/









































































































































































































































Author: Долинский М.С.
Tags: компьютерные технологии программирование информатика
ISBN: 5-469-00444-9
Year: 2005




Text
М. С. Долинский
С^ППТЕР
Алгоритмизация
и программирование
на TURBO PASCAL
от простых до олимпиадных задач
| УЧЕБНОЕ / ПОСОБИЕ
ДЛЯ школьников,
студентов и их
преподавателей
все необходимое для
обучения и самообучения
в полном объеме
и компактной форме
технология разработки
программ
примеры решения
задач и задания
для самостоятельной
работы
ББК 32.973-018я7
УДК 681.3.06(075)
Д64
Д64
Долинский М. С.
Алгоритмизация и программирование на Turbo Pascal: от простых
до олимпиадных задач: Учебное пособие. — СПб.: Питер, 2005. — 237 с.: ил.
ISBN 5-469-00444-9
ББК 32.973-018я7
УДК 681.3.06(075)
Информация, содержащаяся в данной книге, получена из исто
ISBN 5-469-00444-9
© ЗАО Издательский дом «Питер», 2005
Содержание
Введение...................................................................................
От издательства ......у................................................................ 9
10
Глава 1. Программирование на Паскале
1.1 Основные операторы языка и простейшие алгоритмы
Введение а программирование
Стандартная обработка одномерных массивов
Стандартная обработка двумерных массивов
Нестандартные алгоритмы и программы
Задачи для самостоятельного решения .............
1 2. Возможности языка npoi раммирования Паскаль
Компьютерная арифметика
числовые типы данных ............................
Булевский (логический) гиг. boolean
Символьный и строковый типы
Стандартные процедуры и функции преобразования типов . 54
Текстовые файлы 55
1 3. Технология разработки программ 57
Общие сведения 57
Пример решения задачи о поиске прямой . - 58
Пример решения задачи о множестве треутольников 81
Вопросы и ответы............................................... 53
Глава 2. Основы алгоритмизации .................................... 70
2.1 Очередь и стек .. ...................
Физическиепримерыстекаиочереди .. 70
Представление стека в программе 71
Представление очереди в программе 72
Примеры решения задач 73
Дополнительные приемы программирования 81
Использование динамической памяти 86
2 2. Рекурсивные процедуры и функции 93
Примеры решения задач 93
Отладка рекурсивных процедур и функций "2
2.3 Рекуррентные соотношения . 114
Общие сведения о рекуррентных соотношениях .
Рекуррентные соотношения с двумя параметрами 126
Рекуррентные соотношения с тремя и более параметрами 139
Общие приемы решения задач на рекуррентные соотношения 153
2.4 Алгоритмы на < рафах ... 155
Общие сведения об алгоритмах на графах 155
Кратчайшие расстояния на графах ... 156
Поиск в глубину 171
Силоносвязные компоненты и доминантные множества 185
Поиск в ширину . ... . 195
С размерностях, использованных в задачах массивов 201
Обзор представленной теоретической информации 201
2 5 Генерация комбинаторных обьектов 202
Перестановки . . 204
Сочетания 207
Размещения . 208
Перестановки с повторениями 210
Сочетания с повторениями . 212
Глава 3. Дополнительные сведения .. 214
3 1 Аналитическая геометрия на плоскости 214
’очка, прямая, площадь 214
Принадлежностыочки фигуре .. .... 217
Минимальная выпуклая оболочка 219
Основные соотношения в треугольнике .. .220
Задачи для самостоятельного решения 221
3 2 Некоторые факты из теории чисел .... . 224
Свойства X MOO Y .................... 224
Позиционные системы счисления и быстрое вычисление многочлена . 226
Формула вхождения простого множителя в N -факториал ... 230
Свойства наибольшего общего делителя 230
Литература .. 232
Алфавитный указатель .. 234
Введение
В настоящее время программирование вызывает значительный интерес у сту-
дентов и школьников. Многие из них способны самостоятельно изучить необ-
ходимый теоретический материал и выработать практические навыки, исполь-
зуя как учебные (школьные и вузовские), так и личные компьютеры. Однако
существенным сдерживающим фактором является отсутствие необходимой
литературы. Доступная литература по программированию в большинстве сво-
ем представляет пересказ руководств по тому или иному языку программиро-
вания, например [2]. В небольших количествах в библиотеках встречается ли-
тература, в которой описываются и методы алгоритмизации. Но такие книги
часто не привязываются ни к какому языку программирования, например [15],
либо привязаны к устаревшим языкам программирования [3]. Лучшие, по мне-
нию автора, из относительно доступных сегодня учебников по разработке ал-
горитмов [8-11], к сожалению, не содержат никаких сведений о технологии
разработки и отладки программ. Серьезным недостатком при практическом
использовании монографии [11] студентами первого курса и школьниками яв-
ляется также высокий теоретический уровень изложения материала. Общим
недостатком книг, как таковых, является статичность материала, то есть невоз-
можность самопроверки студентом (учеником) качества усвоения им изучае-
мых знаний и закрепления соответствующих навыков. Развитие новых инфор-
мационных технологий и электронных средств распространения информации,
а также многолетнее использование автором вышеуказанных и других подоб-
ных материалов (прежде всего [8-10]) привели к потребности создания нового
учебного пособия. Автор надеется, что оно в большей степени позволит рас-
крыть индивидуальный творческий потенциал каждого студента (ученика) за
счет следующих факторов.
1. Строгая последовательность изложения.
□ Первая глава содержит весь необходимый материал для начального этапа
работы. Не предполагается знание студентом (школьником) каких бы то
ни было сведений из курса информатики — все необходимое, в полном
содержании, но в компактной форме, излагается в тексте. С первых
страниц читатель ориентируется на самостоятельную работу в среде
Турбо Паскаля и перманентное практическое закрепление изученного
материала.
□ Информация подается в порядке возрастания сложности.
Введение
2. Блочность и вложенность уровней сложности при изложении теории. Тем са-
мым обеспечивается возможность пропуска более детального обсуждения теми,
кто понял, и углубления в материал теми, кто не понял.
3. Автономная обратная связь с обучаемыми.
Вся теоретическая информация, а также все практические задания размещены
в курсе «ЭВМ и программирование» на сайте проекта «Дистанционное
обучение», который функционирует на серверах Гомельского государственного
университета им. Ф. Скорины с октября 1999 года. Обучаемый может, используя
Интернет-online (http://dl.gsu.unibel.by) или электронную почту (dl-
service@gsu.unibel.by), послать на проверку собственное решение любой из
приведенных в книге и многих других задач в любое удобное для него время!
Система автоматической проверки присылаемых решений работает ежедневно
и круглосуточно без праздников и выходных и, как правило, обеспечивает
проверку решений в течение нескольких минут. Для тех, кто не имеет доступа
ни к Интернету, ни к электронной почте, предлагается возможность получить
необходимую информацию (теорию, условия задач, тесты, решающие
программы, пакетные файлы для самотестирования) в виде приложения к книге
на дискетах или компакт-диске.
Интеграция этих факторов обеспечивает высокую эффективность учебного про-
цесса, основанного на теоретическом материале и практических заданиях, излагае-
мых в данной книге.
Предлагаемый материал активно использовался автором в практической деятель-
ности по обучению программированию студентов математического факультета
Гомельского государственного университета им. Ф. Скорины и школьников г. Го-
меля. Эффективность внедренной методики подтверждают, в частности, и следу-
ющие факты.
□ С 1997 по 2001 год ровно половину (10 из 20) членов сборной Беларуси на меж-
дународных олимпиадах по информатике (ЮГ1997-2001) составляли гомель-
ские школьники, которые завоевали в общей сложности 5 серебряных и 2 брон-
зовые медали. За этот же периодостальные представители Республики Беларусь
завоевали 2 серебряные и 4 бронзовые медали.
□ Кроме того, за этот же период 3 раза гомельчане (1997-й — Артем Кузнецов,
1999-й — Константин Судиловский, 2000-й — Евгений Гончар) становились
абсолютными победителями Белорусской Республиканской олимпиады по ин-
форматике в личном зачете и дважды (1998-й, 2000-й) — в командном зачете.
Автор надеется, что читатель сможет сам убедиться в достоинствах данной книги
и предлагаемого подхода к обучению и самообучению алгоритмизации и програм-
мированию.
Тем не менее автор будет благодарен за все отклики и замечания (в том числе и пре-
жде всего — критические), присланные на адрес: dolinsky@gsu.unibel.by.
От издательства 9
От издательства
Ваши замечания, предложения и вопросы отправляйте по адресу электронной по-
чты comp@piter.com (издательство «Питер», компьютерная редакция).
Мы будем рады узнать ваше мнение!
Подробную информацию о наших книгах вы найдете на web-сайте издательства
http://www.piter.com.
ГЛАВА 1 Программирование
на Паскале
Цель данного учебного пособия — помочь вам научиться писать программы на язы-
ке программирования Паскаль. Пособие требует от вас активной самостоятельной
работы, без чего этого добиться невозможно.
1.1. Основные операторы языка
и простейшие алгоритмы
Данная книга является результатом многолетней работы автора по обучению
программированию школьников самого различного возраста и выработки соб-
ственной методики обучения на начальной стадии, которая названа автором
«быстрое погружение» в разработку программ на Паскале. Коротко суть этой
методики можно сформулировать так: обучаемому нужно сообщить минимально
необходимое количество информации, но так, чтобы он смог самостоятельно
решать практически любые задачи с числовыми данными. К такой информации
автор относит: целые и вещественные переменные, арифметические и логиче-
ские выражения, операторы присваивания (:=), условия (if ... then ... else ...)
и циклов (for и while).
Введение в программирование
Прежде всего согласуем некоторые понятия. Попробуем сделать это в виде отве-
тов на вопросы.
Зачем нам нужна программа?
Чтобы заставить компьютер выполнить какую-то полезную работу вместо
человека. На начальном этапе вашего обучения программированию —
выполнить какие-то трудоемкие вычисления, например, по обработке
одномерных или двумерных массивов чисел.
Что такое одномерный массив чисел?
Пусть у клоуна в цирке есть 10 бочонков разной высоты, из которых он
собирается построить «пирамиду», ставя один бочонок на другой. Требуется
выяснить: какой высоты будет эта пирамида?
i и простейшие алгоритмы
Для того чтобы правильно ответить на этот вопрос, нужно знать высоты этих бо-
чонков, измеренные, например, в сантиметрах:
25 1030 4054 12 60 90 40 20.
Эти числа, разделенные пробелом, и есть те самые высоты: 25 см — высота первого
бочонка, 10 см — высота второго, и так далее, 20 см — высота десятого бочонка.
Тогда высота пирамиды будет равна:
25 + 10 + 30 + 40 + 54 + 12 + 60 + 90 + 40 + 20 - 381 см.
Эти 10 чисел, которые написаны в одну строку (но можно было бы записать их и в
один столбец), называются одномерным массивом из 10 чисел.
Поскольку в данном массиве все числа целые, то такой массив называется цело-
численным.
Если бы клоун измерял длины своих бочонков не в сантиметрах, а в дециметрах,
тогда массив высот бочонков принял бы такой вид:
2.5 1.0 3.0 4.0 5.4 1.2 6.0 9.0 4.0 2.0.
Теперь наш одномерный массив состоит из вещественных чисел и потому называ-
ется вещественным массивом.
ПРИМЕЧАНИЕ---------------------------------------------------
Заметим, что исторически так сложилось, что в программировании дробная часть от-
деляется от целой символом ». »(точка), а не символом « , »(запятая), как это приня-
то в математике.
А если у клоуна бочонки то ломаются, то теряются, и каждый раз нужно пересчи-
тывать высоту «пирамиды», или мы решили помочь одновременно всем клоунам
мира, выполняющим такой фокус?
Понятно, что можно придумать и более серьезные примеры, когда требуется так
или иначе провести расчеты над числами одномерного массива. И чем больше чи-
сел в этих массивах, тем больше у человека шанс совершить ошибку в расчетах.
Потому спасением человека в таких случаях является возможность написать про-
грамму, которая сможет ввести числа, необходимые для расчетов (здесь человек
окажет компьютеру некоторую помощь — введет исходные данные с клавиатуры),
затем выполнить нужные расчеты и вывести готовый результат. Понятно, что те-
перь необходимо написать программу, которая выполнит все это. Вы можете воз-
разить: так программу написать — это ведь тоже работа! Тем более что иногда про-
вести расчеты при помощи ручки, бумаги и калькулятора гораздо проще и быстрее,
чем писать программу. Это правильно, особенно для тех программ, с которых вы
начнете свое обучение, ио:
1) программа пишется один раз, а использовать ее потом можно бесконечное мно-
жество раз, и в этом заключается основное преимущество даже самых простых
программ;
12
Глава 1. Программирование на Паскале
2) программу можно написать и проверить для массивов из небольшого числа эле-
ментов, из 10 например, азатем использовать ее для тех же расчетов, но уже над
10 миллионами элементов.
Есть, конечно, и другие аргументы в пользу программирования вместо ручной работы,
В этой главе мы постараемся помочь вам научиться писать простейшие програм-
мы на языке программирования Паскаль, которые как раз и умеют вводить с кла-
виатуры персонального компьютера (ПК) исходные одномерные массивы целых
или вещественных чисел, проводить некоторые вычисления, а затем выводить ре-
зультаты на экран (монитор) ПК.
Стандартная обработка одномерных массивов
Текст написанной на языке Паскаль программы, которая решает для нашего клоу-
на задачу подсчета высоты «пирамиды» из бочонков, приведен в листинге 1.1.
I. Пример простейшей Паскаль-программы
a:array [1..10] of integer;
i. s : integer:
writelnf'Введите 10 чисел'):
for i:-l to 10 do readln(a[i]):
s:-0:
for i:-l to 10 do s:-s+a[i]:
writelnf'исходный массив'):
for i:-l to 10 do writefati], ' '):
writein:
writelnf'ответ'):
writeln(s):
readln;
end.
{Суммирование элементов}
{одномерного массива}
{Объявление}
(массива а из 10 элементов)
{переменных i.s}
{Ввод}
{одномерного массива)
{Суммирование)
{одномерного массива)
{Вывод}
{одномерного}
{массива)
{Вывод}
{результата}
Эта же самая программа решает и большое множество других задач, в которых
в конечном счете нужно сложить 10 чисел.
ПРИМЕР
Десятеро друзей решили сделать подарок своему любимому певцу Майклу Джексону,
Каждый разбил свою копилку и внес свой денежный вклад в общее дело. Сколько де-
нег собрали друзья? А вы можете придумать такую задачку, чтобы для ее решения
нужно было сложить 10 чисел?
Понятно, что простейший вариант такой программы должен накапливать сумму,
то есть сначала сложить первые 2 элемента, потом к ним добавить третий и так
далее для всех элементов массива. Последний элемент, который будет прибавлен
к сумме в нашей задаче, — это десятый элемент массива.
Но посмотрим внимательно на текст программы. Первая задача — выяснить и по-
стараться запомнить назначение всех ключевых слов и знаков препинания, исполь-
1.1. Основные операторы языка и простейшие алгоритмы
13
зованных в программе. Ведь программа предназначена для компьютера, а для него
точка — это один символ, запятая — другой. И он просто неправильно поймет про-
грамму, если вы переставите их местами.
Программист при написании программы на языке Паскаль в любом месте может
пользоваться как маленькими, так и большими буквами (или даже перемежать их
в одном слове). С точки зрения программы на языке Паскаль, большие и малень-
кие буквы не различаются, то есть begin, BEGIN или даже BeGiN — это одно и то же
слово! В связи с этим в дальнейшем тексте, для его большей наглядности и читае-
мости, будем придерживаться следующего правила: для написания имен перемен-
ных и массивов непосредственно в тексте программы будут использоваться ма-
ленькие буквы, а в тексте пояснений — большие.
Итак, начинается программа всегда со слова PROGRAM, за которым через пробел
следует имя программы — Sum_1mas в данном примере. Имя программы должно
состоять из латинских букв или цифр, общее количество которых должно быть
не больше 8. Вместо пробела в имени программы можно использовать символ
подчеркивания « _ ». За именем программы обязательно стоит точка с запятой
« ; ». Обратите внимание также, что символ « ; » завершает почти каждую строку
программы. Пропуск этого символа — одна из наиболее распространенных оши-
бок начинающего программиста. Но если символ « ; » стоит не всегда, то как ра-
зобраться: когда его ставить, а когда — нет? Для этого вновь посмотрим на текст
программы:
□ после слов VAR и BEGIN не стоит никаких символов вообще;
□ после слова END в последней строчке программы стоит символ «.» (точка). И все-
гда должен стоять он и только он!
Во всех остальных случаях будем ставить в конце строки символ « ; » до тех пор,
пока не узнаем новых правил по этому поводу.
Особое внимание нужно обратить на комментарии к программе — это все, что
находится между символами « { » и « } ► (то есть открывающими и закрываю-
щими фигурными скобками). Комментарии не принимаются во внимание ком-
пьютером, однако могут быть полезны человеку, который пишет и читает про-
грамму, поясняя, для чего служит (или что делает) та или иная строка
программы.
В комментариях к нашей программе написано, что программа суммирует элемен-
ты одномерного массива, для чего она сначала объявляет все переменные, которые
будет использовать. А именно: массив из 10 чисел, который в программе получил
имя А, а также 2 переменных — I и S. Переменная I будет использоваться для того,
чтобы хранить и изменять номер обрабатываемого элемента. Переменная S будет
использоваться для хранения суммы элементов массива, которые мы уже сложи-
ли. Далее в комментариях написано: одномерный массив вводится, его элементы
суммируются, затем выводятся сам массив и полученный результат суммирова-
Возникает вопрос: зачем выводить исходный массив? Мы ведь его сами и вводи-
ли, мы знаем, какие там числа. Нам нужно было вывести только результат!
Глава 1. Программирование на Паскале
В данной программе вывод исходного массива был сделан по следующим причинам.
1. Чтобы показать, как нужно выводить одномерный массив, если в этом возник-
нет необходимость.
2. На начальном этапе обучения программированию вы, возможно, совершите
какие-то ошибки. Их поиск будет облегчен, если прямо перед вашими глазами
будут находиться одновременно и те числа, которые вы ввели, и те, что ваша
программа получила в качестве ответа для поставленной вами задачи. Вы так-
же можете ошибиться и в самих операторах ввода.
Попробуем проанализировать нашу программу построчно:
program Sum_lmas:
Эта строка определяет начало программы и ее название — Sum_1mas.
Эта строка — сокращение от английского слова «variable», что в переводе означает
«переменная», и она должна следовать во всех ваших программах за словом PROGRAM.
Между ней и строчкой, содержащей слово BEGIN, обязательно должны располагаться
описания всех переменных и массивов, которые вы предполагаете использовать в
программе.
a:array [1..10] of integer:
Строка означает, что в данной программе будет использоваться имя А для обозна-
чения массива (ARRAY) из 10 чисел, которые нумеруются от 1 до 10 ([ 1.. 10]). При
этом числа будут целыми (OF INTEGER), или, как еще говорят, целого типа.
i. s : integer:
Эта строка обозначает, что имена I и S будут использоваться для обозначения двух
переменных — тоже целого типа (INTEGER).
Буквальный перевод этого слова, конечно, известен — «начало». Именно отсюда
начинается «исполняемая» часть программы, где мы пишем распоряжения компью-
теру на выполнение конкретных действий.
writelnf'Введите 10 чисел'):
Слово «write» по-английски обозначает «писать». Имеется в виду, что все располо-
женное между символами « '» и « '» необходимо вывести на экран, то есть в данном
случае мы приказываем компьютеру вывести на свой экран текст Введите 10 чисел.
Это нужно для того, чтобы человек, который будет работать потом с нашей про-
граммой, знал, что он должен ввести исходные данные перед запуском программы
на выполнение.
Что обозначает WRITELN?
«Ln» — это сокращение от английского слова «line», то есть «строка», и наличие
этих букв обозначает, что после завершения вывода этого текста нужно перемес-
тить курсор к началу следующей строки.
Курсор — это специальный символ (знак подчеркивания или прямоугольник), ко-
торый указывает позицию экрана, в которую будет выводиться очередной символ.
for i:-l to 10 do readln(a[i]>:
1.1. Основные операторы языка и простейшие алгоритмы
15
Эта строка в программе обеспечивает ввод в объявленный нами массив А с клави-
атуры 10 чисел.
Дословно эта строчка читается так:
Для I от 1 до 10 делать читать А[1].
Таким образом, компьютер, повинуясь этой строке нашей программы, ждет, пока
мы наберем на клавиатуре число и нажмем клавишу Ввод (Enter). Это число он за-
несет в элемент массива А[ 1 ], то есть первый элемент массива А. Потом компьютер
ждет, пока мы наберем на клавиатуре второе число, чтобы занести его в А[2], и так
далее, до 10-го элемента, который он занесет в А[ 10].
s:-0:
Вспомним, что переменную S мы ввели, чтобы накапливать в ней сумму введен-
ных чисел. Понятно, что начальное значение этой переменной, то есть значение
переменной S, пока мы не начали складывать, должно быть нулевым. Это и обеспе-
чивается данным оператором. Дословно он читается так:
В переменную S занести число 0.
Или так:
Переменной S присвоить значение 0.
for 1:-1 to 10 do s:-s+a[i]:
Дословно эта строка читается так:
Для I от 1 до 10 делать
новое значение переменной S вычислить как результат сложения
старого значения переменной S и элемента массива A[i].
По-другому ее можно читать и так:
Для I от 1 до 10 делать
взять старое значение переменной S.
прибавить к нему значение элемента А[т] и
занести полученную сумму обратно в переменную S.
Это единственная строчка в программе, которая непосредственно решает постав-
ленную задачу — последовательно суммирует введенные 10 чисел в переменной S,
добавляя туда:
□ сначала значение А[ 1 ], то есть первого элемента массива А (первого числа, ко-
торое мы ввели с клавиатуры);
□ потом значение А[2], то есть второго элемента массива А (второго числа, кото-
рое мы ввели с клавиатуры) и т. д.;
□ наконец, значение А[ 10], то есть десятого элемента массива А (десятого числа,
которое мы ввели с клавиатуры).
После завершения выполнения этой строки в переменной S находится искомый
результат — требуемая сумма!
wr1teln('исходный массив'):
Эта строка обеспечивает вывод на экран текста исходный массив, и нужна она
для того, чтобы человек, который будет запускать нашу программу, знал, что
16
Глава 1. Программирование на Паскале
за числа сейчас будут выводиться (числа исходного массива в данном слу-
for i:»l to 10 do write(a[1). ' '):
Дословно эта строка читается так:
Для I от 1 до 10 делать
вывести на экран AC1J. а поток символ пробел (' ').
Следует обратить внимание на то, что используется оператор WRITE, а не WRITELN
(как это было ранее). При этом курсор не переводится к началу следующей стро-
ки, а остается за последним выведенным символом. Таким образом, числа массива А
выводятся одно за другим в одной строке, а чтобы они не «слиплись», мы разделя-
ем их, выводя после каждого числа символ пробел (” ).
Если бы мы использовали оператор WRITELN, то числа выводились бы в столбик,
а это в нашем случае менее наглядно.
writein:
Для того чтобы перевести курсор к началу следующей строки после завершения
вывода всего массива, используется этот оператор. В результате слово «ответ» из
следующего оператора выводится с начала следующей строки.
writeln('ответ'.):
Этот оператор используется, чтобы дать понять, что далее будут сообщены резуль-
таты работы пашей программы.
writeln(s);
Этот оператор выводит значение переменной S, в которой и находится результат
работы программы.
readin:
Этот оператор ожидает нажатия нами клавиши Ввод (Enter) для завершения рабо-
ты нашей программы. Вы можете не использовать его, но это доставит вам некото-
рые неудобства при отладке программ.
end.
Этот последний оператор обязателен в нашей программе. Обязательной является
также и точка после слова END, о которой, к сожалению, часто забывают начина-
ющие программисты.
Мы разобрали первую простейшую программу на Паскале. Ее можно брать за ос-
нову при написании других программ, обрабатывающих одномерные массивы. При
этом изменять надо будет только расчетную часть программы. Объявлять же мас-
сивы и переменные, вводить исходные данные, выводить исходные данные и ре-
зультаты, в точности используя соответствующие части разобранной нами про-
граммы, нужно всегда.
Например, что нужно изменить в нашей программе, если мы захотим не сложить,
а перемножить введенные числа?
Нужно изменить всего лишь 2 символа: + на • и 0 на 1, получив при этом следую-
щую расчетную часть:
s:-l: {Перемножение элементов)
for i:-l to 10 do s:=s*ali): {одномерного массива)
1.1. Основные операторы языка и простейшие алгоритмы
17
Текст этой программы приведен в листинге 1.2.
Листинг 1.2. Программа, перемножающая введенные числа
а:аггау [1..10] of integer:
i. s : integer:
writelnl'Введите 10 чисел'): .
for i:-l to 10 do readln(a[i]):
S:-l:
for i:-l to 10 do s:-s*a[ij:
writeinc исходный пассив'):
for i:=l to 10 do write(a[i]. '
writeln:
writeln('oTBeT'):
writeln(s):
readin:
end.
{Перемножение элементов)
{одномерного массива)
{Объявление)
{массива а из 10 элементов)
{переменных i.s)
{Ввод)
{одномерного массива)
{Перемножение элементов)
{одномерного массива)
{Вывод)
{одномерного массива)
{Вывод)
{результата)
Таким образом, при разработке программ главное — придумать ее расчетную
часть или, иначе, составить алгоритм работы программы. Для большого коли-
чества задач такие алгоритмы уже давно составлены, и вместо того, чтобы «изоб-
ретать велосипед», достаточно изучить их и запомнить, что и предлагается вам
сделать.
Простейшие алгоритмы на одномерном массиве
Рассмотрим наиболее часто употребимые алгоритмы на одномерном массиве:
□ подсчет элементов, обладающих заданным свойством;
□ поиск максимального и минимального элементов;
□ поиск элементов, обладающих заданным свойством.
Подсчет элементов, обладающих заданным свойством
Пусть мы имеем одномерный массив с оценками 10 учеников по информатике.
Требуется посчитать, сколько из них имеют оценку 5. Алгоритм для такой задачи
имеет вид:
s:-0: {Подсчет элементов)
for i:=l to 10 do {равных даннону (5)}
if a[i]=5 then S:-S+1:
По заведенной у нас традиции, рассмотрим алгоритм построчно.
s:-0:
Начальное значение количества отличников по информатике устанавливаем в 0.
for i:=l to 10 do
Обратите внимание, в программе Sum_1mas (см, листинг 1.1) то, что именно нужно
делать (читать элемент с клавиатуры или выводить его на экран), мы описывали в
той же самой строке. А в этот раз — в следующей и поэтому в конце этой строки не
Глава 1. Программирование на Паскале
ставится символ « ; »1 Еще очень важно обратить внимание на то, что следующая
строка пишется со сдвигом вправо на 2 позиции относительно предыдущей стро-
ки. Так мы отмечаем, что эта строка существует не сама по себе, а является продол-
жением предыдущей.
1f a[i]-5 then s:-s+l:
Если A[i ] равно 5, то увеличить значение S на 1. Более подробно это можно прочи-
тать следующим образом: если I-й элемент массива А равен 5, то новое значение
переменной S надо сформировать, сложив старое значение S с 1.
Возвращаемся к задаче об отличниках: если очередной ученик имеет оценку 5, то
его надо посчитать. Но ведь увеличение на 1 — это и есть подсчет.
Вопрос: как подсчитать количество троечников?
s:-0:
for i:-1 to 10 do
if a[i]-3 then S:-S+1;
Как подсчитать количество хорошистов и отличников?
s:-0:
for 1:=1 to 10 do
if a[i>-4 then s:-s+l:
Вообще, в операторе IF (если) можно использовать следующие знаки сравне-
□ = — равно
□ > — больше
□ < — меньше
□ >= — больше либо равно
□ <= — меньше либо равно
□ <> — не равно
Например, сколько человек имеют в качестве оценки не 5?
В операторе IF можно писать и более сложные условия, используя слова AND (и), OR
(или) и скобки.
Например, пусть А[ 1 ] — массив оценок по информатике, а 8(1] — массив оценок
по математике. Как подсчитать количество учеников, которые имеют оценку 5 и
по информатике и по математике?
if (a[i]-5) and (b[i]-5) then s:-s+l:
Как подсчитать количество учеников, которые имеют оценку 5 хотя бы по одному
из этих предметов?
for 1:-1 to 10 do
1.1. Основные операторы языка и простейшие алгоритмы
19
Теперь вы можете решить любую задачу, в которой нужно подсчитать количе-
ство элементов в одномерном массиве, обладающих каким-то свойством. На-
пример, задачи 1 и 5 из приведенных в разделе «Задачи для самостоятельного
решения».
Придумайте задачи, которые решаются подсчетом элементов, обладающих задан-
ным свойством.
Поиск максимального и минимального элементов
Пусть одномерный массив А[ 1 ] содержит числа — рост 10 учеников в сантиметрах.
Требуется найти рост самого высокого из учеников.
s:-atl]:
for 1:-2 to 10 do
if a[i]>s then s:-a[i]:
(Поиск)
(максимального элемента)
По обыкновению, рассмотрим задачу построчно.
ST-atl];
Сначала в переменной 8 запоминаем рост первого ученика.
for i2 to 10 do
Для всех остальных учеников от 2-го до 10-го необходимо проделать следующие
действия:
if a[i]>s then s:-a£1]:
Если рост текущего (I-го) ученика больше, чем тот, что мы помним в переменной
S, то в 8 надо занести это большее значение.
Таким образом, когда эта процедура будет проделана для всех учеников, в пере-
менной S окажется значение, соответствующее максимальному из всех, которые
были введены в массив А.
А если требуется найти не максимальный, а минимальный элемент (то есть рост
самого маленького ученика), что тогда нужно изменить в данном алгоритме?
Верно — вместо знака > (больше) поставить знак < (меньше) в операторе IF. Тогда
получим:
s:°a[l]: (Поиск)
for 1:-2 to 10 do (минимального элемента)
if a[i]<s then s:-a[i]:
Если, например, в задаче требуется найти разность наибольшего и наименьшего
элементов, что тогда делать?
Завести разные переменные для максимального и минимального элементов:
(Поиск)
(максимального элемента)
шах:-а[1]:
for 1:-2 to 10 do
if a[iJxnax then max:-a[i]:
min:-a[l]:
for i:-2 to 10 do
if a[i]<min then min:=a[i]:
(Поиск)
(инициального элемента)
Глава 1. Программирование на Паскале
Конечно, надо не забыть добавить объявление этих переменных:
Van
i.s.HAX.MIN : integer:
Одновременный поиск максимального и минимального элементов в одномерном
массиве можно было записать немного короче:
пих:-а[1]: min:-a[l]:
for i:-2 to 10 do
begin
if a[i]>max then max:-a[i]:
if a[i]<min then min:-a£1J:
end:
s:-max-min:
В данном случае, когда внутри оператора FOR мы хотим выполнить 2 (или более)
оператора IF, необходимо использовать так называемые операторные скобки BEGIN END.
Такую последовательность операторов BEGIN оператор!; оператор 2; END;
принято называть составным оператором.
ПРИМЕЧАНИЕ--------------------------------------------------
Обратите внимание в записи операторов на сдвиги вправо, отражающие вложенность
их выполнения.
Поиск элементов, обладающих заданным свойством
Пусть у нас А[ 1 ] содержит оценки по информатике 10 учеников. Требуется выяс-
нить, имеется ли среди них хоть один ученик, имеющий тройку.
1:-1: {Поиск элементов}
while (i-o-10) and (a[i]<>3) do i:-1+l: {равных данному (3)}
then wr1teln('3 нет ')
else writeln('первая 3 имеет индекс '.!):
Конечно, можно было воспользоваться алгоритмом подсчета элементов, облада-
ющих заданным свойством:
then writein ('троечников нет')
else writein ('троечник есть'):
Правда, в таком варианте нам не удастся выяснить, кто именно — троечник, то есть
каков номер элемента, равного 3?
Можно подправить предыдущий алгоритм следующим образом:
if а[1]-3 then begin s:-s+l: k:-i: end:
if s=0
then writein ('троечников нет')
else writein ('троечник есть, его номер ' ,k):
1.1. Основные операторы языка и простейшие алгоритмы
Но основной недостаток такого подхода заключается в том, что мы вынуждены
просматривать все элементы массива, хотя ответ на свой вопрос мы могли узнать
уже после просмотра первого элемента, если он и оказался троечником. В случае
массива из 10 элементов это, может быть, и не трагедия, а если элементов в масси-
ве 10 миллионов?
На этот случай в языке программирования Паскаль предусмотрен оператор WHILE:
1:-1: {Поиск элеиентов)
while (i<-10) and (a[i]<>3) do 1:-1+1: (равных данному (3))
if i>10
then writein СЗ нет')
else writein ('первая 3 имеет индекс ' .i):
По обыкновению, рассмотрим алгоритм построчно.
I присваиваем значение 1.1 — переменная, в которой хранится номер текущего
элемента массива А.
while (i<-10) and (a[i]<>3) do i;-i+l;
Буквально это читается так:
А применительно к нашей задаче:
Пока (массив не кончился) и
(текущий элемент в массиве не тот. что мы ищем)
(то есть элемент не обладает нужным нам свойством)
делать - взять следующий элемент
Из этого оператора пока программа может выйти одним из двух способов:
1) в процессе прибавления 1 к I (взятия следующих элементов) так и не нашлось
нужного нам элемента;
2) нужный элемент нашелся при некотором I.
then writein СЗ нет ')
else writein ('первая 3 имеет индекс ’.-i): '
Как раз по причине двух вариантов следом за пока и стоит оператор IF (если), анали-
зирующий, как именно он закончился, и выдающий нам соответствующее сообщение.
Еще раз отметим, что основное достоинство такого способа обработки массива за-
ключается в том, что поиск будет прекращен сразу, как только нужный элемент
будет найден.
1.3. Сортировка элементов одномерного массива
for j:-l to 9 do
begin
s:-atjl: k:-j:
for 1:-j+l to 10 do
if a[1]<s
then begin s:-a[i): k:-i end:
a[k]:-a[j):
a[j]:-s:
{Поиск)
{минимально!о)
{элемента)
{Вынос «наверх»)
{минимального элемента)
22 Глава 1. Программирование на Паскале
Предположим, что массив А содержит рост 10 учеников в сантиметрах. Требуется
переместить числа в массиве А таким образом, чтобы каждое последующее число
было больше предыдущего (или равно ему).
ПРИМЕЧАНИЕ------------------------------------------------------
В случае трудностей понимания при первом прочтении этот раздел можно опустить.
Основная идея алгоритма заключается в следующем: 9 раз среди оставшихся эле-
ментов ищется наименьший. Если такой элемент найден, то он меняется в первый
раз с первым элементом, во второй раз — со вторым (на первом месте уже стоит
найденный первый наименьший элемент) и т. д. В 9-й раз выбирается минималь-
ный элемент из 9-го и 10-го элементов и меняется местами с 9-м.
Методические указания по решению задач 1-5, 7, 9, 12,
13 из раздела «Задачи для самостоятельного решения»
Задача 1. Подсчет ненулевых элементов.
s:=e:
for i :=1 to IB do
if a(il<>0 then s:=s+l;
writeln(s):
Задача 2. Подсчет элементов, абсолютная величина которых больше 7.
s:=0;
for 1:=1 to 10 do
if ABS(a[i])>7 then s:=s+l;
writeln(s):
Задача 3. Поиск 7.
while <i<=10) and (a[i]<>7) do i:=i+l:
if i>10
then writeln('HeT')
else writeln('na'):
Задача 4. Разность максимального и минимального элементов.
max:=a[l]: min:=a[l]:
for i :=2 to 10 do
begin
if a[i]>max then max:=a[i);
if a[i]<min then min:=a[i);
writeln(s):
Задача 5. Попарное сравнение двух массивов.
sl:=0: s2:=0; s3:=0:
for i:=l to 10 do
if a(i]>b[i] then sl:=sl+l:
if a(i]=b(i] then s2:=s2+l:
if a[1]<b[i] then s3:=s3+l;
1.1. Основные операторы языка и простейшие алгоритмы
Задача 7. Суммирование и подсчет.
s:=0;
for i:=l to 10 do s:=s+a[i]
r:=s/10;
n:=0;
for 1:=1 to 10 do
if a[i]>r then n:=n+l;
writeln(n):
Задача 9. Поиск максимального элемента и подсчет.
or 1: =1 to 10 do
if a(i]>max then max:=a[i);
for
=1 to 10 do
writeln(s):
Задача 12. Поиск нулевого элемента.
if i>10
then writeln('HeT')
else writeln('первый 0 стоит на позиции ' .i>:
Задача 13. Поиск отрицательного числа с конца массива.
i:=10;
else writeln('последнее число<0 стоит на позиции’.1):
Стандартная обработка двумерных массивов
Значительное количество практических задач требует обработки не одномерных,
а двумерных массивов.
Двумерный массив и его части
Например, рассмотрим двумерный массив из 25 элементов, содержащий 5 строк и
5 столбцов:
5 -2 3 14 И
17 13 1 7 1
5 -2 3 14 20
8 0 9 10 -4
3 -6 3 14 16
Компонентами двумерного массива, требующими специальной обработки, могут
быть его строки, столбцы и диагонали, например:
□ вторая строка:
17 13 1 7 1
24
Глава 1. Программирование на Паскале
□ первая диагональ: 5 13 3 10 16
□ вторая диагональ: И 7 3 0 3
□ третий столбец: 3 13 9 3
□ ит.д.
Индексы элементов двумерного массива
Двумерный массив А из 25 элементов (5 строк и 5 столбцов) имеет такие индексы:
5 -2 3 14 11 -» А[1,1] А[1.2] А[1,3] А[1,4] А[1,5]
17 13 1 7 1 -> А[2,1] А[2,2] А[2,3] А[2,4] А[2.5]
5 -2 3 14 20 -» А[3,1] А[3,2] А[3,3] А[3,4] А[3,5]
8 0 9 10 -4 —> А[4,1] А[4.2] А[4,3] А[4,4] А[4,5]
3 -6 3 14 16 -» А[5,1] А[5,2] А[5,3] А[5,4] А[5,5]
ПРИМЕЧАНИЕ-------------------------------------------------------
Первый индекс — это номер строки, а второй — номер соответствующего столбца.
При обработке в программе всех элементов двумерного массива необходимо пи-
сать вложенные операторы FOR:
FOR I:-l ТО 5 00
FOR J:-l TO 5 00 ... A [ I . J ] ...
Индексы строки и столбца двумерного массива
Рассмотрим в качестве примера индексы второй строки:
А[2,1] А[2,2] А[2,3] А[2,4] А[2,5].
Легко заметить, что первый индекс — номер строки — фиксирован и равен 2 (для 2-й
строки), а второй индекс последовательно пробегает значения от 1 до 5. Поэтому в слу-
чае необходимости обработки 2-й строки двумерного массива достаточно написать:
FOR 1:-1 ТО 5 00 ... А [ 2 . I ] ...
Переменная I может быть по необходимости заменена любой другой, например М:
FOR М:=1 ТО 5 00 ... А [ 2 . И ] ...
Теперь рассмотрим в качестве примера индексы третьего столбца:
А[1.3]
А[2,3]
А[3.3]
А[4,3]
А[5,3]
1.1. Основные операторы языка и простейшие алгоритмы
25
Очевидно, что теперь второй индекс — номер столбца — фиксирован, а первый ин-
декс — номер строки — пробегает последовательно все значения от 1 до 5. Поэтому
цикл обработки элементов третьего столбца должен выглядеть так:
FOR 1:-1 ТО 5 00 ... А [ I . 3 ] ...
Индексы диагоналей двумерного массива
Элементы первой диагонали двумерного массива имеют индексы:
А[1.1]
А[2.2]
А[3,3]
А[4,4]
А[5,5]
Легко заметить, что индекс строки равен индексу столбца для всех элементов пер-
вой диагонали, и потому цикл обработки ее элементов должен выглядеть следу-
ющим образом:
FOR 1:-1 ТО 5 00 ... А [ I . I ] ...
Элементы второй диагонали двумерного массива имеют индексы:
А[1.5]
А[2,4]
А[3.3]
А[4.2]
А[5,1]
Нелегко, но можно заметить, что сумма индексов строки и столбца для всех эле-
ментов второй диагонали постоянна и равна 6 (для массива 5x5; для массива NxN
это будет N+ 1), и потому цикл обработки элементов второй диагонали должен
выглядеть следующим образом:
FOR 1:-1 ТО 5 00 ... А [ I . 6 - I ] ...
Перенос простейших алгоритмов на двумерные массивы
Учитывая все вышеизложенное, можно согласиться с методикой переноса алго-
ритмов с одномерных массивов на двумерные, которая проиллюстрирована на при-
мере алгоритма суммирования элементов:
S :-0:
for 1:-1 to 5 do s:-s*a[1.33:
{Суниирование элеиентов)
{одномерного массива)
{Суммирование элементов)
{второй строки двумерного массива)
{Суммирование элеиентов)
{третьего столбца двумерного массива)
26
Глава 1, Программирование на Паскале
{Суммирование элементов}
{первой диагонали двумерного)
{нассива}
{Суииирование элементов)
{второй диагонали двумерного)
{массива)
{Суммирование элементов)
{двумерного)
{массива)
В чем же заключается эта методика? В замене индексов одномерного массива на
индексы соответственно строки, столбца, первой или второй диагоналей или всего
двумерного массива. В случае обработки всего двумерного массива необходимо
также использовать вложенные операторы FOR.
Объявление, ввод и вывод двумерного массива
В программе, обрабатывающей двумерный массив, необходимо объявлять, вводить
и выводить именно двумерный массив:
van {Обьявление}
агаггау [1..5.1..5] of integer: {массива а)
{из 25 элементов)
writelnf’Введите 25 чисел'): {Ввод)
for 1:-1 to 5 do (двумерного)
for j:=l to 5 do readln(a[i.jl): {массива)
writelnt'исходный массив'): {Вывод)
for i,:-l to 5 do {двумерного)
begin {массива)
for j:-i to 5 do write(a[1.j].' '):
writein:
end:
end.
Изменения по сравнению с объявлением, вводом и выводом одномерного массива
вполне предсказуемы интуитивно: и потому здесь не нужны никакие комментарии.
Методические указания по решению задач 10,11,14,19-21
Задача 10. В двумерном массиве поменять все знаки на противоположные.
Например, пусть входной массив такой:
5 -2 3 14 11
17 13 1 7 1
5 -2 3 14 20
8 0 9 10 -4
3 14 16
-6
1.1. Основные операторы языка и простейшие алгоритмы
27
Тогда выходной должен стать таким:
- 5 2-3 -14 -И
-17 -13 -1 -7 -1
- 5 2-3 -14 -20
- 8 0 -9 -10 4
-3 6-3 -14 -16
Очевидно, расчетная часть программы должна выглядеть следующим образом:
for i:-1 to 5 do
for j:-l to 5 do a[i.j]:--a[i.j]:
Текст самой программы — в листинге 1.4.
Листинг 1.4. Программа замены знаков элементов массива на противоположные
program N10:
a:array [1..5.1..5] of integer:
i.j : integer:
writelnf'Введите 25 чисел’):
for i:-l to 5 do
for j:-l to 5 do readln(a[i.j]);
writelnf'исходный пассив'):
for i:-l to 5 do
begin
for j:-l to 5 do writefati.j],' '):
writein:
for i:-l to 5 do
for j:-l to 5 do at1.j]:—a[1.j]:
writelnf'результирующий пассив'):
for i:-l to 5 do
for j:-l to 5 do writefati.j].' '):
writeln:
{Объявление}
{пассива a)
{из 25 элементов}
{Ввод}
{двумерного}
{массива)
{Вывод}
{исходного}
{двумерного}
{массива}
{Вывод}
{полученного}
{двумерного}
{массива}
Задача 11. В двумерном массиве найти максимальный элемент.
Расчетная часть задачи может выглядеть так:
шах:- а[1.1]
for 1:-1 to 5 do
for j-.-l to 5 do
if max»a[i.j] then max:-a[1,j]:
Задача 14. Выяснить, является ли двумерный массив (5 х 5) «магическим квадратом».
Простейшее решение заключается в том, чтобы:
□ сначала ввести переменные:
S1, S2,..., S5 — суммы строк от первой до пятой;
Глава 1. Программирование на Паскале
Т1, Т2,..., Т5 — суммы столбцов от превого до пятого;
D1, D2 — суммы элементов превой и второй диагоналей;
□ а затем написать оператор IF типа:
if <S1»D2) and (52=02) and (53=02) and ($4=02) and (S5-D2) and
(Tl-02) and (T2-D2) and (T3-D2) and (T4-02) and (T5-02) and <01-02)
then writein ('квадрат магический')
else writeln ('квадрат НЕиагический'):
Некоторые из вас справедливо могут заметить: если массив будет состоять из 100
строк и 100 столбцов, то такое решение очень неудобно. Согласен, тогда надо при-
думать алгоритм, решающий данную задачу наиболее удобным способом. Приду-
мывание новых алгоритмов — это самая сложная задача в программировании. Ей
и посвящена следующая глава. Надеюсь, что когда вам удастся разобраться с мате-
риалом следующего раздела, вы сами придумаете лучший алгоритм решения зада-
Задача 19. Найти количество нулей в заданном столбце.
Расчетная часть программы может быть такой:
readln(j):
writeln(k):
Задачи 20 и 21. Несмотря на сложные и на первый взгляд различные формулиров-
ки, обе требуют найти минимальный элемент из максимальных по строкам. Это
можно сделать, например, так:
for j:-2 to 5 do
if a[i.j]>max£i] then max£i]:-a£i.j]
minmax:-max[lj:
if max[i]<minmax then т1птах:чпах[1]:
writeln(niinmax):
Нестандартные алгоритмы и программы
Вообще, разработка алгоритмов и программ — это не только наука, ио и в значи-
тельной степени — искусство. И поэтому многие считают, что учить разработке
алгоритмов и программ — это все равно что учить человека писать картины или
сочинять стихи и мелодии. Тем не менее существуют некоторые общие сведения,
которые следует сообщить всем желающим научиться разрабатывать алгоритмы.
Ниже вашему вниманию предлагается план, следование которому при разработке
алгоритмов может помочь вам быстрее освоить эту науку (или искусство). Совсем
не обязательно его помнить наизусть. Достаточно пытаться придерживаться его
при разработке алгоритмов для всякой новой программы.
1.1. Основные операторы языка и простейшие алгоритмы 29
План разработки алгоритмов и программ
План заключается в следующем.
1. Переформулировать условия задачи.
2. Выяснить, что — на входе и что — на выходе.
3. Составить тестовые примеры (не забыв о крайних случаях).
4. Решить тестовые примеры вручную.
5. Если задача решается как композиция известных задач, то перейти к пункту 9.
6. Разработать алгоритм программы.
7. Выполнить ручную прокрутку.
8. Если есть ошибки, то перейти к пункту 6.
9. Написать текст программы.
ПРИМЕЧАНИЕ---------------------------------------------------------
Пояснения к этому плану будут приводиться параллельно с применением его для ре-
шения конкретных задач.
Долгий путь к алгоритму
Начнем с задачи 9: дана целочисленная таблица А[1:10], требуется подсчитать,
сколько раз встречается в ней максимальное по величине число.
Для этого надо последовательно пройтись по всем пунктам плана.
1. Переформулировать условия задачи.
2. Выяснить, что — на входе и что — на выходе.
Имеется в виду, что вы должны постараться переформулировать условия так, что-
бы их формулировка содержала минимальное количество слов, а задача при этом
оставалась той же, и однозначно определялось, что нужно вводить (число, одно-
мерный массив чисел, двумерный массив чисел, строку символов) и что нужно
выводить.
Например, для задачи 9 — новая формулировка: в одномерном массиве посчитать
количество максимумов, имея на входе одномерный массив, на выходе — число.
3. Составить тестовые примеры (не забыв о крайних случаях).
4. Решить тестовые примеры вручную.
Прежде чем писать программу, вы должны точно понять, что именно она должна
делать. Кроме того, вы должны строго определить, какую программу вы будете
считать работающей правильно. Именно составление адекватного задаче множе-
ства тестов и позволяет решить эту задачу.
Что такое тест? Это те данные, которые вы должны ввести в вашу программу, и
то, что вы считаете правильным ответом, который и должна выдать ваша програм-
ма в случае ввода этих данных.
Сколько должно быть тестов? С одной стороны, вы должны придумать достаточ-
ное количество тестов, чтобы можно было утверждать, что ваша программа рабо-
Глава 1 Программирование на Паскале
тает верно, если она «проходит» все ваши тесты (то есть для всех входных данных
выведет определенные выходные). С другой стороны, тестов должно быть как мож-
но меньше, потому что, исправив хоть один символ в вашей программе, вы должны
будете перепроверить правильность ее работы на всех ваших тестах.
Кроме того, при составлении тестов необходимо учитывать, что многие програм-
мы должны специальным образом обрабатывать и различные крайние случаи.
Например, для решаемой задачи 9 достаточно следующих тестов.
□ Если таблица имеет вид:
5-2406117024,
то максимум 1:11.
□ Если таблица имеет вид:
5114061170211,
то максимумов 3. Все они одинаковы и равны 11.
□ Если таблица имеет вид:
5555555555,
то все ее элементы — максимумы.
5. Если задача решается как композиция известных задач, то перейти к пункту 9.
На этом этапе вы должны попытаться из известных вам алгоритмов составить
композицию, которая решит данную задачу. Например, для задачи 9 эту ком-
позицию можно составить так:
1) поиск максимального элемента в одномерном массиве;
2) подсчет числа элементов (в одномерном массиве), равных данному (найден-
ному максимальному).
И тогда можно сразу переходить к 9-му пункту плана, то есть непосредственно к
написанию расчетной части программы (листинг 1.5).
Листинг 1.5. Расчетная часть программы решения задачи 9
max а[1]: for 1 2 to 10 do (Поиск) {максимального) {элемента}
if a[1] > max then max:-a[i]: n 0; for 1 1 to 10 do if a[i] - max then n:-n+l: А затеи и собственно программы: {Подсчет элементов) {равных данному (max))
program MaxNumb: a: array [1..10] of integer: (Объявление) (массива а из 10) (элемент)
i.n.max : integer: writeln('Введите 10 чисел'): {переменных i.n.max) {Ввод)
1.1. Основные операторы языка и простейшие алгоритмы
for i:-l to 10 do readln(a[i]):
max := all):
if a[i] > max then max:-a[i]:
{одномерного массива)
{Поиск}
{максимального)
(элемента)
(Подсчет элеиентов)
{равных данному (max))
{Вывод)
{одномерного массива)
(Вывод)
{результата)
for 1 1 to 10 do
if a[i] - max then n:-n+l:
writeln('исходный массив'):
for i:-l to 10 do write(a[i].’ '):
writein:
write!'Кол-во максимальных элементов'):
writelnC одномерного массива - '.n):
end.
Однако такая возможность представляется далеко не всегда. Для примера рассмот-
рим задачу 15: дана целочисленная таблица А[ 1:10], надо подсчитать наибольшее
число идущих в ней подряд одинаковых элементов.
Для повторения проведем начальные этапы разработки алгоритмов и для этой за-
Новая формулировка', в одномерном массиве посчитать наибольшее число идущих
подряд одинаковых элементов, имея на входе одномерный массив, а на выходе —
число.
Что касается полного множества тестов, то в данном случае оно более сложное:
1) А = [5 -2 4 0 6 11 7 0 2 4] - нет подряд идущих;
2) А = [5 555555555] — все подряд идущие;
3) А = [5 114 4 4 11 7 0 2 11] — одна цепочка подряд идущих;
4) А = [5 1144422222] — сначала min, потом max;
5) А = [5 44444422 2] — сначала max, потом min.
Обращаю ваше внимание на необходимость присутствия во множестве тестов
четвертого и пятого. Так, например, если во множестве тестов будет отсутство-
вать тест 4, то, написав программу, которая будет считать первое число идущих
подряд одинаковых элементов, можно, получив правильные ответы на всех остав-
шихся тестах, ошибочно считать, что программа полностью решает поставлен-
ную задачу.
Аналогично в случае, если множество тестов не будет содержать теста 5, то, напи-
сав программу, которая будет считать последнее число идущих подряд одинако-
вых элементов, можно будет получить правильные ответы на всех оставшихся те-
стах и, опять-таки, ошибочно считать, что вами написана программа, полностью
решающая поставленную задачу.
Предположим, что вы составили полное множество тестов. Как же теперь соста-
вить алгоритм, решающий поставленную задачу?
Прежде всего заметим, что раз вы составили тесты и для всех входных данных
вручную посчитали правильные ответы, то вам известен правильный алгоритм
решения задачи. Основная ваша проблема теперь — записать этот алгоритм так,
чтобы он был правильно понят и.выполнен компьютером.
32
Глава 1. Программирование на Паскале
Чтобы помочь формализовать известный вам алгоритм, предлагается использо-
вать следующий мнемонический прием. Представьте, что:
□ на длинном шоссе разложен миллион рядом лежащих табличек, на которых
написаны числа;
□ вам требуется решить задачу для этого миллиона чисел;
□ ходить приходится пешком (поэтому хотелось бы поменьше ходить от числа к
числу, в идеале — прямо от первого до последнего,-не возвращаясь назад);
□ можно на ладони записывать некоторые числа, чтобы не надо было их помнить;
□ сравнивать можно только два числа (оба на ладони, оба на дороге, одно на ладо-
ни, другое на дороге);
□ нужно придумать схему действий (алгоритм), так чтобы на ладони появился
ответ, когда вы доберетесь до конца шоссе.
Другой мнемонический прием разработки алгоритмов можно использовать, когда
вы работаете вдвоем с товарищем. Тогда вы просите товарища составить тест с
большим количеством входных данных, и затем он называет вам эти входные дан-
ные по одному. Вы не имеете права записывать числа, которые он называет, но
можете записывать результаты вычислений над ними. Задач у вас вэтом случае две:
1) получить правильный ответ (сверив его потом с ответом товарища);
2) придумать схему действий (алгоритм), по которой можно получать правиль-
ный ответ всегда (независимо от входных данных).
Попробуем теперь записать алгоритм задачи о подряд идущих элементах для ис-
полнения человеком. Записывать на ладони в этом случае нужно только 2 числа:
□ 1 -е — сколько сейчас одинаковых подряд идущих элементов;
□ 2-е — максимальное число одинаковых подряд идущих элементов, встреченное
до сих пор.
Тогда алгоритм можно написать следующим образом:
Записать на ладони первое число - 1 и второе число - 1
Начиная со второго числа на шоссе и до последнего делать следуюшее
если текущее число на шоссе равно предыдущену
то увеличиваем на 1 первое число на ладони
иначе если первое число на ладони больше второго числа на ладони
то на несто второго числа на ладони записывать превое
(чтобы сохранить наксииун подряд идущих)
на место первого числа на ладони записывать 1
(чтобы начать счет сначала для текущих подряд идущих)
Соответствующий компьютеризованный алгоритм может выглядеть так:
ввод АС1..1О] {разложили числа на шоссе)
max - 1. tek = 1 {записали на ладони 2 числа)
для 1 от 2 до 10 (повторяем для чисел от вторго)
{до десятого)
если А[1] - А[1-1] {если подряд идут)
то tek - tek + 1 (то инкрементируем текущее)
иначе если tek > max то max - tek {иначе если надо меняем макс)
tek - 1 (и начинаем считать сначала)
Вывод max {Выводим результат)
1.1. Основные операторы языка и простейшие алгоритмы
Наконец мы получили алгоритм, и нам кажется, что он — правильный. Что теперь
делать? «Писать по нему программу», — можете ответить вы. Можно, но я все-
таки предлагаю сначала сделать ручную прокрутку, чтобы, еще не садясь за компь-
ютер, найти и исправить как можно больше ошибок в написанном алгоритме.
Что же такое ручная прокрутка1 Это процесс исполнения программы человеком,
как если бы он был компьютером. Основная трудность ручной прокрутки для ав-
тора разработанного алгоритма — забыть суть решаемой задачи, идею алгоритма и
«механически и неукоснительно» исполнять то, что написано в алгоритме (ведь
именно так и будет поступать компьютер).
Обнаружив ошибку, нужно скорректировать алгоритм и вновь попробовать вы-
полнить ручную прокрутку, сначала на этом же тесте, а затем и на других. И так до
тех пор, пока автору не покажется, что его алгоритм правильно работает на всех
Как же выполнять ручную прокрутку?
Прежде всего надо аккуратно выписать алгоритм и тестовый пример, на котором
будет выполняться ручная прокрутка. А затем построчно исполнять алгоритм до
конца.
В качестве тестового примера (назовем его пример 1) выберем массив А с. элемен-
5 1144422222.
Проведем ручную прокрутку для алгоритма поиска наибольшего числа одинако-
вых идущих подряд чисел. Для удобства построим таблицу ручной прокрутки
(табл. 1.1). Каждый этап в ней будет соответствовать одному проходу через цикл в
нашем алгоритме.
Таблица 1.1. Результат выполнения ручной прокрутки на тестовом примере 1
Итак, ручная прокрутка:
Ввод А [1..10]
для 1 от 2 до 10
если А[1] - А[1-1]
то tek - tek * 1
' иначе если tek > шах то max = tek
tek - 1
Вывод (max)
Ответ: 3 (max) - ОШИБКА!!!
34
Глава 1. Программирование на Паскале
Прокомментируем этот пример построчно по ходу выполнения:
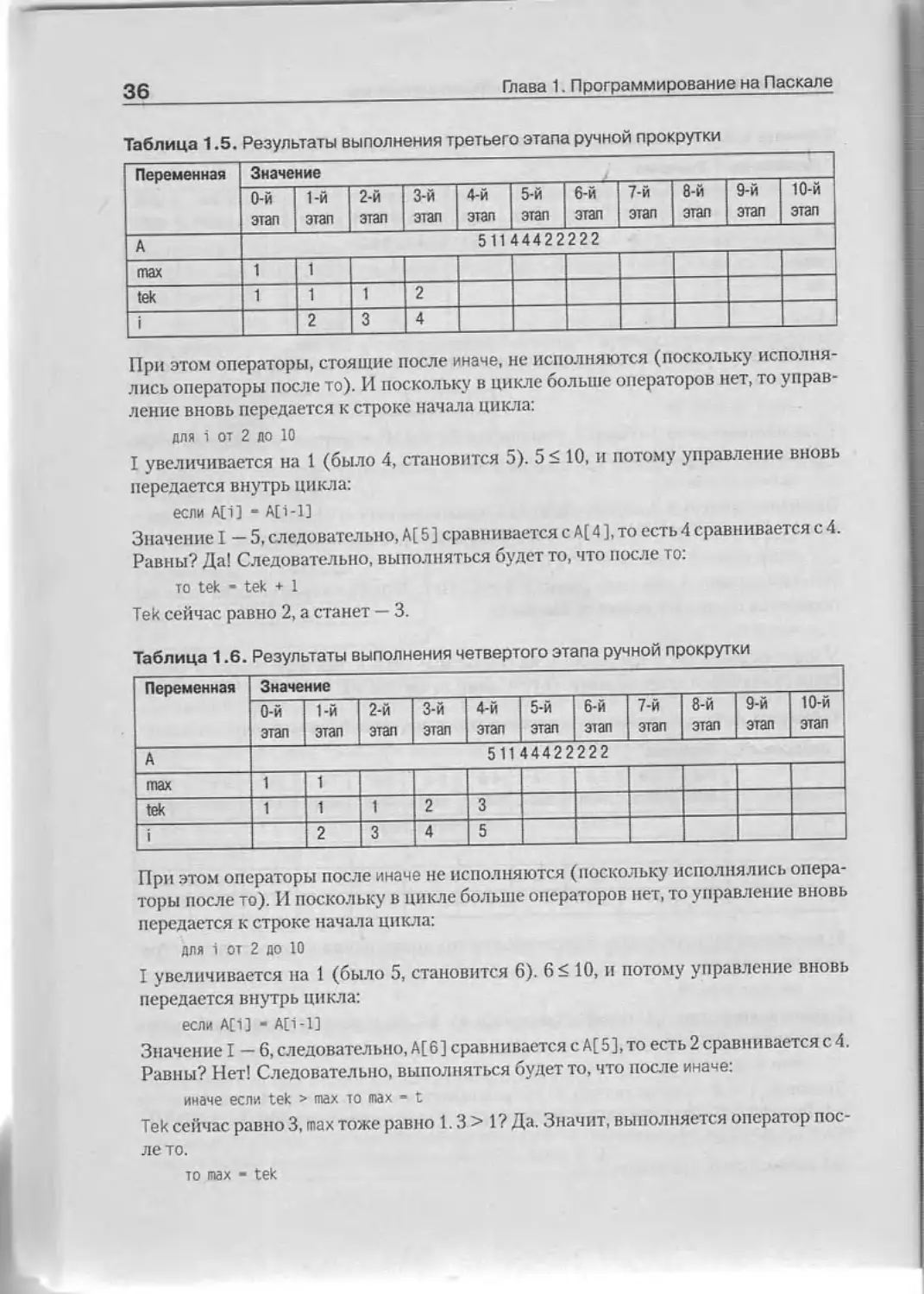
Ввод А[1. .10]
После выполнения этой строчки в памяти компьютера появятся введенные дан-
ные: массив А = [5 1144422222], то есть А[1] - 5, А[2] - И, А[3] = 4.А[ 10] - 2.
Мы помним, что правильный ответ для этого случая — 5 (5 подряд идущих чи-
сел 2; были еще и 3 подряд идущих числа 4, но 5 больше, чем 3, и потому правиль-
ный ответ — 5).
Переменные max и tek получили значение 1; в ручной прокрутке это записывается
I A I max I tek
| 511 44422222 | 1 | 1 |
В принципе, «документирование» ручной прокрутки можно было осуществлять
и горизонтально (табл. 1.2).
Таблица 1.2. Начальный этап ручной прокрутки
Переменная Значение
А 5 11 44422222
max 1
tek 1
В таблице 1.2 показан начальный этап ручной прокрутки, на котором происходит
присвоение значений переменным. Значения max и tek сдвинуты в таблице отно-
сительно друг друга. Этим сдвигом мы отображаем течение времени, то есть что
переменная tek получила свое значение после переменной max.
для 1 от 2 до 10
Переменная I получает значение 2, это значение сравнивается с числом 10,
и так как 2 < 10, то управление передается внутрь цикла:
если А[1] - АС1-1]
Так как значение I — 2, то А[2] сравнивается с А[1], то есть 11 сравнивается с 5.
Равны? Нет! Следовательно, выполняться будет то, что после иначе:
иначе если tek > max то max - tek
Тек сейчас равно 1, пах тоже равно 1. 1 > 1? Нет. Значит, оператор после то —
не выполняется и пока все остается так же, как было.
tek - 1
У нас в таблице tek и так равно 1, но сейчас мы — ПК и, как и он, должны вместо
старого значения занести новое (пусть даже то же самое).
Итог выполнения первого этапа ручной прокрутки в табл. 1.3.
ПРИМЕЧАНИЕ-------------------------------------------------------------
Нулевым этапом в таблице обозначен этап ручной прокрутки, на котором проводи-
'лось присвоение значений переменным (см. табл. 1.1).
1.1. Основные операторы языка и простейшие алгоритмы
35
Таблица 1.3. Результаты выполнения первого этапа ручной прокрутки
Переменная Значение
0-й этап 1-й этап « этап « 9-й этап 10-й
А 511 44422222
max 1 1
tek 1 1
i 2,
И поскольку в цикле больше операторов нет, то управление вновь передается к стро-
ке начала цикла:
иля 1 от 2 до 10
I увеличивается на 1 (было 2. становится 3). 3 < 10, и потому управление вновь
передается внутрь цикла:
если А[1] - А[1-1]
Значение I теперь 3, следовательно, А[3] сравнивается с А[2], то есть 4 сравнивает-
ся с 11. Равны? Нет! Следовательно, выполняться будет то, что после иначе:
иначе если tek > max то max - t
Тек сейчас равно 1, max тоже равно 1.1 > 1? Нет. Значит, оператор после то не вы-
полняется и пока все остается, как было.
tek = 1
У нас в таблице tek и так равно 1, но сейчас мы — ПК и, как и он, должны вместо
старого значения занести новое (пусть даже то же самое).
Таблица 1.4. Результаты выполнения второго этапа ручной прокрутки
для i от 2 до 10
I увеличивается на 1 (было 3, становится 4). 4 < 10, и потому управление вновь
передается внутрь цикла:
если А[1] - А[1-1]
Значение 1 — 4, следовательно, А[4] сравнивается с А[3], то есть 4 сравнивается
с 4. Равны? Да! Следовательно, выполняться будет то, что после то:
то tek = tek + 1
Тек сейчас равно 1, а станет — 2.
36
Глава 1, Программирование на Паскале
Таблица 1.5. Результаты выполнения третьего этапа ручной прокрутки
лись операторы после то). И поскольку в цикле больше операторов нет, то управ-
ление вновь передается к строке начала цикла:
для 1 от 2 до 10
I увеличивается на 1 (было 4, становится 5). 5 < 10, и потому управление вновь
передается внутрь цикла:
если A[i] = A[i-1]
Значение 1—5, следовательно, А[5 ] сравнивается с А[4 ], то есть 4 сравнивается с 4.
Равны? Да! Следовательно, выполняться будет то, что после то:
то tek - tek + 1
Тек сейчас равно 2, а станет — 3.
Таблица 1.6. Результаты выполнения четвертого этапа ручной прокрутки
Переменная Значение
0-й этап и л и
А 511 44422 222
ПИХ 1 1
tek 1 1 1 2 3
। 2 3 4 5
При этом операторы после иначе не исполняются (поскольку исполнялись опера-
торы после то). И поскольку в цикле больше операторов нет, то управление вновь
передается к строке начала цикла:
для 1 от 2 до 10
I увеличивается на 1 (было 5, становится 6). 6 < 10, и потому управление вновь
передается внутрь цикла:
если ACT] - A[i-1]
Значение 1—6, следовательно, А[6] сравнивается с А[5],то есть 2 сравнивается с 4.
Равны? Нет! Следовательно, выполняться будет то, что после иначе:
иначе если tel: > max то max • t
Тек сейчас равно 3, max тоже равно 1.3 > 1? Да. Значит, выполняется оператор пос-
те max - tek
1.1. Основные операторы языка и простейшие алгоритмы
37
И пах получает значение 3.
Напомним размещение операторов:
иначе если tek > max то max - t
tek - 1
Оператор tek = 1 находится после иначе на одном уровне с оператором если. Это
означает, что в случае иначе он обязательно должен быть выполнен:
tek - 1
Таблица 1.7. Результаты выполнения пятого этапа ручной прокрутки
Переменная Значение
0-й этап 3-й 6-й этап 7-й 8-й 10-й
А 511 44422222
max 1 1 3
tek 1 1 1 2 3 1
i 2 3 4 5 6
И поскольку в цикле больше операторов нет, то управление вновь передается к стро-
ке начала цикла:
для 1 от 2 до 10
I увеличивается на 1 (было 6, становится 7). 7 < 10, и потому управление вновь
передается внутрь цикла:
если А[1] - А[т-1]
Значение 1 — 7- Следовательно, А[7] сравнивается с А[6], то есть 2 сравнивается
с 2. Равны? Да! Следовательно, выполняться будет то, что после то:
то tek = tek + 1
Тек сейчас равно 1, станет — 2.
Таблица 1.8. Результаты выполнения шестого этапа ручной прокрутки
торы после то). И поскольку в цикле больше операторов нет, то управление вновь
передается к строке начала цикла:
для 1 от 2 до 10
I увеличивается на 1 (было 7, становится 8). 8< 10, и потому управление вновь
передается внутрь цикла:
если А[т] - А[1-1]
38
Глава 1. Программирование на Паскале
Значение 1 — 8. Следовательно, А[8] сравнивается с А[7], то есть 2 сравнивается
с 2. Равны? Да! Следовательно, выполняться будет то, что после то:
то tek - tek + 1
Тек сейчас равно 2, станет — 3.
Таблица 1.9. Результаты выполнения седьмого этапа ручной прокрутки
Переменная Значение
0-й 2 £ этап 8-й 9-й этап 10-й
А 5 11 44422222
max 1 1 3
tek 1 1 1 3 1 2 3
i 2 3 4 5 6 7 ^8
При этом операторы после иначе не исполняются (поскольку исполнялись опера-
торы после то). И поскольку в цикле больше операторов нет, то управление вновь
передается к строке начала цикла:
для 1 от 2 до 10
I увеличивается на 1 (было 8, становится 9). 9 2 10, и потому управление вновь
передается внутрь цикла:
если А[т] - А[1-1]
Значение 1 — 9. Следовательно, А[9] сравнивается с А[8], то есть 2 сравнивается
с 2. Равны? Да! Следовательно, выполняться будет то, что после то:
. то tek - tek + 1
Тек сейчас равно 3, станет — 4.
Таблица 1.10. Результаты выполнения восьмого этапа ручной прокрутки
Значение
0-й этап этап 9-й этап 10-й этап
А 511 44422222
max 1 1 3
tek 1 1 1 2 4
2 5 6 7 8 9
При этом операторы после иначе не исполняются (поскольку исполнялись опера-
торы после то). И поскольку в цикле больше операторов нет, то управление вновь
передается к строке начала цикла:
для 1 от 2 до 10
I увеличивается на 1 (было 9, становится 10). 10 < 10, и потому управление вновь
передается внутрь цикла:
если А[т] - А[1-1]
1.1. Основные операторы языка и простейшие алгоритмы
39
Значение I — 10. Следовательно, А[10] сравнивается сА[9], то есть 2 сравнивается
с 2. Равны? Да! Следовательно, выполняться будет то, что после то:
то tek - tek + 1
Тек сейчас равно 4, станет — 5.
Таблица 1.11. Результаты выполнения девятого этапа ручной прокрутки
Переменная Значение
0-й 3-й 4-й этап 6-й этап 9-й этап 10-й
А 511 44422 222
max 1 1 3
tek 1 1 1 2 3 1 3 5
i 2 3 4 5 6 7 8 9 10
При этом операторы после иначе не исполняются (поскольку исполнялись опера-
торы после то). И поскольку в цикле больше операторов нет, то управление вновь
передается к строке начала цикла:
для 1 от 2 до 10
I увеличивается на 1 (было 10, становится 11). 11 > 10, и потому цикл завершен и
управление передается к оператору, следующему за оператором цикла:
Вывод (max)
Что у нас находится в переменной шах? 3! Число 3 и будет выведено в качестве
ответа (табл. 1.12). Это — ошибка, ведь правильный ответ — 5 для данного теста.
Таблица 1.12. Итог выполнения ручной прокрутки
Переменная Значение
0-й эгап 3-й этап 6-й этап этап этаЙп 10-й
А 511 44422222
max 1 1 3
tek 1 1 1 2 3 1 2 3 4 5
i 2 3 4 5 6 7 8 9 10 11
Ошибка заключается в том, что в алгоритме не предусмотрен случай, когда наи-
большее число подряд идущих элементов получается в результате завершения
массива, то есть когда соответствующие подряд идущие элементы стоят в конце
массива. Исправить алгоритм легко: достаточно поставить дополнительный опе-
ратор сравнения переменных max и tek после завершения цикла.
Ввод А[1..1О]
max - 1. tek - 1
для.1 от 2 до 10
если А[1] - А[1-1]
то tek - tek + 1
иначе если tek > max то max - tek
40
Глава 1. Программирование на Паскале
tek - 1
если tek > max то max - tek
Вывод (max)
Теперь, когда мы убеждены, что алгоритм работает верно, легко написать по нему текст
соответствующей программы. Как это делается, описывается в следующем подразделе.
Но прежде несколько замечаний относительно ручной прокрутки. Наверное, мно-
гим показалось, что ручная прокрутка — это очень трудоемкий процесс. И неко-
торые попробуют обходиться без него. Это опасный путь, и он может привести
к значительно большей трате времени. В то время как регулярное применение руч-
ной прокрутки приводит к тому, что ваш мозг начинает выполнять эту работу под-
сознательно еще в тот момент, когда вы только сочиняете алгоритм. Это, соответ-
ственно, резко сокращает количество допущенных вами ошибок при разработке
все новых и новых алгоритмов. Кроме того, выполнение ручной прокрутки позволя-
ет легко найти ошибки на стадии отладки.
Перевод алгоритма в Паскаль-программу
Рассмотрим алгоритм и его запись на языке программирования Паскаль:
max - 1. tek - 1 max :• 1: tek := 1:
для 1 от 2 до 10 for i :- 2 to 10 do
то tek - tek * 1
иначе если tekxnax то max-tek
tek - 1
if All] - A[t-1]
then tek :- tek + 1
else begin
if tekxnax then max:-tek:
tek 1:
если tekxnax to max - tek if tek>max then max:-tek:
Вывод (max) writeln (max):
Очевидно, что при выполнении перевода алгоритма в программу следует соблю-
сти следующие нехитрые правила.
1. Все « = » заменить на « : = ».
Ключевые слова заменить их аналогами:
для если то иначе вывод
for if then else writeln
3. В конце операторов поставить символ «;».
4. Наиболее «сложное» правило: в случае, если после для, то или иначе в алгорит-
ме выполняются два или более действия, поставить «операторные скобки»
begin end, которые в алгоритме подразумеваются сдвигами.
5. Все переменные и массивы объявить в программе, а исходные данные — ввести.
В результате получаем текст программы.
Листинг 1.6. Решение задачи о поиске подряд идущих элементов
program MaxSucc:
a: array [1..10] of integer:
i.tek.max : integer:
{Объявление)
{массива а из 10 элекентов)
{переменных i.tek.max)
1.1. Основные операторы языка и простейшие алгоритмы
41
writelnl'Введите 10 чисел'):
for i:-l to 10 do readln(a[i]):
max 1: tek := 1:
for 1 :• 2 to 10 do
if AC13 - A[i-1]
then tek := tek + 1
else begin
if tekxnax then max:-tek:
tek 1:
end:
if tek>roax then max:-tek:
for i:-l to 10 do write(a[i].' '):
writein:
writelnl'Ответ - '.max):
end.
{Ввод)
{одномерного иассива)
(Если идут подряд)
{то считаем их]
{иначе)
{запоиинаеи максимальный)
{начинаем счет сначала)
{Вывод одномерного массива)
{Вывод результата)
Простейшие приемы работы в среде Турбо Паскаль
В данном подразделе в справочном порядке приводятся простейшие приемы ра-
боты в среде Турбо Паскаль по редактированию и отладке программ.
1. Запуск — turbo.
2. Редактирование текстов программ:
□ F3 — загрузка;
□ Ctrl+Y — удалить строку;
□ Delete — удалить символ;
□ Insert — вставка/замена;
□ F2 — сохранить на диск.
3. Выполнение:
□ F8 — выполнить одну строку;
□ F4 — выполнить до позиции курсора;
□ Ctrl+F9 — выполнить до конца;
Q Ctrl+F2 — начать выполнение сначала.
4. Выход —Alt+X.
5. Просмотр значений переменных:
□ Ctrl+F4 — однократный просмотр текущего значения;
□ Ctrl+F7 — добавить переменную в окно просмотра.
6. Изменение размеров и расположения окон:
□ Ctrl+F5 — начать работу с окном;
□ Shift+T/—>/•!•/<-изменить размеры;
□ — переместить.
Методические указания по решению задач 6, 8,
16-18, 22-24
Решение задач 6,8,16-18 не потребует от вас знания нового теоретического мате-
риала. Необходимо только последовательно применять предложенный в этой главе
42
Глава 1. Программирование на Паскале
план разработки алгоритмов и программ, начиная от переформулирования усло-
вия задачи и заканчивая ручной прокруткой, и у вас все должно получиться!
Многолетний опыт автора показывает, что именно на этом этапе и ученик, и учи-
тель могут определить, сможет ли и хочет ли ученик заниматься обучением про-
граммированию.
Для решения задач 22-24 требуется знать несколько новых фактов о языке про-
граммирования Паскаль, которые и приводятся далее.
1. Операция над целыми числами — DIV — получение частного от деления:
В результате выполнения этой операции переменная К получает значение, равное
частному от деления целого числа М на целое число N, например, если М - 11,
a N - 4, то частное от деления 11 на 4 есть 2, и поэтому переменная К получит
значение 2.
2. Операция над целыми числами — MOD — получение остатка от деления:
В результате выполнения этой операции переменная К получает значение, равное
остатку отделения целого числа Н на целое число N. Например, если М - 11, a N = 4,
то остаток от деления 11 на 4 есть 3, и поэтому переменная К получит значение 3.
Задачи для самостоятельного решения
Условия задач взяты из первого учебника по информатике 1985 года, составлен-
ного академиком Ю. А. Ершовым, который полагал, что школьники должны на-
учиться решать такие задачи после двух лет изучения информатики.
Далее используются обозначения:
□ цел. таб. А[ 1:10] — одномерный массив из 10 целых чисел;
□ вещ. таб. А[ 1:10] — одномерный массив из 10 вещественных чисел;
□ цел. таб. А[ 1:5,1:5] — двумерный массив из 25 чисел (5 строк на 5 столбцов).
Условия задач:
1. Найдите число ненулевых элементов в таблице цел. таб. А[ 1:10].
2. Найдите количество элементов в таблице вещ. таб. А[ 1:10], абсолютная вели-
чина которых больше 7.
3. Составьте алгоритм, дающий ответ «да» или «нет» в зависимости от того, встре-
чается или нет число 7 в таблице цел. таб. А[ 1:10].
4. Дана целочисленная таблица А[ 1:10]. Найдите разность наибольшего и наимень-
шего чисел в этой таблице.
5. Даны две целочисленные таблицы А[1:10] и В[1:10]. Подсчитайте количество
таких i, для которых:
2) A[i]-B[i];
3) A[i]>B[i],
1.1. Основные операторы языка и простейшие алгоритмы
43
6. Дана целочисленная таблица А[ 1:10]. Подсчитайте количество таких i, что А[ i ]
не меньше всех предыдущих элементов таблицы (А[ 1 ], А[2] А[ 1-1 ]).
Дана вещественная таблица А[1:10]. Найдите количество элементов этой таб-
лицы, которые больше среднего арифметического всех ее элементов.
8. Дана целочисленная таблица А[1:10]. Заполните вещественную таблицу
В[ 1:10], i-й элемент которой равен среднему арифметическому первых i эле-
ментов таблицы А:
9. Дана целочисленная таблица А[1:10]. Подсчитайте, сколько раз встречается
в этой таблице максимальное по величине число.
10. Дана целочисленная прямоугольная таблица А[1:5,1:5]. Измените все элемен-
ты в этой таблице на противоположные по знаку.
11. Дана целочисленная прямоугольная таблица А[ 1:5,1:5]. Найдите наибольшее
из чисел, встречающееся в этой таблице.
12. Дана целочисленная таблица А[ 1:10]. Проверьте, есть ли в ней элементы, рав-
ные 0. Если есть, то найдите номер первого из них, то есть наименьшее i, при
котором А[ i ] - 0. Если нет — вывести слово «нет».
13. Дана целочисленная таблица А[ 1:10]. Проверьте, есть ли в ней отрицательные
элементы. Если есть, то найдите наибольшее i, при котором А[ 1] < 0.
14. Проверьте, является ли прямоугольная целочисленная таблица А[ 1:5,1:5] «.ма-
гическим квадратом» (это значит, что суммы чисел во всех ее вертикалях, всех
горизонталях и двух диагоналях одинаковы).
15. Дана целочисленная таблица А[ 1:10]. Подсчитайте наибольшее число идущих
в ней подряд одинаковых элементов.
16. Подсчитайте количество различных чисел, встречающихся в цел. таб. А[ 1:10].
Повторяющиеся числа учитывать один раз.
17. Дана целочисленная таблица А[ 1:10]. Постройте цел. таб. BE 1:10], которая со-
держит те же числа, что и таблица А, но в которой все отрицательные элементы
предшествуют всем неотрицательным.
18. Даны целочисленные таблицы А[ 1:10] и В[ 1:10], причем:
А[1] < А[2] < ... < А[10],
В[1] < В[2] < ... < В[10].
Постройте таблицу С[ 1:20], содержащую все элементы таблиц А и В, в которой
С[1] < С[2] < ... < С[20].
19. Дана прямоугольная целочисленная таблица А[1:5]1:5]. Найдите количество
тех чисел i от 1 до 10, для которых A[i,j ] = 0 при некотором числе ], принима-
ющем значения от 1 до 5.
20. Дана прямоугольная целочисленная таблица А[1:5,1:5]. Найдите наименьшее
целое число К, обладающее таким свойством: хотя бы в одной строке таблицы
все элементы не превосходят К.
Глава 1. Программирование на Паскале
21.
22.
23.
24.
Дана прямоугольная целочисленная таблица А[ 1:5,1:5]. Найдите наибольшее
К, обладающее таким свойством: в любой строке таблицы есть элемент, боль-
ший или равный К.
Напишите программу разложения натуральных чисел на простые множители.
Натуральное число называют совершенным, если оно равно сумме всех своих де-
лителей, не считая себя самого (например, 6=1 + 2 + 3— совершенное число).
Напишите алгоритм, проверяющий, является ли заданное число совершенным.
Напечатайте в порядке возрастания первые 1000 чисел, которые не имеют про-
стых делителей, кроме 2,3 и 5. (Начало списка: 1,2,3,4,5,6,8,9,10,12,15...).
1.2. Возможности языка
программирования Паскаль
Предыдущий параграф был ориентирован на «быстрое погружение» вдумчивого
читателя в разработку программ на Паскале. Этих базовых знаний — целые и ве-
щественные переменные, арифметические и логические выражения, операторы
присваивания, условия и циклов — достаточно, чтобы написать решение чуть ли
не любой задачи. Тем не менее язык программирования Паскаль обладает множе-
ством дополнительных возможностей и операторов, упрощающих разработку и от-
ладку программ. Обзору этих возможностей и посвящен данный параграф.
Компьютерная арифметика
Теоретически можно писать программы, не представляя в деталях, а как именно
устроен и работает компьютер, как в нем хранятся данные задачи, как они обраба-
тываются и т. д. Но, имея такое представление, наверняка программы можно пи-
сать быстрее и эффективнее. Автору представляется уместным сравнение с вож-
дением автомобиля. Да, можно ездить на автомобиле, умея его заводить и управлять
им. Однако очевидно, чем больше водитель знает об устройстве автомобиля, тем
более вероятно, что он не попадет в аварию, нажав не вовремя педаль газа или
тормоза, не остановится на середине пути по причине выработки горючего и т. д.
Битовое представление информации в компьютере
Компьютер устроен таким образом, что минимальной единицей хранения информа-
ции в нем является бит, в котором может храниться только одна цифра — 0 или 1.
Интересно, что технология изготовления компьютера может меняться (механиче-
ская, электрическая, электронная, оптическая, биологическая), но в основе всегда
находится возможность представить с помощью тех или иных физических, хими-
ческих или биологических процессов два числа — 0 и 1. Доказано теоретически,
что если есть возможность сделать это, а также обеспечить выполнение двух про-
стых операций НЕ и 2И, то на такой базе можно построить сколь угодно сложный
компьютер! Имеется в виду, что любой компьютер может быть сконструирован из
элементов только этих двух типов.
1.2. Возможности языка программирования Паскаль
45
Поясним, как работает каждый из этих элементов.
□ Элемент НЕ.
На вход поступает сигнал X (напомним еще раз, что он может принимать
только одно из двух возможных значений — 0 или 1).
На выходе этого элемента через некоторое время после изменения значения
на входе изменяется сигнал У— по следующим правилам:
1) если поступила 1, то на выходе появится 0;
2) если поступил 0, то на выходе появится 1.
В виде таблицы эти правила записываются следующим образом:
□ Элемент 2И.
Если на входе оба сигнала равны 1: XI = 1 и Х2 = 1, то сигнал на выходе —
Иначе У =0.
Ниже приведена таблица правил функционирования элемента 2И:
ления любых чисел используются последовательности из 0 и 1, или, как еще гово-
рят, последовательности битов.
Последовательность из 8 битов называется байт.
Вопрос: сколько существует различных 8-битных последовательностей? Или тот
же вопрос, но сформулированный несколько иными словами: сколько различных
чисел можно представить в одном байте?
Попробуем выписать все 8-битные последовательности (табл. 1.13). Для большей
наглядности байт разобьем на 2 части по четыре бита, или, как еще говорят, — пред-
ставим байт двумя тетрадами.
Все ли возможные 8-битные последовательности мы выписали? Ясно, что не все, а
лишь те из них, у которых первые 2 бита — нули. Другими словами, мы выписали
все 6-битные последовательности (если не обращать внимания (или стереть) на
два первых нуля каждой 8-битной последовательности). Всего у нас получилось
46
Глава 1. Программирование на Паскале
64 различных последовательности, которыми можно представить 64 различных
числа — мы их обозначили от 0 до 63.
Таблица 1.13. Числа (от 0 до 63) и соответствующие 8-битные
последовательности — байты
Число Последовательность Число Последовательность
0 0000 0000 32 00100000
1 0000 0001 33 00100001
2 0000 0010 34 00100010
0000 0011 35 00100011
00000100 36 00100100
5 00000101 37 00100101
00000110 38 00100110
00000111 39 00100111
0000 1000 40 0010 1000
9 0000 1001 41 0010 1001
10 0000 1010 42 00101010
11 00001011 43 00101011
00001100 44 00101100
0000 1101 45 00101101
00001110 46 00101110
00001111 47 00101111
16 0001 0000 48 0011 0000
0001 0001 49 0011 0001
18 0001 0010 50 0011 0010
0001 0011 51 0011 0011
20 0001 0100 52 ООП 0100
21 0001 0101 53 0011 0101
22 0001 0110 54 0011 0110
23 0001 0111 55 0011 0111
24 0001 1000 56 0011 1000
25 0001 1001 57 0011 1001
26 0001 1010 58 0011 1010
27 0001 1011 59 ООП 1011
28 0001 1100 60 0011 1100
29 0001 1101 61 0011 1101
30 0001 1110 62 0011 1110
31 0001 1111 63 0011 1111
Сколько же все-таки 8-битных последовательностей? Чтобы выяснить это, нам
нужно написать еще 3 таких таблицы: у чисел первой таблицы первые 2 бита бу-
дут 0 и 1, у второй — 1 и 0 и у третьей — 1 и 1. Всего же последовательностей из
1.2. Возможности языка программирования Паскаль
восьми битов — 256. Попробуйте в качестве упражнения выписать сами все эти
Итак, в одном байте можно представить 256 различных чисел (мы их нумеровали
от 0 до 255).
Задумаемся, а могли ли мы получить это число — 256 — без выписывания всех
возможных 8-битных последовательностей?
Итак, у нас есть всего 8 позиций, в каждой из них может быть одно из двух чисел —
О или 1.
Таким образом, для 2-битных чисел существует 2*2 = 4 варианта, для 3-битных
чисел — 2*2*2 = 8 вариантов, для 4-битных чисел — 2*2*2*2 = 16 вариантов.
Ну а для байта — 2*2*2*2»2*2*2*2- 256 вариантов.
Или с использованием показателя степени это можно записать так
28 - 256.
Читается эта запись так: два, возведенное в восьмую степень (то есть 2 умножен-
ное само на себя 8 раз), равно 256.
□
Шестнадцатеричная система счисления
Еще во время выписывания таблицы 1.13 вы могли заметить, что представление
чисел в виде последовательностей 0 и 1 (или, как еще говорят, в двоичной системе
счисления) чрезвычайно утомительно для человека, хотя именно так они и хра-
нятся в памяти компьютера. Поэтому человек придумал еще один способ пред-
ставления чисел — шестнадцатеричную систему счисления. Эта система обладает
следующим замечательными свойствами.
Шестнадцатеричные числа гораздо более понятны и легче читаемы для челове-
ка, чем двоичные.
Существуют простые способы перевода чисел из десятичной системы счисле-
ния в шестнадцатеричную и обратно.
Существуют чрезвычайно простые способы перевода чисел из шестнадцатерич-
ной системы счисления в двоичную и обратно.
Начнем с самого простого — перевода чисел из двоичной системы в шестнадцате-
ричную и обратно.
Прежде всего нужно запомнить таблицу шестнадцатеричных чисел (табл. 1.14).
Для перевода чисел из двоичной системы в шестнадцатеричную достаточно заме-
нить тетраду на соответствующую ей цифру или букву. Например: 0011 1011 = ЗВ.
Для перевода чисел из шестнадцатеричной системы в двоичную достаточно вы-
полнить обратное действие — заменить букву или цифру соответствующей тетра-
дой (из нижеприведенной таблицы). Например: Cl = 1100 0111.
ПРИМЕЧАНИЕ------------------------------
Пробел между тетрадами оставлен для наглядности.
48
Глава 1, Программирование на Паскале
Таблица 1.14. Системы записи чисел
Десятичная Двоичная
0 0000 0
1 0001 1
2 0010 2
3 0011 3
0100 4
5 0101 5
6 0110 6
7 0111
8 1000 8
9 1001 9
10 1010
11 1011 В
12 1100
13 1101 D
14 1110 Е
15 1111 F
Правила для перевода чисел из десятичной системы счисления в шестнадцатерич-
ную и обратно несколько слЪжнее. Но, поскольку их знание не требуется для по-
нимания дальнейшего материала, они сейчас не приводятся.
Числовые типы данных
В этом подразделе мы рассмотрим способы представления чисел различных ти-
пов в Паскаль-программах. Необходимо понимать, что основные их отличия про-
истекают из того, сколько байт (и соответственно — бит) отводится в памяти ком-
пьютера под число того или иного типа. Размер отведенной памяти определяет
диапазон чисел, которые могут храниться в переменных данного типа.
Классические целые и вещественные типы
В таблицах 1.15 и 1.16 приводятся типы целых и вещестенных чисел, которые мож-
но использовать при программировании на Паскале.
Примеры записи целочисленных констант: -5,1467, $BFO1. Символ $ перед числом
означает, что число представлено в шестнадцатеричной системе счисления.
Примеры записи вещественных констант: 14.7,1.5Е-2. Второе число представляет
пример записи вещественного числа в «научной» нотации и читается как «одна
целая пять десятых умножить на 10 в минус второй степени»:
1.5Е-2 - 1,5 •### КГ2- 1,5 •### 0,01 - 0,015.
Над целыми и дробными числами можно выполнять основные арифметические
действия: +, -, *### (умножение), / (деление). Надо только помнить, что резуль-
тат операции деления должен присваиваться вещественной переменной.
1.2. Возможности языка программирования Паскаль
49
Таблица 1.15. Типы целых чисел
Целый тип Размер памяти (в байтах) Диапазон значений Мах
Shortint 1 -128...127 2’-1
Integer -32 768...32 767
Longint -2 147 648-2 147483 647 2” -1
Byte 1 0...255 2s-!
Word 2 0...65 535 2«-1
Comp 8 -2°-1 ...263 — 1 2°-1
Таблица 1.16. Типы вещественных чисел
Вещественный тип Размер памяти (в байтах) Диапазон значений Число цифр мантиссы
Real 6 2.9х10-»...1,7х10» 11-12
Single 4 1,5х1(Гв...З,4х10в 7-8
Double 8 0,0х1(Гда...1,7х10зм 15-16
Extended 10 3,4х10"48и,..1,1х10<93г 19-20
Листинг 1.7. Деление вещественных чисел
program el:
LI. L2 : integer:
R : real:
begin
read (L1.L2):
writeln (R):
По умолчанию вещественные числа выводятся в «научной» нотации (другое на-
звание, встречаемое в книгах по языку программирования Паскаль, — «в экспо-
ненциальном формате»). Например, если в программе е1 (листинг 1.7) ввести в
качестве исходных данных L1 и L2 числа 5 и 3, то ответ будет выведен в следующем
виде: 1.6666666667Е+00.
Для вывода вещественного числа в более привычном виде можно использовать
такой прием:
writelri(R:0:3):
И будет получен ответ в следующем виде: 1.667.
То есть мы указали компьютеру выводить вещественное число, округляя его до
трех значащих цифр после запятой.
При необходимости использовать типы Single, Double, Extended, Comp нужно поста-
вить соответствующую опцию компилятора {$N+).
Например:
{$№•)
program е2:
50
Глава 1. Программирование на Паскале
LI. L2 : integer:
О : double:
read (L1.L2):
D LI / L2:
writeln (0:0:3);
end.
Для вычисления целочисленных остатка или частного от деления целых чисел
нужно пользоваться функциями MOD или DIV соответственно. Об этом подробнее
уже написано в разделе «Нестандартные алгоритмы и программы».
Переменным целого типа shortint, byte, word, integer, longint нельзя присваивать
значения вещественного типа — возникает ошибка компиляции.
Переменным типа comp можно присваивать вещественные значения, но во время
присваивания значение округляется до целого значения.
Ограниченные типы
Язык программирования Паскаль задуман как строго типизированный язык. Это
сделано для того, чтобы автоматически выявлять как можно больше ошибок в про-
грамме как на стадии компиляции, так и на стадии выполнения.
Попятно, что контрольные проверки во время исполнения программы — это до-
полнительная работа и они могут существенно замедлить выполнение програм-
мы. Поэтому у программиста есть возможности включать/выключать эти провер-
ки разных типов. Первая из таких возможностей — опция R+.
Например, при исполнении программы е2 по умолчанию (то есть с опцией R—
в режиме как можно более быстрого счета без проверки на возможные ошибки) вы
можете ввести числа 30 000 для L1 и 40 000 для L2 и получить неправильный от-
вет— 1,175. Почему? Потому что число 40 000 не может быть размещено целиком
в переменной типа integer. И поэтому туда занесены только младшие биты соот-
ветствующего числа, что и привело к неверному ответу при делении. Если же мы в
этот пример добавим опцию R+:
program е2:
var
LI. L2 : integer:
0 : double:
begin
read (L1.L2):
writeln (0:0:3):
то при попытке ввести число 40 000, которое лежит вне диапазона значений для пе-
ременных типа integer, исполняющая система Паскаля выдаст сообщение об ошибке
Range Check Error и укажет на строку программы, в которой обнаружена эта ошибка.
А если программист хочет усилить контроль? Например, он знает, что некоторые
переменные Day 1 и Day2 будут обозначать номер дня в месяце и потому могут при-
нимать значения только в интервале от 1 до 31. В этом случае он может использо-
1.2. Возможности языка программирования Паскаль
вать ограниченный, или, как еще говорят, интервальный тип, написав в своей про-
грамме следующее:
program e3:
Dayl. Day2 : 1..31:
read (Dayl):
Day2 :- Dayl*l:
writeln (Dayl.' ' ,Day2):
readln:
Теперь при попытке ввести для переменной Dayl число большее, чем 31, или мень-
шее, чем 1 (например, 32 или 0), исполняющая система будет выдавать сообщение
об ошибке, указывая на строку read (Dayl). Более того, если для Day 1 будет введено
число 31, то будет выдана ошибка в строке Day2 := Day 1+1, так как при Dayl - 31 Day2
должно получить значение 32, выходящее за отведенный для Day2 диапазон значений.
При определении интервальных типов в качестве границ диапазонов можно ис-
пользовать числа типа longint, то есть от -2 147 483 648 до 2 147 48? 647.
Еще один эффективный способ возложить дополнительный контроль на исполня-
ющую систему Паскаля, а также сделать текст программы более понятным (или,
как еще говорят, более «читабельным») — это использовать перечислимые типы,
но объяснение этой темы выходит за рамки данного подраздела.
Булевский (логический) тип boolean
Большинство разрабатываемых программ имеет нелинейную структуру, то есть в за-
висимости от определенных значений входных данных могут выполняться раз-
личные части программы. Для управления выбором нужных частей программы
могут быть полезными логические переменные.
Они объявляются в программе при помощи ключевого слово BOOLEAN. Логические
переменные могут принимать только 2 значения false (ложь) и true (истина).
Над логическими переменными определены следующие операции:
1) AND —«И»;
2) OR - «ИЛИ»;
3) XOR — «Исключающее ИЛИ»;
4) NOT - «НЕ».
Логическая переменная может формироваться также в результате арифметических
сравнений: «меньше», «меньше либо равно», «больше», «больше либо равно», «рав-
но» и «не равно» (соответственно <, <=, >, >=, =, о).
Примеры определения и использования:
isEmpty_S : boolean:
OecisionAchieved : boolean:
52
Глава 1. Программирование на Паскале
isEmpty_S true:
OecisionAchieved false:
Объявлены две логические переменные — isEmpty_S и OecisionAchieved, первой при-
своено значение true (истина), второй — значение false (ложь).
OecisionAchieved К - EdgeNumber:
Переменная OecisionAchieved получит значение true, если значение переменной К
равно значению переменной EdgeNumber, и значение false — в противном случае.
То есть это более короткая запись следующего оператора:
if К - EdgeNumber
then OecisionAchieved : true
else OecisionAchieved false
А это операторы для самостоятельного разбора:
isCurrentOecision k > Max_k :
isAHOnetine poO:
Ниже приводится пример организации цикла с использованием логических пере-
менных:
while (k>0) and not OecisionAchieved do ...
то есть:
пока k>0 и OecisionAchieved ложно делать
Снова оператор для самостоятельного разбора:
while not isEmpty_S do ...
Пример использования логических переменных в условном операторе:
if isCurrentMayContinuied and (not IsCut) then k:-k*l:
Если IsCurrentMayContinuied истина и IsCut ложно то k-k+1
И снова оператор для самостоятельного разбора:
if IsCurrentOecision then PutDecision:
Символьный и строковый типы
До сих пор мы изучали программы, которые умеют обрабатывать числа (целые и
вещественные) и массивы чисел. Но в реальной жизни необходимы также и про-
граммы, которые обрабатывают текстовую информацию. Например, программа
создания/редактирования классного журнала, которая должна вводить-выводить
и редактировать фамилии учеников.
Символьный тип char
Как же компьютеру удается обрабатывать буквы, если мы уже договорились, что
в памяти компьютера нет ничего, кроме 0 и 1? Дело в том, что существуют так
называемые таблицы кодировки, в которых каждому символу (буквам, цифрам,
знакам препинания и арифметических операций и т. д.) поставлен в соответствие
свой байт. Когда переменная объявлена как символьная, то соответствующий байт
трактуется исполняющей системой Паскаля не как число, а как символ (при выво-
де на экран, прежде всего). Исторически наиболее распространенной и часто ис-
пользуемой из таких таблиц является таблица ASCII — American Standard Code for
Information Interchange.
1.2. Возможности языка программирования Паскаль
53
Есть три способа записи символьных констант в программе:
□ '«ййй' — непосредственно символ между штрихами;
□ ййййбО — десятичный код символа после йййй;
□ йййй$ЗО — шестнадцатеричный код символа после символа ййй#.
Приведем пример объявления и использования символов:
var ch : char:
ch ReadKey:
if ch-#0
then ch:- ReadKey:
{считывает символ с клавиатуры без отображения)
{для функциональных клавиш коды - 2-байтовые)
{первый байт - 0)
Еще интересней программа считывания символов с клавиатуры и вывода соответ-
ствующего ей кода ASCII. Набрав ее и поработав с ней, вы сможете узнать ASCII-
код любой клавиши. Эта программа требует ввода с клавиатуры одного символа и
выводит его код на экран, до тех пор, пока вы не нажмете клавишу z.
Листинг 1.8. Программа, выводящая на экран код вводимого символа
Program ReadKeys:
uses crt:
var
c: Char:
writeln!'Нажмите любую клавишу'):
с :- ReadKey:
if с-Л
then
c :- ReadKey:
writeln!'функциональная клавиша O-’.Ord(c)):
else writeln!'Вы нажали'" .C, "'ASCII кол - '. Ord(c)>:
until c in ['z'.'Z'.'я'.'Я']
К сожалению, таблиц кодировок символов несколько, и особенно не повезло рус-
ским буквам, которым в разных таблицах кодировки соответствуют разные коды.
Это приводит к необходимости иногда потратить значительные усилия для того,
чтобы прочитать русский текст.
Строковый тип string
Объявление в программе переменной строкового типа выглядит примерно так:
var S:string[36J; (S - сиивольная цепочка длины от 0 до 36)
То есть мы предлагаем зарезервировать в памяти компьютера 36 байт, в которые
и будут заноситься коды символов вводимого текста (в данном случае можно
занести не более 36 символов в переменную S). Число символов не может превы-
шать 255.
Для хранения переменных типа STRING[n ] в памяти отводится п+1 байт.
Способ хранения переменных типа STRING) п ] следующий.
54
Глава 1. Программирование на Паскале
1. Байт 0 хранит текущую длину строки (пусть это число k).
2. Байты 1 - k — занятая (используемая в текущий момент) часть строки.
3. Байты (k + 1) - п — незанятая часть строки.
Над строковыми переменными возможно выполнение следующих действий:
□ Операции:
сравнение ( <, <=, >, >=, =, о );
конкатенация (+).
□ Функции:
Length (S) — вернуть длину строки;
Copy(S,Index,Count) — выделить подстроку;
Pos(subS.S) — найти одну подстроку в другой;
Concat(S1,[S2,...,Sn]) — объединить несколько строк.
□ Процедуры:
Delete (S,Index,Count) — удалить подстроку из S;
Insert (Ssrc.Sdst,Index) — вставить одну строку в другую.
Лучший способ изучения чего-то — это эксперимент: входите в Паскаль, набирае-
те любое из имен функций или процедур, подводите к нему курсор и нажимаете
Ctrl+Fl, вызывая тем самым контекстно-чувствительную помощь (поначалу вас, воз-
можно, будет немного останавливать английский язык, но очень недолго, поверь-
те). Там есть описания, примеры. Примеры можно скопировать и исполнять.
Стандартные процедуры и функции
преобразования типов
Бывает очень полезно переходить от вещественного типа к целому или от сим-
вольного или строчного типа к числовому и обратно. Для этого в Паскале имеются
специальные процедуры и функции преобразования типов. Краткие сведения о
них приводятся далее, более полные — опять же предлагается найти в контекстно-
чувствительной помощи Паскаля.
Таблица 1.17. Специальные процедуры и функции преобразования типов
Функция Тип аргумента Тип результата Преобразование
Odd Целый Булевский true, если аргумент нечетный, иначе - false
Tmnc Вещественный Целый Отбрасывает дробную часть
Round Вещественный Целый Округляет до ближайшего целого
Ord Символьный Целый Выдает порядковый номер аргумента (от 0), имеющего данный тип
Chr 0...255 Символьный Выдает символ с заданным в аргументе порядковым номером
Vai Строчный Числовой Переводит строку в число
a Числовой Строковый Переводит число в строку
1.2. Возможности языка программирования Паскаль
Текстовые файлы
В большинстве олимпиадных задач требуется обеспечить ввод из одного тексто-
вого файла и вывод в другой текстовый файл.
Текстовый файл — это последовательность символьных строк переменной длины,
разделенных специальной комбинацией кодов (как правило, CR или CR LF); завер-
шается кодом EOF, где:
□ CR — символ #10 — «возврат каретки»;
□ LF — символ #13 — «перевод строки»;
□ EOF — символ #26 — «конец файла».
Переменная текстового файла объявляется в программе следующим образом:
var MyBook : text;
Основные интересующие пас операции с текстовыми файлами таковы:
инициализация — связывание имени файловой переменной (МуВоок) с именем
файла надиске; .
открытие на чтение, чтение строки;
открытие на запись, запись строки;
проверка па конец строки, проверка на конец файла;
закрытие.
□
Перенаправление стандартного ввода-вывода
при запуске
Предположим, что у нас есть программа p_cut_v9, ввод которой осуществляет при-
веденная ниже процедура InputData, а вывод — процедура Out. И пусть на диске в
том же каталоге, что и программа p_cut_v9, находится файл с подготовленными
тестовыми данными test7.dat
procedure InputOata:
write!п('Вводите эталонную сунну'):
readln(M):
writeln('Вводите кол-во чисел в последовательности'):
readln(N):
writelп('Вводите числа последовательности’):
for 1:-1 to N do read(Chain[1]):
end:
test7.dat
10
writelnf'Эталонная сунна '.И):
writelnt'Кол-во чисел в последовательности '.N):
writelп('Числа последовательности : '):
for i:=l to N do wr1te(Chain[i].' '): writeln:
Для того чтобы обеспечить ввод программой данных из тестового файла и вывод в
другой файл (в примере — test7.out), достаточно скомпилировать программу и вы-
полнить соответствующую команду:
Глава 1. Программирование на Паскале
О >p_cut_v9 <test7.dat — вводить из файла test7.dat;
□ >p_cut_v9 >test7.out — выводить в файл test7.out;
□ >p_cut_v9 <test7.dat >test7.out — вводить из файла и выводить в файл
test7.out;
□ >p_cut_v9 ctest7.dat >nul — вводить из файла выводить «в никуда».
Перенаправление стандартного ввода-вывода
в программе
Ниже приводится процедура, которая определяет, было ли передано при запуске
программы имя файла, из которого нужно будет вводить данные, и если нет, то
выводится соответствующее сообщение, и программа прекращает свою работу. Если
имя файла передано, то стандартный ввод переопределяется внутри программы
строкой.
Assign! Input.ParamStr(D):
И теперь программа, в которой предполагался стандартный ввод с клавиатуры.
будет вводить данные из указанного файла:
procedure ReadFromFile:
if Parantount < 1
then begin writelnCHer инени файла данных'): halt: end
else writeln!' Файл : '. ParamStr(D):
Assign!Input,ParamStr!1));
Reset(Input):
InputData:
Здесь:
□ ParamCount — функция, возвращающая количество параметров в командной
строке;
□ ParamStr(i) — функция, возвращающая текстовую строку i-й параметр за-
пуска;
□ Input — имя стандартного файла ввода (для read, readin);
□ Output — имя стандартного файла вывода (для write, writeln).
Вызова программы из командной строки
Если программа откомпилирована, то она может быть выполнена с передачей ей
тестового файла в качестве параметра вызова:
c:»p_cut_v9 test7.dat
Простейший пример работы с текстовыми файлами
В листинге 1.9 приводится текст программы, которая должна вводить данные с
клавиатуры (стандартный ввод) и выводить результат на экран (стандартный вы-
вод). Небольшие изменения связаны с переназначениями файлов стандартного
ввода и вывода и закрытием соответствующих файлов.
1.3. Технология разработки программ
Листинг 1.9. Пример работы с '
program е5:
N. М : longint:
Assign(Input.'test?.dat’):
Reset (Input):
{Назначение файла test7.dat - связывание}
{файловой перененной НуВоок с файлом)
{test7.dat}
{Открытие файла на чтение(ввод)}
Read (N.H):
{здесь идет обычная работа, как при работе}
{с клавиатурой)
{например}
{Ввод переменных М и N из файла}
Close (Input)
{после завершения ввода файл лучше}
{закрывать}
Assign (Output.'test?.out'):
Rewrite(Output):
write (N.M):
Close (Output):
end.
(Назначение файла test?.out}
{Открытие файла на запись(вывод))
{здесь идет обычная работа, как}
{при работе с экраном}
{например}
{Вывод переменных п и ш в файл}
{после завершения вывода файл лучше}
{закрывать}
1.3. Технология разработки программ
Данный раздел ориентирован на читателей, имеющих некоторые навыки програм-
мирования на языке Паскаль, и предназначен помочь выработать грамотный стиль
программирования, обеспечивающий производительное программирование и эф-
фективную поддержку продолжительного жизненного цикла разрабатываемых
программ. Кроме того, излагаемый вданном параграфе метод разработки программ
обеспечит в будущем естественный переход обучаемых к объектно-ориентирован-
ному программированию.
Общие сведения
Итак, основные парадигмы разработки программ в предлагаемом методе таковы.
1. Создать полное множество тестов для решаемой задачи.
2. Ввести типы данных, соответствующие существу задачи.
3. Ввести операции над введенными типами данных, которые также должны со-
ответствовать существу задачи. Эти операции реализовать в виде процедур и
функций.
4. Разработку программы вести «сверху вниз», откладывая уточнение деталей,
несущественных для данного уровня разработки программы.
58
Глава 1. Программирование на Паскале
5. При написании собственно текста программы обеспечивать максимальную чи-
табельность, используя адекватные имена переменных, массивов, процедур и
функций, а также разумно комментируя текст программы на стадии ввода (до
начала отладки).
Необходимо отметить, что Паскаль включает встроенные средства поддержки ти-
пов данных, определяемых программистом. Поэтому введение типов данных, со-
ответствующих существу задачи, не только улучшает ясность и читабельность про-
граммы, сокращает ее текст и, соответственно, уменьшает количество логических
ошибок в программе, но и обеспечивает ужесточение контроля над программой со
стороны компилятора и исполняющей системы.
Такая идеология разработки предполагает, что программист определяет новые типы
данных, объявляет переменные введенных типов, разрабатывает функции и про-
цедуры обработки этих переменных (вводит допустимые операции надданными),
конструирует алгоритм обработки введенных данных на базе разработанных про-
цедур и функций, а компилятор и исполняющая система следят за корректным
использованием переменных объявленных типов.
Предлагаемый метод разработки программ далее проиллюстрируем решением двух
Пример решения задачи о поиске прямой
Из заданного множества точек па плоскости выбрать две различные точки так, что-
бы количества точек, лежащих по разные стороны прямой, проходящей через эти
две точки, различались наименьшим образом.
1. Создать полное множество тестов для решаемой задачи.
Таблица 1.18. Примеры тестов
Исходные данные Ответ
1 точка Любая прямая, через нее проходящая
2 одинаковые точки Любая прямая, через них проходящая
2 различные точки Прямая, проходящая через них
Множество точек, только 2 на искомой прямой, различие = 0 Искомая прямая (то есть такая прямая, что количества точек, лежащих по разные стороны этой прямой, различаются наименьшим образом)
Множество точек, 5 точек на искомой прямой, различие = 0 Искомая прямая
Множество точек, только 2 на искомой прямой, различие = 3 Искомая прямая
Множество точек, 5 точек на искомой прямей, различие = 3 Искомая прямая
2. Ввести типы данных, соответствующие существу задачи.
Очевидно, что в данной задаче потребуются типы данных: точка, прямая и мно-
жество точек. Непосредственно на языке программирования Паскаль это мо-
жет быть записано следующим образом:
1.3. Технология разработки программ
59
type TReal - extended:
TPoint - record
x. у: TReal:
end;
Типе - record
А. В. С: TReal;
end:
(Переопределяем вещественный тип)
{Тип ТОЧКА - координаты X и Y)
{Тип ПРЯМАЯ)
{коэффициенты в уравнении)
{Ах + By * С - 0}
TPointsSet - array [1..MaxPointNimber] of Tpoint:
var Pl. P2 : TPoint:
L : TLine:
S : TPointsSet:
3. Ввести операции над введенными типами данных. Эти операции также должны
соответствовать существу задачи и реализовать их в виде процедур и функций.
Для того чтобы выполнить эту работу, предварительно необходимо совершить
одну или несколько итераций семантической разработки алгоритма.
Алгоритм:
1) для всех пар точек построить прямые;
2) для каждой такой прямой посчитать количество точек по разные стороны от
прямой, попутно выбирая минимальные разности;
3) нарисовать картинку решения.
Введем следующие операции (по умолчанию — процедуры):
InitLine( L.P1.P2) — строит прямую L по 2 точкам Р1 и Р2;
Difference(L,S,OnLineCurrent) — функция, вычисляющая разность количеств
точек множества S, лежащих по разные стороны от прямой L, попутно зано-
ся в переменную OnLineCurrent количество точек множества S, расположен-
ных непосредственно на прямой L;
Out (MinDif.Point 1 ,Point2,S) — текстовый вывод результата;
□ DrawResult — графическая иллюстрация.
4. Разработку программы вести «сверху вниз», откладывая уточнение деталей,
несущественных для данного уровня разработки программы.
Теперь можно записать основную часть программы непосредственно на языке про-
граммирования Паскаль, используя введенные операции (листинг 1.10).
□
1.10. Основная часть программы о поиске прямой
for 1:4 to CountPolnts-1 do
begin
if HinDif-0 then break:
' for j:44 to CountPoints do
if MinDif-0 then break:
InitLine(l.S[i].S{j]):
Di f:-01fferencetL.S.OnL1neCurrent):
if MinDIf > Dif
then
{Для точек от первой)
{до предпоследней)
(Если навли. то уходив)
{Для точек от следующей)
{до последней)
{Если нашли, то уходим)
{Строив пряную)
{Вычисляем разность)
{если она меньше)
(минимальной)
продолжение
Глава 1. Программирование на Паскале
Листинг 1.10 (продолжение)
begin
MinDif :- Dif:
Pointl :- 1:
Point2 :- j:
Online :- OnLineCurrent:
(Мининальная разность)
(Нойер 1-й точки)
{Нойер 2-й точки)
{Точек на этой пряной)
{Текстовый вывод)
{Графическая иллюстрация}
end:
Out(MinDif.Pointl.Point2.S):
if DrawFlag then DrawResult:
Затем можно перейти к следующему уровню детализации — реализации введен-
ных в основном теле программы процедур и функций.
Процедура построения прямой:
procedure InitLinelvar Li.TLine: рА. рВ: TPoint):
L.C := pA.Y*(pB.X-pA.X) - pA.X*(pB.Y-pA.Y):
end:
Теоретическая база этой процедуры — известное уравнение прямой по двум точкам:
Преобразуем его в каноническое уравнение прямой:
Получаем: А = У2 - И, В - Х2 - XI, С - И * (Х2 - XI) - XI • ( Y2 - И). Это, соб-
ственно, и реализовано в процедуре InitLine средствами работы с записями языка
программирования Паскаль.
Функция Difference:
□ определяет разность количества точек по разные стороны от прямой;
□ подсчитывает количество точек, лежащих непосредственно йа прямой,
function Difference
(L;TLine: SzTPointsSet: var OnLineCurrent:integer):integer:
0. 1. Temp : integer:
OnLineCurrent 0:
for i.-= 1 to CountPoints do
Temp:-S1gnPoint(L.S[i]):
D :- D + Temp:
if Temp-0 then Inc(OnLineCurrent):
Difference :- abs(D):
end:
{Цикл по всей точкан)
{Вычисляеи знак точки)
{Накапливаеи разность)
{и количество точек на)
{текущей пряной)
{Нан все равно, с какой)
{стороны точек больше)
1.3. Технология разработки программ
61
Заметим, что при реализации этой функции автором введена еще одна функция —
SignPoint(L.P), определяющая знак точки Р относительно прямой L. Таким обра-
зом, появился следующий уровень детализации:
Функция вычисления знака точки относительно прямой:
funct1on SignPoi nt(L:11i ne:P:TPoi nt):i nteger:
var r: Treat;
if abs(r)<-Mistake
then SignPoint О
{Вычисляем знак точки)
{относительно пряной)
(подставляя координаты)
{точки в уравнение)
{пряной)
{О - на пряной)
then SignPoint :•
else SignPoint :
{-1 - на одной стороне)
{1 - на другой стороне)
При сравнении вещественных чисел всегда проверяем их не на равенство, а на то,
чтобы модуль их разности был меньше некоторой маленькой величины (Mistake),
определяемой задаваемой программистом точностью вычислений в разделе кон-
стант, например так:
const
Mistake - le-6: {Mistake = 0.000001}
При написании собственно текста программы необходимо обеспечивать макси-
мальную читабельность, используя адекватные имена переменных, массивов, про-
цедур и функций, а также разумно комментируя текст на стадии ввода текста про-
граммы (до начала отладки).
ПРИМЕЧАНИЕ-----------------------------------------------------
Внимательный читатель обратил внимание, что практически все приведенные фрагмен-
ты программы снабжены информативными комментариями. Кроме того, имена перемен-
ных, массивов, процедур и функций отражают семантику соответствующих понятий.
Пример решения задачи о множестве
треугольников
На плоскости задано множество ЛГ произвольным образом пересекающихся отрез-
ков прямых линий. Перечислить множество всех треугольников, образованных
указанными отрезками.
1. Создание полного множества тестов для решаемой задачи.
Предоставляем читателю возможность решить этот вопрос самостоятельно.
2. Ввести типы данных, соответствующие существу задачи.
Очевидно, что в данной задаче потребуются следующие типы данных: точка,
отрезок, треугольник, множество точек, отрезков и треугольников. Непосред-
ственно на языке программирования Паскаль это может быть записано следу-
ющим образом:.
type
TReal - extended:
TPoint - record
{Переопределяем вещественный тип)
62
Глава 1. Программирование на Паскале
{Тип ТОЧКА - координаты X и Y)
{Тип ОТРЕЗОК)
{точки начала и конца)
{Тип ТРЕУГОЛЬНИК)
{вершины треугольника)
[1,.MaxPointNumber] of TPoint:
[1..MaxSegaentsNumber] of TSegment:
[1..MaxTriangleNuiber] of TTriangle:
: TPoint:
: TSegment:*
: TTriangle;
: TPointsSet:
: TSegmentsSet;
: TTriangleSet:
х. у : TReal:
end:
TSegment - record
A. В : TPoint:
end:
TTriangle - record
А, В. C: TPoint:
end:
TPointsSet - array
TSegmentsSet - array
TTriangleSet - array
Pointl. Point2. Point3
Segl. Seg2. Seg3
Triangle
TrianSet
3. Ввести операции над определенными типами данных, которые также должны
соответствовать существу задачи. Эти операции реализовать в виде процедур
и функций.
Для того чтобы выполнить эту' работу, предварительно необходимо совершить
одну или несколько итераций семантической разработки алгоритма.
Алгоритм:
Вводим массив отрезков
прорисовываем отрезки
кол-во-0
цикл по веек тройкам отрезков
ЕСЛИ все 3 пары отрезков пересекаются
(образуя 3 разные точки )
и эти точки не лехат на одной прямой
ТО 1пс(кол-во).
сохранить номера отрезков.
прорисовать треугольник
вывод (к-во)
Введем следующие операции:
□ FindSIntersectPoint(Seg1,Seg2,Point1).
Определяет, пересекаются ли отрезки Seg1 и Seg2. Если да, то функция
принимает значение «истина» и переменная Pointl будет содержать
координаты точки пересечения.
□ TTriangleInit(Triangle,Point1,Point2,Point3).
Инициализирует треугольник Triangle по трем заданным точкам Pointl.
Point2, Points.
□ TTriangleArea(Triangle).
Вычисляет площадь треугольника Тriangle.
□ IsZero(R).
Выясняет, равна ли вещественная переменная нулю. Как уже говорилось
ранее, в Паскале не рекомендуется вещественные числа просто сравнивать
на равенство.
1.3. Технология разработки программ
63
□ AddT riangle(TrianSet,T riangle).
Добавляет новый треугольник к множеству ранее найденных треуголь-
ников.
□ Out(CountTriangles).
Выводит результат работы программы.
4. Разработку программы вести «сверху вниз», откладывая уточнение деталей,
несущественных для данного уровня разработки программы.
Теперь можно записать основную часть программы непосредственно на языке
программирования Паскаль, используя введенные операции:
CountTriangles:-0:
for il:-l to CountSegments-2 do
begin
Segl:-SS[11J:
for to Countsegments-1 do
Seg2:-SS£12J:
if not FindSlntersectPoint(Segl.Seg2.Po1ntl) then continue:
for 13:-i2+l to CountSegments do
Seg3:-SS[13l:
if not F1ndSInterSectPoint(Segl.Seg3.Point2) or
not Fi ndSInterSectPoi nt(Seg2.Seg3.Poi nt3)
then continue:
TTriangleInit(Triangle.Pointl.Point2.Point3):
if not IsZero (TTriangleArea(Triangle))
then AddTriangle(TrianSet.Triangle):
Out(CountTriangles):
Реализацию введенных процедур предлагается выполнить вдумчивому чита-
5. При написании собственно текста программы обеспечивать максимальную чи-
табельность, используя адекватные имена переменных, массивов, процедур и
функций, а также разумно комментируя текст на стадии ввода текста програм-
мы (до начала отладки).
ПРИМЕЧАНИЕ--------------------------------------------------------------------------
Внимательный читатель обратил внимание, что имена переменных, массивов, проце-
дур и функций отражают семантику соответствующих понятий.
Вопросы и ответы
Изложение решения задач, возможно, некоторым покажется излишне конспектив-
ным, не раскрывающим многие детали и не отвечающим на многие вопросы, кото-
рые могут возникнуть у неискушенного читателя. Это сделано намеренно, для того
чтобы как можно яснее донести суть предлагаемого подхода к решению задач.
Глава 1. Программирование на Паскале
Что касается ответов на возникшие у читателя вопросы, предлагается три способа
разрешения возникшей проблемы.
1. Каждый желающий может включиться в работу проекта «Дистанционное обу-
чение в Беларуси» (WWW:http://dl.gsu.unibel.by, E-mail:dl-service@gsu.unibel.by),
получая через Internet-online и/или по электронной почте теорию, задачи, кон-
сультации, а также возможность посылать свои решения на автоматическое те-
стирование, которое осуществляется ежедневно и круглосуточно без переры-
вов на выходные и праздники.
2. Каждый желающий может послать свой вопрос, возникший по данному мате-
риалу, непосредственно автору по адресу: dolinsky@gsu.unibel.by.
3. Ответы на вопросы, которые поставил сам автор, предсказывая возможное их
появление у читателей, изложены далее.
Вопрос 1. Что такое extended в нижеследующей строке:
type TReal = extended: {Переопределяем вещественный тип)
и зачем вообще нужно было переопределять вещественный тип: можно ведь было
воспользоваться привычным типом real?
Ответ на вопрос 1.
Посмотрим в полную таблицу вещественных типов Паскаля (см. табл. 1.16). Из нее
следует, что типы отличаются друг от друга объемом занимаемой оперативной па-
мяти (в байтах) и, соответственно, диапазоном и точностью представляемых зна-
чений (чем больше байтов оперативной памяти отведено на число, тем точнее оно
представлено в компьютере). Кроме того, время обработки переменных (и особен-
но массивов) различных вещественных типов может существенно отличаться.
Переопределение типа в указанной строке приводит к тому, что наша программа
будет обрабатывать вещественные числа с максимальной точностью.
В то же время, если потребуется изменить тип вещественных чисел (например, на
single — в целях экономии оперативной памяти), для этого будет достаточно за-
менить только одно слово extended на слово single, и все наши переменные, точки,
отрезки и т. д. автоматически также перейдут на новый тип.
Вопрос 2. Все введенные типы TReal, TPoint, TLine и т. д. начинаются с буквы Т —
это обязательно?
Ответ на вопрос 2.
Нет.
Но у многих профессиональных программистов важным правилом становится ис-
пользование так называемой «венгерской нотации», когда одна или несколько букв
перед именем определяют функциональное назначение этого имени (например, Т —
тип, тогда TPoint — тип «точка»). Это позволяет программисту проще ориентиро-
ваться в своей (а тем более в чужой) программе, что особенно важно для программ,
функционирующих и эксплуатирующихся на протяжении нескольких лет.
Вопрос 3. Я еще не работал с записями. Можно ли подробнее пояснить, как их
использовать?
1.3. Технология разработки программ
65
Ответ на вопрос 3.
Лучше, конечно, почитать какую-нибудь книгу по Паскалю (например, [ 1 ] или [2])
и потом попробовать на компьютере, но попробую кратко ответить и я.
Итак, во-первых, мы объявляем новый тип — запись (record):
TPoint - record
х. у : TReal: {Тип ТОЧКА - координаты X и Y}
И переменные этого типа:
К чему это приводит?
В оперативной памяти компьютера резервируется определенное количество ря-
дом лежащих байтов, чтобы потом туда заносить и оттуда выбирать значения со-
ответствующих переменных.
В нашем примере TReal был определен как extended, что означает резервирование
10 байт на каждую такую переменную. TPoint был определен как совокупность двух
вещественных чисел (точка определяется координатами по осям X и У).
Тогда для точек р1 и р2 резервируется по 20 байт (первые 10 - для хранения коор-
динаты по оси X, остальные — для хранения координаты по оси У).
Чтобы инициализировать точку, то есть занести в поля записи значения, соответ-
ствующие какой-то реальной точке, например (2,4), необходимо в программе на-
писать следующее:
Чем удобен тип «запись»?
Тем, что можно обращаться ко всей записи как к единому целому. Например, для
того, чтобы вторая точка была инициализирована теми же значениями, что и пер-
вая, достаточно написать:
Часто необходимо обращаться к полям переменных по отдельности. Например,
если точка р2 на 3 правее и на 1 выше, чем точка pl, то инициализировать ее можно
следующим образом:
Завершая это объяснение, приведем общий вид обращения к полю в записи:
имя_переменной.имя_поля.
И напомним, что обращаться к полям записи можно как па зап ись, так ина чтение,
то есть как в левой, так и в правой части относительно знака присваивания : =.
Вопрос 4. Я не работал еще с процедурами и функциями. Что такое процедура?
Что такое функция? Чем они отличаются друг от друга? Где в программе размеща-
ются процедуры и функции?
Ответ на вопрос 4.
Прежде всего опять-таки посоветую обратиться к учебникам по Паскалю (напри-
мер, [1,2]). Тем не менее приведу краткий ответ и здесь.-
66
Глава 1. Программирование на Паскале
Начнем с определения процедур, которое должно быть до оператора begin, начи-
нающего раздел действий программы:
program ,..
procedure InitLine ...
InitLine
Рассмотрим подробнее определение процедуры InitLine:
procedure InitLinelvar LrTLine: pA, pB: TPoint):
begin
L.A pB.Y - pA.Y;
L.B pA.X - pB.X:
L.C pA.Y*(pB.X-pA.X) - pA.X*(p8.Y-pA.Y):
end:
где
□ InitLine — это имя процедуры;
□ L, pA, pB — параметры процедуры.
Вызов процедуры в теле программы (после соответствующего оператора begin)
может выглядеть следующим образом:
InitLine (L1.P1.P2):
То есть:
инициализировать прянув L1 по точкам Р1 и Р2
Достоинства использования процедур заключаются в том, что после определения
ее можно вызывать множество раз. Это значительно проще, чем каждый раз непо-
средственно кодировать содержание процедуры.
Например, для инициализации прямой Line по точкам Pointl и Point2 достаточно
написать еще один вызов процедуры:
InitLine (Line. Pointl. Point2):
Обратите внимание, что при определении процедуры необходимо указывать типы
параметров процедуры: TLine — для переменной L и TPoint — для переменных рА
и рВ. Имея эту информацию, компилятор контролирует соответствие типов пара-
метров процедуры при вызове (фактических параметров) типам параметров про-
цедуры при ее определении (формальных параметров). Это избавляет программи-
ста от поиска подобных ошибок во время исполнения программы.
Внимательный читатель заметил еще не объясненное слово VAR перед именем пере-
менной L в строке определения процедуры. Это слово определяет, что значение пере-
менной L изменяется в процедуре и должно быть возвращено в главную программу.
И действительно, процедура InitLine и предназначена для того, чтобы по передан-
ным ей значениям координат двух точек вычислять и возвращать коэффициенты
А, В и С канонического уравнения прямой, проходящей через две заданные точки.
1.3. Технология разработки программ
Вспоминаем, что тип TLine, как раз, так и определен:
TLine - record {Тип ПРЯМАЯ}
А. В. С: TReal: {коэффициенты в уравнении}
end: (Ах • By + С - 0)
Таким образом, параметры у процедуры могут быть входные (те, что передаются
ей) и выходные — те, которые она вычисляет и возвращает.
Что будет, если мы не поставим слово VAR перед выходным параметром? Он будет
вычислен в процедуре, но результат вычислений не вернется в главную программу.
А что будет, если мы поставим слово VAR перед входным параметром? В принципе,
ничего страшного. Но если вы в процедуре измените значение такого параметра,
оно вернется в главную программу и затрет соответствующее значение, что может
привести к ошибкам.
Поэтому авторы учебников по Паскалю всегда рекомендуют точно определиться,
должен или нет изменять значение тот или иной параметр в процедуре, и в соот-
ветствии с этим корректно ставить слово VAR.
Для уточнения понятия функции рассмотрим другой пример. Определение:
function Difference
(L:TLine: S:TPo1ntsSet: var OnL1neCurrent:1nteger):integer:
D. i. Temp : Integer:
{Цикл по всей точкам}
{Вычисляем знак точки}
{Накапливаем разность)
{и количество точек на}
(текущей прямой)
{Нам все равно, с какой}
{стороны точек больше}
OnLineCurrent :- 0:
for 1:- 1 to CountPolnts do
begin
Temp :- SignPolntd.SCW:
D : D ♦ Temp:
if Temp=0 then Inc(OnllneCurrent):
Difference :- abs(D):
Вызов:
If-MlnDIf > Differenced.S.OnLineCurrent) then ...
Прежде всего отметим то общее, что связывает процедуры и функции:
□ возможность разделять задачу на логические подзадачи;
□ порядок расположения определения и вызова в программе:
program ...
function Difference ...
If MlnDIf > Difference ...
then...
68
Глава 1. Программирование на Паскале
□ правила определения входных и выходных параметров:
function Difference
(LiTLine: SJPointsSet: var OnLineCurrent:integer):integer:
Здесь функции Difference передаются прямая L и множество точек S, а она через
параметр OnLineCurrent возвращает количество точек из заданного множества,
которые расположены точно на прямой.
А теперь рассмотрим различия. В частности, вызов процедур и функций:
DInitLine(L,Pl,P2):
if MlnDif > Difference ...
then ...
Функция вызвана своим упоминанием в операторе сравнения. Но тогда имени
Difference должно соответствовать какое-то число. Так и есть — функция Difference
возвращает через свое имя число. Для этого в ее определении указывается тип резуль-
тата — integer function Difference (...) : integer, а в теле функции по завершении вы-
числений переменной с именем функции присваивается необходимое значение:
Differente abs(O):
Использование функций вместо процедур во многих случаях делает программу
компактней и наглядней.
Вопрос 5. Я впервые вижу слово break. Что оно означает?
Ответ на вопрос 5.
Речь идет о фрагменте текста программы:
for i:-l to CountPoints-1 do
begin
if M1nDif-0 then break:
for j:-i+l to CountPoints do
begin
if MinDif-0 then break:
{Для точек от первой}
{до предпоследней}
{Если нашли, то уходив}
{Для точек от следующей}
(до последней}
{Если нашли, то уходив)
Во время разработки этой программы выяснилось: если найдена такая прямая, что
количество точек по разные ее стороны равно, то разность этих количеств равна О
и она — минимальна. Найдено решение, и незачем продолжать выполнение программы.
Очень многие в этой ситуации любят использовать оператор GOTO. Так вот. BREAK
выступает в данном случае как аналог оператора GOTO. При этом не указывается
метка перехода, потому что BREAK всегда обеспечивает «Выход из ближайшего внеш-
него цикла» (одного!). Именно поэтому, чтобы выйти из двойного цикла, потребо-
валось два оператора BREAK.
Вопрос 6. Я впервые вижу слово continue. Что оно означает?
Ответ на вопрос 6.
Речь идет о следующем фрагменте текста программы:
for 11:—1 to CountSegments-2 do
Segl:-SS[11]:
for to CountSegnients-1 do
1.3. Технология разработки программ
69
Seg2:=SS[12];
If not FindSInterSectPointlSegl.Seg2.Pointl)then continue:
for 13:-12*1 to CountSegraents do
begin
Seg3:-SS[13J:
If not FindSInterSectPo1nt($egl.Seg3.Point2) or
not F1ndSInterSectPol nt(Seg2.Seg3.Po1nt3)
then continue:
Во время разработки этой программы выяснилось, что в случае, когда отрезки с
номерами 11 и 12 не пересекаются, нет необходимости просматривать все тройки
из отрезков 11,12 и i3 в поисках треугольника. То есть в этот момент нужно просто
перейти к следующему за 12 отрезку, что и выполняет первый оператор CONTINUE.
Второй CONTINUE обеспечивает переход к следующему значению 13 в случае, если
с текущим отрезком 13 не пересекается хотя бы один из отрезков 11 или 12.
Таким образом, CONTINUE — это также специфический аналог оператора GOTO, обес-
печивающий переход на продолжение цикла со следующим значением перемен-
ной цикла.
Вопрос 7. А чем вам так не угодили операторы GOTO? Зачем вместо того, чтобы
пользоваться им одним, выдумываются два (а может, есть и еще?) его аналога?
Ответ на вопрос 7.
Действительно, поскольку любую программу можно написать как используя опе-
раторы GOTO, так и не используя их, то ответ, может быть, покажется спорным. Что ж,
каждый волен считать по-своему. Но многие профессиональные программисты
придерживаются следующей точки зрения.
□ Использование операторов GOTO усложняет логику программы и, соответствен-
но, ее восприятие. Вследствие этого время на отладку программы существенно
зависит от количества операторов GOTO в ней. То есть чем больше операторов
GOTO в программе, тем сложнее ее отладить.
□ Существует порог количества операторов GOTO. То есть если в программе опера-
торов GOTO больше этого значения, программу невозможно отладить вообще.
Считается, что этот порог для каждого программиста индивидуален: один мо-
жет отладить программу с 10 операторами GOTO, другой — с 50. Чтобы не увели-
чивать потенциально необходимое время на отладку своих программ, многие
программисты предпочитают не усложнять себе жизнь и не вводить операторы
GOTO в свои программы.
□ При исполнении программ на конвейерных процессорах использование опера-
тора GOTO может также замедлить исполнение программы, так как он вызывает
перезагрузку регистров ЭВМ и обнуляет очередь готовых к выполнению ко-
манд в процессоре.
ГЛАВА 2 Основы
алгоритмизации
Первая глава представила вдумчивому читателю «быстрое погружение» в язык
программирования Паскаль, средства написания и отладки Паскаль-программ. Она
же дала информацию о базовых начальных алгоритмах на одномерных и двумер-
ных массивах, например: суммирование элементов; подсчет и поиск элементов,
обладающих заданным свойством; нахождение максимального и минимального
элементов. Приведено также несколько методик разработки алгоритмов. Как уже
говорилось ранее, теоретически этого достаточно, чтобы написать программу для
решения любой задачи на языке программирования Паскаль. На практике же ра-
зумнее освоить не только методы разработки новых алгоритмов, но и сами алго-
ритмы, уже разработанные для широкого класса задач. Такие алгоритмы пополня-
ют «арсенал» разработчика программы. Применение известных алгоритмов, их
модификаций и комбинаций существенно сокращает время на решение задач, раз-
работку и отладку программ.
2.1. Очередь и стек
В этом пункте будут подробно рассмотрены свойства двух структур данных: оче-
реди и стека. Суть этих структур становится более ясной, если обратиться к их
английским обозначениям — FIFO и LIFO соответственно:
□ FIFO (First In First Out) — «первый пришел — первый ушел»;
□ LIFO (Last In First Out) — «последний пришел — первый ушел».
Физические примеры стека и очереди
Решение большого количества как олимпиадных, так и практических задач по
программированию требует применения очереди либо стека. Прежде всего рас-
смотрим некоторые физические аналогии стека и очереди.
Пусть на стройку поступают тяжелые бетонные плиты, которые рабочие уклады-
вают одну на другую. Тогда можно говорить, что эта стопка плит и представляет
собой стек: последняя плита, которую положили в стопку, будет первой, которую
из этой стопки заберут.
2.1. Очередь и стек
71
Еще один пример стека представляет собой «рожок» для патронов автомата Ка-
лашникова, запаянный с тыльной стороны. Последний патрон, который затолкали
в «рожок», первым вылетит из автомата при нажатии на спусковой курок.
Показательным примером очереди является очередь в кассу магазина, когда с на-
чала очередь обслуживается кассиром, а к концу очереди подходят новые покупа-
Другой пример очереди можно представить, предположив, что строители не кла-
дут плиты одна на одну, а приставляют одну к другой. И тогда одна бригада заби-
рает плиты из начала очереди, а другая бригада добавляет плиты к ее концу.
Представление стека в программе
И очередь, и стек могут быть представлены и реализованы в программе разнооб-
разными способами, но мы остановимся на самом простом — представлении оче-
реди и стека с помощью массива элементов.
Очевидно, что для стека достаточно иметь дополнительно к массиву одну пере-
менную (обозначим ее для определенности Тор), которая обычно называется вер-
шиной стека. В начале работы программы этой переменной присваивается значе-
Тор 0:
И это означает, что стек в данный момент пуст.
Занести в стек элемент X — это значит выполнить два действия:
1. Увеличить на 1 значение переменной Тор:
2. Поместить в массив Stek по индексу Тор элемент X:
Stek[Top] X:
Взять элемент из стека в переменную Y — значит выполнить другие два действия:
1. Взять элемент из массива Stek в переменную Y:
Y StektTop]-.
2. Уменьшить на 1 значение переменной Тор:
Заметим, что увеличение и уменьшение переменной Тор ровно на 1 могут быть в
Паскале выполнены также с помощью специальных функций:
□ Inc(Top) — эквивалентно Тор : = Тор + 1;
□ Оес(Тор) — эквивалентно Тор : = Тор - 1;
Обычно для большей наглядности и читабельности программ операции работы со
стеком и очередью выделяются в специальные процедуры и функции, например:
Stek : array [1..80] of char:
procedure Put(c:char):
begin
Inc(Top):
{Стек на 80 символов}
{Занести символ в стек)
{Изменить вершину стека}
72
Глава 2. Основы алгоритмизации
{Поместить синвол в стек)
{Стек пустой?)
{Если нет. взять символ из стека)
{Удалить синвол из стека)
(Уменьшить на 1 вершину стека)
Stek[Top]:- с:
procedure Gettvar x:char: var StekEmpty: boolean): {Взять из стека)
StekEmpty:- Top-0;
If not StekEmpty then x StekETop):
end:
procedure Delete: I
Oec(Top): I
end:
При этом размерность массива под стек определяется максимальным количеством
элементов, которое предполагается помещать в стек, и типом хранимых в стеке
элементов.
Понятно, что элементами стека могут быть не только символы. Можно заводить в
программе стеки слов, точек, отрезков, треугольников и т. д., используя средства
Паскаля для определения пользовательских типов данных. Можно также в каче-
стве элементов стека иметь пары чисел, тройки чисел и т. д.
Представление очереди в программе
Очередь, так же как и стек, может быть представлена в программе массивом эле-
ментов. Однако, в отличие от стека, для работы с очередью требуются две допол-
нительные переменные — указатели на начало и конец очереди. Назовем их для
определенности:
□ OueBegin — начало очереди;
□ QueEnd — конец очереди.
В начале работы программы начало очереди устанавливается в 1, а конец — в О,
например, следующими операторами:
OueBegin :- 1:
• QueEnd :- 0:
Тогда, чтобы занести тройку чисел (X,Y,Z) в очередь OUE (в ее конец), необходимо
выполнить следующие действия:
Inc(QueEnd):
OueEQueEnd.l) :- х
0ue[QueEnd,2] :- у
Que[QueEnd.3] :- Z:
Чтобы взять тройку чисел из очереди в переменные X, Y и Z (из начала очереди,
естественно), нужно сделать следующее:
х :- OuetQueBegin.l):
у :- 0ue[QueBegin.2]:
z := 0ue[QueBegin.3]:
Inc(QueBegin):
Внимательный читатель заметил, что в этом случае для работы с очередью исполь-
зуется двумерный массив. Первое измерение определяется предполагаемым мак-
симальным размером очереди, а второе — количеством чисел, принадлежащих од-
{Увеличить переменную - конец очереди)
(Занести в очередь)
(тройку чисел)
{Взять первое число)
{Взять второе число)
(Взять третье число)
{Увеличить указатель начала)
2.1. Очередь и стек
ному элементу в очереди. В нашем случае таких чисел 3 и второе измерение имеет
диапазон 1-3.
Так же как и при работе со стеком, операции работы над очередью обычно выно-
сятся в отдельные процедуры и функции, например:
procedure Put(x.y.StepNumber:integer): {Занести в очередь}
Inc(QueEnd): {Увеличить количество)
QueCOueEnd.il х: {координата по х)
Que[QueEnd.2] у: {координата по у)
Que[QueEnd.3] StepNumber: (номер хода)
end:
procedure Get(var x,y.StepNimber:integer): {Взять из очереди)
begin
х QueCOueBegin.1]: {координата по х)
у QueCOueBegin,2]: {координата по у)
StepNumber QueCOueBegin.3): {номер хода)
Inc(QueBegin): {Изменить начало)
Примеры решения задач
В данном пункте приведены примеры решения нескольких задач с использованием
очереди и стека. Тем, кто использует данный материал для самообучения програм-
мированию, рекомендуется после прочтения условия задачи сначала попытаться
решить ее самостоятельно, не читая материал, Изложенный далее в этом пункте. Если
вам это удастся, то, может быть, и незачем тратить время на дальнейшее чтение.
Задача о ходе конем
Даны обозначения двух полей шахматной доски (например, А5 и С2). Найти ми-
нимальное число ходов, которые нужны шахматному коню для перехода с первого
поля на второе.
Идея решения: вводится очередь возможных ходов коня.
Сначала ставим в очередь все клетки доски, достижимые за один ход. Затем, ис-
пользуя уже имеющиеся в очереди элементы, пополняем очередь полями, которые
можно достичь ровно за 2 хода, и т. д.
Понятно, что каждый раз, ставя клетку в очередь, не лишним является проверить,
не она ли — искомая. Если это так, то мы уже знаем, за сколько ходов сюда добе-
рется конь. При этом механизм очереди обеспечивает то, что это и будет мини-
мальное число ходов.
Более строгий алгоритм решения приводится ниже:
Помещаем в очередь исходное поле коня
Пока (не нашли)
Выбираем из очереди первый элемент - клетку X.Y
Клетки, достижимые из X.Y за ход коня.
если не конечные и еще не помеченные.
помещаем в очередь и помечаем
(если помещаемая клетка - конечная - ОСТАНОВ).
74
Глава 2. Основы алгоритмизации
Главная часть программы, решающей данную задачу, имеет вид:
StartProcess:
StepNumber:-O:
Found (Sx-Ex) and (Sy-Ey):
while (not Found) do
Get(x.y.StepNumber):
Inc(StepNunber):
PutAl1(x.y.StepNunber.Found)
end:
writeln(StepNumber);
end.
{Начало работы)
{Количество шагов - 0)
{Признак завершения работы)
{Пока не нашли)
{Взять координаты и номер шага)
{Увеличить номер шага)
{Занести в очередь все возможные
{ходы)
{Если среди них конечное поле.
{Found-true)
{Вывод номера шага)
Анализ текста главной программы показывает, чтоонаиспользуеттри подпрограммы:
□ Sta rtProcess — для ввода исходных данных и преобразования их к числовому виду;
□ Get — для выборки элементов из очереди; при этом в очереди хранятся число-
вые координаты клетки шахматного поля и номер минимального хода, кото-
рым туда можно прийти;
□
PutAll — для постановки в очередь всех клеток, достижимых ходом коня из те-
кущей. Если одна из этих клеток достижима за минимальное число ходов, то
логическая переменная Found получает значение ИСТИНА.
Полный текст самодокументированной программы (Knight.Pas) решения задачи
приведен в листинге 2.1.
Листинг 2.1. Текст программы решения задачи о ходе конем
Program knightl:
Que : array [1..64.1..3] of Integer;
Marked : array [1.. 8.1..8] of boolean:
StartCell. EndCell : string:
Sx.Sy.Ex.Ey.
x.y.
StepNumber.
QueBegin. QueEnd : integer:
(Очередь ходов)
{Пометки на доске)
{Начальная и конечная)
{позиции - строковые)
{- числовые)
{Текущая позиция)
{Нойер хода)
{Начало и конец очереди)
Found : boolean:
procedure Convert(Cel 1:string: var x.y:1nteger):
s : string:
1 : integer:
begin
c :- Cell[lJ: x :- ord(c) - 96:
s :- copy(Cell.2.1): val(S.y.i):
end:
{Перевод позиции)
{коня от строкового)
{представления к)
{числовому)
(Вместо a-h - 1-8)
{Вместо ’Г-'8'-1-8)
procedure Put(x,у.StepNunber:integer):
{Занести в очередь)
еинажисягойи
:pua
{иэеьэнои}
{и чваРэьо s HaenaHOu}:(jaquiNdaiSAluajjn3xiuajjno)ind иещ
{онэьэяои ан(*-х)аиои) [Aluajjno’xiuajjnaJpaxjeH iou
{и энэов ен *} pue (OAluajjnj) pue (0<Aluajjna)
{и эяэов ен х} pue (6>xiuajjn3) pue (o<xiusjjrr))
{и хан ввоз) pue punoj jou ji
{ieHiaux веионэи oxc) :(Aluajjn>X3) pue (xiuajjn>x3) punoj
{eBox охавЛиах *} : [£'i]sdajs*A =: Aiuajjrrj
{eBox ojaMnai xj ' [Г t]sdajs+x xiuajjnj
i(l)3Ul
{box иниалваиэ иэевэи) uifiaq
{Box чиа и иваен эн еноц} op (8>i) pue (punoj iou) ацци
(евох ОАОШонеое Район} "0-Ц
(Auaux аХннэноя ивпен} -asiej punoj
uj6aq
:ja6axui : xluajjnj 'xiuajang 4
вел
:< (t ’г-) (1- г-) (i г га- г) '<г тнг-т)
{хнехэноя еиээен) (г I )'(г-1 )) - W6iux : sdais
JSUOP
{внох нвох эгмхоиеод} :ua6awi jo [?"Г8 I] *e-ue - lu6iu>
{«box амнжонеоа эииАхэ! aoe} adXj
{чвэРаьо s иАээнес}
:(uea(ooq:punoj jeA:ja6aiui:jaquinNdais ^‘x)llVlnd ajnpaoojd
{оипиеои оХнчвекен нэеканоц} :atui [Xs'xslpaiJew
{чваРаьо а аипиеои аЛнчвеьен) ' (O’^S'XSJVU
{|чнэьаиои эн}resiej [("Иракец op 8 01 1 -:f joj
{ииазвн aos)
{ивэРэьо ПЭНОЦ)
{иваРано овеьен)
{иевэиь я nieeoeePpoaPu)
{невэиь я чАееоееРдоаРц}
{аипиеои аКньаном иэсаин}
{аипиеои аЛнчвеьен иэваиь}
ор 8 01 I -:l “0J
:q-: ризэпо
:( иебэеэпо
:(АЗ‘хз •цазризп-'элиоз
:(X$xs‘ цэоие15)иэлиоэ
ЧЦЭЭРиз мреэв
cdiaoweiSMpeaj
ui6aq
:ja6aiu( : f’t
{оиенен чхинэнеи}
{евох Район)
{A ou ехенивРооя}
{х ou ехенивбоом)
(иВэРэно ей чхвед)
tssaoojpweis aunpaoojp
:pua
:(ui6aaano)oui
:[С'их6Э8ЭП0]апо jaqurinPaiS
:(Z'ui6aaano]ano A
:[I'ui6a8ano]ano x
ux6aq
:(ja6aiu|:jaqunNd81S'^'x JPAjiag aunpaoojp
{оАннееоечвоиэи иаеьаиоц}
{евох Район}
{X ou ехенивРооя}
(х ou ехенивРооя}
{оахээьивох чхиьивэал}
:anjj
rjaoxnNdais
:pua
[Хх]рэхвен
[£-ризэпо]эпо
[гризэпмэпо
[Гризэпозэпо
:(ризапО)Эи!
ихбэч
76
Глава 2. Основы алгоритмизации
Листинг 2.1 (продолжение)
StartProcess:
StepNumber:-0:
Found :- (Sx-Ex) and (Sy-Ey):
while (not Found) do
Gettx.y.StepNumber):
Inc(StepNumber):
PutAlKx.y. StepNumber. Found)
writeln(StepNumber):
{Начало работы}
{Количество шагов - 0}
{Признак завершения работы)
{Пока не нашли}
{Взять координаты и номер шага}
{Увеличить номер шага}
{Занести в очередь все}
{возможные ходы)
{Если среди них конечное)
{поле. Found-true)
{Вывод номера шага}
Задача о вырезании кусков
Из листа клетчатой бумаги размером 8x8 клеток удалили некоторые клетки.
На сколько кусков распадется оставшаяся часть листа?
ПРИМЕР -------------------------------------------------------
Если из шахматной доски удалить все клетки одного цвета, то оставшаяся часть рас-
падется на 32 куска.
Идея: вводится очередь клеток, смежных с текущей. То есть:
1) находим первую невырезанную клетку и помещаем ее в очередь;
2) до тех пор пока очередь не станет пустой, выбираем первый элемент из очереди
и добавляем в очередь все смежные с текущей клетки;
3) когда очередь станет пустой, это будет означать, что первый кусок закончился;
надо опять находить первую невырезанную клетку (не используя клеток пер-
вого куска) и продолжать процесс, пока не закончатся все клетки.
Более строгое изложение алгоритма выглядит так:
Номер куска - 0
Пока есть непомеченная клетка
помешаем ее в очередь и помечаем
1пс(Номер куска)
Пока очередь не пуста
Выбираем клетку из очереди
Все смежные с ней и не помеченные
помещаем в очередь и помечаем.
Приведем текст главной программы, решающей данную задачу:
begin
StartProcess:
StepNumber:-0:
while (Found(x.y)) do
{Начало работы}
{Нойер куска - 0)
{Пока есть непомеченная х.у}
(Помещаем ее в очередь и помечаем}
(Увеличить номер куска на 1}
Inc(StepNumber): ......... .г .
while QueBegin<-QueEnd do (Пока очередь не пуста)
2.1. Очередь и стек
Get(x.y): PutAll(x.y): end: end: {Взять из очереди x.y) {Занести в очередь все возможные ходы)
writeln(StepNunber): {Вывод ноиера шага)
Анализ главной программы показывает, что в ней используются следующие под-
программы и функции:
□ StartProcess — для ввода исходных данных и пометки вырезанных полей;
□ Found<х,у) — для выяснения факта наличия невырезанных и непомеченных кле-
ток и, если такие еще есть, — определения их координат;
□ Get (х,у) — для выборки элементов из очереди;
□ PutAl 1 — для постановки в очередь всех клеток, смежных по сторонам с теку-
Полный текст самодокументированной программы решения этой задачи (Cell.Pas)
приведен в листинге 2.2.
Листинг 2.2. Текст программы решения задачи о вырезании кусков
Program celll:
Oue : array [1..64.1.,23 of integer:
Marked : array [1.. 8.1..8] of boolean:
StepNurber.
QueBegin. QueEnd : Integer:
{Очередь ходов)
{Покетки на доске)
{Текущая позиция)
{Нойер хода)
{Начало и конец очереди)
procedure Putfx.y:integer):
begin
Inc(QueEnd):
QuelQueEnd.l] :- x;
Que[QueEnd,23 :- y:
Marked[x.y] :- true:.
{Занести в очередь)
{Увеличить количество)
{Координата по х)
{Координата по у)
{Поиечаен использованную)
procedure Gettvar x.y:integer):
х := QuelQueBegin.il:
у := Que[QueBegin.23:
Inc(OueBegin):
{Взять из очереди)
{Координата по х)
{Координата по у)
{Изиенить начало)
procedure StartProcess:
i.j.x.y : integer:
begin
for 1:- 1 to 8 do
for j:- 1 to 8 do Marked[iJ3:= false:
readln(n):
for 1:-l to n do
begin
readln(x.y):
{Все клетки)
{не понечены)
продолжение
78
Глава 2. Основы алгоритмизации
Листинг 2.2 (продолжение)
Marked[x.y] :- true:
end:
QueBegin :- 1;
QueEnd :-0:
{Начало очереди)
{Конец очереди)
function FoundCvar x.y:integer):boolean:
van i. j : integer:
for i:-l to 8 do
for j:-l to 8 do
if not MarkedCi.j]
then begin x:-i: y:=j: Found:-true: exit: end:
Found :- false:
procedure PutAll(x,y:integer):
type
King - array [1..4.1..2] of integer:
const
Steps : King -(( 0.-1). ( 0. 1). (-1.
Var 1. CurrentX. CurrentY : integer:
begin
i:-0:
while (i<4) do
begin
inc(i):
CurrentX :- x+steps[i.1]:
CurrentY y+steps[1.2]:
if (CurrentX>0) and (CurrentX<9) and
(CurrentY>0) and (CurrentY<9) and
not Harked [CurrentX.CurrentY]
then Put(CurrentX.CurrentY):
end:
{Занести в очередь)
{асе текущие возможные ходы)
{Возможные ходы коня)
0). ( 1. 0)): {Массив констант)
{Номер возможного хода)
{Пока не нашли и есть ход)
{Делаем следующий ход)
{X текущего хода)
{Y текущего хода)
{X на доске и)
{Y на доске и)
{поле(Х.У>не помечено)
{помещаем в очередь)
StartProcess:
StepNumber:-0:
while (Found(x.y)) do
begin
Put(x.y):
Inc(StepNumber):
while Que8egin<-0ueEnd do
begin
Get(x.y):
PutAlKx.y):
end:
writeln(StepNumber):
{Начало работы)
{Номер куска - 0)
{Пока есть непомеченная х.у)
{Помещаем ее в очередь и помечаем)
{Увеличить номер куска на 1}
{Пока очередь не пуста)
{Взять из очереди х.у)
{Занести в очередь все возможные)
{Вывод номера шага)
Задача о скобках
Дана конечная последовательность, состоящая из открывающих и закрывающих
скобок различных заданных типов. Определить, можно ли добавить в нее цифры
2.1. Очередь и стек
79
и знаки арифметических действий так, чтобы получилось правильное арифмети-
ческое выражение.
ПРИМЕР ------------------------------------------------------------
((ПОПО)) —такая последовательность будетудовлетворять условию задачи, атакая —
([)] — нет.
Идея: вводится стек открывающих скобок.
Во входной строке, по условиям задачи, имеются только открывающие и закрыва-
ющие скобки, а обработка ее ведется посимвольно. Алгоритм можно записать так:
Если входной сиквол - открывающая скобка, то заносим его в стек
Если входной символ - закрывающая скобка, то проводин
дополнительный анализ:
если в стеке аналогичная открывающая скобка.
то скобки парные, удаляем верхнюю скобку из стека
и продолжаем процесс
если в стеке нет элеиентов вообще или
скобка не аналогичная, то ошибка - и останов
Если мы добрались до конца строки, то анализируем стек
Если он не пуст - ошибка, иначе - строка корректная.
Более строгое представление предлагаемого алгоритма:
Пока (не кончились символы и нет ошибки)
ЕСЛИ скобка открывающая
ТО помещаем ее в стек
ИНАЧЕ
ЕСЛИ стек не пуст
ТО
ЕСЛИ скобка парная
ТО удаляем ее из стека
ИНАЧЕ ошибка
ИНАЧЕ ошибка
ЕСЛИ ошибка или стек не пуст
ТО вывод ('Ошибка')
ИНАЧЕ вывод ('Корректно')
Посмотрим на текст главной программы для решения этой задачи:
StartProcess:
while (1<-L) and (not Error) do {Пока не кончилась строка и нет)
{ошибки}
с stroked]: {берем очередной символ)
1f с in ['{’. '('. '['] {Если он - открывающая скобка)
then Put(c) (то помещаем его в стек)
else (иначе)
Get(x.StekEmpty): {пытаемся взять символ из стека)
if (not StekEmpty) {Если удалось - стек не пуст)
then (то)
if (<х-'{') and (с-')')> or {Если скобка - парная)
((х-'(') and (с-')')) or
«х-'[') and (с-']'))
80
Глава 2. Основы алгоритмизации
then Delete
else Error:- true
else Error:- true:
{удаляем закрывающую из стека)
(Скобка непарная - ошибка)
{Стек пуст - ошибка)
Inc(i):
end:
Get(x.StetEmpty):
if Error or (not StekEmpty)
then writeln (’Ошибка')
else writeln ('Корректно')
(Берен следующий синвол)
{Проверяек. пуст ли стек)
{Если ошибка или стек не пуст)
В главной программе используются следующие процедуры:
□ StartProcess — для ввода строки со скобками, определения ее длины L и обну-
ления вершины стека Тор;
□ Put (с) — для помещения символа в стек;
□ Get(x,StekEmpty) — для взятия символа из стека в X, при этом логическая пере-
менная StekEmpty получает значение ИСТИНА, если стек пуст;
□ Delete — для удаления символа из стека.
Полный текст программы, решающей задачу (Stek.Pas), приведен в листинге 2.3.
Листинг 2.3. Текст г
Program stekl:
var
Stek : array [1..80] of char:
Stroka : string:
Top . : Integer:
Error : boolean:
I задачу о скобках
{Стек на 80 символов)
{Вводимая строка)
{Длина строки)
{Вершина стека)
{Признак ошибки)
procedure StartProcess:
readln(Stroka):
L :- length(Stroka):
Top :- 0:
end:
{Вводии строку)
{Вычисляем ее длину)
{Вершина стека - 0)
procedure Put(c:char):
Inc(Top):
StekETop] :- с:
end:
{Занести символ в стек)
{Изменить вершину стека)
{Поместить символ в стек)
procedure Get(var x:char; var StekEmpty: boolean): {Взять из стека)
StekEmpty :- Top-0; {Стек пустой?)
If not StekEmpty then x :- Stek[Top): (Если нет. взять синвол из)
{стека)
procedure Delete: {Удалить символ из стека)
Dec(Top): {Уменьшить на 1 вершину)
nd ' {стека}
2.1 .Очередь и стек
81
StekEmpty : boolean:
StartProcess:
while (1<-L) and (not Error) do {Пока не кончилась строка и нет ошибки)
с := stroked]: {Серен очередной символ}
if с 1п ['{'.'('.’['] {Если он - открывающая скобка)
then Put(c) {то помещаем его в стек)
else {иначе}
Get(x.StekEmpty): {пытаемся взять символ из стека)
if(not StekEmpty) {если удалось - стек не пуст)
then {тогда)
if ((х-'{') and (с-')')) or {если скобка - парная)
((х-’(') and (с-')')) or
((х-Т) and (с-']’))
then Delete {удаляем закрываищуо из стека)
else Error:» true {Скобка непарная - ошибка)
else Error :- true: {Стек пуст - ошибка)
{береи следующий символ)
Gettx.StekEmpty):
if Error or (not StekEmpty)
then writeln ('Ошибка') else writeln
(Проверяем, пуст ли стек)
{Если ошибка или стек не пуст)
('Корректно')
Дополнительные приемы программирования
У тех, кто прочел полные тексты программ, могли возникнуть вопросы по тем при-
емам, которые были в них применены. Кроме того, автор хотел бы и сам обратить
внимание читателей на несколько дополнительных приемов программирования,
примененных при решении указанных задач. Разбору этих приемов и посвящен
данный пункт.
Преобразование символов в числа
Вернемся кзадаче о шахматном коне.
procedure Convert(Ce)].-string: var x.y:1nteger): {Перевод позиции)
var {коня от строкового)
с : char: {представления к)
s : string: {числовому}
1 : integer;
begin
с :- СеП[1]: х ord(c) - 96: {Вместо a-h - 1-8}
s :- copy(Cel1.2.1): val(S.y.i) {Виесто'Г-'8' - 1-8)
end:
Итак, в этой задаче на вход поступают 2 символа, обозначающие положение ис-
ходной клетки коня (и 2 символа для обозначения конечного поля коня). В про-
82
Глава 2. Основы алгоритмизации
грамме нам удобнее преобразовать эти 2 символа в 2 числа, заменив буквы от а до
h на цифры от 1 до 8 и символы от 1 до 8 — на соответствующие числа.
Сначала займемся буквами. Известно, что каждая буква имеет собственный ASCII-
код (число от 0 до 255). При этом латинские буквы имеют коды в порядке возрас-
тания. То есть символ Ь имеет код на 1 больше, чем символ а, символ с имеет код на
1 больше, чем символ Ь, и т. д. Функция ORD(С) как раз и выдает в качестве резуль-
тата код, соответствующий символу с. Например, ord(a) равно 97.
Таким образом, чтобы вместо латинского символа из диапазона a-h получить со-
ответствующее число от 1 до 8, достаточно от кода этого символа отнять 96, что и
делается в приведенном выше фрагменте программы.
Чтобы заменить символ цифры на соответствующее число, используется другой
прием (хотя можно было использовать и тот же). Функция VAL служит для перево-
да чисел из символьного представления в числовое.
Инициализация массива констант
Известно, что вообще конь имеет 8 различных ходов, определяемых соответству-
ющими комбинациями пар из чисел 1, 2, -1, -2. Программа лучше читается, если
использовать в данном случае инициализацию массива констант, определяющих
допустимые ходы коня.
procedure PutAl1(x.y,Sts
:var Found:boolean):
(Занести в очередь}
(все текущие возможные ходы)
(Возможные ходы коня}
type
Knight - array [1..8.1..2] of Integer:
const
Steps : Knight - (( l.-2).( 1. 2).
(Массив констант}
i. CurrentX. CurrentY integer:
Found False:
while (not Found) and (i<8) do
inc(1):
CurrentX
CurrentY _ .............
Found :- (Ex-CurrentX) and (Ey-CurrentY):
if not Found and
(CurrentX>0) and (CurrentX<9) and
(CurrentY>0) and (CurrentY<9) and
not MarkedCCurrentX.CurrentY]
x+stepsCi. 1]:
y+steps(i.2]:
{Наили конечную клетку}
(Нойер возможного хода}
{Пока не нашли и есть ход}
{Делаем следующий ход}
{X текущего хода}
{Y текущего хода)
'' (Это искомая клетка?)
{Если нет и}
then Put(CurrentX.CurrentY.StepNumber);
{поле (X.Y) не)
{помечено}
(помещаем в очередь}
{и помечаем}
Для задачи о разрезании бумаги допустимые «ходы» при постановке клетки в оче-
редь несколько другие, но это отражается фактически только в массиве констант:
2.1 .Очередь и стек
83
procedure PutAl1(х.у:integer):
{Занести в очередь}
{все текущие возможные}
{ходы}
{Возкожные ходы)
King - array [1..4.1..2] of integer:
const
Steps : King-((0.-l).( 0.1). (-1. 0). ( 1. 0)): {Массив констант)
Var 1. CurrentX. CurrentY : integer:
while (i<4) do
begin
iric(1):
CurrentX x+steps[1.1J:
CurrentY ytsteps[1.2]:
if (CurrentX>O)and (CurrentX<9) and
(CurrentY>0) and (CurrentY<9) and
not MarkedCCurrentX.CurrentY]
then Put(CurrentX.CurrentY)
{Номер возможного хода}
{Пока не нашли и есть}
{ход}
{Делаем следующий ход}
{X текущего хода}
{Y текущего хода)
{X на доске и}
(поле(Х-У)не попечено}
{покещаен а очередь}
Глобальные переменные, локальные переменные
и параметры
Неправильное распределение переменных в программе между этими типами при-
водит к увеличению количества потенциальных ошибок в программе и, соответ-
ственно, к затягиванию процесса отладки программы.
Если переменная объявлена внутри процедуры или функции — это означает, что
она объявлена локально. То есть никакие изменения этой переменной внутри дан-
ной процедуры никак не влияют на переменные с тем же именем в других процеду-
рах и функциях и в главной программе. Например, в приведенной выше процеду-
ре PutAll переменные i, CurrentX и CurrentY — локальные.
Если переменная объявлена вне тела процедуры или функции, то она является
глобальной и всякое изменение ее любой процедурой или функцией будет дей-
ствительно для всех процедур и функций, лежащих в файле ниже ее объявле-
И наконец, параметры — это переменные, которые объявляются непосредствен-
но в определении заголовка процедуры и функции, такие как х, у, StepNumber и
Роипй. Очень важно также понимать разницу между возвращаемыми и невозвра-
щаемыми параметрами. Например, параметры х, у и StepNumber — невозвращае-
мые (перед ними нет ключевого слова VAR), и поэтому любые их модификации
в данной подпрограмме никак не отразятся на значениях соответствующих пе-
ременных в вызывающей программе. А вот параметр Found (перед которым сто-
ит ключевое слово var) — это возвращаемый параметр, то есть его значение, вы-
численное в процедуре, изменит соответствующее значение в вызывающей
программе.
Из каких соображений делить переменные между указанными видами?
84
Глава 2. Основы алгоритмизации
1. Если переменная нужна только для промежуточных вычислений, она должна быть
локальной. В частности, переменные цикла FOR обязательно должны быть локаль-
ными переменными. Например, в программе Knight.Pas (см. листинг 2.1) перемен-
ная 1 локально объявлена 3 раза: в процедурах Convert, StartProcess и PutAll.
2. Глобальные переменные — это потенциальный источник трудноуловимых оши-
бок, и пользоваться ими нужно очень осторожно. В программе Knight.Pas, на-
пример, объявлены глобально:
Que: array [1..64.1..3] of integer:
Marked: array Cl..8.1..8] of boolean:
3. Очень удобно пользоваться параметрами для управления разрешением пере-
дачи информации между процедурами. Например, в процедуре Put Al 1 перемен-
ная Found используется для возвращения вызывающей программе информации
о том, было ли среди возможных ходов коня «конечное поле».
(Очередь ходов)
{Поиетки на доске)
Использование логических переменных и массивов
Грамотное использование логических переменных и массивов уменьшает разме-
ры программы и повышает ее наглядность, что в конечном счете сокращает сроки
ее отладки.
Многие начинающие программисты часто используют переменные и массивы со
значениями 0 и 1 вместо логических значений false и true.
Приведем несколько примеров использования логических переменных и масси-
вов в описанных программах:
□ Knight.Pas (задача о коне).
Found :- (Sx-Ex) and (Sy-Ey): {Признак завершения работы)
Здесь переменная Found получает значение ИСТИНА, если верны оба равенства
одновременно (Sx = Ex) и (Sy = Еу). То есть если в процессе перебора найдена
конечная клетка.
while (not Found) do
Пока не найдена - делать
□ Cell.Pas (задача о разрезании на куски, см. листинг 2.2).
function Found(var x.y:integer):boolean:
i.j : integer:
begin
for 1:-l to 8 do
for j:-l to 8 do
if not Marked[i.j]
then begin x:-1: y:-J: Found:-true: exit: end:
Found : false:
Здесь Found — логическая функция, которая получает значение ИСТИНА, если на
доске еще есть непомеченные клетки. В переменных х и у возвращаются
координаты первой найденной свободной клетки. (Обратите внимание на
наличие ключевого слова VAR в определении параметров.) Только если на доске
не осталось непомеченных клеток, функция Found получает значение ЛОЖЬ.
{Пока не нашли)
2.1. Очередь и стек
Здесь же показател ьно использование оператора EXIT для нестандартного выхода
из процедуры.
□ Stek.Pas (задача о скобках, см. листинг 2.3)
procedure GetCvar x:char: var StekEmpty: boolean): (Взять из стека}
StekEmpty Top-0; (Стек пустой?)
If not StekEmpty then x: = Stek[TopJ: {Если нет.взять)
(символ из стека)
end:
Логическая переменная StekEmpty получает значение ИСТИНА, если стек пуст
(Тор = 0), и значение ЛОЖЬ — в противном случае. Это значение используется
для корректной выборки из стека, и оно же возвращается в вызывающую
программу.
if Error or (not StekEmpty) {Если ошибка или стек не пуст)
then writeln ('Оиибка')
else writeln ('Корректно')
Этот фрагмент не требует пояснений, в отличие от случая, когда проводилось
бы сравнение каких-то чисел.
Малая автоматизация тестирования
Итак, вы разработали алгоритм, написали программу, и она уже выдает правиль-
ные ответы на нескольких подготовленных вами тестах. Если все-таки появятся
тесты, на которых она перестанет работать правильно, то придется вносить изме-
нения в программу, добиваясь ее правильной работы и на этих тестах. Но ведь по-
сле изменения кода нужно опять все перепроверять!
Предлагается поступить следующим образом: сразу после того, как вы написали
программу и приступили к ее тестированию (а еще лучше — до того), составить
тесты и разместить их в файлах l.in, 2.in, 3.in и т. д„ l.out, 2.out, 3.out и т. д. Причем
в файлы *.in должно попадать то, что нужно вводить в программу в тесте с соответ-
ствующим номером, а в файлы *.out — данные, которые программа должна выво-
дить в случае правильной работы.
После этого вы составляете два пакетных файла All.bat и Test.bat
1. AlLbat
gecho off
cis
for in (1.2,3.4.5.6.7.8.9) do call test.bat «1
eecho off
program.exe <tl.in output.txt
fc output.txt «.out
В файле All.bat в скобках указываются номера тестов, которые вы подготовили. Он
циклически запускает для всех этих номеров пакетный файл Test.bat (передавая
ему в качестве параметра номер теста).
Файл Test.bat запускает разработанную вами программу (здесь — program.exe) и пе-
ренаправляет ей ввод и вывод (предполагается, что по умолчанию она вводила
Глава 2. Основы алгоритмизации
с клавиатуры и выводила наэкран). При этом в качестве входного подается подго-
товленный вами очередной тест, а в качестве выходного — для сохранения вывода
вашей программы — файл Output.txt. Его содержимое потом сверяется с подготов-
ленными вами эталонными ответами утилитой FC (File Compare), которая должна
быть практически на любом ПК.
Пользуясь запуском All.bat, вы в любой момент, после очередной порции измене-
ний, можете убедиться, что программа работает на всех подготовленных вами тес-
тах, или быстро обнаружить те из них, на которых она еще или уже не работает.
Если ваша программа должна считывать данные из одного файла (например, file.in)
и записывать в другой (например, file.out)> то вы можете слегка подправить пакет-
ный файл test.bat:
@echo off
del file.out
copy “I.in file.in
program.exe
Использование динамической памяти
Оперативную память компьютера можно представить как совокупность смежных
байтов, которые последовательно нумеруются от 0 до максимально возможного
значения. Один байт может хранить число от 0 до 255 (или от -128 до 127) или
символ (русская или латинская буква, цифра, знак операций и т. д.). Последова-
тельности смежных байтов могут использоваться для хранения целых и веществен-
ных чисел либо символьных строк.
В процессе функционирования компьютера его оперативная память используется
исполняемыми на нем программами.
Так, исполняющая среда Паскаля обрабатывает исходный текст вашей программы
и заносит результат обработки в оперативную память в виде двух главных компо-
нент— статической памяти данных и исполняемой части программы. Под стати-
ческой памятью здесь понимается память, которая выделяется под данные, объяв-
ленные в вашей программе в разделе VAR. А под исполняемой частью программы
понимаются операторы, которые записаны в вашей главной программе между begin
и end (а также между begin и end в процедурах и функциях вашей программы).
В Паскале есть ограничение на суммарный размер переменных и массивов, разме-
щаемых в статической памяти, — не более 64 Кбайт. Та часть памяти, которая оста-
ется свободной после загрузки в оперативную память компьютера исполняемых
программ, называется динамической памятью. Именно эта память и может дина-
мически (то есть непосредственно во время исполнения программы) захватывать-
ся вашей программой с помощью процедуры New. А после вызова в вашей програм-
ме процедуры Dispose освобождаемая память дополняет список свободных областей
динамической памяти компьютера.
Захватывая области динамической памяти, когда они действительно нужны, и воз-
вращая, когда не нужны, ваша программа может использовать намного больше
2.1 Очередь и стек
87
оперативной памяти под свои данные. Не только больше, чем 64 Кбайт статиче-
ской памяти, но даже больше, чем есть физически памяти на компьютере.
Единственным средством доступа к динамической переменной (массиву, записи
н т. д.) является указатель на место ее текущего расположения в оперативной па-
мяти. Указатель — это фактически номер байта оперативной памяти, с которого
начинается выделенная область оперативной памяти.
Исторически сложилось, что в IBM PC указатели областей оперативной памяти пред-
ставляются в виде сегмент: смещение. В зависимости от типа процессора и режима функ-
ционирования операционной системы абсолютный адрес указателя (соответствующий
реальный номер байта оперативной памяти) может вычисляться по различным алго-
ритмам. Например, для реального режима в DOS это делается по формуле:
(сегмент)* 16 + смещение.
Теперь научимся использовать динамическую память всвоих программах.
Начнем с примера. Напомним условие одной из решенных ранее задач. Из листа
клетчатой бумаги размером 8x8 клеток удалили некоторые клетки. На сколько
кусков распадется оставшаяся часть листа?
Эту задачу было предложено решать с помощью очереди. Для хранения данных
в этой задаче были использованы два массива:
Que : array [1..64.1..2] of integer; {Очередь ходов}
Marked : array [1..8.1..8] of boolean; {Поиетки на доске}
Массив Marked имеет размеры [1.. 8.1.. 8], потому что по условиям задачи разме-
ры доски — 8x8. Массив Que имеет размеры [ 1.. 64.1.. 2], так как в очереди макси-
мально возможно 64 элемента (все поля доски) и каждый элемент состоит из двух
чисел —х и у — координат клетки, которую мы поставили в очередь.
Пусть теперь задача усложнена следующим образом: из листа клетчатой бумаги раз-
мером N хМ клеток (N > 1, М < 150) произвольным образом удалили К клеток
(1 < К < 22 500). На сколько кусков распадется оставшаяся часть листа?
Попытаемся просто заменить размеры массивов на максимальные, например так:
Que : array [1..22500.1..2] of integer: {Очередь ходов}
Harked : array [1..150.1..150] of boolean; {Пометки на доске)
Тогда во время компиляции получим сообщение «Structure too large», что озна-
чает «слишком много данных в статической памяти». А как же быть? Можно ис-
пользовать динамическую память. Прежде всего — объявить типы массивов TQue и
TMarked и типы указателей на эти массивы TPQue и TPMarked.
type
TQue - array [1..22500.1..2] of byte:
TPQue - ‘TQue:
{Очередь ходов}
(Пометки на доске}
marked - array [1..150.1..150] of boolean:
TPHarked - ‘TMarked:
Затем в раздел «Переменные» (который начинается после ключевого слова VAR
в главной программе) надо завести переменные — указатели на необходимые нам
массивы в динамической памяти.
88
Глава 2. Основы алгоритмизации
var
PQue : TPQue:
PMarked : TPMarked;
Далее в самом начале тела программы следует добавить операторы захвата дина-
мической памяти:
New(PQue): {Захватил память для очереди}
NextPMarked): {Захватил память для пометок}
А также в конце тела программы добавить операторы освобождения динамиче-
ской памяти:
Dispose(PMarked):
Dispose(PQue):
end.
{Вернул память, захваченную для пометок)
{Вернул память, захваченную для очереди}
И наконец, нужно скорректировать операторы обращения к элементам динами-
ческих массивов — везде заменить обращения к статическому массиву Marked} i,j ]
на обращения к динамическому массиву PMarked"[i,j ]. И аналогично обращения
к статическим массивам типа Оие[х,1 ], 0ие}х,2] заменить на обращения к динами-
ческим массивам PQue‘[x,1], Р0ие'[х,2].
Алгоритм решения задачи о вырезании клеток из листа бумаги размером NxM
можно записать так.
Идея: очередь клеток, смежных с текущей.
Номер куска - О
Пока есть непомеченная клетка
помечаем ее в очередь и помечаем
1пс(Номер куска)
Пока очередь не пуста
Выбираем клетку из очереди
Все смежные с ней и не помеченные
помеааек в очередь и помечаем.
Текст соответствующей программы приведен в листинге 2.4.
Листинг 2.4. Текст программы, решающей задачу о вырезании клеток
type
TQue - array [1..22500.1..2] of byte:
TPQue - *TQue:
TMarked - array [1..150.1..150] of boolean;
TPMarked - "TMarked:
{Очередь ходов}
{Пометки на доске}
PQue : TPque:
PHarked : TPMarked:
x.y.n.M.K.
StepNurter.
QueBegin. QueEnd : integer:
procedure Puttx.y:integer);
Inc(QueEnd):
{Номер хода)
{Начало и конец очереди)
{Занести в очередь}
{Увеличить количество)
2.1. Очередь и стек
89
PQue*[QueEnd.l] х:
PQue'WueEnd.2] :-у:
PHarked*[x.y] :- true:
procedure GetCvar x.y:integer);
x PQueA[QueBegin.l]:
у PQueA[(lueBegin.2]:
Inc(QueBegin):
{Координата no x}
(Координата no y)
(Поиечаен использованную}
(Взять из очереди)
{Координата по х)
(Координата по у}
{Изменить начало)
procedure StartProcess:
i.j.x.y : Integer:
readln(N.H): {Вводим размеры поля)
for 1:- 1 to N do (Все клетки)
for j:-l to M do PMarked*[i.j]:-false: {не помечены)
readln(K): (Количество вырезанных)
for 1:-l to К do
readln(x.y): (Вводим вырезанную)
PMarked*[x.y] :- true: {Помечаем ее)
QueBegin :- 1: {Начало очереди)
QueEnd :-0; {Конец очереди)
function Found(var x.y:integer):boolean:
i.j : integer:
for i:-1 to N do
for j:-l to M do
if not PMarkedA[i.j]
then begin x:-i: y:-j: Found:-true: exit: end:
Found false:
procedure PutAll(x.y:integer): (Занести в очередь)
type (все текущие возможные ходы)
King - array [1..4.1..2] of integer: (Возможные ходы коня)
Const Steps: King = (( 0.-1). ( 0. 1). (-1. 0). ( 1. 0»:
Var i. CurrentX, CurrentY : integer:
i:-0: {Номер возможного хода)
while (i<4) do (Пока не наили и есть ход)
begin (Делаем следующий ход)
CurrentX :- x+stepsCi.1] : (X текущего хода)
CurrentY :- y+steps[i.2] : (Y текущего хода)
if (CurrentX>0)and (CurrentX<-N) and (X на доске и)
(CurrentY>O)and (CurrentY<=M) and (Y на доске и)
not PMarkedA[CurrentX.CurrentY] (поле(Х.У)не помечено)
then PuttCurrentX.CurrentY): (Помещаем в очередь и)
{помечаем)
продолжение&
90
Глава 2. Основы алгоритмизации
Листинг 2.4 (продолжение)
end:
{Вызов - МетНарСЭтап работы');)
Procedure HemMap(s:string):
begin
Writeln (S.'MemAvail-'.MemAvail. 'MaxAvail-'. MaxAvail):
end:
MemMapt'Начало работы');
New(PQue):
New(PMarked):
StartProcess:
StepNumber:=0:
while (Found(x.y)) do
МепЯар('Захватил память для очереди'):
MeirMapf'Захватил память для пометок'):
{Начало работы)
{Номер куска - 0)
{Пока есть непомеченная х.у)
Inc(StepNumber);
while QueBegiгк-QueEnd do
{Понеиаем ее в очередь и помечаем)
{Увеличить номер куска на 1)
{Пока очередь не пуста)
PutAll (х.у):
{Взять из очереди х.у)
(Занести в очередь все возможные)
{ходы}
: {Вывод номера шага)
МетМарС'Вернул память для пометок'):
MemMapt'Вернул память для очереди'):
writeln(StepNumber);
Dispose(PHarked): i
Dispose(PQue): 1
ПРИМЕЧАНИЕ---------------------------------------------------
В данной задаче достаточно было заменить только один из статических (например,
Que — как занимающий больше памяти) массивов на динамический, однако замене-
ны оба для лучшей иллюстрации способов замены статических массивов динамиче-
скими.
В программе введена процедура МетМар, которая вызывается в ключевых точках
работы с динамической памятью — при ее захвате и освобождении. Процедура
МетМар, в свою очередь, использует системные функции MemAvail и MaxAvail, смысл
работы которых заключается в следующем:
□ MemAvail — возвращает общий объем свободной оперативной памяти (в теку-
щий момент для прикладной задачи);
□ MaxAvail — возвращает максимальный размер непрерывного участка свободной
оперативной памяти (в текущий момент для прикладной задачи).
МетМар помогает программисту отслеживать количество доступной динамической
памяти в момент начала работы, в процессе выполнения программы на разных ста-
диях обработки и в момент завершения работы программы.
Обычно при работе в DOS или «в режиме эмуляции DOS» пользовательские про-
граммы могут использовать максимально от 400 до 600 Кбайт динамической па-
мяти.
2.1. Очередь и стек
91
В Турбо Паскале невозможно объявить массив, который требует для своего хра-
нения более 64 Кбайт оперативной памяти. Это касается объявлений как в раз-
деле VAR, так и в разделе TYPE. Например, если нам потребуется решить задачу о
кусках при больших ограничениях на Л' и М (пусть N> 1, М < 200), то нельзя
написать так:
type
TQue - array [1..40000.1..2] of byte: {Очередь ходов)
TPQue = “TQue:
TMarked - array [1..200.1..200] of boolean: {Пометки на доске)
TPMarked • “TMarked:
В этом случае для хранения массива типа ТОие потребовалось бы 40 000 * 2 - 80 000
байт, а эта величина превышает 64 Кбайт (напомним, 1 Кбайт = 1024 байта).
Однако мы можем хранить в динамической памяти несколько массивов, каждый
из которых менее 64 Кбайт, но которые вместе хранят необходимый нам объем
информации. При этом несколько усложняется доступ к нужной нам информа-
ции. Например:
type
TQue - array [1..20000.1..2] of byte: {Очередь ходов)
TPQue - “TQue:
TMarked - array [1..200.1..200] of boolean: {Пометки на доске)
TPMarked - “TMarked:
PQuel. PQue2 : TPque:
PMarked : TPMarked:
Begin
New(PQuel): New(PQue2):
New(PMarked):
Для обращения к нашей очереди, размещенной в двух динамических массивах PQuel
и Р0ие2, необходимо модифицировать процедуры Get и Put следующим образом:
{Занести в очередь)
procedure Put(x,y:1nteger):
begin
Inc(QueEnd):
If QueEnd<-20000
then begin
PQuel“[QueEnd.l] :- x:
PQuel“[0ueEnd.2] :- y:
else begin
PQue2“[QueEnd-20000.1] x:
PQue2“[QueEnd-20000.2] :- y:
end:
PHarked“[x.y] :- true:
end:
{увеличить количество)
{координата по х)
{координата по у)
{координата по х)
{координата по у)
{Понечаеи использованную)
procedure Getfvar x.y:integer):
92
Глава 2. Основы алгоритмизации
Р0иеГ[0иевед1п.1):
PQuel*[QueBegin.2]:
{Координата по х)
{Координата по у)
{Координата по х)
{Координата по у)
{Изменить начало)
else begin
х:- PQue2*[QueBegin-20000.1]:
у:- PQue2*[QueBegin-20000.2]:
Inc(QueBegin):
Теперь приведем пример использования динамической памяти для хранения за-
писей (в примере — о координатах точки). Объявляем новый тип — запись, храня-
щая информацию о координатах точки, и указатель на такую запись:
type TPoint - record
х. у : extended:
PPoint - 'TPoint :
{Тил ТОЧКА - координаты X и Y)
{Тип Указатель на точку)
Объявляем переменную типа указатель на точку:
РР : PPoint :
{Переменная типа Указатель на точку)
Захватываем динамическую память под точку:
New(PP): {Захватить в ОП память размером)
{под точку - 2 поля типа extended)
{2*10-20 байт и адрес этой памяти)
{занести в переменную РР)
При обращении к полям записи работаем следующим образом:
РР*.х 1.4: {Сформировать координаты точки)
По завершении обработки освобождаем захваченную динамическую память:
Dispose(PP): {Освободить память, на которую)
(указывает РР)
Стоит также упомянуть об использования динамической памяти для работы с
ASCII-строками. Как известно, строки, объявляемые в Паскале с помощью типа
string, имеют жестко ограниченную длину (не более 255 символов). Развитием
строкового типа является тип "pcha г, который имеет максимальную длину до 65 535
символов. Строка такого типа не содержит собственной длины в начальном байте.
Признаком окончания строки является символ с кодом «0.
В Турбо Паскале имеется модуль STRING, в котором содержится набор разнообраз-
ных функций для работы с такими строками. Например:
□ динамическое создание строк — S : = StrNew(' abcdef');
□ динамическое уничтожение строк — StrDispose(S).
Существуют еще и такие функции, как копирование строк, конкатенация строк,
сравнение строк, поиск по строке и др. Для получения полной информации о фу нк-
2.2. Рекурсивные процедуры и функции 93
циях модуля STRING в среде Турбо Паскаля наберите "pchar и нажмите Ctrl+Fl (по-
лучение контекстно-чувствительной помощи).
2.2. Рекурсивные процедуры и функции
Существует значительный класс задач по программированию, простейшее реше-
ние которых основывается на понимании основ функционирования рекурсивных
процедур и функций и умении конструировать рекурсивные алгоритмы и отлажи-
вать рекурсивные программы.
Примеры решения задач
Изначально автором выбрана методика обучения «на примерах», поскольку она
является наиболее эффективной для обучения сложным или непривычным поня-
тиям. Далее, в порядке возрастания сложности, приводятся примеры, иллюстри-
рующие решение задач с применением рекурсии.
Вычисление наибольшего общего делителя
Программа рекурсивного вычисления наибольшего общего делителя (НОД) двух
чисел а и Ь приведена в листинге 2.5.
Листинг 2.5. Рекурсивное вычисление НОД
program euclid:
then NOD NOD <a-b.b)
1f a<b
then NOD NOD (a.b-a)
else NOD a:
end:
readln (a.b):
writeln (NOD (a.b)):
readln
Эта программа основана на рекурсивном алгоритме Евклида вычисления НОД:
□ искать НОД(а - Ь, Ь), если а > Ь;
□ НОД(а, Z>) < а, если а = Ь\
□ искать НОД(а, Ь - а), если а < Ь.
Словами этот рекурсивный алгоритм можно выразить следующим образом: для того
чтобы найти НОД двух чисел а и Ь, необходимо сравнить эти числа. Если они равны,
то их НОД есть а. Если же одно из чисел больше другого, то нужно из большего
вычесть меньшее и повторно применить вышеизложенный алгоритм к разности
и меньшему из чисел. Процесс завершается, когда числа становятся равными.
94
Глава 2. Основы алгоритмизации
Например, вычисление НОД чисел 12 и 18 по алгоритму Евклида выглядит так:
НОД(12,18) = НОД(12,18 - 12) - НОД(12,6) - НОД(12 - 6,6) - НОД(6,6) - 6.
Атеперь рассмотрим подробнее, как выполняет эту работу программа euclid (см. ли-
стинг 2.5).
Тело главной программы содержит всего две строчки:
readin (а.Ы: {ввести числа, лля которых ищем НОД)
writeln (NOD(a.b)): {вывести результат вычисления функции НОД)
В примере а - 18 и b -12. Поэтому втеле главной программы вызывается функция
NOD( 18,12). Основная работа и выполняется этой рекурсивной функцией NOD:
function NOD (a.b:long1nt):longint:
begin
then NOD NOO (a-b.b)
else
if a<b
then NOD NOD (a.b-a)
else NOO :- a:
end:
Поскольку 18 > 12, то вновь вызывается функция NOD, но уже с параметрами (18 -
12,12), то есть с параметрами (6,12).
Обратите внимание, что функция NOD, не завершив свою работу, сама вызывает
себя, но уже с измененными параметрами. Такие функции называются рекурсив-
ными. Необходимым условием корректной работы рекурсивных функций являет-
ся условие нерекурсивного (то есть без вызова функцией самой себя) вычисления
результата при определенных аргументах вызова. Например, в функции NOD(а, Ь)
таким условием является условие равенства параметров а и Ь.
В нашем примере функция NOD вызовет себя вначале с параметрами (6, 12), а за-
тем — с параметрами (6,6). Это и будет последним вызовом с получением ответа,
а именно — 6. После чего, этот ответ будет последовательно передаваться вызы-
вавшим функциям вплоть до главной программы.
Программу вычисления наибольшего общего делителя чисел а и Ь можно напи-
сать и нерекурсивно, например так, как предложено в листинге 2.6.
Листинг 2.6. Нерекурсивный поиск НОД
program euclid_n:
a. b : longint:
readin (a.b):
while (aob) do
if a»b then a:-a-b else b:=b-a:
- writeln(a):
readln
Некоторые читатели нетерпеливо возразят: так короче и даже понятней, зачем же
тогда нам знать про рекурсивные функции? Могу предложить такой ответ.
2.2. Рекурсивные процедуры и функции 95
•1. Существует огромное количество задач, где нерекурсивные решения гораздо
сложнее рекурсивных.
2. Если алгоритм решения задачи — заведомо рекурсивный, то и написать рекур-
сивную программу легче, так как для написания нерекурсивной нужно разра-
батывать и отлаживать альтернативный алгоритм.
В этих утверждениях можно убедиться, рассмотрев следующие примеры решения задач.
Число сочетаний из N по М
Начнем с треугольника Паскаля (нумерация строк начинается с нулевой):
1 2 1
13 3 1
1 4 6 4 1
1 5 10 10 5 1
1 6 15 20 15 6 1
Вы догадались, как вычисляется следующая строка по предыдущей? Да, верно: каж-
дое число равно сумме двух чисел, расположенных в предыдущей строке непос-
редственно над ним. Например, в 4-й строке (заметим, что нумерация и строк и
столбцов в нашем массиве начинается с 0) 6 = 3 + 3, в 5-й строке 10 = 6 + 4, в 6-й
строке 15 - 5 + 10 и т. д.
А вы можете выписать следующую, 7-ю, строку треугольника Паскаля? Очевидно,
она будет выглядеть вот так:
1 7 21 35 35 21 7 1
Теперь несколько интересных фактов о треугольнике Паскаля, призванных отве-
тить на вопросы типа: зачем нам знать о нем вообще и чем он нам может оказаться
полезным? Например:
(a + Z>)°- 1;
(а + Ь)' = а + Ъ\
(а + b)2 = а2 + 2аЬ + Ь2;
(a + b)3-a3 + 3a2b + 3ab2 + b3;
(а + ЬУ = а* + 4а?Ь + 6a2b2 + iab3 + b*.
Надеюсь, вдумчивые читатели уже догадались, что N-я строка треугольника Пас-
каля дает нам коэффициенты в выражении, которое получается при вычислении
(а + 6)*'- {а + Ь) • (а + Ь) * ... » (а + b) (N сомножителей).
Еще один пример: рассмотрим треугольник Паскаля в виде более привычного нам
двумерного массива размерности Д'строк х М столбцов:
Глава 2. Основы алгоритмизации
1 2 1
13 3 1
1 4 6 4 1
1 5 10 10 5 1
1 6 15 20 15 6 1
1 7 21 35 35 21 7 1
1 8 28 56 70 56 28 8 1
Оказывается, эти замечательные числа отвечают также и на вопросы типа: сколь-
ко существует различных сочетаний из N предметов по М штук? Например, пусть
у нас есть 8 разных мячей, пронумерованных от 1 до 8 соответственно. Сколькими
разными способами мы можем составить тройки мячиков? То есть нам требуется
определить число сочетаний из 8 по 3. В нашем массиве ищем число, стоящее на
пересечении 8-й строки и 3-го столбца. Получаем ответ — 56. А из 4 мячиков по 2?
Правильно, — 6 (4-я строка, 2-й столбец). Выпишем все возможные варианты: 1-й
мячик и 2-й, 1-й и 3-й, 1-й и 4-й, 2-й и 3-й, 2-й и 4-й, 3-й и 4-й.
А если мы хотим выяснить, сколькими способами можно составить тройки из 26
различных мячиков? Строить дальше треугольник Паскаля ручными вычисления-
ми представляется слегка грустным. И потом: не для этого же мы программиро-
вать учимся?
Обозначим C(N, М) число сочетаний из N предметов по М. Коротко это читается
так: «С из Д'по ЛГ». Напомним, уже вычисленные значения: С(8,3) - 56 (С из 8 по
3 равно 56), С(4,2) - 6. Мы затруднились вычислить С(26,3).
Давайте попробуем составить соотношение, вычисляющее следующую строку по
предыдущей (точнее элемент в JW-м столбце ЛГ-й строки, по нужным элементам
строки с номером :V - 1):
C(N, М) = C(N - 1, М - 1) + C(.N - 1, М).
Чтобы вычислить число C(N, М), мы должны сложить число, которое находится
над ним сверху слева C(N - 1, М - 1) и сверху непосредственно C(N - 1, М). Это
выражение верно для случаев М < N (то есть все числа находятся под главной диа-
гональю таблицы).
Кроме того, нам известно, что C(N, 0) - 1, то есть все числа в 0-м столбце равны 1,
и C(N, N) = 1, то есть все числа на главной диагонали равны 1.
И, наконец, все остальные элементы (пустые позиции в таблице) над главной диа-
гональю равны 0. Тогда соотношение для C(N, М) будет корректно применимо ко
всем элементам таблицы.
Таким образом, окончательно правила вычисления элементов в таблице могут
выглядеть следующим образом:
2.2. Рекурсивные процедуры и функции
97
□ C(N,Af)“ L если Л/-0 и ЛГ> 0 или ЛГ-Л/г 0;
□ C(N, М) = 0, если M>N>0;
□ C(N, М) = C(N - 1. М - 1) + C(N - 1, М) в остальных случаях.
А их запись на языке программирования Паскаль в виде рекурсивной функции:
function C(n.m:word) : longint:
begin
If ((m-0) and (n>0)) or (<m-n) and (m>0>)
then C:-l
else If (m>n) and (n>-0)
then C:-0
else C:“C(n-l.m-l)+C(n-l.m)
Тело главной программы выглядит так:
readln(n.m)
wr1teln(C(n.m))
Вся программа представлена в листинге 2.7.
Листинг 2.7. Программа вычисления элементов треугольника Паскаля
Program CNM:
var n.mrword:
function C(n.m:word) : longint:
begin
if ((nr-O) and (n>0)) or ((m-n) and (m>0))
then c:-l
else if (m>n) and (n>-0)
then c:-0
else c:-c(n-l.m-l)+c(n-l.ni)
readln(n.m):
writelnCCC .n.'.'.m.')-',c(n.m)):
readin:
Чтобы вычислить значения в N-й строке, нужно знать некоторые значения в N -1 -й,
N - 2-й и так далее до 0-й строки. Построим список значений для примера С(4,2):
С(4,2) - С(3,1) + С(3,2), С(3,1) - С(2,0) + С(2,1), С(3,2) - С(2,1) + С(2,2),
С(2,0) - 1, С(2,1) - С(1,0) + С(1,1), С(2,1) - С(1,0) + С(1,1),
С(2,2) - 1, С(1,0) - 1, С(1,1) - 1, С(1,0) - 1, С(1,1) - 1.
Гораздо удобнее представлять рекурсивные вычисления в виде дерева'.
С(4,2)
С(3,1) + С(3,2)
С(2,0) + С(2,1) С(2,1) + €(2,2)
1 С(1,0) + С(1,1) С(1,0) + С(1,1) 1
98
Глава 2. Основы алгоритмизации
В данном примере тоже можно было бы написать нерекурсивное решение (остав-
ляем это в качестве необязательного упражнения). Отметим: кроме того, что нере-
курсивное решение еще нужно придумывать (заполняя двумерный массив от 0-й
строки до N-ii), скорее всего, нерекурсивной программе придется делать еще и много
вычислений, результаты которых (как показывает дерево рекурсивных вызовов)
нам вовсе не нужны.
Дерево рекурсивных вызовов — очень важная иллюстрация того, что представля-
ют собой рекурсивные алгоритмы и как их нужно разрабатывать. Если в задаче
требуется исследовать какое-то множество вариантов, которые удобно предста-
вить в виде дерева, то обход этого дерева (и соответственно исследование всех воз-
можных вариантов) удобно обеспечить рекурсивным алгоритмом.
Некоторые читатели могут возмутиться: тут уже четыре абзаца пишут о каком-то
дереве, а его не видно. Что за дерево?
Сначала предлагаю читателю вспомнить, какими бывают деревья поздней осенью,
когда листьев на деревьях уже нет и остаются только ствол и ветки. А потом —
посмотреть на такой схематический рисунок:
О
При известной доле фантазии, можно согласиться, что есть что-то общее с деревом.
Строгое математическое определение понятия «дерево» дается в таком важном разде-
ле математики, как теория графов, и нам еще предстоит с ним познакомиться. А пока
предлагаю остановиться на вышеуказанном интуитивном представлении о дереве.
Количество способов составления суммы М из N чисел
Пусть нам требуется написать программу, которая вводит числа М и N, последова-
тельность из Wчисел — a(i) и подсчитывает количество способов, которым из чи-
сел a(i) можно составить заданную сумму М.
ЗАМЕЧАНИЕ -----------------------------------------------------
Варианты, в которых сумма составляется из одинаковых чисел, но занимающих раз-
личные места в последовательности, будем считать различными способами состав-
ления суммы.
Пример входных данных: М = 10, N - 6, и последовательность чисел —1 10742 3.
То есть нужно составить сумму 10 из элементов данной последовательности 6 чисел.
Имеем следующие варианты:
1) 10-10;
2) 10-7 + 3;
2.2. Рекурсивные процедуры и функции
99
3) 10-7 + 2 + 1;
Таким образом, ответ 4.
Как же его получить? Попятно, что в общем случае нужно перебрать все возмож-
ные комбинации чисел, то есть — все по одному, все сочетания по 2, все сочетания
по 3, все сочетания по 4, все сочетания по 5, и, наконец, проверить сумму всех ше-
сти элементов последовательности. Мы создадим рекурсивный алгоритм, строя-
щий (обходящий) такое дерево, только он будет вести анализ с последнего элемента
до первого. Но прежде еще одни хитрый тест: М - 3, АГ- 3, и последовательность
чисел — 0 0 0. Спрашивается, сколькими способами можно набрать сумму из трех
чисел, каждое из которых равно О? Я считаю, что, по условиям задачи, ответ 8:
□
3 раза берем разные нули по одному;
3 раза берем разные пары нулей;
1 раз берем все нули;
1 раз вообще не берем ни одного из чисел.
Рекурсивный подход, как пояснялось выше, предполагает построение дерева пе-
ребора. Для иллюстрации его возьмем более простой пример: требуется составить
сумму 3 из трех чисел: 1,2 и 3.
Очевидно, ответ: 2 (3 и 1 + 2). Дерево перебора можно изобразить так:
не взяли ничего
ПРИМЕЧАНИЕ-----------------------------------------------------
«!» — обозначает, что мы берем число в предыдущей строке;«~» — обозначает, что мы
не берем число в предыдущей строке.
Итак, функция Find (листинг 2.8) будет иметь 2 параметра; N — номер элемента,
которым мы сейчас достраиваем дерево, и М — сумма, которую мы хотим получить.
Значение функции Find — количество способов, которыми можно составить сум-
му М из N элементов массива а[ i ].
Листинг 2.8. Программа подсчета способов составления суммы М из N чисел
Program F1nd3:
i.n.m : longint:
100
Глава 2. Основы алгоритмизации
Листинг 2.8 (продолжение)
а : array [1..100] of longint:
Function Find (N.M:longint):longint:
begin
if (N-0) and (m-0) then begin Find:-1: exit: end:
if (N-0) and (moO) then begin Find:-O: exit: end:
then Find:-Find(n-l,m)*Find(n-l,m-a[n])
else Find:-Find(n-l.m)
read(m.n):
writeln (Find(N.H)):
end.
Как и раньше, главная программа вводит в нужном порядке необходимые данные
и вызывает рекурсивную функцию (прямо в операторе вывода ответа writeln).
Основная работа рекурсивного алгоритма заключена в строках:
if ((m-a[nl)»O)
then Find:-Find(n-l.m)+Find(n-l,m-a[n])
else Find:-Find(n-l.m)
m-a[n]>=0 — это значит, что сумму М можно набрать как с числом а[п], так и без
него. Количество способов набрать сумму М из N чисел (а[1), а[2],..., а[п]) будет
равно количеству способов набрать из N-1 числа (а[1 ], а[2]....... а[п-1 ]) сумму М
(если а[п) не берем) плюс количество способов набрать из N - 1 числа (а[ 1 ], а[2],
..., а[п-1 ]) сумму М-а[п] (если а[п] берем). Если М-а[п]<0 — то число а[п] не может
участвовать в составлении суммы М. В этом случае количество способов набрать
сумму М из N чисел будет равно количеству способов набрать сумму М из N-1 числа.
Это основной механизм рекурсии, уменьшающий значения ее параметров (ар-
гументов N и М) при вызове рекурсивной функции. Для корректного завершения
рекурсии требуются нерекурсивные ответы при некоторых значениях аргументов
if (N-0) and (m-0) then begin Find:-1: exit: end:
if (N-0) and (m=>0) then begin Find:-O: exit: end:
Если чисел уже нет (N=0) и сумма составлена правильно (М=0), то нашли 1 комби-
нацию, поэтому f ind=1 и выходим из этого вызова рекурсивной функции Find (с по-
мощью оператора exit). Второй оператор if анализирует ситуацию, когда чисел
больше нет (N=0), но сумма не составлена правильно (М<>0), тогда — Find=O и тоже
выход.
Возможно, этот материал вам покажется сложным для понимания, но согласитесь:
решение такой непростой задачи с помощью рекурсивной функции, тело которой
составляет всего 5 строк, оправдывает наши усилия по освоению этого эффектив-
ного метода.
Теперь несколько советов по отладке рекурсивных процедур. Прежде всего полез-
но нарисовать дерево вызовов рекурсивных процедур, соответствующее тестово-
му примеру. Например, в только что разобранном примере оно будет таким:
2.2. Рекурсивные процедуры и функции
101
Find(3,3) взяли/нет
Find(2,0) Find(2,3) 3
Find(i,O) Find(l.l) + Find(l,3) 2
Find(O.O) Find(O,O) + Find(O,l) Find(0,2) + Find(0,3) 1
Поясним словами смысл этого дерева.
□
□
□
Find(3,3) — количество способов, которым можно составить сумму 3 из трех
чисел.
Find(2,0) — количество способов, которым можно составить сумму 0 из двух
чисел. То есть последнее число во введенном массиве — 3 — мы взяли в сумму,
вычли его из суммы, и остаток 0 должны набирать из оставшихся чисел.
Find(2,3) — количество способов, которым можно составить сумму 3 из двух
чисел. То есть последнее число во введенном массиве — 3 — мы не взяли в сум-
му, поэтому не вычитали его из суммы и всю сумму 3 должны набирать из остав-
шихся чисел. И т. д.
Каждое из очередных чисел мы можем взять, уменьшая сумму на его величину,
или не взять, оставляя сумму неизменной. Понятно, что таким образом мы иссле-
дуем все возможные варианты сочетаний чисел из исходной последовательности.
Во время отладки могут пригодиться следующие советы.
1. Визуализировать процесс. Это делается так:
1) внести в окно просмотра переменных параметры вызова N и М;
2) установить курсор на первую строчку в теле рекурсивной функции;
3) использовать клавишу F4 (исполнение до курсора) для наблюдения за зна-
чениями параметров вызова N и М, чтобы видеть, с какими конкретно пара-
метрами выполняется рекурсивная функция в текущий момент;
4) пользоваться командой Ctrl+F3 (показать СТЕК вызовов функций/процедур)
для того, чтобы видеть все осуществленные на текущий момент вызовы ре-
курсивной функции с фактическими значениями параметров; тогда вы смо-
жете реально контролировать рекурсивный обход задуманного вами дерева
в соответствии с определенным вами порядком.
2. К сожалению, Borland Turbo Pascal 7.0 не показывает непосредственно значе-
ния, возвращаемые функциями, в окне просмотра. Поэтому, чтобы увидеть их
во время отладки, наиболее просто поступить следующим образом:
1) объявить локальные переменные в рекурсивной функции;
2) использовать их для промежуточных вычислении, например так:
Function Find (N.M:longint):longint:
Var
kl.k2.k3.k4 : longint:
begin
if (N-0) and (m-О) then begin Find:-1: exit: end:
if (N-0) and (m<>0) then begin Find:-O: exit: end:
if ((m-a[n))>=0)
102 Глава 2. Основы алгоритмизации
begin
kl:-Find(n-l.m):
k2:-F1nd(n-l.m-a[n]):
k3:-kl*k2:
Find:-k3:
end
k4:-Find(n-l.m):
F1nd:-k4:
end:
Конечно, рекурсивная процедура выглядит теперь не так элегантно и компактно,
зато можно видеть в отладчике вычисляемые промежуточные значения результа-
тов и, соответственно, сравнивать их с результатами, полученными при ручной
прокрутке для тестового примера.
Количество представлений числа в виде суммы компонент
Рассмотрим задачу, в которой требуется подсчитать количество различных пред-
ставлений заданного натурального числа N в виде суммы не менее двух попарно
различных положительных слагаемых.
ПРИМЕР ---------------------------------------------------------------------
Для N = 7, ответ — 4, так как 7 = 6 + 1,5 + 2.4 + 3,4 + 2 + 1.
Фактически, как и в задаче, рассмотренной ранее, требуется найти числа, состав-
ляющие в сумме данное.
Отличия же таковы.
1. Числа не вводим, а присваиваем: 1,2.N- 1, и потому тело главной програм-
мы выглядит так:
read(n);
for 1:-1 to n-1 do a[i]:-i:
writeln (Find(N-l.N)):
где Find(N-1,N) находит количество способов представить сумму N из N-1 числа
а[1],а[2]...a[N-1).
2. Сумма должна состоять из не менее двух чисел (в предыдущей задаче предпо-
лагалось, что может быть одно или даже ни одного числа).
3. Будем рассуждать аналогично тому, как это делалось в предыдущей задаче:
основная компонента рекурсивной функции Find(N,M) (где опять М — это сум-
ма, которую нужно набрать, N — количество элементов, которые можно исполь-
зовать) выглядит следующим образом:
if ((m-a[n])>0)
then Find Find(n-l.m) + F1nd(n-l.m-a[nj)
else Find :- Find(n-l.m):
Если m > A[n], то складываем Find(n-1,m) — количество способов, которым можно
из n - 1 элемента набрать сумму М (без элемента а[п]) — и Find(n-1, m-a[n]) — ко-
2.2. Рекурсивные процедуры и функции
103
личество способов, которым можно набрать сумму т-а[ п ] (то есть а[ п ] участвует в
общей сумме). А если ш > а[п], то, понятно, сумму m нужно набирать без элемента
а[п], и поэтому Find := Find(n-1,m).
Случай а[ n ] = m обрабатываем отдельно:
if (m-a[nj)
then begin
if n>-2
then Find:-l+Find(n-l.m)
else Find:-1:
exit:
Если m = a[n], то в случае n >= 2 мы уже нашли один вариант и должны продолжать
искать другие, а в случае п = 1, это — последний вариант.
И наконец, условия обработки ветвей дерева, где нужная сумма не набирается:
if N<-1 then begin Find:°O: exit: end:
Таким образом, окончательно программа Find4 выглядит так, как показано в лис-
тинге 2.9.
Листинг 2.9. Подсчет количества представлений числа в виде суммы компонент
Program Find4:
i.n.m : longint:
a : array [1..100J of longint:
Function Find (N.M:longint):longint:
if (m-atn])
then begin
if n>-2
then Find:-l+Find(n-l.m)
else Find:-1:
end:
if N<-1 then begin Find:=O: exit: end:
if (m-a[n])>0
then Find:- Find(n-l.m) +Find(n-l.m-a[n])
else Find:-Find(n-l.m):
read(n): for i:-l to n-1 do a[i]:-i:
writeln (Find(N-l.N)):
end.
Количество правильных скобочных выражений
Рассмотрим такую задачу: надо подсчитать количество правильных скобочных
выражений из 2 • N круглых скобок. Выражение называем правильным, если оно
состоит из 2 • N символов и:
1) содержит ровно А открывающих скобок и N закрывающих скобок;
2) в любом фрагменте (от начала скобочного выражения до его произвольной по-
зиции) открытых скобок всегда больше, чем закрытых, либо столько же.
104 Глава 2. Основы алгоритмизации
ПРИМЕР ---------------------------------------------------------------------
Для N = 1 правильное скобочное выражение одно: (), для N = 2 правильных скобочных
выражений два: ()() и (О), а для N = 3 — пять: ((()»(()())()(()) (())() ()()().
Из соображений удобства заменим открывающие скобки на 1, а закрывающие — на 0.
Следовательно, нам требуется обойти дерево следующего вида (пример для М= 2):
1
1 О
1 о 1 е о
1 0 1 0 1' 0 1 о
1111 1110 1101 1100 1011 1010 1001 1000
((« ((О (()( (О) ()(( 00 ())( О))
Требуется подсчитать, сколько существует путей, обладающих свойствами:
□ количество единиц равно количеству нулей;
□ в любом фрагменте пути от начала количество единиц больше, чем количество
нулей, либо столько же.
Будем писать рекурсивную функцию:
Function Find (DN.D:longint:var Zero. One : longint)Jongint:
где ON — количество символов в цепочке 1 и 0, представляющей текущее состояние
ветви дерева, которое мы обходим, 0(1 или 0) указывает, по какой ветке мы пой-
дем ниже; Zero — количество нулей в текущей цепочке; One — количество единиц
в текущей цепочке.
Основное выражение рекурсивного вызова будет выглядеть так:
Find:-Find(DN-l,O.Zero, One)+Find(DN-l.l.Zero.One):
То есть количество правильных выражений равно сумме количеств правильных
выражений в ветвях, выбираемых при 0 и 1.
При входе в функцию и выходе из нее с учетом параметра 0 нужно правильно вес-
ти подсчет текущего количества 1 и 0. Кроме того, если нарушается хотя бы одно
из условий корректности (Zero > N или One > N или Zero > One), то эта ветвь «отсека-
Полностью программа представлена в листинге 2.10.
Листинг 2.10. Подсчет количества правильных скобочных выражений
Program Find5:
п, Zero. One : longint:
Function Find (DN.D:longint:var Zero. One: longint):longint:
begin
If 0-0 then Inc(Zero) else Inc(One):
If (Zero>N) or (One>N) or (ZeroXJne)
then begin
Find:-O:
2.2. Рекурсивные процедуры и функци»
105
If 0-0 then Dec(Zero) else Dec(One):
exit:
end:
If DN=1
then if Zero-One then F1nd:-1 else Find:-0
else Find:-Find(ON-l,O.Zero. One)+F1nd(DN-l.l.Zero.One):
If 0-0 then Dec(Zero) else Dec(One):
end:
read(n): Zero :-0: 0ne:-0:
writeln (Find(2*N.l.Zero. One)):
end.
Вывод всех возможных способов
Часто в задачах бывает необходимо не только подсчитать, сколькими способами
можно что-то сделать, но и вывести все эти способы. Добавим это требование в
задачу о различных представлениях заданного натурального N в виде суммы не
менее двух попарно различных положительных слагаемых:
ПРИМЕР -----------------------------
Для N = 7 ответ — 4:7 = 6 + 1,5 +2,4 + 3,4 + 2+1.
Решение, приведенное ранее в пункте «Количество представлений числа в виде
суммы компонент», дополним следующим образом: в рекурсивную функцию Find
добавим еще один параметр — Add типа boolean. Он показывает, добавляли мы или
нет текущий элемент а[ п ]. В главную программу также добавим переменную path
типа st ring, которая будет хранить символы, соответствующие числам — номерам
элементов, — которые выбирались в текущей ветви дерева.
В самой функции Find, если текущий элемент добавляется, то при входе будем
пополнять строку path, а при выходе — будем удалять из нее последний элемент.
Кроме того, при нахождении очередного решения (т = а[п]) будем выводить его,
используя текущее содержимое строки path.
Полное решение поставленной задачи приведено в листинге 2.11.
Листинг 2.11. Количество представлений числа в виде суммы
Program F1nd6;
i.n.m : longint:
a : array [1..100] of longint;
path : string:
Function Find (N.H:longint: Add:boolean):longint:
var
begin
if Add then Path:-Path*chr(a[n*l]):
if <m-a[n])
then
begin
for 1:-1 to length(path) do
продолжение&
106
Глава 2. Основы алгоритмизации
Листинг 2.11 (продолжение)
write(ord(path[i]).'<
writeln CaCnJ):
then Find:-HFind(n-l.m.False)
else Find:-1:
if Add then Delete(Path,Length(Path).l):
exit:
then begin
if Add then OeletelPath.Length(Path).1):exit;
end:
if ((m-a[n])>0)
then Find:- Find(n-l.m,False)
»Find(n-l.m-a[n].True>
else Find:-Find(n-l.m.False):
if Add then Delete(Path,Length(Path).l):
writeln (Hnd(N-l.N.False)):
end.
ПРИМЕЧАНИЕ----------------------------------------------------
Использованный способ хранения пути с помощью строковой переменной path удобен,
кода известно, что число элементов в пути не превышает 255 (максимальная длина сим-
вольной строки типа string) и каждый из элементов (номер) тоже не превышает число 255
(максимальное значение, которое можно занести в байт). Удобство заключается в том,
что весь путь виден в одной переменной, и в том, что имеются стандартные процедуры и
функции обработки символьных строк. В данном примере использованы Length и Delete.
Можно вместо переменной path типа string использовать массив path и самому
написать функции занесения и удаления элемента в этот массив с параллельным
отслеживанием количества элементов в нем.
Вывод одного из возможных способов
Бывают задачи, когда достаточно найти один из возможных способов. Например,
пусть нам требуется написать программу, которая вводит числа M,Nh последова-
тельность из N чисел a(i) и выводит один из способов, которым можно составить
заданную сумму М из чисел a(j).
Для решения задачи модифицируем программу (см. листинг 2.8) следующим об-
разом:
1) в случае нахождения первого решения выводим его и прекращаем выполнение
программы оператором HALT;
2) вводим элементы массива а[ 1 ];
3) превращаем функцию Find в процедуру Find.
Текст переделанной программы — в листинге 2.12.
2.2. Рекурсивные процедуры и функции
107
Листинг 2.12. Подсчет способов составления суммы с выводом одного
из возможных способов
Program Find7:
i.n.m : longint:
a : array [1..100] of longint:
path : string:
Procedure Find (N.HJongint: Add:boolean):
var
begin
if Add then Path:-Path’chr(a[n»l]):
if <m-a[n])
then begin
for i:-l to length(path) do
wr1te(ord(path[i]).'+’):
writeln <a[n]):
halt:
end:
1f N<-1
then begin
if Add then Delete(Path.Length(Path).l):
exit:
end:
if ((m-a[n])>0)
then begin
Find(n-l.m.False):
Find(n-l,m-a[n].True)
else Find(n-l.m.False):
if Add then Delete(Path.Length(Path).l):
end:
begin
read(m):
read<n):
for 1:-l to n do read (a[i]):
path:-”:
Find(N.H.False):
end.
«Играем в домино»
Пусть требуется решить такую задачу: имеется N костей из нескольких комплек-
тов домино. Выстроить из них правильную последовательность максимальной
длины.
ПРИМЕР --------------------------------------------------------
Пусть мы имеем 6 костей: 1 1, 1 2, 4 4, 1 1, 2 3, 2 1. Тогда ответ будет — 5. Одна из
правильных цепочек: 2 1,11,11,12,23.
Рекурсивное решение можем построить из следующих соображений: нам нужно
построить такие деревья для имеющихся костей домино (возьмем для простоты
примера 3 кости и занумеруем их 1,2,3):
108
Глава 2. Основы алгоритмизации
В отличие от предыдущих задач, здесь важен и порядок, в котором выбираются
элементы. При этом нужно помнить, что кость в домино можно поворачивать,
то есть пристраивать к концу цепочки любым из двух концов кости.
Заведем для хранения состояния дерева следующие строковые переменные:
□
Path — хранит текущую цепочку (конкатенация кодов символов, соответству-
ющих номерам выбранных элементов-костей домино);
Free — хранит все неиспользованные в текущий момент кости домино;
Orie — хранит символ ориентации кости в текущей цепочке (D — в порядке вво-
да, I — в обратном порядке);
Start — значение начала текущей цепочки домино;
Finish — значение конца текущей цепочки домино (обе переменные инициали-
зируются значением 1);
Т — текущее количество свободных костей домино, инициализируется количе-
ством введенных костей;
MaxL — текущая максимальная длина пути;
MaxPath — текущий максимальный путь;
а[ i,1 ], a[i,2] — числа на i-й кости домино.
Итак, рекурсивную процедуру Find строим следующим образом;
F1nd(T.Start.Finish)
Для 1 от 1 до Т
Взять свободную кость
Если это начало.
то ее переносиц из свободных в цепочку, ориентация D
по ней инициализируен Start и Finish
F1nd(T-l. Start. Finish)
возвращаен ее из цепочки в свободные
если она подходит 'как есть".
то ее переносии из свободных в цепочку, ориентация О
по ней корректируеи Finish
F1nd(T-l. Start. Finish)
возвращаен ее из цепочки в свободные
иначе
если она подходит "перевернутая".
то ее переносии из свободных в цепочку, ориентация 1
по ней корректируеи Finish
Find(T-l. Start. Finish)
возвращаен ее из цепочки в свободные
Если Длина(Ра111)>Мах1.
то maxL:-Длина(Path). MaxPath:-Path
Если MaxL-N, то вывод Результата (Path. MaxL). останов
Текст программы, реализующей данный алгоритм, приведен в листинге 2.13.
2.2. Рекурсивные процедуры и функции
109
Листинг2.13. Программа-Домино-
program Domino:
а : array [1..100.1..2] of longint:
N. 1. j. MaxL : longint:
Start. Finish : longint:
path.orie.free.
MaxPath : string:
Procedure PutR:
begin
for I:-l to length(MaxPath) do
if orie[i]-'D'
then writeln (a[ord(MaxPath[i]).l],' ',a[ord(MaxPath[i]).2])
else writeln (a[ord(MaxPath[i]).2],' ',a[ord(MaxPath[i]).l]):
writeln (’.ength(MaxPath)):
end:
Procedure Find CT: longint: var Start. Finish:longint):
var L.i.k : byte:
for i:-l to T do
begin
k:-ord(Free[1]):
1f (Start-1)
then
begin
path:=path*chr(k): Delete (Free.i,l):or1e:-orie*'D':
Find(T-l.a[k.l].a[k.2J):
Delete(Path.Length(Path).l); Insert(Chr.(k).Free.i):
Delete(orie.Length(Orie).1):
if (a[k.l]-Finish)
then
begin
path:-path*chr(k): Delete (Free.1.1): orie:-orier'0':
Find(T-l.Start.a[k.2]):
Delete(Path.Length(Path).1): lnsert(Chr(k).Free.i):
Delete(ori e.Length(Ori e).1):
end
else
if (a[k.2]-Finish)
then
path:-path*chr(k): Delete (Free.i.l): orie:-orie»'r:
Find(T-l.Start.a[k.lJ):
Delete(Path.Length(Path).l): Insert(Chr(k).Free.i):
Delete(orie.Length(Orie).1):
end:
end:
if Length(Path)>MaxL
then begin MaxL:-Length(Path): MaxPath:-Path:end:
if MaxL-N then begin PutR: halt: end:
end:
read (N): for i:-l to N do read(a(1.l].a[i.2]): продолжение^
110
Глава 2. Основы алгоритмизации
Листинг 2.13 (продолжение)
MaxL:-O: MaxPath:-": path:-": orie:-": Start:--!: Finish:--!:
free:-": for 1:-1 to N do free:-free*chr(i):
Find (N.Start.Finish): PutR:
end.
ПРИМЕЧАНИЕ-----------------------------------------------------
В данной программе удобство хранения пути в строковой переменной PATH заключа-
ется также и в том, что сохранение нового лучшего пути вместо старого выполняется
всего одним оператором присваивания. При использовании массива это действие
выполнялось бы сложнее. Еще одно достоинство такого подхода (использование стро-
ковой переменной для хранения списков элементов) — возможность использования
стандартной процедуры Insert для возвращения элемента в цепочку свободных FREE.
«Истоки и стоки»
Пусть нам задана карта односторонних дорог между городами. Город, из которого
можно добраться до всех других городов, называется исток. Город, в который можно
добраться из всех других городов; называется сток. Требуется найти все истоки и
ПРИМЕР -------------------------------------------------------
Пусть городов — 6 (пронумерованы от 1 до 6), а дорог — 10: 2-1 (то есть эта дорога
соединяет 2-й город с 1 -м), 2-4,4-1,4-2,4-3,1 -3,3-5,5-3,3-6,6-3. Тогда правиль-
ный ответ такой: истоки — 2 и 4, стоки — 3, 5, 6.
Решение задачи может быть таким.
1. По введенным данным узнаем МахА — максимальный номер города.
2. С помощью рекурсивной процедуры Find строим матрицу достижимости MD (из
какого города в какой можно добраться по заданной сети дорог; если ее элемент
М0[ 1,j ] — 1, то из i-ro города можно попасть в j -й). Для приведенного примера
она будет такой:
0 0 10 11
111111
0 0 10 11
111111
0 0 10 11
0 0 10 11
3. Строки с количеством единиц, большим либо равным МахА - 1, соответствуют
городам-истокам.
4. Столбцы с количеством единиц, большим либо равным МахА - 1, соответствуют
городам-стокам.
Рекурсивная процедура Find весьма похожа на процедуру из рассмотренной зада-
чи про домино: ведь дороги выстраиваются в цепочки по тому же принципу доми-
2,2. Рекурсивные процедуры и функции
но. Отличие только в том, что в данной задаче дороги односторонние и поэтому
процедура Find немного упрощается:
FindCT.Start.Finish)
Взять свободную дорогу
Если это начало. .
то ее переносии из свободных в цепочку
по ней инициализируеи Start и Finish
F1nd(T-l. Start. Finish)
возвращаен ее из цепочки в свободные
если она подходит.
то ее переносии из свободных в цепочку
по ней корректируен Finish
Уточняеи натрицу достижимости MD
F1nd(T-l. Start. Finish)
возвращаем ее из цепочки в свободные
В программе также используются процедуры:
□ Init — для инициализации матрицы достижимости МО по заданной карте дорог;
□ PutR — для анализа матрицы достижимости MD и вывода ответов.
В листинге 2.14 приведен полный текст программы, решающей данную задачу.
Листинг 2.14. Текст программы «Истоки и стоки»
program Istoki_Stoki:
а : array [1..100.1..2] of longint:
MD : array [1..100.1..100] of byte:
N. i. j. MaxA : longint:
Start. Finish : longint:
path.orie.free.
MaxPath : string:
s.p : array [1..100] of longint:
Procedure Init:
begin
MaxA:-0:
for 1 :-l to N Do
begin
if a[i,l]’MaxA then MaxA:-a[i.l]:
if a[i.2]>MaxA then MaxA:-a[1.2]:
end:
for i:-l to MaxA do
for J:-l to MaxA do M0[i.j]:-0:
for 1:-1 to N do MO[a[i.l].a[i.2]]:-l:
end:
Procedure PutR:
for 1:-1 to MaxA do
s[i]:-0: p[1]:-0:
for j:-l to MaxA do
begin
S[1]:=S[i]+MD[i.J]:
продолжение£
Глава 2. Основы алгоритмизации
^P[1]:-P[i]*MD[j.1]:
write ('истоки :'):
for 1:-l to HaxA do
if s[i]>-MaxA-l then write (' '.1):
writeln:
write ('стоки :'):
for 1:-1 to HaxA do
if p[1]>-MaxA-l then write (' '.D:
writeln:
Procedure Find (T: longint: var Start. F1n1sh:longint):
var L.1.k : byte:
for 1:-1 to Т do
k:-ord(Free[i]):
1f (Start-1)
path:-path*chr(k): Delete (Free.1.1):
Find(T-l.a[k.l].a[k.2J):
Delete(Path.Length(Path).1): Insert(Chr(k).Free.1);
end
else
If (a(k.lJ-Flnlsh)
then
begin
path:-path*chr(k): Delete (Free.1.1):
H)[Start.a[k.2]]:-l:
Find(T-l.Start.a[k.2]):
Delete(Path.LengtIK Path).1); !nsert(Chr(k).Free.1):
end
read (N):
for 1:-1 to N do read(a[i.lJ.aCi.23):
Init:
path:-": Start:—1: Finish:—1:
free:-": for i:-l to N do free:-free*chr(i):
Find (N.Start.Finish):
PutR:
Отладка рекурсивных процедур и функций
Область применения рекурсивных алгоритмов — задачи, в которых для нахожде-
ния решения требуется исследовать пространство возможных решений, которое
представимо в виде дерева. Заметим, что рекурсивные алгоритмы исследуют про-
странство решений методом «поиска в глубину», то есть вначале исследуются
варианты «самой левой нижней вершины дерева», а затем осуществляется мето-
дический обход дерева «снизу вверх» и «слева направо». Это обеспечивается по-
2.2. Рекурсивные процедуры и функции
113
гружением в стек переменных каждого вызванного экземпляра рекурсивной про-
цедуры/функции.
Множество переменных экземпляра рекурсивной процедуры/функции может быть
разбито на две группы: локальные и возвращаемые. Клокальным переменным отно-
сятся те переменные, значения которых актуальны внутри процедуры/функции.
Это параметры, объявленные без ключевого слова VAR, и переменные, объявлен-
ные внутри процедуры/функции. К возвращаемым относятся те переменные, из-
менения которых передаются в вызвавшую процедуру/функцию.то есть парамет-
ры, которые объявлены с Ключевым словом VAR. Кроме того, необходимо помнить,
что все экземпляры вызванных рекурсивных процедур/функций имеют доступ на
чтение/запись к глобальным переменным и массивам, объявленным в главной про-
грамме до появления текста рекурсивной процедуры/функции.
Например, рассмотрим начальный фрагмент программы Find7 (см. листинг 2.12):
Program Find7:
i.n.m : longint:
а : array [1..100] of longint:
path : string:
Procedure Find (N.M:longint: Add:boolean):
var
1 : byte:
begin
Здесь, в рекурсивной процедуре Find:
□ N, М, 1, Add — локальные переменные, их значения актуальны только в текущем
экземпляре процедуры Find;
□ а — глобальный массив, доступен всем экземплярам рекурсивной процедуры.
Другой случай:
Procedure Find (Т: longint: var Start. Finish:longint):
Здесь Start и Finish — изменяемые переменные. Их значения передаются между
вызывающей и вызываемой процедурами при входе в процедуру и выходе из нее.
ПРИМЕЧАНИЕ---------------------------------------------------
Важно понимать, что чем больше суммарный размер в байтах локальных и изменя-
емых переменных в рекурсивной процедуре/ функции, тем меньшего размера дере-
во пространства возможных решений может быть обследовано.
Размер стека, используемого программой, можно изменять с помощью директивы
компиляции $М. Более подробно синтаксис и ограничения на размеры стека в ди-
рективе $М (равно как и другую справочную информацию о Паскале) лучше всего
получать через контекстно-чувствительную помощь среды Паскаля: набираете $М,
устанавливаете курсор на эти символы и нажимаете комбинацию клавиш Ctrl+Fl.
Если задача требует обхода дерева возможных решений не «в глубину», а «в ши-
рину» (то есть необходимо исследовать вершины деревьев «по уровням» — снача-
ла весь верхний ряд, затем весь следующий нижний ряд и т. д.), то можно исполь-
Глава 2. Основы алгоритмизации
зовать механизм «очереди». Правда, в этом случае всю заботу о сохранении в оче-
реди необходимых данных и своевременное удаление их из очереди должен взять
на себя программист.
Основное привлекательное свойство программ, использующих рекурсивные про-
цедуры и функции, как раз и заключается в том, что всю работу по управлению
стеком с локальными и возвращаемыми данными всех экземпляров рекурсивных
процедур и функций берет на себя исполняющая система Паскаля. В результате
программа пользователя освобождается от соответствующего кода, становится
более компактной и наглядной. При решении достаточного количества задач для
создания устойчивых навыков корректного рекурсивного программирования та-
кой метод становится чрезвычайно эффективным, особенно в условиях ограни-
ченного времени, отведенного на решение задачи.
Основными недостатками рекурсивного подхода являются ограниченность раз-
меров исследуемого дерева пространства решений и, возможно, неудовлетвори-
тельное время исполнения алгоритма. Первую проблему, как уже писалось, можно
частично решать за счет использования максимальных значений стека в директи-
ве $М, а также за счет аккуратного предельного сокращения суммарного размера
локальных и возвращаемых переменных рекурсивной процедуры/функции. Вре-
мя исполнения можно сокращать, вводя в рекурсивные тела так называемые отсе-
чения — специальные условия, которые сокращают дерево исследования за счет
отсечения поддеревьев, заведомо не содержащих искомых решений. Например, в
программе Find5 (см. листинг 2.10) таким отсечением является условие:
If (Zero>N) or <0ne>N) or (2ero>One)
then begin
F1nd:-0; ... : exit:
Если скобочное выражение уже неправильное, пет смысла рассматривать вариан-
ты достраивания к нему новых скобок.
2.3. Рекуррентные соотношения
Существует ряд задач, в которых из-за внушительных диапазонов исходных дан-
ных рекурсивный подход принципиально не в состоянии обеспечить полное ре-
шение. В этих случаях на помощь приходит родственный подход, который называ-
ется рекуррентным.
Общие сведения о рекуррентных соотношениях
Необходимо отметить, что придумывание рекуррентных соотношений — это про-
цесс, требующий творческого подхода. Это означает, что, понимая смысл термина
рекуррентное соотношение и уже решив несколько задач с его использованием, вы
можете и не придумать корректное рекуррентное соотношение к следующей зада-
че. А все потому, что рекуррентные соотношения составляются с учетом специфи-
ки задач, и часто — очень глубокой специфики. Тем не менее чем больше задач вы
решили методом рекуррентных соотношений, тем выше вероятность, что вам удаст-
2.3. Рекуррентные соотношения
115
ся придумать правильное рекуррентное соотношение для решения вновь встре-
ченной задачи.
Важным достоинством рекуррентных соотношений является простота реализа-
ции. Это означает, что даже в условиях ограниченного времени (например, во
время проведения олимпиады) вы можете потратить час и более времени на при-
думывание, проверку и доказательство корректности рекуррентного соотноше-
ния, а затем 10-15 минут на реализацию, отладку и проверку соответствующей
программы.
Дальнейший материал построен следующим образом: объясняется и иллюст-
рируется основная идея метода рекуррентных соотношений, азатем приводит-
ся решение большого количества задач с белорусских республиканских и меж-
дународных (IOI — International Olympiad in Informatics) олимпиад по
информатике для школьников. При этом приводится не только само рекуррен-
тное соотношение, но и делаются попытки проиллюстрировать ход исследова-
ния специфики задачи для построения корректного рекуррентного соотноше-
После ознакомления с общими сведениями рекомендуется разбор каждой новой
задачи проводить в таком порядке: прочитав условия, отложить материал в сторо-
ну и попытаться решить задачу самостоятельно, вначале любым из приходящих в
голову способов (пусть даже и в условиях гораздо меньших ограничений, чем те,
что реально даны в условиях задачи, например, каким-нибудь простым перебо-
ром), затем все-таки попытаться составить рекуррентное соотношение. Важно
заметить, что ваше простое решение пригодится для проверки правильности со-
ставленного рекуррентного соотношения. Порядок может быть таким: для малень-
ких значений исходных данных вы просчитываете результат вручную. Затем ре-
шаете задачу при существенно меньших, чем указанные в задаче, ограничениях
каким-то из известных вам способов (перебор, рекурсия, очередь и т. д.), и это ре-
шение проверяете на созданных вручную тестах. Зато рекуррентное решение мож-
но будет проверять уже на «частичном решении». Если же вам покажется, что вы
зашли в тупик и дальнейшие размышления не могут привести к полезному ре-
зультату, нужно возвращаться к материалу и прочитать ход анализа специфики
задачи автором.
После этого вновь отложить материал и опять попробовать составить рекуррент-
ное соотношение самостоятельно. Затем, если решить задачу все-таки не удается,
прочитать полное решение и реализовать его на компьютере. Чем полнее и напря-
женнее будет проведенная вами работа над текущей задачей, тем больше шансов,
что вы решите следующую задачу, не прибегая к помощи. Более того, такая работа
над каждой из этих задач приведет к значительному увеличению шансов на то, что
вы решите новые задачи такого класса, которые вам обязательно встретятся. И на-
оборот, поверхностное чтение может привести в лучшем случае к тому, что вы про-
сто поймете и, возможно, запомните решение десятка задач на рекуррентные соот-
ношения. Это, конечно, тоже немало, ведь вам могут встретиться эти либо похожие
задачи. Но автор ставит другую задачу — помочь вам научиться решать новые за-
дачи таким способом.
Глава 2. Основы алгоритмизации
Задача о числах Фибоначи
Рассмотрим классическую для учебных материалов по рекуррентным соотноше-
ниям задачу о числах Фибоначи.
В некоторых источниках эта задача формулируется как «задача о размножении
кроликов»: пусть мы имели одного кролика в «нулевом» поколении и одного
кролика в первом поколении. Известно также, что количество кроликов в сле-
дующем поколении равно сумме количеств кроликов в двух предыдущих поко-
лениях. Требуется вычислить количество кроликов в поколении N(например,
№=10 000).
Последовательность чисел, построенная для поколений от 0-го до 7-го такова:
То есть во 2-м поколении (N= 2) будет 2(1 + 1) кролика, в 3-м —3(1 +2) кролика,
в 4-м — 5 кроликов и т. д.
Эта последовательность чисел и называется последовательностью чисел Фибона-
чи, а сами числа, соответственно, — числами Фибоначи.
Как же найти количество кроликов в заданном поколении N?
Введем одномерный массив К[0.. 10000]. По условию, К[0] = 1, К[1 ] = 1.
Для решения задачи мы заполним элементы массива следующим образом:
for i:-l to N do Ц1]:-К[1-1]+К[1-2]:
И выведем результат так:
wr1teln(K[N]>:
В листинге 2.15 приводится полный текст программы для решения задачи.
Листинг 2.15. Задача о числах Фибоначи
program Fib:
var
К' : array [0..10000] of longint:
i.N : longint:
begin
readln(N);
K[0]:=l: K[l]:-1:
for 1-.-2 to N do K[i]:-K[i-l]+K[i-2]:
writeln(K[N]);
Теперь вернемся к общей терминологии.
Соотношение К[ 1 ] = К[i-1 ] + K[i-2] называется рекуррентным соотношением
для величины К. Сама величина К называется рекуррентной. В слово «рекур-
рентный» здесь вкладывается тот смысл, что следующее значение рекуррент-
ной величины вычисляется по одному или нескольким ее предыдущим значе-
ниям.
Величина 1 называется параметромрекуррентной величины. Например, K[i ] — ре-
куррентная величина от одного параметра 1. Для хранения рекуррентных величин
от одного параметра обычно используется одномерный массив.
2.3. Рекуррентные соотношения
Однако, например, в задаче о числах Фибоначи нам для вычисления следующего
числа нужно знать и, соответственно, хранить всего два предыдущих числа. И по-
этому можно было использовать просто две переменные для их хранения. Про-
грамма могла бы выглядеть в этом случае так, как показано в листинге 2.16.
Листинг 2.16. Задача о числах Фибоначи (второй вариант)
program Fib2:
var
1.N.K0.K1.K2 : longint:
readln(N);
K0:-l: Kl:-1:
for 1:-2 to N do
begin
K2:*K1+KO:
KO:-K1:
Kl:-K2:
end:
writeln(K2)
end.
Заметим попутно, что хотя такое решение выглядит менее понятным и чуть более
сложным, оно может вычислять числа Фибоначи для Nгораздо больших, чем 10 000.
Например, для N= 100 000.
Рекуррентные величины могут иметь более одного параметра. Например, рекур-
рентная величина R(i,j] := R[i-1,j] + R[l-2,j] + ... + R[i-j,j] имеет два параметра,
обозначенных 1 и j. В общем случае для хранения значений рекуррентных вели-
чин от двух параметров в программе используется двумерный массив. Для вычис-
ления элементов очередной строки массива R требуется знать вычисленные значе-
ния j строк (с номерами 1-1, 1-2,..., i-j) над текущей.
Рекуррентная величина R[ p.k.t ] : = max( R[ р- 1,k,t - L[ p] ]+1 ,R[ p-1,k,t ]) имеет три па-
раметра p, k, t. И ее значение для заданных значений этих параметров вычисля-
ется, как видим, несколько сложнее. Для хранения значений рекуррентной вели-
чины от трех параметров обычно используется трехмерный массив. Но бывают
случаи, когда установленные в условиях задачи предельные значения рекуррент-
ных величин велики для того, чтобы одновременно хранить в статической памя-
ти (ограниченной в случае Турбо Паскаля 64 Кбайт) значения рекуррентной ве-
личины для всех возможных значений ее параметров. Тогда хранятся не все,
а только те, которые реально нужны для вычисления новых значений. Понятно,
что программа в этом случае усложняется, иногда незначительно, а иногда — су-
щественно.
Итак, суть метода решения задач с помощью рекуррентных соотношений заклю-
чается в том, чтобы:
□ установить факт возможности решения задачи данным методом, то есть убе-
диться, что рекуррентное соотношение существует и есть смысл тратить время
на его поиски и вывод;
118 Глава 2. Основы алгоритмизации
□ ввести рекуррентную величину от одного, двух, трех или более параметров;
□ определить, как найти результат решения задачи при вычисленных значениях
рекуррентной величины;
□ установить начальные значения рекуррентной величины;
□ исходя из специфики задачи, вывести корректное рекуррентное соотношение
(сточки зрения автора, такое умение — это больше искусство, чем наука; и вдум-
чивое решение большего числа задач на рекуррентные соотношения повышает
вероятность того, что вы овладеете этим искусством);
□ проверить правильность рекуррентного соотношения для значений, просчитан-
ных вручную или вспомогательными программами; в этот момент можно реа-
лизовать саму программу, вычисляющую рекуррентную величину;
□ определить, помещается ли классическое представление выведенной рекуррент-
ной величины в виде массива соответствующей размерности в статическую
память; если нет, то видоизменить рекуррентное соотношение для программы,
корректно функционирующее в заданных ограничениях, и соответствующим
образом скорректировать программу.
ПРИМЕЧАНИЕ-----------------------------------------------------------
Проблема статической памяти — это в значительной степени проблема 16-битных при-
ложений (типа Турбо Паскаль). Для 32-битных средств разработки (Free Pascal, на-
пример) последний пункт имеет меньшую актуальность.
Рекуррентные соотношения с одним
параметром
В данном разделе приводятся задачи, для решения которых необходимо составить
рекуррентное соотношение с одним параметром. Это означает, что вводимая ре-
куррентно-задаваемая величина зависит от одного аргумента.
Задача «Суммы»
Белорусская республиканская олимпиада по информатике, 2000 год. 8-9-й класс.
День 1. Задача 2.
Любое целое число N > 0 можно представить в виде суммы натуральных слага-
емых, каждое из которых является степенью числа 2. Суммы, различающиеся лишь
порядком слагаемых, считаются одинаковыми. Найти К — количество способов,
которыми можно представить число Nв виде суммы натуральных слагаемых, каж-
дое из которых является степенью числа 2. Ограничения: N< 1000.
Например, для N-7:
□ 7-4 + 2+ 1;
□ 7-4 + 1 +1 + 1;
□ 7-2 + 2 + 2+1;
□ 7-2 + 2+1 + 1 + 1;
2.3. Рекуррентные соотношения
119
и, следовательно, К = 6.
В программе, решающей задачу, ввод N будем осуществлять из текстового файла
SUM.IN, а вывод результата (К) — в текстовый файл SUM.OUT. Например:
□ SUM.IN
132
□ SUM.OUT
31196
Попытаемся систематически составить подряд несколько разложений:
№1 N = 2 N = 3 N = 4 N = 5 N = 6 N = 7
1 2 2+1 4+1 4+2 4+2+1
1+1 1+1+1 2+2 2+2+1 4+1+1 4+1+1+1
2+1+1 2+1+1+1 2+2+2 2+2+2+1
1+1+1+1 1+1+1+1+1 2+2+1+1 2+2+1+1+1
2+1+1+1+1 2+1+1+1+1+1
1+1+1+1+1+1 1+1+1+1+1+1+1
Введем обозначение: К( 1) — количество разложений числа 1 по условиям задачи.
Сразу замечаем, что К( 1) = 1, К(2) - 2.
К( 1) = К(1-1), если i — нечетное (в каждой из строк для соответствующего преды-
дущего разложения добавляется +1, а количество строк не меняется). Осталось
выяснить, как искать К( 1) для четного 1.
Естественно предположить, что К( 1) зависит от К(1-1) следующим образом: К( 1) -
= К( 1 -1) + X, то есть количество разложений i-го числа равно количеству разложе-
ний числа 1-1 плюс еще сколько-то. Сколько же?
В качестве примера рассмотрим детальнее разложения при N - 6 и отметим (символом
«!+) те строки, которые перешли в него из разложения N - 5 путем добавления +1:
2+2+1
2+2+2
1+1+1+1+1
Теперь выпишем строки, оставшиеся не помеченными, то есть те, которые добав-
лены по другому закону (как раз и определяющему X):
4+2
2+2+2
120
Глава 2. Основы алгоритмизации
Интересно, что все они составлены из четных чисел. Поделим все эти числа на 2,
получим:
2+1
1+1+1
Теперь обращаем внимание, что это — разложение числа 3, которое можно полу-
чить из числа 6 тоже делением на 2. Итого получаем: X = К( i div 2).
Окончательное рекуррентное соотношение имеет вид:
□ K(i) - K(i-1), если i нечетное;
□ K(i) SK(i-1) +K(i div 2), если i четное.
Проверим наши соображения еще на одном тестовом примере:
N = 7 N = 8
4+2+1 8
4+1+1+1 4+4
2+2+2+1 4+2+2
2+2+1+1+1 (!)4+2+1+1
2+1+1+1+1+1 (!)4+1+1+1+1
1+1+1+1+1+1+1 2+2+2+2
(!)2+2+2+1+1
(!) 2+2+1+1+1+1
(!) 2+1+1+1+1+1+1
(!) 1+1+1+1+1+1+1+1
Не помеченными остались строки:
8
4+4
4+2+2
2+2+2+2
После деления всех чисел на 2 получим:
4
2+2
2+1+1
1+1+1+1
Это как раз и есть разложение числа 4, которое может быть получено из исходного
N = 8 делением на 2. И тогда полное решение задачи может состоять в рекуррент-
ном заполнении массива К[ 1..N] к выводе значения К[Н].
Можно также заметить, что к[ 2] - к[ 1 ] + к[ 2 div 2 ] - к[ 1 ] + к[ 1 ] - 2. То есть к[2 ] можно
вычислять общим порядком. Достаточно задать только начальное значение к[ 1 ].
Полное решение задачи — в листинге 2.17.
2.3. Рекуррентные соотношения
121
Листинг 2.17. Решение задачи «Суммы»
program by00mlt2:
: longint:
: array [1..1000] of longint:
begin
assign (input.'sum.in'): reset(input):
assign (output.'sum.out'): rewrite(output):
readln (N):
k[l]:-l:
for i -2 to N do
if odd(i)
then k[ij:-k[i-l]
writeln(K[N]):
close (input): close (output):
end.
ПРИМЕЧАНИЕ--------------------------------------------------
Здесь Odd(i) — стандартная функция, определяющая, является ли число i нечетным.
Задача «Отбор в разведку»
Четвертьфинал чемпионата мира АСМ по программированию для студентов, Цен-
тральный регион России. 5-6 октября 1999 года.
Из W солдат, выстроенных в шеренгу, требуется отобрать нескольких в разведку.
Для того чтобы сделать это, выполняется следующая операция: если солдат в ше-
ренге больше, чем 3, то удаляются все солдаты, стоящие на четных позициях, или
все солдаты, стоящие на нечетных позициях. Эта процедура повторяется до тех
пор, пока в шеренге останется 3 или менее солдат. Их и отсылают в разведку. Под-
считайте, сколькими способами могут быть сформированы таким образом группы
разведчиков ровно из трех человек. Ограничения: 0 < N< 10 000 000.
Входной файл — INPUT.TXT (содержит число N), выходной файл — OUTPUT.TXT (со-
держит решение — количество вариантов). Время на тест — 5 секунд.
ПРИМЕР -----------------------------------------------------
Для N -10 способов формирования группы разведчиков будет 2, для N = 4 — ни одно-
го, то есть 0.
Обозначим K(N) — количество способов, которым можно сформировать группы
разведчиков из N человек в шеренге. Тогда по условию задачи К( 1) - 0, К(2) = 0,
К(3) - 1. То есть из трех человек можно сформировать только одну группу, из од-
ного или двух — ни одной.
Рассмотрим случай произвольного числа солдат в шеренге. Если N — четное, то,
применяя определенную в задаче операцию удаления солдат в шеренге, мы полу-
чим в качестве оставшихся либо N div 2 солдат, стоящих на четных позициях, либо
N div 2 солдат, стоящих на нечетных позициях. Общее количество способов можно
найти по формуле К( N)_ 2 » К( N div 2) (если N — четное). То есть количество способов
122
Глава 2. Основы алгоритмизации
сформировать группу разведки из солдат, оставшихся па четных позициях, плюс
количество способов сформировать группу разведки из солдат, оставшихся па не-
четных позициях.
Если N нечетно, то у нас останется либо N div 2 солдат, стоявших на четных позици-
ях, либо (N div 2) + 1 солдат, стоявших на нечетных позициях. Общее количество
способов в этом случае K(N) = K(N div 2) + К( (N div 2) + 1).
Таким образом, окончательно рекуррентное соотношение имеет вид:
□ K(N) = 0, если N “ I или N = 2;
□ K(N) -1, если N - 3;
□ K(N) - 2 • K(N div 2), если N — четное;
□ K(N) - K(N div 2) + K((N div 2) + 1), если N - нечетное.
Осталось только обратить внимание на следующие факты.
1. N может достигать 10 000 000, следовательно, нам не удастся разместить в ста-
тической памяти массив для хранения всех значений рекуррентной величины
K(N);
2. На самом деле нам для вычисления ответа для конкретного!! нужно знать мно-
го меньше, чем все значения К( N). Поэтому удобно применить рекурсивное вы-
числение рекуррентной величины К(N):
function KIN:longint):longint:
begin
if N<3
then K:-0
else if N-3
then K:-l
else if odd(N)
then K:- KIN d1v 2) + KIN div 2 + 1)
else K:- 2 * KIN div 2):
Полное же решение данной задачи выглядит так, как показано в листинге 2.18.
Листинг 2.18. Решение задачи «Отбор в разведку»
{Sm 65520.0.0}
program nee4c99g:
N : longint:
function K(N:longint):longint:
end:
assign!input.'input.txt'): reset I i nput):
assignloutput.'output.txt'): rewriteloutput):
read(N):
writelnlKIN)):
closetinput): closeloutput):
end.
2.3. Рекуррентные соотношения 123
Задача «Видеосалон»
Беларусская республиканская олимпиада 1996 года. День 2. Задача 3.
Владелец видеосалона решил получить максимальный доход от своего бизнеса.
В видеосалоне имеется неограниченное количество пустых видеокассет. Продол-
жительность каждой видеокассеты равна L. У владельца есть возможность запи-
сать на видеокассеты Nфильмов продолжительностью А(1), ...,A(N),A(i) < L. При
этом он не может записывать на одну видеокассету один фильм дважды и не мо-
жет оставить на кассете такое пустое место, на которое помещается целиком один
из фильмов, не записанных на этой кассете. Фильмы на кассету пишутся целиком.
Владелец видеосалона стремится таким образом записать фильмы на кассеты, чтобы
для просмотра всех фильмов клиент был вынужден взять напрокат наибольшее число
кассет. Определить это число К. Ограничения: A[i],L,N— натуральные,! < 1000, N <100.
□ Ввод — из файла Input3.txt:
А[1]
ACN]
□ Вывод — в файл output3.txt (К).
Рассмотрим такой случай: пусть L = 100, N = 8, а А[ i ] - [ 2 2 3 3 97 97 97 97 ] (продол-
жительность восьми фильмов).
Поскольку некоторые фильмы могут иметь одинаковую длительность (у нас в при-
мере это тоже есть), чтобы различать эти фильмы при записи, введем обозначения:
2(1)— это значит фильм длительностью 2, первый в исходном списке, или 97(6) —
фильм длительностью 97, шестой в исходном списке. Если бы порядок записи
фильмов на кассеты определял клиент, то в нашем примере, понятно, он выбрал
97(5)+ 2(1),
97(6) + 2(2),
97(7)+ 3(1),
97(8)+ 3(2).
При таком раскладе его оплата за прокат всех фильмов была бы минимальна. Но
коварный владелец видеосалона записывает кассеты сам. Как он их запишет? Было
бы правильно, чтобы вы, прежде чем читать дальше, придумали «хитрый» расклад
самостоятельно. А еще лучше — и способ «хитрого» алгоритма записи фильмов на
видеокассеты.
Сейчас мы попробуем вместе составить этот «хитрый» расклад. Первая кассета
останется такой же: 97(5) + 2(1). А вот на вторую владелец видеосалона предпо-
чтет писать только один новый фильм — 2(2), то есть 97(5) + 2(2). Аналогично он
поступит и с 3-й и с 4-й кассетами:
97(5)+ 3(1),
97(5)+ 3(2).
124
Глава 2. Основы алгоритмизации
Итак, клиент уже вынужден купить 4 кассеты, а ведь он еще не видел трех самых
лучших фильмов — 97(6), 97(7) и 97(8), — для записи которых в «хитром» раскла-
де владельца видеосалона потребуется покупать еще три кассеты:
97(5)+ 2(1),
97(6) + 2(1),
97(7)+ 2(1).
Чем дописывать эти три кассеты из имеющихся «короткометражных» фильмов —
в принципе, безразлично. Например, фильмом 2(1).
С данным раскладом вроде разобрались. А как с другими? И каков алгоритм «хит-
рой» записи фильмов? И наконец, как узнавать требуемое количество видеокас-
сет К по исходным данным L, N, А[ 1 ]?
Если переформулировать задачу, то от нас требуется составить все возможные сум-
мы из сочетаний исходных чисел, и из этих сумм отобрать максимальное количе-
ство так, чтобы последовательность чисел в каждой из сумм отличалась от осталь-
ных выбранных хотя бы на одно число (одинаковые числа, стоящие в исходных
данных на различных позициях, мы считаем различными).
Поскольку более продолжительные фильмы более существенны для процесса за-
писи, исходные данные переупорядочим так, чтобы фильмы шли в порядке убыва-
ния их длин.
Рассмотрим «под микроскопом» одну видеокассету. Она имеет продолжительность
записи L (пусть L минут для определенности). Тогда мы можем рассматривать одну
кассету как одномерный массив S[ 1..L ]. И тогда каждой из вышеупомянутых сумм
соответствует ровно одна позиция в этом массиве. Суммы, превышающие L, будем
отбрасывать (поскольку они нас не интересуют, как комбинации фильмов, не по-
мещающиеся на одной кассете). Будем хранить в S[ j ] единичку, если запись пре-
дыдущего фильма закончилась в позиции j.
Тогда каждый новый фильм мы должны попытаться приписать ко всем возмож-
ным позициям примерно так:
Если s[j]<>0 и j+a[i]<-L то
Если мы нашли место, куда можно «приткнуть» фильм и он поместится до конца
кассеты (а[ i ] — это продолжительность текущего фильма), то помечаем позицию,
в которой закончится этот фильм.
При этом перед первым фильмом S[ j ] - 0 для всех j от 1 до L, a S[0] - 1, то есть
можно писать фильмы с начала кассеты.
Понятно, что вышеуказанную операцию нужно сделать для всех фильмов. Как те-
перь параллельно вести учет количества вариантов?
Заведем еще один массив NS[ 1.1]. Его будем модифицировать параллельно с мас-
сивом S. Но если в S[ j ] мы будем отмечать только факт того, что в этом месте за-
кончена запись предыдущего фильма, то в NS[ j ] мы будем вести учет количества
способов, которыми мы записали фильмы до этого места:
Если s[j]oO и j+a[1]«-L
2.3. Рекуррентные соотношения
ns[j+a[i]] ns[j*a[i]] + max(l.ns[j]):
ns[j]:=O:
Если мы нашли место, куда записать новый фильм, то количество способов «пере-
кочевывает» в конец записи этого фильма, при этом мы должны учитывать, что:
1) количества нужно складывать — старое (ns[ j+a[i ]]) и новое (ns[ j ]);
2) самый первый раз нужно просто прибавить 1 (max(1,ns[j ]));
3) «перекочевывание» количества ns[ j ] означает, что после того, как мы его сло-
жили «вперед», нужно обнулить его в текущей позиции, чтобы избежать «на-
крутки» количества вариантов.
Хорошо, теперь мы для всех сумм S[j] посчитаем, сколькими различными спосо-
бами NS[ j ] можно их получить, используя N фильмов. А какие из этих сумм NS[j ]
нужно складывать, чтобы получить ответ К?
Для ответа на этот вопрос заведем еще один массив: MS[ 1..L]. Вначале все его эле-
менты будут равны 0. А затем будем заносить в MS[ j ] единицу, в том случае, если
мы из этой суммы формировали последующие и, стало быть, эта сумма — проме-
жуточная и ее не надо считать:
Если s£j]ofl и
А для получения ответа К нужно складывать элементы массива ns[j] с конца, до
тех пор пока MS[ j ] = 0:
К:-0: J:=L:
while (ms[j]-O) do
begin
dec(j)
end:
writeln(K);
И наконец, последнее замечание: вообще говоря, нам нужны два массива S: один —
для текущего значения S, а другой — для следующего, чтобы не приписывать фил ьм
сам к себе на одну и ту же кассету. Но мы можем добиться того же эффекта, если
будем работать с одним и тем же массивом S, но обрабатывать его для каждого 1 от
последнего элемента S[L-a[i]] к начальному S[0 J:
for 1:-1 to N do
for j:-L-a[i] downto 0 do
if (s[j]<>0) and (j»a[1]<-L)
Понятно, что s[j ] для j > L-a[i] обрабатывать бесполезно: фильм a[i] заведомо
не поместится на кассете, если писать его с этой позиции j.
Полное решение данной задачи приводится в листинге 2.19.
Листинг 2.19. Решение задачи «Видеосалон-
program by96s2t3:
: array СО..10003 of longint:
126
Глава 2. Основы алгоритмизации
a.m : array [1..100] of integer:
i.J.N.L.K.ka.jk.jb.g.pk. ks.ix : longint:
procedure Sort:
var max : longint:
begin
for i:-l to N-l do
begin
max:-a[i]: k:-i:
for j:=i+l to N do
if a[j]>max
then begin max:-a[j]: k:-j end:
a[k]:-a[i]: a[i]:-<nax:
end:
end:
function max(a,b:longint):longint:
if a>b then max:*a else max:-b
assignfinput.'input3.txt'): reset(input):
assign(output.'output3.txt'); rewritetoutput):
read(L): read(N):
for 1:=1 to N do readtati]):
Sort: s[0]:-l: ns[0]:-0:
for i:-l to N do
for j:-L-a[i] downto 0 do
if (s[j]-=-O) and (j+a[i]<-L)
then
begin
s[j+a[i]]:-l:
ns[j+a[i ]] :-ns[j+a[i]j™ax(l .ns[j]):
ns[j]:-0:
ms[j]:-l:
end:
K:-0: J:-L:
while (ms[j]=0) do
begin K:-K*ns[JJ: dectj) end:
writeln(K):
closetinput): closetoutput):
Рекуррентные соотношения с двумя
параметрами
В данном разделе приводятся задачи, для решения которых необходимо составить
рекуррентное соотношение с двумя параметрами. Это означает, что вводимая ре-
куррентно-задаваемая величина зависит от двух аргументов.
Задача «Треугольник»
ЮГ94. День 1. Задача 1.
2.3. Рекуррентные соотношения
127
5
7
3 8
8 1 О
2 7 4 4
4 5 2 6 5
Изображен треугольник из чисел. Напишите программу, которая вычисляет наи-
большую сумму чисел, расположенных на пути, начинающемся в верхней точке
треугольника и заканчивающемся на основании треугольника. Ограничения:
□ каждый шаг на пути может осуществляться вниз по диагонали влево или вниз
по диагонали вправо;
□ число строк в треугольнике больше 1 и не больше 100;
□ треугольник составлен из целых чисел от 0 до 99.
Первым числом во входном файле с именем INPUT.TXT является количество строк в
треугольнике. В выходной файл с именем OUTPUT.TXT записывается только наиболь-
шая сумма в виде целого числа. Например, для приведенного выше треугольника:
□ INPUT.TXT
5
8 1 О
2 7 4 4
4 5 2 6 5
□ OUTPUT.TXT
30
Рассмотрим последовательно алгоритм нахождения суммы по исходным данным:
3 8 3+7 8+7 -> 10 15 10 15
8 1 0 8+10 i+max(10,15) 15+0 1816 15
2744
45265
3 8 10 15 10 15
8 10 18 16 15 -> 181615
27 4 4 2+18 7+шах(18,16) 4+шах(16.15) 4+15 20 25 20 19
45265
3 8 10 15 1015
8 10 18 16 15 18 1615
27 4 4 20 25 20 19 20 25 20 19
4 5265 4+20 5+тах(20,25) 2+тах(25,20) 6+тах(20,19) 5+19 24 30 27 26 24
128 Глава 2. Основы алгоритмизации
лучили по исходной матрице такую:
10
18
20
24
15
16 15
25 20 19
30 27 26 24
Для вывода результата достаточно найти максимальный элемент в последней
строке.
Теперь формально запишем рекуррентные соотношения, которыми мы пользова-
□ a[i,j] + а[ i-1,j], если, j = 1;
□ a[i,j]<a[i,j] +а[1-1,]-1],если j = 1;
□ а[ i J ] + max(a[i-1,j -1 ],а[1-1 ,j ]) — в остальных случаях для всех строк, начиная
со второй.
Для получения ответа нужно затем найти максимальный элемент в последней стро-
ке. Текст программы решения — в листинге 2.20.
Листинг 2.20. Решение задачи «Треугольник»
Program io04dltl:
а : array [1..100.1..100] of longint:
function max(x.y:longint):longint:
if x>y then max:-x else max:-y:
begin
assignGnput.'input.txt'): reset (input):
assigntoutput.'output.txt'): rewrite (output):
read(n):
for i-.-l to n do
for J:-l to i do read(a[1.j]):
for i:-2 to n do
for j:-l to 1 do
if j-1
then a[i.j]:-ati.j]+a[i-l.j]
else if j-1
then a[i.j]:-a[i.j]*a[i-l.j-l]
else a[i.j]:-a[1.j] + max(a[i-l.j-l].a[i-l.j]):
m:-a[n.l]:
for i:-2 to n do
if a[n.i]>m then m:-a[n.i]:
2.3. Рекуррентные соотношения
129
writeln(m):
close(input): close (output):
end.
ПРИМЕЧАНИЕ
Для лучшей читаемости главного цикла нахождение максимального из двух чисел вы-
несено в отдельную функцию.
Обратите внимание на ввод. По условию задачи вводится не весь двумерный мас-
сив, а только его часть под главной диагональю включительно:
for 1:-1 to n do
for J:-l to 1 do read(a[i.j]):
Изменяются только эти элементы.
Задача «Двоичные числа»
Беларусская республиканская олимпиада 1996 года. День 2. Задача 1.
Среди всех Мбитных двоичных чисел указать количество таких, у которых в дво-
ичной записи нет подряд идущих К единиц. Сами числа выдавать не надо. Д'и К —
натуральные, К < N< 30.
Ввод N и К — из файла1приИ.1х1, вывод М (искомое количество) — в файл Outputl.txt.
ПРИМЕР -------------------------------------------------------------
Пусть N = 3, К= 2. Тогда М = 5. Действительно, среди всех 3-битных двоичных чисел
(ООО, 001,010,011,100,101,110,111) есть 5 чисел (ООО, 001,010,100,101), у которых
в записи 2 единицы не идут подряд.
Введем рекуррентную величину R[i,j] — количество i-битных двоичных чисел,
в двоич ной записи которых нет подряд идущих j единиц. Тогда в качестве ответа к
задаче нас интересует R[N,K).
Прежде всего попытаемся проанализировать закономерности заполнения матри-
цы R[ i,j ]. Если N = 1, то есть только 2 однобитных числа — 0 и 1. Соответственно,
R[ 1,1 ] - 1, то есть существует одно число, в разложении которого нет одной едини-
цы - 0.
R[ 1,j ] “ 2 для всех j > 2, то есть два 1-битных числа, в разложении которых нет
двух (или более) подряд идущих единиц два — 0 и 1. Аналогично R[i,j ] - 2'j для
всех случаев 1 < j, то есть количество i-битных чисел, в разложении которых нет
подряд идущих j единиц, равно самому количеству всех таких чисел.
Очевидно, что R[ 1,1 ] = 1 для всех 1 > 1, то есть существует только одно 1-битное
число, в разложении которого не существует ни одной единицы, — число с нулями
И наконец, R[ 1,1] - 2 » 1 - 1, то есть количество i-битных чисел, в разложении ко-
торых нет 1 подряд идущих единиц, равно количеству всех i-битных чисел без од-
ного (которое и содержит единицы во всех разрядах).
Таким образом, начальное заполнение матрицы R[i,j ] таково:
130
Глава 2. Основы алгоритмизации
1 2 2 2 2 2
1 3 4 4 4 4
1 7 8 8 8
1 15 16 16
1 31 32
1 63
Осталось научиться заполнять таблицу ниже главной диагонали, то есть вычис-
лять R[ i,j ] для случая 1 > j.
Рассмотрим для примера R[ 1,3 ]. Требуется вычислить количество i-битных чисел
(1 > 4), в разложении которых нет подряд идущих 3 единиц. Все i-битные числа —
это объединение следующих групп:
1) все (1-1)-битные числа и 0 на i-й позиции;
2) все (1-2)-битные числа и 01 на последних двух позициях;
3) все (1-3)-битные числа и 011 на последних трех позициях;
4) все (1-3)-битные числа и 111 на последних трех позициях;
Очевидно, что среди последней группы чет ни одного числа, в разложении кото-
рого нет подряд идущих трех единиц.
Все эти группы, по определению, не имеют общих чисел, и, значит, требуемое
количество искомых чисел равно сумме количеств искомых чисел в каждой
группе;
R[i,3] - R[i-1,3] + R[i-2,3] + R[i-3,3].
И в общем случае:
R[i,j ] - R[i-1,j] + R[i-2,j] +... + R[i-j,j].
Полностью программа решения представлена в листинге 2.21.
Листинг 2.21. Текст программы решения задачи «Двоичные числа»
program by96s2tl:
R : array [1..60.1..60] of longint:
1 J.N.K.m.S : longint:
assign (input.’inputl.txf): reset(input):
assigntoutput.'outputl.txt'): rewrite(output):
read(N.K):
for i.-l to N do R(i.l]:=l;
for i:-2 to N do
begin
R[l.i]:-2:
R[1.1]:-2*R[1-1.1-1]+1:
for j:-i+l to N do R£i.j]:-R[1.i]+1:
end:
2.3. Рекуррентные соотношения
131
for i:-3 to N do
for j:-2 to 1-1 do
begin
S:-0:
for m:-l to j do S:-S+R[1-m.jJ:
R[i.j]:-S:
end:
writeln(R[N.K]):
closetinput): closetoutput):
end.
Внимательный читатель, попытавшийся вникнуть глубже в суть предложенных
вычислений, может высказать замечание: для заполнения двумерной матрицы мы
используем тройной цикл. Кроме того, в этом самом внутреннем цикле мы факти-
чески все время складываем почти одни и те же числа. Попробуем улучшить это
решение, опираясь на более тонкие рассуждения.
Пусть мы хотим вычислить вначале:
R[i,j] - R[i-1,j] + R[i-2,j] +... + R[i-j,j].
А перед этим мы вычислили:
R[i-1,j]-R[i-2,j] + R[i-3,j] + .. + R[i-j,j] + R[i-1-j,j].
Можно заметить, что
R[i,j] - R[i-1,J] + (R[i-1,j] - R[i-l-j,j]) -
“2 • Rfi-1J] - R[i-1-jJ].
И тогда программа может выглядеть так, как в листинге 2.22.
Листинг 2.22. Другой вариант решения задачи •Двоичные числа
program by96s2tl:
R : array [0..60.1..60] of longint:
i.j.N.K.m : longint:
assign tinput.'inputl.txt'): resettinput):
assignfoutput.'outputl.txt'): rewritetoutput):
read(N.K):
for i:-.O to N do R[1.l]:-1:
for i:-2 to N do
begin
R[0.i]:-l: R[l.1]:-2:
R[i.1]:-2*R[1-l.i-l]+l:
for j:-1+l to N do R[i.j]:-R[i.i]+1:
end:
for i:-3 to N do
for j:-2 to 1-1 do RCi.j]:-2*R[1-l.J]-R[1-j-l.j]:
writelnfRtN.k]):
closetinput): closetoutput):
132
Глава 2. Основы алгоритмизации
ПРИМЕЧАНИЕ
При решении этой задачи гомельские школьники обратили внимание, что можно уве-
личить N и К до 60 простой заменой типа longint на comp.
Задача «Цветочный магазинчик»
ЮГ99. День 1. Задача 2.
Вы хотите оформить витрину вашего цветочного магазина наилучшим образом.
У вас есть Fбукетов (каждый букет состоит из цветов одного вида, все цветы одно-
го вида собраны в одном букете) и не меньшее количество ваз, расположенных в
ряд. Вазы приклеены к полке и пронумерованы слева направо последовательно от
1 до V, где V — количество ваз. Ваза 1 является крайней левой в ряду, а ваза V—
крайней правой. Букеты можно помещать в разные вазы, и каждый букет имеет
уникальный номер в пределах от 1 до F. Порядок размещения букетов в вазах следу-
ющий: букет с номером i всегда содержится в вазе, которая стоит левее вазы с у-м
букетом, если i < j. Пусть, например, у вас есть букет азалий с номером 1, букет
бегоний с номером 2 и букет гвоздик с номером 3. Все букеты должны быть поме-
щены в вазы. Букет азалий должен быть помещен в вазу, расположенную левее
вазы с бегониями, а букет бегоний — левее вазы с гвоздиками. Если ваз будет боль-
ше, чем букетов, то некоторые вазы останутся пустыми. В вазе может быть не бо-
лее одного букета.
Каждая ваза имеет собственные характеристики, так же как и цветы. Поэтому по-
мещенный в вазу букет имеет некоторую эстетическую характеристику, выражен-
ную целым числом. Значения эстетических характеристик приведены в табл. 2.1.
Пустая ваза имеет значение эстетической характеристики, равное нулю.
Таблица 2.1. Эстетические характеристики букетов в различных вазах
Букет Ваза
1-я 2-я 3-я 4-я 5-я
1-й (азалии) 23 -5 -24 16
2-й (бегонии) 21 -4 10 23
3-й (гвоздики) -21 5 -4 -20 20
Согласно табл. 2.1, азалии прекрасно выглядят во второй вазе и ужасно — в чет-
вертой. Для достижения наилучшего эстетического оформления витрины вы долж-
ны максимизировать сумму значений эстетических характеристик размещений
цветов в вазах, сохраняя требуемое упорядочение букетов. Если существует не-
сколько размещений, имеющих максимальную сумму, то вы должны вывести толь-
ко одно из них.
Ограничения: 1 < F< 100 и F< V < 100, а также -50 < < 50, где Ав — значение
эстетической характеристики, получаемое при помещении i-ro букета в j-ю вазу.
Входной текстовый файл называется flower.inp, и первая его строка содержит два
числа: F, V. Каждая из следующих F строк содержит V целых чисел: A[i,j ] является
j-м числом в (1+1)-й строке входного файла.
2.3. Рекуррентные соотношения 133
Выходной файл — flower.out — состоит из двух строк:
□ первая строка содержит сумму значений эстетических характеристик вашего
размещения цветов в вазах;
□ вторая строка содержит последовательность из F чисел, где k-е число определя-
ет номер вазы, в которую помещен букет к.
Например:
1) flower.inp
3 5
7 23 -5 -24 16
5 21 -4 10 23
-21 5 -4 -20 20
2) flower.out
2 4 5
Проверка: ваша программа должна выполняться не более двух секунд. Частичные
решения в каждом тесте оцениваться не будут.
Итак, мы пытаемся придумать рекуррентное соотношение для приведенного
выше примера. Параметров у нас два: количество ваз и количество букетов.
Пусть r[i,j ] — оценка наилучшего размещения i букетов в j вазах (1 от 1 до F,
j от 1 до V ):
7
5
-21
Начнем со случая, когда букет ровно 1 (азалии). Тогда для заданного количества ваз
нужно просто выбрать лучшую: если ваза одна (первая) — то это она и есть (эстети-
ческая характеристика равна 7), а для всех остальных количеств ваз (2, 3, 4, 5) —
лучше всего поставить этот букет во 2-ю.
Итак, имеем:
7 23 -5 -24 16 7 23 23 23 23
5 21 -4 10 23 х х х х х
-21 5 -4 -20 20 х х х х х
-20 20 х х х х х
Кроме того, очевидно, что если букетов ровно столько же, сколько ваз, то един-
ственный возможный вариант — ставить букет в вазу с таким же номером и затем
складывать соответствующие величины:
7 23 -5 -24
5 21 -4 10
-21 5 -4 -20
16 7 23 23 23 23
23 х 28 х х х
20 х х 24 х х
134
Глава 2. Основы алгоритмизации
Элементы ниже главной диагонали, очевидно, равны нулю (если букетов больше,
чем ваз). Но по условиям задачи всегда обеспечивается количество ваз большее,
чем количество букетов. Поэтому эту часть массива можно не заполнять.
Остальные элементы (выше главной диагонали) логично строить следующим об-
разом: г[2,3] — оптимальное размещение 2 букетов в 3 вазах.
Если мы 2-й букет поставим в 3-ю вазу, то суммарная оценка будет равна:
а[2,3] + г[1,2] --4 + 23 - 19.
Оставшийся один букет можно оптимально разместить в первых двух вазах.
Если мы не ставим 2-й букет в 3-ю вазу, то оптимальное размещение остается преж-
ним, как и оптимальная оценка г[ 2,2] - 28 (размещение 2 букетов в 2 вазах).
По условиям задачи мы должны выбрать лучший вариант — 28.
Получаем:
7 23 -5 -24
5 21 -4 10
-21 5 -4 -20
16 7 23 23 23 23
23 х 28 28 х х
20 х х 24 х х
Аналогично
r[2,4] - max (г[2,3],а[2,4] + г[ 1,3]) - тах(28,10 + 23) - 33.
7 23 -5 -24 16 7 23 23 23 23
5 21 -4 10 23 х 28 28 33 х
-21 5 -4 -20 20 х х 24 х х
Далее:
г[2,5] - max (г[2,4],а[2,5] + г[ 1,4]) - тах(33,23 + 23) - 46.
7 23 -5 -24 16 7 23 23 23 23
5 21 -4 10 23 х 28 28 33 46
-21 5 -4 -20 20 х х 24 х х
r[3,4] - max (г[3,3],а[3,4] + г[2,3]) = max(24,-20 + 28) -24.
7 23 -5 -24 16 7 23 23 23 23
5 21 -4 10 23 х 28 28 33 46
-21 5 -4 -20 20 х х 24 24 х
Наконец:
г[3,5] - max (г[3,4],а[3,5] + г[2,4]) = тах(24,20 + 33) - 53.
7 23 -5 -24 16 7 23 23 23 23
5 21 -4 10 23 х 28 28 33 46
-21 5 -4 -20 20 х х 24 24 53
2.3. Рекуррентные соотношения
135
г [3,5] - 53 — это и есть искомый ответ.
Теперь запишем соответствующие формальные соотношения в общем виде.
Вводим исходные данные:
□ F — количество букетов;
□ V — количество ваз;
□ a[i,j ] — эстетическая характеристика букета 1 в вазе j.
'assign (input.’flower.inp'): reset(input):
read(f.v):
for i:=l to f do
for j:-l to v do read (a[1.j]):
close (input):
Мы знаем, что r[i,j ] — оценка наилучшего размещения 1 букетов в j вазах (1 от 1
до F, j от 1 до V). Тогда:
□ г[1,1]-а[1,1] — один букет в одной вазе — единственное размещение;
□ г[1,1] = г[1-1,1-1] + a[i,i] - 1 букетов в i вазах— единственное размещение
(i-й букет в i-ю вазу);
□ г[ 1,1] = max из а[ 1,1 ], а[1,2],.... а[ 1,1] — если букет один, а ваз несколько, ставим
его в наилучшую для него вазу.
И наконец, общий случай для всех остальных i,j:
r[i,j] = max(r[i,j-1],a[i,j]+r[i-1,j-1]).
То есть оптимальное размещение 1 букетов в j вазах равно лучшему из следующих
размещений:
1. оптимальное старое размещение (1 букетов в ] -1-й вазе);
2. последний букет ставим в новую вазу (с номером ]) и оптимально размешаем
1 - 1-й оставшийся букет в j - 1-х оставшихся вазах.
В программе эта запись примет вид:
г[1.1]:=а[1.1]: {букетов}
for i:-2 to f do r[i.i]:-r[i-l.i-l]+a[i.1J: {сколько и ваз}
Rmax:-a[l.l]: {Один букет}
for 1:-1 to v do
if a[l.i]>Rmax then Rmax:-a[l.i):
R[l.i]:-Rmax
end:
for i:=2 to f do {Общий случай}
for j:-i+l to v do
r[i.j]:-max(r[i.j-l].a[i.j]+r[i-l.j-1]):
Теперь r[f ,v] содержит оценку наилучшего размещения F букетов в V вазах. Одна-
ко по условиям задачи необходимо вывести еще номера ваз, в которые мы поста-
вили букеты. Обратимся еще раз к построенной таблице r[i,j ]:
136
Глава 2. Основы алгоритмизации
7 23 23 23 23
х 28 28 33 46
х х 24 24 53
Восстановим по ней номера ваз, в которые мы ставили букеты для оптимального
размещения. Рассмотрим последнюю строку: наибольшее число в ней — 53, и оно
встречается только в 5-м столбце. Следовательно, последний (3-й) букет мы по-
ставили в 5-ю вазу.
Для того чтобы узнать, в какую вазу попал предыдущий букет (2-й), рассмотрим
предыдущую(2-ю) строку. 5-я ваза уже содержит букет (3-й). Поэтому будем рас-
сматривать таблицу, начиная с4-го столбца (соответствующего 4-й вазе). Наиболь-
шее из оставшихся чисел — 33 — находится в 4-м столбце. "Следовательно, 2-й бу-
кет мы поставили в 4-ю вазу.
Чтобы выяснить, в какую вазу поставили предыдущий (1-й) букет вновь подни-
маемся на строку вверх. Рассмотрим первую строку, начиная с 3-го столбца (4-я и 5-я
вазы уже заняты). Максимальное Числов 1-й строке — 23. Но оно находится и в 3-м
и во 2-м столбцах. Мы должны из них выбрать столбец с наименьшим номером
(то есть 2-й). Итак, букеты были поставлены в вазы с номерами: 2,4 и 5.
Таким образом, для восстановления номеров использованных ваз достаточно в
каждой строке, начиная с последней, находить номер столбца, в котором впервые
встретилось максимальное число — j r[i]. Это и будет номер вазы, в которую по-
ставили i-й букет в оптимальном размещении.
jrrf+l]:-vH:
for i:-f downto 1 do
k:-jr[1+l]-l: rmax:-r(1.k]:
for j:-v downto 1 do
if r[i.j]-rmax then k:-j:
jr[i]:-k:
И наконец, вывод результата в соответствии с требованиями задачи:
assign (output.'flower.out'): rewrite(output):
writeln(r[f.v]):
write <jr[lj):
for 1:- 2 to f do write (' '.MH):
writeln:
close(output):
Полный текст программы — в листинге 2.23.
Листинг 2.23. Решение задачи "Цветочный магазинчик»
program io99dlt2:
var
f.v.i.j.k : integer:
a.r : array [1..100.1..100] of integer:
jr : array [1..100] of integer:
Rmax : longint:
function max(a.b:longint):longint:
2.3. Рекуррентные соотношения
if a>b then nex-.-a else raax:=b:
end:
begin
assign (input.'flower.inp'): reset(input):
read(f.v);
for i:=l to f do
for j:-l to v do read (a[1.j]):
close (input):
rtl.lh-aCl.l]:
for i:-2 to f do r[i.i]:-r[1-l.i-l]*a[i.ij:
RmaX:-a[l.l];
for i:-l to v do
begin
if a[l.1]>ftnax then Rmax:=a[l.i]:
R[l.i]:-Rmax
end:
for i:-2 to f do
for j:-1+l to v do
r[i.j):-max(r[i.j-l].a[i.j>r[i-l.j-ll):
for 1:-f downto 1 do
begin
k:-jr[1+l]-l: rmax:-r[i.k]:
for j:-v downto 1 do
if r(i.j]-nnax then k:-j:
jr[i]:-k:
assign (output.'flower.out'): rewrite(output):
writeln(r[f,vj):
write (MU):
for i:- 2 to f do write (' ’.jr[i]):
writeln:
close(output):
Задача «Палиндром»
Белорусская республиканская олимпиада школьников по информатике, 1997 год.
День 1. Задача 2.
Вводится строка S. Необходимо удалить из нее минимальное количество симво-
лов так, чтобы получился палиндром (то есть строка символов, которая читается
слева направо и справа палево одинаково).
Строка S непустая, имеет длину не более 100 символов и состоит только из про-
писных латинских букв. Строка вводится из файла с именем INPUT.TXT. Длину полу-
чившегося палиндрома и сам палиндром нужно вывести в файл с именем OUTPUT.TXT
(1-я строка — длина палиндрома, 2-я строка — сам палиндром). Если палиндро-
мов несколько, то вывести требуется только один из них.
Пример:
□ INPUT.TXT
AS0DFSA 6
□ OUTPUT.TXT
ASFDDSA
Глава 2. Основы алгоритмизации
Рассмотрим 2 строки: исходную ASDDFSA и перевернутую ASFDDSA. Будем заполнять
двумерный массив K[i,j].
K[i,j ] — максимальная длина общей подстроки от начальной части из 1 символов
исходной строки и начальной части из j символов перевернутой строки.
Для данного примера массив, заполненный значениями рекуррентной величиной
K[i,j ], выглядит следующим образом:
00000000
0 1111111
0 1 2 2 2 2 2 2
0 1 2 2 2 3 3 3
0 1 2 3 3 4 4 4
0 1 2 3 3 4 4 4
0 1 2 3 3 4 5 5
0 1 2 3 3 4 5 6
Понятно, что K[0,i] и К[1,0] равны 0 для всех 1. То есть никакая строка не имеет
общих символов с пустой строкой.
Первая строка имеет все единицы, поскольку первые символы строк (А) совпали
и понятно, что строка длиной 1 не может иметь большую подстроку. И т.д., напри-
мер, К[ 5,6] = 4 означает, что подстрока длиной 5 (ASDDF) имеет со строкой длины 6
(ASFDDSA) максимальную общую подстроку длиной 4 (ASDD).
В общем случае K[i,j ] вычисляется рекуррентно так:
if sl[i]-s2[j]
then k[1.j]:4[i-l.j-l]+l
else k[1.j]:=max(k[1-l.j].k[i,J-l]):
Если i-й символ первой строки совпадает с j-м символом второй строки, то мы
увеличиваем на 1 количество совпавших символов в подстроках из 1 -1 символа в
первой строке и j-1 символа во второй строке. Иначе — выбираем максимальное
значение из ранее совпавших подстрок.
Длину максимальной совпавшей подстроки (длину палиндрома) определяет ве-
личина К[ L,L], где L — длина исходной строки.
Для вывода самой длинной подстроки мы также используем массив К[ 1,j ], восста-
навливая ее обратным движением.
Полный текст программы - в листинге 2.24.
Листинг 2.24. Решение задачи «Палиндром»
program by97slt2:
var
N.L.i.j: byte:
S.P.S1.S2 : str1ng[l00):
К : array [0..100.0..100] of byte:
function max(a.b:byte):byte:
begin
2.3.. Рекуррентные соотношения
139
if a>b then max:=a else max:=b:
end:
begin
assign(input.'input.txt'): reset(input):
assign(output.'output.txt'): rewrite(output):
readln(sl):
s2:-": L:= length(sl) :
for i:-l to I do s2:=sl[i]+s2:
for i:-0 to L do
begin k[0.i]:-0: k[i.0]:-0: end:
for 1:-1 to L do
for j:=l to L do
if sl[iJ-S2CJ3
then k[1.J]:-k£1-l.j-H*l
else k[1.J]:-™ax(k[1-l.j].k[i.j-i]):
writeln(K[L.L]l:
while (k[1’j]<>0) do
begin
while (k[1.j-l]-k[i.j]) do dec(j):
1f Sl[i]-S2[J]
then begin P:=Sl[i]*P: dec(j): end:
dec(i)
end:
writeln(P):
close(input): close(output):
end.
Рекуррентные соотношения с тремя и более
параметрами
В данном разделе приводятся задачи, для решения которых необходимо составить
рекуррентное соотношение с тремя или даже более параметрами. Это означает,
что вводимая рекуррентно-задаваемая величина зависит от трех или более аргу-
ментов.
Задача «Аудиосалон»
Беларусская республиканская олимпиада школьников по информатике, 1997 год.
2-й тур. Задача 2.
Во время трансляции концерта «Старые песни о главном — 3» предприниматель К
решил сделать бизнес на производстве кассет. Он имеет М кассет с длительностью
звучания D каждая и хочет записать на них максимальное число песен. Эти песни
(их общее количество N) передаются в порядке 1,2.N и имеют заранее извест-
ные ему длительности звучания 1(1), 1(2),..., £(ЛГ). Предприниматель может вы-
полнять одно из следующих действий.
1. Записать очередную песню на кассету (если она туда помещается) или пропус-
тить ее.
2. Если песня на кассету не помещается, то можно пропустить песню или начать
ее записывать на новую кассету. При этом старая кассета откладывается, и туда
уже ничего не может быть записано.
140 Глава 2. Основы алгоритмизации
Определить максимальное количество песен, которые предприниматель может
записать на кассеты.
Входные данные записаны в файле KASS.DAT следующим образом: в первой строке
файла находятся числа N, М и D. Начиная со второй строки находятся числа L( 1),
L(2) L<N) (по одному в строке). Все числа — натуральные.
Ответ выводится в файл с именем KASS.OUT.
Например:
□ KASS.DAT
6 2 7
5
2
2
□ KASS.OUT
5
В примере имеется 6 песен с длительностями звучания 5, 2, 2,4,2,3. Требуется
записать максимальное количество из них на 2 кассеты длительностью звуча-
ния по 7.
Введем и будем рассчитывать рекуррентную величину от трех параметров: но-
мера песни, номера кассеты и единицы длительности звучания (минуты — для
определенности) R[p,k,t]. R[p,k,t ] — максимальное количество из первых р пе-
сен, которое можно записать на к кассет, до минуты t на k-й кассете включи-
тельно.
Очевидно, что ответ будет содержаться в R[ N,M,D ]. Понятно также, что начальные
значения R[O,i,j ] равны 0 для всех i и j.
Посмотрим, как заполняется этот массив R при переходе от Р-1-й песни к песне с
номером Р.
□ Р = 0
0000000
0000000
□ Р-1 0000111
□ L[1]-5 1111111
1-ю песню записываем на кассету с 1-й минуты. Эта песня имеет длительность 5.
Поэтому ее запись закончится на 5-й минуте. И это означает, что начиная с 5-й
минуты 1-й кассеты мы можем на данное множество кассет записать 1 песню из
предъявленной 1 песни.
Теперь записываем следующую песню:
□ Р=2 0111112
□ Ц2]-2 2222222
Начиная со 2-й минуты 1-й кассеты можно записать 1 песню из представленных
(если первую песню пропускать, а сразу от начала писать вторую песню). А начи-
2.3. Рекуррентные соотношения
141
ная с 7-й минуты 1 -й кассеты можно записать 2 песни из представленных 2 (с 1-й
по 5-ю минуту будет записана 1-я песня, а с 6-й по 7-ю — 2-я песня).
□ Р = 3 0 1 12222
□ L[3]-2 2333333
Начиная с 4-й минуты 1-й кассеты мы можем записать 2 песни (2-ю и 3-ю зву-
чанием по 2 минуты каждая), а начиная со 2-й минуты 2-й кассеты можем запи-
сать 3 песни (5 + 2 — на 1-ю кассету и 2 — на 2-ю) и т. д.
Очевидно, что при попытке обработать очередную песню мы либо не изменяем
значение элемента массива, либо добавляем к нему 1. Единицу мы добавляем в
том случае, если песня помешается на кассету от начала до текущей минуты (вклю-
чительно).
С учетом всех нюансов рекуррентное соотношение выглядит следующим обра-
if t-L[p]>=0
then R[p.k.t]:-max(R[p-l.k.t-l[p]]+l.R[p-l.k.t])
else R[p.k,t]:=nBX(R[p.k-l.D],R[p-l.k.t]);
Если текущая песня помещается на текущую кассету до кинуты Т
(включая эту минуту Т).
то максимальное количество песен из предъявленных Р песен,
которое нохно записать на К кассет до минуты Т (включит.).
равно максимуму из количества песен, которые удалось
записать до этого места при записи Р-1 песни, и
увеличенного на 1 количества песен, которые удалось
записать до минут T-L1P] включительно
иначе (если текущая песня не помещается на текущую кассету
до минуты Т включительно)
максимальное количество песен будет равно максимуму из
количества песен, которые удалось записать до этого места
при записи Р-1 песни, и количества песен, которое удалось
записать до последней минуты звучания предыдущей кассеты.
Полный текст программы решения задачи — в листинге 2.25.
Листинг 2.25. Решение задачи Аудиосалон-
program by97s2t2:
var
R : array [0..40.0..10.0..60] of byte:
L : array [1..40] of longint:
i.p.k.t.N.H.D : longint:
function max(a.b:longint):long1nt:
if a>b then max:-a else max:=b
end:
begin
assign (input,'kass.dat'): reset(input):
assign!output.'kass.out'): rewrlte(output):
read(N.H.D):
for i:-l to N do read(L[i]):
for k:-l to M do
продолжение i2
Глава 2. Основы алгоритмизации
Листинг 2.25 (продолжение)
for t:-0 to D do R[0.k,t]:-0:
for p:-l to N do
for k:-l to M do
for t:-0 to 0 do
if t-L[p]>-0
then R[p.k.t]:-max(R[p-l.k.t-L[p]]+l.R[p-l.k.t])
else R[p.k.t]:*max(R[p.k-l.O].R[p-l.k.t]):
writeln(R[N,H.D]):
close(input): close(output):
Внимательный читатель, очевидно, заметил, что на самом деле нам нет необходи-
мости хранить весь трехмерный массив в памяти: достаточно хранить только две
его компоненты — «слой» (предыдущая и новая песня). Поэтому можно объявить
массив R следующим образом:
R : array [0..1.0..100.0..100] of byte:
А для переключения «слоев» использовать две переменные: рО (индексирует пре-
дыдущий слой) и р1 (индексирует новый слой).
Тогда расчетная часть программы изменится следующим образом:
р0:-0: р1:-1:
for р:-1 to N do
begin
for k:-l to M do
for t:-0 to D do
if t-L[p]>-0
then R[pl.k.t]:-max(R[pO,k.t-L[p]]*l.R[pO,k.t])
else R[pl.k.t]:-max(R[pl,k-l.D].R[pO.k.t]):
pO:-l-pO: pl:-l-pl:
end:
wri teln(max(R[0.M.0],R[1.M.D])):
А вся программа будет выглядеть так, как показано в листинге 2.26.
Листинг 2.26. Решение задачи “Аудиосалон- (другой вариант)
program by97s2t2:
: array [0..1.0..100.0..100] of byte:
: array [1..40] of longint:
function max(a.b:longint):longint:
if a»b then max:-a else max:-b
assign (input.'kass.daf): reset(input):
assignCoutput.'kass.ouf): rewrite(output):
read(N.M.O);
for 1:-1 to N do read(L[1]):
2.3. Рекуррентные соотношения
143
for k:-l to M do
for t:-0 to 0 do
if t-L[p]>-0
then R[pl.k.t]:4nax(R[pO.k.t-L[p)]*l.R[pO.k.t])
else R[pl.k.t]:4WX(R[pl.k-1.0J.R[p0.k.t]):
pO:-l-pO: pl:*l-pl:
end:
wr1teln(max(R[0.M.D].R[l.M,D])):
closetinput): close(output):
Задача «Лабиринт»
Четвертьфинал чемпионата мира АСМ по программированию для студентов. Цен-
тральный регион России. 5-6 октября 1999 года.
Карта лабиринта представляет собой квадратное поле размером MxN. Некоторые
квадраты этого поля запрещены для прохождения. Шаг в лабиринте — перемеще-
ние из одной разрешенной клетки к другой разрешенной клетке, смежной с пер-
вой по стороне. Путь — это некоторая последовательность таких шагов. Требуется
подсчитать количество различных путей из клетки (1,1) в клетку (N, П) ровно за К
шагов (то есть оказаться в клетке (N, М) после К-го шага). Каждую клетку, вклю-
чая начальную и конечную, можно посещать несколько раз. Начальная и конечная
клетки всегда разрешены для прохождения.
Ограничения: 1 < N < 20,0 < К < 50.
Первая строка входного файла INPUT.TXT состоит всего из двух чисел: N и К, разде-
ленных одним или более пробелами. Следующие N строк, по N символов в каждой,
содержат карту лабиринта, начиная с клетки (1,1). Символ «0» означает не запре-
щенную для прохождения клетку, а символ «1» — запрещенную.
Выходной файл OUTPUT.TXT содержит результат — количество возможных различ-
ных путей длины К.
Время на тест — 15 секунд.
Рассмотрим два примера:
1. INPUT.TXT
000
101
100
OUTPUT.TXT
2. INPUT.TXT
000
111
000
OUTPUT.TXT
144
Глава 2. Основы алгоритмизации
Будем составлять рекуррентное соотношение для величины А[ k,i J ] — количества
способов попасть в клетку (i,j) ровно за к ходов. Понятно, что за 0 ходов можно
попасть только в клетку (1,1). Следовательно, А[0,1,1 ] = 1 и A[O,i,j ] = 0 для всех i и j.
На ходу к в клетку (1, j) по правилам, установленным в задаче, можно попасть (если
она не запрещена для прохождения) только из соседних клеток: (1-1, j), (i+1, j),
(i,j-l),(i, j+1).
Общее количество способов попасть в данную клетку после хода к будет равно
сумме количеств ходов попасть в соседние клетки на предыдущем (к-1)-м ходу,
или 0, если клетка запрещена для прохождения.
Легко подсчитать, что для хранения всех значений рекуррентной величины A[k,i,j ]
требуется 50 * 20 » 20 - 20 000 элементов. Даже 20 000 элементов типа integer не
могут поместиться в статической памяти Турбо Паскаля. Поэтому будем хранить
только реально необходимые два последних слоя.
Полное решение задачи — в листинге 2.27.
Листинг 2.27. Программа «Лабиринт-
(SRt.Nt.Et)
program nee4c99g:
var
А : array [0..1.0..20.0..20] of comp:
c : array [1..20.1..20] of char:
N.K.i.j.kO.kl.m : longint:
begin
ass ign(i nput.'i nput.txt'): reset(input):
assignloutput.'output.txt'): rewrlte(output):
readln(N.K):
for i:-l to N do
for j:-l to N do read(c[i.j]): {Лабиринт)
readln:
end:
for i:-l to N do
for j:-l to N do A[0,i.j]:-0:
for i:-l to N do A[0.0,i]:-0:
for i:-l to N do A[0.i.0]:-0:
A[0.1.1]:-l:
K0:-0: Kl:-1:
for m:-l to К do
for 1:-l to N do
for j:-l to N do
If C[i.j]-'0'
then A[Kl.i,j]:-A[K0,1.j-1] т A[K0,1-l.j] +
A[K0.i.jTl] т A[K0.1+l.j]
else A[Kl.1.j]:-0:
KO:-l-kO: Kl:-l-kl:
if Kl-1
then writeln(A[0.N,N]:0:0)
else writeln(A[l.N.N]:0:0):
close(input): close(output):
2.3. Рекуррентные соотношения
145
ПРИМЕЧАНИЕ-----------------------------------------------------
К сожалению, при ограничениях, приведенных в задаче, количество искомых вариан-
тов может превысить число, помещающееся в величине типа comp. То есть полное
решение задачи требует еще реализации «длинного» сложения. Оставляем это в ка-
честве упражнения всем желающим.
Задача «Юбилей»
Беларусская республиканская олимпиада школьников по информатике, 1998 год.
День 1. Задача 2.
В связи с открытием олимпиады-98 по информатике в Могилеве Wчеловек (N< 10)
решили устроить вечеринку. Для проведения вечеринки достаточно купить MF бу-
тылок фанты, МВ бананов и МС тортов. Требуется определить минимальный взнос
участника вечеринки. Надо учесть, что при покупке определенных наборов товара
действуют правила оптовой торговли: стоимость набора товара может отличаться
от суммарной стоимости отдельных частей.
Написать программу, которая по входным данным определяет минимальный взнос
участника вечеринки. Входные данные находятся в текстовом файле с именем
PART.IN и имеют следующий формат:
□ в первой строке находятся числа N (количество человек, N £10) и И (количество
возможных наборов, <100 000);
□ в каждой из следующих М строк находятся 4 числа: F, В, С (количество бутылок
фанты, штук бананов и тортов в наборе, 0 < F, В, С < 1000) и S (стоимость набора,
S < 100 000);
□ в последней строке находятся числа MF, МВ и МС (MF, mb, MF < 9).
Выходные данные должны находиться в текстовом файле с именем PART.OUT и со-
держать число V — минимальный взнос участника.
Итак, наша задача состоит в том, чтобы с учетом всех скидок сформировать массив
0[0..9,0..9,0..9], где 0[ f ,b,c] — минимальная стоимость приобретения f бутылок фан-
ты, b бананов и с тортов.
Прежде всего разберемся с исходными данными: в условиях сказано, что на вводе ски-
док может быть < 100 000. Но известно, что на вечеринку нужно не более 9 товаров
каждого вида, то есть все скидки можно хранить в sk[f,b,c] — массиве минимальных
скидок на приобретение f бутылок фанты, b бананов и с тортов. Ввод скидок можно
осуществить, вначале прописав массивы 0 и sk значением maxlongint:
for il:-0 to 9 do
for 12:-0 to 9 do
for 13:-0 to 9 do
begin
O[il.i2.13]:naxlong1nt:
sk£11.12.13]:-maxlongint:
end:
Если ничего не покупаешь, то ничего и не тратишь, поэтому обнуляем элемент
о[0,0,0], то есть:
о[0.0.0]:-0:
146
Глава 2. Основы алгоритмизации
Теперь вводим очередную из 100 000 скидок и с ее помощью формируем очеред-
ной элемент в массиве sk. При этом если в скидке фигурирует число (бутылок
фанты, бананов или тортов) больше 9, то мы его заменяем на 9. А в массив sk зано-
сим соответствующую стоимость, только если она меньше той, которая уже про-
писана в массиве.на этой позиции (то есть только если новая скидка лучше ста-
рой).
assign (input.'part.in'): reset(input):
assign (output.'part.out'): rewrite(output):
read(n.m);
for i:-l to m do
read (f.b.c.s):
if f>9 then f:-9:
if b>9 then b:-9:
if c>9 then c:-9:
if sk[f.b.c]>s then sk[f.b.c]:-s:
end:
read(mf.mb.mc):
Теперь нужно, пользуясь массивом скидок SK, рекуррентно сформировать массив 0,
учитывая следующие соображения.
1. Пусть мы имеем оптимальное значение стоимости — о[11,12,13] — приобрете-
ния ровно 11 бутылок фанты, 12 бананов, 13 тортов и имеем скидку S для f бу-
тылок фанты, b бананов, с тортов. Тогда мы можем построить оптимальную стои-
мость для приобретения 11 + f бутылок фанты, 12 + b бананов и 13 + с тортов
как минимальную из о[ i 1+f,12+b,i3+c] и s + о[ 11,12,13].
2. Каждое из чисел 11 + f, 12 + Ь, 13 + с может оказаться больше 9, поэтому мы их
заменяем в этом случае на 9 (в условиях задачи оговорено, что мы можем ку-
пить не менее товаров, чем нам нужно, главное — чтобы по наименьшей стои-
мости).
3. Мы должны применить каждую реальную (не равную maxlongint) скидку из
массива исходных скидок sk к каждой реальной (не равной maxlongint) стоимо-
сти из массива 0.
for f:-0 to 9 do
for b:-0 to 9 do
for c:-0 to 9 do
begin
s:-sk[f.b.cj:
if s=maxlongint then continue:
for 1l:-0 to 9 do
for 12:-0 to 9 do
for 13:-0 to 9 do
begin
if il+f>9 then ilf:-9 else ilf:-il+f:
if 12+b>9 then 12b:-9 else 12b:-12+b:
if i3+c>9 then 13c:-9 else 13c:-13*c:
if (o[il.12.13]oiwxlongint) and
(o[11f.i2b.i3c]> s+ o[il.12.13])
then oCilf.12b.13c3:- st oCil.12.i3]:
end;
2.3. Рекуррентные соотношения
147
ПРИМЕЧАНИЕ--------------------------------------------------
Напомним, что оператор CONTINUE обозначает взятие следующего значения пере-
менной цикла.
Теперь нам осталось найти минимальный элемент части массива оптимальных ски-
док 0[mf ,.9,mb..9,mc..9 ], где mf, mb, me — исходные величины, обозначающие минималь-
ное количество соответствующих продуктов, которое необходимо для вечеринки,
и поделить его на количество участников.
min:-maxlongint:
if o[il.12.i3]<min then min:-o[il,12,13]:
res:-min div n:
И последний штрих: автор задачи В. М. Котов проверял на внимательность участ-
ников олимпиады, указывая в задаче место проведения вечеринки (Могилев). Так
• он намекал, что деньги нужно использовать белорусские, а в то время в белорус-
ских деньгах в обороте не было купюр достоинством меньше сотенных. Значит,
результат нужно округлять до сотен:
res :• trunctmin div (п*100))*100: (округление)
if mln mod (n*100) > 0 then res:-res+100: (до сотен)
Полный текст программы приводится в листинге 2.28.
Листинг 2.28. Программа -Юбилей»
program by98dlt2:
var
il.i2.13. mf.nt.mc.ilf.12b.i3c : byte:
o.sk ; array [0..9.0..9.0..9] of longint:
m.n.f.b.c.s.i.min.res : longint:
for il:=0 to 9 do
•for i2:-0 to 9 do
for 13:-0 to 9 do
o[il.i2.13]:-maxlongint:
Sk[1l.12.i3]:-maxlongint:
end:
O[0.0.0]:-0;
assign (input.'part.in'): reset(input):
assign (output.'part.out'): rewrite(output):
read(n.m):
for 1:-1 to m do
begin
read (f.b.c.s):
if f>9 then f:=9:
if b>9 then b:-9:
if c>9 then c:-9;
if sk[f.b.c]>s then sk[f.b.c]:-s:
end:
for f:-0 to 9 do
for b:=0 to 9 do
продолжение£
148
Глава 2. Основы алгоритмизации
Листинг 2.28 (продолжение)
for с:=0 to 9 do
begin
s:-sk[f.b.c):
if s=maxlongint then continue:
for il:-0 to 9 do
for 12:-0 to 9 do
for 13:-0 to 9 do
begin
if il*f>9 then ilf:-9 else ilf:-il+f:
if i2*t»9 then i2b:-9 else 12b:=12*b:
if 13*c>9 then 13c:-9 else i3c:-13*c:
if (o[11.i2.i3]omaxlongint) and
(o[ilf,12b,13c> s+ otil.12.13])
then oCilf.12b.13c3:- s+ o[1l.12.133:
end:
end:
read(mf.nt.mc):
min:-maxlong1nt:
for il:-mf to 9 do
for 12:-mb to 9 do
for 13:нпс to 9 do
if o[il.i2.13]<min then min:>o[il.12.13]:
res :- trune(min div (n*100))*100: {округление}
if min mod (n*100) > 0 then res:-res*100: (до сотен)
writeln(res):
close(input): close(output):
Задача «Торговые скидки»
101'95 — 7-я Международная олимпиада по информатике (Голландия). День 1.
Задача 2.
В магазине каждый товар имеет цену. Например, цена одного цветка — 2 ICU (ва-
лютные единицы информатики), а цена одной вазы — 5ICU. Чтобы привлечь боль-
ше покупателей, магазин ввел скидки, заключающиеся в том, чтобы продавать на-
бор одинаковых или разных товаров по сниженной цене. Например: три цветка за
5ICU вместо 6 или две вазы вместе с одним цветком за 10 ICU вместо 12.
Напишите программу, вычисляющую наименьшую цену, которую покупатель дол-
жен заплатить заданные покупки. Оптимальное решение должно быть получено
посредством учета скидок. Набор товаров, который требуется купить, нельзя до-
полнять ничем, даже если бы это снизило общую стоимость набора. Для описан-
ных выше цен и скидок наименьшая цена за 3 цветка и 2 вазы равна 14ICU: 2 вазы
и 1 цветок продаются по сниженной цене за 10ICU, а 2 цветка — по обычной цене
3a4ICU.
Входные данные содержаться в двух файлах: INPUT.TXT и OFFER.TXT. Первый файл
описывает покупки («корзину с покупками»). Второй файл описывает скидки.
В обоих файлах содержатся только целые числа. Первая строка файла INPUT.TXT
содержит количество b различных видов товара в корзине (0 < Ь.< 5). Каждая из
следующих b строк содержит значения с, к и р. Значение с — уникальный код то-
вара (1 < с < 999). Значение к задает, сколько единиц товара находится в корзине
2.3. Рекуррентные соотношения
(1 < к < 5). Значение р задает обычную (без скидок) цену единицы товара (12 Р < 999).
Обратите внимание, что общее количество товаров в корзине может быть не более
чем 5*5 “ 25 единиц.
Первая строка файла OFFER.TXT содержит количество s возможных скидок (0 2 s 2 99).
Каждая из следующих s строк описывает одну скидку, определяя набор товаров и
общую стоимость набора. Первое число п в такой строке определяет количество
различных видов товара в наборе (1 2 п 2 5). Следующие п пар чисел (с,к) указыва-
ют, что к единиц товара с кодом с включены в набор для скидки (1 < k<5,1 < с < 999).
Последнее число в строке р определяет уцененную стоимость набора (1 2 р 2 9999).
Стоимость набора меньше суммарной стоимости отдельных единиц товаров в наборе.
Выходной файл OUTPUT.TXT содержит одну строку с наименьшей возможной сум-
марной стоимостью покупок, заданных во входном файле.
Пример ввода и вывода:
□ INPUT.TXT
OFFER.TXT
OUTPUT.TXT
Итак, нам сказано, что товаров может быть не больше пяти видов и каждой единицы
товара не более 5 штук. Тогда исходные данные могут быть преобразованы к виду:
□
□
0[i,j] — комплекты возможных покупок;
I — номер возможного комплекта покупки (скидки);
J — номер товара;
о[ 1, j ] — количество единиц товара j, которое необходимо покупать при исполь-
зовании комплекта 1. i 2 количество товаров + количество скидок, j 2 5;
P[i] — стоимость i-ro комплекта из таблицы o[i,j ].
Например, для исходного примера 0[i,j ] и P[i] выглядят следующим образом:
□ 0[i,j]
P[i]
2 (соответствует строке) 7 3 2
30000
12000
10
□
Требуется найти минимальную стоимость покупки, определяемой м
где К[ 1 ] — количество товаров типа 1, которое нужно приобрести.
Для приведенного примера массив К имеет вид:
IKC1..5],
150
[лава 2. Основы алгоритмизации
Внимательный читатель может заметить, что мы перенумеровали товары от 1 до 5,
а в условиях задачи товары могут иметь любые номера. Это верно, но не более 5
различных номеров. 1-1 поскольку эти номера более нигде не функционируют, мож-
но перенумеровать товары практически сразу после ввода.
Мы вводим товары, которые нужно приобрести с[ i ], их количество k[ i ] и их базо-
вую цену р[1]:
a s s1gn(1nput.'input.txt'): reset(input):
read (b):
for i:-l to b do
begin
readln (c[i].k(i].p[i]):
for j:-l to 5 do o[i.j]:-0:
o[i.1]:-l:
end:
close(input):
Обратите внимание, что мы сразу формируем В строк в таблице 0. Покупки по ос-
новной цене могут участвовать так же, как и скидки!
Следующий этап — ввод скидок. При этом для каждой вводимой скидки мы по-
полняем новую строку с номером кр в массиве комплектов покупок 0 и добавляем
соответствующий элемент в массиве стоимости комплекта Р.
kp:-b:
assignfinput.'offer.txt'): reset(input):
read(s):
for i:-l to s do
read(n):
inc(kp):
for j:-l to 5 do o[kp.j]:-0:
for j:»l to n do
read (cs.ks):
O[kp.F(cs)J:-ks:
end:
read (p[kpj):
close(input):
Хитрость с номерами, которые на вводе могут быть разными (а нам нужно их пере-
вести в соответствующие числа от 1 до 5), «упрятана» в функцию F(cs). cs — это
номер, который мы ввели, a F(cs) — это соответствующий номер в диапазоне от 1
Function F(cs:byte):byte:
var i : byte:
begin
while (c[i]<>cs) do 1nc(i):
if i<-b
then F:-i
else begin writeln ('ошибка'): halt: end:
end:
2.3. Рекуррентные соотношения
151
Идеология этой функции проста: по условию нам известно, что все различные номе-
ра товаров должны быть введены еще при указании товаров, которые нужно купить.
Следовательно, массив с[ i ] содержит все возможные коды товаров. Поэтому каж-
дому из них соответствует свой номер от 1 до 5 в массиве с. Функция для заданного
в качестве параметра кода просто просматривает все элементы в массиве с и находит
его номер. Если такого нет, — это означает ошибку в исходных данных.
Итак, мы сформировали массивы:
□ 0[ 1, j ] — с пятью столбцами и kp - b + s строками, где b — количество товаров,
которые можно покупать, as — количество установленных магазином скидок;
□ P[i] —с kp элементами;
□ К[ 1 ] — с 5 элементами.
В условиях задачи подчеркнуто, что всего может быть не более 5 товаров и каждо-
го из них может быть куплено не более чем 5 единиц.
Введем функцию R[i1,i2,i3,i4,i5], определяющую оптимальную стоимость приоб-
ретения 11 товаров 1-го вида, 12 — 2-го вида, 13 — 3-го, 14 — 4-го и 15 товаров 5-го
вида. При этом 0 £ 11,12,13,14,15 < 5. Очевидно, что R[0,0,0,0,0] = 0, то есть если
ничего не покупать, то ничего и не надо платить.
for I4:=0 to 5 do
For -i:-l to kp do r[o[1.l].o[i.2].o[i.3].o[i.4].o[1.5]]:-p[i]:
Вначале мы установили для всех вариантов максимально возможную цену и обну-
лили стоимость «пустой покупки». А затем внесли стоимости покупок предметов
как по номинальной стоимости, так и с имеющимися скидками. Далее пересчита-
ем стоимость всех возможных вариантов покупок, используя все КР имеющихся
вариантов скидок.
for 1:-1 to kp do
for 15:-0 to 5 do
if (r[1l,12.i3,14.i5]omaxlong1nt)
then
if ((1l+o[1.lJ) in [0..5]) and
((12*0(1.2]) in [0..5]) and
((13+o[i.3]) in [0..5]) and
((14*o[i.4]) in [0..5]) and
((15*0(1.5]) in [0. .53) and
(r[il*o[1.l].12*o[i.2].13*0(1.3].14+0(1.4].15*0(1,5]]>
(r[1J * r[fl.12.13.14.15]))
then r[il*o[i.1].i2+o[i.2],13*o[i.3].14+o[1.4].15+0(1.5]]
p[i] * r(il.12.13.14.15]
152
Глава 2. Основы алгоритмизации
Если у нас есть набор товаров, который можно приобрести по оптимальной цене,
то на основе его .мы строим оптимальные стоимости всех покупок, которые можно
совершить, используя текущую скидку: о[ 1,1], о[1,2], о[i, 3], o[i, 4], о[i, 5]. При
этом единиц товара должно быть от 0 до 5, й новый вариант лучше, если получен-
ная стоимость меньше, чем та, что была рассчитана ранее.
И наконец, в качестве ответа мы выводим вычисленное значение г[к[ 1 ],к[2],к[3],
к[4],к[5]]:
assign(output.'output.txt'): rewrite(output):
writeln(r[k[l].k[2],k[3].k(4].к[5]]):
close(output):
Листинг 2.29. Программа -Торговые скидки-
program io95dlt2:
R : array (0..5.0..5.0..5.0..5.0..5] of longint:
о : array [1..104.1..5] of byte;
c.k array [1..104] of byte:
p : array [1..104] of longint:
b.i.j.kp.s.n.cs.ks.
11.12.13.14.15 : byte;
Function F(cs:byte):byte:
var 1 : byte:
begin
while (c[i]ocs) do inc(i):
if 1<-b
then F:-i
else begin writeln ('ошибка'): halt: end:
procedure ReadData:
assignfinput.'input.txt'); reset(input):
read (b):
for 1:-1 to b do
readln (c[i].k[1].p[i]):
for j:-l to 5 do o[1.J]:-0:
o[1.i]:-l:
end:
closednput):
kp:-b;
assigndnput. 'offer.txt'): resetdnput):
read(s):
for i:-l to s do
read(n):
inc(kp):
for j:-l to 5 do o[kp.J]:-0:
for J:-l to n do
begin read (cs.ks): 0[kp.F(cs)]:-ks: end:
read (p[kpl):
end:
closednput):
end:
2.3. Рекуррентные соотношения
153
ReadData:
for Il:=0 to 5 do
for I2:-0 to 5 do
for I3:=0 to 5 do
for 14:-0 to 5 do
for I5:-0 to 5 do r[il.12.13.14.153:-maxlong1nt:
r[0.0.0.0.0]:-0:
For i:-l to kp do г[о[1.’3.о[1.23.о[1.33.о[1.43.о[1.533:-р[13:
for 1:=1 to kp do
begin
for II:—0 to 5 do
for I2:-O to 5 do
for 13:—0 to 5 do
for I4:-0 to 5 do
for I5:-0 to 5 do
If (r[11.12.13.14,15]omaxlongint)
then
If ((il+oCi.13) in (0..53) and
((12+0(1.2]) in [0. .53) and
. ((13+0(1.33) in [0..5]) and
‘ ((14+0(1.43) in [0..53) and
((15+0(1.53) in CO..53) and
(r[1l+o[1.13.12+0(1,23.13+od.33.14+0(1.43.15+0(1,533>
(p(13+r[1l.12.13.14.153))
then r[1l+0Ci.13.12+0(1.23.13*0(1.33.14*0(1.43.15+0(1,533:-p(13 +
r[il.12.13.14.153
end:
ass1gn(output.'output.txt'): rewrite(output):
wr1teln(r[k[l3.k[23,k[33.k[43.k[533):
close(output):
end.
Общие приемы решения задач на рекуррентные
соотношения
Ранее в данной главе рассмотрено множество задач, для решения которых приду-
мывались рекуррентные соотношения. У некоторых читателей может сложиться
впечатление, что решение каждой такой задачи — это особое искусство. На самом
деле искусством является придумывание такого рекуррентного соотношения для
нового класса задач. Ниже приводятся классы задач, рассмотренные в данной гла-
ве. И тогда, распознав в предложенной вам задаче одну из типовых, можно просто
использовать соответствующее типовое рекуррентное соотношение.
Формирование всех возможных сумм
Допустим, у нас есть набор целых чисел (пусть их N штук со значениями L[ 1 ]) и
нам нужно построить все возможные варианты их сумм. Поступим следующим
образом: заведем одномерный массив (пусть — S[ j ]) с максимальным размером,
равным максимальной из возможных сумм (М — для определенности). Далее цик-
лом по всем имеющимся у нас числам L[i] последовательно модифицируем все
элементы массива S[ j ]:
154
Глава 2. Основы алгоритмизации
for j:-l to N do S[j]:-O:
for 1:-1 to N do
for j:-l to M-L[i] do
if then 5ЦЯП
В результате в массиве S будут стоять единицы на позициях, соответствующих
значениям сумм, которые можно составить из заданных чисел L[i ].
Вспомните, в каких из решенных выше задач в той или иной модификации ис-
пользовался этот прием? Да, верно — в задачах «Видеосалон» и «Аудиосалон». Я бы
добавил в этот список и все задачи о скидках: «Цветочный магазинчик», «Юби-
лей» и «Торговые скидки». Хотя формально там проводилось суммирование эле-
ментов не одномерных массивов, а трехмерных и даже — пятимерных (для послед-
ней задачи).
Восстановление оптимального пути
Если в задаче требуется вывести не только вычисленное оптимальное значение
рекуррентной величины, но и список элементов, обеспечивающих это оптималь-
ное значение, то требуется восстанавливать оптимальный путь. Это делалось в за-
даче «Цветочный магазинчик» (при восстановлении конкретного оптимального
распределения букетов по вазам) и в задаче «Палиндром» (при нахождении кон-
кретных символов из исходной строки, составляющих палиндром максимальной
длины). В обеих задачах пришлось обрабатывать составленные двумерные масси-
вы значений рекуррентных величин «от оптимальных значений к начальным»
(«снизу вверх» и «справа налево»), то есть в порядке, обратном порядку заполне-
ния массива.
Сокращение используемой памяти
Как было сказано вначале, иногда требуется сокращать размер памяти, занима-
емой массивом, хранящим значения рекуррентной величины. Так, при вычисле-
нии чисел Фибоначи мы вместо одномерного массива использовали три перемен-
ные. При решении задачи «Аудиосалон» мы вместо хранения трехмерного массива
всех песен R[0. .100,0. .100,0.. 100] (который и не может поместиться в статической
памяти Турбо Паскаля) хранили значения только двух «слоев»: R[0.. 1,0.. 100,0.. 100],
что потребовало в 50 раз меньше памяти! И наконец, для задачи «Видеосалон» мы
применили обработку одномерного массива S[ 1..100] «с конца», для того чтобы не
хранить две копии (то есть чтобы не превращатьего в двумерный массив S[0.. 1, 1.. 100]).
Рекурсивное вычисление рекуррентных соотношений
Проблему нехватки памяти для вычисления рекуррентных величин в некоторых
случаях можно решать, используя рекурсивные функции для вычисления рекур-
рентных величин, как это сделано в задаче «Отбор в разведку».
Рекуррентные соотношения на строках
Если нам требуется решать задачи на строках, то мы можем, как и в задаче «Па-
линдром», составить рекуррентное соотношение R[i,j] — с целью нахождения
2.4. Алгоритмы на графах
155
оптимального решения для i символов первой строки и j символов второй строки.
Если, например, нужно будет обрабатывать три строки, то будем рассматривать
рекуррентное соотношение от трех параметров: R[i,j,k], где к — первые k символов
третьей строки.
2.4. Алгоритмы на графах
Существует целый класс задач по программированию, которые для упрощения
решения могут быть переформулированы в терминах теории графов. Правда, это
требует владения определенным набором знаний, умений и навыков в области ал-
горитмов на графах.
ПРИМЕЧАНИЕ--------------------------------------------------
Теория графов содержит огромное количество определений, теорем и алгоритмов.
Поэтому излагаемый далее материал не может претендовать, и не претендует, на
полноту охвата. Однако, по мнению автора, предлагаемые сведения являются хо-
рошим компромиссом между объемом материала и его «коэффициентом полезно-
го действия» в практическом программировании и решении олимпиадных задач.
Необходимо отметить, что данный материал в существенной степени опирается
на наличие у обучаемого определенных навыков в использовании рекурсивных
функций и рекуррентных соотношений.
Дальнейшее изложение материала построено следующим образом: сначала при-
водится базовое количество теории, а после — решение большого количества за-
дач из белорусских республиканских и международных (IOI — International Olym-
piad in Informatics) олимпиад по информатике для школьников.
Автор рекомендует после ознакомления с общими сведениями разбор каждой но-
вой задачи проводить в таком порядке: прочитав условия, отложить материал в
сторону и попытаться решить задачу самостоятельно. Если же вам покажется, что
вы зашли в тупик и дальнейшие размышления не могут привести к полезному ре-
зультату, нужно возвратиться к материалу, прочитать полное решение и само-
стоятельно реализовать его на компьютере. Чем полнее и напряженнее будет про-
веденная вами работа над текущей задачей, тем больше шансов, что вы решите
следующую задачу самостоятельно.
Общие сведения об алгоритмах на графах
Прежде всего несколько слов о том, как возникает понятие графа из естественных
условий задач. Приведем несколько примеров.
□ Пусть мы имеем карту дорог, в которой для каждого города указано расстояние
до всех соседних с ним. Здесь два города называются соседними, если существу-
ет дорога, непосредственно их соединяющая.
□ Аналогично можно рассмотреть улицы и перекрестки внутри одного города.
Заметим, что могут быть улицы с односторонним движением.
□ Сеть компьютеров, соединенных проводными линиями связи.
156 Глава 2. Основы алгоритмизации
□ Набор слов, каждое из которых начинается на определенную букву и заканчи-
вается на эту же или другую букву.
□ Множество костей домино. Каждая кость имеет два числа — левую и правую
половину кости.
□ Устройство, состоящее из микросхем, соединенных друг с другом наборами
проводников.
□ Генеалогические древа, иллюстрирующиеродственныеотношення между людьми.
□ И наконец, собственно графы, указывающие отношения между какими-либо
абстрактными понятиями, например числами.
Итак, нестрого граф можно определить как набор вершин (города, перекрестки,
компьютеры, буквы, цифры на кости домино, микросхемы, люди и т. д.) и связей
между ними (дороги между городами; улицы между перекрестками; проводные
линии связи между компьютерами; слова, начинающиеся на одну букву и закан-
чивающиеся на другую или эту же букву; проводники, соединяющие микросхемы;
родственные отношения, например Алексей — сын Петра).
Двунаправленные связи (например, дорога с двусторонним движением) принято
называть ребрами графа-, а однонаправленные связи (дороги с односторонним дви-
жением) — дугами графа.
Граф, в котором вершины соединяются ребрами, принято называть неориентиро-
ванным графом, а граф, в котором хотя бы некоторые вершины соединяются дуга-
ми, — ориентированным графом.
Кратчайшие расстояния на графах
В качестве примера графа рассмотрим такой неориентированный граф с шестью
вершинами:
(1)--(3) (5)
(2)-(4) (6)
Графы можно задавать матрицей смежности. Например, для приведенного выше
графа матрица смежности G выглядит следующим образом:
0 110 0 0
10 0 10 0
10 0 10 0
0 110 0 0
0 0 0 0 0 1
0 0 0 0 1 0
- 1, если есть дуга из i-й вершины в j-ю, и Gs = 0 — в противном случае.
2.4. Алгоритмы на графах
157
Часто представляет интерес также и матрица достижимости графа, в которой Gj -1,
если существует путь по ребрам (дугам) исходного графа из вершины i в вершину/
Например, для графа из рассматриваемого примера матрица достижимости будет
иметь вид:
Граф называется взвешенным, если для его дуг вводятся веса (например, длины
дорог между городами).
Во взвешенном графе G,3 — вес дуги от вершины i к вершине j.
На взвешенных графах можно решать задачу нахождения кратчайшего расстоя-
ния между вершинами.
Простейший для реализации способ нахождения кратчайших расстояний от каж-
дой вершины к каждой — это метод Флойда:
for k:-l to N do
for 1:-l to N do
for j:-l to N do
G[i.j]:=m1n(G[i,j].G[i.k]+G[k,j]);
В результате выполнения этого алгоритма в G[ i,j ] сформируется кратчайшее рас-
стояние от вершины i до вершины j для всех пар вершин в графе. Заметим, что:
1) начальные значения G[i,j] для вершин i и j, между которыми в исходном гра-
фе нет дуги, необходимо инициализировать заведомо чрезвычайно большой
величиной GREAT, например так:
•for i:-l to N do
for j:-l to N do G[1.j]:=GREAT:
здесь GREAT — подходящая по смыслу константа; не рекомендуется использовать
maxlongint в качестве такой константы, поскольку при сложении может
возникнуть переполнение;
2) попутное свойство алгоритма Флойда — возможность построить матрицу до-
стижимости для исходного графа, поскольку если G[ 1, j ] осталось равным GREAT,
то это и означает, что вершина j недостижима из вершины 1;
3) алгоритм Флойда работает также и в том случае, когда некоторые из ребер ис-
ходного графа имеют отрицательные веса, но гарантировано, что в графе отсут-
ствуют циклы с отрицательным весом.
В случаях, когда требуется находить расстояние между двумя конкретными вер-
шинами или расстояние от конкретной вершины до всех остальных, можно для
ускорения работы и сокращения используемой памяти использовать несколько
более сложный метод Дейкстра (как в задачах «Пирамида Хеопса» и «Эх, дороги»).
158
Глава 2. Основы алгоритмизации
Задача «Маневры»
Республиканская олимпиада по информатике, 2000 год.
На территории некоторого государства с сильно пересеченной горной местностью
идут военные маневры между двумя противоборствующими сторонами: «Сини-
ми» и «Зелеными». Особенности ландшафта и сложные климатические условия
вынуждают подразделения обеих сторон размещаться только на территории неко-
торых населенных пунктов. Общее количество населенных пунктов в этом госу-
дарстве равно N.
Тактика ведения боевых действий «Синих» рассчитана па нанесение противнику бы-
стрых и внезапных ударов, что возможно лишь в том случае, если в операциях исполь-
зуются моторизованные части, а их передвижение происходит только по дорогам.
Разнообразие используемой боевой техники приводит к тому, что время переме-
щения различных боевых частей из одного пункта в другой оказывается различ-
ным и определяется величиной V] — скоростью движения подразделений боевой
части, расквартированной ву’-м населенном пункте.
Используя подавляющий перевес в технике, «Синие» планируют организовать
ночной налет на базы противника (под кодовым названием «Зеленые») и полно-
стью их разгромить. Все боевые подразделения «Синих» приступают к выполне-
нию операции одновременно. Если боевая часть «Синих» врывается в населенный
пункт, занятый «Зелеными», то, учитывая фактор внезапности, им удается полно-
стью разгромить эту группировку.
К сожалению, блестящему проведению этой операции помешало то обстоятель-
ство, что спустя время Тпосле начала операции «Зелеными» был осуществлен ра-
диоперехват сообщения о начавшейся операции. После радиоперехвата группиров-
ки «Зеленых» мгновенно рассеиваются в окрестных горах и остаются невредимыми.
Выясните, какое количество группировок противника и в каких населенных пунк-
тах «Синим» все-таки удастся разгромить «Зеленых».
Предполагается, что в начальный момент времени группировки «Зеленых» и «Си-
них» не могут находиться в одном и том же населенном пункте. Если сигнал трево-
ги поступает в тот момент, когда боевая часть «Синих» только врывается в насе-
ленный пункт, занятый «Зелеными», то, используя превосходное знание местности,
«Зеленым» все-таки удается скрыться в горах. Подавляющее превосходство в тех-
нике и живой силе позволяет боевым частям «Синих» организовать из каждой ча-
сти любое количество экспедиций для разгрома «Зеленых». Ничто не мешает одной
экспедиции за время проведения операции уничтожить несколько группировок.
Исходные данные задачи содержатся в файлах М AP.IN и TROOPS.IN. Структура фай-
ла MAP.IN описывает карту местности. В первой строке этого файла содержатся два
целых числа: N — количество населенных пунктов (0 < N < 256) и К — количество
дорог, соединяющих эти населенные пункты (0 < К < 1000). Дороги нигде не пере-
секаются. В последующих К строках файла содержится схема дорог. В каждой строке
записана пара двух натуральных чисел i и j и одно положительное вещественное
число Li j, означающее, что между населенными пунктами i и j существует дорога
длиной Lij километров (Lij < 1000).
2.4. Алгоритмы на графе
159
Содержимое файла TROOPS.IN отражает размещение боевых частей воюющих сто-
рон. Первая строка файла содержит число MF — количество боевых частей «Си-
них». Каждая из последующих HF строк содержат по два числа. Первое — целое
число j — номер населенного пункта, в котором размещается часть; второе — ве-
щественное неотрицательное число Vj — скорость движения боевых колонн этой
части в километрах в час (Vj < 110). Далее в отдельной строке файла записано
число МВ — количество боевых группировок «Зеленых», за которым перечислены
МВ чисел — номеров населенных пунктов, где эти группировки находятся. И нако-
нец, в последней строке файла хранится положительное вещественное число Т, из-
меренное в часах (Т < 24). Все числа в строках файлов разделены пробелами.
Результат решения задачи необходимо вывести в текстовый файл VICTORY.OUT.
В первую строку файла выводится количество разгромленных группировок, а во
вторую — номера населенных пунктов (в порядке возрастания), в которых эти груп-
пировки базировались.
Рассмотрим такой пример:
□ MAP.IN
1 2 80
2 4 25
4 5 10
6 2 5
2 3 40
7 6 10
8 7 15 '
□ TROOPS.IN
2
1 50
6 20
4' 4 5 3 8
. 2.0
□ VICTORY.OUT
Кратко алгоритм решения задачи может быть описан так: методом Флойда вычис-
ляем кратчайшие расстояния от каждой вершины до каждой. Циклом по всем вер-
шинам «Зеленых» и циклом по всем вершинам «Синих» смотрим: если «Синие»
успевают, то соответствующая группировка «Зеленых» разбита.
Рассмотрим решение задачи подробнее. Вначале — ввод исходных данных:
read(N.K): {Ввод количества пунктов и дорог)
for х:-1 to N do {Инициализация дорог для нетода)
{Флойда)
for у:-1 to N do а[х.уЗ:-ЮООООООООООО.О:
for i:-l to К do
begin
read(x.y.z):
a(x,y]:-z: a[y,x]:-z: {Корректировка матрицы смежности)
160
Глава 2. Основы алгоритмизации
read(NtmBlue): {Ввод расположения и скоростей)
{«Синих»)
for i:-l to NumBlue do read(Blue[1].VBlueCi]);
read(NunGreen): {Ввод расположения «Зеленых»)
for i:=l to NunGreen do read(Green[i]):
read(T): {Ввод вреиени проведения)
{операции).
Затем — расчет расстояний между всеми населенными пунктами методом Флойда:
for i:-l to N do
for х;-1 to N do
for y:-l to N do
a[x.y]:-min(a[x,y],a[x.i]+a[i.y] >:
Расчет количества уничтоженных группировок:
Deleted:-!):
for i:=l to NunGreen do {Для всех «Зеленых»)
for j:-l to NumBlue do {Для всех «Синих»)
if a[Green[i].Blue[J]]<Vblue[j]*T {Если «Синие» успеют)
then
begin
inc(Deleted); {Уничтоженных инкренентируен)
Num[Deleted]:-Green[i): {Номер заносим в Num)
break: {Переходим к следуояин «Зеленый»)
end:
Наконец, в соответствии с требованиями задачи сортируем номера уничтоженных
группировок (в массиве Num) и выводим их:
Sort:
writeln!Deleted):
for 1:-1 to Deleted do write(Num[1].' '):
ПРИМЕЧАНИЕ--------------------------------------------------
Размерность исходного графа уменьшена до 100х 100, поскольку 255x255 веще-
ственных чисел не помещается в статической памяти Турбо Паскаля,
Листинг 2.30. Программа "Маневры-
{SR+.E+.N+)
program by00dlm3:
а : array [1..100.1. .100] of single:
blue, green. Num : array [1..100] of longint:
Vblue : array [1..100] of real:
i.j.K.N.x.y.NumBlue.NunGreen.Deleted : longint:
function min(a.b:real):real:
if a<b then min:-a else min:-b
end:
procedure Sort:
for i:-l to Del eted-1 do
begin
x:-Num[i]: y:-1:
2,4. Алгоритмы на графах 161
for j:-i+l to Deleted do
if num[j]<x
then begin x:-Num[j]: y:-j; end:
Nim[y]:-Nun[i]: Num[i]:-x:
end:
assign(input.'map.in'): reset(input):
assignfoutput.'victory.out'): rewrite(output):
read(N.K):
for x:-l to N do
for y:-l to N do a[x.y]:-1000000000000.0:
for i:-l to К do
begin
read(x.y.z):
a[x,y]:=z: a[y.x]:-z:
end:
read(NumBlue):
for i:-l to NumBlue do read(Blue[i].VBlueCi]):
read(taGreen):
for i:-l to NumGreen do read<Green(i]):
read(T):
for 1:-1 to N do
for x:-l to N do
for y:-l to N do
a[x.y]:-mn(a[x.y].a[x.i]+a[i.y]):
Deleted:-0:
for 1:-1 to NurGreen db
for j:-l to NumBlue do
if a[Green[i].Blue[j]]<-Vblue[j]*T+0.00001
then
begin
inc(Del eted):
NumfOeleted]:-Green[i]:
end:
Sort:
writeln(Deleted):
for I:-l to Deleted do write(Num[i].' '):
close(input): close(output):
end.
Задача «Пирамида Хеопса»
Республиканская олимпиада по информатике, 1996 год.
Внутри пирамиды Хеопса есть N комнат, в которых установлены 2М модулей, со-
ставляющих М устройств, каждое из которых состоит из двух модулей, располага-
ющихся в разных комнатах, и предназначено для перемещения между парой ком-
нат, в которых установлены эти модули. Перемещение происходит за 0,5 условной
единицы времени. В начальный момент времени модули всех устройств переходят
в «подготовительный режим». Каждый из модулей имеет свой целочисленный
период времени, в течение которого он находится в «подготовительном режиме».
162
Глава 2. Основы алгоритмизации
По истечении этого времени модуль мгновенно «срабатывает», после чего опять пе-
реходит в «подготовительный режим». Устройством можно воспользоваться толь-
ко в тот момент, когда одновременно «срабатывают» оба его модуля.
Индиана Джонс сумел проникнуть в гробницу фараона (комната 1). Обследовав
ее, он включил устройства и собрался уходить, но в этот момент проснулся храни-
тель гробницы. Теперь Джонсу необходимо как можно быстрее попасть в комнату
Л', в которой находится выход из пирамиды. При этом из комнаты в комнату он
может попадать только при помощи устройств, так как проснувшийся хранитель
закрыл все двери в комнатах пирамиды.
Необходимо написать программу, которая получает на входе описания располо-
жения устройств и их характеристик, а выдает значение оптимального времени и
последовательность устройств, которыми надо воспользоваться, чтобы попасть из
комнаты 1 в комнату Уза это время.
Входной файл — input2.txt, выходной файл — output2.txt
Формат ввода (построчно):
□ М
□ R11T11R12T12
□ ...
□ RM1TM1RM2TM2
То есть вводятся следующие данные:
□ N (2 < N < 100) — количество комнат;
□ Н (Н < 100) — количество устройств;
□ R11 и R12 — номера комнат, в которых располагаются модули устройства 1;
□ Т11,Т12 (Т11,Т12 < 1000) — периоды времени, через которые срабатывают соот-
ветствующие модули.
В выходной файл выводится значение оптимального времени и последователь-
ность устройств, которыми необходимо воспользоваться для достижения нужно-
го результата.
Все числа — натуральные.
В качестве примера рассмотрим следующий:
□ input2.txt
5
15 3 2
112 1
2 5 3 5 ‘
4 4 3 2
3 5 4 5
□ output2.txt
2.4. Алгоритмы на графах
163
Представив комнаты вершинами, а пары устройств (с временами срабатывания) —
взвешенными дугами, можем применить алгоритм Дейкстра для поиска кратчай-
шего пути от первой вершины до последней. Точнее, алгоритм Дейкстра построит
кратчайшие пути от первой до всех остальных, но в данной задаче нас интересует
только кратчайший путь от первой до последней. Нужно учитывать, что дуги су-
ществуют только в моменты, кратные временам срабатывания.
Рассмотрим решение более подробно. Начнем с ввода исходных данных:
read(N.M): for I:-l to N do kG[i]:-O:
begin
read(rl.tl.r2,t2):
nok:= Ctl*t2> div Nod(tl.t2):
{nok - наименьшее общее кратное)
{Nod - наибольший общий делитель)
{чисел tl и t2)
inc(kG[rlJ): G[rl.kg[rl]]:-r2: P[rl.kg[rl]]:-nok:
inc(kG[r2J): G[r2.kg[r2]]:-rl: P[r2.kg[r2]]:-nok:
end:
Исходный граф (no условиям задачи) — неориентированный. Поэтому мы вводим
обе дуги. При этом граф представляется в виде списка дуг, смежных с текущей:
□ kG[ i ] — количество дуг из вершины 1;
□ G[ i,j ] — вершина, в которую из вершины 1 идет дуга с порядковым номером j;
□ Р[ 1>] ] — вес дуги из вершины i в вершину G[i,j ].
Для вычисления NOD используется функция, основанная на алгоритме Евклида:
function Nod <a.b:longint):longint:
Nod:=a:
end:
Затем проводится подготовка к выполнению алгоритма Дейкстра:
for i:-1 to N do {Для всех вершин)
Labl[i]:-FREE:
pred[i]:-l:
d[i]:=maxlongint:
Labl[i]:-DONE:
Pred[l]:-0:
for j:-l to kGEU do
{Помечаем как свободную)
{Предок - первая)
{Расстояние до первой - шах)
{Первая - обработана)
{Предок у первой - 0)
{Расстояние от первой до первой - 0}
{Для всех дуг из первого ребра)
{Расстояние до первой вершины)
{равно весу ребра + 0.5)
Заметим, что в последней строке к весу ребер добавляется 0,5, поскольку, по усло-
виям задачи, перемещение с помощью устройств из одной комнаты в другую зани-
мает 0,5 единицы времени.
Далее идет основной цикл алгоритма Дейкстра:
for 1:=1 to N-1 do
Поиск ближайшей к первой вершине из необработанных
164
Глава 2. Основы алгоритмизации
Пересчет кратчайших расстояний через ближайшую вершину до вершин,
смежных с ближайшей
Первый этап — поиск ближайшей к первой вершины из необработанных:
MinD:-maxlongint:
if (Labi[JO—FREE)
and (d[j]<MinD)
{MinD - шах)
(Для всех вершин)
(если вершина свободна)
(и расстояние от нее до первой)
(вершины меньше MinD)
then
MinD:^d[jl:
Bliz:-j
Labi[Blizi:-DONE:
{Заносим это расстояние в MinD)
(Вершину запоминаем как ближайшую)
{Найденную ближайшую помечаем)
(как обработанную)
Второй этап - пересчет кратчайших расстояний через ближайшую вершину до вер-
шин, смежных с ближайшей:
for j:-l to kG[Bliz] do
if (Labl[G[BliZ. JU-FREE)
{Для всех вершин смежных с)
(ближайшей)
{Если вершина еще не)
(обрабатывалась)
then
begin
NewTime:-Calculat(d[bliz].P[bliz.jl): {Вычислить)
(расстояние до нее)
(в терминах задачи - время)
(перемещения в нее)
(Если новое время лучше)
if d[G[Bliz.j]]> Newline +0.5
then
{заносим его в массив 0)
{указываем ближайшую как)
{предыдущую для текущей)
d[G[Bliz.j]]:- NewTime+0.5:
pred[G[B11z. JD:-Bliz:
При вычислении кратчайшего расстояния до текущей вершины через ближайшую
(в терминах алгоритма Дейкстра) или времени перемещения из первой комнаты
через ближайшую в текущую (в терминах данной задачи) используется функция
Caiculat (T.Tnok):
function Caiculat (T:single: Tnok:longint):longint:
var 1 : longint:
begin
TRes:-0:
while (T>TRes) do inc(TRes.Tnok):
Calculat:-TRes:
end:
Эта функция вычисляет время TRes (оно передается в вызывающую программу
непосредственно через имя функции Caiculat) — ближайшее большее текущего
времени Т (Т равно минимальному значению времени, которое потребовалось, чтобы
оптимальным образом добраться из первой вершины до ближайшей) и кратное
Tnok — периоду срабатывания пары устройств, связывающих комнаты Bliz (бли-
жайшая) и G[Bliz, j] (текущая).
2.4. Алгоритмы на графах
165
После выполнения алгоритма Дейкстра сформированы массивы:
□ d[ j ] — кратчайшее расстояние от начальной вершины до вершины j;
□ pred[ j ] — предок вершины j на оптимальном маршруте.
С учетом этой информации вывод результата осуществляется следующим обра-
tg:-N: i:=0;
while tgoO do
begin
inc(1);
path[i]:-tg:
tg:-predftg]:
end:
{Начиная с последней вершины)
{пока не закончились предшествующие)
{инкрементируем количество вериин в пути)
{Заносим текущую в массив пути)
{Переустанавливаем предыдущую)
writeln!’Оптимальное время: ',D[N]:O:1):
write!'искомая последовательность:'):
for j:-i-l downto 1 do write!' '.pathtj]):
Полный текст программы — в листинге 2.31.
Листинг 2.31. Программа «Пирамида Хеопса»
{SR+.E+.N+}
program by96dls2:
const
FREE-1:
DONE-2:
var
G : arrayil..100.1..100] of byte:
P : arrayil..100.1..100] of longint:
0 : arrayil..100] of single:
Labl.pred.kG : arrayil..100] of byte:
path : arrayil..100] of byte:
1s.tl.t2.nok.Tres,NewTime : longint:
i.J.x.y.A.B.C.N.M.tg.Bliz : byte:
rl,r2 : byte:
Yes : boolean;
MinD : single:
function Nod (a.b:long1nt):longint:
begin
while !a<>b) do
if a>b then a:-a-b else b:-b-a:
Nod:-a:
end:
function Calculat (T:single: Tnok:longint):longint:
var i : longint:
begin
TRes:-0:
while !T>TRes) do inc(Tres.Tnok):
Calculat:-TRes:
assigndnput.'1nput2.txt'): reset(input):
assigntoutput,'output2.txt'): rewrite(output):
read(N.H):
for I:-l to N do kG(i]:-0:
продолжение&
166
Глава 2. Основы алгоритмизации
Листинг 2.31 (продолжение)
for i:-1 to М do
begin
read(rl.tl.r2.t2): nok:- (tl*t2) div Hod(tl.tZ):
1nc(kG[rlJ); G[rl.kg[rl]]:*r2: P[rl.kg[rl]]:-nok:
inc(kG[r2]): G[r2.kg[r2]]:-rl: P[r2.kg[r2]]:-nok:
for i:-l to N do
begin
Labi[1]:-FREE: pred[i]:-l: d[i]:-maxlongint:
end:
Labl[l]:-OONE: Pred[l]:-0: d[l]:-0:
for j:-l to kG[l] do d[G[l.j]]:-P[l.j]+0.5:
for i:-l to N-1 do
MinD:-maxlongint:
for j:-l to N do
if (Labi[JI-FREE) and (d[j]<MinD)
then begin HinO:-d[J]: Bliz:-j end:
Labi[Bliz]:-DONE:
for J:-l to kG[BlizJ do
if (Labl[G[81iz.J]]-FREE)
then begin
NewTime:-Calculat(d[bliz].P[bl1z.j]):
if d[G[Bliz,j]]> NewTime +0.5
then begin
d[G[Bliz.j]]:- NewTime+0.5:
pred[G[Bliz.j]]:-Bliz:
tgf-N: i:-0:
while tg»0 do
begin 1nc(1): path[i]:-tg: tg:-pred[tg): end;
writeln('Оптимальное время: ’.D[N]:O:1):
write('искомая 'последовательность:'):
for j:-i-l downto 1 do writer '.path[JJ):
close(input): close(output):
Задача «Эх, дороги»
Республиканская олимпиада по информатике, 1998 год.
Имеется N городов, которые пронумерованы от 1 до N (где N — натуральное число,
1 < N < 100). Некоторые из них соединены двухсторонними дорогами, которые
пересекаются только в городах. Имеется два типа дорог — шоссейные и железные.
Для каждой дороги известна базовая стоимость проезда по ней.
Необходимо проехать из города А в город В, уплатив минимальную сумму за про-
езд. Стоимость проезда зависит от набора проезжаемых дорог и от способа проез-
да. Так, если вы подъехали к городу С по шоссейной (железной) дороге Х—>С и хо-
тите ехать дальше по дороге С—>У того же типа, то вы должны уплатить только
базовую стоимость проезда по дороге С—> Y. Если тип дороги С—> Yотличен от типа
дороги X—>С, то вы должны уплатить базовую стоимость проезда по дороге С—
плюс 10 % от базовой стоимости проезда по этой дороге (страховой взнос). При
2.4. Алгоритмы на графах
выезде из города А страховой взнос платится всегда. Написать программу, кото-
рая находит самый дешевый маршрут проезда в виде последовательности городов
и вычисляет стоимость проезда по этому маршруту.
Входные данные находятся в текстовом файле с именем TOUR.IN и имеют следую-
щий формат: в первой строке находится число N. Во второй строке — число М (ко-
личество дорог, М — натуральное и М < 1000); в каждой из следующих М строк нахо-
дятся четыре числа: х, у, t и р, разделенные пробелом, где х и у — номера городов,
которые соединяет дорога, т — тип дороги (0 — шоссейная, 1 — железная), ар —
базовая стоимость проезда по ней (р — вещественное, 0 < р < 1000). В последней
строке заданы номера начального и конечного городов А и В.
Выходные данные должны быть записаны в текстовый файл с именем T0UR.0UT
и иметь следующий формат: в первой строке находится число S — стоимость про-
езда по самому дешевому маршруту с точностью 2 знака после запятой. В каждой
из последующих строк, кроме последней, находится два числа — номер очередно-
го города в маршруте (начиная с города А) и тип дороги, по которой осуществляет-
ся выезд из этого города (0 или 1), разделенные пробелом. В последней строке
находится единственное число — номер города В.
Рассмотрим такой пример:
□
T0UR.IN:
Метод Дейкстра непосредственно (города — вершины) не может быть применен,
поскольку оптимальный маршрут может потребовать заезда в один и тот же город
два раза с целью меньше платить за страховой сбор на выезд из этого города.
Вводим 2 • N вершин (где N — число городов). То есть для каждого города — две
вершины: первая, если мы въехали в город по дороге типа 0, вторая — по дороге типа 1.
Теперь можно применять непосредственно метод Дейкстра для вычисления крат-
чайших расстояний от заданного города А до всех введенных вершин. Для конеч-
ного города В мы выбираем лучший из вариантов — заехать в В по дороге типа 0
или по дороге типа 1.
Метод Дейкстра позволяет последовательно сохранять все промежуточные вер-
шины в оптимальном маршруте, что необходимо для вывода полного ответа в за-
данном формате.
Рассмотрим решение задачи более подробно, основываясь на тексте программы-
решения. Ввод исходных данных осуществляется следующим образом:
read(N): {N - число городов}
read(M): {М - число дорог}
168
Глава 2. Основы алгоритмизации
for х—1 to N do
{Устанавливаем)
(между всеми городами)
{максимальную стоимость}
{х - номер города «откуда»)
{у - номер города «куда»)
{t - тип дороги)
.......... ...... {PEx.y.t] - стоимость)
end:......{проезда от х к у по дороге типа t)
read(A.B): {Начальный и конечный пункты маршрута)
Подготовка к выполнению алгоритма Дейкстра:
{При выезде из города}
(страховой взнос}
{платится всегда)
{Для всех городов)
(кратчайшие стоимости до первого)
{по шоссейной дороге}
{по железной дороге)
for t—О to 1 do p[x.y,t]:-MAXR:
for i -1 to M do
readln (x.y.t.ptx.y.t]):
for i:-l to N do
begin
{Для всех городов}
predti.O]—A:
pred[i.l]:-A;
Labl[A.O]:-DONE:
Labi [A. 1]-DONE:
pred[A.0]-0:
pred[A.l]-0:
{Свободны}
{по обоим типам дорог}
{Предыдущий город равен А)
{для обоих типов дорог)
{Начальный город обработан)
{для обоих типов дорог)
(Предыдущий у начального - 0}
(для обоих типов дорог)
Основная часть алгоритма Дейкстра представляет собой цикл по количеству вер-
шин, оставшихся необработанными:
for 1—1 to 2*N-2 do
Поиск ближайшей к первой вершине из необработанных
Пересчет наименьших стоимостей через ближайшую вершину
до вершин, смежных с ближайшей
end;
Первый этап — поиск ближайшей к первой вершины из необработанных:
M1nO:-MaxR:
for t:-0 to 1 do
if (Labl[j.t]-FREE)
and
(minOdLj.t])
then
{MinD - максимум}
{Для всех городов}
{Для дорог обоих типов}
{Если вьезд в город j по дороге типа t}
{еще не обрабатывался и)
{стоимость от города А до города j)
{по дороге типа t меньше, чем MinD. то}
Labi[Bliz.bt]-DONE:
{ее тип - bt)
{минимальную стоимость в MinD}
{Пометить как обработанную вернину)
{с минимальной стоимостью от города А}
{из еще необработанных вернин}
2.4, Алгоритмы на графах
169
Второй этап — пересчет наименьших стоимостей через ближайшую вершину до
вершин, смежных с ближайшей:
for J:=l to N do
if (Labl[j.tl]-FREE)
and (dij.tl]
(Для всех городов)
(Для дорог обоих типов)
(Если дорога до города j типа t необработана)
{и стойкость до нее от вершины А)
(больше, чек)
d[Bliz.bt] + C(tl.bt)*P[Bliz.j.tl]) {стойкость через ближайшую)
then {то}
d[j.tl]:-d[Bliz.bt]+C(tl.bt)*P[Bliz.j.tl]: {закеняен стойкость)
Pred[j.tl]:-Bliz: Typp[J.tl]:=bt: (запонинаен)
end: (предыдущие город и тип дороги}
Вычисляя стоимость проезда через ближайшую вершину, учитываем страховой
сбор при переходе с дороги одного типа на дорогу другого типа с помощью функ-
ции C(t1, t2):
function C(tl.t2:byte):real:
begin
if tl-t2 then £:-1.0 else C:-l.l
Вывод результатов осуществляется так:
{Текущий город - конечный город}
{Тип вьезда -}
{лучший из двух возиожных}
(Текущий тип - выбранный лучший)
(Пока текущий город не равен 0)
if d[B.0]<d[B.1]
then t:-0 else t:-l:
stt[l]:-t:
while (GoO) do
begin
inc(is):
stg[1s]:-pred[G.t]:
NG:*pred[G.t]:
NT:-typp[G.T]:
(Инкреиентируеи количество городов)
{сохраняеи текущий город в путь)
(и его тип)
{Переустанавливаек текущие город)
{и тип на предыдущие город)
writeln(m1n(d[B.O].d[B.l]):0:2): {Выводив нинииальную стойкость)
for i:-is-l downto 1 do writeln(stg[i].' '.stt[i]): (и путь)
writeln(B): (добавляем в путь последний город)
Полный текст программы — в листинге 2.32.
Листинг 2.32. Программа «Эх, дороги»
{SRt.Et.N»)
program by98dlm2:
const
FREE - 0:
DONE - 1:
MAXR - le4:
p : array [1..80.1..80.0..1] of single:
0 : array [1..80.0..1] of single:
pred : array [1..80.0..1] of 0..100:
typp.Labl : array [1..80.0..1] of 0..1:
stg : array [1..100] of 0..100:
170 Глава 2. Основы алгоритмизации
Листинг 2.32 (продолжение}
stt : а
И
N.x.y.A.B.i.к.j.G.NG
t.tl.t2.bt.NT
Ts.Bliz
Mind
Mint.MT
: array £1..100] of 0..1:
: 0..1000:
: 0..100:
: 0..1:
: 0..100:
: single:
: byte;
function C(tl.t2:byte):real:
begin
if tl-t2 then C:-1.0 else C:-l.l
end:
function m1n(x,y:sing1e):single:
if x<-y then min:-x else min:-y
end:
begin
assign(input,'tour.1n'): reset(i nput):
assigntoutput.'tour.out'): rewrite(output):
read(N):
read(M):
for x:-l to N do
for y:-l to N do
for t:-0 to 1 do p[x.y.t]:-MAXR:
for i:-l to H do
begin readln (x.y.t.ptx.y.tj): p[y.x.t]:-p[x.y.t]: end:
read(A.B):
for 1;-1 to N do
for t:-0 to 1 do p[a.i.tj:-l.l*p[a.i.t]:
for i:-l to N do
begin D[i.O]:-P[a.i.O]: D[1.l] : -PCa.i.ll: end:
for i:-l to N do
begin
Labi[i ,01-FREE: Labi£1.1J:-FREE:
pred[1.0]:*A: pred[i.l]:-A:
end:
. Labl£A.O]:-DONE: Labl[A.l]:-DONE: pred[A.0]:-0: Pred[A.l]:-0:
for i:-l to 2*N-2 do
begin
MinO:-MaxR:
for J:-l to N do
for t:-0 to 1 do
if (Labl[j.t]-FREE) and (minD>d[J,t])
then begin
BHz:-j: bt:-t: MinO:-d[j.t]
end:
Labl[Bliz.bt]:-DONE:
for j:=l to N do
for tl:-0 to 1 do
if (Labl£J.tl]-FREE) and
(d[j.tl]>d[Bl1z.bt] + C(tl.bt)*P[Bliz.j.tl])
then begin
d[j.tl]:-d[Bliz.btX(tl.bt)*P(BHz.j.tl]:
Pred[j.tl]:-Bliz: Typp[j.tl]:-bt:
end:
2.4. Алгоритмы на графах
171
G:-B: is:-0:
If d[B.0]<d[B.1] then t:-0 else t:-l:
stt[l]:-t:
while (GoO) do
begin
incfis):
stg[is]:-pred[G.t]: stt[1s+l]:-typp[G.t]:
NG:-pred[G.tJ: NT:-typp[G,T];
G:-NG: t:-NT:
end:
writeln (m1n(d[B.0].d[B.l)):0:2):
for i:=1s-l downto 1 do writeln(stg[i].' '.sttCi]):
close(input): close(output):
Поиск в глубину
Рассмотрим пример неориентированного графа с шестью вершинами:
(1)- (3) (5)
(2)-(4) (6)
При компьютерной обработке граф может быть задан списком ребер (дуг) для каж-
дой вершины. Например, для графа из нашего примера, этот список выглядит так:
1:2,3,4 (то есть 1-я вершина соединена со 2-, 3- и 4-й);
Для хранения этой информации в памяти компьютера можно воспользоваться
двумерным массивом G[1..N,1..M], где N — число вершин в графе, М — максимально
возможное число ребер (дуг) у одной вершины графа. Для удобства обработки этой
информации можно также иметь одномерный массив kG[ 1 Л] количества ребер (дуг)
вершин графа.
Тогда для обработки списка связей текущей вершины U можно написать:
for i:-l to kGCUJ
begin
Тем самым мы получаем обработку дуги, связывающей вершины U и V для всех
вершин, непосредственно связанных с U. ,
Для обработки всех связей всех вершин можно использовать поиск в глубину (DFS —
Depth-First Search):
172
Глава 2. Основы алгоритмизации
for U;-l to N do Color[U]:-WHITE:
for U:-l to N do
If color[U]-WHITE then DFS(U):
Procedure DFS(U:longint):
var
j : longint:
begin
color[U]:-GRAY:
for _):-l to kGtUJ do DFS(G[U.j]):
Введенные обозначения:
1. Color[U] — цвет вершины:
□ WHITE (константа=1) — белый, если мы еще не посещали эту вершину;
□ GRAY (константа=2) — серый, если мы посещали данную вершину;
2. DFS (U) — рекурсивная процедура, которая вызывает себя для всех вершин — по-
томков данной вершины.
То есть для обеспечения поиска в глубину на заданном графе G[1..N,1..M] с количе-
ствами дуг из вершин G[1..N], вначале мы устанавливаем всем вершинам цвет WHITE,
азатем для всех вершин, которые еще не посещались (Color[G[U,j]]=WHITE), вызы-
ваем рекурсивную процедуру DFS.
Таким способом формируются все возможные маршруты в графе. При этом нет
ограничений на то, сколько раз можно использовать душ и заходы в вершины. Если
же, по условиям задачи, потребуется посещать каждую вершину не более одного
раза, чтобы формировать маршруты из несовпадающих вершин, то это может быть
обеспечено в процедуре DFS условным вызовом-.
Procedure DFS(U:longint);
var
j : longint:
begin
COlor[U]:“GRAY:
for j:-l to kG[U] do
if color[G[U.j]]-WHITE then DFS(G[U.j]>:
end:
Если требуется каждую дугу использовать не более одного раза, то можно ввести
расцветку дуг — Colo r[1..N,1..M] — со значениями FREE или DONE, где N — число вер-
шин в графе, а М — максимально возможное число ребер (дуг) у одной вершины
графа.
Процедура DFS формирования таких маршрутов, чтобы каждая дуга использова-
лась в маршруте не более одного раза, будет выглядеть следующим образом:
procedure DFS(v:byte):
var j : byte:
begin
for j:-l to kG[v] do
if (colortv,JJ-FREE)
then
begin
2.4. Алгоритмы на графах
C01or[v.j]:=DONE:
DFS(G[v.j]):
COlor[v.j]:-FREE:
end:
Здесь введены пометки на дуги — Color[v,j]. Color[v,j ] - FREE, если дуга еще не
обработана, и DONE, если она включена в текущий путь.
Если в задаче требуется вывести найденный путь, то для его хранения вводится
специальный массив SLED [1..0], где 0— максимальное количество ребер в пути.
Вершины текущего пути заносятся в этот массив и удаляются из него в процессе
обхода графа: ,
procedure DFS(v:byte):
var j : byte:
begin
for j:-l to kG[v] do
begin
inc(ks): sled[ks]:-G[v.j]:
DFS(GCv.jJ):
dec(ks):
end:
Теперь пора перейти к применению приведенной теоретической информации к
решению конкретных задач.
Задача «Дороги»
Республиканская олимпиада по информатике, 1997 год.
Дана система односторонних дорог, определяемая набором пар городов. Каждая
такая пара (г,у) указывает, что из города г можно проехать в городу, но это не зна-
чит, что можно проехать и в обратном направлении.
Необходимо определить, можно ли проехать из заданного города Л в заданный го-
род В таким образом, чтобы посетить город С и не проезжать ни по какой дороге
более одного раза.
Входные данные задаются в файле с именем PATH.IN следующим образом: в пер-
вой строке находится натуральное N (N <50) — количество городов (города нуме-
руются от 1 до N). Во второй строке находится натуральное М (М <100) — количе-
ство дорог. В каждой из следующих строк находятся пары номеров городов,
которые связывает дорога. В последней, (М + 3)-й, строке находятся номера горо-
дов А, В и С.
Ответом является последовательность городов, начинающаяся городом А и закан-
чивающаяся городом В и удовлетворяющая условиям задачи. Ответ должен быть
записан в файл PATH.OUT в виде последовательности номеров городов (по одному
номеру в строке). Первая строка файла должна содержать количество городов в
последовательности. При отсутствии пути записать в первую строку файла чис-
ло -1.
174
Глава 2. Основы алгоритмизации
PATH.IN
PATH.OUT
Идея решения может быть изложена следующим образом:
Поиск в глубину
Если встречаем вершину В. устанавливаем соответствующий флаг
Если встречаем вершину С и флаг В установлен - выводив результат и
завершаем работу
После завершения поиска (требуемый маршрут не найден) выводим -1
Изложим решение более подробно. Ввод исходных данных осуществляется следу-
ющим образом:
read(N.M):
begin
read(x.y): inc(kGtxJ): Gtx.kGtx]]:-y: colortx.kG[x]}:-FREE:
end:
read(A.B.C):
Здесь, как и прежде, kG[i ] — количество дуг из вершины 1, G[i,j] (для j от 1 до
kG[ j ]) — вершины, с которыми вершина i связана соответствующей дугой. Кро-
ме того, введен цвет дуги: FREE (свободна) и DONE (занята). FREE и DONE — кон-
станты.
Главная программа фактически включает только следующие операторы:
{Установить метку - вершину С ёае не посещали)
{Поиск в глубину от вершины А)
{Вывод признака отсутствия требуемого пути)
DFS(A): .
writeln(-l):
Рекурсивная процедура поиска в глубину от вершины V выглядит следующим об-
разом:
procedure DFSCv:byte):
var j : byte:
begin
for j:=l to kGtv] do
if (colortv.jJ-FREE)
then
begin
if (G[v.j]-B) and (LabC“l)
then begin OutRes: halt; end:
if Gtv.JJ-C then LabC:-l:
colorEv.jh-OONE: 1nc(ks): sledtksj:-Gtv.JJ:
DFS(Gtv.jl):
color[v.j]:-FREE: sledtks]:-0: dec(ks):
if Gtv.j]-C then LabC:-O:
end:
2.4. Алгоритмы на графах
175
Для всех еще не обработанных (color[v,j]=FREE) дуг от текущей вершины выясня-
ем, ведет ли она в конечный пункт, и если город С уже проходили, то осуществля-
ется вызов процедуры вывода результата.
Если текущая дуга ведет в город С, устанавливаем соответствующую метку (LabC=1).
Помечаем дугу как обработанную, заносим ее в массив SLED, который содержит
текущий обрабатываемый путь (KS — количество элементов в нем).
Далее вызываем процедуру DFS от вершины (G[v,j ]), в которую ведет текущая дуга.
Перед выходом из процедуры DFS восстанавливаем состояние, «исходное» перед
ее вызовом: снимаем отметку обработки с дуги (color[ v,j ]: =FREE) и удаляем ее из
массива SLED (dec(ks)). Оператор sled[ks]:=0 выполнять не обязательно, но он пре-
доставляет удобства отладки, — чтобы в массиве SLED ненулевыми были только
реально входящие в путь элементы.
И наконец, процедура вывода результата:
procedure OutRes:
begin
writeln(ks+2):
writeln(A): for i:-l to ks do writeln(sled[i]>: writeln(B):
end:
Поскольку, по алгоритму построения, начальный (А) и конечный (8) города не за-
носились в массив SLED, то они выводятся отдельно, а количество городов в пути
(KS) перед выводом увеличивается на 2.
Листинг 2.33. Программа-Дороги-
program by97d2s3:
const
FREE-1:
DONE-2:
var
G.color : array[l..50.1..100] of byte:
D : array[1..5O] of longint:
kG.sled : array[1..5O] of byte:
path : array[1..100] of byte:
MinD.is : longint:
i.j.x.y.A.B.C.N.M.ks.LabC : byte:
Yes : boolean:
procedure OutRes:
begin
writeln(ks-*2):
writeln(A): for i:-l to ks do writeln(sled[i]): writeln(B):
end:
procedure 0FS(v:byte):
var j : byte:
begin
for j:-l to kG[v] do
if (color[v.j]-FREE)
then
begin
if (G[v,j]=B) and (LabC-1)
then begin OutRes: halt: end:
if G[v,j]=C then LabC:-l:
176 Глава 2. Основы алгоритмизации
Листинг 2.33 (продолжение)
color(v.j]:=OONE: inc(ks): sled[ks]:-G[v.j]:
OFS(G[v.j]):
colortv.j]-FREE: sledtks]:-0: dec(ks);
if Gtv.j]-C then LabC:=0:
end:
assigndnput.'path.in'): reset(input):
assign(output,'path.out'): rewcite(output):
read(N.M):
for 1—1 to H do
begin
read(x.y): IncCkGCx]): G[x.kG[x]]-y: color[x.KGtx]]:-FREE:
end:
read(A.B.C):
LabC:-0;
DFS(A):
writeln(-l):
close(input): close(output):
Задача «Перекрестки»
Республиканская олимпиада по информатике, 1998 год.
Даны декартовы координаты Nперекрестков города, которые пронумерованы от 1
до N. На каждом перекрестке имеется светофор. Некоторые из перекрестков со-
единены дорогами с двусторонним (правосторонним) движением, которые пере-
секаются только на перекрестках. Для каждой дороги известно время, которое тре-
буется для проезда по ней от одного перекрестка до другого.
Необходимо проехать от перекрестка с номером А до перекрестка с номером В за
минимальное время.
Время проезда зависит от набора проезжаемых дорог и от времени ожидания на
пёрекрестках. Так, если вы подъехали от перекрестка X к перекрестку С по дороге
Х-»С и хотите ехать дальше по дороге С-tY, то время ожидания на перекрестке С
зависит от того, поворачиваете ливы налево или нет. Если вы поворачиваете нале-
во, то время ожидания равно D* К, где D равно количеству дорог, пересекающихся
на перекрестке С, а К — некоторая константа. Если вы не поворачиваете налево, то
время ожидания равно нулю.
Написать программу, которая определяет самый быстрый маршрут.
Входные данные находятся в текстовом файле с именем PER.IN и имеют следующую
структуру:
1) в первой строке находится число N (натуральное, < 1000);
2) во второй строке — количество дорог М (натуральное, < 1000);
3) в третьей строке — константа К (натуральное число, < 1000);
4) в каждой из N следующих строк находится пара чисел х и у, разделенных пробе-
лом и являющихся координатами перекрестка (целые числа, не превышающие
по модулю 1000);
2.4. Алгоритмы на графах
177
5) в каждой из М следующих строк находится 3 числа р, г, t, разделенные пробе-
лом, где р и г — номера перекрестков, которые соединяет дорога, а t (натураль-
ное, 2 1000) — время проезда по ней;
6) в последней строке находятся номера начального А и конечного В перекрестков.
Выходные данные должны быть записаны в текстовый файл с именем PER.OUT
и иметь следующий формат:
1) в первой строке находится натуральное число Т — время проезда по самому
быстрому маршруту;
2) в каждой из следующих строк находится одно число — номер очередного пере-
крестка в маршруте (начиная с перекрестка с номером А и кончая В).
В решении алгоритм Дейкстра напрямую не применим, поскольку оптимальное ре-
шение в следующей вершине не является суммой оптимального решения для пре-
дыдущей вершины и веса текущего ребра. Кроме того, вес текущего ребра — непо-
стоянная величина, зависящая оттого, каким поворотом мы вышли из вершины.
Поэтому предлагается решать задачу путем поиска в глубину. При этом разреша-
ется использовать каждую вершину столько раз, сколько у нее есть ребер. Отсека-
ются решения, которые хуже текущего оптимального.
Можно еще ускорить решение, если обеспечивать перебор, начиная с правых по-
воротов (отсечения работали бы более эффективно).
ПРИМЕЧАНИЕ---------------------------------------------------
В тексте задачи это явно не указано, но авторы оригинальных тестов к задаче полага-
ли, что поворот на 180 градусов — это левый поворот (как в армии: поворот на 180 гра-
дусов — через левое плечо).
Рассмотрим решение более подробно. Начнем с ввода исходных данных:
read(N.H.K):
foe i:-l to N do readln(X[i],y[i]);
for 1:-1 to N do Begin kG[1):-0: D[1]:-0: end:
for i:-l to M do
readln(p.r.t): 1nc(kG[pJ): inc(kGCrJ):
G[p.kG[p].l]:-r: G[p.kG[p].2]:-t: inc(D[p]):
G£r.kG[r].13:-p: G[r.kG[r].2]:-t: Inc(D[r]):
readln(vA.vB):
Здесь мы ввели:
□ kG[i] — количество дуг из вершины i;
□ G[i,j,1 ] — вершина, с которой соединена вершина 1 дугой с номером j в списке
всех дуг из вершины 1;
□ G[i,j,2] — время проезда от вершины i до вершины, с которой она соединена
дугой j в списке всех дуг из вершины i;
□ D[ i ] — количество дорог, пересекающихся на перекрестке i (то есть суммарное
количество дуг, исходящих из вершины 1 и входящих в нее);
□ vA и vB — указывают, откуда и куда нужно добираться.
Глава 2. Основы алгоритмизации
Поскольку по условиям задачи дороги двусторонние, то для каждой введенной
дороги мы добавляем в граф две дуги.
Основной алгоритм выглядит следующим образом:
for i:-l to Н do
begin
for j:-l to kG[i] do Color(i.j):-WHITE:
Time[i]:=rnaxlongint: ‘
______ {Все дуги свободны)
{Время маршрута до 1 - максимально)
6ptT:-Maxlongint: {Оптимальное время - максимально)
Sled[l]:-vA; (Заносим а маршрут вершину vA)
kv:-l: {Количество вершин в маршруте = 1)
Timet vA]:-0: {Оптимальное время до вершины vA - 0)
DFS(vA): {Поиск в глубину от вершины vA)
... вывод ответа ...
Рекурсивная процедура DFS(i) обеспечивает выполнение следующей работы:
Procedure DFS(i)
begin
for j:-l to kG[i] do
if G[i.j.l]ovB
then
begin
if colorti.JJ-FREE .
then
begin
... продолжение пути с вызовом OFS
end
end
else
... сравнение пути с текущим оптимальным
end:
end:
Если текущая вершина — конечная (vB), то делаем сравнение пути с текущим оп-
тимальным. Иначе если текущая дуга еще не использовалась (color[i,j]=FREE),
делаем продолжение пути с вызовом DFS. При этом перед входом в DFS помечаем
дугу как использованную (c61or[i.j ]: =DONE), а после выхода — как свободную
(color[i,j]:=FREE).
продолжение пути с вызовом DFS включает в себя следующие операторы:
inc(kv): sle0[kv]:-G[1,j.l]:
NewT 1 me: -T1 me C i ] +G [ i. j, 2 ] +CountT i ms:
if KewTineOptT
then
begin
colorti.j]:-=OONE:
RetTime:-Tire[G[i.j.in:
TimetG(i.j.I]]:=NewTime:
DFSfGti.J.l]):
TimetGti.j.lHr-RetTiine:
(Помешаем в путь новую вершину)
{Вычисляем новое время)
{Если новое время меньше оптимального)
{то продолжаем.иначе - отсекаем)
{Помечаем - ребро использовано)
(Сохраняем старое время)
(Устанавливаем новое время)
(Вызываем поиск от Gti.j.lJ)
(Восстанавливаем старое время)
2.4. Алгоритмы на графах
179
{Помечаем - ребро свободно)
co1or[i.j]:-FREE:
end;
Sled[kv]:-0: dec(kv): {Удаляем вершину из пути)
Для вычисления нового времени здесь используется функция CountTime с пара-
метром kv — номером последней вершины в стеке. Эта функция восстанавливает
номера,вершин прохода через перекресток 12 (из 11 через 12 в 13):
if kv-2 then begin CountTime :=(): exit; end:
11 s1ed[kv-2]:
12 sled[kv-l]:
13 := sledLkv]:
if 13-11 then begin CountTime:-K*D[i2]: exit: end:
Попутно выясняется, что:
1. если вершин в пути всего 2, а значит, не было никакого поворота, то это шаг из
начальной вершины и CountTime = 0.
2. если 11 = 13, то это поворот на 180 градусов, и авторы задачи считают, что это
тоже левый поворот, CountTime = К • D[12], где К — вводимый коэффициент, 12 —
перекресток, D[ 12 ] — количество дорог, входящих в этот перекресток.
Затем из массивов координат перекрестков выбираются координаты текущих пе-
рекрестков: (х1, у1) (откуда), (х2, у2) (через какой) и (хЗ, уЗ) (куда).
yl :-y[il): у2:-у[12]: у3:-у[131:
Вычисление уравнения прямой по точкам (х1, у1)и(х2, у2):
Подстановкой координат (хЗ, уЗ) в уравнение прямой Ах + By + С - 0, построен-
ной по первым двум точкам (х1, у1) и (х2; у2) с учетом крайних случаев, когда
прямая параллельна осям координат, вычисляем, был ли поворот левым или пра-
вым, и, соответственно, устанавливаем значение функции CountTime.
Left := (((x2>xl) and ((А*хЗ+В*уЗ+С)<0))) or
(((x2<xl) and ((A*x3+B*y3+C)<0))> or
((<y2-yl) and (xl>x2) and (y3<yl))> or
(((y2-yl) and (xl<x2) and (y3>yl))) or
(((x2-xl) and (yl>y2) and (x3>xl))) or
(((x2-xl) and (yl<y2) and (x3<xl))) :
if Left
then CountTime:-K*D[12]
else CountT1me:-0:
Сравнение пути с оптимальным выполняется следующим образом:
inc(kv): sled[kv]:-G[1,J.l):
Т :- Т1гае[1]ч6[1.J.2] + CountTime:
if Т < OptT
then begin
OptT:-T:
OptKv:-kv: OptSled:-Sled:
end:
Sled[kv]:-0: dec(kv):
180
Глава 2. Основы алгоритмизации
Таким образом, оптимальное время хранится в переменной OptT, а оптимальный
путь — в массиве OptSled с количеством элементов Opt Kv, И поэтому вывод резуль-
татов выглядит так:
writeln(OptT):
for i:-l to OptKv do writeln(OptSled[t]):
Полный текст программы приводится в листинге 2.34.
Листинг 2.34. Программа «Перекрестки»
program by98d2s2:
Const
FREE = 1:
DONE -2;
Type
intlOOO - 0..1000:
1nt3 - 1..3:
var
G : arrayil..1000.1..10.1..2] of IntlOOO:
Time.D : arrayil..1000] of longint:
x.y.kG.Sled.OptSled.pred : arrayil..1000] of intlOOO:
Color : array[l..100.1..10] of 1nt3:
N.M.K.i.p.r.t.vA.vB.v.kv.OptKv.j : intlOOO:
OptT : longint:
function CountTimed:IntlOOO):longint:
ver
Left : boolean:
1 1.12.13 : intlOOO:
xl.x2.x3.yl.y2.y3.A.B.C : longint:
begin
if kv-2 then begin CountTime.-0: exit: end:
11 := s1ed[kv-2]:
12 :- sledlkv-l]:
13 :- sledlkvj:
if 13-11 then begin CountT1me:-K*D[i2]: exit: end;
xl :- x[il]: x2:-x[12]: x3:-x[13J:
yl :- y[il]: y2:-y[i2]: y3:-y[i3J:
A :-y2-yl;
В := xl-x2:
C :- yl*(x2-xl)-xl*(y2-yl):
Left :- (((x2>xl) and ((A*x3+B*y3+C)<0))) or
(((x2<xl) and ((А*хЗ+В*уЗ-*С)<0))) or
(((y2-yl) and (xl>x2) and (y3<yl))) or
C((y2-yl) and (xl<x2) and (y3>yl))) or
(<(x2-xl) and (yl>y2) and (x3>xl))) or
(((x2-xl) and (yl<y2) and Cx3<xl))> :
if Left
then CountTime:-K*D[i2]
else CountTlme:-0:
end:
Procedure DFSfi:IntlOOO):
var
T : longint;
RetSled.RetPred.RetTime :1ongint;
begin
for j:-l to kGCi] do
2.4. Алгоритмы на графах 181
if G[i.j.l]ovB
begin
if colorli.fl-FREE
then
begin
inc(kv): sled[kv]:-G[i.j.l]:
NewTime:-Tiire[i]+G[i. j ,2]+CountT1me:
if NewTime<OptT
begin
color[i.j]:-DONE:
RetTime: -Ti me[G[ i. j. 1] ]:
Time[G[i.j.l]]:-NewTime:
DFS(G[1.j.l]):
Time[G[i.j.l]]:=RetTime:
color[i.j]:-FREE:
end:
Sled[kv]:-0: dectkv):
begin
inctkv): sled[kv]:-G[i.j.l]:
T Time[i]+G[i.j,2] ♦ CountTime:
if T < OptT
then begin
OptT:-T;
OptKv:=kv: OptSled:=Sled:
end;
Sled[kv]:-0: dectkv):
assigntinput. 'PER.in'): reset(input):
assignloutput.'PER.out'): rewritetoutput):
read(N.M.K):
for- i:-l to N do readln(x[i],y[1J):
for i:-l to N do begin kG[i]:-0: D[i]:=0: end:
for 1:-1 to M do
begin
readln(p.r.t): inc(kG[p]): inc(kG[r]);
G[p.kG[p].l]:-r; G[p.kG[p].2]:-t: inc(D[p]):
G[r.kG[r].l]:-p: G[r.kG[r].2]:-t: Inc(D[r]):
readln(vA.vB):
for i:-l to N do
for j:-l to kG[1] do Color[i.j]:-FREE:
Time[i]:-maxlongint:
end:
Time[vA]:-0: kv:-l; Sled[l]:-vA: OptT:-Maxlongint:
DFS(vA):
writeln(OptT):
for i:-l to OptKv do writeln(OptSled[i]):
closet input): closetoutput):
182 Глава 2. Основы алгоритмизации
Задача «Скрудж Мак-Дак»
Республиканская олимпиада по информатике, 1995 год.
Скрудж Мак-Дак решил сделать прибор для управления самолетом. Как известно,
положение штурвала зависит от состояния входных датчиков, но эта зависимость
довольно сложна. Его механик Винт Р. сделал устройство, вычисляющее эту функ-
цию в несколько этанов с использованием промежуточной памяти и вспомогатель-
ных функций. Для вычисления каждой из функций требуется, чтобы в ячейках
памяти уже находились вычисленные параметры (которые являются значениями
вычисленных функций), необходимые для ее вычисления. Вычисление функции
без параметров может производиться в любое время. После вычисления функции
ячейки могут быть использованы повторно (хотя бы для записи результата вычис-
ленной функции). Структура вызова функций такова, что каждая функция вы-
числяется не более одного раза и любой параметр (имя функции) используется не
более одного раза.
Так как Скрудж не хочет тратить лишних денег на микросхемы, он поставил зада-
чу минимизировать память прибора. По заданной структуре вызовов функций
необходимо определить минимальный возможный размер памяти прибора и ука-
зать последовательность вычисления функций.
□ Структура входных данных (файл INPUT.TXT).
1-я строка: содержит число N — общее количество функций;
2-я строка: содержит имя функции, которую необходимо вычислить;
3-я строка: имя функции кол-во параметров [список имен параметров);
...
(N + 2)-я строка: имя функции кол-во параметров [список имен параметров].
□ Структура выходных данных (файл OUTPUT.TXT).
размер памяти (в ячейках);
имя 1-й вычисляемой функции;
имя 2-й вычисляемой функции;
имя функции, которую необходимо вычислить.
ПРИМЕЧАНИЕ-------------------------------------------------------------
Имя функции — натуральное число от 1 до N.
Например:
□ INPUT.TXT
5
12 2 3
2 О
3 2 4 5
4 0 .
5 О
2.4. Алгоритмы на графах
183
□ OUTPUT.TXT
5
2
Короче говоря, в данной задаче требуется сделать следующее.
1. Найти S — максимальную степень среди тех вершин, что подлежат обходу' (по-
иск в глубину DFS1).
2. Необходимая память вычисляется по формуле MaxS = S + к - 1, где S — найдено
на предыдущем шаге (DFS1), к — максимальное количество вершин одного уров-
ня вложенности с такой же степенью S. Для вычисления к совершается обход
повторным поиском в глубину DFS2.
3. Третьим поиском в глубину DFS3 находим и помещаем в очередь V все вершины,
степень которых равна S.
4. Последним, четвертым поиском в глубину обходим данное дерево в порядке
вершин в очереди V, то есть в первую очередь вычисляем те функции, для кото-
рых требуется максимальная память.
Рассмотрим реализацию алгоритма более подробно. Начнем с ввода исходных дан-
ных:
read(N.FC):
for 1:-1 to N do
begin
read(f.kG[f]):
for j:-l to kG[f] do read(G[f.J3):
end:
Введенные обозначения:
□ N — исходное количество вершин;
□ FC — номер функции, которую нужно вычислить;
□ kG[i] — количество параметров для вычисления функции 1;
□ G[i,j ] — j-й параметр, требуемый для вычисления функции i.
Тело главной программы выглядит так:
for i:-l to N do color[1]:*WHITE; {Пометить свободными все вершины)
DFSl(FC): {Находим S - максимальную степень вершин)
{используемых для вычисления функции FC)
MaxS:-S:
0FS2(FC): {Вычисляем К - количество вершин со степенью S)
{в текущем слое и MaxS - максимальная из)
{значений по слоям величина S+K-1)
kv:-0:
DFS3(FC): {Поместить в массив V все вершины, степень)
{которых равна S. количество таких)
{вершин - в переменной kv)
kr:-0;
for i:-l to kv do DFS4(v[i]>: {Обход графа поиском в глубину начиная)
{с вершин с максимальной степенью из)
Глава 2. Основы алгоритмизации
{массива V. Найденные вершины заносить)
{в массив г)
writeln(MaxS): {Вывод количества ячеек памяти)
for 1:-1 to kr do writeln(r[1]): {Вывод порядка вычисления функций)
Полностью текст программы приведен в листинге 2.35.
Листинг 2.35. Программа «Скрудж Мак-Дак»
program by95d2tl:
WHITE - 1:
GRAY - 2:
BLACK - 3:
var
G : array [1..100.1..100] of longint:
kG.v.color.r : array [1..100] of longint:
N.FC.i.j.s.f.kv.HaxS.kr : longint:
procedure OFSl(u:longint):
i,k : longint:
begin
if s<kG[u] then s:=kG[u]:
for i :-l to kG[u] do DFSKGEu.i]):
end:
procedure DFS2(u:longint):
i.k : longint:
k:-0:
for i:-l to kGEu] do
if kG[G[i.j]]=s then inc(k):
if MaxS<s+k-i then MaxS:=s+k-l:
for 1:-1 to kGEu] do DFS2(G[u.i]):
end:
procedure DFS3(u:longint):
var
i.k : longint:
begin
if kG[u]=s
then
begin
for i:-l to kGEu] do DFS3(G[u.i]):
inc(kv): v[kv]:-u:
end:
end:
procedure DFS4(u:longint):
var
1 : longint:
begin
color[u]:-GRAY:
1f kGEu]<>0
then
2.4. Алгоритмы на графах
185
for 1:-1 to kG[u] do
if color[G[u.i]]<>GRAY
' then DFS4(G[u.iJ):
inc(kr): r[kr]:=u:
end:
begin
assigntinput.'input.txt'): reset(input):
assign(output.'output.txt'): rewrite(output):
read(N.FC);
for 1:=1 to N do
begin
read(f.kG[f]):
for j:-l to kGCfJ do read(G[f.j]):
end: i
for i:-l to N do color[i]:-WHITE:
DFSl(FC):
MaxS:=S: DFS2(FC):
kv:=0: DFS3(FC):
kr:=0: for i:-l to kv do 0FS4(v[i]):
writeln(MaxS):
for i:-l to kr do writeln(r[i]):
close(input): close(output):
end.
Сильносвязные компоненты и доминантные
множества
Подграф графа называется его силъносвязным компонентом, если каждая из вер-
шин подграфа достижима от любой из вершин подграфа.
Доминантное множество — это минимальное множество вершин графа, из кото-
рого достижимы все вершины графа.
Алгоритмы построения сильносвязных компонентов и доминантных множеств
графа рассмотрим на приведенных далее примерах.
Задача «Карточки»
Республиканская олимпиада по информатике, 1994 год.
Есть N карточек. На каждой из них черными чернилами нанисан ее уникальный
номер — число от 1 до N. Также на каждой карточке красными чернилами написа-
но еще одно целое число, лежащее в промежутке от 1 до N (некоторыми одинако-
выми «красными» числами могут помечаться несколько карточек).
Необходимо выбрать из данных N карточек максимальное число карточек таким
образом, чтобы множества «красных» и «черных» чисел на них совпадали..
ПРИМЕР ----------------------------------------------------------
Допустим, N=5, и эти 5 карточек помечены «черными» числами 1,2,3,4,5 и, соответ-
ственно, «красными» числами 3,3,2,4,2. Тогда «правильными» будут карточки с «чер-
ными» номерами 2, 3, 4, поскольку множество «красных» номеров в данном примере
именно такое — 2, 3,4.
186
Глава 2. Основы алгоритмизации
1. Структура входных данных (построчно):
□ N(N<50);
□ «черный»_нбмер_1 «красное»_число_1;
□
□ «Черный»_номер_М «красное»_число_Н.
2. Структура выходных данных:
□ S (количество элементов в выбранном подмножестве элементов);
□ а1 («черные» номера выбранных карточек);
□ ' ...;
□ aS.
□ Пример ввода:
б
1 2
2 3
3 4
4 5
5 1
б б
□ Пример вывода:
Фактически в задаче требуется найти все сильносвязные компоненты представля-
емого карточками ориентированного графа и добавить к ним карточки, на кото-
рых и красным и черным цветом написаны одни и те же числа.
Опишем решение задачи более подробно. Начнем стела главной части программы:
readln(N):
М:=0:
for 1 :-1 to N do
begin
readln(u.v);
1nc(kG[u]>: G[u.kG[u]]:=v:
if u-v
then
begin inc(M): T[M]:-u:end:
BuildDominators:
Reverse:
BuildDominators2:
{Читаем количество карточек}
{Количество карточек в результате}
{Для всех карточек)
{Читаем карточку}
{Пополняем по ней граф}
{Если красное число равно черному}
{заносим карточку в результат}
Рассмотрим процедуру BuildDominators:
{Строим множество доминаторов)
{Обращаем граф)
{Строим множество доминаторов}
{обращенного графа, попутно}
{получая все сильносвязные компоненты графа}
Procedure BuildDominators:
2.4. Алгоритмы на графах
187
Time:-0:
for i:-l to N do
begin
Colorti] WHITE;
Domfi] := WHITE:
CurC[i] := WHITE:
F[i] := 0:
end:
for v:-l to N do
if color[.v3“WHITE
then
begin
DFS(v):
AddDominator(v):
(Время обработки вершин = 0)
{Для каждой вершины i помечаем)
(Вершина свободна)
{Доминаторов нет)
{Свободна на текущем шаге)
{Время завершения обработки - 0)
{Для всех вершин)
{Если вершина v свободна)
{Поиск в глубину от вершины v)
{Добавить найденный доминатор)
Таким образом, на этом этапе обработки вершин графа у нас есть три множества;
□ Don — найденные на текущий момент домииаторы графа;
□ Color — все обработанные вершины;
□ CurC — вершины, обработанные во время поиска в глубину текущей базовой вер-
шины V.
Рекурсивная процедура поиска в глубину выглядит для данной задачи так:
Procedure OFSfi:byte):
var
j : byte:
begin
color[i]:-GRAY:
curC[i]:-GRAY:
inc(Time):
for j:-l to kG[i] do
if curC[G[i.j]]“WHITE
then DFS(G[i.j]):
inc(Time):
if F[i]-0
then F[i]:-T1me:
end:
{Вервина i обработана вообще)
{Вершина i обработана на текущем ыаге)
{Увеличить время обработки вершин)
(Пока у вершины есть наследники)
(Если наследник не обрабатывался)
(на текущем шаге)
{Запустить поиск в глубину от)
{наследника)
(Увеличить время обработки вершин)
(Если вершине 1 не устанавливалось время)
{завершения обработки - то установить)
Процедура AddDominator(v), также вызываемая из процедуры BuildDominators, до-
бавляет в список доминаторов вершину v следующим образом: все вершины, до-
стигнутые из текущей (Си гС[ 1 ] < > WHITE), вычеркиваем из домипаторов, а теку-
щую добавляем в список доминаторов (dom[Domi ]:-GRAY;).
Procedure AddOominator (Oomi:Iongint):
for 1:-1 to N do
if (CurC[i]«WHITE)
then dom[i]:*WHITE:
dom[Domi]:=GRAY:
for i:-l to N do
curCIU:-WHITE:
end:
{Для всех вершин)
(Если она достигнута от текущей)
(вычеркиваем ее из доминаторов)
(Вносим текущуо в список доминаторов)
{Для всех вершин устанавливен отметку)
(недостигнута от текущей)
188
Глава 2. Основы алгоритмизации
Следующий шаг после построения доминаторов исходного графа — транспониро-
вание графа (другими слонами — смена стрелок на дугах на противоположные).
Это делается с помощью процедуры Reverse. Процедура Reverse по исходному гра-
фу G(1..N,1..M], kg[1..N] строит граф B[1..N,1..M], kB[1..N):
Procedure Reverse:
for 1:-1 to N do KB[1]:-0: {Обнуляем количества дуг из вершины 1)
for i:-i to N do
for j:-l to kG[i] do
begin
inc(kB[G[i.j]J): {Инкрементируем количество}
{дуг из вершины i)
b[G[i.JJ.kBCGCI.j]]]:-i: {Добавляем в граф обратную дугу)
end:
end:
Процедура BuildDominators2 строит множество доминаторов на транспонированном
графе, параллельно формируя сильносвязные компоненты (ССК) исходного графа:
Procedure BuiId0ominators2:
T1me:-0:
for i:-l to N do
begin
Color[i]:=WHITE:
CurC[1 ] -.-WHITE:
Kart[1]:-WHITE:
SortF-
for v:-l to N do
If color[Q[v]]-WHITE
then
{Для всех вершин }
{Свободна вообще)
{Свободна в текущем цикле)
{Не входит в ССК)
{Сортируем в порядке убывания времена)
{завершения обработки вершин при)
{построении множества доминаторов исходного)
{графа - результат QC1..N])
{В порядке убывания времен обработки)
{Если вершина свободна)
beDFS2(O[v]):
AddDomi nator2(Q[v]):
end:
for 1:-1 to N do
If (Kart[1]<>WHITE)
then begin
inc(M):
T[H]:-i:
•{Построить доиинатор)
{Добавить доминатор)
{Для всех вершин)
{Если входит в ССК)
(вносим в результат)
SortT: {Сортируем результирующее множество)
writeln(M): for i:=l to M do writeln (Т[Ц): {выводим его)
Процедура DFS2 поиска в глубину по транспонированному графу выглядит следу-
ющим образом:
Procedure 0FS2C1:byte):
Var J : byte:
begin
color[i]:=GRAY: curc[i]:-GRAY:
for j:-l to kB[1] do
2.4, Алгоритмы на графах
189
if color[B[i.j]]-WHITE then DFS2(B[i.j]):
end:
Процедура AddDominator2, обеспечивающая корректное построение доминаторов
транспонированного графа и сильносвязных компонентов исходного (и транспо-
нированного) графа такова:
Procedure AddDominator2 (Domi:longint):
var
MinT. MinK. KS : longint:
FIDom : boolean:
Количество вершин в текущей ССК)
Для всех вершин}
Если вершина достигнута)
инкрементировать кол-во вершин в текущем ССК)
Если в текущем ССК вершин)
больше, чей одна)
... ......... (то внести их всех в КАЙТ)
if CurC[i]oWHITE then Kart[i]:-GRAY:
for i:=l to N do curC[i]:-WHITE: {Сделать все вершины)
{свободными для нового шага)
if Curc[i]<>WHITE
then inc(KS):
if ks>l
then
Полный текст программы, решающей поставленную задачу, приводится в листин-
ге 2.36.
Листинг 2.36. Программа «Карточки-
program by94dltl:
Const
WHITE - 1:
GRAY - 2:
var
G.B : array [1..100,1..100] of byte:
Color.kG.kB.Dorn.CurC.Kart: array [1..100] of byte:
D.F.T.O : array [1..100] of longint;
N.i.j.Time.v.u.H.GRA_Y : longint:
Function maxta.b:longint):longint:
if (a>b) then max:-a else max:=b
Procedure Reverse:
begin
for i:-l to N do KB[i]:=0:
for i:=l to N do
for j.-l to kG[i] do
begin
1nc(kB[G[1.j]]):
b[G[1.j].kB[G[i.j]]]:-i;
Procedure AddDominator (Domi:longint):
begin
for 1:=1 to N do
1f CurC[i]oWHITE then dom[i]:-WHITE:
dom[Domi]:-GRAY;
продолжение&
Глава 2. Основы алгоритмизации
Листинг 2.36 (продолжение)
for i:-l to N do CurC[ij:“WHITE:
end;.
Procedure OFS(i:byte):
Var j : byte;
begin
color[1]:=GRAY; curC[i]:-GRAY; inc(Time):
for j:=l to kG[i] do
if curC[G[i.j]]-WHITE then DFS(G[i.j]):
inc(Time):
if F[i]=0 then F[i]:-Time:
end:
Procedure BuildDaninators:
begin
Time:=0;
for i:-l to N do
begin
Color[i]:-WHITE; Oom[iJ:“WHITE:
CurC[iJ:“WHITE: F[i]:-0:
end:
for v:-l to N do
if color[v]-WHITE
then begin DFS(v): AddDominator(v): end:
end:
Procedure SortF:
i.j.MaxO.k.Temp :longint:
begin
for 1:-1 to N do Q[i]:-i:
for i:-l to N-l do
begin
MaxD:-F[i]: K:=1:
for j:=i+l to N do
if F[j]>MaxO
then begin MaxD:-F[jJ: k:-j: end:
F[k]:-F[1]; F[1]:-MaxD: Temp:=Q[k]:
O[k]:-Q[iJ: Q[i]:-Temp;
Procedure SortT:
i.j.MaxO.k.Temp :longint:
begin
for i:-l to M-l do
begin
MaxD:-T[i]; K:-i;
for j:-i+l to M do
if T[j]<MaxD
then begin MaxD:-T[j]: k:-j: end:
T[k]:-T[i]: T[i]:-MaxD:
Procedure DFS2(1:byte):
var
2.4. Алгоритмы на графах
191
COlor[i]:=GRAY: curcLi]:=GRAY:
for j:=l to kB[i] do
if color[B[i.j]]-WHlTE then DFS2(B[i.j]):
Procedure AddDominator2 (Domi:longint):
MinT. MinK. KS : longint:
FIDom : boolean:
KS:-0:
for i:=1 to N do
if Curc[i]oWHITE then inc(KS):
if ks>l
for i:=l to N do
if CurC[i]oWHITE then Kart[i]:-GRAY:
for i:=l to N do curC[i]:=WHITE:
end:
Procedure BuildDominators2:
begin
Time:“0:
for i:=l to N do
Color[1]:-WHITE:
CurCti] :-WHITE: Kart[i]:-WHITE:
end:
SortF:
for v:=l to N do
if color[Q[v]]-WHITE
then begin DFS2(Q[v]): AddDominator2(Q[v]): end:
for 1:-l to N do
if (KartCiWHITE)
then begin inc(M): T[M]:-i:end:
SortT:
writeln(M):
for i:=l to M do writeln (T[iJ):
assign!input.'input.txt’): reset(input):
assigntoutput.’output.txt’): rewrite(output):
readln(N):
M:-0:
for i:-l to N do
begin
readln(u.v):
inctkGfu]): G[u.kG[u]]:-v:
if u=v then begin inc(M): T[M]:-u;end:
end:
BuildDonrinators: Reverse: 8uildDominators2:
closetinput): closetoutput):
Задача «Межшкольная сеть»
Венгрия, ЮГ96 — Международная олимпиада по информатике.
Некоторые школы связаны компьютерной сетью. Между школами заключены
соглашения: каждая школа имеет список школ-получателей, которым она рассы-
лает программное обеспечение всякий раз, получив новое бесплатное программное
192
Глава 2. Основы алгоритмизации
обеспечение (извне сети или из другой школы). При этом если школа В есть в
списке получателей школы А, то школа А может и не быть в списке получателей
школы В.
Требуется написать программу, определяющую минимальное количество школ,
которым надо передать по экземпляру нового программного обеспечения, чтобы
распространить его по всем школам сети в соответствии с соглашениями (подза-
дача А).
Кроме того, надо обеспечить возможность рассылки нового программного обеспе-
чения из любой школы по всем остальным школам. Для этого расширить списки
получателей некоторых школ, добавляя в них новые школы. Требуется найти ми-
нимальное суммарное количество расширений списков, при которых программ-
ное обеспечение из любой школы достигло бы остальных школ (подзадача В). Одно
расширение означает добавление одной новой школы-получателя в список полу-
чателей одной из школ.
Первая строка входного файла IN PUT.TXT содержит целое число N — количество школ
в сети (2 < N < 100). Школы нумеруются первыми N положительными целыми чис-
лами. Каждая из следующих N строк задает список получателей. Строка с номером
1 +1 содержит номера получателей i-й школы. Каждый такой список заканчивает-
ся нулем. Пустой список содержит только 0.
Программа должна записать 2 строки в выходной файл OUTPUT.TXT: в его первую
строку — решение подзадачи А (положительное целое число), во вторую — реше-
ние подзадачи В.
В качестве примеров входного и выходного файлов можно привести следующие:
□ INPUT.TXT
5
2 4 3 0
0
1 0
□ OUTPUT.TXT
Подзадача А требует найти доминантное множество, то есть минимальное множе-
ство вершин исходного графа, из которого есть «цепи» ко всем остальным верши-
нам графа..
Обходом в глубину, пока есть свободные (неперекрашенные из белого в серый цвет)
вершины, находим все, которые достижимы из данной свободной. И из множества
доминант вычеркиваем все достижимые на текущем ходу и добавляем в множе-
ство доминант исходную свободную.
Подзадача В требует найти количество ребер, которые нужно добавить, чтобы ис-
ходный ориентированный граф стал сильносвязным. По исходному графу строит-
ся транспонированный. Для нового (транспонированного) графа опять строится
доминантное множество.
2.4. Алгоритмы на графах
193
Если и первое, и второе доминантное множества состоят из одного и того же эле-
мента — вершины 1, то граф был силыюсвязный и добавлять ребер не нужно. В лю-
бом другом случае нужно добавить максимум из количеств элементов в построен-
ных доминантных множествах.
ПРИМЕЧАНИЕ--------------------------------------------------
Поскольку почти такая же задача полностью рассмотрена в предыдущем пункте, пол-
ное описание решения здесь не приводится.
Альтернативным решением этой задачи может быть решение с использованием
построения матрицы достижимости методом Флойда. Тогда все вершины разби-
ваются на группы:
1) истоки (в них нет входящих дуг);
2) стоки (из них нет исходящих дуг);
3) промежуточные (есть и входящие, и исходящие).
Ответ подзадачи А — количество истоков. В подзадаче В, если нет ни истоков, ни
стоков, то граф — ССК и добавлять ребер не нужно. Иначе выбираем максималь-
ное из количеств истоков и стоков — это и будет количество ребер, которые нужно
добавить.
ПРИМЕЧАНИЕ--------------------------------------------------
В подзадаче В мы добавляем связи между истоками и стоками, в результате чего граф
и становится сильносвязным компонентом.
Задача «Винни-Пух и Пятачок»
Республиканская школьная олимпиада, 1995 год.
Винни-Пух и Пятачок нанялись защищать компьютерную сеть от хакеров, которые
выкачивали из компьютеров секретную информацию. Компьютерная сеть Винни-
Пуха и Пятачка состояла из связанных между собой больших ЭВМ, к каждой из
которых подключалось несколько терминалов. Подключение к одной из больших
ЭВМ позволяло получить информацию, содержащуюся в памяти этой ЭВМ, а так-
же всю информацию, доступную для других ЭВМ, к которым данная могла направ-
лять запросы. Хакеры и раньше нападали на подобные компьютерные сети, и их
тактика была известна. Поэтому Винни-Пух и Пятачок разработали специальную
программу, которая помогла принять меры против готовившегося нападения.
Тактика хакеров такова: при нападениях они всегда получают доступ к информа-
ции всех ЭВМ сети. Добиваются они этого, захватывая некоторые ЭВМ сети так,
чтобы от них можно было запросить информацию у оставшихся ЭВМ. Вариантов
захвата существует множество. Например, захватить все ЭВМ. Но хакеры всегда
выбирают такой вариант, при котором суммарное количество терминалов у захва-
ченных ЭВМ минимально.
ПРИМЕЧАНИЕ------------------------------------------------------
В сети Винни-Пуха и Пятачка ни у каких двух ЭВМ количество терминалов не совпадает.
194 Глава 2. Основы алгоритмизации
Вам необходимо написать программу, входными данными которой было бы опи-
сание сети, а выходными — список номеров ЭВМ, которые могут быть выбраны
хакерами для захвата сети согласно их тактике. Ввод осуществляется из файла с
именем INPUT.TXT. Возможен также ввод с клавиатуры.
1. Структура входных данных (построчно):
□ N — количество ЭВМ в сети;
□ Т[1] — количество терминалов у первой ЭВМ;
□ Т[2] — количество терминалов у второй ЭВМ;
□ ...;
□ T[N] — количество терминалов у N-й ЭВМ;
□ А[1] В[1] — права на запрос;
□ А[2]В[2];
□ ...;
□ А[К]В[К];
□ 0 0.
А[1] и В[1] — номера ЭВМ; каждая пара A[i] В[ 1 ] обозначает, что ЭВМ с номе-
ров А[1] имеет право запрашивать информацию у ЭВМ с номером В[1] (А[ i ] не
равно B[i]). Последняя строка (0 0) обозначает конец списка прав на запрос.
Числа N и Т[ 1 ] — натуральные; Т[ 1 ] £ 1000, N < 50, К <2450.
2. Структура выходных данных:
□ С[1] С[2]... С[М] — номера захватываемых ЭВМ;
□ М — количество захватываемых ЭВМ.
Например:
□ INPUT.TXT
5
100
2
3
10
1 3
3 2
4 3
□ OUTPUT.TXT
Поиском в глубину находим множество доминаторов сети (истоки графа). Однако
для оптимального выбора машин по количеству терминалов необходимо выбрать
лучшую машину (с наименьшим количеством терминалов) в каждом силыюсвяз-
ном компоненте, Для этого инвертируем граф (меняем направление всех дуг гра-
2.4. Алгоритмы на графах
195
фа на противоположное) и поиском в глубину по инвертированному графу нахо-
дим все его сильносвязные компоненты (последовательные деревья, которые по-
лучаются поиском в глубину). Нас интересуют только сильносвязные компонен-
ты с количеством вершин больше 1. Из их числа находим вершину с минимальным
количеством терминалов и заменяем соответствующий доминатор (если от этой
ССК ранее в доминаторы попала другая вершина).
Опять же полное решение не приводится по причине его сходства с решением за-
дач из двух предыдущих пунктов.
Поиск в ширину
Для множества задач на графах, решение которых сводится к перебору всех воз-
можных путей по ребрам (вершинам), может быть применен метод, называемый
«поиском в ширину». Поиск в ширину подразумевает такой порядок перебора всех
возможных вариантов, при котором вначале рассматриваются все пути из двух вер-
шин (начиная с заданной текущей), затем все пути из трех вершин, четырех и т. д.
Как правило, для организации поиска в ширину используется очередь.
Задача «Уличная гонка»
Голландия, 1.ОГ95 — Международная олимпиада по информатике.
На рисунке изображен пример плана улиц для гонки. Вы видите точки, помечен-
ные числами от 0 до W (где W= 9), а также стрелки, соединяющие их. Точка 0 явля-
ется стартовой, точка N— финишной. Стрелками представлены улицы с односто-
ронним движением. Участники гонки передвигаются от точки к точке по улицам
только в направлении стрелок. В каждой точке участник гонки может выбрать
любую из исходящих стрелок.
Назовем план улиц хорошим, если он обладает следующими свойствами:
1) каждая точка плана может быть достигнута со старта;
2) финиш может быть достигнут из любой точки плана;
3) у финиша нет исходящих стрелок.
Для достижения финиша участник гонки не обязан пройти через все точки. Одна-
ко некоторые точки невозможно обойти. Назовем их неизбежными. В примере
196
Глава 2. Основы алгоритмизации
такими точками являются точки 0,3,6,9. Для заданного хорошего плана ваша про-
грамма должна определить множество неизбежных точек (за исключением старта
и финиша), которые должны посетить все участники (подзадача А).
Предположим, что гонка должна проводиться за два последовательных дня. Для
этой цели план должен быть разбит на два хороших плана: по одному на каждый
день. В первый день стартом является точка 0, а финишем служит некая «точка
разбиения». Во второй день старт находится в этой точке разбиения, а финиш —
в точке N. Для заданного хорошего плана ваша программа должна определить мно-
жество всех возможных точек разбиения (подзадача В).
Точка ^является точкой разбиения для хорошего плана С, если 5 отличается от старта
и финиша С, и план разбивается ею на два хороших плана без общих стрелок и с
единственной общей точкой — S. В примере точкой разбиения является точка 3.
Во входном файле INPUT.TXT описан хороший план, содержащий не более 50 точек
и не более 100 стрелок. В файле имеется N + 1 строка. Первые N строк содержат
конечные точки стрелок, исходящих соответственно из точек от 0 до N -1. Каждая
из этих строк заканчивается числом —2. В последней строке содержится число -1.
Ваша программа должна записать две строки в выходной файл OUTPUT.TXT. Первая
строка должна содержать количество неизбежных точек в заданном плане и номе-
ра этих точек в любом порядке (подзадача А). Вторая строка должна содержать
количество точек в заданном плане и номера этих точек в любом порядке (подза-
дача В).
Входные и выходные данные могут быть, например, такими:
□ INPUT.TXT
1 2 -2
3 -2
3 -2
5 4-2
6 4-2
6 -2
7 8 -2
9 -2
5 9-2
□ OUTPUT.TXT
2 3 6
1 3
Для решения подзадачи А нужно найти все неизбежные точки. Это делается поис-
ком в ширину: если после взятия вершины из очереди она становится пустой, то эта
вершина — неизбежная.
Для решения подзадачи В нужно проверить каждую неизбежную точку, чтобы
выяснить, является ли она точкой разбиения. Для этого удаляем эту точку из гра-
фа и поиском в ширину строим два множества: достижимые точки от начала и недо-
стижимые точки от начала. Если существует хоть одно ребро из недостижимой
точки в достижимую, то текущая неизбежная точка не является возможной точ-
кой разбиения (по определению точки разбиения).
2.4. Алгоритмы на графах
197
Рассмотрим алгоритм решения задачи более подробно. Начнем с тела главной про-
граммы:
InputData:
BFS:
OutSubA:
for к:-1 to SubA do
begin
DelArcs(Duty[k]):
BFS;
RetArcs(Outy[k)):
for i:-0 to N-l do
begin
while (а[1 ,JM) do
begin
if (color[i]-WHITE) and
(color[a[t. j]]oKHITE)
then begin
Duty[k]:-0:
break
inc(j):
end:
end:
end:
OutSubB:
{Ввод исходных данных)
{Поиск в ширину - находим неизбежные точки)
{Вывод ответа для подзадачи А)
{Для каждой неизбежной точки)
{удаляем неизбежную точку)
{Поиск в ширину -}
{Строим множества достижимых Со1бг[1]-1)
{и недостижимых Со1ог[1]-0 вершин)
{Возвращаем неизбежную точку в граф)
{для всех вершин)
{J - номер дуги, исходящей из вершины)
{пока дуга существует)
{Если исходная вершина достижима)
{а конец дуги - недостижима)
{Это - не точка разбиения)
{Перейти к проверке следующей)
{неизбежной точки)
{Взять следующую дугу)
Процедура ввода исходных данных:
{Вывод ответа для подзадачи В)
Procedure Inputdata:
1:4): j:-l: read(a[0.1]):
while (a[i.j]o-l) do
while(a[i.J]o-2) do
begin
1nc(J):
read(a[i.j])
end:
if j >2 then Sort:
readin; 1nc(i):
j:-l: read(a[i.j]);
{Начинаем ввод с вершины 0}
(Пока не закончена обработка вершин)
{Пока не закончена обработка дуг)
{Увеличить номер дуги)
{Прочитать дугу)
{Если дуг больше чем одна, то)
{отсортировать их по возрастанию)
{номера конечной вершины).
{Перейти к считыванию следующей строки)
{Прочитать первый элемент строки)
{Вернуться к началу цикла ПОКА)
{Занести в N номер последней вершины)
Поиск в ширину осуществляется с помощью процедуры BFS (Breadth-First Search).
procedure BFS:
var i.j : longint;
begin
for 1:=0 to N do color[i]:-WHITE: {Все вершины свободны)
color[0]:-GRAY: {Начальная вершина - обработана)
SubA:=0: {Количество неизбежных вершин - 0}
198
Глава 2. Основы алгоритмизации
ВедО:-1:
EndQ:-0:
Put(O):
while (BegQ<=EndQ) do
begin
Get(i):
if BegQ>EndQ
then
begin
inc(SubA);
Color[i]:=ColSubA
end:
j:-l:
while (a[1.j]>=0) do
begin
if color[a[i,j]]-WHITE
then
begin
Put(a[i.j]):
color[a[i.j]]:-GRAY:
end:
inc(j):
end:
end:
{Начало очереди}
{Очередь пуста}
{Поместить в очередь начальную вершину}
{Пока очередь не пуста)
{взять вершину 1 из очереди)
{Если очередь осталась пустой)
{инкрементировать количество)
{неизбежных вершин}
{Пометить неизбежную вершину}
{номер дуги из вершины 1)
{пока дуги не кончились)
{Если вершина a[i.j] свободна}
{поставить ее в очередь}
{пометить вершину a[1.j])
{как использованную)
{взять следующую дугу}
Вывод ответа для подзадачи А и накопление неизбежных точек в массив Duty осу-
ществляется так:
procedure OutSubA:
begin
SubA:-subA-2:
write(subA):
j:-0;
for i:-l to N-l do
if (color[1]-ColSubA)
then
begin
write!' ’.1):
1nc(j):
Duty[j]:-i:
end:
writeln:
{Начальная и конечная точки не}
{считаются неизбежными точками}
{j - количество неизбежных точек}
{Для всех вершин)
{Если она - неизбежная}
{Выводим ее)
{Инкрементируем кол-во неизбежных вершин)
{Запоминаем номер неизбежной вершины}
Полный текст программы — в листинге 2.37.
Листинг 2.37. Программа “Уличная гонка-
program io96d2t4:
Const
White 1:
Gray - 2:
ColSubA - 4;
var
Color.Q,Duty
: array [0..101.0..101] of integer:
: array [0..100] of integer:
2.4. Алгоритмы на графах
199
N.i.j.subA.SubB.BegQ.EndQ.k : longint;.
Procedure Put(x:longint):
Begin inc(EndQ): Q[EndO]:-x: end:
Procedure Get(var x:longint):
Begin x:-Q[BegQ]: inc(BegQ): end;
Procedure Sort:
m.min.rmin.k : longint;
begin
for m:-l to j-2 do
begin
min:=a[1,m]: rmin:-fn;
for k:-m+l to j-1 do
if a[1.k]<m1n
then begin min:«a[i,k]; rmin:-k: end:
a[1.rmin]:-a[i.m]: a[1.m]:min:
end:
Procedure Inputdata:
i:-0: J:-l: read(a[0.1]):
while (a[i,j]o-l) do
begin
while(a[1.J]o-2) do
begin inc(j): read(a[i,j]) end:
if j >2 then Sort:
readln:
inc(i): j:-l: read(a[i,j]>:
end:
N:-1:
end:
procedure OutSubA:
begin
.SubA:-subA-2: write(subA): j:=0: Duty[0]:-0:
for i:-l to N-1 do
if (colorCiJ-ColSubA)
then begin writer '.i): inc(j): Duty[j]:-i: end:
writeln:
procedure BFS:
var i.j : longint:
begin
for i:-0 to N do color[i]:-WHITE:
for 1:-0 to N do Q[i]:-0;
COlor[0]:-GRAY: SubA:-0: BegQ:-l: EndQ:-0;
Put(O):
while (BegQ<=EndQ) do
begin
Get(i):
if BegQ>EndQ
then begin inc(SubA): Color[i]:=ColSubA end:
продолжение
200
Глава 2, Основы алгоритмизации
Листинг 2.37 (продолжение)
while (a[i.j]>-0) do
if color[a[i.j]]=Mi!TE
then begin
PuttaCi.J]):
color[a[i.j]]:-GRAY:
end:
inc(j):
end:
end:
end: -
Procedure OutSubB:
begin
SubB:-O:
for 1:-1 to SubA do
if Duty[i]oO then inc(SubB):
write(subB):
for i:-1 to SubA do
if Duty[i]oQ then writeC '.Duty[i]):
writeln:
Procedure DelArcsfk:longint):
for j:-N Dcwnto 1 do a[k.j+l]:-a[k.j]:
a[k.l]:--2:
for i:-0 to N-l do
begin
j:-l:
while (a[i.j]>=0) do
begin
if a[i.j]-k then a[1.j]:-max1nt:
inc(j):
end:
end:
end:
Procedure RetArcs(k:longint);
begin
for i:-0 to N-l do
begin
j:-l:
while (a[i.j]>-0) do
if a[i.j]=maxint then a[i.j]:-k:
inc(j):
end:
for j:-l to N do a[k.j]:-a[k.j+l]
end:
begin
assigndnput.'input.txt'): reset(input):
assigntoutput.'output.txt'): rewrite(output):
InputData:
BFS: {Поиск в ширину - находим неизбежные точки)
OutSubA:
2.4. Алгоритмы на графах
201
for к:-1 to SubA do
begin
DelArcs(Duty[k]>: BFS: RetArcs(Outy[k]):
for i:-0 to N-l do
begin
j-.-l:
while (a[i,j]>-0) do
begin
if (color[i]-WHITE) and (color[a[i ,j]]oWHITE)
then begin Duty[k]:-O: break end:
1nc(j):
end:
end:
OutSubB:
close(input): close(output):
end.
О размерностях, использованных в задачах
массивов
Внимательный читатель заметил, что в некоторых случаях объявлены массивы
меньшей размерности, чем реально требуется по условиям задачи. Это сделано на-
меренно из следующих соображений.
1. На международных олимпиадах по информатике для школьников с июля 2001
года используются 32-битные компиляторы (Free Pascal и GNU С), для кото-
рых разрешаемые размерности объявляемых массивов существенно больше, чем
те, что требуются по условиям задачи.
2. Основная цель материала — продемонстрировать предлагаемые базовые алго-
ритмы решения задач на графах, и не хотелось усложнять материал, затемняя
тем самым суть базовых алгоритмов.
Обзор представленной теоретической
информации
Цель данного пункта — коротко перечислить теоретические сведения для реше-
ния задач на графах. Читатель может использовать этот перечень для самоконтро-
ля успешности усвоения данного .материала. Если вы понимаете, что скрывается
под приведенным названием, и умеете выполнять названную работу, — значит,
цели, поставленные автором (и вами), достигнуты.
Вот этот перечень вопросов для самоконтроля.
1. Сведение задач к графам.
2. Метод Флойда. Применяется для поиска кратчайших расстояний между всеми
парами вершин графа (одновременно можно построить и сами кратчайшие пути
от каждой вершины до каждой).
3. Построение матрицы достижимости графа.
4. Построение множества истоков и множества стоков (исток — вершина, в кото-
рую нет входящих дуг, сток — вершина, из которой нет исходящих дуг).
202
Глава 2. Основы алгоритмизации
5. Метод Дейкстра. Применяется для поиска кратчайших расстояний от одной
вершины до всех остальных и построения оптимальных маршрутов от одной
вершины до всех остальных.
6. Поиск в глубину. Применяется для решения произвольных задач на графах,
требующих соответствующего порядка обхода («в глубину») графа.
7. Раскрашивая пройденные вершины и (или) дуги, можно управлять порядком
и способами обхода (например, однократное или многократное использова-
ние дуг и вершин).
8. Построение множества истоков и стоков (как истоков на транспонированном
графе).
9. Построение сильносвязных компонент графа. Сильносвязный компонент гра-
фа — это множество вершин, каждая из которых достижима из всех вершин.
10. Поиск в ширину. Применяется для решения произвольных задач на графах,
требующих соответствующего порядка обхода («в ширину») графа. Раскра-
шивая пройденные вершины и (или) дуги, можно управлять порядком и спо-
собами обхода (например, однократное или многократное использование дуг
и вершин).
2.5. Генерация комбинаторных объектов
Существует набор задач, решение которых заключается в генерации всех элемен-
тов таких комбинаторных объектов, как множество всех подмножеств, переста-
новки, сочетания, размещения, перестановки с повторениями, сочетания с повто-
рениями. Для каждого сгенерированного элемента проверяются какие-то свойства
для конкретной задачи.
ПРИМЕЧАНИЕ---------------------------------------------------
В дальнейшем предлагается следующий порядок изложения материала для каждого
комбинаторного объекта: пример, алгоритм, программа, комментарии к программе.
Все программы для большей наглядности оперируют с массивом символов от А до Z.
Очевидно, что предлагаемые алгоритмы и программы практически не изменяются при
работе с массивами элементов любого типа, требуемого по условиям задачи (напри-
мер, массивами чисел, слов, геометрических фигур и т. д.).
Множество всех подмножеств
Пусть мы имеем множество из четырех компонент, которые обозначаем латински-
ми буквами А, В, С, D. И пусть, по условиям задачи, требуется выбрать подмноже-
ство, состоящее из нескольких компонент, обладающее некоторым свойством.
Предлагается такой способ решения задачи: мы генерируем все возможные под-
множества данного множества и для каждого из сгенерированных подмножеств
проверяем, удовлетворяет ли оно заданному свойству.
Альтернативный вариант задачи — подсчитать все подмножества данного множе-
ства, обладающие заданным свойством.
2.5. Генерация комбинаторных объектов
203
Например: для множества из четырех символов Л, В, С, D множество всех подмно-
жеств включает в себя следующие множества:
□ пустое множество;
□ одноэлементные множества: {А}, {В}, {Q, {£>};
□ двухэлементные множества: {Л, В}, {Л, С}, {Л, £>}, {В, С}, {В, О}, {С, О};
□ трехэлементные множества: {Л, В, С], {/1, В, О}, {Л, С, D}, {В, С, D};
□ четырехэлементное множество: {А, В, С, D}.
В случае, когда порядок генерации подмножеств не играет роли (при необходимо-
сти подсчитать все подмножества, обладающие заданным свойством, так оно и есть),
одни из наиболее просто кодируемых алгоритмов генерации множества всех под-
множеств выглядит следующим образом: заведем вектор В, состоящий из четырех
чисел, каждое из которых может принимать значение 0 или 1. И будем считать, что
значение 1 указывает на включение соответствующего по номеру компонента ис-
ходного множества в искомое. Значение 0 указывает на то, что элемент не включа-
ется.
Рассмотрим теперь последовательность двоичных чисел от 0 до 15 и соответству-
ющие им подмножества:
1. {0000} — пустое множество;
2. {0001} - А, {0010} - В, {0100} - С, {1000} — П;
3. {0011} - АВ, {0101} - АС, {0110} - ВС, {1001} - AD, {1010} - BD, {1100} - CD;
4. {0111} -АВС, {1011} - ABD, {1101} -Д СО, {1110} - BCD;
5. {1111} -ABCD.
Таким образом, всего имеется 16 различных подмножеств множества из 4 элемен-
тов. В общем случае множество всех подмножеств множества из N элементов со-
держит 2V элементов.
Алгоритм, обеспечивающий генерацию множества всех подмножеств из N элемен-
тов, может быть неформально описан следующим образом: формируем массив,
состоящий из N нулей, и рассматриваем его как пустое множество. Таким образом,
начальное значение текущего подмножества — пустое множество.
Для получения следующего подмножества из текущего подмножества обрабаты-
ваем текущий массив из чисел 0 или 1 следующим образом: справа (от первого
элемента массива к последнему) ищем первое число, равное 0. Если такое число не
найдено, то текущее подмножество является последним, то есть множеством, со-
стоящим из всех элементов. На этом алгоритм заканчивает свою работу. Если
же элемент, равный 0, найден, то он заменяется на 1, а все числа справа от него
(если таковые имеются) заменяются на нули.
Более формализованно этот алгоритм может быть записан следующим образом:
Ввод (N)
Обнуление массива В из N+1 элемента
Вывод (Пустое множество)
Пока BCN+13-0
204
Глава 2. Основы алгоритмизации
Пока В[1]-1 делать В[1]-0, i’i+1
В[1]-1
Вывод (множества, определяемого массивом В)
Теперь легко написать текст программы, которая считывает число элементов во
множестве (N) и выводит на экран множество всех подмножеств, обозначая эле-
менты соответствующими по порядку латинскими буквами (листинг 2.38).
Листинг 2.38. Программа генерации множества всех подмножеств
const
alphabet : string[26] = 'ABCDEFGHIJKLMNOPORSTUVWXYZ':
var
b : array [1..100] of byte:
N.i : byte:
begin
readln(N);
for i:-l to N*1 do b[i].—0:
writeln ('Пустое множество'):
while (b[N+l]-0) do
while B[i]=l do
begin inc(i): end:
B[1]:-l:
for 1:-1 to n do
if b[i]-l then write(alphabet[i]):
writeln:
ПРИМЕЧАНИЕ-------------------------------------------------------
При необходимости обрабатывать (анализировать) построенные подмножества можно
добавить вызовы процедур обработки, получающие в качестве параметра массив В,
указывающий своими единичными элементами номера элементов множества, вклю-
ченных в текущее подмножество.
Перестановки
Пусть мы имеем 4 компонента, обозначенные буквами А, В, С, D. Тогда множество
всех перестановок из этих компонент будет включать следующие элементы:
ABCD, BACD, CABD, DABC, ABDC, BADC, CADB, DACB, ACBD, BCAD, CBAD,
DBAC, ACDB, BCDA, CBDA, DBCA, ADBC, BDAC, CDAB, DCAB, ADCB, BDCA,
CDBA,DCBA.
Приведем алгоритм построения следующей перестановки 9 компонент, обозначен-
ных цифрами от 1 до 9. Первая из таких перестановок — это:
123456789.
Пусть текущая перестановка из 9 компонент:
19584763 2.
2.5. Генерация комбинаторных объектов 205
Какой будет ‘следующая перестановка, если мы строим перестановки в лексикогра-
фическом порядке (то есть в порядке возрастания величины числа, составленного
из этих цифр)? Правильный ответ таков:
195862-347.
Как он получается? Прежде всего необходимо просматривать исходный массив от
конца к началу, чтобы найти первое число, которое меньше предыдущего; в нашем
случае — это 4 (7 < 6 < 3 < 2, а 4 < 7). Далее среди просмотренных чисел справа от
найденной четверки мы ищем последнее число, которое больше 4. Это число 6 (7 > 4,
6 > 4,3 < 4,2 < 4). Затем меняем эти 2 найденных числа (4 и 6) местами и получаем:
195867432.
И теперь числа (справа от 6), которые составляют убывающую последовательность
(743 2), попарно меняем местами так, чтобы они составили возрастающую после-
довательность (2 34 7):
195862347.
Это и есть следующая перестановка.
А какая перестановка будет последней для данного примера? Надеюсь, что вдум-
чивый читатель догадался и сам:
987654321.
Неформально алгоритм построения очередной перестановки по текущей может
быть записан следующим образом:
□ От конца к началу перестановки ищем первый элемент B[i] такой, что
BC1J <В[1 +1].
□ Запоминаем его индекс — I.
□ От элемента I +1 до конца ищем последний элемент, больший, чем В[ 1 ], и запо-
минаем его индекс — К.
□ Меняем местами эти элементы с номерами I и К.
□ Всю группу элементов от (1 + 1)-го элемента до N-ro попарно меняем местами:
(1 + 1 )-й элемент с N-м, (1 + 2)-й элементе (N - 1)-мит. д.
Формализованный алгоритм генерации всех перестановок из N элементов может
выглядеть следующим образом:
Ввод N
Прописываем массив В последовательно числами от 1 до N
Это первая - начальная - перестановка, выводим ее
Пока (истина)
1-N
Пока (1>0) и (В[1]>=В[1+13). 1-1-1
Если 1=0. то конец работы
Для j от 1+1 до N
если B[j]>B[l], то K-j
Обмен значений ВИЗ и В[к]
206
Глава 2. Основы алгоритмизации
Для j от i*l до (1+ ((N+1-т) div 2))
Обиен значений B[j] и B[N+i+l-j]
Вывод текущей перестановки В
Понятно, что цикл парных перестановок «хвоста» массива В нельзя делать от
(i + 1)-го до N-ro элемента, иначе элементы поменяются местами по два раза и по-
лучится, что ничего не изменилось. Цикл нужно выполнить для половины этого
«хвоста». Этому и служит несколько сложное для понимания значение конечной
переменной цикла: i + (N + 1 - i) div 2.
Листинг 2.39. Программа, генерирующая перестановки из N компонент
const
alphabet : string[26] - 'ABCDEFGHIJKLMNOPQRSTUWXYZ':
var
b : array [1..100] of byte:
N.i.j.k : byte:
Procedure SwapB(i.k:byte):
var x : byte:
begin
x:=B[1]: B[i]:-B[k]: B[k]:-x:
end:
Procedure WriteB:
begin
for 1:-1 to N do write({alphabet[b[i]]):
writeln:
end:
begin
readln(N):
for 1:=i to N do b[i]:-i:
WriteB:
while (true) do
i:-N:
while (i>0) and (B[i]>=B[i+l]) do i:-i-l:
if i-0 then exit:
for j:-i+l to N do
if <B[j]>B[i]) then K:-j:
SwapB(i.k):
for j:-i+l to (1+ ((N+l-i) div 2))
do SwapBtj.N+i+l-j):
writeB:
end.
В программе, генерирующей все перестановки из N компонент, обозначенных за-
главными буквами латинского алфавита (листинг 2.39), введены две процедуры:
WriteB и SwapB.
Процедура WriteB вызывается всякий раз, когда построена очередная перестанов-
ка. В данной программе процедура WriteB просто выводит соответствующую по-
следовательность латинских букв. Процедура SwapB(i.k) введена для упрощения
понимания главной программы. SwapB просто обменивает значениями два элемен-
та массива В, которые имеют индексы, соответствующие значениям параметров
процедуры i и к.
2.5. Генерация комбинаторных объектов 207
Процедура SwapB используется в тексте программы два раза:
1) при обмене значениями двух найденных элементов с индексами I и К;
2) при обеспечении попарного обмена элементов «хвоста», в котором текущий эле-
мент с индексом j обменивается местами со своим «партнером», находящимся на
позиции N + 1 + 1 - j. Таким образом, (I + 1)-й элемент поменяется (при J-I+1)
местами с N-м элементом, (I + 2)-й элемент (при J=I + 2) —c(N - 1)-мит.д.
Общее число перестановок из N элементов равно М (читается — факториал).
Напомним,что№. = 1 »2*3* ...»№.
Сочетания
Пусть имеем 5 компонент, обозначенных латинскими буквами А, В, С, D, Е. Тогда
все сочетания из этих 5 компонент по 3, выписанные в лексикографическом по-
рядке, будут таковы:
□ для букв - ABC, ABD, ABE.ACD, АСЕ, ADE, BCD, ВСЕ, BDE, CDE;
□ для цифр - 123,124,125,134,135,145,234,235,245,345.
Неформально алгоритм генерации последовательности чисел в лексикографиче-
ском порядке можно записать следующим образом: выберем наименьшие М из имею-
щихся N чисел и выпишем их в порядке возрастания (в нашем примере — 12 3),—
это будет начальным сочетанием. Очевидно, что наибольшие И чисел из имеющих-
ся (3 4 5), выписанные в порядке возрастания, составят последнее сочетание.
Для того чтобы по текущему сочетанию получать следующее, можно поступать
таким образом: находим позицию в текущем сочетании, на которой не стоит по-
следнее из возможных значений, и затем увеличиваем его на 1. А все последующие
элементы сочетания получаем увеличением на 1 предыдущего элемента сочета-
ния.
Например, пусть текущее сочетание таково:
135.
Анализ начинаем с последней позиции сочетания. 5 — это последнее возможное
значение, потому переходим к предыдущей позиции. 3 — это не последнее воз-
можное значение для этой позиции (каковым является 4 в данном случае). По-
этому мы его увеличиваем на 1 и получаем 4. Число в следующей позиции полу-
чаем прибавлением 1 к этой 4 и получаем 5. Таким образом следующее сочетание
будет:
14 5.
Более строго этот алгоритм может быть записан следующим образом:
Ввод N. М (из сколька. по сколько)
Заносим в массив В числа от 1 до М
Это первое сочетание, выводим его
Пока (истина)
1-М
Пока (1>0) и (b[i]-N-rn+1). i-1-l
208
Глава 2. Основы алгоритмизации
Если 1=0. то работа завершена
В[1]-В[1]+1
Для j от 1+1 до М B[j]=B[j-l]+l:
Вывод В - следующей перестановки
Листинг 2.40. Программа, выводящая в лексикографическом порядке
все сочетания из N латинских букв по М
uses crt:
const
alphabet : string[26] = ’ABCOEFGHIJKLMNOPQRSTUVWXYZ':
var
b : array [1..100] of byte:
N.M.i.j.k : byte:
Procedure WrlteB:
begin
for i:-lto M do write(alphabet[b[i]]):
writeln:
end:
readln(N.M):
for i:=l to M do b[1]:-i;
WriteB:
while (true) do
begin
1;-H:
while (i>0) and (b[i]-N-m+i) do Dec(i):
if 1-0 then exit:
Inc(B[1J):
for j:-i+l to M do B[j]:-B[j-1]+1:
WriteB:
end:
end.
Напомним, что общее число сочетаний из Wэлементов по Мможет быть вычисле-
но по формуле:
C(N,M) =
jVI
Размещения
Для генерации всех размещений из Wэлементов по М можно воспользоваться ком-
позицией алгоритмов, изложенных выше. То есть генерировать все сочетания из N
по М, а затем для каждого полученного сочетания генерировать все перестановки
из М элементов.
Например, при генерации всех размещений из 5 элементов по 3, в случае, когда
сами элементы обозначены латинскими буквами А, В, С, D, Е, нужно получить сле-
дующую последовательность, представленную для компактности в виде 10 строк,
каждая из которых представляет все возможные сочетания из 3 букв первого эле-
мента строки (первые элементы строк представляют все возможные сочетания из
5 букв по 3):
АВСАСВ ВАСВСА CAB СВА
2.5. Генерация комбинаторных объектов 209
ABD...
АВЕ...
ACD...
АСЕ...
ADE...
BCD...
ВСЕ...
BDE...
CDE CED DCE DEC ECD EDC
Общее количество размещений из У элементов по М может быть найдено по фор-
муле:
(N-M)l'
array [1..100] of byte:
Листинг 2.41. Программа, генерирующая все возможные размещения из N букв по М
const
alphabet : Str1ng[26] - 'ABCOEFGHIJKLMNOPQRSTUVWXYZ';
type
barray - array [1..100] of byte:
var
b : barray:
N.M.i.j.k : byte:
z : longint:
Procedure WrlteB(B:barray):
begin
Inc(Z): Write (Z:3.' :
. for i:-l to M do wrlte(alphabet[b[i]J):
writeln;
end:
Procedure SwapB(var B:barray:i.k:byte):
var x : byte:
begin
x:-B[1]: B[i]:-B[k]: B[k]:-x:
end:
Procedure PermuteAl1(В:ba rray:N:byte):
var l.k.j : byte:
WriteB(B):
while (true) do
begin
1:-N:
while (i>0) and (B[i]>-B[i+1]) do 1:-1-1:
if 1-0 then exit:
for j:-i+l to N do продолжение
Глава 2. Основы алгоритмизации
Листинг 2.41 (продолжение)
if (B[j]>B[i]> then K:-j:
SwapB(B.i.k):
for jz-i+l to (1+ ((N+l-i) div 2)) do SwapBtB.j.N+i+l-j):
WriteB(B):
end:
begin
readln(N.M):
for i:-l to M do b[i]:=i:
PermuteAll(B.M):
while (true) do
while (i>0) and (b[1]-N-m+i) do Dec(i):
if i-0 then exit:
Inc(B[i]):
for j:-i+l to M do B[j]:=B[j-l]+l:
PermuteAll(B.M):
end:
readln:
end.
Приведем некоторые пояснения к программе, которая вводит с клавиатуры числа
N, Н и генерирует все возможные размещения из N букв по М (листинг 2.41).
1. Главная программа вводит числа N, М и генерирует по описанному выше алго-
ритму все сочетания из N по М. Для каждого построенного в векторе В сочетания
вызывается процедура PermuteAU, которой в качестве параметров передаются
текущее сочетание В и количество элементов в нем М. Процедура PermuteAl 1 ге-
нерирует для полученного сочетания все возможные перестановки.
2. Массив В передается в процедуру PermuteAU по значению (при объявлении про-
цедуры при параметре В нет ключевого слова VAR), и потому изменения массива В
в процедуре PermuteAU не влияют на содержимое массива В в главной программе.
3. Для того чтобы процедура SwapB могла обменивать значения в В и возвращать из-
мененный массив в вызывающую ее процедуру PermuteAU, массив В добавлен в
параметры процедуры SwapB с передачей по адресу, используя ключевое слово VAR.
4. Для передачи массива в качестве параметра заведен специальный тип BARRAY.
5. Для подсчета всех сгенерированных размещений используется переменная Z в
процедуре WriteB.
Перестановки с повторениями
Перестановки с повторениями допускают повторное использование элементов.
Пусть мы имеем множество, состоящее из двух символов А и двух символов В.
Тогда все перестановки с повторениями из этих символов будут таковы: ААВВ,
ABBA, BABA, АВАВ, ВААВ, ВВАА.
В общем случае, если имеется Л'1 предметов 1 -го вида, N2 предметов 2-го вида и т. д.,
Nk предметов k-ro вида, то общее количество перестановок может быть вычислено
по формуле:
2,5. Генерация комбинаторных объектов
ЛИ
Алгоритм аналогичен генерации перестановок без повторений, за исключением
формирования начальной перестановки:
1=0:
Для j от 1 до к
Для m от 1 до N[J] 1-1+1: B[1]-J:
В программе генерации перестановок с возвращениями (листинг 2.42) количество
К различных типов предметов, обозначенных латинскими буквами, вводится с кла-
виатуры. С клавиатуры также вводятся количества NN[ j ] предметов каждого типа.
Сумма введенных NN [ j ] определяет общее количество элементов в каждой из ге-
нерируемых перестановок.
Листинг 2.42. Программа генерации перестановок с возвращениями
const
alphabet : string[26] - •ABCOEFGHIJKLMNOPQRSTUVWXYZ':
var
b : array [1..100] of byte:
N.I.j.k.m : byte:
NN : array [1..100J of longint:
Procedure SwapB(i,k:byte):
var x : byte;
begin
x:-B[1J: B[1]:-B[k]: B[k]:-x;
end:
Procedure WriteB:
begin
for 1:-1 to N do write(alphabet[b[1]]):
writeln:
readln(K):
N:-0:
for i:-l to К do
begin read(NN[1]): N:=N+NN[i]: end:
1:-0:
for j:-l to k do
for m:=l to NN[j]
do begin Inc(1): B[i]:-j: end:
WriteB:
while (true) do
begin
i:-N:
while (i>0) and (B[1]>-B[i+l]) do i:-i-l:
if 1-0 then exit:
for j:-1+l to N do if (B[JJ>B[i]) then K:-j:
SwapB(i.k):
for j:-1+l to (1+ ((N+l-1) div 2)) do SwapB(j.N+l+l-j):
WriteB;
end:
212 Глава 2. Основы алгоритмизации
Сочетания с повторениями
Для множества символов от Л до С и размера М = 3 сочетания с повторениями
будут следующими: ССС, ВСС, ВВС, ВВВ, ACC, ABC, ABB, ААС, ААВ, ААА.
Общее количество сочетаний:
где N — количество символов, М — количество символов в сочетании.
Основная идея генерации таких сочетаний с повторениями заключается в следу-
ющем: сочетания записываем в виде (N - 1)-го нуля и М единиц, где единицы заме-
няют символы, а нули — выступают в роли разделителей.
Например:
ЛВВ-1011,ЛЛС-11001,ССС-00111.
Поясним эти примеры.
□ 1011.
Первая цифра 1 означает, что в строке символов присутствует символ Л.
Следующая цифра 0 означает, что символы Л закончились.
Следующая цифра 1 означает, что далее идет символ В.
Следующая цифра 1 означает, что далее идет еще один символ В.
Цифры закончились.
Итак, строка символов ЛВВ была представлена двоичной строкой 1011.
□ 11001.
Первая цифра 1 означает, что в строке символов присутствует символ Л.
Следующая цифра 1 означает, что далее еще раз идет символ Л.
Следующая цифра 0 означает, что символы Л закончились.
Следующая цифра 0 означает, что символы В закончились (отсутствовали).
Следующая цифра 1 означает, что далее идет символ С.
Цифры закончились.
Итак, строка символов ЛЛС была представлена двоичной строкой 11001.
□ 00111.
Первая цифра 0 означает, что в строке символов отсутствует символ Л.
Следующая цифра 0 означает, что в строке символов отсутствует символ В.
Следующая цифра 1 означает, что далее идет символ С (первый символ).
Следующая цифра 1 означает, что далее еще раз идет символ С.
Следующая цифра 1 означает, что далее еще раз идет символ С.
Цифры закончились.
Итак, строка символов ССС была представлена двоичной строкой 00111.
2.5. Генерация комбинаторных объектов
213
При таком подходе для решения задачи достаточно сгенерировать все перестанов-
ки из М единиц и (N - 1)-го нуля.
Листинг 2.43. Программа, генерирующая сочетания с повторениями
alphabet : string[26] = -ABCDEFGHIJKLMNOPQRSTUVWXYZ’:
b : array [1..100] of byte:
N.I.j.k.M.Nl : byte:
Procedure SwapB(i.k:byte):
var x : byte:
begin
x:-B[1]: B[i]:-B[k]: B[k]:-x:
Procedure WrlteB:
var i.j : byte:
begin
j:-l:
for i:-l to N do
if b[1]-0
then Inc(j)
else write(alphabet[j]);
writeln:
begin
readln(Nl.M); N:-N1-1*M;
for i:-l to nl-1 do b[i]:-0:
for i:-nl to nl-wn-1 do b[1]:-l:
WrlteB:
while (true) do
i:-N:
while (1>0) and (B[i]>-B[1«lJ) do i:-i-l:
if i-0 then exit;
for J:—1+1 to N do
1f/B[j]>B[i]) then K:-j:
' SwapB(i.k):
for j:-i+l to (1+ ((N+l-i) div 2)) do
SwapB(j.N+i*l-j):
WrlteB:
end:
Пояснения к программе.
1. Начальная перестановка формируется последовательно из N1-1 нулей и М еди-
ниц.
2. В программе вывода перестановки WriteB осуществлены изменения, соответ-
ствующие замыслу (нули — разделители, единицы — символы). Если текущий
элемент массива В равен 0, то «становится активным» следующий символ. Если
текущий символ массива В равен 1, то текущий активный символ выводится на
экран.
ГЛАВА 3 Дополнительные
сведения
Предыдущая глава была посвящена рассмотрению фундаментальных алгоритмов,
перекрывающих широкий спектр практических потребностей и олимпиадных за-
дач, в том числе: очередь и стек, рекурсия, рекуррентные соотношения и динами-
ческое программирование, графы, генерация комбинаторных объектов. В данной
главе собраны менее значимые факты и алгоритмы, если рассматривать их в срав-
нении с фактами и алгоритмами предыдущей главы. Тем не менее практика пока-
зывает, что информация, собранная в данной главе, также весьма полезна при ре-
шении разнообразных задач на соответствующие тем ы: «аналитическая геометрия
на плоскости» и «некоторые факты из теории чисел». Кроме того, часто задачи
бывают «комбинированными», то есть для решения таких задач необходимы зна-
ния не только предыдущей, но и данной главы.
3.1. Аналитическая геометрия
на плоскости
Огромное количество задач по программированию принадлежит к классу задач
«геометрия на плоскости». Для решения этих задач очень полезно знать некото-
рые факты и формулы из курса аналитической геометрии, которые и приводятся в
данном параграфе.
Точка, прямая, площадь
Точка А на плоскости в декартовой системе координат задается своими координа-
тами по осям OX nOY: А(х1, у\).
Расстояние D между двумя точкам и А(х 1, у!) и В(х2, у2) определяется по формуле:
На языке программирования Паскаль это записывается следующим образом:
D SORT (SQR(xl-x2) + SQR(yl-y2)):
ПРИМЕЧАНИЕ-------------------------------------------
Во всех задачах (если это не оговорено отдельно) координаты точек являются веще-
ственными числами. Соответственно, и расстояние между точками — всегда веще-
ственное число.
3.1. Аналитическая геометрия на плоскости
215
Координаты середины отрезка
Координаты середины отрезка (х,у) с концами в точках (*1, у!) и (х2,у2) опреде-
ляются по следующим формулам:
х! + х2
Х 2 '
Прямая линия на плоскости. Уравнение прямой
Прямая линия на плоскости однозначно определяется любыми двумя точками, ле-
жащими на этой прямой. Однако такое представление прямой (фактически в виде
отрезка) является неудобным для решения задач.
Существует альтернативный способ задания прямой на плоскости — с помощью
уравнения прямой. То есть для любой прямой существует уравнение с двумя пере-
менными х и у следующего вида:
Ах + By + С _ 0.
Это уравнение обращается в тождество при подстановке в качестве х и у коорди-
нат любой точки, принадлежащей данной прямой (Л, В и С — целые или веще-
ственные числа — константы). Именно этот способ задания прямой и использует-
ся при решении задач.
Уравнение прямой, проходящей через две заданные точки
Как было сказано ранее, прямая однозначно определяется любыми двумя точка-
ми, лежащими на ней. Следовательно, зная координаты этих точек, мы всегда мо-
жем составить уравнение прямой.
Пусть прямая проходит через точки с координатами (xl, у 1) и (х2, у2). Тогда коэф-
фициенты в уравнении прямой определяются следующими формулами:
А-у2-у\.
В-х1-х2,
С-у1*(х2-х1)-х1*(у2-у1).
Расстояние отточки до прямой
Расстояние d от точки (xl, у\) до прямой Ах + By + С - 0 определяется по формуле:
|Лх1 + Ву\ + С|
...........
На языке Паскаль это записывается следующим образом:
D ABS(A*xl + В*у1 +С) / SORT (SQR(A) + SQRCB))
216
Глава 3. Дополнительные сведения
Определение точки пересечения двух прямых
Очень часто при решении задач возникает необходимость определения точки пе-
ресечения двух прямых.
Пусть две прямые заданы своими уравнениями:
А lx'+ Bly + Cl = 0, А2х + В2у + С2 - 0.
Тогда для нахождения точки пересечения этих прямых необходимо решить систе-
му, состоящую из этих двух уравнений. Для этого можно воспользоваться теоре-
мой Крамера. Мы ограничимся только выводами из этой теоремы для нашей сис-
темы уравнений.
Введем вспомогательные величины d, dx, dy. Тогда решение системы находится по
формулам:
d = Al* В2-В1* А2,
dx= - Cl * В2 +Bl * С2,
dy = - Al * С2 +Cl * А2.
Если d = 0, то прямые параллельны (если Cl * А2 * С2 * АГ) или совпадают (если
Cl » А2 - С2 * А1). В противном случае (</* 0) прямые пересекаются и координаты
точки пересечения (х, у):
x-dx/d,
y-dy/d.
Перпендикуляр к прямой, проходящий через заданную
точку
Пусть задана прямая Ах + By + С - 0. Коэффициенты в уравнении прямой, перпен-
дикулярной данной и проходящей через точку (xl, у Г) определяются по следующим
формулам:
' А1--В,
В1=А,
С1 “ Вх - Ау.
Построение окружности, описанной около треугольника
Центр окружности, описанной около треугольника, лежит на пересечении середин-
ных перпендикуляров к его сторонам. Следовательно, последовательность действий
по построению описанной окружности должна быть следующей.
1. Найти середины двух любых сторон треугольника.
2. Составить уравнения прямых, на которых лежат эти стороны.
3. Составить уравнения прямых, перпендикулярных этим сторонам и проходя-
щих через их середины.
3.1. Аналитическая геометрия на плоскости
217
4. Найти точку пересечения этих перпендикуляров — центр окружности.
5. Найти радиус окружности как расстояние от центра до любой из вершин тре-
угольника.
Вычисление площадей плоских фигур
Площадь S треугольника с длинами сторон a,bnc удобно определять по формуле
Герона:
5 = Jp(p-a)(p-i)(p-c),
где р = (а + b + с) / 2 — полупериметр.
Площадь круга с радиусом R
Площадь круга S с радиусом R вычисляется по формуле:
S-nR2.
Поскольку в Паскале есть встроенная функция Pi, которая возвращает значение
числа л = 3.1415926535897932385, то вычисление площади круга записывается
следующим образом:
S Pi*SQR(R):
Площадь произвольного плоского многоугольника (не обязательно выпуклого) с вер-
шинами в точках (xl, yl),..., (хп,уп) определяется по формуле:
с _ I у (* ~хм)(Ум + У.)|
|й 2 р
При этом значение х„„ = xl,ynll •“yl. На языке Паскаль это может быть записано
следующим образом:
X[N+1] X[1J: Y[N+1] Y[1J;
S 0:
for 1:- 1 to N do
S: - S + (X[1] - X[1+l])*(Y[i] + Y[1+1J) / 2:
S:-abs(S):
Принадлежность точки фигуре
Данный раздел посвящен алгоритмам, отвечающим на вопрос, находится ли точ-
ка, заданная своими координатами, внутри или на границе фигуры, заданной ко-
ординатами точек, определяющих данную фигуру.
Принадлежность точки треугольнику
Пусть дан треугольник АВС и точка М. Точка М принадлежит области, ограничен-
ной треугольником АВС, если выполняется следующее условие:
б ЛВС “ $лвм + $ЛСМ + $всм-
218 Глава 3. Дополнительные сведения
То есть площадь треугольника АВС равна сумме площадей трех треугольников с
основаниями — сторонами данного треугольника и вершиной в данной точке М.
ПРИМЕЧАНИЕ--------------------------------------------------------
Здесь и везде при сравнении вещественных чисел нужно учитывать погрешность вы-
числений.
С учетом погрешности условие перепишется так:
|^ИВС ~ $АВМ ~ $АСМ ~ $ВСМ I < •
где Pogr — максимальная величина погрешности (например, 0,001).
Принадлежность точки отрезку
Точка С принадлежит отрезку АВ, если для длин отрезков АВ, АСи СВ выполня-
ется равенство:
АВ-АС+СВ
или с учетом погрешности:
\АВ - АС - СВ\< Pogr.
Принадлежность точки прямоугольнику
Пусть прямоугольник со сторонами, параллельными осям координат, задан коор-
динатами своих левой нижней (xl,у\) и правой верхней (х2, г/2) точек. Тогда усло-
вие принадлежности точки с координатами (х, у) этому прямоугольнику запишет-
ся следующим образом:
xl <х<х2 иу1 <у<у2.
Условие нахождения точки внутри прямоугольника записывается так же, только
неравенства в этом случае — строгие.
Угол, под которым виден отрезок из точки
Алгоритм нахождения угла, под которым виден отрезок ВС из точки А, предлага-
ется придумать читателю самостоятельно.
Принадлежность точки внутренности многоугольника
Для проверки принадлежности точки М внутренности произвольного (не обяза-
тельно выпуклого) многоугольника Рс координатами вершин (xl,у!),.... (xN,yN)
можно воспользоваться следующим алгоритмом: вычисляется сумма углов, под
которыми видны ребра многоугольника из точки М.
ЕСЛИ при этой ни один из углов по иодул» не равен Pi и
точка М не совпадает ни с одной из вершин многоугольника Р.
ТО ЕСЛИ | СУММА УГЛОВ ] > Pogr
3.1. Аналитическая геометрия на плоскости
219
ТО точка И лежит внутри многоугольника Р
ИНАЧЕ снаружи
ИНАЧЕ точка И принадлежит границе многоугольника Р
Проверку принадлежности точки границе многоугольника также легко описать, зная
условие принадлежности точки отрезку.
Минимальная выпуклая оболочка
Данный раздел посвящен введению понятия минимальной выпуклой оболочки и
анализу алгоритма ее построения.
Несамопересекающаяся ломаная
Ломаная линия называется несамопересекающейся, если никакие два ее ребра не
пересекаются (кроме пересечений смежных ребер в концах, в том числе — первого
и последнего).
Два отрезка пересекаются, если прямые, на которых они лежат, пересекаются и
точка их пересечения принадлежит обоим отрезкам или один из концов одного
отрезка принадлежит другому отрезку.
Последнее условие здесь необходимо для случая, когда отрезки лежат на одной
прямой и перекрываются. Прямые в этом случае не пересекаются, но ломаную сле-
дует считать самопересекающейся.
Выпуклость многоугольника
Многоугольник является выпуклым в том случае, если все его вершины лежат по
одну сторону от любой из его сторон.
Чтобы выяснить, лежат ли две точки по одну сторону от прямой Ах + By + С = О,
пользуются следующим правилом: две точки лежат по разные стороны от данной
прямой тогда и только тогда, когда при подстановке координат этих точек в урав-
нение прямой получаются значения противоположных знаков.
Построение минимальной выпуклой оболочки множества
точек
Один из алгоритмов построения минимальной выпуклой оболочки множества то-
чек на плоскости выглядит следующим образом.
1. Находим самую «левую» точку множества и принимаем ее за первую вершину
оболочки.
2. В качестве следующей вершины оболочки выбираем ту точку множества, для
которой отрезок, образуемый этой точкой и предыдущей вершиной оболочки,
виден из текущей последней вершины оболочки под максимальным углом. (Для
первой вершины оболочки в качестве предыдущей необходимо взять точку с ко-
ординатами (х + 1, у), где (х, у) — координаты первой вершины.)
3. Пункт 2 повторяется до тех пор, пока очередная найденная вершина не окажет-
ся первой вершиной оболочки.
220
Глава 3. Дополнительные сведения
Основные соотношения в треугольнике
В данном разделе приводятся формулы, связывающие длины сторон и значения
углов треугольника. Решение многих практических и олимпиадных задач базиру-
ется на этих формулах.
Основные соотношения в прямоугольном треугольнике
Пусть задан прямоугольный треугольник с катетами (сторонами, прилежащими
прямому углу) а и b и гипотенузой (стороной, противолежащей прямому углу) с.
Введем обозначения:
□ А1 — угол, противолежащий катету а\
□ В1 — угол, противолежащий катету Ь.
Тогда справедливы следующие соотношения:
с2 = а2 + Ь2 (теорема Пифагора);
sin (Л1) = -, cos (Л1) = -;
sin (Bl) = —, cos (Bl) = —;
tg(Al) = ptg(«l) = l
Заметим, что в Паскале существуют встроенные функции SIN(x) и COS(x) и отсут-
ствует встроенная функция TG(x), поэтому для нахождения тангенса угла следует
пользоваться соотношением:
tg(x) = -n-ty
cos(x)
Используя вышеприведенные соотношения легко:
1) найти третью, зная любые две стороны прямоугольного треугольника;
2) найти две другие стороны и угол, зная одну сторону и угол.
Как найти острый угол, зная две стороны прямоугольного треугольника? Для это-
го необходимо сначала найти тангенс искомого угла (переменная Т), а затем ис-
пользовать встроенную функцию АгсТап:
Al := АгсТап (Т);
Заметим, что и аргумент х в функциях SIN(x), COS(x), и результат у в функции
у:=АгсТап(х) являются углами, измеряемыми в радианах, а не градусах.
Основные соотношения в произвольном треугольнике
Пусть задан произвольный треугольник со сторонами а, Ь, с.
Введем обозначения:
3.1. Аналитическая геометрия на плоскости
221
□ А1 — угол, противолежащий стороне а;
□ В1 — угол, противолежащий стороне Ь;
□ С1 — угол, противолежащий стороне с.
Тогда справедливы следующие соотношения:
а b с , ,
—;—г = —; = —/- -г (теоремасинусов),
sin(Al) sin (Bl) sin (Cl)
c2 = a2 + b2 - 2ab • cos (Cl) (теорема косинусов).
Очевидно, что, зная в треугольнике три стороны или две стороны и угол между
ними или одну сторону и два прилежащих к ней угла и используя эти формулы,
легко найти неизвестные компоненты (стороны и углы) треугольника.
Задачи для самостоятельного решения
ПРИМЕЧАНИЕ-----------------------------------------------------------
Эти задачи для начинающих адаптированы из [8] к системе дистанционного обучения
http://dl.gsu.unibel.by.
Соглашения о выводе результатов вычислений', все выходные данные, которые яв-
ляются вещественными числами, выводятся с точностью до двух знаков после де-
сятичной точки. Условия задач:
1. Даны три числа а, Ь, с. Необходимо определить, существует ли треугольник с
такими длинами сторон.
□ Ввод: длины сторон треугольника а, Ь, с.
□ Вывод: ответ в виде «ДА/НЕТ».
2. Даны четыре числа a, b, с, d. Необходимо определить, существует ли четыре-
хугольник с такими длинами сторон.
□ Ввод: длины сторон четырехугольника a, b, с, d.
□ Вывод: ответ в виде «ДА/НЕТ».
3. Найти взаимное расположение окружности радиуса Я с центром в точке (хО,
уО) и точки А с координатами (х1, у1).
□ Ввод: координаты точки А, координаты центра окружности и ее радиус.
□ Вывод: расположение точки (на окружности/внутри окружности/вне окруж-
ности).
4. Найти взаимное расположение двух окружностей радиусов R1 и R2 с центрами
в точках (х1, у1) и (х2, у2) соответственно.
□ Ввод из файла (построчно):
1) координаты центра первой окружности и ее радиус;
2) координаты центра второй окружности и ее радиус.
222
(лава 3. Дополнительные сведения
□ Вывод: взаимное расположение окружностей (внутри/касаются внутри/
касаются снаружи/снаружи/пересекаются/совпадают).
5. Найти взаимное расположение окружности радиуса R с центром в точке (хО,
уО) и прямой, проходящей через точки с координатами (х1, у1) и (х2, у2).
□ Ввод из файла (построчно):
1) R;
2) XOYO;
3) Х1 Y1;
4) X2Y2.
□ Вывод: взаимное расположение окружностей (пересекаются/не пересека-
ются/касаются).
6. Определите количество точек с целочисленными координатами, лежащих
внутри окружности радиуса R с центром в точке (хО, уО).
□ Ввод: ХО, YO, R.
□ Вывод: количество точек.
7. Найти координаты точек пересечения двух окружностей с радиусами R1 и R2 и
центрами в точках (х1, у1) и (х2, у2) соответственно.
□ Ввод из файла (построчно):
1) Х1 Y1 R1;
2) X2Y2R2.
□ Вывод: координаты точек пересечения по возрастанию X (если X равны, то —
по возрастанию Y). Каждая точка — в отдельной строке.
8. Найти координаты точки, симметричной данной точке М с координатами (х1,
у1) относительно прямой Ах + Вх + С = 0.
□ Ввод из файла (построчно):
1) Х1 Y1;
2) А В С.
□ Вывод: координаты точек.
9. Даны две точки М1(х1, у1) и М2(х2, у2) и прямая Ах + Вх + С - 0. Необходимо
найти на этой прямой такую точку МО(хО; уО), чтобы суммарное расстояние от
нее до двух данных точек было минимальным.
□ Ввод из файла (построчно):
1) координаты первой точки;
2) координаты второй точки;
3) коэффициенты уравнения данной прямой.
□ Вывод: координаты искомой точки.
10. Даны три точки с координатами (х1, у1),(х2, у2)и(хЗ, уЗ), которые являются
вершинами некоторого прямоугольника со сторонами, параллельными осями
координат. Найти координаты четвертой точки.
3.1. Аналитическая геометрия на плоскости
223
11. Даны координаты четырех точек (х1, у1), (х2, у2),(хЗ, уЗ)и(х4, у4). Необхо-
димо определить, образуют ли они выпуклый четырехугольник.
□ Ввод: координаты точек в порядке обхода.
□ Вывод: ответ в виде «выпуклый/невыпуклый».
12. Даны координаты четырех точек (х1, у1), (х2, у2), (хЗ, уЗ)и(х4, у4). Необхо-
димо определить, образуют ли они ромб, квадрат, трапецию.
□ Ввод: координаты точек.
□ Вывод: в виде «ДА/НЕТ» для каждой из фигур.
13. Даны координаты двух вершин (х1, у1)и(х2, у2) некоторого квадрата. Необ-
ходимо найти возможные координаты других его вершин.
□ Ввод из файла (построчно):
1) х1 у1;
2) х2 у2.
□ Вывод: точки в порядке возрастания X, каждая точка — в отдельной строке.
Если X равны, то — смотреть по Y.
14. Даны координаты двух вершин (х1, у1) и (х2, у2) некоторого квадрата, кото-
рые расположены по диагонали, и точка (хЗ, уЗ). Необходимо определить, ле-
жит или не лежит точка внутри квадрата.
□ Ввод из файла (построчно):
1) х1 у1;
2) х2у2;
3) хЗ уЗ.
□ Вывод: в виде «ДА/НЕТ».
15. Даны координаты трех вершин (х 1, у 1), (х2, у2) и (хЗ, уЗ) треугольника. Необ-
ходимо найти координаты точки пересечения его медиан.
□ Ввод: координаты вершин треугольника в порядке обхода.
□ Вывод: координаты точки пересечения медиан треугольника.
16. Даны координаты трех вершин (х1, у 1), (х2, у2) и (хЗ, уЗ) треугольника. Необ-
ходимо найти длины его высот.
□ Ввод из файла (построчно):
1) х1 у1;
2) х2 у2;
3) хЗ уЗ.
□ Вывод: длины высот в порядке возрастания (каждая высота — в отдель-
ной строке).
17. Определить коэффициенты уравнения прямой, параллельной данной прямой,
определяемой уравнением Ах + Вх + С = 0, и проходящей через точку с коор-
динатами (хО, уО).
224 Глава 3. Дополнительные сведения
□ Ввод: координаты точки, через которую проходит прямая, параллельная
данной.
□ Вывод: коэффициенты уравнения прямой, параллельной данной.
18. Определить коэффициенты уравнения прямой, перпендикулярной данной
прямой, определяемой уравнением Ах + Вх+С-0,и проходящей через точку
с координатами (хО, уО).
□ Ввод из файла (построчно):
1) координаты точки;
2) коэффициенты уравнения прямой.
□ Вывод: коэффициенты уравнения прямой, перпендикулярной данной.
3.2. Некоторые факты из теории чисел
Существует значительный класс задач по программированию, простое решение
которых предполагает знание учеником следующих разделов из теории чисел:
□ свойства остатка от деления числа X на число Y (X MOD Y);
□ позиционные системы счисления и быстрое вычисление многочлена;
□ показатель, с которым данное простое Р входит в произведение ЛИ;
□ свойства НОД (наибольший общий делитель).
Изложению соответствующих фактов и примеров их применения к решению кон-
кретных задач и посвящен данный раздел.
Свойства X MOD Y
Пусть X и Y — целые числа. Поделив нацело X на Y, мы получим два числа — част-
ное (обозначим его Q) и остаток (R). В Паскале для нахождения 0 и R имеются
соответствующие операции:
Q X div Y:
R X mod Y:
Рассмотрим некоторые свойства остатка от деления.
1. (А+ В) mod Y=(Amod Y + В mod Y) mod Y.
To есть, чтобы найти остаток от деления суммы двух чисел А и В на число Y,
достаточно найти остатки от деления чисел А и В на Y, сложить полученные числа
и уже для вычисленной суммы взять остаток от ее деления на Y.
Пусть требуется вычислить остаток отделения числа 197 на 5. Традиционный
способ предполагает деление числа 197 на 5 «уголком»:
45
2
3.2. Некоторые факты из теории чисел 225
Получается, что частное — 39, а остаток — 2.
Но ведь частное у нас никто не спрашивал. Значит, скорее всего, мы выполни-
ли лишнюю работу. А давайте подсчитаем, сколько всего действий было вы-
полнено:
1) 3*5 = 15;
2) 19-15 = 4;
3) 9 * 5 = 45;
4) 47-45 = 2.
На самом деле мы выполнили даже еще больше действий. Ведь чтобы найти
цифры 3 и 9 частного, мы должны были подбором искать такую цифру, чтобы
ее произведение на 5 было максимальным, но меньше чем 19 — в первом случае
(когда мы подбирали цифру 3) и меньше чем 47 — во втором случае (когда мы
подбирали цифру 9).
Теперь попробуем решить эту же задачу с помощью свойства 1.
197 mod 5 = (190 + 7) mod 5 -
= ((190 mod 5) + (7 mod 5)) mod 5 =
= (0 + 2) mod 5 = 2.
Очевидно, что такой способ гораздо проще (особенно в более общем случае —
при произвольном А).
2. (А * В) mod Y = ((A mod Y) * (В mod Y)) mod Y.
То есть для того, чтобы найти остаток от деления произведения двух чисел А и В
на число Y, достаточно найти остатки от деления чисел А и В на Y, перемножить
полученные числа и уже для вычисленного произведения взять остаток от его
деления на Y.
Пусть требуется вычислить остаток отделения числа 100 на 7. Традиционный
способ предполагает деление числа 100 на 7 «уголком»:
1001 7
_7 ПГ
Получается, что частное — 14, а остаток — 2.
Теперь попробуем найти тот же результат с помощью свойства 2:
100 mod 7 = (10 * 10) mod 7 =
= ((10 той 7) * (10 mod 7) mod 7 - (3 * 3) mod 7 =
= 9 mod 7 = 2.
Очевидно, что такой способ значительно проще.
226[лава 3. Дополнительные сведения
Позиционные системы счисления и быстрое
вычисление многочлена
Рассмотрим многочлен (полином)-.
а0 + а, • х +... + а„. । * хп~1 + а„ * х".
Пусть нам задан массив коэффициентов многочлена а[0],а[ 1 ] a[n-1 ],а[п] и не-
которое число х, для которого нужно вычислить значение этого многочлена. Тогда
программу можно записать, например, так:
for k:-0 to n do
s: - s + a[k]*y:
у := У * x:
end:
В Паскале нет оператора возведения в степень, и поэтому приходится делать это
умножением в строке у := у • х.
В математике для сокращения записи многочленов используют знак суммы:
£ выражение.
4=о
Читается это следующим образом: сумма выражений, которые стоят за знаком сум-
мы при k от 0 до п.
С использованием такой записи многочлен примет вид:
ЁЛЩх*.
4=0
А правила вычисления модуля от многочлена, вытекающие из свойств 1 и 2, могут
быть записаны следующим образом:
1- S А[£]-х* шосШ = £ А[й](х* mod mod ЛА
2. х* mod М = (х (х*-1 mod М)) mod М (для х < М).
3. (Р + Q)mod М = (Рmod М + Q)mod М (для 0 < М ).
Теперь вернемся к программе вычисления полинома:
S 0: у 1:
for k:=0 to n do
T- s * a[k]*y:
end:
Некоторые читатели уже, наверное, заметили, что можно было написать и так:
3.2. Некоторые факты из теории чисел
227
s := а[0]: у х:
for k:=l to n do
begin
s: = s + a[k]*y: >
у у * x;
Тогда действий и сложения, и умножения стало бы на одно меньше — п и 2п соот-
ветственно.
А можно ли написать эту программу так, чтобы еще уменьшить количество дей-
ствий (сложений и/или умножений)?
Итак, пусть мы имеем полипом:
А = а0 + а,х + «jX2 +... + (0 < ак < N),
который представляет число А в позиционной системе счисления, гдеа4 — цифры,
х — основание системы счисления.
Обозначив at как а[к] и поменяв порядок членов в полиноме на обратный, получим:
А - a[N] *х" + ... + а[к] +... + а[0].
Введем обозначения:
□ S[N]-a[NJ;
□ S[N-1]-S[N].x + a[N-1]-a[N] «x + a[N-1J;
□ S[N-2] = S[N-1] • x + a[N-2] = a[N]« x‘2 + a[N-1] * x + a[N-2);
□ ...;
□ S[O] = S[1] • x + a[0] = a[N] + x"N + a[k-1] * x'[N-1] +... + a[0].
Теперь алгоритм вычисления полинома выглядит следующим образом:
SEN] = a[N] I быстрое вычисление
Для 1 от N до 1 SE1-1] - S[1]*x + а[1-1] ! полинома
А соответствующий фрагмент программы:
• sEn] := а[п]:
for 1:=n downto 1 do s[1-l]:-s[i]*x + aEi-11:
Поскольку каждый раз для вычисления следующего значения S нам нужно только
одно предыдущее, то этот фрагмент программы может быть упрощен:
s а[п];
for i:=n downto 1 do s s*x + а[1-1]:
Теперь наконец можно полностью записать текст программы (листинг 3.1), которая
по заданным аргументу х и коэффициентам полинома а[ i ] вычисляет сам полином.
Листинг 3.1. Программа вычисления полинома
program poly3:
var
а : array [0..100] of longint:
s. у. n. x.i : longint:
begin
readln(x)
readln(n) продолжение #
228
Глава 3. Дополнительные сведения
Листинг 3.1 (продолжение)
for i:-0 to n readln (a[il);
s а[п]:
for i:-n downto 1 do s := s*x + a[i-l]:
writeln (s):
end.
Чем эта программа лучше ранее написанной, в которой было п сложений и 2п
умножений? Тем, что в ней ровно п сложений и п умножений, то есть умножений
стало в два раза меньше. Значит, программе потребуется в два раза меньше време-
ни на выполнение. Существуют задачи, для которых это очень важно.
Задача об остатке полинома
Дано число в Х-ичной системе счисления:
AA-i-A (К S 36).
Найти остаток отделения его па т. Числа К, п и М (как и остаток отделения на т)
представляются в десятичной системе счисления.
Идея решения — воспользоваться свойствами MOD и алгоритмом быстрого вычис-
ления полинома.
Если у нас К — основание системы счисления, тб число a„a„.t...a0нужно вычислять
следующим образом:
S = a[n]K" + a[n-1]K"'’ +... + а[0].
А соответствующий алгоритм выглядит так:
Ввод N. ACO..N], К. М
S - a[n] mod М
Для 1 от п до 1
S - (S*K+ aCi-lJ) mod М
Вывод S
Быстро вычисляем остаток
от деления полинома на М.
пользуясь попутно свойствами М00
Листинг 3.2. Решение задачи об остатке полинома
program poly4;
а : array [0..100] of longint:
s. n. 1. К. М : longint:
begin
read(n)
for i:-0 to n read (a[ij):
read(K.M)
s a[n] mod M;
for 1:-n downto 1 do s := (s*K + a[i-l]) mod M:
writeln (s):
Задача о делимости на 15
Число вводится своим двоичным представлением (длина числа не превышает
10 000 двоичных разрядов). Необходимо определить, делится ли число на 15.
3.2. Некоторые факты из теории чисел 229
Рассуждения будем проводить в шестнадцатеричной системе счисления. К ней
легко перейти, заменяя во введенном двоичном числе тетрады на соответствую-
щие шестнадцатеричные цифры (справа налево).
Аналогично признаку делимости на 9 в десятичной системе счисления, если сум-
ма шестнадцатеричных цифр делится на 15, то и число делится на 15.
Приведем доказательство:
£ а[А]16* = а[0] + S 16а[А]16*-1 =£ «М+S 15а[А]16*~'.
В результате преобразований получились два слагаемых. Второе из них делится
на 15, так как каждый элемент суммы имеет сомножитель 15. Таким образом, ис-
ходное число делится на 15, если сумма цифр числа А делится на 15.
Алгоритм решения задачи может быть записан следующим образом:
Ввод п. а[0..п]
К - (n MOD 4)+1
Преобразование А в Н[0..К]
S - Н[ОЗ
Для 1 от 1 до К
S - ( S + H[i] ) mod 15
Если S-0
то делится
иначе не делится
а[1] - коэффициент при 21
Количество шестнадцатеричных цифр в исходном числе
Строим массив 16-х цифр (числа 0 - 15)
В S заносим младшую цифру
Для всех остальных цифр
складываем цифру с S и берем остаток
Если сунна цифр делится на 15.
то и число делится
иначе нет
ПРЕОБРАЗОВАНИЕ А -> Н
Для 1 от п+1 до 4*К-1 А[1]-0 Дополняем нулями до полной старшую тетраду
Для 1 от 0 до К-1
Формируем по тетраде 16-ю цифру Н[1]
Н[1] = AM + А[т+1]*2 + А[т+2]*4 + А[т+3]*8
Листинг 3.3. Решение задачи о делимости на 15
program poly5:
: array [0..10000] of byte:
s, у. п. 1. К. т : longint:
begin
readln(n)
for i:-0 to n read (a[i]):
К (n mod 4) + 1:
for 1:- n+i to 4*K-1 do a[i]:-0:
for 10 to K-l do
begin
m :- 4*1:
H[i] Atm] + A[m+1]*2 + A[m+2]*4 + A[m+3]*8
end:
s .- H[n] mod 15:
for i:=n downto 1 do s :- (s + H[1-l]) mod 15:
if s-0 then writeln (’Yes') else writeln('No'):
end.
230 Глава 3. Дополнительные сведения
Формула вхождения простого множителя
в N-факториал
Рассмотрим число М. Очевидно, что оно представимо в виде:
АЛ - 2“ * 3й • 5й * 7й.. ...Р*”,
где показатель /^указывает количество чисел Р(простых) в произведении М. Этот
показатель равен:
kP - [7V/P] + [N/P2 ] + ... + [N/Р* ] (пока N> Р*),
где [ У] обозначает целую часть числа Y.
Пояснение смысла формулы:
□ каждое Р-е число делится на Р;
□ каждое Р2-е число делится на Р2;
□ каждое Р3-е число делится на Р3;
□ и т. д, для всех k, пока N > Р*.
Рассмотрим задачу.
Вводится число N. Необходимо найти, сколько нулей стоит в конце числа
N!- 1 ♦ 2 * 3 *... * N.
Идея решения: запишем N! в виде N1 = 2й * Зв » 5й * 7‘7 * ... и посчитаем к2 и к5 (так
как число, представимое в виде произведения простых чисел, может оканчиваться
на ноль/ноли, только среди этих простых чисел присутствуют 2 и 5). Очевидно,
что К (количество нулей) - min (k2, k5) - k5.
Алгоритм:
Ввод N
К - N div 5. D - К
Пока (D >- 5) Пока есть что прибавлять.
D - 0 d1v 5. К - К + 0 вычисляем и прибавляем
Листинг 3.4. Решение задачи о вхождении простого множителя в N!
program pfact:
N. К. D : longint:
begin
readln(N);
К N div 5: 0 K:
while ( D>-5 ) do
begin D 0 div 5: К К + D: end;
writeln(K):
end.
Свойства наибольшего общего делителя
По определению, наибольшим общим делителем (НОД) двух чисел а и Ь называет-
ся наибольшее из чисел, являющихся делителями одновременно и числа а, и чис-
3.2. Некоторые факты из теории чисел
Для чисел 12 и 18 наибольшим общим делителем является число 6. Действительно:
□ делители числа 12:1,2,3,4,6,12;
□ делители числа 18:1,2,3,4,6,9,18.
В школьном курсе математики для нахождения наибольшего общего делителя
предлагался следующий алгоритм: найти все делители каждого из чисел и выбрать
наибольший из общих делителей.
В информатике применяются различные ускоренные варианты нахождения НОД
двух чисел а и Ь, основанные на следующих его свойствах:
(НОД(а-b,b), если а > Ь,
1. НОД = (а,
|нОД(а,6-а), если Ь>а.
2 • НОдГ^,^1 если а и Ь-четны;
НОД =
, если а и b - нечетны.
3. НОД (а, Ь) = НОД (а - Ь, Ь) = НОД (а + Ь, Ь), если а>Ь.
Листинг 3.5. Нахождение НОД
program euclid:
а. b : longint:
function NOD (a,b:longint):longint;
begin
if a>b
then NOO NOD (a-b.b)
else If a<b
then NOO NOO (a.b-a)
else NOO :- a:
end:
begin
readln (a.b):
writeln (NOD (a.b)):
end.
Например, программа euclid (см. листинг 3.5) находит НОД с помощью рекур-
сивной функции NOD(a,b).
Литература
1. Вальвачев А. Н., Крисевич В. С. Программирование на языке ПАСКАЛЬ для
персональных ЭВМ ЕС. — Минск: Высш, шк., 1989.223 с.
2. Емеличев В. А., Мельников О. И., Сарванов В. И., Тышкевич Р..И Лекции по те-
ории графов. — М.: Наука, 1990. 384 с.
3. Зуев Е. А. Программирование на языке TURBO PASCAL 6.0,7.0. — М.: Радио
и связь, 1993.384 с.
4. Касьянов В. Н., Сабельфельд В. К. Сборни к заданий по практикуму на ЭВМ. —
М.: Наука,1986.272 с.
5. Кирюхин В. М„ Лапунов А. В., Окулов С. М. Задачи по информатике: Междуна-
родные олимпиады 1989-1996. — М.: ABF, 1996.272 с.
6. КнутД. Искусство программирования для ЭВМ. Т. 1: Основные алгоритмы. —
М.: Мир, 1976.735 с.
7. КнутД. Искусство программирования для ЭВМ. Т. 2: Получислепные алго-
ритмы. 3-е изд. — М.: Издательский дом «Вильямс», 2000.828 с.
8. КнутД. Искусство программирования для ЭВМ. Т. 3: Сортировка и поиск. —
М.: Мир, 1978.844 с.
9. Кормен Т, Лейзерсон Ч., Ривест Р. Алгоритмы: построение и анализ. — М.:
МЦНМО, 1999.960 с.
10. Котов В. М., Волков И. А., Харитонович А. И. Методы алгоритмизации: Учеб-
ное пособие для 8-го класса общеобразовательной школы с углубленным изу-
чением информатики. — Минск: Народная асвета, 1996.127 с.
11. Котов В. М., Волков И. А., Лапо А. И. Методы алгоритмизации: Учебное пособие
для 9-го класса общеобразовательной школы с углубленным изучением ин-
форматики. — Минск: Народная асвета, 1997.160 с.
12. Котов В. М., Мельников О. И. Методы алгоритмизации: Учебное пособие для
10-11-го классов общеобразовательной школы с углубленным изучением ин-
форматики. — Минск: Народная асвета, 2000.221 с.
13. Кристофидес Н. Теория графов: Алгоритмический подход. — М.: Мир, 1988.
250 с.
Литература
233
14. Липский В. Комбинаторика для программистов. — М.: Мир, 1988.368 с.
15. Новиков Ф. А. Дискретная математика для программистов. — СПб.: Питер, 2000.
304 с.
16. Овсянников А. П., Овсянникова Т. В., Марченко А. П., Прохоров Р. В. Избранные
задачи олимпиад по информатике. — М.: Тровант, 1997.95 с.
17. Окулов С. М. Конспекты занятий по информатике (алгоритмы на графах):
Учебное пособие. — Киров: Вятский госпедуниверситет, 1996.117 с.
18. Шень А. Программирование: теоремы и задачи. — М.: МЦМНО, 1995.264 с.
Алфавитный указатель
А динамическая память, 86 доминантное множество, 185
алгоритм Дейкстра, 157 Евклида, 93 на графах, 155 поиск в глубину, 171 поиск в ширину, 195 построения минимальной выпуклой оболочки, 219 окружности, описанной около треугольника, 216 Флойда, 157 дуга графа, 156 3 задача вывод всех возможных способов, 105 вывод одного из возможных способов, 106 количество правильных скобочных выражений, 103 количество представлений числа как суммы компонент, 102
Б байт, 45 бит, 44 булевский тип данных, 51 В ввод двумерного массива, 26 вещественный тип данных, 49 взвешенный граф, 157 вывод двумерного массива, 26 вызов контекстно-чувствительной помощи, 54 выпуклый многоугольник, 219 Г генерация комбинаторных объектов множество всех подмножеств, 202 перестановки, 204 размещения, 208 сочетания, 207 глобальные переменные, 84 д двумерный массив, 23 декартова система координат на плоскости, 214 количество способов составления суммы М из N чисел, 98 о вырезании кусков, 76 о множестве треугольников, 61 о поиске прямой, 58 о скобках, 78 о ходе конем, 73 о числах Фибоначи, 116 число сочетаний из N по М, 96 И индексы диагоналей двумерного массива, 25 столбца двумерного массива, 24 строки двумерного массива, 24 инициализация массива констант, 82 исток, ПО К координаты середины отрезка, 215 точки на плоскости, 214 пересечения двух прямых, 216 кратчайшие расстояния на графах, 157
Алфавитный указатель
235
Л принадлежность точки
логические переменные и массивы, 51 отрезку, 218 прямоугольнику, 218
локальные переменные, 83 треугольнику, 217
М многоугольнику, 218
малая автоматизация тестирования, 85 простейшие алгоритмы на одномерном массиве, 17
матрица смежности, 156 Простейшие приемы работы в среде
множество всех подмножеств, 203 Турбо Паскаль, 41
н наибольшее число одинаковых подряд процедура Delete, 54 Dispose, 86
элементов, 31 Insert, 54
наибольший общий делитель, 230 процедуры в Паскале, 54
О Р
ограниченные типы, 51 расстояние
одномерный массив, 10, И от точки до прямой, 215
отладка рекурсивных процедур ребро графа, 156
и функции, 112 рекуррентные соотношения
очередь, 70 восстановление оптимального пути, 154
п перевод алгоритма на строках, 154 рекурсивное вычисление, 154 с двумя параметрами, 126
в Паскаль-программу, 40 с одним параметром, 118
перенаправление стандартного с тремя и более параметрами, 139
ввода-вывода сокращение используемой памяти, 154
в программе, 56 формирование всех возможных
при запуске, 55 сумм, 153
перенос алгоритмов на двумерные ручная прокрутка, 33
массивы, 25 перестановки С
с повторениями. 210 сильносвязные компоненты, 185
перпендикуляр к прямой, проходящий символьный тип данных, 52
через точку, 216 сортировка элементов одномерного
план разработки алгоритмов массива, 21
и программ, 29 сочетания с повторениями, 212
площадь стек, 70
круга, 217 сток, 110
произвольного плоского строковый тип данных, 53
многоугольника, 217 треугольника, 217 т
подсчет элементов, обладающих заданным текст программы
свойством, 17 быстрое вычисление полинома, 227
поиск замены элементов, массива
элементов, обладающих заданным на противоположные, 27
свойством, 17, 20 наибольший общий делитель, 231
максимального элемента, 17, 19 об остатке полинома, 228
минимального элемента, 17, 19 суммрование элементов одномерного
преобразование символов в числа, 82 массива, 25
236 _________________________________Алфавитный указатель
текстовые файлы, 55 тест, 29 технология разработки программ, 57 тип данных boolean, 51 comp, 50 record, 65 string, 53 треугольник Паскаля, 95 У уравнение прямой, проходящей через две точки, 215 уравнение прямой на плоскости, 215 формула (продолжение") Герона, 217 функции в Паскале, 54 функции преобразования типов, 54 функция Сору, 54 Length, 54 MaxAvail, 90 MemAvail, 90 Pos, 54 ц целый тип данных, 48 ч число сочетаний, 208
Ф факториал, 207 формула вхождения простого множителя в N!, 230 Ш шестнадцатеричная система счисления, 47
Долинский Михаил Семенович
Алгоритмизация и программирование на Turbo Pascal:
от простых до олимпиадных задач
Учебное пособие
Заведующий редакцией
Руководитель проекта
Литературный редактор
Л. Кривцов
Корректоры
Верстка
А. Келле-Пелле. Д. Стукалин
Лицензия ИД № 05784 от 07.09.01.
Подписано к печати 26.08.04. Формат 70x100/16. Уел. п. л. 19,35.
Тираж 4000. Заказ 877
ОК 005-93, том 2; 95 3005 —литература учебная.
Отпечатано с готовых диапозитивов в ОАО «Техническая книга»
190005, Санкт-Петербург, Измайловский пр., 29