привести значение указанного
типа_данных к типу ссылки на структурный тип. Вы можете использовать кон-
струкцию CAST (REF AS SOURCE) WITH идентификатор, чтобы привести
значение структурного типа к указанному типу_данных. Предложение WITH
позволяет объявить дополнительный идентификатор для приведенного типа
данных.
CAST {(SOURCE AS DISTINCT) | (DISTINCT AS SOURCE)} WITH идентификатор]
[определение jvtemoda [...]
Для пользовательского типа объявляется один или несколько уже существующих ме-
тодов. Метод - это просто специализированная пользовательская функция, которая
создается при помощи инструкции CREATE METHOD (см. CREATE FUNCTION).
Предложение определение_метода не нужно использовать в структурных типах, по-
скольку их методы создаются неявно. Заданные по умолчанию параметры метода
следующие: LANGUAGE SQL, PARAMETER STYLE SQL, NOT DETERMINISTIC,
CONTAINS SQL nRETURN NULL ON NULL INPUT.
282 | Глава 3. Справочник по инструкциям SQL
ADD ATTRIBUTE определение jnuna
К существующему пользовательскому типу добавляется дополнительный атрибут
с использованием формата, описанного ранее для предложения AS. Используется
в инструкции ALTER TABLE.
DROP ATTRIBUTE имя_типа
Из существующего пользовательского типа удаляется атрибут. Используется в ин-
струкции ALTER TABLE.
Общие правила
Вы можете создавать пользовательские типы (UDT), что является еще одним спосо-
бом обеспечения целостности данных в базе и облегчения связанной с этим работы.
Важный момент в пользовательских типах состоит в том, что вы легко можете созда-
вать подтипы. Подтипы - это пользовательские типы, созданные на основе другого
пользовательского типа (супертипа). Подтипы наследуют характеристики соответст-
вующих супертипов. Пользовательский тип, от которого зависят подтипу, называется
родительским типом или супертипом.
Предположим, например, что вы хотите определить общий пользовательский тип
для телефонных номеров с именем phone_nbr. Затем вы сможете легко определить на
основе типа phone nbr новые подтипы - home_phone, work_phone, cell_phone,
pager_phone и т. п. Каждый подтип может наследовать общие характеристики роди-
тельского типа, но и иметь собственные характеристики. В следующем примере мы
создали базовый пользовательский тип money, а затем несколько подтипов.
CREATE TYPE money (phone_number DECIMAL (10,2) )
NOT FINAL;
CREATE TYPE dollar UNDER money AS DECIMAL^10. 2)
(conversion_rate DECIMAL(10,2) ) NOT FINAL;
CREATE TYPE euro UNDER money AS DECIMAL(10,2)
(dollar_conversion_rate DECIMALS 10,2) ) NOT FINAL;
CREATE TYPE pound UNDER euro
(euro_conversion_rate DECIMAL(10,2) ) FINAL;
Советы и хитрости программирования
Самая большая хитрость программирования пользовательских типов состоит в том,
что они просто редко используются и их плохо понимает большинство разработчиков
и администраторов баз данных. Следовательно, проблемы могут возникать просто из-за
недостатка знаний. Однако пользовательские типы предоставляют надежный и эконо-
мящий труд подход к представлению часто используемых элементов базы данных,
таких, например, как адрес (т. е. улица!, улица2, город, штат, почтовый код).
Справочник по командам SQL | 283
DBS
Платформа DB2 поддерживает большинство элементов стандарта ANSI с несколькими
специфическими усовершенствованиями. Синтаксис инструкции CREATE TABLE
следующий.
CREATE [DISTINCT] TYPE имя_типа
[UNDER имя_супертипа]
[AS [новое_имя_пользовательского_типа] тип_данных
[WITH COMPARISONS]
[[NOT] INSTANTIABLE] [INLINE LENGTH int] [WITHOUT COMPARISONS]
[NOT FINAL] MODE DB2SQL
[REF USING тип_данных] [CAST {(SOURCE AS REF) | (REF AS SOURCE)}
WITH идентификатор } ]
[[OVERRIDING] METHOD определение_метода [,...] ]
Синтаксис, приводимый ниже, позволяет изменить существующий пользователь-
ский тип данных в системе DB2.
ALTER TYPE имя_типа {ADD ATTRIBUTE определение_типа |
DROP ATTRIBUTE имя_типа [RESTRICT] |
ADD METHOD определение_метода |
ALTER METHOD имя_метода [[NOT] FENCED] [[NOT] THREADSAFE] |
DROP METHOD имя_метода [RESTRICT] }
Параметры следующие.
DISTINCT
Определяется простой тип. Простой тип всегда основывается на существующих
в DB2 типах данных. Инструкция CREATE DISTINCT TYPE создает одну или
несколько функций для приведения типов между простым типом и его исходным
типом.
WITH COMPARISONS
Обеспечивается поддержка использования операторов сравнения (=, о, <, <=, > и >=)
с простым типом. Это предложение используется только с предложением CREATE
DISTINCT TYPE. Предложение WITH COMPARISONS не следует использовать даже
при создании простого типа, если исходным типом данных является BLOB, CLOB,
DBCLOB, LONG VARCHAR, LONG V4RGRAPHIC или DATALINK.
INLINE LENGTH int
Указывается максимальная длина в байтах (int) столбца структурного типа. Если
предложение опущено, система DB2 вычисляет максимальную длину самостоя-
тельно.
WITHOUT COMPARISONS
Объявляется, что для данного структурного типа не поддерживаются функции
сравнения.
MODE DB2SQL
Это обязательное предложение для сохранения совместимости со стандартом
ANSI.
284 | Глава 3. Справочник по инструкциям SQL
OVERRIDING
Объявляется, что метод подтипа подменяет метод супертипа с тем же именем. Это
предложение позволяет легко переписывать методы в подтипах.
METHOD определение_метода [,...]
Платформа DB2 поддерживает в определении_метода несколько характеристик
процедур SQL и внешних процедур. Если коротко, вы должны определять метод
в инструкции CREATE/ALTER TYPE, но потом вы также должны определить реа-
лизацию метода с помощью инструкции CREATE METHOD. Создание методов
объясняется в разделе «Инструкции CREATE/ALTER FIJNCT1ON/PROCEDURE».
ADD METHOD определение_метода
К существующему типу имя_типа добавляется новый метод опредепение метода.
Однако метод использовать нельзя до тех пор, пока в инструкции CREATE METHOD
не будет определена реализация метода.
ALTER METHOD имяметода
Производится изменение метода, но метод должен быть с предложением LANGUAGE
SQL.
[NOT] FENCED
Указывается, безопасно ли запускать метод при помощи процесса операционной
системы базы данных (NOT FENCED) или небезопасно (FENCED). Методы
с предложением NOT FENCED могут создать проблемы целостности, если не
будут должным образом настроены, чтобы предотвратить ошибки. Это предложение
несовместимо с предложением NOT THREADSAFE.
[NOT] THREADSAFE
Объявляется, что метод можно запускать в одном процессе с другими процедурами
(THREADSAFE) или нельзя (NOT THREADSAFE).
DROP METHOD имя_метода
Удаляется существующий метод имяметода.
RESTRICT
Запрещает удалять атрибут или метод, если тип имя_типа используется в других
существующих объектах, например таблице, представлении, столбце, расширении
индекса и т. п.
В этом примере мы создаем супертип employee и подтип manager.
CREATE TYPE employee AS
(last_name VARCHAR(32),
emp_id INT,
dept REF(dept),
salary DECIMALC10,2))
MODE DB2SQL;
CREATE TYPE manager UNDER emp AS
(bonus DECIMAL(10,2))
MODE DB2SQL;
Справочник по командам SQL | 285
В следующем примере показана более сложная иерархия типов, используемая для
адресов.
CREATE TYPE address_type AS
(streetl VARCHAR(30),
street2 VARCHAR(3O),
city VARCHAR(30),
state VARCHAR(10),
locality_code CHAR(15) )
NOT FINAL
MODE DB2SQL
METHOD SAMEZIP (addr address_type)
RETURNS INTEGER
LANGUAGE SQL
DETERMINISTIC
CONTAINS SQL
NO EXTERNAL ACTION
METHOD DISTANCE (address_type)
RETURNS FLOAT
LANGUAGE C
DETERMINISTIC
PARAMETER STYLE SQL
NO SQL
NO EXTERNAL ACTION
CREATE TYPE spain_address_type UNDER address_type AS
(family_name VARCHAR(30))
NOT FINAL
MODE DB2SQL
CREATE TYPE usa_address_type UNDER address_type AS
(zip VARCHAR(IO))
NOT FINAL
MODE DB2SQL
В приведенном выше примере мы создали тип address_type с двумя подтипами -
spain address type и usa address type.
В следующем примере показано, как создать простой тип в DB2, указывающий
почтовое отделение служащего.
CREATE DISTINCT TYPE mailstop AS CHAR(5)
WITH COMPARISONS;
По существу тип mailstop теперь работает как обычный тип данных и может исполь-
зоваться для создания таблиц, переменных в хранимых процедурах и т. д. Предложение
WITH COMPARISONS заставляет DB2 создать стандартные, существующие системные
286 | Глава 3. Справочник по инструкциям SQL
операторы для использования с данным простым типом. Специфические функции,
такие, как AVG, MIN или LENGTH, могут не работать, если только функция не будет
зарегистрирована для данного типа с помощью инструкции CREATE FUNCTION.
MySQL
Не поддерживается.
Oracle
В Oracle есть инструкции CREATE TYPE и ALTER TYPE, но они не соответствуют
стандарту ANSI. Вместо одной инструкции CREATE TYPE в Oracle используется кон-
струкция CREATE TYPE BODY, определяющая код пользовательского типа, а инструк-
ция CREATE TYPE определяет описание аргументов типа. Синтаксис инструкции
CREA TE TYPE следующий.
CREATE [OR REPLACE] TYPE имя_типа
[AUTHID {DEFINER | CURRENT_USER} ]
{ [ UNDER имя_супертипа] |
{AS | IS} [010 'идентификатор_объекта"]
{OBJECT | TABLE OF тип_данных | VARRAY ( лимит } OF тип_данных} ] }
EXTERNAL NAME имя_внешнего_класса_]ava LANGUAGE JAVA USING определение_данных
{ [ (атрибут тип_данных [,...] [EXTERNAL NAME 'имя'] |
[[NOT] OVERRIDING] [[NOT] FINAL] [[NOT] INSTANTIABLE]
[{ {MEMBER | STATIC}
{вь13ывается_как_функция | вызывается_как_процедура} | конструктор |
карта } [. . . ] ]
[прагма] ] }
Как только тип объявлен, вы заключаете всю логику пользовательского типа
в тело типа (TYPE BODY}. Имя типа для обеих инструкций - CREATE TYPE и CREATE
TYPE BODY - должно быть одним и тем же. Синтаксис инструкции CREATE TYPE
BOD Y следующий.
CREAIE [CR REPLACE] TYPE BODY имя_типа
{AS | IS}
{{MEMBER | STATIC}
{ вызывается _как_функция | вызывается_как_процедура} | конструктор }}[...]
[карга]
Реализация инструкции ALTER TYPE в Oracle позволяет удалять и добавлять атри-
буты и методы типа.
ALTER TYPE имя^типа
{COMPILE [DEBUG] [{SPECIFICATION | BODY}]
[директивы_компилятора] [REUSE SETTINGS] |
REPLACE [AUTHID {DEFINER | CURRENT_USER}] AS .OBJECT
(атрибут тип_данных [,...] [определение_элемента [,...]] ) !
[[NOT] OVERRIDING] [[NOT] FINAL] [[NOT] INSTANTIABLE]
{ {ADD | DROP} { {MAP | ORDER} MEMBER FUNCTION имя_функции
Справочник по командам SQL | 287
(.параметр тип_данных [,...]) } |
{ {MEMBER | STATIC} {вызывается_как_функция | вызывается_как_процедура} |
конструктор | карта } [,., ] |
{ADD | DROP | MODIFY} ATTRIBUTE (атрибут [тип^данных] [,...] ) |
MODIFY {LIMIT int | ELEMENT TYPE тип_данных } }
[ {INVALIDATE |
CASCADE [{ [NOT] INCLUDING TABLE DATA | CONVERT TO SUBSTITUTABLE}]
[FORCE] [EXCEPTIONS INTO имя_таблицы] } ]
Параметры для этих трех инструкций приведены ниже.
OR REPLACE
Если пользовательский тип существует, он создается заново. После повторного
создания типа те объекты, которые зависят от него, помечаются как отключенные
{DISABLE).
AUTHID {DEFINER | CURRENTJJSER}
Определяет, с какими правами доступа выполняются функции и процедуры-члены
и как разрешаются ссылки на внешние имена (отметьте, что подтипы наследуют
стиль прав доступа своего супертипа). Это предложение может использоваться
только с типом OBJECT, но не с типом VARRAY или вложенными таблицами.
Используются следующие ключевые слова.
DEFINER
Функции и процедуры выполняются с привилегиями пользователя, создавше-
го пользовательский тип. Также указывается, что неквалифицированные
имена объектов (имена объектов без указания схемы) в инструкциях SQL
разрешаются в ту схему, к которой принадлежат функции и процедуры-члены.
CURRENT_USER
Функции и процедуры выполняются с привилегиями пользователя, запустившего
пользовательский тип. Также указывается, что неквалифицированные имена
объектов в инструкциях SQL разрешаются в схему пользователя, запустившего
пользовательский тип.
UNDER имя_супертипа
Объявляется, что пользовательский тип является подтипом другого, сущест-
вующего пользовательского типа. Супертип должен быть объявлен с предложением
AS OBJECT. Подтип будет наследовать свойства супертипа, хотя вы можете заменять
и добавлять новые свойства, делая подтип отличным от супертипа.
OID ‘идентификатор_объекта’
Один и тот же идентичный объект с именем идентификатор_объекта объявляет-
ся в нескольких базах данных. Это предложение обычно используется при разра-
ботке картриджей данных Oracle (Oracle Data Cartridge) и редко применяется при
написании стандартных инструкций SQL.
AS OBJECT
Пользовательский тип создается как базовый объектный тип, высший уровень
в иерархии объектов.
288 | Глава 3. Справочник по инструкциям SQL
AS TABLE OF тип_данных
Создается именованная вложенная таблица, относящаяся к пользовательскому
типу тип_данных. Тип данных не может быть NCLOB, хотя CLOB и BLOB допус-
каются. Если тип данных является объектным типом, то столбцы вложенной таб-
лицы должны совпадать с названиями и атрибутами объектного типа.
AS VARRAY (лимит) OF тип_данных
Пользовательский тип создается в виде упорядоченного набора элементов,
которые все относятся к одному типу данных. Параметр лимит - это целое число
от нуля и более. Тип данных должен быть внутренним типом, REF или объектным
типом. Тип VARRAYне должен содержать типов LOB или XMLType.
EXTERNAL NAME имя_внешнего_классаJava
LANGUAGE JAVA USING определение_данных
Связывает класс Java с пользовательским типом SQL, для чего указывается имя
открытого (public) внешнего класса Java. После такого определения все объекты
класса Java должны быть объектами Java. Параметр определение_данных может
представлять собой SQLData, CustomDatum или OraData, согласно документу
«Oracle9i JDBC Developers Guide». Вы можете связывать с одним классом не-
сколько объектных типов Java, однако здесь есть два ограничения. Во-первых, не
связывайте с одним классом два и более подтипа одного типа данных. Во-вторых,
подтипы должны быть непосредственно связаны с соответствующим подклассом
того класса, с которым связан их супертип.
тип_данных
Объявляются атрибуты и типы данных, используемые пользовательским типом.
Платформа Oracle не разрешает использовать ROWID, LONG, LONG ROW
или UROWID. Во вложенных таблицах и типах VARRAY не разрешены атрибуты
AnyType, AnyData и AnyDataSet.
EXTERNAL NAME ‘имя’[NOT] OVERRIDING
Объявляется, что данный метод подменяет метод MEMBER, определенный в супертипе
(OVERRIDING), или же не подменяет (NOTOVERRIDING) (по умолчанию). Это пред-
ложение действует только для предложений MEMBER.
MEMBER | STATIC
Описывается, каким образом подпрограммы связываются с пользовательским
типом в виде атрибутов. Метод, объявленный как MEMBER, имеет неявный
первый аргумент со ссылкой SELF, например объектное_выражение.метод().
Метод, объявленный как STATIC, не имеет неявных аргументов, например
имяjmma.метод)). Для вызова подпрограммы существует следующий синтаксис.
вызывает ся_как_фу акция
Подпрограмма, которая вызывается как функция, декларируется как с исполь-
зованием следующего синтаксиса.
FUNCTION имя_функции (параметр, тип_данных [,...])
возвращает | объект Java
Имя функции не должно быть именем любого существующего атрибута,
включая те, которые наследуются от супертипов. Это предложение позволяет
19 - 2447
Справочник по командам SQL | 289
определить тело пользовательского типа на основе функции PL/SQL без
использования инструкции CREATE TYPE BODY. Параметры возвращает
и объект Java описываются ниже.
вызывается_как_процедура
Объявляется подпрограмма, вызываемая как процедура, для чего используется
следующий синтаксис.
PROCEDURE имя_процедуры (параметр, тип_данных
{AS | IS} LANGUAGE {описание_вызова_]ауа | описание_вызова_с}
Обращайтесь к описанию параметров описание_вызоваJava и описание_вы-
зова_с ниже в этой главе. Имя процедуры не должно совпадать с именем ни
одного из существующих атрибутов, включая те, которые наследуются от
супертипов.
конструктор
Объявляется одно или несколько описаний конструктора, для чего использует-
ся следующий синтаксис.
[FINAL] [INSTANTIABLE] CONSTRUCTOR FUNCTION тип_данных
[ ( [SELF IN OUT тип_данных ,] {параметр тип_данных [,...] ) ]
RETURN SELF AS RESULT
[ {AS | IS} LANGUAGE { описание_вызова_]ауа | описание_вызова_с }
Конструктор - это функция, которая возвращает инициализированный экземп-
ляр пользовательского типа. В спецификацию конструктора всегда входят
предложения FINAL, INSTANTIABLE и SELF IN OUT, поэтому эти ключевые
слова указывать не обязательно. Предложения описание_вызоваJava и описа-
ние_вызова_с можно заменить на блок кода PL/SQL в инструкции CREATE
TYPE BODY (обращайтесь к описаниям предложений описание_вызоваJava и
описание_вызова_с, которые приводятся ниже в этом списке).
карта
Объявляется карта или порядок расположения для супертипа с помощью сле-
дующего синтаксиса.
{МАР | ORDER} MEMBER вызывается_как_функция
Параметр вызывается~как_функция описан выше. При указании предложе-
ния МАР используются более эффективные алгоритмы сравнения объектов,
и этот вариант является наилучшим в тех ситуациях, когда широко исполь-
зуются сортировка или хеш-соединения. Предложение MAP MEMBERS указы-
вает относительное положение данного экземпляра среди всех экземпляров
пользовательского типа. Предложение ORDER MEMBER явно указывает поло-
жение экземпляра, обращаясь к основанной_на_функции подпрограмме,
которая возвращает значение типа NUMBER.
возвращает
Для пользовательского типа объявляется тип возвращаемого значения, для
чего используется следующий синтаксис.
290 | Глава 3. Справочник по инструкциям SQL
RETURN тип_данных [ {AS | IS} LANGUAGE {описание__вызова_^а |
описание_вызова_с}.
объект Java
Объявляется тип возвращаемого значения для пользовательского типа Java.
Используется следующий синтаксис.
RETURN { тип_данных | SELF AS RESULT} EXTERNAL [VARIABLE] NAME
'имя_java'
Если вы используете предложение EXTERNAL, то значение, возвращаемое
публичным методом Java, должно быть совместимо с возвращаемым значением
SQL.
прагма
Для типа объявления ограничение-прагма (т. е. директивы прекомпилятора
Oracle) используется следующий синтаксис.
PRAGMA RESTRICT REFERENCES ( {DEFAULT | имя_метода} ,
{RNDS ! WNDS |RNPS | WNPS | TRUST}[,...] )
Эта функция выходит из употребления, и ее следует избегать. Параметры
синтаксиса предложения PRAGMA таковы:
DEFAULT
Прагма применяется ко всем методам типа, которые не имеют другой
прагмы.
имя_метода
Указывается, к какому конкретно методу применяется прагма.
RNDS
Reads No Database State - запрещается читать базу данных.
WNDS
Writes No Database State - запрещается записывать базу данных.
RNPS
Reads No Package State - запрещается читать пакеты.
WNPS
Writes No Package State - запрещается записывать пакеты.
TRUST
Состояние, в котором ограничения прагмы подразумеваются, но не реали-
зуются принудительно.
описание_вызоваJava
Показывает реализацию метода на Java, для чего используется синтаксис
JAVA NAME 'строка'. Это предложение позволяет определить тело поль-
зовательской функции Java без использования инструкции CREATE TYPE
BODY.
описание_вызова_с
Объявляется описание вызова языка С, для чего используется следующий
синтаксис.
Справочник по командам SQL | 291
C [NAME имя] LIBRARY имя_библиотеки [AGENT IN (аргумент) ]
[WITH CONTEXT] [PARAMETERS (параметр [,..,] ]
Это предложение позволяет определить тело пользовательской функции
на С без использования инструкции CREATE TYPE BODY.
COMPILE
Компилируется описание и тело объектного типа. Это предложение используется
по умолчанию, если не указано предложение SPECIFICATION или BODY.
директивы_компилятора
Указываются специальные значения для компилятора PL/SQL в формате директива =
'значение'. Директивы используются следующие: PLSQL OPTIMIZE_LEVEL,
PLSQL_CODEJYPE, PLSQL_DEBUG, PLSQLJVARNINGS и NLS_LENGTH_SEMANTICS.
В инструкции можно указать значение для каждой только один раз. Директива действу-
ет только в пределах компилируемого модуля.
DEBUG
Генерируется и записывается дополнительный код для отладчика PL/SQL. Не ука-
зывайте одновременно предложения DEBUG и директиву_кампилятора
PLSQL_DEBUG.
SPECIFICATION | BODY
Выберите, что нужно перекомпилировать, спецификацию объектного типа
(SPECIFICATION), созданную в инструкции CREATE TYPE, или тело (BODY),
созданное в инструкции CREATE TYPE BODY.
директивы_компилятора
Указываются специальные значения для компилятора PL/SQL в формате директива =
‘значение’. Директивы используются следующие: PLSQL_OPTIMIZE_LEVEL,
PLSQL_CODE_TYPE, PLSQL_DEBUG, PLSQL_WARNINGS и NLS_LENGTH_
SEMANTICS. В инструкции можно указать значение для каждой только один раз.
Директива действует только в пределах компилируемого модуля.
REUSE SETTINGS
Сохраняются исходные значения директивкомпилятора, упоминавшихся ранее.
REPLACE AS OBJECT
В спецификацию добавляются новые члены-подтипы. Это предложение можно
использовать только в объектных типах.
[NOT] OVERRIDING
Показывает, что метод подменяет метод MEMBER, объявленный в супертипе. Это
предложение применимо только к методам MEMBER, и оно является необходи-
мым для методов, которые определяют (или переопределяют в инструкции
ALTER] метод супертипа. Если предложение опущено, по умолчанию принимается
NOT OVERRIDING.
ADD
В пользовательский тип добавляется новая функция MEMBER, подпрограмма,
основанная на процедуре или функции, или атрибут.
292 | Глава 3. Справочник по инструкциям SQL
DROP
Из пользовательского типа удаляется функция MEMBER, подпрограмма, основан-
ная на процедуре или функции, или атрибут.
MODIFY
Изменяются свойства существующего атрибута пользовательского типа.
MODIFY LIMIT int
Количество элементов в типе VARRAY увеличивается до int, если int больше, чем
текущее число элементов VARRAY. Неприменимо к вложенным таблицам.
MODIFY ELEMENT TYPE тип_данных
Увеличивается точность, размер или длина скалярного типа в VARRAY или во вло-
женной таблице. Если это набор числовых значений {NUMBER), вы можете повы-
сить его точность или масштаб. Если это набор значений RA W, вы можете уве-
личить максимальный их размер. Если это набор значений VARCHAR2 или
NVARCHAR2, вы можете увеличить максимальную длину.
INVALIDATE
Все зависимые объекты становятся недействительными без проведения проверок.
CASCADE
Изменение распространяется на все подтипы и таблицы. По умолчанию в случае
возникновения ошибок в любых зависимых типах или таблицах будет произведен
откат операции.
[NOT] INCLUDING TABLE DATA
Данные, хранимые в столбцах пользовательского типа, преобразуются к самой по-
следней версии типа {INCLUDING TABLE DATA) (по умолчанию) или не преобра-
зуются {NOT INCLUDING TABLE DATA). Если преобразование не производится,
Oracle проверяет метаданные, но не проверяет и не обновляет зависимые данные
таблиц.
CONVERT ТО SUBSTITUTABLE
Используется при изменении типа с FINAL на NOT FINAL. Измененный тип затем
может использоваться в заменяемых таблицах и столбцах, а также в подтипах,
в экземплярах зависимых таблиц и столбцах.
FORCE
Это предложение заставляет операцию CASCADE выполняться без учета ошибок,
обнаруживающихся в зависимых подтипах и таблицах. Все ошибки регистрируются
в ранее созданной таблице EXCEPTIONS.
EXCEPTIONS INTO имя_таблицы
Все сведения об ошибках заносятся в таблицу, заранее созданную при помощи
системного пакета DBMS_UTILITY.CREATE_ALTER_TYPE_ERROR_TABLE.
В следующем примере мы создадим объектный тип Java SQLJ с именем
address_type.
CREATE TYPE address_type AS OBJECT
EXTERNAL NAME 'scott. address' LANGUAGE JAVA
USING SQLDATA ( streetl VARCHAR(30) EXTERNAL NAME 'strr,
streets VARCHAR(3O) EXTERNAL NAME ’str2',
Справочник по командам SQL | 293
city VARCHAR(30) EXTERNAL NAME 'city',
state CHAR(2) EXTERNAL NAME 'st',
locality_code CHAR(15) EXTERNAL NAME 'lc',
STATIC FUNCTION square_feet RETURN NUMBER
EXTERNAL VARIABLE NAME 'square.feet',
STATIC FUNCTION create_addr (str VARCHAR,
City VARCHAR, state VARCHAR, zip NUMBER)
RETURN address_type
EXTERNAL NAME 'create (java.lang.String,
java.lang.String, java.lang.String, int)
return scott.address',
MEMBER FUNCTION rtrims RETURN SELF AS RESULT
EXTERNAL NAME 'rtrim_spaces ( ) return scott.address' )
NOT FINAL;
Мы можем создать пользовательский тип, используя четыре элемента типа
VARRAY.
CREATE TYPE employee_phone_numbers AS VARRAY(4) OF CHAR(14);
В следующем примере мы изменяем созданный ранее тип address_type, добавляя
элемент VARRAY с именем phone_varray.
ALTER TYPE address_type
ADD ATTRIBUTE (phone phone_varray) CASCADE;
В последнем примере мы создадим супертип и подтип с именами menu_item_type
и entry_type соответственно.
CREATE OR REPLACE TYPE menu_item_type AS OBJECT
(id INTEGER, title VARCHAR2(500),
NOT INSTANTIABLE
MEMBER FUNCTION fresh.today
RETURN BOOLEAN)
NOT INSTANTIABLE
NOT FINAL;
В приведенном выше примере мы создали спецификацию типа (но не тело типа),
определяющую элементы, которые могут включаться в меню в кафе. В спецификацию
типа включена подпрограмма-метод с именем fresh_today, индикатор булевого типа,
показывающий, что элемент из меню был сделан в этот день. Предложение NOT
FINAL, которое находится в конце кода, показывает, что данный тип может служить
супертипом (или базовым типом) для других подтипов, которые мы можем создать на
его основе. Так что теперь давайте создадим тип entry_type.
CREATE OR REPLACE TYPE entry_type UNDER menu_item_type
(entre_id INTEGER, desc_of_entre VARCHAR2(500),
OVERRIDING MEMBER FUNCTIOIN fresh_today
RETURN BOOLEAN)
NOT FINAL;
294 | Глава 3. Справочник по инструкциям SQL
PostgreSQL
Платформа PostgreSQL поддерживает инструкцию CREATE TYPE, используемую для
создания нового типа данных, но не поддерживает инструкцию ALTER TYPE. Реализация
инструкции CREATE TYPE в PostgreSQL нестандартная.
CREATE TYPE имя_типа
( INPUT = имя_входной_функции,
OUTPUT = имя_выходной_функции,
INTERNALLENGTH = { int | VARIABLE }
[, DEFAULT = значение']
[, ELEMENT = тип_данных_массива ]
[, DELIMITER = символ_разделитель ]
[, PASSEDBYVALUE ]
[, ALIGNMENT = {CHAR | INT2 | INT4 | DOUBLE} ]
[, STORAGE = {PLAIN | EXTERNAL | EXTENDED | MAIN} ] )
Параметры приведены ниже.
CREATE TYPE имя_типа
Создается новый пользовательский тип данных с именем имя_типа. Длина имени
не может превышать 30 символов, и оно не должно начинаться с символа
подчеркивания.
INPUT = имя _входной^функции
Объявляется имя ранее созданной функции, которая преобразует значения внешних
аргументов в форму, которая может использоваться внутри типа.
OUTPUT - имя_выходной_функции
Объявляется имя ранее созданной функции, которая преобразует внутренние
выходные значения в форму, используемую при отображении.
INTERNALLENGTH = {int | VARIABLE)
Указывается числовое значение (int), показывающее внутреннюю длину нового
типа, если тип данных имеет фиксированную длину. Ключевое слово VARIABLE
объявляет, что внутренняя длина является переменной. По умолчанию принимается
VARIABLE.
DEFAULT - значение
Для типа объявляется значение по умолчанию.
ELEMENT = тип_данных_массива
Объявляется, что тип данных является массивом, а параметр тип_данных_масси-
ва представляет собой тип данных для элементов массива. Например, массив,
содержащий целые числа, следует объявить как ELEMENT - INT4. Как правило,
следует оставить для параметра тип_данных_массива значение по умолчанию.
Единственный случай, когда может понадобиться заменить заданное по умолча-
нию значение, - это создание пользовательского типа фиксированной длины,
состоящего из массива множества идентичных элементов, к которому необходим
прямой доступ через индекс.
Справочник по командам SQL | 295
DELIMITER = символразделитель
Указывается символ, используемый в качестве разделителя между выходными
значениями массива, создаваемого при помощи типа. Используется только с пред-
ложением ELEMENT, По умолчанию - запятая.
PASSEDBYIALUE
Указывается, что для типа данных передаются значения, а не ссылки. Это необяза-
тельное предложение, которое нельзя использовать для типов, значения которых
имеют длину большую, чем длина типа DATUM (в большинстве операционных
систем - 4 байта, на некоторых - 8 байт).
ALIGNMENT = {CHAR | INT2 | INT4 | DOUBLE}
Определяет для типа выравнивание данных при хранении. Разрешается использо-
вать четыре типа, каждый из которых соответствует определенной границе. Тип
CHAR соответствует 1 байту, INT2 - 2 байтам, INT4 - 4 байтам (необходимое тре-
бование для пользовательских типов переменной длины в PostgreSQL). Тип
DOUBLE соответствует 8 байтам.
STORAGE = {PLAIN \.EXTERNAL | EXTENDED | MAIN}
Определяется метод хранения пользовательских типов переменной длины.
(Для типов с фиксированной длиной требуется вариант PLAIN.) Допустимыми яв-
ляются четыре метода.
PLAIN
Пользовательский тип хранится во встроенном виде, если он объявлен как тип
данных для столбца таблицы и не сжат.
EXTERNAL
Пользовательский тип хранится за пределами таблицы. Попытки сжать его не
предпринимаются.
EXTENDED
Пользовательский тип хранится в сжатом виде, если он умещается в таблице.
Если он оказывается слишком длинным, PostgreSQL будет хранить его за пре-
делами таблицы.
MAIN
Пользовательский тип хранится в таблице в сжатом виде. Бывают ситуации,
когда PostgreSQL не может сохранить пользовательский тип в таблице,
потому что он слишком велик. При указании параметра МА IN система больше
всего старается сохранить пользовательский тип вместе со всеми прочими
табличными данными.
Если вы создаете в PostgreSQL новый тип данных, он будет доступен только в те-
кущей базе данных. Владельцем является тот пользователь, который создал этот тип.
Чтобы создать новый тип данных, перед его определением вы должны создать,
как минимум, две функции (см. «Инструкции CREATE/ALTER PROCEDURE/FUNC-
TION»). Если коротко, вы должны создать функцию INPUT, которая предоставляет
типу внешние значения, чтобы они могли использоваться операторами и функциями
внутри типа. Также вы должны создать функцию OUTPUT, которая создает внешнее
296 | Глава 3. Справочник по инструкциям SQL
представление типа данных. Для создания функций INPUT и OUTPUT есть несколько
дополнительных требований.
• Функция INPUT должна либо принимать один аргумент типа OPAQUE, либо при-
нимать три аргумента - OPAQUE, OID и INT4. В последнем случае параметр
OPAQUE представляет собой входной текст в виде строки стиля С, OID - это тип
элемента для массивов, a INT4 - это модификатор типа для целевого столбца
(если известен).
• Функция OUTPUT должна либо принимать один аргумент типа OPAQUE, либо
принимать два аргумента типов OPAQUE и OID. В последнем случае OPAQUE -
это сам тип данных, a OID - это тип элемента для массивов (если необходимо).
Например, мы можем создать пользовательский тип с именем floorplan и исполь-
зовать его при определении столбца в двух таблицах - house и condo.
CREATE TYPE floorplan
(INTERNALLENGTH=12, INPUT=squarefoot_calc_proc,
OUTPUT=out_floorplan_proc);
CREATE TABLE house
(house_plan_id int4,
size floorplan,
descrip varchar(30) );
CREATE TABLE condo
(condo_plan_id INT4,
size floorplan,
descrip varchar(30)
location^id varchar(7) ):
SQL Server
He поддерживается. Новые типы данных можно добавлять в SQL Server при помощи
системной хранимой процедуры sp_addtype, не соответствующей стандарту ANSI.
См. также
CREATE/ALTER FUNCTION/PROCEDURE
DROP
Инструкция CREATE/ALTER VIEW
Эта инструкция создает представление (view), которое также называется виртуальной
таблицей. Представление функционирует так же, как таблица, но в действительности
определяется как запрос. Если на представление есть ссылка в инструкции, резуль-
тирующий набор данных запроса становится содержимым представления на период
действия инструкции. Содержимое представления можно определить с помощью
почти любой допустимой инструкции SELECT, хотя на некоторых платформах огра-
Справочник по командам SQL | 297
ничивается применение некоторых предложений инструкции SELECT и некоторых
наборов операторов.
В некоторых случаях представления можно обновлять, причем изменения пред-
ставления заносятся в основные таблицы. Некоторые платформы поддерживают
материализованные представления (materialized view), т. е. таблицы, которые физически
создаются на основе запроса, подобно представлениям.
Инструкция ALTER VIEW стандартом ANSI не поддерживается.
Платформа Команда
DB2 Поддерживается с вариантами
MySQL Не поддерживается
Oracle Поддерживается с вариантами
PostgreSQL Поддерживается с вариантами
SQL Server Поддерживается с вариантами
Синтаксис SQL2003
CREATE [RECURSIVE] VIEW имя_представления {[{столбец [,...])] |
[OF имя_пользовательского_типа [UNDER имя_супертипа
[REF IS имястолбца {SYSTEM GENERATED | USER GENERATED | DERIVED} ]
[имястолбца WITH OPTIONS SCOPE имя_тзблицы] ] }
AS
инструкциясе1ес! [WITH [CASCADED | LOCAL] CHECK OPTION]
Ключевые слова
CREATE VIEW имя представления
Создается новое представление с указанным именем.
RECURSIVE
Создается представление, которое получает значения из себя самого. Инструкция
должна содержать предложение столбец и не может использовать предложение
WITH.
[(столбец [,...])]
Присваиваются имена всем столбцам представления. Количество объявляемых
здесь столбцов должно совпадать с количеством столбцов, генерируемых ин-
струкцией_зе1ес1. Если предложение опущено, подразумеваются имена столбцов,
откуда были взяты данные. Предложение является обязательным, если имеются
производные столбцы и нельзя сослаться на столбец базовой таблицы.
OF имя пользовательского_типа [UNDER имя_супертипа]
Представление будет основываться на пользовательском типе, а не на указании
столбцов. Объектное представление создается с использованием в качестве столбцов
298 | Глава 3. Справочник по инструкциям SQL
представления всех атрибутов типа. Для создания представления на основе подтипа
используется инструкция UNDER.
REF IS имя ^столбца {SYSTEM GENERATED | USER GENERATED | DERIVED}
В представлении определяется столбец идентификаторов объектов.
имя_столбца WITH OPTIONS SCOPE имя_таблицы
Указывается область действия столбца ссылок представления. (Поскольку столб-
цы создаются на основе типа, список столбцов отсутствует. Поэтому, чтобы ука-
зать опции столбцов, вы должны использовать предложение имя_столбца WITH
OPTIONS SCOPE...}
AS инструкция _select
Указывается конкретная инструкция SELECT, заполняющая представление данными.
[WITH [CASCADED | LOCAL] CHECK OPTION]
Используется только в тех представлениях, которые могут обновлять соответст-
вующие базовые таблицы. Это предложение гарантирует, что только те данные,
которые можно прочитать при помощи представления, могут вставляться, обнов-
ляться или удаляться при помощи представления. Например, если в представле-
нии employees показаны служащие, получающие оклад, и не показаны служащие,
получающие почасовую оплату, то с помощью этого представления нельзя будет
вставлять, обновлять или удалять записи о служащих с почасовой оплатой. Пара-
метры CASCADED и LOCAL предложения CHECK OPTION используются для
вложенных представлений. При указании параметра CASCADED проверка произ-
водится в текущем представлении и во всех представлениях, созданных на его основе.
При указании предложения LOCAL проверка производится только в текущем
представлении, даже если оно создано на основе других представлений.
Общие правила
Представления обычно столь же эффективны, насколько эффективны запросы, на основе
которых они создаются. Поэтому так важно создавать скоростные, хорошо написанные во-
просы. Простейшее представление на основе всего содержимого одной таблицы:
CREATE VIEW employees
AS
SELECT *
FROM employee_tbl;
После имени представления также можно указать список столбцов. Такой необя-
зательный список содержит псевдонимы, служащие именами элементов в резуль-
тирующем наборе данных инструкции SELECT. Если вы используете список столбцов,
вы должны указать имя для каждого столбца, возвращаемого инструкцией SELECT.
Если вы не используете список столбцов, то столбцы представления получат имена
в соответствии с тем, какие столбцы вызывались в инструкции SELECT. Иногда
можно видеть в представлении сложные инструкции SELECT, в которых активно ис-
пользуются предложения AS для всех столбцов, поскольку это позволяет разработчику
представления дать столбцам осмысленные имена, не используя список столбцов.
Справочник по командам SQL | 299
В стандарте ANSI определяется, что вы должны использовать список столбцов
или предложение AS. Однако некоторые разработчики используют более гибкий подход,
поэтому придерживайтесь следующих правил, показывающих, когда следует использо-
вать предложения AS.
• Если инструкция SELECT содержит вычисляемые столбцы, например (salary * 1.04).
• Если инструкция SELECT содержит полностью квалифицированные имена
столбцов, например pubs.scott.employee.
• Если инструкция SELECT содержит несколько столбцов с одинаковыми именами
(хотя и из разных схем или с разными префиксами базы данных).
Ниже приводятся два объявления представления с одним и тем же функциональ-
ным результатом.
- - с использованием списка столбцов
CREATE VIEW title_and_authors
(title, author_order, author, price, avg_monthly_sales,
publisher)
AS
SELECT t.title, ta.au_ord, a,au_lname, t.price, (t,ytd_sales / 12),
t,pub_id
FROM authors AS a
JOIN titleauthor AS ta ON a.au_id = ta.au_id
JOIN titles AS t ON t.title_id = ta.title_id
WHERE t,advance > 0;
- - с использованием предложения AS для каждого столбца
CREATE VIEW title_and_authors
AS
SELECT t,title AS title, ta,au_ord AS author_order,
a.au_lname AS author, t.price AS price,
(t.ytd_sales / 12) AS avg_monthly_sales, t,pub_id AS publisher
FROM authors AS a
JOIN titleauthor AS ta ON a.au_id = ta.au_id
JOIN titles AS t ON t.title_id = ta,title_id
WHERE t. advance > 0
Вы также, можете изменять заголовки столбцов, используя список столбцов.
В следующем примере мы изменим название avg_monthly_sales на avg_sales. Заметьте,
что данный код заменяет имена столбцов, заданные по умолчанию в предложениях AS
(выделено жирным шрифтом).
CREATE VIEW title_and_authors
(title, author_order, author, price, avg_sales, publisher)
AS
SELECT t,title AS title, ta.au_ord AS author_order,
a.au_lname AS author, t.price AS price,
(t.ytd_sales / 12) AS avg_monthly_sales, t,pub_id AS publisher
300 | Глава 3. Справочник по инструкциям SQL
FROM authors AS a
JOIN titleauthor AS ta ON a,au_id = ta.au_id
JOIN titles AS t ON t.title_id = ta.title_id
WHERE t.advance > 0;
Представление стандарта ANSI может обновлять содержимое своей основной
таблицы (таблиц), если оно удовлетворяет следующим условиям.
• В представлении нет операторов UNION, EXCEPT или INTERSECT.
• Создающая представление инструкция SELECT не содержит предложений
GROUP BY или НА PING.
• Создающая представление инструкция SELECT не содержит ссылок на псевдо-
столбцы, не отвечающие стандарту ANSI, например ROWNUM или ROWGUIDCOL.
• Создающая представление инструкция SELECT не содержит предложения DISTINCT.
• Представление не является материализованным.
В следующем примере показано представление с именем california_authors,
с помощью которого можно вносить изменения только в записи об авторах из штата
Калифорния.
CREATE VIEW california_authors
AS
SELECT au_lname, au_fname, city, state
FROM authors
WHERE state = 'CA'
WITH LOCAL CHECK OPTION
В данном представлении разрешено использование инструкций INSERT, DELETE
и UPDATE применительно к базовой таблице и предложение WITH...CHECK гаран-
тирует, что все вставляемые, обновляемые или удаляемые записи будут содержать
значение ‘СА’ в столбце state.
Наиболее важное правило, которое нужно запомнить при обновлении базовой таб-
лицы с помощью представления, состоит в том, что все столбцы таблицы, имеющие
ограничение NOT NULL, при записи нового или измененного значения должны по-
лучать непустое значение. Это можно реализовать явно, вставляя или вводя непустое
значение в столбец или используя значение, заданное по умолчанию. Кроме того,
представления не должны нарушать ограничений, имеющихся в основной таблице.
То есть значения, вставляемые или обновляемые в основной таблице, должны соот-
ветствовать всем ограничениям - уникальным индексам, первичным ключам, про-
верочным ограничениям и т. п.
Советы и хитрости программирования
Представления также можно создавать на основе других представлений, ио этого
делать не рекомендуется, такие действия считаются не очень хорошей практикой.
Такое представление, в зависимости от платформы, может дольше компилироваться,
но иметь ту же производительность, как и транзакции в основной таблице. На других
Справочник по командам SQL | 301
платформах, где каждое представление создается динамически при его вызове, по-
лучение результирующего набора данных во вложенном представлении может занять
больше времени, поскольку для каждого уровня вложения перед возвратом резуль-
тирующего набора данных нужно обработать еще один запрос. Так, в худшем вариан-
те развития событий представление с тремя уровнями вложенности должно со-
вершить три связанных запроса, прежде чем пользователь получит результирующий
набор данных.
Хотя материализованные представления определяются как обычные представле-
ния, они занимают больше места, чем таблицы. Перед созданием материализованных
представлений убедитесь, что у вас достаточно для этого места.
DBS
Платформа DB2 поддерживает несколько расширений стандартной инструкции
CREATE VIEW.
CREATE VIEW имя~представления
{ [ (column ] I [OF имя_типа MODE DB2SQL
{ (REF IS имя_столбца_.1й_объекта USER GENERATED
[UNCHECKED] [, с_опциями] ) |
UNDER имя_родительского_представления INHERIT SELECT PRIVILEGES
[ (c_опциями) ] }
AS
[WITH общее_табличное_выражение [, ...] ]
(инструкция_$е!ect)
[WITH {CASCADE | LOCAL} CHECK OPTION]
Синтаксис инструкции ALTER VIEW следующий.
ALTER VIEW имя_представления
ALTER [COLUMN] имя_столбца ADD SCOPE имя_типа
Параметры для обеих инструкций следующие.
OF itMfi muna MODE DB2SQL
Объявляется, что столбцы представления созданы на основе атрибутов струк-
турного типа имя_типа. Предложение MODE DB2SQL показывает, что тип явля-
ется версией объектного представления для DB2.
REF IS имя столбца уАобъекта USER GENERA TED
Объявляется, что столбец идентификаторов объектов является первым столбцом пред-
ставления. Этот первый столбец в предложении SELECT должен иметь тип REF.
В этом случае идентификатор объекта должен находиться в самом верхнем (корневом)
представлении в иерархии представлений. Предложение USER GENERATED показыва-
ет, что первое значение идентификатора объекта должно быть указано пользователем,
после чего значение начинает поддерживать система.
UNCHECKED
Это предложение показывает, что пользователь уверен в том, что все значения
в первом столбце инструкции SELECT не повторяются и не являются пустыми
302 | Глава 3. Справочник по инструкциям SQL
(NULL). Уникальность можно обеспечивать при помощи ограничений типа
первичный ключ, уникальный ключ, уникальный индекс, определения столбца как
OID или при помощи внешнего метода. Этот параметр является необязательным,
но требуется для представлений в объектной иерархии.
UNDER имя родительского_пр&)ставления INHERIT SELECT PRIVILEGES
Объявляется, что представление является потомком ранее объявленного представле-
ния с именем имя _родительского_представлеиия. Представление-родитель и пред-
ставление-потомок должны принадлежать к одной схеме. Родительское представле-
ние должно быть объявлено с предложением REF, и ссылка на него должна указы-
вать на структурный тип. Указанное родительское представление не может иметь
потомков, относящихся к тому же структурному типу, что и создаваемое представле-
ние. Предложение INHERIT SELECT PRIVILEGES наделяет любого пользователя
или роль, имеющую привилегии SELECT в родительском представлении, привиле-
гиями SELECT в представлениях-потомках.
с_опциями
Объявляются дополнительные опции для столбцов представления. Разрешается
использовать несколько опций, разделяя их запятыми. Полный синтаксис предло-
жения с_опциями следующий.
{имя_столбца WITH OPTIONS {READ ONLY | SCOPE имя_типа} [,...] }
Параметры следующие.
READ ONLY
Указывается, что столбец доступен только для чтения.
SCOPE WMi jnuna
Указывается область действия столбца ссылочного типа, где имя_типа - это имя
объектной таблицы или представления. Область действия является необходи-
мым параметром для столбца, служащего левым операндом оператора разыме-
нования или аргументом функции DEREF.
WITH общее табличиое_выражеиие
Связывает общее табличное выражение с инструкцией SELECT представления.
Это предложение несовместимо с объектными представлениями.
WITH {CASCADE | LOCAL} CHECK OPTION
Объявляется, что все столбцы, создаваемые или обновляемые при помощи пред-
ставления, должны соответствовать определению представления. Следовательно,
строка, которая не может быть возвращена представлением, не может быть вставле-
на или обновлена с его помощью. Если предложение опущено, никакой проверки
вставленных или обновленных данных, помимо проверки ограничений, имеющихся
в исходной таблице, не производится. Предложение WITH CHECK OPTION нельзя
использовать в представлениях, доступных только для чтения, представлениях
с триггером INSTEAD OF, представлениях, которые ссылаются на источник по крат-
кому имени (nickname), в функциях NODENUMBER или PARTITION, в недетерми-
Справочник по командам SQL | 303
нированных функциях или в функциях с внешними действиями. Существуют сле-
дующие параметры предложения WITH CHECK OPTION.
CASCADE
Условия поиска текущего представления наследуют условия поиска обновляе-
мого представления, на котором текущее представление основывается. При
указании этого параметра у текущего представления есть собственное предло-
жение WHERE, которое неявно добавляется ключевым словом AND к предло-
жению WHERE представления, от которого оно зависит.
LOCAL
Условия поиска текущего представления применяются ко всем зависящим от
него представлениям.
ALTER [COLUMN] имя_столбца ADD SCOPE имя_типа
Это предложение позволяет добавить в существующее представление характери-
стики области действия.
Инструкция SELECT в представлении должна быть стандартной инструкцией
SELECT и не может содержать следующих элементов:
• временных таблиц;
• маркеров параметров;
• ссылок на хост-переменные.
Вы можете обойти ограничения параметризованных представлений, создав в таб-
лице SQL пользовательскую функцию.
Простое объектное представление или объектное представление-потомок должно
подчиняться ряду специальных правил.
• Инструкция SELECT представления не может ссылаться на функции DBPARTI-
TIONNUM или HASHEDVALUE, на функции с внешними действиями и на неде-
терминированные функции.
• Представление может содержать одну инструкцию SELECT. Дополнительные ин-
струкции SELECT можно добавлять, поставив между ними предложение UNION ALL.
(9В DB2 запрос с несколькими инструкциями SELECT называется ветвящимся
запросом.)
• Иерархия ветвей (branches) не должна пересекаться.
• Ветви объектного представления не должны содержать предложений GROUP BY
и HAVING.
• Корневое представление должно содержать предложение UNCHECKED, если оно
имеет ветви.
Ниже приводится пример, включающий типы, объектную таблицу и иерархию
представлений, построенную на основе типов people_type и emp_type.
CREATE TYPE people_type
AS (name VARCHAR(20), address VARCHAR(IOO))
MODE 0B2SQL
304 | Глава 3. Справочник по инструкциям SQL
CAST (SOURCE AS REF.) WITH people_func;
CREATE TYPE emp_type
UNDER people_type
AS (title VARCHAR(20), salary DECIMAL(8,2))
MODE DB2SQL
CAST (SOURCE AS REF) WITH emp_func;
CREATE TABLE people
OF people_type
(REF IS people_oid USER GENERATED);
INSERT INTO people (people_oid, name, address)
VALUES (people_func('O'), 'Sammy', '123 Lane');
CREATE TABLE emp
OF emp_type
UNDER people INHERIT SELECT PRIVILEGES;
INSERT INTO emp (people_oid, name, address, title, salary)
VALUES (emp_func('1'), 'Josh', '123 Street', 'Director', 1OOO)
CREATE VIEW people_view
OF people_type
MODE DB2SQL
(REF IS people_view_oid USER GENERATED)
AS SELECT people_func (VARCHAR(people_oid)), name, address
FROM ONLY (people);
CREATE VIEW emp_view
OF emp_type
MODE DB2SQL
UNDER people_view INHERIT SELECT PRIVILEGES
AS SELECT emp_func (VARCHAR(people_oid)), name,
address, title, salary
FROM emp;
SELECT *
FROM people_view;
PEOPLE_VIEW_OID NAME ADDRESS
x'3O' Sammy 123 Lane
x'31' Josh 123 Street
20 - 2447
Справочник по коп
SELECT *
FROM emp_view;
people_view_oid name ADDRESS
TITLE
SALARY
x'31' Josh 123 Street Director 1000.00
Использование предложения WITH CHECK OPTIONS может представлять опреде-
ленные сложности, поскольку вы объединяете условия WHERE либо в восходящем
направлении цепочки зависимостей (CASCADE), либо в нисходящем направлении
(LOCAL). Рассмотрим следующий пример.
. Представление VI является производным таблицы Т.
Представление V2 является производным VI с предложением WITH check_opn
CHECK OPTIONS.
Представление V3 является производным V2.
Представление V4 является производным V3 с предложением WITH check_opn
CHECK OPTIONS.
Представление V5 является производным V4.
В приведенной ниже таблице показаны условия поиска, по которым проверяются
вставляемые и обновляемые строки.
check_opn = LOCAL check_opn = CASCADE
VI проверяется по: — —
V2 проверяется по: V2 V2, VI
V3 проверяется по: V2 V2, VI
V4 проверяется по: V2, V4 V4, V3, V2, VI
V5 проверяется по: V2, V4 V4, V3, V2, VI
Заметьте, что, если вы создаете представление (или любой другой объект)
с именем схемы, которая еще не существует в базе данных, платформа
DB2 неявно создаст схему с этим именем.
MySQL
Не поддерживается.
Oracle
Платформа Oracle поддерживает расширения стандарта ANSI, позволяющие созда-
вать объектно-ориентированные представления, представления типа XMLType и пред-
ставления, поддерживающие LOB и объектные типы.
CREATE [OR REPLACE] [ [NO] FORCE] VIEW имя_представления
{[(столбец [,...]) [предложение_сопзбга1пб{ |
[OF имя_типа {UNDER родмтельское_представление |
306 | Глава 3. Справочник по инструкциям SQL
WITH OBJECT IDENTIFIER {DEFAULT | {атрибут ) )
'.{предложение_сопв^а1п1)~\ ] |
|OF XMLIYPl [ {XMLSCHEMA иг!_схемы_хт1] ELEMENT
{element | url_cxeMH_xird It элемент} ]
WITH OBJECT IDENTIFIER {DEFAULT | {атрибут ]
AS
{инструкция_ее.1 ect)
[WITH iREAD ONLY I CHECK OPTION [CONSTRAINT имя~отранинония] I j
Реализация инструкции ALTER VIEW на платформе Oracle содержит дополнитель-
ные возможности, такие, как добавление, удаление и изменение ограничений, связан-
ных с представлением. Кроме того, инструкция ALTER VIEW явным образом переком-
пилирует недействующее представление, что позволяет выявить ошибки перекомпи-
ляции до выполнения. Такая перекомпиляция позволяет выявить возможные отрица-
тельные влияния изменений, внесенных в базовую таблицу, на зависящие от нее пред-
ставления.
ALIRR VIEW имя_представления
{ADD предложение-constraint ;
MODIFY CONSTRAINT предлсжоние__сопобга1пГ [NOJRELY1 |
DROP {pniMARv KEY ! CONSTRAINT предложение.constraint |
jNIOUF {столбец }
COMF11 -
Параметры инструкций следующие.
OR REPLACE
Существующее представление с именем нмя представления заменяется на повое.
[NO] FORCE
При указании предложения FORCE представление создается независимо от того,
существует1 ли базовая таблица и имеет ли пользователь, создающий представле-
ние, привилегии в базовых таблицах, представлениях или функциях, указанных
в представлении. При указании условия FORCE представление также создается,
невзирая на ошибки, которые могут возникнуть при его создании. При указании
условия NO FORCE представление создается только в том случае, если сущест-
вуют базовые таблицы и соответствующие привилегии.
предложение constraint
Позволяет указат ь ограничения (см. инструкцию CREATE TABLE) для представле-
ний в инструкции CREATE VIEW. При использовании в инструкции ALTER VIEW
эго предложение позволяет изменить указанное, существующее ограничение. Вы
можете определить ограничение на уровне представления (напоминает1 ограниче-
ние уровня таблицы) или иа уровне столбца или атрибута. Заметьте, что, хотя
платформа Oracle позволяет определить ограничения для представления, она не
применяет их принудительно. Система Oracle поддерживает ограничения в пред-
ставлении в режимах DISABLE и NOVALIDATE.
Справочник по командам SQL | 307
OF имя_типа
Объявляется, что представление является объектным представлением типа
имя_типа. Столбцы представления напрямую связаны с атрибутами этого типа.
имяупипа - это ранее объявленный тип (см. инструкцию CREATE TYPE). Для
представлений объектного типа и типа XMLType имена столбцов не указываются.
UNDER родителъское_представление
Объявляется, что представление-потомок основывается на существующем роди-
тельском_представлении. Представление-потомок должно принадлежать к той
же схеме, что и родительское, имя_типа должно быть непосредственным подти-
пом типа родительского_представления, и разрешается использовать только одно
представление-потомок.
WITH OBJECT IDENTIFIER {DEFAULT | (атрибут [,...])
Определяется корневое объектное представление, а также все атрибуты объектно-
го типа, определяющего все строки объектного представления. Атрибуты обычно
соответствуют столбцам первичных ключей базовой таблицы, и они должны од-
нозначно идентифицировать каждую строку таблицы. Это предложение несовмес-
тимо с представлениями-потомками и разыменованными или закрепленными
ЛЕТ^-ключами. При указании ключевого слова DEFAULT используется неявный
идентификатор объекта базовой объектной таблицы или представления.
OF XMLTYPE [ [XMLSCHEMA иг1_схемы_хт1] ELEMENT
{элемент | иг1_схемы_хт1 # элемент} ] WITH OBJECT IDENTIFIER (атрибут [,.])
Представление будет возвращать экземпляры объектов XMLType. При дополни-
тельном указании зарегистрированной схемы XML (иг1_схемы_хт!) и имени эле-
мента вывод XML ограничивается элементом данной схемы XML. Предложение
WITH OBJECT IDENTIFIER указывает идентификатор, однозначно опреде-
ляющий каждую строку представления XMLType. В одном или нескольких атри-
бутах можно использовать неагрегатные функции, например extractValue(), чтобы
получить идентификаторы из результирующего типа XMLType.
WITH READ ONLY
Представление будет использоваться только для извлечения данных, но не для их
модификации.
WITH CHECK OPTION [CONSTRAINT имя ограничения]
Представление будет принимать только те вставленные или обновленные данные,
которые можно вернуть при помощи инструкции SELECT представления. В каче-
стве альтернативы вы можете указать одно предложение CHECK OPTION
имяограничения, существующее в базовой таблице, соблюдение которого вы
хотите обеспечить. Если ограничение не названо, Oracle присваивает ограниче-
нию имя SYS_Cn, где п - целое число.
ADD предложение-constraint
В представление добавляется новое ограничение. Платформа Oracle поддерживает
ограничения только в режимах DISABLE и NOIALIDATE.
308 | Глава 3. Справочник по инструкциям SQL
MODIFY CONSTRAINT предложение constraint [NO]RELY]
Изменяется параметр RELYINORELY существующего в представлении ограниче-
ния. (Предложения RELY и NORELY объясняются в разделе, посвященном ин-
струкции CREATE TABLE.)
DROP {PRIMARY KEY | CONSTRAINT nped.wxeuueconstraint | UNIQUE (столбец [,...])}
Существующее ограничение удаляется из представления.
COMPILE
Представление перекомпилируется.
Любые связи баз данных (dblinks) в инструкции SELECT должны быть объявлены
с помощью инструкции CREATE DATABASE LINK...CONNECT TO. В представлениях,
содержащих ретроспективные запросы (flashback query), предложения AS OF будут
проверяться при каждом вызове представления, а не при компиляции представления.
В следующем примере мы создадим представление и добавим в него ограничение.
С'ЧАЕЕ VIEW саЛ.Ioi':ia_.'4urhcr3 (last_ra"ce. ri ••ct’jnaino,
aurhor.JD L'Ni'Ou HFlv DISABLE NOVALIDAIE,
CCSS7AIB7 id_?K rioARv KEY (aa id) PEI Y DISABLE NOVAlTDAtE)
AS
SEi. 1СГ au„Inane. as_fna"e, au_id
ia0M autbors
WH.-.BF elate 7 'CA';
Нам также может понадобиться создать объектное предо явление в базе данных
и схеме Oracle. В следующем примере создается тип и объектное представление.
DriLA'D iYPc inven l.o.'у .type AS ОВаЕС
) lilTii; ’..чМ(6).
Wj > sr;CL'.' е wrr.C .Гур,
<Пу LuM(3.' );
OiiEAIL VIEW ’.''ventcries OF invento-'y.type
OEJECF IDEi'.'TlOEH (t.itie..id)
AS
SEi EC I i. title., ia, wrhs_lyp(w.wrhs_i(J, w. wrhs_nan'e,
л таса t:on_: a) i. c ty
i TOY jnven!cries i
JC' 3 wareno..ces CK i.wrhc.Jt! - w.wrhsjo;
Представление типа inventory_type можно перекомпилировать следующим образом.
Al IFa VIEw 1пуепгсгу_Гуре COMPILE:
Обновляемое представление в Oracle не может содержать следующего:
• предложений DISTINCT;
• UNION, INTERSECT и MINUS;
• соединений, которые приводят к тому, что вставленные или обновленные данные
затрагивают несколько таблиц;
Справочник по командам SQL | 309
• агрегатных и аналитических функций;
• предложений GROUP BY, ORDER BY, CONNECT BY и START WITH ;
• подзапросов и выражений-коллекций в списке элементов инструкции SELECT
(Подзапросы можно использовать в предложении WHERE инструкции SELECT)-,
• обновления псевдостолбцов и выражений.
На определение представлений-потомков и материализованных представлений
в Oracle накладывается ряд ограничений:
• в представлении-потомке должны использоваться псевдонимы для псевдостолб-
цов ROWID, ROWNUM и LEVEL;
• представление-потомок не может обращаться к псевдостолбцам CURRVAL
и NEXTVAL;
• представление-потомок не может содержать предложения SAMPLE-,
• в представлении-потомке вычисление всех столбцов инструкции SELECT * FROM...
происходит во время компиляции. Таким образом, данные из всех новых столбцов, до-
бавленных в базовую таблицу, не извлекаются в представление-потомок до тех пор,
пока представление не будет перекомпилировано.
Заметьте, что более старые версии системы Oracle поддерживали секционирован-
ные представления. Эта функция удалена. Теперь вы должны использовать явно объ-
явленные разделы.
PostgreSQL
Платформа PostgreSQL поддерживает упрощенный вариант инструкции стандарта
ANSI.
CREATE VIEW имя_представления [(столбец [,...] ) ]
AS инструкция_зе!есб
Платформа PostgreSQL не поддерживает некоторые из наиболее сложных конструк-
ций, которые предлагают другие производители. Однако эта система позволяет создавать
представления на основе таблиц и других объектов, принадлежащих к определенным
классам. Представления PostgreSQL создаются на основе таблиц, но не на основе других
представлений. Представления PostgreSQL всегда доступны только для чтения, и их
нельзя использовать для внесения изменений в соответствующие базовые таблицы.
SQL Server
Платформа SQL Server поддерживает несколько расширений стандарта ANSI, но в ней не
используются простые объектные представления и объектные представления-потомки.
CREATE VIEW имя^представления [(столбец [,.,,])]
[WITH {ENCRYPTION | SCHEMABINDING | VIEW_METADATA} [,...]]
AS
инструкция_зе1есГ
[WITH CHECK OPTION]
310 | Глава 3. Справочник по инструкциям SQL
Реализация инструкции ALTER VIEW к SQL Server позволяет вносить изменения
в существующее представление, не затрагивая прав доступа или зависимых от пред-
ставления объектов.
ALTER VIEW имя-представления [(столбец [,...])]
'WITH {ENCRYPTION | SCHEMABINDING | VIEW_METADATA} [....]]
AS
инструкция_зе!есТ
[WITH CHECK OPTION]
Параметры следующие.
ENCRYPTION
Текст представления шифруется в таблице syscomments. Этот параметр обычно
используют производители программного обеспечения, которые хотят защитить
свой интеллектуальный капитал.
SCHEMABUILDING
Представление связывается с конкретной схемой, и это означает, что ко всем объек-
там представления нужно обращаться по их полному имени (по имени владельца
и имени объекта). Представление и любые таблицы, на которые ссылается предло-
жение SELECT представления, должны иметь полностью квалифицированные
имена, например pubs.scott.employee. В представлениях, созданных с использова-
нием предложения SCHEMABUILDING (и в таблицах, на которые ссылается это
представление), перед удалением или изменением нужно сначала удалить связь со
схемой (при помощи инструкции ALTER VIEW).
VIEW METADATA
Указывается, что SQL Server возвращает метаданные представления (а не метаданные
базовой таблицы) при запросах от таких API, как DBLIB и OLEDB. В представлениях,
созданных или измененных с использованием условия V/EW METADATA, можно об-
новлять столбцы с помощью триггеров INSTEAD OF UPDATE и INSTEAD OF INSERT
WITH CHECK OPTION
Это предложение заставляет представление принимать только такие вставляемые
или обновляемые данные, которые может вернуть инструкция SELECT представ-
ления.
Предложение SELECT представления SQL Server не может:
• содержать предложений COMPUTE, COMPUTE BY, INTO и ORDER BY (предложе-
ние ORDER BY разрешается, если используется предложение SELECT TOP)-,
• ссылаться на временную таблицу;
• ссылаться на табличную переменную;
• ссылаться более чем на 1024 столбца, в это число входят и столбцы, на которые
ссылаются подзапросы.
Ниже мы определяем представление SQL server с предложениями ENCRYPTION
и CHECK OPTION.
Справочник по командам SQL | 311
CREATE VIEW california_authors (last_name, first_name, author_id)
WITH ENCRYPTION
AS
SELECT au_lname, au.fname, au_id
FROM authors
WHERE state = 'CA'
WITH CHECK OPTION
GO
Платформа SQL Server позволяет использовать в представлении несколько ин-
струкций SELECT, если они связаны при помощи предложений UNION и UNION ALL.
SQL Server также позволяет использовать в инструкции SELECT представления функ-
ции и подсказки (hints). Представление SQL Server является обновляемым, если все
перечисленные ниже пункты верны.
• Инструкция SELECT не содержит агрегатных функций.
• Инструкция SELECT не содержит конструкций TOP, GROP BY, DISTINCT или
UNION.
• Инструкция SELECT не содержит производных столбцов (см. SUBQUERY).
• Предложение FROM инструкции SELECT ссылается как минимум на одну табли-
цу.
Платформа SQL Server позволяет создавать индексы по представлениям (см. инструк-
цию CREATE INDEX). Создав уникальный кластеризованный индекс по представлению,
вы заставляете SQL Server сохранить физическую копию представления в базе данных.
Изменения, вносимые в базовую таблицу, автоматически заносятся в индексированное
представление. Индексированные представления занимают место на диске, но дают
прирост производительности. Индексированные представления должны создаваться с ис-
пользованием предложения SCHEMABUILDING.
Система SQL Server также позволяет создавать локальные секционированные пред-
ставления и распределенные секционированные представления. Локальное секциониро-
ванное представление - это секционированное представление, где все представления на-
ходятся на одном сервере SQL. Распределенное секционированное представление - это
секционированное представление, в котором одно или несколько представлений распола-
гаются на удаленных серверах.
В секционированных представлениях должно быть очень четко обозначено проис-
хождение данных из различных источников, и каждый отдельный источник данных
должен соединяться со следующим инструкцией UNION ALL. Более того, все столбцы
секционированных представлений должны быть выделены и идентичны. (Идея состо-
ит в том, чтобы логически разделять данные при помощи клиентского приложения.
После этого SQL Server снова собирает данные при помощи секционированного пред-
ставления.) В следующем примере показано, как данные поступают в представление
из трех разных серверов SQL Server.
312 | Глава 3. Справочник по инструкциям SQL
CREATE VIEW customers
AS
--Выбор из локалов таблиц:; на сервере 'New_York'
SELECT *
"ROM sa".es..archive его. customers A
UNION ALL
SEI EC! >
ГНОМ ’'ousten. sales, archive, goo. o..srorers_K
UNION Al;
SELECI •
IRON Ics-argeler. sales .arernve. dbo. cuctcmers_S
Отметьте, что каждый удаленный сервер (New York, houstoii и los angeles) нужно
определить как удаленный сервер на всех серверах SQL Server с помощью распреде-
ленного секционированного представления. Секционированные представления могут
значительно увеличить производительность, поскольку они распределяют ввод/вывод
и пользователей между многими машинами. Однако их достаточно сложно планиро-
вать, создавать и обслуживать. Обязательно читайте документацию производителя,
где приводятся все детали об изменениях, которые можно сделать, используя секцио-
нированные представления.
При изменении существующего представления SQL Server включает и удерживает
за представлением блокировку схемы до тех пор, пока изменение не будет завершено.
Инструкция ALTER TIEW удаляет все индексы, которые могут быть связаны с представ-
лением. Их нужно будет заново создавать вручную с помощью команды CREATE
INDEX.
См. также
CREATE/ALTER TABLE
DROP
SELECT
SL'BQUERY
Команда DECLARE CURSOR
Команда DECLARE - >то одна из четырех команд, используемых для обработки
курсора, наряду с командами EETCH, OPEN и CLOSE. Курсоры позволяют вести
обработку по одной строке, а не обрабатывать сразу весь набор данных. Команда
DECLARE CURSOR указывает, какие конкретно записи нужно извлекать для
построчного манипулирования из конкретной таблицы или представления.
Иными словами, курсоры являются особенно важными для реляционных баз дан-
ных, поскольку базы основываются на наборах данных, а большинство языков про-
граммирования, ориентированных на работу в клиентах, работают со строками. Эю
важно в силу двух причин. Во-первых, курсоры позволяют программистам создавать
программы, используя методологии, которые поддерживаются их любимым языком
Справочник по командам SQL, | 313
программирования, работающим построчно. Во-вторых, курсоры работают иначе, чем
заданное по умолчанию функционирование некоторых платформ реляционных баз,
которые работают с наборами данных, и это приводит к тому, что на этих платформах
курсоры могут работать значительно медленнее, чем стандартные операции с наборами.
Платформа Команда
DB2 Поддерживается с ограничениями
MySQL Не поддерживается
Oracle Поддерживается с ограничениями
PostgreSQL Поддерживается с ограничениями
SQL Server Поддерживается с ограничениями
Синтаксис SQL2003
DECLARE имя__курсора [ {SENSITIVE | INSENSITIVE | ASENSITIVE} ]
[[NO] SCROLL] CURSOR [{WITH | WITHOUT}'HOLD]
[{WITH | WITHOUT} RETURN}]
FOR инструкция_зе1есб
[FOR {READ ONLY | UPDATE [OF столбец [,...] ]} ]
Ключевые слова
DECLARE имя_курсора
Курсору присваивается имя, уникальное для контекста, в котором он определяется
(например, в базе данных или схеме, в которой он создается). Имя должно быть уни-
кальным в том смысле, что никакие другие курсоры не должны иметь то же имя.
SENSITIVE | INSENSITIVE | ASENSITIVE
Определяется способ взаимодействия курсора с исходной таблицей и резуль-
тирующий набор, который возвращает курсорный запрос. Параметры следующие.
SENSITIVE
База данных будет работать с результирующим набором данных напрямую,
и курсор будет «видеть» изменения в результирующем наборе по мере про-
движения по записям.
INSENSITIVE
База данных будет создавать временную, но отдельную копию резуль-
тирующего набора данных, так что изменения, вносимые в результирующий
набор другими операциями, будут «невидимы» для курсора.
ASENSITIVE
База данных будет сама определять, нужно ли делать копию результирующего
набора. Предложение ASENSITIVE в SQL2003 принято по умолчанию.
[NO] SCROLL
База данных не будет принудительно обеспечивать построчную обработку,
используя команду FETCH NEXT, но для результирующего набора можно исполь-
314 | Глава 3. Справочник по инструкциям SQL
зовать все формы предложения FETCH. При указании предложения NO SCROLL
построчная обработка обеспечивается принудительно.
{WITH | WITHOUT} HOLD
Курсор будет оставаться открытым, если в транзакции встретится инструкция
COMMIT. И наоборот, предложение WITHOUT HOLD определяет, что курсор
должен закрыться, если в транзакции встретится инструкция COMMIT. (Курсор,
в котором используется предложение WITH HOLD, можно закрыть только при
помощи инструкций ROLLBACK или CLOSE CURSOR.)
{WITH\ WITHOUT} RETURN
Используемое только в хранимой процедуре предложение WITH RETURN застав-
ляет базу данных вернуть результирующий набор (если он еще открыт) при за-
вершении работы хранимой процедуры. Предложение WITHOUT RETURN (при-
нимаемое по умолчанию) все открытые курсоры неявно закрываются по заверше-
нии работы хранимой процедуры.
FOR инструкция_ select
Определяется инструкция SELECT, которая создает строки результирующего
набора данных курсора. Как и в обычной инструкции SELECT, результаты запроса
можно отсортировать с помощью предложения ORDER BY.
FOR {READ ONLY\ UPDATE [OF столбец [....] ]}
Указывается, что курсор нельзя обновлять никакими способами (FOR READ
ONLY). Это предложение принимается по умолчанию, если курсор определяется
с параметрами SCROLL или INSENSITIVE, если запрос содержит предложение
ORDER BY или если запрос обращен к необновляемой таблице. В качестве аль-
тернативы вы можете указать предложение FOR UPDATE OF столбец!, епюлбец2
определяя столбцы, для которых вы хотите выполнить инструкции UPDATE.
Вы можете опустить список столбцов в предложении FOR UPDATE OF, и будут
использоваться все столбцы, указанные в курсоре.
Общие правила
Команда DECLARE CURSOR позволяет построчно извлекать записи из таблицы для
манипулирования. Это позволяет производить построчную обработку вместо тради-
ционной обработки наборами данных, которую осуществляет SQL.
В самом первом приближении при работе с курсором используются следующие
шаги.
• Курсор создается командой DECLARE.
• Курсор открывается командой OPEN.
• Операции с курсором производятся при помощи команды FETCH.
• Курсор закрывается командой CLOSE.
В команде DECLARE CURSOR указывается инструкция SELECT. Каждую строку,
возвращаемую инструкцией SELECT, можно извлекать и обрабатывать индивидуально.
В следующем примере для Oracle курсор объявляется в блоке объявлений вместе с не-
Справочник по командам SQL | 315
сколькими другими переменными. После этого в последующем блоке BEGIN...END
курсор открывается, по нему производится выборка, и курсор закрывается.
DECLARE
CURSOR title_price_cursor IS
SELECT title, price
FROM titles
WHERE price IS NOT NULL;
title_price_val title_price_cursor%ROWTYPE;
new_price NUMBER/10,2);
BEGIN
OPEN title_price_Cursor;
FETCH title_price_cur-sor INTO title_price_val;
new_price := "title_price_val.price" * 1.25
INSERT INTO new_title_price
VALUES (title_price_val.title, new_price)
CLOSE title_price_cursor;
END;
Поскольку в этом примере используется PL/SQL, большую часть кода мы в этой
книге разъяснять не будем. Однако в блоке DECLARE ясно видно объявление курсора.
В исполняемом блоке PL/SQL курсор инициализируется командой OPEN, значения
извлекаются командой FETCH и, наконец, курсор закрывается командой CLOSE.
Инструкция SELECT- это основа курсора, так что хорошей практикой является ее
тщательное тестирование перед включением в инструкцию DECLARE CURSOR.
Инструкция SELECT может работать с базовой таблицей или представлением. Поэто-
му курсоры «только для чтения» могут работать с необновляемыми представлениями.
Инструкция SELECT может содержать такие предложения, как ORDER BY, GROUP BY
и HAVING, если эти предложения не обновляют исходную таблицу. Если курсор опре-
делен как FOR UPDATE, то рекомендуется удалять такие предложения из инструкции
SELECT.
Локальные курсоры часто используются в качестве выходных параметров храни-
мых процедур. Поэтому в хранимой процедуре можно определить и заполнить курсор
и передать его вызвавшему ее пакетному заданию или хранимой процедуре.
В следующем простом примере для DB2 мы объявим курсор, который про-
сматривает номера департаментов, названия департаментов и номера менеджеров
в admingroup ‘ХОГ.
EXEC SQL
DECLARE dept_cursor CURSOR
FOR SELECT dept_nbr, dept_name, mgr_nbr
FROM department
WHERE admin_group = 'Х0Г
ORDER BY dept_name ASC, dept_nbr DESC, mgr_nbr DESC;
В следующем примере для Microsoft SQL Server объявляется и открывается курсор
для таблицы publishers. Курсор отбирает из таблицы publishers первую запись, соответ-
316 | Глава 3. Справочник по инструкциям SQL
ствующую инструкции SELECT, и вставляет ее в другую таблицу. Затем он переходит
к следующей записи, потом к следующей - до тех пор, пока все записи не будут обрабо-
таны. И наконец, курсор закрывается и высвобождает память (команда DEALLOCATE
используется только в Microsoft SQL Server).
DECLARE @publisher_name VARCHAR(2O)
DECLARE pub_cursor CURSOR
FOR SELECT pub_name FROM publishers
WHERE country <> 'USA'
OPEN pub_cursor
FETCH NEXT FROM pub_cursor INTO @publisher_name
WHILE @s>FETCH_STATUS = 0
BEGIN
INSERT INTO foreign_publishers VALUES(@publisher_name)
END
CLOSE pub_cursor
DEALLOCATE pub_cursor
В этом примере можно видеть, как курсор передвигается по набору записей.
(Этот пример призван только продемонстрировать данную идею, поскольку в дейст-
вительности существует лучший способ решения данной задачи, а именно инструк-
ция INSERT...SELECT.)
Советы и хитрости программирования
Большинство платформ не поддерживает динамически выполняемые курсоры. Вместо
этого курсоры встраиваются в прикладную программу, хранимую процедуру, пользо-
вательскую функцию и т. п. Иными словами, различные инструкции, связанные с соз-
данием и использованием курсора, обычно применяются только в контексте хранимой
процедуры или другого программируемого объекта базы данных, а не непосредствен-
но в скрипте SQL.
Для упрощения программирования и переноса не используйте предложение
SCROLL или ключевые слова, связанные с чувствительностью (SENSITIVE и пр.).
Некоторые платформы поддерживают для курсоров прокрутку только вперед, так что
вы избежите головной боли в будущем, если выберете самую простую форму курсора.
Курсоры по-разному ведут себя на разных платформах при выходе за пределы
транзакции (например, если происходит откат набора транзакций в середине курсора).
Обязательно познакомьтесь с тем, каким образом ведет себя каждая платформа
в таких ситуациях.
Платформа MySQL не поддерживает курсоры на серверной стороне соединения
в стиле ANSI SQL, но поддерживает мощные программные расширения языка С,
которые обеспечивают аналогичную функциональность.
Справочник по командам SQL | 317
DBS
Платформа DB2 поддерживает базовый вариант инструкции DECLARE CURSOR с не-
которыми вариациями предложений WITH HOLD и WITH RETURN. Синтаксис приве-
ден ниже.
DECLARE имя_курсора CURSOR
[WITH HOLD] [WITH RETURN [{TO CALLER | TO CLIENT}] ]
FOR инструкция_зе1есР
Где:
WITH RETURN [{TO CALLER | TO CLIENT}]
Используемое только в хранимой процедуре предложение WITH RETURN показы-
вает, что бдза данных должна вернуть результирующий набор данных (если он
еще открыт) по завершении работы хранимой процедуры. (Платформа DB2 считает
допустимыми предложения WITH RETURN и для курсоров, не входящих в храни-
мую процедуру, но эти предложения не оказывают никакого эффекта.) Сущест-
вуют следующие опции.
ТО CALLER
Результирующий набор возвращается вызвавшему процессу, например другой
хранимой процедуре или процессу на сервере базы данных. Результирующий
набор также возвращается клиенту, если именно он вызвал хранимую проце-
дуру. Такое функционирование принято по умолчанию для курсоров, встроен-
ных во внешние хранимые процедуры DB2.
ТО CLIENT
Результирующий набор возвращается клиентскому приложению, минуя про-
межуточные процессы, такие, как вложенные хранимые процедуры. Это пред-
ложение нельзя использовать для возврата результирующих наборов в функ-
ции и процедуры.
FOR инструкция_хе1ес1
Определяется инструкция SELECT, лежащая в основе курсора и определяющая строки
результирующего набора данных курсора. Инструкция SELECT не может включать
параметры, но может включать хост-переменные, если они были объявлены до
курсора. Вы также можете использовать в качестве параметра инструкция_8е1ес1 ин-
струкцию SELECT, подготовленную при помощи команды DB2 PREPARE.
В DB2 существует синтаксис, позволяющий явным образом объявить курсор как
доступный только для чтения или как обновляемый в инструкции SELECT (а не в ин-
струкции DECLARE CURSOR).
Если возможность обновления курсора не определена, она неявно определяется
на основе различных правил, которые способствуют улучшению блокировки. Прежде
всего, курсор считается доступным только для чтения (read-only), если его нельзя
удалить. Курсор DB2 можно удалить (deletable), если в нем указано предложение FOR
UPDATE плюс:
• предложение FROM инструкции SELECT ссылается только на одну базовую таб-
лицу или на представление с возможностью удаления;
318 | Глава 3. Справочник по инструкциям SQL
• инструкция SELECT не содержит предложения VALUES, предложения DISTINCT,
предложения GROUP BY, предложения HAVING, предложения ORDER BY, предло-
жения FOR READ ONLY или предложений UNION, EXCEPT или INTERSECT',
• в инструкции SELECT, в списке отбора элементов, нет столбцовых функций.
Столбцы курсора DD2 можно обновлять, если он удовлетворяет требованиям воз-
можности удаления плюс:
• столбцы разрешаются в столбцы базовой таблицы или представления;
• опция связывания LANGLEVEL установлена в MIA, SQL92E, или па столбцы ссы-
лается предложение FOR UPDATE uiicmpyKifuu select.
•»
I •• I
j Курсор DB2 также может ооиовляться, если он определен статически или
। иу д| м в предложении LANGLEVEL указана стандартная опция связывания SQL
(Ml А).
Параметр MIA в LANGLEVEL показывает, что курсор подчиняется прави-
лам SQL92. Параметр SQL92E показывает, что курсор подчиняется упро-
щенным правилам SQL92. Параметр SAAI показывает, что курсор подчи-
няется общим (старым) правшам DB2. Параметр LANGLEVEL назначает-
ся в DB2 при помощи команды PREP.
Платформа DB2 также допускает неоднозначные (ambiguous) курсоры. Неодно-
значный курсор считается обновляемым, если только опция связывания BLOCKING не
установлена в ALL, в каковом случае он будет доступен только для чтения. Курсор
является неоднозначным, если верны все приведенные ниже условия.
• Параметр инструкция select не содержит предложений FOR READ ONLY или
FOR UPDA TE.
• Параметр языкового уровня (LANGLEVEL} установлен в SAA1.
• инструкция select подготовлена динамически.
• В нрот ивном случае существует возможност ь удаления курсора.
Существует пара моментов, на которые следует обратить внимание при работе
с курсорами DB2.
• Значения системных функций, таких, как CURRENT DATE, CURRENT TIME или
CURRENT TIMESTAMP, определяются при открытии курсора, а не при выполне-
нии инструкции FETCH. Поэтому все эти значения в каждой строке резуль-
тирующего набора будут идентичны, ведь значения определялись один раз, когда
курсор открывался.
• Если для хранимой процедуры указан язык, отличный от SQL (например, Java), то
но умолчанию используется предложение WITH RETURN ТО CALLER.
MySQL
Пе поддерживается.
Справочник по командам SQL | 319
Oracle
На платформе Oracle реализация курсоров весьма интересна. В действительности все
инструкции Oracle, связанные с модификациями данных (INSERT, UPDATE, DELETE
и SELECT), неявно открывают курсор. Например, программе на С, обращающейся
к Oracle, не нужно подавать команду DECLARE CURSOR, чтобы извлекать данные
построчно, поскольку такое поведение в Oracle задается по умолчанию. Поэтому
инструкция DECLARE CURSOR используется только в конструкциях PL/SQL, таких, как
хранимые процедуры, и не применяется в.скриптах на «чистом» SQL.
Поскольку в Oracle курсоры можно использовать только в хранимых проце-
дурах и пользовательских функциях, они документируются в справочном ма-
териале PL/SQL, а не в справке по SQL.
В Oracle применяется вариант инструкции DECLARE CURSOR, поддерживающий
параметризованный ввод. Синтаксис приводится ниже.
DECLARE CURSOR имя^курсора [ ( параметр тип_данных [,...] ) ]
IS инструкция_зе1е^
[FOR UPDATE [OF имя_столбца [....]]}]
Где:
параметр тип_даннъгх [,...]) ] IS инструкция_$е1ес1
Определяется инструкция_уе1ес1, которая используется для получения резуль-
тирующего набора данных. Она служит той же цели, что и инструкция ANSI SQL
FOR инструкция_$е1ес1.
FOR UPDATE [OF имя_столбца]
Указывается, что курсор или конкретные столбцы курсора являются обновляемы-
ми. В противном случае курсор считается курсором только для чтения.
В Oracle переменные нельзя использовать в предложении WHERE инструкции
SELECT, если только они заранее не объявлены как переменные. Параметрам в ин-
струкции DECLARE значения не присваиваются. Значения присваиваются в инструк-
ции OPEN. Это важно, потому что системная функция вернет одно и то же значение
во всех строках в результирующем наборе курсора.
PostgreSQL
Платформа PostgreSQL не поддерживает предложения WITH. Она позволяет возвра-
щать результирующий набор данных в двоичном (BINARY), а не в текстовом формате.
Хотя компилятор и не выдаст ошибок при встрече со многими ключевыми словами
стандарта ANSI, реализация инструкции DECLARE CURSOR в PostgreSQL более огра-
ничена, чем это может показаться на первый взгляд.
DECLARE имя-курсора [BINARY] [INSENSITIVE] [SCROLL] CURSOR
FOR HHCTpyKunn_select
[FOR {READ ONLY | UPDATE [OF имя_столбца [,...]]}]
320 | Глава 3. Справочник по инструкциям SQL
Где:
BINARY
Курсор будет извлекать данные в двоичном формате, а не в текстовом.
INSENSITIVE
Показывает, что данные, которые извлек курсор, не зависят от обновлений, вноси-
мых другими процессами и курсорами. Однако такое поведение в PostgreSQL при-
нято по умолчанию, поэтому наличие или отсутствие этого ключевого слова ника-
кого влияния не оказывает.
SCROLL
Это предложение позволяет извлечь несколько строк в одной операции FETCH.
Однако такое поведение в PostgreSQL принято по умолчанию, поэтому наличие
или отсутствие этого ключевого слова никакого влияния не оказывает.
FOR (READ-ONLY | UPDATE}
Показывает, открывается курсор в режиме для чтения или в обновляемом режиме
соответственно. Однако PostgreSQL поддерживает только курсоры только для чте-
ния. Это означает, что предложение FOR READ-ONLY не оказывает никакого эф-
фекта, а предложение FOR UPDATE (имя_столбца) вызовет появление информа-
ционного сообщения об ошибке.
Система PostgreSQL закрывает существующий курсор, если создается заново объяв-
ленный курсор с тем же именем. Двоичные курсоры, как правило, работают быстрее,
поскольку на сервере PostgreSQL данные хранятся в двоичном формате. Однако пользо-
вательские приложения работают только с текстом. Следовательно, вам придется
встраивать обработку двоичных данных для любых курсоров с предложением BINARY.
Система PostgreSQL разрешает использовать курсоры только внутри транзакции.
Вам следует закрыть курсор в транзакционном блоке между BEGIN и COMMIT или
ROLLBACK.
Платформа PostgreSQL не поддерживает явное использование инструкции OPEN.
Курсоры считаются открытыми после объявления. Таким образом, чтобы объявить
и открыть курсор в PostgreSQL, вы должны использовать примерно такой код:
DECLARE pub_cursor CURSOR
FOR SELECT pub_name FROM publishers
WHERE country <> 'USA';
SQL Server
Платформа SQL Server поддерживает стандарт ANSI, а также довольно много расширений,
которые позволяют гибко управлять тем, как курсор перемещается по результирующему
набору и манипулирует данными. Используется следующий синтаксис.
DECLARE имя_курсора [INSENSITIVE] [SCROLL] CURSOR
[LOCAL | GLOBAL] [FORWARD_ONLY | SCROLL]
[STATIC | KEYSET | DYNAMIC | FAST_FORWARD]
[READONLY | SCROLL,LOCKS | OPTIMISTIC]
[TYPE-WARNING]
FOR инструкция-select
[FOR {READ ONLY | UPDATE [OF имя_столбца [,...] ]} ]
Параметры приводятся ниже.
LOCAL | GLOBAL
Ограничивает область действия курсора либо локальным пакетным заданием
Transact-SQL, либо делает курсор доступным для всех пакетных заданий Transact-
SQL, запущенных в ходе текущего сеанса инструкциями OPEN и FETCH. На гло-
бальное имя курсора можно ссылаться из любой хранимой процедуры, функции
или пакетного задания Transact-SQL, запущенного в текущем сеансе. Глобальный
курсор неявно освобождается (deallocate) по завершении сеанса, но локальный
курсор необходимо освобождать вручную. Ключевые слова LOCAL и GLOBAL
являются необязательными. По умолчанию, если не указано ни одно из них, пове-
дение определяется свойством базы данных default to local.
INSENSITIVE | FORWARDjONLY | SCROLL
Определяет, как курсор перемещается по результирующему набору. Есть три варианта.
INSENSITIVE
Результирующий набор создается в виде таблицы в базе TEMPDB. Изменения,
вносимые в базовую таблицу, не отражаются на результирующем наборе данных
курсора. Предложение несовместимо с расширениями инструкции DECLARE
CURSOR, имеющимися в SQL Server, такими, как LOCAL, GLOBAL, STATIC,
KEYSET, DYNAMIC, FAST_FORWARD и т. д. Может использоваться только в ин-
струкции DECLARE CURSOR стиля SQL92, например DECLARE образец
CURSOR INSENSITIVE FOR uHcmpyiafWi_select FOR UPDATE.
FORWARD_ONLY
Показывает, что курсор должен перемещаться от первой к последней записи
в результирующем наборе и единственной поддерживаемой формой инструкции
FETCH является FETCH NEXT. Если не используются ключевые слова STATIC
или KEYSET, предполагается, что курсор объявлен как DYNAMIC. Предложения
FAST_FORWARD и FORWARD_ONLYявляются взаимоисключающими.
SCROLL
Включаются все опции инструкции FETCH (ABSOLUTE, FIRST, LAST, NEXT,
PRIOR и RELATIVE). В противном случае доступна только опция FETCH NEXT.
Если используются ключевые слова DYNAMIC, STATIC или KEYSET, предложе-
ние SCROLL используется по умолчанию. Предложения FAST_FORWARD
и FORWARD_ONLYявляются взаимоисключающими.
STATIC | KEYSET | DYNAMIC | FAST_FORWARD
Определяет, как осуществляется манипулирование данными в результирующем
наборе. Эти параметры несовместимы с предложениями FOR READ ONLY и FOR
UPDATE. Существует четыре опции.
STATIC
Создается временная копия результирующего набора данных, которая сохра-
няется в базе данных tempdb. Модификации, внесенные в исходную таблицу,
322 | Глава 3. Справочник по инструкциям SQL
при обработке курсора не видны. Курсоры с предложением STATIC не могут
изменять данные в исходной таблице или представлении.
KEYSET
В базе данных tempdb создается временная копия результирующего набора
с членством и фиксированным порядком строк (который также называется на-
бором ключей, keyset). Набор ключей связывает данные в результирующем
наборе данных курсора с базовой таблицей или представлением, и курсор
может видеть изменения, вносимые в базовые данные. Измененные или уда-
ленные строки имеют @@FETCH STATUS, равный -2 (если обновление не
проводилось с помощью инструкции UPDATE...WHERE CURRENT OF, в про-
тивном случае они видны полностью), тогда как строки, вставленные другими
пользователями, не видны вообще.
DYNAMIC
Записи в результирующем наборе данных курсора определяются при выпол-
нении каждой операции FETCH. Таким образом, курсоры с предложением
DYNAMIC видят все изменения, вносимые в базовую таблицу или представле-
ние, даже те, которые внесены другими пользователями. Поскольку резуль-
тирующий набор может постоянно изменяться, курсоры DYNAMIC не под-
держивают предложение FETCH ABSOLUTE.
FASTFORWARD
Создается курсор FORWARD ONLYREAD ONLY, который быстро прочитыва-
ет весь результирующий набор курсора сразу.
READ ONLY | SCROLL_LOCKS | OPTIMISTIC
Определяются параметры параллельности и позиционного обновления курсора. Эти
параметры несовместимы с предложениями FOR READ ONLY и FOR UPDATE.
Допустимыми являются следующие параметры.
READ ONLY
Предотвращает обновление курсора и не позволяет ссылаться па курсор в инструк-
циях UPDATE или DELETE, содержащих предложение WHERE CURRENT OF.
SCROLL_LOCKS
Обеспечивает выполнение позиционных обновлений и удалений, блокируя
строки результирующего набора данных курсора по мере того, как курсор их
читает. Блокировка сохраняется до тех пор, пока курсор не будет закрыт и ос-
вобожден. Предложения SCROLL LOCKS и FAST FORWARD являются взаи-
моисключающими.
OPTIMISTIC
Позиционные обновления будут выполняться, если только обновляемая или уда-
ляемая строка в результирующем наборе данных не изменилась с того момента,
когда она была прочитана в курсор. Система SQL Server реализует это путем срав-
нения в столбцах отметки времени или значения контрольной суммы (если отметка
времени отсутствует). Строки в результирующем наборе данных курсора не бло-
кируются. Предложения OPTIMISTIC и FAST FORWARD являются взаимоиск-
лючающими.
Справочник по командам SQL | 323
TYPEJVARNING
Пользователь получает предупреждение, если курсор неявно преобразуется из
одного типа в другой, например SCROLL в FORWARDONLY.
FOR {READ ONLY}
Курсор определяется как доступный только для чтения с помощью стандартного син-
таксиса ANSI. Это ключевое слово несовместимо ни с какими другими, перечислен-
ными выше. Оно может применяться только с предложениями INSENSITIVE,
FORWARD_ONLYн SCROLL.
FOR UPDATE [OF имя_столбца [,...]]
Позволяет обновлять столбцы в курсоре с помощью инструкций UPDATE и DELETE,
содержащих предложение WHERE CURRENT OF. Если предложение FOR UPDATE
используется без списка столбцов, то обновляемыми будут все столбцы курсора.
В противном случае обновляемыми будут только указанные столбцы.
| .. Система Microsoft SQL Server позволяет использовать две базовые формы
'Пу.УЙ1 синтаксиса инструкции DECLARE CURSOR. Эти синтаксические формы
------- несовместимы! Базовые формы синтаксиса таковы: SQL92-coeMecmuMt>iu
и расширения Transact-SQL. Нельзя смешивать ключевые слова этих двух
форм.
8РЕ92-совместимый синтаксис инструкции DECLARE CURSOR выглядит так:
DECLARE имя_курсора [ INSENSITIVE ] [ SCROLL ] CURSOR
FOR инструкция__зе1есб
[ FOR { READ ONLY | UPDATE [ OF имястолбца ] } ]
Расширенный синтаксис Transact-SQL инструкции DECLARE CURSOR выглядит
так:
[ LOCAL | GLOBAL ] [ FORWARD-ONLY | SCROLL ]
[ STATIC | KEYSET | DYNAMIC | FAST.FORWARD ]
[ READ-ONLY | SCROLL-LOCKS | OPTIMISTIC ]
[ TYPE-WARNING ]
FOR инструкция_зе1ес1
[ FOR UPDATE [ OF имя_столбца ] ]
Синтаксис, совместимый c SQL92, поддерживается для того, чтобы ваш код мог
быть' более переносимым. Расширенный синтаксис Transact-SQL позволяет опреде-
лять курсоры с помощью тех же самых типов, которые используются в популярных
API, таких, как ODBC, OLE-DB и ADO, но их можно использовать только в хранимых
процедурах SQL Server, пользовательских функциях, триггерах и в запросах для не-
медленного выполнения (ad hoc query).
Если вы определите курсор в расширенном синтаксисе Transact-SQL, но не опре-
делите поведение для параллельной работы с помощью ключевых слов OPTIMISTIC,
READ-ONLY или SCROLL-LOCKS, то тогда:
324 | Глава 3. Справочник по инструкциям SQL
• по умолчанию курсор станет доступным только для чтения (READ-ONLY), если он
был определен как FASTFORIVARD или STATIC или если пользователь имеет не-
достаточно прав для обновления базовой таблицы или представления;
• по умолчанию курсор будет определен как OPTIMISTIC, если в его определении
указаны ключевые слова DYNAMIC пли KEYSET
Заметьте, что в uncmpyKiiitu_select курсора SQL Server можно использовать пере-
менные, но эти переменные вычисляются при объявлении курсора. Таким образом,
курсор, содержащий столбец, использующий системную функцию GETDATE(), будет
содержать одну и ту же дату в каждой строке результирующего набора данных.
В следующем примере кода для SQL Server мы используем курсор KEYSET для из-
менения пробелов на дефисы в столбце phone таблицы authors.
SET NCCOUNT ON
DECLARE author_name_cursor CURSOR LOCAL KEYSET TYPE_WARNING
TOR SELECT au_fname FROM pubs.dbo.authors
DECLARE @name varchar(40)
OPEN author_naT.c_cursor
FETCH NEXT FROM author_nane_cursor INTO @name
WHILE (@@fetcn_status <> -1)
BEGIN
-- @@fetch_status проверяет ошибки и условия типа 'запись не найдена'
IF (@@>fetch_status о -2)
BEGIN
PRINT 'updating record for ' + @name
UPDATE pubs.dbo.authors
SET phone = replace(phone, ' '-')
WHERE CURRENT OF author_name_cursor
END
FETCH NEXT FROM author_name_cursor INTO @name
END
CLOSE author_naire_cursor
DEALLOCATE author_name_cursor
GO
См. также
CLOSE CURSOR
FETCH
OPEN
Справочник по командам SQL | 325
Инструкция DELETE
Инструкция DELETE удаляет записи из указанной таблицы или таблиц. Инструкции
DELETE, которые выполняются в таблицах, иногда называются поисковыми удалениями
(search deletes). Инструкцию DELETE также можно использовать вместе с курсором.
Инструкции DELETE, действующие на строки курсора, иногда называются позицион-
ными удалениями (positional deletes).
Платформа Команда
DB2 Поддерживается с вариантами
MySQL Поддерживается с вариантами
Oracle Поддерживается с вариантами
PostgreSQL Поддерживается
SQL Server Поддерживается с ограничениями
Синтаксис SQL2003
DELETE FROM { имя_таблицы | ONLY (имя_таблицы') }
[{ WHERE условие_поиска | WHERE CURRENT OF имя_курсора }]
Ключевые слова
FROM имя упаблнцы
Указывается таблица, имя_таблицы, из которой будут удаляться строки. Если схема
в имени таблицы не указана, предполагается текущая схема. В качестве альтернативы
вы можете указать имя однотабличного представления. Ключевое слово FROM явля-
ется обязательным, за исключением инструкции DELETE...WHERE CURRENT OF.
Если не используется предложение ONLY, не заключайте имя_таблицы в скобки.
ONLY (имя_таблицы)
Запрещается каскадное распространение удалений записей на подтаблицы целе-
вой таблицы или представления. Предложение ONLY действует только на объект-
ные таблицы и представления. Если предложение используется в необъектной
таблице или представлении, оно игнорируется и ошибки не вызывает. Если ис-
пользуется ключевое слово ONLY, вы должны заключить имя таблицы в скобки.
WHERE условие_поиска
Для инструкции DELETE определяется поисковый критерий с использованием
одного или нескольких условийпоиска, которые обеспечивают удаление только
указанных строк. Можно использовать любое допустимое предложение WHERE.
WHERE CURRENT OF имя_курсора
Инструкция DELETE ограничивается текущей записью в объявленном и откры-
том курсоре с именем имя_курсора.
326 | Глава 3. Справочник по инструкциям SQL
Общие правила
Инструкция DELETE удаляет строки из таблицы или представления. Пространство,
освобождающееся после удаления, возвращается базе данных, в которой находится
таблица, хотя это может произойти и не сразу.
Простая инструкция DELETE, которая удаляет все записи из данной таблицы, не
имеет предложения WHERE.
DELETE FROM sales;
Вы можете использовать любое допустимое предложение WHERE, чтобы отфильтро-
вать те записи, которые вы хотите удалить, а поскольку все эти операции являются поиско-
выми удалениями, они все включают предложение FROM.
DELETE FROM sales
WHERE qty IS NULL;
DELETE FROM suppliers
WHERE supplierid = 17
OR companyname = 'Tokyo Traders';
DELETE FROM distributors
WHERE postalcode IN
(SELECT territorydescription FROM territories);
В некоторых случаях вам может понадобиться удалить конкретную строку,
которая обрабатывается объявленным и открытым курсором.
DELETE titles WHERE CURRENT OF title_cursor;
В приведенном выше запросе подразумевается, что вы объявили и открыли курсор
с именем title_cursor. Та строка, на которой находится курсор, при выполнении приве-
денной выше команды будет удалена. Обратите внимание, что в приведенном выше
примере позиционного удаления не требуется ключевое слово FROM.
Советы и хитрости программирования
Инструкция DELETE редко используется без предложения WHERE, поскольку такая опера-
ция приведет к удалению всех записей из указанной таблицы. Сначала вам следует подать
команду SELECT с тем же предложением WHERE, которое вы намереваетесь использовать
в инструкции DELETE. Это позволит вам точно знать, какие записи будут удалены.
Если возникает необходимость удалить из таблицы все записи, попробуйте использо-
вать нестандартную инструкцию TRUNCATE TABLE. В тех базах данных, которые под-
держивают эту команду, инструкция TRUNCATE TABLE обычно является более быстрым
методом физического удаления всех строк. Инструкция TRUNCATE TABLE выполняется
быстрее, чем DELETE, поскольку удаления отдельных строк не записываются в журнал.
На некоторых платформах это приводит к тому, что откат инструкции TRUNCATE стано-
вится невозможным. Уменьшение затрат ресурсов на журналирование позволяет сэконо-
мить довольно много времени при удалении большого числа записей. На некоторых плат-
формах перед подачей инструкции TRUNCATE необходимо удалить все внешние ключи.
Справочник по командам SQL | 327
DB2
Платформа DB2 поддерживает стандарт ANSI с дополнением в виде контроля изо-
лирования транзакции и возможности присваивать псевдоним таблице, из которой
будут удаляться записи. Синтаксис следующий.
DELETE FROM { имя_габлицы | ONLY (имя_таблицы) } [AS псевдоним']
[WHERE. {условие_поиска | CURRENT OF имя_курсора}]
[WITH { RR | RS I CS | UR }]
Параметры следующие.
AS псевдоним
Позволяет использовать псевдоним для имени_таблицы. Это особенно полезно при
использовании коррелированных подзапросов. (Обратите внимание, что в DB2 есть
специальный объект alias, который можно создать при помощи инструкции CREATE
ALIAS.) В данном случае термином «псевдоним» называется то, что в стандарте
ANSI SQL называется «.correlation пате», что-то вроде простого краткого имени
(nickname) таблицы или представления.
WITH { RR \RS\CS\UR}
Управляет уровнем изоляции транзакции в инструкции по обновлению данных.
RR - repeatable read (воспроизводимое чтение), RS - read stability (стабильность
чтения), CS - cursor stability (стабильность курсора) и UR - uncommitted read
(чтение незафиксированного).
В DB2 в качестве цели может выступать таблица, обновляемое представление или
краткое имя (nickname). Согласно стандарту ANSI строки будут удаляться из всех под-
таблиц целевой таблицы, если не используется ключевое слово ONLY. Если ключевое
слово ONLY используется, имя_таблицы должно быть заключено в скобки.
Если вы используете предложение ONLY в комбинации с WHERE CURRENT OF,
то инструкция SELECT, определяющая курсор, должна*также содержать предложение
FROM ONLY. Например:
DECLARE CURSOR emp_cursor FOR
SELECT name, address
FROM ONLY (employee);
DELETE FROM ONLY (employee)
WHERE CURRENT OF emp_.cursor;
В приведенном выше коде подразумевается, что employee - это базовая таблица,
для которой существуют подтаблицы. Курсор отберет только те строки, которые со-
держатся в таблице employee, но не в других типах, которые содержатся в подтабли-
цах (parttime, salaried, student). Точно так же и удаление будет иметь место только на
этом уровне иерархии.
MySQL
Платформа MySQL содержит несколько расширений стандарта ANSI, но не под-
держивает предложение WHERE CURRENT OF. Синтаксис следующий.
328 | Глава 3. Справочник по инструкциям SQL
DELETE [LOW_PRTORITYJ [QUICK] [имя_таблицы [.*] [,...] ]
{FROM имя_таблицы [.*] [,...] | [USING имя_таблицы [.*] [,...] ] }
[WHERE условие_поиска]
[ORDER_BY предложение]
[LIMIT количество_.строк]
Параметры следующие.
LO ^PRIORITY
Выполнение инструкции DELETE откладывается до тех пор, пока другие клиенты
не прекратят обращаться к таблице.
QUICK
Не дает системе хранения объединять листы индекса в ходе операции удаления.
DELETE имя таблицы [,...]
Позволяет удалить сразу несколько таблиц. Таблицы перечисляются перед пред-
ложением FROM, и при этом предполагается, что одна или несколько таблиц, ко-
торые указаны в предложении FROM, будут целью операции удаления. Если
перед предложением FROM указано несколько таблиц, то удалены будут все сов-
падающие записи из всех таблиц.
FROM имя таблицы [. *]
Указывается таблица или таблицы, из которых будут удалены записи. (Предложе-
ние .* - это опция, используемая для повышения совместимости с MS Access.)
Если таблицы перечислены перед предложением FROM, то предполагается, что
таблицы, используемые в предложении FROM, применяются для операции соеди-
нения или поиска.
USING имя_таблицы [. *] [,...]
Таблица или таблицы, указанные до предложения FROM, заменяются геми,
которые стоят после предложения FROM.
ORDERLY предложение
Указывается порядок удаления строк. Это предложение полезно только вместе
с предложением LIMIT.
LIMIT количество строк
Система MySQL позволяет при помощи этого предложения наложить произволь-
ное ограничение на количество удаленных записей, по достижении которого
управление снова передается клиенту.
Система MySQL позволяет выполнять удаление сразу в нескольких таблицах.
Например, следующие инструкции DELETE функционально эквивалентны.
DELETE orders FROM customers, orders
WHERE customers.customerid = orders.customeria
AND orders. oroerdate BETWEEN ' 19950101' ANO '1995123Г
DELETE FROM orders USING customers, orders
WHERE customers.customerid = orders.customerid
AND orders.orderdate BETWEEN '1995010Г AND '19951231'
Справочник по командам SQL | 329
В приведенном выше примере мы удалили все заказы (orders), сделанные покупа-
телями (customers) в течение 1995 года. Заметьте, что при подобном множественном
удалении вы не можете использовать предложения ORDER BY и LIMIT.
Также вы можете удалять записи в организованных пакетных заданиях, исполь-
зующих предложения ORDER BY и LIMIT.
DELETE FROM sales
WHERE customerid = 'TORTU
ORDER BY customerid
LIMIT 5
Платформа MySQL имеет несколько функций, ускоряющих операцию удаления.
Например, MySQL возвращает количество удаленных записей по завершении опера-
ции. Однако MySQL вернет ноль, как количество удаленных записей, если удаляются
все записи таблицы, поскольку для MySQL быстрее будет вернуть ноль, чем считать
удаленные строки. В режиме AUTOCOMMIT система MySQL будет даже заменять
инструкцию DELETE без предложения WHERE на инструкцию TRUNCATE, поскольку
инструкция TRUNCATE выполняется быстрее.
Обратите внимание, что скорость операции удаления в MySQL напрямую связана
с количеством индексов таблицы и доступным кешем индексов. Вы можете ускорить
операцию удаления, выполняя данную команду в таблицах с небольшим числом ин-
дексов или без индексов вообще или увеличив размер кеша индексов.
Oracle
Платформа Oracle позволяет удалять строки из таблиц, представлений, материализо-
ванных представлений, вложенных подзапросов и секционированных представлений
и таблиц следующим образом.
DELETE [FROM]
{имя_таблицы | ONLY (имя_таблицы')} [псевдоним']
[{PARTITION (имя^раздела) |
SUBPARTITION (имя_подраздела]}] |
(подзапрос [WITH {READ ONLY |
CHECK OPTION [CONSTRAINT имя_ограничения]}] ) |
TABLE (выражение-ДлЯ-Коллекции] [(+)]}
[WHERE условие~поиска]
[RETURNING выражение [,...] INTO переменная [,...] ]
Параметры приведены ниже.
гшя таблицы [псевдоним]
Указывается таблица, представление, материализованное представление или секцио-
нированная таблица или представление, откуда будут удаляться записи. При жела-
нии вы можете перед именем_табпщы указать схему или указать после имени таб-
лицы соединение с базой данных. В противном случае система Oracle будет исполь-
зовать текущую схему и локальный сервер базы данных. При желании вы можете
присвоить имени_таблицы какой-нибудь псевдоним. Псевдоним является необходи-
мым, если таблица ссылается на атрибут или метод объектного типа.
330 | Глава 3. Справочник по инструкциям SQL
PARTITION имя раздела
Операция удаления применяется к указанному разделу, а не ко всей таблице. При
удалении из секционированной таблицы необязательно указывать имя раздела, но
это во многих случаях помогает уменьшить сложность предложения WHERE.
SUBPARTITION (имя_подраздела)
Удаление применяется к указанному подразделу, а не ко всей таблице.
(подзапрос [WITH {READ ONLY \ CHECK OPTION [CONSTRAINT имя_ограничепия]}])
Указывается, что целью операции удаления является вложенный подзапрос, а не
таблица, представление или другой объект базы данных. Параметры данного
предложения следующие.
подзапрос
Указывается инструкция SELECT, которая представляет собой подзапрос.
Можно создавать любой стандартный подзапрос, но он не может содержать
предложения ORDER BY.
WITH READ ONLY
Указывается, что подзапрос не может быть обновлен.
WITH CHECK OPTION
Система Oracle будет отклонять любые изменения удаленной таблицы, которые
не видны в результирующем наборе данных подзапроса.
CONSTRAINT имярераничения
Система Oracle ограничит вносимые изменения, основываясь на ограничении
с именем имя_ограничения.
TABLE (выражепие_для_коллекции) [ (+) ]
Система Oracle будет обрабатывать выраж-ение_для_коллекции как таблицу, хотя
фактически это может быть подзапрос, функция или другой конструктор коллек-
ции. В любом случае значение, возвращаемое выражением_для_коллекции,
должно представлять собой вложенную таблицу или TARRAY.
RETURNING выражение
Извлекаются строки, затронутые командой там, где команда DELETE обычно воз-
вращает только количество удаленных строк. Предложение RETURNING можно
применять, если целью команды является таблица, материализованное представле-
ние или представление по одной базовой таблице. Если предложение используется
при удалении одиночной строки, то значения из удаленной строки, которые опреде-
ляются выражением, сохраняются в переменных PL/SQL и переменных связывания
(bind variables). Если предложение используется при удалении многих строк, то
значения из удаленных строк, которые определяются выражением, сохраняются
в массивах связывания (bind arrays).
INTO переменная
Указываются переменные, в которые записываются значения, возвращаемые в ре-
зультате работы предложения RETURNING.
При выполнении инструкции DELETE Oracle возвращает освободившееся в таб-
лице (или базовой таблице представления) место обратно в таблицу или индекс, где
хранились данные.
Справочник по командам SQL | 331
Если данные удаляются из представления, представление не может содержать
операций над множествами, ключевого слова DISTINCT, соединений, агрегатной
функции, аналитической функции, подзапросов SELECT, предложения GROUP BY,
предложения ORDER BY, предложения CONNECT BY или START WITH.
Ниже приводится пример, в котором мы удаляем данные с удаленного сервера.
DELETE FROM scott sales@chicago;
В следующем примере мы удаляем данные из производной таблицы, указанной
в выражении для коллекции.
DELETE TABLE(SELECT contactname FROM customers
c WHERE c,customerid = 'BOTTM') s
WHERE s. region IS NULL OR s.country = 'MEXICO';
А вот пример удаления из раздела.
DELETE FROM sales PARTITION (sales_q3_1997)
WHERE qty > 10000;
И наконец, в следующем примере мы используем предложение RETURNING,
чтобы увидеть удаленные значения.
DELETE FROM employee
WHERE job_id = 13
AND hire_date + TO_YMINTERVAL('01-06') =< SYSDATE;
RETURNING job_lvl
INTO :int01;
В предыдущем примере удаляются записи из таблицы employee, а значения
job_lvl возвращаются в заранее определенную переменную :intol.
PostgreSQL
Платформа PostgreSQL использует команду DELETE для удаления строк и всех объяв-
ленных подклассов из таблицы. Во всем прочем инструкция идентична стандарту
ANSI. Синтаксис следующий.
DELETE [FROM] [ONLY] имя_таблицы
[ WHERE условие_поиска | WHERE CURRENT OF имя_курсора ]
При удалении строк только из указанной таблицы используйте дополнительное
предложение ONLY. В противном случае система PostgreSQL удалит записи также из
явно определенной подтаблицы.
Чтобы удалить все записи из таблицы titles, используется следующий код.
DELETE titles
Чтобы удалить из таблицы authors все записи, где фамилия начинается с «Мс»,
используется следующий код.
DELETE FROM authors
WHERE au^lname LIKE 'Mc%'
Удаляем все записи (наименования) titles со старым ID.
332 | Глава 3. Справочник по инструкциям SQL
DELETE titles WHERE title_id >= 40
Удаляем все записи titles, для которых не зарегистрировано продаж.
DELETE titles WHERE ytd_sales IS NULL
Удаляем все записи в одной таблице на основе результатов подзапроса к другой
таблице (в данном случае из таблицы titleauthor удаляются все записи, для которых
в таблице titles встречается слово «computers»).
DELETE FROM titleautnor
WHERE title_id IN
(SELECT title_id
FROM titles
WHERE title LIKE '%computers%')
DISCONNECT
SQL Server
Платформа Microsoft SQL Server позволяет удалять записи как из таблицы, так и из
представлений, описывающих одиночную таблицу. Также SQL Server позволяет исполь-
зовать второе предложение FROM, чтобы можно было использовать конструкции
JOIN. Синтаксис следующий.
DELETE [ТОР количество [PERCENT]] [FROM] имя_таблицы [[AS] псевдоним]
[FROM тоблица_источник [,.,.]]
[ [{INNER | CROSS | [{LEFT | RIGHT | FULL] OUTER}]
JOIN присоединенная-таблица ON условие][, , , .]
[WHERE условие_поиска | WHERE CURRENT OF [GLOBAL] имя_курсора ]
[OPTION (подсказка_для_запроса [,...n])]
Синтаксические элементы описываются ниже.
DELETE имя_таблицы
Позволяет удалять записи из указанной таблицы или представления, фильтруя их
при помощи предложения WHERE. Вы можете удалять записи из представления,
если представление основывается на одной таблице, не содержит агрегатных
функций и производных столбцов. Если вы опустите имя сервера, имя базы
данных или имя схемы при указании таблицы или представления, то SQL Server
будет использовать текущий контекст. Вместо таблицы или представления можно
ссылаться на функцию OPENDATASOURCE или OPENQUERY, как это описывается
в разделе «Инструкция SELECT».
ТОР количество [PERCENT]
Указывается, что инструкция удалит только указанное количество строк. Если
указано ключевое слово PERCENT, то будут извлечены только первые столько
процентов, сколько указано в параметре количество. Если количество представля-
ет собой выражение, например переменную, то его нужно заключить в скобки.
Выражение должно относиться к типу данных FLOAT в диапазоне от 0 до 100,
Справочник по командам SQL | 333
если используется ключевое слово PERCENT. Если слово PERCENT не использу-
ется, то выражение должно относиться к типу данных BIGINT.
FROM таблица_источник
Указывается дополнительное условие FROM, которое устанавливает связь с запи-
сями таблицы в первом предложении FROM с использованием предложения JOIN.
Используется вместо коррелированных подзапросов. Во втором предложении
FROM можно указать одну или несколько таблиц.
[{INNER | CROSS | [{LEFT | RIGHT | FULL] OUTER}] JOIN присоединенная_таблица
ON условие] [,...]
Указывается, при использовании дополнительного предложения FROM, одно или
несколько предложений JOIN. Можно использовать любой тип соединений, под-
держиваемых SQL Server. За дополнительной информацией обращайтесь к разде-
лам «Инструкция JOIN» и «Инструкция SELECT».
GLOBAL имя_курсора
Указывается, что операция удаления должна выполняться применительно к теку-
щей строке открытого глобального курсора. Во всем прочем это предложение
идентично стандартному предложению WHERE CURRENT OF.
OPTION (подсказка_для_запроса [,])
Элементы заданного по умолчанию плана запроса заменяются на ваши собствен-
ные. Поскольку оптимизатор обычно выбирает самый лучший план обработки
любого запроса, мы очень не рекомендуем помещать в ваши запросы подсказки
оптимизатору.
Главное дополнение, которое добавляет SQL Server к стандарту ANSI, - это
второе предложение FROM. Второе предложение FROM позволяет использовать
инструкции JOIN, что значительно облегчает удаление строк из таблицы, указанной
в первом предложении FROM, путем связывания их со строками таблицы во втором
предложении FROM. Например, вы можете использовать довольно сложный подза-
прос, чтобы удалить записи о продажах (sales) компьютерных книг.
DELETE sales
WHERE title.id IN
(SELECT title_id
FROM titles
WHERE type = 'computer')
Однако SQL Server позволяет создать более изящную конструкцию с использова-
нием второго предложения FROM и предложения JOIN.
DELETE s
FROM sales AS s
INNER JOIN titles AS t ON s.title.id = t.title_id
AND type = 'computer'
В следующем примере удаляются все строки с датой order_date до 2003 года
в пакете до 2500 записей.
334 | Глава 3. Справочник по инструкциям SQL
WHILE 1 1
BEGIN
DELETE TOP (2500)
FROM sales_history WHERE order_date <= ’20030101'
IF @@rowcount < 2500 BREAK
END
Вместо старой инструкции SET ROWCOUNT лучше использовать предложение
ТОР, поскольку предложение ТОР открыто для гораздо большего числа алгоритмов
оптимизации. (До SQL Server 2005 инструкция SET ROWCOUNT часто использова-
лась в транзакциях по модификации данных для обработки большого числа строк
пакетами, чтобы журнал транзакций не переполнялся и чтобы блокировка строки не
перерастала в полную блокировку таблицы.)
См. также
INSERT
SELECT
TRUNCATE TABLE
UPDATE
Инструкция DISCONNECT
Инструкция DISCONNECT завершает одно или несколько соединений, созданных
между текущим процессом SQL и сервером базы данных.
Платформа Команда
DB2 Поддерживается с ограничениями
MySQL 11е поддерживается
Oracle Поддерживается с ограничениями
PostgreSQL Нс поддерживается
SQL Server Поддерживается с ограничениями
Синтаксис SQL2003
DISCONNECT {CURRENT | ALL | имя_соединения | DEFAULT}
Ключевые слова
CURRENT
Закрывается текущее активное пользовательское соединение.
ALL
Закрываются все открытые соединения текущего пользователя.
Справочник по командам SQL | 335
Общие правила
Инструкция DISCONNECT используется для завершения указанного сеанса SQL
(имя__соединения), текущего соединения (CURRENT), соединения по умолчанию
(DEFA ULT) или всех соединений пользователя (ALL). Например, мы можем завершить
один сеанс с именем new_york.
DISCONNECT new_york
В следующем примере мы можем прервать все открытые в настоящий момент
сеансы для текущего процесса пользователя.
DISCONNECT ALL
Советы и хитрости программирования
Инструкция DISCONNECT не является универсально поддерживаемой инструкцией
для всех платформ. Не создавайте приложений для нескольких платформ с использо-
ванием инструкции DISCONNECT, если вы не подготовили условия для прерывания
сеансов SQL с помощью методологии, предпочтительной для каждой платформы.
DB2
Платформа DB2 поддерживает инструкцию DISCONNECT стандарта ANSI только для
встроенного кода SQL. Команда DISCONNECT может завершить одно или несколько
соединений только после успешного выполнения операции COMMIT или ROLLBACK
в удаляемом сеансе. Также вы можете использовать инструкцию RELEASE, чтобы
ввести соединение в состояние ожидания разрыва.
MySQL
Не поддерживается.
Oracle
Платформа Oracle позволяет использовать инструкцию DISCONNECT только в своем
инструменте для запросов немедленного выполнения SQL*Plus, при этом используется
следующий синтаксис.
DISCONNECT]
При таком способе применения команда завершает текущий сеанс работы с сервером
базы данных, но во всем прочем позволяет продолжить работу с SQL*Plus. Например,
программист может продолжать редактировать буфер, сохранять выполняемые файлы и т. п.
Однако, чтобы подавать команды SQL, вы должны установить новое соединение. Для
выхода из SQL*Plus и возвращения в файловую систему требуется подать команду EXIT
или QUIT. Например, следующая команда завершает текущее соединение с сервером Oracle.
DISCONNECT;
336 | Глава 3. Справочник по инструкциям SQL
PostgreSQL
He поддерживается. Вместо этого в каждом программном интерфейсе поддерживается
операция разрыва соединения. Например, для Server Programming Interface поддержива-
ется команда SPI_FINISH, а в программном пакете PL/TCL - команда PG CONNECT.
SQL Server
Платформа Microsoft SQL Server поддерживает синтаксис ANSI для инструкции
DISCONNECT только во встроенном SQL (Embedded-SQL, ESQL), но не в инстру-
менте для создания произвольных запросов SQL Query Analyzer. Чтобы явным обра-
зом отсоединиться от сервера Microsoft SQL Server в программе ESQL, используйте
инструкцию DISCONNECT ALL.
См. также
CONNECT
Инструкции DROP
Все объекты базы данных, созданные с помощью инструкций CREATE, могут быть
уничтожены при помощи соответствующих инструкций DROP. На некоторых плат-
формах восстановить объект после удаления можно командой ROLLBACK. Однако на
других платформах инструкция DROP является необратимой и окончательной, поэтому
эту команду следует применять осторожно.
Платформа Команда
DB2 Поддерживается с вариантами
MySQL Поддерживается с ограничениями
Oracle Поддерживается с вариантами
PostgreSQL Поддерживается с ограничениями
SQL Server Поддерживается с ограничениями
Синтаксис SQL2003
В настоящее время стандарт SQL2003 поддерживает возможность удаления объектов
многих типов, многие из которых не поддерживаются большинством производителей.
Синтаксис ANSI SQL2003 имеет следующий формат.
DROP {тип_объекта} имя_объекта {RESTRICT | CASCADE}
Ключевые слова
DROP {тип_объекта} имя_объекта
Указанный объект с именем имя_объекта и относящийся к указанному типу
окончательно и необратимо удаляется. В имени объекта можно не указывать
схему, но в этом случае подразумевается текущая схема. Стандарт ANSI SQL2003
поддерживает длинный список типов объектов, каждый из которых создается
22 - 2447
Справочник по командам SQL | 337
соответствующей инструкцией CREATE. К инструкциям CREATE и соответст-
вующим им инструкциям DROP, описываемым в этой книге, относятся сле-
дующие. DOMAIN FUNCTION METHOD PROCEDURE ROLE RESTRICT | CASCADE SCHEMA TABLE TRIGGER TYPE VIEW
Удаление не выполняется, если существуют зависимые объекты (RESTRICT) или же
все зависимые объекты также удаляются (CASCADE). Это предложение не употреб-
ляется с некоторыми формами инструкции DROP, например DROP TRIGGER, но
для других оно является обязательным, например для DROP SCHEMA. Объясним.
Инструкция DROP SCHEMA RESTRICT может удалить только пустую схему. Если
же схема содержит объекты, операция не будет выполнена. И наоборот, инструкция
DROP SCHEMA CASCADE удалит и схему, и все содержащиеся в ней объекты.
Общие правила
Правила создания или изменения каждого типа объектов приведены в описаниях соот-
ветствующих инструкций CREATE/ALTER.
Инструкция DROP уничтожает уже существующий объект. Объект удаляется
окончательно, и все объекты, обращавшиеся к объекту, немедленно теряют к нему
доступ.
Объект может быть квалифицированным, т. е. вы можете полностью указать
схему, в которой расположен удаляемый объект. Например:
DROP TABLE scott.sales_2004 CASCADE;
Приведенная выше инструкция не только удалит таблицу scott.sales_2004, но
также удалит все представления, триггеры и ограничения, созданные на ее основе.
С другой стороны, инструкция DROP может включать неквалифицированное имя объ-
екта, и тогда подразумевается контекст текущей схемы. Например:
DROP TRIGGER before_ins_emp;
DROP ROLE salesjngr;
В большинстве реализаций команда DROP не будет выполнена, если объект базы
данных использует другой пользователь (хотя это и не рекомендуется стандартом
SQL2003).
Советы и хитрости программирования
Инструкция DROP работает только применительно к существующему объекту подходя-
щего типа, к которому пользователь имеет соответствующие права доступа, обычно
права DROP TABLE. (За дополнительной информацией обращайтесь к разделу
«Инструкция GRANT».) Стандарт требует, чтобы объект мог удалять только его владелец,
338 | Глава 3. Справочник по инструкциям SQL
но в большинстве платформ в этом вопросе допускаются варианты. Например, суперполь-
зователь базы данных обычно может удалить на сервере базы любой объект.
У некоторых производителей команда DROP генерирует ошибку, если объект
базы данных имеет расширенные свойства. Например, Microsoft SQL Server не удалит
реплицируемую таблицу до тех пор, пока вы не исключите ее из репликации.
| ..' ' Важно знать, что большинство производителей не уведомляют вас о там,
что команда DROP вызывала проблему, связанную с зависимостями. Так.
----' если таблица, используемая где-нибудь в базе данных несколькими пред-
ставлениями и записанными процедурами, удаляется, никаких предупреж-
дений не выводится. Эти прочие объекты будут просто выдавать ошибки
при доступе к ним. Чтобы избежать этого, вы можете использовать
в нужном месте синтаксическую конструкцию RESTRICT.
Вы, должно быть, заметили, что стандарт ANSI не поддерживает некоторые рас-
пространенные команды DROP, такие, как DROP DATABASE или DROP INDEX, хотя
платформы всех производителей, описываемые в этой книге, поддерживают эти
команды. Точный синтаксис каждой из этих команд описывается ниже, в разделах,
посвященных разным платформам.
DB2
Платформа DB2 не поддерживает опцию CASCADE. Она поддерживает многие типы
объектов ANSI, а также множество своих собственных типов объектов. Синтаксис
следующий.
DROP {BUFFERPOOL | EVENT MONITOR | [SPECIFIC] FUNCTION |
FUNCTION MAPPING | INDEX | INDEX EXTENSION |
[SPECIFIC] METHOD | NICKNAME | DATABASE PARTITION GROUP |
PACKAGE | [SPECIFIC] PROCEDURE | SCHEMA | SEQUENCE | SERVER |
TABLE [HIERARCHY] | TABLESPACE[S] | TRANSFORMS]
[{ALL | имя_групны}'] FOR | TRIGGER | [DISTINCT] TYPE |
TYPE MAPPING | USER MAPPING FOR {имя_для_авгоризаиии | USER} SERVER |
VIEW [HIERARCHY] | WRAPPER } имя_объекта [RESTRICT]
Правила для инструкций DROP в DB2 не столь четкие, как в стандарте ANSI,
поэтому ниже приводится полный синтаксис каждого из вариантов инструкции DROP.
BUFFERPOOL имя_пула_буферов
Удаляется указанный пул буферов, если ему не назначены табличные пространст-
ва. Память высвобождается немедленно, но дисковое пространство может быть
возвращено только при следующем соединении с базой данных.
EVENT MONITOR имя_монитора_событий
Удаляется указанный монитор событий, если он не установлен в ON.
[SPECIFIC] FUNCTION имя_функции [(тип_данных [,...] )] [RESTRICT]
Удаляется указанная пользовательская функция. Платформа DB2 позволяет исполь-
зовать несколько функций с одним именем. Для удаления таких функций нужно
Справочник по командам SQL | 339
использовать синтаксис DROP FUNCTION имя_функции (типданных [,...] ), указав
тип данных, однозначно определяющий пользовательскую функцию. Дополни-
тельное ключевое слово SPECIFIC используется для определения функций по
уникальному имени, присвоенному каждой из них при создании. Вы можете уда-
лить функцию в момент, когда она используется, не повредив работе пользователя
(если только пользователь не попытается обратиться к функции позже). Однако
нельзя удалить функцию, являющуюся компонентом задания, триггеров, пред-
ставлений и т. п. Вот пример всех трех видов синтаксиса.
DROP FUNCTION sales_summary_1992
DROP FUNCTION sales_summary (int, float)
DROP SPECIFIC FUNCTION products.inventory_level
FUNCTION MAPPING имяу>тображения_функции
Удаляется указанное отображение функции.
INDEX [EXTENSION] имя_индекса [RESTRICT]
Удаляется указанный индекс или при желании расширение индекса, если только
это не первичный ключ или не ограничение UNIQUE. Чтобы удалить первичный
ключ или ограничение UNIQUE, вы должны использовать инструкцию ALTER
TABLE. Предложение RESTRICT является обязательным, если удаляется расшире-
ние индекса.
[SPECIFIC] METHOD имя_метода [(гттуЗаниых [,...])] [FOR имяутта] [RESTRICT]
Удаляется тело указанного метода или специфического метода, за исключением тех,
которые неявно создавались при помощи инструкции CREATE TYPE. Спецификация
метода остается частью определения соответствующего типа, пока не будет удалена
инструкцией ALTER TYPE DROP METHOD. В качестве альтернативы вы можете ис-
пользовать синтаксис DROP METHOD имя_метода (тип_данных1 [...]) для даль-
нейшей идентификации метода по типам данных. Предложение FOR имя_типа
нужно указать, если не было указано предложение SPECIFIC, для того, чтобы ука-
зать тип, из которого удаляется метод. Перед удалением метода необходимо удалить
все его зависимости.
NICKNAME краткоеушя
Удаляется указанное краткое имя. Также удаляются некоторые другие зависимые
объекты, в том числе таблицы материализованных запросов, спецификации индек-
сов, представления (не удаляются, но делаются неработоспособными) и пакеты
(не удаляются, но помечаются как неработоспособные).
DATABASE PARTITION GROUP имяуруппы_разделов
Удаляется указанная группа разделов базы данных и все зависимые от нее объекты
(таблицы, пакеты, ограничения и т. п.) также удаляются или помечаются как нерабо-
тоспособные. Перед этим необходимо удалить из группы разделов все табличные
пространства. Например:
DROP TABLESPACE sales_2004
DROP TABLESPACE sales_2003
DROP DATABASE PARTITION GROUP sales_archive_0304
340 | Глава 3. Справочник по инструкциям SQL
PACKAGE и.мя_пакета [VERSION id версии]
Удаляется указанный пакет имясхемы,id пакета. При желании вы можете также
указать предложение VERSION tdjiepcuu после id_nai<ema, чтобы точнее опреде-
лить пакет.
[SPECIFIC] PROCEDURE имя_процедуры [(тип_данных! [...])] [RESTRICT]
Удаляется указанная пользовательская функция. Платформа DB2 позволяет
использовать несколько функций с одним именем, которые различаются исполь-
зуемыми типами данных. Также вы можете указать удаляемую процедуру при
помощи синтаксиса PROCEDURE имя_процедуры (тип_данных! [,...]).
SCHEMA имя_схемы [RESTRICT]
Удаляется указанная схема. Ключевое слово RESTRICT требует, чтобы перед уда-
лением схема была очищена.
SEQUENCE имя_последователыюсти [RESTRICT]
С сервера удаляется указанная последовательность. Однако с помощью инструк-
ции DROP SEQUENCE нельзя удалить последовательность, созданную для столб-
ца идентификаторов (IDENTITY).
SERVER имясервера
Указанное определение источника данных удаляется из каталога, так же как и все
псевдонимы объектов, расположенных на удаленном сервере. Кроме того, уда-
ляются спецификации индексов, пользовательские функции, пользовательские
отображения типов данных (type mapping) и отображения пользователей, завися-
щие от удаленного сервера. Пакеты и отображения функций, зависящие от удален-
ного сервера, делаются недействительными.
TABLE [HIERARCHY] и.мя_таблицы
С сервера удаляется указанная базовая таблица, объявленная временная таблица,
таблица материализованного запроса или промежуточная таблица (staging table).
Индексы, ограничения, таблицы материализованных запросов и промежуточные
таблицы, которые ссылаются на удаленную таблицу, также удаляются. Подтабли-
цы объектной таблицы автоматически не удаляются, и их необходимо удалить
перед удалением таблицы-родителя. Представления, пакеты и триггеры, которые
ссылаются на удаленную таблицу, становятся неработоспособными. Разрываются
связи во всех столбцах DATAL1NK, хотя и не одновременно. Опция HIERARCHY
служит для удаления указанной иерархии объектных таблиц (т. е. как родитель-
ской таблицы, так и всех ее подтаблиц). В данном синтаксисе имяобъекта - это
имя корневой таблицы в иерархии объектных таблиц. Таблицу нельзя удалить,
если опа имеет атрибут RESTRICT ON DROP.
TABLESPACE[S] имя_табличного_пространства [,...]
Удаляется одно или несколько табличных пространств со всеми объектами в этих
табличных пространствах, если только записанная в этом пространстве таблица не
перекрывает удаляемое табличное пространство, и при этом таблица не перекрывает
еще как минимум одно пространство, или если таблица не содержит предложение
RESTRICT ON DROP. Ключевые слова TABLESPACE и TABLESPACES являются
синонимами.
Справочник по командам SQL | 341
TRANSFORM[S] {ALL | имя_группы} FOR имя_типа
При использовании синтаксиса DROP TRANSFORM ALL FOR имя_типа удаляются
все трансформационные группы. Обратите внимание, что удаляется только транс-
формационная группа, но не пользовательский тип данных. В качестве альтерна-
тивы можно использовать синтаксис DROP TRANSFORM имя_трансформацион-
ной группы FOR имя_типа_данных для удаления одной группы трансформации
из пользовательского типа данных. Например:
DROP TRANSFORM sales_calcs FOR orders
TRIGGER гшя_триггера
Удаляется указанный триггер. Некоторые пакеты после этого могут быть помече-
ны как неработоспособные.
[DISTINCT] TYPE имятипа [RESTRICT]
Удаляется указанный пользовательский тип или при указании ключевого слова
удаляется особый тип. При указании дополнительного ключевого слова RESTRICT
тип не будет удаляться, если он имеет зависимости, например используется
в определении таблицы или представления, имеет подтипы и т. п.
TYPER MAPPING гшя_отображения_типа
Удаляется указанное отображение пользовательского типа, но никакие другие
зависимые объекты не удаляются.
USER MAPPING FOR {имя_пользователя | USER) SERVER имя_сервера
Удаляется отображение указанного пользователя на сервере объединения (federated
server). Если сервер не указан, удаляются все отображения указанного пользовате-
ля. Например, пользователю Dylan больше не нужен источник данных oracle50.
DROP USER MAPPING FOR dylan SERVER oracle50
VIEW [HIERARCHY] имя_представления
Указанное представление удаляется из схемы. Если представление является объек-
том-родителем, то перед его удалением необходимо удалить все представления - его
потомки. Другие объекты, которые прямо или косвенно зависят от этого представле-
ния, - например, триггеры или таблицы материализованных запросов - помечаются
как неработоспособные. При указании ключевого слова HIERARCHY удаляется
родительское объектное представление и все его представления-потомки.
WRAPPER гшя_оболочки
Удаляется указанная оболочка, а также все определения серверов, отображения
пользовательских функций и отображения пользовательских типов данных. При
удалении определений серверов может произойти каскадное распространение
удалений, поскольку объекты, зависимые от определения сервера (такие, как ото-
бражения пользователей и псевдонимы), также удаляются. Если при удалении
определения сервера происходит удаление псевдонима, то объекты, зависящие от
этого псевдонима (такие, как представления и пакеты), становятся неработоспо-
собными.
342 | Глава 3. Справочник по инструкциям SQL
RESTRICT
Это предложение можно дополнительно указывать в FUNCTION, SPECIFIC
FUNCTION, METHOD, SPECIFIC METHOD. PROCEDURE, SPECIFIC PROCEDURE,
SEQUENCE, TYPE и DISTINCT TYPE. Оно является обязательным для предложе-
ний INDEX EXTENSION и SCHEMA. Как и в случае стандарта ANSI, предложение
RESTRICT не дает удалить объект, если существует хоть один зависимый объект.
RESTRICT является действием, принятым по умолчанию.
Если вы не укажете схему при указании имени объекта при удалении, то в дина-
мических инструкциях SQL будет предполагаться текущая схема. Для статических ин-
струкций SQL система DB2 будет применять предкомпиляционную опцию (опцию
связывания) QUALIFIER.
MySQL
Платформа MySQL поддерживает в инструкции CREATE/ALTER очень ограниченное
число объектов. Следовательно, синтаксис инструкции DROP также ограничен и сво-
дится к следующему.
DROP { DATABASE 1 [TEMPORARY] TABLE | INDEX } имя_объекта [,...]
[ON имя_таблицы]
[IF EXISTS] имя_объекта [,...] [RESTRICT |CASCADE]
Синтаксические элементы следующие.
DATABASE имя_базы_данных
Удаляется указанная база данных, включая все объекты, которые она содержит,
такие, как таблицы и индексы. Команда DROP DATABASE удаляет все файлы базы
данных и таблиц из файловой системы, а также двухциферные поддиректории.
Система MySQL возвращает сообщение, в котором указывается, сколько файлов
было удалено из директории базы данных. (Удаляются файлы со следующими рас-
ширениями: .ВАК, .DAT, .frm, .HSH, .ISD, .ISM, .MRG, .MYD, .MYl, .dm и .fm.) Если
база данных является связанной, то удаляются и база данных, и связь. За один раз
вы можете удалить только одну базу данных. Предложения RESTRICT и CASCADE
в инструкции DROP DATABASE не применяются.
[TEMPORARY] TABLE имя_таблицы [,...]
Удаляется одна или несколько указанных таблиц, имена которых разделяются запя-
тыми. MySQL для каждой таблицы очищает ее определение и удаляет три файла
таблицы из файловой системы (.frm, .MYD u .MYI). Выполнение данной команды
влечет за собой фиксирование платформой MySQL всех активных транзакций. При
указании ключевого слова TEMPORAR Y удаляются только временные таблицы, без
совершения активных транзакций и проверки прав доступа.
INDEX имя_индекса ON имя_таблицы
Указанный индекс удаляется из указанной таблицы в версиях 3.22 и выше.
В версиях, предшествующих 3.22, эта команда не выполняет никаких действий,
а в версии 3.22 фактически неявно выполняется команда ALTER TABLE...DROP
Справочник по командам SQL | 343
INDEX. В инструкции DROP INDEX нельзя использовать предложения RESTRICT,
CASCADE и IF EXISTS.
RESTRICT | CASCADE
Нефункциональные предложения. Эти ключевые слова не вызывают ошибки
в MySQL, но они и не выполняют никаких действий.
IF EXISTS
Предотвращает появление сообщения об ошибке, если делается попытка удалить
несуществующий объект. Используется в MySQL: версии 3.22 и выше.
В MySQL поддерживается только удаление базы данных, таблицы (или таблиц)
или индекса из таблицы. Хотя инструкция DROP не будет выдавать ошибок при
использовании ключевых слов RESTRICT и CASCADE, эти предложения не выпол-
няют никаких функций. Предложение IF EXISTS можно использовать, чтобы избежать
появления ошибок при попытке удалить несуществующий объект.
Oracle
Платформа Oracle поддерживает в инструкции DROP большинство ключевых слов
стандарта ANSI, а также множество дополнительных ключевых слов, соответст-
вующих объектам, поддерживаемым только в Oracle. Синтаксис следующий.
DROP {CLUSTER | CONTEXT | DATABASE | DATABASE LINK | DIMENSION |
DIRECTORY | FUNCTION | INDEX | INDEXTYPE | UAVA |
LIBRARY | MATERIALIZED VIEW | MATERIALIZED VIEW LOG |
OPERATOR | OUTLINE | PACKAGE | PROCEDURE | PROFILE |
ROLE | ROLLBACK SEGMENT | SEQUENCE | SYNONYM | TABLE |
TABLESPACE | TRIGGER | TYPE | TYPE BODY | USER | VIEW }
имя_объекта
Правила использования инструкции DROP не такие четкие, как в стандарте ANSI,
поэтому ниже приводится полный синтаксис каждого варианта инструкции DROP.
CLUSTER имя_кластера [INCLUDING TABLES [CASCADE CONSTRAINTS]]
Указанный кластер удаляется из базы данных. (Обратите внимание, что эта ин-
струкция удаляет кластер, а не исключает конкретную таблицу из кластера.) При
указании предложения INCLUDING TABLES удалятся все таблицы, принадлежа-
щие к кластеру. При использовании предложения CASCADE CONSTRAINTS уда-
ляются все ограничения, служащие для обеспечения ссылочной целостности, ко-
торые связаны с таблицами кластера. Инструкция DROP CLUSTER не будет вы-
полнена без предложения CASCADE CONSTRAINTS, если в таблицах, не входя-
щих в кластер, имеются ограничения (например, первичные или внешние ключи),
которые ссылаются на таблицы кластера. Например:
DROP CLUSTER hr INCLUDE TABLES CASCADE CONSTRAINTS;
CONTEXT пространство_имен
Из базы данных удаляется указанный контекст. Пользователей, находящихся
в этот момент в пространстве имен, это не затрагивает, но они не смогут использо-
вать данный контекст при следующей попытке обратиться к нему. Пример:
DROP-r-CONTEXT hr_context
344 | Глава 3. Справочник по инструкциям SQL
DATABASE
База данных удаляется с сервера Oracle.
[PUBLIC] DATABASE LINK имя_связи_с_базой_даиных
Из базы данных удаляется указанная связь с базой данных. Чтобы удалить пуб-
личную связь с базой данных, вы должны указать ключевое слово PUBLIC.
Заметьте, что связь с базой данных не может быть квалифицирована в схему.
Например, чтобы удалить базу данных с именем hq.southeast.term, используется
следующая инструкция.
DROP DATABASE LINK hq.southeast.tenn
DIMENSION имяизмерения
Удаляется указанное измерение. Материализованные представления, созданные
на основе данного измерения, не теряют работоспособности, хотя могут выпол-
няться медленнее, при этом могут переписываться запросы.
DIRECTORY ил1Я_<)иректо/л111
Указанный объект-директория удаляется из базы данных. Не следует применять
эту инструкцию к директориям, содержащим файлы, к которым обращаются про-
граммы PL/SQL и ОС1. В качестве примера удалим директорию imageJiles.
DROP DIRECTORY image_files:
FUNCTION имя_функции
Удаляется указанная функция, если она не является компонентом пакета. Если вы
хотите удалить функцию из пакета, используйте инструкцию CREATE PACKAGE...OR
REPLACE, чтобы переопределить пакет, исключив оттуда функцию, которую вы
хотите убрать. Все локальные объекты, которые зависят от функции или вызывают ее,
становятся неработоспособными, а во всех статистических типах, которые связаны
с этой функцией, эта связь разрывается.
INDEX гшя_индекса [FORCE]
Указанный индекс или предметный индекс (domain index) удаляется из базы дан-
ных. При удалении индекса все объекты, зависящие от родительской таблицы,
становятся неработоспособными, в том числе представления, пакеты, функции
и хранимые процедуры. При удалении индекса неработоспособными становятся
курсоры и планы выполнения, использующие этот индекс, и при следующем вы-
полнении затронутых этой операцией инструкций SQL будет выполняться слож-
ная обработка.
Индексы, за исключением индекс-таблиц, являются вторичными объектами, их
можно удалять и создавать заново без потери пользовательских данных. Индекс-
таблипы (index-organized tables, ЮТ), которые объединяют в одной структуре таб-
личные и индексные данные, нельзя удалять и создавать снова таким же образом.
Индекс-таблицы следует удалять с помощью инструкции DROP TABLE.
Если вы удаляете секционированный индекс, удаляются все его разделы. Если вы
удаляете индекс с комбинированным секционированием, то удаляются все разделы и
подразделы индекса. Если вы удаляете предметный индекс, то вся статистика, свя-
занная с предметным индексом, удаляется, а связи статистических типов разрывают-
Справочник по командам SQL | 345
ся. Дополнительно ключевое слово FORCE применяется только при удалении пред-
метных индексов. Предложение FORCE позволяет удалить предметный индекс, по-
меченный как IN PROGRESS, или удалить предметный индекс, если вызов его под-
программы для индексного типа (indextype) возвращает ошибку. Пример:
DROP INDEX ndx_sales_salesperson_quota;
INDEXTYPE имя_индексного_типа [FORCE]
Удаляется указанный индексный тип, вместе со всеми связанными статистически-
ми типами. Система Oracle также удаляет всю статистику, собранную статистиче-
ским типом. При указании дополнительного ключевого слова FORCE статистиче-
ский тип удаляется, даже если на него ссылается один или несколько предметных
индексов, а соответствующие предметные индексы помечаются как нерабочие
(INVALID). Если вы не используете предложение FORCE при удалении индексно-
го типа, на который ссылаются один или несколько предметных индексов, то ин-
струкция выполнена не будет. Пример:
DROP INDEXTYPE imageindextype FORCE;
JAVA {SOURCE | CLASS | RESOURCE] "имя_объектаJava"
Удаляется указанный источник данных Java, класс Java или объект схемы - ресурс
Java. При указании предложения SOURCE удаляется объект схемы - источник
данных Java и все объекты схемы - классы Java, являющиеся его производными.
При указании ключевого слова RESOURCE будет удален объект схемы - ресурс
Java. Например, чтобы удалить источник MyJavaSource и все зависимые от него
объекты схемы, используется следующая команда.
DROP JAVA SOURCE "MyJavaSource";
LIBRARY имя библиотеки
Удаляется указанная библиотека внешних процедур.
{MATERIALIZED VIEW\ SNAPSHOT] имя_материализованного представления
Удаляется указанное материализованное представление. Для обратной совместимости
вы можете использовать ключевое слово SNAPSHOT вместо слова MATERIALIZED
VIEW. Чтобы удалить материализованное представление, вы должны иметь доста-
точно прав для удаления таблицы, представлений и индексов, которые его оставляют.
Отметьте, что если вы удаляете родительскую таблицу, то материализованные пред-
ставления, созданные на ее основе, не удаляются автоматически. Однако система
Oracle выдаст ошибку при попытке обновления материализованного представления,
родительская таблица которого была удалена. Например, мы можем удалить материа-
лизованное представление salespeople_at_quota.
DROP MATERIALIZED VIEW salespeople_at_quota;
{MATERIALIZED VIEW | SHAPSHOT) LOG ON имя_родительской_таблицы
Удаляется указанный журнал материализованного представления, который распо-
лагается в родительской таблице (которая также называется таблицей-хозяином).
Для обратной совместимости вы можете использовать ключевое слово DROP
SNAPSHOT вместо слова DROP MATERIALIZED VIEW. Теперь, после удаления
346 | Глава 3. Справочник по инструкциям SQL
журнала материализованного представления, материализованные предоставле-
ния для RowID, первичного ключа и подзапроса не могут быть быстро обновляе-
мыми (fast refreshed).
OPERATOR имя оператора FORCE
Из базы данных удаляется указанный пользовательский оператор. Дополнитель-
ное ключевое слово FORCE позволяет удалить оператор, даже если на него ссы-
лаются другие объекты схемы, такие, как триггеры, пакеты, пользовательские
функции и т. п.; в этом случае зависимые объекты становятся неработоспособны-
ми. При попытке удалить пользовательский оператор с зависимостями без ключе-
вого слова FORCE возникает ошибка.
OUTLINE имя_храни.мого_плана_выполнения
Из базы данных удаляется хранимый план выполнения запроса. После удаления
оптимизатор будет генерировать новые планы обработки запросов для тех ин-
струкций SQL, которые использовали этот хранимый план.
PACKAGE [BODY] имя_пакета
Удаляется тело и спецификация указанного пакета. При указании дополнительно-
го ключевого слова BODY удаляется только тело пакета, а спецификация остается
незатронутой. Этот вариант полезен, если вы не хотите делать неработоспособны-
ми зависимые объекты, хотя в этом случае вы не сможете вызывать компоненты
пакета, пока его тело не будет создано заново. В противном случае, если удаляется
и тело и спецификация пакета, система Oracle делает неработоспособными все за-
висимые объекты. (Обратите внимание, что, если вы хотите удалить из пакета
один объект, вам следует использовать инструкцию CREATE PACKAGE
[BODY],..OR REPLACE.) В следующих примерах мы сначала удаляем тело и спе-
цификацию пакета sales_quota_cak, а затем удаляем только тело пакета
regionalsalescalc.
DROP PACKAGE sales_quota_calc;
DROP PACKAGE BODY regional_sales_calc;
PROCEDURE имя_процедуры
Удаляется указанная хранимая процедура. При удалении хранимой процедуры нера-
ботоспособными становятся все зависимые объекты. Зависимые объекты будут воз-
вращать ошибку при обращении к ним до тех пор, пока вы снова не создадите хра-
нимую процедуру. Если хранимая процедура воссоздана и осуществляется обраще-
ние к зависимому объекту, зависимый объект будет перекомпилирован.
PROFILE имя профиля [CASCADE]
Удаляется указанный профиль. При указании дополнительно ключевого слова
CASCADE профиль удаляется у всех пользователей, которым он был присвоен;
ключевое слово CASCADE является необходимым только в том случае, если
профиль был назначен одному или нескольким пользователям. Пользователи,
лишившиеся профиля, получают пароль по умолчанию {DEFAULT). Например,
следующая инструкция удаляет профиль webuser, причем у всех пользователей.
DROP PROFILE web_user CASCADE;
Справочник по командам SQL | 347
ROLE имя_роли
Указанная роль удаляется из базы данных и из всех ролей и пользователей,
которым она была назначена. Использовать эту роль в новых сеансах становится
невозможно, хотя работающие сеансы с этой ролью удаление не затрагивает.
Например, следующая инструкция удаляет роль salesjmgr.
DROP ROLE sales_mgr-
ROLLBA CK SEGMENT имя_ сегмеита_отката
Удаляется указанный сегмент отката, а занимаемое им место возвращается в таб-
личную область, к которой был приписан сегмент отката. Сегмент отката должен
быть включен (on-line) и не должен быть системным сегментом отката (SYSTEM).
(Обратите внимание, что в режиме Автоматического управления отменами (Auto-
matic Undo Management) вы можете только удалять сегменты отката, но не можете
создавать или изменять их.) Например, следующая инструкция удаляет сегмент
отката с именем rbseg_sales_tblspc.
DROP ROLLBACK SEGMENT rbseg_sales_tblspc;
SEQUENCE имя_последовательности
Удаляется указанная последовательность. (Обратите внимание, что единственным
способом перезапуска последовательности является ее удаление и повторное созда-
ние.)
[PUBLIC] SYNONYM имя_синонима [FORCE]
Удаляется указанный личный или публичный [PUIBLIC\ синоним. (Обратите вни-
мание, что единственным способом переопределения синонима является его уда-
ление и повторное создание.) При удалении публичного синонима нельзя указы-
вать схему. Материализованные представления становятся недействительными
при удалении их синонима. Дополнительное ключевое слово FORCE позволяет
удалить синоним, даже если имеются зависимые таблицы и пользовательские
типы. Oracle не поощряет использование предложения FORCE. Например, мы
можем удалить публичный синоним users.
DROP PUBLIC SYNONYM users;
TABLE имяпгаблицы [CASCADE CONSTRAINTS] [PURGE]
Удаляется указанная таблица, очищаются все ее данные, удаляются все индексы
и триггеры, созданные на ее основе (даже те, которые принадлежат к другим схе-
мам), становятся недействительными все права доступа и все зависимые объекты
(такие, как представления, хранимые процедуры и т. п.). В секционированных таб-
лицах Oracle удаляет все разделы (и подразделы). В индекс-таблицах Oracle удаля-
ет все зависимые таблицы соответствий. Связь статистических типов с удаленной
таблицей разрывается. Журналы материализованных представлений, созданных
на основе таблицы, также удаляются при удалении таблицы.
Инструкция DROP TABLE эффективна для стандартных таблиц, индекс-таблиц
и объектных таблиц. Удаляемая таблица перемещается в корзину, если только не
указано ключевое слово PURGE, которое заставляет систему Oracle немедленно
348 | Глава 3. Справочник по инструкциям SQL
освободить все место, занятое таблицей. (Также Oracle поддерживает нестандарт-
ную SQL-команду PURGE, которая позволяет удалить таблицы из корзины без ис-
пользования инструкции DROP TABLE.) Для внешней таблицы инструкция DROP
TABLE удаляет только метаданные. Чтобы удалить файл, связанный с внешней
таблицей, и освободить место, вы должны использовать внешние команды опера-
ционной системы.
Используйте дополнительное предложение CASCADE CONSTRAINTS, чтобы уда-
лить все ограничения для ссылочной целостности по всей базе данных, которые
зависят от первичного или уникального ключа удаленной таблицы. Нельзя уда-
лить таблицу с зависимыми ссылочными ограничениями без использования пред-
ложения CASCADE CONSTRAINTS. В следующем примере удаляется таблица
jobdesc, принадлежащая к схеме ешр, после чего удаляется таблица job и все
ссылочные ограничения, которые зависят от первичного и уникального ключа
таблицы job.
SHOP TABLE emp.job_desc;
DROP TABLE job CASCADE CONSTRAINTS;
TABLESPACE имя_таблг1чного пространства [INCLUDING CONTENTS
[AND DATAFILES]] [CASCADE CONSTRAINTS]
Удаляется указанное табличное пространство (лучше, чтобы оно в этот момент не
использовалось) вместе со всеми файлами данных и временными файлами. Управ-
ляемые системой Oracle файлы данных и временные файлы удаляются из файловой
системы, а файлы данных и временные файлы, управляемые операционной систе-
мой, также можно удалить, если указать дополнительное предложение INCLUDING
CONTENTS AND DATAFILES. Обратите внимание на то, что вы не можете удалить
табличное пространство, если оно содержит предметный индекс, объекты, создан-
ные при помощи предметного индекса, данные, необходимые для отката неза-
вершенных транзакций, а также нельзя удалить табличное пространство SYSTEM.
При указании дополнительного предложения INCLUDING CONTENTS удаляется все
содержимое табличного пространства, и эго предложение является необходимым
для любого табличного пространства, которое содержит объекты базы данных. При
указании дополнительного предложения AND DATAFILES также удаляются соответ-
ствующие файлы операционной системы. При указании дополнительного предложе-
ния CASCADE CONSTRAINTS удаляются все внешние ссылочные ограничения,
которые зависят от первичных и уникальных ключей таблиц, находящихся в таб-
личном пространстве, и это предложение является обязательным, если такие зависи-
мости существуют. В первом из приведенных ниже примеров удаляется табличное
пространство sales_tblspc и все зависимые ссылочные ограничения, а во втором
примере удаляется табличное пространство sales_images_tblspc и соответствующие
файлы операционной системы.
DROP TABLESPACE sales_tblspc
INCLUDING CONTENTS CASCADE CONSTRAINTS;
Справочник no командам SQL | 349
DROP TABLESPACE sales_image_tblspc
INCLUDING CONTENTS AND DATAFILES;
TRIGGER имя_триггера
Из базы данных удаляется указанный триггер.
TYPE [BODY] имятипа [{FORCE | VALIDATE}]
Удаляется спецификация и тело указанного объектного типа, вложенной таблицы
или типа VARRAY, если у типа или таблиц отсутствуют зависимости. Чтобы уда-
лить супертип, тип, связанный со статистическим типом, или тип с любым видом
зависимостей, необходимо использовать ключевое слово FORCE. После этого все
подтипы и статистические типы становятся недействующими. Система Oracle
также удаляет любые публичные синонимы, относящиеся к удаленному типу.
Дополнительное ключевое слово BODY заставляет Oracle удалить только тело
типа, оставив без изменений спецификацию. Дополнительное ключевое слово
VALIDATE используется при удалении подтипов, чтобы проверить наличие храни-
мых экземпляров объектов указанного типа во всех его супертипах. После этого
удаление производится только в том случае, если хранимые экземпляры не об-
наруживаются. Пример:
DROP TYPE salesperson_type;
USER имяпользователя [CASCADE]
Указанный пользователь удаляется из базы данных. По умолчанию Oracle не будет
удалять пользователя, если его схема содержит объекты. Дополнительное ключе-
вое слово CASCADE заставляет Oracle также удалить все объекты пользователя
и по возможности зависимые объекты. Система Oracle не удаляет объекты, отно-
сящиеся к схемам других пользователей, даже если они ссылаются на объекты
удаленной схемы, однако они становятся неработоспособными. Например, сле-
дующая инструкция удаляет пользователя cody и все его объекты.
DROP USER cody CASCADE;
VIEW имя_представления [CASCADE CONSTRAINTS]
Удаляется указанное представление, а все представления, представления-потомки,
синонимы и материализованные представления, которые ссылаются на удаленное
представление, становятся неработоспособными. Дополнительное предложение
CASCADE CONSTRAINTS используется для удаления всех ссылочных ограниче-
ний, зависящих от представления. В противном случае, если существуют зависи-
мые ссылочные ограничения, инструкция DROP выполнена не будет. Например,
следующая инструкция удалит представление active_employees, относящееся
к схеме hr.
DROP VIEW hr.active_employees;
Во всех приведенных выше синтаксических конструкциях параметр имя_объекта
можно заменить на [имя_схемы].гшя_объекта. Если вы опустите имя схемы, будет
подразумеваться схема по умолчанию для пользовательского сеанса. Следовательно,
следующая инструкция DROP удалит указанное представление из схемы sales_archive.
350 | Глава 3. Справочник по инструкциям SQL
DROP VIEW sales_archive.sales_1994;
Если же вашей персональной схемой является схема scott, то следующая команда
будет относиться к представлению scott.sales_1994.
DROP VIEW sales_1994;
PostgreSQL
Платформа PostgreSQL не поддерживает дополнительные ключевые слова RESTRICT
и CASCADE, поддерживаемые стандартом ANSI. Эта платформа поддерживает широкое
разнообразие вариантов инструкции DROP, описываемых следующим синтаксисом.
DROP { AGGEGATE | DATABASE | FUNCTION | GROUP | INDEX |
LANGUAGE | OPERATOR (RULE | SEQUENCE | TABLE | TRIGGER |
TYPE | USER | VIEW } имя_~объекта
Ниже приводится полный синтаксис для каждого из вариантов.
AGGREGATE имя_агрегата ({тип_данных | *})
Удаляется пользовательская агрегатная функция. Параметр тип_()анных - это тип
данных существующей агрегатной функции, но вы можете заменить этот пара-
метр звездочкой (*), которая соответствует любому типу данных. Например, мы
можем удалить агрегатную функцию sales_avg, которую мы создали с помощью
инструкции PostgreSQL CREATE AGGREGATE:
DROP AGGREGATE sales_avg(int4);
DATABASE имя_базы_данных
Удаляется указанная база данных и очищается директория операционной систе-
мы, содержащая все данные базы. Эту команду может выполнить только владелец
базы данных при соединении с базой данных, отличной от удаляемой. Например,
мы можем удалить базу данных sales_archive.
DROP DATABASE sales_archlve;
FUNCTION имя_функции ([тип_данных1 ])
Удаляется указанная пользовательская функция. Поскольку PostgreSQL разрешает
использовать несколько функций с одинаковым именем, различаемых только по при-
нимаемым параметрам, вы должны указать один или несколько параметров, которые
однозначно идентифицируют функцию, которую вы собираетесь удалить. Система
PostgreSQL не выполняет никаких проверок зависимостей в других объектах,
которые могут ссылаться на удаляемую пользовательскую функцию. (Они не будут
работать при вызове несуществующего объекта.) Пример:
DROP FUNCTION median_distribution (int, int, int, int);
GROUP имя_группы
Удаляется указанная группа, но это удаление не затрагивает пользователей, входя-
щих в эту группу. Эта инструкция сходна с инструкцией DROP ROLE других плат-
форм.
Справочник по командам SQL | 351
INDEXимя_иидекса [,...]
Удаляется один или несколько индексов, владельцем которых вы являетесь. Пример:
DROP INDEX ndx_.titles, ndx_authors;
[PROCEDURAL] LANGUAGE название_языка
Удаляется указанный пользовательский язык. При желании вы можете заключить
имя в одинарные кавычки. Обратите внимание, что PostgreSQL не производит
проверку на наличие в базе данных пользовательских функций или триггеров, на-
писанных на указанном языке. Пример:
DROP LANGUAGE php;
OPERATOR id onepamopa ({тип_данных_слева | NONE], {тип_данных_справа | NONE})
Удаляется указанный пользовательский оператор. Значение параметра тип_дан-
ных_слева - это левый аргумент оператора, а тип_данных справа - это правый
аргумент оператора. Предложение NONE можно заменить любым аргументом,
если в данном положении аргумент отсутствует. (PostgreSQL не проводит про-
верку на наличие зависимых методов доступа и классов операторов, которые ссы-
лаются на удаленные операторы). Вы должны выявить и удалить их вручную,
чтобы избежать ошибок при их вызове. Например, первая из следующих инструк-
ций удаляет оператор возведения в степень, а вторая удаляет унарный оператор
изменения знака.
DROP OPERATOR ~ (int4, int4);
DROP OPERATOR ' (NONE, bool);
RULE и.мя правгта [...]
Из базы данных удаляется одно или несколько правил. После этого система PostgreSQL
немедленно прекращает выполнение этих правил и очищает исторические сведения об
их использовании. Пример:
DROP RULE phone_rule;
SEQUENCE имя_последовательности [,...]
Из базы данных удаляется одна или несколько указанных последовательностей.
Поскольку текущая версия PostgreSQL рассматривает последовательности как
таблицы особого типа, работа инструкции DROP SEQUENCE во многом напоми-
нает инструкцию DROP TABLE.
TABLE имя_таблицы [,...]
Из базы данных удаляется одна или несколько таблиц, а также все связанные с ними
индексы и триггеры. Например, в одной инструкции можно удалить сразу несколько
таблиц.
DROP TABLE authors, titles;
TRIGGER имя_триггера ON имя_таблицы
Из базы данных удаляется указанный триггер. Поскольку PostgreSQL требует,
чтобы имя триггера было уникальным только в пределах таблицы, с которой он
352 | Глава 3. Справочник по инструкциям SQL
связан, в разных таблицах может быть много триггеров с такими именами, как
insert_trigger или delete trigger. Пример:
DROP TRIGGER insert_trigger ON authors;
TYPE имя_типа [,...]
Из базы данных удаляется один или несколько существующих пользовательских
типов. Система PostgreSQL не проверяет, какое влияние команда DROP TYPE
может оказать на зависимые объекты, такие, как функции, агрегаты и таблицы.
Вы должны проверять зависимые объекты вручную. (Не удаляйте никакие встро-
енные типы, которые поставляются с PostgreSQL!) Обратите внимание, что реали-
зация типов в PostgreSQL отличается от стандарта ANSI. За дополнительной ин-
формацией обращайтесь к разделу «Инструкция CREATE/ALTER TYPE».
USER имя_пользователя
Из текущей базы данных удаляется указанный пользователь. Эта команда не уда-
ляет никакие объекты, принадлежащие пользователю, такие, как таблицы или
представления, и команда не будет выполнена, если пользователю принадлежит
какая-нибудь база данных. Пример:
DROP USER emily;
PfEIV имя представления [,...]
Из базы данных удаляется одно или несколько существующих представлений.
Обратите внимание, что операции удаления в PostgreSQL не позволяют указывать
базу данных, в которой производится операция (за исключением инструкции DROP
DATABASE). Поэтому вы должны выполнять любую операцию удаления из той базы,
в которой расположен объект, который вы хотите удалить.
SQL Server
Платформа SQL Server поддерживает несколько стандартных вариантов инструкции
DROP. Главное отличие инструкции DROP в SQL Server от инструкции стандарта
ANSI состоит в возможности удалять несколько объектов в одной инструкции.
DROP { DATABASE | DEFAULT | FUNCTION | INDEX | PROCEDURE |
RULE | STATISTICS | TABLE | TRIGGER | TYPE | VIEW } object_name
Ниже приводится полный синтаксис для каждого варианта.
DATABASE имя_базы_данных [,...]
Удаляется указанная база(ы) данных и очищаются все дисковые файлы, исполь-
зуемые базой(ами) данных. Эту команду можно подавать только базе данных mas-
ter. Реплицированные базы данных перед удалением необходимо удалить из схем
репликации, а также нужно удалить базы, в которых записывается журнал. Нельзя
удалить базу данных, если она используется, и нельзя удалять системные базы
данных (master, model, msdb и tempdb). В качестве примера мы удалим одной
командой базы данных nothwind и pubs.
DROP DATABASE northwind, pubs
GO
23 - 2447
Справочник по командам SQL | 353
DEFAULTимя_значения_по_умолчанию [,...]
Удаляется одно или несколько пользовательских значений по умолчанию из теку-
щей базы данных. Заметьте, что при этом удаляются не ограничения DEFAULT,
а только пользовательские значения по умолчанию, созданные при помощи ин-
струкции CREA ТЕ DEFA ULT. (Ограничения DEFA ULT можно удалять при помощи
инструкции ALTER TABLE...DROP CONSTRAINT.) При удалении значения по
умолчанию из столбца в столбцы, которые могут принимать пустые (NULL)
значения, будут вставлены значения NULL. Если же столбец не принимает пустых
значений, возникает ошибка и в столбец не вставляются никакие значения. Если
удаляемый столбец или пользовательский тип данных является связанным, связь
сначала нужно разорвать при помощи системной хранимой процедуры SQL Server
spunbindefault. В следующих двух примерах мы сначала удалим пользователь-
ское значение по умолчанию, а затем удалим значение по умолчанию, предвари-
тельно разорвав связь.
DROP DEFAULT sales_date_default
GO
EXEC sp_unbindefault ' sales, ordjdate'
DROP DEFAULT order_date_default
GO
FUNCTION [схема.]имя_функции [...]
Из текущей базы данных удаляется одна или несколько пользовательских функций.
INDEX имя_таблицы_или_представления.имя_индекса [...]
Один или несколько индексов удаляются из таблиц или индексированных представ-
лений текущей базы данных, а занимаемое ими место возвращается базе данных.
Эту инструкцию не следует использовать для удаления ограничений PRIMARY KEY
или UNIQUE. Удаляйте ограничения при помощи инструкции ALTER TABLE...DROP
CONSTRAINT. При удалении кластерного индекса из таблицы все некластерные
индексы перестраиваются. При удалении кластерного индекса из представления все
некластерные индексы удаляются.
PROCEDURE имя_процедуры [,...]
Из текущей базы данных удаляются одна или несколько хранимых процедур. Систе-
ма SQL Server позволяет использовать несколько версий одной процедуры, раз-
личаемых по номеру версии, но эти версии нельзя удалять по отдельности. Все
версии записанной процедуры должны удаляться одновременно. Системные проце-
дуры (имеющие префикс sp_) удаляются из базы данных master, если они не
обнаруживаются в текущей пользовательской базе данных. Пример:
DROP PROCEDURE calc_sales_quota
GO
RULE имя_правила [,...]
Из текущей базы данных удаляется одно или несколько пользовательских правил.
При удалении правила, данные, находящиеся в столбцах, регулируемых этим пра-
354 | Глава 3. Справочник по инструкциям SQL
вилом, не проверяются. Вам может понадобиться предварительно разорвать связь
правила, используя хранимую системную процедуру SQL Server sp_unbindefault.
В двух следующих примерах мы сначала удалим пользовательское правило,
а затем удалим пользовательское правило, предварительно разорвав связь.
DROP RULE phone_rule
GO
EXEC sp_unbinarule 'authors.phone'
DROP RULE phone_rule
GO
STATISTICS и.мя_таблицы_или_представления.имя_статистики [,...]
Удаляется статистика для одной или нескольких коллекций из таблицы или индек-
сированного представления в текущей базе данных. Удаление статистики оказывает
сильное влияние на производительность обработки запроса, поскольку статистика
позволяет оптимизатору запросов выбирать наилучший план обработки. (Статисти-
ка создается при помощи инструкций CREATE INDEX и CREATE STATISTICS.
Вы можете обновлять статистику при помощи инструкции UPDATE STATISTICS
или извлекать информацию при помощи инструкции DBCC SHOW STATISTICS.)
Например, мы создадим статистику по двум столбцам в двух отдельных таблицах,
а затем удалим ее.
CREATE STATISTICS title_stats ON sales (title_id, ord_num)
WITH SAMPLE 30 PERCENT
GO
CREATE STATISTICS zip_stats ON stores (zip)
WITH FULLSCAN
GO
DROP STATISTICS sales. title_stats, stores.zip_stats
GO
TABLE имя_таблицы
Удаляется указанная таблица, а также все данные, права доступа, индексы, триг-
геры и ограничения этой таблицы. (Параметр имя_таблицы может представлять
собой полностью квалифицированное имя таблицы, например pubs.dbo.sales, или
простое имя таблицы, например sales, если правильно определяются текущая база
и ее владелец.) Представления, функции и хранимые процедуры, которые ссы-
лаются на таблицу, не удаляются и не помечаются как недействительные, но будут
возвращать ошибку, если в их процедурном коде встретится ссылка на отсутст-
вующую таблицу. Обязательно удаляйте такие объекты самостоятельно! Нельзя
удалить таблицу, на которую ссылается ограничение типа FOREIGN KEY. Сначала
нужно удалить ограничение. Точно так же нельзя удалять таблицу, используемую
при репликации; ес нужно сначала удалить из схемы репликации. При удалении
таблицы разрываются связи всех правил и значений по умолчанию. При повторном
создании таблицы эти связи нужно создавать заново.
Справочник по командам SQL | 355
TRIGGER имя_триггера [,...]
Из текущей базы данных удаляется один или несколько триггеров.
TYPE имя_типа [...]
Из текущей базы данных удаляется один или несколько пользовательских типов.
KIEW имя-Представления [,...]
Из базы данных удаляется одно или несколько представлений, в том числе индек-
сированных представлений, а освободившееся место возвращается базе данных.
См. также
CALL
CONSTRAINTS
CREATE/ALTER FUNCTION/PROCEDURE/METHOD
CREATE SCHEMA
CREATE/ALTER TABLE
CREATE/ALTER VIEW
DELETE
DROP
GRANT
INSERT
RETURN
SELECT
SUBQUERY
UPDATE
Оператор для наборов данных EXCEPT
Оператор EXCEPT возвращает результирующий набор для двух или более запросов,
включающий в себя все записи, полученные первым запросом, которые не обнаружи-
ваются в результатах последующих запросов. Если предложения JOIN используются
для получения общих строк для двух и более запросов, предложение EXCEPT исполь-
зуется для отфильтровывания записей, которые присутствуют только в одной из не-
скольких сходных таблиц.
EXCEPT относится к классу ключевых слов, называемых операторами для наборов
данных (set operator). К другим таким операторам относятся INTERSECT и UNION.
(Оператор MINUS - это эквивалент EXCEPT в Oracle; стандарт ANSI использует слово
EXCEPT.) Все операторы для работы с наборами используются для манипулирования
с результирующими наборами сразу нескольких запросов, отсюда и «оператор для
наборов».
Платформа Команда
DB2 Поддерживается с ограничениями
MySQL Не поддерживается
Oracle Поддерживается с ограничениями
356 | Глава 3. Справочник по инструкциям SQL
Платформа
Команда
PostgreSQL Поддерживается с ограничениями
SQL Server Не поддерживается
Синтаксис SQL2003
Технически не существует ограничений на число запросов, которые можно объеди-
нить в операторе EXCEPT. Общий синтаксис следующий.
{SELECT инструкция! | VALUES (,выраж1 [,...] ) }
EXCEPT [ALL | DISTINCT]
[CORRESPONDING [BY (столбец1, столбец2, ...)] ]
{SELECT инструкция2 | VALUES (,выраж2 [,...])}
EXCEPT [ALL | DISTINCT]
[CORRESPONDING [BY (столбец1, столбец2, . . . )] ]
Ключевые слова
VALUES (выраж! [,...])
Генерируется производный набор данных при помощи явно указанных значений
выраж!, выраж2 и т. п. Это по сути результирующий набор данных инструкции
SELECT без синтаксиса SELECT...FROM. Это также называется конструктором
строк, поскольку строки результирующего набора конструируются вручную.
Согласно стандарту ANSI несколько определенных в конструкторе вручную строк
необходимо разделить запятыми и заключить в скобки.
EXCEPT
Определяется, какие строки будут исключены из одного набора данных.
ALL
Учитываются дублирующие строки во всех результирующих наборах.
DISTINCT
Дублирующиеся строки удаляются из всех результирующих наборов перед срав-
нением в предложении EXCEPT. Столбцы, содержащие значения NULL, считаются
дублирующимися. (Если не указаны ключевые слова ALL или DISTINCT,
по умолчанию используется DISTINCT.}
CORRESPONDING [ВТ (столбец/, столбец2, ...)
Определяется, что возвращаться будут только столбцы с указанными именами,
даже если в одном или нескольких запросах используется сокращение в виде звез-
дочки.
Общие правила
Существует только одно важное правило использования инструкции EXCEPT, которое
нужно запомнить.
Порядок, количество и типы данных столбцов должны быть однотипны во всех
запросах.
Справочник по командам SQL | 357
Типы данных не обязательно должны быть идентичны, но они должны быть совмес-
тимы. Например, типы CHAR и VARCHAR совместимы. По умолчанию для резуль-
тирующего набора в каждом столбце будет использоваться размер, соответствующий
самому большому типу в каждом конкретном положении. Например, запрос, извле-
кающий данные из столбцов, содержащих значения типа VARCHAR! 10) и VARCHAR(I5),
будет использовать тип и размер VARCHAR(15).
Советы и хитрости программирования
Ни одна из платформ не поддерживает предложение CORRESPONDING [BY (столбец!,
столбец2,...).
На платформах, которые не поддерживают оператор EXCEPT, вы
можете заменить его подзапросом NOT IN. Однако подзапросы NOT IN
по-другому обрабатывают пустые (null) значения и на некоторых плат-
формах создают разные результирующие наборы.
Согласно стандарту ANSI операторы работы с наборами UNION и EXCEPT имеют
одинаковый приоритет, однако оператор INTERSECT выполняется перед другими
операторами для наборов. Мы рекомендуем явным образом управлять приоритетом
операторов, используя скобки. Это вообще является очень хорошей практикой.
Согласно стандарту ANSI в запросе можно использовать только одно предложение
ORDER BY. Вставляйте его в самый конец последней инструкции SELECT. Чтобы избе-
жать двусмысленности в указании столбцов и таблиц, обязательно присваивайте один
и тот же псевдоним всем соответствующим друг другу столбцам таблиц. Например:
SELECT au_lname AS 'lastname', au_fname AS 'firstname'
FROM authors
EXCEPT
SELECT emp_lname AS 'lastname', emp_fname AS 'firstname'
FROM employees
ORDER BY lastname, firstname
Кроме того, поскольку в каждом списке столбцов столбцы могут указываться с со-
ответственно совместимыми типами данных, на разных платформах СУРБД могут
встречаться разные варианты работы со столбцами разной длины. Например, если
столбец au_lname из первого запроса в предыдущем примере значительно длиннее,
чем столбец emp_lname из второго запроса, то разные платформы могут применять
разные правила определения длины конечного результата. Но, вообще говоря, плат-
формы будут выбирать для результата более длинный (и менее ограниченный) размер.
Каждая СУРБД может применять свои собственные правила использования имени
столбца в том случае, если имена в списках столбцов различаются. В общем случае
используются имена столбцов первого запроса.
358 | Глава 3. Справочник по инструкциям SQL
DB2
Платформа DB2 поддерживает ключевые слова EXCEPT и EXCEPT ALL стандарта
ANSI плюс дополнительное предложение VALUES.
{ SELECT statement! | VALUES (expression!, expressions [,...] ) }
EXCEPT [ALL]
{ SELECT statements | VALUES (expression!, expressions [,...] ) }
EXCEPT [ALL]
Где:
VALUES
Позволяет указывать один или несколько задаваемых вручную столбцов, которые
включаются в окончательный результирующий набор. (Это называется конструк-
тором строк.} В предложении VALUES должно быть указано ровно столько
столбцов, сколько их указывается в запросах оператора EXCEPT.
Хотя инструкция EXCEPT DISTINCT не поддерживается, функциональным эквивален-
том является EXCEPT. Предложение CORRESPONDING не поддерживается. Кроме того,
типы данных LONG VARCHAR, LONG VARGRAPHIC, BLOB, CLOB, DBCLOB, DATALINK
и структурные типы не применяются в предложении EXCEPT, но их можно использовать
в предложении EXCEPT ALL.
Если в результирующем наборе данных есть столбец, имеющий одно и то же имя
во всех инструкциях SELECT, то это имя используется в качестве окончательного
имени для столбца, возвращаемого инструкцией. Если же данный столбец по-разному
называется в разных инструкциях SELECT, то вы должны переименовать столбец во
всех запросах, используя во всех них одно и то же предложение AS псевдоним.
Если в одном запросе используется несколько операторов для работы с наборами
данных, то первым выполняется тот, который заключен в скобки. После этого порядок
выполнения будет слева направо. Тем не менее все операторы INTERSECT выпол-
няются до операторов UNION и EXCEPT.
Например:
(SELECT empno
FROM employee
WHERE workdept LIKE ’E%'
EXCEPT
SELECT empno
FROM emp_act
WHERE projno IN ('IF1000', 'IF2000', ’AD3110’) )
UNION
VALUES ('AA0001'), ('АВОООЭ’). ('АСОООЗ')
В приведенном выше примере из таблицы employee извлекаются идентификаторы
(ID) всех служащих, работающих в департаменте, название которого начинается
с «Е», затем из таблицы учетных записей служащих (empact) исключаются ID тех,
кто занят в проектах IF1000, IF200’ и AD3110. И наконец, добавляется три дополни-
Справочник по командам SQL | 359
тельных ID - АА0001, AB0002 и AC0003 при помощи оператора работы с наборами
UNION.
MySQL
В MySQL оператор EXCEPT не поддерживается. В качестве альтернативы вы можете
использовать операции NOT IN ти NOT EXISTS.
Oracle
Платформа Oracle не поддерживает оператор EXCEPT. Однако в этой системе есть
альтернативный оператор для работы с наборами данных - MINUS, который имеет
аналогичную функциональность.
<SELECT инструкция^
MINUS
<SELECT инструкция2>
MINUS
Предложения MINUS DISTINCT и MINUS ALL не поддерживаются. Платформа
Oracle не поддерживает использование MINUS в запросах в следующих ситуациях.
• Запросы содержат столбцы с типами данных LONG, BLOB, CLOB, BFILE или
VARRAY.
• Запросы содержат предложение FOR UPDATE.
• Запросы содержат выражения с использованием коллекций TABLE.
Если первый запрос в операторе для наборов данных содержит какие-либо выраже-
ния в списке отбора элементов, включите предложения AS и присвойте этим выражениям
псевдонимы. Кроме того, только последний запрос оператора работы с наборами может
содержать предложение ORDER BY.
Например, можно сгенерировать список идентификаторов складов (stores), для
которых нет записей в таблице продаж (sales).
SELECT stor_id FROM stores
MINUS
SELECT stor_id FROM sales
Команда MINUS функционально сходна с запросом NOT IN. Следующий запрос
возвращает те же результаты, что и предыдущий.
SELECT stor_id FROM stores
WHERE stor.id NOT IN
(SELECT stor_id FROM sales)
PostgreSQL
Платформа PostgreSQL поддерживает такие операторы работы с наборами, как
EXCEPT и EXCEPT ALL, используя при этом стандартный синтаксис ANSI SQL.
360 | Глава 3. Справочник по инструкциям SQL
<SELECT инструкция7>
EXCEPT [ALL]
<SELECT инструкция2>
EXCEPT [ALL]
Платформа PostgreSQL не поддерживает операторы EXCEPT или EXCEPT ALL
в запросах с предложением FOR UPDATE. Платформа PostgreSQL не поддерживает
предложение CORRESPONDING. Инструкция EXCEPT DISTINCT не поддерживается,
но EXCEPT является функциональным эквивалентом.
Первый запрос операции с наборами не может содержать предложения ORDER BY
или LIMIT. Последующие запросы в операции EXCEPT или EXCEPT ALL могут со-
держать эти предложения, но такие запросы следует заключать в скобки. В противном
случае крайнее правое предложение ORDER BY или LIMIT бупет применяться ко всей
операции с наборами.
Платформа PostgreSQL определяет порядок выполнения инструкций SELECT
в инструкции с несколькими EXCEPT в направлении сверху вниз, если не применяют-
ся скобки для изменения иерархии инструкций.
Как правило, дублирующиеся строки удаляются из двух результирующих
наборов, если только вы не добавите ключевое слово ALL. Например, можно найти все
заглавия (titles) в таблице authors, для которых нет записей в таблице sales.
SELECT title_id
FROM authors
EXCEPT ALL
SELECT titlejd
FROM sales:
SQL Server
Оператор EXCEPT не поддерживается. Однако в качестве альтернативы вы можете
использовать операции NOT IN и NOT EXISTS совместно с коррелированным подза-
просом. Следующие запросы являются примерами того, как с помощью операций
NOT EXISTS и NOT IN можно реализовать функциональность EXCEPT.
SELECT DISTINCT a.city
FROM pubs..authors AS a
WHERE NOT EXISTS
(SELECT ►
FROM pubs..publishers AS p
WHERE a.city = p.city)
SELECT DISTINCT a.city
FROM pubs..authors AS a
WHERE a.city NOT IN
(SELECT p.city
FROM pubs .publishers AS p
WHERE p.city IS NOT NULL)
Справочник по командам SQL | 361
Как правило, NOT EXISTS работает быстрее, чем NOT IN. Кроме того, существует
тонкий момент, касающийся пустых значений (NULL), в котором операторы IN м NOT
IN отличаются от операторов EXISTS и NOT EXISTS. Чтобы обойти разную обработку
пустых значений, просто добавляйте предложение IS NOT NULL к предложению
WHERE, как мы сделали в предыдущем примере.
См. также
INTERSECT
SELECT
UNION
Оператор EXISTS
Оператор EXISTS проверяет подзапрос на наличие строк.
Платформа Команда
DB2 Поддерживается
MySQL Поддерживается
Oracle Поддерживается
PostgreSQL Поддерживается
SQL Server Поддерживается
Синтаксис SQL2003
SELECT ...
WHERE [NOT] EXISTS {подзапрос)
Параметры и ключевые слова следующие.
WHERE [NOT] EXISTS
Подзапрос проверяется на наличие одной или нескольких строк. Если хотя бы
одна строка удовлетворяет запросу, то возвращается булево значение ИСТИНА.
При указании дополнительного ключевого слова NOT булево значение ИСТИНА
возвращается, если подзапрос не возвращает соответствующих ему строк.
подзапрос
На основе полностью сформированного подзапроса извлекается результирующий
набор данных.
Общие правила
Оператор EXISTS проверяет существование одной или нескольких строк в подзапросе
родительского запроса.
SELECT *
FROM jobs
WHERE NOT EXISTS
(SELECT * FROM employee
WHERE jobs.job_id = employye.job_id)
362 | Глава 3. Справочник по инструкциям SQL
В этом примере проверяется в подзапросе записей с помощью дополнительного
ключевого слова NOT. В следующем примере для извлечения основного резуль-
тирующего набора данных производится поиск специфических записей в подзапросе.
SELECT au_lname
FROM authors
WHERE EXISTS
(SELECT •
FROM publishers
WHERE authors.city = publishers.city)
Этот запрос возвращает фамилии авторов (aulname), которые живут в том же городе,
что и издатели (publishers). Обратите внимание, что можно использовать в подзапросе
звездочку, поскольку подзапрос должен вернуть всего лишь одну запись с булевым значе-
нием ИСТИНА. В таких случаях столбцы не играют роли. Ключевой момент - это сущест-
вование строки.
Советы и хитрости программирования
Во многих запросах оператор EXISTS выполняет ту же функцию, что и ANY. Оператор
EXISTS обычно является наиболее эффективным при использовании с коррелирован-
ными запросами.
Оператор EXISTS семантически эквивалентен оператору ANY.
Подзапрос в операторе EXISTS обычно производит один из двух видов поиска.
Первый вариант - это использование группового символа - звездочки (например,
SELECT * FROM...), и в этом случае вы не извлекаете какой-то конкретный столбец
или значение. Звездочка здесь означает «любой столбец». Второй вариант - выбор
в подзапросе только одного конкретного столбца (например, SELECT aujd FROM).
Некоторые отдельные платформы позволяют выполнять подзапросы по нескольким
столбцам (например, SELECTau_id, aujname FROM...). Однако эта возможность дос-
таточно редкая и ее следует избегать в коде, который нужно переносить на другие
платформы.
Различия между платформами
Все платформы поддерживают оператор EXISTS в том виде, который мы описали
выше.
См. также:
ALL/ANY/SOME
SELECT
WHERE
Справочник по командам SQL | 363
Инструкция FETCH
Инструкция FETCH - это одна из четырех команд, используемых при обработке
курсоров, наряду с DECLARE, OPEN и CLOSE. Курсоры позволяют вести обработку
по одной строке, а не работать сразу со всем набором. Инструкция FETCH помещает
курсор в конкретную строку и извлекает эту строку из результирующего набора.
Курсоры имеют в реляционных базах особую важность, поскольку такие базы ос-
нованы на обработке наборов данных, а большинство клиентских языков програм-
мирования основываются на работе со строками. Так что курсоры позволяют прово-
дить построчные операции вместо операций со всем набором сразу, что лучше соот-
ветствует возможностям клиентской программы.
Платформа Команда
DB2 Поддерживается с ограничениями
MySQL Не поддерживается
Oracle Поддерживается с ограничениями
PostgreSQL Поддерживается с вариантами
SQL Server Поддерживается с ограничениями
Синтаксис SQL2003
SQL2003 Syntax
FETCH [ { NEXT | PRIOR | FIRST | LAST |
{ ABSOLUTE | RELATIVE int } }
FROM ] имя~курсора
[INTO переменна^ [, ]
Ключевые слова
NEXT
Указывается, что курсор должен вернуть запись, которая идет сразу за текущей,
и сделать текущей ту запись, которую курсор вернул. Предложение FETCH NEXT
задано для инструкции FETCH по умолчанию. При этом первая запись извлекается,
если инструкция FETCH осуществляет первую выборку для курсора.
PRIOR
Указывается, что курсор должен вернуть запись, которая идет непосредственно
перед текущей, и сделать текущей ту запись, которую курсор вернул. Инструкция
FETCH PRIOR не возвращает запись, если она осуществляет первую выборку для
курсора.
FIRST
Указывается, что курсор должен вернуть запись, которая является для курсора
первой, и сделать ее текущей.
364 | Глава 3. Справочник по инструкциям SQL
LAST
Указывается, что курсор должен вернуть запись, которая является для курсора
последней, и сделать ее текущей.
ABSOLUTE int
Указывается, что курсор должен вернуть запись, которая имеет номер int в наборе
записей курсора, считая сверху (если int - положительное целое число) или считая
снизу (если int - отрицательное целое число), и сделать эту запись текущей для
курсора. Если int = 0, строка не возвращается. Если значение int переносит курсор за
пределы набора, тогда курсор устанавливается после последней строки (если int -
положительное число) или перед первой строкой (если int - отрицательное число).
RELATIVE int
Указывается, что курсор должен вернуть запись, идущую через int записей после
текущей (если int - положительное число) или через int записей перед текущей
(если int - отрицательное число). Если int = 0, возвращается текущая строка. Если
значение int переносит курсор за пределы набора, тогда курсор устанавливается
после последней строки (если int - положительное число) или перед первой стро-
кой (если int - отрицательное число).
[FROM] имя_кусора
Указывается имя открытого курсора, из которого вы хотите извлечь строки. Курсор
должен быть заранее определен и создан при помощи предложений DECLARE
и OPEN'. Использование ключевого слова FROM является необязательным, но
поощряется.
INTO переменная! [,...]
Данные из каждого столбца курсора сохраняются в локальной переменной.
Каждый столбец курсора должен иметь в предложении INTO соответствующую
переменную совпадающего типа данных. Каждое значение в столбце напрямую
связано с переменными в соответствующих порядковых положениях.
Общие правила
На самом общем уровне курсор должен быть:
1. создан при помощи инструкции DECLARE;
2. открыт при помощи инструкции OPEN;
3. работа с ним должна вестись при помощи инструкции FETCH;
4. закрыт при помощи инструкции CLOSE.
Выполняя эти шаги, вы можете создать результирующий набор данных, сходный
с результатом работы инструкции SELECT, за исключением того, что вы можете рабо-
тать с каждой строкой результирующего набора отдельно. Предположим, например,
что вы создали и открыли в базе данных DB2 курсор с именем employee_cursor,
который содержит три столбца.
DECLARE employee_cursor CURSOR FOR
SELECT Iname, fname, emp_id
FROM employee
Справочник по командам SQL | 365
WHERE hire_date >= '2005-02-15';
OPEN employee_cursor;
Теперь вы можете извлекать значения из курсора при помощи инструкции
FETCH.
FETCH FROM employee_cursor
INTO :emp_last_name, :emp_first_name, :emp_id
Инструкция FETCH позволяет определить положение текущей строки для
курсора. Поскольку в данном примере мы еще не обращались к курсору, он будет рас-
полагаться на первой записи результирующего набора. Вы можете оперировать значе-
ниями в этой строке при помощи любого процедурного кода.
У каждой платформы есть свои собственные правила относительно того, как
используются переменные. Например, в DB2 в качестве префикса имени пере-
менной используется двоеточие, как это показано в приведенном выше при-
мере. Система SQL Server требует использовать знак @, а в Post-greSQL
и Oracle нет префиксов и т. п. Однако в стандарте SQL говорится, что префикс
в виде двоеточия необходим для встроенных языков, таких, как С и COBOL,
хотя для процедурного SQL префикс не требуется.
Курсор находится либо прямо на строке, либо перед первой строкой, либо после
последней. Если курсор располагается на строке, эта строка называется текущей строкой.
Вы можете использовать курсоры для указания положения текущей строки для инструк-
ции UPDATE или DELETE с помощью предложения WHERE CURRENT ROW.
Важно помнить, что результирующий набор курсора не является циркулическим.
То есть, если у вас есть результирующий набор данных, состоящий из 10 записей, и вы
указываете курсору передвинуться вперед на 12 записей, это не означает, что курсор
снова вернется к началу и начнет отсчитывать записи оттуда. По умолчанию курсор
остановится после последней записи, если он двигался вперед, или перед первой запи-
сью, если двигался назад. Например, в SQL Server:
FETCH RELATIVE 12 FROM employee_cursor
INTO @emp_last_name, @>emp_first_name, @emp_id
При выборке значений из базы данных в переменные типы данных и количества
столбцов и переменных должны совпадать. В противном случае возникнет ошибка.
Например:
FETCH PRIOR FROM employee_cursor
INTO @emp_last_name, @>emp_id
Предыдущий пример не будет выполнен, поскольку employee_cursor содержит
три столбца, а операция выборки - только две переменные.
366 | Глава 3. Справочник по инструкциям SQL
Советы и хитрости программирования
Наиболее распространенные ошибки в инструкции FETCH - это несовпадения пере-
менных и значений курсора по количеству, порядку или типу данных. Потратьте
немного времени и убедитесь в том, что вы точно знаете, какие значения содержит
курсор и к каким типам данных они относятся.
Как правило, база данных будет блокировать, как минимум, текущую строку и,
возможно, все строки, используемые курсором. Согласно стандарту ANSI блокировка
курсора не сохраняется при операциях COMMIT и ROLLBACK, хотя в разных плат-
формах существуют варианты.
Хотя здесь инструкция FETCH подробно рассмотрена отдельно от других, с ней
всегда используются инструкции DECLARE, OPEN и CLOSE. Например, каждый раз,
когда вы открываете курсор, сервер потребляет ресурсы памяти. Если вы будете забы-
вать закрывать курсоры, вы можете создать проблемы для системы управления памя-
тью. Каждый объявленный и открытый курсор должен быть в конечном счете обяза-
тельно закрыт.
Курсоры также часто используются в хранимых процедурах или пакетах процедурно-
го кода. Причина состоит в том, что иногда приходится выполнять действия над отдельны-
ми строками, а не над наборами данных. Однако, поскольку курсоры работают с отдельны-
ми строками, а не с наборами, они гораздо медленнее других способов доступа к данным.
Обязательно проведите серьезный анализ своего подхода. Используя вместо курсоров
предложений WHERE и JOIN, можно избежать многих проблем, таких, как запутанные
операции DELETE и очень сложные инструкции UPDATE.
DB2
Курсоры DB2 неявно представляют собой курсоры, которые двигаются только вперед
и всегда - по одной записи за раз. Курсор DB2, в сравнении со стандартом ANSI, - это,
по сузи, курсор FETCH NEXT I. Платформа DB2 не поддерживает такие ключевые
слова, как PRIOR, ABSOLUTE и RELATIVE. Синтаксис инструкции FETCH в DB2 сле-
дующий.
FETCH г FROM ] имя_курсора
{ [INTO переменная? [, |
[USING DESCRIPTOR имЯ-Дескриптора] }
Где:
USING DESCRIPTOR имя рескриптора
Указывается ранее созданная область дескриптора (SQL Descriptor Area, SQLDA)
с именем имя йескриптора, которая будет содержать ноль или более значений,
полученных инструкцией FETCH.
При сохранении выбранных значений в переменных при помощи предложения
INTO система DB2 позволяет вставлять значения LOB в обычные хост-переменпые,
такие, как VARCHAR (если они достаточно велики, чтобы хранить такое значение),
в переменные-локаторы и переменные-файловые ссылки.
Справочник по командам SQL | 367
При сохранении отобранных значений при помощи предложения USING DESCRIPTOR
вы должны знать о нескольких правилах, касающихся областей дескрипторов.
• SQLN показывает количество SQLVAR в SQLDA.
• SQLDABC показывает количество байт хранения, выделенных в SQLDA.
• SQLD показывает количество переменных, используемых в SQLDA при обработке
инструкции. Значение SQLD должно быть больше или равно нулю и меньше или
равно SQLN.
• SQLVAR указывает атрибуты переменных. У дескриптора должно быть доста-
точно места для хранения всех экземпляров SQLVAR. Для вычисления размера
SQLDABS используйте следующую формулу: он должен быть большим или
равным 16 + SQLN*(n), где п - это длина SQLVAR.
Если необходимо настроить столбцы типа LOB или структурного типа, используйте
две записи SQLVAR для каждого выбранного элемента (или столбца из результирующей
таблицы).
Например, в следующей инструкции FETCH используется SQLDA.
FETCH employee_cursor USING DESCRIPTOR :sqlda2
В приведенном выше примере дескриптор :sqlda2 и курсор employee_cursor
должны уже существовать.
MySQL
Не поддерживается.
Oracle
Курсоры Oracle неявно представляют собой курсоры, которые двигаются только
вперед и всегда - по одной записи за раз. Курсор Oracle, в сравнении со стандартом
ANSI, - это, по сути, курсор FETCH NEXT I. Курсоры Oracle должны либо вставлять
извлеченные значения в соответствующие переменные, либо использовать предложе-
ние BULK COLLECT для вставки всех записей результирующего набора в массив.
Платформа Oracle не поддерживает таких ключевых слов, как PRIOR, ABSOLUTE
и RELATIVE. Однако в Oracle есть поддержка как двигающихся вперед, так и про-
кручиваемых курсоров, реализуемая через Oracle Call Interface (OCI). Интерфейс OCI
также поддерживает такие предложения, как PRIOR, ABSOLUTE и RELATIVE, приме-
нительно к курсорам «только для чтения», результирующий набор которых основыва-
ется на целостной по чтению моментальной копии.
Синтаксис инструкции FETCH в Oracle следующий.
FETCH имя_курсора
{ INTO имя_переменной [,...] | BULK COLLECT INTO
[имя_коллекции [,...] [LIMIT int] }
368 | Глава 3. Справочник по инструкциям SQL
Где:
BULK COLLECT INTO имя_коллекции
Извлекается весь набор строк или указанное количество строк (см. LIMIT) в кли-
ентский массив или переменную-коллекцию с именем имя_коллекции.
LIMIT int
Ограничивается количество записей, извлекаемых из базы данных, при использо-
вании предложения BULK. Значение int - это целое, неравное нулю число (или
переменная, представляющая собой целое число).
Платформа Oracle поддерживает динамические SQL-курсоры, текст которых
может генерироваться на ходу. Система Oracle также поддерживает имена курсоров,
которые представляют собой любую допустимую переменную, параметр или хост-
массив. Фактически вы также можете использовать в предложениях INTO пользова-
тельские переменные и переменные типа %ROIVTYPE. Это позволяет создавать гиб-
кие, динамические курсоры при помощи структуры, напоминающей шаблон.
Пример:
DECLARE
TYPE namelist IS TABLE OF employee.lname%TYPE;
names namelist;
CURSOR employee_cursor IS SELECT Iname FROM employee;
BEGIN
OPEN employee_cursor;
FETCH employee_cursor BULK COLLECT INTO names;
CLOSE employee_cursor;
END;
В Oracle инструкция FETCH часто используется в паре с циклом FOR PL/SQL
(или другим типом цикла), при этом в цикле перебираются все строки курсора. Для
определения конца набора строк следует использовать атрибуты курсора %FOUND
и %NOTFOUND. Например:
DECLARE
TYPE employee_cursor IS REF CURSOR RETURN employee%ROWTYPE;
employee_cursor EmpCurTyp;
employee_rec employee%ROWTYPE;
BEGIN
LOOP
FETCH employee „cursor INTO employee_rec;
EXIT WHEN employee _cursor%N0TF0UND;
END LOOP;
CLOSE employee_cursor;
END;
В этом примере используется стандартный цикл PL/SQL с предложением EXIT
для завершения цикла, когда в курсоре не остается больше строк для обработки.
24 - 2447
Справочник по командам SQL | 369
PostgreSQL
Платформа PostgreSQL поддерживает курсоры, прокручиваемые как в прямом, так
и в обратном направлении. Поддерживается стандартный синтаксис, за исключением
ABSOLUTE, FIRST и LAST. Синтаксис инструкции FETCH в PostgreSQL следующий.
FETCH { [ FORWARD | BACKWARD | ABSOLUTE | RELATIVE] }
{ [int | ALL | NEXT | PRIOR ] }
{ IN | FROM } имя_курсора
[ INTO :переменная1 [,...] ]
Где:
FORWARD
Указывается, что курсор должен двигаться в прямом направлении. Если никакой
другой режим не указан, этот вариант принимается по умолчанию.
BACKWARD
Указывается, что курсор должен двигаться в обратном направлении.
ABSOLUTE
Ключевое слово является допустимым, но не связано ни с какими функциями.
RELATIVE
Ключевое слово является допустимым, но не связано ни с какими функциями.
int
Целое число со знаком, которое показывает, на какое количество записей следует
переместить курсор вперед (если число положительное) или назад (если число
отрицательное).
ALL
Извлекаются все записи, остающиеся в курсоре.
NEXT
Извлекается одна следующая запись.
PRIOR
Извлекается одна предыдущая запись.
IN | FROM имя_курсора
Указывается ранее объявленный и открытый курсор, в который извлекаются данные.
INTO переменная
Значение курсора присваивается указанной переменной. Как и в случае с курсора-
ми ANSI, значения, извлеченные курсором, и переменные должны совпадать по
количеству и по типу данных.
Курсоры PostgreSQL должны использоваться в транзакциях, явно открываемых
предложением BEGIN и закрываемых предложением COMMIT или ROLLBACK.
Следующая инструкция PostgreSQL извлекает пять записей из таблицы employee
и отображает их.
FETCH FORWARD 5 IN employee_cursor;
Важно отметить, что PostgreSQL также поддерживает отдельную команду МО VE,
служащую для перехода к указанному положению курсора. От инструкции FETCH
она отличается только тем, что не возвращает значения в переменные.
370 | Глава 3. Справочник по инструкциям SQL
MOVE { [ FORWARD | BACKWARD | ABSOLUTE | RELATIVE] }
{ [int | ALL | NEXT | PRIOR ] }
{ IN | FROM } имя_курсора
Например, в приводимом ниже коде объявляется курсор, пропускаются пять
первых записей, а затем извлекаются значения из шестой.
BEGIN WORK;
DECLARE employee_cursor CURSOR FOR SELECT « FROM employee;
MOVE FORWARD 5 IN employee_cursor;
FETCH 1 IN employee„cursor;
CLOSE employee_cursor;
COMMIT WORK;
Приведенный выше код вернет одну строку из результирующего набора курсора
employeecursor.
SQL Server
Платформа SQL Server поддерживает вариант инструкции FETCH, очень близкий
к стандарту ANSI.
FETCH [ ; NEXT | PRIOR | FIRST | LAST ।
{ ABSOLUTE | RELATIVE int } }
[FROM] [GLOBAL] имя_курсора
[INTO (Элеременная? [, ...] ]
Различия между стандартом ANSI и реализацией SQL Server очень невелики.
Во-первых, SQL Server позволяет использовать переменные вместо значений int
и имя _кур сора. Во-вторых, SQL Server позволяет объявлять и использовать глобаль-
ные курсоры, обращаться к которым может любой пользователь или сеанс, а не
только тот, который создал этот курсор.
Существует несколько правил использования команды FETCH в зависимости от
того, как была подана команда DECLARE CURSOR.
• Если вы объявляете курсор SCROLL SQL-92, то поддерживаются все опции ин-
струкции FETCH, во всех прочих курсорах SQL-92 поддерживается только опция
NEXT. (Существует также альтернативная инструкция DECLARE CURSOR стиля
Transact-SQL.)
• Курсоры DYNAMIC SCROLL поддерживают все опции инструкции FETCH, кроме
ABSOLUTE.
• Курсоры FORWARD-ONLY и FAST FORWARD поддерживают только вариант
FETCH NEXT.
• Курсоры KEYSET, STATIC и SCROLL (если предложения DYNAMIC, FORWARD-ONLY
и FAST FORWARD не указанны) поддерживают все опции инструкции FETCH.
Справочник по командам SQL | 371
Платформа SQL Server также требует использовать помимо инструкции
CLOSE инструкцию DEALLOCATE для освобождения памяти, занятой
курсором.
Ниже приводится полный пример - от объявления и открытия курсора до выпол-
нения нескольких выборок и, наконец, до закрытия курсора и освобождения памяти.
DECLARE @vc_lname VARCHAR(3O), @vc_fname VARCHAR(3O), @i_emp_id CHAR(5)
DECLARE employee_cursor SCROLL CURSOR FOR
SELECT Iname, fname, emp_id
FROM employee
WHERE hire_date <= 'FEB-14-2004'
OPEN employee_cursor
- - Отбираем в курсоре последнюю строку.
FETCH LAST FROM employee_cursor
- - Отбираем строку, стоящую в курсоре сразу перед текущей.
FETCH PRIOR FROM employee_cursor
- - Отбираем пятую строку курсора.
FETCH ABSOLUTE 5 FROM employee_cursor
- - Отбираем строку, идущую через две строки после текущей.
FETCH RELATIVE 2 FROM employee_cursor
- - Отбираем значения, стоящие за восемь строк до текущей, в переменные.
FETCH RELATIVE -8 FROM employee_cursor
INTO @vc_lname, @vc_fname, @i_emp_id
CLOSE employee_cursor
DEALLOCATE employee_cursor
GO
Помните, что в SQL Server вы должны не только закрыть {CLOSE) курсор, но
также освободить память {DEALLOCATE). В некоторых редких случаях вам может
понадобиться снова открыть закрытый курсор. Вы можете повторно использовать
любой курсор, если вы закрыли его, но не освободили память. Курсор полностью
уничтожается только после освобождения памяти.
См. также
CLOSE
DECLARE CURSOR
OPEN
372 | Глава 3. Справочник по инструкциям SQL
Инструкция GRANT
Инструкция GRANT назначает пользователям и ролям привилегии, которые позво-
ляют им обращаться к объектам базы данных и использовать их (т. е. объектные при-
вилегии).
Кроме того, большинство платформ баз данных использует инструкцию GRANT
для обеспечения авторизации пользователей и ролей для создания объектов баз
данных и для запуска хранимых процедур, функций и т. д. (в особенности привилегии
использования).
Платформа Команда
DB2 11оддерживаетея с вариантами
MySQL Поддерживается с вариантами
Oracle 11оддсрживается с вариантами
PostgreSQL Поддерживается с вариантами
SQL Server Поддерживается с вариантами
Синтаксис SQL2003
Синтаксис инструкции GRANT в SQL2003 включает только присвоение объектных
привилегий и ролей конкретному пользователю.
GRANT { {объектная_привилегия [,...] | роль [,...]} }
[ON имя_объекта_базы~\
[ТО получающий__привилегию ]
[WITH HIERARCHY OPTION] [WITH GRANT OPTION] [WITH ADMIN OPTION]
[FROM { CURRENTJJSER | CURRENT_.ROLE [ ]
Ключевые слова
объектная привилегия
Инструкции SQL присваивается одна или несколько привилегий. Можно присваи-
вать несколько привилегий, разделяя их запятыми. Не объединяйте предложение
ALL PRIVILEGES с другими привилегиями, однако остальные виды можно объе-
динять в любом порядке. Существуют следующие привилегии.
ALL PRIVILEGES
Краткое обозначение всех привилегий, которые пользователь может назначить
другим. Это предложение присваивает все привилегии, которые имеет
назначающий пользователь, указанным пользователям, и/или привилегии
применяются к указанным объектам базы данных. Использование такого под-
хода, как правило, не рекомендуется, поскольку это способствует неаккурат-
ному назначению прав доступа.
Справочник по командам SQL | 373
EXECUTE
Предоставляется привилегия запускать любую подпрограмму ANSI SQL. Под
подпрограммой ANSI подразумевается любая хранимая процедура, пользова-
тельская функция или пользовательский метод.
{SELECT | INSERT] UPDATE | DELETE}
Указанному пользователю присваивается соответствующая привилегия при-
менительно к указанному объекту базы данных, например таблице или пред-
ставлению. Вы можете добавить заключенный в скобки список столбцов таб-
лицы, к которым будет применяться привилегия (за исключением инструкции
DELETE).
REFERENCES
Присваивается привилегия использовать столбцы в любом ограничении или
утверждении, а не только во внешнем ключе. Предложение REFERENCES
также позволяет определять детали уровня столбцов (путем использования за-
ключенного в скобки списка со значениями через запятую) для таких инструк-
ций, как INSERT, SELECT и т. п. И наконец, предложение REFERENCES при-
сваивает привилегию создавать и удалять ограничения типа FOREIGN KEY,
которые ссылаются на объект базы данных как на родительский объект.
TRIGGER
Присваивается привилегия для создания триггера, работающего в конкретной
таблице и ее столбцах.
UNDER
Присваивается привилегия для создания подтипов или объектных таблиц.
USAGE
Присваивается привилегия для использования домена, пользовательского
типа, набора символов, сопоставления (collation), последовательности или
перевода.
роль
Заранее созданную роль присваивает ее владелец, который указывается в предло-
жении FROM. Например, администратору базы данных может понадобиться соз-
дать роль с именем Reporter и доступом только для чтения к нескольким табли-
цам. При присвоении этой роли пользователю такойт пользователь получает все
права доступа для чтения, определенные для этой роли. Пользователям можно
присваивать роли, предоставляя им все привилегии, которые имеет данная роль.
ON имя_объекта_базы
Привилегии присваиваются для доступа к конкретному существующему объекту
базы данных, который определяется параметром имя_о&ьекта__базы, представ-
ляющим собой один из следующих синтаксических элементов.
{[TABLE] имя_объекга | DOMAIN имя_объекта |
COLLATION имя_объекта | CHARACTER SET имя_объекта |
TRANSLATION имя_объекта | SPECIFIC ROUTINE имя_подпрограммы }
374 | Глава 3. Справочник по инструкциям SQL
ТО получатель привилегии
Привилегия присваивается указанному пользователю(лям) или роли(лям), обо-
значенным как получатель_привилегии. Можно присваивать привилегии несколь-
ким пользователям и/или ролям, для чего их нужно разделять запятыми. В качест-
ве альтернативы можно присвоить привилегии с ключевым словом PUBLIC, это
означает, что все пользователи (в том числе и те, которые появятся в будущем)
будут иметь указанные привилегии.
WITH HIERARCHY OPTION
Предоставление привилегии с предложением WITH HIERARCHY OPTION позво-
ляет получателю привилегии выполнять операции SELECT не только в указанной
таблице, но и во всех ее подтаблицах. Это относится только к предоставлению
привилегии.
WITH GRANT OPTION
Позволяет получателю привилегий назначать эти привилегии другим пользовате-
лям. Это относится только к предоставлению привилегии.
WITH ADMIN OPTION
Предоставляется возможность присваивать роли. Возможность присваивать роли
отделена от возможности предоставлять привилегии другим пользователям и ролям.
FROM (CURRENTJJSER | CURRENT_ROLE}
Указывается пользователь, предоставляющий указанную привилегию (привиле-
гии), - либо текущий пользователь (CURRENT_USER), либо текущая роль
(CURRENT_ROLE). Это предложение является необязательным и по умолчанию
принимается CURRENT_USER.
Общие правила
Вы можете назначать несколько привилегий для одного объекта в одной инструкции,
хотя не следует смешивать привилегию ALL PRIVILEGES с отдельными ключевыми
словами в одной инструкции GRANT. Вы можете присвоить одному пользователю
конкретную привилегию доступа к конкретному объекту базы данных следующим
образом.
GRANT имя_привилегии ON имя_объекга ТО имя_получателя_привилегии
Например:
GRANT SELECT ON employee TO Dylan;
Вы можете присвоить конкретную привилегию для доступа к конкретному объек-
ту всем пользователям, исподьзуя «пользователя» PUBLIC. Если право предоставляет-
ся пользователю PUBLIC, это означает, что обращаться к объекту может любой и пре-
доставлять специфический доступ к объекту не нужно. Например:
GRANT SELECT ON employee TO PUBLIC;
При предоставлении привилегии нескольким получателям просто разделяйте их
запятыми.
GRANT SELECT ON employee TO Dylan, Matt
Справочник по командам SQL | 375
В приведенном выше примере показано, что вы можете предоставлять привиле-
гии нескольким пользователям, в данном случае Dylan и Matt, а также пользователю
PUBLIC в одной инструкции GRANT. При назначении привилегий доступа к таблице
можно уточнять привилегию на уровне столбцов, указав заключенный в скобки
список столбцов после имени таблицы. Например:
GRANT SELECT ON employee(emp_id, emp_fname, emp_lname, job_id)
TO Dylan, Matt
В предыдущем примере показано, что Dylan и Matt теперь имеют привилегии
доступа к нескольким столбцам таблицы employee.
Советы и хитрости программирования
Представления, в зависимости от реализации базы данных, могут иметь или не иметь
независимого от базовых таблиц предоставления привилегий.
Обратите внимание, что все дополнительные предложения WITH управляют в ин-
струкции дополнительным предоставлением привилегий. Таким образом, следующая
команда предоставляет пользователю Dylan привилегию для выборки записей из таб-
лицы employee.
GRANT SELECT ON employee TO Dylan;
А следующая команда предоставляет пользователю Dylan привилегию для выборки
записей из таблицы employee и также назначает ему привилегию предоставлять
право выборки другим пользователям.
GRANT SELECT ON employee TO Dylan
WITH GRANT OPTION;
Сходным образом вы можете использовать инструкцию REVOKE, чтобы отозвать
привилегию WITH GRANT OPTION, отдельную привилегию SELECT или обе сразу.
В большинстве платформ привилегии уровня пользователей и уровня ролей изо-
лированы. Поэтому пользователь, которому назначено две роли, может иметь четыре
набора привилегий сразу - один раз для себя, один раз для пользователя PUBLIC и по
одному разу для каждой назначенной ему роли. В этой ситуации следует соблюдать
большую осторожность. Чтобы полностью лишить пользователя конкретной привиле-
гии, вы должны отозвать пользовательские привилегии сначала индивидуально,
а затем - в обеих ролях.
DB2
Платформа DB2 в своей реализации инструкции GRANT предоставляет множество
опций. Важно отметить, что привилегии доступа к объектам базы данных (например,
привилегии SELECT в конкретной таблице) обрабатываются так же, как и другие разно-
образные привилегии.
GRANT { [привилегии_базы_данных [,...] ON DATABASE ] |
[ CONTROL ON INDEX имя_индекса~\ |
[ {BIND | CONTROL | EXECUTE} ON PACKAGE имя_пакета ] |
[ EXECUTE ON [SPECIFIC] {FUNCTION | METHOD {* | FOR} | PROCEDURE}
имя_объекта ] |
376 | Глава 3. Справочник по инструкциям SQL
I. {ALTERI.N i CREATEIN | DROPIN] ON SCHEMA «/я. схемы ] |
[ ON SEQUENCE имя^последовательности^ |
[ PASSTHRU ON SERVER имя_сервера ] |
[ объектная^привилегия ON [TABLE] имя^обьекта ] ]
TO [ {USER |GROUP] ]
{ ямя_получателя [,...] I имя._группы [,...] I PUBLIC } ]
[WITH GRAN'I OPTION] | [ USE OF TABLESPACE имя.7абличного_пространства J
Параметры следующие.
'ривилегии_базы -данных
Предоставляется одна или несколько привилегий, которые применимы ко всей
базе данных, а не к одному объекту. Привилегии базы данных таковы:
BIND ADD
Предоставляется право создавать пакеты. Пользователь, создающий пакет,
всегда будет иметь в этом пакете привилегию CONTROL, даже если привиле-
гия BIN DADD позже будет отозвана.
CONNECT
Предоставляется право доступа к конкретной базе данных.
CREATETAB
Предоставляется право создать таблицу базы. Пользователь, создавший таб-
лицу, всегда будет иметь в этой таблице привилегию CONTROL, даже если
привилегия CREATETAB позже будет отозвана.
CREA TE EXTERNAL ROUTINE
Предоставляется привилегия регистрировать внешние подпрограммы. Это
представляет определенную опасность, поскольку внешние процессы могут
иметь вредные побочные эффекты. Подпрограмма после создания будет про-
должать существовать, даже если пользователь лишается привилегии
CREATE EXTERNAL_ROUTINE. (За дополнительной информацией обращай-
тесь к предложению THREADSAFE инструкций CREATE и ALTER для подпро-
грамм в документации DB2.)
CREA TE_NOT_FENCED_ROUTINE
Предоставляется право создавать подпрограммы, которые не ограничиваются те-
кущим процессом пользователя. То есть подпрограммы могут выполняться про-
цессом менеджера базы данных. Предложение CREATE NOT FENCED ROUTINE
является расширением предложения CREATE_EXTERNAL_ROUTINE. Следова-
тельно, вы автоматически получаете последнюю привилегию, если вам присваи-
вается первая. За дополнительной информацией обращайтесь к описанию предло-
жения CREA TE-EXTERNAL-ROUTINE.
DBADM
Предоставляются права суперпользователя, с возможностью создать любой
объект базы, со всеми привилегиями для всех объектов базы данных, и даже
с возможностью предоставлять привилегии другим пользователям.
Справочник по командам SQL | 377
IMPLICITSCHEMA
Предоставляется право неявного создания схемы, хотя эта привилегия не влияет
на возможность создавать схемы и любые объекты в них явным образом.
LOAD
Предоставляется право явным образом загружать (LOAD) указанную базу дан-
ных. Пользователи с правами SYSADM и DBADM, которые автоматически уже
имеют эту привилегию, не нуждаются в явном присвоении других привилегий
для выполнения загрузки базы данных. Однако другие пользователи,
имеющие привилегию LOAD, должны иметь как минимум привилегию
INSERT в таблице, которую им нужно загрузить.
QUIESCE_CONNECT
Предоставляется право доступа к указанной базе данных в то время, когда она
приостановлена.
CONTROL ON INDEX имя_индекса
Предоставляется право удалить ранее созданный индекс с именем имя_индекса.
Это явная привилегия CONTROL для индексов. Она автоматически присваивается
создателю любого индекса.
{BIND | CONTROL | EXECUTE} ON PACKAGE имя_пакета
Присваиваются привилегии, связанные с пакетами. Обратите внимание, что пред-
ложения RUN и PROGRAM являются допустимыми синонимами для EXECUTE
и PACKAGE соответственно. Существуют следующие привилегии, относящиеся
к пакетам.
BIND
Предоставляется право производить связывание и повторное связывание с ука-
занным пакетом. Поскольку все инструкции SQL в пакете проверяются в момент
связывания, пользователь также должен иметь права доступа к каждому объек-
ту, на который ссылаются инструкции пакета.
CONTROL
Предоставляются права для повторного связывания, удаления или выполнения
указанного пакета, а также право назначать привилегии BIND и EXECUTE другим
пользователям. Пользователи, которым назначена привилегия CONTROL, также
автоматически получают привилегии BIND и EXECUTE. Привилегия CONTROL
автоматически присваивается создателю пакета.
EXECUTE
Предоставляется право запускать указанный пакет.
EXECUTE ON [SPECIFIC] {FUNCTION | METHOD {* | FOR] | PROCEDURE}
имя_объекта
Предоставляются права доступа к подпрограмме ANSI (т. е. пользовательской
функции, пользовательскому методу или хранимой процедуре). Элементы этого
предложения следующие.
FUNCTION [схема.]имя_функции
Указывается, что пользователь получает привилегию для выполнения указан-
ной функции. Для имени функции можно указать предложение SPECIFIC.
378 | Глава 3. Справочник по инструкциям SQL
Система DB2 также поддерживает функции без имен. В этом случае нужно ис-
пользовать синтаксис FUNCTION [(параметр [,...] )], где следует указать все
параметры функции. Если параметр схема, не указан, подразумевается теку-
щая схема. Вы можете заменить звездочкой (*) конкретные имена функций,
чтобы предоставить пользователю право выполнения всех функций в текущей
или указанной схеме.
METHOD {* | FOR имя_типа}
Указывается, что пользователь получает право выполнять все методы типа
имя_типа, в том числе те, которые еще не созданы. В необязательном предло-
жении FOR имя_типа называется тип, в котором находится метод. Можно
указать специфическое (SPECIFIC) имя типа. Система DB2 также поддержи-
вает методы без имен. В этом случае нужно использовать синтаксис METHOD
[(параметр [„..] )], где следует указать все параметры метода. В качестве аль-
тернативы вы можете использовать символ-звездочку (*) для обозначения
того, что пользователь получает права во всех типах схемы.
PROCEDURE [схема.]имя_процедуры
Указывается, что пользователь получает привилегию для выполнения всех
хранимых процедур указанной схемы, в том числе тех, которые будут созданы
в будущем. Если параметр схема, не указан, подразумевается текущая схема.
Вы можете заменить звездочкой (*) конкретные имена процедур, чтобы пре-
доставить пользователю право выполнения всех процедур в текущей или ука-
занной схеме.
{ALTERIN | CREATE1N | DROPIN} ON SCHEMA имя_схемы
Предоставляются привилегии, связанные с манипулированием схемой (т. е. на-
бором объектов, принадлежащих пользователю). Подавать эту команду могут
только пользователи с привилегиями SYSADM, DBADM или с привилегиями WITH
GRANT OPTION для всех прав указанной схемы. Элементы этого предложения
следующие.
ALTERIN
Предоставляется право писать комментарии или изменять объекты схемы,
указанной в предложении ON SCHEMA имясхемы.
CREATE IN
Предоставляется право создавать объекты схемы, указанной в предложении
ON SCHEMA имя_схемы.
DROPIN
Предоставляется право удалять объекты схемы, указанной в предложении ON
SCHEMA имя_схемы.
{ALTER | USAGE} ON SEQUENCE гшя_последователыюсти TO PUBLIC
Предоставляются права доступа к последовательности в явно указанной или текущей
схеме (USA GE) или право выполнять инструкцию ALTER SEQUENCE (ALTER).
PASSTHRU ON SERVER имя_сервера
Предоставляется право доступа к внешнему источнику данных с именем
имя_сервера в транзитном (pass-through) режиме.
Справочник по командам SQL | 379
объектная_привилегия
Указываются привилегии для выполнения различных инструкций в таблицах,
представлениях, а также таблицах и представлениях с псевдонимами. Объектные
привилегии можно комбинировать в любом порядке.
ALL [PRIVILEGES]
Краткое обозначение всех привилегий, которые пользователь может предоста-
вить. Ключевое слово PRIVILEGES является необязательным. Присваиваются
все привилегии, которые в настоящий момент назначены пользователю,
которые применяются к указанным объектам базы данных. Сюда входят при-
вилегии SELECT, INSERT, UPDATE и DELETE. Имея привилегию ALL, вы
имеете право добавлять столбцы в таблицу, создавать и удалять первичные
ключи или ограничения по уникальности, создавать и удалять внешние
ключи, создавать и удалять проверочные (CHECK) ограничения, создавать
в таблице триггеры, добавлять и изменять комментарии в таблице, изменять
имя или тип данных столбца с псевдонимом, а также добавлять, сохранять
или удалять имя столбца с псевдонимом. Однако предоставление привилегии
ALL, как правило, не поощряется, поскольку способствует неаккуратному
написанию кода.
ALTER
Привилегия добавлять и изменять столбцы, ограничения, комментарии и триг-
геры в указанной таблице или представлении. Предложение ALTER также
позволяет использовать короткие имена (nicknames) для имен столбцов и типов
данных, а также изменять свойства столбца под данным коротким именем.
CONTROL
Указанному пользователю или роли (или пользователю PUBLIC) присваивается
большое число прав доступа к указанному объекту. Если вы предоставляете при-
вилегию CONTROL для доступа к таблице, то сюда входят привилегии ALTER,
DELETE, INSERT, INDEX, REFERENCES, SELECT и UPDATE. Если вы присваи-
ваете привилегию CONTROL для доступа к представлению, то сюда входят при-
вилегии DELETE, INSERT, SELECT и UPDATE. Для псевдонимов привилегия
CONTROL включает в себя привилегии ALTER, INDEX и REFERENCES.
Получатель привилегии имеет возможность присваивать указанные выше
привилегии другим пользователям, которые могут удалить указанную табли-
цу, представление или псевдоним. Они могут запускать утилиту RUNSTATS
в таблицах и индексах, а также выполнять команду SET INTEGRITY в табли-
цах, материализованных представлениях и промежуточных таблицах.
INDEX
Возможность создать индекс для таблицы или создать спецификацию индекса
для псевдонима. (Создатель индекса сохраняет привилегии CONTROL в соз-
данном им индексе, даже если позже привилегия INDEX будет отозвана.)
(SELECT | INSERT | UPDATE | DELETE}
Данному пользователю присваивается указанная привилегия для доступа к ука-
занному объекту базы, например таблице или представлению. В некоторых
380 | Глава 3. Справочник по инструкциям SQL
случаях эти привилегии также распространяются и на утилиты со сходным
поведением. Например, привилегия INDEX также включает использование ути-
литы IMPORT. Для таблицы вы можете указать заключенный в скобки список
столбцов, на которые распространяется привилегия. Привилегию UPDATE
можно назначать вплоть до уровня столбцов, указав заключенный в скобки
список столбцов, которые нужно сделать доступными для пользователя.
REFERENCES
Предоставляется право создавать и удалять ограничения типа FOREIGN KEY,
ссылающиеся на объект базы данных как на родительский объект. Привиле-
гию REFERENCES можно назначать вплоть до уровня столбцов, указав
заключенный в скобки список столбцов, которые нужно сделать доступными
для получателя.
ТО {[USER | GROUP ]} имя__получателя
Указывается пользователь или пользователи, получающие указанную привилегию
или привилегии. Если существуют пользователь и группа с одинаковым именем,
используйте дополнительные ключевые слова USER или GROUP, чтобы уточнить,
назначается привилегия пользователю или группе. Можно использовать ключевое
слово PUBLIC, чтобы предоставить привилегию роли PUBLIC. Можно указывать
несколько получателей, разделяя их имена запятыми.
WITH GRANT OPTION
Получатель наделяется правом присваивать привилегии другим пользователям.
USE OF TABLESPACE имя_табличного_пространства
Предоставляется право указывать для новых таблиц табличное пространство
с именем имя_табличного_пространства. В результате пользователь наделяется
привилегией USE для этого табличного пространства.
В тех ситуациях, когда существуют пользователь и группа с одним и тем же име-
нем, вы должны использовать ключевое слово GROUP или USER, чтобы система DB2
знала, нужно ли назначить привилегию группе или пользователю. Если вы этого не
сделаете, DB2 сгенерирует ошибку и прекратит выполнение инструкции GRANT.
Например, чтобы предоставить пользователю cmily и группе datareaders привилегии
CONNECT и BINDADD, используется следующая инструкция.
GRANT CONNECT, BINDADD ON DATABASE TO USER emily,
GROUP datareaders
Чтобы предоставить пользователю Dylan и всем пользователям, которым при-
своена роль Admin, контроль над указанным индексом, используется следующая ин-
струкция.
GRANT CONTROL ON INDEX emp_ndx TO dylan, admin;
Вы можете предоставить пользователю право выполнять пакет или производить
связывание с ним без права его удаления.
GRANT BIND, EXECUTE ON PACKAGE d02.sales_processing
TO USER dylan
Справочник по командам SQL | 381
В следующем примере пользователь получает различные привилегии в таблице
sales, а также право передавать эти привилегии другим пользователям.
GRANT DELETE, INSERT, SELECT, UPDATE ON sales TO USER sam
WITH GRANT OPTION
Сходным образом вы можете предоставлять другому пользователю привилегии
доступа к конкретным объектам (в данном случае - к представлению), куда входят
только отдельные столбцы этого объекта.
GRANT UPDATE (sales_qty, sales_discount) ON sales TO USER jake
В DB2 также есть привилегии уровня экземпляра, которые управляются не
при помощи инструкции GRANT. Самое важное - это три параметра кон-
фигурации менеджера базы данных (SYSADMGRP, SYSCTRL_GRP
и SYSMAINT__GRP), которые управляют административным доступом
к экземпляру. Вы можете управлять этими параметрами при помощи
имеющейся в DB2 инструкции UPDATE DATABASE MANAGER CONFIGU-
RATION. Например:
ATTACH DB2;
UPDATE DATABASE MANAGER CONFIGURATION
USING
sysadm_group 'DB2GRP'
IMMEDIATE;
DETACH;
MySQL
Платформа MySQL предлагает дополнительные привилегии доступа, которые глав-
ным образом связаны с манипуляциями с объектами базы данных. Инструкция
GRANT в MySQL доступна начиная с версии 3.22.11 и выше. Ее синтаксис сле-
дующий.
GRANT [ { ALL [PRIVILEGES] |
{SELECT | INSERT | UPDATE} [ (,имя_сголбца [,...]) ] | DELETE |
REFERENCES [ (имя^столбца [,...]) ] } I
[ USAGE ] | [{ALTER | CREATE | DROP}] | [FILE] | [INDEX] | [PROCESS] |
[RELOAD] | [SHUTDOWN] | [CREATE TEMPORARY TABLES] | [LOCK TABLES] |
[REPLICATION CLIENT] | [REPLICATION SLAVE] | [SHOW DATABASES] |
[SUPER] }[,...]
ON {имя_таблицы | * | *.* | имя_базы_данных. *}
{TO имя_получателя [IDENTIFIED BY 'пароль']} [,...]
[WITH GRANT OPTION]
382 | Глава 3. Справочник по инструкциям SQL
Где:
ALL [PRIVILEGES]
Пользователю предоставляются все доступные привилегии, которые применимы
на текущем уровне к одному или нескольким объектам базы данных, за исключе-
нием привилегии WITH GRANT OPTION. Например, инструкция GRANT ALL ON
*. * глобально назначает все привилегии, кроме WITH GRANT OPTION.
SELECT | INSERT | UPDATE | DELETE
Предоставляется право читать, записывать, изменять и удалять данные из таблиц
(и, возможно, из отдельных столбцов таблицы) соответственно. Права уровня
столбца можно указывать для операций SELECT, INSERT и UPDATE, но не DELETE.
Предоставление прав уровня столбца может несколько уменьшить производитель-
ность системы MySQL, поскольку потребуется больше проверок прав доступа.
REFERENCES
Предложение остается нереализованным.
USAGE
Создается пользовательская учетная запись «без привилегий», которая использу-
ется при создании пользователей, не имеющих привилегий.
ALTER | CREATE | DROP
Предоставляется право изменять, удалять или создавать таблицы и другие объекты
базы данных. При использовании предложения CREATE от вас не требуется указы-
вать предложение ON для обозначения конкретной таблицы.
FILE
Предоставляется право загружать данные из файлов или записывать данные в файлы,
используя команды SELECT INTO и LOAD DATA.
INDEX
Предоставляется право создавать или удалять индексы.
PROCESS
Предоставляется право просматривать работающие процессы с помощью инструк-
ции SHOW FULL PROCESSLIST.
RELOAD
Предоставляется право запускать команды FLUSH и RESET.
SHUTDOWN
Предоставляется право использовать команду mysqladmin shutdown для завершения
работы серверного процесса.
CREATE TEMPORARY TABLES
Предоставляется право создавать временные таблицы.
LOCK TABLES
Предоставляется право использовать команду MySQL LOCK TABLES в тех таблицах,
в которых пользователь имеет привилегии SELECT.
REPLICATION CLIENT
Пользователь получает право просматривать метаданные о головных и подчиненных
серверах при репликации.
Справочник по командам SQL | 383
REPLICATION SLAVE
Подчиненный при репликации сервер (slave) получает право читать с головного
сервера (master) двоичный журнал (binlog).
SNOW DATABASES
Пользователь получает право выполнять команду MySQL SHOW DATABASES.
SUPER
Пользователь получает право на одно соединение даже после достижения порога
максимального числа соединений {maxconnections). Пользователи с привилегия-
ми SUPER также могут выполнять такие важные команды MySQL, как CHANGE
MASTER, KILL, mysqladmin debug, PURGE [MASTER] LOGS и SET GLOBAL.
ON [имя таблицы | * | *. * | имя_базы_данных. *}
Предоставляются привилегии для указанной таблицы имя_таблицы, для всех
таблиц текущей базы (используется звездочка, *), для всех таблиц во всех базах
данных (*.*) или для всех таблиц в указанной базе данных (имя_базы_данных.*).
ТО имя_получателя [IDENTIFIED BY 'пароль']} [,...]
Имя пользователя или пользователей, которые получают данную привилегию. Вы
можете указывать несколько пользователей, разделяя их имена запятыми. При предос-
тавлении привилегий новому пользователю вы можете при желании также указать для
этого нового пользователя пароль, используя предложение IDENTIFIED BY.
WITH GRANT OPTION
Получатель наделяется правом присваивать привилегию другим пользователям.
Поскольку в MySQL основной акцент делается на производительности, вы можете
применять серверные настройки для увеличения производительности. Например, вы
можете включить опцию запуска SKIP_GRANT_TABLES для отключения проверки
прав доступа. Это ускорит обработку запросов, но, конечно, никакие проверки прав
доступа производиться не будут. Это означает, что все пользователи будут иметь
полный доступ ко всем ресурсам базы данных.
Ниже перечислены привилегии доступа, которые можно применять в таблицах:
SELECT, INSERT, UPDATE, DELETE, CREATE, DROP, GRANT, INDEX и ALTER.
На уровне столбцов вы можете использовать INSERТ, UPDATE и SELECT.
В любом случае длина имен серверов, таблиц, баз данных и столбцов не должна
превышать 60 символов. Имя пользователя (имя_получ отеля) не должно превышать
16 символов.
Платформа MySQL также поддерживает возможность предоставления прав ука-
занному пользователю на указанном сервере, если параметр имя_получателя имеет
формат пользователь@сервер. В имени получателя можно использовать символы-за-
менители, чтобы предоставить доступ сразу многим пользователям. Кроме того, опу-
щенное имя сервера идентично символу «%». Например:
GRANT SELECT ON employee TO katie@% IDENTIFIED BY 'audi',
annalynn IDENTIFIED BY 'Cadillac',
cody@us% IDENTIFIED BY 'bmw';
384 | Глава 3. Справочник по инструкциям SQL
В приведенной выше инструкции GRANT права для чтения таблицы employee
предоставляются пользователю katie на любом сервере. Сходным образом в инструк-
ции GRANT права для чтения на любом сервере неявно предоставляются пользовате-
лю annalynn. И наконец, инструкция GRANT предоставляет пользователю cody права
для чтения на любом сервере, название которого начинается с US.
Имя пользователя не должно превышать 16 символов. При указании пользователя
можно применить защиту паролем, включив в инструкцию предложение IDENTIFIED BY.
В следующем примере привилегии предоставляются трем пользователям,
имеющим пароли.
GRANT SELECT ON employee TO dylan IDENTIFIED BY 'porsche',
kelly IDENTIFIED BY 'mercedes',
emily IDENTIFIED BY 'saab';
Если в системе MySQL вы назначаете привилегии несуществующему пользовате-
лю, система создает этого пользователя. Две приводимые ниже инструкции создают
пользователя и пароль с глобальными привилегиями и еще одного пользователя,
который привилегий не имеет (привилегия USAGE).
GRANT SELECT ON *.* TO tony IDENTIFIED BY 'humbolt';
GRANT USAGE ON sales.» TO alicia IDENTIFIED BY 'dakota';
| .. j Если не включить в инструкцию GRANT, создающую нового пользователя,
предложение IDENTIFIED BY, то будет создан пользователь без пароля.
----- Такая практика является небезопасной.
Если вы создаете нового пользователя с помощью инструкции GRANT и забываете
указать пароль, вы можете (и это рекомендуется) установить пароль при помощи
команды SET PASSWORD.
Платформа MySQL также позволяет присваивать права на удаленных серверах,
которые указываются при помощи параметра @имя_сервера и включают обоб-
щающий символ %. Например, в следующей инструкции пользователю annalynn пре-
доставляются все привилегии для доступа ко всем таблицам текущей базы данных во
всех серверах домена notforprofit.org,
GRANT ALL ON * ТО annalynn@'%.notforprofit.org';
Привилегии записываются напрямую в системные таблицы, на четыре различных
уровня.
Глобальный уровень
Глобальные привилегии применяются ко всем базам данных на данном сервере
и хранятся в системной таблице mysql.user.
Уровень базы данных
Эти привилегии применяются ко всем таблицам указанной базы данных и хранятся
в системной таблице mysql.db.
25 - 2447
Справочник по командам SQL | 385
Уровень таблицы
Эти привилегии применяются ко всем столбцам таблицы и хранятся в системной
таблице mysql.tables_priv.
Уровень столбца
Эти привилегии применяются к отдельным столбцам таблицы и хранятся в сис-
темной таблице mysql.columns_priv.
Из-за того, что используются обычные и системные таблицы, вы можете создать
избыточные привилегии на различных уровнях. Например, вы можете предоставить
одному пользователю привилегии SELECT в конкретной таблице, а после этого пре-
доставить глобальные привилегии SELECT в этой таблице всем пользователям базы
данных. После этого отменять такие привилегии вам придется по отдельности, чтобы
пользователь точно не имел привилегий SELECT для данной таблицы.
Также системные таблицы являются довольно незащищенными, и возможно изме-
нить права, используя в этих таблицах инструкции INSERT, UPDATE и DELETE, а не
только GRANT и REVOKE. Как правило, все привилегии считываются в память при за-
пуске сервера MySQL. Привилегии для базы данных, таблицы или столбца, присвоен-
ные с помощью инструкции GRANT, становятся доступными сразу и вступают в дей-
ствие немедленно. Пользовательские привилегии, присвоенные при помощи инструк-
ции GRANT, можно увидеть сразу, а в действие они вступают при следующем под-
ключении пользователя. Если вы напрямую изменяете привилегии в системных таб-
лицах, эти изменения не будут видны до тех пор, пока вы не перезапустите MySQL
или пока не подадите команду FLUSH PRIVILEGES.
Oracle
Реализация инструкции GRANT в системе Oracle поддерживает огромное количество
вариантов и изменений. Синтаксис ее следующий.
GRANT { [объекгная_привилегия] [,,..] |
[системная_привилегия'] [,...] |
[роль] [,...] }
[ ON { [имя_схемы. ][обьект] [,...] |
[DIRECTORY имя_объекта-директории] |
[JAVA [ { SOURCE | RESOURCE } ] [имя_схемы. ][обьект] }
ТО {{имя_получателя [,...] | имя_роли [,...] | PUBLIC}
[WITH { GRANT | HIERARCY } OPTION]
[IDENTIFIED BY парольЖПН ADMIN OPTION];
Вы можете присваивать несколько привилегий в одной инструкции, но эти приви-
легии должны относиться к одному типу (объектные, системные или ролевые).
Например, вы можете предоставить пользователю три объектные привилегии
в одной таблице при помощи одной инструкции GRANT, затем при помощи отдельной
инструкции назначить две системные привилегии какой-нибудь роли, а в третьей ин-
струкции присвоить пользователю несколько ролей, но нельзя сделать все это в одной
инструкции GRANT.
386 | Глава 3. Справочник по инструкциям SQL
Ниже приводятся параметры инструкции GRANT платформы Oracle.
объектная_привилегия
Привилегии для доступа к указанному объекту схемы (например, таблице или
представлению) присваиваются указанному получателю (имя_получателя) или
роли. Вы можете объединять в одной инструкции несколько объектных привиле-
гий, объектов схемы или получателей. Однако вы не можете объединять в одной
инструкции присвоение системных привилегий или ролей с присвоением объект-
ных привилегий. Существуют следующие объектные привилегии.
ALL [PRIVILEGES]
Присваиваются все доступные привилегии доступа к объекту схемы. Можно
применять к таблицам.
ALTER
Предоставляется право изменять существующую таблицу при помощи ин-
струкции ALTER TABLE. Можно применять к таблицам и последовательно-
стям.
DEBUG
Предоставляется право обращаться к таблице при помощи отладчика. Этот
доступ применим к любым триггерам таблицы и любой информации о коде
SQL, напрямую обращавшемся к таблице. Можно применять к таблицам,
представлениям, процедурам, функциям, пакетам, объектам Java и типам.
EXECUTE
Предоставляется право запускать хранимую процедуру, пользовательскую
функцию или пакет. Можно применять к процедурам, функциям, пакетам,
объектам Java, библиотекам, типам, индексным типам и пользовательским
операторам.
INDEX
Предоставляется право создавать индексы по таблице.
{ON COMMIT REFRESH | QUERY REWRITE}
Предоставляется привилегия создавать материализованные представления,
обновляющиеся после транзакции (refresh-on-commit), или создавать материа-
лизованное представление для переписывания запросов к указанной таблице.
Применяется только к материализованным представлениям.
{READ | WRITE}
Предоставляется привилегия читать и записывать файлы в директорию, ука-
занную с помощью полного пути к директории операционной системы.
Поскольку система Oracle имеет возможность сохранять файлы за пределами
базы данных, серверный процесс Oracle должен быть запущен пользователем,
имеющим привилегии доступа к указанным директориям. Вы можете
включить в Oracle при помощи этого механизма систему обеспечения безо-
пасности на уровне отдельных пользователей. Обратите внимание, что пред-
ложение WRITE можно использовать только с внешней таблицей, например
файлом журнала или файлом ошибок.
Справочник по командам SQL | 387
REFERENCES
Предоставляется право определять ограничения, обеспечивающие ссылочную
целостность. Можно использовать в таблицах.
{SELECT | INSERT | UPDATE DELETE}
Предоставляется право выполнять соответствующие команды SQL примени-
тельно к указанному объекту схемы. Можно использовать в таблицах, пред-
ставлениях, последовательностях (только SELECT) и материализованных
представлениях (только SELECT). Отметьте, что вы должны предоставить
привилегию SELECT тому пользователю или роли, которому требуется приви-
легия DELETE. Вы можете назначать привилегии на уровне столбцов,
включив в инструкцию, после имени объекта, заключенный в скобки список
столбцов. Это возможно только при предоставлении объектных привилегий
INSERT, REFERENCES или UPDATE в таблице или представлении.
UNDER
Предоставляется право создавать представления-потомки указанного пред-
ставления. Используется только с представлениями и типами.
системная_привилегия
Указанная системная привилегия Oracle назначается одному или нескольким
пользователям или ролям. Например, вы можете предоставлять такие привилегии,
как CREATE TRIGGER или ALTER USER. В обоих случаях предоставление сис-
темной привилегии наделяет пользователя или роль правом выполнять команду
с соответствующим именем. Полный список системных привилегий приводится
в табл. 3.2 ниже в этом разделе.
роль
Роль назначается пользователю или другой роли. Помимо пользовательских ролей
существует несколько готовых системных ролей, поставляемых с Oracle.
CONNECT, RESOURCE и DBA
Предлагаются для обратной совместимости с предыдущими версиями Oracle.
Не используйте эти роли в текущей и более новых версиях Oracle, поскольку
в будущем их поддержка может быть прекращена.
DELETE_CA TALOG ROLE, EXECUTE_CA TALOGJROLE и SELECT СА TALOG_ROLE
Пользователи, которым присвоена эта роль, могут удалять, выполнять и отбирать
данные из словарных представлений и пакетов.
EXP_FULL_DATABASE иIMP_FULL_DATABASE
Пользователи, которым присвоена эта роль, могут запускать утилиты импорта
и экспорта.
AQ_USER_ROLE и AQADMINISTRATORROLE
Пользователи, которым присвоена эта роль, могут использовать или админи-
стрировать такую функциональность Oracle, как Advanced Queuing.
SNMPAGENT
Присваивается только Oracle Enterprise Manager и Intelligent Agent.
388 | Глава 3. Справочник по инструкциям SQL
RECO VER Y_CA TA LOG_O WNER
Предоставляется привилегия создавать пользователей, владеющих собствен-
ным каталогом восстановления.
HSADM1NJROLE
Предоставляется привилегия обращаться к областям словарей данных, ко-
торые используются для поддержки гетерогенных служб Oracle.
ON имя_схемы
Пользователю или роли предоставляется привилегия доступа к объекту схемы.
К объектам базы данных относятся: таблицы, представления, последовательно-
сти, хранимые процедуры, пользовательские функции, пакеты, материализован-
ные представления, пользовательские типы, библиотеки, индексные типы, пользо-
вательские операторы или синонимы всех этих объектов. Если имя схемы не будет
указано, будет подразумеваться схема текущего пользователя.
Платформа Oracle также поддерживает два ключевых слова для особых случаев.
DIRECTORY
Предоставляются права доступа к объекту-директории, который представляет
собой объект Oracle, соответствующий директории в файловой системе.
JAVA
Предоставляются привилегии доступа к Java-объектам схемы SOURCE
и RESOURCE.
ТО {{имяполучателя [...] | имя_рыи[,...] | PUBLIC} [WITH {GRANT\HIERARCY} OPTION]
Указывается пользователь или роль, получающая данную привилегию. Ключевое
слово PUBLIC также можно использовать при отмене привилегии, назначенной
для роли PUBLIC. Можно через запятую перечислить нескольких получателей
привилегии.
WITH GRANT OPTION
Позволяет получателю привилегии назначать эти привилегии другим пользо-
вателям или роли PUBLIC, но никаким другим ролям.
WITH HIERARCHY OPTION
Позволяет получателю привилегии в объекте-родителе получить эти привиле-
гии во всех объектах-потомках. Это касается и всех потомков, которые будут
созданы в будущем. Вы можете использовать эту опцию только при назначе-
нии объектной привилегии SELECT.
IDENTIFIED BY пароль [WITH ADMIN OPTION]
Устанавливается или изменяется пароль, который получатель привилегии должен
использовать, чтобы ему была предоставлена роль.
WITH ADMlN OPTION
Позволяет получателю осуществлять управление ролью, которую вы ему
назначаете. Во-первых, это предложение позволяет получателю назначать
и отзывать роль пользователям и неглобальным ролям. Оно также позволяет
получателю удалить роль или изменить авторизацию, необходимую для дос-
тупа к ней.
Справочник по командам SQL | 389
Назначение привилегий пользователям вступает в силу немедленно. Назначение
ролей вступает в силу немедленно, если роль задействована. В противном случае
назначение вступает в силу после включения роли. Обратите внимание, что роли
можно назначать пользователям и другим ролям (в том числе PUBLIC). Пример:
GRANT sales_reader ТО salesjnanager;
Чтобы предоставлять привилегии доступа к представлению, вы должны иметь
в базовых таблицах представления данные привилегии, с указанием предложения
WITH GRANT OPTION.
Если вы захотите предоставить привилегии всем пользователям, просто назначьте
эти привилегии роли PUBLIC.
GRANT SELECT ON work_schedule TO public;
Тем не менее существуют определенные ограничения в предоставлении систем-
ных привилегий и ролей.
• Привилегия или роль не должна встречаться в инструкции GRANT больше
одного раза.
• Роль нельзя назначить самой себе.
• Роли не могут назначаться рекурсивно, т. е. нельзя назначить роль sales_reader
роли sales_manager, а потом присвоить роль sales_manager роли salesreader.
Вы можете присваивать несколько однотипных привилегий в одной инструкции
GRANT. Однако эти привилегии должны относиться к объектам одного типа.
GRANT UPDATE (emp_id, job_id), REFERENCES (emp_id),
ON employees
TO sales_manager;
В качестве отступления, предоставление любых объектных привилегий доступа
к таблице позволяет пользователю (или роли) блокировать таблицу любым режимом
блокировки, используя инструкцию Oracle LOCK TABLE.
Почти все поддерживаемые Oracle функциональности и команды могут назначать-
ся в виде привилегий в инструкции GRANT (как это показывает табл. 3.2). Привилегии
можно назначать не только применительно к объектам базы данных (таким, как табли-
цы и представления) и системным командам (таким, как CREATE ANY TABLE), но
также и к объектам схем (таким, как DIRECTORY, JAVA SOURCE и RESOURCE).
Параметр ANY, показанный в табл. 3.2, предоставляет права выполнения данной
инструкции применительно к объектам указанного типа, принадлежащим любому
пользователю в схеме. Без опции ANY пользователь сможет применять инструкции
390 | Глава 3. Справочник по инструкциям SQL
только к объектам в своей собственной схеме. Более полный список системных приви-
легий Oracle приведен в табл. 3.2.
Таблица 3.2. Системные привилегии Oracle
Варианты Описание
CREATE CLUSTER Предоставляется право создавать кластеры в схеме, принад- лежащей получателю
{CREATE | ALTER | DROP} ANY CLUSTER Предоставляется право создавать, изменять или удалять кластер в любой схеме соответственно
{CREATE | DROP} ANY CONTEXT Предоставляется право создавать или удалять любое кон- текстное пространство имен соответственно
ALTER DATABASE Предоставляется право изменять базу данных
ALTER SYSTEM Предоставляется право использовать инструкции ALTER SYSTEM
AUDIT SYSTEM Предоставляется право использовать инструкции AUDIT инструкции _sql
CREATE DATABASE LINK Предоставляется право создавать личные связи с базами данных в собственной схеме получателя
CREATE PUBLIC DATABASE LINK Предоставляется право создавать публичные связи с базами
данных
DROP PUBLIC DA TABASE LINK Предоставляется право удалять публичные связи с базами данных
DEBUG CONNECT SESSION Предоставляется право связывать текущий сеанс с отладчиком Java Debug Wire Protocol (JDWP)
DEBUG ANY PROCEDURE Предоставляется право отладки любых объектов PL/SQL в базе данных. Сходно с привилегией DEBUG для всех процедур, функций и пакетов
CREATE DIMENSION Предоставляется право создавать измерения в собственной схеме получателя
{CREATE | ALTER | DROP} ANY DIMENSION Предоставляется право создавать, изменять или удалять измерения в любой схеме
{CREATE | DROP} ANY DIRECTORY Предоставляется право создавать и удалять объекты- директории базы данных
CREATE ROLE Предоставляется право создавать роли базы данных
GRANT ANY ROLE Предоставляется право назначать роль другим пользовате- лям
CREATE INDEXTYPE Предоставляется право создавать индексные типы в собст- венной схеме получателя
{CREATE j DROP | EXECUTE} ANY INDEXTYPE Предоставляется право создавать, изменять, удалять или выполнять индексный тип в любой схеме
Справочник по командам SQL | 391
Таблица 3.2. Системные привилегии Oracle (продолжение)
Варианты Описание
{CREATE | ALTER | DROP) ANY INDEX Предоставляется право создавать, изменять или удалять индекс в любой схеме или индекс для любой таблицы в любой схеме
{CREATE | DROP} ANY LIBRARY Предоставляется право создавать или удалять библиотеки внешних процедур/функций в любой схеме
CREATE MATERIALIZED VIEW Предоставляется право создать материализованное представление в собственной схеме получателя
{CREATE | ALTER | DROP} ANY MATERIALIZED VIEW Предоставляется право создавать, изменять или удалять материализованные представления в любой схеме
GLOBAL QUERY REWRITE Позволяет переписывать запросы с использованием материализованного представления или создает индекс на основе функции, если материализованное представление или индекс ссылается на таблицы или схемы, принадлежа- щие к любой схеме
QUERYREWRITE Позволяет переписывать запросы с использованием материализованного представления или создает индекс на основе функции, если материализованное представление или индекс ссылается на таблицы или схемы, принадлежа- щие к собственной схеме получателя
ON COMMIT REFRESH Создает материализованное представление, обновляемое при выполнении транзакции (refresh-on-commit) во всех таб- лицах базы данных, или преобразует материализованное представление, обновляемое по требованию, в материализованное представление, обновляемое при выполнении транзакции
FLASHBACK ANY TABLE Предоставляется право использовать ретроспективные (flashback) SQL-запросы в любой таблице, представлении или материализованном представлении в любой схеме. Эта привилегия не является необходимой для процедур DBMS_FLASHBACK
CREATE OPERATOR Предоставляется право создавать операторы и их связи в собственной схеме получателя
{CREATE | DROP | EXECUTE} ANY OPERATOR Предоставляется право создавать, удалять и выполнять любой оператор и его связи в любой схеме
{CREATE | DROP | ALTER) ANY OUTLINE Предоставляется право создавать, изменять и удалять хранимые планы выполнения, которые можно использовать в любой схеме, применяющей такие планы
SELECT ANY OUTLINE Предоставляется право создавать личные хранимые планы выполнения на основе публичных
CREATE PROCEDURE Предоставляется право создавать хранимые процедуры, функции и пакеты в собственной схеме получателя
392 | Глава 3. Справочник по инструкциям SQL
Таблица 3.2. Системные привилегии Oracle (продолжение)
Варианты Описание
{CREATE | ALTER | DROP | . EXECUTE) ANY PROCEDURE Предоставляется право создавать, изменять, удалять и выполнять хранимые процедуры, функции и пакеты в любой схеме
{CREATE | ALTER | DROP) PROFILE Предоставляется право создавать, изменять и удалять профили
ALTER RESOURCE COST Устанавливается стоимость ресурсов для сеанса
ALTER | DROP) ANY ROLE Предоставляется право создавать, изменять, удалять и присваивать роли в базе данных
{CREATE | ALTER | DROP) ROLLBACK SEGMENT Предоставляется право создавать, изменять и удалять сег- менты отката
CREATE SEQUENCE Предоставляется право создавать последовательности в собственной схеме получателя
{CREATE 1 ALTER | DROP | SELECT) ANY SEQUENCE Предоставляется право создавать, изменять, удалять и отбирать последовательности в любой схеме базы данных
CREATE SESSION Предоставляется право соединяться с базой данных
ALTER SESSION Предоставляется право использовать инструкции ALTER SESSION
RESTRICTED SESSION Подключение после того, как экземпляр будет запущен инструкцией SQL*PIus STARTUP RESTRICT
CREATE SNAPSHOT Предоставляется право создавать моментальные снимки в собственной схеме получателя
{CREATE | ALTER | DROP) ANY SNAPSHOT Предоставляется право создавать, изменять или удалять моментальные снимки (также называемые материализован- ными представлениями) в любой схеме
CREATE SYNONYM Предоставляется право создавать синонимы в собственной схеме получателя
{CREATE | DROP) ANY SYNONYM Предоставляется право создавать или удалять личные сино- нимы в любой схеме
{CREATE | DROP) PUBLIC SYNONYM Предоставляется право создавать или удалять публичные синонимы
CREATE ANY TABLE Предост авляется право создавать таблицы в любой схеме. Владелец схемы, к которой относится таблица, должен иметь квоту па место в табличном пространстве для храпе- ния таблицы
ALTER ANY TABLE Предоставляется право изменять любую таблицу или представление в схеме
BACKUP ANY TABLE Использование утилиты для инкрементного экспорта объек- тов из схем других пользователей
Справочник по командам SQL | 393
Таблица 3.2. Системные привилегии Oracle (продолжение)
Варианты Описание
DELETE ANY TABLE Удаление строк из таблиц, разделов таблиц и представлений в любой схеме
DROP ANY TABLE Предоставляется право удалять или обрезать таблицы или разделы таблиц в любой схеме
INSERT ANY TABLE Предоставляется право вставлять строки в таблицы и представления в любой схеме
LOCK ANY TABLE Предоставляется право блокировать любые таблицы и представления в любой схеме
UPDATE ANY TABLE Предоставляется право обновлять строки таблиц и представлений в любой схеме
SELECT ANY TABLE Предоставляется право посылать запросы к таблицам, представлениям и моментальным снимкам в любой схеме
{CREATE | ALTER | DROP) TABLESPACE Предоставляется право создавать, изменять и удалять таб- личные пространства
MANAGE TABLESPACE Предоставляется право подключать и отключать табличные пространства, а также запускать и останавливать резервное копирование табличных пространств
UNLIMITED TABLESPACE Предоставляется право использовать неограниченный объем места в любом табличном пространстве. Эта приви- легия подменяет любую назначенную квоту. Если пользова- тель лишается этой привилегии, то объекты пользователь- ской схемы остаются неизменными, ио дальнейшее выделе- ние места прекращается, если только оно не разрешено при помощи специальных квот. Эту системную привилегию нельзя назначать ролям
CREATE TRIGGER Предоставляется право создать триггер базы данных в соб- ственной схеме получателя
{CREATE | DROP) ANY TRIGGER Предоставляется право создавать или удалять триггеры базы данных в любой схеме
ALTER ANY TRIGGER Предоставляется право включать, отключать или компи- лировать триггеры базы данных в любой схеме
ADMINISTER DATABASE TRIGGER Предоставляется право создать триггер в базе данных (вы также должны иметь привилегию CREATE TRIGGER или CREATE ANY TRIGGER)
CREATE TYPE Предоставляется право создавать определения и тела объ- ектных типов в собственной схеме получателя
{CREATE | ALTER | DROP} ANY TYPE Предоставляется право создавать, изменять и удалять определения и тела объектных типов в любой схеме
394 | Глава 3. Справочник по инструкциям SQL
Таблица 3.2. Системные привилегии Oracle (продолжение)
Варианты Описание
EXECUTE ANY TYPE Право использовать и ссылаться на объектные типы и типы- коллекции в любой схеме и вызывать методы объектного типа, если право предоставляется конкретному пользова- телю. Если привилегия EXECUTE ANY TYPE присваивается роли, то пользователи с этой ролью не смогут вызывать методы объектного типа пи в одной схеме
UNDER ANY TYPE Создание подтипов любого родительского объектного типа, такого, как таблица или представление
CREATE USER Предоставляется право создавать пользователей. Эта приви- легия также позволяет указать для пользователя: квоты для любою табличного пространства; определить табличное пространство по умолчанию и временное табличное пространство;. присвоить профиль при помощи инструкции CREATE USER
ALTER USER Предоставляется право изменять любых пользователей. Эта привилегия позволяет се получателю: • изменять пароль и метод аутентификации других пользова- телей; • присваивать квоты в любом табличном пространстве; • определять табличное пространство по умолчанию и временное табличное пространство; • присваиват ь профиль и роли по умолчанию
BECOME USER Предоставляется право стать другим пользователем. (Необ- ходимо для любого пользователя, который выполняет импортирование всей базы данных)
DROP USER Предоставляется право удалять пользоват елей
CREATE VIEW Предоставляется право создавать представления в собствен- ной схеме получателя
{CREATE | DROP} ANY VIEW Предоставляется право создавать и удалять представления в любой схеме
UNDER ANY VIEW Предоставляется право создавать представления-потомки от любого родительского представления
ANALYZE ANY Анализ любой таблицы, кластера или индекса в любой схеме
AUDIT ANY Аудит любою объекта в любой схеме при помощи инструкции AUDITобъекты_схемы
COMMENT ANY TABLE Позволяет писать комментарии к любой т аблице, представ- лению или столбцу в любой схеме
Справочник по командам SQL | 395
Таблица 3.2. Системные привилегии Oracle (продолжение)
Варианты Описание
EXEMPT ACCESS POLICY Позволяет обходить детализованный контроль доступа. Как правило, это не рекомендуется, поскольку после этого поль- зователь может обойти все политики безопасности прило- жений
FORCE ANY TRANSA CT1ON Принудительное выполнение или откат любой транзакции в локальной базе данных и генерация ошибки в распреде- ленной транзакции
FORCE TRANSACTION Принудительное выполнение или откат собственных сомни- тельных транзакций получателя в локальной базе данных
GRANT ANY PRIVILEGE Предоставляются все системные привилегии
GRANT ANY OBJECT PRIVILEGE Предоставляются все доступные объектные привилегии
RESUMABLE Позволяет использовать возможность Resumable Space Allocation (возможность возобновления функционирования после устранения проблемы выделения пространства)
SELECT ANY DICTIONARY Пользователю разрешается подавать запросы к любому объекту словаря данных в схеме SYS
SYSDBA Пользователь получает привилегию RESTRICTED SESSION, а также следующие права: выполнение операций STARTUP и SHUTDOWN', ALTER DATABASE; открывать, монтировать или изменять набор символов; CREATE DATABASE; ARCHIVELOG и RECOVERY
SYSOPER Пользователь получает привилегию RESTRICTED SESSION, а также следующие права: выполнение операций STARTUP и SHUTDOWN', ALTER DATABASE, OPEN/MOUNT/BACKUP; ARCHIVELOG и RECOVERY
Все привилегии, показанные в табл. 3.2 и содержащие ключевое слово ANY,
имеют особое значение. В частности, ключевое слово ANY дает пользователям право
выполнять указанную операцию в любой схеме. Если вы хотите включить сюда все
пользовательские схемы, но исключить схему SYS, установите инициализационный
параметр 07 DICTIONARY-ACCESSIBILITY в заданное для него по умолчанию значе-
ние FALSE.
PostgreSQL
Платформа PostgreSQL поддерживает ту часть параметров инструкции GRANT стан-
дарта ANSI, которые относятся к объектным привилегиям, применяемым к объектам
базы данных, таким, как таблицы. Эта платформа не поддерживает параметры WITH
396 | Глава 3. Справочник по инструкциям SQL
стандарта ANSI, а также такие специальные возможности, как USAGE и UNDER. Син-
таксис инструкции GRANT в PostgreSQL следующий.
GRANT { ALL [PRIVILEGES]
| SELECT
| INSERT
| DELETE
| UPDATE
| RULE
| REFERENCES
I TRIGGERS
I USAGE } [,...]
ON [TABLE] { имя_объекта }[,...]
TO {имя_получателя | GROUP имя_группы | PUBLIC } [,...]
Где:
ALL [PRIVILEGES]
Предоставляются все привилегии, которые может предоставить данный пользова-
тель. Использовать предложения ALL не рекомендуется, поскольку это способст-
вует нечеткости системы привилегий.
{SELECT | INSERT | DELETE | UPDATE]
Указанный пользователь получает указанную привилегию доступа к указанному
объекту базы данных, например таблице или представлению. Для определения
привилегий уровня столбца вы можете использовать заключенный в скобки
список столбцов таблицы. В этом случае привилегии будут касаться только тех
столбцов таблицы, которые входят в этот список.
RULE
Предоставляется право создавать или удалять правило для таблицы или представ-
ления.
REFERENCES
Предоставляется право создавать или удалять ограничения типа «внешний ключ»,
ссылающиеся на объект базы данных как на родительский объект.
TRIGGERS
Предоставляется право создавать триггеры для работы с указанной таблицей и ее
столбцами.
USAGE
Предоставляется право использовать следующие объекты: CHARACTER SET,
COLLATION, TRANSLATION и DOMAIN (пользовательский тип данных).
ON [TABLE] { имя_объекта }
Указывается объект, привилегии доступа к которому предоставляются. Дополни-
тельное ключевое слово TABLE никакой нагрузки не несет. Вы можете предостав-
лять доступ сразу к нескольким объектам, перечислив их имена через запятую.
ТО {имя_получателя | GROUP имя_груты | PUBLIC }
Указывается пользователь или роль или несколько пользователей или ролей, ко-
торые получают данную привилегию. В PostgreSQL слово PUBLIC является сино-
Справочник по командам SQL | 397
нимом для всех пользователей. Система PostgreSQL позволяет назначать права
доступа группе (GROUP) (по сути это роль), если она существует и является до-
пустимой.
Можно назначить сразу несколько привилегий, перечислив их через запятую.
Не объединяйте привилегию ALL [PRIVILEGES] с другими привилегиями, однако ос-
тавшиеся привилегии можно использовать в любых сочетаниях.
Платформа PostgreSQL не поддерживает предложений WITH и прав доступа на
уровне столбцов. В настоящее время, если вам нужно реализовать доступ на уровне
столбцов, вы должны настроить представление так, чтобы отображались только те
столбцы таблицы, которые пользователю можно видеть.
В PostgreSQL создатель объекта имеет все привилегии доступа к нему, но он
может отключить некоторые из собственных привилегий, хотя привилегия создателя
объекта присваивать права доступа к нему не может быть отменена. Также создатель
объекта обладает правом удалять его, и это право у него нельзя отнять. Пользователи,
отличные от создателя объекта, не имеют прав доступа к нему, если эти права не при-
своены специально.
Реализация инструкции GRANT в PostgreSQL работает так, как если бы всегда
было указано предложение WITH GRANT OPTION. Любой пользователь, получивший
привилегию доступа к таблице, может присвоить свою привилегию другим пользова-
телям.
Поддержка инструкции GRANT в PostgreSQL элементарна. В следующем примере
роль PUBLIC получает привилегию INSERT в таблице publishers, а пользователи
Emily и Dylan получают привилегии SELECT и UPDATE в таблице sales.
GRANT INSERT ON publishers TO PUBLIC;
GRANT SELECT, UPDATE ON sales TO emily, dylan;
SQL Server
Реализация инструкции GRANT в SQL Server имеет некоторые отличия от стандарта
ANSI. Не поддерживается стандартное предложение FROM, а также предложения
HIERARCHY и ADMIN. Однако она предоставляет возможность предоставлять
специфические системные привилегии, и предоставлять их из контекста другого
пользователя. Синтаксис приводится ниже.
GRANT { [объектнаЯ-Привилегия] [,...] |
[системная_привилегия'] }
[ON { [обьект] [(столбец [,...])] ]
ТО {имя_получателя [,..,] | роль [,...] | PUBLIC | GUEST }
[WITH GRANT OPTION]
[AS {группа | роль}]
Где:
398 | Глава 3, Справочник по инструкциям SQL
о&ъектные_привилегии
Предоставляются привилегии для выполнения различных операций, которые
можно использовать в любых сочетаниях (за исключением ALL [PR1VELEGES]).
ALL [PRIVELEGES]
Предоставляются все привилегии, назначенные в настоящий момент указан-
ным пользователям и/или для указанных объектов базы данных. Использова-
ние этого предложения не поощряется, поскольку способствует нечеткости
программирования. Предложение ALL могут использовать только пользовате-
ли с системными ролями SYSADMIN и DBOWNER или же владелец объекта.
{SELECT | INSERT | DELETE | UPDATE}
Указанному пользователю присваивается указанная привилегия доступа к ука-
занному объекту (например, к таблице или представлению). Для указания
привилегий уровня столбца используйте список столбцов, заключенный
в скобки. Привилегии будут назначены только для названных столбцов.
REFERENCES
Предоставляется привилегия создавать и удалять ограничения типа «внешний
ключ», ссылающиеся на объект базы данных как на родительский объект.
EXECUTE
Предоставляется право выполнять хранимую процедуру, пользовательскую
функцию или расширенную хранимую процедуру.
системны e_npiieiuieeuu
Предоставляются следующие привилегии, каждая из которых дает право на выпол-
нение соответствующей инструкции.
CREATE DATABASE
CREATE DEFAULT
CREATE FUNCTION
CREATE PROCEDURE
CREATE RULE
CREATE TABLE
CREATE VIEW
BACKUP DATABASE
BACKUP LOG
Привилегия на выполнение инструкции CREATE также подразумевает привиле-
гию на выполнение соответствующих инструкций ALTER и DROP.
ON { [объект] [(столбец [...])]
Указывается объект, право доступа к которому назначается. Это предложение не
требуется при присвоении системных привилегий. Если объект представляет
собой таблицу или представление, вы можете при желании указать привилегии
для конкретных столбцов. Для таблицы или представления вы можете предостав-
лять привилегии SELECT INSERT, UPDATE, DELETE и REFERENCES. Для столб-
цов таблиц и представлений или пользовательской функции вы можете назначать
только привилегии SELECT и UPDATE. Для хранимой процедуры и расширенной
хранимой процедуры вы можете назначать привилегию EXECUTE. Для пользова-
Справочник по командам SQL | 399
тельских функций вы также можете присваивать привилегии REFERENCES. При-
вилегии REFERENCES являются необходимыми для функций и представлений,
созданных при помощи предложения WITH SCHEMABUILDING.
ТО {имя_получателя [,...] | роль [,...] | PUBLIC | GUEST}
Имя пользователя или роли, которому назначается привилегия. Можно указать не-
сколько получателей привилегии, перечислив их имена через запятую. Чтобы пре-
доставить привилегии роли PUBLIC, используйте ключевое слово PUBLIC, подра-
зумевается, что эта роль включает всех пользователей. Платформа SQL Server
также поддерживает роль с именем GUEST, которую используют все пользовате-
ли, которые не имеют никаких других учетных записей в базе данных. Поскольку
SQL Server позволяет использовать две разные модели безопасности (одна, осно-
ванная на базе данных, а другая - на операционной системе Windows), вы можете
предоставлять привилегии пользователю SQL Server, пользователю Windows,
группе Windows или роли базы данных SQL Server. В качестве имени получателя
можно указать любой из упомянутых вариантов.
WITH GRANT OPTION
Позволяет получателю назначать указанную привилегию другим пользователям
и ролям. Использовать предложение WITH GRANT OPTION можно только приме-
нительно к объектным привилегиям.
AS {группа | роль}
Указывается альтернативный пользователь или группа, имеющая в базе данных право
выполнять инструкцию GRANT. Вы можете использовать предложение AS для предос-
тавления привилегий так, как если бы сеанс, в котором происходит назначение приви-
легий, являлся частью контекста группы или роли, отличной от текущей.
Привилегии можно присваивать только в текущей базе данных, и их нельзя при-
сваивать сразу в нескольких базах.
Модель безопасности SQL Server несколько отличается от моделей других
описываемых здесь платформ (и несколько отличается от стандарта
ANSI). Как и в стандарте ANSI, в SQL Server инструкция GRANT использу-
ется для присвоения конкретных привилегий пользователю или роли, а ин-
струкция REVOKE - для удаления этих привилегий. В SQL Server эти коман-
ды дополняет команда DENY, синтаксис которой практически не отлича-
ется от синтаксиса команды REVOKE.
Инструкция DENY в SQL Server позволяет администратору базы данных
полностью запрещать некоторые привилегии пользователя или группы.
Чтобы привилегии можно было предоставлять снова, этот запрет нужно
сначала снять. Инструкция DENY имеет приоритет перед инструкциями
GRANT и REVOKE. Инструкцию DENY можно применять для того, чтобы
полностью снять все привилегии с пользователя, который иначе мог бы по-
лучать привилегии в соответствии с членством в группах Windows или на-
значенными ролями в базе данных SQL Server.
400 | Глава 3. Справочник по инструкциям SQL
В SQL Server существует система приоритета прав доступа. Так, если у пользова-
теля есть привилегия, присвоенная ему как пользователю, но эта привилегия отменена
на уровне группы (членом которой этот пользователь является), то он теряет эту при-
вилегию на обоих уровнях.
В SQL Server также есть несколько фиксированных системных ролей с заранее задан-
ными правами доступа и к объектам, и к командам. Роли SQL Server таковы:
SYSADMIN
Может выполнять любые действия на сервере и имеет доступ ко всем объектам.
SERVERADMIN
Может настраивать параметры конфигурации сервера, а также запускать и оста-
навливать сервер.
SETUPADMIN
Может запускать процедуры и связанные серверы.
SECURITYADMIN
Может читать протоколы ошибок, изменять пароли, администрировать соедине-
ния и предоставлять привилегии CREATE DATABASE.
PROCESSADMIN
Может администрировать процессы, запущенные на SQL Server.
DBCREATOR
Может создавать, изменять и удалять базы данных.
D1SKADMIN
Может администрировать диски и файлы.
BULKADMIN
Может выполнять операции массового копирования (ВСР operations) и подавать
команду BULK INSERT (и обычные команды INSERT) применительно к таблицам
базы данных.
Пользователь с системной ролью SYSADMIN может предоставлять любые права
в любой базе данных на сервере. Пользователи с системной ролью DB_OIVNER
и DB SECURITYADMIN могут предоставлять права доступа к любой инструкции или
объекту в базе данных, которой они владеют. Системные привилегии могут предостав-
лять пользователи с системной ролью DBJDDLADMIN или SYSADMIN, а также владе-
лец базы данных.
Пользователи, которым назначены системные роли, могут назначать эти роли
другим пользователям и учетным записям, но не при помощи инструкции GRANT.
Чтобы присвоить пользователю системную роль, необходимо использовать систем-
ную хранимую процедуру SQL Server, которая называется sp_addsrvrolemember.
Помимо системных ролей уровня сервера существует несколько системных ролей
уровня базы данных. То есть, если предыдущие системные роли распространялись на
все базы данных сервера, следующие роли существуют в каждой базе данных, и область
их действия ограничивается конкретной базой. Эти роли следующие.
26-2447
Справочник по командам SQL | 401
DBOWNER
Может выполнять в базе данных функции всех прочих системных ролей плюс неко-
торые другие задачи по конфигурированию и обслуживанию базы данных.
DB ACCESSADMIN
Может добавлять и удалять в базе данных пользователей Windows и SQL Server.
DB-DATAREADER
Может читать данные во всех пользовательских таблицах базы данных.
DB_DATAWRITER
Может читать, добавлять, изменять и удалять данные во всех пользовательских
таблицах базы данных.
DBDDLADMIN
Может добавлять, изменять и удалять объекты в базе данных, а также выполнять
любые инструкции DDL.
DB SECURITYADMIN
Может осуществлять администрирование ролей и пользователей SQL Server,
а также прав доступа к объектам и инструкциям в базе данных.
DB_BA CKUPOPERA TOR
Может выполнять резервное копирование базы данных.
DB_DENYDATAREADER
Запрещается доступ к базе данных для чтения.
DB_DENYDA ТА WRITER
Запрещается доступ к базе данных для изменения данных.
Как и системные роли уровня сервера, системные роли уровня базы данных
нельзя назначать при помощи инструкции GRANT. Для этого необходимо использовать
системную хранимую процедуру SQL Server под названием sp_addrolemember.
В следующем примере пользователям emily и sarah присваиваются системные
привилегии CREATE DATABASE и CREATE TABLE. После этого группе editors на-
значается несколько привилегий в таблице titles. Затем члены группы editors смогут
назначать права доступа другим пользователям.
GRANT CREATE DATABASE, CREATE TABLE TO emily, sarah
GO
GRANT SELECT, INSERT, UPDATE, DELETE ON titles
TO editors
WITH GRANT OPTION
GO
В следующем примере права доступа предоставляются пользователю базы
данных с именем sam и пользователю Windows с именем jacob.
GRANT CREATE TABLE TO sam, [corporate\jacob]
GO
В следующем примере показано, как предоставить допуски, используя дополнитель-
ное ключевое слово AS. В этом примере пользователь emily является владельцем таблицы
402 | Глава 3. Справочник по инструкциям SQL
salesdetail и предоставляет привилегии SELECT роли salesmanager. Пользователь
kelly, которому присвоена роль sales_manager, хочет предоставить права SELECT поль-
зователю sam, но не может этого сделать, поскольку права были предоставлены роли
salesmanager, а не этому пользователю персонально. Чтобы обойти эту проблему,
пользователь kelly может использовать предложение AS.
-- Исходное присвоение привилегий
GRANT SELECT ON sales_detail TO salesjnanager
WITH GRANT OPTION
GO
-- Kelly передает привилегию пользователю Sam в качестве пользователя,
которому присвоена роль sale_manager
GRANT SELECT ON sales_detail TO sam AS sales_manager
GO
См. также
REVOKE
Оператор IN
Оператор IN позволяет указать список значений либо введенный явным образом, либо
при помощи подзапроса и сравнить некое значение с этим списком в предложении
WHERE или HAVING. Иными словами, вы можете спросить: «Есть значение А в этом
списке значений?»
Платформа Команда
DB2 Поддерживается
MySQL Поддерживается
Oracle Поддерживается с вариантами
PostgreSQL Поддерживается
SQL Server Поддерживается
Синтаксис SQL2003
{WHERE | HAVING | {AND | OR} }
значение [NOT] IN ({сравнит_знач1, сравнит_знач2 [,...] I подзапрос })
Ключевые слова
{WHERE | HAVING | {AND | OR} } значение
Разрешается использовать либо с предложением WHERE, либо с предложением
HAVING. Сравнение, входящее в предложение IN, -также может использоваться
в предложении AND или OR предложений WHERE или HAVING с несколькими
условиями. Параметр значение может относиться к любому типу данных, но обычно
Справочник по командам SQL | 403
представляет собой имя столбца, на который ссылается транзакция, или, возможно,
хост-переменную, если значение используется программно.
NOT
Дополнительное предложение, которое заставляет составлять результирующий
набор из значений, не входящих в список.
IN ({вычисляемое_знач!, вычисляемое_знач2 [,...] | подзапрос })
Определяется список сравнительных значений, по которым будет вестись сравне-
ние. Каждое сравншпелъное_значение должно относиться к тому же или совмести-
мому типу, что и исходное значение. Эти значения подчиняются стандартным пра-
вилам для типов данных. Например, строковые значения должны быть заключены
в кавычки, а целочисленные значения - не должны. В качестве альтернативы ука-
занию конкретных значений вы можете написать в скобках подзапрос, который
возвращает одно или несколько значений совместимого типа данных.
В следующем примере для SQL Server мы ищем в таблице employee базы данных HR
всех служащих, которые живут в штатах Джорджия, Теннеси, Алабама или Кентукки.
SELECT *
FROM hr..employee
WHERE home_state IN ('AL',’GA',’TN','KY')
Также мы можем найти в таблице employee базы данных HR всех служащих,
которые упоминаются в качестве авторов в базе данных PUBS.
SELECT *
FROM hr..employee
WHERE emp_id IN (SELECT au_id FROM pubs..authors)
Вы также можете использовать ключевое слово NOT для создания резуль-
тирующего набора на основе отсутствия какого-то значения. В следующем примере
штаб-квартира компании находится в Нью-Йорке, и многие сотрудники приезжают
из соседних штатов. Мы хотим увидеть всех таких сотрудников.
SELECT *
FROM hr..employee
WHERE home_state
NOT IN ('NY','NJ','MA','CT','RI','DE', 'NH')
Обратите внимание, что Oracle, полностью поддерживая функциональ-
ность стандарта ANSI, расширяет возможности оператора IN, позволяя
сравнивать несколько аргументов. Например, в Oracle допустимо использо-
вание следующей инструкции SELECT... WHERE...IN.
SELECT *
FROM hr..employee e
WHERE (e.emp_id, e.emp_dept) IN
( (242, 'sales'), (442, ’mfg'), (747, 'mkt) )
404 | Глава 3. Справочник по инструкциям SQL
См. также:
ALL/ANY/SOME
BETWEEN
EXISTS
LIKE
SELECT
SOME/ANY
Инструкция INSERT
Инструкция INSERT добавляет строки данных в таблицу или представление.
Платформа Команда
DB2 Поддерживается с вариантами
MySQL Поддерживается с вариантами
Oracle Поддерживается с вариантами
PostgreSQL Поддерживается
SQL Server Поддерживается с вариантами
Инструкция INSERТ позволяет записывать строки в таблицу при помощи одного
из следующих методов.
• Первый метод - это вставка одной или нескольких строк при помощи значений по
умолчанию, указанных для столбца в инструкции CREATE TABLE или ALTER
TABLE.
• Второй, наиболее распространенный метод - объявление реальных значений,
которые будут вставляться в каждый из столбцов записи.
• Третий метод, который заполняет таблицу сразу большим количеством записей, -
это вставка результирующего набора инструкции SELECT.
Синтаксис SQL2003
INSERT INTO [ONLY] {имя_таблицы | имя_представления} [(.столбец: [,...] )]
[OVERRIDE {SYSTEM | USER} VALUES]
{DEFAULT VALUES | VALUES [значение: [,...]) I инструкциЯ-SELECT }
Ключевые слова
[ONLY]
Используемое только в объектных таблицах, это ключевое слово запрещает встав-
лять в подтаблицы значения, которые вставляются в таблицу имя_таблицы.
гшя_таблицы | имя представления] [(столбец! [,...])]
Объявляется обновляемая целевая таблица или представление, в которое будут
вставляться данные. Вы должны иметь привилегию INSERT в таблице или, как
минимум, в тех столбцах, в которые будут вставляться значения. Если информа-
Справочник ио командам SQL | 405
ция о схеме не указывается (пример указания схемы: scott.employee), то подразу-
мевается текущая схема и пользовательский контекст. При желании вы можете
указать список столбцов целевой таблицы, в которые будут вставляться данные.
OVERRIDE {SYSTEM | USER} VALUES
Ключевое слово SYSTEM используется при вставке в столбец литерального значе-
ния, которое иначе будет заменено сгенерированным системой значением, напри-
мер, на автоматически создаваемый последовательный номер. Предложение
OVERRIDE USER VALUES выполняет обратную операцию, т. е. вставляет сге-
нерированные системой значения, даже если пользователь указал собственные.
DEFAULT VALUES
В таблицу вставляются все значения, определяемые параметром DEFAULT столбца
(значения по умолчанию), если таковые существуют, или вставляются пустые значе-
ния (NULL), если не существуют. (Конечно, параметр DEFAULТстолбца также может
быть определен как NULL.) Эта операция вставляет только одну запись. Возможно
появление ошибки, связанной с тем, как построены ограничения FOREIGN KEY
и UNIQUE в целевой таблице, если такие ограничения существуют.
VALUES (значение! [,...])
Указываются конкретные значения, которые будут вставляться в целевую таблицу.
Количество вставляемых значений должно в точности совпадать с количеством
столбцов в списке столбцов. Более того, значения должны быть совместимы по типу
и размеру со столбцами целевой таблицы. Каждое значение в списке значений соот-
ветствует столбцу в списке столбцов с тем же порядковым номером. Таким образом,
данные из первого значения попадают в первый столбец, данные из второго значе-
ния - во второй столбец и т. д. до тех пор, пока все столбцы не будут заполнены. При
желании вы можете использовать ключевое слово DEFAULT, чтобы вставить в стол-
бец значение, заданное по умолчанию, или NULL, чтобы вставить пустое значение.
uucmpyKifwiJSELECT
Строки, извлекаемые инструкцией данной SELECT, вставляются в целевую табли-
цу или представление. Значения, извлекаемые полнофункциональной инструкци-
ей SELECT, должны прямо соответствовать столбцам, указанным в списке столб-
цов. На целевую таблицу или представление нельзя ссылаться в предложениях
FROM или JOIN инструкции SELECT.
Общие правила
Вы можете вставлять значения в таблицы или представления, созданные на основе
одной таблицы. Инструкция INSERT... VALUES добавляет в таблицу одну строку данных,
используя литеральные значения, указанные в инструкции. В следующем примере
в таблицу authors вставляется новая строка, посвященная автору Jessica Rabbit.
INSERT INTO authors (au_id, au_lname, au_fname, phone,
address, city, state, zip, contract )
VALUES ('111-11-1111', 'Rabbit', 'Jessica', DEFAULT,
'1717 Main St', NULL, 'CA', '90675', 1)
406 | Глава 3. Справочник по инструкциям SQL
Каждому столбцу данной таблицы присваивается конкретное литеральное значе-
ние, за исключением столбца phone, которому присваивается значение по умолчанию
(определяемое в инструкции CREATE TABLE или ALTER TABLE), и столбца city,
которому присваивается пустое значение.
Важный момент, который нужно запомнить: вы можете пропускать некоторые
столбцы, устанавливая их в NULL (если они могут принимать значения NULL).
Операция вставки, которая оставляет пустыми некоторые значения, называется час-
тичной вставкой. Ниже приводится операция частичной вставки, которая выполняет
те же действия, что и предыдущая инструкция.
INSERT INTO authors (au_id, au_lname, au_fname, phone, contract )
VALUES ('111-11-1111', 'Rabbit', 'Jessica', DEFAULT, 1)
Объединение инструкции INSERT с вложенной инструкцией SELECT позволяет
быстро занести в таблицу одну или много строк из результирующего набора данных
инструкции SELECT. При использовании инструкции INSERT..SELECTдля вставки из
одной таблицы в другую важно обеспечить совместимость типов данных, возвращае-
мых инструкцией SELECT, с типами данных целевой таблицы. Например, чтобы вста-
вить данные из таблицы sales в таблицу new_sales, можно использовать следующую
инструкцию.
INSERT INTO sales (stor_id, ord_num, ord_date, qty, payterms,
title_id)
SELECT
CAST(store_nbr AS CHAR(4)),
CAST(order_nbr AS VARCHAR(2O)),
order_date,
quantity,
SUBSTRING(payment_terms,1,12),
CAST(title_nbr AS CHAR(1))
FROM new_sales
WHERE order_date >= 01-JAN-2005
-- извлекаются только наиболее новые записи
Вы должны через запятую указать столбцы таблицы, в которые будут помещаться
данные, заключив их в скобки. Этот список столбцов можно опустить, но тогда будут
использоваться все столбцы таблицы, в порядке их расположения. Столбцу с опущен-
ным значением будет присвоено значение по умолчанию (в соответствии с пара-
метром DEFAULT определения столбца таблицы) или, если это значение отсутствует,
NULL. Столбцы в списке столбцов можно указывать в любом порядке, но нельзя
повторять их. Кроме того, столбцы и соответствующие им значения должны быть
совместимы по типу данных и размеру.
В первом из двух приводимых ниже примеров список столбцов опущен, а во
втором используются только значения по умолчанию.
Справочник по командам SQL | 407
INSERT INTO authors
VALUES (’111-11-1111', 'Rabbit', 'Jessica', DEFAULT,
'1717 Main St', NULL, 'CA', '90675', 1)
INSERT INTO temp_details
DEFAULT VALUES
Первая инструкция будет работать только в том случае, если все значения в списке
будут прямо соответствовать размерам и типам данных столбцов целевой таблицы.
При любом несоответствии будет возникать ошибка. Вторая инструкция будет рабо-
тать только в том случае, если для столбцов целевой таблицы определены значения по
умолчанию или если эти столбцы могут принимать пустые значения.
& <
Запуск инструкции INSERT без списка столбцов является очень плохой
практикой, поскольку инструкция перестанет выполняться, если целевая
таблица когда-либо подвергнется изменениям.
Советы и хитрости программирования
Инструкции INSERT никогда не будут выполняться в следующих ситуациях.
• Если типы данных столбца и значения не соответствуют друг другу.
• Если в столбце определено ограничение NOT NULL, а вставляется пустое значение.
• Если вставляется дублирующее значение в столбец с ограничениями PRIMARY
KEY vim UNIQUE.
• Если вставляемые значения не удовлетворяют требованиям проверочных (CHECK)
ограничений.
• Если вставляемое значение не соответствует ограничению FOREIGN KEY, по-
скольку не взято из объявленного первичного ключа другой таблицы.
Наиболее распространенная ошибка при выполнении инструкций INSERT - это не-
совпадение числа столбцов и числа значений. Случайный пропуск значения, соответст-
вующего столбцу - и возникает ошибка, которая препятствует выполнению инструкции.
Инструкция INSERT также не будет выполнена, если тип данных вставляемого
значения не совпадает с типом данных столбца целевой таблицы. Например, нельзя
вставить строку «Hello world» в столбец целочисленного типа. С другой стороны, не-
которые платформы автоматически и неявно выполняют преобразование некоторых
типов. Например, SQL Server автоматически преобразует дату в строковое значение,
пригодное для вставки в столбец VARCHAR.
Еще одна проблема, которая часто встречается при использовании инструкции
INSERT, - это несовпадение размера значения и соответствующего столбца. Напри-
мер, вставка длинной строки в столбец CHAR(5) или вставка очень большого целого
числа в столбец TINYINT вызовет проблему. В зависимости от используемой плат-
формы несовпадение размеров может вызвать прямую ошибку и откат транзакции
или же сервер базы данных может просто обрезать данные до нужной длины.
408 | Глава 3. Справочник по инструкциям SQL
Любой из этих результатов является нежелательным. Проблема также может воз-
никнуть при попытке вставить значение NULL в столбец, который не принимает
пустых значений.
•г»
Большинство проблем в инструкциях INSERT возникает, потому что про-
граммист не очень хорошо знает целевую таблицу. Перед тем, как созда-
вать инструкции INSERT, вы должны обязательно понять таблицу или
представление.
DB2
Платформа DB2 поддерживает инструкцию INSERT стандарта ANSI, за исключением
предложения OVERRIDE, и включает несколько дополнительных синтаксических кон-
струкций, управляющих параметрами изоляции транзакций.
INSERT INTO имя_габлицы [(столбец1 I )]
{VALUES i VALUES (значение1 I инструкция__5Е!ЕСТ }
[ WITH { RR | RS I CS | UR }
Где:
INSERT INTO имяупаблицы [(столбец! [,...] )]
Указывается целевая таблица, представление или псевдоним на сервере DB2.
Целевая таблица или представление могут быть стандартными или объектными.
Представление может основываться на инструкции SELECT, содержащей предло-
жение UNION ALL, если только вставляемая строка полностью соответствует про-
верочным ограничениям одной таблицы.
WITH
Управляет уровнем изоляции транзакций для инструкции по обновлению данных. RR -
repeatable read (воспроизводимое чтение), RS - read stability (стабильность чтения),
CS - cursor stability (стабильность курсора) и UR- uncommitted read (чтение незафик-
сированного). Полное описание уровней изоляции транзакций стандарта ANSI приво-
дится в разделе, посвященном инструкции SET TRANSACTION ISOLATION LEVEL.
Платформа DB2 строго придерживается следующих правил.
• Вставляемые значения должны быть совместимы с типом данных столбца.
• Целочисленные и строковые значения не должны превышать допустимого раз-
мера данных столбца.
• Вставляемые значения должны соответствовать всем проверочным ограничениям
и ограничениям на уникальность.
• Значения, вставляемые во внешний ключ, должны существовать в соответст-
вующем столбце первичного ключа в другом месте базы данных.
Платформа DB2 поддерживает столбцы идентификаторов (identity), т. е. столбцы,
в которых генерируются равномерно возрастающие значения. При вставке в столбец
идентификатора DB2 генерирует новое значение для этого столбца идентификатора. Эти
Справочник по командам SQL | 409
столбцы создаются либо с опцией GENERATED ALWAYS, либо с опцией GENERATED
BY DEFAULT. Если столбец определяется как GENERATED ALWAYS, то вам не нужно
указывать значение для этого столбца. Оставьте здесь значение по умолчанию. Если
столбец определяется как GENERATED BY DEFAULT, вы можете вставить в него собст-
венное значение (непосредственно или при помощи подзапроса) или позволить DB2 сге-
нерировать его. В следующих примерах предполагается, что emp_id - это столбец иден-
тификатора, определенный как GENERATED ALWAYS.
INSERT INTO employee (emp_id, emp_lname, emp_fname)
VALUES (DEFAULT, :var_lname, :var_fname)
INSERT INTO employee (emp_lname, emp_fname)
VALUES (:var_lname, :var_fname)
Обе приведенные инструкции будут выполняться без ошибок.
MySQL
Платформа MySQL поддерживает несколько опций инструкции INSERT, которые
позволили этой платформе заслужить репутацию высокоскоростной.
INSERT [LOW_PRIORITY | DELAYED] [IGNORE]
[INTO] [[имя_базы_данных.]владелец.]имя_таблицы [(столбец1 [,...])]
{VALUES (значение1 [,...]) | инструкция_5Е1.ЕСТ |
SET столбец1=значение1, столбец2=значение2 [,...]}
Где:
LOWPRIORITY
Задерживает выполнение инструкции INSERT до тех пор, пока никакие другие
клиенты не будут читать таблицу. Ожидание может быть довольно длительным.
Предложение LOW PRIORITY не следует использовать в таблицах MylSAM, по-
скольку становится невозможной параллельная вставка.
DELAYED
Позволяет клиенту сразу продолжать работу, даже если вставка еще не завершена.
IGNORE
MySQL не будет пытаться вставлять записи, которые могут дублировать значения
в первичном или уникальном ключе. В противном случае (без этого предложения)
вставка завершится ошибкой, если произойдет такое дублирование. Если дуб-
лирование происходит при указанном предложении IGNORE, дублирующиеся
записи игнорируются, а остальные записи вставляются.
SET столбец = значение
Альтернативная синтаксическая конструкция, которая позволяет указывать значе-
ния целевых столбцов по именам.
Платформа MySQL не поддерживает предложения DEFAULT VALUES
и OVERRIDE стандарта ANSI.
410 | Глава 3. Справочник по инструкциям SQL
Платформа MySQL обрезает часть значения при несовпадении размеров или
типов данных. Так, если вы вставляете значение «10.23 X» в столбец с десятичными
дробями, то из вставляемого значения будет вырезан фрагмент «...X». Если вы попы-
таетесь вставить в столбец числовое значение, выходящее за пределы допустимого
диапазона для этого столбца, то MySQL обрежет это значение. Вставка некорректного
значения даты-времени приведет к тому, что в столбец будет вставлено нулевое значе-
ние. Вставка строки «Hello World» в столбец CHAR(5) приведет к тому, что значение
будет обрезано до пяти символов («Hello»). Обрезание строки применяется в столбцах
типов CHAR, VARCHAR, TEXT и BLOB.
Oracle
Реализация инструкции INSERT в Oracle позволяет вставлять данные в указанную таб-
лицу, представление, раздел, подраздел или объектную таблицу. Также поддержи-
ваются дополнительные расширения, такие, как вставка записей сразу в несколько
таблиц и вставка по условию. Синтаксис следующий.
-- стандартная инструкция INSERT
INSERT [INTO] {имя_таблицы [ [SUB]PARTITION (имя_раздела)] |
(подзапрос) [WITH {READ ONLY j CHECK OPTION
[CONSTRAINT имя_ограничения] }] |
TABLE (коллекция) [(+)]} [псевдоним]
[(столбец1 [,...])]
{VALUES (значение1 [,...]) [RETURNING выражение1 [,...]
INTO переменная1 [,...]] I
SELECT_statement [WITH {READ ONLY |
CHECK OPTION [CONSTRAINT имя_ограничения]} }
-- условная инструкция INSERT
INSERT {[ALL | FIRST]} WHEN условие
THEN cTaHflapTHan_HHCrpyKpnB_INSERT
ELSE CTaHflapTHaB_HHcrpyKpnn_INSERT
Где:
INSERT [INTO]
Одна Или несколько строк вставляются в одну таблицу, представление, материали-
зованное представление или подзапрос. Ключевое слово INTO является необяза-
тельным. Вы можете вставить одну строку, используя предложение VALUES, или
несколько строк, используя подзапрос.
имя_таблицы [[SUB]PARTITION (имя_раздела)]
Указывается, куда будут вставляться данные. Это может быть таблица, представление,
материализованное представление или подзапрос. Для точного указания цели параметр
имя_табтщы можно превратить в [схема.]имя_таблицы[@связь_с_базой__данных].
При желании вы можете указывать схему и удаленный адрес [@связь_с_базой_данных]
цели. Если же вы их не укажете, будет подразумеваться текущая схема и локальная
база данных. При желании вы можете при помощи параметра имяраздела указать
Справочник по командам SQL | 411
раздел (PARTITION) или подраздел (SUBPARTITION), в который будут вставляться
данные, если только не используется объектная таблица или объектное представление.
подзапрос [WITH {READ ONLY | CHECK OPTION [CONSTRAINT имя ограничения]}]
Oracle будет вставлять записи в базовую таблицу или таблицы подзапроса, где
подзапрос - это инструкция SELECT с обычной структурой. По сути, при помощи
подзапроса вы создаете представление «на ходу» и эффект будет тот же самый,
как и при вставке в представление. Это основной способ вставки значений в не-
сколько таблиц одновременно. Все столбцы, определяемые в подзапросе, во всех
его таблицах, должны иметь соответствующее значение для вставки, в противном
случае возникнет ошибка. Многотабличная вставка должна иметь форму подза-
проса. При применении подзапросов можно использовать следующие параметры.
WITH READ ONLY
Показывает, что таблицу, к которой обращается подзапрос, нельзя обновлять
до его завершения.
WITH CHECK OPTION [CONSTRAINT имя .ограничения]
Показывает, что в таблицу или представление нельзя вставлять строки, не
удовлетворяющие проверочному (CHECK) ограничению имя_ограничения.
TABLE (коллекция) [(+)]} [псевдоним]
Платформа Oracle должна обрабатывать коллекцию как обычную цель (т. е. как
таблицу или представление) независимо оттого, представляет ли она собой подза-
прос, столбец, функцию или конструктор коллекций. В любом случае табличная
коллекция должна возвращать вложенную таблицу или набор значений VARRAY.
Поскольку конструкции могут быть очень длинными, вы можете дополнительно
указывать псевдонимы. Псевдонимы нельзя использовать при многотабличной
вставке.
[(столбец! [...])]
Указываются столбцы, в которые будут вставляться данные. Если вы не укажете
столбцы, Oracle будет предполагать, что предложение VALUES или столбцы, возв-
ращаемые подзапросом, в точности соответствуют столбцам целевой таблицы.
Если вы не укажете значения для столбца, определенного как NOT NULL и не
имеющего значения по умолчанию, то возникнет ошибка.
VALUES (значение! [,..]) [RETURNING выражение! [,...] INTO переменная! [,...]]
Значения вставляются в целевую таблицу или представление. Как и в стандарте
ANSI, для каждого столбца должно быть указано соответствующее значение, хотя
в качестве значения можно указывать DEFAULT или, если столбец принимает
пустые значения, можно указать литеральный NULL. Ключевое слово DEFAULT
нельзя использовать при вставке в представления. При многотабличной вставке
предложение VALUES должно возвращать соответствующее значение для каждого
элемента, выбираемого подзапросом. Синтаксис следующий.
RETURNING выражение!
Извлекаются строки, которые вставляет данная операция. Выражение, воз-
вращаемое инструкцией, часто представляет собой вставляемое значение,
но это может быть и другое значение. Например, предложение RETURNING
412 | Глава 3. Справочник по инструкциям SQL
можно использовать для поиска значения автоматически генерируемого
первичного ключа. Операции, работающие с одной строкой, сохраняют
результаты в хост-переменных или переменных PL/SQL, а операции, рабо-
тающие с множеством строк, сохраняют их в массивах связывания (bind array).
Предложение RETURNING можно использовать в таблицах, представлени-
ях, основанных на одной таблице, и материализованных представлениях.
Предложение RETURNING нельзя использовать при многотабличной встав-
ке.
INTO переменная!
Указываются переменные, в которых будут храниться значения, возвращае-
мые предложением RETURNING. Вы должны объявить соответствующую
хост-переменную или переменную PL/SQL для каждого выражения в пред-
ложении RETURNING. Нельзя использовать предложение INTO для сохранения
данных типа LONG, для объектов удаленных баз данных, для представлений
с триггерами INSTEAD OF или для параллельновыполняемых инструкций
INSERT, UPDATE или DELETE.
ALL
Выполняется многотабличная операция вставки. Предложение ALL применяется
только с подзапросами. Если не указано предложение WHEN, все данные, возвра-
щаемые подзапросом, без всяких условий вставляются в указанные таблицы. При
использовании предложения ALL с предложением WHEN выполняются условные
операции вставки, и все предложения WHEN проверяются независимо от резуль-
татов других операций WHEN. Если условие WHEN возвращает значение ИСТИНА,
Oracle выполняет соответствующее предложение INTO. Многотабличную вставку
нельзя сделать параллельной в индекс-таблицах или таблицах с индексом на
основе битовых карт. Такая вставка вообще не разрешена в следующих ситуациях.
• Целью является представление или материализованное представление.
• Целью является таблица на удаленном сервере.
• В инструкции INSERT используется выражение, в котором содержится коллек-
ция таблиц.
• В таблице требуется произвести вставку более чем в 999 столбцов.
• В подзапросе используется последовательность.
FIRST
Платформа Oracle будет проверять предложения WHEN по порядку, и как только
будет обнаружено первое выражение, возвращающее значение ИСТИНА, будет
выполнено соответствующее предложение INTO, а все прочие предложения
WHEN будут опущены.
WHEN условие THEN стандартная_инструкция_1Н5ЕРТ
Указывается условие, и, если это условие оказывается истинным, будет выполнена
операция вставки, указанная в предложении THEN. Условие проверяется для каж-
Справочник по командам SQL | 413
дого столбца в результирующем наборе данных подзапроса. Можно использовать
до 127 предложений WHEN.
ELSE стандартная_инструкция_Ш8ЕЕ Т
Выполняется, если не оказывается истинных условий WHEN.
Платформа Oracle позволяет применять стандартные операции вставки, описанные
в разделе, посвященном стандарту ANSI, такие, как INSERT...SELECT и INSERT... VALUES,
но также имеется очень много вариаций.
При вставке в таблицы, которым присвоены последовательности, обязательно ис-
пользуйте функцию имя_последовательности.пех!уа1, чтобы вставить в последова-
тельность следующий логический номер. Например, предположим, что вы используе-
те последовательность authors_seq для указания значения au_id при вставке значений
в таблицу authors.
INSERT authors (au_id, au_lname, au_fname, contract )
VALUES (authors_seq.nextval, 'Rabbit', 'Jessica', 1)
Извлекая значения для операции вставки, убедитесь, что между выражениями
в предложении RETURNING и переменными в предложении INTO имеется совпадение
один к одному. Выражения, возвращаемые данным предложением, не обязательно
должны быть теми же, которые упоминаются в предложении VALUES. Например,
следующая инструкция INSERT помещает запись в таблицу sales, и при этом помеща-
ет в переменную связывания совершенно другое значение.
INSERT authors (аи_id, au._lname, au_fname, contract )
VALUES ('111-11-1111', 'Rabbit', 'Jessica', 1)
RETURNING hire_date INTO :temp_hr_dt;
Обратите внимание, что предложение RETURNING возвращает значение
hire_date, даже если hire__date не является одним из значений, перечисленных в пред-
ложении VALUES. (В данном примере разумно предположить, что в столбец hire_date
было помещено значение по умолчанию.)
Ниже приводится пример многотабличной вставки в таблицу поиска, содержа-
щую список всех утвержденных проектов (jobs) компании.
INSERT ALL
INTO jobs(job_id, job_desc, min_lvl, max_lvl)
VALUES(job_id, job_desc, min_lvl, max_lvl)
INTO jobs(job_id+1, job_desc, min_lvl, max_lvl)
VALUES(job_id, job_desc, min_lvl, max_lvl)
INTO jobs(job_id+2, job_desc, min_lvl, max_lvl)
VALUES(job_id, job_desc, min_lvl, max_lvl)
INTO jobs(job_id+3, job_desc, min_lvl, max_lvl)
VALUES(job_id, job_desc, min_lvl, max_lvl)
SELECT job_identifier, job_title, base_pay, max_pay
FROM job_descriptions
WHERE job_status = 'Active';
414 | Глава 3. Справочник по инструкциям SQL
И также, чтобы конструкции могли быть еще более сложными, Oracle позволяет
использовать условные многотабличные инструкции INSERT.
INSERT ALL
WHEN job_status = 'Active' INTO jobs
WHEN job_status = 'Inactive' INTO jobs_old
WHEN job.status = 'Terminated' INTO jobs_cancelled
ELSE INTO jobs
SELECT job_identifier, job_title, base_pay, max_pay
FROM job_descriptions;
Заметьте, что если бы вы пропускали в целевой таблице столбцы NOT NULL
в приведенном выше примере, то вам было бы необходимо после каждого предложения
INTO ставить предложение VALUES. В следующем примере показан такой синтаксис.
INSERT FIRST
WHEN job_status = 'Active'
INTO jobs
VALUES!job_id, job_desc, min_lvl, max_lvl)
WHEN job_status = 'Inactive'
INTO joos_old
VALUES(job_id, job_desc, min__lvl, max__lvl)
WHEN job_statas = 'Terminated'
INTO jobs_canceiled
VALUES!jcb_id, job_desc, min_lvl, max_lvl)
WHEN job_status = 'Terminated'
INTO jobs_outsourced
VALUES!job_id, ]ob_desc, min_lvl, max_lvl)
ELSE INTO jobs
VALUES!job_id, job_desc, min_lvl, max_lvl)
SELECT job_identi-fier, job_r:itle, base_pay, max_pay
FROM job_descriptions;
Обратите внимание, что в приведенном выше примере предложение FIRST также
заставляет Oracle выполнить первое условие jobstatus = ‘Terminated’ и вставить записи
в таблицу jobs_cancelled, пропустив операцию вставки в таблицу jobs_outsourced.
Платформа Oracle позволяет вставлять данные в таблицу, раздел или представле-
ние (которые также называются «цель») при помощи обычных инструкций INSERT
или инструкций INSERT режима прямой вставки (direct-path). При обычной вставке
платформа Oracle обеспечивает ссылочную целостность и повторно использует сво-
бодное пространство таблицы-цели. При прямой вставке Oracle добавляет данные
в конец таблицы-цели, не заполняя свободных пространств в других местах таблицы.
При этом методе не используется буферный кеш и данные пишутся прямо в файлы,
отсюда и термин «прямая вставка».
Справочник по командам SQL | 415
Платформа Oracle позволяет использовать подсказки оптимизатору, для
обхода оптимизации запросов, определенной по умолчанию для инструкций
INSERT. Например, вы можете использовать подсказку APPEND, чтобы
инструкция INSERT работала в прямом режиме. За дополнительной
информацией о подсказках, которые можно использовать с инструкцией
INSERT, обращайтесь к документации производителя.
Режим прямой вставки увеличивает производительность при длительных, массиро-
ванных операциях вставки. Ниже приводится список ситуаций, в которых инструкция
INSERT будет выполняться в обычном режиме, а не в режиме прямой вставки.
Изменение данных при помощи инструкций UPDATE или DELETE до инструкции
INSERT в одной с ней транзакции. (Инструкции UPDATE и DELETE можно использо-
вать после инструкции INSERT режима прямой вставки.)
• Инструкция INSERT является распределенной или может стать таковой.
• Цель содержит столбец типа LOB или столбец объектного типа.
• Цель содержит кластерный индекс или индекс-таблицу.
• Цель содержит триггеры или ограничения, обеспечивающие ссылочную целостность.
• Цель реплицируется.
• Для инициализационного параметра ROW_LOCKING установлено значение INTENT.
Кроме того, в Oracle не разрешается посылать запросы к таблице (например, при
помощи инструкции SELECT) в той же самой транзакции после выполнения прямой
вставки в эту таблицу до тех пор, пока не будет подана команда COMMIT.
Платформа Oracle позволяет применять параллельные прямые вставки в несколь-
ко таблиц, но при вставке можно использовать только подзапросы, а не предложения
VALUES.
Вставка данных типа LOB и BFILE - дело довольно хитрое. Перед встав-
кой вы должны проинициализироватъ эти значения пустыми значениями
(NULL). Также сложна вставка в столбец RAW. Если вы вставляете
обычную строку в столбец RAW, то для всех будущих запросов к этому
столбцу будет использоваться перебор всех записей таблицы.
PostgreSQL
Платформа PostgreSQL поддерживает для инструкции INSERT стандарт ANSI. Не под-
держивается предложение ANSI SQL OVERRIDE SYSTEM GENERATED VALUES, но
во всем прочем синтаксис и функциональность соответствуют стандарту. Описание
синтаксиса и использования приводится в разделе «Синтаксис SQL2003».
416 | Глава 3. Справочник по инструкциям SQL
Платформа PostgreSQL пытается выполнить автоматическое приведение
типов, если выражения в предложении VALUE или списке элементов подза-
проса не совпадают с типами данных, определяемых для целевой таблицы
или представления.
SQL Server
Платформа SQL Server поддерживает для инструкции INSERT несколько расширений
стандарта ANSI. Поддерживается несколько функций для работы с наборами строк
(объяснения ниже), а также возможность вставлять результаты из хранимых процедур
и расширенных процедур прямо в целевую таблицу. Синтаксис инструкции INSERT
в SQL Server следующий.
INSERT [INTO] имя_таблицы [(столбец1 [,...])
{[DEFAULT] VALUES |
VALUES (переменная1 [,...]) |
инструкциЯ-SELECT |
EXEC[UTE] имя_процедуры { [[^параметр =] значение {[OUTPUT]} [,...] ] }
Где:
INSERT [INTO] имя_таблицы
Целью для вставки будет таблица, представление или функция, работающая с на-
борами данных (rowset functions). При вставке в представление инструкция INSERT
не может затрагивать более одной базовой таблицы представления, если их несколько.
Функции для наборов данных позволяют SQL Server получать данные из специаль-
ных или внешних источников, таких, как потоки XML, файловые структуры полно-
текстового поиска (особые структуры, которые используются в SQL Server для хра-
нения в базе данных таких вещей, как документы MS Word и презентации MS Power-
Point) и внешних источников данных (таких, как электронные таблицы MS Excel).
Примеры приводятся ниже в этом разделе. В настоящее время SQL Server под-
держивает для инструкции INSERT следующие функции для работы с наборами.
О PEN QUERY
Выполняется транзитная инструкция INSERT для связанного сервера. Это эф-
фективный способ выполнения вложенных инструкций INSERT во внешних
по отношению к SQL Server источниках данных. Источник данных должен
сначала быть объявлен как связанный сервер.
OPENROWSET
Выполняется транзитная инструкция INSERT для внешнего источника дан-
ных. Это предложение сходно с OPEN DATASOURCE, за исключением того,
что предложение OPENDATASOURCE только открывает источник данных, но
не передает в него инструкцию INSERT. Предложение OPENROWSET предна-
значается только для редкого, специального использования.
столбец! [,...]
Указывается один или несколько столбцов целевой таблицы. Список должен быть
заключен в скобки, и его элементы должны разделяться запятыми. SQL Server
27 - 2447
Справочник по командам SQL | 417
автоматически вставляет значения в столбцы IDENTITY, TIMESTAMP и столбцы
с ограничениями DEFAULT
DEFA ULT
Инструкция создаст новую строку, используя все значения по умолчанию, задан-
ные для данной таблицы.
EXEC[UTE] имя_процедуры {[[@параметр =] значение {[OUTPUT]} [,...]]}
Будет выполнена динамическая инструкция Transact-SQL, хранимая процедура, уда-
ленный вызов процедуры (Remote Procedure Call, RPC) или расширенная хранимая
процедура, а результаты будут сохранены в локальной таблице. имя_процедуры - это
имя той процедуры, которую вы хотите выполнить. Также вы можете использовать
любые параметры хранимой процедуры, указываемые как @параметр (знак @ являет-
ся обязательным), присваивать значения параметрам и при желании обозначить какой-
то параметр как выходной (OUTPUT). Столбцы, возвращаемые в результирующем
наборе данных, должны соответствовать по типу столбцам целевой таблицы.
Хотя SQL Server автоматически присваивает значения столбцам IDENTITY и TIMES-
TAMP, платформа не делает этого для столбцов UNIQUEIDENTIFIER. Любой из столб-
цов с первыми типами данных вы можете пропустить в списке значений и в списке
столбцов, однако нельзя пропускать столбцы UNIQUEIDENTIFIER. Чтобы сгенериро-
вать и вставить глобальный уникальный идентификатор (GUID), вы должны использо-
вать функцию NEWID().
INSERT INTO guid_sample (global_ID, sample_text, sample_int)
VALUES (NEWID( ), 'insert first record','10000')
GO
При переносе кода с платформы на платформу помните, что вставка пустой
строки (“”) в столбцы TEXT и VARCHAR в SQL Server приводит к созданию строки
с нулевой длиной. Это не то же самое, что значение NULL, как это интерпретируют
некоторые платформы.
В примерах инструкций INSERT...EXEC, приводимых ниже, сначала создается
временная таблица с именем #ins_exec_container. После этого операция вставки по-
лучает список элементов директории C:\temp и сохраняет его во временной таблице,
а вторая инструкция INSERТ выполняет динамическую инструкцию SELECT.
CREATE TABLE #ins_exec_container (result_text
VARCHAR(300) NULL)
GO
INSERT INTO #ins_exec_container
EXEC master..xp_cmdshell "dir c:\temp"
GO
INSERT INTO sales
EXECUTE ('SELECT * FROM sales_2002_Q4')
GO
418 | Глава 3. Справочник по инструкциям SQL
Такая функциональность может быть весьма полезна в хранимых процедурах,
если, например, вы хотите реализовать бизнес-логику при помощи хранимых про-
цедур Transact-SQL, определять состояние объектов в базе данных и вне ее, а затем
выполнять какие-то действия на основе этих результатов.
Платформа SQL Server позволяет использовать подсказки оптимизатору,
чтобы обойти заданную по умолчанию стратегию оптимизации для ин-
струкций INSERT. Этот тип настройки рекомендуется выполнять только
наиболее компетентным пользователям. Полная информация о том, какие
подсказки можно использовать с инструкцией INSERT, приводится в доку-
ментации производителя.
Оператор для наборов данных INTERSECT
Оператор INTERSECT извлекает идентичные строки из результирующих наборов
одного или нескольких запросов. В некотором отношении оператор INTERSECT очень
напоминает INNER JOIN.
INTERSECT относится к классу операторов для работы с наборами данных (set
operator). К другим таким операторам относятся EXCEPT и UNION. Все операторы
для наборов данных используются для одновременного манипулирования резуль-
тирующими наборами двух и более запросов, отсюда и их название.
Платформа Команда
DB2 Поддерживается с ограничениями
MySQL Не поддерживается
Oracle Поддерживается с ограничениями
PostgreSQL Поддерживается с ограничениями
SQL Server Не поддерживается
Синтаксис SQL2003
Технических ограничений на количество запросов в операторе INTERSECT не существует.
Общий синтаксис следующий.
<инструкция_8ЕЕЕСТ_1>
INTERSECT [ALL | DISTINCT]
[CORRESPONDING [BY (.столбец! столбец2, ...)] ]
< инструкция_8ЕЕЕСТ_2>
INTERSECT [ALL | DISTINCT]
[CORRESPONDING [BY (столбец! столбец2, ...)] ]
Справочник по командам SQL | 419
Ключевые слова
ALL
Включаются дублирующиеся строки из всех результирующих наборов.
DISTINCT
Дублирующиеся строки удаляются из всех результирующих наборов перед срав-
нением, проводимым оператором INTERSECT. Столбцы с пустыми (NULL) значе-
ниями считаются дублирующимися. Если не указано ни ключевое слово ALL, ни
DISTINCT, то по умолчанию подразумевается DISTINCT.
CORRESPONDING
Указывается, что возвращаться будут только те столбцы, которые имеют в обоих
запросах одно имя, даже если в обоих запросах используется обобщающий
символ (*).
BY
Указывается, что возвращаться будут только названные столбцы, даже если запросы
обнаруживают другие столбцы с соответствующими именами. Это предложение
должно использоваться вместе с ключевым словом CORRESPONDING.
Общие правила
Есть только одно важное правило, которое необходимо помнить при работе с опера-
тором INTERSECT.
Порядок и количество столбцов во всех запросах должно быть одинаково. Типы
данных соответствующих столбцов также должны быть совместимы.
Например, типы CHAR и VARCHAR совместимы. По умолчанию для резуль-
тирующего набора в каждом столбце будет использоваться размер, соответствующий
самому большому типу в каждом конкретном положении.
Советы и хитрости программирования
Ни одна из платформ не поддерживает предложение CORRESPONDING [BYстолбец!,
столбец2,...].
йГч
----
Ha платформах, которые не поддерживают оператор INTERSECT, вы
4 можете заменить его подзапросом FULL JOIN.
Согласно стандарту ANSI оператор INTERSECT имеет более высокий приоритет
по сравнению с другими операторами для работы с наборами, хотя на разных плат-
формах приоритет таких операторов обрабатывается по-разному. Вы можете явным
образом управлять приоритетом операторов, используя скобки. В противном случае
СУБД может выполнять их в порядке слева направо или от первого к последнему.
Согласно стандарту ANSI в запросе можно использовать только одно предложение
ORDER BY. Вставляйте его в самый конец последней инструкции SELECT Чтобы избе-
жать двусмысленности в указании столбцов и таблиц, обязательно присваивайте один
и тот же псевдоним всем соответствующим друг другу столбцам таблиц. Например:
420 | Глава 3. Справочник по инструкциям SQL
SELECT a.au_lname AS ’lastname’, a.au_fname AS ’firstname’
FROM authors AS a
INTERSECT
SELECT e.emp_lname AS 'lastname’, e.emp_fname AS ’firstname’
FROM employees AS e
ORDER BY lastname, firstname
Поскольку типы данных столбцов в разных запросах оператора INTERSECT могут
оказываться совместимыми, на разных платформах СУРБД могут встречаться разные
варианты работы со столбцами разной длины. Например, если столбец aulname из
первого запроса в предыдущем примере значительно длиннее, чем столбец
emplname из второго запроса, то разные платформы могут применять разные прави-
ла определения длины конечного результата. Но, вообще говоря, платформы будут
выбирать для результата более длинный (и менее ограниченный) размер.
Каждая СУРБД может применять свои собственные правила использования имени
столбца в том случае, если имена в списках столбцов различаются. Обычно исполь-
зуются имена столбцов первого запроса.
DB2
Платформа DB2 поддерживает ключевые слова INTERSECT и INTERSECT ALL стан-
дарта ANSI плюс дополнительное предложение VALUES.
{ инструкция_5Е\_ЦХ_1 | VALUES (выраж1 [,...] ) }
INTERSECT [ALL]
[CORRESPONDING [BY (столбец1, столбец2, ]
{ инструкция_SELECT_.? | VALUES (выраж2 [,...] ) }
INTERSECT [ALL]
[CORRESPONDING [BY (столбеЩ, столбец2, ...)] ]
Хотя инструкция INTERSECT DISTINCT не поддерживается, функциональным экви-
валентом является INTERSECT. Предложение CORRESPONDING не поддерживается.
Кроме того, типы данных LONG VARCHAR, LONG VARGRAPH1C, BLOB, CLOB,
DBCLOB, DATALINK и структурные типы не применяются в предложении INTERSECT,
но их можно использовать в предложении INTERSECT ALL.
Если в результирующем наборе данных есть столбец, имеющий одно и то же имя
во всех инструкциях SELECT, то это имя используется в качестве окончательного
имени для столбца, возвращаемого инструкцией. Если же в запросах для столбца
используются разные имена, то платформа DB2 сгенерирует для результирующего
столбца новое имя. После этого становится непригодным для использования в предло-
жениях ORDER BY и FOR UPDATE.
Если в одном запросе используется несколько операторов для работы с наборами
данных, то первым выполняется тот, который заключен в скобки. После этого порядок
выполнения будет слева направо. Тем не менее все операторы INTERSECT выпол-
няются до операторов UNION и EXCEPT, например:
Справочник по командам SQL | 421
SELECT empno
FROM employee
WHERE workdept LIKE ’E%'
INTERSECT
(SELECT empno
FROM emp_act
WHERE projno IN ('IF1000', 1IF2000’, ‘АОЗПО’)
UNION
VALUES ('AA0001'), CAB0002'), ('AC0003') )
В приведенном выше примере из таблицы employee извлекаются идентификаторы
(ID) всех служащих, работающих в департаменте, название которого начинается
с «Е». Однако идентификаторы извлекаются только в том случае, если они также суще-
ствуют в таблице учетных записей служащих с именем emp_act и участвуют в проектах
IF1000, IF200' и AD3110.
MySQL
Не поддерживается.
Oracle
Платформа Oracle поддерживает операторы для работы с наборами INTERSECT
и INTERSECT ALL, и при этом используется базовый синтаксис ANSI SQL.
<инструкция_5ЕЬЕСТ_ 1>
INTERSECT
< инструкция_5Е1_ЕСТ_2>
INTERSECT
Платформа Oracle не поддерживает предложение CORRESPONDING. Предложе-
ние INTERSECT DISTINCT не поддерживается, но функциональным эквивалентом
является INTERSECT. Платформа Oracle не поддерживает использование INTERSECT
в запросах в следующих ситуациях.
• Запросы со столбцами LONG, BLOB, CLOB, BFILE или VARRAY.
• Запросы содержат предложение FOR UPDATE или выражения с использованием
коллекций TABLE.
Если первый запрос оператора содержит выражения для отбора элементов,
используйте ключевое слово AS, чтобы присвоить псевдоним столбцу, получившемуся
в результате выражения. Кроме того, только первый запрос оператора работы с на-
борами может содержать предложение ORDER BY.
Например, найдем идентификаторы всех магазинов (stores), в которых были про-
дажи (sales).
SELECT stor_id FROM stores
INTERSECT
SELECT stor_id FROM sales
422 | Глава 3. Справочник по инструкциям SQL
PostgreSQL
Платформа PostgreSQL поддерживает такие операторы работы с наборами, как
INTERSECT и INTERSECT ALL, используя при этом стандартный синтаксис ANSI
SQL.
<SELECT инструкция^
INTERSECT [ALL]
<SELECT инструкция^
INTERSECT [ALL]
Платформа PostgreSQL не поддерживает операторы INTERSECT или INTERSECT
ALL в запросах с предложением FOR UPDATE. Платформа PostgreSQL не поддержи-
вает предложение CORRESPONDING. Инструкция INTERSECT DISTINCT не под-
держивается, но INTERSECT является функциональным эквивалентом.
Первый запрос операции с наборами не может содержать предложения ORDER BY
или LIMIT. Последующие запросы в операции INTERSECT или INTERSECT ALL могут
содержать эти предложения, но такие запросы следует заключать в скобки. В против-
ном случае крайнее правое предложение ORDER BY или LIMIT будет применяться ко
всей операции с наборами. Например, можно найти всех авторов (authors), которые
также являются служащими (employee) и чьи фамилии (last name, Iname) начинаются
с «Р».
SELECT a.au_lname
FROM authors AS a
WHERE a.au_lname LIKE 'P%'
INTERSECT
SELECT e.Iname
FROM employee AS e
WHERE e.Iname LIKE ’W%';
SQL Server
Оператор EXCEPT не поддерживается. Однако в качестве альтернативы вы можете
использовать операции NOT IN и NOT EXISTS совместно с коррелированным подзапро-
сом. За примерами обращайтесь к разделу «Оператор для наборов данных EXCEPT».
См. также
EXCEPT
SELECT
UNION
Справочник по командам SQL | 423
Оператор IS
Оператор IS определяет, является ли значение пустым (NULL) или нет.
Платформа Команда
DB2 Поддерживается
MySQL Поддерживается
Oracle Поддерживается
PostgreSQL Поддерживается
SQL Server Поддерживается
Синтаксис SQL2003
{WHERE | {AND | OR} } выражение IS [NOT] NULL
Ключевые слова
{WHERE | {AND | OR} } выражение IS NULL
Возвращает булево значение ИСТИНА, если выражение равно NULL, и значение
ЛОЖЬ, если выражение не равно NULL. Перед проверяемым выражением может
стоять ключевое слово WHERE или ключевые слова AND или OR.
NOT
Обращает утверждение. Инструкция будет возвращать булево значение ИСТИНА,
если выражение не равно NULL, и значение ЛОЖЬ, если выражение равно NULL.
Общие правила
Поскольку значение NULL является неопределенным, нельзя с помощью сравнения
определить, равно ли данное значение NULL или нет. Например, выражения X = NULL
и X <> NULL неразрешимы, поскольку значение, которому должно быть равно или не
равно X, неопределенно.
Вместо этого вы должны использовать оператор IS NULL. Не заключайте слово
NULL в кавычки, поскольку в этом случае СУРБД интерпретирует значение как слово
«NULL», а не как специальное значение NULL.
Советы и хитрости программирования
Некоторые платформы поддерживают использование операторов сравнения при про-
верке на NULL. Тем не менее все платформы, о которых мы рассказываем в этой
книге, в настоящее время поддерживают ANSI-синтаксис IS [NOT] NULL.
Иногда проверка на NULL сделает ваше предложение WHERE лишь немного
более сложным. Например, вместо простого предиката для тестирования значения
storid
SELECT stor_id, ord_date
FROM sales
WHERE stor_id IN (6630, 7708)
424 | Глава 3. Справочник по инструкциям SQL
вы можете использовать следующий предикат, учитывающий возможность того, что
stor_id может быть равен NULL.
SELECT stor_id, ord_date
FROM sales
WHERE stor_id IN (6630, 7708)
OR stor_id IS NULL
См также
SELECT
WHERE
Предложение JOIN
Предложение JOIN позволяет извлекать строки из двух и более логически связанных
таблиц. Можно определять множество разных условий и типов соединений, хотя типы
соединений на разных платформах весьма различаются.
Платформа Команда
DB2 Поддерживается с ограничениями
MySQL Поддерживается с вариантами
Oracle Поддержи ваегся
PostgreSQL Поддерживается с вариантами
SQL Server Поддерживается с ограничениями
Синтаксис SQL2003
FROM таблица [AS псевдоним] {CROSS JOIN |
{ [NATURAL] [_тип_соединения] JOIN соединяемая_таблица [AS псевдоним]
{ 0N условие~соединения1 [{AND|OR} условие_соединения2] [...] ] |
USING (столбец1 [,.. ]) ? }
[ ]
Ключевые слова
FROM таблица
Определяется первая таблица или представление в соединении.
NATURAL
Указывается, что соединение (внешнее или внутреннее) таблиц должно проводиться
по всем столбцам с идентичными именами. Соответственно не следует указывать
условия соединения при помощи предложений ON или USING. Запрос не будет
выполнен, если этот вид соединения будет производиться в таблицах, не содержащих
столбцов с одинаковыми именами.
Справочник по командам SQL | 425
тип_соединения JOIN соединяемая_таблица
Указывается тип соединения и вторая (и все последующие) таблицы в соединении.
Также вы можете определить псевдонимы для всех соединяемых_таблиц. Типы
соединений следующие.
CROSS JOIN
Создается продукт полного перекрестного соединения двух таблиц. Каждая
запись первой таблицы соединяется со всеми записями второй таблицы, что
создает результирующий набор огромных размеров. Это предложение дейст-
вует так же, как отсутствие условий соединения, и его результат также называ-
ется «координатным продуктом». Использовать перекрестные соединения не
рекомендуется.
[INNER] JOIN
Это предложение указывает, что несовпадающие строки в каждой таблице со-
единения будут отбрасываться. Если тип соединения согласно стандарту ANSI
не указан, этот тип принимается по умолчанию.
LEFT [OUTER] JOIN
Указывается, что записи будут возвращаться из таблицы, находящейся слева
от инструкции JOIN. Если запись, возвращаемая из левой таблицы, не имеет
соответствующей записи в правой таблице, запись все равно извлекается.
В этом случае в столбцах для значений из правой таблицы будут значения
NULL. Хорошей практикой является конфигурирование везде, где это возмож-
но, соединений как левосторонних внешних {LEFT OUTER), чтобы не смеши-
вать левосторонние и правосторонние соединения.
RIGHT [OUTER] JOIN
Указывается, что записи будут возвращаться из таблицы, находящейся справа от
инструкции JOIN. Если запись, возвращаемая из правой таблицы, не имеет соот-
ветствующей записи в левой таблице, запись все равно извлекается. В этом
случае в столбцах для значений из левой таблицы будут значения NULL.
FULL [OUTER] JOIN
Указывается, что возвращаться будут все строки из обеих таблиц независимо
от того, совпадают ли строки в таблицах. Всем столбцам, для которых нет со-
ответствующих значений в соединенной таблице, присваиваются значения
NULL.
UNION JOIN
Указывается, что возвращаться будут все столбцы в обеих таблицах и все
строки каждого столбца. Всем столбцам, для которых нет соответствующих
значений в соединенной таблице, присваиваются значения NULL.
AS псевдоним
Указывается псевдоним или краткое имя для соединяемой таблицы. При указании
псевдонима ключевое слово AS является необязательным.
ON условие_соединения
Соединяются строки таблицы, указанной в предложении FROM, со строками таб-
лицы, указанной в предложении JOIN. Можно использовать несколько предложе-
426 | Глава 3. Справочник по инструкциям SQL
ний JOIN, но они все должны основываться на общем наборе значений. Эти значе-
ния обычно содержатся в столбцах с одинаковыми именами и типом данных,
которые есть в обеих таблицах. Эти столбцы или, возможно, один столбец из
каждой таблицы называются ключом соединения или общим ключом. В большин-
стве случаев, но не всегда ключ соединения - это первичный ключ одной таблицы
и внешний ключ другой таблицы. Если данные в столбцах совпадают, соединение
можно установить.
Соединения также можно создавать при помощи предложения WHERE.
Этот метод часто называется тета-соединением.
Условия_соединения синтаксически описываются следующим образом (заметьте,
что типы соединения намеренно исключены из этого примера).
FROM имя_таблицы1
JOIN имя_таблицы2
ON имя_таблицы1. столбец! = имя_таблицы2. столбец2
[{AND|OR} имя_таблицы!.столбецЗ = имя_таблицы2.столбец4]
[...]
JOIN table_name3
ON имя_таблицы1. столбецА = имя_таблицыЗ. столбецА
[{ANDIOR} имя_таблицы 1. столбецЗ = имя_таблицы2.столбец4]
[JOIN... ]
Для создания предложения JOIN с несколькими условиями используется оператор
AND или OR. Также хорошей практикой является заключение каждой пары соеди-
няемых таблиц в квадратные скобки, если таблиц больше двух. Это значительно
упрощает чтение запроса.
USING (столбец! [,])
Предполагается условие равенства двух или более указанных столбцов,
имеющихся в обеих таблицах. Этот столбец (или столбцы) должен существовать
в обеих таблицах. Написать предложение USING можно несколько быстрее, чем
писать ...ON таблица!.столбецА = таблица?.столбецА, а результаты будут функ-
ционально эквивалентны.
Общие правила
Соединения позволяют извлекать записи из двух (или более) логически связанных
таблиц в один результирующий набор данных. Для выполнения такой операции
можно использовать описанную здесь инструкцию JOIN стандарта ANSI, или так на-
зываемое тета-соединение (theta join). Тета-соединения, в которых для определения
критерия фильтрации данных используется предложение WHERE, являются «старым»
способом соединения.
Справочник по командам SQL | 427
Например, у вас может быть таблица с именем employee, в которую записывается
информация обо всех сотрудниках, поступающих в вашу компанию. В таблице employee,
однако, не содержится подробной информации о работе, которую выполняет сотрудник.
Вместо этого в таблице employee содержится только идентификатор работы (jobid). Вся
информация о работе, например ее название (title) и описание (description), содержит-
ся в таблице, которая называется job. При помощи предложения JOIN вы легко
можете извлечь столбцы из обеих таблиц в один результирующий набор записей.
В следующих примерах запросов иллюстрируется разница между тета-соединением
и инструкцией JOIN стандарта ANSI.
/* тета-соединение */
SELECT emp_lname, emp_fname, job_title
FROM employee, jobs
WHERE employee.job_id = jobs. job_id;
/* ANSI-соединение */
SELECT emp_lname, emp_fname, job_title
FROM employee
JOIN jobs ON employee.job_id = jobs.job_id;
Если в одном запросе вы ссылаетесь на несколько столбцов, имена этих столбцов не
должны быть двусмысленными. Иными словами, столбцы должны либо быть уникаль-
ными, либо на них нужно ссылаться при помощи идентификатора таблицы.
В приведенном выше примере обе таблицы содержат столбец job_id, поэтому к ссылке
на этот столбец нужно добавлять идентификатор таблицы. Те столбцы запроса, которые
существуют не в обеих таблицах, не обязательно сопровождать идентификатором табли-
цы. Однако подобные запросы очень сложно читать. Ниже приводится лучший вариант
предыдущего примера с ANSI-соединением, поскольку в нем для обращения к таблице
используется краткий и легкий для чтения псевдоним е.
SELECT e.emp-lname, e.emp_fname, j.job_title
FROM employee AS e
JOIN jobs AS j ON e. job„.id = j.job_id;
Предыдущие примеры ограничивались эквисоединениями, т. е. соединениями со
знаком равенства (=). Однако вы можете использовать и большинство других операторов
сравнения. В частности, можно использовать соединения со знаками >, <, >=, <=, <> и т. п.
Нельзя производить соединение по большим двоичным объектам (т. е. BLOB)
и прочим большим объектам (CLOB, NCLOB и т. п.). Другие типы данных, как правило,
использовать можно.
Ниже приводятся примеры соединений всех типов.
CROSS JOIN
Ниже приводятся несколько примеров перекрестных соединений. В первом при-
мере показано тета-соединение, в котором опущены условия соединения. Второй
пример написан с использованием предложения CROSS JOIN. Последний запрос,
по сути, похож на первый: в предложении JOIN опущены условия соединения.
428 | Глава 3. Справочник по инструкциям SQL
SELECT *
FROM employee, jobs;
SELECT *
FROM employee
CROSS JOIN jobs;
SELECT *
FROM employee
JOIN jobs;
INNER JOIN
Ниже приводится внутреннее соединение, написанное с использованием более
нового синтаксиса.
SELECT a.au_lname AS ’first name’,
a.au.fname AS 'last name’,
p.pub_nameAS ’publisher’
FROM authors AS a
INNER JOIN publishers AS p ON a. city = p.city,
ORDER BY a.au_lname DESC
В таблице authors есть много авторов, но лишь несколько из них находятся
в городе, совпадающем с городом издателей, указанным в таблице publishers.
Например, приведенный выше запрос, выполненный в базе данных pubs SQL
Server, выдаст следующие результаты.
first name last name publisher
Carson Cheryl Algodata Infosystems
Bennet Abraham Algodata Infosystems
Данное соединение называется внутренним, поскольку только те записи, которые
удовлетворяют условию соединения в обеих таблицах, будут находиться «внутри»
соединения. Вы также можете выполнить такой же запрос на платформах с соот-
ветствующей поддержкой, заменив предложение USING на предложение ON.
SELECT a.au_lname AS 'first name',
a.au_fname AS 'last name',
p.pub_name AS 'publisher'
FROM authors AS a
INNER JOIN publishers AS p USING (city)
ORDER BY a,au_lname DESC
Результаты приведенного выше запроса будут те же самые.
LEFT [OUTER] JOIN
Хорошей практикой является конфигурирование везде, где это возможно, соеди-
нений как левосторонних внешних (LEFT OUTER), чтобы не смешивать лево-
сторонние и правосторонние соединения.
Справочник по командам SQL | 429
В следующем примере мы иллюстрируем левостороннее внешнее соединение,
запрашивая имя издателя для каждого автора (мы также можем заменить предло-
жение USING предложением ON, как показано в примере, посвященном предло-
жению INNER JOIN).
SELECT a.au_lname AS 'first name',
a.au_fname AS 'last name',
p.pub_name AS 'publisher'
FROM authors AS a
LEFT OUTER JOIN publishers AS p ON a.city = p.city
ORDER BY a.au_lname DESC
В приведенном выше примере для каждого автора будет выведено имя издателя,
если существует совпадение, или NULL, если совпадение не существует. Например,
приведенный выше запрос применительно к базе данных SQL Server с именем pubs
возвратит следующий результат.
first name last name publisher
Yokomoto Akiko NULL
White Johnson NULL
Stringer Dirk NULL
Straight Dean NULL
Все данные, которые извлекаются в столбцы слева (из таблицы authors) и не
имеют соответствующего значения в столбце справа (из таблицы publishers, воз-
вращают значение NULL. В результирующем наборе данных значения NULL на-
ходятся там, где нет совпадений данных с условием соединения.
RIGHT [OUTER] JOIN
Предложение RIGHT OUTER JOIN в основном идентично предложению LEFT
OUTER JOIN, за исключением того, что все сдвигается в таблицу, находящуюся
в правой стороне запроса. Ниже приводится пример запроса, выполняемого в базе
данных pubs SQL Server.
SELECT a.au_lname AS 'first name',
a.au_fname AS 'last name',
p.pub_name AS 'publisher'
FROM authors AS a
RIGHT OUTER JOIN publishers AS p ON a.city = p.city
ORDER BY a.au.lname DESC
Данная инструкция возвращает следующий результирующий набор данных.
first name last name publisher
Carson Cheryl Algodata Infosystems
Bennet Abraham Algodata Infosystems
NULL NULL New Moon Books
NULL NULL Binnet & Hardley
430 | Глава 3. Справочник по инструкциям SQL
Все данные возвращаются в правой стороне запроса (отсюда и название RIGHT
OUTER JOIN), а все столбцы слева, для которых не обнаруживается совпадений,
возвращают значения NULL. В результирующем наборе данных значения NULL
находятся там, где нет совпадений данных с условием соединения.
NATURAL [INNER | {LEFT | RIGHT}[ OUTER]] JOIN
Данные соединения заменяют предложения ON и USING, поэтому не используйте
ключевое слово NATURAL с предложениями ON п USING. Пример:
SELECT a.au_lname AS 'first name',
a.au_fname AS 'last name',
p.putrname AS 'publisher'
FROM authors AS a
NATURAL RIGHT OUTER JOIN publishers AS p
ORDER BY a.au_lname DESC
Приведенный запрос будет работать так же, как предыдущие, но только если в обеих
таблицах будет столбец с именем city, который будет единственным общим столб-
цом для этих таблиц. Примерно так же создаются с префиксом NATURAL и другие
типы соединений (INNER, FULL, OUTER).
FULL [OUTER] JOIN
Указывается, что возвращаться будут все записи всех таблиц независимо от совпа-
дений. Если совпадения не обнаруживаются, в результирующий набор помещаются
значения NULL. Обратите внимание, что ключевое слово OUTER является необя-
зательным. Мы возьмем наш предыдущий пример и перепишем его с использованием
предложения FULL JOIN.
SELECT a.au_lname AS 'first name',
a.au_fname AS 'last name',
p.pub_name AS 'publisher'
FROM authors AS a
FULL JOIN publishers AS p ON a.city = p.city
ORDER BY a.au_lname DESC
Полученный результирующий набор, по сути, является комбинацией резуль-
тирующих наборов отдельных запросов с соединениями типа INNER, LEFT
и RIGHT (некоторые записи были убраны для краткости).
first name last name publisher
Yokomoto Akiko NULL
White Johnson NULL
Stringer Dirk NULL
Dull Ann NULL
del Castillo Innes NULL
DeFrance Michel NULL
Carson Cheryl Algodata Infosystems
Справочник по командам SQL | 431
Blotchet-Halls Reginald NULL
Bennet Abraham Algodata Infosystems
NULL NULL Binnet & Hardley
NULL NULL Five Lakes Publishin
NULL NULL New Moon Books
NULL NULL Scootney Books
NULL NULL Ramona Publishers
NULL NULL GGG&G
Как можно видеть, при использовании FULL JOIN в некоторых полученных записях
пустые значения расположены справа, а данные - слева (LEFT JOIN), в некоторых -
все столбцы заполнены данными (INNER JOIN), а в некоторых - пустые значения
расположены слева, а данные - справа (RIGHT JOIN).
Советы и хитрости программирования
Если тип соединения явно не указан, то подразумевается INNER JOIN. Обратите вни-
мание, что существует много типов соединений, каждый из которых имеет свои пра-
вила и функциональность, описанные в разделе «Общие правила».
Как правило, при описании соединений следует предпочитать предложение JOIN
предложению WHERE. Это не только делает код более понятным и позволяет отличать
условия соединения от условий поиска, но также позволяет избегать ошибок, связан-
ных с реализациями внешних соединений с помощью предложений WHERE на неко-
торых платформах.
Мы, как правило, не рекомендуем использовать экономящие труд ключевые слова
типа NATURAL, поскольку это предложение автоматически не обновляется при изме-
нении структуры базовых таблиц. Следовательно, инструкции, в которых используют-
ся данные предложения, могут приводить к появлению ошибок при изменении струк-
туры таблицы, если структура запроса не изменяется.
Не все платформы поддерживают все типы соединений, так что обращайтесь
к описанию платформо-специфической поддержки соединений в соответствующих
разделах.
DB2
Соединения, включающие более двух таблиц, могут быть весьма сложны-
ми. Если в соединении участвует три и более таблицы, лучше подумать
о создании запроса, представляющего собой серию двухтабличных соедине-
ний.
Платформа DB2 поддерживает соединения INNER и OUTER с использованием пред-
ложения ON. Не поддерживаются синтаксические конструкции NATURAL и CROSS,
а также USING. Синтаксис предложения JOIN в DB2 выглядит следующим образом.
432 | Глава 3. Справочник по инструкциям SQL
FROM таблица [AS псевдоним]
{ {[INNER] | [ {LEFT | RIGHT | FULL} [OUTER]]}
JOIN соединяема^таблица [AS псевдоним]
{ ON условие_соединения1 [{AND|OR} условие_соединения2] [...] ] }
[...]
Примеры приводятся в разделе «Общие правила».
MySQL
Платформа MySQL поддерживает большую часть синтаксиса ANSI, за исключением
того, что соединения с префиксом NATURAL поддерживаются только для внешних, но
не для внутренних соединений. Синтаксис предложения JOIN в MySQL следующий.
FROM таблица [AS псевдоним]
{[STRAIGHT.JOIN соединяемая_таблица] |
{ {[INNER] | | [CROSS] |
[NATURAL] [ {LEFT | RIGHT | FULL} [OUTER]]}
JOIN соединяемая_таблица [AS псевдоним]
{ ON условие_соединения1 [{AND|OR} условие_соединения2] [...] ] |
USING (столбец1 [,...]) } } }
[...]
Где:
STRAIGHT JOIN
Заставляет оптимизатор соединять таблицы в том порядке, как они упоминаются
в предложении FROM.
Ключевое слово STRAIGHT JOIN функционально эквивалентно слову JOIN, за
исключением того, что соединения принудительно выполняются в порядке слева
направо. Эта опция нужна, потому что MySQL может, хотя и редко, соединять таблицы
в неверном порядке.
Oracle
Платформа Oracle полностью поддерживает стандартный синтаксис ANSI для предло-
жения JOIN. Однако в Oracle поддержка синтаксиса ANSI появилась, только начиная
с версии 9. Соответственно в более старом коде Oracle используются исключительно
соединения с предложением WHERE. В старом синтаксисе Oracle для внешних тета-
соединений поддерживалось добавление знака + к именам столбцов на стороне, про-
тивоположной внешней таблице. Старый синтаксис внешних тета-соединений
в Oracle исходит из того факта, что в таблицу, поставляющую строки с пустыми значе-
ниями, эти строки были добавлены. Платформа Oracle отражает этот факт, добавляя
«+» к имени столбца на стороне, противоположной направлению соединения.
Например, в следующем запросе производится соединение RIGHT OUTER JOIN
таблиц authors и publishers. Старый синтаксис Oracle будет выглядеть следующим
образом.
28 - 2447
Справочник по командам SQL | 433
SELECT a.au_lname AS 'first name',
a.au_fname AS 'last name',
p.pub_name AS 'publisher'
FROM authors a, publishers p
WHERE a.city(+) = p.city
ORDER BY a.au_lname DESO
Тот же самый запрос, написанный с использованием синтаксиса ANSI, будет вы-
глядеть так.
SELECT a.au_lname AS 'first name',
a.au_fname AS 'last name',
p.pub_nameAS 'publisher'
FROM authors AS a
RIGHT OUTER JOIN publishers AS p ON a.city = p.city
ORDER BY a.au_lname DESC
Дополнительные примеры с использованием предложения JOIN приведены в раз-
деле «Общие правила».
Платформа Oracle - единственная, которая позволяет использовать секциониро-
ванные внешние соединения (partitioned outer joins), которые полезны для заполнения
пустых мест в результирующих наборах, возникающих из-за фрагментированного
хранения данных. Например, предположим, что записи о продукции хранятся в табли-
це manufacturing с двумя ключами - день и идентификатор продукта. В таблице хра-
нятся записи, показывающие количество произведенного продукта в любой день,
когда продукция производилась, но отсутствуют строки, соответствующие дням, когда
продукция не производилась. Такая структура считается фрагментированной, по-
скольку в списке строк не отражены все дни и все продукты. Для проведения расчетов
и создания отчетов хорошо бы создать такой набор данных, в котором производство
каждого продукта было бы отражено по всем дням, независимо от того, производился
продукт или нет. Это можно просто сделать при помощи секционированного внешне-
го соединения, поскольку оно позволяет определить логический раздел и применить
внешнее соединение к каждому значению этого раздела. Ниже приводится пример
с таблицей manufacturing, которая соединяется при помощи внешнего секциониро-
ванного соединения с таблицей times, чтобы создать для каждого значения product_id
полный набор дат в указанном диапазоне.
SELECT times.time_id AS time, product_id AS id, quantity AS qty
FROM manufacturing
PARTITION BY (product_id)
RIGHT OUTER JOIN times
ON (manufacturing.time_id = times.time_id)
WHERE manufacturing.time_id
BETWEEN T0_DATE(' 01/Ю/О5', 'DD/MM/YY')
AND TO_DATE('06/10/05', 'DD/MM/YY')
ORDER BY 2, 1; '
434 | Глава 3. Справочник no инструкциям SQL
Ниже приводится выходной набор данных этого запроса.
time id qty
01-0СТ-05 101 10
02-0СТ-05 101
03-ОСТ-05 101
04-0СТ-05 101 17
05-0СТ-05 101 23
06-ОСТ-05 101
01-0СТ-05 102
02-0СТ-05 102
03-0СТ-05 102 43
04-ОСТ-05 102 99
05-0СТ-05 102
06-0СТ-05 102 87
Чтобы получить такой же результат без использования секционированного внеш-
него соединения, нужно писать более сложный и менее эффективный код.
PostgreSQL
Платформа PostgreSQL полностью поддерживает стандарт ANSI. Примеры приводят-
ся в разделе «Общие правила».
SQL Server
Платформа SQL Server поддерживает соединения типов INNER, OUTER и CROSS с ис-
пользованием предложения ON. SQL Server не поддерживает синтаксические кон-
струкции NATURAL и USING. Синтаксис инструкции JOIN в SQL Server следующий.
FROM таблица [AS псевдоним]
{ {[INNER] | | [CROSS] | [ {LEFT | RIGHT | FULL} [OUTER]]}
JOIN соединяемая__таблица [AS псевдоним]
{ ON условие_соединения1 [{AND|OR}
условие_соединения2] [...] ] }
[...]
Примеры приведены в разделе «Общие правила».
См. также
SELECT
WHERE
Справочник по командам SQL | 435
Оператор LIKE
Оператор LIKE позволяет указывать в предложении WHERE строковый шаблон для
проверки на совпадение в инструкциях SELECT, INSERT, UPDATE и DELETE. Строко-
вый шаблон может включать обобщающие символы. Конкретные обобщающие сим-
волы на разных платформах могут быть разные.
Платформа Команда
DB2 Поддерживается
MySQL Поддерживается с вариантами
Oracle Поддерживается
PostgreSQL Поддерживается с вариантами
SQL Server Поддерживается с вариантами
Синтаксис SQL2003
WHERE выражение [NOT] LIKE строковый_шаблон
[ ESCAPE отменяющая^оследовательность]
Ключевые слова
WHERE выражение LIKE
Возвращает булево значение ИСТИНА, если значение выражения соответствует
строковому_шаблону. Выражение может представлять собой столбец, константу,
хост-переменную, скалярную функцию или их комбинацию. Оно не может пред-
ставлять собой пользовательский тип или некоторые виды объектов LOB.
NOT
Инвертирует предложение. Возвращается булево значение ИСТИНА, если значе-
ние выражения не совпадает со строковым_шаблоном, и ЛОЖЬ, если совпадает.
ESCAPE отменяющая_после()овательность
Позволяет включать в поиск символы, которые в обычных условиях интерпре-
тировались бы как обобщающие символы.
Общие правила
Проверка по строковым шаблонам в предложении LIKE довольно проста, но есть несколько
правил, которые нужно запомнить.
• Значимыми являются все символы, включая пробелы перед строкой и после нее.
• С помощью предложения LIKE можно сравнивать разные типы данных, но строки
в них хранятся по-разному. В частности, вы должны знать о различиях между
типами данных CHAR, VARCHAR и DATE.
• Использование предложения LIKE может заставить систему отказаться от исполь-
зования индексов или использовать альтернативные, менее оптимальные индек-
сы, чем при простой операции сравнения.
436 | Глава 3. Справочник по инструкциям SQL
Стандарт ANSI в настоящее время поддерживает два обобщающих оператора,
которые поддерживаются всеми платформами, описываемыми в этой книге.
%
Соответствует любой строке.
_ (символ подчеркивания)
Соответствует одному любому символу.
В следующем примере первый запрос извлекает все записи о городах, в имени ко-
торых содержится фрагмент «ville». Второй запрос возвращает записи об авторах, имя
которых не похоже на Sheryl или Cheryl (а также Aheryl, Bheryl, Dheryl, 2heryl и т. п.).
SELECT * FROM authors
WHERE city LIKE '%ville%';
SELECT » FROM authors
WHERE au_fname NOT LIKE '_heryl';
Некоторые платформы поддерживают дополнительные обобщающие символы.
Они описываются ниже, в разделах, посвященных конкретным платформам.
Использование предложения ESCAPE позволяет проводить поиск по обоб-
щающим символам, имеющимся в строках в вашей базе данных. При использовании
этого механизма вы обозначаете некоторый символ как отменяющий символ, обычно
это тот символ, который никак не может появиться в строке. Например, вы можете на-
значить отменяющим символом тильду (~), если вы знаете, что она точно не может
встретиться в строке. Любой обобщающий символ, перед которым стоит отменяющая
последовательность, не считается обобщающим, а считается обычным символом.
Например, чтобы просмотреть столбец comment таблицы sales_detail (на SQL Server)
и определить, упоминали ли какие-нибудь покупатели о только что введенной скидке,
можно использовать такой код.
SELECT ord_id, comment
FROM sales_detail
WHERE comment LIKE ’%’%%' ESCAPE
В этом случае первый и последний символы % интерпретируются как обобщающие
символы, а второй символ % интерпретируется просто как символ %, поскольку перед
ним стоит отменяющая последовательность.
Советы и хитрости программирования
Польза предложения LIKE основывается на поддерживаемых им обобщающих опера-
торах. Предложение LIKE возвращает булево значение ИСТИНА, если при сравнении
обнаруживаются совпадающие значения.
Для функционирования предложения LIKE очень важна чувствительность к реги-
стру конкретной СУБД. Например, Microsoft SQL Server по умолчанию не учитывает
регистр (хотя его можно настроить соответствующим образом). Таким образом, SQL
Server будет считать строки DAD и dad одинаковыми. С другой стороны, платформа
Справочник по командам SQL | 437
Oracle учитывает регистр, и строки DAD и dad здесь будут разными. Вот пример,
позволяющий лучше проиллюстрировать это положение.
SELECT *
FROM authors
WHERE Iname LIKE 'LARS%'
Этот запрос для Microsoft SQL Server извлечет из таблицы authors записи, где
фамилия (Iname) имеет вид ‘larson’ или ‘lars’, хотя в запросе поиск определен с исполь-
зованием верхнего регистра (‘LARS%’). В Oracle этот запрос не найдет фамилий ‘Larson’
или ‘Lars’, поскольку Oracle производит сравнение с учетом регистра.
DB2
Платформа DB2 поддерживает синтаксис предложения LIKE стандарта ANSI
SQL2003. Поддерживаются обобщающие символы % и знак подчеркивания (_). Под-
держиваются отменяющие последовательности.
Платформа DB2 учитывает регистр, поэтому здесь реализация предложения LIKE
полностью чувствительна к регистру. Чтобы значения в разных регистрах всегда срав-
нивались без учета регистра, нужно использовать функцию UPPER или TRANSLATE.
Кроме того, DB2 неявно преобразует кодовую страницу шаблона_строки или отме-
няющей_последователъности к кодовой странице выражения, если только они не
определены с предложением FOR BIT DATA.
MySQL
Платформа MySQL поддерживает для предложения LIKE синтаксис стандарта ANSI.
Поддерживаются обобщающие символы % и знак подчеркивания ( _ ). Также под-
держивается предложение ESCAPE.
Кроме того, MySQL поддерживает специальные функции REGEXP и NOT RLIKE,
применяемые при проверке регулярных выражений. MySQL после версии 3.23.4 по
умолчанию не учитывает регистр.
Oracle
Платформа Oracle поддерживает для предложения LIKE синтаксис стандарта ANSI.
Поддерживаются обобщающие символы % и знак подчеркивания ( _ ). Также под-
держивается предложение ESCAPE. Синтаксис предложения LIKE в Oracle сле-
дующий.
WHERE выражение [NOT] {LIKE | LIKEC | LIKE2 |
LIKE4} строковый-Шаблон
[ESCAPE отменяющая_последовательность']
Специфичные для Oracle синтаксические элементы имеют следующие значения.
LIKEC
Используется полный набор символов UNICODE.
LIKE2
Используется набор символов UNICODE USC2.
438 | Глава 3. Справочник по инструкциям SQL
LIKE4
Используется набор символов UNICODE USC4.
Поскольку платформа Oracle учитывает регистр, следует включать выражение,
строковый-Шаблон или и то и другое в функцию UPPER. В этом случае вы всегда
будете сравнивать то, что нужно.
PostgreSQL
Платформа PostgreSQL поддерживает ANSI-синтаксис предложения LIKE. Поддержи-
ваются обобщающие символы % и знак подчеркивания ( _ ). Также поддерживаются
отменяющие последовательности.
PostgreSQL по умолчанию учитывает регистр. Для сравнения без учета регистра
в PostgreSQL существует ключевое слово ILIKE. Также вы можете использовать
оператор — как эквивалент LIKE и —* как эквивалент ILIKE, а также I— и !—* как
эквиваленты NOT LIKE и NOT ILIKE соответственно. Это все расширения стандарта
ANSI, которые существуют в PostgreSQL.
Например, следующие запросы функционально эквивалентны.
SELECT » FROM authors
WHERE city LIKE '%ville';
SELECT * FROM authors
WHERE city " '%ville’;
Поскольку в этих примерах используется нижний регистр, вы можете столкнуться
с проблемой учета регистра. То есть запрос ведет поиск по строке ‘%ville’ в нижнем
регистре, а таблица может содержать значения в верхнем регистре, которые не попа-
дут в результаты - ‘BROWNSVILLE’, ‘NASHVILLE’, ‘HUNTSVILLE’. Эту проблему
можно решить так, как показано в следующем примере.
-- преобразуем значения в верхний регистр
SELECT * FROM authors
WHERE city LIKE UPPER('%ville');
-- производим сравнение без учета регистра
SELECT * FROM authors
WHERE city '%ville';
SELECT * FROM authors
WHERE city ILIKE '%ville';
Вы должны знать (хотя это и выходит за рамки данной книги), что PostgreSQL
также поддерживает регулярные выражения POSIX. Подробности приводятся в опи-
сании платформы.
Справочник по командам SQL | 439
SQL Server
Платформа SQL Server поддерживает ANSI-синтаксис предложения LIKE. Поддержи-
ваются отменяющие последовательности. Поддерживаются также следующие допол-
нительные обобщающие операторы.
[] - соответствует любому значению из указанного набора, например [айс], или
диапазона, например [Л-п].
[Л] - соответствует любому символу, не входящему в указанный набор или диапазон.
Используя дополнительные обобщающие операторы SQL Server, вы получаете
дополнительные возможности. Например, вы можете извлечь записи об авторах,
фамилии которых Carson, Carsen, Karson или Karsen.
SELECT * FROM authors
WHERE au_lname LIKE '[CK]ars[eo]n'
Или вы можете извлечь записи об авторах, фамилии которых заканчиваются на
«arson» или «arsen», но не Larsen или Larson.
SELECT * FROM authors
WHERE au_lname LIKE '[A-Z~L]ars[eo]n'
Помните, что при выполнении операций сравнения строк с использованием
предложения LIKE значимыми являются все символы строки, включая
начальные и конечные пробелы.
См. также
SELECT, UPDATE, DELETE
WHERE
Инструкция MERGE
Инструкция MERGE напоминает инструкцию CASE в DML. Она объединяет инструк-
ции UPDATE и INSERT в одну, сохраняющую функциональность обеих.
По существу, инструкция MERGE проверяет записи в таблице-источнике и целе-
вой таблице. Если записи существуют в обеих таблицах, то эта инструкция на основе
заранее заданных условий обновляет записи в целевой таблице записями, взятыми из
таблицы-источника. Если в целевой таблице не оказывается записей, которые есть
в таблице-источнике, то они вставляются в целевую таблицу. Инструкция MERGE
появилась в версии SQL2003 стандарта ANSI.
Платформа Команда
DB2 Поддерживается
MySQL Не поддерживается
Oracle Поддерживается
PostgreSQL Не поддерживается
SQL Server Не поддерживается
440 | Глава 3. Справочник по инструкциям SQL
Синтаксис SQL2003
MERGE INTO {имя_объекта | подзапрос} [ [AS] alias ]
USING ссылка_на__таблицу [ [AS] псевдоним]
ON условия-поиска
WHEN MATCHED
THEN UPDATE SET столбец = { выражение | DEFAULT } [, ...]
WHEN NOT MATCHED
THEN INSERT [( столбец [, ...])] VALUES (выражение [, ...] )
Ключевые слова
MERGE INTO {имя_объекта | подзапрос}
Объявляется целевой объект для операции слияния. Целевой объект может пред-
ставлять собой таблицу или представление с возможностью обновления (с именем
имяобгъекта) или может быть подзапросом, создающим вложенную таблицу.
[AS] alias
Указывается необязательный псевдоним для целевой таблицы.
USING ссылка__на_таблш1у
Указывается источник для операции слияния: таблица, представление или подза-
прос.
ON условия_поиска
Указывается условие или условия, по которым оценивается совпадение таблицы
источника и целевой таблицы. Синтаксис по существу тот же, что и для предложе-
ния ON инструкции JOIN. Например, при слиянии записей, взятых из таблицы
newhireemp, с таблицей ешр может выглядеть следующим образом: ON
emp.emp_id = new_hire_emp.emp_id.
WHEN MATCHED THEN UPDATE SET столбец = { выражение | DEFAULT } [,...]
Объявляется, что если запись из таблицы-источника совпадает с записью из целе-
вой таблицы (по условию условиеугоиска), то происходит обновление одного или
нескольких указанных столбцов значениями, определяемыми выражением.
WHEN NOT MATCHED THEN UPDATE SET столбец = {выражение | DEFAULT} [,...]
Объявляется, что если запись из таблицы-источника не совпадает с записью из целе-
вой таблицы (по условию условиеуюиска), то происходит обновление одного или
нескольких указанных столбцов значениями, определяемыми выражением.
Общие правила
Правила использования инструкции MERGE достаточно просты.
• Предложения WHEN MATCHED и WHEN NOT MATCHED являются обязательными,
но их нельзя указывать несколько раз.
• Целевая таблица может представлять собой стандартную обновляемую таблицу,
обновляемое представление или обновляемый подзапрос.
• Если ссылка_на_таблицу представляет собой подзапрос, заключайте его в скобки.
Справочник по командам SQL | 441
• Предложение условие_поиска не должно содержать ссылок на пользовательские
функции и хранимые процедуры.
• Предложение условие j-юиска может содержать несколько элементов, которые раз-
деляются операторами AND или OR.
• Если в предложении WHEN NOT MATCHED опущен список столбцов, то будет
подразумеваться полный список всех столбцов целевой таблицы с их обычным
порядковым расположением.
• Другие правила использования инструкции MERGE самоочевидны. Например,
столбцы, упоминаемые в предложении WHEN MATCHED, должны быть обновляе-
мыми.
Советы и хитрости программирования
Инструкцию MERGE часто называют «наложением» (upsert), поскольку она позволяет
в одной операции или вставить набор данных в таблицу, или, если записи уже сущест-
вуют, обновить их новыми значениями.
Единственный сложный аспект инструкции MERGE - это принять саму идею
обработки инструкций INSERT и UPDATE по принципу или-или.
Предположим, что у нас есть две таблицы. В таблице ЕМР хранятся сведения обо
всех сотрудниках компании, которые успешно прошли 90-дневный испытательный
срок при поступлении на работу. Сотрудники, входящие в таблицу ЕМР, также могут
иметь несколько состояний - «работает», «не работает» и «уволен». Прием в компа-
нию каждого нового служащего записывается в таблицу NEWHIRE. Через 90 дней
записи переносятся в таблицу ЕМР, где описываются все обычные сотрудники. Одна-
ко, поскольку наша компания каждое лето принимает практикантов из колледжа,
очень вероятно, что у некоторых из наших новых сотрудников с прошлого года оста-
нутся записи в таблице ЕМР с состоянием «не работает». Эту бизнес-проблему
можно описать при помощи следующего псевдокода.
Для каждой записи в таблице NEW_HIRE
Найти соответствующую запись в таблице ЕМР
Если запись существует в таблице ЕМР
Обновить существующие данные в таблице ЕМР
Иначе
Вставить запись в таблицу ЕМР
Конец оператора Если
Конец оператора Для
Мы можем написать довольно длинную хранимую процедуру, которая будет про-
верять все записи в таблице NEWJHIRE, а затем по условию вставлять (INSERT)
в таблицу ЕМР записи о совершенно новых сотрудниках или обновлять (UPDATE)
записи возвращающихся практикантов. Но следующая инструкция MERGE стандарта
ANSI значительно упрощает этот процесс.
442 | Глава 3. Справочник по инструкциям SQL
MERGE INTO emp AS e
USING (SELECT * FROM new_hire) AS n
ON e. ernpno = n. ernpno
WHEN MATCHED THEN
UPDATE SET
e.ename = n.ename,
e. sal = n.sal,
e.mgr = n.mgr,
e.deptno = n.deptno
WHEN NOT MATCHED THEN
INSERT ( e.ernpno, e.ename, e.sal, e.mgr, e.deptno )
VALUES ( n.ernpno, n.ename, n.sal, n.mgr, n.deptno );
Как можно видеть, инструкция MERGE очень полезна при операциях ввода данных.
DBS
Платформа DB2 поддерживает для инструкции MERGE синтаксис стандарта ANSI.
MySQL
Не поддерживается.
Oracle
Платформа Oracle поддерживает инструкцию MERGE с очень небольшими вариациями,
которые почти все явно видны при сравнении схемы синтаксиса Oracle со схемой
синтаксиса ANSI.
MERGE INTO [схема.] {имя_обьекта | подзапрос} [псевдоним ]
USING [схема.]ссылка_на_таблицу [псевдоним]
ON ( условие_поиска )
WHEN MATCHED THEN
UPDATE SET столбец = { выражение | DEFAULT } [, . . . ]
WHEN NOT MATCHED THEN
INSERT [столбец [, ...] ) VALUES [выражение [, ...]
К различиям между стандартом ANSI и его реализацией в Oracle относятся сле-
дующие.
• Платформа Oracle не позволяет использовать ключевое слово AS для присвоения
псевдонима целевой таблице или таблице-источнику.
• Oracle требует заключать условие_поиска в скобки.
• В предложении WHEN NOT MATCHED требуется указывать список вставляемых
столбцов, хотя в стандарте ANSI это не является обязательным.
За дополнительной информацией обращайтесь к разделам «Общие правила»
и «Советы и хитрости программирования».
Справочник по командам SQL | 443
PostgreSQL
He поддерживается.
SQL Server
He поддерживается.
См. также
INSERT
JOIN
SELECT
SUBQUERY
UPDATE
Инструкция OPEN
Инструкция OPEN является одной из четырех команд, применяемых при работе с курсором,
наряду с DECLARE, FETCH и CLOSE. Курсоры позволяют обрабатывать данные по одной
строке, а не весь набор сразу. Инструкция OPEN открывает существующий на сервере
курсор, который был создан при помощи инструкции DECLARE CURSOR.
Курсоры имеют в реляционных базах особую важность, поскольку такие базы ос-
нованы на обработке наборов данных, а большинство клиентских языков програм-
мирования основываются на работе со строками. Так что курсоры позволяют прово-
дить построчные операции, в то время как реляционные базы данных оперируют
с полным набором записей.
Платформа Команда
DB2 Поддерживается с вариантами
MySQL Не поддерживается
Oracle Поддерживается
PostgreSQL Не поддерживается
SQL Server Поддерживается
Синтаксис SQL2003
OPEN имя_курсора
Ключевые слова
OPEN u.wij<ypcopa
Находится и открывается уже готовый курсор, созданный при помощи инструк-
ции DECLARE CURSOR.
444 | Глава 3. Справочник по инструкциям SQL
Общие правила
На самом общем уровне курсор должен быть:
1. создан при помощи инструкции DECLARE-,
2. открыт при помощи инструкции OPEN-,
3. работа с ним должна вестись при помощи инструкции FETCH-,
4. закрыт при помощи инструкции CLOSE.
Выполняя эти шаги, вы можете создать результирующий набор данных, сходный
с результатом работы инструкции SELECT, за исключением того, что вы можете рабо-
тать с каждой строкой результирующего набора отдельно. Предположим, например,
что вы создали и открыли в базе данных DB2 курсор с именем employee_cursor,
который содержит три столбца.
DECLARE CURSOR employee_cursor FOR
SELECT Iname, frame, emp_id
FROM employee
WHERE hire_date >= ’FEB-14-2004';
Создав курсор, вы можете теперь его открыть и отобрать данные в несколько хост-
переменных.
OPEN employee_cursor;
FETCH NEXT FROM employee_cursor
INTO :emp_last_name, :emp_first_name, :emp_id
Инструкция FETCH позволяет указать положение текущей строки для курсора.
Если вы еще не обращались к курсору, он будет располагаться на первой записи
результирующего набора. Вы можете оперировать значениями в этой строке при
помощи любого процедурного кода.
В следующем характерном примере кода SQL курсор открывается и производится
выборка всех значений имен (first name, fname) и фамилий (last name, Iname) авторов
из таблицы authors.
DECLARE employee_cursor CURSOR FOR
SELECT au_lname, au_fname
FROM pubs.dbo.authors
WHERE Iname LIKE 'K%'
OPEN employee_cursor
FETCH NEXT FROM employee_cursor
BEGIN
FETCH NEXT FROM employee.Cursor
END
CLOSE employee_cursor
Справочник по командам SQL | 445
Советы и хитрости программирования
Наиболее распространенная ошибка при работе с инструкцией OPEN - это отсутствие
правильного закрытия курсора. Хотя инструкция OPEN описывается здесь изолиро-
ванно, она должна всегда составлять группу с инструкциями DECLARE, FETCH
и CLOSE. Хотя, забыв закрыть курсор, вы не получите сообщения об ошибке, курсор
будет продолжать занимать память, другие ресурсы сервера и осуществлять блокиров-
ку до тех пор, пока он будет открыт. Например, если вы забудете закрыть курсоры, вы
можете столкнуться с такой проблемой, как утечка памяти, - каждый открытый
курсор занимает память до тех пор, пока не будет закрыт. Даже если вы не используе-
те курсор, он все равно будет занимать место, которое база данных могла бы исполь-
зовать как-то иначе. Так что потратьте немного времени и убедитесь, что все объяв-
ленные и открытые курсоры в конце концов закрываются.
Курсоры часто используются в хранимых процедурах и пакетах процедурного кода.
Они полезны, если вам нужно выполнить действия над отдельными строками, а не над
всем набором данных сразу. Тем не менее из-за того, что курсоры работают с отдельны-
ми строками, а не с наборами данных, они часто работают медленнее, чем другие спосо-
бы доступа к данным. Обязательно проведите серьезный анализ своего подхода. Исполь-
зуя вместо курсоров хорошо составленные предложения WHERE и JOIN, можно избе-
жать многих проблем, таких, как запутанные операции DELETE и очень сложные
инструкции UPDATE.
DB2
Платформа DB2 поддерживает для инструкции OPEN стандарт ANSI с парой допол-
нений.
OPEN имя_курсора [USING {имя_переменной1 [,,..] | DESCRIPTOR имя_дескриптора}~\
Специфические для DB2 синтаксические элементы следующие.
USING {имя_переменной! [,...] | DESCRIPTOR имя дескриптора}
Указывается список переменных для всех параметров подготовленной инструкции
SELECT. Если в инструкции DECLARE CURSOR подготовленная инструкция
SELECT использовалась с переменными, предложение USING использовать нель-
зя. (Если вы используете предложение USING, а параметров нет, предложение
USING игнорируется.) Элементы предложения USING следующие.
имя_переменной! [„..]
Указывается одна или несколько хост-переменных. Как можно предполагать,
каждая переменная соответствует параметру, стоящему на том же порядковом
месте. Помимо хост-переменных допустимо использование переменных-лока-
торов DB2 и переменных-файловых ссылок. Хост-переменные используются
для статического кода SQL.
DESCRIPTOR имя Дескриптора
Указывается область дескриптора (SQLDA), в которой содержится правильно
составленное описание динамической переменной (переменных) SQL. Пере-
менные дескриптора используются для динамического кода SQL.
446 | Глава 3. Справочник по инструкциям SQL
Например, в следующем коде для DB2 объявляются несколько хост-переменных
(с именами типа hostvarxxx) и динамических переменных (объявляются при помощи
инструкции PREPARE), которые затем используются в курсоре с именем dynamiccursor.
EXEC SQL BEGIN DECLARE SECTION;
static short hostvar_int;
char hostvar_vchar64[65]; (
char statement_str[200];
EXEC SQL END DECLARE SECTION;
EXEC SQL PREPARE statement_name
FROM :statement_str;
EXEC SQL DECLARE dynamic_cursor CURSOR
FOR statement_name;
EXEC SQL OPEN dynamic_cursor
USING :hostvar_int, ;hostvar_vchar64;
MySQL
He поддерживается
Oracle
Платформа Oracle полностью поддерживает стандарт ANSI, к тому же Oracle позволяет
передавать параметры прямо в курсор при его открытии. Делается это при помощи сле-
дующего формата.
OPEN имя_курсора параметр! [,...]
PostgreSQL
В PostgreSQL нет инструкции OPEN CURSOR. PostgreSQL неявно открывает курсор
при его создании инструкцией DECLARE.
SQL Server
Наряду со стандартной инструкцией OPEN SQL Server позволяет использовать гло-
бальные курсоры, для чего применяется следующий синтаксис.
OPEN [GLOBAL] имя_курсора
Где:
имя курсора
Указывается имя курсора или строковая переменная, содержащая имя курсора,
созданного ранее при помощи инструкции DECLARE CURSOR.
GLOBAL
Позволяет ссылаться на курсор многим пользователям, даже если им явным обра-
зом не присвоены права доступа к курсору. Без указания этой опции курсор будет
локальным.
Платформа SQL Server позволяет объявлять курсоры нескольких разных типов.
Если курсор объявлен как INSENSITIVE или STATIC, то инструкция OPEN создает вре-
менную таблицу для хранения результирующего набора данных курсора. Также если
Справочник по командам SQL | 447
курсор объявлен с опцией KEYSET, то автоматически создается временная таблица
для хранения набора ключей.
См. также
CLOSE CURSOR
DECLARE CURSOR
FETCH
SELECT
Предложение ORDER BY
Предложение ORDER BY определяет порядок сортировки результирующего набора
данных, возвращаемого инструкцией SELECT.
Платформа Команда
DB2 Поддерживается с ограничениями
MySQL Поддерживается с ограничениями
Oracle Поддерживается с вариантами
PostgreSQL Поддерживается с вариантами
SQL Server Поддерживается с ограничениями
Синтаксис SQL2003
ORDER BY {выражение_для_сортировки [COLLATE имя^сопоставления]
[ASC | DESC]} [,...]
Ключевые слова
ORDER BY
Указывается, в каком порядке будут отсортированы возвращаемые строки запроса.
Не следует ожидать, что данные будут отсортированы, если вы опустите предложе-
ние ORDER BY, даже если при этом вы указали предложение GROUP BY, и кажется,
что сортировка была проведена.
выражение_для_сортировки
Указывается тот элемент запроса, который будет определять порядок расположе-
ния данных в результирующем наборе. Можно задать несколько выражений для
сортировки. Обычно они представляют собой имена или псевдонимы столбцов из
запроса, но это могут быть также такие выражения, как (зарплата * 1.02). Стан-
дарт SQL92 позволял использовать порядковое расположение выражений для
сортировки. Эта функциональность больше не употребляется, и ее не следует ис-
пользовать в запросах SQL2003.
COLLATE имя_сопоставления
Подменяется заданное по умолчанию сопоставление для выражения_длясортировки
и для предложения ORDER BY используется сопоставление с именем имя_сопостав-
ления.
448 | Глава 3. Справочник по инструкциям SQL
[ASC | DESC]
Указывается, что выражение_для_сортировки должно возвращаться в восходя-
щем (ASC) или нисходящем (DESC) порядке.
Общие правила
В предложении ORDER BY столбцы должны быть перечислены в том порядке, в котором
они упоминаются в списке элементов инструкции SELECT, желательно с использованием
псевдонимов, если они есть. Пример:
SELECT aujname AS first_name, au_lname AS last_name
FROM authors
ORDER BY first_name, last_name
В предложении ORDER BY используется порядок сортировки от главного к второ-
степенному. Это означает, что результирующий набор сначала сортируется по первому
из указанных столбцов, затем одинаковые значения первого столбца сортируются по
второму столбцу, одинаковые значения второго столбца - по третьему столбцу, и т. д.
Индивидуальные параметры сортировки столбцов - COLLATE и ASC/DESC - не зави-
сят от других столбцов предложения ORDER BY. Таким образом, вы можете отсортиро-
вать результирующий набор по одному столбцу по возрастанию, затем перейти к сле-
дующему столбцу и отсортировать набор по убыванию.
SELECT au_fname AS first_name, au_lname AS last_name
FROM authors
ORDER BY au_lname ASC, au_fname DESC
Пустые значения (NULL) при сортировке всегда оказываются рядом (т. е. считаются
одинаковыми). В зависимости от платформы пустые значения могут собираться вверху
или внизу результирующего набора. Следующий запрос для SQL Server:
SELECT title, price
FROM titles
ORDER BY price, title
выдаст следующий результирующий набор (отредактирован для краткости).
title price
Net Etiquette
NULL
The Psychology of Computer Cooking NULL
The Gourmet Microwave 2.9900
You Can Combat Computer Stress!
Life Without Fear
2.9900
7.0000
Onions, Leeks, and Garlic: Cooking Secrets of the Me 20.9500
Computer Phobic AND Non-Phobic Individuals: Behavior 21.5900
But Is It User Friendly? 22.9500
29 - 2447
Справочник по командам SQL | 449
При помощи ключевых слов ASC и DESC можно помещать пустые значения
вверху или внизу результирующего набора. Конечно, все непустые значения также
будут располагаться по возрастанию или по убыванию.
В стандарте ANSI для предложения ORDER BY также поддерживается использо-
вание в выражении_для_сортировки столбцов, которые не упоминаются в списке
элементов инструкции SELECT. Например, в SQL2003 следующий запрос является
допустимым.
SELECT title, price
FROM titles
ORDER BY title_id
В приведенном примере можно видеть, что, хотя в запросе не выбирается столбец
title_id, этот столбец является главным в выражении_для_сортировки. Резуль-
тирующий набор возвращается отсортированным по title_id, даже если этот столбец
не входит в набор.
Советы и хитрости программирования
При использовании операторов для работы с наборами данных (UNION, EXCEPT,
INTERSECT) предложение ORDER BY может содержаться только в последнем запросе.
Не следует использовать предложение ORDER BY в подзапросах любого типа.
Несколько функциональностей, поддерживаемых в SQL92, в стандарте SQL2OO3
были удалены. Вы не должны использовать слдующее.
Ссылки на псевдонимы таблиц
Например, предложение ORDER BY e.emp_id следует заменить предложением
ORDER BY emp id. Если в имени столбца есть двусмысленность, используйте
псевдоним.
Ссылки на порядковое положение
Используйте явные псевдонимы столбцов.
Вы можете проводить сортировку не только по столбцам, но также по выражениям,
использующим имена столбцов и даже константы.
SELECT SUBSTRING(title,1,55) AS title, (price * 1,15) as price
FROM titles
WHERE price BETWEEN 2 and 19
ORDER BY price, title
При сортировке по выражениям, взятым из списка инструкции SELECT, нужно
использовать псевдонимы, чтобы упростить чтение ссылок в предложении ORDER BY
выражение_для_сортировки.
DBS
Платформа DB2 поддерживает синтаксис ANSI, за исключением опции COLLATE.
Кроме того, в этой платформе также есть расширение ORDER OF.
ORDER BY {ORDER OF имя_таблицы | выражение_для_сортировки
[{ASC | DESC}] }
450 | Глава 3. Справочник по инструкциям SQL
Где:
ORDER OF имя_таблицы
Заставляет платформу DB2 сортировать строки родительской таблицы так, как они
отсортированы в подзапросе. Чтобы лучше понять эту идею, вспомните, что DB2 под-
держивает сортировку на уровне подзапроса. Тем не менее отсортированный подза-
прос не будет возвращать отсортированный результирующий набор, если не использу-
ется предложение ORDER BY ORDER OF. Параметр имя_таблицы должен представ-
лять собой имя таблицы, на которую ссылается родительский запрос. Пример:
SELECT qty, price, order_nOr
FROM
(SELECT order_nbr, qty, price FROM sales_Ql_2005
UNION
SELECT order_nbr, qty, price FROM sales_Q2_2005
ORDER BY price, qty, order_nbr) AS ytd_sales
ORDER BY ORDER OF ytd_sales
Платформа DB2 по-прежнему поддерживает функции SQL92, такие, как
сортировка по порядковому положению. По умолчанию DB2 считает значения NULL
самыми большими.
Ниже приводится еще один пример подзапросов с сортировкой. Сначала мы соз-
даем представление с именем best, которое возвращает пять самых продаваемых книг
из таблицы sales, после чего мы находим авторов этих пяти самых продаваемых книг.
CREATE VIEW best(title) AS
SELECT title FROM sales
ORDER BY sold
FETCH FIRST 5 ROWS ONLY
SELECT author
FROM best JOIN authors ON best.title = author.title
ORDER BY ORDER OF best
Платформа DB2 не поддерживает использование предложения ORDER BY для
столбцов следующих типов данных: LONG VARCHAR, CLOB, LONG VARGRAPHIC,
DBCLOB, BLOB и DATAL1NK. Также DB2 не поддерживает сортировку по струк-
турным типам.
MySQL
Платформа MySQL поддерживает стандарт ANSI, за исключением предложения
COLLATE.
Не следует пытаться использовать в предложении ORDER BY столбцы с типом
BLOB, поскольку при такой сортировке используются только первые байты, количест-
во которых определяется параметром max_sort_length. По умолчанию MySQL ставит
пустые значения в самое начало при сортировке по возрастанию и в самый конец -
при сортировке по убыванию.
Справочник по командам SQL | 451
Oracle
Платформа Oracle поддерживает стандарт ANSI, за исключением предложения COLLATE.
Также поддерживаются предложения SIBLINGS и NULLS {FIRST | LAST}. Синтаксис пред-
ложения ORDER BY в Oracle следующий.
ORDER [SIBLINGS] BY
{выражение_для_сортировки [ASC | DESC] [NULLS {FIRST | LAST}]} [,...]
Специфичные для Oracle ключевые слова следующие.
ORDER [SIBLINGS] BY выражение д.ця сортировки
Результирующий набор запроса сортируется в порядке, определяемом выражени-
ем_для_сортировки. Выражение для сортировки может представлять собой имя
столбца, псевдоним, целое число, указывающее порядковое положение столбца, или
другое выражение (например, зарплата * 1.02). Предложение ORDER SIBLINGS BY
заставляет Oracle сохранять сортировку, определяемую иерархическим запросом
{CONNECT BY), а выражение_для_сортировки применять для сортировки равноправ-
ных членов иерархии.
NULLS {FIRST | LAST}
Предложения NULLS FIRST и NULLS LAST показывают, что записи, содержащие
значения NULL, должны при сортировке ставиться первыми или последними со-
ответственно. По умолчанию Oracle ставит пустые значения последними при
сортировке по возрастанию и первыми - при сортировке по убыванию.
Вы можете имитировать функциональность предложения COLLATE в одном сеансе,
используя функцию NLSSORT с параметром NLSSORT. Вы можете имитировать
функциональность предложения COLLATE для всех сеансов на сервере явным обра-
зом, используя инициализационный параметр NLS SORT, или неявно, используя ини-
циализационный параметр NLS_LANGUAGE.
Платформа Oracle продолжает поддерживать выведенные из употребления функ-
ции SQL92, такие, как сортировка по порядковому местоположению. Не следует при-
менять в предложении ORDER BY столбцы LOB, вложенные таблицы или столбцы
VARRAY.
PostgreSQL
Платформа PostgreSQL поддерживает стандарт ANSI, за исключением предложения
COLLATE. Также поддерживается расширение USING.
ORDER BY {выражение_для_сортировки1 [ASC | DESC | USING оператор]} [,...]
Где:
USING оператор
Указывается конкретный оператор сравнения. Так, вы можете проводить
сортировку по операторам >, <, =, >=, <= и т. д. Сортировка по возрастанию анало-
гична USING <, а сортировка по убыванию аналогична USING >.
452 | Глава 3. Справочник по инструкциям SQL
Платформа PostgreSQL при сортировке считает пустые значения (NULL) самыми
большими. Следовательно, эти значения будут находиться в самом конце при
сортировке по возрастанию и в самом начале - при сортировке по убыванию.
SQL Server
Платформа SQL Server поддерживает стандарт ANSI, включая и опцию COLLATE.
Например, следующий запрос возвращает имена авторов из таблицы authors, и при
этом используется сопоставление SQL Latin 1.
SELECT au_fname
FROM authors
ORDER BY au_fname
COLLATE S0L_Latin1_ger)eral_cp1_ci_as
Платформа SQL Server продолжает поддерживать выходящие из употребления
функции SQL92, в том числе возможность указывать столбцы для предложения
ORDER BY по их порядковому номеру.
По умолчанию SQL Server считает пустые значения большими, чем все прочие.
Не следует использовать в параметре вырсыселие_для_сортировки в SQL Server
столбцы типа TEXT. IMAGE и NTEXT.
См. также
SELECT
Инструкция RELEASE SAVEPOINT
Инструкция RELEASE SAVEPOINT удаляет одну или несколько ранее созданных в теку-
щей транзакции точек сохранения.
Платформа Команда
DB2 Поддерживается с вариантами
MySQL Не поддерживается
Oracle Нс поддерживается
PostgreSQL Не поддерживается
SQL Server Нс поддерживается
Синтаксис SQL2003
RELEASE SAVEPOINT имя_гочки_сохранения
Ключевые слова
имя_гпочки_сохранен1гя
Представляет собой именованную точку сохранения (или описание цели), которая
была создана в транзакции ранее, при помощи инструкции SAVEPOINT. Имя
точки сохранения должно быть уникальным в пределах транзакции.
Справочник по командам SQL | 453
Общие правила
Инструкция RELEASE SAVEPOINT используется в транзакции для удаления указанной
точки сохранения. Все точки сохранения, которые были созданы после указанной,
также будут удалены.
Для иллюстрации работы с точками сохранения в следующем коде мы вставим
несколько записей, создадим точку сохранения с именем firstsavepoint, а затем удалим ее.
INSERT authors (au_id, au_lname, au_fname, contract )
VALUES ('111-11-1111', 'Rabbit', 'Jessica', 1);
SAVEPOINT first_savepoint;
INSERT authors (au_id, au_lname, au_fname, contract )
VALUES ('277-27-2777', 'Fudd', 'E.P.', 1);
INSERT authors (au_id, au_lname, au_fname, contract )
VALUES ('366-36-3636', 'Duck', 'P.J.', 1);
RELEASE SAVEPOINT first_savepoint;
COMMIT;
В этом примере удаляется точка сохранения firstsavepoint, после чего в таблицу
authors вставляются все три записи.
В следующем примере мы выполним те же действия, но используем больше точек
сохранения.
INSERT authors (au_id, au_lname, au_fname, contract )
VALUES ('111-11-1111', 'Rabbit', 'Jessica', 1);
SAVEPOINT first_savepoint;
INSERT authors (au_id, au_lname, au_fname, contract )
VALUES ('277-27-2777', 'Fudd', 'E.P.', 1);
SAVEPOINT second_savepoint;
INSERT authors (au_id, au_lname, au_fname, contract )
VALUES ('366-36-3636', 'Duck', 'P.J.', 1);
SAVEPOINT third_savepoint;
RELEASE SAVEPOINT second_savepoint;
COMMIT;
В этом примере при удалении точки сохранения second_savepoint система в действи-
тельности удаляет secondsavepoint и thirdsavepoint, поскольку точка thirdsavepoint
была создана после second ^savepoint.
После удаления точки сохранения ее имя можно использовать снова.
454 | Глава 3. Справочник по инструкциям SQL
Советы и хитрости программирования
Подача инструкции COMMIT или инструкции полного отката ROLLBACK приведет
к удалению всех открытых точек сохранения транзакции. Подача инструкции ROLLBACK
ТО SAVEPOINT возвращает транзакцию к тому состоянию, в котором она находилась
в указанной точке. Поэтому все точки сохранения, объявленные после этой точки, стано-
вятся недействительными.
DB2
Платформа DB2 полностью поддерживает инструкцию RELEASE SAVEPOINT, а также
дополнительное ключевое слово.
RELEASE [ТО] SAVEPOINT имя_точки_сохранения
Где:
ТО
Дополнительное ключевое слово, не несущее никаких функций.
MySQL
Не поддерживается.
Oracle
Не поддерживается,
PostgreSQL
Не поддерживается.
SQL Server
Не поддерживается.
См. также
ROLLBACK
SAVEPOINT
Инструкция RETURN
Инструкция RETURN завершает обработку, которую выполняет функция, вызываемая
SQL (в отличие от функции, вызываемой сервером), или хранимая процедура, и воз-
вращает результирующее значение.
Некоторые разработчики вместо ключевого слова RETURN (стандарт SQL)
используют RETURNS.
„„пом SOL I 455
Платформа Команда
DB2 Поддерживается с вариантами
MySQL Не поддерживается
Oracle Поддерживается
PostgreSQL Поддерживается с ограничениями
SQL Server Поддерживается
Синтаксис SQL2003
RETURN возвращаемое_значение | NULL
Ключевые слова
возвращаем ое_значение
Представляет собой значение, возвращаемое кодом процедуры. Может быть
любым из разнообразных значений.
NULL
Функция завершает работу, не возвращая реального значения.
Общие правила
Инструкция RETURN используется в процедурном коде для завершения обработки.
Например, можно создать пользовательскую функцию, которая принимает сложное
и часто используемое CASE-выражение и при передаче ей параметра возвращает одно
легкое для восприятия значение выражения.
Советы и хитрости программирования
Хотя инструкция RETURN считается в SQL отдельной командой, она сильно связана
с инструкциями CREATE FUNCTION и CREATE PROCEDURE. Следовательно, ин-
струкция RETURN почти всегда является встроенной в одну из этих команд. Чтобы по-
лучить более подробную информацию о реализации инструкции RETURN в контексте
каждой из этих инструкций, обращайтесь к разделам этой книги, посвященным этим
инструкциям, или к документации производителя.
DB2
В DB2 инструкция RETURN используется для выхода из подпрограммы и в процедуре
для возврата целочисленного значения. В пользовательской функции RETURN возвра-
щает значение, вычисленное функцией. Платформа DB2 также позволяет возвращать
результаты на основе запроса, в соответствии со следующим синтаксисом.
RETURN [ {выражение | NULL | WITH имя_таблицы
( столбец ) [AS {инструкция_5ЕбЕСТ'){ } ] инструкция_ЗЕбЕСТ
Где:
выражение
Возвращает константу или переменную клиенту или вызвавшей программе.
456 | Глава 3. Справочник по инструкциям SQL
NULL
Возвращает пустое значение того типа данных, который был указан в вызвавшей
пользовательской функции или методе.
WITH имя_таблицы (столбец [,...] )
Действует как стандартное табличное выражение (иными словами, как своего
рода представление), где каждый столбег{ соответствует столбцу последующей
инструкции SELECT.
AS (uHcmpyKiiwi SELECT) uucmpyiaiwiSELECT
Указывается запись или записи, которые будет возвращать функция, содержащая
данную инструкцию RETURN. Количество столбцов в записи (записях), возвращаемой
второй iiiicmpyKiiueil SELECT, должно совпадать с количеством столбцов в предложе-
нии WITH. Это предложение нельзя использовать в хранимых процедурах.
Если инструкция RETURN используется в процедуре, то значение выражения
должно быть целочисленным, но к пользовательской функции это не относится. Пред-
ложения NULL и WITH столбец AS ииструкция ЗЕТЕСТ можно использовать в поль-
зовательских функциях и методах, но не в хранимых процедурах. Ниже приводится
пример инструкции RETURN.
REGIN
. . . <код SQL>. . .
GO1C E4HOn_HANDLE4
... <код SQL>. .
SUCCESS: RETURN 0
ERROR .RANDLER: RETURN -200
END
Если вам нужно проверять значение, возвращаемое хранимой процедурой, в другой
хранимой процедуре, используйте для этого инструкцию GET DIAGNOSTICS. За допол-
нительной информацией об инструкции GET DIAGNOSTICS обращайтесь к документа-
ции DB2.
MySQL
Не поддерживается. Весь процедурный код в MySQL пишется на С или C++. Для возврата
значения вы можете использовать методы, принятые с С и C++.
Oracle
Платформа Oracle для инструкции RETURN поддерживает стандартный синтаксис ANSI,
за исключением ключевого слова NULL (Oracle поддерживает возврат пустых значений,
но не поддерживает здесь синтаксис ANSI). Платформа Oracle позволяет использовать
предложение RETURN только в пользовательских функциях и пользовательских опера-
торах. Возвращаемое значение не может в инструкции CREATE OPERATOR относиться
к типам данных LONG, LONG RAW или REE. Пользовательские функции PL/SQL полно-
Сирявочник по командам SQL | 457
стью поддерживают булевы типы данных, но нельзя вызвать булеву пользовательскую
функцию из инструкции SQL. Следовательно, просто применяйте для хранения булевых
значений типы INT(0 или 1) или TARCHAR (TRUE или FALSE).
В следующем примере создается функция. Эта функция возвращает значение,
которое сохраняется в переменной projrev вызвавшего функцию сеанса.
CREATE FUNCTION project„revenue (project IN varchar2)
RETURN NUMBER
AS
proj.rev NUMBER/10,2);
BEGIN
SELECT SUM(DECODE(action,'COMPLETED',amount, 0) -
SUM(DEC0DE(action,'STARTED',amount, 0) +
SUM(DECODE(action,'PAYMENT',amount,0)
INTO proj_rev
FROM construction_actions
WHERE project_name = project;
RETURN (proj_rev);
END;
PostgreSQL
Платформа PostgreSQL поддерживает для инструкции RETURN стандартный синтак-
сис ANSI, за исключением ключевого слова NULL.
RETURNS возвращаемое_значение | NULL
Платформа PostgreSQL позволяет определять пользовательские функции либо при
помощи кода SQL, либо при помощи C/C++. (В настоящее время PostgreSQL не под-
держивает хранимые процедуры, но вы можете сымитировать эту функциональность
при помощи пользовательских функций.) В данном обсуждении нас интересуют
только SQL-функции.
Допустимые возвращаемые значения могут относиться к базовому типу, сложно-
му типу, типу SETOF, модификатору OPAQUE или к тому же типу, что и сущест-
вующий столбец. Модификатор типа SETOF используется для возврата инструкцией
RETURNS не одного значения, а набора значений. Модификатор OPAQUE показывает,
что инструкция RETURNS не возвращает значения. Модификатор OPAQUE можно ис-
пользовать только в триггерах.
SQL Server
Платформа SQL Server поддерживает инструкцию RETURN, используя следующий
синтаксис.
RETURN [возвращаемое_целое_значение]
Команда RETURN обычно используется в хранимых процедурах или пользова-
тельских функциях. Эта команда приводит к немедленному и полному выходу из
программы и при желании может возвращать при выходе целочисленное значение.
458 | Глава 3. Справочник по инструкциям SQL
Процедуры SQL Server неявно возвращают ноль, если в определении процедуры нет
инструкции RETURN. Любые команды, которые идут после инструкции RETURN,
игнорируются.
В следующей функции инструкция RETURN возвращает целое число, представ-
ляющее собой вычисленное значение.
CREATE FUNCTION metric_volume -
Ввод размеров сантиметрах.
(©length decimal(4,1),
©width decimal(4,1),
©height decimal(4,1) )
RETURNS decimal(12,3) - кубические сантиметры.
AS
BEGIN
RETURN ( ©length * ©width * ©height )
ENO
GO
REVOKE
В этом примере создается функция, возвращающая вызвавшему ее сеансу вычис-
ленное значение метрического объема.
См. также
CREATE/ALTER FUNCTION PROCEDURE
CREATE/ALTER TRIGGER
Инструкция REVOKE
Инструкция REVOKE имеет две основные формы. Первая форма этой инструкции
отменяет указанные права доступа к инструкциям для пользователя, группы или роли.
Вторая форма этой инструкции отменяет права доступа к конкретным объектам базы
данных или ресурсам.
Платформа Команда
DB2 Поддерживается с вариантами
MySQL Поддерживается с вариантами
Oracle Поддерживается с вариантами
PostgreSQL Поддерживается с вариантами
SQL Server Поддерживается с вариантами
Справочник по командам SQL | 459
Синтаксис SQL2003
Общая форма синтаксиса REVOKE в SQL2003 следующая.
REVOKE { [специальныв-опции] | {привилегия [,...] | роль [,...]} }
ON имя_объекта_базы_данных
FROM имя__получателя [,...]
[GRANTED BY {CURRENT_USER | CURRENT_ROLE} ]
{CASCADE | RESTRICT}
Ключевые слова
специальные опции
Параметр позволяет использовать одну из трех необязательных специальных
опций.
GRANT OPTION FOR
Отменяет назначенную пользователю привилегию WITH GRANT OPTION.
Это означает, что пользователь более не сможет предоставлять другим поль-
зователям права доступа к объекту, но его собственные права доступа остают-
ся неизменными. (Это предложение можно применять для отмены привиле-
гии, но не для отмены роли.) За дополнительной информацией обращайтесь
к разделу «Инструкция GRANT».
HIERARCHY OPTION FOR
Отменяет привилегию WITH HIERARCHY OPTION, которая позволяет пользо-
вателю отбирать данные не только из указанной таблицы, но и из всех ее под-
таблиц. (Это предложение можно применять для отмены привилегии, но не
для отмены роли.)
ADMIN OPTION FOR
Отменяет право назначать роли другим пользователям. (Это предложение
можно применять для отмены привилегии, но не для отмены роли.)
привилегия
Отменяет привилегии доступа к различным инструкциям, которые можно комби-
нировать в любом порядке.
ALL PRIVILEGES
Отменяются все привилегии, назначенные в данный момент указанным поль-
зователям и/или указанным объектам базы данных. Использование этого подхода,
как правило, не рекомендуется, поскольку он способствует неаккуратному
программированию.
EXECUTE
Отменяются права запуска подпрограммы (т. е. хранимой процедуры, пользо-
вательской функции или метода).
{SELECT | INSERT | UPDATE | DELETE}
Отменяется указанная привилегия для указанного пользователя в указанном
объекте базы данных, например таблице или представлении. Можно написать
список столбцов таблицы (заключив его в скобки), к которым отменяются
права доступа по операциям SELECT, INSERT или UPDATE.
460 | Глава 3. Справочник по инструкциям SQL
REFERENCES
Отменяется пользовательское право создавать ограничения и утверждения,
ссылающиеся на объект базы данных как на родительский объект. Можно на-
писать список столбцов таблицы (заключив его в скобки), в которых отме-
няются привилегии.
TRIGGER
Отменяется право пользователя создавать триггеры в указанных таблицах.
В качестве побочного эффекта такой отмены удаляются все триггеры, завися-
щие от этой привилегии.
UNDER
Отменяется право создавать подтипы и объектные таблицы.
USAGE
Отменяется привилегия использования домена, пользовательского типа,
набора символов, сопоставления или преобразования.
роль
Отзывается указанная, уже существующая роль, присвоенная получателю, указанно-
му в предложении FROM. Например, администратор базы данных может создать
роль с именем Reporter, которая имеет только права чтения некоторых таблиц. Когда
роль присваивается пользователю, пользователь получает возможность совершать
все действия, которые разрешены для этой роли. За дополнительной информацией
обращайтесь к разделу «Инструкция GRANT».
ON имя_объекта_базы^данных
Отзываются права доступа к конкретному, существующему объекту базы данных,
указываемому параметром имя^объектабазыданных. Стандарт SQL2003 не
поддерживает системные привилегии, но во многих реализациях существует вари-
ант этого предложения, позволяющий отменять системные привилегии. (Предло-
жение ON при отмене системных привилегий и ролей не используется вообще.)
Объект с именем имя_объекта_базы_данных может представлять собой один из
указанных объектов.
{ [TABLE] имя_рбьекта | DOMAIN имя~объекта |
COLLATION имя_объекта |
CHARACTER SET имя_объекта | TRANSLATION имя~объекта |
TYPE имя_обьекта | [SPECIFIC] {ROUTINE | FUNCTION |
PROCEDURE | METHOD}
имя_объекта }
FROM имя_получателя
Указывается пользователь (пользователи) или роль (роли), которые теряют
данную привилегию. Для того чтобы отозвать привилегии, назначенные глобаль-
ному списку PUBLIC, можно использовать ключевое слово PUBLIC. Можно
перечислить несколько получателей через запятую.
Справочник по командам SQL | 461
FROM {CURRENTUSER | CURRENT ROLE}
Необязательное предложение, указывающее, кто предоставил пользователю при-
вилегию. Например, при использовании предложения ...FROM CURRENTJJSER
привилегия отменяется только в том случае, если ее назначил текущий пользова-
тель. В противном случае инструкция выполнена не будет. Если предложение не
указано, по умолчанию принимается CURRENTJJSER.
RESTRICT | CASCADE
Отмена затрагивает только указанную привилегию {RESTRICT), или отменяется
указанная привилегия и все зависимые от нее привилегии {CASCADE). Могут
быть также удалены объекты, зависимые от привилегии. Обратите внимание, что
инструкция REVOKE...RESTRICT не будет выполнена, если существуют зависи-
мые привилегии. Эти привилегии нужно сначала удалить.
Общие правила
Указанную привилегию доступа к указанному объекту базы данных для одного поль-
зователя можно удалить при помощи инструкции REVOKE имя_привилегии ON
илтцбъекта FROM имя получателя RESTRICT. Указанную привилегию доступа к ука-
занному объекту базы данных для всех пользователей можно удалить при помощи гло-
бального списка PUBLIC.
При отмене привилегий нескольких пользователей просто разделяйте их имена
запятыми. Вы также можете в одной инструкции REVOKE удалять привилегии одного
или нескольких получателей и роли PUBLIC. (Роль PUBLIC подробно описывается
в разделе «Инструкция GRANT». Если право предоставляется роли PUBLIC, это
означает, что каждый пользователь имеет доступ к объекту и ему не нужно получать
индивидуальные права доступа к этому объекту.)
При отмене привилегий доступа к таблице эти привилегии могут распространяться
на уровень столбцов, для чего нужно указать после имени таблицы список столбцов,
заключенный в скобки.
Советы и хитрости программирования
На большинстве платформ привилегии пользовательского и ролевого уровней изо-
лированы. (Запомните, что роль - эю группа привилегий.) Таким образом, пользова-
тель, которому присвоены две роли, может иметь три набора привилегий. В такой си-
туации, чтобы полностью отозвать все права, вам, вероятно, придется отменить поль-
зовательские привилегии напрямую и удалить у пользователя обе роли.
Важной стороной команды REVOKE (и дополняющей ее команды GRANT) являет-
ся то, что некоторые элементы команды связаны с правами уровня объектов, а другие
опции больше ориентированы на роли и административные привилегии. Как правило,
эти операции никогда не объединяются. Различия между правами доступа к объектам
и административными привилегиями объясняются ниже, в разделах, посвященных
каждой из платформ. Например, вам может понадобиться отменить некоторые приви-
легии доступа к объектам, присвоенные роли salesperson или пользователям e_fudd
и prince edward.
462 | Глава 3. Справочник по инструкциям SQL
REVOKE SELECT ON TABLE authors FROM salespeople RESTRICT;
REVOKE ALL PRIVILEGES ON TABLE sales FROM e_fudd,
prince_edward CASCADE;
Специальные опции (GRANT OPTION, HIERARCHY OPTION и ADMIN OPTION)
предназначены для того, чтобы отнимать у пользователей право передавать привиле-
гии другим пользователям. Однако эти предложения не отнимают у первой группы
пользователей право самим использовать эти привилегии. Например, мы больше не
хотим, чтобы те, кому присвоена роль manager, передавали другим пользователям
свои привилегии UPDATE.
REVOKE GRANT OPTION FOR UPDATE ON sales FROM manager CASCADE;
Вы также можете удалять у пользователя ролевые привилегии при помощи команды
REVOKE.
REVOKE manager FROM e_fudd CASCADE;
Распространенной хорошей практикой является как можно более логичное и по-
нятное написание инструкций REVOKE и GRANT. При этом вам следует избегать
предложений CASCADE и ALL PRIVILEGES, поскольку они выполняют такие дейст-
вия, которые вы можете сразу и не увидеть в инструкции.
DB2
Платформа DB2 предлагает в реализации команды REVOKE много разнообразных
дополнительных опций.
REVOKE { )привилегии_базы_данных [,...] ON DATABASE ] |
[CONTROL ON INDEX имя_индекса) |
[ {BIND | CONTROL | EXECUTE} ON PACKAGE имя_пакета ] |
[ {ALTERIN | CREATEIN | DROPIN} ON SCHEMA имя_схемы ] {
[PASSTHRU ON SERVER имя_сервера ] |
[EXECUTE ON [SPECIFIC] {FUNCTION | PROCEDURE |
METHOD} имя~подпрограммы ] I
[объектная_привилегия [,...] ON [TABLE] имя_объекга ] |
[{ALTER I USAGE} ON SEQUENCE имя_последовательности ] |
[USE OF TABLESPACE имя_табличного_пространства ] } }
[FROM [ {USER 'GROUP} ] { имя_получателя [,...] |
имя_группы [....] | PUBLIC } ]
[RESTRICT]
Где:
привилегии_базы_даиных
Отменяется одна или несколько привилегий, применимых ко всей базе данных.
Существуют следующие привилегии базы данных.
В IN DADD
Предоставляется право создавать пакеты.
Справочник по командам SQL | 463
CONNECT
Предоставляется право доступа к конкретной базе данных. Если привилегия
CONNECT отзывается, все прочие явно назначенные привилегии продолжают
существовать, но являются отключенными до тех пор, пока привилегия CON-
NECT не будет предоставлена вновь.
CREATETAB
Предоставляется право создать таблицы.
CREATENOTFENCEDROUTINE
Предоставляется право создавать подпрограммы, которые не ограничиваются
текущим процессом пользователя. То есть подпрограммы могут выполняться
процессом менеджера базы данных.
DBADM
Предоставляются права суперпользователя с возможностью создать любой
объект базы, со всеми привилегиями для всех объектов базы данных, и даже
с возможностью предоставлять привилегии другим пользователям.
IMPLICITSCHEMA
Предоставляется право неявного создания схемы, хотя эта привилегия не
влияет на возможность создавать схемы и любые объекты в них явным обра-
зом.
LOAD
Предоставляется право явным образом загружать (LOAD) указанную базу дан-
ных.
CONTROL ON INDEX имя_индекса
Отменяется право удалить ранее созданный индекс с именем имя_индекса. Если
опущено предложение FROM, подразумевается текущий пользовательский кон-
текст.
{BIND | CONTROL | EXECUTE} ON PACKAGE имя_пакета
Отменяются привилегии, связанные с пакетами. Обратите внимание, что предло-
жения RUN и PROGRAM являются допустимыми синонимами для EXECUTE
и PACKAGE соответственно. Существуют следующие привилегии, относящиеся
к пакетам.
BIND
Предоставляется право производить связывание и повторное связывание с ука-
занным пакетом. Поскольку все инструкции SQL в пакете проверяются в момент
связывания, пользователь также должен иметь права доступа к каждому объек-
ту, на который ссылаются инструкции пакета.
CONTROL
Предоставляются права для повторного связывания, удаления или выполнения
указанного пакета, а также право назначать привилегии BIND и EXECUTE другим
пользователям. Пользователи, которым назначена привилегия CONTROL, также
автоматически получают привилегии BIND и EXECUTE. Привилегия CONTROL
автоматически присваивается создателю пакета.
464 | Глава 3. Справочник по инструкциям SQL
EXECUTE
Предоставляется право запускать указанный пакет. Как и в случае привилегии
BIND, если у пользователя есть привилегия CONTROL, ее нужно удалить для
правильного удаления привилегии EXECUTE.
{ALTERIN | CREATEIN | DROPIN} ON SCHEMA имя_схемы
Предоставляются привилегии, связанные с манипулированием схемой (т. е. набором
объектов, принадлежащих пользователю). В отличие от некоторых других допол-
нительных предложений DB2 для синтаксиса ON SCHEMA требуется наличие
предложения FROM. Использование этой команды не имеет преимуществ перед
конкретными привилегиями, которые были присвоены в схеме. Таким образом,
при помощи предложения ON SCHEMA вы можете отменить привилегии пользо-
вателя или группы, но этот пользователь или группа по-прежнему смогут
выполнять в схеме любые другие операции в соответствии с другими присвоен-
ными правами.
ALTERIN
Предоставляется право писать комментарии или изменять объекты схемы,
указанной в предложении ON SCHEMA имя_схемы.
CREATEIN
Предоставляется право создавать объекты схемы, указанной в предложении
ON SCHEMA имя_схемы.
DROPIN
Предоставляется право удалять объекты схемы, указанной в предложении
ON SCHEMA имя_схемы.
PASSTHRU ON SERVER имя_сервера
Отменяется право доступа к внешнему источнику данных с именем имя_сервера
в транзитном (pass-through) режиме.
EXECUTE ON
Предоставляются права доступа к подпрограмме ANSI (т. е. пользовательской
функции, пользовательскому методу или хранимой процедуре). Элементы этого
предложения следующие.
[SPECIFIC] FUNCTION имя_функции
Указывается, что пользователь теряет привилегию доступа к указанной функции.
Для имени функции можно указать предложение SPECIFIC. Система DB2
также поддерживает функции без имен. В этом случае нужно использовать
синтаксис FUNCTION [(параметр [,...])], где следует указать все параметры
функции. Если параметр имя_схемы не указан, подразумевается текущая
схема. Вы можете заменить звездочкой (*) конкретные имена функций, чтобы
отнять у пользователя право выполнения всех функций в текущей или указан-
ной схеме.
PROCEDURE [схема.]имя_процедуры
Указывается, что пользователь теряет привилегию для выполнения всех хра-
нимых процедур указанной схемы, в том числе тех, которые будут созданы
в будущем. Если параметр схема, не указан, подразумевается текущая схема.
30 - 2447
Справочник по командам SQL | 465
Вы можете заменить звездочкой (*) конкретные имена процедур, чтобы
отнять у пользователя право выполнения всех процедур в текущей или указан-
ной схеме.
[SPECIFIC] METHOD имя_метода
Указывается, что пользователь теряет право выполнять все методы типа имя_типа,
в том числе те, которые еще не созданы. Можно указать специфическое (SPECIFIC)
имя метода. Система DB2 также поддерживает методы без имен. В этом случае
нужно использовать синтаксис METHOD [(параметр [,...])], где следует указать
все параметры метода. В качестве альтернативы вы можете использовать символ-
звездочку (*) для обозначения того, что пользователь теряет права во всех типах
схемы.
объектная ^привилегия
Отменяются привилегии для выполнения различных инструкций в таблицах,
представлениях, а также таблицах и представлениях с псевдонимами. Объектные
привилегии можно комбинировать в любом порядке.
ALL [PRIVILEGES] •
Отменяются все привилегии, присвоенные указанным пользователям и/или
указанным объектам базы данных. Краткое обозначение всех привилегий, ко-
торые пользователь может предоставить. Ключевое слово PRIVILEGES явля-
ется необязательным. Использование этого метода, как правило, не поощряет-
ся, поскольку способствует неаккуратному написанию кода.
ALTER
Отменяется привилегия добавлять и изменять столбцы, ограничения, коммен-
тарии и триггеры в указанной таблице или представлении. Ограничивается воз-
можность использовать псевдонимы (nicknames) для имен столбцов и типов
данных, а также изменять опции столбца для данного псевдонима.
CONTROL
Отзывается право удалять таблицу или представление, а также запускать при-
менительно к ним утилиту RUNSTATS.
INDEX
Отменяется возможность создать индекс для таблицы или создать специфика-
цию индекса для псевдонима.
[SELECT | INSERT | UPDATE | DELETE]
Данный пользователь лишается указанной привилегии доступа к указанному объ-
екту базы, например к таблице или представлению. Можно указать заключенный
список столбцов, в которых вы хотите отменить привилегии SELECT, INSERT или
UPDATE.
REFERENCES
Отменяется право создавать и удалять ссылочные ограничения (такие, как
CHECK и FOREIGN KEY), ссылающиеся на объект базы данных как на роди-
тельский объект.
466 | Глава 3. Справочник по инструкциям SQL
{ALTER | USAGE} ON SEQUENCE имя_последовательности
Отменяются права доступа к последовательности в явно указанной или текущей
схеме (USAGE) или право выполнять инструкцию ALTER SEQUENCE (ALTER).
USE OF TABLESPA СЕ имя_табличного_пространства
Отменяется привилегия USE для табличного пространства. Обратите внимание,
что пользователь может продолжать создавать таблицы в указанном табличном
пространстве, если права доступа к этому табличному пространству представле-
ны роли PUBLIC или если пользователь входит в группу (например, DBADM),
которая имеет право доступа к этому табличному пространству.
FROM {[USER [ GROUP]} имя_получателя
Указывается пользователь или пользователи, теряющие указанную привилегию. Если
существуют пользователь и группа с одинаковым именем, используйте дополнитель-
ные ключевые слова USER или GROUP, чтобы уточнить, удаляется привилегия
у пользователя или у группы. Можно использовать ключевое слово PUBLIC, чтобы
отнять привилегию у роли PUBLIC. Можно указывать несколько получателей, разде-
ляя их имена запятыми.
RESTRICT
Использование этого предложения идентично стандарту ANSI, за исключением
того, что предложение RESTRICT является обязательным для привилегий SCHEMA
и FUNCTION.
Платформа DB2 поддерживает удаление ряда привилегий, описанных выше,
у указанного пользователя. В следующем примере пользователь emily теряет право
создавать таблицы (CREATETAB).
REVOKE CREATETAB ON DATABASE FROM emily
Эта инструкция отнимает право создавать таблицы у пользователя emily.
Следующая инструкция отнимает право создавать пакеты у группы student. Пред-
ложение FROM GROUP должно всегда использоваться в том случае, если существует
пользователь и группа с одинаковым именем.
REVOKE BINDADD ON DATABASE FROM GROUP student
Первая команда следующего примера отменяет привилегию удалять индекс
upkcl_auidind у пользователя dylan и группы пользователей editors, а вторая команда
удаляет привилегию доступа к табличному пространству у пользователя sam.
REVOKE CONTROL ON INDEX upkcl_auidind
FROM USER dylan, GROUP editors
REVOKE USE OF TABLESPACE futures FROM USER sam
В следующем примере право выполнять пакет publications отнимается у группы
editors и пользователя jake.
REVOKE EXECUTE
ON PACKAGE publications
FROM GROUP editors, USER jake
Справочник по командам SQL | 467
В следующем примере у пользователя anna отнимается право создавать новые
объекты в схеме pubs, а вторая команда отзывает привилегию транзитного доступа
к источнику данных east.
REVOKE CREATEIN ON SCHEMA pubs FROM anna
REVOKE PASSTHRU ON SERVER east FROM USER anna
Привилегии доступа к конкретным объектам также легко предоставлять и отме-
нять. В некоторых случаях вы можете подавать одну команду несколькими разными
способами, зависящими от того, хотите ли вы использовать много дополнительных
ключевых слов или нет. Например, следующие две команды делают одно и то же.
REVOKE UPDATE ON employee FROM sam
REVOKE UPDATE ON TABLE employee FROM USER sam
В обоих приведенных выше примерах пользователь sam теряет право обновлять
таблицу employee. Также вы можете объединять в одной команде привилегии уровня
объектов и привилегии пользователей и/или групп. Например, следующая команда
отменяет все привилегии записи (INSERT, UPDATE и DELETE) пользователей katie
и jake, а также группы editors.
REVOKE INSERT. UPDATE, DELETE ON employee FROM USER katie,
USER jake, GROUP editors
В DB2 входит группа PUBLIC, которая включает в себя всех пользователей.
Кроме того, в DB2 существует несколько уровней системных привилегий, которые
изменять нельзя.
SYSADM
Привилегии системного администрирования (наивысший уровень прав). Пользо-
ватели с этим уровнем имеют все привилегии во всех базах данных.
DBADM
Привилегии базы данных. Пользователи с этим уровнем имеют все привилегии
в конкретной базе данных, но они не могут выполнять операции, которые требуют
административного доступа к ресурсам системы (например, инструкцию DB2
CREA ТЕ TABLESPA СЕ).
SYSCTRL
Привилегии контроля работы системы без права доступа к данным. Пользователи
с этим уровнем привилегий имеют возможность создавать, изменять и удалять
базы данных и табличные пространства, а также завершать работу экземпляров
баз данных.
SYSMAINT
Привилегии контроля работы системы без права доступа к данным (более низкий
уровень, чем SYSCTRL). Пользователи с этим уровнем привилегий могут обнов-
лять конфигурационные файлы базы данных, выполнять резервное копирование
и восстановление, а также осуществлять мониторинг работы базы данных.
468 | Глава 3. Справочник по инструкциям SQL
Пользователей можно наделять этими системными привилегиями и лишать этих
привилегий, но нельзя изменять привилегии, входящие в область действия системной
привилегии (т. е. в пределах всей системы, в пределах базы данных и т. п.).
MySQL
Инструкция REVOKE отменяет привилегии, которые ранее были назначены одному
или нескольким пользователям. Платформа MySQL поддерживает многие стандарт-
ные ключевые слова ANSI. Стоит отметить такие исключения, как отсутствие под-
держки слов TRIGGER, EXECUTE и UNDER. В MySQL также есть приятный способ
ускорить глобальное присвоение или отмену привилегий. За описаниями элементов
инструкции, которые здесь не приводятся, обращайтесь, пожалуйста, к разделу, посвя-
щенному стандарту ANSI.
REVOKE [ { ALL [PRIVILEGES] |
{SELECT | INSERT | UPDATE} [ (имя_сголбца [,...]) ] | DELETE ।
REFERENCES [ (имя_столбца [,...]) ] } I
[ USAGE ] | [{ALTER | CREATE i DROP}] | [FILE] | [INDEX] | [PROCESS J I
[RELOAD] | [SHUTDOWN] I [CREATE TEMPORARY TABLES] I [LOCK TABLES] |
[REPLICATION CLIENT] | [REPLICATION SLAVE] | [SHOW DATABASES] |
[SUPER] }[ ...]
ON {имя_таблицы i * I *.* I имя_базы_данных. *}
FROM имя_пользователя [....]
Где:
ALL [PRIVILEGES]
Синоним для ALL PRIVILEGES. В MySQL сюда входят все доступные привиле-
гии, которые применимы на текущем уровне, показанном предложением ON,
за исключением привилегии WITH GRANT OPTION. (Это такие привилегии, как
SELECT, INSERT, UPDATE, DELETE и т. п.)
SELECT | INSERT I UPDATE | DELETE
Отменяется право читать, записывать, изменять и удалять данные из таблиц (и, воз-
можно, из отдельных столбцов таблицы) соответственно.
REFERENCES
Не реализовано.
USAGE
Отменяются все пользовательские привилегии.
{ALTER | CREATE | DROP} ON имя таблицы
Отменяется право изменять, удалять или создавать таблицы и другие объекты
базы данных.
FILE
Отменяется право загружать данные из файлов или записывать данные в файлы,
используя команды SELECT INTO и LOAD DATA.
INDEX
Отменяется право создавать или удалять индексы.
Справочник по командам SQL | 469
PROCESS
Отменяется право просматривать работающие процессы с помощью инструкции
SHOW FULL PROCESSLIST.
RELOAD
Отменяется право запускать команду FLUSH.
SHUTDOWN
Отменяется право использовать команду mysqladmin shutdown для завершения
работы серверного процесса.
CREATE TEMPORARY TABLES
Отменяется право создавать временные таблицы.
LOCK TABLES
Отменяется право использовать команду MySQL LOCK TABLE в тех таблицах,
в которых пользователь имеет привилегии SELECT.
REPLICATION CLIENT
Пользователь лишается права просматривать метаданные о головных и подчинен-
ных серверах при репликации.
REPLICATION SLAVE
Отменяется право читать на подчиненном при репликации сервере (slave) двоичный
журнал (binlog) с головного сервера (master).
SHOW DATABASES
Пользователь лишается права выполнять команду MySQL SHOW DATABASES.
SUPER
Пользователь лишается права открывать одно соединение даже после достижения
порога максимального числа соединений (max_connections). Пользователи с при-
вилегиями SUPER также лишаются возможности выполнять такие команды
MySQL, как CHANGE MASTER, KILL, mysqladmin debug, PURGE [MASTER] LOGS
и SET GLOBAL.
ON {имя^таблицы | * | *. * | имя_базы-данных.*}
Удаляются привилегии для указанной таблицы имя_таблицы, для всех таблиц
текущей базы (используется звездочка, *), для всех таблиц во всех базах данных
(*.*) или для всех таблиц в указанной базе данных (имя_базы_данных.*).
FROM
Удаляются права одного или нескольких пользователей, имена которых разде-
ляются запятыми. Пользовательские имена также могут включать суффикс
@имя_сервера, если вы хотите, чтобы удаление затрагивало конкретный сервер.
У инструкции REVOKE есть ограничения по размеру. Имена пользователей не
могут быть больше 16 символов, а имена серверов, баз данных и объектов базы
данных не могут превышать 60 символов. Имена пользователей могут быть связаны
с конкретным сервером. За подробной информацией обращайтесь к описанию
инструкции GRANT.
470 | Глава 3. Справочник по инструкциям SQL
Реализация инструкции REVOKE в MySQL не отменяет явным образом
права доступа к объектам, которые были удалены. Таким образом, нужно
явно отменять привилегии доступа к таблице, даже если таблица удалена.
Представим, например, что вы удалили таблицу, не отменив сущест-
вующие права доступа. Если позже вы создадите эту таблицу снова, будут
существовать старые привилегии доступа к ней. Точно так же пользова-
тельские привилегии остаются в базе данных даже после удаления пользо-
вателя.
Также нужно отметить, что в MySQL разрешается иметь несколько уровней при-
вилегий. Так, пользователь может иметь доступ к таблице на табличном уровне плюс
дополнительный набор привилегий в той же таблице из-за того, что ему были при-
своены глобальные привилегии уровня базы данных или сервера. Это означает, что
нужно соблюдать осторожность при отмене привилегий, потому что привилегии гло-
бального уровня могут по-прежнему давать пользователю возможность доступа, при-
том, что вы думаете, что вы запретили его!
Первая из приведенных ниже команд отменяет все привилегии доступа к таблице
sales для пользователей emily и dylan, а вторая команда удаляет все привилегии,
которые имеет пользователь sam в базе данных pubs.
REVOKE GRANT OPTION ON sales FROM kelly;
REVOKE ALL ON pubs.* FROM sam;
Oracle
Команда REVOKE не только немедленно отменяет объектные и системные привиле-
гии, она также позволяет отменить назначение роли пользователю (или назначение
роли другой роли). За информацией о конкретных объектных и системных привилеги-
ях, поддерживаемых инструкцией REVOKE, обращайтесь к описанию инструкции
GRANT
Две формы команды REVOKE, REVOKE объектная^привилегия и REVOKE
системная_привилегия, являются взаимоисключающими. Не пытайтесь
выполнить обе операции в одной инструкции. Поскольку полный синтаксис
обеих форм команды очень длинный, обращайтесь к разделу «Инструкция
GRANT» за дополнительной информацией об объектных и системных при-
вилегиях.
Платформа Oracle предоставляет интересную возможность работы с привилегия-
ми. В то время как другие платформы позволяют пользователю иметь более одного
набора привилегий (назначенных ему индивидуально и как члену группы), Oracle
идет на шаг дальше. Пользователь может иметь несколько дарителей, предостав-
ляющих ему доступ к указанному объекту. В этом случае, чтобы пользователь был
Справочник по командам SQL | 471
полностью лишен привилегии, все дарители должны отозвать привилегию. Если хотя
бы один даритель этого не сделает, то пользователь по-прежнему будет иметь данную
привилегию. Для инструкции REVOKE применяется следующий синтаксис.
REVOKE { [объектнаЯ-Привилегия^ [,...] |
[системная_привилегия'] |
[роль] }
[ON { [имя_схемы.][обьект] |
[DIRECTORY имя_объекта-директории~] |
[JAVA [ { SOURCE | RESOURCE } ] [имя_схемы.][обьект]} ]
FROM {имя_получателя [,...] | имя_роли [,...] | PUBLIC}
[CASCADE [CONSTRAINTS] ] [FORCE];
Где:
объектная-Привилегия
Для данного пользователя (имя_получателя'} или роли отменяются указанные при-
вилегии доступа к указанному объекту схемы, например таблице или представле-
нию.
ALL [PRIVILEGES]
Удаляются все назначенные привилегии доступа к указанному объекту схемы.
Поскольку в это число входят также привилегии REFERENCES, вы должны
также включить сюда предложение CASCADE (см. предложение REFERENCES
ниже).
ALTER
Удаляется право изменять существующую таблицу при помощи инструкции
ALTER TABLE.
EXECUTE
Отменяется право запускать хранимую процедуру, пользовательскую функ-
цию или пакет.
INDEX
Отменяется право создавать индексы по таблице.
REFERENCES
Отменяется право определять ограничения, обеспечивающие ссылочную цело-
стность. Требуется использование предложения CASCADE CONSTRAINTS.
{SELECT | INSERT \ UPDATE DELETE]
Отменяется право выполнять соответствующие команды SQL применительно
к указанному объекту схемы. Обратите внимание, что привилегии DELETE
зависят от привилегий SELECT.
системная_привил егия
Указанный пользователь (имя_получателя) или роль лишается указанной систем-
ной привилегии Oracle, например, такой, как CREATE TRIGGER или ALTER USER.
Не используйте предложение ON в варианте инструкции REVOKE систем-
ная-Привилегия. Поскольку существует очень много разнообразных системных
привилегий, обращайтесь за их полным списком в раздел, посвященный реализа-
ции инструкции GRANT в Oracle.
472 | Глава 3. Справочник по инструкциям SQL
роль
Отменяется назначение роли пользователю или другой роли.
ON
Пользователь или роль лишаются привилегии доступа к указанному объекту.
К объектам относятся: таблицы, представления, последовательности, хранимые
процедуры, пользовательские функции, пакеты, материализованные представле-
ния, пользовательские типы, библиотеки, индексные тины, пользовательские
операторы или синонимы всех этих объектов. Если имя схемы не будет указано,
будет подразумеваться схема текущего пользователя. Например, вы можете ото-
звать для данного пользователя привилегии SELECT в таблице scott.authors.
Платформа Oracle также поддерживает два ключевых слова для особых случаев.
DIRECTORY
Указывается объект-директория, доступ к которому прекращается.
JAVA
Указывается Java-объект схемы SOURCE или RESOURCE, доступ к которому
прекращается.
FROM {имя получателя ! имя_роли | PUBLIC}
Указывается пользователь или роль, лишающиеся данной привилегии. Для
отмены привилегий, назначенных роли PUBLIC, можно использовать ключевое
слово PUBLIC. Можно перечислить через запятую несколько получателей.
CASCADE [CONSTRAINS]
Удаляются все ограничения, обеспечивающие ссылочную целостность, которые
в первую очередь зависят от удаляемой привилегии. Это предложение нужно ис-
пользовать только в том случае, если используются предложения REFERENCES
или ALL [PRIVILEGES],
[FORCE]
Это предложение необходимо для отмены объектных привилегий EXECUTE,
относящихся к пользовательским объектным типам, зависящим от типов и таблиц.
Платформа Oracle автоматически распространяет удаление привилегий у пользо-
вателя на всех пользователей, которые получили свои привилегии от этого пользовате-
ля. Кроме того, все объекты, созданные этим пользователем, которые зависят от этой
привилегии (например, хранимые процедуры, триггеры, представления и пакеты, за-
висящие от привилегии SELECT в определенной таблице), становятся неработо-
сопосбными.
Пользователи, которым присвоена системная привилегия GRANT ANY ROLE,
могут отменять назначение любой роли. Командой REVOKE можно отменить только
те привилегии, которые специфически присваивались командой GRANT, но не приви-
легии, которые присваивались при помощи ролей или операционной системы. В подобных
случаях команду REVOKE нужно использовать для удаления привилегии у роли. Все
пользователи, которым назначена данная роль, потеряют эту привилегию.
Ниже приводится пример отмены назначения роли для указанного получателя
и пример отмены назначения системной привилегии для роли.
Справочник по командам SQL | 473
REVOKE read-only FROM sarah;
REVOKE CREATE ANY SEQUENCE,
CREATE ANY DIRECTORY FROM readonly;
Ниже приводится пример, в котором отменяется привилегия REFERENCES с уда-
лением всех зависимых ограничений.
REVOKE REFERENCES
ON pubs_new_york.emp
FROM dylan
CASCADE CONSTRAINTS;
В следующем примере предоставляются все права доступа к указанной таблице,
после чего удаляется одна привилегия.
GRANT ALL PRIVILEGES ON emp TO dylan;
REVOKE DELETE, UPDATE ON emp FROM dylan;
PostgreSQL
Платформа PostgreSQL поддерживает базовые возможности инструкции REVOKE,
относящиеся в первую очередь к отмене прав доступа к таблицам, представлениям
и последовательностям. Не поддерживаются специальные опции стандарта ANSI,
такие, как HIERARCHY OPTION FOR и ADMIN OPTION FOR. Синтаксис следующий.
REVOKE { [ GRANT OPTION FOR ] |
привилегии [,] )
ON {имя__объекта}
FROM {имя_получателя | PUBLIC | GROUP имя_группы}
[ {CASCADE | RESTRICT} ]
Где:
GRANT OPTION FOR
Отменяется право пользователя назначать привилегии другим пользователям.
привилегии
Отменяется право доступа к различным инструкциям, которые можно комбиниро-
вать в любом порядке.
ALL PRIVILEGES
Краткое обозначение всех привилегий, которые может предоставить данный
пользователь. Отменяются все привилегии, назначенные указанным пользова-
телям и/или ролям, или права доступа к указанным объектам базы данных.
Использовать такой подход, как правило, не рекомендуется, поскольку это
способствует неаккуратному программированию.
{SELECT | INSERT | DELETE | UPDATE}
Указанный пользователь лишается указанной привилегии доступа к указанно-
му объекту базы данных, например таблице или представлению. Для отмены
привилегий уровня столбца вы можете использовать заключенный в скобки
список столбцов таблицы.
474 | Глава 3. Справочник по инструкциям SQL
REFERENCES
Пользователь лишается права создавать или удалять ограничения типа «внеш-
ний ключ», ссылающиеся на объект базы данных как на родительский объект.
RULE
Пользователь лишается права создавать или удалять правило для таблицы или
представления.
USAGE
Пользователь лишается права использовать домен, пользовательский тип
данных или набор символов. Это предложение противоположно привилегии
UNDER, которая дает возможность создавать эти объекты.
FROM {имя_получателя [,...] | PUBLIC | GROUP имя_группы}
Указываются пользователь или роль, теряющие данную привилегию. Для отмены
привилегий, назначенных роли PUBLIC (которая подразумевает всех пользователей),
можно использовать ключевое слово PUBLIC. Можно перечислить через запя тую
несколько получателей.
CASCADE | RESTRICT
Операция отмены ограничивается только указанной привилегией (RESTRICT) или
отменяются указанная привилегия и все зависимые от нее привилегии (CASCADE).
Это предложение используется только с предложением GRANT OPTION FOR.
Реализация инструкции REVOKE в PostgreSQL относительно проста. Единствен-
ная проблема состоит в том, что PostgreSQL считает термин GROUP синонимом
термина ROLE. Например, следующая инструкция удаляет несколько привилегий
у группы PUBLIC и группы READ-ONLY.
REVOKE ALL PRIVILEGES ON employee FROM public;
REVOKE SELECT ON jobs FROM read-only;
Платформа PostgreSQL не поддерживает привилегий доступа к отдельным столб-
цам таблицы или представления. Чтобы обойти это ограничение, можно создать пред-
ставление, в которое входят только нужные столбцы, и предоставлять или отменять
права доступа к этому представлению. При отмене привилегии GRANT OPTION FOR
следует обратить особое внимание на зависимости. Если вы будете отзывать привиле-
гию, используя ключевое слово RESTRICT, инструкция не будет выполнена, если
другие пользователи зависят от этой операции. Если вы будете отзывать привилегию,
используя ключевое слово CASCADE, инструкция отменит привилегию не только
у того пользователя, которого она касается, но и у всех зависимых пользователей.
SQL Server
Платформа SQL Server использует инструкцию REVOKE в качестве способа отмены
настроек прав доступа, назначенных данному пользователю. Этот момент важен, по-
скольку SQL Server поддерживает дополнительную инструкцию DENY, которая явно
запрещает пользователю доступ к указанному ресурсу. В SQL Server инструкцию
REVOKE можно использовать для отмены привилегий, назначенных пользователю
Справочник по командам SQL | 475
при помощи инструкции GRANT. Если вы хотите явным образом лишить пользователя
определенной привилегии, вам следует использовать инструкцию DENY.
Платформа SQL Server не поддерживает предложения HIERARCHY OPTION
и ADMIN OPTION стандарта ANSI. Хотя предложение ADMIN OPTION и не поддержи-
вается, в версии команды REVOKE SQL Server есть две административные привилегии
(CREATE и BACKUP). Синтаксис инструкции следующий.
REVOKE [GRANT OPTION FOR]
{ [объектная_привилегия] [,...]|
[системная_привилегия] }
[ON [объект] [(столбец [,...])] ]|
{ТО ! FROM} [имя_получателя [,...] | роль [,...] | PUBLIC | GUEST }
[CASCADE]
[AS {имя_группы | имя_роли} ]
Где:
GRANT OPTION FOR
Пользователь лишается права назначать конкретные привилегии другим пользова-
телям.
объектнаЯ-Иривипегия
Отменяются права доступа к различным инструкциям, которые могут комбиниро-
ваться в любом порядке.
ALL [PRIVELEGES]
Отменяются все привилегии, назначенные в настоящий момент указанным
пользователям и/или для указанных объектов базы данных. Использование
этого предложения не поощряется, поскольку способствует нечеткости про-
граммирования.
{SELECT | INSERT | DELETE | UPDATE}
Указанный пользователь лишается указанной привилегии доступа к указанно-
му объекту (например, к таблице или представлению). Для отмены привиле-
гий уровня столбца используйте список столбцов, заключенный в скобки.
REFERENCES
Отменяется право создавать и удалять ограничения типа «внешний ключ»,
ссылающиеся на объект базы данных как на родительский объект.
RULE
Отменяется право пользователя создавать или удалять правило в таблице или
представлении.
EXECUTE
Отменяется право выполнять хранимую процедуру, пользовательскую функцию
или расширенную хранимую процедуру.
системнаяпривил егия
Отменяется право выполнения следующих инструкций: CREATE DATABASE,
CREATE DEFAULT, CREATE FUNCTION, CREATE PROCEDURE, CREATE RULE,
CREATE TABLE, CREATE VIEW, BACKUP DATABASE и BACKUP LOG.
476 | Глава 3. Справочник по инструкциям SQL
ON [объект] [(столбец [,...])]
Отменяется право доступа пользователя к указанному объекту. Если объект представ-
ляет собой таблицу или представление, вы можете отменять привилегии доступа
к отдельным столбцам. Вы можете отменять в таблице или представлении привилегии
SELECT, INSERT, UPDATE, DELETE и REFERENCES. В столбцах таблицы или пред-
ставления вы можете отменять только привилегии SELECT и UPDATE. Вы можете
отменять привилегии EXECUTE в хранимой процедуре, пользовательской функции
или расширенной хранимой процедуре.
{ТО | FROM] имя получателя | роль | PUBLIC | GUEST
Указываются пользователи или роли, теряющие указанную привилегию. Для
отмены привилегий, назначенных роли PUBLIC (которая подразумевает всех
пользователей), можно использовать ключевое слово PUBLIC. Можно перечис-
лить несколько получателей, разделяя их имена запятыми. В SQL Server также
поддерживается учетная запись GUEST, которую используют все пользователи,
которые не имеют своей записи в базе данных.
CASCADE
Удаляются привилегии пользователей, которые получили свои права через пред-
ложение WITH GRANT OPTION. Это предложение является необходимым при ис-
пользовании предложения GRANT OPTION FOR.
AS {имя группы | имя_роли}
Указываются права, в соответствии с которыми отменяется привилегия. В неко-
торых случаях пользователю могут временно потребоваться права определенной
группы, чтобы отменить указанные привилегии. В этом случае, чтобы получить
такие права, вы можете использовать предложение AS.
Две формы инструкции REVOKE - REVOKE объектная_привилегия и REVOKE
системиаЯ-Привилегия являются взаимоисключающими. Не пытайтесь выполнить
обе операции в одной инструкции. Ключевое синтаксическое отличие между ними со-
стоит в том, что не следует использовать предложение ON при удалении системных
привилегий. Например, чтобы удалить системную привилегию, можно использовать
следующую команду.
REVOKE CREATE DATABASE, BACKUP DATABASE FROM dylan, katie
Если привилегии были присвоены пользователю с применением предложения
WITH GRANT OPTION, то отменять эти привилегии следует с одновременным исполь-
зованием двух предложений - WITH GRANT OPTION и CASCADE. Например:
REVOKE GRANT OPTION FOR
SELECT, INSERT, UPDATE, DELETE ON titles
TO editors
CASCADE
GO
Команду REVOKE можно использовать только в текущей базе данных. Соответственно
всегда неявно предполагаются опции стандарта ANSI CURRENT USER и CURRENT ROLE.
Инструкция REVOKE также используется для отмены всех параметров DENY.
Справочник по командам SQL | 477
>r »
Платформа SQL Server также поддерживает дополнительную инструк-
цию DENY. Синтаксис инструкции DENY идентичен синтаксису инструк-
ции REVOKE. Однако, по сути, они отличаются тем, что REVOKE нейтра-
лизует привилегии пользователя, a DENY их явно запрещает. Используйте
инструкцию DENY, чтобы запретить пользователю или роли доступ к при-
вилегии, даже если привилегия предоставляется явно или через назначение
роли.
Инструкция REVOKE должна использоваться для удаления ранее предоставлен-
ных или запрещенных (DENY) привилегий. Например, пользователь kelly ушла
в продолжительный отпуск по уходу за ребенком. На это время ее доступ к таблице
employee был запрещен. Она вернулась, и мы вновь разрешили привилегии.
DENY ALL ON employee TO Kelly
GO
REVOKE ALL ON employee TO Kelly
GO
В этом примере команда REVOKE не удаляет ее привилегии, она нейтрализует
действие команды DENY.
См. также
GRANT
Инструкция ROLLBACK
Инструкция ROLLBACK возвращает транзакцию в ее исходное состояние или к опреде-
ленной, заранее заданной точке сохранения (SAVEPOINT). Также инструкция ROLLBACK
закрывает все открытые курсоры.
Платформа Команда
DB2 Поддерживается
MySQL Поддерживается с ограничениями
Oracle Поддерживается с вариантами
PostgreSQL Поддерживается с ограничениями
SQL Server Поддерживается с вариантами
Синтаксис SQL2003
ROLLBACK [WORK]
[AND [NO] CHAIN]
[TO SAVEPOINT точка_сохранения)
478 | Глава 3. Справочник по инструкциям SQL
Ключевые слова
WORK
Дополнительное ключевое слово, которое по сути никакой роли не играет.
AND [NO] CHAIN
Инструкция AND CHAIN заставляет СУБД завершить текущую транзакцию, но
среда транзакции (например, уровень изоляции транзакций) остается в общем
пользовании для следующей транзакции. Предложение AND NO CHAIN просто
завершает транзакцию (так система поступает и по умолчанию).
ТО SA VEPOINT имя_точки_сохранения
Позволяет не отменять всю транзакцию, а откатить ее к указанной точке сохранения
(т. е. выполняется частичный откат). Параметр имя_точки_сохранения может пред-
ставлять собой постоянное выражение или переменную. Если нет активных точек со-
хранения, то инструкция возвратит ошибку. Если предложение ТО SAVEPOINT опу-
щено, закрываются все курсоры. Если предложение ТО SA VEPOINTуказано, то закры-
ваются только те курсоры, которые были открыты соответстующей инструкцией
SAVEPOINT.
Помимо отмены одиночных операций по манипуляции данными, таких, как INSERT,
UPDATE или DELETE (или их пакета), инструкция ROLLBACK отменяет транзакции
вплоть до последней поданной инструкции START TRANSACTION, SET TRANSACTION
или SAVEPOINT
Общие правила
Инструкция ROLLBACK используется для отмены транзакции. Ее можно применять
для отмены транзакций, запускаемых явным образом (при помощи инструкции START
TRAN) или неявно, при помощи инициирующей транзакцию инструкции. Также ее
можно использовать для отмены неявных транзакций, запускаемых без инструкции
START TRAN. Инструкции ROLLBACK и COMMIT являются взаимоисключающими.
Большинство людей связывают с термином «транзакция» такие команды, как INSERT,
UPDATE и DELETE. Однако транзакции включают в себя самые разнообразные команды.
Список таких команд разный на разных платформах, но, как правило, сюда входят коман-
ды, которые изменяют данные и структуры базы данных и которые регистрируются ме-
ханизмом ведения журнала базы. Согласно стандарту ANSI, при помощи инструкции
ROLLBACK можно отменить любые инструкции SQL.
Советы и хитрости программирования
Наиболее важная хитрость состоит в том, что некоторые платформы выполняют автома-
тические и неявные транзакции, а другие требуют выполнения явных транзакций. Если
вы сделаете допущение, что платформа использует один метод, а не другой, вы можете
не угадать. Таким образом, при переносе кода с одной платформы на другую нужно сле-
довать стандартному, определенному методу работы с транзакциями. Мы рекомендуем
остановиться на явных транзакциях, где в ее начале используются инструкции SET
TRAN или START TRAN, а в конце - инструкции COMMIT или ROLLBACK.
Справочник по командам SQL | 479
DBS
Платформа DB2 поддерживает базовую форму инструкции стандарта ANSI. Не под-
держивается предложение [AND [NO] CHAIN], (Также обратите внимание, что DB2 не
поддерживает инструкцию START TRANSACTION, поэтому все транзакции в DB2 запус-
каются неявно.) Синтаксис инструкции ROLLBACK в DB2 следующий.
ROLLBACK [WORK] [ТО SAVEPOINT имя_точки_сохранения']
Несколько инструкций SET в DB2 не охватываются системой контроля транзакций, и,
следовательно, их нельзя откатить. Сюда входят следующие инструкции: SET CONNEC-
TION, SET CURRENT DEFAULT TRANSFORM GROUP, SET CURRENT DEGREE, SET CUR-
RENT EXPLAIN MODE, SET CURRENT EXPLAIN SNA PSHOT, SET CURRENT PA CKA GESET,
SET CURRENT QUERY OPTIMIZATION, SET CURRENT REFRESH AGE, SET EVENT MONI-
TOR STATE, SETPASSTHRU, SET PATH, SET SCHEMA и SET SERVER OPTION.
Платформа DB2 выполняет неявный откат, если элемент задания завершается
ошибкой.
При выполнении в DB2 обычного отката (не к точке сохранения) все блокировки,
выполненные элементом задания, снимаются, все открытые курсоры закрываются, ло-
каторы объектов LOB очищаются, и в некоторых случаях откат влияет на кеширова-
ние. Если в DB2 выполняется откат к точке сохранения, то блокировки и локаторы
объектов LOB остаются неизменными, и динамически созданный код SQL остается
работоспособным (хотя его нужно будет обрабатывать заново). Откат к точке сохране-
ния, при котором используются курсоры, несколько более сложен. Если в точке сохра-
нения курсор зависит от кода DDL, он будет помечен как неработоспособный. Если
ссылка на курсор в точке сохранения есть, но в точке сохранения он не зависит от
DDL, тогда курсор остается открытым и указатель курсора помещается перед сле-
дующей строкой. Во всех прочих случаях курсор остается неизменным.
MySQL
Платформа MySQL поддерживает лишь самый простой механизм отката, и даже при
этом вы должны объявлять каждую таблицу, применительно к которой вы можете
выполнить инструкцию ROLLBACK как безопасную для транзакций (transaction safe).
Безопасная для транзакций таблица - это таблица, объявленная со свойством InnoDB
или BDB. За дополнительной информацией обращайтесь к разделу, посвященному
инструкции CREATE TABLE.
ROLLBACK [ТО SAVEPOINT имя_точки_сохранения]
MySQL разрешает выполнять инструкции, связанные с управлением транзакциями,
применительно к небезопасным таблицам, но эти инструкции просто игнорируются,
и выполнение транзакций происходит автоматически. В случае использования инструк-
ции ROLLBACK в небезопасной таблице откат изменений проводиться не будет.
По умолчанию MySQL работает в режиме A UTOCOMMIT, где все модификации данных
автоматически записываются на диск. Вы можете отключить режим A UTOCOMMIT, подав
команду SET A UTOCOMMIT=Q. Вы также можете контролировать автоматическое выполне-
ние транзакций по одной инструкции, используя команду BEGIN и BEGIN WORK.
480 | Глава 3. Справочник по инструкциям SQL
BEGIN;
SELECT ©A:=SUM(salary) FROM employee WHERE job_type=1;
BEGIN WORK;
UPDATE jobs SET summmary=@A WHERE job_type=1;
COMMIT;
Платформа MySQL автоматически выполняет неявную инструкцию COMMIT по
завершении любой из приведенных инструкций: ALTER TABLE, BEGIN, CREATE
INDEX, DROP DATABASE, DROP TABLE, RENAME TABLE и TRUNCATE.
MySQL поддерживает частичный откат с использованием точек сохранения начи-
ная с версии 4.0.14.
Oracle
Oracle поддерживает ANSI-форму инструкции ROLLBACK с дополнительным предло-
жением FORCE.
ROLLBACK [WORK] {[ТО [SAVEPOINT] имя_точки_сохранения] |
[FORCE 'текст']};
Инструкция ROLLBACK удаляет все модификации данных, внесенные в текущей от-
крытой транзакции (или после указанной существующей точки восстановления). Также
снимаются все блокировки, используемые транзакцией, очищаются все точки сохране-
ния, отменяются все изменения текущей транзакции, и транзакция завершается.
Инструкция ROLLBACK...ТО SAVEPOINT производит откат части транзакции,
идущей после точки сохранения. За дополнительной информацией обращайтесь к раз-
делу «Инструкция SAVEPOINT».
Реализация инструкции ROLLBACK в Oracle близка к стандарту ANSI, за ис-
ключением предложения FORCE. Инструкция ROLLBACK FORCE отменяет сомни-
тельную распределенную транзакцию. Чтобы выполнить эту инструкцию, вы должны
иметь привилегию FORCE TRANSACTION. Предложение FORCE нельзя использовать
с предложением ТО [SAVEPOINT]. Инструкция ROLLBACK FORCE может влиять не
на текущую транзакцию, а на транзакцию, указанную в параметре ‘текст ’. Параметр
'текст ’ должен представлять собой локальный или глобальный ID транзакции,
которую вы хотите отменить. (Такие транзакции и их ID подробно описаны в системном
представлении Oracle DBA_2PC_PENDING.)
Например, вам может понадобиться вернуть вашу текущую транзакцию к точке
сохранения salary_adjustment. Две приведенные ниже команды эквивалентны.
ROLLBACK WORK ТО SAVEPOINT salary_adjustment;
ROLLBACK TO salary_adjustment:
В следующем примере мы откатываем сомнительную распределенную транзакцию.
ROLLBACK FORCE '45.52.67'
31-2447
Справочник по командам SQL | 481
PostgreSQL
Платформа PostgreSQL поддерживает базовую форму инструкции ROLLBA СК, но не
поддерживает точки сохранения.
PostgreSQL
{ROLLBACK | ABORT} [WORK | TRANSACTION];
Инструкция ROLLBA СК удаляет все модификации данных, внесенные в текущей
открытой транзакции. Если открытые транзакции отсутствуют, инструкция генериру-
ет ошибку. PostgreSQL поддерживает как предложение WORK, так и предложение
TRANSA CTION. Не поддерживается откат к точке сохранения. Платформа PostgreSQL
поддерживает ключевое слово ABORT как синоним ROLLBACK.
SQL Server
Платформа SQL Server поддерживает ключевые слова WORK и TRAN. Единственное
различие между ними состоит в том, что инструкция ROLLBACK WORK не позволяет
откатывать указанную транзакцию к указанной точке сохранения.
ROLLBACK { [WORK] | [TRAN[SACTION]
[имя_транзакции | имя_точки_сохранения] ] }
Если инструкция ROLLBACK используется без ключевых слов WORK или TRAN,
то она отменяет все открытые в данный момент транзакции. Инструкция ROLLBACK,
как правило, отключает блокировку, но блокировки не снимаются, если происходит
откат к точке сохранения.
SQL Server позволяет указывать помимо имени_точки_сохранения конкретное
имя_транзакции. Вы можете указывать их напрямую или при помощи переменных
в коде Transact-SQL.
Если инструкция ROLLBACK TRANSACTION выполняется в триггере, она отменя-
ет все модификации данных, включая те, которые произвел триггер, до момента
подачи инструкции ROLLBACK. Вложенные триггеры не выполняются, если они идут
в тексте триггера после инструкции ROLLBACK. Однако на инструкции, которые идут
в триггере после ROLLBACK, эта инструкция не влияет. Команда ROLLBACK сходна
с инструкцией COMMIT в плане вложенности, установки в ноль системной перемен-
ной @@TRANSCOUNT (за дополнительной информацией о контроле транзакций во
вложенном триггере SQL Server обращайтесь к разделу «Инструкция COMMIT»).
Ниже приводится пакет Transact-SQL, использующий инструкции COMMIT
и ROLLBACK на Microsoft SQL Server. В этом примере в таблицу sales вставляется
запись. Если при вставке возникает ошибка, происходит откат транзакции. Если встав-
ка проходит успешно, транзакция фиксируется.
BEGIN TRAN - инициализация транзакции
-- сама транзакция
INSERT INTO sales
VALUES('7896','JR3435','Oct 28 1997',25,'Net 60','BU7832')
482 | Глава 3. Справочник по инструкциям SQL
-- обработка ошибки
IF TERROR <> О
BEGIN
- - запись ошибки в журнал событий и переход к окончанию
RAISERROR 50000 'Insert of sales record failed'
ROLLBACK WORK
GOTO end_of_batch
END
- - Если ошибок нет, транзакция фиксируется
COMMIT TRAN
- - метка для GOTO,которая позволяет перейти к окончанию без фиксации транзакции
- - без фиксации транзакции
end_.of_bat.ch:
GO
SAVEPOINT salesl
См. также
COMMIT
RELEASE SAVEPOINT
SAVEPOINT
Инструкция SAVEPOINT
Эта команда разделяет транзакцию на логические точки сохранения. В одной транзак-
ции может быть несколько точек сохранения. Главное преимущество команды SAVE-
POINTсостоит в том, что транзакции можно откатывать частично, к точке сохранения,
используя инструкцию ROLLBACK.
Платформа Команда
DB2 Поддерживается с вариантами
MySQL Не поддерживается
Oracle Поддерживается
PostgreSQL Не поддерживается
SQL Server 11оддержипается е ограничениями
Справочник по командам SQL | 483
Синтаксис SQL2003
SAVEPOINT имя_точки_сохранения
Ключевые слова
SA VEPOINT имя_точки_сохранения
В текущей транзакции устанавливается точка сохранения с именем имя_точки_сохра-
нения.
Некоторые производители позволяют использовать в транзакции точки сохране-
ния с одинаковыми именами, но стандарт ANSI так делать не рекомендует.
Стандарт SQL2003 поддерживает инструкцию RELEASE SAVEPOINT имя_точки_со-
хранения, которая позволяет удалить существующую точку сохранения. За дополнитель-
ной информацией об удалении существующих точек сохранения обращайтесь к разделу
«Инструкция RELEASE SAVEPOINT».
Общие правила
Точки сохранения устанавливаются в пределах транзакции, в которой они определе-
ны. Имена точек сохранения должны быть уникальными в этих пределах. Используй-
те инструкции BEGIN и COMMIT осторожно, поскольку, если вы случайно поставите
инструкцию BEGIN слишком рано или COMMIT - слишком поздно, это может сильно
повлиять на то, как транзакции будут записываться в базу данных. Обязательно вы-
бирайте для точек сохранения понятные имена, поскольку вы будете позже ссылаться
на них в своих программах.
Советы и хитрости программирования
Как правило, повторное использование имени точки сохранения не приведет к ошибке
или выводу предупреждения. Дублирование имени приведет к тому, что предыдущая
точка сохранения с таким именем окажется неработоспособной. Будьте внимательны
при выборе имен для точек сохранения!
При запуске транзакции тратятся ресурсы (а именно блокировки), обеспечи-
вающие транзакционную целостность. Ваша транзакция должна как можно быстрее
завершиться, чтобы блокировки были сняты и другие пользователи могли использо-
вать ресурсы.
DB2
Платформа DB2 поддерживает усовершенствованную версию инструкции SAVEPOINT
по сравнению с той, которая определяется стандартом ANSI.
SAVEPOINT имя_точки_сохранения [UNIQUE]
ON ROLLBACK RETAIN CURSORS [ON ROLLBACK RETAIN LOCKS]
Где:
SA VEPOINT имя точки ^охранения
В текущей транзакции устанавливается точка сохранения с именем имя_точки_сохра-
нения.
484 | Глава 3. Справочник по инструкциям SQL
UNIQUE
Предложение показывает, что точка сохранения должна быть уникальной и что
это имя нельзя использовать повторно или изменять (поддерживается только DB2
для OS/390).
ON ROLLBAСК RETAIN CURSORS
Указывает, что открытые курсоры остаются открытыми при возврате к точке со-
хранения. (Дополнительная информация приводится в разделе «Инструкция
ROLLBACK».)
ON ROLLBA СК RETAIN LOCKS
Указывает, что блокировки сохраняются при возврате к точке сохранения. Это
предложение используется по умолчанию. (Дополнительная информация приво-
дится в разделе «Инструкция ROLLBACK».)
Нужно отметить, что в DB2 точки сохранения не могут быть вложенными. Если
точка сохранения создается в тот момент, когда активна другая точка, возникает ошибка.
Платформа DB2 неявно удаляет все точки сохранения в транзакции после ее фик-
сирования.
В следующем примере мы устанавливаем точку сохранения sales_processing без
явного сохранения блокировок.
SAVEPOINT sales_processing ON ROLLBACK RETAIN CURSORS;
Однако, поскольку блокировки сохраняются по умолчанию, инструкция в следующем
примере по существу является избыточной.
SAVEPOINT sales_processing ON ROLLBACK RETAIN
CURSORS ON ROLLBACK RETAIN LOCKS;
MySQL
He поддерживается.
Oracle
Платформа Oracle полностью поддерживает реализацию стандарта ANSI.
SAVEPOINT имя_точки_сохранения
В следующем примере производится несколько модификаций данных, после чего
выполняется откат к точке сохранения.
INSERT INTO sales
VALUES('7896','JR3435','Oct 28 1997',25,'Net 60','BU7832');
SAVEPOINT after_insert;
UPDATE sales SET terms = 'Net 90'
WHERE sales_id = '7896':
SAVEPOINT after_update;
Справочник по командам SQL | 485
DELETE sales;
ROLLBACK TO after_insert;
PostgreSQL
He поддерживается.
SQL Server
Платформа SQL Server не поддерживает команду SAVEPOINT. Вместо нее использует-
ся команда SA ЕЕ.
SAVE TRANSACTION] имя_точки_сохранения
Кроме того, вместо объявления постоянного имени точки сохранения вы при желании
можете сослаться на переменную, содержащую это имя. Если вы используете перемен-
ную, то она должна относиться к типу CHAR, VARCHAR, NCHAR или NVARCHAR.
Платформа SQL Server позволяет устанавливать в одной транзакции несколько
точек сохранения. Тем не менее будьте осторожны. Из-за того, что SQL Server под-
держивает несколько точек сохранения в одной транзакции, может показаться, что
SQL Server полностью поддерживает вложенные точки сохранения. На самом деле
такие точки не поддерживаются. При каждом выполнении в SQL Server команды для
фиксирования транзакции или создания точки сохранения фиксирование результатов
или откат происходит к последней, открытой точке сохранения.
При выполнении команды ROLLBACK TRAN имя_точки_сохранения SQL Server
выполняет откат транзакции к указанной точке сохранения, а затем продолжает обра-
ботку со следующей допустимой команды Transact-SQL, стоящей после инструкции
ROLLBACK. И,наконец, транзакция должна завершаться инструкцией COMMIT или
последней инструкцией ROLLBACK.
См. также
COMMIT
ROLLBACK
Инструкция SELECT
Инструкция SELECT извлекает строки, столбцы и производные значения из одной или
нескольких таблиц базы данных.
Платформа Команда
DB2 Поддерживается с вариантами
(соединения ANSI поддерживаются)
MySQL Поддерживается с вариантами
(соединения ANSI поддерживаются частично)
486 | Глава 3. Справочник по инструкциям SQL
Платформа Команда
Oracle Поддерживается с вариантами (соединения ANSI поддерживаются)
PostgreSQL Поддерживается с вариантами (соединения ANSI поддерживаются частично)
SQL Server Поддерживается с вариантами (соединения ANSI поддерживаются)
Синтаксис SQL2003
Полный синтаксис инструкции SELECT очень мощный и сложный, но его можно разде-
лить на следующие основные предложения.
SELECT [{ALL | DISTINCT}] отбираемый-Элемент [AS псевдоним] [,...]
FROM [ONLY | OUTER]
{имя_таблицы [[AS] псевдоним] | имя_представления [[AS] псевдоним]} [,...]
[ [тип_соединения] JOIN условие_соединения ]
[WHERE условие_поиска] [ {AND | OR | NOT} условие_поиска [...] ]
[GROUP BY группировка_по_выражению {группировка_по_столбцам | ROLLUP
группировка_по_столбцам | CUBE группировка_по_столбцам | GROUPING SETS (
список_наборов_группировок ) | ( ) | набор-группировок,
список-наборов-группировок }
[HAVING условие_поиска] ]
[ORDER BY {выражение_для_сортировки [ASC | DESC]} [,...] ]
Ключевые слова
Все показанные ниже ключевые слова, за исключением параметра отбираемыйэле-
мент, описываются более подробно в следующем разделе «Общие правила».
[ALL | DISTINCT] отбираемый_элемент
Извлекаются значения, которые образуют результирующий набор данных.
отбираемый_л1емент может представлять собой константу, агрегат или скалярную
функцию, математическое выражение, параметры или переменную или же подза-
прос, но наиболее часто отбираемый_элемент - это столбец таблицы или пред-
ставления. Несколько таких элементов должны разделяться запятыми.
Если данные извлекаются из контекста, отличного от контекста текущего пользо-
вателя, перед столбцом нужно указывать префикс в виде схемы или имени вла-
дельца. Если таблица принадлежит другому пользователю, то в ссылке на столбец
нужно указывать имя этого пользователя. Например, предположим, что пользова-
телю jake нужно обратиться к данным из схемы katie.
SELECT emp_id
FROM katie.employee;
Чтобы извлечь все столбцы всех таблиц или представлений, указанных в предло-
жении FROM, можно использовать краткое написание в виде звездочки ( * ). Хорошей
Справочник по командам SQL | 487
практикой является использование этой формы только в запросах к одиночной
таблице.
Предложение ALL, заданное по умолчанию, приводит к извлечению всех записей,
удовлетворяющих критерию отбора. Предложение DISTINCT заставляет базу
данных отфильтровывать все дублирующиеся записи и возвращать только один
экземпляр из нескольких идентичных записей.
A S псевдоним
Заменяет заголовок столбца (если находится в предложении отбираемый ^эле-
мент) или имя таблицы или представления (если находится в предложении
FROM) более кратким заголовком или именем. Это предложение особенно полез-
но для замены непонятных или длинных имен понятными обозначениями или
если столбец содержит только производные данные, чтобы не было таких назва-
ний, как ORA000189x7/0.02. Это также очень полезно при рефлексивных соеди-
нениях (self-joins) и коррелированных подзапросах, где один запрос ссылается на
одну таблицу несколько раз. Если в списке элементов для отбора или в предложе-
нии FROM содержится несколько элементов, ставьте запятые после предложений
AS. Вводя псевдонимы в запрос, используйте их постоянно.
FROM имя_таблицы
Это предложение служит для указания всех таблиц и/или представлений, из ко-
торых запрос получает данные. Разделяйте имена таблиц и представлений запяты-
ми. Предложение FROM также позволяет назначать псевдонимы длинным именам
таблиц или представлений, а также подзапросам при помощи предложения AS.
Применение кратких псевдонимов вместо длинных имен таблиц и представлений
упрощает программирование. (Конечно, это может нарушить тщательно спла-
нированные администратором базы соглашения об именах, но псевдонимы дейст-
вуют только в пределах одного запроса. Обращайтесь к следующему разделу
«Общие правила».) Предложения FROM могут содержать подзапрос (обращай-
тесь к разделу «Инструкция SUBQUERY»).
ONLY
Указывается, что в результирующий набор данных будут извлекаться только
строки из указанной таблицы или представления, но не строки из подтаблиц
и представлений-потомков. При использовании предложения ONL Y обязательно
заключайте имя_таблицы или имя-Представления в скобки. Предложение
ONLY игнорируется, если в таблице или представлении нет подтаблиц или
представлений-потомков.
OUTER
Указывается, что в результирующий набор данных будут извлекаться как строки
из указанно# таблицы или представления, так и строки из подтаблиц и представ-
лений-потомков. Столбцы подтаблиц (или представлений-потомков) будут добав-
ляться справа, в порядке иерархии подтаблиц, в соответствии с глубиной вложен-
ности. В случае сложной иерархии подтаблицы, имеющие общих родителей, до-
бавляются в порядке создания типов. При использовании предложения OUTER
обязательно заключайте имя_таблицы или имя_представления в скобки. Преддо-
488 | Глава 3. Справочник по инструкциям SQL
жение OUTER игнорируется, если в таблице или представлении нет подтаблиц
или представлений-потомков.
JOIN условие^соединения
Результирующий набор, полученный из таблицы, указанной в предложении
FROM, соединяется с другой таблицей, которая имеет с ней логическую связь, ос-
нованную на общем наборе значений. Эти значения обычно содержатся в столб-
цах с одним именем и типом данных, которые есть в обеих таблицах. Этот столбец
или столбцы в каждой таблице называются ключом соединения или общим
ключом. В большинстве случаев, хотя и не всегда, ключ соединения представляет
собой первичный ключ одной таблицы и внешний ключ другой таблицы. Если
данные в столбцах совпадают, соединение можно выполнить. (Обратите внима-
ние, что соединения можно также осуществлять при помощи предложения
WHERE. Этот метод иногда называют тета-соединением.)
Условия соединения чаще всего описываются следующей формой.
JOIN имя_таблицы2 ON имя_таблицы1. столбец1 <оператор_сравнения>
имя_таблицы2. столбец2
JOIN имя_таблицыЗ ON имя_таблицы1. столбецА < оператор_сравнения >
имя_таблицыЗ. столбецА
Если оператор уравнения представляет собой знак равенства (=), то говорят, что
соединение представляет собой эквисоединение. Однако при сравнении может
использоваться любой допустимый оператор сравнения (с, >, <=, >= или даже <>).
ОператорЛУХ) используется для выполнения соединений с несколькими условиями.
Также вы можете использовать оператор OR для указания альтернативных условий
соединения.
Если тип соединения явно не указан, подразумевается INNER JOIN. Обратите
внимание, что существует много типов соединений, каждый из которых имеет
свои правила и функциональность, которые описываются в разделе «Общие пра-
вила» (и более подробно - в разделе «Инструкция JOIN»). Обратите внимание,
что существует альтернативный подход к указанию условий соединения, при
помощи предложения USING.
USING (имяутолбца [,...])
Играет роль альтернативы предложению ON. Вместо описания условий
соединения просто укажите имяутолбца (или несколько имен столбцов, раз-
деленных запятыми), которое существует в обеих таблицах. (Имена столбцов
в обеих таблицах должны совпадать.) В следующем примере два запроса
имеют идентичные результаты.
SELECT emp_id
FROM employee
LEFT JOIN sales USING (emp_id, region_id);
SELECT emp_id
Справочник по командам SQL | 489
FROM employee AS e
LEFT JOIN sales AS s
ON e.emp_id = s,emp_id
AND e.region_id = s.region_id;
WHERE условие_поиска
Отфильтровывает ненужные данные из результирующего набора запроса, возвра-
щая только те записи, которые удовлетворяют условиямпоиска. Плохо написан-
ное предложение WHERE может ухудшить производительность полезной во всех
прочих отношениях инструкции SELECT, поэтому деталями предложения WHERE
необходимо владеть хорошо. Условия поиска синтаксически описываются сле-
дующим образом.
WHERE [схема.[имя^таблицы.^столбеи, оператор значение
Предложения WHERE обычно сравнивают значения, содержащиеся в столбце таб-
лицы. Значения в столбце сравниваются с помощью какого-нибудь оператора
(за дополнительной информацией обращайтесь к разделу «Операторы» главы 2).
Например, значение в столбце может быть равным (=) данному значению, быть
больше (>) данного значения или входить в диапазон {BETWEEN) значений.
Предложения WHERE могут содержать много условий поиска, соединяемых при
помощи булевых операторов AND и OR. Для определения порядка приоритета ус-
ловий поиска можно использовать скобки. Предложения WHERE могут содержать
подзапросы (обращайтесь к разделу «Инструкция SUBQUERY»).
GROUP BY выражение_длягруппировки
Используется в запросах, применяющих агрегатные функции, такие, как AVG,
COUNT, COUNT DISTINCT MAX, MIN и SUM, для распределения результирующих
запросов по категориям, определенным в выражении_Оля_группировки. (Обсужде-
ние агрегатных функций, существующих в SQL, приводится в главе 4.) Для выраже-
ния_для_группировки предложения GROUP BY существует свой синтаксис.
GROUP BY выра>кение_для_группировки
Где выражение _для_группировки представляет собой следующее.
{ (столбец_для_группировки | ROLLUP (столбец_для_группировки [,...]) |
CUBE (столбец_для_группировки [,...]) | GROUPING SETS
( список_наборов_для_группировки ) I ( ) I набор_для~группировки,
список_наборов_для_группировки }
Обращайтесь к подразделу «Предложение GROUP BY» в разделе «Общие правила» за
дополнительной информацией по ключевым словам ROLLUP, CUBE и GROUPING
SETS.
НА VING условиепоиска
Добавляются условия поиска по результатам предложения GROUP BY, сходные по
форме с предложением WHERE. Предложения HAVING не влияют на строки,
используемые при вычислении агрегатов. Предложения HAVING могут содержать
подзапросы (за дополнительной информацией обращайтесь к разделу «Инструкция
SUBQUERY»).
490 | Глава 3. Справочник по инструкциям SQL
ORDER BY выражение оля сортировки [ASC | DESC]
Указывается способ сортировки результирующего набора по возрастанию (ASC)
или по убыванию (DESC) с использованием выражения_для_сортировки. Выраже-
ние для сортировки представляет собой список столбцов, разделенных запятыми,
по которым нужно производить сортировку.
Общие правила
Каждое предложение инструкции SELECT имеет свою область применения. Поэтому
можно говорить отдельно о предложении FROM, предложении WHERE, предложении
GROUP BY и т. д. Дополнительную информацию и примеры инструкций SELECT вы
можете найти в разделах, посвященных каждому из предложений инструкции. Однако
не в каждом запросе нужно использовать каждое предложение. Минимально необхо-
димыми в запросе являются список отбираемых элементов и предложение FROM.
Поскольку предложение SELECT является очень важным и имеет много опций, мы
разделили раздел «Общие правила» на следующие подразделы.
• Псевдонимы и соединения с использованием предложения WHERE.
• Предложение JOIN.
• Предложение WHERE.
• Предложение GROUP BY.
• Предложение HAVING.
• Предложение ORDER BY.
Псевдонимы и соединения с использованием предложения WHERE
Перед именем столбца может потребоваться указать префикс в виде имени базы дан-
ных, схемы и имени таблицы, поскольку столбцы с одним именем могут присутство-
вать в разных таблицах, на которые ссылается запрос. В следующем примере (для
базы данных Oracle) таблица jobs и таблица employee схемы scott содержат столбец
job_id. Обратите внимание, что в этих примерах таблицы employee и jobs соединяют-
ся при помощи предложения WHERE.
SELECT scott.employee.emp_id.
scott.employee.fname,
scott.employee.Iname,
jobs.job_desc
FROM scott.employee,
jobs
WHERE scott.employee.job_id = jobs.job_id
ORDER BY scott.employee.fname,
scott employee.Iname
Используя псевдонимы, вы можете написать такой запрос быстрее и проще.
SELECT e.emp_id,
е.fname,
Справочник по командам SQL | 491
e.Iname,
j.job_desc
FROM scott.employee AS e,
jobs AS j
WHERE e.job_id = j.job_id
ORDER BY e.fname,
e.Iname
Эти два запроса также иллюстрируют некоторые важные правила, касающиеся
соединений, выполняемых при помощи предложений WHERE.
1. Используйте запятые для разделения элементов в списке_отбираемых_элементов,
элементов в предложении FROM и элементов в выражении_для_сортировки.
2. Используйте предложения AS для определения псевдонимов.
3. Определив псевдонимы, используйте их постоянно, по всей инструкции SELECT.
Вообще говоря, при описании соединений вам следует отдавать предпочтение
предложению JOIN (о котором мы сейчас поговорим), а не предложению WHERE. Это
не только сделает ваш код более понятным и позволит легко отличать условия соеди-
нения от условий поиска, но также устранит саму возможность создания трудно пони-
маемых на интуитивном уровне условий при использовании в некоторых реализациях
предложения WHERE для внешних соединений.
Предложение JOIN
Чтобы выполнить такой запрос, как в предыдущем примере, в стиле ANSI, с использо-
ванием предложения JOIN, укажите первую таблицу, потом ключевое слово JOIN,
а потом вторую таблицу. После имени второй таблицы введите ключевое слово ON
и условие соединения, которое вы использовали бы в старой форме запроса. В следующем
примере показан запрос в стиле ANSI.
SELECT e.emp_id, e.fname, e.Iname, j.job_desc
FROM scott.employee AS e
JOIN jobs AS j ON e.job_id = j.job_id
ORDER BY e.fname, e.Iname;
В качестве альтернативы вы можете использовать предложение USING. Вместо
описания условий соединения просто укажите имя одного или нескольких столбцов
(разделяя их запятыми), которые существуют в обеих соединяемых таблицах. После
этого платформа проверит соединение, основываясь на столбце (или столбцах), при-
сутствующем в обеих таблицах. (Имена столбцов в обеих таблицах должны быть оди-
наковыми.) В следующем примере два запроса дают одинаковый результат. В одном
используется предложение ON, а в другом - предложение USING.
SELECT emp_id
FROM employee
LEFT JOIN sales USING (emp_id, region_id);
492 | Глава 3. Справочник по инструкциям SQL
SELECT emp_id
FROM employee AS e
LEFT JOIN sales AS s
ON e.emp_id = s.emp_id
AND e. region_id = s.region_id;
В стандарте ANSI вы можете указывать несколько разных типов соединений.
CROSS JOIN
Создается продукт полного перекрестного соединения двух таблиц. Каждая
запись первой таблицы соединяется со всеми записями второй таблицы, что соз-
дает результирующий набор огромных размеров. (Конечно, результат может быть
и небольшого размера, если таблицы содержат только четыре записи, но пред-
ставьте, что их по четыре миллиона!) Это предложение действует так же, как от-
сутствие условий соединения, и его результат также называется «координатным
продуктом». Использовать перекрестные соединения не рекомендуется.
[INNER] JOIN
Это предложение указывает, что несовпадающие строки в каждой таблице соеди-
нения будут отбрасываться. Если тип соединения, согласно стандарту ANSI, не
указан, этот тип принимается по умолчанию.
LEFT [OUTER] JOIN
Указывается, что записи будут возвращаться из таблицы, находящейся слева от ин-
струкции JOIN. Если запись, возвращаемая из левой таблицы, не имеет соответст-
вующей записи в правой таблице, запись все равно извлекается. В этом случае
в столбцах для значений из правой таблицы будут значения NULL. Многие профес-
сионалы рекомендуют конфигурировать везде, где это возможно, внешние соедине-
ния как левосторонние {LEFT OUTER), чтобы соблюсти единообразие.
RIGHT [OUTER] JOIN
Указывается, что записи будут возвращаться из таблицы, находящейся справа от
инструкции JOIN, даже если в таблице слева нет соответствующих записей.
В этом случае в столбцах для значений из левой таблицы будут значения NULL.
FULL [OUTER] JOIN
Указывается, что возвращаться будут все строки из обеих таблиц независимо от
того, совпадают ли строки в таблицах. Всем столбцам, для которых нет соответст-
вующих значений в соединенной таблице, присваиваются значения NULL.
Не все типы соединений поддерживаются всеми платформами; за ин-
формацией о специфике разных платформ при поддержке соединений обра-
щайтесь к разделу «Инструкция JOIN».
Справочник по командам SQL | 493
Предложение WHERE
Плохо написанное предложение WHERE может ухудшить производительность полез-
ной во всех прочих отношениях инструкции SELECT, поэтому деталями предложения
WHERE необходимо владеть хорошо. Ниже приводится пример типичного запроса
и предложения WHERE, состоящего из нескольких частей.
SELECT a.au_lname,
a.au_fname,
t2.title,
t2.pubdate
FROM authors a
JOIN titleauthor t1 ON a.au_id = t1.au_id
JOIN titles t2 ON t1.title_id = t2.title_id
WHERE (t2.type = 'business' OR t2.type = 'popular_comp')
AND t2,advance > 5500
ORDER BY t2,title
При обработке этого запроса скобки влияют на порядок проверки условий поиска.
Используйте скобки, чтобы переместить условия поиска вперед или назад по приори-
тету, так же как это делается в уравнениях алгебры.
На некоторых платформах сопоставление, заданное по умолчанию (которое
л также называется порядком сортировки), влияет на то, как предложение
WHERE фильтрует результаты запроса. Например, в SQL Server по умолчанию
принят словарный порядок без учета регистра, поэтому здесь не будет разни-
цы между «Smith», «smith» и «SMITH». Однако в Oracle используется сло-
варный порядок с учетом регистра, так что значения «Smith», «smith»
и «SMITH» будут считаться неодинаковыми.
Предложение WHERE предоставляет гораздо больше возможностей, чем показано
в приведенном примере. Ниже кратко описываются некоторые из наиболее используе-
мых возможностей предложения WHERE. За дополнительной информацией и при-
мерами обращайтесь к разделу «Предложение WHERE».
NOT
Обращает операцию сравнения при использовании синтаксиса WHERE NOT выра-
жение. Таким образом, в запросе вы можете использовать предложения WHERE
NOT LIKE... и WHERE NOT IN...
Операторы сравнения
Наборы значений сравниваются при помощи операторов <, >, о, >=, <= и =.
Например:
WHERE emp_id = '54123'
условия IS NULL или IS NOT NULL
Производится проверка на пустые или непустые значения, для чего используется
синтаксис WHERE выражение IS [NOT] NULL.
494 | Глава 3. Справочник по инструкциям SQL
AND
Объединяет несколько условий. При использовании оператора A ND возвращаются
только записи, удовлетворяющие всем условиям. Максимально допустимое ко-
личество условий определяется платформой. Пример:
WHERE job_id = '12' AND job_status = 'active'
OR
Объединяет альтернативные условия, возвращая записи, которые удовлетворяют
любому из условий. Например:
WHERE job-id = '13' OR job_status = 'active'
LIKE
В запросе будет использоваться строка-шаблон, заключенная в кавычки. Обоб-
щающие символы, поддерживаемые каждой конкретной платформой, подробно
описываются в разделе «Оператор LIKE». Все платформы поддерживают обоб-
щающий символ % (знак процента). Например, чтобы найти все телефонные но-
мера, начинающиеся с кода 415, можно использовать следующее предложение.
WHERE phone LIKE '415%'
EXISTS
Предложение EXISTS используется только с подзапросами и проверяет, существуют
ли данные, удовлетворяющие подзапросу. Как правило, это предложение работает
гораздо быстрее, чем подзапросы WHERE IN. Например, следующий запрос находит
всех авторов (authors), которые также являются служащими (employee).
SELECT au_ iname FROM authors WHERE EXISTS (SELECT last_name FROM employees)
BETWEEN
Определяется, принадлежит ли значение диапазону, лежащему между двумя
значениями (включая и эти два значения). Например:
WHERE ytd_sales BETWEEN 4000 AND 9000.
IN
Выполняется проверка на совпадение значения выражения с одним из значений,
входящих в указанный список. Список может быть литералом, например WHERE
state IN ('or', ЧГ, 'tn', 'ak). Список значений также может быть получен в подзапросе.
WHERE state IN (SELEC" state_abbr FROM territories).
SOME|ANY
Работает так же, как предложение EXISTS, хотя имеет несколько иной синтаксис.
Например, в следующем запросе находятся все авторы (authors), которые также
являются служащими (employee).
SELECT au_lname FROM authors WHERE au_lname = SOME(SELECT last_name FROM employees)
Справочник по командам SQL | 495
ALL
Выполняется проверка соответствия всех записей подзапроса критерию оценки.
Возвращает значение ИСТИНА, если подзапрос возвращает нулевое количество
строк. Пример:
WHERE city = ALL (SELECT city FROM employees WHERE emp_id = 54123)
Предложение GROUP BY
Предложение GROUP BY (как и предложение HAVING) необходимо только в тех запро-
сах, в которых используются агрегатные функции.
Предложение GROUP BY применяется для вывода агрегатного значения по одной
или нескольким строкам, которые возвращает инструкция SELECT, на основе одного
или нескольких неагрегатных столбцов, которые называются столбцами группировки
(grouping columns). Например, ниже приводится запрос, в котором определяется,
сколько людей мы нанимали каждый год в период с 1999 по 2004 год.
SELECT hire_year, COUNT(emp_id) AS 'nbr_emps'
FROM employee
WHERE status = 'ACTIVE'
AND hire_year BETWEEN 1999 AND 2004
GROUP BY hire_year;
Результаты будут следующие.
hire_year nbr_emps
1999 27
2000 17
2001 13
2002 19
2003 20
2004 32
Запросы, в которых используются агрегатные функции, могут предоставить много
видов сводной информации. К самым распространенным агрегатным функциям отно-
сятся следующие.
AVG
Возвращается среднее всех непустых значений в указанном столбце (столбцах).
A VG DISTINCT
Возвращается среднее всех уникальных непустых значений в указанном столбце
(столбцах).
COUNT
Возвращается количество всех непустых значений в указанном столбце (столбцах).
COUNT DISTINCT
Возвращается количество всех уникальных непустых значений в указанном столбце
(столбцах).
496 | Глава 3. Справочник по инструкциям SQL
COUNT (*)
Вычисляется общее количество записей в таблице.
МАХ
Возвращается наибольшее из непустых значений в указанном столбце (столбцах).
мт
Возвращается наименьшее из непустых значений в указанном столбце (столбцах).
SUM
Сумма всех непустых значений в указанном столбце (столбцах).
SUM DISTINCT
Сумма всех уникальных непустых значений в указанном столбце (столбцах).
Некоторые запросы, в которых используются агрегаты, возвращают одиночное
значение. Агрегаты, возвращающие одиночное значение, называются скалярными
агрегатами. Для скалярных агрегатов не требуется предложение GROUP BY.
Например:
--Запрос
SELECT AVG(price)
FROM titles
--Результат
14.77
Запросы, которые возвращают как обычные значения из столбцов, так и значения
из агрегатных функций, называются векторными агрегатами. В векторных агрегатах
используется предложение GROUP BY, и они возвращают одну или несколько строк.
Есть несколько правил, которыми следует руководствоваться при использовании пред-
ложения GROUP BY.
• Помещайте предложение GROUP BY правильно относительно других предложе-
ний - после предложения WHERE и перед предложением ORDER BY.
• В предложении GROUP BY все столбцы должны быть неагрегатными.
• Не используйте в предложении GROUP BY псевдонимы столбцов, хотя использо-
вание псевдонимов таблиц является допустимым.
Предположим, например, что вам нужно узнать общую сумму по нескольким
покупкам по таблице Order_Details, которая выглядит следующим образом.
OrderlD ProductID UnitPrice Quantity
10248 11 14.0000 12
10248 42 9.8000 10
10248 72 34.8000 5
10249 14 18.6000 9
10249 51 42.4000 40
10250 41 7.7000 10
10250 51 42.4000 35
10250 65 16.8000 15
32 - 2447
Справочник по командам SQL | 497
В следующем примере приведен запрос, который даст вам искомый результат.
SELECT OrderlD, SUM(UnitPrice » Quantity) AS 'Order Amt'
FROM order_details
WHERE orderid IN (10248, 10249, 10250)
GROUP BY orderid
Результат будет выглядеть следующим образом.
OrderlD Order Amt
10248 440.0000
10249 1863,4000
10250 1813,0000
Мы можем детализировать агрегаты, используя несколько столбцов для груп-
пировки. Рассмотрим следующий запрос, в котором будет получена средняя цена
наших продуктов, сгруппированная сначала по названию, а потом по величине.
SELECT name, size, AVG(unit_price) AS 'avg'
FROM product
GROUP BY name, size
Результаты будут выглядеть следующим образом.
Name Size avg
Flux Capacitor small 900
P32 Space Modulator small 1400
T ransmorgrifier medium 1400
Acme Rocket large 600
Land Speeder large 6500
Кроме того, предложение GROUP BY поддерживает несколько очень важных до-
полнительных предложений.
GROUP BY[ {ROLLUP | CUBE} ] ([столбец_для_группировки ])
[, список_наборов_для_группировки]
Агрегатные значения результирующего набора группируются в соответствии
с одним или несколькими столбцами для группировки. (Предложение GROUP BY
(столбец_для_группировки без предложений ROLLUP и CUBE является наи-
более простой и часто употребляемой формой предложения GROUP BY}
ROLLUP
Для каждого набора столбцов группировки создаются промежуточные итоговые
значения в форме иерархического результирующего набора. При этом в резуль-
тирующие наборы в иерархическом порядке добавляются промежуточные
и общие итоги. Предложение ROLLUP возвращает одну строку для каждого
столбца группировки, где в столбцах группировки стоят пустые значения и пока-
заны промежуточные и общие итоговые агрегатные значения (которые мы скоро
проиллюстрируем).
498 | Глава 3. Справочник по инструкциям SQL
CUBE
Для всех столбцов группировки создаются промежуточные и перекрестные
итоговые значения. По сути, предложение CUBE позволяет быстро получать
многомерные результирующие наборы из стандартных реляционных таблиц
без особых усилий по программированию. Предложение CUBE особенно по-
лезно при работе с большими объемами данных. Как и предложение ROLLUP,
предложение CUBE создает промежуточные итоги по столбцам группировки,
но сюда также входят строки промежуточных итогов для всех возможных
комбинаций столбцов группировки, указанных в запросе.
GROUP BY GROUPING SETS [ {ROLLUP I CUBE} ] ([столбец_для_группировки [,...]])
{список _наборов_длягруппировки]
Позволяет использовать агрегатные группы по нескольким разным наборам столб-
цов группировки в одном запросе. Это свойство особенно полезно, если вы хотите
получить только часть агрегатного результирующего набора. Предложение GROUP-
ING SETS также позволяет выбрать сравниваемые столбцы группировки, в то время
как предложение CUBE возвращает все столбцы группировки, a ROLLUP -
иерархическую часть столбцов группировки. Как показывает синтаксис, стандарт
ANSI также позволяет объединять предложение GROUPING SETS с предложениями
ROLLUP и CUBE.
Рассмотрим следующие предложения и возвращаемые ими наборы данных, при-
веденные в табл. 3.3.
Таблица 3.3. Варианты синтаксиса предложения GROUP BY
Синтаксис GROUP BY Возвращает следующие наборы
GROUP BY (col_A, col_B, со!_С)______(col_A, col B, со!_С)___________________________
GROUP BY ROLLUP (col_A, col_B, col_C) (col_A, col_B) (со!_А) ()
(col A, col B, col C)
GROUP BY CUBE (col_A, col_B, col_C) (col_A, col_B, col_C) (col_A, col_B) (col_A) (со!_В,
со1 С) (со!В) (со!С) ()
GROUP BY GROUPING SETS Подзапрос:
((col_A, col_B), (col_A, col_C), (col_C)) SELECT *
FROM stores
WHERE stor_id IN
(SELECT stor_id FROM sales
WHERE ord date > ’01-JAN-2004')
Каждый тип предложения GROUP BY возвращает свой набор агрегатных значе-
ний, а также, в случае ROLLUP и CUBE, итоги и промежуточные итоги.
Принцип предложений ROLLUP CUBE и GROUPING SETS будет гораздо понятнее,
если объяснить его на примере. В следующем примере мы запрашиваем данные, пред-
ставляющие собой количество заказов (sales_orders) по годам (order_date) и кварталам
(orderquarter).
Справочник по командам SQL | 499
SELECT order_year AS year, order_quarter AS quarter,
COUNT (*) AS orders
FROM order_details
WHERE order_year IN (2003, 2004)
GROUP BY ROLLUP (order_year, order_quarter)
ORDER BY order_year, order_quarter;
Результат будет следующий.
year quarter orders
NULL NULL 648 -- общее количество
2003 NULL 380 -- количество за 2003 год
2003 1 87
2003 2 77
2003 3 91
2003 4 125
2004 NULL 268 -- количество за 2004 год
2004 1 139
2004 2 119
2004 3 10
Добавление столбцов группировки в запрос дает более подробный резуль
тирующий набор (с большим количеством промежуточных итогов). Мы изменим при-
веденный выше пример, добавив в запрос регион (region) (однако, поскольку количе-
ство столбцов возрастает, мы рассмотрим только первый и второй квартал).
SELECT order_year AS year, order_quarter AS quarter, region,
COUNT (*) AS orders
FROM order_details
WHERE order_year IN (2003, 2004)
AND order_quarter IN (1,2)
AND region IN ('USA', 'CANADA')
GROUP BY ROLLUP (order_year, order_quarter)
ORDER BY order_year, order_quarter;
Результат будет следующий.
year quarter region orders
NULL NULL NULL 183 -- общее количество
2003 NULL NULL 68 -- промежуточный результат за 2003 год
2003 1 NULL 36 -- промежуточный результат по всем регионам в 1кв 2003
2003 1 CANADA 3
2003 1 USA 33
2003 2 NULL 32 -- промежуточный результат по всем регионам во 2кв 2003
2003 2 CANADA 3
2003 2 USA 29
2004 NULL NULL 115 -- промежуточный результат за 2004 год
SOO | Глава 3. Справочник по инструкциям SQL
2004 1 NULL 57 -- промежуточный результат по всем регионам в 1кв 2004
2004 1 CANADA 11
2004 1 USA 46
2004 2 NUlL 58 -- промежуточный результат по всем регионам во 2кв 2004
2004 2 CANADA 4
2004 2 USA 54
Предложение GROUP BY CUBE полезно при выполнении многомерного анализа
агрегатных данных. Как и в случае предложения GROUP BY ROLLUP, возвращаются
промежуточные итоги. Однако в отличие от GROUP BY ROLLUP здесь промежу-
точные итоги возвращаются для всех комбинаций столбцов группировки запроса.
(Как вы увидите, это предложение потенциально увеличивает количество строк в ре-
зультирующем наборе данных.)
В следующем примере мы запрашиваем суммарные данные по количеству заказов
(salesorders) по годам (order date) и кварталам (order quarter).
SEI.ЕСТ o<c'er_year AS year, order_quarter AS quarter,
COUNT (*) AS oroerc
;"-ROM cder details
W4ERF; order^year IN (2003. 2004)
GiiOUR BY Cu3E (oroer__year, crder_ouarter)
ORDER BY order_year; order_quarter:
Результаты будут следующие.
year quarter orcers
NULL NULL 648 -- общее количество
NUL: ’ 226 - промежуточный результат по 1 кв за оба года
NULL 2 ’56 -- промежуточный резугь’а’ по 2 кв за оба года
NULL 3 ’01 -- промежуточный результат по 3 кв за оба года
NULL 4 125 -- промежуточный результат по 4 кв за оба года
2003 NULL 380 -- общее количество за 2003 iод
2003 1 87
2003 2 77
2003 3 9!
2003 4 125
2004 NUll. 268 -- общее количество за 2004 год
2004 1 139
2004 2 119
2004 3 10
Предложение GROUP BY GROUPING SETS позволяет проводить агрегацию по не-
скольким группам в одном запросе. Для каждого набора групп запрос возвращает про-
межуточные итоги, где столбец группировки обозначается как NULL. Если предложе-
ния CUBE и ROLLUP помещают в результирующий набор заранее заданные промежу-
точные итоги, предложение GROUPING SETS позволяет вам управлять тем, какие
Справочник по командам SQL | 501
промежуточные итоги будут включаться в запрос. Предложение GROUPING SETS не
возвращает общего итога.
Используя пример, сходный с приведенными выше примерами для предложений
ROLLUP и CUBE, мы выберем на этот раз промежуточный итог по годам и кварталам,
а также отдельно - по годам.
SELECT order_year AS year, order„quarter AS quarter, COUNT (*) AS orders
FROM order^details
WHERE order„year IN (2003, 2004)
GROUP BY GROUPING SETS ( (order_year, order_quarter), (order_year) )
ORDER BY order_year, order_quarter;
Результаты будут следующие.
year quarter orders
2003 NULL 380 -- итог за 2003 год
2003 1 87
2003 2 77
2003 3 91
2003 4 125
2004 NULL 268 -- итог за 2004 год
2004 1 139
2004 2 119
2004 3 10
Еще предложение GROUPING SETS можно представить как предложение UNION
ALL, примененное к нескольким запросам GROUP BY, ссылающимся на разные части
одних и тех же данных. Вы можете заставить систему добавить промежуточные итоги
в GROUPING SET, просто добавив предложение ROLLUP или CUBE, в соответствии
с которым вы хотите вычислить промежуточные итоги.
Предложения GROUPING SETS можно объединять, чтобы в краткой инструкции
сгенерировать большое число группировок. Объединенные предложения GROUPING
SETS дают продукт перекрестной группировки всех группировок всех наборов, указан-
ных в списке GROUPING SET. Объединенные предложения GROUPING SETS совмести-
мы с предложениями ROLLUP и CUBE. Объединенные предложения GROUPING SETS,
являясь продуктом перекрестной группировки, создадут очень большое количество ко-
нечных группировок даже из небольшого числа объединенных. Например, если мы рас-
ширим табл. 3.3, включив в нее ссылки на объединенные наборы группировок, мы по-
лучим табл. 3.4.
В примере, приведенном в табл. 3.4, объединенные предложения GROUPING
SETS создают большое количество окончательных группировок. Можно представить,
каким большим будет результирующий набор, если объединенные предложения
GROUPING SETS содержат большое количество группировок! Тем не менее получен-
ная информация может быть очень ценной и ее сложно получить как-то еще.
502 | Глава 3. Справочник по инструкциям SQL
Таблица 3.4. Варианты синтаксиса предложения GROUP BY
Синтаксис GROUP BY Возвращает следующие наборы данных
GROUP BY (col_A, col_B, col_C) (col_A, col_B, со!_С)
GROUP GY GROUPING SETS (col_A, col_B) (col_Y, col Z) (col_A, col_Y) (col_A, col_Z) (col_B, col_Y) (col_B, col_Z)
Предложение HAVING
Предложение HAVING добавляет к результату работы предложения GROUP BY усло-
вия поиска. Работа предложения HAVING во многом сходна с работой предложения
WHERE, но оно применяется в предложении GROUP BY. Предложение HAVING под-
держивает все те же условия поиска, что и предложение WHERE, о котором рассказы-
валось выше. Например, в том же самом примере, что и ранее, мы теперь хотим найти
те должности (jobs), на которые назначены более трех человек.
--Запрос
SELECT j.job_desc "Job Description",
C0UNT(e.joo_id) "Nbr in Job"
FROM employee e
JOIN jobs j ON e.job_id = j.job_id
GROUP Bv jjob.desc
HAVING COUNT(e. job..ia) > 3
--Резугота*ь'
coo Description Nbr in Job
Acauisitions Manager 4
Managing Editor 4
Marketing Manager 4
Operations Manager 4
Productions Manager 4
Public Relations Manager 4
Publisher 7
Обратите внимание, что стандарт ANSI не требует, чтобы для предложения
GROUP BY было явно указано предложение HAVING. Например, следующий запрос
к таблице employee является допустимым, поскольку для него существует неявное
предложение GROUP BY.
SELECT COUNT(dept_nbr)
FROM employee
HAVING COUNT(dept_nbr) > 30:
Справочник по командам SQL | 503
Хотя приведенный пример кода допустим, такое применение предложения
HAVING является достаточно редким.
Предложение ORDER BY
Результирующий набор данных можно отсортировать при помощи предложения
ORDER BY, в соответствии с порядком сортировки, указанным для базы данных.
Каждый столбец результирующего набора может быть отсортирован по возрастанию
(ASC) или по убыванию (DESC). (Сортировка по возрастанию принимается по умолча-
нию.) Если предложение ORDER BY не указано, в большинстве реализаций данные
сортируются в порядке физического расположения данных в таблице или в порядке их
расположения в индексе, который используется запросом. Однако при отсутствии
предложения ORDER BY нет гарантии, что результат будет отсортирован. Ниже при-
водится пример инструкции SELECT с предложением ORDER BY в SQL Server.
SELECT e.emp_id "Егор ID",
e,fname "First",
e.Iname "Last",
j.job_desc "Job Desc"
FROM employee e,
jobs j
WHERE e.job_id = j.job_id
AND j.job_desc = 'Acquisitions Manager'
ORDER BY e.fname DESC,
e.Iname ASC
Результаты будут следующие.
Emp ID First Last Job Desc
MIR38834F Margaret Rance Acquisitions Manager
MAS70474F Margaret Smith Acquisitions Manager
KJJ92907F Karla Jablonski Acquisitions Manager
GHT50241M Gary Thomas Acquisitions Manager
После того как результирующий набор будет удовлетворять условиям поиска,
набор сортируется по именам авторов по убыванию. Если имена авторов оказываются
одинаковыми, результаты сортируются по фамилиям и по возрастанию.
Вы можете написать предложение ORDER BY, используя столбцы табли-
цы, которые не входят в число запрашиваемых. Например, можно запро-
сить все значения идентификаторов сотрудников, а сортировку проводить
по именам и фамилиям сотрудников.
Советы и хитрости программирования
Как только таблице или представлению в предложении FROM назначен псевдоним,
используйте для ссылок на эту таблицу или представление в запросе только его
504 | Глава 3. Справочник по инструкциям SQL
(например, в предложении WHERE). Не используйте одновременно в одном запросе
и полное название таблицы, и псевдоним. Избегать такого смешивания следует в силу двух
причин. Во-первых, это просто неаккуратно и затрудняет поддержку кода. Во-вторых,
некоторые платформы возвращают ошибку, если в инструкциях SELECT встречаются
смешанные ссылки. (За информацией об использовании псевдонимов в подзапросах
обращайтесь к разделу «Инструкция SUBQUERY».)
Платформы MySQL и SQL Server поддерживают такие типы запросов, для
которых не требуется предложение FROM. Используйте такие запросы осторожно,
поскольку для стандарта ANSI предложение FROM является обязательным. Запросы
без предложения FROM необходимо будет вручную преобразовывать в форму, соот-
ветствующую стандарту ANSI, или в форму, которая также работает в целевой базе
данных. Некоторые платформы нс поддерживают предложения JOIN в стиле ANSI.
Чтобы окончательно установить, в какой мере различные платформы поддерживают
различные опции команды SELECT, обращайтесь к разделам, посвященным этим
предложениям.
DB2
Платформа DB2 поддерживает все обычные предложения инструкции SELECT стан-
дарта ANSI, такие, как WHERE, FROM, GROUP BY, HAVING и ORDER BY. Платформа
DB2 поддерживает все дополнительные предложения для GROUP BY, включая объе-
диненные предложения GROUPING SETS. Кроме того, DB2 дополняет набор обычных
предложений своими собственными предложениями SELECT INTO и FETCH FIRST.
SELECT ; [ALl. I DISTINCT] } отбир-аемый_элеменг [AS псевдоним) [,...]
[INiO хосг -переменная [,.. ] ]
ERC.M [ONi.Y | CITER] {имя_таблицы I иия_представления I ”ABlE ( {имя функции |
подзапрос} ) [AS псевдоним'] [,.. [ }
[ [тип_соединения) JOIN table? ]
[WHERE условие^поиска] [ {AND | OR i N0T] условие_поиска [,...] ]
[GRO’JP Sv группировка_по.выражению [HAVING условие .поиска] ]
[ORDER RY выражение_для_сортировки '.ASC I DESC] ]
[rErCri -IRST {n> {ROW ! ROWS] ONLY]
Где:
INTO хост-переменная /,.../
Значения, возвращаемые запросом, присваиваются хост-переменным. Если инструк-
ция SELECT возвращает в результирующий набор несколько строк, генерируется
ошибка. Значение каждого отбираемого элемента присваивается объявленной
хост-перемепной в соответствии с их порядковым положением. Если количество
переменных меньше, чем количество значений, возвращаемых инструкцией SELECT,
то выдается предупреждение.
TABLE ({имя функцш! | подзапрос})
Указывается, что запрос будет возвращать результирующий набор функции или
результаты полностью объявленного подзапроса. При вызове табличной функции
имена столбцов табличной функции, указанные в предложении RETURNS
Справочник по командам SQL | SOS
инструкции CREATE FUNCTION, аналогичны столбцам таблицы. Обратите вни-
мание, что вызов функции, вместе со всеми ее параметрами и подзапросом,
должен быть заключен в скобки. Например, следующий запрос получает данные
с международного web-сайта розничной торговли и возвращает результат перевода
единиц иностранной валюты в доллары США.
SELECT columnl
FROM TABLE (curr_conv(CURRENCY, CONVERSION_RATE) ) AS data;
GROUP BY группировка _по_выражению
Платформа DB2 полностью поддерживает предложение GROUP BY стандарта
ANSI, включая предложения ROLLUP, CUBE и GROUPING SETS.
FETCH FIRST [n] {ROW | ROWS}
Указывается максимальное количество строк, которые будет возвращать запрос.
Это предложение используется для того, чтобы сказать, что вам не нужно больше,
чем п строк (где п - положительное целое число от 1 и больше), независимо от
того, сколько строк может быть в базе данных. Это позволяет увеличить произво-
дительность, поскольку потенциально большие результирующие наборы урезают-
ся до приемлемого размера.
DB2 поддерживает четыре возможных типа соединений: INNER, LEFT OUTER,
RIGHT OUTER и FULL OUTER.
INNER JOIN
Из таблиц table I и table2 возвращаются те записи, для которых в обеих таблицах
существуют соответствующие согласно условию соединения записи. Обратите
внимание, что синтаксис FROM tablet, table2 с условиями соединения, указанны-
ми в предложении WHERE, семантически эквивалентен соединению INNER JOIN.
LEFT [OUTER] JOIN
Извлекаются все записи из левой таблицы (т. е. tableL) и соответствующие записи из
правой таблицы (table2) Если в таблице table2 не оказывается соответствующих за-
писей, в соответствующие столбцы помещаются значения NULL. Вы можете приме-
нять этот тип соединения для извлечения всех записей из таблицы даже в том
случае, если в соединяемой таблице отсутствуют соответствия. Пример:
SELECT j.job_id, е.Iname
FROM jobs j
LEFT OUTER JOIN employes e ON j.job_id = e.job_id
ORDER BY j.job_id
RIGHT [OUTER] JOIN
RIGHT [OUTER] JOIN
Извлекаются все записи из правой таблицы независимо от того, есть ли соответст-
вующие записи в левой таблице. Правое соединение аналогично левому, за исключе-
нием того, что дополнительная таблица находится слева.
506 | Глава 3. Справочник по инструкциям SQL
FULL [OUTER] JOIN
Указывается, что возвращаются все строки из обеих таблиц независимо от того, соот-
ветствует ли строка в одной таблице строке в другой таблице. Всем столбцам, для
которых пе г соо тветствий в соединяемой таблице, присваиваются пустые значения.
Платформа DB2 накладывает определенные ограничения на применение предло-
жений ORDER BY или FETCH FIRST в инструкциях SELECT, используемых в подза-
просах. Во-первых, инструкцию SELECT, содержащую предложения ORDER BY или
FETCH FIRST, нужно всегда заключать в скобки, даже при использовании в операции
с наборами. Во-вторых, инструкция SELECT, содержащая предложения ORDER BY
или FETCH FIRST, будет возвращать ошибку, если эта инструкция является главной
для представления или таблицы материализованного запроса, поскольку представле-
ния и материализованные запросы, по сути, нельзя сортировать.
Предложение FETCH FIRST помимо применения для простого ограничения числа
записей в результирующем наборе можно использовать довольно интересным обра-
зом. Например, следующий запрос не ограничивает количество записей, возвращае-
мых запросом, он ограничивает лишь число записей, используемых в подзапросе.
В этом примере мы получим описания первых 10 сотрудников, получающих наиболее
высокую зарплату.
SELECT jobs job_desc
FROM jobs
WHERE joos. job.desc TN
(SELECT employee.job_desc
FROM employee
ORDER BY salary DESC
FETCH FIRST 10 ROWS ONLY);
В приведенном выше примере будут использоваться только первые 10 строк таблицы
employee, хотя запрос верхнего уровня может вернуть любое количество записей.
Также запомните, что сортировка подзапроса никак не влияет на сортировку оконча-
тельного результирующего набора.
MySQL
Реализация инструкции SELECT в MySQL включает в себя частичную поддержку
инструкции JOIN, предложение INTO, предложение LIMIT и предложение PROCEDURE.
MySQL до версии 4.0 не поддерживает подзапросы.
SELECT [DISTINCT ।
DISTINCTROW | ALLj
[STRAIGHT...JOIN][ {SOL_SMALL_RESULT | SQl._BIG_RESULT} ][SQl_BUFFER_RESulT]
[HIGH-PRIORITY]
отбираемый_элемент AS псевдоним [,...]
[INTO {OUTRIDE | DuMPFILE} 'имяфайла' опции]
[FROY имя_таблицы AS псевдоним [,...]
[ { USE INDEX (индекс! [....]) । IGNORE INDEX (индекс! [,...]) } j
Справочник по командам SQL | 507
[тип соединения~][МЫ таблица2] [ON условие_соединения}
[WHERE условие_поиска]
[GROUP BY {целое_число_без~знака | имя_столбца | формула}
[ASC j DESC] [,...] ]
[HAVING условие_поиска]
[ORDER BY { целое_число~без_знака | имя^столбца | формула }
[ASC | DESC] [,...] J
[LIMIT [[начальная_позиция, ] число_строкУ\
[PROCEDURE имя_процедуры (параметр [,...] ) ]
[{FOR UPDATE | LOCK IN SHARE MODE}] ;
Где:
STRAIGHT JOIN
Заставляет оптимизатор соединять таблицы в том порядке, в котором они располо-
жены в предложении FROM.
SQLSMALLRESULT | SQL BIG RESULT
Оптимизатор будет ожидать большой или маленький объем результирующего
набора данных в предложении GROUP BY или DISTINCT. Платформа MySQL соз-
дает временную таблицу, если в запросе есть предложение DISTINCT или GROUP
BY, а эти дополнительные предложения указывают, нужно ли создавать быструю
временную таблицу в памяти (SQL SMALL RESULT) или более медленную вре-
менную таблицу на диске (SQL BIG RESULT).
SQL В UFFER~RESUL Т
Результирующий набор данных принудительно заносится во временную таблицу,
и MySQL может раньше снять блокировки и быстрее передать результирующий
набор клиенту.
HIGH PRIORITY
Запрос получает больший приоритет, чем инструкции, изменяющие данные в таб-
лице. Это предложение следует использовать только в особых высокоскоростных
запросах.
отбираемы й_элемент
Извлекаются указанные столбцы или значения выражений. Столбцы можно ука-
зывать в формате [базаданных.][имя_таблицы.]имя_столбца. Если имя базы
данных или таблицы не указано, подразумевается текущая база данных и таблица.
FROM ... USE INDEX | IGNORE INDEX
Указывается таблица, из которой извлекаются строки. Таблицу можно описать
следующим образом: [база_данных.][имятаблицы]. Платформа MySQL будет
рассматривать запрос как соединение, если в предложении FROM указано
несколько таблиц. Дополнительные предложения FORCE INDEX и USE INDEX
(индекс!, индекс2, ...) и IGNORE INDEX (индекс!, индекс2, ...) позволяют указать,
что база данных должна соответственно использовать или игнорировать указанные
индексы таблицы.
508 | Глава 3. Справочник по инструкциям SQL
INTO {OUTFILE | DUMPFILE} 'имя_файла'
Результирующий набор запроса записывается в файл имя_файла в файловой сис-
теме сервера (опция OUTFILE). Файл с именем имя_файла не должен существо-
вать. При указании опции DUMPFILE записывается непрерывный поток данных,
без разделителей столбцов, строк и без отменяющих символов. Эта опция исполь-
зуется, главным образом, для файлов BLOB. Особые правила использования этого
предложения приведены ниже.
LIMIT [[начальная_позиция,} число_строк]
Ограничивается количество строк, возвращаемых запросом. Возвращается количество
строк, определяемое параметром число_строк, начиная с начальной-Позиции. Если
указывается только одно целое число, то возвращается это количество записей,
а начальной позицией считается ноль.
PROCEDURE имя_ процедуры (параметр [,...] )
Указывается процедура, которая обрабатывает данные в результирующем наборе.
Эта процедура представляет собой внешнюю процедуру, обычно написанную на
С+ по не внутреннюю хранимую процедуру базы данных.
{FOR UPDATE | LOCK IN SHARE MODE}
Выполняется блокировка строк, возвращаемых запросом, с целью их эксклюзив-
ного использования (FOR UPDATE) (если таблица относится к типам InnoDB или
BDB) или блокировка с возможностью чтения (LOCK IN SHARE), чтобы другие
пользователи могли видеть строки, но не могли их изменять.
При использовании предложения INTO держите в памяти пару правил. Во-
первых, выходной файл не должен существовать, поскольку функция перезаписи не
поддерживается. Во-вторых, любой файл, созданный запросом, может быть прочитан
любым пользователем, соединившимся с сервером. (При использовании предложения
SELECT..INTO OUTFILE вы затем можете использовать для быстрой загрузки данных
команду MySQL LOAD DATA INFILE.)
Чтобы лучше управлять содержимым выходного файла при использовании пред-
ложения SELECT...INTO OUTFILE, вы можете использовать следующие опции.
• ESCAPED BY
• FIELDS TERMINATED BY
• LINES TERMINATED BY
• OPTIONALLY ENCLOSED BY
Следующий пример иллюстрирует применение этих дополнительных команд в запросе
MySQL, который возвращает результирующий набор в файл, где в качестве разделителей
используются запятые.
SELECT job„id. emp to, Iname+fname
INTO OUTFIlE "/tmp/employees.text"
FIELDS TERMINATED BY '.' OPTIONALLY ENCLOSED BV '"'
LINES TERMINATED BV "\n"
FROM employee,
Справочник по командам SQL | 509
Платформа MySQL также позволяет использовать инструкции SELECT без пред-
ложения FROM при выполнении простых арифметических операций. Например, сле-
дующие запросы в MySQL являются допустимыми.
SELECT 2+2;
SELECT 565 - 200;
SELECT (365 * 2) * 52;
Платформа MySQL является очень гибкой в вопросе поддержки соединений. Для
выполнения соединений вы можете использовать несколько разных видов синтаксиса.
Например, вы можете явно объявить в запросе соединение при помощи предложения
JOIN и после этого указать условие соединения в предложении WHERE. Другие плат-
формы заставляют вас выбрать один или другой метод и не позволяют смешивать их
в одном запросе. Тем не менее мы считаем, что смешение методов - это, плохая прак-
тика, поэтому в наших примерах используются соединения стиля ANSI.
MySQL поддерживает следующие типы синтаксиса предложения JOIN.
FROM таблица! . таблица2
FROM таблица! {
[CROSS] JOIN таблица2 |
STRAIGHT_JOIN таблица2 |
INNER JOIN таблица2 [ {ON условие__соединения
USING (список_столбцов)} ] |
LEFT [OUTER] JOIN таблица2 {ON условие_соединения |
USING (список„столбцов)} |
NATURAL [LEFT [OUTER]] JOIN таблица2 j
RIGHT [OUTER] JOIN таблица2 [ {ON условие^соединения |
USING (список_столбцов)} ]|
NATURAL [RIGHT [OUTER]] JOIN таблица2 }
Где:
[CROSS] JOIN таблица2
Извлекаются все записи из таблицы! и таблицы2. За дополнительной информа-
цией обращайтесь к разделу «Предложение JOIN».
STRAIGHT JOIN таблица2
Извлекаются все записи из таблицы! и таблицы2, как в любом другом соединении,
но с некоторой особой функциональностью. Обычно в MySQL порядок соедине-
ния таблиц определяется на основе решений, принимаемых оптимизатором.
Однако оптимизатор может случайно выбрать неэффективный порядок таблиц.
Ключевое слово STRAIGHT JOIN заставляет оптимизатор придерживаться того
порядка, в котором таблицы следуют в запросе.
INNER JOIN
Из таблиц 1 и 2 извлекаются те записи, для которых в обеих таблицах есть значения,
соответствующие друг другу согласно условию соединения. Обратите внимание, что
синтаксис FROM таблица!, таблица2 семантически эквивалентен предложению
510 | Глава 3. Справочник по инструкциям SQL
INNER JOIN. При использовании синтаксиса FROM таблица!, таблица? обязательно
указывайте условия соединения в предложении WHERE.
NATURAL
Это предложение используется для объявления условия соединения так, как если
бы использовалось предложение USING с указанием всех столбцов, сущест-
вующих в обеих таблицах. (Пример предложения USING приводится ниже.)
LEFT [OUTER] JOIN
Извлекаются все записи из левой таблицы (г. е. таблицы!) и соответствующие
записи из правой таблицы (т. е. таблицы?). Если в таблице? не обнаруживается
соответствующей записи, в столбцы помещаются пустые значения (NULL). Этот
тип соединения вы можете использовать, чтобы извлечь все записи в таблице,
даже в том случае, если в соединяемой таблице не обнаруживается соответствий.
RIGHT [OUTER] JOIN
Извлекаются все записи из правой таблицы и соответствующие записи из левой
таблицы. Предложение RIGHT JOIN -- это не более чем LEFT JOIN, только в про-
тивоположном направлении. Хорошей практикой является конфигурирование
всех внешних соединений либо как левых (LEFT OUTER JOIN), либо как правых
(RIGHT OUTER JOIN), без смешения этих типов, поскольку чтобы сразу понять,
какой тип используется, нужно изменять образ мышления.
Платформа MySQL предлагает интересную альтернативу стандарту ANSI в вопросе
посылки запросов к таблицам - инструкцию HANDLER. Инструкция HANDLER во многом
напоминает инструкцию SELECT, за исключением того, что инструкция HANDLER обес-
печивает очень высокую скорость чтения данных, которая обходит в MySQL систему
SQL-запросов. Поскольку инструкция HANDLER не является инструкцией SQL, за допол-
нительной информацией обращайтесь к документации zMySQL.
Oracle
В Oracle существует очень большое количество расширений инструкции SELECT по
сравнению со стандартом ANSI. Например, из-за того, что в Oracle допускается исполь-
зование вложенных и секционированных таблиц (см. инструкцию CREATE TABLE),
инструкция SELECT может посылать запросы к структурам подобного рода.
[WITH имя запроса AS (подзапрос) [, . 1 ]
SEt.ECT { ('ALL I DISrINC‘'[? I [UNIQUE)? [подсказки-опгимизатору]
отбираемый_элемент [AS псевдоним] [....]
[INTO {переменная । запись}]
FROM {[ONLY] {[схема. ][имя_таблицы | имя-Представления [
имя_материализованного_ представления] }[&связь_С-базой_данных ]
[AS [OF] {SON | TIMESTAMP} выражение] ;
подзапрос [WITH
{READ ONlV | CHECK OPTION [CONSTRAINT имя_ограничения]}J j
[[VERSIONS 3ETWEEN {SON | TIMESTAMP;- {выраж | MINVALUE AND
{выраж , MAXVAlUE;] AS 0" {SON । T1MES~AMP} выражение'' I
FA8l г (столбец- вложенной- таблицы} [ (н) {
Справочник по командам SQL | 511
{[PARTITION (имя__раздела) |
SUBPARTITION (имя-Подраздела)]}
[SAMPLE [BLOCK] [процент_для_образца] [SEED (начальное-Значение)]} [AS псевдоним]
L. .]
[ [тип~соединения] JOIN условие_соединения [PARTITION BY выражение [,...] ] ]
[WHERE условие_поиска]
[ {AND | OR} условие_поиска [,...] ]
[[START WITH значение] CONNECT BY [PRIOR] условие] ]
[GROUP BY группировка_по_выражению [HAVING условие_поиска] ]
[MODEL предложение_МООЕб]
[ORDER [SIBLINGS] BY выражение_для_сортировки {[ASC | DESC]}
{[NULLS FIRST | NULLS LAST]} ]
[FOR UPDATE [OF [схема. ][таблица. ]столбец] [,...]
{[NOWAIT | WAIT (целое_число)]} ]
Указанные выше предложения соответствуют стандарту ANSI, если противопо-
ложное не указано специально. Также и элементы предложений соответствуют стан-
дарту ANSI, если иное не указано специально. Например, в Oracle предложение
GROUP BY практически совпадает со стандартом ANSI, включая такие составляющие
элементы, как ROLLUP, CUBE, GROUPING SETS, объединенные предложения
GROUPING SETS и предложение HAVING.
WITH нмязсшроса AS (подзапрос)
Ссылка на указанный запрос. Платформа Oracle позволяет присваивать имена
подзапросам. Вы можете ссылаться на подзапрос в нескольких местах, указывая
только его имя. (Oracle оптимизирует данный процесс, обрабатывая подзапрос как
вложенную или временную таблицу.)
ALL | DISTINCT] UNIQUE
Предложения ALL и DISTINCT идентичны предложениям ALL и DISTINCT стандарта
ANSI (см. синтаксис ANSI SQL выше). UNIQUE является синонимом DISTINCT.
Предложение DISTINCT нельзя использовать со столбцами LOB.
подсказки_оптимизатпору
Изменяется заданное по умолчанию функционирование оптимизатора запроса на ука-
занное пользователем поведение. Например, с помощью подсказки можно заставить
Oracle использовать индекс, который система не стала бы использовать, или заставить
игнорировать индекс, который система иначе использовала бы. За дополнительной ин-
формацией о подсказках оптимизатору обращайтесь к документации производителя.
отбираемый -Элемент
Может представлять собой выражение или столбец из указанного запроса, таблицы,
представления или материализованного представления в формате [схема.][имя_таб-
лицы.]имя столбца. Если вы не укажете схему, будет подразумеваться контекст теку-
щей схемы. Платформа Oracle также предусматривает именованные запросы (объяс-
нения приводятся выше, в разделе о предложении WITH), на которые можно ссылать-
ся во многом так же, как на вложенный табличный подзапрос (обращайтесь к разделу
«Инструкция SUBQUERY»). В Oracle именованные запросы называются выносом
512 | Глава 3. Справочник по инструкциям SQL
подзапроса (subquery factoring). Помимо именованных запросов Oracle также под-
держивает подзапросы и обозначение столбцов звездочкой (*) в списке отбирае-
мых ^элементов.
INTO {переменная [,...] \ запись}
Значения результирующего набора записываются в переменные PL/SQL или в запись
PL/SQL.
FROM [ONLY]
Указывается таблица, представление, материализованное представление или под-
запрос, из которого извлекается результирующий набор. Ключевое слово ONLY
является необязательным и применяется только к представлениям, принадлежа-
щим к иерархии. Предложение ONLY используется, если нужно извлечь записи
только из указанного представления, но не из его представлений-потомков.
[AS [OF] {SCN | TIMESTAMP} выражение]
Реализуется ретроспективный SQL-запрос, посредством которого к каждому объ-
екту в списке отбираемых элементов применяется номер системного изменения.
Запрос будет извлекать только те записи, которые существовали на момент ука-
занного номера системного изменения (SCN) или отметки времени. (Эту возмож-
ность также можно реализовать на уровне сеанса, используя встроенный пакет
DBMS FLASHBBACK.) Предложение SCN выражение должно давать в итоге
число, а предложение TIMESTAMP выражение должно давать в итоге момент вре-
мени. Ретроспективные запросы нельзя использовать на связанных серверах.
подзапрос [WITH {READ ONLY] CHECK OPTION [CONSTRAINT имя_ограничения]}]
Предложение описывается отдельно, поскольку Oracle предусматривает дополнитель-
ные способы управления подзапросом. Предложение WITH READ ONLY показывает,
что цель подзапроса нельзя обновлять. Предложение WITH CHECK OPTION показыва-
ет, что при любом обновлении цели подзапроса должны создаваться строки, которые
будут включаться в подзапрос. При использовании предложения WITH CONSTRAINT
для таблицы создается ограничение типа CHECK OPTION с именем имя ограничения.
Обратите внимание, что предложения WITH CHECK OPTIONS и WITH CONSTRAINT
обычно используются в инструкциях INSERT..SELECT.
VERSIONS BETWEEN {SCN | TIMESTAMP} {выраж | MINVALUE AND
{выраж | MAXVALUE}] AS OF {SCN | TIMESTAMP} выражение]
Создается специальный тип запроса с использованием параметровоетроспективно-
го_запроса для получения истории внесенных изменений из таблицы, представления
или материализованного представления. В псевдостолбце VERSIONS_XID указывает-
ся идентификатор транзакции, выполнившей изменение, параметры_ретроспектив-
ного_запроса требуют, чтобы вы указали SCN (номер системного изменения) или от-
метку времени (значение TIMESTAMP) для каждого объекта в списке отбирае-
мых эз&зентов. (Ретроспективные запросы на уровне сеанса реализуются при
помощи пакета DBMS_FLASHBBACK.)
Дополнительное предложение VERSIONS BETWEEN используется для получения
нескольких версий указанных данных, используя либо верхнюю, либо нижнюю
границу SCN (номера) или отметки времени (значение TIMESTAMP), или же при
33 - 2447
Справочник по командам SQL | 513
помощи ключевых слов MINVALUE и MAXVALUE. Без указания этого предложе-
ния возвращаются только последние версии данных. (В Oracle есть несколько
псевдостолбцов, относящихся к версиям, из которых можно получить дополни-
тельные сведения.)
Описанное ранее в этом разделе предложение AS OF определяет SCN или момент
времени, начиная с которого база данных выполняет запрос при использовании
предложения VERSIONS.
Нельзя использовать ретроспективные запросы с предложениями VERSIONS при-
менительно к временным таблицам, внешним таблицам, таблицам в кластере или
представлениям.
TABLE
Это предложение необходимо при запросе к иерархической вложенной таблице.
PARTITION
Запрос ограничивается указанным разделом таблицы. По существу, строки извле-
каются только из указанного раздела, а не из всей таблицы.
SUBPARTITION
Запрос ограничивается указанным подразделом таблицы. Поскольку строки извле-
каются только из указанного подраздела, а не из всей таблицы, уменьшается нагрузка
на каналы ввода-вывода.
SAMPLE [BLOCK] [процент_для_образца] [SEED (начальное_значение)
Это предложение указывает, что записи будут отбираться из случайного набора
строк в результирующем наборе, указанного как процентная доля строк или блоков,
а не из всей таблицы. Предложение BLOCK заставляет Oracle отбирать образцы по
блокам, а не по строкам. Параметр процент_для_образца, который показывает,
какая доля строк или блоков будет включена в образец, может изменяться в преде-
лах от 0.000001 до 99. Дополнительное предложение SEED используется для обес-
печения ограниченной воспроизводимости результатов. При указании начально-
го зиачения Oracle попытается возвращать при разных выполнениях запроса один
и тот же образец. Начальное значение может изменяться от 0 до 4 294 967 295. Если
предложение SEED опущено, то результирующий набор при каждом запросе будет
разный. Отбор образца может использоваться только в запросах к одной таблице.
JOIN
Результирующие наборы из одной или нескольких таблиц объединяются в одном
запросе. Подробно описывается ниже.
PARTITION BY выражение [,...]
Определяется специальный тип запроса, называющийся секционированное внеш-
нее_соединение, в котором стандартный синтаксис внешнего соединения рас-
ширяется путем применения правого и левого внешних соединений к секциониро-
ванию одной или нескольких строк, указываемых при помощи выражения. Этот
запрос особенно полезен при запросах к данным, разбросанным по конкретному
измерению, поскольку он возвращает строки, которые иначе не попали бы в ре-
зультирующий набор. За примерами обращайтесь к подразделу «Oracle» раздела
«Предложение JOIN». Предложение PARTITION BY можно использовать на любой
514 | Глава 3. Справочник по инструкциям SQL
стороне внешнего соединения, что аналогично предложению UNION, применен-
ному к внешним соединениям каждого из разделов секционированного резуль-
тирующего набора с таблицей на другой стороне соединения. (Если данное пред-
ложение опущено, Oracle рассматривает весь результирующий набор как один
раздел.) Предложение PARTITION BY нельзя использовать с предложением FULL
OUTER JOIN.
WHERE... [ [START WITH значение] CONNECT BY [PRIOR] условие]
Предложение фильтрует записи, попадающие в результирующий набор. Платформа
Oracle позволяет использовать в таблицах иерархическую информацию, фильтра-
цию которой можно осуществлять при помощи предложения START WITH. Предло-
жение START WITH указывает строки, которые будут выполнять в результирующем
наборе роль родительских. Предложение CONNECT BY определяет условие соотно-
шения между родительскими строками и их строками-потомками. Ключевое слово
PRIOR используется для указания родительских строк вместо строк-потомков.
В иерархических запросах псевдостолбец LEVEL используется для указания
корневой точки (1), точек-первичных потомков (2), точек-вторичных потомков (3)
и т. д. Также в иерархических запросах доступны такие псевдостолбцы, как
CONNECT. BY1SCYCLE и CONNECT BYJSLEAF. Иерархические запросы являются
взаимоисключающими с предложениями ORDER BY и GROUP BY. Не используйте
эти предложения в запросах, содержащих предложения START WITH или CONNECT
BY. Вы можете сортировать записи одноранговых потомков одной родительской
таблицы при помощи предложения ORDER SIBLINGS BY.
ORDER [SIBLINGS] В Y выражение_для_сортировки {NULLS FIRST | NULLS LAST]}
Результирующий набор запроса сортируется в порядке, определяемом выражени-
ем для сортировки. Это выражение может представлять собой имена столбцов,
их псевдонимы или целые числа, указывающие порядковое положение столбцов.
Предложение ORDER SIBLINGS BY используется при запросах к иерархическим
таблицам с предложением CONNECT BY. Предложение ORDER SIBLINGS BY
заставляет Oracle сохранять сортировку, определяемую предложением CONNECT
BY, и применять ее только к одноранговым строкам (т. е. строкам, находящимся на
одном уровне иерархии). Предложения NULLS FIRST и NULLS LAST указывают,
что записи, содержащие пустые значения, должны ставиться либо в начало, либо
в конец соответственно.
FOR UP DA ТЕ [OF [схема.] ...
Строки в результирующем наборе блокируются, так что другие пользователи не
смогут заблокировать или изменить их до тех пор, пока вы не завершите свою
транзакцию. Предложение FOR UPDATE нельзя использовать в подзапросах, в за-
просах, использующих предложения DISTINCT или GROUP BY, или в запросах,
использующих операторы для работы с наборами данных или агрегатные функ-
ции. Строки-потомки в иерархической таблице не блокируются при запросе к ро-
дительским строкам. Ключевое слово OF используется для блокировки только
указанной таблицы или представления. В противном случае Oracle блокирует все
таблицы и представления, указанные в предложении FROM. При использовании
Справочник по командам SQL | 515
предложения OF столбцы не имеют особого значения, но вы должны использо-
вать реальные имена столбцов, а не псевдонимы. Предложения NOWAIT и WAIT
заставляют Oracle либо возвратить вам управление немедленно (если блокировка
уже установлена), либо подождать перед возвратом управления целоечисло
секунд соответственно. Если не указано ни предложение WAIT, ни NOWAIT, то
Oracle ждет до тех пор, пока строки не станут доступны.
В отличие от некоторых других платформ баз данных Oracle не разрешает исполь-
зовать инструкцию SELECT без предложения FROM, Например, следующий запрос
будет недопустим.
SELECT 2+2;
Чтобы обойти это ограничение, в Oracle существует специальная таблица под на-
званием dual. Каждый раз при выполнении запроса, который не извлекает никаких
данных из пользовательских таблиц, например при выполнении вычисления, исполь-
зуйте синтаксис FROM dual. Все приведенные ниже запросы являются допустимыми.
SELECT 2+2
FROM dual,
SELECT (((52-4) * 5) * 8)
FROM dual;
Реализация инструкции SELECT в Oracle достаточно понятна, если вы хотите
извлечь данные из таблицы. Например, Oracle позволяет использовать именованные
запросы. Именованный запрос - это, по сути, псевдоним всего запроса, который
позволяет экономить время при написании инструкций SELECT с множеством подза-
просов. Например:
WITH pub_costs AS
'(SELECT pub_id, SUM(job_lvl) dept_total
FROM employees e
GROUP BY pub_id),
avg_costs AS
(SELECT SUM(dept_total)/COUNT(‘) avg
FROM employee)
SELECT * FROM pub_costs
WHERE dept_total > (SELECT avg FROM avg_cost)
ORDER BY department_name;
В этом примере мы создаем два именованных подзапроса - pub_costs и avg_costs,
на которые позже будет ссылаться главный запрос. Именованные запросы, по сущест-
ву, аналогичны подзапросам. Однако подзапросы нужно переписовать полностью при
каждом их использовании, а именованные запросы переписывать не нужно.
Платформа Oracle позволяет отбирать строки из одного раздела секционирован-
ной таблицы (при помощи предложения PARTITION) или получать только статистиче-
516 | Глава 3. Справочник по инструкциям SQL
скую выборку строк из результирующего набора в виде процентной доли строк или
блоков. Для этого используется предложение SAMPLE. Например:
SELECT *
FROM sales PARTITION (sales„20C4_q3) sales
WHERE sales.qty > 1000.
SELECT *
FROM sales SAMPLE (12);
Ретроспективные запросы (flashback query) - это возможность Oracle, которая позво-
ляет извлекать результирующие наборы на определенные моменты времени. Например,
мы можем выяснить, какая зарплата была у любого сотрудника вчера, до того как в базу
данных были внесены крупные изменения.
SELECT job-lvl, Iname, fname
FROM employee
AS OF TIMESTAMP (SYS TIMESTAMP - INTERVAL S' DAY).
Еще одно интересное расширение стандартного формата запроса в Oracle - это
иерархический запрос. Иерархический запрос возвращает результаты запросов
к иерархически построенным таблицам в том порядке, какой вы определите. Напри-
мер, следующий запрос возвращает имена сотрудников, их положение в иерархии
(которое отражается местоположением в столбце org_chart), ID сотрудника, ID менед-
жера и ID должности.
SELECT LRAD(' 2«(LEVEL-1)) || Iname AS org_chart,
emp_id, mgr_id, job_id
FROM employee
START WITH job_id - 'Chief Executive Officer'
CONNECT BY PRIOR emp_ia = mgr_id;
ORG_CHART EMPLOYEE_ID MANAGER_ID JOB_ID
Cramer
100 Chief Executive Officer
Devon 108 101 Business Operations Mgr
Thomas 109 108 Acquisitions Manager
Kcskitalo 110 108 Productions Manager
Tonini 111 108 Operations Manager
Whalen 200 101 Admin Assistant
Chang 203 101 Cnief Financial Officer
Gietz 206 203 Comptroller
Bucnanan 102 101 V? Sales
Callahan 103 102 Marketing Manager
Справочник по командам SQL | 517
В приведенном выше запросе предложение CONNECT BY определяет иерархиче-
ское отношение значения emp_id как родительской строки равным значению mgr id
в строке-потомке, а предложение START WITH указывает, с какого места иерархии
должен начинаться результирующий набор.
Oracle поддерживает следующие типы синтаксиса предложения JOIN (за допол-
нительной информацией обращайтесь к разделу «Предложение JOIN»).
FROM таблица? {
CROSS JOIN таблица2 |
INNER JOIN таблица2 [ {ON условие_соединения |
USING (список^столбцов)} ] |
LEFT [OUTER] JOIN таблица2 [ {ON условие_соединения
| USING (список_столбцов)} ] |
NATURAL [LEFT [OUTER]] JOIN таблица2 |
RIGHT [OUTER] JOIN таблица2 [ {ON условие_соединения
| USING (список_столбцов)} ]|
NATURAL [RIGHT [OUTER]] JOIN таблица2
FULL [OUTER] JOIN таблица2 }
[CROSS] JOIN
[CROSS] JOIN
Из таблиц таблица! и таблица2 извлекаются все записи. По смыслу данное пред-
ложение идентично предложению FROM таблица!, таблица2 без указания усло-
вий соединения в предложении WHERE.
INNER JOIN
Из таблиц 1 и 2 извлекаются те записи, для которых в обеих таблицах есть значе-
ния, соответствующие друг другу согласно условию соединения. Обратите внима-
ние, что предложение INNER JOIN по смыслу аналогично предложению FROM
таблица!, таблица2 с указанием условий соединения в предложении FROM.
NATURAL
Это предложение используется для объявления условия соединения так, как если
бы использовалось предложение USING с указанием всех столбцов, общих для
обеих таблиц. (Будьте внимательны, если столбцы имеют одинаковые названия,
но разные типы данных или виды значений!) В соединении типа NATURAL нельзя
ссылаться на столбцы LOB. Если сослаться в таком соединении на столбец LOB
или на столбец-коллекцию, инструкция возвратит ошибку.
LEFT [OUTER] JOIN
Извлекаются все записи из левой таблицы (т. е. таблицы!) и соответствующие
записи из правой таблицы (т. е. таблицы2). Если в таблице2 не обнаруживается
соответствующей записи, в столбцы помещаются пустые значения (NULL). Этот
тип соединения вы можете использовать, чтобы извлечь все записи из таблицы,
даже в том случае, если в соединяемой таблице не обнаруживается соответствий.
Например:
SELECT j.job_id, е.Iname
FROM jobs j
518 | Глава 3. Справочник по инструкциям SQL
LE.C'I OUTER uCIN employee e ON j. job_id = e.job_id
ORDER BY a joo_id
RIGHT [OUTER] JOIN
Извлекаются все записи из правой таблицы и соответствующие записи из левой
таблицы. Предложение RIGHT JOIN - это не более чем LEFT JOIN, за исключени-
ем того, что дополнительная таблица находится слева.
FULL [OUTER] JOIN
Указывается, что будут извлекаться все строки из обеих таблиц независимо от
того, соответствует ли столбец одной таблицы столбцу другой. Всем столбцам,
для которых не находится соответствующего значения в другой таблице, назнача-
ется пустое значение (NULL).
ON условие соединения
Объявляется условие (условия), которое объединяет вместе результирующие наборы
двух таблиц. Делается это в форме объявления столбцов из таблицы! и таблицы?,
которые должны соответствовать условию соединения. Если необходимо проводить
сравнение по нескольким столбцам, используйте предложение AND.
USING (список_столбцов)
Играет роль альтернативы предложению ON. Вместо описания условия соединения
просто укажите имя столбца (или нескольких столбцов через запятую), который
существует в обеих таблицах. Имена столбцов в обеих таблицах должны совпадать
и не должны содержать в качестве префикса имя таблицы или псевдоним. Следующие
два запроса дают одинаковые результаты. Один из них написан при помощи предло-
жения USING, а в другом условия соединения указываются с использованием син-
таксиса ANSI.
SELECT columnl
CROM Too
LEFT JOIN poo USING (colum"1, column2);
SELECT columnl
'ROM foo
lEF~ ..QIN poo ON foo. columnl = poo. columnl
AND foo.columns = poo.column2;
Обратите внимание, что старый синтаксис Oracle использует предложение
WHERE, а внешние соединения описываются при помощи знака (+). Синтаксис соеди-
нений стиля ANSI стал доступен только начиная с Oracle 9i Release 1. Поэтому вы
часто будете сталкиваться в уже существующем коде со старым синтаксисом. Напри-
мер, следующий запрос по смыслу эквивалентен приведенному выше примеру левого
внешнего соединения.
SELECT i.job_id, е.Iname
FROM ;obs j. employee e
WHERE j.job_id = e.job_id (+)
ORDER BY d.job_id
Справочник по командам SQL | 519
Старый синтаксис иногда вызывает проблемы и является сложным для воспри-
ятия. Мы настоятельно рекомендуем использовать стандартный синтаксис ANSI.
Секционированные внешние соединения
Секционированные внешние соединения полезны для извлечения разбросанных дан-
ных, которые иначе не так то просто увидеть в результирующем наборе. (Стандарт
ANSI описывает секционированные внешние соединения, но первой платформой, на
которой они реализованы, является Oracle.) Например, в таблицу product заносятся
сведения обо всех производимых нами продуктах, а в таблицу manufacturing - информа-
ция о том, когда продукты были произведены. Поскольку мы не производим каждый про-
дукт непрерывно, соединенные данные двух таблиц могут быть фрагментированы по
времени.
SELECT manufacturing.time^id AS time, product_name AS name,
quantity AS qty
FROM product
PARTITION BY (product_name)
RIGHT OUTER JOIN times ON (manufacturing.time_id =
product.time_id)
WHERE manufacturing.time_id
BETWEEN T0_DATE('01/10/05', 'DD/MM/YY')
AND T0_DATE('06/10/05', 'DD/MM/YY')
ORDER BY 2, 1;
Возвращается следующий результат.
time name qty
01-0CT-05 flux capacitor 10
02-0CT-05 flux capacitor
03-0CT-05 flux capacitor
04-0CT-05 flux capacitor
05-0CT-05 flux capacitor
06-0CT-05 flux capacitor 10
06-0CT-05 flux capacitor 8
01-0CT-05 transmorgrifier 10
01-0CT-05 transmorgrifier 15
02-0CT-05 transmorgrifier
03-0CT-05 transmorgrifier
O4-OCT-05 transmorgrifier 10
04-0CT-05 transmorgrifier 11
05-0CT-05 transmorgrifier
06-0CT-05 transmorgrifier
Этот пример запроса и результирующий набор показывают, что секционированные
внешние соединения полезно использовать для извлечения результирующих наборов,
которые иначе было бы сложно получить из-за фрагментации данных.
520 | Глава 3. Справочник по инструкциям SQL
Ретроспективные запросы
Также в Oracle 10g поддерживаются ретроспективные запросы (flashback queries) - запросы,
которые отслеживают предыдущие значения результатов, запрошенных в инструкции
SELECT. В следующем фрагменте кода мы выполним обычный запрос к таблице, потом
изменим данные в таблице при помощи предложения UPDATE, а затем выполним запрос
предыдущей версии данных. Сначала выполняем обычный запрос.
SELECT salary PROM employees
WHERE last_name = 'McCreary';
Результат будет следующий.
SALARY
3800
Теперь изменим значение в таблице employees и выполним запрос, чтобы по-
лучить текущее значение.
UPDATE employees SET salary = 4000
WHERE lasL_namo = 'McCreary
SELECT salary FROM employees
WHERE last_name = 'McCreary ';
Результат будет следующий.
SALARY
4000
И наконец, выполним ретроспективный запрос, чтобы увидеть, какой была
зарплата в прошлом.
SELECT salary FROM employees
AS OF 1iMES'rAMP (SYSTIMESTAMP - INTERVAL 'Г DAY)
WHERE last._name - 'McCreary'.
Результат будет следующий.
SALARv
3800
Если бы нам были нужны более подробные сведения, мы могли бы найти все
значения salary за определенный период времени, скажем за последние два дня.
SELECT salary FROM employees
VERSIONS BETWEEN TIMESTAMP
SYSTIMESTAMP - INTERVAL 'Г MINuTF AND
SYSTIMESTAMP - INTERVAL '2' DAY
WHERE last_name = 'McCreary';
Результат будет следующий.
Справочник по командам SQL | 521
SALARY
4000
3800
Предложение MODEL
В Oracle Database 10g входит новое мощное предложение MODEL, которое позволяет
получать в инструкции SELECT результирующие наборы, сходные с электронными таб-
лицами. В частности, предложение MODEL создано для того, чтобы у разработчиков не
было необходимости извлекать данные из базы данных и помещать их в электронную
таблицу, например Microsoft Excel, для дальнейших манипуляций. Это предложение соз-
дает многомерный массив, на ячейки которого можно ссылаться по значениям в измере-
ниях. Например, вы можете создать массив с измерениями «время» и «продукт» и ука-
зать значения, к которым вы хотите осуществлять доступ с использованием комбинации
этих двух измерений. После этого вы можете написать правила, сходные по концепции
с формулами электронных таблиц, которые выполняются и изменяют значения в вашей
модели, а также создают новые значения, а возможно, и новые строки.
Синтаксически предложение MODEL идет после предложений GROUP BY
и НА VING и перед предложением ORDER BY. В схеме синтаксиса инструкции SELECT
для Oracle, приведенной ранее, указано местоположение данного предложения,
а подробно его синтаксис описывается здесь.
MODEL предложение^МООЕ).
предложение^МООЕЕ: [опции] [возвращает] [ссылочные_модели] главная^модель
опции [{IGNORE|KEEP} NAV] [UNIQUE {DIMENSION | SINGLE REFERENCE}]
возвращает ::= RETURN {UPDATED|ALL} ROWS
ссылочные_модели :.= ссылочная_модель [ссылочная_модель. . .]
ссылочная_модель REFERENCE имя~модели ON [подзапрос') столбцьрмодели
[опции]
столбцы_модели ::= [раздел [псевдоним]]
DIMENSION BY [столбец[. столбец...])
MEASURES [столбец[, столбец...])
раздел \= PARTITION BY (столбец}, столбец...])
столбец :: = {имя_столбца\выражение) [AS псевдоним]
главная_модель :: = [MAIN имя__модели] столбцьцмодели [опции] правила
522 | Глава 3. Справочник по инструкциям SQL
правила ::= Z^ULES [ UPSERT | UPDATE ] Г {AUTOMATIC | SEQUENTIAL} ORDER]]
[ITERATE (.число) [UNTIL /условие^завершения)]]
/правило), правило. ,. J)
правило : = [ JPSERГ i UPDATE] ось1лка_на_ ячейку [сортировка), = выражение
ссылка_на_ячейку : : -- многомерно'й_показатель
[многостолбцовый_цикл_Е0Р | индексы_измерений]
многостолбцозая_цикл__ЕОР FOR /измерение). измерение...']') IN (значения^
измерений)
значения_измерений - /{подзапрос\значение_измерения), значение, измерения. . ]})
значение_изморения := /константа), константа...])
индексы^ измерений . . - индекс)., индекс. . . ]
индекс : - {условие* выражение) один_сголбец_длЯ-.цикла}
одностолбцовый-Рикл. РОН :: =FOR измерение {1г-опции_для_Е0Р I 1_1КЕ-опци/_для_ FOR}
in-оиц/и„ДЛЯ-ЕОТ р|\ {{подзапрос | константа], константа. .. ]})
Е1КЕ-опции_дгя_Е0Р::= [LIKE шаблон] FROM стартов_константа ТО конечн^константа
{INCREMENT'DECREMENT} константа_разницы
сортировка :.= ORDER BY /столбец_для_сортировки{, столбец_для._сортировки. . . ])
столбец_для_сортировки ::= {выражение\псевдоним} [ASC|DESC] [NULLS
FIRST|NULLS.LAST]
Параметры предложения MODEL следующие.
/IGNORE’. KEEP} NAV
Указывается, будут ли пустые или отсутствующие значения /NAF) сохраняться пус-
тыми /KEEP), или они должны заменяться заданными по умолчанию подходящими
значениями /IGNORE)', для числовых типов используется ноль, для дат - 1 января
2000 года, для строковых типов - пустая строка и пустое значение для всех прочих
типов.
UNIQUE /DIMENSION | SINGLE REFERENCE}
Определяется область, в пределах которой ссылка на ячейку указывает на уни-
кальное значение. Используйте предложение DIMENSION, чтобы база требовала,
чтобы все возможные ссылки на ячейки (и справа, и слева от правила) указывали
на одиночные значения. Используйте предложение SINGLE REFERENCE, чтобы
Справочник по командам SQL | 523
такая проверка производилась только для тех ссылок, которые расположены
справа от правила.
RETURN {UPDATED | ALL} ROWS
Указывается, будут ли после обработки в модели возвращаться все строки или
только обновленные.
ссылочнаялюдель
Определяется ссылочная модель, по которой нельзя производить вычисления, но
содержащая значения, на которые вы можете ссылаться из основного запроса.
имя_модели ON (подзапрос)
Указывается имя и источник получения строк для ссылочной модели.
псевдоним
Указывается псевдоним для раздела.
DIMENSION BY (столбец/), столбец] )
Указываются измерения для модели. Значения из этих столбцов представляют собой
набор индексных значений, которые используются для указания ячеек в многомерном
адресном пространстве.
MEASURES (столбец[, столбец] )
Указываются значения, связанные с каждой уникальной комбинацией измерений
(т. е. с каждой ячейкой модели).
PARTITION BY (столбец/, столбец])
Модель разделяется на независимые разделы на основе указанных столбцов.
Нельзя разделять ссылочные модели.
главная_модель
Представляет собой модель, над которой вы выполняете действия. Строки из содержа-
щей модель инструкции SELECT поступают в модель, применяются правила и возвра-
щаются результирующие строки.
MAIN имя.модели
С этого предложения начинается определение модели, а также модели присваива-
ется имя.
R ULES [UPSER Т | UPDA ТЕ]
Указывается, что правила могут создавать новые ячейки и обновлять сущест-
вующие (UPSERT) или же только обновлять существующие (UPDATE). Если вы
хотите, чтобы ваша модель могла создавать новые строки в результирующем на-
боре, укажите предложение UPSERT. Это предложение принимается по умолча-
нию. Также вы можете задавать это поведение для каждого правила. См. схему
синтаксиса правило.
{AUTOMATIC | SEQUENTIAL] ORDER
Указывает, будет ли оптимизатор определять порядок выполнения правил (AUTO-
MATIC) или же правила будут выполняться в том порядке, в каком вы их указали
(SEQUENTIAL). По умолчанию принимается SEQUENTIAL.
ITERATE (число)
Весь набор правил будет выполняться несколько раз, количество которых опреде-
ляет параметр число. По умолчанию набор правил выполняется только один раз.
524 | Глава 3. Справочник по инструкциям SQL
UNTIL (условие завершения)
Указывается условие, по выполнению которого итерация завершается. Вы также
должны указать параметр число, которое играет роль защиты от бесконечных циклов.
многомерный_показатель [...]
Ссылка на один или несколько многомерных показателей (measure), указанных
в предложении MEASURE. Если вы ссылаетесь на многомерный показатель, то в син-
таксис должны входить квадратные скобки. Вы должны указать все измерения либо
при помощи подзапроса, либо путем их перечисления, тогда вы сможете сослаться на
многомерный показатель или получить значение показателя, которое связано с этими
измерениями.
многостолбцовый_цикл_ЕОЕ
Цикл FOR, перебирающий сразу несколько измерений. Легче всего представить
это как подзапрос, в котором каждая строка представляет собой конкретную ком-
бинацию измерений.
индексы измерений
Список значений, взятых из столбцов или выражений, которые все вместе иденти-
фицируют уникальную ячейку в модели.
одностолбц овы й_ ц ukmFOR
Цикл FOR, который перебирает значения в одном измерении.
IN ({подзапрос | константа[, константа...]})
Источником значений для цикла ГОЛ может быть подзапрос, а может быть список
постоянных значений.
LIKE шаблон
Позволяет указывать в шаблоне значения измерений. Для указания места, в которое
вставляются значения измерений, используйте знак процента (%). Например, пред-
ложение FOR х LIKE ’А%В' FROM 1 ТО 3 INCREMENT 1 создаст значения 'AIB',
'А2В', 'АЗВ'.
FROM стартов_константа ТО конечн_константа {INCREMENT\DECREMENT}
константа _разницы
Указывается начальное и конечное значение для цикла FOR, а также разница
между последовательными пошаговыми значениями при проходе по циклу.
ORDER BY (столбе1)_для_сортировки[, столбец_для_сортировки...])
Определяет порядок вычислений для ячеек, указанных в левой части правила. Исполь-
зуйте это предложение, если вы хотите применять правило к ячейкам в определенном
порядке. В противном случае у вас не будет гарантий соблюдения порядка при приме-
нении правил к ячейкам.
Ниже приводится список функций, которые были специально разработаны для
использования в предложении MODEL.
CV() или СУ(столбец_измерения)
Возвращается текущее значение из столбца измерения. Может использоваться
только в правой части выражения в правиле. Если используется форма CV(), то
Справочник по командам SQL | 525
столбец измерения определяется неявно, на основе положения вызова функции
в списке значений измерения.
РРЕ8ЕНТННУ(многомерный_показателъ[измерение, измерение.,.], не_пи11, был_пи11)
Возвращается значение, указанное в параметре не_пи11 или был_пи11, в зависимости от
того, было ли значение указанного многомерного показателя пустым на момент
начала обработки модели. На эту функцию можно ссылаться только в правой части
выражения в правиле.
PRESENTV(.',tiioz(MepHbiй_показатепъ[измерение, измерение...],
существовал, не_существовал)
Возвращает значение, указанное в параметре существовал или не существова.з,
если указанный многомерный показатель существовал на момент начала обработ-
ки модели. На эту функцию можно ссылаться только в правой части выражения
в правиле. Вы должны знать, что вопрос о том, существовал ли многомерный по-
казатель, отличается от вопроса о том, был ли он равен NULL.
ITERATION NUMBER
Возвращает нулевое значение (0) при первом выполнении правил, 1 - при втором
выполнении и т. д. Полезно, если вы хотите основывать свои расчеты на количест-
ве выполненных итераций.
В следующем примере демонстрируется, что предложение MODEL наделяет
обычную инструкцию SELECT возможностью создания в результирующем наборе
многомерного массива и вычисления на взаимозависимой основе значений по разным
строкам и разным массивам. Вычисленные значения возвращаются в форме части резуль-
тирующего набора инструкции SELECT.
ELECT SUBSTR(reg ion,1,20) country, SUBSTR(product,1,15) product,
year, sales
FROM sales_view
WHERE region IN ('USA','UK')
MODEL RETURN UPDATED ROWS
PARTITION BY (region)
DIMENSION BY (product, year)
MEASURES (sale sales)
RULES (
sales['Bounce',2006] = sales]' Bounce’,2005] + sales]’Bounce',2004],
sales]'Y Box', 2006] = sales]'Y Box', 2005],
sales]’Byproducts’,2006] - sales]’Bounce’,2006]
+ sales]'Y Box',2006] )
ORDER BY region, product, year;
В этом примере запрос к материализованному представлению sales_view возвра-
щает суммарный объем продаж за промежуток в несколько лет для регионов USA
и UK. Здесь модель располагается между предложением WHERE и предложением
ORDER BY. Поскольку в настоящий момент представление salesview содержит
526 | Глава 3. Справочник по инструкциям SQL
данные за 2004 и 2005 годы, мы указываем правила, позволяющие вычислить значе-
ния для 2006 года.
Предложение RETURN UPDATED ROWS ограничивает результирующий набор
только теми записями, которые были созданы или изменены запросом. После этого
в примере определяется логическое разделение данных с использованием элементов,
полученных из материализованного представления, и с использованием предложений
PARTITION BY, DIMENSION BY и MEASURES. Затем предложение RULES указывает
отдельные многомерные показатели модели, ссылаясь на комбинацию значений
разных измерений во многом так же, как в макросах поиска в электронных таблицах
используются ссылки на диапазоны значений.
PostgreSQL
Платформа PostgreSQL поддерживает простую реализацию инструкции SELECT. Под-
держиваются предложения JOIN и подзапросы. В PostgreSQL также можно создавать
новые временные или постоянные таблицы с использованием синтаксиса SELEСТ...INTO.
SELECT [А'.._ I DLSHNCT [ON (отбираемый элемент [,...]) ] [ [AS псевдоним
[ (.список. псевдонимов) j ] [....[
[INTO [[TEMPjCRARYj [TAB..E] имя новой._таблицы]
[rROM, [ONLY] таблица!]. [,. .] J
[ [тип соединенияи'бА^ :аблица2 [[ON условие .соединения] ’
[USING (список_столбцов)J }
['«HERE условие_поиска]
[GROUP BY выражение..для_дгоцр_Ьу]
[LAVING условие_для_11ао1пд]
[ORDER BY выражение_для_.сортировки [{ASC | DESC
| USING оператор]], . . ] } J
[-0R UPDATE [0е столбец [, . ]]
[LIMIT {число | ALL} {[OFFSET [количествО-Записей]] ]
Где:
[ALL : DISTINCT [ON (отбираемыи_элемеит [,...]) ] ]
Поддерживаются ключевые слова ALL и DISTINCT стандарта ANSI SQL, где
ALL (задано no умолчанию) возвращает все строки (включая дублирующиеся),
a DISTINCT удаляет дублирующиеся строки. Кроме того, предложение DISTINCT
ON удаляет дубликаты только в одном из указанных отбираемых элементов, а не
во всех отбираемых_элементах запроса (см. пример ниже).
отб ираем ы й_эл емен т
Включает все стандартные элементы списка отбираемых элементов, принятого
стандартом ANSI SQL. Помимо обобщающего символа * (звездочка) вы можете
использовать конструкцию имя_таблицы.*, чтобы получить все строки из отдель-
ной таблицы.'
[AS псевдоним [(список псевдонимов)]
Создается псевдоним или список псевдонимов для одного или нескольких столб-
цов (или таблиц в предложении FROM). Предложение AS является необходимым
Справочник по командам SQL | 527
для создания псевдонимов отбираемых элементов, но не для псевдонимов в пред-
ложении FROM. (Некоторые другие платформы считают предложения AS необяза-
тельными.)
INTO [[TEMP]ORARY] [TABLE] имя_новой_таблицы
Из результирующего набора запроса создается новая таблица. Для создания вре-
менных таблиц, которые автоматически удаляются по окончании сеанса, допусти-
мым является синтаксис TEMP или TEMPORARY. В противном случае команда
создает постоянную таблицу. Постоянные таблицы, созданные при помощи этой
инструкции, должны иметь новые, уникальные имена, а временные таблицы
могут иметь те же имена, что и уже существующие таблицы. Если вы создаете
временную таблицу, имя которой совпадает с именем существующей постоянной
таблицы, то временная таблица используется для всех операций, связанных с этим
именем, которые проводятся в данном сеансе. Другие сеансы будут по-прежнему
видеть существующую постоянную таблицу.
FROM [ONLY] таблица! [,...]
Указывается одна или несколько таблиц-источников, в которых находятся данные.
(Обязательно укажите условие соединения или условие WHERE для тета-соедине-
ния, чтобы не получить полный координатный продукт для всех записей во всех
таблицах.) PostgreSQL позволяет использовать в таблицах-потомках наследование
из родительских таблиц. Ключевое слово ONLY используется для того, чтобы
данные не извлекались из таблиц-потомков исходной таблицы. (Вы можете от-
ключить такое наследование на глобальном уровне командой SET SQLJnheritance
ТО OFF.) Платформа PostgreSQL также поддерживает вложенные табличные под-
запросы (см. раздел «Инструкция SUBQUERY»). Предложение FROM не является
необходимым при использовании вычислений.
SELECT 8 * 40;
Платформа PostgreSQL также может включать в инструкции SELECT неявные
предложения FROM при использовании столбцов с указанием схемы. Например,
следующий столбец является допустимым (хотя так делать и не рекомендуется).
SELECT sales. stor_id WHERE sales,stor.id = '6380';
GROUP BY выражение _для _group_by
Позволяет указать выражение для группировки, которое может представлять
собой имя столбца или его порядковый номер (указывающий на его положение
в списке отбираемых элементов). Пример, иллюстрирующий данную концепцию,
приводится чуть ниже, в разделе, посвященном предложению ORDER BY.
ORDER BY выражение для ^сортировки
Позволяет указать выражение для сортировки, которое может представлять собой
имя столбца, его псевдоним или порядковый номер столбца (указывающий на его
положение в списке отбираемых элементов). Например, следующие два запроса
функционально идентичны.
SELECT stor_id, ord_date, qty AS quantity
FROM sales
528 | Глава 3. Справочник по инструкциям SQL
ORDER BY stor_id, ord_date DESC, qty ASC;
SELECT stor_id, ord_date, qty
FROM sales
ORDER BY 1, 2 DESC. quantity;
В инструкциях SELECT, обращающихся к одной таблице, вы можете проводить
сортировку по столбцам, не входящим в список отбираемых элементов. Например:
SELECT •
FROM sales
ORDER BY stor_id, qty;
Предложения ASC и DESC соответствуют стандарту ANSI. По умолчанию прини-
мается предложение ASC. Платформа PostgreSQL считает, что пустые значения
больше всех остальных, поэтому они располагаются в конце при сортировке по
возрастанию (ASC) и в начале - при сортировке по убыванию (DESC).
FOR UPDATE OF столбец [,] LIMIT {число | ALL} ][OFFSET [количество^записей]]
Число строк, возвращаемых запросом, ограничивается максимумом, указанным в це-
лочисленном параметре число. Дополнительное ключевое слово OFFSET заставляет
PostgreSQL пропустить указанное количество_записей, прежде чем начать извлекать
строки. При использовании предложения LIMIT должно обязательно присутствовать
предложение ORDER BY, в противном случае результирующий набор будет неопреде-
ленным. (PostgreSQL версии 7.0 и выше рассматривают предложение LIMIT/OFFSET
как подсказку оптимизатору и используют его для создания оптимальных, но, возмож-
но, очень различных планов обработки запроса.)
PostgreSQL поддерживает удобный вариант предложения DISTINCT - DISTINCT
ON (отбираемый_элемент [,...]). Этот вариант позволяет выбрать, в каких столбцах
будет использоваться удаление дубликатов. Платформа PostgreSQL выбирает резуль-
тирующий набор во многом так же, как для предложения ORDER BY. Вам следует ука-
зать предложение ORDER BY, чтобы не было непредсказуемости при выборе записей.
Например:
SELECT DISTINCT ON (stor_id), ord_date, qty
FROM sales
ORDER BY stor_id, ord_date DESC;
Приведенный выше запрос извлекает самый последний отчет о продажах для
каждого магазина (stor_id) на основе даты самого последнего заказа (ord_date).
Однако без предложения ORDER BY невозможно будет предсказать, какая запись
будет извлечена.
Платформа PostgreSQL поддерживает только следующие типы синтаксиса предложе-
ния JOIN (за подробной информацией обращайтесь к разделу «Предложение JOIN»).
FROM таблица*! {
CROSS JOIN таблица2 I
[INNER] uOIN таблица2 [ {ON условие_соединения |
34 - 2447
Справочник по командам SQL | 529
USING (список_столбцов')} ] |
LEFT [OUTER] JOIN таблица2 [ {ON условие_соединения |
USING (список_столбцов)} ] |
NATURAL [LEFT [OUTER]] JOIN таблица? |
RIGHT [OUTER] JOIN таблица2 [ {ON условие_соединения |
USING (список_столбцов')} ]|
NATURAL [RIGHT [OUTER]] JOIN таблица?
FULL [OUTER] JOIN таблица? }
Где:
[CROSS] JOIN
Извлекаются все записи из таблиц 1 и 2. Синтаксически это предложение анало-
гично предложению FROM таблица!, таблица2. Результатом является коорди-
натный продукт (а это обычно очень плохо!).
INNER JOIN
Из таблиц 1 и 2 извлекаются те записи, для которых в обеих таблицах находятся
соответствующие значения (согласно условию соединения). Обратите внимание,
что синтаксис FROM таблица!, таблица? аналогичен внутреннему соединению
без указания условия соединения (т. е. координатному продукту). Если вы исполь-
зуете синтаксис FROM таблица!, таблица?, то обязательно указывайте условия
соединения в предложении WHERE. Если вы не укажете тип соединения, будет
предполагаться INNER JOIN.
NATURAL
Это предложение используется для объявления условия соединения так, как если
бы использовалось предложение USING с указанием всех столбцов, сущест-
вующих в обеих таблицах. (Будьте осторожны, если столбцы имеют одинаковые
имена, но разные типы данных или вид значений.) Предложение NATURAL и ука-
зание условий соединения при помощи предложений ON или USING являются
взаимоисключающими.
LEFT [OUTER] JOIN
Извлекаются все записи из левой таблицы (т. е. таблицы!) и соответствующие
записи из правой таблицы (таблицы?). Если в таблице? не оказывается соответст-
вующих записей, в соответствующие столбцы помещаются значения NULL. Вы
можете применять этот тип соединения для извлечения всех записей из таблицы
даже в том случае, если в соединяемой таблице отсутствуют соответствия. Пример:
SELECT j,job_id, е.Iname
FROM jobs j
LEFT OUTER JOIN employee e ON j.job_id = e,job_id
ORDER BY d.job_id
RIGHT [OUTER] JOIN
RIGHT [OUTER] JOIN
Извлекаются все записи из правой таблицы независимо от того, есть ли соответст-
вующие записи в левой таблице. Аналог LEFT JOIN.
530 | Глава 3. Справочник по инструкциям SQL
FULL [OUTER] JOIN
Извлекаются все записи, которые извлекает предложение INNER JOIN, а также все
записи, для которых не находится соответствий в левой или правой таблице.
ON усл овие_соедин ен ия
Указывается условие, соединяющее результирующие наборы из двух или более
таблиц. Это условие имеет форму указания столбцов в таблице! и таблице2, которые
должны быть одинаковыми. Если сравнение нужно проводить по нескольким
столбцам, используйте предложение AND.
SQL Server
Платформа SQL Server поддерживает основные элементы инструкции SELECT стан-
дарта ANSI, включая все разнообразные типы соединений. В SQL Server также суще-
ствует несколько вариаций инструкции SELECT, включая подсказки оптимизатору,
предложение INTO, предложение ТОР, варианты предложения GROUP BY, предложе-
ния COMPUTE и WITH OPTIONS.
SELECT {[ALL | DISTINCT] I [TOP число [PERCENT]
[WITH TIES]]} отбираемый_элемент [AS псевдоним]
[INT0 имя_новой_таблицы ]
[FROM {[функции_для_наборов_строк | таблица) [,...]} [AS псевдоним]]
[ [join type]J0IN таблица2 {[ON условие_соединения] ]
[WHERE условие_поиска ]
[GROUP BY {столбец_для_ группировки [,...] | Ai_L}] [ WITH { CUBE | ROLLUP } ]
[HAVING условие_поиска]
[ORDER BY выражение_для_сортировки [ ASC i DESC ] ]
[COMPUTE {агрегация {выражение')} [,...]
[BY выражение [,...] ] ]
[FOR {BROWSE | XML { RAW | AUTO ; EXPLICIT}
[, XMLDATA][, ELEMENTS]}, BINARY BASE64] ]
[OPTION ( <подсказка> [,...]) ]
Где:
TOP число [PERCENT] [WITH TIES]
Указывается количество строк, извлекаемых в результирующий набор запроса
(число). Если указано ключевое слово PERCENT, то извлекается указанная про-
центная доля записей, начиная с первой. Предложение WITH TIES используется
только в запросах с предложением ORDER BY. Это предложение указывает, что из
базового результирующего набора, упорядоченного с использованием предложе-
ния ORDER BY, возвращаются только первые ЮР строк.
INTO имя_новой таблицы
Из результирующего набора запроса создается новая таблица. Вы можете использо-
вать это предложение для создания временных и постоянных таблиц. (За информа-
цией о создании временных и постоянных таблиц обращайтесь к подразделу SQL
Server раздела «Инструкция CREATE/ALTER TABLE».) Команда SELECT...INTO
быстро копирует запрашиваемые строки и столбцы из другой таблицы (таблиц)
Справочник по командам SQL | 531
в новую таблицу без занесения данной операции в журнал. Поскольку операция не
заносится в журнал, на нее не влияют операции COMMIT и ROLLBACK.
FROM {[функции_для_наборов_строк | таблица! [,...]}
Поддерживается функционирование предложения FROM в соответствии со стан-
дартом ANSI, включая вложенные табличные подзапросы. Кроме того, SQL Server
поддерживает набор расширений, называемых функциями для наборов строк (rowset
functions). Эти функции позволяют платформе SQL Server получать данные из специ-
альных источников, таких, как потоки XML, файловые структуры полнотекстового
поиска (особые структуры, используемые в SQL Server для хранения таких объектов,
как документы MS Word и слайды MS PowerPoint, отображаемые в базе данных), и из
внешних источников данных (таких, как листы MS Excel).
Примеры приводятся ниже. (За полным описанием доступных опций предложе-
ния FROM {[функции_для_наборов_строк | таблица! [,...]} обращайтесь, пожа-
луйста, к документации по SQL Server.) В настоящее время SQL Server поддержи-
вает следующие функции для работы с наборами строк.
CONTAINSTABLE
Возвращает таблицу, созданную на основе указанной таблицы, которая
содержит, по меньшей мере, один столбец TEXTwm NTEXTс полнотекстовым
индексированием. Эти записи создаются на основе поиска с полными совпа-
дениями (precise search), нечеткого поиска (fuzzy search), поиска с взвешенны-
ми совпадениями (weighted-match) и поиска с учетом расстояния (proximity
search). Получившаяся таблица потом используется как любой другой
источник данных.
FREETEXTTABLE
Эта функция сходна с CONTAINSTABLE, за исключением того, что записи соз-
даются на основе поиска 'произвольной_строки'. Функцию FREETEXTTABLE
лучше применять в нерегламентированных запросах к полнотекстовым табли-
цам, но этот способ является менее точным, чем CONTAINSTABLE.
OPENDATASOURCE
Предоставляет возможность при помощи OLE DB получать данные из ис-
точников, внешних по отношению к SQL Server, без объявления связанного
сервера, например из электронных таблиц MS Excel или таблиц Sybase Adaptive
Server. Эта функция предназначена для случайных и нерегламентированных
запросов. Если вы часто получаете данные из внешних источников, то вам
следует объявить связанный сервер.
OPENQUERY
Выполняется транзитный запрос к связанному серверу. Это эффективный
метод выполнения вложенного табличного подзапроса к источнику данных,
внешнему по отношению к SQL Server. Источник данных нужно сначала объ-
явить как связанный сервер.
OPENROWSET
Выполняется транзитный запрос к внешнему источнику данных. Эта функ-
ция сходна с OPENDATASOURCE, за исключением того, что функция OPEN-
532 | Глава 3. Справочник по инструкциям SQL
DATASOURCE только открывает источник данных, и он в действительности
не проходит через инструкцию SELECT. Функция OPENROWSET предна-
значена для применения в нерегулярных, нерегламентированных запросах.
OPENXML
Создается напоминающее таблицу представление XML-строки, с возможно-
стью выполнения запроса к нему.
GROUP BY {столбец_для^группировки [,...][ ALL}] [ WITH { CUBE | ROLLUP} ]
Поддерживается стандарт ANSI SQL с несколькими вариантами. Первое заметное
отличие - это синтаксис. Если в стандарте ANSI используется конструкция
GROUP BY [{CUBE | ROLLUP}] (столбец_длягруппировки [,...] ), то в SQL Server
применяется конструкция GROUP BY [ALL] (выражение _для_группировки)
[WITH {CUBE | ROLLUP] ].
Предложение GROUP BY ALL заставляет платформу SQL Server указывать кате-
горию группировки, даже если соответствующий агрегат представляет собой
пустое значение. В норме SQL Server не возвращает категорию, значение которой
равно NULL. Это предложение должно использоваться только с предложением
WHERE. Предложение WITH {CUBE | ROLLUP} заставляет SQL Server создавать
дополнительные высокоуровневые агрегаты суммарных категорий. Проще говоря,
ROLLUP создает промежуточные итоговые значения для категорий, a CUBE соз-
дает сводные итоги для категорий.
ЙГ *
Чтобы отличить обычные пустые значения от пустых значений, создан-
ных при использовании предложений ROLLUP и CUBE, можно использо-
вать функцию GROUPING.
В этом примере группируются значения royalty и создается агрегат по значениям
advance1. К столбцу royalty применяется функция GROUPING.
jSE pubs
SELECT royalty, SUM(advance) 'total advance',
GROUPING(royalty) 'grp'
FROM titles
GROUP BY royalty WITH ROLLUP
В результирующем наборе в столбце royalty есть два значения NULL. Первое
значение отражает группировку пустых значений из данного столбца таблицы. Второе
пустое значение - это суммарная строка, добавленная операцией ROLLUP. Суммарная
строка показывает суммарный аванс по всем группам значений royalty, и она обо-
значается цифрой 1 в столбце grp.
royalty - здесь: авторский гонорар в виде процента с продаж; advance - аванс. - Примеч. пер.
Справочник по командам SQL | 533
Вот результирующий набор.
royalty total advance grp
NULL NULL 0
10 57000.0000 0
12 2275.0000 0
14 4000.0000 0
16 7000.0000 0
24 25125.0000 0
NULL 95400.0000 1
ORDER BY
Обычно работает так, как определено стандартом ANSI SQL. Однако вы должны
помнить, что в SQL Server разрешено использовать различные сопоставления
(collations), которые могут повлиять на определение результирующего набора.
Так, при некоторых сопоставлениях слова «SMITH» и «smith» могут сортировать-
ся по-разному. Также обратите внимание, что нельзя проводить сортировку по
столбцам типов TEXT, NTEXTи IMAGE.
COMPUTE {агрегация (выражение)} [,...] [BY выражение [,...]] ]
Создаются дополнительные агрегаты, обычно итоговые значения, которые помещают-
ся в конец результирующего набора. Предложение BY выражение добавляет в резуль-
тирующий набор промежуточные итоги и контрольные разрывы. Вы можете одновре-
менно использовать в одном запросе предложение COMPUTE и COMPUTE BY. Пред-
ложение COMPUTE BY должно совмещаться с предложением ORDER BY, хотя выра-
жение, используемое в COMPUTE BY, может быть частью вырамсения_для_сортировки.
В качестве агрегата может выступать вызов любой из следующих функций: A VG,
COUNT, MAX, MIN, STDEV, STDETP, PAR, PARP и SUM. Примеры приводятся ниже
в этом разделе.
Предложение COMPUTE, в любой его форме, не употребляется с ключевым
словом DISTINCT или с типами данных TEXT, NTEXT или IMAGE.
FOR {BROWSE | XML { RAW | AUTO | EXPLICIT}
[, XMLDATA][, ELEMENTS][, BINARYBASE64]]
Предложение FOR BROWSE используется для того, чтобы разрешить обновлять
данные в курсоре обзорного режима DB-Library. (DB-Library - это исходная мето-
дология доступа SQL Server, которая в большинстве приложений была вытеснена
методикой OLE DB.) Предложение FOR BROWSE можно использовать только
в таблицах с уникальным индексом и столбцом значений типа TIMESTAMP. Предло-
жение FOR BROWSE нельзя использовать в инструкциях UNION или если активна
подсказка HOLDLOCK.
FOR XML
Используется для извлечения результирующего набора в виде документа
XML только в клиент SQL Server 2000. Далее вы должны определить резуль-
тирующий XML-документ как RAW, AUTO или EXPLICIT. Предложение RAW
преобразует каждую полученную запись во внутренний элемент XML с тегом
534 | Глава 3. Справочник по инструкциям SQL
<row/>. При указании предложения AUTO результаты преобразуются в про-
стое вложенное дерево XML. При указании предложения EXPLICIT дерево
XML преобразуется в явно определенную форму. Однако запрос должен быть
написан таким образом, чтобы необходимая информация о вложенности была
указана явно. При желании вы можете использовать еще несколько управ-
ляющих опций.
XMLDATA
Возвращается схема, прикрепленная к документу XML. Предложение ELEMENTS
возвращает столбцы в виде подэлементов, а не соответствующие им атрибуты
XML.
BINARY BASE64
Возвращаются двоичные данные, закодированные в формат base64. (Двоичный
формат установлен по умолчанию для режима A UTO, но его нужно специально
указать для режимов RAW и EXPLICIT!) Предложение FOR XML нельзя исполь-
зовать в любых подзапросах, нельзя применять совместно с предложением COM-
PUTE и BROWSE, в определениях представлений, в результирующем наборе
пользовательской функции или в курсоре. Предложение FOR XML A UTO и агрега-
ты, а также предложения GROUP BY являются взаимоисключающими.
OPTION ( <подсказка> [,..])
Элементы плана обработки запроса, заданные по умолчанию, заменяются указанными
элементами. Поскольку оптимизатор обычно подбирает самый лучший план обработ-
ки запроса, мы не рекомендуем помещать в запросы подсказки оптимизатору.
Ниже приводится пример инструкции SELECT...INTO в SQL Server. В этом при-
мере с помощью SELECT...INTO создается таблица non_mgr_employees. Таблица со-
держит идентификатор (emp_id), имя (fname) и фамилию (Iname) всех сотрудников,
которые не являются менеджерами. Эти данные берутся из таблицы employee и соеди-
няются с описанием их должности, взятым из таблицы jobs.
--Запрос
SELECT e.emp_id, e.fname, е.Iname,
SUBSTRINGS . job_desc, 1,30) AS job_desc
INTO non_mgr_employee
FROM employee e
JOIN jobs AS j ON e,job_id = j.job_id
WHERE j.job_desc NOT LIKE '%MANAG%'
ORDER BY 2,3, 1
Теперь к созданной и заполненной таким образом таблице можно посылать запросы,
как к любой другой.
I Предложение SELECT...INTO следует использовать только при разработке
базы или в нерабочей базе, поскольку эта операция не регистрируется
в журнале и не может быть отменена.
Справочник по командам SQL | 535
Многие из расширений, которые добавляет платформа SQL Server к стандарту
ANSI, касаются предложения GROUP BY. Например, предложение GROUP BY ALL
заставляет включить в агрегаты пустые значения, которые в противном случае не были
бы включены. Следующие два запроса, по сути, являются одинаковыми, за исключе-
нием ключевого слова ALL, но они создают разные результирующие наборы.
-- стандартное предложение GROUP BY
SELECT type, AVG(price) AS price
FROM titles
WHERE royalty <= 10
GROUP BY type
ORDER BY type
-- результаты
type price
business 17.3100
mod_cook 19.9900
popular_comp 20.0000
psychology 13.5040
trad_cook 17.9700
Сравните co следующим запросом.
-- Используется GROUP BY ALL
SELECT type, AVG(price) AS price
FROM titles
WHERE royalty = 10
GROUP BY ALL type
ORDER BY type
-- Результаты
type price
business 17.3100
mod_cook 19.9900
popular_comp 20.0000
psychology 13.5040
trad_cook 17.9700
UNDECIDED NULL
В предложении COMPUTE существует несколько изменений, которые могут повли-
ять на результирующий набор запроса. В следующем примере показана сумма цен
книг (price), разделенных по типам книг и отсортированных по типу, а потом по цене.
--Запрос
SELECT type, price
FROM titles
536 | Глава 3. Справочник по инструкциям SQL
WHERE type IN (’businesspsychology')
AND price > 10
ORDER BY type, price
COMPUTE SUM(price) BY type
--Результаты
type price
business business business 11.9500 19.9900 19.9900 sum
51.9300
type cnee
psychology 10.9500
psychology 19.9900
psychology 21.5900
sum
52.5300
Если вы не укажете ключевое слово BY, то предложение COMPUTE будет работать
по-другому. Следующий запрос получает общую сумму по ценам и авансам за книги,
стоимость которых превышает 16$.
--Зал рос
SELECT type, price, advance
FROM titles
WHERE p^ice > $16
COMPUTE SUM(price), SUM(advance)
--Результат
type price
advance
cosiness business "19.9900 19.9900 5000 0000 5000.0000
rod_cook 19.9900 .0000
popular_comp 22.9500 7000.0000
popular_comp 20.0000. 8000.0000
psychology 21.5900 7000.0000
psychology 19.9900 2000.0000
Справочник по командам SQL | 537
trad_cook 20,9500
7000,0000
sum
165,4500
sum
41000.0000
Вы даже можете использовать COMPUTE BY и COMPUTE в одном запросе,
вычисляя промежуточные и общие итоги. (Для краткости мы покажем пример запро-
са, но не будем приводить результирующий набор.) В этом примере мы найдем сумму
цен и авансов по типам книг (бизнес и психология), для которых цена превышает 16$.
SELECT type, price, advance
FROM titles
WHERE price > $16
AND type IN ('business','psychology')
ORDER BY type, price
COMPUTE SUM(price), SUM(advance) BY type
COMPUTE SUM(price), SUM(advance)
He забывайте, что при наличии предложения COMPUTE BY вы должны также ука-
зать предложение ORDER BY\ (Если используется предложение COMPUTE, без
ключевого слова BY, то нет необходимости указывать предложение ORDER BY.)
В одном запросе вы можете использовать множество комбинаций - несколько предло-
жений COMPUTE и COMPUTE BY, предложение GROUP BY с предложением COM-
PUTE BY, и даже с предложением ORDER BY. Забавно будет попробовать различные
способы создания запросов с предложениями COMPUTE и COMPUTE BY. Это,
конечно, не развлечение, но что вы хотите? Это же программистская книга!
Платформа SQL Server также включает предложение FOR XML, которое преобра-
зует стандартный результирующий набор в документ XML. Это очень полезная воз-
можность для баз данных в Web. Вы можете посылать запросы с предложением FOR
XML прямо к базе данных или из хранимой процедуры. Например, мы можем
получить результат одного из наших приведенных ранее примеров запросов в виде
документа XML.
SELECT type, price, advance
FROM titles
WHERE price > $16
AND type IN ('business','psychology')
ORDER BY type, price
FOR XML AUTO
538 | Глава 3. Справочник по инструкциям SQL
Результат не слишком красиво выглядит, но его вполне можно использовать.
XMl_F52E2B61-18А1-11d1-B105-00805F49916B
<titles type="business " price="19.9900"
advance="5000.0000"/><titles type="business " price="!9.9900"
advance="5000.0000"/><titles type="psychology" price="19.9900"
advance="2000. 0000"/xtitles type="psychology" price=“2l.5900" advance="70C0.000
Если вы хотите, чтобы схема XML и/или элементы XML были представлены в виде
тегов на выходе, вы можете просто добавить к предложению FOR XML ключевые слова
XMLDATA и ELEMENTS. Такой запрос будет выглядеть следующим образом.
SELECT type, price, advance
FROM titles
WHERE price > $16
AND type IN ('businesspsychology')
ORDER BY type, price
FOR XM_ AUTO, XMLDATA, ELEMENTS
В SQL Server также реализованы еще несколько дополнительных возможностей
для поддержки XML. Например, функцию для работы с наборами строк OPENXML
можно использовать для того, чтобы вставить документ XML в таблицу SQL Server.
Также SQL Server включает системные хранимые процедуры, которые помогают под-
готавливать документы XML и манипулировать ими.
См. также
JOIN
WHERE
Инструкция SET
Инструкция SET присваивает значение переменной времени выполнения. Эти пере-
менные могут быть системными переменными, специфичными для платформы, или
пользовательскими переменными.
Платформа Команда
DB2 Поддерживается
MySQL Поддерживается
Oracle Не поддерживается
PostgreSQL Поддерживается
SQL Server Поддерживается
Синтаксис SQL2003
SET переменная = значение
Справочник по командам SQL | 539
Ключевые слова
переменная
Обозначает системную или пользовательскую переменную.
значение
Обозначает строковое или числовое значение, соответствующее системной или
пользовательской переменной.
Общие правила
Значения переменных устанавливаются на время сеанса. Значения, присвоенные
переменной, должны соответствовать типу данных этой переменной. Например, вы
не можете присвоить строковое значение переменной, которая объявлена с число-
вым типом данных. Команда, с помощью которой переменная создается, на разных
платформах разная. Например, в DB2, Oracle и SQL Server используется инструкция
DECLARE, в которой объявляется имя и тип переменной, однако на других плат-
формах могут использоваться другие способы создания переменных.
Значение, которое присваивается переменной, не обязательно должно быть кон-
стантой. Это может быть динамически генерируемое значение, создаваемое на основе
подзапроса. Например, мы можем присвоить переменной emp_id_var максимальное
значение идентификатора сотрудника (emp_id).
DECLARE emp_id_var CHAR(5)
SET emp~id_var = (SELECT MAX(emp_id)
FROM employees WHERE type = 'F')
В этом примере type F обозначает, что сотрудник работает полный день (full-time)
и состоит на окладе.
Советы и хитрости программирования
Инструкция SET очень легко переносится с платформы на платформу. Только в Oracle
используется несколько другая схема присвоения значения переменной. В следующем
примере мы объявим в SQL Server переменну^ с именем emp_id_var и присвоим ей
значение.
DECLARE emp_id_var CHAR(5) j
SET empjd_var = '67888'
А теперь мы выполним ту же самую операцию для сервера Oracle.
DECLARE emp_id_var CHAR(5); (
emp_id_var := '67888';
DBS
Платформа DB2 поддерживает базовую форму Инструкции SET для присвоения значе-
ний локальным переменным, выходным параметрам или особым регистрам. В одной
инструкции SET можно присваивать сразу несколько значений. Также эта инструкция
540 | Глава 3. Справочник по инструкциям SQL
позволяет присваивать значения столбцам базовой таблицы в триггере. Нельзя при-
своить значения в одной инструкции двум типам переменных.
SET переменная = { значение | NULL | DEFAULT }
Синтаксические элементы в DB2 следующие.
переменная
Указывается целевая переменная. Переменные SQL должны быть объявлены до
использования. Переменная также может обозначать столбец базовой таблицы
триггера.
значение
Указывается значение переменной в соответствии с ее типом данных. При при-
своении значений столбцам в триггере вы также можете использовать ссылки на
корреляционные имена OLD и NEW. За дополнительной информацией об этом
обращайтесь к подразделу, посвященному DB2, раздела «Инструкция CREATE/
ALTER TRIGGER».
NULL
Столбцу и переменной, которые могут принимать значения NULL, присваивается
значение NULL.
DEFAULT
Столбцам, которые создавались с указанием предложения WITH DEFAULT или
IDENTITY, присваивается значение по умолчанию. Это предложение также при-
сваивает пустое значение (NULL) тем столбцам, которые принимают пустые
значения и при этом не определены с предложениями DEFAULT или IDENTITY.
Присвоим значение одной переменной.
SET new_var.order_qty = 125;
Если вы присваиваете значения в одной инструкции сразу нескольким перемен-
ным, то количество переменных слева от знака равенства должно в точности соответ-
ствовать количеству значений справа. Присвоим значения нескольким переменным.
SET new_var. order_qty = 125, new..vaг. discount = A;
При использовании такого варианта, как SET переменная = SELECT ..., значения
результирующего набора инструкции SELECT должны в точности соответствовать
переменным по количеству, положению и типу данных. Если инструкция SELECT не
возвращает никаких значений, то переменным присваиваются значения NULL. Также
для присвоения значений нескольким переменным в одной инструкции вы можете ис-
пользовать инструкцию SELECT...INTO.
MySQL
Ключевое слово SET имеет в MySQL несколько способов использования. Во-первых,
SET - это тип данных MySQL, в котором может быть несколько значений, разделен-
ных запятыми. (За информацией об этой области применения обращайтесь к главе 2,
раздел «Типы данных MySQL».) Кроме того, инструкция SET может присваивать
Справочник по командам SQL | 541
значения пользовательской переменной. Здесь описывается именно этот способ при-
менения. Синтаксис следующий:
SFT ^переменная = значение [,
При присвоении в одной инструкции значений нескольким переменным эти значе-
ния отделяются друг от друга запятыми.
SET new_var.order_.aty - 125. new._var.discount ~ 4;
Кроме того, MySQL позволяет использовать инструкцию SELECT для присвоения
значений переменным точно так же, как это описывается в разделе, посвященном
стандарту ANSI. Однако у метода с использованием инструкции SELECT есть не-
сколько слабых мест. Главная проблема состоит в том, что значения не присваиваются
в инструкции SELECT немедленно. Таким образом, в следующем примере:
SELECI (@>new_var . - tow_id) Л8 а,
(<s>new_var + 3) AS Ь
ЕНОМ Lable_name;
переменная @new_var не получит нового значения row id + 3. Сохранится то значе-
ние, которое опа имела в начале инструкции. Поэтому хорошей практикой является
присвоение переменной только одного значения за раз.
Oracle
Предложение SET как метод присваивания значения переменным в Oracle не под-
держивается. Вместо этого пользовательским переменным значения присваиваются
при помощи оператора присваивания :=. Базовый синтаксис следующий.
переменная значение
PostgreSQL
В PostgreSQL команда SET используется для присваивания значения переменной во
время выполнения.
SET переменная{ ТО | - } { значение | DEFAULT }
Переменной во время выполнения можно присвоить строковое постоянное значе-
ние. При использовании ключевого слова DEFAULT переменной времени выполнения
присваивается значение по умолчанию. Платформа PostgreSQL 7.2 поддерживает сле-
дующие переменные.
CLIENT ENCODING NAMES
Устанавливается мультибайтовая кодировка для клиентских систем PostgreSQL,,
скомпонованных с мультибайтовой поддержкой.
DATESTYLE
Устанавливается стиль, используемый для отображения даты и времени. Поддержи-
ваются следующие стили.
ISO
Дата и время отображаются в формате ГГГГ-ММ-ДД ЧЧ:ММ:СС (заданный
по умолчанию стиль ISO 8601).
542 | Глава 3. Справочник по инструкциям SQL
SQL
Дата и время отображаются в стиле Oracle/Ingres, а не в том стиле, который
предписывается стандартом ANSI SQL.
Postgresql
Дата и время отображаются в длинном формате PostgreSQL, но не длиннее,
чем задано по умолчанию.
German
Дата и время отображаются в виде ДД.ММ.ГГГГ.
Вы можете уточнять стили SQL и Postgresql, используя ключевые слова European,
US и NonEuropean, которые придают датам форматы дд/мм/гггг, мм/дд/гггг
и мм/дд/гггг соответственно. Например: SET DATESTYLE = SQL, European.
SEED
Устанавливается начальное значение для внутреннего генератора случайных
чисел. Значение может представлять собой любое число с плавающей точкой
в диапазоне от 0 до 1, умноженное на 231-1. Это значение также можно устано-
вить при помощи функции PostgreSQL setseed. Например:
SELECT setseed(value);
SEVERJENCODING
Устанавливается мультибайтовая кодировка для серверов, скомпонованных с мульти-
байтовой поддержкой.
Ниже приводится пример установки формата даты и времени стиля Oracle и European.
SET DATESTYLE ТО sql, Eurooean;
SQL Server
Платформа SQL Server поддерживает присваивание значений переменным при
помощи инструкции SET, если эти переменные были ранее созданы при помощи инструк-
ции DECLARE, а также присваивание значений переменным курсоров. (Также SQL Server
использует инструкцию SET для других целей, например для включения и отключения
флагов сеанса командами типа SET NOCOUNT ON.) Синтаксис, специфичный для дайной
платформы, приводится ниже.
SET { { ©переменная = значение}
I { ©курсорная_переменная = { @курсорная_переменная i имя_курсора
I { CURSOR l FORWARD_ONLV । SCROLL J
[ STATIC | KEYSET ; DYNAMIC | FAST-FORWARD ]
[ READ-ONLY | SCROLL-LOCKS | OPTIMISTIC ]
Г TYPE.WARNING ]
FOR инструкция^ЗЕЬЕСТ
[ FOR { READ ONLY | UPDATE [ OF имя_столбца ] }
] } 1 1 1
Справочник по командам SQL | 543
Данная инструкция не поддерживает ключевое слово DEFAULT, но во всех прочих
отношениях поддерживает синтаксис ANSI. Значение имя^сервера должно ссылаться
на соединение, указанное в предыдущей инструкции CONNECT, либо в форме кон-
станты, либо в форме переменной.
Инструкция SET CONNECTION
Инструкция SET CONNECTION позволяет пользователям переключаться между несколь-
кими открытыми соединениями на одном или нескольких серверах баз данных.
Платформа Команда
DB2 Поддерживается с ограничениями
MySQL Не поддерживается
Oracle Не поддерживается
PostgreSQL Не поддерживается
SQL Server Поддерживается с ограничениями
Синтаксис SQL2003
SET CONNECTION {DEFAULT | имя_соединения}
Ключевые слова
имя~соед имения
Указывается имя соединения для текущего сеанса. Если имя_соединения отличается
от имени текущего соединения сеанса, то происходит переключение на указанное
соединение.
DEFAULT
Происходит переключение от любого соединения к соединению, заданному по
умолчанию. Это предложение позволяет быстро переключиться к соединению
по умолчанию, не зная его имени.
Описание
Эта команда не завершает соединение. Она лишь переключается от текущего соедине-
ния к указанному (оно становится текущим) или от текущего соединения к соедине-
нию, заданному по умолчанию. При переключении между соединениями старое
соединение становится бездействующим (без внесения изменений), а новое становится
активным.
Общие правила
Инструкция SET CONNECTION не создает соединения. Она просто переключает кон-
текст. Для создания нового соединения используйте команду CONNECT, а для заверше-
ния соединения используйте команду DISCONNECT
544 | Глава 3. Справочник по инструкциям SQL
Советы и хитрости программирования
Команда SET CONNECTION используется нечасто, поскольку многие пользователи под-
ключаются программно при помощи ODBC, JDBC или других методов соединения.
Однако на тех платформах, которые поддерживают инструкцию SET CONNECTION, эта
команда может быть очень полезна для быстрой смены свойств соединения без разрыва
текущих соединений.
DB2
Платформа DB2 поддерживает следующую базовую форму инструкции SET CONNECTION.
SET CONNECTION имя_сервера
Эта команда DB2 не поддерживает ключевое слово DEFA ULT, но во всех прочих отно-
шениях совместима со стандартом ANSI. Значение в параметре имя_сервера должно
ссылаться на соединение, созданное ранее при помощи инструкции CONNECT.
Ниже приводится полностью встроенный код SQL для DB2, который демон-
стрирует инструкции CONNECT и SET CONNECTION.
EXEC SQL CONNECT TO SQLNUTSHELL;
/» Открывается соединение c SQLNUTSHELL. Будут выполняться инструкции,
ссылающиеся на объекты на сервере SQLNUTSHELL */
EXEC SQL CONNECT TO DB2DEV;
/« Открывается соединение c DB2DEV. Теперь будут выполняться инструкции,
ссылающиеся на объекты на сервере 0B2DEV ♦/
EXEC SQL SET CONNECTION SQLNUTSHELL;
/» Теперь возвращаемся к соединению с сервером SQLNUTSHELL и выполняем
ссылающиеся на объекты на SQLNUTSHELL, Соединение с DB2DEV
по-прежнему доступно, но бездействует, */
MySQL
Не поддерживается.
Oracle
Не поддерживается.
PostgreSQL
Не поддерживается.
SQL Server
Платформа SQL Server поддерживает инструкцию SET CONNECTION, но только во встро-
енном коде SQL, а не в средстве создания произвольных запросов SQL Query Analyzer.
Хотя SQL Server поддерживает весь синтаксис SQL2003 при встраивании кода SQL
в другие программы, например в C++, эта возможность используется нечасто. Большин-
35-2447
Справочник по командам SQL | 545
ство предпочитает использовать вместо нее команду USE. Синтаксис, специфический
для данной платформы, следующий.
SET CONNECTION имя__соединения
Эта команда не поддерживает ключевое слово DEFAULT, но во всем остальном
совпадает с инструкцией стандарта ANSI. Значение в параметре имя соединения
(в форме константы или переменной) должно ссылаться на соединение, указанное
ранее в инструкции CONNECT.
Ниже приводится полная программа на TSQL для SQL Server, демонстрирующая
инструкции CONNECT, DISCONNECT и SET CONNECTION.
EXEC SQL CONNECT TO Chicago, pubs AS chicagol USER sa;
EXEC SQL CONNECT TO new_york.pubs AS new_york1 USER read-only;
- - открываются соединения с серверами "Chicago" и
"new„york"
EXEC SQL SET CONNECTION chicagol;
EXEC SQL SELECT name FROM employee INTO :name;
- - соединение chicagol становится активным, и с ним ведется работа
в данном сеансе
EXEC SQL SET CONNECTION new_york1;
EXEC SQL SELECT name FROM employee INTO ;name;
- - соединение new_york1 становится активным, и с ним ведется работа
в данном сеансе
EXEC SQL DISCONNECT ALL;
- - Завершаются все сеансы, В качестве альтернативы вы можете использовать
- - две команды DISCONNECT, по одной на каждое соединение.
См. также
CONNECT
DISCONNECT
Инструкция SET CONSTRAINT
Инструкция SET CONSTRAINT определяет для текущей транзакции, будут ли откла-
дываемые проверки ограничений выполняться после каждой инструкции DML или
после полного завершения транзакции. Если в сеансе в данный момент нет открытых
транзакций, то инструкция применяется к следующей транзакции.
Платформа Команда
DB2 Не поддерживается
MySQL Не поддерживается
Oracle Поддерживается с вариантами
546 | Глава 3. Справочник по инструкциям SQL
Платформа Команда
PostgrcSQL Поддерживается с вариантами
SQL Server Нс поддерживается
Синтаксис SQL2003
SET CONSTRAINT {имя_ограничения | ALL} {DEFERRED I IMMEDIATE}
Ключевые слова
{имяограничения [,...] ; ALL}
Указывается одно или несколько допускающих задержку ограничений, к которым
применяется инструкция. Ключевое слово ALL устанавливает режим для всех
ограничений текущей транзакции, допускающих задержку.
DEFERRED
Условия, указанные в ограничениях, проверяются по завершении транзакции, а не
после выполнения отдельных инструкций DML.
IMMEDIATE
Условия, указанные в ограничениях, проверяются сразу после выполнения каждой
инструкции DML, а не по завершении всей транзакции.
Общие правила
Инструкция SET CONSTRAINT определяет режим для всех допускающих задержку огра-
ничений в текущей транзакции. Если в данный момент в сеансе отсутствует транзакция,
то инструкция SET CONSTRAINT применяется к следующей транзакции, которая будет
выполняться в сеансе.
В следующем примере устанавливается, что все допускающие задержку транзакции
будут выполняться немедленно после подачи каждой инструкции DML.
SET CONSTRAINT AuL IMMEDIATE;
В следующем примере выполнение двух ограничений и модификация ими данных
откладывается до конца транзакции.
SET CONSTRAINT scott.hr_job_title, scott.enp_bonus DEFERRED:
Советы и хитрости программирования
При создании ограничений их можно определять как DEFERRABLE и NOTDEFFERABLE
(допускающие и не допускающие задержки). Инструкция SET CONSTRAINT не будет
выполнена, если вы примените ее к ограничению, определенному как NOTDEFFERABLE.
DBS
Не поддерживается.
MySQL
Не поддерживается.
Справочник по командам SQL | 547
Oracle
Платформа Oracle поддерживает стандарт ANSI в точности так, как он описан, за исключе-
нием того, что наряду с формой SET CONSTRAINT поддерживается SET CONSTRAINTS.
PostgreSQL
Платформа PostgreSQL поддерживает стандарт ANSI в точности так, как он описан.
В настоящее время PostgreSQL поддерживает SET CONSTRAINT только применительно
к ограничениям типа FOREIGN KEY, но не CHECK и не UNIQUE, которые всегда рас-
сматриваются как IMMEDIATE.
SQL Server
Не поддерживается.
Инструкция SET PATH
Инструкция SET PATH изменяет значение параметра CURRENT PATH, указывая в нем
одну или несколько схем.
Платформа Команда
DB2 Поддерживается с вариантами
MySQL Не поддерживается
Oracle Не поддерживается
PostgreSQL Не поддерживается
SQL Server Не поддерживается
Синтаксис SQLSOO3
SET PATH имя_схемы
Ключевые слова
имя_схемы
В качестве текущего пути указывается одна или несколько схем.
Общие правила
Инструкция SET РА TH указывает одну или несколько схем, которые используются для
уточнения неуточненных имен подпрограмм (т. е. функций, процедур и методов).
В следующем примере для неуточненных имен объектов устанавливается теку-
щий путь (т. е. схема) scott.
SET PATH scott;
Теперь при любом обращении к подпрограммам в текущем сеансе без указания
схемы будет подразумеваться схема scott.
548 | Глава 3. Справочник по инструкциям SQL
Советы и хитрости программирования
При указании нескольких имен схем все эти схемы должны принадлежать к текущей
базе данных. (Схемы не могут находиться в удаленной базе данных.)
Инструкция SET PATH не применяет схему к неуточненным объектам типа таблиц
и представлений. Она применима только к подпрограммам.
DBS
Платформа DB2 поддерживает несколько изменений относительно стандарта ANSI.
SET {[CURRENT] PATH | CURRENT_PATH} =
{имя_схемы | SYSTEM PATH | USER | CURRENT PATH I CURRENT,.PATH} [,...]
Где:
SET {[CURRENT] PATH | CURRENT-PATH} =
Указывается путь. Есть небольшие отличия от синтаксиса ANSI. Обратите внимание,
что знак равенства (=) является обязательным.
1шя_схемы
В качестве текущего пути указывается одна или несколько пользовательских схем.
имя_схемы может быть литералом, хост-переменпой или строковой константой.
SYSTEM PATH
В качестве текущего пути определяется системная схема SYS/BM, SYSFUN или
SYSPROC.
USER
В качестве текущего пути определяется значение специального регистра USER.
(CURRENTPATH \ CURRENTPATH}
Значение специального регистра CURRENT PATH определяется до того, как инструк-
ция SET PATH установит текущий путь.
В следующем примере в качестве текущего пути устанавливаются схема scott
и системные схемы DB2.
SE’ PATH = scott, SYSTEM PATH
MySQL
He поддерживается.
Oracle
He поддерживается.
PostgrsSQL
He поддерживается.
SQL Server
He поддерживается.
См. также
SET SCHEMA
Справочник по командам SQL | 549
Инструкция SET ROLE
Инструкция SET ROLE включает и отключает конкретные роли для текущего сеанса.
Платформа Команда
DB2 He поддерживается
MySQL He поддерживается
Oracle Поддерживается с вариантами
PostgreSQL Не поддерживается
SQL Server Не поддерживается
Синтаксис SQL2003
SET ROLE {NONE | имя__роли}
Ключевые слова
NONE
Присваивает текущему сеансу текущую роль (CURRENTROLE),
имя роли
Связывает с текущим сеансом набор привилегий, присвоенных указанной роли.
Общие правила
Если пользовательский сеанс открывается при помощи инструкции CONNECT, то вы-
полнение инструкции SET ROLE предоставляет этому сеансу привилегии, присвоен-
ные указанной роли. Команду SET ROLE можно использовать только вне транзакций.
Значение, указанное в параметре имя/юли, должно ссылаться на допустимую
роль, существующую на сервере. Имя роли можно указывать либо в виде константы,
либо в виде переменной.
Советь/ и хитрости программирования
Сеансы создаются при помощи инструкции CONNECT, тогда как роли создаются при
помощи инструкции CREATE ROLE.
В большинстве платформ существует метод назначения или изменения роли,
используемой в пользовательском сеансе. Команда SET ROLE является методом
назначения роли в ходе пользовательского сеанса стандарта ANSI, но этот метод не
очень широко поддерживается разными платформами. Обращайтесь к документации
своей платформы, чтобы найти аналогичную команду, поддерживаемую конкретным
производителем.
DB2
Не поддерживается. Платформа DB2 пока не поддерживает и роли.
550 | Глава 3. Справочник по инструкциям SQL
MySQL
Команда SET ROLE не поддерживается. Аналогичный метод управления параметрами
соединения в MySQL настраивается в разделе [client] конфигурационного файла
.ту.сп/в директории home. Например:
[client]
host=server_name
user=user_name
password=client_password
Чтобы быстро переключаться между ролями, вы можете переназначить свойства
host, user и password при помощи присвоения новых значений переменным
MYSQL HOST, USER (только для Windows) и MYSQL_PWD соответственно (метод
с использованием MYSQL_PWD является небезопасным, поскольку другие пользова-
тели могут просматривать этот файл).
Oracle
Когда пользователь инициирует соединение, Oracle явным образом назначает этому
пользователю роли. Роль (роли), с использованием которой работает сеанс, можно из-
менить при помощи команды SET ROLE, если только пользователь имеет соответст-
вующие права доступа. В Oracle используется инициализационный параметр
ENABLEDROLES (файл INIT.ORA), который контролирует максимальное число
ролей, которые могут использоваться одновременно. Синтаксис данной инструкции
в Oracle следующий.
SEI HOLE { имя__роли [IDENTIFIED BY пароль] [,...]
| [А'Л [EXCEPT имя_роли [,...]]
; NONE } ,
Опции команды SET ROLE следующие.
имя роли
Указывается допустимое имя уже существующей роли, права которой будут при-
своены пользователю. Неуказанные роли будут недоступны для текущего сеанса.
Вы можете указать несколько ролей, разделяя их запятыми.
IDENTIFIED В Y пароль
Если у данной роли есть пароль, то с помощью этого предложения можно указать его.
ALL
Включаются все роли, присвоенные текущему пользователю, в том числе те, которые
присвоены через другие роли. Это предложение нельзя использовать с предложением
IDENTIFIED BY.
EXCEPT
Указывается список ролей, которые исключаются из команды SET ROLE ALL.
NONE
Отключаются все роли, в том числе роль по умолчанию.
Справочник по командам SQL | 551
Доступ к ролям, которые имеют пароли, осуществляется только при помощи инструк-
ции SET право имя_роли IDENTIFIED BY пароль. Для примера назначим текущему
сеансу роли read_only и updater с паролями editor и red_marker соответственно.
SET ROLE
read_only IDENTIFIED BY editor,
updater IDENTIFIED BY red_marker;
Чтобы включить все роли, за исключением роли read_write, используется следующая
инструкция.
SET ROLE ALL EXCEPT read_write;
PostgreSQL
Инструкция SET ROLE не поддерживается. Однако поддерживается команда ANSI
SQL SET SESSION AUTHORIZATION, с помощью которой можно получить сходные
результаты.
SQL Server
Не поддерживается.
См. также
CONNECT
DISCONNECT
SET SESSION AUTHORIZATION
Инструкция SET SCHEMA
Инструкция SET SCHEMA изменяет значение параметра CURRENT SCHEMA на указан-
ную пользователем схему.
Платформа Команда
DB2 Поддерживается с вариантами
MySQL Не поддерживается
Oracle Не поддерживается
PostgreSQL Не поддерживается
SQL Server Не поддерживается
Синтаксис SQLSOO3
SET SCHEMA имя_схемы
Ключевые слова
имя_схемы [,...]
В качестве текущего пути указывается одна или несколько схем.
552 | Глава 3. Справочник по инструкциям SQL
Общие правила
Инструкция SET SCHEMA указывает пользовательскую схему, которая будет исполь-
зоваться для уточнения неуточненных имен объектов, таких, как таблицы и представ-
ления.
В следующем примере текущей схемой для неуточненных объектов становится
схема scott.
SET SCHEMA scott;
Теперь, если в текущем сеансе встретится ссылка на объект без указания схемы,
будет подразумеваться, что он относится к схеме scott.
Советы и хитрости программирования
В инструкции SET SCHEMA нельзя указывать схему, находящуюся на удаленной базе
данных.
Инструкция SET SCHEMA не применяется к неуточненным именам подпрограмм
(т. е. функций, процедур и методов). Она применяется только к объектам базы данных,
таким, как таблицы и представления.
DB2
Платформа DB2 поддерживает несколько изменений относительно стандарта ANSI.
SET [CJRHEN'tj SCHEMA = {имя_схемы : USER К,
Где:
SET [CURRENT] SCHEMA
Указывается путь, с небольшими синтаксическими отличиями от стандарта ANSI.
Обратите внимание, что знак равенства (=) является обязательным.
имя_схемы
Указывается имя пользовательской схемы, длиной не более 30 байт, которая будет
использоваться в качестве текущей. Имя схемы может быть литералом, хост-пере-
менной или строковой константой.
USER
В качестве текущего пути указывается значение специального регистра USER.
Во всех прочих отношениях реализация DB2 соответствует стандарту ANSI.
MySQL
Не поддерживается.
Oracle
Не поддерживается.
PostgreSQL
Не поддерживается.
Справочник по командам SQL | 553
SQL Server
He поддерживается.
См. также
SET PATH
Инструкция SET SESSION AUTHORIZATION
Инструкция SET SESSION AUTHORIZATION устанавливает для текущего сеанса иден-
тификатор пользователя.
Платформа Команда
DB2 He поддерживается
MySQL He поддерживается
Oracle He поддерживается
PostgreSQL Поддерживается
SQL Server He поддерживается
Синтаксис SQL2003
SET SESSION AUTHORIZATION имя_пользователя
Ключевые слова
имя пользователя
Для пользователя сеанса и текущего пользователя сеанса SQL устанавливается
контекст, соответствующий имени_пояьзователя. Это имя можно указать в форме литерала,
параметра или хост-переменной.
Общие правила
Эта команда позволяет переключаться между пользователями и работать от их имени.
Советы и хитрости программирования
Некоторые платформы позволяют использовать специальные ключевые слова, такие, как
SESSION USER и CURRENT USER. Обычно SESSION USER и CURRENT USER - это одно
и то же, т. е. имя пользователя активного в данный момент сеанса, указанное в клиенте.
Однако SESSION USER и CURRENT USER могут быть и различными, если используются
такие функции, как SETUID, и другие сходные механизмы.
Для вызова этой команды требуются привилегии суперпользователя, но вы будете
иметь возможность вернуться к исходному пользовательскому сеансу, даже если
права текущего пользовательского сеанса не позволяют запускать команду SET SES-
SION A UTHIORIZA TION.
Также вам может понадобиться проверить значение функций SESSION USER
и CURRENT USER. Для этого используется следующая инструкция SQL.
SELECT SESSION_USER, CURRENTJJSER;
554 | Глава 3. Справочник по инструкциям SQL
Как правило, команду SET SESSION AUTHIORIZATION следует подавать до выполне-
ния транзакций, чтобы установить текущего пользователя и текущий сеанс для всех после-
дующих транзакций. Эту команду следует выполнять как единственную в транзакционном
пакете.
DB2
Не поддерживается. Сходные результаты можно получить при помощи инструкции
CONNECT или путем отсоединения от сервера и повторного соединения с ним.
MySQL
Не поддерживается. Чтобы использовать другой набор пользовательских привилегий,
вы должны отсоединиться от сервера MySQL, а затем соединиться с ним вновь.
Oracle
Не поддерживается. Сходных результатов можно добиться, используя инструкцию
CONNECT или отключившись и вновь подключившись к серверу.
PostgreSQL
Платформа PostgreSQL поддерживает для этой команды стандарт ANSI. Единствен-
ным отличием, к тому же незначительным, является то, что стандарт ANSI не позво-
ляет использовать эту команду в ходе транзакции, a PostgreSQL не принимает это во
внимание.
SQL Server
Не поддерживается. Сходные результаты можно получить, используя инструкцию
CONNECT или отключившись и вновь подключившись к серверу.
См. также
CONNECT
GRANT
SESSION USER
Инструкция SET TIME ZONE
Инструкция SET TIME ZONE изменяет часовой пояс для текущего сеанса, если нужно,
чтобы он отличался от заданного по умолчанию.
Платформа Команда
DB2 He поддерживается
MySQL He поддерживается
Oracle Поддерживается с вариантами
PostgreSQL Поддерживается с ограничениями
SQL Server Не поддерживается
Справочник по командам SQL | 555
Синтаксис SQL2003
SET TIME ZONE {LOCAL | INTERVAL {+ | -} '00:00' [HOUR TO MINUTE]}
Ключевые слова
LOCAL
Часовой пояс текущего сеанса устанавливается равным часовому поясу локального
сервера.
INTERVAL
Устанавливается величина прироста (знак +) или уменьшения (знак - ) относи-
тельно времени, заданного по умолчанию.
INTERVAL
Указывается сдвиг часового пояса относительно Всеобщего скоординированного
времени (UTC) в часах и минутах.
HOUR ТО MINUTE
Указывается тип данных для значения TIME ZONE.
Общие правила
Эта достаточно простая команда устанавливает часовой пояс текущего пользователь-
ского сеанса равным часовому поясу сервера (LOCAL) или определяет его относитель-
но Всеобщего скоординированного времени (Coordinated Universal Time, UTC)
(которое ранее называлось Гринвичским временем - GMT). Таким образом, значение
параметра INTERVAL, равное 2, означает, что часовой пояс устанавливается на два
часа после UTC, а значение, равное -6, означает, что часовой пояс устанавливается на
6 часов до UTC (соответствует часовому поясу центральной части США).
Советы и хитрости программирования
Как и большинство других команд SET, инструкцию SET TIME ZONE можно выполнять
только вне явной транзакции. Иными словами, не нужно заключать команду в инструк-
ции START или BEGIN TRAN и COMMIT TRAN.
DB2
Не поддерживается.
MySQL
Не поддерживается.
Oracle
В Oracle9i и выше вы можете использовать для изменения часового пояса следующий
вариант команды ALTER SESSION.
ALTER SESSION
SET TIME_Z0NE = {'[+ | -] hh:mm'
I LOCAL
| DBTIMEZONE
| 'регион'}
556 | Глава 3. Справочник по инструкциям SQL
Чтобы вернуться к исходному, заданному по умолчанию часовому поясу своего сеанса,
используйте ключевое слово LOCAL. Чтобы сделать ваш часовой пояс часовым поясом
базы данных, используйте ключевое слово DBTIMEZONE. Параметр 'регион' используется
для указания регионального часового пояса, например EST или PST1. Чтобы указать сдвиг
часового пояса в часах и минутах относительно Всеобщего скоординированного времени,
используйте конструкцию типа '-5:00'. Значение '-5:00' означает, что ваше время на 5 часов
ранее Всеобщего скоординированного времени (например, 5:00 у вас - 10:00 - UTC).
Чтобы получить список допустимых имен регионов, используйте следующий запрос.
SELECT tzname FROM v$timezone_names;
Обе приведенные ниже команды устанавливают часовой пояс в Восточное стан-
дартное время. Первая команда добивается этого путем указания сдвига от Всеобщего
скоординированного времени, а вторая - путем указания региона.
ALTER SESSION SET TIME_ZONE = '-5:00':
ALLER SESSION SET TIME_ZONE = 'EST';
Поддержка часовых поясов в Oracle достаточно сложна. В книге Steven Feuerstein
«Oracle PL/SQL Programming» (O'Reilly), в главе о типах данных дата-время, приво-
дится хорошее объяснение.
PostgreSQL
Платформа PostgreSQL позволяет установить часовой пояс сеанса равным заданному по
умолчанию часовому поясу сервера, для чего используются взаимозаменяемые команды
LOCAL и DEFAULT.
SET TIME ZONE {'часовой_пояс’ | LOCAL | DEFAULT };
Существует несколько отличий от стандарта ANSI.
’часовоипояс’
Указывается название часового пояса. Список допустимых значений зависит от
операционной системы. Например, для Linux-серверов база данных часовых
поясов содержится в файле /usr/share/zoneinfo.
LOCAL | DEFAULT
Время текущего сеанса устанавливается в соответствии с принятым по умолча-
нию часовым поясом локального сервера.
Например, ‘PST8PDT’ - это часовой пояс Калифорнии в системах Linux, a ‘Europe/
Rome’ - часовой пояс Италии в системах Linux и других системах. Если вы введете недо-
пустимое значение часового пояса, будет установлен часовой пояс UTC.
Если часовой пояс сдвигается в положительную сторону от UTC, знак «+» является
обязательным. Если вы введете недопустимое значение часового пояса, будет установлен
часовой пояс UTC.
EST- Восточное стандартное время (Атлантическое побережье США); PST - Стандартное
тихоокеанское время (Тихоокеанское побережье США )-Примеч. пер.
Справочник по командам SQL | 557
В следующем примере в качестве часового пояса PostgreSQL устанавливается
Тихоокеанское стандартное время.
SET TIME ZONE 'PST8PDT';
А теперь время текущего сеанса возвращается к часовому поясу, установленному
для сервера по умолчанию.
SET TIME ZONE LOCAL;
SQL Server
He поддерживается.
Инструкция SET TRANSACTION
Инструкция SET TRANSACTION управляет многими характеристиками процесса
модификации данных, и в первую очередь параметрами чтения/записи и уровнем изо-
ляции транзакции.
Платформа Команда
DB2 He поддерживается
MySQL Поддерживается с вариантами
Oracle Поддерживается с ограничениями
PostgreSQL Поддерживается
SQL Server Поддерживается с вариантами
Синтаксис SQL2003
SET [LOCAL]-TRANSACTION [READ ONLY | READ WRITE]
[ISOLATION LEVEL {READ COMMITTED | READ UNCOMMITTED |
REPEATABLE READ | SERIALIZABLE}
[DIAGNOSTIC SIZE int]
Ключевые слова
LOCAL
Параметры транзакции изменяются для текущего сеанса на локальном сервере,
и только на локальном сервере. Если предложение не указано, то изменяются
параметры следующей транзакции, даже если транзакция выполняется на удален-
ном сервере.
READ ONLY
Следующая выполняемая транзакция будет транзакцией только-для-чтения.
По завершении этой транзакции параметры вернутся к состоянию, принятому
по умолчанию.
READ WRITE
Следующая выполняемая транзакция будет иметь возможность читать и записы-
вать данные.
558 | Глава 3. Справочник по инструкциям SQL
ISOLATION LEVEL
Устанавливается уровень изоляции для следующей транзакции сеанса.
READ COMMITED
Транзакция может читать записи, созданные другими транзакциями, только
после их фиксирования.
READ UNCOMMITTED
Транзакция может читать те записи, которые были созданы другими транзак-
циями, но еще не зафиксированы.
REPEATABLE READ
Все сеансы имеют возможность видеть записи, зафиксированные до того, как
начнется их первая транзакция. Другие открытые сеансы могут видеть или изме-
нять только записи, зафиксированные в текущем пользовательском сеансе до того,
как начнется их первая транзакция. Соответственно более поздние транзакции
могут добавлять записи, которые могут стагь видимыми для транзакций более
ранних сеансов, но другим сеансам для отображения этих записей будет нужно
выполнить запрос заново.
SERIALIZABLE
Все сеансы могут видеть записи, зафиксированные до того, как начнется их
транзакция. Другие открытые сеансы могут видеть, но не могут вставлять или
обновлять записи в других пользовательских сеансах до того, пока транзакция
не будет завершена. Этот уровень изоляции является наиболее ограничи-
* вающим, Я он установлен по умолчанию в стандарте SQL2003.
DIAGNOSTIC SIZE int
Указывается количество сообщений об ошибках (int), которые будут регистриро-
ваться для транзакции. Инструкция GET DIAGNOSTICS позволяет получить эти
сообщения об ошибках.
Общие правила
При выполнении команды SET TRANSACTION устанавливаются параметры выполне-
ния следующей транзакции. Поэтому SET TRANSACTION - это временная инструк-
ция, которую следует использовать после завершения одной и перед началом другой
транзакции. (Чтобы запустить транзакцию, указав при этом ее характеристики,
используйте инструкцию START TRANSACTION.) В этой команде можно указать сразу
несколько опций, но только один режим доступа, уровень изоляции и размер диагно-
стики.
Уровень изоляции транзакции показывает, в какой степени транзакция изолирова-
на от других, одновременно выполняющихся сеансов. Уровень изоляции определяет:
• будут ли строки, которые читает или обновляет ваш сеанс, доступны для других,
одновременно выполняемых в базе данных сеансов;
• будут ли действия по обновлению, чтению и записи, выполняемые другими сеан-
сами в базе, затрагивать ваш сеанс.
Справочник по командам SQL [ 559
Если вы не знакомы с уровнями изоляции, обязательно прочитайте подраздел
«Синтаксис SQL2003» в разделе «Инструкция SET TRANSACTION», поскольку объ-
яснения уровней изоляции приводятся только в этом подразделе.
Советы и хитрости программирования
С предложением ISOLATION LEVEL связано несколько функций и аномалий, которые
касаются одновременно выполняемых транзакций, и в частности следующие.
Грязное чтение
Происходит, если транзакция читает записи, измененные другой транзакцией до
завершения этой транзакции. Это позволяет вносить изменения в данные, которые
могут быть еще не зафиксированы в базе данных.
Невоспроизводимое чтение
Происходит, если одна транзакция читает запись в то время, когда другая изменя-
ет ее. Таким образом, если первая транзакция попробует прочитать запись снова,
она не сможет найти ее.
Фантомные записи
Возникают, когда транзакция А читает группу записей, а транзакция В добавляет или
изменяет данные таким образом, что запросу, выполняемому транзакцией А, начина-
ет соответствовать больше записей. Таким образом, транзакция А может прочитать
записи транзакции В, как если бы они были зафиксированы в базе данных, хотя на
самом деле еще возможен их откат. Поскольку транзакция А читает записи, которые
еще не являются постоянными, эти записи называются фантомными.
В табл. 3.5 показано влияние различных уровней изоляции на перечисленные ано-
малии.
Таблица 3.5. Уровни изоляции и влияние на аномалии
Уровень изоляции Грязное чтение Невоспроизводимое чтение Фантомные записи
READ UNCOMMITTED Допускается Допускается Допускается
READ COMMITTED Не допускается Допускается Допускается
REPEATABLE READ Не допускается Не допускается * Допускается
SERIALIZABLE Не допускается Не допускается Не допускается
DB2
Не поддерживается. Платформа DB2 поддерживает все уровни изоляции, но не через
использование инструкции SET TRANSACTION. Управление уровнями изоляции осуще-
ствляется при помощи процесса подготовки программы и параметров сервера, настраи-
ваемых администратором базы.
Хотя платформа DB2 поддерживает уровни изоляции стандарта ANSI, они здесь
называются по-другому. Платформа DB2 также позволяет пользователям определять
уровень изоляции для отдельных инструкций, включая SELECT, DELETE, INSERT
и UPDATE. В DB2 используются следующие названия уровней изоляции.
560 | Глава 3. Справочник по инструкциям SQL
cs
Уровень изоляции Cursor Stability (стабильность курсора) (serializable).
NC
Уровень изоляции No Commit (без фиксации). (Не поддерживается DB2.)
RR
Уровень изоляции Repeatable Read (воспроизводимое чтение).
RS
Уровень изоляции Read Stability (стабильность чтения) (READ COMMITED).
UR
Уровень изоляции Uncommited Read (нефиксированное чтение) (READ UNCOM-
MITTED).
Платформа DB2 также поддерживает две инструкции - CHANGE ISOLATION
LEVEL и SET CURRENT ISOLATION, которые изменяют способ изоляции данных от
других процессов при доступе к базе данных.
MySQL
Платформа MySQL позволяет устанавливать уровень изоляции для следующей отдель-
ной транзакции, для всего сеанса или глобально, для всего сервера. Делается это при
помощи следующего синтаксиса.
SET [GLOBAL I SESSION] TRANSACTION ISOLATION LEVEL
[READ UNCOMMITTED |READ COMMITTED | REPEATABLE READ
I SERIALIZABLE]
По умолчанию MySQL устанавливает уровень изоляции для той транзакции,
которая следует непосредственно за инструкцией.
GLOBAL
Устанавливается уровень изоляции для всех последующих транзакций во всех
пользовательских сеансах и системных процессах.
SESSION
Устанавливается уровень изоляции для всех последующих транзакций текущего
сеанса.
TRANSACTION ISOLATION LEVEL
Устанавливается указанный уровень изоляции транзакций, как это описывалось
ранее в разделе «Инструкция SET TRANSACTION».
Если данная инструкция опущена, по умолчанию используется уровень REPEATABLE
READ.
Для установки уровня изоляции GLOBAL требуется привилегия SUPER. Вы можете
также устанавливать принимаемый по умолчанию уровень изоляции при помощи пере-
ключателя в командной строке исполняемого файла MYSQL (-transaction-isolation^").
Ниже приводится пример, в котором для всех последующих процессов, как пользова-
тельских, так и системных, устанавливается уровень изоляции SERIALIZABLE.
SET GLOBAL TRANSACTION ISOLATION LEVEL SERIALIZABLE;
ЗД-.М47
Справочник по командам SQL | 561
Oracle
Платформа Oracle позволяет перевести транзакцию в режим только-для-чтения,
режим для-чтения-записи, установить уровень изоляции транзакции или указать сег-
мент отката для транзакций.
SET TRANSACTION { [ READ ONLY | READ WRITE ]
| [ ISOLATION LEVEL { READ COMMITTED | SERIALIZABLE} ]
| [ USE ROLLBACK SEGMENT имя_сегмента ]
| NAME 'имя_транзакции'};
Где:
READ ONLY
Следующая транзакция становится транзакцией для чтения с уровнем изоляции
SERIALIZABLE. Это предложение недоступно для пользователя SYS. В сеансах
READ ONLY можно использовать только следующие инструкции: SELECT, ALTER
SESSION ALTER SYSTEM, LOCK TABLE и SET ROLE.
READ WRITE
Тип транзакций по умолчанию в Oracle. Транзакции могут читать и записывать
данные.
READ COMMITTED
Уровень изоляции по умолчанию в Oracle. Соответствует стандарту ANSI.
SERIALIZABLE
Уровень изоляции транзакций, соответствующий стандарту ANSI. Необходимое
условие - инициализационный параметр COMPATIBLE должен быть установлен
в значение 7.3.0 или выше.
USE ROLLBACK SEGMENT имя_сегмента
Указывается, что следующая транзакция, связанная с чтением-записью, будет
записываться в указанный сегмент отката Oracle. Поскольку это предложение при-
менимо только к текущей транзакции, оно должно быть первым предложением
транзакции. Это предложение несовместимо с предложением READ ONLY.
Сегмент отката должен существовать, в противном случае возникнет ошибка.
NAME
Текущей транзакции присваивается имя, длина которого не должна превышать
255 символов. Это предложение полезно в распределенных средах обработки
транзакций, для двухфазной фиксации, поскольку оно позволяет легко опреде-
лить, какие локальные транзакции принадлежат к одной распределенной транзак-
ции.
Вариант USE ROLLBACK SEGMENT можно использовать для регулировки произ-
водительности, направляя долго выполняющиеся транзакции в сегменты отката,
которые имеют достаточно большой размер, чтобы хранить эти данные, а небольшие
транзакции - в небольшие сегменты отката, которые достаточно малы, чтобы хранить
их в кеше.
562 | Глава 3. Справочник по инструкциям SQL
Инструкция SET TRANSACTION должна быть первой в любом пакете SQL, хотя
Oracle, по сути, рассматривает ее как аналог инструкции START TRANSACTION. Так
что вы можете заменять одну инструкцию на другую.
В следующем примере процесс, выполняемый раз в две недели на сервере Chicago,
создает отчет, и на него не оказывают влияния другие пользователи, которые могут
вставлять или обновлять записи.
SET TRANSACTION READ ONLY NAME 'Chicago';
SELECT prod_id, ord^qty
FROM sales
WHERE stor_id = 5;
В следующем примере пакетная обработка, выполняемая поздно ночью, представ-
ляет собой огромную транзакцию, которая переполнила бы любой сегмент отката,
кроме того, который был специально выделен для нее.
SET TRANSACTION USE ROLLBACK SEGMENT huge.tran_01;
PostgreSQL
Инструкция SEI" TRANSACTION в PostgreSQL влияет только на новую, запускаемую
транзакцию. Следовательно, эту инструкцию вам, возможно, понадобится выполнять
перед каждой новой транзакцией. Синтаксис следующий.
SET TRANSACTION ISOLATION LEVEL {READ COMMITTED | SERIALIZABLE};
Где:
READ COMMITTED
Уровень изоляции транзакции устанавливается в READ COMMITTED (соответствует
стандарту ANSI). Этот уровень принимается по умолчанию.
SERIALIZABLE
Уровень изоляции транзакции устанавливается в SERIALIZABLE (соответствует
стандарту ANSI).
По умолчанию PostgreSQL использует уровень изоляции READ COMMITTED.
Вы можете установить используемый по умолчанию уровень изоляции для всех тран-
закций сеанса с помощью любой из приведенных ниже команд.
SET SESSION CHARACTERISTICS AS TRANSACTION ISOLATION LEVEL
{ READ COMMITTED | SERIALIZABLE }
SET default_transaction_isolation =
{ 'read committed' | 'serializable' }
Конечно, вы можете заменить уровень изоляции для любой последующей тран-
закции, используя инструкцию SET TRANSACTION.
Например, вы можете установить для следующей транзакции уровень изоляции
SERIALIZABLE.
SET TRANSACTION ISOLATION LEVEL SERIALIZABLE;
Справочник по командам SQL | 563
Кроме того, вы можете установить уровень SERIALIZABLE для всех транзакций
всего сеанса.
SET SESSION CHARACTERISTICS AS TRANSACTION
ISOLATION LEVEL SERIALIZABLE;
SQL Server
Инструкция SET TRANSACTION в SQL Server устанавливает уровень изоляции для
всего сеанса. Все запросы, которые идут после инструкции SET TRANSACTION, будут
использовать уровень изоляции, указанный в этой инструкции, до тех пор, пока он не
будет изменен.
SET TRANSACTION ISOLATION LEVEL
{ READ COMMITTED
| READ UNCOMMITTED
| REPEATABLE READ
| SERIALIZABLE}
Где:
READ COMMITTED
Уровень изоляции транзакции устанавливается в READ COMMITTED (соответствует
стандарту ANSI). Этот уровень принимается по умолчанию.
READ UNCOMMITTED
Уровень изоляции транзакции устанавливается в READ UNCOMMITTED (соответ-
ствует стандарту ANSI). Эффект аналогичен действию подсказки оптимизатору
NOLOCK.
REPEATABLE READ
Уровень изоляции транзакции устанавливается в REPEATABLE READ (соответст-
вует стандарту ANSI).
SERIALIZABLE
Уровень изоляции транзакции устанавливается в SERIALIZABLE (соответствует
стандарту ANSI). Сходные результаты можно получить с помощью подсказки опти-
мизатору HOLDLOCK.
Например, следующая команда понижает уровень изоляции транзакций для всех
инструкций SELECT сеанса с READ COMMITED до REPEATABLE READ.
SET TRANSACTION ISOLATION LEVEL REPEATABLE READ
GO
См. также
COMMIT
ROLLBACK
564 | Глава 3. Справочник по инструкциям SQL
Инструкция START TRANSACTION
Инструкция START TRANSACTION позволяет использовать все возможности инструкции
SET TRANSACTION и, кроме того, запустить новую транзакцию.
Платформа Команда
DB2 I le поддерживается
MySQL Поддерживается с ограничениями
Oracle 11е поддерживается
PostgreSQL Не поддерживается. См. BEGIN TRAN ниже
SQL Server Не поддерживается. См. BEGIN TRAN ниже
Синтаксис SQL3003
START TRANSACTION [READ ONLY | READ WRITE]
[ISOLATION LEVEL {READ COMMITTED 1 READ UNCOMMITTED I
REPEATABLE READ | SERIALIZABLE}
[DIAGNOSTIC SIZE mt]
Согласно стандарту ANSI единственное отличие между инструкциями SET и START
состоит в том, что SET используется все текущей транзакции, a START считается нача-
лом новой транзакции. Таким образом, параметры SET TRANSACTION применяются
к следующей транзакции, а параметры S7ART TRANSACTION применяются к текущей
транзакции.
Инструкцию START TRANSACTION поддерживает только MySQL, и три произво-
дителя (MySQL, PostgreSQL и SQL Server) поддерживают сходную команду BEGIN
[TRANSACTION]] и ее синоним BEGIN [WORK], Инструкция BEGIN TRANSACTION
объявляет явную транзакцию, но не указывает уровни изоляции.
Общие правила
Единственное существенное правило использования инструкции START TRANSACTION
состоит в том, что вы должны использовать эту инструкцию для управления режимом дос-
тупа, уровнем изоляции или объемом диагностической информации для текущей транзак-
ции. Как только запускается новая транзакция, вы должны либо указывать новые значения
параметров, либо использовать заданные по умолчанию.
Большинство платформ позволяют неявным образом управлять транзакциями, для
чего используется то, что называется режимом автоматической фиксации (autocommit
mode). В этом режиме база данных рассматривает каждую инструкцию как отдельную
транзакцию, с неявными инструкциями BEGIN TRAN и COMMIT TRAN.
Альтернативой режиму автоматической фиксации является явное ручное управле-
ние каждой транзакцией. При явном управлении вы объявляете каждую новую транзак-
цию при помощи инструкции START TRANSACTION. Новая транзакция также может
быть запушена неявно при каждом запуске инициирующей транзакцию инструкции,
такой, как INSERT, UPDATE, DELETE или SELECT. Транзакция не будет фиксироваться
Справочник по командам SQL | 565
или откатываться до тех пор, пока не будет явно выполнена инструкция COMMIT или
ROLLBACK.
Некоторые платформы, а именно DB2 и Oracle, не поддерживают явное объявле-
ние новой транзакции при помощи инструкции START TRANSACTION, но они под-
держивают явную фиксацию, создание точки сохранения и откат транзакции. Другие
платформы, такие, как MySQL, PostgreSQL и SQL Server, разрешают как явное объяв-
ление транзакции при помощи инструкции START TRANSACTION, так и явную фикса-
цию, создание точки сохранения и откат транзакции.
Советы и хитрости программирования
Многие платформы, описываемые в этой книге, по умолчанию работают в режиме
автоматической фиксации. Следовательно, хорошей практикой является использование
явного объявления транзакций только в том случае, если вы применяете этот метод во
всех транзакциях сеанса. Иными словами, не смешивайте неявно и явно объявленные
транзакции в одном сеансе. Каждая явно объявленная транзакция будет зафиксирована
только после выполнения инструкции COMMIT. Точно так же транзакция, завершив-
шаяся неудачно, или та, которая должна быть отменена, должна отменяться явно, при
помощи инструкции ROLLBACK.
Инструкцию START используйте только в nape с COMMIT или ROLLBACK.
Иначе СУБД может не завершить транзакцию до тех пор, пока не встре-
тит инструкцию COMMIT или ROLLBACK. Отсутствие необходимых
инструкций COMMIT (и ROLLBACK) может привести к огромным, плохо
спланированным транзакциям.
Хорошей практикой является использование явных инструкций COMMIT
и ROLLBACK после одной или небольшого числа инструкций, поскольку долго выпол-
няющиеся транзакции могут блокировать ресурсы, не давая доступа к ним другим
пользователям. И не забывайте о фиксации (или откате)! Долго выполняющиеся или
объемные транзакционные пакеты могут переполнить сегменты отката или журналы
транзакций базы данных, особенно если файлы имеют небольшой размер.
DBS
Не поддерживается. Транзакции в DB2 запускаются неявно.
MySQL
Платформа MySQL обычно работает в режиме автоматической фиксации. Это означа-
ет, что изменения записываются на диск автоматически по их завершении. Если по
какой-то причине изменение внести не удается, происходит автоматический откат.
Платформа MySQL поддерживает инструкцию START TRANSACTION, но она
является просто синонимом инструкции BEGIN. Вы можете отложить автоматическую
фиксацию для одной или нескольких инструкций, используя следующий синтаксис
инструкции BEGIN.
566 | Глава 3. Справочник по инструкциям SQL
BEGIN [WORK]
Где:
BEGIN
Обозначает начало одной или нескольких транзакций.
WORK
Дополнительное ключевое слово, не несущее функциональной нагрузки.
Выполнение следующей команды позволяет отключить режим автоматической
фиксации для всех сеансов и процессов.
SET AUTOCOMMIT=O
Как только вы отключили автоматическую фиксацию, для записи любых модифи-
каций на диск становится необходимой инструкция COMMIT, а для отмены внесен-
ных изменений становится необходимой инструкция ROLLBACK. Отключение
режима автоматической фиксации работает только для «таблиц с безопасной транзак-
цией» (transaction-safe tables), таких, как таблицы InnoDB и BDB. Отключение этого
режима в прочих таблицах никакого эффекта не оказывает. Режим остается включен-
ным.
| В ранних версиях MySQL использовался журнал обновлений. Однако журнал
обновлений не поддерживает транзакции ANSI, если только таблицы не
------определены как InnoDB или BDB.
Транзакции сохраняются в двоичном формате в журнале, для чего используется
одна операция записи при выполнении инструкции COMMIT. Ниже приводится пример.
BEGIN:
SELECT @А := SUM(salary)
FROM employee
WHERE type=1;
UPDATE payhistory SET summmary=@A WHERE type=1;
COMMIT;
Откат, выполненный в нетранзакционной таблице, вызывает ошибку
ERWARNINGNOTCOMPLETEROLLBACK, а откат в таблице с безопасными
транзакциями выполняется нормально.
Oracle
Не поддерживается. Транзакции в Oracle запускаются неявно. За дополнительными
сведениями о том, как в Oracle осуществляется управление отдельными транзакциями,
обращайтесь к подразделу Oracle раздела об инструкции SET TRANSACTION.
PostgreSQL
Синтаксис данной инструкции в PostgreSQL следующий.
BEGIN Г WORK | TRANSACTION ]
Справочник по командам SQL | 567
Где:
BEGIN
Обозначает начало одной или нескольких транзакций.
WORK
Дополнительное ключевое слово, не несущее функциональной нагрузки.
TRANSACTION
Дополнительное ключевое слово, не несущее функциональной нагрузки.
Обычно PostgreSQL работает в режиме автоматической фиксации, когда каждая
инструкция по модификации данных или запрос представляет собой отдельную тран-
закцию. Платформа PostgreSQL неявно выполняет инструкцию COMMIT в транзакции,
которая завершается без ошибок. Если при выполнении транзакции возникает ошибка,
то PostgreSQL автоматически выполняет инструкцию ROLLBACK. Инструкция BEGIN
позволяет явно зафиксировать или откатить транзакцию, которая может состоять из не-
скольких инструкций.
Транзакции, обозначенные вручную, в PostgreSQL работают гораздо быстрее транзак-
ций с автоматической фиксацией. Чтобы обеспечить изоляцию транзакции, нужно устано-
вить уровень SERIALIZABLE с помощью инструкции SET TRANSACTION ISOLATION
LEVEL. Платформа PostgreSQL позволяет использовать в блоке BEGIN...СОММIT не-
сколько инструкций по модификации данных (INSERT, UPDATE, DELETE). Однако при
выполнении команды COMMIT выполняется или не выполняется вся такая транзакция.
Команда BEGIN имеет еще один способ применения на тех платформах,
которые поддерживают собственный процедурный язык, т. е. в Oracle
и SQL Server. На этих платформах команда BEGIN без ключевого слова
TRANSACTION используется для обозначения нового блока процедурного
кода. Поэтому для транзакций в PostgreSQL рекомендуется использовать
ключевое слово TRANSACTION, поскольку иначе вы столкнетесь со слож-
ными проблемами переносимости, если вдруг захотите перенести свой код
в Oracle или SQL Server.
Ниже приводится пример инструкции BEGIN TRANSACTION в PostgreSQL.
BEGIN TRANSACTION;
INSERT INTO jobs(job_id, job_desc, min„lvl, max_lvl)
VALUES(15, 'Chief Operating Officer', 185, 135)
COMMIT;
SQL Server
Платформа Microsoft SQL Server поддерживает вместо инструкции START TRANSACTION
стандарта ANSI инструкцию BEGIN TRANSACTION. Также поддерживается пара расшире-
ний, которые облегчают резервное копирование и восстановление транзакций. Синтаксис
Microsoft SQL Server следующий.
568 | Глава 3. Справочник по инструкциям SQL
BEGIN TRANSACTION] [дескриптор_транзакции
[WITH MARK [ 'дескриптор^журнала ] ] ]
Где:
TRANSACTION]
Обозначает начало транзакции. Допустимы ключевые слова TRAN или TRANSACTION,
дескриптор транзакции
Имя длиной до 32 символов, используемое для идентификации транзакции. Также
может быть строковой переменной (CHAR, NCHAR, VARCHAR, NVARCHAR')
длиной до 32 символов. При работе с вложенными транзакциями имя присваива-
ется только внешней.
WITH MARK 'дескриптор_журнала'
Платформа SQL Server помещает в журнал транзакций метку с именем дескрип-
тор_журнала. Это позволяет SQL Server провести восстановление по протоколу
транзакции до указанной метки. По сути это возможность восстановления по
имени метки к состоянию на определенный момент времени для базы данных, на-
ходящейся в режиме восстановления FULL. Предложение WITH MARK должно
использоваться только с именованной транзакцией.
При использовании вложенных транзакций только внешний блок BEGIN...COMMIT
или BEGIN...ROLLBACK может ссылаться на имя транзакции (если оно есть). Как прави-
ло, мы не рекомендуем использовать вложенные транзакции.
Ниже приводится набор инструкций INSERT для SQL Server, которые все выпол-
няются в одной транзакции.
BEGIN TRANSACTION
INSERT into sales VALUES!'7896','JR3435','Oct 28 2003'.25,
'Net 60','BU7832')
INSERT INTO sales VALUES!'7901','JR3435','Oct 28 2003',17,
'Net 30', ’BU7832’)
INSERT INTO sales VALUES!'7907','JR3435'.'Oct 28 2003',6,
'Net 15','BU7832')
COMMIT
GO
Если по какой-то причине любой из этих инструкций приходится ждать своего
выполнения, это означает, что они все будут ждать, поскольку они рассматриваются
как единая транзакция.
См. также
COMMIT
ROLLBACK
Справочник по командам SQL | 569
Инструкция SUBQUERY
Подзапрос (subquery) - это вложенный запрос. Подзапросы могут встречаться в разных
частях инструкций SQL.
Платформа Команда
DB2 Поддерживается
MySQL Поддерживается с ограничениями
Oracle Поддерживается
PostgreSQL Поддерживается
SQL Server Поддерживается
В SQL поддерживаются следующие типы подзапросов.
Скалярные подзапросы
Подзапросы, извлекающие одно значение. Это наиболее широко поддерживаемый
разными платформами тип подзапросов.
Табличные подзапросы
Подзапросы, извлекающие несколько значений. Этот тип подзапросов извлекает
значения из нескольких столбцов.
Вложенные табличные подзапросы
Подзапросы, извлекающие несколько столбцов и несколько строк.
Скалярные и векторные подзапросы на некоторых платформах могут являться
частью выражения в списке отбираемых элементов инструкции SELECT, входить
в предложение WHERE и в предложение HAVING. Вложенные табличные подзапросы,
как правило, встречаются в предложениях FROM инструкций SELECT.
Коррелированный подзапрос - это подзапрос, зависящий от значения во внешнем
запросе. Следовательно, внутренний запрос выполняется по одному разу для каждой
записи, извлеченной внешним запросом. Если существует несколько уровней вложен-
ности подзапросов, коррелированный подзапрос может ссылаться на любой уровень
главного запроса, который выше его собственного уровня.
Функционирование подзапроса подчиняется разным правилам в зависимости от
того, в какое предложение он входит. Степень поддержки подзапросов в разных плат-
формах также различается. Некоторые платформы поддерживают подзапросы во всех
ранее упомянутых предложениях (SELECT, FROM, WHERE и HAVING), а другие плат-
формы - только в одном или двух из этих предложений.
Подзапросы обычно связывают с инструкцией SELECT. Поскольку подзапросы могут
находиться в предложении WHERE, их можно использовать в любой инструкции SQL,
которая поддерживает предложение WHERE, в том числе SELECT, INSERT-SELECT,
DELETE и UPDATE.
570 | Глава 3. Справочник по инструкциям SQL
Синтаксис SQL2003
Скалярные и табличные подзапросы, а также вложенные табличные подзапросы
имеют следующий общий синтаксис.
SELECT столбец1, столбец2, . . . {скалярный подзапрос)
FROM таблицаТ, ... (вложенный табличный подзапрос)
AS имя_ таблицы^ подзапроса]
WHERE: нечто = (скалярный подзапрос)
OR нечто IN (табличный подзапрос)
Коррелированные подзапросы более сложны, поскольку значения таких подзапросов
зависят от значений, извлекаемых главным запросом. Например:
SELECT columnl
FROM tablel AS t1
WHERE foo IN
(SELECT valuel
FROM table2 AS t2
WHERE t2. pk_identifier = t1.fk_identifier)
Обратите внимание, что предложение IN используется только в качестве примера.
Можно использовать любой оператор сравнения.
Ключевые слова
скалярный подзапрос
Скалярный подзапрос добавляется в список элементов инструкции SELECT или
в предложение WHERE или HAVING запроса.
вложенный табличный подзапрос
Вложенный табличный подзапрос добавляется только в предложение FROM, при
этом также используется предложение AS.
табличный подзапрос
Табличный подзапрос добавляется только в предложение WHERE с использованием
таких операторов, как IN, ANY, SOME, EXISTS или ALL, которые действуют на
несколько значений. Табличные подзапросы возвращают одну или несколько
строк, содержащих одно значение.
Общие правила
Подзапросы позволяют получить одно или несколько значений и поместить их в ин-
струкцию SELECT, INSERT, UPDATE или DELETE или в другой подзапрос. Подзапро-
сы можно использовать везде, где разрешено применение выражений. Также подза-
просы часто можно заменить инструкциями JOIN. Производительность подзапросов
может быть ниже, чем производительность инструкций JOIN (это зависит от плат-
формы).
Справочник по командам SQL | 571
»•
Подзапросы всегда заключаются в скобки.
Подзапросы могут использоваться в предложении SELECT со списком элементов,
состоящим как минимум из одного элемента, в предложении FROM для ссылки на одну
или несколько таблиц или представлений или в предложениях WHERE и HAVING.
Скалярные подзапросы могут возвращать только одно значение. Некоторые опера-
торы предложения WHERE принимают только одиночное значение (например, = <, >,
>-, <= и о (или !=)). Если подзапрос возвращает несколько значений в оператор, ко-
торый принимает только одно, то весь запрос выполняться не будет. С другой сторо-
ны, табличные подзапросы могут возвращать несколько значений, и они применяются
только в выражениях, которые принимают несколько значений, например [NOT] IN,
ANY, ALL, SOME или [NOT] EXISTS.
Вложенные табличные подзапросы могут использоваться только в предложении
FROM, и им следует присваивать псевдоним при помощи предложения AS. Резуль-
тирующий набор данных, который возвращает такой запрос, иногда называют произ-
водной таблицей (derived table), и он функционально сходен с представлением
(см. CREATE VIEW). В запросе не обязательно использовать все столбцы производной
таблицы, хотя внешний запрос может работать со всеми.
Коррелированные подзапросы обычно являются компонентами предложения
WHERE или HAVING внешнего запроса (менее распространено использование в списке
элементов инструкции SELECT), и они связаны с предложением WHERE внутреннего
запроса (т. е. подзапроса). (Коррелированные запросы также могут применяться как
вложенные табличные подзапросы, хотя такое использование менее распространено.)
Обязательно включайте предложение WHERE в подзапрос, который вычисляется на
основе связанного значения из внешнего запроса. (Это требование иллюстрируется
выше, в примере коррелированного запроса в схеме синтаксиса ANSI). Важно указывать
как во внешнем, так и во внутреннем запросе псевдоним каждой таблицы, упоминаемой
в корреляционном запросе (этот псевдоним называется корреляционным именем),
используя для этого предложение AS или другой метод. Корреляционные имена позво-
ляют избежать двусмысленности и помогают системе быстро опознать таблицы, исполь-
зуемые в запросе.
Все подзапросы, соответствующие стандарту ANSI, подчиняются следующему
краткому набору правил.
• Подзапрос не может включать в себя предложение ORDER BY.
• Подзапрос нельзя включать в агрегатную функцию. Следующий запрос является
недопустимым: SELECTfoo FROM table! WHERE sales >= AVG(SELECTcolumn!
FROM sales_table...). Обойти это ограничение можно, если выполнить агрегат
в подзапросе, а не во внешнем запросе.
572 | Глава 3. Справочник по инструкциям SQL
Советы и хитрости программирования
Платформы большинства производителей не позволяют ссылаться на большие типы
данных (например, CLOB и BLOB в Oracle и IMAGE и TEXT в SQL Server), а также на
типы-массивы (например, TABLE или CURSOR в SQL Server).
Все платформы поддерживают подзапросы, но не все производители поддержи-
вают все типы подзапросов. В табл. 3.6 показаны типы запросов, поддерживаемые
разными производителями.
Таблица 3.6. Поддержка подзапросов разными платформами
Платформа DB2 MySQL Oracle PostgreSQL SQL Server
Скалярный подзапрос в списке элементов SELECT X V
Скалярный подзапрос в предложении WHERE/ HAVING
Векторный подзапрос в предложении WHERE/ HAVING
Вложенная таблица в предложении FROM
Коррелированный подза- прос в предложении WHERE/HAVING
Подзапросы не ограничиваются только инструкциями SELECT. Их можно также
использовать в инструкциях INSERT, UPDATE и DELETE, которые содержат предложение
WHERE. Подзапросы часто применяются для следующих целей.
• Для указания строк, вставляемых в целевую таблицу с использованием инструкции
INSERT..SELECT, CREATE TABLE...SELECT ww SELECT...INTO.
• Для указания строк представления или материализованного представления в инструк-
ции CREATE VIEW.
• Для указания значений, связанных с существующими строками при помощи инструк-
ции UPDATE.
• Для указания значений для условий в предложениях WHERE и HAVING инструкций
SELECT, UPDATE и DELETE.
• Для создания представления таблицы (таблиц) «на ходу» (т. е. вложенные табличные
подзапросы).
Справочник по командам SQL | 573
Примеры
В этом разделе приводятся примеры, которые одинаково подходят для DB2, MySQL,
Oracle, PostgreSQL и SQL Server.
Ниже показан простой скалярный подзапрос в списке элементов инструкции SELECT.
SELECT job, (SELECT AVG(salary) FROM employee) AS "Avg Sal"
FROM employee
Вложенные табличные подзапросы функционально эквивалентны запросам
к представлениям. В следующем примере мы запросим во вложенном табличном под-
запросе уровень образования (edlevel) и зарплату (salary), а затем выполним агрега-
цию значений производной таблицы во внешнем запросе.
SELECT AVG(edlevel), AVG(salary)
FROM (SELECT edlevel, salary
FROM employee) AS emprand
GROUP BY edlevel
Запомните, что на некоторых платформах такой запрос может не выпол-
питься без предложения AS, в котором производной таблице присваивает-
-----ся имя.
В следующем примере показан стандартный табличный подзапрос в составе пред-
ложения WHERE. В этом случае нам нужны все номера проектов сотрудников из
департамента А00.
SELECT projno
FROM emp_act
WHERE empno IN
(SELECT empno
FROM employee
WHERE workdept = 'AGO')
Приведенный выше подзапрос выполняется во внешнем запросе только один раз.
В следующем примере мы хотим получить имена сотрудников и уровень их
старшинства. Результирующий набор получается при помощи коррелированного под-
запроса.
SELECT firstname, lastname,
(SELECT COUNTQ)
FROM employee senior
WHERE employee.hiredate > senior.hiredate) as senioritype
FROM employee
В отличие от предыдущего, этот подзапрос выполняется по одному разу для
каждой строки, извлекаемой внешним запросом. Время обработки подобных запросов
может быть довольно большим, поскольку внутренний запрос может выполняться
многократно при генерации одного результирующего набора.
574 | Глава 3. Справочник по инструкциям SQL
Коррелированные подзапросы зависят от значений, полученных внешним запро-
сом, которые должны быть получены до того, как будет обрабатываться внутренний
запрос. Такими запросами сложно овладеть, но они предоставляют уникальные про-
граммные возможности. В следующем примере мы получаем информацию о заказах
(orders), где количество проданного (quantity) меньше среднего (average) количества
других продаж товаров того же наименования (title).
SELECT s1 ord_.num, s1.title_id, st. qty
EROM sales AS s1
WHERE st.qty <
(SELECT AVG(s2.qty)
FROM sales AS s2
WHERE s2. title Jd = sl.titlejd)
Той же самой цели мы можем достигнуть, используя рефлексивное соединение
(self-join). Однако бывают ситуации, когда коррелированный подзапрос является един-
ственным способом достижения необходимого результата.
В следующем примере показано, как можно использовать коррелированный под-
запрос для обновления значений в таблице.
UPDATE course SET ends =
(SElECT min(c.begins) FROM course AS c
WHERE c.oegins BETWEEN course.begins AND course.ends)
WHERE EXISTS
(SELECT * FROM course AS c
WHERE c.begins BETWEEN course.begins AND course.ends)
Сходным образом вы можете использовать подзапросы для определения удаляе-
мых строк. В следующем примере коррелированный подзапрос используется для уда-
ления строк из одной таблицы па основе связанных строк другой таблицы.
DELETE FROM course
WHERE EXISTS
(SELECT * FROM course AS c
WHERE course.id > c.id
AND (course.begins BETWEEN c.begins
AND c.ends OR course.ends BETWEEN c.begins AND c.ends))
DB2
Платформа DB2 поддерживает типы подзапросов стандарта ANSI. Разрешается ис-
пользование скалярных подзапросов в списке элементов инструкции SELECT, вложен-
ных табличных подзапросов - в предложении FROM, а также скалярных и векторных
подзапросов в составе предложений WHERE и HAVING. Платформа DB2 позволяет
применять коррелированные подзапросы в списке элементов инструкции SELECT
и в предложениях WHERE и НА TING.
Справочник по командам SQL | 575
MySQL
Платформа MySQL поддерживает применение вложенных табличных подзапросов
в списках элементов и в предложении.
Oracle
Платформа поддерживает подзапросы стандарта ANSI, хотя применяется другая
номенклатура. В Oracle вложенные табличные подзапросы, использующиеся в пред-
ложении FROM, называются встроенными представлениями (inline view). И это пра-
вильно, поскольку вложенные табличные подзапросы - это, по сути, представления,
создаваемые «на ходу». В Oracle подзапросы, которые используются в предложениях
WHERE и HAVING, называются вложенными подзапросами (nested subquery). Oracle
позволяет использовать коррелированные подзапросы в списке элементов инструкции
SELECT и в предложениях WHERE и HAVING.
PostgreSQL
Платформа PostgreSQL поддерживает подзапросы стандарта ANSI в предложениях
FROM, WHERE и HAVING. Однако подзапросы в предложении HAVING не могут
включать в себя предложения ORDER BY, FOR UPDATE и LIMIT. В настоящее время
PostgreSQL не поддерживает подзапросы в списке элементов инструкции SELECT.
SQL Server
Платформа SQL Server поддерживает подзапросы стандарта ANSI. Скалярные подза-
просы можно использовать практически везде, где могут использоваться стандартные
выражения. Подзапросы SQL Server не могут содержать предложений COMPUTE
и FOR BROWSE. Можно использовать предложение ORDER BY, если также использу-
ется предложение ТОР.
См. также
DELETE
INSERT
SELECT
UPDATE
WHERE
Инструкция TRUNCATE TABLE
Инструкция TRUNCATE TABLE - это инструкция, не входящая в стандарт ANSI,
которая необратимо удаляет все строки из таблицы без занесения в журнал удаления
отдельных строк. Эта инструкция быстро удаляет все записи из таблицы, не влияя на
структуру таблицы и не занимая или занимая очень мало места в журналах отката или
журналах транзакций. Однако, поскольку данная операция не журналируется, ин-
струкцию TRUNCATE TABLE нельзя отменить после выполнения.
576 | Глава 3. Справочник по инструкциям SQL
Платформа Команда
DB2 He поддерживается
MySQL Поддерживается
Oracle Поддерживается
PostgreSQL Поддерживается
SQL Server Поддерживается
Стандартный синтаксис de facto
Официально инструкция TRUNCATE TABLE не является стандартной командой ANSI.
Однако есть стандарт, который поддерживают платформы и который имеет следующий
формат.
TRUNCATE TABLE имя_таблицы
Ключевые слова
имя_таблицы
Имя любой таблицы в текущей базе данных или схеме.
Общие правила
Инструкция TRUNCATE TABLE оказывает то же действие, что и инструкция DELETE
без предложения WHERE. Обе инструкции удаляют все строки в данной таблице.
Однако есть два важных отличия. Инструкция TRUNCATE TABLE работает быстрее
и не журналируется, что означает невозможность отката в случае ошибки. Кроме того,
инструкция TRUNCATE TABLE не активирует триггеры, в то время как DELETE акти-
вирует их.
Эту команду следует подавать вручную. Мы настоятельно не рекомендуем ис-
пользовать ее в скриптах или работающих системах, которые содержат невосстанови-
мые данные. Ее нельзя использовать совместно с инструкциями, управляющими тран-
закциями, такими, как BEGIN TRAN и COMMIT.
Советы и хитрости программирования
Поскольку инструкция TRUNCATE TABLE не заносится в журнал, обычно она исполь-
зуется в базах данных, находящихся в процессе разработки. В рабочих базах данных
ее нужно применять осторожно!
: .. Мы настоятельно не рекомендуем вставлять инструкцию TRUNCATE
TABLE в хранимые процедуры или функции рабочего приложения, поскольку
—~J большинство платформ не журналируют эту операцию и не смогут отме-
нить неправильно поданную инструкцию.
Команда TRUNCATE TABLE не будет выполнена, если другой пользователь забло-
кировал таблицу в тот момент, когда команда была подана. Инструкция TRUNCATE
37 - 2447
Справочник по командам SQL | 577
TABLE не активизирует триггеры, но будет работать и при их наличии. Однако
инструкция не сработает, если в данной таблице есть ограничения FOREIGN KEY.
DBS
Версия 8 DB2 не поддерживает инструкцию TRUNCATE TABLE.
MySQL
Платформа MySQL, начиная с версии 3.23, поддерживает базовый формат инструкции
TRUNCATE TABLE.
TRUNCATE TABLE имя
Платформа MySQL получает нужный результат путем удаления и повторного созда-
ния указанной таблицы. Поскольку MySQL хранит каждую таблицу в файле с именем
имя/гт, то для правильной работы команды файл с этим именем должен существовать
в директории, содержащей файлы базы данных.
Например, следующая инструкция удалит все данные из таблицы publishers.
TRUNCATE TABLE publishers
Платформа Oracle позволяет удалить таблицу или индексированный кластер (но не
хеш-кластер). Синтаксис следующий.
TRUNCATE { CLUSTER [владелец, ^кластер
| TABLE [владелец. ]таблица [{PRESERVE | PURGE} MATERIALIZED VIEW LOG]}
[{DROP | REUSE} STORAGE]
Инструкция TRUNCATE TABLE впервые появилась на платформе Oracle, и другие
производители вскоре ввели поддержку этой инструкции. В Oracle к этой инструкции
были добавлены дополнительные возможности, которые часто поддерживаются дру-
гими производителями. Синтаксические элементы в Oracle следующие.
CLUSTER | TABLE
Указывается, будет удаляться индексированный кластер или таблица. Индексиро-
ванный кластер - это конструкция, которая хранит связанные строки двух таблиц
физически на диске рядом друг с другом для ускорения соединения путем умень-
шения нагрузки на каналы ввода-вывода. При удалении индексированного кла-
стера нельзя использовать такие опции, как SNAPSHOT LOG и STORAGE.
PRESER VE MA TER1AL1ZED VIEWLOG
При удалении основной таблицы сохраняются все журналы-снимки.
PURGE MATERIALIZED VIEW LOG
Удаляются все журналы-снимки.
DROP STORAGE
Дисковое пространство, освободившееся при удалении рядов, высвобождается.
REUSE STORAGE
Дисковое пространство, освободившееся при удалении рядов, остается закреплен-
ным за данной таблицей.
Например:
578 | Глава 3. Справочник по инструкциям SQL
TRUNCATE ТАЕкЕ scott.authors
PRESERVE SNAPSHOT LOG REUSE STORAGE
В этом примере удаляются все записи в таблице scott.authors. Сохраняется сущест-
вующий журнал-снимок, и таблица может повторно использовать закрепленное за ней
освободившееся место.
PostgreSQL
Платформа PostgreSQL мало отличается от сложившегося промышленного стандарта.
Было добавлено ключевое слово TABLE.
TRUNCATE [TABLE] имя
Ключевое слово TABLE является необязательным. Например, следующая команда
удаляет все записи из таблицы authors базы данных PostgreSQL.
(RUNCATL autrcrs
SQL Server
Платформа SQL Server поддерживает сложившийся de facto промышленный стандарт.
См. также
DELETE
Оператор для работы с наборами UNION
Оператор для работы с наборами данных UNION объединяет результирующие наборы
двух и более запросов и показывает все строки всех запросов как один резуль-
тирующий набор.
UNION относится к классу операторов для работы с наборами данных (set operator).
К другим таким операторам относятся INTERSECT и EXCEPT (EXCEPT и MINUS
являются функциональными эквивалентами, но EXCEPT входит в стандарт ANSI). Все
операторы для наборов данных используются для одновременного манипулирования
результирующими наборами двух и более запросов, отсюда и их название.
Платформа Команда
DB2 Поддерживается с ограничениями
MySQL Не шмдерживается
Oracle Поддерживается с ограничениями
PostgreSQL Поддерживается с ограничениями
SQL Server Поддерживается с ограничениями
Справочник по командам SQL | 579
Синтаксис SQL2003
Технических ограничений на количество запросов в операторе UNION не существует.
Общий синтаксис следующий.
< инструкция SELECT 1>
UNION [ALL | DISTINCT]
< инструкция SELECT 2>
UNION [ALL | DISTINCT]
Ключевые слова
UNION
Показывает, что результирующие наборы будут объединены в один резуль-
тирующий набор. Дубликаты строк по умолчанию удаляются.
ALL
Объединяются и дубликаты строк из всех результирующих наборов.
DISTINCT
Из результирующего набора удаляются дубликаты строк. Столбцы, содержащие
значения NULL, считаются дубликатами. (Если ключевые слова ALL и DISTINCT не
используются, по умолчанию принимается DISTINCT.')
Общие правила
Существует лишь одно важное правило, о котором следует помнить при использова-
нии оператора UNION: порядок, количество и тип данных столбцов должны быть
идентичны во всех запросах.
Типы данных не обязательно должны быть идентичны, но они должны быть совмес-
тимы. Например, типы CHAR и VARCHAR являются совместимыми. По умолчанию резуль-
тирующий набор использует размер наибольшего из совместимых типов, и в запросе,
в котором объединяются три столбца типа CHAR - CHAR(5), CHAR(IO) и CHAR(12),
результаты будут в формате CHAR(12), а в столбцы меньшего размера будут добав-
ляться дополнительные пробелы.
Советы и хитрости программирования
Хотя согласно стандарту ANSI оператор INTERSECT имеет более высокий приоритет
по сравнению с другими операторами для работы с наборами, на многих платформах
эти операторы рассматриваются как имеющие одинаковый приоритет. Вы можете
явным образом управлять приоритетом операторов, используя скобки. В противном
случае СУБД, скорее всего, будет выполнять их в порядке слева направо.
Предложение DISTINCT может (в зависимости от платформы) потребовать суще-
ственных затрат производительности, поскольку при этом часто требуется дополни-
тельный проход по результирующему набору для удаления дублирующихся записей.
Предложение ALL для увеличения производительности можно указывать во всех
случаях, когда не ожидается наличия дубликатов (или если дубликаты допустимы).
580 | Глава 3. Справочник по инструкциям SQL
Согласно стандарту ANSI в запросе можно использовать только одно предложе-
ние ORDER BY. Ставьте его в конце последней инструкции SELECT. Чтобы избежать
двусмысленности при указании столбцов и таблиц, обязательно присваивайте всем
столбцам всех таблиц соответствующие псевдонимы. Тем не менее при указании имен
столбцов в запросе SELECT...UNION используется только псевдоним из первого запроса.
Например:
SELECT au_lname AS "lastname", au_fname AS "firstname"
FROM authors
UNION
SELECT emp_lname AS ''lastname", emp_fname AS "firstname"
FROM employees
ORDER BY lastname, firstname
Кроме того, поскольку в запросах оператора UNION могут содержаться столбцы
с совстимыми типами данных, возможны вариации поведения кода на разных плат-
формах, особенно в том, что касается длины типа данных столбца. Например, если
столбец aujname первого запроса заметно длиннее столбца emplname второго
запроса, то разные платформы могут применять разные правила определения исполь-
зуемой длины. Однако, как правило, платформы выбирают для результирующего
набора более длинный (и менее ограниченный) тип данных.
Каждая СУРБД может применять свои собственные правила определения имени
столбца, если столбцы в разных таблицах имеют разные имена. Как правило, исполь-
зуются имена из первого запроса.
DBS
Платформа DB2 поддерживает ключевые слова UNION и UNION ALL стандарта ANSI
плюс предложение VALUES.
< инструкция SELECT 1>
UNION [ALL]
< инструкция SELECT 2>
UNION [ALL]
[VALUES (выражение! выражение2, . ,,)] [, (выражение!, выражение2, ..,')] [,.,.]
[,.•]
Где:
VALUES
Позволяет указывать один или несколько наборов определяемых вручную значе-
ний для записей в объединенном результирующем наборе. Каждое из этих значе-
ний должно содержать в точности такое же число столбцов, как в запросах опера-
тора UNION. Строки значений в результирующем наборе разделяются запятыми.
Хотя предложение UNION DISTINCT не поддерживается, функциональным экви-
валентом является предложение UNION. Предложение CORRESPONDING не под-
держивается.
Справочник по командам SQL | 581
С ключевым словом UNION нельзя использовать такие типы данных, как VARCHAR,
LONG VARGRAPHIC, BLOB, CLOB, DBCLOB, DATAL1NK, и структурные типы (но их
можно использовать с предложением UNION ALL).
Если во всех таблицах используется одно имя столбца, в результирующем наборе
используется это имя. Если же имена столбцов различаются, то DB2 генерирует новое
имя столбца. После этого этот столбец нельзя использовать в предложении ORDER BY
или предложении FOR UPDATE.
Если в одном запросе используется несколько операторов для наборов данных, то
первыми выполняются те, которые заключены в скобки. После этого операторы
выполняются в порядке слева направо. Однако все операции INTERSECT выполняются
до операций UNION или EXCEPT. Например:
SELECT empno
FROM employee
WHERE workdept LIKE 'E%'
UNION
SELECT empno
FROM emp_act
WHERE projno IN ('IF1000', 'IF2000', 'AD311O')
UNION
VALUES ( 'АА000Г ), ('AB0002'), ('ACOOO3')
В этом примере мы получаем все ID сотрудников из таблицы employee, которые
состоят в любом департаменте, с названием, начинающимся с «Е», а также ID всех
сотрудников из бухгалтерской таблицы emp_act, которые работают в проектах 'IF10001,
'IF20001, and 'AD3110'. Кроме того, сюда всегда включаются ID сотрудников 'АА000Г,
'АВ0002', and 'АС00031.
MySQL
Не поддерживается.
Oracle
Платформа Oracle поддерживает ключевые слова UNION и UNION ALL стандарта
SQL ANSI. Синтаксис следующий.
< инструкция SELECT 1>
UNION [ALL]
< инструкция SELECT 2>
UNION [ALL]
Oracle не поддерживает предложение CORRESPONDING. Предложение UNION
DISTINCT не поддерживается, но функциональным эквивалентом является предложение
UNION. Платформа Oracle не поддерживает использование предложений UNION ALL
и UNION в следующих ситуациях.
• Запросы, содержащие типы данных LONG, BLOB, CLOB, BFILE или VARRAY
582 | Глава 3. Справочник по инструкциям SQL
• Запросы, содержащие предложение FOR UPDATE или выражение с коллекцией
TABLE.
Если первый запрос в операторе содержит какие-либо выражения в списке эле-
ментов, то присвойте этому столбцу псевдоним при помощи предложения AS. Кроме
того, только последний запрос в операторе может содержать предложение ORDER BY.
Например, вы можете получить все уникальные идентификаторы магазинов
(store_id), без дубликатов используя следующий запрос.
SELECT stor_id FROM stores
UNION
SELECT stor_id FROM sales;
PostgreSQL
Платформа PostgreSQL поддерживает ключевые слова UNION и UNION ALL стандартного
синтаксиса ANSI.
< инструкция SELECT 1>
UNION [ALU
< инструкция SElEC’’ 2>
UNION [ALL]
Платформа PostgreSQL не поддерживает использование предложений UNION
и UNION ALL в запросах с предложением FOR UPDATE. PostgreSQL не поддерживает
предложение CORRESPONDING. Предложение UNION DISTINCT не поддерживается,
но функциональным эквивалентом является предложение UNION.
Первый запрос в операторе не может содержать предложения ORDER BY или
LIMIT. Последующие запросы с предложениями UNION и UNION ALL могут содержать
эти предложения, но такие запросы нужно заключать в скобки. В противном случае
расположенное справа предложение ORDER BY или LIMIT будет применяться ко всей
операции.
Например, мы можем получить имена всех авторов и всех сотрудников, чья фамилия
(Iname) начинается с «Р».
SELECT a.au_lname
FROM autnors AS a
WHERE a.au_lname LIKE 'P%'
cNION
SELECT e.Iname
FROM employee AS e
WHERE e.Iname LIKE 'P%';
SQL Server
Платформа SQL Server поддерживает ключевые слова UNION и UNION ALL стандарт-
ного синтаксиса ANSI.
Справочник по командам SQL | 583
< инструкция SELECT 1>
UNION [ALL]
< инструкция SELECT 2>
UNION [ALL]
SQL Server не поддерживает предложение CORRESPONDING. Предложение
UNION DISTINCT не поддерживается, но функциональным эквивалентом является
предложение UNION.
С предложениями UNION и UNION ALL вы можете использовать инструкцию
SELECT...INTO, но ключевое слово INTO должно находиться в первом запросе
оператора объединения. Специальные ключевые слова, такие, как SELECT ТОР
и GROUP BY...WITH CUBE, можно использовать во всех запросах объединения.
Однако обязательно включайте эти предложения во все запросы объединения. Если
вы используете предложения SELECT ТОР или GROUP BY... WITH CUBE в одном за-
просе, операция выполнена не будет.
Все запросы в объединении должны содержать одно и то же количество столбцов.
Типы данных столбцов не обязательно должны быть идентичны, но они должны быть
неявным образом приводимы друг к другу. Например, совместное применение столб-
цов CHAR и LAR CHAR допускается. При выводе данных SQL Server при определении
размера типа данных для столбца результирующего набора использует размер наи-
большего столбца. Таким образом, если в инструкции SELECT... UNION используются
столбцы CHAR(5) и CHAR(IO), то данные обоих столбцов будут выводиться в столбце
CHAR(IO). Числовые типы данных приводятся и отображаются в виде типа с наиболь-
шей точностью.
Например, в следующем запросе объединяются результаты двух независимых
запросов, использующих предложение GROUP BY... WITH CUBE.
SELECT ta.au_id, C0UNT(ta.au_id)
FROM pubs..titleauthor AS ta
JOIN pubs..authors AS a ON a.au_id = ta.au_id
WHERE ta.au_id >= '722-51-5454'
GROUP BY ta.au_id WITH CUBE
UNION
SELECT ta.au_id, COUNT(ta.au_id)
FROM pubs..titleauthor AS ta
JOIN pubs..authors AS a ON a.au_id = ta.au_id
WHERE ta.au.id < '722-51-5454'
GROUP BY ta.au_id WITH CUBE
См. также
EXCEPT
INTERSECT
MINUS
SELECT
584 | Глава 3. Справочник по инструкциям SQL
Инструкция UPDATE
Инструкция UPDATE изменяет существующие в таблице данные. Соблюдайте особую
осторожность при использовании инструкции UPDATE без предложения WHERE,
поскольку такая инструкция затронет все строки таблицы.
Платформа Команда
DB2 Поддерживается с вариантами
MySQL Поддерживается с вариантами
Oracle Поддерживается с вариантами
PostgreSQL Поддерживается с вариантами
SQL Server Поддерживается с вариантами
Синтаксис SQL2003
UPDATE [ONLY] {имя~таблицы | имя_представления}
SET {{имя_столбца = { ARRAY [значение_массива [,...] ] | DEFAULT |
NULL. । скалярное^выражение},
имя_столбца - { ARRAY | DEFAULT i
NULL । скалярное_выражение }
[. ] [
I ROW = выражение_для_строки [
[ WHERE условие_поиска I WHERE CURRENT OF имя_курсора ]
Ключевые слова
ONLY
Запрещает распространение обновлений на подтаблицы целевой таблицы или
представления. Предложение ONLY влияет только на объектные таблицы и пред-
ставления. Если предложение используется с необъектной таблицей или представ-
лением, возникает ошибка.
имятаблицы | имя представления
Целевая таблица или представление инструкции UPDATE. Вы должны иметь со-
ответствующие права доступа к таблице в соответствии с правилами платформы.
Обновление представлений часто подчиняется особым правилам. Как правило,
обновление представления рекомендуется проводить только в том случае, если
представление создано на основе одной таблицы.
SET
Столбцу или строке присваивается определенное значение.
имя_столбца
Используется вместе с предложением SET (например, SET column! = ‘foo’).
Позволяет присваивать столбцу определенное значение. Вы можете обновлять
значения в нескольких столбцах в одной инструкции, ио нельзя в одной инструкции
обновлять значение одного столбца несколько раз.
Справочник по командам SQL | 585
ARRAY[зиачение^массива [,...]]
Столбцу присваивается значение-массив или пустой массив (ARRAY[/). Эта возмож-
ность не очень широко поддерживается разными платформами.
NULL
Для столбца устанавливается значение NULL.
DEFAULT
Для столбца устанавливается значение, заданное по умолчанию в соответствии со
спецификацией таких значений.
скалярное выражен ие
Столбцу присваивается любое одиночное значение, например строковая константа
или числовое значение, скалярная функция или скалярный подзапрос.
ROW
Используется совместно с предложением SET, но является взаимоисключающим
с конструкцией SET имяутолбца, например SET ROW - ROWf'foo’, ‘bar’). Эта
возможность не очень широко поддерживается разными платформами.
выражение дляутроки
Используется для указания значения для всех столбцов таблицы.
WHERE условие поиска
Определяет поисковый критерий для инструкции UPDATE, чтобы обновлялись
только те строки, которые соответствуют условиюуоиска. Можно использовать
любое допустимое предложение WHERE. Как правило, перед обновлением на со-
ответствие критерию проверяются все строки таблицы. Если критерием поиска
является подзапрос, то этот подзапрос выполняется для каждой строки, что потен-
циально может занять много времени.
WHERE CURRENT OF имяуурсора
Действие инструкции UPDATE ограничивается текущей строкой созданного и откры-
того курсора с именем имяуурсора.
Общие правила
Инструкция UPDATE может использоваться для изменения значения в одном или
сразу нескольких столбцах таблицы или представления. Как правило, значения изме-
няются в одной или нескольких строках одновременно. Новые значения должны быть
скалярными (за исключением выражений, предназначенных для заполнения строк или
массивов). То есть новое значение должно представлять собой одиночное значение,
постоянное на момент выполнения транзакции. Оно может быть литералом, а также
значением, получаемым в функции или подзапросе.
Базовый вариант инструкции UPDATE без предложения WHERE выглядит сле-
дующим образом.
UPDATE: authors
SET contract = О
586 | Глава 3. Справочник по инструкциям SQL
Без предоложеиия WHERE для всех авторов в таблице authors статус contract
устанавливается равным нулю (т. е. у них больше не будет контракта). Также в инструкции
UPDATE значения могут определяться математическими вычислениями.
UPDATE titles
SET price = price *1.1
Эта инструкция UPDATE увеличит цену всех книг на 10%.
Вы можете определять сразу несколько значений в одной инструкции, как в приведен-
ном примере, где мы переводим буквы в именах и фамилиях авторов в верхний регистр.
UPDATE authors SET au^lname = dPPER(au_lname).
au..fname - UPPER(au_fname);
Добавление предложения WHERE к инструкции UPDATE позволяет производить
избирательное изменение записей в таблице.
UPDATE titles
SET type = 'pers_comp',
price r (price « 1."5)
WHERE type = ' pooul ar_corn':
Приведенный выше запрос вносит два изменения во все записи, относящиеся к типу
‘popularcom’. Команда повышает их цену на 15% и изменяет их тип на ‘pers_comp’.
Вы также можете для получения значений, используемых в инструкции UPDATE,
вызывать функции и подзапросы. В некоторых ситуациях вам может понадобиться
измени ть строку, которую обрабатывает уже созданный и открытый курсор. В приве-
денном ниже примере иллюстрируются обе эти идеи.
UPDATE titles SET ytd.sales = (SELECT SUM(qty)
FROM sales
WHERE title./id = 'TC7Z77')
WHERE CURRENT OF title_cursor;
В этом запросе подразумевается, что вы создали и открыли курсор с именем
title_cursor, и этот запрос обрабатывает заголовки с ID, равным ТС7777.
Иногда вам нужно обновлять значения в таблице на основе значений, хранящихся
в другой таблице. Например, если вам нужно обновить дату публикации для всех
книг, написанных определенным автором, вы можете провести поиск по автору и вы-
вести список книг при помощи подзапросов.
uPDA-E titles
SET pubdate 'Jan 01 2002'
WHERE title.id IN
(SELECT title_id
TRCM titleauthor
WHERE au._id IN
(SELECT au.ic
FROM authors
WHERE au_lnaire = 'White'))
Справочник по командам SQL | 587
Советы и хитрости программирования
Инструкция UPDATE изменяет значения существующих записей в таблице или пред-
ставлении. Если вы обновляете представление, то представление должно включать
в себя все необходимые (NOT NULL) столбцы, в противном случае инструкция не
может быть выполнена. Столбцы со значениями DEFAULT обычно можно опускать.
Предложение SET ROW не очень широко поддерживается различными платформами.
Избегайте использовать это предложение. Предложение WHERE CURRENT OF реали-
зуется платформами чаще, но его нужно применять совместно с курсором. Перед
использованием этого предложения убедитесь, что вы понимаете, как используются
и функционируют курсоры.
В интерактивном пользовательском сеансе хорошей практикой является выполне-
ние перед инструкцией UPDATE инструкции SELECT с тем же предложением
WHERE. Эта мера предосторожности позволит вам проверить строки результирующе-
го набора до выполнения самого обновления и позволит удостовериться в том, что вы
не измените того, что изменять не предполагали.
DBS
Платформа DB2 поддерживает большинство стандартных конструкций ANSI. Здесь суще-
ствуют возможности контроля транзакций с указанием уровня изоляции (при помощи
предложения WITH), а также возможность изменения объектных таблиц и представлений.
Предложение SET ROW не поддерживается.
UPDATE [ONLY] ( {имя_таблицы | имя_представления} ) AS псевдоним
SET { {имя_столбца1 = { DEFAULT | NULL | выражение },
имя_столбца2 = { DEFAULT | NULL | выражение }
[,...] ] I
{ (имя_столбца 1[. . имя__а трибута],
имя_столбца2[. . имя_атрибута)[, . . . ] ) =
( {DEFAULT | NULL | выражение},
{DEFAULT | NULL | выражение}}, ... ] ) |
SELECT инструкция }
[WHERE {условие_поиска | CURRENT OF имя_курсора}]
[WITH { RR | RS | CS | UR }]
Где:
AS псевдоним
Указывается псевдоним целевой таблицы или представления. Полезно для тех
инструкций UPDATE, в которых используются длинные предложения WHERE или
коррелированные подзапросы.
..имяатрибута
Указывается имя_атрибута при обновлении столбца объектного типа.
WITH
Управляет уровнем изоляции транзакций для инструкций UPDATE (RR - repeatable
read, RS - read stability, CS - cursor stability и UR - uncommitted read). За подробной
588 | Глава 3. Справочник по инструкциям SQL
информацией об уровнях изоляции транзакций DB2 обращайтесь к разделу, по-
священному инструкции SET TRANSACTION.
В инструкции UPDATE столбцу должно присваиваться только одно значение.
Значение столбцу можно присвоить в одной инструкции UPDATE только один раз.
Если хотя бы одно обновляемое значение нарушает ограничения таблицы или вызыва-
ет какую-то другую ошибку, то ни одно обновление не выполняется. При изменении
значения столбца идентификатора (identity) на текущее значение просто используйте
предложение DEFAULT. (Платформа DB2 полностью поддерживает обновление
структурных типов, но эта возможность используется нечасто и ее довольно сложно
и долго объяснять. За дополнительной информацией по обновлению структурных
типов обращайтесь к документации DB2.)
DB2 позволяет обновлять не только стандартные таблицы и представления, но
и объектные (типизованные). (За дополнительной информацией обращайтесь к разделам,
посвященным инструкциям CREATE TABLE и CREATE TYPE.) Существует несколько
особых правил обновления объектных таблиц и представлений.
• Столбец ID объекта обновлять нельзя.
• Для столбца, который ранее был определен как структурный, нужно использовать
предложение ..wwi_ampu6yma. Имя атрибута должно представлять собой атрибут
структурного типа, к которому относится столбец.
• Для обновления статистики распределения столбцов объектной таблицы требует-
ся указание подтаблицы, в которой впервые появляется столбец.
• Присвоение значений нескольким атрибутам одного столбца структурного типа
производится слева направо в предложении SET со скобками или же (без скобок)
в порядке, определенном в предложении SET.
• Один столбец может указываться в инструкции UPDATE многократно, если при
этом устанавливаются значения для атрибутов.
Обновление значения URL для столбцов DATA LINK идентично его удалению и после-
дующей вставке. Обновление столбца DATALINK значением NULL идентично удалению
значения. Обновление значения комментария в типе DATALINK без переустановления
связи требует передачи пустой строки для значения URL.
Ниже приводится несколько примеров того, как в DB2 происходит обновление
сразу нескольких значений при помощи стандартного предложения SET.
UPDATE employee
SET job=NULL, salary=0, bonus=0, comm=0
WHERE workdept = ''E21'
AND job <> 'MANAGER'
Эту инструкцию можно написать при помощи предложения SET, использующего
скобки.
UPDATE employee
SET (job, salary, bonus, comm) = (NULL, 0, 0, 0)
Справочник по командам SQL | 589
WHERE workdept = ' E2T
AND job <> 'MANAGER'
Ниже приводится пример обновления базовой таблицы типа circles. Атрибутами
типа circles являются владелец (OWNER), радиус (RADIUS), координата X центра
(X_CENTER) и координата Y центра (Y_CENTER). Поскольку столбец С определен
как относящийся к типу circle, инструкция UPDATE изменяет атрибуты одного столбца.
UPDATE CIRCLES
SET (OWNER, С.,RADIUS_LENGTH, C..X_CENTER, C.,Y_CENTER) =
('tony', 5, 18, 22)
WHERE ID = 15
MySQL
Платформа MySQL поддерживает стандарт ANSI с несколькими вариациями, к которым
относятся предложения LOW PRIORITY, IGNORE и LIMIT.
UPDATE [LOW PRIORITY] [IGNORE] имя_таблицы
SET имя^столбца = {скалярное~выражение}
[....]
WHERE условие_поиска
[ORDER BY имястолбца 1 [{ASC | DESC}] [,,..] ]
[LIMIT целое_число)
Где:
LOW PRIORITY
Выполнение инструкции UPDATE будет отложено до того момента, пока ни один
клиент не будет обращаться к таблице.
IGNORE
MySQL будет игнорировать ошибки дубликатов ключей, генерируемые ограниче-
ниями PRIMARY KEY и UNIQUE. Однако обновляться будут только те записи,
которые не приводят к появлению таких ошибок.
ORDER BY
Платформа MySQL будет обновлять строки в порядке, определяемом указанным
столбцом (по возрастанию или по убыванию).
LIMIT целое_число
Ограничивает действие инструкции UPDATE количеством записей, указываемым
параметром целоечисло.
Платформа MySQL поддерживает присвоение значений по умолчанию (DEFAULT)
в инструкции INSERT, но в инструкции UPDATE эта возможность пока не поддерживается.
Следующая инструкция UPDA ТЕ увеличит все цены на книги в таблице titles на 1.
UPDATE titles SET price = price + 1;
В следующем примере действие инструкции UPDATE ограничится первыми 10 запи-
сями таблицы titles, отсортированной по title_id. Также значение price будет обновлено
дважды. Эти два обновления выполняются в порядке слева направо. Сначала цена удваи-
вается, а затем увеличивается на 1.
590 | Глава 3. Справочник по инструкциям SQL
UPDATE titles
SET price = price * 2
price = price - 1
ORDER BY title_id
LIMIT 10;
Oracle
Реализация инструкции UPDATE в Oracle позволяет проводить обновления представ-
лений, материализованных представлений, подзапросов и таблиц в допустимой схеме.
UPDATE L0NLY2
{ [схема. ]{имя_представления | имя_материализованного_представления |
имя_ таблицы}
[@соединение_с_базой_данных] [псевдоним]
{[PARTITION (имя_раздела)] |
[SUBPARTITION {имя_подраздела}]}
I подзапрос [WITH {[READ ONLY] | [CHECK OPTION [CONSTRAINT имя.ограничения] ]
I [TABLE {имя_выражения_для_коллекции} [( + )]]}
SET {столбец! [....] - {выражение [.. .] | подзапрос} I
VALUE [{псевдоним}] = { значение | {подзапрос}},
{ столбец! [, ..] = {выражение [,...] подзапрос} ।
VALUE [{псевдоним}] ~ { значение ! {подзапрос}},
[. ]
WHERE условие_поиска | CURRENT 0Е имя.курсора}
RETURNING выражение [,...] INTO переменная [,...];
Синтаксические элементы версии инструкции UPDATE в Oracle следующие.
ONLY
Платформа Oracle не будет обновлять строки в представлениях-потомках. Применимо
только к представлениям, образующим иерархию.
имя_,материсн1изованного_представлепия
Инструкция UPDATE применяется к существующим моментальным копиям.
@соединение_с базой данных
Инструкция UPDATE применяется к представлению или таблице на удаленном
сервере, доступном через ранее установленное @соединение_сбазой данных,
псевдоним
Указывается псевдоним обновляемой таблицы. В Oracle можно использовать
псевдонимы таблиц, но ключевое слово AS для инструкций UPDATE не под-
держивается. Псевдонимы также можно указывать для предложения VALUE
инструкции UPDATE.
PARTITION
Инструкция UPDATE применяется к указанному разделу, а не ко всей таблице. Указы-
вать имя раздела при обновлении секционированной таблицы необязательно, но это
во многих случаях позволяет уменьшить сложность предложения WHERE.
Справочник по командам SQL | 591
SUBPARTITION
Инструкция UPDATE применяется к указанному подразделу, а не ко всей таблице.
WITH READ ONLY
Указывает, что нельзя обновлять подзапрос. В некоторых случаях транзакция с ин-
струкцией UPDATE может изменить записи, используемые в подзапросе. Предло-
жение WITH READ ONLY препятствует этому.
WITH CHECK OPTION
Платформа Oracle будет отменять все изменения, вносимые в таблицу, которые не
будут входить в результирующий набор запроса.
CONSTRAINT
Изменения будут ограничиваться при помощи указанного ограничения.
SET VALUE
Позволяет определить значения для полной строки любого табличного типа (TABLE).
Предложение SET VALUE очень похоже на SET ROW стандарта ANSI. Вы также
можете указать подзапрос, получающий все значения, необходимые для предложения
SET VALUE.
RETURNING
Извлекаются строки, затронутые инструкцией. Обычно же инструкция UPDATE
возвращает только количество обновленных строк. Если это предложение исполь-
зуется при обновлении одной строки, то значение строки можно сохранить в пере-
менных PL/SQL и в переменных связывания (bind variables). Если предложение
используется при удалении нескольких строк, то значения строк сохраняются
в массивах связывания (bind arrays).
INTO
Указываются переменные, в которые помещаются значения, возвращаемые пред-
ложением RETURNING.
В Oracle есть несколько важных правил, касающихся использования инструкций
UPDATE.
• Инструкции UPDATE не разрешается использовать в таблицах или базовых таб-
лицах представлений, содержащих предметный индекс (domain index) со статусом
FAILED или IN PROGRESS. Инструкцию UPDATE также нельзя использовать
в таблицах, в которых есть раздел индекса со статусом UNUSABLE. (Проблем
с секционированием индексов можно избежать путем установки параметра сеанса
SKIPUNUSABLEINDEXES в TRUE.)
• При обновлении представлений могут возникнуть проблемы, если запрос, соз-
дающий представление, содержит соединение, агрегатную функцию, оператор
для работы с наборами, ключевое слово DISTINCT, предложение ORDER BY, пред-
ложение GROUP BY, предложение CONNECT BY, предложение START WITH, ана-
литическую функцию, выражение для коллекции или подзапрос. (В этих случаях
для обновления базовых таблиц вы можете использовать триггер INSTEAD OF.)
В приведенных ниже фрагментах кода показаны примеры использования рас-
ширений инструкции UPDATE, имеющихся в Oracle. Для начала предположим, что
592 | Глава 3. Справочник по инструкциям SQL
таблица sales выросла в большую, секционированную таблицу. Вы можете провести
обновление конкретного раздела при помощи предложения PARTITION. Например:
UPDATE sales PARTITION (sales_yr_2004) s
SET s.payterms = 'Net 60'
WHERE qty > 100;
Вы также можете использовать предложение SET VALUE, чтобы указать новые
значения для всех столбцов строки, указанной предложением WHERE.
UPDATE big_sales bs
SET VALUE(bs) = (SELECT VALUE(s) FROM sales S
WHERE bs.title_id = s.title_id)
AND bs.stor_id = s.stor_id)
WHERE bs.title_id = 'TC7777';
Вы можете извлечь значения для их просмотра после обновления, используя пред-
ложение RETURNING. В приведенном ниже примере производится обновление одной
строки, а обновленные значения записываются в переменные PL/SQL.
UPDATE employee
SET }ob_id = 13, job_level = 140
WHERE last_name = 'Josephs'
RETURNING last_name, job_id
INTO :var-|, :var2;
PostgreSQL
Платформа PostgreSQL поддерживает стандартный синтаксис ANSI с парой небольших
изменений. Поддерживается добавление предложения FROM. К другим изменениям
относится отсутствие поддержки ключевого слова ARRAY, но наличие поддержки
самих массивов. Синтаксис инструкции UPDATE в PostgreSQL следующий.
UPDATE [ONLY] {имя_таблицы | имя_представления}
SET имя_столбца1 = {DEFAULT | NULL | скалярное_выражение },
имя_столбца2 = {DEFAULT | NULL | скалярное_выражение }
[....]
[FROM {таблица1 [AS псевдоним], таблица2 [AS псевдоним^, . . . ]}]
[ WHERE условие_поиска | WHERE CURRENT OF имя_курсора ]
Большинство синтаксических элементов соответствует стандарту ANSI. Единствен-
ный нестандартный элемент следующий.
FROM
Предоставляет возможность создать для указания обновляемых строк высокоиз-
бирательный критерий на основе соединения. Предложение FROM не нужно, если
при указании строк используется только одна таблица - целевая.
В следующем примере нам нужно обновить значение job_lvl для тех сотрудников,
чей job_id равен 12, a min_Ivl равен 25. Этого можно добиться при помощи большого,
сложного подзапроса, а можно создать соединение при помощи предложения FROM.
38 - 2447
Справочник по командам SQL | 593
UPDATE employee
SET job_lvl = 80
FROM employee AS e, jobs AS j
WHERE e.job_id = j.job_id
AND j.job_id = 12
AND j,min_lvl = 25;
Все прочие аспекты стандарта ANSI поддерживаются в полной мере.
SQL Server
Платформа SQL Server поддерживает большинство основных компонентов инструк-
ции UPDATE стандарта ANSI, но не поддерживаются ключевые слова ONLY и ARRAY
и не поддерживается возможность обновления массивов. В SQL Server функциональ-
ность инструкции UPDATE была расширена путем добавления подсказок по таблице
при помощи предложения WITH, добавления подсказок по запросу при помощи пред-
ложения OPTION, а также введена более надежная обработка переменных. Синтаксис
следующий.
UPDATE {имя_таблицы | имя_представления | набор~строк}
[WITH (подсказка!, подсказка2 [,... ])]
SET {имя_столбца = {DEFAULT | NULL | скалярное_выражение }
| имя_переменной = скалярное_выражение
| имя~переменной = имя_столбца = скалярное_выражение } [,...]
[FROM {таблица! | представление! | вложенная_таблица1 | набор_строк!} [,...]]
[AS псевдоним]
[JOIN {таблица2 [,...]} ]
WHERE {условия | CURRENT OF [GLOBAL] имя^курсора]
[OPTION (подсказка!, подсказка2 [,.. .])]
Синтаксические элементы инструкции UPDATE в SQL Server следующие.
WITH подсказка
Позволяет использовать подсказки по таблицам, заменяя заданное по умолчанию
поведение оптимизатора запросов. Поскольку оптимизатор запросов очень
хорошо выбирает планы обработки, используйте подсказки только в том случае,
если вы очень хорошо понимаете таблицы, индексы и данные, затрагиваемые
операцией. Если такого понимания нет, использование подсказок может привести
не к увеличению, а к уменьшению производительности.
имя_переменной
Переменные SQL Server должны быть объявлены до использования инструкции
UPDATE, в форме DECLARE @переменная. Конструкция SET @перемепная =
столбец! = выражение] устанавливает для переменной значение, равное оконча-
тельному значению обновленного столбца, а конструкция SET @переменная -
столбец], столбец] = выражение устанавливает для переменной значение,
равное значению в столбце до выполнения инструкции UPDATE.
594 | Глава 3. Справочник по инструкциям SQL
FROM
Предоставляет возможность создать для указания обновляемых строк высокоиз-
бирательный критерий на основе соединения. Предложение FROM не нужно, если
при указании строк используется только одна таблица - целевая. Функции для
работы с наборами строк (rowset functions) в SQL Server описываются в разделе
«Инструкция SELECT».
AS псевдоним
Позволяет присвоить легкий в использовании псевдоним таблице, представле-
нию, вложенному табличному подзапросу или функции для работы с наборами
строк.
JOIN
Предоставляется возможность использовать стандартный синтаксис ANSI для со-
единений таблиц совместно с предложением FROM.
GLOBAL
Небольшая вариация предложения WHERE CURRENT OF стандарта ANSI. Пред-
ложение WHERE CURRENT OF имя курсора, используемое в комбинации
с курсором, заставляет платформу SQL Server обновить только одну запись, на ко-
торой в данный момент расположен курсор. Предполагается, что курсор является
локальным, но можно указать и глобальный курсор, используя ключевое слово
GLOBAL.
OPTION подсказка
Позволяет использовать подсказки по запросам, изменяя заданное по умолчанию
поведение оптимизатора запросов. Как и в случае с предложением WITH, исполь-
зуйте подсказки только в том случае, если вы очень хорошо понимаете таблицы,
индексы и данные, затрагиваемые операцией. Если такого понимания нет, исполь-
зование подсказок может привести не к увеличению, а к уменьшению производи-
тельности.
Главное расширение, которое вводит Microsoft SQL Server в инструкцию UPDATE
стандарта ANSI, - это предложение FROM. Предложение FROM позволяет использо-
вать предложение JOIN, что значительно упрощает обновление строк целевой табли-
цы путем связывания строк, указанных в предложении FROM, со строками, обновляе-
мыми компонентом UPDATE имя_табпицы. В следующем примере показано обновле-
ние результата соединения таблиц с использованием стиля ANSI и довольно громозд-
кого подзапроса, а потом - обновление с использованием предложения FROM SQL
Server. Оба запроса выполняют одно и то же действие, но совершенно по-разному.
-- стиль ANSI
UPDATE titles
SET puoaate = GETDATE( )
WHERE title_id IN
(SELECT title_id
"ROM tltleaut.nor
WHERE aj_ic IN
Справочник по командам SQL | 595
(SELECT au_id
FROM authors
WHERE au_lname = 'White'))
-- стиль Microsoft Transact-SQL
UPDATE titles
SET pubdate = GETDATE( )
FROM authors AS a
JOIN titleauthor AS t2 ON a.au_id = t2,au_id
WHERE t2.title_id = titles.title_id
AND a.au_lname = 'White'
Выполнение такого обновления при использовании стиля Transact-SQL сводится
к соединению двух таблиц - authors и titleauthor - с таблицей titles. Для выполнения
той же самой операции с использованием кода ANSI нужно сначала найти значение
au_id в таблице authors и передать его в таблицу titleauthor, а затем нужно найти
значение title_id и передать его в основную инструкцию UPDATE.
В следующем примере обновляется столбец state для первых десяти записей таб-
лицы authors.
UPDATE authors
SET state = 'ZZ'
FROM (SELECT TOP 10 * FROM authors ORDER BY au_lname) AS t1
WHERE authors.au_id = t1.au_id
В этом примере важно обратить внимание на то, что, как правило, довольно
сложно обновить первые п записей при помощи инструкции UPDATE, если нет какой-
нибудь явной последовательности строк, которую можно определить при помощи
предложения WHERE. Однако вложенный табличный подзапрос в предложении
FROM, использующий ключевое слово ТОР для получения первых 10 записей, помо-
гает не тратить силы на дополнительное программирование, которое иначе было бы
необходимо.
См. также
DECLARE
SELECT
WHERE
Предложение WHERE
Предложение WHERE указывает критерий поиска для таких операций, как SELECT,
UPDATE или DELETE. Записи целевой таблицы, которые не удовлетворяют этому
критерию, из операции исключаются. Условия поиска могут включать множество
вариантов, таких, как вычисления, булевы операторы и предикаты SQL (такие, как
LIKE или BETWEEN).
596 | Глава 3. Справочник по инструкциям SQL
Платформа Команда
DB2 Поддерживается
MySQL Поддерживается
Oracle Поддерживается
PostgreSQL Поддерживается
SQL Server Поддерживается
Синтаксис SQL2003
{ WHERE критерий_поиска | WHERE CURRENT OF имя_курсора }
Ключевые слова
WHERE критерийпоиска
Указывается критерий поиска для инструкции, и только те строки, которые удов-
летворяют этому критерию, будут затрагиваться операцией.
WHERE CURRENT ОТ' имя_курсора
Действия инструкции ограничиваются текущей строкой в созданном и открытом
курсоре с именем имя курсора.
Общие правила
Предложения WHERE используются в инструкциях SELECT, инструкциях DELETE,
инструкциях INSERT...SELECT, инструкциях UPDATE, а также в любых инструкциях,
которые могут содержать запрос или подзапрос, например DECLARE, CREATE
TABLE, CREATE VIEW и т. п. К условиям поиска, которые все были описаны в посвя-
щенных им разделах этой книги, относятся следующие.
Условия типа ALL (=ALL, >ALL, <= ALL, SOME/ANY)
Например, чтобы получить сведения об издателях, проживающих в том же городе,
что и авторы, используется следующий запрос.
SELECT pub_name
FROM publishers
WHERE city = SOME (SELECT city FROM authors);
Комбинации (AND, OR и NOT) и иерархия их проверки
Например, чтобы увидеть авторов, объемы продаж книг которых больше или
равны 75 единицам, или вторых авторов с уровнем старшинства большим или
равным 60, используется такой запрос.
SELECT a.au_id
FROM authors AS a
JOIN titleauthor AS ta ON a.au_id = ta.au_id
WHERE ta.title_id IN (SELECT title_id FROM sales
WHERE qty >= 75)
0.R (a.au_id IN (SELECT au_id FROM titleauthor
WHERE royaltyper >= 60)
Справочник по командам SQL | 597
AND a.au_id IN (SELECT au_id FROM titleauthor
WHERE au_ord = 2));
За дополнительной информацией обращайтесь к следующему разделу «Советы
и хитрости программирования».
Операторы сравнения (такие, как =,<>,<,>,< - и >=)
Например, чтобы увидеть имена и фамилии авторов из таблицы authors, у ко-
торых нет контракта (т. е. значение contract равно 0), можно использовать такой
запрос.
SELECT au_lname, au_fname
FROM authors
WHERE contract = 0;
Списки (IN и NOT IN)
Например, чтобы увидеть всех авторов, у которых еще нет книг в таблице titleauthors,
используется такой запрос.
SELECT au_fname, au_lname
FROM authors
WHERE au_id NOT IN (SELECT au_id FROM titleauthor);
Проверка на NULL (IS NULL и IS NOT NULL)
Например, чтобы вывести заголовки книг, для которых количество продаж
с начала года (year-to-date sales, ytd_sales) равно NULL, используем такой запрос.
SELECT title_.id, SUBSTRING(title, 1, 25) AS title
FROM titles
WHERE ytd_sales IS NULL;
..... ~| He указывайте в запросе конструкции типа = NULL. Значение NULL являет-
ся неизвестным, и оно не может быть равным чему-либо. Использование кон-
струкции = NULL - это не то же самое, что оператор IS NULL. За дополни-
тельной информацией обращайтесь к разделу «Оператор IS» выше в данной
главе.
Совпадение с шаблоном (LIKE и NOT LIKE)
Например, получим записи об авторах, чьи фамилии начинаюся с «С».
SELECT au_id
FROM authors
WHERE au_lname LIKE 'C%';
Операторы работы с диапазонами (BETWEEN и NOT BETWEEN)
Например, чтобы увидеть фамилии авторов, расположенные между «Smith» и «White»,
используем следующий запрос.
SELECT au_lname, au^fname
FROM authors
WHERE au^lname BETWEEN 'smith' AND 'white';
598 | Глава 3. Справочник по инструкциям SQL
Советы и хитрости программирования
Для предложения WHERE может потребоваться специальная обработка при работе
с некоторыми типами данных, такими, как LOB, и некоторыми наборами символов,
такими, как UNICODE.
Для определения порядка выполнения операторов в предложении WHERE исполь-
зуются скобки. Заключение предложения в скобки заставляет систему выполнить это
предложение прежде остальных. Скобки можно вкладывать друг в друга, создавая
иерархию выполнения. Первым будет проверяться наиболее глубоко вложенное пред-
ложение. При работе со скобками следует быть осторожным в силу двух причин.
• Количество открывающих и закрывающих скобок должно быть одинаковым. Любое
несоответствие числа открывающих и закрывающих скобок вызовет ошибку.
• Скобки нужно расставлять внимательно, поскольку неправильная расстановка
может существенно изменить результат вашего запроса.
Например, рассмотрим снова следующий запрос, который возвращает шесть
строк из базы данных pubs на платформе SQL Server.
SELECT DISTINCT a.au..id
FROM authors AS a
JOIN titleauthor AS ta ON a.au_id = ta.au_id
WHERE ta.title_id IN (SELECT title_id FROM sales
WHERE qty >= 75)
OR (a au_id IN (SELECT au_id FROM titleauthor
WHERE royaltyper >= 60)
AND a.au_ic IN (SELECT au_id FROM titleauthor
WHERE au_ord = 2))
Результат этого запроса будет следующий.
3U...1O
213-46-8915
724-80-9391
899-46-2035
998-72-3567
Изменение всего лишь одного набора скобок создаст другой результат.
SEtЕСТ DISTINCT a.au_id
FROM authors AS a
JOIN titlea^thor AS ta ON a.au_id = ta.au_id
WHERE (ta.title_id IN (SELECT title_id FROM sales
WHERE qty >= 75)
OR a.au_id IN (SELECT au_id FROM titleauthor
WHERE royaltyper >= 60))
AND a.au_id IN (SELECT au_id FROM titleauthor
WHERE au_ord = 2)
Справочник по командам SQL | 599
В этот раз результат будет такой.
au_id
213-46-8915
724-80-9391
899-46-2035
DB2
Поддерживается так, как описано выше.
MySQL
Поддерживается так, как описано выше.
Oracle
Поддерживается так, как описано выше.
PostgreSQL
Поддерживается так, как описано выше.
SQL Server
Поддерживается так, как описано выше.
См. также
ALL/ANY/SOME
BETWEEN
DECLARE CURSOR
DELETE
EXISTS
IN
LIKE
SELECT
UPDATE
600 | Глава 3. Справочник по инструкциям SQL
4
Функции SQL
Функции - это особый тип команды в наборе команд SQL, а каждый диалект имеет свою
реализацию набора команд. В результате можно сказать, что функции - это команды,
состоящие из одного слова и возвращающие одиночное значение. Значение функции
может зависеть от входных параметров, как, например, в случае функции, вычисляющей
среднее значение в списке значений в базе данных. Однако многие функции не исполь-
зуют никаких входных параметров например, функция, возвращающая текущее системное
время - CURRENT_TIME.
Стандарт ANSI поддерживает несколько полезных функций. В этой главе приво-
дится описание этих функций, а также подробное описание и примеры по каждой из
платформ. Кроме того, у каждой платформы есть длинный перечень своих собствен-
ных, внутренних функций, которые выходят за пределы стандарта SQL. В этой главе
приводятся параметры и описания всех внутренних функций каждой из платформ.
Кроме того, большинство платформ имеют возможность создания пользователь-
ских функций. За дополнительной информацией о пользовательских функциях обра-
щайтесь к разделу «Инструкции CREATE/ALTER FUNCTION/PROCEDURE» главы 3.
Типы функций
Существуют разные способы классификации функций. В следующих подразделах
описываются важные различия, позволяющие понять, как работают функции.
Детерминированные и недетерминированные функции
Функции могут быть детерминированные и недетерминированные. Детерминированная
функция всегда возвращает один и тот же результат при одном и том же наборе вход-
ных значений. Недетерминированные функции могут возвращать разные результаты
при разных вызовах, даже если им передаются одинаковые входные значения.
Почему так важно, чтобы при одинаковых входных параметрах получались одина-
ковые результаты? Это важно потому, что это определяет способ использования функ-
ций в представлениях, пользовательских функциях и хранимых процедурах. Огра-
ничения на разных платформах могут быть разными, но иногда в этих объектах можно
использовать только детерминированные функции. Например, SQL Server может соз-
давать индекс по выражению в столбце, если только это выражение не содержит неде-
терминированных функций. Правила и ограничения на разных платформах разные,
потому обращайтесь при использовании функций к документации производителей.
Агрегатные и скалярные функции
Еще один способ классификации функций - по их возможности работы только с одной
строкой, с коллекцией значений или с наборами строк. Агрегатные функции работают
с коллекцией значений и возвращают одно суммарное значение. Скалярные функции
возвращают одно значение, зависящее от скалярных входных аргументов. Некоторые
скалярные функции, например CURRENT_TIME, не требуют никаких аргументов.
Оконные функции
Оконные функции можно считать сходными с агрегатными функциями в том, что они
могут работать сразу с несколькими строками. Различие в том, каким образом указы-
ваются эти строки. Агрегатные функции работают с наборами строк, указанными
в предложении GROUP BY В случае оконных функций набор строк указывается при
каждом вызове функции и разные вызовы функции в пределах одного запроса могут
работать с разными наборами строк.
Агрегатные функции ANSI SQL
Агрегатные функции возвращают одиночное значение на основе набора других значе-
ний. Если эта функция используется в числе прочих выражений в списке элементов
инструкции SELECT, то инструкция SELECT должна содержать предложение GROUP
BY или HAVING. Предложения GROUP BY или HAVING можно не указывать, если
значение агрегатной функции является единственным значением, возвращаемым
инструкцией SELECT. Поддерживаемые агрегатные функции и их синтаксис перечис-
лены в табл. 4.1.
Таблица 4.1. Агрегатные функции ANSI SQL
Функция Применение
А УС(выражение) Вычисляется среднее значение столбца, определяемого выражением
С0ВВ(зависимая, независимая) Вычисляется коэффициент корреляции
СОиНТ(выражение) Вычисляется количество строк, определяемых выражением
COUNT(*) Вычисляется общее количество строк в указанной таблице или представлении
СО VAR POP (зависимая, независимая) Вычисляется ковариантность генеральной совокупности
COVAR_SAMP (зависимая, независимая) Вычисляется выборочная ковариантность
602 | Глава 4. Функции SQL
Таблица 4.1. Агрегатные функции ANSI SQL (Продолжение)
Функция Применение
СиМЕ_1~ЖТ(список_значений) WITHIN GROUP (ORDER BY список _для_сортировки) Вычисляется относительный ранг гипотетической строки в группе строк, где ранг равен количеству строк, меньших или равных гипотетической строке, деленному на количество строк в группе
DENSE _RA NKfcnucoK значений) WITHIN GROUP (ORDER BY список_ для_сорт ировки) Вычисляется плотный ранг (без пропусков рангов) для гипотетической строки (список_значеиий) в группе строк, генерируемой предложением GROUP BY
М1Н(выра:жение) Вычисляется минимальное значение в столбце, определяе- мом выражением
МАХ(выражеиие) Вычисляется максимальное значение в столбце, определяе- мом выражением
PERCENT_RANK (список_значепий) WITHIN GROUP (ORDER BY список_для_сортировки) Вычисляется относительный ранг гипотетической строки путем деления ранга этой строки за вычетом 1 па количество строк и группе
PERCENTlLE_CONT(np(nfenmwib) WITHIN GROUP (ORDER BY список_для сорт ировки) Генерируется интерполяционное значение, которое, будучи добавленным в группу, будет соответствовать указанному процентилю
PERCENTlLE_DlSC(npouenmwib) WITHIN GROUP (ORDER BYcnu- сок_для_сортировки) Возвращается значение с наименьшим значением кумуля- тивной функции распределения, которое больше или равно указанному процентилю
RANK(cnucoK_3na4enuii) WITHIN GROUP (ORDER BY список_для_сортировки) Генерируется ранг гипотетической строки (список значений) в группе строк, сгенерированной предложением GROUP BY
REGR_AVGX (зависимая, независимая) Вычисляется среднее значение независимой переменной
REGR_AVGY (зависимая, независимая) Вычисляется среднее значение зависимой переменной
REGR_COUNT (зависимая, независимая) Вычисляется количество пар, оставшихся в группе после того, как были удалены пары с одним или несколькими значениями NULL
REGR.JNTERCEPT (зависимая, независимая) Вычисляется отрезок, отсекаемый па оси У у начала координат для трафика линейного уравнения, выровненного методом наименьших квадратов
REGR_R2 (зависимая, независимая) Квадрат корреляционного коэффициента
REGRJLOPE (зависимая, независимая) Определяется наклон графика линейного уравнения, выровненного методом наименьших квадратов
Агрегатные функции ANSI SQL | 603
Таблица 4.1. Агрегатные функции ANSI SQL (Продолжение)
Функция Применение
REGRJXX (зависимая, независимая) Сумма квадратов независимых переменных
REGRJSXY (зависимая, независимая) Сумма произведений каждой пары переменных
REGRJSYY (зависимая, независимая) Сумма квадратов зависимых переменных
5ТППЕУ_РОР(выражение) Вычисляется стандартное отклонение совокупности всех значений выражения в группе
STDDE V_SA МР(выражение) Вычисляется выборочное стандартное отклонение всех значений выражения в группе
SUM (выражение) Вычисляется сумма значений столбца, указываемого выражением
УАР_РОР(выражение) Вычисляется дисперсия для совокупности всех значений выражения в группе
VAR_SAMP(выражение) Вычисляется выборочная дисперсия для всех значений выражения в группе
С технической точки зрения операторы ANY, EVERY и SOME являются агрегатны-
ми функциями. Однако они считаются критериями поиска по диапазону, поскольку
чаще всего их используют именно таким образом. За дополнительной информацией
об этих функциях обращайтесь к разделу «Операторы ALL/ANY/SOME» главы 3.
Количество значений, обрабатываемых агрегатной функцией, может быть
различным и зависит от количества строк, извлекаемых запросом из таблицы. Этим
агрегатные функции отличаются от скалярных функций, которые при каждом вызове
могут работать только со значениями одной строки. Общий синтаксис агрегатной
функции следующий.
имя_агрегатной_функции ([ALL | DISTINCT] выражение)
Именем агрегатной функции может быть AVG, COUNT, MAX, MIN или SUM, как по-
казано в табл. 4.1. Ключевое слово ALL (соответствующее поведению по умолчанию)
применяется для указания того, что при создании агрегатного результата функции
используются все строки. Ключевое слово DISTINCT показывает, что используются только
недублирующиеся значения.
Все агрегатные функции, кроме COUNIT*), при вычислении результата
игнорируют пустые значения (NULL).
604 | Глава 4. Функции SQL
AVG и SUM
Функция A VG вычисляет среднее значение для столбца или выражения. Функция SUM
вычисляет сумму. Обе функции работают с числовыми значениями и игнорируют
значения NULL. Ключевое слово DISTINCT используется для вычисления среднего
или суммы для всех неповторяющихся значений в столбце или выражении.
Стандартный синтаксис SQL
AVG ([ALL | DISTINCT] выражение)
SUM ([ALL | DISTINCT] выражение)
MySQL, PostgreSQL и SQL Server
Все эти платформы поддерживают для этих функций синтаксис SQL2003.
DB2 и Oracle
DB2 и Oracle поддерживают синтаксис ANSI, а также следующий синтаксис для анали-
тических целей.
AVG ([ALL | DISTINCT] выражение) OVER (оконное_предложение)
SUM ([ALL | DISTINCT] выражение) OVER (оконное_предложение)
За объяснениями параметра окониое_предложение обращайтесь к разделу «Оконные
функции ANSI SQL» ниже в этой главе.
Пример
Следующий запрос вычисляет средний объем продаж с начала года для каждого типа
книг.
SELECT type, AVG( ytd_sales ) AS 'average_ytd_sales"
FROM titles
GROUP BY type;
Следующий запрос возвращает суммарный объем продаж с начала года для каждого
типа книг.
SELECT type, SUM( ytd_sales )
FROM titles
GROUP BY type;
Агрегатные функции ANSI SQL | 605
CORR
Функция CORR возвращает коэффициент корреляции между наборами зависимых
и независимых переменных.
Синтаксис SQL2003
Функция вызывается с двумя переменными: одной - зависимой, а другой - независимой.
CORR (зависимая, независимая)
Любая пара, в которой либо одна, либо другая переменная, либо обе сразу равны
NULL, игнорируется. Результат функции будет пустым значением, если все входные
пары включают пустые значения.
Oracle
Платформа Oracle поддерживает синтаксис SQL2003 и следующий аналитический
синтаксис.
CORR (зависимая, независимая) OVER (оконное_предложение)
За объяснениями параметра оконное предложение обращайтесь к разделу «Оконные
функции ANSI SQL» ниже в этой главе.
DB2, MySQL, PostgreSQL и SQL Server
Эти платформы ни в какой форме не поддерживают эту функцию.
Пример
В следующем примере в функции CORR использует данные, показываемые первой
инструкцией SELECT.
SELECT * FROM test2;
Y X
1 3
2 2
3 1
SELECT CORR(y.x) FROM test2;
CORR(Y.X)
-1
606 | Глава 4. Функции SQL
COUNT
Функция COUNT используется для вычисления количества строк в выражении.
Синтаксис SQL2003
COUN7 О)
COUNT ([ALL | DISTINCT] выражение)
COUNT]*)
Подсчитываются все строки в целевой таблице независимо от того, есть в них
пустые значения (NULL) или нет.
COUNT ([ALL | DISTINCT] выражение)
Вычисляется количество строк с непустыми значениями в указанном столбце или
выражении. При использовании ключевого слова DISTINCT игнорируются дуб-
лирующиеся строки и выводится только количество недублирующихся значений.
При использовании ключевого слова ALL возвращается количество непустых значений
в выражении. Эго поведение используется, если не указано слово DISTINCT.
MySQL, PostgreSQL и SQL Server
Все эти платформы поддерживают для функции COUNT синтаксис SQL2003.
DB2 и Oracle
Поддерживают стандартный синтаксис ANSI, а также следующий аналитический син-
таксис.
CO'jNT ({* i [DIS'INCT] выражение)) OVER (оконное_.предложение)
За объяснениями параметра оконное предложение обращайтесь к разделу «Оконные
функции ANSI SQL» ниже в этой главе.
Пример
Этот запрос подсчитывает количество строк в таблице.
SELECT COUNT]*) FROM publishers
Следующий запрос определяет количество стран, в которых находятся издатели.
SELECT COUNT(DISTINCT country) "Counr cf Countries"
FROM publishers
_______
Функция COVARPOP возвращает значение ковариации генеральной совокупности
для набора зависимых и независимых значений.
Синтаксис SQL2003
Переменная вызывается с указанием двух переменных: одной - зависимой и одной
независимой.
Агрегатные функции ANSI SQL | 607
COVAR_POP (зависимая, независимая)
Функция не рассматривает пары, в которых либо зависимая переменная, либо
независимая, либо обе равны NULL. Если после удаления пустых значений строк
в группе не остается, то результатом функции будет NULL.
Oracle
Платформа Oracle поддерживает синтаксис SQL2003 и, кроме того, реализует сле-
дующий аналитический синтаксис.
COVAR_POP (зависимая, независимая) OVER (оконное_предложение)
За объяснениями параметра оконное-Предложение обращайтесь к разделу «Оконные
функции ANSI SQL» ниже в этой главе.
DB2
В DB2 данная функция называется CORRELA TION.
MySQL, PostgreSQL и SQL Server
Эти платформы не поддерживают ни одну из форм функции COVARPOP.
Пример
В следующем примере использования функции COVARPOP используются данные,
выводимые первой инструкцией SELECT.
SELECT * FROM test2;
Y X
1 3
2 2
3 1
SELECT COVAR_POP(y,x) FROM test2;
COVAR_POP(Y, X)
-.66666667
COVAR_SAMP
Функция COVAR SAMP возвращает выборочную ковариацию для набора из зависимой
и независимой переменной.
Синтаксис SQL2003
Переменная вызывается с указанием двух переменных: одной - зависимой и одной
независимой.
608 | Глава 4. Функции SQL
COVAR_SAMP (зависимая, независимая')
Функция не рассматривает пары, в которых либо зависимая переменная, либо
независимая, либо обе равны NULL. Результат функции будет пустым значением,
если все входные пары включают пустые значения.
Oracle
Платформа Oracle поддерживает синтаксис SQL2003 и, кроме того, реализует следующий
аналитический синтаксис.
COVAR_SAMP (зависимая, независимая') OVER (оконное_предложение)
За объяснениями параметра оконное^предложение обращайтесь к разделу «Оконные
функции ANSI SQL» ниже в этой главе.
DB2, MySQL, PostgreSQL и SQL Server
Эти платформы не поддерживают ни одну из форм функции COVARJSAMP.
Пример
В следующем примере использования функции COVAR_SAMP используются данные,
выводимые первой инструкцией SELECT.
SELECT * FROM test2;
Y X
1 3
2 2
3 1
SQL> SELECT COVAR_SAMP(y,x) FROM test2;
COVAR_SAMP(Y,X)
-1
CUME_DIST
Вычисляется относительный ранг гипотетической строки в группе строк. Ранг вычис-
ляется следующим образом.
число_строк_предшествующих_гипотетической + число_строк_равных_гипотетической) /
число_строк_в_группе
Запомните, что в число _строк_в_гру те входит гипотетическая строка, которую
вы указываете при вызове функции.
39 - 2447
Агрегатные функции ANSI SQL | 609
Синтаксис S0L2003
В следующей схеме синтаксиса элементы списка_значений соответствуют по положению
элементам списка_для_сортировки. Следовательно, оба списка должны содержать одина-
ковое число выражений.
СиМЕ_015Т(слисо/<_значений) WITHIN. GROUP (ORDER BY список_для_сортировки')
список_значений :: = выражение [.выражение...]
список_для_сортировки :: = элемент_сортировки1 [, элементы_сортировки... ]
элемент_сортировки ::= выражение [ASC|DESC] [NULLS FIRST|NULLS LAST]
Oracle
Платформа Oracle поддерживает синтаксис SQL2003, а также следующий аналитиче-
ский синтаксис.
CUME_DIST OVER ([секционирование'] сортировка )
За объяснениями предложений секционирование и сортировка обращайтесь к разделу
«Оконные функции ANSI SQL» ниже в этой главе.
DBS, MySQL, PostgreSQL и SQL Server
В этих платформах нет реализации агрегатной функции CUME_DIST.
Пример
В следующем примере определяется относительный ранг новой гипотетической
строки (num = 4, odd - 1) в каждой группе строк из таблицы test4, где группы различаются
по значениям столбца odd.
SELECT * FROM test4;
NUM ODD
0 0
1 1
2 0
3 1
3 1
4 0
5 1
SELECT odd, CUME_DIST(4,1) WITHIN GROUP (ORDER BY num, odd)
FROM test4
GROUP BY odd;
610 | Глава 4. Функции SQL
ODD CUME_DIST(4,1)WITHINGROUP(ORDERBYNUM, ODD)
О 1
1 .8
В группе odd = О новая строка идет после трех строк (0,0), (2,0) и (4,0). Равна она
будет сама себе. Общее число строк в группе будет равно 4, включая саму гипотетиче-
скую строку. Следовательно, относительный ранг будет вычислен следующим образом.
(3 строки предшествующие + 1 равная) /(Зв группе + 1 гипотетическая) = 4/4=1
В группе odd = 1 новая строка будет идти после трех -- (1,1), (3,1) и дубликата
(3,1). Опять только одна равная строка - сама гипотетическая строка. Количество
строк в группе равно 5, включая гипотетическую строку. Относительный ранг будет
следующий.
(3 строки предшествующие + 1 равная) / (4 в группе + 1 гипотетическая) = 4/5=0.8
DEI\ISE_RAI\IK
Для указанной гипотетической строки определяется ее ранг в группе. Этот ранг -
плотный. Ранги не пропускаются, даже если группа содержит строки с одинаковым
рангом.
В следующей схеме синтаксиса элементы списка_значений соответствуют по положе-
нию элементам списка_для_сортировки. Следовательно, оба списка должны содержать
одинаковое число выражений.
DENSE_.RANK(список_значений') WITHIN GROUP (ORDER BY список_для_сортировки)
список_значений ::= выражение [.выражение...']
список_для_сортировки элемент_сортировки1 [,элементы_сортировки... ]
элемент_сортировки ::= выражение [ASCiDESC] [NULLS FIRST|NULLS LAST]
Oracle
Платформа Oracle поддерживает синтаксис SQL2003, а также следующий аналитиче-
ский синтаксис.
DENSE_RANK() OVER (.[секционирование] сортировка )
За объяснениями предложений секционирование и сортировка обращайтесь к раз-
делу «Оконные функции ANSI SQL» ниже в этой главе.
DB2, MySQL, PostgreSQL и SQL Server
В этих платформах нет реализации агрегатной функции DENSE_RANK. Однако DB2
поддерживает DENSE_RANK в виде аналитической функции. За объяснениями обра-
щайтесь к разделу «Оконные функции ANSI SQL» ниже в этой главе.
Агрегатные функции ANSI SQL | 611
Пример
В следующем примере определяется плотный ранг новой гипотетической строки (num = 4,
odd = 1) в каждой группе строк из таблицы test4, где группы различаются по значениям
столбца odd.
SELECT * FROM test4;
ODD
2
3
3
4
5
SELECT odd, DENSE_RANK(4,1) WITHIN GROUP (ORDER BY num, odd)
FROM test4
GROUP BY odd;
ODD DENSE_RANK(4,1)WITHINGROUPfORDERBYNUM,ODD)
4
3
В группе odd = 0 новая строка идет после трех строк (0,0), (2,0) и (4,0), и, таким
образом, ее положение будет 4. В группе odd = 1 новая строка будет идти после трех -
(1,1), (3,1) и дубликата (3,1). В этом случае дубликаты (3,1) будут оба иметь ранг #2,
так что новая строка будет иметь ранг 3. Сравните с функцией RANK, которая дает
другой результат.
MIN и МАХ
Функции МШ(выражение) и МАХ(выражение) определяют минимальное и макси-
мальное значения выражения (строкового, дата/время или числового) в наборе строк.
С этими функциями можно использовать предложения DISTINCT и ALL, но на результат
они не влияют.
Синтаксис SQL2003
MIN( [ALL | DISTINCT] выражение )
MAX( [ALL | DISTINCT] выражение )
612 | Глава 4. Функции SQL
PostgreSQL и SQL Server
Эти платформы поддерживают для функций M1N и МАХ синтаксис стандарта
SQL2OO3.
DBS и Oracle
Платформы DB2 и Oracle поддерживают синтаксис ANSI, а также реализуют следующий
аналитический синтаксис.
MIN( [ALL | DISTINCT] выражение ) OVER (.оконное_предложение')
MAX( [ALL | DISTINCT] выражение ) OVER (оконное_предложение)
За объяснениями параметра оконное_предложение обращайтесь к разделу «Оконные
функции ANSI SQL» ниже в этой главе.
MySQL
Платформа MySQL поддерживает для функций M1N и МАХ стандартный синтаксис
SQL2003. Кроме того, MySQL поддерживает функции LEAST!) и GREATEST() с той
же функциональностью.
Пример
Следующий запрос определяет наилучший и наихудший объем продаж для каждой
книги.
SELECT MIN(ytd_sales), MAX(ytd_sales)
FROM titles;
Агрегатные функции часто применяются в предложениях HAVING запросов, содержа-
щих предложение GROUP BY. Следующий запрос отбирает все категории (типы) книг,
для которых средняя цена книг в категории превышает 15.00$.
SELECT type 'Category', AVG( price ) 'Average Price'
FROM titles
GROUP BY type
HAVING AVG(price) > 15
PERCENT_RAI\IK
Генерируется значение относительного ранга для гипотетической строки путем деле-
ния ранга этой строки, за вычетом 1, на число строк в группе.
Синтаксис SQLS003
В следующей схеме синтаксиса элементы списка_значений соответствуют по положению
элементам списка_для_сортировки. Следовательно, оба списка должны содержать
одинаковое число выражений.
РЕНСЕНТ_НАНК(слисок_значений) WITHIN GROUP (ORDER BY список__для_сорт правки)
список_значений ::= выражение [,выражение. . . ]
Агрегатные функции ANSI SQL | 613
список_для_сортировки ::= элемент_сортировки1 [,элементы_сортировки...]
элемент_сортировки ::= выражение [ASC|DESC] [NULLS FIRST,NULLS LAST]
Oracle
Платформа Oracle поддерживает синтаксис SQL2003, а также следующий аналитический
синтаксис.
PERCENT_RANK() OVER ([секционирование'] сортировка)
За объяснениями предложений секционирование и сортировка обращайтесь к разделу
«Оконные функции ANSI SQL» ниже в этой главе.
DBS, MySQL, PostgreSQL и SQL Server
В этих платформах нет реализации агрегатной функции PERCENTRANK.
Пример
В следующем примере определяется процентный ранг новой гипотетической строки
(num = 4, odd = 1) в каждой группе строк из таблицы test4, где группы различаются по
значениям столбца odd.
SELECT » FROM test4;
NUM ODD
0 0
1 1
2 0
3 1
3 1
4 0
5 1
SELECT odd, PERCENT_RANK(4,1) WITHIN GROUP (ORDER BY num, odd)
FROM test4
GROUP BY odd;
ODD PERCENT_RANK(4,1)WITHINGROUP(ORDERBYNUM, ODD)
0 1
1 .75
В группе odd = 0 новая строка идет после трех строк (0,0), (2,0) и (4,0), и, таким обра-
зом, ее положение будет 4. Ранг вычисляется так: (ранг 4 - 1)/3 строки = 100%. В группе
odd = 1 новая строка будет идти после (1,1), (3,1) и дубликата (3,1). Так что новая строка
будет иметь ранг #4. Вычисление ранга для odd = 1: (ранг 4 - 1 )/4 строки = 3/4 = 75%.
614 | Глава 4. Функции SOL
PERCENTILE-CONT
Генерируется интерполяционное значение, соответствующее указанному процентилю.
Синтаксис SQL2003
В следующем синтаксисе процентиль - это число от 0 до 1.
PERCENTILE_CONT(процентиль) WITHIN GROUP (ORDER BY список_для_сортировки)
список_для_сортировки :: = элемент_сортировки [, элемент_сортировки. . . ]
элемент_сортировки ::= выражение [ASC|DESC] [NULLS FIRSTJNULLS LAST]
Oracle
Платформа Oracle позволяет использовать в предложении ORDER BY только одно
выражение.
PERCENTILE_CONT(процентиль) WITHIN GROUP (ORDER BY выражение)
Кроме того, Oracle позволяет использовать оконный синтаксис.
PERCENTILE_CONT(процентиль) WITHIN GROUP
(ORDER BY список_для_сортировки) OVER (секционирование)
За объяснениями предложения секционирование обращайтесь к разделу «Оконные
функции ANSI SQL» ниже в этой главе.
DB2, MySQL, PostgreSQL и SQL Server
В этих платформах нет реализации агрегатной функции PERCENTILE CONT.
Пример
В следующем примере данные таблицы test4 группируются по столбцу odd и вызывается
функция PERCENTILEJCONT, которая возвращает значение 50-го процентиля для каждой
группы.
SELECT * FROM test4;
NUM ODD
0 0
1 1
2 0
3 1
3 1
4 0
5 1
SELECT odd, PERCENTILE_CONT(O.50) WITHIN GROUP (ORDER BY NUM)
FROM test4
GROUP BY odd;
Агрегатные функции ANSI SQL | 615
ODD PERCENTILE_CONT(O.5O)WITHINGROUP(ORDERBYNUM)
О 2
1 3
PERCENTILEDISC
Из группы возвращается значение, которое имеет наименьшее кумулятивное распре-
деление, большее или равное указанному процентилю.
Синтаксис SQL2003
В следующем синтаксисе процентиль - это число от 0 до 1.
PERCENTILE_DISC(npo«eH7i«7b) WITHIN GROUP (ORDER BY список_для_сортировки)
список_для_сортировки :: = элемент_сортировки [, элемент_сортировки. . . ]
элемент_сортировки ::= выражение [ASC|DESC] [NULLS FIRSTINULLS LAST]
Oracle
Платформа Oracle позволяет использовать в предложении ORDER BY только одно
выражение.
РЕНСЕНТ1ЕЕЛ8С(лроценталь) WITHIN GROUP (ORDER BY выражение)
Кроме того, Oracle позволяет использовать оконный синтаксис.
РЕНСЕМТ1ЕЕ_015С(лроценталь) WITHIN GROUP
(ORDER BY список_дпя_сортировки) OVER (секционирование)
За объяснениями предложения секционирование обращайтесь к разделу «Оконные
функции ANSI SQL» ниже в этой главе.
DBS, MySQL, PostgreSQL и SQL Server
В этих платформах нет реализации агрегатной функции PERCENTILE_DISC.
Пример
Следующий пример сходен с примером функции PERCENTILE_CONT, за исключением
того, что для каждой группы возвращается значение ближайшее, но не превышающее
60-го процентиля.
SELECT * FROM test4;
NUM ODD
0 0
1 1
2 0
3 1
3 1
616 | Глава 4. Функции SQL
4 О
5 1
SELECT odd, PERCENTILE_DISC(O. 60) WITHIN GROUP (ORDER BY NUM)
FROM test4
GROUP BY odd;
PERCENTILE_CONT(O.50)WITHINGR0UP(0RDERBYNUM)
2
3
RANK
Для указанной гипотетической строки вычисляется ранг в группе. Это не плотный
ранг. Если в группе есть строки, имеющие одинаковый ранг, то возможен пропуск ран-
гов. Если вы хотите использовать плотный ранг, применяйте функцию DENSERANK.
В следующей схеме синтаксиса элементы списка_значений соответствуют по положе-
нию элементам спискадлясортировки. Следовательно, оба списка должны содержать
одинаковое число выражений.
К/\М.(список_,значений') WITHIN GROUP (ORDER BY список_для_сортировки')
список_значений выражение [,выражение. ..]
список_для_сортировки := элемент_сортировки [,элемент_сортировки...]
элемент_сортировки ::= выражение [ASC|DESC] [NULLS FIRST|NULLS LAST]
Oracle
Платформа Oracle поддерживает синтаксис SQL2003, а также следующий аналитиче-
ский синтаксис.
RANK() OVER ([секционирование'] сортировка)
За объяснениями предложений секционирование и сортировка обращайтесь к разделу
«Оконные функции ANSI SQL» ниже в этой главе.
DBS, MySQL, PostgreSQL и SQL Server
В этих платформах нет реализации агрегатной функции RANK.
Пример
В следующем примере определяется ранг новой гипотетической строки (num = 4, odd = 1)
в каждой группе строк из таблицы test4, где группы различаются по значениям
столбца odd.
Агрегатные функции ANSI SQL | 617
SELECT * FROM test4;
NUM ODD
О О
1 1
2 О
3 1
3 1
4 О
5 1
SELECT odd, RANK(4, 1) WITHIN GROUP (ORDER BY num, odd)
FROM test4
GROUP BY odd;
ODD RANK(4,1)WITHINGROUP(ORDERBYNUM,ODD)
0 4
1 4
В обоих случаях ранг гипотетической функции будет 4. В группе odd = 0 новая
строка идет после строк (0,0), (2,0) и (4,0), и, таким образом, ее положение будет 4.
В группе odd = 1 новая строка будет идти после (1,1), (3,1) и дубликата (3,1). В этом
случае новая строка идет после трех строк, так что она будет иметь ранг 4. Сравните
с функцией DENSE JUNK.
Семейство функций REGR
В SQL2OO3 определяется семейство функций, имена которых начинаются с REGR_
и которые связаны с различными аспектами линейной регрессии. Эти функции рабо-
тают с линией регрессии, получаемой методом наименьших квадратов.
Синтаксис SQL2003
Ниже приводится синтаксис и краткое описание функций REGR_.
REGRJ УОХ(зависимая, независимая)
Средняя величина (как в AVG(x)) значений независимых переменных.
REGRjyGYJieucuMax, независимая)
Средняя величина (как в A VG(y)) значений зависимых переменных.
REGR COUNTf'iaeucuMan, независимая)
Определяется количество пар чисел, не содержащих пустых (NULL) значений.
REGRJNTERCEPT(3aeucu:.iaH, независимая)
Вычисляется точка пересечения линии регрессии с осью Y (y-intercept).
REGR_R2(3aeucuMaH, независимая)
Вычисляется коэффициент детерминации.
REGR JLOPECiaeucuMaii, независимая)
Вычисляется крутизна линии регрессии.
618 | Глава 4. Функции SQL
REGR SXX(3aeuciiMm, независимая.)
Сумма квадратов значений независимых переменных.
REGR_SXY(3aeucuMctH, независимая)
Сумма произведений каждой пары значений.
REGR_SYY(3aeucuMOH, независимая)
Сумма квадратов значений зависимых переменных.
Функции REGR_ применимы только к парам чисел, содержащим непустые значе-
ния. Пара, содержащая одно или два пустых значения, игнорируется.
DBS и Oracle
Платформы DB2 и Oracle поддерживают синтаксис SQL2OO3 для всех функций
REGR_. Кроме того, DB2 поддерживает укороченное имя REGRJCPT вместо
REGRJNTERCEPT.
Oracle поддерживает следующий аналитический синтаксис.
НЕСА_функция (зависимая, независимая') OVER (оконное_предложение)
За объяснениями параметра оконное ^предложение обращайтесь к разделу «Оконные
функции ANSI SQL» ниже в этой главе.
MySQL, PostgreSQL и SQL Server
Эти платформы не имеют реализации семейства функций REGR_.
Пример
В следующем примере функции REGRJ3OUNTдемонстрируется, что функция игнорирует
пары значений, содержащие одно или два пустых значения. Таблица test3 содержит
три пары непустых чисел и еще три пары, в которых хотя бы одно значение - NULL.
SQL> SELECT « FROM test3;
Y X
1 3
2 2
3 1
4 NULL
NULL 4
NULL NULL
Функция REGR COUNT игнорирует пары, содержащие пустые значения, и считает
только те пары, значения в которых не равны NULL.
SELECT REGR_COUNT(y,х) FROM test3;
REGR._COUNT(Y, X)
3
Агрегатные функции ANSI SQL | 619
Точно так же и все другие функции семейства REGR_ перед вычислениями
отфильтровывают пары, содержащие пустые значения.
STDDEV_POP
Используйте функцию STDDEV_POP, чтобы найти стандартное отклонение совокуп-
ности в группе числовых значений.
Синтаксис SQLS003
STDDEV_POP(числовое_выражение)
DBS и MySQL
Используется функция STDDEV. В DB2 и MySQL функция STDDEV возвращает стан-
дартное отклонение совокупности.
PostgreSQL
В этой платформе нет функции для вычисления стандартного отклонения совокупности.
Oracle
Платформа Oracle поддерживает стандартный синтаксис, а также следующий анали-
тический синтаксис.
STDDEV_POP(числовое_выражение') OVER (оконное_предложение)
За объяснениями параметра оконное^предложение обращайтесь к разделу «Оконные
функции ANSI SQL» ниже в этой главе.
SQL Server
Используйте функцию STDEVP.
Пример
В следующем примере вычисляется стандартное отклонение совокупности для значе-
ний 1, 2 и 3.
SELECT * FROM test;
X
1
2
3
SELECT STDDEV_POP(x) FROM test;
STDDEV_POP(X)
.816496581
620 | Глава 4. Функции SQL
STDDEV.SAMP
Применяйте функцию STDEVSAMP для того, чтобы найти выборочное стандартное
отклонение в группе числовых значений.
Синтаксис SQLS003
STDDEV_SAMP(числовое_выражение)
Oracle
Платформа Oracle поддерживает стандартный синтаксис. Кроме того, в Oracle есть
функция S7DDEV, которая работает почти так же, как STDDEVJSAMP, за исключением
того, что она возвращает ноль (непустое значение), если в наборе есть только одно
значение.
Также Oracle поддерживает аналитический синтаксис.
STDDEV_SAMP(числовое_выражение') OVER (оконное_предло>кение')
За объяснениями параметра оконное_предложение обращайтесь к разделу «Оконные
функции ANSI SQL» ниже в этой главе.
DBS
У этой платформы нет функции для вычисления выборочного стандартного отклонения.
MySQL
В MySQL нет функции для вычисления выборочного стандартного отклонения.
В MySQL есть функция под названием STDDEV, но она возвращает стандартное откло-
нение совокупности.
PostgreSQL
Используйте функцию STDDEV.
SQL Server
Используйте функцию STDEV (одно D1).
Пример
В приведенном ниже примере вычисляется выборочное стандартное отклонение для
значений 1, 2 и 3.
SELECT * FROM test:
X
1
2
3
SELECT STDDEV_SAMP(x) FROM test;
Агрегатные функции ANSI SQL | 621
STDDEV_SAMP(X)
1
VAR_POP
Используйте функцию VARPOP для вычисления дисперсии генеральной совокупности
для набора значений.
Синтаксис SQL2003
VAR_P0P(числовое_выражение)
DB2 и PostgreSQL
Эти платформы не предлагают функций для вычисления дисперсии совокупности.
MySQL
Используйте функцию VARIANCE, которая в MySQL возвращает дисперсию генеральной
совокупности.
Oracle
Платформа Oracle поддерживает стандартный синтаксис, а также следующий анали-
тический синтаксис.
VAR—РОР(числовое_выражение~) OVER (оконное^предложение')
За объяснениями параметра оконное_предложение обращайтесь к разделу «Оконные
функции ANSI SQL» ниже в этой главе.
SQL Server
Используйте функцию VARP.
Пример
В следующем примере вычисляется дисперсия генеральной совокупности для значе-
ний 1, 2 и 3.
SELECT * FROM test;
X
1
2
3
SELECT VAR_P0P(x) FROM test;
VAR_POP(X)
.666666667
622 | Глава 4. Функции SQL
VAR.SAMP
Используйте функцию VAR_SAMP для вычисления выборочной дисперсии набора
значений.
Синтаксис SQL2003
VAR_SAMP (числовое_выражение')
DB2 и PostgreSQL
Эти платформы для вычисления выборочной дисперсии применяют функцию
VAR/ANCE(числовое выражение).
MySQL
В MySQL нет функции для вычисления выборочной дисперсии. Есть функция VARIANCE,
но она возвращает дисперсию генеральной совокупности.
Oracle
Платформа Oracle поддерживает стандартный синтаксис. Вы также можете использо-
вать функцию VARIANCE, которая отличается от VAR SAMP тем, что возвращает ноль
(а не NULL) в случае, если набор содержит только одно значение.
Oracle также поддерживает следующий аналитический синтаксис.
'Р\г{_$М^Р(числовое_выра>кение') OVER (оконное_предложение')
За объяснениями параметра оконное_предложение обращайтесь к разделу «Оконные
функции ANSI SQL» ниже в этой главе.
SQL Server
Используйте функцию VAR.
Пример
В следующем примере вычисляется дисперсия генеральной совокупности для значе-
ний 1,2 и 3.
SELECT » FROM test;
X
1
2
3
SELECT VAR_SAMP(x) FROM test:
VAR_SAMP(X)
1
Агрегатные функции ANSI SQL | 623
Оконные функции ANSI SQL
Стандарт SQL2003 позволяет использовать при вызове агрегатных функций окон-
ное_предложение, которое позволяет превратить эти функции в оконные функции.
Синтаксис оконных функций поддерживают DB2 и Oracle. В этом разделе описывает-
ся применение оконного_предложения в Oracle и DB2.
В Oracle оконные функции, как правило, называются аналитическими функ-
циями.
Оконные, или аналитические, функции сходны со стандартными агрегатными
функциями в том, что они работают с множеством или группами строк в резуль-
тирующем наборе, возвращаемом запросом. Однако группы строк, с которыми рабо-
тают оконные функции, определены не предложением GROUP BY, а предложениями
секционирования и оконными предложениями. Более того, сортировка в этих группах
определяется сортирующим предложением, и этот порядок влияет только на работу
функции, не оказывая влияния на то, в каком порядке строки будут возвращаться
запросом.
Оконные функции - это последнее, что выполняется в запросе, за исключе-
нием предложения ORDER BY. Из-за этого оконные функции нельзя исполь-
зовать в предложениях WHERE, GROUP BY или НА VING.
Синтаксис оконных функций SQL2003
Стандарт SQL2003 предлагает следующий синтаксис для оконных функций.
FUNCTION—NAME(вираж) OVER {имя_окна](спецификация_окна)}
спецификация_окна : := [имя_окна][секционирование][сортировка][кадрирование]
секционирование ::= PARTITION BY знач [,знач...] [COLLATE имя_сопоставления]
сортировка ::= ORDER [SIBLINGS] BY правило [, правило...]
правило ::= [значение]положение]псевдоним} [ASC|DESC] [NULLS {FIRST|LAST}]
кадрирование ::= {ROWS|RANGE} {начало]между} [исключение]
начало ::= {UNBOUNDED PRECEDING]целое_без_знака PRECEDING]CURRENT ROW}
между ::= BETWEEN граница AND граница
граница ::= {начало]UNBOUNDED FOLLOWING] целое_без_знака FOLLOWING}
исключение ::= {EXCLUDE CURRENT ROW|EXCLUDE GROUP
|EXCLUDE TIES|EXCLUDE NO OTHERS}
624 | Глава 4. Функции SQL
Синтаксис оконных функций Oracle
Синтаксис оконных функций в Oracle следующий.
FUNCTION_NAME(выраж) OVER {оконное_предложение}
оконное__предложение ::= [секционирование][сортировка [кадрирование]')
секционирование PARTITION BY знач [,знач...]
сортировка = ORDER [SIBLINGS] BY правило [, правило...]
правило ::= {значение]положение\псевдоним} [ASC|DESC] [NULLS {FIRST!LAST}]
кадрирование {ROWS|RANGE} {не_диапазон\начало AND конец}
не_диапазон ::= {UNBOUNDED PRECEDING
|CURRENT ROW|
[значение PRECEDING}
начало ;:= {UNBOUNDED PRECEDING
(CURRENT ROW|
I значение {PRECEDING!FOLLOWING}}
конец ::= {UNBOUNDED FOLLOWING
(CURRENT ROW|
| значение {PRECEDING(FOLLOWING}}
Синтаксис оконных функций DBS
Синтаксис DB2 сходен с синтаксисом Oracle. Для функций OLAP, ранжирующих
функций и числовых функций DB2 предлагает следующий синтаксис.
FUNCTION_NAME(выраж) OVER {оконное_предложение}
оконное_предложение [секционирование] [сортировка]
секционирование ::= PARTITION BY (знач [,знач. . . ])
сортировка ::= {ORDER BY правило [, правило...] | ORDER OF имя_таблицы }
правило ::= {значение]положение]псевдоним} [ASCIDESC [NULLS {FIRST!LAST}]]
Если в качестве оконных функций используются агрегатные функции (например,
AVG), DB2 позволяет использовать предложение кадрирование.
FUNCTION_NAME(eb/pa«) OVER (оконное_предложение)
оконное_предложение ::= [секционирование] [сортировка [кадрирование]]
[все|кадрирование]
все ::= RANGE UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING
40 - 2447
Оконные функции ANSI SQL | 625
секционирование ::= PARTITION BY (.значение [, значение...])
сортировка ::= {ORDER BY правило [.правило. , .] | ORDER OF имя_таблицы}
правило [значение]положение]псевдоним} [ASC|DESC [NULLS {FIRST|LAST}]]
кадрирование ::= {ROWS | RANGE} [начало_группы] группа_между\конец_группы}
начало_группы ::= {UNBOUNDED PRECEDING\целое_без_знака PRECEDING
{CURRENT ROW}
группа_между ::= BETWEEN {UNBOUNDED PRECEDING) целое_без_знака PRECEDING
|unsigned-integer FOLLOWING|CURRENT ROW}
AND {UNBOUNDED FOLLOWING| целое_без_знака PRECEDING
| целое_без_знака FOLLOWING{CURRENT ROW}
конец_группы :: = UNBOUNDED FOLLOWING) целое_без_знака FOLLOWING}
Секционирование
Секционирование строк, производимое предложением секционирование, сходно с исполь-
зованием предложения GROUP BY в стандартной инструкции SELECT. Предложение
секционирование использует список выражений, которые будут применяться для разделе-
ния результирующего набора на группы. В качестве основы для нескольких примеров
мы будем использовать следующую таблицу.
SELECT * FROM odd_nums;
NUM ODD
0 0
1 1
2 0
3 1
Следующий запрос иллюстрирует результат секционирования по столбцу ODD.
Сумма четных чисел равна 2 (0 + 2), а сумма нечетных -4(1 + 3). Во втором столбце
результирующего набора выводится сумма всех значений раздела, к которому принад-
лежит данная строка. Этот запрос выдает суммарные результаты по каждой строке.
SELECT NUM, SUM(NUM) OVER (PARTITION BY ODD) S
FROM ODD_NUMS;
NUM S
0 2
2 2
1 4
3 4
Без использования секционирования запрос просуммирует все числа в столбце NUM
для каждой строки, ‘возвращаемой запросом. В итоге весь результирующий набор
будет считаться одним большим разделом.
626 | Глава 4. Функции SQL
SELECT NUM, SUM(NUM) OVER () S FROM ODD_NUMS;
NUM S
О 6
1 6
2 6
3 6
Сортировка
Порядок обработки строк аналитической функцией указывается при помощи предло-
жения сортировка. Однако этот порядок не влияет на сортировку результирующего
набора данных. Чтобы задать сортировку результирующего набора, необходимо
использовать предложение ORDER BY. Следующий пример использования функции
F!RST_VALUE для Oracle иллюстрирует влияние разной сортировки разделов.
SELECT NUM,
SUM(NUM) OVER (PARTITION BY ODD) S,
FIRST_VALUE(NUM) OVER (PARTITION BY ODD ORDER BY NUM ASC) first.asc,
FIRST.VALUE(NUM) OVER (PARTITION BY ODD ORDER BY NUM DESC) first_desc
FROM ODD-NUMS;
NUM S FIRST-ASC FIRST_DESC
0 2 0 2
2 2 0 2
14 13
3 4 13
Как можно видеть, предложения ORDER BY в вызовах оконной функции влияют
на сортировку строк в соответствующих разделах при вычислении значений функции.
Так, предложение ORDER BY NUM ASC сортирует разделы по возрастанию и 0 стано-
вится первым значением в разделе с четными числами, а 1 - первым значением в раз-
деле с нечетными числами. Предложение ORDER BY NUM DESC приводит к противо-
положному результату.
Приведенный выше запрос также иллюстрирует и еще один важный
момент - используя оконные функции, вы можете проводить суммирования
и сортировки многими различными способами в одном запросе.
Группировка и обработка методом окна
Многие аналитические функции также позволяют указать виртуальное, сдвигающееся
окно, окружающее строку внутри раздела. Делается это при помощи предложения
кадрирование. Такие сдвигающиеся окна полезны при вычислении промежуточных
значений, например промежуточных сумм.
Оконные функции ANSI SQL | 627
В следующем примере для Oracle предложение кадрирование используется в ана-
литическом варианте функции SUM для вычисления промежуточной суммы значений
в первом столбце. Предложение секционирование не используется, так что каждый
вызов функции SUM работает со всем результирующим набором. Однако предложение
ORDER BY сортирует строки для функции SUM по возрастанию значений в столбце NUM,
а предложение BETWEEN (которое является оконным предложением) приводит к тому,
что в каждый вызов функции SUM включаются только значения до текущей строки.
Каждый следующий вызов функции SUM включает новое значение из столбца NUM,
в порядке от наименьшего значения NUM к наибольшему.
SELECT NUM, SUM(NUM) OVER (ORDER BY NUM ROWS
BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) S FROM ODD_NUMS;
NUM S
0 0
1 1
2 3
3 6
Этот пример довольно простой, поскольку сортировка результирующего набора
совпадает с сортировкой промежуточных сумм. Однако это не обязательно должно
быть так. В следующем примере генерируются те же результаты, но в другом порядке.
Можно видеть, что значения промежуточных сумм соответствуют значениям NUM,
но строки отсортированы не так, как раньше. Сортировка результирующего набора
полностью независима от сортировки, применяемой при вычислениях в оконной
функции.
SELECT NUM, SUM(NUM) OVER (ORDER BY NUM ROWS
BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) S FROM ODD_NUMS
ORDER BY NUM DESC;
NUM S
3 6
2 3
1 1
0 0
Список оконных функций
В стандарте SQL2003 определяется, что любая агрегатная функция может использо-
ваться в качестве оконной функции. Платформы Oracle и DB2 в этом отношении
в довольно большой степени соответствуют стандарту, так что вы можете взять почти
любую агрегатную функцию (и особенно стандартную) и применить в ней оконный
синтаксис, описанный в предыдущих разделах.
Помимо агрегатных функций в стандарте SQL2003 определяются оконные функции,
описываемые в следующих разделах. В настоящее время эти функции реализованы
только в Oracle и DB2. Во всех примерах используется следующая таблица и данные,
628 | Глава 4. Функции SQL
которые являются вариантом таблицы ODDNUMS, использованной ранее для иллюстра-
ции понятий секционирования, сортировки и группировки.
SELECT * FROM test4;
NUM ODD
0 0
1 1
2 0
3 1
3 1
4 0
5 1
Платформо-специфические функции Oracle (в DB2 таких нет) включены в список
в разделе «Платформо-специфические расширения» ниже в этой главе.
________
Вычисляется кумулятивное распределение или относительный ранг текущей строки
относительно других строк в том же разделе. Вычисление производится следующим
образом.
Количество совпадающих или предшествующих строк / Количество строк в разделе
Поскольку результат для данной строки зависит от количества строк, предшест-
вующих данной строке в разделе, нужно всегда указывать при вызове этой функции
предложение ORDER BY.
Синтаксис SQL2003
CUME_DIST( ) OVER {имя_окна \(спецификация_окна')}
DBS
Платформа DB2 не поддерживает оконную функцию CUME_DIST().
Oracle
Платформа Oracle не позволяет использовать в окопном синтаксисе предложение
кадрирование. Обязательным является использование предложения сортировка.
CUME_DIST( ) OVER {[секционирование} сортировка)
Пример
В следующем примере для Oracle функция C.UMEJDIST() используется для генерации
относительного ранга для каждой строки и сортировки по столбцу NUM после секцио-
нирования по столбцу ODD.
Оконные функции ANSI SQL | 629
SELECT NUM, ODD, CUME_DIST( ) OVER
(PARTITION BY ODD ORDER BY NUM) cumedist
FROM test4;
NUM ODD CUMEDIST
О 0 ,333333333
2 О .666666667
4 О 1
1 1 .25
3 1 .75
3 1 .75
5 1 1
Ниже приводится объяснение вычислений ранга строки, в которой значение NUM
равно 0.
1. В соответствии с предложением ORDER BY строки раздела сортируются следующим
образом:
NUM = О,
NUM = 2,
NUM = 4.
2. Перед строкой NUM = 0 нет других строк.
3. Есть только одна строка, с которой совпадает строка NUM = 0, - сама строка NUM = 0.
Поэтому делитель будет равен 1.
4, Всего в разделе три строки, поэтому делимое будет равно 3.
5. Результатом деления 1/3 будет 0.33333 (в периоде), и это видно в выходных данных
примера.
DENSE_RANK
Ранг присваивается всем строкам раздела, который нужно отсортировать в определенном
порядке. Ранг данной строки вычисляется путем подсчета числа строк, предшествующих
данной строке, после чего к результату прибавляется 1. Строки со значениями, которые
в предложении ORDER BY дублируются, будут иметь одинаковый ранг. В отличие от
функции RANK() две строки с одинаковым рангом не будут приводить к появлению
пробелов в нумерации рангов.
Синтаксис SQL2003
DENSE_RANK( ) OVER {имя_окна | (спецификация_окна)}
DB2
Платформа DB2 требует наличия предложения сортировка и не позволяет использовать
предложение кадрирование.
DENSE_RANK( ) OVER ([секционирование] сортировка)
630 | Глава 4. Функции SQL
Oracle
Платформа Oracle также требует наличия предложения сортировка и не позволяет исполь-
зовать предложение кадрирование.
DENSE_RANK( ) OVER ([секционирование'] сортировка)
Пример
Сравните результаты следующего примера для Oracle с тем, который приведен в разделе,
посвященном функции RANK().
SELECT NUM, DENSE_RANK( ) OVER (ORDER BY NUM) rank
FROM test4;
NUM RANK
0 1
1 2
2 3
3 4
3 4
4 5
5 6
Две строки, где значение NUM = 3, обе получают ранг 3. Следующая по возрастанию
строка получает ранг 4. Номера рангов не пропускаются, отсюда и термин «dense»
(плотный).
RANKO
Ранг присваивается всем строкам раздела, которые нужно отсортировать в определенном
порядке. Ранг данной строки вычисляется путем подсчета числа строк, предшест-
вующих данной строке, после чего к результату прибавляется 1. Строки со значениями,
которые в предложении ORDER BY дублируются, будут иметь одинаковый ранг, и это
ведет к появлению пробелов в нумерации рангов.
Синтаксис SQL2003
RANK( ) OVER {имя_окна \(спецификация_окна)}
DB2
Платформа DB2 требует наличия предложения сортировка и не позволяет использовать
предложение кадрирование.
RANK( ) OVER ([секционирование] сортировка)
Oracle
Платформа Oracle также требует наличия предложения сортировка и не позволяет исполь-
зовать предложение кадрирование.
RANK( ) OVER ([секционирование] сортировка)
Оконные функции ANSI SQL | 631
Пример
В следующем примере для Oracle столбец NUM используется для ранжирования
строк в таблице test4.
SELECT NUM, RANK( ) OVER (ORDER BY NUM) rank
FROM test4;
NUM RANK
0 1
1 2
2 3
3 4
3 4
4 6
5 7
Поскольку обе строки, где NUM = 3, получают ранг 4, то следующая по возраста-
нию строка получает ранг 6. Ранг 5 пропускается.
PERCENT_RANK()
Относительный ранг строки вычисляется путем деления ранга этой строки, за выче-
том 1, на количество строк в разделе, также за вычетом 1.
(ранг - 1) / (число строк - 1)
Сравните это вычисление с тем, которое используется в функции CUME_DIST().
Синтаксис SQL2003
PERCENT_RANK( ) OVER {имя_окна \(спецификация_окна)}
DB2
Платформа DB2 не поддерживает оконную функцию PERCENT_RANK().
Oracle
Платформа Oracle также требует наличия предложения сортировка и не позволяет исполь-
зовать предложение кадрирование.
PERCENT_RANK( ) OVER (.[секционирование] сортировка')
Пример
В следующем примере для Oracle относительный ранг присваивается в соответствии
со значениями NUM, секционирование данных производится по столбцу ODD.
SELECT NUM, ООО, PERCENT_RANK( ) OVER
(PARTITION BY ODD ORDER BY NUM) cumedist
FROM test4;
632 | Глава 4. Функции SQL
NUM ODD CUMEDIST
ООО
2 0 .5
4 О 1
1 1 О
3 1 .333333333
3 1 .333333333
5 1 1
Ниже приводится объяснение вычисления ранга строки со значением NUM = 2.
1. Строка NUM = 2 является второй строкой раздела, следовательно ее, ранг будет
равен 2.
2. Вычитаем 1 из 2 и получаем делитель 1.
3. Для делимого возьмем общее число строк раздела, т. е. 3.
4. Вычтем 1 из 3 и получим делимое 2.
5. Результат 1/2 = 0,5, что и видно на примере.
ROWNUMBER
Каждой строке раздела присваивается уникальный номер.
Синтаксис SQLS003
ROW..NUMBER( ) OVER [имя_окна \(спецификация_окна)}
DBS
Платформа DB2 не позволяет использовать предложение кадрирование, а предложение
сортировка здесь необязательное.
ROW..NUMBER( ) OVER ([секционирование'] [сортировка])
Oracle
В Oracle предложение сортировка является обязательным, а предложение кадрирование
не используется.
ROW_.NUMBER( ) OVER ([секционирование] сортировка)
Пример
SELECT NUM, ODD, ROW..NUMBER( ) OVER
(PARTITION BY ODD ORDER BY NUM) cumedist
FROM test4:
NUM ODD CUMEDIST
0 0 1
2 0 2
4 0 3
Оконные функции ANSI SQL | 633
1 1 1
3 1 2
3 1 3
5 1 4
Скалярные функции ANSI SQL
Скалярные функции ANSI SQL при каждом вызове возвращают одно значение. Стандарт
SQL определяет множество скалярных функций, которые можно использовать для
работы со значениями типа дата/время, со строками и числами, а также для получения
системной информации, такой, как имя текущего пользователя или учетной записи.
Скалярные функции делятся на категории, которые перечислены в табл. 4.2.
Таблица 4.2. Категории скалярных функций
Категория Объяснение
Встроенные Выполняют операции над значениями и параметрами, входящими в базу данных. В Oracle термин «встроенные» используется для описания всех специальных функций, которые предлагает Oracle, и которые «встроены» в СУБД. Этот способ применения термина отличается от «встроенных функций», которые мы описываем здесь
CASE и CAST Притом что эти функции оперируют скалярными входными значениями, они выделены в отдельную категорию. Функция CASE привносит в инструкции SQL логику IF-THEN, а функция CAST позволяет производить приведение типов данных
Дата/время Эти функции работают со значениями типа дата/время и возвращают значения в формате дата/время. В стандарте SQL2003 нет функции, которая работала бы со значениями дата/время и возвращала бы значение в этом же формате. Наибо- лее близкой функцией является функция EXTRACT (которая описывается в разделе «Числовые скалярные функции» ниже в этой главе), которая оперирует значениями дата/время и возвращает результат в числовом формате. Функции, которые возвращают значения формата дата/время, но выполняются без аргументов, описываются ниже в разделе «Встроенные скалярные функции»
Числовые Работают с числовыми значениями и возвращают числовые значения
Строковые Работают с символьными значениями (CHAR, VARCHAR, NCHAR, NVARCHAR и CLOB) и возвращают строковое или числовое значение
Встроенные скалярные функции
Во встроенных скалярных функциях SQL2003 указывается текущий пользовательский
сеанс и параметры текущего пользовательского сеанса, такие, как текущие привиле-
гии. Функции CURRENT DATE, CURRENT_TIME и CURRENTTIMESTAMP, упоми-
наемые в табл. 4.3, являются встроенными функциями, относящимися к категории
дата/время. Хотя пять описываемых платформ содержат множество дополнительных
функций, не входящих в число стандартных встроенных функций, в стандарте SQL
определяются только те, которые перечислены в табл. 4.3.
634 | Глава 4. Функции SQL
Таблица 4.3. Встроенные скалярные функции ANSI SQL
Функция Использование
CURRENT-DATE Возвращает текущую дату
CURRENT_TIME Возвращает текущее время
CURRENT_TIMESTAMP Возвращает текущую дату и время
CURRENT_USER or USER Возвращает имя активного в данный момент пользователя сервера базы данных
SESSION_USER Возвращает активный в настоящий момент идентификатор авторизации (Authorization ID), если он отличается от текущего пользователя
SYSTEM-USER Возвращает имя активного в данный момент пользователя операци- онной системы сервера
DBS
Платформа DB2 поддерживает встроенные скалярные функции SQL2003
CURRENT-DATE, CURRENT_TIME, CURRENTTIMESTAMP, CURRENT USER и USER.
Скалярные функции SQL2003 CURRENT ROLE, LOCAL TIME, LOCAL_TIMESTAMP,
SESSIONJJSER и SYSTEMUSER не поддерживаются.
MySQL
Платформа MySQL поддерживает все встроенные скалярные функции SQL2003 плюс
вариант Oracle под названием SYSDATE. Кроме того, MySQL поддерживает функцию
NOW() как синоним функции CURRENT_TIMESTAMP.
Oracle
Платформа Oracle поддерживает функцию USER и функцию SYSDATE как синоним
функции CURRENT_TIMESTAMP. '
PostgreSQL
Платформа PostgreSQL поддерживает все встроенные скалярные функции SQL2003,
за исключением функции SESSION_USER.
SQL Server
Платформа SQL Server поддерживает все встроенные скалярные функции.
Примеры
В приведенных запросах извлекаются значения, возвращаемые встроенными функ-
циями.
/* В MySQL */
SELECT CURRENTTIMESTAMP;
'2001-12-15 23:50:26'
/* DB2 ♦/
Скалярные функции ANSI SQL | 635
VALUES CURRENT JHMESTAMP
'2001-12-15 23.50.26.000000'
/* В Microsoft SQL Server */
SELECT CURRENT_TIMESTAMP
GO
'Dec 15,2001 23:50:26'
/* В Oracle */
SELECT USER FROM dual;
dylan
Функции CASE и CAST
В ANSI SQL2003 есть функция CASE, которую можно использовать для реализации
логики управления обработкой по принципу IF-THEN в запросах и инструкциях, свя-
занных с обновлением данных. Функция CAST предназначена для преобразования
типов данных, и она также входит в стандарт ANSI. Все платформы, описываемые
в этой книге, поддерживают функции CASE и CAST стандарта ANSI.
CASE
Функция CASE позволяет использовать функциональность 1F-THEN-ELSE в инструк-
циях SELECT и UPDATE. Эта функция проверяет список условий и возвращает одно
из нескольких возможных значений.
Инструкция CASE имеет два способа применения: простой и поисковый. Простые
выражения CASE сравнивают одно значение (входное _значение) со списком других
значений и возвращают результат, соответствующий первому совпавшему значению.
Поисковые выражения CASE позволяют проанализировать несколько логических условий,
и как только одно из них оказывается истинным, выражение возвращает соответст-
вующий этому условию результат.
Все платформы поддерживают для функции CASE синтаксис стандарта ANSI
SQL2003.
Синтаксис SQLS003 и описание
-- Простая операция сравнения
CASE входное_значение
WHEN ycnoene_when THEN результирующее_значение
[...n]
[ ELSE альтернативное_результирующее_значение']
END
-- Булева поисковая операция
CASE
WHEN булево_условие THEN результирующее_значение
[...n]
[ELSE альтернативное_результирук>1цее_значение]
END
636 | Глава 4. Функции SQL
В простой функции CASE входное значение проверяется на соответствие каждому
предложению WHEN. Результирующее значение возвращается при первой истинности
условия входное ^значение = условие_when. Если ни одно из условий-when не оказыва-
ется истинным, то возвращается альтернативное результирующее значение. Если
это альтернативное значение не указано, возвращается NULL.
Структура более сложной булевой поисковой операции по сути аналогична структуре
простой операции сравнения, за исключением того, что для каждого предложения
WHEN существует своя булева операция сравнения.
При любом способе применения функции можно использовать несколько предло-
жений WHEN, но необходимо только одно предложение ELSE.
Примеры
Ниже приводится пример операции сравнения, в котором функция CASE изменяет
способ вывода столбца contract, чтобы сделать его более понятным.
SELECT au_fname,
au_lname,
CASE contract
WHEN 1 THEN 'Yes'
ELSE 'No'
END 'contract'
FROM authors
WHERE state = 'CA'
Ниже приводится более сложная поисковая функция CASE в инструкции SELECT,
которая определяет, сколько книг (titles) было продано в разные периоды с начала года.
SELECT CASE
WHEN ytd_sal.es IS NULL THEN 'Unknown'
WHEN ytd_sales <= 200 THEN 'Not more than 200'
WHEN ytd_sal.es <= 1000 THEN 'Between 201 and 1000
WHEN ytd_sales <= 5000 THEN 'Between 1001 and 5000
WHEN ytd_sales <= 10000 THEN 'Between 5001 and 10000
ELSE 'Over 10000'
END 'YTD Sales',
C0UNT(«) 'Number of Titles'
FROM titles
GROUP BY CASE
WHEN ytd_sales IS NULL THEN 'Unknown'
WHEN ytd_sales <= 200 THEN 'Not more than 200'
WHEN ytd_sales <= 1000 THEN 'Between 201 and 1000
WHEN ytd_sales <= 5000 THEN 'Between 1001 and 5000
WHEN ytd_sales <= 10000 THEN 'Between 5001 and 10000
ELSE 'Over 10000'
END
ORDER BY MIN( ytd_sal.es )
Скалярные функции ANSI SQL | 637
Результат будет следующий.
YTD Sales Number of Titles
Unknown 2
Not more than 200 1
Between 201 and 1000 2
Between 1001 and 5000 9
Between 5001 and 10000 1
Over 10000 3
Ниже приводится инструкция UPDATE, которая применяет скидки (discounts) ко
всем книгам (titles). Эта более сложная команда применяет скидку 25% ко всем кни-
гам, связанным с компьютерами, скидку 10% - ко всем прочим книгам и только 5% -
к книгам, продажи которых с начала года (ytd_sales) превысили 10 000 штук. В этом
запросе для изменения цен используется поисковое выражение CASE.
UPDATE titles
SET price = price *
CASE
WHEN ytd_sales > 10000 THEN 0.95 -- 5% discount
WHEN type = 'popular_comp' THEN 0.75 -- 25% discount
ELSE 0.9 -- 10% discount
END
WHERE pub_date IS NOT NULL
Производится сразу три операции обновления в одной инструкции.
CAST
Команда CAST неявно преобразует выражение с одним типом данных в другой тип.
Все производители поддерживают стандартный синтаксис ANSI SQL.
Синтаксис SQL2003 и описание
CAST(выражение AS тип_данных[(длина')']')
Функция CAST преобразует любое выражение, например значение в столбце или
переменную, в другой, указанный тип данных. Для тех типов, которые поддерживают
указание длины (например, CHAR или TARCHAR), можно указать длину.
НУжн0 3,iamb’ что некоторые преобразования, например такие, как пре-
'л'’’ а « образование значений DECIMAL к INTEGER, приводят к операциям округ-
' ления. Кроме того, некоторые преобразования могут завершиться ошиб-
кой, если у нового типа данных нет достаточно места для отображения
преобразованного значения.
638 | Глава 4. Функции SQL
Примеры
В данном примере мы извлекаем объем продаж с начала года (ytd_sales) в тип CHAR
и соединяем его с определенной строкой и частью названия книги. Значение ytd_sales
преобразуется в тип CHAR(5), а заголовок укорачивается, чтобы сделать его более
удобным для чтения.
SELECT CAST(ytd_sales AS CHAR(5)) + ' Copies sold of ’ + CAST(title AS VARCHAR(30))
FROM titles
WHERE ytd_sales IS NOT NULL
AND ytd_sales > 10000
ORDER BY ytd.sales DESC
Результат будет следующий
22246 Copies sold of The Gourmet Microwave
18722 Copies sold of You Can Combat Computer Stress
15096 Copies sold of Fifty Years in Buckingham Paia
Числовые скалярные функции
Список официально утвержденных числовых функций SQL2003 довольно небольшой,
и разные платформы предлагают дополнительные математические и статистические
функции. Платформа MySQL непосредственно поддерживает многие из этих функ-
ций. Другие платформы предоставляют сходные возможности при помощи своих соб-
ственных внутренних функций, но их названия отличаются от тех, которые указаны
в стандарте ANSI. Поддерживаемые числовые функции и их синтаксис описываются
в табл. 4.4.
Таблица 4.4. Числовые функции SQL2003
Функция Применение
ABS Возвращает абсолютное значение числа
MOD Возвращается остаток отделения одного числа па другое
BITJLENGTH Возвращается целое число, показывающее число бит в другом числе
CEIL или CEILING Нецелое число округляется в большую сторону до ближайшего целого. Целое число возвращается без изменений
CHAR_LENGTH Возвращается целое число, показывающее количество символов в строковом выражении
EXP Число возводится в степень, равную математической константе е
EXTRACT Позволяет извлечь дату (YEAR, MONTH, DAY, HOUR, MINUTE, SECOND, TIMEZONEJIOUR или TIMEZONE_MINUTE) из выражения типа дата/ время
FLOOR Нецелое число округляется в меньшую сторону до ближайшего целого. Целое число возвращается без изменений
LN Возвращается натуральный логарифм числа
Скалярные функции ANSI SQL | 639
Таблица 4.4. Числовые функции SQL2003 (Продолжение)
OCTET_LENGTH Возвращается целое число, показывающее количество октетов в другом числе. Это значение аналогично BIT_LENGTH/8
POSITION Возвращается целое число, показывающее начальное положение строки в строке поиска
POWER Число возводится в указанную степень
SQRT Вычисляется квадратный корень числа
WIDTH_BUCKET Присваивается значения столбцам равноширинной гистограммы
ABS
Все платформы поддерживают функцию ABS стандарта SQL2OO3.
Синтаксис SQL2003
ABS (выражение')
Эта функция возвращает абсолютное значение числа в выражении.
Пример
Ниже показано, как используется функция ABS.
/* SQL2003 */
SELECT ABS(-1) FROM NUMBERS
1
BIT_LENGTH, CHARJ.ENGTH, OCTET-LENGTH
Все платформы при поддержке скалярных функций для определения длины выраже-
ний несколько отклоняются от стандарта ANSI. Хотя стандарт платформами и не под-
держивается, существуют функции с другими именами, но аналогичной функциональ-
ностью.
Синтаксис SQL2003
В SQL2003 скалярные функции, определяющие длину значения, принимают выраже-
ние, вычисляют значение, определяют его длину и возвращают ее в виде целого числа.
Функция BIT LENGTH возвращает количество бит в значении выражения. Функция
CHAR LENGTH возвращает количество символов в строковом выражении. Функция
OCTET_LENGTH возвращает количество октетов в строковом выражении. Все три
функции возвращают NULL, если выражение равно NULL.
BIT_LENGTH(выражение)
CHAR_LENGTH( выражение')
OCTET_LENGTH (выражение')
640 | Глава 4. Функции SQL
DBS
Платформа DB2 не поддерживает функции B1T_LENGTH, CHAR_LENGTH
и OCTET_LENGTH. Но DB2 поддерживает скалярную функцию LENGTH(), имеющую
сходные возможности применительно к неграфическим строковым типам. Для гра-
фических строковых типов функция LENGTH() возвращает количество двухбайтных
символов в строке.
MySQL
Платформа MySQL поддерживает функцию CHAR LENGTH и синоним функции
SQL2003 под названием CHARCTER_LENGTH().
Oracle
Ближе всего подходит к реализации функции BIT_LENGTH платформа Oracle. В Oracle
есть функция LENGTHB, которая возвращает целое число, показывающее количество
байт в выражении. Для определения длины выражения в символах в Oracle есть функция
LENGTH() - синоним функции CHAR_LENGTH.
PostgreSQL
Платформа MySQL поддерживает функцию CHARJLENGTH и синоним функции
SQL2003 под названием CHARCTER_LENGTH().
SQL Server
В SQL Server есть функция LEN.
Пример
В следующем примере, в котором приведен код для нескольких баз данных, определя-
ется длина строки и значение помещается в столбец.
/* Для MySQL и PostgreSQL */
SELECT CHAR_LENGTH('hello');
SELECT OCTET_LENGTH(book_title) FROM titles;
/* Для Microsoft SQL Server */
SELECT DATALENGTH(title)
FROM titles
WHERE type = 'popular^comp'
GO
/* Для Oracle и DB2 */
SELECT LENGTH('HORATIO') "Length of characters"
FROM dual;
41-2447
Скалярные функции ANSI SQL | 641
CEIL
Функция CEIL возвращает наименьшее целое число, большее, чем указанное входное
значение.
Синтаксис SQL2003
Стандарт SQL2003 поддерживает две формы этой функции.
CEIL {выражение')
CEILING {выражение)
DBS
Платформа DB2 поддерживает оба варианта синтаксиса SQL2003.
MySQL
Платформа MySQL поддерживает только вариант CEILING.
Oracle
Платформа Oracle поддерживает только вариант CEIL.
PostgreSQL
Платформа PostgreSQL поддерживает оба варианта - CEIL и CEILING.
SQL Server
Платформа SQL Server поддерживает только вариант CEILING.
Примеры
Если вы передаете положительное нецелое значение, то функция CEIL округляет его
до следующего большего целого.
SELECT СЕЩ100.1) FROM dual;
FLOOFK100.1)
101
Однако запомните, что при использовании отрицательных чисел округление идет
до числа с меньшим абсолютным значением.
SELECT СЕЩ-100.1) FROM dual;
FLOOR(-100.1)
-100
Если вам нужна функциональность, противоположная CEIL, используйте функ-
цию FLOOR.
642 | Глава 4. Функции SQL
EXP
Функция EXP возвращает значение математической константы е (приблизительно
2.718281), возведенное в степень, равную указанному числу.
Синтаксис SQL2003
Все платформы поддерживают синтаксис SQL2003.
ЕХР (выражение')
Пример
В следующем примере выводится приблизительное значение константы е.
SELECT ЕХР(1) FROM dual;
ЕХР(1)
2.71828183
Чтобы выполнить обратное преобразование, используйте функцию LN.
EXTRACT
Функцию EXTRACT поддерживают платформы Oracle, PostgreSQL и MySQL. На
других платформах эту функциональность реализуют другие команды.
Синтаксис SQL2003
EXTRACT (часть_даты FROM выражение)
Скалярная функция стандарта SQL2003 EXTRACT используется для извлечения
компонентов даты. Функция EXTRACT принимает в качестве параметров часть_даты
и выражение и на их основе создает значение типа дата/время.
DB2
В DB2 есть свои функции, которые предоставляют те же возможности, что и функ-
ция EXTRACT. Эти функции следующие: DAY, DAYNAME, DAYOFWEEK,
DAYOFWEEK ISO, DAYOFYEAR, DAYS, HOUR, JU LIAN J) AY, MICROSECOND,
MIDNIGHT_SECONDS, MINUTE, MONTH, MONTHNAME, SECOND, TIME, WEEK,
WEEKJSO и YEAR. Примеры использования этих функций приведены в разделе
«Расширения, поддерживаемые DB2» ниже в этой главе. Как и в Oracle, в DB2 есть
функция TOCHAR, с помощью которой можно сформировать строку по значению
типа дата.
Для получения в DB2 частей даты, например года или минут, в виде целых
значений используйте имеющиеся в DB2 специальные функции, а не функ-
цию TO CHAR. Так вы добьетесь большей производительности, поскольку
не нужно будет преобразовывать результирующую строку в целое число.
Скалярные функции ANSI SQL | 643
MySQL
Реализация данной функции в MySQL несколько расширена по сравнению со стан-
дартом ANSI. Стандарт ANSI не предоставляет возможности получить несколько
полей при одном вызове функции EXTRACT (например, DAY_HOUR). Расширения
MySQL пытаются достигнуть того, что можно получить в PostgreSQL путем комби-
нирования функций DATE_TRUNC() и DATE_PART(). Платформа MySQL поддержи-
вает следующие части даты, перечисленные в табл. 4.5.
Таблица 4.5. Части даты в MySQL
Значение Объяснение
SECOND Секунды
MINUTE Минуты
HOUR Часы
DAY Дни
MONTH Месяцы
YEAR Годы
MINUTE_SECOND Минуты и секунды
HOURJ4INUTE Часы и минуты
DAY_HOUR Дни и часы
YEAR-MONTH Годы и месяцы
HOUR_SECOND Часы, минуты и секунды
DAY_MINUTE Дни, часы и минуты
DAY-SECOND Дни, часы, минуты и секунды
Oracle
Платформа Oracle поддерживает синтаксис SQL2003. Части даты перечислены в табл. 4.6.
Таблица 4.6. Части даты в Oracle
Значение Объяснение
DAY День месяца (1-31)
HOUR Поле часа (0-23)
MINUTE Поле минут (0-59)
MONTH Поле месяца (1-12)
SECOND Поле секунд (0-59)
TIMEZONE_HOUR Компонент «час» из поля смещения часового пояса (time zone offset)
644 | Глава 4. Функции SQL
Таблица 4.6. Части даты в Oracle (Продолжение)
TIMEZONE_MJNUTE Компонент «минуты» из поля смещения часового пояса (time zone offset)
TIM EZONE_REG ION Название текущего часового пояса
TIMEZONEABBR Аббревиатура текущего часового пояса
YEAR Поле года
PostgreSQL
Платформа PostgreSQL поддерживает синтаксис SQL2003 и несколько дополнительных
частей даты. Части даты, поддерживаемые PostgreSQL, перечислены в табл. 4.7.
Таблица 4.7. Части даты в PostgreSQL
Значение Объяснение
CENTURY Значение в поле года, деленное на 100
DAY День месяца (1-31)
DECADE Значение в поле года, деленное на 10
DOW День недели (0-6, где воскресенье 0). Этот тип работаег только со значениямиг TIMESTAMP
DOY День года (1-366). Максимальное число для певисокоспых лет - 365. Этот тип работает только со значениями TIMESTAMP
EPOCH Возвращается количество секунд, прошедших между началом отсчета (1970-01-01 00:00:00-00) и данным значением. Для значений до начала отсчета результат будет отрицательным
HOUR Значение в поле часа (0-23)
MICROSECONDS Поле секунд (включая дробные части), умноженное на 1,000,000
MILLENNIUM Год, деленный на 1,000
MILLISECONDS Поле секунд (включая дробные части), умноженное па 1,000
MINUTE Поле минут (0-59)
MONTH Поле месяца (1-12)
QUARTER Квартал года (1-4), к которому относится значение. Этот тип работает только со значениями TIMESTAMP
SECOND Поле секунд (0-59)
TIM EZONEHOUR Компонент «час» из поля смещения часового пояса (time zone offset)
TIMEZONE_MINUTE Компонеш' «минуты» из поля смещения часового пояса (time zone offset)
WEEK Номер недели, к которой относится значение, в году
YEAR Поле года
Скалярные функции ANSI SQL | 645
SQL Server
В SQL Server есть функция Е>АТЕРАЯТ(часть~даты, выражение), которая является
синонимом стандартной функции ЕХТРАСТ(часть_даты, выражение). Платформа
SQL Server поддерживает части даты, перечисленные в табл. 4.8.
Таблица 4.8. Части даты SQL Server
Значение Объяснение
year Поле года выражения дата/время. Для двухциферного и четырехциферного отображения года можно также использо- вать сокращения уу иуууу соответственно
quarter Квартал, к которому относится выражение типа дата/время. Можно также использовать сокращения q и qq
dayofyear День года для выражения типа дата/время. Можно использовать сокращения у и dy
day День месяца для выражения типа дата/время. Можно использо- вать сокращения d и dd
week Номер недели в году для выражения типа дата/время. Можно использовать сокращения wk и ww
weekday День недели для выражения типа дата/время. Можно использо- вать сокращение dw
hour Час для выражения типа дата/время. Можно использовать сокращение hh
minute Минута для выражения типа дата/время. Можно использовать сокращения п и mi
second Секунда для выражения типа дата/время. Можно использовать сокращения s и ss
millisecond Миллисекунда для выражения типа дата/время. Можно исполь- зовать сокращение ms
Пример
В данном примере извлекаются части из нескольких значений дата/время.
/* Для MySQL */
SELECT EXTRACT/YEAR FROM "2013-07-02");
2013
SELECT EXTRACT/YEAR.MONTH FROM "2013-07-02 01:02:03");
201307
SELECT EXTRACT/DAY_MINUTE FROM "2013-07-02 01:02:03");
20102
/* Для PostgreSQL */
SELECT EXTRACT/HOUR FROM TIMESTAMP '2001-02-16 20:38:40');
20
646 | Глава 4. Функции SQL
FLOOR
Функция FLOOR возвращает наибольшее целое значение, которое меньше указанного
входного значения.
Синтаксис SQL2003
Синтаксис SQL2003 поддерживают все платформы.
FLOOR (выражение)
Примеры
Если вы передаете в функцию положительное число, то действие функции будет состоять
в удалении всего, что стоит после десятичной точки.
SELECT FLOOR(100.1) FROM dual:
FLOOR(100.1)
100
Однако запомните, что в случае отрицательных чисел округление в меньшую
сторону соответствует увеличению абсолютного значения.
SELECT FL00R(-100.1) FROM dual;
FLOOR(-1OO.1)
-101
Чтобы получить эффект, противоположный действию функции FLOOR, исполь-
зуйте функцию CEIL.
__
Функция LN возвращает натуральный логарифм числа, т. е. степень, в которую нужно
возвести математическую константу е (приблизительно 2.718281), чтобы в результате
получить заданное число.
Синтаксис SQL2003
LN (выражение)
DB2, Oracle, PostgreSQL
Платформы DB2, Oracle и PostgreSQL поддерживают для функции LN синтаксис
SQL2003. DB2 и PostgreSQL также поддерживают функцию LOG как синоним LN.
MySQL и SQL Server
В MySQL и SQL Server есть своя собственная функция для вычисления натурального
логарифма - LOG.
LOG (выражение)
Скалярные функции ANSI SQL | 647
Пример
В следующем примере для Oracle вычисляется натуральный логарифм числа, прибли-
женно равного математической константе е.
SELECT LN(2.718281) FROM dual;
LN(2.718281)
.999999695
Чтобы выполнить противоположную операцию, используйте функцию ЕХР.
MOD
Функция MOD возвращает остаток от деления делимого на делитель. Все платформы
поддерживают синтаксис инструкции MOD стандарта SQL2003.
Синтаксис SQL2003
MOD (делимое, делитель)
Стандартная функция MOD предназначена для получения остатка от деления дели-
мого на делитель. Если делитель равен нулю, то возвращается делимое.
Пример
Ниже показано, как можно использовать функцию MOD в инструкции SELECT.
SELECT M0D(12, 5) FROM NUMBERS
2
POSITION
Функция POSITION возвращает целое число, показывающее начальное положение
строки в строке поиска.
Синтаксис SQL2003
Р03ТП(М(строка1 IN строка2)
Стандартная функция POSITION предназначена для получения положения первого
вхождения заданной строки (строка!) в строке поиска (строка2). Функция возвра-
щает 0, если строка! не встречается в строке2, и NULL - если любой из аргументов
равен NULL.
DB2
В DB2 есть эквивалентная функция POSSTR.
MySQL
Платформа MySQL поддерживает функцию POSITION в соответствии со стандартом
SQL2003.
648 | Глава 4. Функции SQL
Oracle
В Oracle есть эквивалентная функция INSTR.
PostgreSQL
Платформа PostgreSQL поддерживает функцию POSITION в соответствии со стан-
дартом SQL2003.
SQL Server
В SQL Server есть функции CHARINDEX и PATIIINDEX. Эти функции очень похожи,
за исключением того, что PATHINDEX позволяет использовать обобщающие символы
при указании критерия поиска.
Примеры
Л DB2 »/
SELECT POSSTRC'bar’, 'foobar');
4
/* On MySQL •/
SELECT LOCATE!'bar', 'foobar');
4
/> On MySQL and PostgreSQL */
SELECT POSITION! fu IN 'snafnu');
0
/* On Microsoft SQL Server */
SELECT CHARINDEX( 'de', 'abcdefg' )
GO
4
SELECT PATINDEX! '%fg', 'abcdefg' )
GO
6
POWER
Функция POWER используется для возведения числа в указанную степень.
Синтаксис SQL2003
POWER (.основание, показатель)
Результатом выполнения данной функции является основание, возведенное в степень,
определяемую показателем. Если основание отрицательно, то показатель должен быть
целым числом.
DBS, Oracle, PostgreSQL и SQL Server
Все эти производители поддерживают синтаксис SQL2003.
Скалярные функции ANSI SQL | 649
MySQL
Платформа MySQL поддерживает данную функциональность, Н(
этого ключевое слово POW.
POW (основание, показатель')
Пример
Возведение положительного числа в степень достаточно очевидно.
SELECT POWER(1O,3) FROM dual;
POWER(10,3)
1000
Любое число, возведенное в степень 0, равно 1.
SELECT POWER(O,0) FROM dual;
POWER(O.O)
1
Отрицательный показатель смещает десятичную точку влево.
SELECT P0WER(10,-3) FROM dual;
POWER(10,-3)
.001
SORT
Функция SQRT возвращает квадратный корень числа.
Синтаксис SQL2003
Все платформы поддерживают синтаксис SQL2003.
SORT (выражение)
Пример
SELECT SQRT(100) FROM dual;
SQRT(100)
10
650 | Глава 4. Функции SQL
WIDTH_BUCKET
Функция WIDTH BUCKET присваивает значения столбцам равноширинной гисто-
граммы.
Синтаксис SQLS003
В следующем синтаксисе выражение представляет собой значение, которое присваи-
вается столбцу гистограммы. Как правило, выражение основывается на одном или
нескольких столбцах таблицы, возвращаемых запросом.
WIDTH_BUCKET(выражение, min, max, столбцы-гистограммы)
Параметр столбцы гистограммы показывает количество создаваемых столбцов
гистограммы в диапазоне значений от min до тах. Значение параметра min включает-
ся в диапазон, а значение параметра тах не включается. Значение выражения при-
сваивается одному из столбцов гистограммы, после чего функция возвращает номер
соответствующего столбца гистограммы. Если выражение не подпадает под указан-
ный диапазон столбцов, функция возвращает либо 0, либо max + 1, в зависимости от
того, будет выражение меньшим, чем min, или большим или равным тах.
Примеры
В следующем примере целочисленные значения от 1 до 10 распределяются между
двумя столбцами гистограммы.
SELECT х, WIDTH_BUCKET(x,1,10,2)
FROM pivot;
X WIDTH_BUCKET(X,1,10,2)
1 1
2 1
3 1
4 1
5 1
6 2
7 2
8 2
9 2
10 3
Следующий пример более интересный. 11 значений от 1 до 10 распределяются
между тремя столбцами гистограммы для иллюстрации различия между значением
min, которое включается в диапазон, и значением тах, которое в диапазон не включа-
ется.
SELECT х, WIDTH_BUCKET(x,1, 10, 3)
FROM pivot;
Скалярные функции ANSI SQL | 651
X WIDTH_BUCKET(X,1,10,3)
1 1
2 1
3 1
4 2
5 2
6 2
7 3
8 3
9 3
9.9 3
10 4
Особое внимание обратите на результаты сХ = 1, Х = 9.9 и%= 10. Входное значение
параметра min, т. е. в данном примере - 1, попадает в первый столбец, обозначая нижнюю
границу диапазона, поскольку столбец № 1 определяется как х >= min. Однако входное
значение параметра max не входит в столбец с максимальными значениями. В данном при-
мере число 10 попадает в столбец переполнения, с номером max + 1. Значение 9.9 попадает
в столбец № 3, и это иллюстрирует правило, согласно которому верхняя граница диапазона
определяется как х < max.
Строковые функции и операторы
Основные строковые функции и операторы предоставляют разнообразные возможно-
сти и возвращают в качестве результата строковое значение. Некоторые строковые
функции являются двухэлементными, что означает, что они могут работать одновре-
менно с двумя строками. Стандарт SQL2003 поддерживает строковые функции, перечисленные в табл. 4.9. Таблица 4.9. Строковые функции и операторы SQL
Функция или оператор Использование
Оператор конкатенации Объединяет два и более строковых константных выражения, значения столбцов или переменные в одну строку
CONVERT Преобразует строку в другой формат в пределах одного набора символов
LOWER Преобразует символы строки в нижний регистр
OVERLAY Возвращает результат замены одной подстроки в строке на другую
SUBSTRING Возвращает часть строки
TRANSLATE Преобразует строку из одного набора символов в другой
TRIM Удаляет первые, последние или и те и другие символы из строки
UPPER Преобразует символы строки в верхний регистр
652 | Глава 4. Функции SQL
Оператор конкатенации
В SQL2003 определяется оператор конкатенации (||), который соединяет две отдель-
ные строки в одно строковое значение.
DB2
Платформа DB2 поддерживает оператор конкатенации SQL2003, а также его синоним -
функцию CONCA Т.
MySQL
Платформа MySQL поддерживает функцию CONCAT() - синоним оператора конкате-
нации SQL2003.
Oracle и PostgreSQL
Платформы PostgreSQL и Oracle поддерживают оператор конкатенации SQL2003 в виде
двойной вертикальной черты.
SQL Server
Платформа SQL Server использует знак плюса (+) в качестве синонима оператора конкате-
нации SQL2003. В SQL Server есть системный параметр CONCAT_NULL_YIELDS_NULL,
который регулирует поведение системы, если при конкатенации строковых значений
встречаются значения NULL.
Примеры
/« Синтаксис SQL2003 */
'stringr || 'string2' || 'string3'
'st ring 1string2string3'
/* Для MySQL »/
C0NCAT('stringl', ’string2')
stnng1string2'
Если любое из соединяемых значений - пустое, то возвращается пустая строка.
Кроме того, если в конкатенации принимает участие числовое значение, оно неявно
преобразуется в строковое.
SELECT CONCAT('Му ’bologna 'has ', 'а 'first ', 'name...');
'My bologna has a first name...'
SELECT CONCAT('My ', NULL, 'has ', 'first 'name...');
NULL
Скалярные функции ANSI SQL | 653
CONVERT и TRANSLATE
Функция CONVERT изменяет отображение символьной строки в пределах набора
символов и сопоставления. Например, функцию CONVERT можно использовать для
изменения числа бит, приходящихся на один символ.
Функция TRANSLATE переводит строковое значение из одного набора символов
в другой. Так, функцию TRANSLATE можно использовать для преобразования значения
из набора символов English в набор символов Kanji (японский) или Cyrillic (русский).
Сам перевод уже должен существовать - либо заданный по умолчанию, либо созданный
при помощи команды CREATE TRANSLATION.
Синтаксис SQL2003
CONVERT (,символьное_значение USING имя_символьного_преобразования')
ПЖИ\7Е.(символьное_значение USING имя_перевода')
Функция CONVERT преобразует символьное_значение к набору символов с име-
нем, указанным в параметре имя_символъного_преобразования. Функция TRANSLATE
преобразует символьное_значение к набору символов, указанному в имени перезода.
Среди рассматриваемых платформ только Oracle поддерживает функции CONVERT
и TRANSLATE в том виде, в каком они определяются в стандарте SQL2003. Реализация
функции TRANSLATE в Oracle очень сходна с SQL2003, но не идентична ему. В этой
реализации функция принимает только два аргумента и производит перевод только между
набором символов базы данных и набором символов с поддержкой национального языка.
Реализация функции CONV в MySQL только переводит числа с одного основания
в другое. А вот в SQL Server реализация функции CONVERТ весьма богата возможно-
стями и изменяет тип данных для выражения, но во всех прочих своих аспектах она
отличается от функции CONVERT стандарта SQL2003. Платформа PostgreSQL не под-
держивает функцию CONVERT, а реализация функции TRANSLATE преобразует все
вхождения символьной строки в любую другую символьную строку.
DB2
Платформа DB2 не поддерживает функцию CONVERT, а поддержка функции
TRANSLATE не соответствует стандарту ANSI. Функция TRANSLATE используется
для преобразования подстрок и, как исторически сложилось, является синонимом
функции UPPER, поскольку функция UPPER только недавно была добавлена в DB2.
Если функция TRANSLATE используется в DB2 с единственным аргументом в виде
символьного выражения, то результатом будет та же строка, преобразованная
в верхний регистр. Если функция используется с несколькими аргументами, например
TRANSLATE(ucmo4HUK, замена, совпадение), то функция преобразует все символы
в источнике, которые также есть в параметре совпадение. Каждый символ в источнике,
который находится в том же положении, что в параметре совпадение, будет заменен
символом из параметра замена. Ниже приводится пример.
654 | Глава 4. Функции SQL
TRANSLATE(Hello, World!')
'HELLO; WORLD1'
TRANSLATE('Hello, World!', 'wZ', '1W')
'Hewwo, Zorwd1
MySQL
Платформа MySQL не поддерживает функции TRANSLATE и CONVERT.
Oracle
Платформа Oracle поддерживает следующий синтаксис функций CONVERT и TRANSLATE.
CONVERT(симеольное_значение, целевой_набор_символов, исходный_нпбор_символов')
ТНА№ЕАТЕ(символьное_значение USING {CHAR_CS | NCHAR_CS})
В реализации Oracle функция CONVERT возвращает текст символьногозначения,
преобразованный в целевой_набор_символов. Параметр символьное_значение - это
строка, которую нужно преобразовать, параметр целевой_набор_символов - это назва-
ние набора символов, в который нужно преобразовать строку, а параметр исход-
ный_набор_символов - это набор символов, в котором строковое значение изначаль-
но хранилось.
Функция TRANSLATE в Oracle соответствует синтаксису ANSI, но вы можете вы-
бирать только один из двух наборов символов: набор символов базы данных
(CHAR CS) и набор символов с поддержкой национального языка (NCHAR CS).
В Oracle также поддерживается другая функция, которая также называ-
ется TRANSLATE (без использования ключевого слова USING). Эта функция
TRANSLATE никак не связана с преобразованием наборов символов.
Названия целевого и исходного наборов символов можно передавать либо в виде
строковых констант, либо в виде ссылки на столбец таблицы. Обратите внимание, что
при преобразовании строки в набор символов, в котором отображаются не все пре-
образуемые символы, можно подставлять символы-заменители.
Oracle поддерживает несколько общих наборов символов, к которым относятся наборы
US7ASCIL WE8DECDEC WE8HP.F7DEC, WE8EBCDIC500, WE8PC850h WE8ISO8859PI.
Например.
SELECT COiNVERT( 'Gro2', 'US7ASCII', 'WE8HP')
FROM DUAL;
Gross
PostgreSQL
Платформа PostgreSQL поддерживает инструкцию CONVERT стандарта ANSI, а пре-
образования здесь можно определять при помощи команды CREATE CONVERSION.
Реализация функции TRANSLATE в PostgreSQL предоставляет расширенный набор
функций, которые позволяют преобразовать любой текст в другой текст в пределах
указанной строки.
Скалярные функции ANSI SQL | 655
TRANSLATE (символьная_строка, из_текста, в_текст)
Вот несколько примеров:
SELECT TRANSLATEC'12345abcde', '5а’, ’XX');
'1234XXbcde’
SELECT TRANSLATE(title, ’Computer', 'PC')
FROM titles
WHERE type = 'Personal_computer'
SELECT CONVERT('PostgreSQL' USING iso_8859_1_to_utf_8)
'PostgreSQL'
SQL Server
Платформа SQL Server не поддерживает функцию TRANSLATE. Реализация функции
CONVERT в SQL Server не соответствует стандарту SQL2003. Эта функция в SQL
Server эквивалентна функции CAST.
CONVERT (тип_данных[(длина) | (точность, масштаб)}, выражение^, стиль})
Предложение стиль используется для определения формата преобразования даты.
За дополнительной информацией обращайтесь к документации SQL Server. Ниже
приводится пример.
SELECT title, C0NVERT(char(7), ytd.sales)
FROM titles
ORDER BY title
GO
LOWER и UPPER
Функции LOWER и UPPER позволяют быстро и просто изменить регистр строки,
чтобы символы отображались в нижнем (LOWER) или верхнем (UPPER) регистре.
Эти функции поддерживаются во всех реализациях, описываемых в этой книге.
Разные платформы, кроме того, поддерживают различные другие функции для форма-
тирования текста, которые являются специфичными для конкретной реализации.
Синтаксис SQL2003
LOWER(строка)
ирРЕР(строка)
Функция LOWER преобразует строку в нижний регистр, а функция UPPER, наоборот,
в верхний.
DB2 и MySQL
Эти платформы поддерживают скалярные функции LOWER и UPPER стандарта
SQL2003, а также их синонимы UCASE и LCASE.
656 | Глава 4. Функции SQL
Oracle, PostgreSQL и SQL Server
Эти платформы поддерживают скалярные функции LOWER и UPPER стандарта
SQL2003, и это показано в приведенном ниже примере.
Пример
SELECT LOWER('You Talkin То ME?'), UPPER('you talking to me’!');
you talkin to me?, YOU TALKING TO ME?!
OVERLAY
Функция OVERLAY вставляет одну строку в другую и возвращает результат.
Синтаксис SQL2003
0\/Ш-М(строка PLACING встраиваемая_строка FROM начало
[FOR длина])
Если хотя бы один из входных параметров будет равен NULL, функция возвращает
NULL. встраиваемая_строка заменяет количество символов, указываемое параметром
длина, в указанной строке, начиная с начала. Если длина не указана, то встраивае-
мая_строка заменит все символы, идущие в строке после начала.
DB2, MySQL, Oracle и SQL Server
Эти платформы не поддерживают функцию OVERLAY. Вы можете сымитировать действие
этой функции на этих платформах при помощи комбинации функции SUBSTRING
и оператора конкатенации.
PostgreSQL
Платформа PostgreSQL поддерживает для функции ОVERLAY стандарт ANSI.
Примеры
Ниже приводится пример использования функции OVERLAY.
/* SQL2003 и PostgreSQL */
SELECT OVERLAYC'DONALD DUCK' PLACING 'TRUMP' FROM 8) FROM NAMES;
'DONALD TRUMP'
SUBSTRING
Функция SUBSTRING позволяет извлечь одну строку из другой.
Синтаксис SQL2003
80ВЗ'УПЯЗ(строка_для_извлечения FROM начало [FOR длина]
[COLLATE имя__сопоставления"\)
Если хотя бы один из входных параметров равен NULL, функция SUBSTRING воз-
вращает NULL. Параметр строка_для_экстракции - это исходная строка, откуда
42 - 2447
Скалярные функции ANSI SQL | 657
нужно извлечь символьное значение. Это может быть строковая константа, столбец
таблицы, относящийся к символьному типу, или переменная символьного типа. Пара-
метр начало - это целочисленное значение, указывающее, с какой позиции нужно
начинать извлечение. Необязательный параметр длина - это целочисленное значение,
указывающее, сколько символов нужно извлечь, начиная с начала. Если дополнитель-
ное ключевое слово FOR опущено, то подстрока будет начинаться с начала и продол-
жаться до конца строки_для_извлечения.
DB2
5иВ5ТВ(сгрока_для_извлвчения, начало [, длина']')
Реализация данной функции в DB2, под названием SUBSTR, по большей части функ-
ционально эквивалентна стандартной функции SUBSTRING. Предложение COLLATE
не поддерживается. Если параметр длина опущен, то возвращается оставшаяся часть
строки (начиная с начала).
MySQL
В\)ВВ1В1КВ(строка_для_извлечения FROM начало)
Реализация данной функции в MySQL подразумевает, что символы будут извле-
каться с начала и извлечение будет продолжаться до конца строки.
Oracle
ВВВ5ЛВ(строка_для_извлечения, начало [, длина])
Реализация данной функции в DB2, под названием SUBSTR, по большей части функ-
ционально эквивалентна стандартной функции SUBSTRING. Предложение COLLATE
не поддерживается.. Если параметр начало представляет собой отрицательное число,
Oracle отсчитывает символы от конца строки_для_извлечения. Если параметр длина опу-
щен, извлекается оставшаяся часть строки (от начала).
PostgreSQL
5ВВ8УВ.1Н01(строка_для_извлечения [FROM wa4aao][F0R длина])
Платформа PostgreSQL в основном поддерживает стандарт ANSI, за исключением
того, что не поддерживается предложение COLLATE.
SQL Server
8ВВ8'[ПК01итрока_для_извлечения [FROM wa4aao][F0R длина])
Платформа SQL Server в основном поддерживает стандарт ANSI, за исключением
того, что не поддерживается предложение COLLATE. SQL Server позволяет использо-
вать эту команду применительно к тексту, изображениям и двоичным типам данных,
однако параметры начало и длина показывают здесь не количество символов, а количество
байт.
658 | Глава 4. Функции SQL
Примеры
Эти примеры, как правило, будут работать на всех пяти описываемых в этой книге
платформах. Только второй пример для Oracle, с отрицательным параметром начало,
не будет выполняться на других платформах (конечно, нужно перевести ключевое
слово Oracle SUBSTR в SUBSTRING).
/* Для Oracle, подсчет начинается слева */
SELECT SUBSTR('ABCDEFG',3,4) FROM DUAL;
'CDEF'
/* Для Oracle, подсчет начинается справа */
SELECT SUBSTRf’ABCDEFG',-5,4) FROM DUAL;
'CDEF'
/* Для MySQL */
SELECT SUBSTRI.NG('Be vewy, vewy quiet' FROM 5);
'wy, vewy quiet'
/* Для PostgreSQL или SQL Server */
SELECT au_]name, SUBSTRING(au_fname, 1. 1)
FROM authors
WHERE au_lname = 'Carson'
Carson C
TRIM
Функция TRIM удаляет из указанной символьной строки или значения типа BLOB
первые символы, последние символы или и те и другие сразу. Также эта функция уда-
ляет из указанной символьной строки и другие типы символов. По умолчанию функ-
ция удаляет указанный символ с обеих сторон символьной строки. Если удаляемый
символ не указан, по умолчанию функция удаляет пробелы.
Синтаксис SQL2003
TRIM( [ [{LEADING | TRAILING | BOTH}] [удаляемый_символ] FROM ]
целевая_строка
[COLLATE имя_сопоставленияУ)
Параметр удаляемый_символ указывает символ, который нужно удалить, целе-
вая_строка - это символьная строка, из которой нужно удалить символы. Если удаляе-
мый_символ не указан, функция TRIM удаляет пробелы. Функция COLLATE приводит
результирующий набор данных функции в соответствие с существующим сопоставлением.
DB2
В DB2 есть функции LTRIM и RTRIM, которые удаляют первые или последние пробелы
соответственно.
Скалярные функции ANSI SQL | 659
MySQL, Oracle, PostgreSQL
Эти платформы поддерживают синтаксис функции TRIM стандарта SQL2003.
Microsoft SQL Server
В SQL Server есть функции LTRIM и RTRIM, которые удаляют первые или последние
пробелы соответственно. В SQL Server функции LTRIM и RTRIM не могут применяться
для удаления других видов символов.
Примеры
SELECT TRIM(' wamalamadingdong ');
'wamalamadingdong'
SELECT LTRIM( RTRIM(' wamalamadingdong ') );
'wamalamadingdong'
SELECT TRIM(LEADING '19' FROM '1976 AMC GREMLIN');
'76 AMC GREMLIN'
SELECT TRIM!BOTH 'x' FROM 'xxxWHISKEYxxx');
'WHISKEY'
SELECT TRIM(TRAILING 'snack' FROM 'scooby snack');
'scooby
Платформо-специфические расширения
В следующих разделах приводится полный список и описание всех поддерживаемых
упомянутыми производителями функций. Эти функции специфичны для конкретной
платформы. Так, например, не существует гарантии, что функция MySQL будет под-
держиваться каким-то другим производителем.
Расширения, поддерживаемые DB2
В этом разделе приводится отсортированный по алфавиту список функций DB2, которые
являются специфическими для DB2 и не соответствуют стандарту ANSI. Приводятся
также примеры и соответствующие им результаты.
ABSVAL(4iioio)
Синоним функции АВ8(число). Пример:
VALUES! ABSVAL! -1 ) ) -> 1
АСОВ(число)
Возвращает арккосинус числа в диапазоне от -1 до 1. Результат лежит в диапазоне
от 0 до 1 и выражен в радианах. Например:
SELECT ACOS( 0 ) -> 1.570796
ASCII(meKcm)
Возвращает ASCII-код первого символа текста. Например:
SELECT ASCII!'х') -> 120
660 | Глава 4. Функции SQL
ASIN(4ucjio)
Возвращает арксинус числа в диапазоне от-1 до 1. Результат лежит в диапазоне от
-1/2 до 1/2 и выражен в радианах. Например:
SELECT ASIN( 0 ) -> 0.000000
ATAN(число)
Возвращает арктангенс любого числа. Результат лежит в диапазоне от -1/2 до 1/2,
и выражен в радианах. Например:
SELECT ATAN( 3.1415 ) -> 1.262619
ATAN2(4uc,ioJ, число2)
Возвращает арктангенс числа! и числа2. Значения числа! и числа2 не ограничи-
ваются, но результат лежит в диапазоне от-1 до 1 и выражен в радианах. Функция
ATAN2(x,y) похожа mATAN(y/x), за исключением того, что знаки х и у используют-
ся при определении квадранта числа. Например:
VALUES! ATAN2! 3.1415, 1 ) ) -> +3.08177595443792Е-001
ATANН (число)
Возвращает гиперболический арктангенс числа. Значение числа не ограничивает-
ся, но результат лежит в диапазоне от-1 до 1 и выражен в радианах. Например:
VALUES! ATANH! 0 ) ) -> +0.ООООООООООООООЕ+ООО
ВЮШТ(выражение)
Возвращается целочисленное 64-битовое представление выражения. Выражение
может представлять собой число, символьную строку, дату, время или отметку
времени (timestamp). Например:
SELECT BIGINT! ’1991-11-22’ ) -> 19911122
ВЬОВ(строка [, длина])
Возвращается представление строки в виде BLOB. Строка может представлять
собой строковое представление любого типа. В этом примере возвращаются значения
типа BLOB, созданные на основе таблицы employee_images, которая содержит
двоичную строку «JFIF».
SELECT image FROM employee_images WHERE image LIKE BLOB(')
СНАВ(выражение [, длина])
Возвращается представление выражения в виде символьной строки фиксирован-
ной длины. Дополнительный параметр длина представляет собой атрибут «длина»
возвращаемого символьного значения.
СНВ(число)
Возвращает символ с кодом ASCII, соответствующим указанному числу. Например:
VALUES! CHR(120) ) -> ’х’
CLOB(cmpoKa [, длина])
Возвращается представление строки в виде CLOB.
Платформо-специфические расширения | 661
С0АЬЕ8СЕ(выражение [,...])
Возвращается первый аргумент, не равный NULL. Например:
SELECT COALESCED,2,3) -> 1
CONCAT(cmpoKal, строка2)
Возвращается строка!, сцепленная со строкой2. Эквивалент оператора конкате-
нации (||). Например:
SELECT CONCATC au_lname, au_fname ) FROM authors -> 'JeffersonThomas'
СО8(число)
Возвращает косинус числа как угол, выраженный в радианах. Например:
SELECT COS(O) -> 1.000000
СО8Н(число)
Возвращает гиперболический косинус числа, выраженный в радианах. Например:
VALUES( C0SH(3.1415) ) -> +1.15908832931176Е+001
СОТ(число)
Возвращает котангенс числа. Например:
SELECT С0Т( 3.1415 ) -> -10792.88993953
DA ТЕ(выражение)
Возвращает значение даты из выражения. Если выражение представляет собой
целочисленное значение, то возвращаемая дата будет равна выражение-1 день
после 1 января 0001 года. Например:
SELECT DATE(3) -> '01/03/0001'
DA У(выражение)
Возвращает число дней в выражении типа дата. Например:
SELECT DAY(’1999-04-15') -> 15
DAYNAME(ebipa3icenue)
Возвращает название дня недели в выражении, используя локальные настройки
сервера базы. Например:
SELECT DAYNAME('1999-04-15') -> 'Thursday'
DAYOFWEEK(ebipa)iceHue), DAYOFWEEKJSOfebtpcoicenue), DAYOFYEAR(ebipaoiceHue)
Возвращает номер дня недели или дня года в выражении. Функция DAYOFWEEK
возвращает целое число от 1 до 7, где 1 соответствует воскресенью. Функция
DAYOFWEEK ISO также возвращает число в диапазоне от 1 до 7, но 1 соответст-
вует понедельнику. Функция DAYOFYEAR возвращает целое число в диапазоне от
1 до 366, и это число соответствует номеру дня, начиная с 1 января. Например:
VALUES( DAYOFWEEKU1999-04-15') ) -> 5
VALUES( DAY0FWEEK_IS0('1999-04-15') ) -> 4
VALUES( DAY0FYEAR('1999-04-15') ) -> 105
662 | Глава 4. Функции SQL
DA У8(выражение)
Возвращается число дней, прошедших между датой, указанной в выражении,
и 1 января 0001 года. Пример:
VALUES( DAYS('1999-04-15') ) -> 729859
Е)ВС1.ОВ(выражение [, длина]
Возвращается представление графического строкового типа в виде DBCLOB, где
параметр длина показывает длину возвращаемого значения DBCLOB.
DBPARTITlONNUM(cmoJi6eif)
Возвращается номер раздела базы данных, в котором содержится строка, содержа-
щая столбец. За дополнительной информацией обращайтесь к пользовательской
документации DB2 с описанием функции DBPARTITIONNUM.
DECIMAL (выражение [.точность [.масштаб [,символ_десятичной_точки]) или
ОЕС(выражение [.точность [.масштаб[,символ_десятичной_точки])
Возвращает представление выражения в виде десятичной дроби. Дополнительные
аргументы указывают точность и масштаб результата, а параметр символ_деся-
тичной_точки определяет, какой символ обозначает десятичную точку в выражении
(если она есть).
DECRYPT_B1N(данные [.пароль]) или DECRYPT_CHAR(данные [.пароль])
Возвращает расшифрованные данные, при необходимости можно указать пароль.
Результат функции DECRYPT_BIN относится к типу PARCHAR FOR BIT DATA,
а функция DECRYPT_CHAR возвращает значение типа E4RCHAR.
DEGREESIhuc.io)
Возвращает преобразованное в градусы значение аргумента, выраженное в радиа-
нах. Например:
VALUES( DEGREES(3.1415926) ) -> +1.79999996929531Е+002
DER EF(вы ражен ие)
Из выражения возвращается ссылка на объект. Выражение должно возвращать
значение типа REF. За дополнительной информацией о пользовательских типах
данных обращайтесь к Руководству пользователя DB2.
DIFFEREFCE(ebipajK:enuel, выражение2)
Возвращается различие звучания двух строк на основе их значений SOUNDEX.
Результат представляет собой целое число в диапазоне 0-4, где 4 соответствует
наибольшему совпадению значений SOUNDEX. Пример:
VALUES( DIFFERENCE( 'thimble', 'nimble' ) ) -> 4
DIGITSIhuc.io)
Преобразует числовой аргумент в символьную строку, состоящую из цифр.
Результат выполнения функции DIGITS не содержит символов знака или деся-
тичной точки и слева может дополняться нулями. Например:
VALUES( DIGITS( DEC('-3.1415926', 12, 8) ) ) -> 000031415926
DOUBLE(4uc.io)
Возвращает число, преобразованное к типу DOUBLE.
Платформо-специфические расширения | 663
ENCRYPT(daHHbie [,пароль [.подсказка]])
Возвращает зашифрованные данные, дополнительно можно указать пароль.
Дополнительный аргумент подсказка позволяет пользователю сохранить 32-байт-
ную подсказку пароля, которая встраивается в результирующее значение. Чтобы
получить подсказку, обращайтесь к функции GETHINT. Например:
UPDATE employee SET ssn = ENCRYPT(ssn, 'luvbug', 'Herbie is-a?')
WHERE empid = '54321-AD'
E VENT_MON_STA ТЕ(выражение)
Возвращается значение монитора событий. За подробными сведениями о приме-
нении и существующих мониторах событий обращайтесь, пожалуйста, к пользо-
вательской документации DB2.
FLO А Т(число)
Функция FLOAT является синонимом DOUBLE.
GETHlNT(danHbie)
Возвращается подсказка пароля, закодированная в данных. Аргумент данные
должен быть зашифрован функцией ENCRYPT. Например:
SELECT GETHINT(ssn) FROM EMPLOYEE WHERE empid = '54321-AD'
'Herbie is-a?'
GENERATEJJNIQUE] )
Возвращается 13-байтное значение типа CHAR(13) FOR BIT DATA, которое гаран-
тированно отличается от других значений, полученных при помощи данной функ-
ции, в пределах базы данных. Например:
INSERT INTO employee(id, emp_name)
VALUES(GENERATE_UNIQUE( ), 'Bob Smith')
0РАРН1С(выражение [.длина])
Возвращается представление выражения в виде графической строки фиксированной
длины, где дополнительный параметр длина показывает длину результирующего
значения.
HASHED VAL иЕ(столбец)
Возвращается индекс карты секционирования для строки, содержащей столбец.
За дополнительной информацией, пожалуйста, обращайтесь к описанию функции
HASHEDVALUEQ в пользовательской документации DB2.
НЕХ(выражение)
Возвращается шестнадцатеричное представление выражения. Пример:
VALUES( НЕХ( 255 ) ) -> OOOOOOFF
НОиР(выражение)
Возвращает час из значения дата/время в выражении. Например:
SELECT HOUR(execution_time), C0UNT(*) FROM trades
GROUP BY HOUR(execution_time)
664 | Глава 4. Функции SQL
1
2
8
9
1.0
11
2058
856
912
714
IDENTITY_VAL_LOCAL( )
Возвращает самое последнее значение, присвоенное столбцу идентификаторов
(IDENTITY). Возвращает NULL, если столбец идентификаторов не был вставлен
в таблицу с момента последнего выполнения инструкции COMMIT wm ROLLBACK.
1НЗЕВТ(выражение!, выражение?, выражение?, выражение4)
Заменяет выражение! выражением4, изменяя количество байт, указанное выра-
жением? в положении, указанном выражением?. Например:
VALUES (INSERT!'food', 2, 2, 'аге')) -> fared'
INTEGER(ehipajiceHue)
Возвращает целочисленное представление выражения.
JULIAN DA У(выражение)
Возвращает номер дня юлианского календаря для даты, указанной выражением.
Возвращаемое значение представляет собой количество дней, прошедших между
датой, указанной в выражении, и датой начала юлианского календаря - 1 января
4713 г. до н. э. Например:
VALUES(JULIAN_DAY('1999-04-15')) -> 2451284
LEFT(cmpoKa, длина)
Возвращает первые байты, число которых определяется параметром длина, из
строки. Например:
VALUES(LEFT('Hello. World!', 5)) -> 'Hello'
LENGTH (выражение)
Возвращает целочисленную длину выражения или NULL, если выражение равно
NULL. Например:
VALUES(LENGTH('Hello, World!')) -> 13
LOCATE(nodcтрока, строка [, начальное_положение] )
Возвращает местоположение подстроки внутри строки или 0, если подстрока
в строке не обнаруживается. Дополнительный параметр начальное-Положение
можно использовать для указания стартового положения в пределах строки, с которого
начинается поиск. Например:
VALUES(LOCATE('World', 'Hello, World!')) -> 8
LOG(4iic:io)
Возвращает натуральный логарифм числа. То же, что и LN (число).
Платформо-специфические расширения | 665
ЬОСЮ(число)
Возвращает для числа логарифм с основанием 10. Например:
VALUES(L0G10(50)) -> +1.69897000433602Е+000
L ONG_ VA R CHA R (стр ока)
Возвращает представление строки в виде значения LONG VARCHAR.
LONGVARCHARGRAPHIC(cmpoKa)
Возвращает представление строки в виде значения LONG VARCHARGRAPHIC.
LTRIM(cmpoKa)
Удаляет все символы пробелов, стоящие слева от строки. Например:
VALUES(LTRIM(' HowdyI ')) -> 'Howdy!
MICROSECOND (выражение)
Возвращается часть выражения типа дата/время, соответствующая микросекун-
дам. Например:
VALUES(MICROSECOND(CURRENT_TIMESTAMP)) -> 252270
MIDNIGHTSE CONDS(ebipaoicen ие)
Возвращается число секунд, прошедших от полуночи до времени, указанного
в выражении. Например:
VALUES(MIDNIGHT_SECONDS('08:20:15')) -> 30015
MINUTE (выражение)
Возвращает число минут из времени, указанного в выражении. Например:
VALUES!MINUTE!'08:20;15’)) -> 20
MONTH (выражение)
Возвращает номер месяца из даты, указанной в выражении. Например:
VALUES(MONTH('1999-04-15')) -> 4
MONTHНАМЕ(выражение)
Возвращает название месяца для даты, указанной в выражении, используя текущие
настройки базы данных. Например:
VALUES!MONTHNAME!'1999-04-15')) -> 'April'
MULTIPLY_ALT(4ucaol, число2)
Возвращается произведение числа! и числа2. Функция MULTJPLY_ALT является
хорошей альтернативой стандартному оператору умножения (*), если умножае-
мые числа имеют точность выше 31. Например:
VALUES(MULTIPLY_ALT(DECIMAL('256'), DECIMAL!'256'))) -> 65536
Ниьир(выражение1, выражение2)
Возвращает NULL, если выражение! и выражение2 равны, в противном случае
возвращает выражение!. Например:
VALUES!NULLIF!'1999-04-15’, '2000-04-15')) -> '1999-04-15'
666 | Глава 4. Функции SQL
POSSTR(ucmo4HUK, искомое)
Возвращает местоположение первого вхождения искомого значения в источнике,
где 1 соответствует первому символу. Например:
VALUES(POSSTR(’Hello, World!'World')) -> 8
QUARTERfebipaMcenue)
Возвращает целое число в диапазоне от 1 до 4, указывающее квартал года, к которому
относится дата, определяемая выражением. Например:
VALUES(QUARTER('2004-04-15')) -> 2
RADlANS(ebipaoiceHue)
Для значения выражения, выраженного в градусах, возвращает значение, выра-
женное в радианах. Например:
VALUES(RADIANS(180)) -> +3.14159265358979Е+000
RAISE_ERROR(cocmoHHue_sql, строка_ошибки)
При вызове генерирует ошибку. Эта функция полезна для генерации критических
ошибок в сложных инструкциях SQL и хранимых процедурах. Параметр состоя-
uue_sql используется для передачи информации об ошибке в приложение, выпол-
няющее инструкцию SQL, а параметр строка_ошибки используется для создания
собственного сообщения об ошибке. Например:
SELECT a.au_fname, a.aulname.
CASE WHEN t.ytd_sales = 0 THEN 'no sales'
WHEN t.ytd_sales > 0 THEN 'OK'
ELSE RAISE_ERROR('7000Г , 'Sales should not be negative.')
END
FROM authors a, titleauthor, titles t
WHERE titleauthor.au_id = a.au_id AND
Titleauthor.title_id = t.title_id
GROUP BY a.au_lname, a.au_fname
RAND([na4cuibHoe_4ucJio])
Возвращает случайное число с плавающей точкой в диапазоне от 0 до 1, где пара-
метр начальное_число используется как стартовое значение генератора случайных
чисел.
ЕЕАЬ(число)
Возвращается представление числа в виде значения с плавающей точкой оди-
нарной точности.
ЕЕС2ХМЬ(десятичная_дробъ, формат, строковые_теги, имя_столбца [ . ..])
Возвращает строку XML, содержащую теги XML, а также имена столбцов
и данные из столбцов. Аргументы функции описываются в следующем списке.
десятичная_дробь
Десятичная дробь, большая 0, но меньшая или равная 6.0, которая представляет
собой фактор расширения строковых значений, используемый при компенса-
Платформо-специфические расширения | 667
ции расширения строковых значений из-за замены символов на значения
и элементы XML.
формат
Строка, в которой учитывается регистр и которая может быть равна «COLAT-
TVAL» или «COLATTVALXML». Если в столбцах могут содержаться данные
XML, которые необходимо преобразовать, чтобы получить допустимый код XML,
используйте формат «COLATTVAL». Если столбцы не содержат специальных сим-
волов разметки XML, используйте формат «COLATTVAL XML». Если выбран
формат «COLATTVAL XML», то имена столбцов, содержащие специальные сим-
волы разметки, будут преобразовываться в езсаре-последовательности.
строковыеупеги
Строковое значение, используемое в качестве имени элемента строки, содержа-
щего данные из столбца. Если строковыйтег представляет собой пустую
строку, то используется значение строки. Если строковые_теги содержат
строку, состоящую из одних пробелов, то соответствующий строковый элемент
не попадет в выходные данные.
имяутолбца
Имя столбца, которое будет помещено в результирующий код XML. Например:
SELECT REC2XML(1.3, 'COLATTVAL', 'Author', au_id, au_fname,
au_lname)
FROM AUTHORS WHERE au_id = '172-32-1176'
<Author>
<column name="AU„ID">172-32-1176</column>
<column name="AU_FNAME">Johnson</column>
<column name="AU„LNAME">White</column>
</Author>
КЕРЕАТ(строка, число)
Возвращается символьная строка, представляющая собой строку, повторенную
указанное число раз. Например:
VALUES( CHAR(REPEAT('Duck 3)) ) -> ' Duck Duck Duck'
REPLACE (строка, строка_поиска, строка_замены)
Возвращает строку, где каждое вхождение строки_поиска заменено на стро-
ку_замены. Например:
VALUES( REPLACE('change', 'е', 'Ing') ) -> 'changing'
RlGHT(cmpoKa, число)
Возвращает из строки указанное число байтов, начиная справа. Например:
VALUES( RIGHT('Hello, World! 6) ) -> 'World!'
ROUND(4ucjio [, десятичная_часть])
Производится округление числа до числа знаков после десятичной точки, указан-
ного в параметре десятичная_часть. Заметьте, что параметр десятичная_часть,
668 | Глава 4. Функции SQL
который является целым числом, может быть отрицательным, и в этом случае про-
исходит округление цифр слева от десятичной точки. Пример:
VALUES( R0UND(12345.6789, 2) ) -> 12345.6800
R TRlM(cmpoKa)
Функция возвращает строку, в которой удалены все первые пробелы. Например:
VALUES( RTRIMC welcome '))->' welcome'
SECOND(ebipaoicenue)
Возвращает число секунд из времени, указанного в выражении. Например:
VALUES( SECOND(-08:20:15’) ) -> 15
SIGN (число)
Если число < 0, возвращает -1, если число = 0, возвращает 0, если число > 0, воз-
вращает 1. Например:
VALUESC SIGN(-3.1415926), SIGN(O), SIGN<3.1415926) )
-1.OOOOOOOOOOOOOOE+OOO 0 +1.00000000000000E+000
SIN(HUcno)
Функция возвращает синус числа, выраженного в радианах. Например:
SELECT SIN( 0 ) -> 0.000000
SINH(Hucno)
Возвращает гиперболический синус числа.
SMALLINTfuucjio)
Возвращает представление числа в виде SMALLINT.
SOUNDEX(cmpoica)
Возвращает символьную строку, содержащую фонетическое представление строки.
Эта функция позволяет сравнить английские слова, которые пишутся по-разному,
но звучат сходным образом. Например:
VALUES( SOUNDEX('thimble') ) -> Т514'
ЕРАСЕ(число)
Возвращает строку, состоящую из указанного числа пробелов. Например:
VALUES( SPACE(5) ) -> '
STDDEV({ ALL | DISTINCT} выражение)
Возвращает стандартное отклонение значений, содержащихся в выражении.
Ключевое слово ALL (поведение по умолчанию) показывает, что при вычислении
стандартного отклонения используются все значения, которые есть в выражении.
При указании ключевого слова DISTINCT при вычислении опускаются дубликаты
значений. Например:
SELECT STDDEV( values ) FROM NUMBERS -> 0.0642
SUBSTR(cmpoKa, начало [, длина])
Возвращает часть строки, указанной в байтах длины, начиная с начала. Если пара-
метр длина слишком велик, чтобы могла получиться допустимая подстрока, то
Платформо-специфические расширения | 669
строка дополняется пробелами до нужной длины. Начальная точка (начало) должна
представлять собой целое число в диапазоне от 1 до длины строки. Например:
VALUES( SUBSTR(•Hello, World!8, 5) ) -> 'World'
TABLE_ИАМЕ(объект [, схема])
Функция возвращает неквалифицированное имя объекта после разрешения всех
псевдонимов. Дополнительный аргумент схема указывает схему базы данных,
которую следует использовать при разрешении имени объекта. Например:
VALUES( TABLE_NAME('trades') ) -> 'trades'
TABLE SCHEMA (объект [, схема])
Возвращает, после разрешения всех псевдонимов, имя схемы, к которой принадле-
жит объект. Дополнительный аргумент схема указывает схему базы данных,
которую следует использовать при разрешении имени объекта. Например:
VALUES( TABLE_SCHEMA( ’trades') ) -> 'MYSCHEMA'
TAN(число)
Возвращает тангенс числа, выраженного в радианах. Например:
SELECT TAN( 3.1415 ) -> -0.000093
ТА NH (число)
Возвращает гиперболический тангенс числа.
Т!МЕ(выражение)
Возвращает время из значения выражения. Например:
VALUES( Т1МЕ('2003-04-15 08:20:15') ) -> '08:20:15'
Т1МЕ5ТАМР(выражение! [, выражение?])
Возвращает значение-отметку времени, созданную на основе значений даты
и времени в выражениях 1 и 2. Если указано только выражение!, то оно должно
содержать допустимое значение даты и времени. Если даны оба аргумента,
то выражение! должно содержать допустимое строковое представление даты,
а выражение? - допустимое строковое представление времени. Например:
VALUES( TIMESTAMP('2003-04-15', '08:20:15') )
2003-04-15-08.20.15.000000
T!MESTAMP_FORMAT(cmpoKa, формат)
Возвращает значение типа «отметка времени» (timestamp), извлекая его из строки.
Второй аргумент - формат - это формат отметки времени, используемый в строке.
(Подробно формат отметки времени описывается в разделе, посвященном функции
VARCHARFORMAT.) Например:
VALUES( TIMESTAMP_FORMAT('2003-4-15 08:20:15',
'YYYY-MM-DD НН24:MI:SS') )
2003-04-15-08.20.15.000000
670 | Глава 4. Функции SQL
TIMESTAMPIS0(выражение)
Возвращает отметку времени, получаемую из выражения. Если выражение содержит
только дату, то часть, отведенная времени, будет состоять из нулей. Если выражение
содержит только время, то при создании отметки времени будет использоваться
текущая дата. Например:
VALUES( TIMESTAMP_ISO('2003-04-15') ) -> 2003-04-15-00.00.00.000000
TIMESTA MPDlFF(mun_unmepeajia, ebipaxeHueJsdiff)
Возвращается количество заданных временных интервалов между двумя отметка-
ми времени. Аргумент тип_интервала должен представлять собой число - сте-
пень двойки от 1 до 256, где значения интерпретируются в соответствии со сле-
дующей таблицей.
тип интервала Разница между отметками времени
1 Доли секунды
2 Секунды
4 Минуты
8 Часы
16 Дни
32 Недели
64 Месяцы
128 Кварталы
256 Годы
Параметр выражение Jsdiff должен быть результатом вычитания двух отметок
времени, приведенным к одному значению CHAR(22). Например:
VALUES( TIMESTAMPDIFF( 2, CHAR(CURRENT_DATE - CURRENT_TIMESTAMP) ) )
515
ТО_СНАР(отметка_времени, формат)
Синоним VARCHAR_FORMAT.
TO_DATE(cmpoKa, формат)
Синоним TIMESTAMP FORMAT
TRANSLATE(cmpoKa, выходная_строка, входная_строка [ символ_заполнителъ])
Возвращает строковый эквивалент параметра строка, в котором каждый символ,
имеющийся в выходнойстроке, заменяется соответствующим символом из вход-
ной строки. Дополнительный аргумент символ ^заполнитель может содержать од-
нобайтовый символ, который используется для дополнения выходной_строки,
если она оказывается короче входной_строки. Если один символ появляется
в параметре входная строка несколько раз, то учитывается только первое вхождение,
а остальные игнорируются. Пример:
VALUES( TRANSLATE('123,456,789.45', ) -> '123.456.789.45'
Платформо-специфические расширения | 671
TYPEЮ(е>ыражение)
Возвращается внутренний идентификатор типа для экземпляра пользовательского
структурного типа, на который ссылается выражение. За дополнительной информа-
цией о пользовательских типах обращайтесь к Руководству пользователя DB2.
ТУРЕ_№МЕ(выражение)
Возвращается неквалифицированное имя экземпляра пользовательского струк-
турного типа, на который ссылается выражение. За дополнительной информацией
о пользовательских типах обращайтесь к Руководству пользователя DB2.
TYPE_SCHEMA (выражение)
Возвращается имя схемы для экземпляра пользовательского структурного типа, на
который ссылается выражение. За дополнительной информацией о пользовательских
типах обращайтесь к Руководству пользователя DB2.
VALUE (выражение [,...] )
Возвращает первый непустой аргумент. Например:
VALUES( VALUE( 'Hellol', 5 ) ) -> 'Hello'1
VAR или VARIANCE({ ALL | DISTINCT} выражение)
Возвращает дисперсию значений, содержащихся в выражении. Ключевое слово ALL
(поведение по умолчанию) показывает, что при вычислении стандартного отклонения
используются все значения, которые есть в выражении. При указании ключевого
слова DISTINCT при вычислении опускаются дубликаты значений. Например:
SELECT VARIANCE! values ) FROM NUMBERS -> 987244882.22
VARCUAR(ebipa:>icenue [, длина])
Для значения выражения возвращается его символьное представление переменной
длины. Параметр длина представляет собой атрибут длины результата. Если длина
не указана, то длиной результата будет длина значения выражения.
VARCHAR_FORMA Т(выражение, формат)
Функция возвращает строковое представление отметки времени из выражения
в формате, указываемом аргументом формат. Ниже приводятся значения параметра
формат и их описания.
YYYY
Год, четыре цифры.
ММ
Месяц, две цифры (01-12).
DD
День месяца, две цифры (01, 02,...).
НН24
Час дня, две цифры (00-24).
MI
Минута, две цифры (00-59).
SS
Секунда, две цифры (00-59).
672 | Глава 4. Функции SQL
Например:
VALUES/ VARCHAR_FORMAT( CURRENT_TIMESTAMP,
'YYYY-MM-DD HH24:MI:SS' ) )
2003-06-24 09:37:45
VARGRAPlUC(ebipa3icenue [, длина])
Для значения выражения возвращается его представление в виде графической
строки переменной длины. Параметр длина представляет собой атрибут длины
результата. Если длина не указана, то длиной результата будет длина значения
выражения.
УУЕЕК(выражение)
Возвращает номер недели в году, к которой относится дата, указанная в выражении.
Диапазон результата - от 1 до 54, и неделя начинается с воскресенья. Например:
VALUES( WEEK/'2003-04-15') ) -> 16
№ЕЕК._18О(выражение)
Возвращает номер недели в году, к которой относится дата, указанная в выражении.
Диапазон результата - от 1 до 53, и неделя начинается с понедельника. В первую
неделю года всегда входит 4 января. Например:
VALUESC WEEK_IS0('2003-04-15') ) -> 16
YEA R (выражен ие)
Возвращает год из значения даты в выражении. Например:
VALUES( YEAR/'2004-04-15') ) -> 2004
Расширения, поддерживаемые MySQL
В этом разделе приведен отсортированный по алфавиту список функций, поддержи-
ваемых MySQL, с примерами и соответствующими результатами.
АСОЗ(число)
Возвращает арккосинус числа в диапазоне от -1 до 1. Результат лежит в диапазоне
от 0 до 1 и выражен в радианах. Например:
SELECT ACOS( 0 ) -> 1.570796
ASCII (текст)
Возвращает ASCII-код первого символа текста. Например:
SELECT ASCII/'х') -> 120
ASIN(4uaio)
Возвращает арксинус числа в диапазоне от -1 до 1. Результат лежит в диапазоне от
-1/2 до 1/2 и выражен в радианах. Например:
SELECT ASIN/ 0 ) -> 0.000000
АТАУ’(число)
Возвращает арктангенс любого числа. Результат лежит в диапазоне от -1/2 до 1/2
и выражен в радианах. Например:
SELECT ATAN/ 3.1415 ) -> 1.262619
43 - 2447
Платформо-специфические расширения | 673
ATAN2(x,y)
Возвращает арктангенс двух переменных -хну. Функция ATAN2(x,y) похожа на
ATAN(y/x), за исключением того, что знаки х и у используются при определении
квадранта числа. Например:
ATAN2(3.1415, 1) -> 1.262619
BENCHMARK(C4em4UK, выражение)
Функция выполняет выражение указанное счетчиком количество раз. Значение
результата всегда равно 0. Например:
BENCHMARKS 000000,ATAN2(3.1415, 1)) -> 0
BIN (число)
Возвращает строку, содержащую двоичное значение п, где п - число типа BIGINT.
BIN AR Y(строка)
Преобразует строку в двоичную строку.
В1Т_А\1О(выражение)
Агрегатная функция, выполняющая побитовую операцию И (AND) всех битов
в выражении. Вычисление производится с 64-битовой точностью (BIGINT). Если
соответствующие строки не обнаруживаются, возвращается значение -1. Пример:
BIT_AND(mycolumn) -> 0
В1Т_С(ЖТ(число)
Возвращается количество установленных битов в числе. Например:
BIT_C0UNT(5) -> 2
В1Т_ОВ(выражение)
Агрегатная функция, которая возвращает результат побитовой операции ИЛИ
(OR) всех битов в выражении. Вычисление производится с 64-битовой точностью
(BIGINT). Если соответствующие строки не обнаруживаются, возвращается значе-
ние 0. Пример:
BIT_OR(mycolumn) -> 1
CHAR (число [,...])
Возвращается строка, состоящая из символов, соответствующих кодам ASCII,
указанным в аргументах. Все пустые значения игнорируются. Например:
CHARC120,121,122) -> 'xyz’
COALESCE(cnucoK)
Возвращается первый непустой элемент из списка. Например:
COALESCEC NULL, 1, 2 ) -> 1
COMPRESS(cmpoKa)
Возвращается сжатая версия строки.
674 | Глава 4. Функции SQL
CONCAT_lVS(pa'jdejiumejtb, cmpl, cmp2 [,...])
Особая форма функции CONCAT(), которая вставляет символ-разделитель между
парами соединяемых строковых аргументов. Если параметр разделитель пустой
(NULL), то результатом будет NULL. Пример:
C0NCAT_WS(', au_lname, au_fname ) -> 'Jefferson, Thomas'
CONNECTIONJD()
Возвращается идентификатор соединения. Каждое соединение имеет свой собст-
венный уникальный идентификатор. Например:
CONNECTION_ID( ) -> 305102
CONVLniaio, ucxodiioe ciCHoeauue, конечноеоснование)
Возвращает строковое представление числа, преобразованное из исходного_осно-
вания в конечноеоснование. Если хотя бы один аргумент равен NULL, результат
будет NULL. Например:
C0NV(12,10,2) -> 1100
СОВ(число)
Возвращает косинус числа как величины угла, выраженной в радианах. Пример:
SELECT COS(O) -> 1.000000
CURDATE()
Возвращает текущую дату в формате ГГГГ-ММ-ДД или ГГГГММДД в зависимости
от того, используется функция в числовом или строковом контексте. Пример:
CURDATE( ) -> '2003-06-24'
CURTIME()
Возвращает текущее время в формате ЧЧ:ММ:СС или ЧЧММСС в зависимости от
того, используется функция в числовом или строковом контексте. Пример:
CURTIME( ) -> '20:40:20'
DATA BASE ()
Возвращает имя текущей базы данных. Пример:
DATABASE( ) -> 'PUBS'
DATE_ADD(dama,INTERVAL выраж тип)
DATE_SUB(dama,INTERVAL выраж тип)
ADDDATE(dama,INTERVAL выраж тип)
SUBDATE(dama,INTERVAL выраж тип)
Эти функции выполняют арифметические операции с датами. Функции ADDDATE()
и SUBDATE() являются синонимами функций DATE_ADD() и DATESUBQ. Функция
DATE ADDQ возвращает результат прибавления к указанной дате значения INTERVAL.
Функция DATE SUBf) возвращает результат вычитания значения INTERVAL из ука-
занной даты. Пример:
DATE_ADD('1999-04-15', INTERVAL 1 DAY) -> '1999-04-16'
DATE_SUB('1999-04-15', INTERVAL 1 DAY) -> '1999-04-14'
Платформо-специфические расширения | 675
DATE_FORMAT(dama, формат)
Значение даты форматируется в соответствии с указанным форматом. Ния
приведены существующие обозначения форматов с их описаниями.
%а
Сокращенное название дня (Sun-Sat).
%b
Сокращенное название месяца (Jan-Dec).
%с
Номер месяца (1-12).
%>D
Номер дня в месяце с суффиксом (1st, 2nd, 3rd ...).
%d
Номер дня в месяце из двух цифр (01, 02, ...).
%е
Номер дня в месяце (1, 2, 3...).
%Н
Час (00-23).
%>h
Час (01-12).
%i
Минуты (00-59).
%1
Час (01-12).
%)
Номер дня в году (001-366).
%к
Час (0-23).
%1
Час (1-12).
%М
Полное название месяца (January-December).
%т
Номер месяца (01-12).
%р
А.М. или Р.М.
%г
12-часовое время (чч:мм:сс А.М. или Р.М.).
%S, %s
Секунды (00-59).
%Т
24-часовое время (чч:мм:сс).
%и
Номер недели (00-53, первый день недели - воскресенье).
676 | Глава 4. Функции SQL
%м
Номер недели (00-53, первый день недели - понедельник).
%V
Номер недели (01-53, первый день недели - воскресенье).
%v
Номер недели (01-53, первый день недели - понедельник).
%W
Название дня недели (Sunday-Saturday).
%w
Номер дня недели (0 = Sunday, 6 = Saturday).
%Х
Год из четырех цифр. Первый день недели - воскресенье.
%х
Год из четырех цифр. Первый день недели - понедельник.
%Y
Год из четырех цифр.
%у
Год из двух цифр.
%%
Литерал "%".
Пример:
DATE_FORMAT('1999-04-15’, ’XM-XD-XY’) -> 'Ар гi1-15th-1999’
DA YNA МЕ(дата)
Возвращает название дня недели для указанной даты. Пример:
DAYNAMEC’1999-04-15’) -> Thursday’
DA YOFMONTH(dama)
Возвращает для даты номер дня в месяце, в диапазоне от 1 до 31. Пример:
DAYOFMONTHC 1999-04-15’) -> 15
DAYOFWEEK(dama)
Возвращает число, соответствующее дню недели в дате (1 = воскресенье, 2 = поне-
дельник,...? = суббота). Пример:
DAYOFWEEK('1999-04-15') -> 5
DAYOFYEAR(dama)
Возвращает для указанной даты номер дня в году, в диапазоне от 1 до 366. Пример:
DAYOFYEAR(’1999-04-15’) -> 105
DE С ODE (заш ифрованная_строка, строка_пароля)
Расшифровывает зашифрованную_строку, используя строку_пароля. Зашифрованная
строка должна представлять собой строку, возвращаемую функцией ENCODEQ.
Пример:
DECODE(ENCODE(’foo’,'bar'),’bar’) -> ’too’
Платформо-специфические расширения | 677
DE GREES(4ucno)
Возвращает число, преобразованное из радианов в градусы. Пример:
DEGREES(3.1415926) -> 179.99999692953
ЕЬТ(строка1, строка2, строкаЗ [,...п])
Возвращает строку 1, если п = 1, строку2, если п = 2, и т. д. Если п меньше 1 или
больше числа аргументов, возвращается NULL. Функция ELTQ дополняет функ-
цию FIELD(). Пример:
ELT(1, 'Hi', 'There’) -> 'Hi'
ELT(2, 'Hi', 'There') -> 'There'
EMPTYBLOB и EMPTY CLOB
Возвращаются пустые локаторы значений LOB, которые можно использовать для
инициализации значений BLOB и CLOB, которые нужно создать в инструкции
INSERT или UPDATE.
ENCODE(cmpoKa, строка_пароля)
Функция шифрует указанную строку, используя в качестве пароля строку_пароля.
Для расшифровки используйте функцию DECODE(). Результат представляет собой
двоичную строку той же длины, что и строка. Пример:
DECODE(ENCODE('foo', 'bar'), 'bar') -> 'foo"
ENCRYPT(cmpoKa [, salt])
Функция шифрует строку, используя системный вызов Unix-функции crypt(). Аргу-
мент salt (соль) должен представлять собой строку из двух символов. Пример:
ENCRYPTC'password’) -> 'ZB7yqPUHvNnmo'
EXPORT_SET(6umu, установ, сброс, [разделитель, [число_битов]])
Возвращается строка, которая формируется так: каждый установленный бит в значе-
нии биты приводит к вставке строки установ, а каждый сброшенный бит - к встав-
ке строки сброс. Строки отделяются друг от друга разделителем. По умолчанию это
запятая (,). Количество используемых при формировании строки бит ограничивается
параметром число_битов. По умолчанию это количество равно 64. Пример:
EXP0RT_SET(4, Т , 'F')
F.F.T.F.F.F.F.F.F.F.F.F’F.F.F.F.F.F.F.F.F.F.F.F.F.F.F.F.F.F.F.F,
F, F, F, F, F, F, F, F, F, F, F, F, F, F, F, F, F, F, F, F, F, F, F, F, F, F, F, F, F, F, F, F
FIELD(cmpoKa, строка!, строка2, строкаЗ[,...] )
Возвращается номер строки в пределах указанного списка строковых аргументов.
Если строка не обнаруживается, возвращается ноль. Функция FIELD]) дополняет
функцию ELTQ. Пример:
FIELD('GOOSE’,'DUCK','DUCK’GOOSEDUCK’) -> 3
FIND_IN_SET(cmpoKa, список_строк)
Возвращается номер строки в списке_строк. Строки в списке должны быть разде-
лены запятыми. Эта функция является эквивалентом FIELD(cmpoKa, CONCAT_WS
строка!, строка2, строкаЗ, [,...])). Пример:
678 | Глава 4. Функции SQL
FIND_IN_SET(’b',’a,b,C,d’) -> 2
FORMAT(4iic.io, десятичные_знаки)
Преобразует число в формат #,###,###.## с округлением до указанного числа деся-
тичных_знаков. Если параметр десятичные_знаки равен нулю, то число не будет
иметь десятичной точки и дробной части. Пример:
FORMATC12345.2132,2) -> 12,345.21
F0RMAT(12345.2132,0) -> 12,345
FROMDA УБ(число)
При указании числа дней возвращает дату. Эту функцию не следует использовать
для дат, предшествующих началу григорианского календаря (1582), поскольку при
изменении календаря было потеряно несколько дней. Пример:
FROM_DAYS(888888) -> 2433-09-10
FROM_ UN1XTIME(отметка_времени_итх)
Возвращается представление отметки времени Unix (unix timestamp) в формате
ГГГГ-ММ-ДД ЧЧ:ММ:СС или ГГГГММДДЧЧММСС, в зависимости от контек-
ста использования - строкового или числового. Пример:
FR0M_UNIXTIME(888123892) -> 1998-02-21 21:04:52
FRОМ_ UNIXTIME(отметка_времени_ипix, формат)
Возвращается представление отметки времени Unix (unix timestamp) в формате,
определяемом параметром формат. В качестве формата могут выступать те же
спецификаторы, которые перечислены в разделе, посвященном функции
DATE_FORMAT(). Пример:
FROM_UNIXTIME(888123892,’XY XD ХМ’) -> '1998 21st February'
ОЕТ_ЬОСК(строка, время_ожидания)
Функция пытается получить блокировку на имя, указанное в строке, со временем
ожидания, указанным в параметре время_ожидания. Если блокировка выполняет-
ся успешно, возвращается 1, если возникает ошибка или истекает время ожида-
ния, возвращается NULL. Пример:
GET_LOCK('lochness',10) -> 1
GREATEST(x,y[„..])
Возвращается наибольший из аргументов. Пример:
GREATEST(8,2, 4) -> 8
НЕХ(число)
Возвращается строковое представление шестнадцатеричного числа. Эта функция
является эквивалентом СОХУ(число, 10, 16). Пример:
НЕХ(255) -> FF
НОиЕ(время)
Возвращается значение часа (в диапазоне от 0 до 23) для указанного времени.
Пример:
Платформо-специфические расширения | 679
HOUR('08:20:15’) -> 8
!Е(выражение1, выражение2, выражениеЗ)
Функция возвращает выражение2, если выражение! истинно, и выражениеЗ,
если выражение! ложно. Пример:
IF(1,'yes', 'no') -> 'yes'
IF(0,'yes','no') -> 'no'
!ГИиЬЬ(выражение!, выражение2)
Функция возвращает выражение!, если выражение! не равно NULL, в противном
случае возвращает выражение2. Например:
IFNULLCO,'NULL') -> 0
IFNULL(NULL, 'NULL') -> 'NULL'
INSERT(cmpoKa, положение, длина, новая_строка)
Возвращает строку, в которой, начиная с указанного положения, вставлена
новая строка указанной длины. Например:
INSERT(' paper', 2, 3, 'еа ’) -> 'pear'
INSTR(cmpoKa, подстрока)
Возвращается местоположение первого вхождения указанной подстроки в преде-
лах указанной строки. Например:
INSTR('ducks','с') -> 3
INTERVAL(4Ucno!, число2, числоЗ, число4 [,...])
Возвращает 0, если число! меньше числа2, возвращает 1, если число! меньше числаЗ,
ит. д. Обязательным является соблюдение условия число2<числоЗ<число4<...<числоЫ.
Пример:
INTERVAL(5,1,6) -> 1
INTERVAL^,2,3,7,9) -> 2
!S_FREE_LOCK(блокировка)
Функция возвращает 1, если блокировка снята, и ноль, если блокировка в настоя-
щий момент используется. В случае ошибок функция может возвращать NULL.
Например:
IS_FREE_LOCK('lochness') -> 0
!5!4иЬЬ(выражение)
л Если значение выражения NULL, то функция ISNULLQ возвращает 1, в противном
/ случае возвращается 0. Например:
ISNULL(I) -> 0
ISNULL(NULL) -> 1
LAST_INSER Т_Ю([выражение])
Возвращается последнее автоматически сгенерированное для столбца с признаком
AUTO ^INCREMENT значение. Например:
LAST_INSERT_ID( ) -> 0
680 | Глава 4. Функции SQL
LCASE(cmpoKa)
Синоним функции lower(cmpoKa). Например:
LCASE(’DUCK') -> 'duck'
LEAST(X, Y
При наличии двух или более аргументов возвращает наименьший (с минимальным
значением). Например:
LEASTC1O,5,3,7) -> 3
LEFT(cmpoKa. длина)
Возвращает из указанной строки указанное в параметре длина число символов,
начиная слева. Например:
LEFT('Ducks', 4) -> 'Duck'
LENGTH (строка)
Эта функция возвращает длину строки. Например:
LENGTH('DUCK') -> 4
LOAD F1LE(имя файла)
Функция читает файл и возвращает его содержимое в виде строки. Файл должен
находиться на сервере, и пользователь должен указать полный путь к файлу, а также
иметь права доступа к нему.
LOCATE(nodcmpoKa, строка), POSITION (подстрока IN строка)
Возвращает местоположение первого вхождения подстроки в пределах указанной
строки. Если подстрока в строке не обнаруживается, функция возвращает ноль.
Функция LOCATE является синонимом стандартной функции POSITION(nodcmpoKa
IN строка). Например:
LOCATE('al',’Donald’) -> 4
POSITION!’al’ IN ’Donald’) -> 4
LOCATE(nodcmpoKa, строка, положение)
Возвращает местоположение первого вхождения подстроки в пределах указанной
строки, начиная с указанного положения. Если подстрока в строке не обнаружи-
вается, функция возвращает ноль. Например:
LOCATE!’World', ’Hello, World!') -> 8
LOG(X)
Функция возвращает натуральный логарифм числах. Например:
LOG(5O) -> 3.912023
LOG2(X)
Функция возвращает для числаХ логарифм с основанием 2. Например:
LOG2C50) -> 5.64386
LOGIO(X)
Функция возвращает для числах логарифм с основанием 10. Например:
L0G10C50) > 1.698970
Платформо-специфические расширения | 681
LPAD(cmpoKa, длина, дополняющая_строка)
Эта функция возвращает результат, получающийся при дополнении указанной
строки слева до указанной длины дополняющей_строкой. Пример:
LPAD( 'ticks', 6, 'd') -> 'dducks'
LTRIM(cmpoKa)
Возвращает строку, из которой удалены начальные символы пробелов. Например:
LTRIMC Howdyl ') -> Howdy!
MAKE_SET(6umbi, строка!, строка2 [,...п])
Возвращается набор (строка, содержащая подстроки, разделенные запятыми),
состоящий из строковых аргументов, для которых соответствующий бит в значе-
нии биты является установленным; строка! соответствует биту 0, строка2 -
биту 1 и т. д. Пустые строки в списке из строка!, строка2... в результат не добав-
ляются. Например:
MAKE_SET(1 | 4,'hello','nice','world') -> 'hello,world’
М05(строка)
Для строки вычисляется контрольная сумма MD5. Значение возвращается в форме
32-разрядного шестнадцатеричного числа. Например:
MD5(’somestring’) -> 1f129c42de5e4f043cbd88ff6360486Г
МН\!иТЕ(время)
Из указанного времени возвращаются минуты, в диапазоне от 0 до 59. Например:
MINUTE('08:20:15') -> 20
MONTH(dama)
Из указанной даты возвращается номер месяца, в диапазоне от 1 до 12. Например:
M0NTHC1999-04-15') -> 4
MONTHNAME(dama)
Для указанной даты возвращается название месяца. Например:
MONTHNAME('1999-04-15') -> April'
NOW(), SYSDATEf)
Возвращается текущая дата и время в формате ГГГГ-ММ-ДД ЧЧ:ММ:СС или
ГГГГММДДЧЧММСС в зависимости от того, используется функция в строковом
или числовом контексте. Например:
N0W( ) -> 2003-06-24 20:40:24
SYSDATE( ) -> 2003-06-24 20:40:24
CURRENT.TIMESTAMP -> 2003-06-24 20:40:24
КиЬЬ1Е(выражение I, выражение2)
Функция возвращает NULL, если выражение! равно выражению2. В противном
случае возвращается выражение!. Например:
NULLIF(2,29) -> 2
NULLIF(29,29) -> NULL
682 | Глава 4. Функции SQL
ОСТ(п)
Возвращает восьмеричное представление числа и. Эта функция является эквива-
лентом CONV(«, 10, 8). Если п равно NULL, функция возвращает NULL. Пример:
0СТ(255) -> 377
ORD(cmpoKa)
Возвращает символьный ординал многобайтовой символьной строки. Значение
вычисляется следующим образом: ((код ASCII первого байта)*256+(код ASCII второго
байта)*256*256)+(код ASCII третьего байта)*256*256*256 Если строка не явля-
ется многобайтовой, то эта функция возвращает то же значение, что и функция
ASCIIQ. Пример:
ORD(’29') -> 50
PASSWORD(cmpoKa)
Из обычной текстовой строки создается строка пароля. Эта функция используется
для шифрования паролей MySQL. Пример:
PASSWORD('password') -> 5d2e19393cc5ef67
PERIODADDfnepuod, месяцы)
Функция добавляет количество месяцев, указанное в параметре месяцы, к указан-
ному периоду (в формате ГГММ или ГГГГММ). Возвращает значение в формате
ГГГГММ. Например:
PERI0D_ADD(9902,3) -> 199905
PER!OD_DlFF(nepuodl, период?)
Возвращает количество месяцев между периодом! и периодом?. Значения период!
и период? должны быть в формате ГГММ или ГГГГММ. Пример:
PERI0D_DIFF(9902, 9905) -> -3
Р1()
Возвращает значение константы л. Пример:
Р1( ) -> 3.141593
POW(X, Y), POWER(X, Y)
Возвращается значение X, возведенное в степень Y. Например:
P0W(2, 8) -> 256.000000
QUARTER(dama)
Возвращается квартал года, к которому принадлежит дата (диапазон от 1 до 4).
Например:
QUARTER('1999-04-15') -> 2
RADIANS(X)
Функция возвращает число X, преобразованное из градусов в радианы. Например:
RADIANS(180) -> 3.1415926535898
Платформо-специфические расширения | 683
RAND(), RAND(N)
Функция возвращает случайное число с плавающей точкой в диапазоне от 0 до
1.0. Если указан целочисленный аргумент N, то он используется в качестве
начального значения. Например:
RAND( ) -> 0.29588872501244
RELEASE_ЬОСК(строка)
Снимает блокировку с именем, указываемым строкой, которая была установлена
при помощи функции GETLOCKQ. Функция возвращает 1, если блокировка сни-
мается, или NULL, если указанная блокировка не существует или не установлена
данным процессом (в этом случае блокировка не снимается). Например:
RELEASE_LOCK('lochness') -> 1
REPEAT(cmpoKa, счетчик)
Функция возвращает строку, представляющую собой указанную строку, повторенную
столько раз, сколько указано в параметре счетчик. Например:
REPEAT(’Duck’, 3) -> ’DuckDuckDuck'
REPLACE(cmpoKd, исходная_строка, конечная_строка)
Функция возвращает строку, в которой все вхождения исходной_строки заменены
конечной_строкой. Например:
REPLACE('change', 'е', 'ing') -> 'changing'
REVERSE(cmpoKa)
Функция возвращает обращенную строку. Пример:
REVERSE('STOP') -> POTS'
R[GHT(cmpoKa, длина)
Возвращает из указанной строки указанное в параметре длина число символов,
начиная справа. Например:
RIGHT('Hello, World!', 6) -> 'World!'
ROUND(X[,D])
Функция возвращает аргумент X, округленный до указанного параметром D числа
символов после запятой. Если D = 0, то результат не будет иметь десятичной
точки и дробной части. Пример:
R0UND(12345.6789, 2) -> 12345.68
RPAD(cmpoKa, длина, дополняющая_строка)
Эта функция возвращает результат, получающийся при дополнении указанной
строки справа до указанной длины дополняющей_строкой. Пример:
RPAD('duck',6,'s’) -> 'duckss'
RTRIM(cmpoKa)
Возвращает строку, из которой удалены конечные символы пробелов. Например:
RTRIM(' welcome ') -> 'welcome
684 | Глава 4. Функции SQL
8ЕС_Т0_Т1МЕ(секунды)
Возвращает результат преобразования значения, заданного в секундах, в часы,
минуты и секунды в формате ЧЧ:ММ:СС или ЧЧММСС в зависимости от того,
используется функция в строковом или числовом контексте. Например:
SEC_T0_TIME(256) -> 00:04:16
SECOND(epeMn)
Из значения времени извлекаются секунды (диапазон от 0 до 59). Пример:
SECOND('08:20:15') -> 15
SHA(X) or SHAI(X)
Функция возвращает для X 160-битовую контрольную сумму по алгоритму SHA1.
Например:
SHA(’abc') -> 'a9993e364706816aba3e25717850c26c9cd0d89d'
SIGN(X)
Возвращает знак аргумента в форме -1, 0 или 1 в зависимости от того, является ли
X отрицательным, равным нулю или положительным. Например:
SIGN(-3.1415926) -> -1
SIN (число)
Возвращается синус числа, выраженного в радианах. Например:
SELECT SIN( 0 ) -> 0.000000
SOUNDEX(cmpoKa)
Возвращается фонетическое представление (soundex) строки. Например:
SOUNDEX('thimble’) -> 'Т514'
выражение! SOUNDS LIKE выражение2
Синоним следующей конструкции:
8(Ж0ЕХ(еыражение7) = 801ЖЕХ(еыражение2)
SPACE(n)
Функция возвращает строку, состоящую из пробелов, число которых определяет
параметр п. Например:
SPACE(5) -> '
ЕТЕ>(выражение), STDDEV(ebipaJicenue)
Возвращает для выражения стандартное отклонение. Форма STDDEV() создана
для совместимости с Oracle. Пример:
STD(5) -> NULL
5ТКСМР(выражение!, выражение2)
Функция STRCMP() возвращает ноль, если указанные строки одинаковы, -1 - если
первый аргумент, согласно текущему порядку сортировки, меньше второго, и 1 -
если больше. Например:
STRCMPCDUCKY', 'DUCK') -> 1
STRCMP('DUCK', 'DUCK') -> 0
Платформо-специфические расширения | 685
SUBSTRING(cmpoKa, положение, длина), МЮ(строка, положение, длина)
Из указанной строки возвращается подстрока указанной длины, начиная с указан-
ного положения. Эти функции являются синонимами функции ANSI SQL92
SUBSTRING(cmpoKa FROM положение FOR длина). Пример:
SUBSTRING!'Hello, World!’, 8, 10) -> 'World!'
SUBSTRING!'Hello, World!' FROM 8 FOR 10) -> World!'
SUBSTRING(cmpOKa, положение), SUBSTRING(cmpOKa FROM положение)
Из указанной строки возвращается подстрока, начиная с указанного положения.
Например:
SUBSTRING!'Hello, World!8) -> 'World!'
SUBSTRING!'Hello, World!' FROM 8) -> 'World!'
SUBSTRING_INDEX(cmpoKa, ограничитель, счетчик)
Из указанной строки возвращается подстрока, идущая после указанного счетчи-
ком числа вхождений ограничителя. Например:
SUBSTRING_INDEX(’www.mysql.com’, 2) -> 'www.mysql'
TAN (число)
Возвращается тангенс числа, выраженного в радианах. Например:
SELECT TAN( 3.1415 ) -> -0.000093
TIME FORMAT(время, формат)
Эта функция используется так же, как функция DATE_FORMAT(), но строка
формата может содержать только те части, которые относятся к часам, минутам
и секундам. Другие спецификаторы создают значения NULL и 0. За описаниями
доступных спецификаторов формата обращайтесь к функции DATE FORMATQ.
Пример:
TIME-FORMAT!’2003-04-15 08:20:15’, ’Хг') -> 08:20:15 AM
Т1МЕ_ТО_ВЕС(время)
Возвращается аргумент время, преобразованный в секунды. Например:
TIME_TO_SEC('08:20:15') -> 30015
TOJDAYS(dama)
Для указанной даты возвращается номер дня (количество дней, прошедших с нуле-
вого года). Например:
T0_DAYS('1999-04-15’) -> 730224
TRUNCATE(XJD)
Возвращается число X, дробная часть которого урезана до количества знаков
после запятой, указанного параметром D. Если D = 0, то результат не будет иметь
десятичной точки и дробной части. Например:
TRUNCATE!'123.456', 2) -> '123.45'
TRUNCATE!’123.456’, 0) -> '123'
TRUNCATE!’123.456', -1) -> '120'
686 | Глава 4. Функции SQL
UCA SE(cmpoKct)
Синоним функции UPPER(cmpoKd). Пример:
UCASE('duck') -> 'DUCK'
UNCOMPRESS(cmpoKa)
Возвращается несжатая версия строки.
UNHEX(cmpoKa)
Возвращается двоичная строка, созданная на основе шестнадцатеричных символов
указанной строки.
UNIXTIMESTAMPf), UNIX_TIMESTAMP(dama)
Если эта функция вызывается без аргумента, она возвращает отметку времени Unix
(число секунд, прошедших с 1-01-1970 00:00:00 по Гринвичу). Если функция
UNIX_TIMESTAMP() вызывается с аргументом - датой, то она возвращает число
секунд, прошедших с 1-01-1970 00:00:00 по Гринвичу до указанной даты. Например:
UNIX_TIMESTAMP( ) -> 1056512427
UNIX_TIMESTAMP('1999-04-15') -> 924159600
USER(), SYSTEMJJSERO, SESSION_USER()
Эти функции возвращают имя текущего пользователя MySQL. Например:
USER( ) -> 'login@machine.com'
SYSTEM_USER( ) -> login@machine.com'
SESSION_USER( ) -> 'login@machine.com'
VERSION()
Возвращает строку, показывающую текущую версию MySQL. Например:
VERSION( ) -> '4.0.12-standard'
WEEK(dama), WEEK(dama, начало)
Если функция вызывается с одним аргументом, она возвращает номер недели для ука-
занной даты (диапазон 1-53; на некоторые годы может прийтись начало 53-недели).
Два аргумента позволяют указать, начинается неделя с воскресенья (0) или с поне-
дельника (1). Пример:
WEEK('1999-04-15') -> 15
WEEKDAY(dama)
Возвращает для указанной даты номер дня недели (0 = понедельник, 1 = вторник,...
6 = воскресенье). Например:
WEEKDAY('1999-04-15') -> 3
YEAR(dama)
Извлекает из указанной даты год (диапазон от 1000 до 9999). Например:
YEAR('1999-04-15') -> 1999
Платформо-специфические расширения | 687
YEARWEEK(dama), YEARWEEK(dama, начало)
Для указанной даты возвращается год и неделя. Второй аргумент работает так же,
как второй аргумент функции WEEKQ. Обратите внимание, что год может отличаться
от года в аргументе дата для первой и последней недель года. Пример:
YEARWEEKC 1999-04-15') -> 199915
Расширения, поддерживаемые Oracle
В этом разделе представлен отсортированный по алфавиту список функций SQL, специ-
фичных для Oracle, с примерами и соответствующими результатами.
АСО8(число)
Возвращает арккосинус числа в диапазоне от-1 до 1. Результат лежит в диапазоне
от 0 до 1 и выражен в радианах. Например:
SELECT AC0S( 0 ) FROM DUAL -> 1.570796
ADD MONTH(dama, целое_число)
Возвращает значение даты, к которому прибавлено указанное число месяцев.
SELECT ADD_MONTHS('15-APR-1999', 3) FROM DUAL -> 15-JUL-99
ASCII(meKcm)
Возвращает ASCII-код первого символа текста. Например:
SELECT ASCII('X') FROM DUAL -> 120
ASCIISTR(meKCm)
Преобразует текст из любой кодировки в ASCII-эквивалент. Те символы текста,
которые не имеют эквивалентных символов в кодировке ASCII, будут заменяться
строкой ХАХХ, где АХАХ-код UTF-16. Например:
SELECT ASCIISTR('ABC’) FROM DUAL -> ’\00C4BC
А51М(число)
Возвращает арксинус числа в диапазоне от-1 до 1. Результат лежит в диапазоне от
-Л/2 до л/2 и выражен в радианах. Например:
SELECT ASIN( 0 ) FROM DUAL -> 0.000000
АТАМ(число)
Возвращает арктангенс любого числа. Результат лежит в диапазоне от -л /2 до л/2
и выражен в радианах. Например:
SELECT ATAN( 3.1415 ) FROM DUAL -> 1.262619
ATAN2(4UCiiol, число2)
Возвращает арктангенс числа! и числа2. Значения числа! и числа2 не ограничи-
ваются, но результат лежит в диапазоне от -л до л и выражен в радианах. Функ-
ция ATAN2(x,y) похожа на ATAN(y/x), за исключением того, что знаки х му исполь-
зуются при определении квадранта числа. Например:
SELECT ATAN2(3.1415, 1) FROM DUAL -> 1.26261873
688 | Глава 4. Функции SQL
ВР1ЬЕМАМЕ(директория, имя_файла)
Возвращается локатор BFILE, который связан с физическим двоичным файлом
LOB в файловой системе сервера, который расположен в указанной директории
и имеет указанное имя_файла.
BIN_ТО_NUM(выражение [,...п])
Функция возвращает десятичное число, равное двоичному битовому вектору,
содержащемуся в аргументах выражение. Например:
SELECT BIN_TO_NUM(1,0,1) FROM DUAL -> 5
BITAND(i{enoe_4uaiol, целое_число2)
Возвращается результат побитовой операции И (AND), выполненной над двумя
целыми числами. Например:
SELECT BITAND(101, 2) FROM DUAL -> О
SELECT BITAND(column1, 1) FROM DUAL -> 1
CARDINА ЫТУ(вложенная_таблица)
Возвращается количество элементов во вложенной_таблиц'е (кардинальность).
Если вложенная_таблица пуста, возвращается NULL. Пример:
SELECT CARDINALITY(mytable) FROM DUAL -> 6
CHA R TOROWID(ciMeon)
Значение символьного типа данных (CHAR или FARCHAR2) преобразуется к типу
ROWID.
CHR(4iiaio [USING NCHARjCS])
Возвращается символ, являющийся двоичным эквивалентом числа либо в наборе
символов базы данных (без параметра USING NCHAR_CS), либо в национальном
наборе символов (с параметром USING NCHAR_CS).
COALESCE(chucok)
Возвращается первый непустой элемент списка. Например:
SELECT COALESCE( NULL, 1,2) FROM DUAL -> 1
COLLECT(cm<Mi6eii)
Для каждой группы создается вложенная таблица, включающая в себя все значения
столбца. Это агрегатная функция.
СОМРОВЕ(строка)
Возвращается полностью нормализованная строка UNICODE.
CONCAT(cmpoKal, строка2)
Возвращает результат соединения строки! со строкой2. Функция CONCATэкви-
валентна оператору конкатенации (]|). Пример:
SELECT C0NCAT( au_lname, au_fname ) FROM AUTHORS -> 'JeffersonThomas'
СОНУЕРТ(символьное_значение, целевая_кодировка, исходная_кодировка)
Функция преобразует символьную строку из одного набора символов в другой.
Возвращает символъное_значение, преобразованное из исходной_кодировки в целе-
вую _код ировку.
44 - 2447
Платформо-специфические расширения | 689
СОЯЯ_К(выражение!, выражение2 [, типрезультата])
CORR_S (выражение!, выражение2 [, типрезультата])
Функция CORR K возвращает корреляционный коэффициент тау-б Кендалла,
а функция CORR S возвращает корреляционный коэффициент ро Спирмана для
набора нумерованных пар {выражение! и выражение2). Параметр тип результа-
та (VARCHAR2) можно опустить или использовать одно из следующих значений:
'COEFFICIENT', 'ONE_SIDED_SIG', 'IWO_SIDED_SIG'. При указании значения
'COEFFICIENT' (а также по умолчанию) возвращается коэффициент корреляции.
При указании значения 'ONE_SIDED_SIG' или 'TWO_SIDED_SIG' возвращается
достоверность корреляции с одним или двумя хвостами распределения соответст-
венно.
СО5(число)
Возвращается косинус числа как величины угла, выраженной в радианах. Напри-
мер:
SELECT COS(O) FROM DUAL -> 1.000000
СОВН(число)
Возвращается гиперболический косинус числа. Например:
SELECT C0SH(180) FROM DUAL -> 7.4469E+77
SELECT C0T( 3.1415 ) FROM DUAL -> -10792.88993953
СОТ(число)
Возвращается котангенс числа. Например:
SELECT С0Т( 3.1415 ).-> -10792.88993953
CV([столбецрзмерения])
Эта функция, которая работает только в межстрочных вычислениях внутри пред-
ложения MODEL инструкции SELECT, возвращает текущее значение столбца
измерения. Функцию CV можно использовать только на правой стороне правила,
поскольку она возвращает значение столбца_измерения из левой части того же
правила.
DBTIMEZONE
Возвращает для сервера базы данных смещение часового пояса от всеобщего ско-
ординированного времени (UTC). Например:
SELECT DBTIMEZONE FROM DUAL -> +00:00
ОЕСОВЕ(выражение [, искомое, результат [,...]], [, пормолчанию])
Функция сравнивает выражение с искомым. Если выражение равно искомому, то
возвращается результат. Например:
DECODE ('В','А',1,'В',2,...'Z',26,'?') -> 2
Если совпадение не обнаруживается, функция возвращает значение пормолчанию
или NULL, если это значение опущено. За подробностями обращайтесь к доку-
ментации Oracle. Старайтесь использовать вместо этой функции функцию CASE,
поскольку CASE входит в стандарт ANSI/ISO SQL.
690 | Глава 4. Функции SQL
DECOMPOSE(cmpoKa [{CANONICAL | COMPATIBILITY}])
Функция возвращает строку, разложенную на коды UNICODE. Второй аргумент
показывает тип используемого преобразования. Тип CANONICAL (используется
по умолчанию) позволяет вновь воссоздать исходную строку UNICODE.
ОЕРТН(число)
Возвращается глубина пути, указанного в условии UNDERJPATH XML-запроса.
За дополнительной информацией обращайтесь к справке Oracle SQL Reference.
D ЕЕЕЕ(выражение)
Возвращается объект, на который ссылается выражение. Выражение должно воз-
вращать ссылку (REF) на объект.
Е>иМР(выражение [, формат результата [, начинаяр [длина] ] ])
Функция возвращает значение типа VARCHAR2, содержащее код типа данных,
длину в байтах и внутреннее представление выражения. Значение возвращается
в указанном формате результата. Например:
SELECT DUMP('abc', 1016) FROM DUAL
Typ=96 Len=3 CharacterSet=AL32UTF8: 61,62,63
EMPTYBLOBC ), EMPTYJCLOB( )
Возвращается пустая ссылка на объект LOB, которую можно использовать для ини-
циализации переменной типа LOB. Также ее можно использовать для инициализа-
ции столбца LOB или для очистки атрибута в инструкции INSERT или UPDATE.
EXISTSNODE(:)iaeMn.4Hp, xpath [, пространствормен])
Функция возвращает 1, если запрос на языке XPath в параметре xpath возвращает
из экземпляра хотя бы один узел. В противном случае возвращается 0. Дополни-
тельный параметр пространство имен указывает для запроса пространство имен
XML. За дополнительной информацией о XML-запросах обращайтесь к справке
Oracle SQL Reference.
ЕХТИАСТфкземпляр, xpath [, пространствормен])
Функция возвращает узлы XML из экземпляра, который возвращается при запуске
запроса на языке XPath, содержащегося в параметре xpath. Дополнительный пара-
метр пространствормен указывает для запроса пространство имен XML. За до-
полнительной информацией о XML-запросах обращайтесь к справке Oracle SQL
Reference. Пример:
SELECT EXTRACT( XMLTYPE('<foo><bar>Hello, World! </barX/foo>'),
'/foo/bar' ) from DUAL
<bar>Hello, World1</bar>
ЕХТРАСТУАЕиЕфкземпляр, xpath [, пространствормен])
Функция возвращает значение из узла XML, который возвращается при запуске
запроса на языке XPath, содержащегося в параметре xpath. Дополнительный параметр
пространствормен указывает для запроса пространство имен XML. За дополни-
тельной информацией о XML-запросах обращайтесь к справке Oracle SQL Reference.
Пример:
Платформо-специфические расширения | 691
SELECT EXTRACTVALUE( XMLTYPE('<foo><bar>Hello, World!</bar></foo>'),
'/foo/bar' ) from DUAL
Hello, World!
FIRST
Агрегатная функция, возвращающая из записи определенное значение, которое
стоит первым согласно порядку сортировки, определяемому предложением
ORDER BY. Синтаксис:
агрегат(агрегируемое_выраж) KEEP (DENSE_RANK FIRST ORDER BY выражение [,...n])
где синтаксис выражения следующий:
выражение := [ASC|DESC] [NULLS {FIRST|LAST}]
Запись, имеющая наивысший ранг в порядке сортировки, определенном в выраже-
нии, и будет использоваться в агрегатной функции агрегат. Параметр агрегируе-
мое_выраж представляет собой выражение, передаваемое в агрегатную функцию.
Пример:
SELECT МАХ(с1) KEEP (DENSE-RANK FIRST ORDER BY c2) FROM FIVE_.NUMS
1
FIRSTVALUEIabipaoiceitue IGNORE NULLS) OVER (оконное_предложение)
Возвращается первое значение из отсортированного набора значений. Функция
FIRST_VALUE является аналитической функцией. За подробным объяснением
параметра оконное_предложение обращайтесь к разделу «Оконные функции
ANSI SQL» выше в этой главе. Пример:
SELECT FIRST.VALUE(col1) OVER ( ) FROM NUMS
1
1
1
1
FROM TZfотметка_времени, часовой_пояс)
Возвращается значение отметки__времени, преобразованное к типу TIMESTAMP
WITH TIME ZONE. Параметр отметка_времени должен быть значением типа
TIMESTAMP, а параметр часовой_пояс - строкой в формате TZH:TZM (часы:минуты
для часового пояса). Пример:
SELECT FROM_TZ(TIMESTAMP '2004-04-15 23:59:59', '8:00') FROM DUAL
'15-APR-04 11.59.59 PM +08:00'
GREATEST(ebipcoiceHue [,...])
Возвращает наибольшее из указанного списка выражений. Все выражения после
первого перед сравнением неявно приводятся к типу данных первого выражения.
Например:
SELECT GREATESTC8,2,4) FROM DUAL -> 8
692 | Глава 4. Функции SQL
GROUPJD()
Функция возвращает положительное значение для каждого дубликата группы, возвра-
щаемого запросом с предложением GROUP BY. Эта функция полезна для отфильтро-
вывания дублирующихся групп, создаваемых при использовании предложений CUBE,
ROLLUP и других расширений предложения GROUP BY (см. функцию GROUPING).
GROUPING! имя_столб1}а)
Функция возвращает 1, если запись добавлена при помощи предложений CUBE,
ROLLUP и других расширений предложения GROUP BY, иначе возвращает 0.
Например:
SELECT royalty, SUM(advance) 'total advance',
GR0UPING(royalty) 'grp'
FROM titles
GROUP BY royalty WITH ROLLUP
royalty total advance grp
NULL NULL 0
10 57000.0000 0
12 2275.0000 0
14 4000.0000 0
16 7000.0000 0
24 25125.0000 0
NULL 95400.0000 1
GROUPING_lD(ti.wi_cmai6ifaI [, имя_столбца2])
Возвращается число с основанием 10, которое эквивалентно двоичному значению,
созданному путем конкатенации значений GROUPING по каждому из параметров.
Функция GROUPING JD полезна для получения запроса, содержащего несколько
уровней агрегации, созданных при помощи выражений GROUP BY. Старайтесь
использовать функцию GROUPING ID вместо нескольких функций GROUPING
в одном запросе. Эта функция является кратким эквивалентом такой конструкции:
BIN_T0_NUM( GROUPING!имя,столбца!) [, 6В0иРЖ(имя_столбца2) )
HEXTORA W (строка)
Строка, содержащая шестнадцатеричные цифры, преобразуется в значение RAW.
Например:
SELECT HEXTORAW('OFE’) FROM DUAL -> 'OOFE'
1N1TCA P(строка)
Возвращается строка, в которой первая буква каждого слова - в верхнем регистре,
а все остальные - в нижнем. Например:
SELECT ШТСАР('thomas jefferson’) FROM DUAL -> Thomas Jefferson'
Платформо-специфические расширения | 693
lNSTR(cmpoKal, строка2 [, начинать _c [, вхождение] ] )
Функция возвращает позицию строки2 в строке!. Функция INSTR производит
поиск по строке!, начиная с позиции, указанной в параметре начинатьу (целое
число), и находит указанное вхождение строки2. Пример:
SELECT INSTR('foobar', 'o', 1, 1) FROM DUAL -> 2
Используйте варианты INSTRB для байтов, INSTRC для полных символов UNICODE,
INSTR2 для кодировки UNICODE UCS2 и INSTR4 для кодировки UNICODE UCS4.
1TERA T1ON_N UMBER
Эта функция, которая работает только в межстрочных вычислениях внутри пред-
ложения MODEL инструкции SELECT, возвращает число, показывающее, сколько
раз правила предложения MODEL будут выполняться при обработке запроса.
LAG(ebipa.iicenue [, смещение] [, поумолчанию]) OVER (оконноепредложение)
Аналитическая функция, которая предоставляет доступ к нескольким строкам
таблицы одновременно без использования рефлексивного соединения. Функция
LAG выводит «запаздывающее» значение из результирующего набора, которое
идет после текущей строки с указанным сдвигам. Для первых строк, количество
которых определяется параметром сдвиг, используется значение поумолчанию,
поскольку «запаздывающее» значение для этих строк не определено. За подроб-
ным объяснением параметра оконное_предложение обращайтесь к разделу
«Оконные функции ANSI SQL» выше в этой главе. Пример:
SELECT с1, LAG(d, 2, 0) OVER (ORDER BY c1) FROM FIVEJUMS
1 0
2 0
3 1
4 2
5 3
LAST
Возвращает строку, которая стоит последней согласно порядку сортировки, опре-
деляемому предложением ORDER BY. Синтаксис:
агрегат(агрегируемое_выраж) KEEP (DENSE_RANK LAST ORDER BY выражение [,...n])
где синтаксис выражения следующий:
выражение := [ASC|DESC] [NULLS {FIRST|LAST}]
Запись, имеющая наименьший ранг в порядке сортировки, определенном в выра-
жении, и будет использоваться в агрегатной функции агрегат. Параметр агре-
гируемое_выраж представляет собой выражение, передаваемое в агрегатную
функцию. Пример:
SELECT MIN(c1) KEEP (DENSE_RANK LAST ORDER BY c1) FROM FIVE_NUMS
5
694 | Глава 4. Функции SQL
LAST DAY(dama)
Возвращается дата последнего дня месяца, к которому принадлежит указанная
дата. Например:
SELECT LAST_DAY('15-APR-1999’) FROM DUAL -> 30-APR-99
ЬА5Т_уАЬиЕ(выражение [IGNORE NULLS]) OVER (оконное_предложение)
Возвращается значение, которое стоит последним в отсортированном наборе
значений. За подробным объяснением параметра оконное_предложение обращай-
тесь к разделу «Оконные функции ANSI SQL» выше в этой главе. Пример:
SELECT cl, LAST_VALUE(c-') OVER (ORDER BY c1) FROM FIVE_NUMS
1 5
2 5
3 5
4 0
5 5
LEAD(ebipaJicenue [. смещение] [, по_умолчанию] ) OVER (оконное_предложение)
Аналитическая функция, которая предоставляет доступ к нескольким строкам таб-
лицы одновременно без использования рефлексивного соединения. Функция LEAD
выводит «опережающее» значение из результирующего набора, которое идет перед
текущей строкой с указанным сдвигам. Для последних строк результирующего на-
бора. количество которых определяется параметром сдвиг, используется значение
по умолчанию, поскольку «опережающее» значение для этих строк не определено.
За подробным объяснением параметра оконное_предложение обращайтесь к разде-
лу «Оконные функции ANSI SQL» выше в этой главе. Пример:
SELECT cl. _EAD(cl. 2) OVER (ORDER BY cl) FROM FIVE_NjMS
1 3
2 4
3 5
4
ТЕАЕТ(выражение [... n])
Возвращает наименьшее из приведенного списка выражений. Пример:
SE..ECT ._EAS~( 10,5, 3, 7) FROM DUAL -> 3
LENGTH (cmрока)
Функция возвращает длину строки в виде целого числа или возвращает NULL,
если строка равна NULL. Например:
SELECT LENGTH!’DUCK’) FROM DUAL -> 4
LENGTHB(cmpoKa)
Функция возвращает длину типа char в байтах. Во всех остальных случаях анало-
гична функции LENGTH. Пример:
SELECT LENGTHB('DUCK') FROM DUAL -> 4
Платформо-специфические расширения | 695
Используйте варианты LENGTHS для байтов, LENGTHC для полных символов
UNICODE, LENGTH2 для кодировки UNICODE UCS2 и LENGTH4 для кодировки
UNICODE UCS4.
LNNVL(yc.'ioeue)
Функция возвращает значение ИСТИНА (true), если условие ложно или если один
из операндов условия пустой (NULL). Например:
SELECT COUNT(*) FROM authors WHERE LNNVL( contract <> 1 ) -> 4
LOCALTIMESTAMP [(точность)]
Функция возвращает значение типа TIMESTAMP с текущей датой и временем. Эта
функция сходна с CURRENT_TIMESTAMP, за исключением того, что эта функция
не возвращает в значении TIMESTAMP значение часового пояса (TIME ZONE).
Например:
SELECT LOCALTIMESTAMP FROM DUAL -> ’15-APR-05 03.15.00 PM'
ТОО(основание, число)
Возвращает для числа логарифм с любым основанием. Например:
SELECT L0G(50,10) FROM DUAL -> .58859191
LPAD(cmpoKal, число [, строка2] )
Возвращается строка!, дополненная до длины, указанной параметром число, сим-
волами строки2. По умолчанию строка2 представляет собой одиночный пробел.
Пример:
SELECT LPAD('ucks',5,'d') FROM DUAL -> 'ducks'
LTRIM(cmpoKa [, набор])
Удаляет из строки все символы, входящие в набор, начиная слева. По умолчанию
набор представляет собой одиночный пробел. Пример:
SELECT LTRIMU Howdyl ') FROM DUAL -> 'Howdy!
МАКЕ РЕЕ({имя_таблицы | имя_представления], ключ [,...п])
Создается ссылка (REE) на строку объектного представления или строку объект-
ной таблицы, идентификатор которой основывается на первичном ключе.
MEDIAN (выражение) OVER (секционирование)
Возвращается значение медианы отсортированного набора числовых значений или
значений дата/время. За подробным объяснением параметра секционирование обра-
щайтесь к разделу «Оконные функции ANSI SQL» выше в этой главе. Пример:
SELECT MEDIAN(C1) FROM FIVE.NUMS -> 3
MONTHSJBETWEEN(damal, dama2)
Возвращает количество месяцев между датой! и датой2. Если дата! более позд-
няя, чем дата2, значение будет положительным, если более ранняя - отрицатель-
ным. Например:
SELECT MONTHS_BETWEEN('15-APR-2000', '15-JUL-1999') FROM DUAL -> 9
696 | Глава 4. Функции SQL
NANVL(a, b)
Функция возвращает b, если а не является числом (NaN, Not a Number), иначе воз-
вращает а. Выражение а должно иметь результатом число типа BINARY FLOAT
или BINARY DOUBLE, поскольку только эти два типа могут хранить значения
NaN. Например:
SELECT c1, NANVL(c1. 0) FROM NUMS
1.СЕ+000 1.0Е+000
2.0Е+000 2.0Е+000
Nan 0
NCHAR(4ucno)
Синоним функции CHR(uucjio) USING NCHAR CS.
NEW_TlME(dama, часовой пояс 1, часовой_пояс2)
Возвращает дату и время в часовом_поясе2, используя в качестве исходных значений
указанную дату/время и указанный часовой_пояс 1. Например:
ALTER SESSION SET NLS_DATE_FORMAT = 'DD-MON-YYYY HH12:MI:SS'
SELECT NEW_TTME(TO_DATE( '04-15-99 08:22:3V, 'MM-DD-YY HH12: MI:SS'),
'AST', 'PSI') FROM DUAL
15-APR-2099 04:22:31
Значения часовой_пояс! и часовой_пояс2 могут представлять собой одну из при-
веденных ниже текстовых строк.
AST, ADT: Atlantic Standard or Daylight Time
BST, BDT: Bering Standard or Daylight Time
CST, CDT: Central Standard or Daylight Time
EST, EDT: Eastern Standard or Daylight Time
GMT: Greenwich Mean Time
HST, HDT: Alaska-Hawaii Standard or Daylight Time
MST, MDT: Mountain Standard or Daylight Time
NST: Newfoundland Standard Time
PST, PDT: Pacific Standard or Daylight Time
YST, YDT: Yukon Standard or Daylight Time
NEXT_DAY(dama, строка)
Возвращается дата, соответствующая первому указанному в параметре строка
дню недели, более позднему, чем указанная дата. Аргумент строка должен пред-
ставлять собой полное или сокращенное название дня недели в языке, на котором
пишутся даты в текущем сеансе. Например:
ALTER SESSION SET NLS_DATE_FORMAT = 'DD-MON-YYYY'
SELECT NEXT_DAY('15-APR-1999', 'SUNDAY') FROM DUAL
18-APR-1999
NLS CHARSETD ECL_LEN(4ucjioбайт, id набора символов)
Возвращается объявленная ширина (числобайт) столбца NCHAR с использованием
указанного к/ набора символов столбца.
Платформо-специфические расширения | 697
NLSCHARSET_NAME(noMep)
Функция возвращает в формате VARCHAR2 имя набора символов NLS, соответст-
вующего указанному идентификационному номеру.
NLS_INITCАР (строка [, napaMemp_nls] )
Возвращается строка, в которой первая буква каждого слова преобразована в верхний
регистр, а все остальные буквы - в нижний регистр. napaMemp_nls предоставляет
специальные возможности сортировки, связанные с конкретным языком.
NLS_LOWER(cmpoKa [, параметр_nls])
Возвращается строка, в которой все буквы переведены в нижний регистр, пара-
Memp_nls предоставляет специальные возможности сортировки, связанные с кон-
кретным языком.
NLSSORT(cmpoKa [, параметр_п1$])
Возвращается строка байтов, используемых для сортировки строки. параметр пЕ
предоставляет специальные возможности сортировки, связанные с конкретным языком.
NLS_UPPER(cmpoKa [, napaMempjils] )
Возвращается строка, в которой все буквы переведены в верхний регистр, пара-
метр_п1$ предоставляет специальные возможности сортировки, связанные с кон-
кретным языком.
NTILE(eMpaoiceiiue) OVER ([секционирование] сортировка)
Отсортированный набор данных делится на несколько групп, нумеруемых от 1 до
значения в параметре выражение, и каждой строке присваивается соответст-
вующий номер группы. Строки относятся к группам таким образом, чтобы ко-
личество строк в группах не отличалось более чем на единицу. За информацией
о предложениях секционирование и сортировка обращайтесь к разделу «Оконные
функции ANSI SQL» выше в этой главе. Пример:
SELECT с1, NTILE(4) OVER (ORDER BY c1) FROM FIVE_NUMS
1 1
2 1
3 2
4 3
5 4
NULLIF(выражение 1, выражение2)
Функция возвращает NULL, если выражение! равно выражению2. Если эти
выражения не равны, возвращается выражение!. Значение NULL можно исполь-
зовать в этой функции только в качестве значения выражения2. Например:
SELECT d, с2, NULLIF(c1, с2) FROM NUMS
1 2 1
2 2
3 2 3
NUMTODSINTERVAL('iucjio, строка)
Функция преобразует число в литерал INTERVAL DAY ТО SECOND. Параметр
число может быть числовой константой или выражением, значением которого
698 | Глава 4. Функции SQL
является число (например, столбцом числового типа данных). Второй аргумент,
строка, может принимать значения 'DAY’, 'HOUR', ’MINUTE’ или ‘SECOND’, пока-
зывающие, как следует интерпретировать число. Пример:
SELECT NUMTODSINTERVAL(1OO, 'DAY') FROM DUAL
+000000100 00:00:00,000000000
NUMTODSINTERVAL(4uaio, строка)
Функция преобразует число в литерал INTERVAL YEAR ТО MONTH. Параметр
число может быть числовой константой или выражением, значением которого
является число (например, столбцом числового типа данных). Второй аргумент,
строка, может принимать значения ‘YEAR’ или ‘MONTH’, показывающие, как
следует интерпретировать число. Пример:
SELECT NUMT0YMINTERVAL(100, -YEAR’) FROM DUAL
+000000100-00
NVL(выражение I, выражение2)
Если выражение! равно NULL, то вместо NULL возвращается выражение2.
В противном случае возвращается выражение!. Параметры выражение! и выра-
жение2 могут относиться к любому типу данных. Например:
SELECT NVL(2,29) FROM DUAL -> 2
НУЬ2(выражеиие!, выражениеЗ, выражениеЗ)
Эта функция сходна с NVL, за исключением того, что, если выражение! не равно
NULL, возвращается выражениеЗ, а если выражение! равно NULL, возвращается
выражениеЗ. Параметры выражение!, выражениеЗ и выражениеЗ могут отно-
ситься к любому типу данных, кроме LONG. Например:
SELECT NVL2C1.3,5) FROM DUAL -> 3
ORA_HASH(ebipaotceHue [, сегменты [, начальное_значение]])
Функция вычисляет для выражения хеш-значение и возвращает на основе вычис-
ленного хеш-значения номер сегмента. Дополнительный аргумент сегменты - это
максимальный номер используемого сегмента, который на 1 меньше общего числа
сегментов, поскольку их нумерация начинается с 0. Значение по умолчанию для
параметра сегменты равно 4 294 967 295. Дополнительный аргумент началь-
ное рначение используется в качестве исходного значения для хеш-функции, чтобы
можно было создавать разные результаты на основе одного набора данных, изменяя
только начальное значение. Значение по умолчанию для этого параметра - 0. В при-
веденном примере все числа псевдослучайным образом распределяются между
двумя сегментами и возвращаются все числа, принадлежащие к первому сегменту,
который будет представлять собой выборку из примерно половины значений.
SELECT С1 FROM FIVE_NUMS WHERE
ORA_HASH( C1. 1, TO_CHAR( SYSTIMESTAMP, 'SSSS.FF' ) ) = 0
1
5
Платформо-специфические расширения ( 699
РАТН(число)
Возвращается путь, указанный в условии UNDER_PATH с соответствующей пере-
менной число в XML-запросе. За дополнительной информацией обращайтесь
к справке Oracle SQL Reference.
POWERMULTISET(eji<aiceniiaH_ma6nuiia) POWERMULTISETJIY-CARDINALITY
(вложенная_таблица, кардинальность)
Возвращается вложенная таблица, состоящая из всех вложенных таблиц всех непус-
тых поднаборов данных, входящих в указанную вложенную^таблицу. Функция
POWERMULTISET_P>Y__CARDINALITY имеет дополнительный параметр, который
может использоваться для ограничения поднаборов указанным минимальным
числом элементов (кардинальностью). За дополнительной информацией обращай-
тесь к справке Oracle SQL Reference.
PRESENTNNV(ccbiriKajiaji4eiiKy, выражение!, выражение?)
Используется только в межстрочных вычислениях внутри предложения MODEL
инструкции SELECT. Возвращает выражение!, если ссылка_на_ячейку существу-
ет и не равна NULL, иначе возвращает выражение?.
РРЕ5ЕЫТУ(ссылка_на_ячейку, выражение!, выражение?)
Используется только в межстрочных вычислениях внутри предложения MODEL
инструкции SELECT. Возвращает выражение!, если ссылка_на_ячейку существу-
ет, иначе возвращает выражение?.
PREVIOUS)ссылканая чейку)
Используется только в межстрочных вычислениях внутри раздела ITERATE...[UNTIL]
предложения MODEL инструкции SELECT. Эта функция возвращает значение, храня-
щееся в ссылке_на^ячейку в начале итерации.
RATIO ТО_РЕРОРТ(значения_выражений) OVER (секционирование)
Вычисляется отношение значения в значениях_выражений к сумме всех значе-
ний-выражений в каждом разделе (секции). Если значение_выражения равно
NULL, то значением функции также будет NULL. За описанием предложения сек-
ционирование обращайтесь к разделу «Оконные функции ANSI SQL» выше в этой
главе. Например:
SELECT с1, RATI0_T0„REP0RT(c1) OVER ( ) FROM FIVE_NUMS
1 .066666667
2 .133333333
3 .2
4 .266666667
5 .333333333
RAWTOHEX(raw)
Значение raw преобразуется в строку (символьный тип данных) соответствующих
шестнадцатеричных символов. Пример:
SELECT RAWTOHEX('Hi') FROM DUAL -> 4869
700 | Глава 4. Функции SQL
RAWTON HEX(raw)
Значение raw преобразуется в значение NVARCHAR2 (символьный тип данных)
с соответствующими шестнадцатеричными символами.
РЕЕ(нсевоонимтабл1Н1ы)
Функция REF принимает табличный псевдоним, связанный со строкой объектной
таблицы или объектного представления. Возвращается специальная ссылка на эк-
земпляр объекта, связанный с переменной или строкой.
ЕЕРТОНЕХ(выражение)
Указанное выражение преобразуется в символьное значение, содержащее его ше-
стнадцатеричный эквивалент.
REGEXP JNSTR(cmpoKa, шаблон [, начинателе [, вхождение [, г-опция [, т-параметр] ] ] ])
Возвращается позиция указанного выражения-ша(5ло//а в пределах указанной строки.
Функция REGEXP JNSTR проводит поиск в строке, начиная с позиции, указанной
параметром начинатьс (целое число больше 0), и ищет указанное вхождение данно-
го шаблона. По умолчанию параметры начинать^ и вхождение равны 1. Параметр
r-опция может принимать значения 0 и 1 и определяет, будет ли возвращаемая пози-
ция соответствовать первому символу совпадения с шаблоном или следующему сим-
волу. По умолчанию значение r-опции равно 0, что соответствует первому символу
совпадения с шаблоном. Аргумент т-параметр можно использовать для изменения
поведения функции при определении совпадения. Для него можно указать одно или
несколько из приведенных значений.
7'- при определении совпадения не учитывается регистр.
'с'-- при определении совпадения регистр учитывается.
’п’ — символ совпадает с символами новой строки.
7и' - входная строка считается многострочной; символ ,Л1 соответствует началу
строки, а символ - концу строки.
Пример:
SELECT REGEXP_INSTR( 'Hello, World!’, '([" ]*)!', 1, 1) FROM DUAL -> 8
REGEXP_REPLACE(cmpoKa, шаблон [, новая_строка [.начинать^
[, вхождение [, т-параметр] ] ] ])
Возвращается результат замены всех вхождений указанного выражения-ш«бло//а
в пределах указанной строки на новую_строку. Функция REGEXP REPLACE
проводит поиск в строке, начиная с позиции, указанной параметром начинать с
(целое число больше 0), и ищет указанное вхождение данного шаблона. По
умолчанию параметры начинать с и вхождение равны 1. Аргумент т-параметр
можно использовать для изменения поведения функции при определении совпаде-
ния. Для него можно указать одно или несколько из приведенных значений.
7'- при определении совпадения не учитывается регистр.
'с' - при определении совпадения регистр учитывается.
’п1 - символ совпадает с символами новой строки.
’т' - входная строка считается многострочной; символ ,Л1 соответствует началу
строки, а символ - концу строки.
Платформо-специфические расширения | 701
Пример:
SELECT REGEXP_REPLACE( ’Hello, World!', '([" ]*!)', ’Reader!') FROM DUAL
'Hello, Reader! '
REGEXP_SUBSTR(cmpoKa, шаблон [, начинать_c [, вхождение [, т-параметр]]])
Возвращается подстрока, которая совпадает с указанным выражением-шаблоном
в пределах указанной строки. Функция REGEXPSUBSTR проводит поиск в строке,
начиная с позиции, указанной параметром начинать_с (целое число больше 0),
и ищет указанное вхождение данного шаблона. По умолчанию параметры начинатъ_с
и вхождение равны 1. Аргумент т-параметр можно использовать для изменения
поведения функции при определении совпадения. Для него можно указать одно
или несколько из приведенных значений.
Ч' - при определении совпадения не учитывается регистр.
'с' - при определении совпадения регистр учитывается.
'п'- символ совпадает с символами новой строки.
'т' - входная строка считается многострочной; символ ,Л' соответствует началу
строки, а символ - концу строки.
Пример:
SELECT REGEXP_SUBSTR( 'Hello, World!', '([~ ]*!)') FROM DUAL
'World! '
REMAINDER^, n)
Возвращается остаток от деления т на п. Возвращаемое значение эквивалентно
следующему выражению:
m-n*ROUND(m/n)
В функции MOD вместо функции ROUND используется функция FLOOR. Пример:
SELECT REMAINDER(11, 4), M0D(11, 4) FROM DUAL
-1 3
REPLACE (строка, строка_поиска [, строка_замены] )
Возвращается строка, в которой каждое вхождение строки_поиска заменено
строкой_замены. Например:
SELECT REPLACE('change’, 's’, 'ing') FROM DUAL -> 'changing'
ROUND(4ucno [, число_десятичных_знаков])
Возвращается число, округленное до указанного числа_десятичных_знаков после
запятой. Если число_десятичных_знаков не указано, округление производится до
целого. Обратите внимание, что целочисленный параметр число_деся-
тичных_знаков может быть отрицательным, и при этом округляются цифры слева
от десятичной точки. Пример:
SELECT R0UND(12345.6789, 2) FROM DUAL -> 12345.68
ROUND(dama [формат])
Функция возваращает дату, округленную до единиц, указанных параметром формат.
Если формат не указан, то дата округляется до ближайшего дня. (За дополнительной
702 | Глава 4. Функции SQL
информацией о доступных спецификаторах формата обращайтесь к описанию функ-
ции TO CHAR.) Пример:
SELECT ROUND(TO_DATE('15-APR-1999'), ’MONTH') FROM DUAL
01-APR-1999
RO WIDTOCHAR(rowid), ROWIDTONCHAR(rowid)
Функция ROWIDTOCHAR преобразует значение rowid к типу данных VARCHAR2
длиной 18 символов. Функция ROWIDTONCHAR преобразует значение rowid
к типу данных NVARCHAR2 длиной 18 символов. Пример:
SELECT ROWIDTOCHAR(ROWID) FROM NUMS
ABAsxDAAKAAAAEqAAA
ABAsxDAAKAAAAEqAAB
ABAsxDAAKAAAAEqAAC
ABAsxDAAKAAAAEqAAD
RPAD(cmpoKCiI, число [, строка2])
Возвращается строка!, дополненная справа до указанной длины (параметр число)
строкой2, повторенной необходимое количество раз. По умолчанию строка2
представляет собой одиночный пробел. Например:
SELECT RPAD(’duck’,8,’s') FROM DUAL -> duckssss’
RTR!M(cmpoKa [, набор])
Возвращается строка, из которой удалены все символы справа, входящие в набор.
По умолчанию набор представляет собой одиночный пробел. Например:
SELECT RTRIMC welcome FROM DUAL -> ' welcome'
SCN__ TO_ TIMESTA MP (sen)
Возвращается отметка времени (timestamp), связанная с указанным номером сис-
темного изменения (System Change Number, SCN). Пример:
SELECT SCN_TO_TIMESTAMP(ORA_ROWSCN) FROM NUMS WHERE d = 1
15-APR-04 02 56.05.000000000 PM
SESSIONTIMEZONE
Функция возвращает смещение часового пояса для текущего сеанса. Например:
SELECT SESSIONTIMEZONE FROM DUAL -> -06:00
5ЕТ(вложенная_таблица)
Возвращается вложенная таблица, состоящая из недублирующихся элементов
указанной вложенной_таблицы. За дополнительной информацией обращайтесь,
пожалуйста, к справке Oracle SQL Reference.
SIGN (число)
Если число < 0, возвращает -1, если число - 0, возвращает 0, если число > 0, воз-
вращает 1. Например:
SELECT SIGN(-3.1415926) FROM DUAL -> -1
Платформо-специфические расширения | 703
SIN (число)
Функция возвращает синус числа, выраженного в радианах. Например:
SELECT SIN( 0 ) -> 0.000000
SlNH(4UCjio)
Возвращает гиперболический синус числа. Например:
SELECT SINH(180) FROM DUAL -> 7.4469E+77
SOUNDEX(cmpoKa)
Возвращает символьную строку, содержащую фонетическое представление стро-
ки. Эта функция позволяет сравнить английские слова, которые пишутся по-раз-
ному, но звучат сходным образом. Например:
VALUES! SOUNDEX!'thimble') ) -> 'Т514'
STATSBINOMIALTEST, STATSCROSSTAB, STATSJJEST, STATS_KS_TEST, STATS_MODE,
STATSMWJEST, STATSONEWAYANOVA, STATS TJEST_ONE, STATS T TEST PAIRED,
STATS TJEST_INDEP, STATS J JESTJNDEPU, STATSJVSR JEST
Oracle предлагает множество сложных статистических функций. За дополнитель-
ной информацией о функциях STATSJ обращайтесь, пожалуйста, к справке
Oracle SQL Reference.
STDDEV([DISTINCT \ ALL] выражение) [OVER (оконное предложение)]
Возвращается выборочное стандартное отклонение для набора значений, указы-
ваемых выражением. За подробным описанием параметра оконное преОложение
обращайтесь к разделу «Оконные функции ANSI SQL». Пример:
SELECT STDDEV(coll) FROM NUMS -> 5.71547607
STDDEV SAMP(ehipajicenue) [OVER (оконное_предложение)]
Функция вычисляет накопительное выборочное стандартное отклонение и возвра-
щает квадратный корень выборочной дисперсии. За подробным описанием пара-
метра оконное предложение обращайтесь к разделу «Оконные функции ANSI
SQL». Пример:
SELECT STDDEV_SAMP(col1) FROM NUMS -> 5.71547607
STDDEV POPIebipajicenue) [OVER (оконное предложение)]
Функция вычисляет стандартное отклонение генеральной совокупности и возвра-
щает квадратный корень выборочной дисперсии. За подробным описанием пара-
метра оконное предложение обращайтесь к разделу «Оконные функции ANSI
SQL». Пример:
SELECT STDDEV_P0P(col1) FROM NUMS -> 4.94974747
SUBSTR(cmpoKa, начало [FROM началъное_положение] [FOR длина] )
Обращайтесь к приводимому ниже разделу, посвященному функции SUBSTRB.
Пример:
SELECT SUBSTR!'Hello, World!', 8,10) FROM DUAL -> 'World! '
704 | Глава 4. Функции SQL
SUBSTRB( строка, начало[, длина]] )
Возвращает часть строки, указанной в байтах длины, начиная с начала. Если
параметр длина опущен, возвращаются все символы, начиная с начала. Если пара-
метр начало отрицателен, то он показывает смещение от правого края строки.
Пример:
SELECT SUBSTR ('Hello, World!', 8) FROM DUAL -> World!
Используйте варианты SUBSTRB для байтов, SUBSTRC для полных символов
UNICODE, SUBSTR2 для кодировки UNICODE UCS2 и SUBSTR4 для кодировки
UNICODE UCS4.
SYS_CONNECT_BY_PAТН(столбец, символ)
В иерархических запросах функция SYS_CONNECT_BY_PATH возвращает путь от
корня к узлу, соответствующему указанному столбцу. Параметр символ показыва-
ет символ-ограничитель для узла в возвращаемом пути. За дополнительной ин-
формацией об иерархических запросах Oracle обращайтесь, пожалуйста, к справ-
ке Oracle SQL Reference.
SYS_CONTEXT(npocmpaHcmeo_UMeH, атрибут [, длина] )
Функция возвращает значение атрибута, связанного с контекстом указанного
пространства_имен, которое можно использовать и в инструкциях SQL, и в инструк-
циях PL/SQL. Пример:
SELECT SYS_CONTEXT ('USERENW, 'SESSION—USER') FROM DUAL
'LOGIN'
SYS_DBURIGEN(столбец [, rowid] [,...] [, 'текст( )])
Возвращается URL, который можно использовать в качестве уникальной ссылки на
запись, указанную параметром столбец. Для тех столбцов, которые не содержат
уникальных значений, можно указать после столбца его идентификатор (rowid),
чтобы URL гарантированно указывал только на одну запись. Используйте параметр
'текст( )', если вы хотите, чтобы URL указывал на текст в документе XML, а не на
сам документ.
S YS-EXTRA СТ_ иТС(дата/время)
Функция возвращает аргумент дата/время, преобразованный к Всеобщему ско-
ординированному времени (UTC). Например:
SELECT SYS_EXTRACT_UTC(TIMESTAMP '2004-04-15 11:59:59.00 -08:00')
FROM DUAL
'15-APR-04 07.59.59.000000000 PM'
SYS_GU1D()
Функция создает и возвращает глобальный уникальный идентификатор (GUID)
(в виде значения RAW), состоящий из 16 байт. Например:
SELECT SYS_GUID( ) FROM DUAL -> COFD3FDC30148EAEE030440A49096A41
S YS_ TYPE1D(объектное-Значение)
Возвращается идентификатор типа (type ID) для указанного объектного_значения.
45 - 2447
Платформо-специфические расширения | 705
SYS XMLAGGfebipaMcenue [, формат])
Функция возвращает один документ XML, созданный путем агрегирования докумен-
тов XML или их фрагментов, указанных в выражении. Дополнительный параметр
формат можно использовать для форматирования документа XML. За дополни-
тельной информацией обращайтесь к справке Oracle SQL Reference.
SYS_XMLGEN(выражение [, формат])
Функция возвращает один документ XML, созданный на основе выражения.
Дополнительный параметр формат можно использовать для форматирования
документа XML. За дополнительной информацией обращайтесь к справке Oracle
SQL Reference.
SYSDATE
Функция возвращает текущую дату и время в системе, на которой работает база
данных. Возвращается значение wmDATE. Например:
SELECT SYSDATE FROM DUAL -> 26-JUN-2003
SYSTIMESTAMP
Функция возвращает текущую дату и время в системе, на которой работает база
данных. Возвращается значение типа TIMESTAMP. Например:
SELECT SYSTIMESTAMP FROM DUAL
26-JUN-2003 11.15.00.000000 PM -06:00
TAN (число)
Возвращается тангенс числа, выраженного в радианах. Например:
SELECT TAN( 3.1415 ) FROM DUAL -> -0.000093
TANH (число)
Возвращается гиперболический тангенс числа. Например:
SELECT TANH(180) FROM DUAL -> 1
TIMESTAMP_ТО_5СН(значение_отметки_времени)
Возвращается приблизительный номер системного изменения, связанный с отмет-
кой времени. Возвращаемое значение имеет тип NUMBER.
ТО В INARYDOUBLE (выражение [, формат [, параметр _nls]])
Функция преобразует значение выражения к типу BINARY DOUBLE в формате,
указанном параметром формат. Если выражение относится к символьному типу,
то формат и параметр_пЕ имеют тот же смысл, что и в функции TO CHAR. Если
выражение относится к числовому типу, то параметры формат и параметр_п1з
нужно опустить. Пример:
SELECT d, T0_BINARY_D0UBLE(c1) FROM NUMS
1 1.ОЕ+000
2 2.ОЕ+000
3 3.0Е+000
706 | Глава 4. Функции SQL
TOBINARYFLOAT(выражение [, формат [, параметрjds]])
Функция преобразует значение выражения к типу BINARY FLOAT в формате,
указанном параметром формат. Если выражение относится к символьному типу,
то формат и параметру^ имеют тот же смысл, что и в функции ТО CHAR. Если
выражение относится к числовому типу, то параметры формат и параметру^
нужно опустить. Пример:
SELECT с1, TO_BINARY_FLOAT(c1) FROM NUMS
1 1.ОЕ+ООО
2 2.ОЕ+ООО
3 3.ОЕ+ООО
ТО_СНАК(симво:1ьноеуыражение)
Указанное символьное выражение преобразуется в кодировку базы данных.
Например:
SELECT TO._CHAR( 'Howdy') FROM DUAL
Howdy
TO CHAR (дата | интервал [, формат [, параметрyils]])
Эта функция преобразует дату или интервал в значение типа VARCHAR2
в формате, указанном параметром формат. Если параметр формат опущен, дата
преобразуется в формат, заданный по умолчанию. параметр пТ предоставляет
дополнительные возможности управления форматом. Ниже приводятся доступные
обозначения формата и их описания.
AD или A.D.
Обозначение «до нашей эры».
AM или А.М.
Обозначение «до полудня».
ВС или В. С.
Обозначение «нашей эры».
D
Номер дня недели (1-7).
DAY
Название дня.
DD
Номер дня месяца (1-31).
DDD
Номер дня года (1-366).
DL
Длинный формат даты.
DS
Краткий формат даты.
DY
Сокращенное название дня.
Платформо-специфические расширения | 707
FF
Доли секунды; для указания точности добавьте число (1-9) после обозначения FF.
НН или НН12
Час дня (1-12).
НН24
Час дня (0-23).
J
Номер дня юлианского календаря (число дней, прошедших с 1 января 4713 г.
до н. э.
MI
Минуты (0-59).
ММ
Месяц (01-12).
MON
Сокращенное название месяца.
RM
Номер месяца римскими цифрами (I—XII).
да
Секунды (0-59).
дазда
Число секунд, прошедших после полуночи (0-86,399).
Год из четырех цифр; даты до нашей эры предваряет знак минус.
TS
Краткий формат времени.
TZD
Летнее время (пример: PST (стандартное тихоокеанское время) и PDT (летнее
тихоокеанское время).
TZH
Час с учетом часового пояса.
TZM
Минуты с учетом часового пояса.
TZR
Часовой пояс в регионе.
X
Локальный разделитель целой и дробной части числа.
X YY или YYY
Год из одной, двух или трех цифр.
Y.YYY
Год с запятой.
YYYY
Год из четырех цифр.
Пример:
708 | Глава 4. Функции SQL
SELECT TO_CHAR(TO_DATE('15-APR-1999') ,'MON-DD-YYYY') FROM DUAL
APR-15-1999
TO_CHAR(4ucjio [, формат [, параметр_п1х]])
Указанное число преобразуется в тип VARCHAR2 с указанным форматом. Если
параметр формат опущен, число преобразуется в строку достаточной длины.
параметрах предоставляет дополнительные возможности управления форматом.
Пример:
SELECT T0_CHAR(123.45, '$999.99') FROM DUAL -> $123.45
TO_ CL OB(вы раже ние)
Символьное выражение преобразуется к типу данных CLOB. Пример:
SELECT LENGTH(TO_CLOB('I am a SQL nutl ')) FROM DUAL -> 15
TO_DATE(cmpoKa [, формат [, параметрах]])
Строка (тип данных CHAR или VARCHAR2) преобразуется в тип данных DATE,
параметрах предоставляет дополнительные возможности управления форматом.
Пример:
SELECT TO_DATE('15/04/1999', 'DD/MM/YYYY') FROM DUAL
15-APR-1999
TO_DSlNTERVAL(cmpoKa [, параметр_п1х])
Символьное выражение, указанное в строке, преобразуется в тип данных INTERVAL
DA У ТО SECOND, параметрах предоставляет дополнительные возможности управ-
ления форматом. Пример:
SELECT CURRENT_DATE, CURRENT_DATE-TO_DSINTERVAL('14 00:00:00') FROM DUAL
15-APR-2003 01-APR-2003
TO LONG (столбец long)
Эта функция, которая применяется только к выражениям типа LONG или LONG
RAW, преобразует значения типа LONG_RAW в столбце_1оп§ в значения LOB.
Используется только в списке отбираемых элементов подзапроса SELECT в инструк-
ции INSERT.
ТО_М UL TIB УТЕ(строка)
Возвращается строка, в которой все однобайтовые символы преобразованы в соот-
ветствующие многобайтовые символы.
ТО_ИСНАВ(выражение [, формат [, параметр_nlx]] )
Синоним функции TOCHAR, за исключением того, что возвращаемый результат
имеет тип NCHAR. За информацией о допустимых указателях формата обращай-
тесь к описанию функции TO CHAR.
ТО_НСЕОВ(выражение)
Символьное значение выражения преобразуется в тип данных NCLOB. Например:
SELECT LENGTH(TO_NCLOB(‘I am a SQL nutl')) FROM DUAL -> 15
Платформо-специфические расширения | 709
TO_NUMBER(ebipaaiceHue [, формат [, параметр_nls]])
Эта функция преобразует строку цифр (типа CHAR или VARCHAR2) в значение
числового типа (NUMBER) в формате, определяемом моделью формат, пара-
Memp_nls предоставляет дополнительные возможности управления форматом.
Пример:
SELECT TO_NUMBER('12345’) FROM DUAL -> 12345
TO SINGLE В УТЕ(строка)
Возвращается строка, в которой все многобайтовые символы преобразованы в соот-
ветствующие однобайтовые символы.
ТО_Т1МЕВТАМР(строка [, формат [, napaMemp_nls]])
Символьное выражение, указанное в параметре строка, преобразуется в тип
данных TIMESTAMP. При желании можно указать формат с помощью параметра
формат. параметр_п1$ предоставляет дополнительные возможности управления
форматом. За информацией о допустимых указателях формата обращайтесь к описа-
нию функции TO_CHAR. Пример:
SELECT TO_TIMESTAMP(CURRENT_DATE) FROM DUAL -> 04-MAY-04 12.00.00 AM
TO_TIMESTAMP_TZ(cmpoKa [ формат [, параметр_п1$]] )
Символьное выражение, указанное в параметре строка, преобразуется в тип
данных TIMESTAMP WITH TIMEZONE. При желании можно указать формат с помо-
щью параметра формат, параметр_nls предоставляет дополнительные возможности
управления форматом. За информацией о допустимых указателях формата обращай-
тесь к описанию функции TOCHAR. Пример:
SELECT TO_TIMESTAMP_TZ('15-04-2006', ’DD-MM-YYYY’) FROM DUAL
15-APR-06 12.00.00.000000000 AM -07:00
TO- YMINTER УАЬ(строка)
Функция преобразует символьное выражение, на которое указывает параметр
строка, в тип данных INTERVAL YEAR ТО MONTH. Пример:
SELECT TO_DATE(’29-FEB-2000’)+TO_YMINTERVAL(’04-00') FROM DUAL
29-FEB-04
ТРАНВЕАТЕ(символъное_значение, исходный_тпекст, конечный-Тпекст)
Возвращается символьное_значение, в котором каждое вхождение символа из
исходного_текста заменяется конечным _текстом. Например:
SELECT TRANSLATE(’foobar’, ’fa’, ’bu’) FROM DUAL -> boobur'
TRANSLATE (текст USING [CHARJJS | NCHAR_CSJ)
Указанный текст преобразуется в указанную кодировку. Используйте предложе-
ние CHAR_CS, чтобы преобразовать текст в тип данных CHAR, или используйте
предложение NCHARCS, чтобы преобразовать текст в тип_данных NCHAR.
Например:
SELECT TRANSLATE(N’foobar’ USING CHAR_CS) FROM DUAL
'foobar'
710 | Глава 4. Функции SQL
ТРЕАТ(выражение AS [REF] [схема.]тип)
Эта функция преобразует выражение из типа, в котором оно было объявлено,
в тип, указанный в параметре тип. (За дополнительной информацией об использо-
вании этой функции обращайтесь к справке SQL Reference для Oracle Database.)
TRUNC(ocnoeanue [ число] )
Возвращается основание, урезанное до указанного числа цифр после десятичной
точки. Параметр число может быть отрицательным. При этом урезаются (обнуляются)
цифры слева от десятичной точки. (За дополнительной информацией о допустимых
указателях формата обращайтесь к описанию функции TO CHAR.) Пример:
SELECT TRUNC(’123.456’, 2) FROM DUAL -> 123.45
TRUNC(dama [, формат])
Возвращается дата, урезанная до единиц, указанных в параметре формат. Если
параметр формат опущен, дата урезается до ближайшего целого дня. (За допол-
нительной информацией о допустимых указателях формата обращайтесь к описанию
функции TO CHAR.) Пример:
SElECT rBUNC(TO_DATE( ’ 45/04/1999 ', ' MM/DD/YYYY'), 'YYYY')
FROM DUAL
Щ99
Список спецификаторов формата приводится в описании функции ТО CHAR.
TZ_OFFSET ({выражение | SESSIONTIMEZONE ] DBTIMEZONE})
Функция возвращает для указанного аргумента сдвиг часового пояса. Выражение
(символьного типа) должно представлять собой либо название часового пояса, либо
его сдвиг. Аргументы SESSIONTIMEZONE и DBTIMEZONE показывают часовой
пояс для сеанса или для базы данных соответственно. Пример:
SELEC3 TZ._O.:;FSFT( '+08: 00' ), TZ_OFFSET(SESSIONTIMEZONE) FROM DUAL
t08'00 -07.00
UID
Возвращается целое число, которое однозначно идентифицирует вошедшего в систему
пользователя. Параметры не требуются. Например:
SELECT UID FROM DUAL -> 47
UNlSTR(cmpoKa)
Функция преобразует строку в тип данных NCHAR, и при этом преобразуются все
символы UNICODE, содержащиеся в строке. Пример:
SELECT UNISTRCE1 Nl\00F1o’) FROM DUAL -> 'El Nino'
иРНАТЕХМЦэкземпляр, xpath, выражение [, пространствормен])
Функция производит обновление всех значений в узлах экземпляра, заменяя их значе-
ниями выражения. Обновляются только те узлы, которые возвращает запрос на языке
XPath, содержащийся в параметре xpath. Дополнительный параметр пространст-
вормен указывает пространство имен XML для запроса. За дополнительной ин-
формацией о запросах XML обращайтесь к справке Oracle SQL Reference. Пример:
Платформо-специфические расширения | 711
SELECT UPDATEXML( XMLTYPE!'<foo><bar>Hello, World! </barX/foo>'),
'/foo/bar', '<bar>Bye, World!</bar>' ) from DUAL
Bye, World!
USERENV(omtuu)
Функция возвращает информацию о текущем сеансе в формате VARCHAR2. Эта
функция выходит из употребления и поддерживается только для обратной совмес-
тимости. Она является синонимом функции SYS_CONTEXT('USER_ENV', опция).
Функциональность рассматривается в описании функции SYS_CONTEXT с простран-
ством имен USERENV. Пример:
SELECT USERENV!’LANGUAGE') "Language" FROM DUAL
'AMERICAN,AMERICA,AL32UTF8'
УАЬиЕ(псевдоним__таблицы)
Принимает псевдоним_таблицы, связанный со строкой объектной таблицы, и воз-
вращает экземпляр объекта, хранящийся в данной строке объектной таблицы.
VARIANCE([DISTINCT] выражение) [OVER (оконное-Предложение)]
Функция возвращает для выражения дисперсию, вычисляемую следующим обра-
зом: дисперсия равна 0, если число строк в выражении = 1; дисперсия равна значе-
нию функции VAR_SAMP, если число строк в выражении > 1. За подробным опи-
санием оконного-Предложения обращайтесь к разделу «Оконные функции ANSI
SQL» выше в этой главе. Пример:
SELECT VARIANCE!coll) FROM NUMS -> 32.6666667
УАР-РОР(выражение) [OVER (оконное-Предложение)]
Возвращается дисперсия генеральной совокупности для набора значений в выра-
жении после удаления из набора пустых значений (NULL). За подробным описа-
нием оконного-Предложения обращайтесь к разделу «Оконные функции ANSI
SQL» выше в этой главе. Пример:
SELECT VAR_POP(col1) FROM NUMS -> 24.5
ЕАР_8АМР(выражение) [OVER (оконное-Предложение)]
Возвращается выборочная дисперсия для набора значений в выражении после уда-
ления из набора пустых значений (NULL). За подробным описанием оконного-Пред-
ложения обращайтесь к разделу «Оконные функции ANSI SQL» выше в этой главе.
Пример:
SELECT VAR_POP(col1) FROM NUMS -> 32.6666667
VSIZE (выражение)
Возвращается количество байт во внутреннем представлении выражения. Если
выражение равно NULL, возвращается NULL. Пример:
SELECT vsize(l) FROM DUAL -> 2
XMLAGG (экземпляр [, order_by])
Агрегатная функция, которая возвращает документ XML из таблицы фрагментов
XML, содержащихся в экземпляре. Дополнительное предложение order_by позво-
712 | Глава 4. Функции SQL
ляет сортировать фрагменты XML в результирующем документе. За дополнитель-
ной информацией о запросах XML обращайтесь к справке Oracle SQL Reference.
XMLCOLATTVA [.(выражение [AS псевдоним] [,...])
Возвращается фрагмент XML, получаемый из аргументов выражение. Дополни-
тельное предложение AS можно использовать для изменения значения атрибута
имени. За дополнительной информацией о запросах XML обращайтесь к справке
Oracle SQL Reference.
ХМЬСОХСАТ(экземпляр [,...])
Возвращается экземпляр XML, представляющий собой объединение всех пара-
метров - экземпляров XML. За дополнительной информацией о запросах XML
обращайтесь к справке Oracle SQL Reference.
XMLELEMENT([NAME] имя [, ХМЬАТТК1ВиТЕ$(выражение [AS псевдоним] [])]
[, значение [,...]])
Возвращается объект XMLELEMENT с указанным именем и атрибутами, указанными
в дополнительном предложении XMLATTRIBUTES. Параметры значение указывают
значения для результирующего объекта XMLELEMENT. За дополнительной информа-
цией о запросах XML обращайтесь к справке Oracle SQL Reference.
ХМТЕОВЕ5Т(значение [AS псевдоним] [,...])
Возвращается фрагмент XML, создаваемый из значений, указанных в параметрах
значение. Чтобы изменить имя тега, можно использовать дополнительное предложе-
ние AS. За дополнительной информацией о запросах XML обращайтесь к справке
Oracle SQL Reference.
XMLSEQ UENCE (экземпляр)
Возвращается массив фрагментов XML, созданный на основе узлов верхнего
уровня экземпляра XML, указанного в параметре экземпляр. За дополнительной
информацией о запросах XML обращайтесь к справке Oracle SQL Reference.
XMLTRANSFORM (экземпляр, таблица_стилей)
Возвращается результат применения таблицы стилей XML (указанной в пара-
метре таблица_стилей) к документу XML, содержащемуся в указанном экземп-
ляре. За дополнительной информацией о запросах XML обращайтесь к справке
Oracle SQL Reference.
Расширения, поддерживаемые PostgreSQL
В этом разделе представлен список функций, специфичных для PostgreSQL, с при-
мерами и соответствующими результатами.
А ВВТ1МЕ(отметка_времени)
Значение отметки_времени (timestamp) преобразуется в значение типа ABSTIME.
Эта функция поддерживается для обратной совместимости и может быть удалена
в будущих версиях. Пример:
SELECT ABSTIME(CURRENTTIMESTAMP) -> 2003-06-24 00:19:17-07
Платформо-специфические расширения | 713
АСОВ(число)
Возвращает арккосинус числа в диапазоне от-1 до 1. Результат лежит в диапазоне
от 0 до 1 и выражен в радианах. Например:
SELECT ACOS( 0 ) -> 1.570796
А ОЕ(отметка_времени)
То же, что AGE(CURRENT_DATE, отметка времени).
А ОЕ(отметка_времени, отметка_времени)
Возвращается время между двумя значениями отметка_времени. Например:
SELECT AGE( '2ООЗ-12-ЗГ, CURRENTJIMESTAMP )
6 mens 7 days 00:34:41.658325
АВЕА(объект)
Возвращается площадь объекта. Например:
SELECT AREA( BOX '((0,0),(1,1))’ ) -> 1
ASCII(meKcm)
Возвращает ASCII-код первого символа текста. Например:
SELECT ASCII('х’) -> 120
A SIN (число)
Возвращает арксинус числа в диапазоне от -1 до 1. Результат лежит в диапазоне от
—1/2 до 1/2 и выражен в радианах. Например:
SELECT ASIN( 0 ) -> 0.000000
A7AN (число)
Возвращает арктангенс числа. Результат лежит в диапазоне от -1/2 до 1/2 и выра-
жен в радианах. Например:
SELECT ATAN( 3.1415 ) -> 1.262619
ATAN2(floatl,float2)
Возвращает арктангенс двух чисел с плавающей точкой - float! и float2. Функция
ATAN2(x,y) похожа на ATAN(y/x), за исключением того, что знаки х и у используются
при определении квадранта результата. Например:
SELECT ATAN2( 3.1415926, 0 ) -> 1.5707963267949
ВОХ(прямоугольник, прямоугольник)
Возвращается прямоугольник (BOX), образованный при пересечении двух указанных
прямоугольников. Если два прямоугольника не пересекаются, функция возвращает
NULL. Например:
SELECT ВОХ( BOX '((-1,-1),(1, 1))', BOX '((0,0),(1,1))' )
(1,1),(0,0)
ВОХ(окружность)
Возвращается прямоугольник (BOX), вершины которого пересекают окружност
таким образом, что данный прямоугольник является прямоугольником максималь
ного размера, который может быть вписан в данную окружность. Например:
714 | Глава 4. Функции SQL
SELECT BOX(CIRCLE '((0,0),2.0)’)
(1.41421356237309,1.41421356237309),
(-1.41421356237309,-1.41421356237309)
ВОХ(точка, точка)
Возвращается прямоугольник (BOX), противоположными вершинами которого
являются две указанные точки. Пример:
SELECT В0Х(POINT(0,0), POINT(1,1)) -> (1,1),(0,0)
В ОХ(многоуголъник)
Указанный многоугольник преобразуется в прямоугольник (BOX). Например:
SELECT BOXfPOLYGON ’ ((0, 0), (1,1), (2, 0)) ’) -> (2,1), (0,0)
BROADCAST(uHmepnem-adpec)
Функция создает текстовую строку с широковещательным адресом. Пример:
SELECT BROADCASTC’192.168.1.5/24') -> '192.168.1.255/24'
CBRT(float8)
Возвращается кубический корень числаfloat8. Пример:
SELECT CBRT(8) -> 2
СЕИТЕВ(объект)
Возвращается объект POINT, являющийся центром объекта-аргумента. Например:
SELECT CENTER( CIRCLE '((0,0), 2.0)' ) -> (0,0)
CHAR(meKcm)
Эта функция преобразует текст в тип CHAR.
CHAR_LENGTH(cmpoKa) or CHARACTER_LENGTH(cmpoKa)
Возвращается длина строки в символах.
CIRCLE(npn.MoyrojibHUK)
Возвращает окружность (CIRCLE), вписанную в прямоугольник. Пример:
SELECT CIRCLE(BOX '((0,0),(1,1))') -> <(0.5,0.5),0.7071067811865487
CIRCLE(point,float8)
Указанная точка (объект POINT) преобразуется в окружность (CIRCLE) с радиусом,
указанным параметром floats. Пример:
SELECT CIRCLE(POINT '(0,0)', 2.0) -> <(0,0),27
COALESCE(cnucoK)
Возвращается первое непустое значение списка. Например:
SELECT COALESCE(NULL,1,2,3,NULL) -> 1
СО8(число)
Возвращает косинус числа как угла, выраженного в радианах. Например:
SELECT COS(O) -> 1.000000
Платформо-специфические расширения | 715
СОТ(число)
Возвращает котангенс числа. Например:
SELECT С0Т( 3.1415 ) -> -10792.88993953
DATE_PART(meKcm, значение)
Эквивалент функции ЕХТЯАСТ(текст, значение). За дополнительной информацией
об использовании функции EXTRACT обращайтесь к подразделу, посвященному
этой функции, в разделе «Скалярные функции ANSI SQL».
DA TE TR иХС(точность, отметка-времени)
Функция урезает отметку-времени до указанной точности. Например:
SELECT DATE_TRUNC('hour', TIMESTAMP '2003-04-15 23:58:30')
2003-04-15 23:00:00
DEGREES(float8)
Функция преобразует радианы в градусы. Например:
SELECT DEGREES! 3.1415926 ) -> 179.999996929531
О1АМЕТЕЯ(окружностъ)
Возвращается диаметр окружности. Например:
SELECT DIAMETER(CIRCLE(POINT ’(0,0)’, 2.0)) -> 4
FLOAT(int)
Целое число (int) преобразуется в значение с плавающей точкой.
FLOAT4(int)
Целое число (int) преобразуется в значение с плавающей точкой.
НЕ1СНТ(прямоугольник)
Возвращается размер прямоугольника по вертикали. Например:
SELECT HEIGHT(BOX ’((0,0),(1,1))') -> 1
НОЗТ(интернет-адрес)
Адрес узла извлекается в текстовую строку. Пример:
SELECT H0STC192.168.1.5/24') -> '192.168.1.5'
INITCAP(meKcm)
Первая буква каждого слова преобразуется в верхний регистр. Например:
SELECT INITCAP( 'my name is inigo montoya.' )
'My Name Is Inigo Montoya.'
INTEGERCfloat)
Значение с плавающей точкой преобразуется в целочисленное значение.
INTER TAL(reltime)
Значение типа RELTIME преобразуется в тип INTERVAL.
ISCLOSED(Koumyp)
Функция возвращает 7’, если контур замкнут, и если контур незамкнут. Например:
SELECT ISCLOSED(PATH ’((0,0),(1,1),(2,0))’) -> 't'
SELECT ISCLOSED(PATH ' [(0, 0), (1,1), (2, 0)]') -> 'f
716 | Глава 4. Функции SQL
ISFINITE(интервал)
Функция возвращает ‘f, если интервал открыт, и 7’ в противоположном случае.
Например:
SELECT ISFINITE(INTERVAL '4 hours') -> t'
18Е1Н1ТЕ(отметка_времени)
Функция возвращает если отметка времени недопустима или бесконечна,
и 7’ в противоположном случае. Например:
SELECT ISFINITECTIMESTAMP '2001-02-16 21:28:30') -> 't'
ISOPEN(nymb)
Функция возвращает открытый контур. Например:
SELECT ISOPEN(PATH '((0,0),(1,1),(2,0))') -> f
SELECT ISOPEN(PATH '[(0,0),(1,1),(2,0)]') -> 't'
LENGTH (объект)
Возвращается длина указанного объекта. Пример:
SELECT LENGTH('HowdyI') -> 6
SELECT LENGTH(PATH '((-1,0),(1,0))') -> 4
LOG(float8)
Возвращается логарифм с основанием 10. Например:
SELECT LOG( 100 ) -> 2
LPAD(meKcm, int, текст)
Функция возвращает строку, дополненную слева до указанной длины указанным
текстом. Пример:
SELECT LPAD('Duck', 10, ’s') -> 'ssssssDuck'
LSEGfnpxMoyeoHbHUKj
Функция преобразует диагональ прямоугольника в отрезок прямой. Например:
SELECT LSEG(BOX '((-1,0),(1,0))') -> [(1,0),(-1,0))
LSEG(point, point)
Функция преобразует точки (объекты POINT) в отрезок прямой. Например:
SELECT LSEG(POINT '(-1,0)', POINT '(1,0)') -> [(-1,0),(1,0)]
LTRIM(meKcm)
Возвращается текст, из которого удалены все начальные пробелы. Например:
SELECT LTRIMC Howdyl ') -> 'Howdy!
MASKLEN(cidr)
Возвращается длина сетевой маски в адресе ciclr. Например:
SELECT MASKLEN('192.168.1.5/24') -> 24
NET МА SK(интернет-адрес)
Возвращается сетевая маска для адреса интернет-адрес. Например:
SELECT NETMASK('192.168.1.5/24') -> '255.255.255.0'
Платформо-специфические расширения | 717
NETWORK(uHmepuem-adpec)
Возвращается сетевая часть интернет-адреса. Например:
SELECT NETWORK('192.168.1.5/24') -> '192.168.1.0/24
NPOINTS(object)
Возвращается количество точек в объекте. Например:
SELECT NPOINTSCPOLYGON '((1,1),(0,0))’) -> 2
NULLIF(входноезначен ие, значение)
Функция возвращает NULL, если входное_значение=значение, и
входное значение.
РА TH (многоугольник)
Эта функция преобразует многоугольник в контур. Например:
SELECT РАТН( '((0,0),(1,1),(2,0))' )
((0,0),(1,1),(2,0))
PCLOSE(KOHmyp)
Функция преобразует контур в замкнутый контур. Например:
SELECT PCLOSE(PATH '[(0,0),(1,1),(2,0)]')
((0,0),(1,1),(2.0))
РЦ)
Возвращается константа Л.
POLYGON(Konmyp)
Указанный контур преобразуется в многоугольник. Например:
SELECT POLYGON(PATH '((0,0),(1,1),(2,0))')
((0,0),(1,1),(2,0))
POINT(окружн ость)
Возвращается центр окружности. Например:
SELECT P0INT( CIRCLE '((0,0), 2.0)' ) -> (0,0)
РО1НТ(отрезок1, отрезок2)
Возвращается точка пересечения двух отрезков. Например:
SELECT POINT(LSEG '((-1,0),(1,0))', LSEG '((-2,-2),(2,2))')
(0,0)
РО1НТ(многоугольник)
Возвращается центральная точка многоугольника. Например:
SELECT POINT(POLYGON '((0,0),(1,1),(2,0))')
(1,0.333333333333333)
POLYG ON(прям оу гол ьник)
Возвращается четырехугольный многоугольник. Например:
SELECT P0LYG0N(B0X '((0,0),(1,1))')
((0,0),(0,1),(1,1),(1,0))
718 | Глава 4. Функции SQL
POLYGON(oKpyjiaiocmb)
Синоним функции POLYGON(12, окружность).
POLYGON(4iicjio_eepuiun, окружность)
Возвращается фигура, приближенная к окружности и представляющая собой
многоугольник с указанным числом_вершин. Например:
SELECT POLYGONS, CIRCLE ' ((0,0),2.0)')
((-2.0),
(-0.999999999994107,1.73205080757228),
(1.00000000001179,1.73205080756207),
(2,-2.04136478690279е-11),
(0.999999999976428,-1.73205080758249),
(-1.00000000002946,-1.73205080755187))
POPEN(Konmyp)
Функция преобразует контур в незамкнутый контур. Например:
SELECT POPEN(PATH '((0,0),(1,1),(2,0))')
[(0,0), (1,1). (2,0)]
POIV (число, степень)
Указанное число возводится в указанную степень. Например:
SELECT POWC 2, 3 ) -> 8
RADIANS(float8)
Градусы преобразуются в радианы. Например:
SELECT RADIANS( 180 ) -> 3.14159265358979
RA DIUS(oKpyoicnocmb)
Возвращается радиус окружности. Например:
SELECT RADIUS( CIRCLE '((0,0), 2.0)' ) -> (0.0)
RELTlME(interval)
Значение типа INTERVAL преобразуется в значение RELTIME. Функция под-
держивается для обратной совместимости и может быть удалена в следующей
версии.
ROUNDYiucjto)
Указанное число округляется до ближайшего целого. Например:
SELECT ROUNDC 5.5 ) -> 6
RPAD(meKcm, длина, символ)
Функция возвращает текст, дополненный справа до указанной длины указанны-
ми символами. Пример:
SELECT RPAD('Duck', 10, 's’) -> Duckssssss'
RTRIM (текст)
Возвращается текст, из которого удалены все конечные пробелы. Например:
SELECT RTRIM(' St. Lucia ') -> ' St. Lucia'
Платформо-специфические расширения | 719
SET_MASKLEN(интернет-адрес, размер)
Для сетевой маски интернет-адреса устанавливается длина. Например:
SELECT SET_MASKLEN('192.168.1.5/24', 16)
'192.168.1.5/16'
SIN (число)
Возвращается синус числа, выраженного в радианах. Например:
SELECT SIN( 0 ) -> 0.000000
SUBSTRING(cmpoKa [FROM начало] [FOR число_байт]), SUBSTR(cmpoKa, начало
[, число_байт])
Из указанной строки извлекается подстрока указанной длины (число_байт),
начиная с указанной позиции (начало). Если параметр число_байт опущен, то
возвращается вся оставшаяся часть строки, начиная с позиции начало. Например:
SELECT SUBSTRING( 'Inigo Montoya' FROM 7 FOR 4 ) -> Mont'
TAN (число)
Возвращается тангенс числа, выраженного в радианах. Например:
SELECT TAN( 3.1415 ) -> -0.000093
ТЕХТ(символ)
Указанный символ преобразуется в тип TEXT.
TIMESTAMP(dama [, время])
Значение даты преобразуется в отметку времени (TIMESTAMP).
ТО_СНАВ(выражение, текст)
Указанное выражение преобразуется в строку. Например:
SELECT TO_CHAR(NUMERIC '-125.8', '999D99S') -> 125.80-
SELECT TO.CHAR (interval '15h 2m 12s',’HH24:MI:SS’) -> 15:02:12
TO_DATE(cmpoKa, формат)
Указанная строка преобразуется в дату, а второй аргумент используется как указа-
тель формата. Ниже перечислены существующие спецификаторы формата и их
описания.
AM или А.М.
Обозначение «до полудня».
AD или A.D.
Обозначение «до нашей эры».
ВС или В. С.
Обозначение «нашей эры».
СС
Век из двух цифр.
D
Номер дня недели (1-7).
DD
Номер дня месяца (01-31).
720 | Глава 4. Функции SQL
DDD
Номер дня года (001-366).
DAY
Полное название дня в верхнем регистре.
Day
Полное название дня, начинающееся с большой буквы.
day
Полное название дня в нижнем регистре.
DY
Сокращенное название дня в верхнем регистре.
Сокращенное название дня, начинающееся с большой буквы.
dy
Сокращенное название дня в нижнем регистре.
НН или НН 12
Час дня (01-12).
НН24
Час дня (00-23).
IW
Номер недели года согласно ISO.
J
Номер дня юлианского календаря (число дней, прошедших с 1 января 4713 г.
до н. э.).
MI
Минуты (00-59).
ММ
Номер месяца из двух цифр (01-12).
MON
Сокращенное название месяца в верхнем регистре.
Моп
Сокращенное название месяца, начинающееся с большой буквы.
топ
Сокращенное название месяца в нижнем регистре.
MONTH
Полное название месяца в верхнем регистре.
Month
Полное название месяца, начинающееся с большой буквы.
month
Полное название месяца в нижнем регистре.
MS
Миллисекунды (000-999).
РМ или Р.М.
Обозначение «после полудня».
46 - 2447
Платформо-специфические расширения | 721
Q
Квартал года.
RM
Номер месяца римскими цифрами (I—XII).
гт
Номер месяца римскими цифрами в нижнем регистре (i-xii).
SS
Секунды (00-59).
SSSS
Число секунд, прошедших после полуночи (0-86 399).
TZ
Название часового пояса в верхнем регистре.
tz
Название часового пояса в нижнем регистре.
US
Микросекунды (000000-999999).
W
Номер недели в месяце (1-5).
WW
Номер недели в году (1-53).
Y, YY или YYY
Год из одной, двух или трех цифр.
Y,YYY
Год с разделителем-запятой.
YYYY
Год из четырех цифр.
Пример:
SELECT TO_DATE('05 Dec 2000’, 'DD Mon YYYY’) -> 2000-12-05
TO_NUMBER(cmpoKa, формат)
Указанная строка преобразуется в числовое значение, а второй аргумент исполь-
зуется в качестве указателя формата. Например:
SELECT T0_NUMBER('12,454.8-', ’99G999D9S’) -> -12454.8
ТО_Т1МЕ8ТАМР(текст, формат)
Указанный текст преобразуется в отметку времени (TIMESTAMP), а второй аргумент
используется в качестве указателя формата. (За дополнительными сведениями об
имеющихся указателях формата обращайтесь к описанию функции TO_DATE.)
SELECT TO_TIMESTAMP(’05 Dec 2000’, ’DD Mon YYYY') -> 2000-12-05 00:00:00-08
TRANSLATEfmeKcm, исходные_символы, конечные _символы)
Эта функция преобразует те символы в тексте, которые также присутствуют
в параметре исходные_символы, в конечные^символы. Например:
SELECT TRANSLATE!’foo’, 'fо', ’ab’) -> ’abb'
722 | Глава 4. Функции SQL
TRUNC(float8)
Число float8 округляется (в направлении нуля). Например:
SELECT TRUNC( PI( ) ) -> 3
PARCHAR( строка)
Указанная строка преобразуется в тип PARCHAR.
WIDTH (прямоугольник)
Функция возвращает ширину прямоугольника. Например:
SELECT WIDTH( BOX '((0,0),(3,1))' ) -> 3
Расширения, поддерживаемые SQL Server
В этом разделе приводится отсортированный по алфавиту список функций Microsoft
SQL Server с примерами и соответствующими результатами.
АСОЗ(число)
Возвращает арккосинус числа в диапазоне от -1 до 1. Результат лежит в диапазоне
от 0 до 1 и выражен в радианах. Например:
SELECT ACOS( 0 ) -> 1 570796
APP_NAME()
Возвращается имя приложения для текущего сеанса, которое задает само прило-
жение. Например:
SELECT APP_NAME( ) -> 'SOL Enterprise Manager'
A SCI!(текст)
Возвращает ASCII-код первого символа текста. Например:
SELECT ASCII!’х') -> 120
ASIN(число)
Возвращает арксинус числа в диапазоне от -1 до 1. Результат лежит в диапазоне от
—1/2 до 1/2 и выражен в радианах. Например:
SELECT ASIN( 0 ) -> 0.000000
ATAN(число)
Возвращает арктангенс любого числа. Результат лежит в диапазоне от -1/2 до 1/2
и выражен в радианах. Например;
SELECT ATAN( 3.1415 ) -> 1.262619
ATN2(floatl,float2)
Возвращает угол (в радианах), тангенс которого равен float 1/float2. Например:
SELECT ATN2( 35.175643, 129.44 ) -> 0.265345
BINARY_CHECKSUM(* | выражение [,...n])
Возвращается двоичная контрольная сумма для списка выражений или для строки
таблицы. В приведенном примере извлекается список пользовательских ID, для
которых контрольная сумма сохраненного пароля не совпадает с контрольной
суммой текущего пароля.
Платформо-специфические расширения | 723
SELECT userid AS 'Changed' FROM users WHERE NOT password_chksum =
BINARY_CHECKSUM( password )
СНАЕ(целочисленное_выражение)
Функция преобразует числовой код ASCII в символ. Например:
SELECT CHAR( 78 ) -> 'N'
CHARINDEX(nodcmpoKa, строка [, начальноеj-юложение])
Эта функция возвращает положение первого вхождения подстроки в строке.
На пример:
SELECT CHARINDEX( 'he', 'Howdy, there!' ) -> 9
CHECKSUM]* | выражение [,...n])
Возвращается контрольная сумма (вычисленная по значениям строк или по указанным
выражениям). В приведенном примере извлекается список пользовательских ID, для
которых контрольная сумма сохраненного пароля не совпадает с контрольной
суммой текущего пароля.
SELECT userid AS 'Changed' FROM users WHERE NOT password_chksum =
BINARY_CHECKSUM( password )
CHECKSUM_AGG([ALL | DISTINCT] выражение)
Возвращается контрольная сумма значений в группе. Например:
SELECT CHECKSUM_AGG( BINARY_CHECKSUM(*) ) FROM authors -> 67
СОЛЕЕЗСЕ/выражение [,...n])
Возвращается первый непустой аргумент из списка аргументов. Например:
SELECT C0ALESCE( NULL', 1, 3, 5, 7 ) -> 1
COL_LEN'GTH(ma6jiuifa, столбец)
Возвращается длина столбца в байтах. Например:
SELECT COL_LENGTH('authors', 'au_fname') -> 50
СОЬ_МАМЕ({(1_таблицы, id-Столбца)
Эта функция возвращает имя столбца при указанном 1(1_таблицы и id-Столбца.
Например:
SELECT COL_NAME( OBJECT_ID('authors'), 1 )
CONTAINS({cmo:i6eif | *}, критерий_поиска)
Функция производит поиск в столбцах на предмет полного или нечеткого совпаде-
ния с критерием_поиска. CONTAINS - это сложная функция, используемая для вы-
полнения полнотекстового поиска. За дополнительной информацией обращайтесь
к документации производителя. В приведенном примере из таблицы products извле-
каются все ID продуктов,-Ф названии которых близко друг к другу расположены
слова «peanut» и «butter».
SELECT productid FROM products
WHERE CONTAINS(productname, ’ "peanut” NEAR "butter" ' )
724 | Глава 4. Функции SQL
CONTAINSTAB ЬЕ(таблица, столбец, условие_поиска)
Возвращается таблица с точными и нечеткими совпадениями с заданным услови-
ем_поиска. CONTAINSTABLE - это сложная функция, используемая для выполне-
ния полнотекстового поиска. В приведенном примере из таблицы products извле-
каются все ID продуктов, в названии которых близко друг к другу расположены
слова «peanut» и «butter».
SELECT productid FROM products WHERE CONTAINS
(products, productname, ' "peanut" NEAR "butter" ' )
СОХУЕВТ(тип_данных[(длина)], выражение [, стиль])
Эта функция преобразует один тип данных в другой. Например:
SELECT CONVERT( VARCHAR(50), CURRENT.TIMESTAMP, 1 ) -> '06/29/03'
СОЕ(число)
Возвращается косинус числа как угла, выраженного в радианах. Например:
SELECT COS(O) -> 1.000000
СОТ(число)
Возвращается котангенс числа. Например:
SELECT С0Т( 3.1415 ) -> -10792.88993953
DATABASEPROPERTYEX(база_данных, свойство)
Возвращается свойство или опция базы данных. Например:
SELECT DATABASEPROPERTYEX('pubs', 'Version') -> 539
DA TALENGTH (выражение)
Возвращается число байт в символьной или двоичной строке. Например:
SELECT МАХ( DATALENGTH( au.fname ) ) FROM authors -> 11
DATEADD(4acrrib_ dambt, число, дата)
К указанной дате прибавляется указанное число компонентов даты (например,
дней). Например:
SELECT DATEADD( Year, 10, CURRENT.TIMESTAMP ) -> 2013-06-29 19:47:15.270
0АТЕО1ЕЕ(часть_даты, начальная_дата, конечная_дата)
Вычисляется разность между двумя значениями дат, которая выражается в указанных
частях_даты. Например:
SELECT DATEDIFFC Day, CURRENTJIMESTAMP,
DATEADD( Year, 1, CURRENT_TIMESTAMP ))
366
DATENAME(4acmb_dambi, дата)
Возвращается название части даты (например, название месяца) как компонента
аргумента дата. Например:
SELECT DATENAME(month, GETDATE( )) -> June'
Платформо-специфические расширения | 725
ОАТЕРАРТ(часть_даты, дата)
Возвращается значение части даты (например, час) как компонента аргумента
дата. Например:
SELECT DATEPART(year, GETDATE! )) -> 2003
DAYfdama)
Функция возвращает целое число, соответствующее дню указанной даты. Например:
SELECT DAY('04/15/2004') -> 15
DB ID([имя_базы_даццых])
Возвращается ID базы данных и указанное имя. Например:
SELECT DB_ID( ) -> 5
DB_NAME(id_6a3bi_daHHbix)
Возвращается имя базы данных. Например:
SELECT DB_NAME( 5 ) -> 'pubs'
DEGREES(u исл овоевыражен ие)
Функция преобразует радианы в градусы. Например:
SELECT DEGREES! PI( ) ) -> 180
01РРЕРЕ11СЕ(символьное_выражение, символъное_выражение)
Сравнивает фонетическое представление двух аргументов и возвращает число от
0 до 4. Чем больше результат, тем выше фонетическое совпадение. Например:
SELECT DIFFERENCE! 'moe', 'low' ) -> 3
Е1ЬЕ_Ю(имя_файла)
Возвращается ID файла для указанного логического имени_файла. Например:
SELECT FILE_ID( 'master' ) -> 1
Е1ЬЕ_МАМЕ0с1_файла)
Возвращается логическое имя файла для указанного ID файла. Например:
SELECT FILE_NAME( 1 ) -> 'master'
FILE GR О иР_Ю(имя_файловой_группы)
Возвращается ID файловой группы для указанного логического имени_файло-
вой_группы. Например:
SELECT FILEGROUP_ID( 'PRIMARY' ) -> 1
FILEGROUP_ИАМЕ^_файловой_группы)
Возвращается логическое имя файловой группы для указанного idjfrawio-
войгруппы. Например:
SELECT FILEGROUP_NAME( 1 ) -> 'PRIMARY'
Р1ЕЕОРОиРРРОРЕРТУ(имя_файловой_группы, свойство)
Возвращается значение указанного свойства указанной файловой группы. Например:
SELECT FILEGROUPPROPERTY! 'PRIMARY', 'IsReadOnly' ) -> 0
726 | Глава 4. Функции SQL
FILEPROPERTY((}jawi, свойство)
Возвращается значение указанного свойства указанного файла. Например:
SELECT FILEPROPERTY( 'pubs', 'SpaceUsed' ) -> 160
FULLTEXTCATALOGPROPERTYfuMK-Kamanoza, свойство)
Возвращается значение свойства полнотекстового каталога. Например:
SELECT FULLTEXTCATALOGPROPERTY( 'Cat_Desc', 'LogSize' )
FULL TEXTSER RICE PRO PER TY(свойство)
Возвращаются свойства уровня полнотекстовой службы. Например:
SELECT FULLTEXTSERVICEPROPERTY('IsFulltextlnstalled’) -> 1
РОРМАТМЕ88АОЕ(номер_сообщения, значение_параметра [,... п])
Функция создает сообщение на основе уже существующего в таблице SYSMESSAGES
сообщения (напоминает функцию RAISERROR). Например:
sp_addmessage 50001, 1, 'Table %s has %s rows.'
SELECT FORMATMESSAGE(50001, 'AUTHORS',
(SELECT COUNT(*) FROM AUTHORS) ) 'Table AUTHORS has 23.'
FREETEXT({столбец |*}, произволъная_текстовая_строка)
Функция используется для полнотекстового поиска. Возвращает строки, содержащие
столбец, который совпадает по смыслу, но не в точности по значению с произволъ-
ной_текстовой_строкой. Например:
SELECT « from FREETEXTTABLE (authors, *, 'kev')
GETANSlNULL([6a3aJ>aHHbix])
Функция возвращает значение по умолчанию для параметра, определяющего для
новых столбцов возможность вставки значений NULL (nullability). Например:
SELECT GETANSINULL( ) -> 1
GETDATE( )
Возвращается текущая дата и время. Например:
SELECT GETDATE( ) -> 2003-06-27 19:26:59.893
GETUTCDATE( )
Возвращается текущая дата в виде Всеобщего скоординированного времени
(Universal Coordinated Time, UTC). Например:
SELECT GETUTCDATE( ) -> 2003-06-28 02:26:46.720
GROUPING(uMa_cmo.i6ifa)
Функция возвращает 1, если строка добавлена при помощи предложений CUBE
или ROLLUP. В противном случае возвращает 0. Например:
SELECT royalty, SUM(advance) 'total advance',
GROUPING(royalty) 'grp'
FROM titles
GROUP BY royalty WITH ROLLUP
royalty total advance grp
Платформо-специфические расширения | 727
NULL NULL 0
10 57000.0000 0
12 2275.0000 0
14 4000.0000 0
16 7000.0000 0
24 25125.0000 0
NULL 95400.0000 1
HOST_ID( )
Возвращается ID рабочей станции. Например:
SELECT H0ST_ID( ) -> 216
HOST_NAME( )
Возвращается имя узла для процесса. Например:
SELECT H0ST_NAME( ) -> 'PLATO'
IDENT_CURRENT(имя_таблицы)
Возвращается последнее значение идентификатора (identity), сгенерированного
для указанной таблицы. Например:
SELECT IDENT_CURRENT('jobs') -> 876
IDENT-INCR (таблица_ил и_представл ение)
Возвращается значение инкремента для столбца идентификатора (identity). Например:
SELECT IDENT_INCR(’jobs’) -> 1
ЮЕХТ_5ЕЕО(таблица_или_представление)
Возвращается начальное значение для идентификатора (identity). Например:
SELECT IDENT_SEED('jobs') -> 1
IDENTITY(mun_данных [, началъное-значение, инкремент]) AS имя_столбца
Функция используется в инструкции SELECT INTO для вставки в целевую таблицу
столбца идентификаторов (identity). Например:
SELECT IDENTITY(lnt, 1,1) AS ID
INTO NewTable
FROM OldTable
1ХОЕХ_СОЕ(таблица, 1с1_индекса, idjuuoua)
Функция возвращает имя столбца индекса, принимая в качестве параметров имя таб-
лицы, ID индекса и последовательный номер столбца в ключе индекса. Например:
SELECT INDEX_COL(OBJECT_ID(’authors'), 1, 1) -> NULL
INDEXPR0PERTY(id_ma63uiiM, индекс, свойство)
Эта функция возвращает свойство индекса (например, FILLFACTOR). Пример:
SELECT INDEXPROPERTY(OBJECT_ID('authors'),
'UPKCL_auidind’, 'IsPadlndex')
0
728 | Глава 4. Функции SQL
1SDA ТЕ(выражение)
Функция проверяет, можно ли преобразовать символьную строку в значение типа
дата/время (DATETIME). Например:
SELECT ISDATE(NULL), ISDATE(GETDATE( ))
О 1
ISjvfEMBERJepynna | роль})
Возвращает значение Истина или Ложь (1 или 0) в зависимости от того, является
ли пользователь членом указанной группы Windows NT или роли SQL Server.
Например:
SELECT IS_MEMBER( 'db_owner' ) -> 0
IS SRVROLEMEMBERfponb [, регистрация])
Возвращает значение Истина или Ложь (1 или 0) в зависимости от того, присвоена
ли пользователю указанная серверная роль. Например:
SELECT IS_SRVROLEMEMBER( ’sysadmin’ ) -> 0
18ЕиЬЬ(проверяемое_выражение, значение _для_замены)
Если первый аргумент не равен NULL, возвращается первый аргумент, иначе возвра-
щается второй аргумент. Например:
SELECT ISNULL( NULL, 'NULL' ) -> ’NULL’
ISNUMERlC(ebipaoiceHue)
Проверяет, можно ли преобразовать символьную строку в числовой тип (NUMERIC).
Например:
SELECT ISNUMERIC('3.1415'), ISNUMERIC('IRK')
1 0
ЬЕЕТ(символыюе_выражение, целочисленное_выражение)
Эта функция возвращает из символьного_выраженг1Я столько символов слева,
сколько указано параметром целочислен1юе_выражение. Например:
SELECT LEFT( 'Wet Paint’, 3 ) -> 'Wet'
LEN(строковое вы ражен ue)
Возвращается количество символов в строковом ^выражении. Например:
SELECT LEN( 'Wet Paint' ) -> 9
ЕОО(выражение_типаJloat)
Функция возвращает натуральный логарифм. Например:
SELECT LOG( PI( ) ) -> 1.1447298858494002
LOG 10(выражение_типаJloat)
Функция возвращает десятичный логарифм. Например:
SELECT LOG10( PI( ) ) -> 0.49714987269413385
ЬТЕ1М(символьное_выражение)
Функция удаляет начальные пробелы. Например:
SELECT LTRIM(’ beaucoup ') -> 'beaucoup
Платформо-специфические расширения | 729
MONTH(dama)
Из указанной даты возвращается месяц. Например:
SELECT MONTH( GETDATE( ) ) -> 6
NCHA Р(целочисл енное_выражение)
Возвращается символ UNICODE с указанным в параметре целочисленное_выра-
жение кодом. Например:
SELECT NCHAR(120) -> 'х'
NEWID( )
Создается новый уникальный идентификатор, имеющий тип UNIQUEIDENTIFIER.
Например:
SELECT NEWID( ) -> '32В35185-F55E-4FE0-B2C8-В57В35815С12'
NULLIF(ebipcwcenue, выражение)
Возвращается NULL, если указанные выражения равны. Например:
SELECT NULLIF( 5, 5 ) -> NULL
OBJECTJD(o6n>eKm)
Возвращается ID указанного объекта. Например:
SELECT OBJECT_NAME ( OBJECT_ID('authors') ) -> 'authors'
OBJE C T_NA ME (и1_объекта)
Возвращается имя объекта по указанному ID. Например:
SELECT OBJECT.NAME ( OBJECT_ID('authors') ) -> 'authors'
OBJECTPROPERTY(id, свойство)
Возвращает свойства объектов текущей базы данных. Например:
SELECT OBJECTPROPERTY ( object_id('authors'),'ISTABLE') -> 1
OPEN{[GLOBAL]wM_Kypcopa}\ имя_переменной-курсора}
Открывается локальный или глобальный курсор.
OPENDA ТА SO UR СЕ(имя_поставщика, инициализирующая_строка)
Создается соединение с источником данных без указания имени связанного
сервера. За примером обращайтесь к разделу «Загрузчики» Руководства пользова-
теля SQL Server.
OPEN QUERY (связанный ^сервер, запрос)
Функция посылает запрос к удаленному источнику данных, который ранее был
сконфигурирован как связанный сервер. За примером обращайтесь к разделу
«Загрузчики» Руководства пользователя SQL Server.
OPENROIVSETfiiMHnocmaeujUKa, {источник_данных; й!_пользователя, пароль |
строка_поставщика], {[каталог.][схема.]объект | запрос])
Функция посылает запрос к удаленному источнику данных, не конфигурируя его
как связанный сервер.
730 | Глава 4. Функции SQL
PARSENAME(имяобъекта, чacmъ_объектa)
Для указанного объекта возвращается имя базы данных, имя владельца, имя
сервера или имя объекта. Параметр частъ_объекта представляет собой целое
число от 1 до 4. Например:
SELECT PARSENAME('pubs..authors', 1) -> 'authors
SELECT PARSENAME('pubs..authors', 2) -> NULL
SELECT PARSENAME('pubs.. authors', 3) -> 'pubs'
SELECT PARSENAME('pubs..authors', 4) -> NULL
РАTINDEX('%ma6noH%выражение)
Функция возвращает позицию первого вхождения шаблона в строке. Например:
SELECT PATINDEX('XDuX ’, 'Donald Duck') -> 8
PERMISSlONS([id_o6beKma [, столбец] ])
Возвращается числовое значение, представляющее собой битовую карту допусков
текущего пользователя к указанному объекту или столбцу. Например:
SELECT PERMISSIONS(OBJECT_ID('authors'))&8 -> 8
РЦ )
Возвращается константа л. Например:
SELECT 2*Р1( ) -> 6.2831853071795862
РАР1АХЕ(чис<1Овоевыражение)
Функция преобразует градусы в радианы. Например:
SELECT RADIANS( 90.0 ) -> 1.570796326794896600
RAND([seed])
Возвращается псевдослучайное значение типа FLOAT в диапазоне от 0 до 1.
Например:
SELECT RAND(PI( )) -> 0.71362925915543995
РЕРЫСАТЕ(символъное_выражение, целочисленное_выражение)
Строка повторяется указанное количество раз. Например:
SELECT REPLICATE( ’FOOBAR', 3 ) -> 'FOOBARFOOBARFOOBAR'
REPLA СЕ(строковое_выражение!, строковое_выражение2, строковое_выражениеЗ)
Функция выполняет операцию поиска и замены. Поиск производится в строко-
вом -выражении!, в котором каждое вхождение строкового_выражения2 заменя-
ется на строковое_выражениеЗ. Например:
SELECT REPLACE('Donald Duck’, 'Duck', 'Trump') -> 'Donald Trump'
РЕУЕР8Е(символъное_выражение)
Функция обращает символы строки. Например:
SELECT REVERSE( 'Donald Duck' ) -> 'kcuD dlanoD'
Платформо-специфические расширения | 731
РЮТТ(символъное_выражение, целочисленное^выражение)
Функция возвращает из символьного_выражения указанное (параметром целочис-
ленное выражение) число символов справа. Например:
SELECT RIGHT( 'Donald Duck’, 4 ) -> 'Duck'
ROUND (число, десятичная_часть [, функция])
Эта функция возвращает число, округленное до указанного количества знаков
после запятой. Обратите внимание, что целочисленный параметр деся-
тичная_частъ может быть отрицательным. В этом случае округляются цифры
слева от десятичной точки. Если в качестве параметра функция указано целое
число, не равное нулю, возвращаемое значение будет урезаться, иначе оно будет
округляться. Например:
SELECT ROUND(PI( ), 2) -> 3.1400000000000001
ROWCOUNT_BIG( )
Возвращается количество строк, затронутых последним поданным запросом
(тоже, что @@ROWCOUNT, но возвращаемое значение имеет тип BIGINT).
Например:
SELECT ROWCOUNT_BIG( ) -> 1
RTRIM(символьное^выражение)
Из указанного выражения удаляются конечные пробелы. Например:
SELECT RTRIM(’ beaucoup ’) -> ’ beaucoup'
SIGN(числовое_выражение)
Функция возвращает -1, если аргумент отрицательный, 0, если он равен нулю,
и 1, если аргумент положительный. Например:
SELECT SIGN(-PI( )) -> -1.0
SIN (число)
Возвращается синус числа, выраженного в радианах. Например:
SELECT SIN( 0 ) -> 0.000000
S' О UNDEX(символьное_вы ражен ие)
Возвращается код, состоящий из четырех символов и соответствующий фонетиче-
скому представлению (звучанию) строки. Например:
SELECT SOUNDEX(’char’) -> 'С600'
SPA СЕ(целочисленное_выражение)
Возвращается строка, состоящая из заданного числа пробелов. Например:
SELECT SPACE(5) -> '
STA TSDA ТЕ (id-таблицы, 1(1_индекса)
Возвращается дата и время последнего обновления статистики индекса. Например:
FROM sysobjects о, sysindexes i
WHERE o.name = 'authors' AND o.id = i.id
732 | Глава 4. Функции SQL
UPKCL_auidind 2000-08-06 01:34:00.153
aunmind 2000-08-0601:34:00.170
STDE V(выражение)
Возвращается стандартное отклонение значений в выражении. Например:
SELECT STDEV( qty ) FROM sales -> 16.409201831957116
STDEVP(ebi ражен ue)
Возвращается стандартное отклонение генеральной совокупности значений в выра-
жении. Например:
SELECT STDEVP( qty ) FROM sales -> 16.013741264834152
STR (число [, длина [, десятичная_часть]])
Указанное число преобразуется в символьную строку указанной длины с указан-
ным числом десятичных знаков.
STUFF(cmpoKal, начало, длина, строка2)
Указанное количество символов строки! (параметр длина), начиная с позиции
начало, заменяется символами из строки2. Например:
SELECT STUFF( 'Donald Duck’, 8, 4, 'Trump' ) -> 'Donald Trump'
SUBSTRING(cmpOKa, начало, длина)
Из указанной строки извлекается указанное число символов (длина), начиная
с позиции начало. Например:
SELECT SUBSTRING! 'Donald Duck', 8, 4 ) -> Duck'
S' USER_ID([ имя _учетной ^записи])
Возвращается ID пользователя системы с указанным именем_учетной_записи.
Между прочим, в SQL Server 2000 и выше эта функция всегда возвращает NULL,
так что избегайте ее использовать.
SUSER-SID([uMH_y4emHou_3anucu])
Возвращается ID системы безопасности (Security ID, SID) для текущего пользова-
теля или для указанного имени_учетной_записи. Значение SID возвращается
в двоичном формате. Например:
SELECT SUSER_SID('montoyai')
0x68FC17А71010DE40B005BCF2E443B377
SUSER_SNAME([sid_nonb3oeameHH_cepeepa])
Возвращается имя учетной записи для текущего пользователя или для указанного
ID системы безопасности (Security ID, SID). Например:
SELECT SUSER_SNAME( ) -> 'montoyai'
TAN (число)
Возвращается тангенс числа, выраженного в радианах. Например:
SELECT TAN( 3.1415 ) -> -0.000093
Платформо-специфические расширения | 733
ТЕХТРТР(столбец)
Возвращается указатель на столбец TEXT, NTEXTили IMAGE в формате TARBINARY.
Например:
SELECT TEXTPTR(pr_info)
FROM pub_info WHERE pub_id = '0736’
ORDER BY pub_id
0xFEFF6F00000000005C00000001000100
ТЕХТРАЬ1О(таблица.столбец, текстовый_указателъ)
Функция возвращает значение Истина или Ложь (1 или 0) в зависимости от того,
является ли действительным указатель на столбец TEXT, NTEXT или IMAGE.
Например:
SELECT pub-id, 'Valid (if 1) Text data'
= TEXTVALID ('pub_info.logo', TEXTPTR(logo))
FROM pub_info
ORDER BY pub_id
0736 1
08771
13891
1622 1
17561
9901 1
9952 1
9999 1
TYPEPROPERTY(mun danHbix, свойство)
Функция возвращает информацию о свойствах типа данных. Аргумент тип_дан-
ных может содержать название любого типа данных, а аргумент свойство может
представлять собой строку, содержащую одно из следующих значений.
Precision
Точность для типа данных, т. е. количество цифр или символов, которые он
может хранить.
Scale
Масштаб, т.е. число десятичных знаков для числового типа данных. Если тип
данных не является числовым, возвращается NULL. Например:
SELECT TYPEPROPERTYUdecimal’, 'PRECISION') -> 38
UNICODE(ebipa3iceHue_ncharacter)
Возвращается код UNICODE для первого символа во входном параметре. Например:
SELECT UNICODEC Hellol') -> 72
lJSERJD([nojib3oeamejib])
Возвращается пользовательский ID в текущей базе данных для указанного имени
пользователя. Если параметр пользователь опущен, то возвращается ID текущего
пользователя. Например:
SELECT USER_ID( ) -> 2
734 | Глава 4. Функции SQL
USER_NAME([id])
Возвращается имя текущего пользователя текущей базы данных. Например:
SELECT USER_NAME( ) -> ’montoyai’
РАР(выражение)
Возвращается статистическая дисперсия для значений выражения. Например:
SELECT VAR(qty) FROM sales -> 269.26190476190476
VARP(express ion)
Возвращается статистическая дисперсия генеральной совокупности, представлен-
ной группой из всех значений выражения. Функция VARP является агрегатной.
Например:
SELECT VARP(qty) FROM sales -> 256.43990929705217
YEAR(dama)
Возвращается целое число, представляющее собой значение года, извлеченное из
указанной даты. Например:
SELECT YEAR( CURRENT.TIMESTAMP ) -> 2003
Платформо-специфические расширения | 735
Программирование баз
данных
Хотя SQL играет важную роль в стандартизации связей между различными РСУБД,
есть один еще не описанный момент, касающийся тех, кто хочет писать приложения,
работающие с программным обеспечением баз данных. Это интерфейс прикладного
программирования (Application Programming Interface, API) баз данных, который
используется для передачи инструкций SQL в РСУБД и для получения результатов их
обработки из РСУБД. Хотя все описываемые в этой книге платформы баз данных
предлагают свои собственные интерфейсы для разработчиков приложений, в этой
главе мы сконцентрируемся на двух распространенных API, которые предоставляют
единый интерфейс для работы с разными платформами баз данных. В частности,
в этой главе мы познакомим вас со следующими API.
ADO.NET
ADO.NET - это высокоуровневый интерфейс прикладного программирования баз
данных от компании Microsoft, работающий на платформе NET. API ADO.NET
представляет собой коллекцию интерфейсов .NET, доступ к которым осуществля-
ется с помощью любого языка с поддержкой .NET. Главное преимущество
ADO.NET - это простота использования, переносимость в пределах платформы
.NET, интеграция с XML и доступ к источникам данных, отличным от реляцион-
ных баз данных. Примеры работы с ADO.NET, обсуждаемые в этой книге, написа-
ны на С#, однако доступ к ADO.NET возможен и при помощи Visual Basic, и при
помощи других языков с поддержкой .NET.
JDBC
Интерфейс JDBC, или Java Database Connectivity, был разработан компанией Sun
Microsystems в первую очередь как API баз данных для языка Java. JDBC является
наиболее популярным интерфейсом прикладного программирования баз данных
на языке Java. Он предоставляет возможность перенесения кода с одной операци-
онной системы на другую, предлагает приемлемую производительность для боль-
шинства областей применения, и он достаточно хорошо документирован. Кроме
того, драйверы для большинства баз данных распространяются, как правило, бес-
платно. В этой главе рассматривается JDBC версии 3.0. За дополнительной ин-
формацией обращайтесь, пожалуйста, на сайт http://java.sun.com/jdbc.
Поскольку эта книга является кратким настольным руководством, в этой главе мы
не можем привести всю информацию, необходимую для разработки больших прило-
жений баз данных масштаба предприятия. Однако мы дадим вам достаточно сведений
для начала работы, описав компоненты, которые являются общими для всех приложе-
ний баз данных, как больших, так и маленьких.
Общий обзор программирования баз данных
Успешная разработка приложений баз данных, как больших, так и маленьких, включа-
ет в себя много этапов. Необходимо тщательно продумать архитектуру приложения,
и в особенности следующие моменты.
• Как связать данные в приложении, которые, как правило, имеют объектно-ориен-
тированный характер, с реляционной базой данных.
• Как лучше всего обрабатывать ошибки.
• Как увеличить производительность и расширяемость приложения.
Для типичного приложения базы данных потребуется много различных инструк-
ций SQL. Процесс управления таким количеством инструкций упрощает то, что ин-
струкции SQL в приложении выполняются примерно по одной схеме. На рис. 5.1 при-
ведена диаграмма состояний, показывающая, каким образом инструкции SQL подго-
тавливаются, выполняются, а затем обрабатываются приложением базы данных в про-
цессе взаимодействия с системой управления реляционной базой данных. Диаграмма
состояний разделена на 11 этапов, четыре из которых являются необязательными (на
диаграмме выделены отступом).
Ниже приводится подробное описание каждого из этапов, показанных на рис. 5.1.
1. Установление связи. Установление связи - это первый этап в каждом успешном
приложении базы данных. Именно на этом этапе клиент, т. е. приложение базы
данных, устанавливает физическое соединение с базой, которое будет использо-
ваться для передачи инструкций SQL в базу и для возврата результатов обратно
в клиентское приложение. На деле физическое соединение может осуществляться
через LAN, WAN или даже через простое логическое соединение в тех случаях,
когда сервер и приложение базы данных работают на одной и той же машине.
За дополнительной информацией об установлении соединений обращайтесь
к разделу «Открытие соединения с базой данных» ниже в этой главе.
2. Запуск транзакции (не обязательно). Транзакция может быть запущена таким
образом, чтобы можно было произвести откат вносимых изменений в случае сбоя
или их фиксацию в случае успеха. За дополнительной информацией об управле-
нии транзакциями через API базы данных обращайтесь, пожалуйста, к разделу
«Управление транзакциями» ниже в этой главе.
47 - 2447
Общий обзор программирования баз данных | 737
Рис. 5.1. Диаграмма состояний для выполнения инструкций
3. Создание объекта-инструкции. Большинство современных API баз данных
являются объектно-ориентированными и, следовательно, используют объект,
представляющий инструкцию SQL. Как правило, в приложении одна инструкция
SQL соответствует одному объекту-инструкции. Объект-инструкция содержит
информацию о состоянии, необходимую для выполнения инструкции SQL, саму
инструкцию SQL, а также входные параметры, если таковые существуют.
4. Связывание кода SQL с объектом-инструкцией. После того как объект-инструкция
создан, с ним нужно связать инструкцию SQL. Как только это будет сделано, объект-
инструкцию можно будет выполнять.
5. Связывание входных параметров (не обязательно). Хотя возможность привязы-
вать параметры к «заменителям» в инструкции SQL и не входит в стандарт ANSI
SQL, она поддерживается всеми платформами, описываемыми в этой книге. Если
инструкция SQL имеет «заглушки» для входных параметров, объект-инструкция
должен иметь программные переменные, связанные с каждым из входных
параметров. Если инструкция SQL не имеет входных параметров, то этот этап
можно пропустить. Входные параметры используются для оптимизации произво-
дительности в том случае, если одна инструкция SQL выполняется многократно,
738 | Глава 5. Программирование баз данных
поскольку обработка инструкции на серверной стороне соединения будет произ-
водиться только один раз, при первом выполнении инструкции. Еще одна причина
использования входных параметров - встраивание в инструкции SQL (такие, как
INSERT и UPDATE) двоичных данных, например BLOB.
6. Выполнение объекта-инструкции. После того как объект-инструкция был
успешно создан и проинициализирован инструкцией SQL, этот объект можно
передавать на выполнение. На этом этапе инструкция SQL выполняется на
сервере базы данных.
7. Обработка результатов (не обязательно). После того как сервер базы данных
вернет результирующий набор данных, приложение может произвести его
обработку. Этот этап является необязательным, поскольку он обычно не требуется
для инструкций, которые вставляют или обновляют данные в базе.
8. Повторное выполнение. Если та же самая инструкция должна быть выполнена
заново (в случае ошибки или для выполнения с другими значениями входных
параметров), приложение может вернуться к этапу 6. Если приложению не требу-
ется повторное выполнение той же инструкции, оно переходит к этапу 9.
9. Выполнение другой инструкции SQL. Если в приложении нужно выполнить
другую инструкцию и возможно повторное использование объекта-инструкции,
то предложение может вернуться к этапу 4, иначе нужно перейти к этапу 10.
10. Останов транзакции (не обязательно). Предположим, транзакция была запущена
на этапе 2 и теперь ее нужно либо зафиксировать, либо откатить. Если транзакция
откатывается, то все изменения, которые внес в базу данных объект-инструкция,
будут удалены из базы.
11. Высвобождение ресурсов. После успешного выполнения инструкции и обработки
результатов ресурсы на стороне клиента и сервера нужно освободить, чтобы их
могли использовать другие приложения.
В оставшихся разделах этой главы приводятся примеры того, как следует использо-
вать такие API баз данных, как ADO.NET и JDBC, для создания приложений, которые
выполняют шаги, перечисленные парис. 5.1.
Открытие соединения с базой данных
Перед тем как приложение сможет взаимодействовать с базой данных, оно должно
сначала установить соединение с сервером базы данных. Интерфейсы прикладного
программирования, которые мы описываем в этой книге, преобразуют подробную
низкоуровневую информацию о соединении в несколько простых объектно-ориен-
тированных классов, что позволяет разработчику сконцентрироваться на приложении
базы данных, а не на протоколах и сетевой топологии.
Открытие соединения с базой данных | 739
Открытие соединения с базой данных в ADO.NET
Для открытия соединения в ADO.NET требуется записать в объект-соединение соот-
ветственным образом форматированную строку, а затем вызвать метод Open объекта-
соединения. Объект-соединение может быть одного из трех видов - OdbcConnection,
SqlConnection или OleDbConnection. Объект OdbcConnection разработан для любого
источника данных ODBC, а объект OleDbConnection будет работать с любым поставщи-
ком OLE DB Provider. Чтобы доступ к данным был максимально производительным,
используйте объекты-соединения, специально настроенные на конкретную плат-
форму, например SqlConnection для Microsoft SQL Server. Ниже приводится синтаксис
для создания объекта-соединения в ADO.NET.
{Odbc | OleDb | Sql }Connection connection =
new {Odbc|OleDb18д1}СоппесНоп(строка_соединения);
connection.Open( );
Формат строки соединения аналогичен для всех типов соединений. Этот формат
представляет собой строку пар ключ/значение, разделенных символом «точка с запятой».
Например:
ключ1=значение1; ключ2=значение2; ключЗ=значениеЗ; ...
Хотя формат идентичен для всех типов соединений, сами ключи и значения для
разных типов соединений различны. В табл. 5.1, 5.2 и 5.3 перечислены атрибуты для
трех упомянутых выше типов соединений. Многие платформы поддерживают допол-
нительные атрибуты, которые можно применять в строке_соединения. За перечнем
таких атрибутов обращайтесь, пожалуйста, к соответствующей документации произ-
водителя.
Ниже приводятся примеры двух строк соединения для OdbcConnection.
DSN=MyOracleDSN; UID=scott; PWD=tiger;
DRIVER={SQL Server};SERVER=(local);UID=sa;PWD=;DATABASE=pubs;
Первая строка называет доя соединения имя источника данных (DSN) - MyOracleDSN,
при этом используется имя пользователя scott и пароль tiger.
Вторая строка подключает с помощью драйвера SQL Server базу данных с именем
pubs, расположенную на локальном сервере. Имя пользователя - sa, поле пароля
пусто, и это указывает драйверу, что пароль для пользователя sa не нужен.
Ниже приводится пример строки соединения для объекта OleDbConnection, который
соединяется с источником данных Oracle9i с помощью поставщика MSDAORA OLE DB
и при этом используется пользовательское имя scott и пароль tiger.
Provider=MSDAORA;Data Source=0racle9;User ID=scott;Password=tiger;
И наконец, пример строки соединения для объекта SqlConnection, в котором произво-
дится соединение с источником данных SQL Server на локальном сервере.
Server=(local); UID=sa;PWD=;DATABASE=pubs; Connection Timeout=60;
В табл. 5.1 - 5.3 вы найдете синонимы некоторых ключевых слов. Например, вы
можете равнозначно использовать в коде слова «DSN» и «Data Source Name».
740 | Глава 5. Программирование баз данных
Таблица 5.1. Атрибуты строки соединения объекта OdbcConnection
Ключевое слово Примечания
Data Source Name DSN Для соединения необходимо указать атрибуты DSN, FILEDSN или DRIVER. Атрибут DSN (Data Source Name) - это имя источника данных, известное менеджеру драйверов клиента. Преимуществом использова- ния DSN является то, что DSN можно изменить так, чтобы он указывал на другую платформу прямо во время работы приложений баз данных
User ID UID В этом значении указывается идентификатор пользователя, имеющего право открыть новое соединение
Password PWD Пароль пользователя. Если пользователь не имеет пароля, то это свойство все равно должно присутствовать, но с пустым значением
DSN_File Name FILEDSN Сходный с DSN атрибут FILEDSN представляет собой файл, обычно с расширением DSN, который содержит атрибуты объекта-соединения, необходимые для установления связи. При использовании FILEDSN для соединения может потребоваться указать пароль, поскольку пароли не хранятся в DSN-файлах
Driver Name DRIVER Вместо DSN или FILEDSN можно использовать драйвер. Недостаток прямого использования драйвера состоит в том, что приложение будет зависеть от изменений, вносимых в драйвер, и потребует небольших модификаций, если будет нужно подключиться к другой платформе
SAVEFILE Если в атрибуте SAVEFILE указать допустимое имя файла, то атрибуты соединения будут сохранены в файле после успешного установления соединения. Эта опция доступна только при использовании атрибутов DRIVER и FILEDSN
Таблица 5.2. Атрибуты строки соединения объекта OleDbConnection
Ключевое слово Примечания
Provider Имя поставщика. Эго единственный необходимый атрибут. Указанный поставщик может потребовать дополнительные атрибуты
Таблица 5.3. Атрибуты строки соединения для объекта SqlConnection
Ключевое слово Примечания
Application Name Имя приложения, которое будет отображаться утилитами обслуживания сервера
AttachDBFilcnamc Extended properties Initial File Name Путь к присоединяемой базе данных
Connect Timeout Connection Timeout Количество секунд ожидания, прежде чем попытка соединения будет завершена. По умолчанию 15 секунд
Connection Lifetime Время (в секундах) существования соединения в пуле соединений, если поддержка пулов включена
Открытие соединения с базой данных | 741
Таблица 5.3. Атрибуты строки соединения для объекта SqlConnection (Продолжение)
Ключевое слово Примечания
Connection Reset Указывает, будет ли переустанавливаться соединение при его повторном использовании из пула. По умолчанию true (истина)
Current Language Язык, который будет использоваться в сеансе соединения
Data Source Server Address Addr Network Address Имя или сетевой адрес экземпляра сервера SQL
Initial Catalog Database Имя базы данных
Integrated Security Trusted_Connection Для безопасных соединений устанавливается значение true (истина) или sspi. По умолчанию равно false (ложь)
Max Pool Size Максимально допустимое число одновременно существующих соеди- нений в пуле соединений. По умолчанию 100
Min Pool Size Минимальное количество соединений, хранящихся в пуле. По умолчанию 0
Network Library Net Сетевая библиотека, используемая для установления соединения. Допус- тимые значения: dbnmpntw для Named Pipes, dbmsrpcn для Multiprotocol, dbmsadsn для AppleTalk, dbmsgnet для VIA, dbmsipcn для Shared Memory, dbmsspxn для IPX/SPX и dbmssocn для TCP/IP. По умолчанию dbmssocn для TCP/IP
Packet Size Размер сетевого пакета в байтах. По умолчанию 8192
Password Pwd Пароль пользователя
Persist Security Info Определяет, будут ли параметры соединения, связанные с безопасностью (такие, как пароль) храниться в объекте-соединении после попытки уста- новления соединения или его завершения. По умолчанию false (ложь)
Pooling Определяет, будет ли в соединении использоваться пул соединений. По умолчанию true (истина)
User ID Имя учетной записи пользователя
Workstation ID Имя компьютера, соединяющегося с базой данных
Открытие соединения с безой данных в JDBC
Ниже приводится синтаксис регистрации драйвера в JDBC Driver Manager и после-
дующего открытия соединения.
Class.forName(имя_драйвера);
Connection connection = DriverManager. деКоппесИоп(.строка_соединения,
имя~пользователя, пароль}',
742 | Глава 5. Программирование баз данных
Первый этап в установлении связи в JDBC - это определение задания загрузчику
классов виртуальной машины Java (Java Virtual Machine, JVM) на загрузку соответст-
вующего драйвера JDBC.
Наиболее распространенный метод загрузки драйвера в загрузчика классов - исполь-
зование статического метода forName класса Class. Этот метод дает приложениям
большие возможности по изменению платформы, поскольку виртуальная машина Java
загружает драйвер базы данных прямо «на ходу».
Class.forName( "имя_драйвера" );
После того как драйвер загружен, приложение может устанавливать соединение
путем вызова статического метода getConnection класса JDBC DriverManager. Метод
getConnection принимает три аргумента: строку соединения, имя пользователя и пароль.
Connection connection = DriverManager. getConnection(crpo/<a_coe,w/erm,
имя_пользователя,
пароль);
Строка соединения составляется по следующей схеме имен JDBC URL.
Jdbc:подпротокол: подыми
Ниже приводятся примеры, описывающие, каким образом устанавливаются
соединения с использованием JDBC с базами различных производителей, описанных
в этой книге.
DBS
Class. forName("COM. ibm.db2. jdbc. app. DB2Driver");
Connection connection = DriverManager.getConnection(
"jdbc:db2:DATABASE”, "пользователь”, "пароль” );
MySQL
Class. forNameC'org. gjt,mm. mysql. Driver");
Connection connection = DriverManager.getConnection(
"jdbc:mysql://127.0.0.1:3306/DATABASE",
"пользователь", "пароль" );
PostgreSQL
Class. forNameC'org. postgresql. Driver");
Connection connection = DriverManager.getConnection(
"jdbc:postgresql://127.0.0.1:5432/DATABASE",
"пользователь", "пароль" );
Oracle
Class.forName("oracle.jdbc.driver.OracleDriver");
Connection connection = DriverManager.getConnection(
"jdbc:oracle:thin:©myserver",
"scott","tiger" );
Открытие соединения с базой данных | 743
SQL Server
Class.forName(
"com.microsoft.jdbc.sqlserver.SQLServerDriver"
);
Connection connection = DriverManager.getConnection(
"jdbc:microsoft:sqlserver://SERVER:1433;" +
"DatabaseName=pubs;”,
"пользователь”, "пароль" );
Закрытие соединения с базой данных
Когда приложение заканчивает использовать открытое соединение, это соединение
нужно закрыть. Некоторые API закрывают соединения автоматически при выходе из
приложения, однако лучше закрывать соединения явным образом, когда приложение
завершает доступ к базе данных, чтобы драгоценные ресурсы могли использовать
и другие приложения.
Вызов соответствующих методов закрытия соединения для объектов
ADO.NET и JDBC по окончании работы является необходимым для освобожде-
ния драгоценных ресурсов, которые использует приложение. Как в ADO.NET,
так и в Java нет четко определенных сроков завершения работы объектов.
Поэтому для таких приложений при отсутствии явного закрытия объектов
весьма обычной является ситуация исчерпания ресурсов базы (т. е. числа со-
единений, обработчиков инструкций и памяти).
Закрытие соединения с базой данных в ADO.NET
Чтобы закрыть соединение в ADO.NET, вызовите метод Close объекта-соединения.
connection.Close( );
Закрытие соединения с базой данных в JDBC
Чтобы закрыть соединение в JDBC, вызовите метод close объекта-соединения,
connection.close( );
Управление транзакциями
В большинстве API баз данных существуют методы для управления транзакциями, для
установления точек сохранения и изменения уровня изоляции. В этом разделе описы-
ваются механизмы управления транзакциями в таких API, как ADO.NET и JDBC.
Запуск транзакции
Запуск транзакции - это первый этап в обеспечении неделимости операции при выполне-
нии нескольких инструкций SQL. После начала транзакции изменения, вносимые выпол-
няемыми инструкциями SQL, могут либо фиксироваться и делаться постоянными, либо
отменяться, и в этом случае база данных остается в неизмененном состоянии.
744 | Глава 5. Программирование баз данных
Запуск транзакции в ADO.NET
Чтобы начать транзакцию в ADO.NET, вызовите метод BeginTransaction объекта-
соединения. Возвращается объект Transaction, который можно использовать при соз-
дании объектов Command, которые выполняются в пределах одной транзакции. Чтобы
выполнить объект Command в новой транзакции, вы должны сначала соединить
объект Transaction со свойством Transaction объекта Command. Ниже приводится син-
таксис запуска транзакции путем создания объекта Transaction в ADO.NET.
{Odbc101 eDb|Sql{-Transaction transaction =
connection.BeginTransaction([IsolationLevel.
{Chaos | ReadCommitted | ReadUncommitted IRepeatableRead |
Serializable | Unspecified}] );
{0dbc|01eDb|Sql}Command statement = connection.CreateCommand( );
statement.Transaction = transaction;
При создании объекта Transaction вы можете при желании указывать уровень изо-
ляции, используемый для данной транзакции. Уровень изоляции определяет, насколько
транзакции в базе данных изолированы от влияния других транзакций. Существуют
следующие уровни изоляции.
Chaos
Незавершенные изменения, вносимые другими транзакциями с более высокими уров-
нями изоляции (ReadCommitted, ReadUncommitted, RepeatahleRead или Serializable),
не могут быть изменены.
ReadUncommitted
Самый низкий уровень изоляции в стандарте ANSI. Нет защиты от «грязного чтения»,
невоспроизводимого чтения и фантомных записей.
ReadCommitted
Следующий после ReadUncommitted уровень изоляции стандарта ANSI. Защита от
«грязного чтения».
RepeatableRead
Следующий после ReadCommitted уровень изоляции стандарта ANSI. Защита от
«грязного» и невоспроизводимого чтения.
Serializable
Наивысший уровень изоляции стандарта ANSI. Защита от «грязного чтения», невос-
производимого чтения и фантомных записей.
Unspecified
Уровень изоляции нельзя определить. Как правило, эту опцию не передают
методу BeginTransaction. Его назначение - указание неопределенного состояния
свойства IsolationLevel объекта-соединения. Если объект Transaction содержит
данное значение свойства IsolationLevel даже после того, как ему было присвоено
другое значение, то можно быть уверенным, что база данных не поддерживает
указанный вами уровень изоляции.
За дополнительной информацией об уровнях изоляции обращайтесь к подразделу
«Советы и хитрости программирования» раздела «Инструкция SET TRANSACTION»
главы 3.
Управление транзакциями | 745
Уровень изоляции, используемый при выполнении инструкций SQL, может
оказывать значительное влияние на производительность и масштабируе-
мость приложения, а также на саму РСУБД. При выборе уровня изоляции
используйте самый низкий из обеспечивающих необходимые гарантии изо-
ляции для приложения базы данных.
Запуск транзакции в JDBC
JDBC начинает соединение в режиме A UTO COMMIT, и в этом режиме изменения, вноси-
мые каждой инструкцией SQL, фиксируются по мере их выполнения. Чтобы получить воз-
можность управлять фиксацией изменений, нужно отключить режим AUTO COMMIT.
В JDBC механизм начала транзакции не такой очевидный, как в ADO.NET, где для запуска
транзакции используется метод BeginTransaction. В JDBC транзакция запускается, как
только отключается режим AUTO COMMIT или после фиксации или отката транзакции.
При выполнении фиксации или отката транзакции режим AUTO COMMIT заново не
включается, поэтому нужно будет выполнять много операций фиксации или отката для
множества элементов работы до тех пор, пока соединение не будет закрыто или пока
режим A UTO COMMIT вновь не будет включен. Чтобы отключить режим AUTO COMMIT,
выполните метод setAutoCommit объекта JDBC Connection с аргументом false.
connection.setAutoCommit( false );
Нужно помнить, что вызов метода setAutoCommit для включения/отключе-
ния режима A UTO COMMIT, когда транзакция уже производится, приве-
дет к автоматической фиксации данной транзакции.
Интерфейс JDBC также поддерживает различные уровни изоляции транзакций
через интерфейс JDBC Connection. Для задания уровня изоляции, который будет ис-
пользоваться в новых транзакциях, вызовите метод setTransactionlsolation с одним из
следующих аргументов, указывающих уровень.
TRA NSA CT/ONJJONE
Показывает, что транзакции в данном соединении не поддерживаются. Это значе-
ние, как правило, используется не для установки уровня изоляции, а для запросов
к соединению о поддержке транзакции при помощи метода getTransactionlsolation
интерфейса Connection.
TRANSA CTION_READ_ UNCOMMITTED
Самый низкий уровень изоляции в стандарте ANSI. Нет защиты от «грязного чтения»,
невоспроизводимого чтения и фантомных записей.
TRANSA CTION READ COMMITTED
Следующий после TRANSACTIONJIEADUNCOMMITTED уровень изоляции
стандарта ANSI. Защита от «грязного чтения».
TRANSA CTIONREPEA TABLE READ
Следующий после TRANSACTION_READ_COMMITTED уровень изоляции стан-
дарта ANSI. Защита от «грязного» и невоспроизводимого чтения.
746 | Глава 5. Программирование баз данных
TRANSA CTION SERIALIZABLE
Наивысший уровень изоляции стандарта ANSI. Защита от «грязного чтения», невос-
производимого чтения и фантомных записей.
За дополнительной информацией об уровнях изоляции обращайтесь к подразделу
«Советы и хитрости программирования» раздела «Инструкция SET TRANSACTION»
главы 3.
Ниже приводится пример кода, устанавливающего уровень изоляции транзакций
в JDBC.
connection.setIsolation Level( Connection.TRANSACTION_SERIALIZABLE );
Уровень изоляции, используемый при выполнении инструкций SQL, может
оказывать значительное влияние на производительность и масштабируе-
мость приложения, а также на саму РСУБД. При выборе уровня изоляции
используйте самый низкий из обеспечивающих необходимые гарантии изо-
ляции для приложения базы данных.
Фиксация транзакции
Фиксация транзакции - это метод, позволяющий явно завершить транзакцию и сделать
постоянными внесенные в базу данных изменения.
Фиксация транзакции в ADO.NET
Чтобы зафиксировать транзакцию в ADO.NET вызовите метод Commit объекта Transaction.
transaction. Commit( );
Интерфейс ADO.NET является более объектно-ориентированным, чем многие
другие API баз данных, и это можно видеть по встраиванию транзакции в уникальный
объектный тип. Здесь есть недостаток, состоящий в том, что метод явной остановки
транзакции труднее найти, чем метод запуска транзакции, поскольку они принадлежат
к разным объектным типам. Запомните, что метод запуска транзакции находится
в объекте Connection, а методы фиксации и отката транзакции находятся в объекте
Transaction.
Фиксация транзакции в JDBC
Вызов метода commit объекта Connection завершает транзакцию JDBC и начинает
новую транзакцию.
connection.commit( );
Если соединение находится в режиме AUTO COMMIT, будет сгенерировано
исключение Java типа SQLException, поскольку в соединении не бывает незавершенных
транзакций.
Откат транзакции
Откат транзакции - это метод, позволяющий явно завершить транзакцию и отменить
все модификации, внесенные с момента начала транзакции.
Управление транзакциями | 747
Откат транзакции в ADO.NET
Чтобы выполнить откат транзакции в ADO.NET, вызовите метод Rollback объекта
Transaction.
transaction.Rollback( );
После отката, выполненного в объекте Transaction, нужно вызвать метод Dispose,
чтобы освободить все ресурсы, которые задействовала транзакция.
transaction.Dispose( );
Откат транзакции в JDBC
Откат текущей транзакции в JDBC и запуск новой осуществляется путем вызова
метода rollback объекта Connection.
connection.rollback( );
Если соединение находится в режиме AUTO COMMIT, эта операция генерирует
исключение Java типа SQLException.
Выполнение инструкций
Главная цель при программировании с использованием API базы данных - это выпол-
нение инструкций SQL. В следующем разделе описываются шаги, которые необхо-
димо предпринять, чтобы успешно выполнить простую инструкцию SQL, не возвра-
щающую результатов, такую, как INSERT или UPDATE. В следующем разделе рас-
сматривается более сложная задача по выполнению инструкций, которые возвращают
результаты.
Выполнение инструкций в ADO.NET
В следующем фрагменте кода приводится синтаксис для выполнения инструкции
INSERT при использовании интерфейса ADO.NET.
{Odbc|OleDb|Sql{-Command statement = connection. CreateCommand( );
statement.CommandText = "INSERT INTO authors(au_id, au_lname, " +
au.fname, contract) " +
"VALUES ('xyz', 'Brown', 'Emmit', 1)";
int rowslnserted = statement.ExecuteNonQuery( );
statement.Close( );
Чтобы выполнить инструкцию при помощи интерфейса ADO.NET, выполните
следующие шаги.
1. Создайте объект Command. Для доступа к Microsoft SQL Server используется
объект типа SqlCommand, для доступа к источникам данных ODBC используется
объект типа OdbcCommand, а для доступа к источникам данных OLE-DB исполь-
зуется объект типа OleDbCommand.
{Odbc|OleDb|Sql{Command statement = connection.CreateCommand( );
748 | Глава 5. Программирование баз данных
2. После того как соответствующий объект Command создан, нужно связать с ним
инструкцию SQL (она может быть выполнена только после этого).
statement.CommandText = "INSERT INTO authors(au_id, au_lname, " +
au_fname, contract) " +
"VALUES ('xyz', 'Brown', 'Emmit', 1)";
3. После того как инструкция SQL связана с объектом Command, можно ее выполнять.
int rowslnserted - statement.ExecuteNonQuery( );
Существует три метода, которые можно использовать для запуска на выполнение
объектов Command в ADO.NET.
• ExecuteReader. Выполняются инструкции SQL, которые возвращают строки
(например, инструкции SELECT). Возвращаемое значение записывается в объект
DataReader ADO.NET.
• ExecuteNonQuery. Выполняются инструкции SQL, которые обычно не возвращают
результирующих наборов данных, такие, как INSERT, DELETE и UPDATE. Возвра-
щаемое значение представляет собой целое число, равное количеству строк, затро-
нутых выполнением инструкции.
• ExecuteScalar. Выполняются инструкции SQL, которые возвращают одиночное
значение (например, инструкции, содержащие небольшую агрегатную функцию).
4. После того как объект Command выполнен, его нужно явным образом закрыть,
чтобы освободить ресурсы, выделенные на выполнение инструкций и на соединение
с сервером базы данных. Чтобы освободить эти ресурсы, вызовите метод Dispose
объекта Command.
statement.Dispose();
Ресурсы, занимаемые объектами-инструкциями ADO.NET, освобождаются
при помощи метода Dispose, что отличает эти объекты от других типов
ADO.NET, которые используют метод Close.
Выполнение инструкций в JDBC
В следующем фрагменте кода представлен синтаксис выполнения инструкции
INSERT при использовании интерфейса JDBC.
java.sql.Statement statement = connection.createStatement( );
int rowslnserted = statement.executeUpdate(
"INSERT INTO authors(au_id, au_lname, au_fname, contract) " +
VALUES ('xyz', 'Brown', 'Emmit', 1)" );
statement.close();
1. Для выполнения инструкции SQL сначала нужно создать объект JDBC Statement.
Объект Statement создается путем вызова метода createStatement существующего
объекта-соединения (Connection).
java.sql.Statement statement = connection.createStatement( );
Выполнение инструкций | 749
2. После того как объект Statement создан, можно выполнять инструкцию SQL путем
вызова одного из методов ее выполнения в объекте Statement. В случае запросов,
не возвращающих значения, лучше всего использовать метод executeUpdate.
int rowslnserter = statement.executeUpdate(
"INSERT INTO authors(au_id, au_lname, au_fname, contract) " +
" VALUES ('xyz', 'Brown', 'Emmit', 1)" );
Метод executeUpdate возвращает целочисленное значение, показывающее количе-
ство записей, которые были вставлены, обновлены или удалены в ходе выполнения
инструкции SQL. Если при выполнении инструкции возникает ошибка, генерируется
исключение SQLException.
3. После того как объект Statement был выполнен, его можно выполнить снова или
освободить ресурсы при помощи метода close.
connection.close();
Извлечение данных
Типичная программа, работающая с базой данных, получает данные от сервера базы
и обрабатывает их. Такие программы выполняют инструкции SELECT примерно так
же, как описано в предыдущем разделе. Разница между выполнением инструкции
SELECT и инструкции, которая не возвращает данные, состоит в том, что вы должны
выполнить дополнительный код, обрабатывающий результаты, полученные инструк-
цией SELECT.
Извлечение данных в ADO.NET
Приведенный ниже фрагмент кода на C# выполняет SQL-инструкцию SELECT, которая
получает имена авторов из таблицы authors, а затем перебирает результаты по одной
строке, выводя на печать все имена авторов. Подробные объяснения приводятся в поша-
говых инструкциях ниже.
{Odbc|OleDb|Sql{-Command statement = connection.CreateCommand( );
statement.CommandText = "SELECT au_fname, au_lname FROM authors";
{0dbc|01eDb|Sql}DataReader resultSet = statement.ExecuteReader( );
while( resultSet.Read( ) )
{
String fname = "NULL";
String Iname = "NULL";
if( ! resultSet.IsDBNull( 0 ) ) fname = resultSet.GetString( 0 );
if( ! resultSet.IsDBNull( 1 ) ) Iname = resultSet. GetString( 1 );
System. Console.WriteLine( Iname + ", " + fname );
}
resultSet.Close( );
statement.Close( );
750 | Глава 5. Программирование баз данных
i В ADO.NET порядковые номера столбцов начинаются с нуля (первый стол-
бец - 0, второй - 1 и т. д.), в отличие от JDBC, где номера столбцов начи-
-------- наются с единицы.
Чтобы выполнить при помощи ADO.NET запрос SQL и обработать результаты,
выполните следующие шаги.
1. Создайте объект Command, который будет использоваться для выполнения инструк-
ции SELECT, и свяжите с ним инструкцию SELECT.
{Odbc|OleDbISql(Command statement = connection,CreateCommand( );
statement.CommandText = "SELECT au_fname, au_lname FROM authors";
2. Вызовите метод ExecuteReader объекта Command, создав новый объект DataReader.
{Odbc|OleDb|Sql}DataReader resultset = statement,ExecuteReader( );
while( resultSet.Read( ) )
3. Перебор строк в наборе данных. После выполнения инструкции SELECT извле-
кайте строки при помощи метода Read объекта DataReader. Если вы ожидаете, что
результат будет состоять из нескольких строк, нужно выполнять метод Read из
цикла while.
while( resultSet.Read( ) )
{
4. Загрузив строку данных в объект DataReader, можно извлечь данные из столбцов
при помощи метода Get объекта DataReader. Перед вызовом метода Get мы
проверяем данные на наличие пустых (NULL) значений при помощи метода IsDB-
Null. Если этот метод возвращает значение Истина, тогда значение в строке будет
равно NULL. Существует много типов методов Get для каждого типа столбцов.
Важно использовать тип, соответствующий типу данных столбца, поскольку
преобразование типов не всегда возможно. Список существующих методов Get,
а также типов ANSI SQL, с которыми они должны использоваться, приводится
в табл. 5.4.
String fname = "NULL";
String Iname = "NULL";
if( ! resultSet.IsDBNull( 0 ) ) fname = resultSet.GetString( 0 ):
if( ' resultSet.IsDBNull( 1 ) ) Iname = resultSet.GetStringf 1 );
При создании программы с использованием ADO.NET, которая извлекает данные,
содержащие пустые значения, нужно в целях безопасности перед извлечением значения
проверить его методом IsDBNull объекта DataReader.
5. Метод Read объекта DataReader возвращает значение Ложь (false), когда с сервера
базы данных прочитаны все значения. В этот момент следует вызвать методы
Close объектов Command и DataReader, чтобы освободить ресурсы, используемые
для внутренней обработки инструкции.
resultSet.Close( );
statement.Close( );
Извлечение данных | 751
Таблица 5.4. Методы Get объекта DataReader ADO.NET
Имя метода Описание
GetBoolean(int /) Возвращает булево значение из столбца с номером 1, где i - порядковый номер столбца, начиная с нуля
GetByte(int i) Возвращает однобайтовое значение из столбца с номером г, где 1 - порядковый номер столбца, начиная с нуля. Если длина данных в столбце превышает один байт, никаких преобразований не произво- дится и генерируется исключение InvalidCastException
GetBytes(int i, long datalndex, byte[] buffer, int bufferindex, int length) Возвращает двоичное значение из столбца с номером 1, где i - порядковый номер столбца, начиная с нуля, datalndex - смещение стартовой позиции для чтения от начала значения столбца, buffer - это массив из указанного числа байтов (byte), в который будут копироваться данные, bufferindex - смещение стартовой позиции в пределах буфера для начала записи и length - максимальная длина данных, копируемых в буфер
GetChar(int i) Возвращает одиночное значение char из столбца с номером 1, где 1 - порядковый номер столбца, начиная с нуля. Применяется в столб- цах символьного типа
GetChars(int i, long datalndex, char[] buffer, int bufferindex, int length) Возвращает строку символов из столбца с номером i, где i - порядковый номер столбца, начиная с нуля, datalndex - смещение стартовой позиции для чтения от начала значения столбца, buffer - это массив из указанного числа символов (char), в который будут копироваться данные, bufferindex - смещение стартовой позиции в пределах буфера для начала записи и length - максимальная длина данных, копируемых в буфер
GetDataTypeName(int i) Получает строковое (String) значение, содержащее название типа данных столбца, i - порядковый номер столбца, начиная с нуля
GetDateTime(int i) Возвращает значение типа DateUme из столбца с номером 1, где i - порядковый номер столбца, начиная с нуля. Применяется в столб- цах типа дата/время
GetDecimal(int i) Возвращает одиночное значение типа Decimal из столбца с номером i, где 1 - порядковый номер столбца, начиная с нуля. Применяется в столбцах числового типа
GetDouble(int 0 Возвращает одиночное значение типа Double из столбца с номером i, где i - порядковый номер столбца, начиная с нуля. Применяется в столбцах числового типа
GetFloat(int i) Возвращает одиночное значение типа Float из столбца с номером i, где i - порядковый номер столбца, начиная с нуля. Применяется в столбцах с плавающей точкой
752 | Глава 5. Программирование баз данных
Таблица 5.4. Методы Get объекта DataReader ADO.NET (Продолжение)
Имя метода Описание
Getlnt{ 16,32,64) (inti) Извлекает данные из целочисленных столбцов. Точность воз- вращаемого значения закодирована в имени функции. Используйте функцию Getlntl6 для получения 16-битного целого со знаком типа short, Getlnt32 для получения 32-битного целого со знаком типа int и Getlnt64 для получения 64-битного целого со знаком типа long
GetName(int i) Получает строковое (String) значение, содержащее имя столбца с номером z, где i - порядковый номер столбца, начиная с нуля
GetOrdinal(string имя) Возвращается целочисленное значение, соответствующее порядко- вому номеру столбца с указанным именем
GetString(int i) / Возвращает одиночное значение типа String из столбца с номером i, где i - порядковый номер столбца, начиная с нуля. Применяется в столбцах символьного типа
Помимо методов Get в типе DataReader есть еще три метода, которые часто исполь-
зуются при обработке данных в запросе. Эти три метода перечислены в табл. 5.5.
Таблица 5.5. Часто используемые методы объекта DataReader ADO.NET
Имя метода Описание
CloseQ Закрывает объект DataReader и освобождает ресурсы, занятые данным экземпляром
lsDBNull(int i) Возвращает значение Истина (true), если указанный столбец пустой (NULL), иначе возвращает Ложь (false). / - порядковый номер столбца, начиная с нуля
Read() Извлекает следующую строку, если она доступна, и возвращает значение Истина (true), в противном случае возвращает Ложь (false)
Извлечение данных в JDBC
Приведенный фрагмент кода на Java выполняет SQL-инструкцию SELECT, которая
получает имена авторов из таблицы authors, а затем перебирает результаты по одной
строке, выводя на печать все имена авторов.
java.sql.Statement statement = connection,createStatement( );
java.sql.ResultSet result =
statement. executeQuery("SELECT au_fname, au_lname FROM authors" );
while( result.next( ) ) {
String fname = result.getString( 1 );
if( result,wasNull( ) ) fname = "NULL";
String Iname = result.getString( 2 );
if( result,wasNull( ) ) Iname = "NULL";
System.out,println( Iname + ", " + fname );
48-2447
Извлечение данных | 753
result,close) );
statement.close) );
a В JDBC порядковые номера столбцов начинаются с единицы (первый стол-
«, бец - I, второй - 2 и т. д.), в отличие от ADO.NET, где номера столбцов
начинаются с нуля.
Чтобы выполнить инструкции запроса в JDBC, выполните следующие шаги.
1. Для выполнения инструкции SQL сначала нужно создать объект JDBC Statement путем
вызова метода createStatement существующего объекта-соединения (Connection).
java.sql.Statement statement = connection.createStatement) );
2. Запрос выполняется путем вызова одного из методов execute объекта Statement.
Результирующие наборы данных запроса обрабатываются при помощи объектов
ResultSet, которые возвращает метод executeQuery объекта JDBC Statement.
java.sql.ResultSet result =
statement.executeQuery("SELECT au_fname, au_lname FROM authors" );
3. После создания объекта ResultSet вы можете перебирать строки по очереди путем
вызова метода next. Метод next возвращает булево значение Истина (true) для каж-
дой строки в результирующем наборе и Ложь (false) - после того, как все строки
будут пройдены. Обычной практикой является вызов метода next в цикле while для
обработки строк по одной. Объект ResultSet не начинается на первой строке
результирующего набора, поэтому, перед тем как вызывать любой из методов get,
вы должны предварительно вызвать метод next.
while( result.next) ) ) {
4. Чтобы извлечь данные из столбцов тех строк, которые входят в результирующий
набор, вызовите соответствующий метод get объекта ResultSet. Список доступных
методов get приведен в табл. 5.6. Обратите внимание, что после вызова метода get
данные в столбце проверяются на NULL, поскольку пустое значение нельзя
определить по значению, возвращаемому методом get.
String fname = result.getString) 1 );
if( result.wasNull) ) ) fname = "NULL";
String Iname = result.getString( 2 );
if( result.wasNull) ) ) Iname = "NULL";
При создании программы, использующей JDBC, которая отбирает данные из
столбцов, допускающих пустые значения, в целях безопасности всегда проверяйте
значение, получаемое из объекта ResultSet, на NULL с помощью метода wasNull.
754 | Глава 5. Программирование баз данных
Те методы get в JDBC, которые возвращают объектные типы, будут воз-
вращать значения NULL формата Java, если им приходится возвращать
пустые значения базы данных. Однако это утверждение неприменимо к необъ-
ектным типам, таким, как getlnt(), которые возвращают ноль (0) в ответ
на NULL в базе данных. По этой причине в данной главе используется дополни-
тельный метод wasNullQ для проверки значения на NULL.
5. Освобождайте ресурсы, которые занимают объекты ResultSet и Statement. По
окончании работы с этими объектами вызывайте их методы close, чтобы освободить
ресурсы базы данных.
result.close( );
имя_инсгрукции.с1о s е( );
Таблица 5.6. Методы get объекта ResultSet в JDBC
Имя метода Описание
getBlob({int i | String имя}) Извлекает значение Blob из столбцов типа BLOB, i - порядковый номер столбца, начиная с единицы, пате - имя столбца
getBoolean({int i | String имя}) Извлекает булево значение из столбцов типа BOOLEAN, i - порядковый номер столбца, начиная с единицы, пате - имя столбца
getByte({int i | String имя}) Извлекает байтовое значение из столбцов типа CHARACTER или BINARY, i- порядковый номер столбца, начиная с едини- цы, пате - имя столбца
getBytes({int i | String имя}) Извлекает массив байтов из столбцов типа BINARY, i - порядковый номер столбца, начиная с единицы, пате - имя столбца
getClob({int i | String имя}) Извлекает значение Clob из столбцов типа CLOB. 1 - порядко- вый номер столбца, начиная с единицы, пате - имя столбца
getDate({int i | String имя}) Извлекает значение Date из столбцов типа TEMPORAL, i - порядковый номер столбца, начиная с единицы, пате - имя столбца
getDoublc({int i | String имя}) Извлекает значение Double из столбцов типа DOUBLE PRE- CISION. i - порядковый номер столбца, начиная с единицы, пате - имя столбца
getFloat({int i | String имя}) Извлекает значение Float из столбцов типа REAL, i - порядковый номер столбца, начиная с единицы, пате - имя столбца
getlnt({int i | String имя}) Извлекает значение int из столбцов типа INTEGER, i - порядковый номер столбца, начиная с единицы, пате - имя столбца
Извлечение данных | 755
Таблица 5.6. Методы get объекта ResultSet в JDBC (Продолжение)
Имя метода Описание
getLong({int i | String имя}) Извлекает значение long из столбцов типа INTEGER, i - порядковый номер столбца, начиная с единицы, пате - имя столбца
getRow() Возвращает номер текущей строки
getShort({int 11 String имя}) Извлекает значение short из столбцов типа INTEGER, i - порядковый номер столбца, начиная с единицы, пате - имя столбца
getString({int i | String имя}) Извлекает строковое значение (String) из столбцов типа CHAR- ACTER. i - порядковый номер столбца, начиная с единицы, пате - имя столбца
getTime({int i | String имя}) Извлекает значение Time из столбцов типа TEMPORAL. 1 - порядковый номер столбца, начиная с единицы, пате - имя столбца
getTimestamp({int i | String имя}) Извлекает значение Timestamp из столбцов типа TEMPORAL, i - порядковый номер столбца, начиная с единицы, пате - имя столбца
Помимо этих методов get в типе ResultSet есть еще три метода, которые часто исполь-
зуются при обработке данных запроса. Эти три метода перечислены в табл. 5.7.
Таблица 5.7. Часто используемые методы объекта ResultSet в JDBC
Имя метода Описание
close() Закрывает объект ResultSet и освобождает ресурсы, занятые данным экземп- ляром
next() Переводит объект ResultSet на следующую строку, если она доступна, и воз- вращает значение Истина (true). Если строк больше не осталось, возвращает Ложь (false)
wasNull() Возвращает значение Истина (true), если последний столбец, полученный при помощи метода get, пустой (NULL), иначе возвращает Ложь (false)
Связанные параметры
Одним из самых простых способов оптимизации работы медленно функционирующе-
го приложения базы данных, которое выполняет множество сходных инструкций SQL,
является параметризация наиболее часто используемых инструкций SQL. Параметри-
зация представляет собой способ повторного использования инструкции SQL путем
написания этой инструкции с «заполнителями места» для часто изменяющихся значе-
ний. Этот способ имеет два основных преимущества: возможность меньшего числа
обращений к серверу и повышение эффективности обработки на сервере, поскольку
756 | Глава 5. Программирование баз данных
серверу не приходится каждый раз обрабатывать, планировать и оптимизировать
выполнение часто используемых инструкций SQL.
Параметризованные инструкции полезны при использовании тех строковых и дво-
ичных значений в инструкциях SQL, которые содержат неудобные символы, такие,
как кавычки и оконечные символы NULL, обозначающие конец строки. Такое приме-
нение повышает безопасность приложения базы данных, когда в инструкциях исполь-
зуются входные данные, вводимые пользователем. Ни одно связывание параметра,
исходящее от конечного пользователя, не может выполнить такую модификацию
инструкции, которая позволила бы нарушить секретность данных в базе.
Поскольку настройка параметризованных инструкций ведет к некоторому
повышению затрат ресурсов, хорошей практикой является параметриза-
ция только тех инструкций, которые будут выполняться как минимум
трижды перед закрытием инструкции. Если инструкция выполняется
только один раз, после чего закрывается, то затраты ресурсов на подго-
товку инструкции и связывание параметров могут привести к падению
сетевой производительности приложения.
Связанные параметры в ADO.NET
В следующем фрагменте кода на C# выполняется SQL-инструкция INSERT, которая
добавляет новые записи о продажах в таблицу sales базы данных pubs. Инструкция
INSERT параметризуется для повышения производительности, поскольку нужно,
чтобы объект-инструкция обрабатывался на сервере только один раз.
// Создание объекта Command для инструкций SQL
Statement statement = connection.CreateCommand( );
statement.CommandText =
"INSERT INTO SALES(stor_id,
ord_num,
ord_date,
qty,
payterms,
title_id) " +
''VAtL'ES(@stor_id, @ord_num, @ord_date, @qty, @payterms, @title_id)":
//Подготовка инструкции на сервере
statement.Prepare( ):
// объявление параметров, которые будут связываться
{Odbc|OleDb|Sql}Parameteг stor_id, ord_num, ord_date,
qty, payterms, title_id;
stor_id = statement.Parameters.Add( "@stor_id", DbType.String );
ord_num = statement.Parameters.Add( "@ord_num", DbType. String );
Связанные параметры | 757
ord_date = statement.Parameters,Add( ”©ord_date", DbType.DateTime);
qty = statement.Parameters.Add( "@qty", DbType.Int16 );
payterms = statement.Parameters.Add( "©payterms”, DbType.String );
title_id = statement. Parameters. Add( ”@titl.e_id", DbType. String );
while( GetNextSale(stor_id, ord_num, ord_date, qty, payterms, title_id) )
{
// Выполнение инструкции
int result = statement.ExecuteNonQuery( );
if( result 1=1)
{
// Если результат не равен 1, значит, произошла ошибка.
System.Console.WriteLine( "The INSERT failed.” );
break;
}
}
Для выполнения инструкций co связанными параметрами в ADO.NET
используйте следующие шаги:
1. Как и в предыдущих разделах, мы создаем объект Command ADO.NET и присваи-
ваем ему инструкцию SQL. Различие при использовании связанных параметров
состоит в предложении VALUES инструкции INSERT. В предложении VALUES
содержится шесть именованных заполнителей места для параметров, которые
позже будут связаны с объектом Command. В AD0.NET такие заполнители начи-
наются с символа @, за которым идет идентификатор, который должен быть уни-
кальным в пределах всех заполнителей в инструкции.
Statement statement = connection.CreateCommand( );
statement,CommandText =
"INSERT INTO SALES(stor_id,
ord_num,
ord_date,
qty,
payterms,
title_id) " +
"VALUES(@stor_id, @ord_num, @ord_date, ©qty, ©payterms, @title_id)";
2. Вызываем метод Prepare объекта Command, чтобы подготовить инструкцию SQL
к выполнению. Это уведомляет базу данных о том, что объект Command будет
выполняться со связанными параметрами,
statement.Prepare( );
3. Объявляем объекты-параметры, используя тип параметров, совпадающих с типом
объекта Command: OdbcParameter, OleDbParameter или SqlParameter. После объ-
явления параметров создаем объекты-параметры путем вызова метода Add кол-
лекции Parameters объекта Command и присваиваем возвращаемое значение
объекту Parameter. Первый аргумент, передаваемый методу Add, представляет
758 | Глава 5. Программирование баз данных
собой имя заполнителя, которому параметр будет соответствовать при выполне-
нии. В приведенном ниже примере объект Parameter с именем store_id будет соот-
ветствовать первому элементу предложения VALUES, в котором содержится
заполнитель с именем @store_id. Второй аргумент в методе Add - это тип столбца,
которому заполнитель соответствует на сервере. Список часто используемых
типов приведен в табл. 5.8.
{Odbc|OleDb|Sql}Раrameteг stor_id, ord_num, ord_date,
qty, payterms, title_id;
stor_id = statement.Parameters.Add( "@stor_id", DbType.String );
ord_num = statement. Parameters. Add( "@ord_num", DbType.String );
ord_date = statement.Parameters.Add( "@ord_date", DbType.DateTime);
qty = statement.Parameters. Add( "©qty", DbType.Int16 );
payterms = statement.Parameters.Add( "©payterms", DbType. String );
title_id = statement.Parameters.Add( "@title_id", DbType.String );
4. В этом примере объектам Parameter присваивается значение, получаемое при
вызове пользовательской функции GetNextSale, которая может быть реализована,
например, следующим образом.
static bool GetNextSale(SqlParameter stor_id,
SqlParameter ord_num,
SqlParameter ord_date,
SqlParameter qty,
SqlParameter payterms,
SqlParameter title_id)
{
// Опущен код, который читает
// запись о продаже из файла или введенную пользователем и т.п.
// Если записей больше нет, возвращается false.
if( !more_records ) return false;
// Присваиваем значения объектам-параметрам
stor_id.Value = 1234;
ord_num.Value = "ABCD.123";
ord_date.Value = new DateTime(2003,2, 24);
qty.Value = 50;
payterms.Value = "Net 60";
title-id.Value = "SD2043";
return true;
I
Обратите внимание, что значения параметрам присваиваются прямо через свойст-
во Value объекта Parameter. Объекту-параметру store_id присваивается значение 1234,
а параметру ord_date присваивается объект C# ADO.NET DateTime. Функция возвра-
Связанные параметры | 759
щает значение Ложь (false), если вставляемые в таблицу записи закончились, иначе
возвращается значение Истина (true).
При использовании цикла while программа будет продолжать вставлять новые
записи о продажах в базу данных до тех. пор, пока у функции GetNextSale не закончат-
ся обрабатываемые записи.
while(GetNextSale(stor_id, ord_num, ord_date, qty, payterms, title_id) )
{
5. При вызове метода ExecutedonQuery объекта Command инструкция INSERT
выполняется, а связанные параметры становятся на место соответствующих
заполнителей. Метод ExecuteNonQuery возвращает количество обработанных
строк, которое будет равно 1 в случае успешной вставки одной строки. Это
возвращаемое значение используется для обработки ошибок, и приложение
завершит работу, если инструкция не будет выполнена.
// Выполнение инструкции
int result = statement.ExecuteNonQuery( );
if( result != 1 )
{
// Если результат не равен 1, значит, произошла ошибка.
System,Console,WriteLine( "The INSERT failed." );
break;
}
Таблица 5.8. Часто используемые объектные типы параметров
Объектные типы DbType Описание
AnsiString Символьная строка переменной длины, не содержащая символов Unicode, длиной от 1 до 8000 символов
Ansi Str in gF ixedLength Символьная строка фиксированной длины, не содержащая симво- лов Unicode
Binary Двоичная строка переменной длины - длиной от 1 до 8000 байт
Boolean Может содержать значения Истина (true) или Ложь (false)
Byte Целое число без знака в диапазоне от 0 до 255
Currency Валютное значение в диапазоне от -263 до 263-1
DateTime Значение даты и времени
Decimal Числовое значение в диапазоне от 10’28 до 7.9 * 1028 с 28 значащими цифрами
Double Число с плавающей точкой в диапазоне от 5.0 * 10'324до1.7* Ю308 из примерно 15 цифр
Int{16,32,64} Целое число со знаком. Числовая часть имени показывает число битов точности. Например, Int32 - это 32-битное целое
760 | Глава 5. Программирование баз данных
Таблица 5.8. Часто используемые объектные типы параметров (Продолжение)
Объектные типы DbType Описание
Single Число с плавающей точкой в диапазоне от 5.0 * I0'324 до 1.7 * Ю308 из примерно 15 цифр
String Символьная строка UNICODE переменной длины
StringFixedLength Символьная строка UNICODE фиксированной длины
UInt {16,32,64} Целое число без знака. Числовая часть имени показывает число битов точности. Например, UInt32-3TO 32-битное беззнаковое целое
Связывание параметров в JDBC
Приведенный ниже фрагмент кода Java выполняет SQL-инструкцию INSERT, которая
добавляет новые записи о продажах в таблицу sales базы данных pubs. Инструкция
INSERT параметризуется для повышения производительности.
// Создается объект Command для инструкции SQL
PreparedStatement statement = connection,prepareStatement(
"INSERT INTO SALES(stcr_id,
ord_num,
ord_date,
qty,
payterms,
title_id) " +
"VALUES!?, ?. ?, ?, );
while( getNextSale(statement) )
{
// Выполнение инструкции
int result = statement.executeUpdate( );
if( result != 1 )
{
// Если результат не равен 1, значит, возникла ошибка.
System.out.printin! "The INSERT failed." );
break;
}
}
Связанные параметры | 761
Для выполнения инструкций со связанными параметрами в JDBC
используйте следующиа шаги:
1. Создайте объект JDBC PreparedStatement и передайте параметризованную инструк-
цию SQL в его конструктор. Отличие при использовании связанных параметров -
в предложении VALUES инструкции INSERT. В предложении VALUES содержатся
шесть заполнителей (знаки вопроса), соответствующих параметрам, которые
позже будут связаны с объектом PreparedStatement.
PreparedStatement statement = connection.prepareStatement(
"INSERT INTO SALES(stor_id,
ord_num,
ord_date,
qty,
payterms,
title_id) " +
"VALUES(?, ?, ?, ?, ?, ?)" );
2. В этом примере параметрам присваиваются значения, полученные путем вызова
пользовательской функции getNextSale, которая может быть реализована следующим
образом.
static boolean getNextSale( PreparedStatement statement )
throws SQLException
{
// Опущен код, который читает
// запись о продаже из файла или введенную пользователем и т.п.
// Если записей больше нет, возвращается false.
if( !more_records ) return false;
statement.setString(1, "1234");
statement.setString(2, "ABCD.123");
statement.setDate(3, new java.sql.Date(2003, 2, 24));
statement.setlnt(4,50);
statement.setString(5, "Net 60");
statement.setString(6, "SD2043");
return true;
}
Каждая позиция связывания соответствует ее порядковому положению в инструк-
ции SQL, номера начинаются с 1. Заполнителям присваиваются значения при помощи
методов set объекта PreparedStatement. В табл. 5.9 приводится список часто исполь-
зуемых методов set.
Функция возвращает значение Ложь (false), если больше не остается записей, которые
можно вставить в таблицу. Иначе функция возвращает значение Истина (true).
762 | Глава 5. Программирование баз данных
При использовании цикла while программа будет продолжать вставлять новые
записи о продажах в базу данных до тех пор, пока у функции GetNextSale не закончатся
обрабатываемые записи.
while( getNextSale(statement) )
{
}
3. Инструкция INSERT выполняется при вызове метода executeUpdate объекта Prepared-
Statement, а заполнители заменяются соответствующими связанными параметрами.
Метод ExecuteNonQuery возвращает количество обработанных строк, которое будет
равно 1 в случае успешной вставки одной строки. Это возвращаемое значение
используется для обработки ошибок, и приложение завершит работу, если инструкция
не будет выполнена.
// Выполнение инструкции
int result = statement.executeUpdate( );
if( result 1=1)
{
// Если результат не равен 1, значит, произошла ошибка.
System, out. println( "The INSERT failed." );
break;
}
}
Таблица 5.9. Часто используемые методы set объекта PreparedStatement
Имя метода Описание
setBlob(int /, Blob значение) Элементу под номером i присваивается указанное значение типа Blob
setBoolean(int i, boolean значение) Элементу под номером i присваивается указанное значение типа boolean
setBytc(int i, byte значение) Элементу под номером i присваивается указанное значение типа byte
sctClob(int i, Clob значение) Элементу под номером 1 присваивается указанное значение типа Clob
setDate(int i, Date [, Calendar cal] значение) Элементу под номером i присваивается указанное значение типа Date. Если указан параметр cal, он используется при интерпретации значения Date
setDouble(int i, double значение) Элементу под номером i присваивается указанное значение типа double
setFloat(int i, float значение) Элементу под номером i присваивается указанное значение типа float
setlnt(int i, int значение) Элементу под номером 1 присваивается указанное значение типа int
Связанные параметры | 763
Таблица 5.9. Часто используемые методы set объекта PreparedStatement (Продолжение)
Имя метода Описание
setLong(int i, long значение) Элементу под номером 1 присваивается указанное значение типа long
setNull(int i, int значение) Элементу под номером i присваивается значение NULL, где значение равно одной из целочисленных констант, опреде- ленных в java.sql.Types
setString(intг, String значение) Элементу под номером 1 присваивается указанное значение типа String
setTimestamp(int i, Timestamp [.Calendar cal] значение) Элементу под номером 1 присваивается указанное значение типа Timestamp. Если указан параметр cal, он используется при интерпретации значения Timestamp
Обработка ошибок
Правильное описание обработки ошибок для всех возможных ситуаций в приложении
базы данных может занять целую главу (или даже книгу!). Нам повезло, что API, которые
мы рассматриваем в этой книге, созданы на основе современного языка Java и на
основе среды .NET и содержат собственные механизмы обработки ошибок, которые
упрощают восстановление в случае ошибки.
Обработка ошибок в ADO.NET
Модель обработки ошибок в ADO.NET строится на основе исключений .NET. Функ-
ции и методы, в которых может возникнуть ошибка, можно заключить в блок try/
catch/ftnally. Самой сложной частью обработки ошибок является определение того,
что нужно делать в случае ошибки, а также освобождение ресурсов, занятых создан-
ными объектами. В следующем примере кода приводится схема обработки ошибок,
которую можно успешно использовать в ADO.NET для очистки всех ресурсов
в случае ошибки.
{Odbc|OleDb|Sql}Connection connection = null;
{0dbc|01eDb|Sql}Command statement = null;
{0dbc|01eDb|Sql}DataReader resultSet = null;
try {
// Create and use the Connection, Command, and DataReader objects
connection = new SqlConnection(connection_string);
connection.Open( );
statement = connection.CreateCommand( );
statement.CommandText = SQL;
resultSet = statement.ExecuteReader( );
764 | Глава 5. Программирование баз данных
} catch( Exception e ) {
// Notify user that an error occurred
} finally {
if( resultSet '= null ) resultSet.Close( );
if( statement != null ) statement.Dispose( );
if( connection != null ) connection.Closet );
Если ошибка происходит в блоке try и возникает исключение (в данном случае
типа Exception), то исключение будет перехвачено и будет выполнен код в блоке catch.
Блок finally, который выполняется независимо от того, возникало ли исключение,
должен отвечать за освобождение ресурсов. Трудно определить, какие ресурсы нужно
освободить, если вы не знаете, в каком месте произошла ошибка. Например, если
ошибка возникла при выполнении инструкции SQL, тогда единственное, что нужно
освободить, - это объекты Connection и Statement. В приведенном выше фрагменте
кода исключение, генерируемое объектом ExecuteReader, не даст закрыть объект resultSet,
поскольку ему по-прежнему будет присвоено первоначальное значение null.
Хорошей практикой при программировании является освобождение ресурсов
Л «, в порядке, противоположном тому, в котором они выделялись.
Обработка ошибок в JDBC
Модель обработки ошибок в JDBC основывается на механизме исключений Java, сле-
довательно, стандартную схему обработки ошибок Java - try/catch/finally - можно
применять и в приложениях, использующих JDBC. Приведенный ниже фрагмент кода
Java является примером того, как следует использовать блок try/catch/j'inally для
правильной обработки исключительных ситуаций и освобождения используемых
ресурсов.
Connection connection = null;
Statement statement = null;
ResultSet resultSet = null;
try {
// Create and use the Connection, Statement, and ResultSet objects
connection = DriverManager.getConnection( connection_string );
statement = connection,createStatement( );
resultSet = statement.executeQuery( SQL );
} catch( Exception e ) {
// Then, notify the user of an error.
} finally {
if( resultSet != null )
try{resultSet.close( );} catch(Exception e) {}
if( statement != null )
try{statement.close( );} catch(Exception e) {}
Обработка ошибок | 765
if( connection != null )
try{connection.close( );} catch(Exception e) {}
Если ошибка происходит в блоке try и возникает исключение (в данном случае
типа Exception), то исключение будет перехвачено и будет выполнен код в блоке catch.
Блок finally, который выполняется независимо от того, возникало ли исключение,
должен отвечать за освобождение ресурсов, занятых объектами connection, result set
и statement. Обратите внимание, что каждый объект перед освобождением ресурсов
тестируется на null. Этот тест позволяет применять данный код ко всем ошибочным
ситуациям - код работает, если исключительная ситуация возникает и при открытии
соединения, и при обработке данных результирующего набора. Методы close объектов
JDBC также могут генерировать исключения при освобождении ресурсов, поэтому их
следует заключать в отдельные блоки try/catch. Это несколько затрудняет програм-
мирование, но тем не менее это достаточно просто, если вы будете следовать приве-
денной здесь схеме.
Хорошей практикой при программировании является освобождение ре-
сурсов в порядке, противоположном тому, в котором они выделялись.
Примеры
В предыдущих разделах этой главы мы рассмотрели базовые компоненты обработки
инструкций SQL, имеющиеся в большинстве программ, работающих с базами дан-
ных, но мы не включали сюда полного текста подобных программ. В следующем раз-
деле мы объединили необходимые этапы в небольшую программу, которая выполняет
простую инструкцию SELECT и выводит полученные результаты на экран. Один и тот
же пример приводится для обоих API, рассматриваемых в этой главе.
Приведенные примеры устанавливают соединение с базой данных, выполняют
инструкцию SELECT и выводят на экран результаты. Инструкция SELECT выглядит
следующим образом.
SELECT a.au_lname, a.au_fname, SUM(t.ytd_sales)
FROM authors a, titleauthor, titles t
WHERE titleauthor.au_id = a.au_id and
titleauthor.title_id = t.title_id
GROUP BY a.au_lname, a.au_fname
ORDER BY 3 DESC
В примере указанная инструкция выполняется, а полученный с сервера базы
данных результирующий набор, состоящий из трех столбцов, выводится на экран.
766 | Глава 5. Программирование баз данных
Пример для ADO.NET
Следующая программа на С#, использующая интерфейс ADO.NET, связывается с базой
данных pubs и выводит на экран список авторов из этой базы данных вместе с величи-
ной продаж с начала года. Эту программу можно легко адаптировать под другие виды
обработки, используя методы, описанные в предыдущих разделах этой главы.
using System;
using System.Data.SqlClient;
class ExampleApplication
{
static void Maiл(st ring[] args)
{
String connection_string =
"Server=(local): Trusted_Connection=true;DATABASE=pubs;";
String SQL =
"SELECT a.au_lname, a.au_fname, SUM(t.ytd_sales) " +
"FROM autnors a, titleauthor, titles t " +
"WHERE titleauthor.au_id = a.au_id and " +
titleauthor.title_id = t.title_id ” +
"GROUP BY a.au_lname, a.au_fname " +
"ORDER BY 3 DESC";
SqlConnection connection - null;
SqlCommand statement = null;
SqlDataReader resultSet = null;
try
// создаем объект Connection и соединяемся с сервером
connection = new SqlConnection(connection_string);
connection.Open( );
// создаем объект Command для инструкции SQL
statement = connection.CreateCommand( );
statement.CommandText = SOL;
// Создаем обьект для чтения результирующего набора
resultSet - statement.ExecuteReader( ):
while( resultSet.Read( ) )
// извлекаем данные с сервера и отображаем их
String fname = "NULL"
String Iname = "NULL"
String sales = "ZERO"
lf( 1 resultSet. IsDBNu'll( 0 ) )
Примеры | 767
fname = resultSet.GetString( 0 );
if( ! resultSet. IsDBNuU( 1 ) )
Iname = resultSet.GetString( 1 );
if( ! resultSet.IsDBNull( 2 ) )
sales = resultSet.Getlnt32( 2 ).ToString( );
System.Console.WriteLine( Iname + ", " +
fname + " has sales of " +
sales);
}
}
catch( SqlException e )
{
// Печатаем сообщение об ошибке, если она возникла.
System. Console. W г itetine (" Er го г:'' +e.ToString( ) );
} finally {
// Освобождаем ресурсы
iff resultSet != null ) resultSet.Close( );
if( statement != null ) statement.Dispose( );
iff connection != null ) connection.Close( );
}
}
Пример для JDBC
Следующая программа на Java, использующая интерфейс JDBC, связывается с базой
данных pubs и выводит на экран список авторов из этой базы данных вместе с величиной
продаж с начала года.
import java.sql.*;
public class ExampleApplication
{
public static void main(String[] args)
{
String connection_string =
"jdbc:microsoft:sqlserver://localhost: 1433; " +
"User=montoyai; Password=12345; DatabaseName=pubs;'';
String SQL =
"SELECT a.au_lname, a.au_fname, SUM(t.ytd_sales) " +
"FROM authors a, titleauthor, titles t " +
"WHERE titleauthor.au_id = a.au_id and " +
titleauthor.title_id = t.title_id " +
"GROUP BY a.au_lname, a.au_fname " +
"ORDER BY 3 DESC";
768 | Глава 5. Программирование баз данных
Connection connection = null;
Statement statement = null;
ResultSet resultSet = null;
try
I
Class. forName("com. microsoft. jdbc. sqlserver. SQLServerDriver");
// Создаем объект Connection и соединяемся с сервером
connection = DriverManager.getConnection( connection_string );
// создаем объект Command для инструкции SQL
statement = connection.createStatement( );
// создаем объект для чтения результирующего набора данных
resultSet = statement.executeQuery( SQL );
while( resultSet.next( ) )
{
// Извлекаем данные с сервера и выводим их
String Iname = resultSet.getString( 1 );
if( resultSet.wasNull( ) ) Iname = "NULL";
String fname = resultSet.getString( 2 );
if( resultSet.wasNull( ) ) fname = "NULL";
String sales = resultSet.getString( 3 );
if( resultSet.wasNull( ) ) sales = "ZERO";
System.out.println( Iname + ", " +
fname + " has sales of " + sales);
}
}
catch( Exception e )
{
// Печатаем сообщение об ошибке, если она возникла.
System.out.println("Error:" + e.toString( ) );
} finally {
// Освобождаем ресурсы
if( resultSet != null )
try {resultSet.close( );} catch( Exception e ) {}
if( statement != null )
try {statement.close( );} catch( Exception e ) {}
if( connection != null )
try {connection.close( );} catch( Exception e ) {}
47
Пример
A
Sybase Adaptive Server
По большей части диалект языка SQL, используемый в Microsoft SQL Server и рас-
смотренный в этой книге, применим и к платформе Sybase Adaptive Server Enterprise 12.5.
В этом приложении описываются те типы данных, инструкции, функции и ключевые
слова, которые отличают эти две популярные платформы.
Типы данных Sybase Adaptive Server
В табл. А.1 производится сравнение типов данных, поддерживаемых Sybase Adaptive
Server, с типами, поддерживаемыми Microsoft SQL Server. Хотя используемые типы
в значительной степени перекрываются, есть несколько типов, которые отличаются по
смыслу или отсутствуют на одной из платформ. Если разница между типами сущест-
вует, она отражается в таблице. Типы, которые в таблицу не входят, следует считать
идентичными для обеих платформ.
Таблица А.1. Типы данных Sybase Adaptive Server
Тип данных Sybase adaptive server Тип данных Microsoft SQL Server Примечания
Нет BIGINT Использование типа decimal(19,0) в качестве эквивалента BIGINT позволяет хранить значения того же диапазона
BINARY BINARY Соответствует двоичному значению фик- сированной длины до 255 байт. В Microsoft SQL Server позволяет хранить 8000 байт
CHAR(N) CHAR(N) Хранит символьные данные фиксированной длины. Длина может доходить до размера страницы базы данных
DATETIME DATETIME Хранит дату и время в диапазоне от 1753-01-01 00:00:00 до 12-31-9999 23:59:59. Тип DATETIME может хранить миллисекунды с точностью до 1/300 секунды
Таблица А. 1. Типы данных Sybase Adaptive Server (Продолжение)
Тип данных Sybase Тип данных Microsoft adaptive server SQL Server Примечания
NCHAR(N) Нет Хранит символьные строки фиксированной длины в национальной кодировке. Длина может доходить до размера страницы базы данных. В Microsoft SQL Server тип NCHAR хранит строки, состоящие из символов Unicode
Нет NTEXT Хранит фрагменты текста Unicode длиной до 1 073 741 823 символов
NVARACHAR(N) Нет Хранит символьные строки переменной длины в национальной кодировке. Длина может дохо- дить до размера страницы базы данных. В Microsoft SQL ServerTHH NEARACHAR хранит строки, состоящие из символов Unicode
TIMESTAMP ROWVERSION Уникальное число в базе данных, которое обновляется при каждом обновлении строки
SMALLDATETIME SMALLDATETIME Храпит дату и время в диапазоне от 01-01-1900 00:00 до 31-12-2079 23:59. В отличие от SQL Server Sybase не может хранить даты с разреше- нием до секунд в типе SMALLDATETIME
Нет SQLVARIANT В Sybase нет слабоструктурированного типа, такого, как тип SQL_VARIANTb SQL Server
UNICHAR NCHAR(N) Храпит строки фиксированной длины, состоя- щие из символов UNICODE, длиной до размера страницы базы данных
Her UNIQUEIDENTIFIER Представляет собой значение, уникальное для всех баз данных и всех серверов
UNIVARCHAR NCHAR(N) Храпит строки переменной длины, состоящие из символов UNICODE, длиной до размера страницы базы данных
VARBINARY(N) VARBIN’ARY(N) Описывает двоичное значение переменной длины до 255 байт. В Microsoft SQL Server этот тип может хранить до 8000 байт
VARCHAR(N) VARCHAR(N) Хранит символьные данные фиксированной длины, до размера страницы базы данных
Главные отличия между типами SQL Server и Sybase - это размеры типов,
точность и заданный по умолчанию смысл для типа NCHAR. При переносе данных
с одной платформы на другую важно учитывать эти небольшие отличия, чтобы избе-
жать потерь и урезания данных.
Приложение A. Sybase Adaptive Server | 771
Инструкции Sybase Adaptive Server
Как мы уже видели в предыдущем разделе, поддержка типов в Sybase и SQL Server
в значительной мере перекрывается. В этом разделе мы сравним диалекты языка SQL
в Sybase и SQL Server. В большинстве случаев инструкции SQL Server, описанные в главе 3,
применимы также и к Sybase. В этом разделе описаны те инструкции, в которых эти плат-
формы отличаются друг от друга.
В табл. А.2 перечислены команды SQL, а также даны пояснения по различиям
между SQL Server и Sybase. Хотя большинство инструкций имеют идентичный син-
таксис и смысл, для инструкций, в которых имеются различия, приводится синтаксис
Sybase, а также объяснение различий.
Таблица А.2. Инструкции Sybase Adaptive Server
Команда Примечания
ALTER PROCEDURE Платформа Sybase не поддерживает ключевое слово ENCRYPTION, а также репликацию с использованием ключевых слов FOR REPLICATION
ALTER TABLE Платформа Sybase не поддерживает ключевое слово ROWGUIDCOL, а также ключевые слова CHECK и NOCHECK для включения ограничений. ALTER TABLE имя_таблицы [ADD {имя_столбца тип_данных атрибуты}[,...]] | [DROP имя_столбца [,...]] | [ADD CONSTRAINT {имя_ограничения предложение_для_ограничения] [....]] | [DROP CONSTRAINT имя_ограничения [,,..]] | [MODIFY { имя_столбца тип_данных [[NOT] NULL]}[,...]] | [{ENABLE|DISABLE] имя_триггера]
ALTER TRIGGER В Sybase нет инструкции, эквивалентной инструкции ALTER TRIGGER в SQL Server. Чтобы добиться аналогичного результата, удалите существующий триггер при помощи инструкции DROP TRIGGER, а потом создайте его заново инструкцией CREATE TRIGGER
ALTER VIEW В Sybase нет инструкции, эквивалентной инструкции ALTER VIEW в SQL Server. Чтобы добиться аналогичного результата, удалите существующее представление при помощи инструкции DROP VIEW, а потом создайте его заново инструкцией CREATE VIEW
CALL Не поддерживается ни в SQL Server, ни в Sybase. Аналогичную функциональ- ность имеет команда EXECUTE
CONNECT Поддерживается с вариантами CONNECT ТО имя_сервера
772 | Приложение A. Sybase Adaptive Server
Таблица А.2. Инструкции Sybase Adaptive Server (Продолжение)
Команда Примечания
CREATE DATABASE Создание новой базы данных в Sybase имеет следующий синтаксис: CREATE DATABASE имя_базы_данных [ON { DEFAULT | устройство_базы_данных} [=размер] [, { устройство_базы_данных [=размер]}[,...]] [LOG ON {устройство_журналирования [=размер]}[,... ] [WITH {OVERRIDE | DEFAULT-LOCATION = "путь"}] [FOR {LOAD | PROXY_UPDATE}] • Слово DEFAULT указывает устройство по умолчанию. Эквивалент ключево- го слова PRIMARY в SQL Server. • Параметр размер - это размер базы данных или журнала транзакций в мега- байтах. • устройство_.журналирования - то же, что и в SQL Server. • При указании параметра PROXYJJPDA ТЕ при создании базы данных метадан- ные автоматически извлекаются из указанного места (DEFAULT LOCATION)
CREATE FUNCTION Эго предложение идентично предложению в SQL Server, за исключением того, что не поддерживаются опции VARYING, ENCRYPTION и FOR REPLICATION
CREATE INDEX Есть различия в опциях предложения WITH'. [WITH [{FILLFACTOR = фактор_заполнения | MAX_ROWS_PER_PAGE = количество_строк}] [[, ]RESERVEPAGEGAP = количество_страниц] [[,CONSUMERS = X] [[, ]IGNORE_DUP_KEY] [[.]IGNORE_DUP_ROW | ALLOW_DUP_ROW] [[, ]SORTED_DATA] [[,{STATISTICS USING количество-шагов VALUES] • FILLFACTOR - то же, что в SQL Server. • MAX_ROWS_PER_PAGE - еще один способ управления фактором заполне- ния индекса, но вместо процентной доли страницы используется количество строк. • RESERVEPAGEGAP- метод контроля отношения числа пустых страниц индекса к числу заполненных. Может обеспечить прирост производитель- ности для тех индексов, которые часто увеличиваются в размерах. Допусти- мые значения количества_страниц 0-255, по умолчанию - 0. • IGNOREDUPKEY- то же, что в SQL Server. • IGNOREJDUP_ROW- позволяет создавать кластеризованный индекс но таблицам, содержащим дублирующиеся строки. Хотя по таблице, содержащей дублирующиеся строки, можно создать индекс, любая операция вставки или обновления, ведущая к созданию дубликата строки, будет после создания индекса отменяться.
Приложение A. Sybase Adaptive Server | 773
Таблица А.2. Инструкции Sybase Adaptive Server (Продолжение)
Команда Примечания
CREATE INDEX • Предложение ALLOW_DUP_ROWсходно c IGNOREDUPROW, за исключением того, что оно допускает инструкции INSERT и UPDATE, соз- дающие дубликаты строк. • Предложение SORTED_DATA ускоряет создание индексов для таблиц, которые уже отсортированы на диске. • Предложение WITH STATISTICS USING число_шагов VALUES управляет объемом поддерживаемой статистики, передаваемой в оптимизатор запросов
CREATE PROCEDURE Это предложение идентично предложению SQL Server, за исключением того, что не поддерживаются следующие опции: VARYING, ENCRYPTION и FOR REPLICATION
CREATE ROLE Поддерживается с вариантами. CREATE ROLE имя_роли [WITH PASSWD "пароль" [, {"PASSWD EXPIRATION" | "MIN PASSWD LENGTH" | "MAX FAILED LOGINS" } значение_опции ][,...] ] Эта инструкция создает роль с указанным именем_роли и паролем (необяза- тельным). Уникальной для Sybase является возможность указать простые параметры безопасности для роли
CREATE TABLE Хотя пользователи, применяющие SQL Server или Sybase нерегулярно, не
заметят различий в синтаксисе предложения CREATE TABLE, другие пользо- ватели могут обратить внимание на следующие различия. • Предложение NOT FOR REPLICATION в Sybase не поддерживается. • Атрибут столбцаROWGUIDCOL в Sybase не поддерживается. • Предложение TEXTIMAGE в Sybase не поддерживается. • Для атрибута IDENTITY в Sybase нельзя установить начальное значение или инкремент. Помимо этих небольших изменений есть и другие уникальные для Sybase параметры, перечисленные ниже. CREATE TABLE [имя_базы_данных.[владелец].]имя_таблицы ({имя_столбца тип_данных {[DEFAULT значение_по_умолчанию] | [IDENTITY | NULL | NOT NULL] | [OFF ROW | IN ROW [ (размер_в_байтах) ] ] | REFERENCES [[имя_БД.]владелец.]ссылка_на_таблицу [(ссылка_на_столбец)] {UNIQUE | PRIMARY KEY} [CLUSTERED | NONCLUSTERED] [asc | desc] [WITH { FILLFACTOR = pct, MAX_ROWS_PER_PAGE = количество_строк, } RESERVEPAGEGAP = количество_страниц }] [ON имя_сегмента] | CHECK (условие_поиска) }
774 | Приложение A. Sybase Adaptive Server
Таблица А.2. Инструкции Sybase Adaptive Server (Продолжение)
Команда Примечания
CREATETABLE | [CONSTRAINT имя_ограничения]
(FOREIGN KEY ({имя_столбца}[,...]) REFERENCES
[[имя_базы_данных.] владелец.] ссылка_на_таблицу
[({ссь1лка_на_столбец}[, ...])]
| CHECK (условие_поиска)
({UNIQUE | PRIMARY KEY} [CLUSTERED | NONCLUSTERED]
({имя_столбца [ASC | DESC]}[,...])
[WITH { FILLFACTOR = pct,
MAX_ROWS_PER_PAGE = количество_строк,
RESERVEPAGEGAP = количество_страниц } ]
[ON имя_сегмента]}[,...])
[LOCK {DATAROWS | DATAPAGES | ALLPAGES }]
[WITH { MAX_ROWS_PER_PAGE = количество_строк,
EXP_ROW_SIZE = количество_байтов,
RESERVEPAGEGAP = количество_страниц,
IDENTITY_GAP = value }]
[ON имя_сегмента]
[ [ EXTERNAL TABLE ] AT путь ]
Предложение OFF/ON ROW указывает, хранится ли столбец Java-SQL
физически в пределах строки или за ее пределами. Параметр SIZEJNJ3YTE
указывает максимальный размер для типа IN ROW.
Предложение ASC/DESC определяет порядок сортировки индекса, созданного
для ограничения. По умолчанию принимается порядок по возрастанию (ASC).
Предложение MAX_ROWS_PER_PAGE ограничивает количество строк на странице.
Предложение LOCK определяет стратегию блокировки, используемую в таблице.
Предложение EXP_ROWJSIZE определяет ожидаемый размер строки в байтах.
По умолчанию принимается ноль, и это означает, что нужно использовать
значение, заданное на сервере по умолчанию.
Предложение RESERVEPAGEGAP определяет желаемое соотношение числа
заполненных страниц к числу пустых. Допустимы значения 0-255, по
умолчанию - 0.
Предложение IDENTITY_GAP определяет интервал между последовательны-
ми значениями в столбцах идентификаторов (IDENTITY).
Предложение EXTERNAL TABLE указывает, что таблица хранится вне базы
данных. Эта функциональность используется по умолчанию, так что указы-
вать ее не обязательно.
CREATE Поддержка данной инструкции в Sybase сходна с SQL Server, по имеются сле-
TRIGGER дующие исключения.
Предложение WITH ENCRYPTION не поддерживается.
Предложения AFTER и INSTEAD OF не поддерживаются.
Предложение WITH APPEND не поддерживается.
Предложение NOT FOR REPLICATION не поддерживается.
Функция COLUMNS UPDATED() не поддерживается
Приложение A. Sybase Adaptive Server | 775
Таблица А.2. Инструкции Sybase Adaptive Server (Продолжение)
Команда Примечания
CREATE VIEW Поддержка данной инструкции в Sybase сходна с SQL Server, за исключением того, что не поддерживаются предложения ENCRYPTION, SCHEMABINDING и VIEW-METADATA
DECLARE CURSOR Поддержка данной инструкции в Sybase сходна с SQL Server, за исключением того, что не поддерживаются предложения INSENSITIVE и SCROLL
DELETE Инструкция DELETE в Sybase почти идентична инструкции DELETE в SQL Server. Платформа SQL Server поддерживает предложения WITH и OPTION, которые не поддерживает Sybase. Ниже перечислены параметры, уникальные для Sybase. DELETE [[владелец.]{имя_таблицы | имя_представления}] [FROM {[владелец.] { имя_представления [READPAST] ) имя_таблицы [READPAST] [(INDEX {имя_индекса | имя_таблицы } [PREFETCH paaMep][LRU | MRU])] }}[,...] [WHERE {условия_поиска | CURRENT OF имя_курсора}] ] [PLAN "абстрактный_план"] Предложение READPA ST заставляет сервер пропустить все страницы и строки, заблокированные в данный момент другими транзакциями, и уда- лять только те строки, которые в данный момент не используются. Предложение PREFETCH указывает размер ввода/вывода в килобайтах для таблиц, связанных с кешем. Предложение LRU/MRUуказывает стратегию замены в отношении либо наи- менее используемого буфера, либо самого последнего использованного буфера. Предложение PLAN посылает указанный абстрактный_план оптимизатору запросов как альтернативный план выполнения
DISCONNECT Поддерживается следующая команда: DISCONNECT
DROP ROLE Поддерживается следующий синтаксис: DROP ROLE имя_роли [WITH OVERRIDE] При использовании предложения WITH OVERRIDE игнорируются все ограничения на удаление ролей из базы данных
GRANT Поддержка данной инструкции в Sybase сходна с SQL Server, за исключением того, что в Sybase не поддерживается предложение AS
INSERT Платформа Sybase поддерживает для инструкции INSERT синтаксис SQL99, следовательно, Sybase не поддерживает ни одну из расширенных возможно- стей SQL Server
776 | Приложение A. Sybase Adaptive Server
Таблица А.2. Инструкции Sybase Adaptive Server (Продолжение)
Команда Примечания
FETCH Команда FETCH в Sybase существенно отличается от соответствующей коман- ды SQL Server. Платформа Sybase имеет курсоры последовательного типа на серверной стороне соединения, поэтому предложения NEXT, PRIOR, FIRST и LAST не используются. Кроме того, в Sybase можно использовать список целевых параметров, если между этими элементами и элементами, возвращаемыми инструкцией SELECT при создании курсора, определяется соотношение один-к-одпому. FETCH имя_курсора [INTO список_целевых_параметров] Например: DECLARE authors-Ciirsor CURSOR FOR SELECT au_lname, au_fname FROM authors OPEN authorS-Cursor FETCH authors„cursor INTO @lname, gfname GO
RETURN Инструкция RETURN в Sybase, в отличие от SQL Server, не может возвращать значения NULL
REVOKE Поддержка данной инструкции в Sybase сходна с SQL Server со следующими исключениями. Нельзя использовать предложение ТО вместо FROM. Предложение AS не поддерживается
SAVEPOINT Инструкция, идентичная инструкции SAVE TRANSACTION в SQL Server
SELECT Поддержка инструкций SELECT в Sybase сходна с SQL Server со следующими исключениями. • В Sybase для передачи подсказок оптимизатору выполнения инструкций используется предложение PLAN, а не OPTION. • В Sybase нет предложения ТОР. • Платформа Sybase не поддерживает предложения WITH CUBE и WITH ROLLUP в предложении GROUP BY. • В Sybase есть предложение FOR {UPDATE | READ ONLY}, которое можно использовать только в хранимой процедуре, когда в запросе определяется результат для курсора. • В Sybase есть предложение ATISOLATION{0, I, 2, 3}, с помощью которого при выполнении запроса указывается уровень изоляции, отличный от задан- ного по умолчанию. • В Sybase также есть инструкция SELECT INTO, которая имеет дополнитель- ное, необязательное предложение, управляющее блокировкой: LOCK { DATAROWS | DATAPAGES | ALLPAGES}
SET ROLE Платформа Sybase поддерживает инструкцию SET ROLE, имеющую сле- дующий синтаксис: SET ROLE {"SA_ROLE" 1 "SSO_ROLE" | "OPER_ROLE" | /мя_роли [WITH PASSWD "пароль"]} ( ON | OFF }
Приложение A. Sybase Adaptive Server | 777
Таблица А.2. Инструкции Sybase Adaptive Server (Продолжение)
Команда Примечания
SET TIME Инструкция SET TIMEZONE не поддерживается ни в Sybase, ни в SQL Server
ZONE
START Функциональный эквивалент - BEGIN TRANSACTION, который идентичен
TRANSACTION инструкции SQL Server, за исключением того, что не поддерживаются
параметризованные имена транзакций
UPDATE Инструкция UPDATE в Sybase почти идентична инструкции UPDATE в SQL Server. Платформа SQL Server поддерживает предложения WITH и OPTION, которые не поддерживает Sybase. Ниже перечислены параметры, уникальные для Sybase. UPDATE {имя_таблицы | имя_представления] SET {[{ имя_таблицы.| имя_представления.}] имя„столбца1 = {выраж11NULLI(инструкция_зе!есТ)} | имя_переменной1 = { выраж1|NULL|( инструкция_зе!есР)}} [FROM {имя_представления [READPAST]|имя_таблицы [READPAST] [(INDEX {имя_индекса | имя_таблицы } [ PREFETCH размер ][LRU 1MRU])]}[,...] [WHERE {условия_поиска | CURRENT OF имя_курсора}] [PLAN "абстрактный_план"] • Предложение READPAST заставляет сервер пропустить все страницы и строки, заблокированные в данный момент другими транзакциями, и уда- лять только те строки, которые в данный момент не используются. • Предложение PREFETCH указывает размер ввода/вывода в килобайтах для таблиц, связанных с кешем. • Предложение LRU/MRUуказывает стратегию замены в отношении либо наименее используемого буфера, либо самого последнего использованного буфера. • Предложение PLAN посылает указанный абстрактный_ппан оптимизатору запросов как альтернативный план выполнения
SQL-функции в Sybase Adaptive Server
В этом разделе сравниваются функции, существующие в Sybase и SQL Server. В табл. А.З
приводится список функций, поддерживаемых Sybase, а также описание того, чем эти
функции отличаются от функций SQL Server. Перечислены только те функции, в которых
между платформами существуют различия.
778 | Приложение A. Sybase Adaptive Server
Таблица А.З. Функции, поддерживаемые Sybase Adaptive Server
Функция Sybase Функция SQL Server Примечания
Чтобы получить имя приложе- ния в Sybase, используйте сле- дующую инструкцию SQL: select program_name from master, sysprocesses where spid = @@spid APP_NAME() Возвращает имя приложения для текущею сеанса. Задается приложе- нием
Пет BINARYCHECK-SUM ({* | выражение [,...]}) Возвращает двоичную контрольную сумму для списка выражений или строки таблицы
Пет СА8Т(выражепие AS тиндапных) Преобразует существующее выраже- ние SQL Server к указанному типу данных. В Sybase Adaptive Server Enterprise используйте для этого функцию CONVERT
CHAR_LENGTH(Bbipa>KeiiHc) Нет Возвращает количество символов в выражении. В SQL Server функ- циональным эквивалентом является функция LEN
Пег CHECKSUM([*| выражение [,...]}) Возвращает значение контрольной суммы (вычисленное по указанным значениям строк или выражений)
Her CHECKSUM_AGG ([ALL | DISTINCT] выражение) Возвращает контрольную сумму значений в группе
Нет COALESCE (выра-жепие [,...]) Возвращает первый непустой аргумент из указанного списка
CX)M!’ARE(cHMBjibipa>Kl, симввыраж2 [, |имя_сопостав j Ю_сопостав}]) Нет Возвращает следующие значения, основанные на правилах сопоставле- ния: 1: симв_выраж! больше, чем симв_выраж2. 0: симв_выраж! равно симв_выраж2. -1: симв_выраж1 меньше, чем симв_выраж2
Приложение A. Sybase Adaptive Server | 779
Таблица А.З. Функции, поддерживаемые Sybase Adaptive Server (Продолжение)
Функция Sybase Функция SQL Server Примечания
Нет CONTAINS( {столбец |* }, 'у словие_поиска'}) Производит поиск в столбце на наличие точных или «нечетких» сов- падений с условием _поиска. Эта сложная функция используется для выполнения полнотекстового поис- ка. За дополнительной информацией обращайтесь к документации произ- водителя
Нет CONTAINSTABLE (таблица, столбец, усло- вие_поиска) Возвращает таблицу при наличии точных или «нечетких» совпадений сусловием_поиска. Эта сложная функ- ция используется для выполнения пол- нотекстового поиска. За дополнитель- ной информацией обращайтесь к доку- ментации производителя
Нет COUNT_BIG([ALL | DIS- TINCT] выражение) • То же, что COUNT, но возвращает B1G1NT
Нет DATABASEPROPERTYEX Возвращает опцию или свойство (база_данных, свойство) базы данных
Нет DAY(дата) Возвращает целое число, представ- ляющее собой день, извлеченный из указанной даты
Нет FILE JD('hm4 файла') Возвращает ID файла по указанному логическому имени файла
Нет FILE_NAME(idj]>attna) Возвращает имя файла по указанно- му 1D
Нет FILEGROUP1D Возвращает ID файловой группы по ('имя_файловой_группы') указанному логическому имени фай- ловой группы
Нет FILE_NAME(idj|>afino- вой_группы) Возвращает имя файловой группы по указанному ID файловой группы
Нет FILEGROUPPROPERTY( Возвращает значение указанного имя_файловой_группы, свойства указанной файловой свойство) группы
Нет FILEPROPERTY(HMH 4>a Возвращает значение указанного йла, свойство) свойства указанного файла
Нет FULLTEXTCATALOGPR Возвращает свойства полнотекстово- ОРЕРТУ(имя_каталога, го каталога свойство)
Нет FULLTEXTSERVICEPR OPERTY (свойство) Возвращает свойства уровня полно- текстовых служб
780 | Приложение A. Sybase Adaptive Server
Таблица А.З. Функции, поддерживаемые Sybase Adaptive Server (Продолжение)
Функция Sybase Функция SQL Server Примечания
Нет FORMATMESSAGE (номер_сообщения, значение_парамстра [,... ]) Создает сообщение по сущест- вующему сообщению, взятому из таблицы SYSMESSAGES (сходна с RAISERROR)
Нет FREETEXTTABLE (таблица { столбец |*}, ‘произвольпая_строка' [, первые_п_по_рангу]) Используется для полнотекстового поиска. Возвращает таблицу со столбцами, которые совпадают по смыслу, но не полностью совпадают с указанной произвольной_строкои
Пет GETANSINULL (['база_данных']) Возвращает сведения о допустимо- сти пустых значений (nullability) в новых столбцах
Нет GETUTCDATE() Возвращает дату Всеобщего скоординированною времени (Universal Time Coordinated, UTC)
Нет GROUPING (имя_столбца) Возвращает 1, если строка была добавлена предложением CUBE или ROLLUP, в противном случае воз- вращает 0
HEXTOINT (шестнадцатеричная_строка) Нет Возвращает целочисленный (integer) эквивалент шестнадца- теричного аргумента. В SQL Server соответствующей функцией будет CONVERT(int, шестнадца- теричное_значение). Однако эта функция не работает со строковыми шестнадцатеричными значениями, как в Sybase, а только с настоящими шестнадцатеричными значениями
Нет lDENTJNCR(’Ta6jmna_ или_представление') Возвращает значение инкремента для столбца IDENTITY
Нет IDENT_SEED ('таблица_или_ представление') Возвращает начальное значение для столбца IDENTITY
Нет IDENT_CURRENT ('имя_таблицы') Возвращает последнее значение иден- тификатора {IDENTITY), сге- нерированное для указанной таблицы
Нет ГОЕНТ1ТУ(тип_данных [, нач_значение, инкремент]) As имя_столбца Используется в инструкции SELECT INTO для вставки столбца IDENTITY в таблицу
Приложение A. Sybase Adaptive Server | 781
Таблица А.З. Функции, поддерживаемые Sybase Adaptive Server (Продолжение)
Функция Sybase Функция SQL Server Примечания
Пет INDEXPROPERTY(id_ таблицы, индекс, свойство) Возвращает значение свойства индекса (например, Fill factor)
INTTOHEX (целочисленное_выраж) Нет Возвращает шестнадцатеричную строку, соответствующую целочисленному аргументу. Эквива- лентом в SQL Server является функ- ция CONVERT(VARBINARY(8), целочисленное_выраж)
Нет ISDATE( выражение) Проверяет, может ли символьная строка быть преобразована в значение DATETIME
Нет IS_MEMBER( {'группа' | 'роль'}) Возвращает истину или ложь (I или 0) в зависимости от того, входит ли пользователь в группу Windows NT или ему присвоена роль SQL Server. Эквивалентом в Sybase является функция PROC ROLE
Нет IS_SRVROLEMEMBER ('роль' [,'регистрация']) Возвращает истину или ложь (1 или 0) в зависимости от того, присвоена ли пользователю на сервере указанная роль
Нет ISNUMERIC(Bbipa?KenHe) Проверяет, можно ли символьную строку преобразовать в тип NUMER- IC. В Sybase для этого используется следующая инструкция: SELECT 1 WHERE выражение NOT LIKE %["0-9]%'
ISSEC_SERVICE_ON ('служба_безопасности') Нет Возвращает 1, если указанная слу.ж- ба_безопасности активна, иначе воз- вращает 0
Ictadmin ({{'LASTCHANCE'| 'LOGFULL'} Нет Изменяет значение последнего порога (last-chance threshold) для баз данных или процессов. Полезно для завершения работы зависших процессов
Нет ЕЕРТ(символьное_ выражение, целочислен- ное_выражение) Возвращает часть символьного выражения, начиная с указанного номера символа слева
Нет LEN (строковое_выражение) Возвращает количество символов в выражении. В Sybase функцио- нальным эквивалентом является функция CHAR_LENGTH
782 | Приложение A. Sybase Adaptive Server
Таблица А.З. Функции, поддерживаемые Sybase Adaptive Server (Продолжение)
Функция Sybase Функция SQL Server Примечания
LICENSE_ ENABLED ('свойство') Нет Возвращает 1, если лицензия на свойство активна
Нет MONTH (дата) Возвращает помер месяца из указан- ной даты
MUT_EXCL_ROLES (роль!, роль2 [, {membership | activation )]) Нет Возвращает информацию, связан- ную с взаимоисключающими свой- ствами роли! ироли2
Нет NCHAR(neji04Mcjieii- нос_выражение) Возвращается символ Unicode, соот- ветствующий указанному коду. В Sybase функциональным эквивален- том является функция TO_UNICHAR
Пет NEWID() Создается новый уникальный иден- тификатор, относящийся к тину UNIQUEIDENTIFIER
Нет NULLIF (выражение, выражение) Возвращает NULL, если два указан- ных выражения равны
Нет OBJECTPROPERTY(id, свойство) Возвращает свойства объектов теку- щей базы данных
Нет OPEN {[Global] имя_курсора | имя_переменпой_ курсора] Открывает локальный или глобаль- ный курсор
Нет OPENDATASOURCE(hm я_11оставщика, строка_инициализации) Создает соединение с источником данных без использования имени связанного сервера
Нет OPENQUERY(связан- ный сервер, 'запрос') Выполняет запрос к удаленному источнику данных, ранее сконфи- гурированному как связанный сервер
Нет OPEN- Выполняет запрос к удаленному КО\У8ЕТ('имя_поставщи источнику данных, не сконфи- ка', {'источник_данных'; гурированпому как связанный 'user__id', пароль | сервер 'строка_гюставщика'}, {[каталог.][схема.]объект | 'запрос'})
Нет PARSE- К'АМЕСимяобъекта', часть) Возвращает имя базы данных, имя владельца, имя сервера или имя объек- та для указанного объекта. Параметр часть - целое число от 1 до 4
Приложение A. Sybase Adaptive Server | 783
Таблица А.З. Функции, поддерживаемые Sybase Adaptive Server (Продолжение)
Функция Sybase Функция SQL Server Примечания
PATINDEX ('%шаблон%', выражение) Нет Возвращает позицию первого вхож- дения шаблона в строке
Нет PERMISSIONS (1д_объекта, столбец) Возвращает значение, являющееся битовой картой прав доступа теку- щего пользователя к указанному объекту/столбцу
РКОСКОЕЕ('имя_роли’) Нет Возвращает 0, если текущему поль- зователю не присвоена указанная роль. Функциональным эквивален- том в SQL Server является функция IS_MEMBER
Нет REPLACE(‘CTpoKO- вое_выраж1',' строко- вое_выраж2',' строко- вое_выражЗ') Вхождения второго выражения в первом заменяются третьим. То же, что STUFF
ROLE_CONTAIN('poflb 1 'роль2') Нет Возвращает 1, если роль! входит в роль2
ЯОЕЕ_Ю(имя_роли) Нет Возвращает идентификатор (id) ука- занной роли. В SQL Server исполь- зуйте следующую инструкцию: SELECT uid FROM sysusers WHERE issqlrole <> 0 AND name = имя_роли Эта инструкция возвращает иденти- фикатор роли, соответствующий ука- занному имени _роли
ROLE_NAME(id_poJiH) Нет Возвращает имя роли, соответст- вующее указанному идентифика- тору. В SQL Server используйте сле- дующую инструкцию: SELECT name FROM sysusers WHERE issqlrole <> 0 AND uid = id_ponM
ROWCNT(sysindexes.doampg) Нет Оценивает количество строк в табли- це. В SQL Server те же результаты дает следующая инструкция: SELECT rowcnt FROM sysindexes WHERE name = 'имя_таблнцы’
Нет ROWCOUNT_BIG( ) Возвращает количество строк, затронутых последним запросом (то же, что @@ROWCOUNT)
784 | Приложение A. Sybase Adaptive Server
Таблица А.З. Функции, поддерживаемые Sybase Adaptive Server (Продолжение)
Функция Sybase Функция SQL Server Примечания
Пет SESSIONJJSER Возвращает имя пользователя теку- щего сеанса
SHOW_ROLE( ) Нет Возвращает список ролей текущего пользователя
SHOW_SEC_SERVICES( ) Нет Возвращает список используемых в данный момент служб безопасности
SORTKEY (симв_выраж [, {имя_соноставл | id-Сопоставл}]) Нет Возвращает значение, которое можно использовать для сортировки значений в символьном выражении в соответствии с указанным сопос- тавлением
Нет STATS-DATE(idjia6jiH- цы, к1__индекса) Возвращает дату и время последнего обновления статистики индекса
Нет 8ТОЕУ(выражение) Возвращает стандартное отклоне- ние значений в столбце
Нет 8ТОЕУР(выражение) Возвращает стандартное отклоне- ние генеральной совокупности значений
SUSERJDQ'yMjjanMCb']) Нет Возвращает пользовательский иден- тификатор текущего пользователя или указанной учетной записи. Функциональным эквивалентом в SQL Server является функция SUSERJSID
Нет SUSER_SID(['y4_3anHCb']) Возвращает в двоичном виде Securi- ty ID (SID) текущего пользователя или учетной записи. Функциональ- ным эквивалентом в Sybase является функция SUSER_ID
SUSER_NAME фб_пользователя_сервера]) Нет Возвращает имя учетной записи для текущего пользователя или для ука- занного системного идентификатора учетной записи. Функциональный эквивалент в SQL Server - функция SUSER_SNAME
Нет SUSER_SNAME([sid_noji Возвращает имя учетной записи для ьзователя_сервера]) текущего пользователя или для ука- занного Security ID (SID). Функцио- нальный эквивалент в Sybase - функ- ция SUSER_NAME
50 - 2447
Приложение A. Sybase Adaptive Server | 785
Таблица А.З. Функции, поддерживаемые Sybase Adaptive Server (Продолжение)
Функция Sybase Функция SQL Server Примечания
SYBSENDMSG Ор_адрес, порт, сообщение) Нет Посылает на указанный IP-адрес пакет данных UDP, содержащий ука- занное сообщение
Нет SYSTEM_USER Возвращает имя учетной записи для текущего сеанса
ТО_1ЛЧ1СНАЯ(целое_число) Нет Возвращает одиночный символ Uni- code с указанным в аргументе кодом
Т8Е(ЗиЕЬ(выражение-отмет- ка_времени, литерал-отмет- ка_времени) Нет Возвращает истину, если выраже- ние-отметка времени и литерал- отметка времени совпадают. В SQL Server такой функциональностью обладает знак равенства (=) между двумя значениями
Нет TYPEPROPERTY(rHn_;ia Возвращает информацию о свойст- нных, свойство) вах типов данных
UHIGHSURR (выраж_исЬаг, начало) Нет Возвращает 1, если значение Unicode в выражении_uchar в позиции начало является верхней частью суррогатной пары
ULOWSURR (выраж_исЬаг, начало) Нет Возвращает 1, если значение Unicode в выражении_исЬаг в позиции начало является нижней частью суррогатной пары
Нет UNICODE Возвращает целое значение кода ('выражение_псЬагас'1ег') Unicode, соответствующее первому символу аргумента. Функциональ- ным эквивалентом в Sybase является функция USCALAR
USCALAR(Bbipaa<eHHe_uchar) Нет Возвращает скалярное значение кода первого символа Unicode в выраже- нии_исЬаг. Функциональным эквива- лентом в SQL Server является функ- ция UNICODE
VALID_NAME (имя_пользователя) Нет Возвращает 0, если имя_пользовате- ля не существует ни в одной из баз данных на сервере
VALID_USER(user_id) Нет Возвращает значение 1, если userjd существует в любой из баз данных на сервере
Нет VAR(Bbipaa<eHHe) Возвращает статистическую дис-
Персию для столбца
786 | Приложение A. Sybase Adaptive Server
Таблица А.З. Функции, поддерживаемые Sybase Adaptive Server (Продолжение)
Функция Sybase Функция SQL Server Примечания
Нет УАКР(выражепие) Возвращает статистическую дис- персию для генеральной совокупно- сти всех значений выражения
Нет УЕАИ(дата) Возвращает целое число, представ- ляющее собой год, извлеченный из указанной даты
Ключевые слова Sybase Adaptive Server
Ниже приводится список ключевых
Enterprise.
Sybase Adaptive Server
слов, используемых в
ABSOLUTE ACTION ADD ALL
A1.LOCATE ALTER AND ANY
ARE AR.ITH_OVERH.OW AS ASC
ASSERTION AT AUTHORIZATION AVG
BEGIN BETWEEN BIT- BITJ.ENGTH
BOTH BREAK BROWSE BULK
BY CASCADE CASCADED CASE
CAST CATALOG CHAR CHAR_CONVERT
CHAR_LENGTH CHARACTER CHARACTER-LENGTH CHECK
CHECKPOINT CLOSE CLUSTERED COALESCE
COLLATE COLLATION COLUMN COMMIT
COMPUTE CONFIRM CONNECT CONNECTION
CONSTRAINT CONSTRAINTS CONTINUE CONTROLROW
CONVERT CORRESPONDING COUNT CREATE
CROSS CURRENT CURRENT_DATE CURRENTJTME
CURRENT_TIMESTAMP CURRENTUSER CURSOR DATABASE
DATE DAY DBCC DEALLOCATE
DEC DECIMAL DECLARE DEFAULT
DEFERRABLE DEFERRED DELETE DESC
DESCRIBE DESCRIPTOR DETERMINISTIC DIAGNOSTICS
DISCONNECT D1SKD1STINCT DOMAIN DOUBLE
DROP DUMMY DUMP ELSE
END END-EXEC ENDTRAN ERRLVL
ERRORDATA ERROREXIT ESCAPE EXCEPT
EXCEPTION EXCLUSIVE EXEC EXECUTE
EXISTS EXIT EXP_ROW_SIZE EXTERNAL
EXTRACT FALSE FETCH FILLFACTOR
FIRST FLOAT FOR FOREIGN
Приложение A. Sybase Adaptive Server | 787
FOUND FROM FULL FUNC
FUNCTION GET GLOBAL «0
GOTO GRANT GROUP HAVING
HOLDLOCK HOUR IDENTITY IDENTITY-GAP
IDENTITY JNSERT IDENTITY-START IF IMMEDIATE
IN INDEX INDICATOR INITIALLY
INNER INOUT INPUT INSENSITIVE
INSERT INSTALL INT INTEGER
INTERSECT INTERVAL INTO IS
ISOLATION JAR JOIN KEY
KILL LANGUAGE LAST LEADING
LEFT LEVEL LIKE LINENO
LOAD LOCAL LOCK LOWER
MATCH MAX MAX_ROWS_PER_PAGE MIN
MINUTE MIRROR MIRROREXIT MODIFY
MODULE MONTH NAMES NATIONAL
NATURAL NCHAR NEW NEXT
NO NOHOLDLOCK NONCLUSTERED NOT
NULL NULLIF NUMERIC NUMERICJRUNCATI'
OCTET_LENGTH OF OFF OFFSETS
ON ONCE ONLINE ONLY
OPEN OPTION OR ORDER
OUT OUTER OUTPUT OVER
OVERLAPS PAD PARTIAL PARTITION
PERM PERMANENT PLAN POSITION
PRECISION PREPARE PRESERVE PRIMARY
PRINT PRIOR PRIVILEGES PROC
PROCEDURE PROCESSEXIT PROXY_TABLE PUBLIC
QUIESCE RAISERROR READ READPAST
READTEXT REAL RECONFIGURE REFERENCESREMOVE
RELATIVE REORG REPLACE REPLICATION
RESERVEPAGEGAP RESTRICT RETURN RETURNS
REVOKE RIGHT ROLE ROLLBACK
ROWCOUNT ROWS RULE SAVE
SCHEMA SCROLL SECOND SECTION
SELECT SESSION-USER SET SETUSER
SHARED SHUTDOWN SIZE SMALLINT
SOME SPACE SQL SQLCODE
SQLERROR SQLSTATE STATISTICS STRINGSIZE
STRIPE SUBSTRING SUM SYB_IDENTITY
SYBRESTREE SYB_TERMINATE SYSTEM-USER TABLE
788 | Приложение A. Sybase Adaptive Server
TEMP TEMPORARY TEXTSIZE THEN
TIME TIMESTAMP TIMEZONEJIOUR TIMEZONE_MIN'U1
TO TRAILING TRAN TRANSACTION
TRANSLATE TRANSLATION TRIGGER TRIM
TRUE TRUNCATE TSEQUAI. UNION
UNIQUE UNKNOWN UNPARTITION UPDATE
UPPER USAGE USE USER
USERJDPTION USING VALUE VALUES
VARCHAR VARYING VIEW WAITFOR
WHEN WHENEVER WHERE WHILE
WITH WORK WRITE WRITETEXT
YEAR ZONE
Приложение A. Sybase Adaptive Sei
в
Общие и специфичные для
платформ ключевые слова
В приведенной ниже таблице даны ключевые слова стандарта ANSI и ключевые
слова, специфичные для пяти реализаций SQL на описанных в этой книге платформах
(вместе с Sybase Adaptive Server). Таблицы с ключевыми словами размещены в сле-
дующем порядке.
• Таблица В.1: Общие ключевые слова
• Таблица В.2: Ключевые слова SQL2003
• Таблица В.З: Ключевые слова DB2
• Таблица В .4: Ключевые слова MySQL
• Таблица В.5: Ключевые слова Oracle
• Таблица В.6: Ключевые слова PostgreSQL
• Таблица В.7: Ключевые слова SQL Server
• Таблица В.8: Ключевые слова Sybase Adaptive Server
Таблица В.1. Общие ключевые слова
ADD ALL ALTER AND
AS ASC BY CHECK
COLUMN CREATE DATE DEFAULT
DELETE DESC DROP FOR
FROM IN INTO IS
LIKE NOT NULL ON
OR ORDER REVOKE SELECT
SET TABLE THEN TO
UNIQUE UPDATE WITH
Таблица В.2. Ключевые слова SQL2003
ABSOLUTE ACTION ADD ADMIN
AFTER AGGREGATE ALIAS ALL
ALLOCATE ALTER AND ANY
ARE ARRAY AS ASC
ASSERTION ASSERTION AT ATOMIC
AUTHORIZATION BEFORE BEGIN BIGINT
BINARY BIT BLOB BOOLEAN
BOTH BREADTH BY CALL
CASCADE CASCADED CASE CAST
CATALOG CHAR CHARACTER CHECK
CLASS CLOB CLOSE COLLATE
COLLATION COLLECT COLUMN COMMIT
COMPLETION CONDITION CONNECT CONNECTION
CONSTRAINT CONSTRAINTS CONSTRUCTOR CONTAINS
CONTINUE CORRESPONDING CREATE CROSS
CUBE CURRENT CURRENT-DATE CURRENT_PATH
CURRENTJROLE CURRENT-TIME CURRENT_TIMESTAMP CURRENT_USER
CURSOR CYCLE DATA DATALINK
DATE DAY DEALLOCATE DEC
DECIMAL DECLARE DEFAULT DEFERRABLE
DELETE DEPTH DEREF DESC
DESCRIPTOR DESTRUCTOR DIAGNOSTICS DICTIONARY
DISCONNECT DO DOMAIN DOUBLE
DROP ELEMENT END-EXEC EQUALS
ESCAPE EXCEPT EXCEPTION EXECUTE
EXIT EXPAND EXPANDING FALSE
FIRST FLOAT FOR FOREIGN
Приложение В. Общие и специфичные для платформ ключевые слова | 7'
Таблица В.2. Ключевые слова SQL2003 (Продолжение)
FREE FROM FUNCTION FUSION
GENERAL GET GLOBAL GOTO
GROUP GROUPING HANDLER HASH
HOUR IDENTITY IF IGNORE
IMMEDIATE IN INDICATOR INITIALIZE
INITIALLY INNER INOUT INPUT
INSERT INT INTEGER INTERSECT
INTERSECTION INTERVAL INTO IS
ISOLATION ITERATE JOIN KEY
LANGUAGE LARGE LAST LATERAL
LEADING LEAVE LEFT LESS
LEVEL LIKE LIMIT LOCAL
LOCALTIME LOCALTIMESTAMP LOCATOR LOOP
MATCH MEMBER MEETS MERGE
MINUTE MODIFIES MODIFY MODULE
MONTH MULTISET NAMES NATIONAL
NATURAL NCHAR NCLOB NEW
NEXT NO NONE NORMALIZE
NOT NULL NUMERIC OBJECT
OF OFF OLD ON
ONLY OPEN OPERATION OPTION
OR ORDER ORDINALITY OUT
OUTER OUTPUT PAD PARAMETER
PARAMETERS PARTIAL PATH PERIOD
POSTFIX PRECEDES PRECISION PREFIX
PREORDER PREPARE PRESERVE PRIMARY
PRIOR PRIVILEGES PROCEDURE PUBLIC
792 | Приложение В. Общие и специфичные для платформ ключевые слова
Таблица В. 2. Ключевые слова SQL2003 (Продолжение)
READ READS REAL RECURSIVE
REDO REF REFERENCES REFERENCING
RELATIVE REPEAT RES/GNAL RESTRICT
RESULT RETURN RETURNS REVOKE
RIGHT ROLE ROLLBACK ROLLUP
ROUTINE ROW ROWS SAVEPOINT
SCHEMA SCROLL SEARCH SECOND
SECTION SELECT SEQUENCE SESSION
SESSION-USER SET SETS SIGNAL
SIZE SMALLINT SPECIFIC SPECIFICTYPE
SQL SQLEXCEPT1ON SQLSTATE SQLWARNING
START STATE STATIC STRUCTURE
SUBMULTISET SUCCEEDS SUM SYSTEMJJSER
TABLE TABLESAMPLE TEMPORARY TERMINATE
THAN THEN TIME TIMESTAMP
T1MEZONEHOUR TIMEZONE MINUTE TO TRAILING
TRANSACTION TRANSLATION TREAT TRIGGER
TRUE UESCAPE UNDER UNDO
UNION UNIQUE UNKNOWN UNTIL
UPDATE USAGE USER USING
VALUE VALUES VARCHAR VARIABLE
VARYING VIEW WHEN WHENEVER
WHERE WHILE WITH WRITE
YEAR ZONE
Приложение В. Общие и специфичные для платформ ключевые слова |
Таблица В.З. Ключевые слова DB2
ACQUIRE ADD AFTER ALIAS
ALL ALLOCATE ALLOW ALTER
AND ANY AS ASC
ASUTIME AUDIT AUTHORIZATION AUXILIARY
AVG BEFORE BEGIN BETWEEN
BINARY BUFFERPOOL BY CALL
CALLED CAPTURE CASCADED CASE
CAST CCSID CHAR CHARACTER
CHECK CLOSE CLUSTER COLLECTION
COLLID COLUMN COMMENT COMMIT
CONCAT CONDITION CONNECT CONNECTION
CONSTRAINT CONTAINS CONTINUE COUNT
COUNTBIG CREATE CROSS CURRENT
CURRENT_DATE CURRENT_LC_ CURRENTPATH CURRENT-SERVER
PATH
CURRENTJIME CURRENT- CURRENTJIMEZONE CURRENT_USER
TIMESTAMP
CURSOR DATA DATABASE DATE
DAY DAYS DB2GENERAL DB2SQL
DBA DBINFO DBSPACE DECLARE
DEFAULT DELETE DESC DESCRIPTOR
DETERMINISTIC DISALLOW DISCONNECT DISTINCT
DO DOUBLE DROP DSSIZE
DYNAMIC EDITPROC ELSE ELSEIF
END END-EXEC ERASE ESCAPE
EXCEPT EXCEPTION EXCLUSIVE EXECUTE
EXISTS EXIT EXPLAIN EXTERNAL
FENCED FETCH FIELDPROC FILE
794 | Приложение В. Общие и специфичные для платформ ключевые слова
Таблица В.3. Ключевые слова DB2 (Продолжение)
FINAL FOR FOREIGN FREE
FROM FULL FUNCTION GENERAL
GENERATED GO GOTO GRANT
GRAPHIC GROUP HANDLER HAVING
HOUR HOURS IDENTIFIED IF
IMMEDIATE IN INDEX INDICATOR
INNER INOUT INSENSITIVE INSERT
INTEGRITY INTERSECT INTO IS
ISOBID ISOLATION JAVA JOIN
KEY LABEL LANGUAGE LC_CTYPE
LEAVE LEFT LIKE LINKTYPE
LOCAL LOCALE LOCATOR LOCATORS
LOCK LOCKSIZE LONG LOOP
MAX MICROSECOND MICROSECONDS MIN
MINUTE MINUTES MODE MODIFIES
MONTH MONTHS NAME NAMED
NHEADER NO NODENAME NODENUMBER
NOT NULL NULLS NUM PARTS
OB1D OF ON ONLY
OPEN OPTIMIZATION OPTIMIZE OPTION
OR ORDER OUT OUTER
PACKAGE PAGE PAGES PARAMETER
PART PARTITION PATH PCTFREE
PCTINDEX PIECESIZE PLAN POSITION
PRECISION PREPARE PRIMARY PRIQTY
PRIVATE PRIVILEGES PROCEDURE PROGRAM
PSID PUBLIC QUERYNO READ
Приложение В. Общие и специфичные для платформ ключевые ело
Таблица В. 3. Ключевые слова DB2 (Продолжение)
READS RECOVERY REFERENCES RELEASE
RENAME REPEAT RESET RESOURCE
RESTRICT RESULT RETURN RETURNS
REVOKE RIGHT ROLLBACK ROW
ROWS RRN RUN SCHEDULE
SCHEMA SCRATCHPAD SECOND SECONDS
SECQTY SECURITY SELECT SET
SHARE SIMPLE SOME SOURCE
SPECIFIC SQL STANDARD STATIC
STATISTICS STAY STOGROUP STORES
STORPOOL STYLE SUBPAGES SUBSTRING
SUM SYNONYM TABLE TABLESPACE
THEN TO TRANSACTION TRIGGER
TRIM TYPE UNDO UNION
UNIQUE UNTIL UPDATE USAGE
USER USING VAL1DPROC VALUES
VARIABLE VARIANT VC AT VIEW
VOLUMES WHEN WHERE WHILE
WITH WLM WORK WRITE
YEAR YEARS
Таблица В. 4. Ключевые слова MySQL
ACTION ADD AFTER AGGREGATE
ALL ALTER AND AS
ASC AUTOJNCREMENT AVG AVGROWLENC
BETWEEN BIGINT BINARY BIT
BLOB BOOL BOTH BY
CASCADE CASE CHANGE CHAR
CHARACTER CHECK CHECKSUM COLUMN
796 | Приложение В. Общие и специфичные для платформ ключевые слова
Таблица В.4. Ключевые слова MySQL (Продолжение)
COLUMNS COMMENT CONSTRAINT CREATE
CROSS CURRENT-DATE CURRENT_T1ME CURRENT-T1MESTAX p
DATA DATABASE DATABASES DATE
DATETIME DAY DAY JI OUR DAY_MINUTE
DAYJSECOND DAYOFMONTH DAYOF WEEK DAYOFYEAR
DEC DECIMAL DEFAULT DELAY_KEY_WR1TE
DELAYED DELETE DESC DESCRIBE
DISTINCT D1ST1NCTROW DOUBLE DROP
ELSE ENCLOSED END ENUM
ESCAPE ESCAPED EXISTS EXPLAIN
FIELDS FILE FIRST FLOAT
FLOAT4 FLOATS FLUSH FOR
FOREIGN FROM FULL FUNCTION
GLOBAL GRANT GRANTS GROUP
HAVING HEAP HIGH-PRIORITY HOSTS
HOUR HOUR_MINUTE HOUR-SECOND IDENTIFIED
IF IGNORE IN INDEX
INFILE INNER INSERT INSERTJD
INT INTI 1NT2 INT3
INT4 INT8 INTEGER INTERVAL
INTO IS ISAM JOIN
KEY KEYS KILL LASTJNSERTJD
LEADING LEFT LENGTH LIKE
LIMIT LINES LOAD LOCAL
LOCK LOGS LONG LONGBLOB
LONGTEXT LOW PRIORITY MATCH MAX
MAX_ROWS MEDIUMBLOB MED1UM1NT MEDIUMTEXT
M1DDLEINT MINJIOWS MINUTE MINUTE-SECOND
MODIFY MONTH MONTHNAME MY ISAM
NATURAL NO NOT NULL
NUMERIC ON OPTIMIZE OPTION
OPTIONALLY OR ORDER OUTER
OUTF1LE РАС К_KEYS PARTIAL PASSWORD
PRECISION PRIMARY PRIVILEGES PROCEDURE
Приложение В. Общие и специфичные для платформ ключевые слова | 7
Таблица В. 4. Ключевые слова MySQL (Продолжение)
PROCESS PROCESSLIST READ REAL
REFERENCES REGEXP RELOAD RENAME
REPLACE RESTRICT RETURNS REVOKE
RLIKE ROW ROWS SECOND
SELECT SET SHOW SHUTDOWN
SMALLINT SONAME SQL BIG RESULT SQLBIG-SELECTS
SQL_BIG_TABLES SQLLOGOFF SQL_LOGJJPDATE SQLLOWPRIORITY-
UPDATES
SQL_SELECT_LIMIT SQL_SMALL_RESULT SQL_WARNINGS STARTING
STATUS STRAIGHTJOIN STRING TABLE
TABLES TEMPORARY TERMINATED TEXT
THEN TIME TIMESTAMP TINYBLOB
TINYINT TINYTEXT TO TRAILING
TYPE UNIQUE UNLOCK UNSIGNED
UPDATE USAGE USE USING
VALUES VARBINARY VARCHAR VARIABLES
VARYING WHEN WITH WRITE
ZEROFILL
Таблица В.5. Ключевые слова Oracle
ACCESS ADD ALL ALTER
AND ANY AS ASC
AUDIT BETWEEN BY CHAR
CHECK CLUSTER COLUMN COMMENT
COMPRESS CONNECT CREATE CURRENT
DATE DECIMAL DEFAULT DELETE
DESC DISTINCT DROP ELSE
EXCLUSIVE EXISTS FILE FLOAT
FOR FROM GRANT GROUP
HAVING IDENTIFIED IMMEDIATE IN
INCREMENT INDEX INITIAL INSERT
INTEGER INTERSECT INTO IS
LEVEL LIKE LOCK LONG
MAXEXTENTS MINUS MODE MODIFY
MSLABEL NO AUDIT NOCOMPRESS NOT
798 | Приложение В. Общие и специфичные для платформ ключевые слова
Таблица В.5. Ключевые слова Oracle (Продолжение)
NO WAIT NULL NUMBER OF
OFFLINE ON ONLINE OPTION
OR ORDER PCTFREE PRIOR
PRIVILEGES PUBLIC RAW RENAME
RESOURCE REVOKE ROW ROWID
ROWNUM ROWS SELECT SESSION
SET SHARE SIZE SMALLINT
START SUCCESSFUL SYNONYM SYSDATE
TABLE THEN TO TRIGGER
UID UNION UNIQUE UPDATE
USER VALIDATE VALUES VARCHAR
VARCHAR2 VIEW WHENEVER WHERE
WITH
Таблица В. 6. Ключевые слова PostgreSQL
ABORT ADD ALL ALLOCATE
ALTER ANALYZE AND ANY
ARE AS ASC ASSERTION
AT AUTHORIZATION AVG BEGIN
BETWEEN BINARY BIT BITLENGTH
BOTH BY CASCADE CASCADED
CASE CAST CATALOG CHAR
CHAR_LENGTH CHARACTER CHARACTER_LEN CHECK
GTIl
CLOSE CLUSTER COALESCE COLLATE
COLLATION COLUMN COMMIT CONNECT
CONNECTION CONSTRAINT CONTINUE CONVERT
COPY CORRESPONDING COUNT CREATE
CROSS CURRENT CURRENT-DATE CURRENT SESSK
CURRENT_T/ME CURRENT_TIMESTAMP CURRENT_USER CURSOR
DATE DEALLOCATE DEC DECIMAL
DECLARE DEFAULT DELETE DESC
DESCRIBE DESCRIPTOR DIAGNOSTICS DISCONNECT
DISTINCT DO DOMAIN DROP
ELSE END ESCAPE EXCEPT
EXCEPTION EXEC EXECUTE EXISTS
Приложение В. Общие и специфичные для платформ ключевые сл<
Таблица В.6. Ключевые слова PostgreSQL (Продолжение)
EXISTS EXPLAIN EXTEND EXTERNAL
EXTRACT FALSE FETCH FIRST
FLOAT FOR FOREIGN FOUND
FROM FULL FULL GET
GLOBAL GO GOTO GRANT
GROUP HAVING IDENTITY IN
INDICATOR INNER INPUT INSERT
INTERSECT INTERVAL INTO IS
JOIN LAST LEADING LEFT
LIKE LISTEN LOAD LOCAL
LOCK LOWER MAX MIN
MODULE MOVE NAMES NATIONAL
NATURAL NCHAR NEW NO
NONE NOT NOTIFY NULL
NULL1F NUMERIC OCTET_LENGTH OFFSET
ON OPEN OR ORDER
OUTER OUTPUT OVERLAPS PARTIAL
POSITION PRECISION PREPARE PRESERVE
PRIMARY PRIVILEGES PROCEDURE PUBLIC
REFERENCES RESET REVOKE RIGHT
ROLLBACK ROWS SCHEMA SECTION
SELECT SESSION SESSIONJJSER SET
SETOF SHOW SIZE SOME
SQL SQLCODE SQLERROR SQLSTATE
SUBSTRING SUM SYSTEMJJSER TABLE
TEMPORARY THEN TO TO
TRAILING TRANSACTION TRANSLATE TRANSLATION
TRIM TRUE UNION UNIQUE
UNIQUE UNKNOWN UNLISTEN UNTIL
UPDATE UPPER USAGE USER
USING VACUUM VALUE VALUES
VARCHAR VARYING VERBOSE VIEW
WHEN WHENEVER WHERE WITH
WORK WRITE
Таблица В. 7. Ключевые слова SQL Server
ADD
ALL
ALTER
AND
800 | Приложение В. Общие и специфичные для платформ ключевые слова
Таблица В. 7. Ключевые слова SQL Server
ANY AS ASC AUTHORIZATION
BACKUP BEGIN BETWEEN BREAK
BROWSE BULK BY CASCADE
CASE CHECK CHECKPOINT CLOSE
CLUSTERED COALESCE COLLATE COLUMN
COMMIT COMPUTE CONSTRAINT CONTAINS
CONTAINSTABLE CONTINUE CONVERT CREATE
CROSS CURRENT CURRENT__DATE CURRENT_T1ME
CURRENTJIMESTAMP CURRENTJJSER CURSOR DATABASE
DBCC DEALLOCATE DECLARE DEFAULT
DELETE DENY DESC DISK
DISTINCT DISTRIBUTED DOUBLE DROP
DUMMY DUMP ELSE END
ERRLVL EXCEPT EXEC EXECUTE
EXISTS EXIT FETCH FILE
FILLFACTOR FOR FOREIGN FREETEXT
FREETEXTTABLE FROM FULL FUNCTION
GOTO GRANT GROUP HAVING
HOLDLOCK IDENTITY IDENTITYJNSERT IDENT1TYCOL
IF IN INDEX INNER
INSERT INTERSECT INTO IS
JOIN KEY KILL LEFT
LIKE LINENO LOAD NATIONAL
NOCHECK NONCLUSTERED NOT NULL
NULLIF OF OFF OFFSETS
ON OPEN OPENDATASOURCE OPENQUERY
OPEN ROWSET OPENXML OPTION OR
ORDER OUTER PERCENT PLAN
PRECISION PRIMARY PRINT PROC
PROCEDURE PUBLIC RAISERROR READ
READTEXT RECONFIGURE REFERENCES REPLICATION
RESTORE RESTRICT RETURN REVOKE
RIGHT ROLLBACK ROWCOUNT ROWGUIDCOL
RULE SAVE SCHEMA SELECT
51-2447
Приложение В. Общие и специфичные для платформ ключевые слова |
Таблица В. 7. Ключевые слова SQL Server
SESSIONJJSER SET SETUSER SHUTDOWN
SOME STATISTICS SYSTEM_USER TABLE
TEXTSIZE THEN TO TOP
TRAN TRANSACTION TRIGGER TRUNCATE
TSEQUAL UNION UNIQUE UPDATE
UPDATETEXT USE USER VALUES
VARYING VIEW WAITFOR WHEN
WHERE WHILE WITH WRITETEXT
Таблица В. 8. Ключевые слова Sybase Adaptive Server
ABSOLUTE ACTION ADD ALL
ALLOCATE ALTER AND ANY
ARE ARITH-OVERFLOW AS ASC
ASSERTION AT AUTHORIZATION AVG
BEGIN BETWEEN BIT BIT_LENGTH
BOTH BREAK BROWSE BULK
BY CASCADE CASCADED CASE
CAST CATALOG CHAR CHAR- CONVERT
CHAR_LENGTH CHARACTER CHARACTER-LENGTH CHECK
CHECKPOINT CLOSE CLUSTERED COALESCE
COLLATE COLLATION COLUMN COMMIT
COMPUTE CONFIRM CONNECT CONNECTION
CONSTRAINT CONSTRAINTS CONTINUE CONTROLROW
CONVERT CORRESPONDING COUNT CREATE
CROSS CURRENT CURRENT_DATE CURRENT-TIME
CURRENT- TIMESTAMP CURRENT-USER CURSOR DATABASE
DATE DAY DBCC DEALLOCATE
DEC DECIMAL DECLARE DEFAULT
DEFERRABLE DEFERRED DELETE DESC
DESCRIBE DESCRIPTOR DETERMINISTIC DIAGNOSTICS
DISCONNECT DISK DISTINCT DOMAIN DOUBLE
DROP DUMMY DUMP ELSE
END END-EXEC ENDTRAN ERRLVL
ERRORDATA ERROREXIT ESCAPE EXCEPT
802 | Приложение В. Общие и специфичные для платформ ключевые слова
Таблица В.8. Ключевые елова Sybase Adaptive Server (Продолжение)
ЕХ( EPTION EXCLUSIVE EXEC EXECUTE
EXISTS EXIT EXP ROW SIZE EXTERNAL
EXTRACT FALSE FETCH FILLFACTOR
FIRST FLOAT FOR FOREIGN
FOUND PROM FULL FUNC
FUNCTION GET GLOBAL GO
GOTO GRANT GROUP HAVING
HOLDLOCK HOUR IDENTITY IDENTITY GA P
IDENTITY INSERT IDENTITY START IF IMMEDIATE
IN INDEX INDICATOR INITIALLY
INNER INOl'/’ IN Pl'T INSENSITIVE
INSERT INSTALL INT INTEGER
INTERSECT INTERVAL INTO IS
ISOLATION JAR JOIN KEY
KILL LANGUAGE LAST LEADING
LEET LEVEL LIKE LINENO
LOAD LOCAL LOCK LOWER
MATCH MAX MAXROWS PER PAGE MIN
MINUTE MIRROR MIRROREXIT MODIFY
MODI :LE MONTH NAMES NATIONAL
NATO RAI. NCHAR NEW NEXT
NO NOHOLDLOCK NONCLUSTERED NOT
NULL Nl 'I.LIF NUMERIC NUMERIC TRUNC/ DON
OCTET LENGTH OF OFF OFFSETS
ON ON( E ONLINE ONLY
OPEN OPTION OR ORDER
OUT OUTER OUTPUT OVER
OVERLAPS PAD PARTIAL PARTITION
PERM PERMANENT PLAN POSITION
PRE! LSION PREPARE PRESERVE PRIMARY
PRINT PRIOR PRIVILEGES PROC
PRO( ’EDI IRE PRO( ESSEXIT PROXY TABLE Pl ’BUG
QUIESCE RAISER ROR READ READPAST
Приложение В. Общие и специфичные для платформ ключевые слова | 8(
Таблица В.8. Ключевые слова Sybase Adaptive Server (Продолжение)
READTEXT REAL RECONFIGURE REFERENCES REMOVE
RELATIVE REORG REPLACE REPLICATION
RESERVEPAGEGAP RESTRICT RETURN RETURNS
REVOKE RIGHT ROLE ROLLBACK
ROWCOUNT ROWS RULE SAVE
SCHEMA SCROLL SECOND SECTION
SELECT SESSIONJJSER SET SETUSER
SHARED SHUTDOWN SIZE SMALLINT
SOME SPACE SQL SQLCODE
SQLERROR SQLSTATE STATISTICS STRINGSIZE
STRIPE SUBSTRING SUM SYBJDENTITY
SYBJtESTREE SYB-TERMINATE SYSTEM_USER TABLE
TEMP TEMPORARY TEXTSIZE THEN
TIME TIMESTAMP TIMEZONEJIOUR TIMEZONE-MINUI
TO TRAILING TRAN TRANSACTION
TRANSLATE TRANSLATION TRIGGER TRIM
TRUE TRUNCATE TSEQUAL UNION
UNIQUE UNKNOWN UNPARTITION UPDATE
UPPER USAGE USE USER
USER-OPTION USING VALUE VALUES
VARCHAR VARYING VIEW WAITFOR
WHEN WHENEVER WHERE WHILE
WITH WORK WRITE WRITETEXT
YEAR ZONE
804 | Приложение В. Общие и специфичные для платформ ключевые слова
Предметный указатель
- арифметический оператор
вычитания, 41
- унарный оператор, 43
!< оператор «не меньше», 42
!= оператор «не равно», 42
!> оператор «не больше», 42
# (символ диеза), 161-162
## (двойной диез), 161-162
% остаток от деления, 41
& оператор побитового И, 41
* арифметический оператор
умножения, 41
/ арифметический оператор
деления, 41
| оператор побитового
исключающего ИЛИ, 41
~ унарный оператор, 43
+ сложение, арифметический
оператор, 41
+ унарный оператор, 43
< оператор «меньше», 42
<= оператор «меньше пли
равно», 42
= оператор присваивания, 41
= оператор равенства при
сравнении, 42
> оператор «больше», 42
>= оператор «больше или
равно», 42
(ADO.NET), 760
А
ABS, функция, 640
ABSTIME, функция
(PostgreSQL), 713
ABSVAL, функция (DB2), 660
ACOS, функция
DB2, 660
MySQL, 673
Oracle, 688
PostgreSQL, 713
SQL Server, 723
ADD_MONTHS, функция
(Oracle), 688
ADDDATE, функция (MySQL),
675
ADO.NET, 736
DataReader, методы, 753
Get, 752
выполнение инструкций, 748
закрытие соединения, 744
запуск транзакций, 745
извлечение данных, 750-753
обработка ошибок, 764
откат транзакций, 747
параметры, объектные типы, 760
пример программы для базы
данных, 767
связанные парамезры, 757 -761
соединение с базой данных,
739-741
фиксация транзакций, 747
AGE, функция (PostgreSQL), 714
ALL, оператор, 43, 83-84
ключевые слова, 84
поддержка платформами, 83
различия платформ, 85
синтаксис SQL2003, 83
краткий справочник, 81
правила, 84
советы и хитрости
программирования, 85
ALTER DATABASE,
инструкция (ель инструкции
CREATE/ALTER DATABASE)
ALTER DOMAIN, инструкция,
крат кий справочник, 81
ALTER INDEX, инструкция
(см. CREATE/ALTER INDEX,
инструкции)
ALTER METHOD, инструкция
(см. CREATE/ALTER
METHOD, инструкции)
ALTER PROCEDURE,
инструкции (см. CREATE/
ALTER, FUNCT1ON/PROCE-
DURE, инструкция)
ALTER TABLE, инструкция
(CM. CREATE/ALTER TABLE,
инструкции)
ALTER TRIGGER, инструкция
(см. CREATE/ALTER TRIG-
GER, инструкции)
ALTER TYPE, инструкция
(CM. CREATE/ALTER TYPE,
инструкции)
ALTER VIEW, инструкция
(слг. CREATE/ALTER VIEW,
инструкции)
ALTER, функция, инструкция
(ель CREATE/ALTER,функция
/ PROCEDURE, инструкция)
AND, оператор, 43
ANSI, стандарт, 20
AnsiString, параметрический
объектный гни (ADO.NET), 760
AnsiStringFixedLength,
параметрический
объектный тип (ADO.NET), 760
ANY, оператор, 43, 83-84
ключевые слова, 84
краткий справочник, 81
поддержка платформами, 83
правила, 84
различия платформ, 85
синтаксис SQL2003, 83
советы и хитрости
программирования, 85
APP NAME, функция, 779
SQL Server, 723
AREA, функция
(PostgreSQL), 714
AS ключевое слово н оператор
присваивания, 41
ASCII, функция
DB2, 660
MySQL, 673
Oracle, 688
PostgreSQL, 714
SQL Server, 723
ASCIISTR, функция (Oracle), 688
ASIN, функции
DB2,660
MySQL, 673
Oracle, 688
PostgreSQL, 714
SQL Server, 723
ATAN, функция
DB2, 660
MySQL, 673
Oracle, 688
PostgreSQL, 714
SQL Server, 723
ATAN2, функция
DB2, 660
MySQL, 673
Oracle, 688
PostgreSQL, 714
ATAN'H, функция (DB2), 661
ATN2, функция (SQL Server),
723
AuthorizationlD, 19
AVG, функция, 602, 605
В
BENCHMARK, функция
(MySQL), 673
BETWEEN, оператор, 43, 85-87
ключевые слова, 85
краткий справочник, 81
поддержка платформами, 85
правила, 86
различия платформ, 87
синтаксис SQL2003, 86
советы и хитрости
программирования, 86
BETWEEN, предложение, 628
BFILE, тип данных
Oracle, 59
сравнение платформ, 50
BFILENAME, функция
(Oracle), 689
BIGINT, тип данных
DB2, 54
MySQL, 56
SQL Server, 66, 770
сравнение платформ,50
BIGINT, функция (DB2), 661
B1GSF.RIAL, гни данных
PostgreSQL, 62, 65
сравнение платформ, 53
BIN, функция (MySQL), 673
BfN_TONUM, функция
(Oracle), 689
Binary параметрический объ-
ектный тип (ADO.NET), 760
BINARY, тип данных
SQL Server, 66,770
Sybase adaptive server, 770
сравнение платформ, 50
BINARY, функция (MySQL), 674
BINARYCHECKSUM,
функция, 779
SQL Server, 723
BINARYDOUBLE, тип данных
Oracle, 59
сравнение платформ,50
BINARY FLOAT, тип данных
Oracle, 59
сравнение платформ, 50
BIT VARYING, тип данных
PostgreSQL, 62
сравнение платформ, 51
BIT, тип данных
MySQL, 56
PostgreSQL, 62
SQL Server, 66
сравнение платформ, 50
BITAND, функция
(MySQL), 674
BIT COUNT, функция
(MySQL), 674
BIT_LENGTH, функция, 640
BIT_OR, функция
(MySQL), 674
BITAND, функция (Oracle), 689
BLOB, тип данных
DB2, 54
MySQL, 56
Oracle, 59
сравнение платформ, 51
BLOB, функция (DB2), 661
BOOL, тип данных
MySQL, 56
PostgreSQL, 62
сравнение платформ, 51
Boolean, параметрический объ-
ектный тип (ADO.NET), 760
BOOLEAN, тип данных
PostgreSQL, 62
сравнение платформ, 51
BOX, тип данных
PostgreSQL, 62
сравнение платформ, 51
BOX, функция (PostgreSQL), 714
BROADCAST, функция
(PostgreSQL), 715
BULKADMIN (системная роль
SQL Server), 401
Byte параметрический объект-
ный тип (ADO.NET), 760
BYTEA, тип данных
PostgreSQL, 62
сравнение платформ, 51
С
CALL, инструкция, 87-89
синтаксис SQL2003, 87
DB2, 88
MySQL, 89
Oracle, 89
SQL Server, 90
и инструкция EXECUTE, 88
ключевые слова, 87
краткий справочник, 81
поддержка платформами, 87
правила, 88
советы и хитрости
программирования, 88
CARDINALITY, функция
(Oracle), 689
CASE, функция, 636
CAST, функция, 638, 779
CBRT, функция (PostgreSQL),
715
CEIL, функция, 642
CENTER, функция
(PostgreSQL), 715
Chaos, уровень изоляции (объект
Transaction (ADO.NET), 745
CHAR FOR BIT DATA, тип
данных
DB2, 54
сравнение платформ, 51
CHAR VARYING, тип данных
DB2, 55
Oracle, 61
SQL Server, 69
сравнение платформ, 53
CHAR(), тип данных
SQL Server, 770
Sybase adaptive server, 770
CHAR, тип данных
DB2, 54
MySQL, 56
Oracle, 59
PostgreSQL, 62
SQL Server, 66
сравнение платформ, 51
CHAR, функция
DB2, 660
MySQL, 674
PostgreSQL, 715
SQL Server, 724
CHAR_LENGTH, функция,
640, 779
PostgreSQL, 715
CHARACTER VARYING, тнп
данных
DB2, 55
Oracle, 61
PostgreSQL, 65
SQL Server, 69
сравнение платформ, 53
CHARACTER, тип данных
DB2, 54
MySQL, 56
Oracle, 59
PostgreSQL, 62
SQL Server, 66
сравнение платформ, 51
CHARINDEX, функция
(SQL Server), 724
CHARTOROWID, функция
(Oracle), 689
CHECK, ограничения, 77
CHECKSUM, функция, 779
SQL Server, 724
CHECKSUM_AGG, функция,
779
CHR, функция
DB2, 660
Oracle, 689
CIDR, тип данных
PostgreSQL, 62
сравнение платформ, 51
CIRCLE, тип данных
PostgreSQL, 63
сравнение платформ, 5)
CIRCLE, функция
(PostgreSQL), 715
CLOB, тип данных
DB2, 54
Oracle, 59
сравнение платформ, 51
CLOB, функция (DB2), 525
CLOSE CURSOR, инструкция,
90-92
DB2, 90-91
PostgreSQL, 91
SQL Server, 91
ключевые слова, 90
краткий справочник, 81
поддержка платформами, 90
правила, 90
Синтаксис SQL2003, 90
советы и хитрости
программирования, 90
COALESCE, функция, 779
DB2, 662
MySQL, 674
Oracle, 689
PostgreSQL, 715
SQL Server, 724
Codd, E. F., 16
COL_LENGTH, функция
(SQL Server), 724
COL NAME, функция
(SQL Server), 724
COLLECT, функция (Oracle), 689
COMMIT TO SWITCHOVER
TO, 115
COMMIT, инструкция, 92-96
DB2, 94
MySQL, 94
Oracle, 94
PostgreSQL, 95
SQL Server, 95
ключевые слова, 93
краткий справочник, 81
поддержка платформами, 92
правила, 93
Синтаксис SQL2003, 92
806 | Предметный указатель
соне। ы и хитрости
црщраммирования, 93
COMPARE, функция, 779
COMPOSE, функция
(Oracle), 689
COMPRESS, функция
(MySQL), 674
CONCAT, функция
DB2, 662 '
Oiaclc, 689
CONCAT VVS, функипя
(MySQL), 675
CONNECT, инструкция, 96-100
DH2, 97
Oracle, 98
PostgreSQL, 99
SQL Server, 99
ключевые слова, 96
краткий справочник, 81
поддержка п.чагфор.мами, 96
правила, 97
Синтаксис SQL2003, 96
советы п хит рост и
про। раммирования, 97
CONNECTION-1 D(), функция
(MySQL), 675
CONTAINS, функция, 780
SQL Server, 724
CONTAINSTAB1.E, функция, 780
SQL Server, 725
CON V, функция (MySQL), 675
CONVERT, 293
CONVERT, функция, 654
Oracle, 689
SQL Server, 725
CORR, функция, 602, 606
CORR K, функция (Oracle), 690
COS, функция
DB2, 662
MySQL, 675
Oracle, 690
PostgreSQL, 715
SQL Server, 725
('OSH, функция
DB2, 662
Oracle, 690
СО Т, функция
DB2, 6(>2
MySQL. 675
PostgreSQL, 690, 716
SQL Server, 725
COVNT, функция, 602, 607
( Ol NT BIG, функция, 780
COVARPOP, функция, 602, 607
COVAR SAMP, функция, 602, 608
CREATE/ALTER DATABASE,
инструкции, 100-137
DB2 (см. DB2, CREATE/ALTER
DATABASE, инструкции)
MySQL, 105
Oracle (cm. Oracle, CREATE/
ALTER DATABASE,
инструкции)
PostgreSQL, 126 127
SQL Server (cm. SQL Server,
CREATE/ALTER DATABASE.,
инструкции)
краткий справочник, 81
поддержка платформами, 100
правила, 100
советы и хитрости
программирования, 100
CREATE/ALTER DOMAIN,
инструкции, краткий
справочник, 81
CREATE/ALTER INDEX,
инструкции, 165-185
DB2 (см. DB2, CREA TE/
ALTER INDEX, инструкции)
MySQL, 171
Oracle (см. Oracle, CREATE'
ALTER INDEX, инструкции)
PostgreSQL, 181
SQL Server (cm. SQL Server,
CREATE/ALTER INDEX,
инструкции)
ключевые слова, 166
кратким справочник, 81
общий для платформ
синтаксис, 166
поддержка наш формами, 166
правила, 166
сонеты и хитрости
программирования, 167
CREATE/ALTER METHOD,
инструкции,185-188
DB2, 187
MySQL. 188
Oracle, 188
PostgreSQL, 188
SQL Server, 188
ключевые слова, 185
краткий справочник, 81
поддержка платформами, 185
правила, 186
Синтаксис SQL2003, 185
советы н хитрости
программирования. 187
CREATE/ALTER ROLE,
инструкции, 189-192
DB2, 190
MySQL, 190
Oracle, 190
PostgreSQL, 192
SQL Server, 192
ключевые слова, 189
краткий справочник, 81
поддержка платформами, 189
правила, 189
Синтаксис SQL2003, 189
совет ы и хитрости
программирования, 190
CREATE/ALTER SCHEMA,
инструкции, 193-196
DB2, 194
MySQL, 195
Oracle, 195
PostgreSQL, 196
SQL Server, 196
ключевые слова, 193
краткий справочник, 81
поддержка платформами, 193
правила, 194
Синтаксис SQL2003. 193
советы и хитрости
программирования, 194
CREATE/ALTER TABLE,
инструкции, 196-264
DB2 (см. DB2, CREATE/
ALTER TABLE, инструкции)
MySQL (см. MySQL, CREATE/
ALTER TABLE, инструкции)
Oracle (cm. Oracle, CREA’I Е/
ALLER TABLE, инструкции)
PostgreSQL (cm. PostgreSQL,
CREATE'ALTER TAB1 E,
инструкции)
SQL Server (cm. SQL Server,
( Rl Al I Al 11 R TABLE,
инструкции)
ключевые слова, 198 201
ADD. 200
ALTER, 200
CASCADE. 201
CONSTRAINT. 199
DROP COLUMN. 200
DROP CONSTRAINT. 201
CL OR AL TEMPORARY. 198
LIKE. 199
LOCAL TEMPORARY. 198
ОГ. 200
ON COMMI T, 200
REIMS, 199
RESTRICT 201
имя столбца, / 99
краткий справочник, 81
поддержка платформами, 197
правила, 201 -20.3
Синтаксис SQL2OO3, 197
советы и хитрости
программирования, 203
CREATE/ALTER TRIGGER,
пиструкцип, 264-280
DB2, 269
MySQL, 271
Oracle (см. Oracle. CREATE/
ALTER TRIGGER, инструкции)
PostgreSQL, 275
SQL Server (SQL Server,
CREATE/ALTER TRIGGER,
инструкции)
ключевые слова, 265
краткий справочник, 81
полтержка платформами, 265
правила, 266
Синтаксис SQL2003, 265
советы и хитрост
программирования, 268
CREATE/ALTER TYPE,
ипе грукиип, 280-297
DB2 (см. DB2, CREATE/
ALTER TYPE, инструкции)
MySQL, 287
Oracle (см. Oracle, CREATE/
ALTER TYPE, инструкции)
Предметный указатель | 807
PostgreSQL (см. PostgreSQL,
CREATE/ALTER TYPE,
инструкции)
SQL Server, 297
ключевые слова, 281
краткий справочник, 81
поддержка платформами, 280
правила, 283
Синтаксис SQL2003, 280
советы и хитрости
программирования, 283
CREATE/ALTER VIEW,
инструкции,297-313
DB2 (см. DB2, CREATE/
ALTER VIEW, инструкции)
MySQL, 306
Oracle (см. Oracle, CREATE/
ALTER VIEW, инструкции)
PostgreSQL, 310
SQL Server, 310
ключевые слова, 298
краткий справочник, 81
поддержка платформами, 298
правила, 299
Синтаксис SQL2003, 298
советы и хитрости
программирования, 301
CREATE/ALTER, FUNCTION/
PROCEDURE, инструкции,
137-165
DB2 (см. DB2, CREATE/
ALTER, FUNCTION/PROCE-
DURE, инструкции)
ключевые слова, 138-141
CALL ON NULL INPUT. 140
CASCADE, 141
CONTAINS SQL, 140
CREATE, 138
DETERMINISTIC, 139
DYNAMIC RESULT SETS, 140
IN, 138
LANGUAGE, 139
MODIFIES SQL DATA. 140
NAME, 141
NO SQL, 140
OUT. 138
PARAMETER STYLE, 139
READS SQL DATA. 140
RESTRICT, 141
RETURN NULL ON NULL
INPUT. 140
RETURNS, 139
SPECIFIC, 139
STATIC DISPATCH, 140
блок_кода, 140
MySQL, 154
Oracle (cm. Oracle, CREATE/
ALTER, FUNCTION/PROCE-
DURE, инструкции)
PostgreSQL, 158
SQL Server (cm. SQL Server,
CREATE/ALTER, FUNCTION/
PROCEDURE, инструкции)
краткий справочник, 81
поддержка платформами, 137
правила, 141
Синтаксис SQL2003, 137
советы и хитрости
программирования, 143
CROSS JOIN, 428
CUME_DIST, функция, 603,
609,629
CURDATE(), функция
(MySQL), 675
Currency параметрический объ-
ектный тип (ADO.NET), 760
CURSOR, тип данных
SQL Server, 66
сравнение платформ, 51
CURTIME(), функция
(MySQL), 675
CV, функция (Oracle), 690
D
Data Control Language (DCL), 29
Data Definition Language
(DDL), 29
Data Manipulation Language
(DML), 29
DATABASE(), функция
(MySQL), 675
DATABASEPROPERTYEX,
функция, 780
SQL Server, 725
DATALENGTH, функция
(SQL Server), 725
DATALINK, тип данных
DB2, 54
сравнение платформ, 51
DataRMajkr, методы
^МЯИ*),753
©АТЕ, тип данных
DB2, 54
MySQL, 56
Oracle, 59
PostgreSQL, 63
сравнение платформ, 51
DATE, функция (DB2), 662
DATE_ FORMAT, функция
(MySQL), 675
DATE_ADD, функция
я
(MySQL), 675
DATE_PART,
(PostgreSj®
DATE S№ ф
(MySQL), 675
DATEJTRUNC, функция
(PostgreSQL), 716
DATEADD, функция
(SQL Server), 725
DATEDIFF, функция
(SQL Server), 725
DATENAME, функция
(SQL Server), 725
DATEPART, функция
(SQL Server), 726
DateTime, параметрический
объектный тип (ADO.NET), 760
DATETIME, тип данных
MySQL, 57
PostgreSQL, 63
SQL Server, 66,770
Sybase adaptive server, 770
сравнение платформ, 51
DAY, функция, 780
DB2, 662
SQL Server, 726
DAYNAME, функция
DB2, 662
MySQL, 677
DAYOFMONTH, функция
(MySQL), 677
DAYOFWEEK, функция
DB2, 662
MySQL, 677
DAYOFWEEKJSO, функция
(DB2), 662
DAYOFYEAR, функция
DB2, 662
MySQL, 677
DAYS, функция (DB2), 663
DB ACCESSADMIN (SQL
Server, системная роль), 402
DB_BACKUPOPERATOR (SQL
Server, системная роль), 402
DB_DATAREADER (SQL
Server, системная роль), 402
DB_DATAWRITER (SQL
Server, системная роль), 402
DB_DDLADMIN (SQL Server,
системная роль), 402
DBDENYDATAREADER (SQL
Server, системная роль), 402
DBDENYDATAWRITER (SQL
Server, системная роль), 402
DB_ID, функция
(SQL Server), 726
DB_NAME, функция
(SQL Server), 726
DB_OWNER (SQL Server,
системная роль), 402
DB_SECURITYADMIN (SQL
Server, системная роль), 402
DB2, 32
CALL, инструкция, 88
CLOSE CURSOR,
инструкция, 90
COMMIT, инструкция, 94
CONNECT, инструкция, 97
CREATE/ALTER DATABASE,
инструкции, 100-105
ALIAS, 101
APPLY, 104
AT DBPARITIONNUM, 101
AUTOCONFIGURE, /02
CATALOG TABLESPACE, 102
COLLATE USING, 101
CREATE {DATABASE | DB},
101
DFT_EXTENT_SZ, 102
EXTENTSIZE. 104
MANAGED BY, 104
NUMSEGS, 102
ON, 101
808 | Предметный указатель
OVERHEAD. 105
PREEE TCHST/.E, 104
TEMPORA R}' TA HL ESPA ( E.
H)2
TRANSEERRATE, 105
USER TARl.ESPACE. 102
USING CODESET. 1(11
WITH, 102
определе-
ние тадптногопроетран
ства. / 04
create/ai.i er index,
инструкции, 165 171
ALLOW REVERSE SCANS.
170
ASC. 168
CLUSTER, 169
COLLECT STA TIST ICS. 170
DESC. 168
EXTEND USING. 169
INCLUDE. 169
MINPCTUSED. 169
PCU’REE 169
SPECHTCATION ONLY. 169
creatf/aiter method.
ине гр\ кипи, 1S5
< KI \! I- Al l ER ROEE,
uncipvKiinii. I90
UREA! I:,'Al l l.R SCHEMA,
инструкции, 1 'M
CREAIF/Al.ll.R 1ЛВ1.Е,
инструкции. 202 215
ACTIVATE NOT LOGGED
INITIALLY. 209
ACT!VALE VAI UE
COMPRESSION. 210
ADD. 208
ALTER /COLUMN!. 20S
ALTER /CHECK | EOREIGN
KEY,1. 2OS
APPEND. 210
AS IDENTITY, 2/3
AS. 213
COMPACT. 2/1
( (IMPRESS SYSTEM
DI EH 1.1 2/2
DATA CAPTURE. 207. 209
DEI TNI I’/ON ONE Y 206
DROP. 209
/ TLE LINK CONTROL. 211
GENERATED. 213
IN. 207
LIKE. 206
/ INKTYPE URL. 211
LOCKSE/E, 2/0
LOGGED. 2/1
MODE DR2OPTTONS. 2/2
NL/NE LENGTH. 2/2
NO LINK CONTROL. 21/
NO’/ LOGGED /NIT/ALLY 207
OPTIONS. 208
ORGANISE HY. 207
PARITTTONING KEY 208
PCTEREE. 210
REPLICATED. 208
SCOPE. 2/2
SET MA TERIALIZED
QUERY. 210
UNDER. 205
VALUE (’(IMPRESS ION 207
VOLATILE. 2/0
WITH RESTRK TON DROP.
207
опции производнойтад-
П1цы, 205
параметры копирования. 2.06
промежуточная тадп/ци.
опредс leuue. 206
( IC \: i- \l 11 R TRIGGER,
пне । руКИПИ, 269
CREAI Е/ЛЕ1 ER TYPE.
иисчрукцнп, 2X4 2X7
ADD METHOD. 285
ALTER METHOD. 285
DISTENT 7; 284
DROP METHOD. 285
EEN( ’ED. 285
INLINE LENGTH. 284
ME I HOD. 285
MODE DII2SQI. 284
OVERRIDING 285
RESTRK ”L 285
THREADSU ’E. 285
WITH (’OM PAR ISONS. 284
WITHOUT COMPARISONS.
284
CREAI E.'AI I ER VIEW.
инструкции, 302 306
ttlill CHECK OPTION.
предложение. 306
CREATE Al.l ER. FUNCTION
PROCFDl IRE. inicipvKimii.
143 154
CARDINALITY. 147
(’ONLAINS SQL 145
DIHNEO. 147
EXTERNA/. NAME. /45
/ EN( ’ED. /46
EINAI. CALI. 146
1NIIERI!’SPECIAL REGIS
IERS. 146
language. 145
MODI TIES SQL DATA. 146
NO SQL. 146
PARALLEL. /47
PARAMETER STYLE. 145
PREDK A TES. 147
PROGRAM TYPE. 146
READS SQL DATA. 146
RETURNS. 145
SCRATCHPAD. 146
I’HREADSAEE. 146
TRANSI ’ORM GROUP. 147
DECI . ARE Cl ,RS()R. команда,
3IX
1)1 I E.ТЕ., инструкция, 32X
DISCONNECT инструкция. 336
DROP, инегрукции, 339 343
I DISTINCT! TYPE. 342
HUTT ERPOOL. 339
DATA RASE PARTITION
GROUP. 340
EVENT MONITOR. 339
ISPECHTCI. функция. 339
I ’UNCl’ION MAPPING. 340
INDEX, 340
NICKNAME, 340
PACKAGE. 341
RESTRICT. 343
SCHEMA 341
SEQUENCE. 341
SERVER. 341
TA RLE. 34/
TAHLESPACE, 34/
TRANSI’ORM. 342
TRIGGER. 342
TYPE MA PI’I NG. 342
USER MAPPING I’OR. 342
VIEW 342
WRAPPER. 342
E.X'( 1 PT oncpaiop для
наборов данных, 359
FETCH, ннсфукцня, 3(i7
(iRAN I, инеip\ кипя, 376 3X2
/ALTER | IMAGE,1 ON
SEQUENCE. 379
IALTERIN I CREA/’EIN
DROPIN) ON SCHEMA. 379
/RIND 1 ( ONTROI. | EXI-s
CULL/ ON PACKAGE. 378
CONTROL ON INDEX. 378
EX EC UTE ON. 378
P4SSHIRU ON SERVER. 379
IO USER. 381
USE O’: TARLESPAC E. 38!
WITH GRANT OPTION. 381
(мля'ктные npiancie.'uu. 382
HpiuHiie.’iiu aami даины.х. 176
INSER T, ннс i рукння, 409
IN I FRSI С I oncpaiop i.im
наборов данных, 421
JOIN, пред 1ОЖСН11С. 432
I I JAP, 105
1 IKE, oiiepiuop, 43X
MERGE., HiicipyKiniH, 443
OLE-DB внешние lao.HiHin.ic
нольlOBaicjibcKiie. функции. 149
OPEN, ннсipy кипя, 446
ORDER 13Y, предложение. 450
RFI.F.ASF. SAVEPOINT,
HHcipyKiiiui, 455
RE, I IIRN. inicipy кипя. 465
REVOKE. iiiicipyKiuia. 463 469
ALTERIN | CREAI’EIN
DROPIN / ON SCHEMA. 465
/ RIND (’ONIROL , EXE-
CUTE! ON PA( К AGE. 464
/ALTER | USAGE/ ON
SEOUENCE. 467
CONTROL ON INDEX, 464
EXECUT E ON. 465
I ROM. 467
PASSI’IIRU ON SERVER, 465
RESTRICT. 467
USEOE TARI.ESPACE. 467
аТп.ектная iipimieie.’UH. 466
npueuie.-ini aaibi данных.
463
Предметный указатель | 809
FIRST VALUE, функция
(Oracle), 692
FLOAT, тип данных
DB2, 54
MySQL, 57
Oracle, 60
SQL Server, 67, 67
сравнение платформ, 51
FLOAT, функция
DB2, 664
PostgreSQL, 716
FLOAT4, тип данных
PostgrcSQL, 63
сравнение платформ, 51
FLOAT4, функция (Postgr-
eSQL), 716
FLOATS, тип данных
PostgreSQL, 63
сравнение платформ, 51
FLOOR, функция, 647
FOREIGN KEY, ограничения,
72-7S
CASCADE, ключевое слово, 74
FOREIGN KEY, ключевое
слово, 73
MATCH, ключевое слово, 73
NO ACTION,
ключевое слово, 74
ON DELETE,
ключевое слово, 74
ON UPDATE,
ключевое слово, 74
REFERENCES,
ключевое слово, 73
RESTRICT,
ключевое слово, 74
SET DEFAULT,
ключевое слово, 75
SET NULL,
ключевое слово, 74
FORMAT, функция
(MySQL), 679
FORMATMESSAGE,
функция, 781
SQL Server, 727
FREETEXT, функция
(SQL Server), 727
FREETEXTTABLE, функция,
781
FROM, предложение, 26
FROM DAYS, функция
(MySQL), 679
FROM TZ, функция
(Oracle), 692
FROM UNIXTIME, функция
(MySQL), 679
FULL [OUTER] JOIN, 431
FULLTEXTCATALOGPROP-
ERTY, функция, 780
FULLTEXTSERVICEPROP-
ERTY, функция, 780
G
GENERATE_UN1QUE( ),
функция (DB2), 664
GET DIAGNOSTIC,
инструкция, 89
Get, методы
(ADO.NET DataReader), 752
Get, методы
(JDBC ResultSet), 755
GET LOCK, функция
(MySQL), 679
GETANSINULL, функция, 781
GETDATE( ), функция
(SQL Server), 727
GETH1NT, функция (DB2), 664
GETUTCDATE( ), функция
GETUTCDATE(), функция, 781
GRANT, инструкция, 373-403
DB2, 376-382
MySQL, 382-386
Oracle, 386-396
PostgreSQL, 396
SQL Server, 398-403
ключевые слова, 373
краткий справочник, 82
поддержка платформами, 373
правила, 375
Синтаксис SQL2003, 373
советы и хитрости
программирования, 376
GRAPHIC, тип данных
DB2, 54
сравнение платформ, 51
GRAPHIC, функция (DB2), 664
GREATEST, функция
MySQL, 679
Oracle, 692
GROUP BY, предложение, 490,
496-503
GROUP_1D( ), функция
(Oracle), 693
GROUPING, функция, 781
Oracle, 693
SQL Server, 727
GROUPING ID, функция
(Oracle), 693
H
HASHEDVALUE, функция
(DB2), 664
HAVING, предложение, 490
HEIGHT, функция
(PostgreSQL), 716
HEX, функция
DB2, 664
MySQL, 679
HEXTOINT, функция, 781
HEXTORAW, функция
(Oracle), 693
HOST, функция
(PostgreSQL), 716
HOST_ID( ), функция
(SQL Server), 728
HOST_NAME( ), функция
(SQL Server), 728
HOUR, функция
DB2, 664
MySQL, 679
I
IDENT CURRENT, функция, 781
SQL Server, 728
IDENT INCR, функция, 781
1DENT SEED, функция, 781
IDENTITY, функция, 781
IDENTITY_VAL_LOCAL( ),
функция (DB2), 665
IF, функция (MySQL), 680
IFNULL, функция (MySQL), 680
IMAGE, тип данных
SQL Server, 67
сравнение платформ, 51
IN, оператор,43, 403-404
ключевые слова, 403
краткий справочник, 82
поддержка платформами, 403
Синтаксис SQL2003, 403
INDEX_COL, функция
(SQL Server), 728
INDEXPROPERTY, функция, 782
SQL Server, 728
INET, тип данных
PostgreSQL, 63
сравнение платформ, 51
INIT.ORA, файл, 124
1NITCAP, функция
Oracle, 693
INITCAP, функция
(PostgreSQL), 716
INNER JOIN, 429
INSERT, инструкция, 405-419
DB2.409
MySQL, 410
Oracle, 411-416
PostgreSQL, 416
SQLServer, 417
и операторы, 33, 40
ключевые слова, 405
краткий справочник, 82
поддержка платформами, 405
правила, 406
Синтаксис SQL2003, 405
советы и хитрости
программирования, 408
INSERT, функция
DB2, 665
MySQL, 680
INSTR, функция
Oracle, 694
Int, параметрический объект-
ный тип (ADO.NET), 760
INT, тип данных
DB2, 55
MySQL, 57
SQL Server, 67
сравнение платформ, 51
INT2, тип данных
INT4, тип данных
INT8, тип данных
PostgreSQL, 63
INTEGER, тип данных
812 I Предметный указатель
PostgreSQL, 320
SQL Server, 321-325
ключевые слова, 314
краткий справочник, 81
поддержка платформами, 314
правила, 315-317:
Синтаксис SQL2003, 314
советы и хитрости
программирования, 317
DECODE, функция
MySQL, 677
Oracle, 690
DECOMPOSE, функция
(Oracle), 691
DECRYPT_B1N, функция
(DB2), 663
DECRYPT_CHAR, функция
(DB2), 663
DEGREES, функция
DB2, 663
MySQL, 678
PostgreSQL, 716
SQL Server, 726
DELETE, инструкция, 326-335
DB2, 328
MySQL, 328-330
Oracle, 330-332
PostgreSQL, 332
SQL Server, 333-335
и операторы 33, 40
ключевые слова, 326
краткий справочник, 81
поддержка платформами, 326
правила, 327
Синтаксис SQL2003, 326
советы и хитрости
программирования, 327
DE.NSE_RA.NK, функция, 603,
611,630
DEPTH, функция (Oracle), 691
DEREF, функция
DB2,663
Oracle, 691
DIAMETER, функция
(PostgreSQL), 716
DIFFERENCE, функция
DB2, 663
SQL Server, 726
DIGITS, функция (DB2), 663
DISCONNECT, инструкция,
335-337
DB2, 336
MySQL, 336
Oracle, 336
PostgreSQL, 337
SQL Server, 337
ключевые слова, 335
краткий справочник, 81
поддержка платформами, 335
правила, 336
Синтаксис SQL2003, 335
советы и хитрости
программирования, 336
DISKADMIN (SQL Server,
системная роль), 401
DOUBLE PRECISION, тип
данных
DB2, 54
MySQL, 57
Oracle, 60
PostgreSQL, 63
SQL Server, 67
сравнение платформ, 51
Double, параметрический объ-
ектный тип (ADO.NET), 760
DOUBLE, тип данных
DB2, 54
MySQL, 57
сравнение платформ, 51
DOUBLE, функция (DB2), 663
DROP DATABASE,
инструкция, краткий
справочник, 81
DROP DOMAIN, инструкция,
краткий справочник, 82
DROP INDEX, инструкция,
краткий справочник, 82
DROP METHOD, инструкция,
краткий справочник, 82
DROP ROLE, инструкция,
краткий справочник, 82
DROP TABLE, инструкция,
краткий справочник, 82
DROP TRIGGER, инструкция,
краткий справочник, 82
DROP TYPE, инструкция,
краткий справочник, 82
DROP VIEW, инструкция,
краткий справочник, 82
DROP, инструкции, 337-356
DB2, 339-343
MySQL, 342
Oracle, 344-351
PostgreSQL, 351-353
SQL Server, 353-356
ключевые слова, 337
краткий справочник, 82
поддержка платформами, 337
правила, 338
Синтаксис SQL2003, 337
советы и хитрости
программирования, 338
DROP, функция, инструкция,
краткий справочник, 82
DUMP, функция (Oracle), 691
Е
ELT, функция (MySQL), 678
EMPTY_BLOB( ), функция
(Oracle), 691
EMPTY_CLOB( ), функция
(Oracle), 691
ENCODE, функция
(MySQL), 678
ENCRYPT, функция
DB2.664
MySQL, 678
ENUM, тип данных
MySQL, 57
сравнение платформ, 51
EVENT_MON_STATE,
функция (DB2), 664
EXCEPT оператор для наборов
данных, 356-362
DB2, 359
MySQL, 360
Oracle, 360
PostgreSQL, 360
SQL Server, 361
ключевые слова, 357
краткий справочник, 82
поддержка платформами, 356 ,
правила, 357
Синтаксис SQL2003, 357
советы и хитрости
программирования, 358
EXECUTE, инструкция,
против инструкции CALL, 88
EXISTS, оператор, 43,362-363
краткий справочник, 82
поддержка платформами, 362
правила, 362
различия платформ, 363
Синтаксис SQL2003,362
советы и хитрости
программирования, 363
EXISTSNODE, функция
(Oracle), 691
EXP, функция, 643
EXPORT_SET, функция
(MySQL), 678
EXTRACT, функция, 643
Oracle, 691
EXTRACTVALUE, функция
(Oracle), 691
F
FETCH, инструкция, 364-372
DB2, 367
MySQL, 368
Oracle, 368
PostgreSQL, 370
SQL Server, 371
ключевые слова, 364
краткий справочник, 82
поддержка платформами, 364
правила, 365
Синтаксис SQL2003,364
советы и хитрости
программирования, 367
FIELD, функция (MySQL), 678
FILE_ID, функция, 780
SQL Server, 726
FILE_NAME, функция, 780
FILEGROUP ID, функция, 780
FILEGROUP JN АМЕ,
функции, 780~
FILEGROUPPROPERTY,
функция, 780
FILEPROPERTY, функция, 780
SQL Server, 727
FINDJN_SET, функция
(MySQL), 678
FIRST, функция (Oracle), 692
Предметный указатель | 811
LONGVARCHAR, функция
(DB2), 666
LONG_VARGRAPHIC,
функция (DB2), 666
LONGBLOB, тип данных
MySQL, 57
сравнение платформ, 52
LONGTEXT, тип данных
MySQL, 58
сравнение платформ, 52
LOWER, функция, 656
LPAD, функция
MySQL, 682
Oracle, 696
PostgreSQL, 717
LSEG, тип данных
PostgreSQL, 64
сравнение платформ, 52
LSEG, функция
(PostgreSQL), 717
LTRIM, функция
DB2, 666
MySQL, 682
Oracle, 696
PostgreSQL, 717
SQL Server, 729
м
MACADDR, тип данных
PostgreSQL, 64
сравнение платформ, 52
MAKE REF, функция
(Oracle), 696
MAKE SET, функция
(MySQL), 682
MASKLEN, функция (Postgr-
eSQL), 717
МАХ, функция, 603, 612
MD5, функция (MySQL), 682
MEDIAN, функция (Oracle), 696
MEDIUMBLOB, тип данных
MySQL, 58
сравнение платформ, 52
MEDIUMINT, тип данных
MySQL, 58
MEDIUMTEXT, тип данных
сравнение платформ, 52
MERGE, инструкция, 440-444
DB2, 443
MySQL, 443
Oracle, 443
PostgreSQL, 444
SQL Server, 444
ключевые слова, 441
краткий справочник, 82
поддержка платформами, 440
правила, 441
Синтаксис SQL2003, 441
советы и хитрости
программирования, 442
MICROSECOND, функция
(DB2), 666
Microsoft SQL Server, 10
Microsoft SQL Server,
ключевые слова, 800
MID, функция (MySQL), 686
MIDNIGHT_SECONDS,
функция (DB2), 666
MIN, функция, 603, 612
MINUTE, функция
DB2, 666
MySQL, 682
MOD, функция, 648
MONEY, тип данных
PostgreSQL, 64
SQL Server, 67
сравнение платформ, 52
MONTH, функция, 783
DB2, 666
MySQL, 682
SQL Server, 730
MONTHNAME, функция
DB2, 666
MySQL, 682
MONTHS_BETWEEN,
функция (Oracle), 696
MULTIPLY_ALT, функция
(DB2), 666
MUTEXCLROLES,
функция, 783
MySQL, 32
ALTER TABLE, синтаксис, 216
CALL, инструкция, 89
COMMIT, инструкция, 94
CREATE/ALTER DATABASE,
инструкции, 105
CREATE/ALTER INDEX,
инструкции, 171
CREATE/ALTER METHOD,
инструкции, 188
CREATE/ALTER ROLE,
инструкции, 190
CREATE/ALTER SCHEMA,
инструкции, 195
CREATE/ALTER TABLE
ключевые слова и
параметры, 216-222
CREATE/ALTER TABLE,
инструкции,215-222
ALTER COLUMN, 220
ALTER, 220
AUTOJNCREMENT, 218
AVG_ROW_LENGTH, 219
CHANGE, 220
CHECKSUM, 219
COMMENT, 219
DATA DIRECTORY, 220
DELAY_KEY_WRITE, 219
DROP, 221
ENABLE KEYS, 221
IF NOT EXISTS, 216
IGNORE
imcmpyKifwi SELECT, 220
INDEX DIRECTORY, 220
INSERT-METHOD, 220
MAXROWS, 219
MIN_ROWS, 219
MODIFY, 220
PACK KEYS, 219
PASSWORD, 219
RAID_CHUNKS, 220
RAIDJCHUNKSIZE, 220
RAID_TYPE, 219
RENAME, 221
REPLACE
инструкциЯ-SELECT, 220
ROW_FORMAT, 219
TEMPORARY, 216
TYPE, 217
ключевые слова, 216-222
параметры, 216-222
1тт_ограт1чения, 216
CREATE/ALTER TRIGGER,
инструкции, 271
CREATE/ALTER TYPE,
инструкции, 287
CREATE/ALTER VIEW,
инструкции, 306
CREATE/ALTER, FUNCTION/
PROCEDURE, инструкции, 154
DECLARE CURSOR,
команда, 319
DELETE, инструкция, 328-330
DISCONNECT, инструкция, 336
DROP, инструкции, 343
EXCEPT оператор для
наборов данных, 360
FETCH, инструкция, 368
допустимые символы
в идентификаторах, 36
начальный символ
идентификатора, 37
соединение с использованием
JDBC, 743
типы данных, 55-58
функции,673-687
АСОВ, 673
ADDDATE, 675
ASCII, 673
ASIN, 673
ATAN, 673
ATAN2, 674
BENCHMARK, 674
BIN, 674
BINARY, 674
В IT_AND, 674
BIT_COUNT, 674
BIT OR, 674
CHAR, 674
COALESCE, 674
COMPRESS, 674
CONCAT_WS, 675
CONNECTION_ID(), 675
CONV, 675
COS, 675
COT, 675
CURDATE(), 675
CURTIME0, 675
DATABASE!), 675
DATE_FORMAT, 675
DATE_ADD, 675
DATE_SUB, 675
DAYNAME, 677
DAYOFMONTH, 677
814 | Предметный указатель
DB2, 55
Oracle, 60
PostgreSQL, 63
сравнение платформ, 51
INTEGER, функция
DB2, 665
PostgreSQL, 716
INTERSECT, оператор для
наборов данных, 419-423
DB2.421
MySQL, 422
Oracle, 422
PostgreSQL, 423
SQL Server, 423
ключевые слова, 420
краткий справочник, 82
поддержка платформами, 419
правила, 420
Синтаксис SQL2003,419
советы и хитрости
программирования, 420
INTERVAL DAY ТО SECOND,
тип данных
сравнение платформ, 51
INTERVAL DAY, тяп данных
Oracle, 60
INTERVAL YEAR ТО
MONTH, тип данных
сравнение платформ, 51
INTERVAL YEAR, тип данных
Oracle, 60
INTERVAL, тип данных
PostgreSQL, 63
сравнение платформ, 51
INTERVAL, функция
MySQL, 680
PostgreSQL, 716
INTTOHEX, функция, 782
IS, оператор, 424-425
ключевые слова, 424
краткий справочник, 82
поддержка платформами, 424
правила, 424
Синтаксис SQL2003, 424
советы и хитрости
программирования, 424
IS_FREE_LOCK, функция
(MySQL), 680
ISMEMBER, функция, 782
SQL Server, 729
IS_SEC_SERVICE_ON,
функция, 782
IS_SRVROLEMEMBER,
функция, 782
ISCLOSED, функция
(PostgreSQL), 716
ISDATE, функция, 782
ISFINITE, функция
(PostgreSQL), 717
ISNULL, функция
MySQL, 680
SQL Server, 729
ISNUMERIC, функция, 782
ISOPEN, функция
(PostgreSQL), 717
ITERATIONJNUMBER,
функция (Oracle), 694
J
Java, виртуальная машина
(JVM), загрузчик классов, 743
JDBC
PreparedStatement, методы, 7'63
ResultSet, методы, 756
Get, 755
выполнение инструкций, 749
закрытие соединения, 744
запуск транзакций, 746
извлечение данных, 753-757
обработка ошибок, 765
откат транзакций, 748
пример программы для базы
данных, 768
связанные параметры, 761-764
соединение с базой данных,.
741-744
фиксация транзакций, 747
JDBC (Java Database
Connectivity), 736
JOIN, предложение, 489,492
JOIN, предложение, 82,425-435
DB2,432
MySQL, 433
Oracle, 433
PostgreSQL, 436
SQL Server, 435
ключевые слова, 425-427
поддержка платформами, 425
правила, 427-432
Синтаксис SQL2003,425
советы и хитрости
программирования, 432
типы,428-430
JULIAN_DAY, функция
(DB2), 665
L
LAG, функция (Oracle), 694
LAST, функция (Oracle), 694
LAST DAY, функция (Oracle),
695
LASTJNSERTJD, функция
(MySQL), 680
LAST_VALUE, функция (Ora-
cle), 695
LCASE, функция (MySQL), 681
lct_admln, функция, 782
LDAP (Lightweight Directory
Access Protocol)
на серверах DB2,105
LEAD, функция (Oracle), 695
LEAST, функция
MySQL, 681
Oracle, 695
LEFT [OUTER] JOIN, 430
LEFT, функция, 782
DB2, 665
MySQL, 681
SQL Server, 729
LEN, функция, 782
LENGTH, функция
DB2, 665
MySQL, 681
Oracle, 695
PostgreSQL, 717
LENGTHB, функции
(Oracle), 695
LICENSE_ENABLED,
функция, 783
LIKE, оператор, 43,436-440
DB2,438
MySQL, 438
Oracle, 438
PostgreSQL, 439
SQL Server, 440
ключевые слова, 436
краткий справочник, 82
поддержка платформами, 436
правила, 436
Синтаксис SQL2003,436
советы и хитрости
программирования, 437
LINE, тип данных
PostgreSQL, 64
сравнение платформ, 52
LN, функция, 647
LNNVL, функции (Oracle), 696
LOAD_F1LE, функция
(MySQL), 681
LOCALTIMESTAMP, функция
(Oracle), 696
ЁОСАТЕ(подстрока, строка,
позиции), 681
LOCATE, функция
DB2,665
MySQL, 681
LOG, функция
DB2,665
MySQL, 681
Oracle, 696
PostgreSQL, 717
SQL Server, 729
LOG10, функция
DB2,666
MySQL, 681
SQL Server, 729
LOG2, функция (MySQL), 681
LONG RAW, тнп данных
Oracle, 60
сравнение платформ, 52
LONG VARCHAR FOR BIT
DATA, тнп данных
DB2, 55
LONG VARCHAR, тип данных
сравнение платформ, 52
LONG VARGRAPHIC, тип
данных
DB2, 55
сравнение платформ, 52
LONG, тип данных
Oracle, 60
сравнение платформ, 52
Предметный указатель | 813
NCLOB, тип данных
Oracle, 60
сравнение платформ, 52
NETMASK, функция
(PostgreSQL), 717
NETWORK, функция
(PostgreSQL), 718
NEW TIME, функция
(Oracle), 697
NEWID(), функция, 783
SQL Server, 730
NEXT_DAY, функция
(Oracle), 697
NLS_CHARSET DECL_LEN,
функция (Oracle), 697
NLSCHARSETJD, функция
(Oracle), 698
NLSCHARSETNAME,
функция (Oracle), 698
NLS_INITCAP, функция
(Oracle), 698
NLSLOWER, функция
(Oracle), 698
NLS_UPPER, функция
(Oracle), 698
NLSSORT, функция (Oracle), 698
NOT, оператор, 43
NOW(), функция (MySQL),
682
NPOINTS, функция
(PostgreSQL), 718
NTEXT, тип данных
SQL Server, 67, 771
сравнение платформ, 52
NT1LE, функция (Oracle), 698
NULL, значения, 20
NULLIF, функция, 783
DB2, 666
MySQL, 682
Oracle, 698
PostgreSQL, 718
SQL Server, 730
NUM, тип данных
DB2, 55
NUMBER, тни данных
Oracle, 60
сравнение платформ, 52
NUMERIC, тип данных
DB2, 55
MySQL, 58
Oracle, 61
PostgreSQL, 63, 64
SQL Server, 67, 68
сравнение платформ, 52
NUMTODSINTERVAL, функция
(Oracle), 698
NUMTOYMINTERVAL, функ-
ция (Oracle), 699
NVARACHAR(), тип данных
(Sybase Adaptive Server), 771
NVARCHAR, тип данных
MySQL, 58
SQL Server, 69
сравнение платформ, 52
NVARCHAR2(), тип данных
NVARCHAR2, тип данных
Oracle, 61
NVL, функция (Oracle), 699
NVL2, функция (Oracle), 699
О
OBJECTID, функция
(SQL Server), 730
OBJECT NAME, функция
(SQL Server), 730
OBJECTPROPERTY,
функция, 783
SQL Server, 730
OCT, функция (MySQL), 683
OCTET LENGTH, функция, 640
OdbcConnection
атрибуты строки соединения,
741
OID, тип данных
PostgreSQL, 64
сравнение платформ, 52
OLAP, функции, 25
OleDbConnection
атрибуты строки соединения,
741
OPEN, инструкция, 444-448
DB2,446
MySQL, 447
Oracle, 447
PostgreSQL, 447
SQL Server, 447
ключевые слова, 444
краткий справочник, 82
поддержка платформами, 444
правила, 445
Синтаксис SQL2003, 444
советы и хитрости
программирования, 446
OPEN, функция, 783
SQL Server, 730
OPENDATASOURCE,
функция, 783
OPENQUERY, функция, 783
OPENROWSET, функция, 783
OPERATORS, краткий
справочник, 82
OR, оператор, 43
ORA_HASH, функция
(Oracle), 699
Oracle, 32
ALTER INDEX, синтаксис, 172
ALTER TABLE, инструкция, 255
ALTER TABLE, синтаксис, 224
CALL, инструкция, 89
COMMIT, инструкция, 95
CONNECT, инструкция, 98
CREATE INDEX, синтаксис, 171
CREATE/ALTER DATABASE,
инструкции, 106-126
ACTIVATE, 115
ADD LOGFILE, 119
ADD SUPPLEMENTAL LOG
DATA, 119
ALLOW, 121
ARCHIVELOG, ltd, 119
AUTOMATIC, 120
BACKUP CONTROLFILE
TO, 120
BEGIN BACKUP, 124
BIGFILE, 112
CANCEL, 122
CHARACTER SET, 110
CLEAR LOGFILE, 120
CONTINUE, 121
CONTROLFILE REUSE, 109
CREATE DATAFILE, 118
CREA ТЕ STANDB Y CON-
TROLFILE AS, 120
DATABASE, 121
DATAFILE, III, 118
DEFAULT TABLESPACE, 112
DEFAULT TEMPORARY
TABLESPACE, 112
ENABLE BLOCK CHANGE
TRACKING, 117
ENABLE THREAD, 117
EXTENT MANA GEMENT,
111, 113
FLASHBACK, 117
FOR, 115
FORCE LOGGING, 110, 119
GUARD, 117
LOGFILE, 109, 121
MANAGED STANDBY
DATABASE, 122
MAXDATAFILES, 110
MAXINSTANCES, 110
MAXLOGFILES, 110
MAXLOGHISTORY, 110
MAXLOGMEMBERS, 110
MOUNT, 114
NATIONAL CHARACTER
SET, 111
OPEN, 114
PARALLEL, 116
RECOVER, 120
REGISTER, 115
RENAME FILE, 119
RENAME GLOBAL_NAME
TO, 117
SET DEFAULT
TABLESPACE, 114
SET STANDBY, 115
SET TIME_ZONE, 114
SMALLFILE, 112
STANDBY, 121
START LOGICAL STANDBY
APPLY, 116
SYSAUXDATAFILE, 112
TABLESPACE, 121
TEST, 121
UNDO TABLESPACE, 113
UNTIL, 121
USER SYS IDENTIFIED BY,
109
USER SYSTEM IDENTI-
FIED BY, 109
CREATE/ALTER INDEX,
инструкции, 171-180
ALLOCATE EXTENT, 178
816 | Предметный указатель
DAYOFWEEK, 677
DAYOFYEAR, 677
DECODE, 677
DEGREES, 676
ELT, 676
ENCODE. 676
ENCRYPT. 678
EXPORT JET. 678
FIELD, 678 .
FIND JNJET, 678
FORMAT, 679
FROM JAYS, 679
FROMJJNIXTIME, 679
GET JOCK, 679
GREATEST. 679
HEX, 679
HOUR, 679
IF. 680
1FNULL, 680
INSERT, 680
INTERVAL. 680
ISJREE LOCK, 680
ISNULL, 680
LASTJNSERTJD, 680
LCASE, 681
LEAST. 681
LEFT, 681
LENGTH, 681
LOAD FILE, 681
LOCATE. 681
LOG, 681
LOG 10, 681
LOG2, 681
LPAD, 682
LTRIM. 682
MA KE JET, 682
MD5, 682
MID, 686
MINUTE. 682
MONTH. 682
MONTHNAME, 682
NOW(), 682
NULL1F. 682
OC T, 683
ORD. 683
PASSWORD, 683
PERIODADD, 683
PERIODD1FF, 683
Pl(), 683
POSITION. 681
POW, 683
POWER, 683
QUARTER, 683
RADIANS, 683
RAND( ), 684
RELEASE JOCK, 684
REPEAT, 684
REPLACE. 684
REVERSE, 684
RIGHT, 684
ROUND. 684
RPAD. 684
RTRIM, 684
SECJOJIME, '685
SECOND, 685
SESSIONJISER(), 687
SHA. 685
SHA1, 685
SIGN, 685
SIN. 685
SOUNDEX, 685
SPACE, 685
STD, 685
STDDEV, 685
STRCMP, 685
SUBDATE. 675
SUBSTRING, 686
SUBSTRINGJNDEX, 686
SYSDATE!), 682
SYSTEMJJSER(), 687
TAN, 686
TIME FORMAT, 686
TIMEJOJEC. 686
TO DAYS. 686
TRUNCATE. 686
UCASE, 686
UNCOMPRESS. 687
UN HEX, 687
UNIXJIMESTAMP. 687
USER(), 687
VERSION!), 687
WEEK, 687
WEEKDAY, 687
YEAR, 687
YEARWEEK. 688
GRANT, инструкция, 382-386
INSERT, инструкция, 410
INTERSECT оператор для
наборов данных, 422
JOIN, предложение, 433
LIKE, оператор, 438
MERGE, инструкция, 443
OPEN, инструкция, 447
ORDER BY, предложение, 451
RELEASE SAVEPOINT,
инструкция, 455
RETURN, инструкция, 457
REVOKE, инструкция, 467—471
ROLLBACK, инструкция, 480
savepoint, инструкция, 485
SELECT, инструкция, 507-511
IFOR UPDATE | LOCK IN
SHARE MODE), 509
FROM- USE INDEX, 508
HIGHJRJORITY, 508
IGNORE INDEX, 508
INTO, 509
JOIN, синтаксис, 510
LIMIT, 509
PROCEDURE, 509
SQL_BIG_RESULT, 508
SQLJUFFER RESULT, 508
SQL SMALLJESULT, 508
STRAIGHTJOIN. 508
отбираемый_элемент, 508
SET CONNECTION,
инструкция, 545
SET CONSTRAINT,
инструкция, 547
SET PATH, инструкция, 549
SET ROLE, инструкция, 551
SET SCHEMA, инструкция, 553
SET SESSION AUTHORIZA-
TION, инструкция, 555
SET TIME ZONE,
инструкция, 556
SET TRANSACTION,
инструкция, 560
SET, инструкция, 541
START TRANSACTION,
инструкция, 566
TRUNCATETABLE,
инструкция, 578
UNION оператор для наборов
данных, 582
UPDATE, инструкция, 590
web-сайт, 9
WHERE, предложение, 600
адресация схемы, 38
зарезервированные идентифи-
каторы, 37
ключевые слова, 796
особые Правила, 38
подзапрос, инструкция, 575
размер идентификатора, 36
N
NANVL, функция (Oracle), 697
NATIONAL CHAR VARYING,
тип данных
Oracle, 60
SQL Server, 67
сравнение платформ, 52 '
NATIONAL CHAR, тип данных
Oracle, 60
SQL Server, 67
сравнение платформ, 52
NATIONAL CHARACTER
VARYING, тип данных
MySQL, 58
Oracle, 60
SQL Server, 67
сравнение платформ, 52
NATIONAL CHARACTER, тип
данных
Oracle, 60
SQL Server, 67
сравнение платформ, 52
NATIONAL TEXT, тип данных
SQL Server, 67
сравнение платформ, 52
NATURAL [INNER | {LEFT |
RIGHT}] OUTER! ] JOIN, 431
NCHAR VARYING, тип данных
Oracle, 60
сравнение платформ, 52
NCHAR(), тип данных
SQL Server, 771
Sybase adaptive server, 771
NCHAR, тип данных
MySQL, 58
Oracle, 60
SQL Server, 67
сравнение платформ, 52
NCHAR, функция, 783
Oracle, 697
SQL Server, 730
Предметный указатель | 815
учетные пользовательские
записи по умолчанию в базе
данных, 125
функции,688-713
A COS, 688
ADD_MONTHS, 688
ASCII, 688
ASCIISTR, 688
ASIN, 688
ATAN, 688
ATAN2, 688
BFILENAME, 689
BIN_TO_NUM, 689
BITAND, 689
CARDINALITY, 689
CHARTOROWID, 689
CHR, 689
COALESCE, 689
COLLECT, 689
COMPOSE, 689
CONCAT, 689
CONVERT, 689
CORRK, 690
COS, 690
COSH, 690
CV, 690
DBTIMEZONE, 690
DECODE, 690 '
DECOMPOSE, 691
DEPTH, 691
DEREF, 691
DUMP, 691
параметры_изменения_сек-
ционг1рования_индекса, 178
EMPTY_CLOB( ), 691
EXISTSNODE, 691
EXTRACT, 691
EXTRACTVALUE, 691
FIRST, 692
FIRST_VALUE, 692
FROM TZ, 692
GREATEST, 692
GROUP_ID( ), 693
GROUPING, 693
GROUPING_ID, 693
HEXTORAW, 693
INITCAP, 693
INSTR, 694
ITERATION-NUMBER, 694
LAG, 694
LAST, 694
LAST_DAY, 695
LAST_VALUE, 695
LEAD, 695
LEAST, 695
LENGTH, 695
LENGTHB, 695
LNNVL, 696
LOCALTIMESTAMP, 696
LOG, 696
LPAD, 696
LTRIM, 696
MAKE_REF, 696
MEDIAN, 696
MONTHS_BETWEEN, 696
NANVL, 697
NCHAR. 697
NEW-TIME, 697
NEXT_DAY, 697
NLS_CHA RSET_DECL_LEN,
697
NLS-CHARSETJD, 698
NLS_CHARSET_NAME, 698
NLSJNITCAP, 698
NLS-LOWER, 698
NLSUPPER, 698
NLSSORT, 698
NTILE, 698
NULLIF, 698
NUMTODSINTERVAL, 698
NUMTOYMINTERVAL, 699
NVL, 699
NVL2, 699
ORAHASH, 699
PATH, 700
POWERMULTISET, 700
PRESENTNNV, 700
PRESENTV, 700
PREVIOUS, 700
RATIO-TO REPORT, 700
RAWTOHEX, 700
REF, 701
REFTOHEX, 701
REGEXPINSTR, 701
REGEXP_REPLACE, 701
REG EXP-SUBSTR, 702
REMAINDER, 702
REPLACE, 702
ROUND, 702
ROWIDTOCHAR, 703
RPAD, 703
RTRIM, 703
SCN_TO_T!MESTAMP, 703
SESSIONTIMEZONE, 703
SET, 703
SIGN, 703
SIN, 704
SINH, 704
SOUNDEX, 704
STA TS-BINOMIA L_ TEST,
704
STDDEV, 704
STDDEV-SAMP, 704
STDEV-POP, 704
SUBSTR, 704
SUBSTRB, 705
SYS-CONNECT_BY_PA TH,
705
SYS-CONTEXT, 705
SYS-DBURIGEN, 705
SYS_EXTRACT_UTC, 705
SYS_GUID(), 705
SYS-TYPEID, 705
SYS-XMLAGG, 706
SYS-XMLGEN, 706
SYSDATE, 706
SYSTIMESTAMP, 706
TAN, 706
TANH, 706
TIMESTAMP-TO-SCN, 706
TO_BINARY_DOUBLE, 706
TO_BINARY_FLOAT, 707
TO_CHAR, 707
TO_CLOB, 709
TO_DATE, 709
TO-DSINTERVAL, 709
TO-LOB, 709
TO-MULTI_BYTE, 709
TO NCHAR, 709
TO-NCLOB, 709
TO-NUMBER, 710
TO_SINGLE_BYTE, 710
TO-TIMESTAMP, 710
TO_TIMESTAMP_TZ, 710
TO-YM1NTERVAL, 710
TRANSLATE, 710
TREAT, 711
TRUNC, 711
TZ-OFFSET, 711
UID, 711
UNISTR, 711
UPDATEXML, 711
USERENV, 712
VALUE, 712
VAR-POP, 712
VAR-SAMP, 712
VARIANCE, 712
VSIZE, 712
XMLAGG, 712-713
XMLCOLATTVAL, 713
XMLCONCAT, 713
XMLELEMENT, 713
XMLFOREST, 713
XMLSEQUENCE, 713
XMLTRANSFORM, 713
GRANT, инструкция, 386-396
IDENTIFIED BY, 389
ON, 389
TO, 389
объектнаЯ-Привилегия, 387
роль, 388
системнаЯ-Привилегия, 388
INIT.ORA, файл, 124
INSERT, инструкция, 411-416
ALL, 413
ELSE, 414
FIRST, 413
INSERT, 411
TABLE, 412
VALUES, 412
WHEN, 413
безусловная много-
табличная вставка, 414
имя_таблицы, 411
подзапрос, 412
условная многотабличная
вставка, 413
INTERSECT оператор для
наборов данных, 422
JOIN, предложение, 433
LIKE, оператор, 438
MERGE, инструкция, 443
OPEN, инструкция, 447
ORDER BY, предложение, 452
ORGANIZATION HEAP,
предложение, 251
RELEASE SAVEPOINT,
инструкция, 455
RETURN, инструкция, 457
REVOKE, инструкция, 471-474
818 | Предметный указатель
ASC, /72
BITMAP, 173
CLUSTER, 173
COALESCE, 177
COMPRESS, 176
DEALLOCATE UNUSED,
178
DESC, 173
ENABLE, 177
GLOBAL, 173
INDEXTYPE IS, 173
LOCAL. 174
LOGGING, 176
MONITORING USAGE, 177
NOSORT, 177
PARALLEL. 177
PARAMETERS, 178
RENAME TO, 177
REVERSE, 177
SHRINK SPACE, 179
TABLESPACE DEFAULT.
176
UNUSABLE, 177
UPDATE BLOCK REFER-
ENCES, 178
параметры ^перестройки,
178
физические _атрибуты, 175
CREATE/ALTER METHOD,
инструкции,188
CREATE/ALTER ROLE,
инструкции,190
CREATE/ALTER SCHEMA,
инструкции,195
CREATE/ALTER TABLE,
инструкции, 222-256
ADD -. 231
ADD PARTITION, 246
ALLOC A ТЕ EXTENT, 232
AS объектный_тип, 231
AS подзапрос, 231
CACHE, 239
CLUSTER, 227
COALESCE PARTITION, 246
COALESCE, 232
COMPRESS. 239
DEALLOCATE UNUSED,
232
DROP-, 232
DROP PARTITION, 247
ENABLE ROW MOVE-
MENT, 239
ENABLE TABLE LOCK, 233
EXCHANGE PARTITION,
249
GROUP. 226
LOGGING, 226
MERGE PARTITION, 248
MINIMIZE
RECORDS_PER_BLOCK,
233
MODIFY-, 231
MODIFY DEFAULT
ATTRIBUTES, 244
MODIFY PARTITION, 244
MODIFY SUBPARTITION,
246
MONITORING, 239
MOVE-, 233
MOVE PARTITION, 246
OBJECT IDENTIFIER IS,
231
OF XMLTYPE. 231
OIDINDEX, 231
ON COMMIT, 226
ORGANIZATION EXTER-
NAL. 228
ORGANIZATION HEAP, 227
ORGANIZATION INDEX,
227
PARALLEL, 239
PROJECT COLUMN, 233
RENAME -.232 •
RENAME PARTITION, 247
ROWDEPENDENCIES, 239
SET SUBPARTITION TEM-
PLATE, 244
SET UNUSED-, 232
SHRINK SPACE, 232
SPLIT PARTITION, 247
SUBSTITUTABLE AT ALL
LEVELS, 231
TABLESPACE, 226
TRUNCATE PARTITION. 247
UPGRADE INCLUDING
DATA, 233
xml_schema_spec, 231
XMLTYPE, 231
внешний ключ, ограничение,
256
встроенное_ссы-
лочное_ограничение, 231, 254
описание_секционирова-
ния_таблицы, 241
параметры, 226-234
параметры_обновле-
ния_индекса, 246
параметрЫ-ПодраЗде-
ла_в_разделе, 241
параметры-Секционирова-
ния, 230
параметры_таблич-
ных_ограничений, 226
параметры-физи-
ческих-атрибутов, 226
параметры хранения,
226, 242
параметры-Хране-
ния _раздела, 242
состояние-Ограничения, 254
табличное_ссылочное_огра
ничение, 231, 254
CREATE/ALTER TRIGGER,
инструкции, 271-274
CREATE/ALTER TYPE,
инструкции, 287-294
ADD, 292
AS OBJECT, 288
AS TABLE OF, 289
AS VARRAY, 289
AUTHID, 288
BODY, 292
CASCADE, 293
COMPILE, 292
CONVERT TO SUBSTITUT-
ABLE, 293
DEBUG, 292
DROP, 293
EXCEPTIONS INTO, 293
EXTERNAL NAME, 289
FORCE, 293
INCLUDING TABLE
DATA, 293
INVALIDATE, 293
MEMBER, 289
MODIFY ELEMENT
TYPE, 293
MODIFY LIMIT, 293
MODIFY, 293
OID, 288
OR REPLACE, 288
OVERRIDING, 292
REPLACE AS OBJECT, 292
REUSE SETTINGS, 292
SPECIFICATION, 292
STATIC, 289
UNDER. 288
директивы-Компилятора,
292
тип данных, 289
CREATE/ALTER VIEW,
инструкции, 306-310
DECLARE CURSOR,
команда, 320
DELETE, инструкция, 330-332
DISCONNECT, инструкция, 336
DROP, инструкции, 344-351
[PUBLIC] DATABASE.
LINK, 345
[PUBLIC] SYNONYM;-348
CLUSTER, 344
CONTEXT. 344
DATABASE, 345
DIMENSION, 345
DIRECTORY, 345
FUNCTION, 345
INDEX, 345
INDEXTYPE, 346
JAVA, 346
LIBRARY, 346
MATERIALIZED VIEW, 346
OPERATOR, 347
OUTLINE, 347
PACKAGE, 347
PROCEDURE, 347
PROFILE, 347
ROLE, 348
ROLLBACK SEGMENT, 348
SEQUENCE, 348
SNAPSHOT, 346
TABLE, 348
TABLESPACE, 349
TRIGGER, 350
TYPE, 350
USER, 350 .
VIEW, 350
EXCEPT оператор для
наборов данных, 360
FETCH, инструкция, 368
типы данных, 59-62
52 - 2447
Предметный указатель | 817
зарезервированные идентифи-
каторы, 37
индекс-таблицы (ЮТ), 179-181
индексы,179
ключевые слова, 799
объектные таблицы, 255
основные базы данных, 124
параметры_физических_агрибу
тов, 234
размер идентификатора, 36
секционирование локального
индекса, 174
таблицы, разбитые на разделы
и подразделы, 238-243
изменение, 243-25!
CREATE/ALTER, FUNC-
TION/PROCEDURE,
инструкции, 154-158
AGGREGATE, 155
ALTER, 156
AS, 156
AUTHID. 155
COMPILE, 156
CREATE, 155
IN, 155
IS, 156
LANGUAGE, 156
NOCOPY, 155
OUT, 155
PARALLEL_ENABLE, 155
PIPELINED, 156
блок_кода, 156
допустимые символы в иден-
тификаторах, 36
изменение секционированной
таблицы,249
начальный символ идентифи-
катора, 37
ограничение столбца, 226
основные понятия, 124-126
сжатые таблицы, 238
соединение с использованием
JDBC, 743
Oracle, ключевые слова, 798
ORD, функция (MySQL), 683
ORDER BY, предложение,
448-453, 491, 628
DB2.450
MySQL, 451
Oracle, 452
PostgreSQL, 452
SQL Server, 453
ключевые слова, 448
краткий справочник, 82
поддержка платформами, 447
правила, 449
Синтаксис SQL2003, 448
советы и хитрости
программирования, 450
ORGANIZATION HEAP,
предложение (Oracle), 251
OVERLAY, функция, 657
Р
PARSENAME, функция, 783
SQL Server, 731
PASSWORD, функция
(MySQL), 683
PATH, тип данных
PostgreSQL, 64
сравнение платформ, 52
PATH, функция
Oracle, 700
PostgreSQL, 718
PATINDEX, функция, 784
SQL Server, 731
PCLOSE, функция
(PostgreSQL), 718
PERCENT RANK, функция,
603,613,632
PERCENTILE-CONT, функция,
603,615
PERCENTILE DISC, функция,
603,616
PERIOD_ADD, функция
(MySQL), 683
PER1OD DIFF, функция
(MySQL), 683
PERMISSIONS, функция, 784
PI( ), функция
PI(), функция
MySQL, 683
PostgreSQL, 718
PL/pgSQL, 31
PL/SQL, 30
POINT, тип данных
PostgreSQL, 64
сравнение платформ, 52
POINT, функция
(PostgreSQL), 718
POLYGON, тип данных
PostgreSQL, 65
сравнение платформ, 52
POLYGON, функция
(PostgreSQL), 718
POPEN, функция
(PostgreSQL), 719
POSITION, функция, 648
MySQL, 681
POSSTR, функция (DB2), 667
PostgreSQL ключевые слова,
799
PostgreSQL, 33
CLOSE CURSOR,
инструкция, 90
COMMIT, инструкция, 95
CONNECT, инструкция, 99
CREATE/ALTER DATABASE,
инструкции,126-127
CREATE/ALTER INDEX,
инструкции, 181
CREATE/ALTER METHOD,
инструкции, 188
CREATE/ALTER ROLE,
инструкции, 192
CREATE/ALTER SCHEMA,
инструкции, 196
CREATE/ALTER TABLE,
инструкции,256-259
CREATE/ALTER TRIGGER,
инструкции, 275
CREATE/ALTER TYPE,
инструкции, 295-297
CREATE/ALTER VIEW,
инструкции,310
CREATE/ALTER, FUNCTION/
PROCEDURE, инструкции. 158
DECLARE CURSOR,
команда, 320
DELETE, инструкция, 332
DISCONNECT,
инструкция, 336
DROP, инструкции, 351-353
[PROCEDURAL]
LANGUAGE, 352
A GG EG ATE, 351
DATABASE, 351
FUNCTION, 351
GROUP, 351
INDEX, 352
OPERATOR, 352
RULE. 352
SEQUENCE, 352
TABLE. 352
TRIGGER, 352
TYPE, 353
USER, 353
VIEW, 353
EXCEPT оператор для
наборов данных, 360
FETCH, инструкция, 370
GRANT, инструкция, 396
INSERT, инструкция, 417
INTERSECT оператор для
наборов данных, 423
JOIN, предложение, 435
LIKE, оператор, 439
MERGE, инструкция, 444
OPEN, инструкция, 447
ORDER BY, предложение, 452
RELEASE SAVEPOINT,
инструкция, 455
RETURN, инструкция, 458
REVOKE, инструкция, 474 475
ROLLBACK, инструкция, 482
SAVEPOINT, инструкция, 485
SELECT, инструкция, 527-531
[CROSS] JOIN, 530
ALL, 527
AS. 527
FOR UPDATE OF. 529
FROM. 528
FULL [OUTER] JOIN, 531
GROUP BY, 528
INNER JOIN, 530
INTO, 528
LEFT [OUTER] JOIN, 530
NATURAL, 530
ON, 531
ORDER BY, 528
RIGHT [OUTER] JOIN, 530
отбираемый_элемент, 527
SET CONNECTION,
инструкция, 545
SET CONSTRAINT,
инструкция, 548
SET PATH, инструкция, 549
820 | Предметный указатель
ROLLBACK, инструкция, 481
SAVEPOINT, инструкция, 485
SELECT, инструкция, 511-527
[CROSS/ JOIN, 518
ALL, 512
AS. 513
DISTINCT, 512
FOR UPDATE, 515
EROM, 513
PULL [OUTER] JOIN, 519
INNER JOIN. 518
INTO, 513
JOIN. 514
LEET [OUTER] JOIN, 518
MODEL, предложение, 522
NATURAL, 518
ON, 519
ORDER SIBLINGS BY, 515
PARTITION BY, 514
PARTITION, 514
SAMPLE, 514
SUBPARTITION, 514
TABLE, 514
UNIQUE, 512
USING, 519
VERSIONS BETWEEN, 513
WHERE 515
WITH имя_запроса AS, 512
отбираемый_элемент, 513
подзапрос, 513
секционированные внешние
соединения, 520
SET CONNECTION,
инструкция, 545
SET CONSTRAINT,
инструкция, 547
SET PATH, инструкция, 549
SET ROLE, инструкция, 551
SET SCHEMA, инструкция, 553
SET SESSION AUTHORIZA-
TION, инструкция, 555
SET TIME ZONE,
инструкция, 556
SET TRANSACTION,
инструкция, 562
SET, инструкция, 542
START TRANSACTION,
инструкция, 567
TRUNCATE TABLE
особые правила, 38
параметрыхранения и LOB,
235
подзапрос, 575
резервные базы данных, 124
синтаксис для изменения
существующей базы данных,
107-108
синтаксис для создания новой
базы данных, 106
синтаксис объектной
таблицы, 223
синтаксис таблицы ХМЫУре,
224
системные привилегии; 391-396
{ALTER | DROP) ANY
ROLE, 393
{CREAТЕ | ALTER | DROP |
EXECUTE] ANY PROCE-
DURE, 393
{CREATE | ALTER | DROP |
SELECT] ANY SEQUENCE,
393
{CREATE | ALTER | DROP]
ANY CLUSTER. 391
{CREATE | ALTER | DROP]
ANY DIMENSION, 391
{CREATE | ALTER | DROP]
ANY INDEX, 392
{CREATE | ALTER | DROP]
ANY MATERIALIZED VIEW,
392
{CREATE | ALTER | DROP]
ANY SNAPSHOT, 393
{CREATE ] ALTER | DROP]
ANY TYPE. 394
{CREATE | ALTER | DROP]
PROFILE, 393
{CREATE | ALTER | DROP]
ROLLBACK SEGMENT, 393
{CREATE | ALTER | DROP]
TABLESPACE, 394
{CREATE | DROP | ALTER]
ANY OUTLINE. 392
{CREA ТЕ | DROP | EXECUTE
} ANY INDEXTYPE, 391
{CREATE | DROP | EXE-
CUTE) ANY OPERATOR, 392
{CREATE | DROP ] ANY
DIRECTORY, 391
{CREATE | DROP] ANY
CONTEXT, 391
{CREATE j DROP] ANY
LIBRARY, 392
{CREATE | DROP] ANY
SYNONYM, 393
{CREATE | DROP) ANY
TRIGGER, 394
{CREATE | DROP] ANY
VIEW. 395
{CREATE | DROP] PUBLIC
SYNONYM. 393
ADMINISTER DATABASE
TRIGGER. 394
ALTER ANY TABLE, 393
ALTER ANY TRIGGER, 394
ALTER DATABASE, 391
ALTER RESOURCE
COST, 393
ALTER SESSION, 393
ALTER SYSTEM, 391
ALTER USER, 395
ANALYZE ANY, 395
AUDIT ANY, 395
AUDIT SYSTEM, 391
BACKUP ANY TABLE, 393
BECOME USER, 395
COMMENT ANY TABLE, 395
CREATE ANY TABLE, 393
CREATE CLUSTER, 391
CREATE DATABASE
LINK, 391
CREATE DIMENSION. 391
CREATE INDEXTYPE, 391
CREA ТЕ MA TERIALIZED
VIEW, 392
CREATE OPERATOR, 392
CREATE PROCEDURE, 392
CREATE PUBLIC DATA-
BASE LINK, 391
CREATE ROLE, 391
CREATE SEQUENCE, 393
CREATE SESSION, 393
CREATE SNAPSHOT, 393
CREATE SYNONYM, 393
CREATE TRIGGER, 394
CREATE TYPE, 394
CREATE USER, 395
CREATE VIEW, 395
DEBUG ANY
PROCEDURE, 391
DEBUG CONNECT
SESSION, 391
DELETE ANY TABLE, 394
DROP ANY TABLE. 394
DROP PUBLIC DA TABASE
LINK, 391
DROP USER. 395
EXECUTE ANY TYPE. 395
EXEMPT ACCESS
POLICY, 396
FLASHBACK ANY TABLE, 392
FORCE ANY
TRANSACTION, 396
FORCE TRANSACTION, 396
GLOBAL QUER YREWRITE.
392
GRANT ANY OBJECT
PRIVILEGE. 396
GRANT ANY PRIVILEGE. 396
GRANT ANY ROLE, 391
INSERT ANY TABLE. 394
LOCK ANY TABLE. 394
MANAGE TABLESPACE, 394
ON COMMIT REFRESH, 392
QUERY REWRITE,392
RESTRICTED SESSION, 393
RESUMABLE, 396
SELECT ANY
DICTIONARY, 396 '
SELECT ANY OUTLINE, 392
SELECT ANY TABLE, 394
SYSDBA, 396
SYSOPER, 396
UNDER ANY TYPE, 395
UNDER ANY VIEW, 395
UNLIMITED
TABLESPACE, 394
UPDATE ANY TABLE, 394
хранимая процедураз, 157
параметры _ретроспектив-
ного_запроса, 51,3
подсказка_оптимизатору,
512
ретроспект ивныен
запросы, 521
адресация схемы, 38
вложенные таблицы, 238
глобальная временная таб-
лица, 234
журнал, файлы, 124
Предметный указатель | 819
краткий справочник, 82
поддержка платформами, 453
правила, 454
Синтаксис SQL2003, 453
советы и хитрости
программирования, 455
RELEASE LOCK, функция
(MySQL), 684
RELTIME, функция
(PostgreSQL), 719
REMAINDER, функция
(Oracle), 702
REPEAT, функция
DB2, 668
MySQL, 684
RepeatableRead, уровень
изоляции (объект Transaction
(ADO.NET), 745
REPLACE, функция, 784
DB2, 668
MySQL, 684
Oracle, 702
SQL Server, 731
REPLICATE, функция
ResultSet, методы (JDBC), 756
Get, 755
RETURN, инструкция, 455-459
DB2, 465
MySQL, 457
Oracle, 457
PostgreSQL, 458
SQL Server, 458
ключевые слова, 465
краткий справочник, 82
поддержка платформами, 455
правила, 465
Синтаксис SQL2003, 465
советы и хитрости
программирования, 465
REVERSE, функция
MySQL, 684
SQL Server, 731
REVOKE, инструкция, 459-478
DB2, 463-469
MySQL, 467-471
Oracle, 471-474
PostgreSQL, 474-475
SQL Server, 475-478
ключевые слова, 460-462
краткий справочник, 82
поддержка платформами, 459
правила, 462
Синтаксис SQL2003, 460
советы и хитрости
программирования, 462
RIGHT [OUTER] JOIN, 430
RIGHT, функция
DB2, 668
MySQL, 684
SQL Server, 732
ROLE CONTAIN, функция, 784
ROLE ID, функция, 784
ROLE_NAME, функция, 784
ROLLBACK, инструкция,
478-483
DB2,480
MySQL, 480
Oracle, 481
PostgreSQL, 482
SQL Server, 482
ключевые слова, 479
краткий справочник, 82
поддержка платформами, 478
правила, 479
Синтаксис SQL2003, 478
советы и хитрости
программирования, 479
ROUND, функция
DB2, 668
MySQL, 684
Oracle, 702
PostgreSQL, 719
SQL Server, 732
ROW NUMBER, функция, 633
ROWCNT, функция, 784
ROWCOUNT_BIG( ),
функция, 784
ROWID, тип данных
Oracle, 61
сравнение платформ,52
ROWIDTOCHAR, функция
(Oracle), 703
ROWVERSION, тип данных
SQL Server, 68, 771
сравнение платформ, 52
RPAD, функция
MySQL, 684
Oracle, 703
PostgreSQL, 719
RTRIM, функция
DB2, 669
MySQL, 684
Oracle, 703
PostgreSQL, 719
SQL Server, 732
s
SAVEPOINT, инструкция,
483-486
DB2, 484
MySQL, 485
Oracle, 485
PostgreSQL, 486
SQL Server, 486
ключевые слова, 484
краткий справочник, 82
поддержка платформами, 483
правила, 484
Синтаксис SQL2003, 484
советы и хитрости
программирования, 484
SCN_TO_TIMESTAMP,
функция (Oracle), 703
SEC_TO_TIME, функция
(MySQL), 685
SECOND, функция
DB2, 669
MySQL, 685
SECURITYADMIN (SQL
Server, системная роль), 401
SELECT, инструкция, 486-539
DB2, 505-507
GROUP BY, предложение,
496-503
HAVING, предложение, 503
MySQL, 507-511
Oracle, 511-527
ORDER BY, предложение, 504
PostgreSQL, 527-531
SQLServer, 531-539
и операторы, 33,40
ключевые слова, 487-491
ALL, 487
AS, 488
DISTINCT. 487
FROM, 488
GROUP BY, 490
HAVING, 490
JOIN, 489
ORDER BY, 491
WHERE, 490
краткий справочник, 83
поддержка платформами,
486-487
правила, 491-504
примеры,23-24
Синтаксис SQL2003, 487
советы и хитрости
программирования, 504
SEQUEL (Structured English
Query Language), 15
SERIAL, тип данных
PostgreSQL, 65
сравнение платформ, 53
SER1AL4, тип данных
PostgreSQL, 65
сравнение платформ, 53
SERIAL8, тип данных
PostgreSQL, 65
сравнение платформ, 53
Serializable, уровень изоляции
(Объект Transaction
(ADO.NET), 745
SERVERADMIN (SQL Server,
системная роль), 401
SESSION_USER(), функция
(MySQL), 687
SESSION USER, функция, 785
SESSIONTIMEZONE, функция
(Oracle), 703
SET CATALOG, инструкция,
краткий справочник, 83
SET COLLATION,
инструкция, краткий
справочник, 83
SET CONNECTION,
инструкция,544-546
DB2, 545
MySQL, 545
Oracle, 545
PostgreSQL, 545
SQL Server, 545
ключевые слова, 544
краткий справочник, 83
описание, 544
822 | Предметный указатель
SET ROLE, инструкция, 552
SET SCHEMA, инструкция, 553
SET SESSION AUTHORIZA-
TION, инструкция, 555
SE T TIME ZONE,
инструкция, 557
SET TRANSACTION,
инструкция, 563
START TRANSACTION,
инструкция, 567
SUBQUERY, инструкция, 575
TRUNCATE TABLE,
инструкция, 579
UNION оператор для наборов
данных, 583
UPDATE, инструкция, 593
web-сайт, 10
WHERE, предложение, 600
SET, инструкция, 542
адресация схемы, 38
допустимые символы
в идентификаторах, 36
зарезервированные
идентификаторы, 37
ключевые слова, 799
начальный символ
идентификатора, 37
размер идентификатора, 36
соединение с использованием
JDBC, 743
типы данных, 62-65
функции,713 723
ABSTIME, 713
ACOS, 714
AGE. 714
AREA. 714
ASCII. 714
ASIN. 714
ATAN. 714
ATAN2, 714
BOX. 714
BROADCAST. 715
CBRT, 715
CENTER, 715
CHAR, 715
CHARLENGTH, 715
CIRCLE. 715
COALESCE, 715
COS, 715
COT, 690, 716
DATE PART, 716
DATE TRUNC, 716
DEGREES, 716
DIAMETER. 716
FLOAT, 716
FLOAT4, 716
HEIGHT, 716
HOST, 716
1NITCAP, 716
INTEGER, 716
INTERVAL, 716
ISCI.OSED, 716
1SF1NITE, 717
ISOPEN, 717
LENGTH, 717
LOG. 717
LPAD, 717
LSEG. 717
LTR1M, 717
MASKLEN. 717
NETMASK. 717
NETWORK. 718
NPOINTS, 718
NULLIF, 718
PATH. 718
PCLOSE, 718
PI(). 718
POINT, 718
POLYGON. 718
POPEN, 719
POW, 719
RADIANS, 719
RADIUS, 719
RELTIME, 719
ROUND. 719
RPAD. 719
RTRIM, 719
SETJ4ASKLEN, 720
SIN, 720
SUBSTR, 720
SUBSTRING. 720
TAN. 720
TEXT, 720
TIMESTAMP. 720
TO_CHAR, 720
TO_DATE, 720
TOJNUMBER, 722
TO-TIMESTAMP, 722
TRANSLATE, 722
TRUNC, 723
VARCHAR, 723
WIDTH. 723
POW, функция
MySQL, 683
PostgreSQL, 719
POWER, функция, 649
MySQL, 683
POWERMULTISET, функция
(Oracle), 700
PreparedStatement, методы
(JDBC), 763
PRESENTNNV, функция
(Oracle), 700
PRESENTV, функция
(Oracle), 700
PREVIOUS, функция
(Oracle), 700
PRIMARY KEY, ограничения, 71
PROC ROLE, функция, 784
PROCEDURE, краткий
справочник, 82
PROCESSADMIN (SQL Server,
системная роль), 401
Q
QUARTER, функция
DB2, 667
MySQL, 683
R
RADIANS, функция
DB2, 667
MySQL, 683
PostgreSQL, 719
SQL Server, 731
RADIUS, функция
(PostgreSQL), 719
RAISE_ERROR, функция
(DB2), 667
RAND(), функция (MySQL), 684
RAND, функция
DB2, 667
SQLServer, 731
RANK( ), функция, 631
RANK, функция, 603, 617 ,
RATIO_TO_REPORT, функция
(Oracle), 700
RAW, тип данных
Oracle, 61
сравнение платформ, 52
RAWTOHEX, функция
(Oracle), 700
ReadCommltted, уровень изо-
ляции (объект Transaction
(ADO.NET), 745
ReadUncommitted, уровень
изоляции (объект Transaction
(ADO.NET), 745
REAL, тип данных
DB2.55
MySQL, 58
Oracle, 61
PostgreSQL, 63
SQL Server, 68
сравнение платформ, 52 ,
REAL, функция (j>B2), 667
REC2XML, функция (DB2), 667
REF, функция (Oracle), 701
REFTOHEX, функция
(Oracle), 701
REGEXPJNSTR, функция
(Oracle), 701
REGEXP_REPLACE, функции
(Oracle), 701
REGEXP_SUBSTR, функция
(Oracle), 702
REGR семейство функций, 618
REGR AVGX, функция, 603,618
REGR_AVGY, функция, 603,618
REGR COUNT, функции,
603,618
REGR INTERCEPT, функция,
603, 618
REGR R2, функция, 603, 618
REGR~SLOPE, функция,
603,618
REGR_SXX, функция, 604, 619
REGR SXY, функция, 604, 619
REGRZSYY, функция, 604,619
RELEASE SAVEPOINT,
инструкция, 453-455
DB2,455
MySQL, 455
Oracle, 455
PostgreSQL, 455
SQL Server, 455
ключевые слова, 453
Предметный указатель | 821
AUTO_CLOSE, 134
A UTO_CREATE_STATISTICS,
134
AUTO_SHRINK, 135
A UTO_UPDATE_STATISTICS,
135
COLLATE, 131
CONCA T_NULL_YIELDS_NU
LL, 136
CURSOR_CLOSE_ON_COM
MIT, 134
CURSOR_DEFAULT, 134
FOR LOAD, 131
MODIFY FILE, 130
MODIFY FILEGROUP, 130
MODIFY NAME, 130
MULTI,JUSER, 134
NUMERICROUNDABORT,
136
OFFLINE, 134
ON определение _файла, 128
QUOTED-IDENTIFIER, 136
READ-ONLY, 134
RECOVERY, 136
RECURSIVE-TRIGGERS, 136
REMOVE FILE, 129
REMOVE FILEGROUP, 130
RESTRICTED-USER, 134
SET, 130
SINGLE_USER, 134
TORN_PA GE-DETECTION,
136
WITH, 130
аето_опция, 134
onyuu_sql, предложение, 135
CREATE/ALTER INDEX,
инструкции, 182-185
ASC, 183
CLUSTERED, 183
DESC, 183
DROP-EXISTING, 183
FILLFACTOR, 183
IGNORE-DUP-KEY, 183
ON, 184
PAD_INDEX, 183
SORTJN-TEMPDB, 184
STATISTICS-NORECOMPU
ТЕ, 184
WITH, 183
CREATE/ALTER METHOD,
инструкции, 188
CREATE/ALTER ROLE,
инструкции, 192
CREATE/ALTER SCHEMA,
инструкции, 196
CREATE/ALTER TABLE,
инструкции, 259-264
CHECK CONSTRAINT, 262
CHECK, 261
COLLATE, 262
DEFAULT, 260
ENABLE TRIGGER, 262
FOREIGN KEY, 261
IDENTITY, 260
NOT FOR REPLICATION,
260
PRIMARY KEY, 260
ROWGUIDCOL, 260
TEXTIMAGE_ON, 262
WITH CHECK, 262
CREATE/ALTER TRIGGER,
инструкции, 264-280
CREATE/ALTER TYPE,
инструкции, 297
CREATE/ALTER VIEW,
инструкции, 310-313
CREATE/ALTER, FUNCTION/
PROCEDURE, инструкции,
137-165
@параметр тип данных, 160
CREATE, 160
ENCRYPTION, 161
FOR REPLICATION, 161
RECOMPILE, 161
RETURNS, 161
SCHEMABINDING, 161
WITH, 161
DATETIME, тип данных, 770
DECLARE CURSOR, команда,
321-325
D YNAMIC, 322
FAST_FORWARD, 322
FOR UPDATE, 324
FOR, 324
FORWARD_ONLY, 322
GLOBAL, 322
INSENSITIVE, 322
KEYSET, 323
LOCAL, 322
OPTIMISTIC, 323
READ-ONLY, 323
SCROLL, 322
SCROLL-LOCKS, 323
STATIC ???
TYPE_WARNING, 324
расширенный синтаксис
Transact-SQL, 324
совместимость c SQL-92,
синтаксис, 324
DELETE, инструкция, 333-335
допустимые символы в идеи-
тификаторах, 36
начальный символ идентифи-
катора, 37
ограничители и операторы, 45
основные понятия, 131-134
соединение с использованием
JDBC, 744
типы данных, 66-69
в сравнении с Sybase adap-
tive server, 770-771
DISCONNECT, инструкция, 336
DROP, инструкции, 353-356
DATABASE, 353
DEFAULT, 354
FUNCTION, 354
INDEX, 354
PROCEDURE, 354
RULE, 354
STATISTICS, 355
TABLE, 355
TRIGGER, 356
TYPE, 356
VIEW, 356
EXCEPT оператор для
наборов данных, 362
FETCH, инструкция, 371
GRANT, инструкция, 398-403
INSERT, инструкция, 417
INTERSECT оператор для
наборов данных, 423
JOIN, предложение, 435
LIKE, оператор, 440
MERGE, инструкция, 444
NCHAR(), тип данных, 771
NTEXT, тип данных, 771
OPEN, инструкция, 447
ORDER BY, предложение, 453
RELEASE SAVEPOINT,
инструкция, 455
RETURN, инструкция, 458
REVOKE, инструкция, 475-478
ROLLBACK, инструкция, 482
ROWVERSION,
тип данных, 771
SAVEPOINT, инструкция, 486
SELECT, инструкция, 531-539
COMPUTE, предложение, 536
FOR, 534
FROM, 532
GROUP BY, 533
INTO, 531
OPTION, 535
ORDER BY, 534
TOP, 531
SET CONNECTION,
инструкция, 545
SET CONSTRAINT,
инструкция, 548
SET PATH, инструкция, 549
SET ROLE, инструкция, 552
SET SCHEMA,
инструкция, 554
SET SESSION AUTHORIZA-
TION, инструкция, 556
SET TIME ZONE,
инструкция, 558
SET TRANSACTION,
инструкция, 564
SET, инструкция, 543
SMALLDATETIME, тип
данных, 771
SQL_VARIANT, тип
данных, 771
START TRANSACTION,
инструкция, 568
SUBQUERY
подинструкция, 575
TRUNCATE TABLE,
инструкция, 579
UNION оператор для наборов
данных, 583
UNIQUEIDENTIFIER, тип
данных, 771
UPDATE, инструкция, 594-596
VARB1NARY(), тип
данных, 771
VARCHAR(), тип данных, 771
web-сайт, 10
824 | Предметный указатель
поддержка платформами, 544
правила, 544
Синтаксис SQL2003, 544
советы и хитрости
программирования, 545 .
SET CONSTRAINT,
инструкция,546-548
DB2, 547
MySQL, 547
Oracle, 547
PostgreSQL, 548
SQL Server, 548
ключевые слова, 547
краткий справочник, 83
поддержка платформами, 546
правила, 547
Синтаксис SQL2003, 547
советы и хитрости
программирования, 547
SET DESCRIPTOR,
инструкция, краткий
справочник, 83
SET PATH, инструкция, 548-550
DB2, 549
MySQL, 549
Oracle, 549
PostgreSQL, 549
SQL Server, 549
ключевые слова, 548
поддержка платформами, 548
правила, 548
Синтаксис SQL2003, 548
советы и хитрости
программирования, 549
SET ROLE, инструкция, 550-552
DB2, 550
MySQL, 551
Oracle, 551
PostgreSQL, 552
SQL Server, 552
ключевые слова, 550
поддержка платформами, 550
правила, 550
Синтаксис SQL2003, 550
советы и хитрости
программирования, 550 ,
SET SCHEMA, инструкция,
552-553
DB2, 553
MySQL, 553
Oracle, 553
PostgreSQL, 553 .
SQL Server, 554
ключевые слова, 552
поддержка платформами, 552
правила, 553
Синтаксис SQL2003, 552
советы и хитрости
программирования, 553
SET SESSION AUTHORIZA-
TION, инструкция, 554-555
DB2, 555
MySQL, 555
Oracle, 555
PostgreSQL, 555
SQL Server, 555
ключевые слова, 554
поддержка платформами, 554
правила, 554
Синтаксис SQL2003, 554
советы и хитрости
программирования, 554
SET TIME ZONE, инструкция,
555-558
DB2, 556
MySQL, 556
Oracle, 556
PostgreSQL, 557
SQL Server, 558
ключевые слова, 556
поддержка платформами, 555
правила, 556
Синтаксис SQL2003,556
советы и хитрости
программирования, 556
SET TRANSACTION,
инструкция, 558-564
DB2, 560
ключевые слова, 558
MySQL, 561
Oracle, 562
PostgreSQL, 563
SQL Server, 564
поддержка платформами, 558
правила, 559
Синтаксис SQL2003, 558
советы и хитрости
программирования, 560
SET, инструкция, 539-544
DB2, 540
MySQL, 541
Oracle, 542
PostgreSQL, 542
SQL Server, 543
ключевые слова, 540
краткий справочник, 83
поддержка платформами, 539
правила, 540
Синтаксис SQL2OO3,540
советы и хитрости
программирования, 540
set, методы
(JDBC PreparedStatement), 763
SET, тип данных
MySQL, 58
сравнение платформ, 53
SET, функции (Oracle), 703
SET_MASKLEN, функция
(PostgreSQL), 720
SETUPADMIN (SQL Server,
системная роль), 401
SHA, функция (MySQL), 685
SHA1, функция (MySQL), 685
SHOW_ROLE( ), функция, 785
SHOW_SEC_SERVICES( ),
функция, 785
SIGN, функция
DB2, 669
MySQL, 685
Oracle, 703
SQL Server, 732
SIN, функция
DB2,669
MySQL, 685
Oracle, 704
PostgreSQL, 720
SQL Server, 732
Single, параметрический
объектный тип
SINH, функция
DB2,669
Oracle, 704
SMALLDATETIME, тип данных
SQL Server, 68,771
Sybase adaptive server, 771
сравнение платформ, 53
SMALLINT, тип данных
DB2,55
MySQL, 58
Oracle, 61
PostgreSQL, 63
SQL Server, 68
сравнение платформ, 53
SMALLINT, функция
(DB2), 669
SMALLMONEY, тип данных
SQL Server, 68
сравнение платформ, 53
SOME, оператор, 43,83-84
ключевые слова, 84
краткий справочник, 81
поддержка платформами, 83
правила, 84
различия платформ, 85
Синтаксис SQL2003, 83
советы и хитрости
программирования, 85
SORTKEY, функция, 785
SOUNDEX, функция
DB2.669
MySQL, 685
Oracle, 704
SQL Server, 732 .
SPACE, функция
DB2, 669
MySQL, 685
SQL Server, 732
SQL Server, 33
BIGINT, тип данных, 770
BINARY, тип данных, 770
CALL, инструкция, 90
CHAR(), тип данных, 770
CLOSE CURSOR,,
инструкция, 90
COMMIT, инструкция, 95
CONNECT, инструкция, 99
CREATE/ALTER DATABASE,
инструкции, 127-137
ADD FILEGROUP, 129
ADD LOG, 129
ANSI NULL DEFAULT, 135
ANS1~NULLS,135
ANSI PADDING, 135.
ANSI~WARNINGS, 135
ARITHABORT, 135
Предметный указатель | 823
SQLPL, 15
SQRT, функция, 650
START TRANSACTION,
инструкция,565-569
DB2, 566
MySQL, 566
Oracle, 567
PostgreSQL, 567
SQL Server, 568
поддержка платформами, 565
правила, 565
Синтаксис SQL2003, 565
советы и хитрости
программирования, 566
STATSBINOMIALTEST,
функция (Oracle), 704
STATSJMTE, функция, 785
SQL Server, 732
STD, функция (MySQL), 685
STDDEV, функция
DB2, 669
MySQL, 685
Oracle, 704
STDDEV POP, функция, 604,620
STDDEV SAMP, функция, 604,
621
STDEV, функция, 785
SQL Server, 733
STDEV POP, функция (Ora-
cle), 704
STDEVP, функция, 785
STOP LOGICAL STANDBY
APPLY, 116
STR, функция (SQL Server), 733
STRCMP, функция
(MySQL), 685
String, параметрический объ-
ектный тип (ADO.NET), 760
StringFixedLength,
параметрический объектный
тип (ADO.NET), 760
STUFF, функция
(SQL Server), 733
SUBDATE, функция
(MySQL), 675
SUBQUERY подинструкция,
570-576
DB2, 575
MySQL, 576
Oracle, 576
PostgreSQL, 576
SQL Server, 576
ключевые слова, 571
поддержка платформами,
570,573
правила, 571
примеры,573
Синтаксис SQL2003, 570
советы и хитрости
программирования, 573
SUBSTR, функция
DB2, 669
Oracle, 704
PostgreSQL, 720
SUBSTRB, функция
(Oracle), 705
SUBSTRING, функция, 657
MySQL, 686
PostgreSQL, 720
SQL Server, 733
SUBSTRINGJNDEX, функ-
ция (MySQL), 686
SUM, функция, 604, 605
SUSER ID, функция, 785
SUSER NAME, функция, 785
SUSER SID, функция, 785
SUSER SNAME, функция, 785
SYB SENDMSG, функция, 786
Sybase Adaptive Server
BINARY, тип данных, 770
CHAR(), тип данных, 770
DATETIME, тип данных, 770
NCHAR(), тип данных, 771
NVARACHAR(),
тип данных, 771
SMALLDATETIME, тип дан-
ных, 771
SQL, инструкции, 772-778
TIMESTAMP, тип данных, 771
UNICHAR, тип данных, 771
UNIVARCHAR,
тип данных, 771
VARBINARY(),
тип данных, 771
VARCHAR(), тип данных, 771
и SQL Server, 771
функции, 778-787
инструкции, 772-778
ключевые слова, 787-788, 802
поддерживаемые функции, 779
типы данных, 770
сравнение с SQL Server,
770-771
Sybase Adaptive Server,
ключевые слова, 802
SYS_CONNECT_BY_PATH,
функция (Oracle), 705
SYS_CONTEXT, функция
(Oracle), 705
SYS DBURIGEN, функция
(Oracle), 705
SYS EXTRACT UTC, функция
(Oracle), 705
SYS_GUID(), функция
(Oracle), 705
SYS_TYPEID, функция
(Oracle), 705
SYS XMLAGG, функция
(Oracle), 706
SYS XMLGEN, функция
(Oracle), 706
SYSADMIN (SQL Server,
системная роль), 401
SYSDATE(), функция
(MySQL), 682
SYSDATE, функция (Oracle), 706
SYSTEM_USER(), функция
(MySQL), 687
SYSTEM USER, функция, 786
SYSTIMESTAMP, функция
(Oracle), 706
T
TABLE, тип данных
SQL Server, 69
сравнение платформ, 53
TABLE_NAME, функция
(DB2), 670
TABLE SCHEMA, функция
(DB2), 670
TABLESAMPLE,
предложение, 26
TAN, функция
DB2, 670
MySQL, 686
Oracle, 706
PostgreSQL, 720
SQL Server, 733
TANH, функция
DB2, 670
Oracle, 706
TEXT, тип данных
MySQL, 58
PostgreSQL, 65
SQL Server, 69
сравнение платформ, 53
TEXT, функция
(PostgreSQL), 720
TEXTPTR, функция (SQL
Server), 734
TEXTVALID, функция
(SQL Server), 734
TIME, тип данных
DB2, 55
PostgreSQL, 65
сравнение платформ, 53
TIME, функция (DB2), 670
TIME FORMAT, функция
(MySQL), 686
TIME TO SEC, функция
(MySQL), 686
TIMESPAN, тип данных
PostgreSQL, 65
сравнение платформ, 53
TIMESTAMP, тип данных
DB2, 55
Oracle, 61
PostgreSQL, 65
SQL Server, 69
Sybase adaptive server, 771
сравнение платформ, 53
TIMESTAMP, функция
DB2, 670
PostgreSQL, 720
TIMESTAMPFORMAT,
функция (DB2), 670
TIMESTAMPJSO, функция
(DB2), 671
TIMESTAMP_TO_SCN,
функция (Oracle), 706
TIMESTAMPDIFF, функция
(DB2), 671
826 | Предметный указатель
WHERE, предложение, 600
адресация в схемах, 38
вложенные триггеры, 278
зарезервированные
идентификаторы, 37
ключевые слова, 800
Пользовательские функции
(UDF), 162-164
против Sybase adaptive
server, 771
функции, 778- 787
размер идентификатора, 36
рекурсивные триггеры, 278
системные роли, 401-402
BULKADMIN, 401
DB_ACCESSADMIN, 402
DB_BA СК UPOP ERA TOR,
402
D В _D АТА READER. 402
DB DATA WRITER, 402
DBDDLADMIN, 402
DB_DEN YDA TA REA DER,
402
DB DENYDATAWRITER,
402
DBOWNER, 402
DB_SECURITYADM1N, 402
DBCREATOR, 401
DISKADMIN, 401
PROCESSADMIN, 401
SECURITYADMIN, 401
SERVERADMIN, 401
SETUPADMIN, 401
SYSADMIN, 401
функции,723-735
ACOS, 723
APP NAME. 723
ASCII, 723
ASIN, 723
ATAN, 723
ATN2, 723
BINARY-CHECKSUM, 723
CHAR. 724
CHARINDEX, 724
CHECKSUM, 724
CHECKSUM AGG, 724
COALESCE, 724
COL_LENGTH. 724
COL_NAME, 724
CONTAINS. 724
CONTAINSTABLE, 725
CONVERT, 725
COS, 725
COT, 725
DA TABASEPROPERTYEX,
725
DATA LENGTH, 725
DATE ADD. 725
DATED IFF, 725
DATENAME. 726
DATEPART. 726
DAY. 726
DBJD, 726
DB_NAME, 726
DEGREES. 726
DIFFERENCE, 726
FILEJD, 726
FILE_NAME. 726
FILEGROUP-ID, 726
FILEGROUPNAME, 726
FILEPROPERTY, 726
FORMATMESSAGE, 727
FREETEXT, 727
FREETEXTTABLE, 727
FULLTEXTCA TALOGPROP-
ERTY, 727
FULLTEXTSER VICEPROP-
ERTY, 727
GETANSINULL, 727
GETDATE( ), 727
GETUTCDATE( ), 727
GROUPING, 727
HOSTJD( ), 728
HOST_NAME( ), 728
IDENT-CURRENT, 728
IDENT1NCR, 728
IDENT-SEED, 728
IDENTITY, 728
INDEX-COL, 728
INDEXPROPERTY, 728
IS-MEMBER, 729
IS_SRVROLEMEMBER, 729
ISDATE, 729
1SNULL, 729
ISNUMERIC, 729
LEFT, 729
LEN, 729
LOG, 729
LOG10, 729
LTRIM, 729
MONTH, 730
NCHAR, 730
NEWID( ). 730
NULLIF, 730
OBJECTJD, 730
OBJECT_NAME, 730
OBJECTPROPERTY, 730
OPEN, 730
OPENDATASOURCE, 730
OPENQUERY, 730
OPENROWSET, 730
PARSENAME, 731
PATINDEX, 731
PERMISSIONS, 731
PI( ). 731
RADIANS. 731
RAND, 731
REPLACE, 731
REPLICATE, 731
REVERSE, 731
RIGHT. 732
ROUND, 732
ROWCOUNT_BIG, 732
RTRIM, 732
SIGN, 732
SIN, 732
SOUNDEX. 732
SPACE, 732
STATS-DATE, 732
STDEV, 733
STDEVP, 733
STR, 733
STUFF. 733
SUBSTRING, 733
SUSERJD, 733
SUSER-SID. 733
SUSER-SNAME, 733
TAN, 733
TEXTPTR, 734
TEXTVALID, 734
TYPEPROPERTY, 734
UNICODE, 734
USERJD, 734
USER_NAME, 735
VAR, 735
VARP, 735
YEAR, 735
хранимая (записанная)
процедура, 161-162, 164-'
165
SQL Standard, web-сайт, 10
SQL история и реализации,
15-31
SQL, диалекты, 30
SQL, справочник по командам,
краткий справочник, 81-83
SQL/CLI (Call-Level Interface), 27
SQL/Foundatlon, 27
SQL/Framework, 27
SQL/JRT (Java Routines
and Types), 28
SQL/MED (Management
of External Data), 27
SQL/OBJ (Object Language
Binding), 27
SQL/PSM (Persistent Stored
Modules), 27
SQL/Schemata, 28
SQL/XML, 27, 28
SQL VARIANT, тип данных
SQL Server, 69, 771
сравнение платформ, 53
SQL2003
адресация в схемах, 38
дополнительные пакеты.
свойств, 27
допустимые символы в иден-
тификаторах, 36
зарезервированные идентифи-
каторы, 37
категории и типы данных, 48
классы инструкций, 29
ключевые слова, 790
начальный символ идентифи-
катора, 37
новые возможности, 25
оконный синтаксис, 624
размер идентификатора, 36
структуры данных, 17
числовые функции, 638-652
SQL2003 ключевые слова, 790
SQL92, 26
SQL99, 25
удаленные элементы
BSQL2003.23
SqlConnection
атрибуты строки соединения,
741
Предметный указатель | 825
VARBIT, тип данных
сравнение платформ, 51
VARCHAR FOR BIT DATA,
тин данных
DB2, 55
сравнение платформ, 53
VARCHAR(), тип данных
SQL Server, 771
Sybase adaptive server, 771
VARCHAR, тип данных
DB2.55
MySQL, 58
Oracle, 61
PostgreSQL, 65
SQL Server, 69
сравнение платформ, 53
VARCHAR, функция
DB2, 672
PostgreSQL, 723
VARCHAR_FORMAT,
функция (DB2), 672
VARCHAR2, тип данных
Oracle, 61
сравнение платформ, 53
VARGRAPHIC, тнп данных
DB2, 55
сравнение платформ, 53
VARGRAPHIC, функция
(DB2), 673
VARIANCE, функция
DB2, 672
Oracle, 712
VARP, функция, 787
SQL Server, 735
VERSION(), функция
(MySQL), 687
VSIZE, функция (Oracle), 712
W
WEEK, функция
DB2, 673
MySQL, 687
WEEKJSO, функция
(DB2), 673
WEEKDAY, функция
(MySQL), 687
WHERE, предложение
(SELECT, инструкция)
и логические операторы, 42
и операторы сравнения, 42
WHERE, предложение, 490,
494-496, 596-600
DB2, 600
MySQL, 600
Oracle, 600
PostgreSQL, 600
SQL Server, 600
ключевые слова, 597
поддержка платформами, 597
правила, 597
Синтаксис SQL2003, 597
советы и хитрости
программирования, 599
WIDTH, функция
(PostgreSQL), 723
WIDTH BUCKET, функция, 651
WITHfOUT] SESSION
SHUTDOWN, 116
X
Xbase, 22
XML схема
основанные на пей
таблицы,253
XML, тип данных
Oracle, 61
сравнение платформ, 53
XMLAGG, функция
(Oracle), 712-713
XMLCOLATTVAL, функция
(Oracle), 713
XMLCONCAT, функция
(Oracle), 713
XMLELEMENT, функция
(Oracle), 713
XMLFOREST, функция
(Oracle), 713
XMLSEQUENCE, функция
(Oracle), 713
XMLTRANSFORM, функция
(Oracle), 713
Y
YEAR, функция, 787
DB2, 673
MySQL, 687
SQL Server, 735
YEARWEEK, функция
(MySQL), 688
A
агрегатные функции, 602-623
адресация в схемах, 38
арифметические,
операторы, 41
Б
база данных, объекты
и операторы, 33, 40
базы данных, программирова-
ние (см. программирование баз
данных)
больше (>), оператор, 42
больше или равно (>=),
оператор, 42
Булево сравнение,
операторы, 42
В
Векторые подзапросы
в предложениях
WHERE/HAVING, 573
вложенные скобки
и приоритет операторов, 43
вложенные таблицы
Oracle, 238
в предложении FROM, 573
подзапросы,570
встроенные скалярные
функции, 634
выражения
и приоритет операторов, 44
проверка по диапазону
значений, 86
высвобождение ресурсов, 739
вычитание (-),
арифметический оператор, 41
Г
группировка, предложение
для, 627
д
данные
извлечение, 750-757
ADO.NET, 750-753
JDBC, 753-757
данные, структуры, 17-19
Двенадцать принципов реля-
ционных баз данных, 16
двойной диез, символ (##),
161-162
декларативная обработка, 22
деление (/), арифметический
оператор, 41
детерминированные
функции, 601
диалекты SQL, 30
диез, символ (#), 161-162
доступ, 19
Ж
журнал, файлы (Oracle), 124
3
записи, 19
зарезервированные
слова, 33, 47
И
идентификаторы, 34-39
допустимые символы, 36
зарезервированные, 37
начальные символы, 37
размер, 36
с разделителями, 37
идентификаторы, правила, 36
идентификаторы с разделите-
лями, 35
инструкции
Sybase adaptive server SQL, П2
выполнение, 748-749
повторное выполнение, 739
подготовка и выполнение, 738
инструкции-объекты
выполнение, 739
связь с SQL, 738
создание, 738
инструкция,578
UNION, оператор для наборов
данных, 582
UPDATE, инструкция, 591-593
828 | Предметный указатель
TIMETZ, тип данных
PostgrcSQL, 65
сравнение платформ, 53
TINYINT, тип данных
SQL Server, 69
сравнение платформ, 53
TO_BINARY_D0UBLE,
функция (Oracle), 706
TO_BINARY_FLOAT, функция
(Oracle), 707
TO_CHAR, функция
DB2, 671
Oracle, 707
PostgreSQL, 720
TO_CLOB, функция
(Oracle), 709
TO_DATE, функция
DB2.671
Oracle, 709
PostgreSQL, 720
TO_DAYS, функция
(MySQL), 686
TO DSINTERVAL, функция
(Oracle), 709
TO_LOB, функция (Oracle), 709
TO_MULTI_BYTE, функция
(Oracle), 709
TO_NCHAR, функция (Oracle),
709
TO NCLOB, функция
(Oracle), 709
TONUMBER, функция
Oracle, 710
PostgreSQL, 722
TO_SINGLF._BYTE, функция
(Oracle), 710
TOTIMESTAMP, функция
Oracle, 710
PostgreSQL, 722
TO_TIMESTAMP_TZ,
функция (Oracle), 710
TOUNICHAR, функция, 786
TOYMINTERVAL, функция
(Oracle), 710
Transaction, объект
ADO.NET, 745
JDBC, 746
TRANSACTION_NONE,
уровень изоляции (объект
Transaction (JDBC), 746
TRAN'SACTION_READ_COMMI
TTED, уровень изоляций (Объ-
ект Transaction (JDBC), 746
TRANS ACTI ON_READ_UNCO
MMITTED, уровень изоляции
(Объект Transaction (JDBC), 746
TRANSACTION_REPEATABL
E READ, уровень-Изоляции
(Объект Transaction (JDBC),
746
TRANSACTIONJSERIALIZAB
LE, уровень изоляции (Объект
Transaction (JDBC), 747
Transact-SQL, 30
TRANSLATE, функция, 654
DB2.671
Oracle, 710
PostgreSQL, 722
TREAT, функция (Oracle), 711
TRIM, функция, 659
TRUNC, функция
DB2,671
Oracle, 711
PostgreSQL, 723
TRUNCATE TABLE,
инструкция, 576-579
DB2, 578
MySQL, 578
Oracle, 578
PostgreSQL, 579
SQL Server, 579
ключевые слова, 577
поддержка платформами, 577
правила, 577
синтаксис стандарта defacto, 577
советы и хитрости
программирования, 577
TRUNCATE, функция
DB2,671
MySQL, 686
TSEQUEL, функция, 786
TYPEJD, функция (DB2), 672
TYPEJNAME, функция
(DB2), 672
TYPEJSCHEMA, функция
(DB2), 672
TYPEPROPERTY, функция, 786
SQL Server, 734
TZ_OFFSET, функция
(Oracle), 711
и
UCASE, функция (MySQL), 686
UHIGHSURR, функция, 786
UID, функция (Oracle), 711
Uint, параметрический объект-
ный тип (ADO.NET), 760
ULOWSURR, функция, 786
UNCOMPRESS, функция
(MySQL), 687
UNHEX, функция
(MySQL), 687
UNICHAR, тип данных
(Sybase adaptive server), 771
UNICODE, функция, 786
UNION оператор для наборов
данных, 579-584
DB2, 581
MySQL, 582
Oracle, 582
PostgreSQL, 583
SQL Server, 583
ключевые слова, 580
поддержка платформамй, 579
правила, 580
Синтаксис SQL2003, 580
советы и хитрости
программирования, 580
UNIQUE, ограничения, 76
UNIQUEIDENTIFIER,
тип данных
SQL Server, 69, 771
сравнение платформ, 53
UNISTR, функция (Oracle), 711
UNIVARCHAR, тип данных
(Sybase adaptive server), 771
UNIXTIMESTAMP, функция
(MySQL), 687
Unspecified, уровень изоляции
(Объект Transaction
(ADO.NET), 745
UPDATE, инструкция, 585-596
DB2, 588-589
MySQL, 590
Oracle, 591-593
PostgreSQL, 593
SQL Server, 594-596
и операторы, 33, 40
ключевые слова, 585
поддержка платформами, 585
правила, 586
Синтаксис SQL2003, 585
советы и хитрости
программирования, 588
UPDATEXML, функция
(Oracle), 711
UPPER, функция, 657
LRL
MySQL, 10
Oracle, 10
PostgreSQL, 10
SQL Server, 10
открытый исходный код, 5
UROWID,THn данных
Oracle, 61
сравнение платформ, 53
USCALAR, функция, 786
USER(), функция
(MySQL), 687
USER_ID, функция
(SQL Server), 734
USERJNAME, функция
(SQL Server), 735
USERENV, функция
(Oracle), 712
V
VALID NAME, функция, 786
VALID^USER, функция, 786
VALUE, функция
DB2,672
Oracle, 712
VAR, функция, 786
DB2,672
SQL Server, 735
VAR_POP, функция, 604, 622
Oracle, 712
VAR_SAMP, функция, 604,623
VARBINARY(), тип данных
SQL Server, 771
Sybase adaptive server, 771
VARBINARY, тип данных
SQL Server, 69
сравнение платформ, 53
Предметный указатель | 827
IS, оператор, 424
JOIN subclause, 425
LIKE, оператор, 436
MERGE, инструкция, 441
OPEN, инструкция, 444
ORDER BY, предложение, 448
RELEASE SAVEPOINT,
инструкция, 453
RETURN, инструкция, 465
REVOKE, инструкция, 460
ROLLBACK, инструкция, 478
SAVEPOINT, инструкция, 484
SELECT, инструкция, 487
SET CONNECTION,
инструкция, 544
SET CONSTRAINT,
инструкция, 547
SET PATH, инструкция, 548
SET ROLE, инструкция, 549
SET SCHEMA, инструкция, 552
SET SESSION AUTHORIZA-
TION, инструкция, 554
SET TIME ZONE, инструкция,
556
SET TRANSACTION,
инструкция, 558
SET, инструкция, 540
SOME, оператор, 83
START TRANSACTION,
инструкция, 565
SUBQUERY инструкция, 570
UNION оператор для наборов
данных, 580
UPDATE, инструкция, 585
WHERE, предложение, 596
Система управления реляци-
онной базой данных, (СУРБД),
16-24
системные ограничители, 44
сжатые таблицы в Oracle, 238
символьные строковые кон-
станты (литералы), 39
скалярные подзапросы
в предложении
WHERE/HAVING, 573
скалярные подзапросы в спи-
ске элементов SELECT, 573
скалярные подзапросы, 570
скалярные функции, 602,
634-660
встроенные, 634
категории, 634
скобки
вложенные и приоритет
операторов, 43
сложение (+), арифметический
оператор, 41
соглашение об именах, 34
соединения (с базой данных)
закрытие, 744
открытие, 739-744
ADO.NET, 740-741
JDBC, 741-744
сопоставления, 20
сортировка, предложение, 627
сравнение платформ, 50-53
сравнения операторы, 40, 42
столбец, ограничения уровня, 70
столбцы, 19
строки, обработка, 22
строки,операторы
фильтрации и сравнения, 42
строковые функции и
операторы, 652-660
СУРБД (Система управления
реляционной базой данных),
16-24
суффиксы, 35
схемы, 19
т
таблицы, 19
табличного уровня
ограничения, 70
табличные подзапросы, 570
вложенные, 570
типы данных, 18
DB2, 54-55
MySQL, 55-58
Oracle, 59-62
PostgreSQL, 62-65
SQL Server, 66-69
Sybase adaptive server, 770
транзакции
завершение, 739
закрытие и фиксация, 92
запуск, 737, 744-747
ADO.NET, 745
JDBC, 746
неявные, 93
откат, 747
управление, 744-748
фиксация, 747
явные, 93
У
умножение (*),
арифметический оператор, 41
унарные операторы, 40, 43
Ф
фильтрация, 84
функции, 601-735
ABS, 640
APP_NAME( ), 779
AVG, 602, 605
BINARY CHECKSUM, 779
BIT_LENGTH, 640
CASE, 636
CAST, 638, 779
CEIL, 642
CHAR_LENGTH, 640, 779
CHECKSUM, 779
CHECKSUM_AGG, 779
COALESCE, 779
COMPARE, 779
CONTAINS, 780
CONTAINSTABLE, 780
CONVERT, 654
CORR, 602, 606
COUNT, 602, 607
COUNT_BIG, 780
COVAR POP, 602, 607
COVAR_SAMP, 602, 608
CUME_DIST( ), 629
CUME_DIST, 603, 609
DATABASEPROPERTYEX, 780
DAY, 780
DENSE_RANK( ), 630
DENSE_RANK, 603,611
EXP, 643
EXTRACT, 643
FILEJD, 780
FILE_NAME, 780
FILEGROUPJD, 780
FILEGROUP_NAME, 780
FILEGROUPPROPERTY, 780
FILEPROPERTY, 780
FLOOR, 647
FORMATMESSAGE, 781
FREETEXTTABLE, 781
FULLTEXTCATALOGPRO-
PERTY, 780
FULLTEXTSERVICEPRO-
PERTY, 780
GETANSINULL, 781
GETUTCDATE(), 781
GROUPING, 781
HEXTOINT, 781
1DENT.CURRENT, 781
IDENTJNCR, 781
1DENT_SEED, 781
IDENTITY, 781
INDEXPROPERTY, 782
INTTOHEX, 782
IS.MEMBER, 782
IS_SEC_SERVICE_ON, 782
IS_SRVROLEMF-MBER, 782
ISDATE, 782
ISNUMERIC, 782
lct_admin, 782
L.E1T, 782
LEN, 782
LICENSE-ENABLED, 783
LN, 647
LOWER, 656
MAX, 603, 612
MIN, 603,612
MOD, 648
MONTH, 783
MUT_EXCL_ROLES, 783
NCHAR, 783
NEWID(), 783
NULLIF, 783
OBJECTPROPERTY, 783
OCTET_LENGTH, 640
OPEN, 783
OPENDATASOURCE, 783
OPENQUERY, 783
OPENROWSET, 783
OVERLAY, 657
PARSENAME, 783
PATINDEX, 784
PERCENT_RANK, 603, 613, 632
PERCENTILE-CONT, 603, 615
830 | Предметный указатель
WHERE, предложение, 600
оконные, синтаксис, 625
пользовательские (UDF), 157
таблицы XMLType, 253-255
К
каталоги, 19
кластеры, 19
ключевые слова, 33,47
DB2, 794
Microsoft SQL Server, 800
MySQL, 796
Oracle, 798
PostgreSQL, 799
SQL Server, 800
SQL2003, 790
Sybase adaptive server, 787, 802
общие, 790
конкатенация, оператор, 653
константы (литералы), 33,39
коррелированные подзапросы
в предложении WHERE/HAV-
ING, 573
коррелированные под-
запросы, 570
курсоры (см. CLOSE CURSOR,
инструкция; DECLARE
CURSOR, команда)
Л
логические операторы, 40, 42
М
меньше (<), оператор, 42
меньше или равно (о ),
оператор, 42
метаданные, 21
методы
ADO.NET DataReader, 753
JDBC ResultSet, 756
н
наборы данных, операции, 22
наборы синодов, 20
не больше (!>), оператор, 42
не меньше (!<), оператор, 42
не равно (!=), оператор, 42
педстермппированые
функции, 601
неявные транзакции, 93
О
обработка ошибок, 764-766
ADO.NET, 764
JDBC, 765
общие ключевые слова, 790
объекты, 19
ограинчениестолбца
(Oracle), 226
ограничения,70-78
CHECK, 77
FOREIGN KEY, 72-75
PRIMARY KEY, 71
UNIQUE, 76
область действия, 70
синтаксис, 70
ограничители, 44
оконные функции, 25
оконные функции, 602,624-634
DB2, синтаксис, 625
Oracle, синтаксис, 625
предложение для
группировки, 627
предложение для
секционирования, 626
предложение
для сортировки, 627
Синтаксис SQL2003, 624
операторы, 33, 40-47
строковые, 652-660
оператор побитового ИЛИ, 41
операторы, приоритет, 43
основные базы данных
(Oracle), 124
остаток от деления (%),
арифметический оператор
(SQLServer), 41
отбор (sampling), 26
П
параметризованные
инструкции, 757
параметры
связанные (см. связанные
параметры)
связанные входные, 738
параметры, объектные типы
(ADO.NET), 760
параметры_физических_атриб
утов (Oracle), 234
параметры_хранеиия
(Oracle), 234
побитовое И (&), оператор, 41
побитовое ИЛИ (|),
оператор, 41
побитовое исключающее ИЛИ
(), оператор, 41
побитовые, операторы, 40
подзапросы
во вложенных таблицах, 570
коррелированные, 570
скалярные, 570
табличные, 570
подразделы, разбиение таблиц
Oracle, 238-243
изменение, 243-251
пользователь, 20
потенциальный ключ, 76
представления, 19,22
и операторы, 33,40
префиксы, 35
присваивание (=), оператор, 41
присваивание, операторы, 40
проверка выражений
по диапазону значений, 86
программирование
баз данных, 736-769
общий обзор, 737-739
примеры,767-769
процедурное программирова-
ние, 22
Р
равно (=), оператор сравнения,
42
резервные базы данных
(Oracle), 124
релляциоиные базы данных,
принципы, 16
ресурсы, высвобождение, 739
С
с разделителями, идентифи-
каторы, 35
связанные параметры, 757-764
ADO.NET, 757-761
JDBC, 761-764
связь, установление, 737
секционирование,
предложение, 626
секционированные таблицы
Oracle, 238-243
изменение. 243-251
символ-разделитель
в идентификаторе, 37
Синтаксис SQL2003
ALL, оператор, 83
ANY, оператор, 83
BETWEEN, оператор, 85
CALL, инструкция, 87
CLOSE CURSOR,
инструкция, 90
COMMIT, инструкция, 92
CONNECT, инструкция, 96
CREATE/ALTER METHOD,
инструкции, 185
CREATE/ALTER ROLE,
инструкции, 189
CREATE/ALTER SCHEMA,
инструкции, 193
CREATE/ALTER TABLE,
инструкции, 196
CREATE/ALTER TRIGGER,
инструкции, 264
CREATE/ALTER TYPE, ’
инструкции,280
CREATE/ALTER VIEW,
инструкции, 298
CREATE/ALTER, FUNCTION/
PROCEDURE, инструкции, 137
DECLARE CURSOR,
команда, 314
DELETE, инструкция, 326
DISCONNECT, инструкция, 335
DROP, инструкции, 337
EXCEPT оператор для
наборов данных, 356
EXISTS, оператор, 362
FETCH, инструкция, 364
GRANT, инструкция, 373
IN, оператор, 403
INSERT, инструкция, 405
INTERSECT оператор для
наборов данных, 419
Предметный указатель | 829
Содержание
Предисловие.....
1. История и реализации SQL................................. 15
Реляционная модель и ANSI SQL.............................16
История стандарта SQL ....................................25
Диалекты SQL..............................................30
2. Основные понятия .................................... 32
Платформы баз данных, описываемые в этой книге ........32
Категории синтаксических конструкций ...................33
Типы данных SQL2003 и различных платформ ............. 48
Ограничения.......................................... 69
3. Справочник по инструкциям SQL ...................... 79
Как работать с этой главой ............................79
Поддержка SQL платформами .............................80
Справочник по командам SQL.............................83
4. Функции SQL........................................ 601
Типы функций........................................ 601
Агрегатные функции ANSI SQL ........................ 602
Оконные функции ANSI SQL .............................624
Скалярные функции ANSI SQL ...........................634
Платформо-специфические расширения ...................660
5. Программирование баз данных....................... 736
Общий обзор программирования баз данных ..............737
Открытие соединения с базой данных .................. 739
Закрытие соединения с базой данных ...................744
Управление транзакциями............................. 744
Выполнение инструкций ................................748
Извлечение данных .................................. 750
Связанные параметры ................................ 756
Обработка ошибок......................................764
Примеры ............................................ 766
A. Sybase Adaptive Server.............................. 770
В. Общие и специфичные
для платформ ключевые слова ............................ 790
Предметный указатель................................. 805
PERCENTILEDISC, 603, 616
PERMISSIONS, 784
POSITION, 648
PostgreSQL (cm. PostgreSQL,
функции)
POWER, 649
PROC.ROLE, 784
RANK( ), 631
RANK, 603,617
REGRAVGX, 603, 618
REGR AVGY, 603,618
REGR COUNT, 603, 618
REGR INTERCEPT, 603,618
REGRJ<2,603, 618
REGR SLOPE, 603, 618
REG R SXX, 604, 619
REGR SXY, 604, 619
REGRSYY, 604, 619
REPLACE, 784
ROLE.CONTAIN, 784
ROLE.ID, 784
ROLENAME, 784
ROWNUMBER, 633
ROWCNT, 784
ROW COUNT _BIG( ), 784
SESSION USER, 785
SHOW.ROLEI ), 785
SHOW_SEC_SERVICES( ), 785
SORTKEY, 785
SQL Server, поддерживаемые
(см. SQL Server, функции)
SQL2003 числовые, 638-652
SQRT, 650
STATS DATE, 785
STDDEV POP, 604, 620
STDDEV.SAMP, 604,621
STD EV, 785
STDEVP, 785
SUBSTRING, 657
SUM, 604, 605
SUSER ID, 785
SUSER J9 AM E, 785
SUSERSID, 785
SUSER SNAME, 785
SYB.SENDMSG, 786
Sybase adaptive server
и SQL, Server, 778-787
SYSTEM USER. 786
TO. UNICHAR, 786
TRANSLATE, 654
TRIM, 659
TSEQUEL, 786
TYPEPROPERTY, 786
UHIGHSURR, 786
ULOWSURR, 786
UNICODE, 786
UPPER, 656
USCALAR, 786
VALID.NAME, 786
VAL1DUSER, 786
VAR, 786
VAR.POP, 604, 622
VAR SAMP, 604, 623
VARP, 787
WID TH BUCKET, 651
YEAR, 787
а грегатные, 602 623
дет e p м и и и po ва н 11 ы e, 601
и операторы, 33, 40
недетерминированные, 601
поддержка в DB2 (см. DB2,
функции)
поддержка в MySQL
(см. MySQL,, функции)
поддержка в Oracle
(см. Oracle, функции)
оконные, 25
оконные, 602, 624-634
поддержка в Sybase adaptive
server, 779
скалярные, 602, 634 66)0
встроенные, 634
категории, 634
строковые, 652 -660
типы, 601
числовые, 638- 652
X
хранимые процедуры
и операторы, 33,40
ч
числовой тнн данных унарные
операторы, 43
числовые функции, 638-652
улучшенные, 26
Я
нвпые транзакции, 93
Предметный указатель | 831
категория > базы данных / SQL
SOL. Справочник
Если ваша работа связана с разработкой программного обеспечения,
очень велика вероятность того, что вы в какой-то степени применяете
SQL SQL - это язык баз данных. Он позволяет создавать и обслуживать
объекты баз данных, заносить данные в эти объекты, посылать запросы
к данным, изменять и удалять те данные, которые более не требуются.
Базы данных лежат в основе большинства бизнес-приложений. Если вы применяете
SQL, вам «ужен хороший справочник по этому языку. Хотя SQL - язык стандартизован-
ный, его реализации весьма отличаются от стандарта. Вариантов, вносимых в язык
разными производителями, огромное количество, и разобраться в них поможет эта
книга.
Книга «SQL. СПРАВОЧНИК» - это полезное практическое справочное руководство
по SQL2OO3. В книге описываются все инструкции SQL2OO3, их использование и синта-
ксис, не только с позиции самого стандарта, но и с точки зрения пяти его реализаций
на основных платформах: DB2, Oracle, MySQL, PostgreSQL и SQL Server. В описание
каждой инструкции входят синтаксис команды, как его определяет данный производи-
тель, описание и информативные примеры, иллюстрирующие важные концепции
и способы применения.
Язык SQL - это не только инструкции. Столь же важны типы данных и богатый набор
встроенных функций, так необходимых для реальной работы. В этой книге описыва-
ются типы данных и функции, как они определяются в стандарте, и как они реализо-
ваны производителями платформ. В это издание также включена подробная информа-
ция о синтаксисе новейших оконных функций, которые поддерживаются платформами
DB2 и Oracle.
Книга «SQL. СПРАВОЧНИК» - это не только удобное справочное руководство для опы-
тных SQL-программистов, аналитиков и администраторов баз данных, это также заме-
чательный инструмент для консультантов и других специалистов, которым нужно знать
различные диалекты SQL, распространенные на разных платформах.
A NUTSHELL®
HANDBOOK
ПРИГЛАШАЕМ АВТОРОВ КНИГ ПО КОМПЬЮТЕРНОЙ ТЕМАТИКЕ
КУДИЦ-ОБРАЗ Тел./факс: (095) 333-82-11, 333-65-67 E-mail: zakaz@kudits.ru; http://books.kudits.ru 121354, Москва, а/я 18, "КУДИЦ-ОБРАЗ" м. Калужская © ; "i & © 1 © КТК 214 ISBN 5-957 IIII 9 785957 9-0114-8 IIIII 901142